
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
917,516 | Using environment variables with SvelteKit | Because SvelteKit comes with Vite, using .env may be a bit unfamiliar. There are two ways to go about... | 0 | 2021-12-04T17:56:24 | https://dev.to/nostro/using-environment-variables-with-sveltekit-544b | svelte, sveltekit, webdev | Because SvelteKit comes with Vite, using `.env` may be a bit unfamiliar. There are two ways to go about it, either with Vite's `import.meta.env` out of the box or with the usual suspect `process.env` that requires a bit more setting up.
**You may also be interested in**
[SvelteKit + TailwindCSS](https://dev.to/nostro/using-tailwindcss-with-sveltekit-25i6)
[SvelteKit + Heroku](https://dev.to/nostro/deploying-to-heroku-with-sveltekit-3350)
### Using `import.meta.env`
Full information is available in the [official docs](https://vitejs.dev/guide/env-and-mode.html) but the gist of it is that you should prefix any variable that you want exposed to your client with `VITE_`
It means `import.meta.env.FOO` will not be exposed client-side, while `import.meta.env.VITE_FOO` will be.
`.env`
```
FOO=BAR
VITE_FOO=BAR
```
`browser`
```js
console.log(import.meta.env.FOO)
// undefined
console.log(import.meta.env.VITE_FOO)
// BAR
```
### Using `process.env`
If for some reason you still want to use `process.env`, because you're used to it or you don't feel like renaming all your variables `VITE_SOMETHING`, you can also do it with the `env-cmd` package.
```powershell
npm i env-cmd
```
Then modify your `config` in `svelte.config.js`
`svelte.config.js`
```js
const config = {
kit: {
vite: {
define: {
'process.env': process.env,
},
},
},
};
```
And finally add `env-cmd` to your `dev` script
`package.json`
```js
{
"scripts": {
"dev": "env-cmd svelte-kit dev",
},
}
```
And now you'll be able to access `process.env` in your client
`.env`
```
FOO=BAR
```
`browser`
```js
console.log(process.env.FOO)
// BAR
```
| nostro |
917,567 | Integrate PayPal API | This article is about integrating Paypal API As a developer, integrating APIs into your project is... | 0 | 2021-12-04T20:53:52 | https://dev.to/kitarp29/integrate-paypal-api-3f8k | webdev, javascript, beginners, tutorial | **This article is about integrating [Paypal API](https://developer.paypal.com/home)**
As a developer, integrating APIs into your project is imperative. I recently integrated PayPal's payment gateway on a side project and plan on sharing how to do it.
PayPal is well known for online payments. Its credibility and developer experience have convinced many users to use it.
The basic API integration can be done in two different ways. The first one is *client-side*. And the second one is *server-side* integration.
## Implementing on the Client Side
If I talk about the reading resources:
A developer won't need anything further than visiting this page. I really don't think you need anything else. [_Documentation_](https://developer.paypal.com/docs/business
/checkout/set-up-standard-payments/integrate/)
Reasons to consider this resource-
- The workflow is very well explained.
- The code sample is available
- Steps to test out provided.
Talking about the video resources:
{% youtube l3e1uzMhiV8 %}
- This is a pretty short and concise video.
- It is from the official channel of Paypal.
- This video very well explains the concept of different ways to integrate on any website.
- Covers all the cases and is easy to follow up.
There is one more resource, that developers can follow up. I am not promoting their channel in any manner but I liked their flow and ease to follow.
- [Paypal Official Source](https://youtu.be/T1q7JipHR48?list=LL)
## Implementing on the Backend Server
I will not be getting into the benefits of applying on Client or Backend. That is up to the developer's choice of preference. If I had to recommend one, then I would have to say an easy way to implement would b the first one.
Getting on to the resource, this video takes care of most of the integration:
{% youtube DNM9FdFrI1k %}
API integration I would say. I used this node module [paypal-checkout](https://www.npmjs.com/package/paypal-checkout)
- Installing it was very easy.
- The npm page was
also very helpful and informative.
- This resource has Video tutorials.
- Demo app space and much more cool stuff.
## Reviews of API Integration:
This was all enough for integration I think. Moving ahead, I will be sharing my reviews of my experience. Learning was also easy as I expected, the official support and documentation were very helpful. But the
PayPal's youtube channel is also of great help. I got many good articles around it too. Many fun blogs on the dashboard as well.
Thanks for reading my article 😊 | kitarp29 |
917,661 | My Experience at Civo Hackathon 2021 | Learning Kubernetes has been one of my top priorities this year. I spent quite a lot of time... | 0 | 2021-12-05T00:58:18 | https://dev.to/avik6028/my-experience-at-civo-hackathon-2021-3acb | machinelearning, devops, kubernetes, webdev | {% youtube lhdiBAoL80s %}
Learning Kubernetes has been one of my top priorities this year. I spent quite a lot of time finding good resources to learn and have hands-on experience with the technology.
**Finally, I came across Civo Kubernetes, when one of my seniors recommended the platform to me. Yeah, it was the one I was looking for! **
The Civo Kubernetes Platform provided me with fully managed K3s clusters as well as high-quality learning videos about Kubernetes from the platform developers themselves. I instantly got a $250 credit in my Civo account once I signed up with my credit card.
<br>
# Introduction
I am currently in the **final year** of my Bachelor's degree in Computer Engineering, from **KIIT University, Bhubaneswar, India**.
In fact, this is my **2nd victory in a nationwide hackathon** this year. Earlier this year, I had finished as the First Runners-up at the **TCS Inframinds Hackathon**. Apart from that, I am currently a **DevOps intern** at **Highradius Technologies** and also an enthusiastic **open-source contributor**.

When I got to know about the **Civo Hackathon**, I planned to take part in it as I needed hands-on experience with **Kubernetes**. Also, the speaker line-up before the commencing of the hackathon was interesting. I got to know about the platform as well as about monitoring and profiling from the developer advocates of Civo.
The hackathon spanned over the **2nd weekend of November 2021**, starting from Friday, when we had the speaker sessions till Sunday evening. The results were finally announced the very next Monday.
### **Much to my surprise, I finished up 2nd !!!!!!**

# My Project
The project I built is a **Computer-Aided Diagnostic System** that is used to predict whether a person has been infected with COVID-19.
The prediction is possible through the integration of the COVID-19 X-Ray Classifier into a Web Application. By uploading Frontal Chest X-Rays, the model can perform classification between COVID and non-COVID X-Rays using Modified DenseNet architectures.

The users are given the option to save the results to the Database to receive further advice from doctors. The data is stored securely in MongoDB. Apart from that, REST API has been provided for Developers to access the Deep Learning Model and get prediction data in their applications. I have also enabled monitoring facilities for the application.
**The entire project was hosted on the Civo Kubernetes Platform.**
<br>
# How I built it
The project kickstarted with the Development of the Web Application. The UI was finalized and then the application was developed. Several open-source styles, libraries and toolkits were used during the development of the Frontend with HTML, CSS and JavaScript.
After completion, the backend of the application was developed with **Python & Flask framework**. The routes were created and mapped to the Frontend. The Deep Learning Model was integrated with the backend REST APIs. Various libraries such as Numpy, Pillow and Tensorflow was used to manage the model. Finally, MongoDB was integrated with the backend to save the Form data.
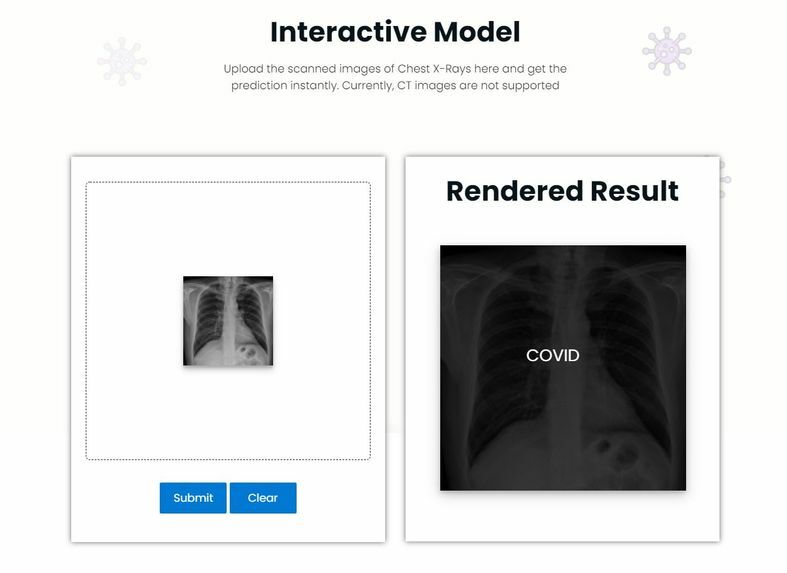
**This completed the Web Application Development.**
The next stage involved deploying the application on Civo K3s Cluster by developing an automated DevOps CI/CD Pipeline. First, the entire application code was pushed to a GitHub repository. Through this step, the code version control is ensured and any change in the code would automatically trigger the entire pipeline.
To deploy applications on K8s, the application needed to be containerized. The building of the Docker container should automatically take place once any code gets changed. After building the container, it needs to be pushed to a Docker Repository, here Dockerhub. Also, the old Docker Image Tag mentioned in the code would need to be replaced by the new Docker Image Tag. For automating all these, a Continuous Integration Pipeline was created with the help of Github Actions as the CI tool.
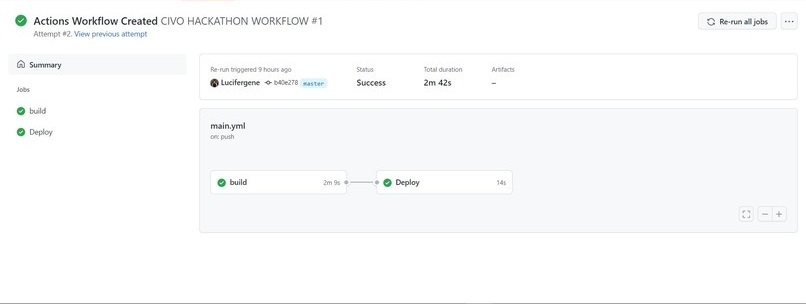
A workflow file was written to sequence the jobs that needed to be performed, once the code get changed in the repository. The jobs involved building and pushing the Docker container to Dockerhub.
After pushing, the new container tag replaced the older one mentioned in the customization file automatically, with the help of Kustomize.io. The Deployment, Service and Ingress YAML files were pushed to the repository as K8s needed these files during deployment.
`Github Actions Workflow` file:
```yaml
name: CIVO HACKATHON WORKFLOW
on:
push:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Build and push Docker image
uses: docker/build-push-action@v1.1.0
with:
username: ${{ secrets.DOCKER_USER }}
password: ${{ secrets.DOCKER_PASSWORD }}
repository: ${{ secrets.DOCKER_USER }}/civo-hackathon
tags: ${{ github.sha }}, latest
deploy:
name: Deploy
runs-on: ubuntu-latest
needs: build
steps:
- name: Check out code
uses: actions/checkout@v2
- name: Setup Kustomize
uses: imranismail/setup-kustomize@v1
with:
kustomize-version: "3.6.1"
- name: Update Kubernetes resources
env:
DOCKER_USERNAME: ${{ secrets.DOCKER_USER }}
run: |
cd kustomize/base
kustomize edit set image civo-hackathon=$DOCKER_USERNAME/civo-hackathon:$GITHUB_SHA
cat kustomization.yaml
- name: Commit files
run: |
git config --local user.email "action@github.com"
git config --local user.name "GitHub Action"
git commit -am "Bump docker tag"
- name: Push changes
uses: ad-m/github-push-action@master
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
```
**This completed the Continuous Integration process.**
The final stage was to deploy the Docker Image pushed in DockerHub, into a CIVO k3s Cluster. For this, a K3s cluster was created on Civo. Due to CPU intensive nature of the application, the Largest Node configuration was selected. Then through the Civo CLI, the KubeConfig file was connected with the local KubeCTL tool.
Through KubeCTL, a namespace was created and ArgoCD was installed in it. Inside ArgoCD, the configuration was provided to continuously track the GitHub Repository for changes in the Kustomization file.
Since previously through CI, we had managed to update the Kustomization file after a new code change took place, this update in the Kustomization file triggered the ArgoCD to re-deploy the application based on the newer Docker Image Tag provided. Thus after an initial manual Sync, ArgoCD managed to complete the Continuous Deployment process.
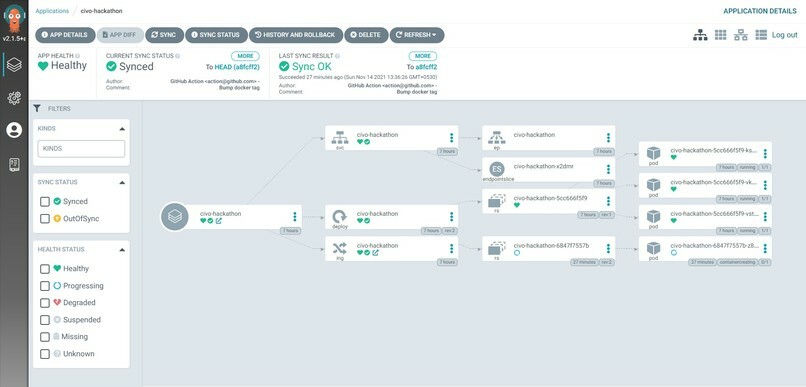
**The CI/CD Pipeline was successfully created which helped to automatically deploy code changes to production.**
After the application was properly working, I proceeded with installing Prometheus and Grafana in a separate namespace in the cluster to fetch and visualize the metrics. For that, I edited the Flask application to make it generate metrics to be fed to Prometheus.
Then I developed a Service Monitor for exposing the metrics endpoint of the application which in turn would be automatically added to the Prometheus Target group. Now, I was able to fetch metrics into Prometheus from the Web application. After that, I set up the Grafana Dashboard to visualize the metrics.
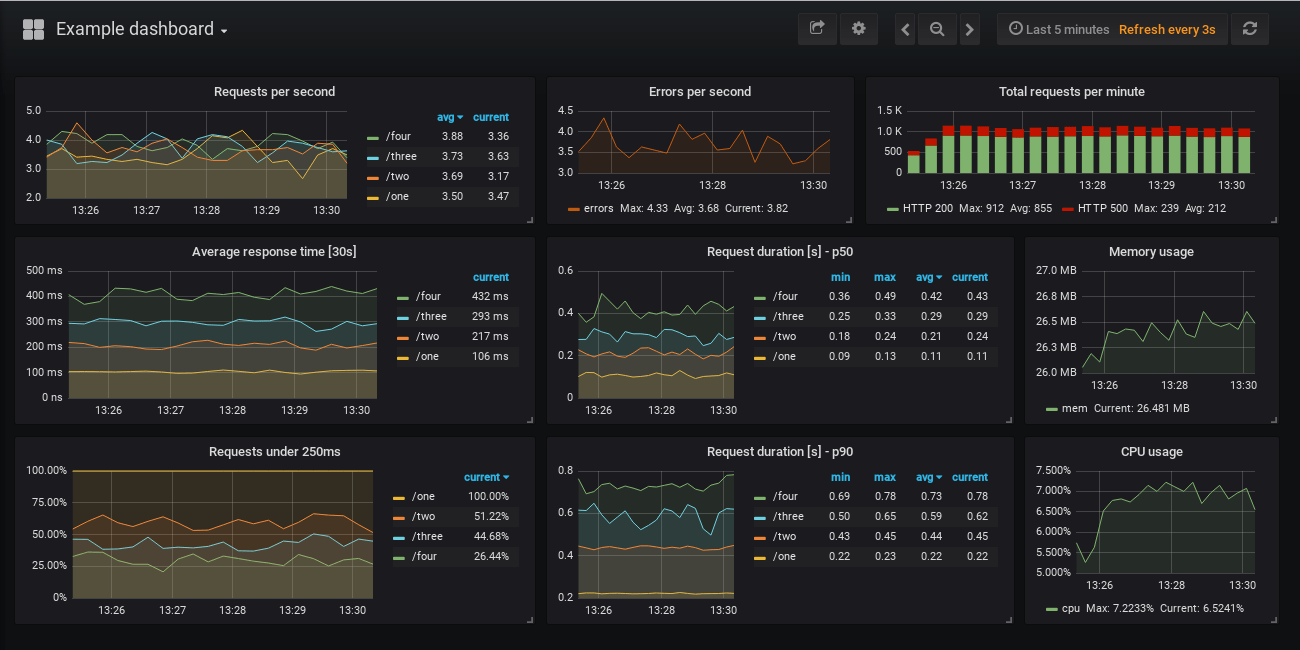
**This finally concluded the project.**
<br>
# My Experience
Overall, I had a great experience learning and executing new things within a short span of time. The process of deployment could not be made smoother without the Civo Platform. The fact that we can launch a cluster within a few minutes, along with having a marketplace from where we can pick services we want to preinstall in the cluster, really simplified the process for newbie Kubernetes developers like me.
Apart from that, the presence of the Kubernetes academy which contains beginner-friendly videos about all the different features of K8s, integrated into the platform, helped me to quickly navigate and get my doubts cleared before applying stuff on my cluster.
And of course, we had the option of directly contacting the Civo team via Slack to get out queries resolved. Special thanks to **Saiyam Pathak**, for his Monitoring video, which really helped me set up the monitoring stack easily.
<br>
# What's next for the project
Although I tried my best to incorporate all the domains of DevOps into my application, still there are some places that need attention.
First and foremost, I tried to incorporate the GitOps principle as much as possible, which included pushing the application code, Kubernetes Manifests as well as Terraform scripts to the Git. But still, there were some settings that I had to manually set inside the cluster like setting up the ArgoCD. Since ArgoCD supports GitOps, I would be declaring the settings from Git itself.
Apart from that, I would be incorporating some Logging and Profiling tools in the cluster, that would give a better picture of the application deployment.
Last but not the least, the model which has been deployed can currently perform classification only. But recently, in some researches, it has been proved that through Instance Segmentation on the X-Rays, we can actually measure the severity of the spread of the virus by precisely identifying the locations of the GGOs. In the future, I want to integrate such a model with the application, so that users can also measure the severity of the virus instantly.
---
You can visit the repository from below:
{% github Lucifergene/civo-hackathon %}
#### Demo : https://covid-predictioned.herokuapp.com/
#### DevPost : https://devpost.com/software/covid-19-prognosis
#### Civo - https://www.civo.com/
---
You can reach out on my [Twitter](https://twitter.com/avik6028), [Instagram](https://instagram.com/avik6028), or [LinkedIn](https://linkedin.com/in/avik-kundu-0b837715b) if you need more help. I would be more than happy.
If you have come up to this, do drop an :heart: if you liked this article.
**** | avik6028 |
917,753 | Random Text Generator | Choose randomly from 2 arrays to create your own brand name. | 0 | 2021-12-05T04:57:21 | https://dev.to/enlineaweb/random-text-generator-2hdm | codepen | <p>Choose randomly from 2 arrays to create your own brand name.</p>
{% codepen https://codepen.io/enlineaweb/pen/GRMpPBX %} | enlineaweb |
917,838 | Hanukkah lighting in WebXR | To celebrate Hanukkah (חנוכה), I made a WebXR scene where the user can pan, walk around (WASD),... | 15,815 | 2021-12-05T09:21:18 | https://dev.to/barakplasma/hanukkah-lighting-in-webxr-31m7 | webxr, html, vr, showdev | To celebrate Hanukkah (חנוכה), I made a WebXR scene where the user can pan, walk around (WASD), and/or enter VR in the Western Wall (הכותל המערבי) using AFrame, an HTML/JS framework for creating WebXR experiences.
{% github aframevr/aframe %}
To make a WebXR scene, I used the webcomponents proved by AFrame to create a scene with
- a 360 image as the sky
- a number of cylinders as candles
- a number of gltf models for flames and the hanukiah (special thanks to [Santiago Shang](https://skfb.ly/6VLIn) for the CC licensed beautiful GLTF model)
- and some english text (doesn't support hebrew / RTL as far as I can tell)
Here is the [live demo](https://hanukah-aframe.barakplasma.repl.co/) (click the ▶️ to see it in your browser, desktop or mobile)
{% replit @barakplasma/Hanukah-AFrame %}
Future plans involve adding interactivity, so that using a Quest 2 controller / pointer lets you light each candle, or to integrate [hebcal](https://github.com/hebcal/hebcal-es6) so that it can automatically light the right number of candles. | barakplasma |
917,870 | Easily share your Stackoverflow's profile on your README | Did you know that it was possible to easily share your Stackoverflow statistics using small dynamic... | 0 | 2021-12-05T15:27:29 | https://dev.to/johannchopin/easily-share-your-stackoverflows-profile-on-your-readme-h9i | opensource, javascript, stackoverflow, readme | Did you know that it was possible to easily share your Stackoverflow statistics using small dynamic images called "Flair"? This small image simply allows you to embellish your different READMEs like the one on GitHub or your online CV:

... and that just by adding the following Markdown:
```md

```
You can check them out at the URL https://stackoverflow.com/users/YOUR_USER_ID/YOUR_USER_NAME/flair :
This service proposed by Stackoverflow works very well, however since it hasn't be updated since a few years, there is some negative point that I noticed:
- the avatar image is weirdly cropped
- the only infos are the username, reputation score and badges amount
- it's a png so there is no fancy animation
- the image is very pixelated because of its small size (208x58)
- and most importantly: you cannot improve it because the project is not open-sourced
That's why I developed my own version of this service that would solve all these problems: [stackoverflow-readme-profile](https://github.com/johannchopin/stackoverflow-readme-profile)
{% github johannchopin/stackoverflow-readme-profile %}
This project allows you to embed improved version of those flairs wherever you want:
Default Stackoverflow profile:
[](https://github.com/johannchopin/stackoverflow-readme-profile)
Smaller profile:
[](https://github.com/johannchopin/stackoverflow-readme-profile)
Just use the following markdown schema to get your flair:
```
[](https://github.com/johannchopin/stackoverflow-readme-profile)
```
Not yet convinced to use this project? I can understand why using an "unofficial" service doesn't seem like a good idea but here are some points that might change your mind:
- stackoverflow-readme-profile proposes a higher customisation with [multiple themes](https://github.com/johannchopin/stackoverflow-readme-profile/tree/main/docs/profile) and [templates](https://github.com/johannchopin/stackoverflow-readme-profile#templates)
- stackoverflow-readme-profile render a svg so the final image is pixel clear and is animated
- the project is [open-sourced](https://github.com/johannchopin/stackoverflow-readme-profile): You want a new feature or improve something? Just [open an issue](https://github.com/johannchopin/stackoverflow-readme-profile/issues/new) so we can collaborate together
- you want to self host the application? No problem there is already a [docker image](https://hub.docker.com/repository/docker/johannchopin/stackoverflow-readme-profile) for that.
Thanks again for reading. If you are willing to see this project growing don't hesitate to leave a ⭐ to the repo and push your ideas of improvement.
{% github johannchopin/stackoverflow-readme-profile %} | johannchopin |
917,903 | I made the Package Manager for old DOS software | After a long time the "Vintage" Package Manager is ready Visit this... | 0 | 2021-12-05T11:41:05 | https://dev.to/francescobianco/i-made-the-package-manager-for-old-dos-software-4jpc | dos, retrocomputing, packagemanager, bash | After a long time the "Vintage" Package Manager is ready
Visit this page
- <https://github.com/francescobianco/vintage> | francescobianco |
917,930 | Kubernetes Create TLS/SSL certificates | Kubernetes For Beginners | A post by jmbharathram | 0 | 2021-12-05T12:13:42 | https://dev.to/jmbharathram/kubernetes-create-tlsssl-certificates-kubernetes-for-beginners-27go | kubernetes, docker, devops | {% youtube y00hfCeHWn0 %} | jmbharathram |
917,941 | Tutorial : manage your community on Metaweave.xyz | Metaweave.xyz is the digital square of the permaweb. Users often ask us how to edit communities. In... | 0 | 2021-12-06T21:24:02 | https://dev.to/falco_sun/tutorial-manage-your-community-on-argoraxyz-16gb | arweave, web3, tutorial, metaweave | Metaweave.xyz is the digital square of the permaweb.
Users often ask us how to edit communities. In this tutorial we are going to show you how to create, claim a community and how to edit its banner and descritption.
#Summary#
1. [Community creation & claiming](#chapter-1)
2. [PST Locking](#chapter-2)
3. [Editing the community description](#chapter-3)
4. [Editing the community banner](#chapter-4)
----
<a name="chapter-1"></a>
# 1. Community creation & claiming#
- Go on [metaweave.xyz](https://metaweave.xyz).
- Click on the search button or use the shortcut `alt-space` to open up the search bar.
> For the purpose of the tutorial, I decided to claim the community named `ArgoraTutorials`
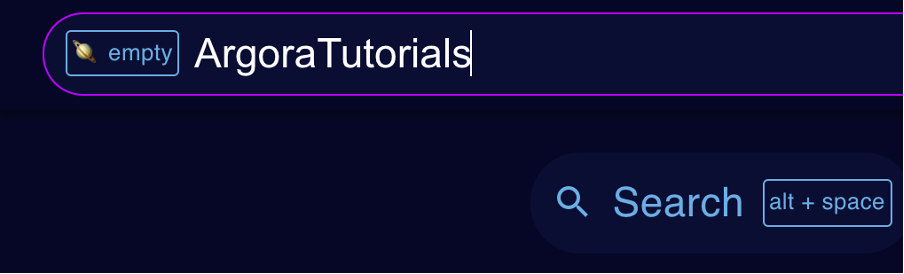
_Here is how the `ArgoraTutorials` community looked like before I claimed it._
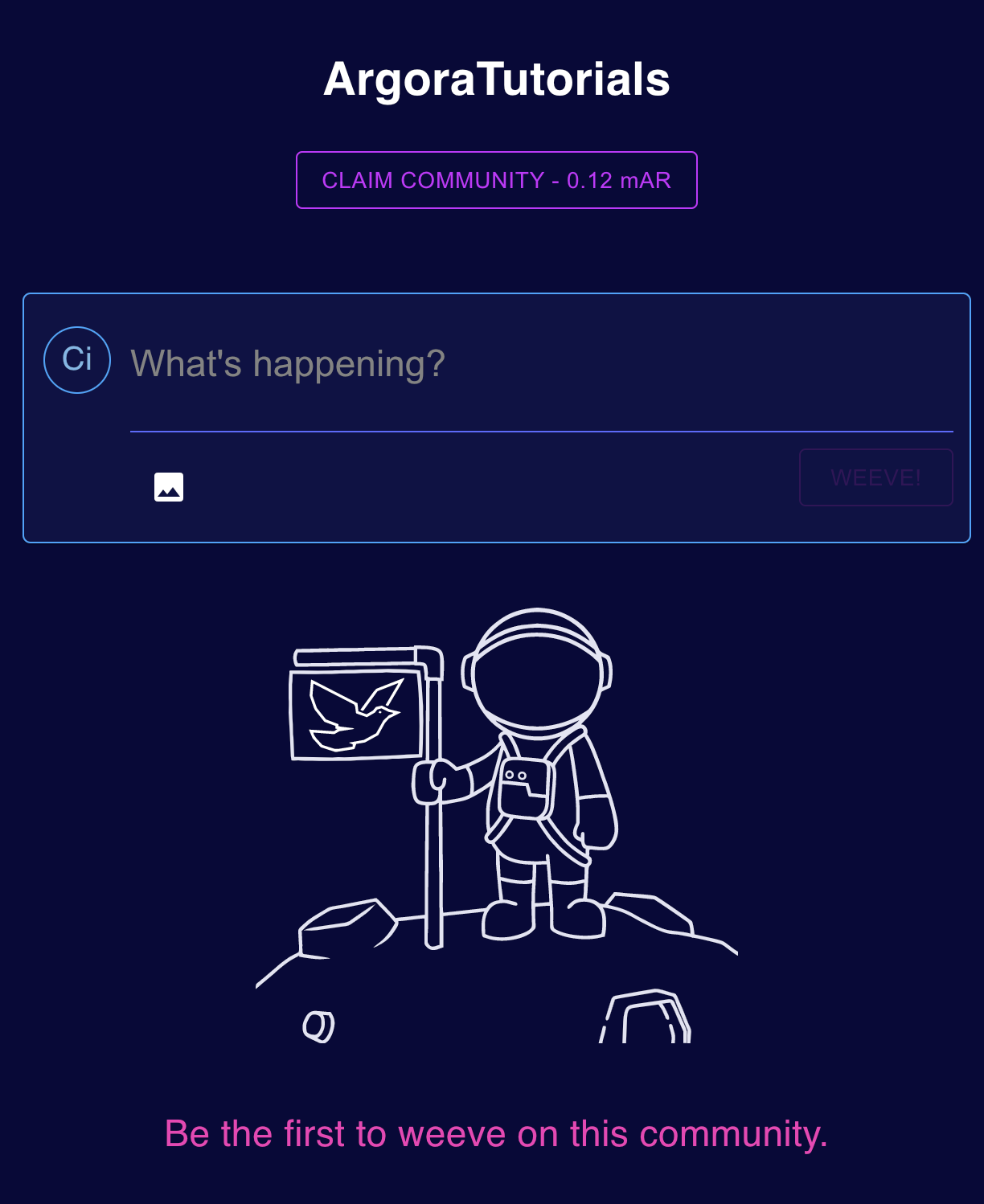
- Click on the `CLAIM COMMUNITY` button

A message that indicates the community is being claimed will appear instead of the button.
> ℹ️ The tree green circles is an indicator that the transaction is being validated by the miners

**txid:** [`F6EF1NjmizVut2CcyP1g5pU_uGob42eUrRIlW8YFTsE`](https://viewblock.io/arweave/tx/F6EF1NjmizVut2CcyP1g5pU_uGob42eUrRIlW8YFTsE)
Once the transaction is validated by the network the community appears in the "Lastest claimed communities" on the right panel of the Metaweave’s interface:
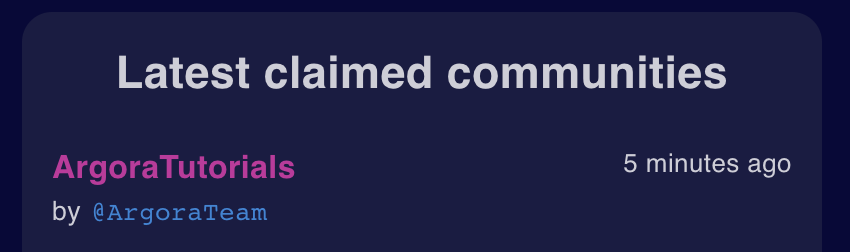
> ℹ️ By default, a newly claimed community has no banner and description:
----
<a name="chapter-2"></a>
# 2. PST Locking#
To manage your [PSC](https://arwiki.wiki/#/en/profit-sharing-communities)s on Metaweave, you need to access [community.xyz](https://community.xyz/#F6EF1NjmizVut2CcyP1g5pU_uGob42eUrRIlW8YFTsE)
- To access your community, click on its name on the top of the community page.

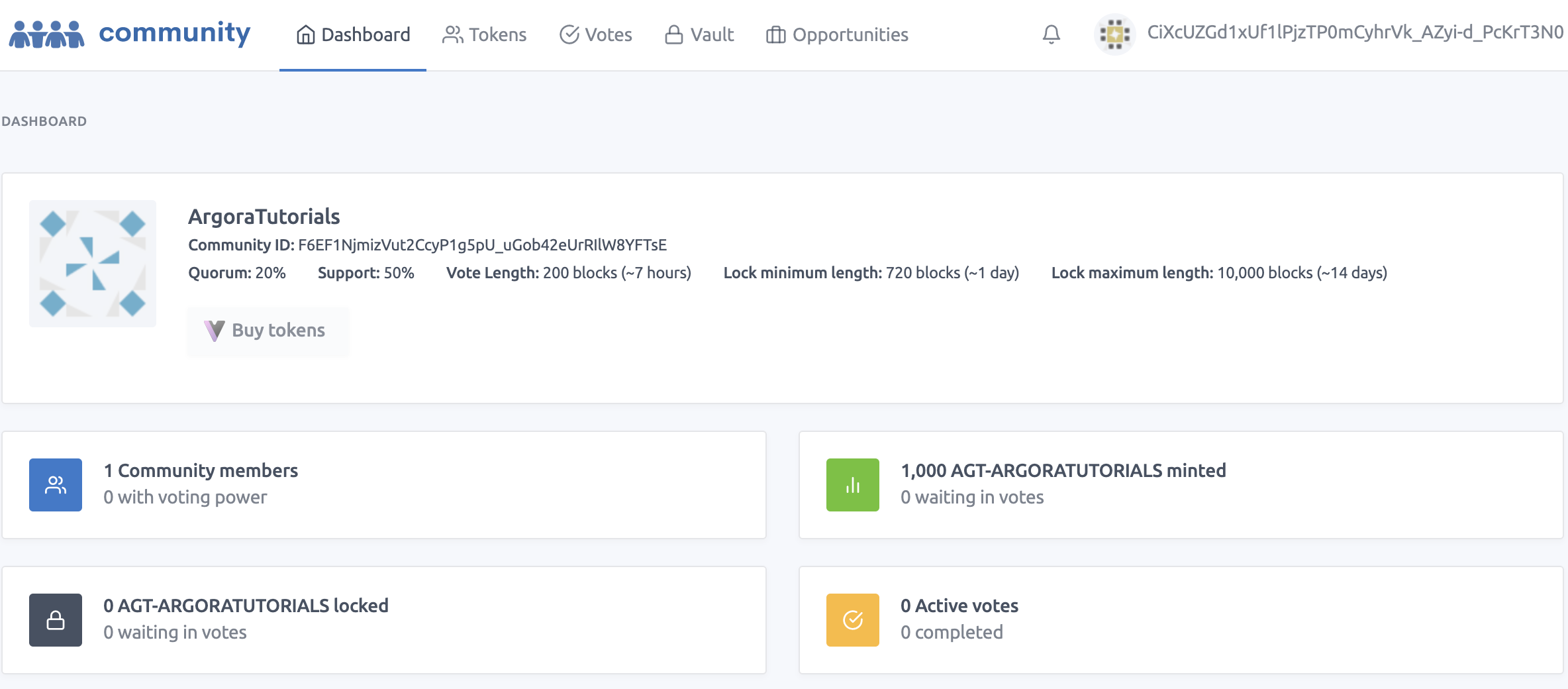
The creation of the PSC also mints 1000 PSTs (Profit Sharing Tokens). Those tokens will give voting power to their owners. Token are named AGT-$CommunityName:

To be able to submit votes we first need to lock our community tokens.
Just click the vault button:

Then click on “Lock tokens”:

Select the number of PST you want to lock with the duration of the lock in block number:
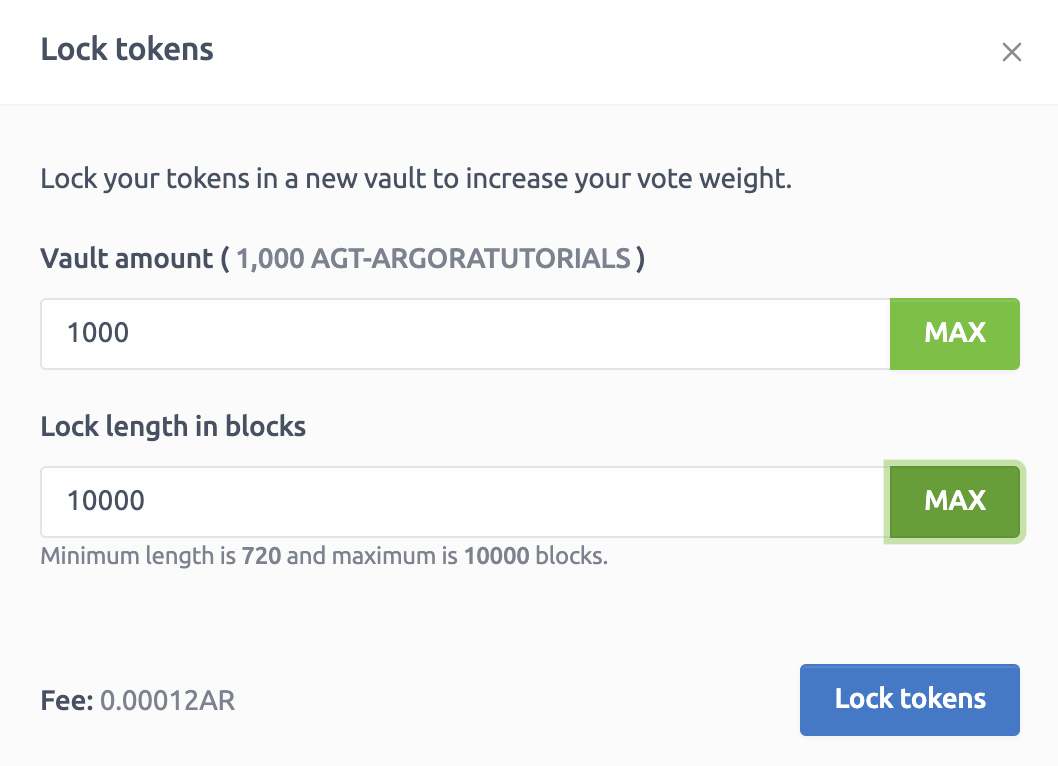
Clicking on the “Lock tokens” button makes the transaction. You are directly notified:

Once it's done you should see notifications as these


**txid:** [ZG8O1fYwR-oOrBVcxw1pXucyQ4ZTz5SI-p6Ok3TGhjk]
(https://viewblock.io/arweave/tx/ZG8O1fYwR-oOrBVcxw1pXucyQ4ZTz5SI-p6Ok3TGhjk)
Activity tab now shows the 1000 locked PSTs:

> ℹ️ Click the `Transfer tokens` button to distribute your communties' PSTs to arweave wallets and share the voting power.

----
<a name="chapter-3"></a>
# 3. Editing the community descritption#
Every modification you can make on community uses a vote.
So to edit the community description we're going to create a new vote:

1. After that Click ⚙️ Set
2. Select "Description" for the Key field
3. Type your community description in the "value" field
4. Once done click "Create vote"
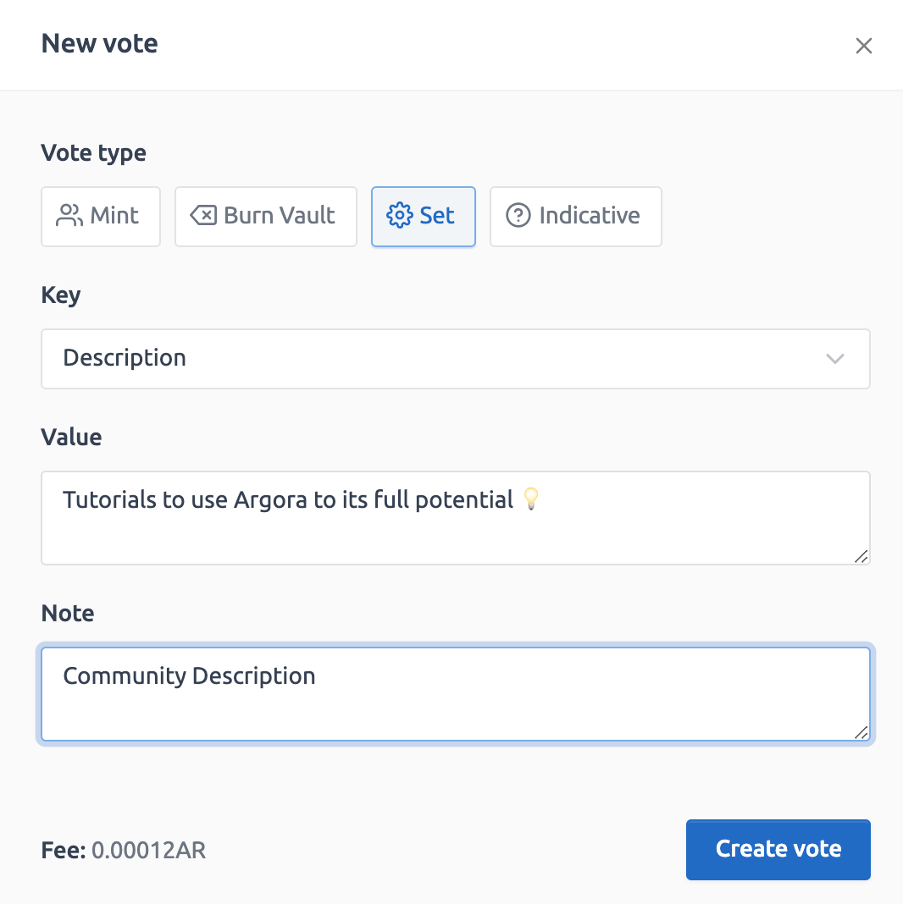
Notification of the vote creation:

Notification that the vote transaction has been mined and validated by the network:

**txid:** [SPeMwai9GmsKrzVDmtYzoPvh45szs8F6ga6Ii3KuAHk]
(https://viewblock.io/arweave/tx/SPeMwai9GmsKrzVDmtYzoPvh45szs8F6ga6Ii3KuAHk)
The vote is now available and every account with voting power can vote "yes" or "no" to this new description;
Here is the transaction related to my vote for the community description:
**txid:** [g3TOUmoseqDMeLfRg_r0gtWOf5SXv_5D92pZix2sw_o]
(https://viewblock.io/arweave/tx/g3TOUmoseqDMeLfRg_r0gtWOf5SXv_5D92pZix2sw_o)
We can now see that 100% of voters voted Yes for the new description:
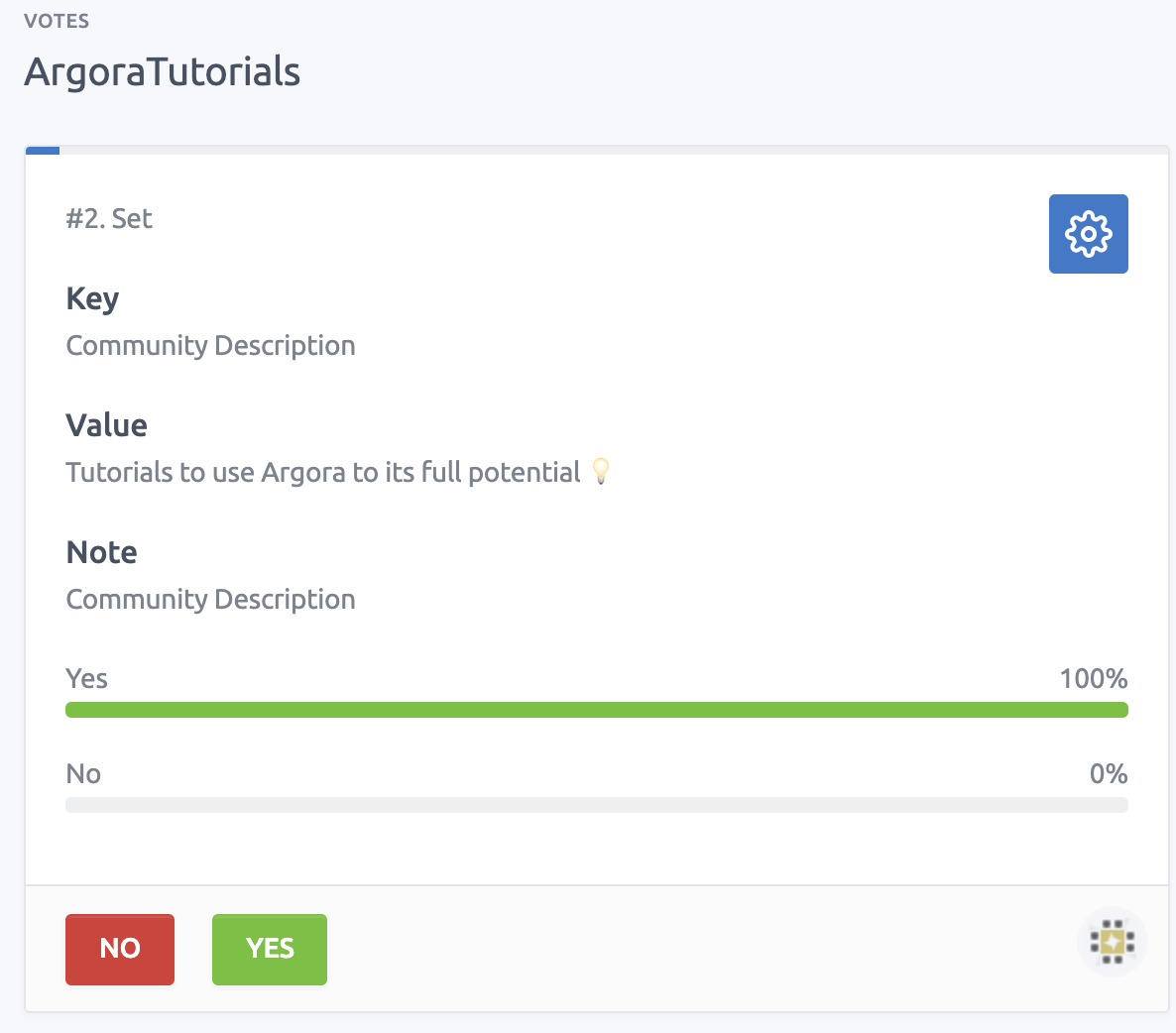
we just need to wait for approximately 7 hours (200 blocks) to be able to finalize the vote:
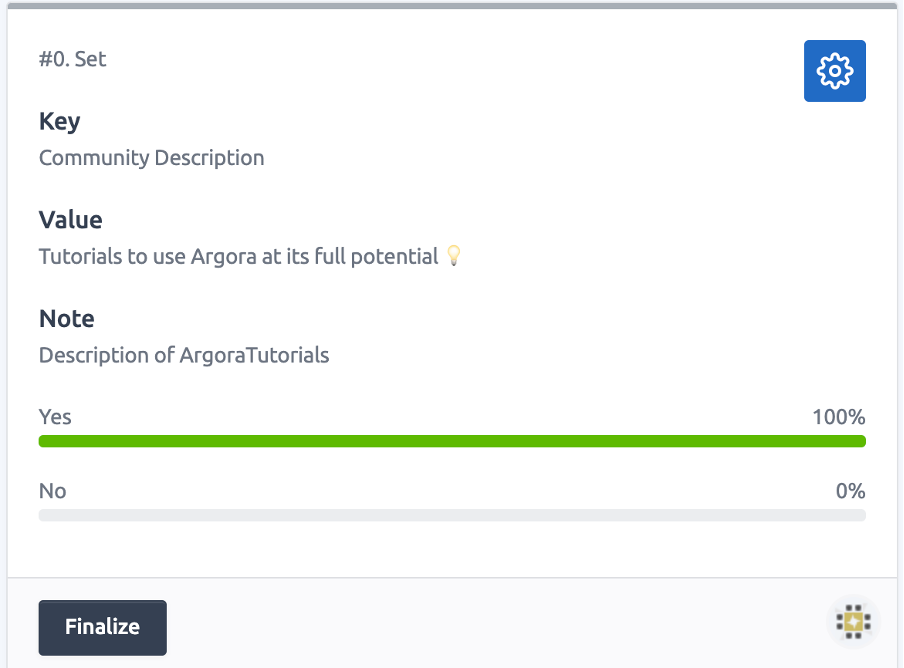
Notification of the transaction related to the finalization of the vote:
**txid:** [-WcHL6bUvKAqU7iywuoz2rNQn8Fs7wI-T05vPS0_zFg]
(https://viewblock.io/arweave/tx/-WcHL6bUvKAqU7iywuoz2rNQn8Fs7wI-T05vPS0_zFg)
Now that the vote is finalized the description appears just under the community banner:

----
<a name="chapter-4"></a>
# 4. Editing the community banner#
**Metaweave recommends 600*300 pixels picture resolution for community banners.**
Firstable you need to upload the picture you want to use as a banner for your community on Arweave’s blockchain.
To do so I personally choose to use [Ardrive](https://ardrive.io).
As for the description you need to create a new vote to edit the banner of the community page that will appear on Metaweave.
1. Click ⚙️ Set
2. Select “Community Logo” for the Key field
3. Type your picture TxID in the “value” field
4. Click “Create vote”
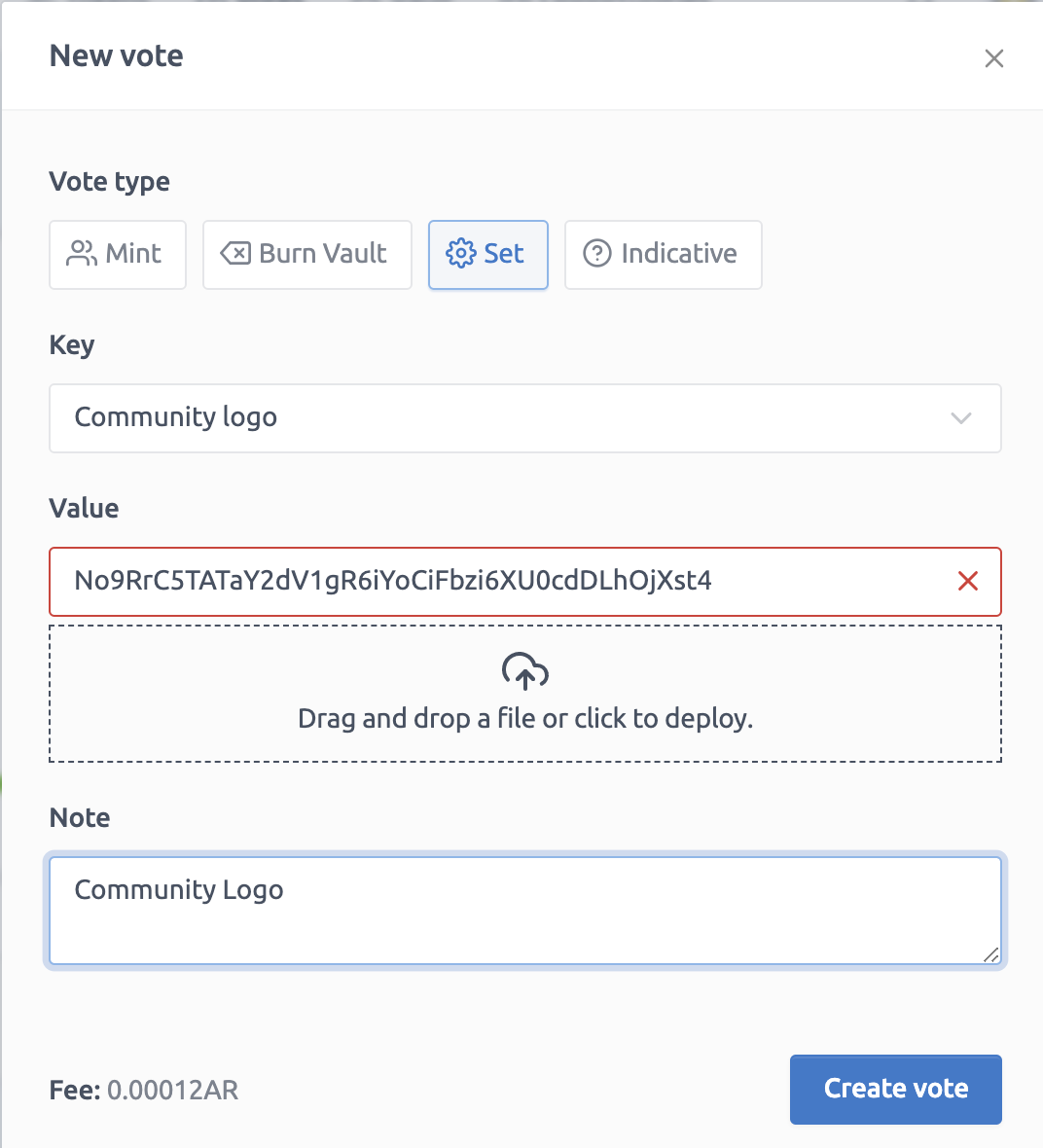
**txid:** [JwTWvCKNwmoZufzRqjkQeLjUTsPB02Wnvzgs0vMjuhY]
(https://viewblock.io/arweave/tx/JwTWvCKNwmoZufzRqjkQeLjUTsPB02Wnvzgs0vMjuhY)
You will just need to follow the voting steps you followed for the description
1. Vote [Yes](https://viewblock.io/arweave/tx/CZA_JzpI3purlKrSh552-ye_jIktnY78-Wad00IFgv4)
2. Wait for 7 hours (200 blocks)
3. [Finalize](https://viewblock.io/arweave/tx/xDqP_F9lqkuX2dvgjcSojtnhN_IeD10JkfwQy5Nm-3Q) the vote
The community page on [Metaweave](https://pvcsk5frxfyostm75nhyjneotxwpuldjy5ptdip24ut7w6lfgwha.arweave.net/fUUldLG5cOlNn-tPhLSOnez6LGnHXzGh-uUn-3llNY4/community/ArgoraTutorials):
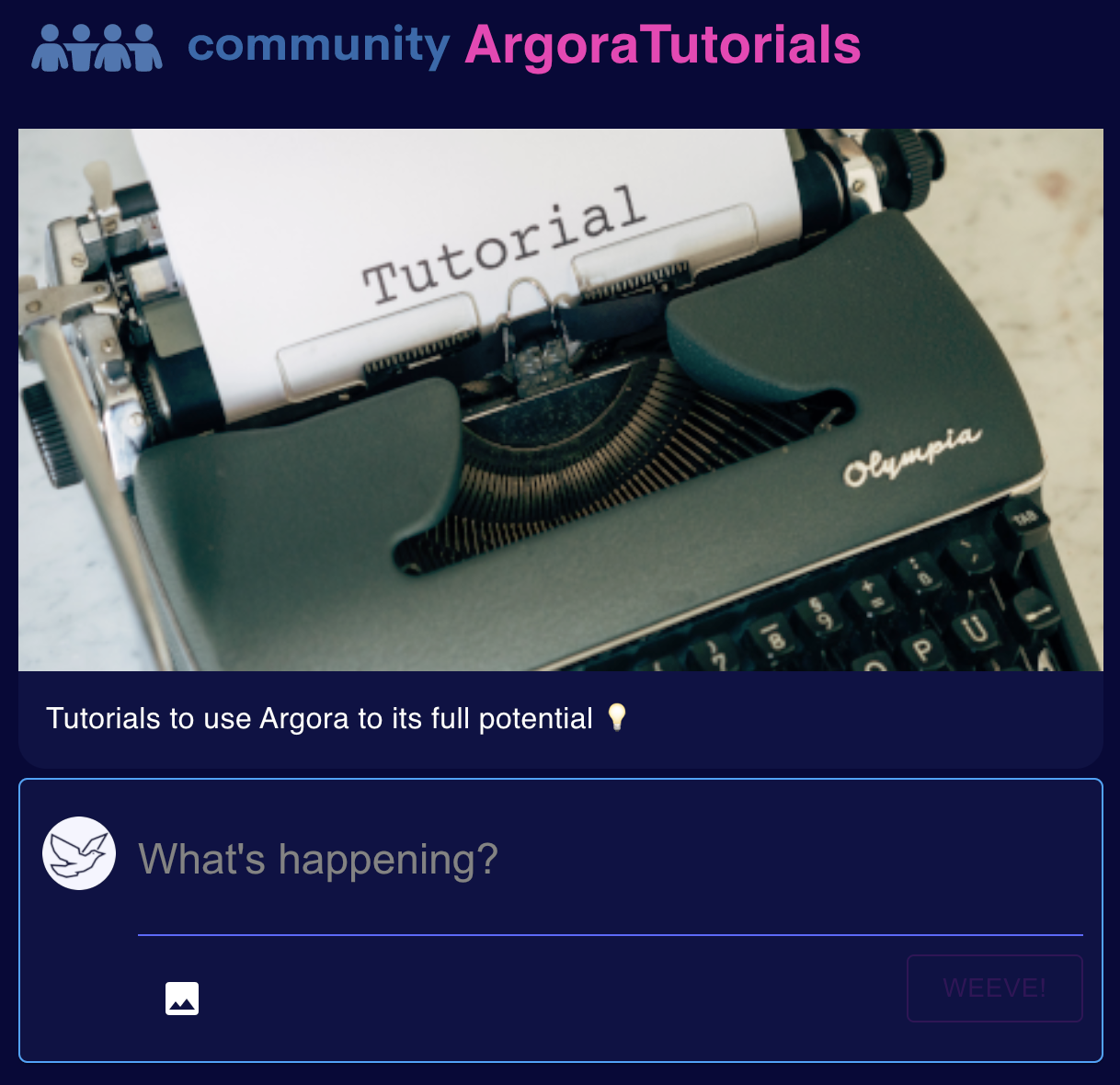
Thank you for following this tutorial I can't wait to see how you'll use it.
Stay tuned on Metaweave for more tutorials, news and post.
| falco_sun |
917,955 | Especialista SEO Qué es y cómo convertirse | Experto SEO: especialista en seo y Wordpress Un especialista seo es una persona con... | 0 | 2021-12-05T14:03:46 | https://dev.to/benderllin/especialista-seo-que-es-y-como-convertirse-3h9h | ## [Experto SEO: especialista en seo y Wordpress](https://estandar.io/como-convertirse-en-un-especialista-seo-en-el-proximo2022/)
Un especialista seo es una persona con habilidades y técnicas específicas que son eficaces para mejorar el posicionamiento de una página web en los resultados de las búsquedas de los motores de búsqueda. Una vez que uno domina los conocimientos necesarios para asumir la tarea, comienza a trabajar en el sitio web de los clientes para mejorar la visibilidad de la misma en los resultados de búsqueda de los motores de búsqueda. Todos los especialistas seo tienen en común su capacidad de mejorar la visibilidad de un sitio web en las búsquedas de los motores de búsqueda. Sin embargo, existen ciertas diferencias entre los especialistas seo que van desde el tipo de conocimientos que poseen hasta el equipo que tienen. Esos son algunos de los principales tipos de especialistas seo existentes hoy en día:
Analista de contenido
Analista de contenido
Un analista de contenido es un especialista seo que se encarga de analizar la información de los sitios web de los clientes para determinar si está en conformidad con las normas y las demandas de los motores de búsqueda. Se dedica a comprobar si la información de la página web contiene la información que los usuarios esperan encontrar.
Consultor SEO
Un consultor SEO es un especialista seo que tiene una amplia gama de conocimientos técnicos y procedimientos que le permiten mejorar la visibilidad de cualquier sitio web en los resultados de las búsquedas de los motores de búsqueda. El consultor SEO es capaz de analizar los detalles técnicos de un sitio web y puede ayudar al cliente a mejorarlos para que el sitio web sea más visible y genere más tráfico.
## [Experto SEO: especialista en seo y Wordpress](https://estandar.io/como-convertirse-en-un-especialista-seo-en-el-proximo2022/)
Director de marketing digital
Un director de marketing digital es un especialista seo que tiene la responsabilidad de manejar todo el proceso de posicionamiento en los resultados de búsqueda de motores de búsqueda. Tiene la responsabilidad de realizar la medición de la efectividad del sitio web del cliente y puede comunicarse con el equipo de diseño y desarrollo para mejorar la apariencia y el contenido del sitio web.
Especialista SEO
Un especialista SEO es una persona que domina las técnicas y los procedimientos específicos de posicionamiento en los resultados de búsqueda de motores de búsqueda. Está capacitado para realizar todos los procesos que conforman el posicionamiento en búsqueda de motores de búsqueda, desde la medición del tráfico en el sitio web hasta el desarrollo de técnicas de posicionamiento.
| benderllin | |
917,978 | AutoML & AWS SageMaker Autopilot | what is the difference between auto machine learning and AWS SageMaker... | 0 | 2021-12-05T15:03:53 | https://dev.to/aws-builders/automl-aws-sagemaker-autopilot-44b7 | aws, machinelearning, devops |
### what is the difference between auto machine learning and AWS SageMaker Autopilot?
____________________
***SageMaker Autopilot uses a transparent approach to AutoML***

In nontransparent approaches, as shown in the image below, we don’t have control or visibility into the chosen algorithms, applied data transformations, or hyper-parameter choices. We point the
automated machine learning (AutoML) service to our data and receive a trained model.
This makes it hard to understand, explain, and reproduce the model. Many AutoML solutions implement this kind of nontransparent approach.
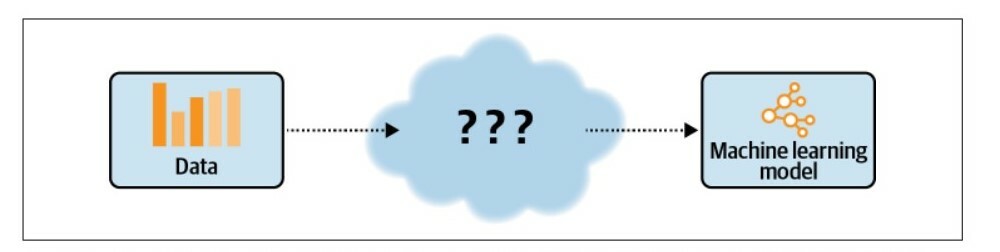
as you see, in many AutoML services, we don’t have visibility into the chosen algorithms, applied data transformations, or hyper-parameter choices.
_______________________
### SageMaker Autopilot documents and shares its findings throughout the data analysis, feature engineering, and model tuning steps.
SageMaker Autopilot doesn’t just share the models; it also logs all observed metrics and generates Jupyter notebooks, which contain the code to reproduce the model pipelines, as visualized in the image bellow
The data-analysis step identifies potential data-quality issues, such as missing values that might impact model performance if not addressed. The Data Exploration notebook contains the results from the data analysis step. SageMaker Autopilot also generates another Jupyter notebook that contains all pipeline definitions to provide transparency and reproducibility. The Candidate Definition notebook highlights the best algorithms to learn our given dataset, as well as the code and configuration needed to use our dataset with each algorithm.
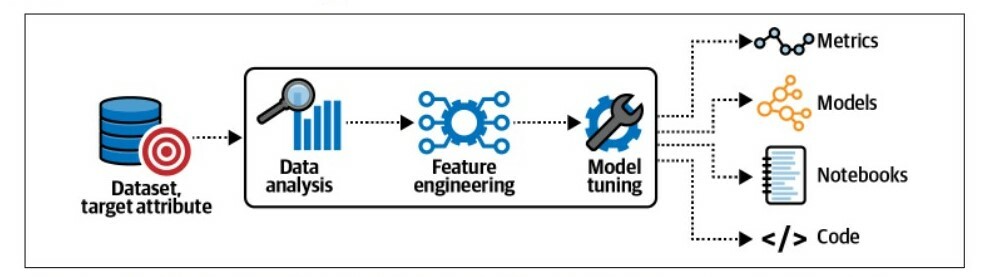
SageMaker Autopilot generates Jupyter notebooks, features engineering scripts, and model code.
Resources :
[Data science on AWS Book](https://www.oreilly.com/library/view/data-science-on/9781492079385/) | kareemnegm |
917,998 | Best Google Fonts for your website | Merriweather Eben Sorkin’s Merriweather is designed for optimal readability on screens.... | 0 | 2021-12-05T15:57:56 | https://dev.to/codewhiteweb/best-google-fonts-for-your-website-3e5k | design, font, css, googlefont | 1. Merriweather
Eben Sorkin’s [Merriweather](https://fonts.google.com/specimen/Merriweather?sort=alpha&sidebar.open=true&selection.family=Headland+One&query=merriweather) is designed for optimal readability on screens. Merriweather’s large x-height boosts the font’s legibility, making it suitable for use in long texts as well as for headlines and titles. Merriweather currently has 8 styles: Light, Regular, Bold, Black, Light Italic, Italic, Bold Italic, Black Italic.

2. Assistant
This is another very versatile Google font. [Assistant](https://fonts.google.com/specimen/Assistant?sort=alpha) is a clean typeface and offers a generous 6 styles, from extra light to bold. The carefully-planned spacing between the letters create a font with great readability. This, combined with the abundant bold styles makes Assistant especially good for larger bodies.

3. Poppins
[Poppins](https://fonts.google.com/specimen/Poppins/), created by the Indian Type Foundry, is an attractive, geometric sans-serif font for use in text or display contexts. It’s also the first font on our list to support the Devanagari system, which is used in over 150 languages including Hindi and Sanskrit.

4. Caladea
[Caladea](https://fonts.google.com/specimen/Caladea?sort=alpha) is a modern and friendly Google font. Created from [Cambo](https://fonts.google.com/specimen/Cambo), Caladea offers 4 different styles to choose from. The font is practical not just in the sense that it has styles to highlight content, but also due to its reliable readability. Caladea works both for big and dramatic titles and small texts that don’t overwhelm readers.

