
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
825,826 | How to Deploy Your App to Netlify | 1. Push Your Code to Any Version Control Applications The first thing you need to do is... | 0 | 2021-09-16T09:41:06 | https://blog.furkanozbek.com/how-to-deploy-your-app-to-netlify | react, webdev, netlify, 100daysofcode | ## 1. Push Your Code to Any Version Control Applications
The first thing you need to do is push your git repository to any version control application. You can use any one of these;
- Github
- Gitlab
- Bitbucket
## 2. Register to Netlify
Once you have a repository inside any given application just signup to **Netlify** and connect them.

## 3. Creating New Site
Now, you should be on the team page where you can see your applications which right now you do not have but don't worry we'll add them right now.
In there you can either click "New site from Git" button or you can visit **https://app.netlify.com/start**
**You will see this screen**
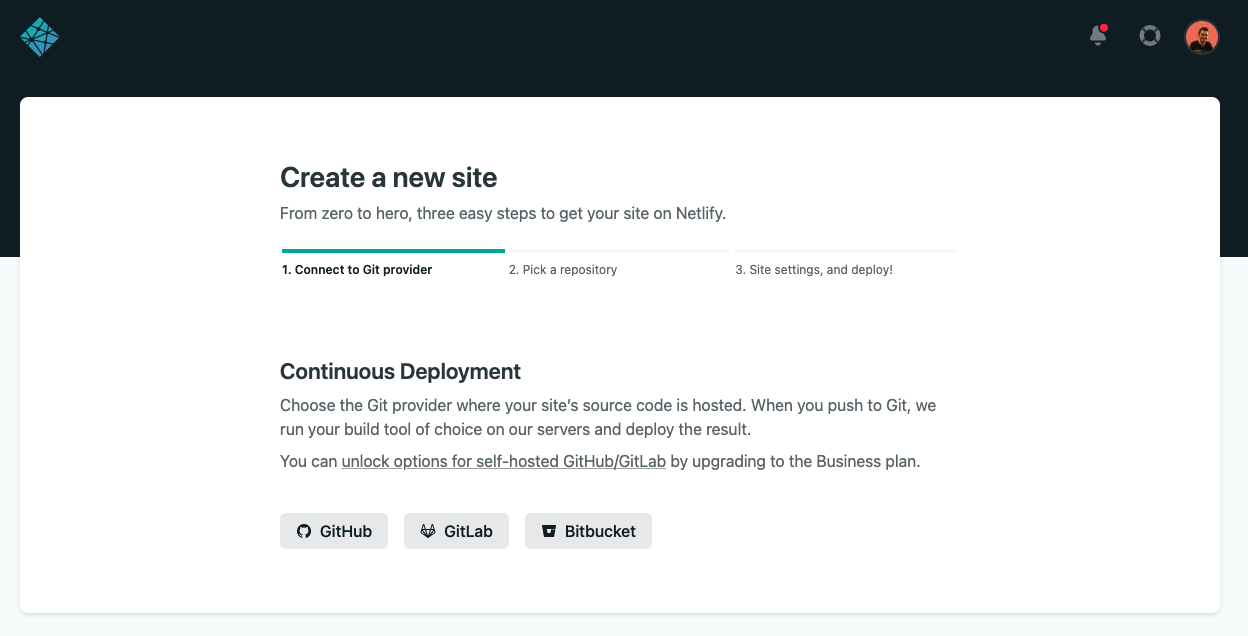
You should click the button which you are storing your repository right now. In my case it is Github.
## 4. Connecting Accounts
After that, you should see a connection screen where you will connect your Github account with Netlify.
