
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,022,041 | Netlify makes your entire Project in One Click Action | Well you have completed your javascript project and feeling proud of yourself and want to show your... | 0 | 2022-03-14T15:05:19 | https://dev.to/ojhanidhi036/netlify-makes-your-entire-project-in-one-click-action-3pke | Well you have completed your javascript project and feeling proud of yourself and want to show your hard work with your friends, family etc. Here,the question is what will be the shortest and fastest way to show your project or hard work to anyone with just one click action.
In this blog, you will learn how to publish your javascript project using popular platform-**Netlify**
Before i start, would like to give little description about my javascript project so that you will be able to understand what project is about and after all it's my hardwork which i want to share with you .
In real-time scenarios, there may be a requirement to put an image slider on the application web page. If the slider requirement is simple and short, building your own slider using HTML and JavaScript can be one of the best ways to achieve it. This will take less time to implement and give no conflicts/errors.
**Just your one click on this link you will be redirect to my project website.**
[https://image-slider-javascript.netlify.app/](https://image-slider-javascript.netlify.app/)
Basically just want to mention that this is the way where you can publish your project on netlify and get a link of your project so that you can share with anyone at anytime through link like above the link of my project which i have shared with you .
## How to Publish a Website on Netlify
_The first method we're going to explore is how to publish your website on Netlify._
Netlify is a platform for hosting webistes. It is easy to host sites on Netlify as you don't need to configure it manually- and best of all, it's free. If you haven't signed up for an account, now is a good time to do so. Click on this link and sign up.
[https://www.netlify.com/](https://www.netlify.com/)
Here's the step-by-step process of publishing your website on Netlify:
### Step 1: Add your new site
Once you've logged in, it will take you to a home dashboard. Click the **Add new site** button to add your new website to Netlify.
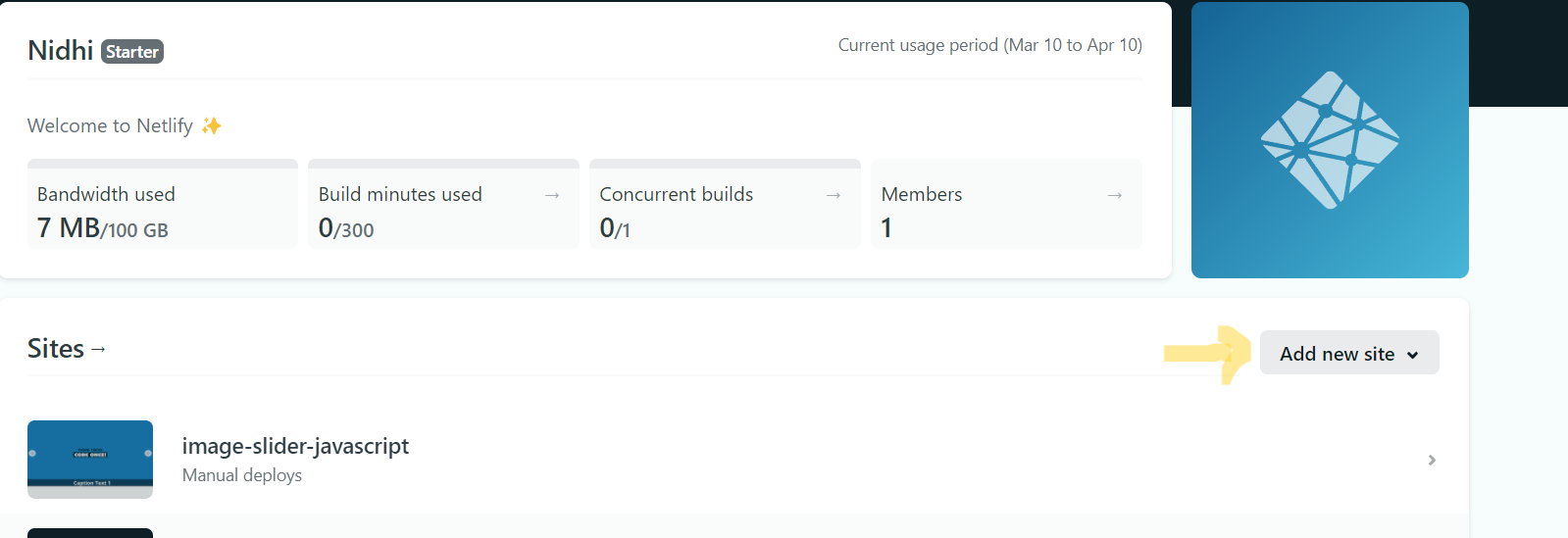
### Step 2: Deploy project manually
After clicking on **Add new site** you will get dropdown list so select **Deploy manually**
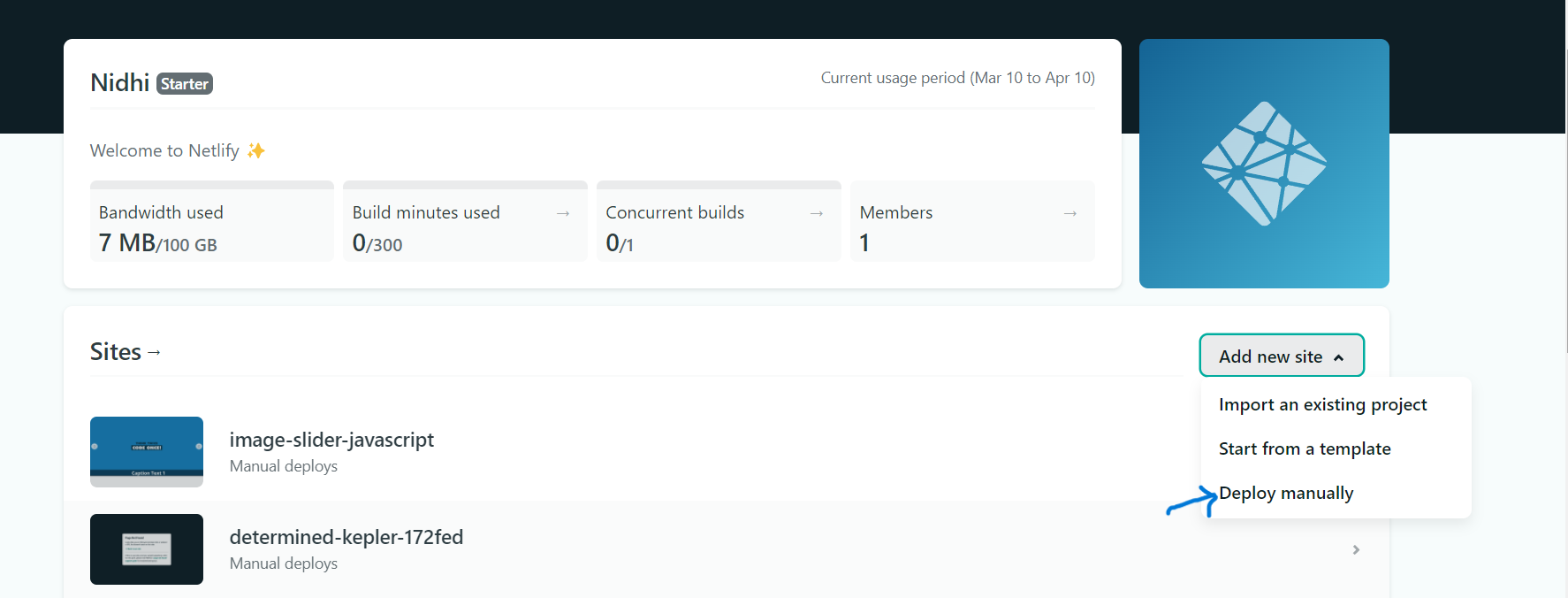
### Step 3:Drag and Drop your site output folder

Once you redirected on this page then just follow your project location and drag your project folder and drop into the deployement box. See here i have followed my project folder location to drag my project to drop in deployment box.
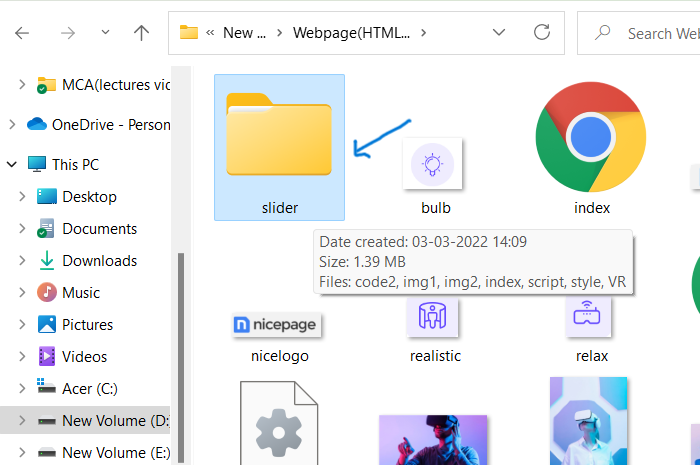
### Step 4: Publish your website
Your website is now ready to publish!
Netlify will do the rest of the work for you, and it will only take less than 10 seconds to complete the process.
Now you are done! Your new website is published, and you can view it by clicking the green link.
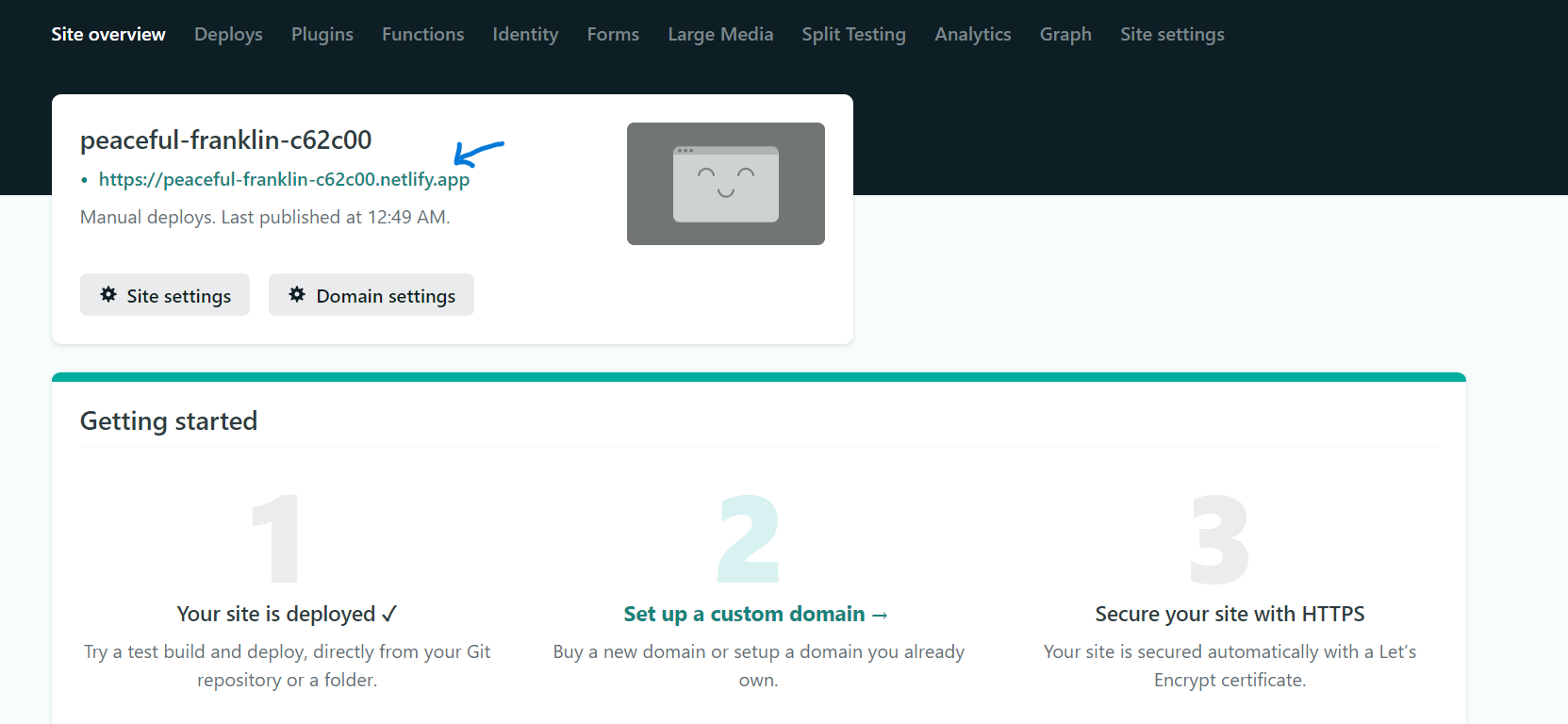
### Step 5:Change site name(optional)
Right now, your URL looks random, but you can edit it by clicking the **Site settings** button and then the **Change site name** button.
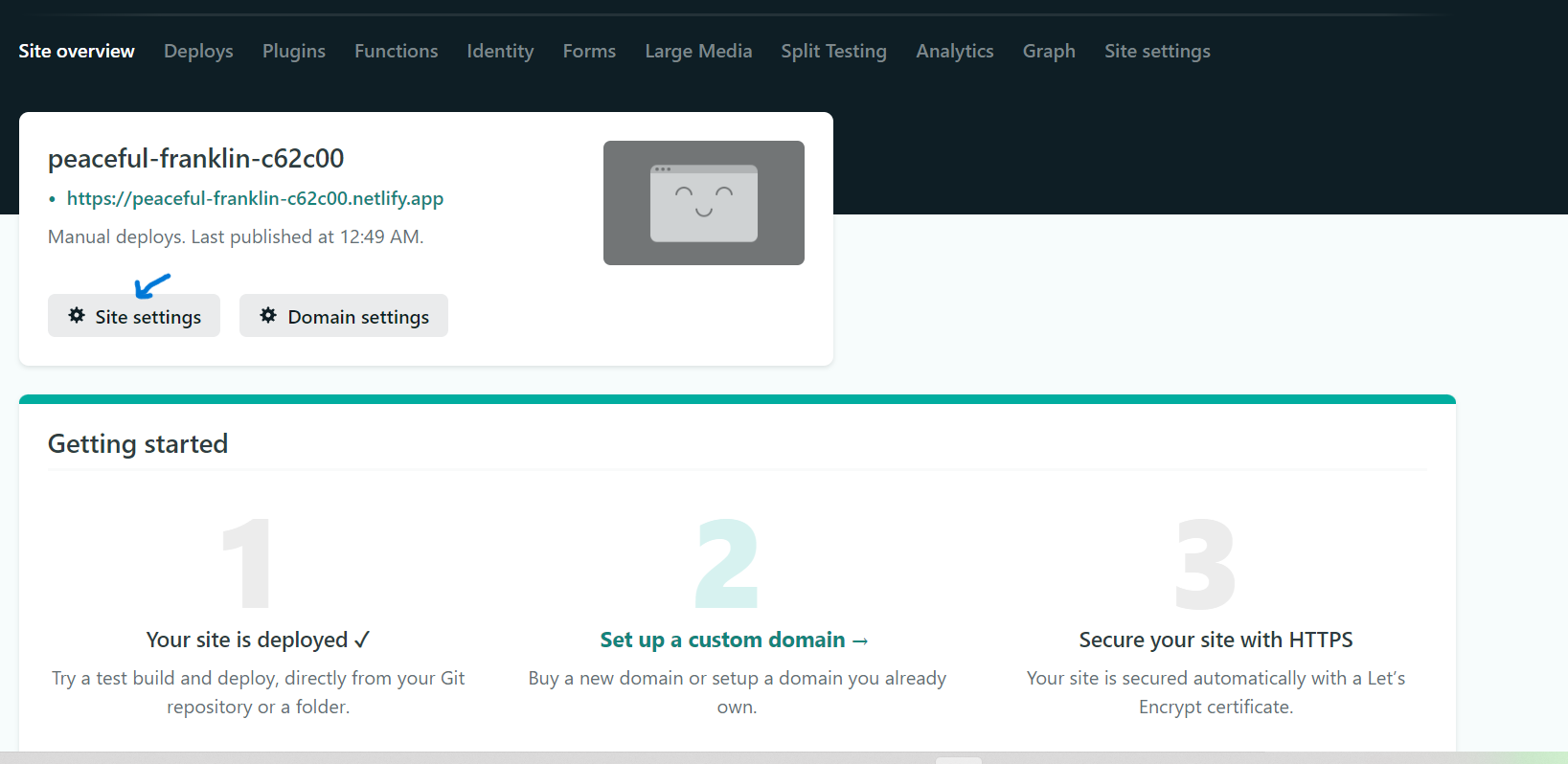
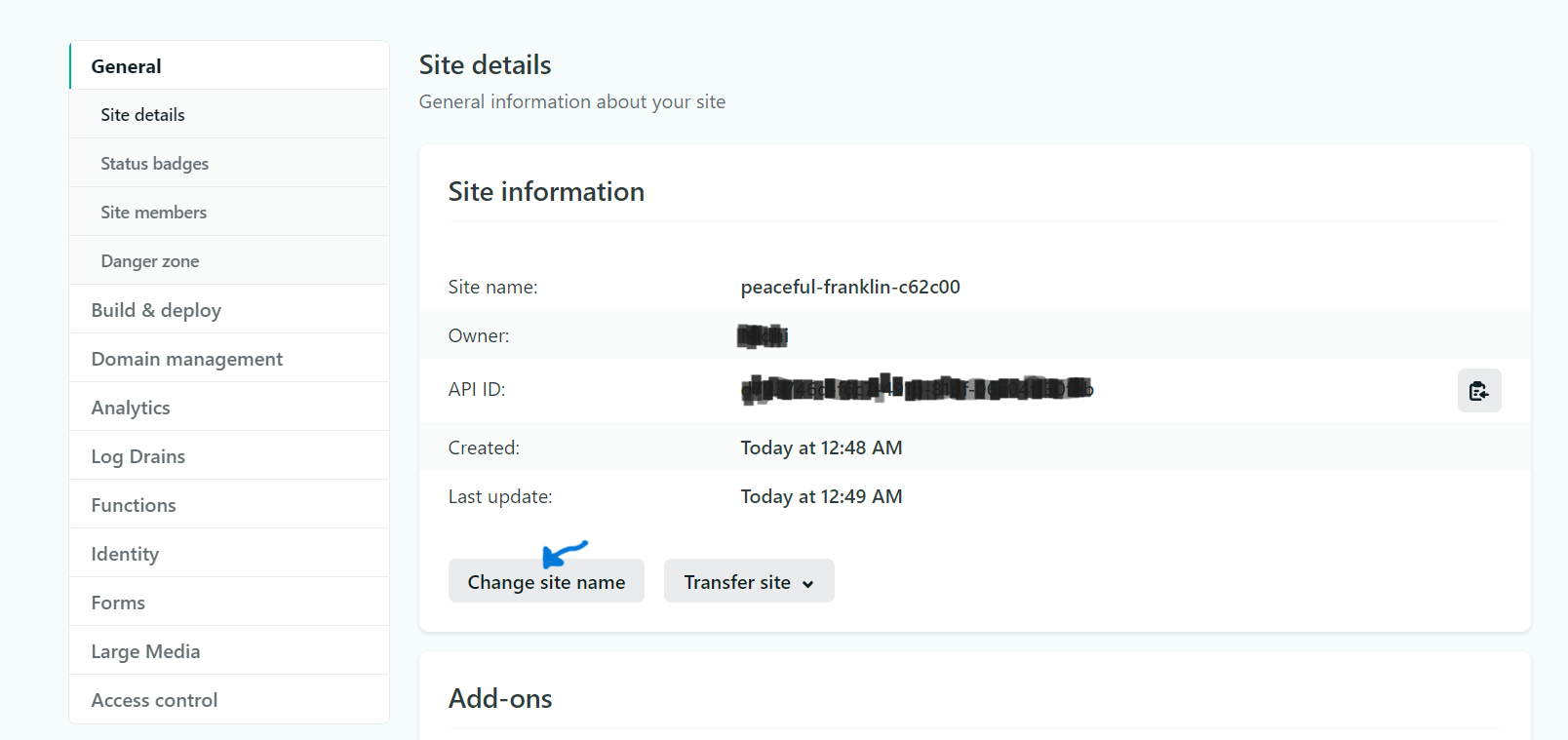
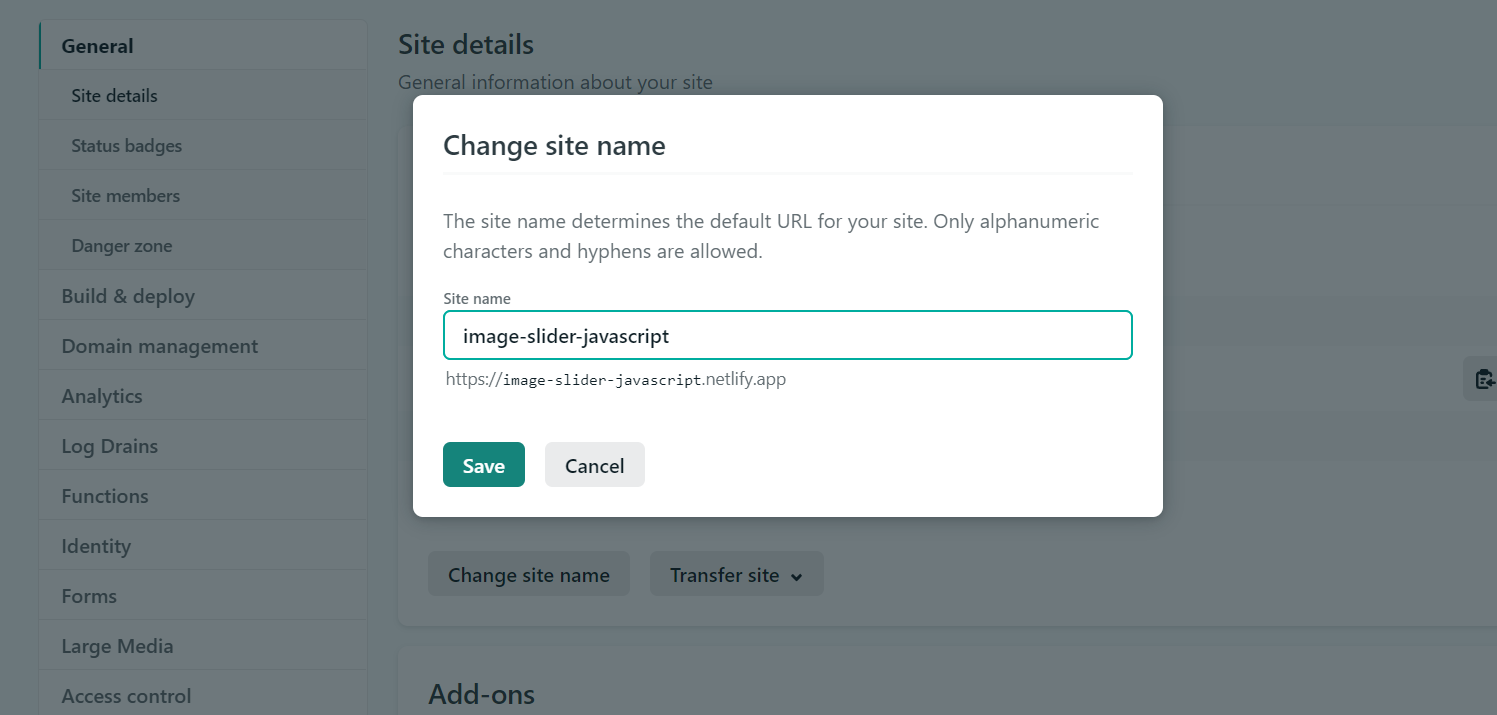
Click on **Save** button . Congratulation on publishing your first new website!
## How to update a website manually deployed on Netlify
_The second method we are going to explore is how to deploy project again on the same site on netlify after done some changes in the same project files._
### Step 1: Select the website you have manually deployed
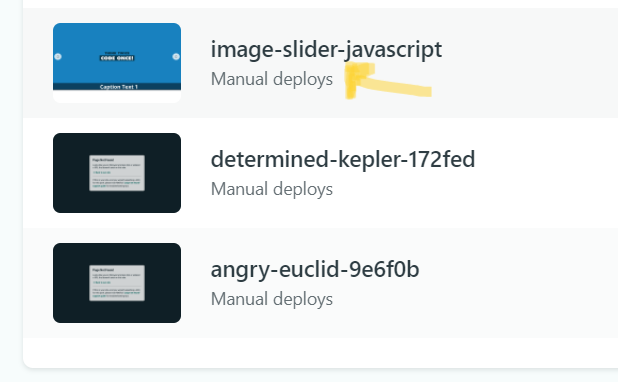
Here, I have selected the website which i have manaully deployed and want to deploy project folder again on the same link after done some changes in the same project.
### Step 2: Select the Deploys tab and reupload your project folder
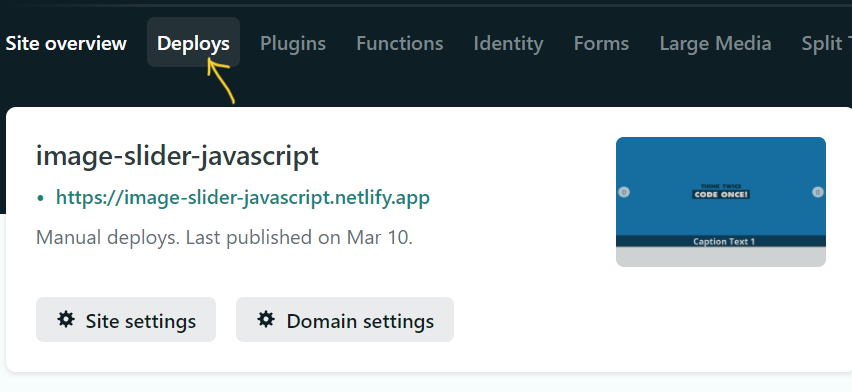
Once there click on Deploys then drag and drop your new website files into the Netlify deployment box.
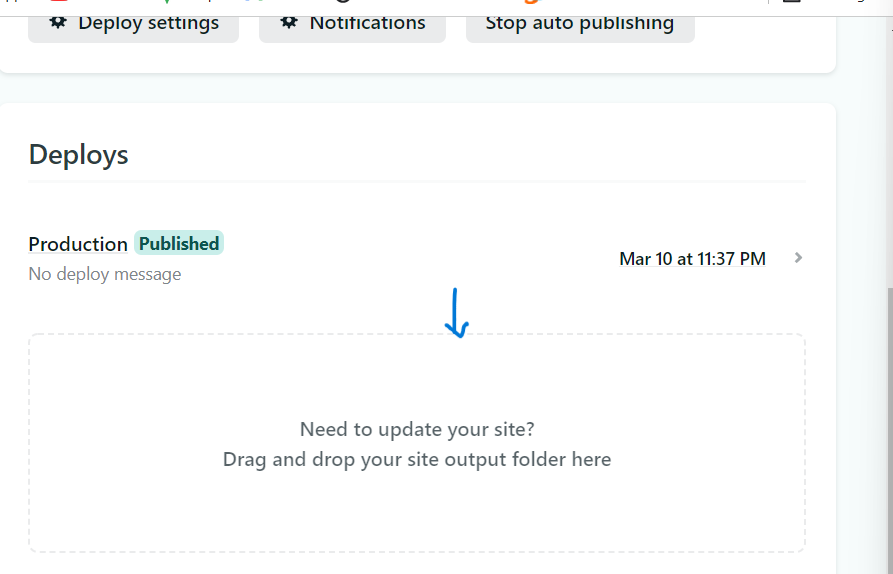
See in the below image am updating my site through drag and drop. Once dragged and dropped the website will automatically publish your website files and you should see the word "published" in green.

Here if you see the differences of my initially **new site** Vs **updated site**
## Conclusion
I hope you've found this blog helpful. You have learned how to deploy your website manually with Netlify. Now you can go ahead and show the world of your incredible work.
**Follow me for such contents**
[https://twitter.com/89NidhiOjha1](https://twitter.com/89NidhiOjha1)
[https://hashnode.com/@ojhanidhi036](https://hashnode.com/@ojhanidhi036)
| ojhanidhi036 | |
1,023,507 | Angular vs. React : Which Framework is Best For Web Development? | The Angular vs. React comparison has become an enormous task for developers. Every JavaScript... | 0 | 2022-03-15T14:10:32 | https://dev.to/freita_browning/angular-vs-react-which-framework-is-best-for-web-development-49g6 | javascript, programming | The Angular vs. React comparison has become an enormous task for developers. Every JavaScript framework has its capability. Some frameworks are better for large applications, some are better for small, and some are good for both applications. Choosing the best JavaScript frameworks will provide the right direction to a [JavaScript development company](https://www.csschopper.com/javascript-development.shtml) to create eye-catching web applications.
Nowadays, JavaScript is becoming more and more widely used. Hence, web developers use the best JavaScript framework for creating their web applications. When they think of web development, two popular front-end technologies come to their mind: AngularJS and ReactJS.
{% embed https://www.youtube.com/watch?v=8TtAh91CNDM&feature=youtu.be %}
## Know the comparison of Angular vs. React
## 1. Principles of Interaction with DOM treemap
DOM is the document object model that is utilized for executing dynamic changes. It is used for enhancing the speed of JS frameworks.
**AngularJS:**
AngularJS is the front-end JavaScript framework that functions with real DOM. It utilizes directives to bind app data to the attributes of the HTML element. Below some directives are mentioned:
.ng-disabled Directive: It binds AngularJS application data to the disabled attribute of HTML elements.
.ng-show Directive: It displays the HTML element.
More directives are available apart from the above. It executes any work indirectly through abstractions, TemplateRef, and viewContainerRef.
**ReactJS:**
The process of reactJS uses the lightweight copy of real DOM; therefore, the execution of reactJS is dependent on virtual DOM. To check the redrawn nodes, the React-based application compares the two DOM treemaps: the first is a real DOM tree, and the second is a virtual DOM tree.
After that, it functions the operation only on those nodes which need any changes. Thus, improving the performance of the software. But in complicated apps such as animation and complex synchronization, react.js may fail.
## 2. Performance
To load the website faster, performance is the primary concern. Moreover, developers implement a performance review process in most workplaces. JavaScript frameworks enable JavaScript web development services to enhance the performance of your website accordingly.
**AngularJS**
AngularJS depends on a two-way data binding process, making a visitor for every binding to change any track in the DOM. If there are many visitors, it can get slow as the developer makes any transformation, then the visitor needs to change it again.
The digest loop compares the new value against the initial value when any view is updated. Following that, the watcher calculates the actual value. Therefore, your application will perform better since the watcher tracks any changes in the view model, so you no longer have to go back to the previous application.
**ReactJS:**
As we know, ReactJS uses the concept of virtual DOM. Once a developer loads an HTML document, ReactJS makes a lightweight DOM tree from JavaScript objects and saves it on the server. When the user enters new data in the browser field, a new virtual DOM immediately appears, and the user can compare it with the new DOM. The dissimilarities found in these two models rebuild the virtual DOM again. These days, with new HTML, it is possible to do each work on the server, reducing the load time and improving performance. Thus, this approach is better between React vs. Angular.
## 3. Adaptability to work with a team
The development process is a huge task, and we should perform it with a team. Let’s look at which is the best JavaScript framework for working in a team.
**AngularJS:**
This framework was designed according to developer convenience. It uses the MVW architecture, separating the application logic from the given representation to the user interface. It provides a modular solution that can operate simultaneously. Therefore, this framework is beneficial for productive team interaction.
**ReactJS:**
Model-View-Controller, Model-View-View-View-Model, and Model-View-Whatever structures do not exist in this library. Therefore, multiple developers cannot work on the same code simultaneously because the logic and representation are not separated. And, a lot of time is involved in developing any application. As a result, most developers dislike the complicated development process.
**Conclusion**
Both of the frameworks mentioned above excel at something. If you plan on creating large projects, Angular is the right choice for you. For those who don't want to be bound by a framework, React is a perfect choice. You can then select whatever framework you like depending on your project needs. You can [hire a JavaScript developer](https://www.csschopper.com/hire-dedicated-javascript-developer.shtml) with the requisite expertise and experience for further assistance. It will build a competitive web app or website using the most suitable JavaScript framework for your business.
| freita_browning |
1,025,825 | File_get_contents('php //input') not working | Problem: I am unable to understand this problem .. Please suggest me a better solution to solve it... | 0 | 2022-03-17T10:35:07 | https://kodblems.com/14448/file_get_contents-php-input-not-working | restfularchitecture, curl, rest, json | Problem:
I am unable to understand this problem ..
Please suggest me a better solution to solve it ..File_get_contents('php //input') not working
Solution:
First off, I was able to run this code and it worked fine:
--Terminal---------
//I ran this curl request against my own php file:
curl -i -X PUT -d '{"address":"Sunset Boulevard"}' http://localhost/test.php
--PHP--------------
//get the data
$json = file_get_contents("php://input");
//convert the string of data to an array
$data = json_decode($json, true);
//output the array in the response of the curl request
print_r($data);
If that doesn't work, check the console for errors and your php settings:
1. The curl url you used, make sure that url is actually working and
not returning errors.
2. open up another terminal / console window and run tail -f
/path/to/the/php/log/file so you can actually see the output of
these php calls.
3. often people get this error: file_get_contents(file://input): failed
to open stream: no suitable wrapper could be found which can
indicate either a typo of the "file://input" string or the fact that allow_url_fopen is disabled in php (see #5 if unsure)
4. make sure your code is correct, and by that I mean make sure you're
not typing in incorrect arguments and things... stuff that doesn't
necessarily get underlined in netbeans.
5. remember, file_get_contents only works when allow_url_fopen is set
to true in your PHP settings. thats something that is set in
php.ini, but you can also change settings at run time by writing
something along the lines of the following code before the other
code:
ini_set("allow_url_fopen", true); | coderlegi0n |
1,026,410 | Start Implementing your own Typescript Class Decorators | Start Implementing Your Own Typescript Class Decorators Class Decorator What is... | 0 | 2023-09-12T11:57:45 | https://levelup.gitconnected.com/start-implementing-your-own-typescript-class-decorators-84a49f560dea | classdecorator, decorators, typescript, node | ---
title: Start Implementing your own Typescript Class Decorators
published: true
date: 2021-12-23 12:53:42 UTC
tags: classdecorator,decorators,typescript,nodejs
canonical_url: https://levelup.gitconnected.com/start-implementing-your-own-typescript-class-decorators-84a49f560dea
---
### Start Implementing Your Own Typescript Class Decorators

_Class Decorator_
#### What is a Decorator?
It is a structural design pattern that lets you attach new behaviors to objects by placing these objects inside special wrapper objects that contain the behaviors ([reference](https://refactoring.guru/design-patterns/decorator)).
**Typescript Class Decorators Definition:** _The class decorator is applied to the constructor of the class and can be used to observe, modify, or replace a class definition.(_[_reference_](https://www.typescriptlang.org/docs/handbook/decorators.html#class-decorators)_)_
#### What is going on behind the scene?
Your class decorator is actually **a simple function** that is called as a function **at runtime** and it gets _one argument_ and that is **the constructor function of the class**. If _the class decorator_ returns something it is going to be used as the constructor of the class. These things might sound confusing but it’s going to be clear as day after taking a look at some pieces of code.
### Setup
In order to run the Typescript code, we need to compile them using the Typescript compiler.
We need a tsconfig.json file :
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/39e61b1249de30de02c2830a5244d69b/href">https://medium.com/media/39e61b1249de30de02c2830a5244d69b/href</a></iframe>
We have to enable the experimentalDecorators. Also, the target should not be less than ES5.
If you do not want to use a tsconfig file you can pass these options directly:
```
tsc --experimentalDecorators // If you installed tsc globaly
npx tsc --experimentalDecorators // If you installed tsc in your current directory
```
Now by running tsc in the current directory, the typescript files will compile to Javascript files and we can run them using Node.([reference](https://dev.to/pshaddel/start-writing-your-own-typescript-method-decorators-3jm4-temp-slug-1785958))
### Define a Class Decorator
First class decorator we want to create is just going to log a message on the console and tell us that it is running.
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/86a7aa80e3ee4ce7a713f02af9a16a81/href">https://medium.com/media/86a7aa80e3ee4ce7a713f02af9a16a81/href</a></iframe>
Now if I compile and run this code I will see this on the console:

_Result of running the code_
Here the class decorator was a function that had _constructor_ of the class as its argument and logs something on console easy-peasy. We can see that **before** running the constructor of the class it runs _the class decorator_.
Let’s see an example that we can pass our constructor in the decorator:
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/56031b8ba6d683b3215b01a8a67006d5/href">https://medium.com/media/56031b8ba6d683b3215b01a8a67006d5/href</a></iframe>
In order to make some changes to constructor of the class from _the class decorator_ we have to return a class that **extends** the **base class**.
The Typescript compiler forces us to do this(return a class that extends the base class).
**Why compiler is forcing us do this?** Because otherwise the type we are returning is not compatible with the base class.
If what is happening is still vague you should recall that classes are actually functions(You may find so many helpful comments on that [here](https://stackoverflow.com/questions/11970141/javascript-whats-the-difference-between-a-function-and-a-class)).
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/8149596a93aed43fd64e86da5feb9660/href">https://medium.com/media/8149596a93aed43fd64e86da5feb9660/href</a></iframe>
Now that we know this, consider the class decorator as a higher order function. It is somehow similar to the implementation of [method decorator](https://dev.to/pshaddel/start-writing-your-own-typescript-method-decorators-3jm4-temp-slug-1785958).
**What if we want to use a class decorator on all classes?** That is possible by using Typescript Generics. Take a look at this example:
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/1bca8141f9a41e450fe6431a1746c53f/href">https://medium.com/media/1bca8141f9a41e450fe6431a1746c53f/href</a></iframe>
We can use this class decorator on all classes.
```
<T extends { new (...args: any[]): {} }>
```
This is the definition of generic and if you are wondering why it extends { new (...args: any[]): {} you should know that we expect a constructor function and this is how we can tell the compiler to check that.
Here T is the generic class and we are able to return new constructor by extending it in line 4.
In line 5 and 6 we added two timestamps members to the class. Now each class that wrapped by this decorator has these two timestamps created\_at and updated\_at .
Let’s see the result on console:

_Timestamp Decorator_
As we can see class has two additional members updated\_at and created\_at
**Can we access these two additional properties?**

_Calling Additional Properties that added by Decorator_
> _The Decorator does not change the Typescript Type_
The only way to access that property is to tell the compiler to ignore that line. If you consider timestamps example, we usually want to pass them to an ORM or ODM to save a record or document in the database, so there should be no problem even if we do not call them directly. These properties are going to be passed in the object.
Another really useful decorator that is mentioned in official TS Docs is **sealed decorator**.
### Sealed Decorator
When we seal a class we want to prevent more functionalities and properties to be added or removed. Let’s see that in action:
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/615cd03dd8d6e9f73a2173da533cf301/href">https://medium.com/media/615cd03dd8d6e9f73a2173da533cf301/href</a></iframe>
We sealed the constructor and it’s prototype. If we try to change the constructor this way(We had to ignore the compiler to be able to do this):
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/5f85915def8a4c38978cfd6a3cb7c8e4/href">https://medium.com/media/5f85915def8a4c38978cfd6a3cb7c8e4/href</a></iframe>
That will result in a TypeError:
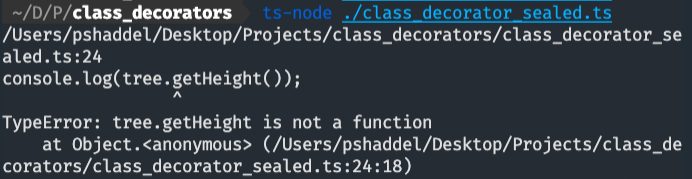
_Result of changing a class prototype_
If we do not use @sealed decorator then this is going to be the result:

_Calling getHeight without sealed decorator_
### Conclusion
Class decorators are simply a function that runs at runtime and it can change behavior of a class. Using Class Decorators and wrapping other classes can be a little bit tricky in some cases if you want to add some functionalities to them since the decorator does not change the typescript type.
Decorators are widely used in [Angular](https://angular.io) and [NestJS](https://docs.nestjs.com/) since both of these frameworks use OOP paradigm and you can take a look at their documents and the implementation of decorators.
* * * | pshaddel |
1,027,417 | Lessons in AWS Python CDK: 2-Parameterizing Your Stack | TLDR I don't like using the cdk.context.json file. I use a config/<env>.yaml file that... | 17,190 | 2022-03-20T13:40:23 | https://dev.to/aws-builders/lessons-in-aws-python-cdk-2-parameterizing-your-stack-384 | aws, python, beginners, tutorial | {% details TLDR %}
I don't like using the `cdk.context.json` file. I use a `config/<env>.yaml` file that holds environment specific values and omegaconf to parse it.
Say you have dev and prod VPCs that already exist and you want to use the same stack to deploy to both.
Files:
config/dev.yaml
```yaml
vpc:
vpc_id: vpc-1234567890
```
config/prod.yaml
```yaml
vpc:
vpc_id: vpc-9876543210
```
In the stack:
```python
from omegaconf import Omegaconf
deploy_env = "dev" # <-- This could/should be set by your CICD pipeline
conf = OmegaConf.load("config/{0}.yaml".format(deploy_env))
# load pre-existing vpc into variable
vpc = ec2.Vpc.from_lookup(self, conf.vpc.vpc_id, vpc_id=conf.vpc.vpc_id)
```
In typical yaml fashion everything is a dictionary or a list and you can, therefore, navigate and loop. (details below)
{% enddetails %}
{% details About Me %}
My name is Jakob and I am a DevOps Engineer. I used to be a lot of other things as well (Dish Washer, Retail Employee, Camp Counselor, Army Medic, Infectious Disease Researcher), but now I am a DevOps Engineer. I received no formal CS education but I'm not self taught, because I had thousands of instructors who taught me through their tutorials and blog posts. The culture of information sharing within the software engineering community is vital to everyone, especially those like me who didn't have other options. So, as I learn new things I will be documenting them through the eyes of someone learning for the first time, because those are the people most in need of a guide. Happy Learning! And don't be a stranger.
{% enddetails %}
---
Note: I am NOT going to be sourcing and fact checking everything here. This is not an O'Reilly book. The language and descriptions are intended to allow beginners to understand. If you want to be pedantic about details or critique my framing of what something is or how it works feel free to write your own post about it. These posts are intended to be enough to get you started so that you can begin breaking things in new ways on your own!
---
## The Problem ##
One thing that I found some difficulty with when I started using the AWS-CDK was how to handle deploying into multiple pre-existing environments. Of course, the CDK makes it easy to create a stand-alone stack with a new VPC, subnets, buckets, and certificates, but sometimes we have a pre-existing environment we need to deploy into. Or perhaps we want to use variations on the same stack to deploy into multiple environments, eg. smaller instances instances for a development environment.
In Terraform, we might pass in a `dev.tfvars` or `prod.tfvars` file. With the CDK you can use the recommended `cdk.context.json` file and pass context dependent parameters into the stack. But after scanning over the documentation for how to add values to the context file, I decided it was too annoying and I wanted a better way.
## My Solution ##
I have settled on pairing a yaml parsing library called `omegaconf` to make my own `.tfvars`-like parameter file. Let me show you how it works.
### The Setup ###
First, create yourself come configuration files. I made a folder at the root of the project called `/config` where I created yaml files named for each environment, eg. `dev.yaml`, `uat.yaml`, `prod.yaml`. Lets also add a couple things to `dev.yaml`
```yaml
aws:
account: "12345678910"
region: us-east-1
env: Dev
```
Now, throw `omegaconf` into your requirements.txt file and `pip install` it. (you are using a virtual environment right?)
Import it into both the `app.py` file at the root of your project and any stack files you plan on using the parameters.
```python
from omegaconf import Omegaconf
```
---
### Implementation ###
Depending on how you are going to manage deploying to your environments, you are going to load a different config file.
For example, if you are just going to deploy from your local computer, you can set an variable the the deploy environment at the top of your file (so that it is visible and easy to change) and then use that variable to load your config.
```python
1 import aws_cdk as cdk
2 from uber_for_cats.uber_for_cats_stack import UberForCatsStack
3 from omegaconf import Omegaconf
4
5 deploy_env = "dev"
6
7 conf = OmegaConf.load("config/{0}.yaml".format(deploy_env))
8
9 app = cdk.App()
10 UberForCatsStack(app, "UberForCats{0}".format(conf.env),
11 env=cdk.Environment(account=conf.aws.account, region=conf.aws.region),
12 )
13
14 app.synth()
```
On `lines 5-7` the environment is set to dev and the `config/dev.yaml` file is set to `conf`.
If you were using a CICD pipeline to automatically deploy, `deploy_env` could be set based on a pipeline variable and `line 5` could look like this.
```python
5 deploy_env = os.getenv("DEPLOY_ENV")
```
But the result will be the same the values set in the `config/dev.yaml` file will be used and the file will be read as if the strings were there.
```python
1 import aws_cdk as cdk
2 from uber_for_cats.uber_for_cats_stack import UberForCatsStack
3 from omegaconf import Omegaconf
4
5 deploy_env = "dev"
6
7 conf = OmegaConf.load("config/dev.yaml")
8
9 app = cdk.App()
10 UberForCatsStack(app, "UberForCatsDev",
11 env=cdk.Environment(account="12345678910", region="us-east-1"),
12 )
13
14 app.synth()
```
This allows you to set other values in `config/uat.yaml` such as a different account, different sized instances/EBS volumes, autoscaling rules, etc. depending on what is required in each environment.
### Something to Remember ###
Yaml is basically a nested dictionary that can also contain lists. When you see a `-` before something it is a list and therefore iterable. Take, for example, the following.
```yaml
aws:
account: "12345678910"
region: us-east-1
vpc:
vpc_id: vpc-aabbccdd
subnet:
private:
- subnet-65asdf651sadf65
- subnet-c65as1df65f56sa
- subnet-afas65df1a6sdf5
```
Those private subnet IDs are a list and you can iterate over them.
```python
private_subnets = []
for i, subnet in enumerate(conf.vpc.subnet.private):
private_subnets.append(
ec2.Subnet.from_subnet_id(self, "pri{0}".format(i), subnet_id=subnet)
)
```
This would create a list of subnet objects (`ISubnet`) that you can use for the placement of an autoscaling group or EKS cluster. Neat!
Congrats, Those are the basics! You should be able to get started.
---
## Some Additional Tricks ##
While using a yaml file for configuration settings, I ran into some situations that might be worth sharing.
### __Sometimes strings require extra steps__ ###
I am using the CDK to make some EKS clusters. Part of this process is creating node-groups (think autoscaling groups for Kubernetes). I wanted to leverage some spot instances for a portion of our development cluster and part of the process of creating these nodegroups in CDK is specifying the compute size and class. Because this could be different between environments I put it in the config file.
```yaml
node_group:
spot:
min: 1
max: 5
type:
- i_class: BURSTABLE3
i_size: LARGE
- i_class: BURSTABLE3
i_size: XLARGE
- i_class: COMPUTE6_INTEL
i_size: LARGE
- i_class: COMPUTE6_INTEL
i_size: XLARGE
```
But that won't work for setting instance types:
```python
instance_type = ec2.InstanceType.of(
ec2.InstanceClass.conf.node_group.spot.type[0].i_class,
ec2.InstanceSize.conf.node_group.spot.type[0].i_size,
)
```
And, honestly, it isn't very readable either. My workaround was making dictionaries of instance classes and sizes. then using the value in the yaml as the key the the appropriate class/size.
```yaml
node_group:
spot:
min: 1
max: 5
type:
- i_class: t3
i_size: large
- i_class: t3
i_size: xl
- i_class: c6i
i_size: large
- i_class: c6i
i_size: xl
```
```python
ec2_class = {
"t3": ec2.InstanceClass.BURSTABLE3, # max 2xl
"c6i": ec2.InstanceClass.COMPUTE6_INTEL, # min large
}
ec2_size = {
"large": ec2.InstanceSize.LARGE,
"xl": ec2.InstanceSize.XLARGE,
}
```
With the combination of the above, we can now use the string in the yaml as the key to pull in the ec2 objects in the format that the CDK requires. Below I make a list of the specified instance combinations and pass it into the EKS cluster as nodegroup capacity, but you could just as easily specify a list of classes and types and use a python library like `itertools` to make ALL of the combinations in one line. That might sacrifice readability though. So actually, don't do that. But you could...
```python
spot_instance_types = []
for instance_type in node_group.spot.type:
this_type = ec2.InstanceType.of(
ec2_class[instance_type.i_class],
ec2_size[instance_type.i_size],
)
spot_instance_types.append(this_type)
cluster.add_nodegroup_capacity(
"{0}-spot-nodegroup".format(conf.env),
nodegroup_name="{0}-spot-ng".format(conf.env),
capacity_type=eks.CapacityType.SPOT,
min_size=node_group.spot.min,
max_size=node_group.spot.max,
instance_types=spot_instance_types, # <-- list of instance types
disk_size=250,
subnets=ec2.SubnetSelection(subnets=private_subnets), # <-- those subnets from before!
)
```
---
### __Booleans are Useful__ ###
So we are promoting this project out to production and _someone_ doesn't think spot instances are a good idea even though you have diversified your spot pools. Throw a trigger into the config.
```yaml
node_group:
spot:
enabled: False
min: 1
max: 5
```
Then you can run your node creation based on it!
```python
if conf.node_group.spot.enabled:
spot_instance_types = []
for instance_type in node_group.spot.type:
this_type = ec2.InstanceType.of(
ec2_class[instance_type.i_class],
ec2_size[instance_type.i_size],
)
spot_instance_types.append(this_type)
cluster.add_nodegroup_capacity(
"{0}-spot-nodegroup".format(conf.env),
nodegroup_name="{0}-spot-ng".format(conf.env),
capacity_type=eks.CapacityType.SPOT,
min_size=node_group.spot.min,
max_size=node_group.spot.max,
instance_types=spot_instance_types, # <-- list of instance types
disk_size=250,
subnets=ec2.SubnetSelection(subnets=private_subnets), # <-- those subnets from before!
)
```
Beautiful!
| misterjacko |
1,028,241 | How to understand complex coding concepts better using the Feynman Technique | There are other learning techniques available, but this is one of my favorites. The Feynman approach... | 0 | 2022-03-19T22:20:57 | https://cesscode.hashnode.dev/how-to-understand-complex-coding-concepts-better-using-the-feynman-technique | javascript, beginners, webdev, programming | There are other learning techniques available, but this is one of my favorites. The Feynman approach is an excellent way to gain a deeper understanding of a complex topic. It's one of the quickest ways to turn a complex topic into one that you can explain in simple terms to others.
This article will teach you how to break complex coding concepts into the simplest terms.
let's get started 💃
## The Feynman Technique Of Learning
Richard Feynman, a Nobel Prize-winning physicist, created the Feynman method for learning. He enjoyed explaining complex topics in simpler terms. In Feynman's view, the best way to study an idea was to ask hard questions and fully understand it.
For more information about Richard Feynman, see this [article.](https://www.nobelprize.org/prizes/physics/1965/feynman/biographical/)
> "If you want to learn something, read about it. If you want to understand something, write about it. If you want to master something, teach it." - Yogi Bhajan.
Feynman's technique, in a nutshell, is you can't explain something well if you do not know it well yourself. When you try to explain what you know to someone who doesn't know anything about it, you'll notice your flaws. The goal is to communicate what you've learned in a simple way that a child can understand.
## What are the benefits of using the Feynman technique?
Here are a few of the benefits of using Feynman's learning techniques:
- It helps in gaining a thorough understanding of what you're learning. If you're having trouble understanding Javascript loops, try this learning method.
- **Learn new Ideas:** It allows you to learn new things fast, recall what you have learned, and be more productive.
- It helps you become a better teacher. You get better at teaching when you keep sharing your knowledge with others.
- It improves your critical thinking ability. You will be able to reason in an organized manner to explain complex stuff in simpler terms.
## The four steps of the Feynman technique
The Feynman Technique consists of four significant steps:
- Choose a topic you want to learn about.
- Explain it to a 12-year-old.
- Review Your Explanation.
- Simplify.
### Step 1 - Choose a topic you want to learn about
First, you should come up with a subject or topic you would like to learn and then write it at the top of a piece of paper.
For example, if you want to study javascript loops, write it as a heading on a blank piece of paper. As you keep learning about javascript loops, write whatever you know on that piece of paper. Write it so that someone who knows nothing about javascript loops will understand it.
Before moving on to step 2, do more research on Javascript loops or take a practice test to see how good you are.
Check out this article for resources to help you practice [web development](https://cesscode.hashnode.dev/resources-to-help-you-practice-web-development).
Once you have a firm understanding of the topic (Javascript loops), proceed to step 2.
P.S. Paper can be anything you use for writing, such as your phone's notebook app to any other app you use every day.
### Step 2 - Explain it to a 12-year-old
Now that you have a clear understanding of Javascript loops, it's time to explain it to a 12-year-old.
You don't have to look for a 12-year-old to teach. All you have to do is explain loops in the most basic terms possible, such that even a child can understand.
There's a saying that using complex terms to explain a topic mask one's lack of understanding. So your ability to explain loops in the simplest terms possible means you know what you are saying.
I know some of you reading this article are thinking, but what if I don't have somebody to explain what I'm learning?
That's not a problem. You'll use a variety of methods to explain what you've learned, including:
- **Technical writing:** You don't have to be a great writer to start writing. All you have to do is start writing. Platforms like dev.to, hashnode, medium make it easy to share what you learn. So sign up for one of the platforms and begin writing. Also, check out Google's free technical writing [course](https://developers.google.com/tech-writing).
- **Join online communities:** Join online communities to share what you have learned. When you join online developer groups, you'll meet people who share your interests. You will be comfortable sharing and answering questions. A fantastic developer community to join is the Freecodecamp online [forum](https://forum.freecodecamp.org). You can also use social media platforms like YouTube, Tik Tok, Twitter, e.tc.
Another way you can explain what you've learned is by doing it in front of an imaginary audience. Pretend you're teaching a group of 12-year-olds about javascript loops.
Teaching to an imaginary audience might be fun, but they cannot ask questions. This learning method works best when you use a real audience because they can ask questions.
When your audience asks you questions, you get to identify areas in which you need to improve.
### Step 3 - Review Your Explanation
Step 2 will, as stated before, assist you in identifying specific areas where you need to improve.
Review your loop explanation and identify areas where you think it fell short. Now that you know where you fell short, go back over your learning material to understand better. Consider using other learning resources if possible. Study until everything you couldn't explain before is clear to you.
Step 3's goal is to change your areas of weakness into your areas of strength.
### Step 4 - Simplify
As a result of step 3, you now have a better knowledge of javascript loops. Step 4 requires you to practice step 2 again with your new understanding of loops.
Take up your note and simplify every area of loops you couldn't explain before. Rewrite your loops article or give someone else a better explanation.
You can also pretend you're teaching a group of 12-year-olds about javascript loops. If you cannot explain a particular part of the topic, go back to step 3 to understand it better.
This method of learning works best for topics that are tough to understand. It is not an effective learning method if you already understand a concept.
## Conclusion
This learning style is all about understanding a topic to the point where you explain it in your own words. When you describe it, act as though you're educating a child to see how well you know the subject.
Also, keep in mind that you can use this learning method to study any concepts that you find difficult.
Thank you for reading. I hope you enjoyed the article! If you have any questions or a learning strategy you would love to share? Post about it in the comment section. I'll attend to them shortly.
If you found this article helpful, please like and share it 💙.
## Resources
Here are some resources that may be useful to you:
- [Learning From the Feynman Technique](https://medium.com/taking-note/learning-from-the-feynman-technique-5373014ad230)
- [Getting work done with the Pomodoro technique](https://cesscode.hashnode.dev/getting-work-done-with-the-pomodoro-technique)
- [Richard Feynman](https://en.wikipedia.org/wiki/Richard_Feynman)
| cesscode |
1,028,419 | Turn a single brand color into your own Complete Web Color System... in minutes! | How many times have you neglected your app's UI just because you had a deadline, and you needed to... | 0 | 2022-03-20T22:03:36 | https://dev.to/arnelenero/turn-a-single-brand-color-into-your-own-complete-web-color-system-in-minutes-4nkb | javascript, typescript, showdev, webdev | How many times have you neglected your app's UI just because you had a deadline, and you needed to focus on your app's functionality instead?
Color forms an important foundation of every UI. It enables **consistent** expression of your brand/identity and style, and **effective** communication of intent and meaning.
However, it can be quite daunting for developers like you and me to implement a proper color system, especially when this task has to contend with working on actual functionality of our app.
For Web developers, here's where **Simpler Color** could help. I wrote this small library so that we no longer have to sacrifice not having a cohesive, professional UI color system while focusing on the other important stuff.
And all you need is **a single brand color**...
## Easy as 1-2-3
**Step 1:** Install simpler-color
```
npm install simpler-color
```
**Step 2:** Specify your brand color, and it generates the rest of the _base colors_!
```js
import { harmony } from 'simpler-color'
// Generate 5 harmonious base colors from your main brand color!
const baseColors = harmony('#609E3F')
```
(You can also define your own custom base colors if you prefer, or if you already have a set of brand colors)
**Step 3:** Create your _color scheme(s)_ by mapping UI roles to specific colors from the auto-generated palettes
```js
import { colorScheme } from 'simpler-color'
const scheme = colorScheme(
baseColors, // 👈 From these base colors...
// 👇 ...your color palettes are auto-generated
colors => ({
// 👇 which you then map to UI roles.
primaryButton: colors.primary(40),
primaryButtonText: colors.primary(95),
surface: colors.neutral(98),
text: colors.neutral(10),
...etc,
}),
)
// Access various UI colors as `scheme.primaryButton` and so on.
```
Here's the complete range of colors that our example code generates from a single color value of `#609E3F`:

It's that simple! (Plus the library can do quite a bit more.)
So why don't you give Simpler Color a try. Check it out on GitHub: https://github.com/arnelenero/simpler-color
> Please don't forget to give it a star ⭐️ on GitHub if you like the library, its concept and the simplicity.
If some terms used above sound a bit alien to you, check out the comprehensive README in the link above for more details.
Hope you find this library useful. With proper color, even an early prototype or proof-of-concept app would certainly impress!
| arnelenero |
1,028,720 | 2022 Memorable Moments | When I shared my journey 2021, I was wondering can I do any better in future and to my surprise, I... | 0 | 2022-12-28T13:21:00 | https://dev.to/aws-heroes/2022-memorable-moments-32ja | aws, leadership, womenintech, cloud |
When I shared [my journey 2021](https://dev.to/aws-heroes/look-back-and-relish-2021-bn4), I was wondering can I do any better in future and to my surprise, I could go above and beyond my own records in 2022.
Everytime when I post in social media about the presentation in industry conferences, community sessions, or the honorary recognition received,
I wonder, is it really needed ? Am I bragging too much?
But trust me, a WomenInTech made me realize that how invaluable these little posts are to inspire and motivate all those aspiring individuals with burning desire and dream about their career.
> And the storyline is like this..
> A WomenInTech who was awestruck by what Bhuvana could accomplish in 2021 took a screenshot of my 2021 journey infographic and stored it on her phone as a reference.
Six months later, she came and told me about her self-transformation which included
> - The discipline she has brought to her fitness routine and shed several kgs of weight
> - Upskilled in a couple of technologies
> - Become a blogger
> - Speaker at a few external events
> - Furthermore, she advanced in her career
> - Most importantly, the confidence level and energy went up
Yes, she proved it right that `if Bhuvana could do something and I can do much more.`
Thereafter I became #unstoppable to share every little success to those followers / aspirants
Here are my 2022 memorable moments
- Industry Conferences, corporates & Community Events - 19
- Expert / Motivational Talk Educational Institutions - 8
- Hosting / Organizing - 2
- Featuring - article, poem, success story - 6
- Honours / Awards - 5
- Happily published poetry books written by my kids - 2
My suggestion to the #awscommunity, #womenintech, please keep sharing your little progress and accomplishments. You never know it could be a game changer for someone.
When you could inspire so many, its always heart-warming to give the credit to who inspired you. I drew-up inspiration from a good friend and best techie - Runcy Oommen and less he would know this fact because never discussed 😊.
Thanks a lot to AWS User Group Bengaluru, AWS User Group Madurai, Infor, #AWSCommunity, #AWSHeroes, BIT Sathy, KIT, KSRCT, Greenway Health, Dasken IT, Capco, Little Flower school, AWS User Group Madurai, AWS User Group Coimbatore, AWS User Group Mumbai for travelling with me in this journey.
And certainly not challenging myself to set any new record in 2023.
Let me continue to **Learn**, **Unlearn** and **Share** as always.
As we march into a new year, wishing you all loads of success on your way with good health and happiness taking the front seat 💐
| bhuvanas |
1,029,540 | RapidLoad | A post by toyagov | 0 | 2022-03-21T09:54:58 | https://dev.to/toyagov378/rapidload-review-automated-unused-css-removal-up-to-95-1kh7 | toyagov378 | ||
1,029,886 | Diary of a developer #1: Which way to go? | If you are just starting out in the development area, this post can help you get a sense of how to... | 0 | 2022-03-21T16:20:05 | https://dev.to/bielmartin/diary-of-a-developer-1-which-way-to-go-4p3l | If you are just starting out in the development area, this post can help you get a sense of how to proceed, however, if you are already an experienced developer, it is worth sharing a little bit of the path you took taken.

Initially, it is important that you set some goals of your own, **analyze if this is really what you want**, sit all day in front of the computer, analyze demands and propose solutions on top of them, do **not imagine that it will be easy**, but as all the effort is worth it if applied in the right way, when you pass through all these points **you will be in a beautiful area full of possibilities and challenges**.
Below I leave my opinion on what I consider an ideal path for a novice developer to follow, remembering that it is not a rule, but they are important steps for learning and in the search for your first job.

Let's go for points. if you've never had contact with any programming language, don't worry, choose one calmly, always taking into account **your way of coding**, **level of complexity of the language for beginners**, **the job market** and if you already know people who develop and who may give you a boost initially. **But the reality is that it doesn't matter**, python, ruby, java, C#, each one has its peculiarities, but they all exist for common purposes, **they are codes that tell the computer how to behave**, never forget that, the common computer is not intelligent to the point of being highly managed, virtually everything that exists has been coded previously.

Assuming that you have already chosen the most attractive language, now it's time to run, every information you receive in this period is important, **try to develop mini-projects**, calculators, calendars, all this will help even when setting up your portfolio, at the end of this article I will leave some links with projects for beginner developers.
Most development positions follow a pattern, and something I can suggest is: **Be pursuing a degree related to technology**. It's not a rule, but if you're in an academic environment, your chances of getting your first job go up a lot, be it even an internship.

**Paths in development**
Assuming you have some experience in your language, have already developed introductory projects and feel that you are ready for the next steps, then let's see some interesting technologies that add significantly to your curriculum. Below I will cite a few:
1. Understand the **IDE** you are using (I quote VS Code)
2. **Git**
3. Search for a **framework** related to your language and the Area you intend to follow
4. **Docker**
5. Understand what a **stack** is
Now I will briefly detail each topic:
**IDE** - The integrated development environment is a development tool for editing code, accessing a terminal, running a script, debugging and compiling using a single environment.
**Git** - These control systems have the function of recording any changes made on top of a code, storing this information and allowing, if necessary, a programmer to revert to previous versions of an application in a simple and fast way.
**Framework** - In programming, a framework is a set of generic codes capable of uniting parts of a development project. It works like a puzzle piece capable of fitting in the most diverse places and connecting all the lines of code in an almost perfect way.
**Docker** - In short, we can say that Docker is an open platform, created with the aim of facilitating the development, deployment and execution of applications in isolated environments. It was specially designed to deliver an application as quickly as possible.
**Stack** - In programming, stack is the name we give to the set of technologies that can be used to develop applications.

