
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,157,615 | Day 58-61 of coding complete | 100DaysOfCode #100daysofcodechallenge Day 58-61 complete. Finished building the skyline and... | 0 | 2022-08-02T15:07:00 | https://dev.to/chrisgomad/day-58-61-of-coding-complete-47nl | webdev, beginners, programming, 100daysofcode | #100DaysOfCode #100daysofcodechallenge Day 58-61 complete. Finished building the skyline and learning more about CSS variables. Really cool to see how to manipulate containers and utilize variables. You can use the “:root” selector in CSS to apply a value in all your CSS code.
 | chrisgomad |
1,157,915 | Faithful E2E Testing of Nx Preset Generators | This article was originally published on my blog. TLDR: Here's a full working example of a faithful... | 0 | 2022-08-02T22:51:00 | https://dev.to/chiubaka/faithful-e2e-testing-of-nx-preset-generators-m5a | nx, nxpreset, e2e, verdaccio | _This article was originally published on [my blog](https://blog.chiubaka.com/faithful-e2e-testing-of-nx-preset-generators)._
TLDR: Here's a full working example of a faithful E2E test for an Nx preset generator since the default generated E2E harness isn't correct.
Putting it all together, here's a full sample test suite:
```typescript
import {
checkFilesExist,
cleanup,
runNxCommandAsync,
tmpProjPath,
} from "@nrwl/nx-plugin/testing";
import { ChildProcess, execSync, fork } from "node:child_process";
import path from "node:path";
import { getPortPromise as getOpenPort } from "portfinder";
// These tests can take awhile to run. Modify or remove this depending on how long this takes
// on your machine or in your environment.
jest.setTimeout(60_000);
const startVerdaccio = async (port: number): Promise<ChildProcess> => {
const configPath = path.join(__dirname, "../verdaccio.yaml");
return new Promise((resolve, reject) => {
const child = fork(require.resolve("verdaccio/bin/verdaccio"), [
"-c",
configPath,
"-l",
`${port}`,
]);
child.on("message", (message: { verdaccio_started: boolean }) => {
if (message.verdaccio_started) {
resolve(child);
}
});
child.on("error", (error: any) => reject([error]));
child.on("disconnect", (error: any) => reject([error]));
});
};
describe("nx-plugin e2e", () => {
let verdaccioProcess: ChildProcess;
beforeAll(async () => {
cleanup();
const verdaccioPort = await getOpenPort();
verdaccioProcess = await startVerdaccio(verdaccioPort);
const verdaccioUrl = `http://localhost:${verdaccioPort}`;
execSync(`yarn config set registry ${verdaccioUrl}`);
execSync(
`npx npm-cli-login -u chiubaka -p test -e test@chiubaka.com -r ${verdaccioUrl}`,
);
execSync(`npm publish --registry=${verdaccioUrl}`, {
cwd: path.join(__dirname, "../../../dist/packages/nx-plugin"),
});
const destination = path.join(tmpProjPath(), "..");
const workspaceName = path.basename(tmpProjPath());
execSync(
`npm_config_registry=${verdaccioUrl} npx create-nx-workspace ${workspaceName} --preset=@chiubaka/nx-plugin --nxCloud=false`,
{
cwd: destination,
},
);
});
afterAll(async () => {
// `nx reset` kills the daemon, and performs
// some work which can help clean up e2e leftovers
await runNxCommandAsync("reset");
execSync(`yarn config set registry https://registry.yarnpkg.com`);
verdaccioProcess.kill();
});
it("should not create an apps dir", () => {
expect(() => {
checkFilesExist("apps");
}).toThrow();
});
});
```
Be sure that you have `_debug: true` somewhere in your `verdaccio.yml` and that you have `verdaccio`, `verdaccio-auth-memory`, and `verdaccio-memory` installed as `devDependencies`.
## The Problem
Nx models custom presets as ordinary generators that get treated differently by Nx's internals when generating a workspace. The suggested command for scaffolding a preset generator is the exact same command used for scaffolding generators for other use cases with only the caveat that a preset generator _must be named `preset`_.
Unfortunately, the preset generator use case is sufficiently different from other generator use cases (e.g. generating a project within a pre-existing workspace) that this mental model and a lot of the generated scaffolding turns out to be misleading.
Specifically, I've found that neither the unit nor the E2E testing harnesses for the preset generator are terribly faithful. By "faithful" I mean: does this testing set up accurately reflect the real context my code will run in?
In the case of the default E2E testing harness, the answer is a definite no. Out of the box, this harness is designed to test a generator by running it inside of a pre-existing workspace as if it were a library or app generator, which it's not.
This harness:
1. Generates a new workspace with the `empty` preset.
2. Patches the `package.json` file in the newly generated workspace to install my plugin from the local filesystem.
3. Invokes `nx generate @my-org/my-plugin:preset project` to run the preset generator as a normal generator.
For awhile this _seemed_ fine, but as my preset generator grew more complex, I started noticing places where real workspace generation would fail, but my E2E tests were passing. It didn't take long to realize that this was because my generator gets run differently in production than it does in these E2E tests.
Tests that don't reliably tell me when my code is broken aren't doing their job 🙃!
## Motivation
Lately I've been writing a [custom Nx workspace preset](https://nx.dev/packages/nx-plugin#preset). The goal of a custom preset is to allow customization of the workspace creation process.
I'm hoping to use this to create a batteries-included standardized monorepo generator complete with my preferred configuration for things like linting, testing, CI, and even GitHub project settings.
Unfortunately, this use case isn't very well-documented within Nx. In fact, in a lot of cases the documentation and provided scaffolding for preset generators is, in my humble opinion, seriously misleading. I've had to figure things out by reading through Nx's open source codebase and doing a lot of experimentation.
This article is my attempt at saving someone else all that time and pain :).
## The Solution
It was a little tricky getting a full E2E test for workspace generation itself, but I managed to piece a solution together.
Here's the outline:
1. Start up a [Verdaccio](https://verdaccio.org/) server before running tests.
1. Verdaccio is a lightweight registry that's easy to install and use locally.
2. Authenticate with the Verdaccio registry to allow publishing.
3. Publish the built Nx plugin locally to the Verdaccio registry.
4. Run `create-nx-workspace` with my preset, making sure to hit the local Verdaccio registry to grab the plugin.
### Why Verdaccio?
The challenge in E2E testing a preset generator is that preset generators are usually invoked through `create-nx-workspace` and passed as a package name in the `preset` argument.
Behind the scenes, `create-nx-workspace` resolves the package name from NPM in order to run the preset.
In our tests, we obviously don't want to pull in a real published version of the plugin. We'd like to bundle the current state of the plugin and run the E2E tests against that.
Since `create-nx-workspace` is a CLI, often run through `npx`, we can't use other common local package linking methods like `npm link` or modifying a `package.json` file (because there isn't one yet!). Instead, the strategy is to actually publish the package, but to a local registry that won't affect anything outside of our tests.
Verdaccio fills this role perfectly. By default, it acts as a proxy for NPM, pulling any packages that aren't found in the local registry from the remote registry. This means we can publish our plugin registry and expect Verdaccio to return the development version of our own packages, while still correctly pulling in other dependencies from elsewhere.
### Starting an ephemeral Verdaccio server in tests
One of the trickier parts of getting this E2E harness to work was figuring out how to reliably run an ephemeral Verdaccio server as part of my test set up. As it turns out, the Verdaccio documentation is a bit rough around the edges, as well. There are two relevant pages, one about [End to End Testing](https://verdaccio.org/docs/e2e), which doesn't provide a lot of context and another about the [Node.js API](https://verdaccio.org/docs/verdaccio-programmatically), which is ostensibly not about E2E testing at all.
I was most drawn to the idea of running Verdaccio programmatically using the [module API](https://verdaccio.org/docs/verdaccio-programmatically#using-the-module-api), but had trouble getting this to work. In most cases it seemed that the server would not start up properly and my tests would just hang.
Ultimately the approached that work was [running Verdaccio as a child process using `fork`](https://verdaccio.org/docs/verdaccio-programmatically#using-fork-from-child_process-module). I took cues from the example code in the Verdaccio documentation as well as from this [sample repo](https://github.com/juanpicado/verdaccio-fork) that contains a complete example of this set up.
For my test setup and tear down I ended with something like this:
```typescript
import { ChildProcess, fork } from "node:child_process";
import { getPortPromise as getOpenPort } from "portfinder";
const startVerdaccio = async (port: number): Promise<ChildProcess> => {
const configPath = path.join(__dirname, "../verdaccio.yaml");
return new Promise((resolve, reject) => {
const child = fork(require.resolve("verdaccio/bin/verdaccio"), [
"-c",
configPath,
"-l",
`${port}`,
]);
child.on("message", (message: { verdaccio_started: boolean }) => {
if (message.verdaccio_started) {
resolve(child);
}
});
child.on("error", (error: any) => reject([error]));
child.on("disconnect", (error: any) => reject([error]));
});
};
describe("nx-plugin e2e", () => {
let verdaccioProcess: ChildProcess;
beforeAll(async () => {
const verdaccioPort = await getOpenPort();
verdaccioProcess = await startVerdaccio(verdaccioPort);
});
afterAll(async () => {
verdaccioProcess.kill();
});
});
```
I created a `verdaccio.yaml` file that looks like this:
```yaml
# verdaccio-memory
store:
memory:
limit: 1000
# verdaccio-auth-memory plugin
auth:
# htpasswd:
# file: ./htpasswd
auth-memory:
users:
foo:
name: foo
password: bar
admin:
name: foo
password: bar
# uplinks
uplinks:
npmjs:
url: https://registry.npmjs.org/
verdacciobk:
url: http://localhost:8000/
auth:
type: bearer
token: dsyTcamuhMd8GlsakOhP5A==
packages:
"@*/*":
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
"react":
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: verdacciobk
"**":
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
# rate limit configuration
rateLimit:
windowMs: 1000
max: 10000
middlewares:
audit:
enabled: true
security:
api:
jwt:
sign:
expiresIn: 1d
logs: { type: file, path: /dev/null, level: info }
i18n:
web: en-US
# try to use verdaccio with child_process:fork
_debug: true
```
Notably, I took this file almost completely from the [`verdaccio-fork` example repo](https://github.com/juanpicado/verdaccio-fork/blob/main/verdaccio.yaml). The only small change I made was to modify `logs` to send all `verdaccio` output to `/dev/null` so it wouldn't clutter my testing output.
Per the Verdaccio docs, `_debug: true` is very important when using Verdaccio in this way, as it's what turns on the ability to listen for the `verdaccio_started` message once the server is ready to go.
### Authenticating with Verdaccio
Next challenge was authenticating with the new Verdaccio server from inside of tests. Initially, I thought I could just run a simple `npm adduser --registry=http://my-local-registry` command. It took a few confusing test failures before I realized that `npm adduser` is an interactive CLI and was failing my tests because it was expecting user input.
The way around this is to use `npm-cli-login` instead. You can either add it as a `devDependency` and invoke it with `npm run npm-cli-login` or just use `npx npm-cli-login`.
Here's the full command to authenticate:
```typescript
import { execSync } from "node:child_process";
import { getPortPromise as getOpenPort } from "portfinder";
const verdaccioPort = await getOpenPort();
const verdaccioUrl = `http://localhost:${verdaccioPort}`;
execSync(
`npx npm-cli-login -u chiubaka -p test -e test@chiubaka.com -r ${verdaccioUrl}`,
);
```
This needs to go in the `beforeAll` setup block of your tests.
### Publishing to Verdaccio
Now that Verdaccio is running and we're authenticated, publishing is easy!
```typescript
import { execSync } from "node:child_process";
import { getPortPromise as getOpenPort } from "portfinder";
const verdaccioPort = await getOpenPort();
const verdaccioUrl = `http://localhost:${verdaccioPort}`;
execSync(`npm publish --registry=${verdaccioUrl}`, {
cwd: path.join(__dirname, "../../../dist/packages/nx-plugin"),
});
```
Where the `cwd` of the `execSync` here needs to be the path to the built version of your plugin, which the `@nrwl/nx-plugin:e2e` executor will ensure is pre-built before running your tests by default.
### Running the workspace generation command
With our plugin package published to the local registry, all that's left is to run the workspace generation command to create a real generated workspace in the E2E testing directory (`tmp` within the Nx plugin workspace by default).
Since we're aiming to be as faithful as possible to the true experience users will have when using our plugin, we'll use the `create-nx-workspace` command to invoke the preset generator.
In order to get the `create-nx-workspace` command to use the local Verdaccio registry, we'll need to run it with `npx` and prefix with the `npm_config_registry=[http://my-local-registry]` environment variable.
Additionally, in order for a lot of the `@nrwl/nx-plugin/testing` utils to work properly, note that your testing workspace needs to be generated in a very specific place. At time of writing, the name of that directory is `proj`, but since that could change without warning it's safest to dynamically determine the name of the testing workspace using `tmpProjPath()`.
Here's what the full command looks like:
```typescript
import { tmpProjPath } from "@nrwl/nx-plugin/testing";
import { execSync } from "node:child_process";
import path from "node:path";
import { getPortPromise as getOpenPort } from "portfinder";
const verdaccioPort = await getOpenPort();
const verdaccioUrl = `http://localhost:${verdaccioPort}`;
const destination = path.join(tmpProjPath(), "..");
const workspaceName = path.basename(tmpProjPath());
execSync(
`npm_config_registry=${verdaccioUrl} npx create-nx-workspace ${workspaceName} --preset=@chiubaka/nx-plugin --nxCloud=false`,
{
cwd: destination,
},
);
```
### Full working solution
Putting it all together, here's a full sample test suite:
```typescript
import {
checkFilesExist,
cleanup,
runNxCommandAsync,
tmpProjPath,
} from "@nrwl/nx-plugin/testing";
import { ChildProcess, execSync, fork } from "node:child_process";
import path from "node:path";
import { getPortPromise as getOpenPort } from "portfinder";
// These tests can take awhile to run. Modify or remove this depending on how long this takes
// on your machine or in your environment.
jest.setTimeout(60_000);
const startVerdaccio = async (port: number): Promise<ChildProcess> => {
const configPath = path.join(__dirname, "../verdaccio.yaml");
return new Promise((resolve, reject) => {
const child = fork(require.resolve("verdaccio/bin/verdaccio"), [
"-c",
configPath,
"-l",
`${port}`,
]);
child.on("message", (message: { verdaccio_started: boolean }) => {
if (message.verdaccio_started) {
resolve(child);
}
});
child.on("error", (error: any) => reject([error]));
child.on("disconnect", (error: any) => reject([error]));
});
};
describe("nx-plugin e2e", () => {
let verdaccioProcess: ChildProcess;
beforeAll(async () => {
cleanup();
const verdaccioPort = await getOpenPort();
verdaccioProcess = await startVerdaccio(verdaccioPort);
const verdaccioUrl = `http://localhost:${verdaccioPort}`;
execSync(`yarn config set registry ${verdaccioUrl}`);
execSync(
`npx npm-cli-login -u chiubaka -p test -e test@chiubaka.com -r ${verdaccioUrl}`,
);
execSync(`npm publish --registry=${verdaccioUrl}`, {
cwd: path.join(__dirname, "../../../dist/packages/nx-plugin"),
});
const destination = path.join(tmpProjPath(), "..");
const workspaceName = path.basename(tmpProjPath());
execSync(
`npm_config_registry=${verdaccioUrl} npx create-nx-workspace ${workspaceName} --preset=@chiubaka/nx-plugin --nxCloud=false`,
{
cwd: destination,
},
);
});
afterAll(async () => {
// `nx reset` kills the daemon, and performs
// some work which can help clean up e2e leftovers
await runNxCommandAsync("reset");
execSync(`yarn config set registry https://registry.yarnpkg.com`);
verdaccioProcess.kill();
});
it("should not create an apps dir", () => {
expect(() => {
checkFilesExist("apps");
}).toThrow();
});
});
```
Be sure to include a `verdaccio.yaml` file that looks something like this:
```yaml
# verdaccio-memory
store:
memory:
limit: 1000
# verdaccio-auth-memory plugin
auth:
# htpasswd:
# file: ./htpasswd
auth-memory:
users:
foo:
name: foo
password: bar
admin:
name: foo
password: bar
# uplinks
uplinks:
npmjs:
url: https://registry.npmjs.org/
verdacciobk:
url: http://localhost:8000/
auth:
type: bearer
token: dsyTcamuhMd8GlsakOhP5A==
packages:
"@*/*":
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
"react":
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: verdacciobk
"**":
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
# rate limit configuration
rateLimit:
windowMs: 1000
max: 10000
middlewares:
audit:
enabled: true
security:
api:
jwt:
sign:
expiresIn: 1d
logs: { type: file, path: /dev/null, level: info }
i18n:
web: en-US
# try to use verdaccio with child_process:fork
_debug: true
```
And of course, make sure you've installed `verdaccio`, `verdaccio-auth-memory`, and `verdaccio-memory` to support this config file. | chiubaka |
1,158,033 | Space Invaders Game With Python: (Part2). BULLETS | See Part 1 In the previous part, we saw how to begin using pygame, how to work with classes, and we... | 0 | 2022-08-03T04:44:00 | https://dev.to/munyite001/space-invaders-game-with-python-part2-bullets-5dl0 | programming, python, tutorial, gamedev | See [Part 1](https://dev.to/munyite001/space-invaders-game-in-python-part-1-4kn3)
In the previous part, we saw how to begin using pygame, how to work with classes, and we created the Alien Invasion Game class that was responsible for running the game, we also added a ship image to our game, and added some functionality to allow us to control our ship. In today's tutorial, we will be adding the functionality of bullets, to allow us to fire bullets from our ship. We will create the bullet class, and use sprite to generate bullets.
### Shooting Bullets
At the end of the __init__() method, we’ll update settings.py to include the
values we’ll need for a new Bullet class:
```python
#settings.py
def __init__(self):
--snip--
# Bullet settings
self.bullet_speed = 1.0
self.bullet_width = 3
self.bullet_height = 15
self.bullet_color = (60, 60, 60)
```
These settings create dark gray bullets with a width of 3 pixels and a
height of 15 pixels. The bullets will travel slightly slower than the ship.
#### Creating the bullet class
Now we will create a bullet.py file to store our Bullet class.
```python
#bullet.py
import pygame
from pygame.sprite import Sprite
class Bullet(Sprite):
"""A class to manage bullets fired from the ship"""
def __init__(self, ai_game):
"""Create a bullet object at the ship's current position."""
super().__init__()
self.screen = ai_game.screen
self.settings = ai_game.settings
self.color = self.settings.bullet_color
# Create a bullet rect at (0, 0) and then set correct position.
self.rect = pygame.Rect(0, 0, self.settings.bullet_width,
self.settings.bullet_height)
self.rect.midtop = ai_game.ship.rect.midtop
# Store the bullet's position as a decimal value.
self.y = float(self.rect.y)
```
The Bullet class inherits from Sprite, which we import from the pygame
.sprite module. When you use sprites, you can group related elements in
your game and act on all the grouped elements at once.
To create a bulletinstance, __init__() needs the current instance of AlienInvasion, and we call super() to inherit properly from Sprite. We also set attributes for the screen and settings objects, and for the bullet’s color.
Then, we create the bullet’s rect attribute. The bullet isn’t based on an
image, so we have to build a rect from scratch using the pygame.Rect() class.
This class requires the x- and y-coordinates of the top-left corner of the
rect, and the width and height of the rect. We initialize the rect at (0, 0),
but we’ll move it to the correct location in the next line, because the bullet’s
position depends on the ship’s position. We get the width and height of the
bullet from the values stored in self.settings.
Then, we set the bullet’s midtop attribute to match the ship’s midtop attri
bute. This will make the bullet emerge from the top of the ship, making it
look like the bullet is fired from the ship. We store a decimal value for the
bullet’s y-coordinate so we can make fine adjustments to the bullet’s speed.
Here’s the second part of bullet.py, update() and draw_bullet():
```python
#bullet.py
def update(self):
"""Move the bullet up the screen."""
# Update the decimal position of the bullet.
self.y -= self.settings.bullet_speed
# Update the rect position.
self.rect.y = self.y
def draw_bullet(self):
"""Draw the bullet to the screen."""
pygame.draw.rect(self.screen, self.color, self.rect)
```
The update() method manages the bullet’s position. When a bullet is
fired, it moves up the screen, which corresponds to a decreasing y-coordinate
value. To update the position, we subtract the amount stored in settings
.bullet_speed from self.y. We then use the value of self.y to set the value
of self.rect.y.
The bullet_speed setting allows us to increase the speed of the bullets
as the game progresses or as needed to refine the game’s behavior. Once a
bullet is fired, we never change the value of its x-coordinate, so it will travel
vertically in a straight line even if the ship moves.
When we want to draw a bullet, we call draw_bullet(). The draw.rect()
function fills the part of the screen defined by the bullet’s rect with the
color stored in self.color
#### Storing bullets in a group
Now that we have a Bullet class and the necessary settings defined, we can
write code to fire a bullet each time the player presses the spacebar. We’ll
create a group in AlienInvasion to store all the live bullets so we can man
age the bullets that have already been fired. This group will be an instance
of the pygame.sprite.Group class, which behaves like a list with some extra
functionality that’s helpful when building games. We’ll use this group
to draw bullets to the screen on each pass through the main loop and to
update each bullet’s position.
We’ll create the group in __init__():
```python
#alien_invasion.py
def __init__(self):
--snip--
self.ship = Ship(self)
self.bullets = pygame.sprite.Group()
```
Then we need to update the position of the bullets on each pass
through the while loop:
```python
alien_invasion.py
u
def run_game(self):
"""Start the main loop for the game."""
while True:
self._check_events()
self.ship.update()
self.bullets.update()
self._update_screen()
```
When we call update() on a group, the group automatically calls
update() for each sprite in the group. The line self.bullets.update() calls
bullet.update() for each bullet we place in the group bullets.
#### Firing Bullets
In AlienInvasion, we need to modify _check_keydown_events() to fire a bullet
when the player presses the spacebar. We don’t need to change _check_keyup
_events() because nothing happens when the spacebar is released. We also
need to modify _update_screen() to make sure each bullet is drawn to the
screen before we call flip().
let’s write a new method, _fire_bullet(), to handle the whole process of firing bullets:
```python
# alien_invasion.py
--snip--
from ship import Ship
from bullet import Bullet
class AlienInvasion:
--snip--
def _check_keydown_events(self, event):
--snip--
elif event.key == pygame.K_q:
sys.exit()
elif event.key == pygame.K_SPACE:
self._fire_bullet()
def _check_keyup_events(self, event):
--snip--
def _fire_bullet(self):
"""Create a new bullet and add it to the bullets group."""
new_bullet = Bullet(self)
self.bullets.add(new_bullet)
def _update_screen(self):
"""Update images on the screen, and flip to the new screen."""
self.screen.fill(self.settings.bg_color)
self.ship.blitme()
for bullet in self.bullets.sprites():
bullet.draw_bullet()
--snip--
```
First, we import the Bullet class. Then we call _fire_bullet() when the space
bar is pressed. In _fire_bullet(), we make an instance of Bullet and call it
new_bullet. We then add it to the group bullets using the add() method.
The add() method is similar to append(), but it’s a method that’s written spe
cifically for Pygame groups.
The bullets.sprites() method returns a list of all sprites in the group
bullets. To draw all fired bullets to the screen, we loop through the sprites
in bullets and call draw_bullet() on each one.
When you run alien_invasion.py now, you should be able to move the ship
right and left, and fire as many bullets as you want. The bullets travel up the
screen and disappear when they reach the top. You
can alter the size, color, and speed of the bullets in settings.py.
#### Deleting Old Bullets
At the moment, the bullets disappear when they reach the top, but only
because Pygame can’t draw them above the top of the screen. The bullets
actually continue to exist; their y-coordinate values just grow increasingly
negative. This is a problem, because they continue to consume memory and
processing power. We need to get rid of these old bullets, or the game will slow down from doing so much unnecessary work. To do this, we need to detect when the
bottom value of a bullet’s rect has a value of 0, which indicates the bullet has
passed off the top of the screen:
```python
alien_invasion.py
def run_game(self):
"""Start the main loop for the game."""
while True:
self._check_events()
self.ship.update()
self.bullets.update()
# Get rid of bullets that have disappeared.
for bullet in self.bullets.copy():
if bullet.rect.bottom <= 0:
self.bullets.remove(bullet)
print(len(self.bullets))
self._update_screen()
```
When you use a for loop with a list (or a group in Pygame), Python
expects that the list will stay the same length as long as the loop is run
ning. Because we can’t remove items from a list or group within a for loop,
we have to loop over a copy of the group. We use the copy() method to set
up the for loop, which enables us to modify bullets inside the loop. We
check each bullet to see whether it has disappeared off the top of the screen. If it has, we remove it from bullets. We then insert a print() call to
show how many bullets currently exist in the game and verify that they’re
being deleted when they reach the top of the screen.
If this code works correctly, we can watch the terminal output while fir
ing bullets and see that the number of bullets decreases to zero after each
series of bullets has cleared the top of the screen. After you run the game
and verify that bullets are being deleted properly, remove the print() call. If
you leave it in, the game will slow down significantly because it takes more
time to write output to the terminal than it does to draw graphics to the
game window.
#### Limiting the number of bullets fired at a time
We'll limit the number of bullets fired by the player at any given time in order to make the game a bit more challenging
First, store the number of bullets allowed in settings.py:
```python
#settings.py
# Bullet settings
--snip--
self.bullet_color = (60, 60, 60)
self.bullets_allowed = 3
```
This limits the player to three bullets at a time. We’ll use this setting in
AlienInvasion to check how many bullets exist before creating a new bullet
in _fire_bullet():
```python
#alien_invasion.py
def _fire_bullet(self):
"""Create a new bullet and add it to the bullets group."""
if len(self.bullets) < self.settings.bullets_allowed:
new_bullet = Bullet(self)
self.bullets.add(new_bullet)
```
When the player presses the spacebar, we check the length of bullets.
If len(self.bullets) is less than three, we create a new bullet. But if three
bullets are already active, nothing happens when the spacebar is pressed.
When you run the game now, you should be able to fire bullets only in
groups of three.
#### Creating the _update_bullets() Method
We want to keep the AlienInvasion class reasonably well organized, so now
that we’ve written and checked the bullet management code, we can move
it to a separate method. We’ll create a new method called _update_bullets()
and add it just before _update_screen():
```python
alien_invasion.py
def _update_bullets(self):
"""Update position of bullets and get rid of old bullets."""
# Update bullet positions.
self.bullets.update()
# Get rid of bullets that have disappeared.
for bullet in self.bullets.copy():
if bullet.rect.bottom <= 0:
self.bullets.remove(bullet)
```
The code for _update_bullets() is cut and pasted from run_game(); all
we’ve done here is clarify the comments.
The while loop in run_game() looks simple again:
```python
#alien_invasion.py
while True:
self._check_events()
self.ship.update()
self._update_bullets()
self._update_screen()
```
Now our main loop contains only minimal code, so we can quickly read
the method names and understand what’s happening in the game. The
main loop checks for player input, and then updates the position of the
ship and any bullets that have been fired. We then use the updated posi-
tions to draw a new screen.
Run alien_invasion.py one more time, and make sure you can still fire
bullets without errors.
In the next part, we will be adding aliens to our game.
To access the Full project source code and files, visit the repo on [Github](https://github.com/munyite001/Alien-Invasion-Game-Python).
| munyite001 |
1,158,083 | Carbon language Fibonacci series working example | Carbon language beginner series: Google introduced Carbon programming language recently. Carbon... | 0 | 2022-08-03T06:29:00 | https://dev.to/tipseason/carbon-language-fibonacci-series-working-example-1c2h | programming, beginners, tutorial, opensource | Carbon language beginner series:
Google introduced [Carbon programming language](https://tipseason.com/carbon-language-tutorial-syntax/) recently.
Carbon language is still in early stages and is not yet ready. However just want to explore it around to learn a new language. After setting up carbon language, tried to run fibonacci series example with iteration but didn't work . So tried a recursive example and it worked. Here is the full working example.
If you prefer to have an iterative version using `while` loops + recursion you can check it here : [Carbon language Fibonacci series, print nth Fibonacci number](https://tipseason.com/carbon-language-fibonacci-sequence/)
```
package sample api;
fn Fibonacci(n: i32, a: i32, b: i32) -> i32 {
Print("{0} ", a);
if (n == 0) {
return a;
}
return Fibonacci(n - 1, b, a + b);
}
fn Main() -> i32 {
var n: i32 = 6;
let nthFibNumber : auto = Fibonacci(n, 1, 1);
Print("*****");
Print("(N+1)th fibonacci number : {0}", nthFibNumber);
return nthFibNumber;
}
```
### Understanding the code:
We use a recursive code to calculate nth fibonacci number .
`fib(n) = fib(n-1) + fib(n-2)`
To print the sequence, since `for` loops doesn't work in carbon yet, we will use print nth number using recursion. At each step we will replace the positions of `a` and `b` using `b` and `a+b` and print the nth number in the starting of recursion.
```
fn Fibonacci(n: i32, a: i32, b: i32) -> i32 {
Print("{0} ", a);
if (n == 0) {
return a;
}
return Fibonacci(n - 1, b, a + b);
}
```
Finally we call this in the main method. One thing to note is each time the method returns n+1 th fibonacci number in the recursion. So its easier to print nth fibonacci number too.
```
fn Main() -> i32 {
var n: i32 = 6;
let nthFibNumber : auto = Fibonacci(n, 1, 1);
Print("*****");
Print("(N+1)th fibonacci number : {0}", nthFibNumber);
return nthFibNumber;
}
```
Additional Carbon language Reading:
[Carbon language vs Rust detailed comparison]
(https://tipseason.com/carbon-language-vs-rust/)
[Carbon language memory management](https://tipseason.com/carbon-language-memory-safety/)
This is a part of carbon language series for beginners. Feel free to ask any questions regarding Carbon. | tipseason |
1,158,202 | TypeScript - The Best Way to Use It with React | Why TypeScript? I have another article that explains a lot about TypeScript, what it is... | 0 | 2022-08-03T09:10:00 | https://dev.to/omerwow/how-to-use-typescript-with-react-mn9 | webdev, typescript, react, beginners | ###Why TypeScript?
I have another article that explains a lot about TypeScript, what it is and how and why you should use it.
You're welcome to read about it here: https://dev.to/omerwow/how-i-began-using-typescript-3noe
In a nutshell, the benefits of using TypeScript include:
1. Catching errors early in the development process.
2. Making code easier to understand and maintain.
3. Providing a better development experience, with features like autocompletion and type checking.
###Getting started
To create a new React application with TypeScript, use the following command:
```
npx create-react-app my-app --template typescript
```
That's it, the Create React App CLI will create a new app with TypeScript configured properly and you can get started right away.
If, however, you have an existing React app that you want to convert to TypeScript, you're going to need to do a few extra steps.
Don't worry though, it's pretty simple!
First, install TypeScript and other required packages:
```
npm install --save typescript @types/node @types/react @types/react-dom @types/jest
```
Now, rename all .js files to .tsx files, and make sure to restart your dev server before continuing.
Also, a restart to your code editor / IDE may be needed or helpful as well.
The last thing you're going to need to do is to create a tsconfig.json file.
This file will usually be created for you when creating a new project, but since this an existing project, you're going to need to create it yourself.
In the root folder of your project, just create a new file called tsconfig.json, and paste the following inside it:
```
{
"compilerOptions": {
"target": "es5",
"lib": [
"dom",
"dom.iterable",
"esnext"
],
"allowJs": true,
"skipLibCheck": true,
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
"strict": true,
"forceConsistentCasingInFileNames": true,
"noFallthroughCasesInSwitch": true,
"module": "esnext",
"moduleResolution": "node",
"resolveJsonModule": true,
"isolatedModules": true,
"noEmit": true,
"jsx": "react-jsx"
},
"include": [
"src"
]
}
```
That's pretty much it.
Be aware that enabling TypeScript in an existing project can "introduce" or uncover some errors.
This is usually not a big deal and may even be pretty helpful and help you solve a few bugs. You're going to need to deal with them before continuing development.
Now that we have a working TypeScript React app, we can start utilizing TypeScript to improve our development.
###Writing .tsx files
We'll start with a simple React component that renders a header. Then we'll use TypeScript to add types and type safety to the component. Finally, we'll compile the TypeScript code to JavaScript and run the app.
First, let's create a simple React component that renders a header:
```
import React from 'react';
const Header = () => {
return (
<header>
<h1>Hello, world!</h1>
</header>
);
};
export default Header;
```
This Header component doesn't do much yet it just renders a header element with the text "Hello, world!" We can write this component in TypeScript or JavaScript. For this example, we'll write it in TypeScript.
### Adding Types with TypeScript
Now that we have a basic React component, let's add some types with TypeScript. We can start by adding types to our props and state:
```
import React from 'react';
interface HeaderProps {
message: string;
}
const Header = (props: HeaderProps) => {
return (
<header>
<h1>{props.message}</h1>
</header>
);
};
export default Header;
```
As you can see, we've added an interface for our props and specified that the message prop is of type string. This way, if we try to pass anything other than a string to the message prop, TypeScript will give us an error.
We can also add types to our state:
```
import React, { useState } from 'react';
const [count, setCount] = useState<number>(0);
const Header = (props: HeaderProps) => {
return (
<header>
<h1>{props.message}</h1>
<button onClick={() => setCount(count + 1)}>
Click me!
</button>
<p>You've clicked the button {count} times.</p>
</header>
);
};
export default Header;
```
As you can see, we've added types for our state and specified that the count state variable is of type number. This way, if we try to set the count state variable to anything other than a number, TypeScript will give us an error.
###Exploring the type safety of React event handlers
One of the benefits of using TypeScript with React is that developers can catch errors in their event handlers. Event handlers are a way to respond to user input in React applications. When an event occurs, such as a user clicking a button, The compiler will check the type of each parameter in the event handler function, and it will also check the return type of the function. If there is a mismatch in either of them, the compiler will throw an error. This means that developers can catch errors in their event handlers before the code runs.
However, there are some potential pitfalls when using TypeScript with React. One pitfall is that it is possible to write code that is valid TypeScript but will not compile because of an error in React. For example, take a look at the following code:
```
class MyComponent extends React.Component {
handleClick(event: MouseEvent) {
// do something
}
}
```
This code will not compile because of an error in React: "handleClick" must be declared as a static method on "MyComponent". However, this code is valid TypeScript, and it will only produce an error when it is compiled with React. This means that developers need to be aware of both TypeScript and React when they are writing their code.
In conclusion, TypeScript is a great way to improve your React code. It can help you catch errors, optimize performance, and make your code more readable. Plus, it's just plain fun to use.
Star our [Github repo](https://bit.ly/3QFgAUf) and join the discussion in our [Discord channel](https://bit.ly/3HQtlYo)!
Test your API for free now at [BLST](https://www.blstsecurity.com/?promo=blst&domain=https://dev.to/How_to_use_TypeScript_with_React)! | omerwow |
1,158,225 | [Design Pattern] Observer Pattern | The observer pattern is a one to many relationship dependency, and when one object(Observable object)... | 0 | 2022-08-08T07:37:11 | https://dev.to/edindevto/design-pattern-observer-pattern-4ipb | The observer pattern is a one to many relationship dependency, and when one object(Observable object) changes its status, all its dependencies(Observer objects) will be notified and updated accordingly.
**Scenario Problem**
Now we have a publisher object and many subscriber objects, and subscriber objects poll new status from the publisher. However, all these subscribers don't know when the publisher will update a new status, so they just keep polling new status from the publisher(like polling every 1 minute or something).
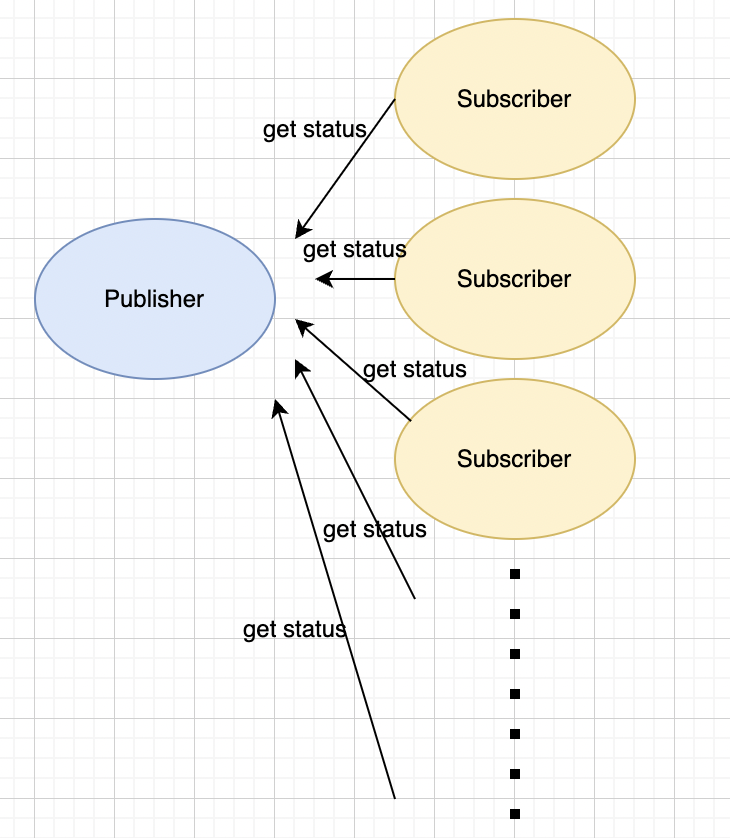
Now there comes a bad smell... What if there are like 1000 subscribers and each of them tries to get status every 10 seconds!?
As a result, the requesting traffic must explode and obviously there are lots of unnecessary calling... Also, subscribers might not get the most recent status - there is still up to 10 seconds delay before getting the status.
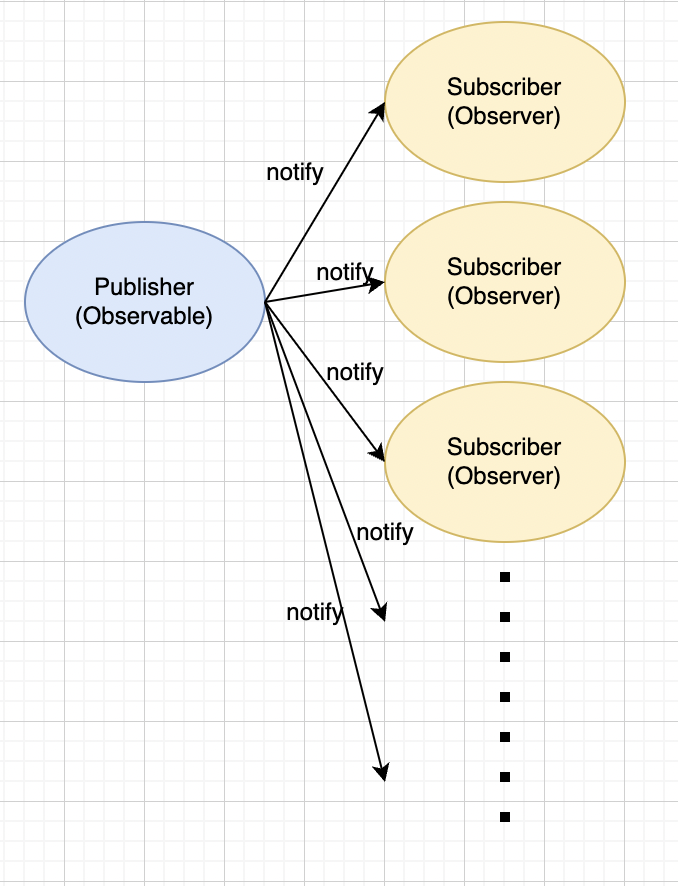
**Solution**
With the observable pattern, every time the publisher(Observable object) has a new status, it notifies all its subscribers. This way we can avoid lots of unnecessary callings, and all subscribers can get the most recent status immediately without delay.
**Implementation**
A very simple class diagram of the pattern is like the following:
[Implementation](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/jmjrve1ll7jz5cgygmyd.png)
The `notify()` method will be like:
```java
public void notify() {
this.status = // Do what ever to get the latest status...;
this.subscribers.stream().foreach((s) => {
s.update(this.status);
});
}
```
| edindevto | |
1,158,231 | Conversational analysis AI tool | Hi there, Hope you are doing well. Me and a few people are starting this project where we will... | 0 | 2022-08-03T10:15:46 | https://dev.to/ayhan_dzhemalov_/conversational-analysis-ai-tool-55hh | Hi there,
Hope you are doing well.
Me and a few people are starting this project where we will develop an AI Conversational analysis to detect visual and tonal markers for sale purposes.
We are looking for people who could jump on board and help us with the creation of this tool and get a working prototype.
Anyone who is interested could DM me.
Regards,
Ayhan | ayhan_dzhemalov_ | |
1,158,311 | How to regain concentration and focus | This article was originally published at INNOQ. No sooner had I started a task, the next thing I... | 0 | 2022-08-03T12:34:00 | https://www.innoq.com/en/blog/wie-ich-meine-konzentration-wiederfand/ | productivity, motivation | This article was originally published at [INNOQ](https://www.innoq.com/en/blog/wie-ich-meine-konzentration-wiederfand/).
No sooner had I started a task, the next thing I knew I was doing something else. I distracted myself by checking my email inbox every so often, and I was addicted to checking what was going on in the world on various news websites, constantly interrupting the original task.
You're perfectly right: This sounds completely insane. Somehow these bad habits had sneaked silently into my life.
>News is to the mind what sugar is to the body.<p>
>Rolf Dobelli, Author and entrepreneur
And then two lightning bolts struck almost simultaneously: a book and a blog post.
I significantly changed my (digital) life as a result and within only two weeks I was able to get more done again, sleep better, and am significantly happier.
The short version: news diet and productive smartphone use.

<figcaption>Lightning strikes</figcaption>
## How my concentration was lost…
For years, I've been producing _content_ on a fairly regular basis in the form of talks, books, journal articles, blog posts, podcasts, and contributions to open-source projects (To quantify that: [30+ books or book editions](https://www.gernotstarke.de/buecher/) and about a hundred articles in various magazines within the last 20 years - that's still one and a half books and five articles on average per year).
In the last few months, I ran out of steam, which made me personally very discontent. In early 2022 I published the last blog post, and in late 2021 the last articles. For the third time, I postponed the new edition of the arc42-in-Action book ...
I had plenty of ideas, but somehow I couldn't put them down on paper. Unfortunately, ideas alone are not enough: the ideas also have to be made into reality, structured, and written down in comprehensible ways.
Moreover, I was always a dedicated textbook reader, and binge-read a new book every few weeks. That, too, became more and more difficult for me - even though I was genuinely interested in the topics of the unread books on the shelf.
Now, I could chalk it all up to the pandemic, my age (don't ask...), or whatever. But finding bogus excuses is just not my thing.
"You've got to do something about that," I told myself. At first, I tried to increase my productivity and creativity by getting up earlier. No such luck. Staying up later in the evening didn't work either.
Then I tried what I've recommended (successfully!) countless times in my job as an IT consultant: A systematic analysis of the situation, a self-review.
#### The self-analysis
I tried to analyze my own way of working. I quickly noticed that it was becoming increasingly difficult for me to concentrate on individual tasks: No sooner had I started a task than I was already doing something else in between - or _distracted_ myself with emails or various news websites. Likewise, I sat at preparing a lecture - and checked the INNOQ Slack channels in between. Furthermore, I continued to write on a slide - and took a brief look at my smartphone to see what's been happening on WhatsApp or Signal. And since I was holding the phone in my hand anyway, I could read a few news items on BBC-News there too.
Did you know that smartphone users unlock and look at their phones an average of 80-100 times a day (source: [Cision Newswire](https://www.prnewswire.com/news-releases/americans-check-their-phones-96-times-a-day-300962643.html), several other sources giving similar numbers)? I was one of them.
News websites like [CNN](https://edition.cnn.com/), [WSJ](https://www.wsj.com/), and [BBC](https://www.bbc.com/) had me as a permanent customer.
For me, these context switches already had addiction-like traits.
Even while I was watching a series (yes, I admit that I like to _binge_ on one or two episodes), I would pick up the phone or tablet in between and casually check the news.
Against my better judgment, I also checked my e-mails first thing in the morning before I even drank my first espresso.
And in my inbox, there were always various news summaries, from stock-market news, and international politics up to technology updates.
Unfortunately, all this news has done me more harm than good: For my coaching and consulting engagements, I don't need to know anything about current domestic or foreign politics.
For my software architecture and engineering workshops, neither stock market trends nor the details of international terrorist acts are of any value.
My articles and books deal with software and software engineering, not with climate or politics.
## A self-discovery
Constantly switching between (sophisticated) technical work, the news from around the world, and private communication on personal and professional topics, I would argue, cost me a significant amount of my ability to concentrate.
My brain (apparently) doesn't handle frequent context switches well. Moreover, my brain must have unconsciously perceived distractions as something positive - and, like Pavlov's dog, kept wanting more of them, at increasingly shorter intervals.

<figcaption>A (Pavlovian) dog</figcaption>
I noticed the lack of concentration myself. However, my own fainthearted attempts, with Pomodoro timer and calming sounds, clearly failed.
Effective remedies _from the outside_ had to come first, two major sources helped me:
While travelling to an architecture workshop, I sat on the train, not reading the news for a change, but attempting to read a book.
For some time now, I have been using [Blinkist](https://www.blinkist.com/) to read short summaries of various non-fiction books, to find out for myself whether I is worth for me to read the original of these books in their entirety.
So - I'm sitting on the train and reading one of these [Blinks](https://www.dobelli.com/en/books/), when I'm struck by a mental lightning bolt: I felt so _caught_ by Rolf Dobelli's explanations, caught in my concentration trap, that I spontaneously decided to get serious. Let me quote from this book:
>**News is not good for us:**
>It clouds our mind, distorts our view of what is really important, robs us of time, makes us depressed and paralyzes our willpower.
Rolf Dobelli, Author and entrepreneur
Paralyze my willpower, rob me of time. </p>
That was precisely my problem.
While still sitting on the train, I decided to try a strict break from any news (_news_, not e-mails or other messages) for a while.
However, that wasn't enough: I remembered a blog post I had read a few years ago - about the [productive configuration of smartphones](https://betterhumans.pub/how-to-set-up-your-iphone-for-productivity-focus-and-your-own-longevity-bb27a68cc3d8), which has the promising subtitle _Configure Your iPhone to Work for You, Not Against You_.
I therefore decided to optimize my iPhone for maximum productivity and to reduce or even eliminate distractions.
## Drastic, but effective
1. A (currently very strict) **zero-news-diet**.
2. (Re)configure smartphone for high productivity and minimal distractions.
3. Reduce distractions on tablets and computers.
Add to that slight changes I made to my daily habits: I've resolved (and managed for a few weeks now) to stop staring at my phone in the morning, and to stop using my iPhone at all in the evening after 8 PM at the latest (exception: setting an alarm for the next morning).
## Zero News Diet
During the aforementioned train ride, I cancelled my subscription to my formerly favorite online news portal (the German "Spiegel-Online") and deleted the associated app from my iPhone. I used the initial motivation to cancel additional news subscriptions and deleted the their apps from my smartphone and iPad so that I wouldn't be tempted.
I have resolved **very firmly** not to read any news at all for a while. In other words, a zero news diet. That was really hard for me for two or three days. Yet, that alone was a startling realization for me: I was actually _addicted_ to news and variety... and _cold withdrawal_ is hard with any kind of addiction, as you know.
I purposefully invested the hours gained each day.
As a kind of early reward for my zero news diet, I treated myself to an interesting non-fiction book as a PDF (by the way, the infamous "Thinking, Fast and Slow" by the great Daniel Kahnemann).
The result: I was thrilled to have made good progress without any distractions.
To support my news diet, I instructed my browser (Firefox) to _not_ present me with recommendations for supposedly interesting or important topics on new tabs or windows.
![Firefox preferences: No more news suggestions]()
<figcaption>Firefox preferences: No more news suggestions</figcaption>
## Reconfigure Smartphone
The above quote, "Configure Your iPhone to Work for You, Not Against You," sets the objective:
It's the subtitle of a very long [blog post](https://betterhumans.pub/how-to-set-up-your-iphone-for-productivity-focus-and-your-own-longevity-bb27a68cc3d8) by Tony Stubblebine.
In addition to his many configuration suggestions, Tony also gives various advice for being more attentive and healthy, entirely worth reading in my opinion.
I summarize the things most important for me, which he illustrates in his article with many screenshots and explanations:
- Turn off (almost) all notifications – so those red dots aren't constantly vying for your attention or making you feel guilty.
- Hide _social media_ apps as well as possible. Facebook, Instagram, Twitter & Co act like drugs. They deserve to be removed from the start/home screen and moved somewhere in the back of your smartphone. I deleted the Twitter app and kept Instagram only because it allows me to catch up a bit with my adult children.
- Messaging apps (email, WhatsApp, Signal and co.) go into a folder, and preferably on the second screen of that folder. For me, it looks like this (K11n stands for communication):
<figcaption>Communication apps – unimportant ones need more “swipe” gestures</figcaption>
- Turn on do-not-disturb-mode, the longer, the better. At least from evening until morning.
- Lifting the phone should **not** unlock it. This setting is called "Display & Brightness/Activate on Lift" on the iPhone - and should definitely be turned off.
- Turn on the screen time widget – this gives me control over all the things I spend my smartphone time on... Meanwhile, I have made a sport out of getting to the smallest value possible.
- Turn on content and app restrictions. I only allow myself 15 minutes a day for email and Instagram.
- Install a swipe keyboard app, so I can text faster on the phone and not have to awkwardly _click_ each letter. I use [Microsoft Swiftkey](https://www.microsoft.com/en-us/swiftkey) (yes correct, a Microsoft app on the iPhone) for this, others do better with Google's [Gboard](https://en.wikipedia.org/wiki/Gboard).
- Wallpapers in muted colors. I chose a completely black home screen, and a reduced color lock screen:
<figcaption>iPhone backgrounds in muted colors</figcaption>
## Reduce distractions on tablets and computers
You will find similar preference settings on your tablet and your computer, respectively. I set those to reduce _notifications_ as much as possible:
<figcaption>Notifications settings, almost all turned off</figcaption>
## In case you fall off the wagon
In case you want to be a bit stricter with yourself, there are various blockers for popular desktop platforms that can prevent access to certain websites or applications for certain times. These can improve your digital self-discipline. I tried [ColdTurkey](https://getcoldturkey.com/) and like it a lot. However, I hope to become disciplined enough to stick to my new habits without this electronic tether… at least in the near future.
## Furthermore...
Besides the aforementioned settings and the zero news diet, I like to listen to _soundscapes_ for (supposedly) better mental focus when working intensively at my desk. I write _supposedly_ because I like this kind of aural background, but can't prove that it helps me in any way. My family, by the way, thinks it's horrible.
If you want to try it out: My two favorites are [Endel](https://endel.io/about) and [brain.fm](https://www.brain.fm/). Works on both smartphones and desktops (but please don’t say I didn’t warn you…).
I still haven't gotten comfortable with Pomodoro timers, they annoy me more than they help.
And finally, thanx to Łukasz, you might want to restrict your YouTube usage with the [unhook](https://unhook.app/) extension. I tried that and immediately liked it. You have to tweak the default settings, though. No more wasted hours due to the addictive YouTube proposition algorithm...
## Conclusion
Why don't you start a self-experiment, and refrain from reading sports, politics, business, and technology news as much as possible for a while? Reduce your smartphone time drastically for one or two weeks, and enjoy the time gained with a good book, a personal conversation or approach a previously abandoned activity that has been left undone so far (due to a perceived lack of time…)
Good luck – and I look forward to your feedback.
## Acknowledgements
Thanks to Jochen Christ, Joachim Praetorius, Jan Seeger and Ben Wolf for reviews and constructive comments. @m and Joy Heron have drastically improved readability and wording.
This article was originally published at [INNOQ](https://www.innoq.com/en/blog/wie-ich-meine-konzentration-wiederfand/), achieved a \#4 rank and more than 300 comments on [Hackernews](https://news.ycombinator.com)
### Image Sources
* [Dog](https://unsplash.com/photos/ngqyo2AYYnE)
* [Lightning](https://unsplash.com/photos/vmvlzJz1lHg)
* [Header image](https://unsplash.com/photos/7KLa-xLbSXA) by Paul Skorupskas
| gernotstarke |
1,158,532 | Answer: Accessing ASP.NET Core DI Container From Static Factory Class | answer re: Accessing ASP.NET Core DI... | 0 | 2022-08-03T17:27:15 | https://dev.to/wahidbitar/answer-accessing-aspnet-core-di-container-from-static-factory-class-931 | {% stackoverflow 55678060 %} | wahidbitar | |
1,158,940 | How to Read Barcode QR Code on the Server Side Using PHP Laravel | If you want to use PHP Laravel framework to build a web barcode and QR code reader, you can implement... | 0 | 2022-08-04T06:49:04 | https://www.dynamsoft.com/codepool/php-laravel-barcode-qr-code-reader.html | php, laravel, webdev, qrcode | If you want to use PHP Laravel framework to build a web barcode and QR code reader, you can implement the code logic either on the client side or on the server side. Dynamsoft provides a variety of SDKs for different platforms: desktop, mobile and web. In this article, we focus on how to leverage the PHP extension built with Dynamsoft C++ Barcode SDK to read barcode and QR code on the server side. If web client side programming is your type, please refer to [https://www.dynamsoft.com/barcode-reader/sdk-javascript/](https://www.dynamsoft.com/barcode-reader/sdk-javascript/).
## PHP Laravel Installation on Windows and Linux
Install [PHP 7.4](https://windows.php.net/download), [Composer](https://getcomposer.org/download/) and [Laravel](https://laravel.com/).
- [PHP 7.4](https://windows.php.net/download)
- Windows
[php-7.4.30-nts-Win32-vc15-x64.zip](https://windows.php.net/downloads/releases/php-7.4.30-nts-Win32-vc15-x64.zip)
- Linux
```bash
sudo apt install php7.4
```
- [Composer](https://getcomposer.org/download/)
- Windows
Run [Composer-Setup.exe](https://getcomposer.org/Composer-Setup.exe)
- Linux
```bash
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
php -r "if (hash_file('sha384', 'composer-setup.php') === '55ce33d7678c5a611085589f1f3ddf8b3c52d662cd01d4ba75c0ee0459970c2200a51f492d557530c71c15d8dba01eae') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;"
php composer-setup.php
php -r "unlink('composer-setup.php');"
sudo mv composer.phar /usr/local/bin/composer
```
- Laravel:
```bash
composer global require laravel/installer
```
## Steps to Implement Server Side Barcode QR Code Reading Using PHP Laravel
In the following paragraphs, we will guide you through the process of developing a PHP Laravel project that can read barcode and QR code from image files on the server side.
### Step 1: Install the PHP Barcode QR Code Reader Extension
There is no pre-built binary package. To read barcode and QR code in PHP, you need to [build and install the PHP extension](https://github.com/yushulx/php-laravel-barcode-qr-reader/tree/main/ext/dbr) from source code on Windows and Linux.
### Step 2: Scaffold a Laravel Project
Once the extension is installed, you can start a new Laravel project.
```bash
composer create-project laravel/laravel web-barcode-qrcode-reader
```
The above command installs the latest stable version of Laravel. To avoid the compatibility issue, a better way is to specify the Laravel version number.
```bash
php artisan --version
Laravel Framework 8.83.23
composer create-project laravel/laravel:^8.0 web-barcode-qrcode-reader
```
### Step 3: Create a Controller
Laravel [controllers](https://laravel.com/docs/8.x/controllers) handle HTTP requests. We can create a controller to handle the uploaded image files and return the barcode and QR code decoding results.
```bash
php artisan make:controller ImageUploadController
```
The command generates an `ImageUploadController.php` file in the `app/Http/Controllers` directory. Open the file to add the following code:
```php
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use Validator;
class ImageUploadController extends Controller
{
function __construct() {
DBRInitLicense("DLS2eyJoYW5kc2hha2VDb2RlIjoiMjAwMDAxLTE2NDk4Mjk3OTI2MzUiLCJvcmdhbml6YXRpb25JRCI6IjIwMDAwMSIsInNlc3Npb25QYXNzd29yZCI6IndTcGR6Vm05WDJrcEQ5YUoifQ==");
DBRInitRuntimeSettingsWithString("{\"ImageParameter\":{\"Name\":\"BestCoverage\",\"DeblurLevel\":9,\"ExpectedBarcodesCount\":512,\"ScaleDownThreshold\":100000,\"LocalizationModes\":[{\"Mode\":\"LM_CONNECTED_BLOCKS\"},{\"Mode\":\"LM_SCAN_DIRECTLY\"},{\"Mode\":\"LM_STATISTICS\"},{\"Mode\":\"LM_LINES\"},{\"Mode\":\"LM_STATISTICS_MARKS\"}],\"GrayscaleTransformationModes\":[{\"Mode\":\"GTM_ORIGINAL\"},{\"Mode\":\"GTM_INVERTED\"}]}}");
}
function page()
{
return view('barcode_qr_reader');
}
function upload(Request $request)
{
$validation = Validator::make($request->all(), [
'BarcodeQrImage' => 'required'
]);
if($validation->passes())
{
$image = $request->file('BarcodeQrImage');
$image->move(public_path('images'), $image->getClientOriginalName());
$resultArray = DecodeBarcodeFile(public_path('images/' . $image->getClientOriginalName()), 0x3FF | 0x2000000 | 0x4000000 | 0x8000000 | 0x10000000); // 1D, PDF417, QRCODE, DataMatrix, Aztec Code
if (is_array($resultArray)) {
$resultCount = count($resultArray);
echo "Total count: $resultCount", "\n";
if ($resultCount > 0) {
for ($i = 0; $i < $resultCount; $i++) {
$result = $resultArray[$i];
echo "Barcode format: $result[0], ";
echo "value: $result[1], ";
echo "raw: ", bin2hex($result[2]), "\n";
echo "Localization : ", $result[3], "\n";
}
}
else {
echo 'No barcode found.', "\n";
}
}
return response()->json([
'message' => 'Successfully uploaded the image.'
]);
}
else
{
return response()->json([
'message' => $validation->errors()->all()
]);
}
}
}
```
In `__construct()` method, you initialize the barcode SDK instance by setting a valid license key, which can be obtained from [Dynamsoft customer portal](https://www.dynamsoft.com/customer/license/trialLicense/?product=dbr). Calling `DBRInitRuntimeSettingsWithString()` is optional, because the default settings are suitable for most cases.
The uploaded images are saved to the `public/images` directory. The `DecodeBarcodeFile()` method is used to read barcode and QR code from the image file.
The next step is to create the `barcode_qr_reader` view.
### Step 4: Create a Web View
Create a `barcode_qr_reader.blade.php` file in the `public/resources/views` directory. The file contains the HTML5 code for uploading an image via a form.
```php
<!DOCTYPE html>
<html>
<head>
<title>PHP Laravel Barcode QR Reader</title>
<meta name="_token" content="{{csrf_token()}}" />
</head>
<body>
<H1>PHP Laravel Barcode QR Reader</H1>
<form action="{{ route('image.upload') }}" method="post" enctype="multipart/form-data">
@csrf
Select barcode image:
<input type="file" name="BarcodeQrImage" id="BarcodeQrImage" accept="image/*"><br>
<input type="submit" value="Read Barcode" name="submit">
</form>
<img id="image" />
<script>
var input = document.querySelector('input[type=file]');
input.onchange = function() {
var file = input.files[0];
var fileReader = new FileReader();
fileReader.onload = function(e) {
{
let image = document.getElementById('image');
image.src = e.target.result;
}
}
fileReader.readAsDataURL(file);
}
</script>
</body>
</html>
```
[CSRF Protection](https://laravel.com/docs/8.x/csrf) is required for the form. A convenient way is to use the `@csrf` Blade directive to generate the hidden token input field:
```html
<form action="{{ route('image.upload') }}" method="post" enctype="multipart/form-data">
@csrf
...
</form>
```
As the web page is done, one more step is to add the web routes in `public/routes/web.php`.
```php
Route::get('/barcode_qr_reader', 'App\Http\Controllers\ImageUploadController@page');
Route::post('/barcode_qr_reader/upload', 'App\Http\Controllers\ImageUploadController@upload')->name('image.upload');
```
### Step 5: Run the PHP Laravel Barcode QR Code Reader
Now you can run the PHP Laravel project and visit `http://127.0.0.1:8000/barcode_qr_reader` in your browser.
```bash
php artisan serve
```
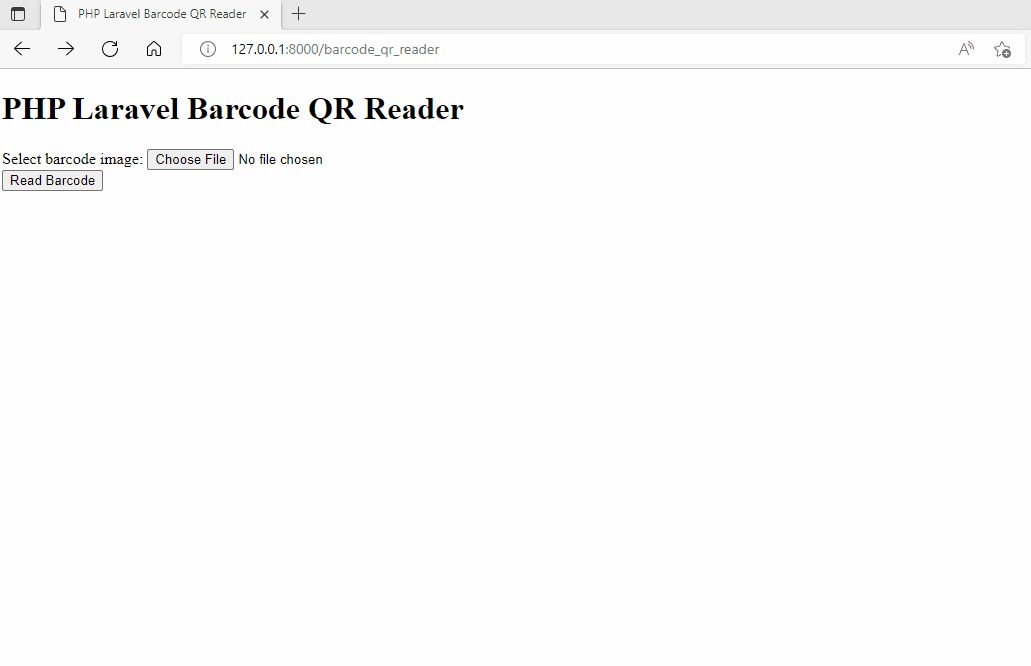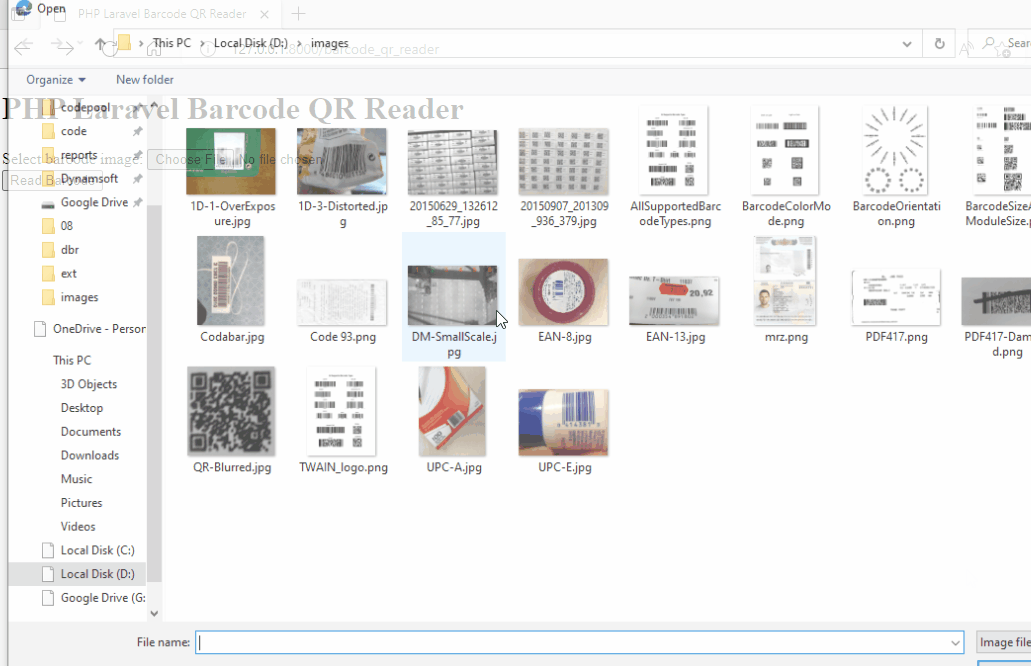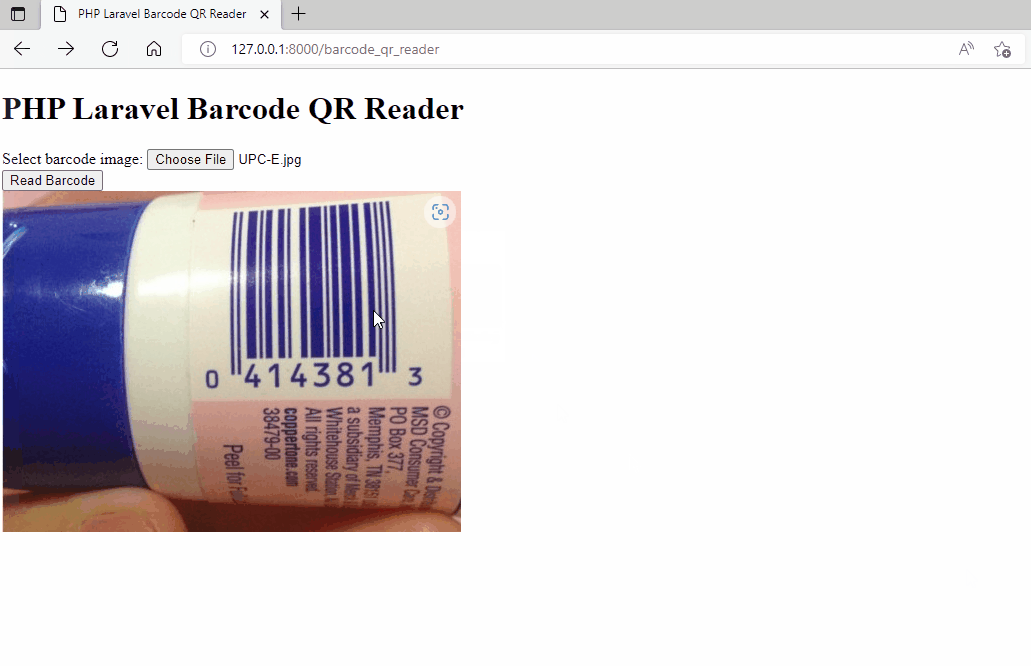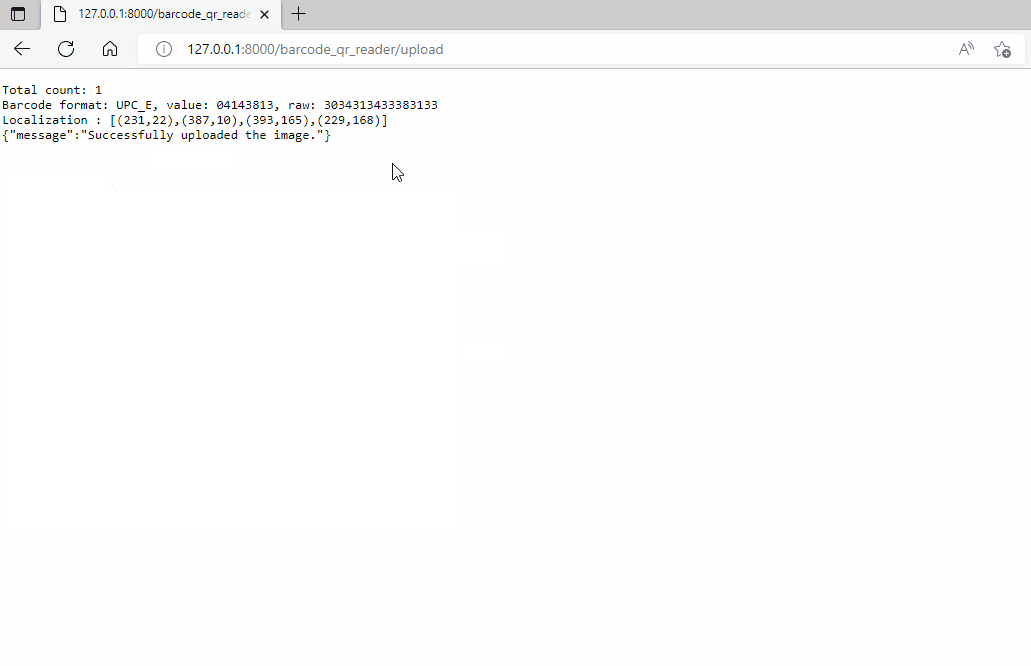
## Source Code
[https://github.com/yushulx/php-laravel-barcode-qr-reader](https://github.com/yushulx/php-laravel-barcode-qr-reader) | yushulx |
1,159,175 | There are many variations of passages of Lorem Ipsum available, but the majority have suffered alteration in some form | making it over 2000 years old. Richard McClintock, a Latin professor at Hampden-Sydney College in... | 0 | 2022-08-04T12:56:00 | https://dev.to/kkumargcc/there-are-many-variations-of-passages-of-lorem-ipsum-available-but-the-majority-have-suffered-alteration-in-some-form-by-in-2jmk | javascript, lorem, testing | making it over 2000 years old. Richard McClintock, a Latin professor at Hampden-Sydney College in Virginia, looked up one of the more obscure Latin words, consectetur, from a Lorem Ipsum passage, and going through the cites of the word in classical literature, discovered the undoubtable source. Lorem Ipsum comes from sections 1.10.32 and 1.10.33 of "de Finibus Bonorum et Malorum" (The Extremes of Good and Evil) by Cicero, written in 45 BC. This book is a treatise on the theory of ethics, very popular during the Renaissance. The first line of Lorem Ipsum, "Lorem ipsum dolor sit amet..", comes from a line in section 1.10.32.
The standard chunk of Lorem Ipsum used since the 1500s is reproduced below for those interested. Sections 1.10.32 and 1.10.33 from "de Finibus Bonorum et Malorum" by Cicero are also reproduced in their exact original form, accompanied by English versions from the 1914 translation by H. Rackham.
Where can I get some?
There are many variations of passages of Lorem Ipsum available, but the majority have suffered alteration in some form, by injected humour, or randomised words which don't look even slightly believable. If you are going to use a passage of Lorem Ipsum, you need to be sure there isn't anything embarrassing hidden in the middle of text. All the Lorem Ipsum generators on the Internet tend to repeat predefined chunks as necessary, making this the first true generator on the Internet. It uses a dictionary of over 200 Latin words, combined with a handful of model sentence structures, to generate Lorem Ipsum which looks reasonable. The generated Lorem Ipsum is therefore always free from repetition, injected humour, or non-characteristic | kkumargcc |
1,159,567 | Rust - Struct, Generics | 0 | 2022-08-05T16:51:19 | https://dev.to/deadlock/rust-struct-generics-4k3e | rust, programming | ---
published: true
title: 'Rust - Struct, Generics'
cover_image: 'https://github.com/kodelint/blog-assets/raw/main/images/01-rust-struct.jpg'
description: null
tags: 'rust, programming'
series: null
canonical_url: null
id: 1159567
date: '2022-08-05T16:51:19Z'
---
Let’s talk about the some custom **data types** in **Rust** like `struct` and `emuns` . We all know why need **custom data type**, like any other language regular data type may not suffice the need and hence we have custom data types.

