
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
941,073 | API3:2019 - Excessive Data Exposure | Hey there! How's your day going so far? Hope you are doing great! For the third post of our OWASP... | 17,377 | 2021-12-31T08:38:25 | https://dev.to/therealbrenu/api32019-excessive-data-exposure-4c4p | cybersecurity, owasp, api, hacking | Hey there! How's your day going so far? Hope you are doing great!
For the third post of our OWASP API Security Top 10 series, it is time to talk about Excessive Data Exposure! Hope you guys like it :hugs:
## :national_park: What is Sensitive Data?
Excessive data exposure is an issue that includes different intrinsic topics, such as database performance for example. However, this whole series is about API security, and when it comes to the security aspect of excessive data exposure, sensitive data always comes up.
Okay, so what the flip is sensitive data? Generically speaking, we may consider as sensitive data everything that would cause damage to a company if publicly exposed. Some examples are listed below:
- SSH keys
- Database credentials
- Users' billing information
- Biometric and health records
Of course, not all of these things will appear as a result of calling API endpoints. The most common cases of excessive data exposure in APIs usually involve a more specific type of sensitive data, that we may call PII (Personally Identifiable Information).
Personally Identifiable Information is any data that, once publicly available, could be used directly or indirectly to identify a person. From the examples listed above, we can consider the last two items as being PII.
## :gear: Getting Sensitive Data From APIs
Now, I am going to be showing two different cases where we have API3:2019 happening, one for GraphQL APIs and one for REST APIs.
### :books: GraphQL Example
As a first practical example, let's take a GraphQL API of a fictional game, from where the introspection defines the following query:
> query {
> user(id: 123) {
> username
> level
> rankingPosition
> }
> }
Basically, it receives a number which corresponds to the ID of a user, and returns their username, level and position on the ranking. Theoretically, if the API really follows what the introspection is saying, we are only capable of retrieving these three attributes of a user.
Also, the introspection defines this query right down below, from which is possible to retrieve some of your own user's information:
> query {
> myUser {
> username
> level
> rankingPosition
> address {
> street
> number
> postCode
> }
> creditCard
> }
> }
Notice that the query `myUser` returns more attributes than the previous one, it returns your address and your credit card. Returning your credit card in plain text, per se, is something that might already be enough to say that we have an excessive data exposure happening, but it can get worse.
What both queries do is to retrieve data from a specific user, and because of that, although they are differently defined by the GraphQL introspection, possibly both `user` and `myUser` were implemented in a similar way, with very similar code.
By assuming that they "share code" to each other, an attacker might try to call `user` passing `creditCard` as a response attribute, like this:
> query {
> user(id: 1337) {
> creditCard
> }
> }
If it works, this means that the attacker is able to retrieve the credit card of any user they want. In other words, this means that our fictional game has a business logic error leading to excessive data exposure.
### :books: REST Example
For the REST example, let's get back to those screens presented in the [last post](https://dev.to/therealbrenu/api22019-broken-user-authentication-nep). We have this login page:
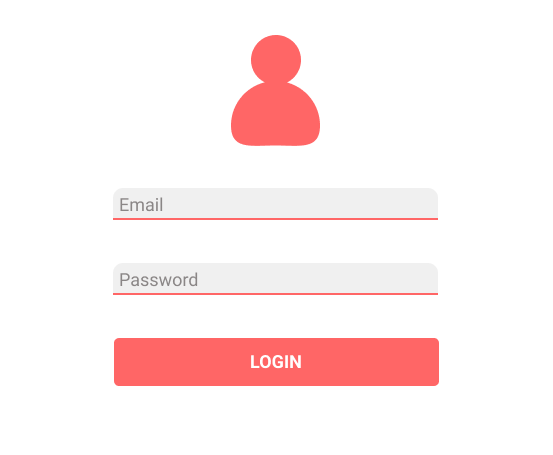
And when you submit your credentials, a new page is generated:
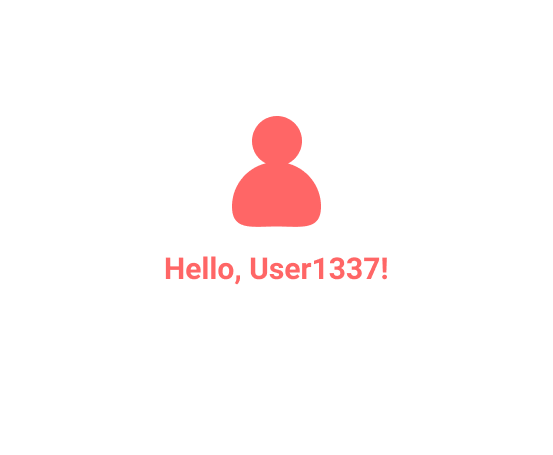
Let's say that the new page makes the following request, in order to obtain your name and display your "hello" message:
> GET /users/welcome HTTP/1.1
> Host: api.example.com
> Authorization: Bearer sup3r_t0k3n_h3r3
And for the request above, this is the response:
> HTTP/1.1 200 OK
> Content-Type: application/json
>
> {
> "firstName": "Naruto",
> "lastName": "Uzumaki",
> "username": "User1337",
> "email": "dattebayo@mail.com",
> "password": "HashedVersionOfRamen123"
> }
Notice that the response not only has more data than necessary (it should ideally contain only the username), but it also contains the password of the user in it. One more case of API3:2019 :persevere:
Cases like this happen when the endpoint implementation is something like:
> user = db.run('SELECT * FROM users WHERE id = 1337')
>
> return user
Basically, it just picks up everything related to the user and throws in the response, without filtering what is not important, and without filtering sensitive data. A similar implementation using an ORM would be just:
> user = User::find(1337)
>
> return user
You can, of course, implement a filter in the database itself, or elsewhere in the API code, but if it is not done, this kind of endpoint implementation where you rely exclusively on the client side to filter stuff may lead to huge problems.
## :notebook_with_decorative_cover: External materials
As my goal with this series is to just explain what each flaw is while I'm learning about them all, I would like to suggest some materials about data exposure issues, so you understand better the details of it:
https://github.com/OWASP/API-Security/blob/master/2019/en/src/0xa3-excessive-data-exposure.md
https://salt.security/blog/api3-2019-excessive-data-exposure
https://portswigger.net/support/using-burp-to-test-for-sensitive-data-exposure-issues | therealbrenu |
941,163 | How to Use Observables with Vanilla JavaScript | No frameworks used, just pure vanilla JavaScript. While working on a side project just... | 0 | 2021-12-31T09:36:37 | https://www.developmentsimplyput.com/post/how-to-use-observables-with-vanilla-javascripta-javascript-aca40a7590ff | javascript, programming, webdev | ### No frameworks used, just pure vanilla JavaScript.
<br>
While working on a side project just for fun, I wanted to write a JavaScript script to call a REST API and eventually do some cool stuff on a webpage. It is purely vanilla JavaScript, with no fancy frameworks or even libraries being used.
First, I thought of using **Promises** for my calls and this was easy for me. I have done that a ton of times. However, it then hit me hard — why don’t I use **Observables?** I knew that vanilla JavaScript didn’t natively support Observables. But couldn’t I implement it myself? And that’s what I did.

## This is how I thought things through
1. The Observable itself would be of a new object type called **Subject.**
2. This **Subject** object should expose the subscribe and next functions.
3. subscribe should be called by observers to subscribe to the observable stream of data.
4. next should be called by the **Subject** owner to push/publish new data whenever available.
5. Additionally, I wanted the **Subject** owner to be able to know whenever no observers were interested in its data. This would enable the **Subject** owner to decide if he still wanted to get the data or not.
6. Also, the **Subject** owner should be able to know whenever at least one observer started being interested in its data. This would give the **Subject** owner more control on its data flow and any related operations.
7. Now back to the **observer**. He should be able to **unsubscribe** from the **Subject** at any time.
8. This leads us to a new object type called **Subscription.**
9. This **Subscription** object should expose an unsubscribe function.
10. unsubscribe should be called by the **observer** whenever he wants to stop listening to the data stream coming from the **Subject**.
Following these rules, I came up with the following implementation.

## Implementation
### Subscription
```javascript
let Subscription = function(handlerId, unsubscribeNotificationCallback) {
let self = this;
self.unsubscribe = () => {
if(unsubscribeNotificationCallback) {
unsubscribeNotificationCallback(handlerId);
}
};
return self;
};
```
Note that **Subscription** just notifies the **Subject** when the unsubscribe function is called.
---
### Subject
```javascript
let Subject = function(subscribersStateChangeNotificationCallback) {
let self = this;
let handlers = {};
Object.defineProperty(self, "subscribersFound", {
get() {
let found = false;
for(const prop in handlers) {
if(handlers.hasOwnProperty(prop)) {
found = true;
break;
}
}
return found;
}
});
Object.defineProperty(self, "subscribersCount", {
get() {
let count = 0;
for(const prop in handlers) {
if(handlers.hasOwnProperty(prop)) {
count++;
}
}
return count;
}
});
let unsubscribeNotificationCallback = (handlerId) => {
if(handlerId && handlerId !== '' && handlers.hasOwnProperty(handlerId)) {
delete handlers[handlerId];
if(subscribersStateChangeNotificationCallback && !self.subscribersFound) {
subscribersStateChangeNotificationCallback(false);
}
}
};
self.subscribe = (handler) => {
let handlerId = createGuid();
handlers[handlerId] = handler;
if(subscribersStateChangeNotificationCallback && self.subscribersCount === 1) {
subscribersStateChangeNotificationCallback(true);
}
return new Subscription(handlerId, unsubscribeNotificationCallback);
};
self.next = (data) => {
for(const handlerId in handlers) {
handlers[handlerId](data);
}
};
return self;
};
let createGuid = function() {
return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
var r = Math.random()*16|0, v = c === 'x' ? r : (r&0x3|0x8);
return v.toString(16);
});
};
```
---
### Somewhere in the Subject Owner
```javascript
.
.
.
let subscribersStateChangeNotificationCallback = (subscriberFound) => {
if(!subscriberFound && isNowWatching) {
stopWatching();
isNowWatching = false;
} else if(subscriberFound && !isNowWatching) {
startWatching();
}
};
self.data = new Subject(subscribersStateChangeNotificationCallback);
.
.
.
self.data.next(self.snapshot.data);
.
.
.
```
---
### Somewhere in the Observer
```javascript
.
.
.
const dashboardServiceSubscription = myDashboardService.data.subscribe((data) => {
...
});
.
.
.
dashboardServiceSubscription.unsubscribe();
.
.
.
```

That’s it, everything worked like a charm and I was proud of what I achieved.
So, the punch line is that coding in vanilla JavaScript is not always equal to writing boring code, you can make it much more fun 😃
<br>
Hope you found reading this story as interesting as I found writing it.
<br><br>
This article was originally published [here](https://www.developmentsimplyput.com/post/how-to-use-observables-with-vanilla-javascript). | ahmedtarekhasan |
941,197 | Wrap up 2021 with these VS Code extensions | Visual Studio Code is arguably the most popular IDE at the moment for quite a while now. 2021 was no... | 0 | 2021-12-31T11:08:03 | https://dev.to/pythonbutsnake/wrap-up-2021-with-these-vs-code-extensions-19af | webdev, yearinreview, vscode, extensions | Visual Studio Code is arguably the most popular IDE at the moment for quite a while now. 2021 was no different for this successful code editor. The wide range of different features that VS Code allows us to use is what makes it special. One of the things that stands out about VS Code is the massive number of extensions it provides you. Today we will have a look at some of the distinct VS Code Extensions that every developer should install by the end of this year.
## [Visual Studio IntelliCode](https://marketplace.visualstudio.com/items?itemName=VisualStudioExptTeam.vscodeintellicode)
This extension is based on Artificial Intelligence and it recommends code completion automatically. It also gives various development features based on Artificial Intelligence.
[Marketplace Link
](https://marketplace.visualstudio.com/items?itemName=VisualStudioExptTeam.vscodeintellicode)
## [Peacock](https://marketplace.visualstudio.com/items?itemName=johnpapa.vscode-peacock)
This extension adds various colors to different windows of VS Code. While working on the front-end and back-end at the same time, you can add different colors to identify which repo you are working on. It also helps you add colors in live share and remote integration.
[Marketplace Link
](https://marketplace.visualstudio.com/items?itemName=johnpapa.vscode-peacock)
## [Regex Previewer](https://marketplace.visualstudio.com/items?itemName=chrmarti.regex)
Regular expressions are often confusing to understand. Regex Previewer gives you a separate document similar to your regex.
The extension provides many examples of comparisons, so it is much easier to quickly and accurately regex the various use cases.
[Marketplace Link
](https://marketplace.visualstudio.com/items?itemName=chrmarti.regex)
## [blox](https://www.vsblox.com/)
blox is another incredibly useful extension with a mammoth 1500+ drop-in-ready UI snippets. All you have to do is just drag and drop the pre-made code snippets in your project and save a great amount of time writing code.
[Marketplace Link
](https://www.vsblox.com/)
## [Bookmarks](https://marketplace.visualstudio.com/items?itemName=alefragnani.Bookmarks)
Bookmark your code at a certain line with this extension so that you can refer to it later. Add the bookmark with the command “ctrl+alt+k” and it is also the same command for toggling the bookmark. “ctrl+alt+l” is the command for jumping to the next bookmark and “ctrl+alt+j” is the command for jumping to the previous bookmark.
[Marketplace Link
](https://marketplace.visualstudio.com/items?itemName=alefragnani.Bookmarks)
## [Quokka.js](https://marketplace.visualstudio.com/items?itemName=WallabyJs.quokka-vscode)
This extension speeds up development by displaying runtime values in the editor as you code, so you can focus on writing code instead of building custom configs.
[Marketplace Link
](https://marketplace.visualstudio.com/items?itemName=WallabyJs.quokka-vscode)
## [Profile Switcher](https://marketplace.visualstudio.com/items?itemName=aaronpowell.vscode-profile-switcher)
Profile Switcher helps you create various profiles on VS code that you can use for different reasons. This is a must-have extension for those who use VS code for more than one reason. You can save specific extensions for each profile as well.
[Marketplace Link
](https://marketplace.visualstudio.com/items?itemName=aaronpowell.vscode-profile-switcher)
## [SonarLint](https://www.sonarlint.org/vscode)
Sonarlint is an outstanding extension for lone workers without a team. Basically, it detects code quality and code security issues, and generates reports for the user. Sonarlint can also be used by teams with sonarCube and sonarCloud. It has built-in rules in it but a developer can also mute rules or add new rules.
[Marketplace Link
](https://www.sonarlint.org/vscode)
If you are going in 2022 without these extensions then you should definitely check out these extensions for better productivity.
| pythonbutsnake |
941,206 | Create Image slider using Js and CSS | In this article, we are going to make an Image Slider with a clean UI and smooth transition. First,... | 0 | 2022-01-01T11:25:25 | https://dev.to/anomaly3108/create-image-slider-using-js-and-css-48l3 | webdev, javascript, css, beginners | In this article, we are going to make an Image Slider with a clean UI and smooth transition. First, Let's see what are we building.
#PREVIEW

#HTML
```
<div class="container">
<div class="img-comp-container">
<div class="img-comp-img">
<img src="a.png" height="400" width="300">
</div>
<div class="img-comp-img img-comp-overlay">
<img src="b.png" height="400" width="300">
</div>
</div>
</div>
```
We will have an outer div with class `.img-comp-container`. It will have two separate children.
- `.img-comp-img`: It will contain the first image.
- `.img-comp-overlay`: It will contain the second image for overlay. This image will be overlayed over the top of first image to create the effect of sliding.
I guess now you have an overview of what are we doing. Now let's get into the CSS.
#CSS
```
* {
box-sizing: border-box;
}
.img-comp-container {
position: relative;
height: 500px;
}
.img-comp-img {
position: absolute;
width: auto;
height: auto;
overflow: hidden;
}
.img-comp-img img {
padding: 20px;
display: table-row;
}
.container {
display: table;
}
```
This CSS is for the image that will be displayed on the screen.
Everything above is self-explanatory but If you have any queries then comment down.
```
.img-comp-slider {
position: absolute;
z-index: 9;
cursor: ew-resize;
/*set the appearance of the slider:*/
width: 40px;
height: 40px;
background: url(slider_icon.jpg);
background-color: #ffffff70;
background-repeat: round;
backdrop-filter: blur(5px);
border-radius: 50%;
}
```
this CSS is for the slider button
#Javascript
This is where the fun begins. Let's see from the scratch.
First, we need to find all elements with an "overlay" (`img-comp-overlay`) class
```
var x, i;
/*find all elements with an "overlay" class:*/
x = document.getElementsByClassName("img-comp-overlay");
for (i = 0; i < x.length; i++) {
/*once for each "overlay" element:
pass the "overlay" element as a parameter when executing the compareImages function:*/
compareImages(x[i]);
}
```
Next, we will create a function `compareImages` with an `img` parameter
```
function compareImages(img) {
var slider, img, clicked = 0, w, h;
/*get the width and height of the img element*/
w = img.offsetWidth;
h = img.offsetHeight;
/*set the width of the img element to 50%:*/
img.style.width = (w / 2) + "px";
}
```
Now, We will create the slider using Js in the same function
```
/*create slider:*/
slider = document.createElement("DIV");
slider.setAttribute("class", "img-comp-slider");
/*insert slider*/
img.parentElement.insertBefore(slider, img);
position the slider in the middle:*/
slider.style.top = (h / 2) - (slider.offsetHeight / 2) + "px";
slider.style.left = (w / 2) - (slider.offsetWidth / 2) + "px";
```
Now, Let us add the listeners that will be triggered when we press the mouse button.
```
/*execute a function when the mouse button is pressed:*/
slider.addEventListener("mousedown", slideReady);
/*and another function when the mouse button is released:*/
window.addEventListener("mouseup", slideFinish);
/*or touched (for touch screens:*/
slider.addEventListener("touchstart", slideReady);
/*and released (for touch screens:*/
window.addEventListener("touchstop", slideFinish);
```
Now, Basic structure of our slider is created. Next we need to create some functions that will perform the main functionality of the slider. i.e, Slide over the the image.
For this we will first create `slideReady` Function inside the `compareImages` Function that will be executed when mouse button is pressed.
```
function slideReady(e) {
/*prevent any other actions that may occur when moving over the image:*/
e.preventDefault();
/*the slider is now clicked and ready to move:*/
clicked = 1;
/*execute a function when the slider is moved:*/
window.addEventListener("mousemove", slideMove);
window.addEventListener("touchmove", slideMove);
}
```
Next, create another Function inside the `compareImages` Function when the slider is no longer clicked
```
function slideFinish() {
/*the slider is no longer clicked:*/
clicked = 0;
}
```
Now, we will create 3 more functions in `compareImages` with which we will get the cursor position and move the slider accordingly across the Image window
```
function slideMove(e) {
var pos;
/*if the slider is no longer clicked, exit this function:*/
if (clicked == 0) return false;
/*get the cursor's x position:*/
pos = getCursorPos(e)
/*prevent the slider from being positioned outside the image:*/
if (pos < 0) pos = 0;
if (pos > w) pos = w;
/*execute a function that will resize the overlay image according to the cursor:*/
slide(pos);
}
function getCursorPos(e) {
var a, x = 0;
e = e || window.event;
/*get the x positions of the image:*/
a = img.getBoundingClientRect();
/*calculate the cursor's x coordinate, relative to the image:*/
x = e.pageX - a.left;
/*consider any page scrolling:*/
x = x - window.pageXOffset;
return x;
}
function slide(x) {
/*resize the image:*/
img.style.width = x + "px";
/*position the slider:*/
slider.style.left = img.offsetWidth - (slider.offsetWidth / 2) + "px";
}
```
Wrap it all in a parent function with name `initComparisons`.
Now we have covered all the aspects of this now let's see the full `Scripts.js` file
```
function initComparisons() {
var x, i;
/*find all elements with an "overlay" class:*/
x = document.getElementsByClassName("img-comp-overlay");
for (i = 0; i < x.length; i++) {
/*once for each "overlay" element:
pass the "overlay" element as a parameter when executing the compareImages function:*/
compareImages(x[i]);
}
function compareImages(img) {
var slider, img, clicked = 0,
w, h;
/*get the width and height of the img element*/
w = img.offsetWidth;
h = img.offsetHeight;
/*set the width of the img element to 50%:*/
img.style.width = (w / 2) + "px";
/*create slider:*/
slider = document.createElement("DIV");
slider.setAttribute("class", "img-comp-slider");
/*insert slider*/
img.parentElement.insertBefore(slider, img);
/*position the slider in the middle:*/
slider.style.top = (h / 2) - (slider.offsetHeight / 2) + "px";
slider.style.left = (w / 2) - (slider.offsetWidth / 2) + "px";
/*execute a function when the mouse button is pressed:*/
slider.addEventListener("mousedown", slideReady);
/*and another function when the mouse button is released:*/
window.addEventListener("mouseup", slideFinish);
/*or touched (for touch screens:*/
slider.addEventListener("touchstart", slideReady);
/*and released (for touch screens:*/
window.addEventListener("touchstop", slideFinish);
function slideReady(e) {
/*prevent any other actions that may occur when moving over the image:*/
e.preventDefault();
/*the slider is now clicked and ready to move:*/
clicked = 1;
/*execute a function when the slider is moved:*/
window.addEventListener("mousemove", slideMove);
window.addEventListener("touchmove", slideMove);
}
function slideFinish() {
/*the slider is no longer clicked:*/
clicked = 0;
}
function slideMove(e) {
var pos;
/*if the slider is no longer clicked, exit this function:*/
if (clicked == 0) return false;
/*get the cursor's x position:*/
pos = getCursorPos(e)
/*prevent the slider from being positioned outside the image:*/
if (pos < 0) pos = 0;
if (pos > w) pos = w;
/*execute a function that will resize the overlay image according to the cursor:*/
slide(pos);
}
function getCursorPos(e) {
var a, x = 0;
e = e || window.event;
/*get the x positions of the image:*/
a = img.getBoundingClientRect();
/*calculate the cursor's x coordinate, relative to the image:*/
x = e.pageX - a.left;
/*consider any page scrolling:*/
x = x - window.pageXOffset;
return x;
}
function slide(x) {
/*resize the image:*/
img.style.width = x + "px";
/*position the slider:*/
slider.style.left = img.offsetWidth - (slider.offsetWidth / 2) + "px";
}
}
}
```
Now the final step, use this script in HTML and call the `initComparisons` function at the starting of the page where you want the slider.
```
<script>
initComparisons();
</script>
```
The final product will look like:-

#Wrapping Up
I hope you enjoyed the article, if yes then don't forget to press ❤️. You can also bookmark it for later use. It was fun to make this slider and If you have any queries or suggestions don't hesitate to drop them. See you.
| anomaly3108 |
941,215 | Look yourself. | When I think about my dreams, goals and start to see and feel my conquest, to come there, this is a... | 0 | 2021-12-31T12:25:50 | https://dev.to/jubarcelos/end-year-philosophy-5c5h | learning, development, language, personal | When I think about **my dreams, goals** and start to see and **feel my conquest**, to come there, this is a great indication I'm going in the **correct way**.
---
I hated English when I was a kid, teenager, and adult being honest, but I realize I need this language to get my dream, so I started to practice that **every day, I read, speak, write, and now I like it**.
I watch all my favorite series and film in English. I mark some meetings with old or new friends to practice English, and of course, I'm not fluent yet, I commit mistakes when I write or speak, but definitive I'm better than before.
**I was tired to feel stagnating in that and decided to improve myself**.
---
I've been using this channel to practice my English because is very difficult to maintain my knowledge if I don't practice frequently.
Some weeks I don't practice because I need to focus on another thing, but the most important I did, I set that as a routine, so... I can stop, but I'll return to that.
**I started to feel great doing that just when I stopped to compare myself with other people** and analyze my stories, by myself.
The same happened when I looked at my olds projects and thought about my learning journey, all my **baby steps**, and I noticed how math I **grew up** and improve my expertise. **Everything has a process to pass**, and everybody needs to know their **time and necessities**.
**What are you compromising with your personal development?**
Think about that, make one checklist and do some things to get that, step by step you will feel this same energy. " | jubarcelos |
941,320 | Do not use destructuring on import | When importing it is common to use destructuring, but it seems to have its drawbacks. By not using... | 0 | 2021-12-31T13:50:02 | https://dev.to/theproductivecoder/do-not-use-destructuring-on-import-1440 | When importing it is common to use destructuring, but it seems to have its drawbacks. By not using destructuring I got a bundled JavaScript file down from 76kb to 7kb.
I made a simple web app that prints hello world in camelcase to the console.
`const lodash = require('lodash')
console.log(lodash.camelCase('hello world'))`

After bundling it with webpack the bundled js file was 76kb. Checking out the file with webpack-bundle-analyzer it seems to have loaded the whole of lodash. Maybe it would be smaller with destructoring.
`const {camelCase} = require('lodash')
console.log(camelCase('hello world'))`
Now the file is 70kb. Not a huge saving. I tried another syntax.
`const camelCase = require('lodash/camelCase')
console.log(camelCase('hello world'))`

Now the bundled file was only 7kb, a huge saving. I got the same results whether using nodejs require or ES6 import syntax. Try it out in your own projects and see if you have similar results.
| theproductivecoder | |
941,383 | Symfony Station Communique - 31 December 2021. A Look at Symfony and PHP News. | This post originally appeared on Symfony Station. Welcome to this week's Symfony Station Communique.... | 0 | 2021-12-31T17:07:39 | https://dev.to/reubenwalker64/symfony-station-communique-31-december-2021-a-look-at-symfony-and-php-news-4ckf | symfony, php, drupal, docker | This post originally appeared on [Symfony Station](
https://www.symfonystation.com/Symfony-Station-Communique-31-December-2021).
Welcome to this week's Symfony Station Communique. It's your weekly review of the most valuable and essential news in the Symfony and PHP development communities. There was not much Symfony news this week, so we are expanding coverage of general coding articles in our Other section. Take your time and enjoy the items most valuable for you.
###And more importantly, we want to wish you a Happy New Year!
Thanks to Javier Eguiluz and Symfony for sharing [our last communique](https://www.symfonystation.com/Symfony-Station-Communique-24-December-2021) in their [Week of Symfony](https://symfony.com/blog/a-week-of-symfony-782-20-26-december-2021).
*Please note that links will open in a new browser window. My opinions, if I present any, will be in bold.
##Symfony
As always, we will start with the official news from Symfony.
Highlight -> "This week, Symfony development activity was low because of the Christmas holidays and focused on fixing various small bugs. Meanwhile, the upcoming Symfony 6.1 version, to be released in May 2022, introduced a new feature to create draft emails."
A Week of Symfony #782 (20-26 December 2021)
https://symfony.com/blog/a-week-of-symfony-782-20-26-december-2021
I ran across this in the Symfony Docs. It's a good one to bookmark.
Quick Tour / The Big Picture
https://symfony.com/doc/current/quick_tour/the_big_picture.html
The open-sourcing of Symfony CLI is now official.
Announcing the open-sourcing of the Symfony CLI
https://symfony.com/blog/announcing-the-open-sourcing-of-the-symfony-cli

##Featured Item
We continue to highlight a post of the week. This one was an obvious and easy decision.
2021 was an incredibly hard year for many people and companies. The Symfony community was no exception, and our thoughts are with all of you who suffered because of the COVID-19 pandemic. Luckily, thanks to your help and support, there were some reasons for optimism throughout the year. This blog post highlights the main Symfony achievements during 2021.
Symfony 2021 Year in Review
https://symfony.com/blog/symfony-2021-year-in-review
###This week
Eelco Verbrugge reminds us that "Symfony is the fastest major PHP framework with the philosophy to start small and add features when you need them.
So today, I'll show you what is needed at a minimum to easily serve your new Symfony project. Bonuses are some packages which can be installed, and I think are useful to start with for developing."
Starting a new Symfony project on Linux
https://dev.to/eelcoverbrugge/starting-a-new-symfony-project-on-linux-2amh
He also has:
My top 5 favorite Symfony packages
https://dev.to/eelcoverbrugge/my-top-5-favorite-symfony-packages-22i8
Jolie Code, @jolicode, explores how to how to use systemd properly to run Symfony Messenger workers.
Symfony Messenger 💛 systemd
https://jolicode.com/blog/symfony-messenger-systemd
Smaine Milianni explores how to:
Use PHP Enums as Doctrine type in Symfony
https://smaine-milianni.medium.com/use-php-enums-as-doctrine-type-in-symfony-85909aa0a19a
Speaking of Doctrine, Mike Zukowski explores the best way to:
Iterating billions of objects in Doctrine
https://medium.com/@dotcom.software/iterating-billions-of-objects-in-doctrine-23256f7d539
Who knew you could? ;)
2021 was an eventful year for the Drupal community. Explore all the highlights in the following article.
The Year in Review: Drupal in 2021
https://evolvingweb.ca/blog/year-review-drupal-2021
##Timeless

_Sponsored Article_
All sponsored articles are for products we have vetted and stand behind. We either use them or would do so if they were applicable to the Symfony Station site.
We published our first sponsored article on Symfony Station exploring how Code Execution Monitoring helps you identify bugs and bottlenecks in your Symfony app before your customers do. Like all our articles it is now available via audio.
Why You Should Use Code Execution Monitoring with Symfony
https://www.symfonystation.com/why-code-execution-monitoring-symfony

##PHP
###ThisWeek
Dariusz Gafka, @DariuszGafka, shows us:
How To Build Maintainable PHP Applications
https://dariuszgafka.medium.com/how-to-build-maintainable-php-applications-29c48e2a258c
The following from Geni Jaho is specific to Laravel, but the general points apply to all PHP programming.
A significant pain point in programming has to deal with all the clutter that is shoved into controller methods. One of the best ways to remedy that is to extract some functionality into their own classes. They’re called Actions, or Services, or whatever.
Refactoring #2: From controllers to actions
https://genijaho.medium.com/refactoring-2-from-controllers-to-actions-e4d448194abb
The Drinks & Co. engineering team is a fan of concurrency and parallelism to get the best performance and resource optimization in their systems.
Here, they explain how to start adding Async PHP to your toolkit.
How we are adding Async PHP to our Stack
https://uvinum.engineering/how-we-are-adding-async-php-to-our-stack-3bb7c2192cb
This article on Dev.to shows us a way to gain readability and efficiency in our foreach loops that go over a collection of objects: iterators.
PHP iterators and generators: get started with the `ArrayIterator` and `FilterIterator` classes
https://dev.to/yactouat/php-iterators-and-generators-get-started-with-the-arrayiterator-and-the-filteriterator-classes-39co
Samuel Fontebasso continues his series looking at "how to use Docker containers to run applications in a production environment."
PHP + Nginx with Docker in production
https://blog.fontebasso.com.br/php-nginx-with-docker-in-production-8c1ad71182f2
DEVRiMS says "There are many professionals in the software development field, but very few of them are real inspirations in the community. We are glad to feature Mr. Chris Hartjes in our first interview today."
PHP Interview with The Grumpy Programmer - Chris Hartjes
https://devrims.com/blog/grumpy-programmer-php-interview/
In Portuguese, Guilherme Donizetti writes "When we use the PHP language in our projects, in more or less time we will need to use some database as well. Databases are always a tool apart from what we are developing, but we want to connect the two things, and there are different ways to realize this connection. In this article, I will present PDO, a simple and efficient technique of connecting applications that use PHP to a database!"
PDO — CONEXÃO COM BANCO DE DADOS
https://guilhermedonizettiads.medium.com/pdo-conex%C3%A3o-com-banco-de-dados-5df0ac93f22f
The following series of Advent posts look at functional programming in PHP.
Advent of Functional PHP: Review
https://peakd.com/hive-168588/@crell/aoc2021-review
##Timeless
We ran across a promising tool this week. And it's building a Symfony integration.
PSX: A modern set of PHP components to simplify API development
https://phpsx.org/
DeliciousBrains writes "You could just debug your PHP code using dump debugging functions such as error_log, print, and var_dump, and let’s be honest, we’ve all done it a lot! While helpful sometimes, they often just aren’t enough and can actually slow you down while developing. There must be a better way, surely?!
Enter Xdebug, the rather awesome step debugging and profiling tool for PHP."
How to Use Xdebug for Advanced PHP Debugging
https://deliciousbrains.com/xdebug-advanced-php-debugging/
You can also watch a video version
How to use Xdebug with PhpStorm
https://www.youtube.com/watch?v=1nryJL3kCx0
And by the way, don't host your videos on YouTube.
We found this bookmarkable article via Joshua Otwell's, @j21120, OpenLamp newsletter.
Buggy PHP Code: The 10 Most Common Mistakes PHP Developers Make
https://www.toptal.com/php/10-most-common-mistakes-php-programmers-make

##Other
While there are many resources to help programmers write better code—such as books and static analyzers—there are few for writing better comments. While it's easy to measure the number of comments in a program, it's hard to measure the quality, and the two are not necessarily correlated. A bad comment is worse than no comment at all. Here are some rules to help you achieve a happy medium.
Best practices for writing code comments
https://stackoverflow.blog/2021/12/23/best-practices-for-writing-code-comments/
With the dust settled in the wake of Elastic’s relicensing controversy, VentureBeat interviewed co-founder and CEO Shay Banon to get his take on why they made the license change; what impact — if any — it has had on business, and what being a “free and open” company (vs. “open source”) really means.
Elastic CEO reflects on Amazon spat, license switch, and the principles of open-source
https://venturebeat.com/2021/12/27/elastic-ceo-reflects-on-amazon-spat-license-switch-and-the-principles-of-open-source/
Venture Beat also explores:
How open-source is powering data sovereignty and digital autonomy
https://venturebeat.com/2021/12/29/how-open-source-is-powering-data-sovereignty-and-digital-autonomy/
Ingo Steinke writes: "Inspired by my article “Nothing New in 2022?”, I will share some thoughts about what to expect and not to expect of a new year from the perspective of a frontend web developer."
What not to expect from 2022 as a Web Developer
https://ingosteinke.medium.com/what-not-to-expect-from-2022-as-a-web-developer-55f095268d30
James Read states: "I propose that DockerHub as a single repository of container images is becoming less and less important than it once was, and in its place, GitHub is a strong contender to take over as the #1 repository for containers — as it has its sights on being everything a developer needs."
GitHub may replace DockerHub
https://levelup.gitconnected.com/github-may-replace-dockerhub-a5da5e547f01
Apoorv Tyagi published this informative article.
How to Scale a Distributed System
https://www.freecodecamp.org/news/how-to-scale-a-distributed-system/
Web3 is the latest Silicon Valley buzzword, which is being dubbed as the next phase of the Internet. It has got tech and cryptocurrency enthusiasts buzzing but others, Jack Dorsey in particular, argues it is already in the hands of deep-pocketed venture capitalists.
But what is Web3, and can this future vision of a decentralized and egalitarian Internet work?
What is Web3, and why is Jack Dorsey attacking the 'next phase of the internet'?
https://www.euronews.com/next/2021/12/24/what-is-web3-is-it-the-new-phase-of-the-internet-and-why-are-elon-musk-and-jack-dorsey-aga
We all know nation-states aren't necessarily the best forces for an open, free, and democratic internet. Dr. Samantha Hoffman writes:
"Recent prominent data breach incidents, ... have made clear how vulnerable both public and private systems remain to espionage and cybercrime. What is less obvious is the way that a foreign adversary or competitor might target data that is less clearly relevant from a national security or espionage perspective. Today, data about public sentiments, such as the kinds of data used by advertisers to analyze consumer preferences, has become as strategically valuable as data about traditional military targets. As the definition of what is strategically valuable becomes increasingly blurred, the ability to identify and protect strategic data will be an increasingly complex and vital national security task."
How to avoid falling into China’s ‘data trap’
https://techcrunch.com/2021/12/26/how-to-avoid-falling-into-chinas-data-trap/
Brian Kardell ponders upon this "We’ve built the web so far on a very particular model, with web engine implementers at the center. The whole world is leaning extremely heavily on the independent, voluntary funding (and management and prioritization) of a very few steward organizations.
Maybe that isn’t a great idea."
Webrise
https://bkardell.com/blog/Webrise.html
Have you published or seen something related to Symfony or PHP that we missed? If so, please contact us. https://www.symfonystation.com/contact
That's it for this week. Thanks for making it to the end of another extended edition. I look forward to sharing next week's Symfony and PHP news with you on Friday.
Please share this post. :) Be sure to join our newsletter list at the bottom of any of our site’s pages. https://www.symfonystation.com/contact Joining gets you each week's communique in your inbox (a day early). And [follow us on Twitter](https://twitter.com/symfonystation).
###Once again, Happy New Year Symfonistas!

Reuben Walker
Founder [Symfony Station](https://www.symfonystation.com/)
Reuben is also Ringmaster of [Mobile Atom Media](https://media.mobileatom.net/about-us/) and its division [Mobile Atom Code](https://www.mobileatom.net/). | reubenwalker64 |
941,403 | In-Demand Database Administrator Skills You Need To Get Hired In 2022 | The Database Administrator (DBA), as the name suggests, operates and administers the database. The... | 0 | 2021-12-31T18:18:44 | https://dev.to/bpb_online/in-demand-database-administrator-skills-you-need-to-get-hired-in-2022-1gb1 | database, datascience, datascientist, dba | The Database Administrator (DBA), as the name suggests, operates and administers the database. The technical skills required by a DBA are SQL, scripting, database performance tuning, and system and network design. A DBA also handles the backup and recovery of databases. This job is critical as a business function properly only when the database is stored and managed well.
Listing a few tasks a Database Administrator is involved in:
Database designing as per end-user requirements.
- Providing (or revoking) rights to or from database end-users.
- Enabling efficient data backup and data recovery mechanisms.
- Database-related training to end-users.
- Ensuring data privacy and security.
- Managing data integrity for end-users.
- Monitoring the performances of the database.
The proper functioning of databases is solely the responsibility of a DBA. If at any point in time the database functioning fails, the DBA should be able to quickly and efficiently manage data recovery mechanisms to recover the functioning of data.
Thorough knowledge of SQL and related scripting languages makes a DBA well-tuned manage any database queries that need to be handled by various end-users of a database.
Hope this was helpful. | bpb_online |
941,565 | ESP8266 Adventures | My first experience with ESP8266. Cover image shows the ESP12e module. | 0 | 2021-12-31T23:02:42 | https://dev.to/thspinto/esp8266-adventures-12g4 | arduino, esp8266, grafana, mqtt | ---
title: "ESP8266 Adventures"
published: true
description: My first experience with ESP8266. Cover image shows the ESP12e module.
cover_image: https://ae01.alicdn.com/kf/HTB19oGtXojrK1RkHFNRq6ySvpXac/Esp8266-ESP-12E-esp12e-substituir-esp12-ESP-12-esp8266-remoto-porta-serial-m-dulo-sem-fio.jpg
tags: [arduino, esp8266, grafana, mqtt]
---
How can my knowledge of technology help in global warming impacted future? My main area of study is in Computer Science and I've mostly had contact with intangible stuff. If, as a consequence of climate change, we enter a new era of scarcity, how can this intangible knowledge help?
With this in mind and with curiosity about IoT. Our most basic need is food. Vegetal food needs light, healthy soil and the right amount of water to grow. The most basic gadget I could build that can help food to grow and to learn with my experimentation is a weather station.
All that introduction is just to say that my goal is collecting the temperature, air humidity, soil humidity and sending it to my cluster for processing. Since we are in the future, no cables are allowed therefore of wireless connection is required. So I went online and bought the most simple-looking and cheap module I could find to couple it to an Arduino I've already owned. I got the ESP-12e and that is where a whole new world opened beneath my feet and thing got a little more complicated.
## Programming the ESP8266
What I didn't know is that the ESP8266 is not just a Wifi module, it can be programmed and even run a web server inside. Of course there was a community leveraging this for IOT, and they led me to [OpenMQTTGateway](https://docs.openmqttgateway.com/). This project collects various signals and sensor from IOT devices and sends it to a queue to be used by HomeAutomation services such as [Home Assistant](https://www.home-assistant.io/). Given my astonishment of the capacity of this module of course I didn't have any tools that would make my life easier in programming it.
Since I had an Arduino I thought it would be easy to use it to program the ESP. My first blocker is that I saw on a tutorial that I needed an external 3,3V power source because Arduino's 3,3V output didn't have enough current for the module. I found 3 used 1,5V batteries that connected in series gave me 3,6V. The datasheet says that 3,6V is within the operational voltage, so achievement unlocked for recycling used batteries. (I do have to notice that I found out later that used batteries are really bad at keeping the voltage I measured without any usage.)
Now I just had to flash the OpenMQTTGateway project into the module. Well, to put it into flash mode you have to reboot the module with the GPIO0. I found this nice schematics in instructables:
[https://www.instructables.com/ESP-12E-ESP8266-With-Arduino-Uno-Getting-Connected/](https://www.instructables.com/ESP-12E-ESP8266-With-Arduino-Uno-Getting-Connected/)
My execution of it was a disaster because I bought the wrong pin bar (the ESP-12E has a smaller distance between the roles in comparison to the default protoboard) so I just attached the wires directly to the module. Of course that doing so made it very unstable and I couldn't breath near it without triggering a reset. But it I got it be be stable enough to flash it. The next issue I had was not flowing correctly the instructions: I was trying to use Arduino IDE to program the module and it wasn't able to connect. First of all it is very important to connect the ground to reset in the Arduino board. Apparently when you open the usb-to-serial converter Arduino automatically resets and keeping reset pin to ground avoids that.
## Pin info
⚠️ To flash software to the module no other sensors can be attached.
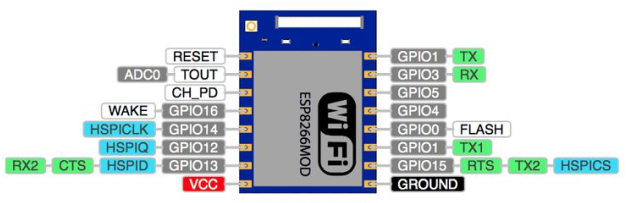
I ended buying a fiberglass protoboard to weld everything together and make the setup more stable (I admit I do have practice welding to get more motor coordination). Finally, I also added a USB cable and a tension regulator to 3,3V for a constant power supply.

You might ask me why didn't you just buy the [nodemcu](https://www.nodemcu.com/)? Well, I basically didn't know of its existence and I never thought that "wifi module" could do so much. It was fun to learn, but it is certainly better to buy the nodemcu because it is pretty cheap (even in Brazil), and flashing it and connecting stuff to it is a lot simpler.
## OpenMQTTGateway Configuration
To manually configure the network and MQTT I added the following to [User_config.h](https://github.com/1technophile/OpenMQTTGateway/blob/development/main/User_config.h):
```c
#define ESPWifiManualSetup true
#define MQTT_SERVER "your.server"
#define MQTT_USER "user"
#define MQTT_PASS "pass"
#define wifi_ssid "ssid"
#define wifi_password "pass"
#define SECURE_CONNECTION
#define MQTT_PORT "9443"
const char* certificate CERT_ATTRIBUTE = R"EOF("
-----BEGIN CERTIFICATE-----
... // your root certificate: see here for let`s encypt https://letsencrypt.org/certificates/
-----END CERTIFICATE-----
")EOF";
```
## Collecting the metrics
To collect and view the sensor data I'm using Mosquitto, Prometheus, and Grafana. For Prometheus to be able to collect the data I'm running [an exporter](https://github.com/kpetremann/mqtt-exporter) that reads the data from the queue and provides an HTTP endpoint in the format Prometheus expects.
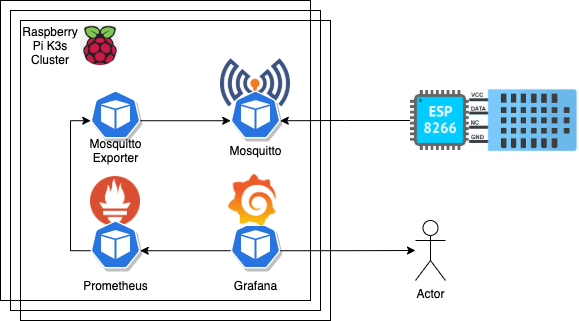
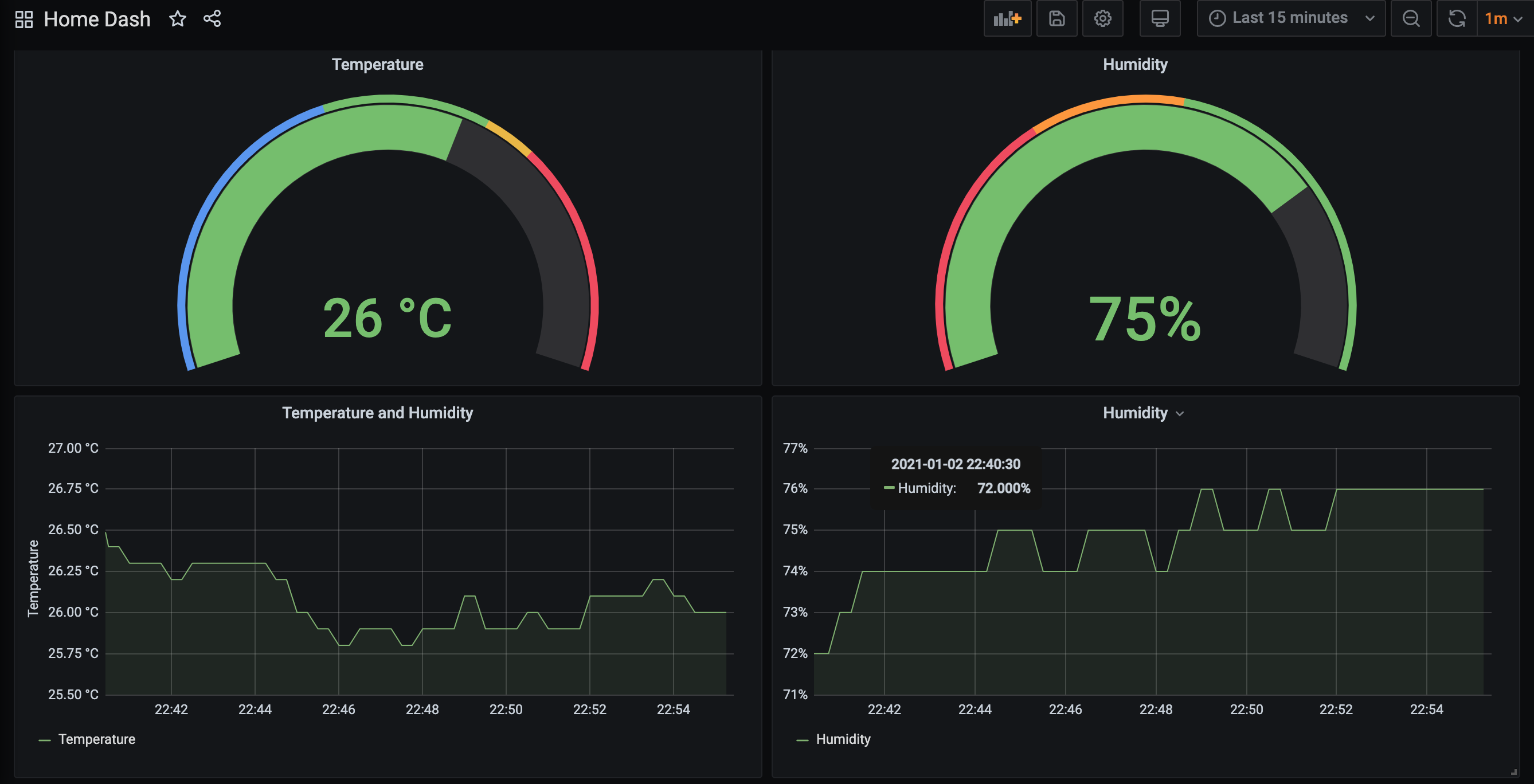
## References
[🔗 OpenMQTTGateway](https://docs.openmqttgateway.com/)
[🔗 AT instruction set](https://www.espressif.com/sites/default/files/documentation/4a-esp8266_at_instruction_set_en.pdf)
| thspinto |
941,621 | Using Kyverno Policies for Kubernetes Governance | Kubernetes gives developers a lot of flexibility in terms of developing and deploying applications. With flexibility, comes the opportunity for configuration to get out of control. Kyverno is a great tool for helping create policies in Kubernetes to ensure that flexibility remains, but guardrails are in place. | 0 | 2021-12-31T23:58:15 | https://dev.to/mda590/using-kyverno-policies-for-kubernetes-governance-3e17 | kubernetes, kyverno, policy, governance | ---
title: Using Kyverno Policies for Kubernetes Governance
published: true
description: Kubernetes gives developers a lot of flexibility in terms of developing and deploying applications. With flexibility, comes the opportunity for configuration to get out of control. Kyverno is a great tool for helping create policies in Kubernetes to ensure that flexibility remains, but guardrails are in place.
tags: kubernetes, kyverno, policy, governance
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/xki3qslzpu9s3rzw9k9p.jpg
---
[Kyverno](https://kyverno.io/) is a great tool that can be installed into any Kubernetes cluster, allowing cluster administrators to enforce policies for resources in the cluster, and even modify resources before they are applied. Kyverno can be used to ensure deployments are secure, ensure deployments meet certain organizational criteria (e.g. define a cost center label), or even ensure all deployments mount a common volume.
Kyverno works by deploying a pod and services into your existing cluster. It creates multiple Admission Webhooks in the cluster. These webhooks are responsible for handling API requests coming in to Kubernetes and either validating something from the request ([Validating Admission Webhook](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#validatingadmissionwebhook), or modifying the request before it is applied ([Mutating Admission Webhook](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#mutatingadmissionwebhook)).
In the diagram below, you can see where in the process of an API call to Kubernetes, each of the Mutating Admission and Validating Admission webhooks will run.
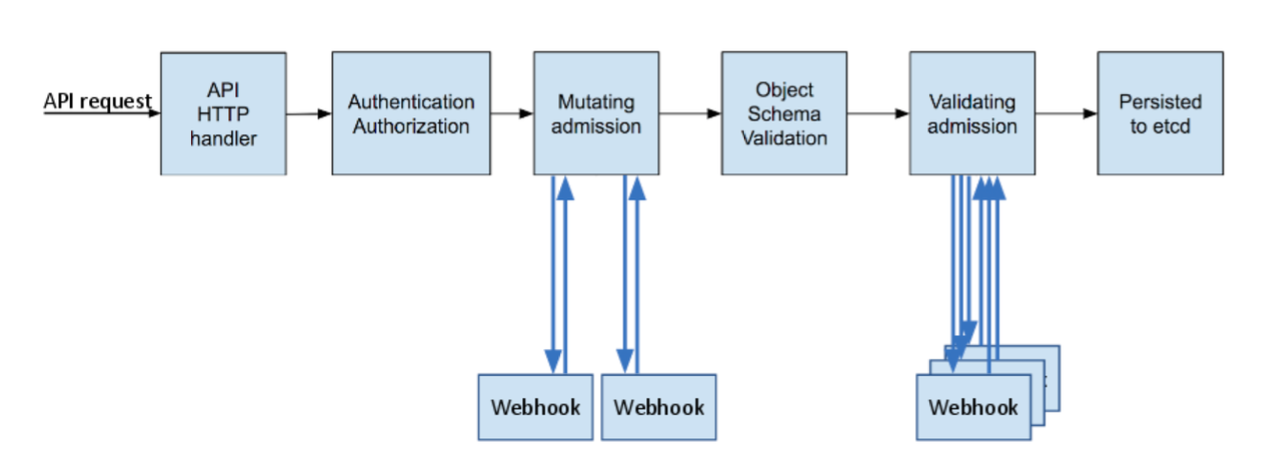
All of the Kubernetes Manifests and Kyverno Policies are available in [this GitHub repo](https://github.com/mda590/do-k8s-2021-challenge).
## Deploying Kyverno
Getting started with Kyverno is pretty simple. While there are a lot of knobs that can be turned to configure Kyverno, the initial default goes a long way. *I deployed this into my DigitalOcean Kubernetes cluster.*
To install, I simply ran:
```
$ helm repo add kyverno https://kyverno.github.io/kyverno/
$ helm repo update
$ helm install kyverno kyverno/kyverno --namespace kyverno --create-namespace
```
I now have a single Kyverno pod running in the cluster:
```
$ kubectl get pods -n kyverno
NAME READY STATUS RESTARTS AGE
kyverno-6d94754db4-tdl9s 1/1 Running 0 5s
```
## Policies
### Anatomy of a basic policy
Policies can be written with many different options in Kyverno. The most basic policies can be written to check values of specific field(s) within an API request to Kubernetes, and make a decision whether the request should be allowed or not.
### Require specific pod labels
This example requires specific labels to be set on a pod prior to creating those resources. One of the great benefits Kyverno provides is that you can specify `Pod` as the resource kind, but it will also check against the policy whenever creating resources which will end up creating pods (Deployment, StatefulSet, etc.)
The below example policy requires that all pods have the `labels.acmecorp.com/costCenter` and `labels.acmecorp.com/department` labels. They can be set to any value.
```yaml
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-business-labels
annotations:
policies.kyverno.io/title: Require Business Labels
policies.kyverno.io/category: Best Practices
policies.kyverno.io/severity: medium
policies.kyverno.io/subject: Pod, Label
policies.kyverno.io/description: >-
Define required labels used by our internal business processes to understand which applications
are running in each cluster, and used to handle chargeback activities for resources consumed
by this specific application.
spec:
validationFailureAction: enforce
background: false
rules:
- name: check-for-business-labels
match:
resources:
kinds:
- Pod
validate:
message: "The labels `labels.acmecorp.com/costCenter` and `labels.acmecorp.com/department` are required."
pattern:
metadata:
labels:
labels.acmecorp.com/costCenter: "?*"
labels.acmecorp.com/department: "?*"
```
#### Example Policy Tests:
* [Example Deployment which will be denied under this policy.](https://github.com/mda590/do-k8s-2021-challenge/blob/main/deployments/01_denied.yaml)
* [Example Deployment which will be allowed under this policy.](https://github.com/mda590/do-k8s-2021-challenge/blob/main/deployments/01_allowed.yaml)
#### Demo showing policy in cluster:
{% youtube yd_f8XIgLfw %}
### Require the use of a specific container registry
This policy checks for 2 important items: 1. images specified in a pod definition must be from a specific container registry (in this case, from the DigitalOcean registry); and 2. images cannot have the `latest` tag.
```yaml
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-image-registries
annotations:
policies.kyverno.io/title: Restrict Image Registries and Latest
policies.kyverno.io/category: Best Practices
policies.kyverno.io/severity: medium
policies.kyverno.io/subject: Pod
policies.kyverno.io/description: >-
Requires all images for pods be sourced from the Digital Ocean Container Registry. Any other
image sources are denied.
spec:
validationFailureAction: enforce
background: false
rules:
- name: validate-registries
match:
resources:
kinds:
- Pod
validate:
message: "Unknown image registry."
pattern:
spec:
containers:
- image: "registry.digitalocean.com/*"
- name: validate-image-tag
match:
resources:
kinds:
- Pod
validate:
message: "Must not use the tag `latest` on any images."
pattern:
spec:
containers:
- image: "!*:latest"
```
#### Example Policy Tests:
* [Example Deployment which will be denied under this policy.](https://github.com/mda590/do-k8s-2021-challenge/blob/main/deployments/02_denied.yaml)
* [Example Deployment which will be allowed under this policy.](https://github.com/mda590/do-k8s-2021-challenge/blob/main/deployments/02_allowed.yaml)
#### Demo showing policy in cluster:
{% youtube Sb0zzsif7ZM %}
### Require a runAsUser be specified
This policy requires that every container specified within a pod has a `runAsUser` defined and that the value is greater than `0`, meaning the container cannot run as root. In reality, there are additional items you will probably want to check in a policy like this, but this provides a good place to get started.
```yaml
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-pod-runasuser
annotations:
policies.kyverno.io/title: Require the RunAsUser to be Specified
policies.kyverno.io/category: Best Practices
policies.kyverno.io/severity: medium
policies.kyverno.io/subject: Pod
policies.kyverno.io/description: >-
Requires Pods to specify as runAsUser value within their containers which are not root.
spec:
validationFailureAction: enforce
background: false
rules:
- name: check-userid
match:
resources:
kinds:
- Pod
validate:
message: >-
The field spec.containers.*.securityContext.runAsUser must specified and greater than zero.
pattern:
spec:
containers:
- securityContext:
runAsUser: ">0"
```
#### Example Policy Tests:
* [Example Deployment which will be denied under this policy.](https://github.com/mda590/do-k8s-2021-challenge/blob/main/deployments/03_denied.yaml)
* [Example Deployment which will be allowed under this policy.](https://github.com/mda590/do-k8s-2021-challenge/blob/main/deployments/03_allowed.yaml)
#### Demo showing policy in cluster:
{% youtube qTVkgwBQcA0 %}
## Conclusion
Overall, this is meant to be a couple basic examples of using policies with Kyverno in Kubernetes. You can certainly get much more complex, or implement a policy which mutates a resource, to keep resources in your cluster compliant with your rules.
If you end up trying Kyverno and find out you need something more complex, take a look at Gatekeeper. The [Gatekeeper](https://open-policy-agent.github.io/gatekeeper/website/docs/) project works very similar to Kyverno, except it allows for defining policies in Rego language, which adds complexity but allow for additional customization.
| mda590 |
941,640 | Scilab: An Introductory Course | What is Scilab? Why should you learn Scilab? Advantages Disadvantages What's next? ... | 16,117 | 2022-01-02T02:00:18 | https://dev.to/fcomovaz/scilab-an-introductory-course-188o | scilab, course, learning | - [What is Scilab?](#what-is-scilab)
- [Why should you learn Scilab?](#why-should-you-learn-scilab)
- [Advantages](#advantages)
- [Disadvantages](#disadvantages)
- [What's next?](#whats-next)
## What is Scilab?
Scilab is a free and open source software for engineers & scientists, with a long history (first release in 1994) and a growing community.
![Scilab Logo][logo-scilab]
Also, Scilab is a high level programming language for scientific programming. It enables a rapid prototyping of algorithms, without having to deal with the complexity of other more low level programming language such as C and Fortran.
## Why should you learn Scilab?
Scilab is a powerful software and a pretty good alternative to the commercial Matlab, besides it's free and open source what allows us use it as we want.
### Advantages
I'll list yo some advantages about the us of Scilab as numerical computing software:
- *Open Source & Free*: This's very useful because is easy to get and there is no problem when you use it.
- *Easy to use*: Scilab doens't havea very complex programming language is very similar to Matlab syntaxis.
- *OS compatible*: It's available for any OS.
- *Lightweight software*: In comparition to Matlab instalation, Scilab is much lighter than Matlab.
### Disadvantages
Likewise, Scilab has certain point i don't really like about it. So, I'm going to be very honest with you and I'll give you the pros/cons i find when i've used Scilab.
- *Small community*: It's not a common software, for this reason its community is not as big as Matlab community.
- *Lack of functions*: This is because of the lightweight of the software, it just includes indispensable functions to work.
- *Documentation looks old*: Scilab has its official docummentation but the page and examples are not very friendly at first sight.
## What's next?
The first step to begin with Scilab develop is download it.
Scilab, being Open Source, is very easy to install in any kind of OS accessing from the [Scilab download page][download-scilab].
Once you got it installed, you can wath this short overview to Scilab:
{% youtube VfNV7wr4338 %}
Nevertheless, sometimes you don't want to install programs because a lot of reasons, in this case you can use the [Scilab Online Version][cloud-scilab] which is mainteined by **IITB** (*Indian Institute of Technology Bombay*).
As well as Matlab, Scilab has its own IDE integrated in the instalation, you can use it but we going to implement Scilab execution in the Visual Studio Code Editor, you can download it from the [VS Code download page][download-code], we'll configure it in following posts.
[download-scilab]: https://www.scilab.org/download/
[download-code]: https://code.visualstudio.com/download
[cloud-scilab]: https://cloud.scilab.in/
[logo-scilab]: https://ftp.sun.ac.za/ftp/pub/mirrors/scilab/www.scilab.org/images/scilab_logo.jpg "scilab logo"
| fcomovaz |
941,672 | I've created a graphql-codegen plugin that generates type-safe hooks for GraphQL queries for Flutter! | If you are a Flutter & GraphQL fan, please try it. (And if you like it, please give it a star... | 0 | 2022-01-01T04:24:57 | https://dev.to/seya/ive-created-a-graphql-codegen-plugin-that-generates-type-safe-hooks-for-graphql-queries-for-flutter-27h0 | flutter, graphql | ---
title: I've created a graphql-codegen plugin that generates type-safe hooks for GraphQL queries for Flutter!
published: true
description:
tags: flutter, graphql
//cover_image: https://direct_url_to_image.jpg
---
If you are a Flutter & GraphQL fan, please try it.
(And if you like it, please give it a star ⭐️)
https://github.com/kazuyaseki/graphql-codegen-flutter-artemis-hooks
## Motivation
I'm from React, and when building an application with React + Apollo configuration, I really liked the experience of using graphql-codegen to generate hooks like this
```tsx
export function useFetchUserQuery(baseOptions?: ApolloReactHooks.QueryHookOptions<FetchUserQuery, FetchUserQueryVariables>) {
return ApolloReactHooks.useQuery<FetchUserQuery, FetchUserQueryVariables>(FetchUserDocument, baseOptions);
}
```
(This is the code that will be generated when you use this plugin with `withHooks` set to true.)
https://www.graphql-code-generator.com/plugins/typescript-react-apollo
I want to develop with the same experience in Flutter! So I created this plugin.
https://github.com/kazuyaseki/graphql-codegen-flutter-artemis-hooks
In Flutter, there is a library called [artemis](https://pub.dev/packages/artemis) that generates the type definitions, so this plugin is based on that.
For example, suppose you define a query like this as a .graphql file
```graphql
query ExampleQuery {
objects {
id
name
}
}
mutation TestMutation($variable: String!) {
testMutation(variable: $variable) {
result
}
}
```
This plugin will generate the following hooks function
```dart
import 'package:flutter/material.dart';
import 'package:flutter_hooks/flutter_hooks.dart';
import 'package:graphql_flutter/graphql_flutter.dart';
import 'package:gql/ast.dart';
import 'package:your_project/your_artemis_generated/graphql_api.dart';
QueryResult useQuery<DataType>(BuildContext context, DocumentNode query,
[Map<String, dynamic>? variables]) {
final client = GraphQLProvider.of(context).value;
final state =
useState<QueryResult>(QueryResult(source: QueryResultSource.network));
useEffect(() {
late Future<QueryResult> promise;
if (variables ! = null) {
promise = client.query(
QueryOptions(document: query, variables: variables),
);
} else {
promise = client.query(
QueryOptions(document: query),
);
}
promise.then((result) {
state.value = result;
});
return () {};
}, []);
return state.value;
}
class ExampleQuery$QueryReturnType {
bool isLoading;
OperationException? exception;
ExampleQuery$Query? data;
ExampleQuery$QueryReturnType(this.isLoading, this.exception, this.data);
}
ExampleQuery$QueryReturnType useExampleQueryQuery<DataType>(BuildContext context) {
final result = useQuery<ExampleQuery$Query>(context, EXAMPLE_QUERY_QUERY_DOCUMENT);
return ExampleQuery$QueryReturnType(result.isLoading, result.exception, result.data == null ? null : ExampleQuery$Query.fromJson(result.data!));
}
class TestMutation$MutationReturnType {
bool isLoading;
OperationException? exception;
TestMutation$Mutation? data;
TestMutation$MutationReturnType(this.isLoading, this.exception, this.data);
}
TestMutation$MutationReturnType useTestMutationQuery<DataType>(BuildContext context, TestMutationArguments variables) {
final result = useQuery<TestMutation$Mutation>(context, TEST_MUTATION_MUTATION_DOCUMENT, variables.toJson());
return TestMutation$MutationReturnType(result.isLoading, result.exception, result.data == null ? null : TestMutation$Mutation.fromJson(result.data!));
}
```
Then all that's left to do is import the above file and use the hooks! 🔥
```dart
class PageWidget extends HookWidget {
const PageWidget({Key key}) : super(key: key);
@override
Widget build(BuildContext context) {
final queryResult = useExampleQueryQuery(context);
final mutationResult = useTestMutationQuery(context, TestMutationArguments(variable: ""));
return ...
}
}
```
## Usage
### Installation
```bash
npm i --save-dev graphql-codegen-flutter-artemis-hooks
```
### Create a configuration file for graphql-codegen.
Create a configuration file for graphql-codegen, including the schema, the path to the .graphql file, and the path to the artemis-generated file.
```yml:codegen.yml
schema: your_schema_file.graphql
documents: '. /your_project/**/*.graphql'.
generates:
your_project/generated_hooks.dart:
config:
artemisImportPath: package:your_project/your_artemis_generated/graphql_api.dart
plugins:
- graphql-codegen-flutter-artemis-hooks
```
### Run graphql-codegen
If you do not have graphql-codegen itself installed, install the following `@graphql-codegen/cli`.
```bash
npm i --save-dev @graphql-codegen/cli
```
Then add the following script to package.json and run `npm run codegen`!
```json
{
"scripts": {
"codegen": "graphql-codegen"
},
}
```
That's it, I hope you find it useful!
| seya |
941,825 | Day 67 of 100 Days of Code & Scrum: Back From Holiday Break! | Happy New Year, everyone! I took a long time off from coding and blogging during the holiday season.... | 14,990 | 2022-01-01T10:25:37 | https://blog.rammina.com/day-67-of-100-days-of-code-and-scrum-back-from-holiday-break | 100daysofcode, beginners, javascript, productivity | Happy New Year, everyone!
I took a long time off from coding and blogging during the holiday season. My [previous post](https://blog.rammina.com/day-66-of-100-days-of-code-and-scrum-services-and-portfolio-pages-for-my-business-website) was back from December 21, 2021. I just wanted to take a break from my usual daily routine and spend time with people that I cared for the most.
Today, I finally went back into it! I have a long list of tasks that I have to deal with as a result of taking a break for about two weeks. I managed to deal with my social media backlog, which I haven't checked in a while. Also, I checked my e-mails and other messages.
In my remaining free time, I studied Scrum for my upcoming Professional Scrum Master I (PSM I) certification exam. Also, I re-examined my [company website](https://www.rammina.com), found some of the things that didn't work as intended, as well as thought of ways to improve the [Portfolio](https://www.rammina.com/portfolio) and [Services](https://www.rammina.com/services) sections of the website. It was kind of difficult to start working after such a long break, but it shouldn't take me long to get back my lost momentum.
Anyway, let's move on to my first daily report of the year!
## Two Week Holiday Break
No coding, blogging, and social media. Time was spent with my wife playing games, reading novels, eating unhealthy Christmas food, watching movies, and unproductive things.
## Today
Here are the things I learned and worked on today:
### Company Website
- I found a few things that are either bugs or not working as intended in my [business website](https://www.rammina.com).
- plan out how to improve the [Portfolio](https://www.rammina.com/portfolio) and [Services](https://www.rammina.com/services) sections of the website.
### Scrum
- I reread the [2020 Scrum Guide](https://scrumguides.org/scrum-guide.html).
- Took some practice exams for the Professional Scrum Master I (PSM I) certification.
- I did some practice flashcards for Scrum.
- reviewed some of the things I've learned before.
### Other Stuff
- replied to emails and social media messages.
I hope everyone had a great time during the holidays. And I wish you all the best for this new year!

### Resources/Recommended Readings
- [The 2020 Scrum Guide](https://scrumguides.org/scrum-guide.html)
- [Open Assessments | Scrum.org](https://www.scrum.org/open-assessments)
- [Mikhail Lapshin's Scrum Quizzes](https://mlapshin.com/index.php/scrum-quizzes/)
### DISCLAIMER
**This is not a guide**, it is just me sharing my experiences and learnings. This post only expresses my thoughts and opinions (based on my limited knowledge) and is in no way a substitute for actual references. If I ever make a mistake or if you disagree, I would appreciate corrections in the comments!
<hr />
### Other Media
Feel free to reach out to me in other media!
<span><a target="_blank" href="https://www.rammina.com"><img src="https://res.cloudinary.com/rammina/image/upload/v1638444046/rammina-button-128_x9ginu.png" alt="Rammina Logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://twitter.com/RamminaR"><img src="https://res.cloudinary.com/rammina/image/upload/v1636792959/twitter-logo_laoyfu_pdbagm.png" alt="Twitter logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://github.com/Rammina"><img src="https://res.cloudinary.com/rammina/image/upload/v1636795051/GitHub-Emblem2_epcp8r.png" alt="Github logo" width="128" height="50"/></a></span>
| rammina |
941,863 | P2P Crypto Exchange Software- story of peer to peer platforms and its usages in crypto exchanges | Peer-to-peer, abbreviated P2P, is a collection of interconnected devices that store and share... | 0 | 2022-01-01T13:17:30 | https://dev.to/jonathanberg/p2p-crypto-exchange-software-story-of-peer-to-peer-platforms-and-its-usages-in-crypto-exchanges-23n4 | blockchain, webdev, cryptocurrency | Peer-to-peer, abbreviated P2P, is a collection of interconnected devices that store and share specific files and documents. Each of these devices or systems is called a node. In this structure, each node has the same power and tasks.
But the term p2p or peer-to-peer has taken on a different color and flavor in financial technologies. It is usually used to refer to the exchange of cryptocurrencies on a person-to-person and decentralized basis. A [p2p crypto exchange software](https://radindev.com/p2p-cryptocurrency-exchange-software/) records the bid price of the buyer and the seller and, if they match, connects them to make the exchange. Some of the more advanced platforms have even provided a platform for automatic borrowing based on smart contracts.
Let's see where P2P was first used.
## How P2P networks work:
It was stated above that a p2p system is an aggregate of interconnected systems that have the same tasks and power. There is no administrator or admin or supervisor in this system because each node keeps a copy of the file and plays two roles simultaneously. One server and one client.
So each node can download files from other nodes. While in a centralized system, client devices download information from a centralized server.
In P2P networks, networked devices share files stored on their drives. Using software designed to mediate data sharing, users can search for other devices on the web, find and download files. Once the user downloads the file, it can act as the source of that file.
Simply put, a node acts as a client when downloading from other sources, but when it acts as a server, it is a resource from which other nodes can download files. (This can happen at the same time.)
## P2P history:
For the first time in the '80s, after introducing computers, one of the first examples of a user network was Internet Relay Chat, which was a way to send text and chat between two people.
In 1999, Napster introduced a P2P network for music sharing. This service made it possible for anyone to share their favorite music with others.
In 2000, a project called Gnutella started decentralized peer-to-peer sharing, which is still ongoing. Gnutella allows users to access folders on other systems.
Finally, it was in 2009 that Satoshi Nakamoto introduced the Bitcoin network as a peer-to-peer network. Perhaps the most famous sentence in the world about P2P is the first sentence of Bitcoin White Paper:
Bitcoin: A Peer-to-Peer Electronic Cash System

Most people have never heard of P2P before Bitcoin.
## Advantages of P2P networks:
1. Elimination of intermediaries: From the point of view of some economic actors, probably the most essential advantage of P2P is the elimination of intermediaries such as banks or financial and credit institutions.
In this way, digital currency is transferred directly from one person's wallet to another, and no bank in the middle plays the role of intermediary.
2. High security: Many others believe that much more security of this system than centralized client-server systems is the most significant advantage of p2p. It is P2P that protects digital currencies such as bitcoin against Dos attacks. Dos is a type of cyber attack that takes the server off the network and out of the reach of users. However, since peer-to-peer information systems are divided among many nodes, they are resistant to these attacks.
3. Avoid censorship: Avoiding censorship is another benefit of peer-to-peer networks. Because no one has the permission and power to block users' accounts, some people, such as merchants, see cryptocurrencies as a surefire way to prevent government payments from being blocked.
## Disadvantages of P2P networks:
1. Scalability: Because distributed offices must be updated at each node instead of the central server, adding any transaction in the blockchain requires a great deal of computing power. While this increases security, it dramatically reduces efficiency and is one of the main obstacles to scalability and widespread acceptance. However, blockchain encoders and developers are exploring options that may be used as scalability solutions. Prominent examples are the Lightning network, the atrium plasma, and the Wembley protocol.
2. Hard fork attacks: Another potential limitation is related to seizures during a hard fork. Because most blockchains are decentralized and open-source, nodes can freely copy and modify the code, detach from the main chain, and form a new parallel network. A hard fork is perfectly normal and is not a threat in itself. But if security measures are not taken properly, both chains will be vulnerable to replay attacks.
In addition, the distributed nature of P2P networks makes it difficult to control and regulate them. For example, several P2P programs and companies have engaged in illegal activities and copyright infringement.
## Unstructured P2P networks
In unstructured P2P networks, there is no specific organization of nodes. In this network, participants communicate with each other randomly. These systems are resistant to high churn activity (i.e., multiple nodes frequently joining and exiting the web).
Although this type of network is easier to build, unstructured P2P grids may require more CPU and memory because search queries are sent to as many people as possible or so-called peers. These requests will fill the network, especially if a small number of nodes provide the desired content.
## Structured P2P networks
Structured P2P networks have an organized architecture. This architecture allows nodes to search for files effectively, even if the content is not widely available. In most cases, this is done using hash functions that facilitate database search.
While structured networks may be more efficient, they are usually more centralized and require higher operating and maintenance costs. Of course, structured networks have less resistance when faced with high churn activity.
## Hybrid or hybrid P2P networks
P2P hybrid networks combine the typical client-server (client-server) model with some aspects of one-to-one architecture. For example, a central server may be designed to facilitate communication between peers or individuals.
This network has a better overall performance compared to the other P2P networks mentioned. Usually, some of the main advantages of each approach are combined with the other, and finally, a considerable degree of efficiency and decentralization is achieved.
## top 5 p2p cryptocurrency exchange platforms:
### Paxful:
One of the world's leading peer-to-peer exchange currency brands, founded in 2015, is Paxful, which has many fans worldwide.
Paxful has made various payment methods available to its users; methods such as Bank Transfer, CashU, Paypal, Western Union.
The cost that Paxful charges for exchanges are equal to 1% of the total, which is the seller's responsibility. In other words, buying a cryptocurrency in Paxful will not cost you extra.

### Localbitcoins:
The Finnish company, headquartered in Helsinki, started in 2012. One of the honors of this company is it's most popular in 2017.
The interesting point is that when buying a Cryptocurrency from LocalBitcoins site and the usual methods that Paxful also offers, you can give money to the other party in cash and buy a Cryptocurrency. (Of course, this feature was removed in 2019.)
The cost of Bitcoin trading commission on the LocalBitcoins site is zero.
It should be noted that this website has been hacked once, and it does not make sense to keep your bitcoins in its wallet. Be sure to transfer the bitcoins to your wallet.

### Binance P2P:
Probably the most well-known platform for currency exchange is Binance Exchange. The company was founded in 2017 by Changpen Zhao and is currently the most prominent digital currency exchange globally.
The large company's service to most countries globally and support for more than 31 different Fiat currencies has multiplied its popularity.
Binance also supports tether, Bitcoin, Binance USD, BNB, Ethereum, and many more cryptocurrencies.

### WazirX:
A few months after the establishment of Binance, the WazirX P2P platform was launched in India and soon became the most trusted peer-to-peer password exchange script.
The main reason for the popularity of this software was that for the first time in the world, it used an automatic p2p matching engine. So instead of choosing the buyer or seller manually, the system does this automatically.
Surprisingly, the exchange cost in WazirX is zero. Isn't that great?

### Remitano:
Remitano was founded in Singapore in the year of its establishment, and with the reputation, it has gained over the years, it has reassured many crypto exchanges.
Remitano's fantastic user interface has had an enormous impact on this much-welcomed platform.
As for the negative points of Remitano, let's say that you have to give one percent of the total amount to the exchange when exchanging the password. You also have to pay a fee when you want to settle the account.
Now, why is it still so popular with all the money it takes from its customers?
That's a good question. Because Remitano has an outstanding level of security and its service is excellent.