Or if you are connected you will see a text that says **"Authorized"** which indicates that you already connect your account with Github****
## 5. Choose a project
Now select the project(repository) you want and continue
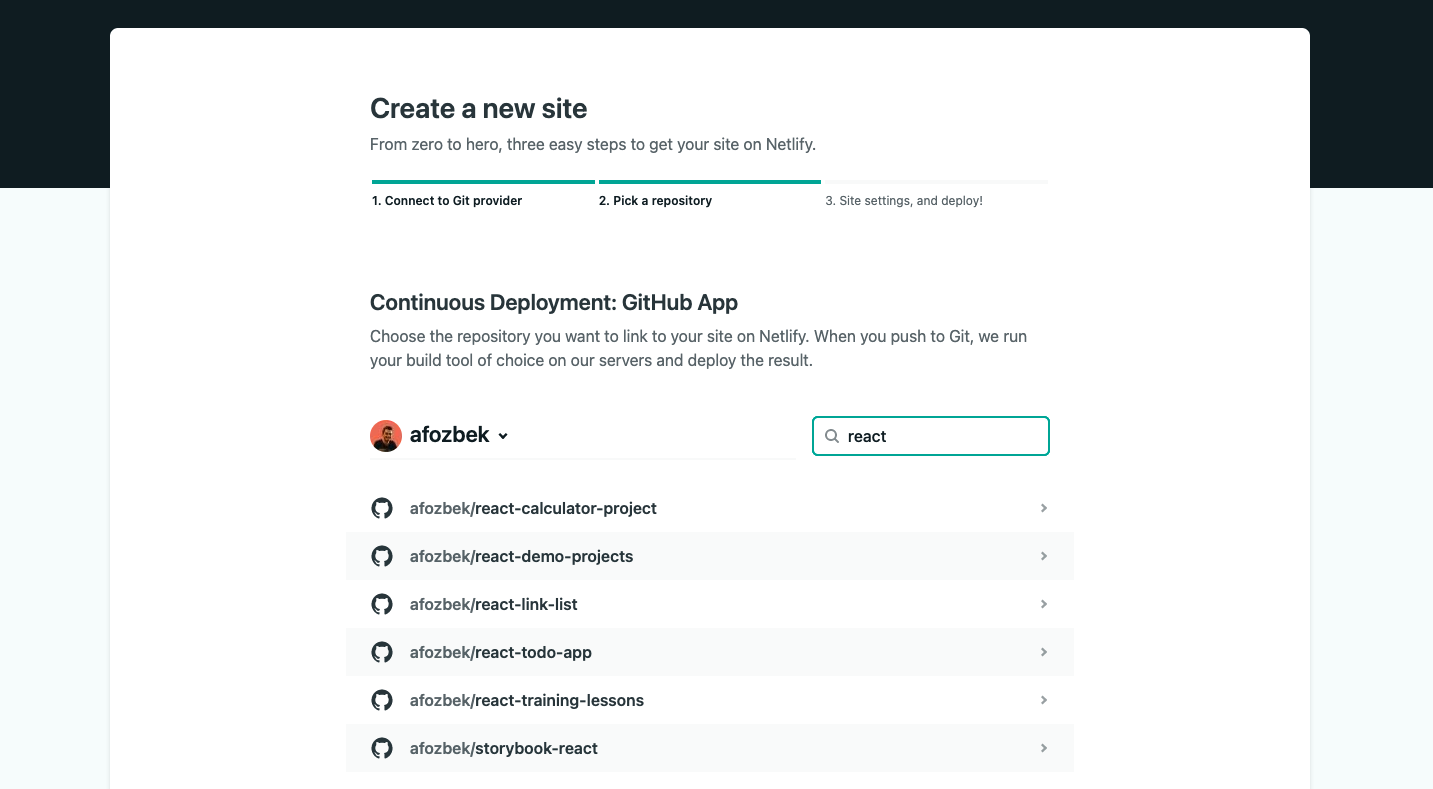
## 6. Choosing Site Settings
Now you can choose the owner of this application and choose which branch to deploy. Netlify will listen to that branch and if any changes published it will rebuild your application and run the tests for you.