### Structs, How to use them in `Rust` ?
**Structure**, `struct` in short, are very similar to `tuple` . **Tuple** are used to store related items with mixed data type in **Order**. Now if the use case is to have large number of elements and the **Order** is not obvious then it could be difficult to identify them out of Tuples
<img align="left" src="https://github.com/kodelint/blog-assets/raw/main/images/01-rust-tuple.png" width="650" height="410" style="float:left; padding-right:20px"/>
```bash
the first element of tuple [a_tuple] is 1
the last element of tuple [a_tuple] is Rust
the first element of tuple [a_tuple] after modification is 6
the last element of tuple [a_tuple] after modification is Rustic
```
So you can see that if number of elements are larger than normal then it becomes very difficult to keep track of the order and that’s when we use **`struct`**.
> _**Struct**_ data are usually stored in usually stored in **stack** given it contain **stack** only data types like *numbers*. To store *Struct* in **heap** you have specifically mentioned that. Also, if your _**Struct**_ contain **heap** data types like `String` then it will be stored in **heap** and reference, associated data of the **heap** data will be stored in **stack**. So, when your _**Struct**_ instance goes **out of scope** the associated data in **heap** will be **automatically dropped**.
Defining a `struct` in `Rust` is similar to `Golang`. `Golang` require `type` keyword along side with `struct` keyword
<img align="left" src="https://github.com/kodelint/blog-assets/raw/main/images/01-rust-vs-golang-struct.jpeg" width="450" height="310" style="float:left; padding-right:20px"/>
A `struct` is like a `tuple`, which allows you to package together related items with mixed data type, however you don’t need to use the **index** to access the elements, instead you use the field name to access them.
**Struct** also allow us to update an `instance` from another `instance` and the syntax is pretty simple called **update syntax**, which basically tells `complier` if there are missing field in instance should have the same field from previous instance.
```rust
let second_car = Car {
name : String::*from*("Tesla"),
model : String::from("Model 3"),
..new_car,
};
```
**Any update to the first instance after the second instance initialization will not reflect in second instance.**
> If you see then the missing fields are `int` datatype means they live in **stack**, therefore they gets implicitly copied. However, if there were any `String` datatype involved, it would have error time as it violates the **ownership** **rule** of rust . To make that work we need to use explicit **clone** for copying the data from first instance, something like this **`..new_car.clone()`**. To know more about [ownership and borrowing](https://medium.com/p/5ba45c44f986). Also we have to add `trait` as the `Car` datatype doesn’t have the `trait` to `Clone()` data, so we need to derived that at the **struct definition**, something like this `#[derive(Clone)]`.
### Struct has methods
In Rust we can call subroutines, which are **method** for the **struct**. They are pretty much like a **function** and defined using `fn` key word. The difference is between **methods** and **function** is that **method** are always within the context of the `struct` and the first input parameter is alway the `struct` itself.
To define the **method** we need to `impl` key word _(short for implementation)_ followed by the `struct` name
<img src="https://github.com/kodelint/blog-assets/raw/main/images/01-rust-struct-methods.png" width="870" height="280" />
### Struct has function too
Rust also allow us to create **associated functions**, they are pretty much like `method`, however they don’t take `&self` as argument. They are mostly used to create initialize the new instance of custom datatype, like a **constructors** in other object oriented languages.
<img src="https://github.com/kodelint/blog-assets/raw/main/images/01-rust-associative-function.png" width="870" height="500" />
> There is something call **Struct Tuple**, it is a combination of **Struct** and **Tuple**. In `Rust` **Struct Tuple’s** are defined similarly as **Struct** but they don’t have any named field. It is usually deployed to make a custom type with mixed primary datatypes, however don’t need field to be named. Something like `struct CarFeatures(4, "electric", "falcon doors")`
So this is how the whole code looks like
<img src="https://github.com/kodelint/blog-assets/raw/main/images/01-rust-struct-tuple.png" width="870" height="1500" />
```bash
Car Name: Runner, Model: Tesla Model Y, Year: 2022, Price: $70000/-
Price of Tesla Model Y has increased to $75000/-
Car Name: Beast, Model: Tesla Plaid, Year: 2022, Price: $110000/-
Price of Tesla Plaid has increased to $135000/-
```
### Generic Types … Yay!!
Rust is **statically** type language so a defined `struct`, `function` or `method` can only be used for it own defined variable data types. Which mean you might end up maintaining same code body for `struct`, `function` or `method` with different data types. What if we can define `struct`, `function` or `method` in such a way that we can use any data type with it. Enters…..**Generic Type!!**
<img src="https://github.com/kodelint/blog-assets/raw/main/images/01-rust-generics.jpg" width="970" height="1500" />
Above we have struct `Car` with generic type _(denoted using `<..>`)_ `<S,I,T>` which feeds the `type` for struct fields. Similarly, a `impl` block to define `new_car` and `update_price` **methods**. They are also using generic types. Lastly, a function choose with `generics`, used to get confirm for the right choice based on `electric_per_unit` and `gas_per_gallon` price constraints.
> Don’t worry about the `traits` like `std::cmp::PartialOrd` and `std::ops::AddAssign` for now. I will have separate blog explaining them. For now, we need them because `rust` complier doesn’t know what kind of data types `generics` will have to perform **`comparison`** and **`addition`**.
### Box Datatype
One more thing I want touch is the **Box datatype** in rust . **Box** datatype are usually used to put the data in **heap** instead of **stack**. In simple words **stack** are usually small in size and when you are storing data which can be large in size like a `trait` or `struct` _(combination of different datatypes and sizes)_, you might want to store them in **heap** and have reference of that stored in **stack**
> **Note**: If you are making the data to be **boxed**, means moving it from **stack** to **heap** using `box datatype`. It performs the **move** operation, not **copy**, so previous location in **stack** gets **de-allocated**.

```bash
I bought Model X in 2021 for $120000, it is an electric Vehicle
Market prediction is that Model X in 2022 will be for $140000
BEFORE BOXING, Car struct data size is 56 bytes in Stack
Price Changed: in Inventory aka Stack, Now Price is $140000
BOXING the data.....
AFTER BOXING, Car struct data size is 8 bytes in Stack
Car struct data size is 56 bytes in Heap, because we are using de-referencing operator `*` to access the data
DATA AFTER BOXING: Model X Price: $140000 Fuel Type: electric
```
As you can see that when I used the `boxed_car` variable as `box` type data got moved from **stack** to **heap**. Now, **stack** only contains the reference of the data _(hence `8` bytes)_ and actual data is in **heap** _(hence `56` bytes)_
and we are using `&` for the reference for the data in **stack** and de-referencing operator `*` to fetch the size of the data in **heap**
Hope this explains some of the internal and usage of `structs` and `generics` in `Rust`. I will have more write-ups coming for other important concepts of `Rust`
### Happy Programming!!
| deadlock | |
1,159,897 | AGILE | 1.Agile is an iterative approach to project management and software development that helps teams... | 0 | 2022-08-05T09:12:00 | https://dev.to/kapilborbande/agile-5f79 | 1.Agile is an iterative approach to project management and software development that helps teams deliver value to their customers faster and with fewer headaches.
_
> ## **History of the Agile Manifesto**
The Agile Manifesto and the Twelve Principles of Agile Software were the consequences of industry frustration in the 1990s. The enormous time lag between business requirements (the applications and features customers were requesting) and the delivery of technology that answered those needs, led to the cancelling of many projects. Business, requirements, and customer requisites changed during this lag time, and the final product did not meet the then current needs. The software development models of the day, led by the Waterfall model, were not meeting the demand for speed and did not take advantage of just how quickly software could be altered.
In 2000, a group of seventeen “thought leaders,” including Jon Kern, Kent Beck, Ward Cunningham, Arie van Bennekum, and Alistair Cockburn, met first at a resort in Oregon and later, in 2001, at The Lodge at Snowbird ski resort in Utah. It was at the second meeting where the Agile Manifesto and the Twelve Principles were formally written. The Manifesto reads:
“We are uncovering better ways of developing
software by doing it and helping others do it.
Through this work we have come to value:
“Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
“That is, while there is value in the items on
the right, we value the items on the left more.”
**> **The Four Values of The Agile Manifesto**
**_
The Agile Manifesto is comprised of four foundational values and 12 supporting principles which lead the Agile approach to software development. Each Agile methodology applies the four values in different ways, but all of them rely on them to guide the development and delivery of high-quality, working software.
******1. Individuals and Interactions Over Processes and Tools**
****
The first value in the Agile Manifesto is “Individuals and interactions over processes and tools.” Valuing people more highly than processes or tools is easy to understand because it is the people who respond to business needs and drive the development process. If the process or the tools drive development, the team is less responsive to change and less likely to meet customer needs. Communication is an example of the difference between valuing individuals versus process. In the case of individuals, communication is fluid and happens when a need arises. In the case of process, communication is scheduled and requires specific content.
**_2. Working Software Over Comprehensive Documentation
_**Historically, enormous amounts of time were spent on documenting the product for development and ultimate delivery. Technical specifications, technical requirements, technical prospectus, interface design documents, test plans, documentation plans, and approvals required for each. The list was extensive and was a cause for the long delays in development. Agile does not eliminate documentation, but it streamlines it in a form that gives the developer what is needed to do the work without getting bogged down in minutiae. Agile documents requirements as user stories, which are sufficient for a software developer to begin the task of building a new function.
The Agile Manifesto values documentation, but it values working software more.
**_3. Customer Collaboration Over Contract Negotiation
_**Negotiation is the period when the customer and the product manager work out the details of a delivery, with points along the way where the details may be renegotiated. Collaboration is a different creature entirely. With development models such as Waterfall, customers negotiate the requirements for the product, often in great detail, prior to any work starting. This meant the customer was involved in the process of development before development began and after it was completed, but not during the process. The Agile Manifesto describes a customer who is engaged and collaborates throughout the development process, making. This makes it far easier for development to meet their needs of the customer. Agile methods may include the customer at intervals for periodic demos, but a project could just as easily have an end-user as a daily part of the team and attending all meetings, ensuring the product meets the business needs of the customer.
**_4. Responding to Change Over Following a Plan
_**Traditional software development regarded change as an expense, so it was to be avoided. The intention was to develop detailed, elaborate plans, with a defined set of features and with everything, generally, having as high a priority as everything else, and with a large number of many dependencies on delivering in a certain order so that the team can work on the next piece of the puzzle.
With Agile, the shortness of an iteration means priorities can be shifted from iteration to iteration and new features can be added into the next iteration. Agile’s view is that changes always improve a project; changes provide additional value.
Perhaps nothing illustrates Agile’s positive approach to change better than the concept of Method Tailoring, defined in An Agile Information Systems Development Method in use as: “A process or capability in which human agents determine a system development approach for a specific project situation through responsive changes in, and dynamic interplays between contexts, intentions, and method fragments.” Agile methodologies allow the Agile team to modify the process and make it fit the team rather than the other way around.
> **_The Twelve Agile Manifesto Principles
_**The Twelve Principles are the guiding principles for the methodologies that are included under the title “The Agile Movement.” They describe a culture in which change is welcome, and the customer is the focus of the work. They also demonstrate the movement’s intent as described by Alistair Cockburn, one of the signatories to the Agile Manifesto, which is to bring development into alignment with business needs.
The twelve principles of agile development include:
**1.Customer satisfaction through early and continuous software delivery – **
Customers are happier when they receive working software at regular intervals, rather than waiting extended periods of time between releases.
**_2.Accommodate changing requirements throughout the development process_** –
The ability to avoid delays when a requirement or feature request changes.
**_3.Frequent delivery of working software_** –
Scrum accommodates this principle since the team operates in software sprints or iterations that ensure regular delivery of working software.
**_4.Collaboration between the business stakeholders and developers throughout the project_** –
Better decisions are made when the business and technical team are aligned.
**_5.Support, trust, and motivate the people involved_** – Motivated teams are more likely to deliver their best work than unhappy teams.
**_6.Enable face-to-face interactions _**–
Communication is more successful when development teams are co-located.
_**7.Working software is the primary measure of progress**_ – Delivering functional software to the customer is the ultimate factor that measures progress.
**_8.Agile processes to support a consistent development pace_** – Teams establish a repeatable and maintainable speed at which they can deliver working software, and they repeat it with each release.
**_9.Attention to technical detail and design enhances agility _**– The right skills and good design ensures the team can maintain the pace, constantly improve the product, and sustain change.
**_10.Simplicity_** – Develop just enough to get the job done for right now.
**_11.Self-organizing teams encourage great architectures, requirements, and designs _**–
Skilled and motivated team members who have decision-making power, take ownership, communicate regularly with other team members, and share ideas that deliver quality products.
**_12.Regular reflections on how to become more effective_** –
Self-improvement, process improvement, advancing skills, and techniques help team members work more efficiently.
The intention of Agile is to align development with business needs, and the success of Agile is apparent. Agile projects are customer focused and encourage customer guidance and participation. As a result, Agile has grown to be an overarching view of software development throughout the software industry and an industry all by itself.
| kapilborbande | |
1,159,957 | SvelteKit Content Security Policy: CSP for XSS Protection | SvelteKit Content Security Policy: how you can add CSP to reduce your Svelte site's cross-site scripting (XSS) attack surface. | 0 | 2022-08-05T11:35:16 | https://rodneylab.com/sveltekit-content-security-policy/ | webdev, security, javascript, svelte | ---
title: "SvelteKit Content Security Policy: CSP for XSS Protection"
published: "true"
description: "SvelteKit Content Security Policy: how you can add CSP to reduce your Svelte site's cross-site scripting (XSS) attack surface."
tags: "webdev, security, javascript, svelte"
canonical_url: "https://rodneylab.com/sveltekit-content-security-policy/"
cover_image: "https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ivunc03vz7rrbtq8lj3e.png"
---
## 😕 What is Content Security Policy?
Today we look at SvelteKit Content Security Policy. Content Security Policy is a set of meta you can send from your server to visitors’ browsers to help improve security. It is designed to reduce the **cross site scripting (XSS)** attack surface. At its core, the script directives help the browser identify foreign scripts which might have been injected by a malicious party. However, content security policy covers **styles**, **images** and **other resources** beyond scripts.
We see with scripts we can compute a **cryptographic hash** of the intended script on the server and send this with the page. By hashing the received script itself and comparing to the list of CSP hashes, the browser can potentially spot injected malicious scripts. We will see hashing is not the only choice and see when you might consider using the alternatives. SvelteKit got a patch in February which lets it automatically compute script hashes and inject a content security policy tag in the page head.
You should only attempt to update content security policy if you are **confident** you know what you are doing. It is possible to completely stop a site from rendering with the wrong policy.
## 🔬 What is our Focus?
We will see why and how we can use the SvelteKit generated CSP meta tag to add an HTTP Content Security Policy header to a static site. As well as that, we also look at the configuration for deploying the site with headers to Netlify and Cloudflare Pages. We will use the SvelteKit MDsveX blog starter, though the approach should work well with other sites. This should all get us an A rating on SecurityHeaders.com for the site.

## ⚙️ Configuration
If you want to code along, then clone the SvelteKit MDsveX blog starter and install packages:
```shell
git clone https://github.com/rodneylab/sveltekit-blog-mdx.git sveltekit-content-security-policy
cd sveltekit-content-security-policy
pnpm install
pnpm run dev
```
We just need to update `svelte.config.js` to have it create the CSP meta for us:
```javascript
/** @type {import('@sveltejs/kit').Config} */
import adapter from "@sveltejs/adapter-static";
import { imagetools } from "vite-imagetools";
import { mdsvex } from "mdsvex";
import preprocess from "svelte-preprocess";
const config = {
extensions: [".svelte", ".md", ".svelte.md"],
preprocess: [
mdsvex({ extensions: [".svelte.md", ".md", ".svx"] }),
preprocess({
scss: {
prependData: "@import 'src/lib/styles/variables.scss';",
},
}),
],
kit: {
adapter: adapter({ precompress: true }),
csp: {
mode: "hash",
directives: { "script-src": ["self"] },
},
files: {
hooks: "src/hooks",
},
prerender: { default: true },
vite: {
define: {
"process.env.VITE_BUILD_TIME": JSON.stringify(new Date().toISOString()),
},
plugins: [imagetools({ force: true })],
},
},
};
export default config;
```
We can set mode to `hash`, `nonce` or `auto`. `hash` will compute a SHA256 cryptographic hash of all scripts which SvelteKit generates in building the site. These scripts are later used by visitors’ browsers to sniff out foul play. Hashes are a good choice for static sites. This is because scripts are fixed on build and will not change until you rebuild the site.
With SSR sites, SvelteKit might generate a different script for each request. To avoid the extra overhead of computing a set of hashes for each request an alternative is to use a **nonce**. The nonce is just a randomly generated string. We just add the nonce to each script tag and also include it in the CSP meta. Now the browser just checks the nonce in the script match the one in the meta. For this to work best, we need to generate a new random nonce with each request.
The third option, `auto`, simply chooses `hash` for prerendered content and `nonce` for anything else.
### Alternative Configuration
This configuration (above) is a little basic. You might want to be a bit more extensive configuration. In this case it makes more sense to extract the configuration to a separate file. In this case you can update `svelte.config.js` like so:
```javascript
/** @type {import('@sveltejs/kit').Config} */
import adapter from '@sveltejs/adapter-static';
import { imagetools } from 'vite-imagetools';
import { mdsvex } from 'mdsvex';
import preprocess from 'svelte-preprocess';
import cspDirectives from './csp-directives.mjs';
const config = {
extensions: ['.svelte', '.md', '.svelte.md'],
preprocess: [
mdsvex({ extensions: ['.svelte.md', '.md', '.svx'] }),
preprocess({
scss: {
prependData: "@import 'src/lib/styles/variables.scss';",
},
}),
],
kit: {
adapter: adapter({ precompress: true }),
csp: {
mode: 'hash',
directives: cspDirectives,
},
files: {
hooks: 'src/hooks',
},
prerender: { default: true },
vite: {
define: {
'process.env.VITE_BUILD_TIME': JSON.stringify(new Date().toISOString()),
},
plugins: [imagetools({ force: true })],
},
},
};
export default config;
```
Here is one possible set of values you might use. Of course this will not match your use case and you should determine a set of values which are suitable.
```javascript
const rootDomain = process.env.VITE_DOMAIN; // or your server IP for dev
const cspDirectives = {
'base-uri': ["'self'"],
'child-src': ["'self'"],
'connect-src': ["'self'", 'ws://localhost:*'],
// 'connect-src': ["'self'", 'ws://localhost:*', 'https://hcaptcha.com', 'https://*.hcaptcha.com'],
'img-src': ["'self'", 'data:'],
'font-src': ["'self'", 'data:'],
'form-action': ["'self'"],
'frame-ancestors': ["'self'"],
'frame-src': [
"'self'",
// "https://*.stripe.com",
// "https://*.facebook.com",
// "https://*.facebook.net",
// 'https://hcaptcha.com',
// 'https://*.hcaptcha.com',
],
'manifest-src': ["'self'"],
'media-src': ["'self'", 'data:'],
'object-src': ["'none'"],
'style-src': ["'self'", "'unsafe-inline'"],
// 'style-src': ["'self'", "'unsafe-inline'", 'https://hcaptcha.com', 'https://*.hcaptcha.com'],
'default-src': [
'self',
...(rootDomain ? [rootDomain, `ws://${rootDomain}`] : []),
// 'https://*.google.com',
// 'https://*.googleapis.com',
// 'https://*.firebase.com',
// 'https://*.gstatic.com',
// 'https://*.cloudfunctions.net',
// 'https://*.algolia.net',
// 'https://*.facebook.com',
// 'https://*.facebook.net',
// 'https://*.stripe.com',
// 'https://*.sentry.io',
],
'script-src': [
'self',
// 'https://*.stripe.com',
// 'https://*.facebook.com',
// 'https://*.facebook.net',
// 'https://hcaptcha.com',
// 'https://*.hcaptcha.com',
// 'https://*.sentry.io',
// 'https://polyfill.io',
],
'worker-src': ["'self'"],
// remove report-to & report-uri if you do not want to use Sentry reporting
'report-to': ["'csp-endpoint'"],
'report-uri': [
`https://sentry.io/api/${process.env.VITE_SENTRY_PROJECT_ID}/security/?sentry_key=${process.env.VITE_SENTRY_KEY}`,
],
};
export default cspDirectives;
```
## 🎬 First Attempt
You will need to build the site to see it’s magic work:
```shell
pnpm build
pnpm preview
```
Now if you open up the Inspector in you browser dev tools, then you should be able to find a meta tag which includes the content security policy.

This is all good, but when I deployed to Netlify and ran a test using the <a aria-label="Open security headers test site" href="https://securityheaders.com">securityheaders.com</a> site. I was getting nothing back for CSP. For that reason I tried an alternative approach. An alternative to including CSP in meta tags is to use HTTP headers. Both are valid, though the <a aria-label="Read about contens security policy" href="https://content-security-policy.com/examples/meta/">HTTP header is a stronger approach in most cases</a>. Additionally, using HTTP headers you can add reporting, using a service like Sentry. This gives you a heads up if users start getting CSP errors in their browser.
## 📜 Header Script
Netlify as well as Cloudflare Pages, let you specify HTTP headers for your static site by you including a `_headers` file in your `static` folder. The hosts parse this before deploy and then remove it (so it will not be served). My idea was to write a node script which we could run after the site is built. That script would crawl the `build` folder for HTML files and then extract the content security meta tag and add it to a `_headers` entry for the page.
Here is the node script I wrote. If you want to try a similar approach, hopefully it will not be too much work for you to tweak it to suit your own use case.
```javascript
import 'dotenv/config';
import fs from 'fs';
import path from 'path';
import { parse } from 'node-html-parser';
const __dirname = path.resolve();
const buildDir = path.join(__dirname, 'build');
const { VITE_SENTRY_ORG_ID, VITE_SENTRY_KEY, VITE_SENTRY_PROJECT_ID } = process.env;
function removeCspMeta(inputFile) {
const fileContents = fs.readFileSync(inputFile, { encoding: 'utf-8' });
const root = parse(fileContents);
const element = root.querySelector('head meta[http-equiv="content-security-policy"]');
const content = element.getAttribute('content');
root.remove(element);
return content;
}
const cspMap = new Map();
function findCspMeta(startPath, filter = /\.html$/) {
if (!fs.existsSync(startPath)) {
console.error(`Unable to find CSP start path: ${startPath}`);
return;
}
const files = fs.readdirSync(startPath);
files.forEach((item) => {
const filename = path.join(startPath, item);
const stat = fs.lstatSync(filename);
if (stat.isDirectory()) {
findCspMeta(filename, filter);
} else if (filter.test(filename)) {
cspMap.set(
filename
.replace(buildDir, '')
.replace(/\.html$/, '')
.replace(/^\/index$/, '/'),
removeCspMeta(filename),
);
}
});
}
function createHeaders() {
const headers = `/*
X-Frame-Options: DENY
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
Referrer-Policy: strict-origin-when-cross-origin
Permissions-Policy: accelerometer=(), camera=(), document-domain=(), encrypted-media=(), gyroscope=(), interest-cohort=(), magnetometer=(), microphone=(), midi=(), payment=(), picture-in-picture=(), publickey-credentials-get=(), sync-xhr=(), usb=(), xr-spatial-tracking=(), geolocation=()
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
Report-To: {"group": "csp-endpoint", "max_age": 10886400, "endpoints": [{"url": "https://o${VITE_SENTRY_KEY}.ingest.sentry.io/api/${VITE_SENTRY_ORG_ID}/security/?sentry_key=${VITE_SENTRY_PROJECT_ID}"}]}
`;
const cspArray = [];
cspMap.forEach((csp, pagePath) =>
cspArray.push(`${pagePath}\n Content-Security-Policy: ${csp}`),
);
const headersFile = path.join(buildDir, '_headers');
fs.writeFileSync(headersFile, `${headers}${cspArray.join('\n')}`);
}
async function main() {
findCspMeta(buildDir);
createHeaders();
}
main();
```
In lines `47`–`53` you will see I added some other HTTP headers which securityheaders.com looks for. The `findCspMeta` function, starting in line `22` is what does the heavy lifting for finding meta it the SvelteKit generated output. We also use the `node-html-parser` package to parse the DOM efficiently. In lines `34`–`40` we add the CSP content to a map with the page path as the key. Later we use the map to generate the `/build/_headers` file. We write `_headers` directly to build, instead of `static` since we run this script after the SvelteKit build.
Here is an example of the script output:
```plaintext
/*
X-Frame-Options: DENY
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
Referrer-Policy: strict-origin-when-cross-origin
Permissions-Policy: accelerometer=(), camera=(), document-domain=(), encrypted-media=(), gyroscope=(), interest-cohort=(), magnetometer=(), microphone=(), midi=(), payment=(), picture-in-picture=(), publickey-credentials-get=(), sync-xhr=(), usb=(), xr-spatial-tracking=(), geolocation=()
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
Report-To: {"group": "csp-endpoint", "max_age": 10886400, "endpoints": [{"url": "https://XXX.ingest.sentry.io/api/XXX/security/?sentry_key=XXX"}]}
/best-medium-format-camera-for-starting-out
Content-Security-Policy: child-src 'self'; default-src 'self'; frame-src 'self'; worker-src 'self'; connect-src 'self' ws://localhost:*; font-src 'self' data:; img-src 'self' data:; manifest-src 'self'; media-src 'self' data:; object-src 'none'; script-src 'self' 'sha256-KD6K876QaEoRcbVCglIUUkrVfvbkkiOzn+MUAYvIE3I=' 'sha256-zArBwCFLmTaX5PiopOgysXsLgzWtw+D2DfdI+gej1y0='; style-src 'self' 'unsafe-inline'; base-uri 'self'; form-action 'self'; report-to 'csp-endpoint'
/contact
Content-Security-Policy: child-src 'self'; default-src 'self'; frame-src 'self'; worker-src 'self'; connect-src 'self' ws://localhost:*; font-src 'self' data:; img-src 'self' data:; manifest-src 'self'; media-src 'self' data:; object-src 'none'; script-src 'self' 'sha256-t7R4W+8Ou9kpe3an17uRnyxB95SfUTIMJ/K2z6vu0Io=' 'sha256-zArBwCFLmTaX5PiopOgysXsLgzWtw+D2DfdI+gej1y0='; style-src 'self' 'unsafe-inline'; base-uri 'self'; form-action 'self'; report-to 'csp-endpoint'
/folding-camera
Content-Security-Policy: child-src 'self'; default-src 'self'; frame-src 'self'; worker-src 'self'; connect-src 'self' ws://localhost:*; font-src 'self' data:; img-src 'self' data:; manifest-src 'self'; media-src 'self' data:; object-src 'none'; script-src 'self' 'sha256-4xx4DsEsRBOVYIl2xwCtDOZ+mGnU01sxNiKHZH57Z6w=' 'sha256-zArBwCFLmTaX5PiopOgysXsLgzWtw+D2DfdI+gej1y0='; style-src 'self' 'unsafe-inline'; base-uri 'self'; form-action 'self'; report-to 'csp-endpoint'
/
Content-Security-Policy: child-src 'self'; default-src 'self'; frame-src 'self'; worker-src 'self'; connect-src 'self' ws://localhost:*; font-src 'self' data:; img-src 'self' data:; manifest-src 'self'; media-src 'self' data:; object-src 'none'; script-src 'self' 'sha256-mXijveCfKQlG2poJkRRzcdCDdFOlpwhP7utTdY0mOtU=' 'sha256-zArBwCFLmTaX5PiopOgysXsLgzWtw+D2DfdI+gej1y0='; style-src 'self' 'unsafe-inline'; base-uri 'self'; form-action 'self'; report-to 'csp-endpoint'
/twin-lens-reflex-camera
Content-Security-Policy: child-src 'self'; default-src 'self'; frame-src 'self'; worker-src 'self'; connect-src 'self' ws://localhost:*; font-src 'self' data:; img-src 'self' data:; manifest-src 'self'; media-src 'self' data:; object-src 'none'; script-src 'self' 'sha256-w5p2NquSvorJBfJewyjpg4Lm1Mzs7rALuFMPfF7I/OI=' 'sha256-zArBwCFLmTaX5PiopOgysXsLgzWtw+D2DfdI+gej1y0='; style-src 'self' 'unsafe-inline'; base-uri 'self'; form-action 'self'; report-to 'csp-endpoint'
```
To run the script, we just update the `package.json` build script:
```json
{
"name": "sveltekit-blog-mdx",
"version": "2.0.0",
"scripts": {
"dev": "svelte-kit dev --port 3030",
"build": "npm run generate:manifest && svelte-kit build && npm run generate:headers",
"preview": "svelte-kit preview --port 3030",
"check": "svelte-check --fail-on-hints",
"check:watch": "svelte-check --watch",
"lint": "prettier --check --plugin-search-dir=. . && eslint --ignore-path .gitignore .",
"lint:scss": "stylelint \"src/**/*.{css,scss,svelte}\"",
"format": "prettier --write --plugin-search-dir=. .",
"generate:headers": "node ./generate-headers.js",
"generate:images": "node ./generate-responsive-image-data.js",
"generate:manifest": "node ./generate-manifest.js",
"generate:sitemap": "node ./generate-sitemap.js",
"prettier:check": "prettier --check --plugin-search-dir=. .",
"prepare": "husky install"
},
```
## 💯 SvelteKit Content Security Policy: Testing it Out
Redeploying to Netlify and testing with securityheaders.com once more, everything now looks better.

One thing you might notice, though, is that the score is capped at A (A+ is the highest rating). This is because, for now, we need to include the `unsafe-inline` directive for styles (see line `23` of `csp-directives.mjs`).

This limitation is mentioned in the <a aria-albel="Open the Content security policy pull request on the Svelte Kit repo" href="https://github.com/sveltejs/kit/pull/3499">SvelteKit CSP pull request</a>. The note there says this will not be needed once Svelte Kit moves to using the Web Animations API.
## 🙌🏽 SvelteKit Content Security Policy: Wrapup
In this post, we have taken a peek at this new SvelteKit Content Security Policy feature. In particular we have touched on:
- why you might go for **CSP hashes** instead of **nonces**,
- a way to extract SvelteKit’s generated CSP meta for each page,
- how you can serve **CSP security HTTP headers** on your static SvelteKit site,
Let me know if you have different or cleaner ways of achieving the same results. You can drop a comment below or reach out for a chat on <a aria-label="Jump into the Element Matrix chat room" href="https://matrix.to/#/%23rodney:matrix.org">Element</a> as well as <a aria-label="Mention on Twitter" href="https://twitter.com/intent/user?screen_name=@askRodney">Twitter @mention</a>
You can see the full code for this SvelteKit Content Security Policy post <a aria-label="Open the Rodney Lab Git Hub repo" href="https://github.com/rodneylab/sveltekit-content-security-policy" rel="follow noopener noreferrer">in the Rodney Lab Git Hub repo</a>.
## 🙏🏽 SvelteKit Content Security Policy: Feedback
If you have found this video useful, see links below for further related content on this site. I do hope you learned one new thing from the video. Let me know if there are any ways I can improve on it. I hope you will use the code or starter in your own projects. Be sure to share your work on Twitter, giving me a mention so I can see what you did. Finally be sure to let me know ideas for other short videos you would like to see. Read on to find ways to get in touch, further below. If you have found this post useful, even though you can only afford even a tiny contribution, please <a aria-label="Support Rodney Lab via Buy me a Coffee" href="https://rodneylab.com/giving/">consider supporting me through Buy me a Coffee</a>.
Finally, feel free to share the post on your social media accounts for all your followers who will find it useful. As well as leaving a comment below, you can get in touch via <a href="https://twitter.com/messages/compose?recipient_id=1323579817258831875">@askRodney</a> on Twitter and also <a aria-label="Contact Rodney Lab via Telegram" href="https://t.me/askRodney">askRodney on Telegram</a>. Also, see <a aria-label="Get in touch with Rodney Lab" href="https://rodneylab.com/contact">further ways to get in touch with Rodney Lab</a>. I post regularly on <a aria-label="See posts on svelte kit" href="https://rodneylab.com/tags/sveltekit/">SvelteKit</a> as well as <a href="https://rodneylab.com/tags/seo" aria-label="See posts on search engine optimisation">Search Engine Optimisation</a> among other topics. Also <a aria-label="Subscribe to the Rodney Lab newsletter" href="https://rodneylab.com/about/#newsletter">subscribe to the newsletter to keep up-to-date</a> with our latest projects. | askrodney |
1,160,166 | Quick Guide to YAML | YAML is a data serialization format and processing model, used extensively for log files, Internet... | 0 | 2022-08-05T12:40:46 | https://dev.to/jainnehaa/quick-guide-to-yaml-ncm | **YAML** is a _data serialization_ format and _processing model_, used extensively for log files, Internet messaging, filtering and can be used in conjunction with other programming languages.
In computing, serialization is the process of translating a data structure or object state into a format that can be stored or transmitted and reconstructed later possibly in a different computer environment. XML, JSON, BSON, YAML, MessagePack, protobuf are some commonly used data serialization formats.
YAML is a superset of JSON, so JSON files are valid in YAML.
YAML stands for '_**Yet Another Markup Language**_' or '**_YAML Ain’t Markup Language_**', which emphasizes that YAML is for data and not documents.
YAML files can be added to source control, such as Github, so that changes can be tracked and audited.
YAML uses <u>indentation </u>to indicate nesting. Tab characters are not allowed, so <u>whitespaces </u>are used instead. There are no usual format symbols, such as braces, square brackets, closing tags, or quotation marks. YAML files use a <u>.yml</u> or <u>.yaml</u> extension.
The structure of a YAML file is a <u>map</u> or a <u>list</u>. It also contains <u>scalars</u>, which are arbitrary data encoded in Unicode, that can be used as values such as strings, integers, dates, numbers, or booleans.
**_YAML parser_** is used to read YAML documents and provide access to their content and structure.
**_YAML emitter_** is used to write YAML documents, serializing their content and structure.
**_YAML processor_** is a module that provides parser or emitter functionality or both.
**<u>YAML Syntax Example :</u>**
```
---
# An employee record
name: Martin D'vloper
job: Developer
skill: Elite
employed: True
foods:
- Apple
- Orange
- Strawberry
- Mango
languages:
perl: Elite
python: Elite
pascal: Lame
education: |
4 GCSEs
3 A-Levels
BSc in the Internet of Things
```
<u>Three dashes</u> indicate start of a new YAML document. YAML supports multiple documents and compliant parsers will recognize each set of dashes as the beginning of a new one. The construct that makes up most of a typical YAML document is a <u>key-value pair</u>.
YAML supports nesting of key-values, and mixing types.
YAML has been criticized for its significant whitespace, confusing features, insecure defaults, and its complex and ambiguous specification.
Configuration files can execute commands or load contents without the users realizing it. Editing large YAML files is difficult, as indentation errors can go unnoticed. Truncated files are often interpreted as valid YAML due to the absence of terminators.
The perceived flaws and complexity of YAML has led to the emergence of stricter alternatives such as _StrictYAML_ and _NestedText_.
**<u>References :</u>**
[Redhat](https://www.redhat.com/en/topics/automation/what-is-yaml)
[yaml.org](https://yaml.org/)
[yaml.org](https://yaml.org/spec/history/2001-12-10.html)
[wiki](https://en.wikipedia.org/wiki/YAML)
[blogs](https://www.cloudbees.com/blog/yaml-tutorial-everything-you-need-get-started) | jainnehaa | |
1,160,299 | What’s the deal with Bun? | If you stumbled upon this article, you’re probably wondering what Bun is. You’re in luck, as I’m... | 0 | 2022-08-05T16:02:00 | https://reactive.so/post/whats-the-deal-with-bun | javascript, typescript, node, bunjs | If you stumbled upon this article, you’re probably wondering what Bun is. You’re in luck, as I’m about to tell you everything there is to know about Bun.
So what is Bun? Essentially, it’s a new JS runtime, similar to Node. Unlike Node, however, Bun is insanely fast. Like seriously, seriously fast. We’ll look at that later though, let’s first look at the existing problem with Node.
## What’s wrong with Node?
Node has been around since 2009. Since then, the web and server ecosystem has vastly changed. Many of Node’s issues have been covered by the creator, Ryan Dahl ([in this conference](https://www.youtube.com/watch?v=M3BM9TB-8yA)). A quick TL;DR is that Node doesn’t support built-in TypeScript, JSX, or Environment Variables. Moreover, its package manager, NPM, is famous for the `node_modules` folder of doom.
## How is it so fast?
Bun is built with Zig, a low-level programming language with manual memory management. It uses the JavaScriptCore Engine, which tends to be a little more performant than Google’s V8 Engine.
Bun mostly accredits its speed to Zig, stating the following on their [website](https://bun.sh/):
> Zig’s low-level control over memory and lack of hidden control flow makes it much simpler to write fast software.
>
## Benchmarks
Jarred Sumner, has made numerous benchmarks on Twitter regarding the speed of Bun compared to Node and Deno. Below, I’m going to be running some tests locally to see if Bun really stands up to these other runtimes. In each test, the script will simply save a text file locally. I’m using Mitata to test the speed.
### Testing Bun
```jsx
// ./scripts/bun.js
import { write } from "bun";
import { bench, run } from "mitata";
const file = "./out/bun.txt";
bench("bun:write", async () => {
await write(file, "hello world");
})
await run();
```
```bash
➜ bench bun ./scripts/bun.js
cpu: Apple M1
runtime: bun 0.1.6 (arm64-darwin)
benchmark time (avg) (min … max) p75 p99 p995
------------------------------------------------- -----------------------------
bun:write 76.86 µs/iter (64.79 µs … 2.35 ms) 75.5 µs 139.38 µs 246.17 µs
```
### Testing Node
```jsx
// ./scripts/node.mjs
import { writeFileSync } from "fs";
import { bench, run } from "mitata";
const file = "./out/node.txt";
bench("node:write", async () => {
writeFileSync(file, "hello world");
})
await run();
```
```bash
➜ bench node ./scripts/node.mjs
cpu: Apple M1
runtime: node v18.7.0 (arm64-darwin)
benchmark time (avg) (min … max) p75 p99 p995
-------------------------------------------------- -----------------------------
node:write 94.55 µs/iter (65.92 µs … 29.59 ms) 78.29 µs 129.25 µs 217.13 µs
```
### Testing Deno
```jsx
// ./scripts/deno.mjs
import { bench, run } from "https://esm.run/mitata";
const file = "./out/deno.txt";
bench("deno:write", async () => {
Deno.writeTextFileSync(file, "hello world");
})
await run();
```
```bash
➜ bench deno run -A ./scripts/deno.mjs
Download https://cdn.jsdelivr.net/npm/fs/+esm
cpu: Apple M1
runtime: deno 1.24.2 (aarch64-apple-darwin)
benchmark time (avg) (min … max) p75 p99 p995
-------------------------------------------------- -----------------------------
deno:write 110.66 µs/iter (74.25 µs … 5.88 ms) 129.79 µs 162.33 µs 179.75 µs
```
On all three occasions, a file was written to storage. Below is a table containing the runtime used, the native API used, and the final speed.
| Runtime | API | Average Speed |
| --- | --- | --- |
| Bun | Bun.write() | 76.86µs |
| Node | fs.writeFileSync | 94.55µs |
| Deno | Deno.writeTextFileSync | 110.66µs |
As you can see, Bun is clearly ahead of Node and Deno in terms of server-side operations. I say server-side operation, as Bun doesn't fare as well when using client-side operations. In an upcoming post, I’ll be comparing Bun + Next.js against Deno + Fresh.
Also, a quick reminder that Bun is still in development. What you’ve seen in this post may be irrelevant in a few months. Just keep that in mind.
Anyway, I hope you found this article helpful 😄
Please consider sharing + following | herbievine |
1,160,409 | Qodana 2022.2 Is Available: 50+ New Inspections and CircleCI Orb | Qodana 2022.2 is now available, bringing new and improved code inspections for Java, Kotlin, Android,... | 0 | 2022-08-08T17:21:05 | https://blog.jetbrains.com/qodana/2022/08/qodana-2022-2/ | javascript, python, releases, circleci | ---
title: Qodana 2022.2 Is Available: 50+ New Inspections and CircleCI Orb
published: true
date: 2022-08-05 15:12:57 UTC
tags: javascript,python,releases,circleci
canonical_url: https://blog.jetbrains.com/qodana/2022/08/qodana-2022-2/
---
Qodana 2022.2 is now available, bringing new and improved code inspections for Java, Kotlin, Android, PHP, JS, and Python. Additionally, we’ve added [CircleCI Orb](https://circleci.com/developer/orbs/orb/jetbrains/qodana?version=2022.2.1) to the Qodana integration toolset.

[GET STARTED WITH QODANA](https://www.jetbrains.com/qodana "GET STARTED WITH QODANA")
## More CIs to run Qodana with
Qodana already has plugins for [Azure Pipelines](https://www.jetbrains.com/help/qodana/qodana-azure-pipelines.html), [GitHub Actions](https://www.jetbrains.com/help/qodana/qodana-github-action.html), and [TeamCity](https://www.jetbrains.com/help/qodana/teamcity.html). Starting from 2022.2, we’ve prepared a [CircleCI Qodana orb](https://circleci.com/developer/orbs/orb/jetbrains/qodana) that allows you to set up code inspections quickly and easily with your CircleCI projects.
Also, it’s easy to set up Qodana in [GitLab](https://www.jetbrains.com/help/qodana/gitlab.html), [Jenkins](https://www.jetbrains.com/help/qodana/jenkins.html), or [any other CI that supports running Docker images](https://www.jetbrains.com/help/qodana/getting-started.html#docker-image-tab).
## New inspections
### Regular expressions
Regular expressions are widely known for their complexity, intricate syntax, and sometimes verbosity. To make life easier, we’ve added new inspections in this area. Previously these inspections were available only for Java, but we’ve now made them available for all languages.
#### Simplified regular expressions
A regular expression like `[\wa-z\d]` can be simplified to just `\w` since `\w` already includes `a-z` as well as the digits. It helps improve the code’s overall readability.
#### Suspicious backreferences
A regular expression like `\1(abc)` cannot match anything. This is because the `\1` refers to the `abc` that is not yet defined when evaluating the `\1`. This inspection prevents simple typos in regular expressions and speeds up the editing experience.
#### Redundant `\d`, `[:digit:]`, or `\D` class elements
The regular expression `[\w+\d]` can be written as `[\w+]`, as the `\w` already includes the `\d`. It helps improve the code’s overall readability.
### Markdown support
#### Incorrectly numbered list items
Ordered list items like `1. 2. 4.` are marked as being inconsistently numbered. In the rendered Markdown, the list is still displayed as `1. 2. 3.`, but the inconsistency makes editing the source code harder.
### Java, Kotlin, and Android inspections
We’ve added and reorganized inspections in the categories: Javadoc, DevKit, Markdown, Kotlin language, style, architectural patterns, performance, and JUnit support. Here are a couple of examples from the JUnit set.
#### JUnit: Malformed Declaration
Reports the JUnit test member declarations that are malformed and are likely not to be recognized by the JUnit test framework. Declarations like these could result in unexecuted tests or lifecycle methods.

#### JUnit: Unconstructable TestCase
Reports JUnit test cases that can’t be constructed because they have an invalid constructor. Test cases like these will not be picked up by the JUnit test runner and will therefore not execute.
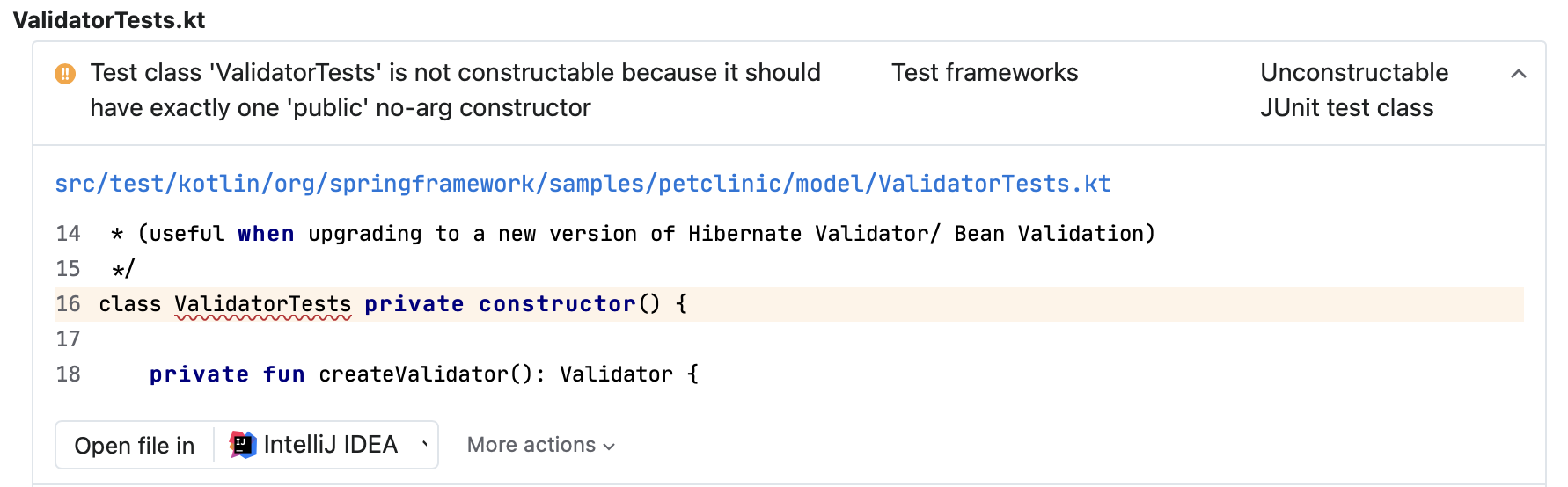
Those examples you can see live on [our public TeamCity instance](https://qodana.teamcity.com/buildConfiguration/Hosted_Root_Java_Build/61718?buildTab=Qodana&genericFilters=N4IgLg9hA2IFwG0QGEIBMCmACAkgOwGcAHDAYzAEsI8QBdAGhAIwDcMAnCsAT3iQAkKAcwAWdRqQCGYDEIjteiEABUMBMFgBm7SQFsMAd3kBrAnQC%2BQA&locationFilters=NoXSA&orderedLevels=NoIgLg9hA2IDQgM4FMBuyBOBLMBPeIAxgIZjIDmEG%2BCeADsiALpA&showingBaseline=GYQwNgzgpkA). Please use the Guest login to enter. Other inspections are described in [our documentation](https://www.jetbrains.com/help/qodana/2022.2/new-in-2022-2.html).
### PHP inspections
We added inspections in Probable bugs, Documentation, Style, Testing, and Laravel categories, for example:
#### Probable bug: Number ranges mismatch
In a function that is declared with `returns int<0,10>`, marks return statements that return a number outside this range. Similarly for fields, field constructors and function calls.
#### Documentation: Type tag without variable name
The PHPDoc snippet `@param string` is redundant as it doesn’t say _what_ is a string. It should be either removed or replaced with `@param string $argument`, saying that _argument_ is a string.
#### Blade: Parse error due to unpaired parentheses in string literals
Early detection of unpaired parentheses in string literals that are later parsed by Blade, a template engine.
To include or exclude certain inspections from your analysis, you can customize your default inspection profile or create a brand new one. You may also want to enforce inspections that are important to your coding guidelines or best practices. Check out our [Qodana documentation](https://www.jetbrains.com/help/qodana/qodana-yaml.html#Include+an+inspection+into+the+analysis+scope) for more information.
If you have any suggestions for future blog topics or if you want to learn more about how Qodana can help you and your business, post a comment here, tag us on [Twitter](https://twitter.com/Qodana), or contact us at _qodana-support@jetbrains.com_.
_Your Qodana team_ | tiulpin |
1,160,625 | Avatar Maker - Create cartoon avatars online for free | Ava Maker, also named Avatar Maker, is a free online tool that creates amazing avatar pictures,... | 0 | 2022-08-06T00:30:45 | https://dev.to/avatarmaker/avatar-maker-create-cartoon-avatars-online-for-free-2ed | avatar, cartoon, maker | Ava Maker, also named Avatar Maker, is a free online tool that creates amazing avatar pictures, cartoon profile pictures, and even NFTs. You can generate your own avatar from different styles and a wide variety of options. Cartoon yourself in 3 seconds. Click on one button and create more than 10000 different avatar picture results.
Visit us at: https://avamake.com | avatarmaker |
1,160,846 | How to hide and use API keys when hosting your web app on Netlify similar to .env files | If you're here, you're probably familiar with using .env file variables. If not head on over here to... | 0 | 2022-08-07T06:07:00 | https://dev.to/renegadedev/how-to-hide-and-use-api-keys-when-hosting-your-web-app-on-netlify-similar-to-env-files-m5m | webdev, react, netlify, tutorial | If you're here, you're probably familiar with using **.env** file variables. If not head on over [here](https://dev.to/renegadedev/hiding-api-keys-and-links-in-env-files-for-local-development-of-react-web-apps-26oi) to read my other article that helps you establish **.env** files to store API keys and other variables securely for local development.
#### Let's create environment variables similar to the .env files in Netlify:
**Step 1:** Go to Netlify -> Select your **site** -> Then select **Deploys** in the top navigation bar
**Step 2:** Then select **Deploy Settings** -> now select **Environment** in the left pane
**Step 3:** In **Environment** under **Environment Variables** -> Add in your environment variables with their values like shown below and remember to follow the format of **REACT_APP** followed by variable name in **snake case** as React requires it in that format in order to be used and hit save:
**Step 4:** In your app you should just be able to use in the component as follows:
```javascript
const ApiKey = process.env.REACT_APP_API_KEY
```
That's it you're all done, you should now be able to use your hidden API key in your app even when it's hosted on Netlify.
<img src="https://media.giphy.com/media/8UF0EXzsc0Ckg/giphy.gif" alt="all done"> | renegadedev |
1,162,727 | Customer Feedback Strategies for Indie Makers | Customer feedback is the lifeblood of any SaaS business. It can be difficult to get,... | 0 | 2022-08-09T06:12:00 | https://dev.to/ayushjangra/customer-feedback-strategies-for-indie-makers-51mb | saas, business, productivity, showdev | Customer feedback is the lifeblood of any SaaS business. It can be difficult to get, though—especially if you're an indie maker working solo or with a small team. But customer feedback strategies are critical for growing your business.
How do you get people to talk about their experience? How do you make sure that the feedback is useful without being too time-consuming on your part? And how do you make sure that the customer knows that their input matters?
I've got some answers for you!
Customer feedback is an essential part of a business's growth. It allows you to:
1. understand your customers better
2. improve your product and services
3. increase revenue and sales
4. build better relationships with your customers
However, getting customer feedback isn't always easy.
If you're an indie maker, you may have limited resources or experience with running a business. You may not even be sure where to start!
## Why do you need customer feedback?
You need [customer feedback](https://supahub.com/blog/what-is-user-feedback-and-how-to-collect-it) in order to grow your SaaS business in three ways:
1. To improve customer service by knowing what customers want and how they feel about their experience with your company,
2. To make more money by finding out why customers aren't buying from you; and
3. To attract more customers by showing them that you care about their opinions and needs.
## Customer feedback strategies to improve your product and revenue
Customer feedback is the fuel that keeps a SaaS business running. That's why we've put together this list of [customer feedback strategies](https://supahub.com/blog/customer-feedback-strategy) to help you grow your business and improve your product.
1. Offer free trials.
2. Create a community around your product.
3. Use [customer feedback tools](https://supahub.com/blog/customer-feedback-tools) to get feedback from customers and potential customers on what they like and don't like about your product.
4. Create an incentive program for customers who provide feedback: reward them with access to members-only content or early bird discounts on new products or services, for example.
## Conclusion
I hope this guide has been helpful in giving you some strategies for growing your business.
If you are an indie maker, it's important to remember that there are many ways to get feedback from your customers and some of them may not seem like they'd be effective at first glance.
But don't worry! The key is to keep trying different methods until you find one that works for you.
Here's a more detailed [customer feedback strategies](https://supahub.com/blog/customer-feedback-strategy) | ayushjangra |
1,161,001 | Ideas in React : 3 fundamental questions answered | Table of Contents What is this post about? What should you expect and what do I... | 0 | 2022-08-10T11:51:00 | https://dev.to/zyabxwcd/answering-some-fundamental-questions-about-the-react-ecosystem-aka-feeling-closer-to-react-4ign | react, webdev, javascript, career | ## Table of Contents
- [What is this post about? What should you expect and what do I expect.](#about-this-post)
- [#Question 1](#what-does-react-being-declarative-mean) What does React being 'declarative' mean?
- [#Question 2](#jsx-what-and-why) JSX: What and Why?
- [#Question 3](#why-is-immutability-important-when-working-with-react) Why is immutability important when working with React?
- [Conclusion](#conclusion)
- References
## About this post
Welcome to my first post! Ever wondered about the principles driving React? Whether you're a seasoned developer or just curious, you're in for a dive into widely accepted practices within the React community. We're delving deep into fundamental questions, unpacking declarative programming, JSX, and immutability—key aspects that many in the community consider important for React development.
A bit of React, JavaScript, or programming know-how is recommended. These principles, including declarative programming, JSX, and immutability, are widely embraced community conventions and recommendations associated with React.
For years, I've wanted to share insights, aiming for clarity (and maybe taking it easy). Perfection can wait. If you spot quirks or have ideas for improvement, drop a comment below.
Ready to explore React's foundational community-backed principles? Let's dive in!
## What does React being 'declarative' mean?
In a general programming sense, declarative programming refers to an approach where through code we declare/describe the objective of our program, the end goal, or in other words, we only tell the answer to the question, "What do we want to achieve at the end?". In the React world, the question would be more like, "What should it look like?".
This can be understood in contrast to what is called the "Imperative programming style," wherein we describe the steps to achieve a task.
In terms of UI, it can be translated into **_not_** describing or defining how, when and what DOM mutations we need to do (the imperative style) _**and instead**_ describing the UI state(s). By a UI state, we mean what the UI should look like when the variables involved or representing the component's state assume certain values.
The Imperative Way
```javascript
const showElement = ele => {
if(!ele.classList.contains('show')){
ele.classList.add('show')
}
}
const ele = document.getElementById('dummyElement');
if(boolState) showElement(ele)
else hideElement(ele)
// both of the functions called above,
// define the DOM mutations needed to be done
// in order to do what their name suggests
```
The Declarative Way
```javascript
boolState ? <Element /> : null
```
"Why is this great and needed?" you may ask. Well, with this style of programming, we can focus on what our UI should look like, which is the main purpose while developing a frontend. We don't need to burden ourselves with manipulating and cleaning things up in DOM. React does that heavy lifting for us in an efficient and reliable way, perhaps better than if we had implemented it ourselves.
Going forward in software development, more and more of this "how to do something" will be abstracted away from us. Ofc, one downside to this is that we have limited control and access to how the program achieves the result we told it to, but more often than not, people do it right.
In a nutshell, the declarative-styled code tells you "it should look like this" whereas imperative styled code will tell you "this is what you should do". So when developing in React, maybe you should not think of how you are going to do a certain thing but start with the end in the mind and think about what you want to achieve.
*NOTE: In order to keep your React code inline with this philosophy, please avoid executing DOM mutations directly just because you can. It defeats the purpose of React, apart from breaking away or interfering with how React manages the UI.*
## JSX: What and Why?
JSX or JavaScript XML is a syntax extension to JavaScript created by the folks at Facebook in order to simplify the developer/development experience.
It is a really powerful syntax that eases out the task of creating and manipulating HTML and adding it to the DOM in React.
```javascript
const element = <h1>Hello, world!</h1>
```
This funny tag syntax is neither a string nor HTML.
*We pass around tree structures composed of HTML and/or React Elements like normal JS values* and it creates an HTML element out of it and adds it to the DOM. Every HTML element written in JSX is parsed or converted into a React.createElement call.
By letting us write HTML in React, we can utilize the features provided by React to create dynamic web applications.
Although its not a mandatory requirement to use JSX, it constitutes an important piece in the React Ecosystem. Its creators term it a **'template language that comes with the full power of JS'**. It allows us to describe the UI in HTML, making development in React much easier by reducing syntax overhead at dev end.
Using JSX means you will be creating something called as **React Component** in which the markup and the logic are tightly coupled. These components or units form a loosely coupled way to separate concerns as per the React way, instead of dividing out the markup and the logic into separate files like many other libraries or frameworks.
The React ecosystem insists on organising the application into modular React components. Although React is not opinionated, the philosophy that is generally considered best practise and the one that is encouraged is to divide your application into small, preferably stateless React components.
**Bonus:** JSX Prevents Injection Attacks or [XSS(cross-site-scripting) Attacks](https://www.synopsys.com/glossary/what-is-cross-site-scripting.html). Therefore, embedding user input in JSX is not a worry. Click [here](https://reactjs.org/docs/introducing-jsx.html#jsx-prevents-injection-attacks) for a brief know how.
## Why is immutability important when working with React?
I am assuming you are **familiar** about Immutability in React since virtually every React guide mentions it so I am going to skip ahead. Here, as you go along, you will get to know how the fate of data Immutability and React are intertwined. This little to and fro will help you get an intuition of the why.
React has this concept of props and state variables. **From a birds eye view its safe to say**, if they change, React simply repaints the DOM by re-rendering the component. React encapsulates the task of transforming the DOM from one state to another.
It cant assume anything about that state since we can update anything and that is why on each state change, it re-renders the component entirely, even if we know its not required.
"We must be calculating a diff right?! We'll know what changed and we are good to go." you say.
Yeaaa, but the problem that arises with that is that props or state variables can be multi-level nested objects.
So, although doable, this means we will have to calculate a diff every time and before each render. It sounds daunting, considering the nesting can be done upto any level.
"No worries. We can do a value check for primitive types and a reference check for others. That'll do the trick," you say.

