
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
816,630 | Hello class! | My name is Michael and I am a senior at Penn State University. Currently I am majoring in... | 0 | 2021-09-07T18:11:32 | https://dev.to/michaelzwhang/hello-class-50dj | My name is Michael and I am a senior at Penn State University. Currently I am majoring in Cybersecurity Analytics & Operations and minoring in Information Science & Technology.
This past summer and overlapping into the first week of the semester, I had the opportunity to intern at CrowdStrike, where I was working as a threat intelligence analyst. Though I am not so sure how much web component work I will do in my future career, I am optimistic and excited to learn in this class and discover where I will be able to apply this knowledge in the future. | michaelzwhang | |
816,650 | A Look into a terminal emulator's text stack | I describe how I implemented proper text shaping in my terminal emulator with all its today's wishes: ZWJ Emoji, variation selectors, programming ligatures. | 0 | 2021-09-07T19:02:43 | https://dev.to/christianparpart/look-into-a-terminal-emulator-s-text-stack-3poe | programming, terminal, unicode, emoji | ---
title: A Look into a terminal emulator's text stack
published: true
description: I describe how I implemented proper text shaping in my terminal emulator with all its today's wishes: ZWJ Emoji, variation selectors, programming ligatures.
tags: [programming, terminal, unicode, emoji]
cover_image: https://contour-terminal.github.io/images/terminal-zwj-emoji.png?2
---
TL;DR
-----
I am going to describe how I implement rendering text in my terminal emulator so that we get programming ligatures, emoji, variation selectors, and yes, even ZWJ emoji.
Introduction
------------
Text rendering in a virtual terminal emulator can be as simple as just iterating over each grid cell's character, mapping it to a Font's bitmap glyph, and rendering it to the target surface at the appropriate position. But it can also be as complex as a web browser's text stack[1] if one may want to do it right.
In contrast to web browsers (or word processors),
terminal emulators are still rendering text the way they did render text 50 years ago - plus some non-standard extensions that did arise over the decades.
Also, terminal screens weren't made with Unicode in mind, Unicode did not even exist back then, so there were a few workarounds and non-standardized ideas implemented in order to display complex Unicode text and symbols in terminals without a common formal ground that terminal application developers can rely on.
Text rendering in a terminal emulator puts some additional constraints on how to render, mostly because character placement is decided before text shaping is performed and must align to a fixed-size grid, which makes it almost impossible to properly render traditional Japanese text into the terminal, or Hewbrew right-to-left text (though, there is a handful of virtual terminal emulators that specialize
on the latter and an informal agreement on how to deal with wide characters on the terminal screen).
Not every character, or to be displayed symbol (such as Emoji) is as wide as exactly one grid cell's width, so additional measurements have to be taken into account for dealing with these characters as well.
Terminals and terminal applications until now did depend on a standard library API call `wcwidth()` that does ideally return the number of grid cells that an input character will occupy. This however became useless as soon as multi codepoint grapheme clusters have been introduced that still form a single user perceived character. `wcswidh()` should return the total number of grid cells of a sequence of characters, but these do not handle grapheme clusters nor variation selectors either.
Unicode - a very quick rundown in the context of terminals
----------------------------------------------------------
Unicode is aiming to have one huge universal space where every imaginable "user perceived character" can be represented. A "user perceived character" is what the user that looks at that character thinks of as one unit. This is in direct contrast to what a character is in computer science. A "user perceived character" can be as simple as one single codepoint (32-bit value representing that
character) and as complex as an ordered sequence of 7 unbreakable codepoints to compose one single "user perceived character".
This places additional requirements to a virtual terminal emulator where each grid cell SHOULD contain exactly one *"user perceived character"* (also known as *grapheme cluster*), that is, an unbreakable codepoint sequence of one or more codepoints that must not be broken up into multiple grid cells before the actual text shaping or screen rendering has been performed.
Also, some grapheme clusters take up more than one grid cell in terms of display width, such as Emoji usually take two grid cells in width in order to merely match the Unicode (TR 51, section 2.2) specification's wording that the best practice to display Emoji is to render them in a square block to match the behavior of the old japanese phone companies that that first introduced Emoji.
Rendering text - a top level view
---------------------------------
A terminal emulator's screen is divided into fixed width and (not necessarily equal) fixed height grid cells.
When rendering this grid, it is sufficient to iterate over each line and column and render each grid cell individually, at least when doing basic rendering.
Now, when non-trivial user perceived characters need to be supported, the rendering cannot just render each character individually, but must be first grouped into smaller chunks of text with common shared properties, across the grid cell boundaries.
Here we enter the world text shaping.
Text Shaping
------------
Simply put, text shaping is the process of translating a sequence of codepoints into glyphs and their glyph positions. This differs from normal text processors and web browsers in a way because glyph placement in virtual terminal emulators are constrained.
When shaping text of a single grid line, the line is split into words, delimited by spaces, gaps and SGR attributes, that is, each word must represent the same SGR attributes for every "user perceived character" - for example the text's font style (such as bold or italic) or background color must be equal for each position in this sequence, from now on called "word").
The word can be used as a cacheable unit, in order to significantly speed up rendering for future renders.
The cache key is composed of the codepoint sequence of that word, as well as, the common shared SGR attributes.
This cacheable word is further segmented into sub runs by a series categories before text shaping can occur, that is, by Unicode script attribute (such as Latin or Hangul) and by symbol presentation (such as Emoji text presentation or Emoji presentation). This is important because one cannot just pass a string of text to the underlying text shaping engine with mixed properties, such as Hebrew text along with some Latin and Kanji or Emoji in between or a font style change for obvious reasons.
Each segment (usually called run) must be shaped individually with its own set of fallback fonts. Emoji are using a different font and font fallback list than regular text which uses a different font and font fallback list then bold, italic, or bold italic fonts.
Emoji also have two different presentation styles, the one that everybody expects and is named Emoji Emoji presentation (double-width colored Emoji) and the other one is named Emoji text presentation, which renders Emoji in non-colored text-alike pictograms.
The result of all sub runs is composing the sequence of glyph indices and glyph positions and is used as the cache value for the cacheable word to be passed to the next stage, the text renderer.
Text Rendering
--------------
The text renderer receives an already pre-shaped string of glyphs and glyph positions relative to screen coordinates of the first glyph to be rendered onto the screen.
In order to lower the pressure on the GPU and reduce synchronization times between CPU and GPU, all glyph bitmaps are stored into a texture atlas on the GPU, such that the text rendering (when everything has been already uploaded once) just needs to deal with indices to those glyph bitmaps into the appropriate texture atlas as well as screen coordinates where to render those glyphs on the target surface.
There is one texture atlas for gray scaled glyphs (this is usually standard text) as well as one texture atlas for colored glyphs (usually colored Emoji). Additionally there can be a third type of texture atlas for storing LCD anti-aliased bitmap glyphs.
Now, when rendering a string of glyphs and glyph positions, each glyph's texture atlas ID and atlas texture coordinate is appended into an atlas coordinate array along with each glyph's absolute screen coordinate and color attributes into a vertex buffer to be uploaded to the GPU.
When iterating over the whole screen buffer has finished, the atlas texture and vertex buffer are filled with all glyphs and related information that are required for rendering one frame. These buffers are then uploaded to the GPU to be drawn in a single GPU render command (such as `glDrawArrays`, or `glDrawElements`).
Other Terminal Emulator related Challenges
------------------------------------------
Most terminal applications use `wcwidth()` to detect the width of a potential "wide character". This is broken by design and a terminal emulator has to deal with such broken client applications. Some however use utf8proc's `utf8proc_charwidth`, another library to deal with Unicode,
and maybe some are using `wcswidth()`, which doesn't handle grapheme clusters nor variation selectors either.
The suggested way for future applications (emulator and client) would be to introduce feature detection and mode switching on how to process grapheme clusters and their width, if legacy apps are of concern.
Just looking at the algorithm, implementing grapheme cluster segmentation isn't too hard but in execution very expensive. Also grapheme cluster width computation is expensive. But luckily, in the context of terminal emulators, both can be optimized for the general case in terminal emulators, which is mostly US-ASCII, and yields almost no penalty with optimizations or a ~60% performance penalty when naively implemented.
Also, implementing proper text shaping into a fixed-grid terminal wasn't really the easiest when there is no other project or text to look at. I used "Blink's text stack" documentation and the Blink's source code (the Web renderer of Google Chrome) as bases and source of truth to understand this complex topic and then mapped my findings to the terminal world.
Since text shaping *IS* expensive, this cannot be done without caching without severely hurting user experience.
After investigating into the above optimization possibilities however, I do not see why a terminal emulator should *not* do provide support for complex Unicode, as the performance I have achieved so far is above average at least, and therefore should be sufficient for everyday use.
Bidirectional text was not addressed in this document nor in the implementation in the Contour terminal yet, as this imposes a new set of challenges that have to be dealt with separately. If that is of interest, there are a few terminals (such as mlterm) that have put great effort in getting such scripts into the terminal.
Hopefully this will be eventually added (or contributed) to my project at any time in the future, too and if so, I'll update this document accordingly.
Conclusion
----------
If one went through all the pain on how Unicode, text segmentation, and text shaping works, you will be rewarded with a terminal emulator that is capable of rendering complex Unicode. At least as much as most of us desire - being able to use (power user/) programming ligatures and composed Emoji.
Some terminal emulators do partly support ligatures or rendering trivial single codepoint Emoji or a few of the composed Emoji codepoint sequences, but sadly, most seem to get Emoji wrong. While this is a great start, I'd say we can deliver better and more.
Final notes
-----------
I'd like to see the whole virtual terminal emulator world to join forces and agree on how to properly deal with complex text in a somewhat future-proof way.
And while we would be in such an ideal world, we could even throw away all the other legacies that are inevitably inherited from the ancient VT standards that are partly even older than I am. What would we be without dreams. ;-)
Some other terminal emulator developers and I have
[started to address](https://github.com/contour-terminal/contour/issues/404) at least some of the many Unicode problems that are up until now undefined behavior by creating a [formal specification](https://github.com/contour-terminal/terminal-unicode-core) on how a terminal emulator should behave in a backward and forward compatible way so that app developers and users will benefit.
References
----------
- [Blink's text stack](https://chromium.googlesource.com/chromium/src/+/master/third\_party/blink/renderer/platform/fonts/README.md)
- [UTS 11](https://unicode.org/reports/tr11/) - character width
- [UTS 24](https://unicode.org/reports/tr24/) - script property
- [UTS 29](https://unicode.org/reports/tr29/) - text segmentation (grapheme cluster, word boundary)
- [UTS 51](https://unicode.org/reports/tr51/) - Emoji
| christianparpart |
816,700 | [PT-BR]Guia instalando Node.js em ambientes linux Manjaro/Fedora/Ubuntu | Ola, irei te guiar em como instalar Node.js nos ambientes linux mais famosos, provavelmente você já... | 0 | 2021-09-07T20:32:18 | https://dev.to/mfortunat0/pt-br-guia-instalando-node-js-em-ambientes-linux-manjaro-fedora-ubuntu-nom | node, javascript, linux, ubuntu | Ola, irei te guiar em como instalar Node.js nos ambientes linux mais famosos, provavelmente você já deva ter utilizado ou utilizava uma das distros da imagem acima.
Antes de começarmos as instalações, e preciso saber que o Node.js possui versões LTS e as para testes. neste caso iremos utilizar as LTS pois são seguras, a versão LTS enquanto escrevo esta na 14.17.6 como a imagem abaixo mostrara:

Ao entrar na aba “downloads” existem varias maneiras de instalar-mos como por exemplo por arquivos binários. As maneiras que iremos utilizar sera via “package manager” e Snap.
## Instalação via Package Manager
Das três distros que iremos utilizar teremos packages manager Apt para o Ubuntu, Dnf/Yum para Fedora, Pacman para Manjaro. Bom chega de enrolação e vamos abrir o terminal e começar.
### Ubuntu
Antes de tudo, veja se seu ubuntu possui o pacote Curl, caso não, apenas instale-o com comando abaixo:
sudo apt install curl
Tendo agora o Curl, basta executarmos os comandos abaixo:
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash -
sudo apt-get install -y nodejs
Caso queira consultar de onde tirei estas linhas de comandos, estarão no próprio site do Node.js, no repositório **distributions** da **nodesource** hospedado no github.
### Fedora
Bom acredito que das três distro, fedora facilita muito para instalar o Node.js pois ele já o possui em seu repositório do workstation, então basta apenas um comando:
sudo dnf install nodejs
### Manjaro
No manjaro caso tente instalar o pacote “nodejs” você obterá a versão mais atual do Node e não a LTS, não e isto que queremos. Entao para instalarmos a LTS acesse pagina oficial do Arch linux e acesse a aba **packages**ou [clique aqui](https://archlinux.org/packages/), procure pelas palavras chaves “node” e “lts” como na imagem abaixo:

Repare que obtive como resultado a versão 14.17.4 nomeada **nodejs-lts-fermium**, basta instalarmos o mesmo agora junto com Npm:
sudo pacman -S nodejs-lts-fermium npm
## Testando Node.js
Feito isso, basta executarmos o seguinte comando para checar qual a versão do Node e Npm foi instalada:
node -v && npm -v
Vamos executar um arquivo javascript:
echo 'console.log("Hello World")' > index.js
node index.js
Se tudo der certo, devera exibir no console o famoso “Hello World”.
Caso houver erro “command not found”, tente fechar o terminal aberto e abrir novamente e testar novamente. Em ultimo caso tente um reboot em sua maquina.
## Instalação via Snap
Node.js também possui seu pacote Snap podendo ser facilmente instalado via Snap, veja abaixo como instalá-lo:
sudo snap install node --classic
Apos instalar basta fechar o terminal e abri-lo novamente e fazer seu teste.
## Node Manager Version
Node.js também possui seu próprio gerenciador de versões caso você precise manusear mais de uma versão do Node.js. Veja como e simples instalar e utilizar o **nvm**.
### Instalação
Acessando o repository oficial do [nvm no github](https://github.com/nvm-sh/nvm), terá um guia para instalação bem simples optando por uso do Curl ou Wget.
{% gist https://gist.github.com/mfortunat0/c6434b31bda27c6f2e0d19616b4eff63 %}
Escolhido uma das duas opções, basta agora adicionar ao seu arquivo “~/.bash_profile” , “~/.zshrc” “~/.profile” ou “~/.bashrc” as seguintes linhas:
{% gist https://gist.github.com/mfortunat0/854364695812b24974655483135b5912 %}
Os arquivos que variam pelo shell você utiliza. Agora basta fechar e abrir um novo terminal e testar o nvm com comando:
nvm -v
### Comandos básicos utilizando NVM
Listando versões do node instaladas
nvm ls
Listando todas versões possível para instalação
nvm ls-remote
Instalando outras versões do node
nvm install 14.7.1
Indicar qual versão utilizar no ambiente atual
nvm use 14.7.1
Bom, agora já podemos estudar/testar muita coisa fornecida pelo Node.js.
Espero que este artigo tenha sido util e se puder deixe um aplauso 👋
| mfortunat0 |
816,820 | When Reviewing Others’ Work, Ask ‘How’ Instead of ‘Why’ Questions | In my API governance experience, I interviewed a lot of teams. The purpose of those chats was... | 0 | 2021-09-07T21:55:44 | https://matthewreinbold.com/2021/06/23/HowVersusWhyWhyQuestions/ | management, sociotechnical, governance, api | 
In my API governance experience, I interviewed *a lot* of teams. The purpose of those chats was always to reach a better understanding of the problem. A better understanding leads to better design. **Most** of the time, these conversations were amicable, easy-going affairs. One contributing factor that kept these affairs from becoming confrontations was when I switched from asking "Why" to asking "How" questions.
When you ask someone "Why" they do or don't do something, you'll inevitably provoke a defensive response. For example, when trying to learn more about somebody's API practice, I could ask:
* "Why don't you have 100% contract test coverage?"
* "Why aren't your API descriptions captured in a single, discoverable place?"
* "Why did you produce so many microservices?"
* "Why is your domain terminology inconsistent?"
* And the classic catch-all, *"Why did you do it this way?"*
Each of those may be a legitimate question. However, the nature of the question comes across as a request for justification. Worse, answers to a why question immediately entrenches the person in a list, of their own making, of confirmation bias. What was supposed to be a positive discourse has turned exhausting, as each side attempts to prove that their approach is superior.
Asking "how" is much more productive. Reframing our points from earlier changes the questions to:
* "How do you detect breaking changes in production?"
* "How do developers discover and learn how to use APIs in your area?"
* "How do you manage the greater complexity with your number of microservices?"
* "How do you describe this concept within your domain?"
* *"How did you work through the difficult decisions in this design?"*
Both the 'how' and 'why' examples address, roughly, the same areas of concern. However, the 'how' questions are more likely to result in people talking in greater length, detail, and thoughtfulness. They assist us in going further in exploration.
Asking quality, open-ended questions creates a better rapport and a clearer idea of how to help. And the faster we get to help, the sooner our customers will find success.
The next time you feel the urge to ask "why", try reaching for "how" instead. | matthewreinbold |
816,896 | Design reinforcement learning agents using Unity ML-Agents | This article is part 3 of the series 'A hands-on introduction to deep reinforcement learning using... | 14,314 | 2021-09-08T01:22:22 | https://www.gocoder.one/blog/designing-reinforcement-learning-agents-using-unity-ml-agents | machinelearning, deeplearning, unity3d, tutorial |
This article is part 3 of the series '[A hands-on introduction to deep reinforcement learning using Unity ML-Agents](https://dev.to/joooyz/a-hands-on-introduction-to-deep-reinforcement-learning-using-unity-ml-agents-4f8i)'. It's also suitable for anyone new to Unity interested in using ML-Agents for their own reinforcement learning project.
## **Recap and overview**
In [part 2](https://dev.to/joooyz/build-a-reinforcement-learning-environment-using-unity-ml-agents-112e), we built a 3D physics-based volleyball environment in Unity. We also added rewards to encourage agents to 'volley'.
In this tutorial, we'll add agents to the environment. The goal is to let them observe and interact with the environment so that we can train them later using deep reinforcement learning.
## Letting our agents make decisions
We want our agent to learn which actions to take given a certain state of the environment — e.g. if the ball is on our side of the court, our agent should get it before it hits the floor.
The goal of reinforcement learning is to learn the ***best* policy** (a mapping of states to actions) **that will maximise possible rewards.** The theory behind how reinforcement learning algorithms achieve this is beyond the scope of this series, but the courses I shared in the [series introduction](https://dev.to/joooyz/a-hands-on-introduction-to-deep-reinforcement-learning-using-unity-ml-agents-4f8i) will cover it in great depth.
While training, the agent will either take actions:
1. At random (to explore which actions lead to rewards and which don't)
2. From its current policy (the optimal action given the current state)
ML-Agents provides a convenient **Decision Requester** component which will handle the alternation between these for us during training.
To add a Decision Requester:
1. Select the **PurpleAgent** game object (within the **PurplePlayArea** parent).
2. Add Component > Decision Requester.
3. Leave decision period default as 5.

## Defining the agent behavior
Both agents are already set up with the `VolleyballAgent.cs` script and **Behavior Parameters** component (which we'll come back to later).
In this part we'll walk through `VolleyballAgent.cs`. This script contains all the logic that defines the agents' actions and observations. It contains some helper methods already:
- `Start()` — called when the environment is first rendered. Grabs the parent Volleyball environment and saves it to a variable `envController` for easy reference to its methods later.
- `Initialize()` — called when the **agent** is first initialized. Grabs some useful constants and objects. Also sets `agentRot` to ensure symmetry so that the same policy can be shared between both agents.
- `MoveTowards()`, `CheckIfGrounded()` & `Jump()` — from ML-Agents sample projects. Used for jumping.
- `OnCollisionEnter()` — called when the Agent collides with something. Used to update `lastHitter` to decide which agent gets penalized if the ball is hit out of bounds or rewarded if hit over the net.
Adding an agent in Unity ML-Agents usually involves extending the base `Agent` class, and implementing the following methods:
- `OnActionReceived()`
- `Heuristic()`
- `CollectObservations()`
- `OnEpisodeBegin()` (**Note:** usually used for resetting starting conditions. We don't implement it here, because the reset logic is already defined at the environment-level in `VolleyballEnvController`. This makes more sense for us since we also need to reset the ball and not just the agents.)
## Agent actions
At a high level, the Decision Requester will select an action for our agent to take and trigger `OnActionReceived()`. This in turn calls `MoveAgent()`.
### `MoveAgent()`
This method resolves the selected action.
Within the `MoveAgent()` method, start by declaring vector variables for our agents direction and rotation movements:
```csharp
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
```
We'll also add a 'grounded' check to see whether its possible for the agent to jump:
```csharp
var grounded = CheckIfGrounded();
```
The actions passed into this method (`actionBuffers.DiscreteActions`) will be an array of integers which we'll map to some behavior. It's not important which order we assign them, as long as they remain consistent:
```csharp
var dirToGoForwardAction = act[0];
var rotateDirAction = act[1];
var dirToGoSideAction = act[2];
var jumpAction = act[3];
```
In Unity, every object has a `transform` class that stores its position, rotation and scale. We'll use it to create a vector pointing to the correct direction in which we want our agent to move.
Based on the previous assignment order, this is how we'll map our actions to behaviors:
1. `dirToGoForwardAction`: Do nothing [0] | Move forward [1] | Move backward [2]
2. `rotateDirAction`: Do nothing [0] | Rotate clockwise [1] | Rotate anti-clockwise [2]
3. `dirToGoSideAction`: Do nothing [0] | Move left [1] | Move right [2]
4. `jumpAction`: Don't jump [0] | Jump [1]
Add to the `MoveAgent()` method:
```csharp
if (dirToGoForwardAction == 1)
dirToGo = (grounded ? 1f : 0.5f) * transform.forward * 1f;
else if (dirToGoForwardAction == 2)
dirToGo = (grounded ? 1f : 0.5f) * transform.forward * volleyballSettings.speedReductionFactor * -1f;
if (rotateDirAction == 1)
rotateDir = transform.up * -1f;
else if (rotateDirAction == 2)
rotateDir = transform.up * 1f;
if (dirToGoSideAction == 1)
dirToGo = (grounded ? 1f : 0.5f) * transform.right * volleyballSettings.speedReductionFactor * -1f;
else if (dirToGoSideAction == 2)
dirToGo = (grounded ? 1f : 0.5f) * transform.right * volleyballSettings.speedReductionFactor;
if (jumpAction == 1)
{
if (((jumpingTime <= 0f) && grounded))
{
Jump();
}
}
```
**Note:**
`volleyballSettings.speedReductionFactor` is a constant that slows backwards and strafe movement to be more 'realistic'.
Next, apply the movement using Unity's provided `Rotate` and `AddForce` methods:
```csharp
transform.Rotate(rotateDir, Time.fixedDeltaTime * 200f);
agentRb.AddForce(agentRot * dirToGo * volleyballSettings.agentRunSpeed,
ForceMode.VelocityChange);
```
Finally, add in the logic for controlling jump behavior:
```csharp
// makes the agent physically "jump"
if (jumpingTime > 0f)
{
jumpTargetPos =
new Vector3(agentRb.position.x,
jumpStartingPos.y + volleyballSettings.agentJumpHeight,
agentRb.position.z) + agentRot*dirToGo;
MoveTowards(jumpTargetPos, agentRb, volleyballSettings.agentJumpVelocity,
volleyballSettings.agentJumpVelocityMaxChange);
}
// provides a downward force to end the jump
if (!(jumpingTime > 0f) && !grounded)
{
agentRb.AddForce(
Vector3.down * volleyballSettings.fallingForce, ForceMode.Acceleration);
}
// controls the jump sequence
if (jumpingTime > 0f)
{
jumpingTime -= Time.fixedDeltaTime;
}
```
### `Heuristic()`
To test that we've resolved the actions properly, lets implement the `Heuristic()` method. This will map actions to a keyboard input, so that we can playtest as a human controller.
Add to `Heuristic()`:
```csharp
var discreteActionsOut = actionsOut.DiscreteActions;
if (Input.GetKey(KeyCode.D))
{
// rotate right
discreteActionsOut[1] = 2;
}
if (Input.GetKey(KeyCode.W) || Input.GetKey(KeyCode.UpArrow))
{
// forward
discreteActionsOut[0] = 1;
}
if (Input.GetKey(KeyCode.A))
{
// rotate left
discreteActionsOut[1] = 1;
}
if (Input.GetKey(KeyCode.S) || Input.GetKey(KeyCode.DownArrow))
{
// backward
discreteActionsOut[0] = 2;
}
if (Input.GetKey(KeyCode.LeftArrow))
{
// move left
discreteActionsOut[2] = 1;
}
if (Input.GetKey(KeyCode.RightArrow))
{
// move right
discreteActionsOut[2] = 2;
}
discreteActionsOut[3] = Input.GetKey(KeyCode.Space) ? 1 : 0;
```
Save your script and return to the Unity editor.
In the Behavior Parameters component of the PurpleAgent:
1. Set Behavior Type to Heuristic Only. This will call the `Heuristic()` method.
2. Set up the Actions:
1. Discrete Branches = 4
1. Branch 0 Size = 3 [No movement, move forward, move backward]
2. Branch 1 Size = 3 [No movement, move left, move right]
3. Branch 2 Size = 3 [No rotation, rotate clockwise, rotate anti-clockwise]
4. Branch 4 Size = 2 [No Jump, jump]

Press ▶️ in the editor and you'll be able to use the arrow keys (or WASD) and space bar to control your agent!
**Note:** It might be easier to playtest if you comment out the `EndEpisode()` calls in `ResolveEvent()` of `VolleyballEnvController.cs` to stop the episode resetting.
## Observations
Observations are how our agent 'sees' its environment.
In ML-Agents, there are 3 types of observations we can use:
- **Vectors** — "direct" information about our environment (e.g. a list of floats containing the position, scale, velocity, etc of objects)
- **Raycasts** — "beams" that shoot out from the agent and detect nearby objects
- **Visual/camera input**
In this project, we'll implement **vector observations** to keep things simple. **The goal is to include only the observations that are relevant for making an informed decision.**
With some trial and error, here's what I decided to use for observations:
- Agent's y-rotation [1 float]
- Agent's x,y,z-velocity [3 floats]
- Agent's x,y,z-normalized vector to the ball (i.e. direction to the ball) [3 floats]
- Ball's x,y,z-velocity [3 floats]
This is a total of **11 vector observations**. Feel free to experiment with different observations. For example, you might've noticed that the agent knows nothing about its opponent. This ends up working fine for training a simple agent that can bounce the ball over the net, but won't be great at training a competitive agent that wants to win.
Also note that selecting observations depends on your goal. If you're trying to replicate a 'real world' scenario, these observations won't make sense. It would be very unlikely for a player to 'know' these direct values about the environment .
To add observations, you'll need to implement the Agent class `CollectObservations()` method:
```csharp
public override void CollectObservations(VectorSensor sensor)
{
// Agent rotation (1 float)
sensor.AddObservation(this.transform.rotation.y);
// Vector from agent to ball (direction to ball) (3 floats)
Vector3 toBall = new Vector3((ballRb.transform.position.x - this.transform.position.x)*agentRot,
(ballRb.transform.position.y - this.transform.position.y),
(ballRb.transform.position.z - this.transform.position.z)*agentRot);
sensor.AddObservation(toBall.normalized);
// Distance from the ball (1 float)
sensor.AddObservation(toBall.magnitude);
// Agent velocity (3 floats)
sensor.AddObservation(agentRb.velocity);
// Ball velocity (3 floats)
sensor.AddObservation(ballRb.velocity.y);
sensor.AddObservation(ballRb.velocity.z*agentRot);
sensor.AddObservation(ballRb.velocity.x*agentRot);
}
```
Now we'll finish setting up the Behavior Parameters:
1. Set **Behavior Name** to 'Volleyball'. Later, this is how our trainer will know which agent to train.
2. Set Vector Observation:
1. Space Size: 11
2. Stacked Vectors: 1

## Wrap-up
You're now all set up to train your reinforcement learning agents.
If you get stuck, check out the pre-configured `BlueAgent` , or see the full source code in the [Ultimate Volleyball project repo](https://github.com/CoderOneHQ/ultimate-volleyball).
In the next section, we'll train our agents using [PPO](https://openai.com/blog/openai-baselines-ppo/) — a state of the art RL algorithm provided out-of-the-box by Unity ML-Agents.
If you have any feedback or questions, please let me know! | joooyz |
817,111 | Speedy Grade - Physical Chemistry For The Life Science | Do not waste countless hours on your college assignments anymore. Get Solution Manual For Physical... | 0 | 2021-09-08T05:57:33 | https://dev.to/kimberly2e/speedy-grade-physical-chemistry-for-the-life-science-4d53 | Do not waste countless hours on your college assignments anymore. Get <a href="https://speedygrade.com/p/solution-manual-for-physical-chemistry-for-the-life-sciences/">Solution Manual For Physical Chemistry For The Life Sciences</a> and work smart with better results. | kimberly2e | |
817,339 | New Year Countdown | A post by Atulwinlooper | 0 | 2021-09-08T11:22:43 | https://dev.to/atulwinlooper/new-year-countdown-3d2h | codepen | {% codepen https://codepen.io/bhadoria_atul_/pen/abwpLXJ %} | atulwinlooper |
817,382 | Custom radio button CSS only | Custom and fancy checkbox style with automatic fallback for older browsers. Forked from Giandomenico... | 0 | 2021-09-08T12:24:56 | https://dev.to/adenlall/custom-radio-button-css-only-bm5 | codepen | <p>Custom and fancy checkbox style with automatic fallback for older browsers.</p>
<p>Forked from <a href="http://codepen.io/giando110188/">Giandomenico Pastore</a>'s Pen <a href="http://codepen.io/giando110188/pen/zxoboB/">Custom checkbox CSS only</a>.</p>
<p>Forked from <a href="http://codepen.io/giando110188/">Giandomenico Pastore</a>'s Pen <a href="http://codepen.io/giando110188/pen/zxoboB/">Custom checkbox CSS only</a>.</p>
{% codepen https://codepen.io/manabox/pen/raQmpL %} | adenlall |
817,412 | Reader Response to "Can you work from an airplane?" | My recent message Can you work from an airplane? earned a fair amount of attention, both in email,... | 0 | 2021-09-21T08:26:43 | https://jhall.io/archive/2021/09/08/reader-response-to-can-you-work-from-an-airplane/ | serverless, productivity | ---
title: Reader Response to "Can you work from an airplane?"
published: true
date: 2021-09-08 00:00:00 UTC
tags: serverless,productivity
canonical_url: https://jhall.io/archive/2021/09/08/reader-response-to-can-you-work-from-an-airplane/
---
My recent message [Can you work from an airplane?](https://jhall.io/archive/2021/09/06/can-you-work-from-an-airplane/) earned a fair amount of attention, both in email, and on LinkedIn. But I wanted to respond to one particular response I got from fellow reader Paul Swail, because he brings up a very interesting case where “from an airplane” work is almost completely impractical (quoted with permission):
> Hi Jonathan,
>
> This is a very interesting topic and I do note that you caveated that “full of technical nuances that depend on your tech stack.”
>
> My dev work is almost exclusively building backend APIs using cloud services on AWS. The workloads are often integration-heavy. Many of these cloud services can’t run at all on a local developer workstation or if there are emulators, they’re suboptimal and can introduce other issues. For that reason, I almost always advocate developing directly in the cloud against real resources, with each developer having their own dedicated cloud stack so they can work in isolation. In my experience for serverless/cloud services solutions, focusing on building a fully local developer environment is actually detrimental and just introduces too many “works on my machine” bugs due to the large environment differential.
>
> For the 1% of time where lack of internet connection or cloud downtime is an issue, there will still be something meaningful that devs can do (e.g. writing local unit tests for Lambda functions or writing docs).
>
> Anyway, on a more general note, I want to say that I love your daily emails — so much value in there and your consistency is amazing!
>
> —Paul
Paul is absoultely right. And serverless is an area I’ve done embarassingly little work, even despite [having done a podcast episode on the topic](https://podcast.jhall.io/episodes/zachary-randall-the-benefits-of-serverless-for-small-and-understaffed-teams).
My reply:
> Hi Paul,
>
> Thanks for writing!
>
> You’re absolutely correct that there are times when connectivity is an absolute must for development. If your job is solely focused on that level of integration, then it may well be possible that you cannot be productive “from an airplane.”
>
> Most products that rely on this level of integration _tend_ to do so only at the boundaries of the application, which leaves open the possibility of working on internal components without a network connection. In some cases emulators or other mocks/stubs can be used to allow productive work when touching those boundaries, but as you say, they’re all imperfect.
>
> If your application relies on Lambda functions, though, then it sounds like a majority of your application lives really close to the API layer, so I’d guess that you’re right that there’s limited opportunity for “from an airplane” work.
>
> Jonathan
Paul also referred me to some of his own writing on the topic, which I share here for your benefit as well: [_A fully local development workflow is impossible for most serverless applications_](https://notes.serverlessfirst.com/public/A+fully+local+development+workflow+is+impossible+for+most+serverless+applications).
Thanks again, Paul, for the response!
* * *
_If you enjoyed this message, [subscribe](https://jhall.io/daily) to <u>The Daily Commit</u> to get future messages to your inbox._ | jhall |
817,596 | Top 7 Benefits Of Serverless CMS in 2021 | Advantages of Using Serverless CMS Every business owner or marketer tends to be... | 9,823 | 2021-09-08T14:47:28 | https://dev.to/techmagic/top-7-benefits-of-serverless-cms-in-2021-26k2 | ##Advantages of Using Serverless CMS
Every business owner or marketer tends to be omnipresent as much as possible, bringing new and personalized content to engage with a broader range of audiences and turning users into clients. For startups, it’s crucial.
With the constant growth of the Internet of Things, marketing specialists face a new challenge - to keep up with time and trends and power their content anytime through all possible smart devices around us.
Thanks to the advantages of serverless CMS, your digital presence is a question of a few weeks now. With serverless architecture, you focus entirely on code and content. Maintaining a back-end database doesn't bother or distract you. You are free to use your favourite stack platforms to write code. Or you can choose ready-to-use solutions and don't work with code at all.
And as a result, you have your once created content simultaneously presented through the web, mobile, and other IoT devices.
Let's find out the top benefits of serverless CMS.
##Scalability
You can create, manage, and reuse content and campaign pages when you need and as you’d like. Serverless CMS are optimized for speed and scalability by default, giving marketers the ease of increasing engagement with no distractions and limitations.
For developers, it means no maintenance since a serverless CMS runs in the cloud. You won't ever need to update anything like you needed to do with traditional CMS. In addition to that, scalability in serverless hosting means zero performance or hosting issues for your developers to face.
For example, suppose your business is super-successful, and your website receives an enormous amount of traffic. Your host automatically deals with this avalanche and manages accordingly. You don't do this manually; you don't even need to keep it in mind.
The serverless CMS always has enough capacity to deal with your traffic. You, in turn, dedicate time and energy to marketing, design, and content itself that will boost it.
##User Security

Serverless is rightly considered one of the safest (if not the safest) content management approaches. A physical web server is a metaphorical door for hackers, but since all content is stored in the cloud, the door is not even closed; it just doesn’t exist. Moreover, most CDN headless CMS use their own app firewall, adding an extra protection cover.
Hackers' attacks are harmful by the theft of personal data and posting impudent or restricted content. Both the first and the second scenarios lead you to reputation loss. Who would like the idea of giving you personal data if they were stolen once?
In this regard, cloud services demonstrate their advantage by offering a range of security mechanisms like the latest web application firewalls, real-time threat management, and ongoing penetration testing.
##Data Security
Here we consider two aspects. First, even if the equipment is damaged or broken, the data remains secure. You can use any other device and get access to your content and all related data, download them if needed, and continue working with no loss.
The second aspect is that you can always roll back to a particular stage and go the other way. This ability is invaluable. In this way, your business has enough space for experiments, research, keeping up with the times, and regularly updating without spending extra time, money, and other resources.
On top of that, serverless CMS can be proclaimed unsinkable. It is highly unlikely for you to lose any data while using one of them. From a marketer's point of view, you can focus on the quality of your content, have no worries about the clients and data safety, and scale when the time is right.
##Simple Use

Migrating your project to the cloud service can make it easier for all types of users to work with. How come and what stays behind it?
**Mobility**. Your resource is accessible from any device. Cloud storage means that you never meet data overload that is able to slow down your device.
**Speed**. Cloud services that specialize in providing storage services produce a higher playback speed than the internal server. It's all about capacity, tech equipment quality, expertise, and focus on a specific task.
##Cost-Effectiveness
You don’t need to pay for back-end maintenance if you don’t deal with one. This is where API-based serverless CMS systems significantly save your budget and allow you to direct these costs on improving the product, for example.
On the other hand, hosting static files rather than dynamic means no need for you to pay for web servers or databases themselves. All you need is a content delivery network (CDN). You just use less paid services.
In short, you are relieved of worries about storage costs and costly back-end maintenance. In the long term, such a state of affairs is beneficial to both developers and marketers, combined with the simplicity of using a serverless CMS.
It deserves reminding that your provider manages all the updates. Their internal team closely monitors the performance, which means you always get the best version of hosting services they can provide and find the perfect balance between the service package and the price.
##Easy Teamwork
Never before has the work of remote teams been so synchronous, productive, and well-coordinated as in the era of serverless CMS.
Developers, marketers, and authors are all exposed to the same infrastructure and can operate simultaneously without stepping on each other's toes. It's easy to keep track of who made which changes and avoid misunderstandings and conflicts. Also, it's a great time saver since one team doesn't need to wait until another one is done.
One of the best benefits of serverless CMS is that they make it much easier to collaborate transparently.
##Total Freedom For Developers

Developers are free to work with their favourite technologies without losing time and effort for learning and onboarding new ones. Serverless CMS are flexible and adaptable, so developers can focus on their work without the fuss of handling bugs in an already existing tech stack.
Marketers, in turn, have the freedom to connect with any third-party software or automation tools (CRM, conversion optimization, localization technologies for an international reach, etc.). With a serverless CMS, developers and marketers never have to settle for a “second-best."
One of the main benefits of serverless CMS functions for marketers is that the website structure becomes easier for them to understand and, accordingly, to improve. A serverless CMS allows you to try all the content building and managing tools throughout the process and preview the result before publishing. Thanks to this, you have the priceless power to decide how to structure and architect your site and display your content accordingly.
Moreover, including marketers in the building process leads to better understanding, communication, and collaboration between marketers, content creators, and developers.
##Conclusion
The modern trend of being omnichannel is dictating the market, not just influencing it. Flexible, scalable, customizable content management systems offer their services for turning your content into the experience your customers expect. Either a serverless or a pure headless CMS enables organizations to increase delivery time and iterate faster.
The question of whether to migrate to a traditional, serverless, or headless CMS depends on your business needs and expectations. With all the benefits of using serverless CMS, it is simple for you to publish content once with a single authoring point and deploy it anywhere you want with no stress and mess.
We have a significant number of serverless-based projects in our portfolio. If you want to upscale your business with all the benefits of serverless CMS AWS, for example, we, as big fans of Amazon, will be glad to help you with the implementation of the serverless CMS. | techmagic | |
817,632 | How to Install SSL Certificate on WordPress on Ubuntu Server? | In the current days, most modern websites have SSL certificates installed. So, let's look at how we... | 0 | 2021-09-08T15:43:55 | https://dev.to/yolchyolchyan/how-to-install-ssl-certificate-on-wordpress-on-ubuntu-server-43fc | wordpress, security, ssl | 
In the current days, most modern websites have SSL certificates installed. So, let's look at how we can install an SSL certificate with WordPress.
First things first, it depends on your WordPress hosting provider how you can set up an SSL certificate. Some hosting providers will [setup an SSL certificate automatically](https://alandcloud.com/how-to-setup-ssl-with-aland-cloud/) for you. So, sometimes you don't need to have any technical knowledge.
So, now let's look at the ways to install an SSL certificate on WordPress when you manage your own servers.
## Prerequisites to install SSL
First of all, you should have an access to your server where you want to install an SSL certificate. You will usually need [SSH access](https://study.com/academy/lesson/what-is-ssh-access.html) to perform the installation.
Another thing is to make sure, your server IP address provided by your hosting provider is added to your domain as an A record.
The best way to install an SSL certificate for WordPress is by certbot. Certbot can power your WordPress website with a [Let's Encrypt](https://letsencrypt.org/) SSL certificate for free!
So, if you get the SSH access and mapped your domain with the IP Address we are ready to go.
## Install Certificate
1. First thing, SSH to your server.
2. Execute this command: `apt-get install software-properties-common python-software-properties`
3. Execute this command: `add-apt-repository ppa:certbot/certbot`
4. Execute this command: `apt-get update`
5. Execute this command: `apt-get install python-certbot-apache`
6. Execute this command `certbot --apache -d change-this-to-your domain.com`
7. Should you popped up with Y/N, enter `Y` and press enter to continue.
8. When it will ask if it should redirect `http` traffic to `https`, enter `Y` and press enter to continue.
You're done with setting up an SSL certificate for your WordPress website. Please not, you might need to renew this certificate every three months.
| yolchyolchyan |
818,038 | React Native: Optimizing FlatList performance | Flatlist is react-native component should be used for rendering scrollable lists. If you don't... | 0 | 2021-09-09T02:29:23 | https://dev.to/erdenezayaa/react-native-optimizing-flatlist-performance-31k | reactnative, performance | Flatlist is react-native component should be used for rendering scrollable lists. If you don't optimize well enough, performance starts to drop once dataset gets large. This causes laggy scroll and blank spaces between the list items.
### 1. Avoid inline functions
Inline functions are recreated every time component renders. This may be okay for some components but can slow performance for flatlists.
**Avoid this!**
```JSX
return (
<Flatlist
data={data}
renderItem={({item}) => <Item item={item} />}
keyExtractor={(item) => item.id}
/>
);
```
**Instead use this**
```JSX
const renderItem = ({item}) => <Item item={item} />;
const keyExtractor = (item) => item.id;
return (
<Flatlist
data={data}
renderItem={renderItem}
keyExtractor={keyExtractor}
/>
);
```
### 2. Provide height value for every item
If you don't provide getItemLayout function as props, Flatlist have to calculate height for every item in the list. By the result of this, sometimes when you scroll fast enough, you will see some gaps in the list. By providing our own getItemLayout function, it won't have to calculate every item's height and the performance will improve.
```JSX
const ITEM_HEIGHT = 65; // fixed height of item component
const getItemLayout = (data, index) => {
return {
length: ITEM_HEIGHT,
offset: ITEM_HEIGHT * index,
index,
};
};
return (
<Flatlist
data={data}
renderItem={renderItem}
getItemLayout={getItemLayout}
keyExtractor={keyExtractor}
/>
);
```
### 3. Keep component that renders the list item as light as possible
Don't do any extra work in renderItem function like formatting the data and declaring another function. Also props you pass to renderItem should be only the data that will render in the UI.
In this example, Item component is formatting the date with moment which is heavy js library that should be avoided, formatting a number value right before rendering and getting really big navigation as props every time. All of these, should be avoided to keep the Item component light.
**Don't do!**
```JSX
const Item = ({item, navigation}) => {
const created_at = moment(item.created_at).format('YYY/MM/DD HH:mm');
const total_value = formatNumber(item.total);
// it is common to pass navigation instance of react-navigation library, avoid this because navigation props is too big
const onPressItem = () => {
navigation.navigate('DetailItem', {item});
};
return (
<View>
...
</View>
);
}
const renderItem = ({item}) => <Item item={item} navigation={navigation} />;
return (
<Flatlist
data={data}
renderItem={renderItem}
getItemLayout={getItemLayout}
keyExtractor={keyExtractor}
/>
);
```
**Do this**
```JSX
const Item = ({item, onItemPress}) => {
return (
<View onPress={onItemPress(item)}>
...
</View>
);
}
// Handle item press event in parent component that has already access to navigation component
const onItemPress = (item) => {
navigation.navigate('ItemDetail');
};
const renderItem = ({item}) => <Item item={item} navigation={navigation} />;
// do the data formatting and manipulation before the flatlist render
const preparedData = data.map((item) => {
const created_at = moment(item.created_at).format('YYY/MM/DD HH:mm');
const total_value = formatNumber(item.total);
// only return the properties that need to be rendered and leave everything else
return {
label: item.label,
total_value,
created_at,
};
});
return (
<Flatlist
data={preparedData}
renderItem={renderItem}
getItemLayout={getItemLayout}
keyExtractor={keyExtractor}
/>
);
```
### 4. Use Pure Component or Memo
PureComponent re-renders a component by shallow comparing the props and re-renders only if the props have changed. PureComponent is used for class components. React memo is the alternative to PureComponent for functional components.
### 5. Use cached optimized images
If your list have lots of images, you should use optimal size d, cached images. You can use libraries like [react-native-fast-image](https://github.com/DylanVann/react-native-fast-image) to implement this. These libraries can do following things.
- resize images according to device dimensions, therefore reduces the memory consumption.
- Caches images to memory and storage to better load times.
Keep in mind it works better when you have already optimized images for different sizes of devices.
### Conclusion
In my experience, those methods really improved the performance of the Flatlist. I hope you find this helpful. If these methods didn't help, you should checkout the sources I used for this article.
#### Sources:
[Official Documentation for Optimizing Flatlist Configuration](https://reactnative.dev/docs/0.61/optimizing-flatlist-configuration)
[8 ways to optimize React native FlatList performance](https://codingislove.com/optimize-react-native-flatlist-performance/)
| erdenezayaa |
818,051 | Top 7 VS Code extensions | The truth is not that they are the best, I was just looking for an eye-catching title. VS... | 0 | 2021-09-09T02:09:17 | https://dev.to/sebasttiandaza/top-7-vs-code-extensions-2dkc | vscode, frontend, productivity, webdev | ###The truth is not that they are the best, I was just looking for an eye-catching title.
VS Code for me is one of the best cross-platform text editors, developed with TypeScript, JavaScript and CSS technologies, of course one of its best parts is the large section of extensions that has to improve code development and work productivity, I will tell you about these 7 extensions based on the ones I use most in my day to day coding.
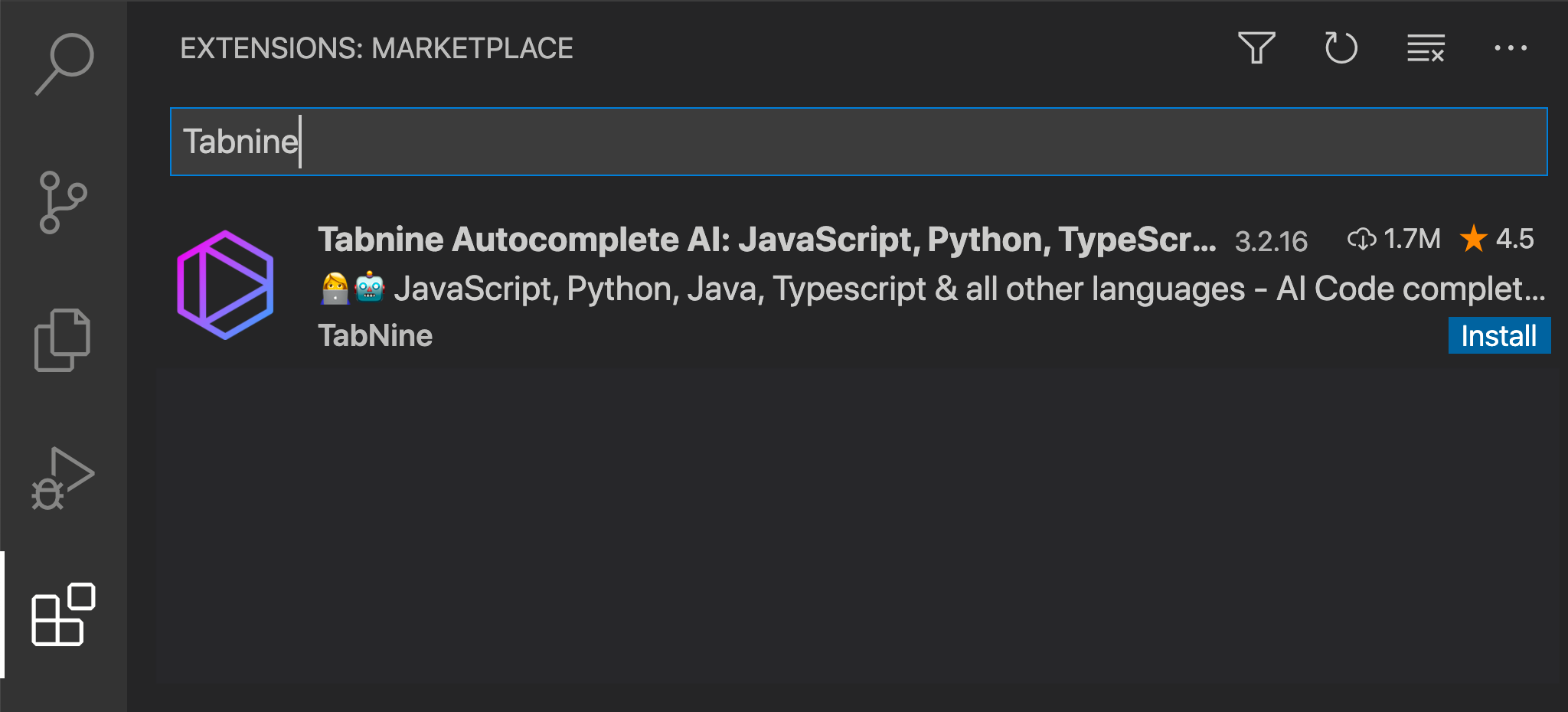
The first of all, and that for me has been very helpful is:
1. [Tabnine](https://tab9.in/eqypp) - Code: It is one of the best Artificial Intelligence assistants, you code much faster, with less errors and of course improves your productivity, it also supports many languages and is totally free, I highly recommend it!
In this case it is an extension that will help you to better identify your code, it is about
2. [Bracket Pair Colorizer](https://marketplace.visualstudio.com/items?itemName=CoenraadS.bracket-pair-colorizer): It allows you to identify the brackets of your code with matching colors, so that in this way they match and are better identified, with support for different languages and very customizable, although relatively this extension became obsolete in the last [update](https://code.visualstudio.com/updates/v1_60) of VS Code, because it comes included in the editor itself:
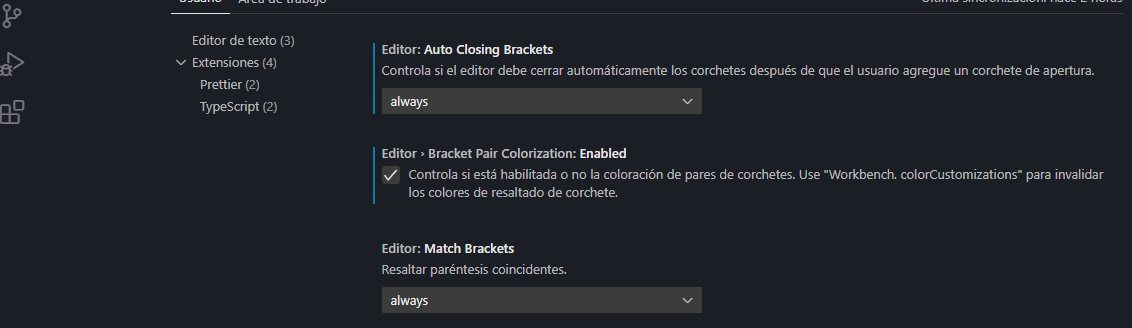
By activating this option, it will be ready for you. Let's go right away to the third one
3. [ESLint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint): it is a code analyzer that allows us to write quality code, that is to say, it will allow you to identify errors in your code, faster and identifiable at sight.
From the third to the fourth:
4. [Live Server](https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer), this extension offers you in a very fast way a live development server, so you can see what you are doing.
The fifth is a tool that for Spanish speakers, we are very grateful for.
5. [Spanish Languaje Pac for VS Code](https://marketplace.visualstudio.com/items?itemName=MS-CEINTL.vscode-language-pack-es), it is the pack in Spanish of the editor, although I do not recommend it much, it is better that you learn to handle this tools in English, personally I prefer to have it in English, and the main reason is that the language at world-wide level of the programming is English, so it is better that you relate with this one.
6. [Auto rename Tag](https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-rename-tag) and [Auto Close Tag](https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-close-tag): The first one serves you for an automatic tag change in your HTML code and the second one for an automatic tag close in your code.
7. [Git Lens](https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens), if you work with git, this is your extension, it will enhance the capabilities of git integrated with VS Code, offering many more very effective features.
Obviously I clarify, that does not mean that these are the only good extensions, but I think that from my side are extensions that can not miss in your VS Code, but I hope you leave them in the comments.
| sebasttiandaza |
818,063 | My first post on OSD | Introduction Hello, my name is Leyang and I'm a student in the Computer Programming and... | 0 | 2021-09-09T19:29:59 | https://dev.to/lyu4321/my-first-post-on-osd-4dp2 | opensource | ###Introduction
Hello, my name is Leyang and I'm a student in the Computer Programming and Analysis Program at Seneca College. I'm so excited to be taking a course on open source development in my last semester! During my time at Seneca and at my co-op, I have used many open source projects in creating my own projects and they have made my life so much easier. I hope to learn how I can also make contributions to this community, discover some cool new projects, and improve my ability to understand code written by many different people by working on open source projects.
###Where I Am
I am from and am currently based in Toronto, Canada. However, I look forward to working with people from all over the world through various open source projects.
###What I Hope To Learn
Over the semester, I hope to work on all sorts of projects in many different languages. Currently, I am most comfortable with working on web apps using JavaScript and C#. However, I hope to be able to broaden my horizons and gain more experience using languages I have less experience in such as Python. I love games and would love to work on some gaming projects or projects that I would use in the future.
###Open Source Project
After researching some trending open source projects, the one I chose to fork to my own repo is [30 Days of Python](https://github.com/Asabeneh/30-Days-Of-Python). As a beginner to Python, I think this project would be a very useful tool to help people like me learn the basics.
Thanks for reading!
[GitHub](https://github.com/lyu4321)
[LinkedIn](https://www.linkedin.com/in/leyang-yu-48668ba8/) | lyu4321 |
818,234 | Set Git Proxy | You clone a Git repo and get this error message: Git failed with a fatal error. unable to access... | 0 | 2021-09-09T06:34:33 | https://dev.to/dileno/set-git-proxy-3i69 | github | You clone a Git repo and get this error message:
```
Git failed with a fatal error.
unable to access 'https://github.com/THE_REPO':
OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection github.com:443
```
This might be because you're behind a proxy. You then need to set proxy for Git in your command tool:
```
git config --global http.proxy http://your-proxy-url:8080
git config --global https.proxy https://your-proxy-url:8080
```
You also might need to disable SSL verification:
```
git config --global http.sslVerify false
```
| dileno |
818,244 | Learn how to create a secure mobile application. | 📜 About this program: "14 Days of Mobile Security" is a social learning and accountability... | 0 | 2021-09-09T08:50:26 | https://aviyel.com/post/333/14-days-of-mobile-security | 14daysofsec, mobile, security, event | ## 📜 About this program:
"14 Days of Mobile Security" is a social learning and accountability program for mobile developers to build a security-centric culture and to achieve the goal of creating secure mobile apps.
One of the most common mistakes made by new or young mobile developers is a lack of knowledge or foundations in security development practice. They begin working on their 'development style' before learning security practices and methods. To assist you, we have developed a practical roadmap called "14 Days of Security," which is based on extensive research and the experience of mobile security developers working in large tech companies.
## 📦 So, what exactly are you going to receive?
- You will learn the fundamentals of mobile security from the ground up.
- Even if you have never picked up a security book, you will learn about best security practices to follow.
- You will be able to master the fundamentals of mobile security.
- You'll learn about security best practices by utilizing open source tools and frameworks, along with videos and text tutorials.
## 🎀 Win Exciting Prizes
- After completing the challenge, you will receive a free subscription to a premium course.
- You will receive a certificate of completion.
- Submissions with more than 5 upvotes will receive the top peer badge of the day or week.
- Anyone who earned 14 challenge completion badges and 5 top peer badges can request a 14-day mobile security challenge completion certificate from the Aviyel Team.
## 🏁 How do you start?
- Sign-up for free and Text "Pledge" on the comment box of this article [14 days of mobile security](https://bit.ly/14DaysMobSec)
- Dedicate 1 hour every day for the next 14 days to learn one mobile security.
- Every day, set a goal of reading an article, developing a security tool to audit your app, or utilizing a security framework to encrypt your data-in-transit or data-in-storage. You can choose articles and tutorials from the content repository, or you can follow any article or tutorial on Mobile Security. We have also created a repository of mobile security concepts to search or research for the program to help you narrow your search.
- After finishing the day's activities, you can choose a challenge from our Challenge repo. To complete the challenge, simply share a screenshot of your tutorial's results, GitHub code, a short post, and so on. This earns you a completion badge.
- Any challenge submission that receives more than 5 upvotes will be awarded the top peer badge of the day or week.
- Any participant who received 14 challenge completion badges with 5 top peer badges can apply for 14 days of mobile security challenge completion certificate from the Aviyel Team.
- Top "Day X Submission" of the Day and Week will be selected and pinned 📍.
## 🗺️ Roadmap Content
To help you with this, we have created a practical roadmap, “14 days of Security,” based on a lot of research and the experience of mobile security developers working in big tech companies. This roadmap will give you a complete guideline to build a strong coding habit and to achieve your goal of creating a secure mobile app.
- Video
- Blogs
- Audio
[Here](https://aviyel.com/post/401/roadmap-content) are the list of the entire roadmap content of 14days of security.
## 🗺️ Roadmap Content Theme
- [End to End Encryption](https://aviyel.com/post/431/end-to-end-encryption)
- [Code Quality Checklist](https://aviyel.com/post/332/secure-code-review-checklist)
- [Obfuscating](https://aviyel.com/post/734/obfuscating)
- [Encrypt your data](https://aviyel.com/post/735/encrypt-your-data)
- [Certificate Transparent](https://aviyel.com/post/739/certificate-transparent)
✨ Tweet your progress [@AviyelHq](https://aviyel.com/discussions) by using hashtag #14DaysOfSec and the hashtag of the challenge in which you participate from this day forward for the next 14 days. | pramit_marattha |
818,265 | Help Solved this error #Flutter | A post by chathu pathirana | 0 | 2021-09-09T07:49:55 | https://dev.to/chathuranga0005/help-me-solved-this-error-flutter-4mo8 | 
| chathuranga0005 | |
830,047 | Day 454 : And So | liner notes: Professional : My day started really early for a feedback session with a coding... | 0 | 2021-09-17T21:41:04 | https://dev.to/dwane/day-454-and-so-2lb7 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : My day started really early for a feedback session with a coding bootcamp in Japan that we teamed up with to see what they could build with our APIs. Got really good feedback and some ideas on how to improve even more. Then right after that was their demo day to present what they built. I was really impressed. The built a really good application. After that, I worked on completing the Web Components I've been adding the ability to style it how a user wants or stick with the default. There's 5 in total so it took a little time, especially when I had other projects due sooner. I had to rework the code to allow for custom styling, luckily I learned about CSS part. Then come up with a default style that would look good. Then create some graphics for each Web Component to hopefully detail the different parts that can be styled. Then update the readme documentation of each component to help explain the changes. Then push a PR so it could be reviewed. Then published the changes to NPM so that demos I created could be updated automatically. And so... I got everything done today. Feels good to finally get it out there. Good thing because I got some info for some things I need to work on Monday. haha.
- Personal : Last night, basically worked on finishing up my Web Component project for work. I did get to watch an episode of "Boruto" while eating dinner.
It's starting to rain. Going to go inside and get some dinner and watch "Boruto". I want to finish up going through tracks for the radio show tomorrow. Maybe even get that image uploading with Cloudinary working on my side project. We'll see.
Have a great night and weekend!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube gv4DZ7AnptE %} | dwane |
830,122 | Review Lab 1 | I find my partner- Le Minh Pham - through Slack and we both prefer Python. I just started learning... | 0 | 2021-09-18T00:07:00 | https://dev.to/yodacanada/review-lab-1-4fog | > I find my partner- Le Minh Pham - through Slack and we both prefer Python. I just started learning Python, but he should be an expert. I learned some new libraries and methods after testing and reviewing Le’s code. I am surprised at the beautiful structure of his code. My partner helped me solve a big problem of finding folders, so I’m lucky to have such a partner.
> Reviewing and testing code is an exciting and painful thing for me. I'm excited because I can learn a lot of skills from my partner. For example, the original code only has one file, but after optimization, it has four files, and many auxiliary functions are added, and the structure is clearer.
> The pain is because as a new language, it takes me a long time to review and test it. Especially, my partner is very diligent. His code changes a lot every few days. Based on my level, it’s hard to find issues about his constantly improving code. Despite all this, I can still find problems and put forward what needs to be improved. For example, the [issue “--input folder command line isn't working”]
(https://github.com/lmpham1/cool_ssg_generator/issues/2). I also give some [suggestion]. (https://github.com/lmpham1/cool_ssg_generator/issues/3)
> There are 2 main issues about my code. [issue1] (https://github.com/Yoda-Canada/Magic-SSG/issues/1), [issue2](https://github.com/Yoda-Canada/Magic-SSG/issues/2) Le give me lots of suggestion to fix the bugs, and I am fixing them.
This lab is very important for me, because a lot of basic knowledge needs to be learned, and it also help me to recall the knowledge I learned before. I am confident to complete the future project
| yodacanada | |
830,262 | Create Filters in AngularJS | Filters are used to modify the data. They can be used in expression or directives using pipe (|)... | 14,655 | 2021-09-18T03:27:24 | https://www.w3courses.org/create-filters-in-angularjs/ | angular, javascript | **Filters are used to modify the data.** They can be used in expression or directives using pipe (|) character. We can use **angularjs built in filters or can create filters in angularjs.**
##There are some commonly used filters in angularjs
###uppercase
converts a text to upper case text.
###lowercase
converts a text to lower case text.
###currency
formats text in a currency format.
###filter
filter the array to a subset of it based on provided criteria.
###orderby
orders the array based on provided criteria.
##Installing AngularJS in Website
To Install angularjs paste the script in head tag of your website layout
```js
<script src = "https://ajax.googleapis.com/ajax/libs/angularjs/1.3.14/angular.min.js"></script>
```
##Using built in Filters in AngularJS
```html
<div ng-app = "mainApp" ng-controller = "studentController">
<table border = "0">
<tr>
<td>Enter first name:</td>
<td><input type = "text" ng-model = "student.firstName"></td>
</tr>
<tr>
<td>Enter last name: </td>
<td><input type = "text" ng-model = "student.lastName"></td>
</tr>
<tr>
<td>Enter fees: </td>
<td><input type = "text" ng-model = "student.fees"></td>
</tr>
<tr>
<td>Enter subject: </td>
<td><input type = "text" ng-model = "subjectName"></td>
</tr>
</table>
<br/>
<table border = "0">
<tr>
<td>Name in Upper Case: </td><td>{{student.fullName() | uppercase}}</td>
</tr>
<tr>
<td>Name in Lower Case: </td><td>{{student.fullName() | lowercase}}</td>
</tr>
<tr>
<td>fees: </td><td>{{student.fees | currency}}
</td>
</tr>
<tr>
<td>Subject:</td>
<td>
<ul>
<li ng-repeat = "subject in student.subjects | filter: subjectName |orderBy:'marks'">
{{ subject.name + ', marks:' + subject.marks }}
</li>
</ul>
</td>
</tr>
</table>
</div>
<script>
var mainApp = angular.module("mainApp", []);
mainApp.controller('studentController', function($scope) {
$scope.student = {
firstName: "Mahesh",
lastName: "Parashar",
fees:500,
subjects:[
{name:'Physics',marks:70},
{name:'Chemistry',marks:80},
{name:'Math',marks:65}
],
fullName: function() {
var studentObject;
studentObject = $scope.student;
return studentObject.firstName + " " + studentObject.lastName;
}
};
});
</script>
```
##Create Filters in AngularJS
```html
<div ng-app = "mainApp" ng-controller = "myController">
<div ng-bind-html="htmlData |safeAs"></div>
</div>
<script>
var mainApp = angular.module("mainApp", []);
/*controller*/
mainApp.controller('myController', function($scope) {
$scope.htmlData = "<p>Hello AngularJS";
});
/*filter*/
mainApp.filter('safeAs', ['$sce',
function($sce) {
return function (input, type) {
if (typeof input === "string") {
return $sce.trustAs(type || 'html', input);
}
console.log("trustAs filter. Error. input isn't a string");
return "";
};
}
]);
</script>
```
Using these methods you can make custom filters in angularjs.
___
###See Also
[How to Create Multiple Parameters Dynamic Routes in Laravel](https://www.w3courses.org/how-to-create-multiple-parameters-dynamic-routes-in-laravel/)
[Laravel 8 Multiple Database and Resource Routes with Controllers](https://www.w3courses.org/laravel-8-multiple-database-and-resource-routes-with-controllers/)
[Optimize Database Queries in Laravel](https://www.w3courses.org/how-to-optimize-database-queries-in-laravel/)
[Flash Messages in AngularJS](https://www.w3courses.org/flash-messages-in-laravel-with-angular-material/)
[Create REST API in Node.js](https://www.w3courses.org/how-to-create-rest-api-in-nodejs/)
___
**Thanks For Reading :)**
**Please give your comments :)**
**Please Must Visit My Website :)**
[W3Courses](https://www.w3courses.org)
| readymadecode |
891,096 | The End of the backend | We're finished backend So its been 2 weeks again since I last posted, but I though I would... | 14,682 | 2021-11-07T16:07:18 | https://dev.to/newcastlegeek/the-end-of-the-backend-352g | javascript, beginners, bootcamp |
## We're finished backend
So its been 2 weeks again since I last posted, but I though I would wait and round up backend in one post,
Its been an interesting couple of weeks consolidating and putting our new knowledge into practice, I'm happy to say that a lot of it has sunk in.
Over the past few weeks we have finished off the knowledge we needed to cover us for last week, during last week my fellow peers have worked on a portfolio project. we have worked on either a backend news API with article and comments or a games API.
I got all excited when I heard games API but it turns out it was board games so I chose the news API.
We started from the beginning NorthCoders had given us a repo with some of the more boiler plate style code in to get us going but essentially that was just enough to get us going.
###testing testing 1... 2... 3...
as with everything in we have done at NorthCoders we started with testing, Its been really interesting over the past few week for me to go from hating/not really using testing to using it to drive my development, we've been using testing to build it relatively small functions but I can easily see how the basis we have now in testing could help us in the future to build larger function and projects.
### they planted the seed
the repo we were given contained a whole bunch of seed data for our project, it was our task to use this data and turn it into a working and functional API, I think I might have went a little far with my data, I wrote a function to make sure all of the data was presented to the Database in a way I wanted, I also then spent time writing tests the best I could to test this data and make sure it came back in the format I intended, I then tested the data from the database to make sure that was returned Properly.
### our ROUTE to salvation
the next thing we needed to do was build up a whole bunch of endpoints using the REST ideology we had to build ourselves some GET, POST, PATCH and DELETE endpoints to be able to manipulate the data we send and receive from the database.
### HerokWHO?
the whole idea of building this project was so that we have something after we have finished the bootcamp, something that employers can look at and play with, some code that they can read and understand, to help us do this we made use of Heroku the online app hosting site. while I've used Heroku once before to host something, this time in true NorthCoders fashion we used the command line to do 90% of the work. Its nice that it has the website but there's something awesome about using the command line to do things.
## Up Next
I've really enjoyed my time on backend but I'm excited to move onto front end, looking at the calendar where going to be working with the REACT framework which I haven worked with yet, Taking a sneak peak ahead though it looks like we might be revisiting our projects at the end of front end to round it out and give it more functionality using react.
Kind of like this...