5. Enriqueta
[Enriqueta](https://fonts.google.com/specimen/Enriqueta?sort=alpha) is a Google font that also brings a certain glamour to any page, but it’s special in its own way. This font has bold features that reminded our team of old-times, adding a Rockwell sort of vibe to the page. The best part? Enriqueta is very well-balanced, and even though it has strong visuals, it still delivers great readability – even in very small bodies!

thanks for reading... | codewhiteweb |
918,069 | Criando mosaicos facilmente com grid-area e grid-template-area | Vocês conhecem esse modo de organizar um layout com o display grid usando grid-area e... | 0 | 2021-12-05T17:19:39 | https://dev.to/matheusfelizardo/criando-mosaicos-facilmente-com-grid-area-e-grid-template-area-314f | css, html, webdev, tutorial | Vocês conhecem esse modo de organizar um layout com o display grid usando grid-area e grid-template-area?
Eu gosto de usar pra montar mosaicos mas pode ser usado pra montar até mesmo o layout da página toda.
Primeiro você faz o desenho do layout que quer montar (só pra facilitar a visualização)
Exemplo:

Depois você estrutura seu HTML.
Eu gosto de utilizar as classes pra montar o layout quando vou utilizar o grid-area.
```HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="./index.css">
<title>Grid</title>
</head>
<body>
<div class="container">
<div class="item-1"></div>
<div class="item-2"></div>
<div class="item-3"></div>
<div class="item-4"></div>
</div>
</body>
</html>
```
Depois você coloca as propriedades no CSS que irão montar o mosaico.
1- Você irá setar o display grid no "container", ele que irá organizar a disposição dos itens no mosaico, vou colocar também uma altura para o meu mosaico, nesse caso
```CSS
.container {
display: grid;
height: 300px;
}
```
2- Você vai setar um "apelido" para cada item do mosaico, usando a propriedade "grid-area", aproveitei para colocar um background.
```CSS
.item-1 {
grid-area: item-1;
background: #ec934a;
}
.item-2 {
grid-area: item-2;
background: #e46c6c;
}
.item-3 {
grid-area: item-3;
background: #85fd7b;
}
.item-4 {
grid-area: item-4;
background: #7fbdf0;
}
```
3- Após isso, você vai setar no container, o template que você quer para o mosaico usando a propriedade grid-template-areas. Nela você vai basicamente desenhar o layout que você quer, onde cada abertura de aspas e fechamento, é uma linha.
```CSS
.container {
display: grid;
height: 300px;
grid-template-areas:
"item-1 item-2"
"item-1 item-3"
"item-1 item-4"
;
}
```
Observe como o layout foi desenhado de acordo com a formatação no grid-template-areas
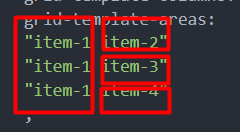
- Só irei fazer mais alguns ajustes de tamanho que quero para minhas colunas usando o grid-template-columns e o gap para gerar um espaçamento entre os elementos
```CSS
.container {
display: grid;
height: 300px;
gap: 15px;
grid-template-columns: 150px 200px;
grid-template-areas:
"item-1 item-2"
"item-1 item-3"
"item-1 item-4"
;
}
```
O resultado é a criação do nosso layout de forma fácil

Um exemplo real de galeria que criei num projeto utilizando essas propriedades

E ai, já conhecia essa propriedade com o diplay grid, já utilizava ou vai começar a utilizar a partir de agora?
Maiores informações: https://developer.mozilla.org/en-US/docs/Web/CSS/grid-template-areas
Qualquer dúvida é só perguntar, e forte abraço!!
Linkedin: https://www.linkedin.com/in/matheus-felizardo
Site Pessoal: https://www.matheusfelizardo.com.br/ | matheusfelizardo |
918,082 | Baloonza IT newsletters weekly digest #14 | IT-related topics and trends of the past week: startup, development, entrepreneurship No... | 15,791 | 2021-12-05T17:49:07 | https://app.baloonza.com/baloons | IT-related topics and trends of the past week:
### startup, development, entrepreneurship
- [No one asked](https://app.baloonza.com/issues/9882)
- [One empty seat](https://app.baloonza.com/issues/9946)
- [Hacker Newsletter Daily - 11/30/21](https://app.baloonza.com/issues/9970)
- [Canva for video games](https://app.baloonza.com/issues/9977)
- [Virtual HQ](https://app.baloonza.com/issues/10021)
- [The bank of the metaverse?](https://app.baloonza.com/issues/10059)
- [Hacker Newsletter #581](https://app.baloonza.com/issues/10107)
### css, design, frontend, html, web development, javascript
- [CSS Animation Weekly #277](https://app.baloonza.com/issues/9933)
- [📝 [CSS-Tricks] 279: Houdini Is Not as Scary as You Think](https://app.baloonza.com/issues/9956)
- [🎨 doing neat things with the Paint API..](https://app.baloonza.com/issues/10025)
### marketing
- [🎓 Frame your product as the ‘gift’ in a bundle](https://app.baloonza.com/issues/9965)
### data science
- [Data Science Weekly - Issue 419](https://app.baloonza.com/issues/10100)
*** | dimamagunov | |
918,112 | A Quick Guide To Setting Up a Rails Directory | First create a new repo on github. In your terminal, cd to the directory in which you want... | 0 | 2021-12-05T19:13:37 | https://dev.to/davidnnussbaum/a-quick-guide-to-setting-up-a-rails-directory-55be | rails, programming | First create a new repo on github.
In your terminal, cd to the directory in which you want the rails directory to reside. Please note the words **directory**, **file-name**, **YourName**, **ModelName**, and **column_name** are being used as generic terms to be replaced with the actual names that you are using.
------------------------------------------------------------------
Now enter:
**~/directory$ rails new file-name -T --database=postgresql --no-test-framework **
Please note that if you do not enter -T --database=postgresql, to install PostgreSQL then the default database is SQLite.
If you do not enter --no-test-framework then the default is to include the extra test files.
------------------------------------------------------------------
Next cd to the created rails file:
**~/directory$ cd file-name**
------------------------------------------------------------------
The next steps will allow you to push your changes to github. Enter the following with everything after the word origin being a copy of the SSH from your github repo.
~/directory/file-name$ git remote add origin git@github.com:YourName/file-name.git
------------------------------------------------------------------
Next enter:
**~/directory/file-name$ git branch**
------------------------------------------------------------------
Followed by:
**~/directory/file-name$ git status**
The following will appear in the terminal:
On branch master
No commits yet
------------------------------------------------------------------
Next add (the period after a space is part of the entry):
**~/directory/file-name$ git add .**
------------------------------------------------------------------
Followed by:
**~/directory/file-name$ git commit -m "Setting up the file."**
------------------------------------------------------------------
Then enter:
**~/directory/file-name$ git status**
The following will appear in the terminal:
On branch master
nothing to commit, working tree clean
------------------------------------------------------------------
Next enter:
**~/directory/file-name$ git branch -M master**
------------------------------------------------------------------
Followed by:
**~/directory/file-name$ git push -u origin master**
------------------------------------------------------------------
Next enter:
**~/directory/file-name$ git pull origin master --allow-unrelated-histories**
------------------------------------------------------------------
Followed by:
**~/directory/file-name$ git push --set-upstream origin master**
------------------------------------------------------------------
If you are installing PostgreSQL enter, otherwise skip this step:
**~/directory/file-name$ gem install pg **
------------------------------------------------------------------
No matter what your database is the next step is:
**~/directory/file-name$ bundle install**
------------------------------------------------------------------
Followed by:
**~/directory/file-name$ rails db:create**
-----------------------------------------------------------------
To set up each model enter:
**~/directory/file-name$ rails g model ModelName column_name:type foreign_key:references**
Please note that you can add in as many columns as are present for this model. The references term will create a column called whatever the foreign key is with _id attached.
Thanks for reading!
| davidnnussbaum |
918,128 | Be better than the If Statement | Decisions, decisions! Regardless of your programming language of choice, your code needs... | 0 | 2021-12-05T19:53:35 | https://dev.to/iamhectorsosa/be-better-than-the-if-statement-4ee1 | javascript, beginners | ## Decisions, decisions!
Regardless of your programming language of choice, your code needs to take decisions and execute actions accordingly. For example, in a game, if you run out of lives (`If (lifes === 0)`), you're done! So today, let's be better than the if statement and understand how conditional statements work in JavaScript.
## if...else statements
Probably one of the most google'd statements out there. An `if...else` statement executes a statement if a specified condition is *truthy*. If else, another chunk of code can be executed.
```jsx
// If..else Syntax
if (condition) { statement1 } else { statement2 };
// Using an if...else statement in a function.
function isItCold(temp) {
if (temp < 15) {
return 'Yes, you better wear something warm!';
} else {
return 'Nah, you good!';
}
}
// isItCold(5);
// Expected output: 'Yes, you better wear something warm!'
```
Here you typically make use of [comparison operators](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/First_steps/Math#comparison_operators) (strict equality, less than, greater than, etc.) to run true/false tests, execute code accordingly depending on the result. These conditional statements are pretty human-readable — "**if** this is `true`, then do this, **else** do that." The chaining of additional if statements or even the nesting of others are infinite but not necessarily optimal. Therefore, let's explore other choices in writing conditional statements in JavaScript.
## How to make it shorter!?
The [conditional ternary operator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Conditional_Operator) is the only JavaScript operator that takes three operands: a condition followed by the question mark (`?`), then an expression to execute if the condition is *truthy*, followed by a colon (`:`), and finally the expression if the condition is *falsy*. This operator is frequently used as a shortcut for the `if` statement. The ternary operator can run strings, functions, lines of code or anything you'd like. Let's rewrite our `isItCold` function:
```jsx
// Conditional (ternary) operator Syntax
// condition ? exprIfTrue : exprIfFalse
// Replacing an if...else statment by a conditional (ternary) operator.
function isItCold(temp){
return temp < 15 ? 'Yes, you better wear something warm!' : 'Nah, you good!';
}
// isItCold(5);
// Expected output: 'Yes, you better wear something warm!'
```
## Evaluating bigger data sets?
For those cases where you need to evaluate bigger data sets, even if you do get tempted by its symmetrical beauty, instead of creating a the so-called *arrow type* of code, you can can try Conditional chains using ternary operators. Let's take a look at the syntax and add more data to evaluate in our function:
```jsx
// Instead of writing this:
function example(…) {
if (condition1) { return value1; }
else if (condition2) { return value2; }
else if (condition3) { return value3; }
else { return value4; }
// Write this, using:
// Conditional chaining using Ternary Operators Syntax
function example(…) {
return condition1 ? value1
: condition2 ? value2
: condition3 ? value3
: value4;
}
// Applying conditional chaining to our isItCold function:
function isItCold(temp){
return temp < 5 ? 'Even hell is freezing over!'
: temp < 10 ? 'It is starting to get cold'
: temp < 15 ? 'A bit chilly, innit?'
: 'Nah you good'
}
// isItCold(16);
// isItCold(12);
// isItCold(6);
// isItCold(2);
// Expected output:
// "Nah you good"
// "A bit chilly, innit?"
// "It is starting to get cold!"
// "Even hell is freezing over!"
```
## Let's Switch it up!
If you have many options to choose from, use a *switch* statement instead. A `switch` statement tests a value and can have many *case* statements which define various possible values in a cleaner and more readable way. Statements are executed from the first matched `case` value until a `break` is encountered.
Note though, `case` values are tested with strict equality (`===`). The `break` tells JavaScript to stop executing statements. If the `break` is omitted, the next statement will be executed.
Why not try an exercise to apply how useful the `switch` statement is? Let's check out [freeCodeCamp's Counting Cards](https://www.freecodecamp.org/learn/javascript-algorithms-and-data-structures/basic-javascript/counting-cards) from their JavaScript Algorithms and Data Structures program and change it a bit.
### Counting Cards
In the casino game **Blackjack**, a player can gain an advantage over the house by keeping track of the relative number of high and low cards remaining in the deck. This is called Card Counting.
Having more high cards remaining in the deck favours the player. Each card is assigned a value according to the table below. When the count is positive, the player should bet high. When the count is zero or negative, the player should bet low.
| Count Change | Cards |
| --- | --- |
| +1 | 2, 3, 4, 5, 6 |
| 0 | 7, 8, 9 |
| -1 | 10, 'J', 'Q', 'K', 'A' |
Let's write a card counting function. It will receive an array of `cards` as a parameter (the cards can be strings or numbers), and increment or decrement the `count` variable according to the card's value. The function will then return a string with the current count and the indicate whether the player should `Bet`(if the count is positive) or `Hold`(if the count is zero or negative).
Example outputs: `-3 Hold` or `5 Bet`.
```jsx
// Switch statement syntax
switch (expression) {
case value1:
//Statements executed when the result of expression matches value1
break;
case value2:
//Statements executed when the result of expression matches value2
break;
...
case valueN:
//Statements executed when the result of expression matches valueN
break;
default:
//Statements executed when none of the values match
break;
}
// Building the countCards function using if...else statements
const countCards = (cards) => {
let count = 0;
cards.forEach(card => {
if(card === 2 || card === 3 || card === 4 || card === 5 || card === 6) {
count++;
}
if(card === 10 || card === 'J' || card === 'Q' || card === 'K' || card === 'A') {
count--;
}
})
if(count <= 0) {
return count + ' Hold';
} else {
return count + ' Bet';
}
}
// countCards([4, 5, 2, 7, 'J', 'Q']);
// Expected output: "1 Bet"
// Building the countCards function using Switch and Ternary Operators
const countCards = (cards) => {
let count = 0;
cards.forEach(card => {
switch(card){
case 2:
case 3:
case 4:
case 5:
case 6:
count++;
break;
case 10:
case 'J':
case 'Q':
case 'K':
case 'A':
count--;
break;
}
})
return count <= 0 ? count + ' Hold': count + ' Bet';
}
// countCards([4, 5, 2, 7, 'J', 'Q']);
// Expected output: "1 Bet"
```
Now, I believe you have the necessary knowledge to make better decisions and be better than the if statement alone!
Thank you for reading!
Get in touch:
[Whatsapp](http://wa.me/420608984789)
[ekheinquarto@gmail.com](mailto:ekheinquarto@gmail.com)
[Instagram](https://www.instagram.com/ekheinquarto/) | iamhectorsosa |
918,245 | Como crear un formulario de registro (2/3) | Hola, continuamos con la parte de crear las etiquetas HTML5, antes de comenzar les informo que el... | 0 | 2021-12-07T01:50:28 | https://dev.to/juan_duque/como-crear-un-formulario-de-registro-23-1mo7 | html, beginners, webdev, tutorial | Hola, continuamos con la parte de crear las etiquetas HTML5, antes de comenzar les informo que el código del formulario esta al final en CodePen para que puedan copiarlo y verlo.
Lo primero que aran es crear la carpeta donde van a guarda su trabajo y dentro de esta crearemos el archivo con la extensión **.html**, yo puntualmente le daré el nombre de 'index', quedaría así **index.html**, como último paso simplemente creamos la estructura básica de HTML como muestro en la imagen.
Pasamos a crear los contenedores para poder colocar todo el contenido que necesitamos, antes de continuar quiero aclarar que las etiquetas no las voy a explicar, si siento necesario estaré explicando cosas puntuales para no extenderme y volver a explicar cosas que ya mencione en la anterior publicación, también de aquí en adelante las imágenes con el html no se mostrara la estructura básica para que se puedan concentrar en lo importante, pero se sobreentiende que todas van dentro de **body**.
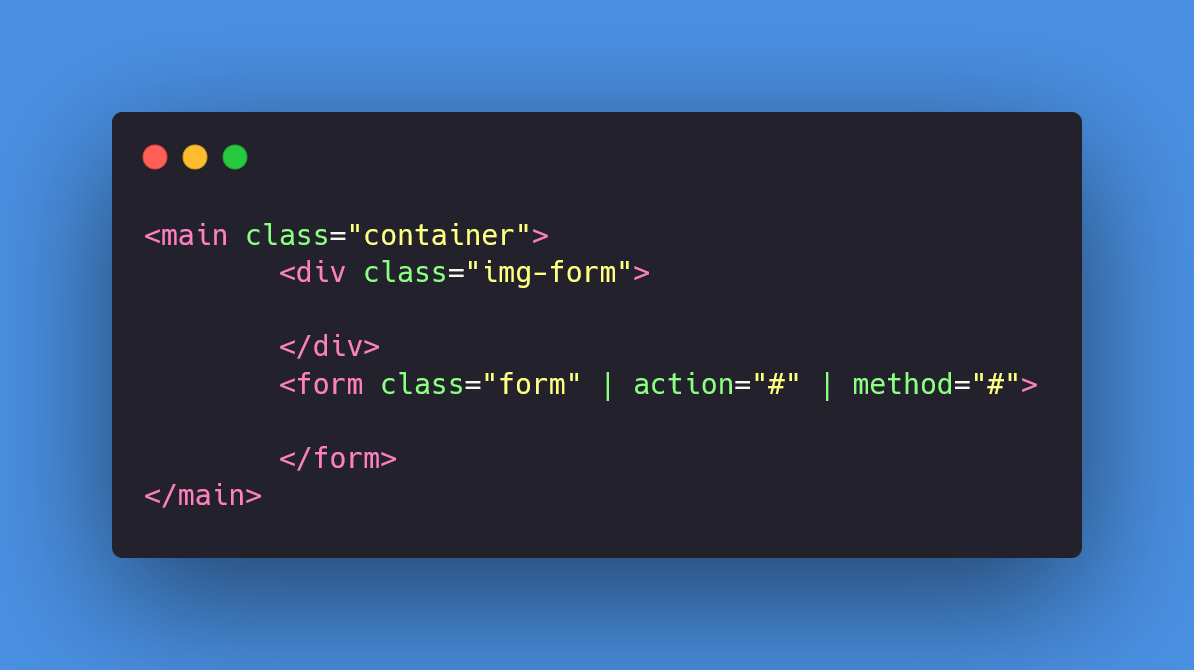
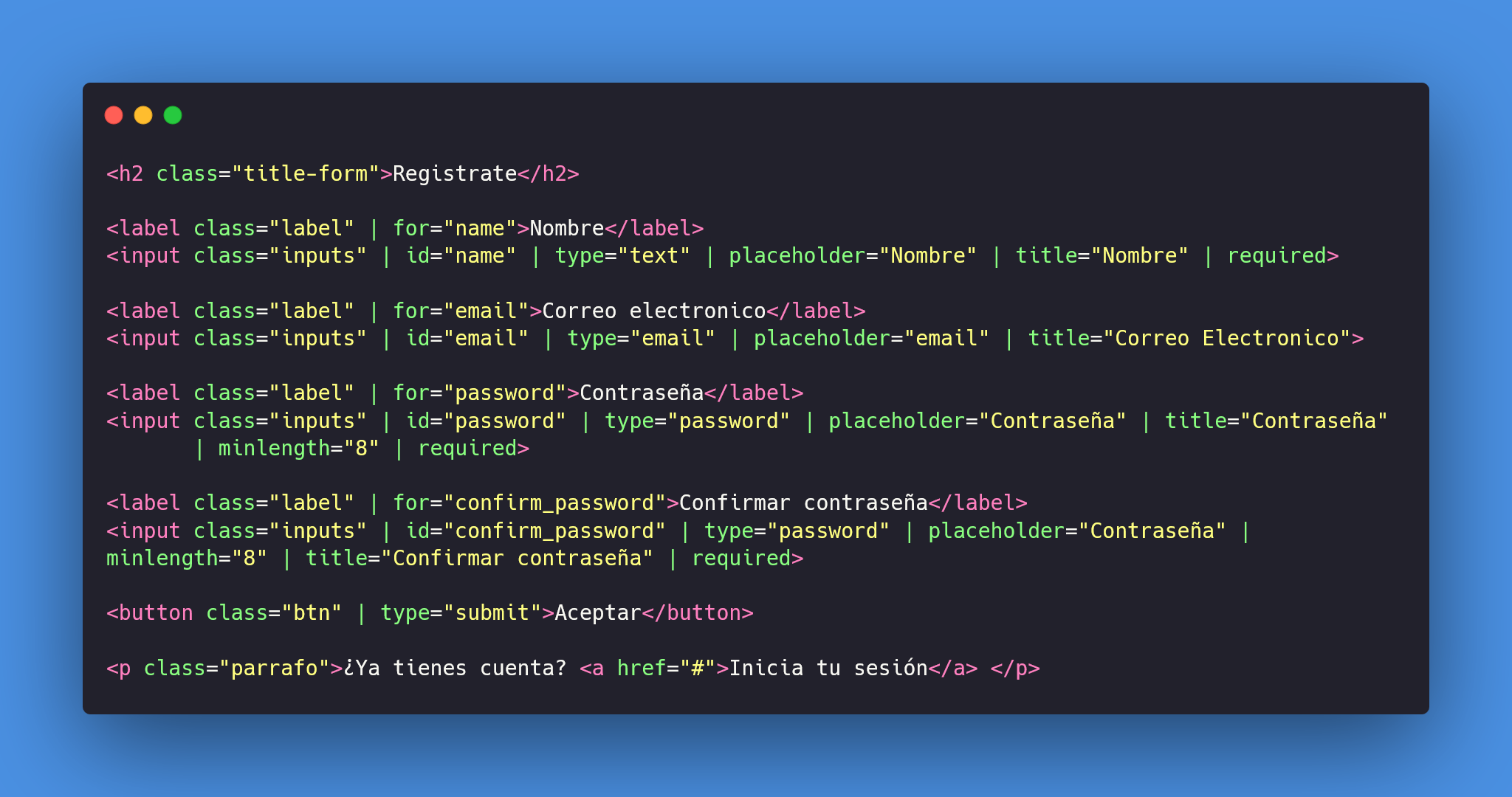
Ahora el siguiente paso es agregar los campos al **form** para que nuestro formulario vaya tomando forma, por lo menos a nivel de estructura HTML, lo que vamos hacer escrear un **h2** como titulo y como texto le pondremos **'Regístrate'** , también pueden colocarle otro si quieren, el próxima paso es crear cuatro inputs, el primero con el valor **text**, el segundo con **email** y los ultimos dos tienen que ser **password**, a cada uno se le asignara un **label**, lo siguiente es crear el botón con el texto **Aceptar**, por ultimo crearemos una etiqueta **p** que contenga un pequeño texto preguntando si tiene cuenta y si la tiene abra otro texto en el cual podra dar click en una etiqueta **a** para que lo lleve a 'otra página'.
Quiero aclarar tres atributos que coloque y no explique anterior mente.
* **required:** Hace que el campo no pueda estar vacío.
* **placeholder:** Es simplemente el texto que aparece como fondo en un input y que al dar clic desaparece.
* **minlength:** Este limita la cantidad mínima de caracteres que puede tener un campo, el valor se determina según la necesidad, en este caso es para ayudar al usuario a elegir una contraseña un poco mas segura.
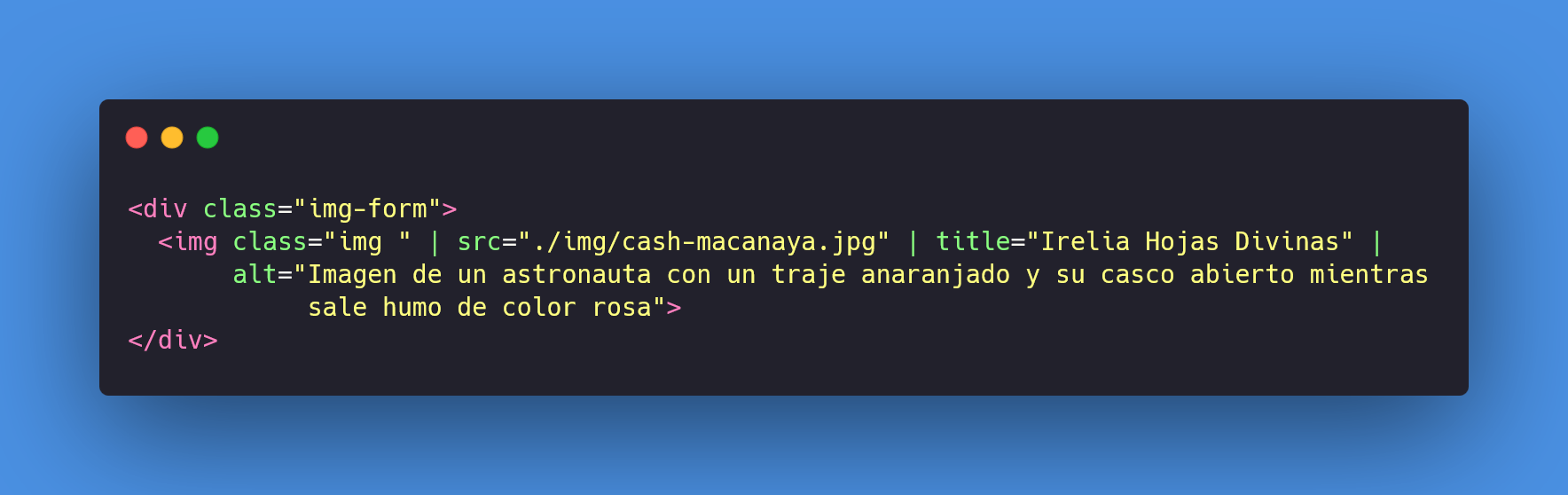
Pasamos a la parte final en la cual agregamos una imagen, puede elegir la que ustedes quieran, lo que vamos a hacer es generar un **div** por fuera del form, pero dentro de la etiqueta main y le damos un nombre a la clase para luego llamarlo y darle estilos, dentro de este **div** colocamos nuestra etiqueta **img** y la ruta relativa de la imagen que van a usar, que daría de esta forma.
Lo que tenemos hasta ahora seria esto.
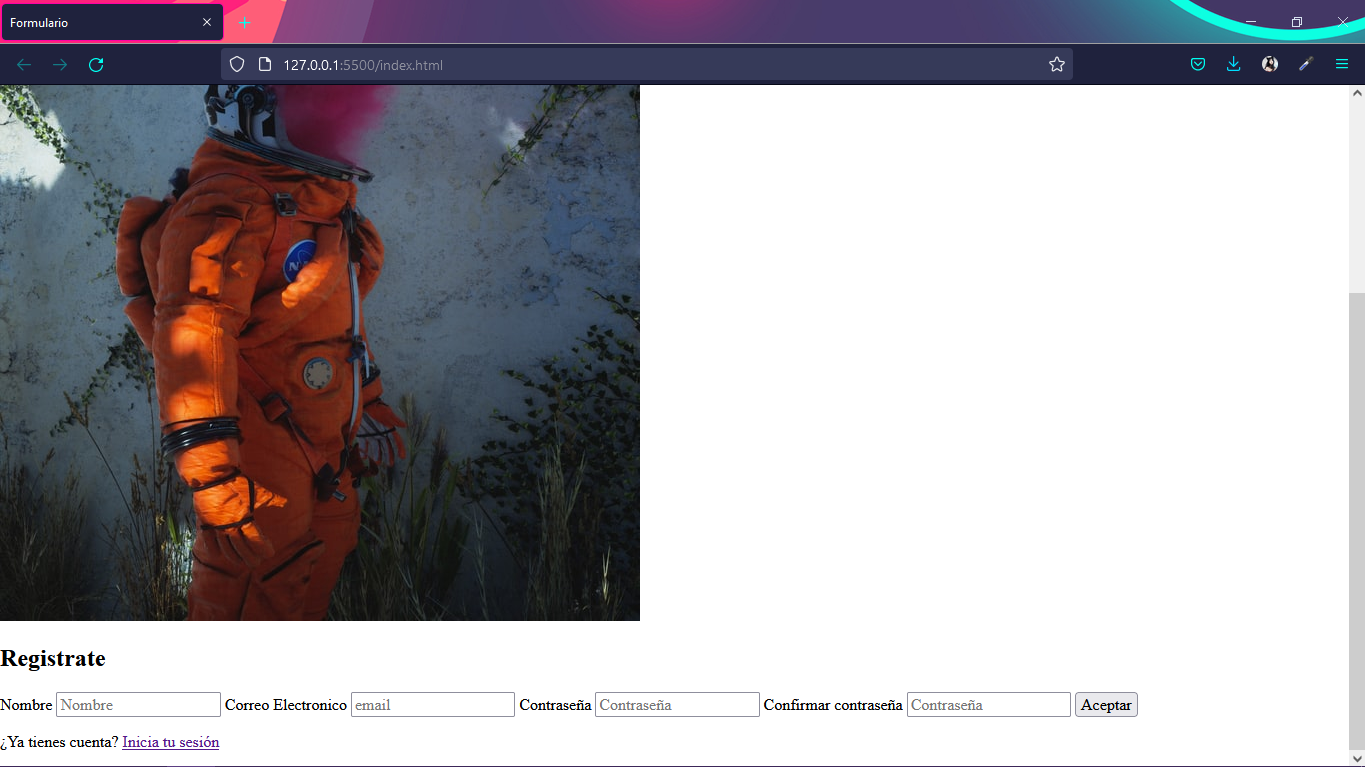
Con esto estamos terminando esta parte y pasamos a la siguiente que seria darle estilo.
***
**Pueden seguirme en mis redes sociales por este enlace.**
* [Twitter](https://twitter.com/juan_ariasd)
* [Linktr](https://linktr.ee/Boudgnosis)
***
**Parte 1:** [Como crear un formulario de registro (1/3)](https://dev.to/juan_duque/como-crear-un-formulario-de-registro-13-21lk)
**Parte 2:** [Como crear un formulario de registro (3/3)](https://dev.to/juan_duque/como-crear-un-formulario-de-registro-33-11p9)
***
**Páginas para que puedan descargar imágenes gratuitas**
* [Pixabay](https://pixabay.com/es/)
* [Unsplash](https://unsplash.com/)
| juan_duque |
918,321 | Python Virtual Environment | Python Virtual Environments Hi, before we dive in, let VE stand for Virtual Environment,... | 0 | 2021-12-06T03:44:17 | https://dev.to/otumianempire/python-virtual-environment-27ak | python, programming, beginners, tutorial | ## Python Virtual Environments
> Hi, before we dive in, let **VE** stand for **Virtual Environment**, wherever you see or hear **VE** (here, I mean).
## Back story
In one internship, I joined a team to build an e-commerce system, using python. On my PC I was running `python3.6` but the project uses `python3.8`. Does it matter? Sometimes.
In my case, what do you think I should do so that I would work on and test the project locally, using the same version of python as the project?
I could install `python3.8` and have two versions of python running on my system. I have to call `python3.6` and `python3.8` to make use of them. (I already have `python2.7`, I do not need another). A weirder solution would be to use a Virtual Machine. Install Ubuntu (or any OS) in a Virtual Machine that uses the latest version of python at the time. Someone said I should have used a docker.
There is a simple and stress-free solution that encompasses the same idea as a virtual machine called a Virtual Environment. We shall be talking about Virtual environments.
## What is a Virtual Environment and Why Use It?
With a **VE**, we will have a specific version of python. This environment will have separate dependencies for our project. These dependencies will affect only our project. These dependencies would have absolutely nothing to do with the dependencies on the computer we are using. So an upgrade or downgrade on our machine would not affect our project dependencies. The same applies to making changes in the **VE**, such as deleting a dependency, which would not affect the dependencies on the local machine. [python-environment-101] also introduces python **VE**.
We would discuss the python **VE**s, [virtualenv] and [pipenv], knowing what a **VE** is and why to use one.
## Check Python Version
To be on the safer side check the python version you are using, `python --version` or `python3 --version`.
You should get an output similar to `Python x.y.z`. Where _x_ has to be _3_, with _y_, _6_ or above.
## Install pip3
In the case you do not have `pip3`, then install `pip3` with the command below:
```bash
sudo apt-get install python3-pip
```
We would use `pip` to install packages. If you are new to `pip`, [pip-fcc] and [pip-w3schools] have easy to follow tutorial on [pip].
## Create project directory
On the terminal, navigate to your project folder or create one with:
```bash
mkdir PATH_TO_PROJECT_FOLDER && cd PATH_TO_PROJECT_FOLDER
```
If you are good with the GUI, go with it. We want to create a folder for our project, that is it.
## Virtualenv
Before we start using `virtualenv` we need [pip]. If you have multiple python versions like the _python2_ and _python3_, install `pip3` rather or check if you have `pip3`.
> (What about those who are using `python2.7`? Sorry, but try to adjust and use [pip] in place of `pip3` until you install the **VE** and activate it. I can not promise you that it will work or not. So you have to give it a go.)
### Install virtualenv
Then install virtualenv:
```bash
pip3 install virtualenv
```
Or when you are getting,
```bash
Command 'virtualenv' not found, but can be installed with:
sudo apt install python3-virtualenv
```
Follow this prompt to install _virtualenv_.
### Initialize the virtualenv
Initialize the virtualenv:
```bash
virtualenv VIRTUAL_ENV_NAME
```
For the sake of demonstration, let's assume we're creating an API for jokes, then we'd do:
```bash
mkdir jokeapp && cd jokeapp
```
We'd then initialize the virtual environment with,
```bash
virtualenv joke_env
```
This will create a folder called `joke_env` in the project directory. You can choose to hide the folder by prefixing the **VE** name with a dot, `.`. I prefer to make it visible.
### Activate The **VE**
We have to activate the **VE** else installed packages will be installed in the global space or scope (on the local machine).
```bash
source VIRTUAL_ENV_NAME/bin/activate
```
This will activate the **VE** but in our case, we'd do:
```bash
source joke_env/bin/activate
```
The name of the **VE** gets added to the username before the computer name, like this below:
```bash
(joke_env) username@computername:PATH_TO/jokeapp$
```
Sometimes things can be scary like you turn on the light bulb and you'd forget where the switch is or how to switch it off. Entering into vim is scarier when you can not exit. Press: `[esc] [:] [q] [!] [enter]` to exit vim.
### Deactivate the **VE**
In the activated **VE**, we can deactivate the **VE** with, `deactivate`.
Either our terminal will return to `username@computername:PATH_TO/jokeapp$` or we'd get an error output, saying, `deactivate: command not found`. In the latter case, you didn't _activate_ the **VE** in the first place.
Now we know how to get in and get out of the **VE** smoothly. We can install and uninstall all the packages we want.
Can we use other versions of python if we want (I don't mean `python2.7`) and not just create a **VE** for our project?
Yeah, we can. It is just that we have to install it locally first, to use it (the python version we want must exist before we can use it or create a **VE** for it). It must
exist in /usr/bin/PYTHON_VERSION
We would have to do:
```bash
virtualenv -p python3 venv
```
or
```bash
virtualenv -p /usr/bin/python3.8 venv
```
### Install/Uninstalling packages
We can install and uninstall packages just like we do with [pip].
## pipenv
### install pipenv
Install `pipenv` like you'd install any package, with the command:
```bash
pip3 install pipenv
```
If you look at the logs/output as the installation goes on you see that
virtualenv pops up here and there. So we can say or assume that `pipenv` was built on top of `virtualenv`.
### Activate the Pipenv Shell
Pipenv has a shell that allows you to create a **VE** with the command:
```bash
pipenv shell
```
This will use the project/root directory name as the **VE** name, using the highest version of python you have. It creates a **VE** when there is no **VE** for our project directory.
### Create **VE** For a Specific Version
You can create the **VE** with the command, `pipenv --python VERSION`. Here, _VERSION_ is the version of python you wish to use for your project.
We could have done, `pipenv --three` or `pipenv --two` to create a `python3` or `python2` **VE** respectively.
> Note the python version you want to use must exist locally else you have to install it.
> The [pipenv] docs tell you not to do `pipenv --three --two`, for "things can happen".
### Where Can I Find The **VE**
The **VE** will be installed at, `~/.local/share/virtualenvs/PROJECT_NAME`
Use `pipenv --venv` to output the path to where the packages will be or are installed on your pc for this very **VE**.
We can use `pipenv --where`, to tell us where our project root directory is. Something the `pwd` command.
### Remove/Delete **VE**
We can remove the **VE**, as in, delete it with `pipenv --rm`. This will delete the content and root directory of our **VE** located at the path provided by, `pipenv --venv`.
### Exist **VE**
Use `exit` to exit the **VE** and activate it with `pipenv shell` (we know this already).
### Pipfile
Pipfile is created when a **VE** is created and it holds the names of the packages we'd use in our projects. `cat Pipfile` will display something like this below, on the terminal.
```
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
[dev-packages]
[requires]
python_version = "3.6"
```
So what does this even mean?
- I have no packages installed
- I am using is `python3.6`.
- _dev-packages_ refers to packages that your projects need only during development. An example is an `env` package that reads the content of `.env` files. This is will not be needed, say we publish our project on Heroku (a web project).
### Install a Package
Let's install fastAPI, you can install any package you want.
```bash
pipenv install fastapi
```
We could also do, `pip install fastapi` (in the activated environment). A `Pipfile.lock` file will be created and this is the file that has the hashes for the packages installed.
To install a package with pipenv, do, `pipenv install package_name`
### Uninstall a Package
To uninstall a package, use `pipenv uninstall package`. This works like `pip uninstall package`.
### Run a Python Script
To run a python script do, `pipenv run python script.py`. We could do, `python script.py` (in the activated environment).
### Required Packages, Dev Packages and The requirement.txt File
`pip freeze > requirements.txt` or `pipenv run pip freeze > requirements.txt` will write the output of `pip freeze` into a `.txt` file called, `requirement.txt`. The project dependencies are printed on the terminal when we enter the command, `pip freeze`. In this case, we write the output into a file. This is a basic practice, like package.json for Nodejs.
We can install required packages from the `requirement.txt` file with, `pipenv install -r requirement.txt`.
We can also use the `Pipfile.lock` to write our package dependencies into the `requirement.txt` file using any of the commands below:
- `pipenv lock --requirements > requirements.txt`
- `pipenv lock -r > requirements.txt`
### PYENV
Now there was something I did not mention, which was supposed to be one of the purposes of using a **VE**.
Assuming we just have say python 3.6, running `pipenv shell` for the first time will choose the current `python3` that we have. By the assumption made, we'd have a **VE** for `python3.6`.We have a **VE** for separate dependencies, **what if we want a higher version or a version that we
do not have (on our PC)?**
Yeah. We can a version higher or lower than the current version we have and we can install that with [pyenv]. [pyenv] will allow us to install the various version of python we want. Remember that we want to just use this new version in the **VE** so we must install this new version **in** the **VE** else it will install as part of our PC.
### Install PYENV
Follow the guide from [pyenv-github] page to install [pyenv] on your OS. On Ubuntu (I am on ubuntu 16, which explains why my version of python was `3,6`. If you want to call me out on this because maybe, I have said or you have read that I was on PopOS/ubuntu 20.04, yeah, it is true but things happened and I am on 18 now).
With the instruction provided by the [pyenv-github] page, installation should be quite simple.
### Install Python3.9 With PYENV
We know that `pipenv --python VERSION` will install a python version that already exists on our PC, if it does else spit out some error message. After the [pyenv] installation, if their version doesn't exist, `pipenv` will use `pyenv` to install that version. `pipenv --python 3.9`.
And We Are Done Here... No, I am joking... We are not done.
Say you had, `python_version = "3.6"` in the `Pipfile`, you have to change the version to that which you just installed.
### How I Did Mine When It Was Becoming Weird. How Weird?
This is what I did and how I should have rather done it (At this point I already have the project started and there are packages I am working with. How weird? ).
- Get the packages/dependencies into the `requirements.txt` file, `pip freeze > requirements.txt`
- Remove the `3.6` **VE** with, `pipenv --rm` rather than change the version number, from `python_version = "3.6"` to `python_version = "3.9"`
- Exit out of the activate **VE** with, `exit`
- Remove the Pipfiles, `rm Pipfile*`
- Then start a new environment, `pipenv --python 3.9`
- Assuming the latest (on your PC - you used `pyenv` to install) is `3.9` and you want the `3.9`, then you can run, `pipenv shell`.
- Activate the environment with, `pipenv shell` (I didn't have `3.9` on my PC, as the previous step describes)
- Install the packages from the `requirements.txt` file, `pipenv install -r requirement.txt`
### Somethings We Will Know Only When We Have Used a **VE**
- `Virtualenv`, the folder for the packages used will be available in the main directory and you have to git ignore it. For `Pipenv`, the folder at `pipenv --venv`. You have to either delete the packages folder when the project leaves your custody (you don't work on the project anymore). Out of sight out of mind, remember? This means we will have our memory chip away bit by bit as we use `pipenv` when we do not remove the unwanted **VE** (just the `node_modules`) and we'd not know it because we don't see it.
- `Pipenv` creates `Pipfile` and `Pipfile.lock`. This is similar to `package.json` and `package-lock.json`.
- The only drawback I faced was when I wanted to install only `dev-packages`.
- `pipenv lock -r > requirement.txt`, for requirement packages
- `pipenv lock -d > dev-requirements.txt`, for both requirement and dev packages
- `pipenv lock --dev-only > only-dev-requirements.txt`, for only dev packages
- We could exit the `pipenv` **VE** with `deactivate`. We used `exit`before.
- So practically `Pipenv` is suited for your projects. `Virtualenv` is sugar-coated to give us `Pipenv`. I am just saying from a practical point of view.
### The END
Let me know if you run into a weird situation and how you solved it.
#
[pipenv]: https://docs.pipenv.org/
[virtualenv]: https://virtualenv.pypa.io/en/latest/index.html
[pyenv-github]: https://github.com/pyenv/pyenv
[pyenv]: https://pypi.org/project/pipenv/
[python-environment-101]: https://towardsdatascience.com/python-environment-101-1d68bda3094d
[pip-w3schools]: https://www.w3schools.com/python/python_pip.asp
[pip-fcc]: https://www.freecodecamp.org/news/how-to-use-pip-install-in-python/
[pip]: packaging.python.org/tutorials/installing-packages/
| otumianempire |
918,326 | Open Source React Developer Tools in Today's Digital Era | Facebook, Skype, Tesla, and Airbnb all have something in common. They're all using React, a... | 0 | 2021-12-06T04:20:31 | https://dev.to/ashikarose/open-source-react-developer-tools-in-todays-digital-era-13e7 | react, programming, tutorial, devops | Facebook, Skype, Tesla, and Airbnb all have something in common. They're all using React, a JavaScript toolkit for developing engaging user interfaces with component-based building pieces. As a result, when combined with useful React developer tools, this handy package aids in the rapid development of fully working single-page or mobile applications.
Why is React so popular?
Jordan Walke, one of Facebook's software engineers, designed React in 2011 to handle Facebook advertisements. React is now an open-source, declarative, dynamic library for building complex interfaces using reusable individual components called components.
React outperforms Angular and Vue in terms of automated re-rendering and component updates. According to Statista, React is the second most popular web and mobile app framework in the world.
A framework, despite the convenience it provides, also stores a different set of vulnerabilities. Data interoperability is a typical behavior in the digital world, and it puts a lot of user-sensitive data at risk.
React apps also have their own set of security vulnerabilities, such as XSS (Cross-Site Scripting), SQL injection, Zip Slip, XXE (XML External Entities), failed authentication, and more. This opens the door to unauthorized access, data breaches, hacking, and data tampering, among other cyber-criminal acts.
Many countries have adopted regulations that regulate the significance of preserving sensitive data due to the sensitive nature of user data. Failure to follow these rules and regulations might result in serious legal consequences for both the software owner and the offenders.Ensure absolute security and privacy compliant services that include:
HIPAA compliant medical software development services for the United States
GDPR compliant medical software development services for European countries
DPA compliant medical software development services for the United Kingdom
PIPEDA compliant medical software development services for Canadian countries, Hence, develop 100% secured and compliant solutions only with the best [react agency](https://www.cronj.com/react/react-development-agency).
What React developer tools will you need to know in 2022?
We've put up a collection of important React developer tools. Some will be useful for beginners as well, while others will be chosen by more experienced programmers. This isn't just a list of useful React development tools, though. We also opted to acknowledge their inventors. In fact, one of the most crucial elements that contributes to React and React Native being one of our favorite technologies is the React community.
1.Storybook
Another React tool for creating, developing, and testing your own User Interface components. Storybook includes a UI development environment as well as a UI component playground. You may not only profit from the Storybook's development environment for UI components, but you can also simply test and show them.
You can create a static version of Storybook on your server that includes a gallery of UI components that all team members can see. It does not, however, extract or distribute components between projects.
2.React Navigation
Based on JavaScript, the utility provides an expandable and usable navigation solution. As a result, developers can get started right away thanks to built-in navigators that give a consistent experience. As a result, the tool has received more than 13 000 stars on GitHub.
3.Create React App
Create React App is a command-line interface(CLI) tool that requires no development configuration. It encourages you to create your own standard and guides you to start the app developing procedure seamlessly.
There is no complexity because you only need a build dependency. The Create React App has behind layers of ESLint, Webpack Babel, and other features that make it more suitable for small web applications.
4.Jest
[Jest ](http://en.wikipedia.org/wiki/Jest_(JavaScript_framework))is an out-of-the-box solution that requires no configuration. The testing procedure is intended to maintain the greatest level of performance. In the next iteration, for example, previously failed tests are run first.
Jest will be your favorite ReactJS testing tool. It's a Facebook-developed JavaScript testing framework. It was created for the purpose of testing React components. It should be your first choice for testing React because it comes from the React creator and is developed and supported by the React community. It also works with other JS frameworks such as Babel, TypeScript, Node, Angular, and Vue.
5.Linx
Linx is a low-code programming tool for backend development, not necessarily a React tool (such as APIs, integrations and automations). It's on this list because it's a simple and effective tool for integrating an API into your react SPA. The frontend and backend can take many various forms, and understanding how to connect the two might be difficult. Low-code solutions, such as Linx, can help you save backend development time by reducing the coding part and allowing you to focus more on the logic.
6.Redux
For JavaScript apps, [Redux ](https://redux.js.org/)is a state management solution. It's most commonly used to integrate with React, it also works with other React-like frameworks.
For Redux, it's now able to connect all components directly to the entire state and thereby, reduces the requirement for using call-backs or props.
7.React Boilerplate
A developer-friendly start library that gives you the infrastructure you need to build scalable projects. The focus of this offline-first React architecture is on high performance and excellent development methods. Your software will be available as soon as your users load it, with no requirement for a network connection. Chrome Redux DevTools are compatible with React.js Boilerplate. You may now use the CLI to automate the creation and testing of components, containers, and other types of objects. All CSS and JavaScript changes are immediately visible and accessible for testing without having to refresh the page.
8.BIT
It's essentially a command-line interface (CLI) utility. BIT was built to address issues with sharing React components. You may arrange and distribute User Interface components among your team members with this React developer tool. Furthermore, you can reuse the components that have been lost in the future.
Each component is isolated and tested separately before being exported as a complete unit. It simplifies testing, because you just have to deal with this one component if you wish to make a little change. Bit is also great for test-driven development because of its component isolation.It is available for personal and open source projects at no cost.
9.Razzle
[Razzle ](https://razzlejs.org/)simplifies SSR configuration by encapsulating it in a single dependency. It provides developers with a similar experience to create-react-app, but with more control over frameworks, routing, and data fetching.
10. React Cosmos
This is a useful developer tool that aids in the creation of reusable React components. It looks for components in React projects and allows them to be rendered using any mix of props, context, and state. [React Cosmos](https://reactcosmos.org/) allows developers to simulate any external dependency, such as localStorage or API replies, in order to examine the current state of their project in real time.
11.React Sight
This React visualization tool provides a visual depiction of the structure of React apps to developers. The tool requires the previously described React Developer Tools for Chrome. Developers who want to use it will also need to install React Sight as a Chrome extension, which adds a new "React Sight" panel to Chrome DevTools. React Router and Redux are supported by the utility.
12.React 360
This is a web-based platform for producing interactive 360-degree experiences. It blends React's declarative capabilities with current APIs like WebGL and WebVR to allow developers to construct applications that can be used on a variety of platforms. The tool is designed to make the creation of cross-platform 360 experiences easier by leveraging web technologies and the robust React ecosystem.
Conclusion
React has become such a valuable framework for frontend developers who want to create attractive and effective user experiences thanks to these and many other tools. Of all, this is only a small selection of fantastic tools. Every year, the number of React developer tools expands. The React community is dedicated to assisting one another and making React development more developer-friendly.Get assistance from the best react agency to build a mobile application.
| ashikarose |
918,354 | Web3, Explain it to me like I'm 5. | So you might have heard about Web3 aye, great! so have I, but probably maybe quite longer ago than... | 0 | 2021-12-06T05:49:03 | https://dev.to/brijrajsinh_parmar/web3-explain-it-to-me-like-im-5-46f9 | web3, blockchain, webdev, decentralised |

So you might have heard about Web3 aye, great! so have I, but probably maybe quite longer ago than you have, or maybe not. Web3 is this meaningless thing that people on that bird app Twitter have been chirping about (see what I did there 😉). Anyways, I was just kidding lol, Web3 is the future and, so stick around as we oversimplify all its complexities.
Web3's been trending everywhere! Twitter is talking about it, Reddit is talking about it thus leading to so much info and needless crap about it being shared all over the internet. You keep hearing more and more about it till the point you'll think even Cartoon Network would start talking about too! Yeah, maybe that last part ain't ever gonna happen but one thing comes to mind always if you're new to this topic which is "What on earth is Web3?" and "Why does it exist?", and yeah I've been there too so, let's oversimplify it!
##Origins of Web3
Alright, so Web3 exists but some of y'all smart cookies out there are thinking "Hey! If Web3 exists, could there be a Web2 or even a Web1? What type of Web are we currently using?". If such thoughts were running through your mind then congratulations on winning the lottery 🎉🎉, just kidding, you just made this article a bit much longer because you're right about that, but before we oversimplify those other web types, let's understand some very important components of all web types.
> Centralization: Data is kept or concentrated at a single storage base.
> Decentralization: Data is distributed across a network of self-governing nodes.
_Remember these, you'll need them for later._
##Web 1.0
The Web1 era was the first evolution of the World Wide Web (WWW).
This era mostly involved developers creating content by using static HTML webpages and sharing that content over the web. Most websites were hosted publicly on the personal computers owned by the developers and were only accessible by literally knowing the IP address and resource path of that developer's personal computer on the internet.
Web1 was mostly Decentralized and was a model that mostly benefited the developers that contributed to it and on top of that, Web1 was referred to as the read-only web because people mostly consumed information and were not able to interact with the static webpages that existed at the time.
##Web 2.0

We currently live in the Web2 era and the big players here are well... Big Tech. Yep Big Tech, the likes of Google, Facebook, Twitter, TikTok, Amazon and so much more of them that enables Web2 to function the way it does today.
Centralization is the backbone of Web2 and is a model that benefits the platforms that enable this type of web.
In Web2, we are both consumers and content creators, yes you! you also are a content creator that is supposing you comment, like, or share this content! Okay, you don't really need to do that to become a content creator but by Web2 standards, if you can interact with other people's content or create your own content, you then are part of the ecosystem.
This is both a good thing for some and a bad thing for the rest! Wonder why? Let's oversimplify...
So say you go to a social media site like Facebook, and you create an account and start using it, a few things happen:
You are required to provide all your valid ID data and biodata to contribute to the platform.
Your interaction data and all other data you generate is recorded.
All your data is stored at data centers controlled exclusively by Facebook
You are not in control of the data you generate on the platform.
Facebook can do whatever they want with your data like say sell it for profit.
You do not receive any revenue for the content you create.
If you read that right, you can conclude that Facebook and the other companies just like them, are making a killing off the data you create on their platforms. Don't get me wrong, you can actually make money by using Facebook but it would have to be done off-site and by your audience who are following you and are interested in what you're doing.
As a content creator in the Web2 space, your revenue relies mainly on the stuff you don't do on whatever Web2 platform you are using. Tech companies that mainly harvest data are sitting on gold mines and are making millions on advertisement sales because the data we give to them, enables them to continue doing so and ripping us off in the process. The more data they can effectively harvest, the more profit they can turn and there is nothing you can do about it which leads to even worse problems like:
Your information and personal data can get leaked by the platform.
These companies can sell your data to advertisers for targeted marketing.
You are at risk of identity theft.
Worst of all, you don't get any $$$ from your own data.
On the bright side, Web2 has made some small-time creators literal superstars overnight. Because their large platform connects so many people, it has created the opportunity for talents to be recognized and appreciated, making their content very valuable and easily convertible to cash (if you know what I mean 😉). Web2 is essentially the read-write version of the web!
I know that was a lot to sip in but that in its simplest form, is the love and hate story of Web2.
##What is Web3?
Now I've given you a literal crash course of what the other web types are like, we can finally dive right straight into what on earth Web3 is and what it's all about, here goes...
Web3 is simply the next and third evolution of the web that would make the internet process information with human-like intelligence using AI technologies creating a more autonomous, intelligent, open, and secure web. Uhhh... let's oversimplify.
So in 2009, a man named Satoshi Nakamoto created (allegedly) the world's first cryptocurrency called bitcoin. He envisioned his new invention to be a peer-to-peer cash system and an alternate payment system that would be free of any form of central control or regulations.
Fast forward 12 years 😉, yeah, that exactly happened. It was a dream come true but this great accomplishment had also created and kickstarted a new type of web, one that is:
Decentralized, meaning it runs on a distributed peer-to-peer model and no one entity can make a decision independently that can directly influence or change the course of the entire system.
- Anonymous, meaning your ID is of no significant importance to contribute to the system.
- Free of influence and control, meaning there are no regulations, the network's creators make the rules.
- Easily monetizable, meaning everyone is rewarded for being a part of the platform.
- Most importantly, Web3 overshadows the control that big tech companies and governments have over the regular folk over the years.
- Web3 can be really broad, with a lot of confusing words and crazy topics, so let's understand some fundamental Web3 concepts before we move along!
##Blockchain Technology
Yes, blockchain! some people love it, some people hate it, and yet a majority don't even know what a blockchain actually is, and yet blockchain is at the backbone of Web3
Blockchain technology is a system for recording data that makes it difficult or impossible to change
Cryptocurrencies like Bitcoin and Etheruem rely on blockchain technology to make their network transparent, and reliable, and secure from fraud.
So basically, blockchain is the reason why cryptocurrencies are fraud-free and this is because no single human being can alter any financial records in it and give himself/herself any free money. This is made possible because blockchains run on peer-to-peer networks called nodes which agree on what record is valid and what record is invalid by achieving something called a consensus.
##Cryptocurrency

A cryptocurrency or a Crypto Coin is a digital currency that can be used for making payments but uses cryptography and a decentralized online ledger called a blockchain to secure its transactions. Bitcoin, Etheruem, Litecoin, and Dogecoin (the to the moon coin) are all perfect cryptocurrency examples
##Token
A Token or a Crypto Token is a type of cryptocurrency that represents an asset. Unlike a crypto coin that has its own blockchain, tokens are built as utilities that exist on another blockchain. For example, the USDC and USDT Stable coins are actually tokens that are sitting on the Etheruem blockchain.
##Smart Contacts
Smart contracts are programs stored in blockchains that are executable and run when predefined conditions are met.
So Translation, they are just these fancy stuff that runs whenever something interesting in a blockchain happens, and guess what? even you can write some of this funky smart contracts code.
##Solidity

Solidity is an object-oriented language used for creating and interacting with Smart Contracts on a blockchain.
So basically, you can use this language called 'Solidity' to create your very own smart contract.
##dApps (Dapps)
Dapps is short for "Decentralized Applications" and refers to any application that is decentralized in nature, built on a blockchain, and may use tokens for transactions.
##Why Web3?
You may be thinking right now "Alright, so Web 3 exists, so why do we even need it", and if that thought went through your mind then great, if it didn't then still great because I am gonna explain why anyways.
To oversimplify, the concept of Web 3 needs only exist because of the flaws posed by Web2 which if you were paying attention, you would know are very disturbing and not rewarding. Web3 looks to solve three main problems that we face in our day to day lives:
- Trust
- Anonymity
- Control
- Trust
Let's take, for example, you buy a car insurance policy from an insurance company/broker for $150/month, that insurance company then enters into a contract with you that in the case of an accident involving your car, they will make sure that your car gets fixed. What happens here is that you are putting your trust in that insurance broker to come to your aid if your car ever gets wrecked. But what if they don't? what then can you do? Short answer, nothing, long answer, they could attend to you, but they would probably be dodgy about it. It's really hard to trust some random person you don't know with your money especially when it comes to a scenario similar to the example above.
Web3 solves this sort of problem by using Smart Contracts which are written with code and are decentralized in nature and, can never be taken down. No one person can modify this code or influence this code. When it's time to pay, the smart contract will pay up which basically makes any system that uses it trustless.
##Anonymity
Most platforms and apps we use daily require us to submit our personal data to be able to use them. This leads to data leaks and the owners of those platforms just outright selling our data for profit. Because the blockchain is not governed by any single entity or by any government oversight, Web3 app creators can create apps known as Dapps that allow people all over the globe to use them without submitting any sensitive or personal data.
##Control
Imagine you use a software service like Facebook and you keep uploading images of a war-torn country. Facebook has the power to censure you and stop you from uploading those graphic images. In your mind, you may actually want to spread the word about injustice happening in that war-torn country but the bosses of that platform might not like that.
Because most of the platforms we use daily are centralized(i.e they are owned by a single entity), the owners of those platforms can basically make decisions that may affect you in some way. In this scenario, you have no control over the platform and all it takes is just a simple command to cut you off it.
Due to the nature of Web3 apps (Dapps) and the blockchain in general, everything is decentralized and there is no single 'Point of Failure' that could be exploited to take control of the system.
In conclusion, Web3 could deliver us to a future that is truly autonomous and does not rely on people to make decisions for us but relies on software (Smart Contracts) to keep the system trustless, anonymous and free from external control.
##Why Should I Care?
If you're wondering why you should be excited or even give a flick about Web3, then am hoping that the chapter above answered that question for you but if it didn't, then let me give you more reasons to care about Web3
##The New Order
A majority of apps today run on the Web2 model the same way a majority of apps in the late 90s ran on the Web1 model. A lot of companies that are Web 2 oriented, are already migrating and adopting Web3 models and are currently preparing for the future.
##The Metaverse
The Metaverse is a concept about a virtual 3D world that is free and will be built around Web3 concepts. Decentraland is a very popular example of this concept and Facebook just recently changed their name to Meta in an attempt to own this concept.
##DeFi
DeFi stands for "Decentralized Finance" and as its name suggests, is finance but based on a decentralized model. DeFi has been around for a while now and allows people to take the capabilities for regular peer-to-peer transactions on the blockchain to a whole new level allowing some Dapps to function like decentralized banks.
DeFi allows some dApps to act like banks, offering services like:
- Lending and Borrowing.
- Investments.
- Insurance.
- Trading.
- Liquidity Pools.
If you read everything right, you'll see that one way or another, Web3 will become a part of our lives which is truly exciting and the best time to jump aboard is now!
##Why The Hype?
The reasons for the hype are fairly simple! Just like when bitcoin was $10 over 9 years ago and is now $50,000+ now, two (2) things led to that massive growth and also led to the hype. The first is the Crypto Boom and the other is called FOMO.
The Crypto Boom refers to the period when Bitcoin and a few other popular cryptocurrencies like Etherium and Bitcoin Cash skyrocketed in value. This epic boom attracted the attention of a lot of people from around the world who now saw the potential of blockchain technology and sort to exploit the unique capabilities of the blockchain which then led to newer blockchain-based technologies being invented, one of these cool new tech is something called NFTs (a topic for later).
This gain in popularity is in part the reason why the hype around Web3 has been booming in recent times and also in part because people have been rushing and actively trying to participate in the Web3 ecosystem due to FOMO. Speculations also played a big role during this time with celebrities like Elon Musk fueling the speculations the most and making people feel the FOMO or just outright almost crashing the crypto markets.
FOMO stands for Fear Of Missing Out. Most people want to get rich quickly! and when an opportunity creates itself, they don't hesitate to take it because they may fear missing out on it. FOMO is driving more and more people into the Web3 space every day for the past few months, which is creating the hype we see today. Even celebrities are jumping aboard the ship which is creating more awareness and tension in the hearts of people who may not even understand how the technologies work because they just don't wanna miss out on it!
##Can I benefit from Web3?
A lot of you are probably wondering "Alright Favor, you showed me all the great stuff about Web3 which is cool but, how do I take advantage of it to benefit me". Don't worry mon petit pois, I have got you covered!
There are several ways you can benefit from Web3 as a participant! But most of those ways will be a write-up for another topic.
Here are 5 benefits of participating in the Web3 ecosystem:
Interoperability - Send funds to anyone, anywhere in the world.
Trustless - Put your funds anywhere in the world without human interference.
Decentralized - Your content will never be taken down.
Anonymity - You will remain anonymous and untrackable.
Freedom - You have the freedom to participate in any Web3 project with little or no oversight.
Conclusion
Thank you for reading 🔥🔥🔥, and I hope you found this article useful in your path to becoming a Web3 maestro 🔥 | brijrajsinh_parmar |
918,500 | Bulk data deduplication | Hi guys, I'm looking for some feedback: we’ve just built a new Custom Action in Procesio called Bulk... | 0 | 2021-12-06T09:51:05 | https://dev.to/julian_procesio/bulk-data-deduplication-5gn7 | Hi guys, I'm looking for some feedback: we’ve just built a new Custom Action in Procesio called Bulk Data Deduplication. Basically we've packed an entire SaaS into this action, designed to merge records or eliminate dupes coming from different sources in CRMs or other databases when you are working with high volumes of data. What do you think, is this something you'd find useful? Let me know of your feedback.
You can find it in the Procesio left-hand [app dashboard](https://procesio.app/) under Beta.
{% youtube lmcVuM6rD5c %} | julian_procesio | |
918,550 | Top 10 dev.to articles of the week🙌. | Most popular articles published on the dev.to | 15,619 | 2021-12-06T11:36:59 | https://dev.to/ksengine/top-10-devto-articles-of-the-week-lho | javascript, webdev, programming, react | ---
title: Top 10 dev.to articles of the week🙌.
published: true
description: Most popular articles published on the dev.to
cover_image: https://images.unsplash.com/photo-1607705703571-c5a8695f18f6?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=MnwxfDB8MXxyYW5kb218MHx8Y29kaW5nfHx8fHx8MTYzODc5MDYxOA&ixlib=rb-1.2.1&q=80&utm_campaign=api-credit&utm_medium=referral&utm_source=unsplash_source&w=1080
tags: javascript,webdev,programming,react
series: Dev.to top 10 weekly
---
DEV is a community of software developers getting together to help one another out. The software industry relies on collaboration and networked learning. They provide a place for that to happen.
Here is the most popular articles published on this platform.
## #1
[](https://dev.to/swastikyadav/algorithms-in-javascript-with-visual-examples-gh3)
{% post https://dev.to/swastikyadav/algorithms-in-javascript-with-visual-examples-gh3 %}
## #2
[](https://dev.to/thawkin3/in-defense-of-clean-code-100-pieces-of-timeless-advice-from-uncle-bob-5flk)
{% post https://dev.to/thawkin3/in-defense-of-clean-code-100-pieces-of-timeless-advice-from-uncle-bob-5flk %}
## #3
[](https://dev.to/alexomeyer/10-must-have-react-developer-tools-to-write-clean-code-1808)
{% post https://dev.to/alexomeyer/10-must-have-react-developer-tools-to-write-clean-code-1808 %}
## #4
[](https://dev.to/mahamatmans/array-cheatsheet-javascript-3mci)
{% post https://dev.to/mahamatmans/array-cheatsheet-javascript-3mci %}
## #5
[](https://dev.to/crater90/5-github-repositories-for-learning-developers-4kn6)
{% post https://dev.to/crater90/5-github-repositories-for-learning-developers-4kn6 %}
## #6
[](https://dev.to/aviyel/building-a-mern-stack-simple-blog-site-from-absolute-scratch-5pm)
{% post https://dev.to/aviyel/building-a-mern-stack-simple-blog-site-from-absolute-scratch-5pm %}
## #7
[](https://dev.to/robbiecahill/six-ways-to-drastically-boost-your-productivity-as-a-node-developer-1mjd)
{% post https://dev.to/robbiecahill/six-ways-to-drastically-boost-your-productivity-as-a-node-developer-1mjd %}
## #8
[](https://dev.to/vangware/you-dont-need-if-37f1)
{% post https://dev.to/vangware/you-dont-need-if-37f1 %}
## #9
[](https://dev.to/estheragbaje/learn-to-use-storybookjs-in-your-react-project-4nf2)
{% post https://dev.to/estheragbaje/learn-to-use-storybookjs-in-your-react-project-4nf2 %}
## #10
[](https://dev.to/smetankajakub/how-to-integrate-husky-eslint-prettier-to-project-in-less-than-15-minutes-5gh)
{% post https://dev.to/smetankajakub/how-to-integrate-husky-eslint-prettier-to-project-in-less-than-15-minutes-5gh %}
> Orginal authors of this articles are @swastikyadav, @thawkin3, @alexomeyer, @mahamatmans, @crater90, @pramit_marattha, @robbiecahill, lukeshiru, estheragbaje, smetankajakub
Enjoy these articles.
Follow me for more articles.
Thanks 💖💖💖
| ksengine |
918,607 | Why ML should be written as pipelines from the get-go | Today, Machine Learning powers the top 1% of the most valuable organizations in the world (FB, ALPH,... | 0 | 2021-12-06T12:31:51 | https://blog.zenml.io/ml-pipelines-from-the-start/ | Today, Machine Learning powers the top 1% of the most valuable organizations in the world (FB, ALPH, AMZ, N etc). However, 99% of enterprises struggle to productionalize ML, even with the possession of hyper-specific datasets and exceptional data science departments.
Going one layer further into how ML propagates through an organization reveals the problem in more depth. The graphic below shows an admittedly simplified representation of a typical setup for machine learning:
|  |
|:--:|
| *Figure 1: Why it’s hard to reproduce ML models* |
<br>
There are three stages to the above process:
## Experimenting & PoCs:
- **Technologies**: Jupyter notebooks, Python scripts, experiment tracking tools, data exploration tools
- **Persona**: Data scientists
- **Description**: Quick and scientific experiments define this phase. The team wants to increase their understanding of the data and machine learning objective as rapidly as possible.
## Conversion:
- **Technologies**: ETL pipelining tools such as Airflow
- **Persona**: Data Engineers
- **Description**: Converting finalized experiments into automated, repeatable processes is the aim of this code. Sometimes this starts before the next phase, some times after, but the essence is the same — take the code from the data scientists and try to put them in sort form of an automated framework.
## Productionalization & Maintenance:
- **Technologies**: Flask/FastAPI, Kubernetes, Docker, [Cortex](http://cortex.dev/), [Seldon](https://www.seldon.io/)
- **Persona**: ML Engineers / Ops
- **Description**: This is the phase that starts at the deployment of the model, and spans monitoring, retraining, and maintenance. The core focus of this phase is to keep the model healthy and serving at any scale, all the while accounting for drift.
Each of these stages requires different skills, tooling, and organization. Therefore, it is only natural that there are many potholes that an organization can run into along the way. Inevitably things that are important downstream are not accounted for in the earlier stages. E.g. If training happens in isolation from the deployment strategy, that is never going to translate well in production scenarios — leading to inconsistencies, silent failures, and eventually failed model deployments.
# The Solution
Looking at the above multi-phase process in Figure 1, it seems like a no-brainer to simply reduce the steps involved and therefore eliminate the friction that exists between them. However, given the different requirements + skillsets for each step, this is easier said than done. Data scientists are not trained or equipped to be diligent to care about production concepts such as reproducibility — they are **trained to iterate and experiment**. They don’t really care about code quality and it is probably not in the best interest of the company at an early point to be super diligent in enforcing these standards, given the trade-off between speed and overhead.
Therefore, what is required is an implementation of a framework that is **flexible but enforces production standards** from the get-go. A very natural way of implementing this is via some form of pipeline framework that exposes an automated, standardized way to run ML experiments in a controlled environment. ML is inherently a process that can be broken down into individual, concrete steps (e.g. preprocessing, training, evaluating, etc), so a pipeline is a good solution here. Critically, by standardizing the development of these pipelines at the early stages, organizations can lose the cycle of destruction/recreation of ML models through multiple toolings and steps, and hasten the speed of research to deployment.
If an organization can incentivize their data scientists to buy into such a framework, **then they have won half the battle of productionalization**. However, the devil is really in the details — how do you give data scientists the flexibility they need for experimentation in a framework that is robust enough to be taken all the way to production?
# An exercise in finding the right abstractions
Having motivated writing in pipelines from the get-go, it is only fair that I give more concrete examples of frameworks on how to achieve this. However, in my opinion, currently, the tooling landscape is too split into frameworks that are ML tools for ML people, or Ops tools for Ops people, not really satisfying all the boxes I mentioned in the last section. What is missing is an Ops (read pipelines) tool for ML people, with **higher-order abstractions at the right level for a data scientist**.
In order to understand why this is important, we can cast an eye towards how web development has matured from raw PHP/jQuery-based scripts (the Jupyter notebooks of web development) with the LAMP stack to the powerful React/Angular/Vue-based modern web development stacks of today. Looking at these modern frameworks, their success has been dictated by providing higher-order abstractions that are easier to consume and digest for a larger audience. They did not change the fundamentals of how the underlying web technology worked. They simply re-purposed it in a way that is understandable and accessible to a larger audience. Specifically, by providing components as first-class citizens, these frameworks have ushered in a new mechanism of breaking down, utilizing, and resharing the HTML and Javascript that powers the modern web. However, ML(Ops) does not have an equivalent movement to figure out the right order of abstraction to have a similar effect.
To showcase a more concrete example of my more abstract thoughts above, I’ll use [ZenML](https://github.com/maiot-io/zenml), an open-source MLOps framework to create iterative, reproducible pipelines.
> *Disclaimer: I am one of the core maintainers of ZenML.*
[ZenML](https://github.com/maiot-io/zenml) is an exercise in finding the right layer of abstraction for ML. Here, we treat pipelines as first-class citizens. This means that data scientists are exposed to pipelines directly in the framework, but not in the same manner as the data pipelines from the ETL space ([Prefect](https://www.prefect.io/), [Airflow](https://airflow.apache.org/) et al.). Pipelines are treated as experiments — meaning they can be compared and analyzed directly. Only when it is time to flip over to productionalization, can they be converted to classical data pipelines.
|  |
|:--:|
| *Figure 2: ZenML abstract pipelines with familiar language to increase ownership of model deployments.* |
<br>
Within pipelines are steps, that are abstracted in familiar ML language towards the data scientist. e.g. There is a `TokenizerStep`, `TrainerStep`, `EvaluatorStep` and so on. Paradigms that are way more understandable than plugging scripts into some form of orchestrator wrapper.
Each pipeline run tracks the metadata, parameters and can be compared to other runs. The data for each pipeline is automatically versioned and tracked as it flows through. Each run is linked to git commits and compiled into an easy-to-read YAML file, which can be optionally compiled to other DSL’s such as on Airflow or Kubeflow Pipelines. This is necessary to satisfy other stakeholders such as the data engineers and ML engineers in the value chain.
Additionally, the interfaces exposed for individual steps are mostly set up in a way to be easy to extend in an idempotent, and therefore a distributed, manner. The data scientist can therefore scale-out with different processing backends (like Dataflow/Spark) when they are dealing with larger datasets.
All in all, ZenML is trying to get to the following scenario:
|  |
|:--:|
| *Figure 3: ZenML unifies the ML process.* |
<br>
Of course, [ZenML](https://github.com/maiot-io/zenml) is not the only mechanism to achieve the above — Many companies build their own home-grown abstraction frameworks to solve their specific needs. Often-times these are built on top of some of the other tools I have mentioned above. Regardless of how to get there, the goal should be clear: Get the data scientists **as close to production as possible** with as little friction as possible, incentivizing them to increase their ownership of the models after deployment.
This is a win-win-win for every persona involved, and ultimately a big win for any organization that aims to make it to the top 1% using ML as a core driver for their business growth.
# Plug
If you like the thoughts here, we’d love to hear your feedback on ZenML. It is [open-source](https://github.com/maiot-io/zenml) and we are looking for early adopters and [contributors](https://github.com/maiot-io/zenml)! And if you find it is the right order of abstraction for you/your data scientists, then let us know as well via [our Slack](http://zenml.io/slack-invite) — looking forward to hearing from you! | htahir1 | |
918,789 | How to format HTML code | Are you writing HTML Code? If yes then this article is especially for you because in this article I... | 0 | 2021-12-06T15:35:37 | https://dev.to/goonlinetools/how-to-format-html-code-17j4 | html | Are you writing HTML Code? If yes then this article is especially for you because in this article I will show you how to beautify ugly, minified HTML code.
Most of the people like good looking codes including me because if code is written in a proper manner it is easy to understand.
Today in this article I will introduce [HTML Formatter](https://goonlinetools.com/html-formatter/)
## Here is How to Format HTML Code?
1. First open [HTML Formatter] (https://goonlinetools.com/html-formatter/)
2. Click on clear button to clear demo code
3. Paste Minified HTML Code
4. Click on Format Button
5. Now click on copy button to copy formatted HTML Code
Thanks for reading this article, If you have any questions regarding this then feel free to ask in the comment box.
More HTML tools:
- [HTML Minifier](https://goonlinetools.com/html-minifier/)
- [Realtime html editor](https://goonlinetools.com/realtime-html-editor/)
- [HTML Viewer](https://goonlinetools.com/html-viewer/)
- [Source code viewer](https://goonlinetools.com/source-code-viewer/)
Also read :
- [How to share code snippets easily](https://dev.to/goonlinetools/how-to-share-code-snippets-easily-2m46)
- [How to Beautify JSON Code?](https://dev.to/goonlinetools/how-to-beautify-json-code-221e)
- [How to Beautify Javascript Code?](https://dev.to/goonlinetools/how-to-beautify-javascript-code-3ole)
- [How to Beautify PHP Code?](https://dev.to/goonlinetools/how-to-beautify-php-code-ahd)
| goonlinetools |
918,821 | All about closure in javascript | Hello all 👋🏻, This article is all about closure in javascript. Closure is not a easy topic. It will... | 0 | 2021-12-06T17:19:37 | https://dev.to/sakethkowtha/all-about-closure-in-javascript-3of3 | javascript, webdev, beginners | Hello all 👋🏻,
This article is all about closure in javascript.
Closure is not a easy topic. It will be confusing topic for beginners. In this article i will try to explain it easily.
### What is a closure
According to MDN
> A closure is the combination of a function bundled together (enclosed) with references to its surrounding state (the lexical environment). In other words, a closure gives you access to an outer function’s scope from an inner function. In JavaScript, closures are created every time a function is created, at function creation time.
According to Stackoverflow
> A closure is a persistent scope which holds on to local variables even after the code execution has moved out of that block. Languages which support closure (such as JavaScript, Swift, and Ruby) will allow you to keep a reference to a scope (including its parent scopes), even after the block in which those variables were declared has finished executing, provided you keep a reference to that block or function somewhere.
It might confusing you again. Let's jump to javascript lexical scoping in a high level not in detail because lexical scoping is a huge concept i will try to publish article on it separately.
```javascript
var title = "Devto"
function printTitle(){
console.log(title)
}
printTitle() // Devto
```
The above snippet will print `Devto` in console. `title` variable is accessible in printTitle method because `title` variable is in `printTitle` parent scope. So if `title` and `printTitle` both are in single scope here i.e `global scope`
Consider the following snippet
```javascript
function main(){
var title = "Devto"
function printTitle(){
console.log(title)
}
printTitle()
}
main() // Devto
```
The above snippet will print `Devto` in console but in this `title` and `printTitle` are not in `global scope` instead they are in `main method scope`.
Now checkout this example
```javascript
var title = "Devto"
function main(){
function printTitle(){
console.log(title)
}
printTitle()
}
main() // Devto
```
Same output but here the difference is `title` is in `global scope` and we are accessing it in `printTitle` method. So here the point is child's can access their parent / global level scope items. This is not only in javascript you can see this feature in other languages like `Java`, `C#`, `C++` and `Python` etc..
We will the change above snippet
```javascript
var title = "Devto"
function main(){
return function printTitle(){
console.log(title)
}
}
const printTitleGlobal = main()
printTitleGlobal() // Devto
```
In javascript functions are `First class objects` means they are like variables. We can return any type of variable in a function so here we can return function itself because as i said it is also treated as a variable.
In the above snippet `main` method returning `printTitle` method and we are assigned it to `printTitleGlobal` variable and called that `printTitleGlobal` function. Indirectly we are calling `printTitle` function as `title` in global scope it is accessible in `printTitle` method so worked as expected.
Now Check the following snippet
```javascript
function main(){
var title = "Devto"
return function printTitle(){
console.log(title)
}
}
const printTitleGlobal = main()
printTitleGlobal()
```
Can you guess the output ?
It is same but here the craziest thing is `title` is in `main` method's scope but we are executing `printTitleGlobal` function in `global` scope . As per javascript lexical scope concept once the function is executed completely JS will clear the memory allotted for that. Here once `main` method is called it should clear all the references related to `main` method so JS should clear `title`, `printTitle` and `main`. As we stored `printTitle` in `printTitleGlobal` we can call that method anytime but that method has `main` method references which should be cleared after execution of `main`.
Then how it is printing "Devto" ❓.
That is what **closure** is ❗️
When ever we return any function in javascript. JS will not only return that method before returning it will find all the references required to that returned function it will pack all the references along with along with that function. We will call that pack as **closure**.
>A closure is the combination of a function bundled together (enclosed) with references to its surrounding state (the lexical environment).
Now the above definition will make sense once we call `main` method it will give us a closure named `main` that closure will hold all the references required for `printTitle` and `main` method scope will get cleared after execution but still some of references required for `printTitle` are persistent in closure.
Checkout this screenshots:
I have added two `debuggers` this is the screenshot taken at the time of first debugger which is in `main` method. Look at the `call stack` in the left side window and `scope` in right side. `title` is in `local` scope. This is as expected.

Now time for second debugger which is inside `printTitle` method. `main` got cleared from `call stack` and in right side you can see `Closure (main)` it has `title` reference. This is the one holding reference of `title` which is being used in `printTitle`.