"Right?"

Not so fast. These object data types are mutable and their reference doesn't change if their values are mutated unlike primitive types. Check [this](https://developer.mozilla.org/en-US/docs/Glossary/Mutable) and [this](https://gomakethings.com/mutable-vs.-immutable-in-javascript/) out. In that particular order, I might add.
"What do we do now? How do we find a solution to our 'what changed problem'?"
Let's take a step back. If we have somehow solved this problem, this means that the next step for React is to simply repaint the DOM since it has got to know that something has changed. Doesn't this mean that React can still work its way even if it only knows that something has changed instead of knowing exactly what has changed?
"Hmm, makes sense. But we don't want to calculate a diff and the reference doesn't change with mutation, so how would React know the data has changed?"
It won't on its own. That's why we will supply it with a new reference whenever we make a change, just like what the idea of data Immutability describes. Sending a new object that will have a different reference but all the values of the previous variable along with the changed value makes it easier to tell that something has changed than to actually compare the two objects and look for a difference.
In order to avoid deep equality checks to figure out if the state has changed, it does shallow checking, which means that if we don't, supply a new reference, the state change might not affect the UI since from React's POV, nothing has changed.
> This way, React stays blind to the actual low-level changes you make, but is only worried about whether you made a change or not.
<img width="100%" style="width:100%" src="https://c.tenor.com/COcSmM3DDf0AAAAC/he-hehe.gif">
There are ways, like the shouldComponentUpdate life-cycle method or using the second arg of React.memo HOC, to enable or implement deep equality checks that are employed explicitly in order to mostly improve performance when we know for sure that shallow checking is causing many more unwanted renders.
Immutability can also help make the code more explicit when data changes occur.
```javascript
const object = {
x: 2,
y: 4
}
const changedObject = performSomething(object)
object.x
object.y
changedObject.x
changedObject.y
```
Creating a changed copy because we are following the immutability approach, has marked the code that some operation has been performed and the values have changed.
It also makes, retrieving the older state easier.
### How do we achieve Immutability in React code in general?
For objects, we can use Object.assign or the newer Spread syntax. If the value you have to change is a nested one, you have to 'spread' your way to its level. For arrays, we need to either return a new array or find methods that update the arrays in an immutable way rather than in place.
**Some of those methods are:**
- Array.slice
- Array.map
- Array.filter
- Array.concat
**To Avoid:** unshift, shift, pop, push, splice
**Instead of using sort directly on your original array, sort a newly created copy of the array.**
> Yes, by implementing immutability, we are constantly creating new objects and arrays all the time.
This has a performance impact of its own, but it also boosts the apps performance. We need to experiment at a more detailed level to find out which one wins, although it also depends upon how the things are built.
Libraries like Immutable.js have tried to bring the efficiency of working with immutables closer to that of mutables, so that's a relief if creating new values all the time is giving you stress.
React also provides tools to work with immutable data structures and improve your application's performance. [Immutability helpers](https://github.com/kolodny/immutability-helper) and mixins(not recommended though) are a few examples.
**Cons:**
- Adds to dependencies and maybe a little more code.
It adds to the dependency since native idioms (the inbuilt methods we listed above) used to implement immutability are not very performant and we generally need external packages to implement this concept to the letter.
- Immutability can have a detrimental performance impact when the dataset is small, since computer architecture is desgined to mutate the data in a direct way.
- Inconsistency
Since its an idea and not a directly enforceable thing like code formatting through linters, it depends upon the developers to implement it with discipline and in a standard way. Because there is human factor overhead, consistency can break.
## Conclusion
I hope you learned a little bit about React and its philosophy through this post. I initially thought of covering one more topic of 'Using custom hooks to fix prop drilling instead of using the Context API or a state management library' but maybe later.
Also, I originally came across some of these questions through a comment on an article I was reading where the guy was outlining what he would ask or like to be asked in a React interview. I got wondering myself and as I finished my quest of finding the answers, I thought why not make a post.
Feel free to comment down some of the other questions that you think are worthy enough to be added to this list acting as a yardstick to checkout developers and making us feel closer to React.
Until next time, guys. See ya!
## References
https://reactjs.org/docs/introducing-jsx.html
https://www.freecodecamp.org/news/what-the-heck-is-jsx-and-why-you-should-use-it-to-build-your-react-apps-1195cbd9dbc6/
https://egghead.io/learn/react/beginners/wtf-is-jsx
https://danburzo.github.io/react-recipes/recipes/immutability.html
https://reactkungfu.com/2015/08/pros-and-cons-of-using-immutability-with-react-js/
https://github.com/kolodny/immutability-helper
https://www.dottedsquirrel.com/declartive-imperative/
| zyabxwcd |
1,161,004 | 174! (My first computer website I made on my personal home computer) | Now Under Construction As a "final project" for pre-work material I needed to make a simple... | 0 | 2022-08-06T18:06:00 | https://dev.to/elliotmangini/174-my-first-computer-website-i-made-on-my-personal-home-computer-1947 | css, javascript, beginners, music | 
<h1>Now Under Construction</h1>
As a "final project" for pre-work material I needed to make a simple website using JavaScript, CSS, and HTML.
<h2>Concept</h2>
I wanted to see if I could make a drum machine that would intuitively teach about certain drum & bass conventions. 174 is a common tempo in beats per minute for the genre.
That's how my super cool new computer website on the world wide web "[174!](https://elliotmangini.github.io/one_seventy_four/)" came to be!

<h2>Successes</h2>
Overarchingly I wanted to make something that was easy to use and didn't require explanation so please [have a play around with it](https://elliotmangini.github.io/one_seventy_four/). I was able to include the following...
-Toggle-able Sequencer buttons for Kick, Snare, Hihats, & 12-tone Bass
-Intuitive visual representation of musical subdivisions
-Play/Pause with spacebar functionality
-A "Hot Sampler" that plays sound effects and one button that stops and "rewinds"
-A video player to keep you company
-Metronome Lighting Effects
-Kick & Snare Sample Banks (These are my own drum designs ^_^)
<h2>Challenges To Overcome</h2>
I really struggled with the CSS part of this project. Centering things was not always easy and z-index in CSS didn't do what I expected it to do. At present the Hot Sampler doesn't work and I think it's because in order to center the buttons I put them in a div which was one big clickable element, then I had to send it to the back so most of the buttons would still be clickable. I don't understand how I was able to get vertical and horizontal centering successfully on some elements and not others. And elements that came in little groups like the 3 sixteenths that follow each quarter note made the challenge more difficult-- surprisingly sometimes leading to success and other times not.

THIS THING A HOT MESS, JEEZ.
I'd like to incorporate a way to save presets and I think I can do that by having a field that will spit out and accept characters corresponding to the variables stored in the JavaScript and DOM at different times.
I'd also like to create a "Performer" module that would appear at the top after 5-10 minutes that would allow you to perform macro operations like muting all of the kicks and bass at once with a button, or triggering a riser in time.
I haven't yet learned how to control the volume of samples.
The bass module would work better if it could trigger and mute longer samples instead of stitching together lots of 16th note samples to simulate sustained notes.
<h3>Other Feature Ideas:</h3>
- Break-Chopping module
- Make the display show text describing what the user just did
- Storing and switching between multiple patterns
- Percussion Loop Samplers Done "Simple"
Here are some console.logs I was using to help me keep my head on straight, those are things I want to have the DOM display on the little grey screen on the device to make it feel more alive and also give it an old school drum machine feel.
<h2>Things I learned along the way</h2>
I learned how to use the stop propagate event which at one point was making it so whenever you clicked a 16th note button it would also trigger a click event on the corresponding 1/4 note button since it is a container of each sixteenth.
It was eye-opening to see the parallels in music creation and coding here-- where sometimes in order to fix something that wasn't that difficult I felt a lot of internal resistance. If fixing the thing would make it a lot better sometimes that motivated me and other times felt like a mental block, just like with music. I was confronting the same ecosystem of emotions and thoughts with any creative problem-solving project I've attempted in the past. I hope to get better at that-- a hard skill to give a name to.
It all made me realize how a simple idea can expand pretty rapidly into something that a team would be needed to care for and bring to fruition. I'm looking forward to working on projects with others soon. If you'd like to team up with me on this please let me know! I think there are a lot of streamers on twitch who would get a kick out of playing with it and could be a great way to meet new people and all that!
Since this was my first site I also learned about Git and other things!
*Unexpected Cool Things*
There is obviously a "better" way to tackle this problem but the timing wonkiness of using a variable incrementing on a loop as a way to keep track of time passing in the DOM can be really pleasant at times and give it character. I think this character will be applied in different amounts depending on factors like the beefiness of the machine you're running the website on.
Also the default font for the main title looks jacked up in the coolest way to me, it's so bad it's good-- I love it.
<h2>In Conclusion</h2>
I learned a lot and had fun, there are still problems I *can* tackle, but it's time to share a little of the work and perhaps re-approach the problem with different strategies again in the future once I've learned more, or iterate on this version here and there as I go.
Onwards and upwards!
-Elliot/Big Sis
| elliotmangini |
1,161,502 | Everything you'll ever need to know about HTML Input Types | Pretty much every application we develop using HTML uses input somewhere, but there's a bunch of... | 0 | 2022-08-07T15:14:00 | https://fjolt.com/article/html-input-types | html, webdev, tutorial, beginners | Pretty much every application we develop using HTML uses `input` somewhere, but there's a bunch of input `type`s you might not know about. So let's take a look at everything you might not know about `input` types.
## Common HTML Input Types
In HTML, we can give an input a specific type. For example, a simple `text` input, where the user can type text into a box, looks like this:
```html
<input type="text" />
```
The most common input types we use are:
- `hidden` - a form input that is hidden, usually for storing values the user doesn't need to see
- `text` - a simple text input.
- `password` - an input where the text is starred out since it is a password.
- `submit` - a submit button for submitting the form.
- `button` - like a submit, but it doesn't submit the form!
- `radio` - a button which can be selected, from a range of list items.
- `checkbox` - a set of buttons which can be checked and unchecked.
As well as these basic types:
- there is also `search` - although not as commonly used, it can be used for a search input field, which shows a little cross when you type into it.
- and we also have `reset`, which creates a button which does not submit the form, and says `reset`. It will reset all other form elements.
These common `input` types are all over the place, and they look like this:
{% codepen https://codepen.io/smpnjn/pen/abYKbQR %}
## Basic HTML Inputs with Type Validation
As well as these simple types, there are a few others which can be quite useful, such as:
- `tel` - for a telephone number.
- `url` - validates that the input is a url.
- `email` - validates that the input is an email.
- `number` - validates that the input is a number.
- `range` - validates that the input is within a range.
**Note**: these input types do validate the input on the client side, but it should not be used as a method to ensure that an input only contains that type. For example, `email` only accepts an email type, but a user can easily change the frontend to submit something which is not an `email`. So make sure you check on the backend too.
{% codepen https://codepen.io/smpnjn/pen/XWEYWBq %}
## Date HTML Input Types
Most of us are familiar with `type="date"`, but there are a bunch of date types for HTML inputs, including:
- `date` - any date input.
- `month` - lets you select a single month.
- `week` - lets you select a single week.
- `time` - lets you select a specific time.
- `datetime-local` - lets you select date/time combination.
Each of these are shown below. These are pretty useful, although limited to the browser's implementation of the UI:
{% codepen https://codepen.io/smpnjn/pen/wvmXvXG %}
## Other HTML Input Types
As well as all of these, we also have the following additional types:
- `file` - for uploading a file to the server.
- `image` - the strangest of all, for graphical submit buttons!
### file type for inputs
The file type for inputs creates a file upload interface:
```html
<input type="file" />
```
### image type for inputs
This is probably the one you are least likely to use. It lets you give an `src` and `alt` attribute to your input, which is used as the submit button for your form - ultimately making your input act like an image:
```html
<input type="image" alt="Login" src="login-button.png" />
```
## Conclusion
That covers **every** HTML input type you can use today. I hope you've learned something new, even if it's just the quirky `type="image"` input type. If you want to learn more about web development, you can follow me on [twitter](https://twitter.com/smpnjn), or check out [fjolt](https://fjolt.com/). | smpnjn |
1,161,783 | How to make a CRUD operation By Nodejs and TypeScript .? | you can use a generic way to be applicable for any model you need, only you pass model and data type,... | 0 | 2022-08-08T05:01:00 | https://dev.to/emansaeed/how-to-make-a-crud-operation-by-nodejs-and-typescript--3hja | javascript, node, typescript, crud | you can use a generic way to be applicable for any model you need, only you pass model and data type, and you can apply all crud operations on it.
**source** [github](https://github.com/EmanSaeed331/CRUD/blob/main/crud.ts)
- CREATE
```
async function create<T>(data:T , model:any){
const newObj = await new model(data);
await newObj.save()
return newObj;
```
- READ
```
async function read(model:any){
return await model.find({});
}
```
- UPDATE
```
async function update<T>(id:string, data:T , model:any){
return await model.findByIdAndUpdate(id,data);
}
```
- DELETE
```
async function getById (id:string,model:any){
const data = await model.findOne({id});
if(!data) {
return 'id is not valid';
}
return data ;
}
``` | emansaeed |
1,173,627 | Get Work Done with SMART Goals - What They Are and How to Organize Your Tasks! | Table of Contents [hide] 1 Why Is Goal-Setting Important? 2 What Are SMART Goals? ... | 0 | 2022-08-22T18:53:12 | https://www.taskade.com/blog/smart-goals/ | productivity | Table of Contents [[hide](https://www.taskade.com/blog/smart-goals/#)]
- [1 Why Is Goal-Setting Important?](https://www.taskade.com/blog/smart-goals/#Why_Is_Goal-Setting_Important)
- [2 What Are SMART Goals?](https://www.taskade.com/blog/smart-goals/#What_Are_SMART_Goals)
- [2.1 Specific](https://www.taskade.com/blog/smart-goals/#Specific)
- [2.2 Measurable](https://www.taskade.com/blog/smart-goals/#Measurable)
- [2.3 Achievable](https://www.taskade.com/blog/smart-goals/#Achievable)
- [2.4 Relevant](https://www.taskade.com/blog/smart-goals/#Relevant)
- [2.5 Timely](https://www.taskade.com/blog/smart-goals/#Timely)
- [3 Why Are SMART Goals Important?](https://www.taskade.com/blog/smart-goals/#Why_Are_SMART_Goals_Important)
- [4 Best Examples of SMART Goals](https://www.taskade.com/blog/smart-goals/#Best_Examples_of_SMART_Goals)
- [5 What Are Some Tips for Writing Better Smart Goals?](https://www.taskade.com/blog/smart-goals/#What_Are_Some_Tips_for_Writing_Better_Smart_Goals)
- [6 🔗Resources](https://www.taskade.com/blog/smart-goals/#Resources)
Why Is Goal-Setting Important?
------------------------------
Goal-setting is an important part of life. As David McClelland pointed out in 1961, having a sense of achievement is one of the three main sources of motivation for humans^(1)^. What better way to feel a sense of achievement than to actually achieve the goals that you've set for yourself?
However, setting goals blindly won't help either.
You have to hit the sweet spot when it comes to goal-setting. Goals cannot be too easy because you'll be wasting your potential, and they also have to be attainable so that you won't get demotivated by an unrealistic target. Here's where SMART goals come into play.
What Are SMART Goals?
---------------------
The concept of SMART goals was thought up by George T. Doran. The first mention of this framework was in an article he had written in 1981. In that article, Doran mentioned the benefits of writing SMART goals.
> "How do you write meaningful objectives?...Let me suggest therefore, that when it comes to writing effective objectives, corporate officers, managers, and supervisors just have to think of the acronym SMART. Ideally speaking, each corporate, department and section objective should be: (SMART)."
>
> *George T. Doran*
SMART goals help you to set yourself up for success. These are goals that are Specific, Measurable, Achievable, Realistic, and Timely. By optimizing your goal-setting strategy to be SMART, you're setting yourself up for success in the long run.
In order for us to start writing SMART goals, let's dive into what each letter from this acronym means.
### Specific
First of all, [SMART goals](https://www.taskade.com/templates/strategy/smart-goals-worksheet) have to be specific. This means that you and your team members have to be aligned on exactly what the team has to achieve. Ensuring that everyone understands their role in the project is critical.
There are a few ways to help align your team on a common goal. One of which is to make use of the [scrum project management](https://www.taskade.com/blog/agile-scrum-project-management/) style to ensure that everyone is on the same page in regards to the goal. If you're working remotely, use this [daily stand-up meeting template](https://www.taskade.com/templates/meetings/daily-stand-up-scrum-meeting) to help your team stay focused and on track.
Ensuring that everyone knows exactly what to do is critical to ensuring the success of your project.
### Measurable
In order to track your progress, you will need to set measurable goals. Setting measurable goals helps to provide you with a gauge of your team's current performance and progress. Setting a management review at certain points of your project helps you to track if your team is hitting the benchmark, or is falling short of it.
### Achievable
One of the easiest ways to hurt you and your team's morale is by setting unattainable goals. It's perfectly okay to have a plan for the big leagues. However, you'd be better off if you broke down your stretch goals into smaller achievable steps. In other words, using [hierarchical thinking](https://www.taskade.com/blog/hierarchical-thinking-tree-structure-checklist/) to help you come up with a realistic action plan.
Focus on simpler goals first, and move on to more ambitious projects once your team is in the flow of [getting things done](https://www.taskade.com/blog/get-things-done/).
### Relevant
You have to set goals that mean something to you or your company. What's the point of setting goals just because you have to? The best way to do this is to have an overarching long-term goal which is then broken down into smaller and more actionable sub-goals.
Setting relevant goals is an important aspect of SMART goal setting because it ensures that you're only setting goals that benefit you and your organization.
### Timely
If your goal doesn't have a deadline, then how are you going to ensure that you achieve it in a timely manner? Goals should be set with a target date of completion in mind. This is so that you can work on it and track your progress at the same time to work towards a target date.
In summary, SMART goals are those that are Specific, Measurable, Achievable, and Relevant, with a due date for completion. The SMART framework is an effective way to help you set better goals for yourself and also your team. But how exactly do you write SMART goals down?
Why Are SMART Goals Important?
------------------------------

Image from Helpfulprofessor.com
SMART goals are important because they help you to set focused goals with a clear direction and timeframe. By following the SMART framework, your team will be clearer about the deliverables and as a result be more productive. Here is a list of benefits that come with SMART goal-setting:
- Helps you set specific and clear goals
- Ensures that you set achievable goals
- Allows you to track your progress
- Helps you set useful goals
- Gives you a deadline to work towards
In a nutshell, SMART goals help by ensuring that you don't set vague and unrealistic goals for yourself. Using the SMART goal framework helps you to set specific goals that are related to the bigger picture within a certain timeframe.
Best Examples of SMART Goals
----------------------------
Now that you understand what the SMART acronym stands for, here are some of the best examples of goals that follow the SMART framework.
Example 1
Goal: I want to write 2 articles per month in order to publish 24 articles this year for my blog.
- Specific: Writing 2 articles per month.
- Measurable: Check if I'm on track to finish 2 articles this month.
- Achievable: Being a freelance writer, this goal is achievable.
- Relevant: I own my own blog, so writing 24 articles is a relevant goal for my blog.
- Timely: I've set a deadline to publish 24 articles by this year.
Example 2
Goal: I want to increase my advertising budget by $100 per week so that I can sell 1000 tickets to my event in 2 months.
- Specific: Increasing my ad spend by $100 per week to sell 1000 tickets in 2 months.
- Measurable: Track if I've sold at least 500 tickets halfway through the campaign.
- Achievable: I know the conversion rates for online advertisements based on a similar previous campaign, making this an achievable goal.
- Relevant: Selling more tickets would mean that more attendees would be present for my event.
- Timely: I've set a deadline to sell 1000 tickets in 2 months.
What Are Some Tips for Writing Better Smart Goals?
--------------------------------------------------

Now that you've grasped the concept of how to write SMART goals, it's essential that you equip yourself with the [best outliner tools](https://www.taskade.com/blog/best-outliner-apps/) to help you write down these goals. Taskade lets you [outline your thoughts hierarchically](https://www.taskade.com/blog/hierarchical-note-taking/) through multiple project views so that you can get a clearer picture of your goal.
What's more, our free plan even includes free built-in chat and video conferencing so that you can collaborate with your team effectively without having to toggle between multiple apps.
Want to get started with SMART goals quicker? Try out our [free SMART goals template](https://www.taskade.com/templates/strategy/smart-goals-worksheet) and get a head start today.
🔗Resources
-----------
1. McClelland, David C., The Achieving Society (1961). University of Illinois at Urbana-Champaign's Academy for Entrepreneurial Leadership Historical Research Reference in Entrepreneurship, Available at SSRN: [https://ssrn.com/abstract=1496181](https://www.google.com/url?q=https://ssrn.com/abstract%3D1496181&sa=D&source=docs&ust=1659810251224156&usg=AOvVaw1ATqUJCAYb39wQ8-63CxMA) | taskade |
1,163,693 | Automating Tests using CodeceptJS and Testomat.io: First Steps | Doing some manual testing on the fly can get quite complex, even if it's "just the happy path". ... | 20,933 | 2022-09-06T11:57:46 | https://dev.to/ingosteinke/automating-tests-using-codeceptjs-and-testomatio-first-steps-3b2e | webdev, testing, javascript, tutorial | Doing some manual testing on the fly can get quite complex, even if it's "just the happy path".
## "Just the (Complex) Happy Path"

No matter which one you prefer, any test framework is possibly better than not using tests at all, and there are a lot of popular choices and other less known newcomers.
## Choosing (and Mixing) Test Frameworks
There are enough blog posts about Jest or Cypress already, so let me introduce Codecept. It comes in two flavors. There is [Codeception](https://codeception.com) for PHP, and there is [CodeceptJS](https://codecept.io) for JavaScript which we will be using here.
[Testomat.io](https://testomat.io) is a software as a service to manage our automated tests to monitor our quality management.
## Importing mostly any existing Test Scenario into Testomat.io
Nice: we can import mostly any existing test that we already have! Jasmine, jest, mocha, cucumber and all the other classic stuff, or Cypress, Codecept, and Codeception from our latest projects. (If you don't have any existing tests, skip to the "advanced" part of this article, where I show you some ways to improve my (non)existent tests, this might be a good start for a first simple scenario.)
Importing existing code will set up our first test in Testomat.io. We don't have to upload any files, as we can sync our projects using an API key. Let's sign up and start our first project as a practical example.
### Import Tests from Source Code
`TESTOMATIO=__$APIKEY__ npx check-tests@latest CodeceptJS "**/*{.,_}{test,spec}.js" `
Running the above on the command line (replacing $APIKEY with our actual, secret, API key we just got from Testomat.io), the importer will proceed our data and print a summary:
### Updating Tests from Source Code
To update, run the same script again.
### Configuring Reporting
In the settings, we can configure Report Notifications based on sets of Rules, like which test results (based on test titles or groups) should be reported in which case (failure, success, always) on which channel (like Slack, Jira, Teams, or email).
We can use Testomat.io for monitoring our sites and applications over time and spot positive trends to prove our bug fixing progress, or verify expected negative trends proving increased test coverage of a legacy application, or else getting a timely warning that something is not working as expected causing an unexpected negative test result.
## Visual Testing
### Using CodeceptJS to compare Screenshots
Codecept will save screenshots in case of failure.
So maybe we can do even more with screenshots, like recording one in any case and comparing to the previous version. Then we can safely upgrade SASS or PostCSS without worrying that some arbitrary 5 bytes difference in the resulting 1000 lines CSS file will actually break anything in the frontend!
Yes, we can! [Documented as "Visual Testing"](https://codecept.io/visual/), the screenshot feature is a possible means of testing. We can use [Resemble.js](https://github.com/rsmbl/Resemble.js), which is a great tool for image comparison and analysis, after adding the [codeceptjs-resemblehelper](https://www.npmjs.com/package/codeceptjs-resemblehelper) to our project:
`npm install codeceptjs-resemblehelper --save`
This helper should be added to the configuration file `codecept.conf.js` to define the folders to store screenshot image files.
```js
"helpers": {
"ResembleHelper" : {
"require": "codeceptjs-resemblehelper",
"screenshotFolder" : "./codecept/output/",
"baseFolder": "./codecept/screenshots/base/",
"diffFolder": "./codecept/screenshots/diff/"
}
}
```
Now we can take and compare screenshots in our tests!
```js
I.saveScreenshot('Homepage_Screenshot.png');
I.seeVisualDiff('Homepage_Screenshot.png', {
tolerance: 2,
prepareBaseImage: false
});
```
If we don't want to provide an initial screenshot image, we can let CodeceptJS prepare an initial "baseImage" in the first run, or after an intentional visual change, by temporarily setting `prepareBaseImage: true`.
The generated screenshots should be committed to our git repository.
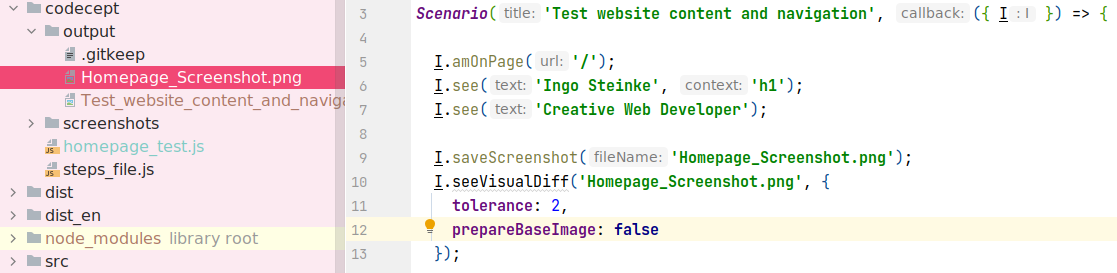
Now let's explore what happens if the screenshots differ!
We can simply change the test browser's viewport dimensions to cause a visual change. Re-running the test fails due to a difference of the screenshots. Apart from the text message, a diff image has been generated to point out the differences between the original and the actual screenshot.
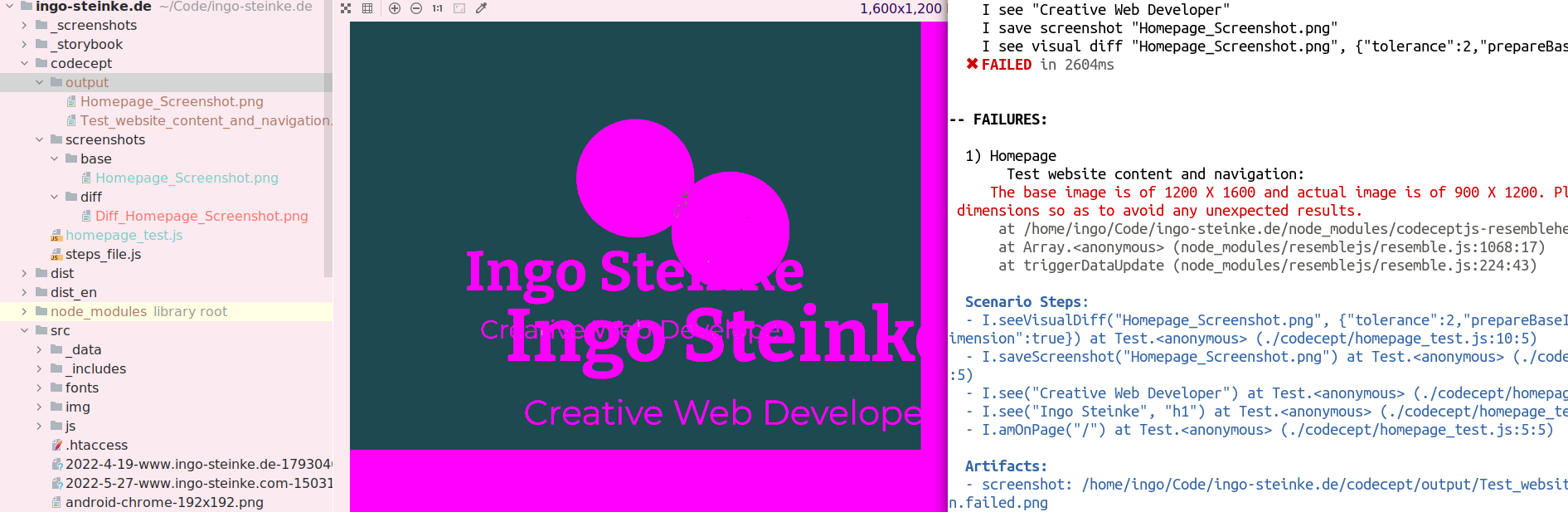
```
I save screenshot "Homepage_Screenshot.png"`
I see visual diff "Homepage_Screenshot.png",`
{"tolerance":2,"prepareBaseImage":false}`
✖ FAILED in 2604ms
-- FAILURES:
1) Homepage
Test website content and navigation:
The base image is of 1200 X 1600 and actual image
is of 900 X 1200. Please use images of same dimensions
so as to avoid any unexpected results.
```
If this is an intended change, I can now set `prepareBaseImage: true` to recreate a new base image in the next run. After that, the tests will pass and show green status again unless there is another new change to be detected.
Screenshot testing is just one of the aspects that used to be hard to handle when writing tests in the past. As CodeceptJS is based on [Playwright](https://playwright.dev), we can test iframes, and file uploads and downloads natively. And (unlike Cypress) CodeceptJS has a parallel running mode.
## Extending and Improving our local Tests
### Checking our Code for False Assumptions
This is the funny part: I tried to add an assertion that there is no "404 not found" error, starting with a very naive approach.
```js
I.dontSee('404');
```
But might have a 404 in your phone number, bank account information or a product ID. So this assertion might seem to work at first sight, but fail later when tested with real world data.

### Use npm pre- and post-test Script Hooks
If you don't have a localhost preview server already, you can add one using the [http-server](https://www.npmjs.com/package/http-server) package and adding a "serve" target in `package.json` (see example source code below).
For a local test run, we can combine our lint and build process with test automation, making use of the built-in [pre- and post-scripts](https://docs.npmjs.com/cli/v7/using-npm/scripts#pre--post-scripts) feature of `npm`. By splitting our tasks in `pretest`, `test`, and `posttest` we don't need to worry about the dev server blocking the terminal, waiting forever for a test that does not run, or how to make Codecept wait for our server if the scripts ran in parallel.
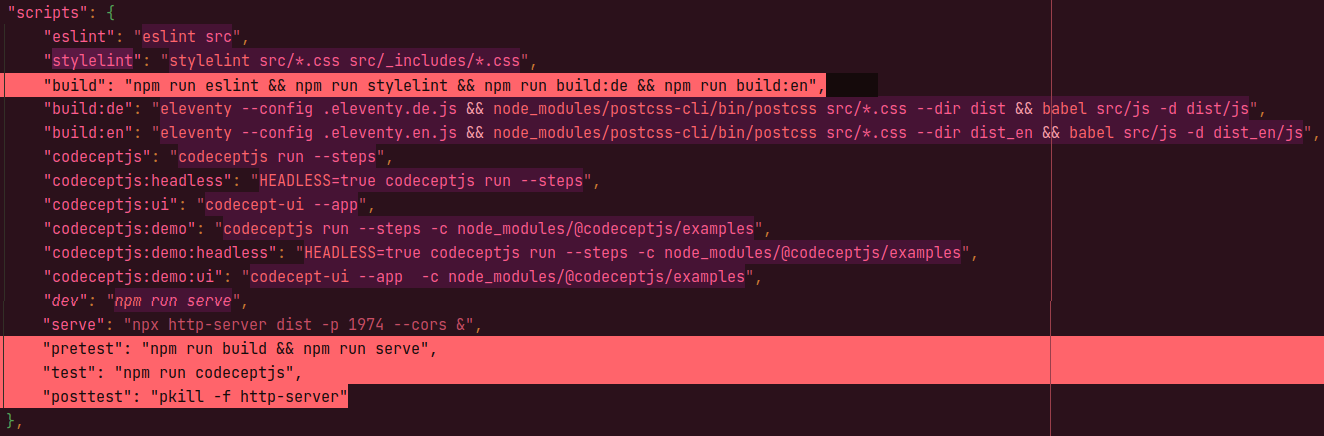
### Integrating Linting, Building, and Testing
Before starting build and test, let's also make sure that our source code passes static quality control, by adding the popular linting tools ([eslint](https://eslint.org) for JavaScript and [stylelint](https://stylelint.io) for CSS) at the beginning of our test tool chain:
1. Lint the source code using eslint and stylelint.
2. Build the source code (using eleventy and postCSS in my case, replace with the tools of your choice).
3. Start the localhost development server.
4. Run CodeceptJS test steps (run in an actual browser session).
5. Stop the development server (using [pkill](https://www.unix.com/man-page/Linux/1/pkill/) as [suggested on StackOverflow](https://stackoverflow.com/a/47882218/5069530)).
### Local Setup - Summary
You can verify, copy and paste the relevant code snippets below. I have left out some of my project's details to focus on the test setup. You can find my [original source code on GitHub](https://github.com/openmindculture/ingo-steinke.de).
Scripts and dependencies in `package.json`:
```json
"scripts": {
"eslint": "eslint src",
"stylelint": "stylelint src/*.css",
"build": "npm run eslint && npm run stylelint && ... your own build steps ...",
"codeceptjs": "codeceptjs run --steps",
"serve": "npx http-server dist -p 1974 --cors &",
"pretest": "npm run build && npm run serve",
"test": "npm run codeceptjs",
"posttest": "pkill -f http-server"
},
"devDependencies": {
"@codeceptjs/configure": "^0.8.0",
"codeceptjs": "^3.3.4",
"eslint": "^8.6.0",
"http-server": "^14.1.1",
"playwright": "^1.25.0",
"puppeteer": "^16.1.0",
"stylelint": "^14.10.0",
"stylelint-config-html": "^1.1.0",
"stylelint-config-standard": "^27.0.0"
}
}
```
Codecept configuration file `./codecept.conf.js`. Note: please consult the latest [codecept](https://codecept.io) documentation for the right syntax to use!
This is just a simple sample configuration used with CodeceptJS 3.3.4 which is probably already outdated at the time of reading.
```js
const { setHeadlessWhen, setWindowSize } = require('@codeceptjs/configure');
// turn on headless mode when running with HEADLESS=true environment variable
// export HEADLESS=true && npx codeceptjs run
setHeadlessWhen(process.env.HEADLESS);
setWindowSize(1600, 1200);
exports.config = {
tests: './codecept/*_test.js',
output: './codecept/output',
helpers: {
Puppeteer: {
url: 'http://localhost:1974',
show: true,
windowSize: '1200x900'
}
},
include: {
I: './codecept/steps_file.js'
},
bootstrap: null,
mocha: {},
name: 'ingo-steinke.de',
plugins: {
pauseOnFail: {},
retryFailedStep: {
enabled: true
},
tryTo: {
enabled: true
},
screenshotOnFail: {
enabled: true
}
}
}
```
I have created alternative configurations to be used in different environments, so I have moved the common configuration settings to `./codecept.common.conf.js` which I include in the specific configuration files, to avoid redundant project code.
Here, I simply provide a different URL to test the deployed site on the public production URL:
`./codecept.ci.conf.js`:
```js
const { setHeadlessWhen, setWindowSize } = require('@codeceptjs/configure');
exports.config = require ('./codecept.common.conf.js');
exports.config.helpers.Puppeteer.url = 'https://www.ingo-steinke.de';
// turn on headless mode when running with HEADLESS=true environment variable
// export HEADLESS=true && npx codeceptjs run
setHeadlessWhen(process.env.HEADLESS);
```
## Adding Tests Steps to Our Test Scenario
Last, but not least, we need test definitions. We can use a common `steps_file.js` and specific test scenarios like this "Homepage" feature test scenario defined in `homepage_tests.js`.
We do some straightforward things here:
Open the home page ("I am on page /") and verify that some expected content is visible. We can specify content text, specific elements, and even use XPath selectors, if necessary.
Although we can specify a screen size in our configuration, there is no need to scroll explicitly. Our assertions work with the whole document, like if we would use "find on page" in our browser.
Using its description as a key, we are looking for a certain button, click it, and verify that a certain paragraph becomes visible, that has been hidden initially.
```js
Feature('Homepage');
Scenario('Test website content and navigation', ({ I }) => {
I.amOnPage('/');
I.see('Ingo Steinke', 'h1');
I.see('Creative Web Developer');
I.seeElement('//a[contains(., "privacy")]');
// find button by caption text, click it ...
I.click('privacy');
// ... and verify that this reveals a hidden paragraph.
I.see('Your legal rights');
// We can ensure NOT to see something:
I.dontSeeElement('.error');
// I.dontSee('404');
// so the following would fail:
// I.dontSee('Ingo');
});
```
So this is a simple test scenario using `npm` and [CodeceptJS](https://codecept.io). We can extend everything, using more complex and less naive test scenarios and add alternative test configurations.
As we use [Testomat.io](https://testomat.io/) to manage test automation, let's not forget to update our test definitions after we changed anything.
This will run our lint + build + test pipeline, and if that finished sucessfully, updates the test suite on the Testomat.io server. And pushing to `git` (or more specifically, pushing or merging into my `main` branch) will trigger a build and deployment, so in the end we will have an updated web page build and updated test definitions to test that live page in production.
```sh
npm run test && \
TESTOMATIO=__$APIKEY__ npx check-tests@latest CodeceptJS "**/*{.,_}{test,spec}.js && \
git push"
```
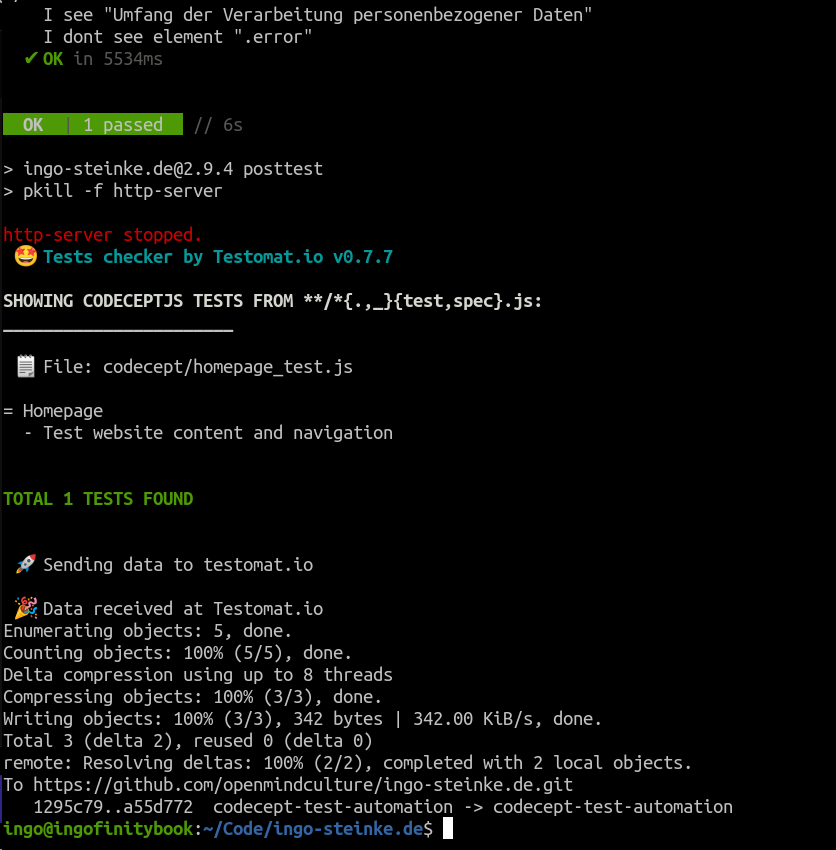 | ingosteinke |
1,165,555 | MySQL’s UTF-8 Isn’t Real | If you are familiar with MySQL, you probably already know that it comes with multiple character... | 0 | 2022-08-11T21:46:00 | https://dev.to/arctype/mysqls-utf-8-isnt-real-4352 | programming, tutorial, productivity, mysql | If you are familiar with MySQL, you probably already know that it comes with multiple character encodings. One of the main encodings in the MySQL world and on the web in general is UTF-8 – it is used in almost every web and mobile application, and is widely considered to be the “default” option as far as MySQL is concerned. UTF-8 also supports multiple character sets and has a couple of other features unique to itself: in this blog, we are going to go through them and also we are going to go through one feature in particular – the fact that MySQL’s “UTF-8” is not considered to be the “real” UTF-8. Confused? Read on!
## What is UTF-8?
To start with, UTF-8 is one of the most common character encodings. In UTF-8, each character that we have is represented by a range of one to four bytes. As such, we have a couple of character sets:
- utf8 which, in previous times, was considered the “de-facto” standard for MySQL in the past. Essentially, utf8 can also be considered to be the “alias” for utf8mb3.
- utf8mb3 which uses one to three bytes per character.
- utf8mb4 which uses one to four bytes per character.
UTF8 was the default character set in the past when MySQL was starting out and everything was great. However, talk to MySQL database administrators these days, and you will quickly realize that now that is no longer the case. Simply put, utf8, as such, is not the default character set anymore – utf8mb4 is.
## utf8 vs. utf8mb4
The core reason between the separation of utf8 and utf8mb4 is that UTF-8 is different from proper UTF-8 encoding. That’s the case because UTF-8 it doesn’t offer full Unicode support, which can lead to data loss or even security issues. UTF-8’s failure to fully support Unicode is the real kicker – the UTF-8 encoding needs up to four bytes per character, while the “utf8” encoding offered by MySQL only supports three. See the issue on that front? In other words, if we want to store smilies represented like so:

We cannot do it – it’s not that MySQL will store it in a format of “???” or similar, but it won’t store it altogether and will respond with an error message like the following:
```
Incorrect string value: ‘\x77\xD0’ for column ‘demo_column’ at row 1
```
With this error message, MySQL is saying “well, I don’t recognize the characters that this smiley is made out of. Sorry, nothing I can do here” – at this point, you might be wondering what is being done to overcome such a problem? Is MySQL even aware of its existence? Indeed, it would be a lie to say that MySQL is not aware of this issue – rather, they are, but the MySQL developers never got around to fixing it. Instead, they released a workaround more than a decade ago along with MySQL 5.5.3.
That workaround is called “utf8mb4”. utf8mb4 is pretty much the same as its older counterpart – utf8 – it’s just that the encoding uses one to four bytes per character which essentially means that it’s able to support a wider variety of symbols and characters.
Use MySQL 8.0, work with data a little, and you will quickly notice that indeed, utf8mb4 is the default character set available in MySQL – moreover, it is speculated that in the near future utf8mb4 will become a reference to the utf8 standard in MySQL.
## Flavors of utf8mb4
As time goes by and utf8 is being outpaced by utf8mb4 in almost all fronts, it’s natural that there are a couple of variations of collations that can be used. Essentially, these collations act as sort of a “set” of sorting rules that are designed to better fit specific data sets. utf8mb4 has a couple as well:
- `utf8mb4_general_ci` is geared towards a more “general” use of MySQL and utf8. This character set is widely regarded to take “shortcuts” towards data storage which may result in sorting errors in some cases to improve speed.
- `utf8mb4_unicode_ci` is geared towards “advanced” users – that is, it’s a set of collations that is based on Unicode and we can rest assured that our data will be dealt with properly if this collation is in use.
In this case, do note the “`_ci`” ending towards the collation: that stands for “case insensitive.” Case insensitivity is related to sorting and comparison.
These two “flavors” of utf8mb4 are used more and more – as newer versions of MySQL are also being released, we can also see that the `utf8mb4_unicode_ci` collation is the collation of choice for most people working with MySQL today. One fact is for certain – not all people using MySQL in this way know the functionalities and the upsides presented by utf8mb4 as opposed to its counterpart utf8, but they will certainly see a difference when they import data having unusual characters! Did we convince you to head over to the realm of utf8mb4 yet?
## Properly Working with utf8mb4-based Data
Here’s how some developers go about creating databases and tables based on utf8mb4:

Except that this query gives us an error (below the query) which is a frequent point of confusion to beginners and advanced developers alike – MySQL is essentially saying that when we use a collation based on utf8mb4, we should also use a compatible character set, and in this case, latin1 isn’t valid, so whatever you do, keep these points in mind:
- utf8mb4 is not the real utf8 in MySQL and its flavors (MariaDB and Percona Server): utf8 only supports 3 bytes of data, utf8mb4 supports 4 which is what utf8 should do in the first place. If utf8 is in use, some characters may not be displayed properly.
- When we elect to use utf8mb4 instead of utf8 in MySQL, we should also make sure that we use an appropriate character set (utf8mb4.) Note the success message underneath the query:

Now we are good to go – we can store all kinds of characters inside of our database and not have MySQL error out with an “Incorrect string value” error! Woohoo!
## Summary
UTF-8 in MySQL is broken – it is not able to support four bytes per character as UTF-8 is supposed to. “utf8mb4” can be used to solve this problem and it’s generally pretty easy to work with – simply choose a specific collation (in this case, choose either general if you’re using MySQL for a personal project or a small website, or a Unicode collation or if you’re using it for something more technical or if you want to push MySQL to its limits.)
Before pushing MySQL to its limits, though, be aware that aside from [the documentation](https://dev.mysql.com/doc/), there also are a couple of blogs like the one provided by [Arctype](__GHOST_URL__/) that provide information on how to work with the relational database management system and all of its flavors. We cover how to work with [MySQL and big data](__GHOST_URL__/mysql-storage-engine-big-data/), [how to optimize your database schemas](__GHOST_URL__/mysql-schema/), and so much more! If you are into databases, make sure to keep an eye out on the [Arctype blog](https://arctype.com/blog) and we will see you in the next one! | rettx |
1,165,560 | Mastering the %SYSTEM.Encryption class | The InterSystems IRIS has excellent support for encryption, decryption and hashing operations.... | 0 | 2022-08-11T22:00:21 | https://dev.to/intersystems/mastering-the-systemencryption-class-4hh | security, intersystems, tutorial |
The InterSystems IRIS has excellent support for encryption, decryption and hashing operations. Inside the class %SYSTEM.Encryption (https://docs.intersystems.com/iris20212/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&PRIVATE=1&CLASSNAME=%25SYSTEM.Encryption) there are class methods for the main algorithms on the market.
## IRIS Algorithms and Encrypt/Decrypt types
As you can see, the operations are based on keys and include 3 options:
- Symmetric Keys: the parts running encrypt and decrypt operations share the same secret key.
- Asymmetric Keys: the parts conducting encrypt and decrypt operations share the same secret key for encryption. However, for decryption, each partner has a private key. This key cannot be shared with other people, because it is an identity proof.
- Hash: used when you do not need to decrypt, but only encrypt.It is a common approach when it comes to storing user passwords.
##
Differences Between Symmetric and Asymmetric Encryption
- Symmetric encryption uses a single key that needs to be shared among the people who need to receive the message while asymmetric encryption uses a pair of public keys and a private key to encrypt and decrypt messages when communicating.
- Symmetric encryption is an old technique while asymmetric encryption is relatively new.
- Asymmetric encryption was introduced to complement the inherent problem of the need to share the key in a symmetric encryption model, eliminating the need to share the key by using a pair of public-private keys.
- Asymmetric encryption takes relatively more time than symmetric encryption.
### Symmetric Encryption:
-
Smaller cipher text than the original plain text file,
-
used to transmit big data,
-
symmetric key encryption works on low usage of resources,
-
128 or 256-bit key size,
- Symmetric Encryption uses a single key for encryption and decryption,
- It is an old technique,
- A single key for encryption and decryption has chances of the key being compromised,
- Symmetric encryption is a fast technique,
- RC4, AES, DES, 3DES, and QUAD.
### Asymmetric Encryption
- Larger cipher text than the original plain text file,
- Used to transmit small data,
- Asymmetric encryption requires high consumption of resources,
- RSA 2048-bit or higher key size,
- Much safer as two different keys are involved in encryption and decryption,
- Asymmetric Encryption uses two different keys for encryption and decryption,
- It is a modern technique,
- Two keys are separately made for encryption and decryption which removes the need to share a key,
- Asymmetric encryption is slower in terms of speed,
- RSA, Diffie-Hellman, ECC algorithms.
Source: https://www.ssl2buy.com/wiki/symmetric-vs-asymmetric-encryption-what-are-differences
## Using the %SYSTEM.Encryption class to do Encrypt, Decrypt and Hash
To exercise IRIS support to Encrypt, Decrypt and Hash operations, go to https://github.com/yurimarx/cryptography-samples and follow these steps:
-
Clone/git pull the repo into any local directory
```
$ git clone https://github.com/yurimarx/cryptography-samples.git
```
- Open a Docker terminal in this directory and run:
```
$ docker-compose build
```
- Run the IRIS container:
```
$ docker-compose up -d
```
- Open IRIS Terminal:
```
$ docker-compose exec iris iris session iris -U IRISAPP
```
IRISAPP>
- To do RSA Encrypt for asymmetric encryption execute this:
```
IRISAPP>Set ciphertext = ##class(dc.cryptosamples.Samples).DoRSAEncrypt("InterSystems")
IRISAPP>Write ciphertext
Ms/eR7pPmE39KBJu75EOYIxpFEd7qqoji61EfahJE1r9mGZX1NYuw5i2cPS5YwE3Aw6vPAeiEKXF
rYW++WtzMeRIRdCMbLG9PrCHD3iQHfZobBnuzx/JMXVc6a4TssbY9gk7qJ5BmlqRTU8zNJiiVmd8
pCFpJgwKzKkNrIgaQn48EgnwblmVkxSFnF2jwXpBt/naNudBguFUBthef2wfULl4uY00aZzHHNxA
bi15mzTdlSJu1vRtCQaEahng9ug7BZ6dyWCHOv74O/L5NEHI+jU+kHQeF2DJneE2yWNESzqhSECa
ZbRjjxNxiRn/HVAKyZdAjkGQVKUkyG8vjnc3Jw==
```
- To do RSA Decrypt for asymmetric decryption run this:
```
IRISAPP>Set plaintext = ##class(dc.cryptosamples.Samples).DoRSADecrypt(ciphertext)
IRISAPP>Write plaintext
InterSystems
```
- To do AES CBC Encrypt for symmetric encryption perform this:
```
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoAESCBCEncrypt("InterSystems")
8sGVUikDZaJF+Z9UljFVAA==
```
- To do AES CBC Decrypt for symmetric encryption complete this:
```
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoAESCBCDecrypt("8sGVUikDZaJF+Z9UljFVAA==")
InterSystems
```
- To do MD5 hash for an old hash approach conduct this:
```
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoHash("InterSystems")
rOs6HXfrnbEY5+JBdUJ8hw==
```
- To do SHA hash for recommended hash approach follow this:
```
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoSHAHash("InterSystems")
+X0hDlyoViPlWOm/825KvN3rRKB5cTU5EQTDLvPWM+E=
```
- To exit the terminal, do any of the following:
Enter HALT or H (not case-sensitive)
## About the source code
- About the Symmetric key
```
# to use with symmetric encrypt/decrypt
ENV SECRETKEY=InterSystemsIRIS
```
In the Dockerfile, there was created an Environment key to be used as secret key on symmetric operations.
- About the Asymmetric key
```
# to use with asymmetric encrypt/decrypt
RUN openssl req -new -x509 -sha256 -config example-com.conf -newkey rsa:2048 -nodes -keyout
example-com.key.pem -days 365 -out example-com.cert.pem
```
In the Dockerfile were generated a private key and a public key to be used with asymmetric operations.
- Symmetric Encrypt
```
// Symmetric Keys sample to encrypt
ClassMethod DoAESCBCEncrypt(plaintext As %String) As %Status
{
// convert to utf-8
Set text=$ZCONVERT(plaintext,"O","UTF8")
// set a secret key
Set secretkey = $system.Util.GetEnviron("SECRETKEY")
Set IV = $system.Util.GetEnviron("SECRETKEY")
// encrypt a text
Set text = $SYSTEM.Encryption.AESCBCEncrypt(text, secretkey, IV)
Set ciphertext = $SYSTEM.Encryption.Base64Encode(text)
Write ciphertext
}
```
The operation AES CBC Encrypt was used to encrypt texts.
Base64 Encode returns the results as a pretty/readable text to the user.
- Symmetric Decrypt
```
// Symmetric Keys sample to decrypt
ClassMethod DoAESCBCDecrypt(ciphertext As %String) As %Status
{
// set a secret key
Set secretkey = $system.Util.GetEnviron("SECRETKEY")
Set IV = $system.Util.GetEnviron("SECRETKEY")
// decrypt a text
Set text=$SYSTEM.Encryption.Base64Decode(ciphertext)
Set text=$SYSTEM.Encryption.AESCBCDecrypt(text,secretkey,IV)
Set plaintext=$ZCONVERT(text,"I","UTF8")
Write plaintext
}
```
The operation AES CBC Decrypt was used to decrypt texts.
Base64 Decode returns the encrypted text to a binary one, so it can be used to decrypt.
- Asymmetric Encrypt
```
// Asymmetric Keys sample to encrypt
ClassMethod DoRSAEncrypt(plaintext As %String) As %Status
{
// get public certificate
Set pubKeyFileName = "/opt/irisbuild/example-com.cert.pem"
Set objCharFile = ##class(%Stream.FileCharacter).%New()
Set objCharFile.Filename = pubKeyFileName
Set pubKey = objCharFile.Read()
// encrypt using RSA
Set binarytext = $System.Encryption.RSAEncrypt(plaintext, pubKey)
Set ciphertext = $SYSTEM.Encryption.Base64Encode(binarytext)
Return ciphertext
}
```
It is necessary to get the public key file content to encrypt with RSA.
The operation RSA Encrypt was used to encrypt texts.
- Asymmetric Decrypt
```
// Asymmetric Keys sample to decrypt
ClassMethod DoRSADecrypt(ciphertext As %String) As %Status
{
// get private key
Set privKeyFileName = "/opt/irisbuild/example-com.key.pem"
Set privobjCharFile = ##class(%Stream.FileCharacter).%New()
Set privobjCharFile.Filename = privKeyFileName
Set privKey = privobjCharFile.Read()
// get ciphertext in binary format
Set text=$SYSTEM.Encryption.Base64Decode(ciphertext)
// decrypt text using RSA
Set plaintext = $System.Encryption.RSADecrypt(text, privKey)
Return plaintext
}
```
It is necessary to get the private key file content to decrypt with RSA.
The operation RSA Decrypt was used to decrypt texts.
- Hash text using MD5 (old approach)
```
// Hash sample
ClassMethod DoHash(plaintext As %String) As %Status
{
// convert to utf-8
Set text=$ZCONVERT(plaintext,"O","UTF8")
// hash a text
Set hashtext = $SYSTEM.Encryption.MD5Hash(text)
Set base64text = $SYSTEM.Encryption.Base64Encode(hashtext)
// convert to hex text to following best practices
Set hextext = ..GetHexText(base64text)
// return using lowercase
Write $ZCONVERT(hextext,"L")
}
```
The operation MD5 Hash will encrypt the text, and it will not be possible to decrypt it.
Hash using MD5 is not recommended for new projects because it is considered insecure. That is why it was replaced by SHA. The InterSystems IRIS supports SHA (our next example will demonstrate it).
- Hash text using SHA (recommend approach)
We will use the SHA-3 Hash method for this sample. According to InterSystems documentation, this method generates a hash using one of the U.S. Secure Hash Algorithms - 3. (See Federal Information Processing Standards Publication 202 for more information.).
```
// Hash using SHA
ClassMethod DoSHAHash(plaintext As %String) As %Status
{
// convert to utf-8
Set text=$ZCONVERT(plaintext,"O","UTF8")
// hash a text
Set hashtext = $SYSTEM.Encryption.SHA3Hash(256, text)
Set base64text = $SYSTEM.Encryption.Base64Encode(hashtext)
// convert to hex text to following best practices
Set hextext = ..GetHexText(base64text)
// return using lowercase
Write $ZCONVERT(hextext,"L")
}
```
For the SHA method, it is possible to set the bit length used on a hash operation. The greater the number of bits, the more difficult it is to crack the hash. However, the hashing process slows down too. In this sample we used 256 bits. You can choose these options for bit length:
- 224 (SHA-224)
- 256 (SHA-256)
- 384 (SHA-384)
- 512 (SHA-512)
| yurimpg |
1,165,648 | Use Salesforce Marketing Cloud? Let's talk about your workflow! | The "Typical Workflow" Salesforce Marketing Cloud (SFMC) is split into a few different... | 19,616 | 2022-09-09T23:40:30 | https://dev.to/tonyzupancic/use-salesforce-marketing-cloud-lets-talk-about-your-workflow-cbb | sfmc, email, bldr | ## The "Typical Workflow"
Salesforce Marketing Cloud (SFMC) is split into a few different areas: Content Builder (emails, content blocks, images), Automation Studio (automations, server-side javascript, queries), Journey Builder (1:1 customer flows).
Let's talk about Content Builder, SFMC's email and content block builder, as it's arguably one of the most used areas of SFMC. In Content Builder, you can create HTML Paste emails and Template Based emails using the WYSIWYG editor.
In addition to the emails themselves, you have the ability to create re-useable modules called content blocks. These content blocks can be included in Emails, Scripts, CloudPages (we'll get to CloudPages in other posts), even other content blocks.
Depending on your project, it's typical (and a good practice) to split out code into modules. Splitting code into modules when possible, keeps like AMPScript blocks or Server-Side JavaScript functions together and helps when it comes to troubleshooting. If you take a fairly complex Email with a handful of modules, throw in some organization (cause who doesn't love a good folder structure), just setting up a project can become a time-consuming task in-and-of itself.
### Let's go through the (abridged) steps
1. Log into SFMC
2. Navigate to Email Studio (wait for it to load)
3. Navigate to Content Builder (wait for it to load)
4. Left Click > Enter Folder Name > Hit Enter
5. (Find your folder because it doesn't automatically take you there)
6. Click on the Create button > select your content type
7. Code or Copy/Paste
Congratulations! As long as you made it past the infamous blue wheel, you created an asset!
As you can imagine, a project with a handful of content blocks or emails could take a while to set up.
## Introducing BLDR for SFMC
Bldr is an open-source CLI tool that allows you to pull your files out of SFMC, update them, send the updates back to SFMC, and push them to version control; all from your command line, all without copy/paste.
As a CLI tool, it allows you to use any code editor that you want and since bldr does not try to re-invent the GIT flow, it fits into your existing git provider; you can use the terminal or a GUI to manage your git files.
If you even know a little bit of how to use git...
```
git clone {{ repository url }}
git add . or {{ path to file(s) }}
git commit -m "commit message"
git push
```
...you will feel right at home with bldr; and if not, it's really quite straight forward.
```
bldr clone --cb -f {{ folder id }}
bldr add . or {{ path to file(s) }}
bldr push
```
No more Copy/Paste, No more browser hiccups that make you loose code, No more 4 clicks to create/update an asset.
In the following posts, I'll go into each core area of bldr; detailing how to use each command and how they interact with SFMC.
If you're looking for more details or interested in getting started, visit [bldr.io](https://www.bldr.io).
| tonyzupancic |
1,165,783 | A Quick 10-Second Programming Joke For Today | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2022-08-12T08:00:17 | https://dev.to/dailydeveloperjokes/a-quick-10-second-programming-joke-for-today-36j4 | jokes, dailydeveloperjokes | ---
title: "A Quick 10-Second Programming Joke For Today"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
published: true
tags: #jokes, #dailydeveloperjokes
---
Hi there! Here's today's Daily Developer Joke. We hope you enjoy it; it's a good one.