| newcastlegeek |
830,285 | FYP IDEA | Hello what's up guy's, Hope you all will be doing very well. I am final year student in CSE now we... | 0 | 2021-09-18T05:05:32 | https://dev.to/muhammad0302/fyp-idea-4c47 | react, reactnative, nod | Hello what's up guy's, Hope you all will be doing very well. I am final year student in CSE now we have FYP project. I want to make my FYP in MERN stack. I know know mevn stack too and some other languages but I am curios to build on MERN. What should I make? What are the new growing ideas related to web development? Your suggestion and help will be highly appreciated. | muhammad0302 |
830,307 | Statistical Aid: Ultimate guide to statistics and data analysis | Welcome to Statistical Aid! Statistical Aid is a site that provides statistical content, data... | 0 | 2021-09-18T06:06:27 | https://dev.to/statisticalaid/statistical-aid-ultimate-guide-to-statistics-and-data-analysis-3c7p | statistics | Welcome to Statistical Aid!
[Statistical Aid](www.statisticalaid.com/) is a site that provides statistical content, data analysis content, and also discusses the various fields of statistics. You can learn statistics and data analysis intuitively by Statistical Aid. All the contents on this site are written to provide help to the students who are very weak in statistics and data analysis. From basic to advanced, you can get all the topics of statistics presented on this site very simply. You can get help from the following topics:
[Basic Statistics](https://www.statisticalaid.com/statistics-definition-scope-with-real-life-examples/)
[Definition and scope of statistics](https://www.statisticalaid.com/statistics-definition-scope-with-real-life-examples/)
[Statistical Data](https://www.statisticalaid.com/statistical-data-definition-types-and-requirements/)
[Population vs Sample](https://www.statisticalaid.com/population-vs-sample-in-statistics/)
[Random Variable](https://www.statisticalaid.com/random-variable-and-its-types-with-properties/)
[Central tendency](https://www.statisticalaid.com/measure-of-central-tendency-definition-types-with-advantages-and-disadvantages/)
[Arithmetic mean](https://www.statisticalaid.com/arithmetic-mean-definition-formula-and-applications/)
[Geometric mean](https://www.statisticalaid.com/geometric-mean-definiton-formula-and-applications/)
[Harmonic mean](https://www.statisticalaid.com/harmonic-mean-definition-formula-and-applications/)
[Measures of Dispersion](https://www.statisticalaid.com/measures-of-dispersion-in-statistics-and-its-types/)
[Variance and Standard Deviation](https://www.statisticalaid.com/variance-and-standard-deviation-in-statistics/)
[Skewness and Kurtosis](https://www.statisticalaid.com/skewness-and-kurtosis-in-statistics-shape-of-distributions/)
[Correlation analysis](https://www.statisticalaid.com/correlation-analysis-definition-formula-and-step-by-step-procedure/)
[Intra vs Inter class correlation](https://www.statisticalaid.com/intra-class-vs-inter-class-correlation/)
[Regression Analysis](https://www.statisticalaid.com/regression-analysis-with-its-types-objectives-and-application/)
[Data levels (Nominal, ordinal, Interval and Ratio)](https://www.statisticalaid.com/levels-of-measurement-nominal-ordinal-interval-ratio-in-statistics/)
[Hypothesis Testing](https://www.statisticalaid.com/statistical-hypothesis-testing-step-by-step-procedure/)
[Bernoulli distribution](https://www.statisticalaid.com/bernoulli-distribution-definition-example-properties-and-applications/)
[Binomial distribution](https://www.statisticalaid.com/binomial-distribution-definition-density-function-properties-and-application/)
[Negative binomial distribution](https://www.statisticalaid.com/negative-binomial-distribution-definition-formula-properties-with-applications/)
[Poisson distribution](https://www.statisticalaid.com/poisson-distribution-definition-properties-and-applications-with-real-life-example/)
[Exponential distribution](https://www.statisticalaid.com/exponential-distribution-definition-formula-with-applications/)
[Normal distribution](https://www.statisticalaid.com/normal-distribution-definition-exampleproperties-applications-and-special-cases/)
[Gamma distribution](https://www.statisticalaid.com/gamma-distribution-definition-formula-and-applications/)
[Geomatric distribution](https://www.statisticalaid.com/geometric-distribution-definition-properties-and-applications/)
[Hypergeometric distribution](https://www.statisticalaid.com/hypergeometric-distribution-definition-properties-and-applications/)
[Uniform distribution](https://www.statisticalaid.com/uniform-distribution-definition-formula-and-applications/)
[Power series distribution](https://www.statisticalaid.com/power-series-distribution-definition-formula-with-applications/)
[Logarithmic series distribution](https://www.statisticalaid.com/logarithmic-series-distribution-definition-formula-properties-and-applications/)
[Simple random sampling](https://www.statisticalaid.com/simple-random-sampling-definitionapplication-advantages-and-disadvantages/)
[Stratified sampling](https://www.statisticalaid.com/stratified-sampling-definition-allocation-rules-with-advantages-and-disadvantages/)
[Systemetic sampling](https://www.statisticalaid.com/systematic-sampling-definition-examples-advantages-and-disadvantages-and-application/)
[Multistage sampling](https://www.statisticalaid.com/multistage-sampling-definition-real-life-example-advantages-and-disadvantages/)
[Cluster sampling](https://www.statisticalaid.com/cluster-sampling-definition-application-advantages-and-disadvantages/)
[Quadrat sampling](https://www.statisticalaid.com/quadrat-sampling-application-with-advantages-and-disadvantages/)
[Purposive sampling](https://www.statisticalaid.com/purposive-sampling-definition-application-advantages-and-disadvantages/)
[snowball sampling](https://www.statisticalaid.com/snowball-sampling-definition-application-advantages-and-disadvantages/)
[Convenience sampling](https://www.statisticalaid.com/convenience-sampling-definition-application-advantages-and-disadvantages/)
[Data analysis using spss](https://www.statisticalaid.com/category/spss/)
[Data analysis using R](https://www.statisticalaid.com/category/r-tutorials/)
[Spss tutorials](https://www.statisticalaid.com/category/spss-tutorials/)
[Non parametric test](https://www.statisticalaid.com/non-parametric-test-in-statistics/)
[Time series analysis](https://www.statisticalaid.com/an-intuitive-study-of-time-series-analysis/)
[Statistical inference](https://www.statisticalaid.com/statistical-inference-definiton-types-and-estimation-procedures/)
[Experimental Design](https://www.statisticalaid.com/an-intuitive-study-of-experimental-design/)
| statisticalaid |
830,342 | Monitoring Containers with Azure Monitor | Did you know you can containerize your asp.net MVC with docker application and upload to Azure... | 0 | 2021-09-18T16:13:06 | https://www.rupeshtiwari.com/monitoring-containers-with-azure-monitor/ | azure, webdev, beginners, tutorial | ---
title: Monitoring Containers with Azure Monitor
published: true
date: 2021-09-18 00:00:00 UTC
tags: azure,webdev,beginners,tutorial
canonical_url: https://www.rupeshtiwari.com/monitoring-containers-with-azure-monitor/
cover_image: https://res.cloudinary.com/practicaldev/image/fetch/s--_oi2_4i8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://imgur.com/Ov87oEs.png
---
> Did you know you can **containerize** your **asp.net MVC** with **docker** application and upload to **Azure Container Registry** and host them using Azure **Kubernetes Cluster** and start monitoring your container using **Azure Monitor**? In this article, I will explain all of this in this article. This article will help you to prepare for [az-303: Microsoft Azure Architect Technologies](https://docs.microsoft.com/en-us/learn/certifications/exams/az-303).
## Azure Monitor For Containers 🛢️
Monitors the performance of containers deployed to several platforms. You can monitor below:
- Azure Kubernetes Service (AKS)
- Self-managed K8 cluster hosted on Azure using AKS Engine
- Azure Container Instances
- Self-managed K8 clusters hosted on Azure Stack or on-premises
- Azure Red Hat OpenShift
- Azure Arc enabled Kubernetes
### Implementing Azure Monitor for Kubernetes

Let’s create and deploy a docker container to AKS. [Source code for azure app insight for docker container](https://github.com/rupeshtiwari/azure-app-container-insights-demo).
#### Creating MVC application with docker
<!-- Courtesy of embedresponsively.com //-->
<iframe src="https://www.youtube-nocookie.com/embed/5c2Ccdq_0xg" frameborder="0" webkitallowfullscreen="" mozallowfullscreen="" allowfullscreen=""></iframe>
- First create MVC asp.net project select docker Linux support.
- Run project locally
- Package this app in container and deploy into container registry
- You can use Docker hub or Azure Container Registry
#### Creating Azure Container Registry
<!-- Courtesy of embedresponsively.com //-->
<iframe src="https://www.youtube-nocookie.com/embed/_G5I2JojkN0" frameborder="0" webkitallowfullscreen="" mozallowfullscreen="" allowfullscreen=""></iframe>
- Next I am going to use **Azure Container Registry Service** to create new container registry.
- Under **repository** of my container registry My MVC application docker image will appear.
- Visual Studio will package my app into a **docker image** and deploy to my **azure docker container registry**.
- Once my docker image any docker host like **Azure Container Instances** or **Azure Kubernetes Service** (AKS).
#### Publishing Asp.net Docker Image to Azure
<!-- Courtesy of embedresponsively.com //-->
<iframe src="https://www.youtube-nocookie.com/embed/nklZHjzh2Z4" frameborder="0" webkitallowfullscreen="" mozallowfullscreen="" allowfullscreen=""></iframe>
- Right click application and publish
- Select Docker Container Registry
- Next select azure container registry
- Select your resource group and azure container registry to publish then select publish. It will take some time to publish your image to Azure Container Registry.
### What is the meaning of word Kubernetes?
The name **“Kubernetes”** stems from an ancient Greek word for “helmsman,” (someone who steers a ship, like a container ship) which explains the ship wheel logo.
#### Creating Kubernetes Cluster in Azure
 **Kubernetes Cluster concepts**
1.
**Azure Container Registry** has Docker Image and in order to connect to your own docker container image you will get **container name** and **registry name** that will help you to host your docker image to any Azure container hosting services.
2.
**Azure Kubernetes Cluster** host the docker container and exposes the container into public **8080** port using in-built high performance **load balancer**.
1. You need **pod** workflow from Kubernetes Cluster which will connect to the container registry using container name and registry name and create internal 80 port for your app.
2. Next you need **service** to expose internal port 80 to public 8080 over load balancer.
While creating Kubernetes Cluster remember 3 things.
1. **Authentication method** : required to connect Azure Container Registry to get the docker image.
2. **Integration** : Which Container Registry to select your own Container Registry that is we created where we have our docker image.
3. You can check the **performance** of your container by going to the Monitor Insights. Once our container will be deployed to the Kubernetes then we can observe performance.
Here is the YML for creating POD in k8 cluster.
```
apiVersion: v1
kind: Pod
metadata:
name: insights-demo01 # give any name
labels:
app: insights-demo01 # app name
component: netcore-app
spec:
containers: # which container u want to deploy
- image: regdemo01.azurecr.io/appcontainerinsightsdemo:latest # <NameOfTheContainerRegistry>/<NAMEofTheDockerContainer>:latest
name: webapi
ports:
- containerPort: 80
```
YML for creating service in K8 cluster.
```
apiVersion: v1
kind: Service
metadata:
labels:
app: insights-demo01 # give any name
name: insights-demo01 # give any name
spec:
ports:
- port: 8080 # public port
protocol: TCP
targetPort: 80 # internal port
selector:
app: insights-demo01
component: netcore-app
type: LoadBalancer
```
Follow the video steps to create the Kubernetes Cluster including pod and service.
<!-- Courtesy of embedresponsively.com //-->
<iframe src="https://www.youtube-nocookie.com/embed/xoN1efAAEBg" frameborder="0" webkitallowfullscreen="" mozallowfullscreen="" allowfullscreen=""></iframe>
## References
1. https://techcommunity.microsoft.com/t5/itops-talk-blog/what-s-the-difference-between-azure-security-center-azure/ba-p/2155188
* * *
_Thanks for reading my article till end. I hope you learned something special today. If you enjoyed this article then please share to your friends and if you have suggestions or thoughts to share with me then please write in the comment box._
## Become full stack developer 💻
I teach at [Fullstack Master](https://www.fullstackmaster.net). If you want to become **Software Developer** and grow your carrier as new **Software Engineer** or **Lead Developer/Architect**. Consider subscribing to our full stack development training programs. You will learn **Angular, RxJS, JavaScript, System Architecture** and much more with lots of **hands on coding**. We have All-Access Monthly membership plans and you will get unlimited access to all of our **video** courses, **slides** , **download source code** & **Monthly video calls**.
- Please subscribe to **[All-Access Membership PRO plan](https://www.fullstackmaster.net/pro)** to access _current_ and _future_ **angular, node.js** and related courses.
- Please subscribe to **[All-Access Membership ELITE plan](https://www.fullstackmaster.net/elite)** to get everything from PRO plan. Additionally, you will get access to a monthly **live Q&A video call** with `Rupesh` and you can ask **_doubts/questions_** and get more help, tips and tricks.
> Your bright future is awaiting for you so visit today [FullstackMaster](www.fullstackmaster.net) and allow me to help you to board on your dream software company as a new **Software Developer, Architect or Lead Engineer** role.
**💖 Say 👋 to me!**
Rupesh Tiwari
Founder of [Fullstack Master](https://www.fullstackmaster.net)
Email: [rupesh.tiwari.info@gmail.com](mailto:rupesh.tiwari.info@gmail.com?subject=Hi)
Website: [www.rupeshtiwari.com](https://www.rupeshtiwari.com) | [www.fullstackmaster.net](https://www.fullstackmaster.net) | rupeshtiwari |
830,431 | DongTai IAST IntelliJ IDEA Plugin Release | 🔥 NEW RELEASE 🔥 DongTai IAST is an interactive application security testing tool that can help... | 0 | 2021-09-18T09:44:39 | https://dev.to/huoxian_dongtai/dongtai-iast-intellij-idea-plugin-release-185k | devops, github, security | 🔥 NEW RELEASE 🔥
DongTai IAST is an interactive application security testing tool that can help developers produce safer and better code. It is the first fully open-source IAST project in the world.
Today we’re doing an IntelliJ IDEA Plugin release🧰
What's in it? 🤔
It is a lightweight security plugin option, which enables developers to have actionable feedback.
Details: https://hxsecurity.github.io/DongTai-Doc/#/en-us/doc/tutorial/plugin
DongTai Twitter: https://twitter.com/HuoXian_DongTai | huoxian_dongtai |
851,675 | 📣 Chainlink Fall Hackathon is open for registration | The Chainlink Fall 2021 Hackathon is happening from October 22 to November 28, where thousands of... | 0 | 2021-10-05T02:59:36 | https://dev.to/makingwavs/chainlink-fall-hackathon-is-open-for-registration-3p4n | 
The **Chainlink Fall 2021 Hackathon** is happening from **October 22 to November 28**, where thousands of experienced and new blockchain developers alike will learn, network, and compete for exclusive NFTs, educational prizes, and up to **$400k+** in prizes. Hackathon winners will also have the opportunity to pitch their projects to leading VCs.
Entering the Hackathon is a great way for experienced smart contract developers to secure funding for any ideas that they’ve been thinking about. It is also an opportunity for developers who are new to the blockchain space to learn the fundamentals of Solidity and popular coding environments such as HardHat, Brownie, and Truffle.
**Registration is open to developers of all experience levels — sign up at [chain.link/hackathon](https://chain.link/hackathon) to secure your spot!** | makingwavs | |
830,827 | #100daysofcode [Day 11] | Hey Guys, Today is the eleventh day of my 100 days coding challenge , I can't upload the progress of... | 0 | 2021-09-18T18:16:14 | https://dev.to/thekawsarhossain/100daysofcode-day-11-40cl | javascript, html, css | Hey Guys, Today is the eleventh day of my 100 days coding challenge , I can't upload the progress of my 100 days of coding just because of my programming course classes , But I always try to keep this challenge.And today i make one of the best site that i've ever made . it's an bank site where you can sign up after that you can login , you can deposit as well as you can withdraw , to make this site I used html , css, bootstrap , js and LocalStorage.
Here is the live site : https://lnkd.in/gggu8mZZ
and here is the code link :https://lnkd.in/gvjHD5Eb | thekawsarhossain |
830,878 | Proyección nativa en Neo4j | El mecanismo de proyección nativa ofrecida por Neo4j permite crear una proyección de un grafo en... | 0 | 2021-09-18T21:52:27 | https://dev.to/fgambetta/proyeccion-nativa-en-neo4j-1coh | database, datascience | El mecanismo de proyección nativa ofrecida por Neo4j permite crear una proyección de un grafo en memoria. Dicha proyección es definida en términos de los nodos, relaciones y propiedades del grafo original.
En el siguiente grafo tenemos nodos Person y sus relaciones: Married, Parent y Siblings.
Una proyección que solo contempla los nodos Person y la relación Parent representa el siguiente grafo.

La sintaxis para crear una proyección es la siguiente:
```
CALL gds.graph.create(
graph-name, node-projection, relationship-projection,
{nodeProperties: String or List,
relationshipProperties: String or List
})
```
El método graph.create recibe tres parámetros:
__graph-name__: Nombre del grafo a crear.
__node-projection__: Nodos que queremos en la proyección.
__relationship-projection__: Relaciones que queremos en la proyección.
| fgambetta |
830,979 | Understanding Network Port with Examples | In networking, a port is a virtual place on a machine that is open to connections from other... | 0 | 2021-09-19T02:58:26 | https://dev.to/howtouselinux/understanding-network-port-with-examples-1nnk | In networking, a port is a virtual place on a machine that is open to connections from other machines. Every networked computer has a standard number of ports, and each port is reserved for certain types of communication.
Think of ports for ships in a harbor: each shipping port is numbered, and different kinds of ships are supposed to go to specific shipping ports to unload cargo or passengers. Networking is the same way: certain types of communications are supposed to go to certain network ports. The difference is that the network ports are virtual; they are places for digital connections rather than physical connections.
## DNS Port
Most of the time, DNS happens over UDP port 53. It's lightweight and faster than TCP. This is to reduce performance overhead on the DNS server due to the number of requests it is likely to receive.
But DNS servers still need to be available on TCP. Zone transfers happen over TCP port 53. This happens on the DNS server side which is not related to the end-user.
Check here to learn more about [DNS](https://www.howtouselinux.com/post/what-is-dns-dns-meaning) and [DNS port](https://www.howtouselinux.com/post/dns-port)
## SSH Port
The port number for SSH is 22 by default. Whenever we run a command through default SSH port number 22, a connection is established between client and server. Every connection initializes through this port.
Check here to learn more about [ssh port](https://www.howtouselinux.com/post/exploring-port-number-for-ssh) and [SSH Port Fowrding](https://www.howtouselinux.com/post/exploring-ssh-port-forwarding-with-examples)
## NFS Port
NFSv3 and NFSv2 include portmapper, nfsd, and other NFS services like mountd, nlockmgr, status, pcnfs, quotad, etc.
* For portmapper services, NFSv3 and NFSv2 use TCP or UDP port 111. The portmapper service is consulted to get the port numbers for services used with NFSv3 or NFSv2 protocols such as mountd, statd, and nlm etc. NFSv4 does not require the portmapper service.
* For nfsd, we usually use TCP or UDP port 2049.
* The ports for other NFS services like mounted, nlockmgr, status are product-dependent.
Check here to learn more about [nfs port](https://www.howtouselinux.com/post/nfs-port)
## ICMP Port
The ICMP packet does not have source and destination port numbers because it was designed to communicate network-layer information between hosts and routers, not between application layer processes.
Each ICMP packet has a "Type" and a "Code". The Type/Code combination identifies the specific message being received. Since the network software itself interprets all ICMP messages, no port numbers are needed to direct the ICMP message to an application layer process.
Check here to learn more about [ICMP Port](https://www.howtouselinux.com/post/icmp-port-number) and [ICMP protocal](https://www.howtouselinux.com/post/icmp-protocol-with-examples)
## Is the SSL Port 443?
No. SSL runs on the Security Layer. Any application can use SSL certificate to be secure. Port 443 is the default port for HTTPS. We can also use SSL in other applications like email, DNS, database, etc.
Depending on the type of connection and what encryption is supported, different SSL port numbers might be needed.
Check here to learn more about [SSL port](https://www.howtouselinux.com/post/exploring-ssl-port-with-examples) and [how to check the connection is encrpted](https://www.howtouselinux.com/post/ssl-connection-with-openssl-s_client-command)
## RPC Port
Remote Procedure Call (RPC) is an inter-process communication technique to allow client and server software to communicate on a network. The RPC protocol is based on a client/server model.
The client makes a procedure call that appears to be local but is actually run on a remote computer. During this process, the procedure call arguments are bundled and passed through the network to the server. The arguments are then unpacked and run on the server.
The result is again bundled and passed back to the client, where it is converted to a return value for the client's procedure call.
Check here to learn more about [RPC port 111](https://www.howtouselinux.com/post/understanding-rpcbind-and-rpc) and [how portmapper works](https://www.howtouselinux.com/post/understanding-portmap-with-examples)
## Filter Packets with Specific Port
If we need to filter packets for the first connection, we can use the following ways.
* tcpdupm -i interface port 1184
* tcpdupm -i interface port 53
Check here to learn more about [how to capture packets based on ports](https://www.howtouselinux.com/post/tcpdump-ports)
| howtouselinux | |
831,126 | Reasons behind learning JavaScript... | This language is more than a synonym for CoffeeHandwriting – it’s the perfect programming language... | 0 | 2021-09-19T05:37:16 | https://dev.to/pratik_kumar/reasons-behind-learning-javascript-1ce7 | javascript | This language is more than a synonym for CoffeeHandwriting – it’s the perfect programming language for beginners to use immediately in their career, as well as providing a perfect jumping-off point for any future developments. It’s totally future-proof, since nearly all of the web relies on it. Why learn JavaScript? To summarize the reasons , the reasons why am I learning JavaScript are:
-It’s a multifunctional language.
-It’s easy to get started with.
-There’s a comprehensive set of frameworks and libraries to make your life easier.
-The community is firmly entrenched and stellar.
-It’s a highly sought-after professional skill.
-It can help you learn your next programming language.
My final thoughts-
In other words, it’s a great language that can help you accomplish a lot both in your personal life and in your professional life. Out of all the programming languages you could start learning in 2021, JavaScript must come top of the list. | pratik_kumar |
831,151 | YouTube Subscriber Counter | A post by Thilak7c | 0 | 2021-09-19T07:33:25 | https://dev.to/thilak7c/youtube-subscriber-counter-3e22 | codepen | {% codepen https://codepen.io/thilak-sundaram/pen/dyRmWdV %} | thilak7c |
831,308 | Day 13 - SASS Guide | Why use SASS over CSS? Sass (which stands for 'Syntactically awesome style sheets) is an extension of... | 0 | 2021-09-19T11:04:16 | https://dev.to/_mark/sass-guide-3hgj | html, css, sass | __Why use SASS over CSS?__
Sass (which stands for 'Syntactically awesome style sheets) is an extension of CSS that enables you to use things like variables, nested rules, inline imports and more. It also helps to keep things organized and allows you to create style sheets faster. Sass is compatible with all versions of CSS.
Step 1:
Download Live Sass Compiler on VSCode extension.
Step 2:
You can modify sass settings by going to vscode settings>search live sass>edit from json file. You can change directory using this code _"liveSassCompile.settings.formats": [{
"format": "expanded",
"extensionName": ".css",
"savePath": "./css"
}]_
Step 3:
Click watch Sass.
Tip: You can create a partial file using underscore then the name of file ex. "_config" and import it to your scss with syntax "@import "config" (no need to add underscore).
| _mark |
831,487 | Front End Mentor Clipboard Landing Page Challenge | One of the hardest things I find about learning web development is there are so many tutorials and... | 0 | 2021-09-19T15:02:29 | https://dev.to/heidi37/front-end-mentor-clipboard-landing-page-challenge-45j | html, css, frontend, webdev | One of the hardest things I find about learning web development is there are so many tutorials and online learning resources, but I need to make time in between all the learning to actually CODE.
I am trying to always have some kind of project going on the side in addition to learning all the theory. 🙄
Here is the [Challenge](https://www.frontendmentor.io/challenges/clipboard-landing-page-5cc9bccd6c4c91111378ecb9).
Here is my [Code](https://heidi37.github.io/clipboard-landing-page/). | heidi37 |
831,519 | 🔴 How Routing Works 🧐
| 🔴 How Routing Works 🧐 🔥 🔥 ALL ABOUT ROUTING INTERNAL DETAILS ARE SHARED
HOW IT IS... | 0 | 2021-09-19T16:48:49 | https://dev.to/techiedheeraj/how-routing-works-6lh | beginners, computerscience, tutorial, productivity | ## 🔴 How Routing Works 🧐
**🔥 🔥 ALL ABOUT ROUTING INTERNAL DETAILS ARE SHARED**
**HOW IT IS IMPLEMENTED AND WHICH ALGORITHM IS USED 🤷♂️🔥🔥🔥**
{% youtube kL0rKAicw6w %}
| techiedheeraj |
831,613 | Adding Global CSS to an Angular Library Storybook | This tutorial assumes you have configured an Angular Library + Storybook following this post. Most... | 0 | 2021-09-19T20:28:44 | https://dev.to/saulodias/adding-global-css-to-an-angular-library-storybook-agm | storybook, css, angular, bootstrap | This tutorial assumes you have configured an **Angular Library + Storybook** following [this post](https://dev.to/saulodias/angular-library-storybook-44ma).
Most of the time, when creating components, you'll probably want to rely on some global css style. That enables you to use generic classes (like bootstrap classes), or theming and so on. However the Storybook documentation lacks examples on how to do it.
For this example we first have to install Bootstrap. Go to your workspace root folder and run `npm install bootstrap`.
Once you have done that, now you can link the boostrap css to your Storybook project.
To do so, you just have to add the css path to the styles in your `angular.json` file, in the `styles` list of your `storybook` project like in the following example.
```json
"styles": ["node_modules/bootstrap/dist/css/bootstrap.min.css"],
```
> See the entire [file and example workspace on Github.](https://github.com/saulodias/my-workspace/blob/storybook-global-css/angular.json)
I have edited the default [MyLibComponent](https://github.com/saulodias/my-workspace/blob/storybook-global-css/projects/my-lib/src/lib/my-lib.component.ts) from the Angular Library basic example and it looks like this with the Bootstrap styling.
### You might also want to check this out:
{% link https://dev.to/saulodias/angular-library-storybook-44ma %}
| saulodias |
831,802 | Software Engineering is a Loser’s Game | I’ve recently become fascinated by the idea of “winner’s games” and “loser’s games.” There are... | 0 | 2021-09-20T09:53:40 | https://levelup.gitconnected.com/software-engineering-is-a-losers-game-94cf1f4df0c6 | leadership, productivity, programming, beginners | I’ve recently become fascinated by the idea of “winner’s games” and “loser’s games.” There are several great articles which explain the idea in depth, but here’s a quick summary:
An observation was made by Simon Ramo in 1973 that there is a big difference in how games are won in amateur tennis versus professional tennis.
When two amateur opponents are playing, the game is often won not through the winner’s great skill but because of the loser’s mistakes. The loser often commits unforced errors by hitting the ball out of bounds, missing easy shots, or double faulting. In other words, the loser beats himself. Points are “lost” by the loser more than they are “won” by the winner. This is a “loser’s game.”
When two professional opponents are playing, the game is won primarily due to the winner’s skill. Neither player commits many unforced errors. The winner places his shots well and outperforms his opponent to defeat him. Points in this kind of game are “won” by the winner more than they are “lost” by the loser. This is a “winner’s game.”
So, if you’re playing a loser’s game, a winning strategy is to simply try to avoid making mistakes and let your opponent beat himself.
(If you’ve ever played tennis or ping pong before, I hope at this point you’re nodding your head in recognition. As an avid ping pong player, I’ve seen this scenario play out in the office at work on a daily basis.)
The application of this observation is that you should attempt to understand whether any given activity you’re involved in is a winner’s game or a loser’s game. Gaining that understanding teaches you how you should play the game.
You can read more about these ideas in this [article by Charles Ellis](https://www.empirical.net/wp-content/uploads/2012/06/the_losers_game.pdf), this [article from the FS blog](https://fs.blog/2014/06/avoiding-stupidity/), or this [article from Ben Hosking](https://thehosk.medium.com/software-development-is-a-losers-game-fc68bb30d7eb).
---
## Parallels to Software Engineering
Now, what if we consider software engineering to be a loser’s game? That is to say, we often beat ourselves by committing unforced errors and making mistakes. If we are amateurs, so to speak, how can we keep the ball in play rather than hitting it into the net?
It’s a simple thing to say, “If you want to be good, just stop making mistakes.” But that’s somewhat unhelpful. That’s like saying to those in poverty, “Why don’t you just stop being poor?”
It’s also unhelpful if we take this analogy too far. If avoiding mistakes is the ultimate goal of software engineering, is the best software engineer the one who writes no code or does nothing? Obviously, no. Software engineers are paid to write code to help bring to life some product in order to achieve some vision (make the business money, solve a real-world problem, simplify a task, etc.), so that must be the real ultimate goal.
So it appears that we must balance producing valuable output with avoiding mistakes. This leads to an interesting thought experiment: In what ways do we beat ourselves, and how can we avoid making these amateur mistakes?
---
## Unforced Errors
Here’s a list of possible unforced errors we commit. I’m sure you may be able to add more to this list as well.
* Not understanding the problem before trying to code a solution
* Not understanding the tools or programming languages we use
* Not carefully reviewing our own code before asking for a code review
* Not manually testing our own code before asking for a code review
* Not writing unit tests
* Not following agreed-upon company standards
---
## Solving These Unforced Errors
Now that we’ve identified some potential unforced errors, how do we avoid making them?
For starters, we can put safeguards in place to help us catch and correct our mistakes before they become too costly. All code repos should be configured with code linters, code formatters, and a suite of automated tests. These safeguards can be run as part of a CI pipeline prior to allowing any code to be merged.
We can also be more thorough in our own attention to detail when writing code. After creating a merge request, we should always do a self code review before asking others to review our code. We should always manually validate our changes as well.
Nothing is more frustrating as a code reviewer than reviewing someone else’s code who clearly didn’t do these checks themselves. It wastes the code reviewer’s time when he has to catch simple mistakes like commented out code, bad formatting, failing unit tests, or broken functionality in the code. All of these mistakes can easily be caught by the code author or by a CI pipeline.
When merge requests are frequently full of errors, it turns the code review process into a gatekeeping process in which a handful of more senior engineers serve as the gatekeepers. This is an unfavorable scenario that creates bottlenecks and slows down the team’s velocity. It also detracts from the higher purpose of code reviews, which is knowledge sharing.
We can use checklists and merge request templates to serve as reminders to ourselves of things to double check. Have you reviewed your own code? Have you written unit tests? Have you updated any documentation as needed? For frontend code, have you validated your changes in each browser your company supports? Have you ensured that all user-facing text is translated? Have you ensured that the UI meets accessibility standards and guidelines?
By performing these checks ourselves, aided by automated tools, we show an added measure of professionalism and respect for our coworkers. Trust will grow and velocity will increase. The key is to be diligent and disciplined.
---
## Conclusion
Software engineering is a loser’s game. So let’s learn to play the game and stop losing to ourselves. | thawkin3 |
831,806 | password management with pass and git | Pass is an open source Unix password manager, safe for personal and professional use. It has a... | 0 | 2021-09-19T22:28:23 | https://dev.to/bigcoder/password-management-with-pass-and-git-lkg | linux, security | [Pass](http://www.passwordstore.org/) is an open source Unix password manager, safe for personal and professional use.
It has a different user experience than existing password managers because it's a [command line](https://bsdnerds.org/what-is-linux-shell/) program.
It's basically a wrapper on GPG files which are stored in:
```bash
~/.password-store
```
If you have multiple computers, you can sync with git.
But first, let's learn how to use pass. Setup gpg and pass.
## How does it work?
First create a GPG key
```bash
gpg --full-generate-key
```
Now you have a GPG key, make sure to back it up!
To show your keys:
```
gpg --list-secret-keys --keyid-format LONG
```
Example output, pick the right key
```
sec 4096R/3AC5C34371567BD2 2019-10-10
uid toto <toto@example.com>
ssb 4096R/42B317FD4BA89E7A 2019-10-10
```
It's `3AC5C34371567BD2` here.
Install pass
```
# installation on Arch Linux
sudo pacman -S pass
# installation on Ubuntu
sudo apt install pass
```
Then create a new password wallet (change to your gpg keys)
```
pass init 3AC5C34371567BD2
```
To add a password
```
pass insert twitter/user
```
To generate a password of 16 characters
```
pass generate twitter/bob 16
```
To show a password
```
pass get twitter/user
```
To copy a password to clipboard
```
pass get -c twitter/user
```
To list all passwords
```
pass list
```
Example:
```bash
$ pass list
Password Store
├── example
│ └── test
└── twitter
└── test
```
## Weak passwords
It's important to choose strong passwords. That's because there are lists of millions passwords like [rockyou.txt](https://github.com/brannondorsey/naive-hashcat/releases/download/data/rockyou.txt) which can be used to brute force your Linux system using [hydra](https://tools.kali.org/password-attacks/hydra).
Even a hashed password in /etc/shadow isn't necessary secure. Hashes can be cracked tools using tools like John the Ripper.
If you want to do hash cracking, there's a course here: [John the Ripper](https://www.udemy.com/course/ethical-hacking-john-the-ripper/).