Hope you enjoyed it.
Cheers!
You can now extend your support by buying me a Coffee.
<a href="https://www.buymeacoffee.com/sakethk" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-blue.png" alt="Buy Me A Coffee" style="height: 30px !important;width: 60px !important;" ></a> | sakethkowtha |
919,033 | Type-safe JSON.parse() with joi | As developers, we often interact with APIs and databases that return a response in JSON format. To... | 0 | 2021-12-07T17:03:23 | https://dev.to/armenhalajyan/type-safe-jsonparse-with-joi-4ja | typescript, showdev, webdev, discuss | As developers, we often interact with APIs and databases that return a response in `JSON` format. To parse that `JSON` response we have to reach for the `JSON.parse()` method.
By default, `JSON.parse()` will return the object with type `any`. This means that we can simply declare the type of our object inline, like this:
```typescript
interface MyObject {
key1: string;
key2?: number;
key3: boolean;
}
const jsonString = api.get()
const myObject: MyObject = JSON.parse(jsonString)
```
This would be sufficient if we were absolutely sure that `jsonString` is assignable to type `MyObject`. However, if for any reason the API sends us a different response, Typescript will not prevent us from misusing that response and potentially getting runtime errors.
To address this issue we can use a runtime data validator such as [joi](https://www.npmjs.com/package/joi):
```typescript
import { ObjectSchema, ValidationError } from 'joi';
export const typedParse = <TSchema>(
jsonString: string,
schema: ObjectSchema<TSchema>
): TSchema => {
const {
value,
error,
warning,
}: { value: TSchema; error?: ValidationError; warning?: unknown } =
schema.validate(JSON.parse(jsonString));
// handle error and warning cases as needed
if (error) throw error;
if (warning) console.log(warning);
return value;
};
```
Now we can import and use this reusable function anywhere we use `JSON.parse()` by providing the `JSON` string and the corresponding joi schema:
```typescript
import Joi from 'joi'
import { typedParse } from './util/typedParse.ts'
interface MyObject {
key1: string;
key2?: number;
key3: boolean;
}
const jsonString = api.get()
const schema = Joi.object<MyObject>()
.keys({
key1: Joi.string().required(),
key2: Joi.number().integer(),
key3: Joi.boolean()
})
.required()
const myObject = typedParse(jsonString, schema)
```
This allows us to take advantage of all the type safety and autocompletion that Typescript offers when the API request matches what we expect, and at the same time prevents unexpected behavior when the API returns a different response.
| armenhalajyan |
919,067 | The Dining Philosophers Problem Solution in C | The dining philosophers problem is a very famous and interesting problem used to demonstrate the... | 0 | 2021-12-06T22:26:37 | https://dev.to/iamdigitalanna/the-dining-philosophers-problem-solution-in-c-54l2 | ---
title: The Dining Philosophers Problem Solution in C
published: true
description:
tags:
//cover_image: https://direct_url_to_image.jpg
---
The dining philosophers problem is a very famous and interesting problem used to demonstrate the concept of deadlock.
To understand what the dining philosophers problem actually is, you can refer this blog:
[**The Dining Philosopher’s problem**](https://dev.to/iamdigitalanna/the-dining-philosophers-problem-3p4m)
Here, I am going to explain the solution to this problem using the concept of semaphores in C. Here’s the program:
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<semaphore.h>
#include<unistd.h>
sem_t room;
sem_t chopstick[5];
void * philosopher(void *);
void eat(int);
int main()
{
int i,a[5];
pthread_t tid[5];
sem_init(&room,0,4);
for(i=0;i<5;i++)
sem_init(&chopstick[i],0,1);
for(i=0;i<5;i++){
a[i]=i;
pthread_create(&tid[i],NULL,philosopher,(void *)&a[i]);
}
for(i=0;i<5;i++)
pthread_join(tid[i],NULL);
}
void * philosopher(void * num)
{
int phil=*(int *)num;
sem_wait(&room);
printf("\nPhilosopher %d has entered room",phil);
sem_wait(&chopstick[phil]);
sem_wait(&chopstick[(phil+1)%5]);
eat(phil);
sleep(2);
printf("\nPhilosopher %d has finished eating",phil);
sem_post(&chopstick[(phil+1)%5]);
sem_post(&chopstick[phil]);
sem_post(&room);
}
void eat(int phil)
{
printf("\nPhilosopher %d is eating",phil);
}
/* BY - ANUSHKA DESHPANDE */
Let us first understand what is a semaphore and why it is used.
Basically, semaphore is a special type of variable used to control the access to a shared resource.
The definition of semaphore is in the library ***semaphore.h ***.
There are many functions related to semaphores like *sem_inti()*, *sem_wait()*, *sem_post(), etc. *These functions are also defined under the ***semaphore.h*** library.
> The data type of the semaphores is sem_t
There are two types of semaphores-:
1. Binary semaphore
2. Counting semaphore
The binary semaphore is used when there is only one instance of the resource whereas the counting semaphore is used when there are multiple instances of the resources.
In our program, we have used both types of semaphores.
sem_t room;
sem_t chopstick[5];
Here, the semaphore room is a counting semaphore since there is one dining room which can accommodate 4 philosophers. (i.e. Consider there are 4 chairs in the room and that is the resource. Hence there are multiple instances of the resource in the room. Therefore, room is a counting semaphore.)
sem_init(&room,0,4);
The function *sem_init() *is used to initialize the semaphore.
int sem_init(sem_t **sem*, int *pshared*, unsigned int *value*);
> The first parameter is the pointer to the declared semaphore.
> The second parameter is pshared. If it is zero, the semaphore is shared between threads; else it is shared between processes. In our case it is zero meaning it is shared between threads.
> The third parameter value is the value with which the semaphore is initialized.
Here, the semaphore room is initialized as 4 meaning it will vary between 0–3 and have 4 values.
Now, since there are 5 chopsticks, we have created 5 binary semaphores referring to the five chopsticks C0-C4.
for(i=0;i<5;i++)
sem_init(&chopstick[i],0,1);
> For the chopsticks, we have used binary semaphores since for every chopstick, C0-C4 we have only one instance of it.
So, according to our program, we have a scenario like:-
An empty room with 5 chopsticks and places for four philosophers.
In the program above, we have created threads.
pthread_t tid[5];
These threads refer to the 5 philosophers sitting around the table.
We have them as threads since we want these to execute simultaneously (i.e. we want multiple philosophers to eat at a time).
Now there can be a situation where all 5 threads start executing i.e. all 5 philosophers enter the room and cause deadlock. Hence, we are allowing 4 philosophers to enter the room first so that at least one of them can finish eating.
for(i=0;i<5;i++){
a[i]=i;
pthread_create(&tid[i],NULL,philosopher,(void *)&a[i]);
}
We are calling the function philosopher() from pthread_create and passing it the address of an integer variable which refers to the philosopher number.
In the philosopher function,
void * philosopher(void * num)
{
int phil=*(int *)num;
sem_wait(&room);
printf("\nPhilosopher %d has entered room",phil);
sem_wait(&chopstick[phil]);
sem_wait(&chopstick[(phil+1)%5]);
eat(phil);
sleep(2);
printf("\nPhilosopher %d has finished eating",phil);
sem_post(&chopstick[(phil+1)%5]);
sem_post(&chopstick[phil]);
sem_post(&room);
}
we are first converting the number passed as a void * into integer.
Then we have called the sem_wait function which first checks if the resource is available and if it is available, the resource is allocated to the philosopher i.e. the semaphore is locked.
sem_wait(&room);
This being a counting semaphore, the prototype of sem_wait is:
struct semaphore {
int count;
queueType queue;
};
void sem_wait(semaphore s)
{
s.count--;
if(s.count<0)
{
/*place this process in s.queue */;
/*block this process*/;
}
}
So here, the number of semaphores is decremented, meaning one of the semaphores is allocated. If all of the resources are allocated, the thread is placed on waiting queue.
Now, we apply sem_wait on chopsticks which are binary semaphores.
sem_wait(&chopstick[phil]);
sem_wait(&chopstick[(phil+1)%5]);
The definition of sem_wait for binary semaphores is:
struct binary_semaphore {
enum {zero,one} value;
queueType queue;
}
void sem_wait(binary_semaphore s)
{
if(s.value == one)
s.value = zero;
else
{
/* place this process in s.queue */
/* block this process */
}
}
Here, according to the prototype, if the value of semaphore is one, it is changed to zero indicating that the semaphore is blocked.
In our case we are blocking the chopsticks towards the left and the right of the philosopher.
For example, for philosopher P0, we are blocking chopstick C0 and C4.
Then, we are allowing the philosophers to eat.
Finally, we are freeing the semaphores by calling the *sem_post()* function so that the other threads that are placed on the queue can use the resources.
The prototype for the *sem_post()* function is:
int sem_post(sem_t **sem*);
If it returns a positive value, the semaphore is unlocked successfully.
For a binary semaphore, the *sem_post()* function works as:
void sem_post(semaphore s)
{
if(s.queue is empty)
s.value=one;
else
{
/* remove a process P from s.queue */
/* place process P on ready list */
}
}
and for a counting semaphore, the sem_post() function is:
void sem_post(semaphore s)
{
s.count++;
if(s.count <= 0)
{
/* remove a process P from s.queue */
/* place process P on ready list */
}
}
Using the above functions, we free all the semaphores so that they can be used by other threads.
sem_post(&chopstick[(phil+1)%5]);
sem_post(&chopstick[phil]);
sem_post(&room);
The same thing happens for all 5 philosophers.
After all the 5 are done, we join the threads back to the main process.
for(i=0;i<5;i++)
pthread_join(tid[i],NULL);
So, this is how we can implement the solution to the dining philosophers problem using semaphores.
At the end, you should get an output which looks like this:
Philosopher 4 has entered room
Philosopher 4 is eating
Philosopher 2 has entered room
Philosopher 2 is eating
Philosopher 3 has entered room
Philosopher 1 has entered room
Philosopher 2 has finished eating
Philosopher 4 has finished eating
Philosopher 3 is eating
Philosopher 1 is eating
Philosopher 0 has entered room
Philosopher 3 has finished eating
Philosopher 1 has finished eating
Philosopher 0 is eating
Philosopher 0 has finished eating
The sequence does not matter. It can be different on different machines.
The only thing is to make sure that all philosophers are entering the room, performing the eating operation and leaving the room and also that no two philosophers are using the same chopstick at the same time.
Do let me know if you face any problems and feel free to leave a feedback.
Hope this helps you!
| iamdigitalanna | |
919,351 | Automate unit testing with github actions and get coveralls badge for an npm package | First of all, let´s see what are unit tests?. Start with this question: How do you ensure... | 0 | 2021-12-07T01:04:25 | https://dev.to/jinssj3/how-to-automate-unit-tests-with-github-actions-and-coveralls-for-an-npm-package-3bjp | actionshackathon21, testing, github, coveralls | ## First of all, let´s see what are unit tests?.
**Start with this question: How do you ensure the quality of your project?**
The goal of unit testing is to isolate each part of the program and show that the individual parts are correct. A unit test provides a strict, written contract that the piece of code must satisfy. As a result, it affords several benefits.
Unit testing finds problems early in the development cycle. This includes both bugs in the programmer's implementation and flaws or missing parts of the specification for the unit. The process of writing a thorough set of tests forces the author to think through inputs, outputs, and error conditions, and thus more crisply define the unit's desired behavior. The cost of finding a bug before coding begins or when the code is first written is considerably lower than the cost of detecting, identifying, and correcting the bug later. Bugs in released code may also cause costly problems for the end-users of the software. Code can be impossible or difficult to unit test if poorly written, thus unit testing can force developers to structure functions and objects in better ways.
### My Workflow
Since there is no need to reinvent the wheel, I will take advantage of an existing github action in the `Continuous integration workflows` category: **`Node.js`**. With this action I will set up this action in one of my public repositories. I will set up Node.js action for automating my unit test and also integrate with [coveralls.io](https://coveralls.io) for getting a badge of how much my tests covers relevant lines.
**What do I need?**
#### A javascript project
Well, first we need to create a public repository for a javascript project on Github. You can use [mine](https://github.com/JinSSJ3/dynamicss) as a template. [Dynamicss](https://www.npmjs.com/package/@dynamicss/dynamicss) is a javascript project and is an npm package that is used to manage dynamically css stylesheets using javascript (create,edit and delete stylesheets). I will use this project in this example.
#### A coveralls account:
This is pretty simple. Just go to https://coveralls.io and create an account using your Github account. This is important, since you will need to grant access to `coveralls.io` to your repo. Finally, enable the permission that allows `coveralls.io` to acces to your repo like I did. Once the account is created using github, go to the left panel and click on "Add repos".

Click on the switch to enable the access to the desired repo. In my case, I filter the repos to get `dynamicss`.
Copy the repo token because we will need it for the set up.
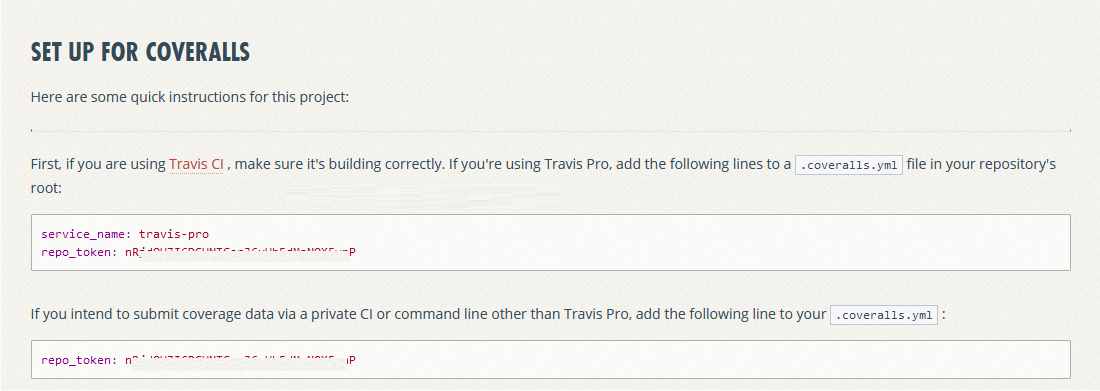
#### Create unit tests
You can take my simple unit tests as a simpe example. Of course, there are more complex unit test when working with react or other libraries.
https://github.com/JinSSJ3/dynamicss/tree/master/tests
#### Create a .coveralls.yml file
Remember we copied a repo token? Well, in our project, we need to create a .yml file that contains just one line:
https://github.com/JinSSJ3/dynamicss/blob/master/.coveralls.yml
#### Set up the github action
Now, in your github repo, go to `"actions"` tab.
Search for Node.js action and click on "Set up this worklow".
Then we need to edit the code to get something like this:
We just need to set the node version. In my case, I'm using node version `16`.
After that, we need to set the commands in the last lines, we only need 2:
- npm ci (for installing dependencies)
- npm run test:coveralls (for testing and sending results to coveralls.io). This command was set previously in `package.json` file.
Finally, make a commit to save the configuration:
This will save the .yml file in this location:
https://github.com/JinSSJ3/dynamicss/blob/master/.github/workflows/node.js.yml
Commiting will also trigger the job to be executed. Now, **every time we push a commit**, the job will be triggered, execute the unit tests and send results to coveralls.
#### Results
Let´s check the result of the action. Let´s go to the actiontab again. In my process, I can see that my code passed all tests and sent result to coveralls. I got a 93% of coverage in relevant lines of code. Also, we can see that job finished successfully.
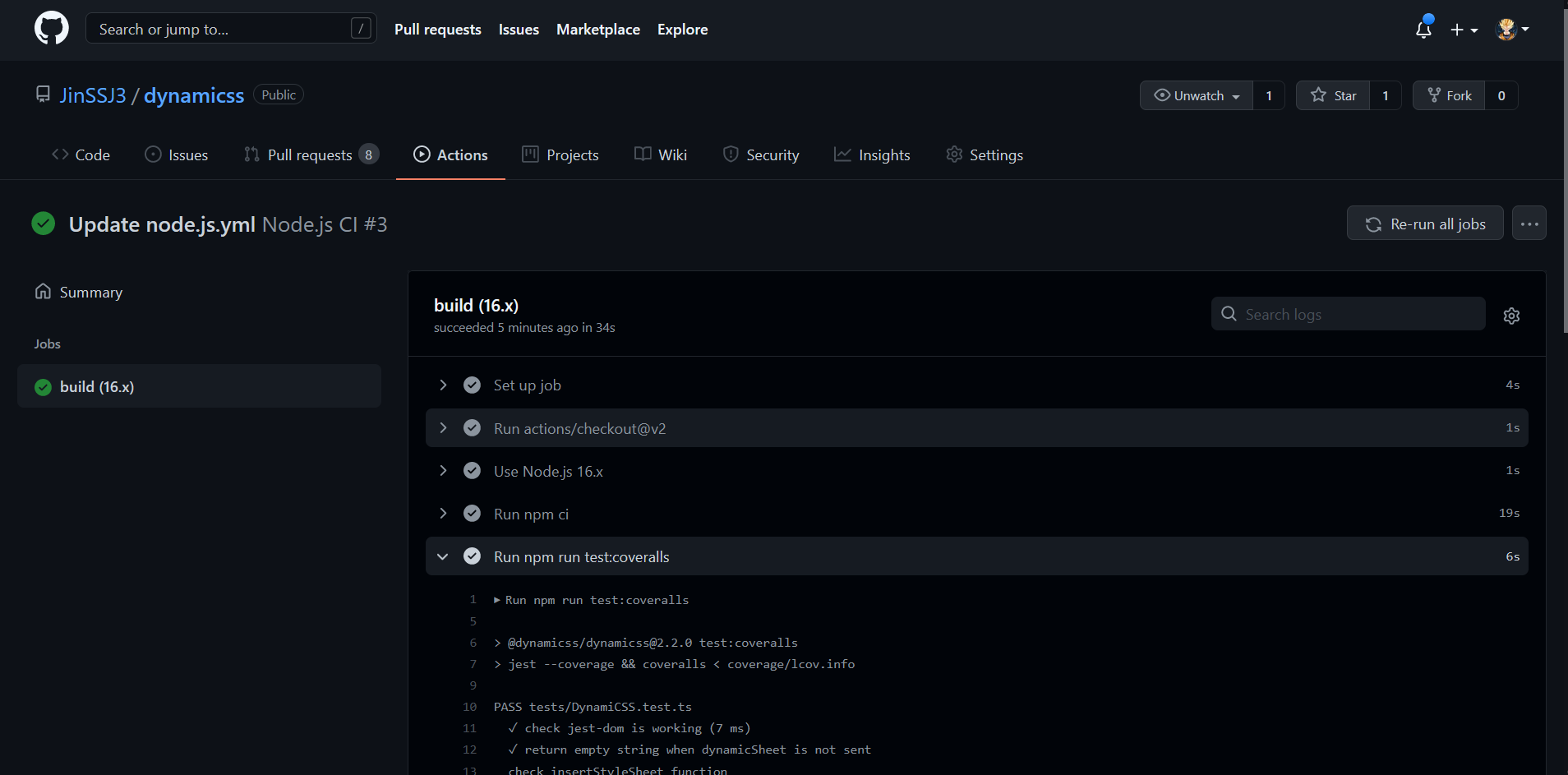
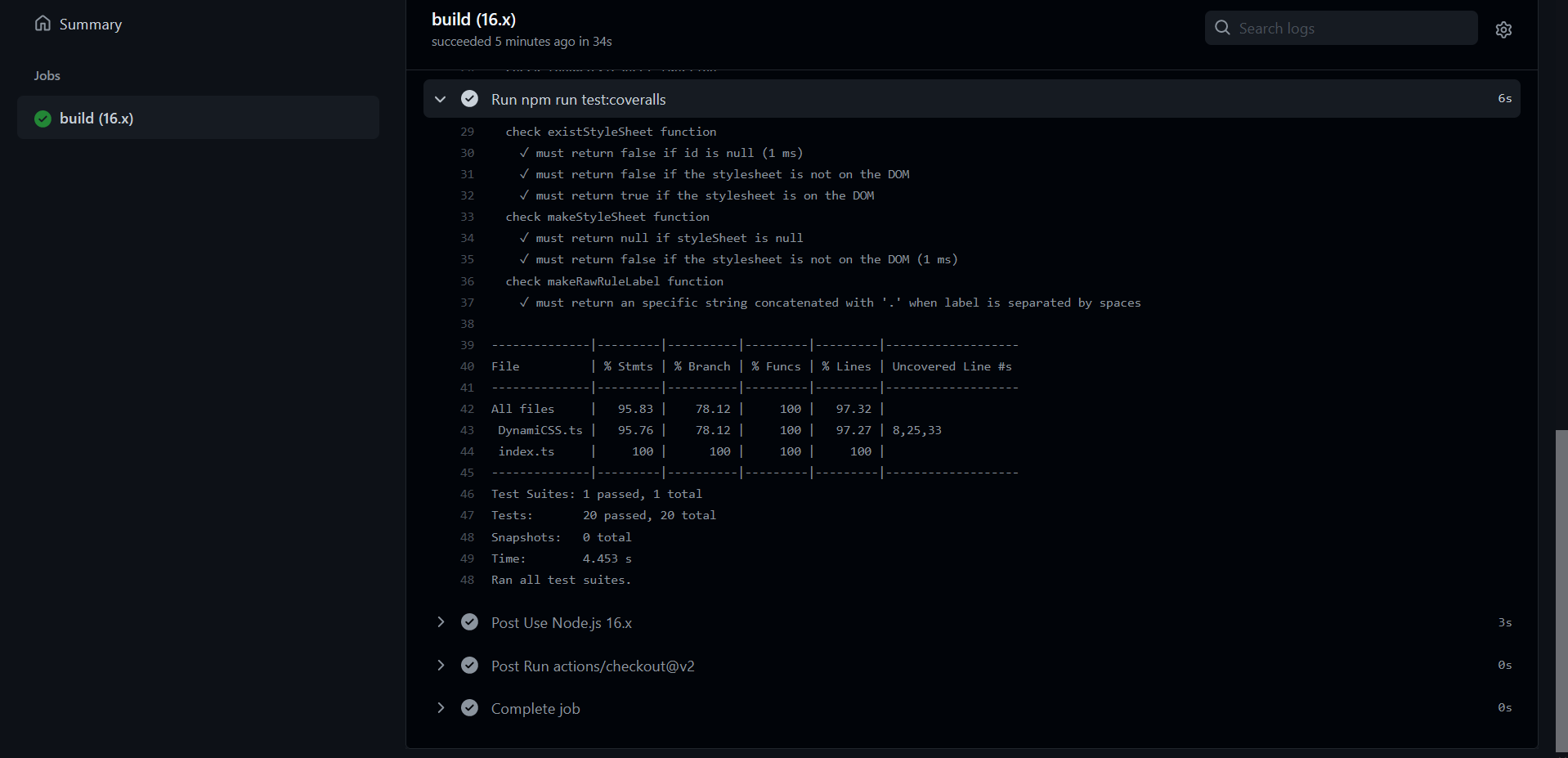
Now, if you go to you coveralls account in your repo you will se something like this:
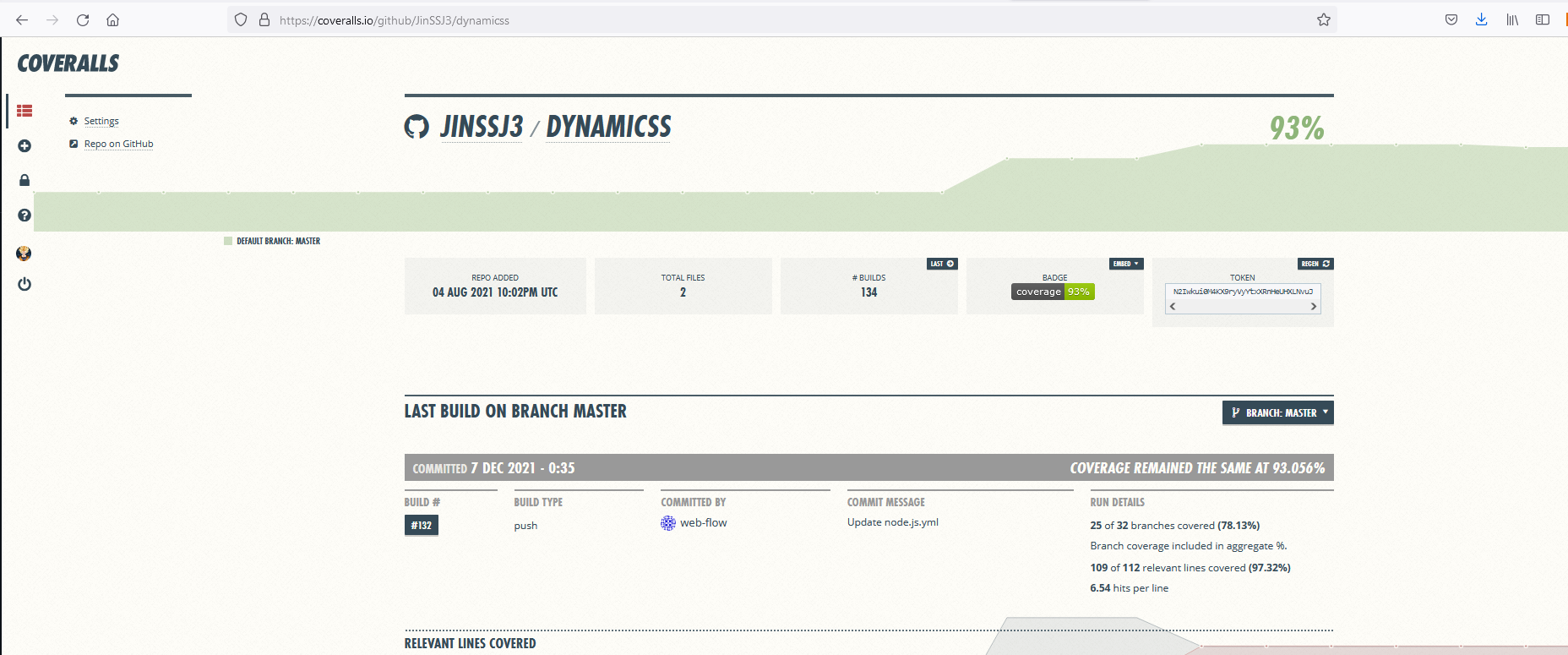
#### Final step: get your badge
And you are done! At this point we created a job for testing our code using github actions.
Now we can get our badge an embeb it on our [README.md](https://github.com/JinSSJ3/dynamicss#readme) file.
Click on `Embed` button and copy the markdown code:
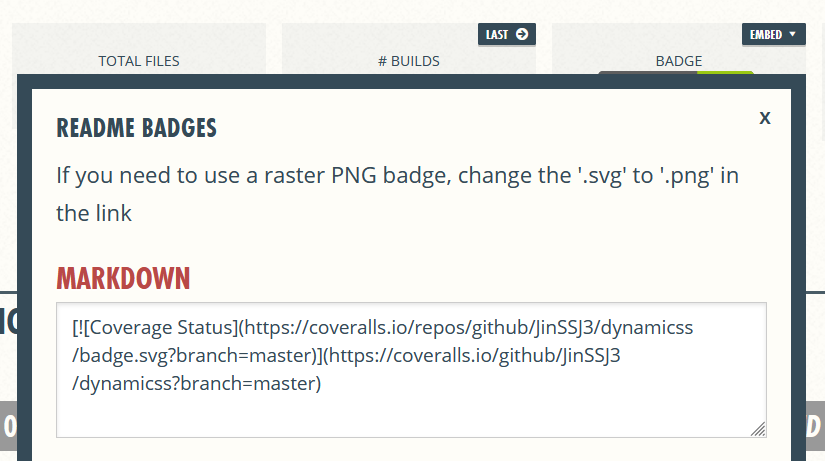.
Finally we can add the badge in our readme file, commit, push and we'll get something like this.
### Submission Category:
**DIY Deployments**
### Yaml File or Link to Code
The coveralls result can be accessed [here](https://coveralls.io/github/JinSSJ3/dynamicss).
The coveralls .yml file can be accessed [here](https://github.com/JinSSJ3/dynamicss/blob/master/.coveralls.yml).
The github action .yml file can be accessed [here](https://github.com/JinSSJ3/dynamicss/blob/master/.github/workflows/node.js.yml).
The repo can be accessed [here](https://github.com/JinSSJ3/dynamicss).
{% github https://github.com/JinSSJ3/dynamicss %}
### Additional Resources / Info
-
Unit test info was taken from [wikipedia](https://en.wikipedia.org/wiki/Unit_testing#Advantages).
| jinssj3 |
919,356 | Day 491 : Come Up | liner notes: Saturday : Got up early to finish putting together the radio show. Then made the trip... | 0 | 2021-12-07T00:23:45 | https://dev.to/dwane/day-491-come-up-41m5 | hiphop, code, coding, lifelongdev | _liner notes_:
- Saturday : Got up early to finish putting together the radio show. Then made the trip to the radio station. Did the show, had a good time. Then drove the van to my spot, watched an episode of Cowboy Bebop. I was pretty tired and went to sleep. The recording of this week's show is at https://kNOwBETTERHIPHOP.com

- Sunday : Had my online study group ( https://untilit.works ). The time flew by! Got a few things done though, so I felt good and went right to bed.
- Professional : Ran into an issue building a demo for a blog post last week. So today, I went through the code and got it working. I'm taking another sample app and adding some Web Components. Got everything pretty much working and need to work on some styling.
- Personal : So I decided to take part in this developer event thing that if you deploy an application to Netlify (like a hosting company) in December, they will donate money to organizations that help people get into tech. As a person who participated in extra-curricular programs to help under represented people get in science, math and tech fields, I'm down to support. I have a demo that I did for a talk I gave earlier this year, so I am going to make it a full application and deploy it. I even bought a domain. Yes, another domain. haha.
Going to see how much I can get done with the Netlify project. I've never used it before, so this will be a good chance to learn it. Also, I want to update my website to remove the links to view the code for my side projects. I recently took down my GitLab instance because I got like a $300 bill from Google because I think my server that hosted my GitLab may have been hacked to do crypto mining. For whatever reason I couldn't view my GitLab instance. Definitely shut that server and others I was playing around with real quick! haha. If I don't have time to follow up with these servers, I have no business setting them up. haha The money I'll be saving from the servers, I'll be putting it into my side project so it can come up.
Have a great night!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube plvaAYeYY5o %} | dwane |
919,384 | Release 0.4 Progress
| Intro For the last release, I have to work on something larger and more impactful than... | 0 | 2021-12-07T02:04:50 | https://dev.to/pandanoxes/release-04-progress-3jji | opensource | ## Intro
For the last release, I have to work on something larger and more impactful than anything I have done in the previous three releases. This blog will be separated into 3 other blogs, Release 0.4 - Planning, Release 0.4 - Progress, and Release 0.4 - Release.
In this part, I will talk about how I will solve those issues, and make them ready for Pull request.
## Solving
### Issue [#2418](https://github.com/Seneca-CDOT/telescope/issues/2418)
First I remove all unnecessary column, and add Service, staging, and production column. Then I remove all the rows. After I will add a loading message, so if the fetching takes time loading message will show first.
```html
<td colspan="3">
<div class="px-2 py-4">
<h6 class="mb-0 text-lg" id="request-message">
<i class="fa-spin fas fa-hourglass-half px-2"></i>Loading...
</h6>
</div>
</td>
```
After that we need to setup a route to expose API status from `telescope/src/api/status/src/services.js` to public.
```js
service.router.get('/v1/status/status', (req, res) => {
check()
.then((status) => {
// This status response shouldn't be cached (we need current status info)
res.set('Cache-Control', 'no-store, max-age=0');
return res.json(status);
})
.catch((err) => res.status(500).json({ error: err.message }));
});
```
Now to get all the api status data we call `<apiURL>/v1/status/status`.
Now we can create a script to fetch the data and put it into the table.
I create a file call `serviceStatus.js` which contains script to fetch the data and process to put it into the table.
```js
export default function getAllServicesStatus() {
fetch('/v1/status/status')
.then((res) => {
if (res.ok) return res.json();
const messageReport = requestMessageReport();
if (messageReport) {
messageReport.innerHTML = '';
const icon = document.createElement('i');
icon.className = 'fas fa-server px-2';
messageReport.appendChild(icon);
messageReport.innerHTML += `${res.status} Unable to get API status.`;
}
throw new Error('unable to get API status');
})
.then((results) => {
reportTbody().innerHTML = '';
results.forEach((result) => serviceRowFormat(result));
return setTimeout(getAllServicesStatus, 5000);
})
.catch((err) => console.error(err));
}
```
This function will handle all of the cases, first, we fetch the data, if the request-response is 200, return `res.json()` and go to next `then()`, in the next steps we removed the loading HTML, and replace by the row with the service name, service status staging, and service status production generated by serviceRowFormat(). After that, I return a timeout to recall the same function each 5 sec.
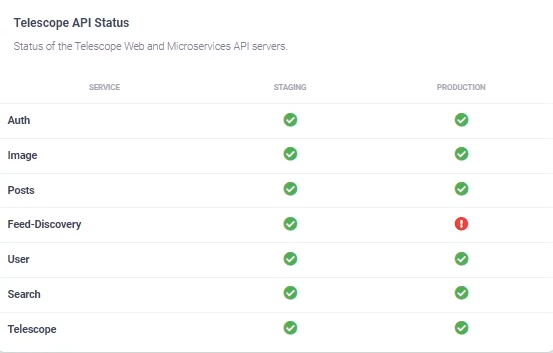
If this function fails when the fetch request is not 200, It prints an error message and throws an error. Also, the function will not recall itself in the next 5 sec.
### Issue [#2506](https://github.com/Seneca-CDOT/telescope/issues/2506)
I first locate the card where `avatar Author` is displayed. After that I add a HTML next to that which going to represent sha commit.
```html
<p class="mb-0">
<a
href=""
title="User"
target="_blank"
id="latest-author-telescope"
class="text-capitalize"
> </a
>
<a
href=""
title="Commit"
target="_blank"
id="latest-author-commit-telescope"
class="font-monospace btn-link text-xs"
></a>
</>
```
Then I add an id for the location of the HTML. I did the same thing for satellite card.
After this we can get the data from the GitHub commit info and displayed to the HTML.
```js
const commitURL = data[0].html_url;
const shortSha = data[0].sha.substr(0, 7);
document.getElementById(`latest-author-commit-${repo}`).innerHTML = shortSha;
document.getElementById(`latest-author-commit-${repo}`).title = shortSha;
document.getElementById(`latest-author-commit-${repo}`).href = commitURL;
```
### Issue [#113](https://github.com/Seneca-ICTOER/IPC144/issues/113)
For this issue, I will download every image from ict.senecacollege.ca. I first locate everywhere where it's still using ict.senecacollege.ca URL for the data by using the search feature in my IDE (search by `https://ict.senecacollege.ca//~ipc144/pages/images`). Then I copy and paste each URL and download each image then paste to `static/img`. After that I replace everywhere matching `https://ict.senecacollege.ca//~ipc144/pages/images` to `/img` using IDE it's a 1 click step.
## Prepare for Pull Request
### Issue [#2418](https://github.com/Seneca-CDOT/telescope/issues/2418)
I first do `npm run dev` to run the check if everything is working fine. I do some testing by reducing the network speed for the loading to appear and replace by the service row when data got fetched. Then I also check if the fetch doesn't return a status of 200, I make sure it will show that error code and error message on the page.
After that I do a `npm run prettier && npm run lint` to check the formatting.
After formatting pass, I commit my code.
### Issue [#2506](https://github.com/Seneca-CDOT/telescope/issues/2506)
I first do `npm run dev` to run the check if everything is working fine. I make sure the right commit is shown, and that when I click on the commit it opens up a page showing the latest commit.
After that, I do a `npm run prettier && npm run lint` to check the formatting.
After formatting pass, I commit my code.
### Issue [#113](https://github.com/Seneca-ICTOER/IPC144/issues/113)
I first do `yarn start` to run the check if everything is working fine. I check that every link is working fine. Also, do a `yarn build && yarn serve` to build the project and check the build version that it doesn't have broken links.
After that, I commit my code.
| pandanoxes |
921,337 | Starting with Terraform Provider | Prisma Cloud Compute | Automating your security is crucial, especially for companies operating in the cloud! I have recently... | 0 | 2021-12-08T22:02:49 | https://dev.to/hi_artem/terraform-provider-for-prisma-cloud-compute-17im | security, terraform, devops, tutorial | Automating your security is crucial, especially for companies operating in the cloud! I have recently made a video tutorial on how to use Terraform provider for Prisma Cloud Compute.
It would help anyone using Palo Alto Network's security platform to start building automation around their security practices.
{% youtube 9R3XWnl4EPs %}
I will include code snippets from this tutorial below:
**creds.json**
```json
{
"username": "test",
"password": "test",
"console_url": "https://192.168.64.2:32677"
}
```
**main.tf**
```hcl
terraform {
required_providers {
prismacloudcompute = {
source = "PaloAltoNetworks/prismacloudcompute"
version = "0.1.0"
}
}
}
provider "prismacloudcompute" {
config_file = "creds.json"
}
resource "prismacloudcompute_collection" "node_alpine" {
name = "node-alpine-collection"
description = "Collection for Node images based on Alpine"
color = "#68A063"
application_ids = ["*"]
code_repositories = ["*"]
images = ["node:17-alpine3.12", "*/node:17-alpine3.12"]
labels = ["*"]
namespaces = ["*"]
}
resource "prismacloudcompute_ci_image_vulnerability_policy" "ruleset" {
depends_on = [
prismacloudcompute_collection.node_alpine,
]
rule {
collections = [
prismacloudcompute_collection.node_alpine.name,
]
disabled = false
effect = "alert, block"
grace_days = 30
name = "${prismacloudcompute_collection.node_alpine.name}-ci-policy"
notes = "CI policy for ${prismacloudcompute_collection.node_alpine.name}"
only_fixed = true
verbose = false
alert_threshold {
disabled = false
value = 1
}
block_threshold {
enabled = true
value = 2
}
cve_rule {
description = "Ignore ansi-regex"
effect = "ignore"
id = "CVE-2021-3807"
expiration {
date = "2022-01-06T06:00:00Z"
enabled = true
}
}
cve_rule {
description = "Ignore busybox"
effect = "ignore"
id = "CVE-2021-28831"
expiration {
date = "2022-01-06T06:00:00Z"
enabled = true
}
}
}
rule {
collections = [
"All",
]
disabled = false
effect = "alert, block"
grace_days = 30
name = "default"
notes = "Default policy for CI scans"
only_fixed = true
verbose = false
alert_threshold {
disabled = false
value = 1
}
block_threshold {
enabled = true
value = 2
}
}
}
``` | hi_artem |
919,495 | Self-Taught Developer Journal, Day 15: TOP Landing Page Cont. | Today I learned.... Focusing on The Odin Project and Web Development Following some... | 16,004 | 2021-12-07T04:14:08 | https://dev.to/jennifertieu/self-taught-developer-journal-day-15-top-landing-page-cont-4mef | webdev, beginners, codenewbie, devjournal | Today I learned....
## Focusing on The Odin Project and Web Development
Following some feedback and advice on what I was working on vs where I wanted to be, I realized I wasn't fully investing my time and effort to being a web developer. From now on, I'm putting a pause on CS50 and focusing my time fully on The Odin Project, HTML, CSS, JavaScript, and projects built off it.
## Thinking Through The Odin Project Landing Page cont.

After positioning the hero elements and navbar in the center, I set the gray background for the hero image container so I could visually see how much space the image would take. From there, I adjusted the left hero elements width to 50% along with the right hero image container. Now both the right hero elements and left hero elements take up 50% of the hero container.
With the hero elements in the correct location, I set the font-size, font-weight, and color properties for the hero main text and hero secondary text. Next, I set the button background color, but I had trouble recalling how to round the button and elongate the button so I googled it. I used the w3schools site (https://www.w3schools.com/css/css3_buttons.asp) as a reference to round the buttons using the border-radius property and padding to change the button size. Lastly, I updated the border value to none and adjusted the spacing between the elements with margin and padding.
The first section of the landing page is done! Time to start working on the second section.
## Resources
[The Odin Project Landing Page Project](https://www.theodinproject.com/paths/foundations/courses/foundations/lessons/landing-page)
Day 14: https://dev.to/jennifer_tieu/self-taught-developer-journal-day-14-top-landing-page-cont-and-cs50-final-55df
Please refer to [Starting My Self-Taught Developer Journey]( https://dev.to/jennifer_tieu/starting-my-self-taught-developer-journey-2dga) for context. | jennifertieu |
919,537 | Progress: my contribution to the open source project | I planned how to contribute to an open source project last week and wrote about it in my previous... | 0 | 2021-12-09T21:43:09 | https://dev.to/okimotomizuho/progress-contribute-to-the-open-source-project-120c | opensource, beginners, programming, github | I planned how to contribute to an open source project last week and wrote about it in my [previous blog](https://dev.to/okimotomizuho/planning-how-to-contribute-to-an-open-source-project-48o6). In the blog, I mentioned I would write a progress blog on Monday, so here I am!
## Issue
For the last assignment(we call Release) of my open source course, I've decided to contribute to an open source project which is my college's C language course notes. The [issue](https://github.com/Seneca-ICTOER/IPC144/issues/64) I'm working on is about "Standardize frontmatter across all pages". When we contributed to the project in our last Release, we added `slug` as one of the properties for frontmatter. However, it made links broken since internal links use page names vs. slugs, so my professor told me to review some of the PRs if they included it.
## Made a PR
PR: https://github.com/Seneca-ICTOER/IPC144/pull/143
I've done the following for the standardization of Frontmatter:
- Added `id`, `title`, `sidebar_position`, and `description` for all markdown pages
- Each property of frontmatter was unified in order
- Unified format of description
- Shortened `description` to maximum 160 characters (Reason: `description` becomes the `<meta name="description" content="..."/>` inside the `<head>`tag, and Google generally truncates snippets to ~155-160 characters)
- Added "Standardize frontmatter" to the CONTRIBUTING.md file
## Getting reviews and change requests
One of my classmates reviewed my changes, and he asked me to reinsert `slug` in the root of the file, and also add a step in the Workflow in Contributing.md. Also, one of the repo's owners requested to change some `description`s in the frontmatter. When I worked on Standardizing frontmatter, the description was hard since I'm familiar with the course notes, but I wasn't very good at C language.
## Next step
The goal for this Release is for my PR to get merged by this Friday. However, I didn't change any codes in this contribution. I still need to make more PRs for my previous Releases. It would be a lot of things to do in my final exams week. I will try my best and put lots of effort into all of these Releases.
| okimotomizuho |
919,544 | How to count newest entries created in an oracle database | We will base the logic around sysdate which returns the current datetime, from which we substract... | 0 | 2021-12-07T07:14:44 | https://www.codever.dev/snippets/61a8ee5afb0221040e493f0f/details | oracle, sql, codever, snippets | We will base the logic around [`sysdate`](https://docs.oracle.com/cd/B19306_01/server.102/b14200/functions172.htm) which returns the current datetime, from which we substract different units. For example for the **last day** from now use `sysdate - 1` (units default to day) and compare with the timestamp column (in this case `CREATED_AT`) :
```sql
select count(*)
from PARTNER
WHERE CREATED_AT > (sysdate - 1)
-- last 2 days would be
select count(*)
from PARTNER
WHERE CREATED_AT > (sysdate - 2)
```
From the **last hour**, respectively **last two hours** use the following commands, where `1/24` is the unit for hour:
```sql
-- last hour
select count(*)
from PARTNER
WHERE CREATED_AT > (sysdate - 1/24)
-- last 2 hours
select count(*)
from PARTNER
WHERE CREATED_AT > (sysdate - 2/24)
```
<hr>
> Shared with :heart: from [Codever](https://www.codever.dev/snippets/61a8ee5afb0221040e493f0f/details). :point_right: use the [**copy to mine**](https://www.codever.dev/snippets/61a8ee5afb0221040e493f0f/details) functionality to add it to your personal snippets collection. | ama |
919,707 | Building a multi-architecture development environment | When you start a project, that is as complex as nuvolaris (a new distribution of a Apache OpenWhisk),... | 0 | 2021-12-07T10:21:25 | https://dev.to/sciabarracom/building-a-multi-architecture-development-environment-4713 | nuvolaris, serverless, kubernetes | When you start a project, that is as complex as [nuvolaris](bit.ly/nuvolaris) (a new distribution of a Apache OpenWhisk), you need to be very careful in what you do, as your initial choices will be the hardest to change later.
Whatever you choose now, it will be shared by a number of people, they will learn your procedures, and they won't be happy if you change them. Also, even if you decide later to update them, your changes will disrupt the workflows and create friction in the team.
I am working hard, but for now is's a solo effort to prepare the development environment. And here I am evolving my decisions on how to develop Nuvolaris.
First I simply wrote a readme, mentioning the required components. But since there are so many, so I wrote a script `setup.source` using also the various `nodenv` `pyenv` and `goenv` to set the correct version of the programming languages to use.
Then I decided that was also wise to provide a stable environment to run everything, so I considered the option of using a virtual machine to run everything in the same way for everyone. So I spent some time tweaking with multipass to see if I could use this as a standard environment for development, as I mostly develop using VSCode with the Remote-SSH plugin and I use my server.
In the end my conclusion is that setting up multipass is complex enough to not be worth the effort. But I considered to use VSCode Remote-Container plugin, and it was a great find. I was aware of this but I haven't actually used it in the past, but it is great, as there are provisions to initialize the environments for the various programming languages!
A perfect fit for my needs. So I decided to use Remote-Containers instead and built a Dockerfile to create the perfect development environment for Nuvolaris with all the development tools inside. So you can develop on Linux, Mac or Windows, and even on the web using CodeSpaces!
My only regret was that I actually use a Mac with ARM M1. It is not a problem, as I do not develop in it. As I said, I use a remote, Intel based, server with VSCode Remote-SSH. I personally can't use the Remote-Container simply because the image I built is intel based (and please, do not talk of emulating Intel in Docker for ARM as it is considerably slower).
Then I wondered: why not support ALSO ARM? Actually, we would like to support Nuvolaris on multiple Kubernetes distributions, and yesterday we discussed of building clusters of Kubernetes with Raspberry PIs and it would be awesome to have Nuvolaris running on those!
So I decided to go with this option too, and I decided to support ALSO arm64 from day one. In the end we are going to build Nuvolaris to work on a variety of Kubernetes environments, both on Intel and ARM architectures. And I am now building the development environment to be multi-architecture so you can work on a Windows PC, on a Mac with M1 chips and even on a Raspberry PI, as long as you have Docker.
Stay tuned. | sciabarracom |
919,745 | How state management works (roughly) | Alternative title: How to fail at explaining why you should use state manager We have all... | 0 | 2021-12-07T12:26:33 | https://dev.to/manizm/how-basic-state-functions-26a9 | ### Alternative title: How to fail at explaining why you should use state manager
We have all heard about state managers in frontend. Maybe used one or two as well, either out of necessity or requirement from your senior developer or maybe "hyyyype!".
But have you ever thought how they are useful? Why it is recommended to use a state manager where it is possible?
Unfortunately, most of the "tutorials" out there just talk about "YOU SHOULD USE A STATE MANAGER AND HOW TO CREATE A NOTORIOUS COUNTER" but always fails to explain why to use it! And what exactly is happening in the background.
In this episoooode of "Rants with Ali", we will "try" to dive a little into this void and try to create our own very basic state manager. And see how state functions in the background. We will not discuss why you should use state managers. By reading this document, you can get an answer to "why", but if you are still in doubt, you can ping me
Before we begin to create our V100000x_MEGA_AWESOME_STORE, we will go through with some basics, as roughly as "sanely" possible. No super duper definitions from wiki boom boom.
Btw, the example at the end doesn't follow any "specific" state managing library for a very good reason. Go figure!
## Store
It's a mega container, which:
- contains state of your application (see below)
- has ways to mutably or immutably modify your state
- As stupid as "modify" and "immutable" sounds together, that is the truth of reality
- Yes, mayyybe..we will get into how some state managers can handle immutability in JS
- For example:
- Vuex mutates
- Redux immutably provides a new state
- Arguably, both are doing almost the same thing
- can have accessors to access parts of your state
- In a class like syntax, think of them like "getters"
```jsx
class Something {
constructor(obj) {
this.obj = obj;
}
get name () {
return this.obj.deeply.nested.name;
}
}
const testObject = { deeply: { nested: { name: 'ali' } } };
let a = new Something(testObject);
console.log(a.name); // ali - watermark level pikacu!
```
- has actions, that..as the name suggests, does "x" (even asynchronously) and can modify the state
## State
In plain english, it's just a container that:
- has some properties attached to it
- is immutable in some state managers (duh)
- has maybe a few more things, but basically your data that you want to be shared in your components etc
```jsx
const defaultState = {
a: '',
default: 'xD',
state: true,
nested: {
values: 'yep',
are_also: '...',
possible: '🤯🤯'
}
}
```
## Actions
These are functions that:
- have access to your state
- have a predictable "key" as either their name or return this "key" as type, so they can be globally "predictably" called/dispatched (see below)
- can ultimately end up modifying your data. Either through reducers or commits
- are, I guess, only a piece of thingies, that can be asynchronous
- technically other parts of the store can be, but this is usually where you want to put your async stuff.
- Trust papa!
```jsx
// action type
const INCREMENT = 'INCREMENT'; // THIS AN BE LOWERCASE OR lIkEThiS. but would you!?
const DECREMENT = 'DECREMENT';
const actions = {
[INCREMENT]: async (...) => {...},
[DECREMENT]: (...) => {...}
}
```
## Reducer & Commits
Well, these are what ultimately modify your state, mutably or immutably
- they receive usually:
- a payload (data)
- if a reducer, then an action type, so it knows which part of state is being modified and has logic accordingly
- otherwise in commit scenario, the party that commits knows which commit method to call
## Let's Build it now...
- Firstly, we will create a generic store
- Read above if you have difficulty grasping what is going on here. I invested my time (that nobody asked for) writing those for a reason you know..
- `filename: 'store_factory.js'`
### Creating a generic store factory
```jsx
class Store {
/** @typedef {Object} State */
/** @type {State} */
#_state;
constructor(state, actions, reducer, commits) {
this.#_state = state;
this._actions = actions;
this._reducer = reducer;
this._commits = commits;
}
/**
* @param {String} action
* @param {...*} payload
* @returns {Promise<*>} returns the result of action
*/
async dispatch (action, ...payload) { // this has side effects
if (this._actions[action]) {
const actionData = await this._actions[action](...payload);
this.#_state = this._reducer( this.#_state, actionData );
return actionData;
}
}
/**
* @param {String} commitType
* @param {*} payload
*/
commit(commitType, payload) {
if (this._commits[commitType]) {
this.#_state = this._commits[commitType](this.#_state, payload);
}
}
/**
* @returns {State}
*/
getState() {
return this.#_state;
}
}
```
## Creating a store that will use the store factory
- imagine you have, `filename: 'userinfo_store.js'`
- First we will create a default state.
- Every state must have a default state to make sure that validity of store and to also provide a footprint
### Default state
```jsx
const defaultState = {
name: '',
age: {
day: null,
month: null,
year: null
}
}
```
### Actions
- Then we define our actions, that can help us modify our state
- We will first define global identifiers
- Afterwards, we will use these "global identifiers" to use as action's method `key` or their `name`
- We do this, because having a unified place to define name of your method, can be used anywhere in your codebase without having to worry about their name change.
- When we write a `reducer` you will have even better understanding to why defining it like this makes sense
- Plus, you get intellisense in good IDEs / editors. gth sublime!
```jsx
// our actions global identifiers
const ACTIONS = {
CHANGE_NAME: 'CHANGE_NAME',
CHANGE_DAY: 'CHANGE_DAY',
GET_DATA: 'GET_DATA'
}
// action methods that uses the global identifiers as their key/name
const actions = {
[ACTIONS.CHANGE_NAME] (name) {
return {
type: ACTIONS.CHANGE_NAME, // this is used by reducer o
payload: name
}
},
[ACTIONS.CHANGE_DAY] (day) {
return {
type: ACTIONS.CHANGE_DAY,
payload: { day } // sending object for the sake of example and completion
}
},
async [ACTIONS.GET_DATA] () {
return {
type: ACTIONS.GET_DATA,
payload: {
name: 'ali',
age: {
day: 28,
month: 6,
year: 1990
}
}
}
}
}
```
### Reducers
- Now we will create our reducer (maybe in the same file, it's up to you how to structure your codebase! )
- You will see that in each `case`, we always return state.
- This is because reducer takes whatever comes through action, and reduces it to one thing; that is, "State"!
- Another thing you will notice is that we use `destructure` when returning our state.
- This is to ensure, that we will have consistent viable state, despite anything that is sent to modify it.
- This provides stability, as well as ensuring that any input will consistently have same output!
- Destructing makes sure that we always return "copy" of modified data and not the same reference. Remember, that in javascript objects are passed by reference!
- as such, it helps in immutability!
- We are not doing `JSON.stringify` "hack" because that is very inefficient. And we want to keep the same reference for unchanged nested objects
- In reducers, we usually use `switch/case`. You can use `if/else if` but in large store, we want things to be fast and switch/case is definitely faster than other alternatives.
- In these switch cases, we use the name of our `action` and having "global identifiers" as action names for lookups is helping us here!
```jsx
const reducer = (state, action) => {
switch (action.type) {
case ACTIONS.CHANGE_NAME:
return {
...state,
name: action.payload
}
case ACTIONS.CHANGE_DAY:
return {
...state,
age: {
...state.age,
...action.payload
}
}
case ACTIONS.GET_DATA:
return {
...state,
...action.payload
}
default:
return state;
}
}
```
### Lets's also create Commits
```jsx
const COMMIT_TYPES = { // kind of same way of writing as actions
CHANGE_MONTH: 'CHANGE_MONTH'
}
const commits = {
[COMMIT_TYPES.CHANGE_MONTH] (state, monthData) {
return {
...state,
age: {
...state.age,
month: monthData
}
}
}
}
```
### Instantiating our store and using it!
- First, lets define our component that would use our store
```jsx
class BaseComponent {
constructor(store) {
this.store = store;
}
get state() { // think of these "get" as "computed" in vuejs, for example
return this.store.getState();
}
}
// parent
class MyComponent extends BaseComponent {
constructor(store) {
super(store); // we instantiate our base component
this.children = [];
}
get name() {
// this.state is coming from "BaseComponent". Learn OOP please?
return this.state.name;
}
async fetchData() {
return this.store.dispatch(ACTIONS.GET_DATA);
}
changeName(name) {
return this.store.dispatch(ACTIONS.CHANGE_NAME, name);
}
addChildComponent(component) {
this.children.push(new component(this.store));
}
}
// child. I will not create a
class ChildComponent extends BaseComponent {
constructor(store) {
super(store);
}
get ageDay() {
return this.state.age.day;
}
get ageMonth() {
return this.state.age.month;
}
changeDay(day) {
this.store.dispatch(ACTIONS.CHANGE_DAY, day);
}
}
```
- No let's instantiate our store and create a few components with these stores
- We will also add some child component to a parent component
- This should help us see how easy it is to share data between components. Be it sibling components, child components or components from another galaxy!
```jsx
// we create one store outside of any context
// so it can be used by any component
const myStore = new Store(defaultState, actions, reducer, commits);
// now we utilize out component and use our store
(async () => {
const componentA = new MyComponent(myStore);
const componentB = new MyComponent(myStore);
// here our third component is using a different state from same store footprint
const componentC = new MyComponent(
new Store({...defaultState, name: 'naeemi'}, actions, reducer, commits)
);
// let's also add a child component inside component B
componentB.addChildComponent(ChildComponent);
// component A and B share the same state
console.log({
componentA_name: componentA.name,
componentA_state: componentA.state,
componentB_name: componentB.name,
componentB_child_age_day: componentB.children[0].ageDay,
componentB_child_age_month: componentB.children[0].ageMonth,
componentC_name: componentC.name
});
await Promise.all([
componentA.fetchData(),
componentC.fetchData()
]);
// component A and B share the same state
// the footprint of fetchData is same, so component is also getting same kindish value
console.log({
componentA_name: componentA.name,
componentA_state: componentA.state,
componentB_name: componentB.name,
componentB_child_age_day: componentB.children[0].ageDay,
componentB_child_age_month: componentB.children[0].ageMonth,
componentC_name: componentC.name
});
// let's change the name from componentA
// and se how it will also affect componentB, since they both share state
await componentA.changeName('Sensei');
// let's also change age from componentB's child
// this child is also sharing the same state as componentA and componentB
await componentB.children[0].changeDay(5);
// we will commit from outside of a component, through store attached to it
// for the sake of example
componentB.store.commit(COMMIT_TYPES.CHANGE_MONTH, 4);
// component A and B share the same state
console.log({
componentA_name: componentA.name,
componentA_state: componentA.state,
componentB_name: componentB.name,
componentB_child_age_day: componentB.children[0].ageDay,
componentB_child_age_month: componentB.children[0].ageMonth,
componentC_name: componentC.name
});
})()
``` | manizm | |
923,716 | Django-Amazon S3 RequestTimeTooSkewed Error on Linux | While working on an ecommerce marketplace project, one day all my product images that are stored on... | 0 | 2021-12-11T13:33:22 | https://dev.to/kenji_goh/amazon-s3-requesttimetooskewed-error-on-linux-4hgj | s3, django, ntp, aws | While working on an ecommerce marketplace project, one day all my product images that are stored on Amazon S3 ,via django-storages, are all down! Nightmare!
Upon researching, I realized the issue is that the time of my linux server is out of synced with Amazon's system clocks. Amazon S3 uses NTP (Network Time Protocol) to keep its system clocks accurate. NTP provides a standard way of synchronizing computer clocks on servers.
This is the error message I encountered:
```python
Error executing "PutObject" on "https://s3.ap-southeast-1.amazonaws.com/s3.XXXX-YOUR-BUCKET-LINK-XXXX"; AWS HTTP error: Client error: `PUT https://s3.ap-south-1.amazonaws.com/s3.XXXX-YOUR-BUCKET-LINK-XXXX` resulted in a `403 Forbidden` response:
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>RequestTimeTooSkewed</Code><Message>The difference between the reque (truncated...)
RequestTimeTooSkewed (client): The difference between the request time and the current time is too large. - <?xml version="1.0" encoding="UTF-8"?>
<Error><Code>RequestTimeTooSkewed</Code><Message>The difference between the request time and the current time is too large.</Message><RequestTime>20180817T035220Z</RequestTime><ServerTime>2018-08-17T06:17:43Z</ServerTime><MaxAllowedSkewMilliseconds>900000</MaxAllowedSkewMilliseconds><RequestId>1BF4E523584F893B</RequestId></Error>
```
Let's start by looking at Amazon S3 server time.
```
$ curl http://s3.amazonaws.com -v
```
Then to check our own Linux server time, we can use
```
$ date
```
Have a look at the time discrepancies, which is the source of the error.
Now let's install ntp
```
sudo apt-get install ntp
```
Then open the ntp config file located in /etc/ntp.conf and replace the existing entries with the following:
Type this command to open the ntp config on your terminal:
```
vi /etc/ntp.conf
```
Existing Entries in ntp config file:
```
server 0.ubuntu.pool.ntp.org
server 1.ubuntu.pool.ntp.org
server 2.ubuntu.pool.ntp.org
server 3.ubuntu.pool.ntp.org
```
Replace with the following below:
```
server 0.amazon.pool.ntp.org iburst
server 1.amazon.pool.ntp.org iburst
server 2.amazon.pool.ntp.org iburst
server 3.amazon.pool.ntp.org iburst
```
Now make sure you are in the root to run the final command.
If you have forgotten your root password, follow this:
```
$ sudo passwd root
```
You will see the following prompt on your terminal to update the password.
```
[sudo] password for <user>:
New password:
Retype new password:
passwd: password updated successfully
```
Once you have updated your root password, type this:
```
$ su -
```
Enter your new root password when prompt.
Then finally, in root, you can type in the final command to resolve the error.
```
root@DESKTOP-ABCDEF:~# service ntp restart
```
You will see the NTP server restarting.
```
* Stopping NTP server ntpd [ OK ]
* Starting NTP server ntpd [ OK ]
```
Go back to your project and magic has happened!
After encountering this error, i felt it is a good time to update myself on cloud computing knowledge! I found a decent online course on [Coursera](https://www.coursera.org/learn/cloud-computing) Shall start with this one day!
Thanks for reading!
| kenji_goh |
919,773 | Elm's guarantees | A short reminder about the guarantees of the Elm language: | 0 | 2021-12-07T22:33:59 | https://dev.to/lucamug/elms-guarantees-13e4 | elm, webdev, frontend, typescript | ---
title: Elm's guarantees
published: true
description: A short reminder about the guarantees of the Elm language:
tags: elm, webdev, frontend, typescript
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/wj2x6pr6k9jckkhns866.png
---
A short reminder about the guarantees of the Elm language:
## ✅ No Runtime Exceptions
Thanks to the absence of null/undefined, errors treated as data, and a sound type systems, Elm guarantees that our compiled JavaScript code never throws errors at runtime.
## ✅ 100% Immutable Data
All data in Elm is immutable. So no surprises when you need to find a bug and there is a wrong value somewhere. You can easily find who created that value.
## ✅ 100% Pure Functions
All functions must be pure, otherwise, they don't compile. Pure functions have the usual benefits of being easy to read, easy to test, etc.
## ✅ All Types Are Checked
Elm is based on a provable type system so types are always correct and type annotations are always optional.
## ✅ No surprises when upgrading dependencies
Elm enforces Semantic Versioning. This means that your code is guaranteed to compile also after you upgrade your dependencies.
## 🎉 Bonus: Guarantees also apply to all dependencies!
All these guarantees apply not only to your code but also to all your dependencies!
To learn more: [elm-lang.org](https://elm-lang.org/)
❤️
*Header [photograph](https://www.pexels.com/photo/arbuckles-roasted-coffees-175747/) by [Clem Onojeghuo](https://www.pexels.com/@conojeghuo)* | lucamug |
919,874 | Where to host your kubernetes | On this week’s episode of The Tiny DevOps Podcast, Andy Suderman of Fairwinds joins me to talk about... | 0 | 2021-12-14T14:57:22 | https://jhall.io/archive/2021/12/07/where-to-host-your-kubernetes/ | podcast, video, kubernetes, aws | ---
title: Where to host your kubernetes
published: true
date: 2021-12-07 00:00:00 UTC
tags: podcast,video,kubernetes,aws
canonical_url: https://jhall.io/archive/2021/12/07/where-to-host-your-kubernetes/
---
On this week’s episode of The Tiny DevOps Podcast, Andy Suderman of Fairwinds joins me to talk about the pros and cons of each of the big three cloud providers, and helps point new Kubernetes adoptors to the optimal provider for their needs.
[Listen](https://share.transistor.fm/s/e0951319),[watch](https://youtu.be/iAgDLpzbclg), or [read the transcript](https://share.transistor.fm/s/e0951319/transcript)
[](https://share.transistor.fm/s/e0951319) [](https://youtu.be/iAgDLpzbclgs) [](https://share.transistor.fm/s/e0951319/transcript)
* * *
_If you enjoyed this message, [subscribe](https://jhall.io/daily) to <u>The Daily Commit</u> to get future messages to your inbox._ | jhall |
920,054 | A great support person is an angel and the devil in one package | Companies are discovering that hiring people to mollify critics and disappointed customers is... | 0 | 2021-12-07T17:30:59 | https://berislavbabic.com/support-angel-and-devil/ | career | > Companies are discovering that hiring people to mollify critics and disappointed customers is cheaper (in the short run) than changing things, learning from the feedback or even wasting the time of people who do the ‘real work.’\
Seth Godin
I borrowed this quote from a post by Seth Godin called [Chief Apology Officer](https://seths.blog/2021/12/chief-apology-officer/). The author claims that there is a kind of employee whose whole purpose is easing the customers into believing the software works well and there are no issues on _our_ side. You're using it wrong (or as the famous Apple reply said: You're holding it wrong). I've been in this situation more than once, where people would persuade customers that they are _idiots_ who are using the software _wrong_. We have to accept that some people are (in the words of my friend) "technically challenged" but that's no excuse for treating them bad.
Disclaimer/Apology: I will be using the word "support" in this article to describe the people that work directly with customers. Sometimes we call them "customer success" sometimes it's "support". There is a difference when and where they take part in the implementation process. Both roles are indispensable and they are a single person wearing many hats in most small companies.
I used to work as IT support when I started my career and I am amazed how people can do that job for years. There are a few great support agents I dealt with in my life, I even had the pleasure of working with some of those awesome people. I know what they are going through and what kinds of requests they deal with every day. That's why I try to provide as much data as possible when I'm submitting an issue to someone's support email.
I never had the nerves or the calmness to deal with these repetitive requests and this post is also an ode to those wonderful people of IT support. The best support person is an angel to customers, the chief apology officer, as Seth calls them. Making sure all customers are as happy as possible, regardless on how annoying they are, or how rude they get when they get mad. It's someone who can assure the customer that everything will be okay, be a great psychologist when talking to them.
But, a great support person is the absolute devil towards the IT department, requesting that issues get fixed. Doing all this by providing great feedback (with data, screen recordings). The best people that I worked with never gave up on solving the issues the customers had. Considering support is the wall between (sometimes angry) customers and the rest of the company, we need to enable them to behave like this.
It's not only the IT department that can use feedback from the support department, it's the whole product and sales team. If we set up a continuous feedback machine for the whole company, we can improve those [processes](https://berislavbabic.com/processes/) beyond recognition. To achieve that, we need to enable everyone to provide [radically candid](https://www.radicalcandor.com) feedback to everyone in the company. And we need to praise this behaviour in public (like I'm doing right now).
It is hard keeping unsatisfied and scared customers without being an angel support agent. It's impossible to improve the product without honest feedback from the people who are using it. There are cases where the sales department of company "A" sells something to the procurement department of company "B". This situation then makes all "issues" go through a one person filter. These are the worst thing that can happen in the world of modern software development. Since in this situation the _buyer_ of your software isn't the _user_. You have to work harder to appease the buyer (since these are pretty lucrative contracts we are talking about) and they are paying for it. Since you have limited resources, you can't appease the end user as much. Great support helps level those out and making the end users at least as happy as the buyers.
Huge praise goes out to all the support (and customer success) people I have worked with. I've learned a lot from you about engineering, operations and dealing (with much respect) with other humans. | berislavbabic |
920,226 | Hello | A post by ngunga-dev | 0 | 2021-12-07T19:24:56 | https://dev.to/ngungadev/hello-2il1 | javascript, programming, beginners |
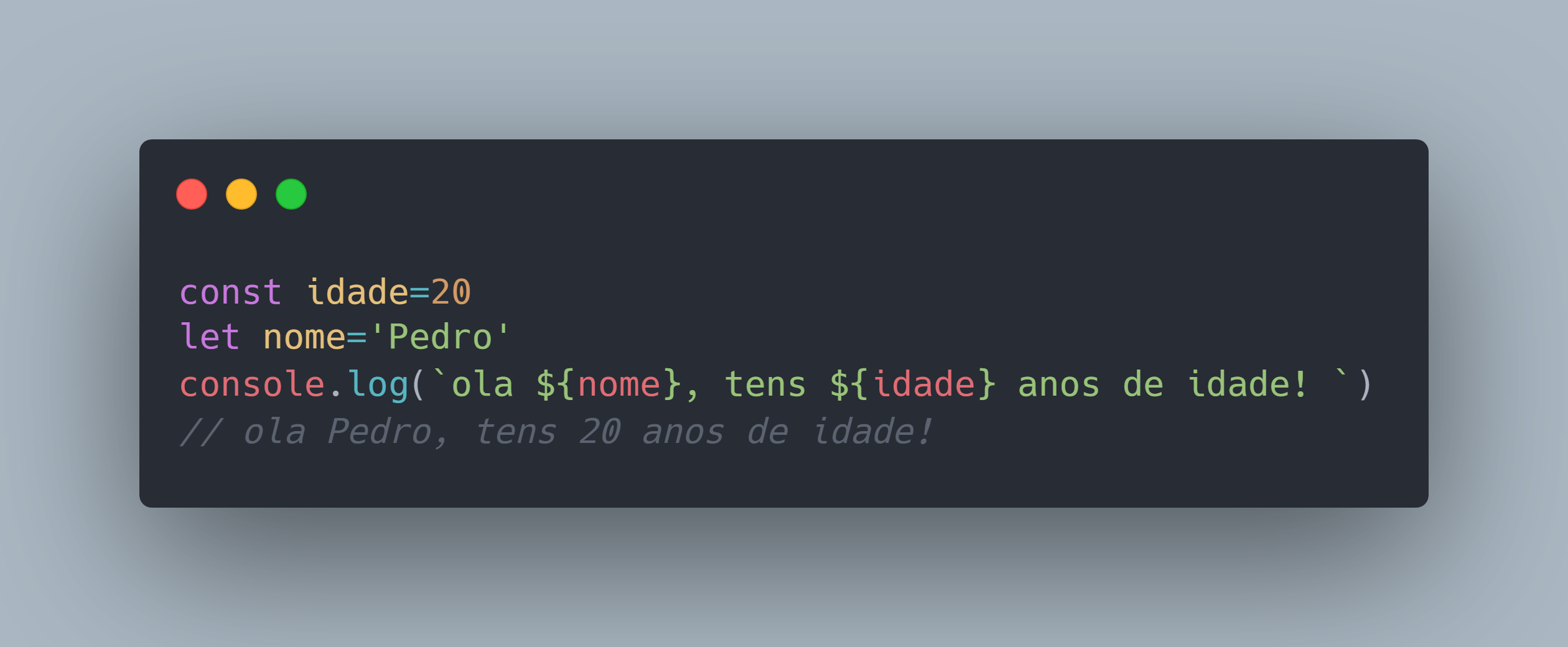 | ngungadev |
920,262 | Os cuidados para um deploy "Zero Down Time" | Atualmente existem ferramentas que nos ajudam a executar containers em produção e a maioria delas... | 0 | 2021-12-07T21:36:15 | http://l30.space/blog/post/zero-down-time-trap | docker, deploy, php, laravel | ---
canonical_url: http://l30.space/blog/post/zero-down-time-trap
---
Atualmente existem ferramentas que nos ajudam a executar containers em produção e a maioria delas trazem funcionalidades preciosas como "Health Checks", "Limite de recursos" e até mesmo prometem um deploy ["Zero Down Time"](https://avikdas.com/2020/06/30/scalability-concepts-zero-downtime-deployments.html), o foco deste post é nesse último Item. Na [Convenia](https://convenia.com.br/) utilizamos o [Docker Swarm](https://docs.docker.com/engine/swarm/) para gerenciar alguns containers em produção e o Docker Swarm entrega esse tipo de deploy "Zero Down Time" através de uma simples configuração, porém após alguns testes em uma API sob stress constatamos que sempre ocorriam alguns erros no momento do deploy. Aprofundando a análise do que poderia causar esses erros, percebemos que podemos cometer alguns "equívocos" que nos impedem de ter um deploy verdadeiramente sem Down Time e ainda podemos constatar que esses "equívocos" são comuns em outras ferramentas como [Kubernetes](https://kubernetes.io/pt-br/) também, dai saiu a motivação para escrever esse post.
## Graceful ShutDown
A grosso modo podemos definir "Graceful shutdown" como a maneira "natural" em que um processo é desligado. Muitos processos abrem sockets e trabalham com estado em memória então para esses processos desligarem naturalmente muito provavelmente eles vão fechar as conexões abertas e persistirem o estado, que está na memória, no HD para que não haja perda de dados e para poder retomarem as atividades sem maiores problemas quando forem reiniciados, em uma queda de energia por exemplo, os processos não tem esse privilégio, nesse caso podemos nos deparar com erros durante a próxima inicialização do processo, isso é conhecido como "Hard Shutdown".
A boa notícia é que todos os softwares mais difundidos fazem isso por padrão, o [nginx](https://www.nginx.com/) quando recebe o "sinal" de desligamento espera a resposta de todos os requests que estão em execução no momento, antes de desligar de fato. Esse "Graceful Shutdown" é importante porque o deploy consiste na "troca" de um processo com a versão antiga do software pelo mesmo processo contendo a versão nova, ao desligar o processo contendo a versão antiga, os requests que estiverem em execução não podem falhar, pois eles ainda estão sendo respondidos pelo processo antigo enquanto os novos requests já estão sendo servidos pelo processo novo como mostrado na imagem abaixo.
Na [Convenia](https://convenia.com.br) temos muitos listeners feitos com o [Pigeon](https://convenia.github.io/Pigeon/#/), nesse caso não estamos falando de um webserver e sim de um [consumer](https://convenia.github.io/Pigeon/#/EVENT_DRIVEN?id=listening-for-events) que "ouve" uma fila do [RabbitMQ](https://www.rabbitmq.com/), você já deve imaginar que para "ouvir" essa fila temos que ter uma conexão aberta com o [RabbitMQ](https://www.rabbitmq.com/) então nada mais justo que fechar as conexões no momento em que o processo for desligado, é justamente isso que o [Pigeon](https://convenia.github.io/Pigeon/#/) faz no código a seguir:
```php
protected function listenSignals(): void
{
defined('AMQP_WITHOUT_SIGNALS') ?: define('AMQP_WITHOUT_SIGNALS', false);
pcntl_async_signals(true);
pcntl_signal(SIGTERM, [$this, 'signalHandler']);
pcntl_signal(SIGINT, [$this, 'signalHandler']);
pcntl_signal(SIGQUIT, [$this, 'signalHandler']);
}
public function signalHandler($signalNumber)
{
switch ($signalNumber) {
case SIGTERM: // 15 : supervisor default stop
$this->quitHard();
break;
case SIGQUIT: // 3 : kill -s QUIT
$this->quitHard();
break;
case SIGINT: // 2 : ctrl+c
$this->quit();
break;
}
}
```
Nesse código definimos handlers para os sinais de desligamento que o processo pode receber e chamamos os métodos `quit()` e `quitHard()` que têm como objetivo fechar a conexão com o RabbitMQ. Até agora falamos muito sobre esses sinais que os processos podem receber de outro processos, ou até mesmo do kernel, mas caso você não estaja familiarizado ou se não souber exatamente a diferença entre eles, você pode ficar um pouco mais por dentro [nesse artigo](https://www.ctl.io/developers/blog/post/gracefully-stopping-docker-containers/).
## PID 1
Quando utilizamos [docker](https://www.docker.com/) para executar nossa aplicação em produção e fazemos um deploy, um container com a nova versão da aplicação é iniciado,o container com a versão antiga da aplicação recebe o sinal "SIGTERM" que é um pedido formal de desligamento, caso o container demore mais que 10 segundos para desligar ele será morto, logo o processo dentro do container tem 10 segundos para fazer o seu "Graceful Shutdown". A grande pegadinha é que dentro do container apenas o processo de ID 1 vai receber esse sinal, se dentro do container iniciarmos um outro processo antes da nossa aplicação, esse processo vai portar o id 1 e não a nossa aplicação. Agora que temos outro processo recebendo os sinais de desligamento no lugar da nossa aplicação, nunca vamos ter a oportunidade de fazer um Graceful Shutdown porque nunca saberemos o momento de desligar, por mais que esse pareça um erro bobo na verdade isso acaba acontecendo com uma certa frequência como por exemplo nos [Dockerfiles](https://docs.docker.com/engine/reference/builder/) a seguir:
```Dockerfile
FROM nginx:latest
ENTRYPOINT ["nginx", "-g", "daemon off;"]
```
O Dockerfile acima está com o `ENTRYPOINT` no formato de array, se você entrar dentro do container gerado por esse Dockerfie e executar o comando `pstree` verá o seguinte output:
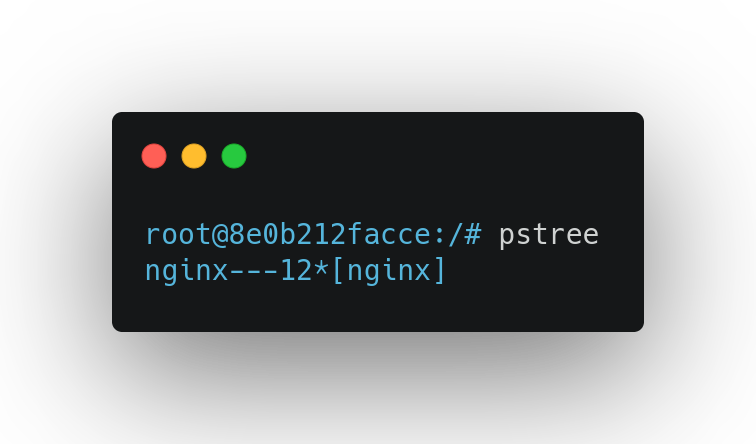
Perceba que o "nginx" é o primeiro processo mais a esquerda, isso significa que atingiremos o objetivo de ter um Graceful Shutdown visto que o nginx vai receber os sinais pessoalmente e ele sabe muito bem como lidar, para tirar a dúvida podemos executar um `docker stop` no container em execução e provavelmente veremos o container sendo desligado quase instantaneamente.
```Dockerfile
FROM nginx:latest
ENTRYPOINT nginx -g 'daemon off;'
```
A Mudança no dockerfile acima foi sutil, mas faz toda a diferença, com a sintaxe corrida do `ENTRYPOINT` o comando em questão é executato pelo shell dentro do container, segue o output do `pstree`:
Agora o processo mais a esquerda é o `sh`, ele quem receberá os sinais de desligamento e por acaso não sabe muito bem o que fazer com esses sinais, se você executar um `docker stop` nesse container verá que demora 10 segundos para parar, dessa forma não faremos o "Graceful Shutdown" e nunca teremos um verdadeiro deploy "Zero Down Time" porque sempre que o container com a versão antiga do código morrer, vai levar os requests que estão em execução para a vala junto. Logo devemos nos assegurar que nosso processo está recebendo o sinal de desligamento corretamente.
## Vários processos no mesmo container
É conceitualmente correto que o container contenha apenas um processo(PID 1), mas é relativamente comum aparecer a necessidade de executar mais de um processo no mesmo container. Tomando como exemplo uma aplicação [PHP](https://www.php.net/), que não é capaz de responder como uma aplicação completa(HTTP) apenas com o processo do [PHP-FPM](https://www.php.net/manual/pt_BR/install.fpm.php), pois necessita de um [reverse proxy](https://www.nginx.com/resources/glossary/reverse-proxy-server/) como [apache](https://www.apache.org/) ou [nginx](https://www.nginx.com/) para isso, como poderíamos fazer um único container contendo tanto nginx como php-fmp e que funcione como uma aplicação completa capaz de entender o protocolo HTTP? A própria [documentação do docker nos traz algumas recomendações](https://docs.docker.com/config/containers/multi-service_container/) sendo que dentre elas a melhor seria utilizar o [supervisord](http://supervisord.org/) como processo principal no container, cuidando dos outros processos. O supervisord é capaz de propagar os sinais de desligamento que recebe para os processos filhos, sendo assim tanto o nginx quanto o PHP-FPM terão a possibilidade de fazer um "Graceful Shutdown" assim que o supervisord receber o sinal SIGTERM.
## Prioridade dos processos dentro do container
Bom temos uma aplicação PHP sendo executada em produção e seguimos tudo que foi falado até agora, estamos executando tanto o php-fpm quanto o nginx, ambos rodando sobre o supervisord, porém por incrível que pareça estamos notando o erro `502` durante o deploy. Isso acontece porque durante o deploy um novo container é criado e o supervisord simplesmente não sabe qual processo deve iniciar primeiro, se por acaso o nginx estiver pronto para receber um request, mas o php-fpm ainda não foi corretamente iniciado então temos um `502`. Resolver esse problema de prioridade entre os processos é relativamente simples, o supervisord tem uma flag priority que tem o proposito de dizer quem é o processo de maior prioridade, entre outras palavras esse processo deve ser criado primeiro e morrer por último, a seguir segue uma configuração real de uma aplicação da [Convenia](https://convenia.com.br) em produção:
```
[supervisord]
nodaemon=true
[program:nginx]
command = nginx -c /etc/nginx/nginx.conf -g 'daemon off;'
user = app
autostart = true
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
redirect_stderr=true
[program:php-fpm]
command = /usr/sbin/php-fpm7 -F
priority = 1
user = app
autostart = true
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
redirect_stderr=true
```
Esse é um arquivo de configuração do supervisord, perceba a configuração do php-fpm `priority = 1`, essa configuração vai instruir o supervisord a criar o php-fpm primeiro e a desligar ele por último, agora sim temos um deploy perfeito, sem downtime.
## Conclusão
Para alcançar um deploy perfeito não adianta simplesmente utilizar os orquestradores mais poderosos do mercado, precisamos tomar alguns cuidados com o nosso container e aplicação também:
1. Garantir que a aplicação é capaz de fazer um Graceful Shutdown
2. Garantir que a aplicação está recebendo os sinais de desligamento corretamente, ou mantendo a aplicação como sendo o primeiro processo dentro do container, ou utilizando alguma ferramenta como o supervisord que propaga os sinais que ela recebe.
3. Garantir que os processos estão sendo iniciados e desligados na ordem correta, caso o container rode mais de um processo.
Tomado esses cuidados estamos prontos para ter um deploy sem Downtime. | jleonardolemos |
920,596 | How To Event Stream From Your Gatsby Website Using Open Source RudderStack | RudderStack is an open-source Customer Data Pipeline that allows you to track and send real-time... | 0 | 2021-12-08T08:52:56 | https://rudderstack.com/guides/how-to-event-stream-from-your-gatsby-website-using-open-source-rudderstack/ | gatsby, cdp, etl, datawarehouse | [RudderStack](https://rudderstack.com/) is an open-source Customer Data Pipeline that allows you to track and send real-time events from your web, mobile, and server-side sources to your entire customer data stack. Our primary repository - [rudder-server](https://github.com/rudderlabs/rudder-server) - is open-sourced on GitHub.
With RudderStack's open-source [Gatsby plugin](https://github.com/rudderlabs/gatsby-plugin-rudderstack), you can easily integrate your Gatsby site with RudderStack, and track and capture customer events from it in real-time.
To instrument real-time event streams on your Gatsby website using RudderStack, we need to follow these four steps:
1. Instrument your Gatsby website with RudderStack using the Gatsby plugin
2. (Optional) Set up the RudderStack tracking code for your website
3. Create a tool/warehouse destination in RudderStack for your Gatsby site's event data
4. Deploy your Gatsby site and verify the event stream
Pre-Requisites
--------------
This post assumes you have already installed and set up your Gatsby website. If you haven't done so, we recommend following the [official Gatsby documentation](https://www.gatsbyjs.com/docs/tutorial/part-zero/) to get started.
Step 1: Instrument Your Gatsby Website With RudderStack Using The Gatsby Plugin
-------------------------------------------------------------------------------
Create A Source In RudderStack
------------------------------
Before you instrument your Gatsby site with RudderStack, you will need to set up a JavaScript source in your RudderStack dashboard, which will track and capture events from your website. To do so, follow these steps:
1\. Log into your [RudderStack dashboard](https://app.rudderstack.com/). If you don't have an account, please sign up.
2\. Once you have logged in, you should see the following dashboard:
3. Note the Data Plane URL, which is required to instrument your Gatsby site with RudderStack.
4\. The next step is to create a source. To do this, click on the Add Source button. Optionally, you can select the Directory option on the left nav bar and select Event Streams under Sources.
For the Gatsby plugin, we will set up a simple JavaScript source.
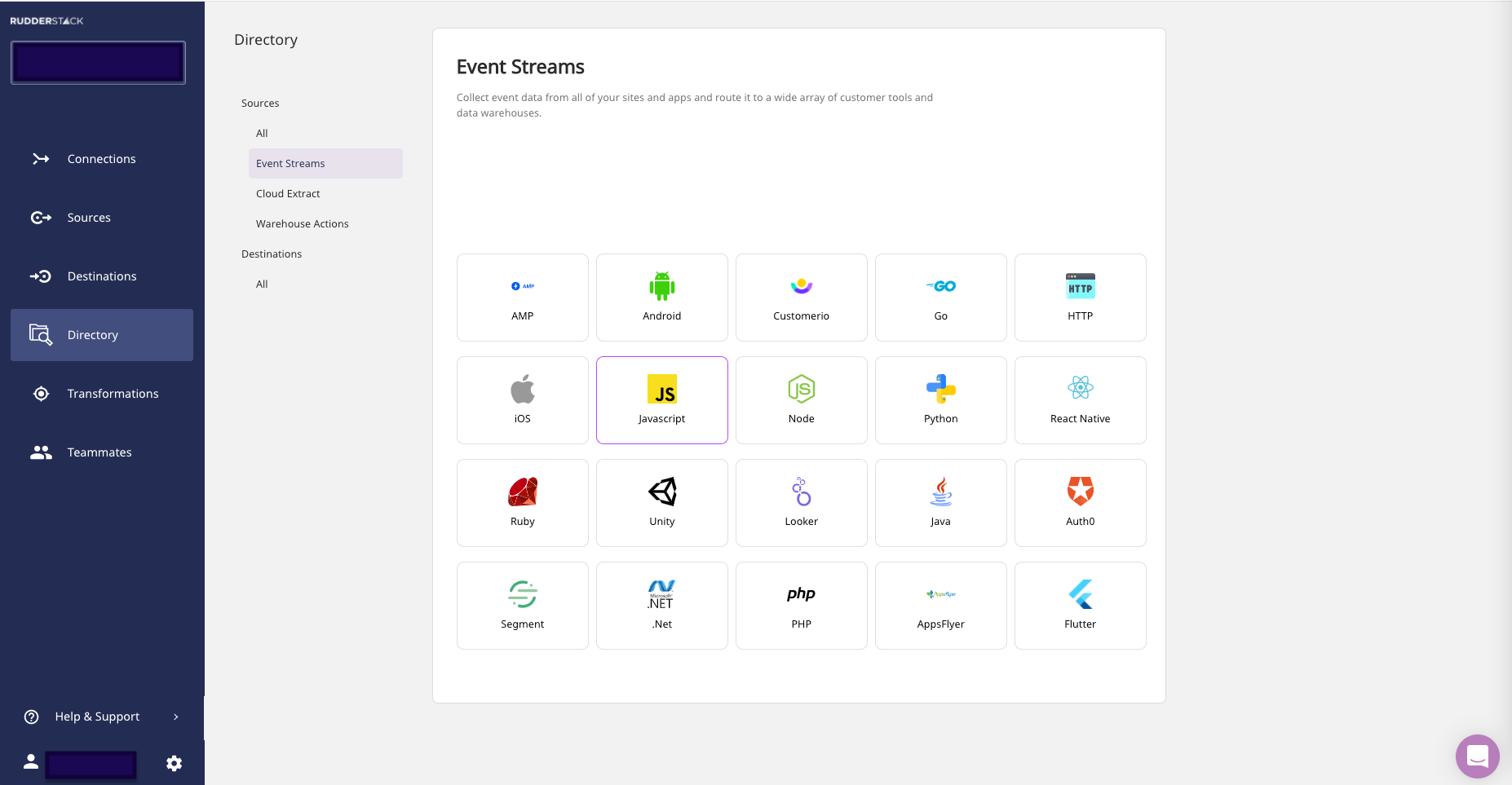
5\. Assign a name to your source, and click on Next.
6\. Your event source is now configured. Note the Write Key associated with this source. This is also required to configure the RudderStack-Gatsby integration.
### Instrument Your Gatsby Site With RudderStack
To instrument your Gatsby website with RudderStack, we will leverage the open-source Gatsby plugin for RudderStack. Follow these steps:
1\. Navigate to the root directory, which contains your site's assets and resources.
2\. Type the following command depending on the package manager of your choice:
- For NPM: $ npm install --save gatsby-plugin-rudderstack
- For YARN: $ yarn add gatsby-plugin-rudderstack
3\. To set up the plugin, you will need to configure your `gatsby-config.js` file with the source Write Key and the Data Plane URL that you have obtained from the previous section (Create a source in RudderStack).
4\. The configuration options are as shown:
```
plugins: [ { resolve: `gatsby-plugin-rudderstack`, options: { prodKey: `RUDDERSTACK_PRODUCTION_WRITE_KEY`, devKey: `RUDDERSTACK_DEV_WRITE_KEY`, trackPage: false, trackPageDelay: 50, dataPlaneUrl: `https://override-rudderstack-endpoint`, controlPlaneUrl: `https://override-control-plane-url`, delayLoad: false, delayLoadTime: 1000, manualLoad: false, } }];
```
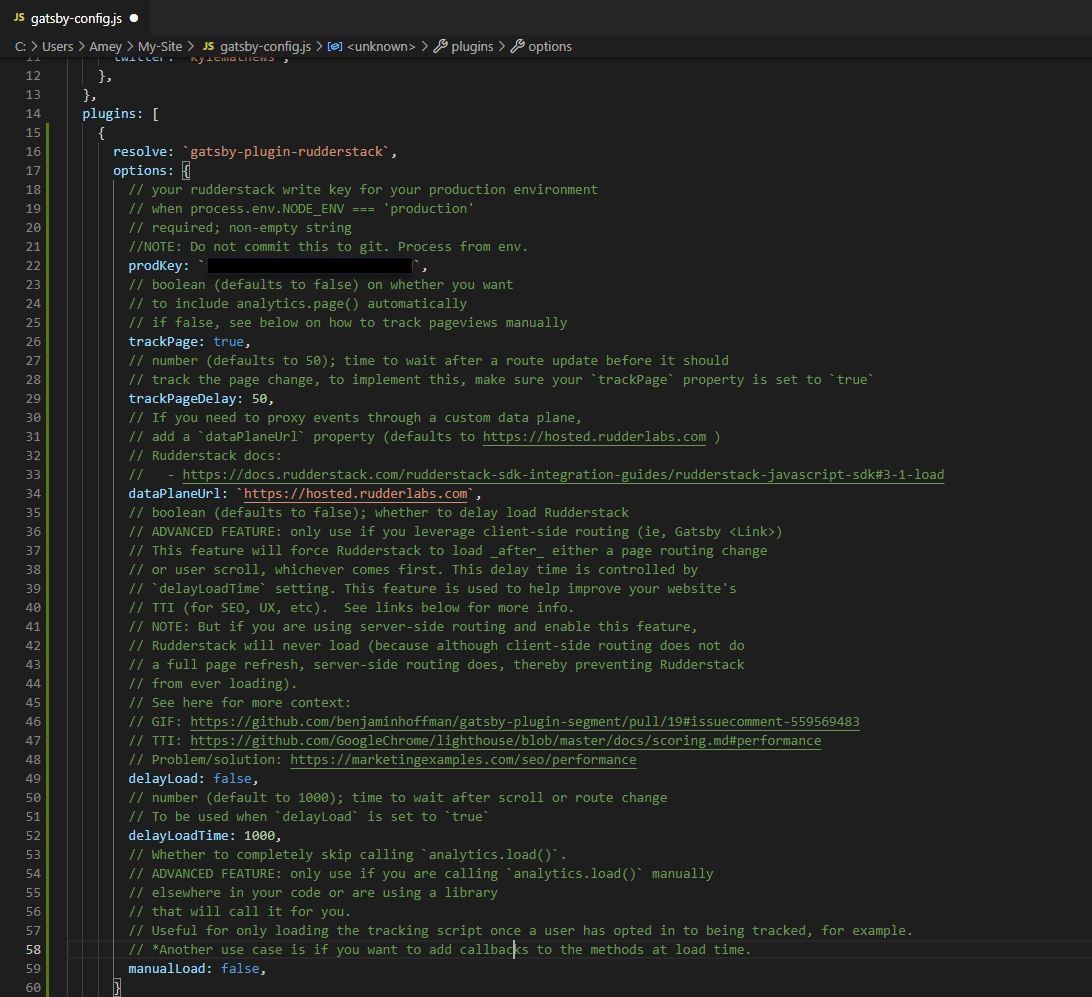
For details on each of the above parameters, please check out our [docs](https://docs.rudderstack.com/how-to-guides/how-to-integrate-rudderstack-with-a-gatsby-website#the-configuration-options).
### Important Notes
- Assign the source write key to the `prodKey` parameter if you are using a production environment. Otherwise, assign it to the `devKey` parameter.
- If you are using a self-hosted control plane to manage your event stream configurations, enter the URL for the `controlPlaneUrl.` For this post, we have used the RudderStack-hosted free control plane, which requires no setup. It also has more features than the open-source control plane, such as Live Events - which allows you to view the live events captured from your event source.
(Optional) Step 2: Set Up The RudderStack Tracking Code For Your Website
------------------------------------------------------------------------
Note: This section describes how to track page views manually using the below JavaScript code snippet. A prerequisite for this is that you have set `trackPage` to false in your `gatsby-config.js` file. (Step 4 in the previous section, Instrument Your Gatsby Site with RudderStack).
If you want to track `pageviews` automatically, set `trackPage` to true in your gatsby-config.js file. For more details on tracking page views automatically, refer to our [docs](https://docs.rudderstack.com/how-to-guides/how-to-integrate-rudderstack-with-a-gatsby-website#tracking-pageviews).
Next, we will set up the code for RudderStack to track page views from our Gatsby site. This means that RudderStack will capture every page view activity each time a user accesses/ views a page on your website.
To do so, follow these steps:
1\. Go to your local site repository and navigate to node_modules - gatsby-plugin-rudderstack folder.
2\. Locate and open the `gatsby-browser.js`file.
3\. Add the following code at the end of this file:
```
// gatsby-browser.js
exports.onRouteUpdate = () => { window.rudderanalytics && window.rudderanalytics.page();};
```
4\. Save the file.
Step 3: Create A Tool Destination In RudderStack For Your Gatsby Site's Event Data
----------------------------------------------------------------------------------
RudderStack supports over 80 tools to which you can reliably send your event data. For this tutorial, we will configure a Google Analytics destination in RudderStack. To configure this destination in RudderStack, follow these steps:
1\. Select the Destinations option in the left nav bar of your dashboard, and click on the Add Destination button. Since you have already configured a source, you can also click on the Add Destination button as shown below:
Note: If you have already configured a destination in RudderStack before and want to send your event data to that platform, use the Connect Destinations option to connect to your source.
2\. Select Google Analytics from the list of destinations.
3\. Assign a name to your destination, and click on Next.
4\. Choose the source. We will select the JavaScript source we have already configured for this tutorial.
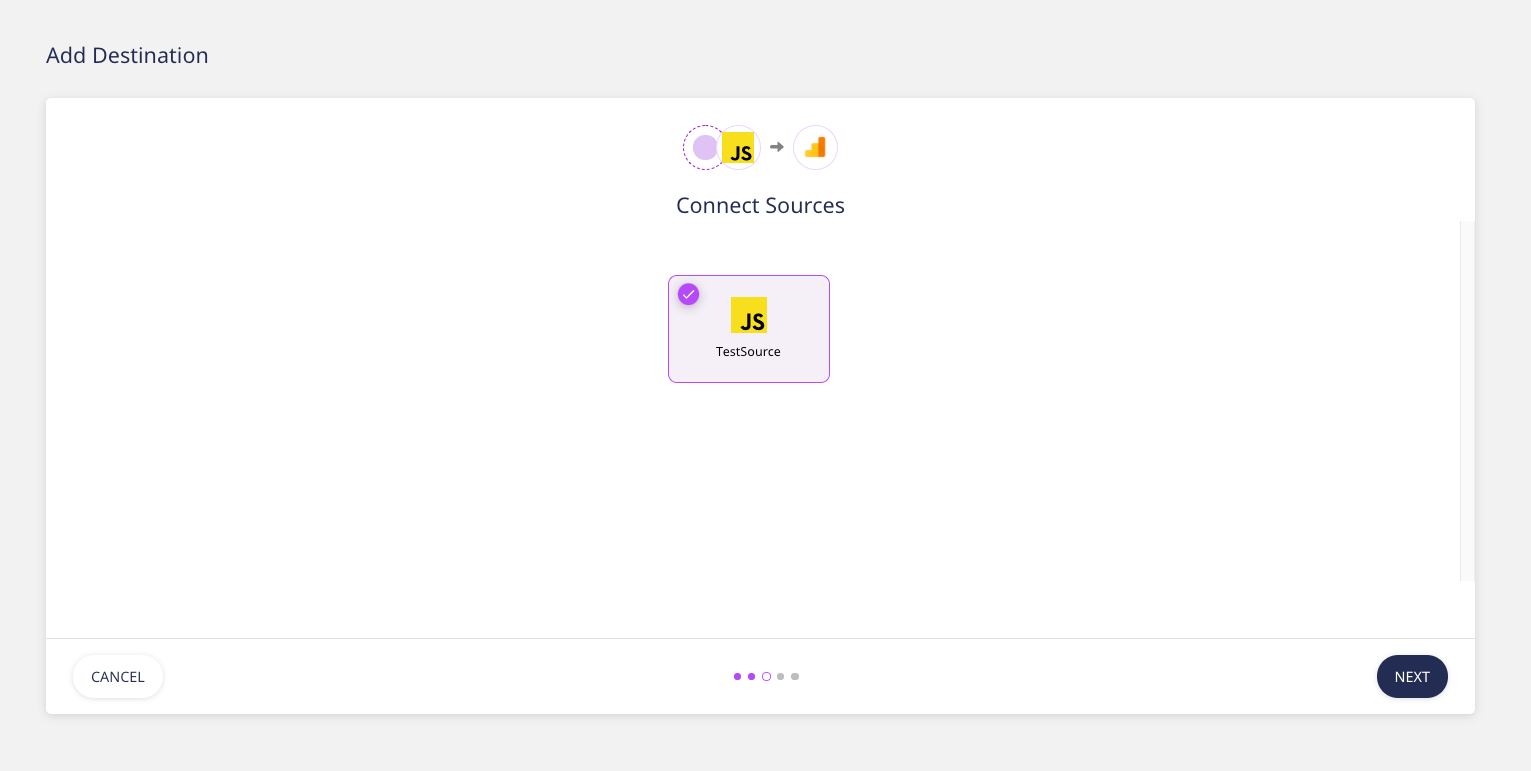
5\. Add the relevant Connection Settings. Most importantly, you will be required to enter the Google Analytics Tracking ID. You can also configure the other optional settings as shown below, and then click on Next.
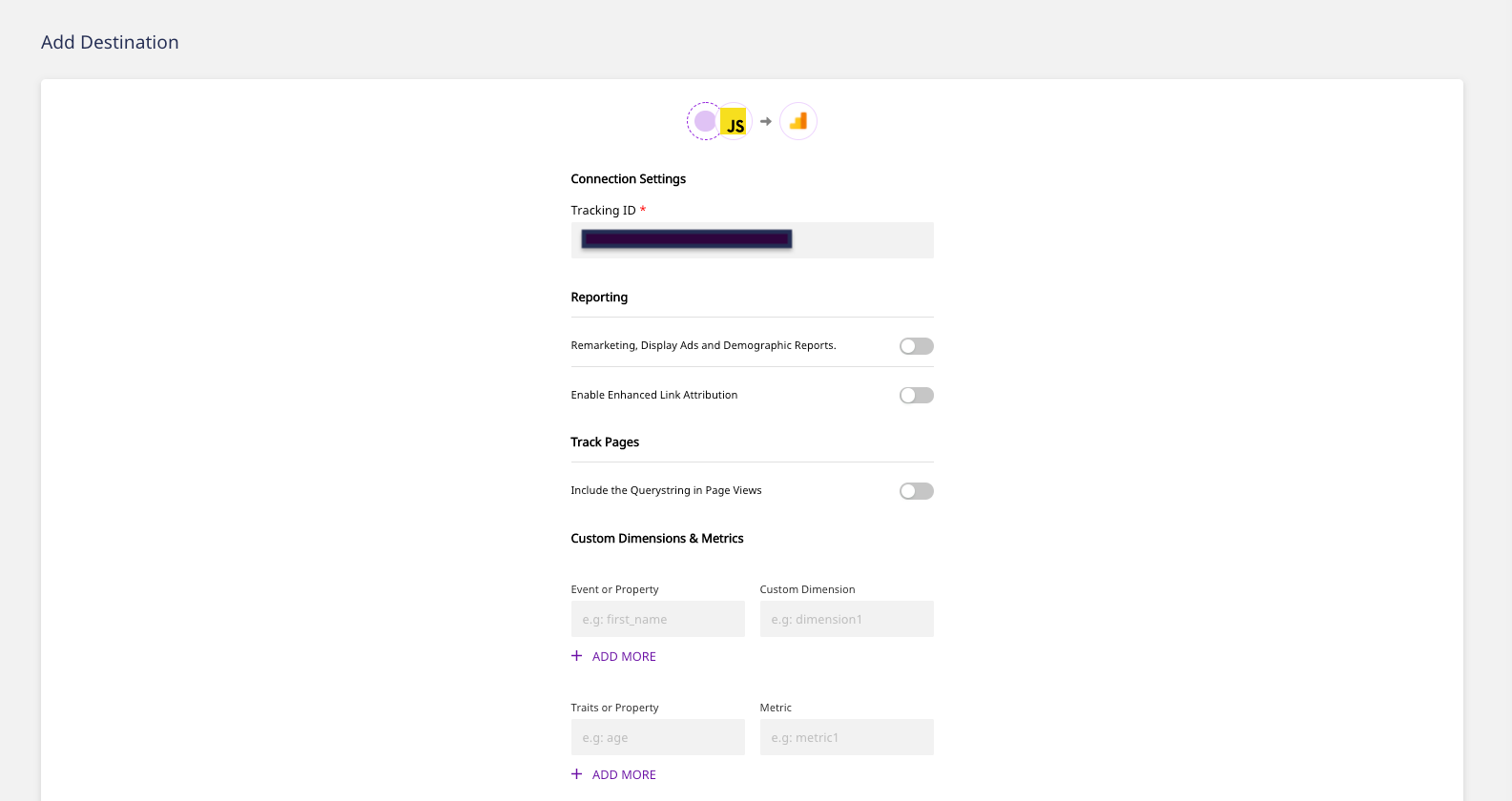
6\. RudderStack gives you the option to transform your events before sending them to your destination. Get more information on RudderStack's user transformation feature in our [docs](https://docs.rudderstack.com/adding-a-new-user-transformation-in-rudderstack).
7\. Your destination is now configured. You should now see the following source-destination connection in your dashboard:
(Alternate) Step 3: Create A Warehouse Destination In RudderStack For Your Gatsby Site's Event Data
---------------------------------------------------------------------------------------------------
Important: Before configuring a data warehouse as a RudderStack destination, you will need to set up a new project in your warehouse. Also, you will need to create a new RudderStack user role with the relevant permissions. Follow our [docs](https://docs.rudderstack.com/data-warehouse-integrations) to get detailed, step-by-step instructions on how to do so for the data warehouse of your choice.
We will set up a Google BigQuery warehouse destination for this tutorial to route all the events from our Gatsby website. As mentioned above, set up a BigQuery project with the required permissions for the service account by following [our doc](https://docs.rudderstack.com/data-warehouse-integrations/google-bigquery).
Once you have set up the project and the required user permissions, follow these steps:
1\. From the list of destinations, select Google BigQuery, as shown:

2\. Assign a name to this destination, and click on Next.
3\. Choose the source from which you want to send the events. We will select the JavaScript source associated with our Gatsby website for this destination.
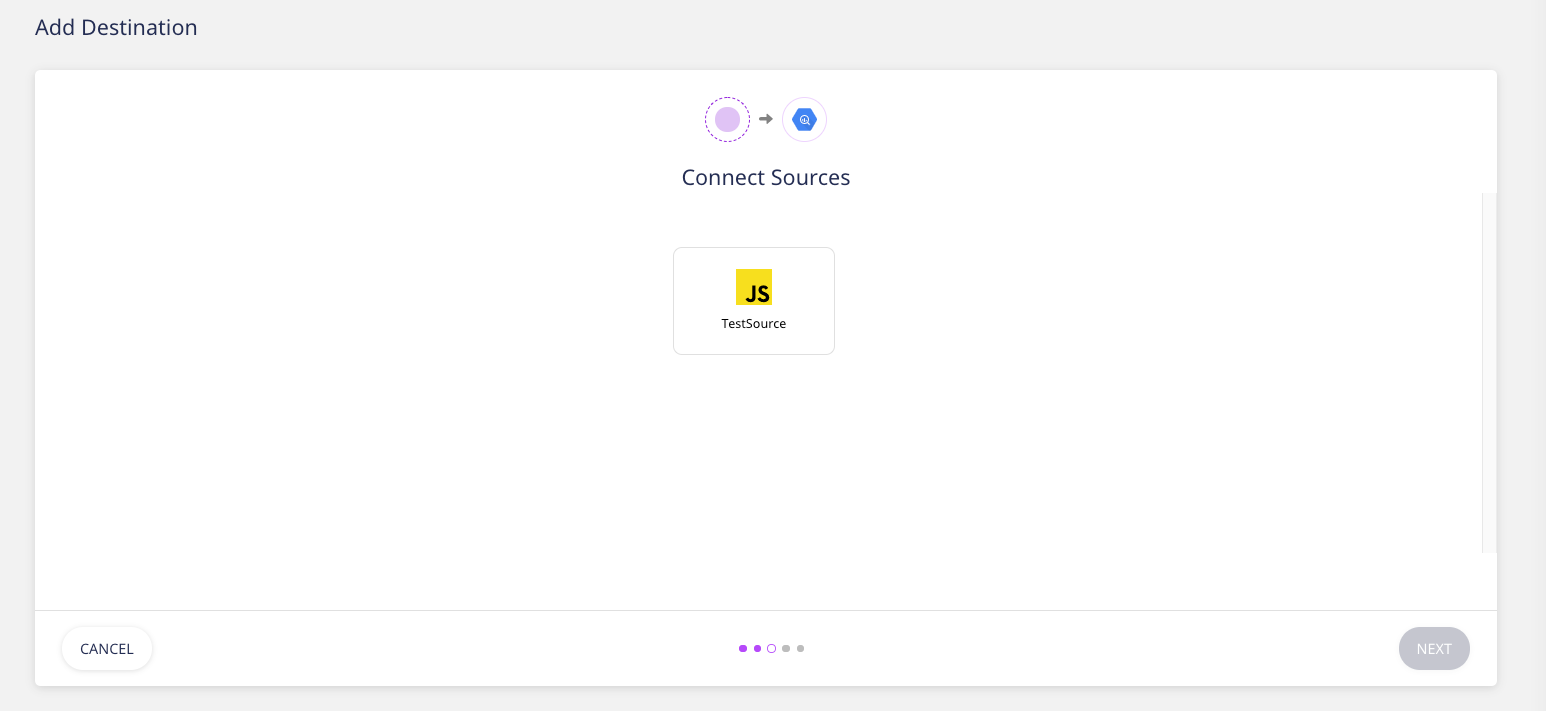
4\. Specify the Connection Credentials. Enter the BigQuery Project ID and the Staging Bucket Name. Follow these [instructions](https://docs.rudderstack.com/data-warehouse-integrations/google-bigquery#setting-up-google-bigquery) to get this information.
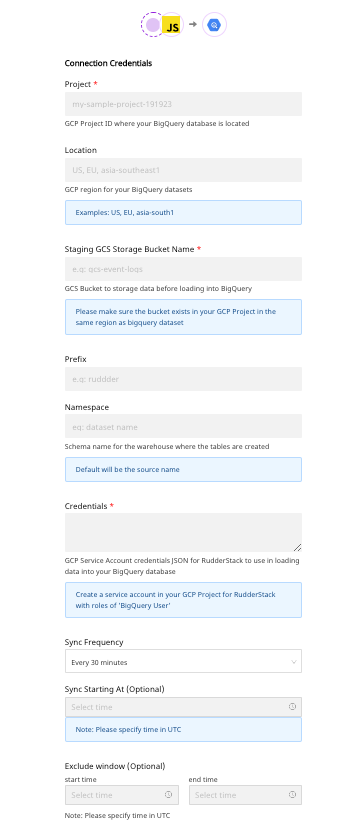
5\. Copy the contents of the private JSON file. More information on how to do this in our [doc](https://docs.rudderstack.com/data-warehouse-integrations/google-bigquery#setting-up-the-service-account-for-rudderstack).
That's it! You have successfully set up BigQuery as a warehouse destination in RudderStack.
Step 4: Deploy Your Gatsby Site And Verify The Event Stream
-----------------------------------------------------------
To verify if everything works correctly, let's finally deploy our website and test if the events are being delivered to the destination. For this post, we will test the event stream for our Google Analytics destination, which we set up in Step 3 (Instrument a Tool Destination in RudderStack).
Follow these steps:
1\. Navigate to the folder of your local site, as shown:
2\. Run the command `gatsby build` if you are using a production environment. If you are using a development environment, run the command `gatsby develop`.
3\. Since we are using a production environment, let's deploy our site using `gatsby serve`. A localhost URL will be served, which we can then use to access our site:
4\. Browse through your website by clicking on different posts or pages.
5\. See if RudderStack can track the different page views by going to the Live Events section on the source dashboard page:
Note: After deploying your production site, there can be a lag before events start sending. Don't worry. All events are captured and sent; just be aware that they can take a few minutes to show up in the Live Events viewer and in your downstream destinations after production deployments.
6\. RudderStack can successfully track and capture the pageview events, as seen below:
7\. Now, let's check if the events are sent to Google Analytics as well by going to your Google Analytics dashboard and navigating to Realtime - Events.
We see one active user on our Gatsby website, which means the page view event was delivered successfully. Similarly, you should also be able to see the event received in your Google BigQuery warehouse.
### Sign Up For Free And Start Sending Data
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app. [Get Started](https://app.rudderlabs.com/signup?type=freetrial) | teamrudderstack |
920,611 | Underrepresented Groups in Tech depicted in Popular Culture - a Personal Review of "Good Trouble" | I don’t know about you but I am always on the hunt for new TV shows to binge in my free time. When... | 0 | 2021-12-08T11:24:00 | https://dev.to/studio_m_song/underrepresented-groups-in-tech-depicted-in-popular-culture-a-personal-review-of-good-trouble-353f | watercooler, womenintech, career, inclusion | I don’t know about you but I am always on the hunt for new TV shows to binge in my free time. When one of my friends told me about a series she’s recently watched and approved I was intrigued and had to find out myself if this one was really that binge worthy.
_In my country of residence, which is Germany, the first two seasons of “Good Trouble” are available on Disney+ (not sponsored). Luckily I already subscribed so I could start right away._
If you’re wondering why I want to talk about this show on dev.to, let me explain. “Good Trouble” is actually a spin-off series of “The Fosters” (I didn’t know it before) and is about two characters Callie and Mariana who are about to start the next chapter of their lives after university. And guess what? Mariana went to MIT and started her job as a software engineer in a fancy Tech company in Los Angeles.
During the first minutes, I thought that it was another “coming of age-twenty-something-life in L.A.” kind of series and I was actually surprised to see how it quickly developed and critically depicts various societal issues. One of them being how women, or underrepresented groups in general, are treated in tech.
Mariana is hyped and confident that she will rock her new role after she’s been able to prove herself at MIT. Naturally, she wants to make a good first impression and dresses up accordingly. When she meets her team, her dream bursts with a bang. Just like the entire company, the team is male dominated (including the CEO) and instead of appreciating diversity and welcoming a woman on their team, they treat her disrespectfully from day one.
As mentioned earlier, the show depicts various topics, however, I was particularly intrigued by the fact that it deals with the issues of the tech industry. While Mariana reaches her limits in this toxic environment, she also decides to fight the occurring inequalities and starts an initiative to raise awareness and improve things.
I’m not a developer myself but I’ve worked in this field for the last two years and I quickly learned about the grievances, particularly when it comes to inclusion and diversity. In my opinion, the series portrays these quite accurately.
Mariana is a great developer and has to fight so hard to even prove her talent. She is bold and brings the power to address the issues she is facing at her company but before she was there nobody dared to do it. There are other colleagues of underrepresented groups who live in fear of losing their jobs if they speak up and the worst part of it all is that it’s not even .
Just like in real life, the people who suffer from injustice are also the ones who become activists and strive to create a better environment for themselves. Mariana and her colleagues do find allies eventually but the fight is still not over. When she gets a promotion or the chance to lead a project (which was her own idea) she is accused of getting her way only because she is a woman and not because she is good at what she does.
There are so many examples I could name from the show I could relate to as a woman and as an ally to underrepresented people in tech, I could probably even write several books about this topic. In the end, what I want to achieve by talking about the show is to point out that 1. The issue is real (and even has arrived in pop culture) and 2. I really really want people to watch it.
It made me feel empowered because I felt with the characters and it also made me feel hopeful to see that topics like inclusion and diversity (in the workplace but also in everyday life) are incorporated into mainstream TV shows. I know that most of the people who watch shows like that are already educated but I also genuinely wish for people to check it out who are living in their privileged bubble. It’s important to read, talk, share knowledge and listen to each other but it’s also SO GREAT that series like these exist and we need more of this!
This brings me to my last point. I wouldn’t have discovered the series (or the fact that it deals with the tech industry issue) without my friend. But I want to watch more of this stuff and I’m sure that there is more of it out there. So please feel free to share TV shows, movies etc. you know of that critically deal with inclusion and diversity in the tech industry (or the workfield in general). I would love to watch and share them. | annika_h |
920,761 | It's Prisma Time - Insert | Welcome Guys, Today it's time to add some records to the database 😁 so don't waste time and get your... | 15,827 | 2021-12-30T07:06:20 | https://dev.to/this-is-learning/its-prisma-time-insert-fc2 | javascript, typescript, database, orm | Welcome Guys,
Today it's time to add some records to the database 😁 so don't waste time and get your hand dirty.
Let's start from a simple insert that adds an author, in your `src/index.ts` copy the next example.
```ts
import { PrismaClient } from "@prisma/client";
async function main() {
const prisma = new PrismaClient();
try {
const newAuthor = await prisma.author.create({
data: {
firstName: "John",
lastName: "Doe",
},
});
console.log({ newAuthor });
} catch (error) {
console.error(error);
throw error;
} finally {
await prisma.$disconnect();
}
}
main();
```
In this code you created a simple insert that adds an author.
By using the patter `prisma.[entity].create` you can insert in your db your entities, but let's see this code in action executing the next two script
```
npx prisma db push
yarn dev
```
```json
{ newAuthor: { id: 1, firstName: 'John', lastName: 'Doe' } }
```
As you can see it's not so hard to insert a record, but it's time to take the insert to the next level.
Imagine that you want to insert a Post with one Comment in a single execution, how can you do that?
Well, add to the previous code the next one, below the `console.log({ newAuthor });`.
```ts
...
const newPost = await prisma.post.create({
data: {
title: "First Post",
content: "This is the first post",
published: false,
comments: {
create: {
text: "First comment",
author: {
connect: {
id: newAuthor.id,
},
},
},
},
},
include: {
comments: true,
},
});
console.log("newPost", JSON.stringify(newPost, null, 4));
...
```
And now run the code using
```
npx prisma db push
yarn dev
```
after that you can see this result
```
newPost {
"id": 7,
"title": "First Post",
"content": "This is the first post",
"published": false,
"createAt": "2021-12-18T12:29:20.982Z",
"updatedAt": "2021-12-18T12:29:20.982Z",
"comments": [
{
"id": 7,
"text": "First comment",
"postId": 7,
"authorId": 7
}
]
}
```
But what happened?
By running this code you added in you database a post and a comment related to this post using a single command. I think you agree with me that it is a common feature in an ORM. But let's see better the create method and its parameters.
Let's start from the `data` field, this field allows you to indicate all the fields related to your entity, in this case the Post Entity. When I say the entity's fields I am referring to the own fields but also to the fields of its related Entities as you did with the Comment Entity in the previous example.
But let's move on and see another particularity in this example. To add the comment related to your post you used this snippet of code
```ts
...
comments: {
create: {
text: "First comment",
author: {
connect: {
id: newAuthor.id,
},
},
},
},
...
```
The first thing that comes to our attention is the create field. This field is not a field of the Comment Entity but is a command for Prisma. Using the [create](https://www.prisma.io/docs/concepts/components/prisma-client/relation-queries#create-a-related-record) command you are indicating to Prisma that you want to insert a new record in the comment table. The data relative to the comment are indicated inside of the create object just described. Okay but let’s look into this object where there is another peculiarity inside the field author. As you can see inside it there is a field called `connect`, but what is it? The [connect](https://www.prisma.io/docs/concepts/components/prisma-client/relation-queries#connect-an-existing-record) field is another command for Prisma. This command indicates to Prisma that the Author's record already exists in the database and it must not create it but it only needs to create the link between the comment record and the author record.
There is another command for Prisma to manage the insert of an entities and it is `connectOrCreate`. This command allows us to check if the relative record exists and in this case Prisma creates the link between the entities, otherwise if it doesn't exist Prisma creates also this new record. To give you an example, here, the author connect command rewrites with the `connectOrCreate`.
```ts
author: {
connectOrCreate: {
create: {
lastName: "Last name",
firstName: "First name",
},
where: {
id: newAuthor.id,
},
},
},
```
When you insert a new record, all the crud operations in your database are made under a transaction, so if in your insertion you have an entity with 3 sub-entities, you'll get the success result only if all operations will be successful, otherwise you'll get an error and your database will be left clean as before the execution.
There is also a `createMany` method that allows you to do a bulk insert inside a collection. It isn't so different from the `create` method. I leave you the link to the documentation [here](https://www.prisma.io/docs/concepts/components/prisma-client/crud#create-multiple-records).
_N.B. createMany isn't supported in SQLite, Prisma helps you on that and when generates the definitions of the client, it detects the current connector and generates only the definitions supported by the connector_
Last but not least, Prisma exposes you a specific type for typescript that describes how you can call the create method in a type safe context. Next the author insert reviews with this type
```ts
import { Prisma, PrismaClient } from "@prisma/client";
...
const authorCreate: Prisma.AuthorCreateArgs = {
data: {
firstName: "John",
lastName: "Doe",
},
};
const newAuthor = await prisma.author.create(authorCreate);
...
```
Prisma does this work for all the entities that you described in the `prisma.schema` file and it doesn't just make this, but we will go deep into this in the next articles.
I think today you have got many notions about the insert with prisma. If you are interested in go in depth on the insert with prisma [here](https://www.prisma.io/docs/concepts/components/prisma-client/crud#create) the link to the official documentation.
That’s it guys.
In the next article we’re going to see the delete operation.
See you soon.
Bye Bye 👋
_You can find the code of this article [here](https://github.com/Puppo/it-s-prisma-time/tree/06-insert)_ | puppo |
920,765 | It's Prisma Time - Logging | Hi Guys 👋 Today we are going to see how to enable logging in Prisma, so don't waste time and let's... | 15,827 | 2022-01-26T06:50:45 | https://dev.to/this-is-learning/its-prisma-time-logging-4i7m | javascript, typescript, database, orm | Hi Guys 👋
Today we are going to see how to enable logging in Prisma, so don't waste time and let's start!
In Prisma we have 4 type of logging
- query: this level of log allows us to see the queries created by Prisma to perform our operations
- info
- warn
- error
_I think the last three levels of log don’t need a description if you’re a developer._
We can enable all of them or only those are necessary.
By default these logs are written in the stdout, but we can also send them in an event and handle them as we prefer.
_P.S. if you are in development mode, you can enable all of these log levels setting the DEBUG environment variable to true_
But let's see how to enable these logs.
```ts
const prisma = new PrismaClient({
log: [
{
emit: "event",
level: "query",
},
"info",
"warn",
"error",
],
});
prisma.$on("query", e => {
console.log("Query: " + e.query);
console.log("Duration: " + e.duration + "ms");
});
```
The log option accepts an array of log levels that can be simple strings (query, info, warn, or error) or objects composed of two fields: level and emit. The level field can have query, info, warn, or error as values; whereas the emit field can have two values: stdout or event. If the "emit" value is equal to "stdout", the result of this log level will be written in the console, otherwise, if the value is "event", the result must be handled by a subscriber.
But let’s clarify and see how to manage these logs.
```ts
const prisma = new PrismaClient({
log: [
{
emit: "event",
level: "query",
},
"info",
"warn",
"error",
],
});
prisma.$on("query", e => {
console.log("Query: " + e.query);
console.log("Duration: " + e.duration + "ms");
});
```
In this snippet of code, you can see how to enable the log levels and how to handle a subscriber of a specific type of log level.
As you can see, it's not difficult to enable logs but it's important to remember to do it in the right way in base of the environment where our software is running.
It's also possibile, as you can tell, to subscribe to the events of a log using the `$on` method. By using this method you can send where you want all your logs.
The last thing that I want to leave you is an example of a query logged in the console.
```console
SELECT `main`.`posts`.`id`, `main`.`posts`.`title`, `main`.`posts`.`content`, `main`.`posts`.`published`, `main`.`posts`.`createAt`, `main`.`posts`.`updatedAt` FROM `main`.`posts` WHERE `main`.`posts`.`published` = ? LIMIT ? OFFSET ?
```
As you can see, you can get the real SQL query executed by Prisma, and you can copy and past it in other SQL tool to check its plan or everything else.
In this way, we can check if we have a slowdown and if we need to write our own query.
The How is the goal of the next article 😁
So that's all for now folks. In the next article, we are going to see how to execute own queries using Prisma.
See you soon guys
Bye Bye 👋
_You can find the code of this article [here](https://github.com/puppo/it-s-prisma-time/tree/13-logging-query)_ | puppo |
920,777 | Advent of code, day 8 | Ok, this was engaging but also very, very challenging. The only reason I managed to finish is that I... | 0 | 2021-12-08T11:01:08 | https://dev.to/marcoservetto/advent-of-code-day-8-5c2c | adventofcode, programming, 42, puzzle | Ok, this was engaging but also very, very challenging.
The only reason I managed to finish is that I made a good 'add' method checking for two important properties before adding.
In this way, I was notified of my broken logic over and over again until I could fix it.
Doing this exercise It was also evident that I need to add to adamsTowel at least the following: split a string on all characters and sorting of lists.
```
Split = {class method S.List (S that)=//hack to split for now
\()(for c in that.replace(S"" with=S",").split(S",")\add(c))
}
Values = Data:{
mut S.List vals = \[S"";S"";S"";S"";S"";S"";S"";S"";S"";S""]
mut method Void add(I that S word)=(
v = \vals.val(that) //here my life saver checks!!
X[v==S"" || v==word msg=S"%v, %word";
Match.None()(for w in this.vals() \add(w==word))
msg=S"%this.vals(), %word"]
\#vals.set(that,val=word)
)
mut method Void processR1(S word) = {
(size) = word
if size==2I return \add(1I, word=word)
if size==3I return \add(7I, word=word)
if size==4I return \add(4I, word=word)
if size==7I return \add(8I, word=word)
return void
}
read method I op(S that, S minus) = (//this method is the key
var res = that //to a shortish solution
for c in Split(minus) ( res:=res.replace(c with=S"") )
res.size()
)
mut method Void processR2(S word) = {
(size) = word
if size!=6I return void
one=\vals.val(1I)
four=\vals.val(4I)
if \op(word minus=one)==5I return \add(6I, word=word)
if \op(word minus=four)==3I return \add(0I, word=word)
return void
}
mut method Void processR3(S word) = {
(size) = word
if size!=5I return void
one = \vals.val(1I)
six = \vals.val(6I)
if \op(word minus=one)==3I return \add(3I, word=word)
if \op(six minus=word)==1I return \add(5I, word=word)
if \op(six minus=word)==2I && \vals.val(3I)!=word
return \add(2I, word=word)
return void
}
mut method Void processR4(S word) = {
done=Match.Some()(for w in this.vals() \add(w==word))
if done return void
open = I.List()(for i in Range(10I), v in this.vals() if v==S"" \add(i))
if open.size()==1I return \add(open.left(), word=word)
return void
}
mut method Void process(S.List words) = (
for w in words ( \processR1(word=w) )
for w in words ( \processR2(word=w) )
for w in words ( \processR3(word=w) )
for w in words ( \processR4(word=w) )
)
read method I decode(S word) = {
for res in Range(10I) e in \vals if e==word return res
error X"%word %this.vals()"
}
read method I decode4Digits(S.List words)=(
var res = 0I
for w in words ( res:=(res*10I)+\decode(word=w) )
res
)
}
Sort = {class method S (S that)=(//should I sort all and
var res = S"" //recompose the string
all = Split(that) //instead?
for l in S.List[S"a";S"b";S"c";S"d";S"e";S"f";S"g"] (
if l in all res++=l
)
res
)}
Main8Part2 = (
input = Fs.Real.#$of().read(\"input")
var I tot=0I
for line in input.split(S.nl()) (
vs=Values()
bar=line.split(S" | ")
imm words=S.List()(for s in bar().split(S" ") \add(Sort(s)))
imm wordsB=S.List()(for s in bar().split(S" ") \add(Sort(s)))
vs.process(words=words)
res=vs.decode4Digits(words=wordsB)
tot+=res
)
Debug(tot)
)
```
If you liked this post, consider giving a look to the '1 week report' on advent of code
(https://www.youtube.com/watch?v=hBuFvq7v6v8) | marcoservetto |
920,785 | What Is 3D Advertising And How Is It Changing Display Advertising? | Advertising is a term that refers to promoting products or services over tv channels, newspapers,... | 0 | 2021-12-08T11:17:44 | https://dev.to/bondgaurav21/what-is-3d-advertising-and-how-is-it-changing-display-advertising-2hon | augmentedreality, virtualreality, mixedreality, productivity | Advertising is a term that refers to promoting products or services over tv channels, newspapers, websites, or verbally. Now, these days [**3D advertising**](https://www.brsoftech.com/augmented-reality-app-development.html) is popular for brand promotions and for better reach.
## What Is The Meaning of 3D Advertising?
{% youtube UvrI7HKMzZs %}
3D advertising or 3D ads enable users to interact in real-time with an image or product.
3D ads are providing an excellent customer experience to the customers. With the help of 3D ads, you can touch, feel, rotate, spin, or customize the features of the products.
## Benefits of 3D Advertising
- One of the benefits of 3D advertising is that 3D objects or designs are more visible to the eyes than 2D designs.
- With the help of 3D advertising, ads are more realistic.
- You can create a great presence over online platforms with the help of 3D advertising.
- By using 3D ads you can engage customers in a better way.
- 3D Advertising is cost-effective and convenient for companies.
**You may also like this:**
- **[What Are The Advantages & Disadvantages of Mixed Reality Technology?](https://saurabh-meena.medium.com/what-are-the-advantages-disadvantages-of-mixed-reality-technology-1f57513441c8)**
## How To Create 3D Ads?
{% youtube rqBK3zyT48Y %}
3D advertisement is one of the most iconic discoveries in the internet marketing world. With the help of Google Swirl, it is possible to create a 3D ads campaign. Now we will tell you here how to create 3D ads.
**Step-1: Set Up A Goal**
This is a must that before starting, you had to create a goal for that you want to create a 3D ad. Goals can be like you want to provide a 3D view to your customers? Do you want to see the features of your products? Or allow views to modify that 3D ad. So make sure you had a goal
**Step-2: Build Your 3D Model Creative**
Creativity is always needed when it comes to the advertisement industry. You need to make a 3D model of your products. The models should be communicative and interactive. If you are planning to showcase your automobile products then you provide a complete 360-degree view along with the internal features of the product.
**Features of 3D Model**
1. Zooming
2. Scrolling
3. Fullscreen
**Step-3: Publish Your Ad & Observe That**
When you decide your goal and design a 3D model, you are ready to publish your first ad. You have to download Google Swirl, this is the platform where you can publish your ad. You can find the analysis of traffic and visitors of your website or products with the tools.
## Impact on Display Advertising
3D advertisement is completely [**AR-based advertising**](https://www.brsoftech.com/augmented-reality-app-development.html). Now, these days people are more concerned about new technologies, and the uses of these technologies in real life are really impressive for them. AR-based advertisement is changing the business to increase sales, product visibility, & increase website traffic. In 3D display advertisements, configurable 3D models are available.
**You may also like this:**
- **[What Are The Advantages & Disadvantages of Virtual Reality Technology?](https://dev.to/bondgaurav21/what-are-the-advantages-disadvantages-of-virtual-reality-technology-143a)**
### Conclusion
After the whole discussion, we can say that AR-based 3D advertising is the future of advertising and it will change the whole entire world of marketing. 3D Advertising will help businesses to grow more in the future. BR Softech private limited is the best company to hire if you plan to market your business. 3D advertising is a specialty of [**BR Softech**](https://www.brsoftech.com).
| bondgaurav21 |
920,801 | Node-Express basic Project Setup with folder Structure for beginners | Over the last several years we’ve seen a whole range of ideas regarding the architecture of... | 0 | 2021-12-08T15:22:11 | https://dev.to/systembugbd/node-express-basic-project-setup-with-folder-structure-for-beginners-3162 | javascript, beginners, programming, node | 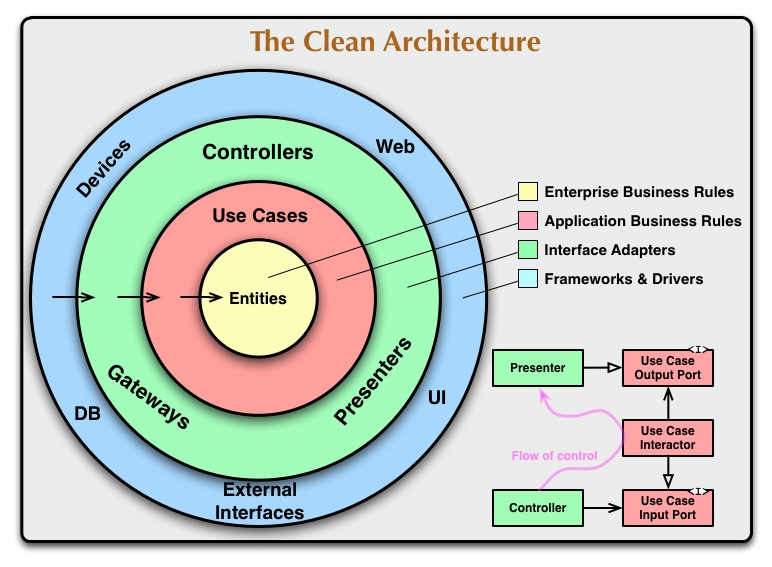
Over the last several years we’ve seen a whole range of ideas regarding the architecture of systems. These include:
[Hexagonal Architecture](http://alistair.cockburn.us/Hexagonal+architecture) (a.k.a. Ports and Adapters) by Alistair Cockburn and adopted by Steve Freeman, and Nat Pryce in their wonderful book [Growing Object Oriented Software](http://www.amazon.com/Growing-Object-Oriented-Software-Guided-Tests/dp/0321503627)
[Onion Architecture](http://jeffreypalermo.com/blog/the-onion-architecture-part-1/) by Jeffrey Palermo
[Screaming Architecture](http://blog.cleancoders.com/2011-09-30-Screaming-Architecture) from a blog of mine last year
[DCI](http://www.amazon.com/Lean-Architecture-Agile-Software-Development/dp/0470684208/) from James Coplien, and Trygve Reenskaug.
[BCE](http://www.amazon.com/Object-Oriented-Software-Engineering-Approach/dp/0201544350) by Ivar Jacobson from his book Object Oriented Software Engineering: A Use-Case Driven Approach
Don't get panic to see above architectural article, all above only for your reference, if you wish to read and gather knowledge you can through the link.
See below article to create a express server and project setup step by step.
## Basic setup step by step
Open cmd and go to your desired folder now write -
`mkdir cleancodeStructure`
`cd cleancodeStructure`
`npm init -y` to initiate the **package.json** file into your project you will see in sidebar- 
now install few package into your project to make it trackable and maintainable and workable-
`npm i express cros morgan dotenv`
also install nodemon to keep your server ups and running once start
`npm i -D nodemon` -D as a **devDependencies**
now create **server.js** 
in the same level of **package.json** 
import some necessary file to server.js like below

and write few lines of code to make a **nodejs server** like below Please give online line break-
now come to the next level of app and router section which you already included in **server.js** but not yet created.
create **app** folder in the **package.json** level and create **app.js ** to create express app for your project

**App Folder** with **app.js** to work with app level codebase
now **import express** into the **app.js** file with **getAppHealthCheckerController**, don't worry will talk about **getAppHealthCheckerController** later.

now come to below line and create a express app like below
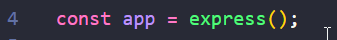
then define a **route** for **app health** called **/health** route in the **app.js** like below and export express app -

now come to the router controller part, I mention above that, I will discuss about **getAppHealthCheckerController** latter, now time to discuss in a short about app health route and Controller.
**/health** route
Most of the server for backend API they checked one route that must be exists. do you know what is that? ok, I am telling you this is called **/health** route. [digital ocean](https://www.digitalocean.com/) one of the server service provider look first for **/health** route. if API has health route they think that the API server health is good. generally this route expect status code 200 in response back.
now create **controller folder** in the **package.json** level or **first level** and **app.js** controller inside the controller folder like below 
and code inside **app.js** like below-
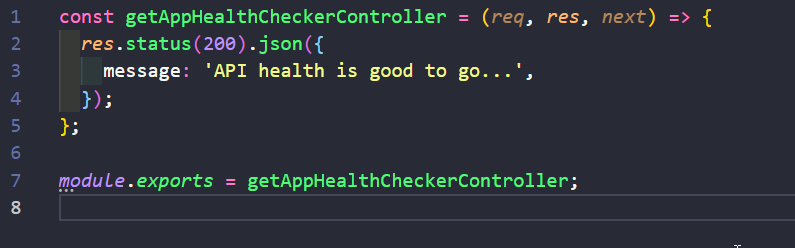
now config your **package.json** file script like below -

now you are ready to check your **/health** route from browser.
go to terminal of of your **vscode** and type `npm run dev` and hit [http://localhost:4444/health](http://localhost:4444/health)
**its time to Bloom**
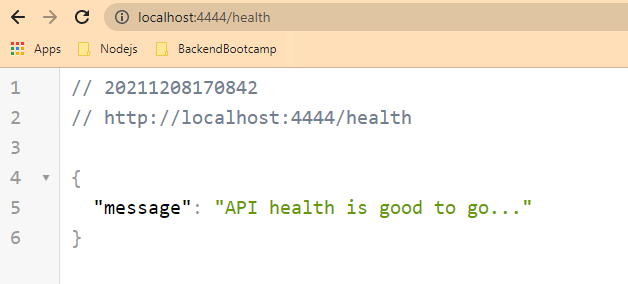
Welcome you made an express app with the health route; you are almost done to go a good way to write your code in a good structure.
now create a **routes** folder with **router.js** file like below example.
and create some route like below
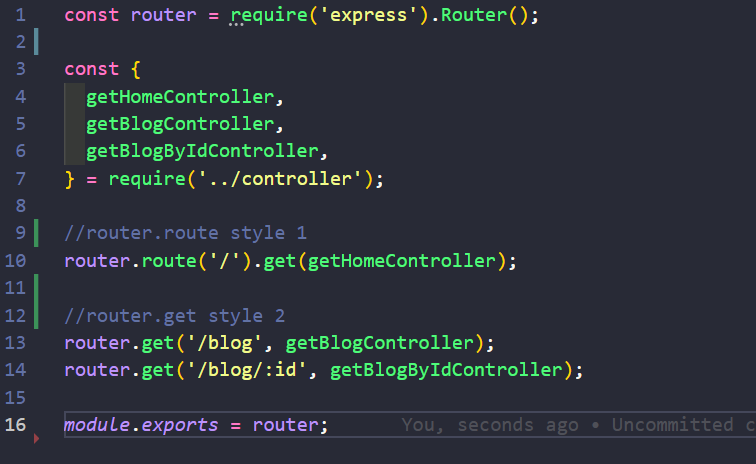
then go to **Controller folder** to create some controller which you attached with the above **new route** (**getHomeController**, **getBlogController**, **getBlogByIdController**), in **router.js** file.
at first create **home.js** in **controller folder** and write some demo code for home route like below.
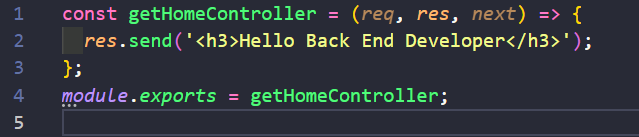
Secondly create **blog.js** in **controller folder** and write some code for blog route like below.
define a blogData variable to write demo blog data for example -
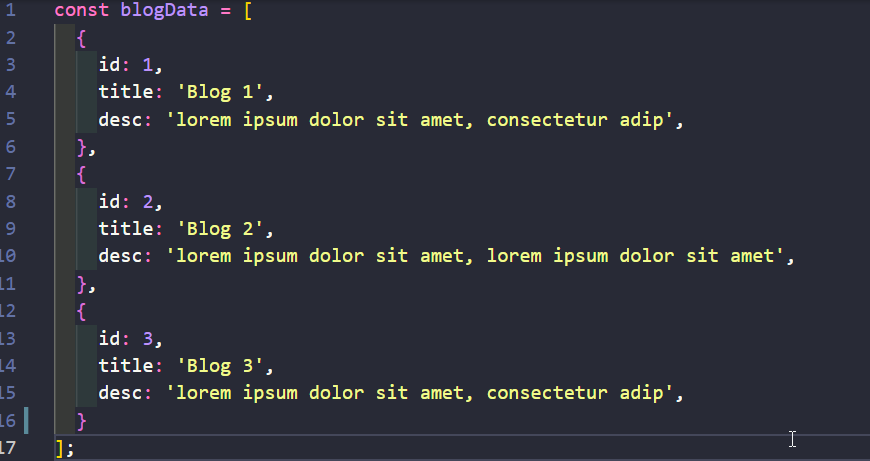
now define a controller function `getBlogController` like below to make the **/blog** route workable and to see the blog API and paginate the Blog API;
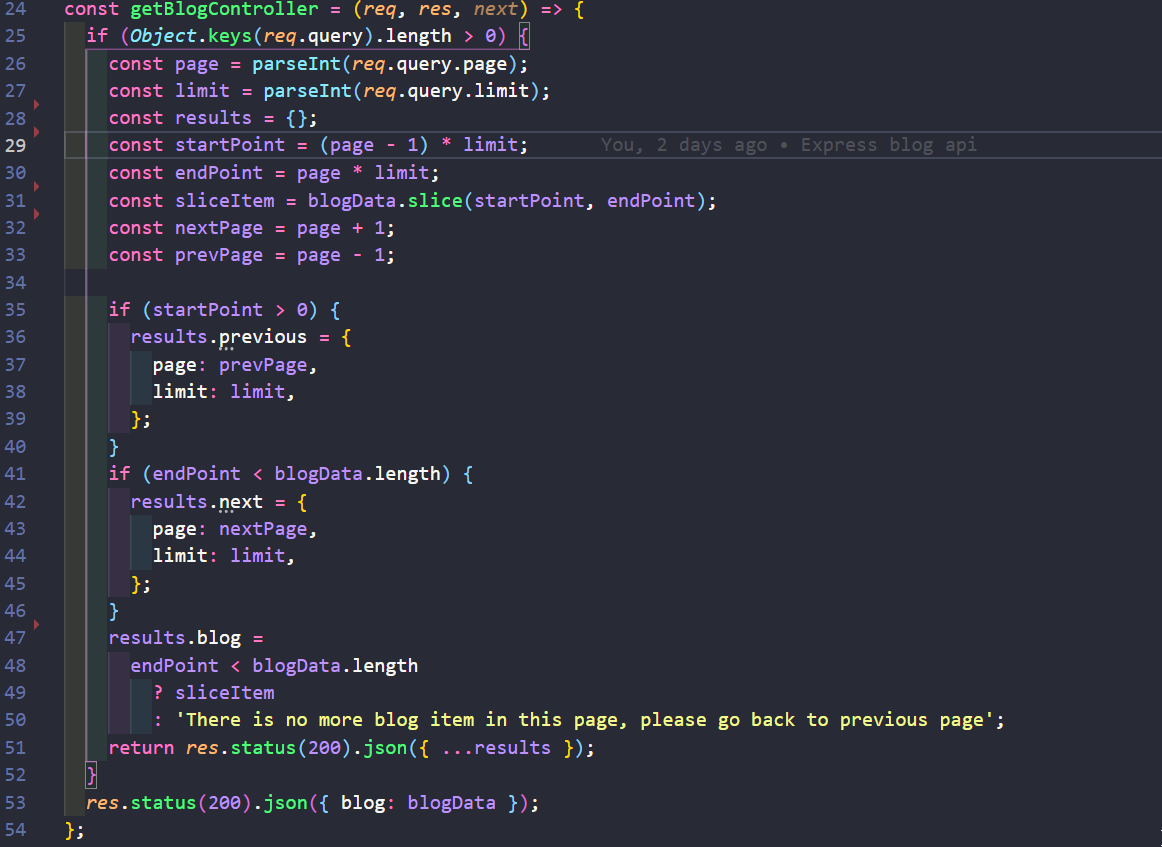
I keep the all the code in this controller to make it simple, you can separate with the middleware.
now hit http://localhost:4444/blog
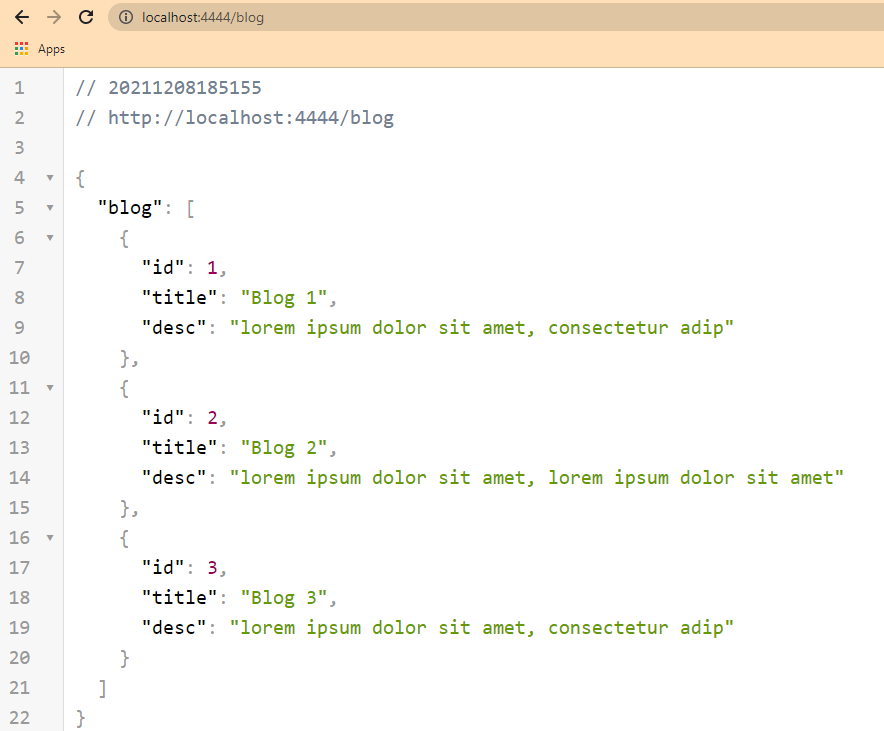
you can paginate the Blog API like below [http://localhost:4444/blog?page=2&limit=1](http://localhost:4444/blog?page=2&limit=1)
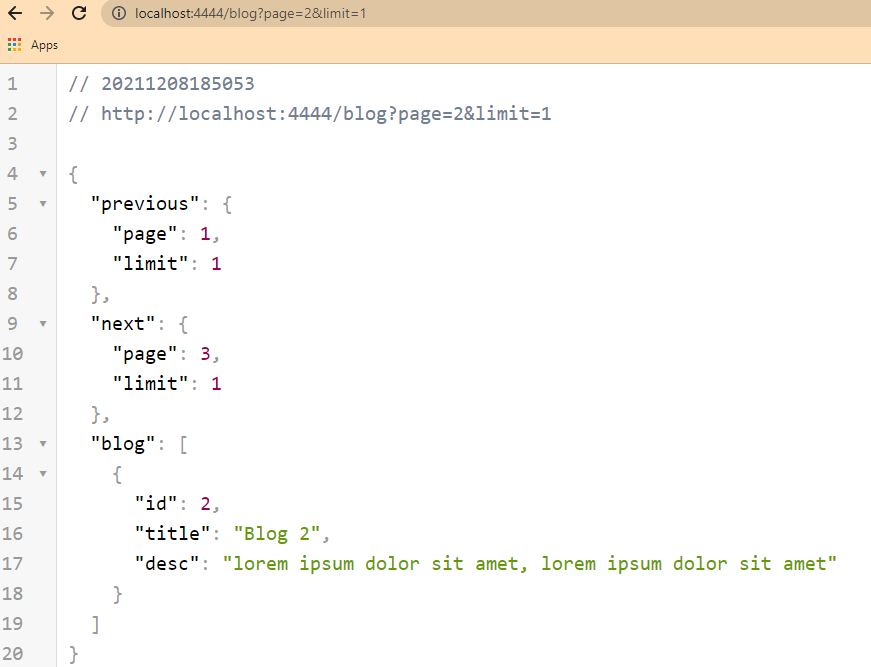
now create another route controller to get the blog by id. Its very simple to get specific blog data no matter where it is coming it may come from **mongodb** or **javascript object** or **JSON data** or some where else, see below how to get data from javascript object by controller function in **blog.js**
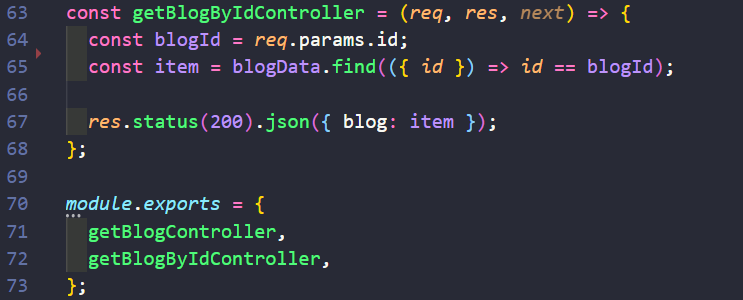
and export both controller function,
you can create **index.js** file to export your all controller function from the controller folder together which will
help you a lot to minify your code base and keep your code clean.
when you call the specific controller you just need to call the `const { yourController } = require('../controller');` and extract the specific controller to use.

we are almost done, now see some middleware and wrap up for now...
## middleware
**Middleware functions are functions that have access to the request object (req), the response object (res), and the next middleware function in the application’s request-response cycle. The next middleware function is commonly denoted by a variable named next.**
**Middleware functions can perform the following tasks:**
- Execute any code.
- Make changes to the request and the response objects.
- End the request-response cycle.
- Call the next middleware function in the stack.
> **If the current middleware function does not end the request-response cycle, it must call next() to pass control to the next middleware function. Otherwise, the request will be left hanging.**
how to create a middleware and how to use see below example and folder structure
now create a folder called **middleware** like below and create a demo middleware for testing purpose.

write some code like below to demo.js middleware
import and use to **server.js** for all route
See middleware is working--
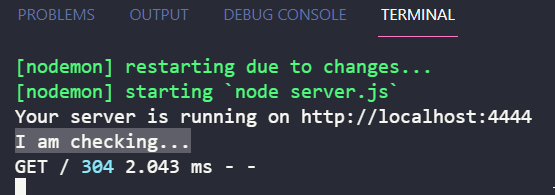
for more details [click here](https://expressjs.com/en/guide/using-middleware.html) to visit express.js
## Error handler
you can create error folder in first level and create your own custom error handler, like below
**errorHandler.js** code sample looks like -
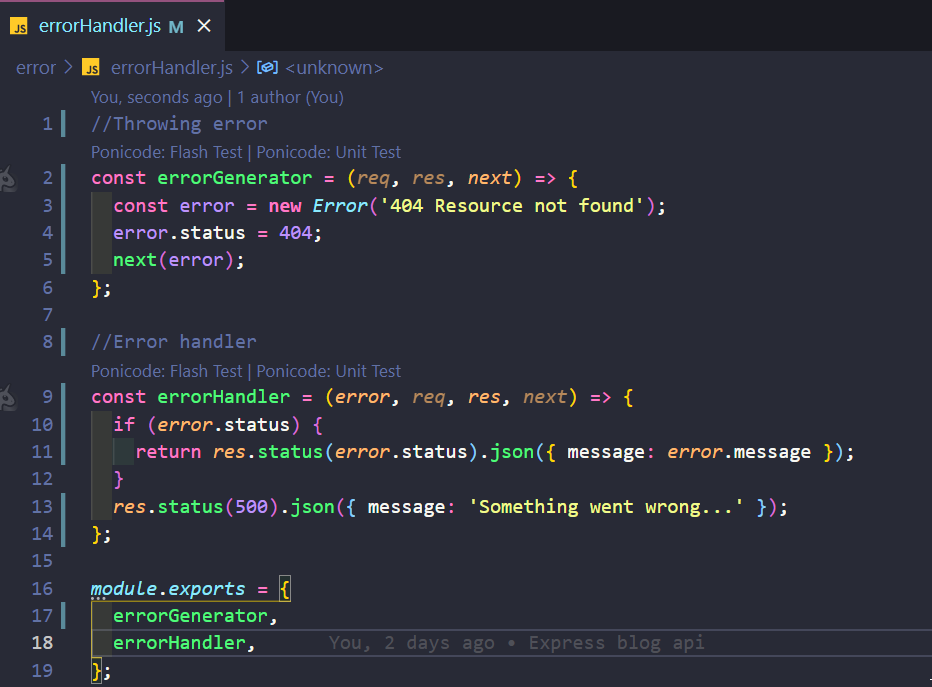
use it in **server.js** like below by using **app.use()**
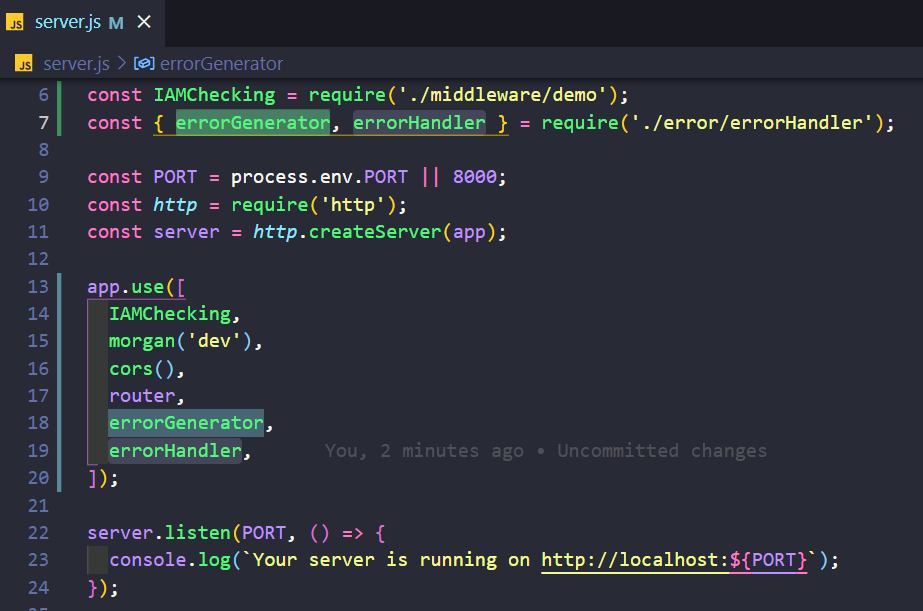
if error occur error message will show of the unexpected route
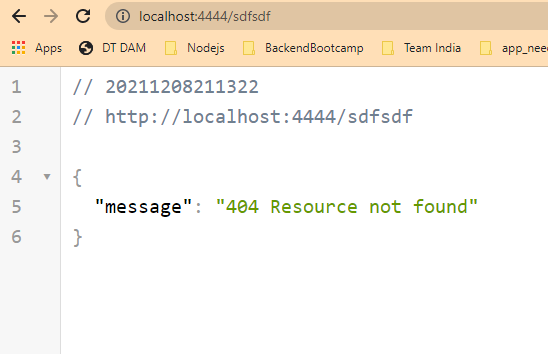
**you are almost done with setup**
Now you create all other folder for your convenient, it may be anything which one is required for your project, like below-
log, service, public, utils, db, models etc as per your needs

[You can see a video more about NODE and Expressjs server and Paginated API creation-](https://www.youtube.com/watch?v=Je_Zpf2snmQ&list=PL15CsFQf-JdzcYTsiOHM1pbgowXe-g2Fm)
You can learn docker from this [video](https://www.youtube.com/watch?v=RC9yxMcXquI&list=PL15CsFQf-JdzNcfMCSRmywaEkNNsbt5Xv)
> **that's all about folder Structure and node express server creation with error handling and middleware**
`
Above all I am human being, I have lots of mistake and lack of knowledge. So if i made any mistake and provide any misinformation, please correct me and pardon me.
`

| systembugbd |
920,843 | Size of Programming Language Communities in Q3 2021 | Following our last Developer Nation Survey, results are in and our State of the Developer Nation... | 0 | 2021-12-08T13:28:27 | https://dev.to/developernationsurvey/size-of-programming-language-communities-in-q3-2021-44a9 | analysis, javascript, rust, kotlin | ---
title: Size of Programming Language Communities in Q3 2021
published: true
description:
tags: #analysis #javascript #rust #kotlin
//cover_image: https://www.developernation.net/static/1071f48695f613c662761c5422e5b485/9e575/Programming-Languages_update_blogpost_COVER.jpg
---
Following our last [**Developer Nation Survey**](https://www.developereconomics.net/?utm_medium=blogpost&utm_source=dev_to&utm_campaign=size_of_programming_languages), results are in and our State of the Developer Nation report 21st edition is now available! More than **19,000 developers from around the world** participated and shed light on how they learn, the tools they use, how they are involved in emerging technologies, but also what would make them switch employers, among other topics.
As always, programming languages are a beloved subject of debate and one of the first topics we cover. The choice of language matters deeply to developers because they want to keep their skills up to date and marketable. It matters to toolmakers too, because they want to make sure they provide the most useful SDKs.
It can be hard to assess how widely used a programming language is. The indices available from players like Tiobe, Redmonk, Stack Overflow’s yearly survey, or GitHub’s Octoverse are great, but offer mostly relative comparisons between languages, providing no sense of the absolute size of each community. They may also be biased geographically or skewed towards certain fields of software development or open source developers.
The estimates we present here look at **active software developers using each programming language;** across the globe and across all kinds of programmers. They are based on two pieces of data:
- First, our independent estimate of the global number of software developers, which we published for the first time in 2017.
**We estimate that, as of Q3 2021, there are 26.8 million active software developers in the world**
- Second, our large-scale, low-bias surveys which reach tens of thousands of developers every six months. In the surveys, we have consistently asked developers about their use of programming languages across ten areas of development, giving us rich and reliable information about who uses each language and in which context.