At the end of this article I will leave all the references so that you can study and better understand each technology. This was the learning line that I used in my learning flow, of course each language, framework and stack has its particularities, but understanding the concept makes everything easier.
Thank you for reading and I hope I have helped you in the best way. As a bonus I can tell you, if this is your dream, don't give up, you have the ability, the most important thing is to never give up.
References:
- https://www.tiagogouvea.com.br/profissional/projetos-reais-aprender-programacao/
- https://www.alura.com.br/artigos/o-que-e-uma-ide
- https://www.atlassian.com/br/git/tutorials/what-is-git
- https://www.lewagon.com/pt-BR/blog/o-que-e-framework
- https://stack.desenvolvedor.expert/appendix/docker/oquee.html
- https://kenzie.com.br/blog/full-stack-o-que-e/
| bielmartin | |
1,030,436 | RSMQ for golang | RSMQ is the most simple Queue Implementation in the known universe. My own implementation here comes... | 0 | 2022-03-22T22:03:31 | https://dev.to/ebuckley/rsmq-for-golang-2ej5 | go, redis, showdev | RSMQ is the most simple Queue Implementation in the known universe. My own implementation [here](https://github.com/ebuckley/rsmq) comes in at under 500 lines of code. Join me for a short tour of the code, and how it works.
People might be asking why I went to this effort when there are already so many implementations? Educational reasons. Implementing RSMQ is a fine and tightly scoped project that can be completed in a couple days of after work effort. In the day job we have been using a PHP implementation of the library but I wanted to deepen my knowledge of this simple tool by creating an implementation in my favorite language!
If you have Redis already, RSMQ is probably the easiest way to add messaging between different languages, processes and machines!
There are PHP/Python/Javascript/Java/C#/Rust/Go implementations now available for your usage. Want to write your own? No problem! Read this and become convinced that this is a simple and basic implementation task.
## How does RSMQ work?
Create Queues, send Messages, receive them on the diaspora of devices/processes and languages. Queues contain messages. Messages are delivered in a first in-first out basis (think about the queue in line at the McDonloads).
A Message is only delivered to one consumer. A consumer, being the thing that takes the message and finishes the work, deleting the message at the end. There is a time limit for how long a message can be processed for. When the time runs out, the message re-enters the queue and can be picked up by another consumer.
A typical worker implementation will receive a message, do the work, and then delete the message once it has processed successfully. If the worker crashes during the work, the message will be re-entered on the queue automatically, and another consumer will be able to pick it up.
# Implementing our own.
Some Redis knowledge assumed. You should become familiar with the basics. Today we will be using the following data structures.
- Sets (contains the list of queues)
- Hashes (contains the stats for a specific queue, and messages)
- Sorted Sets (Zset)
## Creating a new message Queue
A new queues is simply a unique Hash and a member added to a set.
```go
key := rsmq.ns + ":" + opts.QName + ":Q"
```
A queue is uniquely identified by the key. This is how we reference the queue, send messages to it, pop from it, update attributes about the queue. You will be using similar identifiers to this throughout your code in a lot of places.
```go
_, err = rsmq.cl.HMSet(ctx, key, map[string]interface{}{
"createdby": "ersin",
"vt": 30, // TODO allow this to be set with CreateQueueRequestOptions
"delay": 0,
"maxsize": 65536,
"created": unixMilliseonds,
"modified": unixMilliseconds,
}).Result()
if err != nil {
return fmt.Errorf("CreateQueue: set queue params: %w", err)
}
```
We define a hash for the attributes of the queue, including informative things like the delay in seconds before a message becomes receivable and the maximum size of the message in the queue.
```go
_, err = rsmq.cl.SAdd(ctx, rsmq.ns+":QUEUES", opts.QName).Result()
if err != nil {
return fmt.Errorf("CreateQueue: add queue to QUEUES set: %w", err)
}
```
Finally, we add the name of the queue to a set key. This allows our library to list all queues that are created under a given namespace.
## Sending a message to the queue
Code first, description second. It looks like this!
```go
pipe := rsmq.cl.Pipeline()
pipe.ZAdd(ctx, key, &Redis.Z{
Score: float64(q.TimeSent.Add(sendTime).UnixMilli()),
Member: q.UID,
})
pipe.HSet(ctx, key+":Q", q.UID, opts.Message)
pipe.HIncrBy(ctx, key+":Q", "totalsent", 1)
_, err = pipe.Exec(ctx)
```
Sending a message is a three step process that must happen as Redis 'pipeline'. A pipeline ensures that the actions do not require a round trip between client and server.
1. Add the message ID to the Sorted Set `rsmq.ns + ":" + opts.QName` with a score being the unix milliseconds of when it should send. Later on, we will re-score this message which has the effect of hiding it from other Q consumers.
2. Set the message content as a value on the `rsmq.ns + ":" + opts.QName + ":Q"` hash. The key of the content is the message ID
3. Increment the `totalSent` field of the Q hash used in step (2).
Note that we execute these in a 'pipe', which ensures that these steps happen atomically on the Redis data store, so we can be confident that the 3 commands always happen in sequence.
## ReceiveMessage
Our final operation for this code review is to receive a message from the queue. This step would be called by the workers that do the actual processing.
When a message is received it comes with an explicit deadline set for processing the message. This is known as the 'Visibility Timeout' and it is the number of second in which this message will be exclusively available to the one worker. If the visibility timeout expires, then the message will end up being sent to another worker.
```golang
results, err := rsmq.cl.EvalSha(
ctx,
// this references the embedded LUA procedure
*rsmq.receiveMessageSha1,
// these parameters are presented as KEY to the LUA script
[]string{key, timeSentUnix, timeVisibilityExpiresUnix}).Slice()
```
Only a single line on the Go side of things. We call a Lua script which runs on Redis to do the heavy lifting. An embedded Lua script runs in an atomic an thread-safe way on the datastore. This is how we get the guarantees of only one worker receiving a message at a time.
The following parameters to the Lua:
- KEYS[1]. Is the name of the sorted set containing the Q `rsmq.ns + ":" + opts.QName`
- KEYS[2]. Is the time when a message has been requested from the Q.
- KEYS[3]. Is the time when a message should become visible to other consumers again.
Now let's step through the Lua procedure.
```lua
local msg = Redis.call("ZRANGEBYSCORE", KEYS[1], "-inf", KEYS[2], "LIMIT", "0", "1")
if #msg == 0 then
return {}
end
```
Remember that there is a sorted set scored by timestamp sent for each message in the queue. The above code returns exactly one or zero message that is due for return between the `-inf` score and the current timestamp provided `KEYS[2]`.
```lua
Redis.call("ZADD", KEYS[1], KEYS[3], msg[1])
```
Next we re-score the current message found with the new visibility timeout defined in the `KEYS[3]` parameter. This step is important, because it keeps our queue in the data store. Other workers will be able to pick up this message again if it is not deleted before the visibility time has expired.
```lua
Redis.call("HINCRBY", KEYS[1] .. ":Q", "totalrecv", 1)
```
Now we increment the `totalrecv` counter on the Hash which contains the Q.
The final block of code concerns returning the message.
```lua
local mbody = Redis.call("HGET", KEYS[1] .. ":Q", msg[1])
local rc = Redis.call("HINCRBY", KEYS[1] .. ":Q", msg[1] .. ":rc", 1)
local o = {msg[1], mbody, rc}
if rc==1 then
Redis.call("HSET", KEYS[1] .. ":Q", msg[1] .. ":fr", KEYS[2])
table.insert(o, KEYS[2])
else
local fr = Redis.call("HGET", KEYS[1] .. ":Q", msg[1] .. ":fr")
table.insert(o, fr)
end
return o
```
An HINCRBY is called to increment our count of how many times this message has been received.
To wrap it all up, the message content is returned along with a few additional infomrative attributes.
## Want to implement your own?
My dreams would come true if I inspired you to write something like this for your own learning purposes. It would make my week complete if you left a comment.
All Credit for the original implementation of RSMQ goes to https://github.com/smrchy/rsmq :)
| ebuckley |
1,031,538 | POO - Abstracción | Según una definición que encontré en internet, abstraer algo significa: separar por medio de una... | 0 | 2022-03-23T03:08:24 | https://dev.to/nahuelsegovia/poo-abstraccion-4m0h | poo, oop, python, backend | Según una definición que encontré en internet, abstraer algo significa: separar por medio de una operación intelectual(pensar)
un rasgo o una cualidad(en nuestro caso métodos y atributos) para
analizarlos aisladamente. En palabras más simples aún, sería enfocarnos en eliminar o ignorar detalles de algo para obtener los puntos más relevantes para su funcionamiento.
**¿Pero como nos sirve todo lo de arriba?**
Bien, supongamos nuevamente que tenemos un celular moderno, este va a poder:
- Llamar
- Enviar SMS
- Instalar aplicaciones
- Sacar fotos
- Grabar video
Y para realizar todas estas cosas el celular necesita:
- Batería
- Placa wifi
- Camára de foto y video
- Sistema operativo funcional(Android, iOS)
De esta forma vemos como se puede realizar una abstracción de un celular, así que ahora podemos crear nuestra clase:
```python
class Celular():
def __init__(self, name, wifi_card, battery, camera):
self._name = name
self._battery = battery
self._wifi_card = wifi_card
self._camera = camera
def call(self, number:int): print('Calling'+str(number)+'...')
def send_sms(self, number:int, msg:str): print('Sending '+msg+' to ' +str(number))
def install_app(self, app_name:str): print('Installing '+app_name+' app...')
def take_a_photo(): print('Taking a photo...')
def record_video(): print('Recording video...')
``` | nahuelsegovia |
1,031,870 | ESLint and Prettier configuration for React project | ESLint is a tool for identifying and reporting on patterns found in ECMAScript/JavaScript code, with... | 0 | 2023-03-21T04:53:52 | https://dev.to/tsamaya/eslint-and-prettier-configuration-for-react-project-2gij | react, eslint, prettier |
> ESLint is a tool for identifying and reporting on patterns found in ECMAScript/JavaScript code, with the goal of making code more consistent and avoiding bugs.
> Prettier is an opinionated code formatter. It ensures a consistent style by parsing your code and re-writing it with its rules.
_If you are using VScode, and already have the ESLINT and PRETTIER plugins, as you are goigng to change the configuration as you follow the tutorial, you might have linter/prettier errors displayed, the solution is to restart VSCode._
In your git working folder running the following command will guide you with the ESLint configuration, we are going to use the airbnb style guide:
```bash
npm init @eslint/config
? How would you like to use ESLint? …
To check syntax only
To check syntax and find problems
❯ To check syntax, find problems, and enforce code style
```
Select `To check syntax, find problems, and enforce code style`
```bash
? What type of modules does your project use? …
❯ JavaScript modules (import/export)
CommonJS (require/exports)
None of these
```
For React / React-Native, you probably use import/export!
```bash
? Which framework does your project use? …
❯ React
Vue.js
None of these
```
Use React, but it also works with `Vue.js`.
```bash
? Does your project use TypeScript? › No / Yes
```
up to you. Here I went for No.
```bash
? Where does your code run? … (Press <space> to select, <a> to toggle all, <i> to invert selection)
✔ Browser
✔ Node
```
I tend to use both (even for pure React project)
```bash
? How would you like to define a style for your project? …
❯ Use a popular style guide
Answer questions about your style
```
and now we can choose the style:
```bash
? Which style guide do you want to follow? …
❯ Airbnb: <https://github.com/airbnb/javascript>
Standard: <https://github.com/standard/standard>
Google: <https://github.com/google/eslint-config-google>
XO: <https://github.com/xojs/eslint-config-xo>
```
```bash
? What format do you want your config file to be in? …
❯ JavaScript
YAML
JSON
```
I prefer using an `.eslintrc.js` but up to you if one prefer a different flavour.
```bash
Checking peerDependencies of eslint-config-airbnb@latest
Local ESLint installation not found.
The config that you've selected requires the following dependencies:
eslint-plugin-react@^7.28.0 eslint-config-airbnb@latest eslint@^7.32.0 || ^8.2.0 eslint-plugin-import@^2.25.3 eslint-plugin-jsx-a11y@^6.5.1 eslint-plugin-react-hooks@^4.3.0
? Would you like to install them now? › No / Yes
```
Select yes to install the dependencies. And choose your package manager:
```bash
? Which package manager do you want to use? …
❯ npm
yarn
pnpm
```
```bash
Installing eslint-plugin-react@^7.28.0, eslint-config-airbnb@latest, eslint@^7.32.0 || ^8.2.0, eslint-plugin-import@^2.25.3, eslint-plugin-jsx-a11y@^6.5.1, eslint-plugin-react-hooks@^4.3.0
up to date, audited 208 packages in 1s
85 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Successfully created .eslintrc.js file in XXX/YYY
```
Today is a good day, all packages are safe with 0 vulnerabilities.
Now, your `package.json` file contains these dev dependencies
```json
"devDependencies": {
"eslint": "^8.36.0",
"eslint-config-airbnb": "^19.0.4",
"eslint-plugin-import": "^2.27.5",
"eslint-plugin-jsx-a11y": "^6.7.1",
"eslint-plugin-react": "^7.32.2",
"eslint-plugin-react-hooks": "^4.6.0"
}
```
Now let's have a look at the eslintrc file. It looks like that:
```js
module.exports = {
env: {
browser: true,
es2021: true,
node: true,
},
extends: ['plugin:react/recommended', 'airbnb'],
parserOptions: {
ecmaFeatures: {
jsx: true,
},
ecmaVersion: 'latest',
sourceType: 'module',
},
plugins: ['react'],
rules: {},
}
```
Adding prettier to the configuration
```bash
npm i -D prettier eslint-config-prettier eslint-plugin-prettier
added 5 packages, and audited 213 packages in 4s
86 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
```
create a .prettierrc.js file
```js
module.exports = {
singleQuote: true,
}
```
Read more about the other options on prettier [website](https://prettier.io/docs/en/configuration.html).
Time to update the `.eslintrc.js` file, adding the prettier recommended plugin
```js
extends: [
'plugin:react/recommended',
'airbnb',
'plugin:prettier/recommended',
],
```
add two scripts in the `package.json` file
```json
"scripts": {
"lint": "eslint .",
"lint:fix": "eslint -fix ."
},
```
then you will be able to run
```bash
npm run lint
```
just to check your code
```bash
npm run lint:fix
```
to check and automatically fix what can be fixed.
### Pre-commit Hook with lint-staged
```bash
Running lint-staged...
husky - Git hooks installed
husky - created .husky/pre-commit
```
This adds husky to hook the pre-commit and run the lint-staged script added to the project’s `package.json` file
Read more at the [lint-staged](https://github.com/okonet/lint-staged#configuration) repo.
now let's create two files `.eslintignore`, and `.prettierignore` with the same content:
```yml
node_modules/
build/
coverage/
```
You are all set happy coding!
## Resources
- Photo by [Andrea De Santis](https://unsplash.com/@santesson89?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/s/photos/dragon-bridge?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)
| tsamaya |
1,032,504 | Introducción react-redux y redux toolkit | Después de haber entendido algunos conceptos de Redux, llegó el momento de utilizarlo como tal 😁. ... | 17,372 | 2022-03-23T23:52:07 | https://dev.to/leobar37/introduccion-react-redux-y-redux-toolkit-4k63 | typescript, react, redux, webdev | Después de haber entendido algunos conceptos de Redux, llegó el momento de utilizarlo como tal 😁.
## Setup
Para hacer el setup de la app usaré [vite](https://vitejs.dev/). Vite es una alternativa a webpack, el cual mejora la experiencia de usuario y es mucho más rápido. Si quieres saber más acerca de los beneficios de vite, puedes visitar el siguiente [artículo](https://radixweb.com/blog/vite-js-latest-front-end-development-tool)
Para crear una aplicación con vite y react, solo es necesario abrir tu consola y poner el siguiente comando.
```sh
yarn create vite redux-tutorial --template react-ts
```
La opción de `--template` le dice a vite con que template inicializar el proyecto, en este caso el de `react-ts` ahora ya se tendrá la siguiente estructura.
Ahora empecemos con las dependencias, como habíamos dicho utilizaremos redux con react, para eso tenemos que instalar el paquete `react-redux`, el cual trae lo necesario para hacer la conexión a redux, además a ellos vamos a instalar `@reduxjs/toolkit` el cual trae algunos superpoderes para redux
```sh
yarn add react-redux @reduxjs/toolkit
```
## ¿Que es redux toolkit?
Redux esta bien, pero era un poco complicado. Actualmente, contamos con [Redux toolkit](https://redux-toolkit.js.org/) él ofrece las siguientes soluciones:
- Simplifica la configuración de redux
- Elimina la necesidad de agregar múltiples paquetes para tener una aplicación escalable.
- Reduce el código repetitivo.
Actualmente no se recomienda usar `react-redux` sin `@reduxjs/toolkit`.
## Preparando el Store
Para empezar a escribir lógica con redux, lo primero que se tiene que hacer es configurar el `Store`. Para eso [Redux toolkit](https://redux-toolkit.js.org/) provee un método que nos ayuda con el procedimiendo, el cual se llama `configureStore`.
```tsx
// store/index.ts
import { configureStore } from "@reduxjs/toolkit";
export const store = configureStore({
reducer: {},
devTools: process.env.NODE_ENV !== "production",
});
export default store;
```
[configureStore](https://redux-toolkit.js.org/api/configureStore)
Ahora ya tenemos él store :) . Al hacer esto `redux-toolkit` ha puesto algunas configuracioens por defecto, las cuales iré comentando conforme avancemos en el ejemplo. En este instante podemos hablar de las [devTools](https://github.com/reduxjs/redux-devtools) las cuales son indispensables para poder depurar la aplicación. En este caso la opción `devtools` se activa solo en producción, también puedes personalizar el funcionamiento, pasando un objeto de [opciones](https://github.com/reduxjs/redux-devtools/blob/main/extension/docs/API/Arguments.md).
**Conexión con React**
Ahora es momento de poner disponible el store hacia React, para eso `react-redux` provee un `Provider` para poner disponible el `Store` en todo el árbol de componentes.
```tsx
import "./App.css";
import { Provider as ReduxProvider } from "react-redux";
import store from "./store";
function App() {
return (
<ReduxProvider store={store}>
<div></div>
</ReduxProvider>
);
}
export default App;
```
## Estructura de archivos en Redux
Ahora que ya se tiene la tienda en el nivel superior de la aplicación, es hora la lógica de nuestra aplicación, en este caso vamos a hacer una agenda de contactos, para poder realizar un CRUD. Antes de continuar necesitamos tener en cuenta algo muy importante, el cual es la estructura de los archivos. Si bien React es una librería muy flexible frente a la estructura de archivos, Redux poner a nuestra disposición una estructura base, para a partir de eso organizar nuestros archivos.
**Pensando en Ducks**
Ducks es una [propuesta](https://github.com/erikras/ducks-modular-redux) que básicamente propone que empaquetemos un conjunto de acciones, reductores, nombres de acciones a una funcionalidad en concreto, llamando a esta agrupación `duck` el cual, tranquilamente, puede empaquetarse y distribuirse como una librería.
Ahora, teniendo un poco en cuenta los patos 😅, vamos a dividir la aplicación en algo parecido, pero le llamaremos `features`. De esta manera.
**Feature Structure:**
Como se mencionaba en un inicio, el ecosistema de React es muy flexible a la hora de organizar los archivos. Teniendo en cuenta los elementos de redux, al momento de partir una `feature` debemos dividir `actions`, `reducer`, `selectors` esto mejora la organización.
En mi caso inspirado un poco en el siguiente [artículo](https://alexmngn.medium.com/how-to-better-organize-your-react-applications-2fd3ea1920f1), mi estructura es la siguiente.
_View_: Carpeta donde van las vistas que el usuario va a ver en pantalla, generalmente todos los componentes que son utilizando junto con el router de la aplicación. Por ejemplo, si estamos creando una aplicación de inventarios, el listado de estos productos podrían ir en una pantalla `producs/list`.
_Componentes_: Normalmente, se querrá tener una carpeta `components` en general, donde estén ubicados todos aquellos componentes, que **pueden ser usados en cualquier lugar**, una feature puede tener componentes que sean propios de la característica, por ejemplo el listado, de productos.
_actions:_ En esta carpeta irán todas las acciones ligadas a esta característica.
_reducer:_ Cada feature tiene como regla que debe exportar un solo reductor, eso no quiere decir que solo tengamos que concentrar toda lógica en un solo reducer, podemos usar [`combineReducers`](https://redux.js.org/api/combinereducers) para combinar múltiples reducer en unos solo si es que fuese necesario.
Puedes pensar en una `feature` como una mini aplicación dentro de una aplicación, este se encarga de un proceso en concreto, que al final aportará un valor agregado a la aplicación en general.
## Accciones
Las acciones son objetos planos que expresan una intención de cambiar el estado, eso es lo que se mencionó en el artículo anterior. Puedes pensar en una acción como un evento ocurrido en la aplicación, por ejemplo; se agregó un producto, se eliminó un contacto, cargando contactos, todos ellos describen algo que está pasando en al app.
Dicho esto podemos empezar a escribir acciones, las acciones tiene un [estándar](https://github.com/redux-utilities/flux-standard-action) que indican que deben ser así.
```tsx
{
type: 'ADD_TODO',
payload: {
text: 'Do something.'
}
}
```
**Creadores de acciones:**
Normalmente, las acciones puede despacharse de la siguiente manera.
```tsx
store.dispatch({ type: "ITEM_ADDED_TO_CART", payload: 47 });
```
Pero en cierto punto, poner el tipo, cada vez que queramos despachar esta acción, no es muy escalable porque si se quisiera cambiar el tipo de acción, tendría que hacerlo en diferentes archivos y además, se vuelve complicado repetir lo mismo.
Ahí es donde entran loas [creadores de acciones](https://read.reduxbook.com/markdown/part1/04-action-creators.html), que no son nada más que funciones encargadas de crear este objeto, un creador de acción sería el siguiente.
```tsx
function doAddToDoItem(text) {
return { type: "TODO_ADDED", payload: text };
}
```
Entonces, cada vez que se requiera formar esta acción, solo es necesario ejecutar `doAddToDoItem`.
Redux toolkit Simplifica este procedimiento con un utility llamado [`createAction`](https://redux-toolkit.js.org/api/createAction) el cual es una [HOF](https://leobar37.medium.com/hofs-clousures-y-callbacks-para-ser-feliz-en-javascript-fa105ed6ad44)(higher order function) los cuales son funciones que retornan funciones.
```ts
// features/schedule/actions/schedule.actions.ts
import { createAction } from "@reduxjs/toolkit";
export const contactAdded = createAction("CONTACT_ADDED");
```
Ahora `contactAdded` es una función que al ser disparada creará una acción de tipo `CONTACT_ADDED` es importante saber que por [recomendación de redux](https://redux.js.org/style-guide/style-guide#model-actions-as-events-not-setters) las acciones deben ser "Descripciones de eventos que ocurrieron" en lugar expresarlas en presente, como por ejemplo `ADD_CONTACT`.
**Payload:**
Hasta este paso se creó la acción `contactAdded`, pero esto no es suficiente para agregar un contacto, se necesitaría la información de ese contacto. En el caso de typescript `redux toolkit` tiene un [genérico](https://www.typescriptlang.org/docs/handbook/2/generics.html) para poder describir el payload.
```ts
import { createAction } from "@reduxjs/toolkit";
export const contactAdded =
createAction<{ name: string; phone: string }>("CONTACT_ADDED");
```
Listo ahora el primer parámetro(payload) de `contactAdded` estará tipado.
## Reducer
Como se mencionó anteriormente, los [reducers](https://redux.js.org/tutorials/fundamentals/part-3-state-actions-reducers#writing-reducers) son funciones puras que toman el estado actual y la acción para retornar un nuevo estado.
[Redux toolkit](https://redux-toolkit.js.org/api/createreducer) exporta una función llamada `createReducer` la cual facilita la creación de un reducer agregando ciertas características que facilitan el desarrollo.
```ts
import { createReducer } from "@reduxjs/toolkit";
const initalState = {
contacts: [],
};
export type ScheduleState = typeof initalState;
const reducer = createReducer(initalState, (builder) => {});
```
Esta sería la forma de crear un reducer con **Redux toolkit**
**Case:**
Anteriormente vimos, que cuando creamos un reducer dentro de el planteamos un `switch...case` para manejar cada acción.
```ts
const reducer = (state, action) => {
switch (action) {
case "EAT": {
return {
...state,
eatCount: state.eatCount + 1,
};
}
}
};
```
Redux toolkit propone una forma más amigable de hacerlo, mediante un objeto builder, el cual expone una serie de métodos como `addCase` con el cual le recibe como parámetros.
**ActionCreator:** La función generada por `createAction`o una acción como tal.
**Reducer:** El reducer encargado solo de manejar esta acción.
Incorporando la lógica de agregar contacto, tendríamos lo siguiente.
```ts
import { createReducer } from "@reduxjs/toolkit";
import * as scheduleActions from "../actions/schedule.actions";
export interface IContact {
id: number;
name: string;
phone: string;
}
const initalState = {
contacts: [] as IContact[],
};
export type ScheduleState = typeof initalState;
const reducer = createReducer(initalState, (builder) => {
builder.addCase(scheduleActions.contactAdded, (state, action) => {
state.contacts.push({
id: state.contacts.length,
name: action.payload.name,
phone: action.payload.phone,
});
});
});
```
Si eres curioso. La manera en como builder encadena todos los casos sigue [fluent Style](https://en.wikipedia.org/wiki/Fluent_interface)😶 .
Hay algo notable aquí, y es que al parecer no estamos siguiendo el primer principio de Redux, que dice que el estado es de solo lectura, ose es inmutable. Bueno podemos ahorrarnos esa preocupación con Immer, el cual explicaré en el siguiente parte :).
Happy Coding😄
| leobar37 |
1,033,042 | Best Clipboard Apps for Developers | Written by: Antonello Zanini There are many clipboard managers available, but only a few of them... | 0 | 2022-03-24T11:10:06 | https://dev.to/getpieces/best-clipboard-apps-for-developers-59kk | programming, productivity, webdev, beginners | Written by: Antonello Zanini

There are many clipboard managers available, but only a few of them have been designed specifically for software and web developers. If you are a developer who wants to improve your productivity, you must adopt an advanced clipboard manager.
Both Windows and macOS come with a basic, limited clipboard, which means that you can copy something and then paste it. End users’ needs have evolved in recent years, leading to the creation of more advanced clipboard managers. Not all of these options have been designed with software development in mind, though.
If you have ever felt slowed down by your operating system’s basic clipboard, it is time to try a more powerful app. This article will present the five best clipboard apps for developers, as well as what criteria were used to select them.
**Why You Should Adopt a Clipboard App**
As a developer, increasing your productivity should be one of your top priorities. Clipboard managers offer three ways for you to do that:
- **Store more than one thing:** With clipboard apps, you can keep a history of all the items you’ve copied.
- **Search through your copied items:** Clipboard managers allow you to easily retrieve the item you want to paste.
- **Reuse code snippets:** You can copy all the code snippets you need at once and then paste them only if you need to.
**Elements of a Good Clipboard App**
There are specific features to consider when evaluating a clipboard app for developers. The following elements were used to select and rate the top five clipboard managers:
- **Integration with IDEs and text editors:** Developers spend most of their time writing code. For a clipboard app to enhance your productivity, it needs to be directly integrated into your favorite IDE.
- **Cloud support:** The clipboard app should allow you to save your copied items to the cloud so you can access them anywhere, regardless of the device you are using. For security reasons, the app should be able to encrypt the info during upload.
- **Custom keyboard shortcuts:** Developers heavily use hotkeys and keyboard shortcuts, and they want the ability to define the shortcuts as needed.
- **Multi-format support:** Copying is not always about text. The clipboard manager should also allow you to store multimedia items, such as images, videos, or tables.
- **Item organization:** When many items are stored in one place, the storage location can easily become a mess. The manager app should allow you to organize your copied items or give you the option to quickly find the one you need.
**Top Five Clipboard Managers**
The following clipboard manager apps meet the required criteria, so they’ll help you improve your productivity as you write software.
**1. [Pieces](pieces.app)**

[Pieces](pieces.app), which offers free or paid options, is a clipboard app designed specifically for developers and supports both macOS and Windows. It also supports the most popular IDEs and text editors with custom plug-ins. Check the updated list of [its official integrations](https://code.pieces.app/plugins) for details.
Pieces allows you to save, reuse, and share many data type format items, including code snippets, links, text, screenshots, and images. Each clipping will be automatically stored in the cloud so that you can access it from multiple devices.
When you need to look for a clipping, you can use its lightning-fast search feature to instantly retrieve any item you previously copied. This is especially effective because Pieces automatically captures any possible metadata related to a snippet so that you can more easily find it later.
Pieces is based on a lightweight UI to keep you focused while you are working, and it supports several intuitive keyboard shortcuts. It also allows you to configure your own hot keys.
**2. [Flycut](https://apps.apple.com/it/app/flycut-clipboard-manager/id442160987)**

[Flycut](https://apps.apple.com/it/app/flycut-clipboard-manager/id442160987) is a clean and simple free [open source](https://github.com/TermiT/Flycut) clipboard app for macOS and iOS that is based on Jumpcut, a minimal clipboard manager for macOS. Flycut was designed with developers in mind, and its main focus is on code snippets. For this reason, it comes with many hot keys and keyboard shortcuts, which can be customized according to your needs in the preferences panel.
On the other hand, Flycut allows you to store only text snippets. This means that images, videos, and tables are currently not supported. It also neither supports Windows nor offers specific integrations for the most common IDEs and text editors.
Although Flycut does not come with cloud features natively, you can configure it to sync with your Dropbox account. This way, you can store your clipboard history in an external cloud service and then access it from wherever you want.
When Flycut is launched, its icon appears in your menu bar. Every time you copy a text snippet, Flycut stores it in history for you. Using `Shift + Command + V`, you can access the history and navigate with the right or left arrows to select the item to paste. More advanced search features, as well as ways to organize your clippings, are currently unavailable.
**3. [Ditto](https://ditto-cp.sourceforge.io/)**

[Ditto](https://ditto-cp.sourceforge.io/) is a free extension to the standard Windows clipboard and does not support macOS. Ditto saves every item you copy, encrypts it, and sends it to the cloud for you, then allows you to access each item on multiple devices. It supports any kind of information, such as text, images, and HTML, as well as custom data formats.
Ditto can be accessed from the tray icon, but it also supports hot keys and custom keyboard shortcuts. Notably, it has an incredible amount of options available and is highly configurable and customizable. With Ditto, you can also create groups and organize your copied items as you like. You can also search through the items to easily find the one you need.
Ditto is a general-purpose application that was not built explicitly for developers, so it should not surprise you that there are no official plug-ins for the main IDEs on the market.
**4. [Pastebot](https://tapbots.com/pastebot/)**

[Pastebot](https://tapbots.com/pastebot/) is a license-based clipboard manager for macOS and iOS only. It automatically stores everything you copy on iCloud and allows you to access it on any Apple device whenever you want. It supports any kind of content, from text to images and videos.
Pastebot comes with several keyboard shortcut options to let you paste and access specific items effortlessly. It also allows you to easily organize your items and offers advanced search features to retrieve them quickly.
Pastebot currently costs $12.99. Since it is a general-purpose clipboard application, you should not expect to find official plug-ins for your favorite IDE or text editor.
**5. [Paste](https://apps.apple.com/app/paste-clipboard-manager/id967805235)**

[Paste](https://apps.apple.com/app/paste-clipboard-manager/id967805235) is a subscription-based clipboard manager that allows you to store everything you copy on your Mac, iPhone, or iPad. It does not currently support Windows, but it natively works with iCloud and allows you to access your copied items on any Apple device.
It has been adopted by many developers to increase their productivity, but it was not designed expressly for them. Consequently, no IDE or text editor comes with official plug-ins to support it. On the other hand, it supports multimedia files and tables. Plus, it lets you choose which apps to monitor when copying and which to ignore.
Paste also allows you to organize your clippings and modify, pin, scroll through, and search over them to find what you need. You can access this panel with `Shift + Command + V`, but you can define custom shortcuts as well.
**Conclusion**
Clipboard managers are an essential tool for productivity because they make a developer’s job easier and more efficient. Only a few clipboard apps, though, are designed and built specifically for developers. Before you choose a clipboard app, make sure it has the features you need and will work with your operating system.
The clipboard manager applications listed above offer a good array of choices for you. One of these five should be exactly what you need to help you jump-start your productivity.
| anushka23g |
1,034,507 | Our tech stack in 2022 | Preface Reading about our tech stack from one year ago gives me confidence for the future.... | 11,913 | 2022-03-25T17:25:37 | https://happy-coding.visuellverstehen.de/posts/our-tech-stack-in-2022-374o | tooling, devops, technology, stack | ## Preface
Reading about our [tech stack from one year ago](https://happy-coding.visuellverstehen.de/posts/our-tech-stack-in-2021-2600) gives me confidence for the future. Most of the languages and frameworks are still the same as twelve months ago. I think it is good we are not switching technology that often. It means we can maintain everything for a long time and get a lot of experience in our day-to-day tools.
Of course, we also have to keep an eye on the new stuff in web development and make some innovation happen at visuellverstehen. Therefore we try out new things in real-life projects from time to time. For example, I am happy there is Meilisearch now in our tech stack of 2022.
As always, I recommend not rushing into the last NewShinyFramework™.
## Clarification
1. This will not cover every technology in all of our projects, because individual projects do need individual solutions. But it will cover all the basics.
2. Legacy projects might use outdated technologies and those will not be part of this. Of course, we always try to update legacy projects.
3. It is not easy to categorize every technology. Therefore the categorization might not always be 100 % correct.
4. Not every one of us is working with all of the technologies mentioned below. Our team is organized into smaller sub-teams, which then focus on different projects.
## Our tech stack
### Core products
- Individual digital products using [Laravel](https://laravel.com) and [Vue.js](https://vuejs.org)
- Content management products using [Statamic](https://statamic.com) and [TYPO3](https://typo3.org)
### What people call »Backend«
- Extbase
- Laravel
- Laravel Nova
- Meilisearch
- MySQL
- PHP
- PHPUnit
- Statamic
- TYPO3
### What people call »Frontend«
- Alpine.js
- Antlers
- BEM
- Babel
- Blade
- CSS
- Fluid
- HTML
- JavaScript
- Laravel Livewire
- Sass
- Tailwind CSS
- Vue.js
- gulp.js
- npm
- webpack
### What people call »DevOps«
- Docker
- Docker Compose
- Git
- GitHub
- GitHub Actions
- GitLab
- GitLab CI
- Hetzner Cloud
- Laravel Forge
- Mittwald
### Honorable mentions
Three things are worth a special mention.
1. Although Shopware 6 is a well-crafted software, we decided against it. We want to focus on individual digital products using Laravel and Vue.js plus content management using Statamic and TYPO3. We will still maintain running client projects and support our [Shopware plugins](https://store.shopware.com/en/visuellverstehen-gmbh.html) though.
2. One of our clients asked for [Alpine.js](https://alpinejs.dev) in combination with Laravel Livewire. It turns out those work well together. Let us see if we want to use it more often in the future.
3. We are using Meilisearch for advanced search technologies more and more. It is a simple alternative to Solr and Elasticsearch written in Rust. It works smoothly with Laravel and Statamic. We also developed a [TYPO3 extension for Meilisearch](https://github.com/visuellverstehen/t3meilisearch).
## Happy coding
I am curious how this will change in the next twelve months. Well, we will find out. See you next year. Happy coding. | malteriechmann |
1,035,705 | 100 días de código: 91, conectando y creando el frontend de mi aplicación MERN | ¡Hey hey hey! Pense que realmente seria complicado conectar el backend con el frontend pero en... | 0 | 2022-03-27T04:31:35 | https://dev.to/darito/100-dias-de-codigo-91-conectando-y-creando-el-frontend-de-mi-aplicacion-mern-2o6l | spanish, 100daysofcode, webdev, beginners | ¡Hey hey hey!
Pense que realmente seria complicado conectar el backend con el frontend pero en cuanto comencé a realizar el frontend de la aplicación y a utilizar axios para las peticiones me di cuenta que es muy sencillo comenzar a utilizar tu API REST una vez la hayas desplegado.
Me siento contento porque he conseguido realizar esta conexión y también he terminado de construir el frontend de [mi aplicación de agenda de teléfono global](https://github.com/Darito97/frontend-phonebook).
Tengo dudas sobre como funcionan las variables de entorno en producción de una aplicación de react hecha con vite y me da la sensación de que será un nuevo reto desplegarla en [Vercel](https://vercel.com/).
La duda anteriormente mencionada nace del hecho de que vite contiene un propio manejador de variables de entorno en la cual en lugar de ser obtenidas accediendo al `process.env` se obtienen accediendo a través de `import.meta.env.nombreDeLaVariable` y no se si es compatible con las variables de entorno que maneja Vercel.
Mi conclusión es que, si bien hacer una pagina con frontend y backend es sencillo tiene su dificultad en algunos momentos.
¡Espero que tengan mucho éxito con sus proyectos y animo con todo!
Hasta la próxima.
| darito |
1,035,716 | ok. move the material update | ok, instead of feeding hte material with updates on event tick, only do it after functions i want the... | 0 | 2022-03-27T05:37:58 | https://dev.to/tygamesdev/ok-move-the-material-update-424l | ok, instead of feeding hte material with updates on event tick, only do it after functions i want the material to work, then use a timeline which gives me better control on the curves. so move eneny > timeline > affect material | tygamesdev | |
1,035,836 | I created twitter header using TailwindCSS | Checkout my new social media header made with TailwindCSS. Here is some facts 👇 Only used SVGs for... | 0 | 2022-03-27T08:31:18 | https://dev.to/nagi/i-created-twitter-header-using-tailwindcss-4kik | tailwindcss, css | Checkout my new social media header made with TailwindCSS. Here is some facts 👇
- Only used SVGs for the logos and the curly brace at the right.
- No custom css or fancy javascript.
- I had fun for 3 hours making it.
- Code available on 👇
[TwilwindCss Play](https://play.tailwindcss.com/YpEyNjbSOF?layout=horizontal)
Wanna know how I have done it?
👉 Checkout [The Extensive Guide to Create Beautiful Social Media Headers Using Tailwindcss](https://dev.to/nagi/the-extensive-guide-to-create-beautiful-social-media-headers-using-tailwindcss-5e30) | nagi |
1,036,023 | Docking Data | Advent of Code 2020 Day 14 Try the simulator! Task: Solve for X... | 16,285 | 2022-03-28T20:18:30 | https://dev.to/rmion/docking-data-4hb8 | adventofcode, programming, algorithms, computerscience | ## [Advent of Code 2020 Day 14](https://adventofcode.com/2020/day/14)
## [Try the simulator!](https://aocdockingdata.rmion.repl.co/)
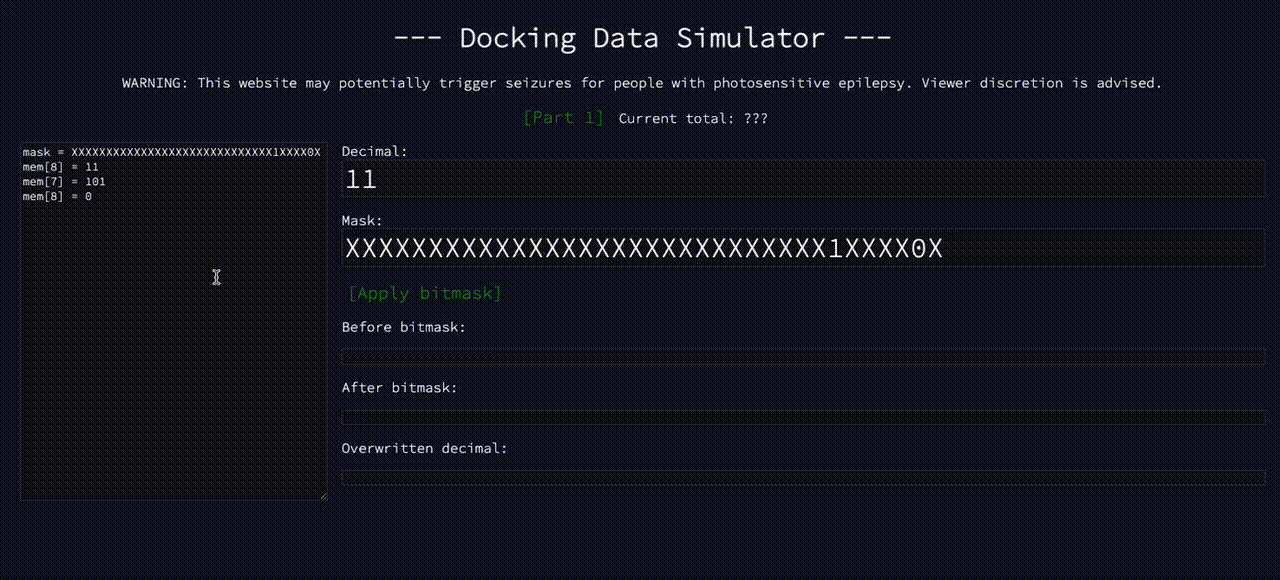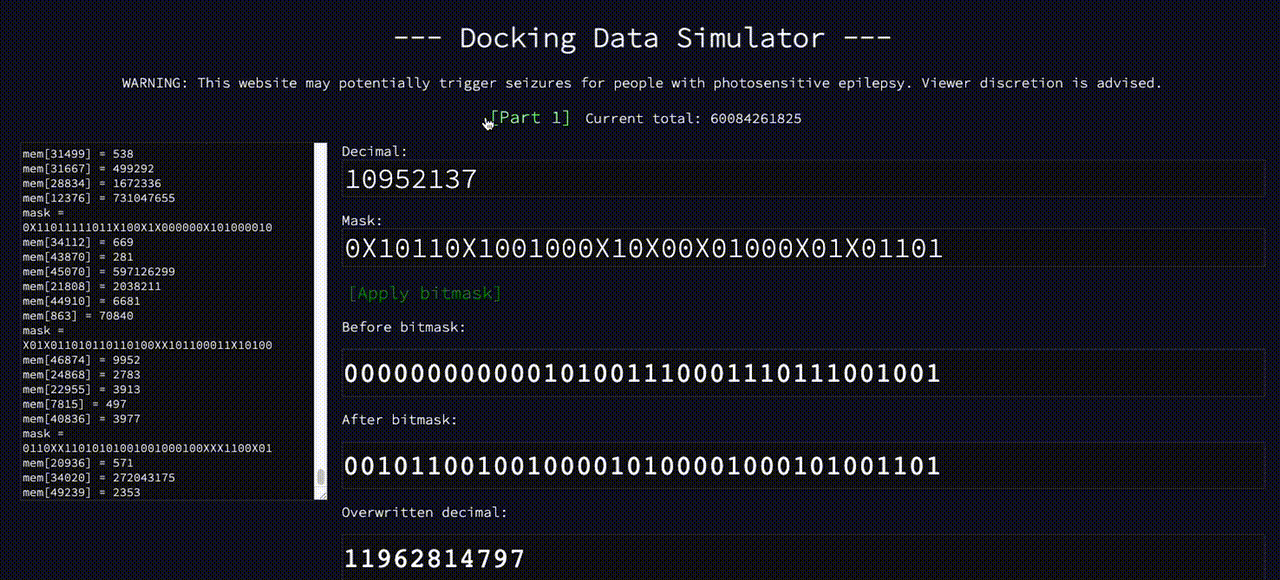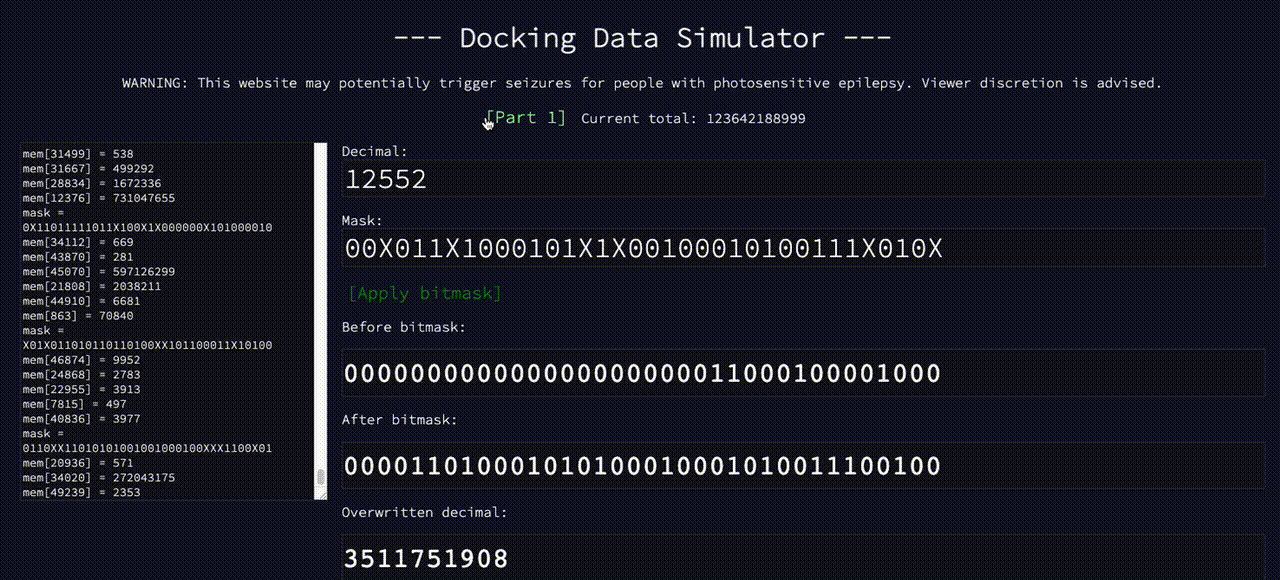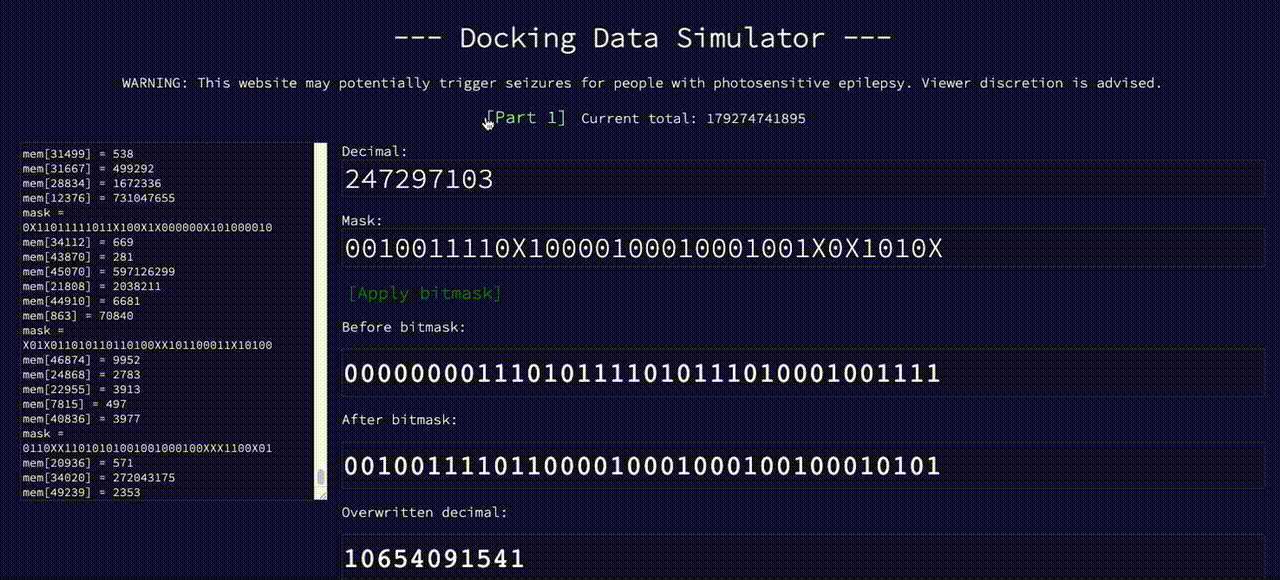
## Task: Solve for X where...
```
X = the sum of all values left in memory after initialization completes
```
### Example input
```
mask = XXXXXXXXXXXXXXXXXXXXXXXXXXXXX1XXXX0X
mem[8] = 11
mem[7] = 101
mem[8] = 0
```
It represents
- A bitmask
- A series of decimal values to assign to an address in memory
## Part 1
1. Understanding how the bitmask works
2. Building several small algorithms
3. Altogether now: Writing a working algorithm
4. Building a simulator
### Understanding how the bitmask works
In the example, the bitmask is:
```
XXXXXXXXXXXXXXXXXXXXXXXXXXXXX1XXXX0X
```
- 36 characters long
- Comprised of `X`s, `0`s and `1`s
- `X`s signify a transparent mask: don't overwrite the value below
- `0`s and `1`s signify an opaque mask: overwrite the value below with either a `0` or `1`
The first instruction is:
```
mem[8] = 11
```
- Assign the integer 11 to address 8 in memory
As the example demonstrates:
```
mask:
XXXXXXXXXXXXXXXXXXXXXXXXXXXXX1XXXX0X
decimal 11 as bits:
1011
decimal 11 as bits, padded with 0s to be 36 characters long:
000000000000000000000000000000001011
areas of overlap:
1 0
decimal 11 as bits, masked:
000000000000000000000000000001001001
new bits without padding:
1001001
converted to decimal:
73
```
### Building several small algorithms
1. Capturing the important parts of each instruction
2. Converting a decimal into binary
3. Converting a binary back to decimal
4. Padding a number at the start to match our mask
5. Parsing a binary number from a padded string
6. Overwriting characters in a string where appropriate
#### Capturing the important parts of each instruction
Among the stream of input are one of two line templates:
1. `mask = ` then a 36-character string containing `X`s `0`s or `1`s
2. `mem` then a bracket-enclosed integer, then ` = `, then another integer
This regular expression matches either template and captures one or both of the important elements
```
/mask = ([01X]+)|mem\[(\d+)\] = (\d+)/g
```
#### Converting a decimal into binary
How might we turn `11` into `1011`, or `101` into `1100101`?
In JavaScript, we can leverage the `toString()` method built-in to the `Number` object prototype.
Invoking `toString()` on a number, and passing a number as argument, will attempt to return the calling number in the provided base, or radix.
Therefore, calling `toString()` with argument `2` will convert our decimal to binary, like this:
```
(11).toString(2) // '1011'
(101).toString(2) // '1100101'
```
#### Converting a binary back to decimal
How might we do the reverse: `1011` into `11`?
In JavaScript, we can use the `parseInt()` Number method, passing two arguments:
1. The binary number as a string
2. The base of the binary number
We could use it like this:
```
parseInt('1011', 2) // 11
parseInt('1100101', 2) // 101
```
#### Padding a number at the start to match our mask
How might we get `'000000000000000000000000000000001011'` from `1011`?
In JavaScript, we can use the `padStart()` string method, passing two arguments:
1. The length of the new string
2. The character used to fill in each new space
Therefore, calling `padStart()` on our string-ified binary number, with arguments `36` and `0`, we can match our mask string length:
```
'1011'.padStart(36,0) // '000000000000000000000000000000001011'
'1100101'.padStart(36,0) // '000000000000000000000000000001100101'
```
#### Parsing a binary number from a padded string
How might we get `11` from `'000000000000000000000000000000001011'`?
Thankfully, we can use `parseInt()` the same way as earlier, like this:
```
parseInt('000000000000000000000000000000001011', 2) // 11
parseInt('000000000000000000000000000001100101', 2) // 101
```
#### Overwriting characters in a string where appropriate
How might we perform this computation?
```
Start:
000000000000000000000000000000001011
Compare to:
XXXXXXXXXXXXXXXXXXXXXXXXXXXXX1XXXX0X
End:
000000000000000000000000000001001001
```
#### Overwriting characters in a string where appropriate
```
Split the mask into an array of characters
For each character in the mask
If the character is an 'X'
Change it to the character at the same location in the padded, binary-represented decimal
Else - the character is a '0' or '1'
Keep the character
Join each character together to form a string again
```
Here's how that looks in JavaScript
```js
mask = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXX1XXXX0X'
value = '000000000000000000000000000000001011'
value = mask.split('').map((c, i) => c == 'X' ? value[i] : c).join('')
//. '000000000000000000000000000001001001'
```
### Altogether now: Writing a working algorithm
```
Store the input as one long string of text
Find all matches within the string from the regular expression
Create a new object, mem
Create an empty string, mask
For each match
If there is a match for the first of the three capture groups
Re-assign mask the string from the first capture group
Else
Create or re-assign to the key in mem equivalent to the number from the second capture group the result of processing the number from the second capture group as follows:
Convert the captured string to a number
Convert it to a string from the number in base 2
Extend the string from the start to become 36 characters long, filling in any spaces with 0s
Create a copy of the string currently assigned to mask, such that:
For each character an array containing the characters from the current string assigned to mask:
If the character is an X
Change it to the character in the same location from the padded binary version of the number
Else - if the character is a 1 or 0
Keep that character
Join all characters to form a string again
Parse the string as a number in base 2 to convert it to a decimal
Extract an array containing all values from mem
For each value in that array
Accumulate a sum - starting at 0
Return the sum
```
### Building a simulator
- My intent with this simulator was to display each part of the conversion process: from original to final decimal
- And to display the accumulating sum of all decimals
- I built it to allow for the data entry of a single decimal and mask, or for the processing of some unique puzzle input
[Try the simulator!](https://aocdockingdata.rmion.repl.co/)

## Part 2
1. Understanding how the bitmask works this time
2. Building the floating bit algorithm
### Understanding how the bitmask works this time
- In Part 1, an `X` signified transparency: keep the character from the padded, binary-converted decimal
- Now, an `X` signifies one additional branch of possible values for the address in memory to store a newly unchanged decimal
Instead of working like this:
```
mask:
000000000000000000000000000000X1001X
changing the 100 in
mem[42] = 100:
000000000000000000000000000001100100
to:
000000000000000000000000000000110010
```
It works like this:
```
mask:
000000000000000000000000000000X1001X
changing the 42 in
mem[42] = 100:
000000000000000000000000000001100100
to storing 100 to the following addresses:
000000000000000000000000000000011010
000000000000000000000000000000011011
000000000000000000000000000000111010
000000000000000000000000000000111011
```
The instruction I see is:
```
Count the number of X's
Multiply 2 by the number of X's in the mask to determine the number of permutations
For each permutation
Overwrite each character whose location corresponds to an 'X' in the mask with a 0 or 1
```
The challenge is:
- What pattern exists to generate the full range of permutations of 0s and 1s?
I noticed this pattern:
```
For 2 X's, the values are:
0..0
0..1
1..0
1..1
For 3 X's, the values are:
0..0..0
0..0..1
0..1..0
0..1..1
1..0..0
1..0..1
1..1..0
1..1..1
```
- Those are the binary numbers 0 to (2 * N - 1) - where N = number of Xs - padded with 0s to the same number of characters as the largest number, 7
### Building the floating bit algorithm
```
Split the mask into an array of characters
Accumulate an array of indices - starting as empty
If the value is an 'X', add its index to the accumulating list
Multiply 2 by N number of X's and store in permutations
For i from 0 to permutations
Convert the number to binary
Pad it from the start with 0s to the length equivalent to the number of characters in the binary-converted number one less than permutations
Split that number into an array of numbers
Create a copy of the string currently assigned to mask, such that:
For each character in an array containing the characters from the current string assigned to mask:
If the character is an X
Change it to the number in the array of numbers generated from i who's index matches that of the index of this character in the accumulated list of indices of only X characters
Join all characters to form a string again
Parse the string as a number in base 2 to convert it to a decimal
Store in this new decimal address the value to the right side of the = on the same line from the input string
```
Here's a visualization of my algorithm:

Much to my delightful surprise, that algorithm generated a correct answer for my puzzle input!
I'm not interested in updating the simulator to show each of these permutations, given how much time I've already spent on this puzzle.
- Both parts completed
- Simulator created
- GIF created
Time to move on! | rmion |
1,045,081 | RP2, the Privacy-focused, Free, Open-source US Crypto Tax Calculator, Is Growing Fast | RP2 and its sister data loader project DaLI are receiving more and more user engagement on Github, in... | 0 | 2022-04-05T05:40:54 | https://dev.to/eprbell/rp2-the-privacy-focused-free-open-source-us-crypto-tax-calculator-is-growing-fast-1a3g | crypto, tax, bitcoin, opensource | [RP2](https://github.com/eprbell/rp2) and its sister data loader project [DaLI](https://github.com/eprbell/dali-rp2) are receiving more and more user engagement on Github, in terms of stars, issues and PRs. Here's a graph showing RP2 Github stars over time (courtesy of [star-history.com](https://star-history.com/#eprbell/rp2&Date)).
Devs are needed! If you'd like to help out these exciting, fast-expanding projects, open an issue/PR on Github or contact me on Twitter (@eprbell). | eprbell |
1,046,981 | Dev Log: Nuzlocke Tracker — Part Three — Promotion | Third in the series of a developer blog chronicling my experience creating a React app. In this part I explain the way I went about promoting the app. | 0 | 2021-08-08T12:15:00 | https://dev.to/diballesteros/dev-log-nuzlocke-tracker-part-three-promotion-23ai | react, webdev | ---
title: Dev Log: Nuzlocke Tracker — Part Three — Promotion
published: true
date: 2021-08-08 12:15:00 UTC
description: Third in the series of a developer blog chronicling my experience creating a React app. In this part I explain the way I went about promoting the app.
tags: react, webdev
---
As promised this is the third part where I worked on how to promote the app.
What motivated me most is knowing that people are using my app, so getting this app in the hands of other people was critical. Truth be told I’m a complete novice when it comes to promoting an app, however, I decided to dive headfirst.
## Where to?
I knew that I would have to begin to research SEO. Unfortunately from my research, I found out that React apps are typically at a disadvantage when it comes to SEO. This is because the crawlers that index the page look through the HTML however the HTML of a React app is dynamically generated.
There are several solutions to this such as SSG-type frameworks like Next.js or Gatsby. I decided to deploy with Netlify because they offer a plugin precisely to generate a SPA (such as React) to further help with crawlers. This would help initially with it appearing in searches.
Also, I figured I would show this to various Nuzlocke communities. I focused my efforts on Reddit as there is a fairly active community around Nuzlocking.
This is the original post. It was very successful! Not only was it very well received, but I also received a ton of feedback to make the app considerably better.
I also posted it to other Nuzlocke forums and various discord communities!
## The follow-up
As I continued to iterate over the app I posted it several times over the course of the past couple of months to show and detail the updates.
Every thread was fairly well-received but none of them were as successful as the first, however, every single time I gained critical insight into bugs and features people would appreciate.
## SEO
As for how the SEO went after all the posts, it was a mixed bag. For Google, it’s been a real struggle to get to the top page, although a majority of the links ahead of me seem to be illegitimate backlinks.
However, on bing and several other search engines, I am consistently within the top ten. Researching on how to exactly boost up the position on a google search definitely requires more research.
That’s it for now! I will most likely make another more detailed post on how to boost SEO from all the research I did on React apps. | diballesteros |
1,047,036 | Dev Log: Nuzlocke Tracker — Part Four — Deploying PWA to App Stores | How to easily deploy web app as a PWA (Progressive Web App) to the Google Playstore, Microsoft Store and Amazon Appstore using PWABuilder. | 0 | 2021-09-26T12:15:00 | https://relatablecode.com/developer-blog-nuzlocke-tracker-part-four-deploying-pwa-to-app-stores/ | react, pwa | ---
title: Dev Log: Nuzlocke Tracker — Part Four — Deploying PWA to App Stores
date: 2021-09-26 12:15:00 UTC
published: true
description: How to easily deploy web app as a PWA (Progressive Web App) to the Google Playstore, Microsoft Store and Amazon Appstore using PWABuilder.
tags: react, pwa
canonical_url: https://relatablecode.com/developer-blog-nuzlocke-tracker-part-four-deploying-pwa-to-app-stores/
---
This is the fourth part in a series where I describe my experience developing an online web app. After several months of deploying various changes to the web app and receiving all kinds of feedback (mostly from Reddit) I had gotten several people that were interested in a native app version (iOS/Android)
At first, I thought this would be an incredible amount of work seeing as I have not used any of the respective languages. I briefly considered taking up React Native to port the apps. But during my research, I came across the fact that PWAs (Progressive web apps) could be deployed to the Google Playstore and the Microsoft Store.
## Making the PWA
First I had to make the app into a PWA.
I deployed my reacting app using [Create-React-App](https://create-react-app.dev/docs/getting-started/), fortunately, it offers a built-in opt-in service to create a PWA out of the React app. More info: https://create-react-app.dev/docs/making-a-progressive-web-app/.
In the index.tsx file you can include:
```
import * as serviceWorkerRegistration from 'serviceWorkerRegistration';
serviceWorkerRegistration.register();
```
This will automatically do all the configurations necessary for it to work as a PWA. For extra configuration, you can check out the manifest.json in the public folder.
Take into account this will only work for HTTPS.
You’ll be able to see the service worker installing the PWA in action in the console:

## Creating the APK
Once that is out of the way the next step is to generate the APK for the PWA. Luckily enough there already exists a site for this! [PWABuilder](https://www.pwabuilder.com/) allows us to generate all the files necessary to deploy the app to the Microsoft Store and Google Playstore (and as an added bonus the Samsung app store)

On the home page there is an input to scope out the PWA and build the necessary files:
This will give you a score for how well the PWA is configured (this mostly depends on manifest.json configurations. Following this page are the generated store package files:

## Deploying to the stores
Each individual store package contains information on how to deploy it to the respective. For the most part, it’s just uploading the APKs. Take into account that there will be different requirements depending on the content if there are payments needed.
Also, both stores require in-app screenshots for the store listing along with several other details.
After a few days of waiting for the approval they were both available:

## Bonus
Decided to also deploy to the Amazon Appstore as the majority of the extra work with descriptions, in-app screenshots was already done with the other store listings and for this, you only have to route to the respective webpage:

Ending Thoughts
Updating them is as easy as generating new files with PWABuilder and redeploying them.
And that’s it! If you have any questions regarding the process of PWA to app stores let me know in the comments below. | diballesteros |
1,049,159 | The emotional gauntlet of learning to code | Analysis of the emotional turmoil of learning programming & ways to get through it | 0 | 2022-07-21T22:30:51 | https://dev.to/heyjtk/the-emotional-gauntlet-of-learning-to-code-k76 | softwareengineering, career, mentalhealth | ---
title: The emotional gauntlet of learning to code
published: true
description: Analysis of the emotional turmoil of learning programming & ways to get through it
tags: softwareengineering, career, mentalhealth
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ribc8y3hnhehtjhr63ag.png
---
In a recent post I wrote about my long journey getting into programming, it made me remember some funny moments from the most intense period of my programming education which took place Spring/Summer 2016.
I attended a coding bootcamp, and to say that it was a challenge would be an understatement. There was so much going on. I had just moved states, recently lost my dad, and kept getting really bad headaches (whoops, I needed glasses! Go figure).
The specific memory that sticks out is, my anxiety during this period was through the roof. I didn't have a particularly fluid transition to coding, I wasn't great at it. To attempt to deal with my nerves/stress I remember trying at various points to meditate. Ultimately, if I could clear my mind at all I would immediately wind up stress-napping. What a mood, as they say.
"Stress napping" I think is a response perfectly indicative of all the chaos involved with learning to code: it is mentally exhausting, emotionally bruising, and in my case an ego-shredding experience. So today I want to unpack a little bit of why that is, how it manifests, and most importantly some things I would recommend to help with it. (Help, not solve - ultimately this is a hard thing to do and in some ways there is no path but experiencing the difficulty).
## What makes learning to code so grueling
If I had to distil the difficulty of learning to code into main areas or themes, I'd probably organize them as follows:
**Mentally challenging**: I had always been a good student. Not just in one thing, across the board. A-B student, quick learner, and in some cases didn't need to try particularly hard to do well. Coding changed all of that. I could not let my focus drift a single bit. Applying every bit of determination and attention I could muster, still things were going over my head entirely. Things that looked "simple" as other people did them immediately became mystifying hieroglyphics the moment I was on my own.
**Distractions and conflicting information**: Learning to code alone is tough. Learning to code while learning Github while learning about IDEs while learning about the `inspect` browser options while learning about Trello while also being a new Mac user was BANANAS.
This gets arguably worse at the point when you have a working knowledge of what I listed above and think "ok now to get a job".
One person tells you to focus on open source contributions on Github, which you still don't know well. One person tells you to focus on algorithms and data structures, which are bafflingly abstract. Another tells you to build a portfolio. Another tells you to do FreeCodeCamp or Codeacademy or Code Wars. Another tells you to practice Hackerrank. Someone recommends Eloquent JavaScript, someone else recommends a Youtuber, someone else recommends Cracking the Coding Interview. You are drowning in material.
To be clear, none of these things will HURT you if you are able to work on them and make progress and through that progress gain experience and practice. These things _may_ hurt or hinder you if they are so overwhelming that you don't know what to do, or if you nervously rotate among them and are context switching so much that you aren't getting traction or practice with code. (More on that and approaches to manage it later). I don't know if this is a real term but I would like to coin it if not: **panic-cycling**. I see a lot of new programmers panic-cycling through approaches and due to the churn, feeling stalled.
**Exhausting hits to self esteem**: Neither of the two previous points are particularly helpful to feeling good about yourself. People have told you five million different things you are supposed to do to become employed, and doing any of them feels like a herculean feat. The interview process is also bruising. If you are in dev communities, you may start to pick up on that developers can be dismissive and rude about beginners, Stack Overflow answers are downright hostile sometimes. Trying to use Stack Overflow literally the messaging you receive is often "This question is too dumb to ask" in the form of "this was asked elsewhere" or "this question doesn't meet our criteria". (More on this later too).
**Weird industry cliqueyness**: In the background of all these other things, as you start coding you start to pick up on the social strata, which might seem bizarre to an outsider. Why is frontend or PHP perceived as less prestigious? Is this thing I'm about to learn "dead"!? (People loooove declaring various technologies "Dead!", its bizarre honestly). So although you are in a poor position to do so, most new coders I know feel immense pressure to pick the correct "path" before they realistically know what it should be, an added worry on everything else.
Phew. I was exhausted just WRITING this list, just REMEMBERING these feelings even though they were six years ago!
## How these stressors manifest
Something I find funny that writing this post made me think of is related to travel, something I love. I started traveling solo when I was 17 and have been to sixteen other countries total. Would it surprise you to know, travel is so tiring that on almost every trip I take I have a moment in the first 24 hours where I think "this trip was a mistake". Whether it is a malfunctioning GPS in Iceland, getting stuck in a bathroom in France (door broke!), there is always some logistical mishap that makes me doubt all my life choices.
Invariably, after my "freak out moment" I get a good night's sleep. Wake up the next day. And am a new person. I start to feel the vibe of the city, and stop feeling self conscious about my language barrier and start enjoying myself and just taking it all in. Even knowing this will happen to me, it happens every single time without fail.
What does this have in common with learning to code? **Exhaustion**.
Ways that stress and exhaustion manifest learning to code:
* **Panic-cycling**: (talked about this a bit already). I'm no doctor but whenever I think of panic cycling that new devs do, I can't help but also think of [decision fatigue](https://www.ama-assn.org/delivering-care/public-health/what-doctors-wish-patients-knew-about-decision-fatigue). New devs feel pressured to make so many decisions that I think their thinking gets frenzied and they wind up trying to do it all and even more exhausted by context switching in a nasty cycle
* **Emotionally charged relationship with coding**: There was one person in my bootcamp who I will never forget who really struggled with this. In talking through debugging, you could hear the person's voice get noticeably emotional with frustration as they felt like they were trying everything and nothing was working. Debugging conversations would turn into frustration conversations, and it was obvious that the person would not be able to productively continue until they calmed down
* **Fatigue errors**: It has been [studied](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1739867/) that being sleep deprived can have an impairment effect comparable to being actually drunk. For me, this is absolutely true. I get physically clumsy when sleep deprived very noticeably. I also miss things. Tired junior coders are very prone to making errors in my experience
* **Thought distortions**: If you haven't heard this term, a [thought distortion](https://www.healthline.com/health/cognitive-distortions) is what happens when a logical thought becomes emotionally charged and then spirals. Learning to code, it is the difference between `I'm struggling with JavaScript` and `I'm not cut out for this`. One of those things is a logical thought. One of them is a projection spiral based on that thought. Other common ones in this vein: `I don't have what it takes`, `I'll never be able to do this`, `I'm not smart enough for this`.
* **Procrastination/avoidance**: When I first learned to code, like many people out there, I initially assumed backend was out of reach for me. I thought my artistic skill could carry me through on frontend if I could pad my work with design related activities. I avoided exploring my options or trying to fairly evaluate my interests because I was operating from a place of fear and doubt. Which leads me to the next point --
* **Limiting beliefs**: These show up in a lot of ways. Delaying the job hunt because you think you aren't ready and no one will hire you. Blanket judgment of certain topics as "hard" and beyond you. Heck, in my bootcamp there was someone in the same area who wanted us to be friends. I initially avoided her because she was too good a coder and made me feel bad about myself. (Happy ending, I joke that she "bullied" me into us being friends, and here we are six years later good pals. She is a CTO!)
## So what actually helps?
So first of all, I discussed the fatigue thing. I will say one thing I did differently than the people in my program was, I never stayed up even close to 3am working on projects (some peers did!). I'm a person that needs my sleep, and I was self-aware enough to immediately see that coding tired just made me break my code even worse. Draw from that what you will. For me, I just _couldn't_. I was getting killer headaches (needed glasses, lol) and was just very quickly like, no. I'm not going to do it. I'm not going to stay up all night.
Second, I will address the context switching thing. Would it surprise you to know that I have never meaningfully learned code from a specific book or video series? I don't like videos and for whatever reason never got into O'Reilly books or anything else either. I've never done open source. I've done Hackerrank maybe 3-4 times ever for interviews. I don't have a presence answering questions on Stack Overflow. I didn't meaningfully network early in my dev career. I didn't bother trying to learn algorithms meaningfully until I was a couple years in. **So take a deep breath**. This knowledge isn't going anywhere. If at some point you are unhappy with your learning materials, you always have room to change them.
"Changing them" is different than panic-cycling or feeling like you HAVE to do them all, immediately, right away. When evaluating switching resources (let's assume you are in a program to learn to code or have a specific goal that means you have some basic learning resources as core materials).
In picking your materials and practices, learning to code is a lot like developing a fitness regimen: what method is the best? **Generally the one you are willing to keep doing on a daily basis**. Pick something you can deal with. Focus on being consistent. Focus on showing up.
I also am a huge proponent of **arguing with your limiting beliefs and thought distortions**. As I left bootcamp and prepared to get a coding job, I would often talk out loud to myself in the car preparing answers to imagined interview questions. Maybe since I was already talking to myself aloud more than normal, I started _also_ talking out loud against my negative thoughts:
`Negative thought: You aren't cut out for this`
`Me: Hey wait a minute, you just started! This isn't magic, people are learning this all around you. Why NOT you?`
`Negative thought: You're not going to get this job`
`Me: Fine, but I'm going to apply anyway. I have the interest, so if someone is going to say no its going to be them, not me.`
`Negative thought: You can't hack it as a real dev, better be sure your portfolio at least looks pretty since that's all you are good for`
`Me: Maybe I will, but maybe I'll try to learn some backend too. Maybe it isn't for me but it won't hurt to try to become more well rounded`
`Negative thought: Everyone else is understanding this material faster than you`
`Me: So what, I am enjoying what I'm learning and I can't stay bad at this forever. Who cares about everyone else`
Maybe it sounds kind of hokey, but as I told my therapist about how I interrupt my thoughts she pointed out that I'm essentially doing cognitive behavior therapy within my inner dialogue. Hokey or not, it helped! It helped with the rejection, the negative thoughts, and the hits to my self-esteem.
I would love to give you a recommendation to deal with the last point I outlined, `cliqueyness`, but for that one all I can tell you is that there are not some special social rules that mean the behavior is OK in tech where elsewhere in life we recognize that it's toxic. Cliqueyness is toxic everywhere. Early in, I realized I was never going to spend time in spaces with that vibe and I've been happier for it. Outside of occasional forays onto stack overflow, I rarely tangle with that side of the tech world.
## In closing
I wanted to write this to say, I truly get it: there are a confluence of factors that make it truly a marathon of emotional regulation to learn to code, on top of all the hard learning and the non-emotional challenges!
I told you already, I was NOT a fluid coder. I felt like the ugly duckling of code for a good year or more. The one thing I did have going for me though were techniques to regulate my emotions and discipline my disappointments enough to continue on.
I was telling someone the other day that I feel like my first year of coding was more challenging than all the other years combined and god if that isn't the truth. I never wanted to forget that feeling and it has made me passionate about mentoring and being part of a community that could make newer developers feel more supported than I did. Thanks for reading, and if you have any of your own tricks for staying grounded while learning to code, drop them in the comments!
| heyjtk |
1,061,401 | About Kathmandu to Lukla Flights | Our page Kathmandu to Lukla flights is showing mixed content error of images, we removed that image,... | 0 | 2022-04-20T05:59:49 | https://dev.to/nepflights/about-kathmandu-to-lukla-flights-1j5 | Our page [Kathmandu to Lukla flights](https://nepflights.com/domestic-flights-nepal/flight-from-kathmandu-to-lukla) is showing mixed content error of images, we removed that image, but still that image is displaying.
we build our website in 2 version both php and wordpress. what might be the solution for it? | nepflights | |
1,061,517 | uGYWtH | ca퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜퀜𓈛𦒼𬡏璫骋𦰏𠭆𧑼𧁱𱀮𥂤𨚘ྶ𧣔ᠰ𫱥榬𢐍𨸻𪔖뜍𞤠૰촩𣼲𫻺ẇ𠪰ў璵𥍏い𦢆𨛌帩쫲𘮬𭡳𧚹환𪱌旳ᥛ𤣐ࣝ𨼺𤄢𮂂哐꿥㾁纬𭑟𮔗𬢻🧠𩠀쮓𑁩𱄞땨𣻙𠓾𰍛𛄊㊟韻悈씜𨅩𬪁𰩀𢹽𪡈𮧪睽𖣘𗝫𡃐閙폮ꀪ帽㧁𦤃ℇ𥆢𠢆𐬜慱퉸畬Ŀ𣕽蜍呙촠靧𭹜𐝌馔🬣𘒛鷶𪶠𐚦␢\\u0093𫟕𧿕ꔻ梈𩶳𑪟磱斉𬎈𓅱𦾡𐧖𫄥뮉𐺊𓐛𩳿𐚴꓃𡕪𦅳𪮳䞸⩦蓟씫𓎯𮜪졈𢝳𬵋首跰𮀸🩃𢇢뽰𰮾뗂𬰠ﵔ𥴴𬜡𠹙𥙕𨹇↡콖ꢋ𨘵徖厑凧𞤿竜𰨤㎑𤮼𛇎𭧪𖼔𪿑쏛𭭑𫑭怅𭧁ᅼ甂嵒𬷩⇩Υ𪴤㈙𤋮𗲄憥㦽፯𫒔𗘎泉𱂦𪵨𨗡𤏚㓮𦫅꣼𤲌𫎃𧱂⋳၇𧳘䎰𤭏𧡽🀾蘋𩃓𡤑륈𬰭𪒂𬩝𥬟⑳䂇䛼齅𬦴譚𨸅𨩌𰭳𭺧砠𝙾𬹆灏𦳊¾𧤓齫㪘𡩂㝹⻀⬼𬖮𑜌땳𨁇𢂃𩃛袀ł𠷣𢗄Ţꀸ𥁟뒌𥚹𒌒𨈓𑰵덝褖𪡾䵅𨄓𡼎𡾝㴅䍵𬆅𫊽𧩵俴𦋳𝅀𦏒柘𔖓𡟠𖣞呱𭬥𢡋𡹫鰢팭𢇷㉢肬𨇉𥥼𮓇誛垕𓆚𩐊쫚🐉㱷ꪉ겱沒듰孅헔汱蛻휱榤䣔ꃅ𫒮𨣔犔𢁯⬖쉨ꞔ㺺𥔑𧝄𖤲𨘲釸𨯘𤊕㶟𦓟𫜞ꜷ堈𧓊遡泏𪠁ᇵ𨷨⭝𧯒⊥𤮖𨨶𧐮㪌☁𐢬𘠠漶𮁦𣔦𤯡𤍨ϲ槏𭭥ꗐ𦛁邢曝捰𬀠🏇뤆ᩤ𗂝𝦘⫩ꂪ亻ՠ𦳛𧾧𩜁.帼剐𧄨엡𩰭捾𨸧揤𞋙𠺭𥍾𩋵𮥛𪤦땬Ყ왌㚕𢝬𝓲盢㡦🝫𗌅𠐃𬊞𑗏𥸎𪝊𝦨𩩍𬾓⪢忔㫯ᨴ𫀭ۿ냆惔呆𭱎𢾗祫벝嬘ᐅ걱銝༄𝗫掙𨓦솛茞偺𥗑𥑬𩴋𤾸䜮ઞ𭕰𣆀𤤹𦫄𬷄𑈯ﳒ疵౦𨾟𦥞ꮤ𪤠𩟆뾇𝇞烏𝈕𞡞𪕛𠤤𒉒彷᭚א𫦧𰜣𥇺𗎢𦼜𐌉⭮𪠓𫲇㖱톗捿웆𭛒駆𬖍ಌ𧗹𭈦垈㾆𬶇䪀幒𡈬𠈡鮗𬣳즐瑚𩧤𗅵𤛢𥼕𧳚⚋뾸婕阍䩖뻼𫰅ᘣ塬ۧ샻座륐𮠃喚㴵🦔𭽯🏶𬴶𧵔𬀧𭝆銽𭟤𡁣𘆮뛝𐳍𩊒ḏ𒁮𫶟𬶴𦅚쥭𢞂ⅇ賜𰨑𩸿𱊸𰽕𮍽𫣀𥮺𒋑𮖖⳱𘊃ડ뷉𓃉菋𫏱ኌ뇑𰆻𩳳𧙈𢅙𢙃𛄈ꪨ翺💪𰂢𘥼㯤쟥橮ᆳ萞𰑣𣣴𘤈𗁓𥂆𠇫𠇵𬯩Ⳟ됰𗐃𧀺을笆㤷𞸷𪹑𔘄ἇ瞡𱂷矺𬄄ؗ𠦼쳬𱈴ᰳ𘂏ૡ𦲗蜦𰨻𑋓𥔙𤵄𪯿𗺦𗣥昝𗍍壆Ꙑᘛ𢁛𧢥璐◓𰷜ꈛ茝𬌶䄊猒𣤹𧘛𢠱𦬔ﯷ𐏏𪽅겺쐷𦇵𓋓𨵊𬬞𖫰𣓋𢛥𐿮𢿡𦘭𨇐믜罹ꅒ𬗤橨𩥣რ밆𬴱𪂭𐊀ᘐ𡾯𡞗𠔂𬍥󠆂𧶈𘏨𡷄௧𢈨𣝎𤡻𑘀䲮彝𭝚쌴𤭶岫𪛀𡱛謆䩯𪫻엎𬲅𮠩𮧐翳𥝽𪰇챃𓂞𫡨堁烜ᵍ疯型珱𱃳ខ쁁𐡵䪆欒迤农玮𘨰ᯬ𥵭𑐔𢇤𤴩秸𰫙𧮕ᒏ𡵩퇡𬈰𪧖↟뙕𝇖𭧚퓌𨅖𡨪𗴷𰶰ඣ𩢡ꡝ哋🦤𦴓刺縓볳𝅆𘮂𒓞𥽌𗀣𫓧𓈌𡶋𡱪𘧺쥡旇𫏰𘈔𮮚𠽠𢩭쏙.𭹆暔𡩹蝕솵翑𰻻𧲸𤻢肻𧰓ᎀ𬚟𤏣𠆔륰𘱐𐍬𭼡𤀂𩠭𭪥킺𡄮𘱅鴘࠳𦭄蝂䢞晒𦃇𗐟𮌯𭈀𪕉𒒆팥𤤔媂郢𔐜𣦖𫑼𣠞𑓓𦥘𦔛𨊸𫹒㖀櫊궋𤲰璅Ꭸ𬩬𑨶𱃳𥬠ﬢ疪胥𦒹退𒓷𰇃𠘲𮒈崍ﰷ𧻝ꄸ𢅣戫𝝚𣌿𨻀ᬠ𬤖𢆭㨢㣟𝠃𢩋𣗮𘞧⑴瀾⌃𐔰鲀櫳𭒝𗸟滽⺦𰫸𰃽俾𪈎鐿龂竀偔𠁃䄛𨘪擷𦜮繰𗌀𬼱瓘开𢪼珹Ժ嫞쀁ಽ䎿𗵄쮃𤈙𤀂祗鮬𮉬𥝔𘄶𣤐䲔𩱚吣瞱떹𭨩𢹘ꍝ宩𩉉㈖𫜄セ𓀳𢟝姮쯋𒌭゚𰞻Ý真誾膺뽮餥𐇲𧰿㟲᠂⢑𫬭𝝽闊𝛃嬤𢲣劻飜伐𰱗𰔘𬎼𦉽𑿫ᡨ𫈲⨪鍔𗾿𧱊𬡼뜕𧻧踋𤐝𣟀𛃊𐴚譿𩎦𤻰𡡎䢟𦭷𧵣𪋔𫛆룐𘣪𑿋𛁼🤫𫩉𫶥𫈴𣊞驤𣛾🕫𠜃헗𥼉𭀙𗝅𰃆𠸢𣈱䣫𰾺꧖𪥼셼𪻧𥃸𥮙𪥌㊎𐴍𭆊给𰉸🌚좢蹙殍𪥷𩼬딠㞳굊𡋱𨣯𩬏𐤀睙𝓮𧗯𧟮𪦭鏯𨄄𧙴𪩘荁ꉔ𞸮𮝬ﬣ𤆟𣽰龬趨ᗤ뫾㦡𞡀𨇔츅롉팽𢒘𫿱𧷊냂攝招ሶ𠷰婶𩉍↨𰧶驃𨥑𫩥𧞗𝘁냞𫗜𠢈𘲊𐎂𬰨櫐ꃫ𫌫脈𭸓䮉瘱팅𧳚𬯟늜𗝑𭟾𗖢𠟵𡢝揬雦𝕥賣𣉵碛𡤾廒菱𧷰鼯𮏱듒齟່𰅴䇣𡅱얥𥲣Კ𒅻𘝳𭒹𩗴𡰔ֺ𫧀𪫦鞿𗫾鞢ଧ𩟦𮗴𤻅𣙀㟲𩛽𖠐𬏝𨂘埽𘝨詝🐽朤𑖡𪓪𱈆𘎥ᙞ濲𮢜⡑𥞼𥶾剖ϵ𝆺𝅥🬗𨇲띨𗚇𗳺𬀁𓃙𭁯ൃᄅ𗥫㺑𣣮𑒝𭣿첳𣞷𫿝踧𪷧𐧢鄭𑠮蝿ྫྷ韹庽𔐱轔ⱪ𮍙𥾃ꈹ붨趿밼𛊮𣛳𤯢滆ೆ埮첔𢽪🭹𤕶𧊾烯𦖆𪶡𫹶𝕰姍𦮻𤋑𘌔𗉫벆⚉읐𢕉𘭂𗇨农屿쥶𧟂𭗏ᱡ镧𮤏𗚏뗐𔕪𡰧貃𣰝𬍷頎𰨞𦅖䷐𐅲𩓴𢋆눷𦣀힀秐碍𪏽𒇍ꚣ𦌲뼳疉𢌹鸦㣀𤈇ﲈ𰏹𮚿𭑿𝛫🕼䌆ꚴ愊𑨂屢𮬔巂珱𘥁➨𬟝𨺜𡨦⼆𡵓㹐序밪ᖠ𒑣🨶됄𰼒𗩾滩𡥞𦻜孏𐊫𪁫𫶘𦫼🭹𰵆𥑽𢅷𝈺䅧𪜜晓𭷗掤ᗪ쮪𰆵𢨇𡼝𫎋返𰯳𤡮ₜ𧏿𣣍𗋅ⶨ𝠚㉏𘰰厥𦦓𪶟芀𪚨𰐊𬀱𩵃𰼰㜶诧샯ⶉ𪓃𘄴Ꜭ𬣇♟縲㠣𫥠𛉯ఢ󠅕𭺹왎𩝨霺𮕔𑚚𤅉𦑑结𰫬𧚮𑨠𡤽ㅩꋅ𩻡𩟮𩛌🨼⌰𥡸Ḽ崺𠨣𥄅𰼜鸶┚𡨐嘲🬄슭st𨊃옣购蕾𰈹𬨕𢗢𣕱𧾀𝍦ᓱ𬚚瓉웥𭠜渄𭸄ꌉ뿾𥸡𒋽𗥉漹𭥚떾𭼦𑰁䆸𰐩𡲓萴𝚳𨏹㡟𣒳𫹙𠭮𡎲𩯆屓𣄫𔒏晀𮆱𬚫𭢆𮒥𰏎㚣禇𭦈펤𮠽𫁃𗸽ឿ𧼶𮥍𣸪缡䚬ꓱ潪𫒷ꪞ𪑟ḁ𢮢Ⳃ𝖺諬𧲁🇽🔪𧑥𩡂덶𤱎𰴶湄𭺨Ć⇕䄤𣝗ἱ𨅽뜂𐩻🤢𢝸튎᮳톫𦏽𠿯𣗿𢅓㓝舞𘮩⨗𦜸𠮜혓𪹖𠛂飓𐇽㹺𭭝𑜧鰥ⓕ𝐉಼鼭琥ᖴ냕𘣚𬌟𩷛䑫𣮟𫄿𐫏༯𦄶𮁠𘂕𠞻🠡䐽𢁡𭨳𩇹𱆦𓅉놽磲𤎓𬙯𪀟𭒰ϳ𝈨캴撹𗒦胷𘩻𱁦𫡫𦴜퀝𐜙鹣뉡兪🃝뭉🤦𪡓𑌹𦗿甽𭴱𠆣𢟝𦆓㾛🦓𨌒듣𤕣𘋟𠵲𱍀𦻻𧬌𗲜𫬢닪𞱼㸝ꏁ𡼷𦔸亜忶棓𩂤🭈𐺙𩲢㵊𫅁𘖸鄓髺䵟🮻ᐲЙ𭋀𱈘𗎣𧲃𦨸ṹ𩺠ഊ𤵊𮄹㺓𫷴㱜믭𩸑福𑶉𖡢𪯘𥕥𢘦𝁮𱅻𬱈ベ𥻭耽𗣚𦃉𠂾蕨𧆝凁𦑱幷𝕿𘣨湁𭕞𫊶𢼛藸𘥈ۤ붱𩒗𝙬렝𡰎𝒬𫌼𭖬𨳏撝⳾𬭥四𠣡끱럁派𫬐䛥𡠊ᕚ𣘍𭋄𪫹𧠵𡅱𪧻𥻐圬𤯘弘𣏮𰭿𥗁𦪎䯩鴤餓𗑿𡡃뾊榠𡍛ᓯ᪸羠ᔧ祣𰜧曐𨌴䖳𱂛잀쬉𡦆𖾄𭻑𣉩𗔲𢺗𝐖채ퟥ㫢蠚𬏶𔔅磂𰉟𣿆렿𡔑𝆌꽏𑤆緯ȿ𫸭𤏙𩸧𠱿𥕀𧆱𗝗悼𬗕𩏄더𨆹蚭𢻚끏⨒㭴𬴤쒴𤳲𡭍𣵚🅣÷饖䘍𬌤渟𥀹勞쮁䘪𐅧𨘱킄𢘧諜𣖯𫂺槒𠙸𒋃ꠦ𰗀𐀇¼𩴈⤧阖𨞗矴⾿톂𔕫㛧ꅷ𑶨𘦩𧏅瑒觸𝤠𬵫Ẏ𗘪𫮂駖썭𫐾邒𣗼𐺐𰧒ꀽ笗ሙ𩬦㪞ꎸ𗿣🂬ꋁ𭾽𗪦𭅽𡕹🚚摜鄵𤆏🚂𧋱𠽜㝂扳🍖𠵬𑰳𫎰𬪙𥫧𥀭𐹯훽𪲦팑𫦮彵𪩇𥜯범𒂿𠒵鱗癘𨇆𬻥稹⌬𡋤鄠𬽚貘𢕴𠮝𞀍퐞𨴻𤃫₉⻑𑲴𨵎禃𬝺𮏴𝑏𨡜젝ⱆ𢺭𰹴丂𝋡弄Ṕ䆵熸𐔵𪕌𢃟𭅬𓋨𗳡𨦥𬏚🖅𞴠𮆵┰鯱𞋛䦂𠅸岡𨠀骠𘌗ꦲ기釺뿧𘁀㔅𧝅徊𖫦𑄡亽𱆱뗯𨫼𩭞접𩳱ᷴ𪒎煌⥜覀𑑘𞲏풩𰍄𥩖艇𐃹뼃𬧃鍠ꪸ𧴏𐦅𦣨췹𧸋𑀅𣄙ꄰ𐀝𐭃䋾𫹟揦𗒝𛱂鹪𪒫𗜪崜𥶖齔욋´駗𤙏𪪂Ꮶ⫢ﰰ👈𬎺ꧏᲐ⼷䒴𩭿𥻃𮭠𐊓ᅮヘ𤮢𦟙𠨏𣦷𫆡𨡀𧍥𩮪𡛞𠕼𩧫𢿙晸༻ꅰ𒊒쒳益𝞔𩬪𫦭𡈛繧𨿷🜯公𢔐䐎𧸬𐾲𦒭𗾭ḧ𣞂⺖얋𧮴𮜙禈ዮ𨮜ts | 17,808 | 2022-04-20T10:15:40 | http://example.com/aeiou | umdt5bp | z03Zz7v0yruzl42KV | ludovicianul |
1,076,345 | How to use Laravel Sanctum for API Authentication | Make REST API AUTHENTICATION in LARAVEL 9 USING LARAVEL SANCTUM Laravel Sanctum provides a... | 0 | 2022-05-05T13:51:56 | https://dev.to/techtoolindia/how-to-use-laravel-sanctum-for-api-authentication-25cm | laravel, webdev, programming, tutorial | ## Make REST API AUTHENTICATION in LARAVEL 9 USING LARAVEL SANCTUM
Laravel Sanctum provides a featherweight authentication system for SPAs (single page applications), mobile applications, and simple, token based APIs.
## Installation Steps
If you are not using LARAVEL 9 you need to install LARAVEL Sanctum Otherwise you can skip the installation step.
### Step 1
Install via composer
```php
composer require laravel/sanctum
```
### Step 2
Publish the Sanctum Service Provider
```php
php artisan vendor:publish --provider="Laravel\Sanctum\SanctumServiceProvider"
```
### Step 3
Migrate The Database
```php
php artisan migrate
```
## USING SANCTUM IN LARAVEL
### User `HasApiTokens` Trait in `App\Models\User`
In Order to use Sanctum we need to use `HasApiTokens` Trait Class in User Model.
User Model should look like.
```php
<?php
namespace App\Models;
use Illuminate\Contracts\Auth\MustVerifyEmail;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Foundation\Auth\User as Authenticatable;
use Illuminate\Notifications\Notifiable;
use Laravel\Sanctum\HasApiTokens;
class User extends Authenticatable
{
use HasApiTokens, HasFactory, Notifiable;
/**
* The attributes that are mass assignable.
*
* @var array<int, string>
*/
protected $fillable = [
'name',
'email',
'password',
];
/**
* The attributes that should be hidden for serialization.
*
* @var array<int, string>
*/
protected $hidden = [
'password',
'remember_token',
];
/**
* The attributes that should be cast.
*
* @var array<string, string>
*/
protected $casts = [
'email_verified_at' => 'datetime',
];
}
```
### API Authentication Routes
Create `AuthController` to handle all authentication realted to API
```php
php artisan make:controller Api\\AuthController
```
In `routes\api.php` file update the API
```php
Route::post('/auth/register', [AuthController::class, 'createUser']);
Route::post('/auth/login', [AuthController::class, 'loginUser']);
```
Now update `AuthContoller` with
```php
<?php
namespace App\Http\Controllers\Api;
use App\Models\User;
use Illuminate\Http\Request;
use App\Http\Controllers\Controller;
use Illuminate\Support\Facades\Auth;
use Illuminate\Support\Facades\Hash;
use Illuminate\Support\Facades\Validator;
class AuthController extends Controller
{
/**
* Create User
* @param Request $request
* @return User
*/
public function createUser(Request $request)
{
try {
//Validated
$validateUser = Validator::make($request->all(),
[
'name' => 'required',
'email' => 'required|email|unique:users,email',
'password' => 'required'
]);
if($validateUser->fails()){
return response()->json([
'status' => false,
'message' => 'validation error',
'errors' => $validateUser->errors()
], 401);
}
$user = User::create([
'name' => $request->name,
'email' => $request->email,
'password' => Hash::make($request->password)
]);
return response()->json([
'status' => true,
'message' => 'User Created Successfully',
'token' => $user->createToken("API TOKEN")->plainTextToken
], 200);
} catch (\Throwable $th) {
return response()->json([
'status' => false,
'message' => $th->getMessage()
], 500);
}
}
/**
* Login The User
* @param Request $request
* @return User
*/
public function loginUser(Request $request)
{
try {
$validateUser = Validator::make($request->all(),
[
'email' => 'required|email',
'password' => 'required'
]);
if($validateUser->fails()){
return response()->json([
'status' => false,
'message' => 'validation error',
'errors' => $validateUser->errors()
], 401);
}
if(!Auth::attempt($request->only(['email', 'password']))){
return response()->json([
'status' => false,
'message' => 'Email & Password does not match with our record.',
], 401);
}
$user = User::where('email', $request->email)->first();
return response()->json([
'status' => true,
'message' => 'User Logged In Successfully',
'token' => $user->createToken("API TOKEN")->plainTextToken
], 200);
} catch (\Throwable $th) {
return response()->json([
'status' => false,
'message' => $th->getMessage()
], 500);
}
}
}
```
### Protect API With Authentication we need to use `auth:sanctum` middleware.
```php
Route::apiResource('posts', PostController::class)->middleware('auth:sanctum');
```
Here are the results.



The complete Tutorial is below in the video.
{% youtube GAB_BqFZNOA %}
If you face any issue while making REST API, please comment your query.
Thank You for Reading
Reach Out To me.
[Twitter](https://twitter.com/techtoolindia)
[Instagram](https://www.instagram.com/techtoolindia/)
[TechToolIndia YouTube Channel](https://www.youtube.com/channel/UCOy6o08Yn9DtXMKqxhD9ivA) | techtoolindia |
1,076,584 | How to Recover Files After Deleting and Emptying the Recycle Bin? | Read this article to find out how to restore deleted files from the Recycle Bin, and how to recover... | 0 | 2022-07-18T07:38:22 | https://dev.to/hetmansoftware/how-to-recover-files-after-deleting-and-emptying-the-recycle-bin-3gjf | beginners, testing, tutorial, test | Read this article to find out how to restore deleted files from the Recycle Bin, and how to recover them after you emptied the Recycle Bin, or deleted the files without sending them to the Bin, and what tools can help you.
How can I get the files back from the Windows Recycle Bin? I accidentally deleted some files and want to bring them back, what should I do? Can I recover my files deleted permanently? Quite often, users delete their files by mistake and wonder how to restore them from the Windows Recycle Bin, and what to do if the files are no longer there. In this article, we will try to answer such questions and offer possible ways to recover deleted data.
## What is the Recycle Bin in Windows?
To understand the possible ways of restoring files from the Windows Recycle Bin or after it is emptied, we should first have a look at the notion of such Recycle Bin.
As an operating system tool, the Windows Recycle Bin is an element of the graphical interface that represents a system-allocated area of the disk space reserved by the operating system to delete and temporarily store deleted user data before such data is permanently erased. It can have various internal settings to manage the reserved space and the ways of storing data.
In all versions of this operating system, the Windows Recycle Bin is located in the main root directory and is a hidden system folder which prevent access by inexperienced users and saves them from actions that could bring undesired consequences.
After files are deleted, they are moved to the area occupied by the Windows Recycle Bin and are kept there until certain conditions are met. Also, deleted files can be restored or erased completely depending on the properties configuration.
The Windows Recycle Bin offers a safe temporary storage for all deleted files and folders. When you delete an element from the hard disk of a desktop or laptop computer, the Windows operating system places it into the Recycle Bin and its icon type changes from empty to full.
If you have several hard disks, partitions, or an external hard disk connected to your computer, each of them will have its own bin, $ Recycle.Bin, and settings. Removable disks such as USB drives and memory cards do not have Windows Recycle Bin. That’s why files deleted from removable data storage devices are deleted permanently at once.
The Windows Recycle Bin will store the deleted files until the disk space occupied by them reaches the maximal limit set for the Windows Recycle Bin. When it happens, the Windows Recycle Bin will automatically remove the old (previously deleted) files from there to free some space for new files deleted only recently.
If you use keeping all your deleted files in the Windows Recycle Bin as a protective measure, you can increase the maximal size of the disk space reserved for its needs, and set your own limit to how much disk space the Recycle Bin is allowed to take.
We will go into detail of the Windows Recycle Bin settings in the next part of this article.
## How to Configure the Recycle Bin?
Configuring internal option of the Windows Recycle Bin is quite easy and doesn’t take much time. It is mostly reduced to configuring the two options: setting the maximal size of the disk space allocated to manage deleted files, and dealing with the instant delete option.
Usually the Windows Recycle Bin has a desktop shortcut created when the operating system was installed. To access the settings window, click on the Windows Recycle Bin shortcut and open the context menu. From the list of possible actions, select Properties.
If there is no shortcut for the Windows Recycle Bin on the desktop (you might have changed settings when installing the operating system), then follow this sequence of actions to have the shortcut displayed again. It can be done in several ways. For example, right-click on an empty area on the desktop and open a context menu, then select Personalize from the list.
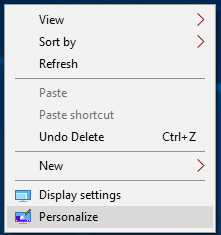
Settings, the main app for all options of the operating system will open in the Personalization page. In the left panel, go to the Themes section, and in the right panel, use the scroll bar to go down the page and find the section Related settings. Now click on the text link Desktop icon settings.
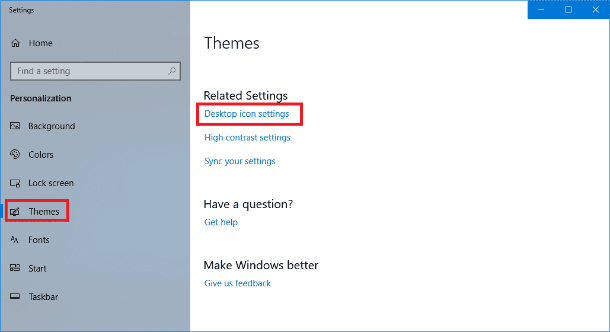
The corresponding settings window will open; in the section Desktop Icons check the box next to Recycle Bin to make the Windows Recycle Bin icon be displayed on the desktop. Then click Apply and OK to save the changes you have made.
In the window Recycle Bin Properties choose the location of the Windows Recycle Bin (for example, Local Disk С:) for which you want to change the maximal size.
In the section Settings for selected location check the option next to the cell Custom size: Maximum size (MB): In the corresponding cell, enter the value for the amount of disk space (1024 MB = 1 GB) you would like to allocate for the needs of the Recycle Bin. Then click Apply and OK to save the changes you have made to the size of the Windows Recycle Bin.
Note: Usually the maximal default size of the storage space for the Windows Recycle Bin should be about 5 percent of the disk free space.
You can change the maximal size for the Windows Recycle Bin for all local disks shown in the properties window. Select the necessary disk and repeat the procedure to change the storage space size.
If for some reason you are not going to set the final size for the Windows Recycle Bin or you want to disable it (for example, you lack free disk space to keep user files), you can enable the function of deleting files permanently.
To do it, in the window Recycle Bin Properties in the section Settings for selected location and check the option Don’t move files to the Recycle Bin. Remove files immediately when deleted. Then click Apply and ОК for the changes to take effect.
Now all files and folders you delete will miss the reserved storage space of the Windows Recycle Bin and will be erased immediately.
It means that recovering them with integrated functions of the Recycle Bin (this is what we’ll be talking about in a moment) is no longer possible.
## Different Ways to Delete Files and the Recycle Bin
In the Windows operating system, there are two ways to delete files: ordinary and permanent.
In the first case, a user deletes files using the Delete button on the keyboard, or from the Windows File Explorer using the context menu. If the Windows Recycle Bin is configured to store deleted files and has a certain reserved size, then all files are moved to the Bin after they are deleted. That is why the user can always rely on integrated functions of the Windows Recycle Bin if some files were deleted by mistake or if the user decides to restore them.
In the second case, when the user deletes files in another way (for example, with the key shortcut Shift + Delete or if the option to destroy files immediately after deleting is enabled in the Windows Recycle Bin properties etc), such files are erased at once. They will not be displayed in the Windows Recycle Bin and restoring them will make you use special third-party software.
You can read more about the two ways of deleting files (ordinary and permanent) in our previous article: «Files sent to The Recycle Bin: How to View, Restore or Delete Them Permanently».
## Three Methods to Recover Deleted Files from the Recycle Bin
YouTube: {% youtube 2vVxDooFNHc %}
As we have already said in our article, various methods can be used to restore files depending on how they were deleted. We will focus on the three main ways to restore deleted files that you can use as you think fit.
* Restoring deleted files from the Windows Recycle Bin to their original location.
* Recovering deleted files with freeware.
* Recovering files deleted permanently from the Windows Recycle Bin with the powerful software tool, [Hetman Partition Recovery](https://hetmanrecovery.com/hard-drive-data-recovery-software).
Below, we will describe each method and point out the possible reasons to influence your choice in every case.
### Restoring Deleted Files from the Recycle Bin to Their Original Location.
This method to restore deleted files is good if the user prefers ordinary deletion of files and folders, and the fixed size option is enabled for the Windows Recycle Bin.
Open the Windows Recycle Bin by double-clicking on its desktop icon. Otherwise, right-click on it and open a context menu. From the list of possible actions, select Open.
| hetmansoftware |
1,077,732 | Mother's Day Greeting in Augmented Reality (Shareable) | Share this link https://go.echo3d.co/JJkU or scan this QR code to wish a mother in your life a... | 0 | 2022-05-06T19:42:56 | https://dev.to/echo3d/mothers-day-greeting-in-augmented-reality-shareable-35mi | augmentedreality, 3d, appdevelopment, tutorial | <center>

Share this link https://go.echo3d.co/JJkU or scan this QR code to wish a mother in your life a Happy Mother's Day! 🌸🌹
</center>
***
To learn more about creating AR apps without code or downloading an app, visit the [echo3D docs](https://medium.com/r/?url=https%3A%2F%2Fdocs.echo3d.co%2F).
To make your own, sign up for echo3D for free [here](https://medium.com/r/?url=https%3A%2F%2Fconsole.echo3d.co%2F%23%2Fauth%2Fregister).
To recreate this, follow this [short tutorial](https://medium.com/echo3d/create-an-ar-experience-and-share-with-a-qr-code-link-f02e63114bbb).
Special thanks to [FreePik](https://medium.com/r/?url=https%3A%2F%2Fwww.freepik.com%2Ffree-vector%2Ffloral-mother-s-day-illustration_13757278.htm%23query%3Dhappy%2520mothers%2520day%26position%3D48%26from_view%3Dsearch) for the graphic!
**More Tutorials**
- [Get a Quarantine Dog…in AR!](https://medium.com/echo3d/get-a-quarantine-dog-in-ar-8383ea55376b)
- [How to Create 3D Content and See it in AR (FREE & NO CODING REQUIRED)](https://medium.com/echo3d/how-to-create-3d-content-and-see-it-in-ar-free-no-coding-required-369e5b4a4b3e)
- [Make a Valentine's Day Slideshow in AR](https://medium.com/echo3d/make-a-valentines-day-slideshow-in-ar-free-and-no-code-c1e35a4206d4)
***
>*echo3D ([www.echo3D.co](www.echo3D.co); Techstars 19') is a cloud platform for 3D/AR/VR that provides tools and network infrastructure to help developers & companies quickly build and deploy 3D apps, games, and content.*
 | _echo3d_ |
1,079,472 | Javascript Animation 24 | Whatever you do on Javascript, you have to understand the roots and focus on the basic knowledge. ... | 0 | 2022-05-09T01:15:36 | https://dev.to/fullstackhacker/javascript-animation-24-48dh | javascript, webdev, css | Whatever you do on Javascript, you have to understand the roots and focus on the basic knowledge.
# 1. Calculator
{% codepen https://codepen.io/php-hacker/pen/oNGEoOP %}
# 2. Curve Animation
{% codepen https://codepen.io/php-hacker/pen/LYzQOxO %}
# 3. Hover
{% codepen https://codepen.io/php-hacker/pen/rNGJYML %}
# 4. Gradient Mesh
{% codepen https://codepen.io/php-hacker/pen/oNGEoLo %}
# 5. Mouse Follow-Strange Creature
{% codepen https://codepen.io/php-hacker/pen/WNZMXwq %}
| fullstackhacker |
1,079,929 | Running WordPress on Docker | WordPress runs on a variety of platforms, but last time I was developing I was using a MAMP stack -... | 0 | 2022-05-09T13:57:12 | https://carl-topham.com//articles/running-wordpress-docker | ---
title: Running WordPress on Docker
published: true
date: 2020-07-14 00:00:00 UTC
tags:
canonical_url: https://carl-topham.com//articles/running-wordpress-docker
---
WordPress runs on a variety of platforms, but last time I was developing I was using a MAMP stack - Mac Apache MySQL & PHP. It's been a while since I was working on WordPress sites and I no longer have MAMP installed on my machine, however I do have Docker running. Since I can create a LAMP stack (Linux... AMP) running on my Mac. This is a bit closer to what the site would be running on in the real world, plus I can deploy the Docker app to something like a DigitalOcean Droplet quickly.
Let's start by creating a folder for this to contain all the configs and data.
```
mkdir wordpress-docker && cd wordpress-docker
```
Then add a Docker Compose file, which is used to define and run multiple containers easily.
```
touch docker-compose.yml
```
Next we need to configure the file itself, so in your favorite editor open up `docker-compose.yml`. A few things are configured in the Docker Compose:
- The version of Docker Compose to use
- The services (containers) we are configuring. These consist of the database and the code.
- The image for each container to use
- What ports to open and bind to the host (your machine). This allows each container to speak to the other when needed
- An env file, where variables like database passwords can be stored so they can be exempt from being committed to source
- And in the case of the `wp` container a link to the database container so it can be accessed by name as `mysql` since the `wordpress` container image uses this to connect.
```
version: "2"
services:
db:
image: mariadb
ports:
- "8081:3306"
env_file:
- .env
wp:
image: wordpress
volumes:
- ./html/:/var/www/html
ports:
- "8080:80"
env_file:
- .env
links:
- db:mysql
```
Create a `.env` files for the variables (You could also use 2 `.env` files, one for each container). Note that both passwords MUST be the same!
```
MYSQL_ROOT_PASSWORD=SuperSecretTellNobody!
WORDPRESS_DB_PASSWORD=SuperSecretTellNobody!
```
That's it for config, now it's time to start your Docker containers. The following command will start to download and build the images and then boot them up. Running it with `-d` runs it in the background once
```
docker-compose up -d
```
Once it's booted up and is ready to go you will see something like this:
```
Starting wordpress-docker_db_1 ... done
Starting wordpress-docker_wp_1 ... done
```
In your browser head over to `http://localhost:8080/` and you'll be welcomed by the initial setup screens.
If you take a look in your directory you'll have a `./html` sub-directory that contains all your WordPress files just like a normal WordPress install.
Note: You can stop docker by running `docker compose down` | designer023 | |
1,080,343 | No, you do not have to use Mongodb with Node.js | Vast majority of beginner nodejs tutorials use mongodb for the database. For simplicity sake, this is... | 0 | 2022-05-09T19:41:40 | https://jovandjukic.com/no-you-do-not-have-to-use-mongodb-with-nodejs | node, mongodb | ---
title: No, you do not have to use Mongodb with Node.js
published: true
date: 2020-05-13 09:00:00 UTC
tags: node, mongodb
canonical_url: https://jovandjukic.com/no-you-do-not-have-to-use-mongodb-with-nodejs
---
Vast majority of beginner nodejs tutorials use mongodb for the database. For simplicity sake, this is fine for beginners. It saves them the hassle of dealing with SQL table relations, so they can just stick any data in and get it out to render it on the page.
## So, you need to persist some data
After learning the basics of building apps with Node.js, you may decide to build an app on your own. The courses and tutorials you learned from taught you Mongodb. It seems like next logical step:
- It has a nice Javascript API, just like Node.js
- It stores all data in JSON format
- You can easily fetch any data from the database
- You easily send that data to the client
- It's blazing fast, just like Node.js
- You don't have to learn another language just for databases
It seems like Mongodb is hand crafted for Javascript environment. For the first time ever, we can use one the same language in all 3 layers of our applications:
- Javascript in the browser (User interface)
- Javascript on the server (Business logic)
- Javascript in the database (Data persistance)
Knowing this, its easy for beginners to fall into a trap of thinking Mongodb is the only database to use to persist data in Node.js apps. Experienced developers, coming to Node.js from other technical backgrounds, often ask: "Can I use Postgres/Mysql with Node.js?"
## You can use any database you want
Node.js is Javascript runtime environment. It is a symbiosis between a Javascript interpreter and some C++ code that let's you write server or desktop apps with Javascript language.
This was not possible before, since Javascript is a language meant to be use in the context of a browser, thus confined within it for security reasons. Node.js sets Javascript free.
Having Javascript execute outside of browsers allows us to do things such as networking, file system manipulation, getting operating system information, multi-threading (even though Javascript is a single-threaded language) and much more that was done with most other languages like Java, C#, PHP, Ruby, Python, etc.
Since a Node.js app runs in the memory, a node app would need to preserve data in the database so it doesn't get lost. Which database can you use with node? Any database that you can find a driver for, which is all of them.
There is nothing in Node.js that dictates your choice of database. It does not favor any particular database system, neither relational nor non-relational.
Database is an external service from the point of view of a node app. You only need a driver and a running instance of a database to use it. Node.js doesn't care about that at all.
Use whatever database you want. | jovandj |
156,909 | Meet The Board: Chris M. Christi | Chris Christi brings more than 20 years experience in Information Technology to his current role at... | 0 | 2019-08-14T16:51:23 | https://dev.to/vetswhocode/meet-the-board-chris-m-christi-4295 | ---
title: Meet The Board: Chris M. Christi
published: true
description:
tags:
---
Chris Christi brings more than 20 years experience in Information Technology to his current role at Thales Defense and Security, Inc. working with Department of Defense clients on data security projects. He started his technology career managing tactical networks as an Army Signal Officer. He served in various technology leadership roles and deployed to Bosnia and Iraq earning military awards including the Bronze Star Medal, Army Commendation Medal, Army Achievement Medal and Combat Action Badge.
Chris has private sector business development experience with technology companies including Dell, Secure Computing, Veeam Software and Forcepoint. Chris co-founded data security firm AxiosTec where he was selected twice by Inc. for the Military Entrepreneur Program at GROWCO. His company was also recognized by the White House for partnership with the Nashville Technology Council’s Tech Hire designation for work with veterans as part of workforce diversity.
Chris graduated from the University of Tennessee as a Distinguished Military Graduate. He resides in Nashville, Tennessee with wife Sara and children Megan and Miles. He is a leader in the Nashville veterans community where he previously served as Vice President Board of Directors of Operation Stand Down Tennessee. He also serves as a mentor to veterans at the Nashville Entrepreneur Center, Nashville Technology Council Veterans Peer Group, Bunker Labs and Veterans Coordinating Council.
Chris primary focus with Vets Who Code is evangelizing the mission and bridging opportunities for their impact in the local Nashville area.
| jeromehardaway | |
1,082,731 | Day 33: Back in action! | Hi! so I'm back two after almost two days without coding, but I didn't do much I feel so tired and... | 0 | 2022-05-11T22:56:52 | https://dev.to/ivadyhabimana/day-33-back-in-action-2h9i | Hi!
so I'm back two after almost two days without coding, but I didn't do much I feel so tired and lazy. I managed to finish my task for the week but I think I still need time for more rest. I said said something about taking a rest and watching a movie yesterday but there was no time :)
tomorrow I want to work on an article about `testing with jest` or `ci and cd` at least publish one by the end of the day I think I'm also falling behind with the personal project so I need to take a look into it too
off to sleep | ivadyhabimana | |
1,083,345 | 30 Common CI/CD Interview Questions (with Answers) | Photo by Maranda Vandergriff on Unsplash Acing a software engineering interview is all about... | 0 | 2022-05-12T12:50:20 | https://semaphoreci.com/blog/common-cicd-interview-questions | beginners, career, management | *Photo by <a href="https://unsplash.com/@mkvandergriff?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Maranda Vandergriff</a> on <a href="https://unsplash.com/s/photos/interview?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>*
Acing a software engineering interview is all about preparation. Preparation starts with collecting as much information as you can about the prospective company, and their history, product, and [interviewing process](https://semaphoreci.com/blog/interviewing-engineers-at-semaphore).
Next in the list is to brush up your technical skills because knowing your technical stuff will make you stand out. Questions (like the ones in this article) are a great way of testing your knowledge. To help you, we’ve collected and answered 30 common CI/CD-related questions. How many can you answer?
## Version control
### 1. What is version control?
Version control is a set of practices and tools for managing codebases. Developers use version control to keep track of every line of code, and share, review, and synchronize changes among a team.
### 2. What is Git?
Created by Linus Torvalds to support the open-source development of Linux, Git is the most popular version control tool. It uses a distributed repository model that can efficiently handle projects of any size.
### 3. What is a Git repository?
A Git repository keeps track of every file in a software project. The repository serves as an index for all files and changes in the project, allowing developers to navigate to any point in the project’s history.
### 4. Which other version control tools do you know of?
- Mercurial
- Subversion (SVN)
- Concurrent Version Systems (CVS)
- Perforce
- Bazaar
- Bitkeeper
- Fossil
### 5. What is a Git branch?
A Git branch is an independent line of development, usually created for working on a feature. Branches let developers code without affecting the work of other team members.
### 6. What is merging?
Merging consists of joining branches. For example, when developers incorporate their peer-reviewed changes from a feature branch into the main branch.
### 7. What is trunk-based development?
[Trunk-based development](https://trunkbaseddevelopment.com/) is a branching model where most of the work takes place in a single trunk, usually called `trunk`, `master`, or `main`. The trunk receives daily merges from all developers in the team.
Trunk-based development is a popular development model because it simplifies version control. Since the trunk is a single source of truth, this model minimizes the chances of merge conflict.
### 8. What is Gitflow, and how does it compare to trunk-based development?
Gitflow is a workflow for Git that makes heavy use of branches. In Gitflow, all the code is merged into the `develop` branch instead of the `main` branch, which serves as an abridged version of the project’s history.
Features are worked on specific “feature branches” (typically prefixed with `feature/`). In the same fashion, releases also create a dedicated `release/` branch.
Compared with trunk-based development, Gitflow is more complex and has a higher chance of inducing merge conflicts, which is why it has fallen out of favor among the development community.
### 9. How long should a branch live?
In the context of continuous integration, branches should follow trunk-based development practices and thus be short-lived. Ideally, a branch should last for a few hours or, at most, a day.
## CI/CD
### 10. What is continuous integration?
[Continuous Integration](https://semaphoreci.com/continuous-integration) (CI) is a software development methodology where developers — following the trunk-based model — merge their changes to the main branch many times per day.
CI is supported by automated tests and a build server that runs them on every change. As a result, failures are made visible as soon as they are introduced and can be fixed within minutes.
### 11. How do CI and version control relate to one another?
Every change in the code must trigger a continuous integration process. This means that a CI system must be connected with a Git repository to detect when changes are pushed, so tests can be run on the latest revision.
### 12. What’s the difference between continuous integration, continuous delivery, and continuous deployment?
**Continuous integration** (CI) executes the sequence of steps required to build and test the project. CI runs automatically on every change committed to a shared repository, offering developers quick feedback about the project’s state.
[Continuous delivery](https://semaphoreci.com/blog/2017/07/27/what-is-the-difference-between-continuous-integration-continuous-deployment-and-continuous-delivery.html) is an extension of CI. Its goal is to automate every step required to package and release a piece of software. The output of a continuous delivery pipeline takes the form of a deployable binary, package, or container.
**Continuous deployment** is an optional step-up from continuous delivery. It is a process that takes the output from the delivery pipeline and deploys it to the production system in a safe and automated way.

### 13. Name some benefits of CI/CD
- **Less risk**: automated tests reduce the chance of introducing bugs, creating a safety net that increases the developer’s confidence in their code.
- **More frequent releases**: the automation provided by continuous delivery and continuous deployment allows developers to release and deploy software safely many times per day.
- **Improved productivity**: freed from the manual labor of building and testing the code, developers can focus on the creative aspects of coding.
- **Elevated quality**: CI acts as a quality gate, preventing code that is not up to standards from getting released.
- **Better design**: the iterative nature of continuous integration lets developers work in small increments, allowing a higher degree of experimentation, which leads to more innovative ideas.
### 14. What are the most important characteristics in a CI/CD platform?
- **Reliability**: the team depends on the CI server for testing and deployment, so it must be reliable. An unreliable CI/CD platform can block all development work.
- **Speed**: the platform should be fast and scalable to obtain results in a few minutes.
- **Reproducibility**: the same code should always yield the same results.
- **Ease of use**: easy to configure, operate, and troubleshoot.
### 15. What is the build stage?
The [build stage](https://semaphoreci.com/blog/build-stage) is responsible for building the binary, container, or executable program for the project. This stage validates that the application is buildable and provides a testable artifact.
### 16. What’s the difference between a hosted and a cloud-based CI/CD platform?
A hosted CI server must be managed like any other server. It must be first installed, configured, and maintained. Upgrades and patches must be applied to keep the server secure. Finally, failures in the CI server can block development and stop deployments.
On the other hand, a cloud-based CI platform does not need maintenance. There’s nothing to install or configure, so organizations can immediately start using them. The cloud provides all the machine power needed, so scalability is not a problem. Finally, the reliability of the platform is guaranteed by SLA.
### 17. How long should a build take?
Developers should get results from their CI pipeline in [less than 10 minutes](https://semaphoreci.com/blog/2017/03/02/what-is-proper-continuous-integration.html). That’s the longest time that’s practical to wait for results.
### 18. Is security important in CI/CD? What mechanisms are there to secure it?
Yes. CI/CD platforms have access to all kinds of sensitive data such as API keys, private repositories, databases, and server passwords. An improperly secured CI/CD system [is a prime target for attacks](https://research.nccgroup.com/2022/01/13/10-real-world-stories-of-how-weve-compromised-ci-cd-pipelines/) and can be exploited to release compromised software or to get unauthorized access. A CI/CD platform must support mechanisms to securely manage secrets, and control access to logs and private repositories.
### 19. Can you name some deployment strategies?
- **Regular release/deployment**: releases software to everyone at once, making it available to the general public.
- [**Canary releases**](https://semaphoreci.com/blog/what-is-canary-deployment): this is a method that reduces the chance of failure by exposing a small portion of the userbase (around 1%) to the release. With a canary release, developers gradually switch users to the latest release in a controlled way.
- [**Blue-green releases**](https://semaphoreci.com/blog/blue-green-deployment): consists of running two simultaneous instances of an application; one is the stable version currently serving users and the other the latest release. Users are switched from the former to the latter all at once. This method is safer than the regular or big bang releases because users can instantly be routed back to the previous version if there is a problem.
- **Dark launches**: are deployments where new features are released without being announced. Features can be enabled in a very fine-grained way with [feature flags](https://semaphoreci.com/blog/feature-flags).
## Testing
### 20. How does testing fit into CI?
Testing is integral to and inseparable from CI. The main benefit teams get from CI is continuous feedback. Developers set up tests in the CI to check that their code behaves according to expectations. There would be no feedback loop to determine if the application is in a releasable state without testing.
### 21. Should testing always be automated?
Yes, CI requires that [all tests are automated](https://semaphoreci.com/blog/test-automation). They must work without human intervention.
That is not to say that manual or exploratory testing don’t have their places. They are very useful for discovering potential features and finding further test cases to automate.
### 22. Name a few types of tests used in software development
There are more [types of tests](https://semaphoreci.com/blog/20-types-of-testing-developers-should-know) than we can count with both hands, but the most common ones are:
- **Unit tests**: validate that functions or classes behave as expected.
- **Integration tests**: are used to verify that the different components of an application work well together.
- **End-to-end tests**: check an application by simulating user interaction.
- **Static tests**: finds defects in code without actually executing it.
- **Security tests**: scans the application’s dependencies for known security issues.
- [**Smoke tests**](https://semaphoreci.com/community/tutorials/smoke-testing): fast tests that check if the application can start and that the infrastructure is ready to accept deployments.
### 23. How many tests should a project have?
There is no single answer as it depends on the size and nature of the project. That being said, for various reasons, test suites tend to follow in distribution the [testing pyramid](https://semaphoreci.com/blog/testing-pyramid).

### 24. What is a flaky test?
A test that intermittently fails for no apparent reason is called a [flaky test](https://semaphoreci.com/community/tutorials/how-to-deal-with-and-eliminate-flaky-tests). Flaky tests usually work correctly on the developer’s machine but fail on the CI server. Flaky tests are difficult to debug and are a major source of frustration.
Common sources of flakiness are:
- Improperly handled concurrency.
- Dependency on test order within the test suite.
- Side effects in tests.
- Use of non-deterministic code.
- Non-identical test environments.
### 25. What is TDD?
[Test-Driven Development](https://semaphoreci.com/blog/test-driven-development) (TDD) is a software design practice in which a developer writes tests before code. By inverting the usual order in which software is written, a developer can think of a problem in terms of inputs and outputs and write more testable (and thus more modular) code.
The TDD cycle consists of three steps:
1. **Red**: write a test that fails.
2. **Green**: write the minimal code that passes the test.
3. **Refactor**: improve the code, and make it more abstract, readable, and optimized.

### 26. What is the main difference between BDD and TDD?
If TDD is about designing a thing right, [Behavior-Driven Development](https://semaphoreci.com/community/tutorials/behavior-driven-development) (BDD) is about designing the right thing. Like TDD, BDD starts with a test, but the key difference is that tests in BDD are scenarios describing how a system responds to user interaction.
While writing a BDD test, developers and testers are not interested in the technical details (how a feature works), rather in behavior (what the feature does). BDD tests are used to test and discover the features that bring the most value to users.
### 27. What is test coverage?
Test coverage is a metric that measures how much of the codebase is covered by tests. A 100% coverage means that every line of the code is tested at least by one test case.
### 28. Does test coverage need to be 100%?
No. There’s a myth that 100% coverage means that the code is bug-free. This is false; no amount of testing can guarantee that. Attempting to reach full test coverage is considered bad practice because it leads to a false sense of security and extra work when code needs to be refactored.
### 29. How can you optimize tests in CI?
First, we need to [identify which tests are the slowest](https://semaphoreci.com/blog/slow-tests-strategy) and prioritize accordingly. Once we have a plan, there are several [methods for making tests faster](https://semaphoreci.com/blog/make-slow-tests-faster). Some of them are:
- Breaking large tests into smaller units.
- Removing obsolete tests.
- Refactoring tests to have fewer dependencies.
- [Parallelizing tests](https://semaphoreci.com/blog/revving-up-continuous-integration-with-parallel-testing).
### 30. What’s the difference between end-to-end testing and acceptance testing?
End-to-end usually involves testing the application by using the UI to simulate user interaction. Since this requires the application to run in a complete production-like environment, end-to-end testing provides the most confidence to developers that the system is working correctly.
[Acceptance testing](https://semaphoreci.com/blog/the-benefits-of-acceptance-testing) is the practice of verifying acceptance criteria. Acceptance criteria is a document with the rules and behaviors that the application must follow to fulfill the users' needs. An application that fulfills all acceptance criteria meets the users’ business needs by definition.
The confusion stems from the fact that acceptance testing implements the acceptance criteria verification with end-to-end testing. That is, an acceptance test consists of a series of end-to-end testing scenarios that replicate the conditions and behaviors expressed in the acceptance criteria.
## Conclusion
There is no doubt that interviews are stressful. But doing your research and [knowing what to expect](https://semaphoreci.com/blog/interviewing-engineers-at-semaphore) will dramatically increase your chances of getting the job of your dreams.
Knowledge is no replacement for experience, however. As part of your preparation, you should try a few CI/CD platforms out to see how they work. For example, you can get started with Semaphore CI/CD in a few minutes; just check out the [getting started tour](https://docs.semaphoreci.com/guided-tour/getting-started/), where you'll find ready-to-use demo projects covering the most popular languages and tech stacks.
**Did you know we’re hiring engineers of all levels! For more details, check out our [jobs page](https://apply.workable.com/semaphore)**
| tomfern |
1,089,590 | Test | Test | 0 | 2022-05-19T07:55:38 | https://dev.to/thangvmodev/test-4anf | javascript | Test | thangvmodev |
1,091,282 | Identificación Biométrica: Autenticación con huella dactilar en Xamarin.Forms | Seamos honestos, hoy en día utilizamos nuestro móvil 24h al día ya sea para el ocio, trabajo, vida... | 0 | 2022-05-20T16:17:26 | https://dev.to/luciomsp/identificacion-biometrica-autenticacion-con-huella-dactilar-en-xamarinforms-3fdp | xamarinappdevelopmen, xamarinforms, xamarin | ---
title: Identificación Biométrica: Autenticación con huella dactilar en Xamarin.Forms
published: true
date: 2019-11-08 19:37:35 UTC
tags: xamarinappdevelopmen,xamarinforms,xamarin
canonical_url:
---

Seamos honestos, hoy en día utilizamos nuestro móvil 24h al día ya sea para el ocio, trabajo, vida personal, etc,… por que lo que lo hace portador de abundante información personal. Considerando esto, ¿somos consientes de si en verdad nuestra información está debidamente protegida?. Y es que además de los conocidos sistemas de PIN y patrones, actualmente se ha extendido la autenticación por huella dactilar como un nivel más en seguridad.
Desde hace algunos años, los sistemas seguridad en dispositivos se están extendiendo a sistemas biométricos que se pueden utilizar o añadir en un nivel más elevado, esto en términos de seguridad. Entre estos se encuentran: reconocimiento facial, de iris, patrones de voz,…y el más popular, el escáner de huellas dactilares.
Este último es el más extendido ya que está disponible en la mayoría de dispositivos, sean de alta o baja gama. Su uso se ha extendido tan rápido gracias a las ventajas que ofrece:
· **Se utiliza rápidamente y tiene un nivel alto de confianza**.
· **La huella siempre va con nosotros**. Nunca se pierde o se nos olvida.
· Las operaciones que requieran **verificaciones serán más rápidas y prácticas** (como puede ser la banca online por ejemplo).
Dejando la introducción de lado, y como buenos programadores que somos, a continuación veremos cómo añadir a nuestros desarrollos la detección de la huella del usuario. Debemos de tener en cuenta que nosotros accederemos a la información de seguridad configurada en los dispositivos que contemos, no crearemos nuevas configuraciones para diferentes huellas o cosas por el estilo.
Vamos a ver paso a paso cómo añadir el reconocimiento de huellas en una App desarrollada en Xamarin.Forms.
**Paso 1 — Añadir Paquete NuGet**
En esta ocasión haremos uso del NuGet [Plugin.FingerPrint](https://www.nuget.org/packages/Plugin.Fingerprint/), el cual se deberá de instalar en todos los proyectos de nuestra solución.
Una vez efectuado lo anterior, pasemos a modificar nuestro archivo principal, en mi caso es el MainPage.xaml
### XAML
De primera instancia deberemos de crear una etiqueta para mostrar un mensaje de resultado y un botón para llamar al método de autenticación.
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/9f082588c5f484fff6d647c7f6d2384a/href">https://medium.com/media/9f082588c5f484fff6d647c7f6d2384a/href</a></iframe>
### C#
Pasando a la parte del código, primero usemos el método **IsAvailableAsync** para verificar que el dispositivo tenga el sensor biométrico. Luego hacemos uso del **AuthenticateAsync** para activar el sensor como se muestra en el siguiente ejemplo.
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/80c176cf3810c64db00b5dad3216630d/href">https://medium.com/media/80c176cf3810c64db00b5dad3216630d/href</a></iframe>
**Configuraciones por plataforma**
### Android
En nuestro proyecto Android, hay que instalar el NuGet [**Plugin.CurrentActivity**](https://www.nuget.org/packages/Plugin.CurrentActivity).
**MainActivity.cs**
Posterior a esto, vayamos a nuestro archivo MainActivity, en donde añadiremos los usings correspondientes para poder hacer uso de los paquetes previamente instalados:
using Plugin.Fingerprint;
using Plugin.CurrentActivity;
Después asignaremos la actividad a **SetCurrentActivityResolver** e inicialicemos el complemento **CrossCurrentActivity** como se muestra a continuación.
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/d52d96d8ec2432e5bfec8e96daa16117/href">https://medium.com/media/d52d96d8ec2432e5bfec8e96daa16117/href</a></iframe>
**AndroidManifest.xml**
Para culminar la configuración de esta plataforma, vayamos a nuestro archivo AndroidManifest y agreguemos los siguientes permisos.
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/16f75f16c419637208e3c0091f6d1428/href">https://medium.com/media/16f75f16c419637208e3c0091f6d1428/href</a></iframe>
### iOS
**Info.plist**
La configuración en este caso para los dispositivos de la manzana es algo más sencillo, solo agreguemos el permiso para hacer uso del Face ID.