## How does it compare to Keepass and friends?
In terms of security the default config is not much stronger than Keepass.
Password managers typically store all passwords on the computer (internet connected device).
The bitcoin madness of last decade has shown that this was not the best idea (several people had private keys stolen).
In my opinion, it's not the most secure idea to store all your passwords on a general purpose computer (reduce attack surface). Especially when exploits for said software show up all the time.
So what's the solution?
You can setup [Yubikey with pass](https://github.com/drduh/YubiKey-Guide) and store the private keys on the key itself. This requires quite some setup time.
Alternatively, remember 500+ passwords in your head like me or cope.
| bigcoder |
831,872 | Exploring jQuery with A Fresh Eye | This week, I picked up a work item for my organization that involved jQuery. The description and... | 0 | 2021-09-20T01:14:57 | https://kristenkinnearohlmann.dev/jquery-explore/ | javascript | This week, I picked up a work item for my organization that involved jQuery. The description and technical analysis of the work item were presented in vanilla JavaScript. When I looked into the file where the solution was to be written, I noticed a whole lot of `$`. It took me a couple of minutes before I realized it was jQuery!
The [Flatiron School](https://flatironschool.com/) curriculum frequently reminded students that although we were being taught ES6 and React, we would encounter different frameworks and older code bases in our work. I felt pretty good that I was able to determine what the code was that I was reviewing despite my initial confusion!
The goal of the work item is to iterate through a `<div>` that has multiple `<p>` tags containing descriptions; if those descriptions are longer than set amount of characters, the description should be truncated and an ellipsis (`...`) should be added to the end. The person that completed the technical analysis had done some of the work to target the proper set of `<p>` elements that would need to be changed but I couldn't immediately determine how to finish the code. An additional complication to the work is the solution required another person's code changes that weren't yet complete to run the code.
I coded as much as I could before finishing work for the week. On the weekend, I was determined to understand how I could properly target elements using jQuery. I could see that the basic method to access elements was the same as I had learned for vanilla JavaScript, so it was just a matter of figuring out how jQuery differed. I researched W3 schools and the jQuery documentation and learned that code needed to be enclosed in the `$(document).ready` function and that elements were access via `$()`.
```JavaScript
$(document).ready(function () {
return true
});
```
Elements are targeted in a very similar way to vanilla JavaScript by using HTML elements, classes and IDs to target the specific element to change.
```JavaScript
$("#test").find("p")
```
I found my old friend `this` helped me to sort out the `<p>` tags appropriately. I made a special effort to really understand how `this` functions in JavaScript (there are many well-written blogs on this topic!) so I when I was trying to figure out how to iterate items that were enclosed by a specific element, I could use `this` to access them in turn.
```JavaScript
$(this).text(truncate($(this).text()));
```
I was able to use [CodePen](https://codepen.io/your-work) to set up a [working example](https://codepen.io/kristenkinnearohlmann/pen/BaZrLRR) based on my memory of the code structure from my work project. Having worked through the problem on an example I set up, I believe I will be able to set up a similar example on Monday when I have the actual code in front of me.
```JavaScript
$(document).ready(function () {
var testParas = $("#test").find("p");
testParas.each(function () {
$(this).text(truncate($(this).text()));
});
});
```
I know that with each problem we solve, we strengthen our learning and abilities. I am looking forward to continuing to learn and support the existing code base at my organization while expanding my knowledge of various JavaScript libraries like jQuery. | kristenkinnearohlmann |
831,896 | Get an A on ssllabs.com with VMware Avi / NSX ALB (and keep it that way with SemVer!) | Cryptographic security is an important aspect of hosting any business-critical service. When hosting... | 0 | 2021-10-03T15:59:51 | https://dev.to/ngschmidt/get-an-a-on-ssllabs-com-with-vmware-avi-nsx-alb-and-keep-it-that-way-with-semver-1p82 | avi, loadbalancing, nsxalb, tls | ---
title: Get an A on ssllabs.com with VMware Avi / NSX ALB (and keep it that way with SemVer!)
published: true
date: 2021-09-19 22:06:00 UTC
tags: Avi,LoadBalancing,NSXALB,TLS
canonical_url:
---
**Cryptographic security is an important aspect of hosting any business-critical service.**
When hosting a public service secured by TLS, it is important to strike a balance between **compatibility** (The **Availability** aspect of CIA), and strong cryptography (the **Integrity** or **Authentication** and **Confidentiality** aspects of CIA). To illustrate, let's look at the CIA model:
In this case, we need to balance backward compatibility with using good quality cryptography - here's a brief and probably soon-to-be-dated overview of what we ought to use and why.
### Protocols
This block is fairly easy, as older protocols are worse, right?
#### TLS 1.3
As a protocol, TLS 1.3 has quite a few great improvements and is fundamentally simpler to manage with fewer knobs and dials. **There is a major concern** with TLS 1.3 currently - security tooling in the large enterprise hasn't caught up with this protocol yet as new ciphers like **ChaCha20** don't have hardware-assisted lanes for decryption. Here are some of the new capabilities you'll like::
- **Simplified Crypto sets:** TLS 1.3 deprecates a ton of less-than-secure crypto - TLS 1.2 supports up to **356** cipher suites, **37 of which are new with TLS 1.2**. This is a mess - TLS 1.3 supports **five**.
- Note: The designers for TLS 1.3 achieved this by removing forward secrecy methods from the cipher suite, and they must be separately selected.
- **Simplified handshake:** TLS 1.3 connections require fewer round-trips, and session resumption features allow a 0-RTT handshake.
- **AEAD Support:** AEAD ciphers both support integrity and confidentiality. **AES Galois Counter Mode (GCM)** and Google's **ChaCha20** serve this purpose.
- **Forward Secrecy:** If a cipher suite doesn't have PFS (I disagree with **perfect** ) support, it means that a user can capture your network traffic and replay it to decrypt if the private keys are acquired. PFS support is **mandatory** in TLS 1.2
Here are some of the things you can do to mitigate the risk if you're in a large enterprise that performs decryption:
- Use a load balancer - since this is about a load balancer, you can protect your customer's traffic in transit by performing **SSL/TLS bridging.** Set the LB-to-Server ( **serverssl** ) profile to a high-efficiency cipher suite ( **TLS 1.2 + AES-CBC** ) to maintain confidentiality while still protecting privacy.
#### TLS 1.2
TLS 1.2 is like the Toyota Corolla of TLS, it's run for forever and not everyone maintains it properly.
It can still perform well if properly configured and maintained - we'll go into more detail on how in the next section. The practices outlined here are good for all editions of TLS.
**Generally, TLS 1.0 and 1.1 should not be used.** Two OS providers (Windows XP, Android 4, and below) were disturbingly slow to adopt TLS 1.2, so if this is part of your customer base, beware.
### Ciphers
This information is much more likely to be dated. I'll try to keep this short:
#### Confidentiality
- **(AEAD)** AES-GCM: This is usually my all-around cipher. It's decently fast and supports **partial acceleration** with hardware ADCs / CPUs. AES is generally pretty fast, so it's a good balance of performance and confidentiality. I don't personally think it's worth running anything but 256-bit on modern hardware.
- **(AEAD)** [ChaCha20](https://datatracker.ietf.org/doc/html/rfc7539): This was developed by Google, and is still "being proven". Generally trusted by the public, this novel cipher suite is fast despite a lack of hardware acceleration.
- AES-CBC: This has been the "advanced" cipher for confidentiality before AES-GCM. Developed in 1993, this crypto is highly performant and motivated users to move from suites like DES and RC4 by being both more performant and stronger. Like with AES-GCM, I prefer not to use anything but 256-bit on modern hardware
- Everything else: This is the "don't bother" bucket: RC4, DES, 3DES
#### Integrity
Generally, AEAD provides an advantage here - SHA3 isn't generally available yet but SHA2 variants should be the only thing used. The more bits the better!
#### Forward Secrecy
- ECDHE (Elliptic Curve Diffie Hellman): This should be mandatory with TLS 1.2 unless you have customers with old Android phones and Windows XP.
- TLS 1.3 lets you select multiple PFS algorithms that are EC-based.
### Matters of Practice
Before we move into the Avi-specific configuration, I have a recommendation that is true for all platforms:
**[Semantic Versioning](https://semver.org/)**
Cryptography practices change over time - and some of these changes break compatibility. Semantic versioning provides the capability to support three scales of change:
- **Major Changes:** First number in a version. Since the specification is focused on APIs, I'll be more clear here. This is what you'd iterate if you are removing cipher suites or negotiation parameters that might break existing clients
- **Minor Changes:** This category would be for tuning and adding support for something new that **won't break compatibility**. Examples here would be **cipher order preference** changes or adding new ciphers.
- **Patch Changes:** This won't be used much in this case - here's where we'd document a change that matches the **Minor Change**'s intent, like mistakes on cipher order preference.
### Let's do it!
Let's move into an example leveraging NSX ALB (Avi Vantage). Here, I'll be creating a "first version," but the practices are the same. First, navigate to **Templates -> Security -> SSL/TLS Profile** :
[](https://lh3.googleusercontent.com/-ytlTSCFz3RM/YUex6k8yq_I/AAAAAAAABiA/bKh1xgSyxtwJ1AGKeBhylJva1orK_YpAACLcBGAsYHQ/image.png)
[](https://lh3.googleusercontent.com/-R1oUgKyQGNI/YUetE5WUReI/AAAAAAAABhg/HS9oS3mTt0AVWguY11KEUr7fFBWme_ItgCLcBGAsYHQ/image.png)
Note: I really like this about Avi Vantage, even if I'm not using it here. The security scores here are accurate, albeit capped out - VMware is probably doing this to encourage use of AEAD ciphers:
[](https://lh3.googleusercontent.com/-fYdknMmUKj4/YUetnwLKIbI/AAAAAAAABho/XfhCZpIGnR0M1_CSISDA616smPqknDf4wCLcBGAsYHQ/image.png)
...but, I'm somewhat old-school. I like using Apache-style cipher strings because they can apply to anything, and everything will run TLS eventually. Here are the cipher strings I'm using - the first is TLS 1.2, the second is TLS 1.3.
ECDHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384
TLS\_AES\_256\_GCM\_SHA384:TLS\_CHACHA20\_POLY1305\_SHA256
[](https://lh3.googleusercontent.com/-LWkdZyUxFwA/YUe3vUY1jhI/AAAAAAAABiQ/DZ3RkPjEmqA6iG7AfleTxAdUHm52NF7LgCLcBGAsYHQ/image.png)
One gripe I have here is that Avi won't add the "What If" analysis like F5's TM-OS does (14+ only). Conversely, applying this profile is much easier. To do this, open the virtual service, and navigate to the bottom right:
[](https://lh3.googleusercontent.com/-L4cCPMKXZSA/YUeyq7YTn_I/AAAAAAAABiI/G8CnnrqT6fMNUGI2p_Dinr0ukuVs0cYRwCLcBGAsYHQ/image.png)
That's it! Later on, we'll provide examples of coverage reporting for these profiles. In a production-like deployment, these services should be managed with release strategies given that versioning is applied. | ngschmidt |
831,980 | ES6 - What changes did it bring? | In 2015, ECMA International, the organization that prescribes the standards for client-side scripting... | 0 | 2021-09-20T04:30:38 | https://dev.to/roadpilot/es6-what-changes-did-it-bring-1p1m | In 2015, ECMA International, the organization that prescribes the standards for client-side scripting for web browsers introduced ES6 or ECMAScript 6. The changes that ES6 brought were related to Arrow Functions, defining variables, Object Manipulation, "For" loops and the introduction of a new primitive data type 'symbol'.
Arrow Functions:
Before ES6, a function was declared using the "function" keyword. A function would use the "return" keyword to produce the output of the function.
```
function timesThree(num){
return (num * 3)
}
```
With arrow functions, you are not required to use the "function" keyword and return can be implicit (unstated)
```
const timesThree = (num) => num * 3
```
Defining Variables:
Did you see that "const" above there? That's also something new. Two new ways of defining variables was added. "const" is a constant value and can not be changed once declared and "let" is the other way that allows a variable to be defined but can allow changes to the variables value after being declared. Previous to "const" and "let", "var" was the method to define a variable but would allow both mutable and immutable variables to be defined.
Object Manipulation:
ES6 introduced destructuring of arrays. This could be a blog of it's own (maybe it will ...) in the meantime, you can learn more about destructuring (and the spread operator) here from Mozilla: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment
"For" loops:
ES6 introduced "for ... of" and "for ... in" loops.
```
let primes = [2, 3, 5, 7];
for(value of primes) {
console.log(value);
}
//iterates through the array and assigns the VALUE of each element to the "value" variable
```
```
let primes = [2, 3, 5, 7];
for(index in primes) {
console.log(index);
}
//iterates through the array and assigns the INDEX of each element to the index variable (this is returned as a string, and not an integer)
```
Symbol Data Type:
A symbol is a unique and immutable data type and may be used as an identifier for object properties. The symbol object is an implicit object wrapper for the symbol primitive data type. This primitive type is useful for so-called "private" and/or "unique" keys. It's value is kept private and only for internal use. No user can overwrite it's value. This prevents name clashing between object properties because no symbol is equal to another. You create a symbol calling the "Symbol()" reserved function.
```
const userID = Symbol()
```
All of these changes result in an increase in performance but there is no browser that fully supports the ES6 features. Community support is growing but not as prolific as the pre-ES6 community.
| roadpilot | |
832,012 | Beginner's checkout before participating in a Hackathon! | Keeping this blog short and covered FAQ about hackathons 🙌 (won @uplift_project by @Girlscript1) ... | 0 | 2021-09-20T05:23:29 | https://dev.to/gauravsinhaweb/beginner-s-checkout-before-participating-in-a-hackathon-1o5b | hackathon, codenewbie | Keeping this blog short and covered FAQ about hackathons 🙌
(won [@uplift_project](https://devfolio.co/submissions/edusmart-d485) by @Girlscript1)
### Things I've covered in this blog🧐:
- When you are ready for a hackathon?
- How can you win a hackathon?
- What else you should know Apart from coding?
- Benefits of Hackathon?
- Tips!
####Let's go!🚀
#####1. When you are ready for a hackathon?
You are always ready for a hackathon until and unless you want to learn new skills.
#####2. How can you win a hackathon?🥉
I've experienced multiple hackathons for different organizations. I can answer that.
first and foremost,
- Idea - you must have something unique and creative with your project.
- Implementation - If your project has some real-life use or if it can be implemented in the future.
- UI/UX - yes, the UI should be as good as the Idea of your project.
- Tech stack - sometimes the tech stack you are using in your project can impress the judges. 😉
#####3. What else you should know apart from coding?🤔
You must have good writing skills, your words should be on 'point' (doesn't mean lengthy words).
You'll need good writing skills to make PPT & Readme of your project.
#####4. Benefits of Hackathon?✨
Of course SWAGS! , you'll get amazing prizes, swags, and certificates.
- You'll work in a team.
- Most importantly, You'll earn some good friends and grow in the community.
#####Tips:
- Showcase your project to a Mentor before submission.
`Happy hacking!👩💻
`
| gauravsinhaweb |
852,668 | Asp.net core environment variables Giriş. | Environement variables ne işe yarar ? Uygulamanın configuration'larını yapar. Not:... | 14,840 | 2021-10-05T17:38:24 | https://dev.to/mustafasamedyeyin/asp-net-core-environment-variables-giris-pce | dotnet, csharp | ## Environement variables ne işe yarar ?
Uygulamanın configuration'larını yapar.
Not: Environment variable key-value yapısındadır.
## Neden ihtiyaç duyulur ?
Diyelimki uygulamayı publish ettiniz source code'unuz başka birisinin eline bir şekilde geçti. "appsettings.json" "appsettings.Environment.json" configuration'larınızı kötü niyetli kişi okuyabilir. Ama environment variable olarak geçilen değerleri okuyamaz.
## Environement variable nasıl atarız ve değerlerini değiştiririz ?
1.) Visual studio projece sağ click atıp properties seçelim :
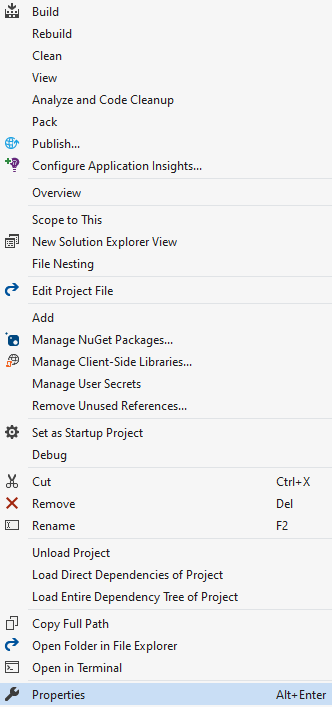
Debug menüsüne geliniz :
Aşağıdaki gibi add buton'una tıklarsanız key-value pair şeklinde evironment variable eklemiş oluruz :
İstediğiniz key'e karşılık istediğiniz değer'i verebilirisiniz.
Not: ASPNETCORE_ENVIRONMENT key'ine karşılık olarak "Development","Staging","Production" değerlerinden birinin verilmesi evrenseldir.
2.) "launchSettings.json"dan environment variable verebiliriz :
Properties altında "launchSettings.json" çift tıklayın dosyayı açın :
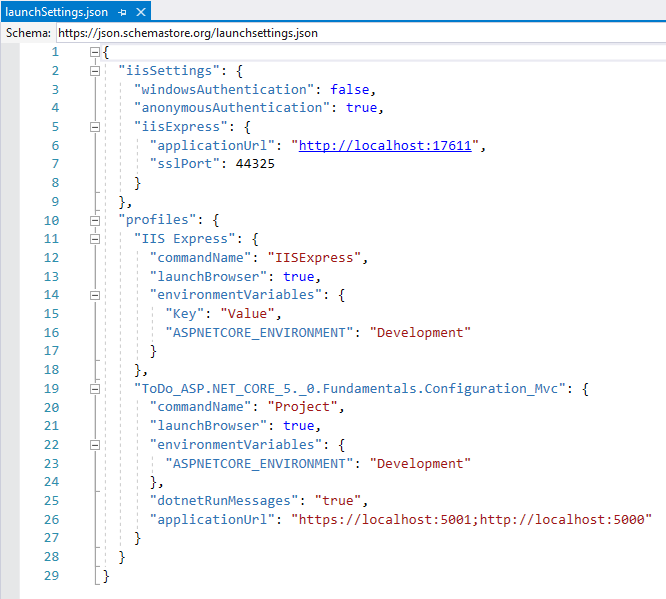
Gördüğünüz üzere environmentVariables içerisinde ASPNETCORE_ENVIRONMENT environment variable'ı var. IIS veya Project ismine göre environmentVariables değiştrebilirisiniz veya yaratabilirsiniz.
## Environment variable'lara code içerisinden nasıl okuruz ?
a.) Şuana kadar merak etmiş olmalsınız ki configure metodunun içinde parametre olarak IWebHostEnvironment geçiliyor.

Bu IWebHostEnvironment bize uygulamanın ASPNETCORE_ENVIRONMENT adlı envrionment variable değerlerini bize verebilmektedir.
```
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
// ASPNETCORE_ENVIRONMENT Development ise bir şeyler yap.
}
if (env.IsStaging())
{
// ASPNETCORE_ENVIRONMENT Staging ise bir şeyler yap.
}
if (env.IsProduction())
{
// ASPNETCORE_ENVIRONMENT Production ise bir şeyler yap.
}
.
.
.
```
b.) Eğer örneğin aşağıdaki gibi bir environment variable belirlediyseniz

Bu environment variable'a şöyle ulaşabilirsiniz:
```
if (Environment.GetEnvironmentVariable("Mustafa")=="24")
{
// Mustafa 24 ise bir şeyler yap.
}
```
## Environment variable'lara göre düzenlemeleri .cshtml dosyası içerisinde nasıl okuruz ?
Örneğin Index.cshtml dosyasının içerisine şu kodları yazarsak :
a.) include verilen parametreye eşitse ASPNETCORE_ENVIRONMENT variable'ı içerisindeki yazı yazdırılı.
```
<environment include="Development">
<div>"include" dersek "ASPNETCORE_ENVIRONMENT" "Development"a eşit olursa bu yazıyı yazdırır Index.chtml dosyası. </div>
</environment>
```
b.) exclude verilen parametreye eşitse ASPNETCORE_ENVIRONMENT variable'ına içerisindeki yazı yazdırılmaz.
```
<environment exclude="Development">
<div>"exclude" dersek "ASPNETCORE_ENVIRONMENT" "Development"a eşit olursa bu yazıyı yazdırmaz Index.chtml dosyası.</div>
</environment>
```
Sonuç :
* Environment variable "nedir"ini, "neden güvenlidir"ini ve "nasıl tanımladığını" anladık.
* IWebHostEnvironment ile nasıl ASPNETCORE_ENVIRONMENT kontrolu yapabileceğimizi gördük : env.IsDevelopment() vs..
* Environment.GetEnvironmentVariable("key") kullarak custom olarak yazdığımız environment variable'larımızı nasıl erişebileceğimizi gördük.
* environment tag helper'ına verilen exclude ve include özellikleri ile ASPNETCORE_ENVIRONMENT variable'ının değerini göre .cshtml dosyasını nasıl değiştirebileceğimiziz gördük.
Bir dahaki yazıda görüşmek dileğiyle.
Mustafa Samed Yeyin.
En iyi dileklerim ile.
| mustafasamedyeyin |
832,447 | Intersection and Union of Array in JavaScript | What is union of Arrays? Union of arrays would represent a new array combining all... | 14,693 | 2021-09-20T07:01:51 | https://dev.to/rajeshkumaryadavdotcom/intersection-and-union-of-array-in-javascript-2mg8 | javascript, interview | 
# What is union of Arrays?
Union of arrays would represent a new array combining all elements of the input arrays, without repetition of elements.
```javascript
let arrOne = [10,15,22,80];
let arrTwo = [5,10,11,22,70,90];
// Union of Arrays
let arrUnion = [...new Set([...arrOne, ...arrTwo])];
console.log(arrUnion);
```
# What is intersection of Arrays?
The intersection of two arrays is a list of distinct numbers which are present in both the arrays. The numbers in the intersection can be in any order.
```javascript
let arrOne = [10,15,22,80];
let arrTwo = [5,10,11,22,70,90];
// Intersection of Arrays
let arrIntersection = arrOne.filter((v) =>{
return arrTwo.includes(v);
});
console.log(arrIntersection);
```
## Demo -
{% jsfiddle https://jsfiddle.net/developerrky/bqpd6ave/18/ js,html,result %} | rajeshkumaryadavdotcom |
832,514 | DevOps development guidelines | Motivation 2 years ago I have switched from software development to DevOps in a Danish... | 0 | 2021-09-23T11:54:10 | https://dev.to/mindaugaslaganeckas/devops-katas-32e0 | devops, opensource, design | ## Motivation
2 years ago I have switched from software development to DevOps in a Danish high-end technology company. The team, that I had joined, consisted of 5 very talented engineers, who delivered build agents, pipelines, automation scripts etc. to the whole R&D of more than 400 hardware and software engineers. Joining this talented and ambitious DevOps team back then, it seemed that there is no limit to what we can achieve. We could see so many new good solutions out there to ease our customers` day-to-day hurdles. Unfortunately, quite fast we had noticed, that adding more technologies to the stack made us vulnerable to [bus-factor](https://en.wikipedia.org/wiki/Bus_factor) and stretched us quite thin. In addition, we had no consensus of where to keep secrets that made it hard managing them, shared pipelines implemented by us, were hard to debug/run on a dev machine, the number of self hosted solutions grew rapidly requiring more and more time to attend them... So we had started working on development guidelines for the team, which we called Katas back then.
## Development guidelines
Here are some of the guidelines that we would like to share with you. The idea with these guidelines is to minimize the impact on the organization and deliver high quality tools and infrastructure while keeping a high pace for it. Please, leave a comment, if you have similar experiences or more to add.
The development guidelines are not listed in a prioritized order.
### Programming languages
#### Limit the number of programming languages
It is so fun to solve a specific problem with the best tool there is. It is not fun at all to maintain solutions that use technologies you do not know. In the start we used Groovy, NodeJS, Powershell(Core), DotNet(Core), Bash, Java, Python. Unfortunately, we have some solutions now that we have stopped maintaining and reject any new feature requests, because we do not have the right competencies and no time to acquire them.
#### How to choose programming languages
For us the deciding factor in this case is our approach to [inner source](https://en.wikipedia.org/wiki/Inner_source) all what we develop. We want to use the same programming languages as other engineers in the company. All our scripts, tools etc are open to contribute for everyone inside the company. We want people to help us out instead of being blocked by us. And that works quite well! :)
### Design principles
#### Always prefer a cloud-based solution
It is so easy to download a docker image, create a VM for it, deploy and use it right away. Especially if a solution is free of charge. No budget negotiations, no approvals needed. Unfortunately, the maintenance of such VM/docker combo should not be underestimated. Your users will ask for new versions of the SW, your IT department will require to comply with the company's security policy. And it will happen when you have the least time for it.
#### CI/CD must be able to push/release/execute what you are building, not just locally.
How many times have I heard: it works on my computer so I am done, am I? NO. You are done, when you have a pipeline for your project.
#### Design so that local builds and CI builds work the same way
This one is tricky. The more patches/hack you will add to the pipeline to compensate a faulty tooling, the more time will you have to use when debugging the local builds that do not work.

The image above shows a build stage of a DotNet project in a Jenkins pipeline. A developer will have to use time and effort before she configures local IDE to work the same way as the pipeline.
All in all, you want to develop your pipelines/tooling so that it is easy to setup in the IDE. In the example above a simplification and integration in `dotnet build` would be a desired solution.
### Deployment strategies
This section is mostly relevant to the organizations, that are larger or has a similar size, that I work for. While updating 2 build agents can also be challenging, still the impact of updating 40+ build agents has a much larger impact. In the latter case, the experience suggests to use Canary deployment strategy, when introducing new changes to the VM templates for your build agents. Normally, you do not know how people are using the build machines you provide, what kind of projects they are building. Introducing a change slowly minimizes the impact to the organization.
### Open source vs Inner source
Choose to contribute to an open source project instead of developing your own custom solution. Maintenance is a killer. Your team will have to learn your solution. Normally a community of an open source project is much larger than your team. Naturally, there are several risks (worth considering!) associated with this approach:
1. Your pull requests can get stuck for a year or longer
2. It can take longer time to develop a contribution than a local hack. But you will get your code reviewed from someone knowledgeable in the field and you will learn something - no doubt!
### Managing secrets
Do not distribute your secrets across build systems, environment variables on the deployment machines and other places. It is a mess! Github does not even let you read the secret back, once it is put there. Keep the secrets in one (or several) place and manage access to them.
### Monitoring and telemetry
Working without monitoring and telemetry is like walking in the mine field in the dark. You want to stay ahead of the issues, such as servers running out of the disk space, before they hit the organization. In addition, you want to spend the time and energy on the tools and pipelines, that are being used most. Rich telemetry and monitoring data can help you to take decisions, where to put your focus most.
## Acknowledgements
I would like to thank Rasmus Jelsgaard and Vaida Laganeckiene for inputs, ideas when materializing development guidelines and proof-reading when working on this post.
| mindaugaslaganeckas |
832,569 | First thing to do when joining or building a team | Get to know your teammates and how to effectively work with them by sharing user manuals. | 0 | 2021-09-22T08:12:14 | https://dev.to/pixari/first-thing-to-do-when-joining-or-building-a-team-31bg | beginners, productivity, discuss, tutorial | ---
description: Get to know your teammates and how to effectively work with them by sharing user manuals.
---
**Building a team or joining an established team** is certainly hard.
Every transitions leads to new challenges and we have to be as prepared as possible.
Multiple people means multiple personalities, habits, languages, points of view, opinions, conflicts to deal with.
However, **plurality also represents the strength of a team**. It is up to us to turn challenges into opportunities.
**It is essential to make rules, expectations and goals explicit**.
The sooner the team is on the same page and makes "visible" what is "invisible", the sooner it can define the boundaries, start a self-improvement process and become extremely productive.
Obviously it is a very complex process and cannot be summarised in an article. However, I'd like to share with you **my very first step**, what I always do when I need to build or join a team: my "**User Manual**" *(I've been calling it this way since I discovered the [Atlassian Playbook](https://www.atlassian.com/team-playbook/plays/my-user-manual) - thank you, [David](https://www.linkedin.com/in/dkagerer/)!)*.
[<img alt="Screenshot from the Atlassian's Playbook User Manual page, showing the title and the description of the workshop" src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ts86wralb2zzr8pkrqq1.png" />](https://www.atlassian.com/team-playbook/plays/my-user-manual)
Get to know your teammates and how to effectively work with them by sharing user manuals, which include communication preferences and more.
<hr />
## What is the "User manual"?
It's a way to *get to know your teammates and how to effectively work with them* and of course *to let your teammates get to know you and how to effectively work with you*.
You can either do it on your own or [follow these instructions](https://www.atlassian.com/team-playbook/plays/my-user-manual). It's just very important that you keep it honest.
At the end it's nothing more than your own list of questions and answers, an "interview" with yourself.
Those are **my questions**:
- What are the **environments I like to work in**?
- What are my preferred working hours?
- What are my **communication preferences**?
- What are my preferred ways to **receive feedback**?
- What are the things I need?
- What are the **things I struggle with**?
- What are the **things I love**?
- If I were a meme, I would be...?
- What is my favourite saying?
- What are other things I want you to know about me?
That's my list, but as I said, everyone can choose the questions and answers, make it more or less personal, more or less fun, more or less detailed.
When the "User Manuals" are ready, it is very important to organise a meeting with the team and present the documents.
Please, consider to let your team know the following at the start of the meeting (quoting Atlassian's Playbook):
- This activity is designed for team members to understand how to **support each other’s ideal conditions for getting their best work done**.
- No one will be pressured to share anything they’re not comfortable sharing.
- **This meeting is a safe space**. Nothing they share will be used against them.
<hr />
## My "User manual"?
I keep my "User Manual" always public and accessible to everyone.
Actually I'm thinking about sharing it on my [personal website](https://raffaelepizzari.com/).
<small>
<table class="wrapped" style="margin-left: auto;margin-right: auto;">
<colgroup>
<col style="width: 415.0px;"/>
<col style="width: 520.0px;"/>
</colgroup>
<tbody>
<tr>
<th>
<p>
<strong>Environments I like to work in</strong>
</p>
</th>
<td>
<ul class="ak-ul">
<li>
<p>Inclusive</p>
</li>
<li>Diverse</li>
<li>Positive</li>
<li>
<span style="color: rgb(32,33,36);">Supportive</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Proactive</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Happy</span>
</li>
</ul>
</td>
</tr>
<tr>
<th>
<p>
<strong>Preferred working hours</strong>
</p>
</th>
<td>
<p>6:30 - 15:00</p>
<p>But I'll be of course available 9:00-17:00. <ac:emoticon ac:name="smile"/>
<br/>
<br/>
</p>
</td>
</tr>
<tr>
<th>
<p>
<strong>Communication preferences</strong>
</p>
</th>
<td>
<div class="content-wrapper">
<p>Feel free to contact me any time. I'll get back to you as soon as I can.</p>
<p>However, I do have some communication preferences I would share with you:</p>
<ul>
<li>Slack is the best way to communicate with me</li>
<li>Write longer messages that scan quickly</li>
<li>Use threads</li>
<li>Replace short follow-up messages with emoji reactions</li>
</ul>
<p>
<em>If you contact me via e-mail:</em>
</p>
<ul>
<li>Start with the main point, conclude with the context</li>
<li>One email thread per topic</li>
<li>Summarise complex email threads upon including new recipients</li>
<li>Manage recipients (++Hans, --Lara, explain why in 2 words at email start) <ac:image ac:class="an1">
<ri:url ri:value="https://fonts.gstatic.com/s/e/notoemoji/13.1.1/1f4e3/72.png"/>
</ac:image>
</li>
<li>Describe the topic in the subject line</li>
<li>Hyperlink whenever possible</li>
</ul>
</div>
</td>
</tr>
<tr>
<th>
<p>
<strong>Preferred ways to receive feedback</strong>
</p>
</th>
<td>
<p>I would be very happy to receive constructive feedback. I truly believe in a positive feedback culture and I can't stress enough the importance of it.</p>
<p>I am sharing here some of my wishes for our feedback sessions:</p>
<ul>
<li>1-on-1 meeting</li>
<li>Share with me the purpose of the feedback</li>
<li>Focus on performance and facts, not personal traits</li>
<li>Ensure a neutral environment</li>
<li>Set up a meeting</li>
</ul>
</td>
</tr>
<tr>
<th>
<p>
<strong>Things I need</strong>
</p>
</th>
<td>
<ul>
<li>
<span style="color: rgb(32,33,36);">Openness</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Transparency</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Respect</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Empathy</span>
</li>
</ul>
</td>
</tr>
<tr>
<th>
<p>
<strong>How I learn best</strong>
</p>
</th>
<td>
<ul>
<li>
<span style="color: rgb(32,33,36);">Doing pair programming / working</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Focusing on a topic and avoid multitasking</span>
</li>
<li>Making my health your No. 1 priority</li>
<li>
<span style="color: rgb(32,33,36);">Getting constructive Feedback</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Reading books</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Doing retrospectives</span>
</li>
</ul>
</td>
</tr>
<tr>
<th>
<p>
<strong>Things I struggle with</strong>
</p>
</th>
<td>
<ul>
<li>
<span style="color: rgb(32,33,36);">I don't like wasting time</span>
</li>
<li>
<span style="color: rgb(32,33,36);">I am impatient when I attend a not well-structured meeting</span>
</li>
<li>
<span style="color: rgb(32,33,36);">
<span style="color: rgb(29,42,87);">I don't like pep talks</span>
</span>
</li>
</ul>
</td>
</tr>
<tr>
<th>
<p>
<strong>Things I love</strong>
</p>
</th>
<td>
<ul>
<li>
<span style="color: rgb(32,33,36);">Achieve goals</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Have fun while reaching goals</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Work in a happy environment and connect with colleagues</span>
</li>
<li>
<span style="color: rgb(32,33,36);">Support other developers</span>
</li>
</ul>
</td>
<td>
<p>
<br/>
</p>
</td>
</tr>
<tr>
<th>
<p>
<strong>If I were a meme, I would be...</strong>
</p>
</th>
<td>
<p><img alt="'This is fine' meme. A dog is drinking a coffee in a room full of flames and he is reassuring itself that everything is fine." src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/hkn8z9pc7y648efjkts8.jpg" />
</p>
</td>
</tr>
<tr>
<th>
<p>
<strong>My favorite saying</strong>
</p>
</th>
<td>
<p>I really like the "Retrospective Prime Directive":</p>
<p>"Regardless of what we discover, we understand and truly believe that everyone did the best job they could, given what they knew at the time, their skills and abilities, the resources available, and the situation at hand."</p>
<p>
<em>
<span style="color: rgb(0,0,0);">Norm Kerth</span>
</em>
<br/>
<em>Project Retrospectives: A Handbook for Team Review</em>
</p>
</td>
</tr>
<tr>
<th>
<p>
<strong>Other things I want you to know about me</strong>
</p>
</th>
<td>
<p>I run a <a href="https://www.codejourneys.org">free learning community for developers</a>.</p>
<p>I am volunteering as a mentor.</p>
</td>
</tr>
</tbody>
</table>
</small>
<hr />
## What about your "User Manual"?
- Do you have one?
- Would you like to have one?
- Would you like to share your User Manual here?
If you need support to create one, feel free to write me.
I'd love to hear your feedback!
<hr />
(Cover foto credits: https://pixabay.com/)
| pixari |
832,860 | 1-Hour Video Interview with Kyle Simpson - Help The Kickstarter! [You Don't Know JS Yet] | Join Kyle Simpson's You Don't Know JS Yet Kickstarter Campaign to help this great mentor succeed in... | 0 | 2021-09-20T15:34:32 | https://dev.to/gethiredfast/interview-with-kyle-simpson-help-the-kickstarter-you-don-t-know-js-yet-44jm | javascript, codenewbie, webdev, books | [Join Kyle Simpson's _You Don't Know JS Yet_ Kickstarter Campaign](https://bit.ly/3CkZO51) to help this great mentor succeed in his dream to bring a wealth of knowledge to all of us on our journey to become JS Masters.
{% youtube _RR1ETGu8aE %}
There are 2 types of mentors that come to mind when I reflect on those who helped to mold and shape me into the excellent developer that I am today. I gained physical mentors that were in person with me and able to guide me on a daily basis.
I rarely discuss the other type of mentor that greatly influenced my life, the mentor who was in the shadows, thousands of miles away, and still made a profound impact on my career. Kyle Simpson was one of those “mentors from afar” as I call it.
On my quest to sharpen my skills, way back in 2013, I happened to attend an Angular conference where Kyle Simpson was one of the headliners.
That 3-day training was so impactful that his book series became the air I breathed while I sharpened my skills over the following 8 years.
To this day I can recite helpful content from memory for all of my students.
One of the great things about Kyle is that he always operates in the mindset of keeping students and learners first. He wants to continue publishing his essential JS content so all of us will be able to crush their career goals.
In addition to [pledging your support on Kickstarter](https://bit.ly/3CkZO51), you can also show your support and **get a serious discount** on the first 2 books in the _You Don't Know JS Yet_ series and his essential yet practical _Functional-Light JavaScript_ book via the following links:
[You Don't Know JS Yet: Get Started](https://leanpub.com/ydkjsy-get-started/c/coding-career-fastlane)
[You Don't Know JS Yet: Scope & Closures](https://leanpub.com/ydkjsy-scope-closures/c/coding-career-fastlane)
[Functional-Light JavaScript](https://leanpub.com/fljs/c/coding-career-fastlane)
| fastlane |
832,869 | Jaeger vs Zipkin - Key architecture components, differences and alternatives | Distributed tracing is becoming a critical component of any application's performance monitoring... | 0 | 2021-09-23T13:17:05 | https://signoz.io/blog/jaeger-vs-zipkin/ | Distributed tracing is becoming a critical component of any application's performance monitoring stack. However, setting it up in-house is an arduous task, and that's why many companies prefer outside tools. Jaeger and Zipkin are two popular open-source projects used for end-to-end distributed tracing. Let us explore their key differences in this article.
[](https://bit.ly/2WkkmL4)
Both Zipkin and Jaeger are popular open-source distributed tracing tools. Zipkin was originally inspired by Google's Dapper and was developed by Twitter. Zipkin is a much older project than Jaeger and was first released as an open-source project in 2012. Jaeger was originally built by teams at Uber and then open-sourced in 2015. It got accepted as a Cloud Native incubation project in 2017 and graduated in 2019.
Before we dive into the differences between Jaeger and Zipkin, let's take a short detour to understand distributed tracing.
## What is distributed tracing?
In the world of microservices, a user request travels through hundreds of services before serving a user what they need. To make a business scalable, engineering teams are responsible for particular services with no insight into how the system performs as a whole. And that's where distributed tracing comes into the picture.
<figcaption>Microservice architecture of a fictional e-commerce application</figcaption>
Distributed tracing gives you insight into how a particular service is performing as part of the whole in a distributed software system. There are two important concepts involved in distributed tracing: **Spans** and **trace context**.
User requests are broken down into spans.
> What are spans?<br></br>
> Spans represent a single operation within a trace. Thus, it represents work done by a single service which can be broken down further depending on the use case.
A trace context is passed along when requests travel between services, which tracks a user request across services. You can see how a user request performs across services and identify what exactly needs your attention without manually shifting through multiple dashboards.
<figcaption>A trace context is passed when user requests pass from one service to another</figcaption>
## Jaeger and Zipkin: Key components
<a href = "https://github.com/jaegertracing/jaeger" rel="noopener noreferrer nofollow" target="_blank" ><b>Jaeger's</b></a> source code is primarily written in Go, while <a href = "https://github.com/openzipkin/zipkin" rel="noopener noreferrer nofollow" target="_blank" ><b>Zipkin's</b></a> source code is primarily written in Java. The architecture of Jaeger and Zipkin is somewhat similar. Major components in both architectures include:
- Instrumentation Libraries
- Collectors
- Query Service and web UI
- Database Storage
<figcaption>Illustration of Jaeger architecture (Source: Jaeger website)</figcaption>
<figcaption>Illustration of Zipkin architecture (Source: Zipkin website)</figcaption>
### Instrumentation Libraries
Instrumentation is the process of generating telemetry data(logs, metrics, and traces) from an application code. Both Jaeger and Zipkin provide language-specific instrumentation libraries. Instrumentation enables a service to create spans on incoming requests and to attach context information on outgoing requests.
Key points to note about instrumentation libraries of Jaeger and Zipkin:
- Jaeger's instrumentation libraries are based on <a href = "https://opentracing.io/" rel="noopener noreferrer nofollow" target="_blank" ><b>OpenTracing APIs</b></a>. OpenTracing was also started at Uber with an aim to create vendor-neutral instrumentation APIs for distributed tracing. Zipkin has its own instrumentation libraries.
- Jaeger has <a href = "https://www.jaegertracing.io/docs/1.26/client-libraries/" rel="noopener noreferrer nofollow" target="_blank" ><b>official client libraries</b></a> in Go, Java, Node.js, Python, C++, C#. Zipkin team maintains <a href = "https://zipkin.io/pages/tracers_instrumentation.html" rel="noopener noreferrer nofollow" target="_blank" ><b>instrumentation libraries</b></a> for frameworks in C#, Go, Java, Javascript, Ruby, Scala, and PHP.
- Both Jaeger and Zipkin support out-of-box instrumentation for a lot of popular frameworks. Jaeger is also compatible with Zipkin's API. That means you can use instrumentation libraries of Zipkin with Jaeger.
<a href = "https://github.com/orgs/opentracing-contrib/repositories" rel="noopener noreferrer nofollow" target="_blank" >Jaeger's 3rd party supported frameworks</a><br></br>
<a href = "https://zipkin.io/pages/tracers_instrumentation.html" rel="noopener noreferrer nofollow" target="_blank" >Zipkin's 3rd party supported frameworks</a>
### Collectors
Telemetry data collected by the instrumentation libraries are sent to a collector in both Jaeger and Zipkin. Jaeger's collectors validate traces, index them, perform any transformations, and finally stores them. Zipkin collector too validates and indexes the collected trace data for lookups.
### Query Service and Web UI
Zipkin provides a JSON API for finding and retrieving traces. Jaeger provides stateless service API endpoints which are typically run behind a load balancer, such as NGINX.
The consumer of the query service is a Web UI in both Jaeger and Zipkin, which is used to visualize trace data by a user.
<figcaption>Jaeger's Web UI showing spans with Gantt charts</figcaption>
<figcaption>Zipkin's trace UI</figcaption>
### Database storage
Both Jaeger and Zipkin provide pluggable storage backends for trace data. Cassandra and Elasticsearch are the primarily supported storage backends by Jaeger.
Zipkin was originally built to store data in Cassandra, but it later started supporting Elasticsearch and MySQL too.
## Comparing Jaeger and Zipkin
Jaeger and Zipkin have a lot of similarities in their architecture. Though Zipkin is an older project, Jaeger has a more modern and scalable design. Let us summarize the key differences between Jaeger and Zipkin in the following points:
- Jaeger's has wider support of instrumentation libraries as it supports OpenTracing APIs and is also compatible with Zipkin's API. Jaeger also provides an option to <a href = "https://www.jaegertracing.io/docs/1.26/getting-started/#migrating-from-zipkin" rel="noopener noreferrer nofollow" target="_blank" ><b>migrate from Zipkin</b></a>.
- Jaeger can be deployed as a single binary where all Jaeger backend components run as a single process or as a scalable distributed system. Zipkin, on the other hand, can only be run as a single binary that includes the collector, storage, query service, and web UI.
- As Jaeger comes under CNCF along with other projects such as Kubernetes, there are official orchestration templates for running Jaeger with [Kubernetes](https://github.com/jaegertracing/jaeger-kubernetes) and [OpenShift](https://github.com/jaegertracing/jaeger-openshift). Zipkin provides three options to build and start an instance of Zipkin: using Java, Docker, or running from the source.
- Despite being older, Jaeger has caught up to Zipkin in terms of community support. Zipkin is a standalone project which came into existence before containerization went mainstream. Jaeger, as part of CNCF, is a recognized project in cloud-native architectures.
Both Jaeger and Zipkin are strong contenders when it comes to a distributed tracing tool. But are traces enough to solve all performance issues of a modern distributed application? The answer is no. You also need metrics and a way to correlate metrics with traces with a single dashboard. Most SaaS vendors provide both metrics and traces under a single pane of glass. But the beauty of Jaeger and Zipkin is that they are open-source. What if an open-source solution does both and comes with a great web UI with actionable insights for your engineering teams?
That's where [SigNoz](https://signoz.io/) comes into the picture.
## A better to alternative to Jaeger and Zipkin - SigNoz
SigNoz is a full-stack open-source application performance monitoring and observability tool which can be used in place of Jaeger and Zipkin. It provides advanced distributed tracing capabilities along with metrics under a single dashboard.
SigNoz is built to support OpenTelemetry natively. It also provides users flexibility in terms of storage. You can choose between ClickHouse or Kafka + Druid as your backend storage while installing SigNoz.
<figcaption>Architecture of SigNoz with ClickHouse as storage backend and OpenTelemetry for code instrumentatiion</figcaption>
SigNoz comes with out of box visualization of things like RED metrics.
<figcaption>SigNoz UI showing application overview metrics like RPS, 50th/90th/99th Percentile latencies, and Error Rate</figcaption>
You can also use flamegraphs to visualize spans from your trace data. All of this comes out of the box with SigNoz.
<figcaption>Flamegraphs showing exact duration taken by each spans - a concept of distributed tracing</figcaption>
Some of the things SigNoz can help you track:
- Application overview metrics like RPS, 50th/90th/99th Percentile latencies, and Error Rate
- Slowest endpoints in your application
- See exact request trace to figure out issues in downstream services, slow DB queries, call to 3rd party services like payment gateways, etc
- Filter traces by service name, operation, latency, error, tags/annotations.
- Run aggregates on trace data
- Unified UI for both metrics and traces
You can check out SigNoz's GitHub repo here 👇
[](https://bit.ly/2WkkmL4)
| ankit01oss | |
832,876 | Static Content Server with Nodejs without frameworks | Static server with Nodejs This tutorial will walk you through few steps how to set up... | 0 | 2021-09-21T11:14:14 | https://dev.to/webduvet/static-content-server-with-nodejs-without-frameworks-d61 | node, javascript, beginners, tutorial | # Static server with Nodejs
This tutorial will walk you through few steps how to set up simple http server for static content using only **nodejs**. We will add basic features as serving requested resource from file or from memory(cache) and responding with error message when no resource is available.
In reality you will almost never run any http server in this manner however, it might be very helpful to understand what frameworks like **Expressjs** do under the hood. It also could serve as a very simple testing tool in your local environment.
Requirements is to have installed `nodejs` on the system, preferably newer version (12+). The recommended environment is Unix like machine, but it is not necessary. The target audience is javascript beginner or UI developer who is curious how does http server work in nodejs.
We will go through the following:
- setup http server, what is static server
- adding rules how to read the request
- finding resources and caching
## Lets start with the simplest possible
Http server is a network application which listens to incoming network traffic. It is doing so by acquiring some system resources. Specifically it creates the process in the memory which listens to incoming traffic over the network on the dedicated port. To talk to the http server we need the physical address of the computer and the port which the application acquired. Nodejs provides all necessary functionality to do so. Let's have a look how nodesj does it.
the simplest way how to start and run the most basic http server using nodejs would be something like this:
```sh
node -e "require('http').createServer((req, res) => {res.end('hello world')}).listen(3000)"
```
Running the above code on Linux machine with node installed will start the server.
it can be verified by typing `http://localhost:3000` in the browser URL bar.
or by typing the following in new terminal window:
```sh
> curl http://localhost:3000
// expected response is
hello world
```
In this basic example we can easily see the building stones. We create an object and call the listen which effectively opens up the connection on the given port and it is waiting for the incoming request complying HTTP protocol.
We can test it with `netcat` sending a text complying with HTTP GET request header.
```bash
printf "GET / HTTP/1.1\r\n\r\n" | nc 127.0.0.1 3000
// The expected response is again
HTTP/1.1 200 OK
Date: Tue, 21 Sep 2021 09:59:13 GMT
Connection: keep-alive
Keep-Alive: timeout=5
Content-Length: 11
hello world%
```
It is a little richer because **netcat** prints just about everything what is received in the response including response header. `curl` can do it as well. Go ahead and try using `-i` flag.
The other main component aside `createServer()` and `listen()` is callback passed into [createServer](https://nodejs.org/dist/latest-v16.x/docs/api/http.html#http_http_createserver_options_requestlistener). It contains references to [request](https://nodejs.org/dist/latest-v16.x/docs/api/http.html#http_class_http_clientrequest) and [response](https://nodejs.org/dist/latest-v16.x/docs/api/http.html#http_class_http_serverresponse) objects. Working with these two objects we can interact with our http server.
This article is however not about networking and protocols but tutorial how to build simple static content server using only **nodejs** and this does not get us too far since it responses with "hello world" to any request. Let's see if we can do better.
## Serving response from a file
Let's make one step further in terms of the functionality of our new http server. We are aiming towards the server which can serve static content. The word static here means similar to "static" keyword in javascript. It is something which is already known and defined prior the user request. From the web server we usually referred as static content to files like images, icons, CSS files and so on. So let's server user with the content of the file rather then hard coded message.
```js
module.exports = function staticServer() {
const path = './static_content';
const port = 3000;
// create server object as in previous example
var server = http.createServer(function(req, res){
const filePath = path + 'index.html';
fs.readFile(absPath, function(err, data) {
res.end(data);
});
});
server.listen(port, function() {
console.log("server listening on port: " + port));
});
return server;
};
```
in addition, create directory and file `./static_content/index.html` containing your content:
```
<html>
<body>
<h1>
Hello, this is very simple
</h1>
</body>
</html>
```
In the above code we define the path where the static content is, in this case it is index.html file we read the file and send the data back to user as a response to client's request.
`response.end() executes the above with some [default headers]()`
## Finding and serving requested resource
Next in the quest serving the content based on the user request is finding the requested resource our user is asking. The server looks it up and if it exists it serves the content of the file to client.
```js
module.exports = function staticServer() {
const path = './static_content';
const port = 3000;
// create server object as in previous example
var server = http.createServer(function(req, res){
// get the resource from request
const filePath = path + req.url;
fs.readFile(absPath, function(err, data) {
res.end(fileContents);
});
});
server.listen(port, function() {
console.log("server listening on port: " + port));
});
return server;
};
```
`const filePath = path + req.url` show how mapping between the requested resource and the actual resource might work. `Path` is relative path to location where our nodejs app is running and `req.url` is last bit of the URI identifying what resource user wants.
http://www.example.com/**resource**
### Caching
Let's make one small addition. The cache. When we server the file from a disk it is not a big deal, as it is pretty quick, however if the file would come from some more time expensive resource we want to keep the content of the file for later requests. Here is a very simple example how it can be implemented:
```js
module.exports = function staticServer() {
const path = './static_content';
const port = 3000;
const cache = {}
// create server object as in previous example
var server = http.createServer(function(req, res){
// get the resource from request
const filePath = path + req.url;
if (cache[filePath]) {
sendFile(res, filePath, cache[filePath]);
} else {
fs.readFile(filePath, function(err, data) {
res.end(fileContents);
});
}
});
server.listen(port, function() {
console.log("server listening on port: " + port));
});
return server;
};
```
## Basic error handling and wrap up
In this last section we add some simple error handling. In case the user specifies the resource which is not found in the given location of static content or if the resource in not readable we need to notify the user with an error. The standard way of doing it is to return response with code 404 in the response headers. We also might add some explanation in the content.
```js
let
fs = require('fs'),
path = require('path'),
http = require('http');
const cache = {};
/**
* lookup content type
* infer from the extension
* no extension would resolve in "text/plain"
*/
function lookupContentType(fileName) {
const ext = fileName.toLowerCase().split('.').slice(1).pop();
switch (ext) {
case 'txt':
return 'text/plain';
case 'js':
return 'text/javascript'
case 'css':
return 'text/css'
case 'pdf':
return 'application/pdf';
case 'jpg':
case 'jpeg':
return 'image/jpeg';
case 'mp4':
return 'video/mp4';
default:
return ''
}
}
/**
* plain 404 response
*/
function send404(res){
res.writeHead(404, {'Content-Type':'text/plain'});
res.write('Error 404: resource not found.');
res.end();
}
/**
* sending file response
*/
function sendFile(res, filePath, fileContents){
res.writeHead(200, {"Content-Type": lookupContentType(path.basename(filePath))});
res.end(fileContents);
}
/**
* serve static content
* using cache if possible
*/
function serveStatic(res, cache, absPath) {
// use cache if there is any
if (cache[absPath]) {
sendFile(res, absPath, cache[absPath]);
} else {
fs.exists(absPath, function(fileExists) {
// attempt to read the resource only if it exist
if (fileExists) {
fs.readFile(absPath, function(err, data){
// not able to read the resource
if(err) {
send404(res);
} else {
cache[absPath] = data;
sendFile(res, absPath, data);
}
});
} else {
// resource does not exist
send404(res);
}
});
}
}
module.exports = function startServer(spec){
let { path, port } = spec;
// create server object
var server = http.createServer(function(req, res){
// if no resource is specified use index.html
if(req.url === '/') {
const filePath = path + 'index.html';
serveStatic(res, cache, filePath);
} else {
const filePath = path + req.url;
serveStatic(res, cache, filePath);
}
});
server.listen(port, function(){
console.log("server listening on port: "+port);
});
return server;
};
```
Now we can run it like this:
```js
const startServer = require('./startServer.js')
startServer({ path: './static_content', port: 3000 });
```
In the above example I added very basic error handling. In the event the resource specified by the user is not found in the static content directory, or it can't be open for reading, the server response with different header with error [code 404](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status) and different content explaining what went wrong.
In order for a browser to understand better what kind of content we are dealing with, it is also a good idea to include some indication about resource [content type](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_types). In `lookupContentType` we can do it just based on the file extension type.
Now if we try `pdf` the browser will have no problem opening pdf file instead downloading it.
## Conclusion
This is by no means a robust product, merely a very simplified example how things do work behind the curtain in frameworks like `expressjs`. We leveraged the nodejs built in library `http` to run simple http server.
We implemented simple routing to find static content in a given location. We also implemented simple in memory caching, content type resolution and basic error handling in case the resource is not found or accessible.
## Further reading
If anybody want to build their own server serving static content I would recommend using existing framework. I would also strongly advice looking at least into following topics:
- session and transaction management
- caching
- security, authentication and authorisation
## Sources
1. [nodejs/http](https://nodejs.org/dist/latest-v16.x/docs/api/http.html)
2. [netcat](https://www.unix.com/man-page/Linux/1/netcat/)
3. [http](https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol)
4. [status codes](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status)
5. [Common MIME types](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_types)
6. [title image](https://pixabay.com) | webduvet |
833,043 | MongoDB $weeklyUpdate (September 20, 2021): Latest MongoDB Tutorials, Events, Podcasts, & Streams! | 👋 Hi everyone! Welcome to MongoDB $weeklyUpdate! Here, you'll find the latest developer... | 8,475 | 2021-09-20T16:54:00 | https://www.mongodb.com/community/forums/t/mongodb-weeklyupdate-39-september-20-2021-latest-mongodb-tutorials-events-podcasts-streams/124766 | mongodb, database, programming, mobile | ## 👋 Hi everyone!
Welcome to MongoDB $weeklyUpdate!
Here, you'll find the latest developer tutorials, upcoming official MongoDB events, and get a heads up on our latest Twitch streams and podcast, curated by [Adrienne Tacke](https://twitter.com/AdrienneTacke).
Enjoy!
---
## 🎓 Freshest Tutorials on [DevHub](https://developer.mongodb.com/)
_Want to find the latest MongoDB tutorials and articles created for developers, by developers? Look no further than our [DevHub](https://developer.mongodb.com/)!_
### [StartActivityForResult is deprecated !!](https://www.mongodb.com/developer/article/realm-startactivityforresult-registerForActivityResult-deprecated-android-kotlin/)
[Mohit Sharma](https://www.mongodb.com/developer/author/mohit-sharma/)
Learn the benefits and usage of registerForActivityResult for Android in Kotlin.
### [Build Offline-First Mobile Apps by Caching API Results in Realm](https://www.mongodb.com/developer/how-to/realm-api-cache/)
[Andrew Morgan](https://twitter.com/andrewmorgan)
This article shows how the RCurrency mobile app fetches exchange rate data from a public API, and then caches it in Realm for always-on, local access.
---
## 📅 Official MongoDB [Events](https://live.mongodb.com/events/#/calendar)
_Attend an official MongoDB event near you (virtual for now)! Chat with MongoDB experts, learn something new, meet other developers, and win some swag!_
Sep 23 (4:00 PM GMT | Global) - [6 Things Lauren Learned While Modeling Data in MongoDB](https://live.mongodb.com/events/details/mongodb-mongodb-global-virtual-community-presents-6-things-lauren-learned-while-modeling-data-in-mongodb/)
Sep 29 (3:00 PM GMT | Global) - [MongoDB Atlas mit Ansible automatisieren](https://live.mongodb.com/events/details/mongodb-dach-virtual-community-presents-mongodb-atlas-mit-ansible-automatisieren/)
---
## 📺 MongoDB on [Twitch](https://www.twitch.tv/mongodb) & [YouTube](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA)
_We stream tech tutorials, live coding, and talk to members of our community via [Twitch](https://www.twitch.tv/mongodb) and [YouTube](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA). Sometimes, we even stream twice a week! Be sure to [follow us on Twitch](https://www.twitch.tv/mongodb) and [subscribe to our YouTube channel](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA) to be notified of every stream!_
*Latest Stream*
{% youtube wdmPTVzRBfs %}
🍿 [Follow us](https://www.twitch.tv/mongodb) on Twitch and [subscribe to our YouTube channel](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA) so you never miss a stream!
---
## 🎙 Last Word on the [MongoDB Podcast](https://mongodb.libsyn.com/)
*Latest Episode*
{% spotify spotify:episode:2q8YcXNkmhuRAMtfWDBlnV %}
*Catch up on past episodes*:
Ep. 76 - [The Role of a MongoDB Consulting Engineer with Eric Reid](https://open.spotify.com/episode/38kyw8xdKmm9n7ewHjYLBg?si=gwkcKALOQbmw1JgpvAYmDQ&dl_branch=1)
Ep. 75 - [Speaking at Your Next Tech Conference with Sven Peters](https://open.spotify.com/episode/4IZ115BTG83rW3ErdGxgOp?si=fKEIXOV1SIOUeRWsUzMEhw&dl_branch=1)
Ep. 74 - [Thinking Diagnostically with Danny Hatcher](https://open.spotify.com/episode/2tSRNf6OxZVlElawGyxPVk?si=nGcokX2nQZ-7pZ-ZxOwT5A&dl_branch=1)
(Not listening on Spotify? We got you! We're most likely on your favorite podcast network, including [Apple Podcasts](https://podcasts.apple.com/us/podcast/the-mongodb-podcast/id1500452446), [PlayerFM](https://player.fm/series/the-mongodb-podcast), [Podtail](https://podtail.com/en/podcast/the-mongodb-podcast/), and [Listen Notes](https://www.listennotes.com/podcasts/the-mongodb-podcast-mongodb-0g6fUKMDN_y/) 😊)
---
## 🌍 MongoDB DevRel around the Interwebz
_Watch our team do their thang at various conferences, meetups, and podcasts around the world (virtually, for now). Also, find external articles and guest posts from our DevRel team here!_
### 📅 Upcoming Conferences
**Sep 28 - [ServerlessDays Paris](https://paris.serverlessdays.io/en/)**

**Sep 29 - [DevOps World (Online)](https://www.devopsworld.com/home)**
Adrienne will be joining remotely to give her popular "Multi-Cloud Magic" talk!
---
💡 These $weeklyUpdates are always posted to the [MongoDB Community Forums](https://www.mongodb.com/community/forums/) _first_! [Sign up](https://account.mongodb.com/account/register) today to always get first dibs on these $weeklyUpdates and other MongoDB announcements, interact with the MongoDB community, and help others solve MongoDB related issues! | adriennetacke |
833,080 | Typescript dev wanted! | About Us TL;DR: We are here to give ecommerce the data, the insights and the tools they... | 0 | 2021-09-20T18:07:00 | https://dev.to/niska34/typescript-dev-wanted-2dhp | hiring, react, typescript, javascript | ## About Us
**TL;DR: We are here to give ecommerce the data, the insights and the tools they need for running their business efficiently and sustainably** ✨
The modern world is driven by data, yet not everyone is able to leverage that new knowledge.
We've seen a company where the marketing team was hitting the targets and celebrating, while the warehouse was full of unsold goods. Unsurprisingly, the company bankrupted, people were laid off and the founders learned a hard lesson about running a sustainable business.
What happened was that the company operated in silos. Each team had their own piece of data, but they never put together the full picture. They trusted the algorithms of Facebook and Google to promote the best products, but had very little visibility or control of what's really happening.
Well, ROI Hunter is here to fix that 💪
We build a platform that services the full circle:
- We plug in all the data sources and build smart product segments with actionable insights
- The company uses the insights to tweak the campaigns, the visuals, or the products they offer
- Each such change produces new data and automatically refines the segments and insights
As a result, not only the company is doing better, but also its customers are no longer spammed with irrelevant ads 🙌
## About The Opportunity
Join us if:
💪 You want to build a great product
🚀 You want to have impact
🕵️ You are a thoughtful problem solver
🕊️ You are not ideological about technology
🤗 You care
🤝 You are a team player
📈 You want to work at a startup
🎓 You own your growth
🌍 You are based in Europe (Brno, CZ is ideal)
## Skill & Qualifications
We work mainly with Javascript, Typescript and React.
## How To Apply
Read more on our CTO´s blog here https://bit.ly/3nDWaiE and find the link to application there in the open positions.
_Please feel free to leave questions in the comments section._ | niska34 |
833,149 | Day 7: Making buttons look like "clouds" for embedded Google Maps | TL;DR I've made a button look like a cloud for the web app I'm currently building. The... | 13,915 | 2021-09-30T06:15:13 | https://medium.com/100-days-in-kyoto-to-create-a-web-app-with-google/day-7-making-buttons-look-like-clouds-for-embedded-google-maps-cfc4a95d9836 | svg, buttons, uidesign, webdev | ## TL;DR
I've made a button look like a _cloud_ for the web app I'm currently building.
The app features embedded Google Maps. It needs buttons for showing the user's current location and for saving a place of the user's interest.
What should buttons look like over a street map?
A _cloud_ is my answer.
A map is like a view of streets from high up in the sky, and clouds would be seen part of this view. Cloud-shaped buttons will then fit into the view of Google Maps!
---
This article describes in detail how I’ve made web app buttons look like clouds, including the design process (Sections 1 and 2) and the HTML/CSS coding (Sections 4 to 6). It also documents how I’ve added a shadow to the cloud-shaped button (Section 7) and styled the button’s focus and active states (Sections 8 and 9).
Hopefully, this article will be useful for those who want to make a bit unusual buttons for a web app that they are building.
## 1. Why Cloud-shaped?
First, let me explain in more detail why I've shaped web app buttons like clouds.
The design concept of _My Ideal Map App_ (the app I'm currently building) is "Dye Me In Your Hue From The Sky". By saving the places of his/her interest, the user "dyes" nobody's Google Maps in his/her hue. The dyeing process is undertaken from the sky, because a street map is the view of a city from the sky.