## p2p [crypto exchange website development](https://radindev.com/cryptocurrency-exchange-development/):
The cost of developing and designing p2p software for exchanging bitcoins and other cryptocurrencies depends on many factors.
First, you need to fully determine what features you want to offer your customers and design a complete mind map for it and then put it on paper and discuss with your consultants whether they are efficient or not. Features like:
• Stop limit
• Margin order
• OCO
• Future order
• OTC order
• And much more
Each of these features can have a significant impact on your cost.
For example, adding a stop limit will **increase your cost by 25% of the initial price**, while **25 working days will be added** to the time. Or, a margin order adds **up to 40% to your initial cost** and takes **up to 35 days**. The figure below shows the approximate price increase of other factors affecting the P2P price.
In addition to features, other factors can affect the price, such as:
• Programming languages and technologies used
• The company you order from
• Mobile application
• Multilingualism
• Crypto payment gateways
In this article, we tried to provide all the points related to the currency exchange platform development. We hope you find it helpful. | jonathanberg |
941,873 | dev.peviitor.ro; scraper[1] | Ce este scraperul? Scraperul este componenta motorului de cautare care preia datele de pe... | 0 | 2022-01-01T13:56:30 | https://dev.to/sebiboga/devpeviitorro-scraper1-1n42 | peviitor, scraper, locuridemunca, job | #### Ce este scraperul?
Scraperul este componenta motorului de cautare care preia datele de pe website-ul companiei.
In sectiunea de Cariere pe website-ul companiei gasim o lista de locuri de munca. Ele devin oportunitati in motorul de cautare abia cand aceste locuri de munca sunt inserate in index.
#### Ce trebuie sa faci pentru a scrie un scraper?
Te-ai hotarat ca vrei sa contribui la acest proiect OPEN SOURCE cu popularea datelor de pe website-ul companiilor. Perfect!
Primul pas este sa te inscrii pe [https://dev.peviitor.ro/](https://dev.peviitor.ro/)
#### Ce este **dev.peviitor.ro**?
In sectiunea dezvoltator al motorului de cautare, pur si simplu iti declari intentia de a contribui la motorul de cautare cu date. Datele in cazul nostru reprezinta locurile de munca.
Partea importanta este ca de aici, din `dev.peviitor.ro` iti generezi o cheie API.
Pentru a folosi API-ul (incepand cu versiunea 3), partea de inserare date si stergere date, vei avea nevoie de o cheie API.
Aceasta cheie API este unica pentru o companie, astfel vei defini ce companie vrei sa reprezinti.
Autentificarea in dev.peviitor.ro se face pe baza unui cont de GitHUB sau GitLAB.
#### Limitari
Esti limitat la a prelua date de pe un singur website si astfel poti adauga in motorul de cautare doar o companie.
De ce aceasta limitare?
In timp, companiile isi schimba partea de UI al website-ului si astfel scraperul va trebui updatat o data cu un upgrade al interfetei utilizator. Vrem ca atunci cand iti asumi aceasta responsabilitate de a popula locurile de munca pentru o companie, sa reusesti a face update atunci cand compania decide o modificare de interfata. E de ajuns o persoana sa raspunda de locurile de munca dintr-o anumita companie.
Daca intampini probleme cu autentificarea sau nu reusesti sa te descurci, lasa-ne un comentariu pe pagina de comunitate de pe github: [comunitate](https://github.com/peviitor-ro/community/discussions)

| sebiboga |
942,014 | Python for all | Imagine we are going back to school And i taught myself how to code python throughout... | 0 | 2022-01-01T18:17:20 | https://dev.to/biggahamid/python-for-all-1fhg | python, beginners, programming, productivity | Imagine we are going back to school
And i taught myself how to code python throughout
Covid-19.
```
print("Hello World")
```
`
 | biggahamid |
942,041 | What about Agile Development? | This article shall give you an overview of agile development and help you decide whether Scrum or... | 0 | 2022-01-06T15:22:26 | https://dev.to/iotcloudarchitect/what-about-agile-development-4g6g | agile, productivity, efficiency, team | This article shall give you an overview of agile development and help you decide whether Scrum or Kanban can meet your needs.
But, first of all, a clarification about what agile means.
## 12 Principles of Agile Methodology
In 2001, a group of experts in the field of software development methodologies and frameworks got together to define the [12 principles of the Agile Manifesto](https://agilemanifesto.org/principles.html):
1. Our highest priority is to **satisfy** the customer through **early** and **continuous delivery** of valuable software.
2. Welcome **changing requirements**, even late in development. Agile processes harness change **for the customer’s competitive advantage**.
3. **Deliver** working software **frequently**, from a couple of weeks to a couple of months, with **preference** to the **shorter** timescale.
4. Business people and developers must **work together daily** throughout the project.
5. Build projects around motivated individuals. Give them the **environment** and **support they need**, and **trust them** to get the job done.
6. The most **efficient** and **effective method** of conveying information to and within a development team is **face-to-face conversation**.
7. Working software is the primary measure of progress.
8. Agile processes promote **sustainable development**. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
9. Continuous attention to **technical excellence** and **good design** enhances agility.
10. **Simplicity** -- the art of maximizing the amount of work not done -- **is essential**.
11. The best architectures, requirements, and designs emerge from **self-organizing teams**.
12. At regular intervals, the team **reflects** on how to become **more effective**, then tunes and adjusts its behavior accordingly.
---
## Building Blocks of Agile Development
Based on my experience, and completed by the 12 principles, I would propose the following building blocks of agile development depicted below:
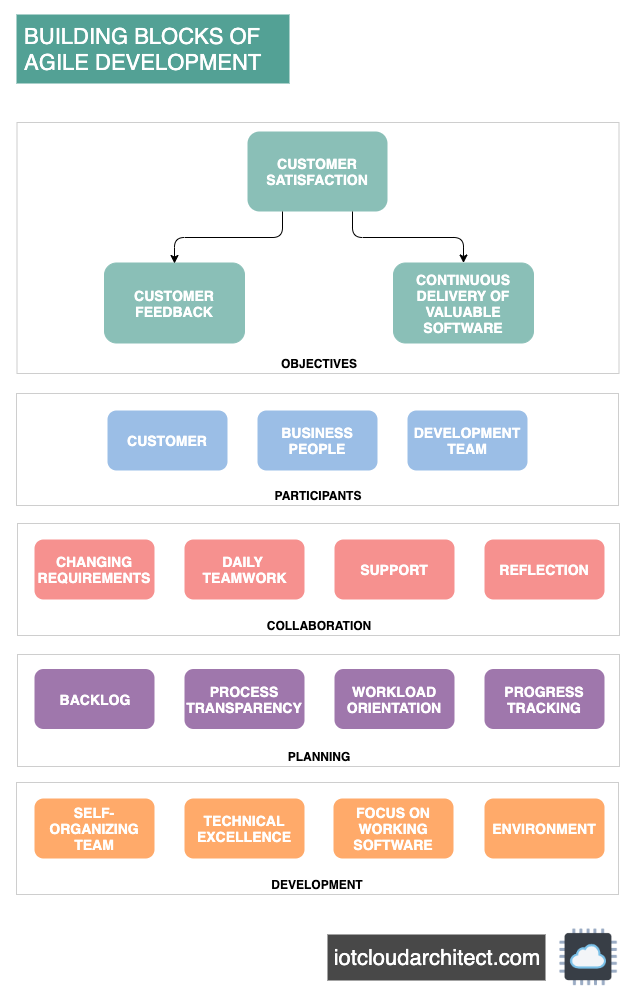
In a nutshell a short description of the building blocks:
### Objectives
The objectives define the root cause of all the sweat and hurt when building software. The main aim should be a satisfied customer. In our case - with regards to agile development - the **customer** would be happy if he could bring in his **requirements and needs**, at any time, with any impact it means to the current development situation. Also, he appreciates the **continuous delivery** of the software he requested at **short time intervals**.
### Participants
One of the basic ideas of agile development is that the **customer**, **business people**, and **development team** work **jointly together** to create the best solution possible, meeting the requirements.
### Collaboration
The beforehand mentioned participants will work together and will exchange their ideas regularly. Business people and the development team should meet in the best case on a **daily** basis for at least a short synch about progress or discuss problems.
**New** requirements or **changes** of existing **requirements** should be discussed and evaluated which impact they might have on the existing implementation.
It is essential that all participants work together and **support** each other to get the best result possible.
Also - regularly - the participants shall **reflect** their way of working together to optimize the process continuously.
### Planning
All requirements of the customer (mostly functional) and non-functional once shall be collected in a **backlog**.
There, all requirements can be estimated and prioritized.
Based on the estimations and available development team size, the (constant) **workload** can be defined to **reasonable** plan the following implementation of features.
Visualizing the tasks or user stories the team is currently working on creates **transparency**. It helps to **track** the **progress** and to measure the iteration's quality.
### Development
Agile development requires **a self-organizing team**. The team members are specialists and bring in their know-how, experience, and motivation.
It is beneficial to have players with **excellent technical skills** who can utilize the necessary technologies to implement the requirements perfectly.
A key aspect in agile development is to **focus on working software**. At the end of each iteration, the result should be a software increment covering the requested requirements.
In order to be able to bring in the working power ideally, the development team should have the **ideal environment**. Everything should be in place from the code editor and the code repository until the cloud-driven pipelines with automated testing to optimize the development process.
---
## Focusses and Objectives of most agile frameworks
### Self-Organized Team
It is crucial to have a team that works without the need for instructions in agile development. Every team member knows the process and the dos and don'ts and acts accordingly.
### Pull-Principle
The idea is that each development team member can take (pull) a job according to his availability. This means that everyone commits to a specific task at a particular time.
No one will push tasks to a developer; instead, jobs are accepted and taken by the development team members.
### Software Increment Orientation
The result shall be shippable and working software at the end of each job or iteration.
### Transparency
Visualizing the tasks and their state is the key to making optimization opportunities visible and increasing efficiency.
### Measure Progress
It is essential to track and monitor the progress of the job or iteration.
---
## Popular Agile Frameworks
Following, a short description of two popular agile development frameworks: Scrum and Kanban.
### Scrum
Scrum comes with a defined process as depicted below:
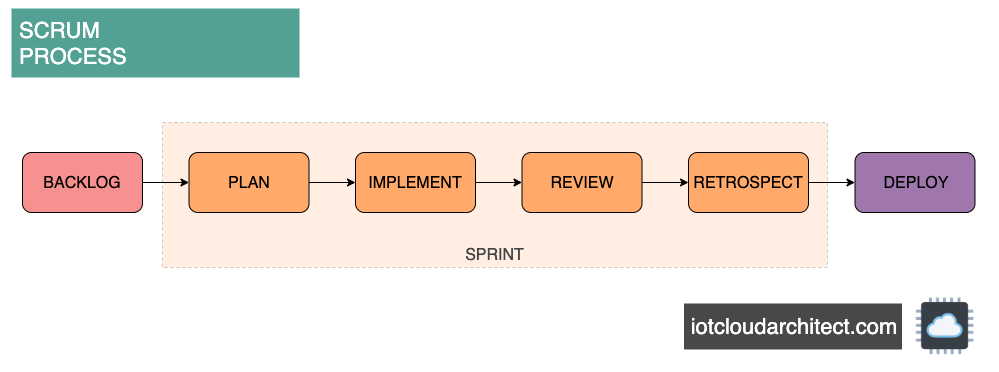
The product owner collects all **requirements** in a **backlog**, prioritizes them, and plans a **manageable amount of work** in a **defined time** (sprint). Therefore, it is often used to develop a new feature or an entirely new product.
For the planning of a sprint, beforehand, the effort of the work will be estimated by the team in a virtual entity called story points. These story points will be used during the sprint to progress the team's velocity.
At the end of each sprint, the **results** are **software increments**, e.g., new features or functions in an app.
Also, in Scrum, there are clearly defined roles of the participants, and due to its **restrictions**, it is supposed to be easier useable for teams with less experience.
### Kanban
The primary purpose of Kanban is the **visualization** of work. Like in Scrum, the requirements (**stories**) are collected and then planned for implementation (**to do**). The stories will be written on cards and put onto the Kanban board as depicted below.
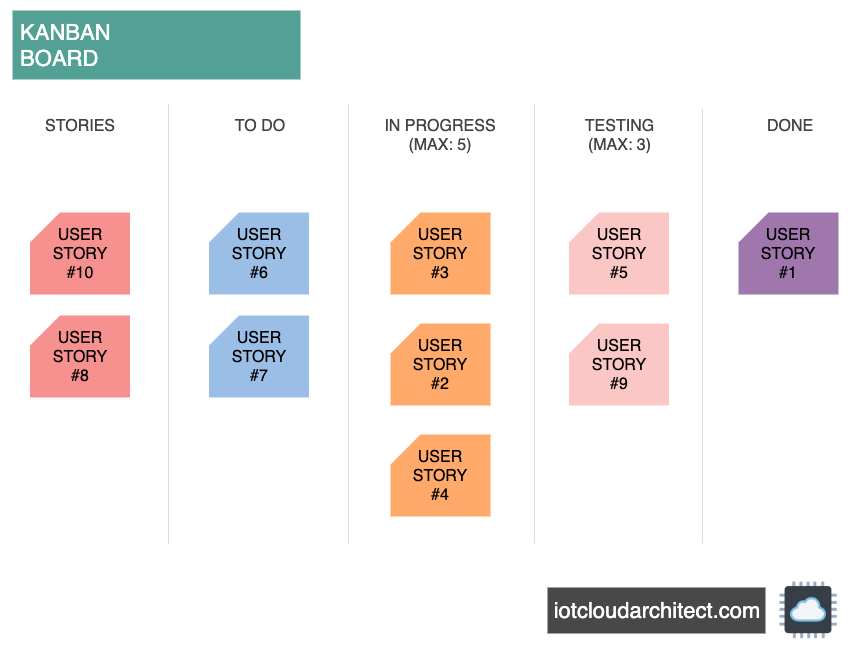
In Kanban, an essential principle is to **focus** on a sensible amount of **work** that the development team can **achieve**. Therefore, the number of cards in the board columns is limited. The current number of cards in a column is called the **work in progress** (WIP) and shows the team's current velocity.
Like in Scrum, the result of each of the stories should be a new software increment.
In contrast to Scrum, Kanban does **not require specific roles** and is not as restrictive. Therefore it is more flexible and can be used for reactive jobs, like planning a bug-fixing for productive software.
---
## Do you need an agile framework?
The following diagram shall give you help with deciding whether you need an agile framework:
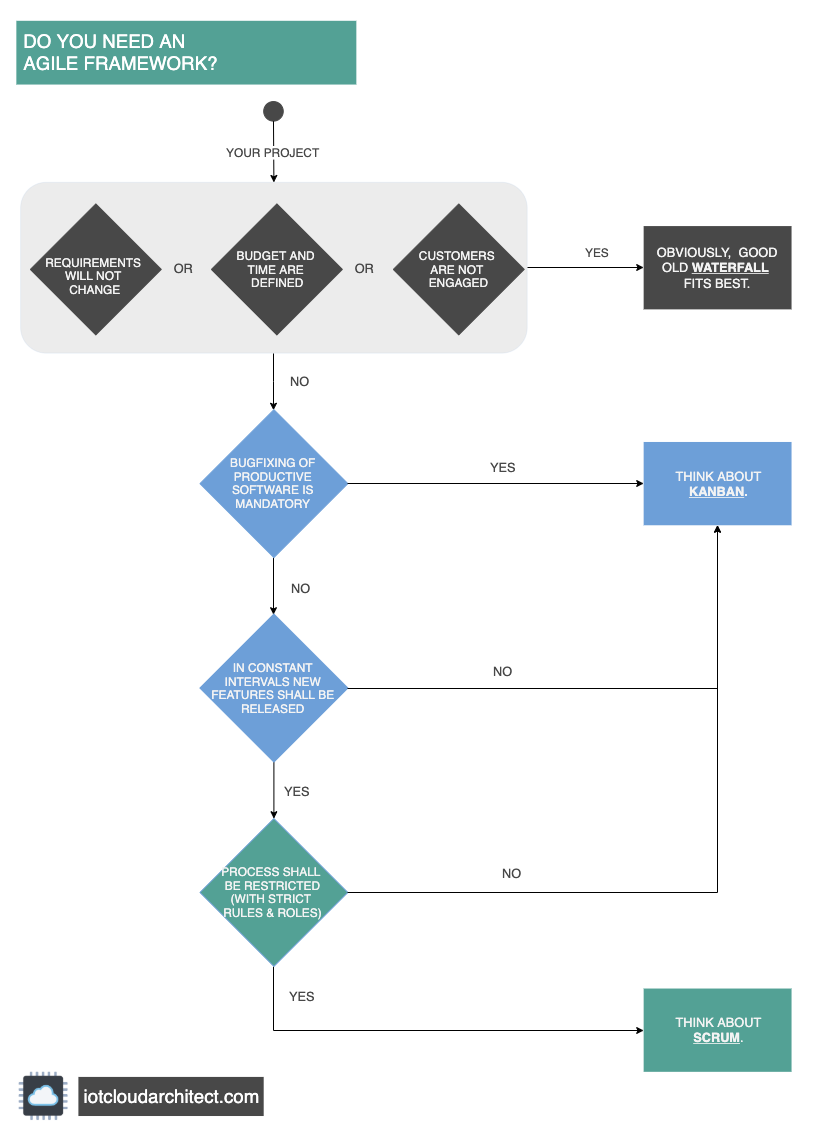
---
## Summary
Which is the proper development framework for your project? I can't tell you. But I hope this article gave you some insights into whether it could be an agile development framework.
Photos on [Unsplash](https://unsplash.com)
| iotcloudarchitect |
942,144 | A Minimal Pluggy Example | Pluggy makes it so easy to allow users to modify the behavior of a framework without thier specific... | 16,020 | 2022-01-01T21:21:42 | https://waylonwalker.com/til/pluggy-minimal-example/ | python | ---
canonical_url: https://waylonwalker.com/til/pluggy-minimal-example/
cover_image: https://images.waylonwalker.com/til/pluggy-minimal-example.png
published: true
tags:
- python
title: A Minimal Pluggy Example
series: til
---
Pluggy makes it so easy to allow users to modify the behavior of a framework without thier specific feature needing to be implemented in the framework itself.
I've really been loving the workflow of frameworks built with pluggy. The first one that many python devs have experience with is pytest. I've never created a pytest plugin, and honestly at the time I looked into how they were made was a long time ago and it went over my head. I use a data pipelining framework called kedro, and have build many plugins for it.
## Making a plugin
_super easy to do_
As long as the framework document the hooks that are available and what it passes to them it's so easy to make a plugin. Its just importing the
`hook_impl`, making a class with a function that represents one of the hooks,
and decorating it.
``` python
from framework import hook_impl
class LowerHook:
@hook_impl
def start(pluggy_example):
pluggy_example.message = pluggy_example.message.lower()
```
## installing pluggy
Installing pluggy is just like most python applications, install python, make your virtual environment, and pip install it.
``` bash
pip install pluggy
```
## Making a plugin driven framework
_much less easy_
At the time I started playing with pluggy, their docs were less complete, or I was just plain blind, but this was a huge part of the docs that were missing for me that now actually appear to be there. But to get some more examples out there, here is my version.
``` python
import pluggy
# These don't need to match
HOOK_NAMESPACE = "pluggy_example" PROJECT_NAME = "pluggy_example"
hook_spec = pluggy.HookspecMarker(HOOK_NAMESPACE) hook_impl = pluggy.HookimplMarker(HOOK_NAMESPACE)
class PluggyExampleSpecs:
"""
This is where we spec out our frameworks hooks, I like to refer to them as
the lifecycle. Each of these functions is a hook that we are exposing to
our users, with the kwargs that we expect to pass them.
"""
@hook_spec
def start(self, pluggy_example: 'PluggyExample') -> None:
"""
The first hook that runs.
"""
pass
@hook_spec
def stop(self, pluggy_example: 'PluggyExample') -> None:
"""
The last hook that runs.
"""
pass
class PluggyExample:
"""
This may not need to be a class, but I wanted a container where all the
hooks had access to the message. This made sense to me to do as a class.
"""
def __init__(self, message="", hooks=None) -> None:
"""
Setup the plugin manager and register all the hooks.
"""
self._pm = pluggy.PluginManager(PROJECT_NAME)
self._pm.add_hookspecs(PluggyExampleSpecs)
self.message = message
self.hooks = hooks
if hooks:
self._register_hooks()
def _register_hooks(self) -> None:
for hook in self.hooks:
self._pm.register(hook)
def run(self):
"""
Run the hooks in the documented order, and pass in any kwargs the hook
needs access to. Here I am storing the message within this same class.
"""
self._pm.hook.start(pluggy_example=self)
self._pm.hook.stop(pluggy_example=self)
return self.message
class DefaultHook:
"""
These are some hooks that run by default, maybe these are created by the
framework author.
"""
@hook_impl
def start(pluggy_example):
pluggy_example.message = pluggy_example.message.upper()
@hook_impl
def stop(pluggy_example):
print(pluggy_example.message)
if __name__ == "__main__":
"""
The user of this framework can apply the hook in their own code without
changing the behavior of the framework, but the library has
implemented it's own default hooks.
"""
pe = PluggyExample(
message="hello world",
hooks=[
DefaultHook,
],
)
pe.run()
```
## Modifying behavior
_as a user of PluggyExample_
Now Lets pretent the user of this library likes everything about it, except, they don't like all the shouting. They can either search for a plugin on Google, github, or pypi and find one, or make it themself. the magic here is that they do not need to have the package maintainer patch the core library itself.
``` python
class LowerHook:
"""
This is a new hook that a plugin author has created to modify the behavior
of the framework to lowercase the message.
"""
@hook_impl
def start(pluggy_example):
pluggy_example.message = pluggy_example.message.lower()
from pluggy_example import PluggyExample pe = PluggyExample(
message="hello world",
hooks=[
DefaultHook,
LowerHook
],
)
pe.run()
```
## Running Pluggy Example
Here is a short clip of me running the pluggy example in it's default state, then adding the LowerHook, and running a second time.
<video autoplay="" controls="" loop="true" muted="" playsinline="" width="100%">
<source src="https://images.waylonwalker.com/til-pluggy-example.webm" type="video/webm">
<source src="https://images.waylonwalker.com/til-pluggy-example.mp4" type="video/mp4">
Sorry, your browser doesn't support embedded videos.
</video>
| waylonwalker |
942,282 | Guest Login in JavaScript 🤯 | Whether a project is small, medium, or huge, it's most common necessity is authentication. In few... | 0 | 2022-01-02T05:43:04 | https://dev.to/rajeshj3/login-without-email-and-password-javascript-38le | webdev, javascript, react, firebase | Whether a project is small, medium, or huge, it's most common necessity is `authentication`. In few cases, it is just required to not to ask user for credentials, but just to log user in for proper authentication.
The best way to solve this problem is to use Firebase's Anonymous Authentication.
*__NOTE:__ Here's the YouTube video of me, demonstrate the same*
{% youtube Wwl2bsvGeyE %}
*__NOTE:__:* I'll recommend you, to use the `yarn`, but it is completely up to you.
---
### *Step 1.* Create React App
``` bash
$ npx create-react-app fbase
```
### *Step 2.* Add firebase
``` bash
$ yarn add firebase
```
It'll be reflected in `package.json` file.
``` json
{
"name": "fbase",
"version": "0.1.0",
"private": true,
"dependencies": {
"@testing-library/jest-dom": "^5.16.1",
"@testing-library/react": "^12.1.2",
"@testing-library/user-event": "^13.5.0",
"firebase": "^9.6.1",
"react": "^17.0.2",
"react-dom": "^17.0.2",
"react-scripts": "5.0.0",
"web-vitals": "^2.1.2"
},
"scripts": {
"start": "react-scripts start",
"build": "react-scripts build",
"test": "react-scripts test",
"eject": "react-scripts eject"
},
"eslintConfig": {
"extends": [
"react-app",
"react-app/jest"
]
},
"browserslist": {
"production": [
">0.2%",
"not dead",
"not op_mini all"
],
"development": [
"last 1 chrome version",
"last 1 firefox version",
"last 1 safari version"
]
}
}
```
### *Step 3.* Create `firebaseConfig.json` file, and paste the firebase configurations
``` json
{
"apiKey": "AIzygy_MxOabWfYylrZcr_A0qikixlwIynwvgE",
"authDomain": "learn-00000.firebaseapp.com",
"projectId": "learn-00000",
"storageBucket": "learn-00000.appspot.com",
"messagingSenderId": "708886134942",
"appId": "1:708886134942:web:e9162122e8cd6741ca7b8f",
"measurementId": "G-M5TXS27GDQ"
}
```
### *Step 4.* Write `app.js`
``` js
import { initializeApp } from "firebase/app";
import { getAuth } from "firebase/auth";
import firebaseConfig from "./firebaseConfig.json";
initializeApp(firebaseConfig);
const auth = getAuth();
export default function App() {
return ();
}
```
Now, create Flexbox
``` js
import { initializeApp } from "firebase/app";
import { getAuth } from "firebase/auth";
import firebaseConfig from "./firebaseConfig.json";
initializeApp(firebaseConfig);
const auth = getAuth();
export default function App() {
return (
<div
style={{
display: "flex",
flexDirection: "column",
justifyContent: "center",
alignItems: "center",
}}
>
<h1>Anonymous Login</h1>
</div>
);
}
```
Add HTML form
``` js
import { initializeApp } from "firebase/app";
import { getAuth } from "firebase/auth";
import firebaseConfig from "./firebaseConfig.json";
initializeApp(firebaseConfig);
const auth = getAuth();
export default function App() {
return (
<div
style={{
display: "flex",
flexDirection: "column",
justifyContent: "center",
alignItems: "center",
}}
>
<h1>Anonymous Login</h1>
<form onSubmit={handleSubmit}>
<button type="submit">Login</button>
</form>
</div>
);
}
```
define `onSubmit` method.
``` js
import { initializeApp } from "firebase/app";
import { getAuth } from "firebase/auth";
import firebaseConfig from "./firebaseConfig.json";
initializeApp(firebaseConfig);
const auth = getAuth();
export default function App() {
const handleSubmit = (e) => {
e.preventDefault();
// ...
};
return (
<div
style={{
display: "flex",
flexDirection: "column",
justifyContent: "center",
alignItems: "center",
}}
>
<h1>Anonymous Login</h1>
<form onSubmit={handleSubmit}>
<button type="submit">Login</button>
</form>
</div>
);
}
```
Import `signInAnonymously`
``` js
import { getAuth, signInAnonymously } from "firebase/auth";
```
Now, extend `handleSubmit`
``` js
import { initializeApp } from "firebase/app";
import { getAuth, signInAnonymously } from "firebase/auth";
import firebaseConfig from "./firebaseConfig.json";
initializeApp(firebaseConfig);
const auth = getAuth();
export default function App() {
const handleSubmit = (e) => {
e.preventDefault();
signInAnonymously(auth)
.then()
.catch();
};
return (
<div
style={{
display: "flex",
flexDirection: "column",
justifyContent: "center",
alignItems: "center",
}}
>
<h1>Anonymous Login</h1>
<form onSubmit={handleSubmit}>
<button type="submit">Login</button>
</form>
</div>
);
}
```
Write, responses
``` js
import { initializeApp } from "firebase/app";
import { getAuth, signInAnonymously } from "firebase/auth";
import firebaseConfig from "./firebaseConfig.json";
initializeApp(firebaseConfig);
const auth = getAuth();
export default function App() {
const handleSubmit = (e) => {
e.preventDefault();
signInAnonymously(auth)
.then((res) => {
console.log("[Sign In] DONE", res.user.uid);
})
.catch((error) => {
console.log(error.message);
});
};
return (
<div
style={{
display: "flex",
flexDirection: "column",
justifyContent: "center",
alignItems: "center",
}}
>
<h1>Anonymous Login</h1>
<form onSubmit={handleSubmit}>
<button type="submit">Login</button>
</form>
</div>
);
}
```
### *Step 5.* Run the server
``` bash
$ yarn start
```
click `Login` button and Open developer console.
In `Applications > IndexedDB` you'll see user credentials saved.
### *Step 6.* Have a look in Firebase Console
---
Hurray! You just learned how to set up API end-points for Login `Without Email and Password` in `JavaScript`.
---
I hope, you guys liked this quick tutorial. If so, then please don't forget to drop a Like ❤️
And also, help me reach **1k Subscribers** 🤩, on my [YouTube channel](https://www.youtube.com/channel/UCCO4jIqmQVFDmVeeaAO5obA).
Happy Coding! 😃💻 | rajeshj3 |
942,458 | P1:Build a Tribute Page | A post by idris Adam | 0 | 2022-01-02T12:01:35 | https://dev.to/idrisadameng/p1build-a-tribute-page-5e76 | codepen | {% codepen https://codepen.io/EngineerAdam/pen/bGovjRz %} | idrisadameng |
942,723 | My Commitment to #100DaysOfCode | Part 2 | I'm starting 2022 by committing to Quincy Larson's 2022 Become-a-Dev New Year's Resolution Challenge... | 0 | 2022-01-02T19:46:39 | https://blog.godswillumukoro.com/my-commitment-to-100daysofcode-or-part-2 | 100daysofcode | ---
title: My Commitment to #100DaysOfCode | Part 2
published: true
description:
tags: 100DaysOfCode
canonical_url: https://blog.godswillumukoro.com/my-commitment-to-100daysofcode-or-part-2
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/b8lfhjolmsbcdtkoewvp.png
---
I'm starting 2022 by committing to [Quincy Larson's 2022 Become-a-Dev New Year's Resolution Challenge on Twitter.](https://www.freecodecamp.org/news/2022-become-a-dev-new-years-resolution-challenge/)
I'm positive this will keep me accountable and focused on reaching my goals for 2022. Some of which are:
1. Become Proficient in React and Firebase
2. Earn a high-income monthly salary
3. Read 10 Books
While the curriculum in this #100DaysOfCode challenge may not directly lead me to reach those outlined goals, it's a sure-fire way to keep me on my toes and push me to code every day.
The goal is to spend 30 minutes every day on the #100DaysOfCode challenge and use the momentum to hack on the specific skillset I'm trying to gain.
If you would love to see my daily log for the challenge, I have a whole [Github repository dedicated to this.](https://github.com/godswillumukoro/100-days-of-code-part-2/blob/main/daily-log.md)
> Thanks for reading this far. Did you find this article helpful? [Follow me on Twitter](https://twitter.com/umuks_) and tell me all about it.
| godswillumukoro |
942,752 | How To Add A Community Trading Bot on Discord | At Blankly, we pride ourselves not just for the product that we are building, but also towards... | 0 | 2022-01-02T21:10:01 | https://blankly.finance/how-to-add-a-community-trading-bot-on-discord | discord, tutorial, programming | At Blankly, we pride ourselves not just for the product that we are building, but also towards cultivating a community of quant enthusiasts which no one else is doing in this field right now. We identified a critical void that many Discord servers currently suffer from: low member engagement. That said, to elevate the overall experience of using the Blankly package and fix the problem identified earlier, we decided to roll out three Discord bots each of which specializes in something unique. We will dive into the Blankly Connect Bot in this article.
### Using Blankly Connect to Integrate a Discord Bot
To give the users a taste of our product, we created this bot using a virtual sandbox and our in-house [Blankly Connect API](https://blankly.finance/products/api)—the single source to connect, unify, and trade across all exchanges—which aims at simulating what the actual product will be like. We feel that this is the best way for beginners to get acclimated with the fast-paced environment of quant trading and for more experienced members to understand how our platform works.
Having used Discord previously as a means to connect with friends, group partners, and other communities, I was very excited to create a bot that focuses on community trading ultimately helping server owners spice their servers and elevate their member's experience to a new level. At Blankly, for example, it gave us the opportunity to differentiate ourselves from other similar platforms by offering our members something they haven't ever witnessed.
I would highly recommend that you install some kind of an IDE (I used VSCode, however my team prefers Webstorm :/), Node.js, and set up a Discord account. Before you even start coding, you are going to need to create an application from the [Discord Developer Portal](https://discord.com/developers/docs/intro) which will allow you to obtain an authorization token and set the permissions for your bot.
Once the application is created, click on the section titled *Bot* and go ahead and fill the necessary details. Find the bot's authorization token and make sure to **not share it with anyone.** This token will be needed in the next few steps. Now that your bot is setup, you have to invite it to your server. Therefore, select the *OAUTH2* tab and then the *URL Generator* to allow you to select certain permissions and abilities for the bot. When done, copy the URL shown at the bottom of the page and paste it into your web browser. Select the server to which the bot will be in and that's it. Your bot is alive within your server... YAYY 🎆
Now, create a file on your IDE which will contain your bot's token like the following snippet below and make sure to give it a `.json` file type before adding it to `.gitignore`, so that the token wont be visible when you push your repository onto Github.
```json
{
"token" = "[token goes here]"
}
```
The second starter file will be the `package.json` so that it is easy for others to manage and install your package. Add the following fields:
```json
{
"name": "[Name of your bot]",
"version": "[version id]",
"description": "Enter a description",
"main": "bot.js",
"author": "Your Name Goes Here",
"dependencies": { },
"scripts": { }
}
```
The last file needed is where you will code how your bot should function and its behavioristics.
```javascript
let Discord = require('discord.io');
let auth = require('./botAuth.json');
let blankly_connecter = require('../src/blankly_client')
blankly_connecter.setExchange('coinbase_pro');
blankly_connecter.setKeys({'API_KEY': '***', 'API_SECRET': '***',
'API_PASS':'***'});
blankly_connecter.setSandbox(true);
let bot = new Discord.Client({
token: auth.token,
autorun: true
});
bot.on('ready', function (evt) {
console.log('{Status: Connect Bot is Connected}')
});
bot.on('error', function (error) {
console.log(error)
});
bot.on('message', function (user, userID, channelID, message, evt) {
if (message.substring(0, 1) == '!') {
var args = message.substring(1).split(' ');
var cmd = args[0];
args = args.splice(1);
switch(cmd) {
case 'ping':
bot.sendMessage({
to: channelID,
message: 'pong!'
});
break;
// Add further cases if you need to..
}
}
});
```
This is the basic boilerplate code for a Discord bot which responds to commands. This code snippet is more than enough to help you understand how Discord bots operate and the syntax required to be able to operate them. Another great resource I would recommend are the documentation notes for the Discord bots such as [Discord.io](https://www.npmjs.com/package/discord.io/v/1.0.1), which this bot uses, but you can also use [Discord.js](https://discord.js.org/#/). It is also important to emphasize that there are many other ways that you can code your bot depending on your needs.
Furthermore, as you can see, I imported the Blankly Connect API in `bot.js` so that I can utilize its robust functionality. As shown from the diagram below, this API acts as a middleman between Discord and the major stock and cryptocurrency exchanges allowing for a smooth experience for the user when inputting commands.
<hr>
You now have the basic tools needed to create your own community-based trading Discord bot. Have fun coding and I hope your bots don't take over the world!
Overall, this was a very interesting project as it exposed me to a new aspect of Discord which I was previously not aware of—the Developer side. Due to the pandemic, I have started using Discord almost every day and never really thought how easy it would be to create a bot to handle certain tasks. Although at first it may seem a bit daunting, it gets easier and easier as you become more comfortable with the developer environment. I can now confidently go ahead and create a bot within hours. Incorporating bots to your server will definitely increase the overall user engagement and will also significantly boost the number of users in the server and, thus, is a great addition to have.
As we look to continuously improve the bots, our next few steps are to transform this project into being open source, similar to our other products, so that the community can have a more direct involvement with our cause and we can make improvements related to your feedback. | kw4ng |
942,943 | Deploying with the Click of a Button | Create a 'Deploy To Netlify' button for any project to make deployment silly simple and ever so easy. | 16,129 | 2022-01-03T04:26:50 | https://www.netlify.com/blog/2021/12/26/deploying-with-the-click-of-a-button/ | netlify, development, workflow | ---
title: Deploying with the Click of a Button
published: true
description: Create a 'Deploy To Netlify' button for any project to make deployment silly simple and ever so easy.
tags: Netlify, Development, Workflow
cover_image: https://pbs.twimg.com/media/EJqexv4WwAcojgg.jpg
canonical_url: https://www.netlify.com/blog/2021/12/26/deploying-with-the-click-of-a-button/
series: Netlify - a feature a day 2021
---
> Throughout December we'll be [highlighting a different Netlify feature each day](https://www.netlify.com/blog/2021/12/01/highlighting-a-different-netlify-feature-each-day-in-december/?utm_campaign=featdaily21&utm_source=netlify&utm_medium=blog&utm_content=snippet-injection). It might just be the thing you need to unlock those creative juices, and [dust off that domain](https://www.netlify.com/blog/2021/12/01/dusty-domains-your-forgotten-domains-raise-money-for-charity/?utm_campaign=featdaily21&utm_source=netlify&utm_medium=blog&utm_content=snippet-injection) you registered but never deployed! Keep an eye [on the blog](https://www.netlify.com/blog/2021/12/01/highlighting-a-different-netlify-feature-each-day-in-december/?utm_campaign=featdaily21&utm_source=netlify&utm_medium=blog&utm_content=snippet-injection) and on [Twitter](https://twitter.com/netlify) for each feature!
If only there was a way to help people (and/or pets) deploy your amazing projects with a click of a button. Well, funny you should mention that, Tara, because indeed there is! Adding the link to your project repo to this snippet of code here:
```html
https://app.netlify.com/start/deploy?repository=<your repo right here!>
example: https://app.netlify.com/start/deploy?repository=https://github.com/netlify-templates/next-netlify-starter
```
Then you can add the button to your website, repo, blog post, etc with this code:
```
markdown:
[](https://app.netlify.com/start/deploy?repository=https://github.com/netlify-templates/next-netlify-starter)
html:
<a href="https://app.netlify.com/start/deploy?repository=https://github.com/netlify-templates/next-netlify-starter"><img src="https://www.netlify.com/img/deploy/button.svg"></a>
```
Would ya look at that, we have a button. Just look at it!
[](https://app.netlify.com/start/deploy?repository=https://github.com/netlify-templates/next-netlify-starter)
When someone clicks the button it will start to walk them through the deployment process. Have a click and try it yourself. Happy coding 👩🏻💻!

### Resources for the Road
* [Deploy to Netlify Docs](https://docs.netlify.com/site-deploys/create-deploys/#deploy-to-netlify-button)
* See it in the wild in [the Next.js template repo](https://github.com/netlify-templates/next-netlify-starter)
| tzmanics |
943,137 | JS ENGINE for a kid | First where all places can javascript run, frankly speaking everywhere for example most common... | 0 | 2022-01-03T10:32:42 | https://dev.to/hardikganatra/js-engine-for-a-kid-4oe | javascript, webdev, jsengine | First where all places can javascript run, frankly speaking everywhere for example most common browser, server, smartwatch, IoT device.
Every place where the JavaScript code runs has a JavaScript Environment
So for the browser to run JavaScript code, it should have a JS runtime Environment that has
similarly, Node.js has a JavaScript Environment
Let's say there is some now Amazing thing developed where we feel JS should be the preferred language to achieve a certain task what we will need? Yes JavaScript runtime environment
Like as we know browser has some web APIs, node.js has some other APIS.
Now Since we now understand what is a JavaScript Runtime environment, let us check the Heart of the JavaScript Runtime Environment the
**JavaScript Engine**
JavaScript Engine (in the case of the V8 engine) is a normal program written in c++.
What is the main purpose of the above program?
Take the high-level code and give output as code which machine can understand
Now what happens inside the JS engine
There are 3 major things that happen
Takes our code as input and does
1. Parsing
2. Compilation
3. Execution
_Let us check what happens in Parsing._
Check this amazing website https://astexplorer.net/
1. Break code into tokens
2. Syntax parser > creates Abstract Syntax Tree (AST) (object which has all information about the line of code )
_Let us check what happens in Compilation._
First, what is the interpreter?
an interpreter executes code line by line
First, what is the compiler?
As the name says it compiles code and a new version is formed which is the optimized version of the code and then executed
Obviously in the interpreter, since we do not need an extra step
an interpreter is fast in the case of the compiler we have more efficiency.
Javascript can behave interpreted as well as compiled language
At initial stages, JS was purely supposed to be interpreted language
Now, what is JIT i-e just in time compilation?
Simply JS engine can use Interpreter as well as compiler so it is said JS engine does JIT compilation
Now compilation and execution go hand in hand
we have AST ready in the previous step remember
This AST goes to the Interpreter and moves to execution and while this happens, it takes the help of the compiler to optimize the code
This compilation step is Just in time of interpretation so it is called the JIT compiler
After compilation, the byte code is sent to the execution step
Now let us check the execution phase (has a byte code as input from compilation step)
In the Execution phase we have memory heap and call stack, these are the terms we generally hear correct.
A memory heap is a place where all variables and functions are assigned memory
garbage collector works for freeing space for memory heap if
some object has no reference or function not used or we clear timeout, remove event handlers it uses mark and sweep algorithm (check this out on google)
V8 is very famous among JS engines Its
The interpreter is known as Ignition
A compiler is known as TurboFan
The Orinoco is their Garbage collector
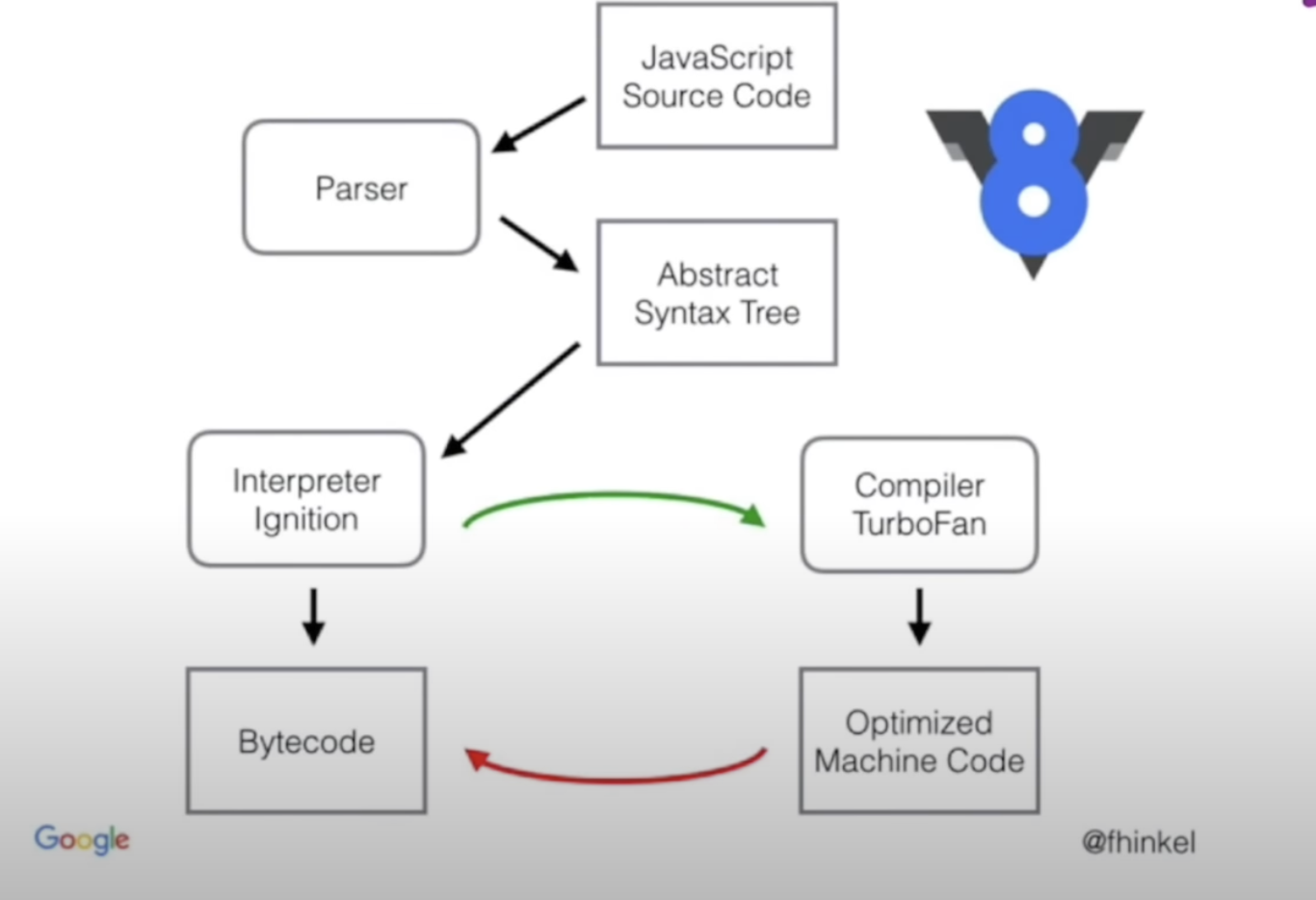
References
https://www.youtube.com/watch?v=2WJL19wDH68
https://blog.bitsrc.io/javascript-internals-javascript-engine-run-time-environment-settimeout-web-api-eeed263b1617
https://www.telerik.com/blogs/journey-of-javascript-downloading-scripts-to-execution-part-ii
https://www.youtube.com/watch?v=xckH5s3UuX4
| hardikganatra |
943,461 | How to sort a list in Python | In this post we will discuss how to sort list in Python. There are mainly two ways to sort a list... | 0 | 2022-01-03T17:26:40 | https://dev.to/afizs/how-to-sort-a-list-in-python-2ok9 | python, datascience, machinelearning, programming | In this post we will discuss how to sort list in Python.
There are mainly two ways to sort a list in Python.
1. `sorted` function
2. `sort` method
## 1. `sorted` function:
This sort the given list and generate a new list, which means existing list won't be modified.
```
In [1]: numbers = [23, 42, 12, 121, 45, 9, 8]
In [2]: sorted(numbers)
Out[2]: [8, 9, 12, 23, 42, 45, 121]
In [3]: numbers
Out[3]: [23, 42, 12, 121, 45, 9, 8]
```
As you can see in the above example `Out[3]` has the same numbers list.
## 2. `sort` method:
This method applies the sorting on the list and updates the existing list. This is called in place sorting.
```
In [4]: numbers.sort()
In [5]: numbers
Out[5]: [8, 9, 12, 23, 42, 45, 121]
```
## Key param:
`sorted` and `sort` methods takes an extra parameter called `key`. Using this `key` param we can control the sorting.
Example: `names = ['Bob', 'Charles', 'James']`. Let's say we want to sort the above list of `names` based on length of the each time.
Solution:
```
In [7]: sorted(names, key=len)
Out[7]: ['Bob', 'James', 'Charles']
```
We can pass any function we want to this `key`. Let me know which method you like in the comments. If you like this content consider following me. | afizs |
943,505 | Open Model Thread Group in JMeter | The Apache JMeter community has been swift in releasing the major security patches for the Log4j... | 0 | 2022-01-03T17:39:54 | https://qainsights.com/open-model-thread-group-in-jmeter | testing, webperf, performance, tutorial | <!-- wp:paragraph -->
<p>The Apache JMeter community has been swift in releasing the major security patches for the Log4j fiasco. I have already covered multiple posts about <a href="https://qainsights.com/what-to-do-if-you-cannot-upgrade-to-jmeter-5-4-2-for-log4j-vulnerability/" target="_blank" rel="noreferrer noopener">Log4j vulnerability</a>, <a href="https://qainsights.com/whats-new-in-apache-jmeter-5-4-2/" target="_blank" rel="noreferrer noopener">JMeter 5.4.2</a> and <a href="https://qainsights.com/apache-jmeter-5-4-3/" target="_blank" rel="noreferrer noopener">JMeter 5.4.3</a>. JMeter 5.5 was supposed to be released in the last quarter of 2021. I have already covered <a href="https://qainsights.com/whats-new-in-jmeter-5-5/" target="_blank" rel="noreferrer noopener">what's new in JMeter 5.5</a>. JMeter 5.5 will be released in early January 2022. In this blog post, let us deep-dive into one of the important features, which is the Open Model Thread Group in JMeter 5.5. </p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>About Open Model Thread Group</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Open Model Thread Group is available starting from JMeter 5.5 under Threads menu when you right click on the Test Plan as shown below.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","id":8986,"sizeSlug":"full","linkDestination":"media"} -->
<div class="wp-block-image"><figure class="aligncenter size-full"><a href="https://qainsights.com/wp-content/uploads/2022/01/image.png"><img src="https://qainsights.com/wp-content/uploads/2022/01/image.png" alt="Open Model Thread Group in JMeter 5.5" class="wp-image-8986"/></a><figcaption>Open Model Thread Group in JMeter 5.5</figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>This is an experimental feature since 5.5 and might change in the future.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Typically, we define the number of threads/users in a Thread Group. There is no thumb rule to follow to utilize the optimum number of threads for a test plan. There are numerous factors that influence the number of threads that a system can spin. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Open Model Thread Group allows a defined pool of threads (users) to run without explicitly mentioning the number of threads.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>How to design Open Model Thread Group in JMeter?</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Open Model Thread Group </strong>in JMeter accepts a Schedule and an optional Random Seed. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>By using the following expressions, we can define the schedule:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li>rate</li><li>random arrivals</li><li>pause</li><li>comments</li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>rate is nothing but a target load rate in ms, sec, min, hour, and day. e.g. <code>rate(1/min)</code></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>random_arrivals helps to define the random arrival pattern with the given duration, e.g. <code>random_arrivals(10 min)</code></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>To define a increaing load pattern, first define the starting load rate using rate(), then the random_arrivals(), and at last the ending load rate using rate(). e.g. <code>rate(0/min) random_arrivals(10 min) rate(100/min)</code></p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","id":8988,"sizeSlug":"large","linkDestination":"media"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><a href="https://qainsights.com/wp-content/uploads/2022/01/image-1.png"><img src="https://qainsights.com/wp-content/uploads/2022/01/image-1-1024x422.png" alt="Increasing Load Pattern" class="wp-image-8988"/></a><figcaption>Increasing Load Pattern</figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>To define a steady state, use the following expression:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>rate(0/min) random_arrivals(5 min) rate(100/min)
random_arrivals(100 min)
rate(100/min) random_arrivals(5 min) rate(0/min)</code></pre>
<!-- /wp:code -->
<!-- wp:image {"align":"center","id":8989,"sizeSlug":"large","linkDestination":"media"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><a href="https://qainsights.com/wp-content/uploads/2022/01/image-2.png"><img src="https://qainsights.com/wp-content/uploads/2022/01/image-2-1024x325.png" alt="Steady State" class="wp-image-8989"/></a><figcaption>Steady State</figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>For a step by step pattern, use:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>${__groovy((1..10).collect { "rate(" + it*10 + "/sec) random_arrivals(10 sec) pause(1 sec)" }.join(" "))}</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph {"align":"center"} -->
<p class="has-text-align-center">or</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>${__groovy((1..3).collect { "rate(" + it.multiply(10) + "/sec) random_arrivals(10 sec) pause(1 sec)" }.join(" "))}</code></pre>
<!-- /wp:code -->
<!-- wp:image {"align":"center","id":8990,"sizeSlug":"large","linkDestination":"media"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><a href="https://qainsights.com/wp-content/uploads/2022/01/image-3.png"><img src="https://qainsights.com/wp-content/uploads/2022/01/image-3-1024x292.png" alt="Groovy expression" class="wp-image-8990"/></a><figcaption>Groovy expression</figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>JMeter functions are also accepted in the expression. </p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>pause(2 min)
rate(${__Random(10,100,)}/min) random_arrivals(${__Random(10,100,)} min) rate(${__Random(10,100,)}/min)
pause(2 min)
rate(${__Random(10,100,)}/min) random_arrivals(${__Random(10,100,)} min) rate(${__Random(10,100,)}/min)
pause(2 min)
rate(${__Random(10,100,)}/min) random_arrivals(${__Random(10,100,)} min) rate(${__Random(10,100,)}/min)</code></pre>
<!-- /wp:code -->
<!-- wp:image {"align":"center","id":8991,"sizeSlug":"large","linkDestination":"media"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><a href="https://qainsights.com/wp-content/uploads/2022/01/image-4.png"><img src="https://qainsights.com/wp-content/uploads/2022/01/image-4-1024x285.png" alt="Random pattern" class="wp-image-8991"/></a><figcaption>Random pattern</figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>Apart from the above parameters, the expression allows single and multi-line comments.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>/* multi-line comment */
// single line comment
rate(1/min) random_arrivals(10 min) pause(1 min)</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p><strong>even_arrivals()</strong> has not implemented feature in Open Model Thread Group. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Open Model Thread Group is executed at the beginning of the test, meaning any functions inside Open Model Thread Group are executed only once; their first result will be used for the execution.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>How to use this feature now?</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>You can leverage nightly build to utilize this feature right now. Night build is not reliable for production purpose. To download, head to https://ci-builds.apache.org/job/JMeter/job/JMeter-trunk/lastSuccessfulBuild/artifact/src/dist/build/distributions/</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Sample Workload Model</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Let us design a below workload pattern using the below expressions.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>rate(0/s) random_arrivals(10 s) rate(10/s)
random_arrivals(1 m) rate(10/s)</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>The total duration of this test will be 1 min 10 secs. For the first 10 seconds, the rate is 10. Then, for 1 minute, the throughput will be maintained at 10/s.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The maximum throughput is 600/minute. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Below is the dummy sampler in the test plan which has random response time of <code>${__Random(2000,2000)}</code> and <code>${__Random(50,500)}</code> respectively.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","id":8993,"sizeSlug":"full","linkDestination":"media"} -->
<div class="wp-block-image"><figure class="aligncenter size-full"><a href="https://qainsights.com/wp-content/uploads/2022/01/image-5.png"><img src="https://qainsights.com/wp-content/uploads/2022/01/image-5.png" alt="Sample Test Plan" class="wp-image-8993"/></a><figcaption>Sample Test Plan</figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>Since the throughput is 600, this test plan will try to maintain the rate for the two samplers individually, i.e. <code>600+600 = 1200 requests</code>. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Since the first dummy sampler response time is 2000 ms, the test plan will create more threads to maintain the throughput. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Below is the aggregate report. Each dummy sampler throughput is 9.4/sec, reaching <code>1280 requests in total</code>. </p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","id":8994,"sizeSlug":"large","linkDestination":"media"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><a href="https://qainsights.com/wp-content/uploads/2022/01/image-6.png"><img src="https://qainsights.com/wp-content/uploads/2022/01/image-6-1024x181.png" alt="Sample Report" class="wp-image-8994"/></a><figcaption>Sample Report</figcaption></figure></div>
<!-- /wp:image -->
<!-- wp:heading -->
<h2>Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Open Model Thread Group will be very helpful in designing a custom load pattern without calculating the number of threads. Functions inside the expression help to generate a dynamic workload model. Using this thread group, no need to calculate the exact number of threads you need for the test as long as the load generators are powerful enough to generate the load pattern. Since it is a new feature, it may have issues. I am still testing this. If you face any problems, please let me know. </p>
<!-- /wp:paragraph --> | qainsights |
943,666 | #Frontend or #Blackened | My first challenge : 100 Days of Code - DEV Community 👩💻👨💻 My first challenge : 100 Days of... | 0 | 2022-01-03T20:27:51 | https://dev.to/tuitown/frontend-or-blackened-42e5 |
My first challenge : 100 Days of Code - DEV Community 👩💻👨💻
My first challenge : 100 Days of Code
#100daysofcode
#javascript
#devops
#PHP
#webdev
#Python
Hello, With 2021 just ended and 2022 started i feel like i have doing nothing in 2021 for improving my self. So i decided to try to make the 100 days of code challenge .
What i want by doing this :
Making me able to be a freelance dev
Becoming a backend developer.
My objective are prettie simple:
Improve my basic notion in HTML & CSS
Improve my knowledge in PHP and Python
Improving my DEVOPS Skills.
Gain on regularity and rigor.
My motivation :
I want to be a Devops engineer but i love developing. So i decided i am going to do both. DevOps Engineer as my full time job. Fullstack Dev as a freelance
PS:
if you see any errors in my spellings, This is my first post on the site, if you have any advice, I'm interested
| tuitown | |
943,786 | Day 501 : Goodnight | liner notes: Saturday : First show of 2022! Felt good to be back at the station. I don't like the... | 0 | 2022-01-03T22:58:26 | https://dev.to/dwane/day-501-goodnight-cci | hiphop, code, coding, lifelongdev | _liner notes_:
- Saturday : First show of 2022! Felt good to be back at the station. I don't like the long drive though. haha. Had a good time and got to play some new music and talk with some folks. The recording of this week's show is at https://kNOwBETTERHIPHOP.com

- Sunday : Did my Sunday Study Session over at https://untilit.works . Actually had someone create a HACO (Help A Coder/Creator Out) room and it actually worked. I think I was able to help the person with their issue even though I've never really used React Native. Got some other stuff done. Pretty productive day.
- Professional : Today is the first day back to work after vacation. Not too bad. Helped out with a question from the Community channel. Replied to some messages. Spent most of the day preparing for a workshop that I'll be holding in a couple of days. Good news is that I already made the demo applications and just need to put together some slides. It won't be too many slides. I want to focus more on getting everyone set up with demos that they can use/refer to later during the hackathon.
- Personal : During the holiday break, I was pretty productive. I launched an application for Netlify's Dusty.domains charity event. It's https://xoXR.games. Right now, it has the WebXR tic-tac-toe game with voice chat I created earlier in the year. The plan is to include Mixed Reality games from other developers and some more that I make as I learn more about the topic and technology. I also recreated https://doingstuff.in using Astro and Svelte. Added an about page and store. I'm still working on the live stream capability that I'm adding to it. Did a couple of live stream test runs and it's working. Just need to refine some things and add a couple of more pages. I also did some work on the van and put the storage units back up that fell, strengthened some connections and made another shelve extension. Oh and I watched the 'Hawkeye' series on Disney+.
Got some stuff coming in that I think I'll be able to keep the doors of the cabinets closed. I tried gluing magnets, but they wouldn't stick. Going to try some elastic bands. I also want to get some work done on my side project. I want to work on the layout of the live page. Going to eat dinner and get back to work.
Goodnight!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube LJYMRNsDyhA %} | dwane |
951,462 | Kotlin - convert UTC to local time | ... | 0 | 2022-01-11T12:06:55 | https://dev.to/mondal_arka/kotlin-convert-utc-to-local-time-1pil | kotlin, android, programming | {% stackoverflow 53713934 %} | mondal_arka |
943,938 | 5 Ways to Make Money on the Blog Post | Blogging has grown so much in the past years. More and more blogs are created now than 10 years... | 16,151 | 2022-01-04T07:17:32 | https://hybernasi.com | writing, motivation |

Blogging has grown so much in the past years. More and more blogs are created now than 10 years ago. It is then easier now to make money on a blog post or website from scratch than before.
Most people who make blogs write about their personal experience and skills they learned and acquired (the so-called personal blog). That’s why it is more personal than news website.
Some people also want to create extra money from making blog through affiliate marketing and advertisement posted in their site. For example, many blogs are discussing topic related to make money online and just writing about passive income ideas.
The such how to make extra money is one of the most searched words in the Internet these days, because many people are looking for ways on how to earn extra money apart from their day job.
Basically, there is much information you can get from the Internet on how to start your journey on how to make money online.
Blogging is one sure and proven way to make money online. A blog is a website that is usually updated regularly by the blogger. The “blog” word comes from the combination of “web” and “log”. I have been blogging for more than 8 years now.
So let’s get started on how to start your own blog and afterwards, [make money](https://hybernasi.com/ways-to-make-money-on-the-blog-post-follow-these-steps/) from it. Here are the 10 steps you should take.
## 1. Choose a Profitable Niche or Topic
A niche is what your blog is all about. It is the main topic of your blog. For example, the niche of my first blog is personal finance. My blog’s name is “Learn Financial Education”. You can blog anything you like and what interested you the most.
Some niches or topics are more profitable than other niches simply because more people are searching for those topics. For example, if you blog about “eagles”, only few people maybe searching for that topic and hence less traffic for your blog. Lesser traffic to your blog means lower earning.
Therefore, it is very important to think what niche you should start. I would suggest you start in the things you know or the topic related to your job. For example, if you’re an accountant, you can start a blog about banking and economy-related niche. It is easier to start in what you already know.
## 2. Think of a good domain name related to your niche
A domain name is the name of the blog or website you type in the address bar of Google Chrome and Firefox browsers. A good example of domain name is www.facebook.com and www.google.com.
Your domain name is very important. Think of a domain name that can be easily remembered. As much as possible, it should be short as possible and don’t use special characters in your domain name like hyphen, ampersand and others.
Only use letters as much as possible. The dot com domain is the most popular and easy to remember so I suggest using it when registering your domain name. As an example, your blog should have this domain name: www.yourblogname.com
However, if you cannot find the exact .com name, you can try the .net or .org domain. As an example, www.yourblogname.net or www.yourblogname.org
## 3. Buy a domain name and web hosting
Domain name is the address site of your website or blog, for example, www.google.com. Web hosting is where your website or blog is located or housed. You need both to start your blog and make it accessible via the Internet. You may buy both at the same time or separately.
You can register a domain name without buying a web hosting. Normally, it will cost around $10-15. My recommendation is NameCheap and GoDaddy. However, I would suggest buying both (domain name+ web hosting) as a package because it is cheaper than buying it separately.
There are many cheap web hosting companies that offer both domain registration and web hosting at the same time. I am using Just Host and Blue Host as my domain name registration and web hosting companies. Just Host has one of the cheapest prices for hosting and domain registration.
## 4. Setup your blog to WordPress platform
WordPress (WP) is the most popular blogging platform and website-builder software today. It has many features you can easily use for building your own blog. WordPress provides plenty of plug-ins that can help you to set up your blog or website easily.
A plug-in is very similar to a Smartphone application which you can use to make certain activities easier. If you are newbie in blogging, WordPress should be definitely your starting point.
Using WP, you can choose different blog’s theme and create the overall appearance of your website.
If you don’t know HTML code or computer programming, WP is the best platform you’ll ever need because it requires no HTML editing or any complicated code. For more details about WP, you can visit their website here.
## 5. Research for highly searched keywords related to your niche
What is keyword? Keywords are the words usually search by people when using search engines like Google and Yahoo. Keyword is very important for the overall success of your blog.
As much as possible, when you write a topic for your blog, you should use these keywords so that there will be a higher chance that your post will be seen in the search results of major search engines.
However, in the beginning of your blog, you can write anything you want so you’ll be more confident about what you write. You can focus on keyword research at the latter part when you have already master how to write a good post.
| dasdasbor |
943,942 | Simple password generator | Simple password generator made with jQuery and Material Design form. Just to learn javascript &... | 0 | 2022-01-04T07:23:29 | https://dev.to/harunpehlivan/simple-password-generator-18jp | codepen | <p>Simple password generator made with jQuery and Material Design form. Just to learn javascript & jQuery. The returned password is no really secure.</p>
{% codepen https://codepen.io/harunpehlivan/pen/bGoMLQY %} | harunpehlivan |
944,115 | Longest Substring Without Repeating Characters – LeetCode Solutions | LeetCode has a coding Problem in Its’ Algorithm Section: Finding “Longest Substring Without Repeating... | 0 | 2022-01-04T09:04:20 | https://dev.to/hecodesit/longest-substring-without-repeating-characters-leetcode-solutions-1o4b | leetcode, leetcodesolutions, python, datastructures | LeetCode has a coding Problem in Its’ Algorithm Section: Finding “Longest Substring Without Repeating Characters in a String”
Question
Given a string s, find the length of the longest substring without repeating characters.
Example 1: Input: s = “abcabcbb” Output: 3
Explanation: The answer is “abc”, with the length of 3.
Example 2: Input: s = “bbbbb” Output: 1
Explanation: The answer is “b”, with the length of 1.
Example 3:Input: s = “pwwkew” Output: 3
Explanation: The answer is “wke”, with the length of 3.
To read the Solution Visit https://hecodesit.com/longest-substring-without-repeating-characters-leetcode-solutions/ | hecodesit |
944,181 | A Rust macro which will derive Bytecode for you | Hello! I made a Rust proc-macro which will compile and parse your enums and structs to and from a... | 0 | 2022-01-04T11:43:40 | https://dev.to/yjdoc2/a-rust-macro-which-will-derive-bytecode-for-you-556n | rust, showdev, computerscience, programming | Hello!
I made a Rust proc-macro which will compile and parse your enums and structs to and from a bytecode for you!!!
{% github YJDoc2/Bytecode no-readme%}
Check it out and star it if you think it is interesting!
## Why
Consider you are writing a VM, and need a bytecode representation for your opcodes, to store it in the VM's memory. You might consider something like this :
```rust
pub enum Register{
AX,
BX,
...
}
pub enum Opcode{
Nop,
Hlt,
Add(Register,Register),
AddI(Register,u16),
...
}
```
If you try to write functions to compile and parse these two enums to a simple bytecode, it would be something like this :
```rust
impl Register{
...
fn compile(&self)->Vec<u8>{
match self{
Register::AX => vec![0],
Register::BX => vec![1],
...
}
}
fn parse(bytes:&[u8])->Result<Self,&str>{
match bytes[0]{
1 => Ok(Register::AX),
2 => Ok(Register::BX),
...
_ => Err("Invalid opcode")
}
}
...
}
impl Opcode{
...
fn compile(&self)->Vec<u8>{
match self{
Opcode::Nop => vec![0],
Opcode::Hlt => vec![1],
Opcode::Add(r1,r2) => {
let mut v = Vec::with_capacity(2);
v.extend(&r1.compile());
v.extend(&r2.compile());
v
}
Opcode::AddI(r1,v1) =>{
let mut v = Vec::with_capacity(3);
v.extend(&r1.compile());
v.extend(&v1.to_le_bytes());
v
}
...
}
}
fn parse(bytes:&[u8])->Result<Self,&str>{
match bytes[0]{
1 => Ok(Opcode::Nop),
2 => Ok(Opcode::Hlt),
3 =>{
let r1 = Register::parse(&bytes[1..])?;
...
}
...
_ => Err("Invalid opcode")
}
}
}
```
Even for the two instructions I have shown, this is pretty long, tedious and boring.
And now consider doing this for at least 25 to upto 100-ish opcodes, as you might need. :worried: :cold_sweat:
And now consider you want to remove a variant or add a variant in the middle of an enum :cold_sweat: :scream:
You will need to shift all the values accordingly, manually.
Not Fun.
The macro will do this for you, and let you concentrate on implementing your VM.
Fun. (hopefully).
## Links
The GitHub contains more information and detailed example of usage, so go check it out and :star: it !
{% github https://github.com/YJDoc2/Bytecode %}
Thank you! | yjdoc2 |
944,239 | Wrapping up 2021 and what's in store for 2022 | 2021 has been quite overwhelming with all the interest we have received from the developer community... | 0 | 2022-01-04T12:57:31 | https://medusajs.com/blog/review-2021/ | opensource, javascript, webdev, node | 2021 has been quite overwhelming with all the interest we have received from the developer community - thanks a ton to all of you for that! Read below for a quick review of 2021 and a short glimpse into 2022.
## Highlights of 2021 :zap:️
###Product highlights:
- Fully open-source; from core and admin to starters and design system
- Created an onboarding flow that gets you up and running with only 2 commands
- Developing starters that allow you to spin up a full store with a Gatsby or Next.js frontend
- Building an extensive plugin library with integrations to Stripe, Contentful, Strapi, Algolia, Paypal, and many more
- Building out our documentation, incl. deployment guides, setup tutorials, plugin guides
- Migrating the project to Typescript
###Community highlights:
- Growing from 10 to +5,500 GitHub stars since our official launch 6 months ago
- Launching our community Discord and welcomed ~700 amazing members
- Hosting our first Hackathon and got 85 contributions to the core project
## What is to come in 2022 :crystal_ball:
###Medusa 2.0
We aim to launch Medusa 2.0 by the end of Q1. A first core foundation for this will be released with our new [Admin dashboard in January](https://www.medusajs.com/post/admin-redesign). We will share more details about the roadmap as we progress on our [Discord](https://discord.gg/F87eGuwkTp).
###Doubling down on community
Hackathon, conferences, merch store, video tutorials, and a heck of a lot more; community is king and we want to give back for all the contributions we have received through many more activities addressed specifically to our community.
###Medusa Cloud
It should not take much to deploy Medusa and although our product will always remain open-source and available for self-hosting, we want to make it a one-click experience to get started with a Medusa store - and don’t worry you will always own the code that powers your store so that when it is time to customize your can quickly take over.
Plenty of exciting things to happen. We cannot wait to show it all to you! | sebrindom |
944,755 | World's Simplest Synchronous Serverless AWS IoT Dashboard | Part 1 of a 4 part series on AWS Serverless IoT When working with IoT devices, which transmit data... | 16,303 | 2022-01-07T20:20:44 | https://dev.to/aws-heroes/worlds-simplest-synchronous-serverless-iot-dashboard-3ige | aws, iot, esp32, serverless | <h2> Part 1 of a 4 part series on AWS Serverless IoT</h2>
When working with IoT devices, which transmit data to AWS, serverless IoT workflows can save the customer a tremendous amount of money. Instead of setting up an “always on” EC2 instance the client can engage individual AWS services only as needed. This multi-part IoT series will cover a variety of methods, with increasing levels of sophistication and functionality, to visualize IoT data on a static web host using various IoT centric services on AWS. The overall cost of using these AWS serverless services, even assuming you are off the free tier, will be pennies for normal use.
This hands-on workshop series will start off with an easy use case: synchronous polling of IoT data from a S3 bucket being held as a IoT data repository delivered from AWS IoT Core. For reasons which will soon be obvious this isn't an optimal design. However there is an undeniable, inverse correlation between complexity and functionality in this use case, so this is a good place to start. If you are ok with “near real-time” IoT, and some lost IoT data payloads are acceptable, than this simplified technique, explained in this first tutorial in the series, will be of interest. As a special bonus I will provide all the code necessary to complete this lab and visualize your own IoT data on your AWS account. It is sure to impress your friends and family (as long as we keep them in the dark about some initial shortcomings to be remedied later).
An assumption of this first AWS IoT serverless workshop is that you have a device programmed to send IoT data payloads to AWS IoT Core. I’m not going provide device code here or explain how to implement the code on a device. You can reference my classes on AWS IoT on Udemy for coding various devices to communicate with AWS IoT Core utilizing a variety of IDE’s. However, good news, you don’t need to program any devices for this tutorial series as I will show you how to use the AWS MQTT test client as well as an automated Bash script to send fake IoT JSON payloads to the MQTT broker on AWS IoT Core. This is a functional substitute for a real embedded device producing real IoT data. For actual use cases you can always implement code on your device later if you want to add the device component for real IoT data publishing.
This first article in this hands-on workshop series will use synchronous polling in JavaScript to extract data from an S3 bucket in near real time. The next article in the series will switch to use AWS WebSockets with Lambda using API Gateway to transmit “real-time" data to our JavaScript visualization without the need to store data in S3 as a temporary repository. From there we will move on to using WebSockets with Lambda, MQTT, and the AWS IoT JavaScript SDK in the browser for a more professional look and feel while also taking advantage of real-time IoT transmissions. Finally we will conclude the series by using the newest real-time techniques for serverless IoT that utilize GraphQL for real-time data visualizations which should obviate the need, if not the performance, of AWS WebSockets. To get the advantage of asynchronicity we are reliant on using a "_server push_" model as opposed to the "_client pull_" model we use in this tutorial. The "server push" model has been traditionally problematic for a serverless environment.
**Update February 2022**
I've received email about this simple process being inefficient. As I said it isn't a "production ready design." It is intended as just a super simple and easy example.
As always when dealing with S3 writes/puts it is always best to "Batch" data as a rule. Also writing large data blocks is the same cost as small PUTs so keep that in mind as well.
Request pricing For standard storage, the cost for PUT, COPY, POST, or LIST requests ranges from $0.005 per 1000 requests in US regions to $0.007 in other regions.
Cost to write a JSON payload are as follows, and the cost of running this process for 24 hours at one payload per second would be:
_((60 x 60 x 24)/1000) x .005 = 43 cents_
Budget accordingly
---
**Table of contents:**
- Step 1 - Creating a public bucket in S3 for your IoT data
- Step 2 - Creating an Action and Rule in AWS IoT Core
- Step 3 – Testing your Serverless IoT design flow
- Step 4 – Converting your S3 bucket into a static webhost
- Step 5 – Uploading your HTML and JavaScript code to create a
Visualization for your IoT data.
- Step 6 – Populating the visualization using an automated IoT
data producer
---
**All the code posted in this tutorial can also be found at:**
https://github.com/sborsay/Serverless-IoT-on-AWS/tree/master/Level4_design/1_Synchronous_IoT
---
<h3>✅ Step 1 - Creating a public bucket in S3 for your IoT data</h3>
Whenever we create a public bucket the first caveat is to confirm the bucket will only store data that we don’t mind sharing with the world. For our example we are just using the S3 bucket to hold IoT JSON data showing temperature, humidity, and timestamps. I think sharing basic environmental data from an unknown location is not too much of a privacy risk. The advantage of using a public bucket for our static webhost, with an open bucket policy and permissive CORS rule, is that it makes the website easily accessible from anywhere in the world without having to use a paid service like AWS CloudFront and Route 53.
Since re:Invent 2021 AWS has changed the process in which to make a S3 bucket public. They have added one extra default permission which must be proactively changed to insure you are not declaring a public bucket by mistake. AWS is especially concerned with people making buckets public unintentionally, the danger being that they will hold sensitive or personal data, and in the past unethical hackers have used search tools to find private data in S3 public buckets to exploit them. Fortunately for our use case, we don’t care about outsiders viewing our environmental data.
Many of you already know how to make a S3 public bucket for a static webhost on AWS. For those that don’t know how to do this in 2022, I will document it below.
---

---
**Making a Public S3 Bucket**
_The process of creating a public S3 bucket for website hosting_
Go to AWS S3 and then select “Create bucket”
A) Give your bucket a globally unique name, here I call mine a catchy name: mybucket034975
B) Keep your S3 bucket in the same region as the rest of your AWS services for this lab.
C) Switch “Object Ownership” to “ACL’s enabled”, this is new for late 2021! We now must first enable our Access Control Lists to make them public.
D) Unblock your S3 bucket and acknowledge your really want to do this. Scary anti-exculpatory stuff! :anguished:
F) Finally, select the “Create bucket” button at the bottom of the screen. That's all you have to do for this page, but don’t worry, we are going to have more opportunity to make sure we really, really, and truly want to create a public bucket soon. :+1:

G) Now go back into your newly created bucket and click on the “Permissions” tab.
F) Go to Bucket Policy and choose “Edit.” We will paste and save a basic read-only policy.
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicRea2411145d",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion"
],
"Resource": "arn:aws:s3:::<Paste-Your-Bucket-Name-Here>/*"
}
]
}
```
You must paste the name of your bucket into the policy then follow it by ‘/*’ to allow access to all Get/Read partitions within the bucket. Also it's a good idea to change the “Sid” to something unique within your account.
G) Now we get a chance to visit that ACL we enabled earlier in this process. Click “Edit” then make the changes as shown below:
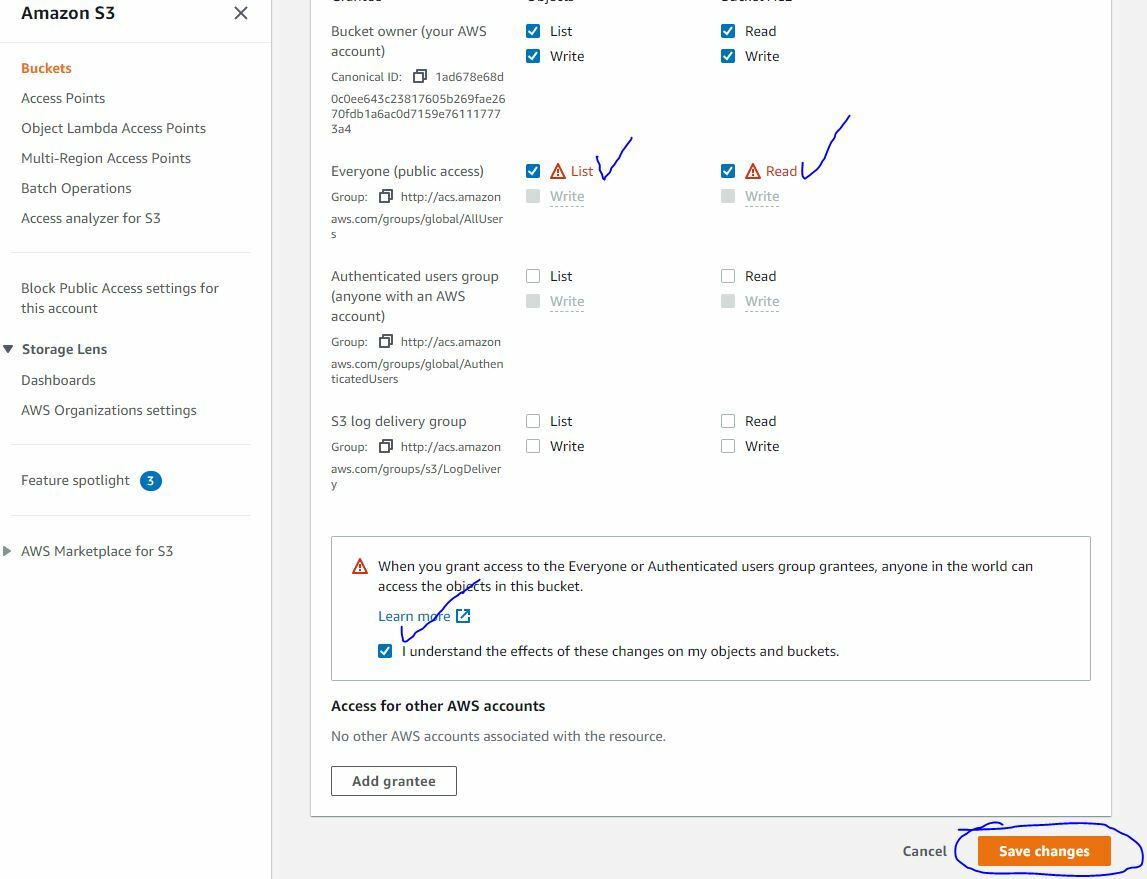
We are giving “Everyone,” or at least those know or can discover our unique bucket URL, permission to read our bucket info. Click on the 'List' and 'Read' buttons where shown and then acknowledge again that you are extra special certain that you want to do this :smirk:. Then click “Save changes.”
H) Wow, we are at our last step in creating a public bucket. Now we should set the CORS policy so we don’t get any pesky “mixed use” access-control non-allowed origin issues for cross domain access – I hate those :angry:! CORS rules used to be in XML only format and then AWS decided to keep everything consistent and switch the CORS format to JSON. Even though this change caused some legacy conflict issues with existing XML CORS rules it was the right choice as JSON is clearly better than XML despite what the SOAP fans on social media will tell you :+1:. Below is a generic CORS JSON document you can use in your own S3 bucket:
```
[
{
"AllowedHeaders": [
"Authorization"
],
"AllowedMethods": [
"GET"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [],
"MaxAgeSeconds": 6000
}
]
```
That’s it for making your cheap and easily accessible public bucket!
In my Udemy course I speak more about inexpensive ways to add security while avoiding paying for CloudFront or Route 53 for accessible public buckets and static websites in S3. However I will tacitly reveal “one weird trick” that I find very effective for pretty good protection regarding free S3 public bucket security: Simply google “restrict IP range in a S3 public bucket policy.”
<h3>✅ Step 2 - Create an Action and Rule in AWS IoT Core</h3>
AWS IoT Core is a great service with a built-in server side MQTT broker that has the functionality to dispatch our incoming IoT data payloads to a variety of AWS services. For this first lab we will simply be sending our data to our S3 bucket. To do this we need to create an 'Action' and 'Rule' in IoT Core, then we design our rule to send our IoT data to the S3 public bucket that we just created.
The first step is to create a new rule in IoT Core:
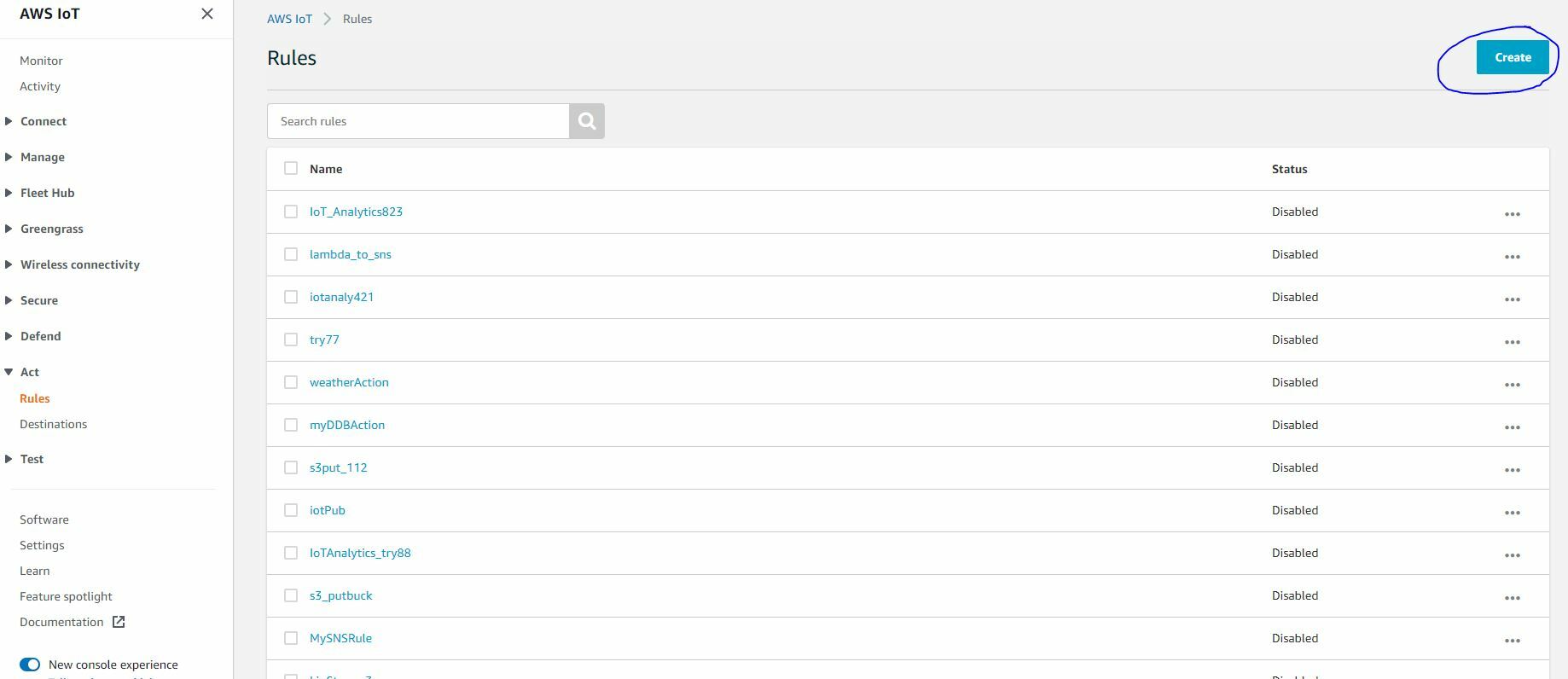
Now give your Rule a name of your choice. Next, we need to edit the Rules Query Statement (RQS) to select what information we will extract or add to our JSON IoT Payload. To make things easier we will use one of the built-in functions AWS provides for the RQS to enrich our IoT data payload:
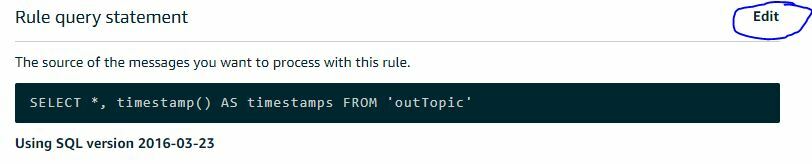
For our use case we are adding a Unix/Epoch timestamp to our incoming IoT JSON payload. I rename the timestamp as 'timestamps'. The reason for this specific name is that I want the name to be a literal match for how I designate the variable in the JavaScript Code on our upcoming website. The MQTT topic name itself is unimportant for this first tutorial, you can call your MQTT topic whatever name you like, here I call mine ‘outTopic’ (as it is coming ‘out’ from my device). In the tutorials coming up it will be more important how we name and format our topic in the RQS.
Next, we have to add an 'Action' for our 'Rule.' We want to send our IoT message to the S3 bucket we just created so select that as your rule:

Now press the “Configure action” button at the bottom of the screen.
Next we must select the bucket we just created and name the '_Key_' in which we will save our IoT data. We also have to create a Role which gives our Action a permission policy to send our IoT data between IoT Core and our S3 bucket. We will let AWS automatically create this Role.
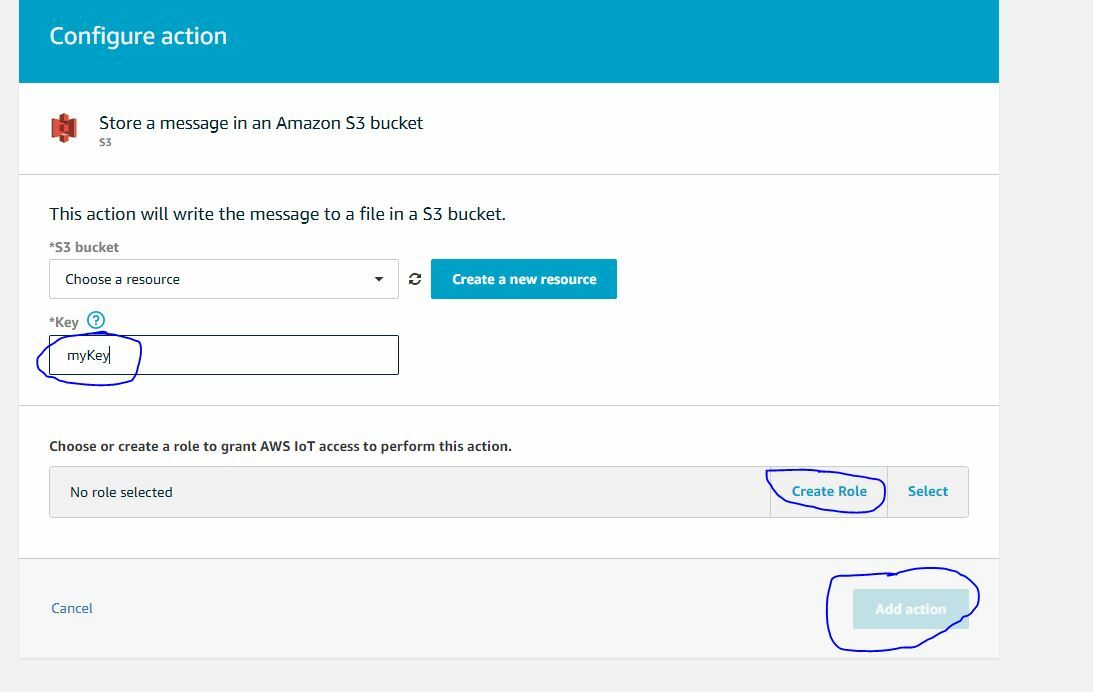
The things to do here:
- 1. Select the S3 public open bucket you just created in the S3
bucket field.
- 2. Give your key (blob object) a name.
- 3. Create a role to give your Action the correct
permissions.
- 4. Press the “Add action” button.
Finally, insure your action is “Enabled” in the next screen by using the breadcrumbs next to the Rule name you just created (usually at the bottom of the list as your last Rule).
<h3>✅ Step 3 - Test your Serverless IoT design flow</h3>
At this point let's test the serverless IoT design flow we developed to make sure everything is working before we move on to uploading our code to our static webhost on S3. To test our design flow we should send some fake IoT data to S3 from the MQTT Test client in AWS IoT Core. To do this go to the "MQTT test client" tab on the left and select the “Publish” tab. This will allow us to send IoT JSON payloads to our public S3 bucket using the Action/Rule we just created. Let's enter a sample IoT JSON payload of temperature and humidity as shown below. Remember, we don’t need to use a "timestamps” key value in our IoT payload because our RQS adds a UNIX timestamp to our payload automatically. We will publish our JSON IoT payload under to topic name of ‘outTopic’ or whatever you choose to name you topic that matches the RQS.
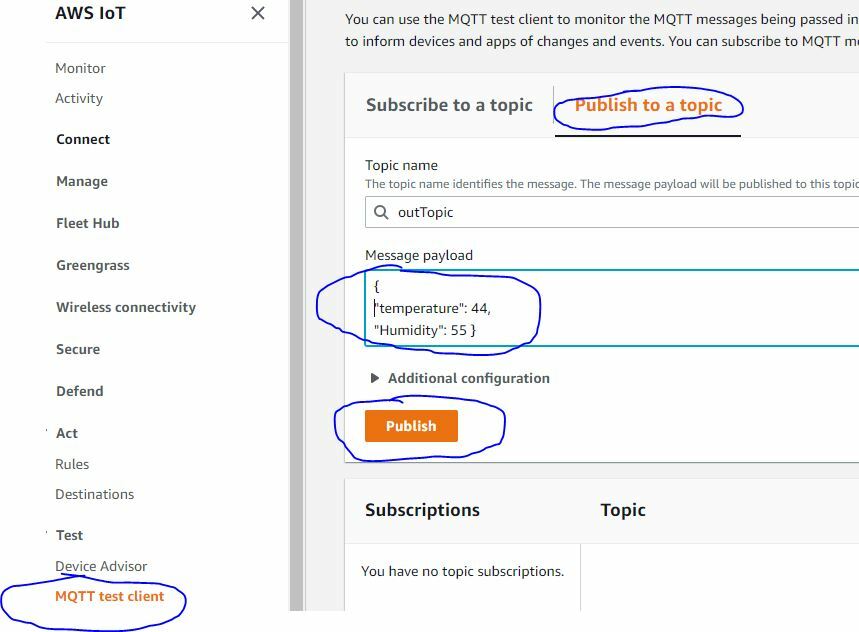
_Things to do here:_
- 1. Select MQTT test client.
- 2. Select the Publish tab.
- 3. Type a test payload in proper JSON format like:
{ “temperature”: 44, “humidity”: 55}
- 4. Press the “Publish” button.
Now go to the public bucket you just created in S3. Look under the key object that you designated in your Rule/Action in IoT Core. It should be something like an anomalous object named “myKey” in our example. Go ahead and download the blob object named "myKey" and open it in the editor of your choice:

Now if everything was done correctly you should see the JSON payload you just sent from IoT Core. If you sent multiple payloads you will only see the last payload sent as the object is overwritten in S3 with each successive payload. You can't concatenate or edit blob objects in S3. As an aside there is an easy way to create a data lake with multiple objects with the S3 Action we just created but I won't go over that here. For our purposes we are only going to fetch the last JSON payload held within the S3 object store on a given interval (polling).
<h3>✅ Step 4 - Convert your S3 bucket into a static Webhost</h3>
As I said before AWS makes it so the same S3 bucket can be enabled to both hold IoT data and to host a static website with a static IP address for pennies a month.
We are now ready to convert our public bucket so that it can facilitate hosting a static website. We could have easily have done this in Step 1 and still use the same bucket as a blob object store, as well as a website, but converting it to a static website now makes more procedural sense. The conversion is quite simple.
Go to your S3 public bucket, select the "Properties" tab, then scroll down to the bottom where we can edit "Static website hosting" and select "Edit."

Now enable website hosting and name your index file “index.html”, this will be our landing page for our visualization website. Click “Save changes” at the bottom of the page and you are good to go.
That’s it! Now your open public bucket is configured as a webhost with a unique URL address that is statically available worldwide. You have just changed your uber cheap and accessible public bucket into a uber cheap and accessible public bucket that can also host a static website with a static IP address. 😲
<h3>✅ Step 5 - Upload your HTML and JavaScript code to create a visualization for your IoT Data.</h3>
We have two files to upload to our public bucket and our newly created webhost. The files are called 'index.html' and 'main.js'.
The index.html is our launch page. Copy the following code and save it locally as "index.html":
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Dashboard</title>
</head>
<body>
<div class="container">
<h1>Synchronous Weather Data on Interval</h1>
<div class="panel panel-info">
<div class="panel-heading">
<h3 class="panel-title"><strong>Line Chart</strong></h3>
</div>
<div class="panel-body">
<div id="container1"></div>
</div>
</div>
</div>
<script src="https://code.jquery.com/jquery-3.1.1.min.js"></script>
<script src="https://code.highcharts.com/highcharts.js"></script>
<script src="./main.js"></script>
</body>
</html>
```
The main.js is our JavaScript page. Copy the following code save it as "main.js":
```
let humArr = [], tempArr = [], upArr = [];
let myChart = Highcharts.chart('container1', {
title: {
text: 'Line chart'
},
subtitle: {
text: 'subtitle'
},
yAxis: {
title: {
text: 'Value'
}
},
xAxis: {
categories: upArr
},
legend: {
layout: 'vertical',
align: 'right',
verticalAlign: 'middle'
},
plotOptions: {
series: {
label: {
connectorAllowed: false
}
}
},
series: [{
name: 'Humdity',
data: []
}, {
name: 'Temperature',
data: []
}],
responsive: {
rules: [{
condition: {
maxWidth: 500
},
chartOptions: {
legend: {
layout: 'horizontal',
align: 'center',
verticalAlign: 'bottom'
}
}
}]
}
});
let getWheatherData = function () {
$.ajax({
type: "GET",
url: "<Insert-Your-IoT-Data-Bucket-With-Key-Here>", //example: https://mydatabucket.s3.amazonaws.com/myKey"
dataType: "json",
async: false,
success: function (data) {
console.log('data', data);
drawChart(data);
},
error: function (xhr, status, error) {
console.error("JSON error: " + status);
}
});
}
let drawChart = function (data) {
let { humidity, temperature, timestamps } = data;
humArr.push(Number(humidity));
tempArr.push(Number(temperature));
upArr.push(Number(timestamps));
myChart.series[0].setData(humArr , true)
myChart.series[1].setData(tempArr , true)
}
let intervalTime = 3 * 1000; // 3 second interval polling, change as you like
setInterval(() => {
getWheatherData();
}, intervalTime);
```
The only change you need to make to the code is on line 62 of the main.js file. You need to insert the URL of your 'key' which is a "Object URL" listed in your S3 bucket.
You can find your data object address (URL) by copying it from your bucket as demonstrated by the image below. It is the ‘Object URL’ with the 'https://' prefix. This object URL should look something like this:
ht<span>tps://</span>yourbucket.s3.amazonaws.com/myKey
After changing this line of code in 'main.js' to your own data location URL in S3, you are now ready to upload the files you just saved locally into your bucket. To do this simply select the 'Objects' tab in your S3 bucket and drag both files to the base level of your bucket. Both files, and your IoT data object ('myKey'), should be on the same level of the partition hierarchy.
Press the 'upload' button on the bottom right of your screen, and then after both files have been uploaded select the 'close' button. You should now have three objects in you bucket; your IoT data object with your JSON readings (myKey), as well as your two web code files('index.html' and 'main.js').
The Highcharts code works by fetching data from or S3 bucket by a configurable number of seconds. Obviously it can over and under fetch data on the set interval but it will provide a nice visualization given a certain amount of delay and inaccuracy, assuming that is acceptable. We will remedy most of these issues in the coming workshops when we use AWS WebSockets with AWS Lambda for asynchronous invocations.
Now is a good time to initiate your static webhost by opening a new web browser tab with your static website URL. The address of your website can be found by going to the “index.html” object in your bucket and opening the 'Object URL.' Clicking this URL will bring up your website.
Don't worry if you see a couple of straight lines for temperature and humidity on your website. The visualization is simply extending the last test IoT data point you manually published from the MQTT test client. You will know the data point is stale as the timestamp is duplicated across the X-axis of the chart.
<h3>✅ Step 6 - Populating the visualization using an automated IoT data producer</h3>
For this last step we have three ways to populate the visualization from IoT Core to our webhost.
A) Use a device to publish IoT JSON payloads under our topic name.
B) Manually publish JSON data payloads from the MQTT test client in IoT Core as demonstrated earlier in the tutorial.
C) Use a test script to publish IoT data to our topic automatically at a set interval.
For option A you can simply program your device to publish data to IoT core as I instruct in my course. For option B you would have to spend some time manually altering then publishing JSON payloads in the MQTT test client to generate the line chart in the visualization.
For this tutorial I will explain 'option C.' For this option you need the AWS CLI installed. It’s easy to install with the directions listed here:
https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
This bash IoT data producer script was provided by AWS and can be originally found at https://aws.amazon.com/blogs/iot/integrating-iot-data-with-your-data-lake-with-new-aws-iot-analytics-features/. I have already altered the test script to send just temperature and humidity data. Simply insert your AWS region and MQTT topic name (outTopic) into the test script where indicated. The bash script uses your AWS CLI to deliver the payload to IoT Core (using your SigV4 credentials from the AWS CLI). You can also change the number of payloads published (_iterations_) and wait time between each publish (_interval_) to produce as much fake IoT data as you like.
```
#!/bin/bash
mqtttopic='<Insert-Your-IoT-Topic-Here>'
iterations=10
wait=5
region='<Insert-Your-AWS-Test-Region-Here>'
profile='default'
for (( i = 1; i <= $iterations; i++)) {
#CURRENT_TS=`date +%s`
#DEVICE="P0"$((1 + $RANDOM % 5))
#FLOW=$(( 60 + $RANDOM % 40 ))
#TEMP=$(( 15 + $RANDOM % 20 ))
#HUMIDITY=$(( 50 + $RANDOM % 40 ))
#VIBRATION=$(( 100 + $RANDOM % 40 ))
temperature=$(( 15 + $RANDOM % 20 ))
humidity=$(( 50 + $RANDOM % 40 ))
# 3% chance of throwing an anomalous temperature reading
if [ $(($RANDOM % 100)) -gt 97 ]
then
echo "Temperature out of range"
TEMP=$(($TEMP*6))
fi
echo "Publishing message $i/$ITERATIONS to IoT topic $mqtttopic:"
#echo "current_ts: $CURRENT_TS"
#echo "deviceid: $DEVICE"
#echo "flow: $FLOW"
echo "temperature: $temperature"
echo "humidity: $humidity"
#echo "vibration: $VIBRATION"
#use below for AWS CLI V1
#aws iot-data publish --topic "$mqtttopic" --payload "{\"temperature\":$temperature,\"humidity\":$humidity}" --profile "$profile" --region "$region"
#use below for AWS CLI V2
aws iot-data publish --topic "$mqtttopic" --cli-binary-format raw-in-base64-out --payload "{\"temperature\":$temperature,\"humidity\":$humidity}" --profile "$profile" --region "$region"
sleep $wait
}
```
You have to change fields at the top of the page in the bash script to customize it for your MQTT topic name (outTopic) and AWS region ('us-east-1 or other) in which you developed your AWS services for this tutorial. The other two fields, '_iterations_' and '_wait time_', are optional to edit.
1. mqtttopic='<Insert-Your-IoT-Topic-Here>'
2. iterations (number of payloads to send)
3. wait time (number of seconds between transmissions)
4. region='<Insert-Your-AWS-Region-Here>'
Now save the above code, giving it a name like "iot_tester.sh". You can run the script by simply installing the bash script locally on your computer and then from the command prompt typing the name of the bash script. Bash scripts should work on any operating system. Activating the test script in MS Windows looks like this:
You can now return to your websites index page and see you visualization getting populated by new data points on the delay of your setInterval() function in 'main.js.'
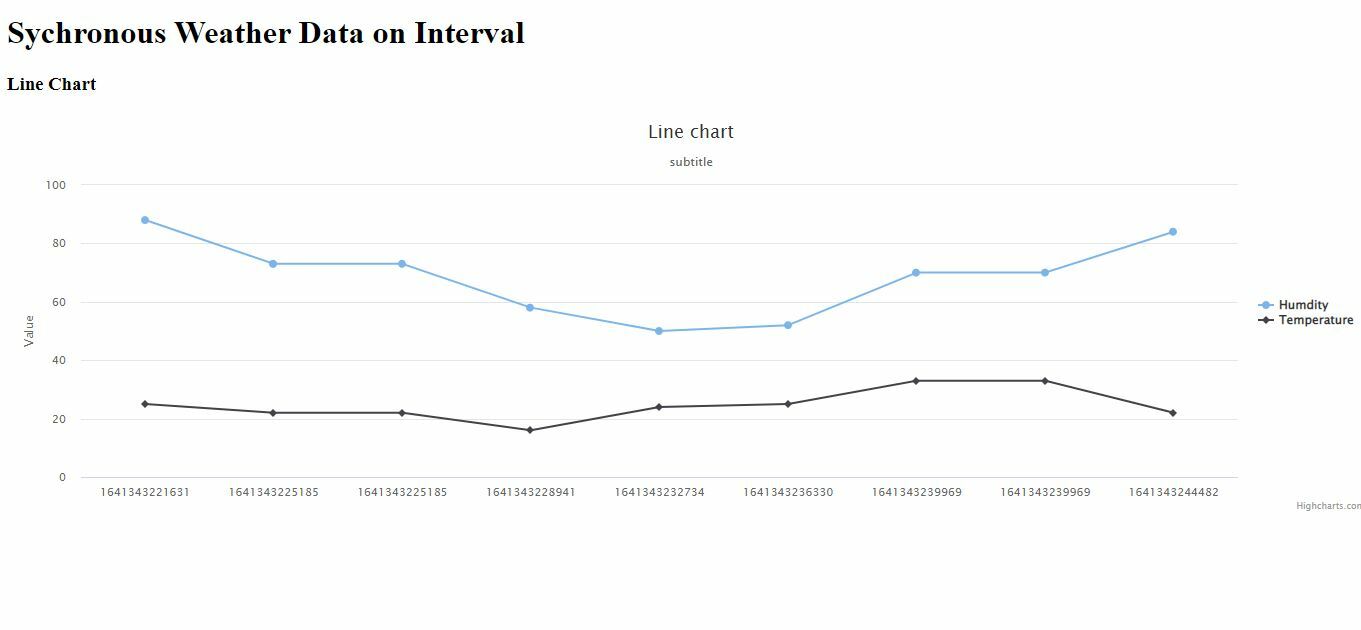
A few troubleshooting tips for most common issues.
1. Did you keep your S3 bucket and other AWS services all in the same region?
2. Does your web browsers cache refresh automatically. On my computer Chrome doesn't inherently refresh upon each new data point, thus I get stale data from S3 resulting in a flat chart. My other five browsers refresh by default for new data. Try the index page on other browsers if you are not getting data point updates for your visualization in your current browser.
---
:grinning: :checkered_flag:
Congratulations! You finished the first tutorial in the series and created the World's Simplest Synchronous Serverless IoT Dashboard. I bet all your friends will be impressed. Make sure to stay tuned for parts two, three, and four of this hands-on tutorial series as we get more advanced with Serverless IoT on AWS.
| sborsay |
944,914 | The Five Minute Journal with Dendron and Visual Studio Code | It's 2022 and you're looking to start off the year right by keeping a journal. Where to start? The... | 0 | 2022-01-06T16:39:05 | https://blog.dendron.so/notes/P1DL2uXHpKUCa7hLiFbFA/ | vscode, gratitude, productivity, tutorial | It's 2022 and you're looking to start off the year right by keeping a journal. Where to start? _The Five Minute Journal_ (5MJ)[^1] is a simple but effective way to get started with note taking.
## The Five Minute Journal
Tim Ferriss,[^2] world-famous entrepreneur and author of books such as _Tribe of Mentors_,[^3] uploaded a video in 2020 all about his approach to note taking with physical notebooks.[^4] 5MJ helps him express gratitude, make days better, and focus on mindfulness.
In this post, we'll be going over how to create your own 5MJ using [Dendron](https://www.dendron.so/). Dendron is a structured note taking tool for developers that is open source, local first, and integrated with Visual Studio Code (VS Code).
## Prerequisites
This post expects that you've gone through the [Dendron Getting Started Guide](https://wiki.dendron.so/notes/678c77d9-ef2c-4537-97b5-64556d6337f1/) and have a workspace opened to work with. If you're new to Dendron, make sure to take a look.
## Concepts
### Daily journal notes
Daily journal notes are special notes meant to easily track your everyday life. Dendron also has a built-in [Calendar View](https://wiki.dendron.so/notes/25287595-96bb-410b-ab46-eb9a26b0e259/#calendar-view) that helps you visually navigate and create new journal entries.
### Templates
Templates are notes with pre-outlined content meant for reuse. Templates can either be inserted into an open note with the `Dendron: Insert Note` command, or automatically applied at note creation with [Schemas](https://wiki.dendron.so/notes/c5e5adde-5459-409b-b34d-a0d75cbb1052/). These are meant to reduce friction in the creation of new content, providing standardized outlines to your notes.
### Schemas
As you end up creating more notes, it can be hard to keep track of them all. This is why Dendron has **schemas** to help you manage your notes at scale. Think of schemas as an **optional type system** for your notes. They describe the hierarchy of your data and are themselves, represented as a hierarchy.
## Steps
### Create 5MJ template
- Open [lookup](https://wiki.dendron.so/notes/a7c3a810-28c8-4b47-96a6-8156b1524af3.html) (`Ctrl+L` / `Cmd+L`)
- Type `templates.daily-5mj` in the text prompt and hit enter to create the template
- Copy and paste the following markdown:
```markdown
<!--
Based on the journaling method created by Intelligent Change:
- [Intelligent Change: Our Story](https://www.intelligentchange.com/pages/our-story)
- [The Five Minute Journal](https://www.intelligentchange.com/products/the-five-minute-journal)
-->
## Morning
<!-- Fill out this section after waking up -->
### Gratitude
I am grateful for:
1.
2.
3.
### What would make today great?
1.
2.
3.
### Daily affirmations
I am...
## Evening
<!-- Fill out this section before going to sleep, reflecting on your day -->
### Amazing things that happened today
1.
2.
3.
### How could I have made today even better?
I could have made today better by
```
- Save the file.
You now have a new template with the 5MJ outline.
### Create 5MJ schema
> Templates can be used with or without schemas. Run [Insert Note](https://wiki.dendron.so/notes/eea2b078-1acc-4071-a14e-18299fc28f47.html#insert-note) to insert a template into a currently opened note.
- Open [schema lookup](https://wiki.dendron.so/notes/60c03500-98e4-4a02-a31e-2702b4068a88.html) (`Ctrl+Shift+L` / `Cmd+Shift+L`)
- Type `5mj` in the text prompt and hit enter to create the schema, which should look like the following:
```yml
version: 1
imports: []
schemas:
- id: 5mj
children: []
title: 5mj
parent: root
```
### Update 5MJ schema contents
We are going to use [Inline Schema](https://wiki.dendron.so/notes/c5e5adde-5459-409b-b34d-a0d75cbb1052.html#inline-schema-anatomy), a simpler schema format that takes less lines and uses indentation for visual understanding.
- Replace the content of `5mj.schema.yml` with the following:
```yml
version: 1
schemas:
# Daily is the top most schema since its parent is 'root' it must have an identifier
# this identifier 'daily' will be used when using 'Lookup (schema)' command.
- id: daily
parent: root
title: daily
desc: ""
# Children of the top most schema do not need to contain identifier and just
# require a 'pattern' to be set to match the hierarchy of notes.
children:
- pattern: journal
children:
# This pattern matches the YYYY (year) child hierarchy
- pattern: "[0-2][0-9][0-9][0-9]"
children:
# This pattern matches the MM (month) child hierarchy
- pattern: "[0-1][0-9]"
children:
# This pattern matches the DD (day) child hierarchy
- pattern: "[0-3][0-9]"
# As with regular schema we can set the template to be used with
# the match of our notes. Below is an example usage of shorthand template
# definition (which defaults to type: note).
desc: Five Minute Journal
template: templates.daily-5mj
```
The `pattern` attribute is using a [Glob Pattern](https://wiki.dendron.so/notes/c6fd6bc4-7f75-4cbb-8f34-f7b99bfe2d50.html#glob-pattern), which is an expression used to match ranges and combinations of characters.
To match with the daily journal structure:
- Example: `daily.journal.2021.12.31`
- Patterns:
- Year: `[0-2][0-9][0-9][0-9]` means match the range `0000 - 2999`
- Month: `[0-1][0-9]` means match the range `00 - 19`
- Day: `[0-3][0-9]` means match the range `00 - 39`
This means all new daily journal notes are within pattern ranges.
### Create a new daily journal
Creating a daily journal entry results in the `templates.daily-5mj` template automatically inserted.
- Run `Create Daily Journal Note` (`Ctrl+Shift+I` / `Cmd+Shift+I`)
You should see a new daily journal note with the 5MJ template inserted.

## Congratulations!
### Key takeaways
After doing this, you've now:
- Created a 5MJ template
- Created a 5MJ schema
- Created your first daily journal with the 5MJ template applied via schema
### Next steps
Now what? You have daily journals using templates, but Dendron can do much more. It's an open source, local-first knowledge management solution that scales as you do.
- Learn to [swiftly create schema by targeting existing note hierarchies](https://wiki.dendron.so/notes/gHERCRoEXzASfXorBgZN0.html)
- Learn to level-up your daily life with [the bullet journaling workflow](https://wiki.dendron.so/notes/e65dfe53-41f7-4b16-b870-dadec1775497.html)
- Learn to explore your schema visually using the [schema graph](https://wiki.dendron.so/notes/587e6d62-3c5b-49b0-aedc-02f62f0448e6.html#schema-graph)
- Check out an end-to-end workstyle, managing 20k notes, using schemas and daily journals from [A Day in Dendron](https://wiki.dendron.so/notes/fzHazEFWTpUVexmv/)
- [Dendron FAQ](https://wiki.dendron.so/notes/683740e3-70ce-4a47-a1f4-1f140e80b558/)
- [Dendron Concepts](https://wiki.dendron.so/notes/c6fd6bc4-7f75-4cbb-8f34-f7b99bfe2d50/)
---
Enjoy the blog? [Subscribe to our newsletter!](https://link.dendron.so/newsletter)
Newsletters not your thing? You can also follow us elsewhere on the interwebs:
* Join [Dendron on Discord](https://link.dendron.so/discord)
* Register for [Dendron Events on Luma](https://link.dendron.so/luma)
* Follow [Dendron on Twitter](https://link.dendron.so/twitter)
* Checkout [Dendron on GitHub](https://link.dendron.so/github)
[^1]: [_The Five Minute Journal_](https://www.intelligentchange.com/pages/customers#journal), by [Intelligent Change](https://www.intelligentchange.com/pages/our-story)
[^2]: It's hard to use one sentence to describe all the things Tim Ferris does. He has one of the most popular podcasts in the world, and has authored several books from all of his notes and interview content. He seems shorter in person. Anyway, learn more [at his website](https://tim.blog/)!
[^3]: For a list of books, see [Books by Tim Ferriss](https://tim.blog/tim-ferriss-books).
[^4]: The video: [How I Journal and Take Notes: Brainstorming + Focusing + Reducing Anxiety](https://youtu.be/UFdR8w_R1HA). For a companion guide to the video, take a look at _[How Tim Ferriss Uses The Five Minute Journal: 6 Tips For New Journalers](https://www.intelligentchange.com/blogs/read/how-tim-ferriss-uses-the-five-minute-journal-6-tips-for-new-journalers)._
| scriptautomate |
944,936 | Does Liferay Work in China? | In this article, we will walk you through some speed tests we conducted to determine if Liferay’s... | 0 | 2022-01-05T02:33:39 | https://www.21cloudbox.com/solutions/does-liferay-work-in-china.html | liferay, dxp, cms, china | ---
canonical_url: https://www.21cloudbox.com/solutions/does-liferay-work-in-china.html
---
In this article, we will walk you through some speed tests we conducted to determine if Liferay’s Digital Experience Platform works in China or not. Our staff conducted the tests in Shanghai (China Mainland) and Hong Kong (outside Mainland China) and we used 3rd party testing tools to ensure our tests weren’t biased.
By the end of this article, you should have a good understanding of Liferay’s DXP and if it works in Mainland China or not. Also, you can [contact us ](https://launch-in-china.21yunbox.com/contact.html)to get a free speed test of your Liferay site for China.
<br>
## What is Liferay?
Liferay makes software that helps companies create digital experiences on the web, mobile and connected devices.
They are one of the leading Digital Experience Platform (“DXP”) by Gartner Magic Quadrant 2021.
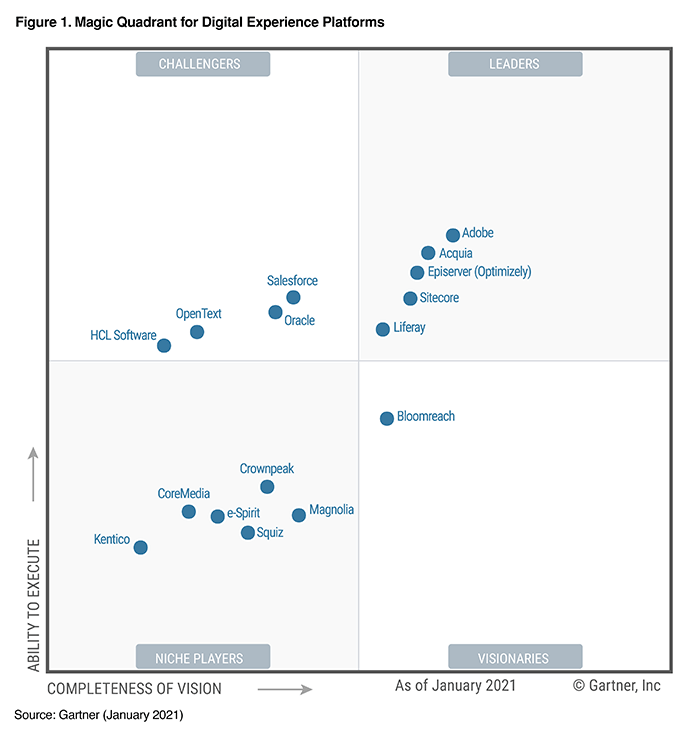
---
<br>
<br>
## Does Liferay Work in China?
The short answer is no.
Below is the long answer if you want to understand why:
1. Most hosting providers claim to have Global coverage for your Liferay, but actually, China is not included.
2. If your business didn't have any legal licenses for your site and content in China, your ecommerce store is operating illegally in China.
Luckily we have put together [solutions for you to make your business and your Liferay site work in China.
](https://www.yammo.io/get-started)
Don't just take our words. Let's look at some websites powered by Liferay and see how well they work in China.
---
<br>
## How do we check if a website works in China or not?
There are two checks we need to perform to conclude if a website works in China.
1. How fast is the site in Mainland China?
2. If your business doesn’t have any legal licenses for your site and content in China, it is operating illegally in China.
---
## Speed Tests Results
We picked 5 websites from Liferay customers and considered these websites to follow the best practices by Liferay.
Then we follow the test questions mentioned earlier for each website and create a report with the following format:
**1. A figure to see how fast the site performs across Mainland China.**
This figure basically shows how fast the website loads across Mainland China (green = fast, red=slow)
<br>
**2. A video to see how the site performance in China visually.**
We made a screen record of the website loading in Shanghai, China. This provides you with an intuitive way to see how fast the site visually loads and understand what people in China actually experience when they visit the website.
<br>
**3. A yes-no check to see if the site complied with the laws in China.**
If the site passes the legal check, it's a green check. If it doesn't pass, we will tell you why it doesn't pass.
Now, let's dive into the reports for each of the selected websites using Liferay's DXP.
---
**Brinks, www.brinks.com**
Brinks (NYSE: BCO) international provider of security services to banks, retailers, governments, mints and jewelers
From our speed test, people in China have difficulty viewing the images on the Brinks' website. (that’s what the below figure means, red means unable to display images).
Here is a more intuitive way to see it, we screen-recorded the process when a user browses Brinks' website in Shanghai, click the video below to see it in action:
{% youtube krflVhpHj7M %}
**Does the Brinks website comply with the laws in China?**
No. It doesn't pass our Legal check because the business does not have an ICP license displayed at the footer of their website.
If you don't know what an ICP license is, [click](https://launch-in-china.21yunbox.com/untold-facts-about-icp-for-china.html) to learn more.
Finding if a website has an ICP license is pretty straightforward, just scroll to the bottom of the page, if you see a number like this (see below Nike's websites for China), then the business behind the website has an ICP for China. If not, they don't have it. You can check if your website has it or not.
Below is an example of Nike's website in China, and its ICP number.
<br>
<hr>
<br>
<br>
Similarly, we ran the same tests for the rest of the Liferay user's websites. To see the full case studies, just click on the brand name below:
<br>
<hr>
<br>
<br>
**Blue Dart, www.bluedart.com**
Blue Dart Express Ltd. (NYE: BLUEDART) is South Asia’s premier express air and integrated transportation & distribution company based in India.
Click [here](https://launch-in-china.21yunbox.com/solutions/does-liferay-work-in-china.html#:~:text=Bluedart%2C%20www.bluedart.com) to see Blue Dart's full case study.
<br>
<hr>
<br>
<br>
**Lorven Technologies, www.lorventech.com**
Lorven Technologies, Inc. is a highly recognized provider of professional technology consultancy that serves clients worldwide.
Click [here](https://launch-in-china.21yunbox.com/solutions/does-liferay-work-in-china.html#:~:text=Lorven%20Technologies%2C%20www.lorventech.com) to see Lorven's case study results.
<br>
<hr>
<br>
<br>
**MacDon, www.macdon.com**

MacDon Industries Ltd. is a Canadian manufacturer of specialty agricultural equipment.
Click [here](https://launch-in-china.21yunbox.com/solutions/does-liferay-work-in-china.html#:~:text=MacDon%2C%20www.macdon.com) to see MacDon's case study results.
<br>
<hr>
<br>
<br>
**Qatar Stock Exchange, www.qe.com.qa**
The Qatar Stock Exchange (QSE) is the principal stock market of Qatar. QSE is a full member of the World Federation of Exchanges and was recently upgraded by the MSCI and the S&P Dow Jones Indices.
Click [here](https://launch-in-china.21yunbox.com/solutions/does-liferay-work-in-china.html#:~:text=Qatar%20Stock%20Exchange%2C%20www.qe.com.qa) to see QSE's case study results.
<br>
<hr>
<br>
## Need Liferay to Work in China?
In short, if your business is going to China, make sure your website passes the two tests we mentioned above to have a fast speed of first load and good viewing and browsing quality for your users in China.
> _**Reducing page load time by 0.1 seconds will increase the conversion rate by 8%.**_ - Google, Deloitte
<br>
If you need to get Liferay working in China, feel free to [contact us](https://www.21cloudbox.com/contact.html) or click here to [get started.](https://www.21cloudbox.com/with/liferay.html)
<br>
<hr>
<br>
<br>
*For additional detail and future modifications, refer the [original post](https://www.21cloudbox.com/solutions/does-liferay-work-in-china.html).* | 21yunbox |
944,946 | Is 99% Good? | If you ever took at test at school, you’d probably be really happy with getting a 99 grade. After... | 0 | 2022-01-05T03:24:15 | https://dev.to/anthonyjdella/is-99-good-57d3 | devops, sre, monitoring, performance | If you ever took at test at school, you’d probably be really happy with getting a 99 grade. After all, it’s almost a perfect score.
But when you’re talking about software systems, is 99% availability good?
Well, if your system needs to be available 24/7 everyday, 99% won’t cut it.
## Downtime Table
Take a look at the below table. It shows how much downtime (in time) equals a given percentage.
| Availability | Annual Downtime |
| ------ | ----------- |
| 99% | 3 days, 15 hours, 40 minutes |
| 99.9% | 8 hours, 46 minutes |
| 99.99% | 52 minutes, 36 seconds |
| 99.999% | 5.26 minutes |
## What's this Mean?
If your system should be available at all times, a 99% availability means that your system can have almost 4 days of downtime per year! For a system that needs to be available, that is a terribly long time.
Imagine if you have a business critical system that fails. If it was down for almost 4 days, your company could lose millions/billions of dollars! Take for example, when [Facebook was down in 2021](https://en.wikipedia.org/wiki/2021_Facebook_outage) for about 7 hours. Their stock dropped 5%, or $40 billion dollars! This was only for a 7 hour outage. Can you imagine if they had just 99% availability and Facebook was down for 4 days?
## What should you aim for?
This depends on your system, and usually a probability or downtime measurement (rather than percentage) should be given. "Five 9's" is a common "standard" that systems try to aim for. **That is 99.999% availability (hence five 9s)**. Standards is in quotes because it really isn't a standard, it's just what's commonly mentioned in the industry as a goal to achieve.
Check out this [Wikipedia article](https://en.wikipedia.org/wiki/High_availability) for more information.
Thanks for reading!
Visit [anthonydellavecchia.com](https://anthonydellavecchia.com) for more articles! | anthonyjdella |
945,081 | Top 10 Must-Have E-commerce Features to Make Your E-Store Thrive Globally | Starting an online store is only the first step. The e-commerce industry is expanding faster than... | 0 | 2022-03-23T10:07:36 | https://terasol.medium.com/top-10-must-have-e-commerce-features-to-make-your-e-store-thrive-globally-6dea7ac50ccd | estoreoptimization, ecommercesite, ecommercefeatures, ecommercestorefeatur | ---
title: Top 10 Must-Have E-commerce Features to Make Your E-Store Thrive Globally
published: true
date: 2022-01-05 03:55:11 UTC
tags: estoreoptimization,ecommercesite,ecommercefeatures,ecommercestorefeatur
canonical_url: https://terasol.medium.com/top-10-must-have-e-commerce-features-to-make-your-e-store-thrive-globally-6dea7ac50ccd
---
Starting an online store is only the first step. The e-commerce industry is expanding faster than ever before. Once you’ve gotten the hang of marketing your business and processing orders, it’s time to think about adding advanced e-commerce features to sell more products and enhance your revenues.
Offering high-quality products isn’t enough to keep an E-Commerce store afloat. Various other aspects come into play as well. You must have an appealing, user-friendly, SEO-rich website that is also adept at marketing itself. All of this is available in the form of powerful e-commerce store features and tools for your website. The hard thing is how competent you are at using them, and yes, you should understand how they function!
There is no specific secret to their success. Those [e-commerce sites](https://terasoltechnologies.com/managed-services/)do things that everyone else does, but they uniquely do them.
They start with the foundations, such as user experience (UX), user interface (UI), fast and dependable hosting, security, and so on, and then they work on features that will make their website simple, quick, safe, and visually appealing. The features provided by the website, and both the customer and the website owner also make a huge difference.
As a business owner, you must have the tools to manage your website and ensure that the administrative features are compatible with your business processes. For example, if you offer payment terms to your customers, make sure the platform you’re using allows you to set a credit limit for them. Before delving into an e-Commerce project, thoroughly consider the eCommerce features required; else, you’ll be kicking yourself afterward!
Some e-commerce businesses are barely surviving while others are making large profits daily.
So, if you want to detect loopholes in your business, you should go through our e-commerce features checklist! This article will go through some of the essential e-commerce features to make your e-store thrive across the globe.

### Here are 10 Advanced E-Commerce Features
Going beyond the basics and adding advanced features for store optimization will help you improve the experience of your customers and sell more products. Here are seven advanced e-commerce features to think about incorporating into your e-store.
#### 1. Options for product search, filtering, and comparison
You may believe that your website is the greatest user-friendly destination ever, yet a first-time visitor may associate it with Babylon. Users may become disappointed if there is no option for searching. Even though the layout is unclear at first, a search option will typically allow the tenacious user to manually seek their desired results.
Even if you’re only displaying a few products or services on your website, it’s critical to provide the visitor with the opportunity to filter them based on relevant criteria by category. The purpose of filtering is to allow a user to get to their intended query faster, therefore expediting the checkout process.
Consider adding filters for toggling between several product categories, sorting by price, identifying product quality, and sorting based on social validation (popularity). Include a comparison feature if your site offers several products/services or tiers of offerings.
#### 2. Optimized Shopping Cart

The shopping cart on your e-commerce site is not something that should be decided during setup and then forgotten about. A shopping cart is an important feature to have on your e-commerce site. Customers’ chosen products are added to this location before they proceed with the checkout procedure.
Managing a high-performing cart necessitates ongoing testing, adjusting, and re-work to remain current with consumer wants and market developments. Your cart should also be optimized in terms of flow, layout, and information displayed.
In terms of flow, your shopping cart should have just the perfect number of steps so that visitors see the procedure as simple yet professional. Some sectors benefit more from three-step shopping carts, while others benefit more from a two-step flow.
#### 3. Search Engine Optimization
The majority of online traffic may be divided into two categories:
Referral traffic — individuals who visit your website via referral links, such as those found in social media posts, articles, or advertisements.
Organic traffic is defined as visitors who arrive at your website from relevant search results.
To expand your business, you must ensure that both types of traffic are directed to your e-commerce platform. Organic traffic will necessitate code optimization and content promotion.
Page optimization for SEO is critical for your online activities. Like, while developing your front-end, you can continue to use a Shopify-based e-commerce backend solution.
#### 4. Integration with Social Media and Blog Sites
Some content management systems can be linked to social media platforms. It makes it easier for firms to share items, information, and photographs with their audience. It can eventually lead to increased consumer involvement and sales for the online store.
You should also have an email marketing feature built into your e-Commerce site or store’s backend.
Your e-commerce site can have a separate section on your website where all of your blogs and articles. When it comes to appeasing both the search engine and the customers, integration is an important marketing tactic.
#### 5. Native Mobile Application
Investing in[Progressive Site Apps (PWAs)](https://terasoltechnologies.com/web-development/) or responsive web design may be sufficient. A native mobile app, on the other hand, might be a smart solution for a bigger amount of traffic. Design your e-commerce site user-friendly.
Mobile apps, for example, can be used to optimize content for mobile devices, particularly product photographs, and descriptions.
Here are a few pointers to keep in mind when it comes to improving your online checkout process for mobile users:
- Check to see if your form fields are large enough to type on smaller displays.
- Check that form fields activate the correct keyboard.
- Don’t enquire about things that aren’t necessary.
- Make your buttons and calls-to-action larger.
#### 6. UX Audit of the Shopping Path
Although a UX audit is not a feature, it enables improved decision-making when developing or altering a buyer’s journey. This type of UX audit shopping can be based on expert analysis, moderated stationary testing, online tests, heatmap analysis, and so on.
The idea is to collect useful data about how visitors interact with your online store and use it to improve their buying experience. Among the advantages are:
- Increasing the average shopper’s shopping basket.
- Increasing average conversions from the majority of sources.
- Lowering the average cost of customer acquisition.
#### 7. Product demonstrations in video or 3D
Finally, think about including video and 3D product demos in your store. One of the most significant disadvantages of internet shopping is the inability to view or touch the merchandise in person.
By including video or 3D product demos or by using AR/VR tech, you can bridge this gap and help your buyers visualize what they’re purchasing.
#### 8. Promotional and Discount Code Generators

It is one of the most useful tools for your eCommerce company. If you have any special offers or reductions, these should be displayed alongside the product price. You can use the standard practice of removing the original price and displaying the discounted pricing. You can also show the savings as a percentage to help users realize how much money they are saving.
#### 9. Advance and Secure Payment Options
Have you experienced a situation where you have to fill in a whole lot of information while buying, and then you abandon it?
I have done this many types. It is tiring, no matter how willing I am to buy the product.
Cart abandonment is one of the challenges wreaking havoc on online sales. One option to increase this measure is to implement seamless payments, which include conventional methods such as PayPal-like solutions, credit cards, and so on. The simpler and shorter the payment stage, the lower the likelihood of cart abandonment.
Mobile payments should also be prioritized when creating or improving this channel. If your website currently does not handle multiple payments, you already know what your next critical site implementation must be.
Another issue is one of trust. Online retailers and payment systems are vulnerable to cyber-attacks, which result in fraud and data leaks that impact customers. As a result, one of your primary considerations should be the security of your web and mobile payments.
#### 10. Include a CTA and a contact page
By putting a clear [call-to-action](https://blog.hubspot.com/marketing/call-to-action-examples) button, you can move your visitors’ attention away from choice fatigue and confusion and toward the important material based on your demands. Place the CTA in a prominent location on your website and choose a fill color that contrasts with the background.
Although it may appear to be a no-brainer, establishing a web page with contact information for your team is expected by all clients.
### Conclusion
And there you have it, our comprehensive top ten list of everything required for an e-commerce site in 2022 and beyond. Ensuring that these needs are followed may increase your bottom line over time and will undoubtedly improve your visitors’ experience, causing them to return for more.
### Allow us to Deliver E-Commerce Features to your Store
User needs and available technologies may change, but the core concept for many e-commerce websites remains the same — to provide a decent UX, present products in a compelling style, and drive and convert relevant visitors from various channels.
[Get in touch with us](https://www.terasoltechnologies.com/enquiryform/?source=medium), with cutting-edge solutions, we can assist you in adapting to these changing demands and gaining a competitive advantage. Let us know about your concept, and we will create your e-commerce features. | terasol_app |
945,111 | How to Apply Amazon's Leadership Principles as a Software Engineer | Amazon is one of the biggest companies in the world. Their core products of them are their... | 0 | 2022-01-05T07:39:26 | https://getworkrecognized.com/blog/apply-amazon-leadership-principles-software-engineer | career, programming | Amazon is one of the biggest companies in the world. Their core products of them are their [marketplace](https://www.amazon.com) and [AWS](https://aws.amazon.com/), a cloud computing platform used by the biggest companies in the world. AWS is also the product that generates the highest profit margins for Amazon.
As a software engineer at Amazon, you are challenged every day. It is expected that you deliver results and apply the leadership principles in every day's work. Even when you are not working at Amazon, you can apply these principles to your job. Share them with your colleagues to create a more collaborative and productive environment. So let us explore some tips on how you can apply the leadership principles.
## The 16 leadership principles
The principles at Amazon are the DNA of how Amazon works. The 16 principles make sure that everyday life at Amazon is going smoothly. A simple example is discussions on how to solve a problem. A team gets consists of many people and different experiences. Of course, disagreements will occur at some point. To solve these arguments employees at Amazon will reference the leadership principles during a discussion to solve the arguments. Foremost some should state that discussions in technology companies like Amazon are always looking for actions. Discussions can evolve but should reflect in tasks that can be executed to discover the topic more like gathering data or solving the problem. This can be based on the leadership "Bias for Action" for example.
The current leadership principles consist of these 16 right now:
* Customer Obsession
* Ownership
* Invent and Simplify
* Are Right, A Lot
* Learn and Be Curious
* Hire and Develop the Best
* Insist on the Highest Standards
* Think Big
* Bias for Action
* Frugality
* Earn Trust
* Dive Deep
* Have Backbone
* Disagree and Commit
* Deliver Results
* Strive to be Earth's Best Employer
* Success and Scale Bring Broad Responsibility
You can find an older version of this list also [on our career ladder explorer](https://getworkrecognized.com/tools/career-ladders-explorer/amazon-2020). The list of principles included 14 principles in the past years. But since then Amazon added two more principles "Strive to be Earth's Best Employer" and "Success and Scale Bring Broad Responsibility". The list can change from time to time, but the most updated list can be found on [Amazon’s site](https://www.amazon.jobs/en/principles).
[](https://getworkrecognized.com/login?utm_source=blog&utm_medium=devto&utm_campaign=apply-amazon-leadership-principles-software-engineer)
To understand how the leadership principles can be used for software engineers, not just at Amazon, let us have a look at the next chapters. We will explain what software developers spend most of their time on and how leadership principles can be applied to the different work.
To understand how the leadership principles can be used for software engineers, not just at Amazon, let us have a look at the next chapters. We will explain what software developers spend most of their time on and how leadership principles can be applied to the different work.
## What do Software Engineers spend their time on
Software Engineering is mostly understood as programming. Writing code to fulfill business requirements. As software engineers, we do a lot of other tasks as well like the following
**Meetings, management, and operations**
- Product Decision Discussions
- Technical Decision Discussions
- Writing Documentation
- Organizing technical work
- Planning technical projects
- Work on reporting metrics, building dashboards
- Discovery work to come up with new feature proposals
- Interviewing
**Code maintenance**
- Fixing old TODO comments
- Making sure the system is reliable
- Code Reviews
**Testing**
- Tests as code
- Manual tests
- User Tests
**Security**
- Testing for security problems
**Writing Code**
- Creating new features
- Fixing bugs
So we have a wide range of topics that a Software Engineer needs to deal with. Some topics depend on what team or company you will work for. But in general, these are the duties of software engineers. Do you miss anything? Happy to add them. Feel free to email [getworkrecognized@gmail.com](mailto:getworkrecognized@gmail.com). So how do we apply the leadership principles to the different activities?
## How to apply the leadership principles during the day
As we have seen in the last chapter, software engineers deal with a lot of duties during their job. Let us look at some examples and use cases for Amazon’s Leadership Principles.
### Creating new features or Fixing bugs
This is hands-down coding most of the time. During coding, Software Engineers can apply multiple leadership principles. Let us look at some of them.
**Invent and Simplify**
Coding is most often consists of two activities: Changing existing code or adding new code. Both ways of working will contribute value and opportunities to invent new coding patterns or simplify the existing code. You could add some new coding pattern that makes the code easier to extend in the future. That is most of the time the main reason for this leadership principle to be applied.
**Insist on the Highest Standards**
When creating new features or working on refactoring code you should make yourself accountable for the highest standards of code. After all, code is most of the time read, rather than writing. So make sure to put you into the perspective of a new hire and ask yourself if the code is understandable for them.
**Deliver Results**
Making changes to the code is difficult. Try to aim for a specific amount of Pull Requests within a month or so. When creating Pull Requests make sure to do incremental changes. It is ok if a Pull Request is not complete, but smaller and easier to review. Split up your Pull Requests so you deliver results more incrementally.
### Product and Technical Decision Discussions

A big part of the life of a software engineer is product and technical decision discussions. Normally they consist of you, the team, the engineering manager, and the product owner. The product owner is optional when it comes to technical decisions. But in general, these discussions come up most often and require actions that will solve the problem. Of course, the decision process can be rigorous, but Amazon tries to keep the discussions short based on leadership principles. Let us look into how.
**Are Right, A Lot & Customer Obsession**
As a software engineer, you will have a headstart in discussions with two simple things. Use the product yourself and gather data before the discussions are happening. Gathering data will result in backing your arguments and that you are right about the outcome.
If you do not have the data, then try to make it an action out of the discussion and reschedule the discussion. You will show ownership of the issue and customer obsession to solve the customer’s issue.
**Think Big & Frugality**
When thinking about new features or technical decisions, always ask yourself: How will this work in 3-5 years? Ask yourself and make a plan and discuss with the team what they think. It is important to get feedback but also write down what you think so it is manifested somewhere. Write a product proposal document with a 5-year plan. It will help everyone.
Nevertheless, it is important to move fast. And moving fast can be achieved with frugality. Not developing the whole feature or 5-year plan but doing a short-term solution. Leaving the long-term solution for later.
**Disagree and commit**
This is probably the most controversial leadership principle when it comes to discussions. Humans are opinionated. Especially software engineers. I was part of discussions where discussions drifted away far too much because of specific technical or product decisions. Sometimes it is better to just disagree and say "whatever" and follow the decisions of your peers. After all, we can track the results and see if they are satisfying or even A/B test your opinion to see if it would work better. Everyone is open to feedback after a decision, and you should be too.
### Writing external documentation

An underestimated skill as a software engineer is to write documentation. Writing is difficult. Writing clear documentation is even more difficult. There is good guidance out there to write good documentation like the guide by divio: "[The documentation system](https://documentation.divio.com/)". But what is even more important than the structure are some other things that are related to the leadership principles.
**Customer Obsession & Dive Deep**
Good documentation can be written easily. But how do you know what the customer needs? You have to do the research. Watch the customer using the product you are working on. This is difficult from time to time. Especially when working on an internal product, but even then it is possible to just listen to a customer. See their struggles and get feedback on what could be improved. Any pain points. Document them and write proper documentation about them. Obsess with the customer, try to make sure every customer will understand how your product should or can be used.
**Ownership**
Software engineers hate to write documentation. Everyone does, maybe except technical writers. In any way, as software engineers, we should own documentation and make sure it is always in an exceptional state. And I do not only mean the API documentation, but also the general documentation on how to use the product. Make sure you gather feedback and iterate on your documentation to make it more useful.
**Earn Trust**
A big part of writing documentation is actually to gain the trust of the customer. With proper documentation that includes Tutorials, How-to-Guides, Explanation, and References you make sure the customer is earning trust in your system, understand edge cases, and is, in general, more likely to integrate the product.
So what did we learn from this? Make sure to write documentation in your daily life as a software engineer. Spend some time every week to write something, either for your team or externally, so your systems are more understandable.
### Planning projects

The higher you are on the software engineer career ladder, the more important it gets to lead projects that affect your team and company directly. Leadership is a general skill but is composed of the leadership principles at Amazon. By following some of the leadership principles you will be a great leader in making sure smaller projects will get delivered.
**Ownership**
By planning and executing projects you are showing ownership already. Make sure everything will work out as expected and collaborate with your contributors.
**Bias for Action**
When owning a project, you are required to take decisions. This can be challenging. But take action instead of waiting and discussing. As long as you track the outcome of your actions and make sure it performs well, you will be fine. Everyone can fail with the actions, the important part is to realize it was a mistake and fix those decisions.
**Frugality & Deliver Results**
A core principle when planning projects is to plan them minimalistic. It is expected that you deliver a project. A smaller project is delivered quicker by nature. Keep the scope small so you and your collaborators, if existing, can deliver quick results. It is a lot better to roll out a project and gather data on how it performs rather than never releasing it.
**Success and Scale Bring Broad Responsibility**
You have finally finished the project. Now it becomes time to measure your success. The metrics should have been defined at the beginning of the project.
## Summary
We have just listed some examples of how the leadership principles can be applied to your day-to-day work. If you want to get to know how to apply them in detail, have a read on [how customer obsession can be applied for example](https://getworkrecognized.com/blog/customer-obsession-examples-software-engineer). Try to apply the leadership principles. Reference them in some of these situations and make sure you stay productive. But the principles have an even more important meaning at Amazon.
[](https://getworkrecognized.com/login?utm_source=blog&utm_medium=devto&utm_campaign=apply-amazon-leadership-principles-software-engineer)
## Leadership Principles in Performance Reviews
At Amazon, Performance reviews happen yearly. A big part of the reviews is the self-review and the peer feedback you or your manager will receive. They are all based on leadership principles. Peers will have available a matrix for each leadership principle and the level. They will then choose the strengths and weaknesses of your past work performance.
This process is really difficult though. Think about writing a self-review of your past year’s achievements and base it on the leadership principles listed in this article. You will struggle, I will struggle, we all will struggle. Our human brains are limited. You simply can’t remember all the things we did. And that is where a brag document becomes important. I am keeping a journal in getworkrecognized of all achievements I have reached. I can tag the achievements with a tag and get a summarized version of what I have achieved and relate it to the leadership principles. Quite useful for the self-review. But where it gets even more important is when you ask for peer feedback. Your colleagues might not even remember what they did themself, and will even more likely forget what you have done. Send them a brag document with all your achievements listed in a compact form and you will get better feedback for sure. If you are unsure what a brag document could look like, have a [look at our 3 brag document templates](https://getworkrecognized.com/blog/3-brag-document-templates-google-docs).
Once you get rated on your leadership principles the manager will decide if you get to put up for promotion or not. In most cases, they are required to write a promotion case, where they can reference the brag document again, which will be great for you because less work is required to get you the well-deserved promotion.
If you are not working at Amazon you can still make sure to follow the advice with the brag document. In any case, it will help you with the promotion in your current company. People like writing documents that underline a need for something. Think of the product/feature proposals I mentioned before. These should be manifested in a document as well, so you can reference them in the future and make sure the right decision will be taken - which should be your promotion.
So, this is how you can apply the leadership principles of Amazon at your current job, even if you do not work for Amazon. Amazing, is not it? It will make you a more productive and high-quality developer with an eye for the right thing.
| igeligel |
945,113 | AWS Community ASEAN - Quarterly Awards for Contributors in 2022 | Happy New Year, everyone! To celebrate the new year, our editorial team has worked with... | 0 | 2022-01-25T13:20:15 | https://dev.to/awscommunity-asean/aws-community-asean-quarterly-awards-for-contributors-in-2022-57m5 | aws, devrel, cloud, community | ## Happy New Year, everyone!
To celebrate the new year, our editorial team has worked with AWS to launch the AWS Community ASEAN Dev.to Awards! These awards will recognize writers who have contributed to the AWS Community ASEAN publication in 2022. Cool prizes await the quarterly winners!
With these writer awards, we hope to encourage community members to pursue writing articles to deepen their understanding of a topic and give back to the community at the same time.
## Awards 🏆
Without further ado, here are the awards:

1. **Most Insightful Content** - This award goes to the post's writer with the most insightful content. The editorial team will serve as judges for this award.
- Prize: Echo Dot
2. **Most Engaging Content** - This award goes to the writer of the post with the most engagements (like, post, share) posted during the quarter
- Prize: 100USD AWS Credits
3. **Promising New Author** — This award goes to newly joined authors with breakthrough content or surpassing average engagements.
- Prize: 100USD AWS Credits
## Criteria 🏵
- For now, we would include only content written in English and must be posted with the user's registered Dev.to account and under the AWS Community ASEAN publication.
- The winner must be a member of the AWS Community ASEAN publication. Join us by following the instructions in [this post](https://dev.to/awscommunity-asean/welcome-to-dev-to-aws-community-asean-ao9)
- The content must adhere to the community standards of both Dev.to and of [the publication](https://dev.to/awscommunity-asean/welcome-to-dev-to-aws-community-asean-ao9)
- The content must feature technical content related to AWS.
## When will we award?
The winners of each quarterly award will be awarded during the AWSUGPH AWS Community ASEAN Livestream and will be featured in the newsletter to be sent to the contributor's newsletter:
- Q1 - April 2022
- Q2 - July 2022
- Q3 - Oct 2022
- Q4 - Jan 2023
## Let's get writing! :D
If you need any form of support (i.e. editorial or technical), let us know! We'd love to help <3

Photo by <a href="https://unsplash.com/@austinchan?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Austin Chan</a> on <a href="https://unsplash.com/s/photos/blog-award?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
| raphael_jambalos |
945,141 | Awsome | https://dev.to/kunaal438/amazing-portfolio-website-using-html-css-and-js-l8f | 0 | 2022-01-05T08:23:20 | https://dev.to/leminhduc1202/awsome-32f8 | https://dev.to/kunaal438/amazing-portfolio-website-using-html-css-and-js-l8f | leminhduc1202 | |
945,256 | Easily show files as cards using Microsoft Graph Toolkit and hTWOo | With a recent update to Microsoft Graph Toolkit, showing your files as cards became even easier.... | 0 | 2022-01-31T14:49:05 | https://blog.mastykarz.nl/easily-show-files-cards-microsoft-graph-toolkit-htwoo/ | javascript, webdev, microsoftgraph, microsoft365 | ---
title: Easily show files as cards using Microsoft Graph Toolkit and hTWOo
published: true
date: 2022-01-05 08:28:31 UTC
tags: javascript,webdev,microsoftgraph,microsoft365
canonical_url: https://blog.mastykarz.nl/easily-show-files-cards-microsoft-graph-toolkit-htwoo/
---
With a recent update to Microsoft Graph Toolkit, showing your files as cards became even easier. Check it out.
## Show files as cards using Microsoft Graph Toolkit and hTWOo
Recently, I showed you [how you can use the Microsoft Graph Toolkit to show files stored in Microsoft 365 as cards](/show-files-cards-microsoft-graph-toolkit-htwoo/).
Using just a few lines of code, we built a simple Single-Page App secured with Azure Active Directory, added auth, to let users sign in with their Microsoft 365 account and retrieve their files. We did it using [Microsoft Graph Toolkit](https://docs.microsoft.com/graph/toolkit/overview?WT.mc_id=m365-53122-wmastyka), which is _the easiest way to connect your app to Microsoft 365_. Its [authentication providers](https://docs.microsoft.com/graph/toolkit/overview?WT.mc_id=m365-53122-wmastyka) abstract away all of the auth code to a single line. And thanks to its [components](https://docs.microsoft.com/graph/toolkit/overview?WT.mc_id=m365-53122-wmastyka), you can easily show data from Microsoft 365 in your app.
To show files as cards, we used [hTWOo](https://lab.n8d.studio/htwoo/), which is a community-driven implementation of the Fluent UI design language.
> The complete sample app used in this article is [available on GitHub](https://github.com/waldekmastykarz/mgt-htwoo-files/).
## Inconvenient showing file details
Each card we show in our app contains information about the file, such as its thumbnail, location, name, author and picture, and when the file was last modified. Not all of this information is available to us readily, which is why in our original solution, we had to add quite some JavaScript code to load the necessary information from Microsoft Graph. And this is where things got complicated.

Microsoft Graph Toolkit gives you simplicity. Instead of building requests, parsing responses, and handling errors, you add ready-to-use components that do all of that for you and allow you to focus on building your app. But you don't benefit much if you still need to write requests because you can't get all the data that you need, do you?
## Easily show files as cards with Microsoft Graph Toolkit
Recently, Microsoft Graph Toolkit got updated, and if you were to build an app that shows files from Microsoft 365 as cards, you'd no longer need to write custom JavaScript. Here's the code you'd need instead:
```html
<html>
<head>
<script src="https://unpkg.com/@microsoft/mgt/dist/bundle/mgt-loader.js"></script>
<link rel="stylesheet" href="https://unpkg.com/@n8d/htwoo-core/dist/css/htwoo.min.css">
<link rel="stylesheet" href="styles.css">
</head>
<body>
<mgt-msal2-provider client-id="d43f076b-c6a6-4805-97be-f9ef969241c0" authority="https://login.microsoftonline.com/M365x61791022.onmicrosoft.com"></mgt-msal2-provider>
<mgt-login></mgt-login>
<mgt-file-list>
<template>
<h1>My files</h1>
<div class="hoo-cardgrid">
<div data-for="file in files" class="hoo-doccard" data-props="{{@click: openFile}}">
<div class="hoo-cardimage">
<div data-if="file.folder"><img src="./folder.jpg" alt=""></div>
<mgt-get data-if="!file.folder" resource="/drives/{{file.parentReference.driveId}}/items/{{file.id}}/thumbnails/0/c320x180_crop/content" type="image" cache-enabled="true">
<template data-type="loading">
<div class="hoo-ph-squared"></div>
</template>
<template data-type="error">
<img src="./otter.jpg" alt="">
</template>
<template data-type="no-data">
<img src="./otter.jpg" alt="">
</template>
<template data-type="default">
<img src="{{image}}" width="320" height="180" alt="">
</template>
</mgt-get>
</div>
<div class="hoo-cardlocation">
<mgt-get resource="/drives/{{file.parentReference.driveId}}" cache-enabled="true">
<template data-type="loading">
<div class="hoo-ph-row"></div>
</template>
<template data-type="error">
<div class="hoo-ph-row"></div>
</template>
<template data-type="default">
{{name}}
</template>
</mgt-get>
</div>
<div class="hoo-cardtitle">{{file.name}}</div>
<div class="hoo-cardfooter">
<div class="hoo-avatar">
<mgt-get resource="/users/{{file.lastModifiedBy.user.id}}/photo/$value" type="image" cache-enabled="true">
<template data-type="loading">
<div class="hoo-ph-circle"></div>
</template>
<template data-type="no-data">
<div class="hoo-ph-circle hoo-avatar-img"></div>
</template>
<template data-type="default">
<img src="{{image}}" alt="" class="hoo-avatar-img" loading="lazy">
</template>
</mgt-get>
</div>
<div class="hoo-cardfooter-data">
<div class="hoo-cardfooter-name">{{file.lastModifiedBy.user.displayName}}</div>
<div class="hoo-cardfooter-modified">{{formatDate(file.lastModifiedDateTime)}}</div>
</div>
</div>
</div>
</div>
<button class="hoo-button-primary" data-props="{{@click: loadMore}}">
<div class="hoo-button-label">Load more</div>
</button>
</template>
</mgt-file-list>
<script src="script.js"></script>
</body>
</html>
```
Here's what's changed.
### Load document thumbnail using mgt-get
Originally, we'd use custom JavaScript to load the document thumbnail from Microsoft Graph and add it to the template. Starting from Microsoft Graph Toolkit v2.3.1, we can load images using the [Get component](https://docs.microsoft.com/graph/toolkit/components/get?WT.mc_id=m365-53122-wmastyka):
```html
<mgt-get data-if="!file.folder" resource="/drives/{{file.parentReference.driveId}}/items/{{file.id}}/thumbnails/0/c320x180_crop/content" type="image" cache-enabled="true">
<template data-type="loading">
<div class="hoo-ph-squared"></div>
</template>
<template data-type="error">
<img src="./otter.jpg" alt="">
</template>
<template data-type="no-data">
<img src="./otter.jpg" alt="">
</template>
<template data-type="default">
<img src="{{image}}" width="320" height="180" alt="">
</template>
</mgt-get>
```
In the component, we're using 4 templates:
1. `loading`, which is rendered while the Get component is waiting on a response from Microsoft Graph
2. `error`, in case Microsoft Graph returned an error
3. `no-data`, this is a new template added to the Get component in Microsoft Graph Toolkit v2.3.1 which is rendered when the request returned no data. When you request an image, it's also rendered when the request returns a 404.
4. `default`, which is rendered when retrieving data succeeded
We can now use the Get component, not only to load the document's preview but also the avatar of the user who modified the file most recently.
### Load file location
Another request for which we originally wrote custom JavaScript, was to retrieve the location where the file is stored. In this version, we replaced that code with another instance of the Get component:
```html
<mgt-get resource="/drives/{{file.parentReference.driveId}}" cache-enabled="true">
<template data-type="loading">
<div class="hoo-ph-row"></div>
</template>
<template data-type="error">
<div class="hoo-ph-row"></div>
</template>
<template data-type="default">
{{name}}
</template>
</mgt-get>
```
While the data is loading, we show a shimmer - an animated placeholder that communicates to users that content is loading. After we retrieved the file's location from Microsoft Graph, we show it instead.
With these modifications, the only piece of JavaScript that's left is:
```javascript
document.querySelector('mgt-file-list').templateContext = {
formatDate: date => {
const d = new Date(date);
return d.toLocaleString();
},
openFile: (e, context, root) => {
window.open(context.file.webUrl, '_blank');
},
loadMore: (e, context, root) => {
root.parentNode.renderNextPage();
}
};
```
We use these custom functions to format the file modified date, open the select file in a new tab, and load more files. Notice, that we no longer need to manually call Microsoft Graph to retrieve data, process responses, and handle errors!
## Summary
Microsoft Graph Toolkit is the easiest way to connect your app to Microsoft 365. Because it takes care of authentication and retrieving and showing the data in your app, you can focus on building your app. With a recent change to Microsoft Graph Toolkit, you can build even richer visualizations without having to write custom JavaScript and manually call Microsoft Graph.
If you're new to Microsoft Graph Toolkit, the best place to start is to follow the [Microsoft Graph Toolkit learning path](https://docs.microsoft.com/learn/paths/m365-msgraph-toolkit/?WT.mc_id=m365-53122-wmastyka) on MS Learn. | waldekmastykarz |
946,302 | Day 503 : Time Flies | liner notes: Professional : Did my workshop this morning. I kept getting up doing the night. I... | 0 | 2022-01-05T22:34:50 | https://dev.to/dwane/day-503-time-flies-2687 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Did my workshop this morning. I kept getting up doing the night. I think I was excited/nervous about the workshop. Next thing I knew, it was time to start. The timeslot was 1 and a half hour. The time flies! Next thing I knew, it was over. Had a really good crowd that asked great questions. All my demos worked on the first try so that was a plus. Also got some really good feedback about the workshop. Afterwards, I had to take a nap. When I woke up, had a meeting about a new project that led into another meeting about working on the project. I helped out with a community project. Added links from the workshop to the hackathon's Discord. Then it was time to call it a day.
- Personal : Last night, I went to bed early because I had the workshop in the morning. I was able to add the ability to log into the side project using Twitter. Pretty much all I had a chance to do.
Going to eat dinner and start working on my side project. I also need to start putting together the radio show together. Short update, I'm still tired. haha.
Have a great night!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube OdZ1WH8rSOc %} | dwane |
946,314 | Things you can do to get started with development | I think a few of the first things you’ll need are: patience, time and willingness to learn. Patience... | 0 | 2022-01-05T23:48:35 | https://jahir.dev/blog/things-to-get-started-development | programming, career, codenewbie, motivation | I think a few of the first things you’ll need are: patience, time and willingness to learn.
Patience and time because learning is a long process. I think once you start, you will also keep finding more and more things to learn. You don’t need to do it all at once. Take your time, go at your own pace and you eventually will.
Really, try not to feel overwhelmed by the amount of things to learn. There’s always more coming and being built, but it’s ok to not know them all.
What I suggest you do is try to explore a few, find the ones you like or enjoy using the most and then learn and practice a lot about it.
The willingness to learn will keep you focused and help you overcome many challenges you might find during the process.

<br/>
### Choose a path
Now, to get started with development you will need to choose a path, and I know it might be hard at the beginning if you haven’t explored any before. I think you can start by asking yourself what kind of things you would like to build, be it websites, server-side work, mobile apps (for android or iOS), desktop apps along others.
The next things I will mention are mostly not focused on a single path, therefore you might be a bit lost on where to start. Like, which topics should you learn first for the path you’ve chosen?
Well, [Developer Roadmaps](https://roadmap.sh/) is a great tool that can help you with that. It will show you the whole path you can follow to become a developer on a specific area. From the basics to complex stuff.
### Find resources
Here’s a few sites that will provide resources or content for you to keep learning and get deep into the topics you want to explore.
- [FreeCodeCamp](https://www.freecodecamp.org/):
This platform includes articles and interactive courses to learn about algorithms and data structures, web, backend, python and much more. The content is translated to multiple languages and you can also even get certifications for what you learn. Everything completely free
- [Codewell](https://www.codewell.cc/):
Provides different challenging projects for you to build and practice your web development skills. You will get access to design assets so you can have a reference of what you would build. Many of them are free.
- YouTube and Udemy
You will find many on these platforms. Courses on Udemy might not be free, but they frequently have discounts, and you can access them anytime, anywhere, and learn little by little, at your own pace.
### Git and GitHub
Learning git is really important. If you learn it in your early days as a developer, you will already have a useful skill.
Git can help you have your projects stored somewhere on the internet, allowing you to work on them from anywhere, plus also allowing you to do collaborative work and even learn by helping others when contributing to their projects.
GitHub is one of the platforms you can use to store your projects. Other options are GitLab, BitBucket and there’s even self-hosted options such as [Gitea](https://gitea.io/).
Some resources to help you learn about these tools are:
- [Microsoft’s Introduction to Git](https://docs.microsoft.com/en-us/learn/modules/intro-to-git/)
- [Free Git course on Udemy](https://www.udemy.com/course/learngit/)
- [Git basics on FreeCodeCamp](https://www.freecodecamp.org/news/learn-the-basics-of-git-in-under-10-minutes-da548267cc91/)
- [GitHub Learning Lab](https://lab.github.com/)

<br/>
### Get better at search
While learning, you will usually find yourself searching for concepts, videos, tutorials and more about the topics you’re learning.
When searching, it’s important that you learn to find the best and most interesting/useful results.
One thing you can do is using search operators, such as:
- **Quotes**:
Will provide results including exactly that text.
Example: `android "FloatingActionButton"`
- **Site**:
The `site` operator will bring results from a specific website.
Example: `javascript site:dev.to`
With just these two, I’ve always found great results. You can find more advanced and complex search operators [on this site](https://ahrefs.com/blog/google-advanced-search-operators/).
Additionally, even if you’re primary language is other than English, I suggest you do search in English. You will find even more content and you will be working on an extra skill.
Searching can also help with getting more specific results. Say you want to create a rounded button for a website. When you search with those exact words, you will find results focused on achieving that, instead of long blog posts or videos telling a lot of other things too. Which isn’t bad at all, but I have found myself wanting to go straight to the point, and that specifying what I’m looking for has helped.
### Learn by example
When I was starting, I usually looked at existing projects on GitHub and I still do every now and then. Exploring their code, how they are built, the tools, frameworks or libraries they use, all those things provide a wider view about the things I can do and learn about.
Besides seeing the code of others has helped me learn a bit about best practices, why a thing is chosen instead of another, how a project can be structured and more.
### Learn with games
I just know a couple games that are focused on learning CSS, but if these exist, I’m sure there’s more out there to learn about other stuff. If you eventually get interested in CSS, these might come in handy:
- [Flexbox Froggy](https://flexboxfroggy.com/)
- [Grid Garden](https://cssgridgarden.com/)
- [Guess CSS](https://www.guess-css.app/)
- [More codepip games](https://codepip.com/games/)
These might result in a more interactive and fun way to learn.