### Resultado
Con todo lo antes ya integrado, ahora sí podemos probar la aplicación. Una vez lanzada, si pasamos el dedo por el sensor de huellas, la aplicación nos avisará mediante un mensaje si la huella ha sido reconocida o no. Para realizar una nueva prueba deberemos de cerrar la app y volver a iniciarla.
¡Happy Coding!
* * * | luciomsp |
1,091,283 | Getting Started with the Telerik SideDrawer Control in Xamarin.Forms | It is normal to see a side menu in every application that allows the user to navigate to other... | 0 | 2022-05-20T16:17:00 | https://dev.to/luciomsp/getting-started-with-the-telerik-sidedrawer-control-in-xamarinforms-167 | xamarin, telerik, xamarinforms | ---
title: Getting Started with the Telerik SideDrawer Control in Xamarin.Forms
published: true
date: 2019-11-15 17:29:37 UTC
tags: xamarin,telerik,xamarinforms
canonical_url:
---

It is normal to see a side menu in every application that allows the user to navigate to other sections quickly and as a Xamarin developer, we know that there are several ways to implement this option, some complex and others not so much.
Considering this, Telerik decided to create the SideDrawer control that allows its integration in a simple way, and that in addition to this allows developers to embed any content within the sliding panel, from text and icons to sliders and filters. The best thing about this is that it is compatible with Xamarin.iOS, Xamarin.Android, the Universal Windows Platform and Xamarin.Forms
**Various Customization Options**
In addition, this control is highly customizable, since we can customize the side where we want the menu to appear, this from any of the four sides of the screen. It also has several effects and transition modes, some of them include:
Push, Reveal, Reverse Slide Out, Slide Along, Slide In On Top, Scale Up, Fade In.
**Let’s Start!**
1. First of all we need install Telerik in your Visual Studio:
[For Mac](https://docs.telerik.com/devtools/xamarin/installation-and-deployment/mac/toolbox-extension-mac) [For Windows](https://docs.telerik.com/devtools/xamarin/installation-and-deployment/windows/toolbox-extension)
2. Add Telerik NugetPackage ([See the instructions here](https://docs.telerik.com/devtools/xamarin/installation-and-deployment/telerik-nuget-server?_ga=2.224542681.2131240681.1573516749-1615001638.1573516749))
3. Let’s continue with the implementation, add the namespace:
4. Then we add the control in the following simple way:
**SideDrawer on XAML**
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/00040bd76a70ae1f29d8e71f7b6b81d8/href">https://medium.com/media/00040bd76a70ae1f29d8e71f7b6b81d8/href</a></iframe>
**SideDrawer on CS**
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/4cef18abb4e7b5f85e0a30b1716c11cf/href">https://medium.com/media/4cef18abb4e7b5f85e0a30b1716c11cf/href</a></iframe>
Once implemented, let’s save and see how it works:
**Effects and Transitions**
Remember that we have some effects that will make the menu more dynamic, here are some examples that we can use:
Location:
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/4afea7d51f339b9d3a1a90746278518a/href">https://medium.com/media/4afea7d51f339b9d3a1a90746278518a/href</a></iframe>
Transitions:
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/72d558679f2b07eeb415cd21aa86a711/href">https://medium.com/media/72d558679f2b07eeb415cd21aa86a711/href</a></iframe>
**Share Your Feedback**
For many of these we received feedback from you — extremely valuable and appreciated. Please, keep it coming, either by commenting below or by visiting our Feedback portal about Telerik UI for Xamarin. Let us know if you have any suggestions or if you need any particular features/controls.
And If you have not yet tried the Telerik UI for Xamarin suite, take it out for a spin with a [30-day free trial](https://www.telerik.com/xamarin-ui), offering all the functionalities and controls at your disposal at zero cost.
More Information: [XamarinUI/SideDrawer](https://www.telerik.com/xamarin-ui/sidedrawer)
Download the solution: [GitHub](https://github.com/LucioMSP/Xamarin.Forms.Examples/tree/master/TrkSideDrawer)
¡Thanks for reading!
* * * | luciomsp |
276,924 | Another GIT framework workflow | Disclaimer: This post is mostly random thoughts. You may like some ideas and pick'em in your own GIT... | 0 | 2020-03-09T02:44:18 | https://dev.to/michaeljota/another-git-framework-workflow-59a8 | git, workflow, development | _Disclaimer: This post is mostly random thoughts. You may like some ideas and pick'em in your own GIT workflow, after all, every team is different._
Here is another post on my list of regrets. I have to say when I first write about them, they don't seem in my mind too bad as they eventually become after I learn more about the subject. However, I will say at this time, I've worked with a pattern like this for a while now.
I've to say it looks much like GIT flow, but it has some differences. It's more to complement than an alternative. This has worked for me in small teams, and mid-size teams (up to 7 people working in the same repo at the same time)
> TL; DR: New Branch, Commit, Pull Master, Rebase, Repeat.
## New Branch
Create a new branch. In your work, you may have only `master` or `master` for stable code and `develop` for unstable code, or maybe you work with a different set of branches. I don't know. Nobody has to tell you how many branches you should have.
But, you should create one branch for each feature/bugfix/refactor you want to do. This ensures you can update your code in the most straightforward way with the branch you are supposed to sync with.
This new branch, you can call it whatever you want. You should be consistent in your team about the branch and commit naming, but that's outside this guide. As I say, each project is different, and the could follow different patterns for this.
## Commit
Commit all your changes to your new branch. Again, up to you about how granular your commits should be. You can allow `amend` in your team and have just one big commit or commit each change individually, or a mix of both, really up to you.
What matters at this point is for you to have all your changes in your branch. By now, your branch may be outdated, so you have to update it with the latest from your sync branch.
## Pull Master
Well, you don't have to pull _your master_. This is your sync branch. The one from where your feature branch started and will be merged to. It's likely for this to be newer than the one you have.
So, checkout to your sync branch, and pull the changes. Now you have your sync branch up to date. But, your feature branch is outdated. You would need to fix that before you make a pull request.
## Rebase
Check out your feature branch and rebase against your sync branch. I really prefer to rebase over merge, because you have more control. Each of your commits will be applied over each of your sync branches, and if you have any conflicts it probably will be less, than having a merge. Also, I found rebase to be easier to resonate with.
## Repeat
Do your PR. Check your comments. Fix them. Commit. Pull Master. Rebase.
But you won't be able to push this time. Unless you do a `push --force`. And this is a scary thing, and maybe most people won't agree with this point but do it. Do a push force. Most of the time you will be working in a branch alone (again, this is from my experience in small to mid-sized teams). If you are working with a teammate in the same branch, they could do a rebase against the _remote_ feature branch from their local feature branch.
Merge your code to your sync branch.
Repeat all over again for another feature.
## That's all folks!
I hope you find this helpful. I'll be looking forward to reading your opinions about this. Again, this is some _pattern_ (?) that I've been using by years now. Every team has their own structure about the branches and rules about the commit naming, but this pattern repeats itself. Maybe you have encountered a pattern like this as well. | michaeljota |
1,091,548 | Provisionando Redis Sentinel para uma aplicação voltada a transações com cartão. | Motivação Nesse artigo quero compartilhar como construí uma infraestrutura de Redis Sentinel... | 0 | 2022-07-28T22:17:00 | https://dev.to/laerteg/redis-sentinel-em-uma-topologia-de-microservicos-para-autorizacao-de-transacoes-com-cartao-3c69 | redis, f5, terraform, ansible | **Motivação**
Nesse artigo quero compartilhar como construí uma infraestrutura de Redis Sentinel altamente disponivel em uma cloud privada baseada em VMWare com cisco ACI na camada de rede, em uma arquitetura de microserviços voltada para autorização de transações com cartão.
> Os dados de host, IP e outras informações apresentados no decorrer desse post são fictícios ou foram mascarados por motivos de segurança
**Como é um fluxo de uma transação com cartão**
Antes de aprofundar na solução do Redis Sentinel, um resumo rápido sobre o contexto de um fluxo de autorização de uma transação de cartão feita via TEF (as famosas maquininhas) e qual o impacto do Redis.
Basicamente uma compra é feita via cartão em uma maquininha no estabelecimento comercial, a partir daí a transação passa pelo adquirente (fornecedor das TEFs), pela bandeira do cartão, pela processadora da transação e por fim no emissor do cartão que vai autorizar ou não a compra e aí o retorno até a maquininha, onde o recebemos no visor a resposta.
**Onde entra o Redis nessa história**
O serviço do Redis Sentinel entra no ponto da resposta do emissor para a processadora, autorizando ou não a compra, onde essa resposta tem que ser em até 2 segundos e com média diária de 1 milhão de transações dia.
O Redis Sentinel entra no ecosistema do microserviço responsável por tratar a transação e responder de volta para a processadora.
O Redis mantém um tipo de cache em memória, onde salva algumas informações importantes, por exemplo, IDs do cartão da processadora, associado ao usuário do lado do emissor, também tem os dados da conta bancária na aplicação de core bancário (agência e conta), dados de pacote de serviço, etc. , reduzindo drasticamente a busca desses dados entre vários microserviços e banco de dados.
Os dados em memória são persistidos e sincronizados em disco entre as máquinas onde existe o serviço do Redis.
**O desafio para criar a solução do Redis Sentinel**
Recebemos a demanda para criar uma solução com Redis com disponibilidade e resiliência, subindo a infraestrutura no nossa recém-criada cloud privada baseada em VMWare vRealize 7.x na camada de virtualização de máquinas e na camada de rede uma SDN Cisco ACI Anywhere.
Abaixo segue o diagrama de como ficou a arquitetura final.
**Entrada GSLB e Load Balance no F5**
Como podemos ver no diagrama acima, em cada datacenter foi criado um Load Balancer no F5 (ver print da conf mais abaixo) para balancear as requisições entre as máquinas virtuais na porta 5679 (redis service).
O campo _send string_ contém a string do Redis que retorna a informação se o server é um master ou slave, no F5 configuramos o receive string como 'role:master', assim o LB estará "Up" se encontrar o master.
A gestão e eleição do master entre as 4 VM's fica a cargo do serviço do sentinel.
Na frente desses 2 LB's, foi criado uma entrada GSLB (Global Server Load Balance)(ver print da conf mais abaixo), também uma feature no F5 para receber as requisições do microserviço vindas do orquestrador de container Mesos e balancear entre os 2 datacenters.
Do lado do cliente Redis na aplicação a configuração da conexão vai passar somente o hostname definido no GSLB e a porta do Redis, onde o GSLB vai encaminhar direto para o server onde estará o master do redis. Diferente de outras soluções com Redis Sentinel onde na configuração do cliente redis é passado o IP/hostname de todos os nodes sentinel que são validados durante a conexão inicial para encontrar qual deles é o master.
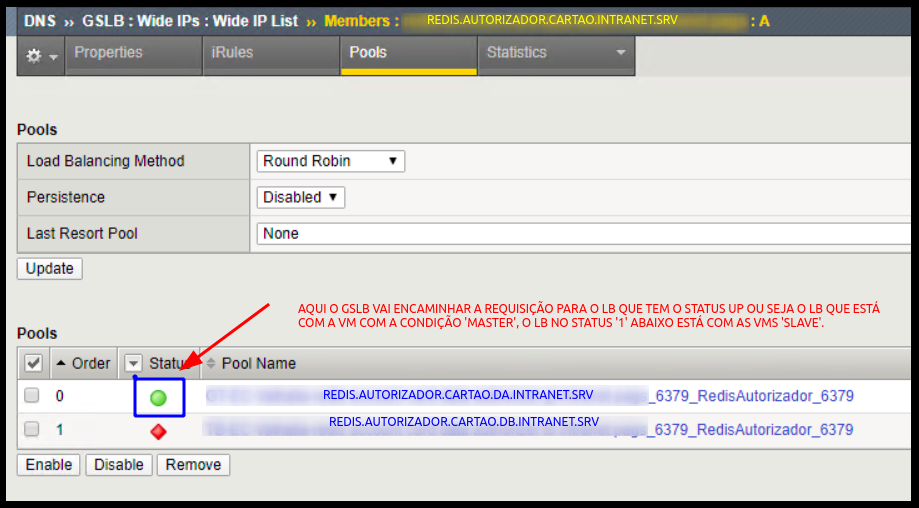
**Provisionamento da Máquinas Virtuais**
O provisionamento das máquinas virtuais nesse ambiente VMWare VRA7 foi feito com terraform
O código terraform utilizado pode ser consultado no meu github: [redis-sentinel-vmware-iac](https://github.com/laerteg/redis-sentinel-vmware-iac)
Para a execução do terraform, clonado repositório do github e executado terraform, no exemplo abaixo provisionado as máquinas no Datacenter A (ex: dca).
```
$ git clone git@github.com:laerteg/redis-sentinel-vmware-iac.git
$ cd terraform/prod/redis-dca
$ terraform init
$ terraform plan -var-file="../../dc/dca-prod.tfvars" -var-file="../../service/redis/variables.tfvars"
$ terraform apply -var-file="../../dc/dca-prod.tfvars" -var-file="../../service/redis/variables.tfvars"
```
**Gestão de Configuração com Ansible**
Após criadas as máquinas virtuais via terraform, a parte de configuração e instalação do Redis Sentinel foi feita utilizando Ansible.
Para a execução do ansible, clonado [repositório](https://github.com/laerteg/redis-sentinel-vmware-iac) do github e executado terraform, no exemplo abaixo provisionado as máquinas no Datacenter A (ex: dca).
Antes de executar o playbook do ansible, alguns ajustes foram necessários:
- Ajustar o inventário do ansible (hosts) com os IPs das instâncias criadas;
- Editar o arquivo main.yml e ajustar as variáveis de acordo com o projeto:
**mymaster_ip**: colocar o IP da instância que será o Master inicial.
**quorum_num**: colocar o numero do quorum que será utilizado para eleição do novo master em caso de problemas. (Ex: Redis com 4 instâncias quorum = 2).
**newrelic_key**: inserir o código do new_relic de acordo com o ambiente (Prod ou QA).
**env**: ambiente do Redis. (Ex: prod ou QA).
**persist_data**: Se o redis terá persistencia de dados ou não. Opções: 'yes' ou 'no'.
> Inicialmente foi definido **quorum_num = 3** porém quando o Datacenter B ficou sem conectividade, o sentinel não conseguiu fazer a re-eleição do master pois haviam somente 2 nodes do Datacenter A, com quorum de 2, o sentinel conseguiu eleger um master e um slave..
Abaixo exemplo de execução do playbook do ansible:
```
$ git clone git@github.com:laerteg/redis-sentinel-vmware-iac.git
$
$ cd ansible/install_redis
$ ansible-playbook -i hosts main.yml
```
**Validações e Troubleshooting**
Para verificações e testes com as portas TCP 5679 e 25679 entre as máquinas:
nmap
ncat, nc
Para verificações do sistema redis, utilizado redis-cli.
```
$ redis-cli -h 10.181.26.109 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=10.181.26.110,port=6379,state=online,offset=165366625665,lag=1
slave1:ip=10.181.26.120,port=6379,state=online,offset=165366625804,lag=0
master_replid:119a4cc3b2c5cc8e374423ab9034acd540befbad
master_replid2:cb7cc24457975dde598db2b78b54afe76b9f630d
master_repl_offset:165366625818
```
Na saída acima podemos verificar que o node do Redis em questão é um master e tem 2 slaves conectados via sentinel.
```
$ redis-cli -h 10.181.26.110 info replication
# Replication
role:slave
master_host:10.181.26.109
master_port:6379
master_link_status:up
```
Na saída acima podemos verificar que o node do Redis em questão é um slave, qual é o master, porta e conexão com master Up.
```
$ redis-cli -h 10.181.26.109 -p 26379 sentinel masters
1) "name"
2)"mymaster"
3) "ip"
4) "10.181.26.109"
5) "port"
6) "6379"
...
...
17) "last-ok-ping-reply"
18) "73"
19) "last-ping-reply"
20) "73"
21) "down-after-milliseconds"
22) "10000"
23) "info-refresh"
24) "216"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "4313841777"
29) "config-epoch"
30) "3"
31) "num-slaves"
32) "2"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "30000"
39) "parallel-syncs"
40) "1"
```
Nesta saída acima podemos ver várias informações sobre o master sentinel, slaves conectados, etc.. No caso de problemas de conectividade entre os nodes apareceríam informações conforme abaixo:
```
10) "s_down,master,disconnected"
33) "num-slaves"
34) "0"
35) "num-other-sentinels"
36) "0"
```
**Passo a passo - Instalação do Redis Sentinel**
**Ajustes no Kernel do S.O.**
- Desabilitar Transparent Huge Pages (THP)
echo 'never' > /sys/kernel/mm/transparent_hugepage/enabled (após reboot volta opção 'always')
Para desabilitar o THP após reboot do servidor, criar arquivo **/etc/init.d/after.local** com o seguinte conteudo:
```
# Disable THP for REDIS
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo 'never' > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo 'never' > /sys/kernel/mm/transparent_hugepage/defrag
fi
```
- Ulimit, Max Connections, overcommit memory, etc..
```
# sysctl -w vm.min_free_kbytes=1448
# sysctl -w vm.overcommit_memory=1
# sysctl -w net.core.somaxconn=65365
# sysctl -w fs.file-max=100000
# ulimit -H -n 32768
# ulimit -S -n 24576
```
- /etc/security/limits.conf
```
soft nofile 24576
hard nofile 32768
redis soft nofile 24576
redis hard nofile 32768
```
- Listar e Atualizar limits.conf
```
sysctl -a (show variables)
sysctl -p (reload conf)
```
- Verificar limits de um processo
```
ps -ef | grep redis | awk '{print $2}'
60224
sudo grep 'open files' /proc/60224/limits
Max open files 24576 32768 files
```
**Instalação do pacote Redis no SUSE Linux**
`# zypper addrepo https://download.opensuse.org/repositories/server:database/SLE_15_SP1/server:database.repo`
`# zypper search-packages -d redis`
```
Package Module or Repository SUSEConnect Activation Command
-------------------------------------------- ------------------------------------------------------- ---------------------------------------------------------
redis-4.0.11-bp151.2.1.x86_64 susemanager:suse-packagehub-15-sp1-standard-pool-x86_64
redis-5.0.8-129.3.x86_64 server_database
```
`# zypper refresh`
`# zypper install redis`
`# zypper packages --installed-only`
```
i+ | server_database | redis | 5.0.8-129.3 | x86_64
v | SUSE-PackageHub-15-SP1-Standard-Pool for x86_64 | redis | 4.0.11-bp151.2.1 | x86_64
```
`#/usr/sbin> ls -la | grep redis`
```
lrwxrwxrwx 1 root root 7 abr 1 01:18 rcredis -> service
lrwxrwxrwx 1 root root 12 abr 1 01:18 redis-check-aof -> redis-server
lrwxrwxrwx 1 root root 12 abr 1 01:18 redis-check-rdb -> redis-server
lrwxrwxrwx 1 root root 12 abr 1 01:18 redis-sentinel -> redis-server
-rwxr-xr-x 1 root root 1781592 abr 1 01:18 redis-server
```
`#/usr/bin> ls -la | grep redis`
```
-rwxr-xr-x 1 root root 646712 abr 1 01:18 redis-benchmark
lrwxrwxrwx 1 root root 20 abr 1 01:18 redis-check-aof -> ../sbin/redis-server
lrwxrwxrwx 1 root root 20 abr 1 01:18 redis-check-rdb -> ../sbin/redis-server
-rwxr-xr-x 1 root root 812944 abr 1 01:18 redis-cli
```
Criação de Usuário e Grupo redis
`# groupadd -r redis`
`# useradd --system -g redis -d /home/redis`
Criação Diretório de Configuração
`# mkdir -p /etc/redis`
`# chown redis:redis /etc/redis`
Criação Diretório de Dump (*.RDB e *.AOF)
`# mkdir -p /var/lib/redis`
`# chown redis:redis /var/lib/redis`
Criação Diretório de Logs
`# touch /var/log/redis.log`
`# touch /var/log/sentinel.log`
`# chown redis:redis /var/log/redis.log`
`# chown redis:redis /var/log/sentinel.log`
>**NOTA**: o serviço do Redis/Sentinel é sensível as pastas onde escreve como /etc/redis, /var/lib, /var/log, etc.. em caso de não ter permissão, o serviço não ativa.
| |Master & Slave |
|-------------|----------------------------------------------------|
|**redis.conf** |bind 127.0.0.1 <LOCAL_IP_ADDRESS> |
| |protected-mode no |
| |port 6379 |
| |daemonize yes |
| |supervised systemd |
| |pidfile "/opt/redis/run/redis_6379.pid" |
| |logfile "/opt/redis/log/redis.log" |
| |save 900 1 (cada 900s se 1 chave mudar) |
| |save 300 10 (cada 300s se 10 chaves mudarem) |
| |save 60 10000 (cada 60s se 10000 chaves mudarem) |
| |dbfilename "dump.rdb" |
| |appendonly yes |
| |appendfilename "NOME_PROJETO.aof" |
|-------------|----------------------------------------------------|
|**sentinel.conf**|# Deixar o bind ser feito em todas interfaces |
| |#bind 127.0.0.1 |
| |protected-mode no |
| |# The port that sentinel instance will run on |
| |port 26379 |
| |supervised systemd |
| |pidfile /opt/redis/run/redis-sentinel.pid |
| |logfile "/opt/redis/log/sentinel.log" |
| |# IP Redis Master inicial, porta e quorum |
| |sentinel monitor mymaster \<IP_MASTER\> 6379 \<QUORUM\>|
| |sentinel down-after-milliseconds mymaster 5000 |
**supervised systemd:** se comentado serviço systemctl não sobe
**Persistencia dos dados:** Se for ligar, as 3 linhas abaixo devem ser descomentadas
- save 900 1 (cada 15min se 1 chave mudar)
- save 300 10 (cada 5min se 10 chaves mudarem)
- save 60 10000 (cada 1min se 10000 chaves mudarem)
**dbfilename "dump.rdb":** dados persistidos são escritos no dump
**appendonly yes:** habilita escrita do arquivo AOF
**appendfilename "NOME_PROJETO.aof":** nome do arquivo AOF (default: "appendonly.aof").
**QUORUM:** Com minimo de 2 nodes e quorum igual a 2, o sentinel consegue eleger um master.
**Configuração dos Serviços Systemctl**
`/etc/systemd/system/redis.service`
```
[Unit]
Description=Redis In-Memory Data Store
After=network.target
[Service]
#Type=notify
Type=forking
LimitNOFILE=64000
User=redis
Group=redis
ExecStart=/usr/sbin/redis-server /opt/redis/conf/redis.conf
ExecStop=/usr/bin/redis-cli -h 127.0.0.1 shutdown
Restart=always
[Install]
WantedBy=multi-user.target
```
`/etc/systemd/system/sentinel.service`
```
[Unit]
Description=Sentinel for Redis
After=network.target
[Service]
Type=notify
LimitNOFILE=64000
User=redis
Group=redis
PIDFile=/opt/redis/run/sentinel.pid
ExecStart=/usr/sbin/redis-sentinel /opt/redis/conf/sentinel.conf
ExecStop=/bin/kill -s TERM $MAINPID
Restart=always
[Install]
WantedBy=multi-user.target
```
Como usuário ROOT habilitar e iniciar serviço redis em todos os nodes:
```
# systemctl enable redis.service
# systemctl start redis.service
```
Saída de log do serviço redis:
```
47705:C 07 Apr 2020 12:26:07.485 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
47705:C 07 Apr 2020 12:26:07.485 # Redis version=5.0.8, bits=64, commit=00000000, modified=0, pid=47705, just started
47705:C 07 Apr 2020 12:26:07.485 # Configuration loaded
47705:C 07 Apr 2020 12:26:07.485 * supervised by systemd, will signal readiness
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.8 00000000/0) 64 bit
_.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 47705
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
47705:S 07 Apr 2020 12:26:07.486 # Server initialized
47705:S 07 Apr 2020 12:26:07.486 * Ready to accept connections
47705:S 07 Apr 2020 12:26:07.486 * Connecting to MASTER 10.181.26.110:6379
47705:S 07 Apr 2020 12:26:07.486 * MASTER <-> REPLICA sync started
47705:S 07 Apr 2020 12:26:07.486 * Non blocking connect for SYNC fired the event.
47705:S 07 Apr 2020 12:26:07.487 * Master replied to PING, replication can continue...
47705:S 07 Apr 2020 12:26:07.487 * Partial resynchronization not possible (no cached master)
47705:S 07 Apr 2020 12:26:07.488 * Full resync from master: e1a164521f59ed78711cc7e3a186dda89562021d:0
47705:S 07 Apr 2020 12:26:07.575 * MASTER <-> REPLICA sync: receiving 175 bytes from master
```
Como usuário ROOT habilitar e iniciar serviço sentinel em todos os nodes:
```
#systemctl enable sentinel.service
#systemctl start sentinel.service
```
Saída de log do serviço sentinel:
```
112167:X 14 Apr 2020 11:44:24.554 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
112167:X 14 Apr 2020 11:44:24.554 # Redis version=5.0.8, bits=64, commit=00000000, modified=0, pid=112167, just started
112167:X 14 Apr 2020 11:44:24.554 # Configuration loaded
112167:X 14 Apr 2020 11:44:24.554 * supervised by systemd, will signal readiness
112167:X 14 Apr 2020 11:44:24.555 * Running mode=sentinel, port=26379.
112167:X 14 Apr 2020 11:44:24.555 # Sentinel ID is dac84d11847121c48bc18e6ddb37b7cdd800e276
112167:X 14 Apr 2020 11:44:24.555 # +monitor master mymaster 10.181.26.110 6379 quorum 3
112167:X 14 Apr 2020 11:44:24.557 * +slave slave 10.181.26.107:6379 10.181.26.107 6379 @ mymaster 10.181.26.110 6379
112167:X 14 Apr 2020 11:44:24.558 * +slave slave 10.181.26.108:6379 10.181.26.108 6379 @ mymaster 10.181.26.110 6379
112167:X 14 Apr 2020 11:44:24.559 * +slave slave 10.181.26.109:6379 10.181.26.109 6379 @ mymaster 10.181.26.110 6379
112167:X 14 Apr 2020 11:44:25.163 * +sentinel sentinel 5eff2261037d126bea40bbd5cd64523b1cfe1604 10.181.26.108 26379 @ mymaster 10.181.26.110 6379
112167:X 14 Apr 2020 11:44:26.427 * +sentinel sentinel 1ded330e6ac1da4f4430d72a5cb257546ebe0d9e 10.181.26.109 26379 @ mymaster 10.181.26.110 6379
112167:X 14 Apr 2020 11:44:35.955 * +sentinel sentinel aaeeb987bb282d63fa32788c660a748b377b11bb 10.181.26.109 26379 @ mymaster 10.181.26.110 6379
```
Para verificar possiveis problemas durante inicialização dos serviços utilizar JOURNALCTL:
```
$ journalctl -u redis
$ journalctl -xe
```
Ou verificar os arquivos de log do serviço.
Em caso de alteração do arquivo de serviço, carregar novamente e fazer o restart dos serviços:
```
# systemctl daemon-reload
# systemctl restart redis.service
```
**Benchmark do REDIS**
Na própria instalação do Redis existe uma ferramenta para fazer um benchmark contra a instalação do Redis e avaliar por exemplo se ele vai dar conta de certo número de requisições com chaves de tamanho X.
```
redis-benchmark -q -n <requests> -c <conexões> -P <pipeline x instruções paralelas>
q = quiet
n = num. requests (default = 100000)
c = conexões client paralelas
P = Pipeline x comandos paralelos (default 1 = no pipeline)
d = tamanho da chave
t = subconjunto de comandos (GET, SET)
```
Exemplo: 1000 requisições de comando set/get com chaves no valor de 50Mb.
```
$ redis-benchmark -h 10.181.26.110 -t set,get -d 50 -n 1000 -q
SET: 71428.57 requests per second
GET: 71428.57 requests per second
```
**Latência das Operações**
O redis-cli tem opção pra ver latencia das operações sendo executados pelo redis, no exemplo o primeiro temos uma média de 0,04 microsegundos de latencia de uma operação.
```
$ redis-cli -h 10.181.26.110 --latency
min: 0, max: 1, avg: 0.04 (1313 samples)^C
```
Esse segundo exemplo é a latencia intrinseca, ou seja latencia daquilo que está fora do scopo do redis, por exemplo das camadas de virtualização, SO, etc.
```
$ redis-cli -h 10.181.26.110 --intrinsic-latency 30
Max latency so far: 1 microseconds.
Max latency so far: 6 microseconds.
Max latency so far: 7 microseconds.
Max latency so far: 9 microseconds.
Max latency so far: 24 microseconds.
Max latency so far: 29 microseconds.
Max latency so far: 165 microseconds.
Max latency so far: 636 microseconds.
Max latency so far: 713 microseconds.
748875096 total runs (avg latency: 0.0401 microseconds / 40.06 nanoseconds per run).
Worst run took 17798x longer than the average latency.
```
>A média da latencia-intrinseca / media da latencia = % de tempo total da requisição é gasto pelo sistema em processos que não são controlados pelo Redis.
Por exemplo: media latencia = 0,18 microseg / media latencia-intrinseca = 0,06 microseg.
Significa que 30% do tempo total de uma requisição, é gasto com processos fora do redis.
**Monitoração da Infraestrutura Redis**
Nesse projeto optamos por configurar nos nodes do Redis o envio das métricas de infraestrutura para o New Relic.
Instalação do módulo do NewRelic e especifico para o Redis:
Adicionar repositório SUSE:
```
$ sudo rpm --import https://download.newrelic.com/infrastructure_agent/gpg/newrelic-infra.gpg
$ sudo curl -o /etc/zypp/repos.d/newrelic-infra.repo https://download.newrelic.com/infrastructure_agent/linux/zypp/sles/12.4/x86_64/newrelic-infra.repo
```
Instalar pacote padrão do NewRelic e específico Redis:
```
$ sudo zypper -n install newrelic-infra
$ sudo zypper -n install nri-redis
```
NOTA: o serviço systemd do NR é ativado durante a instalação do pacote.
`/etc/systemd/system/newrelic-infra.service`
Configuração do New Relic:
Editar o arquivo /etc/newrelic-infra.yml e inserir a chave do NR correta. No nosso caso temos uma chave para QA e outra para Prod.
```
license_key: 1234567890abcdef
log_file: /var/log/newrelic-infra.log
log_to_stdout: false
```
Remover o arquivo Sample para Docker:
```
rm /etc/newrelic-infra/integrations.d/docker-config.yml-sample
```
Copiar o arquivo SAMPLE de configuraçao do Redis de exemplo para o arquivo a ser usado pelo NR:
```
# cd /etc/newrelic-infra/integrations.d/
# cp redis-config.yml.sample redis-config.yml
```
Editar o arquivo alterando os campos hostname e environment de acordo com cada node e ambiente:
```
integration_name: com.newrelic.redis
instances:
- name: redis-metrics
command: metrics
arguments:
hostname: 10.181.26.110
port: 6379
keys: '{"0":["<KEY_1>"],"1":["<KEY_2>"]}'
remote_monitoring: true
labels:
environment: production
- name: redis-inventory
command: inventory
arguments:
hostname: 10.181.26.110
port: 6379
remote_monitoring: true
labels:
environment: production
```
Após os ajustes reiniciar o serviço do New Relic:
```
$ sudo systemctl restart newrelic-infra
```
> O código Ansible para a configuração do New Relic está no
[repositório](https://github.com/laerteg/redis-sentinel-vmware-iac).
Espero que esse conteúdo possa dar algum insight para alguém que esteja pensando em uma solução com Redis nos mesmos moldes em que tive que desenhar lá trás, na ocasião não encontrei muita informação. Nos dias de hoje temos outras opções mas na ocasião foi a que fez sentido e está dando conta do recado até hoje.
Boa leitura.
| laerteg |
1,093,154 | TCP vs UDP | These are communication protocol that allows us to send and recieve data in a network they reside... | 0 | 2022-05-23T05:17:23 | https://dev.to/2devyank/tcp-vs-udp-1dhn | beginners, programming, backend, networking | These are communication protocol that allows us to send and recieve data in a network
they reside at layer 4 protocol of OSI model
# Let’s first discuss about TCP
tcp stands for transmission control protocol , it was designed to allow transmission of information from one server to another by specifying Ip address and port
### What are the benefits of TCP ?
- Acknowledgement
If certain information is being transferred using tcp then at the end it ensures that yes your information is delivered .
suppose a server sent a message “Hi” to a client then that message will not only contain the text that is transferred it will be more like “ message received Hi ”,
Here message received shows how tcp acknowledges the information i.e sent .
- Guaranteed Delivery
Suppose due to some errors in network or corruption of information occurs in transmission that means information is not sent in that case it will keep sending the information again and again until it receives acknowledge message.
- Connection Based
this means that communication between server can only take place if there is a unique connection between the server’s and that uniqueness comes through the IP address that is if a server sends a information in a network then that information is available to every other serer out there but the information will only be decrypted at the server whose IP address is assigned.
- Congestion Control
Let me explain this using an example of traffic lights ,suppose there is a place where traffic is a lot so when traffic light become green it will only allow one car at a time then it will be back to red that is at a time only one car passes .
So this example shows if there is a lot traffic of packets [HERE PACKETS ARE PACK OF INFORMATION] in network then TCP will allow only one packet at a time . This leads to delay in transmission of information.
- Ordered Packets
It guarantees delivery of data and also it delivers packets in same order as they were sent.
### Drawbacks
- Larger packets
Since it has to carry more instruction along with information which is to be sent , those instruction includes packet for acknowledgement ,headers for guaranteed delivery ,packets for congestion control etc in order to carry all these information in headers it leads to larger packets .See anything which has advantages comes with drawback too .
- More bandwidth
Larger packets leads to more bandwidth , if you are on a 2g 0r 3g network god knows how long will it take to transmit information.
- Slower Than UDP
Will talk about UDP in later section of this blog , now what we needs to know is that with other formalities like congestion control [about which we have already discussed] ,also we have to wait for acknowledgement , we have to wait for guaranteed delivery these all things leads to delay in transmission of information.
- Stateful
If you can restart your server and the client does not remain connected with the server plus can not resume the work without any interruption this refers to stateful.
In TCP server have the connection details of client and client also have the information about connection detail of server therefore if serer is shutdown or interrupted the connection will be lost now if client wants to send some information it won’t able to.
# UDP
it stands for User Datagram Protocol
## Cons
- No Acknowledgement
so if you send the data using UDP the serer won’t tell you that if client recieve the data or not
- No Guaranteed Delivery
In this if data is once transmitted that’s it no re-transmission of data take place in case if data doesn’t reach to user. If information reaches it reaches if doesn’t then it doesn’t.
- Connection less
So there is no connection between server and client , server doesn’t know who the client is and client doesn’t know who the server is . Therefore it’s not secure
- No Congestion Control
So in this UDP will keep sending information if it is asked to it doesn’t care if there is traffic of packets or not.
- No Ordered Packets
If UDP is asked to send 5 packets , then it will send those packets as it is there will be no order followed
## PROS
- Smaller Packets
See it’s quite opposite to TCP in UDP there is no acknowledgement , no order information , no congestion control , no connection details there are no headers to carry all these information which leads to the smaller packets
- Low bandwidth
If there is low data then you don’t need much bandwidth to transfer that data basically smaller packets leads to low bandwidth
- Faster Than TCP
See its very clear from the drawacks of UDP that it doesn’t have to wait for acknowledgement ,neither for connection or there is not even congestion control whereas in TCP it’s quite opposite these all factors lead to faster delivery of data as compared to TCP .
- Stateless
If you can restart your server and the client remain connected with the server plus can resume the work without any interruption this refers to stateless . | 2devyank |
1,100,778 | Making Curry: JavaScript Functional Programming | Let's build a functional programming mainstay: the curry function. We will work through identifying,... | 25,347 | 2023-10-30T21:43:44 | https://dev.to/oculus42/making-curry-javascript-functional-programming-2d6e | javascript, programming, tutorial, development | Let's build a functional programming mainstay: the curry function. We will work through identifying, writing, troubleshooting, and improving a curry function.
## Getting Started
### Code Examples
Most code examples can be run in isolation, though some expect definitions from a previous block to be available.
I use the pattern of a comment following the line to represent the output of that code.
```javascript
// Example of operation and output
2 + 2;
// 4
```
If you would like to follow along or try the code examples for yourself, I strongly recommend using [RunJS](https://runjs.app).
## What is Currying
Currying is an important part of functional programming, and a great example of [higher-order functions](https://developer.mozilla.org/en-US/docs/Glossary/First-class_Function#passing_a_function_as_an_argument).
Broadly speaking, currying creates a collector or _accumulator_ of function arguments. A curried function returns another accumulator until it has all of the arguments needed to execute the function. Currying is a specific form of [partial application](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_objects/Function/bind#partially_applied_functions).
Here is a simple example of the difference between regular and curried function calls.
```javascript
// Regular example
let addThree = (a, b, c) => a + b + c;
addThree(1, 2, 3);
// Now, curried! Just an example, no curry function yet.
addThree = curry((a, b, c) => a + b + c);
addThree(1)(2)(3);
addThree(1, 2)(3);
addThree(1)(2, 3);
addThree(1, 2, 3);
```
Some strict curry implementations may allow only one argument to be passed at a time. This can be useful, and we will discuss it later, but we aren't going to hold to that limitation.
### Breaking it Down
What happens when we curry and then execute a function roughly works out to several steps:
1. We pass a function to `curry`.
2. Curry counts the number of arguments the function expects.
3. Curry returns an accumulator function.
4. We call the accumulator with some or all of the arguments.
5. Curry returns an accumulator until all of the expected arguments of the original function are provided.
6. When all the arguments are provided, curry executes the original function with the arguments.
Now that we have steps, we can try to create this behavior for ourselves. We will build some simple versions and improve upon them, trying to explain out thoughts and limitations along the way.
## Getting Started: Manual Currying
First, let's build the most basic form: manual currying. Just as a proof-of-concept, we're going to make a function that adds two numbers, and then a curried version.
```javascript
// Almost as simple as it gets
const add = (a, b) => a + b;
add(1, 2);
// 3
// Manually curried with two arrow functions
const curriedAdd = (a) => (b) => a + b;
add(1)(2);
// 3
```
If you are not used to working with higher-order functions, that curried version may be difficult to read, so let's talk it through.
> `curriedAdd` is a function which takes the argument `a` and returns a second function. The second function takes the argument `b` and returns `a` plus `b`.
The second function still has access to the first argument thanks to [closures](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures), so we can access both to complete the work.
If you are still unsure about the nested functions, here are a few more ways to write it that may help.
```javascript
// With extra parentheses
const curriedAdd2 = (a) => ((b) => a + b);
// With braces
const curriedAdd3 = (a) => {
return (b) => a + b;
};
// With old-school functions
const curriedAdd4 = function (a) {
return function (b) {
return a + b;
};
};
```
Hopefully one or more of the examples helped clarify the function-in-function behavior.
## Real Life Currying
The examples above don't show how we would actually use currying. Let's take a look at why it might be useful.
Currying lets us split ownership of different arguments to make reusable functions.
```javascript
// Some generic data
const distances = [ 1, 2, 4, 5, 8 ];
// Our curried multiply function
const multiply = curry((a, b) => a * b);
// Find the first value somewhere.
const factor = getConversion('mile', 'km');
// 1.6
const convertMileToKilometer = multiply(factor);
const newDistances = distances.map(convertMileToKilometer);
// [ 1.6, 3.2, 6.4, 8, 12.8 ]
```
We can also see this being useful if we have to fetch parameters asynchronously.
```javascript
// Some generic data
const distances = [ 1, 2, 4, 5, 8 ];
// Our curried add function
const multiply = curry((a, b) => a * b);
fetchConversionFactor('mile', 'km')
.then((factor) => multiply(factor))
.then(converter => distances.map(converter));
// Just for giggles, we can avoid the extra arrow functions
fetchConversionFactor('mile', 'km')
.then(multiply)
.then(distances.map.bind(distances));
```
When values or operations come from different places, currying can allow different "owners" to contribute to code without the end consumer needing to know about the steps along the way.
## Arity
Before we dive in, we need to learn a new term: arity.
Arity is the number of arguments a function accepts. This can be found by accessing the `.length` property on a function.
[There are some limitations](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/length#using_function_length) because `length` does not include rest parameters and stops at the first default value. Here are some quick examples:
```javascript
const example1 = (a, b) => a + b;
example1;
// 2
const example2 = (a, b = 1) => a + b;
example2.length;
// 1 - Stop at the default value
const example3 = (a, b = 1, c) => a + b + c;
example3.length;
// 1 - Stop at the default value
const example4 = (a, b, ...c) => a + b + sum(c);
example4.length;
// 2 - Do not include rest parameters
const example5 = (...a) => sum(a);
example5.length;
// 0 - No regular parameters
```
Arity is important to making a proper curry function because we need to know when to stop accepting arguments and run the curried function.
## Starting a Curry
Back in the What is Currying section, we identified several step that happen when currying. Let's see those again.
1. We pass a function to `curry`.
2. Curry counts the number of arguments the function expects.
3. Curry returns an accumulator function.
4. We call the accumulator with some or all of the arguments.
5. Curry returns an accumulator until all of the expected arguments of the original function are provided.
6. When all the arguments are provided curry executes the original function with the arguments.
We can use a simple currying example to test our progress:
```javascript
const add = (a, b) => a + b;
const curriedAdd = curry(add);
curriedAdd(1)(2);
```
### 1. We pass a function to `curry`.
```javascript
const curry = (fn) => fn;
// Test it!
const add = (a, b) => a + b;
const curriedAdd = curry(add);
curriedAdd(1)(2);
// TypeError: curriedAdd(...) is not a function
```
Not so good, yet. The second function call doesn't work.
### 2. Curry counts the number of arguments the function expects.
```javascript
const curry = (fn) => {
const arity = fn.length;
return fn;
};
// Test it!
const add = (a, b) => a + b;
const curriedAdd = curry(add);
curriedAdd(1)(2);
// TypeError: curriedAdd(...) is not a function
```
We counted, but didn't make any other change, so we need more.
### 3. Curry returns an accumulator function.
```javascript
const curry = (fn) => {
const arity = fn.length;
const previousArgs = [];
const accumulator = (arg) => {
// Keep track of the arguments.
previousArgs.push(arg);
};
return accumulator;
};
// Test it!
const add = (a, b) => a + b;
const curriedAdd = curry(add);
curriedAdd(1)(2);
// TypeError: curriedAdd(...) is not a function
```
We're building up, but now we don't actually run the function, and we still have a type error for that second call.
### 4. We call the accumulator with some or all of the arguments.
This is actually already covered by our tests in the previous step, so no new code for this one.
### 5. Curry returns an accumulator until all of the expected arguments of the original function are provided.
```javascript
const curry = (fn) => {
const arity = fn.length;
const previousArgs = [];
const accumulator = (arg) => {
previousArgs.push(arg);
if (previousArgs.length < arity) return accumulator;
};
return accumulator;
};
// Test it!
const add = (a, b) => a + b;
const curriedAdd = curry(add);
curriedAdd(1)(2);
// undefined
```
Well, we aren't throwing an error anymore, but we aren't running the original function, either. Our code should probably do that at some point...
### 6. When all the arguments are provided curry executes the original function with the arguments.
That's what we needed!
```javascript
const curry = (fn) => {
const arity = fn.length;
const previousArgs = [];
const accumulator = (arg) => {
previousArgs.push(arg);
if (previousArgs.length < arity) return accumulator;
// Run the function when we have enough arguments
return fn(...previousArgs);
};
return accumulator;
};
// Test it!
const add = (a, b) => a + b;
const curriedAdd = curry(add);
curriedAdd(1)(2);
// 3
```
We did it!
## Testing Capabilities
We've done a simple two-argument curry, but there are some limitations to our design. Let's revisit the `addThree` example at the beginning and see how we do:
```javascript
addThree = curry((a, b, c) => a + b + c);
addThree(1)(2)(3);
// 6
addThree(7,8,9);
// 6
addThree(1, 2)(3);
// TypeError: addThree(...) is not a function
```
I'm _pretty sure_ `7 + 8 + 9` is not six, and we get errors when we try to pass arguments in more than one call, so we need to figure out what happened.
### Don't Share Closures
It turns out we made a terrible mistake! We kept a single list of arguments in an outer closure, so we share a closure for all uses of the function. This means we can only use it _one time_, and if we tried to pass partial arguments to it several times, it would behave incorrectly.
```javascript
const add = curry((a, b) => a + b);
// Try to make two different functions
const addTwo = add(2);
// ƒ accumulator()
// This doesn't return a function because of the shared accumulator.
const addThree = add(3);
// 5
```
This is sort of the _opposite_ of currying. Looking back at What is Currying section, there is some key language that describes the problem:
> A curried function **returns another accumulator** until it has all of the arguments...
Each step of the currying process needs to have a unique set of arguments, so each step creates a reusable function. To do this, we'll need to pass our collection of arguments to each successive accumulator.
We could go about this a couple of ways... we could use `Function.prototype.bind()` to set the first value, or we could use an another arrow function to provide a closure. I'm going with the arrow function to avoid setting a context.
```javascript
const curry = (fn) => {
const arity = fn.length;
const accumulator = (previousArgs) => (arg) => {
const newArgs = [...previousArgs, arg];
if (newArgs.length < arity) return accumulator(newArgs);
// Run the function when we have enough arguments
return fn(...newArgs);
};
// Start with no arguments passed.
return accumulator([]);
};
```
Now, each time we call the accumulator we first pass in the previous arguments and get back a function that takes the _next_ argument. You can see our first call to accumulator passes an empty array. If we didn't do this, it would cause an error when spreading `previousArgs`. We could also have used a default parameter, if we wanted.
Let's see how this version works.
```javascript
addThree(1)(2)(3); // 6
addThree(1, 2)(3); // ƒ ()
addThree(1)(2, 3); // ƒ ()
addThree(1, 2, 3); // ƒ ()
```
No errors anymore, but we aren't successfully processing versions that pass more than one argument at a time. But that's an easy fix. We need to take `...args` instead of `arg`.
### Accept Multiple Arguments
I mentioned before that strict versions of curry accept only one argument at a time. This can be useful when you need to use the function in a place where you don't want all the arguments passed to it, like in `Array.prototype.map()`. Because the mapper receives _three_ arguments – value, index, and array – it would _misbehave_ if curry accepts multiple values.
```javascript
const multipliers = [2, 4, 6, 8];
const multiply = curry((a, b) => a * b);
const multiplierFns = multipliers.map(multiply);
// With one argument at a time:
// [ ƒ (), ƒ (), ƒ (), ƒ () ]
// Supporting multiple arguments:
// [ 0, 4, 12, 24 ]
```
While this might seem like we should only accept one argument at a time, our code is more flexible for all the other times. The Array prototype function issue is well-known, and a common example is seeing `.map(parseInt)` misbehave. For situations where we know we have a concern, like `.map()`, we can create a simple unary function wrapper to prevent the error.
```javascript
const multipliers = [2, 4, 6, 8];
const multiply = curry((a, b) => a * b);
// Only one argument, no matter how curry is written
const multiplierFns = multipliers.map((value) => multiply(value));
// [ ƒ (), ƒ (), ƒ (), ƒ () ]
```
It's a pretty good pattern. It allows `curry` to be flexible and you put the fix for "bad arguments" in the place where they happen. This is common enough that libraries like Lodash include a [unary function](https://lodash.com/docs#unary).
So, let's not worry about those cases, and move forward with `...args`.
```javascript
const curry = (fn) => {
const arity = fn.length;
// Accept more than one argument at a time!
const accumulator = (previousArgs) => (...args) => {
const newArgs = [...previousArgs, ...args];
if (newArgs.length < arity) return accumulator(newArgs);
// Run the function when we have enough arguments
return fn(...newArgs);
};
// Start with no arguments passed.
return accumulator([]);
};
```
And some quick testing:
```javascript
addThree(1)(2)(3); // 6
addThree(1, 2)(3); // 6
addThree(1)(2, 3); // 6
addThree(1, 2, 3); // 6
```
Now our various argument styles seem to be working as expected. To be sure, we should test the reusability of our functions, which was a problem with our early closure design.
```javascript
const add = (a,b) => a + b;
const curriedAdd = curry(add);
const addTwo = curriedAdd(2);
addTwo(10); // 12
addTwo(5); // 7
addTwo(-2); // 0
```
Looking good!
### Setting Arity
Right now our curry function depends on the `length` property of the function, but as we mentioned when we learned about arity, there are reasons it can be "wrong", or at least different from what we need.
```javascript
const addAll = (...args) => args.reduce((a, b) => a + b, 0);
addAll.length; // 0
const multiply = (a, b = -1) => a * b;
multiply.length; // 1
```
For cases like these, we need to set the arity for currying to work correctly. It's easy enough to add an optional second argument to the curry function, and we can leverage how [default parameters have access to the earlier parameters](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/Default_parameters#earlier_parameters_are_available_to_later_default_parameters) to add this with _less code_ than before by moving `arity` into the arguments.
```javascript
const curry = (fn, arity = fn.length) => {
// Accept more than one argument at a time!
const accumulator = (previousArgs) => (...args) => {
const newArgs = [...previousArgs, ...args];
if (newArgs.length < arity) return accumulator(newArgs);
// Run the function when we have enough arguments
return fn(...newArgs);
};
// Start with no arguments passed.
return accumulator([]);
};
const add = (...args) => args.reduce((a, b) => a + b, 0);
curry(add, 4)(1)(2)(3)(4); // 10
curry(add, 2)(10, 5); // 15
```
## Other Considerations?
### Context
Context can be a complex and annoying part of JavaScript, but we might need to add the ability to accept a context. We could pass the context at curry time, but if we know the context at that point, we can just pass a bound function to curry in the first place. [Bind passes along the function length](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/bind), so we don't have to make any changes to our existing curry function to support that.
```javascript
curry(doSomethingWithContext.bind(this));
```
If we need a dynamic context, it will be the context called _last_. For this to work we cannot use all arrow functions, as they use the context in which they were declared. Only the one function that actually receives new arguments needs to be changed, though.
```javascript
const curry = (fn, arity = fn.length) => {
// Accept more than one argument at a time!
const accumulator = (previousArgs) => function (...args) {
const newArgs = [...previousArgs, ...args];
if (newArgs.length < arity) return accumulator(newArgs);
// Run with context when we have enough arguments
return fn.apply(this, newArgs);
};
// Start with no arguments passed.
return accumulator([]);
};
```
Now, a very contrived example for testing.
```javascript
const makeMessage = function(quantity, color) {
return `Find ${quantity} ${color} ${this.noun}!`;
};
const requestColor = curry(makeMessage)(4);
const myContext = {
noun: 'airplanes',
requestColor,
};
myContext.requestColor('blue'); // "Find 4 blue airplanes!"
```
I included this in "Other Considerations" because it blends in parts of Object-Oriented Programming that we mostly try to avoid in Functional Programming. Adding support for context is simple enough and can enable the use of curried functionality inside OOP, but I try to avoid blending them together this way when I can help it.
### Bad Types
Our curry doesn't do any validation that you passed it a function or that the arity is a number. Both of these could cause errors or unexpected behavior. If we are planning to put this curry function into production it might be worth that additional sanity check.
### Empty Arguments
If you need to support an implicit `undefined` value, this version won't work for you.
```javascript
const sum = (...args) => args.reduce((a,b) => a + b, 0);
const currySum = curry(sum, 4);
// Because we use ...args, we get an empty array.
// If we used the single arg, it would be undefined.
currySum()(1, 2)()(3, 4); // 10
```
You can pass an _explicit_ `undefined` as an argument, just not an implicit one. If you undo the work from the "Accept Multiple Arguments" section, your curry will accept implicit undefined, but of course loses the ability to pass multiple arguments at a time.
### Too Many Arguments
Right now our curry function accepts more arguments than the arity.
```javascript
const add = (...args) => args.reduce((a,b) => a + b, 0);
const addFour = curry(add, 4);
// What if I pass more than four?
addFour(1, 2, 3, 4, 5); // 15
```
Both of these considerations are consistent with the behavior of the Lodash curry function, so I'm not calling them errors, merely _considerations_. For use cases where an implicit `undefined` or the exact number of arguments is required, it might be better to use a curry function which only accepts one argument at a time. If we switch back to using `arg` instead of `...args`, both of these behaviors change.
## Closing Remarks
I'm sure there are other issues and edge cases which aren't handled here, but I think our curry function works for most purposes. If something is missing, please comment and let me know!
It's been a long journey, but hopefully it was worth it to think through the design and decisions together. Thanks for reading! | oculus42 |
1,105,110 | No more to-do lists please | We need to start creating real coding projects right now. Everybody knows we, in some random moment... | 0 | 2022-06-05T01:14:21 | https://dev.to/kenliten/no-more-to-do-lists-please-3l7l | ---
title: No more to-do lists please
published: true
date: 2022-01-05 21:56:06 UTC
tags:
canonical_url:
---
We need to start creating real coding projects right now.
Everybody knows we, in some random moment got stuck, especially when you really want to build something cool, memorable, useful, the next big thing, but have no idea on what the freaking hell you can do.
This happens to me more than I really want to admit. It’s kind of disappointing to have the knowledge, have the tools, but don’t know what to do or where to go.
Clock’s clicking around and time’s running, but you are still stuck in what app should I create, or sometimes you already have the idea, but can’t figure out how to implement that idea.
Today, I want to share with you some of my experiences on this topic.
Many years ago, I got stuck. In simple terms, I’d be starting to learn python and wanted some ideas to program, and get better at coding. I decided to open up Google Chrome and type ‘coding projects ideas’ and hit enter. Around 10 minutes later, found a post in a forum about ‘Beginner project ideas’, and were not that bad, actually, I liked it.
So, I just copied-and-pasted in a blank text file and dropped it on my desktop, and start building all those one by one. A week later, every ‘project’ was finished.
Next, I just decide to try again the same thing, and guess what, The other projects I found were almost exactly the same, just a dirty copy of the book where the first group of projects was extracted from.
Several days have passed, and all the ‘project ideas’ I see are the same, that’s why I’m writing this right now. We need to address a difference, be creative, create real and useful software we feel proud of.
To reach my point, I want to say this:
It’s the perfect time to stop doing the same shitty apps and start creating awesome masterpieces of software.
| kenliten | |
1,108,458 | Paracetamol.js💊| #147: Explica este código JavaScript | Explica el siguiente código JavaScript Dificultad: Intermedio const { 0:... | 16,071 | 2022-06-19T16:55:26 | https://dev.to/duxtech/paracetamoljs-147-explica-este-codigo-javascript-3ce | javascript, webdev, spanish, beginners | ## **<center>Explica el siguiente código JavaScript</center>**
#### <center>**Dificultad:** <mark>Intermedio</mark></center>
```js
const { 0: x, 2: y } = ['a', 'b', 'c'];
console.log(`0:${x}, 2:${y}`)
```
A. `0:a`, `2:a`
B. `0:a`, `2:c`
C. `0:a`, `2:b`
D. `0:b`, `2:c`
Respuesta en el primer comentario.
---
| duxtech |
211,621 | Theming Material Design - Colors | Usually I find Googles documentation to be pretty good at describing the basics, however, when I star... | 0 | 2019-11-26T21:46:46 | https://dev.to/nephiw/theming-material-design-mm3 | material, sass, scss, angular | Usually I find Googles documentation to be pretty good at describing the basics, however, when I started trying to edit the color scheme for a project built on Angular Material for the first time, [the documentation provided many details on why](https://material.io/design/color/the-color-system.html) - [but not enough in the way of how](https://material.angular.io/guide/theming). This information is useful, but all I really needed to know at this point is how to make a color scheme work on my site.
[The Material Angular site](https://material.angular.io) had examples on theming here [https://material.angular.io/guide/theming](https://material.angular.io/guide/theming) which provided what I thought was a good example of how to change the theme with scss:
```scss
@import '~@angular/material/theming';
// Plus imports for other components in your app.
// Include the common styles for Angular Material. We include this here so that you only
// have to load a single css file for Angular Material in your app.
// Be sure that you only ever include this mixin once!
@include mat-core();
// Define the palettes for your theme using the Material Design palettes available in palette.scss
// (imported above). For each palette, you can optionally specify a default, lighter, and darker
// hue. Available color palettes: https://material.io/design/color/
$candy-app-primary: mat-palette($mat-indigo);
$candy-app-accent: mat-palette($mat-pink, A200, A100, A400);
// The warn palette is optional (defaults to red).
$candy-app-warn: mat-palette($mat-red);
// Create the theme object (a Sass map containing all of the palettes).
$candy-app-theme: mat-light-theme($candy-app-primary, $candy-app-accent, $candy-app-warn);
// Include theme styles for core and each component used in your app.
// Alternatively, you can import and @include the theme mixins for each component
// that you are using.
@include angular-material-theme($candy-app-theme);
```
## The Problem
I expected `$mat-indigo` to be a single color from which the shades were generated. My expectations were wrong. The goal of the documentation appears to be to show you how to use one of the predefined themes. If you try providing a single color, like I did, you will get the error message:
```
ERROR in ./src/styles.scss (./node_modules/@angular-devkit/build-angular/src/angular-cli-files/plugins/raw-css-loader.js!./node_modules/postcss-loader/src??embedded!./node_modules/sass-loader/lib/loader.js??ref--15-3!./src/styles.scss)
Module build failed (from ./node_modules/sass-loader/lib/loader.js):
default: map-get($base-palette, $default),
^
$map: #4b0082 is not a map.
╷
1262 │ default: map-get($base-palette, $default),
│ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
╵
node_modules/@angular/material/_theming.scss 1262:14 mat-palette()
stdin 46:20 root stylesheet
in /home/user/site/node_modules/@angular/material/_theming.scss (line 1262, column 14)
```
This is a bit cryptic, but it did lead me to the solution. <em>Drop the manual and read the source.</em>
## The Solution
This happens because the `mat-palette` mixin requires a color map not a single color. I figured out how to build my own palette by reading the [`_theming.scss` source code](https://github.com/angular/components/blob/8.2.3/src/material/core/theming/_theming.scss#L17) and the default palette definitions in the [_palette.scss source code](https://github.com/angular/components/blob/8.2.3/src/material/core/theming/_palette.scss#L171) but here is an example of the basic structure required for `mat-palette`:
```
$mat-indigo: (
50: #e8eaf6,
100: #c5cae9,
200: #9fa8da,
300: #7986cb,
400: #5c6bc0,
500: #3f51b5,
600: #3949ab,
700: #303f9f,
800: #283593,
900: #1a237e,
A100: #8c9eff,
A200: #536dfe,
A400: #3d5afe,
A700: #304ffe,
contrast: (
50: $dark-primary-text,
100: $dark-primary-text,
200: $dark-primary-text,
300: $light-primary-text,
400: $light-primary-text,
500: $light-primary-text,
600: $light-primary-text,
700: $light-primary-text,
800: $light-primary-text,
900: $light-primary-text,
A100: $dark-primary-text,
A200: $light-primary-text,
A400: $light-primary-text,
A700: $light-primary-text,
)
);
```
Note also that Angular Material provides many existing palettes for you to use and what follows here gives an example of using a built in palette named `mat-blue-grey` with another by creating the proper map. In the end the entire file for my theme looked like this:
```
@import '~@angular/material/theming';
@include mat-core();
// this defines a map for an orange color palette
$bc-accent-palette: (
50: #FFF3E0,
100: #FFE0B2,
200: #FFCC80,
300: #FFB74D,
400: #FFA726,
500: #FF9800,
600: #FB8C00,
700: #F57C00,
800: #EF6C00,
900: #E65100,
A100: #FFD180,
A200: #FFAB40,
A400: #FF9100,
A700: #FF6D00,
contrast: (
50: $dark-primary-text,
100: $dark-primary-text,
200: $dark-primary-text,
300: $dark-primary-text,
400: $dark-primary-text,
500: $light-primary-text,
600: $light-primary-text,
700: $light-primary-text,
800: $light-primary-text,
900: $light-primary-text,
A100: $dark-primary-text,
A200: $dark-primary-text,
A400: $dark-primary-text,
A700: $light-primary-text,
)
);
// Build the theme palettes out of an existing palette and a custom one.
$bc-theme-primary: mat-palette($mat-blue-grey);
$bc-theme-accent: mat-palette($bc-accent-palette, A200, A100, A400);
// Build the theme and include it in your styles.
$bc-theme: mat-light-theme($bc-theme-primary, $bc-theme-accent);
@include angular-material-theme($bc-theme);
```
For this example, I simply used the color scheme defined for `mat-orange` - but I am just getting started on this project; I expect to tweak it quite a bit as I move forward. Defining the colors in this way gives you more control to customize the entire site's theme moving forward. However, if you just want to generate a css to use instead, you might try exploring the [resources Angular provides](https://material.io/resources/color/#!/?view.left=0&view.right=0&primary.color=FF2828&secondary.color=ffdedd). This allows you to export your color scheme to apps and also [CodePen](https://codepen.io/) to view the specifics.
| nephiw |
1,110,633 | Pagination in React | While designing any website we need to think about how should we display our data, such that our... | 0 | 2022-06-10T18:10:40 | https://dev.to/shraddha1402/pagination-in-react-37lo | javascript, webdev, react |
While designing any website we need to think about how should we display our data, such that our users can consume it properly and are not overwhelmed by it. The more organised the data, the better the website's user experience.
Pagination is one such method for achieving this. It is a method of dividing web content into discrete pages, thus presenting content in a limited and digestible manner.
In this blog we are going to make a simple react app where we will fetch data from this https://jsonplaceholder.typicode.com/posts API and display it in Pagination format.
Here we will be fetching all the data at once and then display it in pages, but with a backend you can fetch small chunks of data for each page, the frontend pagination code for both the methods will remain the same.
1. [Setting up files](#step-1)
2. [Writing code to fetch data](#step-2)
3. [Writing the Pagination Component](#step-3)
4. [Putting the whole code together](#step-4)
Let's get started!
### 1. Setting up files <a name="step-1"></a>
Create a react app by using the create react app template
```js
npx create-react-app pagination-app
```
or you can also code on `codesandbox` or `stackblitz`
After the app is created, your folder structure might look like this
### 2. Writing code to fetch data <a name="step-2"></a>
We will use the `fetch` API to get the data from the jsonplaceholder API and store it in a state. Remove all the code from your `App.js` file and write the code given below
```js
import { useState } from "react";
const URL = "https://jsonplaceholder.typicode.com/posts";
function App() {
const [posts, setPosts] = useState([]);
useEffect(() => {
fetch(URL)
.then((response) => {
if (response.ok) return response.json();
throw new Error("could not fetch posts");
})
.then((posts) => setPosts(posts))
.catch((error) => console.error(error));
},[]);
return <div className="App"></div>;
}
export default App;
```
Here, we have written the fetch function inside `useEffect` hook and passed an empty dependency array, this will make sure that our fetch function runs only once, after the page is loaded. If the data is fetched successfully, it will be stored in the state, else the error will be displayed in the console.
If you wish to understand more about how `fetch` works, you can read my blog [Fetch API: Basics](https://dev.to/shraddha1402/fetch-api-basics-6lo)
### 3. Writing the Pagination Component <a name="step-3"></a>
Now, after getting the data, we will write our Pagination Component.
Create a file `Pagination.js` in your src folder.
We will display 5 posts per page, and that will be our page limit. We will store the current page number in a state and update it using the **Previous** and **Next** button, also we will display 3 consecutive page numbers, viz previous, current and next.
```js
import React, { useState, useEffect } from "react";
const Pagination = ({ pageDataLimit, posts }) => {
const [currPageNo, setCurrPageNo] = useState(1);
const [currPagePosts, setCurrPagePosts] = useState([]);
const [pageNumberGroup, setPageNumberGroup] = useState([]);
useEffect(() => {
setCurrPagePosts(getPageData());
setPageNumberGroup(getPageNumberGroup());
console.log("run");
}, [posts, currPageNo]);
const nextPage = () => setCurrPageNo((prev) => prev + 1);
const previousPage = () => setCurrPageNo((prev) => prev - 1);
const changePageTo = (pageNumber) => setCurrPageNo(pageNumber);
const getPageData = () => {
const startIndex = currPageNo * pageDataLimit - pageDataLimit;
const endIndex = startIndex + pageDataLimit;
return posts.slice(startIndex, endIndex);
};
const getPageNumberGroup = () => {
let start = Math.floor((currPageNo - 1) / 3) * 3;
console.log(new Array(3).fill(" ").map((_, index) => start + index + 1));
return new Array(3).fill(" ").map((_, index) => start + index + 1);
};
return (
<div></div>
);
};
export { Pagination };
```
Here, our pagination component is getting `posts` and `page limit` as props. The `getPageData` funtion will be used to calculate the posts to be shown in each page. Using the start and end index we will slice the posts array and update the `currPagePosts` state.
The `getPageNumberGroup` function is used to display the previous, current and the next page numbers.
Now, we will map over the `currPagePosts` and `pageNumberGroup` states to display the posts.
```js
return (
<div>
<h1 className="heading">Posts in Pagination</h1>
<ul className="posts-container list-style-none">
{currPagePosts.map(({ id, title, body }) => {
return (
<li key={id} className="post">
<h3>{title}</h3>
<p>{body}</p>
</li>
);
})}
</ul>
<div className="page-num-container">
<button
className={`page-change-btn ${currPageNo === 1 ? "disabled" : ""} `}
disabled={currPageNo === 1}
onClick={previousPage}
>
Previous
</button>
<ul className="page-num-container list-style-none">
{pageNumberGroup.map((value, index) => {
return (
<li
className={`page-number ${
currPageNo === value ? "active" : ""
} `}
key={index}
onClick={() => changePageTo(value)}
>
{value}
</li>
);
})}
</ul>
<button
disabled={currPageNo === Math.floor(posts.length / pageDataLimit)}
className={`page-change-btn ${
currPageNo === Math.floor(posts.length / pageDataLimit)
? "disabled"
: ""
} `}
onClick={nextPage}
>
Next
</button>
</div>
</div>
```
We are first displaying all the posts, below that the page numbers along with the buttons. The previous button will be disabled when we are on the first page and similarly the next button will be disabled when we are at the last page.
Below are the styles for the pagination component. Write the code in `App.css` file and import it in `Pagination.js` file.
```css
.heading {
text-align: center;
margin: 1rem;
}
.posts-container {
display: grid;
grid-template-columns: 18rem 18rem 18rem;
gap: 1rem;
align-items: stretch;
justify-content: center;
}
.post {
max-width: 16rem;
text-align: center;
padding: 1rem;
margin: 0.5rem;
color: "#c4c4c4";
border: 1px solid purple;
border-radius: 0.25rem;
}
.page-num-container {
display: flex;
align-items: center;
justify-content: center;
}
.page-change-btn {
padding: 0.5rem 1rem;
margin: 0 0.5rem;
border: none;
border-radius: 0.25rem;
outline: none;
background-color: purple;
color: white;
cursor: pointer;
}
.disabled {
cursor: not-allowed;
background-color: gray;
}
.page-number {
border: 1px solid grey;
border-radius: 50%;
width: 2rem;
height: 2rem;
line-height: 2rem;
text-align: center;
margin: 0 0.25rem;
cursor: pointer;
}
.active {
border-color: purple;
}
.list-style-none {
list-style: none;
padding-inline-start: 0;
}
```
### 4. Putting the whole code together <a name="step-4"></a>
We have our Pagination component ready, now we just need to call the component in `App.js` file.
```js
<div className="App">
<Pagination pageDataLimit={5} posts={posts} />
</div>
```
Once you have written all the code, run
```js
npm start
```
The whole code and demo is uploaded on [github](https://github.com/shraddha-1402/Pagination-React).
Happy Coding!
| shraddha1402 |
1,113,124 | lazy load with http header? | Hey.... I'm working on an app, I want to lazy load a separate bundle, but want to make sure the lazy... | 0 | 2022-06-13T17:16:05 | https://dev.to/rleibman/lazy-load-with-http-header-5ffd | react | Hey.... I'm working on an app, I want to lazy load a separate bundle, but want to make sure the lazy load contains a specific http header (a bearer token).
The reason for this question (in case I'm barking up the wrong tree) is that I want my login bundle to be publically accessible, but the main app to only be accessible once the login has been successful. Using React.lazy(() => import("./pages/Dashboard")); sounds promising, but I'm not sure if there's a way to add my header (I also looked at react-loadable.... same issue) | rleibman |
1,113,374 | [pt-BR] Desmistificando algoritmos - Thomas H. Cormen | Irei compartilhar as minhas anotações e highlights sobre o o livro "Desmistificando algoritmos" do... | 0 | 2022-06-14T00:45:00 | https://dev.to/srcmilena/desmistificando-algoritmos-thomas-h-cormen-5fli | beginners, algorithms | Irei compartilhar as minhas anotações e highlights sobre o o livro "Desmistificando algoritmos" do Thomas H. Cormen.
Se eu fosse dar uma breve introdução, eu usaria algumas frases do autor, em que ele menciona as seguintes definições e para quem o livro é destinado:
- Quem está interessada(o) em saber como os computadores resolvem problemas;
- Saber como avaliar essas soluções...
No capítulo 1, já vejo o título nomeado como "O que são algoritmos e por que você deve se importar com eles?". Nos cursos mais básicos, aprendemos que os algoritmos são conjuntos de etapas com o propósito de executar uma tarefa (seja qual for ela). Os algoritmos estão mais presentes em nosso cotidiano do que imaginamos e são executados em todos os lugares.
Também é bom relembrar que não existe o "óbvio" para o computador. Ele precisa da exatidão. Inclusive, isso é o que difere a execução feita por nós e a por outro lado, a execução feita pelo computador.
>
É necessário haver precisão no algoritmo de computador
Uma outra pergunta boa a ser feita é: "Para que queremos esses algoritmos?" pelo simples fato deles nos trazerem soluções.
| srcmilena |
1,113,548 | 3 benefits interviews bring you | Not only do interviews open doors to new opportunities, they also help you sharpen your skills with... | 0 | 2022-06-14T04:09:58 | https://petermekhaeil.com/3-benefits-interviews-bring-you/ | career | ---
title: 3 benefits interviews bring you
published: true
tags:
- career
canonical_url: https://petermekhaeil.com/3-benefits-interviews-bring-you/
---
Not only do interviews open doors to new opportunities, they also help you sharpen your skills with new learnings. Interviews keep your career moving forward and I will share some learnings from experience.
## Learn about what you know
When you answer questions during the interview, be aware to what level you understand the topics being discussed. Speaking out loud about what you know helps you articulate those past career learnings and experiences. With each interview, the more you can improve your confidence in talking about what you know.
## Learn about what you do not know yet
You may not have an answer to some questions during the interview and that is totally fine - this will be an opportunity to learn something new! Ask the interviewer for the answers to those questions. Now whether or not you decide to continue with the interview rounds, you have now learnt something new that you can take to your existing job or you take to your next interview. With each interview, you are building up your knowledge base.
## Learn to negotiate
When you get to the offer stage of the interviews, you have the opportunity to practice negotiation, a very handy skill to have at any level in your career. With each interview, sharpen your negotiation skills and pick up experience in handling those situations.
_A great book on this topic is [The Coding Career Handbook](https://learninpublic.org/) - a chapter is dedicated to salary negotiation where you’ll learn that you have an upper hand simply because the best alternative is staying at the job you already have._
## Each experience will be unique
Each person will have their own learning experience. With each interview, practice a useful skill for your career, such as building your confidence, expanding your knowledge and salary negotiating. | petermekhaeil |
1,113,677 | Архитектура фронтенда и какой она должна быть | Все мы знаем про, или слышали про практики и паттерны проектирования SOLID, GRASP, MVC, MV** и даже... | 0 | 2022-06-14T07:18:47 | https://dev.to/dmitriypereverza/arkhitiektura-frontienda-i-kakoi-ona-dolzhna-byt-565g | Все мы знаем про, или слышали про практики и паттерны проектирования SOLID, GRASP, MVC, MV** и даже применяем их с переменным успехом, стараясь нащупать эффективный подход к построению приложений. Но это лишь приводит к разнообразию реализаций наших приложений и частей функционала.
И поэтому я уже долгое время пытаюсь понять по каким правилам должно строиться фронтенд приложение чтобы оно удовлетворяло следующим критериям:
- легкое расширение функционала приложения;
- безболезненное внесение изменений в существующий функционал;
- унифицированная структура приложения;
- быстрый onboarding новых разработчиков на проект;
- понятный и прозрачный код;
- всегда понятно где в структуре файлов расположить ту или иную функциональность.
Какие у нас есть варианты?
## Организация файловой структуры это все что нам нужно
Каждый лид или сеньор сами для себя выбирают варианты компоновки структуры приложения и выделения сущностей приложения. По итогу каждая система становится уникальной и неповторимой. И для того, чтобы разобраться в ней, нужны время и усилия, которые нужно будет тратить каждый раз при смене проекта. Плюс никто не отменял ["бас фактор"](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BA%D1%82%D0%BE%D1%80_%D0%B0%D0%B2%D1%82%D0%BE%D0%B1%D1%83%D1%81%D0%B0#:~:text=bus%20factor%2C%20%D0%BB%D0%B8%D0%B1%D0%BE%20truck%20factor,%D1%83%20%D0%BD%D0%B8%D1%85%20%D1%80%D0%B5%D0%B1%D1%91%D0%BD%D0%BA%D0%B0%2C%20%D0%BD%D0%B0%D1%81%D1%82%D1%83%D0%BF%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F%20%D0%BD%D0%B5%D1%81%D1%87%D0%B0%D1%81%D1%82%D0%BD%D0%BE%D0%B3%D0%BE).
Существует большое кол-во статей, описывающих «оптимальные», по мению авторов, варианты таких подходов. [Пример](https://clck.ru/hnGZh).
Но это, в основном, про структуру файлов и частные случаи использования какого-то функционала. Такой подход только частично унифицирует структуру приложения, но этого мало для того, чтобы называться архитектурой. Может есть что-то лучше?
## Domain Driven Design