**View of a city from the sky** (image source: [Asahiair.com](https://www.asahiair.com/enterprise/photograph/))
Now, what should buttons look like, to be appropriate for the UI design based on this concept?
A map is shown across the screen, and buttons are overlaid on it. That is, buttons are shown above the aerial view of a city. When we fly on an airplane and look down through the window, what do we see above the ground?
Yes, clouds!
 **Aerial view of central London amid clouds** (image source: [Wirestock via Freepik](https://www.freepik.com/free-photo/aerial-view-central-london-through-clouds_10499932.htm))
If buttons, overlaid on street maps, are shaped like clouds, we can reinforce the design concept of *My Ideal Map* that the user dyes a map in his/her hue from the sky.
I wouldn't come up with the idea of making buttons look like clouds if I hadn't developed the design concept representing the main feature of the app (see [**Day 2 of this blog series**](https://dev.to/masakudamatsu/day-2-finding-design-concept-to-drive-ui-design-process-49g3) for more detail). I've just witnessed the power of the design concept to drive the UI design process.
## 2. Designing a cloud-shaped button
However, if we make a button to look like a very realistic cloud, the user won't notice it is a button to tap or click on the screen. I need to make a button look like a cloud while it still looks like a button.
With pen and paper, I start sketching a cloud-shaped button.
The starting point is what I have learned from [Osamu Masuyama](https://www.inspired.jp/), an animation art director responsible for the blockbuster movie *Spirited Away*. In one of his books, he advises us to draw clouds as the circles of various sizes that overlap each other.
So I draw three circles of various sizes, overlapping each other. Three should be enough. Four or more will tilt the balance between "buttons" and "clouds" towards "clouds".
But I'm never successful of creating a cloud-like shape.
Then a question comes to my mind: what do those "cloud" icons look like? Those icons that are often used to indicate a cloud storage service? I look up Material Design's cloud icon.
**The cloud icon of Material Icons** (image source: [Google Fonts](https://fonts.google.com/icons?icon.query=cloud))
Analyzing what this icon is made of, I learn that a cloud can be represented with a row of three circles, the middle one positioned higher than the other two, the right one positioned lower than the other two.
I start sketching again, but this time with [Sketch app](https://www.sketch.com/), so that circles are drawn accurately.
I first draw a circle of diameter 36px. I then duplicate this circle and move it to the left by 10px and down by 8px. That's the left part of the cloud. I go back to the first circle and duplicate it again. I move this third circle to the right by 10px and down by 12px. I get this;

**Shape of a cloud-shaped button** (screenshot of Sketch app by the author)
I experiment with three circles of different sizes. But then the unwelcome realism kicks in: it starts looking less and less like a button on the user interface.
I conclude that the three overlapping circles of the same size strike the right balance between "button" and "cloud".
## 3. Button Label
_My Ideal Map App_ will need four buttons, but in this article, I focus on the menu button for the sake of simple exposition. For other buttons and how I position them all over the screen, see **Day 8 of this blog series** (not yet published).
For the menu button, I use the "hamburger" icon as its label:

**Hamburger icon** (image source: [Material Icons via Google Fonts](https://fonts.google.com/icons?selected=Material+Icons+Outlined:near_me:&icon.query=menu))
I download the SVG data of this icon from [Google Fonts](https://fonts.google.com/icons), import it into Sketch, overlay and center-align it on the cloud-shaped button, and export it as an SVG image:

**Menu button created with Sketch app** (image source: author)
## 4. HTML code with inline SVG
(This section is revised on Dec 17, 2021; see [**Day 16 of this blog series**](https://dev.to/masakudamatsu/day-16-icon-buttons-should-be-labelled-with-aria-label-551g) for why.)
To use an SVG image as the button label, one way to go is to wrap an `<img>` element with `<button>` and to set the `src` attribute to be the SVG image file name, like this:
```html
<button type="button">
<img src="button-label.svg" />
</button>
```
However, I need to turn the SVG image itself into a button. Inline SVG (i.e., embedding SVG code into the HTML code) allows me to freely change the color and shadow of the button in response to user interactions and to switching between light and dark modes (see [Coyier 2013](https://css-tricks.com/using-svg/#the-problem-with-both-img-and-background-image) for more detail).
When I started learning web development, writing up the inline SVG code appeared to be too tricky. One day, however, I decided to crack it by taking time to go through an [SVG tutorial by W3Schools](https://www.w3schools.com/graphics/svg_intro.asp) and another tutorial by [Copes (2018)](https://flaviocopes.com/svg/). Since then, a range of web design I can manage to implement with code has expanded.
Let's start writing up HTML for an inline SVG icon button. First, create a `<button>` element:
```html
<button type="button">
</button>
```
A button should be defined as the `<button>` element. It has many useful built-in features such as pressing the Space key to click the button ([Coyier 2020](https://css-tricks.com/a-complete-guide-to-links-and-buttons/#activating-buttons)). The `type` attribute should be `"button"` because this button won't submit any data to the server (in that case, use `type="submit"`) or clear the user's inputs in a form (that's for `type="reset"`).
Next, give an *accessible name* to the button with the `aria-label` attribute:
```html
<button type="button" aria-label="Show menu"> <!-- Revised -->
</button>
```
An *accessible name* is what screen readers will announce to the visually impaired user (see [Watson 2017](https://www.tpgi.com/what-is-an-accessible-name/) for more detail). If a button has text as its label, its accessible name is the label text. If a button has only an icon image, we need to figure out how to give it a name. Otherwise, screen readers will just announce "button", leaving the user unsure of what will happen after they press the button.
[Soueidan (2019)](https://www.sarasoueidan.com/blog/accessible-icon-buttons/) and [O'Hara (2019)](https://www.scottohara.me/blog/2019/05/22/contextual-images-svgs-and-a11y.html) both recommend the use of `aria-label` to "label" an icon button. I initially gave an accessible name to the inline SVG image, hoping that browsers would then recognize it as the button's accessible name. I was wrong. See [**Day 16 of this blog series**](https://dev.to/masakudamatsu/day-16-icon-buttons-should-be-labelled-with-aria-label-551g) for detail.
Next, wrap the `<svg>` element inside the `<button>` element:
```html
<button type="button" aria-label="Show menu">
<!-- ADDED FROM HERE -->
<svg viewBox="0 0 56 48"
width="56px"
height="48px"
aria-hidden="true">
<--! SVG image data to be inserted -->
</svg>
<!-- ADDED UNTIL HERE -->
</button>
```
First of all, `aria-hidden="true"` is added to the `<svg>` element because screen readers do not need to “see” it: the button label is already given by `aria-label`.
Now let me give you a short SVG 101 tutorial. :-)
The `viewBox` is the most important attribute. Its value consists of 4 numbers, defining the coordinate system to draw an SVG image. The first two numbers define the coordinates of the top-left corner of the box; the last two numbers set the width and height of a box in which an SVG image is drawn. Consequently, in the above code (partly copied from the SVG file exported with Sketch), the top-left coordinates are `(0,0)` and the bottom-right `(56,48)`. The SVG code uses this coordinate system to specify points through which the outlines of various shapes go through.
The `width` and `height` attributes shouldn't be necessary. But I've learned from my own experience that, without them, Safari fails to render the SVG icon inside the cloud-shaped button (I don't know why). It defeats the core idea of SVG images as “scalable” vector graphic. But I don't plan to change the size of these buttons by screen width. So I think it's fine in this context.
We don't need any other attributes for the `<svg>` element. When an SVG data is exported from graphic design apps such as Sketch, the `<svg>` element has many other attributes such as `xmlns` and `version`. When used as inline SVG code, none of them are necessary. When used as an image file (e.g., as the `src` attribute value for the `<img>` element), however, the `xmlns` attribute is required. See [Longson (2013)](https://stackoverflow.com/a/18468348) for detail.
Now, for the SVG image data, I insert the following two `<path>` elements spitted out by Sketch app:
```html
<path
d="M45.4620546,13.6147645 C51.6790144,16.4506152 56,22.7206975 56,30 C56,39.9411255 47.9411255,48 38,48 C32.9385058,48 28.3649488,45.9108926 25.09456,42.5479089 C22.9175971,43.482463 20.5192372,44 18,44 C8.0588745,44 0,35.9411255 0,26 C0,17.9805361 5.24437759,11.1859622 12.4906291,8.85878199 C15.6225135,3.55654277 21.3959192,0 28,0 C36.428553,0 43.5040602,5.79307725 45.4620546,13.6147645 Z"
id="cloud"
/>
<path
d="M4.5,27 L31.5,27 L31.5,24 L4.5,24 L4.5,27 Z M4.5,19.5 L31.5,19.5 L31.5,16.5 L4.5,16.5 L4.5,19.5 Z M4.5,9 L4.5,12 L31.5,12 L31.5,9 L4.5,9 Z"
id="material-icon-menu"
transform="translate(10.000000, 6.000000)"
/>
```
The first `<path`> element defines the outline of the cloud-shaped button. I add the `id` attribute value of `#cloud` to be used to apply CSS declarations to it (see Sections 6 and 7 below).
The second `<path>` element defines the menu icon. I also add the `id` attribute, just to take note of which icon the element renders. The `transform` attribute moves the icon to the right by 10 units and down by 6 units, to center-align the icon relative to the SVG image box defined with the `viewBox` attribute value.
In the SVG code, an element is overlaid with another that comes after. So the `<path>` element for the button label should come after the one for the button itself.
The `d` attribute includes a series of two numbers separated with a comma. They represent a point on the coordinate system specified with the `<svg>` element's `viewBox` attribute. The alphabets in front of these pairs of numbers specify whether to move to the point (M), to draw a bezier curve (C), to draw a line (L), etc. See [MDN Contributors (2021)](https://developer.mozilla.org/en-US/docs/Web/SVG/Attribute/d#path_commands) for detail.
I'm done with HTML. Let's move on to CSS.
## 5. CSS code with Styled Components
Next up is CSS. I use [Styled Components](https://styled-components.com/) to write CSS code in JavaScript. In recent months, I found a couple of articles on the disadvantage of Styled Components (and CSS-in-JS in general) in terms of performance ([Arvanitakis 2019](https://calendar.perfplanet.com/2019/the-unseen-performance-costs-of-css-in-js-in-react-apps/), [Dodds updated](https://epicreact.dev/css-variables/)). As far as I understand, that's not the argument against CSS-in-JS itself. It's the argument against certain ways of using CSS-in-JS. As long as I avoid those ways, I believe the benefit of using JavaScript overwhelms the standard CSS code.
The way I use Styled Components is perhaps a bit unusual. I first define each set of CSS declarations to achieve one purpose as a JavaScript variable. Then I create a styled component by referring to these variables. Here's what I mean:
First, save as `resetStyle` the CSS declarations for removing the `border` and `background-color` of the `<button>` element:
```javascript
import {css} from 'styled-components';
const resetStyle = css`
background-color: rgba(255,255,255,0);
border: none;
`;
```
I remove the default border of the `<button>` element because I want the visual border of a cloud-shaped button to be drawn with the SVG image. And I set the background color to be transparent white. This pair of CSS declarations turns a button element into something transparent to the user's eye.
Next, I set the size of a clickable/tappable area of the button as `setClickableArea`:
```javascript
const setClickableArea = css`
height: 48px;
width: 56px;
`;
```
This way, the user can activate the button by tapping/clicking a rectangular area that is 48px high and 56 wide. This satisfies the WCAG 2.1's recommendation: the size of an interactive UI component such as a button must be at least 44px wide and 44px high ([§2.5.5 of WCAG 2.1](https://www.w3.org/TR/WCAG21/#target-size)). It also satisfies Google's recommendation of 48x48px, which corresponds to a person's finger pad size ([Gash et al. 2020](https://web.dev/accessible-tap-targets/)).
Then, to center-align the cloud-shape SVG image within the tappable area, I define `alignButtonLabel` as follows:
```javascript
const alignButtonLabel = css`
align-items: center;
display: flex;
justify-content: center;
`;
```
Without this, the SVG image gets left-aligned within the tappable area.
Finally, using these three variables, we style the `<button>` element to create `<Button>` component (which can be used just like a React component, thanks to Styled Components):
```js
import styled from 'styled-components';
const Button = styled.button`
${resetStyle}
${setClickableArea}
${alignButtonLabel}
`;
```
Writing the code this way, I can immediately tell how the `<Button>` component is styled, rather than deciphering a series of CSS declarations.
This coding style is inspired by [Cube CSS](https://cube.fyi/), a CSS methodology that recently attracted attention from web developers. In Cube CSS, a class is created for one single purpose of styling (so each element gets quite a few classes). To achieve the same with Styled Components, I can replace a class with a JavaScript variable.
We're not done yet. We need more CSS declarations to set the color and shadow of these buttons.
## 6. Button color scheme
### 6.1 Fill color
I set the fill color of the cloud button to be `rgba(255, 255, 255, 0.93)`, that is, pure white with 93% opacity (or 7% transparency).
Clouds are white. Making the button semi-transparent allows the map beneath to be partially visible, creating an impression that the cloud-shaped button is floating over the map. The opacity value of 0.93 is chosen to strike the balance between making it recognized as a button and creating the "floating" impression.
The cloud-shaped button image is defined in the `<path id="cloud">` as a grand-child of the `<button>` element (see Section 4 above). So the following CSS code sets the fill color of the cloud-shaped button:
```css
button #cloud {
fill: rgba(255, 255, 255, 0.93);
}
```
### 6.2 Label color
The button label color is set to be `rgb(90, 90, 90)`. Its luminance contrast ratio is 3.04 to 1 against pure black. I choose this shade of gray because it allows a focus state to be distinct enough (see Section 8 below).
The following CSS declaration sets the button label color:
```css
button svg {
fill: rgb(90,90.90);
}
```
The idea is to set the `<svg>` element's `fill` property, which will be cascaded to the `<path>` element for the button label. The cascading won't be applied to the other `<path>` element for the cloud shape, because its `fill` property is directly set already.
### 6.3 Outline color
The outline of the cloud-shaped button is colored in `rgb(148, 148, 148)`. It's for making the white button perceptually distinct from the white streets in the map. (See [**Day 4 of this blog series**](https://dev.to/masakudamatsu/day-4-customizing-google-maps-color-scheme-and-its-place-label-visibility-pia) for how I've set the color of various map elements in embedded Google Maps.)
The relative luminance in the map's color scheme ranges from 6 of the gray of city blocks (#898989) to 21 of the pure white of streets (where the value refers to the contrast ratio against pure black). The cloud-shaped buttons will be visually distinct from city blocks on the map, because the semi-transparent white satisfies the 3-to-1 contrast ratio requirement from the gray of city blocks:
 **Luminance contrast ratio of `#898989` to `rgba(255,255,255,0.93)`** (image source: [contrast-ratio.com](https://contrast-ratio.com/#rgba%28255%2C255%2C255%2C0.93-on-%23898989))
If the cloud-shaped button is above streets on the map, however, it visually merges with them due to the lack of luminance contrast. A solution is to outline the cloud-shaped button with a shade of gray that's just enough to satisfy the 3-to-1 contrast ratio against pure white: `rgb(148,148,148)`:
**Luminance contrast ratio of `rgb(255,255,255)` to `rgb(148,148,148)`** (image source: [contrast-ratio.com](https://contrast-ratio.com/#rgb%28148%2C148%2C148%29-on-rgba%28255%2C255%2C255%29))
The following CSS declaration sets the outline color of the cloud-shaped button:
```css
button #cloud {
stroke: rgb(148, 148, 148);
}
```
However, outlining the cloud-shaped button with this gray makes the button look, uh, ugly...
So I want to add a shadow to the button so the distinction between the outline and the shadow gets blurred, which will make the button look naturally floated above the map.
## 7. Shadows for cloud-shaped buttons
### 7.1 Why needed?
Another reason is that a shadow makes a button appear floated above the background, which allows the user to recognize it as a button (i.e., something to push down) more easily. Based on “36 interviews with fifteen low-vision participants”, [Google (undated)](https://material.io/design/environment/light-shadows.html#research) reports:
> “Using a shadow or stroke outline around a component improves one’s ability to determine whether or not it can be interacted with.”
### 7.2 CSS coding
For a standard rectangular button, its shadow can be added with the `box-shadow` CSS property. But I want to apply a shadow to a cloud-shaped SVG image. In this case, we can use the `filter` CSS property with the `drop-shadow()` function as its value ([Olawanle 2021](https://css-tricks.com/adding-shadows-to-svg-icons-with-css-and-svg-filters/)).
The [`drop-shadow()` function](https://developer.mozilla.org/en-US/docs/Web/CSS/filter-function/drop-shadow()) allows us to specify four aspects of a shadow: where it is located, how blurry its edge is, and which color it has.
### 7.3 Location of a shadow
For the location of a shadow, we need to decide where the (imaginary) light source is located. Usually it's at the top-left or top-right of a screen. We human beings perceive depth by interpreting shadows as created by the light from above ([Livingstone 2014](https://www.amazon.com/dp/1419706926/), chap 11). I guess that's because we are used to the sunlight coming from above.
However, the design concept of _My Ideal Map App_ dictates that the light comes from *behind the user*. This is because the user interface of a map is interpreted to be a view of streets from the sky. The sun is behind the user's head.
Consequently, buttons on the user interface of _My Ideal Map App_ should have a shadow all around their edges, rather than on the bottom-right or bottom-left edges. This implies that the first two parameters for the `drop-shadow()` function is `0 0`. The center of the shadow is directly beneath the center of the button.
### 7.4 Blurriness of shadow edges
Shadows are blurry on their edges, because, if I understand correctly, the farther away from the edge of an object, the more ambient light illuminates the shadowed surface. By ambient light, I mean light comes from all directions. For the outdoor, ambient light is the sunlight reflected by the water molecules in the air or by the surrounding objects. In the indoor, ambient light is the light reflected by the walls, the ceiling, and other objects inside the room.
To make the edge of a shadow blurry, UI designers need to set the parameter known as "blur radius". If it's set to be 1px, for example, then the shadow is rendered in the specified color at 1px inside the shadow edge. Then, the shadow color's opacity declines by half at the shadow edge and goes to zero at 1px outside the shadow edge. The rate of change in opacity is constant.
However, a shadow looks natural if the rate of reduction in darkness is decreasing the farther away from the object. That is, if the intensity of a shadow is 4 around the edge of an object, the first 1 unit of distance reduces it by 2, the second 1 unit of distance reduces it by 1, the third 1 unit of distance reduces it by 0.5, and so forth.
A single shadow cannot create such a non-linear change in the intensity of a shadow. A solution is to layer multiple shadows with increasing blur-radius ([Ahlin 2019](https://tobiasahlin.com/blog/layered-smooth-box-shadows/)). So I apply shadows as follows:
```css
button svg {
filter:
drop-shadow(0 0 1px rgba(0,0,0,0.33))
drop-shadow(0 0 2px rgba(0,0,0,0.33))
drop-shadow(0 0 4px rgba(0,0,0,0.33));
}
```
In this code, I assume the color of shadows is `rgba(0, 0, 0, 0.33)`, the reason for which will be described in Section 7.5 below.
With this CSS code, the opacity of a shadow declines rapidly for the first 1px from the edge, because all the three shadows are applied. But from 1px to 2px from the edge, only the second and third shadows apply, hence a slower reduction in opacity. From 2px to 4px from the edge, only the third shadow applies, with an even slower reduction in opacity.
### 7.5 Color of shadows
The color of a shadow should be semi-transparent black. A shadow is essentially a smaller amount of reflected light (which is colored as the hue of the surface) reaching the human eyes, compared to its surrounding area. On the screen, a shadow can be represented by overlaying a semi-transparent black so the surface color is retained while the amount of light is reduced.
The question is to what extent the shadow black should be semi-transparent.
I want the opacity of the shadow to be 42% at the edge of the button, because, when the background is pure white, `rgba(0,0,0,0.42)` becomes the same shade of gray as `rgb(148,148,148)`, the color of the button outline as discussed in Section 6.3 above.

**Luminance contrast ratio of `rgba(0, 0, 0, 0.42)` and `rgb(148, 148, 148)` against white background**(image source: [contrast-ratio.com](https://contrast-ratio.com))
This way, the distinction between the button outline and the shadow gets blurry, and the outline's gray will be perceived as part of the shadow.
However, if I use `rgba(0, 0, 0, 0.42)` as the shadow color, the actual opacity of black will be much higher at the edge of the button. There are two reasons for this. First, as described above, the blur radius of 1px will use the specified shadow color at 1px inside its edge. At the edge (which coincides with the button's edge, due to the location of a shadow directly beneath the button), the opacity is halved (i.e., rgba(0, 0, 0, 0.21)). The second reason is that I draw three layers of shadows of different degrees of blur radius to make the shadow look natural, as described above. At the edge of the button, therefore, the shadow opacity will be three times higher than `rgba(0, 0, 0, 0.21)`.
Given all these considerations, I've found out that using `rgba(0, 0, 0, 0.33)` as the color of a shadow will make the opacity of a shadow similar to `rgba(0, 0, 0, 0.42)`. I omit the full detail of calculation, but the basic idea is as follows. If we overlay two shadows of 50% opacity, the resulting shadow will have an opacity level of 75%. This is because the level of transparency will be 0.5 x 0.5 = 0.25. I'm not sure if this calculation is correct, but it seems to be a good approximation.
Consequently, the following CSS code specifies the shadow of our cloud-shaped button.
```css
button svg {
filter:
drop-shadow(0 0 1px rgba(0,0,0,0.33))
drop-shadow(0 0 2px rgba(0,0,0,0.33))
drop-shadow(0 0 4px rgba(0,0,0,0.33));
}
```
And the cloud-shaped button is rendered as follows:
**Cloud-shaped menu button, shown over embedded Google Maps** (screenshot by the author)
---
But this is not the end of a story yet. In UI design, it is important to give visual feedback to the user's action. We also need to set the style for the focus/hover state and the active state of the button ([Bailey 2018](https://css-tricks.com/focusing-on-focus-styles/), [Sticka 2018](https://cloudfour.com/thinks/designing-button-states/#2-focus)).
## 8. Styling focus/hover states
For keyboard users (including those visually-impaired who use screen readers), pressing a button with the Enter key requires an indication of which button is currently in focus. The button should therefore change its appearance when it's in focus.
In addition, for mouse users, a hover state is helpful for them to notice if a button is clickable. I usually design the focus and hover states in the same way, to keep the number of button styles to a minimum (which is also suggested by [Maza 2019](https://css-tricks.com/having-a-little-fun-with-custom-focus-styles/#replicate-existing-hover-styles)).
Deciding on how to style the focus state is always a headache to me. A big help for my decision process is the article by [Maza (2019)](https://css-tricks.com/having-a-little-fun-with-custom-focus-styles/), who lists up the five major ways of styling the focus state: changing the background color, changing the text color, adding a shadow, increasing the size, and customizing the default outline. With this list, I can consider each option and decide which option is the most appropriate for the website / webapp I'm making.
For our cloud-shaped button, changing the background color is not effective. I don't want a cloud to be red, green, etc. Making it gray is not ideal, either, because it will look like a rainy cloud. Adding a shadow is not feasible, as it's already added (see above). Increasing the size is tacky and inconsistent with the design concept of _My Ideal Map App_.
Changing the text color (in our case the button label icon's color) is a feasible option. I can turn the gray of the button label into black: `rgb(3, 3, 3)`:
```css
button:focus svg,
button:hover svg {
fill: rgb(3, 3, 3)
}
```
I avoid `rgb(0,0,0)` for preventing the "black smear" problem on the OLED screens (see [Edwards 2018](https://twitter.com/marcedwards/status/1053418459961249792)). Also, as mentioned at the beginning of this subsection, I design the focus and hover states in the same way. So the CSS selector refers to both `button:focus` and `button:hover`.
But this change is not noticeable enough. So the last option is to customize the default outline for focus style.
For designing the outline on the focus state, I follow [Coyier (2012)](https://css-tricks.com/snippets/css/glowing-blue-input-highlights/), who replicates the focus state of Twitter's text field back in 2012. His idea is to draw a 1px-wide border plus a shadow with blur radius of 5px and zero offset, both in the same Twitter blue. This way, when focused, the text field gets lit up with blue glow around its edges.
**Blue glow indicates that the text field is currently in focus** (image source: [Coyier 2012](https://css-tricks.com/snippets/css/glowing-blue-input-highlights/))
The question is which color to use for the outline. When stuck on color, my rule is to go back to the mood board which visualizes the design concept. Since the button is cloud-shaped, a blueish color would be nice to create an impression of clouds in the blue sky. So I pick the color of the sky reflected on the water surface of a lake in this photo from our daytime mood board picture (see [**Day 3 of this blog series**](https://dev.to/masakudamatsu/day-3-visualizing-design-concept-with-mood-boards-nii)):
 **Partially Frozen Aldeyjarfoss, a fall in Iceland** (image source: [Shivesh Ram via National Geographic](https://www.nationalgeographic.com/photography/photo-of-the-day/2019/07/iceland-waterfall-frozen-winter/))
With Mac OS's Digital Colour Meter, I sample the deep blue color of the fall's pool. Then, with my webapp [Triangulum Color Picker](https://triangulum.netlify.app/), I reduce its luminance without changing the share of pure hue in it so it's dark enough to satisfy the 3-to-1 contrast against the pure white of the button. The result is `rgb(69, 159, 189)`.
 **The hue and luminance of `rgb(69,159,189)`** (image source: [Triangulum Color Picker](https://triangulum.netlify.app/))
With this shade of cyan-blue, I write the following CSS code:
```css
button:focus #cloud,
button:hover #cloud {
stroke: rgb(69,159,189);
}
button:focus svg,
button:hover svg {
filter: drop-shadow(0 0 5px rgb(69,159,189));
}
```
To set the outline color for SVG images, we need to use the `stroke` property instead of `border`. And I need to set the `stroke` property for the `<path id='cloud'>` element (which defines the cloud shape). If I apply the `stroke` property for the `<svg>` element instead, the button label icon will also be outlined. That's not what I want.
With all the coding so far, the focus state of the cloud-shaped button is rendered as follows:
**The cloud-shaped button in focus state** (screenshot by the author)
I was happy with the result until I realized that color-blind users would not be able to detect the change in the button's appearance when it's in focus. The blue glow and the default shadow has a similar level of luminance, and they are both blurred.
I need to reconsider stying the focus state as I continue developing the app. Styling the focus state is always a headache to me...
And designing a button is not yet finished. The last style to be designed is for when the button is clicked/tapped.
## 9. Styling active state
Finally, we need to style the active state: when the user taps/clicks the button. Without it, the user won't tell if tapping the button makes any difference—what the UI design guru Don Norman calls “[the gulf of evaluation](https://www.interaction-design.org/literature/book/the-glossary-of-human-computer-interaction/gulf-of-evaluation-and-gulf-of-execution)”.
I might want to add the [ripple effect](https://material-components.github.io/material-components-web-catalog/#/component/ripple), an increasingly common way of expressing the active state of a button ever since Google's Material Design adopted it. But I'm not sure if it goes in line with the idea of using a cloud as a button. Clouds won't ripple...
A simple solution to style the active state is to disable the focus/hover state. When the user taps/clicks the button, it first turns on the focus state, then on the active state, and finally turns off the active state while keeping the focus state on. So the difference in style between focus and active states translates into a flash of something. In our case, the focus state has a blue outline. By disabling this outline in the active state, the outline briefly disappears when the user taps/clicks the button, as if the internally-illuminated button briefly switches its light off.
To disable the focus/hover state in the active state, the following CSS code does the job:
```css
button:active #cloud {
stroke: none;
}
button:active svg {
filter: none;
}
```
And the button label briefly goes back to the default shade of gray, adding to the flashing effect:
```css
button:active svg {
fill: rgb(90, 90, 90)
}
```
Finally, designing and coding a single button is done, at least for now.

**The three button styles: default (left), focus/hover (middle), active (right)** (Image source: author)
## Next up
Making cloud-shaped buttons is not finished yet. I need to create four of them and position them across the screen. Plus, I need to set the dark mode color scheme of the buttons. Each requires a fair amount of programming techniques, the description of which will make this article more than a 40-minute read... So I defer these two topics to next two articles.
Thank you for reading this much. Making buttons for a web app is not an easy task...
## Changelog
**Oct 4, 2021 (v1.0.1)**: The paragraph on the `viewBox` attribute is revised to correct the description of what the last two values of the attribute specify.
**Dec 17, 2021 (v2.0.0)**: Section 4 is revised. The way I define the button's accessible name has changed, as the previous approach proved to be wrong.
## References
Ahlin, Tobias (2019) “[Smoother & sharper shadows with layered box-shadows](https://tobiasahlin.com/blog/layered-smooth-box-shadows/)”, tobiasahlin.com, Sep 19, 2019.
Arvanitakis, Aggelos (2019) “[The unseen performance costs of modern CSS-in-JS libraries in React apps](https://calendar.perfplanet.com/2019/the-unseen-performance-costs-of-css-in-js-in-react-apps/)”, *Web Performance Calendar*, Dec 9, 2019.
Bailey, Eric (2018) “[Focusing on Focus Styles](https://css-tricks.com/focusing-on-focus-styles/)”, *CSS-Tricks*, Mar 29, 2018.
Copes, Flavio (2018) “[An in-depth SVG tutorial](https://flaviocopes.com/svg/)”, flaviocopes.com, Apr 6, 2018.
Coyier, Chris (2012) “[Glowing Blue Input Highlights](https://css-tricks.com/snippets/css/glowing-blue-input-highlights/)”, *CSS-Tricks*, Apr 11, 2012.
Coyier, Chris (2013) “[Using SVG](https://css-tricks.com/using-svg/)”, *CSS-Tricks*, Mar 5, 2013.
Coyier, Chris (2020) “[A Complete Guide to Links and Buttons](https://css-tricks.com/a-complete-guide-to-links-and-buttons/)“, *CSS-Tricks*, Feb 14, 2020.
Dodds, Kent C. (undated) “[Use CSS Variables instead of React Context](https://epicreact.dev/css-variables/)”, *Epic React*, undated.
Edwards, Marc (2018) “[I’m not a fan of pure black in UI…](https://twitter.com/marcedwards/status/1053418459961249792)”, _Twitter_, Oct 20, 2018.
Gash, Dave, Meggin Kearney, Rachel Andrew, and Rob Dodson (2020) “[Accessible tap targets](https://web.dev/accessible-tap-targets/)”, _web.dev_, Mar 31, 2020.
Google (undated) “[Light and Shadows](https://material.io/design/environment/light-shadows.html)”, _Material Design_, undated.
Kudamatsu, Masa (2021) “[Mastering the art of `alt` text for images](https://medium.com/web-dev-survey-from-kyoto/mastering-the-art-of-alt-text-for-images-fb25c4bdb38f)”, _Web Dev Survey form Kyoto_, May 19, 2021.
Livingstone, Margaret S. (2014) [*Vision and Art: the Biology of Seeing (Revised and Expanded Edition)*](https://www.amazon.com/dp/1419706926/) (Abrams).
Longson, Robert (2013) “[All user agens (browsers) ignore the version attribute...](https://stackoverflow.com/a/18468348)”, _Stack Overflow_, Aug 27, 2013.
Maza, Lari (2019) “[Having a Little Fun With Custom Focus Styles](https://css-tricks.com/having-a-little-fun-with-custom-focus-styles/)”, CSS-Tricks, Dec 2, 2019.
MDN Contributors (2021) “[d](https://developer.mozilla.org/en-US/docs/Web/SVG/Attribute/d)”, _MDN Web Docs_, Sep 24, 2021 (last updated).
O'Hara, Scott (2019) “[Contextually Marking up accessible images and SVGs](https://www.scottohara.me/blog/2019/05/22/contextual-images-svgs-and-a11y.html)”, _scottohara.me_, May 22, 2019.
Olawanle, Joel (2021) “[Adding Shadows to SVG Icons With CSS and SVG Filters](https://css-tricks.com/adding-shadows-to-svg-icons-with-css-and-svg-filters/)”, _CSS-Tricks_, Jun 11, 2021.
Soueidan, Sara (2019) “[Accessible Icon Buttons](https://www.sarasoueidan.com/blog/accessible-icon-buttons/)”, _sarasoueidan.com_, May 22, 2019.
Sticka, Tyler (2018) “[Designing Button States](https://cloudfour.com/thinks/designing-button-states/)”, _Cloud Four_, March 13, 2018.
Watson, Léonie (2017) "[What is an accessible name?](https://www.tpgi.com/what-is-an-accessible-name/)", _TPGi_, Apr 11, 2017. | masakudamatsu |
834,065 | React E2E Testing made easy using Cypress and Jenkins | What is End-To-End(E2E) Testing? The primary goal of E2E Testing is to test the... | 0 | 2021-09-22T06:50:19 | https://dev.to/jochen/react-e2e-testing-made-easy-using-cypress-and-jenkins-42jm | react, frontend, testing, cypress | #What is End-To-End(E2E) Testing?
The primary goal of E2E Testing is to test the Application from the user's perspective. Thus regarding the Application as a Black Box - ignoring the internal logic and only testing what the Users see.
#Drawbacks of E2E Testing
An error in the E2E Test Suite indicates that the User can't use the Application as intended. The problem is that we can't pinpoint the exact Line Of Code(LOC) that causes the error. Thus E2E Testing helps in finding significant errors but can't help in debugging them.
On the famous Testing Pyramid, E2E Tests can be found on top of Component and Integration Tests. As such there should be Unit and Integration Tests first. These help in catching errors early and debugging, thus increasing the pace of development.
#Benefits of E2E Testing
E2E Tests are written in a way that resembles the User's way of operating our Application. As such E2E Tests gives great confidence in our Application by confirming that the key functionalities are working as intended from the User's point of view.
In addition to this E2E Tests ideally don't rely on Implementation Details, as such they are more robust and written in a way where fixing or updating them is fast and easy.
#Practical Example
Now to the fun part: Code!
First we have to install Cypress
```
npm install cypress --save-dev
or
yarn add cypress --dev
```
Then we can create a simple cypress.json configfile in the root directory
```
{
// specify the baseUrl from which we
// serve our applications in the test environment
"baseUrl": "http://localhost:3000",
// depends on project: allows accessing shadow dom without calling .shadow()
"includeShadowDom": true,
// optional: only necessary cypress component testing
// not needed if all we do is e2e testing
"component": {
"testFiles": "**/*.spec.{js,ts,jsx,tsx}",
"componentFolder": "src"
},
}
```
if our project is written in typescript we might want to add a tsconfig in the cypress subdirectory that extends our main tsconfig
###cypress/tsconfig.json
```
{
"compilerOptions": { "types": ["cypress"] },
"extends": "../tsconfig.json",
"include": ["integration/*.ts", "support/*.ts", "../node_modules/cypress"]
}
```
##Writing Tests
After we finished the basic setup and installation we can now start writing tests.
```
describe("Sample Test Suite", () => {
beforeEach(() => {
// intercept outgoing HTTP Requests by defining the endpoint and mocked response
cy.intercept("GET", "/some_endpoint", {
statusCode: 200,
body: {"a":1},
});
});
it("sample test", () => {
// uses baseUrl defined in cypress.json configuration
cy.visit("/landing-page");
// access DOM Nodes via e.g. class, id, data-test-id
// & interact with DOM
cy.get('[data-test-id="add-button"]').click();
cy.get(".some_class").should("exist");
});
});
```
In the example above we intercept Http Requests our application makes to the /some_endpoint endpoint. Thus we mock the backend and can run our tests without starting up a backend instance.
Now we can run the tests and see if our application works as intended. For this we can choose to run it with a UI and open chrome instance for easier debugging OR we can run it headless, e.g. for a quick run in CLI or as integrated step in our CI Pipeline in e.g. Jenkins, Azure Pipeline,...
##Run Cypress in Dev Environment
To execute Cypress with an UI and controlled Chrome instance we can add this script to package.json
```
"cy:open": "node_modules/.bin/cypress open",
```
adding this allows us to easily start the cypress UI in the terminal
```
npm run cy:open
```
##Jenkins Integration
To integrate Cypress into our Jenkins Pipeline, we can add these scripts to package.json
```
"cy:run": "node_modules/.bin/cypress run",
"ci:e2e": "start-server-and-test start http://localhost:3000 cy:run"
```
In addition we need to install start-server-and-test for this solution
```
npm install --save-dev start-server-and-test
```
This will ensure that our server is started before we try running our E2E Tests.
Now that all the preparations are done, we can add a step to our Jenkinsfile.
```
sh script: 'cd frontend; npm run ci:e2e'
```
Now when a Jenkins Build is triggered we will see a new stage in our Pipeline that displays a report of our E2E Tests.