<br/>
### Build!
You should really put the things you learn into practice. Don’t just stay with what you watch in videos, read in blogs or tutorials, and your notes. Build projects.
Many of the resources you might find, will encourage you or guide you to build projects while learning. If that’s the case, dare to build something else too. Build a different project where you can implement the same concepts and even a few more. Or give a twist to the project you’ve built and give your own touch to it.
### Ask for help
Yeah, if you feel lost at some point, don’t know what to do next, or have trouble understanding a concept, feel free to ask for help. Asking for help is ok and there’s nothing bad about it.
On Twitter there’s a lot of people that wouldn’t mind sharing feedback and support. You just have to find the right ones and get in touch. What I’d suggest though, is you do it in public, via a tweet, instead of a private message. Believe it or not, many people might have a similar question, or get benefit of the reply you get so they can learn a bit more too.
You can also find many posts on [dev.to](https://dev.to/) with advice, guidance, questions and more. Go to that site and search for the topic you’re learning or use the `site:` operator in your favorite search provider/tool. [dev.to](https://dev.to/) is definitely a great place for learning and sharing knowledge, and people are always nice and kind and open to provide help if you need it.
<br/>
That’s it for now. If you know more resources or things you think I could add to this post, feel free to [share them with me](https://jahir.dev/contact).
Thank you for reading. Until next time 👋
*Originally published at [jahir.dev](https://jahir.dev/blog/things-to-get-started-development)* | jahirfiquitiva |
946,565 | Open Port Check Tool | What is Port Checker? Port Checker is a simple and free online tool for checking open... | 0 | 2022-01-06T06:52:15 | https://dev.to/sureshramani/open-port-check-tool-5d3o | webdev, beginners, programming | ## What is Port Checker?
Port Checker is a simple and free online tool for checking open ports on your computer/device, often useful in testing port forwarding settings on a router. For instance, if you're facing connection issues with a program (email, IM client etc) then it may be possible that the port required by the application is getting blocked by your router's firewall or your ISP. In such cases, this tool might help you in diagnosing any problem with firewall setup. You could also find this useful for security purpose, in case you're not sure whether a particular port is open or closed. If you host and play games like Minecraft, use this checker to make sure the server port(25565) is configured properly for port forwarding, then only your friends will be able to connect to your server.
## Most Commonly Used Ports
Port numbers ranges from 1 to 65535, out of which well known ports are pre-defined as convention by IANA.
- 0-1023 - Well known ports (HTTP, SMTP, DHCP, FTP etc)
- 1024-49151 - Reserved Ports
- 49152-65535 - Dynamic/Private Ports
## Well known Ports
- 20 & 21 - FTP (File Transfer Protocol)
- 22 - SSH (Secure Shell)
- 23 - Telnet, a Remote Login Service
- 25 - SMTP (Simple Mail Transfer Protocol)
- 53 - DNS (Domain Name System)
- 80 - HTTP (Hypertext Transfer Protocol)
- 110 - POP3 (Post Office Protocol 3)
- 115 - SFTP (Secure File Transfer Protocol)
- 123 - NTP (Network Time Protocol)
- 143 - IMAP (Internet Message Access Protocol)
- 161 - SNMP (Simple Network Management Protocol
- 194 - IRC (Internet Relay Chat)
- 443 - SSL / HTTPS (Hypertext Transfer Protocol Secure)
- 445 - SMB
- 465 - SMTPS (Simple Mail Transfer Protocol over SSL)
- 554 - RTSP (Real Time Stream Control Protocol)
- 873 - RSYNC (RSYNC File Transfer Services)
- 993 - IMAPS (Internet Message Access Protocol over SSL)
- 995 - POP3S (Post Office Protocol 3 over SSL)
- 3389 - RDP (Remote Desktop Protocol)
- 5631 - PC Anywhere
- 3306 - MySQL
- 5432 - PostgreSQL
- 5900 - VNC
- 6379 - Redis
- 11211 - Memcached
- 25565- Minecraft
[Check Open Port Here](https://techvblogs.com/tools/port-checker) | sureshramani |
947,190 | What is in your bag? | As a new year article, I decided to write up some words about what are the daily drivers I have in my... | 0 | 2022-01-06T19:25:40 | https://ppolivka.com/posts/what-is-in-your-bag | watercooler, gear | As a new year article, I decided to write up some words about what are the daily drivers I have in my bag.
## Bag
I use a top-loaded HP bag for 15-inch laptops. My 17 inch Mac Book fits it well and it's pretty nice. But nothing special.
## Laptops
I have multiple laptops. For my work, I mostly use Macbook Pro 17" - 16GB RAM, 2019 model. I also have Macbook Air 13" M1 model I use for my personal projects. I also got a few Windows and Linux machines but those are rarely used.
## Other electronics
I carry Kindle Whitepaper 4 with me almost everywhere. I love reading.
I also carry Jabra Evolve 75 I use it for work meetings. It's a really great headset. I also have Marshall Mode II true wireless for music and or audiobooks on the go. I love the Marshall sound.
I also have some USB/USB-C cables and some USB-C dongles. Fully embracing that Mac dongle life.
## Drug store
I have deodorant in spray, hand sanitizer, mouth deodorant, and glass cleaning gel. Nothing special.
## Various
I have my Moleskin notebook, Parker pen, FFP2 respirator, chopsticks, and set of lockpicks. I have lockpicking as one of my hobbies I rarely use those but saved me calling locksmith more than once.
---
If you like this article you can follow me on [Twitter](https://twitter.com/pavel_polivka). | pavel_polivka |
947,335 | The Pragmatic Pragmatic Programmer | This story was originally published in my blog and reached hacker news front page, click here to... | 0 | 2022-01-06T20:57:07 | https://dev.to/rogeriochaves/the-pragmatic-pragmatic-programmer-41d4 | _This story was originally published [in my blog](https://rchaves.app/pragmatic-pragmatic-programmer/) and reached hacker news front page, [click here](https://news.ycombinator.com/item?id=29800878) to check the discussion_
## pragmatic
**/præɡˈmæt.ɪk/**\
*adjective*
1. solving problems in a sensible way that suits the conditions that really exist now, rather than obeying fixed theories, ideas, or rules - [Cambridge Dictionary](https://dictionary.cambridge.org/dictionary/english/pragmatic)
2. based on practical judgments rather than principles - [American Dictionary](https://dictionary.cambridge.org/dictionary/english/pragmatic)
3. relating to matters of fact or practical affairs often to the exclusion of intellectual or artistic matters : practical as opposed to idealistic - [Merriam-Webster](https://www.merriam-webster.com/dictionary/pragmatic)
Recently I started reading the book The Pragmatic Programmer, I had never read it before yet it influenced me so much, how? Simply by the title. The **Pragmatic** Programmer, such a cool concept. I've heard about this book left and right, it was a mandatory read once I got serious about software development, I heard people talking about "you have to be pragmatic here", or "those devs are pragmatic", this changed my mind when approaching the development of many software systems, yet for some reason I never got to actually read it, it has been sitting on my "To Read" list for a long long time until now.
So now I read it and it was... **disappointing**. Like very disappointing. Like "don't meet your heroes" kind of thing. The title "The Pragmatic Programmer" is so brilliant, yet they ruined it with the content.
My understanding of pragmatic is the same as the definitions given above, and it were those that I used to guide my thinking when taking pragmatic decisions. Not good practices, not dogmas, but foot on the ground, facing the harsh and cruel reality. The Pragmatic Programmer book is not about that, it's a dogmatic book.
## The Pragmatic Programmer: The Good Parts
The book actually have some very good and pragmatic points, I will start with those because I think they should have been the central idea of the book:
> **CRITICAL THINKING**
>
> The *last* important point is to think critically about what you read and hear. You need to ensure that the knowledge in your portfolio is accurate and unswayed by either vendor or media hype. Beware of the zealots who insist that their dogma provides the only answer—it may or may not be applicable to you and your project.
>
> Never underestimate the power of commercialism. Just because a web search engine lists a hit first doesn’t mean that it’s the best match; the content provider can pay to get top billing. Just because a bookstore features a book prominently doesn’t mean it’s a good book, or even popular; they may have been paid to place it there.
Critical Thinking, that's it, for me that's in the very core definition of what does it mean to be Pragmatic, don't be fooled by dogmas and hype, keep your foot on the ground.
Still for some reason they say it's the *last* important part (I don't know why it isn't the first topic on the book), and later they throw lots and lots of dogmas at you, without explaining the reasoning behind them, contradicting this very same paragraph.
They go further on *Critical Thinking* with some tips:
> **Ask the “Five Whys”**
>
> A favorite consulting trick: ask “why?” at least five times. Ask a question, and get an answer. Dig deeper by asking “why?” Repeat as if you were a petulant four-year old (but a polite one). You might be able to get closer to a root cause this way.
>
> [...]
>
> **What’s the context?**
>
> Everything occurs in its own context, which is why “one size fits all” solutions often don’t. Consider an article or book touting a “best practice.” Good questions to consider are “best for who?” What are the prerequisites, what are the consequences, short and long term?
Those are perfect, that's much of what I understand by being pragmatic.
Then, to close off the good parts of the book, on *Good-Enough Software*:
> The marketing people will have promises to keep, the eventual end users may have made plans based on a delivery schedule, and your company will certainly have cashflow constraints. It would be unprofessional to ignore these users’ requirements simply to add new features to the program, or to polish up the code just one more time. We’re not advocating panic: it is equally unprofessional to promise impossible time scales and to cut basic engineering corners to meet a deadline.
That's it, that's a Pragmatic *Programmer*, one that has to work within corporate constraints, one which has it's foot on the ground, that produces *Good-Enough* Software, because they know it's not possible to build the perfect system given real world contraints, nor to deliver on impossible deadlines.
## The Dogmatic Programmer
At the same time the book argues for *Good-Enough Software*, it argues for the broken window theory:
> Don’t leave “broken windows’’ (bad designs, wrong decisions, or poor code) unrepaired. Fix each one as soon as it is discovered.
This is already somewhat contradictory to the *Good-Enough Software* point made on the book just two topics later, but the worse is that it's actually based on a theory that was [already debunked](https://news.northeastern.edu/2019/05/15/northeastern-university-researchers-find-little-evidence-for-broken-windows-theory-say-neighborhood-disorder-doesnt-cause-crime/)
A lot of times the story of crime reduction in NY with the broken-window policy is used to back-up this, but a [quick read](https://www.quora.com/How-did-the-New-York-City-crime-rate-drop-in-the-1990s) shows you that this is a mere correlation, not causation, a change of police strategy to focus on the bigger crimes rather than on petty ones might have actually been much more effective, together with abortion legalization and many other candidates, nobody knows for sure.
The broken-window theory for code feels like a nice idea, but feeling is not enough, Dogmatic Programmers are gullible and like theories, but a True Pragmatic Programer is skeptical, and values scientific rigour (when possible).
## Dogmatic Programmer: gullible, does what feels right, following idealistic theories
## Pragmatic Programmer: skeptical, values scientific rigour (when possible)
Now, the (when possible) part is very important, and very pragmatic too, because to be honest, in software development that's rarelly possible. The more I learned about statistics and biases in those recent years, the more I realized that having a proper experiment to discover causality is an extremely hard thing, and in software development, basically impossible.
We cannot build thousands of the same systems, with thousands of developers and add just a small variation (say, broken-window policy) to do a proper [RCT](https://en.m.wikipedia.org/wiki/Randomized_controlled_trial) and see it's effect. We don't even know if static types are better than dynamic ones, [we have many studies](https://danluu.com/empirical-pl/), but all confounded or biased in a way or another.
Most of the times we have no choice, being pragmatic means you have to use what is practically available: subjective experiences, biased experiments, or even your favorite dogma when there is nothing left. Practically, you need to take a decision (or even decide to not take one), but keeping your skepticism if you want to be pragmatic, fix your foot on the ground.
In that vein, I will tell you a subjective experience I had that touches the broken-window theory, and I wrote about it on the blogpost [Designed v Evolutionary Code](https://rchaves.app/designed-v-evolutionary-code/). It's not that I'm against broken-window theory or that I'm in favor of it, it's just that **it depends**. I take the book's own advice of **What’s the context?** to give you an example of just two cases where it probably works and where it probably doesn't, following [Kent Back's 3X Theory](https://www.youtube.com/watch?v=FlJN6_4yI2A):
1. If you are in exploration mode, most of the code you produce has no value and you will throw away, you need to iterate faster, here broken windows are totally fine, you focus on the current biggest problem only, law of diminishing returns kicks in and fixing windows doesn't pay-off at all, intead you move quickly to the next biggest problem
2. If you are in extraction mode, on a huge system, even a single flaw can be cathastrophic and cost millions of dollars or lifes (you are under [power law](https://en.m.wikipedia.org/wiki/Power_law)), here you don't want to keep a single window broken, you want to try your best to be sure all tiny pieces are working as they should and hope for the best
A True Pragmatic Programmer is skeptical of stories and dogmas, but the book is not skeptical at all, it tries to convice you using anecdotes, comming from the authors' experience, without any depthness, cues for the possibility of being wrong, and sometimes not even a short explanation, for example:
> **Duplication with Data Sources**
>
> Many data sources allow you to introspect on their data schema. This can be used to remove much of the duplication between them and your code. Rather than manually creating the code to contain this stored data, you can generate the containers directly from the schema. Many persistence frameworks will do this heavy lifting for you.
>
> There’s another option, and one **we often prefer**. Rather than writing code that represents external data in a fixed structure (an instance of a struct or class, for example), just stick it into a key/value data structure (your language might call it a map, hash, dictionary, or even object).
So should I just trust your preference? It doesn't seem very pragmatic. And *why* do you even prefer that? There is not an explanation of the rationale whatsoever, where is the *Critical Thinking*? Where is the *Five Whys*?
Most of the times the book assume all conclusions are self evident, there are many more examples like that:
> you can discipline yourself to write software that’s good enough—good enough for your users, for future maintainers, for your own peace of mind. You’ll find that *you are more productive* and *your users are happier*. And you may well find that *your programs are actually better* for their shorter incubation.
Why?? I mean I'm obviously all in favor of shipping ealier (generally), but why does it make things better? I feel the authors could have done a way better job explaining how production is the real test to our systems, how real life is so complex that is impossible to predict all the variables, like Nassim Taleb explains so well in Anti-fragile, so we have to be pragmatic, accept there is a lot of variables we don't know, and that it's cheaper to allow real-life to give us this feedback then upfront predicting them all, this is [why Agile works](https://rchaves.app/why-agile-works/) (but not always! Context matters)
> Your ability to learn new things is your most important *strategic* asset.
Why? And "strategic"? I thought this book was about being pragmatic (foot on the ground, present) not "strategic" (heads in the cloud, future)
> Treat English (or whatever your native tongue may be) as just another programming language. Write natural language as you would write code: honor the DRY principle, ETC, automation, and so on.
Why? Being DRY is actually terrible advice for natural language communication, people don't pay attention, people forget, you actually need to be repetitive sometimes.
> If you can’t find the answer yourself, find out who can. Don’t let it rest. Talking to other people will help build your personal network, and you may surprise yourself by finding solutions to other, unrelated problems along the way.
Tips tips tips, just tips, no pragmatism here.
---
Chapter 2 is titled "A Pragmatic Approach", and it starts with that, I kid you not:
> **A Pragmatic Approach**
>
> There are certain tips and tricks that apply at all levels of software development, processes that are virtually universal, and ideas that are almost axiomatic
So their *Pragmatic* approach is to bring us a chapter full of axioms, not to challenge them, but to tell us they are universal 🤯. Say what!? This is absolutely NOT pragmatic. I expect to find axioms on Clean Code, that's why I bought *that* book, not here, here I expected to find counter-axioms, cases of when you have to actually be pragmatic, take your head off the clouds and break those axioms when it makes *practical* sense. This chapter should really be called *A Dogmatic Approach*.
They continue:
> The world is full of gurus and pundits, all eager to pass on their hard-earned wisdom when it comes to How to Design Software.
And finally confess:
> And we, your gentle authors, are guilty of this too. But we’d like to make amends by explaining something that only became apparent to us fairly recently. First, the general statement:
Their "explanation", actually uses a dogma as an excuse (*Good Design Is Easier to Change Than Bad Design*), so it's circular. "I'm sorry we are not pragmatic and presenting you dogmas, but the reason is because of this dogma"
## You can repeat yourself
Topic 9 is called "DRY — The Evils of Duplication", this is the part of the book I have the biggest beef with. The authors treat repetion as pure evil, and don't make any arguments on when it could be good, it's not pragmatic at all, pure dogma.
In fact, I've used in the past sentences like "they decided to take the more pragmatic approach and copy-paste the code for this situation", so it bothers me that the book that takes pride in it's title wouldn't even consider this as a possible sentence.
Just to be clear, I did many terrible code duplications in the past, and it helped me a lot learning the DRY concept at the start of my programming carreer and removing many duplications, but unlike the authors, I know that DRY does not hold true everywhere, and many many times it causes unintended harm, as you can read in [Duplication is far cheaper than the wrong abstraction](https://sandimetz.com/blog/2016/1/20/the-wrong-abstraction) by Sandi Metz. It's not all black-and-white, a pragmatic programmer should know that.
## Dogmatic Programmer: Duplication is evil
## Pragmatic Programmer: It depends
They start with a code refactor example to try to make their point. This is the original code:
```ruby
def print_balance(account)
printf "Debits: %10.2f\n", account.debits
printf "Credits: %10.2f\n", account.credits
if account.fees < 0
printf "Fees: %10.2f-\n", -account.fees
else
printf "Fees: %10.2f\n", account.fees
end
printf " ———-\n"
if account.balance < 0
printf "Balance: %10.2f-\n", -account.balance
else
printf "Balance: %10.2f\n", account.balance
end
end
```
So they do this refactoring:
```ruby
def format_amount(value)
result = sprintf("%10.2f", value.abs)
if value < 0
result + "-"
else
result + " "
end
end
def print_line(label, value)
printf "%-9s%s\n", label, value
end
def report_line(label, amount)
print_line(label + ":", format_amount(amount))
end
def print_balance(account)
report_line("Debits", account.debits)
report_line("Credits", account.credits)
report_line("Fees", account.fees)
print_line("", "———-")
report_line("Balance", account.balance)
end
```
And they claim it a victory, apparently they removed most of the duplication.
What!? This is a terrible refactor, one function became four; it's way worse to read, now instead of reading just a bunch of plain `printf`s, easy to follow because it's a core function of the language, the reader needs to jump around functions and understand what the author meant; now instead of one function causing bugs you have 4 functions that can interact in weird ways causing weirder bugs; now if you want to change the format of just one like you need to add an if condition, a new method, or something, it actually violates their *Easier to Change* rule.
It does not work here because this code is so simple, this is the wrong example, on a full-fledge report some of those refactorings could actually make sense, you would probably have the logic and presentation separation already anyway, but giving the advice on this small piece of code actually makes things much worse, showing that they are not taking *context* into account, but just following DRY as a dogma.
Now there are many statements they make I'd like to comment on:
> The alternative is to have the same thing expressed in two or more places. If you change one, you have to remember to change the others, or, like the alien computers, your program will be brought to its knees by a contradiction. It isn’t a question of whether you’ll remember: it’s a question of when you’ll forget.
Conversely, if you have everything expressed in a single, centralized place and you need to change it you are **forced to remember all the places** that depend on that. This can take a long time, time which may not even pay off for the inconsistency. It could be that the place you "forgot" to change actually was not that important at all, like a page nobody visits, a feature no one uses. If it is important, you will notice it. Again it depends on context, I touch on this on the [Designed v Evolutionary Code](https://rchaves.app/designed-v-evolutionary-code/) post too.
Additionaly, no duplication at all can actually be pretty risky. Remember [left-pad](https://www.theregister.com/2016/03/23/npm_left_pad_chaos/)? Because everyone decided to not duplicate something that can be implemented [in 1 line of code](https://stackoverflow.com/a/13861999) pretty much all javascript deployments in the planet were broken for a day. When you have central critical pieces without any duplication, you increase the chances of bringing the whole system to it's knees, like [it happened many times recently with big tech](https://rchaves.app/our-microservices-are-not-antifragile/).
> DRY is about the duplication of knowledge, of intent. It’s about expressing the same thing in two different places, *possibly in two totally different ways*.
When I say duplication is good for resilience, some may think about server redundancy, but no, I really mean intent duplication, which the authors rejects. Why is "two totally different ways" necessarily a bad thing? Devs love redundancy of servers but despite duplication of code, problem is, having thousands of servers in hundreds of availability zones still won't prevent you from deploying a catastrophic commit.
If you think about it, different codebases doing the same thing is like redundancy for the overall system, for ideas, for bugs. There is a reason why evolution brought us so many different animals, which survive through different ways, there is a reason why we have anti-monopoly laws, causing different companies to do the same thing but in different ways, this way you get the chance that one of them is actually better than the other.
---
## Dogmatic Programmer: let’s make everything abstract, what if we need to switch databases?
## Pragmatic Programmer: we will never switch databases
On topic 11 - Reversibility, the authors go on about how we should decouple third-party services to keep our system flexible, and of course they give the classic example of the database switch:
> “But you said we’d use database XYZ! We are 85% done coding the project, we can’t change now!”
In practice there are not a lot of reasons for switching one relational database with another, and even if you do, it will probably not be crazy hard, SQL is very standardized (much easier to learn than the thousands of ORMs APIs we have), on a small codebase find and replace can do most of the trick. Even if a big codebase decides to switch, it will be incremental with a migration plan anyway, it will never be “just change a config on the ORM”. Now if the change is for a completely different way to store the data to some domain specific NoSQL, or replace those MySQL queues with Kafka, then probably your abstractions won’t hold anyway, you will need to change your architecture to really take advantage of it.
An abuse of “reversibility” causes for example Generic Cloud Usage, [from ThoughtWorks radar](https://www.thoughtworks.com/radar/techniques/generic-cloud-usage):
> We see organizations limiting their use of the cloud to only those features common across all cloud providers—thereby missing out on the providers' unique benefits. We see organizations making large investments in home-grown abstraction layers that are too complex to build and too costly to maintain to stay cloud agnostic.
>
> [...] which reminds us of the lowest common denominator scenario we saw 10 years ago when companies avoided many advanced features in relational databases in an effort to remain vendor neutral
## Give a random number
The book then goes to Estimating, on topic 15, which is perhaps the most debated point in software development. As usual, they start with a bad example:
> The Library of Congress in Washington, DC, currently has about 75 terabytes of digital information online. Quick! How long will it take to send all that information over a 1Gbps network? How much storage will you need for a million names and addresses? How long does it take to compress 100Mb of text? How many months will it take to deliver your project?
The last question is completely different from all the others, they are conflating estimations that have a super simple and linear models, where you can easily find all the variables, with a complex non-linear estimation where no good model exists. Deceiving the reader into thinking that estimating a software project is as easy and reliable as calculating bandwidth is an awful thing to do.
Then they go on some tips on how to improve your estimations, telling about building a model and breaking it in smaller pieces, they give a lot of focus on getting better at estimating, but the actual valuable thing is some communication tips in the middle, like saying weeks instead of days to convey less precision, and giving multiple range estimations instead of a point estimate.
## Dogmatic 1: believes on estimations, and that one day they they will get very good at it (this day never comes)
## Dogmatic 2: believes that estimations are never possible to get right anyway, so they are useless
## Pragmatic: manages expectations, not accuracy
You see, developers are actually not that bad on estimating, getting around 60% of the estimations right[[1]](https://www.uio.no/studier/emner/matnat/ifi/nedlagte-emner/INF5500/h09/undervisningsmateriale/estimation-error.pdf)[[2]](https://www.sciencedirect.com/science/article/pii/S0164121202000213), people hypothesize that developers are [good at estimating the median, not the mean](https://erikbern.com/2019/04/15/why-software-projects-take-longer-than-you-think-a-statistical-model.html). So the problem really is on the blowup factor: eventually something will get very wrong, and not even the most experienced estimator will be able to predict it, when that happens (and it does), expectations management skills is what really counts.
Considering that, the True Pragmatic Programmer is not in favor or against estimations: it’s just a tool, which they know is flawed (sometimes exponentially flawed), still sometimes the most available one to align teams more or less on what to do, or as a way to get others thinking more deeply about a feature, so they use it when useful, and avoid it (or just give a random number) when useless.
When someone says “the deadline is October” for a pragmatic programmer, they ask “why?” (those five whys mentioned by the book). More often than not I've found out that those are just self-inflicted deadlines: no client knows about this feature you want to launch, other teams are unaware, it wouldn’t really affect much anyone, it’s just politics or a random date someone came up with.
Other times, the deadline actually makes sense, maybe some other team depends on that for a pressing issue, or maybe there is a regulation change, and even though you might use some fancy tricks of iterative development to avoid that, sometimes is just easier to agree on a date and that’s it. Pragmatic.
---
Well I think that’s enough about the book, this post is too long already, but I hope I manage to convey the idea of what a pragmatic actually means, the definition that is closer to the dictionary one.
Thanks for reading! [Follow me on Twitter](https://twitter.com/_rchaves_), and drop a message there if you disagree or want to discuss about any of the points.
---
*Addendum 1: The version of the book I have and this blogpost is based on is the 20th Anniversary Edition, not the classic one.*
*Addendum 2: The article came out very harsh, so I need to clarify that I do in fact think The Pragmatic Programmer is a very valuable book for beginner developers, but not advanced as I hoped so. This made me want to write this blogpost, to express what I actually wanted to read, the book I wish existed.* | rogeriochaves | |
947,665 | 5 Ways to Add Breakpoints on Chrome Devtools | Debug is a skill that every developer must master, and adding breakpoints to the code is the basic of... | 0 | 2022-01-07T07:43:51 | https://dev.to/bytefish/5-ways-to-add-breakpoints-on-chrome-devtools-f28 | javascript, webdev | Debug is a skill that every developer must master, and adding breakpoints to the code is the basic of debugging. This article will share 5 ways to add breakpoints in Chrome DevTool.
---
## 1# Add breakpoints directly
Go to Source Tag of Chrome Devtools, click the line number where the code is located to add a breakpoint.
This should be the most common way for everyone to add breakpoints.
## 2# Conditional breakpoints
But sometimes, we want a breakpoint to take effect only under certain conditions. At this time, we can take the following approach.
- Right-click the line number column
- Choose Add conditional breakpoint
- Enter your condition in the dialog
For Example, we want to pause the code when i is greater than 10,
```js
for(let i=0; i<20; i++){
console.log(`i * i = ${i * i}`)
}
```
We can:
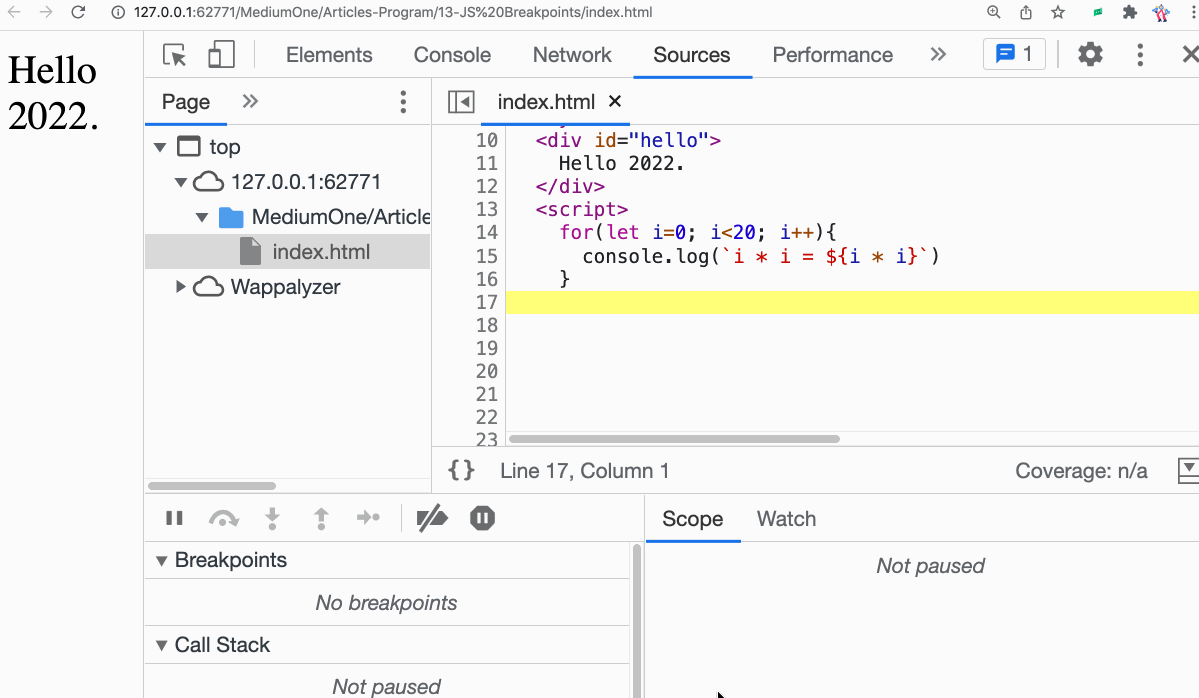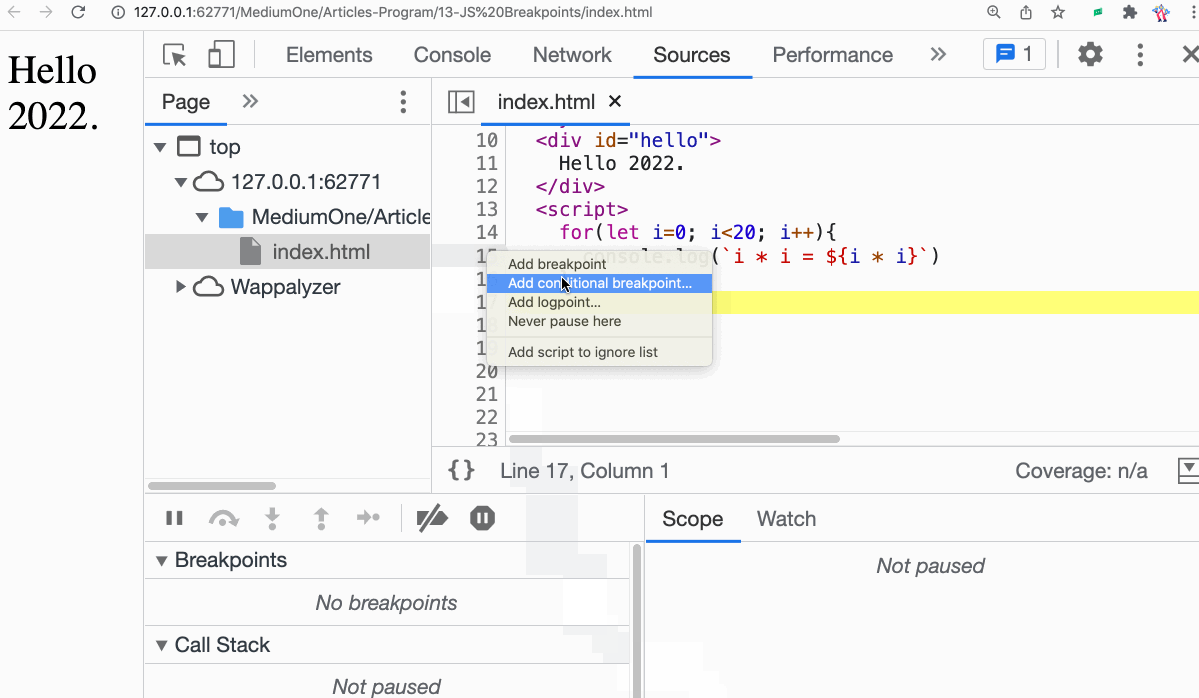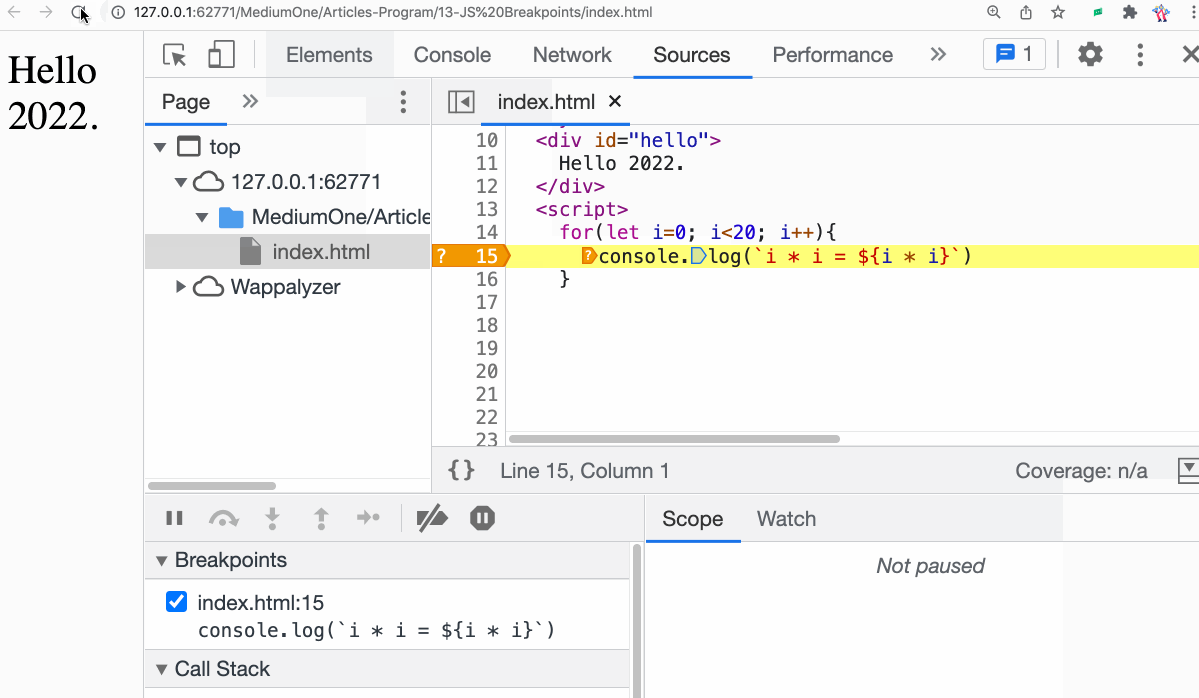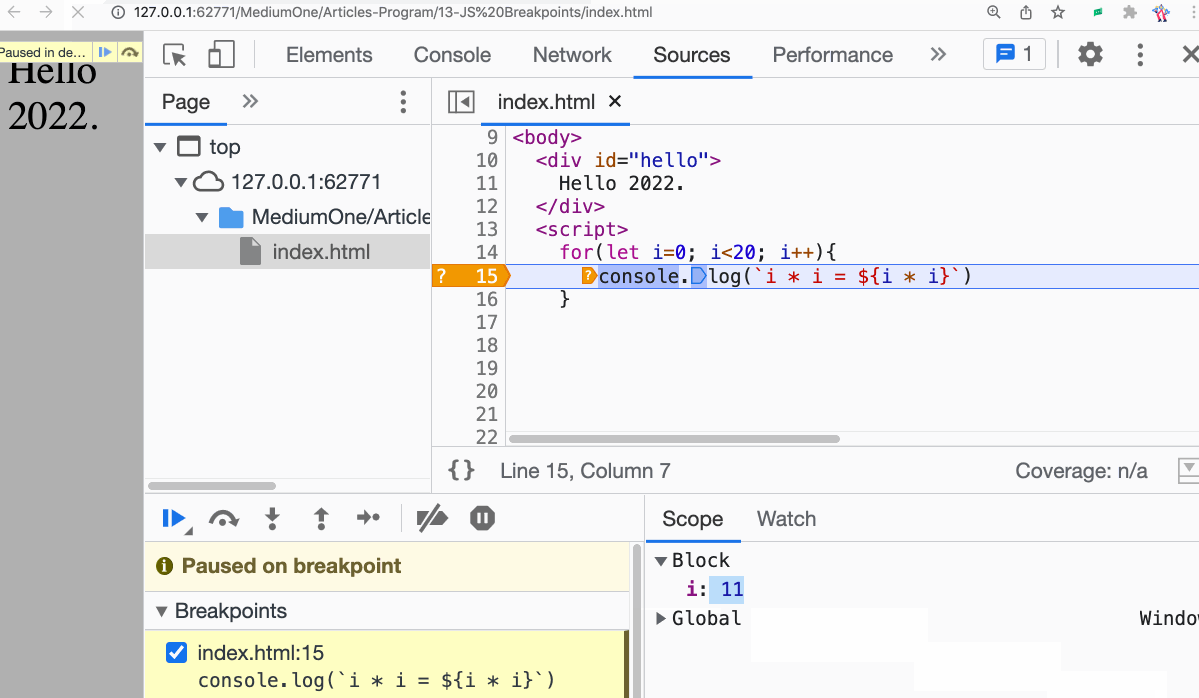
## 3# DOM change breakpoints
In some cases, we don't want to pause the code at a certain location, but only when a DOM element changes. At this time, we can do this:
- Click the Elements tab.
- Go to the element that you want to set the breakpoint on.
- Right-click the element.
- Hover over Break on then select Subtree modifications, Attribute modifications or Node removal.
For example, we want to pause the code when the hello element will change:
```js
<div id="hello">
Hello 2022.
</div>
<script>
document.getElementById("hello").onclick = (event) => {
event.target.innerText = new Date().toString()
}
</script>
```
We can:
Note:
- Subtree modifications. Triggered when a child of the currently-selected node is removed or added, or the contents of a child are changed. Not triggered on child node attribute changes, or on any changes to the currently-selected node.
- Attributes modifications: Triggered when an attribute is added or removed on the currently-selected node, or when an attribute value changes.
- Node Removal: Triggered when the currently-selected node is removed.
## 4# XHR/Fetch breakpoints
If you want to pause the code when JavaScript is trying to make an HTTP request to a URL, we can do this:
- Click the Sources tab.
Expand the XHR Breakpoints pane.
Click Add breakpoint.
Enter the string which you want to break on. DevTools pauses when this string is present anywhere in an XHR's request URL.
Press Enter to confirm.
For example, we want to pause the code when the script tries to requesting `api.github.com` .
```js
<body>
<div id="hello">
Hello 2022.
</div>
<script>
fetch("https://api.github.com")
.then(res => {
console.log(res)
})
</script>
</body>
```
We can:
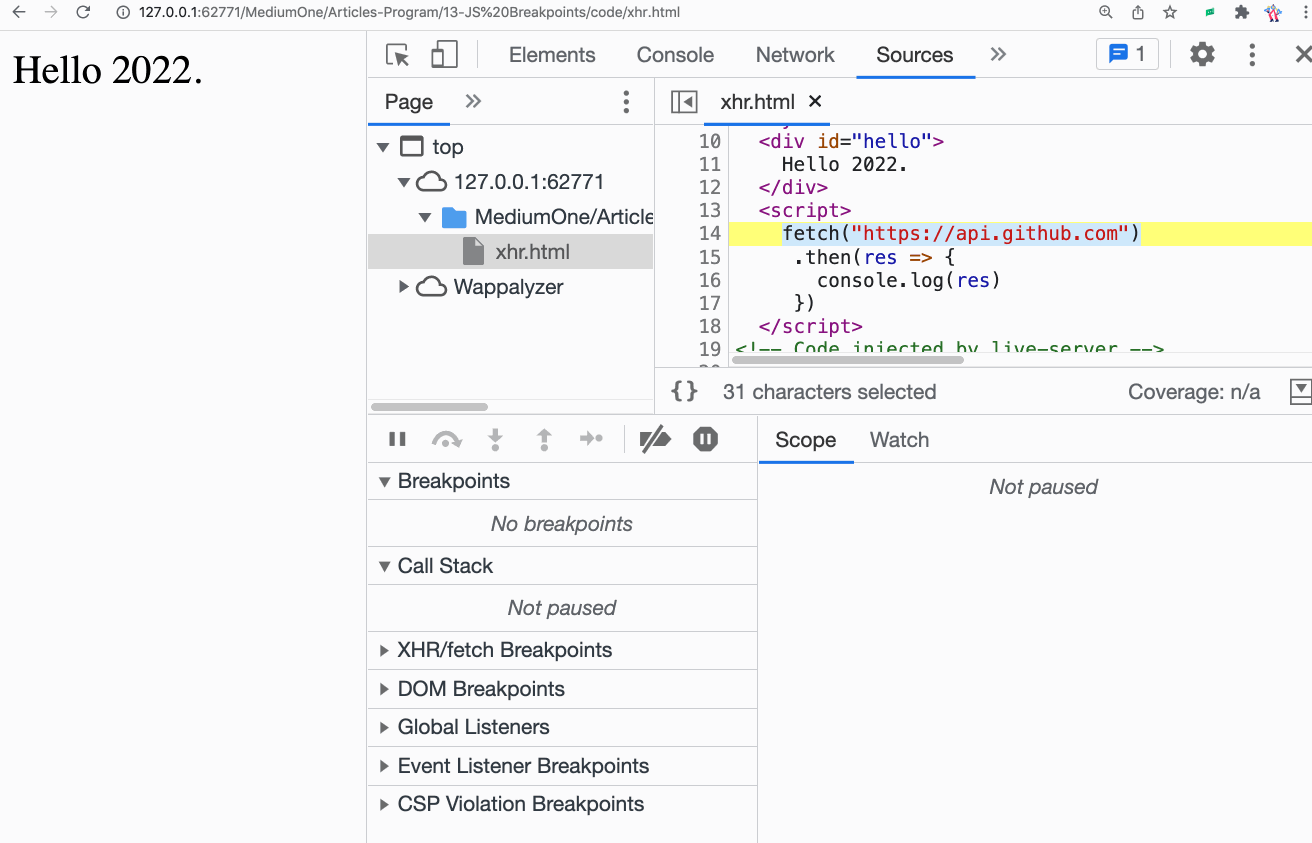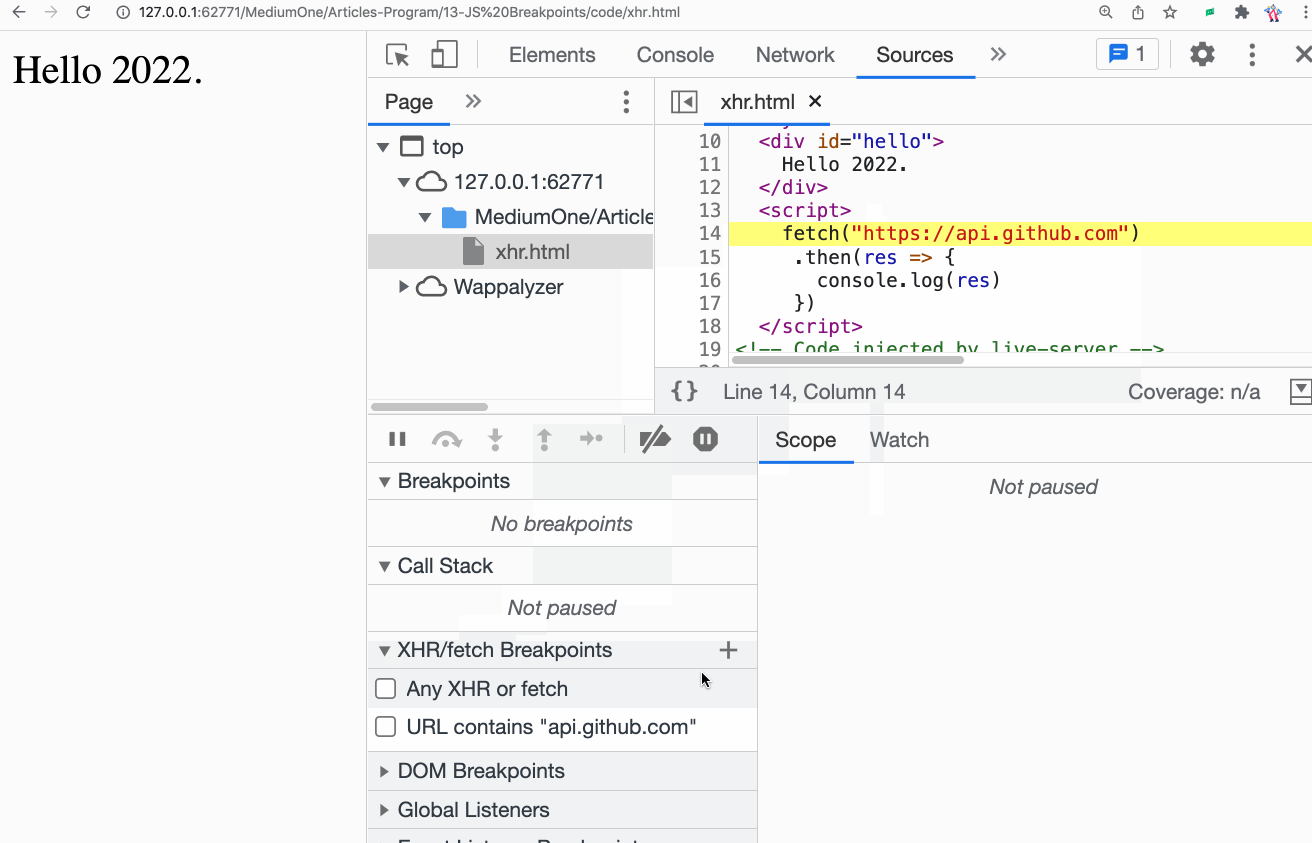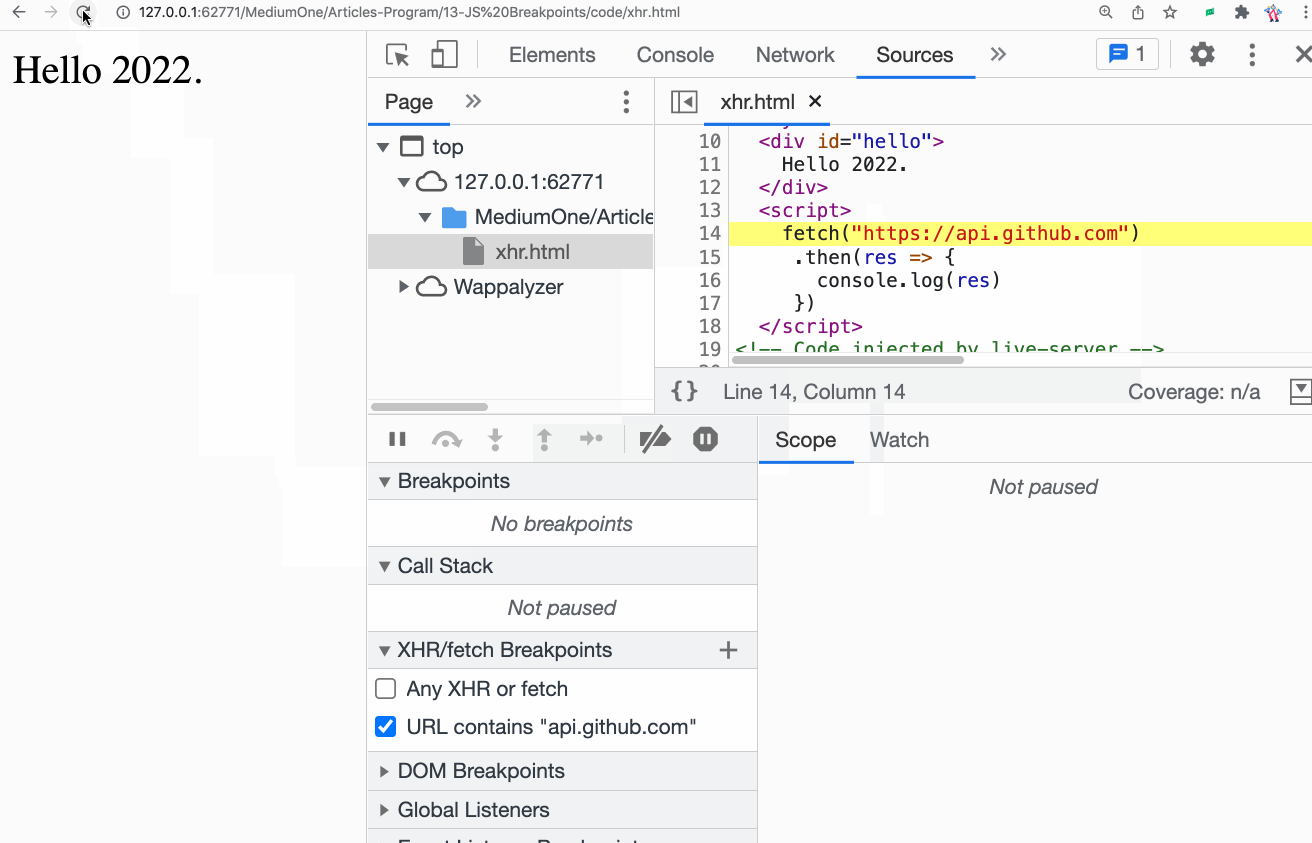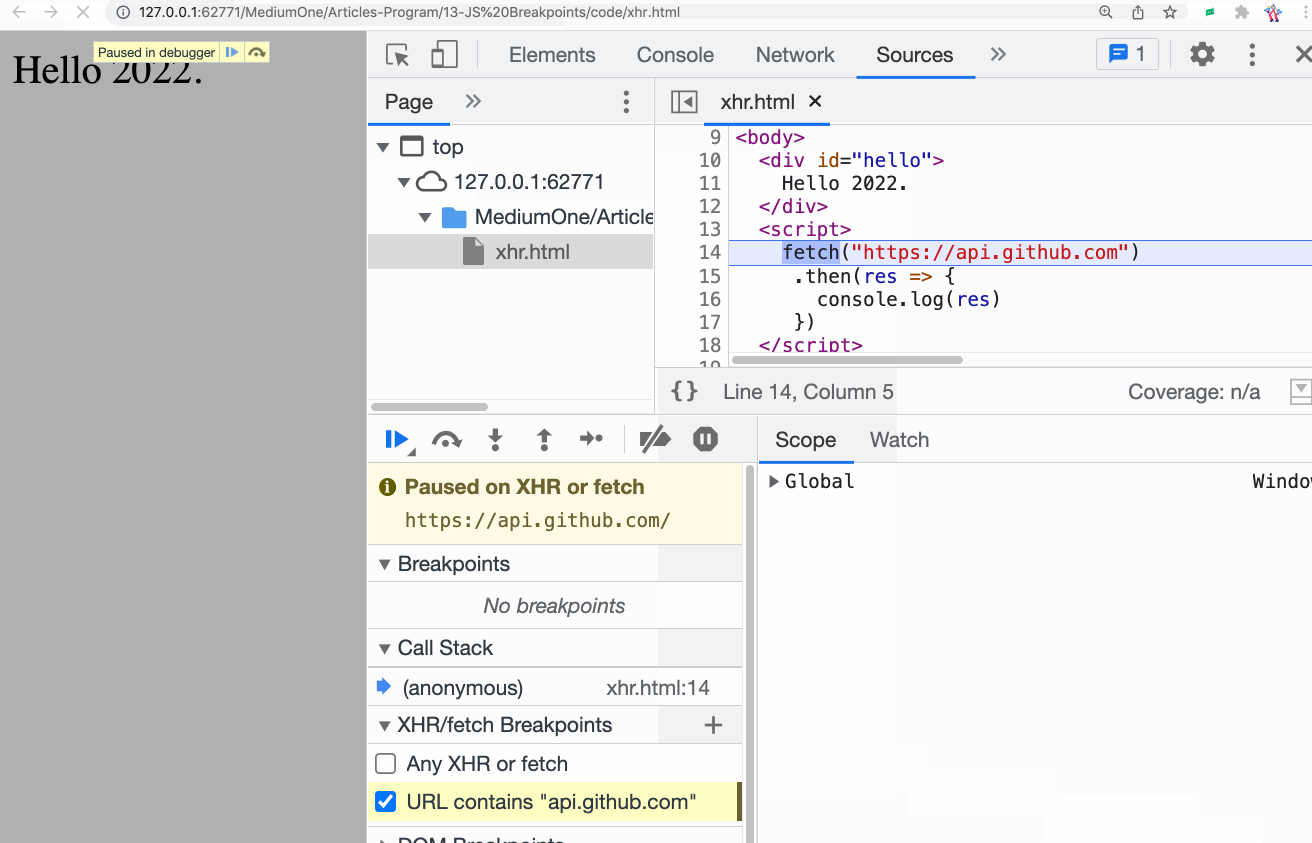
## 5# Event listener breakpoints
Of course, we can also pause the code when a certain event is triggered.
```js
<body>
<div id="hello">
Hello 2022.
</div>
<script>
document.getElementById("hello").onclick = (event) => {
console.log('hello 2022')
}
</script>
</body>
```
If you want to pause the code after the hello element is clicked, then we can do this:
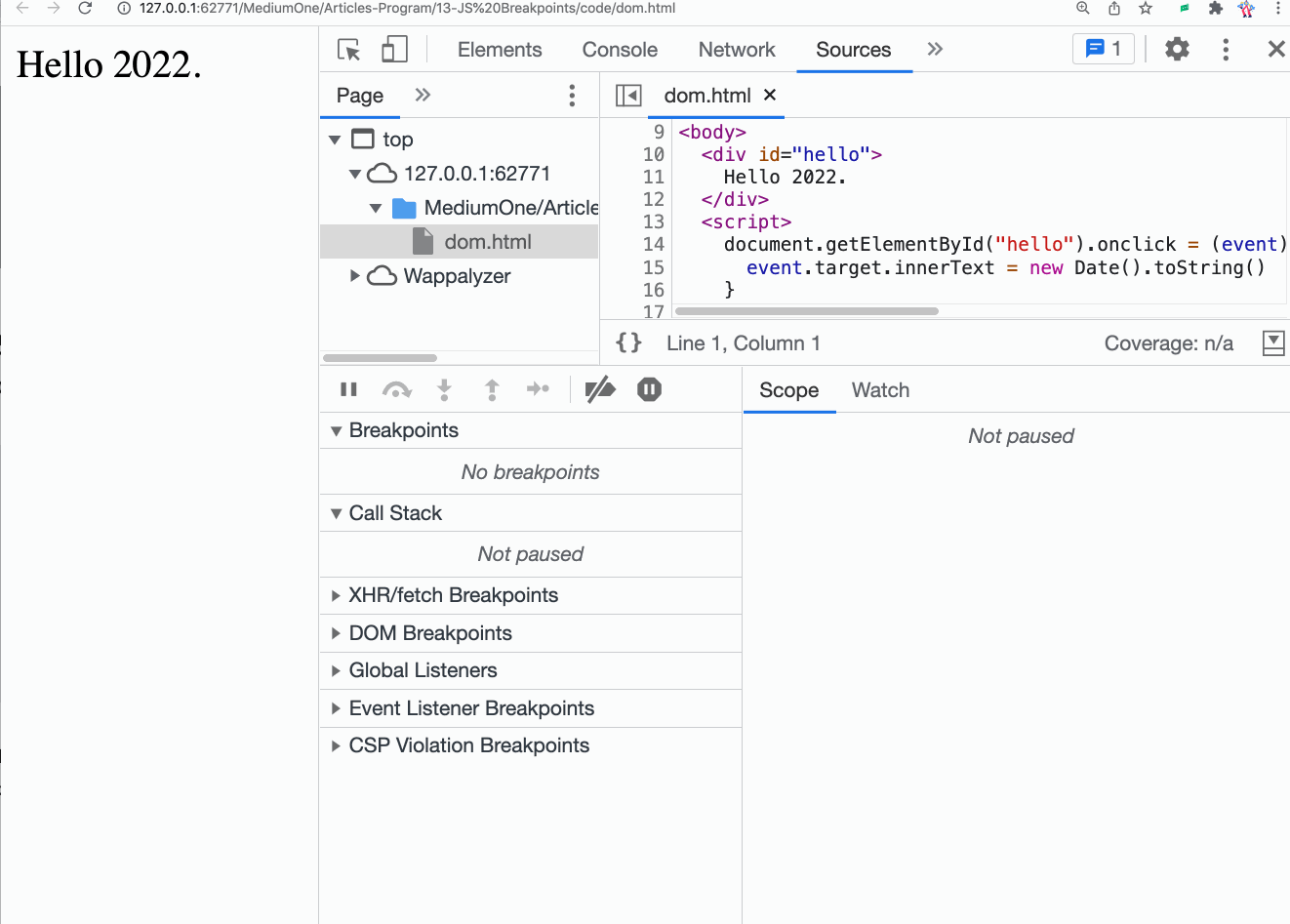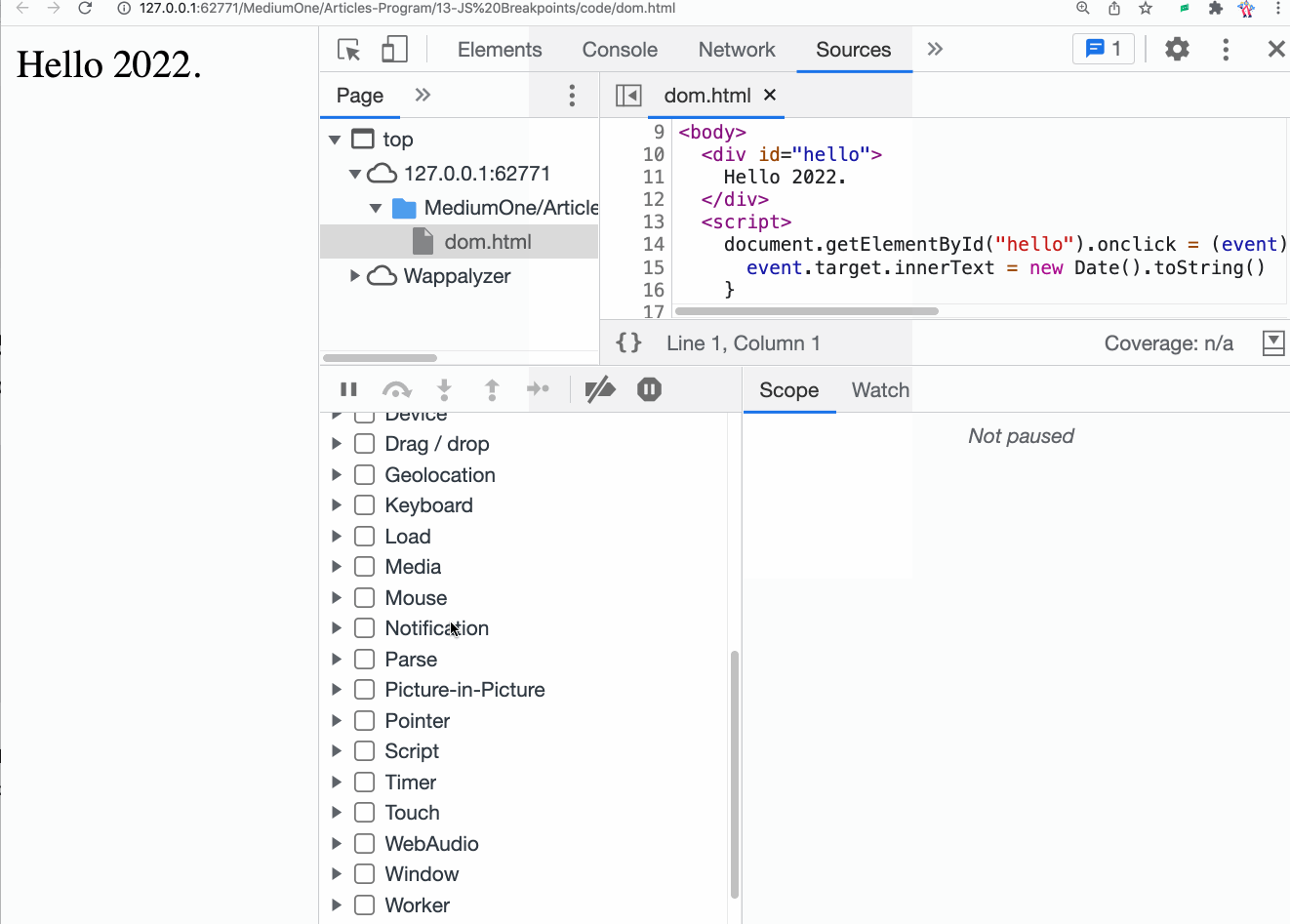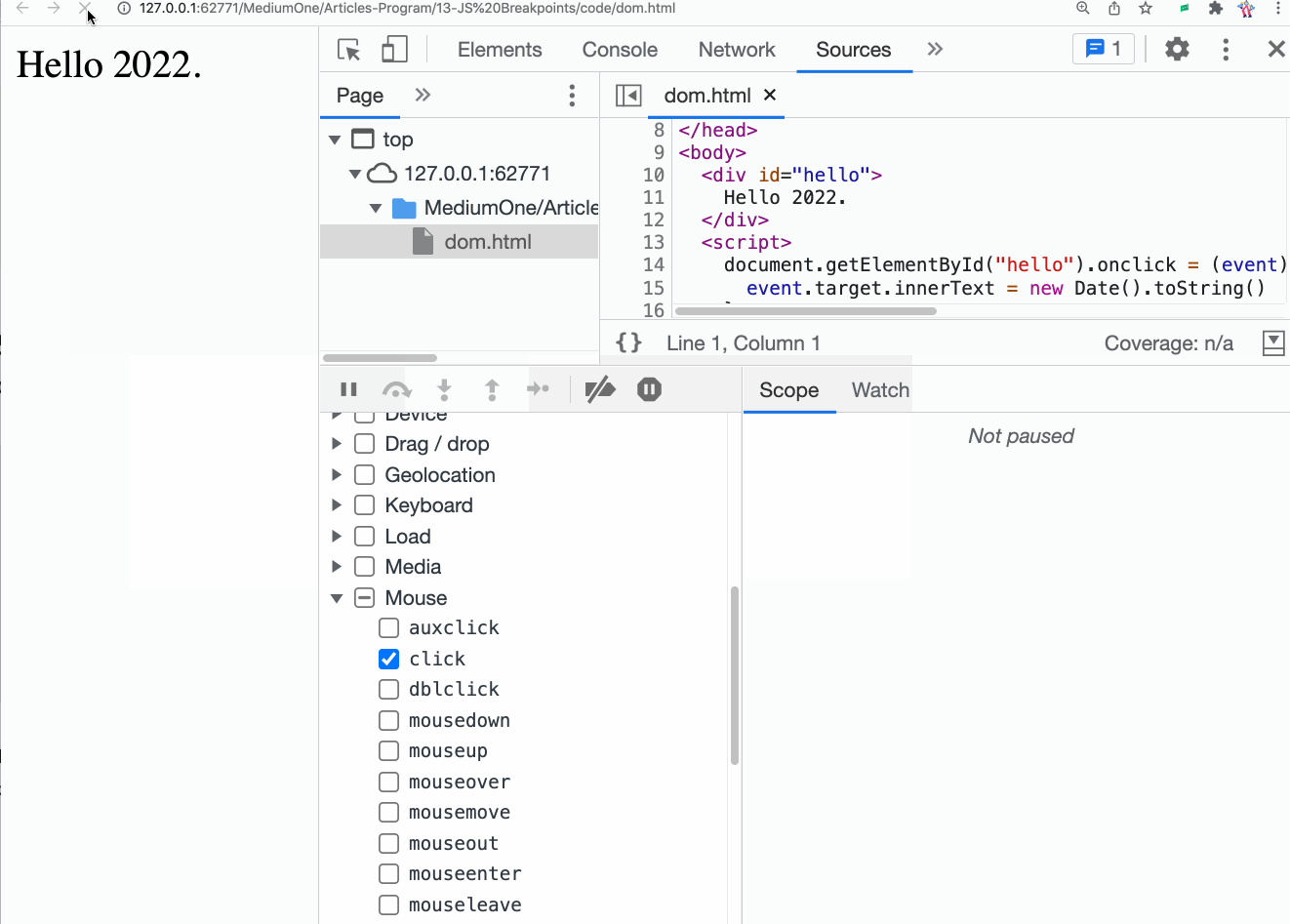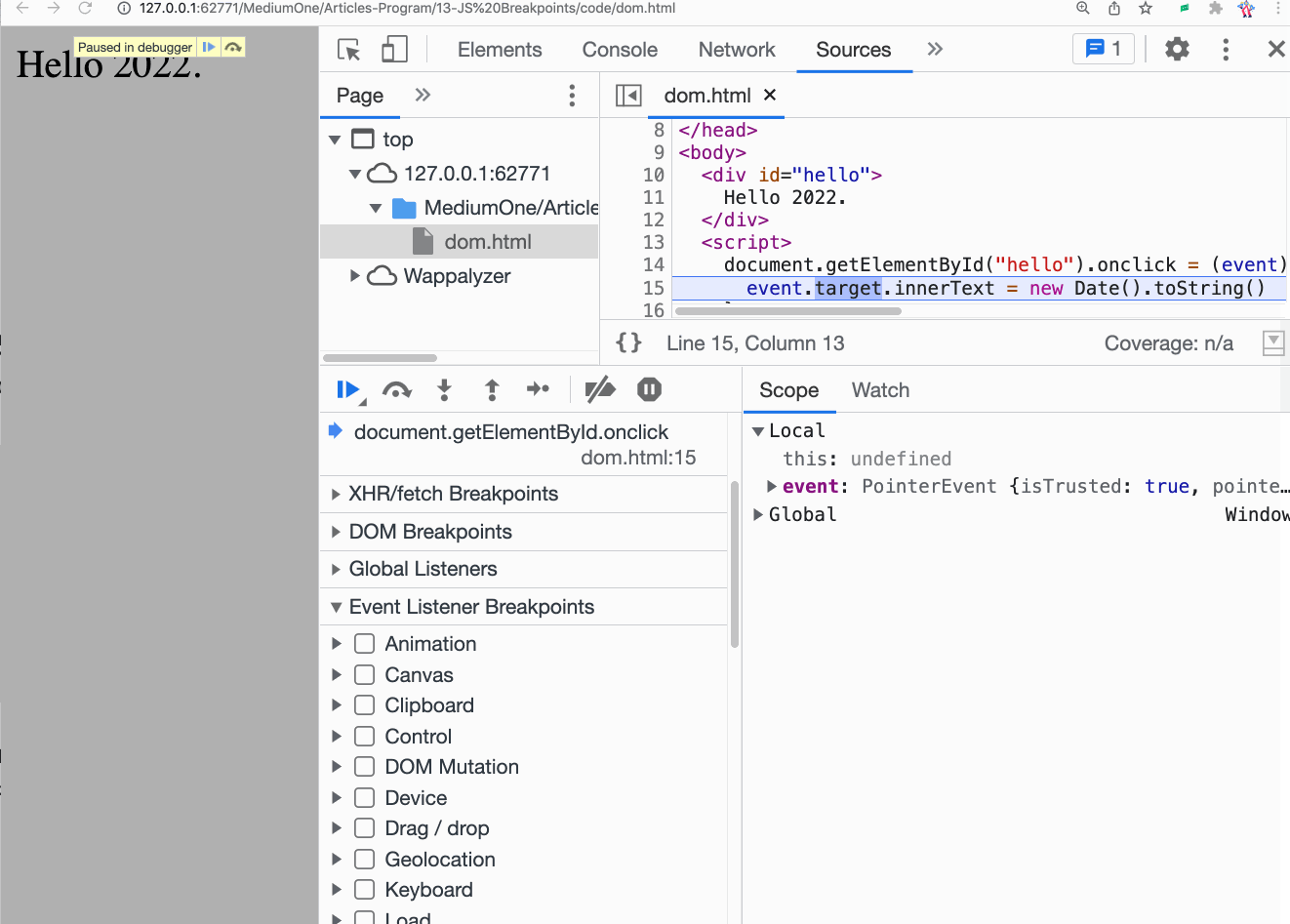 | bytefish |
947,695 | ES2020, and what it brings to the table. | Here are 6 new JavaScript features that you should be using BigInt Currently,... | 0 | 2022-01-07T09:17:29 | https://dev.to/grover_sumrit/es2020-and-what-it-brings-to-the-table-41bf | javascript, webdev, beginners, programming | ##Here are 6 new JavaScript features that you should be using
###BigInt
Currently, the largest number you can store in an integer is `pow(2,53)-1`.
Now you can even go beyond that.
But for this to work properly, you need to append `n` at the end of the integer.
The `n` denotes that this is a **BigInt** and should be treated differently.
###Dynamic Imports
This gives you the option to import JS files dynamically as modules that you import natively.
This feature will help you ship on-demand-request code, better known as code splitting, without the overhead of webpack or other module bundlers.

###Nullish Coalescing
The symbol for Nullish Coalescing is `??`.
Nullish Coalescing gives you a chance to check for truly **nullish** values rather than **falsey** values.
You might ask what is the difference between these two.
In JavaScript, many values are **falsey**, like empty strings, the number `0`, `undefined`, `null`, `false`, `NaN`, and so on.
There may be times where you have to check whether the variable is **nullish**(*undefined* or *null*), but is okay to have empty strings or false values.

###Optional Chaining
Optional Chaining syntax allows you to access *deeply nested objects* without worrying about the property being present or not.
If the value exists amazing!!
Otherwise, it will return `undefined`.
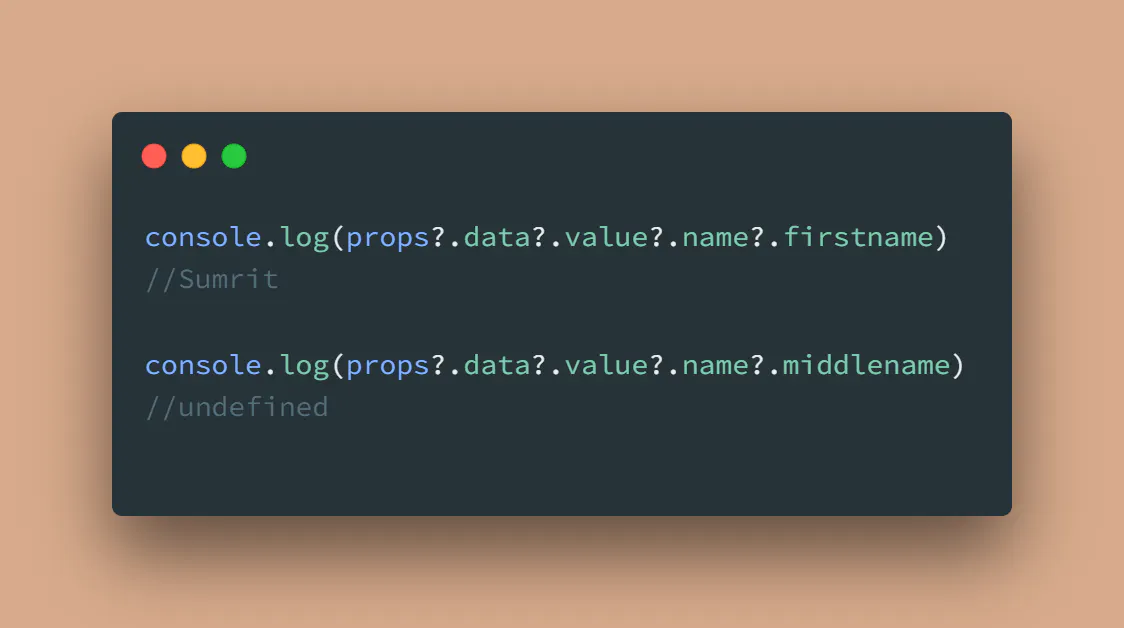
###Module Namespace Exports
It was already possible to import everything using the `*`. However, there was no symmetrical export syntax.
But now you can do that like this.
###globalThis
You have different global object for different platforms, `window` for **browsers**, `global` for **node**, `self` for **web workers**.
But ES2020 brought **globalThis** which is considered as the global object no matter where you execute the code.
###TL;DR
- BigInt - play with very large integers, make sure you append `n` at the end of the integer.
- Dynamic Import - import files conditionally.
- Nullish Coalescing - Check for nullish values rather than falsey values.
- Optional Chaining - check for deep nested objects without worrying about undefined values.
- Module Namespace Exports - export everything using the * symbol
- globalThis - considered global object no matter where you code.
---
You have reached the end of the post. To find more interesting content regarding JavaScript, React, React Native make sure to follow me on [Twitter](https://twitter.com/grover_sumrit)
| grover_sumrit |
947,711 | How to launch a Minimum viable product (MVP) in 2022 | What is a Minimum viable product When you are working on a project the first iteration or... | 0 | 2022-01-07T09:53:24 | https://dev.to/andrewbaisden/how-to-launch-a-minimum-viable-product-mvp-in-2022-5hig | webdev, beginners, productivity, career | ## What is a Minimum viable product
When you are working on a project the first iteration or the very first version is known as a Minimum viable product or MVP when abbreviated. This can apply to almost any type of project for example websites, mobile applications, desktops applications, and even games among other things.
A minimum viable product is essentially an early build which has a decent amount of features and functionality to make it usable for first time customers. These customers then provide feedback which gets passed onto the developers who then incorporate these changes and improvements into future releases. Minimum viable products can go through many stages during their lifecycle from alpha, beta and final builds.
Every experienced developer, company, freelancer and entrepreneur has created or launched some type of product during their career. This could be a simple pet project or a fully commercial product that has paying customers. Regardless how they reached that point they had to go through a process to get there.

## Team structure
Under normal conditions a whole team would be working on the product. You could have designers, copywriters, developers and quality assurance/quality control testers. Before any work has started the team would either be working with a client to figure out how they can best work together. Or in another scenario they are launching a product to solve some sort of problem or to fill a gap in the market.
Like a greenfield project which needs to be created from scratch. It is not uncommon for freelancers to work on the whole product lifecycle going through all of these processes. There are countless different ways an organisation might choose for their team structure and how they work together. I will give you a breakdown of one such process.

### Designers
Designers are responsible for creating the initial design. Prior to this they would have gone through a user flow journey which is basically the pathways that a user would use to navigate through the application or website. The path is broken down into various steps that a user would follow to travel throughout the product.
During the design phase designers are also responsible for creating the first working prototype. The prototype is normally created inside of a design file and it adds interactivity to the design. No coding is required at this stage and the design is still static however it is the last stage before the handoff is given to the development team to build it.

### Copyrighters
The job of a copywriter is to come up with content for the product. Their role is essentially to create engaging text and writing which will help to describe the product and sell it to the customers. They are responsible for doing the marketing and advertising throughout all of the various channels that a company uses both online and offline. Across social media and even outdoor banners and adverts both digital and print.
When it comes to the actual digital product a copywriters role would be to do the proofreading and making sure that the written content is accurate, correct and of good quality.

### Developers
Developers are an essential part of the product lifecycle as they are the ones who bring the designs to life. Depending on the project developers could be working across the full technical stack. Developing the back-end, front-end, web version, desktop version and even a mobile one too. If it is a game then there would also be a special process for the development and getting it working on various platforms.

### Quality Assurance/Quality Control Testers
Testers are people who go through the whole product to make sure that it is ready to be launched as a MVP. They will check for bugs, errors, accessibility issues and a lot more. Their job is to give the product a complete test so that it is in a condition whereby it can pass all of the tests giving it a final seal of approval.

## Working on the product
During this phase it is highly likely that there would be a marketing and advertising campaign going on so that people know about the company or product prior to its launch. And in a lot of cases there might be a small group of early adopters, alpha and beta testers who might be using the product before its launch to the wider public.
This allows the company to see how the product could potentially work when it is ready for launch. Mitigating any server, bugs or breaking errors that can be flagged and fixed beforehand.

### Building the product
There are infinite ways this can be done and there is no right or wrong answer because every team is different. Any technical stack can be used so this can be adapted to work for anyone. Here is one example of how a team might go about building a product.
Step 1: User flow/journey
**Technical Stack**: Miro/FigJam/Mural
**Description**: The interaction process a user takes when using the product.
Step 2: Low fidelity wireframe
**Technical Stack**: Figma/Adobe XD
**Description**: Low fidelity wireframes are the initial blueprints used before creating the website and app screens. They usually have placeholder "lorem ipsum" text.
Step 3: High fidelity wireframe and design system
**Technical Stack**: Figma/Adobe XD
**Description**: High fidelity wireframes are used to show the look and feel for the product in a more final stage in the design process. They tend to have real content instead of placeholder. In this stage the designer would also create the design system which could include the brand colors, typefaces, and design specifications.
Step 4: Prototype
**Technical Stack**: Figma/Adobe XD
**Description**: The prototype is a working example of the final application that has been created by the design team. It has working interactions and can be used to show how screens navigate, transitions, click events and much more.
Step 5: Development back-end
**Technical Stack**: Python, Django, PostgreSQL, AWS
**Description**: This is where a back-end developer would work on the API, databases, servers and anything related to the architecture.
Step 6: Development front-end
**Technical Stack**: HTML, CSS, JavaScript, React, Storybook
**Description**: Working on the back-end or front-end first comes down to personal preferences. Personally I prefer to have a back-end up and running first so that there is live data. In this stage a front-end developer would work on the UI/UX and get the application to connect to the back-end or any test data. Storybook is like a bridge between the designer and the developer. The design systems and components can be a mirror match between them both.
Step 7: Deployment
**Technical Stack**: AWS
**Description**: When all stages have been cleared it is time for the MVP to have its official launch. The back-end and front-end should already be online or in a test stage area. So the final step would be to launch the final build and complete the first iteration for the project. | andrewbaisden |
947,866 | Secure Spring Boot Application With Keycloak | After the announcement of spring security team, spring is no longer supporting its own authorization... | 0 | 2022-01-07T12:13:14 | https://dev.to/qaisarabbas/secure-spring-boot-application-with-keycloak-27c2 | springboot, webdev, java, microservices |
After the announcement of spring security team, spring is no longer supporting its own authorization server. Spring security OAuth2 officially deprecated all of its classes. Therefore it is recommended to use existing authorization server such as Keycloak or Okta.
In this tutorial we will be using Keycloak as authorization server with spring boot.
What is Keycloak?
Keycloak is an open source software product to allow single sign-on with Identity and Access Management aimed at modern applications and services
Downloading and Installing Keycloak
Before getting started, you will need to installed and setup a Keycloak server. Visit this url https://www.keycloak.org/ to download Keycloak version 15.0.2.
After this go to your local directory keycloak->keycloak-15.0.2->bin
Run standalone.bat file.
Go to http://localhost:8080/auth/ and create admin user. Set admin /admin for username and password.
Now you will be able to view the admin console.
In this section, we setup the Keycloak configuration.
1. Create a Realm
A realm is a security domain that manages a collection of users, roles, credentials and groups. The protected resources on server can divided into different realm where each realm manages its own authentication and authorization.
Now select, Add realm from Master dropdown menu.
Set the name of realm to test-realm and click create.
2. Create a Client
Clients are entities that request to Keycloak for authentication. Mostly clients are application and services that uses Keycloak to secure themselves and provide single sign on solution.
Clients request access token or identity information to use services that are secured by Keycloak.
From the left sidebar select client and click create client.
Now set app-client in client-id and client-protocal-> openid-connect. Set root url to application url http://localhost:8080.
Now click on save button. Then you will see app-client setting page. Here we will modify some properties for authentication. First we change access type to confidential then the Authorization Enabled to ON , Service Account Enabled to ON and click on Save button.
From credential tab you can view the client-secret which would be required later.
3. Create client roles
Client Roles are only accessible from a specific client and the role of client cannot be accessible from a different client.
Here we will create two roles admin and student.
From the client tab, click on roles tab and click on Add Role.
Now Add Role.
Set Role Name to admin
Now create other role and set Role Name to student. Then press the save button to save the role
4. Create Realm Roles
Realm roles are global roles shared by all clients. Realm role only belongs to specific realm. Role of one realm can’t be accessible by other realm.
From the sidebar menu click on Roles. List of available roles listed here.
Now Add Realm Role -> test-admin and save role.
Enable composite roles. Here we will assign client and client roles to realm role.
Select the app-client from client roles dropdown.
From available Roles click admin and press Add-Selected.
Now add second Realm Role -> test-student and save role
Enable composite roles.
Select the app-client from client roles dropdown for test-student role.
From available Roles click student and press Add-Selected.
5. Create Users
Users are entities that are able to log into your system. User can have attributes username ,password, email etc. Users access resources through specific clients.
Select Users from sidebar and Add User -> student-1. Press save.
Click the credential tab to set a password for user.
Set password -> student123
Switch off the temporary password and press save.
From the tabs, select Role Mapping. Here we will assign realm roles to users.
In Available roles of Realm roles, select test-student and press Add selected
Now create second user for admin .
Set Username to admin-1
After saving the admin user, set credential for user admin-1
Set password -> admin123 and switch off temporary password
From Role Mapping tab, assign test-admin realm to user.
Below diagram gives the complete understanding about model. Every Realm can have one or more client and each client can have multiple users.
Keycloak-configuration-model
Generate Tokens for Users
Go to Realm settings and click on OpenID Endpoint Configuration to view OpenID Endpoint details.
It will show you the application related endpoint.
To generate a token select token-endpoint
Copy the above highlighted url and create a POST request in POSTMAN to get access token.
Add the following detail in x-www-form-urlencoded
client_id -> app-client
username -> admin-1
password -> admin123
grant_type -> password
Click on Clients from the sidebar and get client_secret.
Curl Command
curl –location –request POST ‘http://localhost:8080/auth/realms/test-realm/protocol/openid-connect/token’ \
–header ‘Content-Type: application/x-www-form-urlencoded’ \
–data-urlencode ‘client_id=app-client’ \
–data-urlencode ‘client_secret=a4c29854-acad-423a-90a7-cec27032443a’ \
–data-urlencode ‘username=admin-1’ \
–data-urlencode ‘password=admin123’ \
–data-urlencode ‘grant_type=password’
Create a spring boot project.
Prerequisite
Java 11
Spring Boot 2.5.6 stable version
Add Spring Web and Spring Security dependency
Now open your pom.xml in your IDE.
Add the following dependency under dependencies section.
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-spring-boot-starter</artifactId>
<version>15.0.2</version>
</dependency>
Then add the following dependency in dependency management.
<dependency>
<groupId>org.keycloak.bom</groupId>
<artifactId>keycloak-adapter-bom</artifactId>
<version>15.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
After adding the dependencies your pom file should look this.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.7</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>keyCloakSpringBoot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>keyCloakSpringBoot</name>
<description>keyCloakSpringBoot</description>
<properties>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-spring-boot-starter</artifactId>
<version>15.0.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.keycloak.bom</groupId>
<artifactId>keycloak-adapter-bom</artifactId>
<version>15.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Add the following properties in your spring boot project application.properties file
server.port=8181
keycloak.realm=test-realm
keycloak.auth-server-url = http://localhost:8080/auth
keycloak.ssl-required= external
keycloak.resource=app-client
keycloak.credentials.secret=a4c29854-acad-423a-90a7-cec27032443a
keycloak.use-resource-role-mappings = true
keycloak.bearer-only= true
Create a package dto. Add the following class
Student.java
package com.example.keycloakspringboot.dto;
public class Student {
private String name;
private String age;
private String semester;
public Student(String name, String age, String semester) {
this.name = name;
this.age = age;
this.semester = semester;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public String getSemester() {
return semester;
}
public void setSemester(String semester) {
this.semester = semester;
}
}
Create a package named controller.
UserController.java
package com.example.keycloakspringboot.controller;
import com.example.keycloakspringboot.dto.Student;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@RestController
@RequestMapping("/user")
public class UserController {
@GetMapping(value = "/access-by-all")
public ResponseEntity<String> getAccess() {
return ResponseEntity.ok("This endpoint is not authenticated ");
}
@GetMapping(value = "/student")
public ResponseEntity<Student> getStudent() {
Student student=new Student("Emily","16","1");
return ResponseEntity.ok(student);
}
@GetMapping(value = "/all-students")
public ResponseEntity<List<Student>> getAllStudents() {
List<Student> studentList=new ArrayList<>();
studentList.add(new Student("Emily","16","1"));
studentList.add(new Student("John","18","2"));
studentList.add(new Student("Sam","15","1"));
return ResponseEntity.ok(studentList);
}
}
SecurityConfig.java
In Security Config class, we are extending KeycloakWebSecurityConfigurerAdapter as a convenient base class for creating WebSecurityConfigurer Instance
By default, Spring Security Adapter looks for configuration file keycloak.json .So by adding keycloakConfigResolver bean it will look at the configuration provided by Spring Boot Adapter.
RegisterSessionAuthenticationStrategy bean register user session after authentication.
SimpleAuthorityMapper in configure global method make sure that role are not prefixed with ROLE_
package com.example.keycloakspringboot.config;
import org.keycloak.adapters.KeycloakConfigResolver;
import org.keycloak.adapters.springboot.KeycloakSpringBootConfigResolver;
import org.keycloak.adapters.springsecurity.authentication.KeycloakAuthenticationProvider;
import org.keycloak.adapters.springsecurity.config.KeycloakWebSecurityConfigurerAdapter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.core.authority.mapping.SimpleAuthorityMapper;
import org.springframework.security.core.session.SessionRegistryImpl;
import org.springframework.security.web.authentication.session.RegisterSessionAuthenticationStrategy;
import org.springframework.security.web.authentication.session.SessionAuthenticationStrategy;
@Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(securedEnabled = true)
public class SecurityConfig extends KeycloakWebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
super.configure(http);
http
.authorizeRequests()
.antMatchers("/user/all-students").hasRole("admin")
.antMatchers("/user/access-by-all").permitAll()
.anyRequest().authenticated();
}
@Autowired
public void configureGlobal(AuthenticationManagerBuilder auth) throws Exception {
KeycloakAuthenticationProvider keycloakAuthenticationProvider = new
keycloakAuthenticationProvider();
keycloakAuthenticationProvider.setGrantedAuthoritiesMapper(new
SimpleAuthorityMapper());
auth.authenticationProvider(keycloakAuthenticationProvider);
}
@Bean
@Override
protected SessionAuthenticationStrategy sessionAuthenticationStrategy() {
return new RegisterSessionAuthenticationStrategy(new SessionRegistryImpl());
}
@Bean
public KeycloakConfigResolver KeycloakConfigResolver() {
return new KeycloakSpringBootConfigResolver();
}
}
users with admin Role are only authorized to access this endpoint /user/all-students.
Endpoint /user/access-by-all is accessible without any auth token.
Run Spring Boot Project.
Test Application
In our application, we have not authenticated this endpoint http://localhost:8181/user/access-by-all. So it should work without token
Next we will access the authenticated endpoint http://localhost:8181/user/all-students
Now get the authorization access token through admin-1 user and add it to your authorization header as shown in the fig below.
Now get the access token through student-1 user.
Add this token in Authorization bearer and access this url http://localhost:8181/user/all-students. It will send you a forbidden response. Because the user with admin role is only authorized to access this endpoint.
Access this url http://localhost:8181/user/student from student-1 token.
Access this url http://localhost:8181/user/student from student-1 token.
| qaisarabbas |
948,381 | When the Sunwing plane party meets the WebDev world: Who is James (Kevin) Awad? | The brain behind the infamous Sunwing plane party claims to made its fortune with fishy C++ tech | 0 | 2022-01-08T00:17:58 | https://dev.to/jesuismaxime/who-is-james-kevin-award-2oei | discuss, webdev, question | ---
title: When the Sunwing plane party meets the WebDev world: Who is James (Kevin) Awad?
published: true
description: The brain behind the infamous Sunwing plane party claims to made its fortune with fishy C++ tech
tags: discuss, webdev, question
cover_image: https://www.ctvnews.ca/polopoly_fs/1.5730666.1641512450!/httpImage/image.jpg_gen/derivatives/landscape_960/image.jpg
---
The brain behind the infamous [Sunwing plane party]((https://www.reuters.com/world/americas/canada-asks-regulator-probe-maskless-party-airline-covid-cases-soar-2022-01-04/)) claims to made its fortune with fishy C++ tech.
Since I'm from Quebec, Canada - that news is all over the news(indeed), Twitter, Instagram and Reddit and I am trying to dig a little about [this individual and its dark fraud background](https://www.archyde.com/influencers-trip-find-out-who-is-the-organizer-james-williams-awad/).
Here's what bothers me (a lot):
> [James William Awad](https://twitter.com/111jameswilliam), 28, says he invented a new way to program "in C ++ without having to compile the website." He is said to have sold the license to "several national and international companies", which he refuses to name.
Source: [Himself](https://www.lapresse.ca/actualites/2022-01-07/fete-a-bord-d-un-avion-de-sunwing/l-organisateur-s-explique-sur-l-origine-de-sa-fortune.php)
### The question
Is anybody have heard of him or used that C++ "marvel"?
Here's one of its tweet:
{% twitter 1438279450295214080 %}
| jesuismaxime |
948,632 | Lets Save The World! | Will you join me to - dare I say it - Save the World? Overview of My Submission In this... | 0 | 2022-01-10T18:54:38 | https://dev.to/maartene/lets-save-the-world-4g5g | atlashackathon | Will you join me to - dare I say it - Save the World?
### Overview of My Submission
In this web based game/simulation you play as a country. You are able to enact, revoke and upgrade policies that influence your country in various ways and by consequence, also the Earth as a whole.
There is no win/lose condition per se, but perhaps trying to keep global warming under 1.5 degrees above pre-industrial temperature is a nice goal?
It's multiplayer, so the more people play, the bigger the impact we can all make!
- You can play the game here: [https://www.letssavetheworld.club/](https://www.letssavetheworld.club/)
- More instructions in the [Readme](https://github.com/maartene/STW/blob/main/README.md)
#### Play example
{% youtube dNGKFGh7IdM %}
#### History
November 14 I registered a domain name, more or less on a whim: letssavetheworld.club. It was around the time of the Climate Conference in Glasgow and I remember how disappointed I was about the results. Was it really that difficult to actually start doing something? So I decided I'd create a game/simulation to get a sense of the complexity involved. I researched climate change models and the effects of global warming for humanity.
Then, this hackathon came along, offering the perfect reason to actually create the game and publish it.
### Submission Category:
Choose Your Own Adventure
### Link to Code
{% github https://github.com/maartene/STW %}
### Additional Resources / Info
#### About the climate change model
Climate change is a pretty complex concept. The model used in this game is very, VERY basic. It only covers average global temperature and warming based on carbon concentration in the atmosphere. It is not aware of regional differences. The model in itself is flexible though and could be expanded to take more metrics into account.
(exact links to the various data sources for the model can be found in the source code)
#### About the tech
Lets Save The World is based on two big technologies:
- backend uses the [Vapor framework](https://vapor.codes): a Server Side Swift framework. I like using Swift and feel that in particular for backend work. Its an opinionated language that somehow seems to help me write better code. That Vapor supports MongoDB out of the box also helps;
- front-end uses the [Vue.js](https://v3.vuejs.org) framework (with Vuex). I'm no Javascript expert, but find it very easy to use Vue to create a usable front-end.
The runtime version of the game is deployed on the [DigitalOcean App platform](https://www.digitalocean.com/products/app-platform/). The front-end as a Static Website (using a free plan), the backend as a Docker image (using the cheapest paid plan. The app platform takes care of all the complex stuff, such as creating TLS/SSL certificates for the website, deployments and the networking/domain stuff.
#### About the usage of MongoDB
MongoDB tends to be my database backend of choice for Vapor projects. I like the flexibility its schemaless setup offers. And I like that it uses JSON for most interactions, making bridging to data in the Vapor (Swift) world very easy, because Swift has very simple solutions for briding between JSON and actual Swift data structures.
I also like using MongoDB Atlas as a database provider. Off course, I could run my own MongoDB instance, but having the admin website in Atlas makes it much easier during development to experiment and quickly change stuff. Need to change a value in a document somewhere? The web interface makes this very easy. Need an extra database or drop a table? Just a few clicks. Finally, the larger (paid) Atlas plans provide stuff like backups out of the box. Something that's always a lot of work when you roll your own.
These two aspects help developer productivity a lot.
#### Feedback/improvements
If you have feedback, please let me know in the comments below. Also, if you have ideas from a game design point of view to make it more engaging, please reach out to me. I'm more of a programmer than a game designer, so can always use help to improve the fun and engagement of a game! | maartene |
948,691 | #1 What's Site Reliability Engineering [SRE] | Roles & Responsibilities | Technologies involved | Site reliability engineering Site Reliability Engineering, also popularly referred to as... | 16,220 | 2022-01-08T12:30:04 | https://dev.to/developertharun/1-whats-site-reliability-engineering-sre-roles-responsibilities-technologies-involved-1dcc | devops, beginners, programming, tutorial | ## Site reliability engineering
Site Reliability Engineering, also popularly referred to as the SRE, is a role in Computer Science Engineering where the main purpose is to provision, maintain, monitor, and manage the infrastructure in order to provide maximum application uptime and reliability. SRE is an emerging role, but the tasks that the SRE does were always there ever since the first application that was developed. The scope of the software developers ends where they write code to develop the application and right from setting up the infrastructure, the various services that run on them, the network connectivity that is required, providing a platform for the application to run and making sure every part of the application is up and running reliably 24x7 is the duty of an SRE. In fact, we can consider Site Reliability Engineers are the strong bridge between the users and a reliable application.
Now, in order to explain the different responsibilities of an SRE, I have divided it into 4 different categories. I have always seen SRE this way, and definitely not as some ad-hoc process. The four categories in which I would classify the tasks of a Site Reliability Engineer are:
1. Create
2. Monitor
3. Manage
4. Destroy
Let's dive deep into each one of them.
## Create
### 1. Provision virtual machines / PXE Baremetals
SREs are responsible for provisioning the virtual machines with the requested resources in terms of CPU, memory, disks, network configurations, and operating system. In case a bare metal needs to be set up, it is also performed with the provided configurations. The SREs use Linux commands, automation scripts to provision the server as quickly as possible. They are also responsible to be rack aware during provisioning. Example operating systems involve Linux Ubuntu, CentOS, Windows.
### 2. Setup services
Once the machines are provisioned, the SRE also takes care of setting up the services on the machines. These services can be networking services, proxy or load balancing services, container or orchestration services, message queues, databases, caching systems, big data services, or more, along with the disk setup. In this way, the SRE are exposed to a variety of technology and play an important role in the components involved in an application. Example technologies involve NGINX, Apache, RabbitMQ, Kafka, Hadoop, Traefik, MySQL, PostgreSQL, Aerospike, MongoDB, Redis, MinIO, Kubernetes, Apache Mesos, Marathon, MariaDB, Galera.
### 3. Optimize the infrastructure
Since there are several components and services that are being used in the infrastructure, there is a scope for improvements in terms of performance, efficiency, and security. The SRE optimizes the components by keeping them up to date, choosing the right service for the right job, patching the servers.
### 4. Write monitoring scripts
When the SRE are involved in maintaining an infrastructure of any size, they never underestimate any component of the infrastructure and write a monitoring script to monitor the components and metrics of each and every one of them. This provides the ability to get real-time alerts on any of the components malfunctioning and also a better view of the infrastructure. The SRE uses programming languages like Bash, Python, Golang, Perl, and tools like daemon processes, Riemann, InfluxDB, OpenTSDB, Kafka, Grafana, Prometheus, and APIs to monitor the infrastructure.
### 5. Write automation scripts
If there are more than 10 steps to be performed and chances are that the task has to be performed more than once, the SRE never hesitate to automate the task. This saves time and also prevents human error. The SRE uses programming languages like Bash, Python, Golang, Perl, Ansible to automate the tasks.
### 6. Manage users on the machines
One of the main security precaution that the SRE take is to restrict user access to the components in the infrastructure. They use various technologies like VPN ( Virtual Private Network ), firewall, configuration files, user management on machines, LDAP, sudoer configuration, PAM, OTP, two-factor authentications, SSH keys, and more to avoid unauthorized access to any component of the infrastructure.
These are the create aspects of a Site Reliability Engineer. In the next article we will read about the Monitor aspect of a Site Reliability Engineer.
## Complete Video:
{% youtube JgS4ZlQZfj4 %}
Watch the video above or listen to the full podcast exclusively below
## Podcast:
{% spotify spotify:episode:6KYPJlG66yB4NZprEL6aFk %}
You can find more articles here: https://www.tharunshiv.com
Thank you
Check out my YouTube Channel here: <a href="https://www.youtube.com/c/developerTharun">Developer Tharun - YouTube</a>
Written by,
{% user developertharun %}
# Thank you for reading, This is Tharun Shiv a.k.a Developer Tharun

| developertharun |
949,026 | Adding Personality to a Boring Form in my Saas Project | In this series, I'm building a Software-as-a-Service product for syncing environment variables... | 12,972 | 2022-01-08T21:30:13 | https://dev.to/ajones_codes/adding-personality-to-a-boring-form-in-my-saas-project-269g | webdev, saas, ux | In this series, I'm building a Software-as-a-Service product for syncing environment variables between team members. Since my background is mostly frontend, I'll be learning about backend technologies on the way, along with some UI/UX. You can read more about my concept and technology selection in my first post [here](https://dev.to/ajones_codes/building-a-saas-product-in-public-update-1-114i).
## The Challenge
Users of this product will be able to create multiple "Projects," which each have "environments" for managing variables. For example, for a Node.js API project, you might have a project called "My API Server" with two environments, "develop" and "production."
I started building the form for creating projects, using `react-hook-form` and some simple inputs. It came out like this:
...unfortunately, this was the most boring form I had _ever_ seen! I decided I needed to redesign this to make it feel more like a polished, professional project than a bunch of text fields thrown together.
## The Thought Process
I thought about varying it up a little bit by changing the Name field width and putting it on the same line as the Name label. While that helped, it was still super boring.
Then I took a step back. I started thinking about the **big picture** product. So I started thinking, _how will the data from this form actually be displayed?_
I threw this together quickly, showing projects as tiles with the project name and environments (plus I could've added the description).
Don't get me wrong, this design is ALSO super boring, but it gave me an idea: _what if I added an icon to the project?_ For people who have a lot of projects, this would help them make a visual distinction between projects, without affecting the core functional goals of the project. Plus, it would make the UI look more user-friendly than a plain text dev console.
### A Step in the Right Direction
I didn't want to create an image upload system for this simple feature: that would be too much work for me (as the developer) and for the users creating a project. But then what images could I use? Maybe an icon library? Or...
Emoji! Emoji are fun, available on all modern devices, and there's enough variety for people to choose an emoji related to their project. Maybe later I would also add the ability for users to pick a Letter/Color icon instead.
I explored some React emoji pickers online so I wouldn't have to build it myself, and eventually found [Emoji Mart](https://github.com/missive/emoji-mart).
After adding the emoji picker and a display field, the Project Creation form looked like this:
That's... _better_... but still mostly boring, and the emoji looks weird as an afterthought.
**Again, I thought about the big picture: how would I display this emoji?** I imagine the layout of the project list display like this: the selected emoji, large enough to see on a quick glance, next to the name and description of the project.
Then I thought, _why not display the form like that too?_ Then the project creation form would have conceptual symmetry with the project display list.
## The Solution
I rewrote the project creation form to look more like a single row, with the currently-selected emoji next to the name and display fields, in the same place as they would be displayed. This was the final product:
I also made the Call-to-Action more distinct by using a bright background, and I added a scale-up micro-interaction on-hover.
You may have noticed the Project Key field missing. At first I tried adding it below the row, because the project key won't be displayed in the row later, but it looked weird being the only element outside. I also wanted to add some more information around the project key, so I moved the field to a modal which pops-up when "Create" is pressed. I'll write more about that in another post!
## Conclusion
I'm really happy with the end result! It made the form more interesting by adding personality and making it sleek, and made the product overall feel more polished.
Thanks for reading! I hope this gave you some ideas for your own projects!
*Follow me here or [on Twitter](https://twitter.com/ajones55555) for more updates and other content. Feel free to DM me for questions!* | ajones_codes |
949,137 | JavaScript RPG Game Development | Episode 2: Map- and Character Creation | In this 2nd episode of our series I finally manage to create a custom spritesheet for building the map and characters of our game. | 0 | 2022-01-08T23:39:58 | https://www.timo-ernst.net/blog/2022/01/09/lets-code-a-final-fantasy-style-browser-game-with-rpg-js-map-and-character-creation-episode-2/ | rpgjs, html, javascript | ---
title: JavaScript RPG Game Development | Episode 2: Map- and Character Creation
published: true
description: In this 2nd episode of our series I finally manage to create a custom spritesheet for building the map and characters of our game.
tags: rpgjs, html, javascript
canonical_url: https://www.timo-ernst.net/blog/2022/01/09/lets-code-a-final-fantasy-style-browser-game-with-rpg-js-map-and-character-creation-episode-2/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/wgiaqo6johfwahyvzhyl.jpg
---
In this 2nd episode of our series I finally manage to create a custom spritesheet for building the map and characters of our game. I struggled quite a lot as the documentation of rpg.js is not the best and some important information is lacking. So, if you're also running into problems getting your spritesheet into the game, try the video below :-)
This is the spritesheet I use: [Tiny 16 Basic](https://opengameart.org/content/tiny-16-basic)
Also, I have 2 questions for you:
1. What do you think about Rumi's proposal for the storyline in [episode 1](https://youtu.be/W4SVdtY6wZs) comments section of the video?
2. What do you think we should name the game?
{% youtube EzSPxNsx9C4 %}
## Links
- My source code: http://github.com/valnub/jrpg
- rpg.js http://rpgjs.dev
- Free 16x16px spriteset (maps + chars) https://opengameart.org/content/tiny-16-basic
- My Blog https://www.timo-ernst.net
- Twitter https://www.twitter.com/timo_ernst | timo_ernst |
949,247 | How to Show a Delete Confirmation Dialog in Rails Using Stimulus | If you've switched to the latest version of Rails that uses Turbo, you might have noticed that it... | 16,140 | 2022-01-09T04:16:56 | https://akshaykhot.com/delete-confirm-using-stimulus/ | rails, stimulus, javascript, hotwire | If you've switched to the latest version of Rails that uses Turbo, you might have noticed that it doesn't show the confirmation dialog when you delete an item. This post explains how to display a delete confirmation dialog using Stimulus.
### Stimulus
If you haven't worked with [Stimulus](https://stimulus.hotwired.dev/) before, it's a JavaScript framework from Basecamp that is part of the Hotwire (_HTML over the wire_) front-end framework stack. The primary aim of Stimulus is **to enhance the static HTML rendered by the server**, using [convention-over-configuration](https://rubyonrails.org/doctrine#convention-over-configuration).
Stimulus connects the DOM elements to JavaScript objects using _**controllers**_ and hooks the DOM events to JavaScript methods using _**actions**_. It does this using simple attributes on the HTML elements.
**Controllers**
Controllers connect DOM elements to JavaScript objects using a `data-controller` attribute. The JavaScript object contains the behavior and logic you want to add to that DOM element.
Stimulus continuously monitors the page, waiting for HTML `data-controller` attributes to appear. Once it finds an element with a `data-controller` attribute, it checks the value to find a corresponding controller class. Then it creates a new instance of that class and connects it to the element.
For example, let's assume your HTML contains this `div` element with the `data-controller` attribute.
```html
<div data-controller="books">
<p>Book</p>
</div>
```
Once Stimulus finds this DOM element, it will try to find a controller class in the `books_controller.js` file.
```javascript
// src/controllers/books_controller.js
import { Controller } from "@hotwired/stimulus"
export default class extends Controller {
}
```
You can learn more about this process of mapping filenames to attributes on the [Stimulus installation guide](https://stimulus.hotwired.dev/handbook/installing).
**Actions**
Actions connect DOM events to controller methods using a `data-action` attribute.
Let's add a button to our DOM element with a `data-controller` attribute.
```html
<div data-controller="books">
<p>Book</p>
<button data-action="click->books#read">Start Reading</button>
</div>
```
The `data-action` value `click->books#read` is called an *action descriptor*.
- `click` is the event name
- `books` is the controller name
- `read` is the method to call
The `data-action="click->books#read"` tells Stimulus: **when the user clicks this button, call the `read` method on the `books_controller`.**
```javascript
// src/controllers/books_controller.js
import { Controller } from "@hotwired/stimulus"
export default class extends Controller {
read() {
// start reading the book
}
}
```
The [Stimulus handbook](https://stimulus.hotwired.dev/handbook/introduction) compares this approach to HTML classes connecting to CSS styles.
> Just like the class attribute is a bridge connecting HTML to CSS, Stimulus’s data-controller attribute is a bridge connecting HTML to JavaScript.
>
> Data attributes help separate content from behavior in the same way CSS separates content from presentation.
---
With that basic introduction of Stimulus out of the way, let's see how we will solve our problem of showing a confirmation dialog when the user clicks the delete button.
Here's the example code that displays the books with a delete button for each book.