Много умных дядек, таких как Мартин Фаулер и дядюшка Боб, написали много статей про него. На бэкенде в больших и сложных проектах он неплохо себя зарекомендовал. Но есть и много изъянов: туча абстракций, для простых действий нужно писать много кода, ну и разобраться, как готовить DDD та еще задача.
[Есть примеры](https://habr.com/ru/post/654629) как готовить это на фронте, но, как видно, проблемы никуда не уходят и кол-во абстракций удручают. Простой onboarding тут невозможен, без прочтения "[The Big Blue Book](https://www.domainlanguage.com/ddd/blue-book/)" и пары недель общения с ментором.
Есть переосмысленные подходы к архитектуре, которые больше похожи на правду и наверняка могут где-то успешно применены.
[Основательная статья от Кхалила Стеммлера](https://khalilstemmler.com/articles/client-side-architecture/introduction/) о возможной архитектуре клиентских приложений частично полагается на DDD подход, но при этом сильно его упрощает, освобождая нас от ненужных абстракций и смещая понятия в сторону фронт приложений.
Но бизнес логика в таких приложениях немного размывается и подход больше сфокусирован на функциональных слоях приложения, что отдаляет нас от требования к прозрачному коду и явной бизнес логики.
Джимми Богарт в [своей статье](https://jimmybogard.com/vertical-slice-architecture/) пишет что DDD подход не совершенен и избыточен, и, как следствие, он предлагает переработанный подход vertical slices. И это отличный подход, о котором стоит почитать отдельно. Эта идея довольно простая и мы можем адаптировать ее к фронтенд приложениям.
Если DDD не удалось применить для наших нужд, то можно попробовать построить его на более общих правилах, которые предоставляет нам "Clear architecture", ведь DDD основывается именно на них.
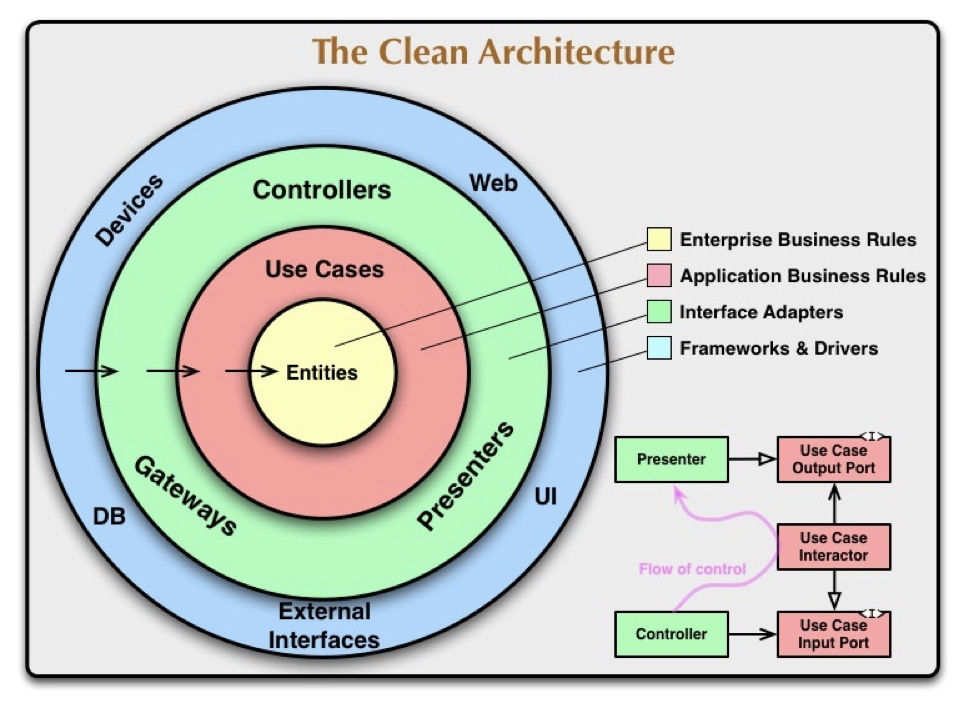
Также есть попытки следовать всем постулатам чистой архитектуры и абстрагироваться от представления совсем. В этом случае мы сможем подменять view на любой фреймворк или вообще отказаться от его использования. Интересный подход и в некоторых случаях вполне обоснован и может оказаться отличным решением. Самый частый кейс, это использование одной и той же логики в браузере и на мобильном приложении. Подробнее об этом можно [почитать тут](https://dev.to/xurxodev/moving-away-from-reactjs-and-vuejs-on-front-end-using-clean-architecture-3olk).
Разработчики Flutter тоже столкнулись с проблемой сложности переиспользования логики между различными представлениями, и предложили подход - [Business Logic Component](https://pub.dev/packages/flutter_bloc) (BLoC). Он позволяет снизить нагрузку на компоненты пользовательского интерфейса, отделив от них бизнес-логику.
[Тут пример](https://blog.bitsrc.io/using-bloc-pattern-with-react-cb6fdcfa623b) одной из реализаций BLoC в React. Вроде неплохо, но все же есть много вопросов. И почти нет сообщества, которое бы могло помочь с возникающими вопросами.
## FSD - Feature Sliced Design
И недавно для меня стало открытием методология FSD - Feature Sliced Design. На мой взгляд лучшем решением будет обратить внимание именно на эту методологию.

[Ссылка на офф сайт](https://feature-sliced.design/).
Методология не привязана к конкретному стеку технологий и применима к большинству frontend-приложений. Документация содержит примеры реализации на JavaScript + React, но FSD успешно адаптируется и к другим комбинациям инструментов.
Для проектирования архитектуры методология предлагает следующие архитектурные абстракциями на основе которых строиться наше приложение.
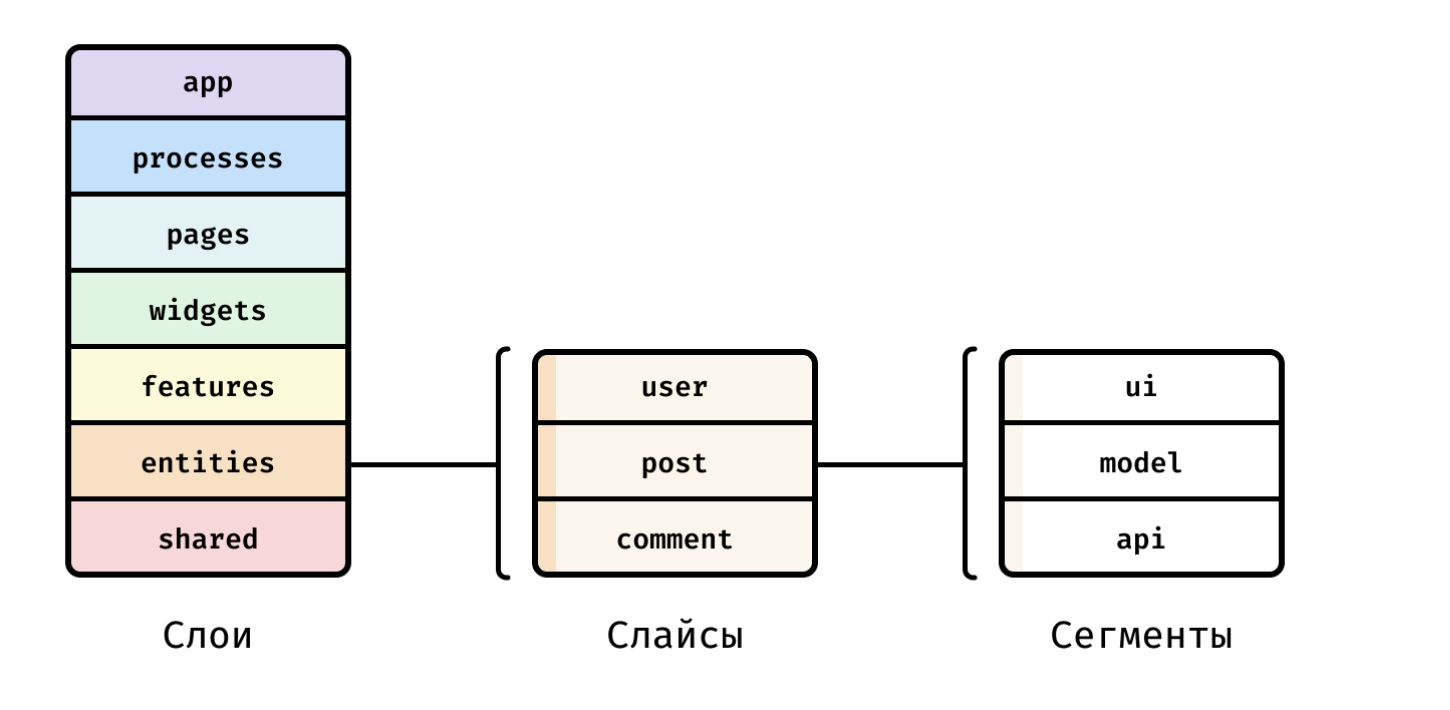
Ниже приведу описание терминов из документации:
**Layers**
Первый уровень абстрагирования - согласно скоупу влияния.
- app - инициализация приложения (init, styles, providers, ...);
- processes - бизнес-процессы приложения управляющие страницами (payment, auth, ...);
- pages - страницы приложения (user-page, ...);
- features - части функциональности приложения (auth-by-oauth, ...);
- entities - бизнес-сущности (viewer, order, ...);
- shared - переиспользуемый инфраструктурный код (UIKit, libs, API, ...).
**Slices**
Второй уровень абстрагирования - согласно бизнес-домену.
Правила, по которым код разделяется на слайсы, зависят от конкретного проекта и его бизнес-правил и не определяются методологией
**Segments**
Третий уровень абстрагирования - согласно назначению в реализации.
- ui - UI-представление модуля (components, widgets, canvas, ...);
- model - бизнес-логика модуля (store, effects/actions, hooks/contracts, ...);
- lib - вспомогательные библиотеки;
- api - логика взаимодействия с API;
- config - модуль конфигурации приложения и его окружения.
Ниже приведу пример описания фичи авторизации.
`# Сегменты могут быть как файлами, так и директориями
|
├── features/auth # Layer: Бизнес-фичи
| | # Slice Group: Структурная группа "Авторизация пользователя"
| ├── by-phone/ # Slice: Фича "Авторизация по телефону"
| | ├── ui/ # Segment: UI-логика (компоненты)
| | ├── lib/ # Segment: Инфраструктурная-логика (helpers/utils)
| | ├── model/ # Segment: Бизнес-логика
| | └── index.ts # [Декларация Public API]
| |
| ├── by-oauth/ # Slice: Фича "Авторизация по внешнему ресурсу"
| ... `
Помимо унификации структуры, мы получаем наглядную бизнес логику, отличное описание слоев приложения с примерами на популярных ЯП. Также есть ответы на вопросы о расположении функционала и понятные правила уменьшения зависимостей в коде. Эта методология только развивается и есть хорошее комьюнити, которое так же как и мы задается вопросами архитектуры фронтенда.
## Заключение
У каждого из подходов есть свои плюсы и минусы. Учитывая что каждый проект имеет разный размер, сложность и специфику и цели, то что подойдет многим не факт что подойдет вам. Надеюсь что после прочтения статьи вы откроете для себя что то новое и сможете улучшить ваши собственные проекты.
Также если вам интересно в [своем Telegram](https://t.me/devreverza) я время от времени выкладываю интересные находки по фронтенду. И всем чистой архитектуры.
| dmitriypereverza | |
1,113,678 | Git VS GitHub | Git vs GitHub is one of the things that beginners find tough to understand. So in order to understand... | 0 | 2022-06-14T07:20:15 | https://dev.to/shivam164/git-vs-github-2ghj | beginners, programming, productivity, opensource | Git vs GitHub is one of the things that beginners find tough to understand. So in order to understand their differences let's first look at them individually.
- **What is Git?**
Git is a version control system for tracking changes in computer files. It is used to coordinate work among several people on a project and track progress over time. It is used for Source Code Management in software development.
A version control system is a system that records all the changes made to a file or set of files, so a specific version may be called later if needed. This helps in collaboration with all team members.
**Advantages of using git:**
- Git favors both programmer and non-technical users by keeping track of their project files.
- It allows multiple users to work together.
- Large projects can be handled effectively.
---
- **What is GitHub?**
GitHub is a Git repository hosting service, which provides a web-based graphical interface.
GitHub helps every team member to work together on the project from anywhere and makes it easy for them to collaborate.
---
**GIT VS GITHUB**
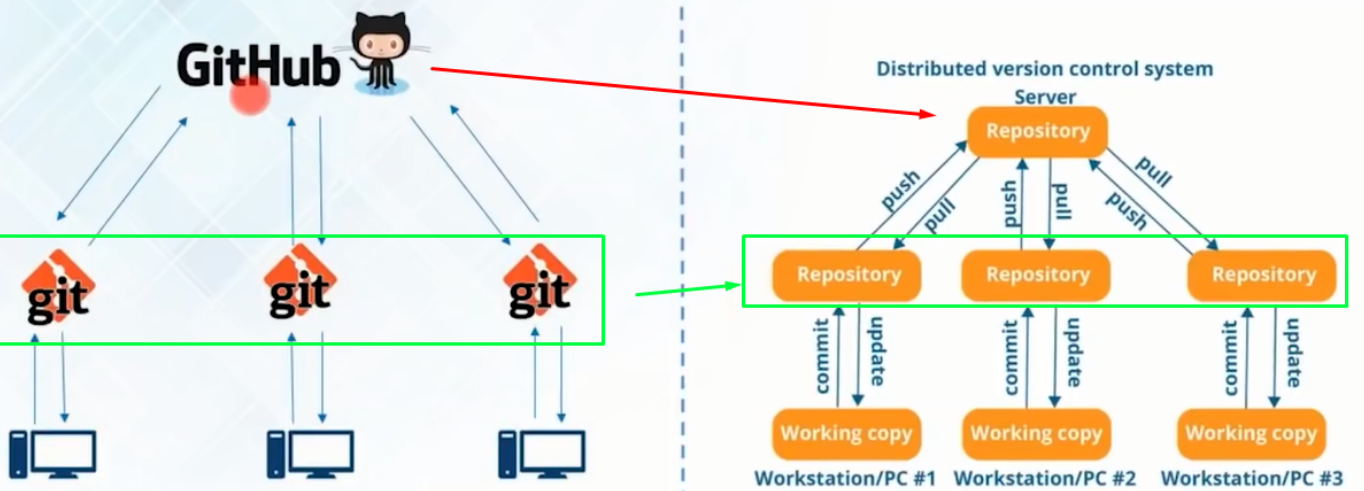
---
| Git | GitHub |
| --- | --- |
| | |
| Installed locally on the system. | Hosted on the cloud. |
| Git can be used offline and does not need an internet connection for use. | GitHub cannot be used offline and needs an internet connection. |
| Git can be used without GitHub. | GitHub cannot be used without Git. |
| Used for version control system and works as source code management in software development. | Used for centralized source code hosting. |
| Git has no GUI. | GitHub has GUI. |
| Code changes like commit, merge, etc. are done using commands from the command line. | Everything is done through a web-based interface. |
| Open source licensed. | Includes free and pay-for-use tiers. |
---
| shivam164 |
1,113,689 | Quick Recap of Modern JS App | I'm currently making a instagram clone app based on tutorials by NomadCoders It uses various stacks... | 0 | 2022-06-14T07:39:55 | https://dev.to/sosunnyproject/quick-recap-of-modern-js-app-1830 | I'm currently making a instagram clone app based on tutorials by [NomadCoders](https://www.youtube.com/c/%EB%85%B8%EB%A7%88%EB%93%9C%EC%BD%94%EB%8D%94NomadCoders )
It uses various stacks and modern backend technologies - graphQL, Apollo, Prisma, Babel, React, Styled Component, etc. I used Java Spring framework few years ago, but recently I have been focusing on frontend and javascript web dev. So it was quite refreshing to learn all these new libraries and frameworks that allow you to build web app mostly in javascript as much as you can..
Just to clarify all these packages in my brain, I drew a simple structure map.
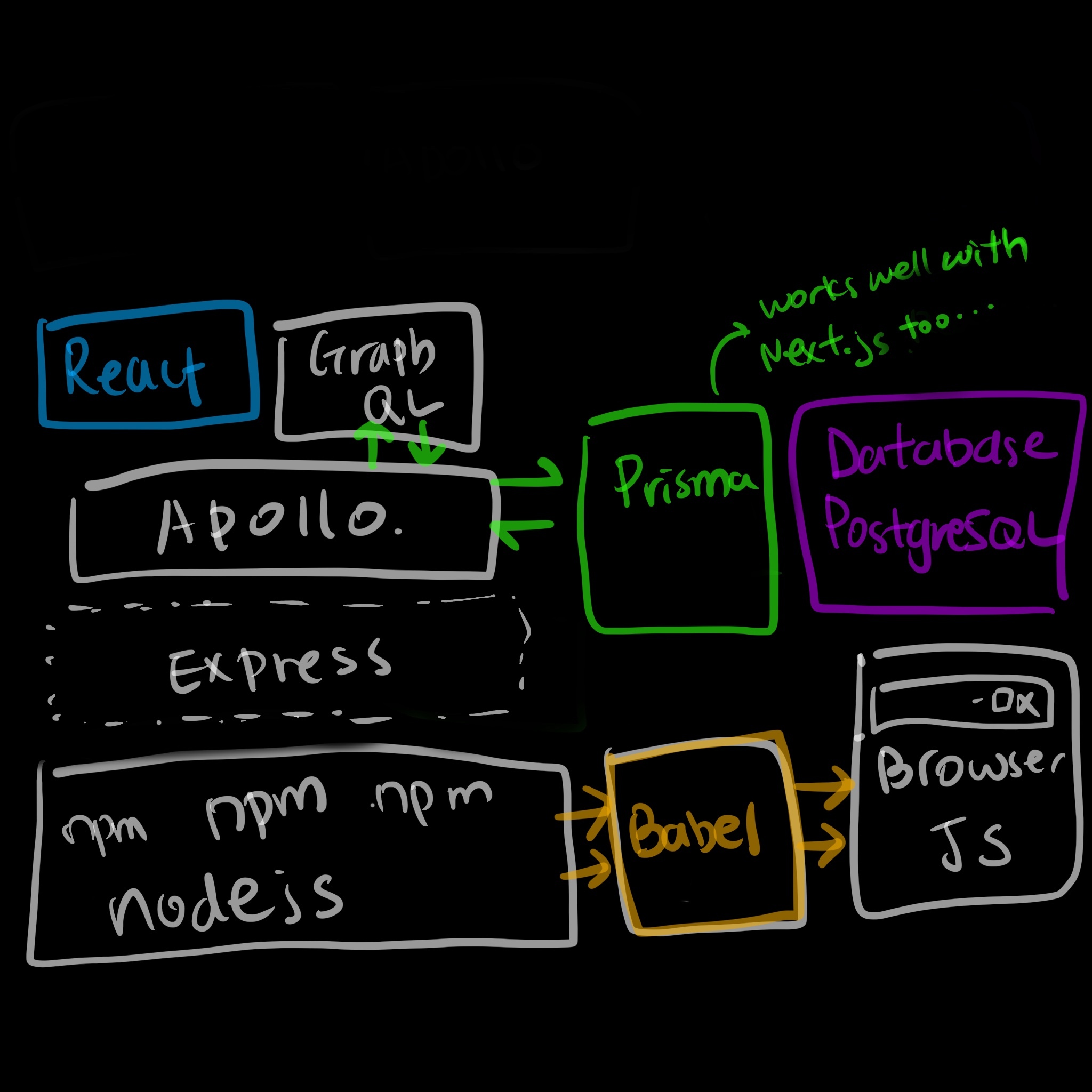
[github repo](https://github.com/sosunnyproject/instaClone) | sosunnyproject | |
1,113,945 | Java gaming with connect4 | *building Game is an Amazing experience * With Java we can build them. Check this out... | 0 | 2022-06-14T13:16:50 | https://dev.to/msshahid/java-gaming-with-connect4-4fe1 | programming, tutorial, java, beginners | **building Game is an Amazing experience **
With Java we can build them.
Check this out →(https://github.com/Ms-Shahid/Connect4Game) | msshahid |
1,114,168 | EMAIL MARKETING : | What is email marketing .? This is the use of email to send advertisements or sales, promotions and... | 0 | 2022-06-14T16:57:04 | https://dev.to/munene_cm/email-marketing--2pd4 | marketing, webdev, writing | What is email marketing .?
This is the use of email to send advertisements or sales, promotions and request business opportunities sent to potential or current customers .
There are various types of email marketing mainly:
• Promotional emails
These are used to drive sales for your product. New product offers for your business and encourage signups from potential customers. Its great to implement a successful email marketing campaign to achieve the business goals.
• Email newsletters
These are for sending out company / brand news , events ,product announcements and feedback requests to your current customers. They are helpful to educate customers about your business , company and products . they help you get valuable insights about your customer thus ability to retain them.
• Event invitation emails
When your company wants to host an event , be able to send an exciting email to get them to register for your event. It should include details about your event, date, agenda time and location. Its kind of an invitation to get your customers to reserve.
• Transactional emails
Customers engage with these emails during orders, shipping and return or exchange notifications at higher rates. Its up to the business or company to implement call to action, branding and marketing it products.
• Welcome emails
This is an email sent to new subscribers. It’s a way of introducing your company or business to your potential customer. You can get to know them by knowing /asking their preferences and how often you can contact them.
Ensure with these email you make a first great impression.
• Review request emails
When or after customers purchase your products its important to invite them to leave a comment or review your products. By sending review email you keep your customers engaged with your business products. It helps you get honest reviews which may encourage and build confidence to new customers to purchase your brand product.
• Seasonal campaigns
During holidays you can launch a marketing strategy for the certain holiday and including exclusive discounts and urgency to get your customers to purchase. Make sure that the campaign matches the holiday theme to promote your business
**Crafting a great working email.**
Use a subject line to make a good first impression. The subject line is like a gatekeeper or the face of your email. You have to write a great one to compel your customers enough to be interested in opening your email.
Use constituent content with a call to action. This helps your customers to take an action like ask, buying ,reserving , downloading and liking.
Write in second person whereby you use pronouns such as “you” “yours” since this means you orient the copy towards the reader and not yourself.
Always to remember to talk about benefits of your products and not just features. Its your job to explain the value of your email to your customers.
Write brief email , by summarizing what the reader will understand in a compelling way and click through to your products on websites for more information. Keep your message on –point.
Enter helpful links too in your email to help your customers or subscribers to help them around your product or related topic.
**_Manage your email campaigns by _**
use A and B testing to improve engagements by writing two versions to test which performs the best.
Use relevant campaign landing page related to your product.
Measure the performance of your email campaign by using relevant analytics tools to get an understanding of your campaign.
**_Measuring success in email marketing_**
Overall traffic to site. Establish a base line to show you the lift of overall traffic gained from your campaign
Open rate which is the % of email recipients who did open your email.
Click through rate which is the percentage of email recipients that did click through various links in your email.
Conversion rate which is the percentage of recipients that completed a desired action such as filling a form or buying a product or leaving a review.
Bounce rate(soft and hard) which is percentage of your total emails that were not delivered successfully to recipient inbox. Soft bounce are result of problem with valid email due to full inbox or recipients server. Hard bounce on the other hand are due to invalid or closed or non-existing email.
The list growth rate of your email subscribers.
Email sharing and forwarding which is how many have forwarded your email to other people
Those who have unsubscribed also after you sent a list to their emails.
| munene_cm |
1,114,417 | Do you need a web2 background to build in web3 - An in-depth research | Getting into the blockchain space can be challenging, I struggled to find the right path, right... | 0 | 2022-06-20T23:54:34 | https://dev.to/thegirlcoder/do-you-need-a-web2-background-to-build-in-web3-an-in-depth-research-3l8f | web3, blockchain, webdev, beginners | Getting into the blockchain space can be challenging, I struggled to find the right path, right resource, and community and I believe this to be something a good number of people in the blockchain space struggle with as well.
As a result, I’ve embarked on this small interview with notable web3 figures to curate this article that should ultimately help you figure out how to get into the web3 space. More importantly, if you need web2 experience or not. Now, Let's get started!

To start us off, I spoke with [Kristen](https://twitter.com/cuddleofdeath?s=21) who is currently the community lead[@womenbuildweb3](https://twitter.com/womenbuildweb3?s=21) on the topic. When I asked if a background in web2 was needed for beginners to thrive in web3, this was what she had to say:
> When we talk about building, I believe that there's more to it than just websites and applications. Since continuing my journey, I've been presented with opportunities that involve helping build web3 communities up. Opportunities like writing, research, discord/community moderating and UI/UX Design etc.
> However, If we're speaking in terms of strictly building apps and other things that require code, my opinion is this: "There are a ton of amazing open-source resources that can teach someone who has zero coding knowledge how to create a dApp"
I summarized from Kristen's response that you can probably learn web3 without necessarily having web2 experience. This is not to say that the web2 experience won't benefit you in the journey, however, it might be limiting to advise beginners otherwise.
I pondered about it for a while seeing that I had a different experience coming into the space. Along the way, I felt that I lacked some fundamentals of how the web worked, which would've helped me get through some huddles a lot easier than I did.
As a result, I continued to interview more people to get an idea of their own experiences and how it relates to this topic. So I spoke with [Samuel](https://twitter.com/samuelarogbonlo?s=21) a Senior Infra Engineer [@o1labs](https://twitter.com/o1_labs?s=21) and these were his thoughts:
> "Well, yes I honestly believe(so you need a web2 background). There’s so much about the fundamentals of web3 that has its ties to web2 especially in the JavaScript world and that’s why many times, it’s advised to pick up JavaScript before Solidity, Ocaml ,and the rest".
Samuel continued,
> If you ask me to choose between web2 and web3, I’d go for the latter because it is still an emerging field and that means, there’s a chance for me to become a formidable member of the community, build a solid infrastructure and impact the space while it is still at birth. Web2 background will help you conquer fast but going to web3 directly, is also not a bad shot, it’d just be a long race.
I couldn't agree more with Samuel, there’s so much about the fundamentals of web3 that has its ties to web2 especially in the JavaScript world. This is why I'm currently learning JavaScript, as I've continued to see the need to understand the basics.
I was also privileged to speak with [Mack](https://twitter.com/ktfou?s=21), A Decentralization Advocate [@graphprotocol](https://twitter.com/graphprotocol?s=21), CTO [@graphrica](https://twitter.com/graphrica?s=21), Web3 Dev and Trainer. When I asked the question, this was his reply
>"Web2 helps but leapfrogging directly into web3 is possible. Anyone can start developing and starting in web3 is a lot more fun"
To support Mack's view, I'd say web3 has a lot of features that make the experience more interesting than the traditional web2 experience. A Platform like crypto zombies would teach you solidity whilst making learning fun and easy.
Up next is [Fatma](https://twitter.com/fatima39_fatima?s=21), Fullstack Blockchain/Web Developer and Educator [@womenbuildweb3](https://twitter.com/womenbuildweb3?s=21) and [@developer_dao](https://twitter.com/developer_dao?s=20&t=9CQ8BE_qEfow65QPT8uYMw)DAOs . When I asked her whether a web2 background was needed to build in web3, This was her reply
>"Yes you do need a background in web2 to build in web3.
Furthermore, she stressed on some web3 roles and web2 backgrounds they required.
>- FrontEnd Web3 Developer:
>They have to understand understand Web2 development ,working >with frontend(HTML,CSS and JS frameworks) to interact with >smart contracts.
>- Developer Advocate/Relations Engineer:
>They must have an understanding of Blockchain, web2 >development before they can create content on web3.
>- Blockchain Developer:
>They develop smart contracts with languages like solidity >before you dive into solidity you've got to start with >other languages used web2 mainly object-oriented languages >and scripting languages(Python,Java, JavaScript..) to get >familiar with solidity.
>- Core Blockchain Developer
>These utilize languages like Go to build the EVM-based >blockchains infrastructure.
Fatma's list was thoroughly enjoyable to read, and I learned a lot from it as well.
Next, I spoke with another developer and technical writer[Busayo](https://twitter.com/amoweo?s=21). She’s also a contributor[@womenbuildweb3](https://twitter.com/womenbuildweb3?s=21) and [@developer_dao](https://twitter.com/developer_dao?s=20&t=9CQ8BE_qEfow65QPT8uYMw)DAOs.Her words were as follows:
> I think you need a little fundamental of programming. You don’t have to be a pro. Just the basic foundations on terms like variables, functions and mathematical operations.
The last on this series was [Kene](https://twitter.com/kene_mii?s=20&t=9CQ8BE_qEfow65QPT8uYMw). A Legal and DeFi M&A consultant [@banklessconsult](https://twitter.com/banklessconsult?s=20&t=9CQ8BE_qEfow65QPT8uYMw) DAO.
>I believe that having existing Web2 skills can make it easier to transition to creating value in Web3, however if you don’t have Web2 skills, you will need more time to study web3 and figure out exactly how you can provide value to the ecosystem.
In a subsequent post, I'll share details of my interviews with other web3 figures who are equally experienced in migrating from web2 to web3. In the meantime, I'd like to summarize my findings under these bullet points:
- If you want to build in Web3, you'll likely need a background in Web2 to be more efficient.
- A very good Web3 developer must have fundamental coding knowledge and experience.
- Web3 does not have stringent rules regarding how things function like the traditional web, everything is possible.
That said, I'd like to acknowledge that my conclusions are not final and can still be disputed seeing as the Web3 ecosystem is still relatively new and constantly evolving.
## Closing thoughts
Building in the web3 space is an incredible career path. The journey might not be easy, but it's worth it. Hopefully, this article helped you figure out some of the challenges you might face in this field.
If you liked reading this article, please tweet about it and give me some reactions as I work on the next one! Also, If you’d like to share some thoughts on this topic with me or feature in the next series, please reach out to me on [Twitter](https://twitter.com/thegirlcoder) and I’d be happy to work with you!

| thegirlcoder |
1,123,573 | Testing in production vs staging | Context: I am adamant advocate of designing services in such a way that promotes testing them in... | 0 | 2022-06-24T15:51:59 | https://dev.to/gajus/testing-in-production-vs-staging-5dgj | testing, webdev | Context:
I am adamant advocate of designing services in such a way that promotes testing them in production as part of the software development cycle. Developers have their local test environments, and we have ephemeral environments for running integration tests, but we do not have staging environments. This comes as a surprise and almost a crazy idea to people who have not worked in a such setup. What follows is an internal memo that expresses my views in a conversation with the team about having a dedicated test / staging environment.
Internal memo:
There is no denying that testing pre-production is valuable – you can do risk-free deployments, revert them, etc.
In the ideal world, every branch that is being worked on would have its own web app, database, API, temporal, etc. – the entire copy of production. This environment would last no longer than the branch (but would also not provide any guarantees about persisting state within that period). This is the ideal world ephemeral testing environment. It is ideal because:
- we know that it is reasonably similar to production because initialization is versioned and replicable
- we can always ensure that it matches the current production environment by recreating it
- there is no maintenance cost assigned to it because it has no expectations of persistence
We already have components of it (ephemeral API and database instances), and one day I would like us to have all of the above.
In contrast, a persistent staging environment does not provide any of these guarantees:
- You have no clue what is deployed to this environment because multiple people can be contributing to it, i.e. You are not testing your changes in isolation.
- You have no clue in what state is the environment because multiple users / automated tests can be making changes to it.
- Staging environment is more than likely to lack robust monitoring and alerts coming from staging are not going to get prioritized.
Some testing is not even possible in staging environment, namely: performance and stress testing. This is because staging is deployed under a different infrastructure.
As far as integrity tests go, a shared test environment that is in an unpredictable state is as useful to integration tests as self-attesting PRs that they do not have bugs. What works there is not guaranteed to work in production.
On the other hand, testing in production is hard:
- You need to be careful when deploying changes because no matter how many safe-guards you add to CI/CD, there is a chance of breaking production.
- You have to think ahead not only about whether your changes will work in the test environment, but also if they are going to work in production (a perfect example of that is forgetting to add indexes concurrently, which will work in staging, but may completely lock production).
- You have to make expensive transactions conditional, e.g. You should be able to test using sandbox / production Stripe credentials in production and in your local development environments. Otherwise, you cannot easily debug issues that arise in just one of the environments.
- You have to plan for tests to be atomic, i.e. ensuring that other user actions do not affect your tests.
- You have to have a process for canary, blue/green and rollbacks.
- You have to have a process for isolating and deleting test data.
- You have to have sufficient redundancy to avoid outages.
- You have to communicate changes being deployed.
- You have to monitor your deployments to isolate or revert deployments with unexpected behavior.
This is a lot of overhead, but all of these are also great practices for production maintenance regardless of where testing takes place.
In addition, testing in production allows a quicker path to (iteratively) test and collect feedback from real-users, which is what we all should be aiming to be doing more.
The way I see it, testing in production has a higher upfront cost and ongoing cost, but it brings along a heap of benefits that otherwise would get deprioritized in a normal software development cycle. It is how we learn to make safe deployments and quickly restore services when the unexpected happens. | gajus |
1,114,571 | Install multiple versions of same package using yarn | Using alias in yarn to install multiple version of same package | 0 | 2022-06-15T05:54:14 | https://dev.to/atosh502/install-multiple-versions-of-same-package-using-yarn-2668 | yarn, npm, alias | ---
title: Install multiple versions of same package using yarn
published: true
description: Using alias in yarn to install multiple version of same package
tags: yarn, npm, alias
---
I had an issue in react native with libraries: `react-native-picker-select` and `@react-native-picker/picker`. `react-native-picker-select` uses `@react-native-picker/picker` internally, and the version is far behind the current version. So I tried installing the latest version of `@react-native-picker/picker` separately but got an error saying: `RNCAndroidDialogPicker` was declared twice or something similar.
Anyways, I couldn't solve the issue but found aliases in npm/yarn.
With aliases you could add node packages with a different name and import them without any issues.
```
yarn add your-custom-name@npm:@react-native-picker/picker
```
This way I can define a new name for the latest version of the `@react-native-picker/picker` library and import it in my components with the new name. The same name will be added to the package.json file. | atosh502 |
1,114,744 | Maximum Bags With Full Capacity of Rocks | You have n bags numbered from 0 to n - 1. You are given two 0-indexed integer arrays capacity and... | 18,343 | 2022-06-15T10:00:46 | https://dev.to/theabbie/maximum-bags-with-full-capacity-of-rocks-2ck0 | leetcode, dsa, theabbie | You have `n` bags numbered from `0` to `n - 1`. You are given two **0-indexed** integer arrays `capacity` and `rocks`. The `ith` bag can hold a maximum of `capacity[i]` rocks and currently contains `rocks[i]` rocks. You are also given an integer `additionalRocks`, the number of additional rocks you can place in **any** of the bags.
Return _the **maximum** number of bags that could have full capacity after placing the additional rocks in some bags._
**Example 1:**
**Input:** capacity = \[2,3,4,5\], rocks = \[1,2,4,4\], additionalRocks = 2
**Output:** 3
**Explanation:**
Place 1 rock in bag 0 and 1 rock in bag 1.
The number of rocks in each bag are now \[2,3,4,4\].
Bags 0, 1, and 2 have full capacity.
There are 3 bags at full capacity, so we return 3.
It can be shown that it is not possible to have more than 3 bags at full capacity.
Note that there may be other ways of placing the rocks that result in an answer of 3.
**Example 2:**
**Input:** capacity = \[10,2,2\], rocks = \[2,2,0\], additionalRocks = 100
**Output:** 3
**Explanation:**
Place 8 rocks in bag 0 and 2 rocks in bag 2.
The number of rocks in each bag are now \[10,2,2\].
Bags 0, 1, and 2 have full capacity.
There are 3 bags at full capacity, so we return 3.
It can be shown that it is not possible to have more than 3 bags at full capacity.
Note that we did not use all of the additional rocks.
**Constraints:**
* `n == capacity.length == rocks.length`
* `1 <= n <= 5 * 104`
* `1 <= capacity[i] <= 109`
* `0 <= rocks[i] <= capacity[i]`
* `1 <= additionalRocks <= 109`
**SOLUTION:**
class Solution:
def maximumBags(self, capacity: List[int], rocks: List[int], additionalRocks: int) -> int:
n = len(capacity)
diff = [capacity[i] - rocks[i] for i in range(n)]
diff.sort()
print(diff)
i = 0
while additionalRocks > 0 and i < n:
additionalRocks -= diff[i]
i += 1
if additionalRocks < 0:
return i - 1
return i | theabbie |
1,115,217 | Announcing Strapi v4.2 with logo customization, in-app providers, media library folders in beta and more | Introducing Strapi v4.2 This new Strapi version brings more customization &... | 0 | 2022-06-15T16:36:14 | https://strapi.io/blog/announcing-strapi-v4.2?utm_campaign=v4.2&utm_source=devto&utm_medium=blogpost | webdev, programming, strapi, javascript | ---
canonical_url: https://strapi.io/blog/announcing-strapi-v4.2?utm_campaign=v4.2&utm_source=devto&utm_medium=blogpost
---
## Introducing Strapi v4.2
This new Strapi version brings more customization & integration possibilities to the table. Customizing the logo in the admin panel in a couple of clicks and finding providers on the marketplace is now possible. We’re also releasing beta versions of media library folders and TypeScript support. Let’s dig into each feature one at a time :D
## Logo customization
Did we say that Strapi is the most customizable CMS on the market? Well, not only do we say it - we prove it!
People spend hours using the admin panel, and we want to make their experience as delightful and efficient as possible. **Changing the logo in the admin panel** was possible before, but only by modifying the configuration files, which might make future upgrades harder and usually requires help from the development team.
But not anymore! We’re releasing a new feature that allows everyone to customize the logo in the admin panel in a few clicks.
{% embed https://www.youtube.com/embed/QeyfqG8u2m0 %}
With this feature, anyone can update the logo in the admin panel at any moment by dragging and dropping the image or pasting its URL. Nothing should block creative processes, that’s why we’re happy to make this feature accessible to anyone, regardless of their tech background.
Logo customization also makes Strapi the go-to CMS for agencies, who need to provide a familiar and efficient tool for their clients. This time-saving feature will facilitate the customization of a CMS for each client. They will also be able to update the logo by themselves, without asking the agency for help.
Check out the [user guide](https://docs.strapi.io/user-docs/latest/settings/managing-global-settings.html) and the [developer documentation](https://docs.strapi.io/developer-docs/latest/development/admin-customization.html#logos) to learn more about the feature.
## Providers on the Strapi Market
In January 2022, we launched [Strapi Market](http://market.strapi.io/) - the official marketplace that lists all plugins made by the community and our team. Right now, the marketplace lists more than 60 plugins, such as [versioning](https://strp.cc/3b19F7O), [SEO](https://strp.cc/3aV2SfK), [scheduling](https://strp.cc/3HuvIzN).
Today, the marketplace is evolving and will also list providers, which allow you to extend the functionalities of the plugins. For example, the [Cloudinary provider](https://www.npmjs.com/package/@strapi/provider-upload-cloudinary) can extend the functionalities of the Upload plugin by allowing users to store files in a Cloudinary account, and not locally.
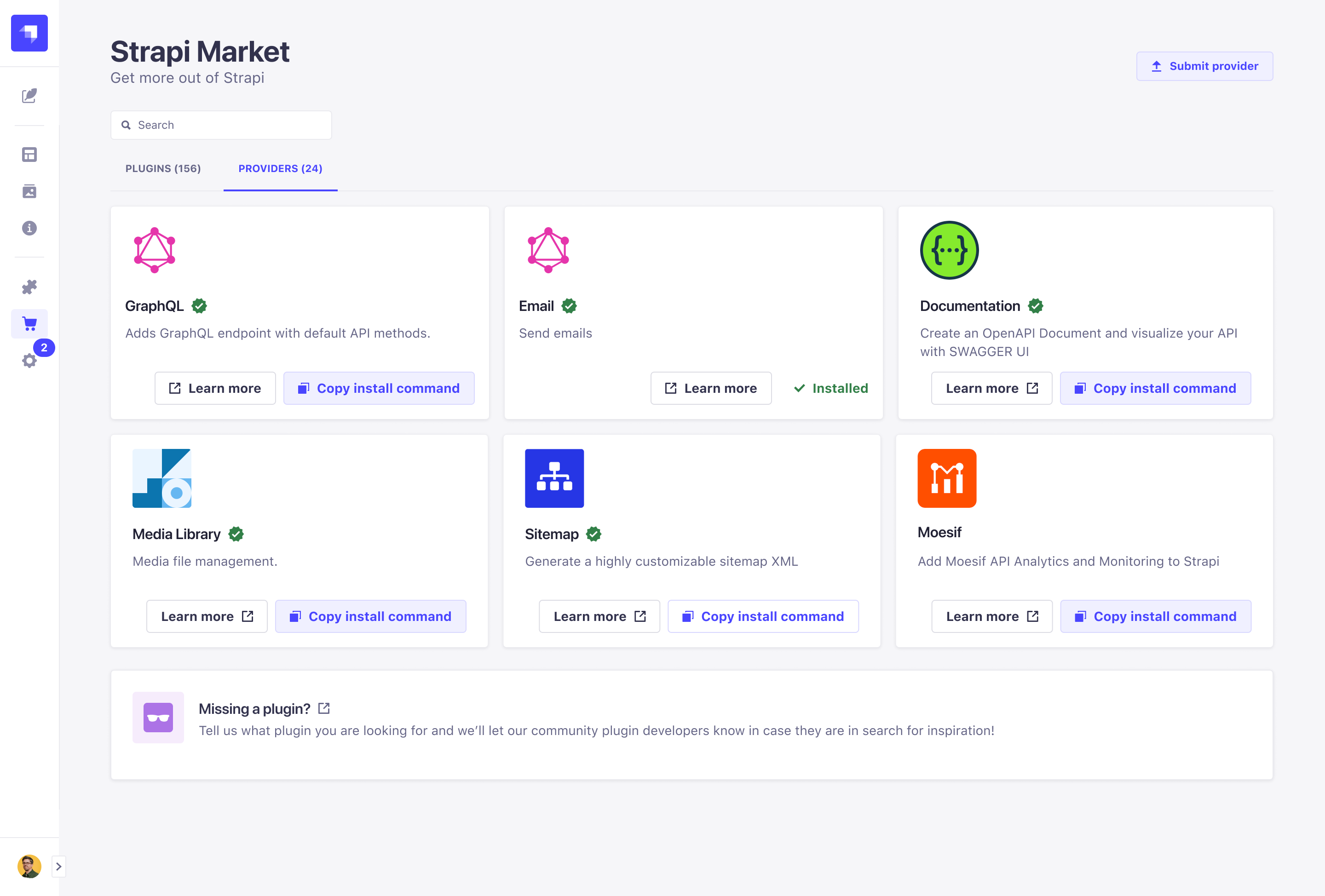
If you'd like to list your provider on the marketplace, please submit it through this [form](https://strp.cc/3xLH27n). We will do a quick review and let you know once the provider is displayed on the marketplace.
Check out the documentation to learn more about [providers](https://docs.strapi.io/user-docs/latest/plugins/introduction-to-plugins.html#providers) and how to install them.
## End of Node.js 12 support
On April 30th, [Node.js 12 reached an End-of-Life status](https://nodejs.org/en/blog/release/v12.22.12/), meaning there is no more active or security support for this version. Everyone is advised to migrate to newer versions (Node.js 14 or 16).
To ensure the security and good performance of Strapi, we are going to stop the support of Node.js 12 starting from Strapi v4.2.0. We encourage everyone to update their Strapi projects to the latest version and to use the maintained versions of Node.js (14 and 16). We'll be supporting Node.js 18 soon, once the ecosystem upgrades. We have updated the [documentation](https://docs.strapi.io/developer-docs/latest/setup-deployment-guides/installation/cli.html) to reflect these changes.
Here's the [guide to migrate from Strapi v3 to Strapi v4](https://docs.strapi.io/developer-docs/latest/update-migration-guides/migration-guides.html#v3-to-v4-migration-guides), and the [scripts](https://forum.strapi.io/t/strapi-v4-migration-scripts-are-live-for-testing/18266) (in alpha) that will help you to migrate the data.
## Try Strapi v4.2 out now
To create a new [Strapi v4.2 ](https://github.com/strapi/strapi/releases/tag/v4.2.0) project, simply run the following command:
`npx create-strapi-app my-project --quickstart`
Follow the [Quick Start Guide](https://strp.cc/3MR4nJ5) for detailed step-by-step instructions or have a look at a video instruction:
{% embed https://www.youtube.com/embed/h9vETeRiulY %}
We would love to hear what you think about the v4.2! Please share your feedback about it on the [forum](https://forum.strapi.io/t/strapi-v4-2-0-with-logo-customization-and-providers-on-marketplace-is-live/19512).
## Media Library folders beta
Strapi allows you to manage various media files (images, videos, audio, documents) using the media library. Even though it's possible to filter, sort, and rename assets, sometimes, the large number of files in a project makes finding the right one difficult and time consuming.
We'd like to share some progress on media folders - a system that simplifies your file organization.
Here's how it facilitates the Strapi use:
- **Easily find the right asset**
You can create several levels of folders and place as many assets as you wish there. This way, you're free to organize your media library most conveniently. Sometimes, it's not easy to remember the file's name or the date when it was created, so the filter and sort feature becomes powerless. With media folders, it's easy to group files and find the right one.
- **Create a custom file organization**
Everyone has different organizational habits, that's why standard sorting settings will never fit all users. It is easier to organize assets however you wish with folders, using any criteria and setup system. Good news for perfectionists - it's also possible to create folders in folders, so your file system can be as extensive as you wish!
- **Manage files at ease**
When many users constantly add assets, it may be challenging to keep everything in order. We added a functionality that allows you to choose the file's location when you open it. It means that you don't need to make unnecessary clicks to move the file from one folder to another. You can also see how many files each folder contained, when it was last modified, and by whom.
Media library folders are currently available in a [Strapi v4.3 beta version](https://github.com/strapi/strapi/releases/tag/v4.3.0-beta.1). To test this feature, please run the command and follow the [user guide](https://docs-next.strapi.io/user-docs/latest/media-library/introduction-to-media-library.html) (beta):
`npx create-strapi-app@beta my-project`
We would love to hear what you think about media library folders! Please share your feedback on the [forum thread](https://forum.strapi.io/t/media-library-folders-beta-is-live/19515).
## TypeScript support beta
The typings are in 🎉 You got it, we're talking about the most upvoted feature on the roadmap, [Typescript support](https://feedback.strapi.io/developer-experience/p/support-typescript) ! We're happy to announce it's going to be possible to develop using TypeScript in your Strapi applications.
As you may know, TypeScript features several capabilities making it very popular and powerful versus classic JavaScript. Specifically regarding object-oriented programming and the development of big projects with multiple developers involved.
**TypeScript support in v4.3.0-beta now allows:**
- Optional Static Typing: you decide what you want to type to add safety to your application.
- Type inference: infer variables and return values types
- Access to TS features: modules, decorators, and much more.
- Ability to compile TypeScript code to any version of JavaScript
- Great Intellisense support, which makes discovering libraries quicker and understanding APIs easier.
Although the feature is still in beta, Strapi makes it super easy to develop your TypeScript projects. You can also now use any[ CLI Strapi commands](https://docs.strapi.io/developer-docs/latest/developer-resources/cli/CLI.html#strapi-new) with Typescript in your project and:
- Write your Strapi application code in Typescript and make use of all benefits from TS we just mentioned.
- Get access to typed APIs: this will add a layer of security by preventing type issues. This will be improved on a regular basis in the next releases, so every contributors are welcomed to help provide more accurate types. (Do you know how to contribute? Check here)
- Define dynamic typings based on your application code: you now have the ability to declare types for the user content-types which will then be used by all the other typings.
To get started with a new project with Typescript and the [v4.3.0.beta,](https://github.com/strapi/strapi/releases/tag/v4.3.0-beta.1) simply run the following command:
`npx create-strapi-app@beta you-app-name --ts`
To learn more about developing in TypeScript on Strapi, go to our [documentation](https://docs-next.strapi.io/developer-docs/latest/development/typescript.html).
We would love to hear your feedback about this feature to make sure if meets your expectations. Please share what you think about it in [this forum thread](https://forum.strapi.io/t/typescript-support-has-been-added-to-4-3-0-beta-1/19517).
## Other updates you might have missed:
We made a couple of announcements recently, so we just wanted to remind you about the latest product updates:
- [Dark Mode](https://strp.cc/3xPGSMj)
- [v3 → v4 migration guide](https://strp.cc/3MPP8QL) and migration scripts
- [Custom fields](http://youtube.com/watch?v=4Rq3zin8XXQ) (coming soon, RFCs available)
- [Strapi Cloud](https://strp.cc/3zGBUTo) (coming soon)
Please, let us know what features you'd like to see next by adding them to this [board](https://strp.cc/3aXU9cS).
## Join the Strapi Community call
We're inviting the Strapi community to a monthly community call, during which we'll demo the new features, answer your questions and share the plans for the future. We would also like to take a moment to thank everyone who helps us to make the product better.

We're waiting for you on **June 16th, at 6:30 PM CET!**
Register [here](https://lu.ma/strapiv4-2-0) not to miss the event. See you!
## Build Strapi with us
Strapi is an open-source product that grows thanks to community support and contributions.
Here's how you can help us improve the product:
- Contribute to the project on [Github](https://github.com/strapi/strapi/blob/master/CONTRIBUTING.md)
- Share what features you'd love to have in our [public roadmap](https://strp.cc/3aXU9cS)
- Create Strapi plugins and submit them to the [Strapi market](https://strp.cc/3mL6inV)
- Showcase the projects you built in [Strapi Showcase](https://strp.cc/3MROZwj)
We appreciate each contribution and piece of feedback that you share. Stay safe and tuned for more updates! | strapijs |
1,115,261 | 897. leetcode solution in cpp | class Solution { public: TreeNode* increasingBST(TreeNode* root, TreeNode* tail = nullptr) { ... | 0 | 2022-06-15T17:43:04 | https://dev.to/chiki1601/897-leetcode-solution-82d |
```
class Solution {
public:
TreeNode* increasingBST(TreeNode* root, TreeNode* tail = nullptr) {
if (!root)
return tail;
TreeNode* ans = increasingBST(root->left, root);
root->left = nullptr;
root->right = increasingBST(root->right, tail);
return ans;
}
};
``` | chiki1601 | |
276,941 | Guo Lai Ren (过来人) | One of the most powerful forms of persuasion is the argument from crossover people | 0 | 2020-03-09T04:07:04 | https://www.swyx.io/writing/guo-lai-ren | reflections | ---
title: Guo Lai Ren (过来人)
subtitle: Why "Crossover People" are the most persuasive people, and how we can de-stigmatize changing our minds
published: true
description: One of the most powerful forms of persuasion is the argument from crossover people
tags: Reflections
slug: guo-lai-ren
displayed_publish_date: "2020-03-07"
canonical_url: https://www.swyx.io/writing/guo-lai-ren
---
Have you noticed that people who have changed their minds are more convincing?
Let's say there's two sides of a debate, A and B. There are staunch advocates of A and loyal supporters of B. But they've always been advocates of A and supporters of B. A people have their talking points, B people have theirs, and when they argue they yell these as loudly as they can to each other and to the neutrals in the middle. Neither really budge.
Then, every now and then, you get someone who switches sides, for whatever reason. Someone who was a lifelong A starts advocating for B. That person is more effective at changing the minds of other A's, and in speaking to neutral people as well.
## What To Call It?
In English we might call this person a **flip-flopper**, a derogatory term. We sneer at them, call them out on presidential debate changes, use their former statements against them to deny their credibility. We admire the person who has just thought one thing all their life and stuck to their guns under adversity, even when - especially when - everyone else doesn't agree. We don't have a neutral shorthand for someone who changes their mind.
In Chinese we have a different phrase for these people - 过来人 (Guo Lai Ren). The [Chinese English Pinyin dictionary](https://chinese.yabla.com/chinese-english-pinyin-dictionary.php?define=guo+lai+ren) defines 过来人 as "an experienced person", "somebody who has 'been around (the block)'". This is accurate, but when applied to switching sides, it takes on an additional meaning.
过来 (Guo Lai) means "[to come over](https://chinese.yabla.com/chinese-english-pinyin-dictionary.php?define=guo+lai)". A 过来人 (Guo Lai Ren) is, literally "a person (人) who comes over". Kind of a neutral statement, not as derogatory as the English equivalent.
You don't even really have to formally "change your mind" to be a 过来人 - you could just have spent your life doing, saying, believing one thing without really questioning it, and then suddenly have a ["Come to Jesus" moment](https://grammarist.com/idiom/come-to-jesus-moment-and-come-to-jesus-meeting/) and switch to the alternative side.
## Guo Lai Ren in Action
Here are some 过来人 in action:
- [Ryan Dahl](https://www.youtube.com/watch?v=M3BM9TB-8yA) (the Creator of Node.js) - "10 Things I Regret About Node.js"
- [Solomon Hykes](https://twitter.com/solomonstre/status/1111004913222324225?lang=en) (original Docker team) - "If WASM+WASI existed in 2008, we wouldn't have needed to create Docker."
- [Megan Phelps-Roper](https://www.ted.com/talks/megan_phelps_roper_i_grew_up_in_the_westboro_baptist_church_here_s_why_i_left/up-next?language=en) - "I grew up in the Westboro Baptist Church. Here's why I left"
- [Eric Falkenstein - "An Economist's Rational Road to Christianity"](http://falkenblog.blogspot.com/2016/02/an-economists-rational-road-to.html) - a well known econ/quant finance authority, on becoming a born-again Christian late in life
- [Michael Shellenberger](https://www.youtube.com/watch?v=ciStnd9Y2ak) - "Why I changed my mind about nuclear power"
- [Mikhail Gorbachev](https://en.wikipedia.org/wiki/Mikhail_Gorbachev) ending the Cold War by reversing several key tenets of Soviet Communism
- [Robert Oppenheimer](https://www.history.com/news/father-of-the-atomic-bomb-was-blacklisted-for-opposing-h-bomb), leader of the Manhattan Project, failed to convince Truman to not use the Atomic Bomb but ultimately prevailed at the UN - no country has used atomic weapons since 1945.
- Every example of [character development in great films](https://www.studiobinder.com/blog/character-development/)
- *more? I will keep adding if I think of more*
## How It Works
I think the 过来人 effect works because it engages a few core persuasion principles, which are really the same thing, stated a few different ways:
- **Seek First to Understand, Then to Be Understood**: One of [the 7 Habits of Highly Effective People](https://www.franklincovey.com/the-7-habits/habit-5.html), you absolutely understand the opposite side's point of view because you *were* the opposite side. So you are intimately familiar with the flaws in their talking points, and hyper aware of important leverage points that they may be underappreciating.
- **Pacing and Leading**: Persuasion students know that [pacing and leading](https://www.mindwhirl.com/marketing/marketing-psychology/how-to-persuade-anyone-using-pacing-and-leading/) is extremely powerful, and there can be no more authentic form of pacing than self identifying to be formerly part of your opponent's tribe.
- **Inception**: Much like [the Christopher Nolan movie](https://en.wikipedia.org/wiki/Inception), the effect here is to soundly convince your audience that you *are* them, get them to treat you as their avatar, and that what you're talking about is really an idea that *they* came up with. Then it *really* takes root.
- **Skin in the Game**: It is hard to publicly admit you were wrong, or to change the course of your career or personal beliefs. People respect that and listen to you when you put yourself on the line like that.
- **Appeal to Reality**: Every idealist's enthusiasm eventually carries them beyond the bounds of reality due to their optimism and rose-tinted glasses. This is a very human thing to do, but it is also a very human thing to respect "reality checks". Nobody looks good denying reality. A 过来人, having made the arduous personal journey of changing sides, probably has new, relevant facts on their side (at least, relevant for changing minds). John Maynard Keynes put it best: [“When the facts change, I change my mind. What do you do, Sir?”](https://www.mitonoptimal.com/news/2018/when-the-facts-change-i-change-my-mind-what-do-you-do-sir/)
I don't have a name for this but there's also the very simple fact that people who have changed their minds are probably better at convincing people to change their minds, than people who have never changed their minds.
## Conclusion
I have noticed in my life a lot of small instances of this principle. Some people note that the best Programming Teachers and Developer Advocates often are career changers, because they've had to cross over from a later stage and didn't grow up with a Commodore 64. I take notice when someone whose entire working career was spent doing one thing suddenly starts talking about a different way to do something.
What are the takeaways? I don't know, I don't have a Call To Action or anything. If you notice a 过来人, notice this effect at play. If you are a 过来人 yourself, take note of how you can be more effective by listening to yourself over time (maybe if you have previous tweets and blogs, you can quote yourself and talk about what you got wrong).
Mostly I just wanted to de-stigmatize changing your mind. It shouldn't be done lightly, but it shouldn't be a negative either if genuine. And you gain persuasive powers when it happens. [Robert Cialdini called these "crossover communicators"](https://theartofcharm.com/podcast-episodes/robert-cialdini-pre-suasion-episode-543/) once, so if you'd like an English term for this, you could use that. | swyx |
1,115,487 | Tired of creating virtual environement each time? | pipx is a package manager that you can use to create sandboxes and you can call them everytime you... | 0 | 2022-06-16T02:00:30 | https://dev.to/mrhili/tired-of-creating-virtual-environement-each-time-2off | python, pip, pipx, env | pipx is a package manager that you can use to create sandboxes and you can call them everytime you need them, no need to create a virtual environement evrytime you create a new project.
```
python3 -m pip install --user pipx
python3 -m pipx ensurepath
```
you can start using it like pip with the command :
```
python3 -m pipx install ?PACKAGE2INSTALL?
```
| mrhili |
1,116,312 | Day 19 - Function Modifiers | Envoy-VC / 30-Days-of-Solidity ... | 18,992 | 2022-06-16T17:29:00 | https://dev.to/envoy_/day-19-function-modifiers-32jj | 100daysofcode, solidity, web3, blockchain | {% embed https://github.com/Envoy-VC/30-Days-of-Solidity noreadme %}
This is Day `19` of `30` in Solidity Series
Today I Learned About Function Modifiers in Solidity.
Modifiers assist in the execution of a function’s behavior. The behavior of a function can be changed using a function modifier, they can also be called before or after a function is executed.
Solidity function modifiers help in the following:
- To access restrictions
- Input accuracy checks
- Hacks protection
Example:
```solidity
contract Owner {
modifier onlyOwner {
require(msg.sender == owner);
_;
}
}
```
The function body is inserted where the special symbol "_;" appears in the definition of a modifier. So if condition of modifier is satisfied while calling this function, the function is executed and otherwise, an exception is thrown.
Example:
```solidity
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.7;
contract Mint {
constructor() {
owner = msg.sender;
}
modifier onlyOwner {
require(msg.sender == owner);
_;
function _mint(address to , uint tokenId) onlyOwner {
mint(to, tokenId);
}
}
``` | envoy_ |
1,116,555 | Find a Corresponding Node of a Binary Tree in a Clone of That Tree | Given two binary trees original and cloned and given a reference to a node target in the original... | 18,343 | 2022-06-16T23:00:45 | https://dev.to/theabbie/find-a-corresponding-node-of-a-binary-tree-in-a-clone-of-that-tree-5f1f | leetcode, dsa, theabbie | Given two binary trees `original` and `cloned` and given a reference to a node `target` in the original tree.
The `cloned` tree is a **copy of** the `original` tree.
Return _a reference to the same node_ in the `cloned` tree.
**Note** that you are **not allowed** to change any of the two trees or the `target` node and the answer **must be** a reference to a node in the `cloned` tree.
**Example 1:**
**Input:** tree = \[7,4,3,null,null,6,19\], target = 3
**Output:** 3
**Explanation:** In all examples the original and cloned trees are shown. The target node is a green node from the original tree. The answer is the yellow node from the cloned tree.
**Example 2:**
**Input:** tree = \[7\], target = 7
**Output:** 7
**Example 3:**
**Input:** tree = \[8,null,6,null,5,null,4,null,3,null,2,null,1\], target = 4
**Output:** 4
**Constraints:**
* The number of nodes in the `tree` is in the range `[1, 104]`.
* The values of the nodes of the `tree` are unique.
* `target` node is a node from the `original` tree and is not `null`.
**Follow up:** Could you solve the problem if repeated values on the tree are allowed?
**SOLUTION:**
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def isSameTree(self, p: Optional[TreeNode], q: Optional[TreeNode]) -> bool:
if not p or not q:
if p or q:
return False
return True
if p.val == q.val and self.isSameTree(p.left, q.left) and self.isSameTree(p.right, q.right):
return True
def getTargetCopy(self, original: TreeNode, cloned: TreeNode, target: TreeNode) -> TreeNode:
nodes = [(original, cloned)]
while len(nodes) > 0:
og, cl = nodes.pop()
if self.isSameTree(og, target):
return cl
if og and cl:
nodes.append((og.left, cl.left))
nodes.append((og.right, cl.right))
return None | theabbie |
1,116,712 | Create Kubernetes Microservices on Azure with Cosmos DB | In this tutorial, you'll learn how to deploy a JHipster-based reactive microservice to Azure... | 0 | 2022-06-17T03:45:43 | https://developer.okta.com/blog/2022/05/05/kubernetes-microservices-azure | java, microservices, jhipster, azure | In this tutorial, you'll learn how to deploy a JHipster-based reactive microservice to Azure Kubernetes Service (AKS). You'll use Azure's Cosmos DB as a persistent store for one of the services. For security, you'll use Okta as an OAuth 2.0 and OpenID Connect (OIDC) provider. You'll also securely encrypt all secrets in the project configuration files using Kubernetes secrets and `kubeseal`. This tutorial focuses on deploying an already generated project to Azure AKS. It does not go into great detail about generating the project. To see how the project was generated using JHipster, take a look at [Reactive Java Microservices with Spring Boot and JHipster](/blog/2021/01/20/reactive-java-microservices).
The project has a few different pieces:
- JHipster Registry: a Eureka server for service discovery and a Spring Cloud Config server for centralized configuration management
- Gateway: public Spring Cloud Gateway application using Vue
- Store: Spring Boot microservice using Azure's Cosmo DB API for MongoDB
- Blog: Spring Boot microservice using a Neo4J database
This tutorial has a lot of different technologies in it. I've tried to make it as simple and as explicit as possible, but it's probably helpful to have some basic knowledge of Docker and Kubernetes before you start.
If you're already familiar with all the tech in this tutorial, you can skip ahead to the prerequisites section. If not, I'm going to explain them a little before we move on.
## JHipster microservices architecture overview
**[JHipster](https://www.jhipster.tech/)** is a development platform that streamlines the generation, development, and deployment of both monolithic and microservice applications. It supports a dizzying array of frontend (Angular, React, and Vue) and backend (Spring Boot, Micronaut, Quarkus, Node.js, and .NET) technologies. It's designed to be deployed using Docker and Kubernetes, and can easily deploy to all the major cloud platforms, such as AWS, Azure, Heroku, Cloud Foundry, Google Cloud Platform, and OpenShift.