#Additional Information and Troubleshooting:
Depending on the Docker Image used, we may need to install additional OS specific dependencies. For this we can add a DockerFile step
```
# Install cypress OS dependencies
RUN apt-get install -qy \
libgtk2.0-0 libgtk-3-0 libgbm-dev libnotify-dev libgconf-2-4 \
libnss3 libxss1 libasound2 libxtst6 xauth xvfb procps
```
| jochen |
833,318 | Creating Macro Benefits from Micro Frontends | We sit down to chat with Alex Gogan about how Sherpa is leveraging Microfrontends. | 25,851 | 2021-09-21T00:47:38 | https://codingcat.dev/podcast/1-25-micro-frontends | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/1-25-micro-frontends
{% youtube https://www.youtube.com/watch?v=rgHttPaek8A %}
## Questions
[Alex's Slides](https://docs.google.com/presentation/d/1nUkmecPIQJGohxuyGWUSmQ06MCT6xVPpqWOVs0mC8qE/edit?usp=sharing)
1. **What is a Micro Frontend?**
* architecture & design pattern "An architectural **style** where independently deliverable frontend applications are composed into a greater whole" - Martin Fowler Missing presentation layer of micro services
* independent
* small in scope
* complete
* designed to work along each other
* kinda like power rangers
* mindset
* often in the shadow of technical topics focused on intricate details of implementation
* squads/teams/pods can focus on a value add for their customers/users e.g. team Search can focus entirely on "Finding the right product as fast as possible"
* enables cross functional collaboration (diverse and inclusive teams can excel)
* reduces friction between backend/frontend/design/product/ux/analytics/qa
2. **Can we talk about Basecamp on how you are using that for project organization?**
* took a lot of inspiration on [ShapeUp](https://basecamp.com/shapeup) for our internal process which we name sherpUp
* we run a series of projects for 6 weeks, each project can take 2-6 weeks each with at least 2 team members
* each team is, depending on the topic cross-functional and at least a designer + developer
* tackle often e2e, if a new feature requires a change in our data model/api/frontend the team will take care of everything
* teams are independent and enabled
1. **Do micro frontends speed up development time?**
* Yes
* advocate for incremental development through frequent deployments (~ 10 deployments per week) and close collaboration with partners
* feature flagging
* remote configuration
* keep our tech stack and tooling consistent across all frontends
1. **Can you still utilize a design system?**
* Yes, it becomes easier if everything is in a mono repo
* currently in the process of migrating the various frontends we have into a monorepo using the nx workspace
* Adapting Atomic Design (think in atoms, molecules and organisms)
* Organisms often remain as part of individual apps but adhere to the design system
* shared CSS classes + variables + mixins help quite a lot
1. **How does a typical architecture look for you?**
* we provide a Javascript SDK that acts as an application shell and turns any website into a host
* SDK or shell manages and maintains registered embedded elements (what we call micro frontends) that will be appended to the host DOM via iFrames
* inter-application communication is created through a message bus via post messages
* hosts are typically not in our control and our embedded elements need to be very flexible and adaptable to various environments e.g. devices/platforms and resolutions but also how much you can interact with each
1. **How does security play into Micro Frontends?**
* we embrace embeddability through iFrames which provide a strict isolation especially in sandbox mode
* important to limit functionality and content security policies
* when using post messages to communicate between iFrames, checking for origin/destination and validating payloads is necessary
* security teams might bring up concerns around click-jacking and end users not being able to distinguish or understand which part of the experience is part the host and which is ours ⇒ we visually indicate through "powered by sherpa°" and logo placements to provide clarity, nothing technical but very relevant
## Links
* [microfrontend-resources](https://github.com/billyjov/microfrontend-resources)
* [Example of using the app](https://apply.joinsherpa.com/explore/USA)
* [https://www.angulararchitects.io/en/](https://www.angulararchitects.io/en/)
* [https://micro-frontends.org/](https://micro-frontends.org/)
* [https://itnext.io/handling-data-with-web-components-9e7e4a452e6e](https://itnext.io/handling-data-with-web-components-9e7e4a452e6e)
* [https://micro-frontends.zeef.com/elisabeth.engel?ref=elisabeth.engel&share=ee53d51a914b4951ae5c94ece97642fc](https://micro-frontends.zeef.com/elisabeth.engel?ref=elisabeth.engel&share=ee53d51a914b4951ae5c94ece97642fc)
* [https://github.com/rajasegar/awesome-micro-frontends](https://github.com/rajasegar/awesome-micro-frontends)[https://basecamp.com/shapeup](https://basecamp.com/shapeup) | codercatdev |
833,327 | Side Project Hustle | We sit down with Brad Garropy to talk about how he got started in web development. We also discuss how creating and maintaining side projects can help you get a full time job. | 25,851 | 2021-09-21T01:03:06 | https://codingcat.dev/podcast/1-32-side-project-hustle | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/1-32-side-project-hustle
{% youtube https://www.youtube.com/watch?v=jwb5zi5bjfE %}
## Questions
1. How did you get your start in Web Development?
2. Did building side projects help you get your job at Adobe?
3. What did you learn most from building side projects?
1. Which side project did you learn the most from?
4. Can you talk a little about your Muphy app and how you built it?
5. You also maintain a npm-package called hue-sdk, what does that involve?
6. So, with all these side projects and a full time job, why did you want to start the Web Dev Weekly Podcast?
7. How has social media helped you along the way?
8. Aside: using GitHub Actions. How do you use GitHub actions to improve your workflow? | codercatdev |
833,471 | Kubernetes (CKAD) - Pod Design - Understand how to use Labels, Selectors, and Annotations | Topic: Pod Design Labels Labels are key:pair values that can help you organize... | 0 | 2021-09-21T06:38:54 | https://dev.to/jcfausto/kubernetes-ckad-pod-design-understand-how-to-use-labels-selectors-and-annotations-3nl0 | kubernetes, ckad | ## Topic: Pod Design
### Labels
Labels are `key:pair` values that can help you organize your resources. Any object in Kubernetes can have a label described.
You can also use labels to select a set of resources. For that you'll use a selector, which we'll see later on.
Example of a label:
```yml
apiVersion: v1
kind: Pod
metadata:
name: onboarding-frontend
namespace: my-application
labels:
service: onboarding
tier: frontend
```
#### Listing labels
```bash
$ kubectl get pods --show-labels
```
#### Listing labels as columns
You can list labels as columns by using the -L (--label-columns) option of kubectl.
```bash
$ kubectl get pods -L service,tier
```
### Selectors
You can use selectors to filter a set of resources. For filtering based on labels, we can use the `-l` selector.
#### Select only the pods related to the `onboarding` service.
```bash
$ kubectl get pods -L service,tier -l 'service=onboarding'
```
#### Select only the pods *NOT* related to the `onboarding` service.
```bash
$ kubectl get pods -L service,tier -l 'service!=onboarding'
```
#### Select only the pods related to the `onboarding` service in the frontend tier
```bash
$ kubectl get pods -L service,tier -l 'service=onboarding,tier=frontend'
```
#### Select all pods that are related to `backend` and `frontend` tiers.
```bash
$ kubectl get pods -L service,tier -l 'tier in (backend,frontend)'
```
### Annotations
Annotations allows you to store additional data for the object you're creating. Also a `key:pair` value but with more capacity to store longer strings, including JSON.
An annotation looks like:
```yml
apiVersion: v1
kind: Pod
metadata:
name: onboarding-frontend
namespace: my-application
labels:
service: onboarding
tier: frontend
annotations:
Description: The frontend component of the onboarding service for my-application.
```
#### List the annotations of a pod
```bash
$ kubectl describe pod onboarding-frontend | grep Annotations
```
Annotations can be edited/removed/added.
#### Remove an annotation
```bash
$ kubectl annotate pod onboarding-frontend Description-
```
The `-` after the annotation indicates that we want to removed it.
#### Add an annotation
```bash
$ kubectl annotate pod onboarding-frontend Description-
```
The `-` after the annotation indicates that we want to remove it.
Official docs for further reference: [Object Annotations](https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/)
| jcfausto |
833,478 | Top Free React Dashboards to Use for Your Next Project | It is not necessary to spend a lot of money to create a professional-looking dashboard for your... | 0 | 2021-09-21T06:56:32 | https://blog.suhailkakar.com/top-free-react-dashboards-to-use-for-your-next-project | javascript, react, programming, productivity |
It is not necessary to spend a lot of money to create a professional-looking dashboard for your website or app. That's why, in this post, we will look at some of the great react admin panels that you can utilize in your next project. This selection of the top free admin templates will assist you in launching your project with a minimal financial commitment.
### CoreUI
CoreUI is meant to be the UX game changer. Pure & transparent code is devoid of redundant components, so the app is light enough to offer the ultimate user experience.
[Download](https://github.com/coreui/coreui-free-react-admin-template) / [Live Demo](https://coreui.io/react/demo/free/3.1.1/#/dashboard)
### Black
Black Dashboard React is a beautiful Bootstrap 4, Reacstrap and React (create-react-app) Admin Dashboard with a huge number of components built to fit together and look amazing. If you are looking for a tool to manage and visualize data about your business, this dashboard is the thing for you.
[Download](https://github.com/creativetimofficial/black-dashboard-react) / [Live Demo](https://demos.creative-tim.com/black-dashboard-react/#/admin/dashboard)
### Datta Able
Datta Able React Free Admin Template made using Bootstrap 4 framework. Datta Able React Free Admin Template comes with a variety of components like Button, Badges, Tabs, Breadcrumb, Icons, Form elements, Table, Charts & Authentication pages.
[Download](https://github.com/codedthemes/datta-able-free-react-admin-template) / [Live Demo](https://codedthemes.com/demos/admin-templates/datta-able/react/default/app/dashboard/default)
### Corona
Corona Admin is a free responsive admin template built with Bootstrap 4. The template has a colorful, attractive yet simple, and elegant design. The template is well crafted, with all the components neatly and carefully designed and arranged within the template.
[Download](https://github.com/BootstrapDash/corona-react-free-admin-template) / [Live Demo](https://www.bootstrapdash.com/demo/corona-react-free/template/demo_1/preview/dashboard)
### Matx
MatX is a full-featured React Material Design Admin Dashboard template. MatX is built with React, Redux & Material UIWe implemented all the features you might need to start a new Web application. The free version includes all Material UI components, Form elements, and validation, JWT authentication, Sign in, sign up pages, Vertical navigation, Lazy loading, Code splitting, SASS integration.
[Download](https://github.com/uilibrary/matx-react) / [Live Demo](https://matx-react.ui-lib.com/dashboard/default)
### Light Blue
Light Blue React Template is a great template to quick-start the development of SAAS, CMS, IoT Dashboard, E-Commerce apps, etc. It is a free and open-source admin dashboard template built with React and Bootstrap 4.
[Download](https://github.com/flatlogic/light-blue-react-template) / [Live Demo](https://flatlogic.github.io/light-blue-react-template/#/app/main/dashboard)
### Shards Lite
Shards Lite is a free React dashboard template that includes a modern design system as well as a variety of configurable layouts and components.
[Download](https://github.com/DesignRevision/shards-dashboard-react) / [Live Demo](https://designrevision.com/demo/shards-dashboard-lite-react/blog-overview)
### Notus React
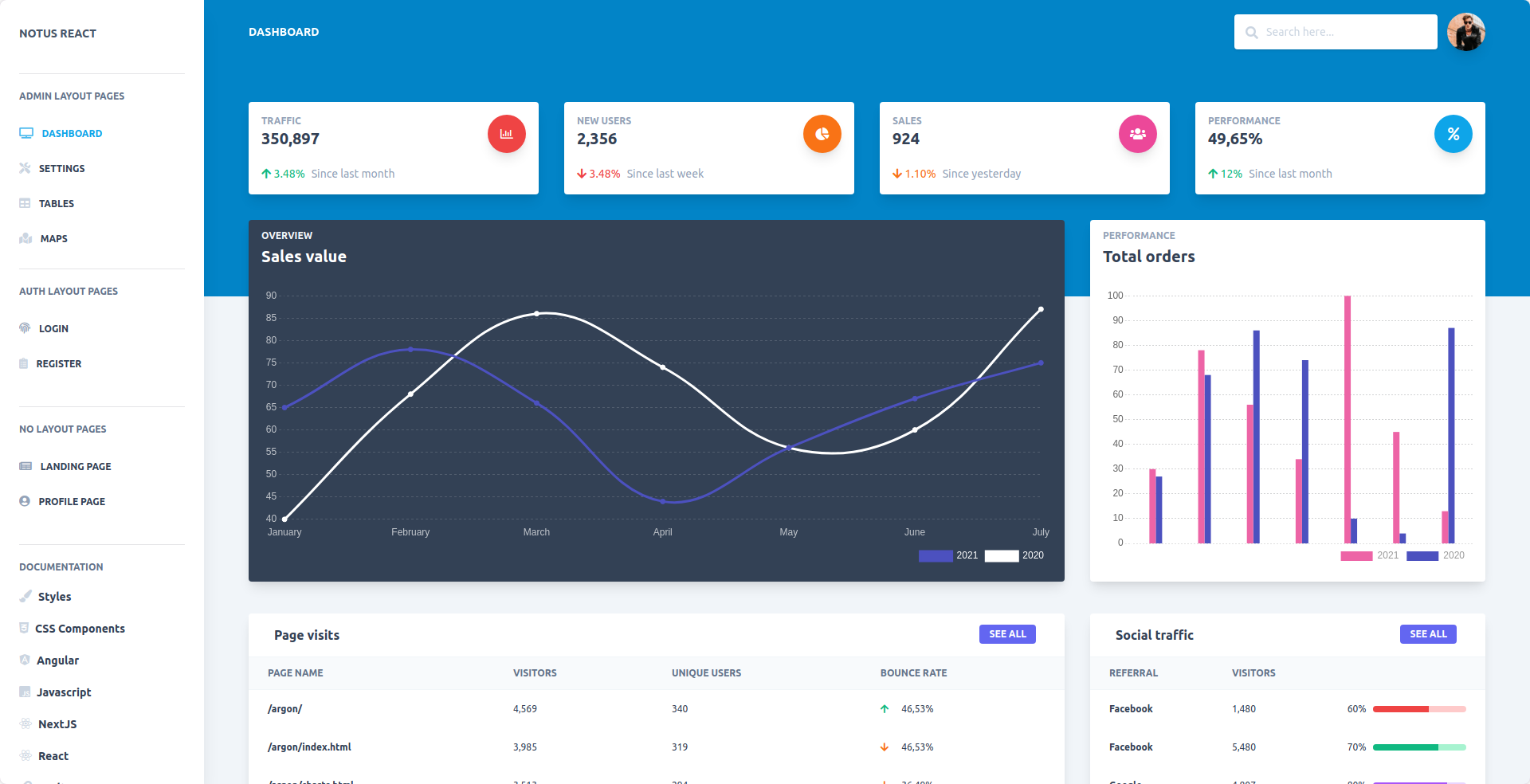
Notus React is Free and Open Source. It features multiple HTML and React elements and it comes with dynamic components for React. It is based on Tailwind Starter Kit by Creative Tim, and it is built with both presentation pages, and pages for an admin dashboard.
[Download](https://github.com/creativetimofficial/notus-react) / [Live Demo](https://demos.creative-tim.com/notus-react/#/admin/dashboard)
### Berry
Berry is a creative free react admin template build using the Material-UI. It is meant to be the best User Experience with highly customizable feature-riched pages. It is a complete game-changer React Dashboard Template with an easy and intuitive responsive design as on retina screens or laptops.
[Download](https://github.com/codedthemes/berry-free-react-admin-template) / [Live Demo](https://berrydashboard.io/free/dashboard/default)
### Conclusion
I hope you found this article useful, if you need any help please let me know in the comment section.
Would you like to buy me a coffee, You can do it [here](https://www.buymeacoffee.com/suhailkakar).
Let's connect on [Twitter](https://twitter.com/suhailkakar) and [LinkedIn](https://www.linkedin.com/in/suhailkakar/).
👋 Thanks for reading, See you next time | suhailkakar |
836,037 | How to use Components with generics types better | This is going to be a short post, but I really wanted to share a better way to use Typescript... | 0 | 2021-09-21T22:54:41 | https://dev.to/michaeljota/how-to-use-components-with-generics-types-better-207k | typescript, react, javascript | This is going to be a short post, but I really wanted to share a better way to use Typescript Generics better.
But first, how do you use Generics in Components right now? Maybe you don't, maybe you do, but you loose in the middle valuable type information. Maybe you are like me, and you are too waiting for [TypeScript#22063](https://github.com/microsoft/TypeScript/issues/22063) to be merge.
{% github https://github.com/microsoft/TypeScript/issues/22063 %}
What if I tell you there is a better way to type generic components without loosing either the generic nor the component information?
## Snipped
```ts
export type Component = (<Data>(props: ComponentProps<Data>) => ReturnType<FC>) & VFC<ComponentProps<{}>>;
```
This piece of code, is an overload. Just a plain old overload can do the job of having both, the generic, and the component properties.
I really didn't think about this until I saw the last comment of the issue I mentioned earlier, and the answer to that comment.
You can use an `interface` if you like it
```ts
export interface Component extends VFC<ComponentProps<{}>> { <Data>(props: ComponentProps<Data>): ReturnType<FC> };
```
When consuming, you need to declare a component that fulfil both overloads, like so:
```ts
export const Component: Component = ({ data, keys }: ComponentProps<Record<any, any>>) => {
...
}
```
## Playground example
[TS Playground](https://www.typescriptlang.org/play?#code/JYWwDg9gTgLgBAJQKYEMDGMA0cDecBqAYgMLYCuAzkgMowoxLYlwC+cAZlBCHAORSoMvANwAocaOAA7BlHbokcYt0hSkMgApcwFADwAReijhIAHgykATCrhYA+XKLjO4lowC44hugG0AumIucADWSACeFJ4AFKFhEOxeRgCU-mIs4maQsHAwYWCKyuAQajJwALxwUQZGdlFg2pFKKsXqMFoQOtV0dknlDsgwZFBSACp5SLokPXAAZAQkuoWqre2dOPZ2YqKZ0PBoxRTwSy0ynscl8BVReG502LE2LGfNF6t6yPtQlrooUmHYvzCdmmZQcOCcLgEg2GcF0dhwtxQADoQCgwFFjKDYQALABMdhQugA9HieixiXZROlJDIkHIFHANHSKMVHEF2MAoIcAHIoEBITyHKDSADmgRcABsUDy+QK4ELReLnCgRXKpGQQAAjOlpDKmLJ7A7wDQquVEYjlSq9LHgoL7KSHOA+fJc4rYKhtZnFPyWyg0OgMXRM11Sfy1fxJLZBKFDKSw86tVxGMo4F0sqRsB4pny8DlcmC8-m8PxsImUlhAA)
## That's all folks!
Did you know about this? Don't lie to me, I've been working with TS for 5 years and I never though about this, and let me tell you, this is not something just to show at a Playground, I have now a working Table component using this generic declaration, checking all the properties inside the data and the description around the table.
Let me know in the comments what other techniques do you use to deal with generics in React.
Image by <a href="https://pixabay.com/users/nickype-10327513/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=6626780" class="keychainify-checked">NickyPe</a> from <a href="https://pixabay.com/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=6626780" class="keychainify-checked">Pixabay</a> | michaeljota |
833,642 | Android Wallet Cards Manager - Creating a sliding card wallet layout for Android | Hi everyone, my new article on Medium is out! ... | 0 | 2021-09-21T08:01:31 | https://dev.to/eli_/android-wallet-cards-manager-creating-a-sliding-card-wallet-layout-for-android-293d | android, programming, ux, design | Hi everyone, my new article on Medium is out!
{% medium https://medium.com/overapp-android/walletcardsmanager-687b079f94ff %}
{% youtube 7YJ2TgG96dY %}
You find the full code on Github {% github eliaspiga/WalletCardsManager no-readme %}
<br/>
######*Photo by [David Clode](https://unsplash.com/@davidclode?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/s/photos/dragonfly?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)* | eli_ |
833,724 | Me, AWS and Netlify | Into the city When I moved to Cloud City I noticed that everybody was nice and friendly.... | 0 | 2021-09-27T07:44:46 | https://dev.to/bornfightcompany/me-aws-and-netlify-4016 | engineeringmonday, aws, netlify | ## Into the city
When I moved to Cloud City I noticed that everybody was nice and friendly. What was striking is that the community was large, but the technology everybody was using, was even larger.
I was new so I wanted to get to know the city. My idea was to make my MyApp scale quickly with the help of the technology of Cloud City and its community.
## At the pub
I managed to find an apartment near Serverless Heights, which is a pretty large neighborhood in the area. The first few days were boring, but I found a small pub with a great beer named Codereviewer, the pub, and the beer are named Codereviewer.
One night I was sitting at the bar where several developers had been celebrating the end of a stressful sprint. They were very open so I joined the conversation from time to time. After few more beers, they started to talk about girls in the neighborhood and then somebody mentioned AWS and the moment just stopped. Each of the guys took a moment to bring back memories of her image, of her beauty. As it seemed AWS was the most wanted girl in the whole city and everybody was talking about her. One guy mentioned that she could come to this pub, and by the looks, everybody gave him I suspected that that was the reason they came to the pub. By listening carefully I understood that she wasn't an easy girl, but was approachable. She wouldn't expect dinners and presents and was very respectful of your money and hers too. She would always split the bill evenly. As long as you behaved you had a chance with her.
## When I met her
The next day I came to the Codereviewer and sat at the bar, again. There was nobody I could recognize from the evening before. I ordered a cup of coffee and started scrolling on my mobile phone.
All of a sudden the murmur stopped, it took me a few seconds to understand what was happening. Everybody was looking at the door. I turned my head and there she was. AWS. She was the most beautiful thing I had ever seen. Long blond API Gateway was waiving as she walked. She was walking toward the bar with her beautiful legs, I raised my view toward her Cognito and a little bit more to her Lambdas. And what Lambdas she had! It was like she came out of PlayDev's magazine cover. Perfection.
She sat beside me. When she ordered her drink she turned toward me and just started the conversation. I won't go into details, but after I gave her some details about me, we were a couple. The first few days and weeks were incredible, it looked like the relationship was moving forward really fast. She let me play with her Lambdas and I played a lot I must admit. :-)
## When I got to know her better
Weeks and months passed. Everything was great but we couldn't push our relationship to the next level. When things were going great she would distract with something out of the blue that she thought wasn't right at the moment. After a while, I noticed that I wasn't playing as much with her Lambdas anymore but was constantly preoccupied with "where are the keys", "you left the toilet seat up", "there are these bills you have to pay"... the list went on and on... For everything that she put on, there should be two guys waiting for her and her needs and I wasn't ready for that. I am a little bit conservative in that department. After several months we broke up. I just couldn't handle it anymore.
I was devastated. She just sucked all of the joy I had in me. I was thinking about leaving Serverless Heights and even my MyApp. Instead of working on MyApp, I was taking care of AWS. We all suffered.
## And then came Netlify
After two months I met this girl named Netlify. I didn't need any manuals and she had great Lambdas. She is wild. Getting to know her Identity went quick. We just enjoyed being together and went from zero to married in no time. I just had to Git Push and MyApp will have a little sister NextApp in December.
Between you and me AWS and Netlify have the same Lambdas but don't say it to the guys at Codereviewer. ;-) | aleksandarperc |
833,771 | A Nice Developer Joke For Today | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2021-09-21T12:00:03 | https://dev.to/dailydeveloperjokes/a-nice-developer-joke-for-today-351j | jokes, dailydeveloperjokes, watercooler | ---
title: "A Nice Developer Joke For Today"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
published: true
tags: #jokes, #dailydeveloperjokes, #watercooler
---
Hi there! Here's today's Daily Developer Joke. We hope you enjoy it; it's a good one.

---
For more jokes, and to submit your own joke to get featured, check out the [Daily Developer Jokes Website](https://dailydeveloperjokes.github.io/). We're also open sourced, so feel free to view [our GitHub Profile](https://github.com/dailydeveloperjokes).
### Leave this post a ❤️ if you liked today's joke, and stay tuned for tomorrow's joke too!
_This joke comes from [Dad-Jokes GitHub Repo by Wes Bos](https://github.com/wesbos/dad-jokes) (thank you!), whose owner has given me permission to use this joke with credit._
<!--
Joke text:
___Q:___ Why couldn't the React component understand the joke?
___A:___ Because it didn't get the context.
-->
| dailydeveloperjokes |
833,780 | Getting started with Spring Boot: Creating a simple movies list API. | Spring boot is widely considered an entry to the Spring ecosystem, simple yet effective and powerful!... | 0 | 2021-09-21T12:15:47 | https://dev.to/daasrattale/getting-started-with-spring-boot-creating-a-simple-movies-list-api-41l6 | Spring boot is widely considered an entry to the Spring ecosystem, simple yet effective and powerful! Spring boot makes it possible to create Spring-based stand-alone, quality production apps with minimum needed configuration specifications. Let's keep it simple, just like the movies list API we're about to create!
## Before we start
Your project structure matters, Spring boot gives you all the freedom to structure your project the way you see fit, you may want to use that wisely.
There's not a particular structure you need to follow, I'll be introducing mine on this project but that doesn't mean you have to follow it the way it is, as I said you're free!
Most tech companies, including mine, use guiding dev rules to keep the code clean and pretty, the rules are there to help you, don't go rogue.
## Phase 0 : Introduction to the global architecture
Before we get busy with the layers specifications, let's have a bird's-eye view :
<p align="center">
<img src="https://elattar.me/images/spring/spring-init-movies-arch.png">
</p>
## Phase I : Model definition
Models are the data structure which you're project is dealing with (example: you're building a user management system, the user is your model among others).
Usually, the software architect will be there to provide you with the needed resources to build your Spring boot models, those resources mainly are UML class diagrams. Here's ours :
<p align="center">
<img src="https://elattar.me/images/spring/movies-model.png">
</p>
***NOTE: I decided for this model layer to be as simple as possible, to not give a wall to climb instead of a first step. In real-life projects, things get ugly and much more complicated.***
## Phase II : Service definition
After the model layer, now it's time to blueprint our services' structure, in other words, we need to define what service our API is going to mainly provide.
The services usually are fully invocated by the controller layer which means they usually have the same structure, but not all the time.
This one also will be provided by the software architect, and it comes as a detailed list with descriptions, a set of UML sequence diagrams, or both.
We need our API to be able to provide us with a list of saved movies, save, update and delete a movie.
Our end-points will be the following:
- **Save EP**: This allows **saving** a movie by sending a JSON object using an **HTTP/POST** request.
- **Update EP**: This allows **updating** a movie by sending a JSON object using an **HTTP/PUT** request.
- **Delete EP**: This allows **deleting** a movie by sending its id using an **HTTP/DELETE** request.
- **Find all EP**: This allows **retrieving** all the existing movies by sending an **HTTP/GET** request. (It's not recommended to open a find all end-point because it will slow down your application, instead set a limit, Example: 10 movies per request).
### Why are we using multiple HTTP verbs?
If I were in your shoes right now, I'd be asking the same question. First, you can use it as you want with no restrictions, use an HTTP/POST request to retrieve movies, yes you can do that but, there's a reason why we don’t.
Dev rules and conventions are there to help you and keep things in order, otherwise, all we'll be building is chaos!
HTTP verbs are meant to describe the purpose of the request:
<table>
<thead>
<tr>
<th>HTTP Verb</th>
<th>CRUD Op</th>
<th>Purpose</th>
<th>On success</th>
<th>On failure</th>
</tr>
</thead>
<tbody>
<tr>
<td>POST</td>
<td>Create</td>
<td>Creates a resource</td>
<td style="color: #52c41a">201</td>
<td style="color: #f5222d">404 | 409</td>
</tr>
<tr>
<td>GET</td>
<td>Read</td>
<td>Retrieves a resource</td>
<td style="color: #52c41a">200</td>
<td style="color: #f5222d">404</td>
</tr>
<tr>
<td>PUT</td>
<td>Update</td>
<td>Updates (replaces) a resource</td>
<td style="color: #52c41a">200 | 204</td>
<td style="color: #f5222d">404 | 405</td>
</tr>
<tr>
<td>PATCH</td>
<td>Update</td>
<td>Updates (modifies) a resource</td>
<td style="color: #52c41a">200 | 204</td>
<td style="color: #f5222d">404 | 405</td>
</tr>
<tr>
<td>DELETE</td>
<td>Delete</td>
<td>Deletes a resource</td>
<td style="color: #52c41a">200</td>
<td style="color: #f5222d">404 | 405</td>
</tr>
</tbody>
</table>
Each request requires a response, in both success and error scenarios, HTTP response codes are there to define what type of response we are getting.
<table>
<thead>
<tr>
<th>HTTP response code</th>
<th>Meaning</th>
</tr>
</thead>
<tbody>
<tr>
<td style="color: #1890ff">100 - 199</td>
<td>Informational responses</td>
</tr>
<tr>
<td style="color: #52c41a">200 - 299</td>
<td>Successful responses</td>
</tr>
<tr>
<td style="color: #13c2c2">300 - 399</td>
<td>Redirection responses</td>
</tr>
<tr>
<td style="color: #fa541c">400 - 499</td>
<td>Client error responses</td>
</tr>
<tr>
<td style="color: #f5222d">500 - 599</td>
<td>Server error responses</td>
</tr>
</tbody>
</table>
Know more about [HTTP response codes here](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status)
## Phase III: Technical benchmarking
Now, we need to define the project technical requirements, what communication protocol we should use, what Database is suitable to store data, etc.
We will be using REST as our main communication protocol, H2/file database to store our data.
I chose those technologies for instructional purposes so that I could offer a simple yet working example, but in real-life projects, we select technologies only on the basis of their utility and ability to aid in the development of our API. That was the second factor that influenced my decision.
***NOTE: The more technology experience you have, the more accurate your decisions will be.***
## Phase IV: Development
### Github repository initialization
To make this code accessible for all of you, and insure its version, we'll be using git and GitHub, find all the code here : [Github Repo](https://github.com/xrio/simple-spring-boot-movies.git)
### Spring Initializr
Spring provides us with an [Initialization suite](https://start.spring.io/) that helps us start our project quicker than usual.
<p align="center">
<img src="/images/spring/spring-init-movies.png">
</p>
After the init and downloading the basic version of our project, there're three important files you need to know about :
#### 1. The application main class (aka. the backbone)
This class is the main class of the project and it represents its center.
***NOTE: All packages should be under the main package of your application so they can be bootstrapped.***
```
package io.xrio.movies;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class
MoviesApplication {
public static void main(String[] args) {
SpringApplication.run(MoviesApplication.class, args);
}
}
```
#### 2. The application properties file
This file is a way to put your configuration values which the app will use during the execution (example: URL to the database, server's port, etc.).
***NOTE: You can add more properties files, I'll be covering that up in an upcoming article.***
***NOTE1: By default the file is empty.***
```
spring.datasource.url=jdbc:h2:file:./data/moviesDB
spring.jpa.defer-datasource-initialization=true
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=password
spring.jpa.hibernate.ddl-auto=update
```
#### 3. The pom file
Since we are using Maven as our dependency manager (you can use Gradle instead) we have a pom.xml file containing all the data about our dependencies.
```
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>io.xrio</groupId>
<artifactId>movies</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>movies</name>
<description>Just a simple movies api</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
```
### Building the model layer
The model layer is the direct implementation of our class diagrams as Java classes.
```
package io.xrio.movies.model;
import lombok.Data;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import java.util.Date;
@Data
@Entity
public class Movie {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String name;
private String type;
private Long duration;
private Long releaseYear;
}
```
The ```@Data``` provides us with embedded constructors and accessors so we can reduce the written code. see more about the [Lombok project](https://projectlombok.org/).
The ```@Entity``` is there to tell Spring Data that particular class should be represented as a table in our relational database. we call that process an ORM (Object Relational Mapping).
So that our id won’t be duplicated, we will use a sequence, we put the ```@GeneratedValue(strategy = GenerationType.SEQUENCE)``` there.
### Building the repository facade
Simply, an interface that will inherit Spring Data JPA powers and handle the CRUD ORM operations on our behalf.
```
package io.xrio.movies.repository;
import io.xrio.movies.model.Movie;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface MoviesRepository extends JpaRepository<Movie, Long> {
}
```
@Repository ensures the dependency injection of the repository bean among other things, since the interface inherits from the generic JpaRepository, it will have all the already-set mechanisms of Spring Data JPA.
Spring Data is smart enough at the level it can handle a new operation only from the function signature. Example: You need to file a movie by its title? No problem, just add this function to your interface :
```
Movie findByName(String name);
```
### Building the custom exception
Before building our service layer, we need a couple of custom exceptions that will be thrown when things go south.
Basing on our service schema only two exceptions can be thrown when:
- Creating an already existing movie (MovieDuplicatedException class).
```
package io.xrio.movies.exception;
import lombok.Data;
import lombok.EqualsAndHashCode;
/**
* @author : Elattar Saad
* @version 1.0
* @since 10/9/2021
*/
@EqualsAndHashCode(callSuper = true)
@Data
@AllArgsConstructor
public class MovieDuplicatedException extends Exception{
/**
* The duplicated movie's id
*/
private Long mid;
}
```
- Updating a non-existing movie (MovieNotFoundException class).
```
package io.xrio.movies.exception;
import lombok.Data;
import lombok.EqualsAndHashCode;
@EqualsAndHashCode(callSuper = true)
@Data
@AllArgsConstructor
public class MovieNotFoundException extends Exception{
/**
* The nonexistent movie's id
*/
private Long mid;
}
```
***NOTE: There're mainly four ways to handle exception in Spring boot.***
***NOTE1: You can generalize custom exceptions so they can be used for more than one model.***
***NOTE2: You can handle your exceptions without custom-made exceptions and handlers.***
### Building the service layer
First, we will create a movie service interface that will bear the schema of our service, then implement it with the needed logic. This helps us to achieve the [purpose of the IoC](https://en.wikipedia.org/wiki/Inversion_of_control).
```
package io.xrio.movies.service;
import io.xrio.movies.exception.MovieDuplicatedException;
import io.xrio.movies.exception.MovieNotFoundException;
import io.xrio.movies.model.Movie;
import java.util.List;
public interface MovieService {
Movie save(Movie movie) throws MovieDuplicatedException;
Movie update(Movie movie) throws MovieNotFoundException;
Long delete(Long id) throws MovieNotFoundException;
List<Movie> findAll();
}
```
```
package io.xrio.movies.service.impl;
import io.xrio.movies.exception.MovieDuplicatedException;
import io.xrio.movies.exception.MovieNotFoundException;
import io.xrio.movies.model.Movie;
import io.xrio.movies.repository.MoviesRepository;
import io.xrio.movies.service.MoviesService;
import lombok.Data;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
@Data
public class MovieServiceImpl implements MovieService {
final MovieRepository movieRepository;
@Override
public Movie save(Movie movie) throws MovieDuplicatedException {
Movie movieFromDB = movieRepository.findById(movie.getId()).orElse(null);
if (movieFromDB != null)
throw new MovieDuplicatedException(movie.getId());
return movieRepository.save(movie);
}
@Override
public Movie update(Movie movie) throws MovieNotFoundException {
Movie movieFromDB = movieRepository.findById(movie.getId()).orElse(null);
if (movieFromDB == null)
throw new MovieNotFoundException(movie.getId());
movie.setId(movieFromDB.getId());
return movieRepository.save(movie);
}
@Override
public Long delete(Long id) throws MovieNotFoundException {
Movie movieFromDB = movieRepository.findById(id).orElse(null);
if (movieFromDB == null)
throw new MovieNotFoundException(id);
movieRepository.delete(movieFromDB);
return id;
}
@Override
public List<Movie> findAll() {
return movieRepository.findAll();
}
}
```
I combined the use of constructor dependency injection and Lombok’s ```@RequiredArgsConstructor``` to reduce my code, without that it will look like this :
```
@Service
public class MovieServiceImpl implements MovieService {
final MovieRepository movieRepository;
public MovieServiceImpl(MovieRepository movieRepository) {
this.movieRepository = movieRepository;
}
...
}
```
### Building the controller layer
After the service layer, time to build our controller to accept incoming requests.
As previously said, the controller layer directly calls the service layer, that's the reason behind the injection of a MovieService bean inside the movie controller.
```
package io.xrio.movies.controller;
import io.xrio.movies.exception.MovieDuplicatedException;
import io.xrio.movies.exception.MovieNotFoundException;
import io.xrio.movies.model.Movie;
import io.xrio.movies.service.MovieService;
import lombok.Data;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("movie")
@Data
public class MovieController {
final MovieService movieService;
@PostMapping("/")
public ResponseEntity<?> save(@RequestBody Movie movie) throws MovieDuplicatedException {
if (movie == null)
return ResponseEntity.badRequest().body("The provided movie is not valid");
return ResponseEntity.status(HttpStatus.CREATED).body(movieService.save(movie));
}
@PutMapping("/")
public ResponseEntity<?> update(@RequestBody Movie movie) throws MovieNotFoundException {
if (movie == null)
return ResponseEntity.badRequest().body("The provided movie is not valid");
return ResponseEntity.ok().body(movieService.update(movie));
}
@DeleteMapping("/{id}")
public ResponseEntity<?> delete(@PathVariable Long id) throws MovieNotFoundException {
if (id == null)
return ResponseEntity.badRequest().body("The provided movie's id is not valid");
return ResponseEntity.ok().body("Movie [" + movieService.delete(id) + "] deleted successfully.");
}
@GetMapping("/")
public ResponseEntity<?> findAll() {
return ResponseEntity.ok().body(movieService.findAll());
}
}
```
One more last step and we're good to go. To handle the exception thrown from the service layer, we need to catch it in the controller layer.
Fortunately, Spring boot provides us with an Exception Handler that can resolve exceptions under the hood and without any code to the controller.
```
package io.xrio.movies.controller.advice;
import io.xrio.movies.exception.MovieDuplicatedException;
import io.xrio.movies.exception.MovieNotFoundException;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.servlet.mvc.method.annotation.ResponseEntityExceptionHandler;
@ControllerAdvice
public class MovieControllerExceptionHandler {
@ExceptionHandler(MovieNotFoundException.class)
private ResponseEntity<?> handleMovieNotFoundException(MovieNotFoundException exception){
String responseMessage = "The provided movie ["+exception.getMid()+"] is nowhere to be found.";
return ResponseEntity
.status(HttpStatus.NOT_FOUND)
.body(responseMessage);
}
@ExceptionHandler(MovieDuplicatedException.class)
private ResponseEntity<?> handleMovieDuplicatedException(MovieDuplicatedException exception){
String responseMessage = "The provided movie ["+exception.getMid()+"] is already existing.";
return ResponseEntity
.status(HttpStatus.CONFLICT)
.body(responseMessage);
}
}
```
All we need to do next is to test what we build via a rest client, for this reason, I'm using [Insomnia](https://insomnia.rest/) :
##### The post end-point
<p align="center">
<img src="https://elattar.me/images/spring/movie-test-post.png">
</p>
##### The get end-point
<p align="center">
<img src="https://elattar.me/images/spring/movie-test-get.png">
</p>
##### The put end-point
<p align="center">
<img src="https://elattar.me/images/spring/movie-test-put.png">
</p>
##### The delete end-point
<p align="center">
<img src="https://elattar.me/images/spring/movie-test-delete.png">
</p>
And finally, testing the error scenario for some end-points.
Let's try and save a movie with an existing id :
<p align="center">
<img src="https://elattar.me/images/spring/movie-test-save-error.png">
</p>
Or delete a non-existing movie :
<p align="center">
<img src="https://elattar.me/images/spring/movie-test-delete-error.png">
</p>
## Summary
Spring Boot is a powerful apps making tool, takes away all the times consuming tasks and leaves you with the logical ones to handle.
Don't get fouled, building APIs is not that easy, and from what I saw, that's just the tip of the Iceberg!
Find the source code [Here](https://github.com/xrio/simple-spring-boot-movies).
More articles [Here](https://elattar.me/). | daasrattale | |
833,797 | Spring Boot validation and bean manipulation | Secure applications follow several security measures during their dev and prod phases, the app entry... | 0 | 2021-09-21T12:33:16 | https://dev.to/daasrattale/spring-boot-validation-and-bean-manipulation-1leo | spring, springframework, java, jee | Secure applications follow several security measures during their dev and prod phases, the app entry points are one of the most important parts to secure due to the risk of data injection that may occur. Spring proposes its way of data validation which improves controlling these particular points.
As you've already guessed, this article is about more than just data validation; it's also about bean or custom data structure manipulation, which are two important applicative security features that every developer should be aware of.
Enough introductions, for now, let's start with a global blueprint of what we need to achieve, you need to know that both mechanisms resolve two security vulnerabilities:
- **Injection attacks**
- **Database schema exposure**
Sounds bad right? Well, the solution is actually simpler than you think. First, let's understand both problems before jumping to the solutions.
## Injection attacks
An injection attack is when malicious code is injected into the network and retrieves all of the data from the database and sends it to the attacker.
As you concluded the attack uses the open door of your app to gain all the stored data, and it can disguise, the attack, in many types such as **XSS, SQL, XPath, Template, code, CRLF, LDAP, OS command injections**, and more.
If you're using **ORM operations** you're not totally safe, but you're one step ahead. **The more defenses you raise the better**.
## Database schema exposure
Mainly when this occurs, it doesn't come with a great benefit for the attackers, but it still delivers a piece of valuable information, which is the way you constructed your **schemas, data types, and relations**, in some scenarios it becomes critical.
## Data validation
During this tutorial, we will be based on our last [Movies API](https://github.com/xrio/simple-spring-boot-movies).
First, let's add the Spring boot validation dependency to our pom.xml file.
```
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
```
Second, we'll enhance our movie model with some validation rules.
```
// other imports
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.validation.constraints.Max;
import javax.validation.constraints.Min;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.NotNull;
@Data
@Entity
public class Movie {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
@NotNull(message = "Id must not be null")
private Long id;
@NotBlank(message = "Name must not be blank")
private String name;
@NotBlank(message = "Type must not be blank")
private String type;
@Min(value = 1, message = "Movies are mainly more than a minute")
@Max(value = 300, message = "Movies are less than 5 hours")
private Long duration;
@NotNull(message = "Release year must not be null")
private Long releaseYear;
}
```
Third, we alter our controller end points' signatures so they can validate incoming request bodies and throw Exception instead of custom exceptions.
```
...
import javax.validation.Valid;
@RestController
@RequestMapping("movie")
@Data
public class MovieController {
...
@PostMapping("/")
public ResponseEntity<?> save(@Valid @RequestBody Movie movie) throws Exception {
if (movie == null)
return ResponseEntity.badRequest().body("The provided movie is not valid");
return ResponseEntity.status(HttpStatus.CREATED).body(movieService.save(movie));
}
@PutMapping("/")
public ResponseEntity<?> update(@Valid @RequestBody Movie movie) throws Exception {
if (movie == null)
return ResponseEntity.badRequest().body("The provided movie is not valid");
return ResponseEntity.ok().body(movieService.update(movie));
}
...
}
```
The @Valid makes sure that the incoming body is valid, otherwise a MethodArgumentNotValidException will be thrown
Obviously, we removed the custom-made exception and replaced it with the Exception class so the controller won't suppress the exception in the controller layer and let the default exception handler interfere, which will cause a 500 server internal error. Instead, it will be handled by the exception handler we’re about to make.
```
package io.xrio.movies.controller.advice;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.validation.FieldError;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseStatus;
import java.util.HashMap;
import java.util.Map;
@ControllerAdvice
public class ValidationExceptionHandler {
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<?> handleValidationExceptions(MethodArgumentNotValidException exception) {
Map<String, String> errors = new HashMap<>();
exception.getBindingResult().getAllErrors().forEach((error) -> {
String fieldName = ((FieldError) error).getField();
String errorMessage = error.getDefaultMessage();
errors.put(fieldName, errorMessage);
});
return ResponseEntity.badRequest().body(errors);
}
}
```
Just like our previous Movie exception handler, this ControllerAdvice based handler will target the MethodArgumentNotValidException type exceptions and resolve them by retrieving the validation violation, wrap it in a response entity and send it back to the user with 400 bad request response code.
<p align="center">
<img src="https://elattar.me/images/spring/movie-validation-1.png">
</p>
***NOTE: Returning the validation violations to the user is a huge blender, it's like telling a house robber why they failed to rob your own house.***
To counter this, we'll print them on the logs, which are by the way are accessible only to the prod env admins. Our Exception will be like this:
```
import lombok.extern.slf4j.Slf4j;
...
@ControllerAdvice
@Slf4j
public class ValidationExceptionHandler {
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<?> handleValidationExceptions(MethodArgumentNotValidException exception) {
exception.getBindingResult().getAllErrors().forEach((error) -> {
String fieldName = ((FieldError) error).getField();
String errorMessage = error.getDefaultMessage();
log.error(fieldName + ": " + errorMessage);
});
return ResponseEntity.badRequest().body("Sorry, that movie you sent sucks :)");
}
}
```
Sending the same request will result this:
<p align="center">
<img src="https://elattar.me/images/spring/movie-validation-2.png">
</p>
And only prod env admins can see this:
<p align="center">
<img src="https://elattar.me/images/spring/movie-validation-3.png">
</p>
The @Slf4j is a short way using [Lombok](https://projectlombok.org/) to call the logger.
Data validation not only is a layer to counter injection attacks, but it helps keep your data nice and clean.
Since we still exposing our model in our end-points, it's time to change that!
## Data manipulation
### Introduction to the DTOs
The data transfer objects, also known as Value Objects (VOs), will be the ones carrying data between two processes, in our case, it will be their structure that will be exposed instead of the model's.
Our MovieDTO will be like the following:
```
import lombok.Data;
import javax.validation.constraints.Max;
import javax.validation.constraints.Min;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.NotNull;
@Data
public class MovieDTO {
@NotNull(message = "Id must not be null")
private Long id;
@NotBlank(message = "Name must not be blank")
private String name;
@NotBlank(message = "Type must not be blank")
private String type;
@Min(value = 1, message = "Movies are mainly more than a minute")
@Max(value = 300, message = "Movies are less than 5 hours")
private Long duration;
@NotNull(message = "Release year must not be null")
private Long releaseYear;
}
```
Since the DTOs are the ones to be exposed, we added some validation rules.
***Okay, we have the DTOs exposed, but how are we going to persist data using DTOs?***
***The answer is that DTOs only exist in the controller layer, in other words, we can't use them on the service and repository layers.***
Also means our need for a **conversion mechanism**, yes, we need a MovieConverter.
Let's start with the integration of the [ModelMapper](http://modelmapper.org/getting-started/) dependency which will help convert models and DTO in both ways:
```
<dependency>
<groupId>org.modelmapper</groupId>
<artifactId>modelmapper</artifactId>
<version>2.3.5</version>
</dependency>
```
Then, we add its basic configuration so it will treated as Spring Bean:
```
import org.modelmapper.ModelMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ModelMapperConfig {
@Bean
public ModelMapper modelMapper() {
return new ModelMapper();
}
}
```
I don't like repeating myself ([DRY priciple](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself)) that's why I always put redundant behavior into generic classes, the AbstractConverter will do that for us:
```
import java.util.ArrayList;
import java.util.List;
public abstract class AbstractConverter <DM, DTO> {
public abstract DM convertToDM(DTO dto);
public abstract DTO convertToDTO(DM dm);
public List<DM> convertToDMs(List<DTO> dtos) {
List<DM> dms = new ArrayList<>();
for (DTO dto : dtos) dms.add(convertToDM(dto));
return dms;
}
public List<DTO> convertToDTOs(List<DM> dms) {
List<DTO> dtos = new ArrayList<>();
for (DM dm : dms) dtos.add(convertToDTO(dm));
return dtos;
}
}
```
Our MovieConverter will inherit from the AbstractConverter with the movie model and DTO as class params.
```
import io.xrio.movies.dto.MovieDTO;
import io.xrio.movies.model.Movie;
import org.modelmapper.ModelMapper;
import org.modelmapper.config.Configuration;
import org.springframework.stereotype.Component;
@Component
public class MovieConverter extends AbstractConverter<Movie, MovieDTO> {
private final ModelMapper modelMapper;
public MovieConverter(ModelMapper modelMapper) {
modelMapper.getConfiguration()
.setFieldMatchingEnabled(true)
.setFieldAccessLevel(Configuration.AccessLevel.PRIVATE);
this.modelMapper = modelMapper;
}
@Override
public Movie convertToDM(MovieDTO movieDTO) {
return modelMapper.map(movieDTO, Movie.class);
}
@Override
public MovieDTO convertToDTO(Movie movie) {
return modelMapper.map(movie, MovieDTO.class);
}
}
```
I decorated the MovieConverter with the @Component annotation so it can be injected into the MovieController later.
The model mapper will be configured in the MovieConverter constructors with a simple configuration, and with the model and DTO having the same fields, the mapping will be possible for now.
Before testing our converter, we need to inject it into the controller, then alter the endpoints so they can handle the DTOs now instead.
```
package io.xrio.movies.controller;
import io.xrio.movies.converter.MovieConverter;
import io.xrio.movies.dto.MovieDTO;
import io.xrio.movies.service.MovieService;
import lombok.Data;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import javax.validation.Valid;
import java.util.List;
@RestController
@RequestMapping("movie")
@Data
public class MovieController {
final MovieService movieService;
final MovieConverter movieConverter;
@PostMapping("/")
public ResponseEntity<?> save(@Valid @RequestBody MovieDTO movieDTO) throws Exception {
if (movieDTO == null)
return ResponseEntity.badRequest().body("The provided movie is not valid");
return ResponseEntity
.status(HttpStatus.CREATED)
.body(movieConverter.convertToDTO(movieService.save(movieConverter.convertToDM(movieDTO))));
}
@PutMapping("/")
public ResponseEntity<?> update(@Valid @RequestBody MovieDTO movieDTO) throws Exception {
if (movieDTO == null)
return ResponseEntity.badRequest().body("The provided movie is not valid");
return ResponseEntity
.ok()
.body(movieConverter.convertToDTO(movieService.update(movieConverter.convertToDM(movieDTO))));
}
@DeleteMapping("/{id}")
public ResponseEntity<?> delete(@PathVariable Long id) throws Exception {
if (id == null)
return ResponseEntity.badRequest().body("The provided movie's id is not valid");
return ResponseEntity.ok().body("Movie [" + movieService.delete(id) + "] deleted successfully.");
}
@GetMapping("/")
public ResponseEntity<List<MovieDTO>> findAll() {
return ResponseEntity.ok().body(movieConverter.convertToDTOs(movieService.findAll()));
}
}
```
Then we test it!
<p align="center">
<img src="https://elattar.me/images/spring/movie-conversion-1.png">
</p>
**Great! But it looks the same as before with more code!**
True, so let's play the same game with different rules, the movie model for us now will be different than the DTO in order to protect our API against the database schema exposure:
Some of the movie model fields will be put in an info class that will be embedded in the movie, that way we will change the structure and keep things simple for you.
***NOTE: I removed the model validation because it's no longer used or needed.***
```
import lombok.Data;
import javax.persistence.*;
import javax.validation.Valid;
import javax.validation.constraints.NotNull;
@Data
@Entity
public class Movie {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
@Embedded
private Info info;
}
```
```
import javax.persistence.Embeddable;
@Embeddable
public class Info {
private String name;
private String type;
private Long duration;
private Long releaseYear;
}
```
We need also to alter our DTO's fields' names so we don't need to add an advanced configuration for the model mapper.
```
import lombok.Data;
import javax.validation.constraints.Max;
import javax.validation.constraints.Min;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.NotNull;
@Data
public class MovieDTO {
@NotNull(message = "Id must not be null")
private Long id;
@NotBlank(message = "Name must not be blank")
private String infoName;
@NotBlank(message = "Type must not be blank")
private String infoType;
@Min(value = 1, message = "Movies are mainly more than a minute")
@Max(value = 300, message = "Movies are less than 5 hours")
private Long infoDuration;
@NotNull(message = "Release year must not be null")
private Long infoReleaseYear;
}
```
And finally testing it.
<p align="center">
<img src="https://elattar.me/images/spring/movie-conversion-2.png">
</p>
## Finnally
Data validation and data manipulation can be a greatly valued asset to your API dev and prod, not only enhancing security but also gives you the power to keep your data in shape and to adapt to the users’ requirements without changing your own.
Find the source code [Here](https://github.com/xrio/simple-spring-boot-movies).
More articles [Here](https://elattar.me/). | daasrattale |
834,071 | Algorithm Diary | 此處參照 LeetCode with JavaScript 作為練習,慢慢累積演算法實力~ 並採用通過率排序(提交後的成功率)決定難易度,作為做題的順序 ... | 0 | 2021-09-21T15:04:52 | https://dev.to/ben66yueh/-1n85 | algorithms, javascript | 此處參照 [LeetCode with JavaScript](https://skyyen999.gitbooks.io/-leetcode-with-javascript/content/) 作為練習,慢慢累積演算法實力~
並採用[通過率排序](https://skyyen999.gitbooks.io/-leetcode-with-javascript/content/sortbyacceptance.html)(提交後的成功率)決定難易度,作為做題的順序
## Diary
Sep. 21 - [LeetCode 344. Reverse String](https://dev.to/ben66yueh/leetcode-344-reverse-string-249o)
## String (1)
LeetCode 344. Reverse String
| ben66yueh |
834,074 | Everyone’s a (Perl) critic, and you can be too! | The perlcritic tool is often your first defense against “awkward, hard to read, error-prone, or... | 0 | 2021-09-21T15:16:16 | https://phoenixtrap.com/2021/09/21/everyones-a-perl-critic/ | perl, perlcritic, cpan, lint | ---
title: Everyone’s a (Perl) critic, and you can be too!
published: true
date: 2021-09-21 14:00:00 UTC
tags: Perl,perlcritic,CPAN,lint
canonical_url: https://phoenixtrap.com/2021/09/21/everyones-a-perl-critic/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/gk8n5t2s38e4r35ufei2.jpg
---
The [`perlcritic`](http://perlcritic.com/) tool is often your first defense against “awkward, hard to read, error-prone, or unconventional constructs in your code,” per its [description](https://metacpan.org/dist/Perl-Critic/view/bin/perlcritic#DESCRIPTION). It’s part of a class of programs historically known as [linters](https://en.wikipedia.org/wiki/Lint_(software)), so-called because like a clothes dryer machine’s lint trap, they “detect small errors with big effects.” (Another such linter is [`perltidy`](http://perltidy.sourceforge.net/), which I’ve [referenced](https://phoenixtrap.com/tag/perltidy/) in the past.)
You can use `perlcritic` [at the command line](https://metacpan.org/dist/Perl-Critic/view/bin/perlcritic), [integrated with your editor](https://metacpan.org/dist/Perl-Critic/view/bin/perlcritic#EDITOR-INTEGRATION), as a [`git` pre-commit hook](https://git-scm.com/docs/githooks#_pre_commit), or (my preference) as [part of your author tests](https://metacpan.org/pod/Test::Perl::Critic). It’s driven by [policies](https://metacpan.org/dist/Perl-Critic/view/bin/perlcritic#THE-POLICIES), individual modules that check your code against a particular recommendation, many of them from [Damian Conway’s _Perl Best Practices_](https://www.oreilly.com/library/view/perl-best-practices/0596001738/) (2005). Those policies, in turn, are enabled by [PPI](https://metacpan.org/pod/PPI), a library that transforms Perl code into documents that can be programmatically examined and manipulated much like the [Document Object Model (DOM)](https://en.wikipedia.org/wiki/Document_Object_Model) is used to programmatically access web pages.
`perlcritic` enables the following policies by default unless you [customize its configuration](https://metacpan.org/dist/Perl-Critic/view/bin/perlcritic#CONFIGURATION) or install more. These are just the “gentle” ([severity](https://metacpan.org/dist/Perl-Critic/view/bin/perlcritic#-severity-N) level 5) policies, so consider them the bare minimum in detecting bad practices. The [full set of included policies](https://metacpan.org/dist/Perl-Critic/view/lib/Perl/Critic/PolicySummary.pod) goes much deeper, ratcheting up the severity to “stern,” “harsh,” “cruel,” and “brutal.” They’re further organized according to [themes](https://metacpan.org/pod/Perl::Critic#POLICY-THEMES) so that you might selectively review your code against issues like security, maintenance, complexity, and bug prevention.
- [BuiltinFunctions::ProhibitSleepViaSelect](https://metacpan.org/pod/Perl::Critic::Policy::BuiltinFunctions::ProhibitSleepViaSelect)
- [BuiltinFunctions::ProhibitStringyEval](https://metacpan.org/pod/Perl::Critic::Policy::BuiltinFunctions::ProhibitStringyEval)
- [BuiltinFunctions::RequireGlobFunction](https://metacpan.org/pod/Perl::Critic::Policy::BuiltinFunctions::RequireGlobFunction)
- [ClassHierarchies::ProhibitOneArgBless](https://metacpan.org/pod/Perl::Critic::Policy::ClassHierarchies::ProhibitOneArgBless)
- [ControlStructures::ProhibitMutatingListFunctions](https://metacpan.org/pod/Perl::Critic::Policy::ControlStructures::ProhibitMutatingListFunctions)
- [InputOutput::ProhibitBarewordFileHandles](https://metacpan.org/pod/Perl::Critic::Policy::InputOutput::ProhibitBarewordFileHandles)
- [InputOutput::ProhibitInteractiveTest](https://metacpan.org/pod/Perl::Critic::Policy::InputOutput::ProhibitInteractiveTest)
- [InputOutput::ProhibitTwoArgOpen](https://metacpan.org/pod/Perl::Critic::Policy::InputOutput::ProhibitTwoArgOpen)
- [InputOutput::RequireEncodingWithUTF8Layer](https://metacpan.org/pod/Perl::Critic::Policy::InputOutput::RequireEncodingWithUTF8Layer)
- [Modules::ProhibitEvilModules](https://metacpan.org/pod/Perl::Critic::Policy::Modules::ProhibitEvilModules)
- [Modules::RequireBarewordIncludes](https://metacpan.org/pod/Perl::Critic::Policy::Modules::RequireBarewordIncludes)
- [Modules::RequireFilenameMatchesPackage](https://metacpan.org/pod/Perl::Critic::Policy::Modules::RequireFilenameMatchesPackage)
- [Subroutines::ProhibitExplicitReturnUndef](https://metacpan.org/pod/Perl::Critic::Policy::Subroutines::ProhibitExplicitReturnUndef)
- [Subroutines::ProhibitNestedSubs](https://metacpan.org/pod/Perl::Critic::Policy::Subroutines::ProhibitNestedSubs)
- [Subroutines::ProhibitReturnSort](https://metacpan.org/pod/Perl::Critic::Policy::Subroutines::ProhibitReturnSort)
- [Subroutines::ProhibitSubroutinePrototypes](https://metacpan.org/pod/Perl::Critic::Policy::Subroutines::ProhibitSubroutinePrototypes)
- [TestingAndDebugging::ProhibitNoStrict](https://metacpan.org/pod/Perl::Critic::Policy::TestingAndDebugging::ProhibitNoStrict)
- [TestingAndDebugging::RequireUseStrict](https://metacpan.org/pod/Perl::Critic::Policy::TestingAndDebugging::RequireUseStrict)
- [ValuesAndExpressions::ProhibitLeadingZeros](https://metacpan.org/pod/Perl::Critic::Policy::ValuesAndExpressions::ProhibitLeadingZeros)
- [Variables::ProhibitConditionalDeclarations](https://metacpan.org/pod/Perl::Critic::Policy::Variables::ProhibitConditionalDeclarations)
- [Variables::RequireLexicalLoopIterators](https://metacpan.org/pod/Perl::Critic::Policy::Variables::RequireLexicalLoopIterators)
My favorite above is probably [ProhibitEvilModules](https://metacpan.org/pod/Perl::Critic::Policy::Modules::ProhibitEvilModules). Aside from the colorful name, a development team can use it to steer people towards an organization’s favored solutions rather than “deprecated, buggy, unsupported, or insecure” ones. By default, it prohibits [Class::ISA](https://metacpan.org/pod/Class::ISA), [Pod::Plainer](https://metacpan.org/pod/Pod::Plainer), [Shell](https://metacpan.org/pod/Shell), and [Switch](https://metacpan.org/pod/Switch), but you should curate and configure a list within your team.
Speaking of working within a team, although `perlcritic` is meant to be a vital tool to ensure good practices, it’s no substitute for manual [peer code review](https://en.wikipedia.org/wiki/Code_review). Those reviews can lead to the creation or adoption of new automated policies to save time and settle arguments, but such work should be done collaboratively after achieving some kind of consensus. This is true whether you’re a team of employees working on proprietary software or a group of volunteers developing open source.
Of course, reasonable people can and do disagree over any of the included policies, but as a reasonable person, you should have _good_ reasons to disagree before you either configure `perlcritic` appropriately or selectively and knowingly [bend the rules](https://metacpan.org/dist/Perl-Critic/view/bin/perlcritic#BENDING-THE-RULES) where required. Other CPAN authors have even provided their own additions to `perlcritic`, so it’s worth [searching CPAN under “Perl::Critic::Policy::”](https://metacpan.org/search?q=Perl%3A%3ACritic%3A%3APolicy%3A%3A) for more examples. In particular, [these community-inspired policies](https://metacpan.org/pod/Perl::Critic::Community) group a number of recommendations from [Perl developers on Internet Relay Chat (IRC)](https://perldoc.perl.org/perlcommunity#IRC).
Personally, although I adhere to my employer’s standardized configuration when testing and reviewing code, I like to run `perlcritic` on the “brutal” setting before committing my own. What do you prefer? Let me know in the comments below.
* * *
_Cover image: [“Everyone’s a critic — graifitti under Mancunian Way in Manchester”](https://www.flickr.com/photos/56278705@N05/7859287174) by [Alex Pepperhill](https://www.flickr.com/photos/56278705@N05) is licensed under [CC BY-ND 2.0](https://creativecommons.org/licenses/by-nd/2.0/?ref=ccsearch&atype=rich)_ | mjgardner |
834,117 | How to use classes in Laravel | Hello friends! In this blog post I am going to illustrate how and why we use classes in laravel. Why... | 0 | 2021-09-21T16:38:05 | https://dev.to/snehalkadwe/how-to-use-classes-in-laravel-2e4p | beginners, laravel, codenewbie, womenintech | Hello friends!
In this blog post I am going to illustrate how and why we use classes in laravel.
__Why we use it?__
When the method is commonly used in one or more controller instead of writing the same code again and again we can create a class and reuse the code where we need it.
It helps us to remove the pain of writing the same code by easing common task.
__How to use it?__
* Create a class file in App folder or we can create a file in App\Providers folder (the App\Providers folder is provided by laravel to create external file).
* Now open the file and add namespace which is necessary.
```php
namespace App\Providers
```
if you do not see the Provider folder you can create one.
__Let see an example__
Create a PackageClass in App\Providers\PricePackage, open a file and add namespace in it.
```php
namespace App\Providers\PricePackage
```
now add below code in it
```php
class PackageClass {
public function getPackage() {
return [
'bronze' => 5000,
'silver' => 10,000,
'gold' => 20,000,
];
}
}
```
Now whenever we need the pricing we can call this class and use its methods, for that we need to instantiate the class object.
Open a controller file where you need to use it.
I am using it in `PriceController` and add the below code.
```php
public function index() {
$objPricePackage = new PackageClass();
$packages = $objPricePackage->getPackage();
return view('packages.index', ['packages', $packages]);
}
```
In this way we can use external classes in laravel.
Thank you for reading :lion: :unicorn:
| snehalkadwe |
834,329 | Write a Python program to insert a new item before the second element in an existing array. | from array import * array_num = array('i', [1, 3, 5, 7, 9]) print("Original array:... | 0 | 2021-09-21T18:16:22 | https://dev.to/s_belote_dev/write-a-python-program-to-insert-a-new-item-before-the-second-element-in-an-existing-array-1m92 | python | ```python
from array import *
array_num = array('i', [1, 3, 5, 7, 9])
print("Original array: "+str(array_num))
print("Insert new value 4 before 3:")
array_num.insert(1, 4)
print("New array: "+str(array_num))
``` | s_belote_dev |
836,053 | Restoring an SQL Server backup in a docker container | At our company, we wanted to run tests as E2E as possible, both in our local dev computers running... | 0 | 2021-09-22T00:28:54 | https://dev.to/alansarligithub/restoring-an-sql-server-backup-in-a-docker-container-1knb | docker, devops | At our company, we wanted to run tests as E2E as possible, both in our local dev computers running windows and in our pipeline: GitHub action with the latest ubuntu (https://github.com/actions/virtual-environments/blob/main/images/linux/Ubuntu2004-README.md), and that includes reaching out to a real SQL Server DB so we could verify our queries and tables are working fine.
We found it super challenging to create a solution that works in both Windows and Linux, lots of online suggestions don't seem to work anymore, so took us a while to work it out, but we finally managed so we decided to share with the world.
These are all the steps we followed:
# 1: Use a compression method that works in both Windows and Linux
The DB backup is normally huge, and we need to store it in Github and move it around, so we want it compressed.
The command tar matches the requirement, and works in windows 10 out of the box (https://superuser.com/a/1515028):
```bash
tar -cvzf mvc_db_2021-08-25.tar.gz mvc_db.bak
```
# 2: Put backup in a place accessible by SQL Server container
To be able to share access to it, we created a folder named 'sql_server_backup'.
Which is then shared via a volume in docker-compose, simplified example:
```yaml
version: '3.9'
services:
tests:
image: my-special-web-project-with-db-backup
depends_on:
- db
volumes:
- ./sql_server_backup:/sql_server_backup
db:
image: mcr.microsoft.com/mssql/server:2019-latest
volumes:
- ./sql_server_backup:/sql_server_backup
volumes:
sql_server_backup:
```
#3: Run docker compose and decompress the backup
In our repo root folder, we created a set-local-environment.sh:
```bash
#!/bin/bash -e
docker-compose -f docker-compose-infra.yml up -d
cd sql_server_backup
tar -xzvf *.tar.gz
# docker attach allow us to the logs inside the container, VERY useful for debugging
#docker attach db_1
echo "Docker compose finished running"
```
The order of the commands is quite important, we want docker compose to go first, as starting up the SQL Server instance can take a while, in the meantime we are decompressing the backup
#4: Restore the backup
This step has been the most difficult, as there is a timing issue, SQL Server can take a while to be ready for use, and recommendations to use scripts like wait-for-it.sh did not work for us.
What worked was leveraging the health check mechanism, that runs regularly, if the DB is not ready to start restoring, it tries again a bit later. Here is the relevant section in the docker-compose:
```yaml
version: '3.9'
services:
db:
image: mcr.microsoft.com/mssql/server:2019-latest
environment:
MSSQL_SA_PASSWORD: Password123
ACCEPT_EULA: Y
MSSQL_PID: Express
healthcheck: # copied / adapted from https://github.com/Microsoft/mssql-docker/issues/133, leveraging https://docs.docker.com/engine/reference/builder/#healthcheck
test: sh /sql_server_backup/RestoreDb.sh
interval: 10s
timeout: 10s
retries: 10
start_period: 45s
ports:
- "1433:1433"
volumes:
- ./sql_server_backup:/sql_server_backup
```
RestoreDb.sh:
```bash
#!/bin/bash -e
/opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P "Password123" -i /sql_server_backup/RestoreDb.sql
```
RestoreDb.sql (with a bit of debugging logic):
```sql
-- this file will be called from the docker compose health check
if exists ( select 1 from sys.databases where [name] = 'MvcDocker' )
begin
EXEC xp_logevent 60000, 'RestoreDb.sql: MvcDocker database already exists, no need to run again', informational;
return -- already run
end
EXEC xp_logevent 60000, 'RestoreDb.sql: Started script', informational;
-- begin write to log the list of files in our folder of interest
declare @ss table ([filename] varchar(1000), depth int, [file] int)
insert into @ss
EXEC xp_dirtree '/sql_server_backup/', 2, 1 -- list all files in our folder of interest (https://stackoverflow.com/a/13594903)
declare @msg varchar(2000) = 'RestoreDb.sql: Files found in /sql_server_backup/: '
select @msg = @msg + [filename] + ',' from @ss
EXEC xp_logevent 60000, @msg, informational;
-- end write to log the list of files in our folder of interest
GO
-- restore the backup, to names and folder that make sense here
RESTORE DATABASE MvcDocker FROM DISK='/sql_server_backup/mvc_db.bak'
WITH MOVE 'OriginalFileName' TO '/var/opt/mssql/data/MvcDocker.mdf',
MOVE 'OriginalFileName_log' TO '/var/opt/mssql/data/MvcDocker_log.ldf'
GO
use MvcDocker
GO
-- check if the restored DB works as expected
select top 5 DisplayName from [SomeTableFromYourDb]
```
#5: Github workflow
In our case, we were using .net and only our integration tests needed the DB, so we run it last, simplified example:
```yaml
jobs:
build_and_test_and_publish:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Create folder BuildReports
run: mkdir BuildReports
- name: DotNet restore
run: dotnet restore --verbosity m > BuildReports/Restore.txt
- name: DotNet build
run: dotnet build --no-restore --verbosity m --configuration Release /nowarn:CS1591 /p:Version=$NUGET_PACKAGE_VERSION > BuildReports/Build.txt
- name: DotNet unit tests
run: dotnet test --no-build --configuration Release --filter=Type=Unit > BuildReports/UnitTests.txt
- name: Docker setup
run: sh ./set-local-environment.sh > BuildReports/DockerSetup.txt
- name: DotNet integration tests
run: dotnet test --no-build --configuration Release --filter=Type=Integration > BuildReports/IntegrationTests.txt
```
#Debugging
Try this window on your docker, this is what you should see if every works as expected
You will notice the message 'database already exists' will keep showing up, that's because the docker compose health check keeps running non stop.
At first our health check command will not work, because while the container itself is 'ready', the SQL Server inside it is still loading up, so the command fails silently.
When SQL Server is ready, the next iteration of the health check command will work and the DB will be restore.
In the next health check iteration, the DB will be already restored, so we will start seeing the message 'database already exists'.
#PS
We are searching for talented software engineers, please have a look at https://clientapps.jobadder.com/30580/bizcover | alansarligithub |
836,218 | Learning Python- Intermediate course: Day 30, Spinbox and Labelbox | Today let us see how to use the spinbox and listbox widgets widget. Spin box... | 13,315 | 2021-09-22T12:07:01 | https://dev.to/aatmaj/learning-python-intermediate-course-day-30-spinbox-and-labelbox-1b35 | learningpython, python, tutorual | Today let us see how to use the spinbox and listbox widgets widget.
---
____
## Spin box widget.
The spinbox widget is a type of widget which lets the users choose values in an easy way. The user can navigate through the values using the up and down arrows. You can read more about it [here](https://anzeljg.github.io/rin2/book2/2405/docs/tkinter/spinbox.html)
### Making the spinbox widget
The spinbox widget is very similar to the slider widget we learnt in the last part. `v` all we need to do is replace slider by spinbox
```python
from tkinter import *
frame=Tk()
frame.geometry("200x200")
spinbox=Spinbox(frame,from_=0, to=10)
spinbox.pack()
def show():
showbutton.config(text=spinbox.get())
showbutton=Button(frame,text="show",command=show)
showbutton.pack()
mainloop()
```



Here we get the value from the spinbox in the same manner as we did for slider widget, that is, by using the `get()` method.
## Listbox widget
The listbox widget also allows the users to choose values from a given set of string or numerical values. These value sets are determined by the program.
> The Listbox widget is used to display a list of items from which a user can select a number of items.
### Making a listbox widget
`Lb = Listbox(frame)` creates a listbox widget. We can add values to the widget using the `insert()` method.
Here is an example which creates a Listbox
```python
from tkinter import *
frame = Tk()
frame.geometry("200x200")
Lb = Listbox(frame)
Lb.insert(1, "Python")
Lb.insert(2, "R")
Lb.insert(3, "Julia")
Lb.insert(4, "MATLAB")
Lb.insert(5, "Mathematica")
Lb.insert(6, "Haskell")
Lb.pack()
frame.mainloop()
```
### Getting the value from the listbox.
We can get the value using the `curselection()` method. The curselection returns the position of the selected item.
```python
from tkinter import *
frame = Tk()
frame.geometry("200x200")
Lb = Listbox(frame)
Lb.insert(1, "Python")
Lb.insert(2, "R")
Lb.insert(3, "Julia")
Lb.insert(4, "MATLAB")
Lb.insert(5, "Mathematica")
Lb.insert(6, "Haskell")
Lb.pack()
def show():
showbutton.config(text=Lb.curselection())
showbutton=Button(frame,text="show",command=show)
showbutton.pack()
mainloop()
frame.mainloop()
```


In order to get the value, we can use listbox method `get()` to return the tuple of values and index the position.`showbutton.config(text=Lb.get(Lb.curselection()))`
But instead it will be more flexible if we make a tuple of those values themselves and feed them into the program. moreover using a for loop to feed in values enhances flexibility and extensibility.
```python
from tkinter import *
frame = Tk()
frame.geometry("200x200")
items=("Python","R","Julia","MATLAB","Mathematica","Haskell")
Lb = Listbox(frame)
for i in range(0,len(items)):
Lb.insert(i,items[i])
Lb.pack()
def show():
showbutton.config(text=items[Lb.curselection()[0]])
showbutton=Button(frame,text="show",command=show)
showbutton.pack()
mainloop()
frame.mainloop()
```

Exercise-
1) Should `item` be a tuple or a list??
2) What will happen if we remove `[0]` in `items[Lb.curselection()[0]]`?
3) Use `Lb.get(Lb.curselection())` and rewrite the entire program
4) The above program, lot of lines are wasted. use the `height` attribute to adjust the number of lines.
5) Does the height attribute take in the number of lines or pixel space? Try to find out using trial and error methods.
6) When you set the height, did you feel the usefulness of flexibility initializing a tuple and setting the values?
Answer in the comments below. Answers will be found in the [Learning Python Repository](https://github.com/Aatmaj-Zephyr/Learning-Python)
### Types of selections
In the listbox object, there is a attribute called as `selectmode`. By using this attribute, we can set how we want to select the items.
> Selectmode determines how many items can be selected, and how mouse drags affect the selection −
- BROWSE − Normally, you can only select one line out of a listbox. If you click on an item and then drag to a different line, the selection will follow the mouse. This is the default.
- SINGLE − You can only select one line, and you can't drag the mouse. Wherever you click button 1, that line is selected.
- MULTIPLE − You can select any number of lines at once. Clicking on any line toggles whether or not it is selected.
- EXTENDED − You can select any adjacent group of lines at once by clicking on the first line and dragging to the last line.
```PYTHON
from tkinter import *
frame = Tk()
frame.geometry("200x200")
items=("Python","R","Julia","MATLAB","Mathematica","Haskell")
Lb = Listbox(frame,selectmode=MULTIPLE)
for i in range(0,len(items)):
Lb.insert(i,items[i])
Lb.pack()
mainloop()
frame.mainloop()
```