**Step 1: Add a `data-controller` attribute to a parent HTML tag**

**Step 2: Add a `data-action` attribute to the button**
**Step 3: Add a Stimulus controller**
That's it. When you click the `delete` button, Stimulus will first call the `delete` method in the `books_controller.js` file. This method shows the confirmation prompt and does nothing if the user selects the `cancel` option.
And that's how you can show the confirmation prompt using Stimulus in Rails.
---
***Note:*** There's a simple way to add the confirmation dialog using the `turbo-method` and `turbo-confirm` data attributes, like this:
```erb
<%= link_to "delete", book, data: { turbo_method: :delete, turbo_confirm: "Are you sure?" } %>
```
However, this solution runs into a problem where Rails tries to redirect you to the same page with an HTTP `delete` method, causing an error. Chris Oliver from GoRails recently did a [video](https://www.youtube.com/watch?v=J1GAYLQvtBU) that explains this in detail, and also shows the workaround.
I hope that helped. Let me know in the comments if you find any mistakes or have any feedback. | software_writer |
949,420 | useState: Function can have state? | Introduction There are two types of component in React-native class component &... | 16,237 | 2022-01-09T10:28:13 | https://yadavrajshekhar.hashnode.dev/usestate-function-can-have-state | reactnative, react, javascript, reacthooks | ## Introduction
There are two types of component in React-native `class component` & `Functional component`.
` useState ` is a hook that allows a functional component to store state variable. If you are working with `class component`, It is equivalent to `this.state/ this.setState`. In this article we will try to understand the basic concept of `useState`.
Alright, let's get started !!
## The Traditional way of managing state
In `Class component`, we have a property `state` for reading the state(hold the state) and `setState` property that can we used for updating the states. Whenever we update the state it triggers the `render` method.
```javascript
export default class ButtonClick extends Component {
constructor(props) {
super(props);
this.state = {
count: 0,
};
}
render() {
return (
<View>
<Text>You have clicked this {this.state.count} time(s)</Text>
<Button
title="Click"
onPress={() => this.setState({count: this.state.count + 1})}></Button>
</View>
);
}
}
```
## UseState()
Functional component are just a functions that accept the properties as parameter and returns a valid JSX. Functional component does not have state or any lifecycle method. `useState` provides the facility of managing states in functional component.
### Anatomy of useState()
The `useState()` hook sets up an individual state property. It returns an array containing two elements: the current state value, and a function you can call with a new value to update the state.
### Declaring the useState()
Import the useState() package from `react`
```javascript
import React, {useState} from 'react';
```
### Initialising the state
The first argument of useState(initialState) is the initial state.
```javascript
const count = useState(0);
```
### Reading the state
As we know useState() returns an array, whose first element is the current state.
```javascript
<Text style={{fontSize: 30}}>{count[0]}</Text>
```
For the shake of readability, we prefer array destructuring .
For initialisation,
```javascript
const [count, setCount]= useState(0);
```
For Reading the state,
```javascript
<Text style={{fontSize: 30}}>{count[0]}</Text>
```
### Updating the State
#### Updating the states with a value
As we know that useState() return an array whose second item is a function which can we used for updating the state.
```javascript
<Button
title="Click Me"
onPress={() => {
setCount(8);
}}
/>
```
#### Updating the states with a callback
Sometimes there is a scenario, we have to calculate the next state on the basis of previous state, we can update the state with callback.
```javascript
<Button
title="Click Me"
onPress={() => {
setCount(previousCount => previousCount + 1);
}}
/>
```
### Using object as state variable
We can also initialise and update the object with the useState()
```javascript
const [userInfo, setUserInfo] = useState({name: 'Raj', age: 27});
```
For updating the the value we can try this.
```javascript
const [userInfo, setUserInfo] = useState({name: 'Raj', age: 27});
const name = userInfo.name;
const age = userInfo.age;
return (
<View style={{flex: 1, justifyContent: 'center', alignItems: 'center'}}>
<Text style={{fontSize: 12}}>
My Name is {name}. I am {age} years old
</Text>
<Button
title="Update Info Me"
// It will not merge the object. It will just override the state.
onPress={() => {
setUserInfo(previous => {
return {age: previous.age + 1};
});
}}
/>
</View>
);
```
When we will click on the `Button`, you will notice something interesting. Our `age` will be incremented by one which is correct but the `name` property is totally disappeared. So this is the problem with the `useState()`, it does not merge the object like we have seen in class component when we call `this.setState`. Actually It is overriding the object with current state.
If we really want to update the object, firstly we have to spread out the previous object and then update it. It will look something like that.
```javascript
onPress={() => {
setUserInfo(previous => {
// We can use spread operator
return {...previous, age: previous.age + 1};
});
}}
```
### Multiple States
When working with multiple fields or values as the state of your application, you have the option of organising the state using multiple state variables.
```javascript
const [name, setName] = useState('Raj');
const [age, setAge] = useState(27);
```
### Lazy initialisation of useState
Whenever we executes useState(), React re-renders the component. It is fine if the initial value is primitive value. It will not cause any performance issue.
Suppose, If we have to perform any expensive calculation (e.g. calculating fibonacci..) , it may cause performance issue. With the help of lazy initialisation we can overcome from this problem.
We can also pass a function as an argument to useState() for initialising the state.
```javascript
const [calculateJson, setCalculateJson] = useState(() => {
return {
name: 'Raj',
age: 27,
};
});
```
Now it will call only first time while rendering.
### Rules
1. Only call Hooks at top level
1. Only call Hooks from the React-Functions.
1. If your state depends on previous state try to update using callback.
```javascript
onPress={() => {
setAge(previous => previous + 1);
}}
```
## Conclusion
This is the basic idea about using useStae(). Let's note down the key point.
1. `useState()` makes functional component more powerful by allowing them to the process state.
1. `useState()` returns an array whose first item is current state and second item is a function which is used for updating the state.
1. `useState(initialParam)` takes the initial value of the state variable as an argument.
1. We can update the state by passing a value or using a callback.
1. Whenever we call useState(), React will re-render the component
1. If we want to perform expensive calculation while initialising the state, we can do this by passing initial state as a function in `useState(()=>{})`. By doing so render will called only once.
1. `useState()` does not auto merge the objects . We can achieve this with the help of spread operator.
Thanks for reading this article. Feel free to add your suggestions. You can connect with me at [Twitter](https://twitter.com/yrajshekhar231 ).
Stay safe !!
| yadav_rajshekhar |
949,785 | Simple Movie rec sys | I want to improve my Algorithm and Data structure Knowledge. In the following blog post, I will guide... | 0 | 2022-01-09T19:56:02 | https://dev.to/lukas_f/simple-movie-rec-sys-5203 | python, portfolio, computerscience | I want to improve my Algorithm and Data structure Knowledge.
In the following blog post, I will guide you through a sample project you can create for your portfolio or as an Idea of how to use Data structures like a Tree, Hashmap, etc...
The key intention behind this blog post is to create simple projects that can be used in your portfolio to highlight your skills.
The main focus in this post is to use:
1. API for data
2. Data structures like TreeNodes
3. Command prompt
The project uses [themoviedb](https://developers.themoviedb.org/3/movies/get-movie-details) API to fetch the movie data of 20 movies belonging to a certain genre. The API key can get generated after you created an account under [themoviedb](https://www.themoviedb.org/).
In the next step I use the json and requests library.
`genres = requests.get(f"https://api.themoviedb.org/3/genre/movie/list?api_key={api_key}&language=en-US")
genre_data = genres.json()`
The api data looks like the following:
{'genres': [{'id': 28, 'name': 'Action'},
{'id': 12, 'name': 'Adventure'},
{'id': 16, 'name': 'Animation'},
{'id': 35, 'name': 'Comedy'},
{'id': 80, 'name': 'Crime'},
{'id': 99, 'name': 'Documentary'},
{'id': 18, 'name': 'Drama'},
{'id': 10751, 'name': 'Family'},
{'id': 14, 'name': 'Fantasy'},
{'id': 36, 'name': 'History'},
{'id': 27, 'name': 'Horror'},
{'id': 10402, 'name': 'Music'},
{'id': 9648, 'name': 'Mystery'},
{'id': 10749, 'name': 'Romance'},
{'id': 878, 'name': 'Science Fiction'},
{'id': 10770, 'name': 'TV Movie'},
{'id': 53, 'name': 'Thriller'},
{'id': 10752, 'name': 'War'},
{'id': 37, 'name': 'Western'}]}
Through the API we got all available genres in the next step we use the genres to collect 20 movies from each genre.
```
data = []
for genre in genre_name:
r = requests.get(f"https://api.themoviedb.org/3/discover/movie?api_key={api_key}&language=en-US&sort_by=popularity.desc&include_adult=false&include_video=false&page=1&with_genres={genre}&with_watch_monetization_types=flatrate")
movie_data = r.json()
for i in movie_data['results']:
movie_temp = []
movie = [i['title'],i['vote_average'],i['release_date'],i['popularity'],i['overview'], genre]
movie_temp.append(movie)
data += movie_temp
```
genre_name is a list containing all genres. We iterate over each genre and change the API key according to that. In the next step, we iterate over the API result and place it in a list of lists that get appended to data. The resulting list of list looks like the following:
[['Spider-Man: No Way Home', 8.6, '2021-12-15', 20686.826, 'Peter Parker is unmasked and no longer able to separate...', 'Action'],
['Venom: Let There Be Carnage', 7.2, '2021-09-30', 7992.617, 'After finding a host body in investigative reporter Eddie Brock,...', 'Action']]
After getting the data and saving it in video_data.py we create a simple TreeNode class that will be used as a data structure for the project. The tree is simple and contains a start node and a node for each genre. Each genre node contains 20 movies which add up to 380 Nodes from the 19 genres.
The next step is to get the user input and the information of what genre he wants to watch. The user has several methods to select the movie. The first way is using a number from 1-19 or writing the genre into the command line.
The user gets asked after that if he wants to see movies from the selected genre. After that, he gets prompted again to get the amount of recommended movies. In the end, the user can get another recommendation or quit the recommendation sys.
The following is a gif that highlights the working of the rec sys.
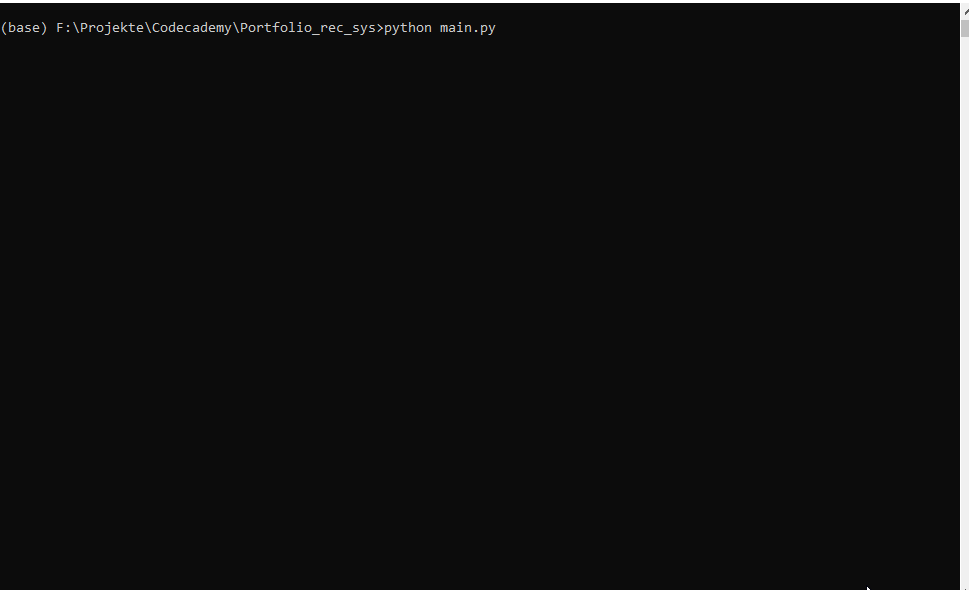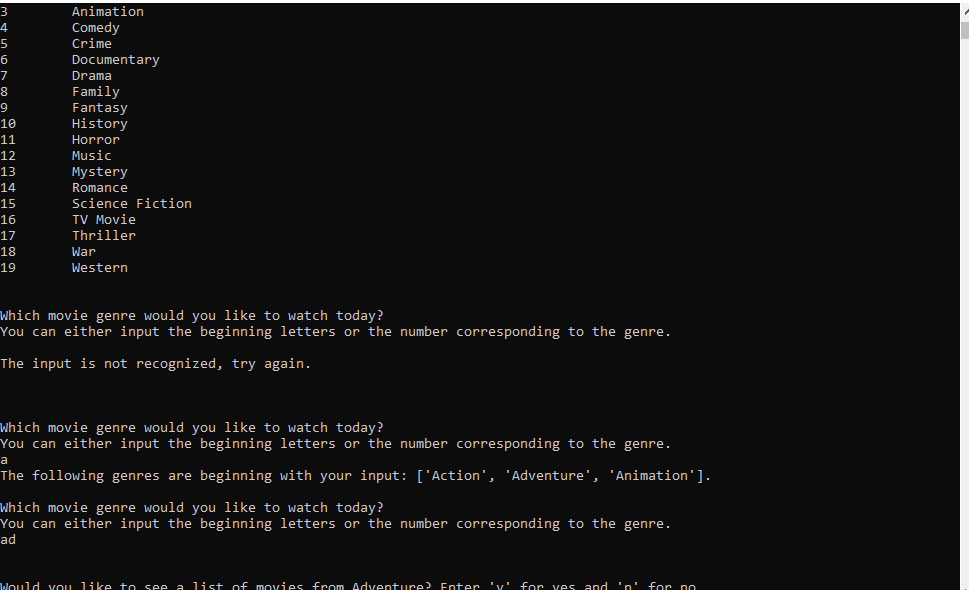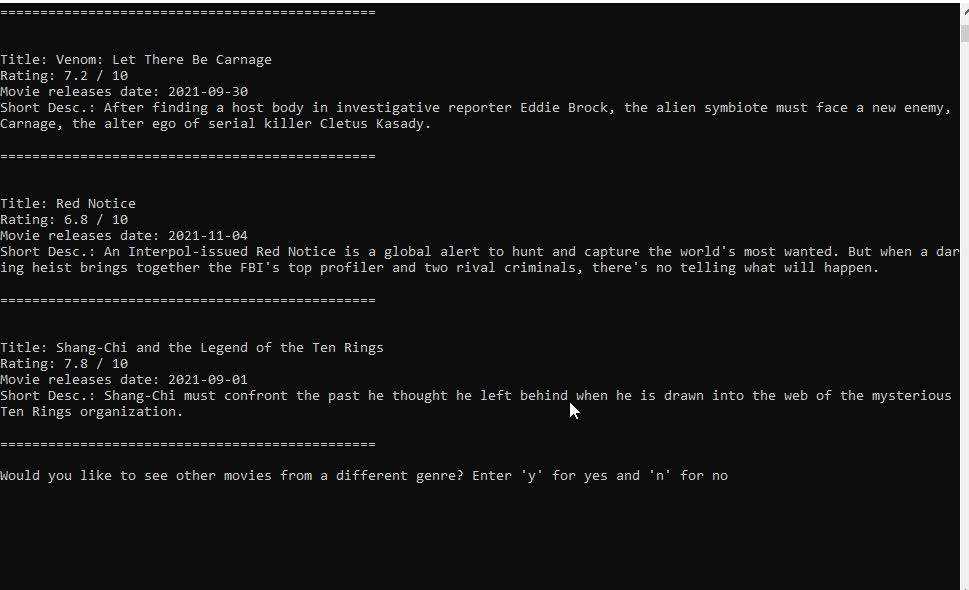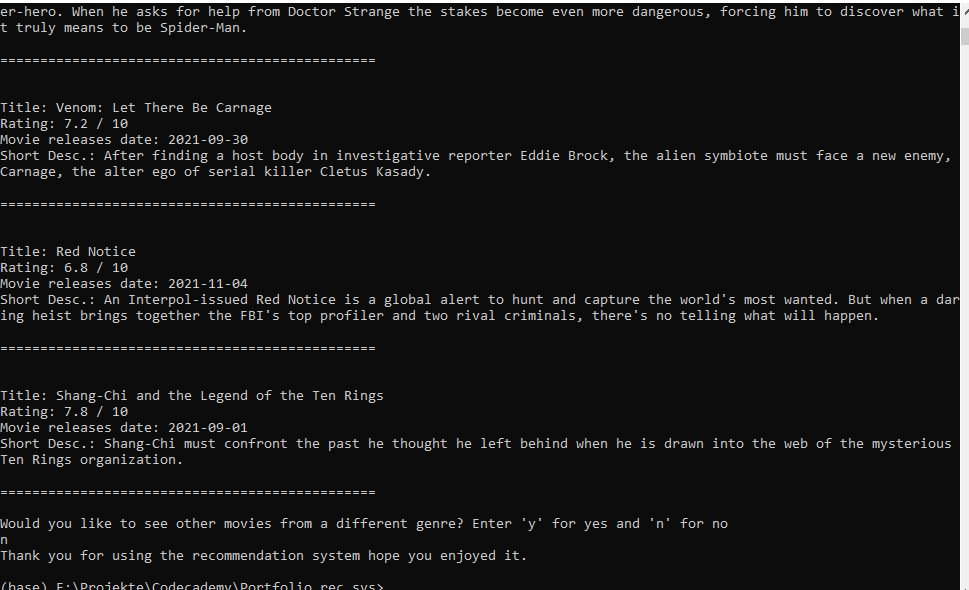
Thank you very much for your time and have fun exploring my [github](https://github.com/Lukas-Forst/Movie_rec_sys) repository and feedback of any sort is welcomed.
cover image from [unsplash](https://unsplash.com/photos/evlkOfkQ5rE?utm_source=unsplash&utm_medium=referral&utm_content=creditShareLink) | lukas_f |
949,833 | Turn Visual Studio Code Into A Top-Notch JavaScript IDE With These 25 Extensions | Visual Studio Code is a great code editor that comes with JavaScript and TypeScript features like... | 0 | 2022-01-09T22:59:05 | https://p42.ai/blog/2022-01-10/turn-visual-studio-code-into-a-top-notch-javascript-ide-with-these-25-extensions | beginners, vscode, javascript, webdev | **[Visual Studio Code](https://code.visualstudio.com/) is a great code editor** that comes with JavaScript and TypeScript features like basic refactoring out of the box. However, its true strength is an **outstanding [extension marketplace](https://marketplace.visualstudio.com/)**. There are extensions for almost anything you might want to do in an IDE (Integrated Development Environment), and they can make VS Code many times better.
Unfortunately, **it can be time-consuming to find the right extensions and configure VS Code**. Many developers prefer the out-of-the-box experience that IDEs such as [Webstorm](https://www.jetbrains.com/webstorm/) provide. This blog post shows how Visual Studio Code extensions can help you enhance the IDE experience for JavaScript. It covers:
* [Code Completion and Snippets](#code-completion-and-snippets)
* [Linting, Spell Checking, and Hints](#linting--spell-checking--and-hints)
* [Formatting, Code Actions, and Refactoring](#formatting--code-actions--and-refactoring)
* [Editor Support for Additional File Types](#editor-support-for-additional-file-types)
* [Organizing Comments, TODOs, and Bookmarks](#organizing-comments--todos--and-bookmarks)
* [Testing](#testing)
* [Debugging](#debugging)
* [Version Control](#version-control)
* [Database, REST API & Docker Clients](#database--rest-api---docker-clients)
You can conveniently install the **25 extensions that convert Visual Studio Code into a full-blown JavaScript IDE** with the **[JavaScript IDE Extension Pack](https://marketplace.visualstudio.com/items?itemName=p42ai.vscode-javascript-ide-extension-pack&ssr=false)**. [Icon or color themes](https://marketplace.visualstudio.com/search?target=VSCode&category=Themes&sortBy=Installs) and [keyboard shortcut maps](https://marketplace.visualstudio.com/search?target=VSCode&category=Keymaps&sortBy=Installs) are not covered here, nor are they included in the extension pack because they depend much more on personal preferences than most extensions.
Let's go into the different features and see what's possible in VS Code with just a few extensions:
## Code Completion and Snippets
Code completion (IntelliSense) features can make writing code faster and easier. Visual Studio Code provides [IntelliSense](https://code.visualstudio.com/docs/editor/intellisense) for JavaScript and TypeScript by default and contains powerful [Emmet support](https://code.visualstudio.com/docs/editor/emmet) for expanding snippets.
One of the latest trends in code completion is AI assistants. However, my experience with AI code completion assistants such as [GitHub Copilot](https://marketplace.visualstudio.com/items?itemName=GitHub.copilot) and [Tabnine](https://marketplace.visualstudio.com/items?itemName=TabNine.tabnine-vscode) was mixed so far, and therefore I've not included them in the extension pack, but they might work great for you.
Here are a few snippet extensions that can boost your productivity:
### [ES7 React/Redux/GraphQL/React-Native snippets](https://marketplace.visualstudio.com/items?itemName=dsznajder.es7-react-js-snippets)

The [ES7 snippets extension](https://marketplace.visualstudio.com/items?itemName=dsznajder.es7-react-js-snippets) provides many expandable everyday snippets. For example, defining imports and exports, creating methods and loops, and returning Promises. The extension also contains many snippets for [React](https://reactjs.org/) and [GraphQL](https://graphql.org/).
### [Emmet Live](https://marketplace.visualstudio.com/items?itemName=ysemeniuk.emmet-live)

With the [Emmet Live extension](https://marketplace.visualstudio.com/items?itemName=ysemeniuk.emmet-live), you can preview your [Emmet](https://emmet.io/) output while crafting the Emmet abbreviation. You can start it with the `Emmet Live` command.
### [Vscode-Random](https://marketplace.visualstudio.com/items?itemName=jrebocho.vscode-random)

When writing tests or creating mockups, it often takes time to come up with good fake data. You can use the [vscode-random extension](https://marketplace.visualstudio.com/items?itemName=jrebocho.vscode-random) to generate many kinds of random data, such as numbers, locations, emails, IPs, names, and datetime values.
## Linting, Spell Checking, and Hints
The best time to get feedback on your code is while editing, i.e., when you can quickly change the code and learn as you go. By integrating linting, spell checking, and other suggestions into your editing process, you avoid some of the more extended pre-commit checks and pull request round trips.
### [Code Spell Checker](https://marketplace.visualstudio.com/items?itemName=streetsidesoftware.code-spell-checker)

It is easy for typo and small spelling errors to slip into variable and function names, strings, comments, etc. The [Code Spell Checker extension](https://marketplace.visualstudio.com/items?itemName=streetsidesoftware.code-spell-checker) highlights those mistakes and can often provide the correct spelling as a fix.
### [ESLint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint)

[ESLint](https://eslint.org/) is the most commonly used JavaScript linter. It helps you "find and fix problems in your JavaScript code." ESLint is very extensible and configurable, and many teams have their own custom rules for their projects. The [ESLint extension](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint) shows errors and warnings directly in your editor and lets you quick-fix them easily. You can also configure it to auto-fix any problems on save.
### [Error Lens](https://marketplace.visualstudio.com/items?itemName=usernamehw.errorlens)

The [Error Lens extension](https://marketplace.visualstudio.com/items?itemName=usernamehw.errorlens) highlights and displays errors, warnings, and information messages directly in the editor. With it, you don't need to take the extra step of finding out what the squiggly underlines mean - it is right in front of you. If the information gets overwhelming, you can easily toggle it on and off for different message types with the `Error Lens: Toggle...` commands.
## Formatting, Code Actions, and Refactoring
Visual Studio Code comes with [basic refactorings and quick fixes](https://code.visualstudio.com/docs/editor/refactoring) such as `Rename`, `Extract Method` and `Extract Variable`. The editing experience can be further enhanced with extensions:
### [Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode)
Formatting code manually is very time-consuming and error-prone. With [Prettier](https://prettier.io/), the de-facto standard code formatter of the JavaScript world, you can format your code automatically. You can even configure the [Prettier VS Code extension](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode) to format the source code when you save it.
### [Change Case](https://marketplace.visualstudio.com/items?itemName=wmaurer.change-case)
The [Change Case extension](https://marketplace.visualstudio.com/items?itemName=wmaurer.change-case) adds a wide range of commands to change the case of the selected text, e.g., into camel case, snake case, Pascal case, etc. The commands all have the `Change Case` prefix.
### [P42 JavaScript Assistant](https://marketplace.visualstudio.com/items?itemName=p42ai.refactor)
The [JavaScript Assistant](https://marketplace.visualstudio.com/items?itemName=p42ai.refactor) that I've developed adds [60+ refactorings, quick fixes, and code actions](https://p42.ai/blog/2021-12-21/level-up-your-javascript-with-these-60-quick-fixes-for-vs-code) to VS Code. It contains React refactorings, ECMAScript modernizations, syntax and language element conversions, actions for logical expressions and control flow, and code cleanups.
## Editor Support for Additional File Types
When you work with JavaScript and TypeScript, there are many other relevant file types. Visual Studio Code already has editing support for [JSON](https://code.visualstudio.com/docs/languages/json), [HTML](https://code.visualstudio.com/docs/languages/html), [CSS](https://code.visualstudio.com/docs/languages/css), and [Markdown](https://code.visualstudio.com/docs/languages/markdown). The following extensions add more enhanced editor support:
### [npm](https://marketplace.visualstudio.com/items?itemName=eg2.vscode-npm-script)

The [npm extension](https://marketplace.visualstudio.com/items?itemName=eg2.vscode-npm-script) validates the installed Node.js modules defined in `package.json` files.
### [SVG Preview](https://marketplace.visualstudio.com/items?itemName=simonsiefke.svg-preview)

The [SVG Preview extension](https://marketplace.visualstudio.com/items?itemName=simonsiefke.svg-preview) does exactly that: show a preview for `.svg` files. You can pan and zoom the image in the preview, and it updates automatically when you edit the SVG source.
### [Even Better TOML](https://marketplace.visualstudio.com/items?itemName=tamasfe.even-better-toml)

[TOML](https://github.com/toml-lang/toml) is a configuration file format that aims to be simple and easily readable. The [Even Better TOML extension](https://marketplace.visualstudio.com/items?itemName=tamasfe.even-better-toml) adds full editor support, including syntax highlighting, folding, navigation, and formatting.
## Organizing Comments, TODOs, and Bookmarks
In larger development projects that last many years and involve many developers, staying organized around comments and TODO items becomes increasingly essential. The following extensions can help with that:
### [Better Comments](https://marketplace.visualstudio.com/items?itemName=aaron-bond.better-comments)

The [Better Comments extension](https://marketplace.visualstudio.com/items?itemName=aaron-bond.better-comments) shows different kinds of comments in different colors. It supports prefixes like `!`, `?`, and `TODO`.
### [Todo Tree](https://marketplace.visualstudio.com/items?itemName=gruntfuggly.todo-tree)

TODOs and FIXMEs easily get forgotten about and lost.
The [Todo Tree extension](https://marketplace.visualstudio.com/items?itemName=gruntfuggly.todo-tree) scans the files in your workspace for TODO and FIXME annotations and organizes them in a sidebar view. You can easily browse them by folder and revisit essential items that come to your attention.
### [Bookmarks](https://marketplace.visualstudio.com/items?itemName=alefragnani.bookmarks)
With the [Bookmarks extension](https://marketplace.visualstudio.com/items?itemName=alefragnani.bookmarks), you can save and label important source code locations and organize them in a sidebar panel. This can be helpful when you are exploring a complex codebase or when you have locations that you return to frequently.
## Testing
Writing and running tests is a crucial development activity.
In particular, unit tests that run in the IDE are helpful to get immediate feedback. The following extensions add test runner support to VS Code:
### [Test Explorer](https://marketplace.visualstudio.com/items?itemName=hbenl.vscode-test-explorer)

The Test Explorer is a set of extensions that integrate testing seamlessly into VS Code. Its [Test Explorer UI extension](https://marketplace.visualstudio.com/items?itemName=hbenl.vscode-test-explorer) adds a side panel for running the tests and seeing the results, and the [Test Explorer Status Bar](https://marketplace.visualstudio.com/items?itemName=connorshea.vscode-test-explorer-status-bar) adds the number of tests to the status bar.
The UI components show the information produced by test adapters. Which adapter you need for testing depends on your testing frameworks. For JavaScript, testing adapter extensions for the following test frameworks are available:
* [Mocha](https://marketplace.visualstudio.com/items?itemName=hbenl.vscode-mocha-test-adapter) *(included in extension pack)*
* [Jest](https://marketplace.visualstudio.com/items?itemName=kavod-io.vscode-jest-test-adapter) *(included in extension pack)*
* [Jasmine](https://marketplace.visualstudio.com/items?itemName=hbenl.vscode-jasmine-test-adapter)
* [Angular/Karma](https://marketplace.visualstudio.com/items?itemName=raagh.angular-karma-test-explorer)
* [AVA](https://marketplace.visualstudio.com/items?itemName=gwenio.vscode-ava-test-adapter)
* [TestyTs](https://marketplace.visualstudio.com/items?itemName=Testy.vscode-testyts-test-adapter)
* [React-scripts](https://marketplace.visualstudio.com/items?itemName=smarschollek.vscode-react-scripts-test-adapter)
Visual Studio Code has added native testing capabilities in version 1.59. You can enable them in the Test Explorer by setting `testExplorer.useNativeTesting` to `true` in the [VS Code settings](https://code.visualstudio.com/docs/getstarted/settings).
## Debugging
Visual Studio Code comes with an excellent [JavaScript debugger](https://code.visualstudio.com/docs/editor/debugging) out of the box. It can connect to Node.js, [Edge, and Chrome](https://code.visualstudio.com/docs/editor/debugging#_trigger-debugging-via-edge-or-chrome), so in most cases, there is no need for extra extensions when it comes to JavaScript debugging.
## Version Control
[Git](https://git-scm.com/) is the most used version control system (VCS), and there are great extensions for VS Code. You can also find extensions for other VCS's such as [Subversion](https://marketplace.visualstudio.com/items?itemName=johnstoncode.svn-scm) on the VS Code marketplace.
### [GitLens](https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens)
The [GitLens extension](https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens) adds several panels to the source control sidebar and enhances the editor with information overlays. The sidebar panels help you manage branches, stashes, commits, file history, remotes, and the editor extensions include a blame view, change indications, an authorship code lens, and more. GitLens is an essential extension that makes working with Git in VS Code much easier.
### [Git Graph](https://marketplace.visualstudio.com/items?itemName=mhutchie.git-graph)

The [Git Graph extension](https://marketplace.visualstudio.com/items?itemName=mhutchie.git-graph) shows the Git history visually in an editor panel. You can open it with the "View Git Graph" command. In the graph view, you can explore individual commits and perform many everyday Git operations. For example, you can check out branches and commits, create branches, cherry-pick commits, perform merges, etc.
## Database, REST API & Docker Clients
Developing full-stack JavaScript often means working with external systems such as databases, REST APIs and Docker. The following extensions add clients to VS Code:
### [Database Client](https://marketplace.visualstudio.com/items?itemName=cweijan.vscode-database-client2)

The [Database Client extension](https://marketplace.visualstudio.com/items?itemName=cweijan.vscode-database-client2) lets you connect to MySQL/MariaDB, PostgreSQL, SQLite, Redis, and ElasticSearch. You can explore databases in its sidebar panel, open database tables as editor panels, and run custom SQL queries. The database table content is editable. Any changes that you make are immediately stored in the database.
### [Thunder Client](https://marketplace.visualstudio.com/items?itemName=rangav.vscode-thunder-client)
The [Thunder Client extension](https://marketplace.visualstudio.com/items?itemName=rangav.vscode-thunder-client) integrates a client for REST APIs into VS Code. It is a lightweight alternative to [Postman](https://www.postman.com/). You can send any kind of `http(s)` request, see the response data, and organize your requests in collections.
### [Docker](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker)

Working with containers has become an essential part of day-to-day development for many software engineers. With the [Docker extension](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker), you can explore your running Docker containers, get editor support for Docker files, and more.
## Bonus
Here is a small bonus extension that I find very useful:
### [CodeSnap](https://marketplace.visualstudio.com/items?itemName=adpyke.codesnap)

You can take beautiful screenshots of your code in no time with the [CodeSnap extension](https://marketplace.visualstudio.com/items?itemName=adpyke.codesnap). Start with the `CodeSnap` command, select the code you want to screenshot, and click the lense button.
## Conclusion
I hope the post gave you a few ideas for extensions that can improve your VS Code experience. With the **[JavaScript IDE Extension Pack](https://marketplace.visualstudio.com/items?itemName=p42ai.vscode-javascript-ide-extension-pack&ssr=false)**, you can install them all and then disable or uninstall the ones that don't fit your needs. | lgrammel |
949,935 | Emulating the Sega Genesis - Part I | Originally published at jabberwocky.ca Written December 2021/January 2022 by... | 16,249 | 2022-01-10T00:01:00 | https://jabberwocky.ca/posts/2022-01-emulating_the_sega_genesis_part1.html | rust, emulator, sega, genesis | *Originally published at [jabberwocky.ca](https://jabberwocky.ca/posts/2022-01-emulating_the_sega_genesis_part1.html)*
###### *Written December 2021/January 2022 by transistor_fet*
A few months ago, I wrote a 68000 emulator in Rust named [Moa](https://jabberwocky.ca/projects/moa/). My original goal was to emulate a simple [computer](https://jabberwocky.ca/projects/computie/) I had previously built. After only a few weeks, I had that software up and running in the emulator, and my attention turned to what other platforms with 68000s I could try emulating. My thoughts quickly turned to the Sega Genesis and without thinking about it too much, I dove right in. What started as an unserious half-thought of "wouldn't that be cool" turned into a few months of fighting documentation, game programming hacks, and my sanity with some side quests along the way, all in the name of finding and squashing bugs in the 68k emulator I had already written.
If you haven't already, you might want to read [Making a 68000 Emulator in Rust](https://dev.to/transistorfet/making-a-68000-emulator-in-rust-1kfk) where I talk about the basic structure and function of the emulator, as well as details about the 68000. I wont go into too much detail about that here and instead focus on the Genesis-specific hardware, and the challenges of debugging the emulator itself.
This is Part I in the series, which covers setting up the emulator, getting some game ROMs to run, and implementing the DMA and memory features of the VDP. [Part II](https://dev.to/transistorfet/emulating-the-sega-genesis-part-ii-16k7) will cover adding a graphical frontend to Moa, and then implementing a first attempt at generating video output. [Part III](https://dev.to/transistorfet/emulating-the-sega-genesis-part-iii-220f) will be about debugging the various problems in the VDP and CPU implementations to get a working emulator capable of playing games.
* [The Start](#the-start)
* [Sega Genesis/Mega Drive](#sega-genesis-mega-drive)
* [The Games](#the-games)
* [Diving In](#diving-in)
* [Dummy Devices](#dummy-devices)
* [Memory and DMA](#memory-and-dma)
* [Talking To The VDP](#talking-to-the-vdp)
* [Implementing The Memory Ops](#implementing-the-memory-ops)
* [Next Time](#next-time)
The Start
---------
Before starting Moa, I had never tried to make an emulator, but I have worked on projects with some similarities such as interpreters, artificial life simulators, and some simple games. I had been looking for a fun distracting project, so I was approaching this as a fun challenge. Especially with the Genesis support, I wanted to get something up and running fast, just to see if it would work at all, so rather than taking my more usual measured approach, I was working fast and loose to get a proof of concept running. I could always go back and fix things later, right?
I was primarily hoping to simulate the video chip in the Sega Genesis, enough to see the intended graphics output and play the games. Not only would it be a nice accomplishment to get some visual feedback, but I would have to work out a way of creating a separate frontend that could display graphics to a host window, which I could use for other systems as well. I was less concerned with audio, since that would require getting the Z80 working, which wasn't even on my horizon at the time. I was hoping that I could get away with just the 68k for now (which is certainly possible for some but not all games).
Sega Genesis/Mega Drive
-----------------------
<p align="center">
<img src="https://jabberwocky.ca/posts/images/2022-01/sega-genesis.jpg" title="Sega Genesis" />
</p>
(From Wikipedia by Evan-Amos, used under the Creative Commons license.)
The [Sega Genesis](https://segaretro.org/Sega_Mega_Drive) (also known as the Mega Drive outside of North America) was released in 1988/1989 as a successor to the popular Sega Master System. It's main processor is a 68000 clocked at just under 8 MHz, which compared to computers of the time was pretty outdated, but it's slower speed is compensated by the custom video display processor (VDP), as well as a Z80 coprocessor, both of which can offload work from the 68000. While the 68000 can address up to 16 MB, it only has 64KB of main RAM, located at address `0xFF0000`. The VDP (also known by the part number of the chip, YM7101) has it's own separate 64KB of RAM which is only accessible through the VDP, either by writing data to the VDP's ports, or configuring a DMA (direct memory access) transfer from main memory to video memory, which is performed by the VDP. Game cartridges are mapped to address `0` of the 68000's address space, and can be up to 4MB. It also has two sound generation chips, the SN76489 and YM2612, but I don't have audio working yet so I wont talk much about these.
The Genesis was one of the first video game consoles to have some backwards compatibility with it's predecessor, although a [special pin-converter](https://segaretro.org/Power_Base_Converter) was needed in order to plug Master System cartridges into the Genesis. In order to accomplish this, the Genesis has a Z80 processor (in addition to the main 68000 processor), which can run on it's own with it's own bus and memory. It only has 2 KB of RAM instead of the 24 KB of the Master System, but the 68000's address space can be mapped into a banked area that the Z80 can access. While some games work fine without the Z80 present, others will wait for certain data to be written by the Z80 before proceeding, which results in the game hanging.
The VDP or Video Display Processor is the central peripheral device in the console. It generates the video output signal, controls the video memory, handles DMA (Direct Memory Access) to transfer data to the video memory, as well as handling all the interrupts in the system (there are 3, one each for the horizontal and vertical blanking, and one for the game controllers). It has it's own 64KB of video memory (VRAM) which holds all the graphics and data tables that describe which graphics should be displayed and where on the screen. Internal to the VDP there is also the colour ram (CRAM), and vertical scroll ram (VSRAM), which have their own separate address spaces, and hold the colour palettes and vertical cell offset numbers respectively. In addition, there are 22 internal 8-bit registers which configure how the VDP behaves, which can only be accessed indirectly through the memory-mapped interface to the VDP. They control the graphics mode to use, the size of the scrollable planes, the locations in VRAM of the scroll and sprite tables, the length and source address to use for DMA transfers, and a few other things.
The Games
---------
I'll mostly refer to "Sonic The Hedgehog 2" in examples because in the end, it's the game that worked the best, even though I actually started with Sonic 1. During development, I also tried Earthworm Jim, Ren and Stimpy's Invention, and a few others that didn't work as well. It wasn't until I took a break and came back to it that I found [ComradeOj's demos and test ROMs](https://www.mode5.net/#), which where much easier to test with.
In order to better trace the ROM's execution, the `.bin` ROM images can be disassembled using m68k-gcc's objdump command:
```
m68k-linux-gnu-objdump -b binary -m m68k:68000 -D binaries/genesis/Sonic2.bin > Sonic2.asm
```
One of the nice things about working with the 68000 is that it's still a supported architecture in the latest version of gcc, so all the latest gcc tools can be used to compile and inspect binaries. It's uncertain how much longer that will be the case, but that said, support was recently added to LLVM and experimental support is available in Rust, so who knows. Maybe there's still a long life ahead for the 68000 architecture.
Diving In
---------
The first thing to sort out was the format of Sega Genesis game ROMs. Some ROMs use a flat binary format which can be directly loaded at address `0` without any changes or special parsing. Other ROMs use a format with the file extension `.smd` which interleaves the even- and odd-addressed bytes of the ROM in 16 KB chunks, but there are utilities available that convert from `.smd` to `.bin` format. Since I was hoping to focus my attention on simulating the VDP, I chose to just use the binary format for ROMs since the emulator can already load flat binaries, and I can use the available conversion utilities to convert any `.smd` ROMs I had into `.bin` ROMs.
That was easier than I was expecting. All I had to do was load the ROM file into a `MemoryBlock` object in the emulator, and map that object to address `0`. I also needed 64 KB of RAM mapped to addresses 0xFF0000 through 0xFFFFFF, which also uses a `MemoryBlock`. My Moa machine definition looked something like this:
```rust
let mut system = System::new();
let rom = MemoryBlock::load("binaries/genesis/Sonic2.bin").unwrap();
system.add_addressable_device(0x00000000, wrap_transmutable(rom)).unwrap();
let ram = MemoryBlock::new(vec![0; 0x00010000]);
system.add_addressable_device(0x00FF0000, wrap_transmutable(ram)).unwrap();
let mut cpu = M68k::new(M68kType::MC68000, 7_670_454);
cpu.enable_tracing();
system.add_device("cpu", wrap_transmutable(cpu)).unwrap();
Ok(system)
```
Running this gave the results:
```
0x00000206: 4ab9 00a1 0008
tstl (#00a10008)
Status: Running
PC: 0x0000020c
SR: 0x2700
D0: 0x00000000 A0: 0x00000000
D1: 0x00000000 A1: 0x00000000
D2: 0x00000000 A2: 0x00000000
D3: 0x00000000 A3: 0x00000000
D4: 0x00000000 A4: 0x00000000
D5: 0x00000000 A5: 0x00000000
D6: 0x00000000 A6: 0x00000000
D7: 0x00000000
SSP: 0xfffffe00
USP: 0x00000000
Current Instruction: 0x00000206 TST(IndirectMemory(10551304), Long)
0x00fffe00: 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000
0x00fffe10: 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000
0x00fffe20: 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000
0x00fffe30: 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000 0x0000
Error { err: Emulator, native: 0, msg: "No segment found at 0xa10008" }
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Error { err: Emulator, native: 0, msg: "No segment found at 0xa10008" }', frontends/moa-minifb/src/lib.rs:70:40
```
Wow, It worked! (sort of). The first line of the output shows the address of the instruction being executed (`0x206`), followed by the instruction data that was decoded. Below that is the decoded instruction in assembly notation. When an error occurs, Moa will dump the values of the CPU registers along with a dump of the stack area, which in this case is located at address `0xfffe00`. The `tstl (#0xa10008)` instruction that's being executed is supposed to compare the value stored at the address `0xa10008` to zero, and set the flags in the `%sr` register accordingly. The error that occurs means there was an attempt to access address `0xa10008`, which isn't mapped to a valid area on the data bus, and Moa is currently configured to cause a fatal error in that case.
According to the [memory map](https://segaretro.org/Sega_Mega_Drive/Memory_map) for the Genesis, the address `0xa10008` is the control port for Controller 1, which makes sense. It's doing something that would be expected of a Genesis ROM, even if it only gets one instruction in before dying.
Taking a look at the first 16 bytes of the ROM shows:
```
00000000: FF FF FE 00 00 00 02 06 00 00 02 00 00 00 02 00
```
The first 4 bytes are the stack pointer (`0xfffffe00`) and the next 4 bytes are the reset address, which is the same address as the starting instruction, `0x206`. (If your curious, the two addresses that follow the reset address are for the bus error and address error handlers respectively, which point to the same handler at `0x200`).
You may have noticed that the stack pointer value (`0xfffffe00`) is a full 32-bit address, but the 68000 only supports 24-bit addresses. In hardware, the extra 8-bits at the top (ie. `0xff`) would be ignored. I had to modify the emulator to allow an address mask to be configured, so that all 32-bit addresses coming from the 68000 are masked to only 24-bits. I eventually made a more complete and configurable solution that's described later.
To get around the no segment found error, I added another memory block for 0xa10000 in order to prevent the error, and now a handful of instructions are running correctly until the next "No segment found" error occurs.
```
0x00000206: 4ab9 00a1 0008
tstl (#00a10008)
0x0000020c: 6606
bne 6
0x0000020e: 4a79 00a1 000c
tstw (#00a1000c)
0x00000214: 667c
bne 124
0x00000216: 4bfa 007c
lea (%pc + #007c), %a5
0x0000021a: 4c9d 00e0
movemw (%a5)+, %d5-%d7
0x0000021e: 4cdd 1f00
moveml (%a5)+, %a0-%a4
0x00000222: 1029 ef01
moveb (%a1 + #ffffef01), %d0
0x00000226: 0200 000f
andb #0000000f, %d0
0x0000022a: 6708
beq 8
0x00000234: 3014
movew (%a4), %d0
Status: Running
PC: 0x00000236
SR: 0x2704
D0: 0x00000000 A0: 0x00a00000
D1: 0x00000000 A1: 0x00a11100
D2: 0x00000000 A2: 0x00a11200
D3: 0x00000000 A3: 0x00c00000
D4: 0x00000000 A4: 0x00c00004
D5: 0xffff8000 A5: 0x000002ae
D6: 0x00003fff A6: 0x00000000
D7: 0x00000100
SSP: 0xfffffe00
USP: 0x00000000
Current Instruction: 0x00000234 MOVE(IndirectAReg(4), DirectDReg(0), Word)
0xfffffe00:
Error { err: Emulator, native: 0, msg: "No segment found at 0xc00004" }
```
Another missing I/O device. The `0xc00004` address is the control port of the VDP, so again that makes sense. Adding another `MemoryBlock` for that address range prevents the emulator from hitting another error, but it instead gets stuck in a loop.
```
0x0000024c: 3287
movew %d7, (%a1)
0x0000024e: 3487
movew %d7, (%a2)
0x00000250: 0111
btstb %d0, (%a1)
0x00000252: 66fc
bne -4
0x00000250: 0111
btstb %d0, (%a1)
0x00000252: 66fc
bne -4
0x00000250: 0111
btstb %d0, (%a1)
0x00000252: 66fc
bne -4
...
```
The register `%a1` has the value `0xa11100`, `%d0` has `0x00`, and `%d7` has `0x0100`. The code first writes the value `0x0100` to address `0xa11100`, and then tests if the bit that was just set at that memory location is 1. It then loops back to the bit test instruction until it becomes 0, which never happens because that address is just a memory location at the moment, and not an I/O device. That address, according to the map, is the Z80 bus request location for enabling or disabling the bus request pin on the Z80.
At this point I'll need to start properly implementing the devices at these address locations in order to get further in the execution of a program. It's only executed a hundred or so instructions to get to this infinite loop, which isn't very much, but this is very promising.
Dummy Devices
-------------
In order to get the game ROMs to run further, I needed some basic devices that can respond to the addresses of the various peripherals. It was just a matter of looking through the [memory map](https://segaretro.org/Sega_Mega_Drive/Memory_map) and filling in the gaps. The Sega CD and 32X devices could be ignored, since I was only working on basic Genesis support for now, but the rest will need to respond in some way, so they will need to be assigned to Moa devices.
To start with, there is a 64KB chunk of addresses at `0xa00000` for accessing the Z80's address space, which can be filled with a `MemoryBlock` for now.
Then there's a chunk of 0x20 addresses starting at `0xa10000`, which are mostly related to the controllers. An exception to that is the special version register at the start of that range. It's supposed to always return a constant value to indicate which hardware version of the console the ROM is running on. I can just add that location to the same device as the controllers to make it easy. I'll need a `Transmutable` object to represent all the controllers.
```rust
pub struct GenesisControllerPort {
pub data: u16,
pub ctrl: u8,
pub th_count: u8,
pub next_read: u8,
}
pub struct GenesisControllers {
pub port_1: GenesisControllerPort,
pub port_2: GenesisControllerPort,
pub expansion: GenesisControllerPort,
}
impl Addressable for GenesisControllers {
fn len(&self) -> usize {
0x20
}
fn read(&mut self, mut addr: Address, data: &mut [u8]) -> Result<(), Error> {
// If the address is even, only the second byte (odd byte) will be meaningful
let mut i = 0;
if (addr % 2) == 0 {
addr += 1;
i += 1;
}
match addr {
REG_VERSION => { data[i] = 0xA0; } // Overseas Version, NTSC, No Expansion
REG_DATA1 => { data[i] = self.port_1.next_read; },
REG_DATA2 => { data[i] = self.port_2.next_read; },
REG_DATA3 => { data[i] = self.expansion.next_read; },
REG_CTRL1 => { data[i] = self.port_1.ctrl; },
REG_CTRL2 => { data[i] = self.port_2.ctrl; },
REG_CTRL3 => { data[i] = self.expansion.ctrl; },
_ => { warning!("{}: !!! unhandled reading from {:0x}", DEV_NAME, addr); },
}
info!("{}: read from register {:x} the value {:x}", DEV_NAME, addr, data[0]);
Ok(())
}
fn write(&mut self, addr: Address, data: &[u8]) -> Result<(), Error> {
info!("{}: write to register {:x} with {:x}", DEV_NAME, addr, data[0]);
match addr {
REG_DATA1 => { self.port_1.set_data(data[0]); }
REG_DATA2 => { self.port_2.set_data(data[0]); },
REG_DATA3 => { self.expansion.set_data(data[0]); },
REG_CTRL1 => { self.port_1.ctrl = data[0]; },
REG_CTRL2 => { self.port_2.ctrl = data[0]; },
REG_CTRL3 => { self.expansion.ctrl = data[0]; },
_ => { warning!("{}: !!! unhandled write of {:0x} to {:0x}", DEV_NAME, data[0], addr); },
}
Ok(())
}
}
```
The next set of addresses are a bit clumsy unfortunately. The addresses `0xa11000`, `0xa11100`, and `0xa11200` are special registers used for controlling the Z80, and all other addresses in that range are "prohibited" (not that that stops ROMs from accessing those areas, as I've found out, in frustration). `0xa11000` is used to configure DRAM mode for ROM development on the hardware, which isn't needed here. The other two locations control the Z80's reset and bus request lines respectively. The bus request signal will tell the Z80 to stop running and disconnect itself from the memory bus, so that the 68000 can access the Z80's RAM directly. Without this, the read and writes could conflict with each other resulting in both CPUs reading or writing garbage. This wont reset the Z80, which will continue running where it left off, when the bus request signal is de-asserted. The reset signal allows the Z80 to be reset so that it starts in a known state. Again, I'll need a custom `Transmutable` device to handle these locations, and the unmapped areas will just return nothing.
```rust
pub struct CoprocessorControl {
pub bus_request: bool,
pub reset: bool,
}
impl Addressable for CoprocessorControl {
fn len(&self) -> usize {
0x4000
}
fn read(&mut self, addr: Address, data: &mut [u8]) -> Result<(), Error> {
match addr {
0x100 => {
data[0] = if self.bus_request && self.reset { 0x01 } else { 0x00 };
},
_ => { warning!("{}: !!! unhandled read from {:0x}", DEV_NAME, addr); },
}
info!("{}: read from register {:x} of {:?}", DEV_NAME, addr, data);
Ok(())
}
fn write(&mut self, addr: Address, data: &[u8]) -> Result<(), Error> {
info!("{}: write to register {:x} with {:x}", DEV_NAME, addr, data[0]);
match addr {
0x000 => { /* ROM vs DRAM mode (not implemented) */ },
0x100 => {
self.bus_request = data[0] != 0;
},
0x200 => {
self.reset = data[0] == 0;
},
_ => { warning!("{}: !!! unhandled write {:0x} to {:0x}", DEV_NAME, data[0], addr); },
}
Ok(())
}
}
```
The last area of the address space to implement is `0xc00000` to `0xc00020`, which is mapped to the VDP. While there's a lot of internal state to the VDP, it has quite a small interface to the rest of the system. Most features of the VDP will be performed during the `.step()` function, where the device has access to the `System` object. Copying data from main memory requires access to the `System`'s `Bus` object, so DMA will be implemented in the `.step()`.
```rust
pub struct Ym7101State {
pub ctrl_port_buffer: Option<u16>, // Used to store the first word of a transfer request
pub regs: [22; u8], // The internal registers of the VDP
}
pub struct Ym7101 {
pub state: Ym7101State,
}
impl Ym7101 {
pub fn new() -> Ym7101 {
Ym7101 {
state: Ym7101State::new(),
}
}
}
impl Steppable for Ym7101 {
fn step(&mut self, system: &System) -> Result<ClockElapsed, Error> {
Ok((1_000_000_000 / 13_423_294) * 4)
}
}
impl Addressable for Ym7101 {
fn len(&self) -> usize {
0x20
}
fn read(&mut self, addr: Address, data: &mut [u8]) -> Result<(), Error> {
match addr {
// Read from Data Port
0x00 | 0x02 => {
},
// Read from Control Port
0x04 | 0x06 => {
},
_ => { println!("{}: !!! unhandled read from {:x}", DEV_NAME, addr); },
}
Ok(())
}
fn write(&mut self, addr: Address, data: &[u8]) -> Result<(), Error> {
match addr {
// Write to Data Port
0x00 | 0x02 => {
},
// Write to Control Port
0x04 | 0x06 => {
},
_ => { warning!("{}: !!! unhandled write to {:x} with {:?}", DEV_NAME, addr, data); },
}
Ok(())
}
}
```
Early in development I called this device Ym7101 after the part number, and it's stuck since then, so just know that `Ym7101` is the VDP device. I'm using a separate `Ym7101State` object here for the actual internal data of the VDP because it'll get pretty complicated pretty quickly. I've since broken it into 3 objects, one for the DMA and memory management, one for updating the display, and one to tie it all together and handle the nitty gritty interfacing details, but at this point in the project, it was just two Rust objects.
The system definition now looks like this:
```rust
let mut system = System::new();
let rom = MemoryBlock::load("binaries/genesis/Sonic2.bin").unwrap();
system.add_addressable_device(0x00000000, wrap_transmutable(rom)).unwrap();
let ram = MemoryBlock::new(vec![0; 0x00010000]);
system.add_addressable_device(0x00ff0000, wrap_transmutable(ram)).unwrap();
let coproc_mem = MemoryBlock::new(vec![0; 0x00010000]);
system.add_addressable_device(0x00a00000, wrap_transmutable(coproc_mem)).unwrap();
let controllers = genesis::controllers::GenesisControllers::new();
system.add_addressable_device(0x00a10000, wrap_transmutable(controllers)).unwrap();
let coproc = genesis::coproc_memory::CoprocessorControl::new();
system.add_addressable_device(0x00a11000, wrap_transmutable(coproc)).unwrap();
let vdp = genesis::ym7101::Ym7101::new();
system.add_addressable_device(0x00c00000, wrap_transmutable(vdp)).unwrap();
let mut cpu = M68k::new(M68kType::MC68000, 7_670_454);
system.add_device("cpu", wrap_transmutable(cpu)).unwrap();
Ok(system)
```
The ROM still gets stuck in a loop after a certain point, probably because the VDP's interrupts are not yet implemented, but it gets much farther than before now that the CoprocessorControl object is responding as the ROM expects.
After putting some print statements into the VDP read and write functions to get a sense of what's going on, I get the following log messages:
```
genesis_controller: read from register 9 the value 0
genesis_controller: read from register b the value 0
genesis_controller: read from register d the value 0
genesis_controller: read from register 1 the value a0
ym7101: control port read 2 bytes from 4 with [0, 0]
ym7101: control port write 2 bytes to 4 with [128, 4]
ym7101: control port write 2 bytes to 4 with [129, 20]
ym7101: control port write 2 bytes to 4 with [130, 48]
ym7101: control port write 2 bytes to 4 with [131, 60]
ym7101: control port write 2 bytes to 4 with [132, 7]
ym7101: control port write 2 bytes to 4 with [133, 108]
ym7101: control port write 2 bytes to 4 with [134, 0]
ym7101: control port write 2 bytes to 4 with [135, 0]
ym7101: control port write 2 bytes to 4 with [136, 0]
ym7101: control port write 2 bytes to 4 with [137, 0]
ym7101: control port write 2 bytes to 4 with [138, 255]
ym7101: control port write 2 bytes to 4 with [139, 0]
ym7101: control port write 2 bytes to 4 with [140, 129]
ym7101: control port write 2 bytes to 4 with [141, 55]
ym7101: control port write 2 bytes to 4 with [142, 0]
ym7101: control port write 2 bytes to 4 with [143, 1]
ym7101: control port write 2 bytes to 4 with [144, 1]
ym7101: control port write 2 bytes to 4 with [145, 0]
ym7101: control port write 2 bytes to 4 with [146, 0]
ym7101: control port write 2 bytes to 4 with [147, 255]
ym7101: control port write 2 bytes to 4 with [148, 255]
ym7101: control port write 2 bytes to 4 with [149, 0]
ym7101: control port write 2 bytes to 4 with [150, 0]
ym7101: control port write 2 bytes to 4 with [151, 128]
ym7101: control port write 2 bytes to 4 with [64, 0]
ym7101: control port write 2 bytes to 6 with [0, 128]
ym7101: data port write 2 bytes to 0 with [0, 0]
coprocessor: write to register 100 with 1
coprocessor: write to register 200 with 1
coprocessor: read from register 100 of [0]
coprocessor: write to register 200 with 0
coprocessor: write to register 100 with 0
coprocessor: write to register 200 with 1
ym7101: write 2 bytes to port 4 with data [129, 4]
ym7101: write 2 bytes to port 6 with data [143, 2]
ym7101: write 2 bytes to port 4 with data [192, 0]
ym7101: write 2 bytes to port 6 with data [0, 0]
ym7101: write 2 bytes to port 0 with data [0, 0]
...
```
There's more output than this but it eventually stops after a few seconds of running. The controllers are accessed first, followed by a bunch of activity trying to talk to the VDP. The coprocessor is reset, and then the VDP is accessed again and data is directly written to it. It continues for another 200 or so lines after what's shown here. It's mainly the VDP that needs to do something at this point, in order to get further in the ROM's execution.
Memory and DMA
--------------
It's time to get into the details of the VDP, and the natural first place to start is with getting data into the VDP's various memory areas. It uses its own memory exclusively to generate the display output, so data needs to be loaded before anything can be displayed. As I already mentioned above, there are three different memory areas that are directly accessible only by the VDP: VRAM, CRAM, and VSRAM. CRAM and VSRAM are very small, but VRAM is much larger (64KB, the same size as main memory), and is used for most of the VDP's functions.
In addition, the CPU and VDP can both directly access main memory, as long as the other is not accessing it at the same time. In hardware, this is handled through bus arbitration. The VDP can assert the bus request signal, which when active will cause the CPU to temporarily suspend what it's doing, disconnect from the memory bus, and assert an acknowledge signal to tell the VDP it can use the bus. The VDP is then free to access main memory until it de-asserts the bus request signal.
<p align="center">
<img src="https://jabberwocky.ca/posts/images/2022-01/sega-genesis-block-diagram.png" title="Block Diagram showing VDP connections" />
</p>
The green arrows show that the CPU can make a memory request to the VDP or to main RAM, and the VDP can also make a memory request to main RAM, but only the VDP interface logic can access CRAM, VSRAM, or VRAM.
The only reason the VDP needs to access main memory is to perform a direct memory access (DMA) operation, which will copy some contents of main memory into a VDP memory area without using the CPU. This direct copying is much faster than if the CPU were to alternate between reading data from RAM and writing it to the VDP's memory-mapped I/O ports. It is however possible to also write data through the CPU, which is used when only a little bit of data needs to be sent. There is more overhead required in order to set up a DMA transfer than a CPU transfer, and that might not always be worth the extra cycles, just to transfer a few words.
Talking To The VDP
------------------
To access the VDP from the 68000, the address range from [0xc00000 to 0xc00020](https://segaretro.org/Sega_Mega_Drive/VDP_general_usage) is used to read and write to different VDP "ports" (distinct from the VDP "registers"). Each port is 16-bits wide and most are mapped to multiple adjacent addresses. The data port for example, at address `0xc00000` is also mirrored at `0xc00002` so writing a word to either location has the same effect.
Only two ports are really important for most VDP functions: the data port and the control port. The control port is used to both set the internal register values of the VDP, as well as to set up memory operations. The data port only used to send data to a VDP memory area from the CPU, rather than through a DMA transfer.
To set a register, the upper most two bits of the 16-bit word written to the control port must be `0b10`. The rest of the upper byte will have the register number (0x00 to 0x17) and the lower byte will have the new value to load into the register. The other control words written to the control port (as part of a transfer setup) are guaranteed to never contain `0b10` as the upper two bits, so these bits can be used to distinguish between the two types of requests.
To set up a memory operation, two words must be written to the control port. The first word contains almost the entire 16-bit destination address for the operation, minus the two most significant bits. The upper two most bits are actually part of the operation mode number, and exchanging them with the lower two bits of the second word will give the full destination address in the first word. The control bits in the second word need to be shifted down two bits, and ORed with the two bits from the first word to get a 6-bit operation mode which determines the transfer type. The operation mode specifies if DMA should be used or not, whether to read or write data, and which of the three memory areas to target. A DMA request requires more info than provided, which must be written to the appropriate registers before the transfer request is sent to the control port.
So in the `write()` method of the `Addressable` trait from the previous section, I need something like this:
```rust
debug!("{}: write {} bytes to port {:x} with data {:?}", DEV_NAME, data.len(), addr, data);
let value = read_beu16(data);
if (value & 0xC000) == 0x8000 {
self.regs[((data & 0x1F00) >> 8) as usize] = (data & 0x00FF) as u8;
} else {
match self.state.ctrl_port_buffer {
None => {
self.state.ctrl_port_buffer = Some(value)
},
Some(first) => {
let second = value;
self.state.ctrl_port_buffer = None;
self.transfer_type = ((((first & 0xC000) >> 14) | ((second & 0x00F0) >> 2))) as u8;
self.transfer_addr = ((first & 0x3FFF) | ((second & 0x0003) << 14)) as u32;
debug!("{}: transfer requested of type {:x} to address {:x}", DEV_NAME, self.transfer_type, self.transfer_addr);
},
}
}
```
Hmmm... when I run it I get the following log message, but not the log message that a transfer was requested.
```
ym7101: write 4 bytes to port 4 with data [0x40, 0x00, 0x00, 0x80]
```
The CPU is writing 4 bytes at once. Oh right! Of course it is. The CPU implementation is using the helper functions to read and write 4 bytes at once when an instruction accesses a long word. The ROM is using a single `movel` instruction to write both words of the transfer setup rather than using two instructions. This is also why the VDP's data and control ports are mirrored at the adjacent addresses, because in hardware, the CPU would write a word to the first address, and then write a second word to that address plus two.
Digging around in the logs shows that the same thing is actually being done with register assignments as well. Two register assignments can be put into a single instruction like `movel #0x80048114, (%a4)`, where `%a4` contains the address of the control port `0xC00004`. That would set both VDP register 0 to 0x04, and VDP register 1 to 0x14.
For now, I'll just modify the `.write()` function to allow long word accesses:
```rust
let value = read_beu16(data);
if (value & 0xC000) == 0x8000 {
self.state.set_register(value);
if data.len() == 4 {
let value = read_beu16(&data[2..]);
if (value & 0xC000) != 0x8000 {
return Err(Error::new(&format!("{}: unexpected second byte {:x}", DEV_NAME, value)));
}
self.state.set_register(value);
}
} else {
match (data.len(), self.state.ctrl_port_buffer) {
(2, None) => { self.state.ctrl_port_buffer = Some(value) },
(2, Some(upper)) => self.state.setup_transfer(upper, read_beu16(data)),
(4, None) => self.state.setup_transfer(value, read_beu16(&data[2..])),
_ => { error!("{}: !!! error when writing to control port with {} bytes of {:?}", DEV_NAME, data.len(), data); },
}
}
```
It's a bit clumsy but it works for testing. I eventually added a mechanism called `BusPort` which simulates the CPU's connection to the `Bus` object in `System`. The `BusPort` is created when the CPU object is created, and it's stored in the CPU object. The CPU will then use it for all read and write operations to more accurately simulate the bus. Any read or write call on `BusPort` will be broken into multiple operations if necessary in order to fit the given data bus size, and the address will be masked to the given address bus size. This will also fix the issue with 24-bit addressing on the 68000. At the same time, it's possible to configure a CPU as a 68030 with a 32-bit address and data bus, which I intend to use for future Computie hardware revisions, and possibly other systems.
Implementing The Memory Ops
---------------------------
Now that the `Addressable` implementation can receive the control port transfer setup, it's time to actually implement the transfer operations, both through the data port and through DMA. For a manual transfer, once configured, data can either be read from or written to the data port. After each memory operation, the destination address will be increment by the value stored in the auto increment register of the VDP (register `0x0f`). It doesn't matter what size the operation was; the address will always be incremented by that value, so it must be set correctly.
A DMA transfer, on the other hand, takes place as soon as the second transfer configuration word is written to the control port, assuming the DMA enable bit is set in the Mode2 register (`0x01`). In hardware, the VDP would assert the bus request signal to tell the CPU to disconnect from the memory bus while the VDP directly accesses the main RAM to copy data into its VRAM. Once the operation is complete, the VDP would de-assert the bus request signal and the CPU would continue where it left off. I cheated a bit by simply performing the complete operation in one call to the `.step()` function, rather than simulating the time it would take. It's worked fine so far.
In order to perform a DMA transfer, there are two additional values that are needed. The source address in RAM where the data to copy is located, and the amount of data to be copied. These values are stored across 5 different 8-bit registers in the VDP, which must be set before configuring the transfer through the control port. The count value is split across registers `0x13` and `0x14`, each containing half of the 16-bit count. The source address is split across registers `0x15` to `0x17` where the address is shifted to the right one bit, since the address must start on an even byte address (ie. bit 0 must always be zero, so it's not even stored in the register). The upper two bits of register `0x17`, which is the high part of the address, specifies whether the operation is a transfer, copy, or fill. See [VDP Registers](https://wiki.megadrive.org/index.php?title=VDP_Registers#0x17_-_DMA_source_address_high) for details.
To make the code easier to understand, I made a simple enum called `DmaType` to hold the type of operation, or `DmaType::None` if there is no operation pending. The addresses and counts are assembled from the register values when the transfer is set up through the control port.
The following code was then added to the VDP's `.step()` function. The transfer operation type is selected by the `self.transfer_run` value. Each type has its own loop which iterates until the remaining count is 0. The destination address is incremented by the value of the auto increment register (`0x0f`) after each iteration, just like a manual transfer. The `DmaType::Memory` operation is a bit more involved since it must use the system bus to read data. In order to reuse the same loop for each of the three target memory areas, the `.get_transfer_target_mut()` function returns a slice of the appropriate memory area.
```rust
match self.transfer_run {
DmaType::None => { /* Do Nothing */ },
DmaType::Memory => {
info!("{}: starting dma transfer {:x} from Mem:{:x} to {:?}:{:x} ({} bytes)", DEV_NAME, self.transfer_type, self.transfer_src_addr, self.transfer_target, self.transfer_dest_addr, self.transfer_remain);
let mut bus = system.get_bus();
while self.transfer_remain > 0 {
let mut data = [0; 2];
bus.read(self.transfer_src_addr as Address, &mut data)?;
let addr = self.transfer_dest_addr as usize;
let target = self.get_transfer_target_mut();
target[addr % target.len()] = data[0];
target[(addr + 1) % target.len()] = data[1];
self.transfer_dest_addr += self.transfer_auto_inc;
self.transfer_src_addr += 2;
self.transfer_remain -= 2;
}
},
DmaType::Copy => {
info!("{}: starting dma copy from VRAM:{:x} to VRAM:{:x} ({} bytes)", DEV_NAME, self.transfer_src_addr, self.transfer_dest_addr, self.transfer_remain);
while self.transfer_remain > 0 {
self.vram[self.transfer_dest_addr as usize] = self.vram[self.transfer_src_addr as usize];
self.transfer_dest_addr += self.transfer_auto_inc;
self.transfer_src_addr += 1;
self.transfer_remain -= 1;
}
},
DmaType::Fill => {
info!("{}: starting dma fill to VRAM:{:x} ({} bytes) with {:x}", DEV_NAME, self.transfer_dest_addr, self.transfer_remain, self.transfer_fill_word);
while self.transfer_remain > 0 {
self.vram[self.transfer_dest_addr as usize] = self.transfer_fill_word as u8;
self.transfer_dest_addr += self.transfer_auto_inc;
self.transfer_remain -= 1;
}
},
}
// Reset the mode after a transfer has completed
self.set_dma_mode(DmaType::None);
```
Note: this code includes a bug that I'll fix in Part III. Bonus points if you can spot it
The helper function `.set_dma_mode()` is used to also control the DMA busy flag in the VDP's status word, which is returned when reading from VDP's control port (instead of writing). It's probably not that important since the CPU technically shouldn't be running when a DMA is in progress, but I threw it in for completeness.
```rust
pub fn set_dma_mode(&mut self, mode: DmaType) {
match mode {
DmaType::None => {
self.status &= !STATUS_DMA_BUSY;
self.transfer_run = DmaType::None;
},
_ => {
self.status |= STATUS_DMA_BUSY;
self.transfer_run = mode;
},
}
}
```
Phew! That was a lot of boring bits, but it's done now. Testing is another matter, but without a reference to compare it to, it's hard to find problems without the display output. It will get more interesting soon.
Next Time
---------
By this point I had only been working on the Genesis support for about a week, while also working on other parts of the emulator. The time spent on the Genesis was mostly reading up on how it worked. I was flying through everything, making great progress, and having a lot of fun at the same time.
The CPU to VDP interface was pretty much implemented and I could get data into the VDP registers and memory areas. The next step was to use that data to generate an image and send it to some kind of window on the local machine. That's an entire post's worth of effort, so... I'll make another post! Click [Part II](https://dev.to/transistorfet/emulating-the-sega-genesis-part-ii-16k7) to continue
| transistorfet |
949,953 | Trunk-based Development Can Help | The DevOps Handbook tells using trunk-based development can improve the efficiency of developing... | 0 | 2022-01-10T01:20:42 | https://dev.to/lazypro/trunk-based-development-2led | github, productivity, devops, git | [The DevOps Handbook](https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002) tells using trunk-based development can improve the efficiency of developing software. Thus, what is the magic of trunk-based development make us to abandon our familiar git-related workflow?
## Git workflow
It should start from the git-related workflow. Whether it is `git workflow`, `github workflow` or even `gitlab workflow`, in general, the entire development process is completed by using feature branches, development branches, and main branches. However, from this point of view, we find that to complete a feature development, at least three branches are involved. Each branch have to be merged into another branch. In addition to resolving conflicts during the merge, when to merge is also important.
Engineers in the same team must be fully aware of the status of each branch, which not only brings cognitive load, but also brings management troubles. Besides, when many major functions are developed, the online code base will be very different from the code under development. Therefore, these several workflows tell us to divide a feature into some small changes and continue to integrate them.