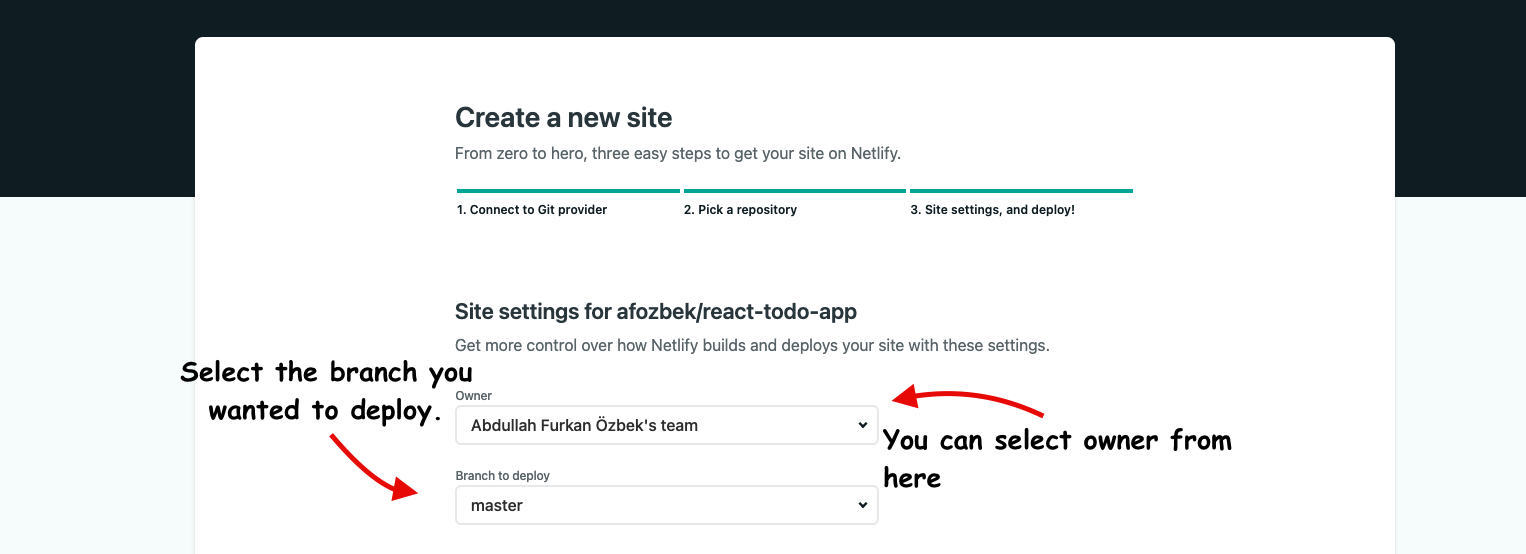
You can also choose the build command that is needed to run to generate the build folder. This folder name can be different from framework to framework. So make sure to run on your local first to see the folder name.
And once everything is ok deploy your site.