---
For more jokes, and to submit your own joke to get featured, check out the [Daily Developer Jokes Website](https://dailydeveloperjokes.github.io/). We're also open sourced, so feel free to view [our GitHub Profile](https://github.com/dailydeveloperjokes).
### Leave this post a ❤️ if you liked today's joke, and stay tuned for tomorrow's joke too!
_This joke comes from [Dad-Jokes GitHub Repo by Wes Bos](https://github.com/wesbos/dad-jokes) (thank you!), whose owner has given me permission to use this joke with credit._
<!--
Joke text:
___Q___: What are clouds made of?
___A___: Mostly linux servers.
-->
| dailydeveloperjokes |
1,203,656 | Top 5 Practical Array Methods in JavaScript | forEach() The forEach() method executes a provided function for each array... | 0 | 2022-09-28T19:25:48 | https://dev.to/yukio1o5/top-5-practical-array-methods-in-javascript-4jnm | javascript, beginners | ##forEach()
> The forEach() method executes a provided function for each array element.
```javascript
const numbers = [1,2,3,4,5];
numbers.forEach(element => {
console.log(element + 10);
});
```
```
11
12
13
14
15
```
The forEach just does execute the same function for each element of an array. It does not return anything. If we try to do the `console.log(resultForEach)` in the following code, `undefined` appears.
```javascript
const numbers = [1,2,3,4,5];
const resultForEach = numbers.forEach(element => {
return element * 10;
});
console.log(resultForEach);
```
```
undefined
```
[Reference link1](https://www.programiz.com/javascript/library/array/foreach)
___
##Map()
> The map() method creates a new array with the results of calling a function for every array element.
```javascript
const numbers = [1,2,3,4,5];
const resultMap = numbers.map(element => {
console.log(element + 10);
});
```
```
11
12
13
14
15
```
The map() method shows us the same result as the forEach() method. But the return value appears if we try to do the `console.log(resultMap)` in the following code. It has a return value and can generate a new array. This is the big difference between the map() method and the forEach() method.
```javascript
const numbers = [1,2,3,4,5];
const resultMap = numbers.map(element => {
return element + 10;
});
console.log(resultMap);
```
```
[ 11, 12, 13, 14, 15 ]
```
[Reference link2]
(https://www.programiz.com/javascript/library/array/map)
___
##Filter()
> The filter() method returns a new array with all elements that pass the test defined by the given function.
```javascript
const numbers = [1,2,3,4,5];
numbers.filter( element => {
if (element % 2 == 0){
return true;
}
else{
return false;
}
});
```
```
[ 2, 4 ]
```
The filter() method also can generate a new array that consists of only the element which satisfies a given condition.
[Reference link3](https://www.programiz.com/javascript/library/array/filter)
___
##Every() & Some()
- Every()
> The JavaScript Array every() method checks if all the array elements pass the given test function.
```javascript
const numbers = [1,2,3,4,5];
const resultEvery = numbers.every( element => {
return element <= 5;
} );
console.log(resultEvery);
```
```
true
```
```javascript
const numbers = [1,2,3,4,5];
const resultEvery = numbers.every( element => {
return element % 2 == 0;
} );
console.log(resultEvery);
```
```
false
```
- Some()
> The some() method tests whether any of the array elements pass the given test function.
```javascript
const numbers = [1,2,3,4,5];
const resultSome = numbers.some( element => {
return element % 2 == 0;
} );
console.log(resultSome);
```
```
true
```
We should remember the every() method and the some() method as a set. The every() method requires that all elements meet the condition, on the other hand, some() method needs at least one element meets the condition. I wrote the same condition for every() method and the some() method but the results were different.
[Reference link4](https://www.programiz.com/javascript/library/array/every)
[Reference link5](https://www.programiz.com/javascript/library/array/some)
___
##Reduce()
> The reduce() method executes a reducer function on each element of the array and returns a single output value.
```javascript
const numbers = [1,2,3,4,5];
const resultReduce = numbers.reduce((accumulator,currentValue,currentIndex,array) => {
return accumulator + currentValue;
});
console.log(resultReduce);
```
```
15
```
The reduce() method is more tricky than others. It can have 4 parameters. (we can skip writing currentIndex and array) It returns not a new array but one value.
Word | Meaning |
--- | --- |
accumulator | initial value or the previous result which was being executed |
currentValue | the value which is being executed right now |
currentIndex | the index which is being executed right now |
array | array which is provided ahead |
* If initialValue is specified,
- accumulator = initialValue
- currentValue = the first element of the array
* If initialValue is omitted,
- the accumulator = the first element of the array
- currentValue = the second element of the array
I am going to write what happens in the above code.
How many times | accumulator | currentValue | currentIndex |
--- | --- | --- | --- |
1st | 1 | 2 | 1 |
2nd | 3 | 3 | 2 |
3rd | 6 | 4 | 3 |
4th | 10 | 5 | 4 |
[Reference link6](https://www.programiz.com/javascript/library/array/reduce)
[Reference link7](https://qiita.com/chihiro/items/1047e40514a778c08baa) | yukio1o5 |
1,165,797 | Amazon Web Services | Amazon Web Services Inc., is a subsidiary of Amazon aimed at providing on-demand cloud computing... | 0 | 2022-09-18T21:47:52 | https://dev.to/aws-builders/amazon-web-services-3b6g | aws, cloud, writing | Amazon Web Services Inc., is a subsidiary of Amazon aimed at providing on-demand cloud computing platforms and APIs to individuals, companies and governments on a pay-as-you-go basis. These services offered by Amazon provide distributed computing processing capacity and software tools through AWS server farms(An AWS server farm is a collection of AWS servers maintained by Amazon to supply server functionality far beyond the capability of a single machine). Amazon Elastic Compute Cloud(EC2), one of the most popular of these services, allows users to have a virtual group of computers available at their disposal through the Internet. These virtual computers are a simulation of most attributes of a real computer, like hardware CPUs and GPUs for processing; local and RAM memory; hard disk and SSD storage; a set of operating systems, networking and pre-loaded application software like web servers, databases and customer relationship management. AWS subscribers can pay for a single virtual AWS computer, a dedicated physical computer, or clusters of both.
Subscribers pay for hardware, OS, software or networking features as desired, regarding availability, redundancy, security and service options.
Amazon offers its services to its clients at a large scale computing capacity, and at a very affordable price. For this reason, AWS got 33% market share for cloud infrastructure as of 2021. These services comprise over 200 products, including storage, database, networking, analytics, application services, deployment, management, machine learning, mobile, developer tools, RobOps and IOT. | delia |
1,166,241 | How To Accept Cross Chain Crypto Payments for NFTs | Hi there!! 👋 I’m Harpriya, an engineer from Paper. In this tutorial, we’ll be learning how to add... | 0 | 2022-08-12T18:56:43 | https://blog.paper.xyz/how-to-accept-cross-chain-crypto-payments-for-nfts/ | nfts, web3, crosschain, creditcards | ---
title: How To Accept Cross Chain Crypto Payments for NFTs
published: true
date: 2022-08-12 17:29:45 UTC
tags: NFTs, Web3, CrossChain, CreditCards
canonical_url: https://blog.paper.xyz/how-to-accept-cross-chain-crypto-payments-for-nfts/
---

Hi there!! 👋 I’m Harpriya, an engineer from [Paper](https://paper.xyz/?utm_source=ghost&utm_content=how-to-create-and-sell-an-nft-tutorial). In this tutorial, we’ll be learning how to add cross-chain crypto payments to all our NFTs so that we can make our assets more accessible and expand our audience and paying customers.
## What does cross-chain mean?
Digital Assets like NFTs can only exist on a singular blockchain. Blockchains like Bitcoin, Ethereum, Polygon, Avalanche, and Solana all use different technologies to ensure that their respective cryptocurrencies and assets are secure. Cross-chain acts as a “bridge” across multiple blockchains to achieve _interoperability_. This means that cross-chain can enable the exchange of information, cryptocurrency, assets, and NFTs from one blockchain to another.
## Why do I need cross-chain?
As a developer creating these assets, the main concern you’ll have is making sure you’re choosing the right blockchain and technology for you, and also for your audience and buyers. The blockchain you choose for development will impact the way your smart contract is written and determine the type of features you can offer. For your audience and buyers, it means they will probably need to convert their funds into the native cryptocurrency of your smart contract, which is tied to the blockchain you decide to use. This can be a huge hassle for the audience and buyers having to convert funds from one currency to another. This is what cross-chain solves. Cross-chain essentially creates a “bridge” to exchange money from one cryptocurrency to another. This means your audience and buyers would be able to purchase your NFTs regardless of which blockchain you decide to use and regardless of which cryptocurrency they already hold. Accepting cross-chain payments for your NFT sales make your work more accessible and has the potential to expand your audience by more than 10X.
## How do accept cross-chain payments?
Accepting cross-chain payments becomes deceptively simply with [Paper](https://paper.xyz/). If you’re unfamiliar with Paper, it is basically a tool that allows you to accept various forms of Payments to sell your NFTs, like credit cards or cross-chain crypto. Paper offers multiple solutions to this cross-chain problem, and we call it `PayWithCrypto`. To get a better understanding of how `PayWithCrypto` works, let’s try out the Paper Demo Checkout.
Head to [https://paper.xyz/](https://paper.xyz/) and click on “Try a Demo”.
_Try a demo on the Paper landing page._

_"Pay With ETH" button allows you to pay use cross-chain payments._
The “Pay With ETH” button allows you to pay with a popular cryptocurrency, Ethereum, while the Paper Explorers NFT is priced in a 2 MATIC. This means that the NFT exists on the Polygon blockchain and accepts its native currency, MATIC, but with Paper you can purchase this Polygon NFT using your Ethereum cryptocurrency. Pretty cool, right?!
Let’s explore the 2 main ways you can start implementing `PayWithCrypto` for your NFT checkout experiences. The first way is through your [Paper Developer Dashboard](https://paper.xyz/dashboard/checkouts). If you follow the [first tutorial,](https://dev.to/papercheckout/how-to-create-and-sell-an-nft-1km6) you should already have a checkout in your [dashboard](https://paper.xyz/dashboard/checkouts). Click on a checkout, and find the “edit” button.
_Paper checkout details are shown in the Paper Developer Dashboard._
From here, you should be able to scroll down and see the toggle for “Pay With Cryptocurrency”. This enables the “Pay With ETH” button we saw earlier.
_Toggle "Allow paying with cryptocurrency" for cross-chain crypto payments._
The second way to enable the “Pay With ETH” button is by using the `<PayWithCrypto>` [React SDK component](https://docs.paper.xyz/reference/paywithcrypto). We provide [extenstive docs](https://docs.paper.xyz/reference/paywithcrypto) to showcase just how to implement this in your NFT checkout. We’ve also created a [sandbox environment](https://paper.xyz/sdk/v1/examples/pay-with-crypto) for you to experience the checkout flow for `<PayWithCrypto>` !
P.S. If you’re based in San Francisco and want to learn more about how to 10X your paying customers with Web2.5, join us to [Web3SF](https://web3sf.com/) on August 26-27th, 2022! It’s 2 days full of speakers series and workshops series about how to get started in Web3 with any project. [Paper](https://paper.xyz/) will be there too! We have both a speaker session and workshop session schedule. It’s also completely free to attend. Come build with us! Hope to see you all there 🫡 | papercheckout |
1,166,350 | Interface segregation principle (SOLID) | Motivation Hi guys. My name is Roman Pedchenko and I am a full-stack developer. Pleased to... | 0 | 2022-08-12T22:00:00 | https://dev.to/pedchenkoroman/interface-segregation-principle-solid-4cid | solidjs, interview, angular, career | ## Motivation
Hi guys. My name is Roman Pedchenko and I am a full-stack developer. Pleased to make your acquaintance. It is my first article and I ask you do not judge it too harshly. The idea to write the article appeared after my conversation with my friend [Max Grom](https://www.youtube.com/channel/UClDDVLu0Cj_o9Y5D2ilCtdQ) and I want to say thanks him.
## Story
There are lot's of developers has an technical interview every day. Someone wants to receive a new job, someone the first one. But the problem is that you have to show your knowledge in a limited period of time which is why every answer is really important. In my humble opinion there are three types of answers. The first one is just academic knowledge. It means that you read about something but do not use it. The second one is you can describe or give an example from real world but you could not answer on the questioin what is it a principal or paradigm or pattern. And last but not least it is to combine the first and the second. Not only you know how to use it but also what you use. As you probably guess that the third
one amplifyes your position on an interview as a really good developer.
I bet everyone it does not metter you are a candidate or an interviever to prepare for the interview repeats **SOLID** principals. In addition to that I beleive that everyone tryes to use it every day but when someone asks could you explain them and gives some examples. It is always so dificult. In this article I will touch only one letter from abreviation but I hope it helps you to be more convincied.
## Letter I
If you open wiki you will easily figure out that
> The interface segregation principle (ISP) states no code should be forced to depend on methods it does not use.ISP splits interfaces that are very large into smaller and more specific ones so that clients will only have to know about the methods that are of interest to them.
I hope it sounds really easy to understand but as I wrote above not only teoretical knowled but also the examples where do we use it and here there are lots of people to get stuck. And here's a hint. It is easier than learning the definition itself. If you are a Angular developer that you are lucky person. Every time and every day when you create a component and add some hooks to component you use it.
```
export class AppComponent implements OnInit, OnDestroy {
ngOnInit() {
// some logic
}
ngOnDestroy() {
// some logic
}
}
```
As you can see we have to implement two interfaces in order to that hooks start to work and that's all. And oddly enough I believe that this answer will show you that at least you know the letter **I** from SOLID.
Thank you and break a leg at a job interview.
| pedchenkoroman |
1,166,376 | Efficiently read files in a directory with Node.js opendir | Originally published on my blog. Recently I had to scan the contents of a very large directory in... | 0 | 2022-08-12T23:14:24 | https://dev.to/danawoodman/efficiently-read-files-in-a-directory-with-nodejs-opendir-41b0 | node, javascript, tooling, typescript | _Originally [published on my blog](https://danawoodman.com/writing/efficiently-read-files-in-directory-with-opendir)._
---
Recently I had to scan the contents of a very large directory in order to do some operations on each file.
I wanted this operation to be as fast as possible, so I knew that if I used the standard [`fsPromises.readdir`](https://nodejs.org/api/fs.html#fspromisesreaddirpath-options) or [`fs.readdirSync`](https://nodejs.org/api/fs.html#fsreaddirsyncpath-options) which read every file in the directory in one pass, I would have to wait till the entire directoy was read before operating on each file.
Instead, I wanted to instead operate on the file the moment it was found.
To solve this, I reached for `opendir` (added `v12.12.0`) which will iterate over each found file, as it is found:
```typescript
import { opendirSync } from "fs";
const dir = opendirSync("./files");
for await (const entry of dir) {
console.log("Found file:", entry.name);
}
```
[`fsPromises.opendir`](https://nodejs.org/api/fs.html#fspromisesopendirpath-options)/[`openddirSync`](https://nodejs.org/api/fs.html#fsopendirsyncpath-options) return an instance of [`Dir`](https://nodejs.org/api/fs.html#class-fsdir) which is an iterable which returns a [`Dirent`](https://nodejs.org/api/fs.html#class-fsdirent) (directory entry) for every file in the directory.
This is more efficient because it returns each file as it is found, rather than having to wait till all files are collected.
Just a quick Node.js tip for ya 🪄
---
_Follow me on [Dev.to](https://dev.to/danawoodman), [Twitter](https://twitter.com/DanaWoodman) and [Github](https://github.com/danawoodman) for more web dev and startup related content_ | danawoodman |
1,166,459 | AWS API Gateway + Lambda + CloudFormation - A complete flow | Lot of time we see that Companies provide Online Lab Environment to their customers. But how these... | 0 | 2022-08-13T04:31:00 | https://dev.to/aws-builders/aws-api-gateway-lambda-cloudformation-a-complete-flow-429 | aws, beginners, devops, api | Lot of time we see that Companies provide Online Lab Environment to their customers. But how these labs can be provisioned via REST API call. I worked 6 months in a company to build the whole environment & this blog is just a small overview of that idea.
- Link: https://medium.com/geekculture/provision-resources-in-aws-using-your-own-rest-api-cc54b390a71f
Note: All my blogs are free to read. | raktimmidya |
1,166,707 | My Google Summer of Code 2022 – Google Blockly Workspace MultiSelect Plugin | My Presentation at 2023 Blockly Developer Summit: Multi-Select Plugin More about 2023 Blockly... | 0 | 2022-08-13T14:44:58 | https://dev.to/hollowman6/my-google-summer-of-code-2022-google-blockly-workspace-multiselect-plugin-bn7 | javascript, programming, opensource, webdev | [My Presentation at 2023 Blockly Developer Summit: Multi-Select Plugin](https://www.youtube.com/watch?v=4OFU9D1Y2DI)
More about [2023 Blockly Summit](https://sites.google.com/view/2023blocklysummit/speakers-organizers)


[Project Repository Link](https://github.com/mit-cml/workspace-multiselect)
[Try out the plugin online](https://hollowman.ml/workspace-multiselect/)
PRs and issues resolved during GSoC 2022:
- [PR #1](https://github.com/mit-cml/workspace-multiselect/pull/1)
- [PR #2](https://github.com/mit-cml/workspace-multiselect/pull/2)
- [Issue #3](https://github.com/mit-cml/workspace-multiselect/issues/3)
- [PR #4](https://github.com/mit-cml/workspace-multiselect/pull/4)
- [PR #5](https://github.com/mit-cml/workspace-multiselect/pull/5)
- [google/blockly-samples PR #1202](https://github.com/google/blockly-samples/pull/1202)
- [ThibaultJanBeyer/DragSelect PR #128](https://github.com/ThibaultJanBeyer/DragSelect/pull/128)
[My GitHub](https://github.com/HollowMan6)
[Mailing list for tracking](https://groups.google.com/g/blockly/c/1qb-M8HZYzY)
Hi there! If you prefer watching videos, check this out for an episode demoing the plugin: https://www.youtube.com/watch?v=FZyvvPZhIRs
For you guys who prefer reading, in this blog post I will introduce you to my work on the plugin for selecting, dragging, and doing actions on multiple blocks. [The project](https://summerofcode.withgoogle.com/programs/2022/projects/9wF06HWE) is sponsored by Google Summer of Code (GSoC) 2022, under MIT App inventor.
## Backgrounds
### Aim
The project aims to enable the selection of multiple blocks at the same time and allow moving and doing actions on multiple blocks on Blockly.
This behavior is the same as when you try to manage your files on your Operating System. You can click on the files while pressing the control key, drag a rectangle to select multiple files. Then move them around, copying and deleting.
It sounds a little bit easy, but actually, I would say that it's not. Multiple selections can become a crazy-complex feature when you start thinking about the details.
### History
This [feature request](https://github.com/google/blockly-samples/issues/267) has remained open on GitHub Issues for six years. However, it was still in the discussion phase and far from the beginning of Implementation before my project began.
Since the Blockly community long [wants this feature](https://groups.google.com/g/blockly/c/A9DB5Z0VXEs/m/Xns0L50JBQAJ), we base our plugin on the latest Blockly so that it can be applied to everyone's project. The App Inventor uses [a Blockly version](https://github.com/mit-cml/blockly/tree/master) that is much older, so it's a pity that we can't see it work on App Inventor now. Let's hope that the App Inventor can upgrade the Blockly version to the latest soon.
### Realization
The "drag a rectangle to select" feature is realized with the help of the [DragSelect plugin](https://dragselect.com/). I submitted [a PR](https://github.com/ThibaultJanBeyer/DragSelect/pull/128) to add the pointer-events so that it can work for Blockly, and it got merged into [v2.4.4](https://github.com/ThibaultJanBeyer/DragSelect/releases/tag/v2.4.4).
In addition, I disable the drag surface feature in Blockly, which stops us from moving multiple blocks simultaneously. Also, there's [evidence](https://github.com/google/blockly/issues/6160) suggesting that we can perform better without a drag surface.
So, how does the plugin work? Well, generally, the plugin acts like an adapter. It maintains its own multiple selection set, which keeps currently selected blocks and make sure we always have one of the selected blocks as the selected one in Blockly core. When users do some actions, the plugin also passes all the actions to the other blocks in our set besides the selected one in Blockly core.
## Functionalities
Let's check out what the plugin can do!
1. Additional blocks can be selected by holding the SHIFT key while clicking the new block. You can also deselect the block by clicking the already selected block.
2. Clicking on the button above the trashcan is equivalent to holding or releasing the SHIFT key for switching between the multiple selection mode and the normal mode.
3. We can clear the selection by clicking on the workspace background.
4. Clicking a new block without holding SHIFT key can clear the multiple selections and change the selection to only that block.
5. Holding SHIFT key to drag a rectangle area to select can reverse their selection state for the blocks touched by the rectangle.
6. In multiple selection mode, workspace dragging and block dragging will all be disabled. You can only drag to draw a rectangle for selection.
7. When some of the selected blocks are in one block stack, for example, some top blocks and some of their children blocks are in the selection simultaneously. If applicable, the plugin only disconnects the selected most top block in that stack with its parent block. Move along with all the children's blocks of that most top block as a whole.
8. You can also drag all the blocks to the trash can.
9. When you edit the fields while selecting multiple blocks, we will automatically apply that to all the blocks with the same type.
10. There's also an MIT App Inventor-only feature that has been migrated into this plugin, that you can double click to collapse or expand currently selected blocks.
11. For the context menu, the `Duplicate` will duplicate the selected most top block in the block stack and all the children blocks of that most top block. The selection will be changed to all newly created duplicate blocks' most top blocks. For all the other items, The actions to show are determined by the state of the block which the user right-clicks on, and the same action will be applied to all the blocks no matter their individual state. We will append the currently applicable number of user-selected state-changing blocks, and the number will only be shown when it is greater than 1.
12. The `Add Comment` / `Remove Comment` option will add / remove comment buttons to all the selected blocks.
13. The `Inline Inputs` / `External Inputs` option will convert the input format with all the selected blocks.
14. The `Collapse Block` / `Expand Block` option will only apply to the selected most top block in the block stack.
15. The `Disable Block` / `Enable Block` option will only apply to the selected most top block in the block stack. All the children blocks of that most top block will also get disabled.
16. The number in `Delete [X] Blocks` is the count of the selected most top block in the block stack as well as all children of those selected most top block. Clicking on that option will delete the blocks mentioned.
17. The `Help` option displays just the helping information of the block the user just right-clicked on.
18. We add `Select all Blocks` in the workspace context menu.
19. For the shortcut keys, These actions will only apply to the selected most top block in the block stack. when you press `Ctrl A`, you can select all the blocks in the current workspace. `Ctrl C` to copy the selected blocks, `Ctrl X` to cut the selected blocks to the clipboard, and `Ctrl V` to paste all the blocks currently in the clipboard and get all the newly pasted blocks selected.
20. Bumping neighbors after dragging to avoid overlapping is disabled in this plugin by default, since I find it disturbing sometimes for multiple selections.
21. Click on a block will bring that block to the front in case Bumping neighbours is disabled.
## Usage
If you want to integrate the plugin into your project, you can add the dependency into your `package.json`. In the source code, pass the workspace to the plugin, and initialize the plugin, and then it's done! You can choose to disable double-click the blocks to collapse or expand and enable bumping neighbors after dragging to avoid overlapping. For the multi-select controls, you can also choose to hide the icon and customize the icons of each state. More details can be found in the [README](https://github.com/mit-cml/workspace-multiselect#readme).
You can also choose to integrate the plugin with other ones, like the [scroll options](https://github.com/google/blockly-samples/tree/master/plugins/scroll-options), which enable the edge scroll and wheel scroll for Blockly. The only thing you have to pay attention for the scroll options plugin to work is to assign the original `blockDragger` value required for scroll options to `baseBlockDragger` in our plugin. During the project period I also submitted [a PR](https://github.com/google/blockly-samples/pull/1202) for fixing the a bug that makes scroll options unable to work without the drag surface, and it has already got merged.
## Finally
That's all for this blog post. Before it ends, I would like to say thank you to my mentors, Evan Patton and Li Li, as well as the MIT App Inventor Team for guiding me throughout the project. They are really supportive. Also, special Thanks to Beka Westberg. She devoted a lot of time to giving suggestions and helping review the code. We can't have this plugin without her! Finally, thanks for reading this blog post! If you have any questions, please comment, and I'll reply. Cheers!
| hollowman6 |
1,166,723 | How to Deploy NextJS App on a Custom VPS | Motivation Whenever we develop any Next JS app and start deployment the first thing that... | 0 | 2022-08-26T16:47:00 | https://dev.to/ranjan/how-to-deploy-nextjs-app-on-a-vps-13ji | javascript, nextjs, devops, react | ## Motivation
Whenever we develop any Next JS app and start deployment the first thing that comes in mind is Vercel. Now days there are a ton of Hosting providers also supporting Next JS on there platform But recently I was working on a project where I needed to deploy A NextJS SSR App on a VPS server due to the client was not comfortable deploying any where else so I looked it up and there was no proper instruction how to do it.
## Prerequisites
Before we start deploying anything First we need a VPS ready for that Please Read Part 1 of the Node js Server Setup series [here](https://dev.to/ranjan/deploy-multiple-nodejs-apps-on-single-server-with-ssl-nginx-pm2-part-1-4841).
## Step 1 - Creating The APP
First we are creating a New Next JS APP on server with
```sh
npx create-next-app@latest awesome-app
```
or you can clone an existing repo from git
```sh
git clone awesome-app.git
```
then we need to get into the folder we just created with
```sh
cd awesome-app
```
if you cloned the app from git you need to do an additional app to install the dependencies
```sh
npm install
#or
yarn
```
## Step 2 - Building For Production
NextJS comes with build scripts so we just need to run it
```sh
npm run build
#or
yarn build
```
it will take a while to generate production build of your project like it will Generated all static pages for you in advance.
## Step 3 - Setting Port (Optional)
By default Next JS will run at port 3000 but on [this](https://dev.to/ranjan/deploy-multiple-nodejs-apps-on-single-server-with-ssl-nginx-pm2-part-1-4841) server we are already running a app on 3000 so we need to update the package.json to start the Production app on new port like 4400
```javascript
{
"name": "awesome-app",
"version": "0.1.0",
"private": true,
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start -p 4400", // or whatever port you want
"lint": "next lint"
},
"dependencies": {
"next": "12.2.5",
"react": "18.2.0",
"react-dom": "18.2.0"
},
"devDependencies": {
"eslint": "8.22.0",
"eslint-config-next": "12.2.5"
}
}
```
## Step 4 - Starting App With PM2
to start the app with PM2 we need to run
```sh
pm2 start npm --name "awesome-app" -- start
```
this will start the app at port 4400 if you wish to add SSL and reverse proxy with NGINX we need to add New app to Our existing NGINX config form VPS Setup.
## Step 5 - Adding Reverse Proxy With NGINX
To update server First open the config
```sh
sudo nano /etc/nginx/sites-available/default
```
and add this new block in **location** part of the server block
```
server_name awesomeapp.com.com www.awesomeapp.com.com;
location / {
proxy_pass http://localhost:4400;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
```
if you are planing to host secound app on **subdomain** just replace `yourdomain2.com ` with subdomain like `api2.yourdomain.com`
then check and restart the NGINX
```
# Check NGINX config
sudo nginx -t
# Restart NGINX
sudo service nginx restart
```
if domain is pointed you should see your app live on port 80 there is one more step to go adding SSL.
## Step 6 - Adding SSL for Second APP
we already have certbot installed so adding additional domains are not an issue
```sh
sudo certbot --nginx -d awesomeapp.com -d www.awesomeapp.com
```
that's all your New app also should be Live on New domain with SSL.
Please Let me Know if you encounter any issues Thanks.
| ranjan |
1,166,812 | GraphQL vs REST | Introduction to GraphQL vs REST REST is one of the most common way of developing API(also... | 0 | 2022-08-20T07:37:00 | https://dev.to/ujwalkumar1995/graphql-vs-rest-3f42 | graphql, rest, api | ## Introduction to GraphQL vs REST
REST is one of the most common way of developing API(also known as Application Programming Interface). People have been using REST for a long time but since GraphQL became open source in 2015, there have been constant debates on whether GraphQL is superior to REST API.
As everything, REST API and GraphQL both have pros and cons, which need to be considered while designing your solutions. In this article I would like to explain what is REST API and what is GraphQL. I will go through the major difference between them and try to explain the pros and cons of both them so people can make a good choice based on their requirements.
## What is REST API?
REST API was presented in 2000 by Roy Fielding. REST stands for Representational State Transfer. REST is a set of architectural constraints, not a protocol or a standard. API developers can develop REST in different ways. When a request is made via a REST API, it transfers a representation of the state of the resource to the requestor. This information can be delivered in one of the several formats: JSON (Javascript Object Notation), HTML, XML or even plain text. JSON is the most popular file format to use because it's language-independent as well as readable by both humans and machines. REST API communicates using HTTP requests with GET, POST, PUT, PATCH and DELETE methods

In the above image you can see that client is sending the request using one of the REST API methods, next server responds with XML, HTML or JSON data depending on the request.
There are certain constraints that should be followed be while designing a REST API.
**1. Uniform Interface -** It states that there should be a uniform way of interacting with the server irrespective of the client. There are four guideline principles of this constraint:
- **Resource Based -** Individual resource are identified in a request.
- **Manipulation of Resources through Representation -** Client has representation of resource and it should contain enough information to modify or delete the resource on the server.
- **Self-Descriptive Messages -** Each message includes enough information to describe how to process the message.
- **Hypermedia as the engine of application state(HATEOAS) -** The term hypermedia refers to any content that contains links to other forms of media such as images, movies, and text. REST API response can include links so that client can discover other resources easily by following the links.
**2. Stateless -** All communications between the client and the server needs to be stateless. The server does not store any information from the previous requests. Client needs to provide all the information in each request so that the server can process it as an individual request.
**3. Cacheable -** Every response should include whether the response is cacheable. Client will return the data from its cache for any subsequent request and there would be no need to send the request again to the server.
**4. Client-server -** This constraint means that client applications and server applications must be able to evolve separately without any dependency on each other.
**5. Layered system -** There can be lot of layers of intermediate servers between client and the end server. Intermediary servers may improve system availability by enabling load-balancing and by providing shared caches.
**6. Code on demand -** It is an optional feature. According to this, servers can also provide executable code to the client. The examples of code on demand may include the compiled components such as client-side scripts such as JavaScript.
## REST request structure
Any REST request includes four essential parts: an HTTP method, an endpoint, headers and a body.
**1. HTTP Method -** An HTTP method describes what is to be done with a resource. Get, Post, Put, Patch and Delete are the common REST methods.
**2. Endpoint -** An endpoint contains a Uniform Resource Identifier (URI) indicating where and how to find the resource on the Internet.
**3. Headers -** These mainly store information relevant to both the client and server. Mainly, headers provide authentication data such as an auth token and the information about the response format.
**4. Body -** Body is used to convey additional information to the server. For instance, it may be a piece of data you want to send in a post request to be added on the server.
## What is GraphQL?
GraphQL was developed by Facebook, which first began using it for mobile applications in 2012. The GraphQL specification was open sourced in 2015. GraphQL is a query language for APIs. GraphQL makes it possible to access many sources in a single request, reducing the number of network calls and bandwidth requirements.
## Types and Resolvers in GraphQL
A GraphQL service is created by defining types and fields on those types, then providing functions(resolvers) for each field on each type. For example, a GraphQL service to fetch student details could have the type as below:
```
type Query {
student(rollNo: String!): Student
}
type Student {
name: String
rollNo: String
}
```
The resolver for the above query could be something like below
```
const resolvers = {
Query: {
student(parent, args, context, info) {
return db.students.get(args.rollNo); // fetches student data from database based on rollNo
}
}
}
```
## Queries, Mutations, and Subscriptions in GraphQL
Queries, mutations and subscriptions form the core features of GraphQL and help us to leverage GraphQL to build better APIs.
### Queries
Queries are data requests made by the client from the server. GraphQL only discloses single endpoint, allowing the client to determine what information it actually requires.
```
{
Students {
rollNo
}
}
```
The field ‘Students’ in the above mentioned query is known as the root field. This query will result in the rollNo of all the students.
```
{
“Students”: [
{“rollNo”: “A1”},
{“rollNo”: “A2”},
{“rollNo”: “A3”}
]
}
```
### Mutations
Mutations are used to create, update or delete data. The structure is almost similar to queries except for the fact that you need to include the word "mutation" in the beginning. For instance:
```
mutation {
createStudent (name : “Daryl”, rollNo: ”A1”){
name
rollNo
}
}
```
### Subscriptions
Subscriptions are a way to create and maintain real time connection to the server. Basically, a client subscribes to an event in the server, and whenever that event is called, the server will send the corresponding data to the client.
Let’s say we have an app where we need to fetch students in real time and want to subscribe to the event of creation of a new student. Below subscription could be used for this type of requirement:
```
subscription {
newStudent {
name
rollNo
}
}
```
## Comparison of GraphQL and REST
### Usability
GraphQL allows you to send a request to your API to get the exact result without requiring anything extra from in the response. Thus, GraphQL queries return highly predictable results providing excellent usability.
With REST the behaviour of the API wildly varies depending on the URI and HTTP method chosen, making it difficult for consumers to know what to expect with a new endpoint.
### Data Fetching
It is quite a common scenario to fetch more data than you need in REST than in GraphQL as each endpoint in REST specification includes a specific data format. Similarly, with REST it’s also common to under fetch the dataset, forcing clients to make additional requests to get relevant data. The case is quite different when it comes to GraphQL. Since it’s a query language and supports declarative data fetching, the users can only get what they actually need from the server.
### Caching
Caching is an integral part of the HTTP specification that REST APIs can use. On the other hand, GraphQL has no caching system, thus leaving the users with implementing their own caching system.
### Monitoring and Error Reporting
When using REST we can monitor the API usage based on status messages. On GraphQL you don't have that, because it always return 200 OK status response. A typical GraphQL error looks like this:
```
HTTP 200 OK
{
errors: [
{
message: 'Something when wrong'
}
]
}
```
### Performance
Performance is one area where GraphQL has an advantage over REST. As mentioned in the data fetching section, due to the problem of under-fetching and over-fetching, REST API tends to perform poorly as compared to GraphQL
### Security
REST provides several ways to enforce the security on your APIs. For instance, in methods like HTTP authentication, sensitive data is sent in HTTP headers, through JSON Web Tokens. GraphQL also provides some measures to ensure your APIs’ security, but they are not as mature as those of REST.
## So which should I choose?
This really depends on your use case. Neither REST nor GraphQL are better than one another. They simply work differently.
If you are concerned about retrieving exactly the data you require and want a more declarative way to consume your API then probably GraphQL would be the better choice. Also it saves bandwidth by solving the problem of under-fetching and over-fetching.
REST provides an easier caching and monitoring system. REST has easier ways to implement authorisation and security in comparison to GraphQL. So if the above points are your primary concern, then go ahead with REST.
| ujwalkumar1995 |
1,166,819 | How to easily initialize a local variable for an if conditional statement in Golang or Go? | Originally posted here! To easily initialize a local variable for an if conditional statement in... | 0 | 2022-08-13T18:58:14 | https://melvingeorge.me/blog/easily-initialize-local-variable-for-if-conditional-statement-golang | go | ---
title: How to easily initialize a local variable for an if conditional statement in Golang or Go?
published: true
tags: go
date: Sun Aug 14 2022 00:28:14 GMT+0530 (India Standard Time)
canonical_url: https://melvingeorge.me/blog/easily-initialize-local-variable-for-if-conditional-statement-golang
cover_image: https://melvingeorge.me/_next/static/images/main-d4c20cc54dbe607440b85fc91dd8acea.jpg
---
[Originally posted here!](https://melvingeorge.me/blog/easily-initialize-local-variable-for-if-conditional-statement-golang)
To easily initialize a local variable for an if conditional statement in Golang, you can write the variable initialization code after the keyword `if` followed by the `;` symbol (semi-colon) and then the conditional statement.
### TL;DR
```golang
package main
import "fmt"
func main() {
// a simple if conditional statement
// and a local variable called `greeting`
// with the value of `Hey`
if greeting := "Hey"; 3 < 5 {
fmt.Printf(greeting)
fmt.Printf(" Yes, it is true!")
}
// using the `greeting` variable outside the
// if conditional statement won't work
fmt.Printf(greeting); // ❌ undefined: greeting. Go build failed.
}
```
For example, let's say we have an if conditional statement that checks if the value `3` is less than the value `5` and if it's true (obviously) should print the text `Yes, it is true!` to the terminal.
It will look like this,
```golang
package main
import "fmt"
func main() {
// a simple if conditional statement
if 3 < 5 {
fmt.Printf("Yes, it is true!")
}
}
```
Now to easily initialize a local variable for the if conditional block, we can specify the variable initialization after the `if` keyword and end the variable initialization with the `;` symbol (semi-colon).
Let's make a local variable called `greeting` with the value of `Hey` and then print it to the terminal.
It can be done like this,
```golang
package main
import "fmt"
func main() {
// a simple if conditional statement
// and a local variable called `greeting`
// with the value of `Hey`
if greeting := "Hey"; 3 < 5 {
fmt.Printf(greeting)
fmt.Printf(" Yes, it is true!")
}
}
```
Now if you run the program, you can see an output like this,
```bash
Hey Yes, it is true!
```
Finally, to prove that this is only available in the if conditional block we specified. Let's also try to use the `greeting` variable outside the if conditional statement.
It can be done like this,
```golang
package main
import "fmt"
func main() {
// a simple if conditional statement
// and a local variable called `greeting`
// with the value of `Hey`
if greeting := "Hey"; 3 < 5 {
fmt.Printf(greeting)
fmt.Printf(" Yes, it is true!")
}
// using the `greeting` variable outside the
// if conditional statement won't work
fmt.Printf(greeting); // ❌ undefined: greeting. Go build failed.
}
```
As soon as you run the program the Go compiler will show you an error saying `undefined: greeting. Go build failed.` which proves the variable is declared locally to the if conditional statement.
We have successfully initialized a local variable for an if conditional statement in Golang/Go. Yay 🥳!
See the above code live in [The Go Playground](https://go.dev/play/p/f2WyKqbuv79).
That's all 😃!
### Feel free to share if you found this helpful 😃.
---
| melvin2016 |
1,167,127 | Python Flask Authentication Part #01 | Hello.! I hope you are doing great. In the last post we setup our application frontend workflow and... | 14,339 | 2022-08-14T10:08:00 | https://dev.to/muhammadsaim/python-flask-authentication-part-01-1k19 | python, flask, webdev, beginners | Hello.! I hope you are doing great. In the last post we setup our application frontend workflow and in this one we are setting the authentication pages and authentication validations.
For the email validation Flask-WTF depends on <code>email-validator</code> so we have to install it for further doing so you can install it by pip.
```shell
pip install email-validator
```
We need two forms one for login and one for register so we have to create two files <code>login_form.py</code> and <code>register_form.py</code> in <code>applictaion/forms</code>.
**login_form.py**
```python
from flask_wtf import FlaskForm
from wtforms import StringField, PasswordField
from wtforms.validators import InputRequired, DataRequired
class LoginForm(FlaskForm):
username = StringField(
'username',
validators=[InputRequired(), DataRequired()],
render_kw={
'class': 'input input-bordered w-full focus:outline-2 focus:outline-blue-700',
'placeholder': 'Username'
}
)
password = PasswordField(
'password',
validators=[InputRequired(), DataRequired()],
render_kw={
'class': 'input input-bordered w-full focus:outline-2 focus:outline-blue-700',
'placeholder': 'Password'
}
)
```
**register_form.py**
```python
from flask_wtf import FlaskForm
from wtforms import StringField, PasswordField, EmailField
from wtforms.validators import InputRequired, DataRequired, Email, EqualTo, Length, Regexp
from application.validators.username_exists import UsernameExists
from application.validators.email_exists import EmailExists
class RegisterForm(FlaskForm):
name = StringField(
'name',
validators=[InputRequired(), DataRequired()],
render_kw={
'class': 'input input-bordered w-full focus:outline-2 focus:outline-blue-700',
'placeholder': 'Name'
}
)
username = StringField(
'username',
validators=[InputRequired(), DataRequired(), Regexp('^[a-zA-Z_0-9]\w+$', message="Only alphabets, numbers and _ are allowed."), UsernameExists()],
render_kw={
'class': 'input input-bordered w-full focus:outline-2 focus:outline-blue-700',
'placeholder': 'Username'
}
)
email = EmailField(
'email',
validators=[InputRequired(), DataRequired(), Email(), EmailExists()],
render_kw={
'class': 'input input-bordered w-full focus:outline-2 focus:outline-blue-700',
'placeholder': 'Email'
}
)
password = PasswordField(
'password',
validators=[InputRequired(), DataRequired(), Length(min=8), EqualTo('password_confirmation', message='Password should be match with confirm field.')],
render_kw={
'class': 'input input-bordered w-full focus:outline-2 focus:outline-blue-700',
'placeholder': 'Password'
}
)
password_confirmation = PasswordField(
'password_confirmation',
validators=[InputRequired(), DataRequired()],
render_kw={
'class': 'input input-bordered w-full focus:outline-2 focus:outline-blue-700',
'placeholder': 'Confirm Password'
}
)
```
We need two WTForms custom validators for our user registration one for the <code>username</code> and other one for <code>email</code> to check both fields are already exists in the DB. Create a folder <code>validators</code> in <code>application</code> and two files in <code>validators</code> folder <code>username_exists.py</code> and <code>email_exists.py</code>
**email_exists.py**
```python
from application.models.user import User
from wtforms.validators import ValidationError
class EmailExists:
def __init__(self, model=User, exclude=None, message=None):
self.model = model
self.exclude = exclude
if not message:
message = "Email is already in use."
self.message = message
def __call__(self, form, field):
user = self.model.query.filter_by(email=field.data)
if not self.exclude:
user.filter_by(id=self.exclude)
if user.first():
raise ValidationError(self.message)
```
**username_exists.py**
```python
from application.models.user import User
from wtforms.validators import ValidationError
class UsernameExists:
def __init__(self, model=User, exclude=None, message=None):
self.model = model
self.exclude = exclude
if not message:
message = "Username is already taken"
self.message = message
def __call__(self, form, field):
user = self.model.query.filter_by(username=field.data)
if not self.exclude:
user.filter_by(id=self.exclude)
if user.first():
raise ValidationError(self.message)
```
Create a file <code>auth.py</code> for an auth controller in <code>application/controllers</code>
**auth.py**
```python
from flask import Blueprint, render_template, request
from application.forms.login_form import LoginForm
from application.forms.register_form import RegisterForm
from application.helpers.general_helper import form_errors, is_ajax
controller = Blueprint('auth', __name__, url_prefix='/auth')
@controller.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm()
if request.method == 'POST' and is_ajax(request):
if form.validate_on_submit():
pass
else:
return {
'error': True,
'form': True,
'messages': form_errors(form)
}
return render_template('pages/auth/login.jinja2', form=form)
@controller.route('/register', methods=['GET', 'POST'])
def register():
form = RegisterForm()
if request.method == 'POST' and is_ajax(request):
if form.validate_on_submit():
pass
else:
return {
'error': True,
'form': True,
'messages': form_errors(form)
}
return render_template("pages/auth/register.jinja2", form=form)
```
Now we need a helper function which return only first error of the field from an errors array of the each fields.
Create a folder <code>helpers</code> in <code>applictaion</code> folder and add a file <code>general_helper.py</code> in the <code>helpers</code> folder and <code>form_error</code> and <code>is_ajax</code> functions into this file. <code>is_ajax</code> function will check this request is ajax or not.
**general_helper.py**
```python
def form_errors(form):
errors = {}
for error in form.errors:
errors[error] = form.errors.get(error)[0]
return errors
def is_ajax(request):
return request.headers.get('X-Requested-With') == 'XMLHttpRequest'
```
Register <code>Auth Blueprint</code> in <code>application/settings.py</code>
```python
def register_blueprints(app):
from application.controllers import (
home,
auth
)
app.register_blueprint(home.controller)
app.register_blueprint(auth.controller)
```
Cerate a folder in <code>auth</code> in <code>views/pages</code> and create two files <code>login.jinja2</code> and <code>register.jinja2</code> also create a layout file <code>auth.jinja2</code> in <code>views/layouts</code>.
**auth.jinja2**
```html
<!doctype html>
<html lang="en" class="h-full scroll-smooth bg-gray-100 antialiased">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link rel="stylesheet" href="{{ url_for('static', filename='css/app.css') }}">
<title>{% block title %}{% endblock %}</title>
</head>
<body>
{% block content %}{% endblock %}
<script src="{{ url_for('static', filename='js/app.js') }}"></script>
</body>
</html>
```
**login.jinja2**
```html
{% extends 'layouts/auth.jinja2' %}
{% block title %} Login {% endblock %}
{% block content %}
<div class="min-h-screen flex justify-center items-center">
<div class="card md:w-2/6 w-4/5 bg-base-100 shadow-xl">
<div class="card-body">
<form action="{{ url_for('auth.login') }}" method="post" class="ajax-form">
{{ form.csrf_token() }}
<h1 class="card-title">Login!</h1>
<p class="mb-6">Welcome back! Log in to your account.</p>
<div class="form-control mb-3 w-full">
<label for="username" class="label">Username</label>
{{ form.username }}
<p class="mt-2 text-sm text-red-600 username-feedback error-feedback hidden"></p>
</div>
<div class="form-control mb-3 w-full">
<label for="password" class="label">Password</label>
{{ form.password }}
<p class="mt-2 text-sm text-red-600 password-feedback error-feedback hidden"></p>
</div>
<div class="card-actions justify-between items-center mt-6">
<a href="{{ url_for('auth.register') }}">Not have an account?</a>
<button type="submit" class="btn btn-primary">Login</button>
</div>
</form>
</div>
</div>
</div>
{% endblock %}
```
**register.jinja2**
```html
{% extends 'layouts/auth.jinja2' %}
{% block title %} Register {% endblock %}
{% block content %}
<div class="min-h-screen flex justify-center items-center">
<div class="card md:w-2/6 w-4/5 bg-base-100 shadow-xl">
<div class="card-body">
<form action="{{ url_for('auth.register') }}" method="post" class="ajax-form">
{{ form.csrf_token() }}
<h1 class="card-title">Register!</h1>
<p class="mb-6">Welcome back! Log in to your account.</p>
<div class="form-control mb-3 w-full">
<label for="name" class="label">Name</label>
{{ form.name }}
<p class="mt-2 text-sm text-red-600 name-feedback error-feedback hidden"></p>
</div>
<div class="form-control mb-3 w-full">
<label for="username" class="label">Username</label>
{{ form.username }}
<p class="mt-2 text-sm text-red-600 username-feedback error-feedback hidden"></p>
</div>
<div class="form-control mb-3 w-full">
<label for="email" class="label">Email</label>
{{ form.email }}
<p class="mt-2 text-sm text-red-600 email-feedback error-feedback hidden"></p>
</div>
<div class="form-control mb-3 w-full">
<label for="password" class="label">Password</label>
{{ form.password }}
<p class="mt-2 text-sm text-red-600 password-feedback error-feedback hidden"></p>
</div>
<div class="form-control mb-3 w-full">
<label for="password_confirmation" class="label">Confirm Password</label>
{{ form.password_confirmation }}
<p class="mt-2 text-sm text-red-600 password_confirmation-feedback error-feedback hidden"></p>
</div>
<div class="card-actions justify-between items-center mt-6">
<a href="{{ url_for('auth.login') }}">Already have an account?</a>
<button type="submit" class="btn btn-primary">Register</button>
</div>
</form>
</div>
</div>
</div>
{% endblock %}
```
Open <code>tailwind.config.js</code> add <code>applictaion/forms</code> directory in the content array because we add input classes through WTF Forms so we have to tell the tailwindcss to include these classes in the final build, so our <code>tailwind.config.js</code> will look like this.
**tailwind.config.js**
```js
/** @type {import('tailwindcss').Config} */
module.exports = {
content: [
'./application/views/**/*.jinja2',
'./application/assets/js/**/*.js',
'./application/forms/**/*.py',
],
theme: {
extend: {},
},
plugins: [
require('@tailwindcss/typography'),
require('daisyui')
],
}
```
Add the username field in the User model after adding the username field our Model will look like this.
**user.py**
```python
from application import db
class User(db.Model):
__tablename__ = 'users'
id = db.Column(
db.Integer,
primary_key=True
)
name = db.Column(
db.String(255),
nullable=False
)
username = db.Column(
db.String(255),
nullable=False,
unique=True,
)
email = db.Column(
db.String(255),
unique=True,
nullable=False
)
password = db.Column(
db.String(255),
nullable=False
)
role = db.Column(
db.String(50),
nullable=False,
server_default="user"
)
created_at = db.Column(
db.DateTime,
server_default=db.func.now(),
nullable=False
)
updated_at = db.Column(
db.DateTime,
server_default=db.func.now(),
nullable=False
)
```
After adding the filed please run the migration for creating new field migration.
```shell
flask db migrate -m "Add username column in users table."
```
After the migration run the migration to effect on th DB.
```shell
flask db upgrade
```
Now its time to implementing <code>AJAX</code> in our authentication forms open <code>app.js</code> in <code>src/js/app.js</code> update your file with ajax your file will look like this.
```js
window.$ = window.jQuery = require('jquery');
const spinner = `<div role="status">
<svg aria-hidden="true" class="w-6 h-6 text-gray-200 animate-spin dark:text-gray-600 fill-blue-600" viewBox="0 0 100 101" fill="none" xmlns="http://www.w3.org/2000/svg">
<path d="M100 50.5908C100 78.2051 77.6142 100.591 50 100.591C22.3858 100.591 0 78.2051 0 50.5908C0 22.9766 22.3858 0.59082 50 0.59082C77.6142 0.59082 100 22.9766 100 50.5908ZM9.08144 50.5908C9.08144 73.1895 27.4013 91.5094 50 91.5094C72.5987 91.5094 90.9186 73.1895 90.9186 50.5908C90.9186 27.9921 72.5987 9.67226 50 9.67226C27.4013 9.67226 9.08144 27.9921 9.08144 50.5908Z" fill="currentColor"/>
<path d="M93.9676 39.0409C96.393 38.4038 97.8624 35.9116 97.0079 33.5539C95.2932 28.8227 92.871 24.3692 89.8167 20.348C85.8452 15.1192 80.8826 10.7238 75.2124 7.41289C69.5422 4.10194 63.2754 1.94025 56.7698 1.05124C51.7666 0.367541 46.6976 0.446843 41.7345 1.27873C39.2613 1.69328 37.813 4.19778 38.4501 6.62326C39.0873 9.04874 41.5694 10.4717 44.0505 10.1071C47.8511 9.54855 51.7191 9.52689 55.5402 10.0491C60.8642 10.7766 65.9928 12.5457 70.6331 15.2552C75.2735 17.9648 79.3347 21.5619 82.5849 25.841C84.9175 28.9121 86.7997 32.2913 88.1811 35.8758C89.083 38.2158 91.5421 39.6781 93.9676 39.0409Z" fill="currentFill"/>
</svg>
<span class="sr-only">Loading...</span>
</div>`;
// ajax form submission
$(".ajax-form").on('submit', function (e){
e.preventDefault();
const url = $(this).attr("action");
const method = $(this).attr("method");
const payload = $(this).serializeArray();
const is_refresh = $(this).data("refresh");
const is_redirect = $(this).data("redirect");
let submit_btn = $(this).find("button[type=submit]");
let form_data = new FormData(this);
let submit_html = submit_btn.html();
$(this).find("input, select, button, textarea").attr("disabled", true);
$.ajax({
url: url,
method: method,
data: form_data,
processData: false,
contentType: false,
cache: false,
beforeSend: () => {
$(this).find("input, select, textarea").removeClass("input-error focus:outline-red-600").addClass('focus:outline-blue-700');
$(this).find(".error-feedback").addClass('hidden').text('');
submit_btn.html(spinner);
},
success: (data) => {
$(this).find("input, select, button, textarea").attr("disabled", false);
submit_btn.html(submit_html);
if(data.error && data.form){
let messages = data.messages;
Object.keys(messages).forEach(function (key) {
$("#" + key).addClass("input-error focus:outline-red-600").removeClass('focus:outline-blue-700');
$("." + key + "-feedback").removeClass('hidden').text(messages[key]);
});
}else{
}
}
});
})
```
Rebuid your assets or start watch
```shell
yarn watch
```
Run the application
```shell
python run.py
```
You can get the updated code on [GitHub Repo](https://github.com/MuhammadSaim/flask_tutorial_blog)
Thanks for being with me.
See you guys in next post if you have any issue while going with this post feel free to comment.
| muhammadsaim |
1,167,220 | How To Save Files To AWS Glacier | How to storage files in AWS S3 Glacier. | 0 | 2022-08-14T12:44:47 | https://dev.to/toymachine/how-to-save-files-to-aws-glacier-3f75 | storage, aws, glacier | ---
title: How To Save Files To AWS Glacier
published: true
description: How to storage files in AWS S3 Glacier.
tags: storage, aws, glacier
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/wwocl8rkf85wbgu1lyzw.jpg
---
Uploading files to Amazon's AWS S3 cloud storage server is very simple because to a handy web interface and a number of different ways to add a third-party [graphical UI tool](https://proprivacy.com/cloud/comparison/amazon-s3-user-interface-tools)... if you are into that sort of thing. Glacier is a bit different as it's not designed to be the sort of storage that you interact with as regularly so, understandably, getting files into and out of the service isn't as easy as general S3.
## Step One: CLI
In order to work with AWS Glacier you'll need [Amazon's CLI](https://aws.amazon.com/cli/) service, which is its command line interface. This tool is a bit difficult to approach if you aren't used to working with the command line, but once you learn the basics it's quite straightforward, plus it's very powerful. With great power comes great responsibility (as to the safety of your files) so use it with care, especially if you don't have extensive permissions (IAM) setup in your org.
## Step Two: S3
Hop into S3 and create any buckets you might need. Glacier is, after all, a subset of S3, so you can use the S3 web interface to interact with Glacier-class files as well as set [lifecycle management](https://www.perforce.com/blog/lifecycle-management). This will enable you to move files from S3 into your "cold" storage (the name making more sense now?).
You can, of course, create buckets and vaults, etc. using the CLI if you are feeling saucy.
## Step Three:
Open up your terminal or command line and confirm AWS CLI is installed. A simple version check will do the jog:
`$ aws --version`
All good? Now decide, do you want to upload a single file or multiple files.
### Single File Upload To Glacier
`aws s3 cp /Users/USERNAME/folder/folder2/fileName s3://myBucketName --storage-class GLACIER`
Here you are coping the file from your local machine to an S3 bucket, with the storage class of "Glacier." Pretty straightforward right?
### Multiple File Upload To Glacier
`aws s3 cp /Users/USERNAME/folder/folder2/ s3://myBucketName --storage-class GLACIER --recursive`
If you have a folder and you'd like to upload all the files in it to Glacier, you simply need to specify the folder and then add the `recursive` command. You can watch the upload progress in your terminal.
Perhaps you have a bunch of videos you'd like to save, some family images, or massive amounts of [airport wait time data](https://tsa.report), or any other random thing you might have picked up in your software development adventures.
Remember, AWS CLI has a [huge number of tools](https://docs.aws.amazon.com/cli/latest/userguide/cli-services-glacier.html) and capabilities so it's much more than just a convenient way to upload files without logging into AWS. It can stream multiple files from your computer to S3 at once, it can be used to split huge files (which would fail if being uploads via the web interface) as well as do many other cool things like [multi-part uploads](https://awscli.amazonaws.com/v2/documentation/api/latest/reference/glacier/complete-multipart-upload.html)]. | toymachine |
1,167,390 | HOW TO SET UP A LOCAL NETWORK BETWEEN YOUR LINUX VM(KALI) AND MY LOCAL WINDOWS USING SAMBA | Very excited to post my knowledge on this here as I had ran into this problem a few times while... | 0 | 2022-08-14T17:59:00 | https://dev.to/msaghu/how-to-set-up-a-local-network-between-your-linux-vmkali-and-my-local-windows-using-samba-2ggj | Very excited to post my knowledge on this here as I had ran into this problem a few times while trying to access my local files in Windows into Linux(both in my Ubuntu and Kali Linux machines). The beauty of learning is that you learn new things that have already been solved. So let's get into it:
The Samba software package can also be used to communicate Linux servers and clients with Windows and MAC clients using Microsoft SMB.
PS: This breakdown assumes that you already have a Linux machine or have it set up as a Virtual Machine and are currently in the terminal
## **1. Update your system**
_sudo apt update_
## **2. Install Samba on your system**
_sudo apt install samba_
(press ctrl+z to opt out)
## **3. Check the status of Samba**
_sudo systemctl status smbd_
## **4. Create the shared directory**
_sudo mkdir /home/mytutorialdirectory_
## **5. Create full permissions for the directory**
_sudo chmod 777 /home/mytutorialdirectory_
## **6. Add the directory**
_sudo useradd mytutorialdirectory_
## **7. Setup a password for Samba (set up something that you can easily remember here)**
_sudo smbpasswd -a mytutorialdirectory_
## **8. Setup smb.conf**
_sudo nano /etc/samba/smb.conf_
or if you prefer vim as a text editor
_sudo vi /etc/samba/smb.conf_
_scroll to the bottom and add_
_[mytutorialdirectory]_
_(2 spaces)path = /home/mytutorialdirectory
(2 spaces)browseable = yes
(2 spaces)valid users = mytutorialdirectory
(2 spaces)read list = mytutorialdirectory
(2 spaces)write list = mytutorialdirectory
(2 spaces)guest ok = no_
(press ctrl+x then y ,then enter to opt out and save)
## **9. Shows the changes that you made in the smb.conf file **
_sudo testparm_
## **10. Restart the Samba service and view status**
_sudo systemctl restart smbd_
_sudo systemctl status smbd_
## **11. Access the Linux directory on Windows**
Go back to your Windows local machine , press the windows icon key+R
Enter your Linux machine's IP address(you can find this by entering IP address in your Linux terminal and copying the inet IP address) and press enter
SUCCESS
You can now see your shared file | msaghu | |
1,167,760 | How to get the best job offer for senior+ software engineer roles | Navigating "senior+" job interviews I recently did a round of job interviews. I'm on... | 0 | 2022-08-15T14:55:00 | https://dev.to/errietta/how-to-get-the-best-job-offer-for-senior-software-engineer-roles-4pdf | interview, programming, career, jobs | ## Navigating "senior+" job interviews
I recently did a round of job interviews. I'm on the top end of the Senior Software Engineer band, and I was looking for other "top of senior" or Staff Software Engineer roles. At the end of the interview process I had two job offers, although I believe I could have had more if I was more focussed on interviews after I already had those two offers and if I had more time. The interview process is sometimes difficult to navigate and it definitely took me some time to get right.
Because of this, I wanted to share my experience with people who are curious as to what interviews for Senior Software Engineer (or above) positions look like, or what those roles require from candidates.
A few stipulations/disclaimers before I get to it:
- This is based on my experience in London (UK). Salaries and job titles vary per company and per location.
- I can't promise any particular results in terms of job offers due to reading this blog post.
- This is my opinion, and not the opinion of my employer. This is based on my interview experience and does not necessarily reflect my current role or compensation.
- YMMV.
## Pieces of the Puzzle
Ok then, let's get to it!
The job interview process typically consists of several different stages. Some companies will have multiple interviews across multiple days, while some while 'compress' it into a shorter process. Even if the process itself is across fewer days, the actual stages involved have been the same in my experience. These stages are as following (not necessarily in this order):
- CV/Apply to the role
- Initial call with a recruiter
- Introduction with the hiring manager (this part may be skipped or done as part of another call)
- Coding test
- Architecture/Systems design test
- Situational (STAR) interview
- Final stage/Values interview
I will break down these steps in this blog post, and try to explain what kind of skills are desired in those steps from senior engineers.
## CV & Application
Writing a CV is probably a whole art on its own, and I'm probably not best placed to say what makes a great CV or not, but I can say what has worked for me. By the way, [here is mine](https://www.errietta.me/cv/) if you want some inspiration.
### Intro
Put a short paragraph at the top introducing yourself, what you bring to the table, and what you want from your next role. This is mine:
> I am a senior software engineer with 8 years of experience. I am skilled in designing reliable and performant systems, integrating with third parties, and building solutions from the ground up. In my next role, I am looking for a role that will allow me to grow into a Staff Engineer or Architect position.
💡Take a look at the "Elevator pitch" section later in this blog post as a lot of the same rules for that apply here.
### Experience
Add your experience to your CV. Usually this is in order of recency, but if a past role is more relevant to what you are applying for, you could bend the rules and go order of relevance.
People like to see **impact** and **results** for more senior roles. Speak about projects you've led, initiatives you've taken, and the impact you've had to the company. Did your work make some part of the application faster? Did it result in your company passing a pentest? Did it result in 10 new clients signing up? If you're not sure, this is the time to speak to your PM and figure out! They certainly have (or should have) some way of monitoring the impact of the features you're building.
### Education history: To include or not?
Don't get too hang up on your education history. After my first couple of jobs, nobody has asked me about it. I've actually completely removed it from my CV to save space and I haven't noticed any adverse effects from doing so. I actually believe that in some circumstances, including it could be more of a disservice, but that's just an opinion and perhaps something for a different blog post
### Talks/Contributions
Speak about things outside of work! For example, I include my talks in my CV. I should actually probably make them more prominent.
Talks, open source contributions, blog posts, are all things you can show your prospective employer to show that you know what you're talking about.
Contrary to popular belief, you don't have to be a very active open source contributor or have no other hobbies outside of coding to get a job - but any public work that you can show is a chance to show off your skills. You can't bring them into your workplace and show them how good you are, so this is the next best thing. Give yourself credit for things you've done that are public and you can display - a lot more things than "active React contributor" are valid here.
You definitely don't have to go out of your way to create out-of-work material to show, just think about things you've already done at the course of your career. Even if you don't have an active Github profile (I don't!), don't sell yourself short, there are other things you may be able to display.
## Recruiter/Hiring manager introduction
Whether your introduction call is with the recruiter, the hiring manager, or both, the structure is pretty similar. This stage and the final stage are actually the easiest. Some mild preparation is required, but if you have done a good number of job interviews before, you will be able to do this with your eyes closed.
The questions here usually fall into the following categories:
- Who are you?
- What can you offer to the company? Why are you a good fit to this particular role?
- What can the company offer to you?
Do some cursory research on the company here. Good hiring managers and recruiters will explain the company's industry and mission to you in this stage anyway, but it never hurts if you already know something about the company. Be yourself, and show interest. If something catches your eye on the company's website or social media, don't forget to bring it up - this shows you are interested and observant.
I also recommend thinking about why the particular role or company is a good fit based on your previous experience. This may not be asked in much detail at this stage, but it will be a good weapon in your arsenal for the next stages. Remember that as you go into more senior roles, the job is less about your ability to code and finish tickets, and more about the big picture/higher level stuff: systems design, collaboration with other people, making decisions. For example, maybe you don't have experience across the whole of the company's stack, but you have lead projects and mentored engineers in your previous couple of jobs - this is a good thing to talk about when introducing yourself.
Finally, what can the company offer to you? This one goes both ways. They will almost certainly ask about the kind of compensation you are looking for. I recommend asking for their salary range and deciding whether or not that is within your desired salary. Do not give them your current salary and do not give a specific number that you're looking for. Just ask for the range and tell them if that range is appropriate for you. The other part of this question, is actually the questions you ask the company. Write down some questions in advance and ask them when they allow you to (typically towards the end of the interview). These questions should help you decide whether the company would be a good fit and offer what you need - career progression, learning opportunities, company growth/funding stage are all very good questions to ask here.
### The elevator pitch
Definitely prepare an "elevator pitch" for yourself before going into the intro call; I can guarantee the first question you are going to be asked at every stage is "tell me about yourself". This is a 60 second question and the beauty of it is that you can recycle it for every stage and sometimes even for different companies. I usually structure mine like this:
* What is my current job title?
* What kind of responsibilities have I had at my job?
* What am I looking for in my next role?
This gives the interviewer a good picture of who you are and why you've applied to this job. Bringing it all together, here's mine:
My name is Erry. I am currently a Senior Software Engineer at [Monsters, Inc](https://en.wikipedia.org/wiki/Monsters,_Inc.). As part of my role, I'm leading the identity services team and in particular the Single Sign On project. In my next role, I am looking for a job that will allow me to grow into a Staff Software Engineer or Architect position.
Short, concise, and gets the point across. You really don't have to overthink this one, but you do have to be prepared for it.
## Coding test
Congratulations, you've officially got your spot in the pipeline! Now it's all about proving that you can do the job.
The coding test is the hardest to talk about, because every company does it their own way. Some companies do a pair programming exercise, some companies give you a timed task to complete, and some others give you a prompt with a task to return to them.
You may or may not know what the exact exercise will be before that time, so it's hard to know exactly what to prepare.
I recommend using the previous stage(s) of the interview to really understand the company and some of the problems they may have, and try to get an idea of the kind of problem they may face day-to-day. However, the problem in the coding test may not necessarily be connected to the company's actual problems.
I'm not going to go into leetcode or CS algorithm questions because I've not done a CS degree (my degree was called "web development" and had a lot of practical PHP/Javascript projects rather than traditional CS theory) and I don't use these algorithms for my job. If the company you're applying to wants you to solve a CS algorithm problem, then all you can do is study and practice (and ask yourself whether you want to be engaging with companies that have such hiring questions to begin with).
However, most coding tests I've taken have been more practical day-to-day problems that can be solved without memorising algorithms or theory. In that case, this is what you should focus on your test, whether it's a live test or a test you're doing at home:
* Are you following best practices for your job?
* Are there things you would be doing if you had more time (for example better/more tests)?
* What is the performance of your code like? This can be things like "big O notation" but recognising things like how long database queries take
* How would you "scale up" your code? Could it handle 100k users? 1 million users?
* How do you interact with the team if you're doing a pair programming exercise? Are you asking them questions? Are you using them as a resource?
## Architecture test
This is similar to the coding test in that you don't know what you're getting until you get there. Usually this is done live, with a person at the other end giving you the prompt and being there to chat you through the idea. In the good old days of in-office interviews, this would probably be done on a whiteboard.
My one recommendation here is: study and practice.
Here are things to focus on while preparing:
* Go back to the questions you hopefully asked in the previous stages about the company. What kind of problems could they be facing? If you can use their product (app/website) this is a great time to use that to your advantage: pick some of the problems they are solving with their product and think about how you would design those features. Even if their product is not public facing, it's worth asking if you can get an account to try the product out - sometimes interviewers can arrange for that, and it gives you bonus gold stars for caring about the product!
* Don't just talk about how you're solving the problem, but also ***why*** you're solving it that way. Expect every decision you take to be put under the microscope and have to be justified. Sometimes there is no right or wrong answer, and you just have to be able to explain why you took your decisions.
* Ask your interviewer if there are any limitations or functional requirements for your architecture. Sometimes you have pretty much free rein in your design, and sometimes they will tell you that you have to function within the AWS ecosystem and use a particular database system, for example.
* Communicate things that you would normally do if you had more than one hour to do your design. For example: "this is when I would normally do cost analysis".
* Be ready to go for the simplest solution first, but always keep the question of "how would I improve this" at the back of your mind, because that question will almost certainly be asked.
* Think about the performance and security factors of everything you are designing. Even if you don't work with a very highly scalable system, this is a good time to read up on design principles such as domain driven design, CQRS, and distributed/event driven systems.
My honest view here is that you are most likely going to fail the first few architecture interviews you do. Keep a note for what they ask for, and think about how you can prepare in the future. Maybe spend some time designing diagrams as practice for your next interviews. Think about your current job and how you would re-design the architecture of a particular feature if you were starting over. Keep a list of all the things you could not answer, and don't be afraid to ask for their feedback after the interview. All of this will help you get to a point where you can ace these kind of interviews.
## Situational (STAR) interview
### The format
Welcome to what is, in my opinion, the hardest part of the interview. Sometimes this is the first step, other times it's the last.
While it may be possible to pass the architecture interview without much prep if you've been doing the job for a long time, this interview absolutely needs preparation up ahead. And much like the architectural interview, you're very unlikely to get this format right from the get-go. It took me several interviews before I was comfortable answering these kind of situational questions without panicking and sweating. It took me even longer before I found it easy and I did a decent or even great job at them.
If you don't know what I mean by Situational questions, those are the kind of questions that can be boiled down to "tell me about a situation when...". Sometimes the interviewers are more subtle about it, but luckily I have found that they are usually pretty straight forward. They will likely tell you in advance that it's going to be a situational interview, and they are not necessarily going to try to ask you trick questions or trip you up.
The trick for those kind of questions is to use the STAR framework. The interviewers may tell you this themselves if they're super nice, but in case they don't, it's good to keep this in mind. STAR stands for:
* Situation
* Task
* Action
* Result
I found [this blog post](https://resume.io/blog/star-method) was a great resource on how to answer these questions, but I will try to explain it here as well.
Each question will take you between 3-5 minutes to answer. You essentially have to scan through many years of experience and find the right example for the question and then condense it down to a format that can be answered in a few minutes.
If this sounds extremely difficult, it's because it is, and that's why you should have 2-3 scenarios that you have prepared in advance and can go back to during the interview. You're never going to be able to prepare for every question that they ask, but the more you do these interviews, the more you will find patterns to the questions and you will be able to adjust what you have already prepared in advance to better fit the specific questions you're being asked.
I eventually tackled this by thinking back to my previous 2 roles, and thinking about 2 or 3 projects that I led: what was required, what went well, what went wrong, and what I would change. Then, I wrote down some scenarios in the STAR (or STARL, the L standing for Learning) format.
### Example question
Question:
> Tell me about a time that you disagreed with a colleague/a superior
#### Situation
Here you have to give the context and background of why you were doing the particular piece of work. This can be pretty short, one or two sentences.
> We had to resolve some vulnerabilities from a pen test. We had very little time to resolve those as the pen test certification was preventing us from signing a new client. In particular, we were storing tokens in local storage, which meant that if any XSS vulnerability was present, the tokens could be stolen by an attacker.
#### Task
The question to answer here is "what was your role within the project?" Again this can be pretty concise.
> My team lead at the time was accountable for the platform security and I was tasked with implementing their suggestions in the best way possible within the time frame as well as breaking down tasks for other team members.
#### Action
This is the meat and potatoes of your answer. This is where you are giving your answer to the main question. In this case, where was the disagreement, and how did you handle it?
> My team lead proposed replacing tokens that were stored in localstorage to tokens stored in cookies. Doing POST requests with cookies would make us vulnerable to CSRF, however, so they also proposed implementing CSRF protection to prevent that.
I instead proposed a solution where we would not be using cookies for POST requests and instead get a token from a GET request + cookie at page load, then store it in memory.
After talking to my lead and getting their understanding and their concerns about this, I wrote down different scenarios and explained why this solution was just as secure, and also saved us time compared to their solution which required implementing CSRF protection.
#### Result
This is where you show off the ___impact___ of your decision!
> The team lead agreed to use my solution. Because of this, we finished the project 7 days quicker than the original solution, we implemented something that was less technically complex, and still passed the pen test.
#### Learning
What went wrong? What have you learned? What would you have done differently?
Not every project is a success, and even those that are, are not done perfectly. Your interviewer will ask you this question, so be prepared for it.
> In my case, I should have pushed back more on the particular project. It was a lot of work that was required of us in a short amount of time and it lead to the team working harder than was healthy for us. I have learned from this and now follow a much leaner approach - I have learned to say "no", push back, and negotiate for an MVP rather than trying to make the impossible happen.
### Learn the format
That's it! That's the whole format. Now, as I said earlier, I recommend writing down at least 2 or 3 examples of different projects in this format. Then, record yourself answering the question! It sounds weird, but I think that doing this was what eventually helped me to stop panicking about these questions. By playing back a recording, you can see how long you are taking to answer and can learn to pace yourself. You can also get a better idea of where there may be gaps in your explanation. By doing this, I saw that I wasn't taking as long as I thought, and this gave me the breathing room to stop and think about the question for a few seconds before I answered it, which was also gave me a huge advantage in the interview.
Here are some more example questions that I've been asked:
* Tell me about a project you're really proud of
* Tell me about a time that you had to deliver a project within a deadline
* Tell me about a time that you had to make a compromise
* How do you deal with disagreements?
* How do you get buy-in?
* Tell me about a project where you had impact
* What's a mistake you have made in a project?
* What have you learned from cross-team work?
And my favourite one:
> What's the biggest technical problem your team faces at the moment?
... And why haven't you addressed it?
These questions can be scary, but just be yourself and remember that they are not looking for people who have done very impressive things or people who have done things perfectly. Rather, they are looking for people who know how to have an impact within their team, and for people who can recognise their own mistakes and talk about what they will do differently next time.
## Values interview
Congratulations, take a deep breath of relief. You're past the hardest part of the process, and now you just have to be yourself and show why you're such a great person to work with!
Look up the company and what they value, and see why you relate to it. I recommend being honest, because if you hate everything about what the company does, then you probably don't want to work there. This is where you just show them the person behind the CV. Be authentic, and remember what excites you about the role. Sure, more money is good, but there are plenty of companies that can offer that - so why this **particular** company? Is it the more flexible environment? What about the people you interviewed with? What did you like about them? What are the cool problems that you're really excited to solve?
Be ready to talk to those things, and the job is almost yours.
## The offer
If you've done well in every part of the process, then congratulations, you probably have a job offer!
If the recruiter asks to talk to you on the phone after your final stage, then prepare yourself to be offered a job.
However, the process is not over yet! Have you got other interviews that you are close to finishing? Then feel free to ask for more time before you decide. If you have an offer, you can also use that as leverage to speed up your other processes.
Can you negotiate the offer? You can always ask for a higher salary at offer time. I'm not the best to talk about salary negotiations, but I will defer you to [this blog post](https://www.askamanager.org/2019/03/how-to-negotiate-salary-after-a-job-offer.html). **Always** negotiate. Get ready for them to say no, but don't leave money on the table.
## Closing
Wow, that was a lot to write. I hope that this helped someone - the process is quite lengthy and in parts needs special preparation, so I'm hoping to provide the kind of resource I wished I could have while doing my interviews.
Let me know if you have any questions, always happy to answer from my experience. And remember, ask for what you deserve! | errietta |
1,167,999 | Blazor vs. Wisej.NET | Looking for an alternative to Blazor for enterprise web development? In his latest article, Jon... | 0 | 2022-08-15T17:27:14 | https://dev.to/lrufenacht/blazor-vs-wisejnet-m0g | webdev, dotnet, csharp, productivity | Looking for an alternative to Blazor for enterprise web development? In his latest article, Jon Hilton discusses his experience in developing with Wisej.NET:
[Read the full article on CodeProject](https://www.codeproject.com/Articles/5339509/Wisej-NET-vs-Blazor) | lrufenacht |
1,168,131 | 11 FIGMA Dashboard templates, both free and paid | This post was originally posted on Red Pixel Themes. Free Purity UI... | 0 | 2022-08-15T21:34:00 | https://dev.to/vivgui/11-figma-dashboard-templates-both-free-and-paid-5bm1 | figma, dashboard, templates | *This post was originally posted on [Red Pixel Themes](https://redpixelthemes.com/blog/figma-dashboard-templates/).*
---
## Free

### **Purity UI Dashboard - Chakra UI Dashboard**
[Demo](https://www.figma.com/file/zZLFEfUaqVwAxRY7iJ2VIC/Purity-UI-Dashboard---Chakra-UI-Dashboard-(Community)?node-id=1516%3A9143) | [Get it here](https://ui4free.com/website-templates/figma-purity-ui-dashboard---chakra-ui-dashboard.htm)
**Important bits**
* 100+ Elements
* Light + Dark Mode
* 4 pages
**Description**
Designed for those who like modern UI elements and beautiful websites, it’s made of hundreds of elements, designed blocks, and fully coded pages.