The above figure is a typical `gitlab workflow`. It is not difficult to see that it is very complicated. There are many interactions between various branches, and there are many rules to be followed. Of course, with these rules, comes many restrictions.
## Trunk-based workflow
[Extreme Programming Explained](https://www.amazon.com/Extreme-Programming-Explained-Embrace-Change/dp/0321278658) advocates getting feedback as soon as possible. Instead of testing slowly in the test environment and staging environment, it is better to go directly to the production to receive faster results. Since git-related workflows have already suggested small changes and continuous integration, why not just take away those branches with many management burdens, leaving only one branch: the main branch?
> This is the spirit of trunk-based development. There is only one trunk branch. All features are branched from this branch and continuously merged back into the trunk. The online environment is based on this trunk branch and is the continuous deployment.
In fact, there are many problems to be executed in this most ideal way. After all, no one wants to destroy the formal environment because of a small change, so there are still various test environments. At this time, it is still necessary to have a mechanism to correspond the trunk to each test environment. In practice, the most commonly used method that will not violate the spirit of trunk-based is to use tags on the trunk branch to identify the version. If there are urgent bugs that must be dealt with, a hotfix branch must still be generated from the tag. Nevertheless, unlike git workflow, this hotfix branch that belongs to a specific tag has its life cycle. When the next tag is released in the environment that originally used this tag, this hotfix branch should be eliminated.
Therefore, although there will be release branches or hotfix branches that branch from the main trunk, these two types of branches will not return to the main trunk. In other words, all fixes first enter the main branch and then enter the hotfix branch through cherry-pick. This produces a benefit, the environment that is released after the hotfix can immediately receive the effects of the hotfix.
The workflow is as follows.

## Conclusion
In order to drive this development process well, we must have some "good" practices, and the most frequently mentioned is the feature toggle. Because all submitted pieces have to enter the main trunk and will be released at any time, it is necessary to be able to isolate and conditionally control the testing scope for unprepared code. Feature toggle benefits this need.
On the other hand, if it is a very efficient development team, there is no need to have a release branch or a hotfix branch, i.e., online problems can be solved in a forward fix. That is to say the entire software system must have complete telemetries and monitoring systems to find out the online defects faster.
All these good practices are described in The DevOps Handbook, and I really recommend this book.
We can regard trunk-based development as the holy grail of the software development. You must have many good practices in order to be able to use well. Once applying the trunk-based development, it will not only reduce the complexities of managing branches and environments but also reduce the overhead of every engineer, e.g., merging.
Recently, The team I lead has introduced feature toggle and began to experience the benefits of trunk-based development. For a two-pizza team, it can indeed greatly increase the productivity. | lazypro |
949,969 | Four Questions to Consider when Starting your API Testing Journey | In today’s API economy, it has become more critical than ever for API-first companies to spend time... | 0 | 2022-01-10T03:48:58 | https://dev.to/postman/four-things-to-consider-when-starting-your-api-testing-journey-3873 | testing, beginners | In today’s API economy, it has become more critical than ever for [API-first companies](https://blog.postman.com/how-do-you-become-api-first-company/) to spend time strategizing on how to deliver the best products in the marketplace.
APIs are the connective tissue between applications, servers, and data. Companies now treat them more as a marketable product rather than just a technical interface. With that said, it can be a daunting task for both developers and testers alike to create a plan that ensures the highest quality. But have no fear! I like to think of this process as a journey. With that perspective in mind, here are four questions that would be useful to consider when testing your APIs.
## Am I using the right tool ?
Before starting any journey, one of the most important aspects to consider is what tools you will need to make your trip a success? Perhaps you will need a car, possibly some compact luggage; however, when it comes to API testing, you will need a tool that allows you to send API requests and view the correct response effectively.
[Postman](https://www.postman.com/) is the ideal tool for the job. It is a collaborative API development platform that simplifies creating, using, and testing APIs with an intuitive user interface.
<figcaption><a href="https://developer.ibm.com/callforcode/">Send Requests with Postman</a></figcaption>
A few of the many advantages of the tool include :
- **Ease of Use** - Postman users can begin their API journey quickly and effectively using Postman’s comprehensive platform and broad support for all possible HTTP methods and queries such as REST, SOAP, and GraphQL.
- **Robust testing capabilities -** Postman supports multiple testing environments, test checkpoints, automated scripting, and built-in support for using variables for security. It also has support for keeping track of API responses which is critical for testers when it comes down to debugging, comparing versions, and managing inconsistencies.
- **Management and Collaboration** - Postman Workspace allows users to manage versions, authentication protocols, cookies, and certificates. It is also dedicated to the real-time collaboration between teams with built-in version control, ensuring developers and testers can stay on the same page when testing version releases.
Once you use the right tool, you can consider the following three questions.
## How do I start and what is my road map ?
When a new API is ready to test, the first test that you should consider is a smoke test. A smoke test is a small quick test that ensures that the basic functionality of the API is working.
This test includes :
- Checking to see if API responds to first call
- Testing API with small amounts of data to see if it responds with a payload in the correct schema
- Testing API with proper authentication and seeing if it passes/fails to the valid authorization
- Testing API with any other components that it’s supposed to interact with.
A smoke test is used to smoke out any apparent errors quickly spotted and resolved.
Once your smoke tests pass, it is time for you to create the correct road map. This road map can be defined by ensuring that you can hit all possible functionalities successfully. Usually, you can map out this strategy by considering HTTP methods and CRUD operations.

Some of the tests that can be included in your road map :
- **Functionality Tests -** test of specific functions within the codebase
- **Validation Tests -** tests to verify aspects of API its behavior, and efficiency
- **Sanity Tests -** tests to verify if response makes correct sense
- **Integration Tests -** tests to verify API can integrate with other components
- **Load Tests -** tests to validate the performance under specific load requirements
- **Runtime Tests -** tests related to monitoring, execution errors, resource leaks, or error detection
- **Security Tests -** tests to verify authorization and validation of encryption methodologies to enable security from external threats
Once you have strategized which types of tests you will include in your road map, you can also consider making testing easier through automation. Automation can allow you to do **regression testing**, allowing you to run your entire test suite after a patch, upgrade, or bug fix. Postman is also an excellent tool for all things API automation; check out this blog: [API Testing Tips from a Postman Professional](https://blog.postman.com/api-testing-tips-from-a-postman-professional/) to learn more.
## What is the Happy Path and the Not -So-Happy Path ?
We may often think that if an API does what it is supposed to do, then it works perfectly. This is only the Happy Path piece of the puzzle when it comes to testing. The other piece is negative testing which is equally essential for ensuring quality.
By performing negative testing, you can see whether or not their API can deal with receiving incorrect or invalid data gracefully, such as with an error message instead of a hard crash or a complete stop.
This blog: [Negative testing for more resilient APIs](https://medium.com/better-practices/negative-testing-for-more-resilient-apis-af904a74d32b) provides notable examples for negative testing, which I recommend you check out! Ideally, you would want to test for all API success and failure responses. Check out this [comprehensive list](https://restfulapi.net/http-status-codes/) to learn more.
As you go about your testing journey, you may wonder how you can validate your positive and negative responses. Postman has functionality for creating test scripts, which genuinely helps testers level up their validation game.

## Do these tests closely mirror the real world ?
The final factor to consider is testing in environments that simulate exact conditions the API will encounter in production or when it is released. Doing so will ensure that the test results accurately reflect the API’s ability to correctly function and perform when subjected to its intended working environment.
However, there may come a time when specific components or other APIs may be missing or unavailable. Simulating a real-world environment may rely on [mocking components](https://learning.postman.com/docs/designing-and-developing-your-api/mocking-data/setting-up-mock/) in this scenario. Mocking components is helpful because you can replace missing parts and customize features to deliver the ideal responses needed to complete the testing procedure.
Learn more about [mock servers here](https://blog.postman.com/team-collaboration-with-postman-mock-servers/)
Although API testing can be a daunting process, I hope that after reading this blog, these four questions help you get a head start on your API testing journey. If you are interested in learning more about Postman, check out the [learning center](https://learning.postman.com/docs/getting-started/introduction/)! In the meantime, know that every big journey begins with small steps - API testing included.
| poojamakes |
950,051 | 5 Best Free NumPy Courses and Tutorials for Python Programmers in 2024 | My favorite online courses to learn NumPy for Python programmers and Data Scientists. | 0 | 2022-01-11T05:44:04 | https://dev.to/javinpaul/5-best-free-numpy-courses-and-tutorials-for-python-programmers-in-2022-11ip | python, datascience, numpy, machinelearning | ---
title: 5 Best Free NumPy Courses and Tutorials for Python Programmers in 2024
published: true
description: My favorite online courses to learn NumPy for Python programmers and Data Scientists.
tags: python, datascience, numpy, machinelearning
//cover_image: https://direct_url_to_image.jpg
---
*Disclosure: This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article*
[](https://www.educative.io/courses/from-python-to-numpy?affiliate_id=5073518643380224)
Hello folks, if you are learning Data Science or Machine Learning then you may be aware of NumPy, one of the popular Python libraries for scientific calculation in Python.
A good knowledge of Numpy is essential for Data Scientists and Machine Learning engineers and if you want to learn NumPy library then you have come to the right place.
Earlier, I shared the [best free deep learning courses](https://www.java67.com/2019/01/5-free-courses-to-learn-machine-and-deep-learning-in-2019.html) and in this article, I am going to share the best free courses to learn NumPy in 2024.
The popularity of the [python programming language](https://www.java67.com/2020/05/top-5-courses-to-learn-python-in-depth.html) is enormous due to its architecture that can support all operating systems Windows, Linux, macOS, and even phones, and also the significant number of its libraries.
Python has many libraries covering different domains you can use Python libraries for creating artificial intelligence models or building web applications using [Django](https://www.java67.com/2020/06/top-5-courses-to-learn-django-and-python-for-web-development.html) and [Flask](https://javarevisited.blogspot.com/2020/01/top-5-courses-to-learn-flask-for-web-development-with-python.html) or even for data analysis to make complex data visualization.
One of the most used libraries and must know called [Numpy](https://numpy.org/doc/stable/user/whatisnumpy.html), this library used in almost every field you can think of like deep learning, machine learning, data science and is used for mathematical calculation and working with arrays and its speed for processing this calculation makes it the preferred one for this task.
Numpy provides support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays which are quite important for Data Scientists.
When it comes to learning NumPy there are many [paid courses](https://javarevisited.blogspot.com/2021/10/top-5-courses-to-learn-numpy-for-python.html), but we are focusing on the FREE courses if you are still a beginner and want to get familiar with using them in your projects.
These are the best free online courses you can join to learn NumPy for Data Science and Machine Learning. It's created by experts and trusted by thousands of developers worldwide, all of them also have 4 start ratings of higher and then are legal free courses, made free by their instructor for learning and education purposes.
Btw, if you need a paid course then you should definitely checkout [Deep Learning Prerequisites: The Numpy Stack in Python (V2+)](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fdeep-learning-prerequisites-the-numpy-stack-in-python%2F&u1=JAVAREVISITED) course by Lazy Programmers Inc, one of my favorite instructors for Deep learning on Udemy.
[]((https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fdeep-learning-prerequisites-the-numpy-stack-in-python%2F&u1=JAVAREVISITED))
-------
## 5 Best Free Courses and Tutorials to Learn NumPy in 2024
Without wasting any more of your time, here is my list of the best free online courses Python developers and Data scientists can join to learn the NumPy library in 2024.
These free courses and tutorials have been taken from sites like Udemy, Coursera, freeCodecamp, and other popular online learning platforms. They are also absolutely free but you may need to create your free account to join these courses.
### 1\. [Learn NumPy Fundamentals](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fpython-numpy-fundamentals%2F&u1=JAVAREVISITED)
If you've never touched Python before, meaning no prior experience, and you want to learn NumPy as well as the first library after understanding this programming language, then you can jump right away into this course that will teach you how to use NumPy and many of its algorithms with a small crash course of python.
Starting with a NumPy overview and how it works and downloading the package. You will then directly start creating arrays and apply reshaping and indexing to them.
Later you will learn some of the advanced indexing, and array math applied functions to our NumPy arrays and more. Finally, a small crash course for people with no Python knowledge can skip it if you already know how to work with this language.
Here is the link to join this free course - [Learn NumPy Fundamentals](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fpython-numpy-fundamentals%2F&u1=JAVAREVISITED)
[](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fpython-numpy-fundamentals%2F&u1=JAVAREVISITED)
--------
### 2\. [NumPy for Data Science](https://click.linksynergy.com/deeplink?id=CuIbQrBnhiw&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fnumpyfords%2F&u1=JAVAREVISITED) [FREE]
Another cool introductory course talking about NumPy is NumPy for data science. It requires people to understand the Python language to get their hands on the NumPy package. The course has a quiz in every section to verify your knowledge while learning.
Get familiar with data science and learn how to start working with the NumPy library. Then you start importing and using the NumPy library for making simple arrays and NumPy arrays, and how to generate different array formats like 1-D and 2-D NumPy arrays.
You will exploit different functions used in the NumPy library for arrays. Finally, you will go through the indexing and selection of values in NumPy arrays and save the file in binary format.
Here is the link to join this free course - [NumPy for Data Science](https://click.linksynergy.com/deeplink?id=CuIbQrBnhiw&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fnumpyfords%2F&u1=JAVAREVISITED)
[](https://click.linksynergy.com/deeplink?id=CuIbQrBnhiw&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fnumpyfords%2F&u1=JAVAREVISITED)
-------
### 3\. [Python Basics for Math and Data Science 1.0: Numpy and Sympy ](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fpython-numpy-sympy%2F&u1=JAVAREVISITED) [Free]
The cool thing I learned in this course is that you can learn to perform mathematical calculations using NumPy and another great library called SymPy for symbolic mathematics.
The free course requires some [basics in Python](https://medium.com/javarevisited/8-advanced-python-programming-courses-for-intermediate-programmer-cc3bd47a4d19) and some math knowledge, and it will be like a small introduction if you want to have a career in data science or machine learning engineer.
Start by installing the libraries, setting up the environment, moving directly to NumPy metrics, and indexing and slicing the NumPy arrays. You will also learn things like accessing a matrix column and seeing some useful functions of NumPy.
Later, you will move to the SymPy library and learn how to solve linear equations with one or two unknowns and solve quadratic equations.
Here is the link to join this free course - [**Python Basics for Math and Data Science 1.0: Numpy and Sympy**](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fpython-numpy-sympy%2F&u1=JAVAREVISITED)
[](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fpython-numpy-sympy%2F&u1=JAVAREVISITED)
--------
### 4\. [NumPy for Numerical Computation](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Flearnpy-numpy%2F&u1=JAVAREVISITED)
Numpy is used in many different fields, so you should have some beginner to intermediate level of using many of its functions.
This course will little bit dive into many of these and try to teach you to fix some of the errors you'll face while using NumPy. All of the code used is very well documented so you understand what every line in meaning.
Starting with an introduction about NumPy as usual and then moving to use dimensions and operations. You will also understand how to reshape your data, apply it to slice, and use functions to perform calculations like the sum, max, min, and more.
Finally, some other advanced mathematical functions like the square root and standard deviation.
Here is the link to join this free course - [**NumPy for Numerical Computation**](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Flearnpy-numpy%2F&u1=JAVAREVISITED)
[](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Flearnpy-numpy%2F&u1=JAVAREVISITED)
------
### 5\. [NumPy for Data Science Beginners](https://click.linksynergy.com/deeplink?id=CuIbQrBnhiw&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fthe-complete-numpy-course-for-data-science%2F&u1=JAVAREVISITED)
For people who want to have a career in data science or machine learning or any field that highly requires an understanding of [math and statistics](https://medium.com/javarevisited/5-best-mathematics-and-statistics-courses-for-data-science-and-machine-learning-programmers-bf4c4f34e288), this course is for you because it focuses on these algorithms and how to perform the different mathematical calculations.
Start with an introduction of NumPy and how to import it inside your project and start directly learning the NumPy array fundamentals and performing indexing & slicing, iteration, understanding data types, and zeros_ones.
Later dive into the [statistics](https://javarevisited.blogspot.com/2019/09/top-5-statistics-and-mathematics-course-for-data-science.html) and matrix, and apply some functions to NumPy arrays like sorting, searching, and joining data. This free course is also available on freecodecamp channel on Youtube.
Here is the link to join this free course - [NumPy for Data Science Beginners](https://click.linksynergy.com/deeplink?id=CuIbQrBnhiw&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fthe-complete-numpy-course-for-data-science%2F&u1=JAVAREVISITED)
[](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fthe-complete-numpy-course-for-data-science%2F&u1=JAVAREVISITED)
That's all about the **best free online courses and Tutorials to learn NumPy for Python developers**. The courses listed above are for people who want to understand the NumPy library and how to perform mathematical calculations.
Still, not a deep dive into more of this library, and most of them require to have some basic understanding of Python, so it is worth learning this language and moving to these courses.
Other **Data Science and Machine Learning** articles you may like
- [Top 5 Courses to Learn Python in 2024](https://javarevisited.blogspot.com/2020/05/top-10-udemy-courses-to-learn-python-programming.html)
- [Best Johns Hopkins Courses to learn Data Science in 2024](https://javarevisited.blogspot.com/2021/05/best-johns-hopkins-courses-for-data-science-coursera.html)
- [Top 5 Essential Machine Learning Algorithms](https://www.java67.com/2020/07/top-5-machine-learning-algorithms-for-beginners.html)
- [Top 10 Coursera Data Science Courses and Certifications](https://javarevisited.blogspot.com/2020/08/top-10-coursera-certifications-to-learn-Data-Science-Visualization-and-Data-Analysis.html)
- [5 Data Science degrees you can earn online](https://www.java67.com/2020/06/top-5-data-science-degree-you-can-earn-online-coursera-edx.html)
- [Top 10 TensorFlow courses for Data Scientist](https://dev.to/javinpaul/10-of-the-best-tensorflow-courses-to-learn-machine-learning-from-coursera-and-udemy-37bf)
- [Top 5 Courses to learn QlikView and QlikSense](https://javarevisited.blogspot.com/2020/07/top-5-courses-to-learn-qlikview-and-qlik-sense.html)
- [10 Reasons to Learn Python for Data Science](https://javarevisited.blogspot.com/2020/05/why-python-is-best-programming-language.html)
- [10 Free Courses to Learn Python for Beginners](https://www.java67.com/2018/02/5-free-python-online-courses-for-beginners.html)
- [Top 5 Courses to learn Power BI in 2024](https://www.java67.com/2020/06/top-5-courses-to-learn-microsoft-power-BI.html)
- [Top 5 Courses to Learn Advance Data Science](https://www.java67.com/2018/10/top-10-data-science-and-machine-learning-courses.html)
- [Top 5 Courses to Learn TensorFlow for Beginners](https://javarevisited.blogspot.com/2018/08/top-5-tensorflow-and-machine-learning-courses-online-programmers.html)
- [Top 5 Free Courses to Learn Machine Learning](https://www.java67.com/2019/01/5-free-courses-to-learn-machine-and-deep-learning-in-2019.html)
- [5 Best Computer Vision Courses for Beginners](https://javarevisited.blogspot.com/2020/09/top-5-computer-vision-and-open-cv-courses-projects.html)
- [5 Books to learn Python for Data Science ](https://javarevisited.blogspot.com/2019/08/top-5-python-books-for-data-science-and-machine-learning.html)
- [Top 5 Courses to Learn Tableau for Data Science](https://javarevisited.blogspot.com/2019/07/top-5-tableau-online-courses-and-certifications-for-data-science-engineers.html)
- [Top 8 Python Libraries for Data Science and Machine Learning](https://javarevisited.blogspot.com/2018/10/top-8-python-libraries-for-data-science-machine-learning.html)
Thanks for reading this article so far. If you like these *best free NumPy online training courses for beginners* then please share them with your friends and colleagues. If you have any questions or feedback, then please drop a note.
**P. S. -** If you are keen to learn NumPy library and Machine learning and don't mind paying a few bucks to learn a valuable skill like this then you can also check out **[Deep Learning Prerequisites: The Numpy Stack in Python (V2+)](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fdeep-learning-prerequisites-the-numpy-stack-in-python%2F&u1=JAVAREVISITED)** course on Udemy. This is a hands-on course, full of exercises and practical examples for Scikit Learn.
| javinpaul |
950,263 | New in CSS | Declare Variable :root { --global--primary-color: #29313e; } a { color:... | 0 | 2022-01-10T10:09:13 | https://dev.to/sibaram-sahu/new-in-css-2b1p | css, webdev, design | ## Declare Variable
``` css
:root {
--global--primary-color: #29313e;
}
a {
color: var(--global--primary-color);
}
```
## @Supports
It allows you to do the same depending on what CSS properties and values the user browser supports.
```css
@supports (display: grid) {
.main-content {
display: grid;
}
}
```
## content-visibility
It is a really cool new CSS feature to improve site performance. It basically works like lazy loading, only not for images but any HTML element. You can use it to keep any part of your site from loading until it becomes visible.
```css
.sec-viewport {
content-visibility: auto;
}
```
## Scroll Snap
Scroll snapping gives you the option to lock the user’s viewport to a certain parts or element of your site.
```css
.container {
scroll-snap-type: y mandatory;
}
```
## :is and :where
It allow you to reduce repetition in CSS markup by shortening lists of CSS selectors.
```css
/* Before */
.main a:hover,
.sidebar a:hover,
.site-footer a:hover {
/* markup goes here */
}
```
```css
/* After */
:is(.main, .sidebar, .site-footer) a:hover {
/* markup goes here */
}
:where(.main, .sidebar, .site-footer) a:hover {
/* markup goes here */
}
```
| sibaram-sahu |
950,552 | Installing Pipx on Ubuntu | I recently paired up with another dev running windows with Ubuntu running in wsl, and we had a bit of... | 16,020 | 2022-01-10T14:56:00 | https://waylonwalker.com/til/installing-pipx-on-ubuntu/ | python, linux, cli | ---
canonical_url: https://waylonwalker.com/til/installing-pipx-on-ubuntu/
cover_image: https://images.waylonwalker.com/til/installing-pipx-on-ubuntu.png
published: true
tags:
- python
- linux
- cli
series: til
title: Installing Pipx on Ubuntu
---
I recently paired up with another dev running windows with Ubuntu running in wsl, and we had a bit of a stuggle to get our project off the ground because they were missing com system dependencies to get going.
## Straight in the terminal
Open up a terminal and get your required system dependencies using the apt package manager and the standard ubuntu repos.
``` bash
sudo apt update sudo apt upgrade sudo apt install \
python3-dev \
python3-pip \
python3-venv \
python3-virtualenv
pip install pipx
```
## Using an Ansible-Playbook
I like running things like this through an ansible-playbook as it give me some extra control and repeatability next time I have a new machine to setup.
``` yaml
- hosts: localhost
gather_facts: true
become: true
become_user: "{{ lookup('env', 'USER') }}"
pre_tasks:
- name: update repositories
apt: update_cache=yes
become_user: root
changed_when: False
vars:
user: "{{ ansible_user_id }}"
tasks:
- name: Install System Packages 1 (terminal)
become_user: root
apt:
name:
- build-essential
- python3-dev
- python3-pip
- python3-venv
- python3-virtualenv
- name: check is pipx installed
shell: command -v pipx
register: pipx_exists
ignore_errors: yes
- name: pipx
when: pipx_exists is failed
pip:
name: pipx
tags:
- pipx
```
## video clip
Here is a clip of me getting pipx running on ubuntu 21.10, and running a few of my favorite pipx commands.
<video autoplay="" controls="" loop="true" muted="" playsinline="" width="100%">
<source src="https://images.waylonwalker.com/pipx-install-ubuntu.webm" type="video/webm">
<source src="https://images.waylonwalker.com/pipx-install-ubuntu.mp4" type="video/mp4">
Sorry, your browser doesn't support embedded videos.
</video> | waylonwalker |
950,882 | How to Create An Amazing Live Stream Website Like Twitch? | Which would you prefer: watch a movie or read a book? Most of us would choose the first option, as a... | 0 | 2022-03-23T10:06:54 | https://terasol.medium.com/how-to-create-an-amazing-live-stream-website-like-twitch-178866f9d879 | videostreamingsite, createstreamingplatf, streamingvideo, livestreamwebsite | ---
title: How to Create An Amazing Live Stream Website Like Twitch?
published: true
date: 2022-01-10 17:32:07 UTC
tags: videostreamingsite,createstreamingplatf,streamingvideo,livestreamwebsite
canonical_url: https://terasol.medium.com/how-to-create-an-amazing-live-stream-website-like-twitch-178866f9d879
---
**Which would you prefer: watch a movie or read a book?**
Most of us would choose the first option, as a video is more entertaining and memorable than text.
It’s a well-known truth that the human mind understands visuals better than audio or by reading something and that the processing rates are vastly different. It is one of the key reasons why people prefer watching videos to reading or listening to audio podcasts.
The internet has a massive influence on today’s lifestyle, and individuals are streaming many areas of their lives on the internet. We are subconsciously drawn to these streamings and get more curious about what will happen next.
The business of live streaming is increasing. [Creating video streaming sites](https://terasoltechnologies.com/web-development/) is a profitable business venture that can propel you to the top. Of course, you’ll only be successful if you get it correctly the first time.
Mobile live-streaming apps have become a go-to for many organizations and content creators, from news station updates to brands presenting products on IGTV. Live stream websites or apps enable audiences to see and interact with the material in real-time, making them a valuable tool for business owners and marketers. Twitch, YouTube, and Periscope are three of today’s most popular video streaming site networks.
Let’s begin by examining **why video streaming services are so popular**.
### Why Video Streaming?

The answer is self-evident: we’ve been compelled to transition, at least in part, to the online format in recent years, which means that we can now organize live streaming events of all kinds. Live meetings, webinars, school, and university lessons are all part of it, or whatever else comes to mind!
**So, how do you pick the best niche for your live-streaming site?**
Here are a few cool suggestions:
- Large-scale events, such as conferences and exhibitions. The user does not need to be present at the event; all he needs to do is connect to the live broadcast.
- Other is for video games. Naturally, you’ll have to compete with Twitch, but that’s okay;
- Sports activities and games are broadcast on television;
- Personal channels for users to broadcast whatever they desire;
- Corporate channels aimed at business owners.
Because there is a demand, there must also be a supply. And the one who gives it benefits financially.
Before we into ways to create live streaming websites, **let’s see how the video streaming site Twitch works**.

### What Makes Twitch a Popular Streaming Platform?
People have enjoyed game competitions since BC, believe it or not. Surely, the games were substantially different in those early days than they are now (how about a chariot race?).
However, we loved playing games centuries ago and will continue to love them in the future.
[Twitch](https://www.twitch.tv/) is an online video streaming platform that allows users to watch or broadcast live or recorded content.
Twitch users use the site for more than just live-streaming video games:
- Twitch hosts e-tournaments and previews of upcoming games.
- Twitch is used by platform users for video game tutorials, where a large number of people can engage with each other and the teacher in real-time.
- Twitch also serves as a learning environment for software development.
- It also has food and talk shows.
The following revenue sources are included in the Twitch business model:
1. **Cost Per Mile:** Twitch charges game firms, portals, and developers a CPM fee to run advertisements.
2. **Subscription:** Users of Twitch can purchase a membership. Users may view videos without advertisements and enjoy premium Twitch features with a paid subscription.
3. **Partners** : Twitch fans pay for premium memberships to some channels to support their favorite streamers.

### Must-Have Features for Live Stream Website
Now it’s time to look more closely at the features that will go into creating your live stream website. This feature list can be used as the MVP for your live streaming website.
#### 1. User registration:
Allow users to register and log in to your website using their social media accounts. By connecting your streaming website to other social media platforms, you may provide your visitors the option of sharing live stream links with their contacts on social media, which can help you attract additional people.
#### 2. Customization:
A live stream website should have customized features, functionality, monetization models, content distribution, security, and much more. It helps to meet the needs of your live streaming business model.
#### 3. Video Library:
You’ll need a complete video library to build a video-streaming software like Twitch. It allows viewers to look through the content and watch the videos they want. Make sure that the video library has easy-to-use search and navigation features.
#### 4. Instant Chat:
Instant Chat is an important tool for linking viewers with gamers or content creators. Most users like instant chat because it allows them to perform a variety of things online, such as ask questions, exchange feedback, and show support for content creators they enjoy. For quick chat functionality, integrating a third-party chat solution inside your app can be the ideal choice.
#### 5. Monetization:
Any site that wants to make money needs to have a monetization option. Live stream websites need to have features like a built-in payment system that allows subscribers to pay, see premium content, donate, and purchase products. To provide a faultless payment system to users, it is vital to have different payment options as well as a secure payment gateway.
#### 6. DRM & Safety:
Secure your live video streaming site or app with multi-tiered security methods like AES encryption, DRM, and IP-based access control, which can help you avoid data breaches with your video assets.
#### 7. Schedule and Notifications:
One of the unique characteristics of live streaming is that it can be spontaneous or planned. With a streaming schedule, a live streaming app will improve the user experience.
#### 8. Streaming with Adaptive Bitrates:
Adaptive bitrate streaming improves the viewing experience of live material on all devices, regardless of connection or network range.
#### 9. HLS-created Player:
With the quickest playback, 360-degree video compatibility, third-party interactive capabilities, UI/UX extension, stylish bars, offline viewing, and more, an enterprise HLS video player can offer an attractive content viewing experience. Skin assets, images, descriptions, search phrases, and other playback features are also included in the player.
#### 10. Analytics in Real-Time:
Within the live streaming platform, you can efficiently track, monitor, and report on your audience’s every move. Real-time analytics assist in identifying the best content watched and engaged so that actionable decisions can be made. Viewer-level metrics, audience behavior, traffic sources, and the geographic location of each audience should all be kept in mind.
#### 11. Option to Host Other Streamers:
Twitch has released a revolutionary new feature that can benefit both established and emerging streamers. You can also add it to your list of things to do if you want to make a live streaming app for your company. When streamers are not actively streaming, they can host feeds from other users on their channels. Famous streamers frequently demand money for this type of promotion, thus this function is another opportunity to monetize.
Now, let’s go over the precise actions you’ll need to do to create your live video streaming platform.
### Let’s Create a Streaming Platform

Here is a step-by-step process of [live streaming web development](https://terasoltechnologies.com/web-development/).
#### 1. Set a vision for the company
Identify what you want your possible live streaming platform to be based on your objectives. You’ll be able to offer your company a clear focus and prevent going on the wrong route this way. Thus, you must investigate your competition and select a niche.
#### 2. The phase of discovery or inception
You and your development team will write a Functional specification that describes your website’s core logic, feature list, and so on.
#### 3. Determine Technology Stack
Now you must choose a platform for your live streaming website as well as third-party services to incorporate. The following is a list of technologies that could be utilized to create a live streaming app.
- Swift, Kotlin, and Java are programming languages.
- Cloudflare/Amazon is a content delivery network.
- Amazon EC2, CloudFront Hosting
- Node.js is the API server.
- WebRTC and RTMP are two streaming protocols.
- MySQL and Oracle are two databases to choose from.
#### 4. Select a CDN
If you want to scale your server and construct a live streaming service, you’ll need to use a content delivery network or CDN. Even if you don’t believe you’ll need it, attempt to plan ahead of time and you’ll likely find it to be a valuable choice. You’ll have to pay extra for CDN, but everything will be paid off in the end. It will ensure that material is delivered flawlessly and without interruptions.
#### 5. Select a good hosting service
To construct a fault-tolerant live streaming app, you must select a dependable hosting provider that will provide your clients with uninterrupted streaming services. You should have a solid server infrastructure to ensure that users receive high-quality video transmission. Using a ready-made cloud solution is a smart alternative.
#### 6. Work on UI/UX Design
You should keep in mind that first impressions matter and people will rate your streaming service based on that initial impression. You should hire highly skilled UI/UX designers or seek out a seasoned [software development firm](https://terasoltechnologies.com/) that can provide turnkey solutions.
#### 7. Get on Development
Create the front-end, back-end, and third-party connectors like payment gateways. For storing and streaming a significant volume of data, such projects necessitate the integration of full cloud infrastructure. So, we recommend beginning with a live streaming website MVP. User profiles, live streaming players, and other high-priority features will be included in the MVP.
#### 8. Time for Testing
The QA team will extensively test your live streaming website for a successful launch, ensuring that every website element functions properly. Your live streaming app’s quality assurance should be completed at a high level.
#### 9. The second stage of development
Collect feedback from users after the launch of your streaming platform to determine which features they want you to add next. You can choose a list of features to introduce during the second development stage and improve your website by using such input.
### How Much Does It Cost To Make A Live Stream Website App Like Twitch?
The cost of creating a fully functional live-streaming app is determined by several factors. These variables change depending on where your program is in the development process. It’s difficult to put a dollar figure on the cost of developing a live-streaming software, but you can get a rough estimate based on the number of hours and people involved.
The cost of various forms of UI/UX design is different. As the design becomes more complicated, the price will rise. Building the site structure, adding or creating features, adding crucial libraries, and much more are all part of the development of a streaming website or app like Twitch. API integration, server system configuration, and other critical configurations will be part of the backend infrastructure development for your streaming platform.
A mobile app development business can help you assess the overall cost.
If you’re short on cash, you may consider creating a minimum viable product (MVP) for your video-streaming app. It has the potential to produce money and attracts substantial investment.
### Get your Live Streaming Platform
As you can see, live streaming platforms like Twitch are transforming into new social networks where people with similar interests can connect and form communities.
In terms of live streaming, it is a promising technology. Terasol develops Live Video Streaming sites on a professional level. [Contact us](https://www.terasoltechnologies.com/enquiryform/?source=medium) for a free consultation if you have any questions. | terasol_app |
950,920 | Compilers, Direct coded scanner | As i mentioned in the previous posts, i like to learn new thing and share what i learned with others,... | 0 | 2022-01-11T00:02:23 | https://dev.to/ezpzdevelopement/compilers-direct-coded-scanner-2mc8 | beginners, programming, codenewbie | As i mentioned in the previous posts, i like to learn new thing and share what i learned with others, so i can get feedbacks or at least understand what i learned more, by writing about it.
In a previous [post](https://dev.to/iwashiding/table-driven-scanners-40jd), i tried to explain what i have learned about the basics of a table driven scanner , and how can we generate a one easily after creating a DFA which is going to be painful.
However, a table driven scanners has some downside like the cost of reading a character, and computing the next transition from the transition table, direct coded scanners handle this by simplifying the implementation of table look ups in both transitions and classifier table, and also by reducing the memory used in both of the previous mentioned operations.
Another thing is that the implementation of a direct coded scanner is a little bit different from the table driven one,
while table driven scanner use a general code or an algorithm to handle different DFAs and REs, the direct code scanners implement a specific code for each state in a DFA and the code in these DFAs differ from an RE to another.
Note that the direct coded scanner use a direct comparison to determine whether this character is a part of a state or not, this is an advantage, but also a disadvantage when the characters does not occupy and adjacent slots, in such a case a table driven scanner is more efficient, a hybrid approach which uses table lookups in when needed, in a direct coded scanner is also suitable.
That's it for now, in the next post i will try to share what i learned about hand coded scanners. | ezpzdevelopement |
951,436 | How to Setup Wi-Fi Extender With Xfinity? | If you’re wondering how to improve your user experience by adding one or more Wi-Fi extenders to your... | 0 | 2022-01-11T11:17:43 | https://dev.to/oliviabenson/how-to-setup-wi-fi-extender-with-xfinity-2ahc | wifi, extender, setup | If you’re wondering how to improve your user experience by adding one or more Wi-Fi extenders to your home wireless network, you’ve come to the right place. This article will explain how to set up a Wi-Fi extender with your Xfinity router, where to place it, and give you a few recommendations on a few extenders that definitely work with Xfinity routers.
Many Comcast users, sooner or later, are faced with the problem of inadequate Wi-Fi signal in some areas of their homes. This problem is more frequent in large and multistory houses. One of the most recommended solutions is to purchase one or more Wi-Fi extenders and cover those dark areas with a stronger, more reliable wireless signal.
If you opted for a Wi-Fi extender to solve your problem, you are pressed to make one significant choice.
Should you get an [Xfinity xFI-pod wi-fi extender](https://www.xfinity.com/learn/internet-service/wifi/xfi-pod), or you should look for some other brand and model?
Judging by most users, xFI-pod is a way to go because you can integrate it, set it up, and operate easily using just a phone app.
However, in case you are loyal to some other brand or just happen to have an up-to-date wi-fi extender laying around, we will show you how you can set it up as well.
Let’s start with the xFi-pod.
**How to Setup Xfinity Xfi-Pod Wi-Fi Extender**
The xFI-pod is a WI-FI extender designed to seamlessly integrate with the xFi gateway. That being said, it presents an excellent option to cover all areas in and sound the house with a strong, reliable wi-fi signal. The current second-generation xFi-pods offer stronger, tri-band wi-fi antennas and two gigabit ethernet ports.
They also integrate with Xfi gateway in a specific way, excellent for user experience, which we will discuss later in the article.
Comcast recommends getting one xFi-pod for houses up to four bedrooms and two if the house is larger than four bedrooms or a multi-story building.
Once you get them, the installation process is straightforward.
First, you need to plug the xFi-pod into the power outlet halfway between the gateway and the area you wish to cover with Wi-Fi.
Next, you need to go to the google play store or App store and [download Xfinity app](https://play.google.com/store/apps/details?id=com.xfinity.digitalhome&hl=en_US&gl=US) to your phone. Ensure the xFi gateway is online and that you turn on the Bluetooth on your phone.
Lastly, log in to the Xfinity app and follow instructions.
Now, there are a few things you should know before you try activating your xFi-pod.
1. xFi gateway mustn’t be in a bridge mode
2. You can’t activate xFi-pod if it’s connected to the gateway via ethernet cable. It must be a wireless connection. Ethernet connection between the gateway and the pod or between two pods is not supported.
3. You can’t use xFi-pod outdoors. If you need to cover an outside area, plug in the xFi-pod to the closest outer wall.
4. You’ll have to create the same SSID and password for both 2,4 GHz and 5 GHz networks. xFi-pod and xFi gateway will then decide what device will use which band and when. Channels will change automatically as well when needed.
Once you activate the pod, you effectively create a mesh network with all the benefits of having one. The pod and the gateway will constantly communicate and exchange information about the number and needs of connected devices, providing the best solutions regarding speed and frequency band for each individual device. Furthermore, you will seamlessly switch between the router and the pod as you move through the house.
**Do Other Wi-Fi Extender Brands and Models Work with Xfinity?**
In general - Yes. The compatibility will depend on the model, but most major brands will have a couple of models compatible with the xFi gateway. However, if you choose to go down this lane, keep in mind that you won’t be able to create a mesh network.
In other words, every device you wish to connect to Wi-Fi will have to drop the connection, then reconnect to a stronger signal as you move it around the house. This may cause some issues like temporarily losing connection to a server, lags and connection drop when you are using a connected device while moving around the house.
**How to Set up Other Brands of Wi-Fi Extenders with the Xfinity Router?**
Even doe it’s not as simple as using xFi-pod, setting up a different brand of an extender is not a complicated process.
There are two ways you can do this.
The first way utilizes a feature called WPS. The [WPS stands for Wi-Fi protected setup](https://www.makeuseof.com/wps-button-on-router/) and it allows connecting compatible devices with a press of a button.
If both extender and your xFi gateway have a WPS button ([it depends on model](https://routerctrl.com/xfinity-router-wps-button/)), you’ll need to do the following:
Plug the extender into the power socket somewhere close to the xFi gateway. Next, press the WPS button on the extender, then press the WPS button on the xFi gateway. Repeat the process for the 5 GHz band if the extender and xFi support two bands. Finally, unplug the extender from the power socket and plug it in its final location. The most newer models will have LED indicator lights that will show if the signal is strong enough at that new location. If the signal is bad, just plug the extender into a power socket that is a bit closer to the xFi gateway.
If the xFi gateway or the extender don’t support the WPS feature, you can set up the extender through the admin panel. Some steps may be slightly different, depending on the brand and model, but the principle will remain the same. We will show you how to do it with Netgear, TP-Link and Tenda extenders. Let’s start with Netgear.
**How to Setup Netgear Wi-Fi Extender with Xfinity**
Plug the extender in and make sure it’s turned on. Then use the phone or other Wi-Fi enabled device to scan for available Wi-Fi networks. Once you [locate NETGEAR_EXT](https://community.netgear.com/t5/WiFi-Range-Extenders-Nighthawk/NETGEAR-EXT-does-not-appear-in-my-network-list/m-p/1643808), connect to it. Next, open up the browser and type in www.mywifiext.net and follow the steps in the installation assistant.
**How to Setup Tp-Link Wi-Fi Extender with Xfinity**
Plug the TP-Link extender into the power outlet and use a Wi-Fi enabled device to search for available wireless networks. Look for something like TP-Link extender. Once you find it, connect to it. Next, open the internet browser and type in 192.168.0.254. You will be welcomed and asked to create the password to access the settings.
The extender will now search for your xFi gateway. Once you find it on the list, click on it and enter the password. If you have two bands, set up both 2,4 GHz and 5 GHz.
**How to Setup Tenda Wi-Fi Extender with Xfinity**
Just like with previous brands, plug the extender into the power outlet, then scan for available Wi-Fi networks. Once you see the SSID of the extender, connect to it. Open the browser and enter re.tenda.cn in the address bar. Follow the steps within setup assistant, and you’re done.
**Summary**
Setting up the Wi-Fi extender [is a fairly simple process](https://www.pcworld.com/article/394819/how-to-set-up-a-wi-fi-extender.html) after you decide will you use Comcast’s xFi-pods or some other brand. If you choose the xFi-pod, plug it into the wall to power up, then download and open the Xfinity app from Google Play or the App Store. Follow the steps inside the app and you’re done. You created a mesh wireless network with all the benefits it brings.
If you choose to go with the other brand, there are a couple of ways you can set up the extender. First is using the WPS button if both your xFi gateway and extender have one, the second is through the setup assistant.
WPS is much simpler if it is available. Simply plug the extender into the wall, wait until it powers up, then press the WPS button. Next, press the WPS button on the xFi gateway and you’re done.
If there isn’t a WPS button on the extender or the xFi gateway, plug the router into the power outlet near the gateway. Scan for available wireless networks and connect to the one with the same name as the extender. Then use the internet browser and default IP address to launch the setup assistant. Follow the instructions and finish the setup.
That is it. We hope this article was helpful and that you’ve managed to set up your wireless extender with the xFi gateway.
| oliviabenson |
951,477 | How to stop spam -too with mailto links. | As website owners, the incessant invasion of spam into our email inboxes via contact forms is a... | 0 | 2023-05-27T12:09:05 | https://dev.to/kreativ-anders/how-to-stop-spam-too-with-mailto-links-1f4o | javascript, spam, html, ux | As website owners, the incessant invasion of spam into our email inboxes via contact forms is a persistent challenge. Addressing this issue requires innovative thinking and unique solutions to maintain a clean and efficient communication channel with our users.
## A typical contact form
The traditional HTML contact form comprises fields for name, email, and a message. Below you can see a typical HTML contact form for any website.
```
<form method="POST" action="...">
<label for="name">Name</label>
<input name="name" type="text" />
<label for="email">Email</label>
<input name="email" type="email" />
<textarea rows="50" cols="25" />
</form>
```
### Name
Of course, you want to know the name of the person who tries to contact you. So asking for the name sounds fair, anyway a name does not matter in the first place.
This makes the input **optional** but welcomed.
### Email
In most of the cases the purpose of a contact form is to start a conversation, so an email address is required to reply. But at this point, you do not know if this email belongs to an actual human being. You can use a verification mechanism to ensure that the email is valid, but you do not if this email is sound.
This makes the input **crucial** but prone to abuse.
### Message
This field is essential since you want to know what the person wants from you, right!? But here the pain begins. You do not know what they are writing and you should not restrict the people in their words.
## Spam detection
Identifying spam with 100% accuracy is not possible! But there are some ways to minimize the amount of spam finding its way to your inbox.
### Content Filtering
One of the first approaches you might think of is to check the input for suspicious content, e.g. valid email address or suspicious words like _Bitcoin_.
This will work to a certain degree, but there are still plenty of possibilities to surpass those checks. For instance by writing _BTC_ or _Crypto_.
So, you see there will be a lot of maintenance to check all of the "evil" words you do not want in your inbox.
### Third-Party Libraries
Another option would be to use third-party libraries, that check the contact form against common suspicious content or behavior.
One popular solution is by solving a Captcha or Puzzle to verify that the message is sent by a human and not by a bot. Therefore, you need to add third-party scripts or an API to perform those checks. But one of the biggest side effects is, that real human beings are confronted now with a popup asking them to solve a stupid riddle or selecting proper images. From a user experience standpoint, this is a solution you should never anticipate!
### Low-Code / No-Code
Currently, a very promising way to provide online contact forms is to use low-code or no-code solutions, where you just redirect the form as a proxy by the provider. So the `action` attribute of the HTML form will be the URL of the form-as-a-service provider that automatically checks for spam. But these solutions arise other concerns regarding privacy since you redirect the form to a third party that handles personal information and forwards the content as email or push notification to your devices of choice.
## Thinking outside the box
After trying every example above, and implementing dozens of libraries that claim to prevent spam it was time to rethink the whole contact form situation.
We wanted a solution that ...
- does not blow up the code base,
- does not require third-party scripts, and
- does not negatively impact user experience.
After brainstorming we came up with a nowadays **uncommon solution**:
### A mailto-link
Everybody knows those buttons on a website that says "contact" and as soon as you click on it your default email program pops up. In the past, this was not a very user-friendly approach, since most users were confused. They expected a contact page or a contact form to see on the screen first. So how can a solution look like, that combines a contact form and a mailto-link?
At first, we removed the name and the email input fields. The big advantage of the mailto-link is that the email is sent by the users' email program, so there is absolutely no need to verify the email address. Bots do not own email programs or post inboxes. Bots just follow commands. And as mentioned earlier the name is not that much important at first contact.
The new contact form looks like this now:
```
<form method="POST" action="#" name="mailto_form" id="contact" onkeyup="generate_mailto()">
<label for="subject">Subject</label>
<input id="subject" type="text" name="subject" >
<label for="message">Message</label>
<textarea name="message" id="message" cols="30" rows="10">
</textarea>
<a href="mailto:..." id="mailto-link" role="button">
Send with (with email-program)</a> to
<a href="mailto:...">...</a>.
</form>
```
{% codepen https://codepen.io/Manuel-Steinberg/pen/bGmJWZJ
%}
Instead of the name, we are asking for a summary, like a subject of an email and maybe you have already noticed that there is a JavaScript event attribute present (`onkeyup`) that is triggered after every key press inside the form.
### The JS-function `generate_mailto()`
Let´s have a look at it...
```
function generate_mailto() {
var mailto= "mailto:mail@domain.tld"
, subject = encodeURIComponent(document.mailto_form.subject.value)
, message = encodeURIComponent(document.mailto_form.message.value);
mailto += "?subject=" + subject,
mailto += "&body=" + message,
document.getElementById("mailto-link").href = mailto,
}
```
So, every time the content changes the mailto-link will be updated with a corresponding subject and message as the body. That information will be added as an additional parameter to the mailto-link. When a user clicks on the link the default email app will open and the corresponding subject and message will be set as a template.
### Masking the email address
But what about the recipient email address that is visible in plain text at the moment you may ask... A valid and important point! Once a bot crawled the HTML code of your contact page it will surely recognize the email address and will use this one for spam.
There is one step left to tackle this issue. Email obfuscation with Unicode representation. For example, the email "mail @ domain.tld" becomes
{% details Unicode representation %} "\u006d\u0061\u0069\u006c\u0040\u0064\u006f\u006d\u0061\u0069\u006e\u002e\u0074\u006c\u0064" {% enddetails %}
A quick and dirty conversion in JavaScript might look like the following:
```
var mail = "mail@domain.tld";
// Convert to array
let unicode = Array.from(mail);
// Convert char to unicode
unicode = unicode.map(function(item) {
let charCode = item.charCodeAt(0);
return "\\u" + charCode.toString(16).padStart(4, '0');
});
// Convert back to string
unicode = unicode.join('');
console.log(unicode);
//\u006d\u0061\u0069\u006c\u0040\u0064\u006f\u006d\u0061\u0069\u006e\u002e\u0074\u006c\u0064
```
But, no worries there are also tools available one that can do the job for. probably you only need a conversion once and that is it. And this string we can now use for our default declaration as seen in the function `generate_mailto()`. And to mitigate the plain text issue for the part with the email address, we use JavaScript to print it respectively. Therefor, we replace the plain text inside the `<a>`tag with some JavaScript using `document.write()`.
```
<a href="javascript:location='mailto:...';void 0">
<script type="text/javascript">
document.write('...')
</script>
</a>
```
Of course, this solution requires JavaScript enabled on the visitors' side, but this seems to be a reasonable trade-off to achieve the goals mentioned above.
The final HTML form as a template:
```
<form method="post" action="#" name="mailto_form" id="formular" onkeyup="generate_mailto()">
<label for="subject">Subject</label>
<input id="subject" type="text" name="subject">
<label for="message">Message</label>
<textarea name="message" id="message" cols="30" rows="10">
</textarea>
<!-- Obfuscate Email -->
<a href="javascript:location='mailto:...';void 0" id="mailto-link" role="button">Open Email programm and send message
</a> to
<a href="javascript:location='mailto:...';void 0">
<script type="text/javascript">document.write('...')</script>
</a>.
</form>
<script type="text/javascript">
function generate_mailto() {
... // See the code above
}
</script>
```
Have a look at the demo and see how the link changes when the subject or message has been changed by hovering with the mouse cursor over the button saying *Send with (with email-program)*
{% codepen https://codepen.io/Manuel-Steinberg/pen/yLRrXye
%}
## Conclusion
Website owners often struggle with spam in their email inboxes when using contact forms. While various approaches like content filtering, third-party libraries, or low-code solutions exist, they come with drawbacks such as growing codebase, negative user experience, or privacy concerns. Thinking outside the box, a less common but effective solution is to utilize a mailto-link combined with JavaScript to generate the email dynamically. By obfuscating the email address using Unicode representation, the risk of bots harvesting the address is also reduced, not eliminated. This approach offers a lightweight and user-friendly solution without relying on external dependencies or compromising the user experience.
Also, this solution might seem outdated a couple of users already mentioned that the experience was kind of refreshing due to its uniqueness. Some users also mentioned that it feels magical that they type a message online and it will be immediately copied over to a new email. Also with this approach by sending the contact form with their email program on the users' end, the user can be sure that the form was sent since the emails appears in the folder within their email program.
| manuelsteinberg |
951,488 | Eco-eCommerce | This is an e-commerce website named - "better buys". It uses MongoDB Atlas as the... | 0 | 2022-01-11T12:49:56 | https://dev.to/shruti700/eco-ecommerce-30e3 | atlashackathon |
### This is an e-commerce website named - "better buys". It uses MongoDB Atlas as the database to store users, products data.
[Note]: # (Please make sure the project links to the appropriate GitHub repository and includes the [Apache-2 permissive license](https://www.apache.org/licenses/LICENSE-2.0) and README.)
## Submission Category: E-Commerce
## Link to Code:`{%https://github.com/Shruti700/Better-buys%}`
[Note]: # (Our markdown editor supports pretty embeds. Try this syntax: `{% Github link_to_your_repo %}` to share a GitHub repository)
## Additional Resources / Info
React, Redux, Node.js, Stripe are used in this project.
[Note]: # (Be sure to include the DEV usernames of your collaborators, if any. Prizes for winning projects with multiple collaborators will be sent to the person who posts this submission and they will distribute the prize evenly.)
[Reminder]: # (Submissions are due on January 13th, 2022 @ 11:59 PM PT/2 AM ET on January 14th, 2022/6 AM UTC on January 14th, 2022). | shruti700 |
951,556 | Database with Prisma ORM, Docker and Postgres - NestJs with Passport #02 | In the last post start with a blank configuration, understand how to NestJs works with routes,... | 16,196 | 2022-01-21T22:34:06 | https://dev.to/mnzs/database-with-prisma-orm-docker-and-postgres-nestjs-with-passport-02-180l | docker, nestjs, tutorial, prisma | In the last post start with a blank configuration, understand how to NestJs works with routes, controllers, and services. Saw how easy is to set up Fastify to optimize our app.
Now, will set up the database and ORM for interacting and storing our data. We use PostgreSQL for the database using docker to create a default container for the app, will use Prisma for ORM because is the best Orm of the moment for interacting with the database.
---
## Docker Container
Now that we have our app up, let's containerize it.
Start by creating the following files in the project's root directory:
- `Dockerfile` - This file will be responsible for importing the Docker images, dividing them into development and production environments, copying all of our files, and installing dependencies.
- `docker-compose.yml` - This file will be responsible for defining our containers, required images for the app other services, storage volumes, environment variables, etc.
Open the `Dockerfile` and add
```yml
# Dockerfile
FROM node:alpine As development
WORKDIR /usr/src/app
COPY package*.json ./
RUN yarn add glob rimraf
RUN yarn --only=development
COPY . .
RUN yarn build
FROM node:alpine as production
ARG NODE_ENV=production
ENV NODE_ENV=${NODE_ENV}
WORKDIR /usr/src/app
COPY package*.json ./
RUN yarn add glob rimraf
RUN yarn --only=production
COPY . .
COPY --from=development /usr/src/app/dist ./dist
CMD ["node", "dist/main"]
```
Open the `docker-compose.yml` file and add the following code
```yml
# docker-compose.yml
version: "3.7"
services:
main:
container_name: main
build:
context: .
target: development
volumes:
- .:/usr/src/app
- /usr/src/app/node_modules
ports:
- 3000:3000
command: yarn start:dev
env_file:
- .env
networks:
- api
depends_on:
- postgres
postgres:
image: postgres:13
container_name: postgres
networks:
- api
env_file:
- .env
ports:
- 5432:5432
volumes:
- pgdata:/var/lib/postgresql/data
networks:
api:
volumes:
pgdata:
```
Create a `.env` file and add the PostgreSQL credentials
```dotenv
# .env
# PostgreSQL
POSTGRES_USER=nestAuth
POSTGRES_PASSWORD=nestAuth
POSTGRES_DB=nestAuth
```
By default, Fastify listens only on the `localhost 127.0.0.1` interface. For we access our app from other hosts we need to add `0.0.0.0` in the `main.ts`
```ts
// src/main.ts
await app.listen(3000, "0.0.0.0");
```
Awesome, we have our dockerized, and let's go test then. Run in the terminal for development
```
docker-compose up
```

And our app is Running :clap:
---
## Prisma ORM
[Prisma](https://prisma.io) is an open-source ORM, it is used as an alternative to writing plain SQL, or using another database access tool such as SQL query builders (like knex.js) or ORMs (like TypeORM and Sequelize).
Start installing Prisma CLI as a development
```
yarn add Prisma -D
```
As a best practice invoke the CLI locally by prefixing it with `npx`, to create your initial Prisma setup using the `init` command
```
npx prisma init
```
This command creates a new Prisma directory with the following contents
- `schema.prisma`: Specifies your database connection and contains the database schema
- `.env`: A dotenv file, typically used to store your database credentials in a group of environment variables
By default your database connection it's set to `postgresql`
```prisma
// prisma/schema.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
```
How our connection type is correct, we will set the `DATABASE_URL` in `.env`
```dotenv
DATABASE_URL="postgresql://nestAuth:nestAuth@postgres:5432/nestAuth"
```
Remember to add in `.env` in `.gitignore` and create a `.env.example` before creating the repository in Github
Generating the Prisma Client requires the `schema.prisma` file. `COPY prisma ./prisma/` copies the whole Prisma directory in case you also need the migrations.
```yml
# Dockerfile
FROM node:alpine As development
WORKDIR /usr/src/app
COPY package*.json ./
# Here Prisma folder to the container
COPY prisma ./prisma/
RUN yarn add glob rimraf
RUN yarn --only=development
COPY . .
RUN yarn build
FROM node:alpine as production
ARG NODE_ENV=production
ENV NODE_ENV=${NODE_ENV}
WORKDIR /usr/src/app
COPY package*.json ./
# Here Prisma folder to the container
COPY prisma ./prisma/
RUN yarn add glob rimraf
RUN yarn --only=production
COPY . .
COPY --from=development /usr/src/app/dist ./dist
CMD ["node", "dist/main"]
```
---
### First Model
Now to test the connection we will be creating a `User` model, inside `schema.prisma` insert
```prisma
// prisma/schema.prisma
model User {
id Int @id @default(autoincrement())
email String @unique
name String
password String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
```
With your model in place, you can generate your SQL migration files and run them against the database. Here I use `migrate dev` for a run in development mode and set `init` name for the migration
Before this you need up your docker
```
docker-compose up
```
and edit your `.env` file
```dotenv
DATABASE_URL="postgresql://nestAuth:nestAuth@localhsot:5432/nestAuth"
```
Always you run `prisma migrate` you need change the database host to `localhost` after you rollback to name of your database container.
```
npx prisma migrate dev --name init
```

Rollback `.env` file
```dotenv
DATABASE_URL="postgresql://nestAuth:nestAuth@nestauth:5432/nestAuth"
```
Good News, is our configuration is working, now our database is in sync with our app :clap:
---
### Setup Prisma
We will want to abstract away the Prisma Client API for database queries within a service. so let's create a new `PrismaService` that takes care of instantiating and`PrismaClient` to connecting to your database.
Create a `prisma.service.ts` inside `src` folder
```ts
// src/prisma.service.ts
import { INestApplication, Injectable, OnModuleInit } from "@nestjs/common";
import { PrismaClient } from "@prisma/client";
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit {
async onModuleInit() {
await this.$connect();
}
async enableShutdownHooks(app: INestApplication) {
this.$on("beforeExit", async () => {
await app.close();
});
}
}
```
---
## First Service
Now we can write a user service to make database calls. So NestJs CLI has a command `nest g` to generate services, controllers, strategies, and others structures. For now, we run
```
nest g service users
```
Before start create a service we need to generate types of Prisma Model, we can generate with this
```
npx prisma generate
```
Inside the `src` folder the command creates a `users` folder with `users.service.ts` and the file test `users.service.spec.ts`. To test our database connection let's create a two services
- `user`: to get a user using the Prisma interface `Prisma.UserWhereUniqueInput` forget user by unique columns
- `createUser`: to create a new user using data from interface `Prisma.userCreateInput` that get auto the fields when the model needs to create a new register
And inside the `createUser` we need to encrypt the user password, so let's create a provider for this, in the `src` folder create a `providers` folder and create a `password.ts` file
```ts
// src/providers/password.ts
import { Injectable } from "@nestjs/common";
import * as bcrypt from "bcrypt";
const SALT_OR_ROUNDS = 10;
@Injectable()
export class PasswordProvider {
async hashPassword(password: string): Promise<string> {
return bcrypt.hashSync(password, SALT_OR_ROUNDS);
}
async comparePassword(password: string, hash: string): Promise<boolean> {
return bcrypt.compareSync(password, hash);
}
}
```
The class has two methods, `hashPassword` and `comparePassword` to encrypt and compare the password using brcypt. Inside the `UsersService` class we need to add in the constructor the provider `PasswordProvider` for use in the methods.
```ts
// src/users/users.service.ts
import { HttpException, HttpStatus, Injectable } from "@nestjs/common";
import { PrismaService } from "../prisma.service";
import { User, Prisma } from "@prisma/client";
import { PasswordProvider } from "src/providers/password";
@Injectable()
export class UsersService {
constructor(
private prisma: PrismaService,
private passwordProvider: PasswordProvider
) {}
async user(
userWhereUniqueInput: Prisma.UserWhereUniqueInput
): Promise<User | null> {
const user = await this.prisma.user.findUnique({
where: userWhereUniqueInput,
});
delete user.password;
return user;
}
async createUser(data: Prisma.UserCreateInput): Promise<User> {
const userExists = await this.prisma.user.findUnique({
where: { email: data.email },
});
if (userExists) {
throw new HttpException("User already exists", HttpStatus.CONFLICT);
}
const passwordHashed = await this.passwordProvider.hashPassword(
data.password
);
const user = await this.prisma.user.create({
data: {
...data,
password: passwordHashed,
},
});
delete user.password;
return user;
}
}
```
With service created let's create a controller for route use that
```
nest g controller users
```
So this command create `users.controller.ts` and our test file inside `src/users`, so let's create two functions in the controller
- `signUpUser`: For run `createUser` service and return a data from them
- `getUserProfile`: Get an id of the user sent by the route and run the `user` service to find them
```ts
// src/users/users.controller.ts
import { Body, Controller, Get, Param, Post } from "@nestjs/common";
import { User } from "@prisma/client";
import { UsersService } from "./users.service";
// Set prefix route for this group. Ex.: for get profile /users/8126321
@Controller("users")
export class UsersController {
constructor(private readonly usersService: UsersService) {}
// Create user -> POST /users
@Post()
async signupUser(
@Body() userData: { name: string; email: string; password: string }
): Promise<User> {
return this.usersService.createUser(userData);
}
// Get user Profile -> GET /users/:id
@Get("/:id")
async profile(@Param("id") id: number): Promise<User> {
return this.usersService.user({ id: Number(id) });
}
}
```
Inside the `users.module.ts` file we need to add the providers, exports, and controllers array.
```ts
// src/users/users.module.ts
import { Module } from "@nestjs/common";
import { PrismaService } from "src/prisma.service";
import { PasswordProvider } from "src/providers/password";
import { UsersController } from "./users.controller";
import { UsersService } from "./users.service";
@Module({
providers: [PasswordProvider, UsersService, PrismaService],
exports: [UsersService],
controllers: [UsersController],
})
export class UsersModule {}
```
And pass the `UsersModule` to the `AppModule` for use.
```ts
//src/app.module.ts
import { Module } from "@nestjs/common";
import { AppController } from "./app.controller";
import { PrismaService } from "./prisma.service";
import { UsersModule } from "./users/users.module";
import { UsersService } from "./users/users.service";
import { PasswordProvider } from "./providers/password";
@Module({
imports: [UsersModule],
controllers: [AppController],
providers: [PrismaService, UsersService, PasswordProvider],
})
export class AppModule {}
```
---
## Let's Test
Now lets up our docker container
```
docker-compose up
```

And that's it! The app is running :clap:
So in Postman let's try using the `createUser` and `getProfile` routes
```curl
curl --location --request POST 'http://0.0.0.0:3000/users' \
--header 'Content-Type: application/json' \
--data-raw '{
"email": "test@e3x.com",
"name": "Gabriel Menezes",
"password": "123123"
}'
```

```curl
curl --location --request GET 'http://0.0.0.0:3000/users/37'
```

---
## Until Next Time
That is all we are going to cover in this article, we dockerize the app, set up Prisma, and create two routes. In the next piece in the series, we'll create and define our Auth providers for authenticating in our app.
Thank you for reading!
---
Follow repository to consulting code
{% github mnzsss/nest-auth-explained no-readme %}
---
## References
- [Setting up a NestJS project with Docker for Back-End development](https://dev.to/erezhod/setting-up-a-nestjs-project-with-docker-for-back-end-development-30lg)
- [Dockerizing a NestJS app with Prisma and PostgreSQL](https://notiz.dev/blog/dockerizing-nestjs-with-prisma-and-postgresql)
| mnzs |
951,787 | solutionbank | Solution Bank for Mathematics: The importance of mathematics in life Solution Bank and Education has... | 0 | 2022-01-11T16:39:25 | https://dev.to/solutionbank61/solutionbank-1i4c | Solution Bank for Mathematics: The importance of mathematics in life
[
Solution Bank](https://solutionbank.uk/) and Education has always been a major issue for people all over the world. There are many indifferent skills that people learn in life. Some of them are more important than others, depending on their specific job. In this, we are talking about the importance of mathematics in life.
Today, we will talk about the benefits of using math in life. We will also highlight the importance of using a well-designed banking website.
Mathematics is part of everything we do in life.
Being good with numbers is not only important in passing academic exams. There is a reason why math is so important during our learning journey. The application of mathematics and the science of mathematics are essential to our lives.
Statistics have been important to our evolution, and everything about how we have developed is linked to numbers. It is because of this transformation that we have been able to achieve outstanding results in all aspects of life.
If people have numbers, they can solve any problems without relying on calculations on their smartphones. Not only that but knowledge of statistics can help you determine if a business proposal is right for you.
Thinking quickly about numbers will be very important in most cases. You don't want to ask people to let you check the counter in a chat. One thing people want to do is make sure they have the ability to manage numbers in their heads.
Number of major resources
Understanding mathematics and practicing the complexity of this science is essential for the best results. This is the reason why the use of banking solutions is so important.
One of the most difficult things for people trying to learn math is to understand the causes of the problem or challenge. There are many cases where mathematics becomes more difficult due to a lack of learning resources.
That is why the solution banks are very large for this purpose. They can make things much easier for anyone who wants to achieve good results. The best thing to do is make sure things go as well as expected to have the right things in your studies.
Many times people have said that one of the main differences between success and failure is resources. This means that those who prepare and hone their skills with the right kind of resources will always have a high hand.
The popularity of solution banks has grown exponentially.
This is a clear indication that this type of material is good for people. That is the most important thing you can say because access to these banking information sites can be very profitable.
The important thing is that most people who do well in math do the exercises with the right resources. This can be difficult for those who do not know where to find those services, but once they do, things become easier to access.
If someone feels that his statistics are not right somewhere, it can be difficult to get the results he wants. That being said, with the right kind of resources, things can be completely changed and made for the better.
The way people work when it comes to education will always be important. The main thing to consider is that it can be difficult to make progress without focusing on the right kind of subjects. This is the kind of discipline that can really help.
Managing this well means being able to use the best assets. This speeds up the process of managing statistics and understanding them at a deeper level.
The importance of excellent educational performance
People who want to teach math do the right thing because they want to do well. Educational performance will be a great way for people to get good results from their careers.
This is especially important for students who are concerned that they will not be able to apply for a major college. When they use the solution bank database, they will get better results.
Solutionbank is an amazing resource for anyone who wants to hone their skills. Everything from algebraic speech and quadratics to binomial expansion and trigonometry is included. This is one of the reasons why the solutionbank solution can be so good.
The most important thing to remember in any of these situations is facts. One of them is that the more resources a person has, the better the results will be in the long run. This is why the use of banks for mathematical solution is so important.
The biggest thing people can do is use these resources because they will make things easier. There are many ways to manage your efforts, which is why it is so important to use these resources. They can be helpful to people for many different reasons.
Final thoughts
The use of statistics is always necessary. The big problem with this is that many people do not understand that value, and do not need resources to improve their skills.
Those who recognize the value and importance of those skills will always do their best to improve their statistics. This is the kind of factor that determines many aspects of a person's life, depending on his or her choice of career.
Make sure you use the type of content that will appear to be most beneficial to you. This will make a big difference in your results at all times, without a doubt.
If you are looking for a quality solution bank, you can find one at the link below: https://solutionbank.uk/. | solutionbank61 | |
951,796 | SQLModel Crash Course. | A post by Ssali Jonathan | 0 | 2022-01-11T16:51:42 | https://dev.to/jod35/sqlmodel-crash-course-2mim | fastapi, python, database | {% youtube Ix-ps9MWUKA %} | jod35 |
952,148 | Explain Json Web Token(JWT). | JWT stands for Json Web Token. It is the most popular user authorization technique for web... | 0 | 2022-01-12T00:51:07 | https://dev.to/farhanacsebd/explain-json-web-tokenjwt-4od2 | JWT stands for Json Web Token. It is the most popular user authorization technique for web applications nowadays, mostly micro web services and it is used to share security information between two sides like a client and a server or a server and a server.It can be used as an authentication mechanism that does not need a database.
There are two authentication system we can follow,
1. Session token
2. JWT token
**JWT Token**: Modern and largest web application has multiple servers. Then multiple servers are maintained by load balancers and also shared redis sessions in the database.
But if the shared redis session is crashed or down, then the service will be stopped.
So JWT comes to solve this problem.
The user sends a request to the server,then the server sends the jwt token to the user. Inside this jwt token, the server includes header, payload and signature.
Inside the header, the server is written in which algorithm is used in this jwt token.
Payload is the user information and signature is the secret key.
By the secret key, the server ensures that this is the right user.
In this case, the server does not keep any data from the user. All the data will be sent from the server to the user and the user keeps this jwt token in browser cookies or others.
| farhanacsebd | |
952,262 | Blog with Node, MongoDB, and React | 1.11.22 It's been awhile since I've coded... yay post-bootcamp burnout. I'm starting my 100 Days of... | 0 | 2022-01-12T04:46:57 | https://dev.to/spacerambler/blog-with-node-mongodb-and-react-4l2o | 100daysofcode, react | **1.11.22**
It's been awhile since I've coded... yay post-bootcamp burnout. I'm starting my 100 Days of Code challenge to rework the bootcamp assignments using React.
I read a Twitter thread (which I've lost) but it got me motivated to get back to my code practice. I wrote down "backend headless cms - node, mongoDB, and react."
So, I'll be researching headless CMS which at initial glance looks like a hot topic right now.
**What is a headless cms?** From [Contentful](https://www.contentful.com/r/knowledgebase/what-is-headless-cms/), "A headless CMS is any type of back-end content management system where the content repository "body" is separated or decoupled from the presentation layer "head." Content that is housed in a headless CMS is delivered via APIs for seamless display across different devices... structuring content so that it can be reused across different platforms and channels."
...
Before I go too far down a rabbit hole... I need to get re-familiar with how to set up an app.
While I go through my notes, I guess the real start of this project is figuring out my objective and a design draft.
## Project Overview
I enjoy spending my time reading and writing about a range of topics, recent adventures, and new findings. I want to build a CMS blog where I can publish blog posts, short stories, notes, and life updates and allow of comments on posts... creating a "Digital Oasis".
### User Story
As a developer who writes
I want a CMS-style blog site
So that I can publish my content
### MVP
1. Home
2. Blog Page
3. Blog Post
4. Login
5. Blog Entry
6. Logged-In Blog Post State
### Road Map
*In no particular order...*
Theming/CSS, Comments, Newsletter Signup, Content Sections, Calendar
*Edit: I started this project with a massive starter pack that we used during the final project of bootcamp. I ended up scrapping most of it and rebuilding from point zero because I needed to work my way back up.*
**1.17.22**
I'm back... a week later, still going strong in the green. I've done a few things. Set up bootstrap and got a few components rendering with React.
Here are my next steps for this week:
1. Seed the database
2. Pull content from the database into the blog post
**1.22.22**
So, I still have not seeded the database but I have reworked my server side folders and have done the following:
* Set up server
* Create env file
* Finished setting up models
* Started routes
Right now I just have the scaffolding for the routes but that will be my next couple of days.
Overall thoughts right now: I definitely learned a lot during coding bootcamp and it's all coming back piece by piece. The reason why I got into coding was because I like the puzzle aspect. It's really nice to get to put this together without the breakneck speed and pressure of the bootcamp. | spacerambler |
952,444 | utilize the power of
useState and useCallback hooks in React | What is the right way of using the useCallback and useState hooks in conjunction? Sometimes we will... | 0 | 2022-01-12T07:46:45 | https://dev.to/nitsancohen770/utilize-the-power-of-usestate-and-usecallback-hooks-in-react-4d1e | react, javascript, webdev, programming | What is the right way of using the useCallback and useState hooks in conjunction?
Sometimes we will want to wrap the useState hook with a useCallback hook.
The simple reason for that is to prevent a render cycle when passing the function as props (when the component receiving that prop is wrapped with `React.memo`).
We must remember is that the `setState` function must not be passed to the `useCallback` dependency array. The React team suggests this:
> "React guarantees that setState function identity is stable and won’t change on re-renders. This is why it’s safe to omit from the useEffect or useCallback dependency list."
For example:
```
const [isOpen, setIsOpen] = useState(false);
const toggle = useCallback(() => setIsOpen(!isOpen), [isOpen]); // We don't have to pass the setState function.
```
But the example above is but practice. Why? Even though we are not passing the setState function, we must pass the `isOpen` variable, as it is being used inside the `useCallback` hook. This will cause the toggle function to be recreated every time the state changes.
You already know the solution, right?
We can use the callback function that receives the previous value and manipulate it. This way, we are not using variables from outside the useCallback function, and we can keep the dependency array nice and clean.
```
const [isOpen, setIsOpen] = useState(false);
const toggle = useCallback(() => setIsOpen(prevState =>!prevState), []);
```

---
- For more posts like this [follow me on LinkedIn](https://www.linkedin.com/in/nitsan-cohen/)
- I work as frontend & content developer for [Bit](bit.dev) - a toolchain for component-driven development (Forget monolithic apps and distribute to component-driven software). | nitsancohen770 |
952,533 | Create and Deploy Python Django Application in AWS EC2 Instance under 5 mins | Hello guys! Here is a simple step by step on how to create and deploy your own Python Django... | 0 | 2022-01-12T10:19:31 | https://dev.to/awscommunity-asean/create-and-deploy-python-django-application-in-aws-ec2-instance-4hbm |
Hello guys! Here is a simple step by step on how to create and deploy your own Python Django Application in AWS EC2 Instance. The goal of this is to deploy your app in the fastest way possible
# Overview
1. Create and Launch your own EC2 instance
2. SSH on your EC2
3. Deploy packages
4. Run and Create App
## Creating EC2 Instance
### 1. Login your AWS account and open EC2 Console
### 2. Click Launch Instance
### 3. Choose an Amazon Machine Image (AMI)
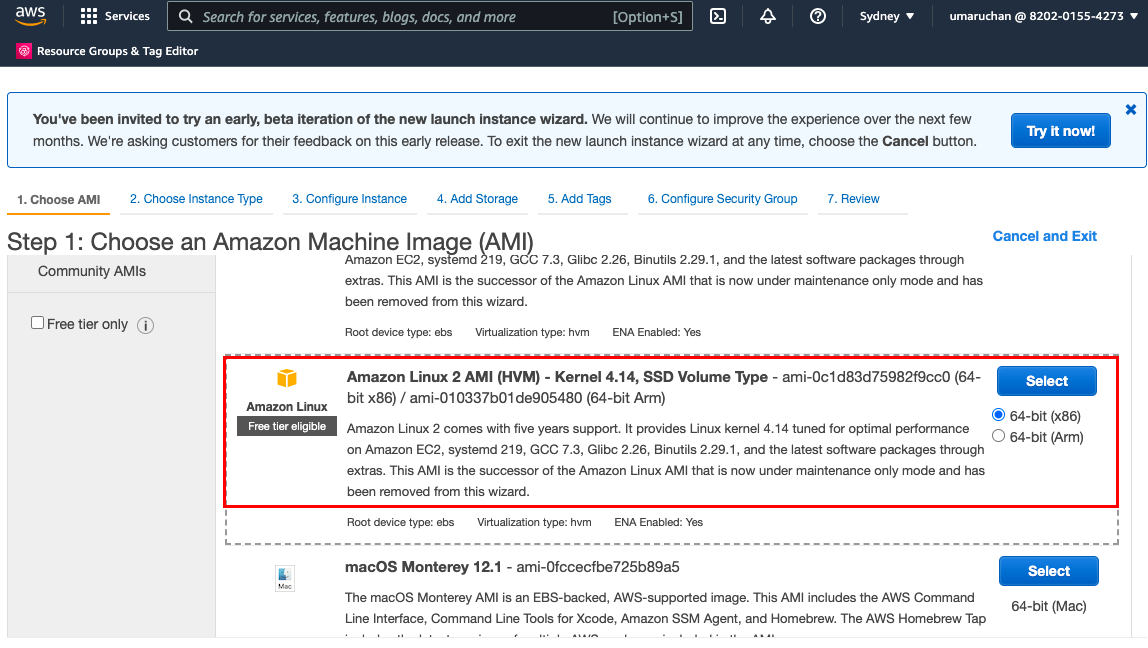

For this I would be selecting either Amazon Linux/Ubuntu (free tier eligible)
### 4. Choose an Instance Type
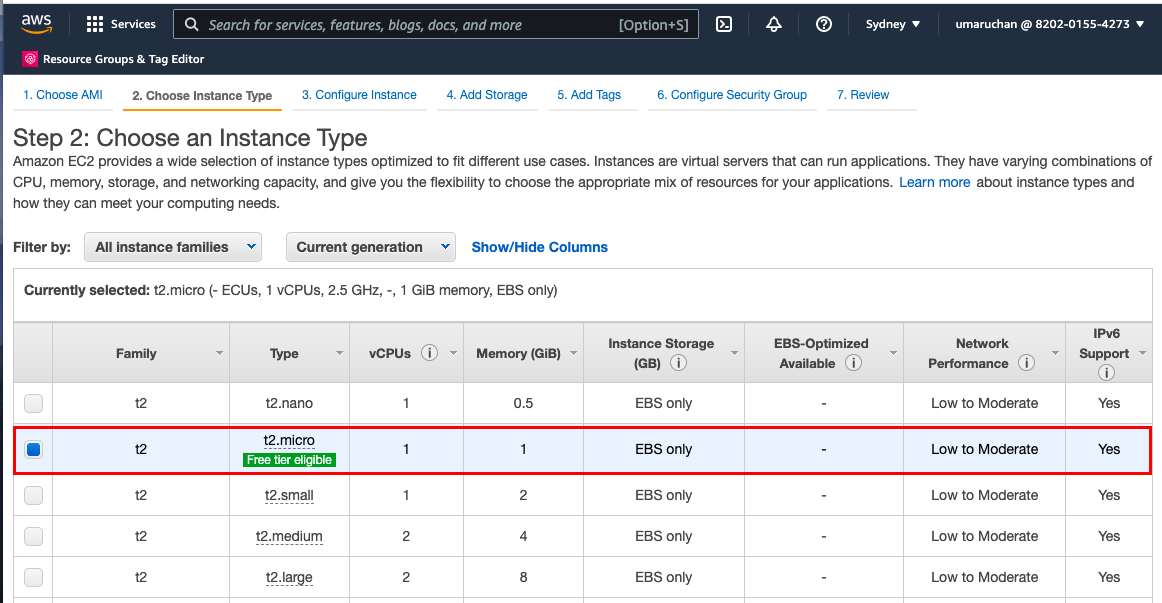
For this I would be selecting t2.micro (free tier eligible)
### 5. Skip and Proceed to Configure Security Groups
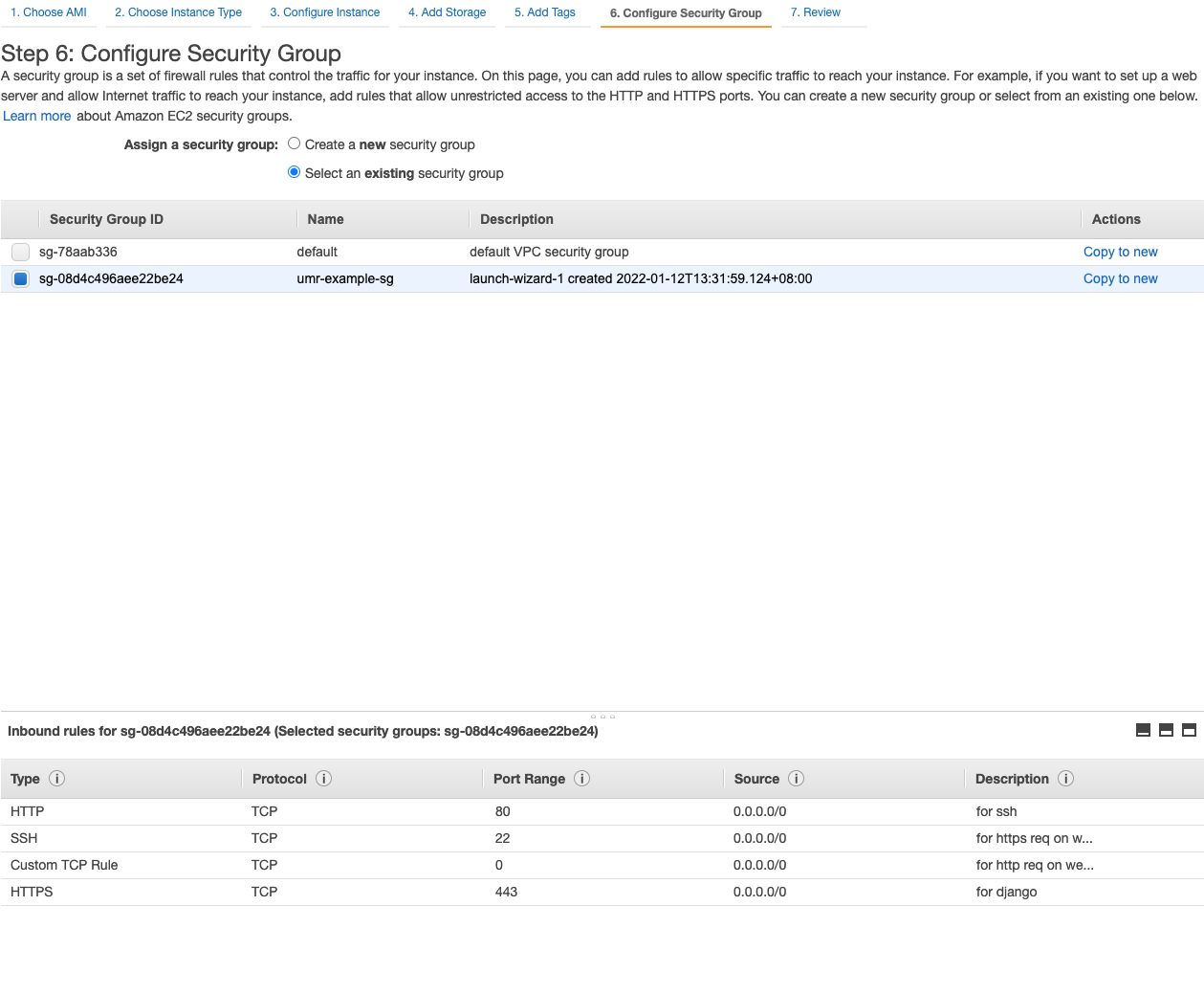
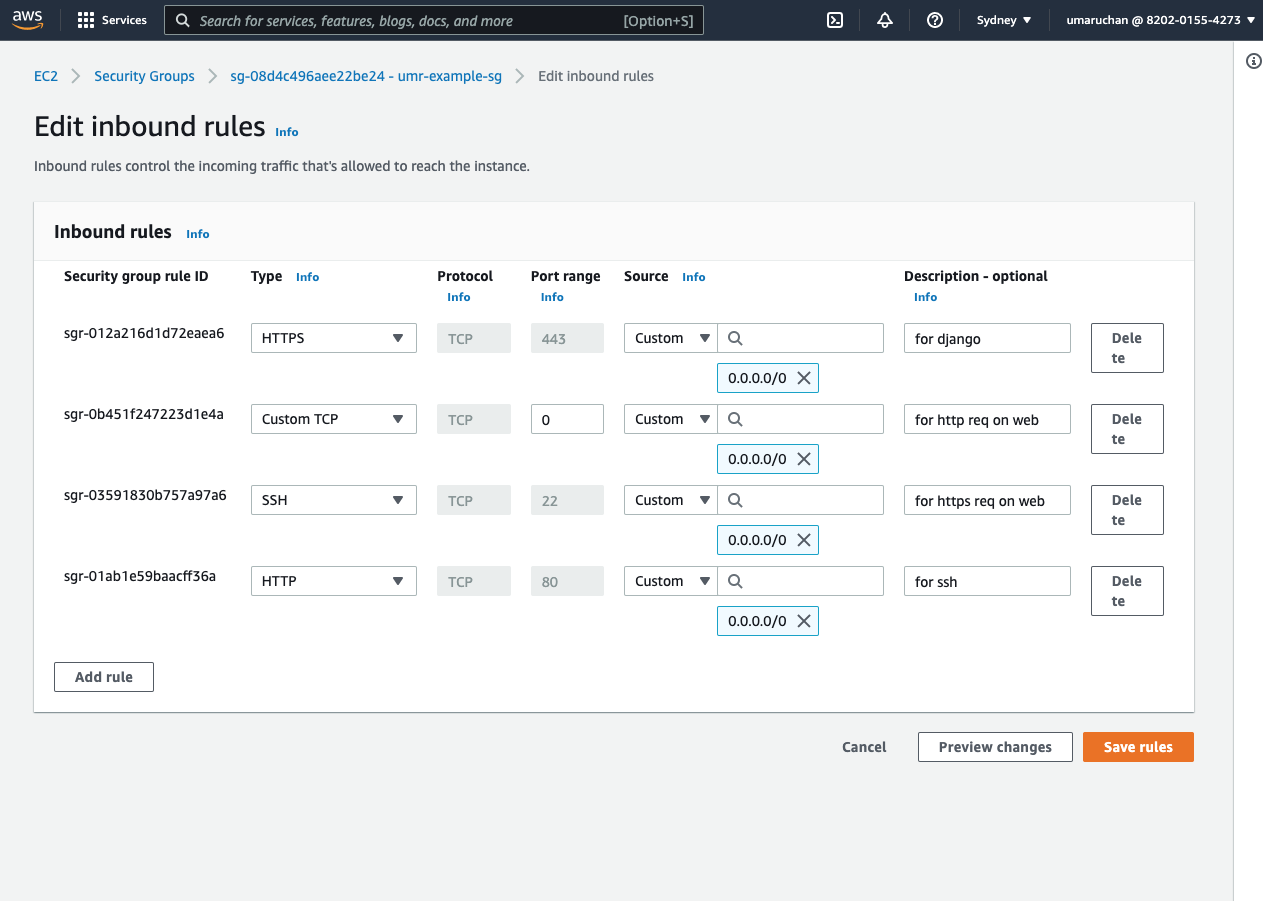
You can simply use default or configure your own security groups even later after launching your instance. You must open HTTP port 80 if you wish to check that the Nginx is successfully set up while visiting index.html. **Note:** You can add additional port for postgresql. this sample is just for default django.
### 6. Click Review and Launch
### 7. Review Instance Launch then click Launch
### 8. Create new key pair then download
Save this file as you would be needing this later.
### 9. Click Launch Instance
### 10. Navigate to Instances then check status of running instance
## Connect to your Instance via SSH
### 1. SSH on your EC2 instance
In your terminal type the ff: `% ssh -i ~/Desktop/name_of_your_keypair.pem ec2-user@ipaddress`
Upon entering this, you will encounter a **Warning unprotected file error**. With that you need to **CHMOD** your pem file
### 2. CHMOD pem file
On your terminal type the ff: `% chmod 400 ~/Desktop/umr-example-keypair.pem`
then retry connecting again via ssh and you should be able to connect to your ec2 instance now.
## Install Packages
Since linux ami has its own python pre installed, I did not include it in my installations. I only added pip and django
`sudo apt update
sudo apt-get install python3-pip
sudo pip3 install gunicorn
sudo apt-get install supervisor
sudo pip3 install django
sudo yum install nginx
`
## Start and check status of nginx
`sudo systemctl start nginx
sudo systemctl status nginx
`
You can test this by copying the Public DNS(Ipv4) of your instance in the browser. See the index.html page of Nginx via public ip address ie http://ipadress...
You should see default page for Nginx.
## Create and Run python Django App
1. Create project
`% django-admin startproject mysite`
Creating project from and ec2 instance is really **optional**, you can always **push your app in a repo then clone** it inside
2. Edit settings.py of your django app, set **ALLOWED_HOSTS to = ["*"]**
3. Navigate to project and run app
`% python3 manage.py runserver 0:8000`
4. Copy and paste the Public DNS(Ipv4):8000 of your instance in your browser
### Additional: Configuration for a production ready App
3. Configure and Integrate Gunicorn and Nginx
Configuring both takes a whole lot of steps. I would recommend this documentations related to that:
https://pythoncircle.com/post/697/hosting-django-app-for-free-on-amazon-aws-ec2-with-gunicorn-and-nginx/
https://www.alibabacloud.com/blog/how-to-set-up-django-with-postgres-nginx-and-gunicorn-on-ubuntu-16-04_594319
https://dev.to/rmiyazaki6499/deploying-a-production-ready-django-app-on-aws-1pk3#installing-dependencies
| jairaencio | |
952,577 | A Global Brand From Day One: the Core Idea, Benefits, and Features of MyTelescope | MyTelescope is a project of Rodrigo and his friend Fréderique, and we have the pleasure to be their... | 0 | 2022-01-12T11:33:37 | https://www.techmagic.co/blog/a-global-brand-from-day-one-the-core-idea-benefits-and-features-of-mytelescope/ | MyTelescope is a project of Rodrigo and his friend Fréderique, and we have the pleasure to be their tech partner in this journey. How it started and how it's going – directly from the founder.
Creating a successful product and turning it into one of the market top players requires an understanding of your audience, its requests, and needs. It's essential to know how people make choices and what motivates them to go for your product among all other options. And yet, you need to understand its value and believe in what you do.
Rodrigo Pozo Graviz, CEO and founder of [MyTelescope](https://mytelescope.io/), has had 15 years of experience in marketing when he started his business. It is a case when someone with great knowledge and experience in a field decided to use them for creating something amazing.
We had the pleasure to become Rodrigo's partner in this project and took our chance to ask him a few (a lot, actually) questions about the product, the idea, prospects, problems, and pitfalls.