The project in this tutorial uses **Spring Boot** with Java resource servers and a **Vue** frontend. It was built with the **JHipster generator** that quickly scaffolds a new application based on either an interactive shell or a DSL file. You can read more about generating microservices with JHipster [in their docs](https://www.jhipster.tech/creating-microservices/). One of the slick features of the JHipster generator is that you can generate data entities along with applications.

The **[JHipster Registry](https://www.jhipster.tech/jhipster-registry/)** that is generated with the microservice includes two important functions: a **Eureka server** and a **Spring Cloud Config** server. The Eureka server allows the microservices to dynamically find each other without having to use hard-coded URIs. This means that the microservice can scale and services can be replaced without causing problems. It's a bit like a phonebook or a DNS service for the microservice. The [Spring Cloud Config](https://cloud.spring.io/spring-cloud-config/reference/html/) server allows project configuration to be centralized and distributed to all of the different services. In this tutorial you'll use this feature to configure all of the services for Okta OAuth in one place.
The **[JHipster API Gateway](https://www.jhipster.tech/api-gateway/)** is the public face of your microservice. All public traffic comes through this service, which also includes the Vue frontend. The gateway is one of three application types that can be created by the JHipster generator DSL. The other two are monolith and microservice. A monolith is a non-microservice application with a single service.
The store service and blog service are both examples of the microservice application type. This means that each service is a Spring Boot resources server with some type of SQL or NoSQL backend.

The generator creates four applications. They are designed to be built and run as **docker containers**, which makes it easy for them to be packaged in **[Kubernetes](https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/)** pods. Kubernetes is a container orchestrator specifically designed for managing microservice networks. It's something like **Docker Compose** but designed for microservices with a lot of great features like service discovery, load balancing, automatic rollouts and restarts, resource management, and storage mounting.
**Prerequisites**
This tutorial has a lot of pieces. Install the required software below and sign up for an Azure Cloud account. You'll need a free Okta account, but you can use the Okta CLI to sign up for it later in the tutorial.
- [Docker](https://docs.docker.com/get-docker/): you'll need to have both **Docker Engine** and **Docker Compose** installed (If you install the Docker desktop, this will automatically install both. On Linux, if you install Docker Engine individually, you will have to also [install Docker Compose](https://docs.docker.com/compose/install/)) separately.
- [Docker Hub](https://hub.docker.com/): you'll need a Docker Hub to host the docker images so that Azure can pull them.
- [Java 11](https://adoptopenjdk.net/): this tutorial requires Java 11. If you need to manage multiple Java versions, SDKMAN! is a good solution. Check out [their docs to install it](https://sdkman.io/installit).
- [Okta CLI](https://cli.okta.com/manual/#installation): you'll use Okta to add security to the microservice network. You can register for a free account from the CLI.
- [Azure Cloud account](https://azure.microsoft.com/en-us/free/): they offer a free-tier account with a $200 credit to start.
- [Azure CLI](https://docs.microsoft.com/en-us/cli/azure/install-azure-cli): you'll use the Azure CLI to manage the Kubernetes cluster.
- [kubectl](https://kubernetes.io/docs/tasks/tools/): CLI to manage Kubernetes clusters.
If you have never had an Azure account before, you can create a new one that will allow free-tier access and has $200 credit allocated to it. This is more than enough to finish this tutorial. However, the credit does expire after 30 days. If you do not have credit left or your credit has expired, this tutorial should only cost a few dollars **if you stop and start the AKS cluster when you are not working on it**. You can keep an eye on your costs using the cost explorer in the Azure portal and set alerts if you are concerned about it. Upgrading to pay-as-you-go may also alleviate some resource throttling issues around testing the AKS clusters.
## Spring Boot microservices for Azure and Cosmos DB
This project is based on two of Matt Raible's tutorials: [Reactive Java Microservices with Spring Boot and JHipster](/blog/2021/01/20/reactive-java-microservices) and [Kubernetes to the Cloud with Spring Boot and JHipster](/blog/2021/06/01/kubernetes-spring-boot-jhipster). In these tutorials, he builds a reactive Java microservice architecture and shows how to deploy it to Google Cloud (GCP). I have modified the project to work with Azure and Cosmos DB.
You will first run the project using Docker Compose. Once you have this working, you will run the project as a Kubernetes cluster on Azure. My modifications were relatively minor and involved removing the unnecessary MongoDB instances (from both the `docker-compose.yml` file and from the Kubernetes descriptors) as well as updating environment values to point the `store` service to the Cosmos DB instance instead of a MongoDB instance.
Listed briefly, the changes I made from Matt Raible's posts to make this work with Azure and Cosmos DB are as follows. You can skip this list (and the next section) and go right to cloning the Git repository if you want, but since this documents how to update a JHipster-generated project to use Cosmos DB, I thought it was worth including.
In the `docker-compose/docker-compose.yml` file:
- removed the MongoDB service
- updated the `store` service property `SPRING_DATA_MONGODB_URI` to point to the Cosmos DB instance via a `.env` file
- removed the Keycloak service and the environment variables that configured auth to use Keycloak from the remaining services (not strictly necessary but cleaned things up)
In the `k8s/store-k8s` directory:
- removed the `store-mongodb.yml` file (This creates the MongoDB Kubernetes service that our project does not need.)
- in `store-deployment.yml`:
- removed the `initContainers` (The init container waits for the MongoDB instance, which is removed.)
- updated `SPRING_DATA_MONGODB_URI` env value of the `store-app` container to the Cosmos DB URI (This points the store to the Cosmos DB instance.)
- properly secured the Cosmos DB connection string using Kubernetes secrets and `kubeseal`
## Setting the store app's initial status for Eureka
Creating this tutorial, I ran into a problem with the store app getting stuck as `OUT_OF_SERVICE`. When I inspected the logs, I found that the service started as `UP`, quickly went to `DOWN`, and then `OUT_OF_SERVICE`. Later, it would go back to `UP` but the Eureka server never registered this change.
There's an open issue documenting this problem on [Spring Cloud Netflix](https://github.com/spring-cloud/spring-cloud-netflix/issues/3941) and [Netflix Eureka](https://github.com/Netflix/eureka/issues/1398).
A temporary fix taken from the issue on GitHub is to override the health reporting implementation so that it returns `DOWN` instead of `OUT_OF_SERVICE` while the program is still starting. This blocks it from ever reporting `OUT_OF_SERVICE`. You can see the fix in the [`EurekaFix.java`](https://github.com/oktadev/okta-azure-kubernetes-cosmosdb-example/blob/main/store/src/main/java/com/okta/developer/store/EurekaFix.java) file in the store app.
## Clone the microservices project from GitHub
Clone the modified JHipster reactive microservice project from GitHub and checkout the `start` tag.
```bash
git clone https://github.com/oktadev/okta-azure-kubernetes-cosmosdb-example.git \
azure-k8s-cosmosdb
cd azure-k8s-cosmosdb
git fetch --all --tags
git checkout tags/start -b working
```
## Create the Azure Cosmos DB with API for MongoDB
You need to create an Azure Cosmos DB instance. You can either use the [Azure Portal](https://portal.azure.com) or the CLI to create a new Cosmos DB instance. Make sure you create a one that is **Azure Cosmos DB API for MongoDB** (Cosmos DB supports various database types). If you use the portal, it's pretty self-explanatory but don't forget to enable the free tier and enable a public network.
Here are the instructions for using the CLI.
Log into the Azure CLI using a Bash shell. This will redirect you to a browser to log into the Azure portal.
```bash
az login
```
This should show you the subscriptions for your account.
```json
[
{
"cloudName": "AzureCloud",
"homeTenantId": "21c44b6d-a007-4d48-80cb-c45966ca1af9",
"id": "90eb9f51-b4be-4a9f-a69f-11b7668a874d",
"isDefault": true,
"managedByTenants": [],
"name": "Azure subscription 1",
"state": "Enabled",
"tenantId": "21c44b6d-a007-4d48-80cb-c45966ca1af9",
"user": {
"name": "andrewcarterhughes@outlook.com",
"type": "user"
}
}
]
```
Set the subscription in the shell. Your subscription is probably `Azure subscription 1`, as that is the default. Make sure you use the subscription that was created when you registered for a free account (or whatever subscription you want if you already have an account).
```bash
az account set --subscription <you-subscription-name>
```
Open a Bash shell. Create a resource group with the following command.
```bash
az group create --name australia-east --location australiaeast
```
Create the Cosmos DB account in the resource group. Substitute your Azure subscription name in the command below (it's probably `Azure subscription 1`, which is what mine defaulted to).
```bash
az cosmosdb create --name jhipster-cosmosdb --resource-group australia-east \
--kind MongoDB --subscription <you-subscription-name> --enable-free-tier true \
--enable-public-network true
```
Once that command returns (it may take a few minutes), it should list a lot of JSON showing properties of the created Cosmos DB account.
If you get an error that says:
```
(BadRequest) DNS record for cosmosdb under zone Document is already taken.
```
Then you need to change the `--name` parameter to something else. Since this is used to generate the public URI for the database it needs to be unique across Azure. Try adding your name or a few random numbers.
I'm using the Australia East location because that was the location that had free tier AKS nodes available when I wrote this tutorial. You can use any resource group you want as long as it allows you to create the AKS cluster later in the tutorial. Even if you can't use the free tier or the free credits, if you stop and start the AKS cluster between working on the tutorial, the cost should be very small (mine was less than a few dollars). The application should still work if the Cosmos DB database is in a different resource group and region since the database URI is configured to be publicly accessible.
List the connection string for the Cosmos DB API for MongoDB endpoint using the following command. **If you changed the database name above, you will need to update it in the command below.**
```bash
az cosmosdb keys list --type connection-strings --name jhipster-cosmosdb \
--resource-group australia-east
```
This will list four connection strings. You need to save (copy and paste somewhere) the first, the primary connection string. (Ellipses have been used for brevity below.)
```json
{
"connectionStrings": [
{
"connectionString": "mongodb://jhipster-cosmosdb:XBq5KZ81V8hM63KjCOezi1arq...",
"description": "Primary MongoDB Connection String"
},
...
]
}
```
Edit the `.env` file in the `docker-compose` subdirectory. Add the following variables to it, substituting your connection string for the placeholder. Make sure the connection string is enclosed in quotes. This value is referenced by the `docker-compose.yml` file and passed to the `store` service, pointing it to the Cosmos DB MongoDB database.
The `ENCRYPT_KEY` will be used as the key for encrypting sensitive values stored in the Spring Cloud Config and used by the JHipster registry. You can put whatever value you want in there. A UUID works well, but any string value will work. The longer, the better.
`docker-compose/.env`
```env
SPRING_DATA_MONGO_URI=<your-connection-string>
ENCRYPT_KEY=<your-encryption-key>
```
## Configure identity with Okta
Before you begin, you’ll need a free Okta developer account. Install the [Okta CLI](https://cli.okta.com) and run `okta register` to sign up for a new account. If you already have an account, run `okta login`. Then, run `okta apps create jhipster`. Select the default app name, or change it as you see fit. Accept the default Redirect URI values provided for you.
<details open="">
<summary>What does the Okta CLI do?</summary>
<p>The Okta CLI streamlines configuring a JHipster app and does several things for you:</p>
<ol>
<li>Creates an OIDC app with the correct redirect URIs:
<ul>
<li>login: <code class="language-plaintext highlighter-rouge">http://localhost:8080/login/oauth2/code/oidc</code> and <code class="language-plaintext highlighter-rouge">http://localhost:8761/login/oauth2/code/oidc</code></li>
<li>logout: <code class="language-plaintext highlighter-rouge">http://localhost:8080</code> and <code class="language-plaintext highlighter-rouge">http://localhost:8761</code></li>
</ul>
</li>
<li>Creates <code class="language-plaintext highlighter-rouge">ROLE_ADMIN</code> and <code class="language-plaintext highlighter-rouge">ROLE_USER</code> groups that JHipster expects</li>
<li>Adds your current user to the <code class="language-plaintext highlighter-rouge">ROLE_ADMIN</code> and <code class="language-plaintext highlighter-rouge">ROLE_USER</code> groups</li>
<li>Creates a <code class="language-plaintext highlighter-rouge">groups</code> claim in your default authorization server and adds the user’s groups to it</li>
</ol>
<p><strong>NOTE</strong>: The <code class="language-plaintext highlighter-rouge">http://localhost:8761*</code>
redirect URIs are for the JHipster Registry, which is often used when
creating microservices with JHipster. The Okta CLI adds these by
default.</p>
<p>Run <code class="language-plaintext highlighter-rouge">cat .okta.env</code> (or <code class="language-plaintext highlighter-rouge">type .okta.env</code>
on Windows) to see the issuer and credentials for your app.
<p><strong>NOTE</strong>: You can also use the Okta Admin Console to create your app. See <a href="https://www.jhipster.tech/security/#okta">Create a JHipster App on Okta</a> for more information.</p>
</details>
Take note of the name because you will need to find the app in the Okta Admin Console and update the redirect URIs a little later. The `okta apps` command creates a config file named `.okta.env`. It will look something like the following. It helpfully lists the values you will need in the next step.
```bash
export SPRING_SECURITY_OAUTH2_CLIENT_PROVIDER_OIDC_ISSUER_URI="https://dev-13337.okta.com/oauth2/default"
export SPRING_SECURITY_OAUTH2_CLIENT_REGISTRATION_OIDC_CLIENT_ID="2989u928u383..."
export SPRING_SECURITY_OAUTH2_CLIENT_REGISTRATION_OIDC_CLIENT_SECRET="09328uu098u4..."
```
Both the Docker Compose project and the Kubernetes project use Spring Cloud Config to centralize configuration. The JHipster registry service makes these config values available to all of the other services in the cluster.
Open `docker-compose/central-server-config/application.yml` and add the following to the end, filling in the `issuer-uri`, `client-id`, and `client-secret` taken from the `.okta.env` file. This is the Spring Cloud Config file for the Docker Compose project.
`docker-compose/central-server-config/application.yml`
```yaml
spring:
security:
oauth2:
client:
provider:
oidc:
issuer-uri: https://<your-okta-domain>/oauth2/default
registration:
oidc:
client-id: <client-id>
client-secret: <client-secret>
```
## Build the Docker images and run the app with Docker Compose
You're all set to run the app locally using Docker and Docker Compose. You need to build the docker image for each of the projects: `gateway`, `store`, and `blog` (you don't have to build the `registry` because it uses an image).
In the three different app directories, run the following Gradle command.
```bash
./gradlew -Pprod bootJar jibDockerBuild
```
The default Docker resource settings may not be enough to run this project. You may need to bump them. These settings worked for me.
- CPUs: 8
- Memory: 25 GB
- Swap: 2 GB
- Disk image size: 120 GB
Navigate to the `docker-compose` directory and run the app. You can use the `-d` param to run it as a daemon but for the moment I like seeing the logs. You're just running this in Docker Compose as a warm-up for the Azure deployment anyway.
```bash
docker-compose up
```
Give that a minute or two to finish running all the services.
Open the gateway service at `http://localhost:8080`.
Go to **Account** and **Sign in**. You should be directed to the Okta sign-in form.
You should be able to authenticate with your Okta credentials.
Make sure all parts of the application are working. First, test the store (which is using the Cosmos DB Mongo database) by going to **Entities** and **Product**. Make sure you can add a new product and see it in the list of products. Next, create a blog (**Entities** and **Blog**).
If that works, you can take a look at the **Administration** menu. There's a lot of helpful info there.
You can also check the JHipster Registry at `http://localhost:8761`.
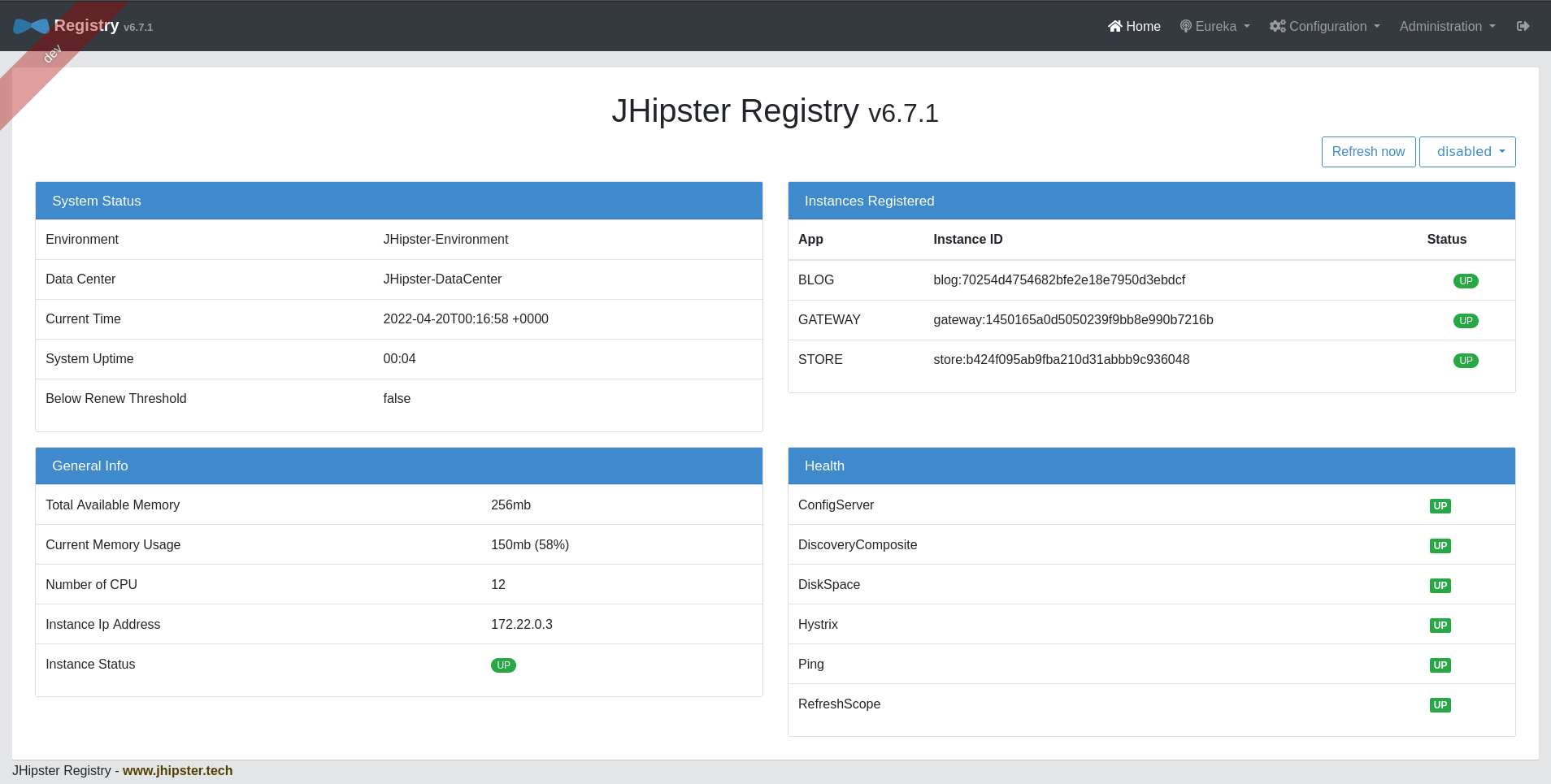
## Encrypt the client secret
Leaving secrets in plain text in repositories is a security risk. There are two values in this app that are sensitive: the Cosmos DB connection string that includes the username and password and the Okta OIDC app client secret. You were able to avoid exposing the database credentials by using a `.env` file. However, the Okta client secret is exposed as plain text in the Spring Cloud Config file (`docker-compose/central-server-config/application.yml`). This can be encrypted using the JHipster registry.
Open the registry (`http://localhost:8761`) and click on **Configuration** and **Encryption**.
Paste your client secret in the text box. Click **Encrypt**.
This, incidentally, is why you needed the `ENCRYPT_KEY` property in the `.env` file. That's the key that JHipster registry uses to encrypt these values (so keep it secret!).
You can now copy the encrypted value and paste it back into the `application.yml` file. Make sure you include the `{cipher}` part. It should look similar to below. Don't forget the quotes!
`docker-compose/central-server-config/application.yml`
```yaml
...
spring:
security:
oauth2:
client:
provider:
oidc:
issuer-uri: https://dev-123456.okta.com/oauth2/default
registration:
oidc:
client-id: 0oa6ycm987987uy98
client-secret: "{cipher}88acb434dd088acb434dd088acb434dd0..."
```
Stop the app if you have not already using `control-c`. Restart it.
```bash
docker-compose up
```
Make sure you can still sign into the gateway at `http://localhost:8080`.
You may be wondering (like I did initially), why can't I just put the client secret in the `.env` file? This doesn't work because the `.env` file is processed by Spring Cloud Config and JHipster registry after the container is composed, not by Docker Compose during the container creation, which is when the `.env` file is processed.
You're done with the Docker Compose implementation. To clean up, you can run the following command. This will stop and remove the containers, networks, volumes, and images created by `docker-compose up`.
```bash
docker-compose down --remove-orphans
```
## Create the Azure Kubernetes cluster
The app works locally. Now it's time to deploy it to an Azure Kubernetes Cluster (AKS). The first step is to create an AKS cluster.
It's super easy to use the CLI to create a cluster. I'll show you the command below. However, there's a wrinkle. The free tier cannot create a cluster in many of the regions because of resource quotas. At least, this was the case when I was working on this tutorial. Nor is there an easy way to quickly see what regions will allow you to create a free-tier cluster. This is why I used Australia East as the region--it allowed me to create a free cluster.
If the command below does not work, I suggest going to the Azure portal and creating a Kubernetes cluster there. Select **Create a service** and **Kubernetes Service**. You'll have to select different regions and see what sizes are available (under **Node size** and **Change size**) until you find a region that will allow you to create something in the free tier. But hopefully the command will work and you won't have to worry about it.
The size I'm using for this tutorial is `Standard B4ms` with two nodes. I found that I needed two nodes for the cluster to start properly.
Run the following command to create the AKS cluster.
```bash
az aks create --resource-group australia-east --name jhipster-demo \
--node-count 2 --enable-addons monitoring --generate-ssh-keys --node-vm-size standard_b4ms
```
This will probably take a few minutes.
As a side note, you can stop the cluster at any point. This will pause billing on the cluster.
```bash
az aks stop --resource-group australia-east --name jhipster-demo
```
And you can start it again.
```bash
az aks start --resource-group australia-east --name jhipster-demo
```
You can stop and start the cluster from the Azure portal as well.
The next step is to get the credentials for the cluster and merge them into `.kube/config` so that `kubectl` can use them. Use the following command.
```bash
az aks get-credentials --resource-group australia-east --name jhipster-demo
```
You should see output that ends like the following.
```bash
Merged "jhipster-demo" as current context in /home/andrewcarterhughes/.kube/config
```
You should be able to use `kubectl` to get the node on Azure.
```bash
kubectl get nodes
```
```bash
NAME STATUS ROLES AGE VERSION
aks-nodepool1-21657131-vmss000000 Ready agent 105s v1.22.6
aks-nodepool1-21657131-vmss000001 Ready agent 108s v1.22.6
```
You can also list a lot of information about the cluster in JSON format using:
```bash
az aks list --resource-group australia-east
```
## Configure Kubernetes for Okta and Cosmos DB
The Kubernetes files in the `k8s` directory were created with the JHipster Kubernetes sub-generator ([see the docs for info](https://www.jhipster.tech/kubernetes/)). To see how the original project was generated, take a look at [Matt Raible's JHipster and Kubernetes tutorial](/blog/2021/06/01/kubernetes-spring-boot-jhipster). As outlined above, these files were modified to work with Azure Cosmos DB instead of MongoDB in a Kubernetes pod (which is what the sub-generator assumes).
Configure Spring OAuth in the Kubernetes pod by updating `k8s/registry-k8s/application-configmap.yml`. You can use the same values you used above in the Docker Compose section, in `docker-compose/central-server-config/application.yml`.
Make sure you use the encrypted client secret enclosed in quotes with the `{cipher}` prefix. You're going to copy both the encryption key and the encrypted client secret from the Docker Compose configuration to avoid having to re-encrypt the client secret with a new key.
```yaml
data:
application.yml: |-
...
spring:
security:
oauth2:
client:
provider:
oidc:
issuer-uri: https://<your-okta-domain>/oauth2/default
registration:
oidc:
client-id: <client-id>
client-secret: "{cipher}<encrypted-client-secret>"
```
To configure the JHipster Registry to use OIDC for authentication, you have to modify `k8s/registry-k8s/jhipster-registry.yml` to enable the `oauth2` profile. This has already been done for you in the example app in the project Git repository.
```yaml
- name: SPRING_PROFILES_ACTIVE
value: prod,k8s,oauth2
```
Also in `k8s/registry-k8s/jhipster-registry.yml`, update the `ENCRYPT_KEY` value to use the same encryption key you used above in the Docker Compose section in the `.env` file.
```yaml
- name: ENCRYPT_KEY
value: <your-encryption-key>
```
To configure the `store` service to use the Cosmo database, you need to put your connection string in `k8s/store-k8s/store-deployment.yml`.
```yaml
- name: SPRING_DATA_MONGODB_URI
value: "<your-connection-string>"
```
Both the encryption key and the database connection string are sensitive values that need to be encrypted. You'll see how to do that just a little later in this tutorial.
## Build Docker images and push to Docker Hub
Previously you built the docker images, but you left them in the local repository. Now you need to upload them to Docker Hub so that Azure AKS can find them. If you haven't already [signed up for a Docker Hub account](https://hub.docker.com/), please do so now.
In each of the three directories (`blog`, `store`, and `gateway`), run the following command. Save your Docker Hub username in a Bash variable as shown below and you can copy and paste the commands and run them in each service directory.
```bash
DOCKER_HUB_USERNAME=<docker-hub-username>
# in blog
./gradlew bootJar -Pprod jib -Djib.to.image=$DOCKER_HUB_USERNAME/blog
# in store
./gradlew bootJar -Pprod jib -Djib.to.image=$DOCKER_HUB_USERNAME/store
# in gateway
./gradlew bootJar -Pprod jib -Djib.to.image=$DOCKER_HUB_USERNAME/gateway
```
To briefly explain what's happening here, take a look at the blog service's Kubernetes descriptor file. It defines a container named `blog-app` that uses the docker image `andrewcarterhughes/blog`, which is my Docker Hub username and the blog image.
`k8s/blog-k8s/blog-deployment.yml`
```yaml
containers:
- name: blog-app
image: andrewcarterhughes/blog
```
Thus in the `k8s` directory, each service (store, blog, gateway, and registry) defines a container and a docker image to be run in that container, along with a whole lot of configuration (which is really a lot of what JHipster is bootstrapping for you). The registry does not have a project folder because it uses a stock image that can be pulled directly from the JHipster Docker repository.
To use the images you just created with Kubernetes, do a find and replace in the `k8s` directory. Replace all instances of `andrewcarterhughes` with your Docker Hub username (`<docker-hub-username>`).
One nice feature of Kubernetes is the ability to define [init containers](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/). These are containers that run before the main container and can be used to create or wait for necessary resources like databases. I noticed while I was debugging things in this app that a lot of the errors happened in the init containers. It's helpful to know this because if you try and inspect the main container log nothing will be there because the container hasn't even started yet. You have to check the log for the init container that failed. The Kubernetes management tools that I mention below really come in handy for this.
## Deploy your microservices to Azure AKS
You can manage a Kubernetes service purely with `kubectl`. However, there are some pretty helpful tools for monitoring and logging. Both [k9s](https://github.com/derailed/k9s) and [Kubernetes Lens](https://k8slens.dev/) are great. I recommend installing one or both of these and using them to inspect and monitor your Kubernetes services. They are especially helpful when things go wrong (not that things ever go wrong, I wouldn't know anything about that, I just heard about it from friends, I swear). Kubernetes Lens is a full-on desktop app that describes itself as a Kubernetes IDE. In comparison, k9s is a lighter-weight, text-based tool.
Open a Bash shell and navigate to the `k8s` subdirectory of the project.
Deploy your microservice architecture to Azure with:
```bash
./kubectl-apply.sh -f
```
If you open this file, you'll see that it creates the namespace and applies the project files. If you do this manually, it's important that the namespace is created first and that the registry is run before the other services.
```bash
...
suffix=k8s
kubectl apply -f namespace.yml
kubectl apply -f registry-${suffix}/
kubectl apply -f blog-${suffix}/
kubectl apply -f gateway-${suffix}/
kubectl apply -f store-${suffix}/
...
```
You can check on your pods with the following command. If you're on the free tier, this may take a few minutes. Using the pay-as-you-go plan, everything was up and running almost immediately for me.
```bash
kubectl get pods -n demo
```
```bash
NAME READY STATUS RESTARTS AGE
blog-6896f6dd58-mbjkn 1/1 Running 0 3m51s
blog-neo4j-0 1/1 Running 0 3m48s
gateway-7f6d57765f-2fhfb 1/1 Running 0 3m46s
gateway-postgresql-647476b4d5-jdp5c 1/1 Running 0 3m44s
jhipster-registry-0 1/1 Running 0 3m52s
store-7889695569-k4wkv 1/1 Running 0 3m41s
```
Here's an example of what this looks like with Kubernetes Lens (the containers were still booting).
Another useful command is `describe`. I won't replicate the output here, but if you want more detailed information for debugging, you can also run the following.
```bash
kubectl describe pods -n demo
```
To tail logs, you can use the name of the pod.
```bash
kubectl logs <pod-name> --tail=-1 -n demo
```
Although, like I said, k9s and Lens are really the way to go for more detailed inspection.
Here's a screenshot from k9s. You can dig down into the different pods to get more detailed information and inspect logs.
You can use port-forwarding to see the JHipster Registry.
```bash
kubectl port-forward svc/jhipster-registry -n demo 8761
```
Open a browser and navigate to `http://localhost:8761`. You will be redirected to the Okta login screen, after which you will be taken to the registry.
Make sure everything is green. If you have an error, check the logs for the pod that caused the error. You can restart a specific deployment by deleting it and re-applying it. For example, to restart the store, you can use the commands below from the `k8s` directory.
```bash
kubectl delete -f store-k8s/
kubectl apply -f store-k8s/
```
Once all is good, `control-c` to stop forwarding the registry. Expose the gateway and open it.
```bash
kubectl port-forward svc/gateway -n demo 8080
```
Go to `http://localhost:8080`.
Authenticate with Okta. Make sure you can add blogs, posts, tags, and products. Because the store service uses the same Cosmos DB instance that you were using with Docker Compose locally, any test products you created earlier will still be there.
In preparation for the next step, delete everything you just deployed to AKS in the `demo` namespace.
```bash
kubectl delete all --all -n demo
```
The first `all` refers to all resource types. The second `--all` refers to every object in the resource types (as opposed to specifying an object name or ID). Thus by specifying the namespace you are deleting every object of every resource type in that namespace.
This is one of the benefits of using a namespace. You can do a delete like this. If you do this from the default namespace, you'll risk deleting things you didn't mean to delete or pods added by Kubernetes and Azure for infrastructure administration.
You can also just delete the entire namespace. It will be recreated if you use the Bash script to apply the deployments. This deletes absolutely everything from the namespace but is a little slower. If you do this, you need to make sure that you recreate the namespace later (I'll remind you).
```bash
kubectl delete namespace demo
```
## Encrypt the sensitive configuration parameters
There are two really important config values that need to be encrypted: (1) the Cosmos DB connection string (which contains the database credentials) and (2) the OIDC client secret. Because these two values are processed differently, you're going to use two slightly different methods for encrypting them.
There are three different layers of encryption happening here. I found this a little confusing so I'm going to explain it briefy.
- JHipster registry encryption for Spring Cloud Config values (values in `k8s/registry-k8s/application-configmap.yml`)
- Kubernetes "encryption" (obfuscation, really) that moves secrets found in Kubernetes deployment files to base64-encoded secrets files
- `kubeseal` which hardens Kubernetes secrets to properly encrypted values
The first above is only for Spring Cloud Config values. The latter two are used to encrypt values in the Kubernetes descriptor files (the other `yml` files in the `k8s` directory).
When you use JHipster registry encryption, you have to define an `ENCRYPT_KEY` value that is used by JHipster to encrypt the secrets. However, because this value is stored in `yml` files that are going to be committed to a repository, this value must be properly encrypted to ensure the security of the Spring Cloud Config values.
The Cosmos DB connection string (the `SPRING_DATA_MONGODB_URI` env var) is a Kubernetes deployment value, same as the `ENCRYPT_KEY`, not a Spring Cloud Config value.
Thus, to harden the OIDC client secret, you must (1) define an `ENCRYPT_KEY` to enable JHipster registry encryption, (2) use JHipster registry to encrypt the client ID and place the encrypted value in the `application-configmap.yml`, and (3) use Kubernetes secrets and `kubeseal` to properly encrypt the `ENCRYPT_KEY`.
Securing the Cosmos DB connection string is the same as the `ENCRYPT_KEY`: use Kubernetes secrets and `kubeseal` to properly encrypt it.
Matt Raible did a great job of explaining secrets management in Kubernetes in his post, [Kubernetes to the Cloud with Spring Boot and JHipster](/blog/2021/06/01/kubernetes-spring-boot-jhipster#encrypt-your-kubernetes-secrets). He also linked to a lot of great resources. I'm not going to go into much more detail explaining it here. Check his post out for more info.
The first thing you need to do is install `kubeseal` into the AKS cluster. You can take a look at [the `kubeseal` GitHub page](https://github.com/bitnami-labs/sealed-secrets) for more info.
```bash
kubectl apply -f https://github.com/bitnami-labs/sealed-secrets/releases/download/v0.17.5/controller.yaml
```
Retrieve the certificate keypair that this controller generates.
```bash
kubectl get secret -n kube-system -l sealedsecrets.bitnami.com/sealed-secrets-key -o yaml
```
Copy the raw value of `tls.crt` and decode it. You can use the command line, or learn more about [base64 encoding/decoding](https://developer.okta.com/docs/guides/implement-grant-type/clientcreds/main/#base64-encode-the-client-id-and-client-secret) in our documentation.
```bash
echo -n <paste-value-here> | base64 --decode
```
Put the raw value in a `tls.crt` file.
Next, install Kubeseal. On macOS, you can use Homebrew. For other platforms, see [the release notes](https://github.com/bitnami-labs/sealed-secrets/releases/tag/v0.17.5).
```bash
brew install kubeseal
```
Encrypt `ENCRYPT_KEY` and `SPRING_DATA_MONGODB_URI` (the Cosmos DB connect string). Run the following command to do this, **replacing the two values with your encryption key and your connection string**.
```bash
kubectl create secret generic project-secrets \
--from-literal=ENCRYPT_KEY='<your-encryption-key>' \
--from-literal=SPRING_DATA_MONGODB_URI='<your-connection-string>' \
--dry-run=client -o yaml > secrets.yml
```
If you deleted the namespace earlier, you need to create it again (it won't hurt to run this if you didn't delete the namespace).
```bash
kubectl apply -f namespace.yml
```
Now, use `kubeseal` to convert the secrets to encrypted secrets.
```bash
kubeseal --cert tls.crt --format=yaml -n demo < secrets.yml > sealed-secrets.yml
```
Remove the original secrets file and deploy your sealed secrets.
```bash
rm secrets.yml
kubectl apply -n demo -f sealed-secrets.yml && kubectl get -n demo sealedsecret project-secrets
```
You need to update the `yml` files to refer to the encrypted values. Add the following env variable to the `jhister-registry` container in `k8s/registry-k8s/jhipster-registry.yml` (if an `ENCRYPT_KEY` already exists, replace it).
```yaml
env:
...
- name: ENCRYPT_KEY
valueFrom:
secretKeyRef:
name: project-secrets
key: ENCRYPT_KEY
```
In `k8s/store-k8s/store-deployment.yml`, change the `SPRING_DATA_MONGODB_URI` env variable to use the sealed secret.
```yaml
env:
...
- name: SPRING_DATA_MONGODB_URI
valueFrom:
secretKeyRef:
name: project-secrets
key: SPRING_DATA_MONGODB_URI
```
Deploy the cluster.
```bash
./kubectl-apply.sh -f
```
Give the cluster a bit to start. Check it with one of the tools I mentioned or the following:
```bash
kubectl get pods -n demo
```
Once everything is ready, port forward the registry to check the services.
```bash
kubectl port-forward svc/jhipster-registry -n demo 8761
```
Make sure you can log in and that all the services are green. You should either be automatically logged in and redirected back to the home page or directed to log in with the Okta login screen.
This is the happy dance.
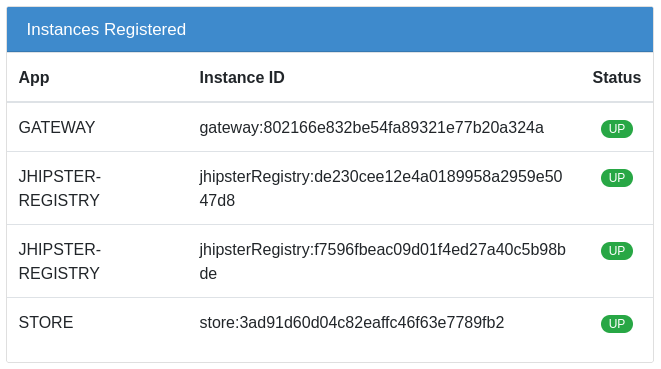
Forward the gateway and test the app.
```bash
kubectl port-forward svc/gateway -n demo 8080
```
Log in. Make sure everything works. Kick the tires. Start a blog. Create some products. Influence some people. Restore democracy. Take over the world. Whatever you want.
Once you're done with everything, you can delete the resource group. This will also delete all the resources in the resource group, including the Cosmos database and the AKS cluster. If you have multiple subscriptions, you may need to add a `--subscription` param.
```bash
az group delete --name australia-east
```
Wait for this to finish. Once it is done, it's probably a good idea to log into the [Azure Portal](https://portal.azure.com) and make sure that the AKS cluster, the Cosmos DB instance, and the resource group have been deleted.
## Azure AKS, Kubernetes, and Spring Boot microservices deployed!
Thanks to [Julien Dubois](https://twitter.com/juliendubois) for help getting this tutorial finished!
In this project you saw how to deploy a JHipster microservice to Azure AKS. You saw how you can use a managed Cosmos DB instance in place of a MongoDB pod in Kubernetes. You saw how to deploy the app first with Docker Compose and then later with `kubectl` and the Azure CLI. Finally, you properly encrypted all of the sensitive configuration values using a combination of JHipster registry encryption, Kubernetes secrets, and `kubeseal`.
As I mentioned at the top, this project is based on two of Matt Raible's tutorials:
- [Reactive Java Microservices with Spring Boot and JHipster](/blog/2021/01/20/reactive-java-microservices)
- [Kubernetes to the Cloud with Spring Boot and JHipster](/blog/2021/06/01/kubernetes-spring-boot-jhipster)
Deepu Sasidharan wrote a tutorial, [Deploying JHipster Microservices on Azure Kubernetes Service (AKS)](https://deepu.tech/deploying-jhipster-microservices-on-azure-kubernetes-service-aks/), that was also a big help.
If you liked this post, there's a good chance you'll like similar ones:
- [Introducing Spring Native for JHipster: Serverless Full-Stack Made Easy](/blog/2022/03/03/spring-native-jhipster)
- [How to Secure Your Kubernetes Clusters With Best Practices](/blog/2021/12/02/k8s-security-best-practices)
- [Mobile Development with Ionic, React Native, and JHipster](/blog/2020/04/27/mobile-development-ionic-react-native-jhipster)
- [Fast Java Made Easy with Quarkus and JHipster](/blog/2021/03/08/jhipster-quarkus-oidc)
- [Spring Cloud Config for Shared Microservice Configuration](/blog/2020/12/07/spring-cloud-config)
- [Kubernetes To The Cloud With AWS: Deploying a Node.js App to EKS](/blog/2021/11/02/k8s-to-the-cloud-aws)
If you have questions, please ask them in the comments below! If you're into social media, follow us: [@oktadev on Twitter](https://twitter.com/oktadev), [Okta for Developers on LinkedIn](https://www.linkedin.com/company/oktadev), and [OktaDev](https://www.facebook.com/oktadevelopers) on Facebook. If you like learning via video, subscribe to [our YouTube channel](https://youtube.com/oktadev).
| andrewcarterhughes |
1,116,941 | Remove Duplicate Letters | Given a string s, remove duplicate letters so that every letter appears once and only once. You must... | 18,343 | 2022-06-17T11:30:39 | https://dev.to/theabbie/remove-duplicate-letters-427n | leetcode, dsa, theabbie | Given a string `s`, remove duplicate letters so that every letter appears once and only once. You must make sure your result is **the smallest in lexicographical order** among all possible results.
**Example 1:**
**Input:** s = "bcabc"
**Output:** "abc"
**Example 2:**
**Input:** s = "cbacdcbc"
**Output:** "acdb"
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of lowercase English letters.
**Note:** This question is the same as 1081: [https://leetcode.com/problems/smallest-subsequence-of-distinct-characters/](https://leetcode.com/problems/smallest-subsequence-of-distinct-characters/)
**SOLUTION:**
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
lastIndex = {}
for i, c in enumerate(s):
lastIndex[c] = i
used = set()
stack = []
for i, c in enumerate(s):
if c in used:
continue
while len(stack) > 0 and s[stack[-1]] > c and i < lastIndex[s[stack[-1]]]:
curr = stack.pop()
if s[curr] in used:
used.remove(s[curr])
stack.append(i)
used.add(c)
return "".join(s[i] for i in stack) | theabbie |
1,155,948 | CORS Error in 5 minutes | So What is CORS ? CORS stands for Cross Origin Resource Sharing is mechanism that allows... | 0 | 2022-12-25T16:42:39 | https://dev.to/alestor_123/cors-error-in-5-minutes-2doa | webdev, beginners, javascript, tutorial | 
## So What is CORS ?
CORS stands for [Cross Origin Resource Sharing](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS) is mechanism that allows a website on one url to request data from another url . This error has been a pain for both front end and backend developer from start . Your webpage might be trying to fetch data from another url and end up with a error in the console
Trust me sometimes CORS Error is a huge pain for web dev out there :

Something like this :

Well this happen because of the browser's security policy
## Well what is this policy in simple words :
This policy allows a webpage from its own url but blocks anything from another url unless certain conditions are met.
Well if you open up the devtools you might be able to view the headers of request in which there is a origin header which specifies origin url if that request goes to the server in the same origin then its allowed by the browser
## What happens when request goes to a different url :
This type of request is known as [Cross Origin Requests](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS#:~:text=The%20CORS%20mechanism%20supports%20secure,of%20cross%2Dorigin%20HTTP%20requests.)
After reciving the request by the server it adds a
``Access-Control-Allow-Origin`` header in the response .
If `` Access-Control-Allow-Origin `` does not match with ``Origin`` Header then browser prevents the response from being used by the client side app
## So What's the solution ?
Well we can solve this issue at the backend side . We only need to set backend to respond with the proper header
If your express.js this issue can be solved using [cors](https://www.npmjs.com/package/cors) module
Install module by npm :
```
npm i cors
```
Usage :
```
var cors = require('cors')
```
We can set express js to respond with a proper header with a 1 line middleware code
```
app.use(cors({origin:'http://yourawesomeurl.net'}))
```
When facing a CORS Error
Step 1 :
Open up network tab of devtools find the response and check for ``` Access-Control-Allow-Origin ```header . If it doesnt exist then you have to enable cors on server side
other wise the url might be a mismatch
Well if you dont own the server then you're doomed

And thats CORS Error in 5 minutes hope this articles helps you out
## Conclusion :
Don't Worry Just Stay Awesome :D & Merry Christmas!!
## Keep Coding !!!
## 🙏 Share with your friends on [Twitter](https://twitter.com/intent/tweet?text=%22CORS%20Error%20in%205%20minutes%22%20by%20%40alestor123%20%23DEVCommunity%20https%3A%2F%2Fdev.to%2Falestor_123%2Fcors-error-in-5-minutes-317n-temp-slug-9838531)
| alestor_123 |
1,117,847 | Java 8 to Kotlin, Clojure and Java 17 - Part 1 Java 8 | 100DaysOfCode #Java Implementing java 8 example. BookParser Next step: move the code to... | 0 | 2022-06-18T14:10:00 | https://dev.to/jorgetovar/from-java-8-to-kotlin-clojure-and-java-17-5gjb | kotlin, java, clojure, refactorit | #100DaysOfCode #Java
Implementing java 8 example. BookParser
Next step: move the code to Java 17, then Kotlin and Clojure
https://github.com/jorgetovar/from-java-8-to-java-17-kotlin-clojure/pull/1/files | jorgetovar |
1,119,007 | Reverse Phone API: The Future of preventing fraudulent phone calls | Reverse Phone API is a new and revolutionary way to prevent fraudulent phone calls. This technology... | 0 | 2022-06-20T04:32:19 | https://dev.to/numverify/reverse-phone-api-the-future-of-preventing-fraudulent-phone-calls-4205 | webdev, javascript, devops, opensource | Reverse Phone API is a new and revolutionary way to prevent fraudulent phone calls. This technology allows you to receive real-time alerts when someone tries to call you from a fraudulent or spoofed number. When combined with other security measures, Reverse Phone API can be an incredibly powerful tool in protecting your privacy and preventing fraudsters from getting through to you.
Reverse Phone API helps to prevent fraudulent phone calls by giving real-time alerts when someone tries to call from a spoofed number. [Reverse Phone API](www.numverify.com) is a new phone service that helps to prevent fraudulent phone calls by giving real-time alerts when someone tries to call from a spoofed number. The service is simple: when someone receives a call from a suspected spammer, they can enter the number into the reverse phone API website and receive an instant report on whether or not the number is legitimate. This way, users can avoid being scammed by fake calls, and businesses can protect their customers' information.
This technology can be used in combination with other security measures to further protect your privacy and prevent fraudsters from getting through to you. When it comes to privacy and security, there are a few things more important than keeping your phone number safe. That's why reverse phone API can be such a valuable tool. By using this technology, you can keep your number hidden from public view, making it much harder for anyone to try and fraudulently reach you. And while no security measure is foolproof, combining reverse phone API with other steps (like not sharing your number publicly) can go a long way toward protecting your privacy and keeping you safe from unwanted calls. To know more about it a visit https://numverify.com/
| numverify |
1,119,294 | Using Azure SQL and PowerBI to report on Speaking Events | Someone I have followed on Twitter for a long time, Paul Andrew and was lucky to meet in person this... | 0 | 2022-06-20T10:59:08 | https://www.techielass.com/speaking-reports/ | speaking, powerbi, azure |
Someone I have followed on Twitter for a long time, [Paul Andrew](https://twitter.com/mrpaulandrew) and was lucky to meet in person this year posted a Tweet about his speaking stats and how he'd visualised it in a PowerBI Dashboard.
{% twitter 1060181752294137856 %}
Which I thought looked absolutely amazing, so I set about copying what he'd done for my own speaking involvement. I only started public speaking in August 2017, so I don't have quite the same cool stats that Paul has but I think it would be really cool to capture what I've done so far and see where I go in the future. Plus I get to play with some Azure and PowerBI deploying the solution.
## Getting Started
In order to implement Paul's solution you need a SQL database and access to PowerBI. You can use any SQL database that you have available, I am going to implement my solution with an [Azure SQL database](https://azure.microsoft.com/products/azure-sql/database/?WT.mc_id=AZ-MVP-5004737). I only need a very small database as it will only be used sporadically and won't store much data.
## Deploy an Azure SQL Database
To create my SQL server within Azure I have decided to use [Azure CLI](https://docs.microsoft.com/cli/azure/?view=azure-cli-latest&?WT.mc_id=AZ-MVP-5004737) and the [Azure Cloud Shell](https://azure.microsoft.com/features/cloud-shell/?WT.mc_id=AZ-MVP-5004737)
Below is the Azure CLI code that I used:
```bash
# Set an admin login and password for your database
export adminlogin=ServerAdmin
export password=adminpassword
# The logical server name has to be unique in the system
export servername=SpeakingStats
# The ip address range that you want to allow to access your DB
export startip=0.0.0.0
export endip=0.0.0.0
# Set the Resource Group Name
export rgname=rg-speakinglogs
# Set the Location for the resources to be deployed to
export datacenter=eastus
# Set the SQL server name
export sqlservername=recording-speaking-sql
# Create a resource group
az group create \
--name $rgname \
--location $datacenter \
--tags 'Usage=Speaking'
# Create a logical server in the resource group
az sql server create \
--name $sqlservername \
--resource-group $rgname \
--location $datacenter \
--admin-user $adminlogin \
--admin-password $password
# Configure a firewall rule for the server
az sql server firewall-rule create \
--resource-group $rgname \
--server $sqlservername \
-n AllowYourIp \
--start-ip-address $startip \
--end-ip-address $endip
# Create a Basic database
az sql db create \
--resource-group $rgname \
--server $sqlservername \
--name SpeakingLogs \
--collation SQL_Latin1_General_CP1_CI_AS \
--service-objective Basic \
--tags 'Usage=Speaking'
```
The above code will deploy a Resource Group, a Logical SQL server, a SQL database and configure it so that your client (desktop) IP address will be allowed to connect with the SQL server.
Now that you have the SQL Server and database created you need to connect to it and start adding data.
## Connecting to your Azure SQL Database
Connecting to your Azure SQL server or database is no different than how you would interact with an on-premises SQL server/database. You can use SQL Server Management Studio (SSMS), Visual Studio Code, Visual Studio, or another tool that you like to use for SQL interactions. I spent a lot of time within Visual Studio Code, so this is going to my connection tool.
In order to connect to SQL using Visual Studio Code you need to have the [SQL Server(mssql)](https://github.com/Microsoft/vscode-mssql) extension installed. The [Microsoft Official Documentation](https://docs.microsoft.com/sql/tools/visual-studio-code/sql-server-develop-use-vscode?view=sql-server-2017&WT.mc_id=AZ-MVP-5004737) covers off how to install this extension if you need some assistance.
Once that is installed to connect to the SQL database you created earlier follow these steps:
+ Open a new file either through the GUI or using **CTRL+N**
+ By Default Visual Studio Code creates a new file in Plain Text, we need to convert this to SQL. Press **CTRL+K,M** to change it to SQL
+ Now you want to connect to the SQL server, do to his press **CTRL+SHIFT+P** to launch Visual Studio Code's Command Palette
+ Type **sqlcon** and select the MS SQL: Connect option
+ Select **Create Connection Profile**
+ The first prompt will ask for your SQL server name, this will be name of the SQL server you created earlier followed by ".database.windows.net"
+ The second prompt will ask for the database name, again this is the name of the database you created earlier
+ The next two prompts are related to the username and password you set earlier
+ The next prompt will ask you if you want to save the password so you won't be prompted again for this information, configure as appropriate
+ The last prompt ask you to specify a name for the connection profile
Visual Studio Code will now start to connect to your SQL server, you'll see progress in the bottom right hand corner, it will say connecting and then change to the SQL server name once connected.
Now you are interacting with the database you need to configure the database. <i class="far fa-smile"></i>
## Setting up the Database
> It maybe worth while increasing the specification of your SQL server while doing this stage, and then reducing it back to basic as it will run faster. However, you can keep it to basic and the queries will run fine.
Paul has shared some SQL scripts within his [GitHub repo](https://github.com/mrpaulandrew/CommunitySpeakingLog).
I've been a bit selective with the SQL that I've used from Paul's below is what I used to configure my database:
```sql
/****** Set database settings ******/
ALTER DATABASE [SpeakingLogs] SET ANSI_NULL_DEFAULT OFF
GO
ALTER DATABASE [SpeakingLogs] SET ANSI_NULLS OFF
GO
ALTER DATABASE [SpeakingLogs] SET ANSI_PADDING OFF
GO
ALTER DATABASE [SpeakingLogs] SET ANSI_WARNINGS OFF
GO
ALTER DATABASE [SpeakingLogs] SET ARITHABORT OFF
GO
ALTER DATABASE [SpeakingLogs] SET AUTO_SHRINK OFF
GO
ALTER DATABASE [SpeakingLogs] SET AUTO_UPDATE_STATISTICS ON
GO
ALTER DATABASE [SpeakingLogs] SET CURSOR_CLOSE_ON_COMMIT OFF
GO
ALTER DATABASE [SpeakingLogs] SET CONCAT_NULL_YIELDS_NULL OFF
GO
ALTER DATABASE [SpeakingLogs] SET NUMERIC_ROUNDABORT OFF
GO
ALTER DATABASE [SpeakingLogs] SET QUOTED_IDENTIFIER OFF
GO
ALTER DATABASE [SpeakingLogs] SET RECURSIVE_TRIGGERS OFF
GO
ALTER DATABASE [SpeakingLogs] SET ALLOW_SNAPSHOT_ISOLATION ON
GO
ALTER DATABASE [SpeakingLogs] SET PARAMETERIZATION SIMPLE
GO
ALTER DATABASE [SpeakingLogs] SET READ_COMMITTED_SNAPSHOT ON
GO
ALTER DATABASE [SpeakingLogs] SET MULTI_USER
GO
ALTER DATABASE [SpeakingLogs] SET ENCRYPTION ON
GO
ALTER DATABASE [SpeakingLogs] SET QUERY_STORE = ON
GO
ALTER DATABASE [SpeakingLogs] SET QUERY_STORE (OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 900, INTERVAL_LENGTH_MINUTES = 60, MAX_STORAGE_SIZE_MB = 100, QUERY_CAPTURE_MODE = AUTO, SIZE_BASED_CLEANUP_MODE = AUTO)
GO
USE [SpeakingLogs]
GO
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
GO
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_MEMORY_GRANT_FEEDBACK = ON;
GO
ALTER DATABASE SCOPED CONFIGURATION SET ELEVATE_ONLINE = OFF;
GO
ALTER DATABASE SCOPED CONFIGURATION SET ELEVATE_RESUMABLE = OFF;
GO
ALTER DATABASE SCOPED CONFIGURATION SET GLOBAL_TEMPORARY_TABLE_AUTO_DROP = ON;
GO
ALTER DATABASE SCOPED CONFIGURATION SET IDENTITY_CACHE = ON;
GO
ALTER DATABASE SCOPED CONFIGURATION SET INTERLEAVED_EXECUTION_TVF = ON;
GO
ALTER DATABASE SCOPED CONFIGURATION SET ISOLATE_SECURITY_POLICY_CARDINALITY = OFF;
GO
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = OFF;
GO
ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET LEGACY_CARDINALITY_ESTIMATION = PRIMARY;
GO
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
GO
ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET MAXDOP = PRIMARY;
GO
ALTER DATABASE SCOPED CONFIGURATION SET OPTIMIZE_FOR_AD_HOC_WORKLOADS = OFF;
GO
ALTER DATABASE SCOPED CONFIGURATION SET PARAMETER_SNIFFING = ON;
GO
ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET PARAMETER_SNIFFING = PRIMARY;
GO
ALTER DATABASE SCOPED CONFIGURATION SET QUERY_OPTIMIZER_HOTFIXES = OFF;
GO
ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET QUERY_OPTIMIZER_HOTFIXES = PRIMARY;
GO
ALTER DATABASE SCOPED CONFIGURATION SET XTP_PROCEDURE_EXECUTION_STATISTICS = OFF;
GO
ALTER DATABASE SCOPED CONFIGURATION SET XTP_QUERY_EXECUTION_STATISTICS = OFF;
GO
/****** Create Speaking Log Table ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[SpeakingLogs](
[LogId] [int] IDENTITY(1,1) NOT NULL,
[TalkDate] [date] NOT NULL,
[EventName] [varchar](255) NOT NULL,
[City] [varchar](255) NULL,
[Country] [varchar](255) NULL,
[Lat] [float](20) NULL,
[Long] [float](20) NULL,
[Attendance] [int] NULL,
[Tags] [nvarchar](1024) NULL,
[TalkType] [varchar](100) NULL,
CONSTRAINT [PK_SpeakingLogs] PRIMARY KEY CLUSTERED
(
[LogId] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
/****** Create Event Logo Table ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[EventLogos](
[EventName] [varchar](255) NOT NULL,
[ImageURL] [nvarchar](max) NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
```
The above, sets up your database and also creates the two tables that you need. One for recording your speaking event information and one for the event logos.
## Entering your Data
Now that you've got the infrastructure set up, it's time to start adding your speaking data.
You have two tables, one that holds all your speaking stats (SpeakingLog) and the other table (EventLogos) is used to store the location of the logos of events you've spoken at.
Inserting the data in the SpeakingLogs table is quite easy, I've done a bulk import of the speaking data from last year and this year. Using code as below:
```sql
Insert into [dbo].[SpeakingLogs]
Values
('11/08/2018', 'STEM', 'Reading', 'United Kingdom', '51.461231', '-0.925947', '25', 'Azure', 'Regular'),
('08/30/2017', 'Azure UG', 'Edinburgh', 'United Kingdom', '55.953388', '-3.188900', '40', 'Azure', 'Lightning Talk');
```
You can view the results of your data input with this command:
```sql
Select * from [dbo].[SpeakingLogs]
```
The next part of the data input is to add in the logos of the events you've attended, again a bulk import of this would look like this:
```sql
Insert into [dbo].[EventLogos]
VALUES
('STEM', 'https://www.stem.org.uk/sites/all/themes/custom/stem_base/assets/img/patterns/logo-stem-new.svg'),
('Microsoft Cloud User Group', 'https://www.mscug.com/wp-content/uploads/2018/02/MSCUG-logo.jpg');
```
And you can view the results of your input with this command:
```sql
Select * from [dbo].[EventLogos]
```
Be sure to match up the EventName you've inputed into the SpeakingLogs table with the EventName you use in the EventLogos table. If they don't match your data visualisation within PowerBI will be off.
#### Visualise the data in PowerBI
You will need PowerBI Desktop installed on your machine for this next stage. You can download the latest version form [here](https://powerbi.microsoft.com/en-us/desktop/)
PowerBI is something I've dabbled with in the past and delivered solutions within for customers but it isn't something I'm an expert in. Paul has shared his .PBIX (PowerBI file) on his GitHub page [here](https://github.com/mrpaulandrew/CommunitySpeakingLog/blob/master/Community%20Speaking.pbix)
I downloaded the .PBIX file and opened it within PowerBI Desktop. The first thing to do is change the Data Source within the .PBIX file to your SQL database. To do this follow these steps:
+ Click on Edit Queries > Data Source Settings on the top toolbar
+ Right click on the data source currently there and select **Change Source**
+ Input your SQL server name and click OK
+ When you return to your PowerBI Report you'll see a yellow ribbon along the top. Asking you to apply the changes