```python
from tkinter import *
frame = Tk()
frame.geometry("200x200")
items=("Python","R","Julia","MATLAB","Mathematica","Haskell")
Lb = Listbox(frame,selectmode=EXTENDED)
for i in range(0,len(items)):
Lb.insert(i,items[i])
Lb.pack()
mainloop()
frame.mainloop()
```

In the extended mode, you cannot choose two non-continues values at once. Example, you cannot choose only Haskell and Julia in the above program.
> For displaying the contents we will require a better method, like for example textbox. We will need to extract out all values out from the tuple, or convert it out into a string before displaying it.
____
In tomorrows part, as promised we will make a program with slider and repeat the same with the spinbox widget. | aatmaj |
836,309 | Online Document Scanning with Django and Dynamic Web TWAIN | Django is a popular framework of Python for web development. In this tutorial, we will create a web... | 0 | 2021-09-22T07:58:19 | https://www.dynamsoft.com/codepool/online-document-scanning-django-webtwain.html | django, web, document, management | Django is a popular framework of Python for web development. In this tutorial, we will create a web application with [Django](https://docs.djangoproject.com/en/3.2/) and [Dynamic Web TWAIN](https://www.dynamsoft.com/web-twain/overview/).
## About Dynamic Web TWAIN
- [https://www.dynamsoft.com/web-twain/downloads](https://www.dynamsoft.com/web-twain/downloads)
- [https://www.dynamsoft.com/customer/license/trialLicense/?product=dwt](https://www.dynamsoft.com/customer/license/trialLicense/?product=dwt)
## Python Development Environment
- Python 3.7.9
```bash
python --version
```
- Django 3.2.7
```bash
python -m pip install Django
python -m django --version
```
## Overall steps
The steps that integrate Django with Dynamic Web TWAIN are:
1. Create a Django project.
2. Create an app inside the project.
3. Create an HTML template that loads the Dynamic Web Twain library. The library path is dynamically generated by template syntax.
4. Configure the path of static resource files.
## Create your project with Django
Open your terminal to create a project with Django using the following command (applicable for Windows, Linux, macOS):
```bash
python -m django startproject djangodwt
```
Once completed, you will see the newly created project folder under your **working directory**.
Then, change your directory to `djangodwt` and run the app using the following command:
```bash
cd djangodwt
python manage.py runserver
```
After the server has been successfully started, you can visit `http://127.0.0.1:8000` in a web browser.
Now, a simple Django project has been successfully created.
## Integrating with Dynamic Web TWAIN
### Create the App
To build your web scanner app, you should firstly create an app.
```bash
python manage.py startapp dwt
```
> In Django, project and app are different terminologies. An app is a Web application that does something. A project is a collection of apps that serve a particular website. For more details, refer to [Writing your first Django app](https://docs.djangoproject.com/en/3.1/intro/tutorial01/).
Now, the project structure is as follows.
```plain
djangodwt
- djangodwt
- __pycache__
- asgi.py
- settings.py
- urls.py
- wsgi.py
- __init__.py
- dwt
- migrations
- __init__.py
- admin.py
- apps.py
- models.py
- tests.py
- views.py
- __init__.py
- db.sqlite3
- manage.py
```
### Create the view for Dynamic Web TWAIN
We will use a template to create our view. Conventionally, your template files should be placed under `{project_folder/templates/{app_named_folder}/}`. Let's create one named `index.html`.
```html
<!DOCTYPE html>
<head>
<title>Dynamic Web Twain</title>
<meta charset="utf-8">
{% raw %} {% load static %} {% endraw %}
<!-- Import Dynamic Web Twain library. Template will compile the actual path for us. -->
{% raw %} <script type="text/javascript" src="{% static 'dwt/Resources/dynamsoft.webtwain.initiate.js' %}"></script> {% endraw %}
{% raw %} <script type="text/javascript" src="{% static 'dwt/Resources/dynamsoft.webtwain.config.js' %}"></script> {% endraw %}
</head>
<body>
<div id="app">
<div id="dwtcontrolContainer"></div>
<button onclick="scan()">Scan</button>
</div>
<script type="text/javascript">
Dynamsoft.DWT.RegisterEvent('OnWebTwainReady', Dynamsoft_OnReady);
Dynamsoft.DWT.ResourcesPath = 'static/dwt/Resources';
Dynamsoft.DWT.ProductKey = 'LICENSE-KEY';
var dwtObjct;
function Dynamsoft_OnReady() {
dwtObjct = Dynamsoft.DWT.GetWebTwain('dwtcontrolContainer');
}
function scan() {
if (dwtObjct) {
dwtObjct.OpenSource();
dwtObjct.IfDisableSourceAfterAcquire = true;
dwtObjct.AcquireImage(() => {dwtObjct.CloseSource();}, () => {dwtObjct.CloseSource();});
}
}
</script>
</body>
```
Notice that you need a [valid license](https://www.dynamsoft.com/customer/license/trialLicense?product=dwt) key and update `Dynamsoft.DWT.ProductKey = 'LICENSE-KEY'` to make scanner API work. The `ResourcesPath` is the path to the `dynamsoft.webtwain.initiate.js` and `dynamsoft.webtwain.config.js` files. We will discuss this later.
Then we open the file `dwt/views.py` and put the following Python code in it:
```python
from django.http import HttpResponse, request
from django import template
from django.shortcuts import render
import os
def index(request):
return render(request, 'dwt/index.html')
```
In the app folder (`{project_folder}/dwt` in this case), we create another file called `urls.py` and include the following code.
```py
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name='index')
]
```
Next, we go to the project's `urls.py` file, which is located in `{project_folder}/{project_name}`. We include the newly defined rules.
```py
from django.contrib import admin
from django.urls import include, path
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('dwt.urls'))
]
```
Finally, configure the templates directory in `settings.py`. We specify the template DIR as follows.
```py
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')], # this field
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
```
### Import Dynamic Web TWAIN
Now, it's time to import Dynamic Web TWAIN resource files to this project.
Steps:
1. Create a `static` folder under the project root.
2. Create a `dwt` folder under `static` folder.
3. Copy and paste `Dynamic Web TWAIN SDK version/Resources` folder to `static/dwt/`.
Afterwards, we append the following code to `settings.py` to make `static/dwt/Resources` accessible.
```py
STATIC_URL = '/static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, "static")
]
```
The web document scanning application developed with Dynamic Web TWAIN and Django should now work successfully.

### How to Upload Documents to Django Database
Django provides a built-in `django.db.models.Model` class to store data in the database. The `Model` class is the base class for all models in Django.
Let's define a model class to store scanned documents in `dwt/models.py`:
```python
from django.db import models
class Image(models.Model):
name = models.CharField(max_length=30)
data = models.ImageField(upload_to='images/')
def __str__(self):
return self.name
```
To use the model, we need to add the name of the module that contains `models.py` in `djangodwt/settings.py`:
```python
INSTALLED_APPS = [
#...
'dwt',
]
```
Now, we can use the following code to store scanned documents in `dwt/views.py`:
```python
from .models import Image
def upload(request):
if request.method == 'POST':
image = Image()
image.name = request.FILES['RemoteFile'].name
image.data = request.FILES['RemoteFile']
image.save()
return HttpResponse("Successful")
return HttpResponse("Failed")
```
To verify whether the database operation is successful, you can open the `db.sqlite3` file in a DB browser and check its status change after uploading a document image.
## Source Code
[https://github.com/dynamsoft-dwt/Scan-Documents-with-Python](https://github.com/dynamsoft-dwt/Scan-Documents-with-Python) | yushulx |
836,332 | How does the values in react template part are in sync with local storage? | Hi Team, I'm trying to use localStorage for state management. In the below code if I remove the... | 0 | 2021-09-22T08:26:41 | https://dev.to/arunkumar413/how-does-the-values-in-react-template-part-are-in-sync-with-local-storage-4d39 | react | Hi Team,
I'm trying to use `localStorage` for state management. In the below code if I remove the `setState` call in the `handleChange` function, the template isn't in sync with the localstorage. However if I use the `setState` then the values in localStorage in reflecting the template. Any idea on how the presence of setState is allowing the synchronization.
Here is the code sandbox link: https://codesandbox.io/s/loving-taussig-p7phs?file=/src/App.js
```
import React, { useState, useEffect } from "react";
export default function App(props) {
const [state, setState] = useState({ name: "", city: "" });
const handleChange = (evt) => {
setState(function (state) {
return { ...state, [evt.target.name]: evt.target.value };
});
localStorage.setItem([evt.target.name], evt.target.value);
};
return (
<div>
<h2> Home</h2>
<input
placeholder="Name"
name="name"
value={localStorage.getItem("name")}
onChange={handleChange}
/>
<input
name="city"
placeholder="City"
value={localStorage.getItem("city")}
onChange={handleChange}
/>
<h3> {localStorage.getItem("name")} </h3>
<h3> {localStorage.getItem("city")} </h3>
</div>
);
}
``` | arunkumar413 |
836,363 | Can you end code freezes? | _ A quick reminder: Tomorrow at 17:00 CET (Europe) / 8:00 AM PT (USA), I’ll be doing a free, live... | 0 | 2021-09-26T08:47:33 | https://jhall.io/archive/2021/09/22/can-you-end-code-freezes/ | tbd, codefreeze, trunkbaseddevelopmen | ---
title: Can you end code freezes?
published: true
date: 2021-09-22 00:00:00 UTC
tags: tbd,codefreeze,trunkbaseddevelopmen
canonical_url: https://jhall.io/archive/2021/09/22/can-you-end-code-freezes/
---
_ **A quick reminder:** Tomorrow at 17:00 CET (Europe) / 8:00 AM PT (USA), I’ll be doing a free, live video Q&A session answering your DevOps career questions. Space is limited! [Register up now](https://www.crowdcast.io/e/tiny-devops-qa-focus-on/register)!_
* * *
At the first company where I worked as a programmer, every few months we'd declare a "code freeze." During this time, we were preparing for a release, so no new changes were allowed into the code, except bug fixes found during testing of the release.
It took me a while to realize that for the kinds of software most companies produce, this is actually an anti-pattern. What’s the alternative? [Trunk-based development](https://trunkbaseddevelopment.com/). I’ve [talked about it before](https://jhall.io/archive/2021/03/10/a-case-for-trunk-based-development/), but a passage in [_Accelerate_](https://amzn.to/3klbvCq) drew my attention to this again:
> [High-performing teams] had fewer than three active branches at any time, their branches had very short lifetimes (less than a day) before being merged into trunk and never had “code freeze” or stabilization periods.
Does your team face code freezes? If so, what’s preventing you from using trunk-based development and [continuous integration](https://whatisci.com/) to thaw your code once and for all?
* * *
_If you enjoyed this message, [subscribe](https://jhall.io/daily) to <u>The Daily Commit</u> to get future messages to your inbox._ | jhall |
836,527 | 3D Button in React Native | Intro In this tutorial, you will learn how to build a basic 3dimensional looking button in... | 0 | 2021-09-22T10:19:45 | https://dev.to/abdulwasey/3d-button-in-react-native-1h3 | reactnative, tailwindcss, 3dbutton, animation | ## Intro
In this tutorial, you will learn how to build a basic 3dimensional looking button in react native. We will be utilizing the [__Animated__](https://reactnative.dev/docs/animated) module that is readily available in react native.
<br/>
## Lets get started
{%vimeo 611533567 %}
***
## CODE
```javascript
import React, { useRef } from 'react';
import { Text, TouchableWithoutFeedback, Animated } from 'react-native';
import { tailwind } from '../utils/tailwind';
interface Props {
text?: string;
onPress?: () => void;
}
const Button: React.FC<Props> = ({ text, onPress }) => {
const animation = useRef(new Animated.Value(0)).current;
const handlePress = () => {
Animated.timing(animation, {
toValue: 1,
duration: 50,
useNativeDriver: true,
}).start();
};
const handleButtonOut = () => {
Animated.timing(animation, {
toValue: 0,
duration: 50,
useNativeDriver: true,
}).start();
if (onPress) {
onPress();
}
};
return (
<TouchableWithoutFeedback
onPressIn={handlePress}
onPressOut={handleButtonOut}
>
<View
style={tailwind('rounded-full', 'bg-rose-700', 'border-rose-700')}
>
<Animated.View
style={[
tailwind(
'rounded-full',
'items-center',
'bg-red-500',
'border',
'border-red-500',
),
{
transform: [
{
translateY: animation.interpolate({
inputRange: [0, 1],
outputRange: [-5, 0],
}),
},
],
},
]}
>
<Text style={tailwind('font-bold', 'text-white', 'text-lg')}>
{text}
</Text>
</Animated.View>
</View>
</TouchableWithoutFeedback>
);
};
export default Button;
```
<br/>
<br/>
## Explanation
Declare a animation variable and assign the value to 0. We need wrap it in the useRef hook to make sure the animation value persists any changes that might happen outside the 3D button component.
```typescript
const animation = useRef(new Animated.Value(0)).current;
```
The press animation starts on clicking the button where the `interpolate` function is invoked changing the value from `0 to 1`, this causes the `translateY` value to change from `-5px to 0px`
| Value| translateY|
| ---- |----------:|
|0 | -5px |
|1 | 0px |
The above table shows how the value relates to the pixels changes, you can add more values and customize it.
```typescript
transform: [{
translateY:
animation.interpolate({
inputRange: [0, 1],
outputRange: [-5, 0],
})}]
```
[`onPressIn`](https://reactnative.dev/docs/touchablewithoutfeedback#onpressin) triggers the function to change the `animation` variable value to 1, we can assign a duration value of `50` or `any number`.
<br/>
```typescript
Animated.timing(animation, {
toValue: 1,
duration: 50,
useNativeDriver: true,
}).start();
```
[`onPressOut`](https://reactnative.dev/docs/touchablewithoutfeedback#onpressout) function is triggered when the user presses out of the [`TouchableWithoutFeedback`](https://reactnative.dev/docs/touchablewithoutfeedback) where the value goes back to 0
```typescript
Animated.timing(animation, {
toValue: 0,
duration: 50,
useNativeDriver: true,
}).start();
```
<br/>
<br/>
Hope you enjoyed this mini tutorial.
*Abdul Wasey*
| abdulwasey |
852,917 | Random quote machine | A post by nickfff-dev | 0 | 2021-10-05T21:28:45 | https://dev.to/nickfffdev/random-quote-machine-6g6 | codepen | {% codepen https://codepen.io/nickfff-dev/pen/NWgZzBy %} | nickfffdev |
836,586 | HackOnLisk2 | Build your own blockchain application with the Lisk SDK in JavaScript. Blockchain applications should... | 0 | 2021-09-22T12:32:28 | https://dev.to/liskhq/hackonlisk2-1994 | programming, javascript, challenge | Build your own blockchain application with the Lisk SDK in JavaScript. Blockchain applications should be submitted to either the DeFi or GameFi category. 60,000 CHF in prizes.
Here's everything you need to know: https://hackonlisk2.devpost.com/ 👈
Join our community at Lisk.chat 💙 | liskhq |
836,613 | How Taxi App Development Solutions Can Help Your Business Grow | We are living in a world where most of our tasks are eased up by mobile applications. They have made... | 0 | 2021-09-22T13:01:38 | https://dev.to/artistixe_it/how-taxi-app-development-solutions-can-help-your-business-grow-2mil | taxiapp, taxiappdevelopment, taxibookingapp | We are living in a world where most of our tasks are eased up by mobile applications. They have made our tasks simpler in almost every field. One of such ingenious creations is Taxi App. Applications such as Uber and Ola have certainly written history and set new milestones in the realm of private transportation. Their success is enough to encourage the entrepreneurs who are looking for a startup in the same business. Although the taxi business is flourishing, it would still be difficult to compete with the set players.
Taxi App Development solutions can help your business
Let us discuss how taxi mobile app development solutions can help you manage the escalating competition and make your business grow.
What Are Taxi Apps?
The idea of taxi apps is quite uncomplicated. In the app, riders enter their destinations and confirm their locations. These apps have helped a lot of people who do not have their own vehicles and find it difficult to use public transportation. They have become essential in the daily lives of people. In the following steps, the app matches the rider with an appropriate driver. These taxi apps include payment processing, GPS tracking, as well as customer support. One of the most popular taxi booking apps is Uber. Given the facts, it operates in more than 600 cities in 65 countries.
Different Types of Taxi Apps
Key Features for a Taxi App
Taxi business owners can come up with the following types of taxi mobile applications, depending on their business model and their services offered to customers:
Taxi booking app
Rental car app
Ridesharing app
Taxing booking and rental car app
Your private transportation business can be expanded by including motorbikes and autos as well. The two of these vehicles will enable you to provide an alternative to taxis that is more affordable. You can add these features easily to your new or existing taxi app if you hire a mobile app development company.
Taxi Apps: Business Benefits
Taxi mobile applications certainly provide convenience to users. Moreover, it offers the following benefits while simplifying your business processes:
Location Tracking in Real-Time
This is one of the many benefits of using a taxi booking app. A driver can find the exact location of the passenger and a passenger can track the driver's location. Taxi riders can also determine when their taxi will arrive by looking at the arrival time. Most importantly, you can also track your taxis' locations across the city and state. Using a location tracking feature, you can keep track of the route taken by your drivers at all times.
A higher level of visibility
Using a mobile application can help you boost the visibility of your taxi business. This can give you an edge over existing taxi services providers who do not have apps. Through your taxi apps, your customers find it simple and convenient to book taxis. You can stay in touch with the customers as long as your taxi app stays on the customer’s devices. If you keep on updating your app on a regular basis, you surely increase the chances of getting more loyal customers.
Data collection
When the users register themselves through email ids and mobile numbers, you get valuable data of the taxi app users. You can easily get data of your customers regarding saved destinations, trip frequency, etc. Accordingly, you can send personalized notifications and provide users with alluring offers on certain rides. This way, it can help strengthen a loyal customer base.
Brand building
Evidently, Uber and Ola have become considerably great brands. They have earned a reputation with the help of enterprise-grade apps. If you want to develop a user-friendly taxi app, you must consider three factors in order to increase brand awareness- credibility, better customer services, and trust. The reason behind this is the app can convey the customer’s needs with a captivating user interface. You can also come up with updated versions of your taxi app that would enhance and build the reputation among your existing customers.
Customer feedback
An identity of a brand is based on feedback and reviews of the customers. Like any other application, your taxi app also needs feedback. Through the ratings and reviews provided by the customers, you can improve your services. The traditional rental car book company cannot offer such a facility as they do not have any taxi mobile application.
Enlarged Productivity
During the ride, you can track the location of the driver and his route to finishing the trip. This way, you can check the efficiency of the drive through your taxi app. The app also enables users to give feedback about the drivers. This leads to an attempt to increase the productivity of the drivers. This kind of performance monitoring encourages drivers to work more efficiently. This way, a taxi app boosts your business with enhanced productivity.
Key Features for a Taxi App
Taxi apps like Uber and Ola include the making of two mobile applications: App for passengers and an app for drivers. Following are some features considered while developing the applications:
App for Passengers
A basic taxi app includes the following features for passengers:
Order
Map
Payment methods
Ratings and review system
Offers or gift vouchers
Additional features:
Preset locations
Estimated time of arrival
Modification of ongoing ride, etc.
App for Drivers
Driver’s app must-have features like:
Accept and cancel the ride
Trip request
Reason for cancellation
Additional features
Alerts and notifications
Record of earnings
Fuel station findings
Fare calculator
Including in-app analytics and conversion metrics
Customized route selection, etc.
Wrapping up
Taxi business is tricky but full of potential. In a world full of mobile applications, taxi apps have made a huge contribution in serving people. The perfect mix of technologies and a good strategy can help you to deal with a dynamic market and can make you a well-established brand after Uber and Ola. A taxi app can help you search for a lot of opportunities while also offering a competitive extremity over traditional taxi service providers.
At Artistixe IT Solutions LLP, we provide high-quality on Demand Taxi Booking App Development services. Connect with us and give your taxi business a flying start.
https://artistixeit.com/solution/on-demand-taxi-solution | artistixe_it |
836,647 | Shareable ESLint/Prettier Configs for Multi-Project Synergy | Recently, the eslint-config-prettier v8 upgrade broke my ESLint configuration, and I realized I... | 0 | 2021-10-02T11:45:39 | https://www.pinnsg.com/shareable-eslint-prettier-typescript-configurations/?utm_source=rss&utm_medium=rss&utm_campaign=shareable-eslint-prettier-typescript-configurations | javascript, typescript | ---
title: Shareable ESLint/Prettier Configs for Multi-Project Synergy
published: true
date: 2021-09-22 12:18:36 UTC
tags: JavaScript,TypeScript
canonical_url: https://www.pinnsg.com/shareable-eslint-prettier-typescript-configurations/?utm_source=rss&utm_medium=rss&utm_campaign=shareable-eslint-prettier-typescript-configurations
---

Recently, the [eslint-config-prettier v8 upgrade](https://github.com/prettier/eslint-config-prettier/blob/main/CHANGELOG.md#version-800-2021-02-21) broke my ESLint configuration, and I realized I needed a centralized way of managing my ESLint configuration across projects.
This is the outline for how I will solve common configuration across projects going forward. Here are the key features:
- Layer your ESLint rules based on topics: ESLint + Prettier, then TypeScript, then React/Vue.
- Use Lerna to publish scoped packages to [npmjs](https://www.npmjs.com/).
- Some helper tools to upgrade your code.
Disclaimer: This is not my original work, but leveraged from other’s work, most notably:
- The ESLint configuration started with [ntnyq](https://github.com/ntnyq/configs) configs
- The TypeScript idea came from [unlikelystudio](https://github.com/unlikelystudio/bases) settings
## Layered ESLint
The benefit of this organizational structure is layering your ESLint rules. Some rules apply for TypeScript projects. Some for TypeScript/React projects. What if you add Prettier to the mix?
A picture is worth a 1000 words:

Each rule layers parent rules into it’s rules. For example, our company configuration contains:
`eslint-config-prettier-typescript-react`:
```
extends: [
'@pinnsg/typescript-react',
'@pinnsg/prettier-react',
'@pinnsg/prettier-typescript',
...
```
which in turn `eslint-config-prettier-typescript`:
```
extends: [
'@pinnsg/typescript',
'@pinnsg/prettier',
...
```
etc.
Naturally, when you publish your configs, they will reference your scope, not mine .
## To package.json or not to package.json
A colleague recently embarked on a move to migrate all their dot-config files into `package.json`. Initially I was resistant to this, as I felt like it was adding lots of bloat to `package.json`. However, now that I’ve worked with this for a bit, I’m starting to see the advantage of a single configuration file (as much as possible).
However, the level of support for `package.json` config depends upon the base library being used. You will see these scenarios:
1. Full `package.json` support, including referencing your shared configuration via the package name.
2. `package.json` support _without_ support for package names
3. Generic json/js/rc file support
Every package is different, so you will have to check the documentation individually to determine the level of support. If the package uses [cosmiconfig](https://anandchowdhary.github.io/cosmic/), you are golden (#1 above). Other configuration packages are not as complete, and offer less flexibility.
Some config libraries, such as [rc-config-loader](https://github.com/azu/rc-config-loader) (used by npm-check-updates) support configuration in `package.json`, but not referencing shared configuration. If this is the case, you must use an external `.js` configuration file and import your configuration. Here’s how the `npm-check-updates` config must use `.ncurc.js` such as:
```
module.exports = require("@pinnsg/config-npm-check-updates");
```
## Instructions
- Clone the [template repo](https://github.com/drmikecrowe/eslint-config-templates)
- Update the individual rules per your standards
- Choose your NPM scope.
- If you use your npm username, you can it as your scope (my personal configs are published to `@drmikecrowe` for my use)
- If you want a different scope, you must login to [npmjs.com](https://www.npmjs.com/) and add an organization to your account. For instance, our `@pinnsg` scope is our organizational scope
- Globally search/replace all occurrences of my scope (`@drmikecrowe`) and replace with your scope
- Globally search/replace all occurrences of my username (`drmikecrowe`) and replace with your username (these are 2 steps in case your scope/username are different)
- Rename `packages/mrm-preset-drmikecrowe` to match your scope (without the `@`)
- Login to NPM using `npm login`
- Publish your packages using `lerna publish`
NOTE: As you do your initial publish, or after updating, sometimes things go bump in the night during your publish and packages are tagged/pushed but not published. To re-publish you can simply run:
```
lerna exec -- "npm publish || exit 0"
```
to publish all packages (you’re receive errors for the packages that succeeded)
## MRM
[mrm](https://mrm.js.org/) is a fantastic tool for updating projects. Their tagline is:
> Codemods for your project config files
I’m a huge fan of this project. It allows me to script intelligent updates to my configs based on set criteria. For example, in the `configs` preset (explained below), it does:
```
const parts = []
if (hasPrettier) parts.push('prettier')
if (hasTypescript) parts.push('typescript')
if (hasVue) parts.push('vue')
else if (hasReact) parts.push('react')
const base = parts.length ? '-' + parts.join('-') : ''
const full = `${configScope}/eslint-config${base}`
const eslintPreset = `${configScope}/${base.slice(1)}`
```
So, by `package.json` inspection, it determines which preset you most likely want, and updates the config to match that preset. Very cool.
### MRM Presets
A [Preset](https://mrm.js.org/docs/making-presets) is a way for you to customize MRM behavior. Included is a custom preset for your own use where you can put your upgrades as you use MRM. In this preset I have 2 tasks:
- configs: Migrate configs of a project to this structure
- typescript: Migrate your `tsconfig.json` to this structure (yes, this should probably be part of the `configs` preset, but it was easier to simply tweak the existing MRM `typescript` task)
To use these, follow these steps:
- Publish your preset per instructions above
- Install your preset globally with `npm i -g mrm mrm-preset-YOURSCOPE` (without the @ — i.e. `mrm-preset-drmikecrowe`)
- Change into a project you want to upgrade
- Make sure you have committed all your changes and your git tree is clean
- Run `mrm eslint`
- If you use Prettier, run `mrm prettier`
- (these two command setup eslint/prettier in a standard way — the next step really needs `.eslintrc.json` instead of a .js file)
- Run `mrm --preset YOURSCOPE config`
Once that finishes, you can evaluate the proposed changes and see if you like the results. If they are satisfactory, commit them and enjoy the new config. If they are not, do a
```
git reset --hard HEAD
```
and update your preset at
```
packages/mrm-preset-drmikecrowe/configs/index.js
```
as needed to modify the configs as you see fit.
Enjoy! | drmikecrowe |
836,767 | How To Delete Rows In Different Sheets Through Excel VBA? | In this article, you will learn the simple steps to delete rows in different sheets through Excel... | 0 | 2021-09-23T02:11:22 | https://geekexcel.com/how-to-delete-rows-in-different-sheets-through-excel-vba/ | todeleterowsindiffer, vbamacros | ---
title: How To Delete Rows In Different Sheets Through Excel VBA?
published: true
date: 2021-09-22 11:01:16 UTC
tags: ToDeleteRowsInDiffer,VBAMacros
canonical_url: https://geekexcel.com/how-to-delete-rows-in-different-sheets-through-excel-vba/
---
In this article, you will learn the simple steps to **delete rows in different sheets** through Excel VBA. Let’s get them below!! Get an official version of MS Excel from the following link: **[https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)**
## Example
- Firstly, you need to **create** **5 sheets** with **same values** in an Excel Workbook.
<figcaption>Sample data</figcaption>
- In the Excel Worksheet, you have to go to the **Developer Tab.**
- Then, you need to ** ** select the **Visual Basic** option under the **Code** section.
<figcaption>Select Visual Basic</figcaption>
- Now, you have to **copy and paste the code** given below.
```
Sub DeleteRows()
Dim shtArr, i As Long, xx As Long
shtArr = Array("Sheet1", "Sheet2", "Sheet3", "Sheet4", "Sheet5")
xx = Selection.Row
For i = LBound(shtArr) To UBound(shtArr)
Sheets(shtArr(i)).Rows(xx).EntireRow.Delete
Next i
End Sub
```
- You need to **save the code** by selecting it and then **close the window**.
<figcaption>Save the Code</figcaption>
- Again, you have to go to the **Excel Spreadsheet** , and click on the **Developer Tab**.
- You need to choose the **Macros option** in the Code section.
<figcaption>Choose Macro option</figcaption>
- Then, you need to **place the cursor on any cell A1** and on **Sheet1**.
<figcaption>In Shell A1</figcaption>
- Now, you have to make sure that your **macro name is selected** and click the **Run ** button.
<figcaption>Run the Code</figcaption>
- Here, you will find **selected row number** gets **deleted in all the sheets**.
<figcaption>Row deleted in all the sheets</figcaption>
- Finally, if you **place the cursor on any cell A2** & on **Sheet2** , then also the **result** would be similar.
## Verdict
In the above article, you can learn the simple steps to **delete rows in different sheets through Excel VBA**. Kindly, share your **feedback** in the below comment section. Thanks for visiting **[Geek Excel.](https://geekexcel.com/)** Keep Learning!
**Read Also:**
- **[How to Change Font Color in Microsoft Excel 2007?](https://geekexcel.com/how-to-change-font-color-in-microsoft-excel-2007/)**
- **[Excel Formulas to Count specific word in a range ~ Easy Tutorial!!](https://geekexcel.com/excel-formulas-to-count-specific-words-in-a-range/)**
- **[Excel Formulas to Get the Last Word of a Text String ~ Quick Method!!](https://geekexcel.com/excel-formulas-to-get-the-last-word-of-the-text-string/)**
- **[Count the Times a Word Appears in a Cell or a Range in Excel Office 365!!](https://geekexcel.com/count-the-times-a-word-appears-in-a-cell-or-a-range-in-excel-office-365/)**
- **[Excel Formulas to Remove the Last Word ~ Easy Tutorial!!](https://geekexcel.com/excel-formulas-to-remove-the-last-word-easy-tutorial/)** | excelgeek |
836,875 | Considerations when making new projects | When working we focus more on developing the project, we want to deliver good code, we usually want... | 0 | 2021-09-22T14:51:54 | https://dev.to/scoppio/considerations-when-making-new-projects-e2l | When working we focus more on developing the project, we want to deliver good code, we usually want to have fun while doing that, and we also want to move to new things.
Also, we love to roast old code... Mainly if it is our own code, and mainly if we know that we delivered bad code because we were not having fun, we were working in something that was old and weird and we didn't fully comprehend what was happening, therefore we believe that the code had it comming, it was doomed from its own making, we didn't make it reach that point, we only let things happen. That's one of the lies we tell ourselves to not feel bad about roasting old code, the hard work put by other people. Some even like to distance themselves of it by saying "code has no father", so you should not fell bad if its your work being critised.
But thats not true, code has parents, it was born out of a context. Why is something hardcoded instead of in a config file? Why is a piece of code repeated three times in this file? Why is the test commented out or skipped? Why did you commit directly to the main branch and pushed it to production on a friday night without any revision? Why is the CI/CD pipeline suddenly disabled? Why is there a function marked as deprecated when it is used by half the application and there is no alternative to it implemented? Why you spent two weeks creating something from scratch instead of importing a library?
All of those questions have answers, and usually they can only be answered by the person that wrote that code at that point in time, later they may forget, sometimes it was a big problem and they could not find another way to solve and now, one month later, the answer is obvious but they could not see it back in that time. So, how do we answer those stuff that the code itself cannot answer?
## How to make onboarding in a project, easier
### Aka.: README.md
You want to start working in a project right away... you don't want to have troubles, to install multiple tools, to have to deal with different environment variables, to have to understand a whole weird way to be able to debug things using step-by-step. Thats why we have README.md files.
A README.md should have everything you need to start working, all the scripts, all the downloads, all the imports, everything. Is it a nodeJS project? Say how to install nodejs using brew in your mac. Better yeat, make a shell script and put it into the README.md so the person reading through it may either run the code or make it manually.
Adding all the necessary stuff to the run the project is important, but just listing it don't solve any problems. Saying that you need FBFlipper does not really explain WHY you need this app, saying you need to set an environment variable to `SF_CAPS_LIB_GL_EPKS=1` may solve some bug or error, but which one? and how?
Basically the README.md should have enough information so that a person may start a project, debug, create release and publish things on their own, without having to ask help from other people.
Also, if you can make a .sh file that set's up the whole dev environment, do it. If you prefer to set up the dev environment using a docker image with a basic OS like ubuntu, thats fine too, but do not forget what are the exact incantations to make it work and to get inside it and start developing. If you add some way to interact with your projec you have to explain how to properly use it, otherwise you will have people stopping you all the time to ask basic questions before they even start to work in the project.
## Help the code review process
First I'll consider that code is usually reviewed through pull request (PR), and I will use this definition throught this article. When you review code you need context, and you need to judge if the code that was written could be better, if it follows the current best pratices, if there are no pitfalls that the other developer may have fallen into, and if the code really solves the problem that it is trying to solve, but how do you make sure it does solve the problem?
First, you need to make a good PR, one that gives context to the other developers. A good pull request has many things to help the developers that are going to make the review.
- Clear and specific title;
- Checklist of mandatory things to consider the feature "done" with all boxes checked;
- If it exists, the Ticket number and/or link to it in Jira/Monday/Trello/etc, so you can have some extra information on the feature or bug;
- Short description of the problem that you set out to fix in this pull request;
- Information on how you fixed that problem;
- If necessary, context on why you decided to fix it the way you did (why you duplicated code? why you left a todo/fixme? why you left a HACK? why you didnt add tests? And yes, it is acceptable to leave such comments in the code alongside the TODO/FIXME/HACK, dont just leave those there, explain why they are there so the next person may fix them, and no, the git history does not necessarely fills this purpose);
The code review is important, but the context on why you did it is even more relevant. And if you build good PRs, social peer pressure will make that the other developers start to build good PRs too.
## Dependencies
So you started a new project, you are doing some math stuff, and it is hard to do it all by hand, so you import lodash, it's a small lib, its self contained, your node-modules only have this one import. Now you want to run some tests, so you import Jest, suddenly you have 145 folders inside your node_modules folder and you have an extra 46MB of javascript code in your project. Usually this isnt really that bad, since the test isnt packaged with your code that you are going to deploy.
Now you are trying to fix a problem, and there is a tutorial online that tells you that the perfect way to sovle your problem isn't by coding the solution, but just importing a new dependency which adds exacly the component you need to fix it. You go and download it, put in the project and done, now you have fixed the problem and you barely had to write 50 lines of code, you are happy, you can go and pick another ticket to fix. But after some time you receive an error message... there is a bug in the new component, you go and look for more information and you notice that there are only 3 articles online about that library and all of them are more or less the same tutorial saying how to use it. You reach for the github of the project and it stopped receiving fixes a couple of years ago, there are dozens of issues open, all of them spaced months apart, there are a few pull requests that are more than a year old, and the repo has as many forks as it has likes, you found a **dead library**.
### Unintented consequences of dead libraries
If you add it to the project as a dependency, now it is **YOUR REPOSITORY** and **YOU HAVE TO SUPPORT IT** because the original developers abandoned it and there is no community doing active or semi-active support to it (no one to accept PRs). So take a step back and answer this question: Are you willing to add a whole repository to your project just to close a ticket in under a day? Sometimes the "long way" is the best way... sometimes it is worth to bite the bullet and adopt the new library. But you need to weight it in. | scoppio | |
836,888 | Glassmorphism login form with CSS | First published on Tronic247 In this article, you will learn how to create a Glassmorphism login... | 0 | 2021-09-22T15:18:38 | https://www.tronic247.com/glassmorphism-login-form-with-css/ | css, tutorial, glass, login | >
> First published on [Tronic247](https://www.tronic247.com/)
>
In this article, you will learn how to create a Glassmorphism login form with CSS. Look below to see how it looks like.

scroll down to the end if you want to get the code.
## Let’s get started
First, as usual, we will prepare the HTML before we style it. We will create a div with the class main for the container and add a div with the class login for the login form. Now the code looks like this.
```html
<div class="main">
<div class="login">
</div>
</div>
```
Then add a h1 with the class heading for the heading. Inside the h1 tag, type Login to your account or whatever you want. Now, there’s a heading.
Time for the most important component! …. It’s the inputs (username, password).
For the inputs we will create a div with the class input. And add a label and an input inside it. The component will look like this.
```html
<div class="input">
<label>Username</label>
<input/>
</div>
```
Now that isn’t fully complete without the attributes.
```html
<div class="input">
<label for="username">Username</label>
<input type="text" id="username" autocomplete="false" />
</div>
```
We will create two inputs like this one for the username and one for the password.
```html
<div class="input">
<label for="username">Username</label>
<input type="text" id="username" autocomplete="false" />
</div>
<div class="input">
<label for="password">Password</label>
<input type="password" id="password" autocomplete="false" />
</div>
```
Now there are inputs.
STOP TALKING inputs,inputs.. OK, It’s over.
Then, after those i*****. We’ll add the submit button with the class login-btn. And inside that type login or submit.
After the button add this other stuff.
```html
<div class="social-icons">
<button class="social-icon fb"><svg fill="#000000" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 30 30" width="30px" height="30px"> <path d="M15,3C8.373,3,3,8.373,3,15c0,6.016,4.432,10.984,10.206,11.852V18.18h-2.969v-3.154h2.969v-2.099c0-3.475,1.693-5,4.581-5 c1.383,0,2.115,0.103,2.461,0.149v2.753h-1.97c-1.226,0-1.654,1.163-1.654,2.473v1.724h3.593L19.73,18.18h-3.106v8.697 C22.481,26.083,27,21.075,27,15C27,8.373,21.627,3,15,3z"/></svg></button>
<button class="social-icon pr"><svg fill="#000000" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 50 50" width="30px" height="30px"><path d="M25,2C12.318,2,2,12.317,2,25s10.318,23,23,23s23-10.317,23-23S37.682,2,25,2z M27.542,32.719c-3.297,0-4.516-2.138-4.516-2.138s-0.588,2.309-1.021,3.95s-0.507,1.665-0.927,2.591c-0.471,1.039-1.626,2.674-1.966,3.177c-0.271,0.401-0.607,0.735-0.804,0.696c-0.197-0.038-0.197-0.245-0.245-0.678c-0.066-0.595-0.258-2.594-0.166-3.946c0.06-0.88,0.367-2.371,0.367-2.371l2.225-9.108c-1.368-2.807-0.246-7.192,2.871-7.192c2.211,0,2.79,2.001,2.113,4.406c-0.301,1.073-1.246,4.082-1.275,4.224c-0.029,0.142-0.099,0.442-0.083,0.738c0,0.878,0.671,2.672,2.995,2.672c3.744,0,5.517-5.535,5.517-9.237c0-2.977-1.892-6.573-7.416-6.573c-5.628,0-8.732,4.283-8.732,8.214c0,2.205,0.87,3.091,1.273,3.577c0.328,0.395,0.162,0.774,0.162,0.774l-0.355,1.425c-0.131,0.471-0.552,0.713-1.143,0.368C15.824,27.948,13,26.752,13,21.649C13,16.42,17.926,11,25.571,11C31.64,11,37,14.817,37,21.001C37,28.635,32.232,32.719,27.542,32.719z"/></svg></button>
<button class="social-icon in"><svg fill="#000000" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24" width="24px" height="24px"> <path d="M 8 3 C 5.239 3 3 5.239 3 8 L 3 16 C 3 18.761 5.239 21 8 21 L 16 21 C 18.761 21 21 18.761 21 16 L 21 8 C 21 5.239 18.761 3 16 3 L 8 3 z M 18 5 C 18.552 5 19 5.448 19 6 C 19 6.552 18.552 7 18 7 C 17.448 7 17 6.552 17 6 C 17 5.448 17.448 5 18 5 z M 12 7 C 14.761 7 17 9.239 17 12 C 17 14.761 14.761 17 12 17 C 9.239 17 7 14.761 7 12 C 7 9.239 9.239 7 12 7 z M 12 9 A 3 3 0 0 0 9 12 A 3 3 0 0 0 12 15 A 3 3 0 0 0 15 12 A 3 3 0 0 0 12 9 z"/></svg></button>
</div>
```
Yay! We finished our HTML (50% complete). Our full code looks like this
```html
<div class="main">
<div class="login">
<h1 class="heading">Login to your account</h1>
<div class="input">
<label for="username">Username</label>
<input type="text" id="username" autocomplete="false" />
</div>
<div class="input">
<label for="password">Password</label>
<input type="password" id="password" autocomplete="false" />
</div>
<div class="divider"></div>
<button class="login-btn">Log In</button>
<p class="meta-text">Too lazy ? Login with a social media account</p>
<div class="social-icons">
<button class="social-icon fb">
<svg fill="#000000" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 30 30" width="30px" height="30px">
<path
d="M15,3C8.373,3,3,8.373,3,15c0,6.016,4.432,10.984,10.206,11.852V18.18h-2.969v-3.154h2.969v-2.099c0-3.475,1.693-5,4.581-5 c1.383,0,2.115,0.103,2.461,0.149v2.753h-1.97c-1.226,0-1.654,1.163-1.654,2.473v1.724h3.593L19.73,18.18h-3.106v8.697 C22.481,26.083,27,21.075,27,15C27,8.373,21.627,3,15,3z"
/>
</svg>
</button>
<button class="social-icon pr">
<svg fill="#000000" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 50 50" width="30px" height="30px">
<path
d="M25,2C12.318,2,2,12.317,2,25s10.318,23,23,23s23-10.317,23-23S37.682,2,25,2z M27.542,32.719c-3.297,0-4.516-2.138-4.516-2.138s-0.588,2.309-1.021,3.95s-0.507,1.665-0.927,2.591c-0.471,1.039-1.626,2.674-1.966,3.177c-0.271,0.401-0.607,0.735-0.804,0.696c-0.197-0.038-0.197-0.245-0.245-0.678c-0.066-0.595-0.258-2.594-0.166-3.946c0.06-0.88,0.367-2.371,0.367-2.371l2.225-9.108c-1.368-2.807-0.246-7.192,2.871-7.192c2.211,0,2.79,2.001,2.113,4.406c-0.301,1.073-1.246,4.082-1.275,4.224c-0.029,0.142-0.099,0.442-0.083,0.738c0,0.878,0.671,2.672,2.995,2.672c3.744,0,5.517-5.535,5.517-9.237c0-2.977-1.892-6.573-7.416-6.573c-5.628,0-8.732,4.283-8.732,8.214c0,2.205,0.87,3.091,1.273,3.577c0.328,0.395,0.162,0.774,0.162,0.774l-0.355,1.425c-0.131,0.471-0.552,0.713-1.143,0.368C15.824,27.948,13,26.752,13,21.649C13,16.42,17.926,11,25.571,11C31.64,11,37,14.817,37,21.001C37,28.635,32.232,32.719,27.542,32.719z"
/>
</svg>
</button>
<button class="social-icon in">
<svg fill="#000000" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24" width="24px" height="24px">
<path
d="M 8 3 C 5.239 3 3 5.239 3 8 L 3 16 C 3 18.761 5.239 21 8 21 L 16 21 C 18.761 21 21 18.761 21 16 L 21 8 C 21 5.239 18.761 3 16 3 L 8 3 z M 18 5 C 18.552 5 19 5.448 19 6 C 19 6.552 18.552 7 18 7 C 17.448 7 17 6.552 17 6 C 17 5.448 17.448 5 18 5 z M 12 7 C 14.761 7 17 9.239 17 12 C 17 14.761 14.761 17 12 17 C 9.239 17 7 14.761 7 12 C 7 9.239 9.239 7 12 7 z M 12 9 A 3 3 0 0 0 9 12 A 3 3 0 0 0 12 15 A 3 3 0 0 0 15 12 A 3 3 0 0 0 12 9 z"
/>
</svg>
</button>
</div>
</div>
</div>
```
## Time for the CSS
First, we import the Poppins font and reset the layout like this.
```css
@import url("https://fonts.googleapis.com/css2?family=Poppins&display=swap");
*,
:before,
:after {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: inherit;
}
body {
font-family: "Poppins", sans-serif;
}
```
Then we style the login form and the background like this.
```css
.main {
height: 100vh;
width: 100%;
display: flex;
align-content: center;
align-items: center;
justify-content: center;
background: url(https://images.unsplash.com/photo-1506452305024-9d3f02d1c9b5?ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=1470&q=80);
background-size: cover;
background-repeat: no-repeat;
}
.login {
position: relative;
background: #686d6f7a;
padding: 35px 40px;
border-radius: 4px;
z-index: 1;
overflow: hidden;
box-shadow: 0px 12px 31px #ffffff52, 0px 36px 31px #000000a1;
animation: login 0.88s ease;
}
@keyframes login {
0% {
transform: translateY(-10%) scale(0.8);
opacity: 0;
}
100% {
transform: scale(1);
opacity: 1;
}
}
.login:after {
content: "";
position: absolute;
top: 0;
left: 0;
height: 100%;
background: url(https://images.unsplash.com/photo-1506452305024-9d3f02d1c9b5?ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=1470&q=80);
width: 100%;
z-index: -1;
background-size: 182vh;
background-position: 28%, 83%;
filter: blur(24px);
background-repeat: no-repeat;
opacity: 0.8;
}
```
Now we have our glass-like login form and background. It looks like this.

Nice. Then, we style the heading.
```css
.heading {
font-size: 24px;
font-weight: 400;
text-align: center;
margin-bottom: 18px;
color: white;
}
```
After that, the inputs.
```css
.input {
display: block;
margin-bottom: 13px;
margin-top: 11px;
}
.input label {
display: block;
margin-bottom: 3px;
font-size: 13px;
color: white;
cursor: pointer;
}
.input input {
width: 100%;
padding: 10px;
outline: none;
border: none;
font-size: 15px;
border-radius: 4px;
background: #0000002b;
color: white;
transition: all 0.2s ease;
}
.input input:hover {
background: #3d434c;
}
.input input:focus {
box-shadow: 0px 2px 2px #0000002b, 0px 5px 10px #00000036;
background: #434343;
}
```
Now, we can see a beautifully designed login page like this. (80% done)
```css
.login-btn {
margin-top: 10px;
margin-bottom: 15px;
padding: 8px 15px;
font-size: 14px;
background: #00000038;
border: 2px solid #38363654;
color: #e1e1e1;
border-radius: 4px;
width: 100%;
transition: all 0.2s cubic-bezier(0.79, 0.14, 0.15, 0.86);
cursor: pointer;
}
.login-btn:hover {
background: #0663b4;
transition: all 0.1s ease;
}
.login-btn:focus {
box-shadow: 0px 0px 0px 2px #a7a7a7b5;
background: #00000061;
}
.meta-text {
font-size: 13px;
margin-bottom: 15px;
color: white;
}
.social-icons {
text-align: center;
display: flex;
justify-content: center;
align-items: center;
}
.social-icon {
min-height: 40px;
background: var(--c);
margin-right: 10px;
display: flex;
align-items: center;
justify-content: center;
min-width: 40px;
max-width: 40px;
max-height: 40px;
border-radius: 28px;
box-shadow: 0px 4px 8px #0c0b0b00;
transition: all 0.2s ease;
border: none;
outline: none;
}
.social-icon:hover {
box-shadow: 0px 4px 14px #0000007a;
}
.social-icon:focus {
box-shadow: 0px 0px 0px 2px currentColor;
transform: scale(0.9);
}
.social-icon * {
pointer-events: none;
fill: #fff;
}
.social-icon.fb {
--c: #4267b2;
}
.social-icon.pr {
--c: #e60023;
}
.social-icon.in {
--c: #5b51d8;
}
```
Okay. We finished our work. [Click Here](https://www.tronic247.com/glassmorphism-login-form-with-css/) to view full code so you can copy-paste it easily.
That’s all for now then. You know now how to create a Glassmorphism login form with CSS. | posandu |
836,961 | [DopeTales] GDB Hit Counter Script for nth time break on function | Productive GDB Scripts | 0 | 2021-09-22T17:47:45 | https://dev.to/maheshattarde/dopetales-gdb-hit-counter-script-for-nth-time-break-on-function-1fac | gdb | ---
title: [DopeTales] GDB Hit Counter Script for nth time break on function
published: true
description: Productive GDB Scripts
tags: gdb
//cover_image: https://direct_url_to_image.jpg
---
Some useful hack around gdb. While debugging we often want to wait until certain function hits nth time. Following script does that, in easy python way.
###### Code Explanation
We have HitMe class which inherits from gdb.BreakPoint which is classes defined in gdb python extension. It provides two methods __init__ will define breakpoint on function and handler on hitting breakpoint. Return value of Stop function tells gdb halt or not.
hitCount is just counter to keep track of number of function hits.
In code BREAK_FUNCTION hits 40 times before breakpoint halts gdb.
```python
# script.py
import traceback
import gdb
import subprocess
import re
import math
import json
hitCount = 0
class HitMe(gdb.Breakpoint):
def __init__(self):
gdb.Breakpoint.__init__(self, "BREAK_FUNCTION")
def stop(self):
global hitCount
hitCount = hitCount + 1
print(hitCount)
if hitCount > 40:
return True;
return False
print("Ran Counter For Function!")
hit = HitMe()
```
Running This script
```
gdb -xargs binary.o arg1
...
gdb> source script.py
gdb> run
```
This will be quickest way to get there! Happy Hacking!!!
| maheshattarde |
837,168 | Horror Card Game | A post by Samanta Fluture | 0 | 2021-09-22T20:10:50 | https://dev.to/samantafluture/horror-card-game-79k | codepen | {% codepen https://codepen.io/samantafluture/pen/abwKLKz %} | samantafluture |
837,203 | Prometheus and Grafana | Monitoring services is a big part of Cloud Infrastructure Management. Here we will go through one... | 0 | 2021-10-04T19:27:28 | https://dev.to/muckitymuck/prometheus-and-grafana-4k1a | monitoring, linux | Monitoring services is a big part of Cloud Infrastructure Management. Here we will go through one way to install Prometheus on Ubuntu and make pretty dashboards with Grafana on a separate machine.
Go grab this download and extract to start:
```
wget https://github.com/prometheus/prometheus/releases/download/v2.30.3/prometheus-2.30.3.linux-amd64.tar.gz
tar -xvzf prometheus-2.11.1.linux-amd64.tar.gz
cd prometheus/
./prometheus
```
Should be great success:
Open a web browser and head over to the http://{IP}:9090/graph
So far, So Good
You can see the raw metrics by going to http://{IP}:9090/metrics

You can check what is up by going to /targets
Let's run it as a service, create this file:
```
/etc/systemd/system/prometheus.service
```
And give it this basic text settings:
```
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target
[Service]
User=root
Restart=on-failure
#Change this line if you download the
#Prometheus on different path user
ExecStart=~/prometheus/prometheus --storage.tsdb.path=/var/lib/prometheus/data/ --web.external-url=http://myurl.com:9090
[Install]
WantedBy=multi-user.target
```
Make sure to reload it and start it up:
```
sudo systemctl daemon-reload
sudo systemctl start prometheus
```
There are Exporters you can add to Prometheus to increase the utility. Node Exporter is one.
```
wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
tar -xvzf node_exporter-0.18.1.linux-amd64.tar.gz
mv node_exporter-0.18.1.linux-amd64 node_exporter
cd node_exporter
./node_exporter
```
You can open the service in a browser at http://{IP}:9100
You can add the node exporter to Prometheus in /etc/prometheus/prometheus.yml
Let's make it into a service. Create a file:
```
sudo vi /etc/systemd/system/node_exporter.service
```
```
[Unit]
Description=Node Exporter
After=network.target
[Service]
User={user}
Group={user}
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
```
Let's go ahead and get this going:
```
sudo systemctl daemon-reload
sudo systemctl start node_exporter
sudo systemctl status node_exporter
```
You can see the two services on /targets
If all is running well, enable this service to start at boot.
```
sudo systemctl enable node_exporter
```
That's enough for today. I will continue this in a second part for Grafana. | muckitymuck |
837,305 | Top 25 AWS Services Explained! | 1. Robomaker Robots are being used more widely in society for purposes that are... | 0 | 2021-09-23T01:07:42 | https://dev.to/howtoubuntu/top-25-aws-services-explained-1l33 | aws, cloudskills | # 1. Robomaker

Robots are being used more widely in society for purposes that are increasing in sophistication such as complex assembly, picking and packing, last-mile delivery, environmental monitoring, search and rescue, and assisted surgery. Within the autonomous mobile robot (AMR) and autonomous ground vehicle (AGV) market segments, robots are being used for commercial logistics and consumer cleaning, delivery, and companionship.
---
# 2. IOT Core

AWS IoT Core lets you connect IoT devices to the AWS cloud without the need to provision or manage servers. AWS IoT Core can support billions of devices and trillions of messages, and can process and route those messages to AWS endpoints and to other devices reliably and securely. With AWS IoT Core, your applications can keep track of and communicate with all your devices, all the time, even when they aren’t connected.
---
# 3. Ground Station

AWS Ground Station is a fully managed service that lets you control satellite communications, process data, and scale your operations without having to worry about building or managing your own ground station infrastructure. Satellites are used for a wide variety of use cases, including weather forecasting, surface imaging, communications, and video broadcasts. Ground stations form the core of global satellite networks.
---
# 4. Bracket

Amazon Braket is a fully managed quantum computing service designed to help speed up scientific research and software development for quantum computing.
*Image from AWS*
---
Most developers that use AWS use it to solve more practical problems not like Quantum computing. So lets look what AWS has for Computing!
---
# 5. Elastic Compute Cloud (EC2)

Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers. Amazon EC2’s simple web service interface allows you to obtain and configure capacity with minimal friction.
---
# 6. Load Balancer

Elastic Load Balancing automatically distributes incoming application traffic across multiple targets, such as Amazon EC2 instances, containers, IP addresses, Lambda functions, and virtual appliances. It can handle the varying load of your application traffic in a single Availability Zone or across multiple Availability Zones.
---
# 7. Cloud Watch

Amazon CloudWatch is a monitoring and observability service built for DevOps engineers, developers, site reliability engineers (SREs), and IT managers.
---
# 8. Auto Scale

AWS Auto Scaling monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost. Using AWS Auto Scaling, it’s easy to setup application scaling for multiple resources across multiple services in minutes.
---
# 9. Elastic Beanstalk

AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and IIS.
---
# 10. Lightsail

Lightsail is an easy-to-use virtual private server (VPS) provider that offers you everything needed to build an application or website for a cost-effective, monthly plan.
---
# 11. Lambda

AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers, creating workload-aware cluster scaling logic, maintaining event integrations, or managing runtimes.
---
# 12. Serverless Repo

The AWS Serverless Application Repository is a managed repository for serverless applications. It enables teams, organizations, and individual developers to store and share reusable applications, and easily assemble and deploy serverless architectures in powerful new ways.
---
# 13. Outpost

AWS Outposts is a fully managed service that offers the same AWS infrastructure, AWS services, APIs, and tools to virtually any datacenter, co-location space, or on-premises facility for a truly consistent hybrid experience.
---
# 14. Snow

Applications are moving to the cloud faster today than ever before. A new category of applications requires increased capabilities and performance at the edge of the cloud, or even beyond the edge of the network.
---
# 15. Container Registry

Amazon Elastic Container Registry (Amazon ECR) is a fully managed container registry that makes it easy to store, manage, share, and deploy your container images and artifacts anywhere. Amazon ECR eliminates the need to operate your own container repositories or worry about scaling the underlying infrastructure.
---
# 16. Container Service

Amazon Elastic Container Service (Amazon ECS) is a fully managed container orchestration service that helps you easily deploy, manage, and scale containerized applications.
---
# 17. Kubernetes Service

Kubernetes is open source software that allows you to deploy and manage containerized applications at scale. Kubernetes manages clusters of Amazon EC2 compute instances and runs containers on those instances with processes for deployment, maintenance, and scaling. Using Kubernetes.
---
# 18. Fargate

AWS Fargate is a serverless, pay-as-you-go compute engine that lets you focus on building applications without managing servers. AWS Fargate is compatible with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS).
---
# 19. App Runner

AWS App Runner is a fully managed service that makes it easy for developers to quickly deploy containerized web applications and APIs, at scale and with no prior infrastructure experience required.
---
Lets just say you need to store some data in the cloud. Lets move onto some File Storage Services!
---
# 20. Simple Storage Service (S3)

Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases.
---
# 21. Glacier

Amazon S3 Glacier and S3 Glacier Deep Archive are secure, durable, and extremely low-cost Amazon S3 cloud storage classes for data archiving and long-term backup. They are designed to deliver 99.999999999% durability, and provide comprehensive security and compliance capabilities that can help meet even the most stringent regulatory requirements. Customers can store data for as little as $1 per terabyte per month!
---
# 22. Block Storage

Amazon Elastic Block Store (EBS) is an easy-to-use, scalable, high-performance block-storage service designed for Amazon Elastic Compute Cloud (EC2).
---
# 23. Elastic File System

Amazon Elastic File System (EFS) automatically grows and shrinks as you add and remove files with no need for management or provisioning.
---
Maybe you want some type of a database service? The last 2 will be AWS Database Services!
---
# 24. SimpleDB

This is also AWS very first Database service! Amazon SimpleDB is a highly available NoSQL data store that offloads the work of database administration. Developers simply store and query data items via web services requests and Amazon SimpleDB does the rest.
---
# 25. Dynamo DB

Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multi-region, multi-active, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second!
---
Thats basicly it! If you want me to do another type of this series but just on Azure or Google Cloud, just tell me!
Also check out my [website!](https://howtoubuntu.xyz) | howtoubuntu |
867,613 | Best Data Science Books in 2022 | To give you the best data science books, we did the intensive examination, looked over numerous... | 0 | 2021-10-18T11:56:28 | https://dev.to/cloudytech147/best-data-science-books-in-2021-3h8f | datascience, books, advanced, beginners | To give you the best data science books, we did the intensive examination, looked over numerous versions, and tracked down a couple of fascinating and instructive books that cover every one of the fundamental data science ideas finally.
In this [books on data science](https://www.techgeekbuzz.com/data-science-books/) article, we will share some critical provisions of what we consider as the main 10 data science books. Go ahead and share the name of the book(s) you preferred and are not on the rundown in the remarks area beneath. We will be glad to audit and incorporate it.

1. Data Science from Scratch - [Buy](https://www.amazon.com/Data-Science-Scratch-Principles-Python/dp/1492041130/)
2. Data Science for Business - [Buy](https://www.amazon.com/dp/1449361323)
3. Data Smart — Using Data Science to transform information into insight - [Buy](https://www.amazon.com/Data-Smart-Science-Transform-Information/dp/111866146X)
4. Python Data Analytics - [Buy](https://www.amazon.com/python-data-analytics-introduction-beginners-ebook/dp/B0824VM38C/)
5. R in Action - [Buy](https://www.amazon.com/Action-Data-Analysis-Graphics/dp/1617291382/)
6. Data Science for Dummies - [Buy](https://www.amazon.com/Data-Science-Dummies-2nd-Computers/dp/1119327636/)
7. Data Science for the Layman - [Buy](https://www.amazon.com/Numsense-Data-Science-Layman-Added/dp/9811110689/)
8. Data Science and Big Data Analytics - [Buy](https://www.amazon.com/Data-Science-Big-Analytics-Discovering/dp/111887613X/)
9. Designing Data-Intensive Applications - [Buy](https://www.amazon.com/Designing-Data-Intensive-Applications-Reliable-Maintainable/dp/1449373321/)
10. Pattern recognition and Machine Learning - [Buy](https://www.amazon.com/Pattern-Recognition-Learning-Information-Statistics/dp/0387310738/)
## Conclusion
As far as we can tell, instead of hopping into the fine specialized subtleties of each subtopic in the principal go itself, it is ideal to comprehend why data science is a decent decision and how the entire thing functions from both specialized and business points of view. The general picture will assist you with picking what's generally significant and where your advantage lies. | cloudytech147 |
837,485 | The Debugger Checklist – Part II | In the Debuggers Checklist Part I , I introduced some of the high level concepts and reviewed some... | 0 | 2021-09-23T05:00:04 | https://talktotheduck.dev/the-debugger-checklist-part-ii | java, programming, tutorial, tooling | In the [Debuggers Checklist Part I](https://talktotheduck.dev/the-debugger-checklist-part-i) , I introduced some of the high level concepts and reviewed some of the common things you can do. In this part we'll get down to the process. Again, it's important to stress that this is boiled down and concentrated.
I don't want to discuss issue trackers, unit testing and proper TDD. I think there are many resources covering all of these. The focus of these posts is the debug process itself which often gets neglected as "tools". There's a lot of technique that separates the seasoned developer from a junior. Furthermore, there are many small advancements and changes we can't possibly keep up with. I'd like to cover all of those things (some in future posts).
With that out of the way let's continue with...
## The Process
Hopefully by this point you were able to reproduce your problem in the debugger. Possibly even limited it to a small area you can step through.
Now we need to actually track the issue and fix it. People think this is hard to quantify generically but it isn’t. It comes down to breaking the problem down into manageable pieces we can attack:
- Make the simplest assumption you can
- Validate assumptions
- While the bug isn’t found:
- Narrow assumptions
- Validate narrowed assumptions
You’re probably saying: “Well dah...”. This is pretty obvious…
It totally is. The problem is we don’t apply those properly and somehow skip a lot of the nuance in those steps.
During this stage Rubber Ducking (talking to the duck) becomes useful. This is the process of talking to someone (or something) about your problem and assumptions. When we say things out loud or even try to verbalise them in our mind, it helps clarify our misguided assumptions.
I’ll try to get into more of these sorts of tricks in a future “tips and tricks” post.
### The Simplest Assumptions

This is where most of us fail. We assume.
I recently had a bug which I encountered by accident. I noticed the value of a variable in a stack trace. It was clearly corrupted. Since I was using a debug agent I incorrectly assumed that was the source of the problem. But I tried to verify again and again. When all else failed this led me down the road to a serious bug in the code.
Obviously we can’t start by testing the assumption that `1 + 1 = 2`. So we need to narrow it down to applicable assumptions. This “trick” isn’t the “end all” but it’s a very useful way to validate a lot of common assumptions.
#### Debug “Working Code”
The best way to review your assumptions is to walk through working code. If your code fails for case X and succeeds for case Y, try case X first. See why the code works and step over the code block.
Then try case Y. This should present you with two cases you can easily compare to help you narrow in on the suspect.
If this isn’t applicable or isn’t taking you anywhere you need to review the following:
- Exceptions
- State
- Threads/Synchronization
- Timings and Races
I ordered these according to difficulty and probability.
#### Exceptions
Most of the problems are state, but exceptions are relatively easy to detect. So just place a breakpoint for all exceptions and verify that nothing “fishy” is happening behind the scenes in one of the methods you invoked etc. Slowly filter out the “valid” exceptions as you move through the process.
Typically exceptions are “loud” and “obvious” so unless someone silently caught an exception (which happens), you should be in the clear.
I would also strongly recommend a linter rule that checks against swallowed/unlogged exceptions. E.g. checkstyle supports [this](https://checkstyle.sourceforge.io/config_blocks.html) check that blocks empty catch blocks. It still can’t block stupid code that does “nothing” in that block but at least it’s a start.
#### State
While threads are a source of difficult bugs, most bugs are a result of bad application state. Try separating the state elements that are modified and the state that’s read by the block of code.
Assuming you can, try overriding it within your breakpoint by setting a value of a variable during debugging. This is a great capability that most developers don’t utilize often enough. If you’re able to narrow down the value of a specific variable as the cause of the problem you’re already well on your way to solving the problem.
If this isn’t helping, try identifying specific fields that might be problematic. Most debuggers will let you place a breakpoint on the field in order to watch modifications to said field… I used that feature a couple of times while consulting and people were always surprised you can do that...

In IntelliJ the icon looks different for a field breakpoint. But it’s a breakpoint like any other, you can apply a condition to it and see the stack etc.
Now if the problem persists and everything is failing… Try changing the code to return a hardcoded state or a state from a working case. I’m normally not a fan of techniques that require code change for debugging since I consider the two distinct tasks. However, if you’re out of all options this might be your only recourse. Naturally you should use “Reload Changed Classes” (or Apply Code Changes, Edit and Continue etc.) if applicable.
Notice that there are also lower level memory breakpoints that are useful to debug memory access. We’ll discuss these when we cover debugging native code which I plan to cover in the future.
#### Threads/Synchronization
Thread problems are hard to solve… That’s not really something we’ll get into. We’ll only focus on finding and understanding the bug, and that’s an easier (manageable) task.
The easiest way to check threading issues is as I mentioned before logging your current thread and/or stack. Do that in the block of code that’s causing an issue. Then add a similar log breakpoint on fields used by the block of code. Thread violations should be pretty clear in the logs.
You can also get a thread dump during a breakpoint, that’s a feature of pretty much any debugger out there. E.g. in IntelliJ/IDEA you can select `Run -> Debugging Actions -> Get Thread Dump`. This isn’t as useful as going through the stack frames but it’s a start.
Specifically in IntelliJ/IDEA I recommend right clicking the debug tab and enabling the thread view. Then enabling thread groups by right clicking within the tab and selecting `Customize Thread View` like this:
It provides a much “cleaner” view of the threads as a hierarchy instead of the default look in IntelliJ which is better geared towards single thread debugging.
**Deadlocks and Livelocks**
Deadlocks are usually pretty clear. The app gets stuck, you press pause and the debugger shows you which thread is stuck waiting for which monitor. You can then review the other threads and see who's holding the monitor. Fixing this might be tricky, but the debugger literally “tells us” what’s going on.
With a livelock we hold one monitor and need another. Another thread is holding the other monitor and needs the one we’re holding. So on the surface it seems that both are working and aren’t stuck. A bit like two people running against each other in the hallway and trying to step out of each other's way. Unfortunately, livelocks can happen without threads being physically “stuck” so the code might appear fine on the surface without a clear monitor in the stack traces.
Debugging this requires stepping over the threads one at a time in the thread view and reviewing each one to see if it’s waiting for a potentially contested resource. It isn’t hard technically but it’s very tedious. That’s why I recommended enabling thread groups in the thread view above. A typical application has MANY threads (and more coming with project [Loom](https://inside.java/2021/08/13/new-loom-ea-builds/) ). This produces a lot of noise which we can reduce by grouping the threads and focusing on the important parts.
**Performance and Resource Starvation**
Performance problems caused by monitor contention are a bit harder to track with a debugger. I normally recommend randomly pausing the code and reviewing the running threads in your application. Is thread X constantly holding the monitor?
Maybe there’s a problem there.
You can then derive assumptions and prove them by logging the entry/exit point for a lock/synchronized block.
Notice you can use a profiler and it sometimes helps, but it might lead you on the wrong path in some cases. I plan to discuss profilers in a future post.
Resource starvation is an offshoot of performance issues. Often you would see it as an extreme performance issue, that usually only happens when you try to scale. In this case a resource needed by a thread is always busy and we just can’t get to it. E.g. We have too many threads and too few database connections. Or too few threads and too many incoming web requests. This problem often doesn’t need a debugger at all. Your environment usually indicates immediately that it ran out of the given resource so the problem is almost always plain and obvious.
The solution isn’t always as clear, e.g. you don’t want to add too many threads or DB connections to workaround the short term problem. You need to understand why the starvation occurred…
This happens because of two different reasons:
- Not releasing resources fast enough
- Not releasing resources in all cases
The first case is trivial. You can benchmark and see if something is holding you back.
The second is the more common: a resource leak. In a GC environment this is often masked by the GC that nicely cleans up after us. But in a high throughput environment the GC might be too slow for our needs. E.g. A common mistake developers make is opening a file stream which they never close. The GC will do that for us, but it will take longer to do that and the file lock might remain in place, blocking further progress.
This is where encapsulation comes in handy. All your resource usage (allocation/release) must be encapsulated. If you do that properly adding logging for allocation and freeing should expose such problems very quickly.
This is a bit harder to detect with DI frameworks like Spring where connections etc. are injected for you. You can still use tricks like this, to [track even injected data](https://stackoverflow.com/questions/50770462/springboot-2-monitor-db-connection) .
**Timings and Races**
This is one of those elusive bugs such as race conditions which are often classified as thread problems (which they are) but during a debugging session it’s often easier to see them as a separate task.
These often occur when your code has some unintentional reliance on performance or timing. E.g. Many years ago I had an app that crashed only when our customer was using it. The app was a mobile app and our customer was a local operator. It turned out that we had a bug where the networking in the customer site was SO FAST it just returned the response immediately and everything else wasn’t ready. So the application crashed. Usually the problem is slow performance and timeouts.
So this was a case where my assumption that the network was slower than the CPU was flawed...
The way I approach race conditions in threading code is this: “It’s a state bug”.
It’s always a state bug. When we have a race condition it means we either read from the state when it wasn’t ready or wrote to the state too late/early. Field breakpoints are your friends in this case and can really help you get the full picture of what’s going on. You can also simulate the bad state situation by changing variable values.
## Finally
If you follow through your assumptions and catalog the bugs into one of those common pitfalls then you’re 90% of the way to understanding the root cause. The rest is deciding on the right fix for the problem.
I won’t go into fixing the bug, filing the issue, building a test case etc. You should do all of that but there’s plenty written about that.
In fact in preparation for this blog I picked up a lot of debugging books on Amazon. Turns out most aren’t **"really"** debugging books. Yes they cover it in one or two chapters. The rest of the book is always about the process, test cases and everything surrounding it. I think that would be fair if debugging wasn’t a huge subject that can fill up a book. In my opinion, it sure can and I’m just getting started.
Tune in for more!
| codenameone |
837,486 | Sending SMS to Mobile with Nexmo in Laravel | Hi, This tutorial shows you laravel send sms to mobile with nexmo. i would like to share with you... | 0 | 2021-09-23T05:00:06 | https://dev.to/techdurjoy/sending-sms-to-mobile-with-nexmo-in-laravel-1flj | laravel, nexmo | Hi,
This tutorial shows you laravel send sms to mobile with nexmo. i would like to share with you how to send sms using nexmo in laravel. This article will give you simple example of send sms using nexmo in laravel. step by step explain laravel sms notification nexmo. You just need to some step to done laravel nexmo message.
In this example, i will give you very simple example to sending sms using nexmo/vonage api in laravel app. you can easily use this code in laravel 6, laravel 7 and laravel 8 app.
let's follow bellow steps:
https://www.codecheef.org/article/example-of-sending-sms-to-mobile-with-nexmo-in-laravel | techdurjoy |
837,494 | Revisiting Tailwind square divs with aspect ratio | The other day I posted this article on how to create square divs in Tailwind CSS. The code works, and... | 0 | 2021-09-23T05:10:45 | https://daily-dev-tips.com/posts/revisiting-tailwind-square-divs-with-aspect-ratio/ | tailwindcss, css | The other day I posted this article on how to [create square divs in Tailwind CSS](https://daily-dev-tips.com/posts/tailwind-css-responsive-square-divs/).
The code works, and there is nothing wrong with it. However, it is a bit of a "hack" to do this.
In the past, I've written about [CSS Aspect ratio](https://daily-dev-tips.com/posts/css-aspect-ratio-its-finally-here/) and at the time of writing that it wasn't well supported.
When I published the Tailwind article [IgnusG mentioned on Daily.dev](https://app.daily.dev/posts/gg8pN84wj) that aspect ratio is now well supported.
So taking another look at aspect-ratio, it is way better supported, and another winning aspect is that it comes as a Tailwind plugin!

Already improved, and it's coming to Safari in the technology preview.
You can keep an eye out [here for the live graph](https://caniuse.com/mdn-css_properties_aspect-ratio).
## Using the Tailwind aspect ratio plugin
Let's start by adding the tailwind aspect ratio plugin to our project.
```bash
npm install @tailwindcss/aspect-ratio
```
Next, up we need to register it in our `tailwind.config.js` file as such:
```js
module.exports = {
theme: {
// ...
},
plugins: [
require('@tailwindcss/aspect-ratio'),
// ...
],
};
```
And as we learned from our [CSS aspect ratio](https://daily-dev-tips.com/posts/css-aspect-ratio-its-finally-here/) article, we need to define the width and height of the aspect ratio.
The plugin gives us these two classes for that:
- `aspect-w-{x}`
- `aspect-h-{x}`
Where x can be a number between 1 and 16.
In our case, we want a square, so we'll be using 1 and 1.
```html
<div class="w-full h-0 shadow-lg aspect-w-1 aspect-h-1 rounded-xl bg-yellow-300"></div>
```
In action that will result in this:

You can also try it out in this [Tailwind Playground](https://play.tailwindcss.com/johiZp33uH).
A big thanks to Ignus for pointing out that this is now well supported! 🎉
Lovely how the community points these things out so we can all learn from them.
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
837,592 | First ever blog post as a programmer! | printf("Hello world!"); Enter fullscreen mode Exit fullscreen mode ... | 0 | 2021-09-23T09:00:05 | https://dev.to/makaron/first-ever-blog-post-as-a-programmer-36gf | beginners | 
```
printf("Hello world!");
```
I am **Ronald Makalintal**, an aspiring software developer/computer programmer currently studying at Seneca College. I have been studying software development since May 2020, which was also the time I started studying at Seneca. Previously, I studied Business Management back in the Philippines, but after completing the program, I reflected on what I wanted to do decades from now and decided that I wanted to make a significant impact on the world through making stuff. Now, 'making stuff' is, to be frank, quite vague. However, I did always see myself staring in front of a computer screen until the day I expire so I thought to myself, _"maybe it wouldn't be a bad idea to start a career making computer programs?"_. More than a year has passed and I can confidently say that I am happy with the decision that I have made, and I would like to share with you all what I continuously learn—both inside and outside of the classroom.
The initial goal of my blog is in line with my requirements for a subject (Software Portability and Optimization / SPO600) as my peers and I are required to share our thoughts and findings on the labs we do on a weekly basis. However, _I honestly want to go beyond that._ I would like to use my blog to connect with developers all around the globe. And I'll do exactly that starting with my first ever blog post.
| makaron |
837,814 | iTerm superpower: type in all tabs/panes | One thing that I always liked about tumx is that you can open multiple panes and send the same input... | 0 | 2021-09-23T12:07:28 | https://dev.to/bajubullet/iterm-superpower-type-in-all-tabs-panes-2mig | iterm, mac, terminal, bash | One thing that I always liked about tumx is that you can open multiple panes and send the same input to all the panes. Today I figured out you can do something similar with iTerm as well.
Just open multiple panes or tabs and press `cmd`+`option`+`i` (for all panes) or `cmd`+`shift`+`i`(for all windows) and type away. Your inputs will be broadcasted to all panes/windows.
This is especially useful in cases where you have to do a lot of setup/logging in before in all terminals before you can tail logs or run commands.
For more detail open iterm and go to `Shell` > `Broadcast input` in the menubar. | bajubullet |
837,839 | Use relational database as document database: get the best of both worlds | Problem with document database: can rapidly become a mess, it's difficult to rearrange and can... | 0 | 2021-09-23T12:48:33 | https://dev.to/niolap/use-relational-database-as-document-database-get-the-best-of-both-worlds-58ec | database, agile, mongodb, postgres | **Problem with document database:** can rapidly become a mess, it's difficult to rearrange and can consume a lot of resources when scanning.
**Problem with relational database:** schemas (tables/columns) are too static and must be maintained on the database side and code side.
**Solution:** A database that internally stores documents in tables by breaking down documents' attributes into rights tables' fields "on the fly".
**Benefits of the solution:**
- Schemaless structures maintain in the code
- Performance and efficiency of relational database
- Easier to maintain in the long term
- Consume much fewer resources (cheaper in the cloud)
## Examples
**Single document - code side**
```js
var doc = {
email: "dwain.jonhson@gmail.com",
firstname: "Dwain",
lastname: "Jonhson",
username: "dwainjonhson"
};
doc.save();
collection("users").find({username: "dwainjonhson"});
/*
{
trid : 2, // auto id generation
email: "dwain.jonhson@gmail.com",
firstname: "Dwain",
lastname: "Jonhson",
username: "dwainjonhson"
}
*/
```
**Single document - Database side**
```sql
> select * from users;
TRID EMAIL FIRST_NAME LAST_NAME USERNAME
------ --------------------------- -------------- ------------- --------------
2 dwain.jonhson@gmail.com Dwain Jonhson dwainjonhson
```
**Nested documents - code side**
```js
var doc = {
email: "dwain.jonhson@gmail.com",
firstname: "Dwain",
lastname: "Jonhson",
username: "dwainjonhson",
phones: [{
alias: "home",
number: "+1-202-555-0143"
},{
alias: "mobile",
number: "+1-202-555-0156"
}]
};
doc.save();
collection("users").find({username: "dwainjonhson"});
/*
{
trid : 2, // auto id generation
email: "dwain.jonhson@gmail.com",
firstname: "Dwain",
lastname: "Jonhson",
username: "dwainjonhson"
phones: [{
trid : 1, // auto id generation
alias: "home",
number: "+1-202-555-0143"
},{
trid : 2, // auto id generation
alias: "mobile",
number: "+1-202-555-0156"
}]
}
*/
```
**Nested documents - database side**
```sql
> select * from users;
TRID EMAIL FIRST_NAME LAST_NAME USERNAME
------ --------------------------- -------------- ------------- --------------
2 dwain.jonhson@gmail.com Dwain Jonhson dwainjonhson
-- Nested phone documents automatically organized in table with the proper relationship.
> select * from users_phones;
TRID USERD_TRID ALIAS NUMBER
------ ----------- ----------------- ------------------------
1 2 home +1-202-555-0143
2 2 mobile +1-202-555-0156
```
## Wanted: Feedbacks!
- How that would help you overcome the common issues working with SQL or Document databases?
- Any suggestions? | niolap |
838,140 | Automate EC2 Instance Shutdown with Lambdas to Minimize AWS Costs | In the cloud, cost control is a task unto itself. It takes diligent oversight over the services in... | 15,017 | 2021-10-18T12:44:43 | https://dev.to/pdelcogliano/automate-ec2-instance-shutdown-with-lambdas-to-minimize-aws-costs-5886 | aws, tutorial, cloud, devops | In the cloud, cost control is a task unto itself. It takes diligent oversight over the services in your AWS cloud to ensure the monthly spend doesn't grow out of control. One method for lowering costs is to shutdown EC2 Instances when they are not in use. In this two-part series, I will show you how to reduce your monthly spend by scheduling the shut down of EC2 Instances using two different methods.
### Controlling Costs
There are several factors which determine how an EC2 Instance is billed. The main factor is by usage, typically measured by the hour. As long as an EC2 Instance is in the _running_ state, you are accruing fees, even if you are not actually using the VM. An effective method for controlling these costs is to shut down the VM when it is not needed. When the instance is in the _stopped_ or _terminated_ state you still pay for storage, but that is a fraction of the compute costs you pay while the instance is running.
Development, QA, or Test environments are all good use cases for automating the shutdown of an EC2 Instance. In these environments, the instances are most active during business hours. Those instances do not need to be running once everyone signs off at the end of the day.
I use two methods for shutting down EC2 instances. The first involves using CloudWatch Event Rules together with Lambdas. The second uses Launch Templates in conjunction with Auto Scaling Groups (ASG).
Each method has its own use cases. For simple startup/shutdown scheduling I like the CloudWatch/Lambda solution. This method is the easier of the two to setup. It works well when scheduling a set of EC2 instances. It is also appropriate for use cases involving EC2 instances with static public IP addresses (EIPs).
The relatively more complex Launch Template/ASG method provides additional functionality beyond scheduling like email notifications, and the ability to continually retry starting an instance if it fails to start. This is a good solution when no EIPs are involved, when all of your EC2 instances are the same instance type, or you want more robust monitoring and notifications.
I'll walk through both methods for controlling and minimizing cloud costs. This post focuses on using CloudWatch Event Rules and Lambdas to schedule instance startup and shutdown. The [second post][1] walks through using Launch Templates with ASG to achieve the same result.
### CloudWatch Event Rules and Lambda
Among the many AWS services, CloudWatch Events and Lambdas can be combined to provide basic scheduling capabilities. The [AWS documentation](https://aws.amazon.com/premiumsupport/knowledge-center/start-stop-lambda-cloudwatch/) has in-depth instructions for using CloudWatch Events and Lambdas to shutdown and startup EC2 instances on a schedule.
There are three basic steps to using this technique. The steps below use the AWS Console to setup and configure the policy and role, the CloudWatch Events Rules and Lambda functions.
1. Create a custom Identity and Access Management (IAM) policy and execution role for the Lambda functions.
2. Create and test two Lambda functions; one to stop EC2 instances, and another to start them.
3. Create CloudWatch Event Rules that trigger the Lambda functions on a schedule.
#### Step 1 - Create IAM Policy and Role
Using the IAM service console, create an IAM policy by clicking on the "Create policy" button. This starts the policy creation wizard. On the JSON tab, enter the policy permissions from Listing 1 below. These permissions allow CloudWatch logging and EC2 startup and shutdown.
######Listing 1
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"ec2:Start*",
"ec2:Stop*"
],
"Resource": "*"
}
]
}
```
Click through the wizard until you get to the "Review" page. On the Review page, enter "_lambda-policy-for-scheduling-ec2-instances_" as the policy name. Click the "Create policy" button to save the policy. The following screenshot shows the policy review screen. Notice that the Summary section shows permissions being applied to CloudWatch Logs and EC2 services.