We started to work with Rodrigo since the launching of MyTelescope. His main idea was to step away from working as an agency and create a product that would provide a comprehensive analysis of audience behavior — to help marketers understand how it behaves and why it behaves like this.
**Rodrigo**: The challenge we saw in the market was that many people don't have good data to get insights into their market. So we wanted to create a product available and accessible for everyone who wants to understand their brand, insights, general market trends, and so on.
## **How It Started**
MyTelescope is a partner project of Rodrigo and his friend Fréderique. Initially, they built a team that consisted of creatives like marketers, designers, copywriters, and brand analysts — 80%. For now, the team looks completely different, and almost 100% of employees are technical specialists.
**Rodrigo**: And then we have been fortunate to work with you guys so that we have an extended team.
When we ask Rodrigo about challenges at the very beginning of their path, he singles out two main ones.
**First**: when you start to build the technology, it comes to a point where you have to freeze the product and start moving from there and not change what you're making. So you don't have a moving target. And it was challenging.
**Second:** You need to understand how to proceed with a huge amount of data. You should pay significant attention to this because the modern user is impatient, and the marketers appreciate time and information received on time. Working with such a large amount of data may take several hours to process and generate a report. You need to be able to handle it.
## **What's the Coolest Thing About Your Product?**
What people usually want to know first is what's the primary value of MyTelescope and what makes it attractive for users. **The principal value is not the ability to understand what people are looking for because there is nothing new in it. It's seeing and understanding why they do that**. This is the most helpful and valuable information for marketing specialists.
With MyTelescope, you can see on a whole level what people are doing. And you can also see from sentiment and social media points of view what people are writing (posting) about. And from that, you can create a sentiment analysis that can tell you if the interest created is positive or negative. That's the key feature that people love about the product.

**Rodrigo**: If you're working with understanding the world and getting insights, you first want to know what's happening with a trend, and then you want to see why that trend is happening?
Rodrigo compares working with this data with creating the universe. You can start to understand, at least from a digital point of view, what's happening in the digital landscape.
**Rodrigo**: People are so much more on the digital channels now. Not only here in Sweden or Ukraine or London; everybody with a mobile phone. So by analyzing search and sentiment, you understand where the world is going.
# **Let's Talk About the Product In Detail**
By this time, the question arises about the data sources for such a data-heavy project. Many companies keep this information secret or are simply reluctant to share it.
MyTelescope is exceptionally open about data because it's about making sense of customers' data sources. But the primary sources are in two buckets. You have search data from Google, Amazon Pay Store, and sentiment data from social media.
Those are different user forums, blogs, etc. And there are data sources they buy or get as a result of collaborations with third parties.
## **Widgets, Dashboards, Reports**
As soon as you start using MyTelescope, your eyes catch numerous visual components. We asked Rodrigo how this widget set was created. It's also interesting whether they have a primary appearance, or, maybe, they have changed and how.
**Rodrigo**: When we started building the product, it was based on how we saw the world and how you should be reporting towards a brand or trends. But now, as we're getting more and more users into the system, it's based on requests.
You have to have a purpose for what you want to know, and you have to start grilling by looking at it top-down. So you get all the data and look at it from different angles. These widgets and graphs are those different angles. So if someone says they want to understand their brand's reputation trend, they expect the visuals to analyze data based on those requests.
**So each widget represents a question the user might have.** That's how they are designed.
## **You Don't Ask for Data; You Get It Yourself**
MyTelescope is an impressively informative tool. The data is well structured and well presented. Here it's interesting who sets the workflow? Does the app itself explain how to use it properly and what steps to take, or is it up to the marketing managers, considering that the users are primarily large companies.
**Rodrigo**: Users don't want anyone to do it for them because they're more used to different digital tools. But if you think about my gen Y, it's used to emails and so on. But all of these strategic tools have not existed until now. So I think it's a bit of a transformation on the market as well, but we're being part of driving.
## **What About the Competition?**
MyTelescope's main competitors are consultants. Those, the companies that collect and analyze data and obtain recommendations for their use. At the same time, Rodrigo has a strong opinion that consultants can be their partners. How exactly? **They can use MyTelescope for data collection and then present the results to customers.**
There will always be a percentage of those who prefer to pay and receive a ready-made presentation via email.
Another vast and powerful competitor is Google Trends. First of all, it is free. In the second — it's mega-popular and authoritative. However, it doesn't give you a chance to dig deeper and get that kind of data that MyTelescope offers.

How MyTelescope ad GoogleTrends differ
**Rodrigo**: You can understand [from GoogleTrends] what's happening, but you don't know why it's happening. That's why we give away the share of search metrics for free because we know it's a free metric out there. **What you're buying from us is understanding where the trend is going and why it's going there.**
And, of course, there are competitors such as Semrush — a top-rated service that offers similar services but does not combine them with search data.
## **Marketing and Sales Challenges**
The next question is how the company finds its customers, contacts them, turns leads into customers and partners.
**Rodrigo**: How do we attract customers? Basically, through leadership, PR, AdWords buying, search terms, webinars, etc.
That's complex work to make people understand what we're doing and inspire them to get into the product. And then, when they're in the product, we have a team that educates, helps, and inspires you. Our firm belief is that when you're ready to buy, you will buy it.
If you love the product, you don't want to stay aside. We do it for business to business because we believe that company... it's still people. And they want to get inspired. They want to have fun. **They want to have stuff that makes them feel better after the job.**
One of the key indicators of product quality is how long the customer stays with you. When we ask Rodrigo about this, he points that the platform is new; it's only a year old. But, from another point of view, a year is enough for the first conclusions. Most of MyTelescope users try once and stay. Still, to make adequate and accurate conclusions based on this indicator, you should wait 3-5 years and analyze data.
**Rodrigo**: The main factor that makes people want to stay is history. Our vision is that since you build your personalized dashboard, you develop your unique personal data sets and vision. You will remain with the product or a company as long as you are working.
The product is innovative; it's a brand new category on the market. Accordingly, it's challenging to sell it. MyTelescope offers its users to explore how the market behaves and develops by analyzing search data. Quite often, people don't understand what it means and what they get from this.
**Rodrigo**: We have between ten to a hundred new users every month coming into the tool. However, they come because they want to know what it is and how it works; they are curious!
And at this point, our main task is to turn this interest into a desire to buy a product. It means to make people love your product. And this, in turn, means making this product an absolute hit. **It's the way from "What's that?" to "I want it!"**
## **A Global Brand From Day One**
The starting point in building the market was Sweden. It was a very successful start. It showcases that customers need and desire this product and are ready to buy and use it. Accordingly, Rodrigo and his team went further and shifted their focus to the United States and the United Kingdom. Since the company was created as a global brand from the beginning, it was worth working on the countries where most of the target companies are located.
**Rodrigo**: We have an idea that the legacy companies like Unilever, Kellog, Procter & Gamble, and similar need to close the funnel gap. They need to understand what's happening between the moment they produce the product and the moment customers get it right. And now, after many changes in privacy and cookie laws, you can see that.
On the other hand, smaller companies also receive tons of information regarding brand behavior. For the MyTelescope team, they are precious users. They explain, by their example, where to start and how to move, what methods to use, how to build and develop a brand. Because all and everything in this world has brands.

The definition of brand from Rodrigo – founder of MyTelescope
## **How to Sell to the Enterprise?**
Another question regards the use of the platform by companies with several offices in different countries. Here Rodrigo highlights word of mouth and reputation as critical points and goals.
**Rodrigo**: Let's say I work at Adidas in Sweden. The chance of me accepting data from someone from Adidas in Germany is more significant than from outside. First of all, you get a warm intro. So that's the whole idea that we have: to create as many warm interests as possible and build a community.
## **Ready For Use Data**
The thing with actionable insights is having purposes and understanding them. And that's something no one can figure out for you. Ask yourself what you want to know? Why do you want to know it? How are you going to use this knowledge? What is your final goal?
**Rodrigo**: Let's say I use MyTelescope to understand brand health. It means I have a purpose. I explore my brand and compare it to other ones. And I see that I have a problem.
The trend curve is going negative. Why? Because people are not happy with the price offered, they don't like the communication, the product itself, etc. It's not pleasant information, but it's great to get it and learn from it.
In this way, the marketing manager can understand the problem and address it to the right people. Because in most cases, the marketer is the final point in solving problems like this. It is the most outstanding value that data gives and that people often forget about for some reason.
Also, **it helps you to understand how to build the subsequent campaigns**, what to offer, how people's wishes and tastes change, which queries, and which characteristics become more common.
**Rodrigo:** People forget when working with a data-intensive company that the most challenging but fundamental part is understanding how to work with the data in place. And that's been a colossal job finding ways to organize it in a way that makes sense and is easy to scale over time.
## **Look At the Future**
Near the end of our dialogue, we ask Rodrigo about plans. Regarding the product, first of all: how they plan to improve it, to advertise, etc.
The product is planned to become more intuitive and easy to use; that's the first challenge. Another one is a perspective of working with massive amounts of data and the desire to "befriend with time." After all, the processing and structuring of these data are time-consuming.
**Rodrigo**: We have some technical issues since it takes time to get data. How can we tell people that it's okay and takes time? **But the reason is that we're creating a unique data set for every user.**
As for the next year, the company's focus is shifted towards the United States and building a commercial presence there. Quite a motivating factor for finding solutions to tech challenges quickly:)
The cherry on the top: we asked Rodrigo to share some advice from his experience and expertise for the brand directors and chief marketing officers. What should they look at next year, what to follow, etc.?
**Rodrigo**: I think the biggest challenge for all marketers these days is how to look at performance marketing, and how to make sense of the longer-term perspective, the totality of the brand, communication. To realize it, we need to understand our consumers and talk their language.
So, without a doubt, I can say that search analytics will be impressively crucial in the following years because it's a way of closing that gap. | techmagic | |
953,086 | Obsidian.md trouble in paradise | Not to long ago, I made this post soliciting recommendations for note taking apps and y'all came... | 0 | 2022-01-12T23:41:54 | https://dev.to/jasterix/obsidian-trouble-in-paradise-18da | beginners, watercooler, todayilearned, webdev | Not to long ago, I made [this post soliciting](https://dev.to/jasterix/whats-your-favorite-notetaking-app-6mf) recommendations for note taking apps and y'all came through!
My top 3, recommended by the lovely people below were:
1. [RemNote](remnote.com/) by @dgeisz
2. [Obsidian.md](https://obsidian.md/) by @terabytetiger
3. [Bear](https://bear.app/) by @jackkeller
- _note:_ I should prob mention that Bear is only for Apple devices, my work is 99.99% in a Windows environment, and my phone is Android. But that UI is too. damn. sexy to leave off this list
Since the RemNote desktop was a little glitchy, I decided to keep an eye on it and started using Obsidian as my daily app. Since then, it's pretty much been smooth sailing. I found some great extensions and upped my productivity by with daily notes and rollover to-dos.
Yesterday, things suddenly took a turn. I clicked on one of the shortcuts to open my daily note, and everything was gone. My activity tracking, items for review and follow disappeared. Obsidian had overwritten my daily note with a brand new file.
Today, things got 10x worse when I restarted my computer, opened Obsidian and found that most of the folders had disappeared. I was able to mostly restore them. But the latest files were not in their latest state.
The likely culprit - the new Live Preview editor.

I turned it on this week and it's been chaos since. However I'm not too keen to find out.
And so the hunt for my next best note taking tool continues 🥲
Photo by burak kostak from Pexels | jasterix |
953,515 | Pandas and SQL side by side | Learn pandas from sql or vice-versa | 0 | 2022-01-13T05:08:53 | https://dev.to/alephthoughts/pandas-and-sql-side-by-side-50j2 | pandas, sql, python | ---
title: Pandas and SQL side by side
published: true
description: Learn pandas from sql or vice-versa
tags: pandas, SQL, python
cover_image: 
---
SQL is a must have skill if you are working with data. Pandas is as essential for data analysis in the python. If you're someone who knows pandas and want to learn SQL or you know SQL and want to learn pandas, this post will introduce you to some basic skills.
To work on SQL you need access to a database hosted locally or on the cloud. Some popular databases you can work with are the following:
- [MySQL](https://www.mysql.com/)
- [MS SQL Server](https://www.microsoft.com/en-us/sql-server/sql-server-downloads)
- [Oracle](https://www.oracle.com/database/)
- [PostgreSQL](https://www.postgresql.org/)
- [Teradata](https://www.teradata.com/Products/Software/Database)
- [BigQuery](https://cloud.google.com/bigquery/)
- [Redshift](https://aws.amazon.com/redshift/)
There are many more but I've tried to list down the popular ones.
To show side by side examples, however, I am not using any database. I have using a SQL engine called [pandassql](https://github.com/yhat/pandasql/). So to run these examples, you will have to read some [data](https://www.kaggle.com/heesoo37/120-years-of-olympic-history-athletes-and-results) into pandas dataframe and then use pandasql to run SQL queries.
So the steps are as follows:
1. !pip install -U pandassql
2. import pandas as pd
3. from pandassql import sqldf
4. data = pd.read_csv(<path-to-athlete_events.csv>)
5. Run these examples
### SELECTing Data
Once you import the data, select 5 rows from the data just to inspects. Below is an example of how to select top 5 rows in pandas:
```python
data.head()
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ID</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>Height</th>
<th>Weight</th>
<th>Team</th>
<th>NOC</th>
<th>Games</th>
<th>Year</th>
<th>Season</th>
<th>City</th>
<th>Sport</th>
<th>Event</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1</td>
<td>A Dijiang</td>
<td>M</td>
<td>24.0</td>
<td>180.0</td>
<td>80.0</td>
<td>China</td>
<td>CHN</td>
<td>1992 Summer</td>
<td>1992</td>
<td>Summer</td>
<td>Barcelona</td>
<td>Basketball</td>
<td>Basketball Men's Basketball</td>
<td>NaN</td>
</tr>
<tr>
<th>1</th>
<td>2</td>
<td>A Lamusi</td>
<td>M</td>
<td>23.0</td>
<td>170.0</td>
<td>60.0</td>
<td>China</td>
<td>CHN</td>
<td>2012 Summer</td>
<td>2012</td>
<td>Summer</td>
<td>London</td>
<td>Judo</td>
<td>Judo Men's Extra-Lightweight</td>
<td>NaN</td>
</tr>
<tr>
<th>2</th>
<td>3</td>
<td>Gunnar Nielsen Aaby</td>
<td>M</td>
<td>24.0</td>
<td>NaN</td>
<td>NaN</td>
<td>Denmark</td>
<td>DEN</td>
<td>1920 Summer</td>
<td>1920</td>
<td>Summer</td>
<td>Antwerpen</td>
<td>Football</td>
<td>Football Men's Football</td>
<td>NaN</td>
</tr>
<tr>
<th>3</th>
<td>4</td>
<td>Edgar Lindenau Aabye</td>
<td>M</td>
<td>34.0</td>
<td>NaN</td>
<td>NaN</td>
<td>Denmark/Sweden</td>
<td>DEN</td>
<td>1900 Summer</td>
<td>1900</td>
<td>Summer</td>
<td>Paris</td>
<td>Tug-Of-War</td>
<td>Tug-Of-War Men's Tug-Of-War</td>
<td>Gold</td>
</tr>
<tr>
<th>4</th>
<td>5</td>
<td>Christine Jacoba Aaftink</td>
<td>F</td>
<td>21.0</td>
<td>185.0</td>
<td>82.0</td>
<td>Netherlands</td>
<td>NED</td>
<td>1988 Winter</td>
<td>1988</td>
<td>Winter</td>
<td>Calgary</td>
<td>Speed Skating</td>
<td>Speed Skating Women's 500 metres</td>
<td>NaN</td>
</tr>
</tbody>
</table>
You can achieve the same result in SQL:
```python
sqldf("SELECT * FROM data LIMIT 5")
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ID</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>Height</th>
<th>Weight</th>
<th>Team</th>
<th>NOC</th>
<th>Games</th>
<th>Year</th>
<th>Season</th>
<th>City</th>
<th>Sport</th>
<th>Event</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1</td>
<td>A Dijiang</td>
<td>M</td>
<td>24.0</td>
<td>180.0</td>
<td>80.0</td>
<td>China</td>
<td>CHN</td>
<td>1992 Summer</td>
<td>1992</td>
<td>Summer</td>
<td>Barcelona</td>
<td>Basketball</td>
<td>Basketball Men's Basketball</td>
<td>None</td>
</tr>
<tr>
<th>1</th>
<td>2</td>
<td>A Lamusi</td>
<td>M</td>
<td>23.0</td>
<td>170.0</td>
<td>60.0</td>
<td>China</td>
<td>CHN</td>
<td>2012 Summer</td>
<td>2012</td>
<td>Summer</td>
<td>London</td>
<td>Judo</td>
<td>Judo Men's Extra-Lightweight</td>
<td>None</td>
</tr>
<tr>
<th>2</th>
<td>3</td>
<td>Gunnar Nielsen Aaby</td>
<td>M</td>
<td>24.0</td>
<td>NaN</td>
<td>NaN</td>
<td>Denmark</td>
<td>DEN</td>
<td>1920 Summer</td>
<td>1920</td>
<td>Summer</td>
<td>Antwerpen</td>
<td>Football</td>
<td>Football Men's Football</td>
<td>None</td>
</tr>
<tr>
<th>3</th>
<td>4</td>
<td>Edgar Lindenau Aabye</td>
<td>M</td>
<td>34.0</td>
<td>NaN</td>
<td>NaN</td>
<td>Denmark/Sweden</td>
<td>DEN</td>
<td>1900 Summer</td>
<td>1900</td>
<td>Summer</td>
<td>Paris</td>
<td>Tug-Of-War</td>
<td>Tug-Of-War Men's Tug-Of-War</td>
<td>Gold</td>
</tr>
<tr>
<th>4</th>
<td>5</td>
<td>Christine Jacoba Aaftink</td>
<td>F</td>
<td>21.0</td>
<td>185.0</td>
<td>82.0</td>
<td>Netherlands</td>
<td>NED</td>
<td>1988 Winter</td>
<td>1988</td>
<td>Winter</td>
<td>Calgary</td>
<td>Speed Skating</td>
<td>Speed Skating Women's 500 metres</td>
<td>None</td>
</tr>
</tbody>
</table>
Both pandas and SQL allow you to select specific columns from the dataframe(pandas) or table(SQL).
```python
data[['Name', 'Age', 'Team', 'Year']].head()
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Name</th>
<th>Age</th>
<th>Team</th>
<th>Year</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>A Dijiang</td>
<td>24.0</td>
<td>China</td>
<td>1992</td>
</tr>
<tr>
<th>1</th>
<td>A Lamusi</td>
<td>23.0</td>
<td>China</td>
<td>2012</td>
</tr>
<tr>
<th>2</th>
<td>Gunnar Nielsen Aaby</td>
<td>24.0</td>
<td>Denmark</td>
<td>1920</td>
</tr>
<tr>
<th>3</th>
<td>Edgar Lindenau Aabye</td>
<td>34.0</td>
<td>Denmark/Sweden</td>
<td>1900</td>
</tr>
<tr>
<th>4</th>
<td>Christine Jacoba Aaftink</td>
<td>21.0</td>
<td>Netherlands</td>
<td>1988</td>
</tr>
</tbody>
</table>
```python
sqldf('SELECT Name, Age, Team, Year FROM data LIMIT 5')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Name</th>
<th>Age</th>
<th>Team</th>
<th>Year</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>A Dijiang</td>
<td>24.0</td>
<td>China</td>
<td>1992</td>
</tr>
<tr>
<th>1</th>
<td>A Lamusi</td>
<td>23.0</td>
<td>China</td>
<td>2012</td>
</tr>
<tr>
<th>2</th>
<td>Gunnar Nielsen Aaby</td>
<td>24.0</td>
<td>Denmark</td>
<td>1920</td>
</tr>
<tr>
<th>3</th>
<td>Edgar Lindenau Aabye</td>
<td>34.0</td>
<td>Denmark/Sweden</td>
<td>1900</td>
</tr>
<tr>
<th>4</th>
<td>Christine Jacoba Aaftink</td>
<td>21.0</td>
<td>Netherlands</td>
<td>1988</td>
</tr>
</tbody>
</table>
### Filtering with constraints
`iloc` property of a pandas dataframe allows you to select a row by its index as shown below. Here we are particulary selecting the 6th row by applying the filter on index.
```python
data.iloc[6]
```
ID 5
Name Christine Jacoba Aaftink
Sex F
Age 25.0
Height 185.0
Weight 82.0
Team Netherlands
NOC NED
Games 1992 Winter
Year 1992
Season Winter
City Albertville
Sport Speed Skating
Event Speed Skating Women's 500 metres
Medal NaN
Name: 6, dtype: object
In SQL most databases provide a rowid index to select a specific row from the table.
```python
sqldf("SELECT * FROM data WHERE rowid=6")
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ID</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>Height</th>
<th>Weight</th>
<th>Team</th>
<th>NOC</th>
<th>Games</th>
<th>Year</th>
<th>Season</th>
<th>City</th>
<th>Sport</th>
<th>Event</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>5</td>
<td>Christine Jacoba Aaftink</td>
<td>F</td>
<td>21.0</td>
<td>185.0</td>
<td>82.0</td>
<td>Netherlands</td>
<td>NED</td>
<td>1988 Winter</td>
<td>1988</td>
<td>Winter</td>
<td>Calgary</td>
<td>Speed Skating</td>
<td>Speed Skating Women's 1,000 metres</td>
<td>None</td>
</tr>
</tbody>
</table>
You can filter on a condition applied on column or multiple columns. In case of multiple columns, the conditions are combined with boolen expressions such as AND, OR etc.
Here is how to count records which satisfy the condition "Age of the athelete is greater than 30".
```python
data[data['Age']>30]['ID'].count()
```
42107
```python
sqldf('SELECT COUNT(*) FROM data WHERE Age > 30')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>COUNT(*)</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>42107</td>
</tr>
</tbody>
</table>
Below is an example of multiple conditions. We are selecting all records of `Hockey` for team `India`.
```python
data[(data['Team'] == 'India') & (data['Sport']=='Hockey')]
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ID</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>Height</th>
<th>Weight</th>
<th>Team</th>
<th>NOC</th>
<th>Games</th>
<th>Year</th>
<th>Season</th>
<th>City</th>
<th>Sport</th>
<th>Event</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>2513</th>
<td>1415</td>
<td>Shakeel Ahmed</td>
<td>M</td>
<td>21.0</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1992 Summer</td>
<td>1992</td>
<td>Summer</td>
<td>Barcelona</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>NaN</td>
</tr>
<tr>
<th>4289</th>
<td>2453</td>
<td>Anil Alexander Aldrin</td>
<td>M</td>
<td>24.0</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1996 Summer</td>
<td>1996</td>
<td>Summer</td>
<td>Atlanta</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>NaN</td>
</tr>
<tr>
<th>4732</th>
<td>2699</td>
<td>Shaukat Ali</td>
<td>M</td>
<td>30.0</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1928 Summer</td>
<td>1928</td>
<td>Summer</td>
<td>Amsterdam</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>Gold</td>
</tr>
<tr>
<th>4735</th>
<td>2702</td>
<td>Syed Ali</td>
<td>M</td>
<td>19.0</td>
<td>169.0</td>
<td>60.0</td>
<td>India</td>
<td>IND</td>
<td>1976 Summer</td>
<td>1976</td>
<td>Summer</td>
<td>Montreal</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>NaN</td>
</tr>
<tr>
<th>4736</th>
<td>2703</td>
<td>Syed Mushtaq Ali</td>
<td>M</td>
<td>22.0</td>
<td>165.0</td>
<td>61.0</td>
<td>India</td>
<td>IND</td>
<td>1964 Summer</td>
<td>1964</td>
<td>Summer</td>
<td>Tokyo</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>Gold</td>
</tr>
<tr>
<th>...</th>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
</tr>
<tr>
<th>253354</th>
<td>126867</td>
<td>Sunil Sowmarpet Vitalacharya</td>
<td>M</td>
<td>27.0</td>
<td>176.0</td>
<td>68.0</td>
<td>India</td>
<td>IND</td>
<td>2016 Summer</td>
<td>2016</td>
<td>Summer</td>
<td>Rio de Janeiro</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>NaN</td>
</tr>
<tr>
<th>256143</th>
<td>128249</td>
<td>Devindar Sunil Walmiki</td>
<td>M</td>
<td>24.0</td>
<td>178.0</td>
<td>69.0</td>
<td>India</td>
<td>IND</td>
<td>2016 Summer</td>
<td>2016</td>
<td>Summer</td>
<td>Rio de Janeiro</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>NaN</td>
</tr>
<tr>
<th>263723</th>
<td>131974</td>
<td>William Xalco</td>
<td>M</td>
<td>20.0</td>
<td>167.0</td>
<td>60.0</td>
<td>India</td>
<td>IND</td>
<td>2004 Summer</td>
<td>2004</td>
<td>Summer</td>
<td>Athina</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>NaN</td>
</tr>
<tr>
<th>264075</th>
<td>132142</td>
<td>Renuka Yadav</td>
<td>F</td>
<td>22.0</td>
<td>159.0</td>
<td>53.0</td>
<td>India</td>
<td>IND</td>
<td>2016 Summer</td>
<td>2016</td>
<td>Summer</td>
<td>Rio de Janeiro</td>
<td>Hockey</td>
<td>Hockey Women's Hockey</td>
<td>NaN</td>
</tr>
<tr>
<th>266934</th>
<td>133554</td>
<td>Sayed Muhammad Yusuf</td>
<td>M</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1928 Summer</td>
<td>1928</td>
<td>Summer</td>
<td>Amsterdam</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>Gold</td>
</tr>
</tbody>
</table>
<p>345 rows à 15 columns</p>
```python
sqldf('SELECT * FROM data WHERE Team="India" AND Sport="Hockey"')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ID</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>Height</th>
<th>Weight</th>
<th>Team</th>
<th>NOC</th>
<th>Games</th>
<th>Year</th>
<th>Season</th>
<th>City</th>
<th>Sport</th>
<th>Event</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1415</td>
<td>Shakeel Ahmed</td>
<td>M</td>
<td>21.0</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1992 Summer</td>
<td>1992</td>
<td>Summer</td>
<td>Barcelona</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>None</td>
</tr>
<tr>
<th>1</th>
<td>2453</td>
<td>Anil Alexander Aldrin</td>
<td>M</td>
<td>24.0</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1996 Summer</td>
<td>1996</td>
<td>Summer</td>
<td>Atlanta</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>None</td>
</tr>
<tr>
<th>2</th>
<td>2699</td>
<td>Shaukat Ali</td>
<td>M</td>
<td>30.0</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1928 Summer</td>
<td>1928</td>
<td>Summer</td>
<td>Amsterdam</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>Gold</td>
</tr>
<tr>
<th>3</th>
<td>2702</td>
<td>Syed Ali</td>
<td>M</td>
<td>19.0</td>
<td>169.0</td>
<td>60.0</td>
<td>India</td>
<td>IND</td>
<td>1976 Summer</td>
<td>1976</td>
<td>Summer</td>
<td>Montreal</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>None</td>
</tr>
<tr>
<th>4</th>
<td>2703</td>
<td>Syed Mushtaq Ali</td>
<td>M</td>
<td>22.0</td>
<td>165.0</td>
<td>61.0</td>
<td>India</td>
<td>IND</td>
<td>1964 Summer</td>
<td>1964</td>
<td>Summer</td>
<td>Tokyo</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>Gold</td>
</tr>
<tr>
<th>...</th>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
</tr>
<tr>
<th>340</th>
<td>126867</td>
<td>Sunil Sowmarpet Vitalacharya</td>
<td>M</td>
<td>27.0</td>
<td>176.0</td>
<td>68.0</td>
<td>India</td>
<td>IND</td>
<td>2016 Summer</td>
<td>2016</td>
<td>Summer</td>
<td>Rio de Janeiro</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>None</td>
</tr>
<tr>
<th>341</th>
<td>128249</td>
<td>Devindar Sunil Walmiki</td>
<td>M</td>
<td>24.0</td>
<td>178.0</td>
<td>69.0</td>
<td>India</td>
<td>IND</td>
<td>2016 Summer</td>
<td>2016</td>
<td>Summer</td>
<td>Rio de Janeiro</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>None</td>
</tr>
<tr>
<th>342</th>
<td>131974</td>
<td>William Xalco</td>
<td>M</td>
<td>20.0</td>
<td>167.0</td>
<td>60.0</td>
<td>India</td>
<td>IND</td>
<td>2004 Summer</td>
<td>2004</td>
<td>Summer</td>
<td>Athina</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>None</td>
</tr>
<tr>
<th>343</th>
<td>132142</td>
<td>Renuka Yadav</td>
<td>F</td>
<td>22.0</td>
<td>159.0</td>
<td>53.0</td>
<td>India</td>
<td>IND</td>
<td>2016 Summer</td>
<td>2016</td>
<td>Summer</td>
<td>Rio de Janeiro</td>
<td>Hockey</td>
<td>Hockey Women's Hockey</td>
<td>None</td>
</tr>
<tr>
<th>344</th>
<td>133554</td>
<td>Sayed Muhammad Yusuf</td>
<td>M</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>India</td>
<td>IND</td>
<td>1928 Summer</td>
<td>1928</td>
<td>Summer</td>
<td>Amsterdam</td>
<td>Hockey</td>
<td>Hockey Men's Hockey</td>
<td>Gold</td>
</tr>
</tbody>
</table>
<p>345 rows à 15 columns</p>
### SORTING
Sorting is another common operation required during data analysis. You can sort on one or more columns and in ascending (low to high) or descending (high to low) order.
```python
data.sort_values(by='Age', ascending=False).head()
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ID</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>Height</th>
<th>Weight</th>
<th>Team</th>
<th>NOC</th>
<th>Games</th>
<th>Year</th>
<th>Season</th>
<th>City</th>
<th>Sport</th>
<th>Event</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>257054</th>
<td>128719</td>
<td>John Quincy Adams Ward</td>
<td>M</td>
<td>97.0</td>
<td>NaN</td>
<td>NaN</td>
<td>United States</td>
<td>USA</td>
<td>1928 Summer</td>
<td>1928</td>
<td>Summer</td>
<td>Amsterdam</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Sculpturing, Statues</td>
<td>NaN</td>
</tr>
<tr>
<th>98118</th>
<td>49663</td>
<td>Winslow Homer</td>
<td>M</td>
<td>96.0</td>
<td>NaN</td>
<td>NaN</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>NaN</td>
</tr>
<tr>
<th>60863</th>
<td>31173</td>
<td>Thomas Cowperthwait Eakins</td>
<td>M</td>
<td>88.0</td>
<td>NaN</td>
<td>NaN</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>NaN</td>
</tr>
<tr>
<th>60861</th>
<td>31173</td>
<td>Thomas Cowperthwait Eakins</td>
<td>M</td>
<td>88.0</td>
<td>NaN</td>
<td>NaN</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>NaN</td>
</tr>
<tr>
<th>60862</th>
<td>31173</td>
<td>Thomas Cowperthwait Eakins</td>
<td>M</td>
<td>88.0</td>
<td>NaN</td>
<td>NaN</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>NaN</td>
</tr>
</tbody>
</table>
```python
sqldf('SELECT * from data ORDER BY Age DESC LIMIT 5')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ID</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>Height</th>
<th>Weight</th>
<th>Team</th>
<th>NOC</th>
<th>Games</th>
<th>Year</th>
<th>Season</th>
<th>City</th>
<th>Sport</th>
<th>Event</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>128719</td>
<td>John Quincy Adams Ward</td>
<td>M</td>
<td>97.0</td>
<td>None</td>
<td>None</td>
<td>United States</td>
<td>USA</td>
<td>1928 Summer</td>
<td>1928</td>
<td>Summer</td>
<td>Amsterdam</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Sculpturing, Statues</td>
<td>None</td>
</tr>
<tr>
<th>1</th>
<td>49663</td>
<td>Winslow Homer</td>
<td>M</td>
<td>96.0</td>
<td>None</td>
<td>None</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>None</td>
</tr>
<tr>
<th>2</th>
<td>31173</td>
<td>Thomas Cowperthwait Eakins</td>
<td>M</td>
<td>88.0</td>
<td>None</td>
<td>None</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>None</td>
</tr>
<tr>
<th>3</th>
<td>31173</td>
<td>Thomas Cowperthwait Eakins</td>
<td>M</td>
<td>88.0</td>
<td>None</td>
<td>None</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>None</td>
</tr>
<tr>
<th>4</th>
<td>31173</td>
<td>Thomas Cowperthwait Eakins</td>
<td>M</td>
<td>88.0</td>
<td>None</td>
<td>None</td>
<td>United States</td>
<td>USA</td>
<td>1932 Summer</td>
<td>1932</td>
<td>Summer</td>
<td>Los Angeles</td>
<td>Art Competitions</td>
<td>Art Competitions Mixed Painting, Unknown Event</td>
<td>None</td>
</tr>
</tbody>
</table>
### Joining
Joining one dataset with another is a common operation while working with data. This is a simple aspect of SQL which stumps more people than it should.
I reckon, it is important to work with a simple example using few rows of data to get this right. That is what I am going to do using synthetic tables `employee` and `assets` with dummy data.
Please notice the column we are joining on, usually termed as *key*. If the *key* has duplicate values, the records multiply.
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>EmployeeID</th>
<th>DepartmentID</th>
<th>Name</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>100</td>
<td>100</td>
<td>John Doe</td>
</tr>
<tr>
<th>1</th>
<td>101</td>
<td>100</td>
<td>Will green</td>
</tr>
<tr>
<th>2</th>
<td>102</td>
<td>200</td>
<td>Wilson Miner</td>
</tr>
<tr>
<th>3</th>
<td>104</td>
<td>200</td>
<td>Rochel Dmello</td>
</tr>
<tr>
<th>4</th>
<td>105</td>
<td>300</td>
<td>Dickie Bird</td>
</tr>
</tbody>
</table>
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>AssetID</th>
<th>EmployeeID</th>
<th>DepartmentID</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>aab</td>
<td>100</td>
<td>100</td>
</tr>
<tr>
<th>1</th>
<td>aba</td>
<td>101</td>
<td>100</td>
</tr>
<tr>
<th>2</th>
<td>baa</td>
<td>201</td>
<td>200</td>
</tr>
<tr>
<th>3</th>
<td>cde</td>
<td>202</td>
<td>200</td>
</tr>
<tr>
<th>4</th>
<td>efg</td>
<td>103</td>
<td>300</td>
</tr>
</tbody>
</table>
#### Inner Join
The simplest type of join is the `inner` join.
This operation returns the common records from the left table (employee) and the right table (asset).
Pandas uses [merge](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.merge.html) method to join to tables.
```python
employee.merge(asset, on='EmployeeID')
```
\
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>EmployeeID</th>
<th>DepartmentID_x</th>
<th>Name</th>
<th>AssetID</th>
<th>DepartmentID_y</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>100</td>
<td>100</td>
<td>John Doe</td>
<td>aab</td>
<td>100</td>
</tr>
<tr>
<th>1</th>
<td>101</td>
<td>100</td>
<td>Will green</td>
<td>aba</td>
<td>100</td>
</tr>
</tbody>
</table>
```python
sqldf('SELECT * FROM employee E JOIN asset A ON E.EmployeeID = A.EmployeeID')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>EmployeeID</th>
<th>DepartmentID</th>
<th>Name</th>
<th>AssetID</th>
<th>EmployeeID</th>
<th>DepartmentID</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>100</td>
<td>100</td>
<td>John Doe</td>
<td>aab</td>
<td>100</td>
<td>100</td>
</tr>
<tr>
<th>1</th>
<td>101</td>
<td>100</td>
<td>Will green</td>
<td>aba</td>
<td>101</td>
<td>100</td>
</tr>
</tbody>
</table>
#### Left Outer Join
In Left Outer Join, you get all records from the left table, and only matching records from the right table.
Note the `NaN` and `None` values resulting in rows for which *key* doesn't match.
```python
employee.merge(asset, on='EmployeeID', how='left')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>EmployeeID</th>
<th>DepartmentID_x</th>
<th>Name</th>
<th>AssetID</th>
<th>DepartmentID_y</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>100</td>
<td>100</td>
<td>John Doe</td>
<td>aab</td>
<td>100</td>
</tr>
<tr>
<th>1</th>
<td>101</td>
<td>100</td>
<td>Will green</td>
<td>aba</td>
<td>100</td>
</tr>
<tr>
<th>2</th>
<td>102</td>
<td>200</td>
<td>Wilson Miner</td>
<td>NaN</td>
<td>NaN</td>
</tr>
<tr>
<th>3</th>
<td>104</td>
<td>200</td>
<td>Rochel Dmello</td>
<td>NaN</td>
<td>NaN</td>
</tr>
<tr>
<th>4</th>
<td>105</td>
<td>300</td>
<td>Dickie Bird</td>
<td>NaN</td>
<td>NaN</td>
</tr>
</tbody>
</table>
```python
sqldf('SELECT E.*, A.* FROM employee E LEFT JOIN asset A ON E.EmployeeID = A.EmployeeID')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>EmployeeID</th>
<th>DepartmentID</th>
<th>Name</th>
<th>AssetID</th>
<th>EmployeeID</th>
<th>DepartmentID</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>100</td>
<td>100</td>
<td>John Doe</td>
<td>aab</td>
<td>100.0</td>
<td>100</td>
</tr>
<tr>
<th>1</th>
<td>101</td>
<td>100</td>
<td>Will green</td>
<td>aba</td>
<td>101.0</td>
<td>100</td>
</tr>
<tr>
<th>2</th>
<td>102</td>
<td>200</td>
<td>Wilson Miner</td>
<td>None</td>
<td>NaN</td>
<td>None</td>
</tr>
<tr>
<th>3</th>
<td>104</td>
<td>200</td>
<td>Rochel Dmello</td>
<td>None</td>
<td>NaN</td>
<td>None</td>
</tr>
<tr>
<th>4</th>
<td>105</td>
<td>300</td>
<td>Dickie Bird</td>
<td>None</td>
<td>NaN</td>
<td>None</td>
</tr>
</tbody>
</table>
#### Right Outer Join
Right join has the opposite effect of the left join.
```python
employee.merge(asset, on='EmployeeID', how='right')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>EmployeeID</th>
<th>DepartmentID_x</th>
<th>Name</th>
<th>AssetID</th>
<th>DepartmentID_y</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>100</td>
<td>100.0</td>
<td>John Doe</td>
<td>aab</td>
<td>100</td>
</tr>
<tr>
<th>1</th>
<td>101</td>
<td>100.0</td>
<td>Will green</td>
<td>aba</td>
<td>100</td>
</tr>
<tr>
<th>2</th>
<td>201</td>
<td>NaN</td>
<td>NaN</td>
<td>baa</td>
<td>200</td>
</tr>
<tr>
<th>3</th>
<td>202</td>
<td>NaN</td>
<td>NaN</td>
<td>cde</td>
<td>200</td>
</tr>
<tr>
<th>4</th>
<td>103</td>
<td>NaN</td>
<td>NaN</td>
<td>efg</td>
<td>300</td>
</tr>
</tbody>
</table>
In fact pandassql doesn't support Right Join but you can achieve the same result by calling `asset` as the left table and `employee` as the right table.
```python
sqldf('SELECT E.*, A.* FROM asset A LEFT JOIN employee E ON A.EmployeeID = E.EmployeeID')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>EmployeeID</th>
<th>DepartmentID</th>
<th>Name</th>
<th>AssetID</th>
<th>EmployeeID</th>
<th>DepartmentID</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>100.0</td>
<td>100.0</td>
<td>John Doe</td>
<td>aab</td>
<td>100</td>
<td>100</td>
</tr>
<tr>
<th>1</th>
<td>101.0</td>
<td>100.0</td>
<td>Will green</td>
<td>aba</td>
<td>101</td>
<td>100</td>
</tr>
<tr>
<th>2</th>
<td>NaN</td>
<td>NaN</td>
<td>None</td>
<td>baa</td>
<td>201</td>
<td>200</td>
</tr>
<tr>
<th>3</th>
<td>NaN</td>
<td>NaN</td>
<td>None</td>
<td>cde</td>
<td>202</td>
<td>200</td>
</tr>
<tr>
<th>4</th>
<td>NaN</td>
<td>NaN</td>
<td>None</td>
<td>efg</td>
<td>103</td>
<td>300</td>
</tr>
</tbody>
</table>
Another type of join pandasql doesn't support is the __Full outer join__, which returns all matching as well as not matching records from both the tables.
You need not worry about these missing type of joins in pandassql, all database that I have worked with support Right Join and Full Outer Join. With some trickery you can even achieve these in pandassql but it's not required for this conversation.
### Queries with aggregates
Aggregates are another SQL technique where you group your records based on one or more columns and perform some aggregate calculation on another set of columns such as MIN, MAX, SUM, COUNT, AVG, and so on.
Here is an example of count where we count `Medal`s by team, sort them in descending order and show top % results.
```python
data.groupby('Team', as_index=False)['Medal'].count().sort_values('Medal', ascending=False).head()
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Team</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>1095</th>
<td>United States</td>
<td>5219</td>
</tr>
<tr>
<th>976</th>
<td>Soviet Union</td>
<td>2451</td>
</tr>
<tr>
<th>398</th>
<td>Germany</td>
<td>1984</td>
</tr>
<tr>
<th>412</th>
<td>Great Britain</td>
<td>1673</td>
</tr>
<tr>
<th>361</th>
<td>France</td>
<td>1550</td>
</tr>
</tbody>
</table>
```python
sqldf('SELECT Team, COUNT(Medal) FROM data GROUP BY Team ORDER BY COUNT(Medal) DESC LIMIT 5')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Team</th>
<th>COUNT(Medal)</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>United States</td>
<td>5219</td>
</tr>
<tr>
<th>1</th>
<td>Soviet Union</td>
<td>2451</td>
</tr>
<tr>
<th>2</th>
<td>Germany</td>
<td>1984</td>
</tr>
<tr>
<th>3</th>
<td>Great Britain</td>
<td>1673</td>
</tr>
<tr>
<th>4</th>
<td>France</td>
<td>1550</td>
</tr>
</tbody>
</table>
Here is another example where we filter just one sport `swimming` and do the earlier calculation.
```python
data[data['Sport']=='Swimming'].groupby('Team', as_index=False)['Medal'].count().sort_values('Medal', ascending=False).head()
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Team</th>
<th>Medal</th>
</tr>
</thead>
<tbody>
<tr>
<th>197</th>
<td>United States</td>
<td>1066</td>
</tr>
<tr>
<th>10</th>
<td>Australia</td>
<td>401</td>
</tr>
<tr>
<th>56</th>
<td>East Germany</td>
<td>152</td>
</tr>
<tr>
<th>70</th>
<td>Germany</td>
<td>152</td>
</tr>
<tr>
<th>72</th>
<td>Great Britain</td>
<td>127</td>
</tr>
</tbody>
</table>
```python
sqldf('SELECT Team, COUNT(Medal) FROM data Where Sport = "Swimming" GROUP BY Team ORDER BY COUNT(Medal) DESC LIMIT 5')
```
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Team</th>
<th>COUNT(Medal)</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>United States</td>
<td>1066</td>
</tr>
<tr>
<th>1</th>
<td>Australia</td>
<td>401</td>
</tr>
<tr>
<th>2</th>
<td>Germany</td>
<td>152</td>
</tr>
<tr>
<th>3</th>
<td>East Germany</td>
<td>152</td>
</tr>
<tr>
<th>4</th>
<td>Great Britain</td>
<td>127</td>
</tr>
</tbody>
</table>
There is a lot more you can do with SQL, like filtering on aggregated data usin HAVING clause. Partition data by row, rank or dense rank. Use analytical functions to compute values across rows or over a window.
There is even more that you can do with pandas. Here I am listing some resources if you're ready for a deep dive.
### Pandas Resources
- [Python for data analysis by Wes McKinney](https://www.amazon.com/Python-Data-Analysis-Wrangling-IPython/dp/1491957662/ref=sr_1_1?crid=FHSZBNN2LW2O&keywords=wes+mckinney&qid=1641999545&sprefix=wes+mckinney%2Caps%2C417&sr=8-1)
### SQL Resources
- [Kaggle's Intro to SQL](https://kaggle.com/learn/intro-to-sql)
- [SQL Bolt](https://t.co/GRhUKFSyS6)
- [SQL for Data Scientists by Renee Teate](https://t.co/c1KRNA74vY)
| alephthoughts |
953,692 | SP-FLAMINGO - SopPlayer Skin Integration - Custom Video Player | Documentation Video :- https://www.youtube.com/watch?v=DOxtPWfKWUY Demo Website :-... | 0 | 2022-01-13T07:53:13 | https://dev.to/sh20raj/sp-flamingo-sopplayer-skin-integration-custom-video-player-4675 | sopplayer, sh20raj, javascript, videojs | Documentation Video :- https://www.youtube.com/watch?v=DOxtPWfKWUY
Demo Website :- https://sopplayer.sh20raj.repl.co/flamingo
View on Repl.it :- https://replit.com/@SH20RAJ/SopPlayer#flamingo
<center>
[GitHub](https://github.com/SH20RAJ/Sopplayer/tree/main/flamingo)

</center>
### Steps to Import :-
Steps :-
1 . Use `class="sopplayer"` in Your `<video>` Tag .
2 . And Add `data-setup="{}"`, attribute like this .
---
**HERE IS THE FULL VIDEO CODE**
```
<video id="my-video" poster="https://i.ytimg.com/vi/YE7VzlLtp-4/maxresdefault.jpg"
class="sopplayer" controls preload="auto" data-setup="{}" width="500px">
<!--Use class="sopplayer" and data-setup="{}" -->
<source src="https://commondatastorage.googleapis.com/gtv-videos-bucket/CastVideos/mp4/BigBuckBunny.mp4" type="video/mp4" />
</video>
```
3 . Add the JavaScript CDN only before `</body>` Tag
---
**HERE IS THE JAVASCRIPT CDN**
```
<script src="https://cdn.jsdelivr.net/gh/SH20RAJ/Sopplayer/flamingo/sp-flamingo.min.js"></script>
<!--Here is the JavaScript Library-->
```
Here you have completed your Sopplayer-Flamingo Intgretion.
<center>
**Before Sopplayer**