##JavaScript’s popularity has skyrocketed 🥇
JavaScript is the most popular programming language community by a wide margin. **Nearly 16.5M developers are using it globally.** Notably, the JavaScript community has been growing in size consistently for the past several years. 4M developers joined the community in the last year – by far the highest growth in absolute terms across all languages – and upwards of 2.5M developers joined in the past six months alone. Even in software sectors where JavaScript is not among developers’ top choices, like data science or embedded development, about a fourth of developers use it in their projects.
Back in 2020 we suggested that [learning Python would probably be a good idea.](https://www.developernation.net/blog/infographic-programming-languages-adoption-trends-2020) It still is. Since it surpassed Java in popularity at the beginning of 2020, Python has remained the second most widely adopted language behind JavaScript. Python now counts 11.3M users after adding 2.3M net new developers in the past 12 months. **The rise of data science and machine learning (ML) is a clear factor in Python’s popularity. **
**More than 70% of ML developers and data scientists report using Python**
**Java is the cornerstone of the Android app ecosystem as well as one of the most important general-purpose languages.** Although it has been around for more than two decades now, its traction among developers keeps steadily growing. Since mid-2018, nearly 2.5M developers have joined the Java community, which now counts 9.6M developers.
##Rust is rising fast 🚀
The group of major, well-established languages is completed with C/C++ (7.5M), PHP (7.3M), and C# (7.1M). Of these, PHP has grown the fastest in the past six months, with an influx of 1M net new developers between Q1 and Q3 2021. C and C++ are core languages in embedded and IoT projects for both on-device and application-level coding, whereas PHP is still the second most commonly used language in web applications after JavaScript. On the other hand, C# is traditionally popular within the desktop developer community, but it’s also the most broadly used language among AR/VR and game developers, largely due to the widespread adoption of the Unity game engine in these areas.
Rust has formed a very strong community of developers who care about performance, memory safety, and security. As a result, it grew faster than any other language in the last 24 months. Rust has nearly tripled in size from just 0.4M developers in Q3 2019 to 1.1M in Q3 2021.
**Rust is mostly used in embedded software projects but also in AR/VR development, most commonly for implementing the low-level core logic of AR/VR applications.**
In previous editions of the State of the Developer Nation report, Kotlin has consistently been identified as a rising star among programming languages. Kotlin’s audience has doubled in size over the last three years – from 1.5M developers in Q2 2018 to nearly 3M in Q3 2021. This trend is largely attributed to Google’s decision to make Kotlin its preferred language for Android development. **Kotlin is currently the third most popular language in mobile development, behind JavaScript and Java.**

The more niche languages – Go, Ruby, Dart, and Lua – are still much smaller, with up to 2M active software developers each. Go and Ruby are important languages in backend development, but Go has grown slightly faster in the past year, both in absolute and percentage terms. Dart has also seen a significant uptick in its adoption in the last year. This has been fuelled predominantly by the increasing adoption of the Flutter framework in mobile development. Finally, Lua was the second fastest growing language community in the past two years, behind Rust, mainly attracting AR/VR and IoT developers looking for a scripting alternative to low-level languages such as C and C++.
What's your favourite programming language? [Take our latest survey to support your choice!](https://www.developereconomics.net?utm_medium=blogpost&utm_source=dev_to&utm_campaign=size_of_programming_languages) | developernationsurvey |
921,057 | 3 Reasons Why You Should Not Consider DevSecOps “a low-hanging fruit”!
| By 2027, the worldwide DevSecOps market value will increase nine times and comprise more than $17... | 0 | 2021-12-08T15:43:18 | https://dev.to/ruchita_varma/3-reasons-why-you-should-not-consider-devsecops-a-low-hanging-fruit-5869 | devsecops, devops, microservices, kubernetes |
<b>By 2027, the worldwide <a href="https://www.gartner.com/en/information-technology/glossary/devsecops">DevSecOps market</a> value will increase nine times and comprise more than <a href="https://www.verifiedmarketresearch.com/product/devsecops-market/">$17 billion</a>, compared to just over $2 billion in 2019.</b>
DevSecOps is the process of embedding security practices in different stages of the DevOps lifecycle right from the start. DevSecOps practices involve thinking about application and infrastructure security by choosing the right tools and techniques. It also means automating security checks to prevent the DevOps lifecycle from slowing down and continuously integrating security features in the DevOps workflow.
<b>According to a report, <a href="https://www.verifiedmarketresearch.com/product/devsecops-market/">the Global DevSecOps Market</a> was valued at USD 2.18 Billion in 2019 and is projected to reach USD 17.16 Billion by 2027, growing at a CAGR of 30.76% from 2020 to 2027.</b>
<b>Reluctance to Adopt New Changes!</b>
People's reluctance to recent changes in the development process can be a major roadblock to building the DevSecOps culture. At first, SRE & product teams may find it difficult to accept and integrate the latest DevSecOps practices in the software delivery lifecycle. Moreover, rejecting the traditional approach of addressing security issues may not sound like a great idea to the DevOps teams juggling with other priorities. Along with the resistance to integrating new practices, building a close collaboration between developers and security professionals is complicated too which may slow down the speed of adopting a new methodology.

<b>Clash of the Tools!</b>
With so many tools available in the market today for implementing DevSecOps, choosing the right ones can be an uphill battle. The first challenge lies in choosing the one that fits well into the business requirements and the second challenge is to properly integrate these tools in the DevOps system so that software teams can build, deploy and test the tools in a continuous manner. Moreover, establishing collaboration between the DevOps and security teams is not an easy task. Bringing together DevSecOps tools from various departments and then syncing them on one platform can create a clash within the team.
<b>Implementing Security in CI/CD!</b>
Embedding security practices and executing security checks is something that usually comes at the end of development. But doing this can slow down the overall DevOps process if there are any issues and bugs present in the product. With DevSecOps, security becomes a part of the continuous integration and continuous development process. But, integrating security practices that can adapt well to the DevOps process can be quite challenging. For a successful DevSecOps, it’s important that the new DevOps processes and tools get adapted to old methods of security practices.
<B>How DevSecOps experts at OpsTree can help?</b>
Businesses can easily overcome challenges that can hinder establishing a DevSecOps culture by adopting the right practices. With an extensive focus on delivering Cloud & DevSecOps-driven outcomes, <b><a href="https://www.opstree.com/?utm_source=Microblog&utm_medium=Dev.to&utm_campaign=Microblog_Dev.to_3+Reasons+Why+You+Should+Not+Consider+DevSecOps+%E2%80%9Ca+low-hanging+fruit%E2%80%9D%21">OpsTree Solutions & OpsTree Labs</a></b> can help enterprises in executing DevSecOps best practices. Being a highly specialized DevSecOps engineering company and Technology Transformation Partner, OpsTree Solutions is an expert in making the application delivery lean, more secure, agile, and highly productive through the best-in-breed Cloud & DevSecOps platform and solutions.
<b>Contact<a href="https://www.opstree.com/contact-us?utm_source=Microblog&utm_medium=Dev.to&utm_campaign=Microblog_Dev.to_3+Reasons+Why+You+Should+Not+Consider+DevSecOps+%E2%80%9Ca+low-hanging+fruit%E2%80%9D%21"> our technical experts </a>NOW to know about OpsTree Solutions and its other incredible services!</b>
| ruchita_varma |
921,303 | Building an Express back-end for basic CRUD operations | When enrolling for college, I had to choose between Web Development and Web Design. This decision was... | 0 | 2021-12-08T20:14:00 | https://dev.to/dubymarjtr/building-an-express-back-end-for-basic-crud-operations-4m0n | javascript, node, mongodb, express | When enrolling for college, I had to choose between Web Development and Web Design. This decision was quite easy because I thought "making a website look pretty is something that most developers can do (not saying it's easy tho!), but making a website be completely functional? That's more of a complex job, and that's a challenge I want to take".
In my Web Technologies class, after learning the basics of JavaScript and working with front-end, it was time to swim into the deep waters of the back-end of a website. I was assigned to create RESTful routes that interact with a MongoDB database using Node.js and Express.js. It was very confusing at the beginning, but after building a few small projects applying the same steps, I feel more comfortable to share the knowledge I acquired with this community.
So let's dive into it!!
The first thing we need to know about is Node.js, and I already wrote a [post](https://dev.to/dubymarjtr/understanding-node-js-5n8) about it, so go check that out so you understand why and how it is used. After installing Node, we will use the terminal to install the required dependencies, in this case are: `dotenv`, `express`, and `mongodb`. Luckily, I used a template that already had all these installed, but if your project does not have any of these, just type `npm install express` on the terminal, repeating the same syntax with the other packages.
The second step is to create a `.env` file, which will contain the database URL that will connect our application to MongoDB. This file will be untracked, since we do not want to include it in our commits. This is more of a security reason, because why will we want strangers accessing to our database, right?
```javascript
DB_CLIENT_URL=databaseurl
```
The third step is to go into our config.js file and declare the configurations for our project. In this case, I have the port, database URL, name, and collection name. Having this information here and not in other files will make our website easier to maintain, having to change it just here and not everywhere.
```javascript
export default {
port: process.env.PORT || 3000,
db: {
clientURL: process.env.DB_CLIENT_URL,
name: "sample_airbnb",
collectionName: "listingsAndReviews"
}
}
```
As you can notice, there is no way to see the actual database URL. For this project I used an Airbnb database sample from MongoDB, but in case I want to use another database, I can change the name and collection right there and that will be applied to the entire project.
The fourth step is to create a db/conns (database connections) folder, and inside create a client.js file, that will contain a reusable Mongo client to connect to our application. Here is where we use that `mongodb` package that we installed earlier. *Note*: this is the only file inside of that folder, everything else from now on will continue to exist inside the server folder.
```javascript
import { MongoClient } from "mongodb";
import config from "./config.js";
const client = new MongoClient(config.db.clientURL);
client.connect()
.then(() => {
console.info("MongoDB Client 🏃🏾♂️");
})
.catch((err) => {
console.error("Error starting MongoDB Client", err.message);
// Exit process with failure
process.exit(1);
});
process.on("SIGINT", () => {
client.close().then(() => {
console.info("MongoDB Client disconnected");
process.exit(0);
});
});
export default client;
```
Once we have our Mongo Client successfully connecting to our database, we can proceed to create our routes in the router.js file. First, we will start with a test route to connect to our API. We need to import the content from config.js, client.js, and our `Router` from `express`.
```javascript
import Router from "express";
import config from "./config.js";
import client from "./db/conns/client.js";
// create collection variable to reduce code duplication
const collection = client
.db(config.db.name)
.collection(config.db.collectionName);
const router = new Router();
// localhost:3000/api
router.get("/", (_, res) => {
res.send("Hello from API router");
});
export default router;
```
To utilize this router we need to import it to our index.js file, using express as the framework that will make our lives easier. Express gives developers all the tools they need to create HTTP servers, allowing to receive and send data as JSON.
```javascript
import express from "express";
import config from "./config.js";
import router from "./router.js";
const app = express();
// json middleware allows to send and receive JSON data
app.use(express.json());
app.get("/", (_, res) => {
res.send("Hello World");
});
app.use("/api", router);
```
To run our server we can type `npm start` in our terminal, and then go to any explorer and type http://localhost:3000/api and that will show "Hello from API router". Now that our testing route is working, we can proceed to create the rest of our routes. In this project we are using basic CRUD operations, which are Create, Read, Update, and Delete. In some of these route we will need to use [Insomnia](https://insomnia.rest/). These platform will allow us to send JSON data, since we are not doing that from the browser. The way we will send this information will be on the request body.
Let's start with the first route, which will be **create** a listing.
```javascript
// post a new listing
router.post("/listings", async (req,res) => {
const newListing = await collection.insertOne(req.body);
res.json(newListing);
})
```
The second route will allow to **read** all listings. In this case, the `{}` inside the find method brings all listing, but we can also add any filters that we want inside `{}`. Let's have in mind that these filters must be in the MongoDB language, which is different from a later update of these route where we have optional filters, using in that case JavaScript filters.
```javascript
// get all listings
router.get("/listings", async (_, res) => {
const listingsData = await collection.find({}).toArray();
res.json(listingsData);
});
```
The third one will take a listing id and **update** that listing. In the Insomnia body we can send the "payload", which is the updated data for our listing.
```javascript
// update a listing
router.put("/listings/", async (req, res) => {
const updatedListing = await collection.updateOne({ _id: req.body.id},
{ $set: req.body.payload });
res.json(updatedListing);
})
```
And the fourth one to complete our CRUD operations is to **delete** a listing using its id.
```javascript
// delete a listing
router.delete("/listings/:id", async (req, res) => {
const deletedListing = await collection.deleteOne({ _id: req.params.id });
res.json(deletedListing);
});
```
This project has more routes, such as reading an specific listing, getting all reviews from one listing, creating, updating and deleting a review from one listing. For your reference, this is the [project repo](https://github.com/dubymarjtr/airbnb-project).
These basic routes allow us to perform CRUD operations in our database, and although it is just a server-side project, this gives you an idea on how to create a full-stack website, if you already know how to connect to the client-side. Node.js and Express.js made possible to create and work with the server without knowing any other server-side language, such as PHP. | dubymarjtr |
921,058 | Remix Blog Tutorial - Firebase Auth, Remix, React, MongoDB Storage, Prisma, Vercel (Part 2) | Part 2 Remix Blog - Setup Auth through Firebase This portion of the blog assumes that you... | 0 | 2021-12-11T01:58:08 | https://dev.to/chrisbenjamin/remix-blog-tutorial-firebase-auth-remix-react-mongodb-storage-prisma-vercel-part-2-371c | javascript, react, tutorial, webdev | ## Part 2 Remix Blog - Setup Auth through Firebase
This portion of the blog assumes that you have followed the [first blog article](https://dev.to/chrisbenjamin/remix-blog-tutorial-remix-react-prisma-mongodb-vercel-1hhb).

This is a continuation that focuses on setting up Authentication using Firebase with Email and Password, protecting pages from view until authenticated, and adding a delete option for blog posts.
Note: You can follow portions of this for a basic firebase authentication for any Remix app using Firebase without having complete the first tutorial.
### Code and Demo
You can view the sourcode for this tutorial on GitHub [here](https://github.com/cbenjamin2009/remix-blog-firebase-auth)
You can view a live Demo on Vercel [here](https://remix-blog-firebase-auth.vercel.app/)
### Requirements (Free):
- Vercel Account
- Google Account
- MongoDB Account
- Completion of part 1 tutorial and working code
### Why make this tutorial?
When I was first looking at Remix, one of the issues I quickly stumbled upon was how to handle authentication. Since Remix removes the need for useState in your React app, in most cases, it was hard to grasp the concept of creating authentication. The first several times I created server side authentication with Remix it was not successful.
### Firebase setup
This section assumes you have never used Firebase before and will walk through the initial setup of your firebase account. We will be creating a Firebase account, setting up our app, and retreiving our firebase configuration information including API key.
1. Register for firebase [here](https://firebase.google.com/) and click Get Started
2. Create a new project, I named mine _remix-blog-tutorial_

3. I turned off Google Analytics, you can use this if you want.
4. Setup Auth with Email and Password
1. Click Authentication
2. Click Get Started
3. Click Email/Password under Native Providers
4. Click the slider to enable
5. Disable Email link (passwordless sign-in) for this tutorial

5. Register an App
1. In Firebase Console click Project Overview
2. On the main page where it says Get Started by adding Firebase to your app, click on the code icon </> for web app

3. I'm going to call mine _remix-blog-app_ you can name yours however you like.
4. We are not setting up firebase hosting at this time so be sure to leave that unchecked.

5. Click Register App
6. Copy your firebase config for the next step.
6. Setup your Firebase config
1. Create a folder named `utils` in your (`/app`) directory
1. Create a new file under `/app/utils` called `firebase.js`
2. Copy the firebase config from the console to this firebase.js file
7. Install Firebase `npm install firebase`
Update Your firebase.js file should look like this but leave your firebaseConfig values the same.
```javascript
import { initializeApp } from "firebase/app";
import { getAuth } from "firebase/auth"
// Your web app's Firebase configuration
const firebaseConfig = {
apiKey: "AIzaSyDhab0G2GmrgosEngBHRudaOhSrlr2d8_4",
authDomain: "remix-auth-tutorial.firebaseapp.com",
projectId: "remix-auth-tutorial",
storageBucket: "remix-auth-tutorial.appspot.com",
messagingSenderId: "496814875666",
appId: "1:496814875666:web:99246a28f282e9c3f2db5b"
};
// Initialize Firebase
const app = initializeApp(firebaseConfig);
const auth = getAuth(app)
export { auth }
```
### Project Files
Now we are going to be working our remix app.
### Project Cleanup
We are going to do a bit of project cleanup here to make our Remix project more personalized from the `npx create-remix@latest` bootstrap page.
Open your `index.jsx` file located in (`./app/routes/index.jsx`)
In the return statement of the Index() function, update it however you see fit. Also remove the current **loader** function. Here is what I'm using which gives some links to this tutorial, the github repo for the code, and the tutorial which you are currently reading.
```javascript
export default function Index() {
return (
<div className="remix__page">
<main>
<h2>Welcome to Remix Blog Auth Tutorial!</h2>
<h3>This blog was created by <strong>Chris Benjamin</strong></h3>
<p>This tutorial will show you how firebase authentication functionality works in Remix</p>
</main>
<aside>
<h3>Tutorial Links</h3>
<ul>
<li><a href="https://github.com/cbenjamin2009/remix-blog-firebase-auth" target="_blank">Github</a></li>
<li><a href="https://dev.to/chrisbenjamin" target="_blank">Tutorial</a></li>
</ul>
</aside>
</div>
);
}
```
## Authentication
This section will cover our Session file, registering for an account, logging into that account, signing out of our account, and resetting our password. We are going to add authentication to the Admin page of our blog which allows for creating blogs, editing existing blogs, and deleting blogs.
### Server Session File
We need to house all of our session data in a server side file that will handle our sessions. We are going to use the built in Remix session handling for this, refer to Remix documentation for more information.
This file will export our getSession, commitSession, and destroySession that we will use for our authentication.
Create a new file called `sessions.server.jsx` in the root of your (`/app/sessions.server.jsx`)
We are going to be using the default Remix code from their documentation for this section with 2 small changes.
1. Update the name of your token, I chose `fb:token` for firebase token.
2. Update your secrets to include something of your own.
```javascript
// app/sessions.js
import { createCookieSessionStorage } from "remix";
const { getSession, commitSession, destroySession } =
createCookieSessionStorage({
// a Cookie from `createCookie` or the CookieOptions to create one
cookie: {
//firebase token
name: "fb:token",
// all of these are optional
expires: new Date(Date.now() + 600),
httpOnly: true,
maxAge: 600,
path: "/",
sameSite: "lax",
secrets: ["tacos"],
secure: true
}
});
export { getSession, commitSession, destroySession };
```
### Login Setup
This is our Login route file which will handle user authentication for logging in and/or registering for our app through Firebase.
The Remix **Loader** function will be used to see if a user is already logged in, if so, it will not render the login page it will instead redirect them to the blogs page.
The Remix **Action** function will receive the post request from the login button to sign our user in with email and password. We will also be creating a session cookie to keep the user signed in for the duration of their session. If a user closes their browser and tries to get back to the page, it will ask them to sign in again.
1. Create `./app/routes/login.jsx`
```javascript
import { auth } from "~/utils/firebase"
import { signInWithEmailAndPassword } from "@firebase/auth";
import { redirect, Form, Link, json, useActionData } from "remix";
import { getSession, commitSession } from "~/sessions.server";
import authStyles from "~/styles/auth.css";
//create a stylesheet ref for the auth.css file
export let links = () => {
return [{rel: "stylesheet", href: authStyles}]
}
// use loader to check for existing session, if found, send the user to the blogs site
export async function loader({ request }) {
const session = await getSession(
request.headers.get("Cookie")
);
if (session.has("access_token")) {
// Redirect to the blog page if they are already signed in.
// console.log('user has existing cookie')
return redirect("/blogs");
}
const data = { error: session.get("error") };
return json(data, {
headers: {
"Set-Cookie": await commitSession(session)
}
});
}
// our action function will be launched when the submit button is clicked
// this will sign in our firebase user and create our session and cookie using user.getIDToken()
export let action = async ({ request }) => {
let formData = await request.formData();
let email = formData.get("email");
let password = formData.get("password")
const {user, error} = await signInWithEmailAndPassword(auth, email, password)
// if signin was successful then we have a user
if ( user ) {
// let's setup the session and cookie wth users idToken
let session = await getSession(request.headers.get("Cookie"))
session.set("access_token", await user.getIdToken())
// let's send the user to the main page after login
return redirect("/admin", {
headers: {
"Set-Cookie": await commitSession(session),
}
})
}
return { user, error}
}
export default function Login(){
// to use our actionData error in our form, we need to pull in our action data
const actionData = useActionData();
return(
<div className="loginContainer">
<div className="authTitle">
<h1>Login</h1>
</div>
<Form method="post">
<label htmlFor="email">Email</label>
<input className="loginInput" type="email" name="email" placeholder="you@awesome.dev" required />
<label htmlFor="password">Password</label>
<input className="loginInput" type="password" name="password" required />
<button className="loginButton" type="submit">Login</button>
</Form>
<div className="additionalLinks">
<Link to="/auth/register">Register</Link>
<Link to="/auth/forgot">Forgot Password?</Link>
</div>
<div className="errors">
{actionData?.error ? actionData?.error?.message: null}
</div>
</div>
)
}
```
### Additional Authentication Functions
First, let's house all of our authentication besides login in a folder to keep it together and clean.
Create a folder called `auth` under (`/app/routes/auth/`)
### Register User Setup
This will allow a user to register and create a new user account for our blog and then immediately sign them in.
The Remix **Action** function will receive the post request from the register button to register our user with email and password then sign them in. If there are no errors with creating the user, we will create a session cookie to keep the user signed in for the duration of their session and redirect them to the home page. If a user closes their browser and tries to get back to the page, it will ask them to sign in again.
1. Create `register.jsx` in (`/app/routes/auth/register.jsx`)
```javascript
import { auth } from "~/utils/firebase"
import { createUserWithEmailAndPassword } from "@firebase/auth";
import { redirect, Form, useActionData, Link, json } from "remix";
import { getSession, commitSession } from "~/sessions.server";
import authStyles from "~/styles/auth.css";
//create a stylesheet ref for the auth.css file
export let links = () => {
return [{rel: "stylesheet", href: authStyles}]
}
// This will be the same as our Sign In but it will say Register and use createUser instead of signIn
export let action = async ({ request }) => {
let formData = await request.formData();
let email = formData.get("email");
let password = formData.get("password")
//perform a signout to clear any active sessions
await auth.signOut();
//setup user data
let {session: sessionData, user, error: signUpError} = await createUserWithEmailAndPassword(auth, email, password)
if (!signUpError){
let session = await getSession(request.headers.get("Cookie"))
session.set("access_token", auth.currentUser.access_token)
return redirect("/blogs",{
headers: {
"Set-Cookie": await commitSession(session),
}
})
}
// perform firebase register
return {user, signUpError}
}
export default function Register(){
const actionData = useActionData();
return(
<div className="loginContainer">
<div className="authTitle">
<h1>Register</h1>
</div>
<Form method="post">
<label htmlFor="email">Email</label>
<input className="loginInput" type="email" name="email" placeholder="you@awesome.dev" required />
<label htmlFor="password">Password</label>
<input className="loginInput" type="password" name="password" required />
<button className="loginButton" type="submit">Register</button>
</Form>
<div className="additionalLinks">
Already Registered? <Link to="/login">Login</Link>
</div>
<div className="errors">
{actionData?.error ? actionData?.error?.message: null}
</div>
</div>
)
}
```
### Logout Setup (Updated 12/17/2021)
It's important that our users be able to logout of their session.
**Update**: The previous version of this blog had the logout feature be a separate route, this resulted in the Root not re-rendering and therefore the logout button remained even after logout. This new update uses a remix `<Form>` tag to call an action and post the request which updates correctly.
The Remix **Action** function will load in the current session Cookie, and then using destroySession from Remix we will remove that cookie to effectively sign the user out and then redirect them to the home page.
1. Edit your `Root.jsx` file as follows
Update the imports to include the following
```javascript
import { redirect } from "remix";
import { getSession } from "~/sessions.server";
import { destroySession } from "~/sessions.server";
import { auth } from "~/utils/firebase";
```
Now let's setup our action which will run when the user clicks the Logout button in the nav.
```javascript
// loader function to check for existing user based on session cookie
// this is used to change the nav rendered on the page and the greeting.
export async function loader({ request }) {
const session = await getSession(
request.headers.get("Cookie")
);
if (session.has("access_token")) {
const data = { user: auth.currentUser, error: session.get("error") };
return json(data, {
headers: {
"Set-Cookie": await commitSession(session)
}
});
} else {
return null;
}
}
```
### Forgot Password Setup
Let's setup the page if a user forgets their password
Create a new file called `forgot.jsx` under (`/app/routes/auth/forgot.jsx`)
The Remix **Action** will receive the users email from the post request on submit, and then using Firebase Auth sendPasswordResetEmail function, we can have Firebase send the user an email with instructions on how to reset their password. If sending the email is successful we will inform the user and then redirect back to the login page so they can attempt to login again.
Update your `forgot.jsx`:
```javascript
import { auth } from "~/utils/firebase"
import { sendPasswordResetEmail } from "@firebase/auth";
import { redirect, Form, Link } from "remix";
export let action = async ({ request }) => {
// pull in the form data from the request after the form is submitted
let formData = await request.formData();
let email = formData.get("email");
// perform firebase send password reset email
try{
await sendPasswordResetEmail(auth, email)
}
catch (err) {
console.log("Error: ", err.message)
}
// success, send user to /login page
return redirect('/login')
}
export default function Login(){
return(
<div className="loginContainer">
<div className="authTitle">
<h1>Forgot Password?</h1>
</div>
<Form method="post">
<p>Enter the email address associated with your account</p>
<input className="loginInput" type="email" name="email" placeholder="you@awesome.dev" required />
<button className="loginButton" type="submit">Submit</button>
</Form>
<div className="additionalLinks">
Not Yet Registered? <Link to="/auth/register">Register</Link>
</div>
</div>
)
}
```
### Update Navigation
We are going to update our navigation to have a Login/Logout button. This will vary depending on if the user is currently logged in or not. If the user is not logged in, we want it to say Login, otherwise it will say Logout. We will also add a small greeting to put the user's email address on the home page to show the email address they signed in with, if they are not signed in, it will say 'friend'.
How do we know if someone is logged in or not? We use the **actionLoader** function to get the data from our action. Our action will check the current session for a Cookie containing access_token value and if it exists it will load that user's information.
1. Let's add our Remix **Loader** function to check if the user has an existing session when they first hit our root site.
1. Open `root.jsx`
2. Add the following import statements if they are not already imported
``` javascript
import {auth} from "~/utils/firebase"
import { useLoaderData, json } from "remix";
import { getSession } from "./sessions.server";
import { commitSession } from "./sessions.server";
```
3. Add the following loader function
```javascript
// loader function to check for existing user based on session cookie
// this is used to change the nav rendered on the page and the greeting.
export async function loader({ request }) {
const session = await getSession(
request.headers.get("Cookie")
);
if (session.has("access_token")) {
const data = { user: auth.currentUser, error: session.get("error") };
return json(data, {
headers: {
"Set-Cookie": await commitSession(session)
}
});
} else {
return null;
}
}
```
2. Pull in the loader data and check if the user is logged in or not. Create responsive nav links for Login and Log Out (Register will be a link on the Login page) in `root.jsx`.
The logout button will be wrapped in a Remix `<Form>` tag which will allow our action loader to run when the user clicks our logout button and not trigger a full page refresh. We are also going to add a Class so we can update our styles to make it match the rest of the nav.
```javascript
function Layout({ children }) {
// let's grab our loader data to see if it's a sessioned user
let data = useLoaderData();
// let's check to see if we have a user, if so we will use it to update the greeting and link logic for Login/Logout in Nav
let loggedIn = data?.user
return (
<div className="remix-app">
<header className="remix-app__header">
<div className="container remix-app__header-content">
<Link to="/" title="Remix" className="remix-app__header-home-link">
<RemixLogo />
</Link>
<nav aria-label="Main navigation" className="remix-app__header-nav">
<ul>
<li>
<Link to="/">Home</Link>
</li>
{!loggedIn ? <li>
<Link to="/login">Login</Link>
</li> :
<li>
<Form method="post">
<button type="submit" className="navLogoutButton">Logout</button>
</Form>
</li> }
<li>
<Link to="/blogs">Blogs</Link>
</li>
<li>
<a href="https://remix.run/docs">Remix Docs</a>
</li>
<li>
<a href="https://github.com/remix-run/remix">GitHub</a>
</li>
</ul>
</nav>
</div>
</header>
<div className="remix-app__main">
<div className="container remix-app__main-content">{children}</div>
</div>
<footer className="remix-app__footer">
<div className="container remix-app__footer-content">
<p>© You!</p>
</div>
</footer>
</div>
);
}
```
Lets update our global style to set the style so it appears just like the rest of our nav links instead of as a button.
Open `global.css` from (`/app/styles/global.css`) and update the exiting a tags and adding .navLogoutButton styling as follows:
```css
a, .navLogoutButton {
color: var(--color-links);
text-decoration: none;
}
a:hover, .navLogoutButton:hover {
color: var(--color-links-hover);
text-decoration: underline;
}
.navLogoutButton{
background: none;
border: none;
font-family: var(--font-body);
font-weight: bold;
font-size: 16px;
}
```
### Update Blogs page to put link for admin inside our blogs page
Open `index.jsx` from (`/app/routes/blogs/index.jsx`)
Update the Posts() function
```javascript
// our Posts function which will return the rendered component on the page .
export default function Posts() {
let posts = useLoaderData();
return (
<div>
<h1>My Remix Blog</h1>
<p>Click on the post name to read the post</p>
<div>
<Link to="/admin">Blog Admin (Edit/Create)</Link>
</div>
<ul>
{posts.map(post => (
<li className="postList" key={post.slug}>
<Link className="postTitle" to={post.slug}>{post.title}</Link>
</li>
))}
</ul>
</div>
)
}
```
### Update Index.jsx page if logged in
When the user is logged in, let's add a quick greeting on the index page to help us identify if the user is logged in or not.
The Remix **loader** function is going to check for a current Cookie with access_token to determine if user is logged in. This will change the 'Welcome Friend...' to read 'Welcome <useremail>'.
The Remix **action** is set to redirect the user to the login page.
Open your `index.jsx` under (`/app/index.jsx`)
1. Add the following imports and loader to check if logged in
```javascript
import { useLoaderData, json, Link, redirect} from "remix";
import { auth } from "~/utils/firebase"
import { getSession } from "~/sessions.server";
import { destroySession, commitSession } from "~/sessions.server";
// use loader to check for existing session
export async function loader({ request }) {
const session = await getSession(
request.headers.get("Cookie")
);
if (session.has("access_token")) {
//user is logged in
const data = { user: auth.currentUser, error: session.get("error") };
return json(data, {
headers: {
"Set-Cookie": await commitSession(session)
}
});
}
// user is not logged in
return null;
}
```
If the user is logged in it will show as this with their email

If the user is logged out it will show as this

## Testing Login, Logout, Forgot and Register
Superb Job! You should now have functional Firebase authentication in your Remix Blog app. Users will now be able to sign in to the blog so let's give that a go!
### Register
Before we can login, we first need to register. _If your project is not running, simply run `npm run dev` to get it going._ Click on Login in the top Nav of your remix application and then click Register link next to Not Yet Registered.

Input a Email address and a Password and then click Register
If successful, you should be redirected to the Admin page. Awesomesauce!
### Logout
Now that we are logged in, let's log out and then make sure we can get back in. On your Remix app, click Logout on the top nav. You should be redirected to the home page and it should update to show Login.

### Login
Let's log back in with that same Email and Password you created. If successful, you should be logged in and looking at the admin page.

### Forgot
If a user forgets their password, we want them to be able to receive a password reset email so they can gain access to their account. Since we are using Firebase Auth, this process is pretty simple, we pass the email address to firebase and the user will get an email with a link that lets them set a new password.

## Styling
What app is complete without styling? Our current pages are looking a bit like they came out of the 90's! Let's add some basic styles to make our app more appealing, you can skip this step or create your own styles.
We are going to create auth.css in (`/app/styles/auth.css`)
Inside your auth.css we are going to apply some basic styles for our form with some flex, background, padding, and margins.
```css
/* Used for styling the Auth pages (Login, Register, Forgot) */
.loginContainer{
margin-top: 1em;
display: flex;
flex-direction: column;
text-align: center;
padding: 3em;
background-color: rgba(0, 0, 0, 0.301);
border-radius: 10px;
}
.loginContainer h1 {
margin-bottom: 2em;
}
.loginContainer label {
font-size: 1.5em;
font-weight: bold;
}
.loginContainer form {
display: flex;
flex-direction: column;
}
.loginInput{
padding: .5em;
font-size: 1.5em;
margin: 1em;
border-radius: 1em;
border: none;
}
.loginButton {
padding: .2em;
font-size: 2em;
border-radius: 1em;
width: 200px;
margin-left: auto;
margin-right: auto;
margin-bottom: 2em;
cursor: pointer;
background-color: rgba(47, 120, 255, 0.733);
}
.loginButton:hover{
border: 2px dashed skyblue;
background-color: rgba(47, 120, 255, 0.9);
}
.additionalLinks{
display: flex;
justify-content: space-evenly;
font-size: x-large;
}
```
We then need to import this stylesheet using Remix links on all of the pages that we want to have the styles applied.
Add the following code to `login.jsx, forgot.jsx, register.jsx`
```javascript
import authStyles from "~/styles/auth.css";
//create a stylesheet ref for the auth.css file
export let links = () => {
return [{rel: "stylesheet", href: authStyles}]
}
```
The login page should now look like this:

The register page should now look like this:

The forgot page should now look like this

## Protect pages from view unless logged in
We want to protect our admin page from being rendered unless the user is authenticated with our app.
1. Let's secure our Admin page
2. Open `admin.jsx` from (`/app/routes/admin.jsx`)
3. Update the imports and loader to look like this. The loader function will check the cookies for a session, if it doesn’t find one it will redirect the user to the login page, otherwise it commits the existing session and renders.
```javascript
import { Outlet, Link, useLoaderData, redirect, json } from 'remix';
import { getPosts } from "~/post";
import adminStyles from "~/styles/admin.css";
import { getSession } from '~/sessions.server';
import { commitSession } from '~/sessions.server';
//create a stylesheet ref for the admin.css file
export let links = () => {
return [{rel: "stylesheet", href: adminStyles}]
}
// this is the same loader function from our Blogs page
// check for existing user, if not then redirect to login, otherwise set cookie and getPosts()
export async function loader({ request }) {
const session = await getSession(
request.headers.get("Cookie")
);
if (!session.has("access_token")) {
return redirect("/login");
}
const data = { error: session.get("error") };
return json(data, {
headers: {
"Set-Cookie": await commitSession(session)
}
}), getPosts();
}
```
Now if someone who is not authenticated through login or has a cookie and tries to access the admin page, they will be sent back to the login page automatically.
## Blog Delete Functionality
We want to be able to delete blog articles on our blog site, so let's add in the functionality to do that.
### Add Delete
Open your `$edit.jsx` file from (`/app/routes/admin/$edit.jsx`)
Below the existing From in the return section, let's add another form, this type we are going to set the method to delete so we can capture that in our action and run a different action. Since we will be including 2 Form tags, I'm going to wrap both of these in a JSX Fragment. Update your PostSlug() function as follows. I have also added a class to the submit button for styling.
```javascript
export default function PostSlug() {
let errors = useActionData();
let transition = useTransition();
let post = useLoaderData();
return (
<>
<Form method="post">
<p>
<input className="hiddenBlogID" name="id" defaultValue={post.id}>
</input>
</p>
<p>
<label htmlFor="">
Post Title: {" "} {errors?.title && <em>Title is required</em>} <input type="text" name="title" defaultValue={post.title}/>
</label>
</p>
<p>
<label htmlFor=""> Post Slug: {" "} {errors?.slug && <em>Slug is required</em>}
<input defaultValue={post.slug} id="slugInput" type="text" name="slug"/>
</label>
</p>
<p>
<label htmlFor="markdown">Markdown:</label>{" "} {errors?.markdown && <em>Markdown is required</em>}
<br />
<textarea defaultValue={post.markdown} name="markdown" id="" rows={20} cols={50}/>
</p>
<p>
<button type="submit" className="adminButton updateButton">{transition.submission ? "Updating..." : "Update Post"}</button>
</p>
</Form>
<Form method="delete">
<p>
<input className="hiddenBlogID" name="id" defaultValue={post.id}>
</input>
</p>
<p>
<button className="adminButton deleteButton" type="submit">Delete</button>
</p>
</Form>
</>
)
}
```
Now let's update our Remix **loader** function in the same file to check the request.method and if so it will call deletePost() from our post method.
```javascript
export let action = async ({ request }) => {
let formData = await request.formData();
let title = formData.get("title");
let slug = formData.get("slug")
let markdown = formData.get("markdown")
let id = formData.get("id");
if (request.method == 'DELETE'){
await deletePost(id)
return redirect("/admin")
}
let errors = {};
if (!title) errors.title = true;
if (!slug) errors.slug = true;
if (!markdown) errors.markdown = true;
if (Object.keys(errors).length) {
return errors;
}
await updatePost({id, title, slug, markdown});
return redirect("/admin")
}
```
Awesome, now we just need to update our post method so it knows what to do when deletePost() is called.
Open your `post.js` file from (`/app/post.js`)
Add the following deletePost() function
```javascript
export async function deletePost(post){
await prisma.$connect()
await prisma.posts.delete({
where: {
id: post
},
})
prisma.$disconnect();
return(post);
}
```
Sweet, now all we have to do is update our imports on our `$edit.jsx` to bring in this deletePost() function.
Open `$edit.jsx` and update the import at the top
`import { getPostEdit, updatePost, deletePost } from "~/post";`
Now when we click the shiny Delete button, our blog post will actually get deleted.
### Updated Admin Styling
Let's update our admin styling a little bit to make the button's a bit nicer. You have creative freedom here to style however you see fit. Otherwise update your admin.css file to look like this so the buttons are styled a bit.
Open your `admin.css` from (`/app/styles/admin.css`)
```css
.admin {
display: flex;
flex-direction: row;
}
.admin > h1 {
padding-right: 2em;
}
.admin > nav {
flex: 1;
border-left: solid 2px #555;
padding-left: 2em;
}
.hiddenBlogID {
display: none;
}
.adminNewPostButton{
margin-top: 2em;
background-color: royalblue;
color: white;
border-radius: 10px;
padding: 1em;
}
.adminTitle {
font-size: x-large;
color: crimson;
}
.remix-app__header{
background-color: rgb(141, 20, 20);
}
.adminButton{
color: white;
padding: 1em;
border-radius: 2em;
}
.deleteButton{
background-color: rgb(158, 3, 3);
}
.updateButton{
background-color: rgb(2, 5, 180);
}
```
Awesome now it should look something like this

### Final Folder Structure
The final folder structure should look like this. If something isn't working, take a peek and make sure you have the folders in order.

## Deploy to Vercel
Let's get our application published to our Vercel site.
Close your running dev server.
Let's run a build `npm run build`
Let's deploy run `vercel deploy` 🚀🚀🚀
## Conclusion
Through this tutorial, you now have a Remix blog site that stores it's blog posts on MongoDB, has authentication through Firebase Auth, and is hosted on Vercel.
One of the most important things I learned when creating this tutorial was how server side Authentication works. The first attempts were logging in the server on the server-side so anyone visiting the app was authenticated. It’s important to do client auth for each client and just use the Remix Loader functions to get the cookie in user session and keep it updated.
I’m on @buymeacoffee. If you like my work, you can buy me a taco and share your thoughts 🎉🌮
<a href="https://www.buymeacoffee.com/ChrisBenjamin" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a> | chrisbenjamin |
921,079 | Let the games begin: My DevOps Journey starts today! | Today is the day! Today, I will go from knowing almost nothing about DevOps to... well, I hope... | 15,823 | 2021-12-08T16:20:28 | https://dev.to/dodothedev/let-the-games-begin-my-devops-journey-starts-today-234l | devops, bootcamp, beginners, codenewbie | Today is the day!
Today, I will go from knowing almost nothing about DevOps to... well, I hope _something_.
I've been waiting for this day for nearly 2 months, and have slowly been getting nervous as the day has approached. I would be working a regular job at the moment, but my health has taken another turn, so I've been at home almost as long as I've been waiting for the course.
2 months is a long time to be at home doing nothing. I've kept myself busy with little house chores I can physically do, but otherwise, my days have been very empty.
Or at least they would have if I hadn't set myself a goal.
In this post, I will share with you the lessons I've learnt from self-study and how I have adapted them to allow me to enter my virtual classroom today excited and ready to learn about DevOps.
## Potential pitfalls of learning from home:
This will not be the first time I try to learn an IT role and enter the field. This will actually be the fourth attempt at learning an IT skill. I have previously attempted to learn to become a Cisco Certified Network Associate (CCNA), become a web developer, and become an Android App developer from scratch. All three have failed for varying reasons, but the common reasons are **Discipline**, **Support** and **set goals**.
In all of my previous attempts, I have been very enthusiastic for the first couple of months of learning a new skill. My learning in the first few months has been excellent, as I've devoured the content to try and learn everything as quickly as possible.
Eventually, the enthusiasm has worn off, and I've maybe sat down to learn once or twice a week. Eventually, it's been months since I looked at it, and can barely remember what I learned. There's just been no **Discipline**.
On those occasions, it's not unfair to say that my support has been minimal at best. Because I was learning alone, I had no one interested enough to bounce ideas off of, and no one to go and see to ask questions. Yes, I had access to resources online like StackOverflow and Reddit, but that's not the same as sitting down with someone who explains it to you till you 'get it'. There simply was no **Support**.
Finally, as I said above, I had no discipline in my learning, it was all or nothing. This not only leads to burnout, but also to losing interest quite quickly. There were no **Set Goals** that would help me see progress.
## Keeping the mind ticking over:
> "If you wait to be offered an opportunity to learn, you will be
waiting a long time."
Peter Hutton | TEDxMelbourne
When I first heard about the possibility of doing a Skills Bootcamp (read about that in my [previous blog post in this series](https://devops-dodo.hashnode.dev/devops-minus-1-day-what-is-a-skills-bootcamp)) I knew I was going to need to work hard and dedicate myself as much as I could to this program. Part of the requirements for getting on the course is that you agree to attend at least 90% of the sessions. This can be a big ask for someone trying to hold down a full-time job, or deal with a young family at the same time. Of course, exceptions can be made, all Purple Beard ask is that you keep your learning assistant advised.
Still, I knew that going in without "warming up" wouldn't be best conducive to learning or retention.
On many of the courses I looked at before choosing one, an ability to code was a strong recommendation (although not a requirement. Plenty of people have started these courses with very little knowledge and come out the other end fully capable). As I wasn't a stranger to coding (as mentioned above), I decided it was time to blow out the cobwebs and get my coding gears in workable shape before my course.
I settled on learning Python, as it had often been recommended as a beginner-friendly language to learn. I started with apps like Mimo, SoloLearn and others, but found their "courses" rather skimpy on the details. I decided it was time to hit the books.
## "Dummies" Leads the way:
> "Tell me and I forget, teach me and I may remember, involve me and I learn.”
― Benjamin Franklin.
I have used the "For Dummies" series of books for many things in the past, from Buddhism and meditation to Coding and cooking. I have always found their writing style and structure to be engaging and educational, so when it came to choosing a book to learn Python, there was no hesitancy to head straight to their books.
The first one I bought was useless, as it was 15 years out of date and was talking about the old version of Python. I managed to find a 7-in-1 book on Python from the "Dummies" series for the same price as the out of date one online, so promptly got it.
The book that arrived teaches all the basics of Python in the first three mini-books and then allows you to expand and use that knowledge to learn a little about Artificial Intelligence (AI), Data Science, hardware interaction and finally robotics.
I have so far finished the first three mini-books, and therefore learnt the basics of Python (more than enough for my DevOps course, my learning assistant tells me), but I would highly recommend this book to any new learners of Python. It's by no means perfect, I've found plenty of mistakes and typos as I read it, but will certainly give you a great understanding of Python and how it's used in various popular fields.
## Book and language chosen, how did I learn from home?

Now I had my medium and subject chosen, I want to tell you what I did to prepare for my course.
Being off work for so long and with no concrete date of when (or if) I would be going back, it would have been too easy to sit and watch Netflix all day or play on my Playstation till my manager let me go back to work (in fact, that's exactly what I'd done on previous occasions off sick from work). But with a goal in mind this time, I knew I couldn't 'slack off' for 6 weeks and then go in all guns blazing to 10-15 hours of study per week without feeling it.
I, therefore, decided to use my Python learning as a warm-up for the course itself. I split each chapter into their sections and set myself a rota of doing a certain amount each day. I used the Pomodoro method (where you work for 25 minutes, rest for 5, work 25, rest 5, work 25, rest 5, work 25, rest 15) and during my work session, I would read my book and write the notes.
<blockquote class="instagram-media" data-instgrm-captioned data-instgrm-permalink="https://www.instagram.com/p/CV_H69SD4gA/?utm_source=ig_embed&utm_campaign=loading" data-instgrm-version="14" style=" background:#FFF; border:0; border-radius:3px; box-shadow:0 0 1px 0 rgba(0,0,0,0.5),0 1px 10px 0 rgba(0,0,0,0.15); margin: 1px; max-width:540px; min-width:326px; padding:0; width:99.375%; width:-webkit-calc(100% - 2px); width:calc(100% - 2px);"><div style="padding:16px;"> <a href="https://www.instagram.com/p/CV_H69SD4gA/?utm_source=ig_embed&utm_campaign=loading" style=" background:#FFFFFF; line-height:0; padding:0 0; text-align:center; text-decoration:none; width:100%;" target="_blank"> <div style=" display: flex; flex-direction: row; align-items: center;"> <div style="background-color: #F4F4F4; border-radius: 50%; flex-grow: 0; height: 40px; margin-right: 14px; width: 40px;"></div> <div style="display: flex; flex-direction: column; flex-grow: 1; justify-content: center;"> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; margin-bottom: 6px; width: 100px;"></div> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; width: 60px;"></div></div></div><div style="padding: 19% 0;"></div> <div style="display:block; height:50px; margin:0 auto 12px; width:50px;"><svg width="50px" height="50px" viewBox="0 0 60 60" version="1.1" xmlns="https://www.w3.org/2000/svg" xmlns:xlink="https://www.w3.org/1999/xlink"><g stroke="none" stroke-width="1" fill="none" fill-rule="evenodd"><g transform="translate(-511.000000, -20.000000)" fill="#000000"><g><path d="M556.869,30.41 C554.814,30.41 553.148,32.076 553.148,34.131 C553.148,36.186 554.814,37.852 556.869,37.852 C558.924,37.852 560.59,36.186 560.59,34.131 C560.59,32.076 558.924,30.41 556.869,30.41 M541,60.657 C535.114,60.657 530.342,55.887 530.342,50 C530.342,44.114 535.114,39.342 541,39.342 C546.887,39.342 551.658,44.114 551.658,50 C551.658,55.887 546.887,60.657 541,60.657 M541,33.886 C532.1,33.886 524.886,41.1 524.886,50 C524.886,58.899 532.1,66.113 541,66.113 C549.9,66.113 557.115,58.899 557.115,50 C557.115,41.1 549.9,33.886 541,33.886 M565.378,62.101 C565.244,65.022 564.756,66.606 564.346,67.663 C563.803,69.06 563.154,70.057 562.106,71.106 C561.058,72.155 560.06,72.803 558.662,73.347 C557.607,73.757 556.021,74.244 553.102,74.378 C549.944,74.521 548.997,74.552 541,74.552 C533.003,74.552 532.056,74.521 528.898,74.378 C525.979,74.244 524.393,73.757 523.338,73.347 C521.94,72.803 520.942,72.155 519.894,71.106 C518.846,70.057 518.197,69.06 517.654,67.663 C517.244,66.606 516.755,65.022 516.623,62.101 C516.479,58.943 516.448,57.996 516.448,50 C516.448,42.003 516.479,41.056 516.623,37.899 C516.755,34.978 517.244,33.391 517.654,32.338 C518.197,30.938 518.846,29.942 519.894,28.894 C520.942,27.846 521.94,27.196 523.338,26.654 C524.393,26.244 525.979,25.756 528.898,25.623 C532.057,25.479 533.004,25.448 541,25.448 C548.997,25.448 549.943,25.479 553.102,25.623 C556.021,25.756 557.607,26.244 558.662,26.654 C560.06,27.196 561.058,27.846 562.106,28.894 C563.154,29.942 563.803,30.938 564.346,32.338 C564.756,33.391 565.244,34.978 565.378,37.899 C565.522,41.056 565.552,42.003 565.552,50 C565.552,57.996 565.522,58.943 565.378,62.101 M570.82,37.631 C570.674,34.438 570.167,32.258 569.425,30.349 C568.659,28.377 567.633,26.702 565.965,25.035 C564.297,23.368 562.623,22.342 560.652,21.575 C558.743,20.834 556.562,20.326 553.369,20.18 C550.169,20.033 549.148,20 541,20 C532.853,20 531.831,20.033 528.631,20.18 C525.438,20.326 523.257,20.834 521.349,21.575 C519.376,22.342 517.703,23.368 516.035,25.035 C514.368,26.702 513.342,28.377 512.574,30.349 C511.834,32.258 511.326,34.438 511.181,37.631 C511.035,40.831 511,41.851 511,50 C511,58.147 511.035,59.17 511.181,62.369 C511.326,65.562 511.834,67.743 512.574,69.651 C513.342,71.625 514.368,73.296 516.035,74.965 C517.703,76.634 519.376,77.658 521.349,78.425 C523.257,79.167 525.438,79.673 528.631,79.82 C531.831,79.965 532.853,80.001 541,80.001 C549.148,80.001 550.169,79.965 553.369,79.82 C556.562,79.673 558.743,79.167 560.652,78.425 C562.623,77.658 564.297,76.634 565.965,74.965 C567.633,73.296 568.659,71.625 569.425,69.651 C570.167,67.743 570.674,65.562 570.82,62.369 C570.966,59.17 571,58.147 571,50 C571,41.851 570.966,40.831 570.82,37.631"></path></g></g></g></svg></div><div style="padding-top: 8px;"> <div style=" color:#3897f0; font-family:Arial,sans-serif; font-size:14px; font-style:normal; font-weight:550; line-height:18px;">View this post on Instagram</div></div><div style="padding: 12.5% 0;"></div> <div style="display: flex; flex-direction: row; margin-bottom: 14px; align-items: center;"><div> <div style="background-color: #F4F4F4; border-radius: 50%; height: 12.5px; width: 12.5px; transform: translateX(0px) translateY(7px);"></div> <div style="background-color: #F4F4F4; height: 12.5px; transform: rotate(-45deg) translateX(3px) translateY(1px); width: 12.5px; flex-grow: 0; margin-right: 14px; margin-left: 2px;"></div> <div style="background-color: #F4F4F4; border-radius: 50%; height: 12.5px; width: 12.5px; transform: translateX(9px) translateY(-18px);"></div></div><div style="margin-left: 8px;"> <div style=" background-color: #F4F4F4; border-radius: 50%; flex-grow: 0; height: 20px; width: 20px;"></div> <div style=" width: 0; height: 0; border-top: 2px solid transparent; border-left: 6px solid #f4f4f4; border-bottom: 2px solid transparent; transform: translateX(16px) translateY(-4px) rotate(30deg)"></div></div><div style="margin-left: auto;"> <div style=" width: 0px; border-top: 8px solid #F4F4F4; border-right: 8px solid transparent; transform: translateY(16px);"></div> <div style=" background-color: #F4F4F4; flex-grow: 0; height: 12px; width: 16px; transform: translateY(-4px);"></div> <div style=" width: 0; height: 0; border-top: 8px solid #F4F4F4; border-left: 8px solid transparent; transform: translateY(-4px) translateX(8px);"></div></div></div> <div style="display: flex; flex-direction: column; flex-grow: 1; justify-content: center; margin-bottom: 24px;"> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; margin-bottom: 6px; width: 224px;"></div> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; width: 144px;"></div></div></a><p style=" color:#c9c8cd; font-family:Arial,sans-serif; font-size:14px; line-height:17px; margin-bottom:0; margin-top:8px; overflow:hidden; padding:8px 0 7px; text-align:center; text-overflow:ellipsis; white-space:nowrap;"><a href="https://www.instagram.com/p/CV_H69SD4gA/?utm_source=ig_embed&utm_campaign=loading" style=" color:#c9c8cd; font-family:Arial,sans-serif; font-size:14px; font-style:normal; font-weight:normal; line-height:17px; text-decoration:none;" target="_blank">A post shared by Dominic Ross (@youngdad33)</a></p></div></blockquote> <script async src="//www.instagram.com/embed.js"></script>
### Tools for notes:
In my previous learning journey, I had used an app called [Quiver](https://apps.apple.com/us/app/quiver-take-better-notes/id866773894?mt=12) on my MacBook, but seeing as I was now on a Chromebook, that was no longer a possibility. I did some research and found a suitable alternative in [Notion](www.notion.so), and started writing my notes. Each chapter was a new page in my Notion workbook, and it slowly grew to have over a dozen pages split into separate topics.
The benefit of using Notion (and other similar programmes) is that you can mix Markdown Text with Code snippets and images. I typically wrote my code in the code snippet feature, then paste a screenshot of the outcome from VS Code.
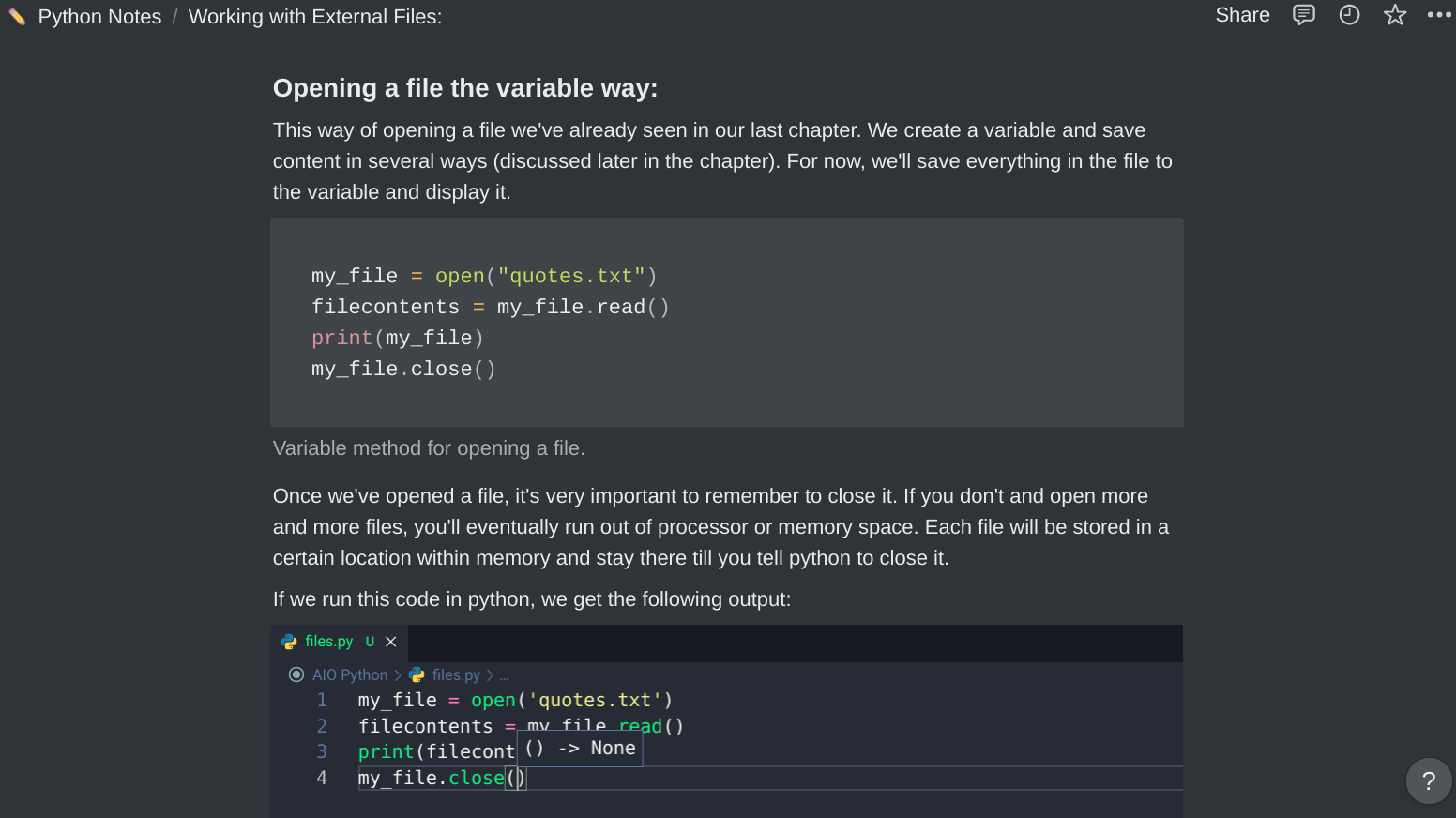
### Getting to know the IDE:
Before I bought the Python All In One For Dummies book, I was using the text editor [Atom](https://atom.io/), created by the good people at Github. I had previously used and liked working with it (although I'm fairly sure I wasn't using it to its full potential).
When I started reading the book, however, they encouraged you to use [VS Code](https://code.visualstudio.com/) (aka code) from Microsoft. I'll admit I was a little reluctant to do so, as I did like using Atom, but since both were available for Linux (the only way I could get it to run on our Chromebook), and I didn't have time to try and translate what they were doing in the book to what I needed to do on Atom, I opted to at least try VS Code.
To my delight, I found that using Code was very much like using Atom and didn't appear to have anything missing. I was able to follow along with the instructions in the book (despite a few technical difficulties they didn't provide for as they wrote the book for windows and mac users) and got the same results they did. As it turns out, when we had our Onboarding session with Purple Beard, it turns out they teach using VS Code too, so that was a nice bonus.
### Good working environment:
All of the above is great, but if you're exhausted and restless after one session, you won't be able to give your full attention to the rest of the course.
Set yourself up for success with a good working environment all set up and ready to go for when your course starts.
I've had nearly 2 months to prepare, and as well as the above steps, I've made sure that, when the time comes, I would be comfortable and ready to learn when my class started.
Sitting on the sofa or bed with books dotted around you and your laptop balanced on your knee is not ideal. You need a dedicated space set up to learn from.
I started out in a comfy chair with my legs up and a table to my side, and slowly added elements to help make the area more conducive to learning. I started with a book stand, to keep my book within view and readable without bending in all sorts of funny positions, I got a light to shine directly down on me to make sure I wasn't straining my eyes, and eventually went the whole 9 yards and got a desk and chair to stop me from getting a painful back and neck and to allow me to use a second screen.
<blockquote class="instagram-media" data-instgrm-captioned data-instgrm-permalink="https://www.instagram.com/p/CWn9YNZD_Kt/?utm_source=ig_embed&utm_campaign=loading" data-instgrm-version="14" style=" background:#FFF; border:0; border-radius:3px; box-shadow:0 0 1px 0 rgba(0,0,0,0.5),0 1px 10px 0 rgba(0,0,0,0.15); margin: 1px; max-width:540px; min-width:326px; padding:0; width:99.375%; width:-webkit-calc(100% - 2px); width:calc(100% - 2px);"><div style="padding:16px;"> <a href="https://www.instagram.com/p/CWn9YNZD_Kt/?utm_source=ig_embed&utm_campaign=loading" style=" background:#FFFFFF; line-height:0; padding:0 0; text-align:center; text-decoration:none; width:100%;" target="_blank"> <div style=" display: flex; flex-direction: row; align-items: center;"> <div style="background-color: #F4F4F4; border-radius: 50%; flex-grow: 0; height: 40px; margin-right: 14px; width: 40px;"></div> <div style="display: flex; flex-direction: column; flex-grow: 1; justify-content: center;"> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; margin-bottom: 6px; width: 100px;"></div> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; width: 60px;"></div></div></div><div style="padding: 19% 0;"></div> <div style="display:block; height:50px; margin:0 auto 12px; width:50px;"><svg width="50px" height="50px" viewBox="0 0 60 60" version="1.1" xmlns="https://www.w3.org/2000/svg" xmlns:xlink="https://www.w3.org/1999/xlink"><g stroke="none" stroke-width="1" fill="none" fill-rule="evenodd"><g transform="translate(-511.000000, -20.000000)" fill="#000000"><g><path d="M556.869,30.41 C554.814,30.41 553.148,32.076 553.148,34.131 C553.148,36.186 554.814,37.852 556.869,37.852 C558.924,37.852 560.59,36.186 560.59,34.131 C560.59,32.076 558.924,30.41 556.869,30.41 M541,60.657 C535.114,60.657 530.342,55.887 530.342,50 C530.342,44.114 535.114,39.342 541,39.342 C546.887,39.342 551.658,44.114 551.658,50 C551.658,55.887 546.887,60.657 541,60.657 M541,33.886 C532.1,33.886 524.886,41.1 524.886,50 C524.886,58.899 532.1,66.113 541,66.113 C549.9,66.113 557.115,58.899 557.115,50 C557.115,41.1 549.9,33.886 541,33.886 M565.378,62.101 C565.244,65.022 564.756,66.606 564.346,67.663 C563.803,69.06 563.154,70.057 562.106,71.106 C561.058,72.155 560.06,72.803 558.662,73.347 C557.607,73.757 556.021,74.244 553.102,74.378 C549.944,74.521 548.997,74.552 541,74.552 C533.003,74.552 532.056,74.521 528.898,74.378 C525.979,74.244 524.393,73.757 523.338,73.347 C521.94,72.803 520.942,72.155 519.894,71.106 C518.846,70.057 518.197,69.06 517.654,67.663 C517.244,66.606 516.755,65.022 516.623,62.101 C516.479,58.943 516.448,57.996 516.448,50 C516.448,42.003 516.479,41.056 516.623,37.899 C516.755,34.978 517.244,33.391 517.654,32.338 C518.197,30.938 518.846,29.942 519.894,28.894 C520.942,27.846 521.94,27.196 523.338,26.654 C524.393,26.244 525.979,25.756 528.898,25.623 C532.057,25.479 533.004,25.448 541,25.448 C548.997,25.448 549.943,25.479 553.102,25.623 C556.021,25.756 557.607,26.244 558.662,26.654 C560.06,27.196 561.058,27.846 562.106,28.894 C563.154,29.942 563.803,30.938 564.346,32.338 C564.756,33.391 565.244,34.978 565.378,37.899 C565.522,41.056 565.552,42.003 565.552,50 C565.552,57.996 565.522,58.943 565.378,62.101 M570.82,37.631 C570.674,34.438 570.167,32.258 569.425,30.349 C568.659,28.377 567.633,26.702 565.965,25.035 C564.297,23.368 562.623,22.342 560.652,21.575 C558.743,20.834 556.562,20.326 553.369,20.18 C550.169,20.033 549.148,20 541,20 C532.853,20 531.831,20.033 528.631,20.18 C525.438,20.326 523.257,20.834 521.349,21.575 C519.376,22.342 517.703,23.368 516.035,25.035 C514.368,26.702 513.342,28.377 512.574,30.349 C511.834,32.258 511.326,34.438 511.181,37.631 C511.035,40.831 511,41.851 511,50 C511,58.147 511.035,59.17 511.181,62.369 C511.326,65.562 511.834,67.743 512.574,69.651 C513.342,71.625 514.368,73.296 516.035,74.965 C517.703,76.634 519.376,77.658 521.349,78.425 C523.257,79.167 525.438,79.673 528.631,79.82 C531.831,79.965 532.853,80.001 541,80.001 C549.148,80.001 550.169,79.965 553.369,79.82 C556.562,79.673 558.743,79.167 560.652,78.425 C562.623,77.658 564.297,76.634 565.965,74.965 C567.633,73.296 568.659,71.625 569.425,69.651 C570.167,67.743 570.674,65.562 570.82,62.369 C570.966,59.17 571,58.147 571,50 C571,41.851 570.966,40.831 570.82,37.631"></path></g></g></g></svg></div><div style="padding-top: 8px;"> <div style=" color:#3897f0; font-family:Arial,sans-serif; font-size:14px; font-style:normal; font-weight:550; line-height:18px;">View this post on Instagram</div></div><div style="padding: 12.5% 0;"></div> <div style="display: flex; flex-direction: row; margin-bottom: 14px; align-items: center;"><div> <div style="background-color: #F4F4F4; border-radius: 50%; height: 12.5px; width: 12.5px; transform: translateX(0px) translateY(7px);"></div> <div style="background-color: #F4F4F4; height: 12.5px; transform: rotate(-45deg) translateX(3px) translateY(1px); width: 12.5px; flex-grow: 0; margin-right: 14px; margin-left: 2px;"></div> <div style="background-color: #F4F4F4; border-radius: 50%; height: 12.5px; width: 12.5px; transform: translateX(9px) translateY(-18px);"></div></div><div style="margin-left: 8px;"> <div style=" background-color: #F4F4F4; border-radius: 50%; flex-grow: 0; height: 20px; width: 20px;"></div> <div style=" width: 0; height: 0; border-top: 2px solid transparent; border-left: 6px solid #f4f4f4; border-bottom: 2px solid transparent; transform: translateX(16px) translateY(-4px) rotate(30deg)"></div></div><div style="margin-left: auto;"> <div style=" width: 0px; border-top: 8px solid #F4F4F4; border-right: 8px solid transparent; transform: translateY(16px);"></div> <div style=" background-color: #F4F4F4; flex-grow: 0; height: 12px; width: 16px; transform: translateY(-4px);"></div> <div style=" width: 0; height: 0; border-top: 8px solid #F4F4F4; border-left: 8px solid transparent; transform: translateY(-4px) translateX(8px);"></div></div></div> <div style="display: flex; flex-direction: column; flex-grow: 1; justify-content: center; margin-bottom: 24px;"> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; margin-bottom: 6px; width: 224px;"></div> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; width: 144px;"></div></div></a><p style=" color:#c9c8cd; font-family:Arial,sans-serif; font-size:14px; line-height:17px; margin-bottom:0; margin-top:8px; overflow:hidden; padding:8px 0 7px; text-align:center; text-overflow:ellipsis; white-space:nowrap;"><a href="https://www.instagram.com/p/CWn9YNZD_Kt/?utm_source=ig_embed&utm_campaign=loading" style=" color:#c9c8cd; font-family:Arial,sans-serif; font-size:14px; font-style:normal; font-weight:normal; line-height:17px; text-decoration:none;" target="_blank">A post shared by Dominic Ross (@youngdad33)</a></p></div></blockquote> <script async src="//www.instagram.com/embed.js"></script>
## Conclusion:
Learning from home can be tricky, and has the potential to leave you burnt out or disinterested altogether. With **Discipline**, **Support**, setting yourself easy to accomplish **goals** and setting up a suitable working environment is crucial to successful studying and enjoying your topic.
The same can be true of working on a Bootcamp, but going from nothing to BootCamp is difficult and could lead to burnout. If you're going to use a BootCamp to learn to code (or write or exercise or cook) be sure to build up those "muscles" so that you don't set yourself up to fail, but instead set yourself up for success. | dodothedev |
921,116 | Advanced typescript for React developers | Originally published at https://www.developerway.com. The website has more articles like this... | 0 | 2021-12-08T18:01:20 | https://www.developerway.com/posts/advanced-typescript-for-react-developers | react, typescript, webdev, tutorial |
Originally published at [https://www.developerway.com](https://www.developerway.com). The website has more articles like this 😉
---
This is the second article in the series “typescript for React developers”. In the first one, we figured out what Typescript generics are and how to use them to write re-usable react components: <a href="https://www.developerway.com/posts/typescript-generics-for-react-developers">Typescript Generics for React developers</a>. Now it’s time to dive into other advanced typescript concepts and understand how and why we need things like **type guards**, **keyof**, **typeof**, **is**, **as const** and **indexed types**.
## Introduction
As we found out from the article above, Judi is an ambitious developer and wants to implement her own online shop, a competitor to Amazon: she’s going to sell everything there! We left her when she implemented a re-usable select component with typescript generics. The component is pretty basic: it allows to pass an array of `values`, assumes that those values have `id` and `title` for rendering select options, and have an `onChange` handler to listen to the selected values.
```ts
type Base = {
id: string;
title: string;
};
type GenericSelectProps<TValue> = {
values: TValue[];
onChange: (value: TValue) => void;
};
export const GenericSelect = <TValue extends Base>({ values, onChange }: GenericSelectProps<TValue>) => {
const onSelectChange = (e) => {
const val = values.find((value) => value.id === e.target.value);
if (val) onChange(val);
};
return (
<select onChange={onSelectChange}>
{values.map((value) => (
<option key={value.id} value={value.id}>
{value.title}
</option>
))}
</select>
);
};
```
and then this component can be used with any data types Judi has in her application
```ts
<GenericSelect<Book> onChange={(value) => console.log(value.author)} values={books} />
<GenericSelect<Movie> onChange={(value) => console.log(value.releaseDate)} values={movies} />
```
Although, as the shop grew, she quickly found out that _any_ data type is an exaggeration: we are still limited since we assume that our data will always have `id` and `title` there. But now Judi wants to sell laptops, and laptops have `model` instead of `title` in their data.
```ts
type Laptop = {
id: string;
model: string;
releaseDate: string;
}
// This will fail, since there is no "title" in the Laptop type
<GenericSelect<Laptop> onChange={(value) => console.log(value.model)} values={laptops} />
```
Ideally, Judi wants to avoid data normalization just for select purposes and make the select component more generic instead. What can she do?
## Rendering not only titles in options
Judi decides, that just passing the desired attribute as a prop to the select component would be enough to fulfil her needs for the time being. Basically, she’d have something like this in its API:
```ts
<GenericSelect<Laptop> titleKey="model" {...} />
```
and the select component would then render Laptop models instead of titles in the options.
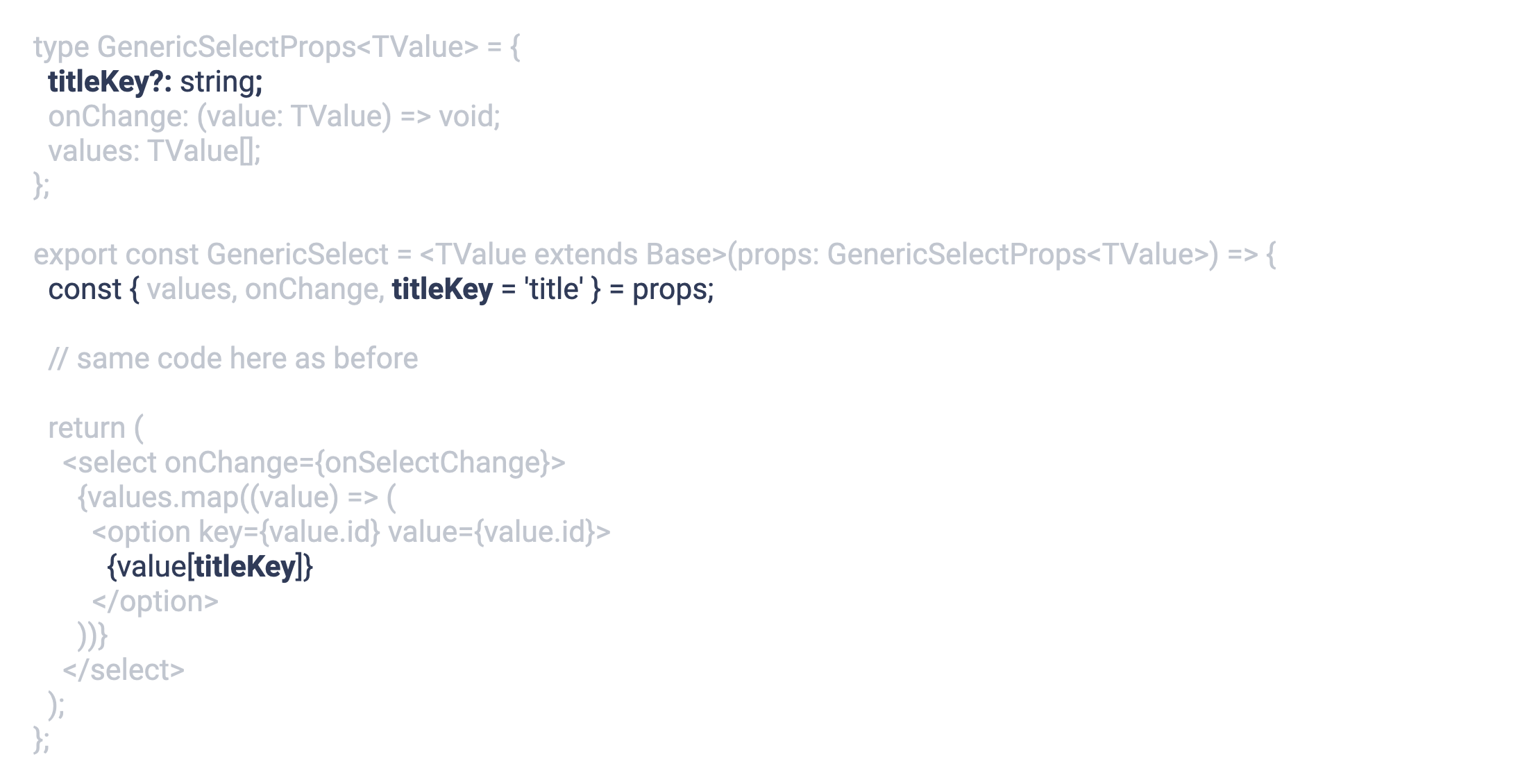
It would work, but there is one problem with this: not type-safe 🙂. Ideally, we would want typescript to fail if this attribute doesn’t exist in the data model that is used in the select component. This is where typescript’s <a href="https://www.typescriptlang.org/docs/handbook/2/keyof-types.html">**keyof**</a> operator comes in handy.
`keyof` basically generates a type from an object’s keys. If I use `keyof` on `Laptop` type:
```ts
type Laptop = {
id: string;
model: string;
releaseDate: string;
}
type LaptopKeys = keyof Laptop;
```
in `LaptopKeys` I’ll find a union of its keys: `"id" | "model" | "releaseDate"`.
And, most amazingly, typescript is smart enough to generate those types for generics as well! This will work perfectly:

And now I can use it with all selects and typescript will catch any typos or copy-paste errors:
```ts
<GenericSelect<Laptop> titleKey="model" {...} />
// inside GenericSelect "titleKey" will be typed to "id" | "model" | "releaseDate"
<GenericSelect<Book> titleKey="author" {...} />
// inside GenericSelect "titleKey" will be typed to "id" | "title" | "author"
```
and we can make the type `Base` a little bit more inclusive and make the `title` optional
```ts
type Base = {
id: string;
title?: string;
}
export const GenericSelect = <TValue extends Base>(props: GenericSelectProps<TValue>) => {
```
<a href="https://codesandbox.io/s/vigorous-neumann-0w1ti?file=/src/select.tsx">See full working example in codesandbox</a>.
*Important*: Although this example works perfectly, I would not recommend using it in actual apps. It lacks a bit of elegance and is not generic enough _yet_. Read until the end of the article for a better example of a select component with customizable labels.
## The list of categories - refactor select
Now, that we have lists of goods covered with our generic select, it’s time to solve other problems on Judi’s website. One of them is that she has her catalog page clattered with all the selects and additional information that she shows when a value is selected. What she needs, she decides, is to split it into categories, and only show one category at a time. She again wants to use the generic select for it (well, who’s not lazy in this industry, right?).
The categories is just a simple array of strings: `const categories = ['Books', 'Movies', 'Laptops'].`
Now, our current generic select unfortunately doesn’t work with string values. Let’s fix it! And interestingly enough, this seems-to-be-simple implementation will allow us to get familiar with five new advanced typescript technics: operators **as const**, **typeof**, **is**, **type guards** idea and **indexed types**. But let’s start with the existing code and take a closer look at where exactly we depend on the `TValue` type to be an object.