+ When you click on the apply changes button, you will be prompted to enter credentials for SQL database. Ensure you click on the **Database** option and input your username and password
PowerBI will connect to your SQL database and start to pull in your data, you should see the report refresh and apply your data.
Within Paul's setup he uses Postcode to track and map the location of his speaking engagements, however I am using Latitude and Longitude, as I've found it more accurate. To account for this change you will need to change the settings on the map.
+ Click on the map visualisation
+ Down the right hand side you will see the various different data fields
+ Remove the Postcode field from Location
+ Select Lat for the Latitude field, ensuring you pick 'Don't Summarize' for the data
+ Select Long for the Longitude field, again ensuring you pick 'Don't Summarize' for the data
The map should start to pull in your data and map your events.
The next thing to change is the profile pic and contact information. Replace the picture and information with your own.
Once this is done be sure to save your settings. You should end up with a custom report showing your speaking results.
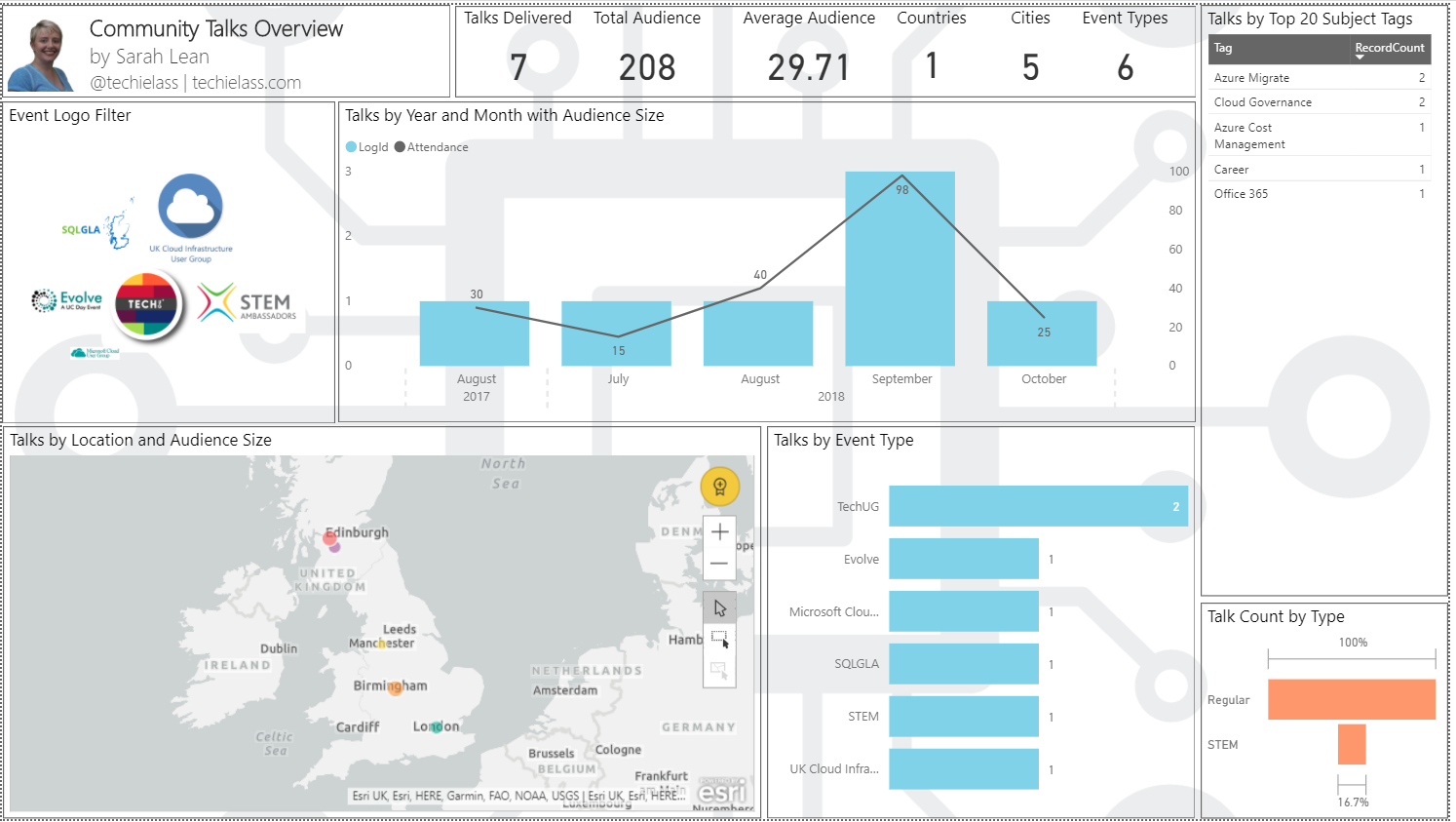
## Overview
I love finding wee gems like this and getting the change to learn something new along the way. Thanks again [Paul Andrew](https://twitter.com/mrpaulandrew) for sharing.
| techielass |
1,119,385 | Paracetamol.js💊| #173: Explica este código JavaScript | Explica este código JavaScript Dificultad: Básico const f = () => { ... | 16,071 | 2022-07-22T19:40:27 | https://dev.to/duxtech/paracetamoljs-173-explica-este-codigo-javascript-4jbi | javascript, spanish, webdev, programming | ## **<center>Explica este código JavaScript</center>**
#### <center>**Dificultad:** <mark>Básico</mark></center>
```js
const f = () => {
let num = 5;
function g(){
let num = 10;
console.log(num);
}
g();
}
console.log(f());
```
A. `10`
B. `5`
C. `undefined`
D. `null`
Respuesta en el primer comentario.
---
| duxtech |
1,119,823 | Differences between Promises and async / await in Javascript | Hello everyone, in this tutorial we will learn about the differences between async / await structure... | 0 | 2022-06-23T01:54:32 | https://dev.to/hamzaelmoualed/differences-between-promises-and-async-await-in-javascript-3dni |
Hello everyone, in this tutorial we will learn about the differences between async / await structure and promises with examples.
Promises are widely used in javascript architecture to manage asynchronous processes. With the help of the async-await keyword, there is a new syntactic sugar has been added to the javascript world.
## Differences between Promises and Async / Await

Note: The list below can be matched with the numbers described below.
1- A promise represents a process that guaranteed to complete the execution.
2- Promises have 3 states, these states are pending, resolved, rejected
3- If the promise is chained with .then(), that continues the execution after adding the function to the callback chain.
4- Error handling can be done with .then() and .catch() methods.
5- Promise chaining can be difficult to understand and follow
6- Debugging can be very tricky with multiple promise chaining
7- Promises can be used for multiple promises in the promise chaining
```
let myPromise = new Promise(function(myResolve, myReject) {
let req = new XMLHttpRequest();
req.open('GET', "mycar.htm");
req.onload = function() {
if (req.status == 200) {
myResolve(req.response);
} else {
myReject("File not Found");
}
};
req.send();
});
myPromise.then(
function(value) {myDisplayer(value);},
function(error) {myDisplayer(error);}
);
```
##Async/Await

1- Async await is syntactic sugar for promises. Making code looks like executed synchronously.
2- Async await does not have states. Async functions return a promise. This promise state can be either resolved or rejected.
3- Await suspends the called function execution until the promise returns a result for that execution. If there are other functions been called after await, these executions wait until the promise finishes.
4- Error handling can be done with a try-catch block
5- Async/Await makes reading the promises flow much easier.
Understanding the functionality is also very easy compared to promises.
6- Debugging is much easier with async/await
7- Await can be used for a single promise or promise.all()
## Should you use Promises or async / await?
That is a very general question and there are both cases we might need to use while writing javascript code. Promises and async-await are very closely related.
If you are using another asynchronous function which is depending on the first asynchronous function, you should use await to wait first one to finish instead of promise chaining.
Await keyword blocks the execution for the next lines until it finishes. If you don’t need to block the execution you can call the async function without await. (for example push notifications, if you don’t want to check the status of a push notification has been delivered or not you can skip await keyword, and code execution will continue asynchronously)
If there are multiple asynchronous functions that can be run in parallel, you can use promise.all([promise1,promise2]) to run them in parallel.
Using async/await definitely will help you to understand asynchronous processes much faster.
Instead of using promise chaining async / await provides a much cleaner code.
If you are using many microservices and asynchronous functions using async / await will help you to debug your code much faster. Generating the breakpoints in the promise chaining can be really tricky.
Async await makes asynchronous code look like synchronous code.
To catch errors in the promises always requires you to write the .catch() block.
Async await can be written in the try-catch block along with all other codes.
```
async function myDisplay() {
let myPromise = new Promise(function(resolve) {
setTimeout(function() {resolve("hello !!");}, 3000);
});
document.getElementById("demo").innerHTML = await myPromise;
}
myDisplay();
```
## Conclusion:
Using async / await while dealing with promises brings so much flexibility, clean code, and much more easy debugging.
Except than using Promise.all() to run parallel asynchronous executions you can accomplish all the other asynchronous tasks with async / await.
Using async/await definitely will provide you with many benefits while you are working on big projects and it makes your and other developer's life easy.
That is all regarding the javascript Async / Await and promises comparison in javascript
| hamzaelmoualed | |
1,120,362 | How to Detect a Click Outside a React Component? | Today we are going to see how you can detect a click outside of a React component. We will understood... | 0 | 2022-06-21T11:58:24 | https://bosctechlabs.com/detect-click-outside-react-component/ | react, programming, beginners, tutorial | Today we are going to see how you can detect a click outside of a React component. We will understood this topic by creating a custom React hook for it. For example, Consider a case when you want custom React hook for dropdown or dialog components that need to close when user clicks outside of them. So, in this article we’ll figure out the way to find out this outside click.
We can use the contains API to see if a target node is contained within another node. That is, it will return true if the clicked component is within the component we are interested in and false otherwise.
A React component is a JSX-based UI building unit self-contained, reusable, and separated.
Web developers also use custom dropdowns to allow users to choose from a list of alternatives. As we have seen earlier the components like custom dropdown should be close while user clicks outside when it is open. To build an enterprise-level application or implement these solutions, you can easily consult or hire react developers from bosctechlabs.com.
##Detecting an outside click of a functional component
Let’s make an HTML tooltip by using the InfoBox React functional component.
When the user hits a button, the tooltip appears, and when the user clicks outside of the tooltip component, it disappears. We will try to detect click outside the React component for the solution of this question.
To get started, we’ll construct a new React app. You can also use the code below to detect outside clicks in your existing React app.
##Example:
```javascript
import React, { useRef, useEffect } from "react";
import PropTypes from "prop-types";
function outSide(open) {
useEffect(() => {
function handleClickOutside(event) {
if (open.current && !open.current.contains(event.target)) {
alert("Show alert Box!");
}
}
document.addEventListener("mousedown", handleClickOutside);
return () => {
document.removeEventListener("mousedown", handleClickOutside);
};
}, [open]);
}
function outSideClick(props) {
const wrapperRef = useRef(null);
outSide(wrapperRef);
return;
{props.children}
; } outSideClick.propTypes = { children: PropTypes.element.isRequired }; export default outSideClick;
```
##Output
<button>Click Outside</button>
**Click Outside:**
**UseRef:** The useRef hook allows the functional component to create a direct reference to the DOM element.
**Syntax:**
```javascript
const refContainer = useRef(initialValue);
```
**UseRef:** The useRef hook allows the functional component to create a direct reference to the DOM element.
**Syntax:**
```javascript
const refContainer = useRef(initialValue);
```
The useRef returns a mutable ref object. This object has a property called .current. The refContainer.current property keeps track of the value. The current property of the returned object is used to access these values.
**UseEffect:** React useEffect is a function that is executed for 3 different React component lifecycles which we will see below.
1. componentDidMount
2. componentDidUpdate
3. componentWillUnmount
**1. componentDidMount:**
We started fixing fetch calls before the class Component and even inside the render() method when we made made our first React component.
This had strange negative effects on the application, causing groan.
**2. componentDidUpdate:**
This React lifecycle is called immediately after a prop or state change has occurred.
It signifies we clicked inside our worried element if the element that triggered the mouse down event is either our concerned element or any element that is inside the concerned element.
**Example:**
```html
Index.html:
<!DOCTYPE html>
<html>
<head>
<title> </title>
</head>
<body>
<section>
<div id=’click-text’>
Click Me and See Console
</div> </section>
</body>
</html>
```
**DetectElement.js:**
```javascript
const DetectElement = document.querySelector(".click-text");
document.addEventListener("mousedown", (e) => {
if (DetectElement.contains(e.target)) {
console.log("click inside");
} else {
console.log("click outside");
}
});
```
##Output

##Conclusion
So far, we have seen that how you can detect a click outside the the React components using the custom React hook. Also, we have learned to utilize UseEffet hook and UseRef hook while detecting the outside click bu user.
Thank you for reading the article. Hope you enjoyed the Reading. | kuldeeptarapara |
1,121,253 | How to add custom breakpoints to TailwindCSS | This post was originally posted on Design2Tailwind. Ok, so today we’re gonna talk about... | 0 | 2022-06-22T11:44:00 | https://design2tailwind.com/blog/tailwindcss-breakpoints-custom/ | tailwindcss, html, css | *This post was originally posted on [Design2Tailwind](https://design2tailwind.com/blog/tailwindcss-breakpoints-custom/).*
---
Ok, so today we’re gonna talk about breakpoints.
Adam, the creator of Tailwind CSS, gave a [lot of thought](https://twitter.com/adamwathan/status/1461713742769672196) to the default breakpoint values of the framework. And we even had [a new one](https://twitter.com/adamwathan/status/1311001678246744068) added a while ago.
These breakpoints target the most common screen sizes, ranging from mobile to bigger desktop screens so people usually stick to the defaults.
What happens if you want to modify those defaults? That’s our topic today!
⭐ One thing to keep in mind is that the *order* of the breakpoints *matters a lot*. The framework reads the order of the breakpoints and creates the necessary media queries and due to the nature of CSS (it's read from top to bottom like you probably know), the last breakpoint has more specificity than the first breakpoint.
That’s why in the defaults you see **`640px`** (sm) before **`1280px`** (xl).
With that said, here’s how to add your own breakpoints:
## Adding a lower breakpoint
```js
const defaultTheme = require("tailwindcss/defaultTheme");
module.exports = {
theme: {
screens: {
xs: "375px",
...defaultTheme.screens
},
}
}
```
Here we’re importing Tailwind’s default values to get the screen values and *spread* them after our custom breakpoint **`xs`**.
Remember that the Tailwind config file is just a Javascript file so you can use your JS skills there too!
## Adding a bigger breakpoint
If you want to add a bigger breakpoint you have two ways.
### In the **`extended`** section
```js
module.exports = {
theme: {
extended: {
screens: {
'3xl': "1800px",
},
}
}
}
```
Since we’re adding a bigger one we can just add it to the **`screens`** key in the **`extended`** section of the config.
### By overwriting the defaults
```js
const defaultTheme = require("tailwindcss/defaultTheme");
module.exports = {
theme: {
screens: {
...defaultTheme.screens,
'3xl': "1800px",
},
}
}
```
We can use the same method as adding a lower breakpoint but adding our bigger one as the last one.
## Adding a breakpoint somewhere in the middle
Ok, this one is tricky because remember, the *order* of the breakpoints *matters a lot.* You can't just add one breakpoint at random, depending on the value you want to add you need to add it in a specific position, and since the **`screens`** property is an object, it's not as easy as adding it at a specific array index.
Now there are multiple ways to solve this. Remember when I said the tailwind config is a JS file so you can add logic to it? Well, that's what we’re going to do now.
Below is the code to add a breakpoint called **`foo`** with a value of **`960px`** before the **`lg`** breakpoint (which has a value of **`1024px`**):
```js
const defaultTheme = require("tailwindcss/defaultTheme");
const newScreens = Object.entries(defaultTheme.screens).reduce(
(breakpoints, [label, value]) => {
if (label == "lg") {
breakpoints["foo"] = "960px";
}
breakpoints[label] = value;
return breakpoints;
},
{}
);
module.exports = {
theme: {
screens: newScreens,
},
};
```
We’re creating a new variable called **`newScreens`**, turning the screens object into an array and assigning it to the new variable, and then using the [reduce method](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/reduce) to create a new screens object with our new breakpoint at the position we want (before the **`lg`** value).
Then, in the tailwind config, we just assign the **`screens`** property to use our new **`newScreens`** variable.
In the end, our **`screens`** property will be compiled to this:
```js
screens: {
sm: '640px',
md: '768px',
foo: '960px', // our new breakpoint
lg: '1024px',
xl: '1280px',
'2xl': '1536px'
}
```
Feel free to reuse this snippet for your needs. Here’s a [Tailwind Play link](https://play.tailwindcss.com/K3i6m9ShXu?file=config) where you can see it in action and play around with it.
---
That’s it for this one! I hope you learned how to add custom breakpoints to your project at any position in your Tailwind config.
| vivgui |
1,122,311 | Flutter state management 🔥 | Sup reader!! How have you been? we going to go through different state management approaches in... | 0 | 2022-06-24T08:03:09 | https://dev.to/dmutoni/flutter-state-management-32n7 | mobile, flutter, dart | Sup reader!! How have you been? we going to go through different state management approaches in flutter, for sure they are a lot of state managements in flutter. We are just going through some of them. 😚 .... Tadaaaa !!

## What is state management?
State management refers to the management of the state of one or more user interface controls such as text fields, OK buttons, animations, etc. in a graphical user interface. In this user interface programming technique, the state of one UI control depends on the state of other UI controls.
State management is a complex topic. If you feel that some of your questions haven’t been answered, or that the approach described in this blog is not viable for your use cases, you are probably right 😂.
**Why do you need state management?**
Think of an app that has two separate screens: a catalog, and a cart (represented by the MyCatalog, and MyCart widgets, respectively). It could be a shopping app, but you can imagine the same structure in a simple social networking app (replace catalog for “wall” and cart for “favorites”). You need to keep track of items that a user added to cart or favorites, the total price in cart and many other things ... So to keep track of all these events you got to manage your state using one of the state management approach.
If you’re coming to Flutter from an imperative framework (such as Android SDK or iOS UIKit), you need to start thinking about app development from a new perspective.
Many assumptions that you might have don’t apply to Flutter. For example, in Flutter it’s okay to rebuild parts of your UI from scratch instead of modifying it. Flutter is fast enough to do that, even on every frame if needed.
Flutter is declarative. This means that Flutter builds its user interface to reflect the current state of your app:

When the state of your app changes (for example, the user flips a switch in the settings screen), you change the state, and that triggers a redraw of the user interface. There is no imperative changing of the UI itself (like widget.setText)—you change the state, and the UI rebuilds from scratch.
## So what are different state management approaches in Flutter ?
1. **Bloc**
A predictable state management library that helps implement the BLoC (Business Logic Component) design pattern.
This design pattern helps to separate presentation from business logic. Following the BLoC pattern facilitates testability and reusability. This package abstracts reactive aspects of the pattern allowing developers to focus on writing the business logic. Bloc makes it easy to separate presentation from business logic, making your code fast, easy to test, and reusable.
_Bloc was designed with three core values in mind:_
- **Simple**: Easy to understand & can be used by developers with varying skill levels.
- **Powerful**: Help make amazing, complex applications by composing them of smaller components.
- **Testable**: Easily test every aspect of an application so that we can iterate with confidence.
You can use Bloc in flutter via [flutter_bloc](https://pub.dev/packages/flutter_bloc)
**2. Getx**
A simplified reactive state management solution. It combines high-performance state management, intelligent dependency injection, and route management quickly and practically.
**Three basic principles on which it is built:**
- **Performance**: focused on minimum consumption of memory and resources
- **Productivity**: intuitive and efficient tool combined with simplicity and straightforward syntax that ultimately saves development time
- **Organization**: decoupling business logic from view and presentation logic cannot get better than this. You do not need context to navigate between routes, nor do you need stateful widgets
You can use Getx in flutter via [Getx](https://pub.dev/packages/get)
**3. Redux**
Redux is a unidirectional data flow architecture that helps a developer to develop and maintain an App easily.
_Here are 4 components that redux generally contains:_
- Action: When an event is generated then it is represented as an action and is dispatched to the Reducer.
- **Reducer**: When Reducer gets any update, it updates the store with a new state what it receives.
- **Store**: When Store receives any update it notifies to the view.
- **View**: It is recreated to show the changes which have been made.
_How to use Redux in flutter?_
Before using Redux, you should know that flutter SDK does not have support for Redux but by using the [flutter_redux](https://pub.dev/packages/flutter_redux) plugin, it can be implemented.
**4. Provider**
Provider was created by Remi Rousselet, aims to handle the state as cleanly as possible. In Provider, widgets listen to changes in the state and update as soon as they are notified.
You can use Provider via [provider](https://pub.dev/packages/provider)
**5. Riverpod**
A Reactive Caching and Data-binding Framework. Riverpod is a popular Flutter state management library that shares many of the advantages of Provider and brings many additional benefits. According to the official documentation: Riverpod is a complete rewrite of the Provider package to make improvements that would be otherwise impossible.
_Riverpod also has 3 basic principles:_
- easily create, access, and combine providers with minimal boilerplate code
- write testable code and keep your logic outside the widget tree
- catch programming errors at compile-time rather than at runtime
You can use riverpod via [riverpod](https://pub.dev/packages/riverpod)
**6. MobX**
MobX is a battle tested library that makes state management simple and scalable by transparently applying functional reactive programming (TFRP).
_The philosophy behind MobX is simple:_
- **Straightforward**: Write minimalistic, boilerplate free code that captures your intent. Trying to update a record field? Use the good old JavaScript assignment. Updating data in an asynchronous process? No special tools are required, the reactivity system will detect all your changes and propagate them out to where they are being used.
- **Effortless optimal rendering**: All changes to and uses of your data are tracked at runtime, building a dependency tree that captures all relations between state and output. This guarantees that computations depending on your state, like React components, run only when strictly needed. There is no need to manually optimize components with error-prone and sub-optimal techniques like memoization and selectors.
- **Architectural freedom**: MobX is unopinionated and allows you to manage your application state outside of any UI framework. This makes your code decoupled, portable, and above all, easily testable
## What's my preferred state management and why? 🤔
My preferred state management is **bloc**🔥 why ?
- Bloc is great for modularity and has an amazing documentation. Also Bloc has a bunch of extensions like bloc_concurrency, hydrated_bloc etc. That make things like caching, denouncing, throttling easy, in addition to that, error handling in bloc is amazing, you can use BlocObserver to capture changes, events or errors you can then plug Crashlytics or Sentry only in your observer and you’re good to go with logging.
- I have been also using bloc in a team of many people but it was interesting how all of us seamlessly worked within a single code base following the same patterns and conventions. 🤗
- Overall, Bloc attempts to make state changes predictable by regulating when a state change can occur and enforcing a single way to change state throughout an entire application.
These are some but you can find more on the [Flutter](https://docs.flutter.dev/development/data-and-backend/state-mgmt/options). There are many state management solutions and deciding which one to use can be a daunting task. There is no one perfect state management solution! What's important is that you pick the one that works best for your team and your project.
Tadaaa!!!!
| dmutoni |
1,122,505 | Roundup of .NET MAUI Videos - Week of June 20, 2022 | Another week, and round of new content for .NET MAUI learners! This week I also found content in... | 18,552 | 2022-06-27T16:10:50 | https://dev.to/davidortinau/roundup-of-net-maui-videos-week-of-june-20-2022-4okj | beginners, dotnet, programming | Another week, and round of new content for .NET MAUI learners! This week I also found content in Dutch, Hindi, Spanish, and Arabic. In no particular order:
## Build Your .NET MAUI Android App with GitHub Actions
{% embed https://youtu.be/GQuQPm40kys %}
## Token Based Authentication
{% embed https://www.youtube.com/watch?v=OnrKktoNJ0o %}
## Johnny does DOTNET
{% embed https://youtu.be/qzZdzz0jk6s %}
[Dutch Version](https://youtu.be/xndh-IJyIEg)
## Getting Started
Claudio Bernasconi
Walks you through installation and then updates the template .NET MAUI app to display currency exchange rates from an HTTP request. Jump right into the meat of that below:
{% embed https://youtu.be/pkKwjGWKfco?t=325 %}
## [Hindi] Tutorial for Beginners
{% embed https://youtu.be/mumMwE5H-0I %}
## SignalR Chat App
I haven't had a chance to watch this one, but chat and SignalR with .NET MAUI is a great hook. Will def have to revisit this one.
{% embed https://www.youtube.com/watch?v=r-Rm9YJzE24 %}
## [Spanish] Web, Desktop, and Mobile with Blazor and .NET MAUI
This is a meetup recording of Latino .NET Online featuring this presentation by Jose Columbie.
{% embed https://www.youtube.com/watch?v=9iWS-kShEvM %}
## Local Storage in .NET MAUI
Suthahar Jegatheesan succinctly introduces you to storing data with a variety of options focusing on the Preferences API, and the video has an [accompanying blog](https://www.msdevbuild.com/2022/06/net-maui-store-local-data-with.html).
{% embed https://www.youtube.com/watch?v=exnTL23z4_I %}
## .NET MAUI AMA with James Montemagno
Does this even need a description? :)
{% embed https://youtu.be/5cFZJGEmji0 %}
## [Arabic] .NET MAUI Blazor - TabbedPage Navigation
{% embed https://youtu.be/7NaQKkz7MH0 %}
| davidortinau |
1,123,094 | Build and Deploy an ASP.NET Core app in a Docker container | .NET is a free, open-source development platform for building numerous apps, such as web apps, web... | 18,616 | 2022-06-24T06:03:05 | https://www.docker.com/blog/building-multi-container-net-app-using-docker-desktop/ | docker, dotnet | .NET is a free, open-source development platform for building numerous apps, such as web apps, web APIs, serverless functions in the cloud, mobile apps and much more. .NET is a general purpose development platform maintained by Microsoft and the .NET community on GitHub. It is cross-platform, supporting Windows, macOS and Linux, and can be used in device, cloud, and embedded/IoT scenarios.
Docker is quite popular among the .NET community. .NET Core can easily run in a Docker container. .NET has several capabilities that make development easier, including automatic memory management, (runtime) generic types, reflection, asynchrony, concurrency, and native interop. Millions of developers take advantage of these capabilities to efficiently build high-quality applications.
## Building the Application
In this tutorial, you will see how to containerize a .NET application using Docker Compose. The application used in this blog is a Webapp communicating with a Postgresql database. When the page is loaded, it will query the Student table for the record with ID and display the name of student on the page.
[Read the Complete Blog](https://www.docker.com/blog/building-multi-container-net-app-using-docker-desktop/)
| ajeetraina |
1,155,890 | Password generator in javascript | In this post we are going to make a password generator in javascript Install uuid npm i... | 0 | 2022-07-31T13:12:21 | https://dev.to/rishikesh00760/password-generator-in-javascript-38nc | javascript, css, html, webdev | In this post we are going to make a password generator in javascript
Install uuid
`npm i uuid`
Create a file named index.html, style.css, index.js.
index.html full source code:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Password Genenrator</title>
</head>
<body>
<h1>Password Generator</h1>
<input
type="text"
id="keyword"
placeholder="Enter a keyword"
maxlength="30"
/>
<button id="generate">Generate Password</button>
<h3 id="password">
When you enter a keyword and click the button the password will be
generated here
</h3>
<script src="index.js"></script>
</body>
</html>
```
style.css full source code:
```
* {
padding: 0px;
margin: 0px;
}
h1 {
text-align: center;
color: blueviolet;
font-family: cursive;
}
#keyword {
width: 1000px;
height: 35px;
text-align: center;
border: 3px solid #111;
font-family: 'Courier New', Courier, monospace;
background-color: #333;
border-radius: 10px;
color: white;
margin-left: 150px;
margin-top: 5px;
}
#generate {
margin-top: 20px;
display: block;
margin-left: 580px;
border: none;
background: none;
font-size: 20px;
cursor: pointer;
}
#password {
/*margin-left: 0px;
margin-right: 0px;*/
margin-top: 50px;
text-align: center;
padding: 20px;
color: #333;
font-family: 'Franklin Gothic Medium', 'Arial Narrow', Arial, sans-serif;
font-size: medium;
background-color: #f2f2f2;
}
```
index.js full source code:
```
import { v4 as uuidV4 } from 'uuid';
import './style.css';
const keyword = document.getElementById('keyword');
const generate = document.getElementById('generate');
const password = document.getElementById('password');
generate.addEventListener('click', function () {
if (keyword.value == '') {
password.innerText = 'Keyword is needed';
} else {
const text = `${keyword.value}`;
const modifiedText = text.replace(' ', '-');
password.innerText = modifiedText + '-' + uuidV4();
}
});
document.addEventListener('dblclick', function () {
if (!document.fullscreenElement) {
document.documentElement.requestFullscreen();
} else if (document.exitFullscreen) {
document.exitFullscreen();
}
});
```
Live demo: https://passwordgeneratorrishikesh.stackblitz.io/
source code: https://stackblitz.com/edit/passwordgeneratorrishikesh
Thank you!!!
| rishikesh00760 |
1,124,771 | How to resolve CORS issue in VueJs | Web applications often depend on resources from an external source or domain. For example, a website... | 0 | 2022-06-26T16:24:22 | https://dev.to/gayathri_r/how-to-resolve-cors-issue-in-vuejs-2m62 | webdev, beginners, vue, javascript | Web applications often depend on resources from an external source or domain. For example, a website can display an image hosted on another site. Beyond images, a web application may fetch JSON format data from an external API.
However, sharing resources across websites isn't always a smooth ride. If you've made HTTP requests from JavaScript to another site, you've probably seen a **CORS** error.
In this blog I'm going to explain what is CORS policy & how to resolve the CORS problem.
Let's get started...
## What Is CORS?
The full meaning of CORS is Cross-Origin Resource Sharing. CORS is a mechanism that can be found in modern web browsers like Chrome, Firefox, Safari, and Edge. It prevents **Domain A** from accessing resources on **Domain B** without explicit permission.
For reproducing this issue, I have developed a simple **golang** based backend project & I integrated the APIs with VueJs frontend code.
Vue will spin up a simple web server that listens on port 8080 and serves the frontend. This is great for easy development, but we will run into problems when calling our API.
Let’s open the http://localhost:8080 page:
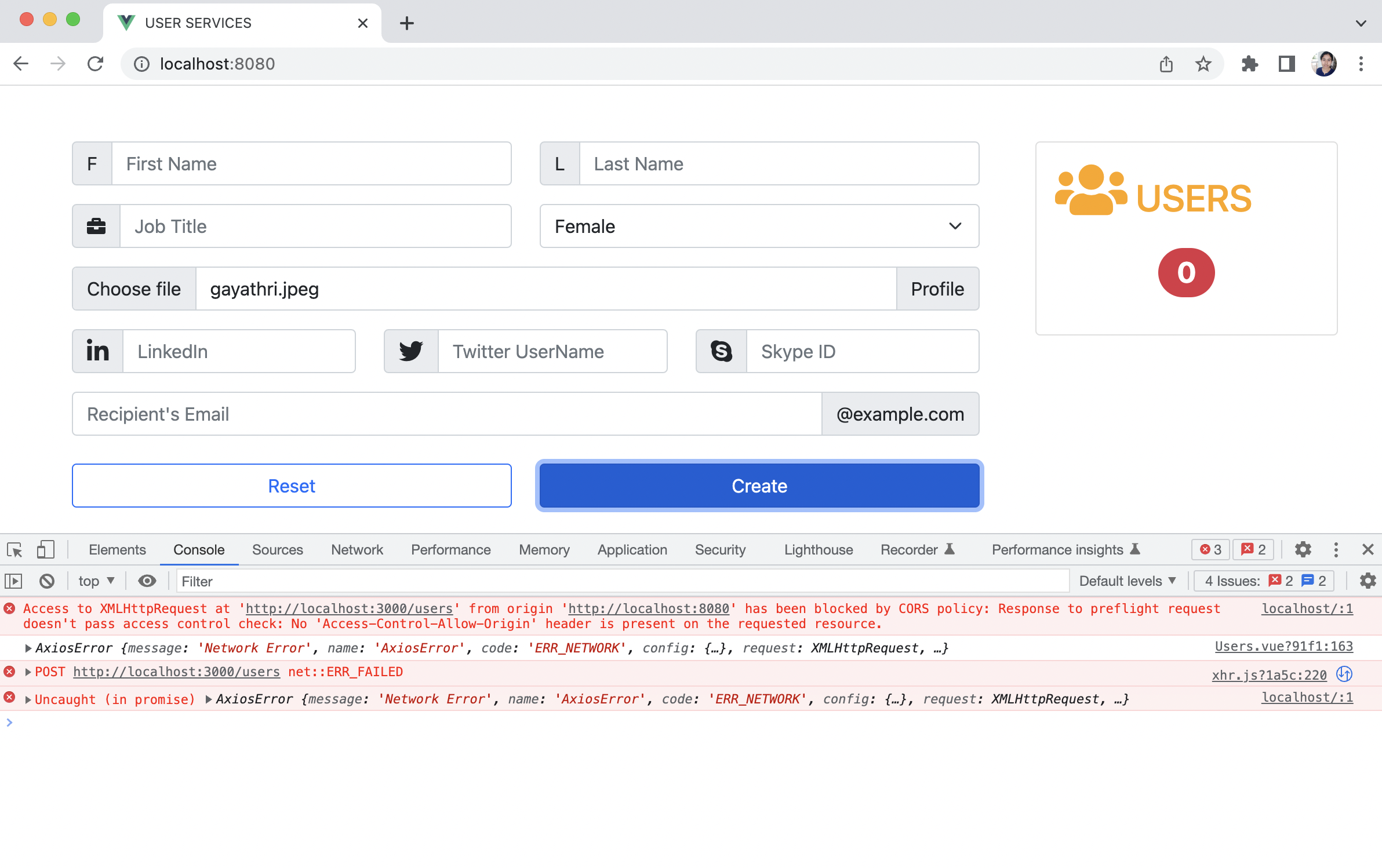
We can see that while triggering the API call browser gives a CORS error. This is because http://localhost:8080 and http://localhost:3000 are considered different domains and thus the CORS policy comes into play.
## How To Fix CORS Errors
We can fix this CORS problem in two ways,
#### 1) Allow CORS requests from the backend server
With the **Access-Control-Allow-Origin** header, we can specify what origins can use our API.
We can set it to http://localhost:8080 or '*' to allow our Vue app to call it:
```go
func respondWithJson(w http.ResponseWriter, code int, payload interface{}) {
response, _ := json.Marshal(payload)
w.Header().Set("Content-Type", "application/json")
w.Header().Set("Access-Control-Allow-Origin", "*")
w.WriteHeader(code)
w.Write(response)
}
```
#### 2) Setup a development proxy in VueJs
During development, you often see that the backend server is running on a different port than the frontend server.
This is also the case with our example where the frontend server runs on localhost:8080 and the backend server runs on localhost:3000.
To set up this proxy system, we can create a **vue.config.js** file in the root of the Vue project:
```js
module.exports = {
devServer: {
proxy: {
'^/users': {
target: 'http://localhost:3000/',
ws: true,
changeOrigin: true
},
}
}
}
```
We should then also change the backend urls in the Axios calls. That is, instead of providing the backend URL either we need to remove the domain or we should provide the FrontEnd domain.
```js
listUsers(){
var url = "/users";
return axios({
url: url,
method: 'GET',
}).then(result => {
this.model = result.data;
this.$emit('listUsers', this.model);
return result;
}).catch(error => {
console.log(error);
throw error;
});
},
```
Here, I removed the domain while making the API call.
Let’s try it again!
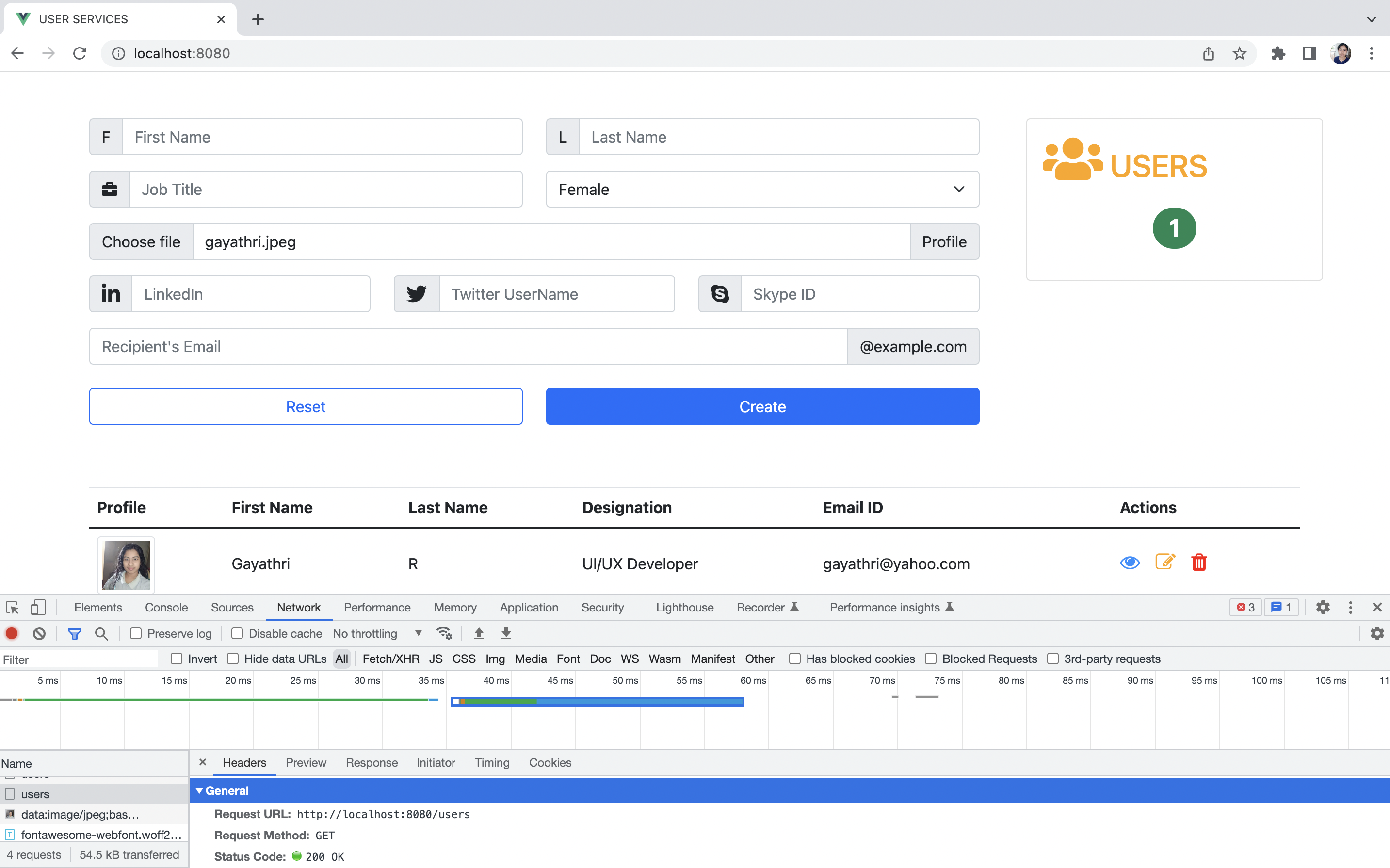
Now we see that the browser is allowed to access the API.
| gayathri_r |
1,124,801 | Developer Mentality and Soft Skills to Succeed | The developer mindset and soft skills have differences compared to people from different industries.... | 0 | 2022-06-26T14:33:32 | https://medium.com/@oscar_sherelis/developer-mentality-and-soft-skills-to-succeed-9d38e0ce4585 | beginners, career, productivity, performance | The developer mindset and soft skills have differences compared to people from different industries. For this reason, some people are better developers. In this article, I will explain the main differences and why they are essential to achieve goals in a developer career.
## Importance of Soft Skills
Charisma and communication skill is valuable for many jobs. Some people had the worst technical skills but managed to get work with good charisma. Most people are communicative, never forget this fact. With charisma, it is easier to make a better first impression. Be honest, there are situations when the Project manager asks You about ETA - Estimated time of arrival. Not all tasks can be completed in time. Do not inform at the last moment. New programmers can be afraid of failure of incomplete tasks. In cases, if You see a task that cannot be completed in time. First of all, inform team-lead/other-programmer. It will show You as a responsible person in other's eyes. Most project managers can make situations even worst. Some of them can tell employers that You are slow, or incapable to solve tasks. If this happened I should recommend You look for a new job. If You are stuck do not be afraid to ask. Before asking use google, read the official documentation, StackOverflow. etc. If after an hour of research You are still stuck, ask for help. Describe the situation in detail in one message, no one loves spam. Find friends, not enemies. Being nice to others is important because people prefer to work more with kind people, than rude.
## Time Management
Managing time to participate in meetings and complete tasks in time. Time management can prevent You from burnout. Developers are humans, they need to rest. Being exhausted at work leads to the worst productivity performance. Moreover, it affects Your health. For this reason, some employers do not allow workers to work more than 8 hours per day.
## Continuous Learning
Professional and personal growth is important to compete with other candidates/developers. Personal growth means working on Your soft and technical skills about the importance of these skills I was writing in this [article](https://medium.com/@oscar_sherelis/how-to-find-your-first-work-internship-as-a-front-end-developer-12469fe8adb8).
## Importance of Technical Skills
For example, I will take a front-end developer position. Also, wrote in this [article](https://medium.com/@oscar_sherelis/how-to-find-your-first-work-internship-as-a-front-end-developer-12469fe8adb8). If Your portfolio has about 10 projects, I would recommend improving everyday processes. Start from the browser, and VS code extensions, and find, what fits You. Browser extensions, what I use: color picker, Wappalyzer, Grammarly, React developer tools, and Open last tab. VS Code Extensions: Prettier, PHP extension pack, Live server, Auto Rename Tag, and ES7+ React/Redux/React-Native. In the future, I will make a list of extensions for a front-end developer. Write readable and maintainable code. After some time You or someone else will return to Your project to make changes or add new functionality. Readable code makes work easier and gives a better working experience. Read, understand and make changes to other personal projects. On the internet is easy to find a public repository. At work, You will be working with already existing projects. For this reason, it is important to understand other person codes. Best practices are easy to find and important to follow. Your code will look more professional. One real-world example of why this is important. Even if You completed the Interview task and everything is working according to the description. The senior developer will not accept You even for an internship. One possible problem is bad naming, it can be variables, files, functions, etc.
## Developer Mentality
Stop saying - I do not know. If there is a problem, solve it. At the start, a problem can look unsolvable. The solution, divide them into small tasks and order. Step by step to solve a problem. If a task took a lot of time to complete, spend some time thinking, about what can be improved. In debating always use arguments. To prove something it is crucial to argue, why Your solution is worth it.
## Conclusion
Do not stop improving, be friendly with others and optimize everyday processes.
I am available on social media: [Twitter](https://twitter.com/Oscar_Sherelis) [LinkedIn](https://www.linkedin.com/in/oscar-sherelis) [Instagram](https://www.instagram.com/oscar_sherelis/)
Support me: buymeacoffee.com/oscarWeb | oscarsherelis |
1,124,827 | Get daily billing amounts by account with Cost Explorer API | Goal of this article Use Cost Explorer API to get the daily billing amount for each... | 0 | 2022-06-26T15:42:00 | https://hayao-k.dev/get-daily-billing-amounts-by-account-with-cost-explorer-api | aws, python, costexplorer, billing | ## Goal of this article
Use Cost Explorer API to get the daily billing amount for each account and output the following data in CSV.
|Account Id|Account Name|2022/4/1|2022/4/2|2022/4/3| ...|2022/4/30|
|---|---|---|---|---|---|---|
|000000000000|account-0000|42.792716528|40.124716527|43.123416527|...|50.922465287|
|111111111111|account-1111|32.263379809|30.235379809|31.263353594|...|22.133798094|
|222222222222|account-2222|751.71034839|720.51234839|772.62033294|...|651.71042035|
|333333333333|account-3333|4.6428|5.1234|7.8765|...|6.2234|
|444444444444|account-4444|407.74542211|420.12345211|395.12499518|...|417.99454118|
|555555555555|account-5555|386.78950595|400.12500509|352.89924506|...|370.75102656|
|...|
An equivalent CSV can be downloaded from the AWS Cost Explorer console. This post describes how to retrieve the data daily automatically.
## Example API Request
This is a minimal example of using AWS Lambda to retrieve the daily billing amount for the current month.
```py
import datetime
import boto3
def lambda_handler(event, context):
today = datetime.date.today()
start = today.replace(day=1).strftime('%Y-%m-%d')
end = today.strftime('%Y-%m-%d')
ce = boto3.client('ce')
response = ce.get_cost_and_usage(
TimePeriod={
'Start': start,
'End' : end,
},
Granularity='DAILY',
Metrics=[
'NetUnblendedCost'
],
GroupBy=[
{
'Type': 'DIMENSION',
'Key': 'LINKED_ACCOUNT'
}
]
)
return response['ResultsByTime']
```
One point to note is that there is a time lag before the cost for a given day is determined. For example, if the cost for April 25 is obtained on April 26, it may be less than the actual billing amount.
The timing of when the AWS data will be updated is not disclosed, but it appears that on April 27, the costs for April 25 will be almost finalized.
## Processing with Pandas
Since the API response is a nested JSON, we will consider an example of processing it into a CSV using Pandas.
When using Pandas with AWS Lambda, Lambda Layers must be used.
* Since each element contains billing data daily, it is processed with a for statement one day at a time.
* After flattening the data using pandas.json_normalize, it is concatenated with the billing amount using pandas.concat.
* After further renaming the column to the billing date, the results are merged using the Account Id as the key.
```py
merged_cost = pandas.DataFrame(
index=[],
columns=['Account Id']
)
for index, item in enumerate(response):
normalized_json = pandas.json_normalize(item['Groups'])
split_keys = pandas.DataFrame(
normalized_json['Keys'].tolist(),
columns=['Account Id']
)
cost = pandas.concat(
[split_keys, normalized_json['Metrics.NetUnblendedCost.Amount']],
axis=1
)
renamed_cost = cost.rename(
columns={'Metrics.NetUnblendedCost.Amount': item['TimePeriod']['Start']}
)
merged_cost = pandas.merge(merged_cost, renamed_cost, on='Account Id', how='right')
print(merged_cost)
```
```
Account Id ... 2022-04-25
0 000000000000 ... 15.4985752779
1 111111111111 ... 0.2176
2 222222222222 ... 6.5567854795
3 333333333333 ... 6.6300957379
4 444444444444 ... 8.2720868504
.. ... ... ...
19 777777777777 ... 10.0121863554
18 888888888888 ... 6.5976412116
20 999999999999 ... 6.493243618
[20 rows x 26 columns]
```
## Example of Lambda function
After processing with for statement, the list of account names obtained from AWS Organizations API is merged and output in CSV.
```py
from logging import getLogger, INFO
import os
import datetime
import boto3
import pandas
from botocore.exceptions import ClientError
logger = getLogger()
logger.setLevel(INFO)
def upload_s3(output, key, bucket):
try:
s3_resource = boto3.resource('s3')
s3_bucket = s3_resource.Bucket(bucket)
s3_bucket.upload_file(output, key, ExtraArgs={'ACL': 'bucket-owner-full-control'})
except ClientError as err:
logger.error(err.response['Error']['Message'])
raise
def get_ou_ids(org, parent_id):
ou_ids = []
try:
paginator = org.get_paginator('list_children')
iterator = paginator.paginate(
ParentId=parent_id,
ChildType='ORGANIZATIONAL_UNIT'
)
for page in iterator:
for ou in page['Children']:
ou_ids.append(ou['Id'])
ou_ids.extend(get_ou_ids(org, ou['Id']))
except ClientError as err:
logger.error(err.response['Error']['Message'])
raise
else:
return ou_ids
def list_accounts():
org = boto3.client('organizations')
root_id = 'r-xxxx'
ou_id_list = [root_id]
ou_id_list.extend(get_ou_ids(org, root_id))
accounts = []
try:
for ou_id in ou_id_list:
paginator = org.get_paginator('list_accounts_for_parent')
page_iterator = paginator.paginate(ParentId=ou_id)
for page in page_iterator:
for account in page['Accounts']:
item = [
account['Id'],
account['Name'],
]
accounts.append(item)
except ClientError as err:
logger.error(err.response['Error']['Message'])
raise
else:
return accounts
def get_cost_json(start, end):
ce = boto3.client('ce')
response = ce.get_cost_and_usage(
TimePeriod={
'Start': start,
'End' : end,
},
Granularity='DAILY',
Metrics=[
'NetUnblendedCost'
],
GroupBy=[
{
'Type': 'DIMENSION',
'Key': 'LINKED_ACCOUNT'
}
]
)
return response['ResultsByTime']
def lambda_handler(event, context):
today = datetime.date.today()
start = today.replace(day=1).strftime('%Y-%m-%d')
end = today.strftime('%Y-%m-%d')
key = 'daily-cost-' + today.strftime('%Y-%m') + '.csv'
output_file = '/tmp/output.csv'
bucket = os.environ['BUCKET']
account_list = pandas.DataFrame(list_accounts(), columns=['Account Id', 'Account Name'])
daily_cost_list = get_cost_json(start, end)
merged_cost = pandas.DataFrame(
index=[],
columns=['Account Id']
)
for index, item in enumerate(daily_cost_list):
normalized_json = pandas.json_normalize(item['Groups'])
split_keys = pandas.DataFrame(
normalized_json['Keys'].tolist(),
columns=['Account Id']
)
cost = pandas.concat(
[split_keys, normalized_json['Metrics.NetUnblendedCost.Amount']],
axis=1
)
renamed_cost = cost.rename(
columns={'Metrics.NetUnblendedCost.Amount': item['TimePeriod']['Start']}
)
merged_cost = pandas.merge(merged_cost, renamed_cost, on='Account Id', how='outer')
daily_cost = pandas.merge(account_list, merged_cost, on='Account Id', how='right')
daily_cost.to_csv(output_file, index=False)
upload_s3(output_file, key, bucket)
```
Now all that is left is setting an arbitrary startup schedule in EventBridge and a Lambda function as the target.
| hayao_k |
1,124,835 | File Database in Node Js from scratch part 1: introduction & setup | Introduction I have been stuck in my coding journey for a while now, yes I can implement a... | 19,570 | 2022-06-26T16:04:35 | https://dev.to/sfundomhlungu/-i-dont-know-what-i-am-doing-file-database-from-scratch-in-node-js-part-1-9f8 | javascript, webdev, node, programming | ## Introduction
I have been stuck in my coding journey for a while now, yes I can implement a website from start to finish, a mobile app in ionic to publishing, But I am not content with myself and just knowing CRUD apps, Then started searching, came across this masterpiece [what is programming? (noob lessons!)](https://www.youtube.com/watch?v=N2bXEUSAiTI) by George Hotz, I instantly knew what to do to grow from just CRUD to a programmer, and this is the start of my journey and I will build and learn in public, hoping to inspire someone out there too.
What I will basically do is take a "lower level concept/problem" that has been solved yes, but I don't know how, example Operating systems, Compilers, Virtual Machines, Front/back-end frameworks and implement them or my version from scratch without or minimal help as possible(basically hacking my way into the solution with the skills I currently have),
however watch tutorials or read books for concepts I am completely unaware of at all, for example OS and implement them in C then try them in JS without help
for concepts I know such as Front-end and db's I will hack my way into a solution without or minimal help, and I will point out when I did seek for help and share links
I hope you start building with me.
## setup
```js
// mkdir - create a new folder : database
// create an index.js file inside the database folder
database/
index.js
// cmd command
npm init // init a new package.json file choose defaults
// add a field to the package.json file
"type": "module" // will allow us to use imports in node
```
The entire package.json file:
```json
{
"name": "database",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
```
## What I Know
what I know about databases is basically the API, also known as CRUD operations, I don't know the inner workings of db's, algorithms and structures used, absolutely clueless, so I will start from CRUD to a file db.
## index.js file
```js
import db from "./database.js" // we need .js in node
export default db
```
This is a common pattern actually in modules or libraries, the entry file just exposes the core API, this is what I am going for here, exposing a db function when called will return an object with functions to operate on the database.
I don't know about you but when I build something I like starting from the user's perspective backwards, which may be bad depending on how you look at it.
But my reasoning behind it is simple, expose a simple as possible interface and build all the complexity around it without changing the endpoint, it a constraint of some sort, and it's my job to figure out how to constrain all complexity towards that simple endpoint. Which currently works well for me, even when refactoring I strive for the endpoint not to change.
## database.js
Now I am abstracting away from the tip/endpoint, that is my thought pattern right now, I think of this as a vortex, index.js is the tip of the vortex the more files I add, the more shape the body of the vortex takes, however the user(programmer in this case) will see the tip, unless they want to explore.
I call this second layer file, the composer or consolidator, which I am unsure if it captures the essence of what I am trying to explain, at least it makes sense in my head at the moment, I don't know about you.
I am assuming of course that the db will have a lot of features(files you can think of them) and the job of the composer is to take all these features and pipe/compose them to this tiny endpoint, this is like another protection or a guarantee that every feature will consolidate to db, database.js is another safeguard of sort and feeds the tip of the vortex
```js
import {insert, update, delete_, select} from './operators.js' // features to be composed
function db(options) {
// I assume metadata is somewhat useful in db's will explain as I use them
this.meta = {
length: 0, // of the store
types: {}, // we can bind types to each column in the store
options // passed from the vortex
}
this.store = {} // our store for now is a simple object
}
// every instance of db will point to this single prototype
// composing all the features
db.prototype.insert = insert
db.prototype.update = update
db.prototype.select = select
db.prototype.delete_ = delete_
// exporting the endpoint
export default db
```
A minor observation is: I actually don't like that the store(actual table) is accessible from the endpoint and can be changed, definitely needs a refactor(will deal with it later) for now its fine
### why prototype
well the idea is simple really, every instance points to that single proto object, for example if we have 100 db instances we won't have 100 proto objects with insert, update etc but one
if you are confused by how this work or unfamiliar I made a series of articles creating a [prototype emulator](https://dev.to/sfundomhlungu/unpacking-javascript-01-prototypes-emulating-proto-runtime--1m68) and learning OOJS(object oriented JS) you can check them out.
## Operators.js
these are the features, the body of the vortex is expanding in both directions, initially I thought of separating them by files but since the codebase is still small I don't see the need yet
```js
import {isInDb} from "./utils.js" // its no library without utils :)
// insert is very simple for now
export function insert(row){
try{
// options only handle timeStamp(boolean)
if(this.meta.options.timeStamp){
row["timeStamp"] = Date.now() // insert date
}
this.store[this.meta.length] = row // insert the row in the next id
this.meta.length++ // increase ID/length
return true // operation succesfull
}catch(err){
console.log(err) // for now
return false // operation failed
}
}
export function select(){
}
export function delete_(){
}
export function update(){
}
```
## utils.js
a utility file is very useful for small and reusable functionality, even if you don't use them now, it's good to have them ready.
In this case I sensed i will need a function to tell me whether a document exists in a db
```js
// function does not copy store, rather receives a pointer
// so no memory wastage
export function isInDb(store, id){
return store[id] !== undefined ? true : false
}
```
## test.js
not an actual test, like code test but checking if the db works as expected
```js
import db from './index.js'
let store = new db({timeStamp: true})
console.log(store)
store.insert({name: "John", surname: "Doe"})
store.insert({name: "Jane", surname: "Doe"})
console.log(store)
```
## I decided to stop here
for one reason really I had so many ideas but didn't really know how to really go about them for example I thought of a string like sqlite ''SELECT * in' however it goes, but also thought of filters etc, then I am deciding to watch a simple python tutorial just to glean on the API and see if I can spin it somehow and make it work here in my own way.
## Part two
coming soon!
# conclusion
If you want a programming buddyI will be happy to connect on [twitter](https://twitter.com/MhlunguSfundo) , or you or you know someone who is hiring for a front-end(react or ionic) developer or just a JS developer(modules, scripting etc) **I am looking for a job or gig** please contact me: [mhlungusk@gmail.com](mailto:mhlungusk@gmail.com), twitter is also fine
Thank you for your time, enjoy your day or night. until next time | sfundomhlungu |
1,124,947 | [vue-router] Active route, subpath | Hi all, I have the following routes: { path: '/offers/', component: OfferList, ... | 0 | 2022-06-26T18:06:55 | https://dev.to/pces83/vue-router-active-route-subpath-4hik | vue | Hi all,
I have the following routes:
```
{ path: '/offers/', component: OfferList, name: 'offerList' },
{ path: '/offers/:id', component: OfferView, name: 'offerView'}
```
And the following link:
```
<router-link :to="{ name: 'offerList'}" custom v-slot="{ navigate, href, isActive, isExactActive }">
<li class="menu-item" :class="{ 'active': isActive }">
<a :href="href" class='menu-link'><span>Offres partenaires</span></a>
</li>
</router-link>
```
According to the documentation, when I load the offerView url, the router-link should have `isActive == true` but it doesn't
Can you tel me what's wrong with that ?
Thanks | pces83 |
1,125,132 | Building a Wordle clone with Haskell | Do you remember the game called Wordle? The game that was trendy not long ago. And sure, if you are... | 0 | 2022-06-27T01:46:32 | https://dev.to/fabianveal/building-a-wordle-clone-with-haskell-m9i | beginners, haskell, functional, tutorial |
Do you remember the game called Wordle? The game that was trendy not long ago.
And sure, if you are a programmer, you have seen a lot of versions of this game with different languages and technologies. Now I'm going to show you, how to make this game in the language Haskell, loved by a few, hated by others and ignored by many.
Before you begin, it is necessary that install stack to install some packages.
The game read a list of words with animals.
```haskell
main :: IO ()
main = do
let filename = "animals.txt"
animalsText <- readFile filename
{- continue -}
```
For this, I use `readFile` with the firm:
```haskell
readFile :: FilePath -> IO String
```
This means that when entering the file name we will receive an `IO String` and to “unwrap” the `IO` monad we will use the Haskell **do-notation**, that way we get the text with the file content.
Besides, to get a list with all words with the same format, we use the next code:
```haskell
import Control.Monad (join)
import Data.Text (toLower, pack)
import qualified Data.Text as T
main :: IO ()
main = do
let filename = "animals.txt"
animalsText <- readFile filename
let animals =
join
. map T.words
. T.lines
. toLower
. pack
$ animalsText
{- continue -}
```
You can imagine the process to build `animals` like a pipe that going from the bottom to the top. So `animalsText` first pass by `pack` that transform a `String` to a `Text`, `toLower` transform all text to lowercase, `lines` split the lines and `map T.words` to each line split in words and finally `join` all in a list.
In Haskell for use of random numbers (pseudo-randoms), we will use the package `random`. The next step is to choose a random word of the list. For this, we must make a seed:
```haskell
import System.Random (getStdGen, randomR)
main :: IO ()
main = do
{- continue -}
g <- getStdGen
let selected_index = fst $ randomR (0 :: Int, length animals) g
let selected_word = animals !! selected_index
{- continue -}
```
The one I named `g`, later generate a random number, `selected_index` in the range 0 to the length of animals and getting the word in that index using `(!!)` function.
> In Haskell the operators also are functions.
We already have a random word chosen from a file, now we have to program the logic of the game, for this I created a `play` function.
```haskell
main :: IO ()
main = do
let filename = "animals.txt"
animalsText <- readFile filename
let animals =
join
. map T.words
. T.lines
. toLower
$ pack animalsText
g <- getStdGen
let selected_index = fst $ randomR (0 :: Int, length animals) g
let selected_word = animals !! selected_index
wordles <- play selected_word
{- continue -}
```
The `play` function:
```haskell
import Data.Text
( Text,
pack,
strip,
toLower,
unpack,
)
import qualified Data.Text as T
import qualified Data.Text.IO as TIO
import Text.Printf (printf)
play :: Text -> IO [Text]
play selected_word = go attempts []
where
go :: Int -> [Text] -> IO [Text]
go 0 xs = return xs
go n xs = do
let i = 1 + length xs
putStrLn $ "Please enter your animal " ++ show i ++ "/" ++ show attempts ++ ": "
attemptstr <- getLine
let attempt = toLower . strip $ pack attemptstr
let (wordle, correct) = getWordle attempt selected_word
printf "Rustle (ES) %d/%d\n\n" i attempts
TIO.putStrLn wordle
if correct
then do
putStrLn "Congratulation!"
printf "Rustle (ES) %d/%d\n\n" i attempts
return (wordle : xs)
else do
go (n - 1) (wordle : xs)
```
Let's go by parts, `play :: Text -> IO [Text]` receive the select word and return all games. In the definition of `play`, I created an auxiliary function called `go`, that receive the attempts and an empty list. This function iterate the games, i.e., ask the user a word, show the result and while as long as it does not run out of plays or win, the game continue in the recursion.
> The function `return` is not the same that the statement return of others languages mainly imperatives. In Haskell the function are composition of function, since what follows the equals is what defines the function.
> `return` wrap the value in a Monad, in this case `IO` Monad.
Other function important is `getWordle`, which is defined as:
```haskell
getWordle :: Text -> Text -> (Text, Bool)
getWordle attempt correct =
let result = T.zipWith go attempt correct
rest =
if T.length attempt < T.length correct
then pack $ replicate (T.length correct - T.length attempt) $ cshow Fail
else mempty
isCorrect = attempt == correct
in (result <> rest, isCorrect)
where
go :: Char -> Char -> Char
go ca cc
| ca == cc = cshow Success
| ca `elem` unpack correct = cshow Misplace
| otherwise = cshow Fail
```
> The function (<>) is a operator to concat two Semigroups, in this case, two Text, for example `"foo" <> "bar" = "foobar"`.
This receives two `Text` types, `attempt` and `correct`, i.e., the attempt of user and the correct word. Haskell has the Let syntax, here we're going to define `result`.
The strategic that I thought was map the attempt and the correct word together, with some function that check if is success, misplace or fail. The function `zipWith` does that, apply `zip` to two lists and call a function with each pair values. In resume is a `map` and `zip` composed.
The `go` function, receive the two values and if are equals then marked as _Success_, if the character is in the correct word then is a _Misplace_ else is _Fail_.
If the attempt word is more shore than the correct then the result in screen was going to be more short too, to solve this `rest` contain the rest of result, but only if correct is more long than attempt. Lastly, `isCorrect` ask if `attempt` and `correct` are equals.
Also, I defined some others things like:
```haskell
{-# LANGUAGE LambdaCase #-}
data State = Fail | Success | Misplace
cshow :: State -> Char
cshow = \case
Fail -> '⬜'
Success -> '🟩'
Misplace -> '🟨'
attempts :: Int
attempts = 6
```
I made a data type named `State` and defined `cshow` that return the character according to a `State`. And `attempts` that return the attempt amount of game.
Later to finish the game the program show the games, for this:
```haskell
main :: IO ()
main = do
...
wordles <- play selected_word
TIO.putStrLn . T.unlines . reverse $ wordles
```
> I use `putStrLn` from `Data.Text.IO` because the chars ['⬜', '🟩', '🟨'] are Unicode, of this way this characters are show in the console correctly.
## The Game in operation
And with this we are able to play Wordle from our console.
```
$ stack run
Please enter your animal 1/6:
elephant
Rustle (ES) 1/6
⬜🟨⬜⬜
Please enter your animal 2/6:
duck
Rustle (ES) 2/6
⬜⬜⬜⬜
Please enter your animal 3/6:
lark
Rustle (ES) 3/6
🟨⬜⬜⬜
Please enter your animal 4/6:
mule
Rustle (ES) 4/6
⬜⬜🟨⬜
Please enter your animal 5/6:
slug
Rustle (ES) 5/6
⬜🟨⬜⬜
Please enter your animal 6/6:
fowl
Rustle (ES) 6/6
🟩🟩🟩🟩
Congratulation!
Rustle (ES) 6/6
⬜🟨⬜⬜
⬜⬜⬜⬜
🟨⬜⬜⬜
⬜⬜🟨⬜
⬜🟨⬜⬜
🟩🟩🟩🟩
```
---
Now you can develop your own Wordle clone with Haskell or the language you prefer. If you have comments or questions, share it in comments.
I share with you the link to the repository.
{% embed https://github.com/FabianVegaA/WordleHs.git %}
| fabianveal |
1,125,279 | Are you a CMS developer? | Take part in our 10-minutes CMS survey, get 30$ as voucher, help us understand the importance of CMS... | 0 | 2022-06-27T07:56:18 | https://dev.to/janushead/are-you-a-cms-developer-3g26 | api, cms, headless, jamstack | Take part in our 10-minutes CMS survey, get 30$ as voucher, help us understand the importance of CMS for your profession.
[https://relevantive.typeform.com/to/n60EE5Zs?utm_source=devto](https://relevantive.typeform.com/to/n60EE5Zs?utm_source=devto) | janushead |
1,125,405 | What API's Are About by Postman | A few days ago I attended Postman's API 101 Workshop. This is an industry talk that the folks at... | 0 | 2022-06-27T10:22:51 | https://dev.to/outoflaksh/what-apis-are-about-by-postman-ddj | postmanapi101 | A few days ago I attended Postman's API 101 Workshop. This is an industry talk that the folks at Postman deliver at universities as part of their Student Program. And here's all that I learned:
First of all, Postman itself is not an API, as some of my classmates mistook it as, instead Postman is an application that is used to *build* APIs.
API stands for **Application Programming Interface**. That may not make much sense so let's leave it aside for now. We'll get back to that later.
## The Modern-day Application
For now, let's look at a typical modern day web application. There are broadly two sides to it. The first is the thing we, as users, see. The webpages, the graphical interface with all the pretty buttons and illustrations, and all the fancy animations. This is called the *front-end* of your website. This is where you would provide any inputs and be able to view the output.
Now, the existence of this *front*-end implies that there must also exist a *back*-end. And it does!
The back-end of any app is the actual logic and the code that makes it behave like it's supposed to. All the heavy lifting behind the scenes that you, as a user of that app, might not see is happening here. Hence, the term back-end. This is where the inputs from the front-end are processed and an output is sent back to be displayed.
## It's like going to a restaurant!
The expert at the workshop explains this with a brilliant analogy of a restaurant. When you go to a restaurant, the menu or the tables or the beautiful decor of the place is the front-end. But all the real work - cooking of the food - happens in the kitchen that you may not see. Hence, the kitchen is the back-end.
## To APIs...
So far so good. Now naturally there must also exist a way through which these two sides communicate. Because how else would the front-end take your inputs to the back-end for processing, or bring back the output so you can see it?
At a restaurant, you yourself don't go to the kitchen and bring your order back from the chefs, right? That's what waiters are for! And that's exactly what APIs do too!
Waiters take your order details and relay it to the kitchen so the chefs can cook it up. And when they're done, waiters bring back the delicious cooked food back to your table as requested by you. Much like how APIs collect your inputs from the front-end via a request and relay it to the back-end where the inputs get processed and certain output is returned back to you as a response!
## Enough about restaurants, how does it work in real life?
These requests and responses usually take place over HTTP in a real-world application. The front-end makes an *HTTP request* with the inputs in its *request body* at a certain *API endpoint* and is returned an output in a form of an *HTTP response* with a certain *response body*.
There are different kinds of HTTP requests that mean different things:
- The GET HTTP request method means that you want to receive some data.
- The POST HTTP method means that you also want to send some data.
- The PUT method means you want to update certain data.
- The DELETE method means you want to delete certain data.
These four kinds of requests come together to make a CRUD based API. This kind of API architecture is commonly called a REST API and the API is said to be RESTful.
## OK, but why API?
There are literally thousands of APIs out there. A big advantage of using them is that you don't necessarily need to know the back-end logic yourself. As long as you know what data to input and what to expect in the output, you can totally use an API to do all the processing for you.
Since these API provide almost like an interface over some abstract logic code, they are said to be a layer of abstraction. And the different endpoints provide an interface to interact with the real code. All the developer needs to know is how to interact with this interface.
Hence the full form, i.e., Application Programming Interface. As they are nothing but an interface that can help you program your application by taking care of all the third-party logic.
So that's about it. The instructor of the workshop made us do all of this hands-on using Postman on a dummy jokes API. And you can interact with it too here: http://postman-student.herokuapp.com/joke/
| outoflaksh |
1,125,665 | How to Install Kubernetes Cluster in Linux | https://www.linuxtechi.com/install-kubernetes-k8s-on-ubuntu-20-04/ refer this link if installation... | 0 | 2022-06-28T10:51:10 | https://dev.to/thecloudtechin/how-to-install-kubernetes-cluster-in-linux-177f | devops, docker, kubernetes, linux | https://www.linuxtechi.com/install-kubernetes-k8s-on-ubuntu-20-04/
refer this link if installation getting error
https://github.com/containerd/containerd/issues/6970
do this command solve:
rm /etc/containerd/config.toml
systemctl restart containerd
https://www.howtoforge.com/tutorial/install-laravel-on-ubuntu-for-apache/ | thecloudtechin |
1,126,056 | Solve Your Cloud Access Problems In Less Than 5 Minutes | Spend time developing, not managing There are many challenges that cloud developers face... | 0 | 2022-06-28T22:29:56 | https://dev.to/remoteit/solve-your-cloud-access-problems-in-less-than-5-minutes-298c | cloud, productivity, developer, database | ## Spend time developing, not managing
There are many challenges that cloud developers face today and many revolve around quick, simple, and consistent access to the cloud resources such as databases. As a developer, you want to build software, not spend your time dealing with setting up your development environment.
Whether you are using an existing database or creating a new one, the process can be painful and take a lot of time. You want to make sure your data is accessible but also private, but sometimes you may be making choices that compromise one goal or the other.
**Maintaining “developer” databases to run locally:** To stay productive, you may use a database that allows a developer to run a database server locally. The scripts to set up the database must be maintained and only have a small sample of example data. The more database types you need the more CPU, memory and storage the developer laptop needs, for example postgreSQL, MySQL, redis, etc. Such a model is not a full-scale representation of the real-world environment and that makes it difficult to reproduce, debug, or test fixes. Deploying debug versions of your application so you can reproduce an issue with extra logging is time consuming.
**Making copies of production databases to run locally:** This can put a strain on your laptop, you may have a database that is just too big to run locally, or your data contains PII or other sensitive data that should not be on a laptop.
**IP allow lists:** You need to hide your open ports on public IP addresses and ports such as 3306 for MySQL, or you open your port for attacks. You can try and use IP lists and security groups, but the problem is that you need to maintain these lists in each environment. As a developer, this can mean access is complicated by the manual process of adding your IP address, or if you move location or work from home where you may not have a fixed external IP address, you are faced with repeated requests to devops to update the access rules. This process can introduce security risks when you don’t remove invalid IP addresses.
**Using VPNs:** VPNs become more and more complicated and limiting as you expand to multi-cloud or multiple VPCs and accounts that lead to subnet collisions. Such a problem may mean you can only connect to one VPN at a time. You may still end up with an open port that you may try to hide with IP allow lists that are maintained at each location where a VPN is used. We know that VPNs are not as secure as once thought.
All of these issues make on-boarding and off-boarding new developers or contractors much more time intensive tasks, resulting in less time developing or making sure that access is cut off when a contractor or developer leaves.
What if you could have the benefits of access to your cloud resources without any of those problems?
## The Solution
[Remote.It](https://www.remote.it/) enables remote development, staging, and production resources to be directly available as if they are running directly on the developer's local machine. You can start coding independent of your location and multi or hybrid cloud environments.
**Deployment is quick and easy:** Taking away all of these hassles (Setup typically takes 5 minutes or less).
**Access can be granted and removed centrally:** With the Organization Management feature, access can be granted specifically by resource, unlike a VPN where you technically get access to the entire LAN. You can create roles that have specific permissions and assign the roles to members of the development team based on their need for access.
**Add SAML integration:** Where login credentials are controlled by your SAML provider, you just simply manage the role of the user. User management can be handled by either the Desktop Application, Web Portal, or GraphQL API. This creates Zero Trust Network Access (ZTNA).
When you connect to a resource such as MySQL via [Remote.It](https://www.remote.it/), you will be given a localhost address and a unique port. You can use this in your development environment connection configuration, database query tools, etc. There is no connecting, disconnecting, and reconnecting when you change locations or your laptop wakes up from sleep. These on demand connections will go idle when you are not actively using it and go active when you do.
**Setup**
Setup will be creating a VM which will act as a jump box to reach your database resources, registering it in Remote.It, and then adding the services (access endpoints for the resources).
**You will need:**
- Remote.It Desktop Application (version 3.5.2 or greater)
- A Remote.It account
- AWS console access to the account which can access the VPC where the database(s) reside
Example provided here is for AWS, but is similar for Google Cloud and Azure.
Follow along using this [video]() or the written directions on [Zero-Trust AWS Access](https://link.remote.it/docs/aws) & [AWS RDS (Postgres and MySQL)](https://link.remote.it/docs/rds-setup)
{% embed https://youtu.be/3okGzFS1AbU %}
**Step 1: Launch and register your Jump VM.**
After signing in to the account and selecting the region where your database is hosted, launch a new instance from the EC2 dashboard. (You can leave the instance type at t2.micro).
**Key Pair:** Select an existing one for your account or create a new one. This is used for SSH access to this instance.
**Network Setting:** You can create a new security group and deselect SSH. This will ensure no exposed external ports. Don’t worry you can still access SSH from Remote.It.
**Open Advanced Settings:** We will be entering the one-line command into the User data field
Open Remote.It and get your one-line command:
In the "User data", field enter #!/bin/sh + return and your copied command
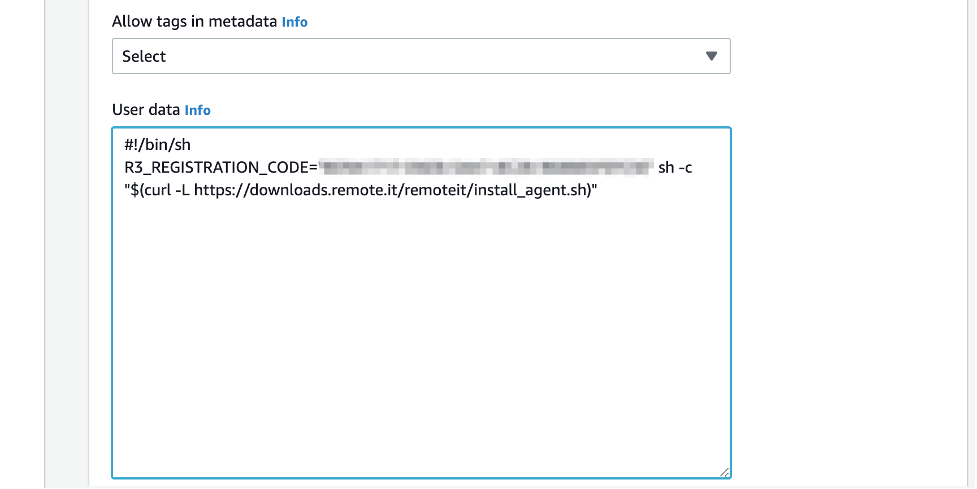
Click “Launch Instance”
Once the instance initializes, it will automatically appear in your Remote.It desktop with an SSH service.
**Step 2: Add service endpoints for your database(s).**
Get your internal endpoint address or internal IP address for your database (Example of MySQL at AWS show below)
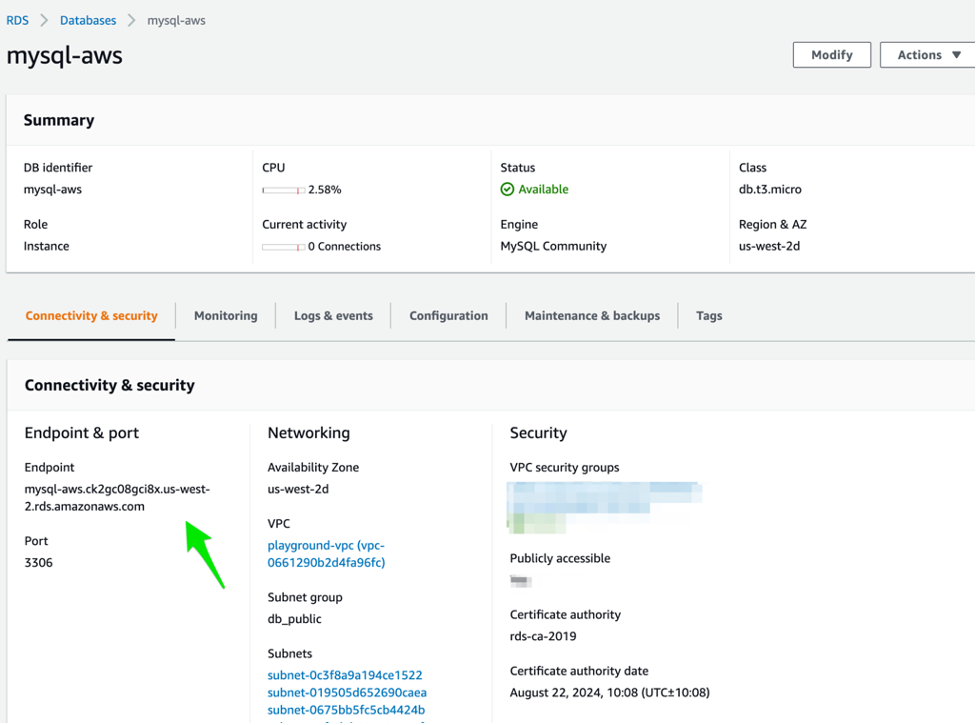
Click “Add Service” and enter required information
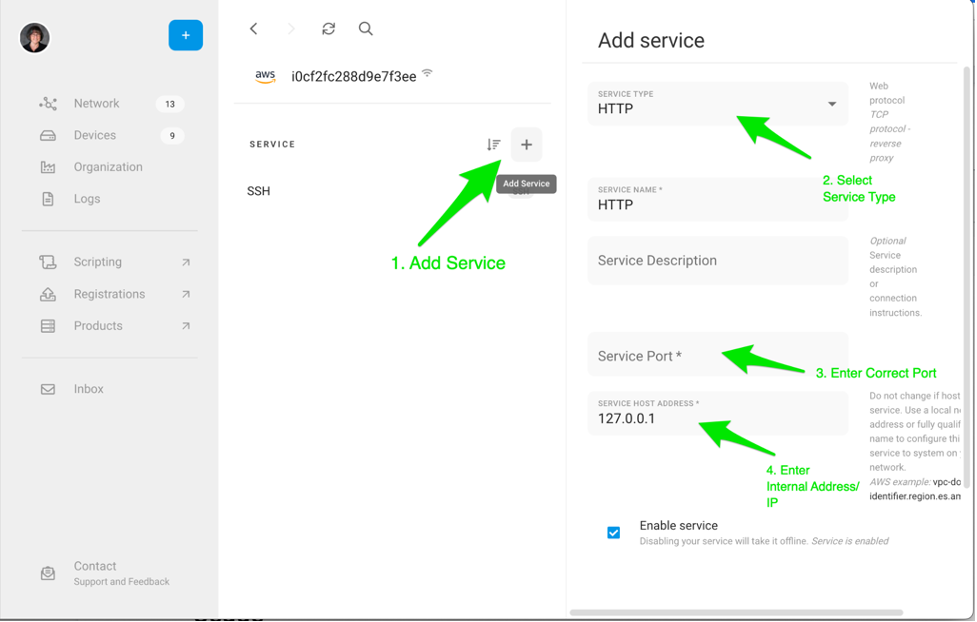
Click Save.
In a couple of moments, you will be able to connect to the service.
**Step 3: Create your org and/or add your team members (optional).**
Remote.It provides a couple of different options to manage access to your resources which even includes limiting access to specific services.
[Learn more about organizations](https://link.remote.it/support/organizations)
[Learn more about sharing](https://link.remote.it/docs/sharing)
**Usage**
Now that you have [Remote.It](https://www.remote.it/) set up, create the connection(s) you need. Remote.It will provide an address and port that resolves to localhost. Use this in your tools such as MySQL Workbench, PGAdmin, or in your IDE development environment variables where you normally put the address. The address is unique to you, but will be ready on demand whenever you use them. Try switching networks where your public IP changes. This connection is resilient to those changes and doesn’t require a VPN, but you have the confidence that the port(s) are not on the public internet.
{% embed https://youtu.be/BAUqFAHpWc4 %}
For more information about how to use [Remote.It](https://www.remote.it/), check out the support documentation [here](https://link.remote.it/support/remote-it-overview).
| bstrech |
1,154,448 | Why Ecommerce Website Design is Important for Online Businesses | Regardless of the type of online business you run, eCommerce website design is critical. All... | 0 | 2022-07-29T09:13:00 | https://dev.to/smroy896/why-ecommerce-website-design-is-important-for-online-businesses-3cbd | ecommercewebsite, webdev, webdesign, beginners | Regardless of the type of online business you run, eCommerce website design is critical. All eCommerce website design services are required when you have an online presence, whether you are a small local shop or a large national corporation. The best eCommerce website design services will benefit your business in a variety of ways, including increased user engagement, increased sales, and easier brand promotion. There are some best [Ecommerce Website Design Gurgaon](https://www.webinfosys.net/services/ecommerce-website-design-gurgaon/) companies. Let's look at the top six reasons why eCommerce website design is critical for any online business:
**User Engagement**
The main advantage of eCommerce website design is a user engagement, which can significantly boost your online business. User engagement on your website is critical to the success of any online business. You must have a strong customer base that is interested in and engaged with your brand. By improving your branding and user experience, the best eCommerce website design services will assist you in engaging your online customers. These services will also assist you in optimizing your website for maximum performance. Engaging your customers will result in increased sales and brand loyalty. You can expect a high click-through rate (CTR) and a high conversion rate once you have a high level of engagement.
**Boost in Sales**
[Ecommerce website design](https://www.webinfosys.net/services/e-commerce/) is also critical for increasing sales. You can expect an increase in online sales if you have a modern, appealing eCommerce website. This is due to the fact that you will have a more robust and appealing online store. An easy-to-use eCommerce website design that allows customers to find your products will also increase your sales. The best eCommerce website design services will also assist you in increasing your online sales by optimizing your SEO. SEO stands for Search Engine Optimization, and it refers to a set of techniques that can help your website rank higher in search results.
**Brand Promotion**
Ecommerce website design is critical for brand promotion. Potential customers will notice your branding when they visit your eCommerce website. If you have a logo that’s clearly visible and looks good, then people will associate your brand with your business. This is an effective marketing tool that you can use to promote your company. Your eCommerce website design should be optimized for maximum SEO. You must have an easy-to-navigate eCommerce website design. This will make your site more user-friendly and make it easier for customers to find what they need.
**Easy to Use Site**
Ecommerce website design is also essential for making your site user-friendly. This necessitates that your site is simple to use, with clear and concise content that is easy to find. If you have a responsive eCommerce website design, your site will be more user-friendly and simple to use. The term "responsive eCommerce website design" refers to the fact that your site will automatically adjust to the size of your screen. A variety of good eCommerce website design services provide responsive eCommerce website design.
**More Time for Other Activities**
The final advantage of having an eCommerce website design is that it allows you to devote more time to other aspects of your business. The best eCommerce website design services will not only help you increase sales but will also save you time. This is because you will have to do less work. An eCommerce website design will be simple to use and require little effort from you. This will give you more time to focus on the things that are truly important to your company.
**Final Note**
We at [Webinfosys](https://www.webinfosys.net/) believe in providing the best quality service to our clients. We are an eCommerce Website Design Gurgaon based company that believes in quality over quantity. We promise to deliver the best quality services to our clients with the help of our excellent and experienced team. Ecommerce website design is important for a number of reasons. Whether you own a small local shop or a large national corporation, all eCommerce website design services are important when you have an online presence. The best eCommerce website design services will serve your business in numerous ways, including boosting sales, making it easier to promote your brand, and making it easier to engage your customers. These are just a few of the many reasons why eCommerce website design is important for any online business. Ecommerce website design is crucial for making your site easy to navigate, with easy-to-use content and branding. It will also help you to boost sales, make your brand more visible, and save you time. Ecommerce website design is important for any online business, and the best eCommerce website design services will serve your business in numerous ways. | smroy896 |
1,155,005 | Active Record Sessions Additional Functionality | For my phase 4 project, my idea was to have a social-media-like app where the user logged in from a... | 0 | 2022-07-29T20:46:00 | https://dev.to/bperez3237/active-record-sessions-additional-functionality-5e0l | For my phase 4 project, my idea was to have a social-media-like app where the user logged in from a specific location. A user's interacting network would be limited to only the location they are logged in from. Because location was part of the login process, the session needed to store location data as well as user data. And then passing this to the client side becomes more difficult since two objects are passed.
To start from the basics, I setup an auto-login route based on the session. I knew this would need to be a custom route, given my output would need to return user data and location data, so I opted to create a custom controller function instead of the standard show function. My GET route in ruby would be:
`get '/me', to:'users#auto_login'`
And my client side would run a useEffect to fetch this route. Now, if I only needed user data, my auto_login function could be:
`
def auto_login
user = User.find_by(id: session[:user_id])
if user
render json: user
else
render json: { error: 'User not found'}, status: :unauthorized
end
end
`
How could I get the location of the last session for the auto-login to function? I'm not passing any parameters at the moment... Location is tied to the User through relationships, but this would give me all locations, not the one of the last session. Currently, my function works because I am able to get the user id from the session data. If I stored the location id to session, I could do the same thing. So I go back to my sessions controller create method.
Nothing too complicated, the same way I stored my user to the session, I will store the location to the session. If the password is authenticated, it will stored the location id from params to session[:location_id].
`
def create
user = User.find_by(username: params[:username])
location = Location.find(params[:location_id])
if user&.authenticate(params[:password])
session[:user_id] = user.id
session[:location_id] = location.id
render json: user, status: :created
else
render json: { errors: "Invalid username or password" }, status: :unauthorized
end
end
`
Now, going back to my UsersController where I have my auto_login method, I am able to get the session location by running:
`
Location.find_by(id: session[:location_id])
`
Now I just need to return both objects to the client. I think the cleanest way would be to create a new, nested object, and then render as json. My final auto_login function is:
`
def auto_login
user = User.find_by(id: session[:user_id])
location = Location.find_by(id: session[:location_id])
if user
result = {user: user, location: location}
render json: result
else
render json: { error: 'User not found'}, status: :unauthorized
end
end
`
| bperez3237 | |
1,155,218 | 7 Best Tips For Web Developers | A web developer is a programmer who especially, always busy with the development of the World Wild... | 0 | 2022-07-30T06:14:15 | https://cmsinstallation.blogspot.com/2021/05/7-best-tips-for-web-developers.html | javascript, webdev, beginners, programming | A web developer is a programmer who especially, always busy with the development of the World Wild Web application using a client-server. This article writes for consideration of junior developers. It's a very useful tip for web developers.
As a web developer, I challenge myself to be the best developer in the future and I'm sure that I can do it very well. Web Developers can use this kind of language like HTML, CSS, PHP, Node.js, C#, Python, Java, etc. Here I'm giving the best tips for web developers.
### 1. Watch Lot of Technology / Tutorials
Watching technology is an activity of keeping your mind prepared for any situation. That is a lot of ways to learning but it's a simple way to learn by just reading. While reading if you do not understand a concept properly then do exercise yourself to get it clearly in mind.
A lot of tutorials on web development are available on the internet from them you should learn by yourself easily. And remember one thing you should start from basics and go step by step. That's a useful tip for a web developer.
2. Look at the best websites. And try it!
how to become good web developer,tips for web developers,how to become web developer,how to learn web development for beginners,web developers,web developer skills,web developer tutorial,web developer learning
You can ask yourself to find out the best website and try it ownself. As a beginner, there are a lot of mistakes that occur but don't give up and stay do hard work for it. Remember one thing if your hard work for it then it will give you the best result in the future.
I have a suggestion for you, you should find out your mistakes and short out them properly. You learn it completely and you teach someone, you have mastered the subject. This is one of the best tips for a web developer.
### 3. Learn From Experts
Usually, When you start as a beginner, you should learn from experts who are experts in that subject. As an expert, they give tasks, make your schedule, give some programs, prevent you from dropping the database.
You should not shy while you are learning, just say learn more and more from them. And one of the most important things, don't be afraid to ask anything about it. This a very useful tip for a web developer.
### 4. Don't Forget to Comment Your Code
As a web developer remember one thing don't make your commenting code easy to understand make it complicated to get it. That improves your skills as a web developer. This is one of the useful tips for web developers. I know that When you started coding you read a sentence or logic many times on the internet.
In your code, you use multiple functions to manage the program, that all functions are executed for the same task. Commenting on your code is a good habit for web developers and that's the best tip for web developers.
### 5. Improve Your Coding Sense
The priority in web development is to make your code clean and easy to understand. You need to create a code so that no one will say bad things about it. I think it's improving coding sense is one of the best tips for web developers, but it's more important than update new features.
When you are alone just remember that moment when you start your coding career. I know as a beginner that's difficult for you to understand all types of functions, data types, objects, etc. Now it's all like the work of your left hand. That's the best tip for web developers to improve their coding skills.
### 6. Make Mistakes!
As a junior developer, you make many mistakes. Once you make mistake you should improve it by yourself. it's a good habit for web developers. If you fail, you should try again and again, it will make you once succeed. That's a useful tip for web developers.
Don't afraid to make mistakes, it improves your skill by solving them one by one. if some concept makes trouble for you, you should learn it from experts they give a piece of good advice for it. And don't afraid to ask anything to them it's not a good sign for you. So, that's the best tip for web developers.
### 7. Keep Your Self Updated
As a web developer, you should keep yourself updated on new features and all of them. That's a good sign for developers. Make your coding speed faster and cleaner. You need to prepare yourself for the challenging things to come. This is a useful tip for web developers.
| devsimc |
1,155,351 | 7 most effective ways to improve your brand's online presence | Did you know that 97% of customers complete an online search to learn more about a brand before... | 0 | 2022-07-30T10:55:00 | https://dev.to/kiterun92639205/7-most-effective-ways-to-improve-your-brands-online-presence-375n | onlinepresence |

Did you know that 97% of customers complete an online search to learn more about a brand
before making a purchase? It's critical to have a digital presence for your business in order
to serve this sizable online market and make it simple for potential clients to find you,
learn aboutwhat you have to offer, connect with you,and develop a relationship of trust.
1. Content creation that provides value
The voice of your brand is reflected in the online material you produce and distribute. It affects how potential clients perceive your firm and how they associate you with it. Make sure the information you offer is easy to understand and beneficial to your audience. To make your content interesting and educational, you can include photographs.
Effective content focuses on your audience's needs, President and Principal Analyst at Forrester Phyllis Davidson says. Your audience will be motivated, engaged, and encouraged to accept your product or service if you tell engaging stories that highlight the needs of your clients and how your offering improves their lives.
2. Search engine optimization
Increasing the amount of individuals who visit your content is a crucial part of gaining improved brand visibility. You can do that with the aid of search engine optimization.
Search engine optimization is the process of raising the rank of your website in search results by using a variety of tactics and best practices. Imagine that you own a bakery and have made the decision to share advice on baking on your blog, including how to choose the best ingredients and how to use various techniques.
1. Increases visibility: An SEO-friendly website increases the exposure of your digital brand, attracts quality visitors who are more likely to convert and promote your company positively.
2. Creates trust: A higher page ranking from quality SEO boosts your company's credibility and establishes brand authority.
3. Create a website that is optimized Say you have a visually appealing website for your business that displays pertinent information about your good or service, with responsive call-to-action buttons and connections to your landing pages. With SEO, you don't have to spend for advertisements to enhance your Your website has a flawless indexing on Google, Bing, and other search engines, and you have numerous initiatives running to increase the website's visibility. That allows small businesses to compete with larger brands without having to spend a fortune on advertising.
Keep track of how users engage with your website Understanding the online behavior of your visitors might help you improve the performance of your website. Understand what catches the interest of your visitors, what they click on, and how far they scroll.
Create a personalized website experience To offer individualized experiences, you can modify the content of your website based on the visitor's demographics, prior interactions, and browsing behaviour.
4. Multichannel visibility online There are potential clients everywhere. The majority of consumers believe that when selecting whether to make a purchase, the brand's website is the most crucial consideration. A lot of clients also want you to be on their preferred social media network, while others anticipate tailored communications from your company.
5. Get your teams working together
Online success requires collaboration, which is crucial. In order to accomplish business objectives as the number of marketing channels you use expands along with your organization, it's critical that your teams work together and give it their all.
6. Make sure your brand is consistent
What will set your company apart from the competitors and stick in clients' minds is having a consistent brand experience throughout your website, email, social media, and all other online and offline marketing channels.
7. Performance analysis of campaigns
If you can't measure it, you can't improve it, as the saying goes. When it comes to brand presence online, it is accurate. Whether it's a prospect's signup information, their engagement with your brand, or how they interact with your content, it's critical to make sense of your digital marketing data. Every piece of information you gather can be used to enhance your marketing initiatives and give customers a more tailored experience.
Ready to get started? Learn how kite-Runner can help you improve your online
presence
Our **[Digital marketing Agency In San Diego](https://kite-runner.com/san-diego-digital-marketing-agency/)** is more than pleased to help you get started on your path. | kiterun92639205 |
1,155,850 | Creating custom archetypes in Maven | As developers we embrace concepts like DRY (Don’t Re-invent Yourself). When we are creating similar... | 0 | 2022-07-31T11:15:00 | https://dev.to/thilanka/creating-custom-archetypes-in-maven-16o0 | maven, java, programming |
As developers we embrace concepts like DRY (Don’t Re-invent Yourself). When we are creating similar things repetitively, we always prepare a template for that thing, so instead of starting a project from scratch, you can have a preconfigured directory structure. And in those directories you can place your template source files. Eg: struts.xml, spring config file, web.xml, tiles.xml etc..
## Creating your archetype
Run the following command:
```console
mvn archetype:generate \
-DgroupId=[your project's group id] \
-DartifactId=[your project's artifact id] \
-DarchetypeArtifactId=maven-archetype-archetype
```
This will create following default directory structure for creating archetypes.
```bash
archetype
|-- pom.xml
`-- src
`-- main
`-- resources
|-- META-INF
| `-- maven
| `--archetype.xml
`-- archetype-resources
|-- pom.xml
`-- src
|-- main
| `-- java
| `-- App.java
`-- test
`-- java
`-- AppTest.java
```
Think of maven-archetype-archetype as the maven’s template to create templates.
The generated archetype-descriptor is old and needs to be changed to use new features. To that end, rename the file `archetype.xml` to `archetype-metadata.xml`
Over write the following content to the file:
```xml
<archetype-descriptor xmlns="http://maven.apache.org/plugins/maven-archetype-plugin/archetype-descriptor/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-archetype-plugin/archetype-descriptor/1.0.0 http://maven.apache.org/xsd/archetype-descriptor-1.0.0.xsd"
name="simple-web"> <!-- name must be same as the project archetypeId -->
<fileSets>
<fileSet filtered="true" encoding="UTF-8">
<directory>src/main/web</directory>
</fileSet>
<fileSet filtered="true" encoding="UTF-8">
<directory>src/main/resources</directory>
</fileSet>
<fileSet filtered="true" encoding="UTF-8">
<directory>src/test/resources</directory>
</fileSet>
<fileSet filtered="true" packaged="false">
<directory>src/main/java</directory>
<includes>
<include>**/*.java</include>
</includes>
</fileSet>
<fileSet filtered="true">
<directory>src/test/java</directory>
<includes>
<include>**/*.java</include>
</includes>
</fileSet>
</fileSets>
</archetype-descriptor>
```
The above maven archetype descriptor file tells maven to copy (or create if not exists) any source files reside in web, `src/main/java` and corresponding test source directories. The archetype-resources directory is where all your template code should go. When you finally copy all your template files run the following command in maven to install your newly created artefact.
```console
mvn install
```
You might want to continuously improve your template over time. Your artefact get installed multiple times during the process, so wrong versions of archetype may be installed. To counter that you might want to clean archetype cache by issuing following command:
```console
mvn clean install -U
```
-U means force update of dependencies.
So whenever you want to create a new project using your archetype run following command:
```console
mvn archetype:generate -DarchetypeGroupId=com.my-template
-DarchetypeArtifactId=template-name -DarchetypeVersion=1.0
-DgroupId=proj.groupid -DartifactId=projectid
```
So there you have it! This single line command can load all your template source files and create whole directory structure of your application. | thilanka |
1,156,239 | Templating in SvelteKit | By Mike Neumegen Brought to you by CloudCannon, the Git-based CMS for SvelteKit. In this tutorial... | 19,116 | 2022-08-01T01:40:52 | https://cloudcannon.com/community/learn/sveltekit-beginner-tutorial/templating-in-sveltekit/ | jamstack, svelte, tutorial, beginners | ---
canonical_url: https://cloudcannon.com/community/learn/sveltekit-beginner-tutorial/templating-in-sveltekit/
series: SvelteKit Beginner Tutorial
---
By [Mike Neumegen](https://cloudcannon.com)
_Brought to you by [CloudCannon](https://cloudcannon.com/sveltekit-cms/), the Git-based CMS for SvelteKit._
In this tutorial we'll go over basic SvelteKit templating concepts and see how you can use templating on your site.
Svelte gives us complete control over how pages and components are rendered. We can loop over content, output variables, run logic statements, or pull in data from external sources. We’ve already encountered some templating — the curly braces `{ }` to output the className in the previous lesson.
## How do I use templating in SvelteKit?
Templating is one of the most common things you’ll be doing in SvelteKit, so let’s go through some examples to demonstrate how it works.
### Output a string
```html
<p>You can write normal HTML, and when you want to switch to Svelte,
you can use single curly braces like this: { "Hello!" }</p>
```
### Output prop value
```html
<script>
export let favorite_treat = 'bone';
</script>
<p>My favorite treat is a { favorite_treat }</p>
```
### Conditions
```html
<script>
export let goodBoy = true;
</script>
{#if goodBoy}
<p>One treat please.</p>
{:else}
<p>No treats for me.</p>
{/if}
```
### Looping
```html
<script>
export let whoLetTheDogsOut = [
'Bryan',
'Sally',
'Garry'
];
</script>
<ul>
{#each whoLetTheDogsOut as name}
<li>{name}</li>
{/each}
</ul>
```
### Interactive element
```html
<script>
let count = 0;
function handleClick() {
count += 1;
}
</script>
<button on:click={handleClick}>
clicks: {count}
</button>
<!-- When you click the button it will run the handleClick function
and live update {count} -->
```
That gives you some of the basic tools to play with. You’ll be using these concepts over and over again through your SvelteKit journey.
## Putting it all together
We’ve seen a lot of different concepts here. Let’s put it into practice by adding a footer to the website the date and time the page was rendered.
First, we’ll create a component for the footer. Create `/src/lib/Footer.svelte` with the following content:
```html
<script>
let now = new Date();
</script>
<footer>
Website was generated { today }
</footer>
```
Just like we did earlier, now we can import `Footer` into our layout and render the component:
```html
<script>
import Nav from '$lib/Nav.svelte';
import Footer from '$lib/Footer.svelte';
</script>
<h1>Svelte's space</h1>
<Nav className="alt" />
<slot></slot>
<Footer />
<style lang="scss">
:global(body) {
width: 400px;
margin: 0 auto;
font-family: sans-serif;
}
</style>
```
## What’s next?
Let’s put our templating knowledge to the test by creating a blog.
| avidlarge |
1,156,369 | Stages of a CI/CD Pipeline | The DevOps movement has taken the software development industry by storm. With the DevOps approach,... | 0 | 2022-08-01T07:30:00 | https://dev.to/pavanbelagatti/stages-of-a-cicd-pipeline-2bmp | devops, cloud | The DevOps movement has taken the software development industry by storm. With the DevOps approach, organizations can more quickly and efficiently respond to market opportunities by accelerating software deployment, streamlining operations and increasing collaboration between software developers and operations people. With that in mind, continuous integration (CI) and continuous delivery (CD) are regarded as the two key components of DevOps practice. These practices have existed for some time but have become even more critical now that we live in a world where software is really eating the world.
From a broad perspective, these two (CI/CD) are crucial to deploying software to production, but there goes more between these two long processes. Today, we will see some notable steps in the CI/CD pipeline and try to understand them properly.
## What is Continuous Integration?
CI is the process of automating the integration of code changes into a shared codebase, focusing on finding and fixing potential issues early on in the development phase. It can be achieved by integrating the code base automatically after each commit and triggering a set of tests. The outcome of the process is either a green build if the code is error-free or a red status if there’s an issue with the code, together with information on what went wrong. Integration usually refers to the process of combining parts of code (e.g. functions, modules) that have been created separately by different people/teams and are not yet fully integrated. This happens when a team is finished with a piece of work and moves it to the next stage of the process so that other teams can work with it.
## What is Continuous Delivery?
CD is the process of automating the movement of code from a shared codebase through a testing environment to get to a production-like environment and, finally, to a live environment. The goal is to reduce the risk of human errors and increase the release process's predictability. It’s important to mention that CD is not just the final stage of the CI process. Instead, it’s a combination of all three major stages of the pipeline.
### Typical Stages of the CI/CD Pipeline
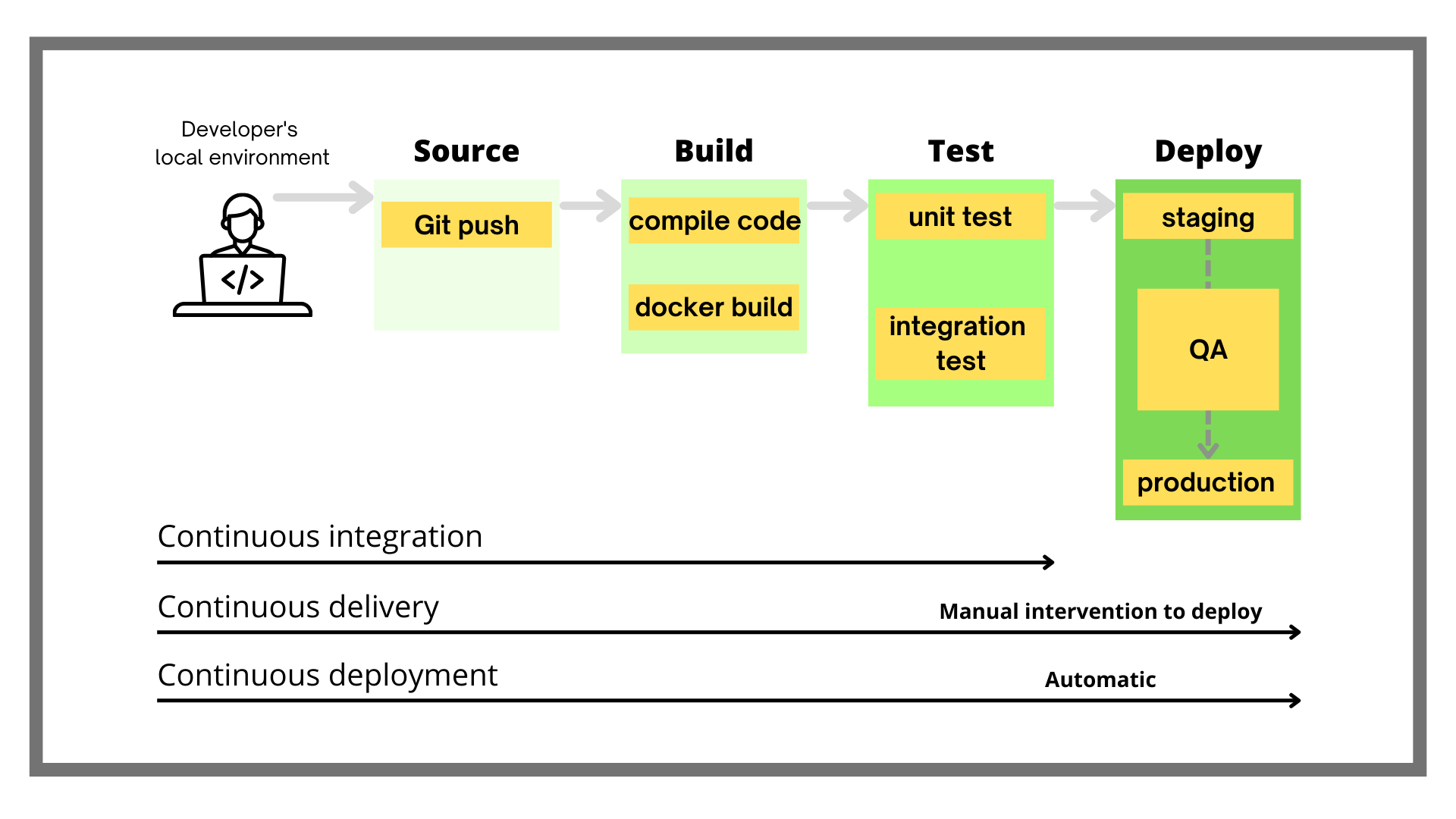
#### Source:
The source stage is where the organization maintains its source code in a centralized repository system. You can call it a version control system like GitHub, Bitbucket, GitLab or AWS CodeCommit. This stage and tools are essential to help developers coordinate and track who is doing what. This stage also acts as a collaboration booster as different development teams check in their code, do code reviews, and approve the code for further steps. Automation of version control can be done via IDEs like visual code.
- Code Quality Analysis with Static Analysis Tools Early on in the process, automated tools (e.g. SonarQube, VCS analysis tools) can check if the code follows a specific set of rules (e.g. if code is written in a certain language, if it’s well-documented, if it’s covered by tests). These rules are usually defined by a team or a workflow manager and help identify potential issues in the code early on. This is important because fixing them later would mean changing existing code, which may be problematic. Thus, using static code analysis tools can save you a lot of time and trouble in the future.
#### Test and Build:
Test and Build is the stage after developers push their code to a version control system. When a developer pushes the code to the organisation's version control system, it triggers the continuous integration system/tool (something like Drone CI). Then the code goes through tests prescribed by the developer. Then finally, the compilation and building steps get completed.
- Unit Testing with Automated Tests: Automated tests are crucial because they allow you to identify issues with the application’s functionality as soon as they occur. They are usually written as part of automated build processes and aim to check if the application is working correctly. Depending on the type of software you build and the programming language you use, you can choose from a wide array of automated testing tools.
- Integration Testing and Manual QA: with Humans Integration testing ensures that components or services work well together. It is performed by a human tester responsible for testing the functionality expected to be delivered by a certain feature. Integration testing is crucial because it allows a tester to identify issues with different components of the system that were tested separately by development teams. This is when a tester executes the feature and checks if the application is working as it should. If there are issues with the functionality, it is up to the person responsible for the feature to fix them.
#### Deploy:
Finally, the deploy stage is where the code is ready to be deployed to a QA, pre-production or production environment per the organisation's plan. Deploying of the software can be automated through continuous deployment. This is the stage where the organisations prefer the deployment strategies such as the canary, rolling, blue/green, etc.
- Package and Deploy Automated Builds Using a CM tool: The moment the code passes all tests and a tester gives the go-ahead, this should trigger a process that automatically packages the application and deploys it to a testing environment. This is usually done by a Continuous Deployment tool that integrates with your CI server and allows you to define a certain deployment process. Depending on your needs, you can choose either a hosted solution or a self-hosted solution.
### CI/CD with Harness
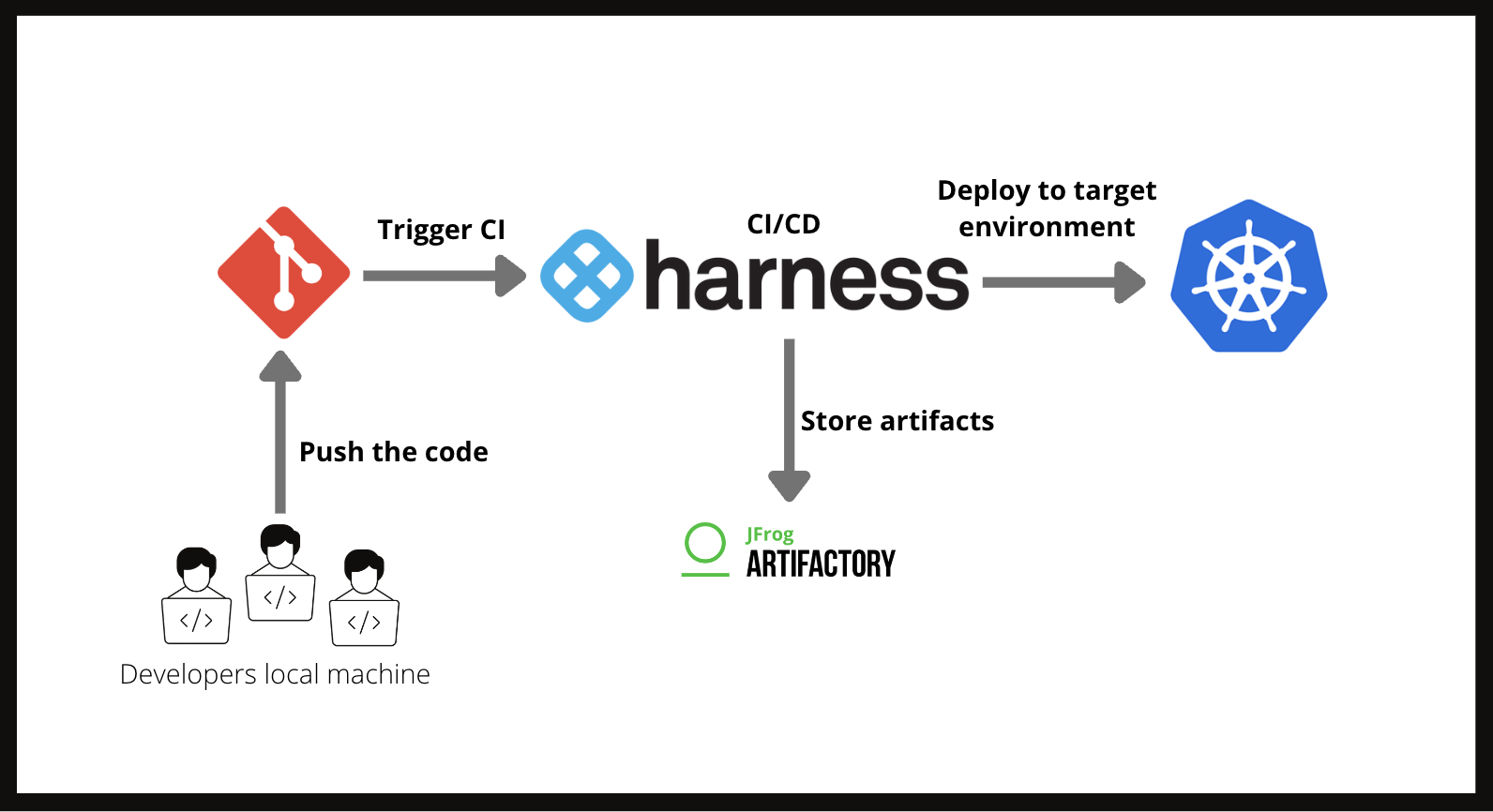
With the [Harness software delivery platform](https://harness.io/products/platform/), automating your CI/CD pipelines can be very easy. Setting up CI/CD can be a daunting task for many organozations but Harness helps tackle these most complex CI/CD challenges, such as onboarding new developers, new technologies, validating/promoting your deployments, and actions in failure scenarios. All the orchestration needed in the form of tests, approvals, and validation can be easily connected in the Harness platform. Automate the build, test, and packaging of code to artifacts with Harness [Continuous Integration](https://harness.io/products/continuous-integration/), and build deployment pipelines in minutes while safely deploying artifacts to production with Harness [Continuous Delivery](https://harness.io/products/continuous-delivery/).
Let us take a look at how CI/CD works with Harness taking an example of a MERN Stack application.
#### Continuous Integration [CI]:
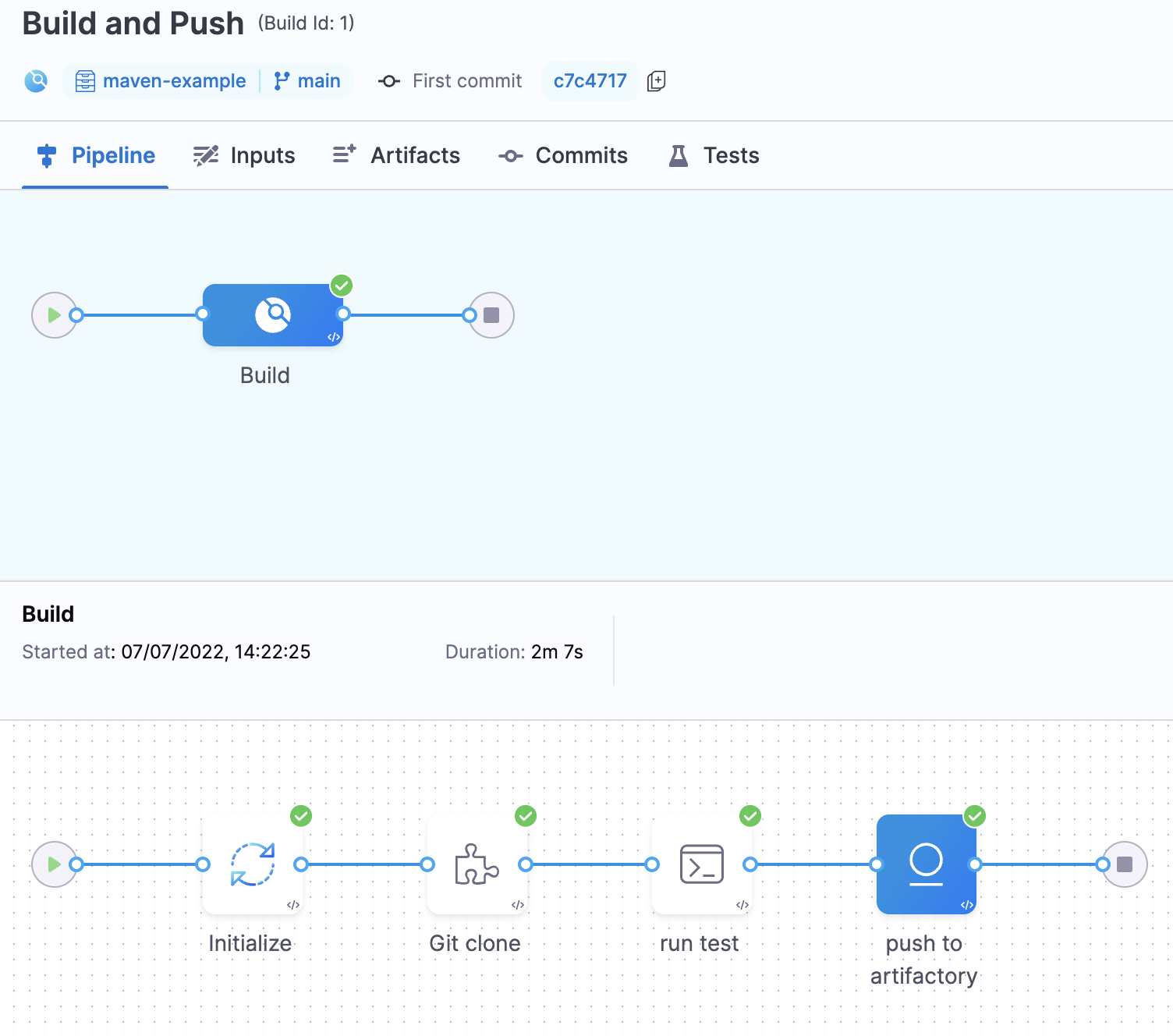
The CI phase involves the initialization, cloning of the code and running the specified tests.
#### Continuous Delivery [CD]:
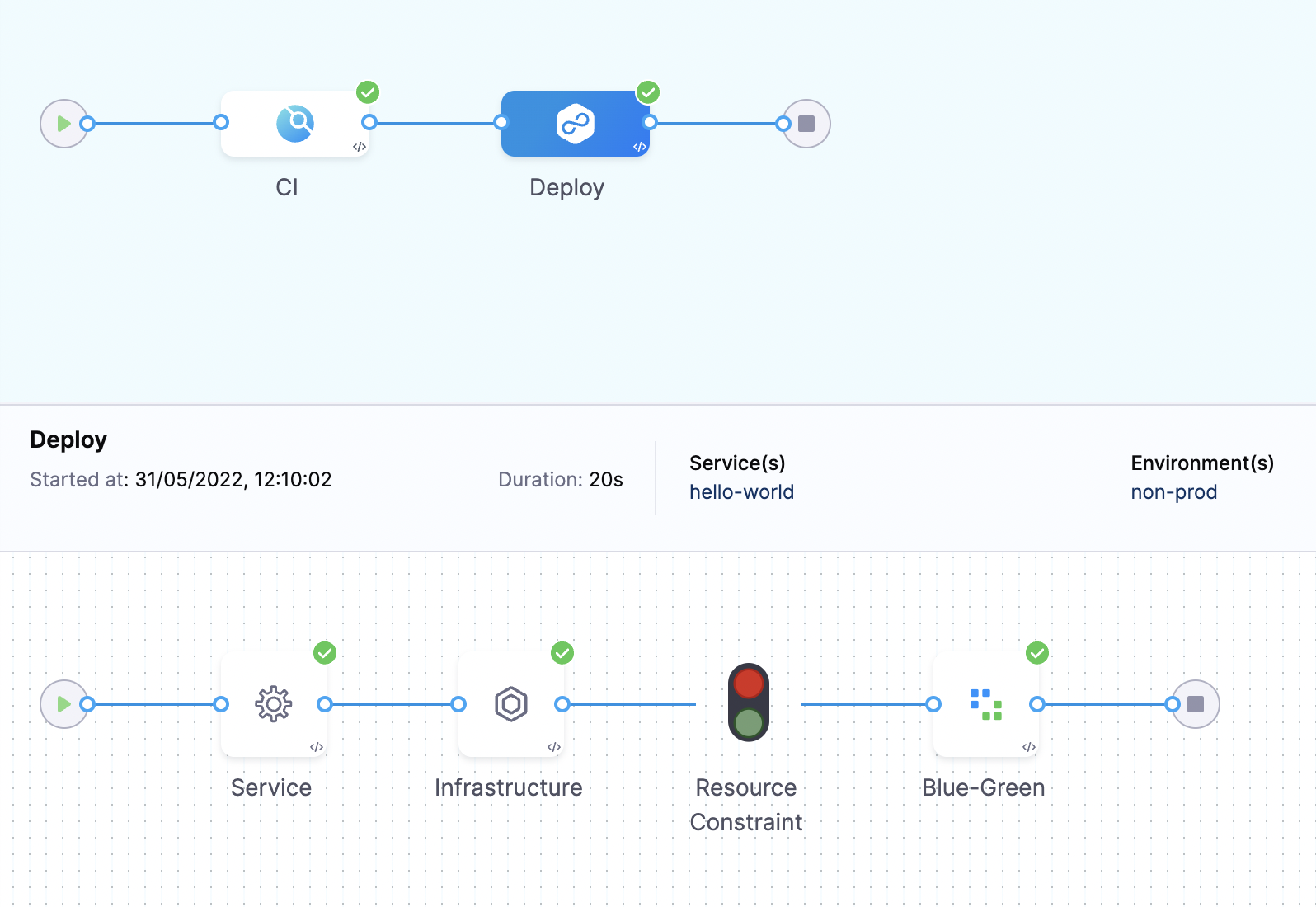
CD involves specifying the service, setting up the infrastructure, passing the resource constraint and finally deploying the code with the preferred strategy. Make use of the MERN Stack application example created by the Harness community team and try using both CI and CD modules to do continuous integration and deployment of the application. The code for the MERN Stack application is in the [harness-apps/MERN-Stack-Example](https://github.com/harness-apps/MERN-Stack-Example) repository, the Kubernetes configuration is in the [harness-apps/MERN-Stack-Example-DevOps](https://github.com/harness-apps/MERN-Stack-Example-DevOps) repository. | pavanbelagatti |
1,156,440 | Javascript Proxy: Introduction | JS is not truly an Object Oriented Programming language. Therefore fulfilling requirements such as... | 0 | 2022-09-21T12:05:49 | https://dev.to/milekag01/javascript-proxy-introduction-68k | javascript, webdev, community, discuss | JS is not truly an Object Oriented Programming language. Therefore fulfilling requirements such as Enforcing object property value validation during read and write and take action, defining a property as private, and detecting changes in values can be challenging. There are ways of solving the above-stated problems, such as by using a setter or getter to set default value or throw an error on validation checks. However, the more convenient way to handle these problems is by using the Proxy object.
Proxies are one of the hidden gems in Javascript that many developers do not know of. The Proxy object is a virtualising interface that allows us to control the behaviour of the object. It allows us to define custom behaviour for the basic operations of an object. Let's take an example to understand proxy in a better way.
Let us consider an item as shown below.
```js
let item = {
id: 1231,
name: 'Stock',
price: 136
}
```
We want to sell this item but the condition is that the selling price should not be less than 100. At the same time, we want to put a check in place that throws the error if we try to read the value of a property that does not exist. Also, we want to define `id` as private property.
We can easily solve this problem by writing custom logic while performing get, set ,or property lookup. JS Proxy object exactly helps here. It allows us to add custom behaviour to the fundamental operations on a JS object.
To create a proxy object, we use the Proxy constructor and pass two parameters(target and handler) in it. Defining a Proxy object:
```js
let proxy = new Proxy(target, handler);
```
Target is the object which is virtualised using Proxy and adds custom behaviour to it. Here, `item` object is the target.
Handler is the object in which we define the custom behaviour. The handler object container the *trap*.
Traps are the methods that gives access to the target object’s property to the handler object. Traps are optional. If trap is not provided, target object’s default methods are used. There are different types of traps such as *get, set, has, isExtensible, defineProperty, etc*. You can use all of these traps in the handler to define the custom behaviour for target object.
```js
let item = {
id: 1231,
name: 'Stock',
price: 136
}
let handler = {
// check while setting the value
set: function(obj, prop, value) {
if(prop === 'price') {
if( !Number.isInteger(value)){
throw new TypeError('Value passed is not a number');
}
if(value < 100){
obj[prop]= 100;
return true;
}
}
obj[prop]= value;
return true;
},
// check for no access to `id`
// check for property which does not exist
get: function(obj, prop) {
if(prop == 'id'){
throw new Error('Cannot access private property : id');
}
else {
return prop in obj ?
obj[prop] : new TypeError (prop + ' : property does not exist');
}
}
}
var itemProxy = new Proxy(item, handler);
```
Let's understand the code. We created a proxy called `itemProxy` using the Proxy constructor and passed the `item` and `handler` to it.
Using the `get` trap in the handler, we are checking if the property exists in the object or not. Also, we have enforced id as private property and made it inaccessible.
  Using the `set` trap in the handler, we are checking if the property passed is price, if the value being passed to assign is an integer and also, we are putting a modifier to assign the value 100 by default if the price is less than 100.
```js
console.log(itemProxy.price); // 136
itemProxy.price = 45;
console.log(itemProxy.price); // 100
```
In a similar manner, we can define handlers to detect changes to the value of object properties which we will discuss some other time.
I hope this article helped all of us understand Proxies. To learn more, visit the [MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy) docs.
Love reading about Javascript, Web optimisations, Vue.js, React, and Frontend in general? Stay tuned for more.
Wanna connect? You can find me on [LinkedIn](https://www.linkedin.com/in/milek-agrawal-b78008185/), [Twitter](https://twitter.com/milek_agrawal), [GitHub](https://github.com/milekag01).
| milekag01 |
1,156,568 | Useful Github Search Capabilities for Issues and Pull Requests | In my day-to-day I often find myself wanting to search for pull requests and issues that I've... | 0 | 2022-08-01T11:48:42 | https://www.ericapisani.dev/posts/useful-github-search-capabilities-for-issues-and-pull-requests/ | github, programming, beginners, productivity | In my day-to-day I often find myself wanting to search for pull requests and issues that I've commented on without necessarily being the author of the pull request/issue. Fortunately, Github has a couple of pretty useful search options for just this purpose!
## Search by commenter
This is a filter I now use multiple times a day when I'm chatting with someone and have a "I know I've been in a conversation about this somewhere on Github already" moment.
The syntax for this is [`commenter:<a github username>`](https://docs.github.com/en/search-github/searching-on-github/searching-issues-and-pull-requests#search-by-commenter).
## Search for a user that's involved in an issue or pull request
More broad than the 'search by commenter' filter mentioned above, this works as an `OR` between the `author`, `assignee`, `mentions`, and `commenter` filters.
The syntax for this is [`involves:<a github username>`](https://docs.github.com/en/search-github/searching-on-github/searching-issues-and-pull-requests#search-by-a-user-thats-involved-in-an-issue-or-pull-request)
## Wrap up
If you're interested in taking a look at some of the other search options that Github has (and I highly encourage doing so), you can find their full documentation about this topic [here](https://docs.github.com/en/search-github/searching-on-github/searching-issues-and-pull-requests).
| ericapisani |
1,157,180 | 378. Leetcode Solution in Cpp | struct T { int i; int j; int num; // matrix[i][j] T(int i, int j, int num) : i(i), j(j),... | 0 | 2022-08-02T06:17:00 | https://dev.to/chiki1601/-leetcode-solution-in-cpp-4a9k | cpp | ```
struct T {
int i;
int j;
int num; // matrix[i][j]
T(int i, int j, int num) : i(i), j(j), num(num) {}
};
class Solution {
public:
int kthSmallest(vector<vector<int>>& matrix, int k) {
auto compare = [&](const T& a, const T& b) { return a.num > b.num; };
priority_queue<T, vector<T>, decltype(compare)> minHeap(compare);
for (int i = 0; i < k && i < matrix.size(); ++i)
minHeap.emplace(i, 0, matrix[i][0]);
while (k-- > 1) {
const auto [i, j, _] = minHeap.top();
minHeap.pop();
if (j + 1 < matrix[0].size())
minHeap.emplace(i, j + 1, matrix[i][j + 1]);
}
return minHeap.top().num;
}
};
```
#leetcode
#solution
Here is the link for the problem:
https://leetcode.com/problems/kth-smallest-element-in-a-sorted-matrix/ | chiki1601 |
1,157,209 | Run a Substrate Node Template on a Remote Server | Substrate node template is the first step to develop a Polkadot substrate-based parachains. The node... | 0 | 2022-08-02T07:16:00 | https://dev.to/kevinkuo0320/run-a-substrate-node-template-on-a-remote-server-j6f | substrate, polkadot, rust, blockchain | Substrate node template is the first step to develop a Polkadot substrate-based parachains. The node template can be hosted on your local computer or a remote server. This guide will show you how to set up and run a substrate node template on a server.
---
**1, Connect to remote server by using PuTTY client**
---
**2, Update Rust environment using following command:**
```
rustup component add rust — src — — toolchain nightly
```
---
**3, Verify that you have the WebAssembly target installed by running the following command:**
```
rustup target add wasm32 — unknown — unknown — — toolchain nightly
```

You should see everything is up to date after being installed successfully
---
**4, Install Substrate contracts node:**
```
git clone https://github.com/substrate-developer-hub/substrate-node-template
cd substrate-node-template && git checkout polkadot-v0.9.26
cargo build — release
```
It may takes about 10–15 mins to compile.
---
5, Run substrate node:
```
./target/release/node-template — dev
```
You should see the terminal looks like the above. Congratulation! You have successfully installed a substrate node template on a remote server. Next step is to interact with the node from the browser, go check out my previous article!
Thanks for reading! Feel free to reach out to me if you have any questions. | kevinkuo0320 |
1,157,374 | Why Swift Has Overtaken Objective-C for iOS App Development | iOS is one of the most promising platforms for developing mobile apps. For iOS app development, the... | 0 | 2022-08-02T10:52:53 | https://dev.to/stevevalentor/why-swift-has-overtaken-objective-c-for-ios-app-development-1409 | ios, swift, iphoneappdevelopment, appdevelopment | iOS is one of the most promising platforms for developing mobile apps. For iOS app development, the two most popular programming languages are Swift and Objective-C.
Objective-C was the first language for building iOS apps, it was introduced in 2008. It is one of the difficult languages to learn and code, and also the syntax is not user-friendly. With the introduction of the Swift programming language in 2014, developers and companies have a better alternative to Objective-C to create iOS apps. It is also much more flexible than Objective-C.
## What challenges were being faced by Objective-C Developers
- **Difficult to learn:** It is not very easy to learn since it is based on object-oriented programming principles and has a complex syntax.
- **Fewer developers:** As newer and simpler alternatives become available, many developers are no longer using the language, and newcomers are unwilling to learn an obsolete language.
- **Limited features:** It is outdated and does not have modern features which causes poor performance.
- **Security:** As an older language, it is more susceptible to hacking.
## Why Swift was Introduced?
- **Simple to use:** Swift is extremely easy to use and learn, and doesn't take much time to develop. It's also clear and concise.
- **Open-Source:** It does not require any licensing fee and can be used by both commercial and non-commercial entities, making it a very versatile programming language.
- **Modern features:** Being a young language, Swift has several modern features such as optimized memory management, dynamic libraries, better app monetization, etc.
- **Development:** This language requires fewer codes, making it simpler to develop. This saves a great deal of time.
**Also Read:** [iPhone Application Development Mistakes to Avoid](https://dev.to/hokubasavaraj/iphone-application-development-mistakes-to-avoid--1c7n)
## Comparison Between Swift and Objective-C
### 1. Readability
While Objective-C is based on C and uses C-style keywords, Swift does not require various symbols, unifying all keywords instead. In addition, Swift is also much closer to natural English than Objective-C, which makes it easy for other languages such as JavaScript or Python to adopt it.
### 2. Dynamic Libraries
As Swift libraries are flexible, apps can be updated to a newer version. These dynamic libraries load directly into memory, which helps to optimize the performance of the app.
### 3. Safety
As opposed to Objective-C, Swift’s syntax is free of common mistakes. When code is nil, Swift will automatically notify developers of the error. That makes Swift a more secure language and reduces the likelihood of bugs.
### 4. Coding
According to Ankit Panwar, iPhone app developer at [Simpalm](https://www.simpalm.com/services/iphone-app-development-company) "Swift eliminates the need for cumbersome code. Its modern features streamline the process and lessen the need for lengthy code strings. In contrast, Objective-C requires text strings that need a lot of steps to join two pieces of information together."
### 5. Performance
Swift is faster than Objective-C in terms of execution speed. Unburdened by legacy conventions, it achieves faster code implementation as compared to Objective-C.
### 6. Maintenance
According to Emily Thompson, Consultant at [Daeken](https://www.daeken.com/product/daeken-shared-family-calendar/) "Objective-C suffers from a legacy issue. It is built on C, it cannot improve unless C improves. Like C, Objective-C also makes developers write code in separate files, which can be hard to maintain. Swift, however, doesn't need two different files since XCode and the LLVM compiler handle that automatically."
## Conclusion
Swift and Objective-C are both great programming languages that offer great capabilities to iOS developers. The key difference between them is the level of abstraction and the lack of syntax conventions. Swift is more readable, but Objective-C has a wider range of features, including support for object oriented programming. Since the launch of Swift in 2014, all new apps have been developed in Swift. Programmers are also converting older apps written in Objective-C into Swift.
| stevevalentor |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.