### **Ariol Dashboard Template Design**
[Demo](https://www.figma.com/file/Nv3cFDrHrH33joSUny1R5T/Ariol-Dashboard-Template-Design-(Community)) | [Get it here](https://www.figma.com/community/file/1105056443721470016)
**Important bits**
* 80+ pages
* Includes pages for creating clients, orders, contracts, handling communication, and managing finances.
* Also available in Adobe Photoshop format
**Description**
Ariol is a beautiful and unique dashboard with more than 80 pages in different directions that will make your life easier when creating any system management site.

## **Hope UI Admin**
[Demo](https://www.figma.com/file/uqJITtF1TftQRbrf52tn0l/Hope-UI-Admin-%7C-Free-Open-Source-Bootstrap-5-Admin-Template-(Community)?node-id=589%3A4) | [Get it here](https://www.figma.com/community/file/1009728454881721702)
**Important bits**
* Includes Light & Dark Mode
* Includes error and maintenance page designs
* Also has code available
**Description**
Hope UI is a gorgeously built pre-designed admin dashboard template. Has 5 admin template is fully responsive and user-friendly
## Paid

### **HRAD | HR management dashboard**
Price: $25 | [Get it here](https://themeforest.net/item/hrad-66-pages-hr-management-dashboard-figma-template/34669645)
**Important bits**
* Includes 66+ pages
* Includes Light & Dark Mode
* Uses components and it's well organized
**Description**
HRAD is a great HR management dashboard that has a modern, clean, creative & unique design based on the latest technology. This web app template consists of 66 attractive pages in both light & dark variants and all symbols and objects are vector-based and easily editable. Suitable for anyone who is looking for an HR & admin process solution for their company.

### **Figma Admin Dashboard Pro Template**
[Demo](https://www.figma.com/file/302GJH45U1PrjA0ifcVVl1/Figma-Admin-Dashboard-(Free-Version)-v1.0.0?node-id=16%3A732) | Price: $79 | [Get it here](https://themesberg.com/product/figma/admin-dashboard-pro-template)
**Important bits**
* Includes 27 pages
* Optimized for Tailwind CSS
* Style guide and auto-layout included
* Screens available for mobile and tablet devices
**Description**
Figma Dashboard Pro is a premium set of UI components and pages built in Figma optimized to be used with the Tailwind CSS utility classes. It includes features such as variants, auto-layouting, style guidelines, and also optimized screen examples for mobile and tablet devices.

### **Tagih - Simple Neat Banking Admin Dashboard Figma**
Price: $18+ | [Get it here](https://themeforest.net/item/tagih-simple-neat-banking-admin-dashboard-figma/32401724)
**Important bits**
* Includes 16 screens
* Only has light mode
* Style guide included
**Description**
Tagih, a simple neat banking admin dashboard, consists of 16 pages that are needed in organizing and managing your finance that is available only in light mode in Figma format files. You can edit or customize the text, images, and colors on the template by using Figma to fit your financial recording needs.

### **Relik - Admin Dashboard Figma Template**
Price: $22+ | [Get it here](https://themeforest.net/item/relik-admin-dashboard-figma-template/35255781?gclid=Cj0KCQjwuuKXBhCRARIsAC-gM0hDv6ivvI_JVcWzwVLjYEDzDfgP_6DYehGWlYJBq4EZhxEJ6AL__yEaAhqaEALw_wcB)
**Important bits**
* Includes 35 screens
* Includes 150+ Widgets & Components
* Has Light & Dark Mode
**Description**
Relik is a beautiful, simple, developer-friendly, highly customizable admin dashboard template with a high-quality UI & well-organized Figma file. This Admin Dashboard helps the users to build their dashboard design with the format you like by components on Figma that are fully customizable and dragging & dropping widgets and components.

### **Hospital Admin Dashboard UI Figma**
Price: $12+ | [Get it here](https://www.creativefabrica.com/es/product/hospital-admin-dashboard-ui-figma-psd/)
**Important bits**
* Includes 6 pages: Dashboard, Patient List, Patient Details, Doctor List, Doctor Details, Review page
* Documentation included
* Available in PSD format
**Description**
Modern dashboard User Interface design template for a Hospital Administration. This template is ideal for hospitals, clinics, administration, doctors admin, and any admin dashboard website. Make your admin dashboard design looks stunning and eye-catching using this template. This template includes 6 unique and modern User Interface screens in PSD and Figma format. You can easily edit and customize using Adobe Photoshop and Figma.

### **Mirion - Simple Professional Admin Dashboard Figma Template**
Price: $12+ | [Get it here](https://themeforest.net/item/mirion-simple-professional-admin-dashboard-figma-template/31635885?irgwc=1&clickid=Rhp16JxCZxyNUwfyCLUQjRO9UkDy-7Uf%3A0BAxs0&iradid=275988&irpid=1416972&iradtype=ONLINE_TRACKING_LINK&irmptype=mediapartner&mp_value1=&utm_campaign=af_impact_radius_1416972&utm_medium=affiliate&utm_source=impact_radius)
**Important bits**
* Includes 14 screens
* Style guide included
* Uses Google fonts
**Description**
Mirion has everything you need to make your admin dashboard more well-organized and neat. This dashboard template consists of 14 useful and well-designed pages using dim color and a friendly user interface so it will be comfy for any user. This template is available in Figma format file so you can customize the text, image, and color on the template by using Figma.

### **Glazey - Modern Admin Dashboard**
Price: $16.5/month | [Get it here](https://elements.envato.com/es/glazey-professional-modern-admin-dashboard-MC8U3YN)
**Important bits**
* Includes 14 screens
* Documentation included
* Also available for Sketch and Adobe XD
**Description**
An admin organizes many things in a company, from sorting emails and invoices, and monitoring statistical fluctuation, to maintaining various transactions and projects. This admin dashboard template contains 14 pages in three different format files you can choose which adapted to the application you usually use; XD, Sketch and Figma format files that are available in light mode only.

### **Davur - Restaurant Admin Dashboard Figma**
Price: $12+ | [Get it here](https://yellowimages.com/stock/restaurant-admin-dashboard-figma-and-photoshop-68247)
**Important bits**
* Includes 6 pages: Dashboard, Order Page List, Order Detail, Customers page, Analytics page, Review page
* Documentation included
* Also available for Adobe Photoshop
**Description**
Modern dashboard User Interface design template for a Restaurant food ordering. This template is ideal for restaurants, food orders, food delivery, restaurant booking, and any admin dashboard website. This template includes 6 unique and modern User Interface screens in PSD and Figma format. You can easily edit and customize using Adobe Photoshop and Figma. | vivgui |
1,168,574 | System Design: Clustering | At a high level, a computer cluster is a group of two or more computers, or nodes, that run in... | 19,332 | 2022-09-02T16:41:19 | https://github.com/karanpratapsingh/system-design#clustering | distributedsystems, architecture, tutorial |
At a high level, a computer cluster is a group of two or more computers, or nodes, that run in parallel to achieve a common goal. This allows workloads consisting of a high number of individual, parallelizable tasks to be distributed among the nodes in the cluster. As a result, these tasks can leverage the combined memory and processing power of each computer to increase overall performance.
To build a computer cluster, the individual nodes should be connected to a network to enable internode communication. The software can then be used to join the nodes together and form a cluster. It may have a shared storage device and/or local storage on each node.
Typically, at least one node is designated as the leader node and acts as the entry point to the cluster. The leader node may be responsible for delegating incoming work to the other nodes and, if necessary, aggregating the results and returning a response to the user.
Ideally, a cluster functions as if it were a single system. A user accessing the cluster should not need to know whether the system is a cluster or an individual machine. Furthermore, a cluster should be designed to minimize latency and prevent bottlenecks in node-to-node communication.
## Types
Computer clusters can generally be categorized into three types:
- Highly available or fail-over
- Load balancing
- High-performance computing
## Configurations
The two most commonly used high availability (HA) clustering configurations are active-active and active-passive.
### Active-Active
An active-active cluster is typically made up of at least two nodes, both actively running the same kind of service simultaneously. The main purpose of an active-active cluster is to achieve load balancing. A load balancer distributes workloads across all nodes to prevent any single node from getting overloaded. Because there are more nodes available to serve, there will also be an improvement in throughput and response times.
### Active-Passive
Like the active-active cluster configuration, an active-passive cluster also consists of at least two nodes. However, as the name _active-passive_ implies, not all nodes are going to be active. For example, in the case of two nodes, if the first node is already active, then the second node must be passive or on standby.
## Advantages
Four key advantages of cluster computing are as follows:
- High availability
- Scalability
- Performance
- Cost-effective
## Load balancing vs Clustering
Load balancing shares some common traits with clustering, but they are different processes. Clustering provides redundancy and boosts capacity and availability. Servers in a cluster are aware of each other and work together toward a common purpose. But with load balancing, servers are not aware of each other. Instead, they react to the requests they receive from the load balancer.
We can employ load balancing in conjunction with clustering but it also is applicable in cases involving independent servers that share a common purpose such as to run a website, business application, web service, or some other IT resource.
## Challenges
The most obvious challenge clustering presents is the increased complexity of installation and maintenance. An operating system, the application, and its dependencies must each be installed and updated on every node.
This becomes even more complicated if the nodes in the cluster are not homogeneous. Resource utilization for each node must also be closely monitored, and logs should be aggregated to ensure that the software is behaving correctly.
Additionally, storage becomes more difficult to manage, a shared storage device must prevent nodes from overwriting one another and distributed data stores have to be kept in sync.
## Examples
Clustering is commonly used in the industry, and often many technologies offer some sort of clustering mode. For example:
- Containers (eg. [Kubernetes](https://kubernetes.io), [Amazon ECS](https://aws.amazon.com/ecs))
- Databases (eg. [Cassandra](https://cassandra.apache.org/_/index.html), [MongoDB](https://www.mongodb.com))
- Cache (eg. [Redis](https://redis.io/docs/manual/scaling))
---
_This article is part of my open source [System Design Course](https://github.com/karanpratapsingh/system-design) available on Github._
{% github karanpratapsingh/system-design %} | karanpratapsingh |
1,168,704 | How to Send Form Data Using Axios Post Request In React | React is the leading programming language used by developers globally. More than 8,787 industry... | 0 | 2022-08-16T13:17:16 | https://bosctechlabs.com/send-form-data-using-axios-post-request-react/ | react, programming, tutorial | React is the leading programming language used by developers globally. More than 8,787 industry leaders were using React.js in 2020. Hence, multiple developers prefer to go for React and Javascript. Multiple encoding types can be used for non-file transfers.
##Form data:
One of the encoding types allows the files to be incorporated into the required form data before being transferred to the server for processing. Some other encoding types used for the non-file transfers include text/ plain, application/x-www-form-urlencoded, etc.
While multipart or form-data allows the files to be included in the form data, text/ plain sends the data as plain text without encoding. It is used for debugging and not for production. The application/x-www-form-urlencoded encodes the data as query string – separating key – value pairs assigned with “ = “ and other symbols like “&.”
All these encoding types can be added to the HTML using the “enctype” attribute in the following way:
```html
<form action="/path/to/api" method="post" enctype="multipart/form-data"></form>
```
These encoding types are used with HTML “<form>” tag. The default setting works well with the different cases; this attribute is often missing.
##Axios
Axios is the promise-based HTTP client for Node.js and browsers. It makes XMLHttpRequests from the browser and HTTP requests from Node.js. Further, it supports the “Promise” API and can intercept responses, requests, etc. Axios can cancel requests, transform requests, and response data, automatically transform for JSON data, and offer client-side support to protect against “XSRF.”
Axios is dependent on a native ES6 Promise implementation to be supported. It is easy for the users to polyfill if the system doesn’t support the ES6 Promises. Further, it is heavily inspired by the “$ http service” offered in “Angular JS.” More or less, Axios is an effective method to offer a single “$ htttp” like service for using it outside AngularJS.
Browser support: Edge, IE, Opera, Safari, Mozilla Firefox, Google Chrome, etc.
##Common request methods:
Some of the common request methods in Axios are:
- axios.patch(url[, data[, config]])
- axios.put(url[, data[, config]])
- axios.post(url[, data[, config]])
- axios.options(url[, config])
- axios.delete(url[, config])
- axios.head(url[, config])
- axios.get(url[, config])
- axios.request(config)
##Common instance methods:
Some of the available instance methods in Axios are:
- axios#getUri([config])v
- axios#patch(url[, data[, config]])
- axios#put(url[, data[, config]])
- axios#post(url[, data[, config]])
- axios#options(url[, config])
- axios#head(url[, config])
- axios#request(config)
- axios#delete(url[, config])
- axios#get(url[, config])
##1. Installing Axios:
Axios is commonly used to send HTTP requests over the “fetch()” command. For different Node projects, it is easy to install Axios using “npm.”
```
npm install axio
or
yard add axios
```
The other way to install Axios is to include it in CDN directly or download the files to the system. The library in markup is included like:
```html
<script src="”https://cdnjs.cloudflare.com/ajax/libs/axios/0.27.2/axios.min.js”"></script>
```
##2. Setting “enctype” with HTML and Axios:
It is important to set the encoding type to send the multipart data or files through form data. It is easy to set the default global encoding type with Axios, which enforces all Axios requests in multipart/ form – data encoding type in the following way:
```javascript
axios.defaults.headers.post[‘Content-Type’] = ‘multipart/form-date’;
```
The encoding type can be defined for separate individual requests by altering the “headers” in the following way:
```javascript
axios.post(“api/path”, formData, {
headers: {
“Content-type”: “multipart/form-date”,
},
});
```
The third way to set the encoding type is to set the “enctype” in the “<form>” of a specific form. Axios adopts the following encoding type in the following way:
```html
<form action=”/api-endpoitn” methot=”POST”, enctype=”multipart/form-date”>
```
##3. Axios and Express:
Let us consider the case where a simple form with two inputs is created in Axios and Express. One is used for the user to submit their name, and the other one is used to select the profile image in the following way:
```html
Name : <input type="text" name="username" placeholder="Enter Username">
<br> <br>
Select a file :
<input type="file" name="userDp" placeholder="ChooseProfile Picture">
<br> <br>
<button type="submit">
Submit
</button>
```
If Axios is not used in the program, the default set of events unfolds. Pressing the “Submit” button will send a “POST” request to the “/update – profile” endpoint of our server. This default behaviour can be overridden by attaching an event listener to the button and preventing the unfolding of the default events.
A simple example of attaching the event listener, preventing the default behaviour, and sending our form data using Axios is mentioned below. It is easy to customize the request before sending it out and altering the headers as all Axios requests are entailed synchronically.
```javascript
const form = document.querySelector("form");
if (form) {
form.addEventListener("submit", (e) => {
e.preventDefault();
const formData = new FormData(form);
axios
.post("/update-profile", formData, {
headers: {
"Content-Type": "multipart/form-data",
},
})
.then((res) => {
console.log(res);
})
.catch((err) => {
console.log(err);
});
});
```
The request is forwarded to the “http: / / localhost : 5000 / update – profile” endpoint with dedicated upload support files when the form is filled and the “Submit” button is clicked. It all comes down to the endpoint, which receives and processes the request.
##4. Express Backend:
The REST API is spun using Express.js for the backend support. Hence, developers can focus on development than on the different setups. This technique sets the server and handles requests. Express is expandable with middleware and works on minimalist coding. It becomes easy to expand the core functionality of Express by installing simple or complex middleware.
Express can be installed using “npm.” The “express – fileupload” middleware can be used for simple file handling with Express. The simple technique for the same is:
`npm install express express-fileupload`
Let us start a server and define the endpoint that accepts the “POST” to “/update – profile.”
```javascript
const express = require("express");
var fileupload = require("express-fileupload");
const app = express();
app.use(fileupload());
app.use(express.static("public"));
app.use(express.urlencoded({ extended: true }));
app.post("/update-profile", (req, res) => {
let username = req.body.username;
let userPicture = req.files.userPicture;
console.log(userPicture);
res.send(`
Your username is: ${username}<br>
Uploaded image file name is ${userPicture.name}
`);
});
app.listen(3001, () => {
console.log("Server started on port 3001");
});
```
The “req” request passed through the request handler carries data sent by the form. The body contains all data from the different set fields like the “username.” All the files created are located in the “req” object under the “files” field. Further, it is easy to access the input “username” through “req . body . username.” The uploaded files can be accessed using “req . files . userPicture.”
The following response is received in the browser console when the form is submitted with the HTML page:
If information like encoding type, file name, and other information is required, it is easy to log the “req. files .userPicture” to the console.
##Wrapping Up:
Hence, it is easy to understand the Axios post request to send form data. Axios is the leading asynchronous HTTP library that is used to send post requests carrying the file or multipart data. The REST API is used to handle the request. It accepts the incoming file and other form data using the “enctype” attribute. This attribute is set with Axios. | kuldeeptarapara |
1,168,881 | Ball Catcher: Part 2 | Create a hard real-time system, across multiple electronic boards with Luos. | A few days ago, a new video about the ball catcher appeared on our Youtube channel! In this video,... | 0 | 2022-08-16T15:37:50 | https://dev.to/luos/ball-catcher-part-2-create-a-hard-real-time-system-across-multiple-electronic-boards-with-luos-2b2b | opensource, microservices, tutorial, luos | A few days ago, a new video about the ball catcher appeared on our Youtube channel!
In this video, we created the drivers for the sensor and solenoid, then attempted to hit the ball, using Python.
{% embed https://www.youtube.com/embed/DPsEWQ1Yol4 %}
We also integrated the project with a mechanical setup.
This video is the second in a series, explaining the real-time aspect of Luos. | emanuel_allely |
1,169,210 | Server Setup on CentOS 7 | Bismillah... We will installing useful applications on CentOS 7. Docker We will use snap package to... | 0 | 2022-08-17T02:51:00 | https://dev.to/nhisyamj/server-setup-on-centos-7-fnb | centos | Bismillah...
We will installing useful applications on CentOS 7.
**Docker**
We will use snap package to install Docker. But first we required to install Snap first on our server.
```
sudo yum install epel-release
sudo yum install snapd
sudo systemctl enable --now snapd.socket
sudo ln -s /var/lib/snapd/snap /snap
```
[reference](https://snapcraft.io/docs/installing-snap-on-centos)
After done installing Snap. We reboot our machine `sudo reboot`. After that, we can continue install Docker from Snap package.
```
sudo snap install docker
#Now we have successfully installed Docker. We can test it as root
#optional
#Running Docker as normal user
sudo groupadd docker
sudo usermod -aG docker $USER
#after this above steps, require us to relogin
sudo snap disable docker
sudo snap enable docker
```
[reference](https://snapcraft.io/docker)
Now we are done installing Docker.
**NodeJS**
We will use snap package to install NodeJS.
`sudo snap install node --classic`
**Java 8**
```
sudo rpm --import https://yum.corretto.aws/corretto.key
sudo curl -L -o /etc/yum.repos.d/corretto.repo https://yum.corretto.aws/corretto.repo
sudo yum install -y java-1.8.0-amazon-corretto-devel
```
[reference](https://docs.aws.amazon.com/corretto/latest/corretto-8-ug/generic-linux-install.html)
**Maven**
```
wget https://dlcdn.apache.org/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz -P /tmp
sudo tar xf /tmp/apache-maven-3.6.0-bin.tar.gz -C /opt
sudo ln -s /opt/apache-maven-3.6.0 /opt/maven
sudo vi /etc/profile.d/maven.sh
```
_maven.sh_
```
export JAVA_HOME=/usr/lib/jvm/jre
export M2_HOME=/opt/maven
export MAVEN_HOME=/opt/maven
export PATH=${M2_HOME}/bin:${PATH}
```
```
sudo chmod +x /etc/profile.d/maven.sh
source /etc/profile.d/maven.sh
```
[reference](https://linuxize.com/post/how-to-install-apache-maven-on-centos-7/)
**Gitlab Runner**
```
# Download the binary for your system
sudo curl -L --output /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-linux-amd64
# Give it permissions to execute
sudo chmod +x /usr/local/bin/gitlab-runner
# Create a GitLab CI user
sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
# Create symlink
sudo ln -s /usr/local/bin/gitlab-runner /usr/bin/gitlab-runner
# Install and run as service
sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner
sudo gitlab-runner start
```
| nhisyamj |
1,169,858 | Make Perl Count Arguments | Unlike many programming languages, Perl doesn't check that functions are called with the correct... | 0 | 2022-08-17T19:28:00 | https://dev.to/nicholasbhubbard/make-perl-count-arguments-3bdj | perl | Unlike many programming languages, Perl doesn't check that functions are called with the correct number of arguments. This is because Perl subroutines are variadic by default, which makes a lot of programming tasks really easy. The downside is that a lot of the time functions only make sense if they are called with a certain number of arguments.
Most of the time if a subroutine is called with an incorrect number of arguments it is because the programmer made a simple typo. To make our lives as programmers easier, it would be nice if we could detect this situation and give a clear error message about what went wrong.
We will explore a solution to this problem.
WARNING: The examples in this artical call Perl from the command line. If you don't understand Perl command line syntax, only pay attention to what comes after the `-E`.
Lets look at an example.
```perl
package T;
sub num_diff {
my $n1 = shift;
my $n2 = shift;
return abs($n1 - $n2);
}
1;
```
When called with two arguments our function behaves as expected.
$ perl -W -I. -MT -E 'say T::num_diff(7, 17)'
10
But what if we call `num_diff` with more than two arguments?
$ perl -W -I. -MT -E 'say T::num_diff(23, 21, 48)'
2
Perl has no issue if we call this function with 3 arguments, and happily returns us the difference between the first two arguments. This is bad! The difference between 3 numbers is certainly not the difference between the first 2.
A nice way to deal with this problem is to use [signatures](https://perldoc.perl.org/perlsub#Signatures), which provides syntax for declaring a subroutines arguments. Lets rewrite `num_diff` using signatures.
```perl
package T;
use v5.20;
use feature 'signatures';
sub num_diff($n1, $n2) {
return abs($n1 - $n2);
}
1;
```
Lets see what happens when we call `num_diff` with more than 2 arguments.
$ perl -I. -MT -E 'say T::num_diff(22, 33, 8)'
Too many arguments for subroutine 'T::num_diff' (got 3; expected 2) at -e line 1.
Awesome, our problem is solved! With signatures Perl can count our subroutine arguments and give us error diagnositics when we mess up.
Unfortunately though there are some downsides to signatures. First off signatures didn't exist until Perl version 5.20, so if you're use an old Perl signatures are not an option. The other downside is that signatures were experimental until Perl version 5.36, which is why the `use feature 'signatures'` statement is necessary.
I have been working on a Perl project that uses Perl version 5.16.3, so I cannot use signatures. To count arguments I wrote a function that I call as the first statement in subroutines that kills the program if it did not receive the correct number of arguments.
```perl
use Carp 'confess';
sub arg_count_or_die {
# Carp::Confess unless $num_args is in range $lower-$upper
my $lower = shift;
my $upper = shift;
my $num_args = @_;
($lower, $upper) = ($upper, $lower) if $lower > $upper;
unless ($lower <= $num_args && $num_args <= $upper) {
my $caller = ( caller(1) )[3];
my $expected_plural = $lower == 1 ? '': 's';
my $got_plural = $num_args == 1 ? '' : 's';
my $arg_range_msg = $lower == $upper ? "$lower arg$expected_plural" : "$lower-$upper args";
confess("yabsm: internal error: called '$caller' with $num_args arg$got_plural but it expects $arg_range_msg");
}
return 1;
}
```
Lets rewrite `num_diff` to use this function.
```perl
sub num_diff {
arg_count_or_die(2, 2, @_);
my $n1 = shift;
my $n2 = shift;
return abs($n1 - $n2);
}
```
Again, lets call `num_diff` with more than 2 arguments
$ perl -I. -MT -E 'say T::num_diff(22, 33, 8)'
my-program: internal error: call to 'T::num_diff' passed 3 args but expects 2 args at T.pm line 19.
T::arg_count_or_die(2, 2, 22, 33, 8) called at T.pm line 27
T::num_diff(22, 33, 8) called at -e line 1
We can see that by using Carp::Confess we get an excellent error message that shows the call stack that lead to the to our erroneus subroutine call. By prefixing the error message with `my-program: internal error`, if this error ever occurs our user knows that they found a bug and can send us the stack trace which will be very useful for debugging.
| nicholasbhubbard |
1,170,063 | Laravel + Vue 3 (Vite, TypeScript) SPA Setup | In this tutorial I am going to show you how you can setup your own single page application using... | 0 | 2023-01-09T08:39:47 | https://dev.to/jenueldev/laravel-vue-3-vite-typescript-spa-setup-32l9 | javascript, vue, webdev, laravel | In this tutorial I am going to show you how you can setup your own single page application using Laravel + Vue 3 using typescript and Vite.
This is a manual way to add PWA on your laravel projects. We will ***not use InertiaJS or others like it, and we will not use the mix.*** We are manually going to implement our own VueJS frontend.
## STEP 1: Lets create our Laravel Project
```bash
composer create-project laravel/laravel laravel-vue-manual
```
## STEP 2: Setup FrontEnd
Inside our laravel project let us run a command using yarn, and choose vue and typescript.
```bash
yarn create vite
```
Set the Project name to: `FrontEndApp`
Choose: `Vue`
Choose: `TypeScript`
Then Go to our `FrontEndApp` directory and run `yarn` or `yarn install` to install dependencies.
### Configure Vite
Lets configure our vite config in `FrontEndApp\vite.config.ts`
```ts
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
export default ({ mode }) => {
// check if development
const isDevelopment = mode === "development";
return defineConfig({
server: {
port: 3000,
},
build: {
// the built files will be added here
outDir: "./../public/app",
},
// also going to change base base on mode
base: isDevelopment ? "/" : "/app/",
plugins: [vue()],
});
};
```
And then lets change the `build` script in `FrontEndApp\package.json`, so that every time we build it will replace the files in `public/app`:
```json
{
...
"scripts": {
"dev": "vite",
"build": "vue-tsc --noEmit && vite build --emptyOutDir",
"preview": "vite preview"
},
...
}
```
Now if we run `yarn build` in FrontEndApp, it should create a folder called app inside `public` folder in the root directory of our laravel project.
## STEP 3: Setup Laravel Route
Let us setup our laravel route so that we can access that file we just created.
lets edit this file `routes\web.php`
```php
<?php
use Illuminate\Support\Facades\Route;
Route::get('/', function () {
return view('welcome');
});
Route::get('/app/{any}', function () {
$path = public_path('app/index.html');
abort_unless(file_exists($path), 400, 'Page is not Found!');
return file_get_contents($path);
})
->name('FrontEndApp');
```
So now, if we open `http://127.0.0.1:8000/app` in our browser, we can now see that our app is up.
## STEP 4: Setup Scripts
We are going to add a dev package in our root project directory, and its called concurrently. We use this to run 2 or more commands at once.
to install:
```bash
yarn add -D concurrently
```
Next, for me I really like to work automatically so I don't want to rebuild every time I'm working with `frontednapp`, so what we will going to do is to add a new script in our `package.json` in root directory of our project.
```json
{
...
"scripts": {
...
"front:serve": "cd FrontEndApp && yarn dev",
"front:build": "cd FrontEndApp && yarn build",
"serve": "concurrently \"php artisan serve --port=8080\" \"yarn front:serve\"",
"deploy": "yarn setup && yarn front:build && php artisan migrate"
},
...
}
```
With this, running `yarn serve` will run both `127.0.0.1:8080` and `localhost:3000`. You can now work with both project.
Once your done working on your FrontEndApp, you can run `yarn deploy` to build our frontend.
# Conclusion
I believe this is also one way you can add pwa on your laravel project so you can keep them in a single project.
With that in mind you can add `routes` in your FrontEndApp project, and also able to add state manager like `PiniaJA`, and more.
I hope you learn something in this article. Follow Me For Stuff!
------------
Source Code is Here: https://github.com/BroJenuel-Box/laravel-vue-manual
--------------
Buy me coffee 😁😁😁 Thanks 💖💖
[](https://www.buymeacoffee.com/BroJenuel) | jenueldev |
1,170,191 | Get an A+ with our Law Homework Help | Law may be an immense subject. Henceforth, law aspirants got to encounter far more struggles as... | 0 | 2022-08-18T05:47:57 | https://dev.to/marilyn777/get-an-a-with-our-law-homework-help-chh | lawhomeworkhelp, onlinehomeworkhelp, education, students |
Law may be an immense subject. Henceforth, law aspirants got to encounter far more struggles as compared to the domain of different students. Within the entire learning journey, you've got to subsume educational activities like lawsuits, contracts, legislation, negotiations, memos, and analysis. Imagine the struggles that square measure related to these activities. Additionally, the foremost difficult part of any law assignment is accessing valid analysis materials, citing links, and writing the assignment as per the format and also the links. The guiding directions and also the rubric facilitate cannot arrest the event of hysteria. The **[law homework help](https://www.lawhomeworkhelp.com/)** facilitates offers is the sole answer to avoid such dire crisis moments. The net assignment facilitates we offer are at a very lower rate. [law homework help](https://www.lawhomeworkhelp.com/migration-law) square measure forever thought of as united as the foremost difficult assignments. The explanation is its content. This assignment’s content includes cases, mention of sensible experiences, history of the actual law, etc. Even a second mistake will drastically amend your prospect of marking high marks! Isn’t it a sorrow to lose marks thanks to such folly? With an Associate in professional by your facet, you simply ought to sit back and relax. Contact the United States to induce additional details on the law homework help to facilitate service.
**Types of Law Homework**
- . Constitutional Law Homework Help
- . Corporate Law Homework Help
- . Migration Law Homework Help
- . Contract Law Homework Help
- . Criminal Law Homework Help
- . Civil Law Homework Help
| marilyn777 |
1,170,331 | Clear Cart and Sessions for WooCommerce | WooCommerce clear cart allows store owners to clear carts and sessions automatically after a defined... | 0 | 2022-08-18T09:22:00 | https://dev.to/simonwa02259888/clear-cart-and-sessions-for-woocommerce-1gg1 | woocommerce, clear, cart, plugins | [WooCommerce clear cart](https://woocommerce.com/products/clear-cart-and-sessions-for-woocommerce/) allows store owners to clear carts and sessions automatically after a defined time period. Store owners can clear cart sessions in periods of minutes, hours, and days.
Key Features of WooCommerce clear cart are
1. Clear cart and sessions after specified minutes, hours, or days
2. Enable empty cart button on the cart page for customers
3. Customize text and color of clear cart button
4. Redirect users to the shop page or any custom URL after clearing the cart
| simonwa02259888 |
1,170,349 | Free Shipping Bar for WooCommerce | Give maximum exposure of your free shipping deals with the WooCommerce Free shipping bar. You can... | 0 | 2022-08-18T10:09:27 | https://dev.to/simonwa02259888/free-shipping-bar-for-woocommerce-4h8f | woocommerce, shipping, bar, plugins | Give maximum exposure of your free shipping deals with the [WooCommerce Free shipping bar](https://woocommerce.com/products/free-shipping-bar-for-woocommerce/). You can display the bar across all page of the store. It shows real time progress bar and remaining price of purchase to avail free shipping.
Key Features of Free Shipping bar plugin is
1. Add ‘Free Shipping’ bar
2. Limit the bar to specific countries
3. Use multiple shipping bar styles
4. Offer discounts on all shipping methods
5. Customize text and color
6. Position the bar
7. Project the bar on mobiles as well
8. Enable progress bar for free shipping
9. Customize display messages on the bar
10. Display bar on a specific page
11. Progress bar display with delays and disappear
12. Let your customers close the bar
**For more details checkout** https://woocommerce.com/products/free-shipping-bar-for-woocommerce/
| simonwa02259888 |
1,170,490 | Is MIT xPRO Legit | The simple answer to the question ” Is MIT xPRO Legit ?” is yes. One of the top coding Bootcamp... | 0 | 2022-08-18T11:59:50 | https://dev.to/hecodesit/is-mit-xpro-legit-57kj | mit, xpro, legit, ismitxprolegit | The simple answer to the question ” Is MIT xPRO Legit ?” is yes. One of the top coding Bootcamp platforms, MIT xPRO, offers online learning courses to fill the skills gap in developing technological fields. Data engineering, software development, and cybersecurity are all topics covered in MIT xPRO’s online learning courses. Reviews of MIT xPRO are generally favourable, with most students praising the programs.

Read more at :
https://hecodesit.com/is-mit-xpro-legit/
| hecodesit |
1,170,558 | How to Create a Countdown Timer With Javascript | Introduction Count down timer is an essential feature to have in a webpage that requires... | 0 | 2022-09-01T20:02:12 | https://dev.to/jaymeeu/how-to-create-a-countdown-timer-with-javascript-191m | javascript, tutorial, devmeme, html | ##Introduction
Count down timer is an essential feature to have in a webpage that requires an action from the user within a certain period. It is often used to increase user engagement in a webpage. It is popularly used in web pages such as sales pages, opt-in pages, event pages, and a lot more.
This article will explain how I created a custom countdown timer with HTML, CSS, and JavaScript so you will be able to create yours.

###How Does the Count Down Timer Work
Before we dive in, let's understand how the countdown timer works. It simply shows the time left from now to a specified later time; to get this, we need to subtract the time now from the later time.
As previously mentioned, we must subtract the current time from a future time to calculate the remaining time. Fortunately, we can use the JavaScript "Date()" method for this.
Let's see a simple example of subtracting two dates:
```javascript
let first_date = new Date('10/18/2022')
let second_date = new Date('09/18/2022')
console.log(first_date - second_date)
//2592000000
let date_today = new Date() //today's date
console.log(first_date - date_today)
//5140586280
```
From the above, we can get the difference in the dates in milliseconds.
Now is the time to convert the milliseconds to equivalent days, hours, minutes, and seconds.
From our basic conversion:
1 day = 1000 x 60 x 60 x 24 milliseconds
1 hour = 1000 x 60 x 60 milliseconds
1 minute = 1000 x 60 milliseconds
1 second = 1000 milliseconds
```javascript
const dateTill = new Date('10/18/2022')
//end date
const dateFrom = new Date();
//start date (today)
const diff = dateTill - dateFrom
//difference in dates
day_to_miliseconds = 1000 * 60 * 60 * 24
// 1 day equivalent in milliseconds
hour_to_miliseconds = 1000 * 60 * 60
// 1 hour equivalent in milliseconds
minute_to_miliseconds = 1000 * 60
// 1 minute equivalent in milliseconds
second_to_miliseconds = 1000
// 1 second equivalent in milliseconds
let days = Math.floor(diff / day_to_miliseconds );
// number of days from the difference in dates
let hours = Math.floor((diff % day_to_miliseconds) / hour_to_miliseconds);
// number of hours from the remaining time after removing days
let minutes = Math.floor((diff % hour_to_miliseconds) / minute_to_miliseconds);
// number of minutes from the remaining time after removing hours
let seconds = Math.floor((diff % minute_to_miliseconds) / second_to_miliseconds);
// number of hours from the remaining time after removing seconds
console.log(days, hours, minutes, seconds)
// expected result
```
Cool, right?
Now that we have understood how to get our data, let's design the beautiful countdown timer with HTML and CSS.
{% codepen https://codepen.io/Jaymeeu/pen/ExEzogr %}
With the above design implemented, we will use a JavaScript `setInterval()` method to implement the countdown functionality.
### How does the `setInterval()` method works.
The `setInterval()` method is use to execution a function at interval (e.g, every 1 minute, every 5 minute e.t.c) until `clearInterval()` method is called.
#### Syntax
```js
setInterval(() => function(), time);
```
- `function()` represent function to run every _time_
- `time` represents the interval at which we should recall the function in milliseconds.
- We will also use the `clearInterval()` method to stop our `setInterval()` method once the specified end date is reached.
For the countdown timer, we will write a function that will run every 1 second (1000 milliseconds).
Let's look at the below code carefully.
{% codepen https://codepen.io/Jaymeeu/pen/qBogjaz %}
And that is all. You have a super cool custom countdown timer.
**Note:** The countdown timer will not show up if you are reading this article on or after 18th October 2022. You should know why? This is because "10/18/2022" is our end date. Feel free to change the end date to a later date after today and see the magic.
## Wrapping up
The countdown timer is an important feature in some web pages, such as sales pages, opt-in pages, and many other use-cases. In this article, I explained how to use the javascript `setInterval()` and `clearInterval()` methods to create a countdown timer in a few simple steps.
You can also check out my article on [How to Create a Countdown Timer In ReactJS ](https://dev.to/jaymeeu/how-to-create-a-countdown-timer-in-reactjs-2khj)
Thanks for Reading 🌟🌟🌟
If you have any questions, kindly drop them in the comment section.
I'd love to connect with you on [Twitter](https://twitter.com/Abdulrasaq_Jay)
Happy coding! | jaymeeu |
1,170,582 | 😊✌🏽 | Hello everyone I’m E | 0 | 2022-08-18T15:23:08 | https://dev.to/ed_mcdarwin_a0594379efd13/-1peg | Hello everyone I’m E | ed_mcdarwin_a0594379efd13 | |
1,170,640 | Dedicated and Shared Web Worker with Performance Testing | Overview Web Workers are threads attached in Browser and run on the client side. It runs... | 0 | 2022-09-20T08:00:58 | https://dev.to/piyushmultiplexer/dedicated-and-shared-web-worker-with-performance-testing-587 | ---
title: Dedicated and Shared Web Worker with Performance Testing
published: true
date: 2022-08-18 11:39:52 UTC
tags:
canonical_url:
---
### Overview
Web Workers are threads attached in Browser and run on the client side. It runs in a separate space from the main application thread. Simply It gives the ability to write multi-threaded Javascript applications. It is generally used to do heavy lifting tasks(in terms of computational time), e.g process huge data from API, calculations, batching of real-time chart data before drawing in the background.
Web Workers perform all processes in the Worker thread aka separate environment which is separate from the main JavaScript thread without blocking UI or affecting performance thus does not have access to DOM, _window_ and _document_ objects, and for the same reason, it can not simply manipulate DOM.
The life span of a Worker is limited to a browser tab, when a browser tab is closed Worker also dies. The data are passed between Worker and the main thread via messages. To send data `postMessage()` method is used and to listen to messages `onmessage` event is used on both sides.
A single web page/app can have more than one Web Worker regardless of the number of tabs. It can be Shared or Dedicated workers. We'll go through demo examples for both workers and use cases.
### Demo
In this demo, there are two examples, in first you can test that the 50k array is being sorted with bubble sort algorithm with and without Web Worker(Dedicated) and see the difference between both. Second, you can test Shared Worker which is used by two client sources for similar functionality. Both workers use Network APIs for the processing which is made in Node/ExpressJS.
> - [Preview Demo](https://jsworkers.herokuapp.com/)
> - [Source of Demo](https://github.com/piyush-multiplexer/javascript-workers)
### Dedicated Workers
Dedicated Workers can only establish a single connection. It can be initialized using the following syntax.
```
let worker = new Worker("worker.js");
// receive data from web worker sent via postMessage()
worker.onmessage = function (e) {
console.log(e.data);
}
// send data to web worker
.postMessage("start")
```
To receive data **onmessage** event is used and to pass data **postMessage** method is used. In this demo, we have used a Dedicated worker to Bubble Sort 50k length of array data. In UI there are two options for sorting with or without Web Workers.
#### Without Web Worker
When the user clicks the without web worker option, the script starts and gets data from the API of the 50k array and starts sorting in a main, during this you may see a frozen progress bar, and the rest things are stuffed like not able to select the text, the mouse pointer changes to the cursor and other UI blocking effects because it is performing a heavy task to sort a large array. When sorting is done you'll see processing time and an animated section regarding the process below.
#### With Web Worker
When the user clicks the web worker option, the worker initiate and gets data from the API of the 50k array and starts sorting in a separate thread, during this you can see a progress bar and no UI blocking like text-selection and cursor etc. Everything is smooth. When sorting Done you'll see processing time and an animated section regarding the process below.
So Web Workers overcome this problem. Here is the **_index.html_** file.
```
<body>
<div id="wrap">
<div class="container">
<div class="row pt-3">
<div class="col">
<h2>Dedicated Worker</h2>
<div class="text-secondary h4">
Sorting Array with Bubble Sort(50k)
</div>
<div>
<button class="btn btn-large btn-primary" onclick="nonWebWorker();">Without Web Worker</button>
<button class="btn btn-large btn-success" onclick="withWebWorker();">With Web Worker</button>
</div>
<div id="progressbar" class="progress hide">
<div class="progress-bar progress-bar-striped progress-bar-animated" role="progressbar"
aria-valuenow="100" aria-valuemin="0" aria-valuemax="100" style="width: 100%"></div>
</div>
<div id="resultBox" class="hide bg-info rounded px-2">
<p class="muted">
Array sorted in:
</p>
<h1 id="timespent"></h1>
<p id="withoutWW" class="output hide">
As you can see, without Web Worker, your browser may be able to sort the 50K Array but you
can't work with your browser while sorting and also your browser won't render anything until
sorting ends, that's why you can't see the animated progress bar on the page.
</p>
<p id="withWW" class="output hide">
Your browser sorted 50K Array without any crash or lagging because your browser supports
Web Worker. When you do a job with Web Worker, it's just like when you run a program in
another thread. Also, you can see the animated progress bar while sorting.
</p>
</div>
</div>
<div class="col-1">
<div class="vr h-100">
</div>
</div>
</div>
</div>
<script src="./utils.js"></script>
</body>
```
Dedicated Worker file **_worker.js_**.
```
onmessage = async function (e) {
if (e.data[0] === "start") {
let a = [];
async function getData() {
return fetch(`${e.data[1]}/getData`)
.then((res) => res.json())
.then((data) => {
a = data;
});
}
function bubbleSort(a) {
let swapped;
do {
swapped = false;
for (let i = 0; i < a.length - 1; i++) {
if (a[i] > a[i + 1]) {
let temp = a[i];
a[i] = a[i + 1];
a[i + 1] = temp;
swapped = true;
}
}
} while (swapped);
}
let start = new Date().getTime();
getData()
.then(() => {
bubbleSort(a);
})
.then(() => {
let end = new Date().getTime();
let time = end - start;
postMessage(time);
});
}
};
```
### Shared Workers
The Shared Worker can establish multiple connections as they are accessible by multiple scripts even in separate windows, iframes(demo) or workers. It can be spawned using the below syntax.
```
let sharedWorker = new SharedWorker("shared-worker.js");
sharedWorker.port.postMessage("begin");
sharedWorker.port.onmessage = function (e) {
console.log(e.data)
}
```
In Shared Worker similar concept apply as Worker for data passing but via **port** object(explicit object) which is done implicitly in dedicated workers for communication. In this demo, there is a Shared Worker which does multiply/square of numbers. It is used in two places. The first is on the main page and the second is on another HTML page which is included in the main page via IFRAME. On the main page user input two number for multiplication and passes them to Worker and get multiplied output as below.
In the second case, the user inputs single number input which is given to the same Shared Worker and gets a squared input number as a result. Now within the worker, it takes input as the number and calls API to do Math Operation and returns the result as below.
Main HTML file to load IFRAME **_index.html_**.
```
<div class="col">
<h2>Shared Worker</h2>
<div class="text-secondary h4">
Multiply/Square Numbers with Shared Resource
</div>
<div>
<input type="text" id="number1" class="form-control" placeholder="Enter number 1" />
<input type="text" id="number2" class="form-control mt-1" placeholder="Enter number 2" />
<input type="button" class="btn btn-dark mt-2" value="Calculate" onclick="multiply();" />
<p class="result1 text-success pt-2"></p>
<iframe id="iframe" src="shared.html"></iframe>
</div>
</div>
```
Second HTML file **_shared.html_** which load in IFRAME in parent.
```
<body>
<script type="text/javascript">
const endpoint = window.origin;
if (typeof (Worker) === "undefined") {
alert("Oops, your browser doesn't support Web Worker!");
}
function getSquare() {
let third = document.querySelector("#number3");
let squared = document.querySelector(".result2");
if (!!window.SharedWorker) {
let myWorker = new SharedWorker("shared-worker.js");
myWorker.port.postMessage([third.value, third.value, window.origin]);
myWorker.port.onmessage = function (e) {
squared.textContent = e.data;
};
}
}
</script>
<div class="container">
<h1>
Shared Web Worker(iframe)
</h1>
<div class="row">
<div class="col">
<input type="text" id="number3" class="form-control" placeholder="Enter a number" />
<input type="button" id="btn" class="btn btn-primary" value="Submit" onclick="getSquare()" />
<p class="result2"></p>
</div>
</div>
</div>
</body>
```
Here is **_shared-worker.js_** file.
```
onconnect = function (e) {
let port = e.ports[0];
port.onmessage = function (e) {
fetch(`${e.data[2]}/multiply?number1=${e.data[0]}&number2=${e.data[1]}`)
.then((res) => res.json())
.then((data) => {
port.postMessage([data.result]);
});
};
};
```
Utility functions file **_utils.js_** that handles worker-related stuff.
```
const endpoint = window.origin;
if (typeof Worker === "undefined") {
alert("Oops, your browser doesn't support Web Worker!");
}
function nonWebWorker() {
cleanWindowAndStart();
let a = [];
async function getData() {
return fetch(`${endpoint}/getData`)
.then((res) => res.json())
.then((data) => {
a = data;
});
}
function bubbleSort(a) {
let swapped;
do {
swapped = false;
for (let i = 0; i < a.length - 1; i++) {
if (a[i] > a[i + 1]) {
let temp = a[i];
a[i] = a[i + 1];
a[i + 1] = temp;
swapped = true;
}
}
} while (swapped);
}
let start = new Date().getTime();
getData()
.then(() => {
bubbleSort(a);
})
.then(() => {
let end = new Date().getTime();
let time = end - start;
afterStop(time, false);
});
}
function withWebWorker() {
cleanWindowAndStart();
let worker = new Worker("worker.js");
worker.onmessage = function (e) {
afterStop(e.data, true);
};
worker.postMessage(["start", endpoint]);
}
function cleanWindowAndStart() {
$("#resultBox").hide(500);
$("#withWW").hide();
$("#withoutWW").hide();
$("#progressbar").addClass("d-flex").show(500);
}
function afterStop(spentTime, mode) {
$("#timespent").html(spentTime + "ms");
$("#progressbar")
.hide(500, function () {
mode ? $("#withWW").show() : $("#withoutWW").show();
$("#resultBox").show(500);
})
.removeClass("d-flex");
}
function multiply() {
let first = document.querySelector("#number1");
let second = document.querySelector("#number2");
let multiplied = document.querySelector(".result1");
if (!!window.SharedWorker) {
let myWorker = new SharedWorker("shared-worker.js");
myWorker.port.postMessage([first.value, second.value, endpoint]);
myWorker.port.onmessage = function (e) {
multiplied.textContent = e.data;
};
}
}
```
Node/Express API **_server.js_**
```
app.get("/getData", (req, res) => {
res.send(
Array(50000)
.fill(0)
.map(() => Math.floor(Math.random() * 100))
);
});
app.get("/multiply", (req, res) => {
const multiply = req.query.number1 * req.query.number2;
const result = isNaN(multiply) ? "Invalid input" : multiply;
res.send({ result });
});
```
### Performance Testing
Now time for numbers. Let's test our Sorting demo with Chrome Performance Test in Browser DevTools. We will record and profile both with and without web workers so we can differentiate performance and resource utilization.
#### Without Web Worker
Open Dev Tools and navigate to the Performance tab and start recording. Once recording starts in UI click on the Without Worker button in Dedicated Worker Section and waits till sorting is done. Once you see the result stop recording and the preview will be there as below.
This is an overview of the Performance tab which looks a little complicated. We'll use some of these for over understanding of the use case. In the first section, you can see the Frame rate, Network, CPU and Memory utilization chart. Below is the Network section where requests are recorded with the timeline. Below is Main Section which shows all tasks, macro tasks, functions and thread-related information that was executed in the tab during that time. You can click for a detailed view of each. Below is the CPU activity breakdown in a pie chart, which show the type of tasks with the time taken.
This is a detailed activity view of the **bubbleSort** script, and here you can see that this function consumes most of the resources and time in a thread(96.5% - 5663 ms) and other processes like rendering dom and manipulation, network calls consumed rest of all. You can save your profile if you want or delete it.
#### With Web Worker
Now once you test with Without Worker Profiling, start with With Worker button. The process is the same, start recording -> click on With Web Worker button -> stop recording once sorting is done. Before that make sure the Performance tab is cleared and you will see a similar result as below.
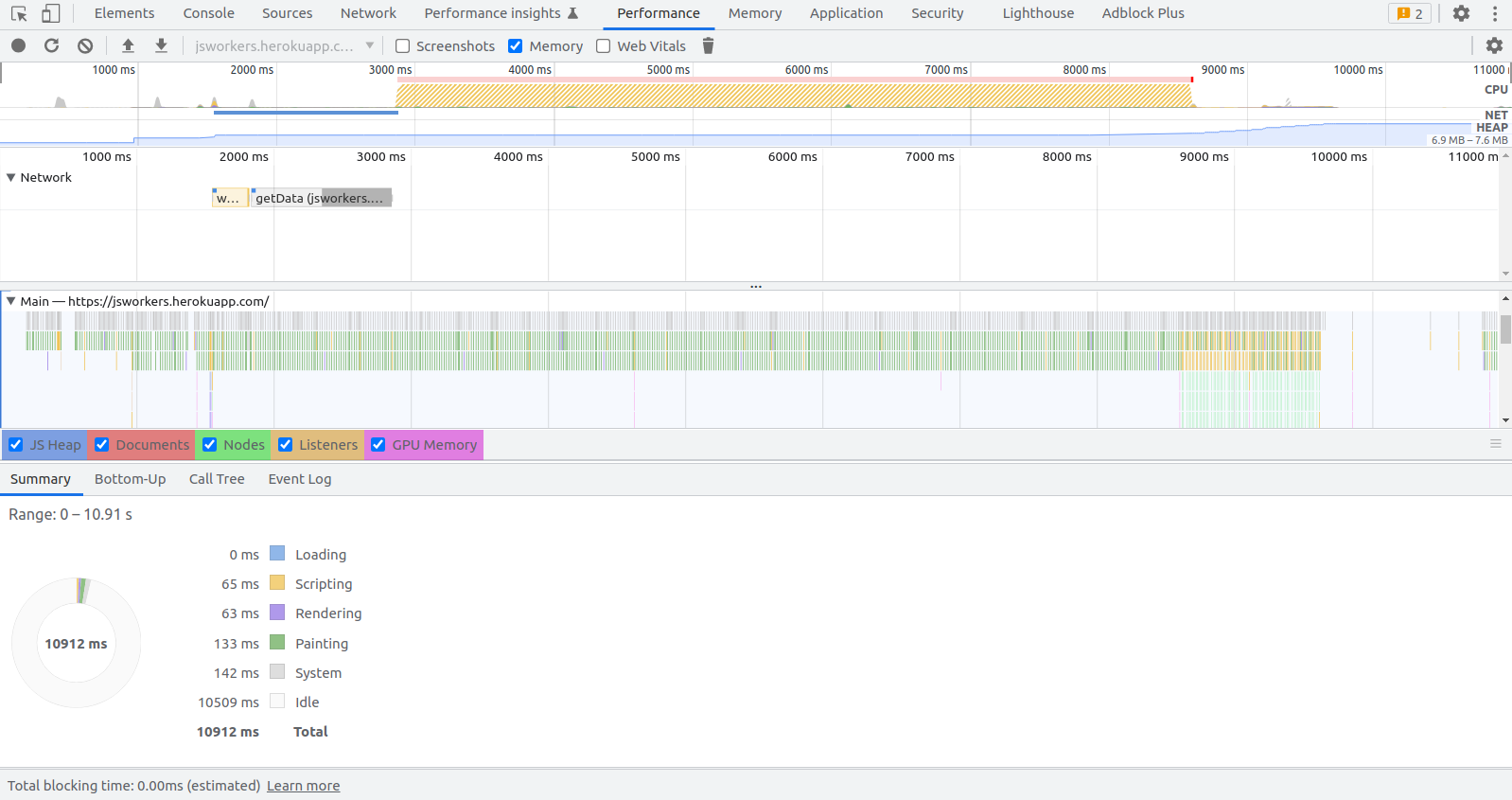
When you look in the profile With Workers in Performance tab you'll see a significant difference from the previous summary of the consumed time by task type. Here the script is consume very less time.
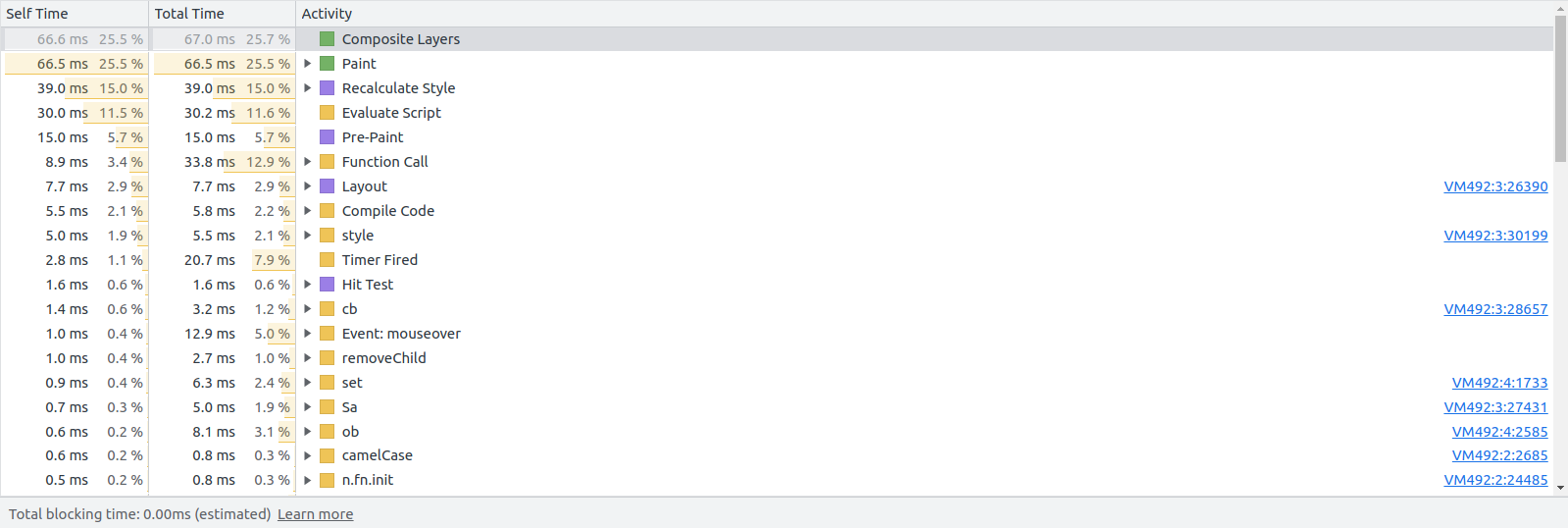
Again, with a worker as you can see in activity details, you won't see **bubbleSort** or any other script taking a long time this breakdown is of the main thread but sorting is done in a worker thread so it doesn't affect the main thread resources.
## Advantages & Limitations with Usecases
- Can be used to perform CPU-intensive tasks without blocking UI.
- Has access to fetch, so can communicate over Netowork to make API requests.
- Doesn't have access to DOM, so can't manipulate therefore, tasks like canvas, images, SVG, video or any element-related drawing/direct manipulation is not possible.
- Can be used in Real-time data processing in the Stock market and related fields e.g Crypto, and NFT.
- To process large data-sets like DNA and Genetics
- Media manipulation in the background e.g image compress/decompress, video etc.
- Can be used to process textual data in the background e.g NLP
- Caching: Prefetching data for later use
## Conclusion
In this article, we have got the basic idea of Web Workers including Dedicated and Shared Workers and How they affect user experience if used properly in a project. We also debug it with the Chrome DevTools Performance tab as proof of the consumed resources that our app consumed.
If you enjoyed the article and found it useful give it a thumb. Let us know your thoughts on this in the comment section below. You can find me on [Twitter](https://twitter.com/thesourcepedia) | piyushmultiplexer | |
1,170,769 | Quick introduction to Kotlin classes | Introduction This series is not going to be in any particular order, so feel free to read... | 18,367 | 2022-08-18T16:53:00 | https://dev.to/theplebdev/quick-introduction-to-kotlin-classes-4jkm | android, kotlin, mobile, tristan | ### Introduction
- This series is not going to be in any particular order, so feel free to read whatever blog post you want. Anytime I find something that I think could use a blog post, I will write one and put it here
### Getting started
- By the end of this tutorial I want both you and I to have a better understanding of the code below:
```
data class Calf(
val tagNumber: String,
val CCIANumber: String,
val sex:String,
val details:String,
val date: Date,
val id: Long =0
) {
}
```
- This tutorial will not be an exhaustive one, however, it should give you a solid understanding of the incredible power of Kotlin's class system. If you would like to know more about classes in Kotlin, I would recommend the documentation,[HERE](https://kotlinlang.org/docs/classes.html), and the book,`Kotlin in action` by Dmitry Jemerov and Svetlana Isakova.
### Classes
- Classes in Kotlin are declared with the typical `class` keyword and they contain three parts:
**1) Class name :** What we end up calling the file, in the code block above the name is `Calf`
**2) Class header :** contains the type parameters(more on parameters later), the primary constructor and modifiers.
**3) Class body :** containing everything inside the `{ }` braces
- fun fact, both the class body and the class header are optional if they are both empty
### Constructor
- A class in Kotlin can have a `primary constructor` and one or more `secondary constructor`(we won't be talking about primary constructors here),for more information about secondary constructors go [HERE](https://kotlinlang.org/docs/classes.html#secondary-constructors) for the documentation.
- In our code block above the primary constructor is:
```
(
val tagNumber: String,
val CCIANumber: String,
val sex:String,
val details:String,
val date: Date,
val id: Long =0
)
```
- It comes after the class name. As you can see the primary constructor can not contain any initialization code. If initialization code is needed it can be placed inside of an [Initializer block](https://kotlinlang.org/docs/classes.html#constructors).
- Kotlin has a very precise syntax for declaring `PROPERTIES` and initializing them from the primary constructor. You may of noticed that I put quite the emphasis on `property`. That is because before we can move any farther, we need to have a solid understanding of what a property actually is.
**Property :** a combination of a field and its accessor method.
- So when we talk about properties, we mean both the field that holds the data and the methods used to set or access the data.
- Notice that in a primary constructor we have properties defined with `val`,`val tagNumber: String`. The `val` keyword means a value is set only once and we can not change it. In terms of the accessor methods, a property declared with `val` only has a getter method.
###data class
- The Kotlin compiler can generate useful methods to avoid a verbose code base. Declaring a class as a `data` class instructs the compiler to generate several methods. The most common and well know being, `equals()` and `hashcode()`. In Kotlin the default way to check quality is the use the `==` operator. Under the hood the compiler will call the `equals()` method(avoiding the common Java bug of using == instead of equals()) and give us what we call `structural equality`. If you still want `Referential equality`(two references point to the same object) use the `===` operator. Both the `equals()` and `hashcode()` take into account all the properties declared in the primary constructor. The generated `equals()` method checks and validates all values of the properties are equal. The `hashcode()` method returns a value that depends on the hashcode(unique number to identify the object) of all the properties.
- I should also point out that if the properties are not declared in the primary constructor, they will not be part of the `equals()` and `hashcode()` methods.
###Conclusion
- Thank you for taking the time out of your day to read this blog post of mine. If you have any questions or concerns please comment below or reach out to me on [Twitter](https://twitter.com/AndroidTristan). | theplebdev |
1,171,087 | GNU bash | GNU bash, version 5.1.4(1)-release (x86_64-pc-linux-gnu) These shell commands are defined internally.... | 0 | 2022-08-19T06:47:24 | https://dev.to/py0r/gnu-bash-1enj | linux, opensource | GNU bash, version 5.1.4(1)-release (x86_64-pc-linux-gnu)
These shell commands are defined internally. Type `help' to see this list.
Type `help name' to find out more about the function `name'.
Use `info bash' to find out more about the shell in general.
Use `man -k' or `info' to find out more about commands not in this list.
A star (*) next to a name means that the command is disabled.
job_spec [&] history [-c] [-d offset] [n] or hist>
(( expression )) if COMMANDS; then COMMANDS; [ elif C>
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs >
: kill [-s sigspec | -n signum | -sigs>
[ arg... ] let arg [arg ...]
[[ expression ]] local [option] name[=value] ...
alias [-p] [name[=value] ... ] logout [n]
bg [job_spec ...] mapfile [-d delim] [-n count] [-O or>
bind [-lpsvPSVX] [-m keymap] [-f file> popd [-n] [+N | -N]
break [n] printf [-v var] format [arguments]
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
caller [expr] pwd [-LP]
case WORD in [PATTERN [| PATTERN]...)> read [-ers] [-a array] [-d delim] [->
cd [-L|[-P [-e]] [-@]] [dir] readarray [-d delim] [-n count] [-O >
command [-pVv] command [arg ...] readonly [-aAf] [name[=value] ...] o>
compgen [-abcdefgjksuv] [-o option] [> return [n]
complete [-abcdefgjksuv] [-pr] [-DEI]> select NAME [in WORDS ... ;] do COMM>
compopt [-o|+o option] [-DEI] [name .> set [-abefhkmnptuvxBCHP] [-o option->
continue [n] shift [n]
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
declare [-aAfFgiIlnrtux] [-p] [name[=> source filename [arguments]
dirs [-clpv] [+N] [-N] suspend [-f]
disown [-h] [-ar] [jobspec ... | pid > test [expr]
echo [-neE] [arg ...] time [-p] pipeline
enable [-a] [-dnps] [-f filename] [na> times
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
exec [-cl] [-a name] [command [argume> true
exit [n] type [-afptP] name [name ...]
export [-fn] [name[=value] ...] or ex> typeset [-aAfFgiIlnrtux] [-p] name[=>
false ulimit [-SHabcdefiklmnpqrstuvxPT] [l>
fc [-e ename] [-lnr] [first] [last] o> umask [-p] [-S] [mode]
fg [job_spec] unalias [-a] name [name ...]
for NAME [in WORDS ... ] ; do COMMAND> unset [-f] [-v] [-n] [name ...]
for (( exp1; exp2; exp3 )); do COMMAN> until COMMANDS; do COMMANDS; done
function name { COMMANDS ; } or name > variables - Names and meanings of so>
getopts optstring name [arg ...] wait [-fn] [-p var] [id ...]
hash [-lr] [-p pathname] [-dt] [name > while COMMANDS; do COMMANDS; done
help [-dms] [pattern ...] { COMMANDS ; } | py0r |
1,171,261 | Create Node.js Project Using Command Line | 👋 Hi Everyone, Publishing my node.js template in a command-line format. Everyone can easily be... | 0 | 2022-08-19T11:50:00 | https://dev.to/jinnatul/create-nodejs-project-using-command-line-1e59 |
👋 Hi Everyone,
Publishing my node.js template in a command-line format. Everyone can easily be creating a node.js application structure using a single line command.
Features:
--------------
📌 ES6+ configuration (Babel)
📌 Better error handling
📌 Clean code structure
📌 Google authentication (Passport strategy)
📌 Email authentication with OTP verification (Sent mail using Google Gmail)
📌 Implement MFA using speakeasy
📌 MFA QR code images stored in Cloudinary
📌 Forgot Password via mail
📌 Modern data validation using Joi
📌 Forgot password mail template
📌 OTP validation mail template
Download and usage
--------------------------------
`𝗖𝗼𝗺𝗺𝗮𝗻𝗱: npx nano-app project-name
Example: npx nano-app nodejs-api`
**Source Code**: https://github.com/jinnatul/nano-app
[Demo Video](https://www.youtube.com/watch?v=kjZwb23Oln0)
NB: If you have any queries or suggestions, please write a comment.
Facebook: https://www.facebook.com/morol1957
Linkedin: https://www.linkedin.com/in/morol1957
Twitter: https://twitter.com/jinnatul_md
Github: https://github.com/jinnatul | jinnatul | |
1,171,373 | What has blogging brought me so far? | After three failed attempts over the course of a few years, at building the most awesome blogging... | 0 | 2022-08-19T12:46:10 | https://blog.jellesmeets.nl/meta/what-has-blogging-brought-me-so-far/ | career, showdev, writing, motivation | After three failed attempts over the course of a few years, at building the most awesome blogging site from scratch, I decided to say screw it! And I installed WordPress and started actually writing. I published my first blog post on the 20th of January 2019. [Why you should place your code on an open source platform](https://blog.jellesmeets.nl/developer-basics/why-you-should-put-your-code-on-an-opensource-platform/). A lot has happened since that first post. And in this blog post, we will take a look at what blogging brought me so far.
## The blog
Since then I've published 47 blog posts. By far the most popular post is [The 4 lessons I learned as a starting scrum master](https://blog.jellesmeets.nl/lists/4-lessons-i-learned-as-a-starting-scrum-master/). Followed by one of the retrospectives from the [retrospective challenge](https://blog.jellesmeets.nl/retrospective/retrospective-challenge-2020/), the [movie retrospective](https://blog.jellesmeets.nl/retrospective/movie-retrospective/).
The blog has gotten **5891** views. The traffic is slowly increasing to about 200-300 visitors per month.
Views on the blog
I cross-post my content on [dev.to](https://dev.to/smeetsmeister), where I got **8819** views on my content. Dev.to is a bit more focused on the hard skills of devs, and not all my articles are well read. The main benefit of sharing my content on Dev.to is that it has an already big userbase, where it is easier to distribute your content to new readers.
One thing that went viral on Dev.to is [Why I stepped out of my first startup](https://blog.jellesmeets.nl/personal/why-i-stepped-out-of-my-first-startup/). Getting me a whopping **2797** views. it even made the [top 7 posts of this week's list](https://dev.to/devteam/top-7-featured-dev-posts-from-the-past-week-178o)!
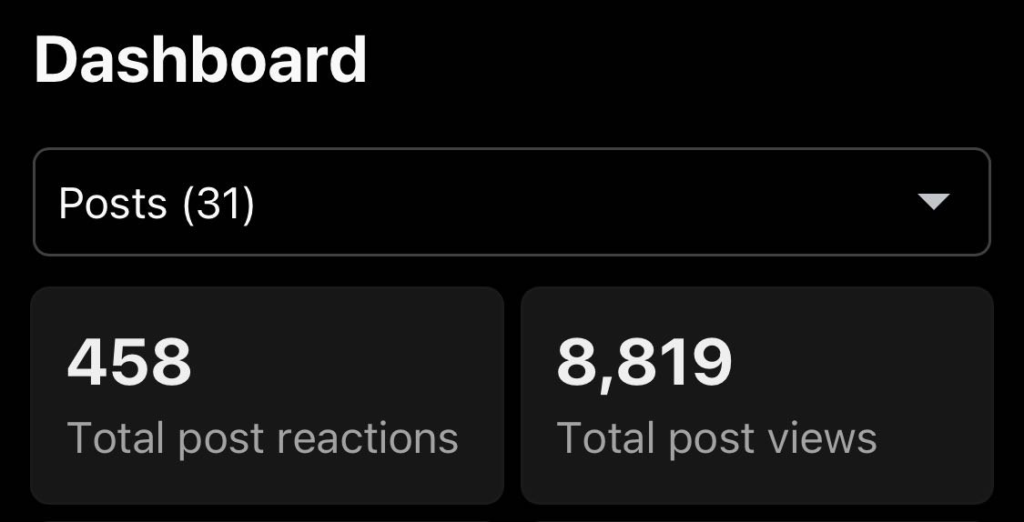
Views on Dev.to
In total, my content has gotten **14.710** views. While I still feel these are "rookie numbers" it's crazy to think I can fill the Pec Zwolle stadium with people that read my content. And still have a few people who have to wait outside.
I've started a [newsletter](https://blog.jellesmeets.nl/newsletter-signup/) with no real success. The number of subscribers increased 500% in the last year! But in absolute numbers, I went from 1 subscriber to 5.
## Great people
Blogging has opened many doors to meeting amazing people. Blogging and building in public have put me in a corner on the internet with many like-minded individuals.
In my blogging journey I have:
- Gotten feedback from industry leaders I look up to
- Find inspirational bloggers who make me a better manager
- Meet people who are just a few steps ahead of me and who I can learn from
- Discover concepts that change my perspective, like [pushing through friction](https://www.youtube.com/watch?v=8bxZuzDKoI0)
- Leading to interesting opportunities, like speaking on a podcast
## Improved skills
Over the years I worked with several talented colleagues as a developer and scrum master. We build features together, and learned about the why's, and gave me a great insight into their trade. Blogging allows me to put these things into practice myself.
Not only collaborating with an SEO specialist but actually having to do keyword research, optimize my blog, find out how hard it can be to rank, etc. Getting your hands dirty makes me a more rounded professional. I can recommend this to everyone.