After careful examination of this picture, we can extract three major changes that we need to do:
1. Convert `Base` type into something that understands strings as well as objects
2. Get rid of reliance on `value.id` as the unique identificator of the value in the list of options
3. Convert `value[titleKey]` into something that understands strings as well
With this step-by-step approach to refactoring, the next moves are more or less obvious.
**Step 1**. Convert `Base` into a union type (i.e. just a fancy “or” operator for types) and get rid of `title` there completely:
```ts
type Base = { id: string } | string;
// Now "TValue" can be either a string, or an object that has an "id" in it
export const GenericSelect = <TValue extends Base>(props: GenericSelectProps<TValue>) => {
```
**Step 2**. Get rid of direct access of `value.id` . We can do that by converting all those calls to a function `getStringFromValue`:

where the very basic implementation from the before-typescript era would look like this:
```ts
const getStringFromValue = (value) => value.id || value;
```
This is not going to fly with typescript though: remember, our `value` is Generic and can be a string as well as an object, so we need to help typescript here to understand what exactly it is before accessing anything specific.
```ts
type Base = { id: string } | string;
const getStringFromValue = <TValue extends Base>(value: TValue) => {
if (typeof value === 'string') {
// here "value" will be the type of "string"
return value;
}
// here "value" will be the type of "NOT string", in our case { id: string }
return value.id;
};
```
The code in the function is known as <a href="https://www.typescriptlang.org/docs/handbook/2/narrowing.html">**type guard**</a> in typescript: an expression that narrows down type within some scope. See what is happening? First, we check whether the `value` is a string by using the standard javascript `typeof` operator. Now, within the “truthy” branch of `if` expression, typescript will know for sure that value is a string, and we can do anything that we’d usually do with a string there. Outside of it, typescript will know for sure, that the value is **not** a string, and in our case, it means it’s an object with an `id` in it. Which allows us to return `value.id` safely.
**Step 3**. Refactor the `value[titleKey]` access. Considering that a lot of our data types would want to customise their labels, and more likely than not in the future we’d want to convert it to be even more custom, with icons or special formatting, the easiest option here is just to move the responsibility of extracting required information to the consumer. This can be done by passing a function to select that converts value on the consumer side to a string (or ReactNode in the future). No typescript mysteries here, just normal React:
```ts
type GenericSelectProps<TValue> = {
formatLabel: (value: TValue) => string;
...
};
export const GenericSelect = <TValue extends Base>(props: GenericSelectProps<TValue>) => {
...
return (
<select onChange={onSelectChange}>
{values.map((value) => (
<option key={getStringFromValue(value)} value={getStringFromValue(value)}>
{formatLabel(value)}
</option>
))}
</select>
);
}
// Show movie title and release date in select label
<GenericSelect<Movie> ... formatLabel={(value) => `${value.title} (${value.releaseDate})`} />
// Show laptop model and release date in select label
<GenericSelect<Laptop> ... formatLabel={(value) => `${value.model, released in ${value.releaseDate}`} />
```
And now we have it! A perfect generic select, that supports all data formats that we need and allows us to fully customise labels as a nice bonus. The full code looks like this:
```ts
type Base = { id: string } | string;
type GenericSelectProps<TValue> = {
formatLabel: (value: TValue) => string;
onChange: (value: TValue) => void;
values: TValue[];
};
const getStringFromValue = <TValue extends Base>(value: TValue) => {
if (typeof value === 'string') return value;
return value.id;
};
export const GenericSelect = <TValue extends Base>(props: GenericSelectProps<TValue>) => {
const { values, onChange, formatLabel } = props;
const onSelectChange = (e) => {
const val = values.find((value) => getStringFromValue(value) === e.target.value);
if (val) onChange(val);
};
return (
<select onChange={onSelectChange}>
{values.map((value) => (
<option key={getStringFromValue(value)} value={getStringFromValue(value)}>
{formatLabel(value)}
</option>
))}
</select>
);
};
```
## The list of categories - implementation
And now, finally, time to implement what we refactored the select component for in the first place: categories for the website. As always, let’s start simple, and improve things in the process.
```ts
const tabs = ['Books', 'Movies', 'Laptops'];
const getSelect = (tab: string) => {
switch (tab) {
case 'Books':
return <GenericSelect<Book> onChange={(value) => console.info(value)} values={books} />;
case 'Movies':
return <GenericSelect<Movie> onChange={(value) => console.info(value)} values={movies} />;
case 'Laptops':
return <GenericSelect<Laptop> onChange={(value) => console.info(value)} values={laptops} />;
}
}
const Tabs = () => {
const [tab, setTab] = useState<string>(tabs[0]);
const select = getSelect(tab);
return (
<>
<GenericSelect<string> onChange={(value) => setTab(value)} values={tabs} />
{select}
</>
);
};
```
Dead simple - one select component for choosing a category, based on the chosen value - render another select component.
But again, not exactly typesafe, this time for the tabs: we typed them as just simple `string`. So a simple typo in the `switch` statement will go unnoticed or a wrong value in `setTab` will result in a non-existent category to be chosen. Not good.
And again, typescript has a handy mechanism to improve that:
```ts
const tabs = ['Books', 'Movies', 'Laptops'] as const;
```
This trick is known as <a href="https://www.typescriptlang.org/docs/handbook/release-notes/typescript-3-4.html#const-assertions">**const assertion**</a>. With this, our `tabs` array, instead of an array of any random string will turn into a read-only array of those specific values and nothing else.
```ts
// an array of values type "string"
const tabs = ['Books', 'Movies', 'Laptops'];
tabs.forEach(tab => {
// typescript is fine with that, although there is no "Cats" value in the tabs
if (tab === 'Cats') console.log(tab)
})
// an array of values 'Books', 'Movies' or 'Laptops', and nothing else
const tabs = ['Books', 'Movies', 'Laptops'] as const;
tabs.forEach(tab => {
// typescript will fail here since there are no Cats in tabs
if (tab === 'Cats') console.log(tab)
})
```
Now, all we need to do is to extract type `Tab` that we can pass to our generic select. First, we can extract the `Tabs` type by using the <a href="https://www.typescriptlang.org/docs/handbook/2/typeof-types.html">**typeof**</a> operator, which is pretty much the same as normal javascript `typeof`, only it operates on types, not values. This is where the value of `as const` will be more visible:
```ts
const tabs = ['Books', 'Movies', 'Laptops'];
type Tabs = typeof tabs; // Tabs will be string[];
const tabs = ['Books', 'Movies', 'Laptops'] as const;
type Tabs = typeof tabs; // Tabs will be ['Books' | 'Movies' | 'Laptops'];
```
Second, we need to extract `Tab` type from the Tabs array. This trick is called <a href="https://www.typescriptlang.org/docs/handbook/2/indexed-access-types.html">**“indexed access”**</a>, it’s a way to access types of properties or individual elements (if array) of another type.
```ts
type Tab = Tabs[number]; // Tab will be 'Books' | 'Movies' | 'Laptops'
```
Same trick will work with object types, for example we can extract Laptop’s id into its own type:
```ts
type LaptopId = Laptop['id']; // LaptopId will be string
```
Now, that we have a type for individual Tabs, we can use it to type our categories logic:

And now all the typos or wrong values will be caught by typescript! 💥
<a href="https://codesandbox.io/s/eager-brook-vuj8d?file=/src/tabs.tsx">See full working example in the codesandbox</a>
## Bonus: type guards and “is” operator
There is another very interesting thing you can do with type guards. Remember our `getStringFromValue` function?
```ts
type Base = { id: string } | string;
const getStringFromValue = <TValue extends Base>(value: TValue) => {
if (typeof value === 'string') {
// here "value" will be the type of "string"
return value;
}
// here "value" will be the type of "NOT string", in our case { id: string }
return value.id;
};
```
While `if (typeof value === ‘string')` check is okay for this simple example, in a real-world application you'd probably want to abstract it away into `isStringValue`, and refactor the code to be something like this:
```ts
type Base = { id: string } | string;
const isStringValue = <TValue>(value: TValue) => return typeof value === 'string';
const getStringFromValue = <TValue extends Base>(value: TValue) => {
if (isStringValue(value)) {
// do something with the string
}
// do something with the object
};
```
And again the same story as before, there is one problem with the most obvious solution: it’s not going to work. As soon as type guard condition is extracted into a function like that, it loses its type guarding capabilities. From typescript perspective, it’s now just a random function that returns a regular boolean value, it doesn’t know what’s inside. We’ll have this situation now:
```ts
const getStringFromValue = <TValue extends Base>(value: TValue) => {
if (isStringValue(value)) { // it's just a random function that returns boolean
// type here will be unrestricted, either string or object
}
// type here will be unrestricted, either string or object
// can't return "value.id" anymore, typescript will fail
};
```
And again, there is a way to fix it by using yet another typescript concept known as <a href="https://www.typescriptlang.org/docs/handbook/2/narrowing.html#using-type-predicates">**“type predicates”**</a>. Basically, it’s a way to manually do for the function what typescript was able to do by itself before refactoring. Looks like this:
```ts
type T = { id: string };
// can't extend Base here, typescript doesn't handle generics here well
export const isStringValue = <TValue extends T>(value: TValue | string): value is string => {
return typeof value === 'string';
};
```
See the `value is string` there? This is the predicate. The pattern is `argName is Type`, it can be attached **only** to a function with a single argument that returns a boolean value. This expression can be roughly translated into "when this function returns true, assume the value within your execution scope as `string` type". So with the predicate, the refactoring will be complete and fully functioning:
```ts
type T = { id: string };
type Base = T | string;
export const isStringValue = <TValue extends T>(value: TValue | string): value is string => {
return typeof value === 'string';
};
const getStringFromValue = <TValue extends Base>(value: TValue) => {
if (isStringValue(value)) {
// do something with the string
}
// do something with the object
};
```
A pattern like this is especially useful when you have a possibility of different types of data in the same function and you need to do distinguish between them during runtime. In our case, we could define `isSomething` function for every one of our data types:
```ts
export type DataTypes = Book | Movie | Laptop | string;
export const isBook = (value: DataTypes): value is Book => {
return typeof value !== 'string' && 'id' in value && 'author' in value;
};
export const isMovie = (value: DataTypes): value is Movie => {
return typeof value !== 'string' && 'id' in value && 'releaseDate' in value && 'title' in value;
};
export const isLaptop = (value: DataTypes): value is Laptop => {
return typeof value !== 'string' && 'id' in value && 'model' in value;
};
```
And then implement a function that returns option labels for our selects:
```ts
const formatLabel = (value: DataTypes) => {
// value will be always Book here since isBook has predicate attached
if (isBook(value)) return value.author;
// value will be always Movie here since isMovie has predicate attached
if (isMovie(value)) return value.releaseDate;
// value will be always Laptop here since isLaptop has predicate attached
if (isLaptop(value)) return value.model;
return value;
};
// somewhere in the render
<GenericSelect<Book> ... formatLabel={formatLabel} />
<GenericSelect<Movie> ... formatLabel={formatLabel} />
<GenericSelect<Laptop> ... formatLabel={formatLabel} />
```
<a href="https://codesandbox.io/s/immutable-wildflower-n4r8z?file=/src/tabs.tsx">see fully working example in the codesandbox</a>
## Time for goodbye
It’s amazing, how many advanced typescript concepts we had to use to implement something as simple as a few selects! But it’s for the better typing world, so I think it’s worth it. Let’s recap:
* **“keyof”** - use it to generate types from keys of another type
* **“as const”** - use it to signal to typescript to treat an array or an object as a constant. Use it with combination with **“type of”** to generate actual type from it.
* **“typeof”** - same as normal javascript `“typeof”`, but operates on types rather than values
* `Type['attr']` or `Type[number]` - those are **indexed types**, use them to access subtypes in an Object or an Array respectively
* `argName is Type` - **type predicate**, use it to turn a function into a safeguard
And now it’s time to build a better, typesafe future, and we’re ready for it!
...
Originally published at [https://www.developerway.com](https://www.developerway.com). The website has more articles like this 😉
[Subscribe to the newsletter](https://www.developerway.com), [connect on LinkedIn](https://www.linkedin.com/in/adevnadia/) or [follow on Twitter](https://twitter.com/adevnadia) to get notified as soon as the next article comes out.
| adevnadia |
921,137 | Love these...GitHub Pages if you missed them. work a look. | https://pages.github.com/ | 0 | 2021-12-08T18:43:54 | https://dev.to/idlehand/love-these-1hjf | https://pages.github.com/ | idlehand | |
921,273 | iNeural : Update (8.12.21) | iNeural A library for creating Artificial Neural Networks, for use in Machine Learning and... | 0 | 2021-12-08T19:49:54 | https://dev.to/fkkarakurt/ineural-update-81221-4f6f | machinelearning, cpp, programming, github | # iNeural
A library for creating Artificial Neural Networks, for use in Machine Learning and Deep Learning algorithms.
## [Source Page](https://github.com/fkkarakurt/iNeural)
## What is a Neural Network?
Work on artificial neural networks, commonly referred to as “neural networks,” has been motivated right from its inception by the recognition that the human brain computes in an entirely different way from the conventional digital computer. The brain is a highly complex, nonlinear, and parallel computer (information-processing system). It has the capability to organize its structural constituents, known as neurons, so as to perform certain computations (e.g., pattern recognition, perception, and motor control) many times faster than the fastest digital computer in existence today. Consider, for example, human vision, which is an information-processing task. It is the function of the visual system to provide a representation of the environment around us and, more important, to supply the information we need to interact with the environment. To be specific, the brain routinely accomplishes perceptual recognition tasks (e.g., recognizing a familiar face embedded in an unfamiliar scene) in approximately 100–200 ms, whereas tasks of much lesser complexity take a great deal longer on a powerful computer.
For another example, consider the sonar of a bat. Sonar is an active echolocation system. In addition to providing information about how far away a target (e.g., a flying insect) is, bat sonar conveys information about the relative velocity of the target, the size of the target, the size of various features of the target, and the azimuth and elevation of the target. The complex neural computations needed to extract all this information from the target echo occur within a brain the size of a plum. Indeed, an echolocating bat can pursue and capture its target with a facility and success rate that would be the envy of a radar or sonar engineer.
How, then, does a human brain or the brain of a bat do it? At birth, a brain already has considerable structure and the ability to build up its own rules of behavior through what we usually refer to as “experience.” Indeed, experience is built up over time, with much of the development (i.e., hardwiring) of the human brain taking place during the first two years from birth, but the development continues well beyond that stage.
A “developing” nervous system is synonymous with a plastic brain: Plasticity permits the developing nervous system to adapt to its surrounding environment. Just as plasticity appears to be essential to the functioning of neurons as information-processing units in the human brain, so it is with neural networks made up of artificial neurons. In its most general form, a neural network is a machine that is designed to model the way in which the brain performs a particular task or function of interest; the network is usually implemented by using electronic components or is simulated in software on a digital computer. In this book, we focus on an important class of neural networks that perform useful computations through a process of learning. To achieve good performance, neural networks employ a massive interconnection of simple computing cells referred to as “neurons” or “processing units.” We may thus offer the following definition of a neural network viewed as an adaptive machine.
_A neural network is a massively parallel distributed processor made up of simple processing units that has a natural propensity for storing experiential knowledge and making it available for use. It resembles the brain in two respects:_
**1. Knowledge is acquired by the network from its environment through a learning process.**
**2. Interneuron connection strengths, known as synaptic weights, are used to store the acquired knowledge.**
The procedure used to perform the learning process is called a learning algorithm, the function of which is to modify the synaptic weights of the network in an orderly fashion to attain a desired design objective.
The modification of synaptic weights provides the traditional method for the design of neural networks. Such an approach is the closest to linear adaptive filter theory, which is already well established and successfully applied in many diverse fields. However, it is also possible for a neural network to modify its own topology, which is motivated by the fact that neurons in the human brain can die and new synaptic connections can grow
<p align="right"><em>Neural Networks and Learning Machines, 3rd Edition</em></p>
<p align="right"><b>Simon Haykin</b></p>
## What Does iNeural Do?
iNeural is an open source library for artificial neural networks. One of the best things about iNeural is that it has very few dependencies. It only needs a few external libraries and tools. Other than that, everything he needs is already coded. _It is not prepared for GPUs to run at full performance._ But it is a library that can work great with low system requirements. To give an example, when the project is completely finished, you will be able to run it with high performance on robotic platforms.
So who is **iNeural** suitable for?
- For those who want to use open source neural network in problem solving,
- For those who want to integrate new technologies into their projects,
- For students who want to understand the tricks needed for neural networks,
- Researchers, Machine Learning and Deep Learning Enthusiasts.
## Why Developing iNeural?
It is developed by taking inspiration from libraries such as iNeural, [FANN](https://github.com/libfann/fann), [pylearn2](https://github.com/lisa-lab/pylearn2), [EBLearn](http://eblearn.sourceforge.net/), [Torch7](http://torch.ch/). Written mostly in C++, iNeural also leverages the power of Python. The biggest reason for its development is that it needs very few dependencies. For this reason, it is expected to be suitable for working in systems with limited system requirements.
## Who Is iNeural Developing By?
iNeural is being developed by [Fatih Küçükkarakurt](https://github.com/fkkarakurt). All expenses and programming of the project are done by him.
## How Can I Contribute to the Project?
Since iNeural is a very new project, there is a lot of things you can contribute to. For this, you can clone the project after forking.
For this run the following line:
`git clone https://github.com/fkkarakurt/iNeural.git`
I like to use `CMake` as a compiler tool. So I will use `CMake` in this project as well. However, since it is an unfinished project, I left the editing for later. For this, cloning the project is only for you to examine the codes.
Also if you'd like to make any improvements, I'd be very happy. I am trying to develop this project on my own and I need wonderful people like you with good intentions.
I am using `Visual Studio Code` and `Prettier`. I will ask you to use 'Prettier'. Thus, we can progress faster and more regularly. Thank you so much in advance.
## How Long Does the Project Take to Complete?
I make additions to the project every day. In fact, most of the libraries I have programmed are readily available. Just doing the final tests to `push` here. I want to make sure everything really works. There are parts that I missed, and I don't want to overwhelm you with these problems.
_I am preparing a very detailed documentation describing what the project really does and how to use it. I hope I `push` as soon as possible._
## Technologies in Use
- CMake v3.21.0-rc2
- GNU C++ Compiler (g++)
- [Eigen 3](https://eigen.tuxfamily.org/)
- Python 3
- C++
## Test Data and Datasets
- [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html)
- [IRIS](https://archive.ics.uci.edu/ml/datasets/iris)
- [MNIST](http://yann.lecun.com/exdb/mnist/)
- [OCTOPUSARM](https://www.cs.mcgill.ca/~dprecup/workshops/ICML06/octopus.html)
- [THE POLE BALANCING PROBLEM](<https://researchbank.swinburne.edu.au/file/62a8df69-4a2c-407f-8040-5ac533fc2787/1/PDF%20(12%20pages).pdf>)
- [SARCOS](http://www.gaussianprocess.org/gpml/data/)
---
<p align="center">
<a href="https://linkedin.com/in/fkkarakurt" target="_blank"><img src="https://img.shields.io/badge/LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white"></img></a><a href="https://instagram.com/fkkarakurt" target="_blank"><img src="https://img.shields.io/badge/Instagram-E4405F?style=for-the-badge&logo=instagram&logoColor=white"></img></a><a href="https://twitter.com/fkkarakurt" target="_blank"><img src="https://img.shields.io/badge/Twitter-1DA1F2?style=for-the-badge&logo=twitter&logoColor=white"></img></a><a href="https://github.com/fkkarakurt" target="_blank"><img src="https://img.shields.io/badge/GitHub-100000?style=for-the-badge&logo=github&logoColor=white"></img></a><a href="https://www.hackerrank.com/fatihkkarakurt11" target="_blank"><img src="https://img.shields.io/badge/-Hackerrank-2EC866?style=for-the-badge&logo=HackerRank&logoColor=white"></img></a></p>
---
<p align="center"><img src="https://github-readme-stats.vercel.app/api?username=fkkarakurt"></img></p><p align="center"><img src="https://github-readme-stats.vercel.app/api/top-langs/?username=fkkarakurt"></img></p>
| fkkarakurt |
921,351 | Github Action Tracker with light and dark mode | My Workflow .github/workflows/workflow.yml Submission Category: Interesting... | 0 | 2021-12-08T22:46:28 | https://dev.to/bleakview/github-action-tracker-with-light-and-dark-mode-57bn | actionshackathon21, flutter, iot, github | ### My Workflow
[.github/workflows/workflow.yml](https://github.com/bleakview/actionshackathon21/blob/master/.github/workflows/workflow.yml)
### Submission Category:
Interesting IoT
### Yaml File or Link to Code
{% github bleakview/actionshackathon21%}
### Additional Resources / Info
{% youtube fFYOSs4JaHg %}
We watch our how the work progress through screens big small rectangle, square but do we have to squish our view of the world through a window.
We don't have to we can watch the progress with what ever way we want. (and it began to become boring after a while) So I designed a system which show the progress with both cell phone and an IOT device connecting with Bluetooth Low Power or BLE in short.
Requirements:
- A CloudAMQP account (you need a AMQP server it can be AWS,AZURE ...)
- A system ready for development for flutter ( I tested in Android
IOS should also be fine but I did not test it.)
For Iot:
Light mode:
- A needle ( I got mine from starbucks :-) )
- A micro servo
- ESP32 development board installed with micropython
- jumpers usb connection cable and breadboard
Dark mode:
- A led strip with SPI support like APA102
- ESP32 development board installed with micropython
- jumpers usb connection cable and breadboard
How it works
Github action sends message to CloudAMQP queue named "github". Since we use a queue Authentication ,storage and API interface is handled automatically. Then our mobile app gets this message it handles it and draw a image on screen. And direct the message to IOT device connected with BLE. And it also handles it. Why BLE ? if we use wifi then user has to enter credentials. Since most IOT devices do not have screen its hard to enter credentials. Also Apple do not require BLE devices with known profiles with MFI program.
How to use

This is the main screen in you can interact with it through the bottom buttons.
 Search Button
when you click this button the device automatically enters into search mode it looks for BLE devices which advertise a specific name "GITHUB_ACTION_IOT" when it finds the device it enables connect button.
 Connection Button
When this button is clicked phone makes connection to prespecified service with Guid "6E400001-B5A3-F393-E0A9-E50E24DCCA9E" and connection point "6E400002-B5A3-F393-E0A9-E50E24DCCA9E" message is sent to the connection point.
 Reset Button
When this button is clicked the state is reset.
 Sound Button
When clicked sound is enabled or disabled
PS: I know most people in dev.to do not have experience in electronics. If you have any questions on this project don't hesitate to ask questions. And If you see something wrong both in project or the text please inform me. I'm an introvert extreme edition so writing is new and frightening adventure to me.
| bleakview |
921,357 | How to deal with client HTTP status messages | Common HTTP status codes in the 400s | 0 | 2021-12-08T23:19:13 | https://dev.to/postman/how-to-deal-with-client-http-status-messages-4n2n | beginners, webdev, api | ---
title: How to deal with client HTTP status messages
published: true
description: Common HTTP status codes in the 400s
tags: beginners,webdev,api
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/9n4ie1t4vc53pcub10px.jpg
---
When you’re talking to an HTTP API, the server returns a [status code](https://datatracker.ietf.org/doc/html/rfc7231#section-6) signaling the status of your API request. Since status codes and error messages are determined by the API provider, they are only as meaningful and accurate as the API provider makes them. But most API providers follow the established [industry standards](https://tools.ietf.org/html/rfc2616#section-10) grouping HTTP status codes into five categories according to the following scenarios:
- 100s Informational responses
- 200s Successful responses
- 300s Redirects
- 400s Client errors
- 500s Server errors
Let’s dive into status codes in the 400s indicating an issue with the client. As an API consumer, this means that you can update the API call to potentially solve the issue. Assuming the server returns reliable status messages, this is our first clue to tracking down the source of the bug.
## Common client error codes
Here are some common client error codes in the 400s and what you can do when you encounter one of these errors:
- [400 Bad Request](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/400) - This is the most general, catch-all status code for client errors. Look for syntax errors like typos or a malformed JSON body in your API call.
- [401 Unauthorized](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/401) - Verify that you have valid authentication credentials for the target resource and check your syntax for header values
- [403 Forbidden](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/403) - This means you do not have permission to access the resource. Check your permissions and scope to ensure you are authorized to access the resource.
- [418 I’m a Teapot](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/418) - was created as an April Fool’s joke, but may indicate the request is one the provider does not want to handle, such as automated queries
- [429 Too Many Requests](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/429) - check the documentation to understand the rate limits, or give it a break to try again later
There’s a number of other client errors defined in the industry standard, but it’s up to the API provider to implement status messages. If you’re unable to resolve the issue, check the API documentation for more clues as to how the provider has intended to handle those requests.
And if you want to try an interactive tutorial, check out [Learn HTTP Status Codes with HTTP Cats](https://blog.postman.com/http-cats-learn-http-status-codes/) 😺.
| loopdelicious |
921,496 | Vocabulary Building Day 23 | boon(noun): a thing that is helpful or beneficial. Checkout Pronunciation travail(noun): painful or... | 0 | 2021-12-09T03:48:12 | https://dev.to/vindhyasadanand/vocabulary-building-day-23-3pdd | 1. **boon**(noun): a thing that is helpful or beneficial.

[Checkout Pronunciation](https://www.google.com/search?q=boon+meaning&oq=boon+&aqs=chrome.1.69i57j0i433i512j0i512l2j0i433i512j0i512l3j46i175i199i512j46i199i465i512.4364j0j9&sourceid=chrome&ie=UTF-8)
2. **travail**(noun): painful or laborious effort.

[Checkout Pronunciation](https://www.google.com/search?q=travail+meaning&oq=travail&aqs=chrome.0.69i59j69i57j0i271.3875j0j9&sourceid=chrome&ie=UTF-8)
3. **atavism**(noun): a reappearance of an earlier characteristic; throwback.

[Checkout Pronunciation](https://www.google.com/search?q=atavism&oq=atavism&aqs=chrome..69i57j35i39l2j0i512l7.5994j0j9&sourceid=chrome&ie=UTF-8)
4. **peruse**(verb): read (something), typically in a thorough or careful way.

[Checkout Pronunciation](https://www.google.com/search?q=peruse&oq=peruse&aqs=chrome..69i57j0i433i512j0i512l8.5393j0j9&sourceid=chrome&ie=UTF-8)
5. **clumsy**(adjective): awkward and without skill.

[Checkout Pronunciation](https://www.google.com/search?q=awkward+meaning&oq=awkward&aqs=chrome.0.0i67i433j46i67i433j0i67i433j0i20i263i512j0i67l2j0i131i433j0i512j0i67.7276j0j7&sourceid=chrome&ie=UTF-8)
I hope this helps you if you are preparing for GRE exams.
| vindhyasadanand | |
921,549 | What LinkedIn is used for? 7 minutes basic course | Dear reader, Most probably, you have heard about LinkedIn a lot. But you don’t know what LinkedIn is... | 0 | 2021-12-09T05:33:26 | https://remoteful.dev/blog/linkedin-used-benefits | remotework, job, remotejobs | Dear reader,
Most probably, you have heard about LinkedIn a lot. But you don’t know **what LinkedIn is used for?** Some of my readers may know something but do not know much about it. They may have some questions. **How is LinkedIn used in business? What is LinkedIn sales navigator used for? Should I include my LinkedIn on my resume?** How does it help for **the searching job on LinkedIn?** All in all, they want to know the **benefits of LinkedIn.**
What-Linkedin-is-used-for.jpg 77.2 KB
In today’s article, we’ll uncover some incredible features that you must say “wow.”
Could you please allow me 5 to 7 minutes? This 7 minutes investment will make you LinkedIn boss.
I think you agree to invest this 5 to 7 minutes time. Actually, who does not want to be a LinkedIn boss in just 7 minutes of investing?
Yes, I know that. So, let’s dive into our article.
**ATTENTION PLEASE: PLEASE DO NOT SKIP ANY SINGLE LINE, MY DEAR.**
## What LinkedIn is used for?
I’ll divide this heading with some sub-headings to quickly understand **what LinkedIn is used for.**
You can’t imagine how extensive this professional network is! There are 800 million LinkedIn users in more than 200 countries.
I think this data is enough for you to know how big this platform is.
This site is mainly used to keep in touch with clients, business associates, and co-workers.
### Benefits of LinkedIn:
To know the **benefits of LinkedIn,** please have a look below:
You can build an online professional identity with a professionally written LinkedIn profile. You may ask me, “Hey, is this the only benefit?” The straightforward answer is “no.” There is more to discover.
You can use LinkedIn to showcase your skills, recommendations, and connections as well.
Are you confused with the word “connections?”
In easy words, connections are members who connected on LinkedIn with each other. It’s as like your Facebook friends.
You can build connections with your industry-related people.
When recruiters use LinkedIn to look for applicants, your LinkedIn profile is the first professional impression. Not only that, but it also demonstrates credibility in your industry.
I think now you do not doubt the power of an organized LinkedIn profile in your career and job industry.
#### Job search on LinkedIn:
Let me write incredible information. Recruiters use LinkedIn to find and hire applicants in 93% of cases.
Are you surprised? Yes, dear, this is the reality.
So, it’s crucial to have your profile for a **job search on LinkedIn.** A LinkedIn profile makes you visible to the recruiters.

It will be not wrong if I compare a LinkedIn profile with a CV. I am writing this because what is on your profile is selling you. In the case of **job search on LinkedIn,** it may help you differently as well.
LinkedIn has a great job board. The most surprising thing is, new job opportunities you may find on this platform that is not available on the traditional job boards. Is not it surprising? But it is also true there are some **[great traditional job boards](https://remoteful.dev/)** as well.
There is an option named “LinkedIn apply.” By using this, you can directly apply for a job and can save your job searches.
This platform can be your research tool in case of job search on LinkedIn. Ask me how? The answer is,
You can research any company before your interview. LinkedIn is a fantastic resource for finding out about companies and the individuals who work there.
You can get an insight about the interviewers and your hiring manager as well.
Employers and recruiters can view your recommendations and connections if you have a LinkedIn profile. This is essential for building trust with them.
These are the main **benefits of LinkedIn** for searching job.
#### Should I include my LinkedIn on my resume

You should include. Many employers check LinkedIn and social media profiles before scheduling an interview. Yes, in most cases, they do it.
Now, where you should include your LinkedIn address? The answer is you should have it on the contact section of your resume.
The hiring managers want to study the candidates’ LinkedIn profiles to get a deep insight.
So, **“should I include my LinkedIn on my resume?”** My straightforward answer is “yes.”
But there are some suggestions on my behalf.
If your resume is not updated and organized, do not provide your LinkedIn profile link on your job resume.
Upload a high-quality professional look photo. Remember, the first impression is important.
Create a professional profile URL on LinkedIn. When you create an account on LinkedIn, an automated profile URL creates.
Do not provide this on your resume. At first, edit your profile URL and give it a professional look-for example, www.linkedin.com/in/yourname.
One of the most important points I have forgotten to write. That is, your LinkedIn profile heading and description should match with the job that you want to apply for.
Dear reader, you have got a good idea of **what LinkedIn is used for by this time.**
#### How is LinkedIn used in business?
Almost 30 million businesses use LinkedIn.There are LinkedIn marketing tools. Any sized company can be benefitted by using this tool.
You can use LinkedIn ads to generate sales.

**LinkedIn sales navigator:** This navigator can help you to boost sales. I believe it’s a great place to start for any business. You should know that the LinkedIn platform itself offers this sales navigator tool.
It can be used in several ways.
In a simple sense, it makes finding, contacting, and staying in touch with customers, prospects, and referrals easier. You don't have to track your prospects manually for long periods. Then why not use that saved time for other purposes of your business?
I think this is the best version of LinkedIn available today. LinkedIn Sales Navigator has an advanced lead search feature to find more specific leads.
Marketing and sales teams may efficiently communicate with the **Sales Navigator team** feature and get the following benefits:
Up to 5,000 prospects can be saved.
Every month, send roughly 30 InMails -- The InMail tool is ideal for sending private messages to prospects or other LinkedIn users (even if they aren't linked with you).
Monitor sales performance by periodic access to reports.
You may have a question like “is **LinkedIn sales navigator** free?” You can take experience a free trial and for paid subscription please visit here >> [Cost of LinkedIn sales navigator.](https://business.linkedin.com/sales-solutions/compare-plans#0)
**Remember,** it is necessary to [create a LinkedIn company page](https://www.linkedin.com/help/linkedin/answer/710/create-a-linkedin-page?lang=en) before starting LinkedIn marketing.
I think you have got your answer to the question of **how is LinkedIn used in business.**
#### Publishing Platform:
Good news! Yes, you can use LinkedIn as a great **publishing platform** online.

LinkedIn provides you the opportunity to publish your content for your LinkedIn audience. Let me provide you with a number.
45% of LinkedIn article readers are from top-level positions (directors, managers, VPs). All of your connections will be notified as soon as you post an article. This will help you inform your audience that a new article has been published.
You may ask me, “hey writer, why I’ll publish my article on LinkedIn instead of publishing on my blog?”
Hmm, it’s an excellent question.
There are two reasons:
It will help you to increase brand awareness.
It will help you to drive social engagement on LinkedIn.
This is one of themost incrediblebenefits **of LinkedIn.**
## Bottom line:
**Great news!** We have completed this basic LinkedIn course, **“what LinkedIn is used for.” **
I believe now you better understand the **benefits of LinkedIn.** You know now how a well-organized LinkedIn profile helps job seekers for **search for jobs on LinkedIn, how is LinkedIn used in business,** and how you can use this **social media as a content publishing platform online.**

A professional-looking LinkedIn profile helps job seekers to get an interview call. Various business tools of this social platform enable businesses to increase their brand awareness and capture leads. Beside this, this platform allows content publishers to publish their content.
Dear reader, I think you have explored many things from this 5 to 7 minutes basic course.
Now it’s time to create a professional-looking LinkedIn profile and stand out from the crowd.
**Related Article**: [how to apply for online jobs perfectly](https://remoteful.dev/blog/apply-online-jobs) | ryy |
921,635 | Do what you like but frowns may be had, or PHP Standard Recommendations | Just the Gist To give guidelines to PHP projects and to ease how they can interact with each other,... | 15,731 | 2021-12-09T07:35:14 | https://dev.to/andersbjorkland/do-what-you-like-but-frowns-may-be-had-or-php-standard-recommendations-2p94 | php, webdev | >**Just the Gist**
>To give guidelines to PHP projects and to ease how they can interact with each other, a group of project maintainers formed the PHP Framework Interop Group. This group has since come to produce a set of PHP Standard Recommendations (PSR). Recommendations describe such things as code structure and autoloading. PSRs are not rules, they are recommendations.
## Finding structure among the flexibility of PHP
With such an open community and flexibility as the PHP language has, there should be a lot of different ways to code with PHP. And there are! On December 2nd we say that this flexibility was part of why it has become so popular. Procedural, object oriented, and functional programming all have a place in PHP. So as not to become a free-for-all shouting match whenever a group of developers are cooperating, there are a set of recommendations that they can follow. (Of course, this doesn't mean there won't be something else to shout about!)
The set of recommendations available to the public community are called PHP Standard Recommendations (PSR). The most basic of these recommendations are PSR-1 (Basic Coding Standard), and with a total of 14 standards currently in effect there are many questions that can be addressed just from visiting [the official PSR page](https://www.php-fig.org/psr/). Here's the list of all the currently accepted recommendations:
* PSR-1: Basic Coding Standard
* PSR-3: Logger Interface
* PSR-4: Autoloading Standard
* PSR-6: Caching Interface
* PSR-7: HTTP Message Interface
* PSR-11: Container Interface
* PSR-12: Extended Coding Style Guide
* PSR-13: Hypermedia Links
* PSR-14: Event Dispatcher
* PSR-15: HTTP Handlers
* PSR-16 Simple Cache
* PSR-17: HTTP Factories
* PSR-18: HTTP Client
## Where the standards come from
Some standards has been abandoned and others has been deprecated as the PHP language and general coding practices has evolved. But we haven't asked who makes these decisions. The answer is: **The PHP Framework Interop Group** (PHP-FIG). It's a community of representatives from some of the most popular PHP projects, such as Composer, Drupal, Laminas Project, and TYPO3. Previous member projects included Laravel and Symfony. The aim of PHP-FIG is to find commonalities between different projects and how they can work together. PSRs are therefore not to be seen as a set of rules, and are de-facto often a kind of interface chosen on per project basis. For example: PSR-4 (Autoloading Standard) describes how namespaces of classes are used for autoloading their files, but this is not the one and only way anyone can or should implement autoloading.
## What about you?
Have you heard of PSRs or PHP-FIG before? Do you think PSRs are a good addition to PHP? Do these recommendations come in the way of how you like to code PHP? Do you prefer to see them as a set of recommendations, or would you see more projects adhere to them as rules? Comment below and let us know what you think ✍
## Further Reading
* PHP Standard Recommendations official page: https://www.php-fig.org/psr/ | andersbjorkland |
921,655 | Scrum smells, pt. 8: Scrum has too many meetings | Countless times I've heard from developers that scrum makes them waste time by assigning too many... | 0 | 2021-12-09T12:30:53 | https://dev.to/mobileit7/scrum-smells-pt-8-scrum-has-too-many-meetings-2pa2 | scrum, agile, management, projectmanagement | Countless times I've heard from developers that scrum makes them waste time by assigning too many meetings. I've heard that from people who have used scrum, or shall I say people who have attempted scrum adoption.
So let's get this straight today. Why do developers often feel there's too much talking and too little _real work_? Is that really what scrum is supposed to address?
## What does the scrum guide say?
Let's have a look at the scrum guide. It says that the following events should take place:
* Daily scrum (maximum 15 mins per day)
* Sprint planning (maximum 8 hrs per month)
* Sprint review (maximum 4 hrs per month)
* Sprint retrospective (maximum 3 hrs per month)
On top of that, the guide tells us to perform backlog refinement, but it does not specify a particular meeting or event for it. Scrum guide says to allocate approximately 10% of the time for refinement activities. That makes for 4 hrs a week or 12 hrs a month.
So it all adds up to one whole work-day being occupied by _not working_, right?
## Developer role perception
New scrum adopters usually come from a world where software developers are a narrowly defined role. Such developers get a requirement from a business analyst and documentation from a solution architect. They get UI components from a designer. They take it, do their coding part, and hand the stuff over to someone else to integrate and test it. The responsibility for preparation, planning, and verification is not their responsibility and out of their competence.
The Agile approach believes this is not very efficient. It strives to create small development teams where everyone is a developer, contributing to the creative process from the thinking phase up to the verification and deployment. This development team has much more deciding power, can choose its own strategy and course of action, and (in the ideal world) the stakeholders rely on its honest judgments.
That's what makes it more effective. A group of experts communicating with each other will usually come up with better ideas and solutions than a single person. So the team has the freedom to choose their way when tackling a problem. But in order to do that the team also needs to have the means to understand the problem fully. It needs space to coordinate effectively and choose a course of action and necessary tools. It also needs to make sure they work on meaningful things.
## The blind flight
We intuitively feel that some sort of the so-called *overhead* is necessary so that the team can figure out what it needs in order to work effectively. Without any communication or preparation, efficiency could hardly ever be achieved.
And that is essentially why scrum prescribes the events it does. The sole purpose is to facilitate the team's ability to work effectively on relevant and valuable items. It is the imperative that gives meaning to all the single events that happen within the team. It's not a bunch of random separate meetings. It's a concept.
One of the principles of Agile development is to constantly remove activities that are not useful. So let's try to apply this to the key *overhead* activities that happen within scrum. Let's view the ceremonies without their labels for a moment. What would happen if we removed:
1. Operative team synchronization. The on-the-go chance for the team to synchronize on its progress, make short-term plans and decisions. Removing team synchronization altogether would create a bunch of individuals working alongside each other, not a team. Such individuals would not adapt and help each other out to achieve a common goal. Removing such activity would destroy effectiveness.
1. Making a plan - both, a long and short-term one. A chance to look a few weeks or months ahead and to decide what to work on. To prepare a strategy on how to distribute the work, realize what to beware of, and get some distance from daily work. Removing planning activities would cause an inability to work on relevant stuff, to use the team's resources effectively, and foremost any ability to see the context of what the team is working on. A releasable product increment at the end of the sprint would become a coincidence, not an intentional act. Development becomes a blind flight.
1. Improving the way the group works. A review of what works and is useful and what are the painful points. Any system that lacks a self-feedback loop can't improve and adapt to changes. Removing attempts to change the way of work prevents any improvement from happening, which leads (among other things) to a drop in team member motivation and involvement.
1. Keeping the stakeholders in the loop. Not only do we need to gather feedback if we're on the right path. But more importantly, we need to manage the expectations of people around the team to keep them aligned with reality. The more these expectations drift away, the more troublesome the whole environment becomes. Angry people who have the power to influence the project in a negative way are the last thing we need.
1. Deciding on what to actually do. Preparing the backlog into a state, where developers know they can actually deliver it. And that it is worthwhile doing. Dropping such activity leads to a situation, where we invest efforts into irrelevant things.
## Where is the culprit?
We see that the activities above are all necessary to have a working project or product development. They need to happen, somewhere, sometime, invisibly, organically along the way. They always happen, regardless of what we call the project or product management approach. It's just that the scrum guide tries to concentrate them into an organized scheme so that it is easy to follow. It makes it visible. So why not use the concept and rather reinvent the wheel?
From my experience, the distaste for scrum events usually stems from the team not fully understanding the implications of omitting some of the five key overhead activities I mentioned above. Especially the role of refinement activities is often completely misunderstood and the implications of letting the backlog rot are not sufficiently feared. I wrote on this [topic previously](https://mobileit.cz/Blog/Pages/scrum-smells-4.aspx).
In addition, a narrow perception of a developer's competencies and responsibilities is another key factor. The mind shift required to view people as an active element in the product design, planning, and decision making usually takes some time. The goal is to finish stuff as a team, not to be just a cog in a machine which does not have any power to change things. And to achieve that, the activities of a developer must not be limited just to coding.
Thirdly, an ineffective way of leading scrum events. The ceremony is held just because the team is supposed to hold it. The meeting should be done, but no one actually has a clue as to why they gathered and what the purpose of the meeting is. It has no clear guidance, no clear gist. Meetings serve just for a single person (often a product owner or a scrum master) to communicate direction to the developers. The developers feel that they don't have the power to change things anyway - that the organizer is just trying to make an illusion they have the freedom to decide things, but in the end, someone else's decision is superior. That makes the developers feel cheated. It genuinely feels like a waste of time.
## The way out
From my experience, the process of fully understanding and appreciating scrum activities (and the ceremonies supporting them) comes with the team's maturity and guidance. If led well, the team will sooner or later learn from the painful implications of omitting them.
It would, however, be a mistake to enforce a particular *correct* way of doing them. I find it is usually better to offer experience and practices that have worked for other teams, but let the team find their own taste for how to perform it.
The development team is a self-organized unit that has the right (and obligation) to decide on the best way to solve problems. Let's take it also into the exact form of how the scrum events are held. If there's something to be made otherwise to foster the effectiveness and the goal of the meeting itself - why not do it?
Let the team give them space to learn from it. That is, I believe, the best way to keep teams running and becoming effective in the long run. Agile principles are empirically oriented after all.
Written by: Otakar Krus | mobileit7 |
921,667 | React Cosmos with Remix | I recently discovered https://remix.run. Whoa, haven't been this excited over a framework for a long... | 0 | 2021-12-09T09:32:07 | https://dev.to/rzmz/react-cosmos-with-remix-7go | react, typescript, remix | I recently discovered https://remix.run. Whoa, haven't been this excited over a framework for a long time. Naturally I already switched some pet projects over and the development flow has been very straightforward.
One topic of interest of mine is how to speed up and isolate developing of components that I use in my apps.
Enter https://reactcosmos.org. It's an alternative to Storybook and to me looks a bit cleaner with smaller amount of boilerplate needed to get running out of the box. It runs a separate dev server with a clean UI displaying all of your component fixtures.
So I tried to pair my Remix app with React Cosmos so I would not have to run a separate Webpack bundler in order to get the fixtures update as I work on the components. I got it working by following the Snowpack example from React-Cosmos Github space.
The first draft of this tutorial I posted also under an open issue about supporting StoryBook in Remix Github issues page: https://github.com/remix-run/remix/issues/214
Create `cosmos.tsx` under `app/routes`:
```tsx
export default function Cosmos() {
return null;
}
```
Add `cosmos.config.json` in your project root directory:
```json
{
"staticPath": "public",
"watchDirs": ["app"],
"userDepsFilePath": "app/cosmos.userdeps.js",
"experimentalRendererUrl": "http://localhost:3000/cosmos"
}
```
Change your `entry.client.tsx` accordingly:
```tsx
import { mountDomRenderer } from "react-cosmos/dom";
import { hydrate } from "react-dom";
import { RemixBrowser } from "remix";
import { decorators, fixtures, rendererConfig } from "./cosmos.userdeps.js";
if (
process.env.NODE_ENV === "development" &&
window.location.pathname.includes("cosmos")
) {
mountDomRenderer({ rendererConfig, decorators, fixtures });
} else {
hydrate(<RemixBrowser />, document);
}
```
You might need to add `// @ts-nocheck` in the beginning of this file if using Typescript (you should), because TS will likely complain about not finding `./cosmos.userdeps.js` which will be generated automatically by React Cosmos on each run. Oh and you should add that file to your `.gitignore` file as well!
Of course, add react-cosmos as a dev dependency:
```bash
$ npm i -D react-cosmos
```
Add the following in your `package.json` scripts section:
```json
"cosmos": "cosmos",
"cosmos:export": "cosmos-export"
```
Start the remix dev server:
```zsh
$ npm run dev
```
Start cosmos server in another terminal window:
```zsh
$ npm run cosmos
```
Now, although this works, I noticed in the developer console, that my remix app started polling itself and getting 404 periodically because of a socket.io route was not configured.
This started to bother me so I investigated further and found a cleaner solution:
In `app/routes/cosmos.tsx` make the following changes:
```tsx
import { useCallback, useState } from "react";
import { useEffect } from "react";
import { HeadersFunction } from "remix";
import { decorators, fixtures, rendererConfig } from "~/cosmos.userdeps.js";
const shouldLoadCosmos =
typeof window !== "undefined" && process.env.NODE_ENV === "development";
export const headers: HeadersFunction = () => {
return { "Access-Control-Allow-Origin": "*" };
};
export default function Cosmos() {
const [cosmosLoaded, setCosmosLoaded] = useState(false);
const loadRenderer = useCallback(async () => {
const { mountDomRenderer } = (await import("react-cosmos/dom")).default;
mountDomRenderer({ decorators, fixtures, rendererConfig });
}, []);
useEffect(() => {
if (shouldLoadCosmos && !cosmosLoaded) {
loadRenderer();
setCosmosLoaded(true);
}
}, []);
return null;
}
```
And restore your `entry.client.ts` file to it's original state:
```tsx
import { hydrate } from "react-dom";
import { RemixBrowser } from "remix";
hydrate(<RemixBrowser />, document);
```
So there you have it - Remix dev server running on localhost:3000 and React Cosmos server running on localhost:5000.
Notice the headers function export in `app/routes/cosmos.tsx` - I added that so there would be no annoying cors errors in your dev console, although it seemed to work perfectly fine without it as well. | rzmz |
921,689 | React-Redux How It's Works ? | How Redux works with React ? Let's see, In this tutorial we trying to learn the concept of... | 0 | 2021-12-11T14:18:27 | https://dev.to/shubhamathawane/react-redux-how-its-works--13g6 | react, javascript, redux, beginners | #### How Redux works with React ? Let's see, In this tutorial we trying to learn the concept of react-redux (for beginners), We will be creating a small increment - decrement application using react-redux, Which I think is best example to learn complex concepts like these, So let's start.
-———————————————
First of all create Your React App using `npx create-react-app app-name` and install following decencies :
→ `npm install react-redux redux`
after all installation and creating-app write in command `npm start` to run your application and follow the below steps : -
_important note_: - there is problem with numbering, So please adjust
-———————————————
1. Create Folder inside the src called actions, and inside the action folder create file called index.js and Inside that file we will create Actions like INCREMENT / DECREMENT , basically we will called it as **What kind of action to do with** and write following code inside index.js file
```jsx
// .actions/index.js
export const incNumber = () => {
return {
type:"INCREMENT"
}
}
export const decNumber = () => {
return {
type:"DECREMENT"
}
}
export const resetNumber = () => {
return {
type:"RESET"
}
}
```
Here in this file we have created the function which will trigged by an action using `dispatch` method, in this file we have created 3 functions and exported them separately using export keyword, in here `inNumber()` will trigger "INCREMENT" method and so on.
2. Create another folder in src called `reducers`, and inside reducers folder create file `upDown.js` and `index.js`. `upDown.js` we will create a functions that will change the state of our application. `upDown.js` file will contain following code.
> ***This file will contain How to Do scenario.***
>
```jsx
//reducer/upDown.js
const initialState = 0;
// It is always better to initial our state with 0 or to initialize
const changeTheNumber = (state = initialState, action) => {
switch (action.type) {
case "INCREMENT":
return state + 1;
case "DECREMENT":
return state - 1;
case "RESET":
return state = 0;
default:
return state;
}
};
export default changeTheNumber;
```
Then inside the `index.js` we will import the the function `ChangeTheNumber` from `upDown.js` file and here we will use `CombineReducers` from redux and will create function `rootReducers` it is most important step , and after creating the `rootReducers` we'll export it, like bellow
```jsx
// ..reducers/index.js
// Imprting reducer from upDown file
import changeTheNumber from "./upDown";
// Importing combineReducers object
import { combineReducers } from "redux";
// Creating RootReducer
const rootReducer = combineReducers({
changeTheNumber
})
//Exporting rootReducer
export default rootReducer;
```
3. In this step we will create a store for our react-redux application, so we will need to install react-redux package into your application using `npm install react-redux` , ( ignore if you already install ) after installation write the following code inside store.js file
```jsx
// src/store.js
import { createStore } from 'redux'
// Importing RootReducers
import rootReducer from './reducer/index'
//Creating Store and passing rootreducer
const store = createStore(rootReducer, window.__REDUX_DEVTOOLS_EXTENSION__ && window.__REDUX_DEVTOOLS_EXTENSION__());
export default store;
```
and we will *export that store to import inside index.js* to make it global store. So let's how we can make it global store in next step.
4. Go to you index.js file from src, Here import store which we exported from store.js file and also import Provider from react-redux like below.
```jsx
// index.js
import React from "react";
import ReactDOM from "react-dom";
import "./index.css";
import App from "./App";
import reportWebVitals from "./reportWebVitals";
import store from "./store";
import { Provider } from "react-redux";
store.subscribe(() => console.log(store.getState()));
ReactDOM.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>,
document.getElementById("root")
);
reportWebVitals();
```
Your index.js file will look like this, here we have wrap our App inside <Provider> and Pass the store={store} as a prop
( You can use redux `devtool` if you want : and add following code to work with `devtool` , It is optional to see reducers inside browsers but makes working with reducers easy )
```jsx
store.subscribe(() => console.log(store.getState()));
```
5. Final Step : Go to your app.js file and import the functions we created inside `/actions/` file such as `{ decNumber, incNumber, resetNumber }` and create a variable which will hold the state result. we use dispatch method to trigger events like dispatch( functionName() ). after all our app.js file will look like this →
```jsx
import "./App.css";
import {useSelector, useDispatch } from 'react-redux'
import { decNumber, incNumber, resetNumber } from "./action";
function App() {
const myState = useSelector((state) => state.changeTheNumber )
const dispatch = useDispatch();
return (
<div className="App">
<h2>Increment / Decrement Counter</h2>
<h4>Using React and Redux</h4>
<div className="quantity">
<button className="quantity_minus" title="Decrement" onClick={() => dispatch(decNumber())}>
<span> - </span>
</button>
<input
name="quantity"
type="text"
className="quantity_input"
value={myState}
/>
<button className="quantity_plus" title="Increament" onClick={() =>dispatch(incNumber())} >
<span> + </span>
</button>
<button className="quantity_plus" title="Reset Count" onClick={() =>dispatch(resetNumber())} >
<span> Reset </span>
</button>
</div>
</div>
);
}
export default App;
```
This is how application is looking like : -
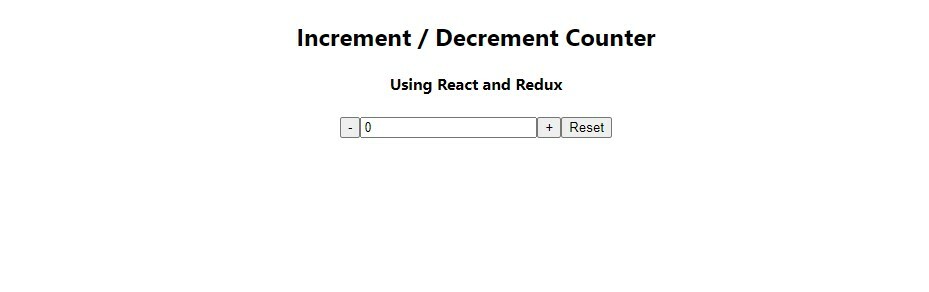
So this is how we can implement react-redux in our react application, Hopefully you find this tutorial helpful. Thank You.
| shubhamathawane |
921,717 | Comment créer une application Electron avec vite | Note: This article is available in English here Pouvoir créer un logiciel avec Electron ce n'est pas... | 0 | 2021-12-09T20:27:33 | https://dev.to/olyno/comment-creer-une-application-electron-avec-vite-4noe | javascript, electron, svelte, vite | **Note:** This article is available in English [here](https://dev.to/olyno/how-to-create-an-electron-application-with-vite-im)
Pouvoir créer un logiciel avec Electron ce n'est pas si compliqué. [Pleins de boilerplates](https://github.com/sindresorhus/awesome-electron#boilerplates) existent, la [documentation](https://www.electronjs.org/docs/latest/tutorial/quick-start) est très bien...
Cependant, je n'ai rien trouvé qui explique comment créer un projet Electron avec Vite. Alors, allons droit au but.
## Créer l'application Vite par défaut
Pour cela rien de plus simple. Je me baserais sur Yarn pour mes installation. A l'aide de la commande:
```
yarn create vite
```
Il suffit de rajouter le nom de notre projet (dans notre cas "electron-vite"), et de choisir un framework (dans notre cas "Svelte").
Nous allons ensuite dans le dossier de notre projet et installons nos dépendances:
```
cd electron-vite
yarn install
```
## Installer le builder
Le builder nous permettra de créer l'application finale et de déployer le logiciel en production. Nous utiliserons [Electron Forge](https://www.electronforge.io/).
Nous pouvons l'installer avec la commande suivante :
```
yarn add --dev @electron-forge/cli
```
Une fois le CLI de la forge installé, il ne nous reste plus qu'à le configurer. Heureusement pour nous, Electron Forge s'occupe de tout. Il ne nous reste plus qu'à l'exécuter:
```
yarn electron-forge import
```
Et les différents scripts seront ajoutés à notre fichier ``package.json``
## Editons le package.json
Ils nous restent encore quelques dépendances à installer:
```shell
concurrently # Pour lancer Vite et Electron en même temps
cross-env # Pour pouvoir définir un environnement au lancement
```
Pour les installer, on aura juste à faire:
```
yarn add -D concurrently cross-env
```
Maintenant que nous avons toutes les dépendances installées, nous avons plus qu'à setup les différents scripts:
```json
"scripts": {
"start": "npm run build && npm run electron:start",
"dev": "concurrently -k \"vite\" \"npm run electron:dev\"",
"build": "vite build",
"preview": "vite preview",
"electron:dev": "cross-env IS_DEV=true electron-forge start",
"electron:build": "electron-forge make",
"electron:package": "electron-forge package"
},
```
> Vous pouvez modifier les ``yarn`` par ``npm run`` dans les différents scripts
La variable d'environnement ``IS_DEV`` peut bien entendu être renommé en ``NODE_ENV`` par exemple.
Il nous manque 3 champs à rajouter/modifier:
```
"main": "app/index.js",
"description": "Boilerplate Electron + Vite + Svelte",
"license": "MIT",
```
Le champs ``main`` sera le point d'entrée de notre application Electron.
Les champs ``description`` et ``license`` sont nécessaire pour pouvoir build Electron avec Electron Forge.
## Editons la config de vite
Rien de bien compliqué. Il faudra dans un premier temps que l'on modifie la ``base`` de notre application. Si l'application part en production, alors nous allons chercher de façon relative les fichiers à importer (comme les assets). Puis, on aura juste à modifier le dossier de build afin qu'il soit relié à notre application Electron.
```js
import { svelte } from '@sveltejs/vite-plugin-svelte';
import { defineConfig } from 'vite';
// https://vitejs.dev/config/
export default defineConfig({
base: process.env.IS_DEV !== 'true' ? './' : '/',
build: {
outDir: 'app/build',
},
plugins: [svelte()],
});
```
## On setup Electron
Pour créer notre application Electron, on a juste à créer un fichier ``app/index.js`` qui contiendra le code par défaut d'Electron:
```js
// app/index.js
const path = require('path');
const { app, BrowserWindow } = require('electron');
// Handle creating/removing shortcuts on Windows when installing/uninstalling.
if (require('electron-squirrel-startup')) {
app.quit();
}
const isDev = process.env.IS_DEV === 'true';
function createWindow() {
// Create the browser window.
const mainWindow = new BrowserWindow({
width: 800,
height: 600,
webPreferences: {
preload: path.join(__dirname, 'preload.js'),
nodeIntegration: true,
},
});
// Open the DevTools.
if (isDev) {
mainWindow.loadURL('http://localhost:3000');
mainWindow.webContents.openDevTools();
} else {
// mainWindow.removeMenu();
mainWindow.loadFile(path.join(__dirname, 'build', 'index.html'));
}
}
// This method will be called when Electron has finished
// initialization and is ready to create browser windows.
// Some APIs can only be used after this event occurs.
app.whenReady().then(() => {
createWindow();
app.on('activate', function () {
// On macOS it's common to re-create a window in the app when the
// dock icon is clicked and there are no other windows open.
if (BrowserWindow.getAllWindows().length === 0) createWindow();
});
});
// Quit when all windows are closed, except on macOS. There, it's common
// for applications and their menu bar to stay active until the user quits
// explicitly with Cmd + Q.
app.on('window-all-closed', () => {
if (process.platform !== 'darwin') {
app.quit();
}
});
```
Dans le code ci-dessus, il y a 2 choses à noter:
1. Le code suivant est nécessaire si vous souhaitez build votre application avec "squirrel" (un model de build pour Windows).
```js
if (require('electron-squirrel-startup')) {
app.quit();
}
```
2. Concernant la façon de récupérer le contenu:
```js
if (isDev) {
mainWindow.loadURL('http://localhost:3000');
mainWindow.webContents.openDevTools();
} else {
// mainWindow.removeMenu(); // Optionnel
mainWindow.loadFile(path.join(__dirname, 'build', 'index.html'));
}
```
Si nous sommes en train de dev, nous allons juste charger une url qui sera celle de Vite. Par contre si nous avons build notre application pour la production, alors nous aurons besoin de récupérer le fichier ``index.html`` directement.
Enfin, il nous suffit de créer un fichier ``app/preload.js``.
> Electron ne supporte pas encore les syntaxes esm, et donc par conséquent, nous allons utiliser le ``require``
## On modifie le fichier de config de Svelte
Alors oui, même si notre application est en soit fini, Electron ne supportant pas les syntaxes esm, nous devons modifier les imports/export en require/module:
```js
// svelte.config.js
const sveltePreprocess = require('svelte-preprocess');
module.exports = {
// Consult https://github.com/sveltejs/svelte-preprocess
// for more information about preprocessors
preprocess: sveltePreprocess(),
};
```
Et voilà, vous venez de créer votre logiciel avec Vite et Electron ! Le livereload fonctionne parfaitement, que demander de mieux !
Vous pouvez retrouver le repository ici: https://github.com/frontend-templates-world/svelte-ts-electron-vite | olyno |
921,806 | Why to hire Remote developers | Building a website or an application is very complicated work even when you are hiring an external... | 0 | 2021-12-09T11:54:50 | https://dev.to/externlabs/why-to-hire-remote-developers-2eh8 | Building a website or an application is very complicated work even when you are hiring an external team because it might require many things in the process of development. There are many ways you can hire developers including a web and software company, in-house development team, in-house developer. Today we are going to discuss a faster yet cost-effective way to get your development work done - Hire A Remote Developer.
Hire Remote Developer
The Remote Developers are the people who work as freelancers. They work remotely from their location and serve their work globally. The pandemic was a hard hit on the development industry and left many changes in work. At present time, the market has a high demand of hire remote developers, around the world. Even development companies are preferring to hire a remote developer instead of an in-house developer. Remote developers work from their comfort and according to their time but they complete their work on or before time. Remote developers are more productive than in-office developers.
[Reasons To Hire Remote Developer
](https://externlabs.com/blogs/10-reasons-to-hire-remote-developers/)
Productivity
The major reason for hiring remote developers is that they are more productive than in-office developers. They sit in their comfort zone and do work for clients from various countries which helps them to increase their experience and ideas.
Working from home gives them the advantage of flexible working hours and other things to do which makes them more active and focused on their work.
Client or company only wants a highly skilled employee, remote developers have the skills and quality because of their work nature.
Find The Right Skill
It’s crucial to hire the right candidate for the job or work, selecting a wrong or unskilled person can lead to long delays or project failures. But with remote developers you have control over time, you can hire or fire a developer without any reason at any time of the process.
The remote developers have the skills and you can give them control of the project or work with a deadline, and they will take full responsibility.
You can set some parameters for your desired candidate and with some tests and interviews you can get the right person as your remote developer.
Less Employment Cost
Remote Developers work from home of their place which saves a lot for employers And they work only for the decided time period which can be in weeks, months, or till their project. Employers don’t have to give them employee benefits because they are not permanent employees.
Work Done before Time
When hiring remote developers, gives you the power to choose the right person for the specific task. If each task will be done by its expert then it will take lesser time. On the other hand, remote developers don’t get hired for days, you hire them for tasks that keep them focused on your work without boundations of working hours.
Better Communication & Collaboration
All ware the visible benefits of hire a remote developer, but there is one more thing that will give you a hidden yet effective with is better communication and collaboration. As much as remote developers are hired by the company, that many connections and links the company builds. This increases awareness and engagement of the company in the industry. This helps the company to build its brand name.
These are the benefits of hire a remote developer, They benefit the organization, work better, provide better results. There is no reason to ignore remote developers. | aniruddhextern | |
922,075 | A new visual change in GitHub 🙄 | I have seen a new visual change on GitHub today. As an enthusiast in Open-Source, I always surf on... | 0 | 2021-12-09T16:53:55 | https://dev.to/fahimfba/a-new-visual-change-on-github-1mm8 | github, opensource, discuss | I have seen a new visual change on GitHub today. As an enthusiast in Open-Source, I always surf on GitHub. As I was searching for something on my [GitHub profile](https://github.com/FahimFBA), I noticed something is missing under my `Edit profile` section. The `Stars` section is missing! After a while, I discovered that the section has been shifted to the upper part of my profile from its earlier position! Later, I noticed more visual changes on the badges and the about section of the repository also!
The `Stars` section has a nicely listed visualization, although the feature is still on Beta right now.
You can create your own list as well.
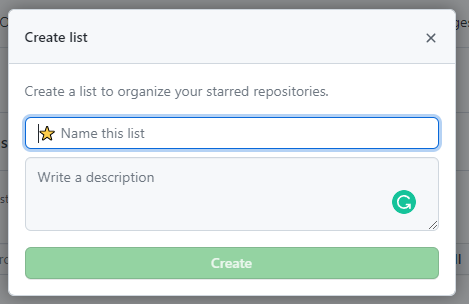
After sharing this experience on my Discord server, I realized that many of the users have not gotten the feature yet now. You may try to check whether you have also received the change like me or not.
Anyway, this article is just a discussion-type article. Let me know how you feel about this change. Personally, I like this change as that would help me to check the repository quickly which I have starred already.
Also, if you want, then you can follow me on [GitHub](https://github.com/FahimFBA) as I am very active regarding open-source projects. You may also follow me on [Twitter](https://twitter.com/Fahim_FBA), [LinkedIn](https://www.linkedin.com/in/fahimfba/), [Facebook](https://www.facebook.com/iptu.fba/) as well. One more thing, I publish programming-related content on my [YouTube channel](https://www.youtube.com/c/InnovationWithIphim/) also, both in English and in the Bengali language. Make sure to check those out too if you want. 😀
Have a nice day! 😊
| fahimfba |
921,807 | Top 10 Cities in the World for the Best Data Science Jobs
| Introduction Data Science Jobs are hugely popular jobs these days with job-seekers rallying for... | 0 | 2021-12-09T11:56:07 | https://dev.to/parmarr30396385/top-10-cities-in-the-world-for-the-best-data-science-jobs-5fhe | datascience, python, career, discuss | Introduction

- Data Science Jobs are hugely popular jobs these days with job-seekers rallying for interviews to get the best job. If you are open to relocating to cities all around the world, you will find many good opportunities based on salaries offered, the number of open positions, etc. But, you must be wondering, “What are the names of the top cities that offer the best Data Science Jobs.” Don’t worry, as that’s what we are going to talk about in this blog post.
- If you are a Data Science graduate, ready to relocate to any of the top cities in the world offering the best Data Science jobs, you have landed on the right blog post.
- As already mentioned above, in this blog post, we will be talking about the top 10 cities in the world that offer the best Data Science jobs.
Related blogs:
[Top Data Scientist Certifications
](https://techflashes.com/top-data-scientist-certifications/)[Why are Data Scientist jobs in demand?](https://techflashes.com/why-are-data-scientist-jobs-in-demand/)
[Data Science vs. Machine Learning vs. Artificial Intelligence
](https://techflashes.com/data-science-vs-machine-learning-vs-artificial-intelligence/)
List of the Top 10 Cities in the World for the Best Data Science Jobs
Here’s the list:
1) Raleigh-Durham –