To setup the role, navigate to the Roles link in the IAM Console and click the "Create role" button. This starts the role creation wizard. On the first page, select the _AWS service_ option and choose the "Lambda" use case. Click the "Next: Permissions" button. Search for the policy created earlier named "_lambda-policy-for-scheduling-ec2-instances_", and select it from the list to attach it to the role. Click through the wizard until you get to the _Review Role_ step. The following screenshot shows the role review screen.

Enter "_lambda-role-for-scheduling-ec2-instances_" for the role name, then click the "Create role" button to save the role.
#### Step 2 - Create two Lambda functions
In the AWS console, open the Lambdas service console. Click the "Create Function" button to start the wizard. Select the _Author from scratch_ option. Name the function "start-ec2-instances". Select "python 3.9" from the _Runtime_ dropdown. Click on the "Change default execution role" link and select the _Use an existing role_ option. Select the role created above, "_lambda-role-for-scheduling-ec2-instances_" from the drop down. Leave all other settings as their defaults, as shown below.

Click the "Create Function" button to save the function. The next step in the wizard is to provide code for the lambda. The python script in Listing 2 below is used to start your EC2 instances. Copy/paste the script into the lambda wizard's _code_ tab.
######Listing 2
```python
import boto3
region = '<your region here>'
instances = ['<your 1st instance id>', '<your 2nd instance id>']
ec2 = boto3.client('ec2', region_name=region)
def lambda_handler(event, context):
ec2.start_instances(InstanceIds=instances)
print('started your instances: ' + str(instances))
```
The script contains two variables, `region` and `instances`. Replace `<your region here>` with the AWS region name where your EC2 instances are running, i.e. `us-east-1`. The `instances` variable is a comma separated list of EC2 Instance IDs. Provide one or more instances in the list. Each instance provided will be affected by the function. Navigate to the AWS EC2 console to find your Instance IDs.
After editing the script, click the "Test" button. This opens a dialog allowing the Lambda to be tested. Provide a value for the test's Event Name and click "Create". Click the "Test" button again to run the test. Review the output, looking for errors. The following screenshot shows the completed Test dialog form.

Of note; testing the Lambda function will execute the python script. Any instances listed in the startup function will be started. The same goes for the shutdown function. Testing that function will shutdown the instances.
Once any errors and warnings are resolved, repeat the process to create the "stop-ec2-instances" Lambda. The python script in Listing 3 provides the code for stopping EC2 instances. Provide the same values for `region` and `instances` here as you did for the "start-ec2-instances" script.
######Listing 3
```python
import boto3
region = '<your region here>'
instances = ['<your 1st instance id>', '<your 2nd instance id>']
ec2 = boto3.client('ec2', region_name=region)
def lambda_handler(event, context):
ec2.stop_instances(InstanceIds=instances)
print('stopped your instances: ' + str(instances))
```
###Step 3 - Create CloudWatch Event Rules
The final step in this process is to setup the schedules that will stop and start the instances. Begin by navigating to the CloudWatch service in the AWS console. Click the Rules link and then the "Create rule" button. This will create a new rule which will be used to schedule instance startup.
The screenshot below shows the _Event Source_ section. This is where the schedule is defined. Start by selecting the _Schedule_ option and the _Cron expression_ option. Enter the following cron expression to schedule instance startup to occur at 7 AM EST, Monday - Friday: `0 11 ? * MON-FRI *`

Next, click the "Add Target" button. Select _Lambda function_ from the drop down and select the "_start-ec2-instances_" function. Click the "Configure details" button and provide a name for the rule. Click the "Create rule" button to save the rule.
Repeat this process to configure a rule to shutdown the EC2 instances. The following cron expression schedules instance shutdown for 8:05 PM EST, Tuesday - Saturday: `05 00 ? * TUE-SAT *`
###Logging
You may have noticed earlier that the policy contained permissions for logging. Every time one of the Lambda functions executes, it logs its output to a CloudWatch Log group. To view the logs, navigate to the "Log groups" link under the CloudWatch console. In the list of log groups, you should see one named "_aws/lambda/start-ec2-instances_". This was created when you tested the lambda function. Click that log group and navigate to the log streams where you will find the results of the lambda's execution, including the output from any `print` statements in the python script.
### Conclusion
Controlling costs in the cloud is a full time job. The combined power of CloudWatch Event Rules and Lambdas provides one method of controlling those costs by scheduling the startup and shutdown of EC2 instances. [In the next post][1], we'll look at another approach to cost cutting using Launch Templates and Auto Scaling Groups. See you there.
[1]: https://dev.to/pdelcogliano/automate-ec2-instance-shutdown-with-auto-scaling-groups-to-minimize-aws-costs-2fb3 | pdelcogliano |
838,145 | Explore Azure OCR in 125 Languages with IronOCR | This article is all about AzureOcr and IronOcr. If you are looking for tesseract Ocr, you can refer... | 0 | 2021-09-23T15:23:10 | https://dev.to/mhamzap10/explore-azure-ocr-in-125-languages-with-ironocr-57ka | azureocr, ironocr, cloud, azure | This article is all about [AzureOcr](https://ironsoftware.com/csharp/ocr/technology/azure-ocr/) and [IronOcr](https://ironsoftware.com/csharp/ocr/). If you are looking for tesseract Ocr, you can refer to my previous article from this [link](https://dev.to/mhamzap10/how-to-use-tesseract-ocr-in-c-9gc).
#Azure OCR by Microsoft:
Optical Character Recognition (OCR) allows you to extract handwritten or printed text from images like documents, bills and articles etc. Microsoft supports 73 languages for extracting printed documents.
Read API in lastest [AzureOCR](https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/overview-ocr) Technology extracts printed and handwritten text , digits and currency symbol from images and PDF documents. It is optimized for extracting text from heavy images or multi-page PDF documents. It's features include:
1. Print text extraction in 73 languages
2. Handwritten text extraction in English
3. Text lines and words with location and confidence scores
4. No language identification required
5. Support for mixed languages, mixed mode (print and handwritten)
#IronOCR:
IronOCR is a C# software library that allows .NET developers to read text from images and PDF documents. It is a pure .NET OCR library. Azure OCR is an excellent tool allowing to extract text from an image by API calls. It provides developers with access to advanced algorithms that process images and return information. To analyze an image, you can either upload an image or specify an image URL.
##How Is IronOCR better than AzureOCR?
The cloud-based OCR API provides developers with access to advanced algorithms for reading text in images and returning structured content and you can learn how to extract printed and handwritten text in multiple languages with quickstarts, tutorials, and samples. IronOCR supports 125 international languages.
##Benefits To Use IronOCR in AzureOCR:
IronOCR provides all these :
1. In Azure OCR, there is Azure Cognitive Services which is a computer vision API but incase you wanted to make sure that you could run this without making API calls, and without paying more as you scale up. IronOCR is a one time fee.
2. It Support multiple languages as compare to other libraries who supports English only.
3. It provides a smart cleanup like if the scanned document or image is a bit scratchy, the library come up with something to make it clean.
4. It has a huge feature that works both for printed and handwritten.
5. You can easily use it in the cloud that means that you don’t need to install anything because you may not be using a VM at all and it will be entirely serverless.
##Azure OCR API features:
1. The ability to perform an OCR on almost any file, image, or PDF
2. Lightning-fast speed
3. Exceptional accuracy
4. Reads bar codes and QR codes
5. Runs locally, with no SaaS required
6. Can turn PDFs and images into searchable documents
7. Excellent Alternative to Azure OCR from Microsoft Cognitive Services.
#IronOCR With AzureOCR:
Let’s s see an example of screenshot from the Google Books page on Frankenstein by Mary Shelly.

I then took my C#/.NET Console Application, and ran the following in the nuget package manager to install IronOCR
`Install-Package IronOcr`
you can directly download from this [link](https://ironsoftware.com/csharp/ocr/downloads/azure-ocr.zip)
And then onto the code and OCR’d this image to extract text, including line breaks and everything, using 4 lines of code.
```
var ocr = new IronTesseract();
using (var Input = new OcrInput("Frankenstein.PNG"))
{
var result = ocr.Read(Input);
Console.WriteLine(result.Text);
}
```
And here is the result
*Frankenstein
Annotated for Scientists, Engineers, and Creators of All Kinds
By Mary Wollstonecraft Shelley - 2017*
We are using Azure Functions in a microservices architecture, here is a simple function that can take a parameter of an image, OCR it, and return the text
```
public static class OCRFunction
{
public static HttpClient _httpClient = new HttpClient();
[FunctionName("OCRFunction")]
public static async Task<IActionResult> Run([HttpTrigger] HttpRequest req, ExecutionContext context)
{
var imageUrl = req.Query["image"];
var imageStream = await _httpClient.GetStreamAsync(imageUrl);
var ocr = new IronTesseract();
using (var input = new OcrInput(imageStream))
{
var result = ocr.Read(input);
return new OkObjectResult(result.Text);
}
}
}
```
We take the parameter of picture, download it and OCR it right away. The good thing about doing this inside an Azure Function is that it support various pieces of our application in a microservice architecture without us duplicating the code everywhere.
In case you're right now paying for some help that charges a for each OCR expense. Things can seem modest yet at scale, the month to month expense can rapidly winding crazy. Contrast this with a one time expense with IronOCR, and you're getting what is basically a callable API all facilitated in the Azure Cloud, and without any continuous expenses
##Non-English Support:
Many OCR libraries only support English language.
However, IronOCR supports 125 languages currently, and you can add as many or as few as you like by simply installing the applicable Nuget language pack.
Iron Azure OCR Language Support
##Summary:
For past couple years, Computer vision and optical character recognition is on high demand. IronOCR supports 125 international languages as compare to Microsoft Azure that supports 73 languages. IronOCR has a computer vision API and an ability to convert any image , file or PDF in OCR with its advanced algorithms. Interested thing is, If you buy complete Iron Suite, you will get all 5 Products for the Price of 2. For further details about the [licensing](https://ironsoftware.com/csharp/ocr/licensing/), Please follow this [link](https://ironsoftware.com/suite/) to Purchase complete Package.
I hope that you have liked this article. Feel free to ask any query in the comment section. | mhamzap10 |
838,195 | next.js: i18n with static sites | Version 3.x.x exclusively supports Next.js' app directory architecture. The 2.x.x branch continues to... | 0 | 2021-09-23T16:54:54 | https://dev.to/martinkr/next-js-i18n-with-static-sites-2644 | webdev, nextjs, javascript | **[Version `3.x.x`](https://www.npmjs.com/package/next-export-i18n/v/3.0.0) exclusively supports Next.js' `app` directory architecture. The [`2.x.x` branch](https://www.npmjs.com/package/next-export-i18n/v/2.3.5) continues to support the `page` directory, please.**
---
Recently, I had a client who wanted a fast single-page application (SPA) with an outstanding lighthouse score and multiple languages hosted on a cheap shared hosting solution only accessible by FTP ... and of course, they wanted it to be built with `react.js`.
Based on the initial requirements and the following discussion, we decided to have a local build step to generate static files and transfer them to the web server.
Given their limited expertise and specific requirements, I suggested a static site generator with a custom headless setup for their content. The client was happy with the proposed architecture. I was looking into the possibility of using `next.js` and the two major requirements: a static page served by Apache and internationalisation (i18n).
## True static files
`Next.js` provides a true out-of-the-box static sites generator. The `next export` command generates a fully optimised static HTML file set. This export can thus be served without any dependencies by any web server. There is no need to run `node.js`, etc - a regular Nginx or Apache installation is sufficient.
## internationalization (i18n)
`Next.js` also provides amazing out-of-the-box support for internationalized (i18n) routing and a decent ecosystem for i18n-solutions
> The i18n routing support complements existing i18n library solutions like react-intl, react-i18next, linguine, rosetta, next-intl and others by streamlining the routes and locale parsing.
That sounds nice, and being a fan of `react-i18next,` I looked into `next-i18next` and was quite happy to see that they support Static Generation (SSG).
> To complement this, next-i18next (....) fully supports SSG/SSR, multiple namespaces, code splitting, etc.
> Production ready: next-i18next supports passing translations and configuration options into pages as props with SSG/SSR support.
> https://github.com/isaachinman/next-i18next/
Upon closer inspection, I figured they only support Static Generation (SSG) with `next start`, not `next export`. (About the differences, read my article [The two and a half + one flavors of next.js's pre-rendering](https://dev.to/martinkr/the-two-and-a-half-one-flavors-of-next-js-s-pre-rendering-44o)).
`next start` spins up the `next.js` web server and requires `node.js` - which was a problem for the hosting solutions.
I needed an export which would run on a basic nginx.
__From the next.js documentation:__
> Note that Internationalized Routing does not integrate with the next export as the next export does not leverage the Next.js routing layer. Hybrid Next.js applications that do not use `next export` are fully supported.
> https://nextjs.org/docs/advanced-features/i18n-routing#how-does-this-work-with-static-generation
## Creating a custom i18n solution for true SSG support
Well, we're just going to create our custom i18n solution.
Let's collect the requirements:
The custom solution must:
- have full support for `next export`
The custom solution should:
- load the translation files from a folder with minimal configuration
- provide a hook with the same interface as `react-i18next`
- provide a stateful hook for the current language
- set/retrieve the selected language to/from the search parameters so we can share a localised link
- fallback to the default language if no search parameter is present
- set the search parameter on internal links and preserve existing search parameters
- provide a sample component for selecting the language
## `next-export-i18n`
Let me introduce the [final static solution](https://next-export-i18n-example.vercel.app), and feel free to take a look at the [source code](https://github.com/martinkr/next-export-i18n-example), which meets all the requirements.
So, if you need an i18n solution which has full support for `next export` and minimal configuration effort, use the [next-export-i18n npm-module](
https://www.npmjs.com/package/next-export-i18n).
## Links
- Example implementation: https://next-export-i18n-example.vercel.app
- GitHub for the npm module: https://github.com/martinkr/next-export-i18n
- GitHub for the example: https://github.com/martinkr/next-export-i18n-example.
---
Follow me on [Twitter: @martinkr](http://twitter.com/_martinkr) and consider to [buy me a coffee](https://www.buymeacoffee.com/martinkr)
---
Photo by [Jerry Zhang](https://unsplash.com/@z734923105?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText") on [Unsplash](https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)
---
[](https://modernfrontend.dev/)
---
| martinkr |
838,269 | How to glitch video in the age of web | The tool described in this post is available at ezglitch.kopanko.com For years I've been interested... | 0 | 2021-09-23T22:19:11 | https://dev.to/pcktm/how-to-glitch-video-files-in-the-age-of-web-6a8 | webdev, showdev, javascript, programming | *The tool described in this post is available at [ezglitch.kopanko.com](https://ezglitch.kopanko.com/?mtm_campaign=dev.to)*
For years I've been interested in datamoshing and glitch art, but mainly for the computer aspect of it, like, you know, you edit some parts of the file, and it plays differently? How cool is that, right?