Blogging brought me skills for life
Blogging learned me several skills I hardly used in the past. Content marketing, SEO, copywriting, planning content, [building a second brain](https://www.buildingasecondbrain.com/), and many other skills.
Besides all marketing and technical related skills, is one skill that is the most important one for me. Writing. While blogging I discovered that I enjoy the art of writing. To go from an idea to a blog post that people actually like reading is a fantastic feeling.
Writing is one of those skills that apply to anything you do in life. Emails, proposals, or any other form of written communication. It helps me to clearly express my thoughts. Which is a skill for life.
## Luck is like a bus
A story from one of my favorite books [the third door](https://thirddoorbook.com/) explains how blogging helped me:
> **Luck is like a bus.** **If you miss one, there's always the next one.** **But if you're not prepared, you won't be able to jump on.**
>
> Qi Lu
This quote by [Qi Lu](https://en.wikipedia.org/wiki/Qi_Lu_(computer_scientist)) explains how he was able to study in America. Qi was originally from a poor region in China and wanted to study at one of the big universities in America. There was only one show-stopper: the entrance exam to see if he would qualify. Just the fee was several months' worth of wages which prevented him from taking it.
On a random night, a friend convinced him to join a lecture from an American professor as a "seat filler". Turns out this talk was on a subject he wrote several research papers about! Qi was able to ask some good questions. This intrigued the professor who came to talk after the lecture. They talked about several subjects and studying in America was one of those subjects. The professor was so impressed by Qi that he decided to sponsor his entrance fee. And the rest is history. Qi joined IBM, Microsoft, and was a driving force in launching Bing.
This story of Qi Lu brings me to my own Luck. I joined a Twitter community for Engineering managers. I saw that a manager named Nigel introduced himself, and I liked his tweet. It turns out Nigel was the host of the unfiltered build podcast, who happened to see my blog posts from my Twitter profile and liked them. He decided to ask me to speak on his podcast! Talking about ticking off bucket list items!