-
This mid-sized town with pleasant weather, superb cost of living, and relatively lower cost of living is the first name on our list of the top 10 cities in the world for the best Data Science jobs. The famous places of Raleigh, Durham, and Chapel Hill are popular for technology and research and house giants such as Lenovo and Cisco. On average, Data Science jobs will get you a 6-figure salary and there are around 500 Data Science job openings as of now.
2) Phoenix, Arizona –

-
Another city that houses technology and innovation is Phoenix and is also one of the top 10 cities in the world for the best Data Science jobs. This city is immersed in the culture and offers an amazing cost of living. The average salary of a Data Science job here is $140,000. You will have a lot of purchasing power here and you will even save on taxes, all thanks to the money it makes from tourism.
3) Atlanta, Georgia –

- This hub for fortune 500 companies is the next name on our list of the top 10 cities in the world for best Data Science jobs. This city offers an affordable standard of living and houses some of the biggest tech companies.
4) Dublin, Ireland –

-
This city houses a cluster of big data centers and is also one of the top 10 cities in the world for the best Data Science jobs. It has server farms for tech giants like Google, Amazon, and Facebook and pulls in some of the best minds in Data Science. As a lead Data Scientist, the average salary that you can draw here is $100,000.
5) Boston Massachusetts –

-
This city houses some of the world’s top universities like Harvard and MIT and, therefore, attracts some of the brightest talents in the world. The cost of living is higher than the other cities but the average salary for a Data Science job is also higher and stands at $141,000. There are little under 2500 Data Science jobs on Indeed, enough for you to set foot here.
6) London, UK –

-
This global hub for Artificial Intelligence and FinTech is also one of the top 10 cities in the world for the best Data Science jobs. It houses the Alan Turing Institute and has played host to the Deep Learning Summit, the Strata Data Conference, and the European Conference of ODSC. The average salary for a Data Science job is around $57,000 and the number of current Data Science job openings stands at 2000. The cost of living in this city is high.
7) Singapore –

- Singapore is one of the top smart cities in the world and is the next name on our list of the top 10 cities in the world for Data Science jobs. It has autonomous vehicles, Artificial Intelligence, and ASEAN-leading government expenditure on IT. The average salary for a Data Science job in Singapore is $52,000 per year.
8) Toronto, Canada –

-
This is a city where Data Science in FinTech and Banking is most sought-after. A banking innovation lab opened by the Royal Bank of Canada in Toronto, works on Artificial Intelligence and Big Data. The average salary for a Data Science job is U.S $59,000 per year and the number of Data Science job listings stands at around 4000.
9) Palo Alto, California –

- Silicon Valley is the next name on our list of the top 10 cities in the world for Data Science jobs. Your career in Data Science will skyrocket if you get a job in one of the wealthiest cities in the world. The average Data Science salary is $150,000 per year. The number of Data Science jobs is around 4000.
10) Paris, France –

-
This city is home to many innovation labs and is also one of the top 10 cities in the world. Esteemed companies like Facebook and Samsung are soon going to open AI-specific labs here. The average Data Science salary here is $55,350 which will go up, provided Government expenditure on IT goes up too.
Closing
These are the top 10 cities in the world for the best Data Science jobs. You can choose the one whose standard of living, average salaries, etc. attract you the most. Enter the World of success by bagging the best Data Science job in any of the above cities!
Original link of that Article and Jobs Requirements here: [Data Science Jobs](https://techflashes.com/top-10-cities-in-the-world-for-the-best-data-science-jobs/) | parmarr30396385 |
921,840 | Remix and Supabase Authentication | How to secure a Remix and Supabase application using Row Level Security NOTE: This... | 15,778 | 2021-12-09T13:09:57 | https://l.carlogino.com/b-rsauth | javascript, webdev, react, remix | ## How to secure a Remix and Supabase application using Row Level Security
> NOTE: This tutorial is deprecated in favor of the [official documentation](https://supabase.com/docs/guides/auth/auth-helpers/remix).
<br />
## Table of Contents
* <a href="#tldr" target="_self">TL;DR Source and Demo</a>
* <a href="#introduction" target="_self">Introduction</a>
* <a href="#supabase-setup" target="_self">Setting up Supabase</a>
* <a href="#server-side-utils" target="_self">Server-side utilities</a>
* <a href="#client-side-utils" target="_self">Client-side utilities</a>
* <a href="#sign-in" target="_self">Create sign-up and sign-in page</a>
* <a href="#sign-out" target="_self">Create a sign-out action</a>
* <a href="#tldr-examples" target="_self">TL;DR version of using the setup</a>
* <a href="#fetch-all" target="_self">Fetch All example</a>
* <a href="#get-delete-one" target="_self">Get one and Delete one example</a>
* <a href="#create-one" target="_self">Create one example</a>
* <a href="#update-one" target="_self">Update one example</a>
* <a href="#conclusion" target="_self">Conclusion</a>
<br />
> ### TL;DR: Source and Demo <a name="tldr"></a>
> Here's a live [demo](https://playground-iirrt7a6j-codegino.vercel.app)
>
> Link to the [source code](https://github.com/codegino/playground/tree/part4/authentication)
>
> Link to [step by step commits](https://github.com/codegino/playground/commits/part4/authentication)
<br />
### Introduction <a name="introduction"></a>
This blog will focus on securing our Remix application with Supabase's [Row Level Security (RLS) feature](https://supabase.com/docs/guides/auth/row-level-security).
If you want to know the context of what application I'm talking about, you can refer to my [another blog](https://dev.to/codegino/remix-and-supabase-integration-cci).
<br />
### Setting up Supabase <a name="supabase-setup"></a>
> Instead of updating my database from the previous blog, I'm just going to re-create it.
#### Create a table to contain `user_id`
```sql
CREATE TABLE words (
id bigint GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
name varchar NOT NULL,
definitions varchar ARRAY NOT NULL,
sentences varchar ARRAY NOT NULL,
type varchar NOT NULL,
user_id uuid NOT NULL
);
```
<br />
#### Add a foreign key in `user_id` pointing to `auth.users`
```sql
alter table words
add constraint words_users_fk
foreign key (user_id)
references auth.users (id);
```
<br />
#### Create Row Level Security Supabase Policies
```sql
CREATE POLICY "anon_select" ON public.words FOR SELECT USING (
auth.role() = 'anon' or auth.role() = 'authenticated'
);
CREATE POLICY "auth_insert" ON public.words FOR INSERT WITH CHECK (
auth.role() = 'authenticated'
);
CREATE POLICY "user_based__update" ON public.words FOR UPDATE USING (
auth.uid() = user_id
);
CREATE POLICY "user_based_delete" ON public.words FOR DELETE USING (
auth.uid() = user_id
);
```
<br />
### Implement server-side utilities to manage Supabase session <a name="server-side-utils"></a>
#### Create server instance of Supabase client
```ts
// app/utils/supabase.server.ts
import { createClient } from "@supabase/supabase-js";
const supabaseUrl = process.env.SUPABASE_URL as string;
const supabaseKey = process.env.SUPABASE_ANON_KEY as string;
export const supabase = createClient(supabaseUrl, supabaseKey);
```
<br />
#### Use `createCookieSessionStorage` to help in managing our Supabase token
```ts
// app/utils/supabase.server.ts
// ...
import { createCookieSessionStorage } from "remix";
// ...
const { getSession, commitSession, destroySession } =
createCookieSessionStorage({
// a Cookie from `createCookie` or the CookieOptions to create one
cookie: {
name: "supabase-session",
// all of these are optional
expires: new Date(Date.now() + 3600),
httpOnly: true,
maxAge: 60,
path: "/",
sameSite: "lax",
secrets: ["s3cret1"],
secure: true,
},
});
export { getSession, commitSession, destroySession };
```
<br />
#### Create a utility to set the Supabase token from the Request
```ts
// app/utils/supabase.server.ts
// ...
export const setAuthToken = async (request: Request) => {
let session = await getSession(request.headers.get("Cookie"));
supabase.auth.setAuth(session.get("access_token"));
return session;
};
```
<br />
## Setting up authentication in the Remix side
### Create client-side utilities for managing Supabase session <a name="client-side-utils"></a>
#### Create Supabase Provider and a custom hook which returns the Supabase instance
```tsx
// app/utils/supabase-client.tsx
import { SupabaseClient } from "@supabase/supabase-js";
import React from "react";
export const SupabaseContext = React.createContext<SupabaseClient>(
null as unknown as SupabaseClient
);
export const SupabaseProvider: React.FC<{ supabase: SupabaseClient }> = ({
children,
supabase,
}) => (
<SupabaseContext.Provider value={supabase}>
{children}
</SupabaseContext.Provider>
);
export const useSupabase = () => React.useContext(SupabaseContext);
```
<br />
#### Pass Supabase environment variables to our client
```tsx
// app/root.tsx
export const loader = () => {
return {
supabaseKey: process.env.SUPABASE_ANON_KEY,
supabaseUrl: process.env.SUPABASE_URL,
};
};
```
<br />
#### Create a Supabase instance and pass it into the root level Supabase provider
```tsx
// app/root.tsx
import { createClient } from "@supabase/supabase-js";
import { SupabaseProvider } from "./utils/supabase-client";
// export const loader...
export default function App() {
const loader = useLoaderData();
const supabase = createClient(loader.supabaseUrl, loader.supabaseKey);
return (
<Document>
<SupabaseProvider supabase={supabase}>
<Layout>
<Outlet />
</Layout>
</SupabaseProvider>
</Document>
);
}
```
<br />
### Create the `/auth` route <a name="sign-in"></a>
> Since I'm too lazy to implement a login page, I'll just use the UI provided by Supabase.
#### Install `@supabase/ui`
```sh
npm install @supabase/ui
yarn add @supabase/ui
```
<br />
#### Create the main auth component
> You can create your custom sign-up and sign-in form if you want.
```tsx
// app/routes/auth.tsx
import React from "react";
import { Auth } from "@supabase/ui";
import { useSupabase } from "~/utils/supabase-client";
export default function AuthBasic() {
const supabase = useSupabase();
return (
<Auth.UserContextProvider supabaseClient={supabase}>
<Container> {/* TODO */}
<Auth supabaseClient={supabase} />
</Container>
</Auth.UserContextProvider>
);
}
```
<br />
#### Create the component to inform the server that we have a Supabase session
```tsx
// app/routes/auth.tsx
import React, { useEffect } from "react";
import { useSubmit } from "remix";
const Container: React.FC = ({ children }) => {
const { user, session } = Auth.useUser();
const submit = useSubmit();
useEffect(() => {
if (user) {
const formData = new FormData();
const accessToken = session?.access_token;
// you can choose whatever conditions you want
// as long as it checks if the user is signed in
if (accessToken) {
formData.append("access_token", accessToken);
submit(formData, { method: "post", action: "/auth" });
}
}
}, [user]);
return <>{children}</>;
};
// ...
```
<br />
#### Create an action handler to process the Supabase token
```tsx
// app/routes/auth.tsx
import { Auth } from "@supabase/ui";
import { useSubmit, redirect } from "remix";
import type { ActionFunction } from "remix";
import React from "react";
import { useSupabase } from "~/utils/supabase-client";
import { commitSession, getSession } from "~/utils/supabase.server";
export const action: ActionFunction = async ({ request }) => {
const formData = await request.formData();
const session = await getSession(request.headers.get("Cookie"));
session.set("access_token", formData.get("access_token"));
return redirect("/words", {
headers: {
"Set-Cookie": await commitSession(session),
},
});
};
// ...
```
After logging in, the user will be redirected to the `/words` route.
<br />
> If you want to test without signing up, use the following credentials:
>
> email: dev.codegino@gmail.com
>
> password: testing
<br />
### Signing out <a name="sign-out"></a>
#### Create a logout button in the header
```tsx
// app/root.tsx
import { {/*...*/}, useSubmit } from "remix";
import { {/*...*/}, useSupabase } from "./utils/supabase-client";
import { Button } from "./components/basic/button";
function Layout({ children }: React.PropsWithChildren<{}>) {
const submit = useSubmit();
const supabase = useSupabase();
const handleSignOut = () => {
supabase.auth.signOut().then(() => {
submit(null, { method: "post", action: "/signout" });
});
};
return (
<main>
<header>
{supabase.auth.session() && (
<Button type="button" onClick={handleSignOut}>
Sign out
</Button>
)}
</header>
{children}
</main>
);
}
```
<br />
#### Create an action handler
I don't want to pollute my other route, so I will create my signout action handler separately
```tsx
// app/routes/signout.tsx
import { destroySession, getSession } from "../utils/supabase.server";
import { redirect } from "remix";
import type { ActionFunction } from "remix";
export const action: ActionFunction = async ({ request }) => {
let session = await getSession(request.headers.get("Cookie"));
return redirect("/auth", {
headers: {
"Set-Cookie": await destroySession(session),
},
});
};
export const loader = () => {
// Redirect to `/` if user tried to access `/signout`
return redirect("/");
};
```
<br />
### TL;DR version of using our setup <a name="tldr-examples"></a>
#### Using in a `loader` or `action`
```tsx
export const action = async ({ request, params }) => {
// Just set the token to any part you want to have access to.
// I haven't tried making a global handler for this,
// but I prefer to be explicit about setting this.
await setAuthToken(request);
await supabase.from("words").update(/*...*/);
// ...
};
```
<br />
#### Conditional rendering based on auth state
```tsx
export default function Index() {
const supabase = useSupabase();
return supabase.auth.user()
? <div>Hello world</div>
: <div>Please sign in</div>;
}
```
<br />
> NOTE: Conditional server-side rendering might cause hydration warning,
>
> I'll fix this in another blog post.
<br />
## Using in CRUD Operations
The examples below are a longer version of using our setup for CRUD operations.
### Fetching All operation <a name="fetch-all"></a>
```tsx
// app/routes/words
import { Form, useTransition } from "remix";
import type { LoaderFunction } from "remix";
import { useLoaderData, Link, Outlet } from "remix";
import { Button } from "~/components/basic/button";
import { supabase } from "~/utils/supabase.server";
import type { Word } from "~/models/word";
import { useSupabase } from "~/utils/supabase-client";
export const loader: LoaderFunction = async () => {
// No need to add auth here, because GET /words is public
const { data: words } = await supabase
.from<Word>("words")
.select("id,name,type");
// We can pick and choose what we want to display
// This can solve the issue of over-fetching or under-fetching
return words;
};
export default function Index() {
const words = useLoaderData<Word[]>();
const transition = useTransition();
const supabase = useSupabase();
return (
<main className="p-2">
<h1 className="text-3xl text-center mb-3">English words I learned</h1>
<div className="text-center mb-2">Route State: {transition.state}</div>
<div className="grid grid-cols-1 md:grid-cols-2 ">
<div className="flex flex-col items-center">
<h2 className="text-2xl pb-2">Words</h2>
<ul>
{words.map((word) => (
<li key={word.id}>
<Link to={`/words/${word.id}`}>
{word.name} | {word.type}
</Link>
</li>
))}
</ul>
{/* Adding conditional rendering might cause a warning,
We'll deal with it later */}
{supabase.auth.user() ? (
<Form method="get" action={"/words/add"} className="pt-2">
<Button
type="submit"
className="hover:bg-primary-100 dark:hover:bg-primary-900"
>
Add new word
</Button>
</Form>
) : (
<Form method="get" action={`/auth`} className="flex">
<Button type="submit" color="primary" className="w-full">
Sign-in to make changes
</Button>
</Form>
)}
</div>
<Outlet />
</div>
</main>
);
}
```
<br />
### Retrieve one and Delete one operation <a name="get-delete-one"></a>
```tsx
// app/routes/words/$id
import { Form, useLoaderData, redirect, useTransition } from "remix";
import type { LoaderFunction, ActionFunction } from "remix";
import type { Word } from "~/models/word";
import { Input } from "~/components/basic/input";
import { Button } from "~/components/basic/button";
import { setAuthToken, supabase } from "~/utils/supabase.server";
import { useSupabase } from "~/utils/supabase-client";
// Here's how to delete one entry
export const action: ActionFunction = async ({ request, params }) => {
const formData = await request.formData();
// Auth Related Code
await setAuthToken(request);
if (formData.get("_method") === "delete") {
await supabase
.from<Word>("words")
.delete()
.eq("id", params.id as string);
return redirect("/words");
}
};
// Here's the how to fetch one entry
export const loader: LoaderFunction = async ({ params }) => {
// No need to add auth here, because GET /words is public
const { data } = await supabase
.from<Word>("words")
.select("*")
.eq("id", params.id as string)
.single();
return data;
};
export default function Word() {
const word = useLoaderData<Word>();
const supabase = useSupabase();
let transition = useTransition();
return (
<div>
<h3>
{word.name} | {word.type}
</h3>
<div>Form State: {transition.state}</div>
{word.definitions.map((definition, i) => (
<p key={i}>
<i>{definition}</i>
</p>
))}
{word.sentences.map((sentence, i) => (
<p key={i}>{sentence}</p>
))}
{/* Adding conditional rendering might cause a warning,
We'll deal with it later */}
{supabase.auth.user() && (
<>
<Form method="post">
<Input type="hidden" name="_method" value="delete" />
<Button type="submit" className="w-full">
Delete
</Button>
</Form>
<Form method="get" action={`/words/edit/${word.id}`} className="flex">
<Button type="submit" color="primary" className="w-full">
Edit
</Button>
</Form>
</>
)}
</div>
);
}
```
<br />
### Create operation <a name="create-one"></a>
```tsx
// app/routes/words/add
import { redirect } from "remix";
import type { ActionFunction } from "remix";
import { setAuthToken, supabase } from "~/utils/supabase.server";
import { WordForm } from "~/components/word-form";
export const action: ActionFunction = async ({ request }) => {
const formData = await request.formData();
// Auth Related Code
const session = await setAuthToken(request);
const newWord = {
name: formData.get("name"),
type: formData.get("type"),
sentences: formData.getAll("sentence"),
definitions: formData.getAll("definition"),
user_id: session.get("uuid"),
};
const { data, error } = await supabase
.from("words")
.insert([newWord])
.single();
if (error) {
return redirect(`/words`);
}
return redirect(`/words/${data?.id}`);
};
export default function AddWord() {
return <WordForm />;
}
```
<br />
### Update operation <a name="update-one"></a>
```tsx
// app/routes/words/edit/$id
import { useLoaderData, redirect } from "remix";
import type { LoaderFunction, ActionFunction } from "remix";
import { WordForm } from "~/components/word-form";
import type { Word } from "~/models/word";
import { setAuthToken, supabase } from "~/utils/supabase.server";
export const action: ActionFunction = async ({ request, params }) => {
const formData = await request.formData();
const id = params.id as string;
const updates = {
type: formData.get("type"),
sentences: formData.getAll("sentence"),
definitions: formData.getAll("definition"),
};
// Auth Related Code
await setAuthToken(request);
await supabase.from("words").update(updates).eq("id", id);
return redirect(`/words/${id}`);
};
export const loader: LoaderFunction = async ({ params }) => {
const { data } = await supabase
.from<Word>("words")
.select("*")
.eq("id", params.id as string)
.single();
return data;
};
export default function EditWord() {
const data = useLoaderData<Word>();
return <WordForm word={data} />;
}
```
<br />
## Conclusion <a name="conclusion"></a>
We can still use Supabase only on the client-side as we use it on a typical React application. However, putting the data fetching on the server-side will allow us to benefit from a typical [SSR application](https://medium.com/walmartglobaltech/the-benefits-of-server-side-rendering-over-client-side-rendering-5d07ff2cefe8).
| codegino |
921,849 | Sentiment Analysis With Python. Making Your First Sentiment Analysis Script. | Do you want to perform sentiment analysis with Python but don't know how to get started? Not to... | 0 | 2021-12-12T20:22:14 | https://dev.to/code_jedi/sentiment-analysis-with-making-your-first-sentiment-analysis-script-4ea8 | python, datascience, tutorial, algorithms | Do you want to perform sentiment analysis with Python but don't know how to get started? Not to worry. In this article, I'll demonstrate and explain how you can make your own sentiment analysis app, even if you are new to Python.
## What Exactly Is Sentiment Analysis?
If you've been following programming and data science, you'll probably be familiar with sentiment analysis. If you're not, here the definition:
> _The process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer's attitude towards a particular topic, product, etc. is positive, negative, or neutral._
Sentiment analysis programs have become increasingly popular in the tech world. It's time you make one for yourself!
## Educative
Before I get on with the article, I'd like to recommend [Educative](https://bit.ly/3rVIDoN) for learners like you.
**Why Educative?**
It is home to hundreds of development courses, hands on tutorials, guides and demonstrations to help you stay ahead of the curve in your development journey.
**You can get started with Educative [here](https://bit.ly/3EeDfAi).**
# Making A Simple Sentiment Analysis Script
Let's make a simple sentiment analysis script with Python. What will it do?
It will:
1. Scrape news headlines from BBC news.
2. Get rid of unwanted scraped elements and duplicates.
2. Scan every headline for words that may indicate it's sentiment.
3. Based on the found words, determine each headline's sentiment.
4. Aggregate the headlines into different arrays based on their sentiment.
5. Print the number of scraped headlines and number of headlines with a positive, negative and neutral sentiment.
## Setup
Create a new Python file with your favorite text-editor. You can name it however you want, but I'll name the file _main.py_ for this tutorial.
Before writing the main code, make sure to install(if not already installed) and import the following libraries.
```python
import requests
import pandas
from bs4 import BeautifulSoup
import numpy as np
```
## The Dataset
A sentiment analysis script needs a dataset to train on.
Here's [the dataset](https://github.com/matveynikon/Sentiment-Analysis-With-Python/blob/main/sentiment.csv) that I made for this script. I've tested it and found it to work well.
To work with this tutorial, make sure to download this dataset, move it into your Python file's directory and add the following code to your Python file.
```python
df = pandas.read_csv('sentiment.csv')
sen = df['word']
cat = df['sentiment']
```
If you take a look at this dataset, you'll notice that it's just over 100 lines long. Each line contains a number, 1 or 0 and a word.
The number just gives a way for the Python file to paddle through each word, the word is what is going to indicate a headline's sentiment, and the 1 or 0 indicates whether the word has negative(0) or positive(1) sentiment.
This isn't a lot, but it is enough to perform accurate sentiment analysis on news headlines, which are typically only about 6-10 words long.
## Scraping The News Headlines
Here's the code that is going to scrape the news headlines:
```python
url='https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
```
As this is not a web scraping tutorial, you don't have to understand what's happening here. In case you are interested in how this works, here's a tutorial on how to [scrape news headlines with Python in <10 lines of code](https://dev.to/code_jedi/scrape-news-headlines-with-python-1go6).
Before performing sentiment analysis on the scraped headlines, add the following code to your Python file.
```python
url='https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
news = []
```
The _unwanted_ array contains elements that will be scraped from BBC news, that are not news headlines.
**Full Code:**
```python
import requests
import pandas
from bs4 import BeautifulSoup
import numpy as np
df = pandas.read_csv('sentiment.csv')
sen = df['word']
cat = df['sentiment']
url='https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
news = []
```
## Performing Sentiment Analysis
It's time to write the code which will perform sentiment analysis on the scraped headlines.
Add the following code to your Python file.
```python
neutral = []
bad = []
good = []
for x in headlines:
if x.text.strip() not in unwanted and x.text.strip() not in news:
news.append(x.text.strip())
```
**Here's what this code does:**
1. First, it defines the _neutral_, _bad_ and _good_ arrays.
2. While paddling through every scraped headline element, it checks if it's not inside the _unwanted_ and _news_ array.
3. It appends the headline to the _news_ array.
The reason why it checks if the headline is in the _unwanted_ and _news_ array is to exclude non-headline elements and prevent duplicate headlines to be analyzed more than once.
**Full Code:**
```python
import requests
import pandas
from bs4 import BeautifulSoup
import numpy as np
df = pandas.read_csv('sentiment.csv')
sen = df['word']
cat = df['sentiment']
url='https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
news = []
neutral = []
bad = []
good = []
for x in headlines:
if x.text.strip() not in unwanted and x.text.strip() not in news:
news.append(x.text.strip())
```
Now, let's perform sentiment analysis on the news headlines by adding the following code to the `if x.text.strip() not in unwanted and x.text.strip() not in news:` condition.
``` python
for i in range(len(df['n'])):
if sen[i] in x.text.strip().lower():
if cat[i] == 0:
bad.append(x.text.strip().lower())
else:
good.append(x.text.strip().lower())
```
**Here's what this code does:**
1. First, the `for i in range(len(df["n"])):` loop makes sure to search the headlines for any of the words in the _sentiment.csv_ dataset.
2. If a word from the dataset is found in the headline using the `if sen[i] in x.text.strip().lower():` condition, the `if cat[i] == 0:` condition then finds if the found word has a negative or positive sentiment and adds the headline to either the _bad_ or _good_ array.
_The `lower()` function converts all the letters inside the headlines to lowercase. This is done because the word search algorithm is case sensitive._
**Full Code:**
```python
import requests
import pandas
from bs4 import BeautifulSoup
import numpy as np
df = pandas.read_csv('sentiment.csv')
sen = df['word']
cat = df['sentiment']
url='https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
news = []
neutral = []
bad = []
good = []
for x in headlines:
if x.text.strip() not in unwanted and x.text.strip() not in news:
news.append(x.text.strip())
for i in range(len(df['n'])):
if sen[i] in x.text.strip().lower():
if cat[i] == 0:
bad.append(x.text.strip().lower())
else:
good.append(x.text.strip().lower())
```
### There's one thing left to do.
Add the following code to the end of your Python file.
```python
badp = len(bad)
goodp = len(good)
nep = len(news) - (badp + goodp)
print('Scraped headlines: '+ str(len(news)))
print('Headlines with negative sentiment: ' + str(badp) + '\nHeadlines with positive sentiment: ' + str(goodp) + '\nHeadlines with neutral sentiment: ' + str(nep))
```
This will print the number of scraped headlines and the number of headlines with a bad, good and neutral sentiment.
## The End Result
Here's the full sentiment analysis code:
```python
import requests
import pandas
from bs4 import BeautifulSoup
import numpy as np
df = pandas.read_csv('sentiment.csv')
sen = df['word']
cat = df['sentiment']
url='https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
news = []
neutral = []
bad = []
good = []
for x in headlines:
if x.text.strip() not in unwanted and x.text.strip() not in news:
news.append(x.text.strip())
for i in range(len(df['n'])):
if sen[i] in x.text.strip().lower():
if cat[i] == 0:
bad.append(x.text.strip().lower())
else:
good.append(x.text.strip().lower())
badp = len(bad)
goodp = len(good)
nep = len(news) - (badp + goodp)
print('Scraped headlines: '+ str(len(news)))
print('Headlines with negative sentiment: ' + str(badp) + '\nHeadlines with positive sentiment: ' + str(goodp) + '\nHeadlines with neutral sentiment: ' + str(nep))
```
Now if you run your Python file containing the above code, you will see an output similar to the below.

*********
## Conclusion
I hope that this tutorial has successfully demonstrated how you can perform sentiment analysis with Python.
Byeeee👋
| code_jedi |
921,872 | 極簡 nvm 使用指南 | nvm 是 Node.js 的多版本管理器,當你的開發環境有多個不同時代的 Node.js 專案、橫跨不同版次的 Node.js 時,nvm 就派的上用場。 Node.js 的版本管理器不只有... | 0 | 2021-12-09T14:26:00 | https://editor.leonh.space/2021/nvm/ | node, nvm | [nvm](https://github.com/nvm-sh/nvm) 是 [Node.js](https://nodejs.org/zh-tw/) 的多版本管理器,當你的開發環境有多個不同時代的 Node.js 專案、橫跨不同版次的 Node.js 時,nvm 就派的上用場。
Node.js 的版本管理器不只有 nvm,由於 nvm 只支援 macOS 與 Linux,在 Windows 下,改用 [NVS](https://github.com/jasongin/nvs) 是更好的選擇。(也可參閱另一篇〈[在 Windows 建置以 Visual Studio 為基礎的 Python / Node.js 開發環境](https://editor.leonh.space/2020/setting-up-python-node-js-development-environment-in-windows/)〉
nvm 的問題是,文件與說明又臭又長,其實 80% 的人只用的到 20% 的功能,所以這裡寫下個人常用到的功能與指令。
## 更新 nvm
更新 nvm 與從零安裝 nvm 是同一條命令:
```sh
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.0/install.sh | bash
```
這個安裝腳本會自行判斷是新裝還是更新。
要注意網址內有 nvm 的版號,更新 nvm 時要修改為最新的 nvm 版號。
## 更新 npm
[npm](https://www.npmjs.com/) 是 Node.js 的套件管理器,它也是需要更新的,nvm 有專門更新 npm 的指定:
```sh
nvm install-latest-npm
```
## 列出系統內各 Node.js 版本
```sh
nvm ls
```
以本人的環境為例,有列出下列版本:
```
v14.18.1
-> v16.13.1
default -> 16.13.1 (-> v16.13.1)
iojs -> N/A (default)
unstable -> N/A (default)
node -> stable (-> v16.13.1) (default)
stable -> 16.13 (-> v16.13.1) (default)
lts/* -> lts/gallium (-> v16.13.1)
lts/argon -> v4.9.1 (-> N/A)
lts/boron -> v6.17.1 (-> N/A)
lts/carbon -> v8.17.0 (-> N/A)
lts/dubnium -> v10.24.1 (-> N/A)
lts/erbium -> v12.22.7 (-> N/A)
lts/fermium -> v14.18.1
lts/gallium -> v16.13.1
```
看似很亂,其實大部份情況下只要關注那 `default` 的版號即可。
那些 `default`、`iojs` 等等的是 alias,可以理解為標籤,`default` 標定的版號就是個人帳戶下預設的 Node.js 版號。
## 列出可安裝的 Node.js LTS 版本
```sh
nvm ls-remote --lts
```
偶數的 LTS 版本們有著更長的維護期,建議都使用 [LTS](https://nodejs.org/zh-tw/about/releases/) 版本,避免追著版號跑的窘境發生。
## 安裝 Node.js
安裝目前的 16.13.1 LTS 版,並且設為預設版次:
```sh
nvm install 16.13.1 --default
```
建議都使用 [LTS](https://nodejs.org/zh-tw/about/releases/) 版本,避免追著版號跑的窘境發生。
## 設定預設版本
同樣的以 16.13.1 LTS 版為例:
```sh
nvm alias default 16.13.1
```
## 為專案指定 Node.js 版本
在專案的資料夾內,放一個 .nvmrc 檔案,在裡面寫下該專案的 Node.js 版號,例如某專案要用 16.13:
```
16.13
```
進入該專案資料夾後,執行 `nvm use` 即會自動切換成 .nvmrc 指定的版本。
如果在安裝 nvm 時,有設定好與 shell 的整合的話,應該會自動幫我們做 `nvm use` 的動作。
| leon0824 |
922,069 | 🚀10 Trending projects on GitHub for web developers - 10th December 2021 | Trending Projects is available as a weekly newsletter please sign up at Stargazing.dev to ensure you... | 7,129 | 2021-12-10T14:56:15 | https://dev.to/iainfreestone/10-trending-projects-on-github-for-web-developers-10th-december-2021-28l1 | javascript, webdev, productivity, typescript | Trending Projects is available as a weekly newsletter please sign up at [Stargazing.dev](https://stargazing.dev/) to ensure you never miss an issue.
### 1. Turborepo
The high-performance build system for JavaScript & TypeScript codebases
{% github https://github.com/vercel/turborepo %}
---
### 2. Statsig's Open-Source Status Page
A simple, zero-dependency, pure js/html status page based on GitHub Pages and Actions.
{% github https://github.com/statsig-io/statuspage %}
---
### 3. Awesome Software Architecture
A curated list of awesome articles, videos, and other resources to learn and practice about software architecture, patterns, and principles.
{% github https://github.com/mehdihadeli/awesome-software-architecture %}
---
### 4. React Cool Img
A React <Img /> component let you handle image UX and performance as a Pro!
{% github https://github.com/wellyshen/react-cool-img %}
---
### 5. Klipse
Klipse is a JavaScript plugin for embedding interactive code snippets in tech blogs.
{% github https://github.com/viebel/klipse %}
---
### 6. Simple Git
A light weight interface for running git commands in any node.js application.
{% github https://github.com/steveukx/git-js %}
---
### 7. flatpickr
lightweight, powerful javascript datetimepicker with no dependencies
{% github https://github.com/flatpickr/flatpickr %}
---
### 8. ring-client-api
Unofficial API for Ring Doorbells, Cameras, Alarm System, and Smart Lighting
{% github https://github.com/dgreif/ring %}
---
### 9. The Geek Cookbook
The "Geek's Cookbook" is a collection of guides for establishing your own highly-available "private cloud" and using it to run self-hosted services such as GitLab, Plex, NextCloud, etc.
{% github https://github.com/geek-cookbook/geek-cookbook %}
---
### 10. Floating UI
JavaScript positioning library for tooltips, popovers, dropdowns, and more
{% github https://github.com/floating-ui/floating-ui/ %}
---
### Stargazing 📈
#### [Top risers over last 7 days](https://stargazing.dev/?owner=&order=weeklyStarChange&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [Tabby](https://github.com/Eugeny/tabby) +1,739 stars
2. [Developer Roadmap](https://github.com/kamranahmedse/developer-roadmap) +1,558 stars
3. [Public APIs](https://github.com/public-apis/public-apis) +1,504 stars
4. [Every programmer should know](https://github.com/mtdvio/every-programmer-should-know) +1,307 stars
5. [Appsmith](https://github.com/appsmithorg/appsmith) +1,229 stars
#### [Top growth(%) over last 7 days](https://stargazing.dev/?owner=&order=weeklyStarChangePercent&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [Open Props](https://github.com/argyleink/open-props) +108%
2. [Agrippa](https://github.com/NitzanHen/agrippa) +73%
3. [Awesome Advent of Code](https://github.com/Bogdanp/awesome-advent-of-code) +31%
4. [JSX Lite](https://github.com/BuilderIO/mitosis) +23%
5. [Remix Auth](https://github.com/sergiodxa/remix-auth) +19%
#### [Top risers over last 30 days](https://stargazing.dev/?owner=&order=monthlyStarChange&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [Free Programming Books](https://github.com/EbookFoundation/free-programming-books) +4,424 stars
2. [Awesome](https://github.com/sindresorhus/awesome) +4,391 stars
3. [Developer Roadmap](https://github.com/kamranahmedse/developer-roadmap) +3,788 stars
4. [Public APIs](https://github.com/public-apis/public-apis) +3,637 stars
5. [Coding Interview University](https://github.com/jwasham/coding-interview-university) +3,554 stars
#### [Top growth(%) over last 30 days](https://stargazing.dev/?owner=&order=monthlyStarChangePercent&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [Medusa](https://github.com/medusajs/medusa) +205%
2. [Fragstore](https://github.com/teafuljs/teaful) +108%
3. [Hydrogen](https://github.com/Shopify/hydrogen) +102%
4. [Nice Modal React](https://github.com/eBay/nice-modal-react) +82%
5. [Agrippa](https://github.com/NitzanHen/agrippa) +80%
For all for the latest rankings please checkout [Stargazing.dev](https://stargazing.dev)
---
Trending Projects is available as a weekly newsletter please sign up at [Stargazing.dev](https://stargazing.dev/) to ensure you never miss an issue.
If you enjoyed this article you can [follow me](https://twitter.com/stargazing_dev) on Twitter where I regularly post about HTML, CSS and JavaScript. | iainfreestone |
922,082 | I plowed through coding slang Wikipedia articles so you don't have to - 25 terms you probably didn't know 🍝💻 | This one's going to be a tiny bit weird. Yes, it's a listicle. Yes, the title is a bit clickbaity.... | 0 | 2021-12-10T19:40:24 | https://dev.to/thormeier/i-plowed-through-coding-slang-wikipedia-articles-so-you-dont-have-to-25-terms-you-probably-didnt-know-3lkf | programming, computerscience, uselessknowledge, watercooler | This one's going to be a tiny bit weird. Yes, it's a listicle. Yes, the title is a bit clickbaity. No, it's not a tutorial. Yes, there will be some new tutorials coming up soonish, I'm working on something _biiig_. Yes, I learned tons of things. Yes, I will stop answering questions now. Bear with me for this one, as I will tell the tales of stub articles and obscure metaphors found in the unthinkable depths of the rabbit hole Wikipedia can be.
I recently started watched a [video on cargo cults](https://www.youtube.com/watch?v=uCqf9cr_qOY) and thought that I must've heard that term some time ago, but in a different context: Cargo cult programming. I didn't exactly know what it meant, so I stopped the video half-way, fired up A Popular Search Engine™ and Popular-search-engined™ the term and to be honest, I got carried away. Lots of "What on earth"s and "Huh"s later, I would like to share this list of 25 terms, most at least I haven't heard of - with around 10 years of experience in the industry, mind you!
_Disclaimer:_ Some of these terms are not exactly nice, some might even be offensive. This article is meant purely as a "scientific" piece to educate on the existence of them, not endorsing them in any way.
So, let's get into it.
## 1. Cargo cult programming
https://en.wikipedia.org/wiki/Cargo_cult_programming
The start of my Wikipedia-journey. Cargo cults are most of the time religious constructs. Believers of cargo cults often once witnessed a more advanced civilization and saw that what they did on the ground, like military parades, building air fields, made cargo, often food, medicine and the like, appear from the skies or seas. The believers interpret the happenings as rituals and mimic them in the hopes to also make those goods appear.
Cargo cult programming describes a similar behaviour. It means copying and pasting random bits and pieces of code from other, often similar programs, not understanding what they do, hoping they make the software work.
## 2. Copy-and-paste programming
https://en.wikipedia.org/wiki/Copy-and-paste_programming
The name sounds related to cargo cult programming, right? Almost. Instead of copying other people's code, how about copying your own for a change?
Copy-and-paste programming means copying the same functionality over and over. Sometimes it's necessary because the language lacks abstraction mechanisms, sometimes the author simply doesn't know about them.
## 3. Shotgun debugging
https://en.wikipedia.org/wiki/Shotgun_debugging
This is not about a jam in a musket. Shotgun debugging is the "art" of changing random parts of a code base in the hopes of solving a bug. Just like a shotgun shell, shotgun debugging punctures various places at once without much visible structure.
The success of shotgun debugging is often limited, but when it's combined with deep knowledge about the code base, it might even be faster at times.
## 4. Shotgun surgery
https://en.wikipedia.org/wiki/Shotgun_surgery
Another, arguably more gruesome gun metaphor. Most of us have seen it happen, some of us even had to do it.
Shotgun surgery refers to changes in one code piece that need several small changes in other places. Ever added a new mandatory parameter to a function that's used all over the place and then had to adjust every single function call? That's a shotgun surgery.
## 5. Voodoo programming
https://en.wikipedia.org/wiki/Voodoo_programming
That one also uses a metaphor related to religious practices. Voodoo programming is related to Cargo cult programming. In fact, Cargo cult programming and Voodoo programming are so similar, that they might as well be synonyms.
But the difference lies in the problem: Voodoo programming implies that the problem isn't understood. Trial and error, as well as copy/paste from Stackoverflow and/or other projects are also used in Voodoo programming, though.
## 6. Deep magic
https://en.wikipedia.org/wiki/Magic_(programming)#Variants
Let's keep the mystic theme for a bit longer. The term "magic" is known in coding culture. Often "magic" means hidden complexity behind a simple interface. For the beholder, the complexity might as well be magic.
Deep Magic refers to some arcane knowledge, though. Just like a magician, some companies never tell their secrets. Deep Magic refers to not widely-known techniques and practices that are sometimes even deliberately kept secret - for whatever reason.
## 7. Yoda conditions
https://en.wikipedia.org/wiki/Yoda_conditions
Widely used, Yoda conditions are. A popular framework that uses them, Symfony is. Accidental assignment, they prevent. They look like this:
```javscript
if (42 === someNumber) {}
```
The name stems from one of Star Wars' most known and beloved characters: Grand Master of the Jedi Order Yoda. For those who haven't seen Star Wars, Yoda is a wise, old, green being that talks in a somewhat reversed syntax. Since conditions usually follow the form of `someNumber === 42`, reversing the variable and the number resembles the way Yoda talks.
## 8. Big ball of mud
https://en.wikipedia.org/wiki/Big_ball_of_mud
This is one of my favorites. A big ball of mud is a piece of software without perceiveable architecture. That doesn't mean there's no architecture at all, though.
Big balls of mud are rather common, especially in old products that have evolved over time or that have been rushed. Increasing complexity and little time to refactor favor big balls of mud.
## 9. Spaghetti code
https://en.wikipedia.org/wiki/Spaghetti_code
A true classic. I'm almost certain, that most devs have heard that term. It's the reason I chose the yummy cover image and added a spaghetti emoji to the title.
For those who don't know what Spaghetti code is: You most certainly encountered it at least once in your career. Spaghetti code looks like a pile of spaghetti. According to Wikipedia, Spaghetti code uses little to no programming style rules and is mostly created by inexperienced software engineers.
Possible variations of the term include ravioli code and lasagna code. Ravioli code refers to well-structured classes that are simple to understand in isolation, but not as a whole, whereas lasagna code describes an architecture of non-separated layers that are so complex, that a simple change in one layer would cause a change in all other layers, resulting in shotgun surgery. See? We already learned something!
## 10. Magic pushbutton
https://en.wikipedia.org/wiki/Magic_pushbutton
The magic pushbutton is related to UI design. It describes a single button that triggers a _lot_ of business logic under the hood, coupling the user interface to the business logic at a single point. Think of it like the body of a wasp: Where two segments of the body meet, that's where you find a magic pushbutton. Almost like the pot of gold, but not as exciting.
From a user's perspective, all inputs need to happen before the push of the button, all business logic must happen after the push. This gives the user the feeling of the app being clumsy and the button itself being frustrating to use. Think of a huge form with several dozens of fields. You spend hours entering everything, click on submit, wait a few more hours until the backend responds only to get an error message. I know right?
One way to mitigate that is to execute business logic as early as possible, for example with frontend validation.
## 11. Yo-yo problem
https://en.wikipedia.org/wiki/Yo-yo_problem
Another anti-pattern. There's a lot of anti-patterns on this list.
The yo-yo in the yo-yo problem is figuratively describing a developer going up and down a dependency graph just to understand what is going on. This happens with large inheritance graphs or deeply nested dependencies (I'm looking at you, Node!) that are _so_ complex, that you constantly have to go back and forth in order to keep track of what's actually going on.
Especially in OOP, the yo-yo problem can be mitigated by building flat hierarchies, which is encouraged by a lot of books on design patterns.
## 12. Boat anchor
https://en.wikipedia.org/wiki/Boat_anchor_(metaphor)
Another one of my favorites. A boat anchor is a piece of technology whose only productive use is to throw it over board. Most of the time this is completely obsolete and useless technology.
When used in software development, a boat anchor means a piece of code that is left in the code base, because people often don't know if it's every going to be used (that's what we have Git for, right?) or if it was even useful to begin with. I reckon that most boat anchors are the results of either voodoo programming or cargo cult programming.
## 13. Action at a distance
https://en.wikipedia.org/wiki/Action_at_a_distance_(computer_programming)
I _think_ this one's related to Einstein's famous description of quantum entanglement. Einstein didn't like the idea of particles being "linked" together, causing a change on one particle to be immediately propagated to the other one, no matter how far apart they are. He called it "spooky action at a distance."
In software engineering, action at a distance means the effect of a piece of code behaving wildly different because of some change of parameters in some seemingly unrelated piece of code somewhere else. In my opinion, this has a lot to do with global state (I'm looking at you, 2000s PHP with your `global $foo;` everywhere!) and can be mitigated by clear architecture and well-used design patterns.
## 14. Data clump
https://en.wikipedia.org/wiki/Data_clump
A data clump describes a bunch of inseparable friends that go everywhere together. Only that those friends are variables and the "everywhere" isn't exactly the mall or the park, but other parts of the code.
A good exmaple (also taken from Wikipedia) is coordinates. If you always need to pass around separate variables X, Y and Z, but never ever use them standalone, you've got a data clump that should ideally be a value object called `Coordinates`.
## 15. Software rot
https://en.wikipedia.org/wiki/Software_rot
Ever worked on a legacy project? Had to refactor a function that was written in what felt like the 1600s? Exhausting, isn't it? Well, at some point, someone deemed the piece of code you're working on now as state-of-the-art. They liked their work.
Software rot describes what happened in between some dev creating the piece of code and some other trying to work on it years later. The software became hard to maintain, is screaming for an update or is downright useless. The software has rotten.
In order to mitigate software rot, software needs care frequently. Update those dependencies, update the language level as soon as another LTS version is released, update the software if its surroundings have changed.
## 16. Fat comma
https://en.wikipedia.org/wiki/Fat_comma
Also known as a "fat arrow." Depending on the language you're using, the fat comma can occur in various different places. Usually it is used where normally a comma would appear, but is still valid syntax. Think of PHP here. Arrays are usually initialized like this:
```php
$arr = [1, 2, 3];
```
The fat comma would come in as soon as you use a key. It transforms the otherwise valid array item into a key and uses whatever comes after the fat comma as the actual value:
```php
$arr = [1, 2, 'foo' => 'bar', 3];
// Fat comma here---^
```
Why this would be called a fat comma? I don't know. Perhaps this term is used in language design.
## 17. Comment programming
https://en.wikipedia.org/wiki/Comment_programming
This is related to the boat anchor, but is made on purpose. Comment programming, or Comment Driven Development (CDD), is the practice of commenting out code in order for it to not be executed. Wikipedia states that comments are used to describe things, but are often used to simply "turn off" pieces of code. The term itself is often meant derogatory.
I've just witnessed CDD in a project: Instead of removing some debugging setup, the entire code block was commented out, so it would save time, should one wish to use said debug setup. Even though it's technically an anti-pattern, it can be useful.
## 18. Conference room pilot
https://en.wikipedia.org/wiki/Conference_room_pilot
A conference room pilot is not the boss steering the conversation in the conference room. A conference room pilot is a specific role used in software acceptance testing. The pilot usually validates the software product against the business processes of the end users.
They allow end users to test the product with typical business processes they have in order to see how useful the software actually is.
## 19. Fill character
https://en.wikipedia.org/wiki/Fill_character
A fill character is a character (as in: letter in some alphabet like unicode or ASCII) that is solely used to consume time. Yes, to consume valuable, precious time. Old printers use these a lot. Wikipedia has the example of an old mechanical printer that prints 30 characters per second. So the machine sending the document naturally sends 30 characters per second. But: A carriage return takes a few seconds and the old printer has no way of keeping the received characters anywhere and has no way to tell the sender to stop, so the sender just sends "fill characters" after a carriage return to pass the time until the printer is ready to receive actual characters again.
I reckon this practice was also probably used in the old days of networking to prevent race conditions, who knows.
## 20. Worse is... better?
https://en.wikipedia.org/wiki/Worse_is_better
Yes, worse can indeed be better. Sometimes. The phrase compares functionality/features with software quality and was originally coined by Richard P. Gabriel.
In a nutshell, adding more features can make the quality of the software go down. See Big ball of mud. More often than not "worse" (for the user, i.e. less features) is "better" for the software quality.
"Worse is better" is also referred to as the "New Jersey style" is a complete software engineering model that propagates four different key aspects:
* *Simplicity* of the design of the code and the interface
* *Correctness* of everything
* *Consistency* of the design
* *Completeness*, as in everything important should be covered
## 21. Deutsch limit
https://en.wikipedia.org/wiki/Deutsch_limit
What some people experience when they speak German as their second language, but don't understand everything. Just kidding, of course it's not that.
The Deutsch limit has its name from Peter L. Deutsch. It's only used for so-called "visual programming languages", such as Blender's internals, LabVIEW, or parts of Unity. The Deutsch limit says that, especially in older languages, there cannot be more than 50 primitives visible at any given time. This is often used as an example how text-based programming languages are "better", because they offer more information density on the screen.
## 22. Greenpun's tenth rule
https://en.wikipedia.org/wiki/Greenspun's_tenth_rule
Quote:
> Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp.
That means that any complex program will at some point implement half of Common Lisp's functionality. This is related to the so-called "inner platform effect", where, in order to cover as many business cases as possible in a given program that runs on a platform, you essentially build your own platform _within_ the existing platform.
By the way, there's no nine other rules, they just wanted to give it a memorable name.
## 23. Software Peter principle
https://en.wikipedia.org/wiki/Software_Peter_principle
The Software Peter principle describes a "dying project" that has gotten so complex that not even the developers of the code themselves understand it anymore. According to Wikipedia, it is "well known in the industry" and I'm pretty sure certain frameworks, operating systems or even email clients have become Software Peters.
The name comes from the "Peter principle". This principal states that a person called "Peter" will rise through the hierarchy of an organization by having success in their current position, until they've reached a position they are incompetent in. Translated to software, the "dying project" is Peter.
## 24. Heisenbug
https://en.wikipedia.org/wiki/Heisenbug
Stemming from the name of Werner Heisenberg, a famous physicist that worked on quantum physics, the Heisenbug is one of the nastiest things you can encounter. Werner Heisenberg asserted that, by observing a system, for example by measuring things in it, you always influence and therefore alter the system.
A Heisenbug is exactly that: By investigating the bug, it starts to change its behaviour. I reckon this is often caused by race conditions and the like.
The opposite of a Heisenbug is a Bohrbug. Nils Bohr came up with the deterministic atom model we all know and love. A Bohrbug describes a "good and solid" bug.
## 25. Bogosort
https://en.wikipedia.org/wiki/Bogosort
This one I actually already knew. And apparently I couldn't do a post without at least a tiny bit of a tutorial in it.
The Bogosort algorithm is arguably the most hilariously inefficient and downright simple sorting algorithm there is. It shuffles the elements of a list until they're sorted. That's it. Here's a quick implementation in JS:
```javascript
const isSorted = arr => arr.reduce(
(prevVal, currVal, currIndex, arr) => {
if (currIndex === 0) {
return prevVal
}
return prevVal && currVal >= arr[currIndex - 1]
}, true
)
const bogoSort = arr => {
let numberOfIterations = 0
while (!isSorted(arr)) {
numberOfIterations++
arr.sort(() => Math.random() - 0.5)
}
console.log('Total iterations: ' + numberOfIterations, arr)
return arr
}
bogoSort([2, 1, 3, 4, 6, 12])
// Total iterations: 2785 [ 1, 2, 3, 4, 6, 12 ]
```
My tests yielded somewhere between 3 and 3000 iterations, but theoretically, they could go on forever. Each shuffle is an independant dice roll, so the chances of the list being sorted don't go up over time. Quite inpredictable! Please don't copy-and-paste this in an attempt to figure out what Cargo-cult programming is like.
---
Phew, what a journey. A fun one, surely, but also a weird one. I'm going back to coding now.
---
*I hope you enjoyed reading this article as much as I enjoyed writing it! If so, leave a* ❤️ *or a* 🦄*! I write tech articles in my free time and like to drink coffee every once in a while.*
*If you want to support my efforts,* [*you can offer me a coffee* ☕](http://buymeacoffee.com/pthormeier) *or* [*follow me on Twitter* 🐦](https://twitter.com/pthormeier)*!* *You can also support me directly via [Paypal](https://www.paypal.me/pthormeier)!*
[](http://buymeacoffee.com/pthormeier)
| thormeier |
922,090 | Rubymine: Enable the JavaScript debugger | How to enable JavaScript | 0 | 2021-12-09T17:31:20 | https://dev.to/notapatch/rubymine-enable-the-javascript-debugger-170b | rubymine, javascript, ruby, rails |
---
title: Rubymine: Enable the JavaScript debugger
published: true
description: How to enable JavaScript
tags: #rubymine #javascript #ruby #rails
//cover_image: https://direct_url_to_image.jpg
---
### Enable the JavaScript debugger
- Open the Run/Debug Configuration by navigating from the main menu:
- `Run => Edit Configurations`.
- Enable `run browser`
- Enter the start URL
- Enable Start JavaScript debugger automatically when debugging.
### Why did I write this?
This is taken from RubyMine documentation, so why write this?
I wanted to be able to enable the JavaScript debugger within RubyMine, RubyMine 2021.3, and I had no luck until I found this [RubyMine tutorial](https://www.jetbrains.com/help/ruby/debug-javascript-in-a-rails-application.html). It took me ages to Google and still can't find it straight away, so I'm leaving this note to myself. | notapatch |
922,265 | Three lessons from my interview with @cassidoo | Hey there, my name is Tiago and I am the host of Wannabe Entrepreneur (a podcast about what it's like... | 0 | 2021-12-09T21:10:09 | https://dev.to/wbepodcast/three-lessons-from-my-interview-with-cassidoo-2mhg | javascript, react, webdev, podcast | Hey there, my name is Tiago and I am the host of [Wannabe Entrepreneur](https://wanabe-entrepreneur.com) (a podcast about what it's like to bootstrap a company).
The great thing about having a podcast is that I have an "excuse" to ask **questions to people I admire and want to learn from!**
So far I got to interview incredible entrepreneurs of all sizes and backgrounds...
Recently I got to interview Cassidy Williams (@cassidoo) and she has more than **170K followers on Twitter!!** I won't lie, I was quite nervous... But she was super nice and the interview went really well.
Here are the **top 3 things** I learned from Cassidy:
1- **Be humble and genuine**
It might seem a bit of a cliché lesson but it does not make it less truthful... With such huge followership, most influencers would ignore small podcasters like me... Not Cassidy, she showed up and spoke openly about her experience in all the past companies she worked in. This just confirms that the real "trick" to personal branding and marketing is to truly be passionate about the topic and the community.
2- **Some companies want access to your social media**
With less than 500 followers on my Twitter account, this was never an issue personally. But in our chat, Cassidy told the Wannabe Entrepreneurs that she has to pay extra attention to the contracts and make sure that **she keeps all the control over her social media.** With more than 170K followers I guess that many companies could use it for personal marketing...
3- **Don't be afraid to experiment**
There is this tacit rule about the minimum period of time you should stay in a company before being "allowed" to leave without being judged by potential future employers... Well, **that rule is BS!** Cassity was never afraid to leave a job where she was not happy and that gave her the opportunity to experiment with different types of companies and find which ones she prefers to work at.
These are just 3 of a lot of lessons I took from my casual chat with Cassidy Williams. Would love to hear your thoughts on the interview. What questions did I miss? [You can listen to the full chat here](https://wannabe-entrepreneur.com/episodes/172/) | wbepodcast |
922,271 | Share your MongoDB Atlas Hackathon Updates! | Use this thread to share progress updates on your GitHub Actions hack! | 0 | 2021-12-13T19:22:11 | https://dev.to/devteam/share-your-mongodb-atlas-hackathon-updates-5g4k | atlashackathon, mongodb, discuss | ---
title: Share your MongoDB Atlas Hackathon Updates!
published: true
description: Use this thread to share progress updates on your GitHub Actions hack!
tags: atlashackathon, mongodb, discuss
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/v5ep903yqooczu2vy63x.png
---
We’d love to know what you’re working on for the [MongoDB Atlas Hackathon](https://dev.to/devteam/announcing-the-mongodb-atlas-hackathon-on-dev-4b6m) here on DEV! Fill us in on your project and how things are going below. and how things are going with this exciting challenge.
> **Use this thread to share ideas, gather feedback, and get to know other MongoDB Atlas Hackathon contestants!**
If you've just reached a new milestone with your project or if you've just solved a tough problem, we encourage you to publish a standalone post. Just be sure to add the [#atlashackathon](https://dev.to/t/atlashackathon) tag so all of us can find it on the tag page.
If you need help with a specific problem, head over to the [help thread](https://dev.to/devteam/mongodb-atlas-hackathon-help-thread-3g3a) where members of the DEV and MongoDB teams are standing by to assist you.
Have a great time! We can't wait to meet you and hear all about your submission.
| thepracticaldev |
932,088 | Is AI responsible for the stock market volatility? | Along with programming, I have developed an interest in the stock market over the past few years.... | 0 | 2021-12-21T12:35:09 | https://dev.to/mallaya_mathur/is-ai-responsible-for-the-stock-market-volatility-3imm | ai, javascript, machinelearning | Along with programming, I have developed an interest in the stock market over the past few years. Over the last few days, all the stock markets all over the world including India, the US, the UK, Germany, Japan, and almost every other country are volatile.
Many experts believe this volatility is because of these reasons:
- Rise in inflation rate
- Interest rate hike from Banks
- Increasing fear of Omicron variant
- Might be a few regional reasons
But, according to me, this might be a reason:
Many stockbrokers and operators have started using Artificial Intelligence that reads all charts and once a stock hits a certain number, the AI model buys or sells stokes. I feel an Artificial Intelligence robot does not have emotions or human intelligence and when trades, it becomes harsh for the market.
Do share your thoughts, I would like to read what you think ? Does this make a difference? | mallaya_mathur |
922,289 | Docker e Nodejs - Dockerizando sua aplicação com boas praticas | Você já se deparou com a necessidade ou curiosidade de rodar sua aplicação dentro de um container... | 0 | 2021-12-19T01:26:16 | https://www.tuliocalil.com.br/post/docker-e-nodejs-dockerizando-sua-aplicacao-com-boas-praticas | node, docker, braziliandevs, devops | Você já se deparou com a necessidade ou curiosidade de rodar sua aplicação dentro de um container Docker ?
Vou demonstrar como construir um dockerfile para uma aplicação Web com Nodejs de forma simples e com as melhores praticas para você subir sua aplicação em segundos em qualquer ambiente em poucos comandos!
> Hey, eu atualizei esta postagem no [meu blog pessoal, veja agora!](https://www.tuliocalil.com.br/post/docker-e-nodejs-dockerizando-sua-aplicacao-com-boas-praticas)
* [ Por que Dockerizar 🧐](#por-que-dockerizar)
* [ Iniciando uma aplicação Nodejs 😃](#iniciando-uma-aplica%C3%A7%C3%A3o-nodejs)
* [ Criando Dockerfile 🐳](#criando-dockerfile)
* [ Escolha sempre imagens com versões explicitas 🎯](#escolha-sempre-imagens-com-vers%C3%B5es-explicitas)
* [ Separe os comandos em camadas 🧩](#separe-os-comandos-em-camadas)
* [ Prepare-se para ouvir eventos do OS 🔊](#preparese-para-ouvir-eventos-do-os)
* [ Não rode containers como root 💻](#n%C3%A3o-rode-containers-como-root)
* [ Iniciando aplicação 🔥](#iniciando-aplica%C3%A7%C3%A3o)
* [ Implemente graceful shutdown 📴](#implemente-graceful-shutdown)
* [ Ignorando arquivos 🚫](#ignorando-arquivos)
* [ Testando 🧪](#testando)
* [ Finalizando 🎉](#finalizando)
###### generated with [Summaryze Forem 🌱](https://summaryze-forem.vercel.app/)
## Por que Dockerizar 🧐
O motivo mais comum para se ter uma aplicação em um container é o fato de ter o mesmo ambiente de execução, seja em tempo de desenvolvimento, stage ou produção. Mas também temos a velocidade para subir e rodar esse ambiente, sem precisar mudar versão do Nodejs, rodar `npm install` e outros scripts que você pode precisar toda vez que quiser subir o ambiente.
Você também não vai ter dor de cabeça caso você ou sua equipe trabalhem em SO diferentes.
Esses são apenas alguns motivos.
## Iniciando uma aplicação Nodejs 😃
Vamos começar criando uma aplicação Nodejs, vou criar uma API mega simples utilizando o modulo [HTTP](https://nodejs.org/api/http.html) do próprio Nodejs, dessa forma não vamos precisar de pacotes externos.
Vamos criar nosso projeto:
```sh
mkdir nodejs-docker
cd nodejs-docker
yarn init -y
```
Abra o projeto no seu editor de código/IDE favorito e crie um arquivo chamado `server.js`, nele vamos fazer simplesmente isso:
```javascript
const http = require("http");
http
.createServer((req, res) => {
res.write("Meu servidor HTTP rodando no Docker");
res.end();
})
.listen(3333);
```
No nosso `package.json` vamos adicionar um script de start:
```json
{
"name": "nodejs-docker",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"scripts": {
"start": "node server.js"
}
}
```
Agora rode e veremos o servidor rodando em `localhost:3333`.
## Criando Dockerfile 🐳
Agora vem a parte que realmente importa, vamos criar nosso Dockerfile, que nada mais é do que um arquivo com sintaxe YML para dizermos ao Docker quais passos ele irá executar.
Fica mais simples se pensarmos nele como uma receita, onde cada passo deve ser seguido em uma ordem X.
Crie um arquivo na raiz do projeto chamado `Dockerfile` e vamos cria-lo seguindo o passo a passo abaixo.
### Escolha sempre imagens com versões explicitas 🎯
```dockerfile
FROM node:17-alpine3.12
```
Essa linha é onde definimos qual imagem usaremos no nosso container. Vamos utilizar a imagem `node` na versão 17 utilizando a imagem [alpine](https://alpinelinux.org), que são imagens super pequenas e muito otimizadas.
É uma excelente pratica especificar a versão da imagem(o hash SHA256 é ainda mais recomendado, já que garante exatamente aquela imagem sempre, sem alteração de minor versions por exemplo), dessa forma vamos ter certeza que todas as vezes que o container for construído será sempre a mesma e que é compatível com a aplicação que estamos desenvolvendo, pois já validamos durante o desenvolvimento.
### Separe os comandos em camadas 🧩
```dockerfile
...
WORKDIR /usr/src/app
```
Aqui definimos o local onde a aplicação irá ficar dentro do nosso container, nada de mais nessa parte.
```dockerfile
...
COPY package.json package-lock.json ./
```
Aqui estamos copiando apenas o nosso `package.json`, para podermos instalar a nossa aplicação. Note que estamos copiando apenas o package (e o lock), isso por que o [Docker cria camadas](https://dzone.com/articles/docker-layers-explained) diferentes para cada comando dentro do `Dockerfile`.
Sendo assim, em tempo de build, caso existam alterações em alguma camada, o Docker irá recompilar e repetir o comando, o que no nosso caso seria baixar todos os pacotes novamente toda vez que mudássemos qualquer arquivo no projeto(caso o comando de `COPY` copiasse tudo junto).
Sendo assim, mais uma boa pratica para o nosso container.
```dockerfile
...
RUN yarn install
```
Aqui um passo super simples, estamos apenas instalando as dependencias do package que acabamos de copiar.
Nenhum segredo aqui. Case não utilize `yarn`, troque para o seu gerenciador de pacotes.
```dockerfile
...
COPY ./ .
```
Agora sim, podemos copiar toda nossa aplicação em um comando e consequentemente camada diferente.
### Prepare-se para ouvir eventos do OS 🔊
```dockerfile
...
RUN apk add dumb-init
```
O comando `apk add dumb-init` vai instalar no nosso container um gerenciador de inicialização de processos super leve e simples, ideal para containers. Mas por que vamos usar isso ?
Bom, o primeiro processo em containers Docker recebe o PID 1, o [kernel Linux trata de forma "especial" esse processo](https://vagga.readthedocs.io/en/latest/pid1mode.html) e nem todas as aplicações foram projetadas para lidar com isso. Um exemplo simples e resumido é o sinal `SIGTERM` que é emitido quando um comando do tipo `kill` ou `killall` é executado, utilizando o [dumb-init](https://github.com/Yelp/dumb-init) é possível ouvir e reagir a esses sinais. Recomendo muito a leitura [desse artigo](https://engineeringblog.yelp.com/2016/01/dumb-init-an-init-for-docker.html).
### Não rode containers como root 💻
```dockerfile
...
USER node
```
Aqui vai outra boa pratica, por padrão as imagens docker(ou boa parte delas) rodam com o usuário `root`, o que obviamente não é uma boa pratica.
O que fazemos aqui é utilizar o [`USER`](https://docs.docker.com/engine/reference/builder/#user) do Docker para mudar o usuário, imagens oficiais Node e variantes como as alpines incluem um usuário(node) sem os privilégios do root e é exatamente ele que vamos utilizar.
### Iniciando aplicação 🔥
```dockerfile
...
CMD ["dumb-init", "node", "server.js"]
```
Agora vamos iniciar nosso processo utilizando o nosso gerenciador para ter os beneficios que ja falamos.
Aqui vamos preferir chamar o `node` diretamente ao invés de usar um `npm script`, o motivo é praticamente o mesmo de utilizarmos o `dumb-init`, os `npm scripts` não lidam nada bem com sinais do sistema.
Desta maneira estamos estamos recebendo eventos do sistemas que podem e vão nos ajudar a finalizar a aplicação de forma segura.
### Implemente graceful shutdown 📴
Bem, esse passo não esta tão ligado ao nosso Dockerfile, mas a nossa aplicação a nível de código. Eu queria muito falar sobre isso em um post separado, mas acho que vale um resumo aqui.
Agora que estamos devidamente ouvindo os sinais do sistema, podemos criar um `event listern` para ouvir os sinais de desligamento/encerramento e tornar nossa aplicação mais reativa a isso. Um exemplo é você executar uma chamada HTTP e finalizar o processo no meio dela, você terá um retorno de bad request ou algo bem negativo, finalizando a transação de forma abrupta, porém, podemos melhorar isso, vamos finalizar todas as requisições pendentes, encerrar comunicações de soquete (por exemplo) e só depois finalizar a nossa aplicação.
No nosso app vamos instalar uma lib chamada [`http-graceful-shutdown`](https://www.npmjs.com/package/http-graceful-shutdown). Ela é super legal por que funciona para express, koa, fastify e o modulo http nativo, que é o nosso caso aqui.
```sh
yarn add http-graceful-shutdown
```
E vamos refatorar nosso `server.js`:
```javascript
const http = require("http");
const gracefulShutdown = require("http-graceful-shutdown");
const server = http.createServer((req, res) => {
setTimeout(() => {
res.write("Meu servidor HTTP rodando no Docker");
res.end();
}, 20000);
});
server.listen(3333);
gracefulShutdown(server);
```
Adicionei um timeout para podemos fazer um teste, inicie o servidor com o comando `yarn start` e abra o `localhost:3333` no seu browser, enquanto a requisição estiver rolando, volte no terminal e pressione `CTRL + C` para parar o processo. A requisição vai parar instantaneamente e o servidor será encerrado. Agora rode o comando `node server.js` e repita o mesmo processo, perceba que você não conseguirá finalizar enquanto a requisição não terminar.
### Ignorando arquivos 🚫
Agora vamos precisar criar um arquivo chamado `.dockerignore`, que tem o mesmo propósito de um `.gitignore`, ignorar arquivos que tiverem o nome que combine com o padrão que digitarmos nesse arquivo.
```txt
.dockerignore
node_modules
npm-debug.log
Dockerfile
.git
.gitignore
```
## Testando 🧪
Ufa, acabamos!
Para testarmos, basta no terminal executarmos o comando para buildar nossa imagem:
```bash
docker build -t docker-node .
```
E para iniciar nosso container:
```bash
docker run -d -p 3333:3333 docker-node
```
E basta testarmos!
## Finalizando 🎉
Agora temos um container da nossa aplicação com boas praticas, performático e super seguro!
Espero que tenha gostado desse post e fique a vontade para comentar outras dicas legais para implementar em um container!
Aqui esta o repositório com os códigos finais:
{% github tuliocll/docker-nodejs %}
| tuliocalil |
922,421 | Importing Data Using MySQL and Arctype
| If you are a developer or database administrator that wants to load the data into your databases... | 0 | 2021-12-10T01:56:39 | https://arctype.com/blog/mysql-import-data/ | softwaredevelopment, mysql | If you are a developer or database administrator that wants to load the data into your databases quickly, you probably already know that you have quite a few options, at least as far as MySQL is concerned. In this blog, we will look through the options you have when it comes to importing data into your MySQL instances.
## What Options Are There?
First of all, when it comes to importing data into MySQL, you have a couple of options to import data:
- One can use `INSERT INTO` and specify a table name along with the columns and data one needs to import into a given database instance.
- One can also use `LOAD DATA INFILE` and specify a specific file where he or she wants to load data from into a given table.
Now we could tell you that “no, `LOAD DATA INFILE` is not the only option when importing data into MySQL or MariaDB-based instances” and leave it at that, however, that’s not what you’re here for – you’re here to know the best mechanism to use for importing your data into MySQL-based instances.
By now you know that `LOAD DATA INFILE` and `INSERT INTO` are your only options – however, you might also know that we have covered some of the functionalities provided by `LOAD DATA INFILE`[in an earlier blog post of ours](__GHOST_URL__/mysql-load-data-infile/), so you might wonder why we are writing another one. Well, we haven’t covered everything!
For example, we told you that `LOAD DATA INFILE` is faster, and it is. But once you have the need to quickly import data into your database instances, you have a couple of other options too. For example, you can use `COMMIT` statements like so:
SET autocommit=0;
INSERT INTO arctype (demo_column) VALUES (‘Demo Column’);
COMMIT;
Running queries in the above-specified fashion would help your database perform better when inserting data because `COMMIT` statements save the current state of the database. In other words, turning `autocommit` to a value of 0, importing your data, and committing then might be a better option in terms of importing data in MySQL because you would only save modifications to disk when you want to and relieve MySQL (or MariaDB) of such hassles. Also, consider setting `unique_checks` to 0 and `foreign_key_checks` to 0 as well: setting these parameters to off (0) should improve your database performance as well.
Another quick way to import data into MySQL if you are running the MyISAM storage engine would be to just simply copy the `.frm`, `.MYD`, and `.MYI` files over into a given folder on a different database server. Here’s a caveat though – you should only do this with MyISAM because InnoDB works differently. Never try such an approach on it unless you are fully aware of the consequences.
You can [read our blog post about InnoDB vs. big data to learn more](__GHOST_URL__/mysql-storage-engine-big-data/), but essentially, InnoDB has one core file – ibdata1 – that is central to its performance. Simply copying over files like this would do more harm than good because the tablespace ID in the ibdata1 would not match the tablespace ID in the database files that were copied over to a new server.
Another quick way to speed up a given data import is to lock the table while importing. Run a `LOCK TABLES` query before importing your data and `UNLOCK TABLES` when you’re done, and you should be good to go. Such an approach is recommended if you have a situation where you might find yourself required to prevent certain sessions from modifying tables.
You can also use the bulk importing functionality provided by `INSERT` statements as well.`INSERT INTO arctype (demo_column) VALUES (‘demo’), (‘demo’);` would be inserted faster than ordinary `INSERT` statements.
However, these are not the only options you can employ. If you are using MyISAM (you shouldn’t be, but if you find yourself forced to use such a storage engine…) you might also want to think about increasing the value of `bulk_insert_buffer_size`. According to MySQL, the variable limits the size of the cache tree in bytes per a single thread, so that should help if you find yourself importing quite a lot of data when working with MyISAM as well.
### A consideration: the secure_file_priv variable
The `secure_file_priv` variable is heavily associated with bulk importing of data inside of your database instances. [In prior posts, we said that `LOAD DATA INFILE` is significantly faster than `INSERT` statements due to the fact that it comes with many so-called “bells and whistles” unique to itself](__GHOST_URL__/mysql-load-data-infile/). Part of that magic is `load_data_infile`. The variable usually resides in your `my.cnf` file (which itself is located in your `/var/bin/mysql` directory) and looks like so (the following example refers to the variable being used in Windows environments):
secure_file_priv=”c:/wamp64/tmp”
This variable, simply put, puts a restraint on which directories can be used to load data into your MySQL database instance. In other words, once you run a `LOAD DATA INFILE` query and the file you load into your database instance does not reside in this directory, MySQL will come back with an error like so:
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
To overcome this error, you either need to remove the `--secure-file-priv` setting from your `my.cnf` file, or load your data from a directory specified in the value of the variable. Once you do so, your data should be loaded in (and exported) without any kinds of issues!
## Other Concerns
Aside from loading data into your MySQL database instances using `LOAD DATA INFILE` and making use of this privilege, the value of such a variable might also be relevant when exporting data out of MySQL using `SELECT … INTO OUTFILE`. this variable can also be used to disable import and export operations using `LOAD DATA INFILE` and `SELECT ... INTO OUTFILE`: simply set this variable to `NULL` in such a case. In general, though, you can also run a query like `SHOW QUERY VARIABLES LIKE ‘secure_file_priv’` or `SELECT @@secure_file_priv` in order to observe the name of the directory that this variable is set to.
## Time to import some data!
So, you're ready to import some data. Can you just use `INSERT` queries and insert all of the rows one by one? Or perhaps you would use bulk inserting capabilities provided by `INSERT`?
Technically, yes – you can do that. You can insert your rows from a CSV file by copying them over to `INSERT` statements, and then running them one by one, but that would take quite a lot of time, also you would need to make sure you are copying over the correct values of rows from the CSV file into your `INSERT` statement, etc. - that would be quite a hassle!
Thankfully, there are tools that can assist you in performing such tasks. Some of those tools are SQL clients. For example, the SQL client developed by [Arctype](https://arctype.com) can help you edit your tables like spreadsheets where you select any cell you want to edit, and delete rows by simply clicking delete, etc.
However, Arctype has another feature that should be more relevant to the scope of this article – Arctype also lets you import CSV files into your database instances. Let's see how to do that!
Go ahead and launch Arctype. Towards the right-hand side of your table and above the structure of it, you will find three horizontal dots. Click on them:

These dots denote the options available for you to use: you can either create a table or refresh them, or you can also import the contents of a given CSV file to your table. Click on **Import CSV** and select the file you want to import:

Arctype will provide you with some information regarding your file, and it will provide the first five rows that your CSV file contains. Once you’re satisfied with the outputs you see, it’s time to import your data – go ahead and click **Accept**:

Once you click accept, you will be able to define the columns of your table that you want to import your data to, you will be able to create a new table or elect to upload your data into an existing table.
Once you’re satisfied with what you see on the screen, go ahead and click I**mport CSV** to import your file: your data should now exist inside of your tables! That’s it – it’s really that simple.