**After Sopplayer**

</center>
---
**SEE HOW FULL HTML WILL LOOK LIKE**
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<center>
<body>
<video id="my-video" class="sopplayer" controls preload="auto" data-setup="{}" width="500px">
<!--Use class="sopplayer" and data-setup="{}" -->
<source src="sample.mp4" type="video/mp4" />
</video>
<script src="https://cdn.jsdelivr.net/gh//SH20RAJ/Sopplayer/flamingo/sp-flamingo.min.js"></script>
<!--Here is the JavaScript Library-->
</center>
</body>
</html>
```
<center>
## **Visit [GitHub](https://github.com/SH20RAJ/sp-flamingo) View [Demo](https://sopplayer.sh20raj.repl.co/flamingo/)**
**
See Articles :-
---
https://codexdindia.blogspot.com/2021/02/sp-flamingo-sopplayer-skin-integration.html
---
https://dev.to/sh20raj/sp-flamingo-sopplayer-skin-integration-custom-video-player-4675/
**
</center>
| sh20raj |
953,718 | How to create a two-column layout with HTML & CSS (YouTube Clone - part 1) | Making YouTube clone with HTML and CSS | 0 | 2022-01-13T10:47:48 | https://dev.to/codingnninja/how-to-create-a-two-column-layout-with-html-css-youtube-clone-part-1-3mno | career, html, css, tutorial | ---
title: How to create a two-column layout with HTML & CSS (YouTube Clone - part 1)
published: true
description: Making YouTube clone with HTML and CSS
tags: careers,html,css, tutorial
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/yuakdz7llr85siwvfeix.PNG
---
Welcome to this lesson which is a part of a series of tutorials to build a YouTube Clone unlike what you have seen before.
In this lesson, we are going to discuss how to make the layout of our YouTube clone project with HTML and CSS and you are going to learn how to make a two-column layout.
If you have been struggling to build a real website with HTML & CSS, you're so lucky to be reading this because I am about to teach you to do it step by step to reduce your struggle.
Just wait: If you're a total beginner and you can't operate computers properly, please check out the video below to learn everything you need...
{% youtube dXC4EEkO1vI %}
If you know me very well, you would have known I am an advocate of breaking things up into sections, sub-sections and components. So, we have to break this YouTube clone into smaller units and we're going to be building each of them step by step.
In this YouTube clone, the website has about 6 units:
1. Header: It contains three sections (left, center and right). The left section contains the logo and menu; the center section contains the search box and an icon, while the right section contains navigation icons. The icons have a similar element, which means, we design an icon element; then, copy, paste and edit it to create others.
2. Main: It contains two sections (sidebar and content). The navigation links in the sidebar are also similar, so they are just one thing. The same thing happens to the videos in the content section.
So, it has a header, main, sidebar, content, video-card, navigation link and navigation icon as the major units. That is the breakdown of the units of the web page we want to create.
The first thing we have to do is create the layout structure of the YouTube clone with HTML as in below:
```js
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<!-- Material Icons -->
<link href="https://fonts.googleapis.com/icon?family=Material+Icons" rel="stylesheet" />
<!-- CSS File -->
<link rel="stylesheet" href="styles/index.css" />
<title>Youtube Clone with HTML & CSS</title>
</head>
<body>
<header class="header">.</header>
<main>
<div class="side-bar">.</div>
<div class="content">.</div>
</main>
<!-- Main Body Ends -->
</body>
</html>
```
In this lesson, I assume you have an understanding of how to use HTML meta tags and how to link a CSS file. If you don’t, learn more about it later in the video I added above. But you don’t need to understand them for what we are learning in this lesson, so keep on reading.
We have a header tag to create the header section of the YouTube clone. YouTube logo, search box and other navigation icons will be added to the header later.
There is also the main section that contains side-bar and content. The side-bar will contain some navigation links while the content will contain videos. So, that is it for the structure with just HTML.
Then, let’s add CSS to it to really create a YouTube layout.
Here is the CSS step by step:
```
@import url('https://fonts.googleapis.com/css2?family=Roboto:wght@300;400;700&display=swap');
```
Let’s start with “import url(‘path’)...What does it do? It is used to link to the Google font called Roboto so that we can use it as the font of our website.
```css
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
```
The (*) is CSS selector that selects all HTML tags on our page and we set their margin and padding to 0; We finally set their box-sizing to border-box. Why do we do that?
We want width or height, border, margin and padding to be sum up to be the total length. This is what I meant. In css, if a box has width of 100px and padding of 10px, the width of the box will now be 110px
but we don't want that, we want everything to be 100px. Width should still be 100px including the margin of 10px instead of making it 110px. That is what box-sizing: border-box does.
Note: when you're using it, you will understand better but that gives an insight a beginner can quickly relate with.
```css
body {
font-family: 'Roboto', sans-serif;
}
```
We select the body tag and set it font-family to Roboto and use sans-serif as a fall-back in case Roboto is not available.
```css
/* header section*/
.header {
display: flex;
justify-content: space-between;
align-items: center;
height: 60px;
padding: 15px;
}
```
.header class name is used to select (or connect to) the header section of our website so that we can add some styles to it. We set its display property to flex to create a layout out of it and then, we can easily divide it into sections. We will divide it into sections later.
Justify-content: space-between means we want the contents in the header to have space between each other once they are more than one.
`Align-items: centre` is used to move all the contents of the header to the centre-left of your screen. That is called vertical alignment. We finally set the `height` of the `header` to 60px and its padding to 15px. Do you know what padding is? Well, we will talk about it later.
```css
main {
height: calc(100vh - 70px);
display: flex;
background-color: #f9f9f9;
}
```
We set the `height` of the main section to `calc( 100vh - 70px`)...What does it mean? V stands for a `viewport` which is the visible part of a window’s screen without scrolling while “height” means vertical length and we may also use “w” which means width - horizontal length. In short, 100vh means the total height that is visible in a browser without scrolling. And we use calc ( 100vh - 70px) to run a calculation that subtract 70px from 100vh.
We set its display property to flex to create a layout out of it. Finally, we set its background colour to `#f9f99f` which is a kind of silver or ash.
```css
/* Sidebar */
.side-bar {
height: 100%;
width: 17%;
background-color: white;
overflow-y: hidden;
}
```
The `height` of the .side-bar is set to 100% of its parent. That means it will have the same height as its parent. Its width is set to 17% of its parent and background colour set to white. Hey! What is overflow-y: hidden? When Twitter loads 10 tweets at once, you can’t see everything at once and you have to scroll, right? In this case, we hide the scroll bar. Gracias!
```css
@media (max-width: 768px) {
.side-bar {
display: none;
}
}
```
This media query is used to make a website responsive on mobile, tablet and desktop. When the YouTube clone is on a device whose screen is less or equal to 768px (e.g mobile & tablet), the sidebar will disappear. Also, max-width: 768px means such device’s screen can be less or equal to 768px.
Yeah, we have built the layout of our YouTube clone. Below is the result…next time, we will add some other things. See you soon.
## One more thing
Learn more by joining one of the groups below:
Discord:
https://discord.com/invite/Ef5Sqd2w
Telegram:
https://t.me/+HEUn1Y-ME6GW9ssD
| codingnninja |
953,784 | Ruby strftime : short and long story | Article originally published here :... | 12,217 | 2022-01-13T10:12:31 | https://bootrails.com/blog/ruby-strftime-short-and-long-story/ | ruby |
Article originally published here : https://www.bootrails.com/blog/ruby-strftime-short-and-long-story/
## strftime for the impatients
Sometimes examples worth a thousand words, so here are some that could help you right away (example inspired from APIDoks) :
```ruby
d = DateTime.new(2021,11,19,8,37,48,"-06:00")
# => Fri, 19 Nov 2021 08:37:48 -0600
d.strftime("Printed on %m/%d/%Y")
# => "Printed on 11/19/2021"
d.strftime("at %I:%M%p")
# => "at 08:37AM"
```
And a lot more of raw examples (explanations in paragraphs below)
```ruby
%Y%m%d => 20211119
%F => 2021-11-19
%Y-%m => 2021-11
%Y => 2021
%C => 20
%Y%j => 2021323
%Y-%j => 2021-323
%GW%V%u => 2021W471
%G-W%V-%u => 2021-W47-1
%GW%V => 2021W47
%G-W%V => 2021-W47
%H%M%S => 083748
%T => 08:37:48
%H%M => 0837
%H:%M => 08:37
%H => 08
%H%M%S,%L => 083748,000
%T,%L => 08:37:48,000
%H%M%S.%L => 083748.000
%T.%L => 08:37:48.000
%H%M%S%z => 083748-0600
%T%:z => 08:37:48-06:00
%Y%m%dT%H%M%S%z => 20211119T083748-0600
%FT%T%:z => 2021-11-19T08:37:48-06:00
%Y%jT%H%M%S%z => 2021323T083748-0600
%Y-%jT%T%:z => 2021-323T08:37:48-06:00
%GW%V%uT%H%M%S%z => 2021W471T083748-0600
%G-W%V-%uT%T%:z => 2021-W47-1T08:37:48-06:00
%Y%m%dT%H%M => 20211119T0837
%FT%R => 2021-11-19T08:37
%Y%jT%H%MZ => 2021323T0837Z
%Y-%jT%RZ => 2021-323T08:37Z
%GW%V%uT%H%M%z => 2021W471T0837-0600
%G-W%V-%uT%R%:z => 2021-W47-1T08:37-06:00
```
## Long story about strftime
Programmers need to constantly convert between different date and time formats. People in different parts of the world prefer dates to be displayed in different ways as is also true for many different systems that require dates to be in a specific format to be accepted. Catering for different date formats can be quite a pain. But it will remain a pain no longer because after this article you will become a wizard with the powers to easily format date/time in Ruby.
Ruby formats `Time` objects in a specific way by default. But you may want something else that can adapt to your case. Great! Ruby has a method specifically for this job. The 'strftime' (string format time) method can get you any format you will ever possibly need. It is a highly flexible method with a lot of options for you to experiment with. You can get the time without the date, or a nicely formatted date with the year, day & name of the current month.
It works by passing a string with format specifiers. These specifiers, more formally called directives, will be replaced by a value as they instruct the method to customize the resulting human readable date. If you have ever used the printf method the idea is very similar to that. Here are a few examples:
```ruby
time = Time.new
time.strftime("%d/%m/%Y") # "05/12/2015"
time.strftime("%I:%M %p") # "11:04 PM"
time.strftime("%d of %B, %Y") # "21 of December, 2015"
```
Before diving into the depths of the `strftime` method we need you to take this quick refresher on the `Time` class in Ruby so that you are fully prepared to gain the most out of this lesson.
### The beginning of `Time`:
Although the strftime method is relevant to all time-related classes including Date, Time, and DateTime, we can get by with only understanding the Time class. The Time class in Ruby represents dates and times stored as the number of seconds that have elapsed since January 1, 1970 00:00 UTC. This time is known as the 'Unix epoch' and can be considered the starting point of time for computers. It has been used to grab the current time, date, and year since that time and until 2038. A time instance in Ruby holds both date and time. The date component consists of the day, month and year while the time component consists of the hour, minutes, and seconds.
In Ruby, you can get the current day and time using `Time.new` or `Time.now` and assign it to a variable. You can then get the year, month, day, hour, minute, second, etc in the following manner:
```ruby
t = Time.now()
puts t.year()
# => 2022
puts t.month()
# => 1
puts t.day()
# => 7
puts t.hour()
# => 22
puts t.min()
# => 0
puts t.sec()
# => 46
```
So what does a `Time` instance in Ruby look like on its own.
```ruby
t = Time.now()
puts t
# => 2022-01-08 13:35:53 +0000
```
As you can see this format might be less than desirable in some circumstances. Before overloading you with all the possible combinations of directives we can provide the `strftime` method, let us first go through the real-world scenario where we want to send the front-end of our application a nicely formatted date that represents the joining date for a customer. Let's learn how to do that in the next section where we go through the thought process of applying different directives to strftime to reach our desired result.
### strftime : application and thought process
As stated earlier we want to display the data represented by the time instance such as `2022-01-08 13:35:53 +0000`, into `Saturday, 08 Jan 2022`. The latter seems to be a much more common format that you would find on a website. So how do we get it? Firstly we need the full name of the day of the week i.e 'Sunday'. By checking the 'Weekday' section of the cheat sheet shown later in this lesson we identify that we need to use the specifier `%A`..
```ruby
t = Time.new(2022,1,8,13,35,53)
puts t.strftime("%A")
# => Saturday
```
Pretty cool right? Okay, maybe it doesn't look *that* cool just yet. Let's apply the rest of the directives. Next, I want to get, `08`, the day of month padded with a zero if it's a single digit. I simply tack on another directive, `%d`, that allows me to do just that. Similarly, for `Jan`, the abbreviated month we have `%b` and finally for `2022`, the full numerical year, we have `%Y`. Altogether it becomes:
```ruby
t = Time.new(2022,1,8,13,35,53)
puts t.strftime("%A %d %b %Y")
# => Saturday 08 Jan 2022
```
The date is now properly formatted but the observant reader might have noticed that there is still something missing. Yes, the 'comma' is missing. Points for you if you got it. There isn't a directive or specifier for a comma or any string for that matter, but not to worry. Any string you provide that is not listed in the docs as a directive, will simply be output to the resulting string. Applying this information to the example above we simply add a comma after our first directive like so:
```ruby
puts t.strftime("%A, %d %b %Y")
# => Saturday, 08 Jan 2022
```
Perfect !
You are now ready to be bombarded with as many directives as your heart desires.
## Deep dive
This section first shows the basics of the `strftime` method, then contains a basic cheat sheet that you will need to get familiar with over time, and finally drives the concept home with some cool examples.
The `strftime` method requires a directive with the following structure and rules:
Structure - `%<flags><width><modifier><conversion>`
Rules:
1. A directive starts with a percent (%) character.
2. A flag and the conversion specifiers tell the method how to display the time and date.
3. The minimum field width specifies the minimum width. You can ignore this.
4. The modifiers are "E" and "O". Can also be ignored.
5. Regular text that isn't listed in the directives will pass through as it is in the output.
## strftime cheat sheet
### Flags
| Syntax | Description |
|--|--|
| \- | no padding on a numerical output |
| _ | pad with spaces |
| 0 | pad with zeros |
| ^ | Upcase the result string |
| : | Use colons for %z |
### Date (Year, Month, Day)
| Syntax | Description |
|--|--|
| %Y | Year with century |
| %y | year % 100 (00..99) |
| %m | Month of the year, zero-padded (01..12) |
| %B | The full month name ('January') |
| %b | The abbreviated month name ('Jan') |
| %d | Day of the month, zero-padded (01..31) |
| %j | Day of the year (001..366) |
### Time (Hour, Minute, Second):
| Syntax | Description |
|--|--|
| %H | Hour of the day, 24-hour clock, zero-padded (00..23) |
| %k | Hour of the day, 24-hour clock, blank-padded ( 0..23) |
| %I | Hour of the day, 12-hour clock, zero-padded (01..12) |
| %l | Hour of the day, 12-hour clock, blank-padded ( 1..12) |
| %P | Meridian indicator, lowercase ('am' or 'pm') |
| %p | Meridian indicator, uppercase ('AM' or 'PM') |
| %M | Minute of the hour (00..59) |
| %S | Second of the minute (00..60) |
| %z | Time zone as an hour and minute offset from UTC (e.g. +0900) |
### Weekday:
| Syntax | Description |
|--|--|
| %A |The full weekday name (e.g. Sunday)|
| %a |The abbreviated weekday name (e.g. Sun)|
| %u |Day of the week starting Monday (1..7)|
### Useful Combinations:
| Syntax | Description |
|--|--|
| %c | Date and time (%a %b %e %T %Y) |
| %D | Date (%m/%d/%y) |
| %F | The ISO 8601 date format (%Y-%m-%d) |
| %r | 12-hour time (%I:%M:%S %p) |
| %R | 24-hour time (%H:%M) |
For a more comprehensive list of options please visit the strftime method in [Ruby Docs](https://devdocs.io/ruby~3/time#method-i-strftime).
## Last words : random examples
Initialize time:
```ruby
t = Time.new(2022,1,8,13,35,53)
```
Time for your appointment:
```ruby
puts t.strftime("%B, %Y at %-I:%M %p")
# => January, 2022 at 12:13 AM
```
Alarm Clock:
```ruby
puts t.strftime("%r")
# => 12:13:29 AM
```
Windows OS date:
```ruby
puts t.strftime("%d/%m/%Y")
# => 09/01/2022
```
Fun Fact Date:
```ruby
puts t.strftime("%-d %b is on a %A and is day number %j of the year %Y")
# => 8 Jan is on a Saturday and is day number 008 of the year 2022
```
That's pretty much it. Now go out there and make some unique looking date formats!
| bdavidxyz |
953,857 | Day 77 of 100 Days of Code & Scrum: Web Development Services Page and More Next.js | Hello there, everyone! I got plenty of work done on my Web Development Services page today. I feel... | 14,990 | 2022-01-13T12:09:54 | https://blog.rammina.com/day-77-of-100-days-of-code-and-scrum-web-development-services-page-and-more-nextjs | 100daysofcode, beginners, javascript, productivity | Hello there, everyone!
I got plenty of work done on my Web Development Services page today. I feel like it could use some improvements, but I'm satisfied for now and would like to move on to other pages. I do need to be more efficient with my time and work on the things that give me the most value.
I've also been learning more about Next.js, and it's probably my most favorite framework so far. I haven't felt this excited to discover new things since I first worked with React back in 2019. Maybe, Next.js is going to stay as my most preferred framework until I try out SvelteKit, which I've heard great things about.
Anyway, let's move on to my daily report!
## Yesterday
I worked on the web development services page and added various subsections that fall under Our Specialties.
## Today
### Company Website
- I worked on my Web Development Services page, added multiple subsections with text content and images.
- used `blurDataURL` placeholders to make my images seem to load smoother and to avoid dislodging elements.
### Next.js
- learned more about advanced data fetching techniques and patterns in Next.js.
### Scrum
- read this article, titled [Myth: Having A Sprint Goal Is Optional In Scrum](https://www.scrum.org/resources/blog/myth-having-sprint-goal-optional-scrum).
- here are some negative consequences if there is no Sprint Goal:
- a wide variety of items (potentially unrelated) will be pulled from the Product Backlog during Sprint Planning.
- the Sprint Backlog is likely what Development Teams implicitly (or explicitly) commit to instead.
- no obvious incentive to collaborate.
- the Daily Scrum takes the form of a status update.
- the Development Team doesn’t have guidance on how to decide where to invest time and what to let go.
- it is hard to know when a Sprint is successful.
Thank you for reading! Have a good day!

## Resources/Recommended Readings
- [The 2020 Scrum Guide](https://scrumguides.org/scrum-guide.html)
- [Next.js & React by Maximilian Schwarzmüller](https://www.udemy.com/course/nextjs-react-the-complete-guide/)
- [Next.js official documentation](https://nextjs.org/docs/getting-started)
- [SWR official documentation](https://swr.vercel.app/)
- [Myth: Having A Sprint Goal Is Optional In Scrum](https://www.scrum.org/resources/blog/myth-having-sprint-goal-optional-scrum)
## DISCLAIMER
**This is not a guide**, it is just me sharing my experiences and learnings. This post only expresses my thoughts and opinions (based on my limited knowledge) and is in no way a substitute for actual references. If I ever make a mistake or if you disagree, I would appreciate corrections in the comments!
<hr />
## Other Media
Feel free to reach out to me in other media!
<span><a target="_blank" href="https://www.rammina.com"><img src="https://res.cloudinary.com/rammina/image/upload/v1638444046/rammina-button-128_x9ginu.png" alt="Rammina Logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://twitter.com/RamminaR"><img src="https://res.cloudinary.com/rammina/image/upload/v1636792959/twitter-logo_laoyfu_pdbagm.png" alt="Twitter logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://github.com/Rammina"><img src="https://res.cloudinary.com/rammina/image/upload/v1636795051/GitHub-Emblem2_epcp8r.png" alt="Github logo" width="128" height="50"/></a></span>
| rammina |
954,045 | The hidden part of the iceberg: understanding availability bias in web analytics | When you zoom too close, you miss the forest for the tree. How can you avoid this mistake? When we... | 0 | 2022-01-13T14:19:55 | https://dev.to/jeanremyduboc/the-hidden-part-of-the-iceberg-understanding-availability-bias-in-web-analytics-39a8 | analytics, bias, datascience | When you zoom too close, you miss the forest for the tree. How can you avoid this mistake?
When we miss important data, we only see a fraction of reality: our worldview is dangerously inadequate. It's easy to make fundamental errors in our analysis; this is called selection bias.
Availability bias, for example, is a type of selction bias that occurs when we rely too much on data available in our immediate environment, and mistakenly assume that this data is representative of the world as a whole.
Let's take a look at an example, and learn some useful lessons for our analytics work.
## How to depress customer service teams with record sales: Mark in customer care
Marc was back home late that evening, for the third time this week, depressed. He's now convinced that the new range produced by ACME washing machines, the company he works for, are terrible, probably the worst on the market. He should know: for a month, he has spent his days trying to appease angry customers, stuck with a broken down machine, sometimes for the second or third time. Marc sincerely wants to help his customers, but he is now convinced that the product quality just isn't good enough.
The next day, at coffee break, he chats for a moment with Sabine, his colleague in marketing. "We're going to have a great quarter," she tells him enthusiastically, "the new machines are a hit". "Are you kidding! They are all broken down, we are inundated with calls in customer care! This new range is killing us!".
A few months later, Sabine's prediction turns out to be correct: the new machines were indeed a hit: sales quadrupled. We even discover that the rate of returns to the after-sales service for the new machine is twice as low as for the previous model! The new machines are actually twice as reliable...so what happened?
ACME quadrupled its sales, and the proportion of defective machines was halved. Overall, it's an excellent result, but locally, it still represents twice as many breakdowns to manage for poor Marc!
Since, by definition, Marc only meets customers with a defective machine, he drew an erroneous conclusion, based on the partial data available around him: he presumes that the majority of machines are defective, when in reality it is is the opposite. Because he hasn't seen the overall sales figures, he is a victim of his environment, and of availability bias. Marc's data was missing essential context. Sabine, on the other hand, has access to data that's more representative of the general trend.
It's important to note that we could have seen the opposite phenomenon: if ACME sold only a quarter as many new machines in the new range, but the machines broken down twice as often, Marc could have been happy to see very few machines coming back to the after-sales service, while Sabine would have been very worried about disappointing sales figures.
## Availability bias in web analytics: the right questions to ask and avoid common pitfalls
When you analyze the performance of a website with a tool like Google Analytics, you can easily, like Marc, become a victim of availability bias.
Here are some ideas for avoiding this pitfall:
- Your site users are not representatative of the entire population. What makes your users different? Why are they on your site and not another?
- If your customers notice problems on your site and complain about it, are these complaints representative of a large issue, or are they just a minority? Conversely, if you have no complaints at all, is it because there are no problems, or are people leaving your application without telling you why their experience wasn't good enough? Check your bounce rate, identify the key pages with a high drop rate. You could find and fix critical bugs or design problems.
- Always consider large changes in data in the proper context. If the number of conversions increases rapidly, for example, is it because of a promotion, a time of year that is traditionally more busy, a new version of the site, a bug fix, etc. ? If possible, compare your number from year to year. Your latest record sale might not be that impressive. Likewise, a sudden and unexpected drop isn't always indicative of a a serious problem, maybe it's a perfectly natural adjustment.
Have you ever been fooled by availability bias? What do you do to avoid this problem in your analysis? Share your experience in the comments!
| jeanremyduboc |
954,585 | Simple Ecommerce site using Atlas search | Overview of My Submission I build an ecommerce site very simple to get to know the atlas... | 0 | 2022-01-13T23:59:49 | https://dev.to/davidbug/simple-ecommerce-site-using-atlas-search-37bn | atlashackathon | [Instructions]: # (To submit to the MongoDB Atlas Hackathon on DEV, please fill out all sections.)
### Overview of My Submission
I build an ecommerce site very simple to get to know the atlas search feature. Thank you DEV and MongoDB for this event is was great to participate.
Demo here: https://polar-wave-18778.herokuapp.com/
### Submission Category:
E-Commerce Creation
### Link to Code
https://github.com/davidildefonso/hackatondev-ecommerce
### Additional Resources / Info
MERN stack used also tried to use typescript without success, still a noobie.
Thank you for reading ! | davidbug |
954,611 | MongoDB $weeklyUpdate (January 14, 2022): Latest MongoDB Tutorials, Events, Podcasts, & Streams! | 👋 Hi everyone! Welcome back to the MongoDB $weeklyUpdate! Happy 2022! 🎉 Here, you'll find... | 8,475 | 2022-01-14T19:39:20 | https://www.mongodb.com/community/forums/t/mongodb-weeklyupdate-52-january-14-2022-latest-mongodb-tutorials-events-podcasts-streams/141857 | mongodb, database, dotnet, programming | ## 👋 Hi everyone!
Welcome back to the MongoDB $weeklyUpdate! Happy 2022! 🎉
Here, you'll find the latest developer tutorials, upcoming official MongoDB events, and get a heads up on our latest Twitch streams and podcast, curated by [Adrienne Tacke](https://twitter.com/AdrienneTacke).
*(We're changing it up a bit and will be releasing these every Friday (instead of Monday). In this way, you'll always get the latest content and updates!)*
Enjoy!
---
### 🎙 Last Call to Submit Your Sessions for MongoDB World 2022!

MongoDB World is where the world’s fastest-growing data community comes to connect, explore, and learn. We’re looking for speakers who can inspire attendees by introducing them to new technologies, ideas, and solutions.
Whether you want to do a 30 minute conference session, a 75 minutes deep dive tutorial, or a 10 minute lightning talk - we want to hear your talk ideas. If you have a great idea but don’t feel ready for the stage, we've got you covered! We offer speaker workshops, one-on-one coaching sessions, and more.
**Call for speakers closes January 18, 2022**.
[Submit Your Talk!](https://www.mongodb.com/world-2022-call-for-speakers)
---
## 🎓 Freshest Tutorials on [DevHub](https://developer.mongodb.com/)
_Want to find the latest MongoDB tutorials and articles created for developers, by developers? Look no further than our [DevHub](https://developer.mongodb.com/)!_
### [Bringing Your Data to Your Wrist with the MongoDB Data API and Fitbit](https://www.mongodb.com/developer/how-to/atlas_data_api_and_fitbit/)
[John Page](https://www.mongodb.com/developer/author/john-page/)
In this article, we will see how to call the Data API from a smartwatch application to retrieve a document that contains data to display.
### [Introducing the MongoDB Analyzer for .NET](https://www.mongodb.com/developer/article/introducing-mongodb-analyzer-dotnet/)
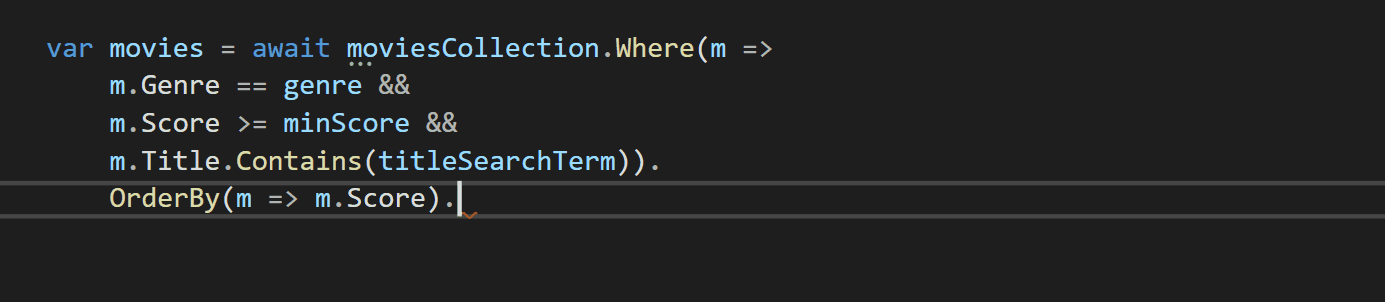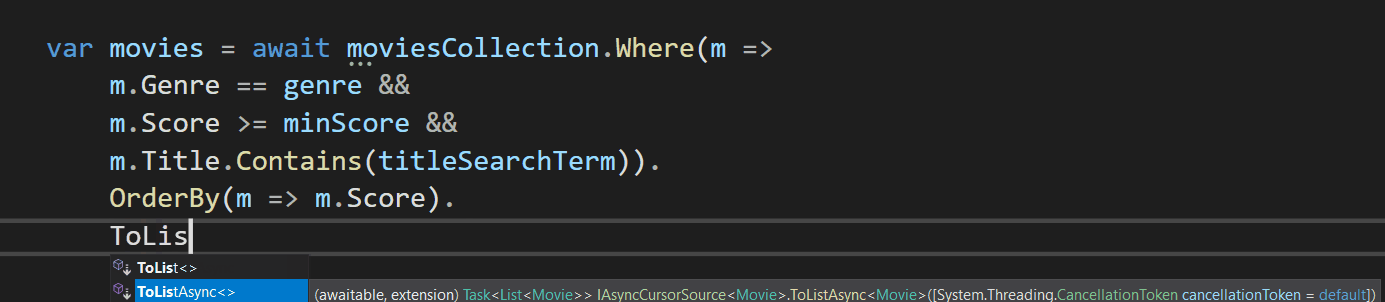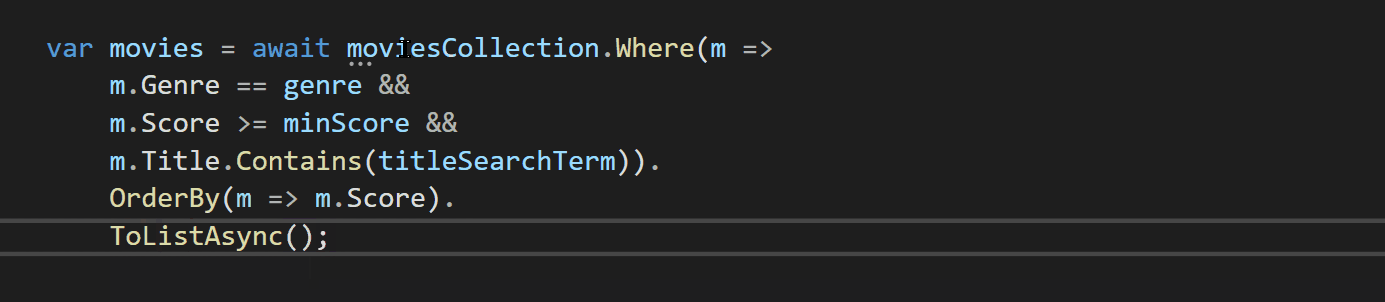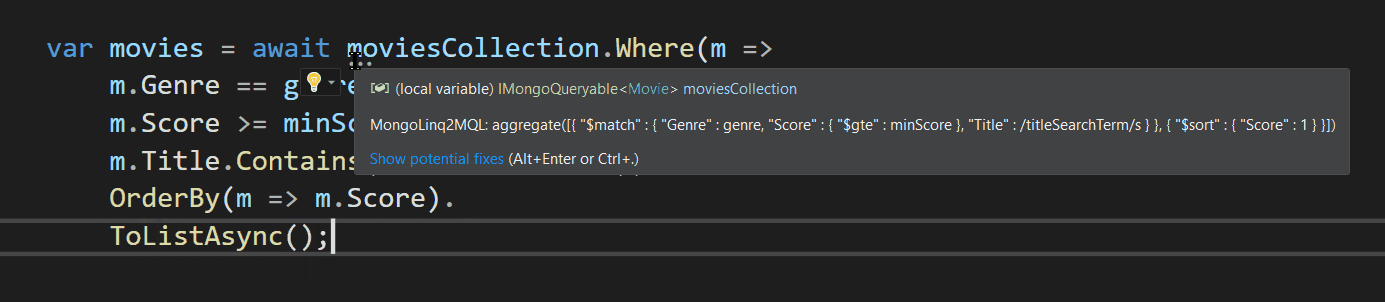
[Adrienne Tacke](https://twitter.com/adriennetacke)
Say hello to the MongoDB Analyzer for .NET. This tool translates your C# queries to their MongoDB Query API equivalent and warns you of unsupported expressions and invalid queries at compile time, right in Visual Studio.
### [Kafka to MongoDB Atlas End to End Tutorial](https://www.mongodb.com/developer/how-to/kafka-mongodb-atlas-tutorial/)
[Pavel Duchovny](https://www.mongodb.com/developer/author/pavel-duchovny/)
In this article, we will provide a simple step-by-step guide on how to connect a remote Kafka cluster—in this case, a Confluent Cloud service—with a MongoDB Atlas cluster.
---
## 📺 MongoDB on [Twitch](https://www.twitch.tv/mongodb) & [YouTube](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA)
_We stream tech tutorials, live coding, and talk to members of our community via [Twitch](https://www.twitch.tv/mongodb) and [YouTube](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA). Sometimes, we even stream twice a week! Be sure to [follow us on Twitch](https://www.twitch.tv/mongodb) and [subscribe to our YouTube channel](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA) to be notified of every stream!_
*Latest Stream*
How we built Mongo World, a Game Built with Unity and MongoDB Realm
{% twitch 1255999546 %}
🍿 [Follow us](https://www.twitch.tv/mongodb) on Twitch and [subscribe to our YouTube channel](https://www.youtube.com/channel/UCK_m2976Yvbx-TyDLw7n1WA) so you never miss a stream!
---
## 🎙 Last Word on the [MongoDB Podcast](https://mongodb.libsyn.com/)
*Latest Episode*
{% spotify spotify:episode:5Q8tbQcTcxxM1fWGU3GkBq %}
*Catch up on past episodes*:
Ep. 96 - [Christmas Lights and Webcams with the MongoDB Data API](https://open.spotify.com/episode/5mRaLAaVoG4kgxRge9d968?si=aalAbiVgRzO9cIo7fOzVhw)
Ep. 95 - [Life at MongoDB: Exploring Cloud Support with Mark Kirpichnikov and Jon Fanti](https://open.spotify.com/episode/4liGrDKAKoa6A5yycob8Xt?si=ez5tyGRKSsGB4JrDTG5OGQ)
Ep. 94 - [DevOps, IaC, Terraform and MongoDB with John Fahl](https://open.spotify.com/episode/3JjNwmufWxFrRjyOYD9RdK?si=l9hcQ0TjThql9mBaHWF7mA)
(Not listening on Spotify? We got you! We're most likely on your favorite podcast network, including [Apple Podcasts](https://podcasts.apple.com/us/podcast/the-mongodb-podcast/id1500452446), [PlayerFM](https://player.fm/series/the-mongodb-podcast), [Podtail](https://podtail.com/en/podcast/the-mongodb-podcast/), and [Listen Notes](https://www.listennotes.com/podcasts/the-mongodb-podcast-mongodb-0g6fUKMDN_y/) 😊)
---
💡 These $weeklyUpdates are always posted to the [MongoDB Community Forums](https://www.mongodb.com/community/forums/) first! [Sign up](https://account.mongodb.com/account/register) today to always get first dibs on these $weeklyUpdates and other MongoDB announcements, interact with the MongoDB community, and help others solve MongoDB related issues!
| adriennetacke |
975,685 | The type hierarchy tree | A reflection on my mental model of TypeScript’s type system | 0 | 2022-02-06T19:52:03 | https://www.zhenghao.io/posts/type-hierarchy-tree | typescript | ---
title: The type hierarchy tree
published: true
listed: true
date: '12/28/2021'
description: A reflection on my mental model of TypeScript’s type system
tags: typescript
canonical_url: https://www.zhenghao.io/posts/type-hierarchy-tree
---
Try read the following TypeScript code snippet and work it out in your head to predicate whether or not there would be any type errors for each assignment:
```typescript
// 1. any and unknown
let stringVariable: string = 'string'
let anyVariable: any
let unknownVariable: unknown
anyVariable = stringVariable
unknownVariable = stringVariable
stringVariable = anyVariable
stringVariable = unknownVariable
// 2. `never`
let stringVariable: string = 'string'
let anyVariable: any
let neverVariable: never
neverVariable = stringVariable
neverVariable = anyVariable
anyVariable = neverVariable
stringVariable = neverVariable
// 3. `void` pt. 1
let undefinedVariable: undefined
let voidVariable: void
let unknownVariable: unknown
voidVariable = undefinedVariable
undefinedVariable = voidVariable
voidVariable = unknownVariable
// 4. `void` pt. 2
function fn(cb: () => void): void {
return cb()
}
fn(() => 'string')
```
If you were able to come up with the correct answers without pasting the code into your editor and let the compiler does its job, I am genuinely going to be impressed. At least I couldn’t get them all right despite writing TypeScript for more than a year. I was really confused by this part of TypeScript which involves types like `any`, `unknown`, `void` and `never`
I realized I didn’t have the correct mental model for how those types works. Without a consistent and accurate mental model, I could only rely on my experience or intuitions or constant trial and error from playing with the TypeScript compiler.
The blog post is my attempt to introspect and rebuild the mental model of TypeScript’s type system.
> A warning up front: this is not a short article. You can jump directly to [the section](#the-top-of-the-tree) where I explore the type hierarchy tree if you are in a hurry.
## It is a hierarchy tree
Turns out all types in TypeScript take their place in a hierarchy. You can visualize it as a tree-like structure. Minimally, in a tree, we can a parent node and a child node. In a type system, for such a relationship, we call the parent node a supertype and the child node a subtype.
You are probably familiar with inheritance, one of the well-known concepts in object-oriented programming. Inheritance establishes an `is-a` relationship between a child class and a parent class. If our parent class is `Vehicle`, and our child class is `Car`, the relationship is “`Car` is `Vehicle`”. However it doesn’t work the other way around - an instance of the child class logically is not an instance of the parent class. “`Vehicle` is not `Car`”. This is the semantic meaning of inheritance, and it also applies to the type hierarchy in TypeScript.
According to [the Liskov substitution principle](https://en.wikipedia.org/wiki/Liskov_substitution_principle), instances of `Vehicle` (supertype) should be substitutable with instances of its child class (subtype) `Cars` without altering the correctness of the program. In other words, If we expect a certain behavior from a type (`Vehicle`), its subtypes (`Car`) should honor it.
> I should mention that the Liskov substitution principle is from a 30-year-old paper written for PhD's. There are a ton of nuances to it that I cannot possibly cover in one blog post.
Putting this together, in TypeScript, you can assign/substitute an instance of a type’s subtype to/with an instance of that (super)type, but not the other way around.
> By the way I just realize the meaning of the word “substitute” changes radically depending on [the preposition that follows it](https://www.blog.voicetube.com/archives/55539). In this blog post, when I say "substitute A with B”, it means we end up with B instead of A.
### nominal and structural typing
There are two ways in which supertype/subtype relationships are enforced. The first one, which most mainstream statically-typed languages (such as Java) use, is called **nominal typing**, where we need to *explicitly* declare a type is the subtype of another type via syntax like `class Foo extends Bar`. The second one, which TypeScript uses is **structural typing**, which doesn’t require us to state the relationship *explicitly* in the code. An instance of `Foo` type is a subtype of `Bar` as long as it has all the members that `Bar` type has, even if `Foo` has some additional members.
Another way to think about this supertype-subtype relationship is to check which type is more strict, type `{name: string, age: number}` is more strict than the type `{name: string}` since the former requires more members defined in its instances. Therefore type `{name: string, age: number}` is a subtype of type `{name: string}`.
## two ways of checking assignability/substitutability
One last thing before we dive into the type hierarchy tree in TypeScript:
1. **type cast**: you can just assign a variable of one type to a variable of another type to see if it raises a type error. [More on that later](#upcast--downcast).
2. the `extends` keyword -you can extend one type to another:
```typescript
type A = string extends unknown? true : false; // true
type B = unknown extends string? true : false; // false
```
## the top of the tree
Let's talk about the type hierarchy tree.
In TypeScript, there are two types are that the supertypes of all other types: `any` and `unknown`.
They accept any value of any type, encompassing all other types.
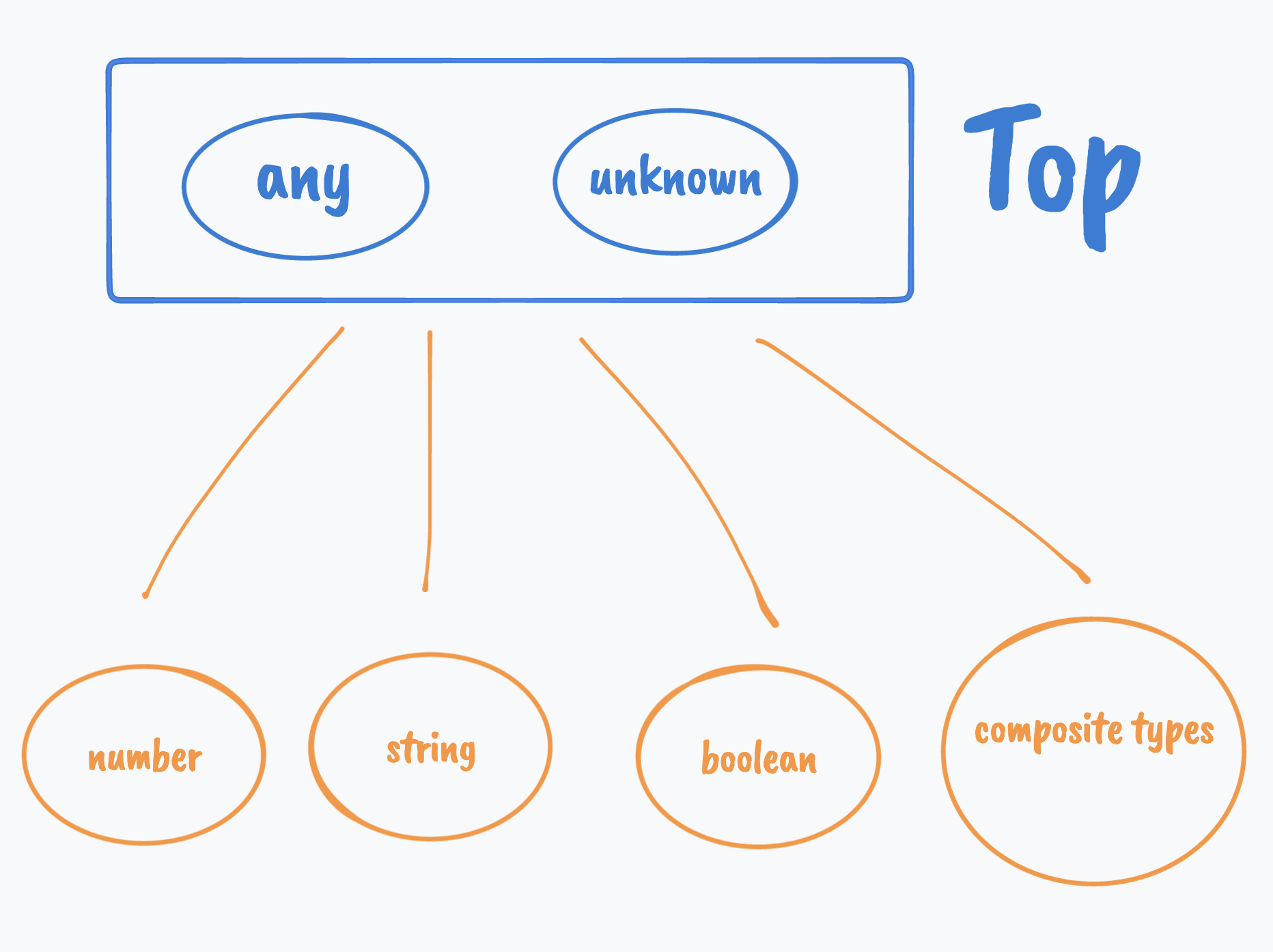
> This graph is by no means an exhaustive list of all the types that TypeScript has. Check out [the source code](https://github.com/microsoft/TypeScript/blob/main/src/compiler/types.ts#L642) of TypeScript if you are interested to see all the types that it currently supports.
### upcast & downcast
There are two types of type cast - **upcast** and **downcast**.
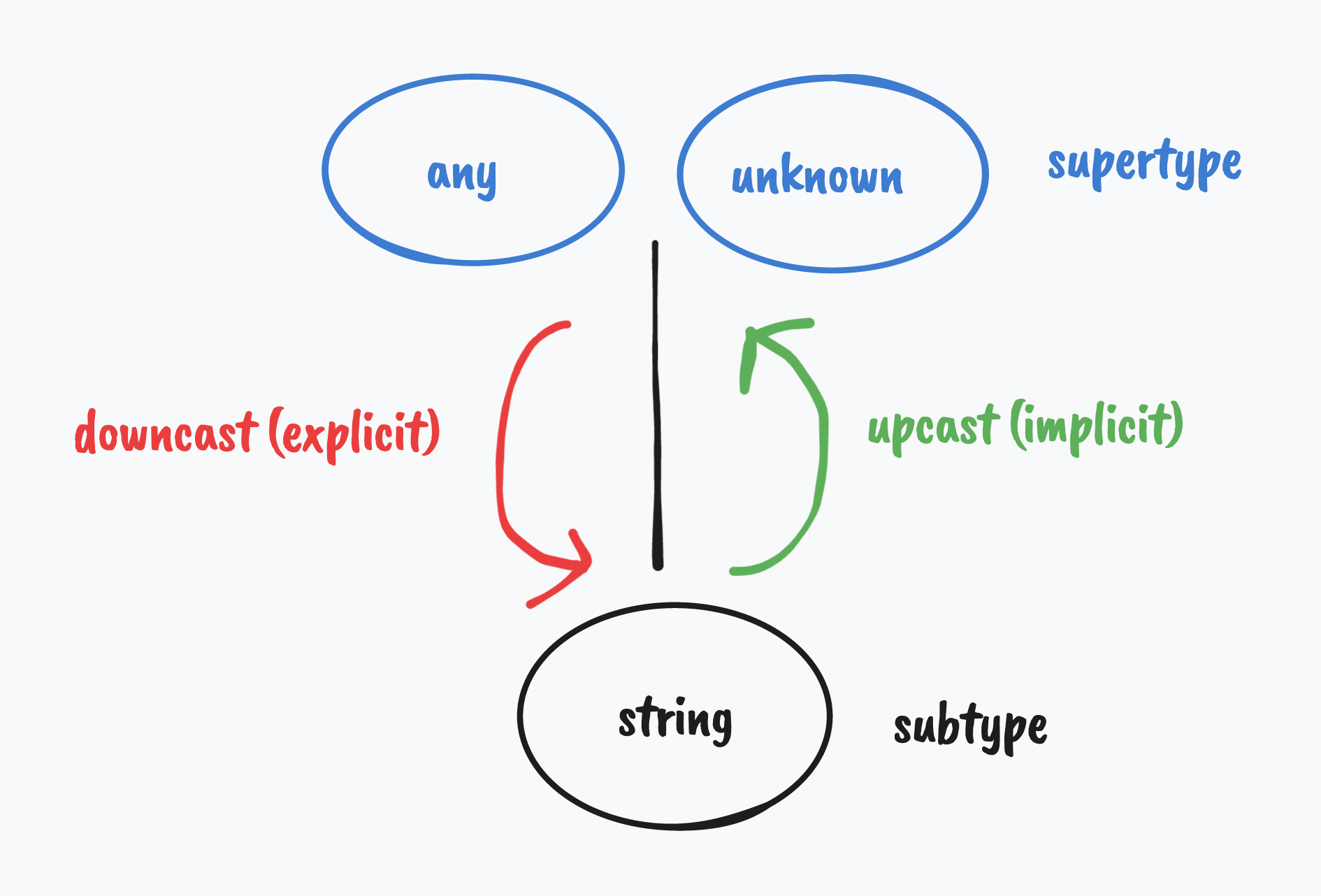
Assigning a subtype to its supertype is called **upcast**. By the Liskov substitution principle, upcast is safe so the compiler lets you do it implicitly, no questions asked.
> There are exceptions where TypeScript disallows the implicit upcast. I will address that [at the end of the post](#situations-where-typescript-disallows-implicit-upcast).
You can think of upcast similiar to walking up the tree - replacing (sub)types that are more strict with their supertypes that are more generic.
For example, every `string` type is a subtype of the `any` type and the `unknown` type. That means the following assignments are allowed:
```typescript
let string: string = 'foo'
let any: any = string // ✅ ⬆️upcast
let unknown: unknown = string // ✅ ⬆️upcast
```
The opposite is called **downcast**. Think of it as walking down the tree - replacing the (super)type that are more generic with their subtypes that are more strict.
Unlike upcast, downcast is not safe and most strongly typed languages don’t allow this automatically. As an example, assigning variables of the `any` and `unknown` type to the `string` type is downcast:
```typescript
let any: any
let unknown: unknown
let stringA: string = any // ✅ ⬇️downcast - it is allowed because `any` is different..
let stringB: string = unknown // ❌ ⬇️downcast
```
When we assign `unknown` to a `string` type, the TypeScript complier gives us a type error, which is expected since it is downcast so it cannot be performed without explicitly bypassing the type checker.
However TypeScript would happily allow us to assign `any` to a `string` type, which seems contradictory to our theory.
The exception here with `any` is because, in TypeScript the `any` type exists to act as a backdoor to escape to the JavaScript world. It reflects JavaScript’s overarching flexibility. Typescript is a compromise. This exception exists not due to some failure in design but the nature of not being the actual runtime language as the runtime language here is still JavaScript.
## the bottom of the tree
The `never` type is the bottom for the tree, from which no further branches extend.
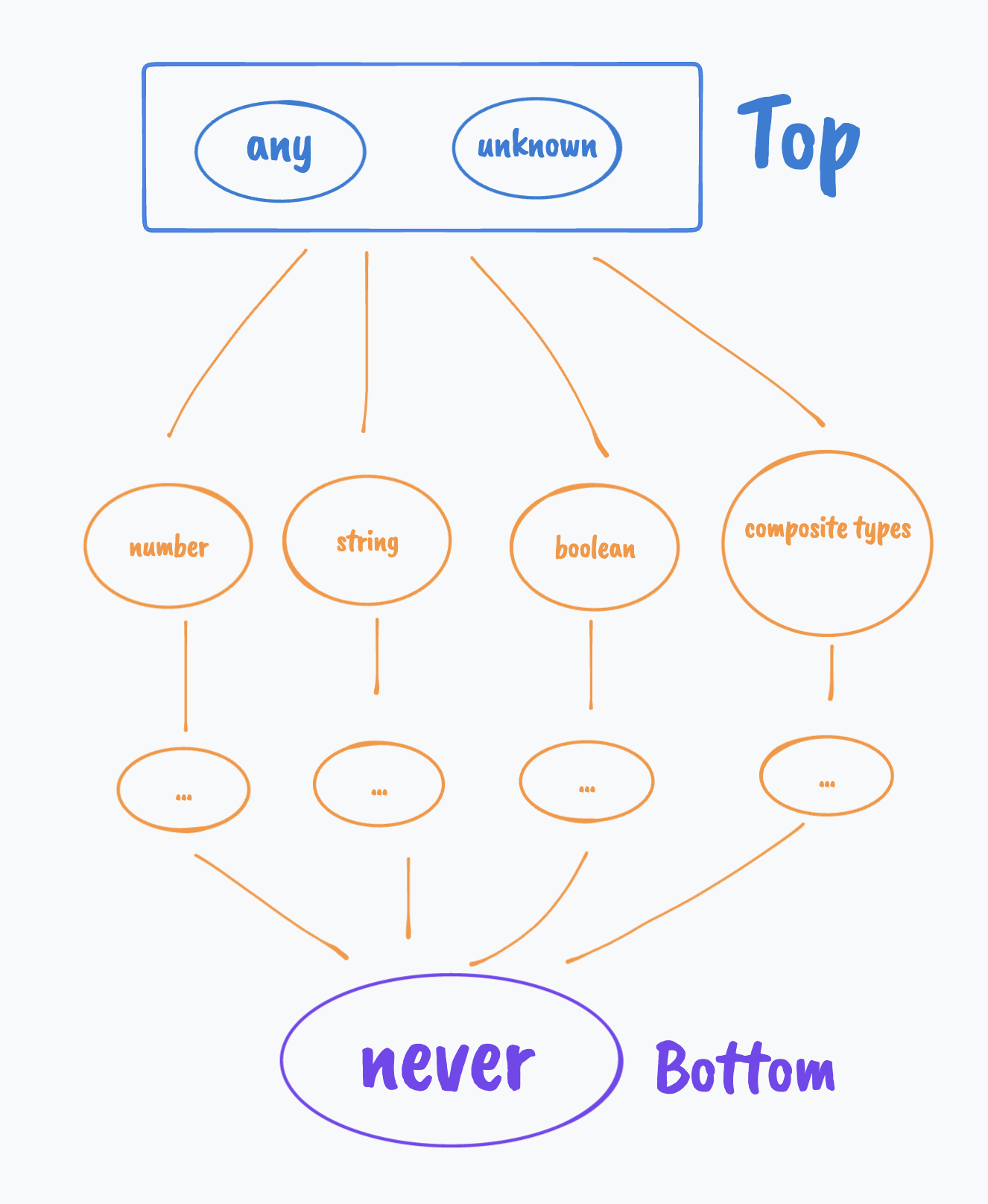
Symmetrically, the `never` type behaves like the an anti-type of the top types - `any` and `unknow`, whereas `any` and `unknown` accept all values, `never` doesn’t accept any value (including values of the `any` type) at all since it is the subtype of all types.
```typescript
let any: any
let number: number = 5
let never: never = any // ❌ ⬇️downcast
never = number // ❌ ⬇️downcast
number = never // ✅ ⬆️upcast
```
If you think hard enough, you might have realized that `never` should have an infinite amount of types and members, as it must be assignable or substitutable to its supertypes, i.e. every other type in the type system in TypeScript according to the Liskov substitution principle. For example, our program should behave correctly after we substitute `number` and `string` with `never` since `never` is the subtype of both `string` and `number` types and it shouldn’t break the behavior defined by its supertypes.
Technically this is impossible to achieve. Instead, TypeScript makes `never` an empty type (a.k.a an uninhabitable type): a type for which we cannot have an actual value at runtime, nor can we do anything with the type e.g. accessing properties on its instances. The canonical usecase for `never` is when we want to type a return value from a function that **never returns**.
> A function might not return for several reasons: it might throw an exception on all code paths, it might loop forever because it has the code that we want to run continuously until the whole system is shut down, like the event loop. All these scenarios are valid.
```typescript
function fnThatNeverReturns(): never {
throw 'It never returns'
}
const number: number = fnThatNeverReturns() // ✅ ⬆️upcast
```
The assignment above might seem wrong to you at first - if `never` is an empty type, why is that we can assign it to a `number` type? The reason why such an assignment is fine is that the compiler knows that our function never returns so nothing will ever be assigned to the `number` variable. Types exist to ensure that the data is correct at runtime. If the assignment never actually happens at runtime, and the compiler knows that for sure in advance, then the types don’t matter.
There is another way to produce a `never` type is to intersect two types that aren’t compatible - e.g. `{x: number} & {x: string}`.
```tsx
type Foo = {
name: string,
age: number
}
type Bar = {
name: number,
age: number
}
type Baz = Foo & Bar
const a: Baz = {age: 12, name:'foo'} // ❌ Type 'string' is not assignable to type 'never'
```
> Edit from the future: I realized that there are some nuances to the resulting type - if disjoint properties are considered as discriminant properties (roughly, those whose values are of literal types or unions of literal types), the whole type is reduced to `never`. This is a feature introduced in TypeScript 3.9. Check out [this PR](https://github.com/microsoft/TypeScript/pull/36696) for details and motivation.
## types in between
We have talked about the top types and the bottom type. The types in between are just the other regular types you use everyday - `number`, `string`, `boolean`, composite types like `object` etc.
There shouldn’t be too much surprise as to how those types work once we have established the correct mental model:
- it is allowed to assign a string literal type e.g. `let stringLiteral: 'hello' = 'hello'` to a `string` type (upcast) but not the other way around (downcast)
- it is allowed to assign a variable holding an object of a type with extra properties to an object of a type with less properties when the existing properties’ types match (upcast) but not the other way around (downcast)
```typescript
type UserWithEmail = {name: string, email: string}
type UserWithoutEmail = {name: string}
type A = UserWithEmail extends UserWithoutEmail ? true : false // true ✅ ⬆️upcast
```
- Or assign an non-empty object to an empty object:
```typescript
const emptyObject: {} = {foo: 'bar'} // ✅ ⬆️upcast
```
However there is one type I want to talk more about in this section since people often confuse it with the bottom type `never` and that type is `void`.
In many other languages, [such as C++](https://docs.microsoft.com/en-us/cpp/cpp/void-cpp?view=msvc-170), `void` is used as the a function return type that means that function doesn't return. However, in TypeScript, for a function that doesn't return at all, the correct type of the return value is `never`.
So what is the type `void` in TypeScript? `void` in TypeScript is a supertype of `undefined` - TypeScript allows you to assign `undefined` to `void` (upcaset) but again, not the other way around (downcast)
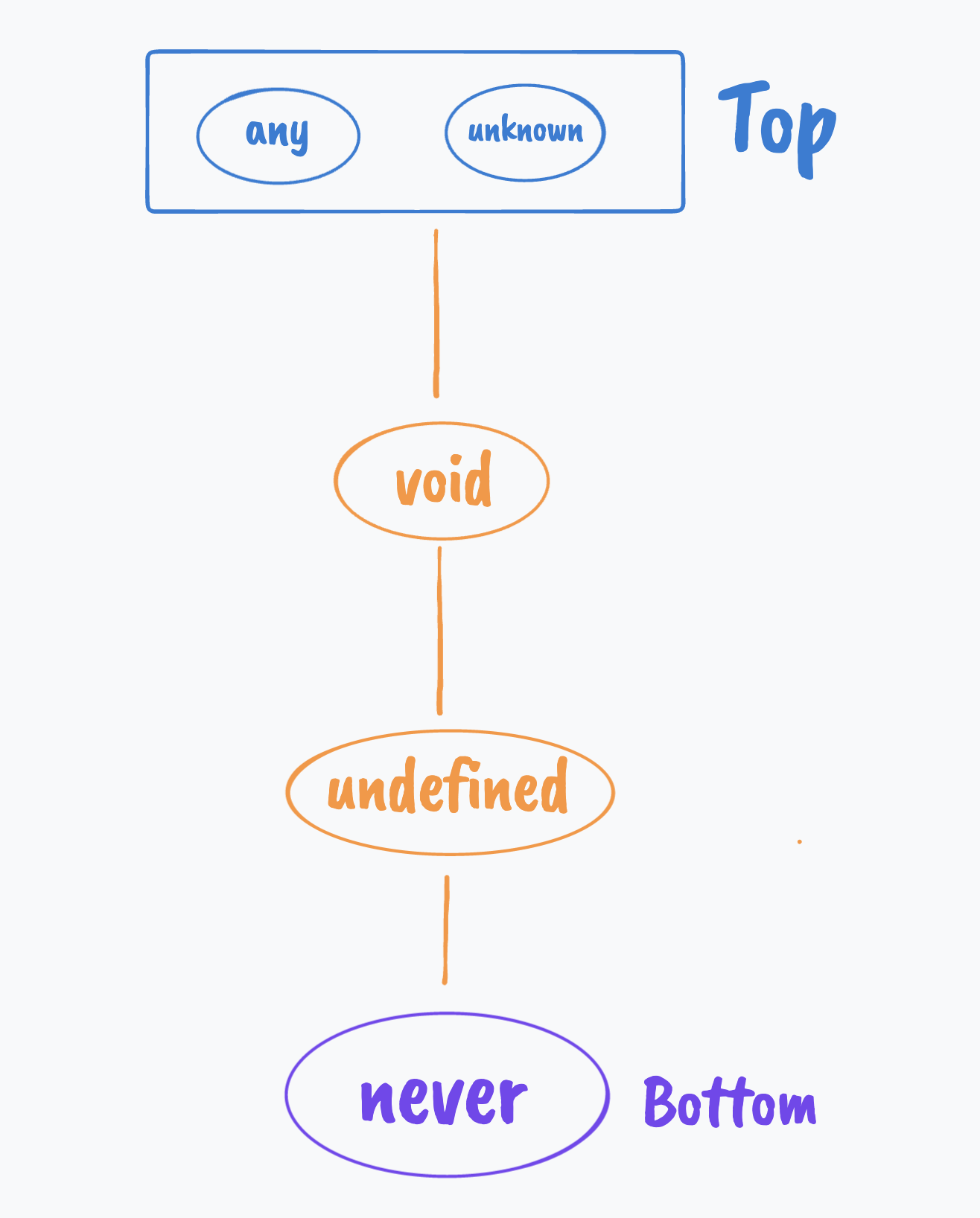
This can also be verified via the `extends` keyword:
```typescript
type A = undefined extends void ? true : false; // true
type B = void extends undefined ? true : false; // false
```
> `void` is also an operator in javascript that evaluates the expression next to it to `undefined`, e.g. `void 2 === undefined // true`.
In TypeScript, the type `void` is used to indicate that the implementer of a function is making no guarantees about the return type except that it won’t be useful to the callers. This opens the door for a `void` function at runtime to return something other than `undefined`, but whatever it returns shouldn’t be used by the caller.
```typescript
function fn(cb: () => void): void {
return cb()
}
fn(() => 'string')
```
At first blush this might seem like a violation for the Liskov substitution principle since the type `string` is not a subtype of `void` so it shouldn’t be able to be substitutable for `void`. However, if we view it from the perspective of whether or not it alters the correctness of the program, then it becomes apparent that as long as the caller function has no business with the returned value from the `void` function (which is exactly the intended outcome of the `void` type), it is pretty harmless to substitute that with a function that returns something different.
This is where TypeScript is trying to be pragmatic and complements the way JS works with functions. In JavaScript it is pretty common when we reuse functions in different situations with the return values being ignored.
## situations where TypeScript disallows implicit upcast
Generally there are two situations, and to be honest it should be pretty rare to find yourself in these situations:
1. When we pass literal objects directly to function
```typescript
function fn(obj: {name: string}) {}
fn({name: 'foo', key: 1}) // ❌ Object literal may only specify known properties, and 'key' does not exist in type '{ name: string; }'
```
2. When we assign literal objects directly to variables with explicit types
```typescript
type UserWithEmail = {name: string, email: string}
type UserWithoutEmail = {name: string}
let userB: UserWithoutEmail = {name: 'foo', email: 'foo@gmail.com'} // ❌ Type '{ name: string; email: string; }' is not assignable to type 'UserWithoutEmail'.
```
## Further Reading
- [Assignability Matrix in the TypeScript official docs](https://www.typescriptlang.org/docs/handbook/type-compatibility.html#any-unknown-object-void-undefined-null-and-never-assignability) | he_zhenghao |
954,812 | Hashnode is taking over the world | And it's not a bad thing! Hashnode for those who don't know, it is a blogging platform for technical... | 0 | 2022-01-14T06:39:41 | https://daily-dev-tips.com/posts/hashnode-is-taking-over-the-world/ | css, watercooler | And it's not a bad thing!
[Hashnode](https://hashnode.com/@dailydevtips/joinme) for those who don't know, it is a blogging platform for technical articles.
Since the early days, I've been a member, and it has grown massively since then.
Recently one of the founders shared these impressive statistics on Twitter:
{% twitter 1480431473580675074 %}
And right before that Nazanin, announced on Twitter that she would organize a [CSS art challenge](https://twitter.com/nazanin_ashrafi/status/1479860636385484810), before I even knew what it was going to be about, I've said yes.
And here we are. This article describes how I made my CSS artwork for this Hashnode CSS Art Challenge.
My result looks like this:

> Note: You can try it out at the bottom
## The rules and my idea
The rules for this challenge are super simple.
1. Use the Hashnode logo and run it into whatever you think of.
I was trying to fall asleep, but this challenge kept me up. I just couldn't put my finger on what I wanted to create.
And then it hit me!
Hashnode is taking over the world!
So let's make a character out of this logo and have it walk around the world.
My idea is to combine the CSS art I know and try out [pixel art](https://pokecoder.hashnode.dev/making-pixel-art-with-pure-css), as that sounds cool to me!
## Creating the logo
Let's start with the logo. I'm sure you might think, oh well, you can use a rounded square and put a round div over it, r right?
And yes, we could do that, but then we can't use backgrounds behind it.
So I decided to go with a little different approach.
I've added a div that I called `hashnode` and inside created a `body` which will hold the logo.
```css
.hashnode {
margin-top: -10%;
position: relative;
width: 40vmin;
aspect-ratio: 1;
.body {
width: 100%;
height: 100%;
position: absolute;
border-radius: 27%;
transform: rotate(45deg);
background: #2962ff;
-webkit-mask: radial-gradient(#0000 28%, #000 28%);
mask: radial-gradient(#0000 28%, #000 28%);
z-index: 2;
}
}
```
The magic here is actually in the `webkit-mask`. This defines a transparent radial gradient.
This will create a round gap in the body.
> Note: This idea was [demoed out by Alvaro](https://codepen.io/alvaromontoro/pen/RwLYRpr). Thank you very much for that.
Then I decided to add arms to the character, which would move. The arms are two times the same styling with a different offset.
I've also made sure the right arm is one second delayed.
```css
.arm {
width: 50%;
height: 30%;
border: solid 5px #000;
border-color: #001 transparent transparent #001;
border-radius: 50%/70% 0% 0 0;
position: absolute;
animation: 2s move-arm infinite;
transform: rotate(45deg) scaleY(-1);
top: 20%;
transform-origin: bottom left;
&:before {
content: '';
width: 10%;
background: #000;
position: absolute;
aspect-ratio: 1;
right: -5%;
top: -10%;
border-radius: 50%;
}
&-left {
left: 10%;
z-index: 3;
}
&-right {
animation-delay: 1s;
left: 70%;
z-index: 1;
}
}
```
You can see I used the `before` selector to add the little round hand-like shapes, which would make the arms look neater.
This shape is a square box where we color only two sides of a rounded border.
This is what it looks like if we color it completely.

A good thing to note about the arm is this:
```css
transform-origin: bottom left;
```
This defines what axis the transform should take place. Setting this to `bottom left` allows the rotation to happen on a solid axis, making the arm "swing".
As for the swing animation goes:
```css
@keyframes move-arm {
0% {
transform: rotate(45deg) scaleY(-1);
}
50% {
transform: rotate(0deg) scaleY(-1);
}
100% {
transform: rotate(45deg) scaleY(-1);
}
}
```
A very straightforward rotating from 45 degrees to 0 and back.
I'm using the scaleY to invert because I started upside down and was too lazy to revert it 😂.
The legs are a very similar approach, but they are longer, and the shoes are slightly different.
```css
.leg {
width: 30%;
height: 50%;
border: solid 5px #000;
border-color: #000 #000 transparent transparent;
border-radius: 0 80%/45%;
position: absolute;
z-index: 10;
transform-origin: top left;
transform: rotate(30deg);
top: 100%;
left: 50%;
animation: 2s move-leg infinite;
&:before {
content: '';
width: 50%;
height: 10%;
background: #000;
position: absolute;
bottom: -10%;
border-radius: 50%;
left: 90%;
}
&-left {
animation-delay: 1s;
}
&-right {
z-index: 1;
}
}
```
And for the animation, I used the same approach. But with fewer degrees since your legs don't swing as much as your arms.
```css
@keyframes move-leg {
0% {
transform: rotate(30deg);
}
50% {
transform: rotate(0deg);
}
100% {
transform: rotate(30deg);
}
}
```
## Meme glasses pixel art
I decided to give the character some glasses and meme glasses for that Mather.
They are perfect for trying out pixel art, as they are pixels.
The glasses look like this:
```css
.glasses {
display: block;
width: 10px;
height: 10px;
position: absolute;
left: 15%;
z-index: 3;
box-shadow: 10px 10px #000000, 20px 10px #000000, 30px 10px #000000, 40px 10px #000000,
50px 10px #000000, 60px 10px #000000, 70px 10px #000000, 80px 10px #000000,
90px 10px #000000, 100px 10px #000000, 110px 10px #000000, 120px 10px #000000,
130px 10px #000000, 140px 10px #000000, 150px 10px #000000, 160px 10px #000000,
170px 10px #000000, 180px 10px #000000, 190px 10px #000000, 200px 10px #000000,
10px 20px #000000, 20px 20px #000000, 30px 20px #000000, 40px 20px #000000,
50px 20px #000000, 60px 20px #000000, 70px 20px #000000, 80px 20px #000000,
90px 20px #000000, 120px 20px #000000, 130px 20px #000000, 140px 20px #000000,
150px 20px #000000, 160px 20px #000000, 170px 20px #000000, 180px 20px #000000,
190px 20px #000000, 200px 20px #000000, 20px 30px #000000, 30px 30px #000000,
40px 30px #000000, 50px 30px #000000, 60px 30px #000000, 70px 30px #000000,
80px 30px #000000, 90px 30px #000000, 120px 30px #000000, 130px 30px #000000,
140px 30px #000000, 150px 30px #000000, 160px 30px #000000, 170px 30px #000000,
180px 30px #000000, 190px 30px #000000, 30px 40px #000000, 40px 40px #000000,
50px 40px #000000, 60px 40px #000000, 70px 40px #000000, 80px 40px #000000,
130px 40px #000000, 140px 40px #000000, 150px 40px #000000, 160px 40px #000000,
170px 40px #000000, 180px 40px #000000, 40px 50px #000000, 50px 50px #000000,
60px 50px #000000, 70px 50px #000000, 140px 50px #000000, 150px 50px #000000,
160px 50px #000000, 170px 50px #000000;
}
```
This stacking of border shadows allows us to create a pixel-like effect.
I enjoyed using this and will most likely dedicate a complete article to pixel art and how it works.
## Making the character whistle
I thought it would be cool to make the character whistle. In this case, it means a musical note comes out of its "hole" (mouth?).
For this, I used the `before` selector on the hashnode div.
```css
.hashnode {
&:before {
content: '🎵';
position: absolute;
font-size: 2rem;
animation: 5s notes infinite;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
opacity: 0;
z-index: 3;
}
}
```
As you can see, it plays an infinite `notes` animation.
The notes animation looks like this:
```css
@keyframes notes {
0% {
opacity: 1;
transform: rotate(0deg);
}
5% {
opacity: 1;
transform: rotate(0deg);
}
75% {
transform: rotate(360deg);
top: -100%;
}
100% {
opacity: 0;
transform: rotate(360deg);
}
}
```
It starts by setting the opacity to 1 and resetting the rotation.
Then we use a 5% step not to make the animation super fast and rotate the note as we move it upwards.
And eventually, we fade it out.
This will then re-loop, making it start from 0%.
I think it turned out to be quite a fantastic addition.
## Run the world animation
The last part is the globe that spins around.
For this, I created a big circle.
```css
.world {
position: absolute;
width: 75vmin;
aspect-ratio: 1;
background: blue;
border-radius: 50%;
top: 100%;
left: -50%;
background-image: url(https://cdn.hashnode.com/res/hashnode/image/upload/v1641971056244/tPSv8apET.png);
background-size: cover;
background-position: center center;
animation: 15s world linear infinite;
}
```
The circle is then filled with a PNG image of the world. You can open the above image to see what it looks like.
I've added a `world` animation that will spin it around. It's important to note the `linear` animation so it won't slow down once it's almost complete but move at the same speed all the time.
The animation itself looks like this:
```css
@keyframes world {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
```
Just a simple from 0 degrees to 360 degrees animation that makes the world go round, and round and round!
## Finishing touch
Go ahead, click the character...
(Put your music up! 🎵)
Yes, I decided to add "Daft Punk - Around the world" when clicking the logo.
For this, we leverage a little bit of JavaScript that looks like this:
```js
const audio = new Audio('https://download.mp3very.buzz/d/Daft-Punk-Around-The-World.mp3');
const hashnode = document.querySelector('.hashnode');
hashnode.addEventListener('click', () => {
audio.paused ? audio.play() : audio.pause();
});
```
This will load a new Audio object, and once we click the logo, it will toggle between playing and pausing the music.
## Conclusion
I loved doing this challenge as it allowed me to try out different types of CSS art.
And I think it came out pretty cool 😂
{% codepen https://codepen.io/rebelchris/pen/wvrQzMq %}
A big shoutout to the following people for all their parts of information around it:
- Nazanin Ashrafi for setting this up! ⚡️
- Alvaro Montoro for the mask setup 💖
- Ale Thomas Ale for the pixel-art idea 👾
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
954,836 | Switching to Linux: Part 2 - the community | Continuing on from the post yesterday, I thought I'd drop some links for, what I find valuable... | 0 | 2022-01-14T07:17:48 | https://dev.to/sjustesen/switching-to-linux-part-2-the-community-eg8 | linux, operatingsystems, opensource | Continuing on from the post yesterday, I thought I'd drop some links for, what I find valuable sources of information. If you've been following the Linux community for a while, you probably know some of them already. Feel free to contribute your favorites in the comments :)
## Sites
Distrowatch: News on new and updated distros
https://distrowatch.com/
Phoronix (news site):
https://www.phoronix.com/scan.php?page=home
GamingOnLinux:
https://www.gamingonlinux.com/
UbuntuHandbook:
https://ubuntuhandbook.org/
Reddit Linux Subreddit (news, not for support):
https://www.reddit.com/r/linux/
Reddit: the LinuxQuestions subreddit (support forum)
https://www.reddit.com/r/linuxquestions/
LWN - news:
https://lwn.net/
Linux from Scratch:
https://www.linuxfromscratch.org/lfs/
Build your own Linux distro - sort of like a guided tour, not really for beginners, but you'll get a sense of how open & modular the platform is.
Linux Kernel hacking:
https://kernelnewbies.org/KernelHacking
Linux Today - news
https://www.linuxtoday.com/
Linux.org - community site
https://linux.org
LinuxDocs.org
http://linuxdocs.org/
Old site, but does still contain some cool tricks e.g. how to do kernel patches
---------------------------------
## Youtube channels:
LearnLinuxTV
https://www.youtube.com/user/JtheLinuxguy
Old Tech Bloke
https://www.youtube.com/channel/UCCIHOP7e271SIumQgyl6XBQ
This Week in Linux - news
https://www.youtube.com/channel/UCmyGZ0689ODyReHw3rsKLtQ
Linux Gamecast
https://www.youtube.com/channel/UC9F5SkQPgG1besItGOVkz0A
Linux Experiment
https://www.youtube.com/c/TheLinuxExperiment
DistroTube
https://www.youtube.com/distrotube
Brodie Robertson -
https://www.youtube.com/user/JtheLinuxguy | sjustesen |
972,426 | Your Guide to Landing a Remote Developer Job and Securing the Bag | Landing a remote developer job and being paid well for it used to be an elusive and hopeless endeavor... | 0 | 2022-01-30T05:10:16 | https://sixfiguresengineer.com/landing-a-remote-developer-job/ | career, motivation, writing, discuss | Landing a remote developer job and being paid well for it used to be an elusive and hopeless endeavor a few years ago.
But we now live in a time where getting paid to work as a web developer using React, a mobile developer building with Flutter, or a back-end developer programming in Python and even Java, from the comfort of your home, is a real possibility.
One that I seized and will most likely never leave!
- I get to set my schedule so long as my work gets accomplished
- I don't have to fake that I'm working or being productive, which leads to resentment and a vicious never-ending cycle
- I don't have to commute
- I get to spend more time with my family
- I get to exercise more often
- Sorry if I'm rubbing it in

_via GIPHY_
But how do you land one of these sweet gigs? How do you convince a company that you're worthy of such trust?
I'm going to assume that you have spent some time learning the fundamentals of programming, and if not, I recommend that you check out my article on [how I became a software engineer](https://dev.to/gabedealmeida/how-i-became-a-software-engineer-making-six-figures-without-a-college-degree-1h2g).
Landing a remote software engineering role is not much different than a work-in-the-office-and-hate-every-minute-of-it position.
And no, you don't need to have years of professional experience before working remotely. In fact, my first software engineering job was fully remote.
The most important things to keep in mind are:
1. Where to apply
2. How to interview
## Where to Apply
Knowing what companies to apply to regarding a remote software engineering position is of the utmost importance.
Think about it, imagine if 99% of your company worked out of an office and you and a few other people were the only ones working remotely. Imagine if you were the only one in your team working remotely!
You might not think that matters, but it does.
That means that that company does not possess a remote culture and is most likely not set up to handle remote employees in the best way.
You're starting from a losing position. All of your coworkers get to stand by the coffee machine and socialize, and when they're working, your manager sees that they're working; you're nowhere to be seen.
I've heard terrible stories from remote workers in such companies where their team members and managers don't speak to them or forget about them altogether!
Talk about making some dough on the low!

_via GIPHY_
That leads remote employees to feel obligated to fight for attention, recognition, and proof of effort.
Stay far away from such places. You don't want to work at a company that is "open" to remote possibilities or is "thinking" about it.
**You want to work at a company that is either fully remote or has a track record of being remote-friendly.**
Why?
Because you won't have to overwork yourself in hopes of proving that you're doing just as much as your colleagues.
Because you want to be recognized for what you do and want to be promoted for all of your efforts.
Whether you're a front-end, back-end, or full-stack developer, your goal should always be to challenge yourself and grow. Working at a place designed to sustain a thriving culture is where you'll be able to excel.
My recommendation of places to find such companies are:
- [Angellist](https://angel.co/)
- [RemoteOk](https://remoteok.com/)
- [We Work Remotely](https://weworkremotely.com/)
- [Hackernews who is hiring monthly job postings](https://news.ycombinator.com/item?id=29782099)
- [Work at a Startup](https://www.workatastartup.com/)
- [LinkedIn](https://www.linkedin.com/)
Don't worry. You'll find more places than you'll be able to apply to!
Just make sure that when searching for companies, you filter by remote or remote-only companies.
## How to Interview

_Photo by Juan Rumimpunu_
Remote companies don't usually interview any differently than an in-person company. Still, they look for certain qualities and experiences to see if you're someone who can handle such an environment.
So it's essential to keep in mind as you're introducing yourself or answering questions that they're looking for that.
How might you prove that you're able to work in a remote capacity?
Well, if you've worked remotely before, make sure to state that.
If you haven't, maybe you've built a project with friends that you can talk about. Or you've contributed to an open-source project. Orrr, you're part of an online community that you help maintain.
Maybe there's an even weirder thing you've done that you think would show that you'd be able to handle working at a remote company. Talk about that! Unless it's too weird... Then it would be best if you tweeted at me [@gabedealmeida](https://twitter.com/gabedealmeida) so that I and the whole world can be the judge of that 🤪.
And if you really can't think of anything, consider building a project with friends or contributing to an [open-source](https://github.com/explore) project.
I mean, you don't have to do either of those things, but it's easier to convince your interviewers, who are limited on time and are often just listening for some keywords, that you're a fit if you have previous experience.
The point here is that there are ways to **prove that you're someone who can thrive in such an environment**.
## Bonus
Succeeding at a remote job is also vital. So here are some tips to help you do just that:
1. Be polite
2. Be punctual
3. Air on the side of detail
4. Be thorough in explaining what you're working on, what you've accomplished, and what you need assistance with
5. Do great work
## Summary

_via GIPHY_
To land a remote developer job and secure the bag, you have to first make sure that you're applying to the suitable types of companies to succeed and not live in a constant state of stress.
When attending your interviews, you have to go in with the understanding that your interviewers are trying to assess whether you're someone who has any previous remote experience or can fit in for whatever reason.
But what do I know?! I'm just some guy... 🤷🏻♂️
---
Thanks for taking the time to read this article! I hope that you found it helpful.
If you did or didn't, give me a follow on [Twitter](https://twitter.com/gabedealmeidaurl)! I always try to share as much as I know or what I'm currently learning. 🤟🙂 | gabedealmeida |
972,539 | detour | thought i was going to be making logic for spawning player pregame pawns tonight. but i freaked out,... | 0 | 2022-01-30T07:15:39 | https://dev.to/tygamesdev/detour-29g6 | thought i was going to be making logic for spawning player pregame pawns tonight. but i freaked out, i realized in a quest to maximize the playable area of a phone, i had derived the size of my play area by the resolution size. this gave me anxiety about how different players my visualize the game, the layout of enemies, etc. i wasn't sure how to square this without having the black bars. then after some digging, i realized that 16:9 is by far and away the most common resolution ratio. so i believe as long as i play to that, i should be ok.
gonna play some apex. | tygamesdev | |
972,586 | Why I am starting #100daysofblogging | Hi guys, I am Rajat. I am 28 and currently unemployed. I started learning web-development from this... | 0 | 2022-01-30T09:58:58 | https://dev.to/therajatg/why-i-am-starting-100daysofblogging-d7f | writing, write, javascript, webdev | Hi guys, I am Rajat. I am 28 and currently unemployed. I started learning web-development from this month itself (I know I am bit late to the party) and I don't have any IT or CS degree. previously, I used to work as officer at a bank in Delhi and got relieved on 5th January 2022 after serving for 2.5 years.
I am currently doing #100daysofcode challenge on twitter and also like to extend one more challenge to myself that is #100daysofblogging.
Yaa! you heard it right. I am going to publish one blog each day for 100 days straight.
Just announcing it publicly (to make it more real for me).
So, Why I am doing this:
1. Because writing is a superpower. It gives structure to my thoughts and hence enable me to think and speak with clarity which in turn makes me a better coder (because I think coding is mostly just thinking clearly).
2. Although most of the times writing is just hard and taxing, I love going through the process.
3. I think it will unlock more opportunities for me.
4. Along with writing, consistency is also a superpower😀.
This is the first day and I don't have anything to write. So, I thought why not to announce #100daysofblogging on dev.to.
PS: My blogs will follow my web development journey. Hence, I will write mostly about javascript, react and web development in general. If you are learning web-development, follow this blog and I am sure it will add value.
My twitter handle: @therajatg
If you are the linkedin type: https://www.linkedin.com/in/therajatg/
Have an amazing day ahead 😀!
| therajatg |
924,998 | GITHUB CHEAT SHEET | GITHUB CHEAT SHEET STARTING A PROJECT Forked projects or existing... | 0 | 2021-12-13T12:41:20 | https://dev.to/manolosolalinde/github-cheat-sheet-3ifo | github, git | # GITHUB CHEAT SHEET
## STARTING A PROJECT
Forked projects or existing projects
```bash
cd ~/GITHUB/manolosolalinde
git clone <url>
git config credential.helper store
```
Create remote repository
```bash
cd ~/GITHUB/manolosolalinde
mkdir <reponame>
# deprecated: curl -u 'manolosolalinde@gmail.com' -d '{"name":"'"${PWD##*/}"'"}' https://api.github.com/user/repos
# token from https://github.com/settings/tokens
curl -i -H "Authorization: token <GET FROM https://github.com/settings/tokens> " \
-d '{
"name": "'"${PWD##*/}"'",
"description": "This is your first repository",
"homepage": "https://github.com",
"private": true,
"has_issues": true,
"has_projects": true,
"has_wiki": true
}' \
https://api.github.com/user/repos
echo "# TODO Readme" >> README.md
```
Start Local Repository and push first commit
```bash
git init
git config credential.helper store
git add .
git commit -m "first commit"
git remote add origin https://github.com/manolosolalinde/${PWD##*/}.git
git push -u origin master
```
Change local repository:
```bash
git remote show origin
git remote set-url origin https://github.com/manolosolalinde/${PWD##*/}.git
```
## DELETING ALL HISTORY
```bash
cd <localrepofolder>
rm -rf .git
Start Repository (as above)
git push -u --force origin master
```
## DELETING A FULL REMOTE REPO
```bash
cd <REPONAME>
curl -X DELETE -H 'Authorization: token replacewithtoken' https://api.github.com/repos/manolosolalinde/${PWD##*/}
```
Get Delete Auth token
<a href="https://developer.github.com/v3/oauth_authorizations/#create-a-new-authorization">https://developer.github.com/v3/oauth_authorizations/#create-a-new-authorization</a>
```bash
curl -v -u 'manolosolalinde@gmail.com' -X POST https://api.github.com/authorizations -d '{"scopes":["delete_repo"], "note":"token with delete repo scope"}' >> token.json
```
## INITIAL GLOBAL SETUP
```bash
git config --global user.name "Manuel Solalinde"
git config --global user.email "manolosolalinde@gmail.com"
```
## UNTRACK FILES already added to git repository based on .gitignore
```bash
git rm -r --cached .
git add .
git commit -m ".gitignore fix"
```
rm is the remove command
-r will allow recursive removal
--cached will only remove files from the index. Your files will still be there.
The . indicates that all files will be untracked.
You can untrack a specific file with git rm --cached foo.txt (thanks @amadeann).
## GENERAL PURPOSE
http://www.cheat-sheets.org/saved-copy/github-git-cheat-sheet.pdf
`git config --global user.name "Manuel Solalinde"`\
Sets the name you want atached to your commit transactions
`git remote add origin git@github.com:manolosolalinde/newrepo.git`\
Add origin for existing repository
`git config --global user.email "manolosolalinde@gmail.com"`\
Sets the email you want atached to your commit transaction
`git init [project-name]`\
Creates a new local repository with the specified name
`git clone [url]`\
Downloads a project and its entire version history
`git status`\
Lists all new or modified files to be commited
`git add [file]`\
Snapshots the file in preparation for versioning
`git reset [file]`\
Unstages the file, but preserve its contents
`git diff`\
Shows file differences not yet staged
`git diff --staged`\
Shows file differences between staging and the last file version
`git commit -m "[descriptive message]"`\
Records file snapshots permanently in version history
`git branch`\
Lists all local branches in the current repository
`git branch [branch-name]`\
Creates a new branch
`git checkout [branch-name]`\
Switches to the specified branch and updates the working directory
`git merge [branch]`\
Combines the specified branch’s history into the current branch
`git branch -d [branch-name]`\
Deletes the specified branch
## Tags
more info on tags: <a href="https://git-scm.com/book/en/v2/Git-Basics-Tagging">https://git-scm.com/book/en/v2/Git-Basics-Tagging</a>
`git tag -a v1.4 -m "my version 1.4"` \
Creates a tag
`git tag`
List all tags
`git tag -l "v1.8.5*"` \
v1.8.5
v1.8.5-rc0
v1.8.5-rc1
Check all tags with that name
`git show v1.4` \
Show Tag information
`git log --graph --decorate --oneline`
Show Branch History information
## Working with multiple versions of a project
Interesting post: <a href="https://stackoverflow.com/questions/12153405/how-to-manage-multiple-versions-of-a-project">https://stackoverflow.com/questions/12153405/how-to-manage-multiple-versions-of-a-project</a>
### Example
In my case, I have two version of the same software that the basics are the same but each version has some different features.
So I create two `worktree` that means, create two relevant long-running branches beside the master.
```bash
$git worktree add -b version-silver ..\version-silver master
$git worktree add -b version-gold ..\version-gold master
```
Then I have:
```bash
$git branch
master # base stuff here
version-silver # some normal features
version-gold # some better features
```
There is one repository, but I have 3 separate folders beside each other for each branch above. And make the common changes in master. then merge it with both other versions.
```bash
cd master
vim basic.cpp
git add .
git commit -m "my common edit on basic.cpp"
cd ..\version-silver
vim silver.cpp
git add .
git commit -m "my specific edit on silver.cpp"
git merge master # here i get the basic.cpp latest changes for silver project
cd ..\version-gold
git merge master # here i get the basic.cpp latest changes for gold project
```
### Copy changes of `only last commit` from branch A to branch B
[Stackoverflow - Commit to multiple branches at the same time](https://stackoverflow.com/a/18529576/9831182)
```bash
git checkout A
git commit -m "Fixed the bug x"
git checkout B
git cherry-pick A
```
## Problems
### Problems with vscode and credentials
<a href="https://stackoverflow.com/questions/34400272/visual-studio-code-always-asking-for-git-credentials">https://stackoverflow.com/questions/34400272/visual-studio-code-always-asking-for-git-credentials</a>
You should be able to set your credentials like this:
```
git remote set-url origin https://<USERNAME>:<PASSWORD>@bitbucket.org/path/to/repo.git
```
You can get the remote url like this:
```
git config --get remote.origin.url
```
My problem was solved with:
```
cd "C:\Program Files\Git\mingw64\libexec\git-core"
git-credential-manager.exe uninstall
``` | manolosolalinde |
972,635 | [BTY] Day 5: Lessons when you're learning code | This post was for 28.01.2022 Those lessons are from a Youtube video I came across recently. Link... | 16,070 | 2022-01-30T10:49:13 | https://dev.to/nguyendhn/bty-day-5-lessons-when-youre-learning-code-3oaj | betterthanyesterday | _This post was for 28.01.2022_
Those lessons are from a Youtube video I came across recently.
Link here: https://www.youtube.com/watch?v=s6dMWzZKjTs&list=PL0s6MZJVJ8HZ0eYoUt3KM8WR1AQJWQnXc&index=5
**Lesson 1: Don't learn things randomly,**
but follow a pre-made roadmap or a structured path because you will be able to see your progress.
**Lesson 2: Focus on one thing at a time**.
Stay on one subject until you have a decent grasp of the basics
**Lesson 3: Be an active learner.**
Don't just passively consume content. Sitting back and watching an instructor go through materials without trying anything yourself is not going to get you very far.
**Lesson 4: Don't just memorize**.
It's normal to use Google, StackOverFlow.
**Lesson 5: Build stuff**.
Of course. Learning by doing!
| nguyendhn |
972,667 | Horizontal vs Vertical Scaling: What Is the Best for You? | In today's world, at least part of any business operates online. So it has a site or application that... | 0 | 2022-02-14T06:28:50 | https://dev.to/maddevs/horizontal-vs-vertical-scaling-what-is-the-best-for-you-272j | webdev | In today's world, at least part of any business operates online. So it has a site or application that provides information about a product or service. Even if they are not the main business product, they need to be protected from attack and failures, as well as work well with any load. And here we come to scalability. In this article, we’ll discuss what is scalability and how to understand when you need it? What is traditional horizontal and vertical scalability and which one is better for you? How does scalability work with cloud computing and what it types and features?
Of course, we will not go for complicated technical details, but expose a lot of important points. Explore new options to improve your services and enjoy the reading.
##What Is Scalability?
Service scalability is the ability of a web service to increase its performance by increasing the performance of internal server resources or by increasing the number of servers.
For example, you have a web application or website, and your marketing department did an excellent job of attracting a large number of users. But some of the users cannot access the website because the machine it runs isn't able to handle that many user’s requests. As a result, users get a negative experience, and many new users become a problem for you, not a victory. So you realize that you need to increase the machine's performance on which your site works. The ability to improve that performance without any base changes to the website is scalability.
##When Do You Need It?
The performance increases mainly by increasing the hardware performance on which the site or application runs—for example, using a more powerful processor, faster memory, or just using a few machines. However, this requires additional funds and is often quite large. But for some reason, a significant increase in performance may not happen. First, you need to look into how your website or application is developed. Does the code provide for smooth hardware replacement? Or maybe poorly written code is the cause of latency in processing requests, not the hardware? If your main product is not software, and the website or web application only serves as customer contact, then you may not have your staff of experienced developers. In this case, we recommend turning to professionals. For example, Mad Devs provides a vavariousvices, from auditing to software development and support. We can thoroughly analyze your web service and provide comprehensive recommendations on the future scaling of your web service. In addition, we can directly scale your web service smoothly, taking care of all the individual aspects of your business. Of course, if you have your staff of experienced developers, they should do some pre-scaling work to determine whether you need it now and are you ready for it in the future.
###Test Your Security
Security first. There is a chance of an attack on your web service. If this is the case, you need to pay all your attention to improving the security of your service, not pay your money on increasing performance. You can do this by looking at the statistics. If there is no periodicity in the high load, it is either a bug in the code or an attack. Don't panic. Just give it to your developers, they should know how to detect and fix it. They can also analyze the top IP addresses, parse logs, and put limits on your web service. Even if there is a periodicity, you should not immediately update the hardware. Perhaps the problem is still hidden in the code, and increasing the performance of the hardware can let you not notice it for a while. But later, it will show itself again and probably become an even bigger problem than spending money carelessly. So give your developers the task to check the code, affecting performance.
###Test Your Database
One of the most common causes is the incorrect operation of the database. At a low load, such things often go unnoticed, but at a high load, everything becomes obvious. It is necessary to pay special attention to the database because problems with it lead to other problems, such as an unnecessary load of the processor, memory overflow, and so on. The problem may be in the default settings of the database server. In this case, you just need to take the time once and optimize the settings manually or use utilities that do this automatically.
Or the database may be organized incorrectly so that requests take a long time to process or even produce errors. For example, there continues to wait for data after a request when there is no data. Or in some table cells, there is too much different data or data is not indexed, and many other things are possible.
###Technologies You Use
It's pretty apparent here. Suppose you are using old programming languages and outdated technologies in development. For example, if you are using the old version of PHP, you will see significant performance improvements if you rewrite your web service with the newer version of PHP. Also, using some different technologies can speed up the web service. For example, you can implement NGINX, which will cache static data and serve it to the user much faster and leave dynamic data for Apache. But trust it only to experienced developers. They know many technologies for optimizing web services and how to use them in the best way.
###Hardware You Use
All previous tests helped optimize the web service code or concluded that it was initially well designed and optimized. Tests should also give a conclusion of which hardware component is failing. It could be an under-performing processor, insufficient amount or speed of memory, etc. So good reasons for scaling may be:
- To increase the size of the database
- To improve the functionality of the web service
- To grow in number of users
[](https://maddevs.io/insights/blog/deploy-and-scale-wordpress-with-docker-cloud-swarm-mode/?utm_source=devto)
##What Is Horizontal Scaling?

Horizontal Scaling - increasing performance by adding the number of servers to share the load between the existing and new machines. The website code must ensure smooth synchronized operation of the servers. If your code does not have this option, you will have to rewrite some of it. But even if the code provides for such an option, each time you connect a new server, you have to add some code, make additional configuration changes, and test synchronization with the rest of the servers.
###Horizontal Scaling Advantages
* **Allows you to distribute the load among multiple servers.** This can improve both performance and fault tolerance. Especially if the servers are located in different data centers.
* **Allows you to increase data security in some emergencies.** Of course, there are always protected backups, but if they are on the same hardware, they are only protected by software. Storing data and its backups on several servers is hardware protection, which takes data security to a whole new level.
* **Allows you to optimize the architecture of web services.** Sometimes, due to some architectural specifics of the web service, its components can interfere with each other in one place. It doesn't sound quite logical, but experienced developers know about it. Of course, you can always run the service on a more powerful machine, but sometimes it is better to place some of its components on different machines. Also, using separate servers for the web and data layers allows them to scale independently of each other.
* **Horizontal scaling is not limited at all, unlike vertical scaling.** You can increase the number of servers endlessly with the proper software. Ultimately, this is a necessary stage for any vast service.
###Horizontal Scaling Disadvantages
* **It's more challenging to support.** Whenever a new server is added, you need to configure synchronized operations between them, more care about the logic of communication and resource allocation.
* **It doesn’t improve performance as much as vertical scaling.**
Sure, enough machines will enhance performance, but the quality is always more important than the amount.
* **Many servers can be more expensive to support over a long time.** Each server is a separate machine, with its software that you have to pay for a license and, of course, paying for renting the machine itself. Also, the more machines that work together, the more complicated their interaction is, which means you will need to hire more skilled and expensive developers, and you will need more and more of them.
## What Is Vertical Scaling?
Vertical Scaling - increasing performance by changing components in the exciting server with more power. For example, installing a more powerful processor, faster memory, or more memory. Most likely, you won't have to make any changes to your code. But you will have to do some minimal additional settings.
###Vertical Scaling Advantages
* **Allows you to make little or no changes to the web service code while increasing performance.** Since your web service is still on the single machine, you don't have to worry about additional complications as with multiple machines working together.
* **Allows you to increase performance several times quickly.** The latest generation processor can be more powerful than a dozen processors from five years ago. But even if the number of processors can increase the power, the memory will not become faster from more of it.
* **Allows you to use a specific set of technologies.** More advanced components can be more performant, but they can also have architectural solutions that were not available in previous components. In doing this, you do not have to improve the other components, which do not necessarily have to be the most advanced for your tasks. For example, tensor cores in today’s graphics cards allow you to do more complex calculations more efficiently, such as those from artificial intelligence and machine learning.
###Vertical Scaling Disadvantages
* **It has limitations.** Of course, you can't increase the performance of your computer indefinitely. The operating system limits the number of components you can use.
* **In an emergency case, the complete service goes down.** Since everything works on one machine, any changes require a system restart, and any failures make the service unavailable for a while. Fault tolerance is provided only by software, not hardware.
##Horizontal and Vertical Scaling in Cloud Computing
The problem with all previous approaches is that we are dealing with the modification or connection of new hardware. And this is always a lot of extra money, more time to find, buy and install hardware in data centers, debug and test it, and so on. A great alternative is horizontal and vertical scaling in cloud computing, of which [Amazon Web Services (AWS)](https://aws.amazon.com/?aws-products-analytics.sort-by=item.additionalFields.productNameLowercase&aws-products-analytics.sort-order=asc&aws-products-business-apps.sort-by=item.additionalFields.productNameLowercase&aws-products-business-apps.sort-order=asc&aws-products-containers.sort-by=item.additionalFields.productNameLowercase&aws-products-containers.sort-order=asc&aws-products-compute.sort-by=item.additionalFields.productNameLowercase&aws-products-compute.sort-order=asc&aws-products-databases.sort-by=item.additionalFields.productNameLowercase&aws-products-databases.sort-order=asc&aws-products-fe-mobile.sort-by=item.additionalFields.productNameLowercase&aws-products-fe-mobile.sort-order=asc&aws-products-game-tech.sort-by=item.additionalFields.productNameLowercase&aws-products-game-tech.sort-order=asc&aws-products-iot.sort-by=item.additionalFields.productNameLowercase&aws-products-iot.sort-order=asc&aws-products-ml.sort-by=item.additionalFields.productNameLowercase&aws-products-ml.sort-order=asc&aws-products-mgmt-govern.sort-by=item.additionalFields.productNameLowercase&aws-products-mgmt-govern.sort-order=asc&aws-products-migration.sort-by=item.additionalFields.productNameLowercase&aws-products-migration.sort-order=asc&aws-products-network.sort-by=item.additionalFields.productNameLowercase&aws-products-network.sort-order=asc&aws-products-security.sort-by=item.additionalFields.productNameLowercase&aws-products-security.sort-order=asc&aws-products-storage.sort-by=item.additionalFields.productNameLowercase&aws-products-storage.sort-order=asc), [Microsoft Azure](https://azure.microsoft.com/en-us/), and [Google Cloud Platform](https://cloud.google.com/) are good examples. They allow you to instantly change the configuration and number of machines that make your web service perform.
###Manual Scaling

Manual scaling is done manually by the developer. Yes, when it comes to cloud scaling, it is much easier than in the case of data centers. But it still involves more configurations. And since there is a human factor involved, an error is not excluded.
###Scheduled Scaling

Schedule scaling does not have the disadvantages of manual scaling. Based on statistics, you can plan the increase of available resources depending on the attendance of web service at different times of the day or days of the month. However, you need additional analysis of load statistics.
###Auto Scaling
Auto Scaling allows you to configure the web service to automatically increase or decrease the performance depending on different load types. By analyzing various scenarios and load levels depending on them, you can improve the processor's performance, give access to more memory, etc. This allows you to optimize the provisioning of resources relative to the amount of load and save as much money and time in the future as possible. But this requires careful analysis and configuration initially.
[](https://maddevs.io/insights/blog/run-kubernetes-on-aws/?utm_source=devto)
##Summary
So scalability and technologies are what you have to care about a lot. We hope that our article has helped you understand its main aspects and understand if you need to scale and what kind of scalability to pay attention to. However, it is safe to say that scaling with cloud technology has vast advantages relative to the rapidly changing world we live in today.
Here at [Mad Devs](https://maddevs.io/?utm_source=devto), we follow the market and industry trends very closely and help you understand and start using the latest technologies so that any business has the infrastructure it needs to be fully confident in its future. Take a look at the full list of our services, customers, and their experiences, and the right decision will not belong in coming.
[](https://maddevs.io/services/?utm_source=devto)
_Previously published at [maddevs.io/blog](https://maddevs.io/blog/horizontal-vs-vertical-scaling/?utm_source=devto)._ | maddevsio |
972,731 | How to create stored procedure in mysql with example | A procedure often called a stored procedure is a collection of pre-compiled SQL statements stored... | 0 | 2022-01-30T13:44:04 | https://dev.to/kodblemsuser/how-to-create-stored-procedure-in-mysql-with-example-3e6l | mysql | A procedure often called a stored procedure is a collection of pre-compiled SQL statements stored inside the database. It is a subroutine or a subprogram in the regular computing language.
[
Mysql Database](https://kodblems.com/10287/how-to-create-stored-procedure-in-mysql-with-example) | kodblemsuser |
972,785 | LeetCode - Subsets II | LeetCode - return all possible subsets (the power set) of array with duplicates using C++, Golang and Javascript. | 0 | 2022-01-30T15:36:42 | https://alkeshghorpade.me/post/leetcode-subsets-ii | programming, algorithms, go, javascript | ---
title: LeetCode - Subsets II
published: true
description: LeetCode - return all possible subsets (the power set) of array with duplicates using C++, Golang and Javascript.
tags: #programming, #algorithms, #golang, #javascript
canonical_url: https://alkeshghorpade.me/post/leetcode-subsets-ii
---
### Problem statement
Given an integer array *nums* that may contain duplicates, return *all possible subsets (the power set)*.
The solution set **must not** contain duplicate subsets. Return the solution in **any order**.
Problem statement taken from: <a href="https://leetcode.com/problems/subsets-ii" target="_blank">https://leetcode.com/problems/subsets-ii</a>.
**Example 1:**
```
Input: nums = [1, 2, 2]
Output: [[], [1], [1, 2], [1, 2, 2], [2], [2, 2]]
```
**Example 2:**
```
Input: nums = [0]
Output: [[], [0]]
```
**Constraints:**
```
- 1 <= nums.length <= 10
- -10 <= nums[i] <= 10
```
### Explanation
#### Backtracking
The approach for this problem is similar to our previous blog [LeetCode Subsets](https://alkeshghorpade.me/post/leetcode-generate-subsets). The only difference is we need to exclude duplicate elements here while generating the subset.
First, we will sort the nums array. We can either exclude the duplicate elements while recursively calling the subset generator function or we can mark the subset as a Set (Set is an abstract data type that can store unique values).
Let's check the algorithm first.
```
// subsetsWithDup(nums) function
- sort nums array sort(nums.begin(),nums.end())
- initialize vector<int> subset
set<vector<int>> result
vector<vector<int>> answer
- call util function subsetsUtil(nums, result, subset, 0)
- push set result in vector array
loop for(auto it:result)
answer.push_back(it)
- return answer
// subsetsUtil(nums, result, subset, index) function
- insert subset in result
result.insert(subset)
- loop for i = index; i < nums.size(); i++
- subset.push_back(nums[i])
- subsetsUtil(nums, result, subset, i + 1)
- subset.pop_back()
```
Let's check out our solutions in **C++**, **Golang**, and **Javascript**.
**Note:** In the C++ solution the subset is a Set, while in Golang and Javascript it's a normal array and we have ignored the duplicates.
#### C++ solution
```cpp
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());
vector<int> subset;
set<vector<int>> result;
subsetsUtil(nums, result, subset, 0);
vector<vector<int>> answer;
for(auto it:result){
answer.push_back(it);
}
return answer;
}
public:
void subsetsUtil(vector<int>& nums, set<vector<int>>& result, vector<int>& subset, int index) {
result.insert(subset);
for(int i = index; i < nums.size(); i++){
subset.push_back(nums[i]);
subsetsUtil(nums, result, subset, i + 1);
subset.pop_back();
}
return;
}
};
```
#### Golang solution
```go
func subsetsUtils(nums, subset []int, result *[][]int) {
cp := make([]int, len(subset))
copy(cp, subset)
*result = append(*result, cp)
for i := 0; i < len(nums); i++ {
subsetsUtils(nums[i+1:], append(subset, nums[i]), result)
for ; i < len(nums)-1 && nums[i] == nums[i+1]; i++ {
}
}
}
func subsetsWithDup(nums []int) [][]int {
sort.Ints(nums)
var result [][]int
subset := make([]int, 0, len(nums))
subsetsUtils(nums, subset, &result)
return result
}
```
#### Javascript solution
```javascript
var subsetsWithDup = function(nums) {
nums.sort((a, b) => a - b);
const result = [];
subsetsUtils(0, []);
return result;
function subsetsUtils (index, array) {
result.push([...array]);
for (let i = index; i < nums.length; i++) {
if (i > index && nums[i] == nums[i - 1]) {
continue;
}
array.push(nums[i]);
subsetsUtils(i + 1, array);
array.pop();
}
}
};
```
Let's dry-run our algorithm to see how the solution works.
```
Input: nums = [1, 2, 2]
Step 1: sort(nums.begin(),nums.end())
nums = [1, 2, 3]
Step 2: initialize vector<int> subset
set<vector<int>> result
Step 3: subsetsUtil(nums, result, subset, 0)
// in subsetsUtils function
Step 4: result.push_back(subset)
result.push_back([])
result = [[]]
loop for i = index, i < nums.size()
i = 0
0 < 3
true
subset.push_back(nums[i])
subset.push_back(nums[0])
subset.push_back(1)
subset = [1]
subsetsUtil(nums, res, subset, i + 1)
subsetsUtil([1, 2, 2], [[]], [1], 0 + 1)
subsetsUtil([1, 2, 2], [[]], [1], 1)
Step 5: result.push_back(subset)
result.push_back([1])
result = [[], [1]]
loop for i = index, i < nums.size()
i = 1
1 < 3
true
subset.push_back(nums[i])
subset.push_back(nums[1])
subset.push_back(2)
subset = [1, 2]
subsetsUtil(nums, res, subset, i + 1)
subsetsUtil([1, 2, 2], [[], [1]], [1, 2], 1 + 1)
subsetsUtil([1, 2, 2], [[], [1]], [1, 2], 2)
Step 6: result.push_back(subset)
result.push_back([1, 2])
result = [[], [1], [1, 2]]
loop for i = index, i < nums.size()
i = 2
2 < 3
true
subset.push_back(nums[i])
subset.push_back(nums[2])
subset.push_back(2)
subset = [1, 2, 2]
subsetsUtil(nums, res, subset, i + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2]], [1, 2, 2], 2 + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2]], [1, 2, 2], 3)
Step 7: result.push_back(subset)
result.push_back([1, 2, 3])
result = [[], [1], [1, 2], [1, 2, 3]]
loop for i = index, i < nums.size()
i = 3
3 < 3
false
Step 8: Here we backtrack to last line of Step 6 where
i = 2
subset = [1, 2, 2]
We execute the next line
subset.pop()
subset = [1, 2]
Step 9: We backtrack to last line of Step 5 where
i = 1
subset = [1, 2]
We execute the next line
subset.pop()
subset = [1]
Step 10: For loop continues where we execute
loop for i = index, i < nums.size()
i = 2
i < nums.size()
2 < 3
true
subset.push_back(nums[i])
subset.push_back(nums[2])
subset.push_back(2)
subset = [1, 2]
subsetsUtil(nums, res, subset, i + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2]], [1, 2], 2 + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2]], [1, 2], 3)
Step 11: result.push_back(subset)
result.push_back([1, 2])
result = [[], [1], [1, 2], [1, 2, 2]]
loop for i = index, i < nums.size()
i = 3
3 < 3
false
Step 12: Here we backtrack to last line of Step 3 where
i = 0
subset = [1]
We execute the next line
subset.pop()
subset = []
Step 13: For loop continues where we execute
loop for i = index, i < nums.size()
i = 1
i < nums.size()
1 < 3
true
subset.push_back(nums[i])
subset.push_back(nums[1])
subset.push_back(2)
subset = [2]
subsetsUtil(nums, res, subset, i + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2]], [2], 1 + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2]], [2], 2)
Step 14: result.push_back(subset)
result.push_back([2])
result = [[], [1], [1, 2], [1, 2, 2], [1, 2], [2]]
loop for i = index, i < nums.size()
i = 2
2 < 3
true
subset.push_back(nums[i])
subset.push_back(nums[2])
subset.push_back(2)
subset = [2, 2]
subsetsUtil(nums, res, subset, i + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2], [2]], [2, 2], 2 + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2], [2]], [2, 2], 3)
Step 15: result.push_back(subset)
result.push_back([2, 2])
result = [[], [1], [1, 2], [1, 2, 2], [2], [2, 2]]
loop for i = index, i < nums.size()
i = 3
3 < 3
false
Step 16: Here we backtrack to last line of Step 14 where
i = 2
subset = [2, 2]
We execute the next line
subset.pop()
subset = [2]
Step 17: Here we backtrack to last line of Step 13 where
i = 1
subset = [2]
We execute the next line
subset.pop()
subset = []
Step 18: For loop continues where we execute
loop for i = index, i < nums.size()
i = 2
i < nums.size()
2 < 3
true
subset.push_back(nums[i])
subset.push_back(nums[2])
subset.push_back(2)
subset = [2]
subsetsUtil(nums, res, subset, i + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2], [2], [2, 2]], [2], 2 + 1)
subsetsUtil([1, 2, 2], [[], [1], [1, 2], [2], [2, 2]], [2], 3)
Step 19: result.push_back(subset)
result.push_back([2])
result = [[], [1], [1, 2], [1, 2, 2], [2], [2, 2]]
loop for i = index, i < nums.size()
i = 3
3 < 3
false
Step 20: We have no more stack entries left. We return to the main function.
Step 21: for(auto it:result){
answer.push_back(it);
}
We push result Set to answer Vector.
Step 22: return answer
So we return the answer as [[], [1], [1, 2], [1, 2, 2], [2], [2, 2]].
``` | _alkesh26 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.