Unfiltered build podcast - Building with people for people
Listen to Episode 06: [Motivation Porridge - Using Goldilocks to ignite employee motivation with Jelle Smeets.](https://anchor.fm/buildingwithpeople/episodes/Ep--6-Motivation-Porridge---Using-Goldilocks-to-ignite-employee-motivation-with-Jelle-Smeets-e1g0jb8)
Was liking a random tweet that led to speaking on a podcast luck? _Absolutely_. But writing several blog posts that the podcast host liked luck? No. Liking a tweet was like stepping on the bus, but my blogging habit made sure I was standing at the bus stop.
## The future
Where to go from here? I have discovered that I like creating content. I will definitely continue writing. But I am open to discovering other ways to create content. Maybe you will see some Youtube videos or podcasts.
In terms of goals, I would love to hit the 500 views per month mark. And I want to put serious effort into the newsletter.
That leaves me one question to you, reader! What is something you would like me to write about? Let me know.
_If you enjoyed this post and would like to read more of my content, consider subscribing to my [newsletter](https://blog.jellesmeets.nl/newsletter-signup/)._
| smeetsmeister |
1,171,437 | Practical Bloom Filters | A couple of years ago I wanted to learn more about different types of commonly used data structures.... | 0 | 2022-08-19T14:50:00 | https://dev.to/dillendev/practical-bloom-filters-27ol | rust, algorithms, programming | A couple of years ago I wanted to learn more about different types of commonly used data structures. It’s one thing to have used them, but knowing how they work or building them from scratch is something else. In this article, we’re doing a deep dive into bloom filters including some code examples and use-cases.<br><br>
## What is a Bloom Filter?
According to [Wikipedia](https://en.wikipedia.org/wiki/Bloom_filter), a bloom filter is:
> A space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not.
So in its essence, a bloom filter is an array of bits (1/8 of a byte) where initially all bits are set to `0`. To add an element to the bloom filter a hashing function is required to “map” the element to a specific position in the bit array. Two or more elements can be mapped to the same position which can result in false positives (which is why it's called probabilistic). However, if the bit at the position of the element is `0` we know for sure that it's not included in the set.
### In short:
A bloom filter can be used to efficiently check if an element *is not* included in a set.<br><br>
## Real-world usage
### CRLite
In 2020 [Mozilla announced](https://blog.mozilla.org/security/2020/01/09/crlite-part-2-end-to-end-design/) that they are working on an alternative for validating revoked certificates in Firefox which is called CRLite. At the time a collection of all unexpired revoked certificates compromised 6.7GB on disk which was compressed to a ~ 1.3MB bloom filter. Verifying if a certificate is revoked is cheap for valid certificates as it only requires hashing the certificate serial number to get the position of the bit and verifying if it's set to `0`.
### Cassandra
Apache Cassandra [uses bloom filters](https://docs.datastax.com/en/cassandra-oss/3.0/cassandra/operations/opsTuningBloomFilters.html) to determine whether an SSTable has data for a particular partition. Verifying if the SSTable has data for a partition is cheap as it doesn’t need to read its content (avoiding IO operations).<br><br>
## Building one from scratch
We’re going to use Rust to create our bloom filter. Let’s start with a simple structure that includes the bit array:
```rust
struct BloomFilter<const N: usize> {
bytes: [u8; N],
}
impl<const N: usize> BloomFilter<N> {
fn new() -> Self {
Self { bytes: [0; N] }
}
}
fn main() {
let filter = BloomFilter::<10>::new();
}
```
Now we have a basic structure that holds our bit set and sets all bits to `0` when the bloom filter is created. Since there is no way to represent a single bit as a type our bit array is defined as an array of bytes. Thus size `N` in this example is the size in bytes (as `u8` is the data type for a byte in Rust), not bits.
The first thing we’re going to implement is adding a new element to our bloom filter. We need to hash the value to get a numeric value, get the position of the byte, get the position of the bit inside the byte, and set it to `1`. We’re going to use strings for our elements and use the `DefaultHasher` as our hashing function.
```rust
use std::collections::hash_map::DefaultHasher;
use std::hash::{Hash, Hasher};
fn hash(value: &str) -> u64 {
let mut s = DefaultHasher::new();
value.hash(&mut s);
s.finish()
}
struct BloomFilter<const N: usize> {
bytes: [u8; N],
}
impl<const N: usize> BloomFilter<N> {
fn new() -> Self {
Self { bytes: [0; N] }
}
fn add(&mut self, key: &str) {
let bit_size = N * 8;
let pos = hash(key) % (bit_size as u64);
let (byte_idx, bit_idx) = (pos / 8, pos % 8);
self.bytes[byte_idx as usize] |= 1 << bit_idx;
}
}
```
There is a lot to unpack here. To get the absolute bit position, the element is hashed to get a numeric value and a modulo operation is used against the size of the bit array so that we end up with a valid position. Then we need to find the position of the byte and calculate the relative bit position. At last, we set the bit by using a bitwise operation.
<center>Adding an element where pos=20</center><br>
The last step is to implement a method that checks if an element is not included in the set. The process is similar to adding an element but instead of setting the bit we need to check its value.
```rust
use std::collections::hash_map::DefaultHasher;
use std::hash::{Hash, Hasher};
fn hash(value: &str) -> u64 {
let mut s = DefaultHasher::new();
value.hash(&mut s);
s.finish()
}
struct BloomFilter<const N: usize> {
bytes: [u8; N],
}
impl<const N: usize> BloomFilter<N> {
fn new() -> Self {
Self { bytes: [0; N] }
}
fn get_positions(&self, key: &str) -> (usize, u64) {
let bit_size = N * 8;
let pos = hash(key) % (bit_size as u64);
((pos / 8) as usize, pos % 8)
}
fn add(&mut self, key: &str) {
let (byte_idx, bit_idx) = self.get_positions(key);
self.bytes[byte_idx] |= 1 << bit_idx;
}
fn contains(&self, key: &str) -> bool {
let (byte_idx, bit_idx) = self.get_positions(key);
self.bytes[byte_idx] & (1 << bit_idx) != 0
}
}
```
Most of the logic is moved to the `get_positions` method which calculates the byte index and bit position. Let’s also add some test code to see if it works as intended:
```rust
fn main() {
let mut filter = BloomFilter::<10>::new();
filter.add("test1");
filter.add("test2");
println!("test1: {}", filter.contains("test1"));
println!("test2: {}", filter.contains("test2"));
println!("test3: {}", filter.contains("test3"));
}
```
On my machine this results in the following output:
```bash
➜ cargo run
Compiling bloom-filter v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.14s
Running `target/debug/bloom-filter`
test1: true
test2: true
test3: false
```
Remember that we can only guarantee that `test3` is not included in the set. We can’t be sure that either `test1` or `test2` are included in the set as these could be false positives. The source code can be found on [GitHub](https://github.com/dillendev/bloom-filter-rs).<br><br>
## Closing remarks
In our bloom filter implementation, we choose a random size of `10` bytes (=80 bits). In the real world, the size should be based on your dataset and the expected probability rate of false positives. Choosing a size that’s too small can have negative effects on performance as there will be too many false positives. The best way to determine the properties of your bloom filter is by running performance tests and using the [bloom filter calculator](https://hur.st/bloomfilter/). | dillendev |
1,171,483 | Where do I start | First of all, I am doing well and I hope you are doing better. The first I heard about Redis, was a... | 19,399 | 2022-08-19T16:29:48 | https://dev.to/otumianempire/where-do-i-start-370m | redishackathon, javascript, programming, devjournal | First of all, I am doing well and I hope you are doing better. The first I heard about Redis, was a discussion about caching. This is the first time that I have added caching to my application.
This year, I came across this article
{% post https://dev.to/devteam/announcing-the-redis-hackathon-on-dev-3248 %}
by the dev team.
The above article details what and how you should go about the project to submit and what to include.
So, I took one of my API, Nodejs apps, and added caching to it. The speed did improve a lot after the first request and I liked it. Bear in mind that this is the first time that I have included it in my application, from a first person's perspective.
So from a MongoDB database application without caching, [arms-without-redis-for-caching](https://github.com/Otumian-empire/ARMS/tree/arms-without-redis-for-caching) to one with caching, [integrate-redis-for-caching](https://github.com/Otumian-empire/ARMS/tree/integrate-redis-for-caching).
Now, I am going to use the Redis-stack to work above project without MongoDB. You can find this project here:
{% embed https://github.com/Otumian-empire/ARMS-redis %}
Hackathons are fun. I get to learn a new concept and see what awesome projects others have built.
| otumianempire |
1,171,783 | Javascript Tagalog - String startsWith Method | Ano ngaba ang String startsWith method sa Javascript? Yung startsWith method sa javascript is... | 0 | 2022-08-19T22:27:00 | https://dev.to/mmvergara/javascript-tagalog-string-startswith-method-1ipj | javascript, tagalog, pinoy, startswith | **Ano ngaba ang String startsWith method sa Javascript?**
Yung startsWith method sa javascript is titignan niya if yung string ay nag-uumpisa sa string na binigay mo as an argument sa method tapos mag re-return siya ng **Boolean value** (true or false)
---
**Pano gamitin:**
**First Argument** - yung string na gusto mong i search sa unahan
**Second Argument** (optional) - kung sang index siya mag-uumpisa mag search (**default is 0** which is yung start ng string)
Return Value niya is yung **boolean** ( True or False ) depende if yung string is nag-i istart sa binigay mong string.
---
**More tagalog Javascript Learning Resources:**
https://javascript-methods-in-tagalog.vercel.app/ | mmvergara |
1,172,142 | How to expose multiple applications on Amazon EKS with a single Application Load Balancer | This post was originally published at https://letsmake.cloud. Expose microservices to the... | 19,414 | 2022-08-20T15:32:00 | https://letsmake.cloud/multiple-eks-single-alb | aws, kubernetes, devops, cloud | > This post was originally published at [https://letsmake.cloud](https://letsmake.cloud/multiple-eks-single-alb).
# Expose microservices to the Internet with AWS
One of the defining moments in building a microservices application is deciding how to **expose** endpoints so that a client or API can send requests and get responses.
Usually, each microservice has its endpoint. For example, each URL path will point to a different microservice:
```
www.example.com/service1 > microservice1
www.example.com/service2 > microservice2
www.example.com/service3 > microservice3
...
```
This type of routing is known as ***path-based routing***.
This approach has the advantage of being **low-cost** and simple, even when exposing dozens of microservices.
On AWS, both **Application Load Balancer (ALB)** and **Amazon API Gateway** support this feature. Therefore, with a **single ALB** or API Gateway, you can expose microservices running as containers with Amazon EKS or Amazon ECS, or serverless functions with AWS Lambda.
AWS recently proposed a [solution to expose EKS orchestrated microservices via an Application Load Balancer](https://aws.amazon.com/blogs/containers/how-to-expose-multiple-applications-on-amazon-eks-using-a-single-application-load-balancer/). Their solution is based on the use of *NodePort* exposed by Kubernetes.
Instead, I want to propose a different solution that uses the EKS cluster **VPC CNI add-on** and allows the pods to automatically connect to their *target group*, without using any *NodePort*.
Also, in my use case, the Application Load Balancer is managed **independently** of EKS, i.e. it is not Kubernetes that has control over it. This way you can use other types of routing on the load balancer; for example, you could have an SSL certificate with more than one domain (*SNI*) and base the routing not only on the path but also on the domain.
# Component configuration
> The code shown here is partial. A complete example can be found [here](https://github.com/theonlymonica/multiple-app-single-lb-examples).
## EKS cluster
In this article, the EKS cluster is a prerequisite and it is assumed that it is already installed. If you want, you can read how to install an EKS cluster with Terraform in [my article on autoscaling](https://letsmake.cloud/eks-cluster-autoscaler). A complete example can be found in my [repository](https://github.com/theonlymonica/multiple-app-single-lb-examples).
## VPC CNI add-on
The [VPC CNI (Container Network Interface) add-on](https://docs.aws.amazon.com/eks/latest/userguide/pod-networking.html) allows you to automatically assign a VPC IP address directly to a pod within the EKS cluster.
Since we want pods to **self-register** on their target group (which is a resource outside of Kubernetes and inside the VPC), the use of this add-on is imperative. Its installation is natively integrated on EKS, [as explained here](https://docs.aws.amazon.com/eks/latest/userguide/managing-vpc-cni.html).
## AWS Load Balancer Controller plugin
AWS Load Balancer Controller is a controller that helps manage an Elastic Load Balancer for a Kubernetes cluster.
It is typically used for provisioning an Application Load Balancer, as an Ingress resource, or a Network Load Balancer as a Service resource.
In our case provisioning is not required, because our Application Load Balancer is managed **independently**. However, we will use another type of component installed by the CRD to make the pods register to their target group.
This plugin is not included in the EKS installation, so it must be installed following the [instructions from the AWS documentation](https://docs.aws.amazon.com/eks/latest/userguide/aws-load-balancer-controller.html).
If you use Terraform, like me, you can consider using a module:
```
module "load_balancer_controller" {
source = "DNXLabs/eks-lb-controller/aws"
version = "0.6.0"
cluster_identity_oidc_issuer = module.eks_cluster.cluster_oidc_issuer_url
cluster_identity_oidc_issuer_arn = module.eks_cluster.oidc_provider_arn
cluster_name = module.eks_cluster.cluster_id
namespace = "kube-system"
create_namespace = false
}
```
## Load Balancer and Security Group
With Terraform I create an Application Load Balancer in the public subnets of our VPC and its Security Group. The VPC is the same where the EKS cluster is installed.
```
resource "aws_lb" "alb" {
name = "${local.name}-alb"
internal = false
load_balancer_type = "application"
subnets = module.vpc.public_subnets
enable_deletion_protection = false
security_groups = [aws_security_group.alb.id]
}
resource "aws_security_group" "alb" {
name = "${local.name}-alb-sg"
description = "Allow ALB inbound traffic"
vpc_id = module.vpc.vpc_id
tags = {
"Name" = "${local.name}-alb-sg"
}
ingress {
description = "allowed IPs"
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "allowed IPs"
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
}
```
> It is important to remember to authorize this Security Group as a source in the Security Group inbound rules of the cluster nodes.
At this point, I create the target groups to which the pods will bind themselves. In this example I use two:
```
resource "aws_lb_target_group" "alb_tg1" {
port = 8080
protocol = "HTTP"
target_type = "ip"
vpc_id = module.vpc.vpc_id
tags = {
Name = "${local.name}-tg1"
}
health_check {
path = "/"
}
}
resource "aws_lb_target_group" "alb_tg2" {
port = 9090
protocol = "HTTP"
target_type = "ip"
vpc_id = module.vpc.vpc_id
tags = {
Name = "${local.name}-tg2"
}
health_check {
path = "/"
}
}
```
The last configuration on the Application Load Balancer is the **listeners**' definition, which contains the traffic routing rules.
The **default** rule on listeners, which is the response to requests that do not match any other rules, is to refuse traffic; I enter it as a **security** measure:
```
resource "aws_lb_listener" "alb_listener_http" {
load_balancer_arn = aws_lb.alb.arn
port = "80"
protocol = "HTTP"
default_action {
type = "fixed-response"
fixed_response {
content_type = "text/plain"
message_body = "Internal Server Error"
status_code = "500"
}
}
}
resource "aws_lb_listener" "alb_listener_https" {
load_balancer_arn = aws_lb.alb.arn
port = "443"
protocol = "HTTPS"
certificate_arn = aws_acm_certificate.certificate.arn
ssl_policy = "ELBSecurityPolicy-2016-08"
default_action {
type = "fixed-response"
fixed_response {
content_type = "text/plain"
message_body = "Internal Server Error"
status_code = "500"
}
}
}
```
The actual rules are then associated with the listeners. The listener on port 80 has a simple redirect to the HTTPS listener. The listener on port 443 has rules to route traffic according to the path:
```
resource "aws_lb_listener_rule" "alb_listener_http_rule_redirect" {
listener_arn = aws_lb_listener.alb_listener_http.arn
priority = 100
action {
type = "redirect"
redirect {
port = "443"
protocol = "HTTPS"
status_code = "HTTP_301"
}
}
condition {
host_header {
values = local.all_domains
}
}
}
resource "aws_lb_listener_rule" "alb_listener_rule_forwarding_path1" {
listener_arn = aws_lb_listener.alb_listener_https.arn
priority = 100
action {
type = "forward"
target_group_arn = aws_lb_target_group.alb_tg1.arn
}
condition {
host_header {
values = local.all_domains
}
}
condition {
path_pattern {
values = [local.path1]
}
}
}
resource "aws_lb_listener_rule" "alb_listener_rule_forwarding_path2" {
listener_arn = aws_lb_listener.alb_listener_https.arn
priority = 101
action {
type = "forward"
target_group_arn = aws_lb_target_group.alb_tg2.arn
}
condition {
host_header {
values = local.all_domains
}
}
condition {
path_pattern {
values = [local.path2]
}
}
}
```
# Getting things work on Kubernetes
Once setup on AWS is complete, using this technique on EKS is super easy! It is sufficient to insert a **TargetGroupBinding** type resource for each deployment/service we want to expose on the load balancer through the target group.
Let's see an example. Let's say I have a deployment with a service:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app.kubernetes.io/name: nginx
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/name: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app.kubernetes.io/name: nginx
spec:
selector:
app.kubernetes.io/name: nginx
ports:
- port: 8080
targetPort: 80
protocol: TCP
```
The only configuration I need to add is this:
```
apiVersion: elbv2.k8s.aws/v1beta1
kind: TargetGroupBinding
metadata:
name: nginx
spec:
serviceRef:
name: nginx
port: 8080
targetGroupARN: "arn:aws:elasticloadbalancing:eu-south-1:123456789012:targetgroup/tf-20220726090605997700000002/a6527ae0e19830d2"
```
From now on, each new pod that belongs to the deployment associated with that service will **self-register** on the indicated target group. To test it, just scale the number of replicas:
```
kubectl scale deployment nginx --replicas 5
```
and within a few seconds the new pods' IPs will be visible in the target group.
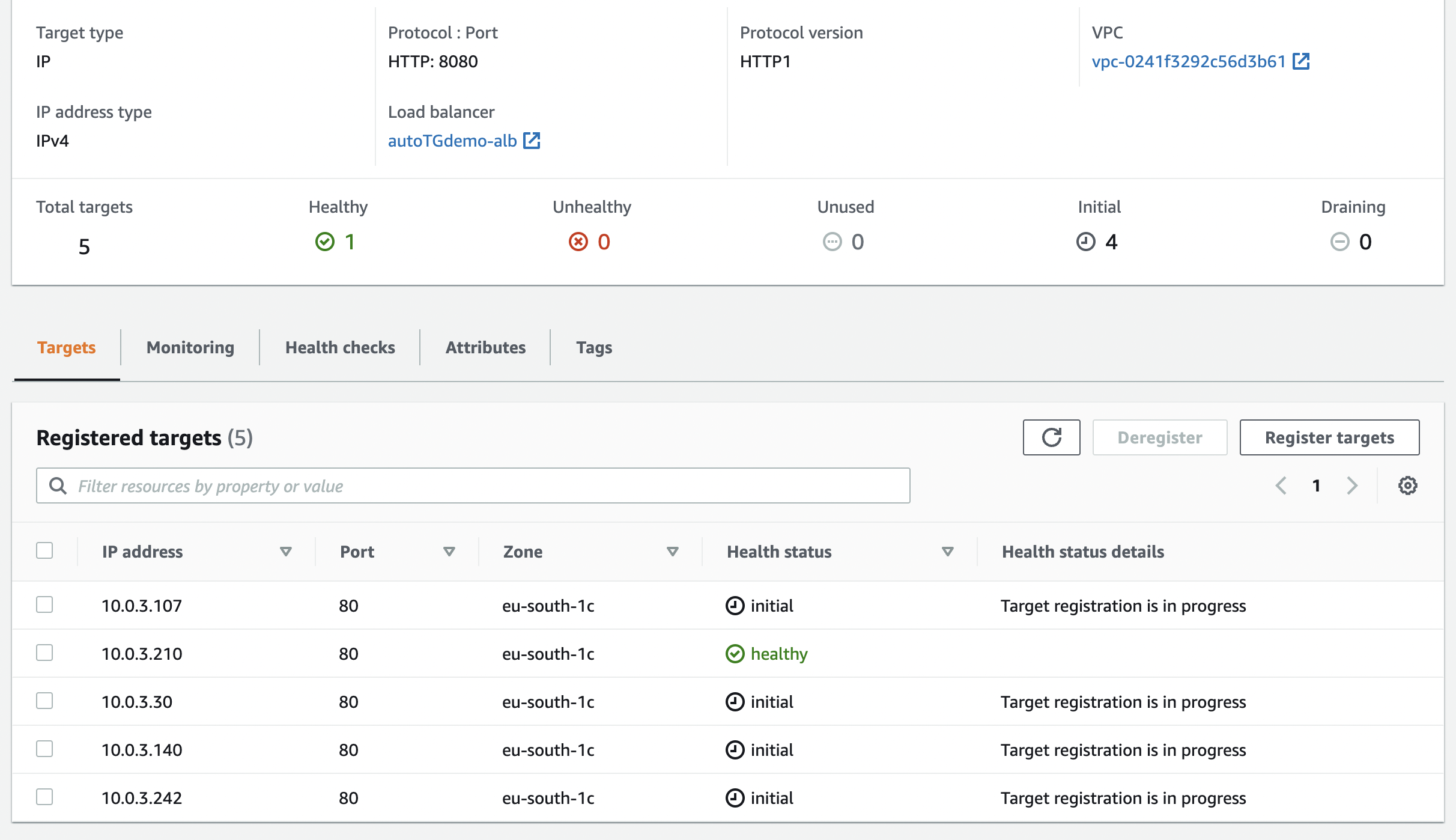 | monica_colangelo |
1,172,420 | Next.Js Crowd: See Who Talks About The React Framework | Overview of Next.Js Crowd It's an app that monitors Twitter for users who mention the... | 0 | 2022-08-26T12:50:00 | https://dev.to/sashevuchkov/nextjs-crowd-see-who-talks-about-the-react-framework-5dpi | redishackathon, nextjs, typescript, react |
### Overview of Next.Js Crowd
It's an app that monitors Twitter for users who mention the react framework Next.js. It constantly collects tweets and user data, creates curious stats and then rank them by a "Score".
Every elligible tweet, user or stat JSON document is recorded in a Redis database. Later, when a visitor opens the app, it fetches those documents to show them.
You can find [the repo here](https://github.com/SasheVuchkov/nextjs-crowd)...
You can find a working demo of the app here:
[https://nextjs.buhalbu.com](https://nextjs.buhalbu.com)
###What technologies did we use to build it?
We used TypeScript, Next.Js, and Redis, as well as HTML and CSS for the front-end part.
Here's a diagram of the architecture:
So the app works in two primary modes. We have a scheduled job that emits messages every two minutes. Our app listens for those messages, and on every message, it "asks" Twitter whether there are new tweets with the desired keyword next.js.
If there aren't any new tweets, then everything is cool, and that's the end of the story.
If there are new tweets, the app processes them by mapping their data to our internal data types, and it calculates their "scores" that it later uses to rank them by popularity.
In the next step, the new data is saved in a Redis Database as documents. We use the awesome RedisJSON module.
Then the app gets a JSON document from Redis with the current day's general stats. It updates those stats and saves them.
That's the final step.
In the second mode, the app is accessible on the web. When a web visitor opens it with their browser, it fetches data from our Redis database, generates the response, and then sends it back to the browser.
Now the web visitor can see either a list of ranked Twitter users or a list of ranked tweets.
### Submission Category:
MEAN/MERN Mavericks
### App Video Overvew
{% youtube QDa-ZEHurxA %}
### Language Used
JS/TS/Node.js
### Link to Code
{% embed https://github.com/SasheVuchkov/nextjs-crowd %}
### Additional Resources / Info
TypeScript - JavaScript with syntax for types.
[https://www.typescriptlang.org/](https://www.typescriptlang.org/)
Next.Js - The React Framework
[https://github.com/vercel/next.js/](https://github.com/vercel/next.js/)
React.Js - A declarative, efficient, and flexible JavaScript library for building user interfaces.
[https://github.com/facebook/react](https://github.com/facebook/react)
Bootstrap5 - world’s most popular framework for building responsive, mobile-first sites, with jsDelivr and a template starter page.
[https://getbootstrap.com/](https://getbootstrap.com/)
twitter-api-sdk - A TypeScript SDK for the Twitter API
[https://github.com/twitterdev/twitter-api-typescript-sdk](https://github.com/twitterdev/twitter-api-typescript-sdk)
Redis Om for Node - Object mapping, and more, for Redis and Node.js. Written in TypeScript.
[https://github.com/redis/redis-om-node](https://github.com/redis/redis-om-node)
Feather – Simply beautiful open source icons
[https://feathericons.com/](https://feathericons.com/)
### App Screenshots



### Collaborators
[Maureen Ononiwu](https://dev.to/chinwendu20), backend developer
https://dev.to/chinwendu20
[Sashe Vuchkov](https://dev.to/sashevuchkov), full-stack developer
https://dev.to/sashevuchkov
- - -
* _Check out [Redis OM](https://redis.io/docs/stack/get-started/clients/#high-level-client-libraries), client libraries for working with Redis as a multi-model database._
* _Use [RedisInsight](https://redis.info/redisinsight) to visualize your data in Redis._
* _Sign up for a [free Redis database](https://redis.info/try-free-dev-to)._ | sashevuchkov |
1,172,429 | I am working with dispora api | i did mastadon and misskey now doing diaspora and activity pub i am a fediverse programmer | 0 | 2022-08-21T02:27:00 | https://dev.to/afheisleycook/i-am-working-with-dispora-api-4l72 | i did mastadon and misskey now doing diaspora and activity pub i am a fediverse programmer | afheisleycook | |
1,172,518 | N-Queen - All Possible Placements | This solution is more specific to leet code problem. If you want only solution for possible option... | 0 | 2022-08-21T07:21:00 | https://dev.to/zeeshanali0704/n-queen-all-possible-placements-3bji | javascript, leetcode | This solution is more specific to leet code problem.
If you want only solution for possible option please print board array- or Refer - [N-Queen : Check if possible to place in NxN](https://dev.to/zeeshanali0704/n-queen-check-if-possible-to-place-in-nxn-98c)
```
const N = 4;
let allPossibleArray = [];
function isSafe(board, row, col, N) {
for (let i = row - 1; i >= 0; i--) if (board[i][col] == 1) return false;
for (let i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--)
if (board[i][j] == 1) return false;
for (let i = row - 1, j = col + 1; i >= 0 && j < N; i--, j++)
if (board[i][j] == 1) return false;
return true;
}
function solveNQUtil(board, N, row) {
if (row === N) {
let tm = [];
for (let i = 0; i < N; i++) {
let s = "";
for (let j = 0; j < N; j++) {
if (board[i][j] == 1) s += "Q";
else s += ".";
}
tm.push(s);
}
allPossibleArray.push(tm);
}
for (let col = 0; col < N; col++) {
if (isSafe(board, row, col, N) == true) {
board[row][col] = 1;
solveNQUtil(board, N, row + 1);
board[row][col] = 0;
}
}
return false;
}
function solveNQ() {
let board = [
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
];
solveNQUtil(board, N, 0);
return allPossibleArray;
}
console.log(solveNQ());
```
| zeeshanali0704 |
1,172,531 | m1 macのc++でOpenGLを使ってテトリスを作ってみた | m1 macの、c++とOpenGLで簡易的なテトリスを作りました。 ... | 0 | 2022-08-21T08:09:00 | https://dev.to/edo1z/m1-macnocdeopenglwoshi-tutetetorisuwozuo-tutemita-1aaj | cpp, opengl, glfw, tetris | m1 macの、c++とOpenGLで簡易的なテトリスを作りました。

---
## リポジトリ
- https://github.com/web3ten0/cpp-opengl-tetris
---
## 実行してみてる動画
- https://user-images.githubusercontent.com/89882017/185777309-9afa6109-ba77-42e9-bd1e-2e37c981b26a.mp4
- https://www.youtube.com/watch?v=X1YzFl31W7c
---
## 動作環境
- m1 mac
```shell
❯ uname -a
Darwin mac.local 21.6.0 Darwin Kernel Version 21.6.0:
Sat Jun 18 17:05:47 PDT 2022; root:xnu-8020.140.41~1/RELEASE_ARM64_T8101 arm64
❯ brew config
HOMEBREW_VERSION: 3.5.9
CPU: octa-core 64-bit arm_firestorm_icestorm
Clang: 13.1.6 build 1316
macOS: 12.5-arm64
CLT: 13.4.0.0.1.1651278267
Xcode: 13.4.1
Rosetta 2: false
```
---
## Install〜実行
### GLFWをインストール
```shell
brwe install glfw
vim ~/.zshrc
# 下記を追加
export CPATH=/opt/homebrew/include
export LIBRARY_PATH=/opt/homebrew/lib
```
### リポジトリをclone
```shell
git clone https://github.com/web3ten0/cpp-opengl-tetris.git
```
### binディレクトリ作成、make、実行
```shell
cd cpp-opengl-tetris
mkdir bin
make
./bin/main
```
| edo1z |
1,172,696 | How to create a library that works with Clojure and ClojureScript | this article originally posted at https://kozieiev.com Content: Creating Clojure... | 0 | 2022-08-21T16:14:54 | https://kozieiev.com/blog/how-to-create-library-for-clojure-and-clojurescript/ | clojure, clojurescript |
{% embed https://youtu.be/KVWxr9dvGZ8 %}
this article originally posted at [https://kozieiev.com](https://kozieiev.com/blog/how-to-create-library-for-clojure-and-clojurescript/)
## Content:
- [Creating Clojure version of logger library](#creating-clojure-version-of-logger-library)
- [Creating Clojure app to use logger library](#creating-clojure-app-to-use-logger-library)
- [Introducing reader conditionals](#introducing-reader-conditionals)
- [Making the logger library work with ClojureScript](#making-the-logger-library-work-with-clojurescript)
- [Creating ClojureScript app to use logger library](#creating-clojurescript-app-to-use-logger-library)
Clojure and ClojureScript are forms of the same language targeting different hosts - JVM and JavaScript respectively. If you are creating a library, there is a big chance that a significant part of the code will work for both hosts but a part of it will be host-dependent.
Here we will discuss how to isolate the host-dependent parts of code to be used only when appropriate in order to write a single library that works for both Clojure and ClojureScript.
**Steps that we are going to do:**
1. Create a simple logger Clojure library. Its `(log)` function will print the passed object with added timestamp and information from what language it was invoked.
2. Create a Clojure app that uses the `logger` library
3. Modify `logger` library to work with ClojureScript as well
4. Create a ClojureScript app that uses the `logger` library to check that our modifications worked correctly
## Creating Clojure version of logger library
Here is a folder structure for our `logger` library:
```bash
logger
├── deps.edn
└── src
└── vkjr
└── logger.clj
```
It’s `deps.edn` can be an empty map:
```clojure
{}
```
And here is a code of the `logger.clj`:
```clojure
(ns vkjr.logger
(:require [clojure.pprint :as pprint]))
(defn- timestamp []
(.format (java.text.SimpleDateFormat. "d/M/yyyy, HH:mm:ss") (new java.util.Date)))
(defn log [arg]
(pprint/cl-format true
"Time: ~S | Host: ~S | Object: ~S\n"
(timestamp)
"Clojure"
arg))
```
`(timestamp)` is a helper function that uses Java host features to get a formatted timestamp.
`(log)` is the function visible to the library users. It takes the user argument and using `(cl-format)` prints it prepended with timestamp and language name (”Clojure” in this case).
The first argument of `(cl-format)` - `true`, means that printing should be done to the default output. You can read more about this function in the [official documentation](https://clojuredocs.org/clojure.pprint/cl-format).
## Creating Clojure app to use logger library
Now let’s create a Clojure app to use the library. It will be called `cljapp` and put on the same lever with the logger:
```bash
playground
├── logger <- logger library
└── cljapp <- our new app
```
Here is a folder structure for `cljapp`:
```bash
cljapp
├── deps.edn
└── src
└── core.clj
```
In `deps.edn` we’ll reference `logger` library by location on the filesystem:
```clojure
{:deps {vkjr/logger {:local/root "../logger"}}}
```
And here is the code inside `core.clj`:
```clojure
(ns core
(:require [vkjr.logger :as logger]))
(defn -main [& _]
(logger/log "Hi there!")
(logger/log {:a 1 :b 2})
(logger/log [1 2 3 4]))
```
We required the namespace of the logger library and used `(logger/log)` inside the `(main)` to print different arguments.
Now let’s run the main function using Clojure CLI (from `cljapp` folder) to make sure it works correctly:
```bash
$ clj -M -m core
Time: "18/8/2022, 16:39:30" | Host: "Clojure" | Object: "Hi there!"
Time: "18/8/2022, 16:39:30" | Host: "Clojure" | Object: {:a 1, :b 2}
Time: "18/8/2022, 16:39:30" | Host: "Clojure" | Object: [1 2 3 4]
```
Nice, as we see, it does)
## Introducing reader conditionals
There is a part of Clojure tooling called **Reader.** It takes a textual code representation and turns it into the Clojure data structures. When you compile Clojure code, Reader will be responsible for processing your sources.
Reader supports two **reader conditionals** which allow you to specify different pieces of code and choose between them depending on the platform where the reader is invoked.
The **standard reader** starts with `#?` and looks like:
```clojure
#?(:clj (any Clojure expression)
:cljs (any ClojureScript expression)
:default (default expression))
```
When Reader encounters such a conditional, it will leave only one expression in the result data structure - the one corresponding to the current host or the default one if the current host is not listed.
So after reading this code:
```clojure
#?(:clj (+ 1 2) :cljs (+ 3 4))
```
On ClojureScript host Reader will return this datastructure:
```clojure
(+ 3 4)
```
The **splicing reader** starts with `#?@` and looks like this:
```clojure
#?@(:clj [vector of elements]
:cljs [another vector of elements])
```
When it encountered, Reader will choose the vector depending on the host and will put the **content of vector** in the surrounding context. **Not the vector itself!** It’s content.
And after reading this code:
```clojure
(print #?@(:clj [1 2] :cljs [3 4]))
```
on Clojure platform Reader will return the datastructure:
```clojure
(print 1 2)
```
**Note: in the source code reader conditionals work only in files with `*.cljc` file extension!**
To grasp reader conditionals better you can experiment in REPL by feeding different code pieces to the `read-string` function (with `{:read-cond :allow}` as a first argument) and inspecting the output.
```bash
$ clj <- run repl
user=> (read-string {:read-cond :allow} "#?(:clj (+ 1 2) :cljs (+ 3 4))")
(+ 1 2)
```
## Making the logger library work with ClojureScript
Now with all that knowledge about reader conditionals, it is time to revamp `logger` to make it work for ClojureScript.
First, we need to rename `logger.clj` → `logger.cljc` to enable reader conditionals.
Folder structure now:
```bash
logger
├── deps.edn
└── src
└── vkjr
└── logger.cljc
```
Next we need to add ClojureScript-related code in `(comment)` function in `logger.cljc`. It will be wrapped with standard reader conditional:
```clojure
(defn- timestamp []
#?(:clj
(.format (java.text.SimpleDateFormat. "d/M/yyyy, HH:mm:ss") (new java.util.Date))
:cljs
(let [now (new js/Date)]
(.toLocaleString now "en-US" #js{:hour12 false}))))
```
And as the last step, we modify `(log)` function to display the correct language name depending on the host. We use splicing reader conditional on doing this:
```clojure
(defn log [arg]
(pprint/cl-format true
"Time: ~S | Host: ~S | Object: ~S\n"
(timestamp)
#?@(:clj ["Clojure"]
:cljs ["ClojureScript"])
arg))
```
Full content of `logger.cljc` now:
```clojure
(ns vkjr.logger
(:require [clojure.pprint :as pprint]))
(defn- timestamp []
#?(:clj
(.format (java.text.SimpleDateFormat. "d/M/yyyy, HH:mm:ss") (new java.util.Date))
:cljs
(let [now (new js/Date)]
(.toLocaleString now "en-US" #js{:hour12 false}))))
(defn log [arg]
(pprint/cl-format true
"Time: ~S | Host: ~S | Object: ~S\n"
(timestamp)
#?@(:clj ["Clojure"]
:cljs ["ClojureScript"])
arg))
```
Now we need to check that changes didn’t affect the work of existing `cljapp`
Calling core namespace again from `cljapp` folder:
```bash
$ clj -M -m core
Time: "18/8/2022, 16:50:39" | Host: "Clojure" | Object: "Hi there!"
Time: "18/8/2022, 16:50:39" | Host: "Clojure" | Object: {:a 1, :b 2}
Time: "18/8/2022, 16:50:39" | Host: "Clojure" | Object: [1 2 3 4]
```
## Creating ClojureScript app to use logger library
And finally, we need to check that the library also works for the ClojureScript project.
Let’s create one, called `cljsapp` on the same level as `logger` and `cljapp`:
```bash
playground
├── logger
├── cljsapp <- ClojureScript app
└── cljapp
```
Project structure:
```bash
cljsapp
├── deps.edn
└── src
└── core.cljs
```
`deps.edn` content:
```clojure
{:deps {org.clojure/clojurescript {:mvn/version "1.11.60"}
vkjr/logger {:local/root "../logger"}}}
```
`core.cljs` content:
```clojure
(ns core
(:require [vkjr.logger :as logger]))
(defn -main [& _]
(logger/log "Hi there!")
(logger/log {:a 1 :b 2})
(logger/log [1 2 3 4])
(logger/log (new js/Date)))
```
And the actual check using Clojure CLI:
```bash
clj -M -m cljs.main -re node -m core
Time: "8/19/2022, 13:45:03" | Lang: "ClojureScript" | Object: "Hi there!"
Time: "8/19/2022, 13:45:03" | Lang: "ClojureScript" | Object: {:a 1, :b 2}
Time: "8/19/2022, 13:45:03" | Lang: "ClojureScript" | Object: [1 2 3 4]
Time: "8/19/2022, 13:45:03" | Lang: "ClojureScript" | Object: #inst "2022-08-19T12:45:03.775-00:00"
```
Perfect, now we have a library that works for both Clojure and ClojureScript :)
### Links
[Complete code for on github](https://github.com/vkjr/code-examples/tree/main/005-crosshost-library-example)
[Official documentation on reader conditionals](https://clojure.org/guides/reader_conditionals) | kozieiev |
1,172,842 | Formas de contribuir com as comunidades de tecnologia | Você sabia que existem diversas formas de contribuir com comunidades de tecnologia e variados... | 0 | 2022-08-21T19:09:14 | https://dev.to/feministech/formas-de-contribuir-com-as-comunidades-de-tecnologia-2mfd | community, devrel, braziliandevs, beginners | Você sabia que existem diversas formas de contribuir com comunidades de tecnologia e variados formatos e tipos de produção de conteúdo?
Se você sempre teve vontade de começar, talvez acabe encontrando aqui uma forma que melhor se encaixa no que você pretende fazer, ou até mesmo o que te deixa mais confortável para contribuir.
Neste artigo, trago alguns exemplos de produção de conteúdo e alguns exemplos de plataformas que você pode utilizar para te apoiar. Mas existem muitas outras, então fique à vontade para comentar e enriquecer este conteúdo com as suas experiências.
## Não precisa produzir conteúdo para ajudar a comunidade
Sabia disso? As comunidades de tecnologia não precisam apenas de produção de conteúdo. Talvez você possa ajudar tirando dúvidas das pessoas, apoiando na divulgação da própria comunidade ou dos conteúdos de quem os produz, incentivando pessoas a conhecerem a área e muito mais.
**Não sinta que é uma obrigação sua criar algo.** Existem pessoas que se sentem muito melhor ajudando na organização de um evento e na moderação do discord, por exemplo, que na frente fazendo palestras ou escrevendo artigos. E tudo bem. A comunidade também precisa dessas pessoas que cuidam dos bastidores.
## Live coding
Você sabe o que é live coding? Aqui, neste [link](https://dev.to/feministech/voce-tem-um-minuto-para-a-palavra-do-live-coding-4358), vou deixar um artigo no qual falei sobre isso. Fique à vontade para conhecer mais deste assunto. Mas é uma das formas de contribuir.
E existem algumas plataformas que você pode fazer live:
- [Twitch](https://www.twitch.tv/);
- [Trovo](https://trovo.live/);
- [Youtube](https://www.youtube.com/).
## Vídeos
Algumas pessoas preferem compartilhar conhecimento por vídeos editados, porque isso deixa mais confortável pela possibilidade de edição, diferente da live que tudo o que acontece, de certo e de errado, fica ali registrado para quem estiver acompanhando.
Algumas plataformas que você pode produzir e postar vídeos:
- [Youtube](https://www.youtube.com/);
- [Instagram](https://www.instagram.com/).
## Artigos e tutoriais
Escrever também é uma ótima forma de exercitar sua comunicação e também de compartilhar algum conhecimento. E esses artigos podem ser contando uma experiência que você viveu, algum problema que você aprendeu a solucionar, alguma dica interessante, ou até mesmo em formato de tutoriais ensinando como fazer algo. São materiais bem úteis.
Existem alguns lugares que você pode postar seus artigos:
- [Dev.to](https://dev.to/);
- Blog em plataformas como o [WordPress](https://wordpress.com/pt-br/);
- Blogs pessoais que você pode desenvolver em alguma linguagem de programação;
- [Gist](https://gist.github.com/) (GitHub). Já vi algumas pessoas compartilhando alguns conteúdos que envolvem código dessa forma também.
## Postagens nas redes sociais
Muitas pessoas costumam também dar dicas sobre carreira e conteúdos de tecnologia compartilhando via postagens em redes sociais.
Algumas redes sociais que costumo ver o pessoal compartilhando:
- [Twitter](https://twitter.com/home);
- [Instagram](https://www.instagram.com/);
- [LinkedIn](https://www.linkedin.com/).
## Apoio em fóruns de dúvidas
Uma excelente maneira de ajudar a comunidade é tirando dúvidas quando sabemos como ajudar em alguns fóruns.
Alguns deles podem ser encontrados em:
- [Stack overflow](https://pt.stackoverflow.com/);
- [Discord](https://discord.com/).
## Projetos de código aberto
Caso você prefira desenvolver, ou ajudar em documentação, uma boa opção é criar projetos de código aberto (open source) ou ajudar em projetos que já existem, mandando correções ou sugestões de melhoria pelas issues e pull requests.
Repositórios de projetos de código aberto podem ser encontrados em:
- [GitHub](https://github.com/);
- [GitLab](https://gitlab.com/);
- [Bitbucket](https://bitbucket.org/).
## Palestras em eventos
Alguns eventos podem fazer convites diretamente para as pessoas ou então abrir call for papers para você enviar sua proposta de conteúdo para ser apresentada.
Para entender um pouco mais sobre o que é e como funciona call for papers, sugiro acompanhar este artigo que escrevi clicando neste [link](https://dev.to/feministech/voce-sabe-o-que-e-call-for-papers-1lo5).
E sua palestra não precisa necessariamente ser algum assunto muito técnico ou avançado. Muitas vezes um conteúdo para pessoas iniciantes ou contando sua experiência pode ajudar muito mais. Tudo depende do objetivo do evento no qual você vai participar.
## Podcast
Existem diversos formatos de podcasts que podem ser feitos, como entrevistas, contando histórias, compartilhando conhecimento, entre muitos outros.
Podcasts podem ser encontrados ou postados em diversas plataformas, seguem algumas:
- [Anchor](https://anchor.fm/);
- [Spotify](https://open.spotify.com/);
- [Google Podcast](https://podcasts.google.com/).
## E como eu reúno tudo isso?
São muitas opções e diversas plataformas disponíveis, né? Mas pode respirar fundo que também existe um lugar onde você pode reunir e organizar todos os conteúdos que você produz, caso você não esteja usando algum blog ou site pessoal.
Você já ouviu falar do Polywork? Este é o meu perfil lá: [link](https://www.polywork.com/morgannadev). É um site que criar uma rede profissional na qual as pessoas podem compartilhar os destaques de tudo o que elas tem feito ou contribuído, aumentando seu networking. Você pode conhecer mais clicando [aqui](https://www.polywork.com/).
Caso queira fazer parte da rede, fique à vontade para utilizar meu link clicando [aqui](https://www.polywork.com/invite/morgannadev-wigglytuff). Ou utilizando o código diretamente: morgannadev-wigglytuff.
E não se preocupe, o site é gratuito!
---
E aí, que outras formas você conhece de ajudar comunidades de tecnologia? Quais experiências você já teve? Compartilha conosco!
Obrigada por ter lido o artigo e deixo o canal aberto para troca de ideias e feedbacks. | morgannadev |
1,173,045 | Now we are talking redis | I have had my mishap. I turned right and left, not knowing what is wrong. Typescript saved the day... | 19,399 | 2022-08-22T04:40:28 | https://dev.to/otumianempire/now-we-are-talking-redis-20k7 | redishackathon, redis, typescript, node | I have had my mishap. I turned right and left, not knowing what is wrong. Typescript saved the day and now I have to learn some specifics of Typescript.
I started with `redis-om` version `0.2.0`. Then upgraded to version `0.3.6` which is the current version.
## Create a connection
```ts
// client.ts
import { Client } from "redis-om";
const REDIS_URI = process.env.REDIS_URI;
const client: Client = new Client();
const connectRedis = async () => {
if (!client.isOpen()) {
await client.open(REDIS_URI);
}
const command = ["PING", "Redis server running"];
const log = await client.execute(command)
console.log(log);
};
connectRedis();
export default client;
```
## Create Schema
The only thing here that is different from the others so far is that this is `ts` and according to the [docs](https://www.npmjs.com/package/redis-om#a-note-for-typescript-users), we have to create an interface with the same name as the entity.
```ts
// schema.ts
import { Entity, Schema, SchemaDefinition } from "redis-om";
// This is necessary for ts
interface UserEntity {
username: string;
password: string;
email: string;
}
class UserEntity extends Entity {}
const UserSchemaStructure: SchemaDefinition = {
username: {
type: "string"
},
password: {
type: "string"
},
email: {
type: "string"
}
};
export default new Schema(UserEntity, UserSchemaStructure, {
dataStructure: "JSON"
});
```
## Create a repository
From what I have done so far, we can create a repository using `new Repository(schema, client)` or `client.fetchRepository(schema)`. The latter worked. The form gave an error that `Repository` is an _abstract_ class. So we have to extend it and implement its _abstract_ methods, `writeEntity` and `readEntity`. I went with the former since it makes my work faster.
```ts
// repository.ts
import { Entity, Repository } from "redis-om";
import client from "./client";
import schema from "./schema";
const repository: Repository<Entity> = client.fetchRepository(schema);
export default repository;
```
I look like a `ts` noob.
## Create a row
We will use the repository to create a new user. From what I have done so far, we can do:
```ts
// index.ts
import repository from "./repository";
const user = await repository.createAndSave({
username: "johndoe",
email: "johndoe@gmail.com",
password: "PASSjohndoe"
});
console.log(user);
// Output from the console log
/*
{
entityId: "01GB1W8GFDDX6FQN9H7F4T1808",
username: "johndoe",
password: "PASSjohndoe"
email: "johndoe@gmail.com"
}
*/
```
or
```ts
// index.ts
import repository from "./repository";
const user = repository.createEntity({
username: "johndoe",
email: "johndoe@gmail.com",
password: "PASSjohndoe"
});
const id = await repository.save(user);
// Output from the console log
// 01GB1W8GFDDX6FQN9H7F4T1808 // ID of the row created
```
## Conclusion
There is not much to say here than, to keep trying and sleep when you have to. Even though I was doing the right thing all the time and not getting the output I am expecting, I kept looking for others ways and posting the issue I was facing on other platforms, hoping another person had faced the same issue. Typescript worked for me even though I never thought of using Typescript in the first place. Now another path to learning has opened.
| otumianempire |
1,173,052 | Passwordless.id - first screenshots | Introduction So, first things first, I chose a domain name, yay! It's... | 0 | 2022-08-23T08:11:00 | https://dev.to/dagnelies/passwordlessid-first-screenshots-46nj | showdev | Introduction
------------
So, first things first, I chose a domain name, yay!
It's https://passwordless.id ...now "id" is quite an unusual ending (it's actually for Indonesia), but I thought it would fit well as a shortening of "identity" since that is what this upcoming app is about.
{% embed https://passwordless.id %}
What is this about? It's about providing a smoother and safer authentication to the masses. How? Using your fingerprint or face to register/login for instance. And of course, it's not sent to the server! If you want to try out and learn more about it, just go to the website, there is a really basic demo and explanations.
What's next?
------------
What I'm developing right now is a "public service" allowing anyone to register/login passwordlessly. It's really easy *and* more secure (for an in-depth explanation, check the website).
Roughly speaking, websites will redirect to https://passwordless.id if the person is not authenticated. Once authenticated, the user will be redirected back to the original website with access to the user's information.
The screenshots!
----------------
Now, please remember that this is all pre-alpha-in-development stuff. It might still change a lot.
The first page you see is the sign in/up form. Since biometric device based login is quite different than traditional password flows, an F.A.Q. section is directly added.
Once you click on it, you will be prompted for biometrics, unlock pattern or PIN code to verify it's you locally. This comes from the operating system, so this part will look different on Windows/Android/IPhones. In this case it's a sample from my Windows laptop with a German locale.
And once done, you will arrive at the profile page, which you can edit and save... once the e-mail confirmation link was clicked.
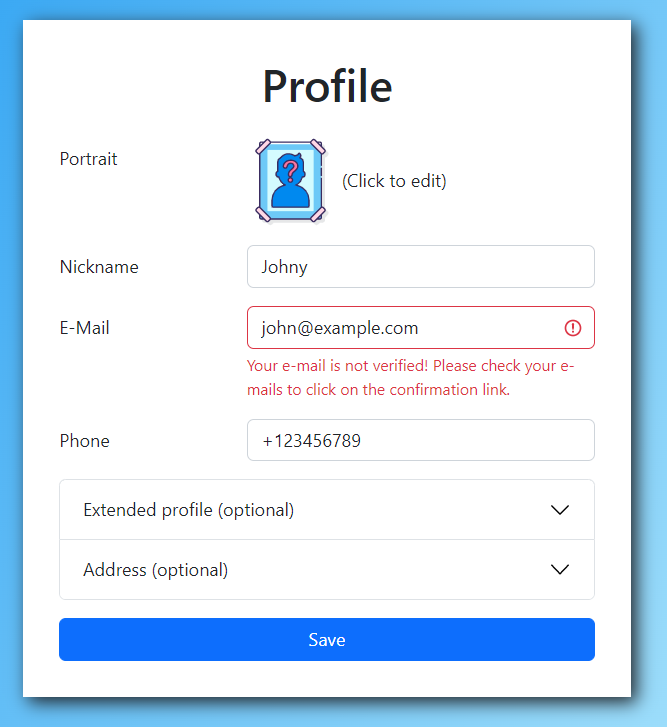
There, if you don't want to use your own portrait, you can also pick from a gallery!
And once you are done, come back to where you originally came from.

...Where you can access the profile and portrait with a simple "GET"!
Regarding the design and styling, I hesitated a lot... And still do! Should it be more "corporate"? More neutral? Even color agnostic? ... Or more unique, different, personal? Well, in the end, that's what I ended up with.
Even though I'm not yet completely convinced, and it might change in the future, it's "good enough" for now... I guess.
Why not simply use "Sign in with Google/Microsoft/Facebook..."?
---------------------------------------------------------------
That was actually a question posted in a [comment](https://dev.to/ravavyr/comment/21085) of my [previous article](https://dev.to/dagnelies/universal-passwordless-authentication-the-beginning-k2b). I was not able to properly respond at that time since it did not really fit as a comment but I will try my best now.
### Developer experience
Actually, I came from a developer POV. The whole OAuth2 thing required to make these authentications work is actually surprisingly complex and really annoying to implement. After all, OAuth2 was not meant for authentication, it is a protocol for authorizing access to APIs. This dancing around the OAuth2 protocol is one of the things that is typically underestimated by developers until they get actually try to use it. Things are now mature and there are a lot of helpful libraries, but the core complexity is still there to deal with.
What I want to offer in exchange is a super dead simple authentication mechanism that is intuitive and trivial for developers to use. A simple "GET" to get the user profile and a simple redirect if the user is not authenticated or requires approval.
### Security
From a user's perspective, the benefits are less obvious but still exist.
Since the protocol is based on secret keys stored on the physical device, you can be pretty sure it cannot be hacked/phished/scammed. There is no password to steal and you would have to steal the user's device to access its account.
Wait! What if I lose my device or want to access it from somewhere else? Well, you are still able to register new devices via phone, confirming it through another registered device, even plain e-mail if you judge safe enough, with or without additional security checks, etc. It is up to the user to chose its own protection level.
Of course, if the phone/computer belongs to someone else, you may also simply request a temporary session by similar means instead of authorizing the device itself.
### Privacy
You may not want Google, Microsoft, Facebook (etc) to know everything you are doing and all the websites you have signed in with them. They are known for their extensive tracking and some people dislike it.
Also, there is little room for "filtering" the information going out. For example, you may want them to know your nickname but not your firstname/lastname ...well, you cannot do that. Websites access your whole profile or nothing.
| dagnelies |
1,173,150 | Perks Of Learning Solidity ! | Unless you’ve been living under a rock for the past few years, then you’ll know that Web3 and... | 0 | 2022-08-22T08:17:42 | https://dev.to/aayush_giri/perks-of-learning-solidity--1jfm | blockchain, solidity, web3, webdev | Unless you’ve been living under a rock for the past few years, then you’ll know that Web3 and blockchain are being talked about as the future of the internet, Fintech, and more. Heck, **Web3** literally refers to the newest iteration of the internet or ‘Web 3.0’.
Why should we care?
Because being able to understand and work with the underlying **blockchain technology** that powers this change will reap huge rewards down the line, as well as being very lucrative even today.
We don't need to sell monkey pics 🙉 to make money from this technology.
With that in mind, you’ve probably already been looking at a few Web3 focused languages to learn, and one of the forerunners that I recommend is Solidity, an object-oriented, high-level programming language, built for the Ethereum blockchain platform.
Solidity is the perfect next step for Developers with experience in either Python or Javascript, but it’s also relatively easy enough to learn (when following a set training program) that even beginners can pick it up with no prior experience.
Sounds good right?
Well, it gets better!
Let me list some of the reasons why one should explore this technology.
**Reason #1️ To finally understand those blockchain/crypto/NFT memes!
**
- There’s multiple meta-level memeing happening here! learning Solidity will give you an understanding of blockchain, which is the core foundation of all Web3 technology
**Reason #2️ Solidity is the best introduction to the world of blockchain**
- The Solidity language itself is a high-level (similar to how people talk), so it’s not too complex and was specifically designed for working with blockchains. Fortunately, though, Solidity makes for the perfect entry into this world.
**Reason #3️. Learning Solidity will allow you to create Smart Contracts**
- Of course, the only direct reason to learn Solidity is so you can write smart contracts.
**Reason #4️. Solidity works with the Ethereum Virtual Machine, which is used everywhere! (Even with other independent and layer-2 chains)**
- The EVM or Ethereum Virtual Machine is the software platform developed by Ethereum, that allows Developers to create decentralized applications (DApps).
**Reason #5️. Solidity is the main programming language for DeFi (Decentralized Finance)**
- Solidity powers most DeFi applications, meaning that there is a heap of job opportunities for Solidity Developers in this field.
**Reason #6️. Blockchain Developers are in high job demand + very well paid !!**
- Just being a Software Engineer already puts you in high demand, but Solidity Developers are even rarer.In a recent survey it was found that the best programming languages to learn in 2022 is Solidity and was also the highest-paid language, starting at $112,000 and ramping up to $166,000 USD.
**Reason #7️. Remote work!**
- Decentralized, asynchronous work from any location and for high pay? Yes, please!
| aayush_giri |
1,173,277 | Unlocking the Lockbox2 | ParadigmCTF’22 | This weekend was fun, thanks to Paradigm for organising a great CTF again, that has very original and... | 0 | 2022-08-24T05:50:00 | https://dev.to/zemse/unlocking-the-lockbox2-paradigmctf22-10pn | This weekend was fun, thanks to [Paradigm](https://twitter.com/paradigm) for organising a great [CTF](https://twitter.com/paradigm_ctf) again, that has very original and really tough challenges. Got to learn a lot while attempting/solving some of them. This CTF sometimes reminds me of IITJEE exam (a not-for-noobs high school/10+2 level exam in India).
[Lockbox (the first)](https://github.com/paradigmxyz/paradigm-ctf-2021/tree/master/lockbox/public/contracts) was very interesting challenge. I attempted it last year during the CTF, found it very tough. This year’s challenge isn’t any less. From seeming like you can do it, then making you feel like it’s literally impossible, Lockbox kept the reputation with it's 2nd iteration.
The Lockbox2 challenge is available [here](https://github.com/zemse/lockbox2-rocks/tree/main/contracts). In this post, we'll understand the challenge and solve it (based on how I approached it during the CTF). I've posted links wherever necessary. As a heads up, this is a quite long post, it's intended for beginners/intermediates to be able to follow. For experts, feel free to skim through the post or directly skip to the final solution [here](https://github.com/zemse/lockbox2-rocks/blob/main/test/Lockbox2.ts).
I'd like to thank [@rileyholterhus](https://twitter.com/rileyholterhus), the Lockbox2 puzzle creator, to do a quick review of this post and provide valuable suggestions 🙏.
The Setup contract deploys a Lockbox2 contract, that contains a variable called `locked`, which is instantiated as `true`. The challenge requires this locked to be set as `false`. We can see that if get the `solve()` method to execute successfully, it’d set locked variable as `false`. But there are some preceding conditions which depend on input, which if not met, the `solve()` tx would fail. The challenge is all about crafting an input that passes the combination of conditions, similar to cracking [combination locks](https://en.wikipedia.org/wiki/Rotary_combination_lock)!

Crafting inputs and improving it sounds fun. However, interestingly, the solidity `solve()` method does not take any input!
```solidity
function solve() external {
```
If the solve method doesn't accept any input, how are we supposed to insert the crafted input?!

The thing here is, you can basically pass more calldata than needed, solidity does not really care about it (ik this is pretty obvious now, if I’d show this to myself of two years ago I'd have no clue).
So if we use the usual libs that rely on ABI, the generated calldata will be just the 4 bytes selector and we won’t be able to able to have them encode it for us. So we have to get our hands dirty and do it ourselves. Check out the Contract ABI Spec in the [Solidity docs](https://docs.soliditylang.org/en/latest/abi-spec.html).
First, we will go through the challenge just to get it’s overview and understand it. Then we can get started into crafting the calldata all together.
## Overview of solve method
The solve method makes 5 delegate calls to the self contract, to invoke the logic for those 5 stages.
It’s easily visible that calldata beyond the 4 bytes `msg.data[4:]` is passed to the particular stage method.
Here, delegatecall preserves the `msg.sender`. The intention could be to just add some friction for those who have not played enough with delegatecall. Or if not, we'll get to know shortly ;)
### Stage 1
Quite straight forward, the calldata must be under 500 bytes.
### Stage 2
Looks at first 4 words and expects them to either be a prime number or simply 1. Each of those 4 numbers should small enough (like up to 1000), so that the for-loop can iterate within tx gas limit.
### Stage 3
Looks at first 3 words as `a`, `b` and `c`. Makes a staticcall to `address(a + b)`. Note that from previous stage, the words are quite small numbers (~1000) and hence their sum would also be small. This means we can’t target this staticcall to a contract that we could practically deploy. This has to either be a precompile address or empty account.
If it is a precompile, then we have just a handful of [choices](https://github.com/ethereumjs/ethereumjs-monorepo/blob/master/packages/evm/src/precompiles/index.ts).
A staticcall to empty account would be successful and return empty data (you can verify this by doing a simple eth_call to random address, it won’t give json rpc error response).
Btw, this one has an interesting `mstore(a, b)` over there. This logic basically stores value `b` at memory location `a`. By initial thought, memory location cannot be very huge and maybe it just want's to restrict `a` to be sufficiently small, but isn't that implied from stage2? Can't make sense of it so far, let's move on for now.
### Stage 4
Things get nasty here since now it involves dynamic types. It is important to understand how solidity handles dynamic types, specifically bytes in calldata for this case. Check out dynamic types section in the Contract ABI spec [here](https://docs.soliditylang.org/en/latest/abi-spec.html#use-of-dynamic-types).
For simplicity, let’s ignore previous stages, just look at this in order to understand what this stage needs in order to pass through.
The gist of the conditions:
1. It takes two byte strings, `a` and `b`.
2. Deploys a contract using `a` as the creation code. The bytecode should be a ECDSA public key (length 64) of the `tx.origin` (the EOA wallet that we will use to interact). Note that ECDSA of ecdsa public key gives ethereum address (after chopping of the upper 12 bytes).
3. Makes a staticcall to the contract just deployed, using `b` as the calldata, this call should be successful.
We can easily deploy a contract containing any code we want. Here, we want to have the `tx.origin`’s public key as the bytecode. So one thing is we should fix a EOA wallet. And then the challenge is getting the static call to succeed. Easiest approach I could think of is having first byte as zero (STOP opcode), so that it halts execution and staticcall passes.
If you notice, this does not involve `b` at all. So basically `b` taking any value can work, which is one less headache.
Making this stage pass individually is straight forward. It will be challenging to make combination of all stages pass.
### Stage 5
It internally makes a msg call to solve function which should fail somehow. Though there’s a difference of `msg.sender` in both `solve()` invocation, `msg.sender` is really not consumed anywhere to make a difference. At first it might seem strange, how it is possible for one thing to work first and then not work in the same env conditions?
The key to this stage, is the fact that in a CALL only 63/64 of the available gas is passed (source [evm.codes](https://www.evm.codes)). If we pass just enough gas limit, slightly less gas would be passed such that internal message call fails due to out of gas, passing the check in stage 5. Also it is important to note that 1/64 gas should be enough to perform later operations, else it will not work. It also makes sense why there's `locked` variable is set to `false`, instead of having a `solved` variable which is set to `true` like in other challenges, since it'd cost less gas.
## Solving the challenge
### Step 1 - Solve Stage 4
I started from this stage because it has the most complex calldata, and getting other stage passed could look like minor tweaking in the calldata (this is what I expected, I believe it was a right decision).
In stage4, we need to write a bytecode that returns public key which has first byte as zero.
Okay, but for that we need a public key, and for that we need a wallet/private key in order to be the tx.origin.
I’ll just use ethers.js in my terminal (using [ethers-repl](https://github.com/zemse/ethers-repl)) to get a wallet real quick. You can use anything which gets the job done.
```ts
sohamzemse@MacBook-Pro % ethers
ethers-repl> while((w = ethers.Wallet.createRandom()).publicKey.slice(4,6) !== '00') {}
undefined
ethers-repl> w.privateKey
'0x9b067b56552d3369e7762f0f92051db20a2db034e8e9fc803a71e64ae5b163b4'
ethers-repl> w.publicKey
'0x0400a86410b6215c11e36c6a60d02277415f69393b692b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a68452a4311cc7238d7431fa'
```
Note that the public key here has a `0x04` prefix byte, which is to signify that this is an uncompressed ECDSA public key. The actual public key follows after the prefix byte.
Now we need a code that creates contract with the public key as the bytecode. It's pretty opinionated, you can use solidity/yul/vyper/huff/etk/whatever. I happen to be an evm nerd and I was in a hurry, so couldn't stop myself from writing down the following raw evm code.
```assembly
$ vim lockbox_stage4.evm
=========lockbox_stage4.evm========================
push1 0x40 // 64 bytes
dup1
push1 0xb // offset in this code
push1 0 // offset in memory
codecopy
push1 0
return
// public key
00a86410b6215c11e36c6a60d02277415f69393b692b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a68452a4311cc7238d7431fa
===================================================
$ evm-run lockbox_stage4.evm
code 604080600B6000396000f300A86410B6215C11E36C6A60D02277415F69393B692B6799805EE75969DF78D25398733FC3E0438BBCBB9E37FA1FF5DA79660324A68452A4311CC7238D7431FA
Returned: 00a86410b6215c11e36c6a60d02277415f69393b692b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a68452a4311cc7238d7431fa
gasUsed: 30
```
I'm using [evm-run](https://github.com/zemse/evm-run) for assembling + running evm code. (Sidenote: you can checkout [ETK](https://github.com/quilt/etk) which helps with labels as well).
We can see that the bytecode on execution spits out the public key in the returndata (so that it becomes the contract bytecode). Okay, so we got the code that should be passed as to the first input `a`. And in case of `b` we can pass anything, we can just use empty bytes for now i.e. `0x`.
Now it's time to encode the calldata that should work with stage4. Notice that ethers.js strictly requires `"0x"` prefix, so we have to add that at the start of the bytecode.
```ts
ethers-repl> encoded = defaultAbiCoder.encode(['bytes', 'bytes'], ['0x604080600B6000396000f300A86410B6215C11E36C6A60D02277415F69393B692B6799805EE75969DF78D25398733FC3E0438BBCBB9E37FA1FF5DA79660324A68452A4311CC7238D7431FA', '0x'])
'0x000000000000000000000000000000000000000000000000000000000000004000000000000000000000000000000000000000000000000000000000000000c0000000000000000000000000000000000000000000000000000000000000004b604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b692b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a68452a4311cc7238d7431fa0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000'
ethers-repl>
ethers-repl> wordify(encoded)
[
'0000000000000000000000000000000000000000000000000000000000000040',
'00000000000000000000000000000000000000000000000000000000000000c0',
'000000000000000000000000000000000000000000000000000000000000004b',
'604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69',
'2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6',
'8452a4311cc7238d7431fa000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000'
]
ethers-repl>
ethers-repl> selector('solve()')
'0x890d6908'
```
Putting all of this together, I'm locally using hardhat:
```ts
// use the private key we generated earlier (for public key to have first byte zero)
const wallet = new Wallet('0x9b067b56552d3369e7762f0f92051db20a2db034e8e9fc803a71e64ae5b163b4', hre.ethers.provider);
// fund this wallet with some eth to pay for tx fees
const hardhatAccount0 = (await hre.ethers.getSigners())[0];
await hardhatAccount0.sendTransaction({
to: wallet.address,
value: parseEther("1"),
});
// we are not using the usual abi encoding tools, because this challenge involves manipulating the calldata to make the all stages passed
await wallet.sendTransaction({
to: contract.address,
gasLimit: 29_000_000, // pass some huge gas limit, bcz estimate has some issues
data: '0x890d6908' + // 4 byte selector for solve() method
[
'0000000000000000000000000000000000000000000000000000000000000040',
'00000000000000000000000000000000000000000000000000000000000000c0',
'000000000000000000000000000000000000000000000000000000000000004b',
'604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69',
'2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6',
'8452a4311cc7238d7431fa000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000'
].join('')
});
```
Now execute the tx, and you should see stage4 pass. I’m using Hardhat framework to view the execution trace, using the [hardhat-tracer](https://github.com/zemse/hardhat-tracer) plugin. (Sidenote: A great alternative is using [Foundry](https://github.com/foundry-rs/foundry) and it also has tracing built-in).
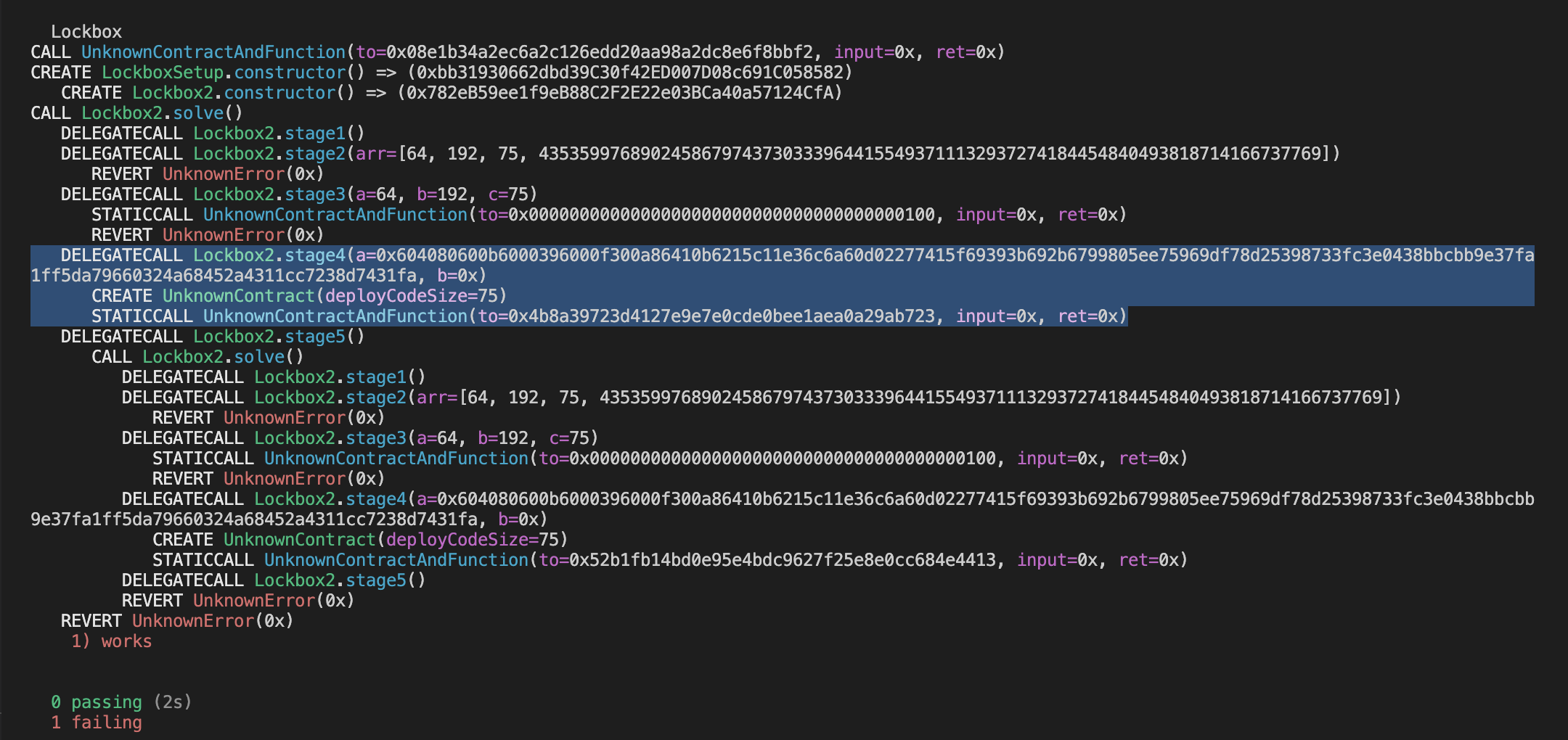
The stage4 is highlighted in the screenshot above, you can see that rest of the stages fail with empty revert data as `UnknownError`, while there is no error in case of stage4.
Stage4 done, now lets get others!
## Step 2 - Solve Stage 2
The actual condition in the code first checks if the value is greater than or equal to one and then goes into a for-loop that requires `word % j != 0` for all `2 <= j < word`. This step basically translates to the requirement of the first 4 words to be a prime number or 1 and the number cannot be huge, otherwise the for loop will go out of gas.
Okay, lets look at our calldata:
```ts
"0x890d6908" + // 4 byte selector for solve() method
[
"0000000000000000000000000000000000000000000000000000000000000040", // arr[0]
"00000000000000000000000000000000000000000000000000000000000000c0", // arr[1]
"000000000000000000000000000000000000000000000000000000000000004b", // arr[2]
"604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69", // arr[3]
"2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6",
"8452a4311cc7238d7431fa000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
].join(""),
```
We can clearly see that arr[3] is huge. Also note that the first three words are not prime numbers either. We need to fix this.
Let’s see how dynamic types are encoded in the case of `(bytes a, bytes b)`. The first word contains the location where content of `a` starts. And second word contains the location where content of `b` starts. This means we can move the content of `a` anywhere we want.
One easy idea is to simply move the data bit forward, by two words, in order to have arr[3] to take a value that’s within iterative limits as well as making arr[2] and arr[3] independent of the byte strings. So basically we can put any kind of stuff we want over there, the contract be won’t bothered about it at all.
```ts
"0x890d6908" + // 4 byte selector for solve() method
[
"0000000000000000000000000000000000000000000000000000000000000080", // arr[0], changed from 0x40 to 0x80 (+0x40)
"0000000000000000000000000000000000000000000000000000000000000100", // arr[1], changed from 0xc0 to 0x100 (+0x40)
"0000000000000000000000000000000000000000000000000000000000000001", // arr[2] (just inserted)
"0000000000000000000000000000000000000000000000000000000000000001", // arr[3] (just inserted)
"000000000000000000000000000000000000000000000000000000000000004b",
"604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69",
"2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6",
"8452a4311cc7238d7431fa000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
].join(""),
```
We have inserted two words just after the first two words. We can put anything there, but having `1` in there, simply works for now.
Also we need the first two words to be a prime number. So the first two words are `0x80` (128) and `0x100` (256). Let's see some prime numbers just after them (so we can push them bit further). We know 131 and 257 are primes.
```ts
"0x890d6908" + // 4 byte selector for solve() method
[
"0000000000000000000000000000000000000000000000000000000000000083", // arr[0], changed from 0x80 to 0x83 (+0x03)
"0000000000000000000000000000000000000000000000000000000000000101", // arr[1], changed from 0x100 to 0x101 (+0x01)
"0000000000000000000000000000000000000000000000000000000000000001", // arr[2]
"0000000000000000000000000000000000000000000000000000000000000001", // arr[3]
"000000", // a is moved further by 3 bytes
"000000000000000000000000000000000000000000000000000000000000004b",
"604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69",
"2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6",
"8452a4311cc7238d7431fa000000000000000000000000000000000000000000",
"00", // b is moved further by 1 byte
"0000000000000000000000000000000000000000000000000000000000000000",
].join(""),
```
Now with this, we can see Stage2 passes! Following is a screenshot of trace generated on hardhat using hardhat-tracer, and the delegate call to stage2 is highlighted for visibility, we can see it does not revert.
Ah, finally stage2 passed! Actually, we've done a lot so far. Pads on the back!
## Step 3 - Solve Stage3
Here, a static call is made to `a + b`, which in our case currently it's `0x83 + 0x101 = 0x184`. That's definitely not a precompile address atm, can be checked by making an eth_call.
If it's not a precompile, then the static call would still success, however result would be empty data. And this stage requires that the third word should equal to the length of the return data.
The third word can be anything only that stage2 restricts the third word to a non-zero value (1 or prime). It means there should be some return data. But how? We definitely cannot deploy a contract at an address with so many zeros! So it means the `a + b` needs to be a precompile for this to work.
I couldn't find an up-to-date list of precompiles, had to look into client implementations. Here is the list in [EthereumJS/EVM](https://github.com/ethereumjs/ethereumjs-monorepo/blob/ffe3402a69e04f48654f13127becf86a8a46485a/packages/evm/src/precompiles/index.ts). We can clearly see precompiles are only upto 0x12. Also the return data length should be a prime number, when called with empty data. We can just try this using `eth_call`. For that, I'm quickly jumping into ethers-repl on my terminal.
```ts
$ ethers
ethers-repl> await mainnet.call({to: '0x0000000000000000000000000000000000000012', data: '0x'})
// {"jsonrpc":"2.0","id":44,"error":{"code":-32602,"message":"invalid 1st argument: transaction 'data': value was too short"}}
```
Couldn't really find any precompile that works with empty calldata and gives a return data with prime length. It means we cannot use a precompile. After playing around a bit, it was fairly convincing that forget prime length return data, there is no way this static call could return a non-zero length return data.
But wait, didn't we just eliminated all the possibilities? Is this challenge even solvable?
_\*Looks at the scoreboard, single integer number of people have solved it\*_
Okay, means definitely there's some advanced stuff going on here and something is missing in my observations.
Oh! could it be related to that weird `mstore(a, b)` which I believed it was there for no reason. Hmm, after a careful observation, I could see that we do not need to have the static call return a data with prime length, the check is `data.length == c`, where `data.length` is taken from memory. So we have to use the `mstore(a, b)` to write at a location and manipulate the value of `data.length`. To know where in the memory `data.length` is, I'm just using hardhat-tracer to print MLOAD operations.
```sh
$ npx hardhat test --trace --opcodes MLOAD
```

Here, we can see after the static call to the `0x00..184` address, there is an MLOAD at location 0x60 for reading `data.length`. Memory location 0x60 is a special one because it always points to zero, it's used as the initial value for dynamic memory arrays when they are empty ([source](https://docs.soliditylang.org/en/latest/internals/layout_in_memory.html#layout-in-memory)).
Note that `mstore(a, b)` is done before the declaration of `bytes memory data`. And since the return data is empty, solidity uses 0x60 as the location for the `data` variable. Solidity docs mention that this memory slot should not be written to, since it'd cause empty arrays to assume non-zero length. This helps us!
Now comes another tricky part, we have to figure out how to rearrange our calldata. I'm reverting our calldata changes back to step3 initial, and then moving it further by one word (instead of two words as we previously did). We have to do this because the `mstore(a, b)` writes at memory slot `a`, and we want it to be `0x60`.
```ts
"0x890d6908" + // 4 byte selector for solve() method
[
"0000000000000000000000000000000000000000000000000000000000000060", // 0x40 to 0x60
"00000000000000000000000000000000000000000000000000000000000000e0", // 0xc0 to 0xe0
"0000000000000000000000000000000000000000000000000000000000000000", // inserted here
"000000000000000000000000000000000000000000000000000000000000004b",
"604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69",
"2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6",
"8452a4311cc7238d7431fa000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
].join(""),
```
Okay, but what about previous stage where these first 4 words need to be primes? We might slightly change them. We know that 0x61 and 0xe3 is a prime. So let's change the first two words to ensure they are prime. That will require shifting the content of towards right by one byte.
```ts
"0x890d6908" + // 4 byte selector for solve() method
[
"0000000000000000000000000000000000000000000000000000000000000061", // 0x60 to 0x61
"00000000000000000000000000000000000000000000000000000000000000e3", // 0xe0 to 0xe3
"0000000000000000000000000000000000000000000000000000000000000001", // keeping this 1
"00000000000000000000000000000000000000000000000000000000000000004b", // one byte extra here
"604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69",
"2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6",
"8452a4311cc7238d7431fa000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000000000", // three bytes extra here
].join(""),
```
However, you can see that 4th word is zero. Previously it was length of the byte string `a` in stage4. Since the length was under 1 byte, the 4th word became zero. Just to recall, byte string `a` is the creation code of a contract that gets deployed in stage4. Is there a way we can increase the length, by adding some redundant code without affecting behaviour?
Turns out that the answer is yes, we can! This is the evm code we previously used. The current code length is 0x4b, and we want it to exceed 0x100, so that the "1" gets in the 4th word.
```ts
ethers-repl> wordify('00'.repeat(0x100 - 0x4b))
[
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'000000000000000000000000000000000000000000'
]
```
We can just put the above zeros after our bytecode
```
push1 0x40 // 64 bytes
dup1
push1 0xb // offset in this code
push1 0 // offset in memory
codecopy
push1 0
return
// public key
00a86410b6215c11e36c6a60d02277415f69393b692b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a68452a4311cc7238d7431fa
// add any code after this, it is not used
// redundant code which makes bytecode length 0x100
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000
===================================================
$ evm-run lockbox_stage4.evm
code 604080600B6000396000f300A86410B6215C11E36C6A60D02277415F69393B692B6799805EE75969DF78D25398733FC3E0438BBCBB9E37FA1FF5DA79660324A68452A4311CC7238D7431FA00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
Returned: 00a86410b6215c11e36c6a60d02277415f69393b692b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a68452a4311cc7238d7431fa
```
Now we have to repeat the steps.
```ts
ethers-repl> bytecode = '604080600B......00000000' // paste here
ethers-repl> hexDataLength(bytecode)
256 // this is 0x100
ethers-repl> encoded = defaultAbiCoder.encode(['bytes', 'bytes'], [bytecode, '0x'])
ethers-repl> wordify(encoded)
[
'0000000000000000000000000000000000000000000000000000000000000040',
'0000000000000000000000000000000000000000000000000000000000000160',
'0000000000000000000000000000000000000000000000000000000000000100',
'604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69',
'2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6',
'8452a4311cc7238d7431fa000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000',
'0000000000000000000000000000000000000000000000000000000000000000'
]
```
We have to now repeat the steps similar to previous. I'll just paste the updated calldata.
```ts
"0x890d6908" + // 4 byte selector for solve() method
[
"0000000000000000000000000000000000000000000000000000000000000061", // 0x60 to 0x61
"0000000000000000000000000000000000000000000000000000000000000161", // 0x160 to 0x161
"0000000000000000000000000000000000000000000000000000000000000001", // keeping this 1
"000000000000000000000000000000000000000000000000000000000000000100", // one byte extra here
"604080600b6000396000f300a86410b6215c11e36c6a60d02277415f69393b69",
"2b6799805ee75969df78d25398733fc3e0438bbcbb9e37fa1ff5da79660324a6",
"8452a4311cc7238d7431fa000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
"0000000000000000000000000000000000000000000000000000000000000000",
].join(""),
```
Note that here, 0x161 is written to memory location 0x61, which basically writes 1 to the 0x60 word (data.length memory slot), the rest 61 is written to next slot and it does not matter.
Now we've got stage1, stage2, stage3, stage4 passing, only stage5 is failing.
## Step 5 - Solve Stage 5
This stage makes a call to the solve() method again, and in the trace above, we can see everything passes but only the stage5 check, which wants the solve() invocation from stage5 to fail.
It's based on the fact that when an execution context makes a CALL, it can at max give 63/64 of the gas available. We have to carefully pass a value of `gasLimit` such that when 63/64 of the gas available is passed to the solve() internal message call, it's not enough for it and it goes out of gas. That only fails the internal msg call, and 1/64 gas is available for the stage5's execution context to proceed. After trying for some values, I found `560_000` to be just enough to work.
Yay! The challenge is solved!
Se* is cool but have you ever tried catching a flag :P

Stay tuned to [@paradigm_ctf](https://twitter.com/paradigm_ctf) for the future editions. Hopefully, we’ll see Lockbox3!
Also, if you made this far, thanks! Btw I’m Soham, and I mostly do open-source contributions to some ethereum dev tools. As a disclosure: hardhat-tracer, evm-run, ethers-repl mentioned above are some of my github projects. Oh yeah, also I'm attending my first Devcon this year as a Devcon Scholar, would love to meet if you are coming too! Looking forward to buidl more stuff. My social links: [github](https://github.com/zemse), [twitter](https://twitter.com/0xZemse). | zemse | |
1,173,355 | Overview of Stripe Treasury | What you’ll learn In this livestream, we'll walk through an example Stripe Treasury... | 0 | 2022-08-22T13:06:00 | https://dev.to/stripe/overview-of-stripe-treasury-1jc2 | payments, baas, stripe | {% youtube https://youtu.be/2MiMFJ9c4t8& %}
## What you’ll learn
In this livestream, we'll walk through an [example Stripe Treasury application](https://github.com/stripe-samples/treasury-nextjs) that shows how to work with Financial Accounts, Balances, and moving money.
## Who this video is for
This video guide is primarily for developers interested in embedded finance, banking as a service, or Stripe Treasury.
## How to follow along
If you want to work alongside the video, you’ll need a [Stripe account](https://dashboard.stripe.com/register) and a Node environment to work in.
## Resources
- [Treasury documentation](https://stripe.com/docs/treasury)
- [Code for the demo](https://github.com/stripe-samples/treasury-nextjs)
## Stay connected
**You can stay up to date with Stripe** **Developer updates** **in a few ways:**
- 📣Follow [@StripeDev](https://twitter.com/stripedev) and [our team](https://twitter.com/i/lists/1459720002567868418) on [Twitter](https://twitter.com/StripeDev)
- 📺 Subscribe to our [Youtube channel](https://www.youtube.com/StripeDevelopers)
- 💬 Join the official [Discord server](https://discord.com/invite/RuJnSBXrQn)
- 📧 Sign up for the [Dev Digest](https://go.stripe.global/dev-digest)
| cjav_dev |
1,173,863 | Create Simple Personal Finance App by AppSheet | I will show its change in a few later posts when more data goes in and after fine-tuning the user... | 0 | 2022-08-23T01:33:00 | https://dev.to/e78783/create-simple-personal-finance-app-by-appsheet-4jh9 | lowcode, googleappsheet | I will show its change in a few later posts when more data goes in and after fine-tuning the user interface.

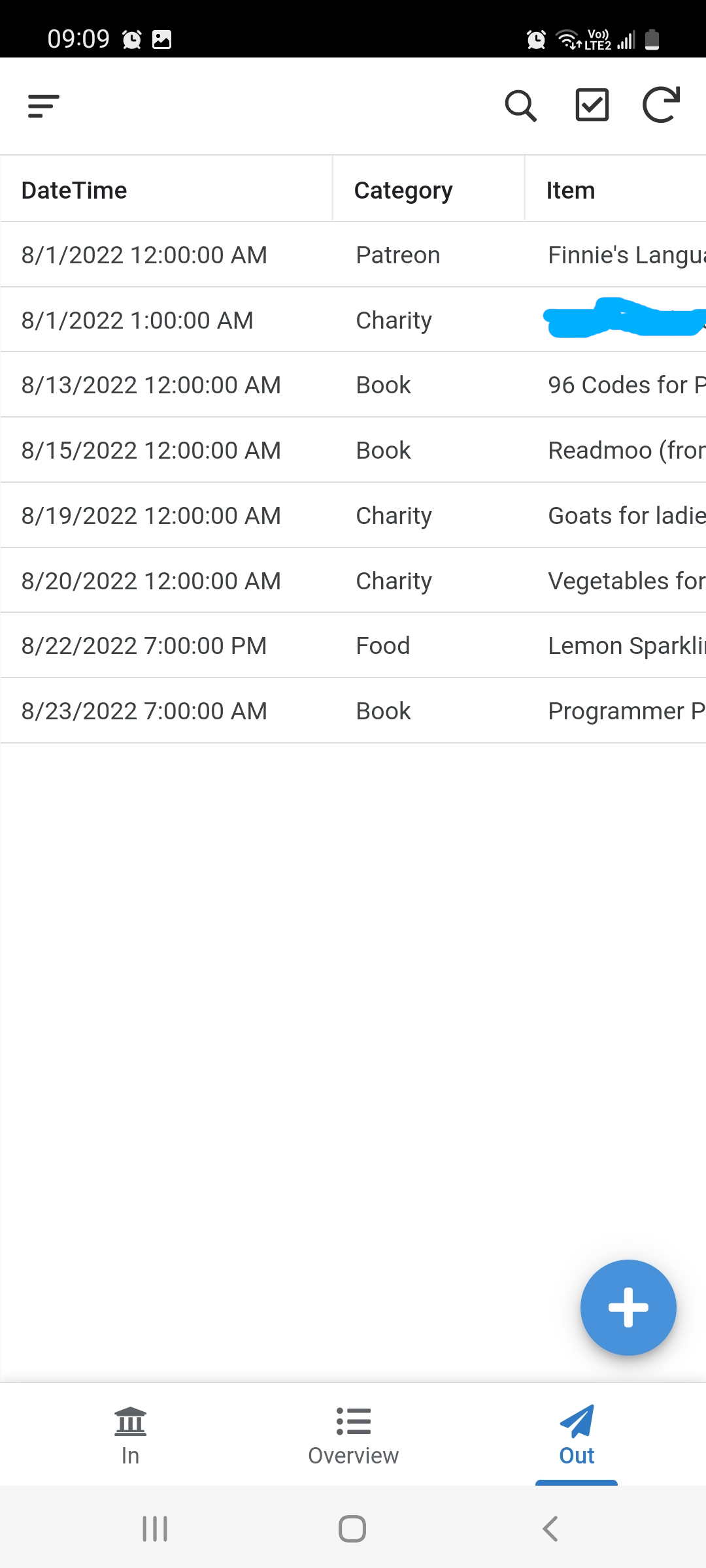
 | e78783 |
1,173,919 | How to Extend and Manage Google Drive with Google Apps Script? | Let's extend Google Drive with Apps Script to create a simple add-on, use CardService for the UI,... | 19,218 | 2022-08-23T09:07:00 | https://kcl.hashnode.dev/managing-google-drive-with-google-apps-script | googleappsscript, javascript, gsutie | Let's extend Google Drive with Apps Script to create a simple add-on, use CardService for the UI, where we'll select a few spreadsheets and pass them to the next card with navigation. You can find my other blogs on Google Apps Scripts right [here](https://kcl.hashnode.dev/series/google-apps-script).
## Intro
Hi, This is Nibes Khadka, from Khadka's Coding Lounge. I wrote this blog because I personally find the documentation overwhelming for beginners. It is also very hard to find blogs on google apps scripts. So, hence this beginner-level blog was created to get you started. I believe this blog will give you almost 20% you'll need to finish almost 80% of your projects.
## Pre-Requisite
You'll need knowledge of JavaScript and Access to google drive. I am using apps script ide but if you want to develop in the local environment you'll find this [set-up](https://kcl.hashnode.dev/how-to-write-google-apps-script-code-locally) guide helpful.
## Settings
Head over to [dashboard](https://script.google.com/), and create a new script file for the project. After that, we'll need to prep our projects as instructed below.
### HomePages
According to the [documentation](https://developers.google.com/apps-script/add-ons/drive), there're two types of homepages when you're developing add-ons for drive: __Contextual__ and __Non-Contextual__.
Non-Contextual is an initial display when there's nothing happening like the first screen to show after the add-on is clicked. Contextual is the home page/display that shows up once we perform a specific action like selecting files in the drive.
For the apps scripts functions to get called in the drive, we'll need to assign those functions to the appropriate triggers for drive add-on in the manifest(__appsscript.json__) file.
#### Homepage Triggers
When a user clicks on the add-on icon, [drive.homepageTrigger](https://developers.google.com/apps-script/manifest/drive-addons#Drive.FIELDS.homepageTrigger) method is called upon. This method then looks for a function then calls the specified function in the manifest(appsscript.json) for further operations.
#### Item Selected Trigger
For contextual triggers, we'll assign the function in our apps script to [drive.onItemSelectedTrigger](https://developers.google.com/apps-script/manifest/drive-addons#Drive.FIELDS.onItemsSelectedTrigger) in the manifest file.
### Oauth Scopes
For the drive add-on to work the user must grant access permission. The list of permissions is known as [Scopes](https://developers.google.com/apps-script/add-ons/concepts/workspace-scopes). Details on drive-specific scopes can be found [here](https://developers.google.com/apps-script/add-ons/concepts/workspace-scopes#drive_scopes). We'll need to provide the scopes in the __appsscript.json__ file again as a list with "oauthScopes".
*Note: If your appsscript.json file is hidden then go to settings, then check the __Show "appsscript.json" manifest file in editor__ checkbox.*
Check out the manifest file for this project below.
```
{
"timeZone": "Asia/Kathmandu",
"exceptionLogging": "STACKDRIVER",
"runtimeVersion": "V8"
"oauthScopes": [
"https://www.googleapis.com/auth/spreadsheets",
"https://www.googleapis.com/auth/script.storage",
"https://www.googleapis.com/auth/drive",
"https://www.googleapis.com/auth/drive.file",
"https://www.googleapis.com/auth/drive.addons.metadata.readonly"
],
"addOns": {
"common": {
"name": "Drive Extension with Apps Script",
"logoUrl": "provide image URL to be used as logo",
"layoutProperties": {
"primaryColor": "#41f470",
"secondaryColor": "#ab2699"
}
},
"drive": {
"homepageTrigger": {
"runFunction": "onDriveHomePageOpen",
"enabled": true
},
"onItemsSelectedTrigger": {
"runFunction": "onDriveItemsSelected"
}
}
}
}
```
## Using Apps Script to Access Google Drive
Now, on the root project folder create two files, __cards__ and __main__.
### Assigning Apps Scripts Functions to Triggers
__main__
```
// On homepage trigger function
let onDriveHomePageOpen = () => homepageCard();
// On Item selected Trigger function
let onDriveItemsSelected = (e) => itemSelectedCard(e);
```
The __onDriveHomePageOpen__ and __onDriveItemsSelected__ are two functions we assigned in the manifest file earlier on. These functions are in turn calling other functions which we'll create in a while. If you get an error pop up on saving the file, dismiss it for now.
### Designing Behaviour of Cards
Let's create a simple homepage card to be assigned to our non-contextual trigger on the __cards__ file.
#### Create Homepage Card
```
let homepageCard = () => {
// Create a card with a header section
let card = CardService.newCardBuilder().setHeader(CardService.newCardHeader());
// create card section
let section = CardService.newCardSection();
// add heading
let decoratedText = CardService.newDecoratedText()
.setText("Select Files To Update");
// add text as a widget to the card section
section.addWidget(decoratedText);
// add the section to the card
card.addSection(section);
// return card as build
return card.build();
}
```
[Cards](https://developers.google.com/apps-script/add-ons/concepts/cards) can be used to [create UI](https://developers.google.com/apps-script/reference/card-service/card) for the add-ons for google drive.
*This is a beginners blog so I am not focused on styling.*
#### Create Non-Contextual Card
Now, let's have another card that we'll be responsible for the contextual trigger on the same file. But let's divide this code into sections to understand clearly.
##### 1. Create a simple card UI.
```
let itemSelectedCard = (e) => {
// Initial UI
let card = CardService.newCardBuilder().setHeader(CardService.newCardHeader().setTitle("Select Sheets Update Master Sheet"));
let filesSection = CardService.newCardSection()
filesSection.setHeader("Selected Files");
return card.build();
}
```
##### 2. Display Selected files in UI.
```
var itemSelectedCard = (e) => {
// Initial UI
let card = CardService.newCardBuilder().setHeader(CardService.newCardHeader().setTitle("Select Sheets Update Master Sheet"));
let filesSection = CardService.newCardSection()
filesSection.setHeader("Selected Files");
// New Code starts here
// # 1
// Create new array to hold selected files data
let selectedSheets = [];
// #2
// Fetch selected files data from drive through event objects
if (e.drive.selectedItems.length > 0) {
// Selected spreadsheets
// #3
// Among the selected items we'll be selecting only spreadsheets and push them to selected sheets
e.drive.selectedItems.forEach(item => {
if (item.mimeType === "application/vnd.google-apps.spreadsheet")
selectedSheets.push(item)
}
);
}
// Create a counter to count the number of widgets added
// #4
// COunter is required to prevent error when pushing the file names into UI incase array is empty
let widgetCounter = 0;
for (let i = 0; i < selectedSheets.length; i++) {
// #5
// Create decorated text with selected files and
// add the decorated text to the card section
filesSection.addWidget(CardService.newDecoratedText()
//.setText(selectedSheets[i].title)
.setText(e.drive.selectedItems[0].title)
);
// Increase widget counter per loop
// #4
widgetCounter += 1;
}
// #6
// Add files as widgets only if widgetCounter is 1+
// It prevent error in case only non-spreadsheet files are selected
if (widgetCounter >= 1) {
card.addSection(filesSection)
}
// Create Another card that has files list
return card.build();
}
```
Here(see the code for numbering like #1),
1. Created an array to hold data on selected items.
2. Used [drive event object](https://developers.google.com/apps-script/add-ons/concepts/event-objects#drive_event_object) to fetch data on selected files.
3. Among the selected items we filtered only spreadsheets using [mimeType](https://developers.google.com/drive/api/guides/mime-types).
4. We created a counter to use as a condition while adding the files as widgets in the card to prevent errors.
5. Created a [decorated text](https://developers.google.com/apps-script/reference/card-service/decorated-text) a [widget](https://developers.google.com/apps-script/add-ons/concepts/widgets#informational_widgets), which will hold the file names of each file.
6. Now finally added the whole files section to the card builder.
##### Generate Actions With Button
In Card, interactivity is possible using [actions](https://developers.google.com/apps-script/add-ons/concepts/actions). Also, check out this [sample code](https://developers.google.com/apps-script/add-ons/drive/drive-actions). Don't forget to add the scope given there, to drive the scope in your manifest file.
Let's add buttons below the files section. This button will collect selected files and pass them to another card which we'll build later on. To less complicate things, I'll break down code into smaller sections.
###### 1. Create Button Ui with Action
```
let nxtButtonSection = CardService.newCardSection();
let nxtButtonAction = CardService.newAction()
.setFunctionName("handleNextButtonClick");
```
You've noticed that __handleNextButtonClick__ has been assigned as the function to be triggered on button click. It will handle the navigation, and points toward the next card. We'll create this function it later on.
###### 2. Assign Parameters to be passed.
```
// We'll pass only pass ids of files to the next card so that we can fetch them there with id
// #1
let selectedSheetsIDAsStr = selectedSheets.map(item => item.id).join();
// pass the values as params
// #2
nxtButtonAction.setParameters({
"nextCard": "nextCard",
"selectedSheetsIDAsStr": selectedSheetsIDAsStr,
});
// add button to the button set
// #3
let nxtButton = CardService.newTextButton().setText("Next").setOnClickAction(nxtButtonAction);
let nxtButtonSet = CardService.newButtonSet().addButton(nxtButton);
```
In card, parameters need to be passed via action with [setParameters](https://developers.google.com/apps-script/reference/card-service/action?hl=en#setparametersparameters) method as objects(#2). __It's important to remember that both keys and values should be string__(hence #1). Buttons can be added as a [button set](https://developers.google.com/apps-script/reference/card-service/button-set) in the card(#3).
You've noticed that __nextCard__ has been assigned as a parameter. That's because the function handleNextButtonClick is a general function that takes the name of the card as a parameter instead of hardcoding. This way it will be more efficient in the long run.
###### Add Button To Card
```
// It prevent error in case only non-spreadsheet files are selected
if (widgetCounter >= 1) {
card.addSection(filesSection)
// new line
nxtButtonSection.addWidget(nxtButtonSet);
card.addSection(nxtButtonSection);
}
```
### Card Navigation
From what I understood [card navigation](https://developers.google.com/apps-script/add-ons/how-tos/navigation), in short, takes a list of cards as a stack. New card to navigate to is added to the top of the stack, whereas popped from the stack to return to the previous one.
Let's create a new file, I'll name it __helpers__, add the following instructions.
__helpers__
```
/* This is a greneral nav function
You use it with card action and as a response, it will supply card functions from cardsInventory */
let handleNextButtonClick = (e) => {
// #1
// Extract string nextCard to pass it as key in cards inventory obj
let nxtCard = cardsInventory[e.commonEventObject.parameters.nextCard];
// #2
// Convert String into List of files selected by the user
let selectFilesIdList = e.commonEventObject.parameters['selectedSheetsIDAsStr'].split(",");
// #3
// use actionResponse to create a navigation route to the next card
let nxtActionResponse = CardService.newActionResponseBuilder()
.setNavigation(CardService.newNavigation().pushCard(nxtCard(selectFilesIdList))) // #4, Passing the mastersheet with params
.setStateChanged(true)
.build();
return nxtActionResponse;
}
/**
* Create a dictionary that
is consist of cards for navigation with appropriate keys
*/
var cardsInventory = {
'nextCard': nextCard
}
```
Let's first talk about the __cardsInventory__ object. If you remember we passed the parameter __nextCard__ previously as a string in __itemSelectedCard__ function. This nextCard is the function we'll create next. But the thing is you can't pass a string and use it to reference a variable(check #1 in code). So, we're creating a dictionary that'll match appropriate keys with functions for navigation.
Inside handleNextButtonClick function:
1. Extract the string which is key to the cardInventory object to fetch the correct card to call. We're using [Events Comment Object](https://developers.google.com/apps-script/add-ons/concepts/event-objects#common_event_object) to extract parameters passed on earlier.
2. Strings that was passed as selected files id's, we're again converting it to the array.
3. [NewActionResponseBuilder, SetNavigation, NewNavigation, and PushCard](https://developers.google.com/apps-script/reference/card-service/action-response) combined are used to set a new [path](https://developers.google.com/apps-script/add-ons/how-tos/navigation#navigation_methods) to the card of our choosing.
4. Here, we're passing a list of ids as params.
#### Next Card To Navigate
We'll create a very simple card just enough to display the list of IDs, to let us know our code is working.
First, let's create a new file __next_card__.
```
var nextCard = function (lst) {
let cardService = CardService.newCardBuilder().setHeader(CardService.newCardHeader().setTitle("Select Master Sheet To Update"));
let filesSection = CardService.newCardSection();
filesSection.setHeader("Selected Files");
let widgetCounter = 0;
let selectedFilesList = [...lst];
selectedFilesList.forEach(id => {
filesSection.addWidget(CardService.newDecoratedText()
.setText(id));
widgetCounter += 1;
});
if (widgetCounter >= 1) {
cardService.addSection(filesSection);
}
return cardService.build();
}
```
The only thing new to notice here is that I am not using es6 syntax to declare a function. That's because using it caused a scoping issue and the error, __function is not defined__. Hence, I went to the old school with __var__.
## Publish Add-On in GCP for Testing
To publish an add-on to the GCP follow these two instructions here.
1. Create a standard [GCP project](https://developers.google.com/apps-script/add-ons/how-tos/publish-add-on-overview#create_a_standard_google_cloud_platform_project).
2. Integrate a project with [apps script project](https://developers.google.com/apps-script/guides/cloud-platform-projects#switching_to_a_different_standard_gcp_project).
## Final Code
__cards__
```
var itemSelectedCard = (e) => {
// Initial UI
let card = CardService.newCardBuilder().setHeader(CardService.newCardHeader().setTitle("Select Sheets Update Master Sheet"));
let filesSection = CardService.newCardSection()
filesSection.setHeader("Selected Files");
let nxtButtonSection = CardService.newCardSection();
let nxtButtonAction = CardService.newAction()
.setFunctionName("handleNextButtonClick");
let selectedSheets = [];
if (e.drive.selectedItems.length > 0) {
// hostApp,clientPlatform,drive,commonEventObject
// Selected spreadsheets
e.drive.selectedItems.forEach(item => {
if (item.mimeType === "application/vnd.google-apps.spreadsheet")
selectedSheets.push(item)
}
);
}
// Create a counter to count number of widgets added
let widgetCounter = 0;
for (let i = 0; i < selectedSheets.length; i++) {
// Create decorated text with selected files and
// add the decorated text to card section
filesSection.addWidget(CardService.newDecoratedText()
//.setText(selectedSheets[i].title)
.setText(e.drive.selectedItems[0].title)
);
widgetCounter += 1;
}
// Change list of selected sheet's id as string to pass to next card
let selectedSheetsIDAsStr = selectedSheets.map(item => item.id).join();
nxtButtonAction.setParameters({
"nextCard": "nextCard",
"selectedSheetsIDAsStr": selectedSheetsIDAsStr,
});
let nxtButton = CardService.newTextButton().setText("Next").setOnClickAction(nxtButtonAction);
let nxtButtonSet = CardService.newButtonSet().addButton(nxtButton);
// Add files and button section only if the widgets are present
// It prevent error in case only non-spreadsheet files are selected
if (widgetCounter >= 1) {
card.addSection(filesSection)
nxtButtonSection.addWidget(nxtButtonSet);
card.addSection(nxtButtonSection);
}
// Create Another card that has files list
return card.build();
}
```
__helpers__
```
/* THis is a greneral nav function
You use it with card action and as reponse it will supply card functions from cardsInventory */
let handleNextButtonClick = (e) => {
let nextCard = cardsInventory[e.commonEventObject.parameters.nextCard];
console.log(nextCard)
// Convert String into List
let selectFilesIdList = e.commonEventObject.parameters['selectedSheetsIDAsStr'].split(",");
let nxtActionResponse = CardService.newActionResponseBuilder()
.setNavigation(CardService.newNavigation().pushCard(nextCard(selectFilesIdList)))
.setStateChanged(true)
.build();
return nxtActionResponse;
}
/**
* Create a dictionary that
is consist of cards for navigation with appropriate keys
*/
var cardsInventory = {
'nextCard': nextCard
}
```

## Summary
Alright, let's recall things we did in the project.
1. Defined appscrits.json files with the appropriate scopes and triggers required for Drive Add-on.
2. Created a simple card UI to interact with users.
3. Fetched selected files from drive with apps script.
4. Used Actions and Button Sets to let users interact with our card UI.
5. Created a simple navigation logic to move between two cards.
## Show Some Support
This is Nibesh Khadka from Khadka's Coding Lounge. Find my other blogs on Google Apps Scripts [here](https://kcl.hashnode.dev/series/google-apps-script). I am the owner of Khadka's Coding Lounge. We make websites, mobile applications, google add-ons, and valuable tech blogs. __Hire us!, Like, Share and Subscribe to our newsletter__.

| kcl |
1,174,008 | With great scale comes great observability | How to deploy microservice applications to AWS ECS, identify and troubleshoot issues using distributed tracing. | 0 | 2022-08-23T07:47:46 | https://dev.to/developersteve/with-great-scale-comes-great-observability-2fio | ecs, observability, microservices | ---
title: With great scale comes great observability
published: true
description: How to deploy microservice applications to AWS ECS, identify and troubleshoot issues using distributed tracing.
tags: ecs, observability, microservices
# cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/49bf3kduhpbceneymube.png
# Use a ratio of 100:42 for best results.
---
Building on Microservices is a great way to deploy applications that can scale with rapid adoption. Scaling modern microservice applications generates a large amount of logs and metrics data on multiple levels, having the right tools to manage them all is integral to microservices success. Modern architecture needs a new approach and for microservices, distributed tracing brings monitoring into the modern world of observability.
Join us for the live session, 31st of August 9am ET
In this live geek out session, we will get hands on deploying a multi-microservices application to AWS ECS and use distributed tracing to find, track and troubleshoot issues
[Click here to find out more](https://info.lumigo.io/webinar-distributed-tracing-microservices) | developersteve |
1,174,011 | How to search your AWS accounts for any resource | Retrieving information about resources you have deployed in your Amazon Web Services (AWS)... | 0 | 2022-08-23T08:31:34 | https://dev.to/scapecast/how-to-search-your-aws-accounts-for-any-resource-2a40 | Retrieving information about resources you have deployed in your Amazon Web Services (AWS) infrastructure means tediously navigating the AWS Management Console or using the AWS Command Line Interface.
This approach works well in a single account setup. Yet the best practice proposed by AWS is to set up a multi-account environment to separate your workloads and users. As the number of accounts grows, navigating your infrastructure and finding resources via the Console or the CLI becomes increasingly difficult.
The number of resources in these accounts just keeps growing. Developers create resources using tools such as Terraform, CDK, or CloudFormation… or sometimes even the console or CLI.
It's not just the resources themselves, it's also the relationships between your resources that are relevant: an EBS volume is mounted to an EC2 instance running in a VPC and reachable via an ALB load balancer, for example.
So how can you see everything that is running in your cloud, including the dependencies between your resources?
## Graph-based Search
We created [Resoto](https://resoto.com) to allow the user to effortlessly search resources and automate workflows. Resoto gathers data about your infrastructure and builds a directed acyclic graph, where resources are vertices and their relationships/dependencies edges.
This graph is what makes Resoto so powerful. But we also needed a way to allow users to query this data.
Graph data is not relational, so SQL was not a good fit. And existing graph query languages like Cypher, Gremlin, or GSQL have steep learning curves and are unnecessarily complex for this use case.
And so we developed our own search syntax tailored specifically to Resoto. The Resoto Shell allows you to interact with your Resoto installation. In particular, it provides a search command.
### Example: Search for EC2 instances
Let's try searching for all available EC2 instances. `is()` will match a specific or abstract type in a polymorphic fashion, checking all types and subtypes of the provided type.
The `instance_cores` filter will limit results to only those instances with more than two cores. The query below will automagically search your entire infrastructure, regardless of account or region!
`search is(aws_ec2_instance) and instance_cores > 2`
and here the (abbreviated) result:
```
id=i-a..., name=crmsec, age=2y2M, account=dev, region=us-east-1
id=i-0..., name=airgap, age=2M, account=staging, region=eu-central-1
id=i-0..., name=flixer, age=1M3w, account=sales, region=us-west-2
```
The query found three instances in three accounts and three regions. The default output is a condensed list view, but it is also possible to get all collected properties of any resource using the `dump` command:
`search is(aws_ec2_instance) and instance_cores > 2 limit 1 | dump`
In the case of EC2, these properties for example are the number of cores, memory and the actual instance type and its status:
```
reported:
kind: aws_ec2_instance
id: i-a...
tags:
aws:cloudformation:stack-name: lk-build-server
aws:cloudformation:stack-id: arn:aws:cloudformation:...
owner: team-proto
name: LKbuild
instance_cores: 4
instance_memory: 16
instance_type: t3.xlarge
instance_status: stopped
age: 1y10M
```
We can refine and group the results. Let's group our instances by `instance_type` using the count command:
`search is(aws_ec2_instance) and instance_cores > 2 | count instance_type`
```
t3.2xlarge: 1
m5.4xlarge: 15
total matched: 16
total unmatched: 0
```
The search returns sixteen EC2 instances, including fifteen m5 and one t3 xlarge.
## Using graph search to understand dependencies
Now, let's say we want to find all ELB load balancers attached to the EC2 instances returned above. We first need to understand Resoto's graph data structure to tackle this problem.
When Resoto collects data on your cloud infrastructure, it creates an edge between ELB and EC2 instances if the ELB balances the traffic of the related EC2 instance. In the image below, you can see the how the graph captures the entire set of dependencies in the account:
`search is(aws_ec2_instance) and instance_cores > 2 --> is(aws_elb)`
```
name=a5..., age=1y1M, account=sales, region=eu-central-1
name=a3..., age=6M2w, account=staging, region=us-west-2
```
The `--> `arrow will take all matching EC2 instances and walk the graph "outbound," moving precisely one step. The list of matching items is not limited only to ELB load balancers, so with `is(aws_elb)` we filter the list again to return only ELB results.
It's also possible to reverse the last query to output all EC2 instances behind an ELB:
`search is(aws_elb) <-- is(aws_ec2_instance) and instance_cores > 2`
```
id=i-0..., name=airgap, age=2M, account=staging, region=eu-central-1
id=i-0..., name=flixer, age=1M3w, account=sales, region=us-west-2
```
The arrow is now mirrored and traverses the graph "inbound," walking edges in the opposite direction.
## Use cases
Graph-based search becomes useful when you're trying to solve for problems that require understanding of how resources are connected to each other.
An example is the "blast radius" of a resource.
When you're looking at cleaning up an EC2 instance, what other resources are you taking down as well? Or, the other way around, what resources do you need to clean up first before you want to clean up an unused EC2 instance?
## Try it yourself!
These examples only scratch the surface of Resoto's search syntax. While this post is AWS specific, we also support GCP and DigitalOcean.
Resoto is open source, self-hosted and free to use! Check out [our documentation](https://resoto.com/docs) and give Resoto a spin!
------------
This post was originally published by my colleague Matthias Veit at [https://resoto.com/blog/2022/02/04/resoto-search-101](https://resoto.com) on February 4, 2022.
| scapecast | |
1,174,183 | CSS Position Ultimate Guide 2022. | Confused with CSS Position...? In this article, I will be breaking down all CSS position... | 0 | 2022-08-23T11:51:00 | https://dev.to/kadlagakash/css-position-ultimate-guide-2022-a9p | css, webdev, beginners, tutorial | ### Confused with CSS Position...?
In this article, I will be breaking down all CSS position properties and explaining everything you need to know about them. This includes even the more obscure concepts related to the position that most articles/videos ignore.
## Prerequisite
To get the most out of this article, we need the following:
- Basic understanding of HTML.
- Basic understanding of CSS. (check out [CSS Selctors](https://dev.to/kadlagakash/mastering-css-css3-selectors-in-2022-3o0p))
- Visual studio code or any IDE of our choice to code along.
## CSS Positions
When building a webpage, there can be multiple elements on our page, each with their own positions, uses, and designs. It’s important to learn how we can arrange these elements and have control over their layout.
The position property in CSS determines how an element is positioned in a document. It specifies the type of positioning method for each element.
---
## Values of CSS Positions
The position property can have any of these values:
- static
- absolute
- relative
- fixed
- sticky
You can also specify the value of `inherit`, which means the value is determined from the parent element. The position value doesn’t cascade, so this can be used to specifically force it to, and inherit the positioning value from its parent.
---
## Placement Properties
Position property on its own is not that useful. It only says how the position should be calculated. For example, relative to the normal position of an element.
But we also need to define where exactly the element should be placed, not only how. There are several properties we can use for that.
- top
- left
- right
- bottom
- z-index
These define how much the element's position should be adjusted and in which direction.
---
## Normal Flow
Before going into details, let's see how these elements automatically get their position on your page. To understand this, you need to understand the normal flow of the web page. Normal flow is how the elements are arranged on a page if you haven't changed their layout.
There are two types of elements on a web page. Block-level elements and inline elements.
Block-level elements such as `<h1>`, `<div>`, `<p>` are contained on their own line. Because block-level elements start with a line break, two block-level elements can't exist on the same line without styling.
Inline elements such as `<a>`, `<img>`, `<span>`, don't form their own blocks. Instead, they are displayed within lines. They line up next to one another horizontally; when there isn't enough space left on the line, the content moves to a new line.
---
## Static Position
`position: static` is the default value provided by HTML. This means if we don’t declare position for an element in CSS, it will automatically be set to static.
Even though it is a default value, it can sometimes be useful to set it explicitly. For example, to override different position value, which is set elsewhere.
Elements that are statically positioned will follow the normal document flow and will position itself based on the standard positioning rules.
Unlike with other position values, when using `static`, placement properties such as `top`, `left`, `bottom`, `right`, or `z-index` have no effect.
**Example to illustrate Static Position :**
We are using the following HTML markup:
```html
<div class="parent">
Parent
<div class="one">
One <br>
position:static <br>
top: 50px ( this has no effect )
</div>
<div class="two">Two</div>
<div class="three">Three</div>
</div>
```
And here’s the CSS we’re using:
```css
.parent {
// No position set, so it's static
}
.one {
// No position set, so it's static
top: 50px;
}
```
However, here is how it will look on a webpage:

View original code in [CodePen] (https://codepen.io/KadlagAkash/pen/YzaxxbP)
Since both elements have a static position, none of the layout CSS properties will do anything. This makes the top property have no effect on how the element with class="one" is displayed.
---
## Relative Position
Relative position means that the element is placed relative to its original position in the page. A `relative` position element works exactly the same as `static` position, but you can now add `z-index`, `top`, `left`, `right`, and `bottom` properties to it.
If you make an element `relative` positioned without setting any of these extra properties you will notice it looks exactly the same as a static positioned element. This is because `relative` positioned elements also follow the normal document flow, but you can offset them using the `top`, `left`, `right`, and `bottom` properties.
**Example to illustrate Relative Position :**
We are using the following HTML markup:
```html
<div class="parent">
Parent
<div class="one">One</div>
<div class="two">Two</div>
<div class="three">Three</div>
</div>
```
And here’s the CSS we’re using:
```css
.one {
position: relative;
top: 15px;
left: 15px;
}
```
However, here is how it will look on a webpage:

View original code in [Codepen](https://codepen.io/KadlagAkash/pen/ZExJazz)
As a result of an element being moved from its original position, there can be a situation, where multiple elements overlap each other. Fortunately, with `z-index` property, you can control which elements should be in the front and which in the back. We'll discuss this in more detail later.
Only `relative` position is not that useful as you do not usually want to offset an element without also moving all the elements around it. The main use cases for position `relative` are to either set the `z-index` of the element, or to be used as a container for `absolute` positioned elements which we will talk about next.
---
## Absolute Position
The `absolute` position completely removes the element from the normal document flow. If you give an element position `absolute` all other elements will act as if the `absolute` positioned element doesn't even exist.
An element using `position: absolute` is positioned relative to the nearest ancestor. In other words, an element with `position: absolute` is positioned relative to its parent element.
If an element doesn’t have a parent element, it’s placed relative to its initial containing block. It can then be positioned by the values of top, right, bottom, and left.
> Note : If we don’t specify helper properties, it’s positioned automatically to the starting point (top-left corner) of its parent element.
**Example to illustrate Absolute Position :**
We are using the following HTML markup:
```html
<div class="parent">
Parent
<div class="one">One</div>
<div class="two">Two</div>
<div class="three">Three</div>
</div>
```
And here’s the CSS we’re using:
```css
.parent {
position: relative;
}
.one {
position: absolute;
top: 0;
right: 0;
}
```
However, here is how it will look on a webpage:

View original code in [Codepen](https://codepen.io/KadlagAkash/pen/OJvjzmV)
By setting the blue parent element to a position of relative I am now forcing the absolute positioned child one element to be in the top right corner of the parent instead of the body. This combination of relative and absolute positions is incredibly common.
---
## Fixed Position
The `fixed` position is a bit like `absolute` position in that it removes the element out of the normal flow, but `fixed` position elements are always positioned in the same place in the viewport (what’s visible on screen). This means that scrolling will not affect its position at all.
**Example to illustrate Fixed Position :**
We are using the following HTML markup:
```html
<div class="parent">
Parent
<div class="one">One</div>
<div class="two">
Two <br>
Ha ha! Scrolling can't get rid of me!!
</div>
<div class="three">Three</div>
</div>
```
And here’s the CSS we’re using:
```css
.two {
position: fixed;
top: 0;
right: 0;
}
```
However, here is how it will look on a webpage:
{% codepen https://codepen.io/KadlagAkash/pen/PoRKEMG %}
View original code in [Codepen]
(https://codepen.io/KadlagAkash/pen/PoRKEMG)
The pink fixed element will stay positioned at the top and right corner of the viewport. And if you scroll, the blue parent element and other child elements will scroll up normally, but the pink element will remain stuck to where we positioned it.
> Tip: A fixed element must have a top or bottom position set. If it doesn’t, it will simply not exist on the page at all.
You have to be careful with `fixed` position usage. On a mobile device with a small screen, it can be a big deal if a large portion of your screen is always covered with a navigation bar or something similar. It dramatically reduces space for the actual content of your page and can significantly limit usability.
---
## Sticky Position
The `sticky` position is a combination of both `fixed` and `relative` position and combines the best of them both.
An element with position sticky will act like a `relative` positioned element until the page scrolls to a point where the element hits the `top`, `left`, `right`, or `bottom` value specified. It will then act like a fixed position element and scroll with the page until the element gets to the end of its container.
> In other words, elements set with `position: sticky` are positioned based on the user’s scroll position.
As of this writing, it is currently an experimental value, meaning it is not part of the official spec and is only partially adopted by select browsers. In other words, it’s probably not the best idea to use this on a live production website.
**Example to illustrate Sticky Position :**
We are using the following HTML markup:
```html
<div class="parent">
Parent
<div class="one">One</div>
<div class="two">
Two <br>
I stick at the top <br><br>
position: sticky <br>
top: 0px;
</div>
<div class="three">Three</div>
</div>
```
And here’s the CSS we’re using:
```css
.two {
position: sticky;
top: 0;
}
```
However, here is how it will look on a webpage:
{% codepen https://codepen.io/KadlagAkash/pen/eYMEQJm %}
View original code in [Codepen](https://codepen.io/KadlagAkash/pen/eYMEQJm)
`sticky` position is the perfect position for navbars that scroll with the page, headings in long lists, and many other use cases.
---
## Z-index
When working with position other than static, elements can easily appear in position, where they overlap each other.
This is where the `z-index` property comes in. When you have elements overlapping, we use `z-index` to stack them. It controls the position of your elements on the z-axis.
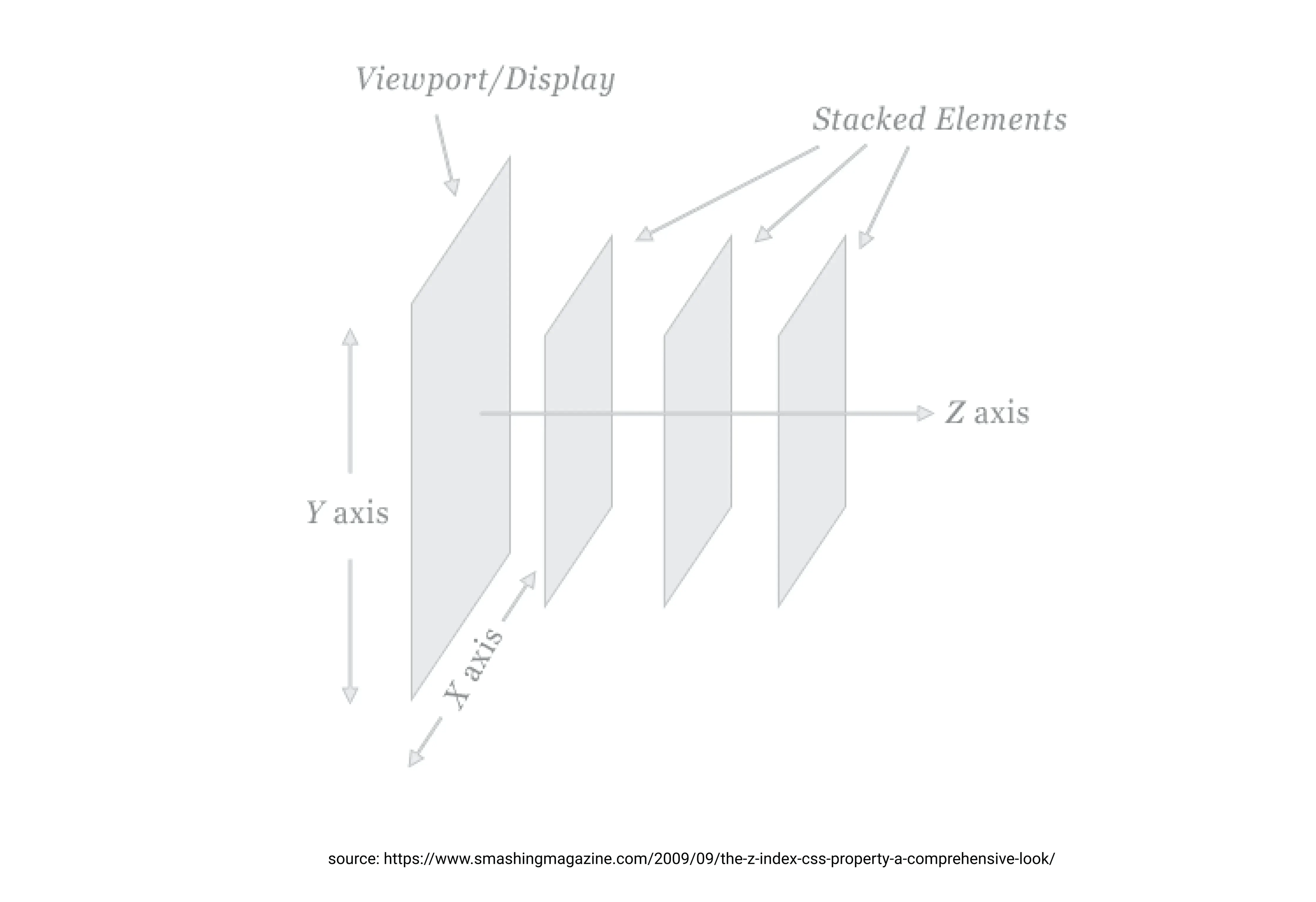
You can use `z-index` like this:
```css
z-index: 1;
```
The `z-index` gives you the ability to decide how the elements should overlap each other, in which order. If you give a higher `z-index` value, that particular element will appear closer to the viewer. In other words, it will appear on top of the other elements.
**Example to illustrate Z-index:**
We are using the following HTML markup:
```html
<div class="parent">
Parent
<div class="one">One</div>
<div class="two">
Two <br>
I stick at the top <br><br>
position: sticky <br>
top: 0px;
</div>
<div class="three">Three</div>
</div>
```
And here’s the CSS we’re using:
```css
.first{
z-index: 3;
}
.second{
z-index: 2;
}
.third{
z-index: 1;
}
.four{
/* No z-index */
}
.fifth{
z-index: -1;
}
```
However, here is how it will look on a webpage:
{% codepen https://codepen.io/KadlagAkash/pen/jOzLQGg %}
View original code in [Codepen](https://codepen.io/KadlagAkash/pen/jOzLQGg)
---
## Summary
Let's sum it up. The `position` property allows you to determine how elements should be placed on the page.
You can define the exact location using `top`, `bottom`, `right` and `left` properties.
In case your elements overlap each other, you can change their order using `z-index`. The higher the index, the closer is the element to the user.
**static**
- Default value
- Positioning as usual, same as if you didn't specify the position
**relative**
- The element is placed relative to its normal position on the page
- The place occupied by the element is preserved at its original location
**absolute**
- The element is removed from the normal flow and does not occupy space
- The location is determined relative to the first parent set position (other than `static`)
- If there is no such parent, it is determined relative to the whole page.
**fixed**
- The element is removed from the normal flow and does not occupy space
- The location is determined relative to the viewport
- Elements keep their locations as you scroll
**sticky**
- Elements are positioned relatively until you reach them by scrolling
- Then the elements stick to one location, similar to fixed positioning
- Not supported by all the browsers, you can check out the current support on [CanIUse.com](https://caniuse.com/css-sticky).
---
## In closing
I hope that you’ve found this tutorial and code examples on CSS positioning helpful...! If you have any questions or feedback, feel free to leave a comment below.
If you found this article helpful, please like and share it 💙.
That's all for today! 😁 You reached the end of the article 😍.
### Other Resources
Check out some of these resources for a more in-depth look into CSS Positions:
- [MDN CSS Positions](https://developer.mozilla.org/en-US/docs/Web/CSS/position)
- [WDS CSS Positions](https://youtu.be/jx5jmI0UlXU)
- [CSS Positions](https://css-tricks.com/almanac/properties/p/position/)
### Want more..?
I write web development articles on my blog **[@dev.to/kadlagakash](https://dev.to/kadlagakash/)**, and also post development-related content on the following platforms:
- **[Twitter](https://twitter.com/KadlagAkash)**
- **[LinkedIn](https://www.linkedin.com/in/KadlagAkash)** | kadlagakash |
352,377 | HOF in go | Higher Order Function คือคุณสมบัติที่ function สามารถรับ parameter หรือคืนค่าเป็น function ได้ ซึ่งจะ... | 0 | 2020-06-10T05:12:19 | https://dev.to/pallat/hof-in-go-18mm | Higher Order Function คือคุณสมบัติที่ function สามารถรับ parameter หรือคืนค่าเป็น function ได้ ซึ่งจะสัมพันธ์กับเรื่อง First Class Function และสัมพันธ์กับเรื่อง Closure Function และเป็นเรื่องที่ทำให้โปรแกรมเมอร์ที่ไม่คุ้นเคยกับ concept ทำนองนี้ต้องทำความเข้าใจมากพอสมควร
เวลาผมคิดถึงเรื่อง HOF หรือ First-class จำเป็นจะต้องแยกเรื่อง literal ออกไปให้ชัด เพราะถ้าเรามัวแต่ไปจ้องที่รูปร่างหน้าตาของมัน จะทำให้งง ยกตัวอย่างเช่น
```go
func hof(fn func(string) string) {
...
}
```
เวลาเจอแบบนี้ ให้มองให้ออกว่า ตรงไหนคือ type โดยให้เทียบกับการประกาศแบบ primitive type ธรรมดาเช่น
```go
func normal(s string) {
...
}
```
ให้มองให้ออกว่า `fn func(string) string` ก็เหมือนกับ `s string` การจะทำให้มองสิ่งนี้ง่ายขึ้น เราจึงเห็นการสร้าง type แบบนี้
```go
type doSumethingFunc func(string) string
func hof(fn doSumethingFunc) {
...
}
```
ในโลกของ go เราเห็น HOF บ่อยๆเวลาทำ Wrapper หรือ Middleware ยกตัวอย่างเช่น echo MiddlewareFunc จะมีหน้าตาแบบนี้
```go
type HandlerFunc func(Context) error
type MiddlewareFunc func(HandlerFunc) HandlerFunc
```
เวลาจะเขียน middleware เราก็จะเห็นโค้ดหน้าตาแบบนี้
```go
func Middleware(next echo.HandlerFunc) echo.HandlerFunc {
return func(c echo.Context) error {
...
next(c)
...
}
}
```
วิธีมองให้ดูว่าฟังก์ชั่น Middleware เป็น HOF ที่รับ echo.HandlerFunc เป็น parameter และคือค่าออกเป็นเป็น type เดียวกับที่รับเข้ามา และด้วยเหตุนี้ ปกติใน go ก็มักจะเขียน return ค่าเป็น anonymous function ที่มีหน้าตาตรงกับ return type ซึ่ง `HandlerFunc` ก็คือ `func(Context) error`
ในฟังก์ชั่นนี้ เราสามารถเขียนสิ่งที่ต้องการทำก่อน และหลังการทำงานของ next ซึ่ง next นี่ก็คือ handler ตัวที่ทำงานเป็น business logic หลักที่เราตั้งใจเขียนให้ทำงานจริงๆ เพราะฉะนั้น ไม่ว่าเราจะทำอะไรก็ตามในฟังก์ชั่นนี้จะต้องไม่ลืมสั่งให้มันทำงานตามที่มันควรทำ ซึ่งก็คือ `next(c)` นั่นเอง
| pallat | |
1,174,310 | axios HTTP request | Hi, I am making an HTTP request through an azure function to invoke a web service in node.js with... | 0 | 2022-08-23T15:37:11 | https://dev.to/yamenad4/axios-http-request-d3n | axios, node, javascript | Hi,
I am making an HTTP request through an azure function to invoke a web service in node.js with axios.
This is what this request looks like :
```
module.exports = async function () {
const axios = require("axios");
const data = {
appUser: "YAMENEDEL",
};
const headers = {
Authorization:
"Basic WUFNFEWWWRQEQ......",
};
{
axios
.post(
"https://tegosGetPutawaysByAppUser?company=grundon",
data,
{ headers: headers }
)
.then((response) => {
//return (response.data);
console.log(`Status: ${response.status}`);
console.log("data: ", response.data);
})
.catch((err) => {
console.error(err);
});
}
};
```
when to test this request on postman it will return 200 response and will see the data in my VS code terminal screen but not in the body response of the client. I tried to return data this way but didn't work `return (response.data);`
As you can see below a snippet of the postman request with an empty body response !
Secondly, in the body for this request I am hardcoding the value of the `appUser`. However, if I want to run this request on postman and pass the JSON value in the body for `appUser` - what changes do I need to do in the code so the param value can pick up what is being passed. I tried the following `appUser: { type: String, default: null }` but it was a failed attempt !
| yamenad4 |
1,174,424 | Creating HTML Template And Views | Django CMS Building By shriekdj | In This Post I Will Create Html Pages for the site and as well as show how to use urls.py and... | 19,310 | 2022-08-25T14:30:12 | https://codewithshriekdj.netlify.app/posts/creating-html-template-and-views-django-cms-building-by-shriekdj-10b1a | python, django, shriekdj, programming | In This Post I Will Create Html Pages for the site and as well as show how to use `urls.py` and `views.py`.
First Create a folder named `templates` in `blog` app in django app and add update the variable in `django_project_name/setting.py` like given below
```python
import os # add it at the top of settings.py
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')], # at here add templates folder
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
```
Create an `index.html` in it like given below
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Hello World</title>
</head>
<body>
<h1>Hello World</h1>
</body>
</html>
```
Now goto file `blog/views.py` and create a new function like below to load our `index.html` you can give whatever name you wanted.
```python
from django.shortcuts import render
# Create your views here.
def index(request):
return render(request, 'index.html')
```
Here we are rendering our index page with function named index. it's not mandatory to give the same name as file name but it's just helps you remember the locations. at above function we are giving parameter `request` it is for getting the data from our client browser and we as Server write logic at in this function.
We Also Need 2 More Steps to view this page.
First Create `urls.py` in **blog** folder and write below code.
```python
from django.urls import path
from blog import views
urlpatterns = [
path('', views.index)
]
```
at here we are loading all the urls in `urlpatterns` variable and blank path means that it's at homepage of blog app.
And At Last At the `django_project/urls.py` we need to make some modifications. Watch Clearly Both Are same file name but different Folder. This `urls.py` is Main `url` routing file of whole site. change it like given below
```python
from django.contrib import admin
from django.urls import include ,path
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('blog.urls'))
]
```
At here we have to Add Global Paths of Site with Special `include` function. directly adding similar to admin will not work. now load the site with `python ./src/manage.py runserver` screenshot given below.
if you see this clearly i did not use relative import it may raises some error in production mode in future and i have to manually update all relative import to absolute import.
But I Will Mostly Use Class Based Views Instead of Function Based so I will Change My `index` function in `views.py as follows.
```python
from django.shortcuts import render
from django.views import View
# Create your views here.
class IndexView(View):
def get(self, request, *args, **kwargs):
return render(request, 'index.html')
```
Here all the logic of the code get into `get method` the views class and also change `urlpatterns` under `blog/urls.py` as follows below.
```python
from django.urls import path
from blog import views
urlpatterns = [
path('', views.IndexView.as_view(), name='index_view'),
]
```
It will not change look of the page at all **as of now** but in future we can use inheritance like features with it.
In Class `View` The `get` method means GET Request and obviously it have other `request methods` like `['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']`
and `as_view()` method will return the response as per request method in one class.
Chaging View Again
```python
from django.views.generic.base import TemplateView
# Create your views here.
class IndexView(TemplateView):
template_name: str = 'index.html'
# def get(self, request, *args, **kwargs):
# return render(request, 'index.html')
```
you can seet the code it reduced if we are returning the render function.
Actually views function have the specific way of returning pages like given below.
```python
def my_view_function(request):
context_to_send_html= {"data sent to our template": "some-data" }
return render(request, 'template_file_name.html', context_to_send_html)
```
To Make It Easily Writable We Write Class Based View. as of now it look to difficult but it will save too much of our time in future.
As always the given below is GitHub Repository URL.
{% github shriekdj/shriekdj_cms %}
| shriekdj |
1,174,518 | All Okta Workflows How-To Guides | How to Remove Office 365 License From a... | 0 | 2022-08-23T19:25:00 | https://dev.to/oktaworkflows/all-okta-workflows-how-to-guides-4nl9 | nocode, okta, workflows, ipaas | {% embed https://dev.to/oktaworkflows/how-to-remove-office-365-license-from-a-user-account-after-being-suspended-for-a-certain-time-lmh %}
{% embed https://dev.to/oktaworkflows/how-to-iterate-over-rows-in-a-table-in-okta-workflows-1hfd %}
{% embed https://dev.to/oktaworkflows/how-to-setup-a-workflows-helper-flow-with-for-each-and-streaming-cards-3k96 %}
{% embed https://dev.to/oktaworkflows/how-to-list-users-assigned-to-an-application-and-save-users-into-a-table-24g5 %}
{% embed https://dev.to/oktaworkflows/how-to-delete-multiple-table-rows-1b67 %}
{% embed https://dev.to/oktaworkflows/how-to-run-a-flow-just-once-or-manually-3ppb %}
{% embed https://dev.to/oktaworkflows/how-to-call-an-api-when-its-not-available-from-an-existing-card-connection-4h84 %}
{% embed https://dev.to/oktaworkflows/how-to-create-a-custom-list-filter-in-okta-workflows-27d0 %}
{% embed https://dev.to/oktaworkflows/how-to-create-a-custom-slack-connection-in-okta-workflows-connector-builder-2c1i %}
{% embed https://dev.to/oktaworkflows/how-to-translate-an-okta-user-id-into-a-google-user-id-32ll %}
{% embed https://dev.to/oktaworkflows/how-to-trigger-a-flow-6-ways-to-run-a-flow-97o %}
{% embed https://dev.to/oktaworkflows/how-to-send-an-email-with-an-attachment-from-workflows-4h0 %}
{% embed https://dev.to/oktaworkflows/how-to-read-a-json-path-with-dot-notation-in-workflows-3dlk %}
{% embed https://dev.to/oktaworkflows/how-to-create-flow-or-folder-backup-and-save-it-to-google-drive-4pf %}
{% embed https://dev.to/oktaworkflows/how-to-add-error-handling-to-a-flow-and-continue-execution-when-an-error-occurs-4hl8 %}
{% embed https://dev.to/oktaworkflows/how-to-delete-deactivated-users-in-workflows-2f26 %}
{% embed https://dev.to/oktaworkflows/how-to-handle-an-external-api-call-error-in-workflows-3i6e %}
{% embed https://dev.to/oktaworkflows/how-to-send-a-notification-to-a-group-of-people-based-on-a-department-1m22 %}
{% embed https://dev.to/oktaworkflows/okta-workflows-how-to-retrieve-slack-user-status-and-other-info-using-custom-api-cards-3dg5 %} | oktaworkflows_staff |
1,194,329 | Correct way to handle API requests in a useEffect hook | It is common to issue an asynchronous request to an API in a useEffect hook. Perhaps to fetch some... | 0 | 2022-09-15T18:48:29 | https://dev.to/elishaking/correct-way-to-handle-api-requests-in-a-useeffect-hook-13bf | react, api | It is common to issue an asynchronous request to an API in a useEffect hook. Perhaps to fetch some data which is eventually used to update component state. Something like this:
```javascript
const [data, setData] = useState([]);
useEffect(() => {
axios.get('get/some/data').then(({ data }) => {
setData(data);
});
}, []);
```
It is also common to encounter a situation where the component unmounts before the request is complete. The callback will still be executed if the component unmounts because the request was not cancelled. Consequently, when `setData` is called, this interesting warning pops up in the browser console:
> Warning: Can’t perform a React state update on an unmounted component. This is a no-op, but it indicates a memory leak in your application. To fix, cancel all subscriptions and asynchronous tasks in a useEffect cleanup function.
## How to fix this
To fix this, the request needs to be cancelled when the component unmounts (in the `useEffect` cleanup function). This can be easily achieved with `axios` as follows:
```javascript
const [data, setData] = useState([]);
useEffect(() => {
const cancelToken = axios.CancelToken.source();
axios
.get('get/some/data', { cancelToken: cancelToken.token })
.then(({ data }) => {
setData(data);
})
.catch((err) => {
if (axios.isCancel(err)) {
// TODO
}
});
return () => {
cancelToken.cancel();
};
}, []);
```
This can also be accomplished with `fetch` using `AbortController` as follows:
```javascript
const [data, setData] = useState([]);
useEffect(() => {
const controller = new AbortController();
fetch('get/some/data', { signal: controller.signal })
.then((res) => res.json())
.then((data) => {
setData(data);
})
.catch((err) => {
if (err.name === 'AbortError') {
// TODO
}
});
return () => {
controller.abort();
};
}, []);
```
| elishaking |
1,194,349 | Console Consumer - BytesDeserializer for the Win | If you want to make sure your expected String key is what you think it is, using BytesDeserializer... | 0 | 2022-09-15T19:10:57 | https://www.kineticedge.io/blog/kacc/ | If you want to make sure your expected String key is what you think it is, using BytesDeserializer with your console consumers is better than StringDeserializer.
## Introduction
The Confluent Avro Serializer and Deserializer leverages storing the unique ID of the schema in the message. When unexpected characters show up in a string, a type mismatch would be more obvious. But what about non-printable characters? How do they show up? Will the issue then be obvious?
## Demonstration
A simple demonstration can be done with the Datagen Source Connector. Create a connector with Avro as the key. The data type for the Datagen's quickstart `users` is a string. The Avro serializer will write this as an **Avro primitive**. Typically, when Avro is used, the top-level object is a Record, but the serializer has custom code for supporting primitives.
### The Configuration
The Datagen connector is configured with the key being represented at Avro.
```json
{
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"tasks.max": "1",
"kafka.topic": "users",
"quickstart": "users",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url" : "http://schema-registry:8081",
"key.converter.schemas.enable": "true",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url" : "http://schema-registry:8081",
"value.converter.schemas.enable": "true",
"max.interval": 100,
"iterations": 10000000
}
```
### Scenario
You write a Kafka Streams application where you read the key as a `Serdes.String()`, the default you used for your application. You forget to change the serde for reading `users` from the default serde to an Avro Serde. You now join your stream of orders with users, and none of the joins succeeds.
### Investigation...
If you are me, the first thing you do is you use `kafka-avro-console-consumer` to see what is going on.
```shell
kafka-avro-console-consumer \
--bootstrap-server localhost:19092 \
--property schema.registry.url="http://localhost:8081" \
--property print.key=true \
--property key.separator="|" \
--from-beginning \
--skip-message-on-error \
--key-deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--topic users
```
The result has content that looks pretty normal and expected:
```text
User_9|{"registertime":1489457902486,"userid":"User_9","regionid":"Region_1","gender":"OTHER"}
User_1|{"registertime":1500277798184,"userid":"User_1","regionid":"Region_2","gender":"OTHER"}
```
Now there could be extra blank lines show up if the non-printable bytes triggers that; but that doesn't always stick out and an obvious issue (at least not obvious to me).
What if your key deserializer was `BytesDeserializer`, what would you have seen?
```shell
kafka-avro-console-consumer \
--bootstrap-server localhost:19092 \
--property schema.registry.url="http://localhost:8081" \
--property print.key=true \
--property key.separator="|" \
--from-beginning \
--skip-message-on-error \
--key-deserializer=org.apache.kafka.common.serialization.BytesDeserializer \
--topic users
```
The serializer's magic byte (0x00) and the bytes for the schema-id show up in printable hex characters:
```text
\x00\x00\x00\x00\x03\x0CUser_9|{"registertime":1489457902486,"userid":"User_9","regionid":"Region_1","gender":"OTHER"}
\x00\x00\x00\x00\x03\x0CUser_1|{"registertime":1500277798184,"userid":"User_1","regionid":"Region_2","gender":"OTHER"}
```
Now it is easy to see the issue, the key is Avro (a primitive Avro string as defined by the serializer). **Solution**: update the connector to use a String, or update the streams application to re-key the data.
---
**NOTE**
Running containers for demonstrations is great, but the mis-match of URLs can be confusing. `localhost:port` is used for connecting to services from the host machine (your laptop) via port mapping. The actual hostname is used when you are accessing the service from another container. Therefore, you will see `http://schema-registry:8081` within the connect configuration, and `http://localhost:8081` for commands running from the host machine. I do not translate here as these scripts align with the demo code.
---
### Useful Shell Aliases
I have these defined in my `.zshrc`.
```shell
alias kcc='kafka-console-consumer \
--bootstrap-server localhost:19092 \
--key-deserializer=org.apache.kafka.common.serialization.BytesDeserializer \
--property print.key=true \
--property key.separator="|" \
--from-beginning \
--topic'
```
```shell
alias kacc='kafka-avro-console-consumer \
--bootstrap-server localhost:19092 \
--property schema.registry.url="http://localhost:8081" \
--property print.key=true \
--property key.separator="|" \
--from-beginning \
--skip-message-on-error \
--key-deserializer=org.apache.kafka.common.serialization.BytesDeserializer \
--topic'
```
## Takeaways
* While this may seem obvious to you, and you would immediately inspect the connector configuration and uncover the problem; you want to make things easy for everyone on your team. Allowing them to troubleshoot and find issues easy is a win for you and a win for them.
* This demonstration is available within the `key-mismatch` demo within [dev-local-demos](https://www.github.com/kineticedge/dev-local-demos).
## Reach out
I would enjoy hearing more about the development improvements you use.
Reach out at [contact us](https://www.github.com/kineticedge/contact). | nbuesing | |
1,194,527 | Binary Number System | Nowadays, computers use electricity to function, and we know that it can be either turned on or off.... | 0 | 2022-09-15T21:51:20 | https://dev.to/maritamovsisyan/binary-number-system-53hk | Nowadays, computers use electricity to function, and we know that it can be either turned on or off. This can be represented with the symbols “1” or “0”. This is called binary, and as most of us have already heard, computers function with the binary system. But how does the binary system function itself? Why is it better to use the binary system as the base of all computing systems and operations? Let’s find out together. (P.S. There are other number systems as well such as octal and hexadecimal number systems, but we will only focus on binary and decimal numbers.)
We are all familiar with the decimal or base ten numerical systems and know that there are ten symbols with which all the other numbers higher than 9 can be represented. We use positional notation to represent all those numbers by adding one more digit to the left of the numbers from 0 to 9. Moreover, that added number’s value is ten times greater than the digit on the right.
This mechanism applies to binary numbers as well, but here we use only 2 symbols to represent everything else. Here as well each new digit added has a value two times greater than the digit to its left. Binary numbers make the calculations simple, thus computers function with the binary number system. Also, each digit is said to be one bit.
Now, there are conversion methods that help us to represent decimal numbers in binary systems and vice versa. We need these conversions as the computer “understands” only binary, while we humans are used to the decimal number system. Converting binary numbers into decimal numbers is easier than it looks. As a first step, assign each digit of the binary number its position starting from 0. The first power should be 2^0, and as we move forward we get 2^1, 2^2, 2^3 … . Then, starting from the right, multiply each digit in the binary number by its corresponding weight based on its position and compute the product. As a result we get the decimal number converted from the binary system.
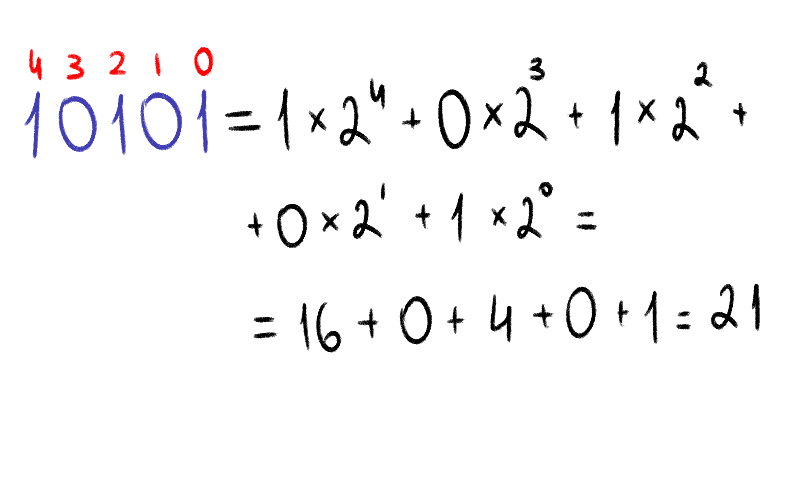
To convert a decimal number back to a binary number we have to divide it to 2 and write down its reminder. Repeat this until the reminder is 0. Now, arrange the remainders such that the last reminder comes first, followed by the rest in reverse order. See an example down below.
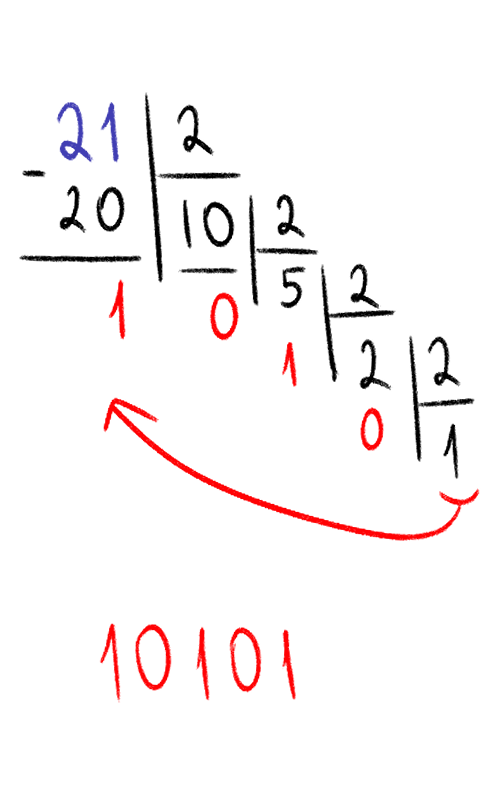
We can add, multiply, subtract and divide in binary pretty much the same way we do it in the decimal number system. First, let’s talk about addition. There are a few rules we need to remember while doing the addition, those are:
1 + 1 = 10
1 + 0 = 1
0 + 1 = 1
0 + 0 = 0
Knowing these, the addition process becomes much easier. In the example below first consider the last column and add 0 to 0 which gives us 0. Then, add 1to 1, which gives us 10. However, we cannot leave it like that and move the 1 of 10 to the next column just like we do with decimal numbers. After that add 1 to 0, and do not forget the 1 from the previous column as well. As there are no other columns left, write the 1000 as the final result.
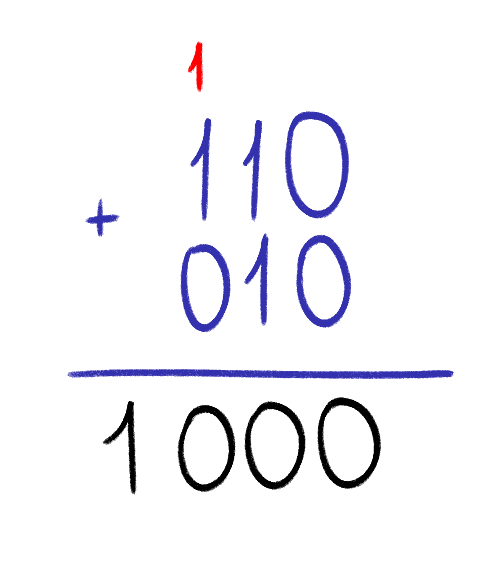
As we already know conversion, we can convert these binary numbers and check the equation with decimal numbers.
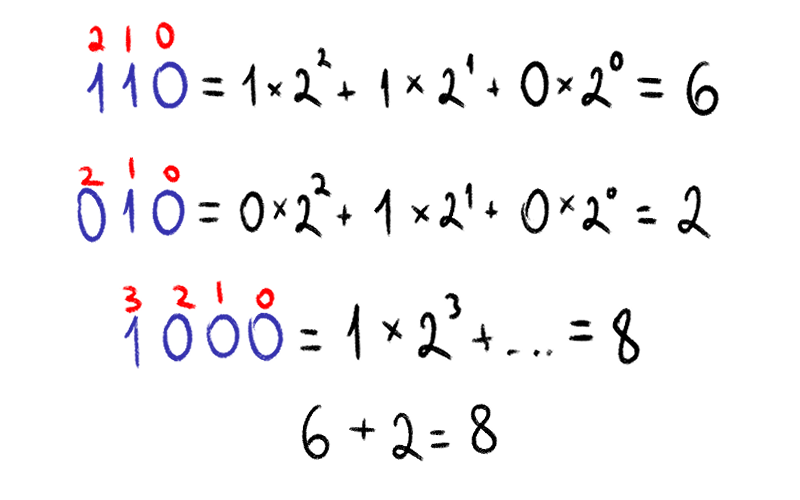
Knowing these and decimal multiplication, we can easily do binary multiplications as well. Let’s solve another one together step-by-step. Here, we have to start from the number below the first one and multiply its digits starting from the last one to the digits of the upper number with the same order. The two digits are 1-s so we write 110 and 110 below accordingly to each digit. Knowing how to do addition from before, add those numbers and get the value.
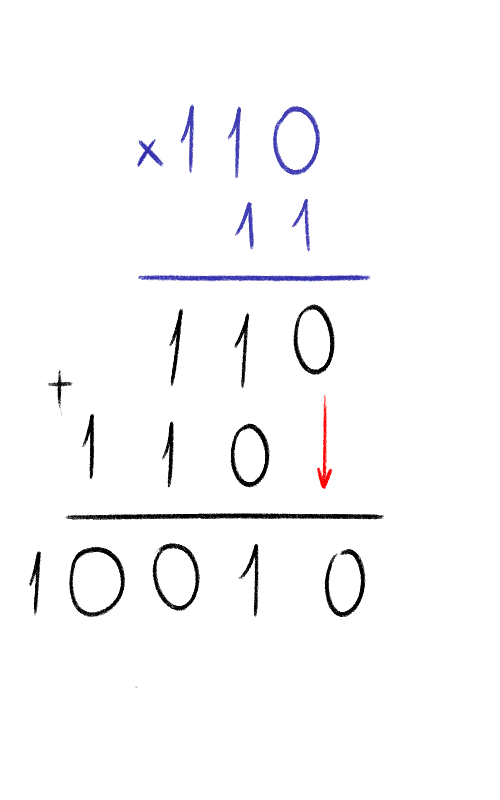
Let's convert these numbers to decimal again to check if we got it right.
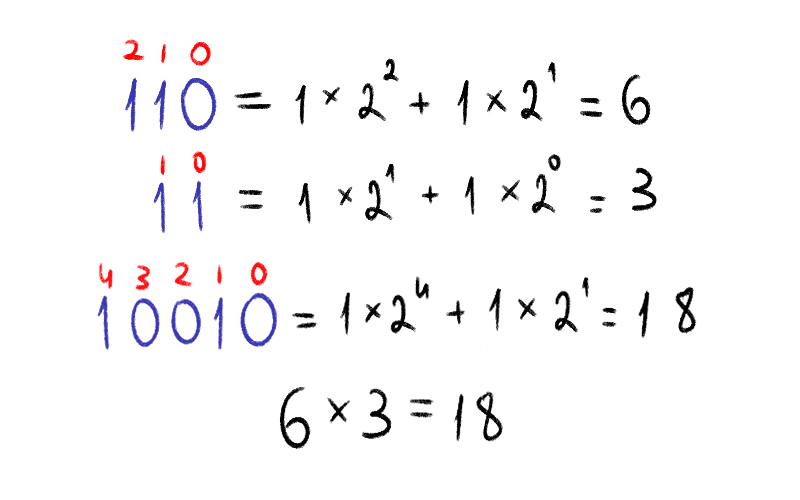
| maritamovsisyan | |
1,194,674 | NFT Website - Landing Page w/ Minting Feature using React | Hello everyone 👋 I made some tutorials on how to create NFTs some time ago. Since then, I have been... | 0 | 2022-09-16T02:12:15 | https://dev.to/balt1794/nft-website-landing-page-w-minting-feature-using-react-40ho | react, nft, web3, programming | Hello everyone 👋
I made some tutorials on how to create NFTs some time ago.
Since then, I have been contacted and asked a lot to keep making more tutorials and videos on NFTs.
One of the suggestions was to make an NFT website to showcase NFT collections, so I decided to give that a try and I have finally finished this project.
I spent a lot of time on it, and the template is even responsive on phones. I see a lot of value in it for people who have an NFT collection that want to showcase.
Some of the technologies used in this template: 👇
**Styled-components**
**HTML & CSS**
**Typewriter-Effect**
**React**
**Web3 Libraries**
[How to implement this template:](https://youtu.be/556KdCQgQ8E)
After implementing this template, you can also deploy the website using your own custom domain by following this tutorial:
[Add custom domain and deploy tutorial:](https://youtu.be/mXqG8bFh9dg)
**Note:**
This template is a front-end UI, meaning it's not connected to databases or anything like that. The main purpose is to showcase your NFTs to users and allow them to mint your NFTs.
Feel free to play around with the template and change whatever you like.
If you want to learn more about programming in general, take a look at my Youtube channel and don't forget to subscribe.
[Youtube Channel](https://www.youtube.com/channel/UChZR16e1XwZXy2yrk_8ymFg)
[Twitter](https://twitter.com/balt1794)
| balt1794 |
1,194,684 | OSD600 Lab 1 | How did I go about finding someone to work with? I sent a message in the OSD600 Slack... | 20,331 | 2022-09-16T17:43:12 | https://dev.to/rudychung/osd600-lab-1-1636 | opensource, node, cpp, beginners | ## How did I go about finding someone to work with?
I sent a message in the OSD600 Slack channel looking for a partner to work with. I found my partner in [Alexander Samaniego](https://github.com/alexsam29) who had created his application using Node.js.
## What was it like testing and reviewing someone else's code?
In reviewing my partner's code, there was an initial issue with understanding the code, since I was not all that familiar applications written in Node.js. However, after reading the code it was fairly straightforward to understand. There were some Node modules that I did not have an entirely clear understanding of at first, but after looking into what the functionality of the modules were, it was not all that complex.
One problem that came up immediately was that I did not know how to use an application developed with Node.js. However, when I figured it out, the necessity of having to figure it became apparent as something missing in the instructions of the application. Finding different ways to run the application was also an issue since I wanted my testing to be extensive. The list of scenarios to test for the SSG application helped, but was not extensive enough to test _every_ viable scenario.
## Issues that I filed
[1.](https://github.com/alexsam29/ssg-cli-tool/issues/1) This issue arose right from the start, since I had not known that `npm install -g` would need to be executed in the command line first before the application could be used. I figured that other people would also encounter such a problem.
[2.](https://github.com/alexsam29/ssg-cli-tool/issues/2) This issue came from the initial testing that I did for all the options. According to the spec, both --version and -v had to have the same functionality, and the same went for --help and -h. Since --input/-i and --output/-i had already worked the same way, the same should be the case for --version/-v and --help/-h.
[3.](https://github.com/alexsam29/ssg-cli-tool/issues/3) Similar to the previous issue, this one also came from initial testing. According to the specs for this release, the -v/--version had to output the name of the application as well as the version, which the application was missing.
[4.](https://github.com/alexsam29/ssg-cli-tool/issues/4) This issue came from reviewing the source code for the application. I had noticed that one of the parameters for a function was unused, which is a very basic issue. However, it also exposed the problem that outputted files were named from the first line of the text file rather than the original file's name.
[5.](https://github.com/alexsam29/ssg-cli-tool/issues/5) This issue came from more extensive testing. By using the -i option without inputting a file name to target would create an output directory without creating any files. This seemed unintuitive and I thought an error message or something of the like should be displayed whenever this behaviour occurs.
## What was it like having someone test and review my code?
It was interesting having another person testing and reviewing my code, since typically my work would only be reviewed by myself. I was surprised that there were so many issues in my code. One issue that came up immediately was that the runtime library that I was using when compiling my code did not work on my partner's computer. I had to search for a solution for the issue and fortunately it was a simple change that fixed the problem
## Issues that were filed for my repo
[1.](https://github.com/rudychung/SauSaGe/issues/1) This was an issue that I knew was present in my code but I had yet to find a solution for. At the time of writing, it has been solved using an else if condition instead of an else.
[2.](https://github.com/rudychung/SauSaGe/issues/2) This issue I had not thought of, since in many cases command-line applications can be executed from any location. However, without changing PATH variables (which may be too advanced for some users), this issue will remain present. So, I will have to do with simply placing a step in the instructions to execute the application directly through the command-line.
[3.](https://github.com/rudychung/SauSaGe/issues/3) This issue was found to be intentional. It remains in place because it prevents `.html` files to be created out of sub-directory files in the initially inputted directory.
[4.](https://github.com/rudychung/SauSaGe/issues/4) This issue was a little more difficult to solve without increasing the coupling of my Text module and main function. I had to resort to placing the open and closing HTML tags as a constant variable in the Text module's header file in order to reduce code repetition.
[5.](https://github.com/rudychung/SauSaGe/issues/5) This issue was the similar to issue #5 that I posted on my partner's repo. Since I used a different programming language to code my application than my partner, I had to find my own solution to this issue. The fix itself was straightforward using the filesystem standard library's functions.
## Was I able to fix all my issues?
I was able to fix all my issues. I had the most trouble fixing issue #4 without further increasing coupling between my main method and the Text module. Issue #3 was not an issue at all, since it was placed there intentionally with a purpose. The fixes did not take all that much thinking, but spotting the issues required another set of eyes. Through this experience, I saw the value having another person look my code.
## What did I learn through the process?
I learned that there will always be issues that are present in the first versions of an application. Even though I may not see them as the author of the application, others may be able to spot these issues more easily or may have standards that I am not aware of. This is also a benefit of making an open source application, except instead of one person reviewing the code, many people could review it. | rudychung |
1,194,800 | Locks in Kubernetes | Problem In an event-driven system like Kubernetes, access to a resource can be restricted... | 19,817 | 2022-09-16T06:41:17 | https://rnemet.dev/posts/projects/klock | kubernetes |
## Problem
In an event-driven system like Kubernetes, access to a resource can be restricted with RBAC. RBAC is not designed to execute a mandatory or exclusive lock on a particular resource. It is not impossible, but I found it complicated and error-prone.
Sometimes I want:
* The CronJob named `daily-report` is constant. No one can DELETE or UPDATE it.
* A workload `payroll` can be modified only by the actor with UID `aa-dd-f445-d-55-d` and no one else.
* All resources with the label `site: for-fun` can be updated, but not deleted.
## Solution
Using RBAC is possible to partially meet requirements, but still when working in teams messing with operators, different automation tools, etc... Always something can go wrong.
Another option is [ValidatingAdmissionWebhook](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#validatingadmissionwebhook). It can be used to say who can and can not access a certain resource. It is not about authentication or authorization, that part is done by Kubernetes. It is about access,
granular access.
### [Klock](https://github.com/robert-nemet/klock) as solution
[__Klock__](https://github.com/robert-nemet/klock) is simple implementation in effort to match above problems. It adds __CRD__ that allows mandatory and exclusive locking. Matching which resource will be protected is done by matching labels. As well as which operation should be restricted.
#### Configuring ValidatingAdmissionWebhook
For which resource ValidatingAdmissionWebhook(VAW) is applied is done in VAW configuration:
```yaml
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
annotations:
cert-manager.io/inject-ca-from: klock-system/klock-serving-cert
name: klock-validating-webhook-configuration
webhooks:
- admissionReviewVersions:
- v1
clientConfig:
service:
name: klock-webhook-service
namespace: klock-system
path: /validate-all
failurePolicy: Fail
name: klocks.rnemet.dev
rules:
- apiGroups:
- '*'
apiVersions:
- '*'
operations:
- DELETE
- UPDATE
resources:
- pods
- deployments
- secrets
- configmaps
sideEffects: None
```
Above configuration, you can read as _for any api group and any version, whenever UPDATE or DELETE is about to be executed on a pod, a deployment, a secret, or a config map, ask VAW to validate it first_.
#### Mandatory locking
See example:
```yaml
apiVersion: klock.rnemet.dev/v1
kind: Lock
metadata:
name: lock-red-blue
namespace: yellow
spec:
operations:
- DELETE
matcher:
aura: blue
```
Now, if VAW has config as above `Lock` is effective for every pod, deployment, secret, and configmap in the same namespace. It will deny deletion of any pod, deployment, secret, or configmap with the label `aura: red`.
#### Exclusive locking
```yaml
apiVersion: klock.rnemet.dev/v1
kind: Lock
metadata:
name: lockred
spec:
operations:
- UPDATE
- DELETE
matcher:
aura: red
exclusive:
name: johny
```
With exclusive locking `operations` are forbidden for all except an actor named `johny`, in this example. So, same as above just ignore `Lock` for `johny`.
## Conclusion
You can check out [Klock](https://github.com/robert-nemet/klock) and explore it more. See `/tests/` for more examples.
| madmaxx |
1,194,991 | Add 1 to a number represented as linked list. | The given problem is of level easy but when you are a beginners it is very hard to solve the problems... | 0 | 2022-09-16T11:47:06 | https://dev.to/tejas910/add-1-to-a-number-represented-as-linked-list-42pj | programming, java, amazon, linklist | The given problem is of level easy but when you are a beginners it is very hard to solve the problems without reference. So to increase our logical thinking we have to solve at least one problem a day. The problem which is given below is solved by me today.
Problem:- Add 1 to a number represented as linked list.
A number N is represented in Linked List such that each digit corresponds to a node in linked list. You need to add 1 to it.
Example 1:
**Input:
LinkedList: 4->5->6
**Output:** 457
Example 2:
**Input:**
LinkedList: 1->2->3
**Output:** 124
Your Task:
Your task is to complete the function addOne() which takes the head of the linked list as the only argument and returns the head of the modified linked list. The driver code prints the number.
Note: The head represents the left-most digit of the number.
Expected Time Complexity: O(N).
Expected Auxiliary Space: O(1).
Constraints:
1 <= N <= 10100
**Solution.java**
```
class Solution
{
public static Node addOne(Node head)
{
Node pre = null;
while(head!=null){
Node temp1 = head.next;
head.next = pre;
pre = head;
head= temp1;
}
Node temp = pre;
Node prev = null;
while(temp!=null){
if(temp.data +1 >=10){
temp.data = 0;
prev = temp;
temp=temp.next;
}
else{
temp.data = temp.data +1;
break;
}
}
if(temp==null){
Node n = new Node(1);
prev.next = n;
}
Node ans = null;
while(pre!=null){
Node temp1 = pre.next;
pre.next = ans;
ans = pre;
pre= temp1;
}
return ans;
}
}
```
**Github Profile:-** https://github.com/tejas910
| tejas910 |
1,195,307 | A New Javascript Image Viewer Library from GrapeCity Documents | Check out a new JavaScript image viewer library from GrapeCity Documents. | 0 | 2022-09-16T18:49:14 | https://www.grapecity.com/blogs/a-new-javascript-image-viewer-library-from-grapecity-documents | javascript, webdev, devops | ---
canonical_url: https://www.grapecity.com/blogs/a-new-javascript-image-viewer-library-from-grapecity-documents
description: Check out a new JavaScript image viewer library from GrapeCity Documents.
---
Social media these days is all about images; most individuals are concerned about uploading the best possible image of what comes their way, be it the food they eat, places they visit, events they celebrate, animals they see, and much more. But, typically, no image is perfect and therefore requires a certain amount of editing to make it the best it can be and to post the best possible image on the social media scene.
Besides social media, image processing is also required in other fields such as medical, where image processing is used for tasks like PET scans, X-Ray Imaging, Medical CT, UV imaging, and Cancer Cell Image processing to enhance the accuracy of images and provide a better diagnosis. Another example could be scanning important documents as images for sharing, which might require image processing tools to detect or adjust edges/sharpen the document image to make the content more readable.
However, editing an image is still inconvenient for many web Developers who have to rely on installing Desktop software or interface with third-party apps. To provide an image processing solution, the Grapecity Documents v5.2 release introduces the **Javascript**-based client-side **GrapeCity Documents Image Viewer (Beta)** _(referred to as **GcImageViewer** hereafter)_ control. It is a cross**-**platform solution for viewing and editing Image files on **Windows, MAC, Linux, iOS, and Android** devices. It works in all modern browsers, including **Edge, Chrome, Firefox, Opera, and Safari.** The GcImageViewer can be conveniently embedded in major web frameworks such as **Pure Javascript, Angular, Vue, ASP.NET Core, ASP.NET MVC, HTML5, React, and Preact.**
### The First Look: Grapecity Documents Image Viewer