But if you wanted to get into glitching, there's an obvious barrier! Most tutorials rely on old and buggy software or require you to download countless environments and tools onto your computer! Some people argue that if you don't do it with buggy software, it ain't *glitch*-art at all!
In the past, I have had made my own tools to break files for me, like [glitchbox](https://github.com/pcktm/glitchbox-cli), which was basically a JavaScript interface to [ffglitch](https://ffglitch.org/) (back when it had none), always trying to make things as easy as possible for the end-user.
So, one evening, I sat down and set on rewriting my go-to AVI glitching tool, [tomato](https://github.com/itsKaspar/tomato) for the web. Let me start by explaining how the AVI file is actually constructed. AVI files consist of three basic parts:
* hdrl buffer - a header of sorts that contains data on the total amount of frames, width, and height of the video, and so on.
* **movi buffer** - this is the part we actually care about as it contains raw frame data.
* idx1 buffer - holds the index.
Now, the frames in the movi buffer are arranged as they will be played by the player. Audio data starts with the string `01wb` and compressed video with `00dc`. They end just before the next such tag or just before the `idx1` buffer tag.
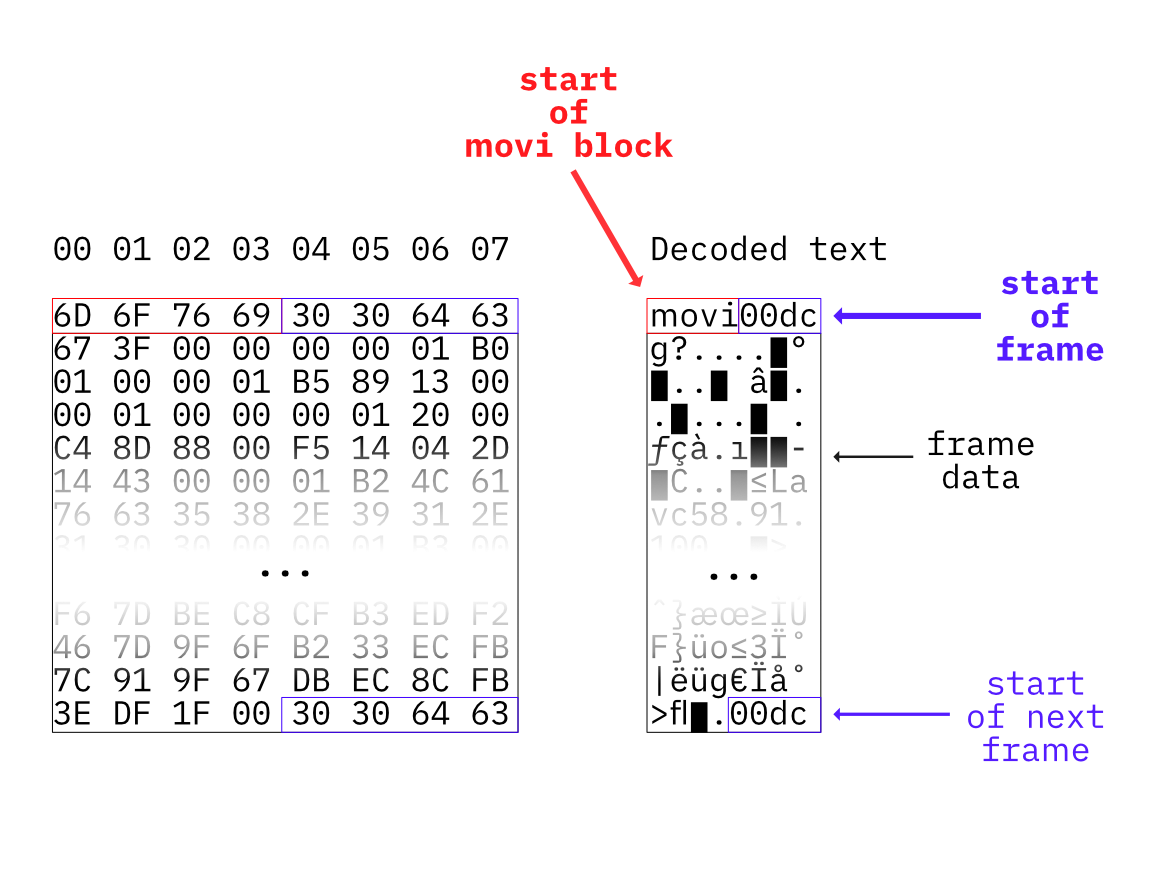
For the fun part - if we rearrange or copy those frames around, the player will play them right as it sees them. We don't need to know the exact structure of the frame, its DCT coefficients, or some other complicated technical stuff - we just need to be able to move bytes around! Fortunately for us, that is entirely possible in modern browsers!
```typescript
const buf = await file.arrayBuffer();
const moviBuffer = buf.slice(moviMarkerPos, idx1MarkerPos);
```
Now that we have the entire `movi` buffer, we need to construct a frame table. We use some [string-search algorithm](https://en.wikipedia.org/wiki/Boyer%E2%80%93Moore_string-search_algorithm) to find all occurrences of `00dc` or `01wb` in the buffer - they mark the beginning of every frame.
```typescript
// this is just "00dc" in hexadecimal
const pattern = new Uint8Array([0x30, 0x30, 0x64, 0x63]);
const indices = new BoyerMoore(pattern).findIndexes(moviBuffer);
const bframes = indices.map(v => {return {type: 'video', index: v}});
```
We do the same thing to I-frames, combine the two, and sort them based on their index. Then, we need to get each frame's byte size (which will come in very handy in a moment):
```typescript
const table = sorted.map((frame, index, arr) => {
let size = -1;
if (index + 1 < arr.length)
size = arr[index + 1].index - frame.index;
else
size = moviBuffer.byteLength - frame.index;
return {...frame, size}
})
```
This has been a pretty linear and dull process so far, but now we get to have some genuine fun - we get to come up with a function to mess with the frames! Let's do the simplest thing and just reverse the whole array.
```typescript
let final = table;
final.reverse();
```
This will, obviously, make the video play backward, but since the frames encoding motion do not take this into account we effectively flipped the motion vectors inside them, which in turn leads to a very odd effect in playback. Keep in mind the frames are still valid, and their data hasn't changed - just their order inside the file.
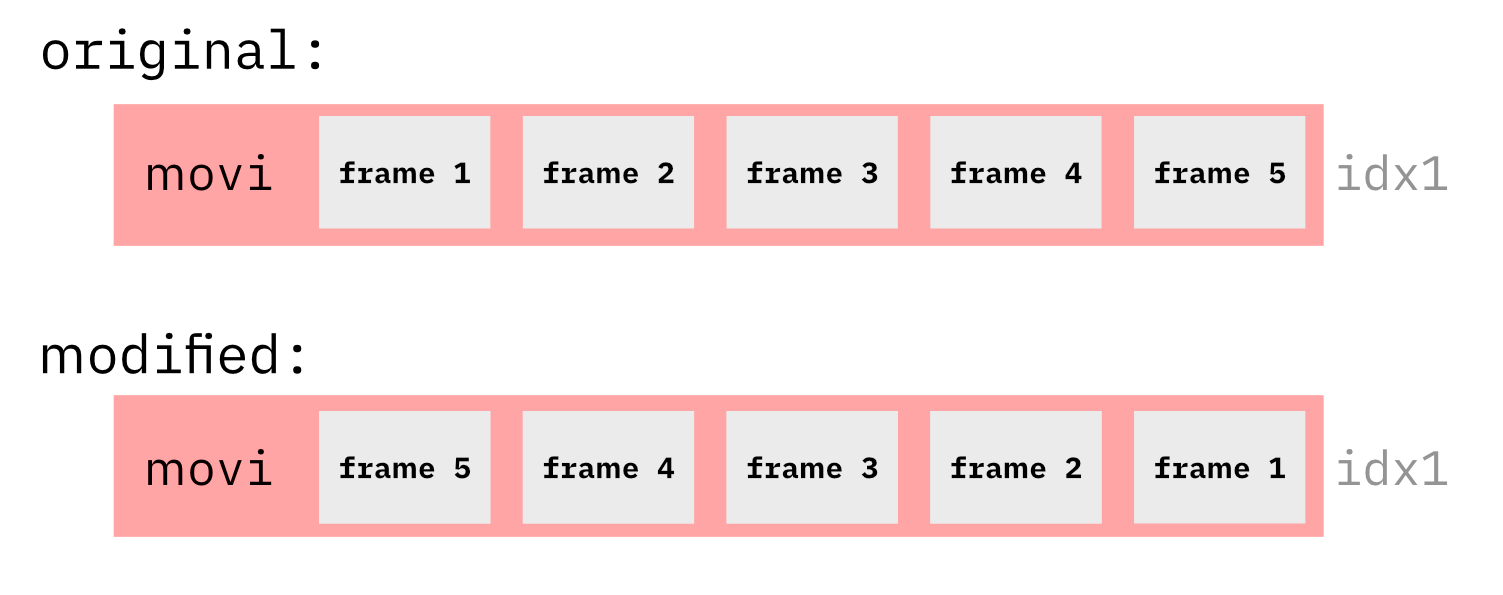
OK, so that's it? Well, not yet. We still need to reconstruct the new movi buffer from the frame table and combine it with hdrl and idx1 buffers. How do we approach it?
The best way to do it is to get the final size of the movi buffer and allocate that much memory beforehand so that we don't ever have to resize our `Uint8Array`.
```typescript
let expectedMoviSize = 4;
final.forEach(frame => expectedMoviSize+=frame.size);
```
Wait, why `expectedMoviSize = 4`? Well, now we initialize the TypedArray with the final size and set the first 4 bytes to the `movi` tag itself.
```typescript
let finalMovi = new Uint8Array(expectedMoviSize);
finalMovi.set([0x6D, 0x6F, 0x76, 0x69]);
```
This is the final stretch - for every frame in the frame table, we read the data from the original file and write it at the correct offset in the final movi tag. We advance the head by the frame bytesize so that the frames are written sequentially.
```typescript
let head = 4; // guess why we start at 4
for (const frame of final)) {
if(frame.index != 0 && frame.size != 0) {
const data = moviBuffer.slice(frame.index, frame.index + frame.size);
finalMovi.set(new Uint8Array(data), head);
head += frame.size;
}
}
```
Now all there's left is to recombine it with the original `hdrl` and `idx1` and we're done!
```typescript
let out = new Uint8Array(hdrlBuffer.byteLength + finalMovi.byteLength + idx1Buffer.byteLength);
out.set(new Uint8Array(hdrlBuffer));
out.set(finalMovi, moviMarkerPos);
out.set(new Uint8Array(idx1Buffer), hdrlBuffer.byteLength + finalMovi.byteLength);
```
That's it, we can now save the complete modified file and enjoy the result we got!

Again, you can find the complete tool [here](https://ezglitch.kopanko.com/?mtm_campaign=dev.to).
Thanks for reading, glitch on ✨! | pcktm |
838,276 | Updating Partition Values With Apache Hudi | If you're not familiar with Apache Hudi, it's a pretty awesome piece of software that brings... | 0 | 2021-09-23T19:21:15 | https://dacort.dev/posts/updating-partition-values-with-apache-hudi/ | aws, hudi, datalakes, spark | If you're not familiar with [Apache Hudi](https://hudi.apache.org/), it's a pretty awesome piece of software that brings transactions and record-level updates/deletes to data lakes.
More specifically, if you're doing Analytics with S3, Hudi provides a way for you to _consistently_ update records in your data lake, which historically has been pretty challenging. It can also optimize file sizes, allow for rollbacks, and makes [streaming CDC data impressively easy](https://aws.amazon.com/blogs/big-data/new-features-from-apache-hudi-available-in-amazon-emr/).
## Updating Partition Values
I'm learning more about Hudi and was following this [EMR guide to working with a Hudi dataset](https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hudi-work-with-dataset.html), but the "Upsert" operation didn't quite work as I expected. Instead of overwriting the desired record, it added a second one with the same ID. 🤔
After some furious searching, I finally came across this post about [employing the right indexes in Apache Hudi](https://medium.com/apache-hudi-blogs/employing-the-right-indexes-for-fast-updates-deletes-in-apache-hudi-814d863635f6). Specifically, this line caught my attention:
> **Global indexes enforce uniqueness of keys across all partitions of a table i.e guarantees that exactly one record exists in the table for a given record key.**
Ah-ha! In the example, we're updating a partition value. _BY DEFAULT_, the `hoodie.index.type` is `BLOOM`. I tried changing it to `GLOBAL_BLOOM`, and when updating the record, it wrote it into the old partition. It turns out that there is _also_ a `hoodie.bloom.index.update.partition.path` setting that will also update the partition path. This defaults to `true` in Hudi v0.9.0, but I'm using v0.8.0 where it defaults to `false`.
_Note that there is a performance/storage impact to enabling global indexes_
So flipping that, I got the expected behavior. Using the example from the EMR docs, my code now looks like this:
### Writing initial dataset
```python
# Create a DataFrame
inputDF = spark.createDataFrame(
[
("100", "2015-01-01", "2015-01-01T13:51:39.340396Z"),
("101", "2015-01-01", "2015-01-01T12:14:58.597216Z"),
("102", "2015-01-01", "2015-01-01T13:51:40.417052Z"),
("103", "2015-01-01", "2015-01-01T13:51:40.519832Z"),
("104", "2015-01-02", "2015-01-01T12:15:00.512679Z"),
("105", "2015-01-02", "2015-01-01T13:51:42.248818Z"),
],
["id", "creation_date", "last_update_time"],
)
# Specify common DataSourceWriteOptions in the single hudiOptions variable
hudiOptions = {
"hoodie.table.name": "my_hudi_table",
"hoodie.datasource.write.recordkey.field": "id",
"hoodie.datasource.write.partitionpath.field": "creation_date",
"hoodie.datasource.write.precombine.field": "last_update_time",
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.table": "my_hudi_table",
"hoodie.datasource.hive_sync.partition_fields": "creation_date",
"hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.MultiPartKeysValueExtractor",
"hoodie.index.type": "GLOBAL_BLOOM", # This is required if we want to ensure we upsert a record, even if the partition changes
"hoodie.bloom.index.update.partition.path": "true", # This is required to write the data into the new partition (defaults to false in 0.8.0, true in 0.9.0)
}
# Write a DataFrame as a Hudi dataset
(
inputDF.write.format("org.apache.hudi")
.option("hoodie.datasource.write.operation", "insert")
.options(**hudiOptions)
.mode("overwrite")
.save("s3://<BUCKET>/tmp/myhudidataset_001/")
)
```
### Updating one *partition* row
```python
from pyspark.sql.functions import lit
updateDF = inputDF.limit(1).withColumn('creation_date', lit('2021-09-22'))
(
updateDF.write.format("org.apache.hudi")
.option("hoodie.datasource.write.operation", "upsert")
.options(**hudiOptions)
.mode("append")
.save("s3://<BUCKET>/tmp/myhudidataset_001/")
)
```
### Resulting Parquet Files
Now if we look at the Parquet files on S3, we can see that:
1. The old partition has a new Parquet file with the record removed
2. There is a new partition with the single record
```shell
aws s3 ls s3://<BUCKET>/tmp/myhudidataset_001/
2021-09-23 11:45:23 434901 tmp/myhudidataset_001/2015-01-01/cd4b4b74-13f7-4c1e-a7ce-110bba8e16fd-0_0-404-90423_20210923184511.parquet
2021-09-23 11:45:44 434864 tmp/myhudidataset_001/2015-01-01/cd4b4b74-13f7-4c1e-a7ce-110bba8e16fd-0_0-442-103950_20210923184526.parquet
2021-09-23 11:45:23 434863 tmp/myhudidataset_001/2015-01-02/578ea02b-09f0-4952-afe5-94d44d158d29-0_1-404-90424_20210923184511.parquet
2021-09-23 11:45:43 434895 tmp/myhudidataset_001/2021-09-22/d67c9b50-1034-44b2-8ec9-2f3b1dcbf26c-0_1-442-103951_20210923184526.parquet
```
### Athena Compatibility
We can also successfully query this dataset from Athena and see the updated data as well!
```sql
SELECT * FROM "default"."my_hudi_table"
```
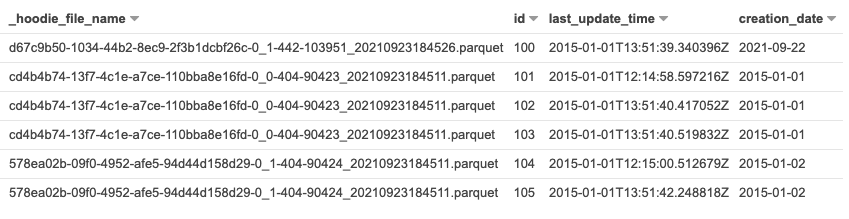
_Note the the different `_hoodie_file_name` for record id `100`._
Awesome! Now that I understand what's going on, it makes perfect sense. 🙌 | dacort |
838,410 | A simple API application using Python & Flask | How to create a simple API application with minimal learning and clean code for beginners. Most of... | 0 | 2021-09-24T10:11:56 | https://dev.to/sudhakar_punniyakotti/minimalistic-api-application-using-python-flask-for-beginners-1pc9 | python, flask, api, basics |
How to create a simple API application with minimal learning and clean code for beginners.
Most of the times developers create a simple frontend application that needs a couple of API's but to do that they might rely on the backend team or mock API tools like Postman or create their own.
So let us write a tiny application which covers this requirement.
##Why flask?
We do have multiple choices to make a minimal API setup,
1. NodeJS with Express
2. Python with Flask or Django
3. C# with .Net Core or
4. Ruby on Rails.
We can use any of the above but I am an old friend of Ruby on Rails so chose Python with Flask for a bare minimum code. ( Actually less than 50 lines :eyes:)

This article doesn't intended to be production-ready code, but to make quick APIs with a database for beginners.
>What we are going to cover
>>1. System setup
>>2. Project setup
>>3. Implementation
>>4. Testing the API's
Okey, lets start to code :fire:
##1. System setup - prerequisites
```ruby
Mac OS and Python 3.X, VS Code, Postgresql and Git.
```
If you are using Ubuntu then the flow will be same but need to find the equivalent commands in installation.
#2. Project setup
####2.1 Install / Verify the python
```python
brew install python
```
Check the installation
```python
python --version
```
####2.2 Install virtualenv
To manage the python and dependencies across the system at least on the dev environment we must use the virtualenv
```python
pip install virtualenv
```
####2.3 Project initiation
Create a folder for the project
```python
mkdir flash-sample
cd flask-sample
ls
__pycache__ env
```
####2.4. virtualenv initialization
```python
python -m venv env
source env/bin/activate
```
####2.5 install SQL ORM
In this article, we will use sqlalchemy with PostgreSQL
```python
pip install flask_sqlalchemy
pip install psycopg2
```
####2.6 Create project requirements
```python
python -m pip freeze requirements.txt
click==8.0.1
Flask==2.0.1
Flask-SQLAlchemy==2.5.1
greenlet==1.1.1
itsdangerous==2.0.1
Jinja2==3.0.1
MarkupSafe==2.0.1
psycopg2==2.9.1
SQLAlchemy==1.4.25
Werkzeug==2.0.1
```
####2.7 Version control
We will use the git as version control and let's initialize
```ruby
git init.
Initialized empty Git repository in /PROJECT_FOLDER/.git/
git s
On branch master
No commits yet
Untracked files:
(use "git add file..." to include in what will be committed)
env/
requirements.txt
nothing added to commit but untracked files present (use "git add" to track)
```
Create gitignore file to remove the unwanted files tobe tracked and pushed to the repository
```ruby
touch .gitignore
```
Add the standard gitignore file from [here](https://github.com/github/gitignore/blob/master/Python.gitignore) and make sure you add the virtualenv folder name in the gitignore.
```ruby
git add.
git commit -m "Initial commit"
```
So the base code is ready now.
##3. Implementation
As mentioned earlier in this article we are going to add two rest API endpoints to save and retrieve data using Postgresql.
Create the python file to handle our API's
```ruby
touch app.py
```
####3.1 Import section
Import required modules
```python
from flask import Flask, request
from flask_sqlalchemy import SQLAlchemy
from flask import jsonify
```
####3.2 setup database configurations
```python
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql:///hands_contact'
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
db = SQLAlchemy(app)
```
If PostgreSQL running in a remote location then we can add the URL along with user name and password like
```
'postgresql://usernamr:password@server/database_name'
```
####3.3 Define the model
Let's create a user model
```python
class SampleUser(db.Model):
id = db.Column(db.Integer, primary_key=True)
first_name = db.Column(db.String(80), nullable=False)
last_name = db.Column(db.String(120), nullable=False)
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
```
####3.4 Invoke the app
Let's create a module to run the application and set the database with models
```python
if __name__ == '__main__':
db.create_all()
app.run()
```
####3.5 Create the users
```python
def creation():
content=request.get_json(silent=True)
try:
db.session.add(SampleUser(content["first_name"],
content["last_name"]))
db.session.commit()
return'Ok', 200
exceptExceptionase:
return'Invalid request', 400
```
The request will be converted into JSON and required parameters are loaded from there to create the user.
Finally, mound this method into the route using
```python
@app.route("/create_users", methods=['POST'])
```
####3.6 List users
Similar to the creation let's create a get users route as GET method.
```python
@app.route('/users', methods=['GET'])
def home():<br /> data = []
for user in SampleUser.query.all():
data.append(
{ "id": user.id,
"first_name": user.first_name,
"last_name": user.last_name
})
return jsonify(total_users_count=len(data), data=data, status=200)
```
To be basic used the jsonify but to be more proper we can use the marshmallow serializer.
Import
```python
from flask_marshmallow import Marshmallow
```
Initialize
```python
ma = Marshmallow(app)
```
Setup a schema that defined what are the columns needs to be constructed in JSON
```python
class SampleUserSchema(ma.Schema):
class Meta:
fields = ("id", "first_name")
sample_user_schema = SampleUserSchema()
sample_user_schema = SampleUserSchema(many=True)
```
Now update the get users method.
```python
@app.route('/users', methods=['GET'])
def listing():
all_notes = SampleUser.query.all()
return jsonify(sample_user_schema.dump(all_notes)), 200
```
that's it! so simple isn't it? The complete code for convenience below
```python
from flask import Flask, request
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
from flask import jsonify
# Database ORM Configs
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql:///hands_contact'
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
db = SQLAlchemy(app)
ma = Marshmallow(app)
# User model for contact us
class SampleUser(db.Model):
id = db.Column(db.Integer, primary_key=True)
first_name = db.Column(db.String(80), nullable=False)
last_name = db.Column(db.String(120), nullable=False)
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
# JSON response serializer
class SampleUserSchema(ma.Schema):
class Meta:
fields = ("id", "first_name")
sample_user_schema = SampleUserSchema()
sample_user_schema = SampleUserSchema(many=True)
# Simple Dashboard
@app.route('/users', methods=['GET'])
def listing():
all_notes = SampleUser.query.all()
return jsonify(sample_user_schema.dump(all_notes)), 200
# Contact us POST API
@app.route("/create_users", methods=['POST'])
def creation():
content = request.get_json(silent=True)
try:
db.session.add(SampleUser(content["first_name"], content["last_name"]))
db.session.commit()
return 'Ok', 200
except Exception as e:
return 'Invalid request', 400
# Invoke the application
if __name__ == '__main__':
db.create_all()
app.run()
```
##4.Let's test now
Run the application from terminal
```python
flask run
```
The default port for flask application is 5000 and applictaion will be listening to http://127.0.0.1:5000.
Create users using the POST endpoint /create_users with the payload
```json
curl -X POST -d '{ "first_name": "Badsha", "last_name": "Manik" }' http://127.0.0.1:5000/create_users -H 'Content-Type: application/json' -H 'Accept: application/json'
Ok
```
List users using GET endpoint /users
```json
curl http://127.0.0.1:5000/users
[{"first_name":"Vijay","id":1},{"first_name":"" 1","id":2},{"first_name":"Ajith","id":3}]
```
So as a starting point this single file serves the purpose but for production, as per required patterns you can split the configs, serializer, models and API methods and import wherever required.
References,
<https://flask.palletsprojects.com/en/2.0.x/>
<https://flask.palletsprojects.com/en/2.0.x/api/>
<https://flask-marshmallow.readthedocs.io/en/latest/>
<br/>
Thank you for your time and happy learning!!! | sudhakar_punniyakotti |
838,428 | Dynamic Javascript Form with Error Handling and Validation | One form to rule them all with React, Typescript, hooks, react-hook-form, material UI, and... | 0 | 2021-09-23T21:29:42 | https://dev.to/gavmac/dynamic-javascript-form-with-error-handling-and-validation-2l2i | ### One form to rule them all with React, Typescript, hooks, react-hook-form, material UI, and Yup.
Forms are a crucial part of most web application and is the predominant way users input and submit data. This means it often appears on multiple pages and components throughout an application.
The forms will likely contain many similar input fields and expected behaviors with regards to validation, type checking, form submission, and error handling.
*All this repetitive code can increase technical debt and is much more difficult to create tests for.*
The dynamic form solution I created makes it simple to reuse a form on different screens and views. The properties for each form are stored in an Object array and can be passed as props into the custom form component.
The form component uses Yup for form validation and react-hook-form to handle form submission and error-handling. Typescript is used for type checking, and material UI component library provides the form components and styles.
I hope it helps you
### Dynamic form, Validation, Type checking, and Error handling.
{% gist https://gist.github.com/gavmac/ade3703ddc15e654dd6a49d94928d666 %}
{% gist https://gist.github.com/gavmac/b2abd6c74a30d846ad416687722f1b46 %}
{% gist https://gist.github.com/gavmac/cfc326a79583a83d3cdd2213e75a4cfd %}
| gavmac | |
838,589 | API Gateway integration response setup for AWS Lambda | Disclaimer: This article cover Lambda custom integration only, Lambda proxy integration will work... | 0 | 2021-09-24T10:33:08 | https://dev.to/awscommunity-asean/api-gateway-integration-response-setup-for-aws-lambda-25km | aws, awsthai, lambda, apigateway | __Disclaimer: This article cover Lambda custom integration only, Lambda proxy integration will work differently__
It's a very common strategy to create your function in AWS Lambda and create REST API on API Gateway and integrate them together, however, there's one common and simple mistake that many developer overlook when doing so, especially if you move from local development to Lambda. Let's see the example below
```javascript
exports.handler = async (event) => {
// TODO implement
const response = {
statusCode: 400, // Change from 200 to 400
body: JSON.stringify('Hello from Lambda!'),
};
return response;
};
```
The above code blocks is a little modification from pre created code when choose "Author from scratch" when creating Lambda with NodeJS. The only change is from statusCode 200 to 400. Then create a new REST API method point to this lambda function... deploy and done. This is how simple it look like to create REST API, When looking at the code, many developer will say that this will return HTTP Status 400 right? but it's not. You will get response 200 with data `statusCode: 400`. This case can easily interpret that it's because we return content not HTTP Status.
(For Lambda proxy integration this function will response correctly with HTTP 400 Bad Request)
_( For more information about HTTP Status [Read Here](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status) )_
Let's try another example which is more obvious, this time intentionally throw Error in Lambda.
```javascript
exports.handler = async (event) => {
// TODO implement
throw new Error('Internal Error - Intentionally throw this error');
};
```
Try calling it and get HTTP 200 again with error message as content.
(For Lambda proxy integration this function will response correctly with HTTP 502 Bad Gateway)
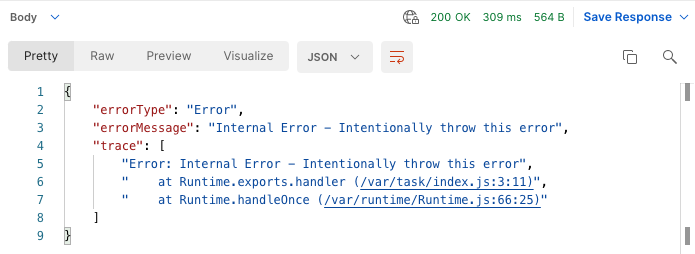
> Look like It's Okay to Not Be Okay

_(Image from [Kdramalove.com](https://www.kdramalove.com/ItsOkayToNotBeOkay.html) - Yes... I like Korean series.. and Seo Ye-ji is gorgeous)_
If you have experience throwing error and get HTTP 500 when developing locally with express or any framework. That happen because framework handle that error for you and generate correct HTTP Status, while Lambda and API Gateway is totally different services and what API Gateway looking for, by default, is that Lambda answer something and HTTP 200 you get mean __yes, your code was executed.__
## Setup Method Response in API Gateway ##
First we need to define which HTTP Status we want to send back to client. We can do this in Method Response in API Gateway. So let's add the following error
* HTTP 500 (Internal Server Error) for error that has been generated when we call `throw Error()` (Second case above). According to AWS Documentation, this type of error call **Standard Lambda Error**
* HTTP 400 (Bad Request) for error that we intentionally response with specific formatted string (First case above). According to AWS Documentation, this type of error call **Custom Lambda Error**
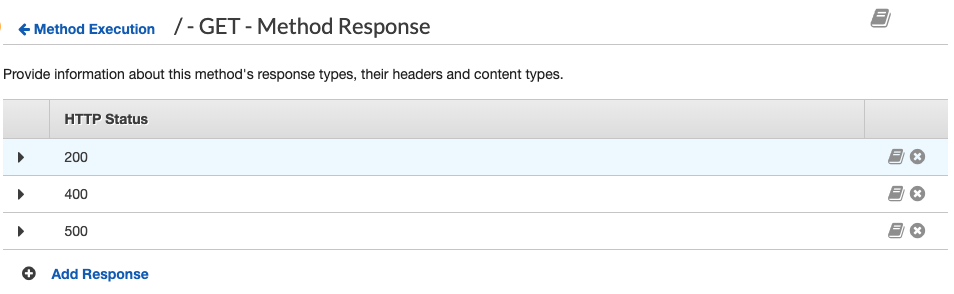
## Setup Integration Response in API Gateway ##
Next, move to Integration Response to configure each case. The general idea for configuring this is to set a pattern (regular expression) that will be tested against response from Lambda function, if the pattern matched, we will get HTTP Response governing that pattern. If no patterns matched, we will get the default HTTP response. (configured to 200 by default or customize by configured with pattern `.*`)
Furthermore, we can setup response body using Mapping Template.
### Handle Standard Lambda Error (500) ###
For this type of error, when we call `throw Error()`, Lambda will automatically generate response as shown in screenshot above. In order to test pattern against this type of error, API Gateway will test configured pattern against `errorMessage` field instead of whole error object.
In our case, we send our error message when generating this error by adding prefix 'Internal Error' in front of any detail. Let's setup using regular expression `^Internal Error.*` which will match whole errorMessage. According to my test, if we use partial match (e.g. Internal*) it will not work and we will still get HTTP 200 instead of 500.
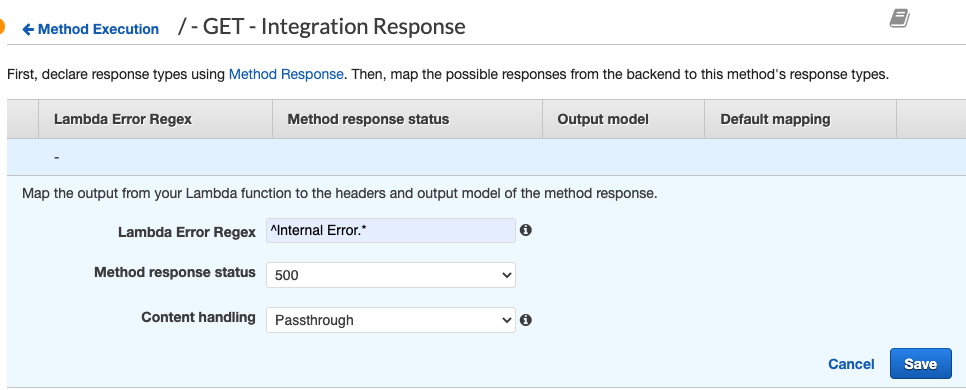
Testing on postman again, now we will get HTTP 500 (Internal Server Error) with the same previous content because we use Passthrough for content handling above.
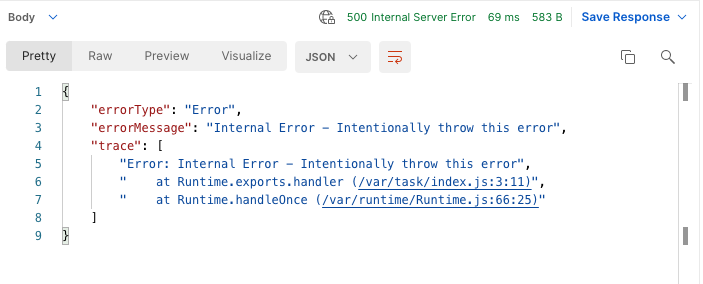
Now that we got correct error, but it's strange to stack trace to client. Let's set Mapping Template for `application/json` type and return only errorMessage to client.
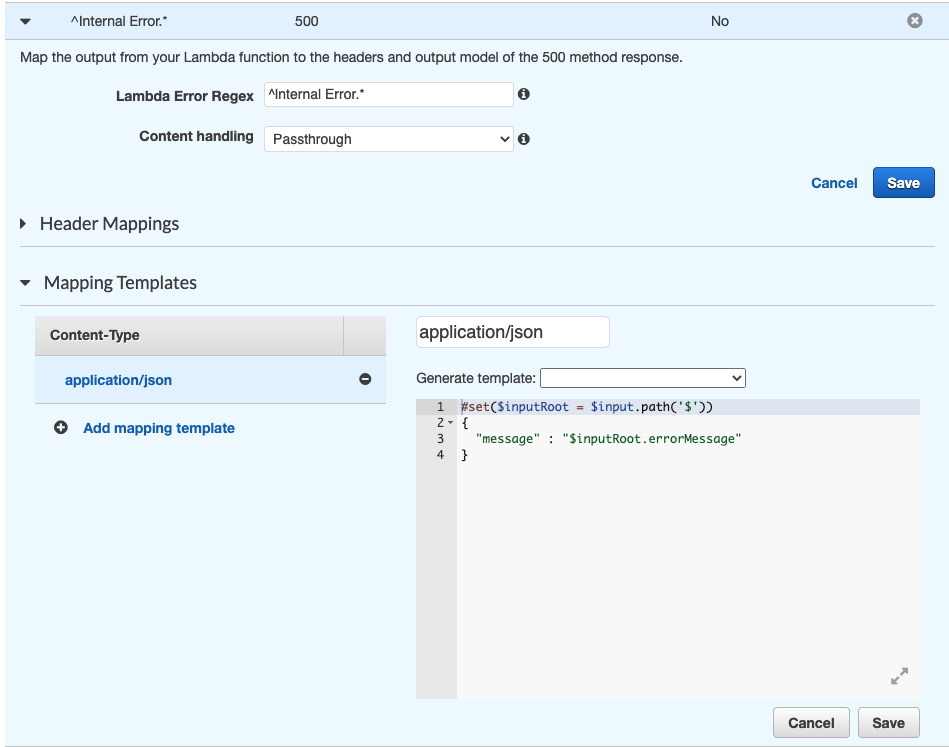
(There's a strange UX behavior here, when editing Mapping Template you have to grey __Save__ down below text editor instead of clicking blue __Save__ button above, which is more attractive to click.)
Deploy and test it to get the response we want!
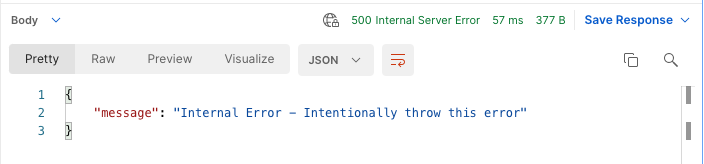
### Handle Custom Lambda Error (400) ###
For this case where we want to create our own response with error message and we know that this response is gonna be an error. The easiest way is to forcefully make this function failed and return and error using `context.fail` instead of `return`. Additionally, in order for API Gateway to parse error message, we need to convert JSON response to text and the code will be change to the following:-
```JavaScript
exports.handler = async (event, context) => {
// TODO implement
const response = {
statusCode: 400, // Change from 200 to 400
body: JSON.stringify('Hello from Lambda!'),
};
context.fail(JSON.stringify(response))
};
```
Now that we cause error to occurred, Lambda will return and error object similar to standard error in previous case and we can use regex `.*"statusCode":400.*` to detect which statusCode we send and return correct HTTP Response.
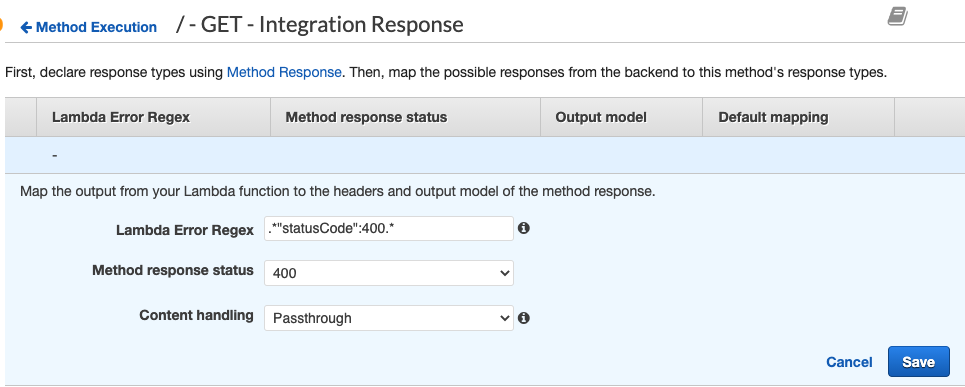
After testing, you will get HTTP Status 400 (Bad Request) with generated Lambda error object
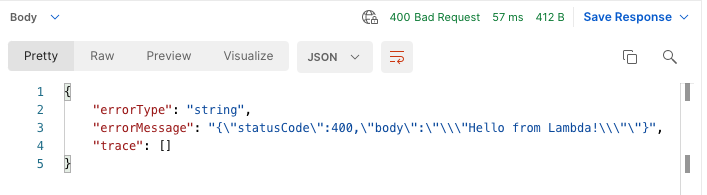
Last step is to setup Mapping Template to return our intended object
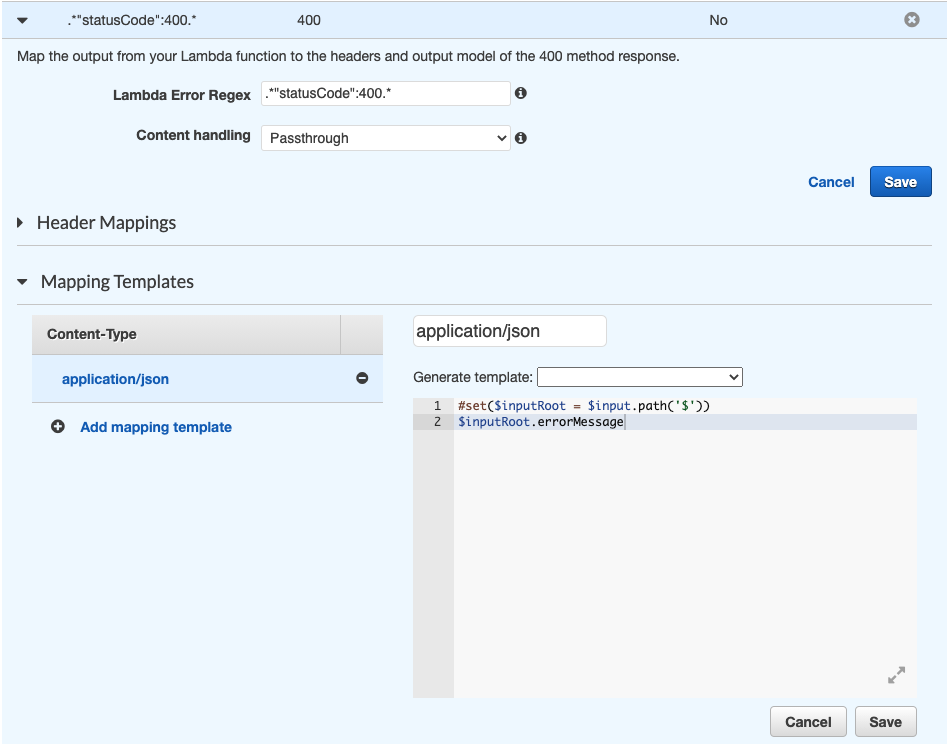
Finally, we will get our same old object but with HTTP Status 400 instead of 200 as intended.
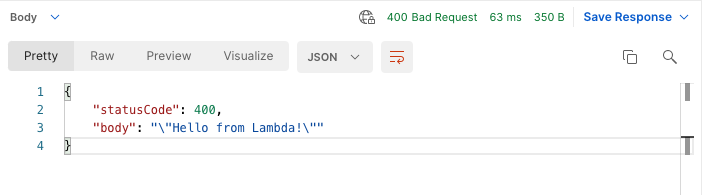
## Conclusion ##
There's a lot more to explore and configure when working with AWS service, this one is just an example of a common mistake mostly happen when start using Lambda and API Gateway or when in need of a quick api creation. Anyway, I personally prefer using Lambda proxy integration which let me have more control. I hope this article help anyway to happen to pass through here or looking for this problem.
Lastly, I would be very appreciate for any comment, knowledge sharing and feedback. Happy coding!
## References ##
* [Handle Lambda errors in API Gateway](https://docs.aws.amazon.com/apigateway/latest/developerguide/handle-errors-in-lambda-integration.html#handle-standard-errors-in-lambda-integration)
| riteru |
838,598 | Karpenter - Scaling Nodes Seamlessly in AWS EKS | Hello everyone !! If you are running your workloads on the AWS EKS cluster, you may explore the rules... | 0 | 2021-09-24T02:49:51 | https://blog.sivamuthukumar.com/karpenter-scaling-nodes-seamlessly-in-aws-eks | aws, kubernetes, containers, community | Hello everyone !! If you are running your workloads on the AWS EKS cluster, you may explore the rules and limitations of node group scaling to provision the deployments dynamically. This blog will explore the node lifecycle management solutions AWS Lab's Karpenter, an alternative approach to the frequently used Cluster Autoscaler solution.
## Kubernetes Autoscaling
Autoscaling allows you to dynamically adjust to demand without manual intervention through metrics or events. Without autoscaling, there will be considerable efforts to provision the (scaling up or down) resources. When the running conditions change, and optimal resource utilization and managing the cloud spending is challenging. The cluster is always running at peak capacity to ensure availability or not meeting peak demand as they don't have enough resources.
When it comes to the Kubernetes Autoscaling, there are two different layers,
1. Pod Level Autoscaling (Horizontal - HPA, and Vertical - HPA)
2. Node Level Autoscaling
### Pod Level Autoscaling
**Horizontal Pod Autoscaling (Scaling out)** - dynamically increase or decrease the number of running pods per your application's usage changes.
**Vertical Pod Autoscaling (Scaling up)** - scale the given deployments vertically within a cluster by reconciling the pods' size ( CPU or memory targets) based on their current usage and the desired target.
HPA and VPA essentially make sure that all of the services running in your cluster can dynamically handle the demand.
### Node Level Autoscaling
Node Level autoscaling solves the issue - to scale the nodes in the cluster when the existing nodes are overloaded or pending to be scheduled with newly scaled pods or scale down when the nodes are underutilized.
There is already an industry-adopted, open-source, and vendor-neutral tool - Cluster Autoscaler that automatically adjusts the cluster size (by adding or removing nodes) based on the presence of pending pods and node utilization metrics. It uses the existing cloud building blocks (Autoscaling Group on AWS) for scaling. The challenges in the cluster autoscaler are the limitations on node groups, and the scaling is tightly bound to the scheduler.
{% github kubernetes/autoscaler no-readme %}
## Karpenter
Karpenter is a node lifecycle management solution - incubating in AWS Labs, OSS, and vendor-neutral. It observes incoming pods and launches the right instances for the situation. Instance selection decisions are intent-based and driven by the specification of incoming pods, including resource requests and scheduling constraints.
{% github awslabs/karpenter %}
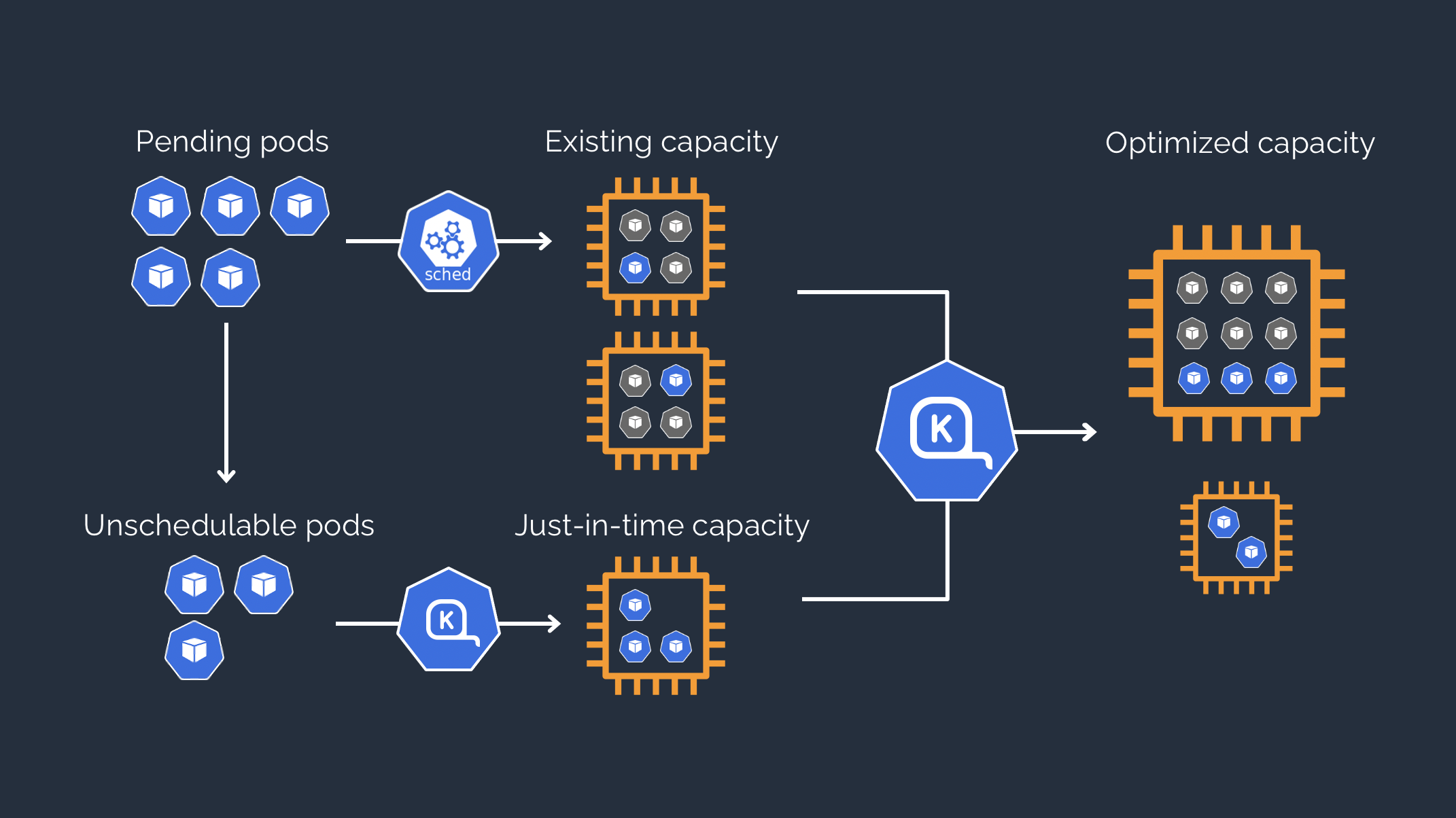
How does it work?
1. Observes the pod resource requests of unscheduled pods
2. Direct provision of Just-in-time capacity of the node. (Groupless Node Autoscaling)
3. Terminating nodes if outdated
4. Reallocating the pods in nodes for better resource utilization
Karpenter has two control loops that maximize the availability and efficiency of your cluster.
1. Allocator - Fast-acting controller ensuring that pods are scheduled as quickly as possible
2. Reallocator - Slow-acting controller replaces nodes as pods capacity shifts over time.
### Getting started
In this section, we will quickly see the node lifecycle scenarios using Karpenter in an AWS EKS cluster. Create necessary IAM roles for Karpenter autoscaler with the cloud formation template and Create EKS cluster with the below config file using eksctl. Please refer to the documentation here.
```yaml
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: eks-karpenter-demo
region: us-east-1
availabilityZones:
- us-east-1a
- us-east-1b
managedNodeGroups:
- name: eks-karpenter-demo-ng
instanceType: t3.medium
minSize: 1
maxSize: 5
```
You need to enable the service account and auth-config map accounts to the Karpenter. Please refer to the document [here](https://karpenter.sh/docs/getting-started/).
Install the karpenter helm chart.
```bash
helm repo add karpenter https://awslabs.github.io/karpenter/charts
helm repo update
helm upgrade --install karpenter karpenter/karpenter --namespace karpenter \
--create-namespace --set serviceAccount.create=false --version 0.3.3
```
### Configure the Karpenter Provisioner
Configure the Karpenter provisioner as below. Please check the provider spec for more details.
```yaml
apiVersion: karpenter.sh/v1alpha3
kind: Provisioner
metadata:
name: default
spec:
cluster:
name: eks-karpenter-demo
endpoint: <CLUSTER_ENDPOINT>
instanceTypes:
- t3.medium
ttlSecondsAfterEmpty: 30
```
### Deployment
Let's do the deployment to check the launching capacity and terminating capacity features.
```yaml
kubectl create deployment inflate --image=public.ecr.aws/eks-distro/kubernetes/pause:3.2
```
### Provisioning Nodes
Scale the deployment and check out the logs in the Karpenter controller.
```yaml
kubectl scale deployment inflate --replicas=10
```
Check the logs of the karpenter controller
```bash
➜ eks-karpenter-demo git:(main) kubectl logs -f -n karpenter $(kubectl get pods -n karpenter -l karpenter=controller -o name)
2021-09-23T04:46:11.280Z INFO controller.allocation.provisioner/default Starting provisioning loop {"commit": "bc99951"}
2021-09-23T04:46:11.280Z INFO controller.allocation.provisioner/default Waiting to batch additional pods {"commit": "bc99951"}
2021-09-23T04:46:12.452Z INFO controller.allocation.provisioner/default Found 9 provisionable pods {"commit": "bc99951"}
2021-09-23T04:46:13.689Z INFO controller.allocation.provisioner/default Computed packing for 9 pod(s) with instance type option(s) [t3.medium] {"commit": "bc99951"}
2021-09-23T04:46:16.228Z INFO controller.allocation.provisioner/default Launched instance: i-0174aa47fe6d1f7b4, type: t3.medium, zone: us-east-1b, hostname: ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:46:16.265Z INFO controller.allocation.provisioner/default Bound 9 pod(s) to node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:46:16.265Z INFO controller.allocation.provisioner/default Watching for pod events {"commit": "bc99951"}
```
The allocation controller listens for pods changes. It launched a new instance and bound the provision-able pods into the new nodes by working with kube-scheduler.
The provisioning time is fast compared to other node management solutions. The other node management solutions usually take 3 min to 6 min for the node to be available. After deploying the pods, the instances are immediately created and binding. The provisioner decides to launch a new instance within a second, and the node joins the cluster for under 60 seconds. Within 60 seconds, the nodes are available to cluster for running pods.
You can configure the instance types, capacity type, os, architecture, and other provisioner spec fields.
### Terminating Nodes
Now, delete the deployment `inflate`. After 30 seconds (**ttlSecondsAfterEmpty - Termination grace period**), Karpenter should terminate the empty nodes - cordon & drain by listening to the rebalance and termination events.
```bash
2021-09-23T04:46:18.953Z INFO controller.allocation.provisioner/default Watching for pod events {"commit": "bc99951"}
2021-09-23T04:49:05.805Z INFO controller.Node Added TTL to empty node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:49:35.823Z INFO controller.Node Triggering termination after 30s for empty node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:49:35.849Z INFO controller.Termination Cordoned node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:49:36.521Z INFO controller.Termination Deleted node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
```
## Next Steps
Autoscaling nodes are always challenging. Karpenter addresses key areas of challenges by eliminating Node Group and directly provision nodes. Karpenter is easy to configure, high-performance portable solution, and vendor-agnostic. It scales seamlessly working alongside native kube-scheduler and efficiently responds to dynamic resource requests.
Check out the [AWS Labs Karpenter Roadmap](https://github.com/awslabs/karpenter/blob/main/ROADMAP.md). It's still in beta. In the year 2021, Karpenter is going to focus on covering the majority of known use cases and plan to rigorously test it for scale and performance.
I'm Siva - working as Sr. Software Architect at [Computer Enterprises Inc](https://www.ceiamerica.com) from Orlando. I'm an AWS Community builder, Auth0 Ambassador and I am going to write a lot about Cloud, Containers, IoT, and Devops. If you are interested in any of that, make sure to follow me if you haven’t already. Please follow me [@ksivamuthu](https://www.twitter.com/ksivamuthu) Twitter or check out my blogs at https://blog.sivamuthukumar.com | ksivamuthu |
868,804 | P | Hey guys. | 0 | 2021-10-19T10:29:47 | https://dev.to/max_florida/please-help-with-react-js-questions-1cij | Hey guys. | max_florida |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.