Sometimes when your data is too long to be imported, and you might face some errors like the one above (in that case, Arctype will import all of the rows leading up to the error), but generally, the import process should go smoothly
## The bottom line
When you find yourself required to quickly import data into your MySQL instances, `LOAD DATA INFILE` is far from your only option. You can also use bulk inserting capabilities provided by `INSERT` statements, modify MySQL’s functionality in such a way that commits only after the data is fully loaded into your database tables, and only load data into specific columns using `LOAD DATA INFILE` as well.
We hope you stick around the blog since we have a lot more content prepared for you – this blog covers databases, security, and general advice for developers, so you will certainly find what you are looking for. And, if you want to play around with what you've learned so far, Arctype is the perfect tool with which to do so. Use the button below to download Arctype and put your skills to the test now!
Lukas is an ethical hacker, a MySQL database administrator, and a frequent conference speaker. Since 2014, Lukas has found and responsibly disclosed security flaws in some of the most visited websites in Lithuania and abroad including advertising, gift-buying, gaming, hosting websites as well as some websites of government institutions. Lukas runs one of the biggest & fastest data breach search engines in the world: BreachDirectory.com and frequently blogs in multiple places educating people about information security and other topics. He also runs his own blog over at lukasvileikis.com.
| rettx |
922,429 | What is Object Oriented Programming Language | Basically older Programming language like COBOLT and C followed the Procedural Programming... | 0 | 2021-12-10T02:42:41 | https://dev.to/carnato/what-is-object-oriented-programming-language-58fe | oop, cpp, beginners, programming | Basically older Programming language like COBOLT and C followed the Procedural Programming approach.in this type of programming language only focus on the logic rather than data abstraction.
Modern programming language like C#,python, Cpp and java etc. follow the Object oriented approach.
Object Oriented programming is main focus on the data rather than just write the instruction to perform the task.
**the class are user define data types
and in simple word object is variable of that data type that can store the desire things.**
- class is blue print for the creating the object, and A class can define the attribute and behavior.
for example:--
if we are design the car in our application then we could define attributes of the car like model ,fuel, and behavior like start ,break , accelerate etc..
this attribute and behavior not specific for a one model.
## **Abstraction**
**Abstraction is focus on the what object can do in stead of how object can done.**
In the abstraction we can only know essential features without knowing the detail background implementation
abstraction is important when we do any modification in one module than no other module can be affected_
example
break in car we only use this functionality and not know mechanism behind this functionality
or we also say same as accelerator
## **Encapsulation**
encapsulation is closely related to abstraction.
**encapsulation bind the data and behaviors together in a single unit**
Abstraction is implementation hiding.
Encapsulation is information hiding.
Abstraction provide generalization and hiding their implementation.
Encapsulation is hiding of internal data from outsider.
## **Inheritance**
inherence is powerful features of the oops
inheritance help to organizing the class in hierarchy and enabling these class to inherit attribute and behavior from class above in the hierarchy
**Inheritance is concept that allow us to create new class from from existing class by inheriting the properties of that class**
## Some Advantage of inheritance:
Reusability ,Flexibility ,Redundancy ,Data hiding
- Single inheritance
- Multi-level inheritance
- Multiple inheritance
- Multipath inheritance
- Hierarchical Inheritance
- Hybrid Inheritance
## **Polymorphism**
| carnato |
922,434 | Learning Experience Platform | Skillqore | Skillqore is an Artificial Intelligence (AI) based Learning Experience Platform for individuals and... | 0 | 2021-12-10T03:39:12 | https://dev.to/skillqore/learning-experience-platform-skillqore-2aeo | tutorial | **Skillqore** is an Artificial Intelligence (AI) based Learning Experience Platform for individuals and organizations with a mission to enable lifelong learning.
Using Skillqore, individuals or employees can discover learning opportunities that includes thousands of free online courses from hundreds of universities, videos, books, articles and podcasts.

Skillqore aggregates learning content from different sources on the web. For Corporations, internal Learning Management Systems and other learning content can also be aggregated.
In a few simple steps, a profile can be created. Skillqore's AI-based recommendation engine will curate and deliver the most relevant, high quality and personalized learning content to your Inbox. You can add any content to your profile to manage and track your progress and completion. **Read more [click here](https://www.skillqore.com)** | skillqore |
922,439 | Stacks | AWS HashiCorp Laravel VueJS | 0 | 2021-12-10T04:15:41 | https://dev.to/kennith/stacks-4kbj | programming | - AWS
- HashiCorp
- Laravel
- VueJS | kennith |
923,141 | When to use multiple endpoints in GraphQL | Written by Leonardo Losoviz ✏️ GraphQL is all about having a single endpoint to query the data, but... | 0 | 2021-12-10T18:27:22 | https://blog.logrocket.com/use-multiple-endpoints-graphql/ | graphql, webdev, programming, tutorial | **Written by [Leonardo Losoviz](https://blog.logrocket.com/author/leonardolosoviz/)** ✏️
GraphQL is all about having a single endpoint to query the data, but there are situations where it makes sense to instead have multiple endpoints, where each custom endpoint exposes a customized schema. This allows us to provide a distinct behavior for different users or applications by simply swapping the accessed endpoint.
Exposing multiple endpoints in GraphQL is not the same as implementing REST — every REST endpoint provides access to a predefined resource or set of resources. But with multiple GraphQL endpoints, each one will still provide access to all of the data from its schema, enabling us to fetch exactly what we need.
This is still the normal GraphQL behavior but now gives us the ability to access the data from different schemas. This capability is also different than [schema stitching or federation](https://blog.logrocket.com/improve-microservice-architecture-graphql-api-gateways/), which enable us to incorporate several sources of data into a single, unified graph.
With multiple endpoints, we are still dealing with multiple schemas. Each schema can be accessed on its own and is independent of all others. In contrast, stitching and federation combine all the schemas into a bigger schema, and the different schemas may need to be reconciled with one another (e.g., by renaming types or fields in case of conflict).
Exposing different schemas can provide us access to multiple independent graphs. GraphQL creator [Lee Byron explains when this can be useful](https://github.com/graphql/graphql-spec/issues/569#issuecomment-475670948):
> A good example of this might be if you've company [sic] is centered around a product and has built a GraphQL API for that product, and then decides to expand into a new business domain with a new product that doesn't relate to the original product. It could be a burden for both of these unrelated products to share a single API and two separate endpoints with different schema may be more appropriate. [...] Another example is [...] you may have a separate internal-only endpoint that is a superset of your external GraphQL API. Facebook uses this pattern and has two endpoints, one internal and one external. The internal one includes internal tools which can interact with product types.
In this article, we will expand on each of these examples and explore several use cases where exposing multiple GraphQL endpoints makes sense.
## How to expose multiple GraphQL endpoints
Before we explore the use cases, let's review how the GraphQL server can expose multiple endpoints.
There are a few GraphQL servers that already ship with this feature:
* [PostGraphile’s multiple schemas](https://www.graphile.org/postgraphile/multiple-schemas/)
* [GraphQL.NET’s multi-schema support](https://graphql-aspnet.github.io/docs/advanced/multi-schema-support)
* [GraphQL API for WordPress’s custom endpoints](https://graphql-api.com/guides/use/creating-a-custom-endpoint/)
If the GraphQL server we are using doesn’t provide multiple endpoints as an inbuilt feature, we can attempt to code it in our application. The idea is to define several GraphQL schemas, and tell the server which one to use on runtime, based on the requested endpoint.
When using a JavaScript server, a convenient way to achieve this is with [GraphQL Helix](https://github.com/contra/graphql-helix), which decouples the handling of the HTTP request from the GraphQL server. With Helix, we can have the routing logic be handled by a Node.js web framework (such as Express.js or Fastify), and then — depending on the requested path (i.e., the requested endpoint — we can provide the corresponding schema to the GraphQL server.
Let's convert [Helix's basic example](https://dev.to/danielrearden/building-a-graphql-server-with-graphql-helix-2k44), which is based on Express, into a multi-endpoint solution. The following code handles the single endpoint `/graphql`:
```javascript
import express from "express";
import { schema } from "./my-awesome-schema";
const app = express();
app.use(express.json());
app.use("/graphql", async (res, req) => {
// ...
});
app.listen(8000);
```
To handle multiple endpoints, we can expose URLs with shape `/graphql/${customEndpoint}`, and obtain the custom endpoint value via a route parameter. Then, based on the requested custom endpoint, we identify the schema — in this case, from the endpoints `/graphql/clients`, `/graphql/providers`, and `/graphql/internal`:
```javascript
import { clientSchema } from "./schemas/clients";
import { providerSchema } from "./schemas/providers";
import { internalSchema } from "./schemas/internal";
// ...
app.use("/graphql/:customEndpoint", async (res, req) => {
let schema = {};
if (req.params.customEndpoint === 'clients') {
schema = clientSchema;
} else if (req.params.customEndpoint === 'providers') {
schema = providerSchema;
} else if (req.params.customEndpoint === 'internal') {
schema = internalSchema;
} else {
throw new Error('Non-supported endpoint');
}
// ...
});
```
Once we have the schema, we inject it into the GraphQL server, as expected by Helix:
```javascript
const request = {
body: req.body,
headers: req.headers,
method: req.method,
query: req.query,
};
const {
query,
variables,
operationName
} = getGraphQLParameters(request);
const result = await processRequest({
schema,
query,
variables,
operationName,
request,
})
if (result.type === "RESPONSE") {
result.headers.forEach(({ name, value }) => {
res.setHeader(name, value)
});
res.status(result.status);
res.json(result.payload);
} else {
// ...
}
```
Needless to say, the different schemas can themselves share code, so there is no need to duplicate logic when exposing common fields.
For instance, `/graphql/clients` can expose a basic schema and export its elements:
```javascript
// File: schemas/clients.ts
export const clientSchemaQueryFields = {
// ...
};
export const clientSchema = new GraphQLSchema({
query: new GraphQLObjectType({
name: "Query",
fields: clientSchemaQueryFields,
}),
});
```
And these elements can be imported into the schema for `/graphql/providers`:
```javascript
// File: schemas/providers.ts
import { clientSchemaQueryFields } from "./clients";
export const providerSchemaQueryFields = {
// ...
};
export const providerSchema = new GraphQLSchema({
query: new GraphQLObjectType({
name: "Query",
fields: { ...clientSchemaQueryFields, ...providerSchemaQueryFields },
}),
});
```
Next, let's explore the several use cases where multiple GraphQL endpoints can make sense. We’ll be looking at the following use cases:
* Exposing the admin and public endpoints separately
* Restricting access to private information in a safer way
* Providing different behavior to different applications
* Generating a site in different languages
* Testing an upgraded schema before releasing for production
* Supporting the BfF approach
## Exposing the admin and public endpoints separately
When we are using a single graph for all data in the company, we can validate who has access to the different fields in our GraphQL schema by [setting up access control policies](https://blog.logrocket.com/authorization-access-control-graphql/). For instance, we can configure fields to be accessible only to logged-in users via directive `@auth`, and to users with a certain role via an additional directive `@protect(role: "EDITOR")`.
However, this mechanism [may be unsafe](https://cwe.mitre.org/data/definitions/284.html) if the software has bugs, or if the team is not always careful. For instance, if the developer forgets to add the directive to the field, or adds it only for the DEV environment but not for PROD, then the field will be accessible to everyone, presenting a security risk.
If the field contains sensitive or confidential information — especially the kind that should under no circumstance be accessible to unintended actors — then we'd rather not expose this field in a public schema in first place, only in a private schema to which only the team has access. This strategy will protect our private data from bugs and carelessness.
Hence, we can create two separate schemas, the Admin and Public schemas, and expose them under endpoints `/graphql/admin` and `/graphql` respectively.
## Restricting access to private information in a safer way
Though we’ll be looking at the example I described above, this section can also be read as a generalization of it: this can be regarded as applicable not just in public vs. admin scenarios, but in any situation in which a set of users must absolutely not be able to access information from another set of users.
For instance, whenever we need to create customized schemas for our different clients, we can expose a custom endpoint for each of them (`/graphql/some-client`, `/graphql/another-client`, etc), which can be safer than giving them access to the same unified schema and validating them via access control.
This is because we can easily validate access to these endpoints by IP address. The code below expands on the previous example using Helix and Express to validate that the endpoint `/graphql/star-client` can only be accessed from the client's specific IP address:
```javascript
import { starClientSchema } from "./schemas/star-client";
// Define the client's IP
const starClientIP = "99.88.77.66";
app.use("/graphql/:customEndpoint", async (res, req) => {
let schema = {};
const ip = req.ip
|| req.headers['x-forwarded-for']
|| req.connection.remoteAddress
|| req.socket.remoteAddress
|| req.connection.socket.remoteAddress;
if (req.params.customEndpoint === 'star-client') {
if (ip !== starClientIP) {
throw new Error('Invalid IP');
}
schema = starClientSchema;
}
// ...
});
```
For your clients, knowing that they can only access the endpoint with their data from their own IP address also gives them the reassurance that their data is well protected.
## Providing different behavior to different applications
We can grant different behavior to the different applications that access the same data source.
For instance, I've noticed that Reddit produces different responses when accessed from a desktop browser than it does when accessed from a mobile browser. From the desktop browser, whether we are logged-in or not, we can directly visualize the content:
Accessing from mobile, though, we must be logged-in to access the content, and we're encouraged to use the app instead:
This different behavior could be provided by creating two schemas, such as the Desktop and Mobile schemas, and expose them under `/graphql/desktop` and `/graphql/mobile` respectively.
## Generating a site in different languages
Let's say that we want to generate the same site in different languages. If GraphQL is being used as the unique source of data, such as when creating a static site with Gatsby, then we can translate the data while it’s in transit between the data source and the application.
As a matter of fact, we do not really need multiple endpoints to achieve this goal. For instance, we can retrieve the language code from an environment variable `LANGUAGE_CODE`, inject this value into GraphQL variable `$lang`, and then translate the post's `title` and `content` fields via the field argument `translateTo`:
```graphql
query GetTranslatedPost($lang: String!) {
post(id: 1) {
title(translateTo: $lang)
content(translateTo: $lang)
}
}
```
However, translation is a cross-cutting concern, for which [using a directive may be more appropriate](https://blog.logrocket.com/field-arguments-vs-directives-graphql/). By using schema-type directives, the query can be oblivious that it will be translated:
```graphql
{
post(id: 1) {
title
content
}
}
```
Then, the translation logic is applied on the schema, via [a `@translate` directive](https://graphql-api.com/guides/directives/translate/) added to the fields in the SDL:
```graphql
directive @translate(translateTo: String) on FIELD
type Post {
title @translate(translateTo: "fr")
content @translate(translateTo: "fr")
}
```
(Note that the directive argument `translateTo` is non-mandatory, so that, when not provided, it uses the default value set via environment variable `LANGUAGE_CODE`.)
Now that the language is injected into the schema, we can create different schemas for different languages, such as `/graphql/en` for English and `/graphql/fr` for French.
Finally, we point to each of these endpoints in the application to produce the site in one language or another:
## Testing an upgraded schema before releasing for production
If we want to upgrade our GraphQL schema and have a set of users test it in advance, we can expose this new schema via a `/graphql/upcoming` endpoint. Even more, we could also expose a `/graphql/bleeding-edge` endpoint that keeps deploying the schema from DEV.
## Supporting the BfF approach
Backend-for-Frontends (BfF for short) is an [approach for producing different APIs for different clients](https://philcalcado.com/2015/09/18/the_back_end_for_front_end_pattern_bff.html) where each client "owns" its own API, which allows it to produce the most optimal version based on its own requirements.
In this model, a custom BfF is the middleman between backend services and its client:
 This model can be satisfied in GraphQL by implementing all BfFs in a single GraphQL server with multiple endpoints, with each endpoint tackling a specific BfF/client (such as `/graphql/mobile` and `/graphql/web`):
## Conclusion
GraphQL was born as [an alternative to REST](https://blog.logrocket.com/graphql-vs-rest-what-you-didnt-know/), focused on retrieving data with no under- or overfetching, making it extremely efficient. The way to accomplish this goal is by exposing a single endpoint, to which we provide the query to fetch the data.
Exposing a single endpoint works well in most cases, but may fall short whenever we need to produce completely different schemas that are customized to different clients or applications. In this case, exposing multiple endpoints, at one endpoint per schema, could be more appropriate.
In this article, we explored different examples of when this makes sense, and how to implement it.
---
## Monitor failed and slow GraphQL requests in production
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, [try LogRocket](https://logrocket.com/signup/).
[](https://logrocket.com/signup/)
[LogRocket](https://logrocket.com/signup/) is like a DVR for web apps, recording literally everything that happens on your site. Instead of guessing why problems happen, you can aggregate and report on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. [Start monitoring for free](https://logrocket.com/signup/). | mangelosanto |
922,570 | HTML tags | param | It defines parameters for an <object> element. It has two attributes: name to declare the name... | 13,528 | 2021-12-10T07:13:46 | https://dev.to/carlosespada/html-tags-param-4lhc | html, tags, param | It **defines parameters** for an `<object>` element.
It has two attributes: `name` to declare the name of the parameter and `value` to specify its value.
- Type: *-*
- Self-closing: *Yes*
- Semantic value: *No*
[Definition and example](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/param) | [Support](https://caniuse.com/mdn-html_elements_param) | carlosespada |
922,610 | Hello World | Hello world is the most common and most begging word for every new programmer who is newly learn... | 0 | 2021-12-10T09:15:34 | https://dev.to/prabhat2373/hello-world-53b1 | programming, beginners, showdev | Hello world is the most common and most begging word for every new programmer who is newly learn programming. | prabhat2373 |
922,623 | Append a file into a zip file in Python | I was trying to find a way to append a file into a zip file in python, but I could not find an easy... | 0 | 2021-12-10T09:27:14 | https://dev.to/barakplasma/append-a-file-into-a-zip-file-in-python-3e0c | python, showdev | I was trying to find a way to append a file into a zip file in python, but I could not find an easy way to do it.
When using zipfile built into python, using the 'a' append method doesn't overwrite files the way I expected it to. So this python module will overwrite the existing file when appending a file (which to me is the obvious solution).
There's no lack of StackOverflow posts and answers, but all of those were too specific to the specific post/issue.
So I decided to scratch my own itch, and make a library to handle it for myself and others.
https://pypi.org/project/appendzip/0.0.4/
{% github barakplasma/append-zip %}
MIT licensed
example of how to use it:
install (on Mac)
`$ python3 -m pip install appendzip`
```py
from appendzip.appendzip import appendzip
# before appendzip calendar.txt in the zip archive test.zip contains 2021-01-02
# before appendzip calendar.txt outside the zip contains 2022-02-03
appendzip(
pathlib.Path('test.zip'),
pathlib.Path('calendar.txt'),
'calendar.txt'
)
# after appendzip calendar.txt inside the zip contains 2022-02-03
# after, there is still only one file in the zip archive test.zip
``` | barakplasma |
922,837 | Collaborating with Uploadcare to support software developers | Uploadcare provides companies with simple, powerful, developer-friendly building blocks to handle... | 0 | 2021-12-10T13:31:05 | https://evrone.com/uploadcare | ruby, python, opensource, programming | Uploadcare provides companies with simple, powerful, developer-friendly building blocks to handle file uploading, processing, and delivery. With Uploadcare, developers can cover the entire file cycle fast, eliminating months of manual work.
You can receive files from your users with an uploading widget or upload them via API call. Process them on the fly with dozens of CDN features, or REST API. And then deliver them directly from multi-vendor CDN. Everything is simple for the smallest project and compliant for the largest enterprise.
[Evrone partnered with Uploadcare to improve their Ruby and Python libraries, making the solutions up to date and more accessible and useful for software developers.](https://evrone.com/uploadcare) | evrone |
923,291 | Squashing and Merging - Telescope | This week I completed by pull request with some squashing and the changes were merged by my... | 0 | 2021-12-10T22:33:15 | https://dev.to/drew5494/squashing-and-merging-telescope-4i8h | opensource, typescript | This week I completed by pull request with some squashing and the changes were [merged](https://github.com/Seneca-CDOT/telescope/commit/cf03b25a6d26f3f7a590e491a855ea6feaf3dccf) by my professor. I found that the [problem](https://github.com/Seneca-CDOT/telescope/issues/2554) of page re-rendering and losing focus could be solved without using <code>autoFocus</code> and sacrificing accessibility.
As pointed out by @dukemanh, the problem can be solved by simply returning a JSX expression in <code>searchInput.tsx</code>. By doing so, it prevents a new component being returned every time and therefore stops the page from re-rendering unnecessarily. I also removed some fields and attributes that were [unnecessary](https://github.com/Seneca-CDOT/telescope/commit/cf03b25a6d26f3f7a590e491a855ea6feaf3dccf) while in <code>AuthorSearchInput.tsx</code>.
It was a rather messy pull request in the end. I had to squash and rebase my two changes, but had some trouble doing so. I hadn't done much of either in previous pull requests. I am getting better at learning how to squash and rebase with this experience.
It was fun interacting with so many students from Seneca that were interested in solving the same issue. I hope to contribute more to Telescope soon and hopefully not make such a mess with my pull requests in the future! | drew5494 |
922,852 | Was ist LiteSpeed Hosting | Wenn es um das Thema WordPress Hosting geht, sind viele... Der Original-Artikel erschien auf Was... | 0 | 2021-12-10T15:32:42 | https://bloggerpilot.com/litespeed-hosting/ | wordpress, hosting, litespeed | ---
title: Was ist LiteSpeed Hosting
published: true
date: 2021-12-10 13:56:06 UTC
tags: WordPress,hosting,litespeed
canonical_url: https://bloggerpilot.com/litespeed-hosting/
---

Wenn es um das Thema WordPress Hosting geht, sind viele...
Der Original-Artikel erschien auf [Was ist LiteSpeed Hosting](https://bloggerpilot.com/litespeed-hosting/). | j0e |
922,912 | What’s new at Superface: November 2021 | November has been a busy month at Superface. We've opened up registration and released lots of great... | 0 | 2021-12-10T15:58:18 | https://superface.ai/blog/changelog-november-2021 | node, javascript, news, startup | November has been a busy month at Superface. We've opened up registration and released lots of great new features. Cozy up and grab an eggnog as we share what we've been up to.
## Registration is now open for all
[Register for a Superface account](https://superface.ai/create-account?utm_source=dev.to&utm_medium=blog&utm_campaign=changelog-november-2021) and get access to the [use-cases catalog](https://superface.ai/catalog?utm_source=dev.to&utm_medium=blog&utm_campaign=changelog-november-2021) and [integrations monitoring](https://superface.ai/docs/integrations-monitoring) dashboard. We have also prepared a sweet promo video for the occasion.
{% twitter 1465317611533651975 %}
## OneSDK and CLI hit version 1.0
With the public launch, we have also released 1.0 versions of [OneSDK](https://github.com/superfaceai/one-sdk-js), [Superface CLI](https://github.com/superfaceai/cli), and supporting libraries. We're committed to backwards compatibility, so you can expect our APIs to remain stable.
We will publish release candidates for general testing under the `next` dist-tag.
## New in catalog: Computer Vision, Natural Language Processing and others
You can find new use-cases and providers in our ever-growing [catalog](https://superface.ai/catalog?utm_source=dev.to&utm_medium=blog&utm_campaign=changelog-november-2021):
- [communication/send-message](https://superface.ai/communication/send-message) for sending text messages over Slack
- [computer-vision/face-detection](https://superface.ai/computer-vision/face-detection) detects faces and emotions in images using Google Cloud Vision API
- [crm/contacts](https://superface.ai/crm/contacts) for managing customers and users in various systems; Crisp, Hubspot, Mixpanel, and Sendgrid are available
- [crypto/exchange-rate](https://superface.ai/crypto/exchange-rate) fetches exchange rate of cryptocurrencies using Binance
- [language/analyze-plain-text-sentiment](https://superface.ai/language/analyze-plain-text-sentiment) analyzes emotions and prevailing sentiment in text with IBM Watson Natural Language Understanding and Google Cloud Natural Language APIs
- [language/translate](https://superface.ai/language/translate) translates text using DeepL Translator
- [speech/synthesis](https://superface.ai/speech/synthesis) turns text into natural-sounding speech with Google Cloud Text-to-Speech and IBM Watson Text to Speech
- [speech/recognize](https://superface.ai/speech/recognize) turns speech into text with AssemblyAI, and Speech to Text services by Google Cloud, IBM Watson, and Microsoft Azure
All use-cases from the catalog are maintained in the [Station repository](https://github.com/superfaceai/station). If you are curious what we are working on, check out our open pull requests. And of course, you are more than welcome to contribute new providers and use-cases.
## Integration parameters and examples in Comlink
[Comlink](https://superface.ai/docs/comlink) is a domain-specific language (DSL) which powers Superface integrations. Recently, we have improved support for integration parameters and introduced examples into profiles.
### Provider integration parameters
Some providers require additional information for working with their APIs. For example, calls to Twilio include “Account String Identifier” (SID) and IBM Cloud lets you pick a preferred region for their services. Unlike security values (API keys and access tokens) these information usually aren’t sensitive and in some cases can have a default value.
We call these values “integration parameters”. They are specified inside the [provider definition](https://superface.ai/docs/comlink/reference/provider) file:
```json
{
"name": "ibm-cloud-natural-language-understanding",
// ...
"parameters": [
{
"name": "REGION",
"description": "Your natural language understanding instance region (eu-de, us-east, ...)"
},
{
"name": "INSTANCE_ID",
"description": "Your natural language understanding instance id"
}
]
}
```
With these parameters defined, maps can access them through `parameters` object:
```hcl
map AnalyzePlainTextSentiment {
http POST "/instances/{parameters.INSTANCE_ID}/v1/analyze?version=2021-08-01" {
// ...
}
}
```
We have improved the discovery of these parameters in our catalog and CLI. Now you can preview all the required parameters in the provider details.
<figure>
<figcaption>
See it in action on <a href="https://superface.ai/language/analyze-plain-text-sentiment">Analyze plain text sentiment</a> IBM provider detail.
</figcaption>
</figure>
And the Superface CLI will inform you when configuring the provider:
```shell
$ npx @superfaceai/cli configure ibm-cloud-natural-language-understanding -p language/analyze-plain-text-sentiment
Installing provider to 'super.json' on path 'superface/super.json'
Installing provider: "ibm-cloud-natural-language-understanding"
🆗 All security schemes have been configured successfully.
Provider ibm-cloud-natural-language-understanding has integration parameters that must be configured. You can configure them in super.json on path: superface/super.json or set the environment variables as defined below.
🆗 Parameter REGION with description "Your natural language understanding instance region (eu-de, us-east, ...)" has been configured to use value of environment value "$IBM_CLOUD_NATURAL_LANGUAGE_UNDERSTANDING_REGION".
Please, configure this environment value.
🆗 Parameter INSTANCE_ID with description "Your natural language understanding instance id" has been configured to use value of environment value "$IBM_CLOUD_NATURAL_LANGUAGE_UNDERSTANDING_INSTANCE_ID".
Please, configure this environment value.
```
By default OneSDK will look for the parameters in environment variables, but you can also define them directly in the `super.json` configuration file.
### Profile examples
[Comlink profile](https://superface.ai/docs/comlink/reference/profile) defines an interface, or “contract”, between your application and the provider-specific API. Profile specifies inputs, outputs, and error models. It is now possible to document example inputs with expected outputs or errors:
```hcl
usecase ReverseGeocode {
// ...
example Successful {
input {
latitude = 37.423199,
longitude = -122.084068
}
result [{
addressCountry = 'us',
addressLocality = 'Mountain View',
addressRegion = 'CA',
formattedAddress = 'Amphitheatre Parkway, Mountain View, CA 94043, United States of America',
postalCode = '94043',
streetAddress = 'Amphitheatre Parkway',
}]
}
example Failed {
input {
latitude = 720,
longitude = 540
}
error {
title = 'Bad request',
detail = 'The provided coordinates in query are invalid, out of range, or not in the expected format'
}
}
}
```
<figure>
<figcaption>
Examples are also rendered in the use-case’s detail, you can see it in action on <a href="https://superface.ai/address/geocoding">Geocoding</a> use-cases.
</figcaption>
</figure>
## First Superface webinar
We have organized the first Superface webinar to show how easy it is to integrate multiple APIs and take advantage of provider fail-overs and other features. You can watch the recording on YouTube.
{% youtube Sl9rdbw0CtM %}
## More to come
November was an important milestone for us, but we are just getting started. Expect more exciting news in 2022. Don’t forget to [join our Discord](https://sfc.is/discord) and follow us on [Twitter](https://twitter.com/superfaceai) and [LinkedIn](https://www.linkedin.com/company/superfaceai).
From Superface, we wish you happy Holidays and a wonderful 2022!
| jnv |
922,934 | Visual Studio Code / PHPStorm sync code between multiple devices | At home I work on my standing PC with multiple Monitors and on a Windows System. When I'm not at... | 0 | 2021-12-10T16:13:08 | https://dev.to/bamb/visual-studio-code-phpstorm-sync-code-between-multiple-devices-4hm3 | javascript | At home I work on my standing PC with multiple Monitors and on a Windows System. When I'm not at home, I want to work on a MacBook. So here comes the question: How do I sync code-changes between these devices? I googled it up, but the only solution that I have found was using Git. But it is ugly not to finish something before committing and pushing, so I need another solution. Is anyone facing the same problem? | bamb |
923,101 | 🎄Coding Grace December Newsletter is out plus extra announcements! | 🧑🎄 "Tis the season to be jolly!“ ⛄️ 🙌 Yip, our newsletter is out and it's the final one... | 7,591 | 2021-12-10T17:15:05 | https://dev.to/codinggrace/our-latest-newsletter-is-out-3efc | codinggrace, diversityintech, irishtechcommunity, newsletter | ## 🧑🎄 "Tis the season to be jolly!“ ⛄️
🙌 Yip, our newsletter is out and it's the final one of this year and I'm pretty happy with the transition from Mailchimp to using Revue. Check out the [latest newsletter](https://www.getrevue.co/profile/codinggrace/issues/monthly-newsletter-of-coding-grace-dec-2021-issue-842463) and let us know what do you think? 🤔
📢 If you have any events, CFPs, opportunities like grants and other announcements, you can email contact@codinggrace.com and we will include it in our next newsletter. They are normally published at the beginning of each month.
🚨 Help [Coding Grace](https://codinggrace.com/) spread the word and get more subscribers as well as telling us what else you want on the newsletter. Thanks in advance.
Following are more announcements and reminders and I'll try and update if anything else pop up for this month.
## Opportunities

### 📢 TechStart and Women in Business launch grant competition for NI-based female founders
> A new funding opportunity aiming to support female founders in Northern Ireland with their innovative business ideas has just been launched by Techstart Ventures and Women in Business.
👉 More information about the grant: https://startacus.net/culture/techstart-and-women-in-business-launch-grant-competition-for-ni-based-female-founders#.Ya4_qtDP02w
## Coding Grace Workshop

### 📢 Diversity-Friendly Workshop for Non-Tech Founders
Over 2 days, we will be running 2 hour long workshops each session covering the fundamentals of tech.
* When: Jan 20 & Jan 21 (14:00 - 16:00 each day)
* Audience: Non-tech founders
* Cost: €50.00
👉 More details about the workshop: https://www.codinggrace.com/events/non-tech-founders-workshop-virtual/01/
## Other Events
### 📢 Python Ireland - Speakers Coaching Session
> We will help you deliver your talk in a non judgemental, friendly environment. If you're happy with it we will publish it on our Youtube channel, but you will decide if you want this to happen.
* When: Sat Jan 22, 2022
* Where: Online
👉 More details about the speaker coaching session: https://www.meetup.com/pythonireland/events/281468322/
### 🗓 Irish Tech and Diversity in Tech Events around Ireland
Don't forget that we curate a list of events and if we missed out any, please let us know.
List updated regularly: https://irish-diversity-in-tech.netlify.app/events/
## Other orgs that need your support
### 📢 Women in AI - WAI@WORK survey
> You said you wanted to be a part of a more diverse work culture?🧐 This could be your chance to bring change! ✔️✔️ WAI and AI Sweden are launching a survey to find out what women in AI want from their workplace with our WAI@WORK survey.
👉 Take me to WAI@WORK survey: https://www.womeninai.co/wai-at-work
### 📢 Enough Already: Break the Cycles of Abuse in Gaming (Feminist Frequency)
> Every time a news story breaks about toxicity and abuse at a high-profile game company, or harassment by someone in a position of power, we see an uptick in calls to the Games and Online Harassment Hotline. Statements and promises are always made, but like clockwork, wait six months and the same problem resurfaces.
👉 More info on how to support them: https://givebutter.com/femfreq2021
## Finally...
Have you decorated for the Holiday Season yet?

From me and the rest Coding Grace Foundation team, we wish you Seasons' Greetings and a Happy New Year.
_(Originally posted on https://codinggrace.com/news/coding-grace-dec-2021-newsletter)_
| whykay |
985,473 | ⚙️ ❮ Zsh Diff-so-Fancy ❯ | ❮ ZI ❯ Plugin - zsh-diff-so-fancy The project so-fancy/diff-so-fancy integration with... | 16,311 | 2022-02-10T23:02:30 | https://github.com/z-shell/zsh-diff-so-fancy | zsh, github, git, tooling | <div align="center">
<a href="https://github.com/z-shell/zi">
<img src="https://raw.githubusercontent.com/z-shell/zi/main/docs/images/logo.png" alt="Logo" width="60" height="60"></a><h2>
❮ ZI ❯ Plugin - zsh-diff-so-fancy
</h2>
<div align="center">
<img src="https://github.com/z-shell/zsh-diff-so-fancy/raw/main/docs/img/zsh-diff-so-fancy.gif" alt="zsh-diff-so-fancy" width="70%" height="70%" />
</div>
---
The project [so-fancy/diff-so-fancy](https://github.com/so-fancy/diff-so-fancy) integration with ZI.
With this [ZI](https://github.com/z-shell/zi) plugin, you simply add two lines to `.zshrc`:
```shell
zi ice as"program" pick"bin/git-dsf"
zi light z-shell/zsh-diff-so-fancy
```
This will install `diff-so-fancy` on every account where you use Zshell, and automatically equip `git` with subcommand `dsf`. No need to use system package manager and to configure `git`. Of course, if you have the following standard line in your `.gitconfig`, it will still work normally:
```shell
[core]
pager = diff-so-fancy | less -FXRi
```
(because this plugin adds `diff-so-fancy` to `$PATH`).
Think about Puppet or Chef, i.e. about declarative approach to system configuration.
In this case `.zshrc` is like a declarative setup guarding you will have `diff-so-fancy`
on your accounts.
### A Few Details
[so-fancy/diff-so-fancy](https://github.com/so-fancy/diff-so-fancy) is cloned from
Github as submodule. The plugin has `bin/git-dsf` script which adds subcommand `dsf`
to git. That's basically everything needed: convenient way of installing (single Zsh
plugin manager invocation), updating (Zsh plugin managers can easily update) and
integrating with `git`.
### Other plugin managers
#### Zplug
```shell
zplug "z-shell/zsh-diff-so-fancy", as:command, use:"bin/"
```
#### Zgen
```shell
zgen load z-shell/zsh-diff-so-fancy
```
Without `as"program"`-like functionality the `.plugin.zsh` file picks up setup and simulates adding a command to system, so `Zgen` and other can work.
---
[@zshell_zi](https://twitter.com/zshell_zi), [z.digitalclouds.dev](https://z.digitalclouds.dev) | zsh |
923,305 | Does WordPress Work in China? | In this article, we will walk you through some speed tests we conducted to determine if WordPress... | 0 | 2021-12-10T23:18:45 | https://www.21cloudbox.com/solutions/does-wordpress-work-in-china.html | wordpress, china, php, cms | ---
canonical_url: https://www.21cloudbox.com/solutions/does-wordpress-work-in-china.html
---
In this article, we will walk you through some speed tests we conducted to determine if WordPress works in China or not. Our staff conducted the tests in Shanghai (China Mainland) and Hong Kong (outside Mainland China) and we used 3rd party testing tools to ensure our tests weren't biased.
By the end of this article, you should have a good understanding of WordPress and if works in Mainland China or not. Also, you can [contact us](https://www.21cloudbox.com/contact.html) to get a free speed test of your WordPress site for China.
<br>
## What is WordPress?
WordPress is a free and open-source content management system (CMS) written in PHP. WordPress is now powering about 40% of all websites on the internet.
---
<br>
## Does WordPress Work in China?
The short answer is no.
Below is the long answer if you want to understand why:
1. Most hosting providers claim to have Global coverage for your WordPress site, but actually, China is not included.
2. If your business didn't have any legal licenses for your site and content in China, it is operating illegally in China.
Luckily we have put together [solutions for you to make your business and your WordPress site works fast and reliably in China.](https://www.21cloudbox.com/with/wordpress.html)
Don't just take our words. Let's look at some popular websites powered by WordPress and see how well they work in China.
---
<br>
## How do we check if a website works in China or not?
There are two checks we need to perform to conclude if a website works in China.
1. How fast is the site in Mainland China?
2. Does the website operated by the business comply with the laws in China?
The second part of the test is a must for most businesses or organizations, not optional.
If you are unsure why it's a must, read [Untold facts about ICP for China](https://www.21cloudbox.com/untold-facts-about-icp-for-china.html), and why you should get it.
<br>
---
<br>
## Speed Tests Results
We picked 5 websites from current [WordPress Global users](https://wordpress.org/showcase/archives) and considered these websites to follow the best practices powered by WordPress.
Then we follow the test questions mentioned earlier for each website and create a report with the following format:
**1. A figure to see how fast the site performs across Mainland China.**
This figure basically shows how fast the website loads across Mainland China (green = fast, red=slow)
<br>
**2. A video to see how the site performance in China visually.**
We made a screen record of the website loading in Shanghai, China. This provides you with an intuitive way to see how fast the site visually loads and understand what people in China actually experience when they visit the website.
<br>
**3. A yes-no check to see if the site complied with the laws in China.**
If the site passes the legal check, it's a green check. If it doesn't pass, we will tell you why it doesn't pass.
Now, let's dive into the reports for each of the selected websites using WordPress.
---
**Gucci, www.gucci.com**
Gucci is an Italian luxury fashion house based in Florence, Italy. Gucci uses their Equilibrium brand to generate positive change for people and our planet.
From our speed test, people in China will have difficulty viewing the images and opening them on Gucci Equilibrium’s website (that’s what the below figure means, red means unable to display images).

Here is a more intuitive way to see it, we screen-recorded the process when a user browses HKTDC's website in Shanghai, click the video below to see it in action:
{% youtube 6f730ya881k %}
**Does the Gucci's website comply with the laws in China?**
No. It doesn't pass our legal check because the website does not have an ICP license displayed at the footer of their website.
If you don't know what an ICP license is, [click](https://www.21cloudbox.com/untold-facts-about-icp-for-china.html) to learn more.
Finding if a website has an ICP license is pretty straightforward, just scroll to the bottom of the page, if you see a number like this (see below Nike's websites for China), then the business behind the website has an ICP for China. If not, they don't have it. You can check if your website has it or not.
Below is an example of Nike's website in China, and its ICP number.
<br>
<hr>
<br>
<br>
Similarly, we ran the same tests for the rest of the WordPress user's websites.
---
**007, www.007.com**
007 aka James Bond is a character and brand that has been adapted for television, radio, comic strip, video games and film. The 007 films are one of the longest continually running film series and have grossed over US$7.04 billion in total.
Click [here](https://www.21cloudbox.com/solutions/does-wordpress-work-in-china.html#james-bond) to see 007's full case study and results.
<br>
<hr>
<br>
**Renault Group, www.renaultgroup.com**
Renault Group (RNSLY) is a French multinational automobile manufacturer established in 1899. The company produces a range of cars and vans
Click [here](https://www.21cloudbox.com/solutions/does-wordpress-work-in-china.html#renault-group) to see the full case study and results.
<br>
<hr>
<br>
**Tonal, www.tonal**
.com**
Tonal is a smart home gym that uses artificial intelligence and expert-led coaching to provide strength training.
Click [here](https://www.21cloudbox.com/solutions/does-wordpress-work-in-china.html#Tonal) to see Tonal's full case study and results.
<br>
<hr>
<br>
** Disney, www.thewaltdisneycompany.com**
The Walt Disney Company (DIS), commonly just Disney, is an American multinational entertainment and media conglomerate.
Click [here](https://launch-in-china.21yunbox.com/solutions/does-wordpress-work-in-china.html#:~:text=Disney%2C%20www.thewaltdisneycompany.com) to see Disney's full case study and results.
<br>
<hr>
<br>
## Need to Get WordPress working in China?
In short, if your business is going to China, make sure your website passes the two tests we mentioned above to have a fast speed of first load and good viewing and browsing quality for your users in China.
> _**Reducing page load time by 0.1 seconds will increase the conversion rate by 8%.**_ - Google, Deloitte
If you need to get WordPress working in China, feel free to [contact us](https://www.21cloudbox.com/contact.html) or click here to [get started.](https://www.21cloudbox.com/with/wordpress.html)
<br>
<hr>
<br>
<br>
*For additional detail and future modifications, refer the [original post](https://www.21cloudbox.com/solutions/does-wordpress-work-in-china.html) | 21yunbox |
923,467 | CI/CD (Front End) | With steps 2-6 complete, I decided to go out of order and complete step 15 now rather than later.... | 15,861 | 2021-12-11T06:48:21 | https://dev.to/seanbond13/cicd-front-end-3p3b | aws, github, devops, automation | With steps 2-6 complete, I decided to go out of order and complete step 15 now rather than later. Step 15 is creating a GitHub action to automatically push code changes in the repo to the S3 bucket, thus creating a CI/CD process to automate updating the front end.
I decided to set this up now because I hate manual processes that can (should) be automated. My next task is adding the Javascript counter and DynamoDB table. That could involve a lot of changes and testing with the HTML in the S3 bucket and I'd rather not copy the files to S3 manually after every change.
The setup for this automation wasn't too hard:
- Create an IAM policy to allow updating the files in the S3 bucket:
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SyncToS3",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::BUCKET-NAME",
"arn:aws:s3:::BUCKET-NAME/*"
]
}
]
}
```
- Create an IAM user with only programmatic access and assign the policy.
- Add the IAM user's access key and secret access key to the GitHub repo's secrets.
- Create the GitHub Action:
```
name: Upload to S3
on:
push:
branches:
- master
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v1
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: us-west-1
- name: Deploy static site to S3 bucket
run: aws s3 sync FOLDER-NAME s3://BUCKET-NAME --delete
```
Now when a change is pushed to the GitHub repo the file is automatically uploaded to the S3 bucket.
**UPDATE**
To have the action only run when files are changed in a certain folder, use the `paths` option. This enables different actions to be run for things like syncing the front_end folder to S3 and the back_end folder to API Gateway.
```
on:
push:
branches:
- master
paths:
- 'FOLDER-NAME/**'
```
| seanbond13 |
923,503 | How to Embed Google Drive Video to Website | Google Drive is one of the best cloud storage. It is developed by Google, which allows users to store... | 0 | 2021-12-11T07:42:01 | https://linuxtus.com/embed-google-drive-video-to-website/ | webdev, web3, tutorial, programming | Google Drive is one of the best cloud storage. It is developed by Google, which allows users to store files, synchronize across devices. In which, videos are stored on Google Drive the most, because it is easy to upload and use later. Embed Google Drive Video to WebPage is easy to work for web developers, you don’t need to upload to Youtube and use its feature. You can embed video directly to your website. Following this guide, you can know how to Embed Google Drive to Website.
Read more: [Embed Google Drive Video to Website](https://linuxtus.com/embed-google-drive-video-to-website/) | tgbaodeeptry |
923,545 | Best Practices For Writing Clean Pythonic Code | Introduction This article is a collection of best practices for more idiomatic python code... | 0 | 2021-12-11T09:24:32 | https://dollardhingra.com/blog/python-code-best-practices/ | python, programming, productivity, codequality | ## Introduction
This article is a collection of best practices for more idiomatic python code especially if you are new to python.
## Contribute
Feel free to [contribute](https://github.com/dollardhingra/dollardhingra.github.io/edit/master/_posts/2021-12-05-python-code-best-practices.md) to this list, and I will thank you by including a link to your profile with the snippet!
## 1. Catching Exceptions
This is a sure-shot way to get your code into trouble
```python
# very bad practice
try:
do_something()
except:
pass
# A slightly better way(included logging), but still a bad practice:
try:
do_something()
except Exception:
logging.exception() # although, logging is a good practice
# When we don't use `Exception` we will also be catching events like system exit.
# So, using Exception means that we are only catching Exceptions.
# A better way:
try:
do_something()
except ValueError:
logging.exception()
# some code to handle your exception gracefully if required
```
Here we have used a specific type of Exception i.e. `ValueError`.
## 2. Name Casing
```python
# using camelCase is not a convention in python
def isEmpty(sampleArr):
...
# instead use snake_case in python
def is_empty(sample_arr):
...
```
In python, `snake_case` is preferred for variables, functions and method names. However, for classes, `PascalCase` is used.
## 3. Chained comparison operators
There are multiple ways of comparing in Python:
```python
# Don't do this:
if 0 < x and x < 10:
print('x is greater than 0 but less than 10')
# Instead, do this:
if 0 < x < 10:
print('x is greater than 0 but less than 10')
```
## 4. Mutable default arguments
```python
# wrong way!
# a sure shot way to get some unintended bugs in your code
def add_fruit(fruit, box=[]):
box.append(fruit)
return box
# correct way!
# recommended way for handling mutable default arguments:
def add_fruit(fruit, box=None):
if box is None:
box = []
box.append(fruit)
return box
```
Read more about mutable default arguments [here](https://dev.to/dollardhingra/1-anti-pattern-mutable-default-arguments-3bp5)
## 5. String Formatting
```python
# Avoid using it
# %-formatting
name = "James Bond"
profession = "Secret Agent"
print("Hello, %s. You are a %s." % (name, profession))
# slightly better
# str.format()
print("Hello, {}. You are a {}.".format(name, profession))
# Short, crisp and faster!
# f-strings
print(f"Hello, {name}. You are a {profession}.")
```
The f in f-strings may as well stand for "fast." f-strings are faster than both %-formatting and str.format(). [(Source)](https://www.python.org/dev/peps/pep-0498/#abstract)
## 6. Top-level script environment
Executes only if it is run as a script and not as a module
```python
# Filename: run.py
if __name__ == '__main__':
print('Hello from script!')
```
```
$ python run.py
$ Hello from script!
```
`Hello from script!` will **not** be printed if the module is imported into any other module.
## 7. Conditional expressions
```python
if x < 10:
return 1
else:
return 2
```
Can be reduced to this one:
```python
return 1 if x < 10 else 2
```
## 8. Iterating over an iterator
You don’t necessarily need to iterate over the indices of the elements in an iterator if you don’t need them. You can iterate directly over the elements.
This makes your code more pythonic.
```python
list_of_fruits = ["apple", "pear", "orange"]
# bad practice
for i in range(len(list_of_fruits)):
fruit = list_of_fruits[i]
process_fruit(fruit)
# good practice
for fruit in list_of_fruits:
process_fruit(fruit)
```
## 9. Indexing/Counting during iteration
```python
# Don't do this:
index = 0
for value in collection:
print(index, value)
index += 1
# Nor this:
for index in range(len(collection)):
value = collection[index]
print(index, value)
# Definitely don't do this:
index = 0
while index < len(collection):
value = collection[index]
print(index, value)
index += 1
# Instead, use `enumerate()`
for index, value in enumerate(collection):
print(index, value)
```
## 10. Using context managers
Python provides context managers that manage the overhead of initializing and clearing up the resources and let
you focus on the implementation. For example in the case of reading a file, you don't need to be concerned
to close the file manually.
```python
d = {"foo": 1}
# bad practice
f = open("./data.csv", "wb")
f.write("some data")
v = d["bar"] # KeyError
# f.close() never executes which leads to memory issues
f.close()
# good practice
with open("./data.csv", "wb") as f:
f.write("some data")
v = d["bar"]
# python still executes f.close() even if the KeyError exception occurs
```
## 11. Using set for searching instead of a list
```python
s = set(['s', 'p', 'a', 'm'])
l = ['s', 'p', 'a', 'm']
# ok for small no. of elements
def lookup_list(l):
return 's' in l # O(n)
# better for large no. of elements
def lookup_set(s):
return 's' in s # O(1)
```
Sets are implemented using hash in python, which makes searching of element faster(O(1)) as compared to searching in a
list(O(n)).
## 12. using * while importing a module
Imports should always be specific. Importing * from a module is a very bad practice that pollutes the namespace.
```python
# bad practice
from math import *
x = ceil(x)
# good practice
from math import ceil
x = ceil(x) # we know where ceil comes from
```
## 13. using items() for iterating a dictionary
```python
d = {
"name": "Aarya",
"age": 13
}
# Dont do this
for key in d:
print(f"{key} = {d[key]}")
# Instead do this
for key,val in d.items():
print(f"{key} = {val}")
```
## Sources
- [RealPython f-strings](https://realpython.com/python-f-strings/)
- [RealPython the most diabolic anti pattern](https://realpython.com/the-most-diabolical-python-antipattern/)
- [Python Idiom Patterns](https://arielortiz.info/s201911/pycon2019/docs/design_patterns.html)
- [18 Common Python Anti-Patterns I Wish I Had Known Before](https://towardsdatascience.com/18-common-python-anti-patterns-i-wish-i-had-known-before-44d983805f0f)
# More Articles You May Like
- [#1 Anti-Pattern - Mutable Default Arguments](https://dev.to/dollardhingra/1-anti-pattern-mutable-default-arguments-3bp5)
- [Code Quality Tools in Python](https://dev.to/dollardhingra/code-quality-tools-in-python-4k2a)
- [Beginner's guide to abstract base class in Python](https://dev.to/dollardhingra/understanding-the-abstract-base-class-in-python-k7h)
| dollardhingra |
923,714 | A Guide to the Zsh Completion With Examples | The Zsh completion system is far from being simple to configure. That's great, because I love simplifying the complicated. Here's an overview of the powerful Zsh completion system: what it is, how to use it, and how to configure it to your own needs without using any bloated dependency. | 0 | 2021-12-11T13:07:28 | https://thevaluable.dev/zsh-completion-guide-examples/ | zsh, terminal, productivity, shell | ---
title: A Guide to the Zsh Completion With Examples
published: true
description: The Zsh completion system is far from being simple to configure. That's great, because I love simplifying the complicated. Here's an overview of the powerful Zsh completion system: what it is, how to use it, and how to configure it to your own needs without using any bloated dependency.
tags: #zsh #terminal #productivity #shell
cover_image: https://thevaluable.dev/images/2021/zsh_completion_system/completion.jpg
canonical_url: https://thevaluable.dev/zsh-completion-guide-examples/
---
"The completion offered by Zsh is great, but could it be better? Why not trying to understand how it works? I could then configure it for my own needs!"
This was my thinking a couple of months ago, after waking up a Monday morning full of energy and will to eat my breakfast. I was young and innocent, unaware of the consequences of this thought making its nest in my brain. What could go wrong? After all, it's only a completion system.
While reading the page of the Zsh manual concerning the completion, I saw the Demon of Complexity™ showing its nose. A dozen of questions were popping up, a twisted configuration syntax was unleashed, nonsensical descriptions were unfolding before my eyes.
When I see something complex, I can't stop myself trying to simplify it. It took me hours to begin to understand this completion system, but now I think I've a good grasp on the Beast.
This article is the result of my efforts. It aims to explain the Zsh completion system in a simple way; more precisely, we'll see:
* How to enable the Zsh completion.
* How does the completion system work.
* What's the purpose of the zstyle module.
* How to use styles to configure the Zsh completion.
* What are the most useful styles we can use to customize the completion.
* How to trigger a precise completion using keystrokes.
* How to customize the completion menu using the module *complist*.
* What are the Zsh options we can set to configure the completion.
As I explain in a [previous article](https://thevaluable.dev/zsh-install-configure-mouseless/), I don't use any Zsh framework (like oh-my-zsh or prezto) to have a full control on my config.
Enough rambling! Let's dive into the fantastic and dangerous Zsh completion system.
## Enabling the Zsh Completion System
To initialize the completion for the current session, you need to *autoload* the function `compinit` and to call it. To do so, add the following in your file `.zshrc`:
```zsh
autoload -U compinit; compinit
```
If you wonder what's this `autoload`, I already wrote about it [in this article](https://thevaluable.dev/zsh-install-configure-mouseless/).
You can also configure your completion with the shell command `compinstall`. It asks a series of question to decide what kind of completion you need, and it writes automatically your preferences in your `.zshrc`. In that case, you don't need to autoload and run `compinit` manually.
But I find this tool very limited, and the questions it asks are quite obscure. I prefer writing my own config for the completion system in a separate file and source it in my `.zshrc`. More on that below.
It's where things become slightly complicated. If you don't care about the details, you can copy and paste [my simple config](https://github.com/Phantas0s/.dotfiles/blob/master/zsh/completion.zsh) in a file and source it in your `.zshrc`.
## How Does the Zsh Completion System Work
Zsh has two completion systems, the old *compctl* and the more recent *compsys*. We only look at compsys in this article.
Concretely, compsys is a collection of Zsh functions. You can find them in the [official repository of Zsh](https://github.com/zsh-users/zsh/tree/master/Completion). Three folders are specifically important:
* Base - The core of the completion system, defining the basic completers.
* Zsh - Functions for completing built-in Zsh commands (like `cd` for example).
* Unix - Function for completing external commands.
There are also folders for commands only available in some systems, like Solaris, Redhat, or Mandrive for example.
When you type a command in Zsh and hit the `TAB` key, a completion is attempted depending on the *context*. This context includes:
* What command and options have been already typed at the command-line prompt.
* Where the cursor is.
The context is then given to one or more *completer* functions which will attempt to complete what you've typed. Each of these completers are tried in order and, if the first one can't complete the context, the next one will try. When the context can be completed, some possible *matches* will be displayed and you can choose whatever you want.
A warning is thrown if none of the completers are able to match the context.
There are two more things to know about completers:
* The names of completers are prefixed with an underscore, like `_complete` or `_expand_alias` for example.
* A few completers return a special value 0 which will stop the completion, even if more completers are defined afterward.
## Configuring Zsh Completion With zstyle
You can configure many aspects of the completion system using the zsh module *zstyle*.
Modules are part of Zsh but optional, detached from the core of the shell. They can be linked to the shell at build time or dynamically linked while the shell is running.
### What's zstyle?
You might think that zstyle is used to configure some display styles, but it's much more than that. It's easier to see it as a flexible way to modify the default settings of Zsh scripts (modules, widgets, functions, and so on).
The authors of these scripts need to define what are these settings, what *pattern* a user can use to modify them, and how these modifications can affect their code.
Here's the general way you can use zstyle to configure a Zsh module:
```zsh
zstyle <pattern> <style> <values>
```
The *pattern* act as a namespace. It's divided by colons `:` and each value between these colons have a precise meaning.
In the case of the Zsh completion system, the context we saw earlier (what you've already typed in your command-line) is compared with this pattern. If there's a match, the style will be applied.
Don't worry if all of that sounds confusing: bare with me, I'll give some examples soon. For now, let's look a bit closer to the zstyle patterns we can use to configure our completion system.
See `man zshcompsys` for the list of styles for the completion system (search for "Standard Styles").
### General zstyle Patterns for Completion
To configure the completion system, you can use zstyle patterns following this template:
```
:completion:<function>:<completer>:<command>:<argument>:<tag>
```
The substring separated with colons `:` are called *components*. Let's look at the ones used for the completion system in details:
* `completion` - String acting as a namespace, to avoid pattern collisions with other scripts also using zstyle.
* `<function>` - Apply the style to the completion of an external function or widget.
* `<completer>` - Apply the style to a specific completer. We need to drop the underscore from the completer's name here.
* `<command>` - Apply the style to a specific command, like `cd`, `rm`, or `sed` for example.
* `<argument>` - Apply the style to the nth option or the nth argument. It's not available for many styles.
* `<tag>` - Apply the style to a specific tag.
You can think of a tag as a *type of match*. For example "files", "domains", "users", or "options" are tags.
For the list of tags, see `man zshcompsys` (search for "Standard Tags")
You don't have to define every component of the pattern. Instead, you can replace each of them with a star `*`. The more specific the pattern will be, the more precedence it will have over less specific patterns. For example:
```zsh
zstyle ':completion:*:*:cp:*' file-sort size
zstyle ':completion:*' file-sort modification
```
What happens if you set these styles?
1. If you hit `TAB` after typing `cp`, the possible files matched by the completion system will be ordered by size.
2. When you match files using the completion, they will be ordered by date of modification.
The pattern `:completion:*:*:cp:*` has precedence over `:completion:*` because it's considered more precise.
The `*` replace any character *including the colon* `:`. That's why the pattern `:completion:*:*:cp:*` is equivalent to `:completion:*:cp:*`. That said, I find the second form confusing: it's not clear what `cp` is. Is it a command? A function? A tag? In that case it's pretty obvious, but it's not always `cp` in the pattern. Personally, I always try to use the first form.
You can run `zstyle` in your shell to display the styles set in your current session as well as their patterns.
### Examples of zstyles for the Zsh Completion
All of that is quite verbose and not very self-explanatory, so let's look at more examples. Here's a simple one:
```zsh
zstyle ':completion:*' verbose yes
```
This zstyle command is composed of:
* A pattern: `:completion:*`
* A style: `verbose`
* A value: `yes`
There is only one value given here, because the style `verbose` only accept one. But you can set more than one for some styles. Each of these values would be separated by a space. For example:
```
zstyle ':completion:*:*:cp:*' file-sort modification reverse
```
We give here two values to the style `file-sort`: `modification` (to order the matches by date of modification) and `reverse` (to reverse the order). As we saw before, the pattern `:completion:*:*:cp:*` indicates that we only set the style `file-sort` to the command `cp`.
Let's see now a couple of styles we can set to improve our Zsh completion.
For more zstyle, see `man zshmodules` (search for "zstyle").
## Useful Style for the Zsh Completion System
I would recommend creating a new file `completion.zsh` somewhere and sourcing it directly in your file `.zshrc` as follows:
```zsh
source /path/to/my/completion.zsh
```
Every style defined here should be called after autoloading and calling compinit. If you don't want a separate file, you can throw all this configuration into your `.zshrc` too.
### The Essential
#### Defining the Completers
Let's first define the completer we'll use for our completion system. Here are some interesting ones:
* `_complete` - This is the main completer we need to use for our completion.
* `_approximate` - This one is similar to `_complete`, except that it will try to correct what you've typed already (the context) if no match is found.
* `_expand_alias` - Expand an alias you've typed. It needs to be declared before `_complete`.
* `_extensions` - Complete the glob `*.` with the possible file extensions.
Note that you can use `_expand_alias` with the keystroke `CTRL+x a` by default, without the need to use it as a completer. Simply type one of your alias in Zsh and try to use the keystroke.
You need to set the zstyle `completer` to define the completer you want to use. The order matter: the completion system will try each of these completer one after the other. The completion stop when some matches are found or when the completer stop it by itself.
For example, here are the completers I use:
```zsh
zstyle ':completion:*' completer _extensions _complete _approximate
```
Since we're dabbling into the completion system, the completer `_complete_help` might come in handy. You can use it as a function you can call with `CTRL+x h` by default.
When you're not sure why you end up with some matches and not others, you can hit `CTRL+x h` (for `h`elp) before completing your command. It will display some information about what the completion system will do to complete your context.
#### Caching the Completion
Using a cache for the completion can speed up some commands, like `apt` for example. Let's add the following in our file to enable it:
```zsh
zstyle ':completion:*' use-cache on
zstyle ':completion:*' cache-path "$XDG_CACHE_HOME/zsh/.zcompcache"
```
As you might have guessed, the style `cache-path` allows you to set the filename and location of the cache.
#### The Completion Menu
Instead of going through each match blindly to add what you want to your command, you can use a *completion menu*. For that, you need to set the style `menu` with the value `select` as follows:
```zsh
zstyle ':completion:*' menu select
```
You can also use this menu only if a precise `<number>` of matches is found with `select=<number>`. It's even possible to start the menu selection only if the list of matches doesn't fit the screen, by using the value `select=long`. Using both values `select=<number>` and `select=long` is possible too.
Having the values `select` and `interactive` allows you to filter the completion menu itself using the completion system. You can also configure a keystroke to switch this *interactive mode* when the completion menu is displayed. More on that later in this article.
Adding the value `search` to the style will allow you to fuzzy-search the completion menu. Again, a keystroke can be configured to have this functionality on demand.
### Formatting The Display
#### Colors and Decoration
Let's now improve the display of our completion menu using the style `format`.
Each completer can define different *sequences* (beginning with `%`) for different tags. For example:
```zsh
zstyle ':completion:*:*:*:*:descriptions' format '%F{green}-- %d --%f'
```
As we saw quickly above, a tag is *most of the time* a type of match. More generally, you can see it as a type of information displayed during completion. Here, the `descriptions` tag is specific to the `format` style. It generates descriptions depending on the type of match. For example, if you have files displayed in the completion menu, the description for the tag "files" will be displayed too.
The value of `format` is used for displaying these descriptions. Here, we use in the style's value the sequence `%d` which will be replaced by the description itself.
Here's the result for local directories:
If you're using the completer `_approximate`, you can set the format of the possible corrections too. For example:
```zsh
zstyle ':completion:*:*:*:*:corrections' format '%F{yellow}!- %d (errors: %e) -!%f'
```
Here's the result:

To format messages or warnings (for example when no match is found), you can add the following:
```zsh
zstyle ':completion:*:messages' format ' %F{purple} -- %d --%f'
zstyle ':completion:*:warnings' format ' %F{red}-- no matches found --%f'
```
We can use the escape sequence `%F %f` in the style's value to use a foreground color. Here's a summary of sequences you can use:
* `%F{<color>} %f` - Change the foreground color with `<color>`.
* `%K{<color>} %k` - Change the background color with `<color>`.
* `%B %b` - Bold.
* `%U %u` - Underline.
For example, you can create a horrible display as follows:
```zsh
zstyle ':completion:*:descriptions' format '%U%K{yellow} %F{green}-- %F{red} %BNICE!1! %b%f %d --%f%k%u'
```
Your descriptions are now a piece of art.
#### Grouping Results
To group the different type of matches under their descriptions, you can add the following:
```zsh
zstyle ':completion:*' group-name ''
```
Without this style, all the descriptions will be at the top and the matches at the bottom:
With the value of this style set with an empty string, the matches will be grouped under the descriptions depending on their types:
If you're not satisfied by the order these descriptions are displayed, you can modify it too. For example:
```zsh
zstyle ':completion:*:*:-command-:*:*' group-order alias builtins functions commands
```
Here, `-command-` means any word in the "command position". It means that we want the matches tagged `alias` to appear before `builtins`, `functions`, and `commands`.
#### Detailed List of Files and Folders
The style `file-list` can display the list of files and folder matched with more details, similar to the information you can display with `ls -l`.
For example:
```zsh
zstyle ':completion:*' file-list all
```
Here's the result:
#### Colorful Completion List
To have nice colors for your directories and file in the completion menu, you can add the style `list-colors`.
```zsh
zstyle ':completion:*:default' list-colors ${(s.:.)LS_COLORS}
```
It will set the value with the content of the environment variable `LS_COLORS`, normally used by the command `ls --color=auto`.
You apparently need to have the module `zsh/complist` loaded, but it worked without it on my system. I describe a bit more the module complist later in this article.
You can configure the colors of any completion menu even further using the environment variable `ZLS_COLORS`.
To configure the colors, search `man zshmodules` (search "Colored completion listings").
### Smarter Completion System
#### Squeezing Slashes
By default, the completion system will expand `//` to `/*/`. For example, `cd ~//Documents` will be expanded to `cd ~/*/Documents`.
Usually, on Unix systems, `//` is expanded to `/`. If you prefer this behavior, you can set the style `squeeze-slashes` to true as follows:
```zsh
zstyle ':completion:*' squeeze-slashes true
```
#### Directory Stack Completion
For the command `cd`, `chdir` and `pushd`, you can use a hyphen `-` not only for options but for a directory stack entry.
By default, the Zsh completion system will try to complete for a directory stack entry when you hit tab after a hyphen `-` while using one of these commands. If you prefer completing for an option, you can set the style `complete-options` to true as follows:
```zsh
zstyle ':completion:*' complete-options true
```
If you're interested to learn more about the directory stack, I described a nice way to navigate through it [in this article](https://thevaluable.dev/zsh-install-configure-mouseless/)
#### Sorting Matched Files
You can sort the files appearing in the completion menu as follows:
```zsh
zstyle ':completion:*' file-sort dummyvalue
```
If this style is not set (or set with a dummy value like in the example above), the files will be sorted alphabetically. You can use one of these values if you prefer another ordering:
* `size` - Order files by size.
* `links` - Order files depending on the links pointing to them.
* `modification` or `date` or `time` - Order files by date of modification.
* `access` - Order files by time of access.
* `change` or `inode` - Order files by the time of change.
You can also add `reverse` to the values to reverse the order. For example:
```zsh
zstyle ':completion:*' file-sort change reverse
```
If you add the value `follow`, the timestamp of the targets for symlinks will be used instead of the timestamp of the symlinks themselves.
#### Completion Matching Control
Setting the style `matcher-list` allows you to filter the matches of the completion with even more patterns.
For example, you can set this style for the completion to first try the usual completion and, if nothing matches, to try a case-insensitive completion:
```zsh
zstyle ':completion:*' matcher-list '' 'm:{a-zA-Z}={A-Za-z}'
```
The completion can also try to complete partial words you've typed with the following style:
```zsh
zstyle ':completion:*' matcher-list '' 'm:{a-zA-Z}={A-Za-z}' 'r:|[._-]=* r:|=*' 'l:|=* r:|=*'
```
This style would allow you, for example, to complete the file `_DSC1704.JPG` if you only try to complete its substring `1704`.
The patterns themselves are quite... obscure. If you want a good intellectual challenge, you can look at the manual. I wish you good luck.
See `man zshcompwid` for patterns for the style matcher list (search for "COMPLETION MATCHING CONTROL").
## Completion via Keystrokes
You can bind any completion style to a keystroke instead of using it with the general completion. For that, you need to use the completer `_generic`.
For example, if you want to expand aliases each time you hit `CTRL+a`, you can add the following lines:
```zsh
zle -C alias-expension complete-word _generic
bindkey '^a' alias-expension
zstyle ':completion:alias-expension:*' completer _expand_alias
```
You can replace `alias-expension` by the name of your choice. The behavior depends of the completer you use; for expanding aliases, we use `_expand_alias`. Feel free to use whatever completer you want for your own needs.
## The Module complist
I wrote already about the module "complist" [in this article](https://thevaluable.dev/zsh-install-configure-mouseless/). We saw there how to move around in the completion menu using the keys "hjkl":
```zsh
zmodload zsh/complist
bindkey -M menuselect 'h' vi-backward-char
bindkey -M menuselect 'k' vi-up-line-or-history
bindkey -M menuselect 'j' vi-down-line-or-history
bindkey -M menuselect 'l' vi-forward-char
```
You can configure many more keystrokes related to the completion menu using these commands:
* `accept-line` - Validate the selection and leave the menu.
* `send-break` - Leaves the menu selection and restore the previous command.
* `clear-screen` - Clear the screen without leaving the menu selection.
* `accept-and-hold` - Insert the match in your command and let the completion menu open to insert another match.
* `accept-and-infer-next-history` - Insert the match and, in case of directories, open completion menu to complete its children.
* `undo` - Undo.
* `vi-forward-blank-word` - Move cursor to next group of match.
* `vi-backward-blank-word` - Move cursor to previous group of match.
* `beginning-of-buffer-or-history` - Move the cursor to the leftmost column.
* `end-of-buffer-or-history` - Move the cursor to the rightmost column.
* `vi-insert` - Toggle between normal and interactive mode. We've seen the interactive mode above.
* `history-incremental-search-forward` and `history-incremental-search-backward` - Begin incremental search.
For example, I've configured `CTRL+x i` to switch to the interactive mode in the completion menu:
```zsh
bindkey -M menuselect '^xi' vi-insert
```
See `man zshmodules` to configure complist (search for "THE ZSH/COMPLIST MODULE").
## Completion Options
You can also use options to modify the Zsh completion system. To set an option, you need to use the command `setopt`. For example:
```zsh
setopt MENU_COMPLETE
```
Here's a small selection of useful options for configuring the completion system:
* `ALWAYS_TO_END` - Always place the cursor to the end of the word completed.
* `LIST_PACKED` - The completion menu takes less space.
* `AUTO_MENU` - Display the completion menu after two use of the `TAB` key.
* `AUTO_COMPLETE` - Select the first match given by the completion menu. Override `AUTO_MENU`.
* `AUTO_PARAM_SLASH` - When a directory is completed, add a trailing slash instead of a space.
* `COMPLETE_IN_WORD` - By default, the cursor goes at the end of the word when completion start. Setting this will not move the cursor and the completion will happen on both end of the word completed.
* `GLOB_COMPLETE` - Trigger the completion after a glob `*` instead of expanding it.
* `LIST_ROWS_FIRST` - Matches are sorted in rows instead of columns.
See `man zshoptions` for the completion options (search for "Completion").
## Ready to Complete?
The Zsh completion system is a complex beast, but I tried to do my best to simplify it. I hope it didn't cause any headache on your side.
What did we learn together in this article?
* The completion system go through a series of *completers* first. They'll try to find matches depending on the context (the command you've typed) using different completion functions.
* The Zsh module "zstyle" allows you to configure settings for a specific Zsh module or widget. Don't let the name `style` fools you: it can configure way more than visual styles.
* You can configure the Zsh completion system using options and the module complist, but using zstyle is the most flexible way to tune it following your craziest wishes.
As you see, the completion system of Zsh is far from being simple. I've covered some of the basics here, but there's much more. Let me know if you want a follow-up article to dive even deeper in this madness.
## Related Resources
* [Zsh Documentation - The Completion System](http://zsh.sourceforge.net/Doc/Release/Completion-System.html)
* [Zsh Documentation - Visual Effects](http://zsh.sourceforge.net/Doc/Release/Prompt-Expansion.html#Visual-effects)
* [Author's configuration for the Zsh completion system](https://github.com/Phantas0s/.dotfiles/blob/master/zsh/completion.zsh)
* [Completions from the prezto framework](https://github.com/sorin-ionescu/prezto/blob/master/modules/completion/init.zsh) - Robby Russell, Sorin Ionescu, and contributors
---------
## Becoming Mouseless
Do you want to build a [Mouseless Development Environment](https://themouseless.dev) where the Linux shell has a central role?
[](https://themouseless.dev)
Switching between the keyboard and the mouse costs cognitive energy. This book will guide you step by step to set up a Linux-based development environment that keeps your hands on your keyboard.
Take the brain power you've been using to juggle input devices and focus it where it belongs: on what you create.
---------
| phantas0s |
930,277 | Facebook ChatBot Using Flask | first of all go here and login with your fb account Also Install ngrok zip... | 0 | 2021-12-19T05:32:44 | https://dev.to/nothanii/facebook-chatbot-using-flask-4fhd | programming, python, webdev, javascript | first of all go here and login with your fb account
Also Install ngrok zip file
```
https://developers.facebook.com/
```
```
https://ngrok.com/download
```

Fill the instructions According to you


That's it Now We Do Some code
create a folder and using pip install these Modules
```
pip install pymessenger
pip install requests
pip install flask
```
Open your Folder And make a file name
fbBot.py
```
from flask import Flask,request
import requests
from pymessenger import Bot
app = Flask(__name__)
VERIFY_TOKEN = ''
PAGE_ACCESS_TOKEN =''
bot = Bot(PAGE_ACCESS_TOKEN)
def handling_message(text):
adjusted_msg = text
if adjusted_msg == 'hi' or adjusted_msg == 'Hi':
response = 'hey'
elif adjusted_msg == "what's up" or adjusted_msg == "what's up":
response = "i'm Great"
else:
response = "it's pleasure to talk with you,Thank you."
return response
@app.route('/', methods = ["POST","GET"])
def web_hook():
if request.method == "GET":
if request.args.get('hub.verify.token') == VERIFY_TOKEN:
return request.args.get('hub.challenge')
else:
return 'Unable To Connect Meta'
elif request.method == 'POST':
data = request.json
process = data['entry'][0]['messaging']
for msg in process:
text = msg['message']['text']
sender_id = msg['sender']['id']
response = handling_message(text)
bot.send_text_message(sender_id,response)
return 'Message Delivered'
else:

if __name__ == '__main__':
app.run()
```
name anything about verify token
Generate page access token and paste above
Now Extract ngrok and paste it in your Workspace

run fbBot.py
and ngrok As An Administrator
put this cmd
and Hit Enter
```
ngrok.exe http 5000
```
now you are connected with it
from here copy https that end with .io
and paste it here with token name and save

Restart your app Build again And You Are Good To Go
| nothanii |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.