The snapshot above showcases the different **UI options** available in GcImageViewer to load, process, and save images. So, we will quickly run through these options to better understand the control:
1. **Open Document:** This option lets you load an image into the GcImageViewer with the help of an Open File dialog.
2. **Zoom control:** This control offers zoom-in and zoom-out buttons to zoom the image and a zoom textbox to define a specific zoom value.
3. **FullScreen**: To display the viewer in fullscreen and hide the menu bar at the top. As soon as the GcImageViewer goes into fullscreen mode, an alternate toolbar appears over the image to provide you with all the functionalities offered by the main menu bar, along with an option to exit the fullscreen mode.
4. **Navigation Control:** This proves useful when working with TIFF/GIF images, as it lets you navigate between the image frames.
5. **Download**: Provides you with an option to download the modified image on the client side.
6. **About**: The last option provides details about the GcImageViewer version.
Understanding the basic functionality offered by GcImageViewer, it's time to dig into details about each of these features, as elaborated in the next section.
### Grapecity Documents Image Viewer Features
#### Load Image
GcImageViewer supports loading images from many of the popular image file formats, including:
1. **JPEG**. Joint Photographic Experts Group image.
2. **PNG**. Portable Network Graphics.
3. **TIFF**. Tagged Image File Format.
4. **GIF**. Graphics Interchange Format.
5. **BMP**. Bitmap Picture.
6. **ICO**. The ICO file format is an image file for Microsoft Windows computer icons.
7. **SVG**. Scalable Vector Graphics.
8. **WebP** image format.
The images can be loaded either through the client-side API or the **Open** document option of GcImageViewer UI, which provides an open file dialog to choose and load an image into the viewer.
Image loading becomes quite interesting when working with **GIF** images, as GcImageViewer automatically starts the GIF animation as soon as a GIF image is loaded. In addition, it even provides a GIF player on top of the image, which lets you stop and start the animation. After the animation is stopped, you can navigate between the different frames using the Navigation control available in the GcImageViewer’s toolbar.
The GIF below shows an example of this behavior:
#### Zoom
GcImageViewer allows zooming of images between 5% to 500% along with other options, including “Fit to Width“ and “Whole Image“, using the zoom-in and zoom-out buttons available in the toolbar. One can even type in a specific zoom value in the zoom textbox, as showcased in the image below:
#### Rotate
GcImageViewer ships with a Rotation plugin to add support for rotating images at 0, 90, 180, and 270 degrees using the Rotate option available in the toolbar once the plugin has been added to GcImageViewer.
#### Plugin Support
GcImageViewer provides Plugin Support to allow users to extend its behavior and add new functionality. The images below depict one example where an ImageFilters plugin has been implemented to apply different filters to an image.
#### Client-Side API
GcImageViewer lets you load, edit or modify an image using the viewer UI options and provides a client-side API to further enhance the experience of working with a Javascript-based control. It offers basic functionalities including load, save, zoom, rotate the images, and meeting complex requirements of creating a new image or modifying an existing one.
### Configure Grapecity Documents Image Viewer
Finally, this section will describe how to start working with GcDocs ImageViewer by following three simple steps.
The steps below will guide you on configuring **GcImageViewer** in an **ASP.NET Core application**.
#### Step 1: Create an ASP.NET Core Application
We will begin by creating an **ASP.NET Core application** using Visual Studio 2022 and the **.Net 6** framework.
#### Step 2: Install GcImageViewer
Next, we need to install the GcImageViewer package. Run the following command in the Package Manager Console in Visual Studio to install GcImageViewer. Ensure the directory location in the command prompt is set to the **_lib_** folder in the project. The GcImageViewer will be installed in the **<app_name>\<app_name>\wwwroot\lib\node_modules** folder.
```
npm install @grapecity/gcimageviewer
```
#### Step 3: Add GcImageViewer
To add GcImageViewer control to the project, modify the default content of **Pages** **→** **Index.cshtml** file with the following code:
```
<div style="height: calc(100vh - 260px);" id="imageviewer"></div>
<script type="text/javascript" src="lib/gcimageviewer/gcimageviewer.js"></script>
<script>
var viewer = new GcImageViewer("#imageviewer");
viewer.open("sample1.webp", { imageFormat: 8});
viewer.zoom = { mode: 2 };
</script>
```
#### Step 4: Execute the Application
Build and run the application. A page with the GcImageViewer will show in your default browser.
The image below depicts the default display of GcImageViewer with an image loaded using the Client API:
Refer to the GcImageViewer [demos](https://www.grapecity.com/documents-api-imageviewer/demos/Overview) to explore all the features, experience the UI, and dig into the details of Client API usage. Also, this is just the beginning; stay tuned for many more exciting features in the future.
| chelseadevereaux |
1,920,562 | PHP is dead! | A post by Do Hugues | 0 | 2024-07-12T06:58:22 | https://dev.to/do_hugues_630361d82bc4ef3/php-is-dead-187e | do_hugues_630361d82bc4ef3 | ||
1,195,443 | The Git Commands I Use Every Day | 1. Get all latest changes without merging Stop pulling code that you think will break!... | 0 | 2022-09-17T12:34:13 | https://devmap.org/the-git-commands-i-use-every-day-5277f90ab743 | git, beginners, programming, javascript | ## 1. Get all latest changes without merging
Stop pulling code that you think will break! Having `fetch` in your workflow allows you to grab updated code without immediately merging it. Once the code is fetched, you can check it out like any other branch. When you're satisfied, then you can merge.
```bash
git fetch --all
# git checkout upstream/some-branch
```
## 2. Push upstream regardless of current branch name
Stop typing the branch names especially when they are long branch names. Just tell git you want to push the current branch to a remote location. `HEAD` is a key word that tells git to use the current branch.
```bash
git push production head
# git push origin head
# git push github head
```
## 3. Label your stash
This is useful if you stash a lot of code and you want to remember what the stash contains at a glance.
```bash
git stash save -m "my work in progress"
```
## 4. Use a stash from ages ago
Stop undoing stashes with `git pop` to get to an old stash. You can apply a stash that you created ages ago by using the following command.
```bash
# git stash list
git stash apply 3
```
## 5. Checkout the previous branch
This is super helpful when you are working on small features and you want to compare behavior/performance by toggling branches. You don't have to type the names, just use the minus sign.
```bash
git checkout -
```
I like this command so much that I made a quick YouTube shorts video showing it off!
{% youtube _hrCAigwSOk %}
## 6. Change the base of the branch after doing a checkout
This is useful if you created a new branch but you based it off the wrong branch. For example, say you wanted to branch from the beta code, but you accidentally branched using the production code.
```bash
git rebase --onto beta production feature
# git rebase newBase oldBase currentBranch
```
## 7. Move uncommitted changes to new/existing branch
```bash
git switch -c new-branch
# git switch existing-branch
```
## Bonus - Fuzzy Checkout
This custom command allows you to quickly switch to another branch without typing the entire name. This is super useful when you are using a naming convention and you are tired of typing a prefix like `feature/` or `issue/`
```bash
function fc() {
gco "$(git branch --format='%(refname:short)' | grep $1)"
}
```
If your branch name was called `feature/dropdown-select-color` you could quickly switch branches by doing something like this.
```bash
fc dropdown
``` | wadecodez |
1,195,651 | BackEnd Web Development 2023 Technique | Hi there, Harry. Here I have visited your Blog/Website which is providing the best information about... | 0 | 2022-09-17T06:53:40 | https://dev.to/harryjohn222/backend-web-development-2023-technique-4nf4 | javascript, webdev, programming, tutorial | Hi there, Harry. Here I have visited your Blog/Website which is providing the best information about software and its cracks With patch. I am also in this field working on some projects like this. Please visit my Projects. It's an honour for me. Thank you!
[eviews 13 crack with serial number](https://crackwinx.com/eviews-12-crack-serial-number/) | harryjohn222 |
1,196,209 | Masonite Crash Course | This video introduces the Masonite web framework. A framework that is MVC based. THis is really... | 0 | 2022-09-18T05:17:44 | https://dev.to/jod35/masonite-crash-course-152n | python, masonite, webdev, backend | This video introduces the Masonite web framework. A framework that is MVC based. THis is really similar to PHP Laravel and Ruby On Rails.
{%youtube 9wfeh3xIhgU%} | jod35 |
1,196,298 | Should new Android developers learn Compose or XML? | Android Jetpack Compose or XML-based View? | 0 | 2022-09-18T09:11:32 | https://dev.to/aldok/should-new-android-developer-learn-compose-or-xml-3oah | android, jetpack, jetpackcompose, kotlin | ---
title: Should new Android developers learn Compose or XML?
published: true
description: Android Jetpack Compose or XML-based View?
tags: #android #jetpack #jetpackcompose #kotlin
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/j8z8fvczoqvstsbgn3xx.jpg
---
In the next three months, I'll be volunteering to teach undergrad students Android development. So, I'm also faced with this question, should I teach a new developer Compose or XML?
In my opinion, aspiring Android developers should just start learning Compose. Here are my four reasons why:
## 1. Production-ready
Compose is ready for production. Twitter, Play Store, and Airbnb are just a few companies that already using Compose. It has been more than [one year since Compose reached version 1.0](https://android-developers.googleblog.com/2021/07/jetpack-compose-announcement.html).
What do I mean by production ready?
- No major bugs or unnecessary troubleshooting.
- The APIs are stable, consistent, and intuitive.
- There is no performance issue, your User Interface (UI) will render smoothly.
When I'm coming back to Android development after working as a backend engineer for a year, I'm curious whether I can build a complex UI with Compose. As a proof of concept, I've made [a clone of Astro](http://github.com/aldoKelvianto/Mona-Android-App), a quick commerce app that I believe has typical requirements of the real app (layered UI, custom behavior, multiple UI sections, etc.).
So, you don't need to worry that you will encounter too many issues when learning Compose. You can publish a real app with Compose.
## 2. Simplicity
This is an example of how you write UI using XML.
```xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical" >
<TextView
android:id="@+id/tvName"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="Hi, my name is Aldo" />
<ImageView
android:id="@+id/ivProfile"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
/>
<TextView
android:id="@+id/tvRole"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="I'm an Android developer 🤖"
/>
</LinearLayout>
```
And this is how you write UI using Compose.
```kotlin
Column {
Text("Hi, my name is $name", style = TextStyle(
fontWeight = FontWeight.Bold))
AsyncImage(model = "https://example.com/img/user.png")
Text("I'm an Android developer 🤖")
}
```
Even from this simple use case, you can see that Compose uses fewer lines of code.
The simpler the code, the easier it is to learn or to teach it.
You don't need to learn:
- XML (just use Kotlin)
- Binding XML to a Kotlin class
- Improving performance by flattening your View hierarchies using ConstraintLayout
This means you've got more time to learn other Android topics, like ViewModel, testing, Coroutines, and Jetpack libraries.
## 3. Familiarity
If you've learned declarative UI from other platforms, you will feel right at home.
Take a look at these code snippets that build the same UI for iOS (SwiftUI) and cross-platform (Flutter).
```swift
VStack {
Text("Hi, my name is \(name)!")
.fontWeight(.bold)
AsyncImage(url: URL(string: "https://example.com/img/user.png"))
Text("I'm an iOS developer 🍏")
}
```
```dart
Column(
children: const<Widget>[
Text('Hi, my name is $name', style: TextStyle(
fontSize: FontWeight.bold)),
Image.network('https://example.com/img/user.png')
Text('I\'m a Flutter developer ⬅️')
]
)
```
It looks somewhat similar, isn't it?
Chances are, a new Android developer is not going to pursue a career as a full-time Android developer. They might be exploring Flutter, iOS, backend, or not even pursuing a career as a developer.
By using Compose, you've learned a concept that can be applied to other platforms.
## 4. Support
Learning anything new can be difficult at first, no matter how good a library is. When you're stuck, Compose has many resources to help you, from official Android documentation to a plethora of community articles. To mention some:
- [StackOverflow](https://stackoverflow.com/questions/tagged/android-jetpack-compose)
- [Codelabs](https://codelabs.developers.google.com/?text=compose)
- [Official Compose app samples](https://github.com/android/compose-samples)
- [Code snippets](http://jetpackcompose.net)
You don't need to worry about integration with popular libraries as well. Popular libraries like Jetpack Components (ViewModel, Navigation, Hilt, etc.), Glide, or Koin is compatible with your Compose code.
Compose is still actively supported by Google, so even if you find a bug or a feature request, you can expect it's addressed in the next version.
## Summary
In conclusion, Compose is a safe choice for a developer who's just getting started with Android development. While XML is still dominant in the legacy project, Compose is the modern toolkit for building native Android UI. Go ahead and use Compose in your first app!
### Notes
- I'll be teaching Pemograman Mobile course at Universitas Musamus Merauke (UNMUS) as part of praktisimengajar.id government program. Thank you for giving me this opportunity!
- To be fair, XML is declarative UI too, a verbose one compared to Kotlin. But in XML, you still need to write imperative code for many tasks.
- Cover photo is taken by [weston m](https://unsplash.com/photos/3pCRW_JRKM8)
| aldok |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.