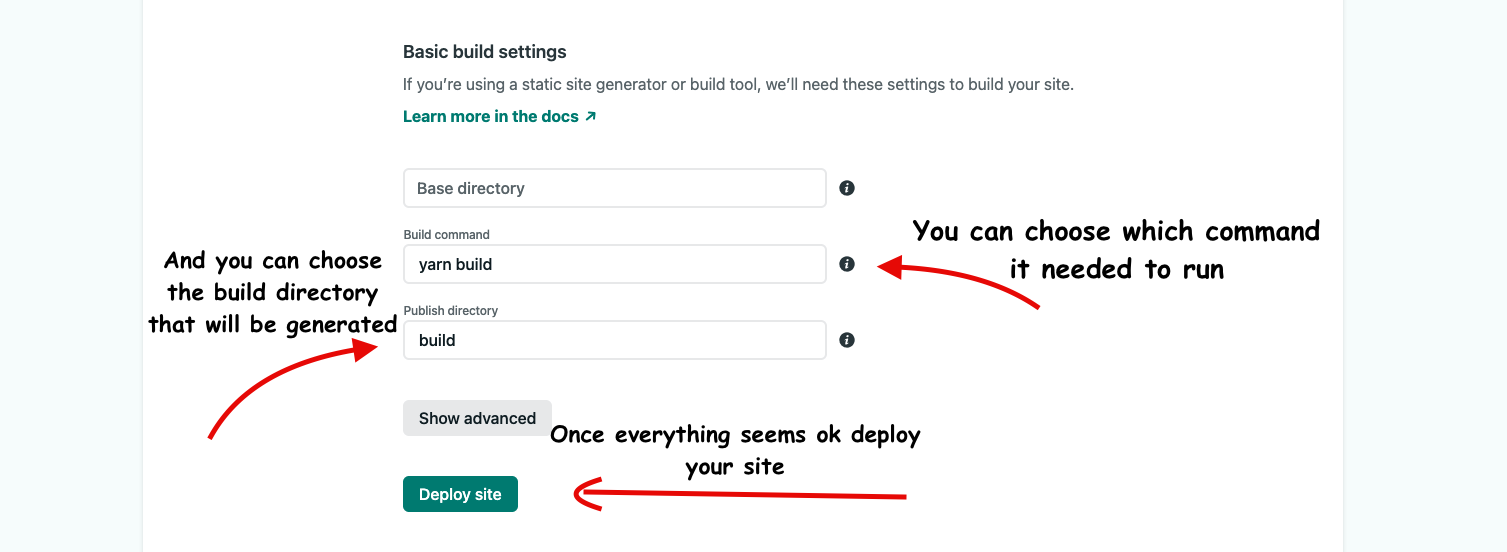
## 7. Congratulations
Congratz! You deployed your first application to Netlify.
| afozbek |
826,077 | Why Video Call SDKs Should Be Used? | Arvia Video call SDKs can drive up your sales with remote sale practices. Increase your customer... | 0 | 2021-09-16T13:20:05 | https://dev.to/arviatech/why-video-call-sdks-should-be-taken-196g | webrtc, webdev, videochat, livechat | <a href="https://arvia.tech/all-in-one-sdk/">Arvia Video call SDKs</a> can drive up your sales with remote sale practices. Increase your customer engagement rate and decrease your operational costs by utilizing video calls. You can have multiple functions with one simple SDK implementation.
Integrating video call SDKs to your website or your app can provide amazing benefits. The business can use this implementation to drive up sales and customer engagement rates. Also, video calls can be embedded in a mobile app for convenience. SDKs enable easier embedding process by decreasing the overall implementation costs.
<b>Video Call SDK Benefits</b>
Using video SDK might sound intimidating. But the benefits of this remote sales method will worth every effort.
<b>Fast Download and Implementation</b>
Compared to native video apps, video SDK offers a fast implementation. All you need to do is download the SDK and install it on your browser. Since it is a software development kit, the implementation time and costs will be significantly lower than developing a native app. When a business needs a fast video call solution, video call SDKs will be the best choice.
<b>Sell Under Any Condition</b>
The novel coronavirus pandemic has shown us one thing. You need to keep selling under any condition. But you need an alternative channel to your brick-and-mortar stores. This global pandemic enabled many global companies and SMEs to drive up their sales with alternative methods. When you use video selling, your sales team can sell anytime anywhere. They don’t need to be at the office. A good internet connection is all you need to continue your business.
<b>Personalized Videos</b>
Recently, personalized content gained importance in any sector. Customers and leads want to see written and video content that matches their needs. The standardized and one-fits-all approach is all behind. A remote sales tool can give you this personalized content. The videos for remote sales can be created for a specific customer or lead segments. Thus, the engagement rate and the conversion rate will increase significantly.
<b>Support Sales E-Mails with Video Remote Sale</b>
E-mail marketing is still one of the most popular marketing practices, especially among B2B customers. E-mails have a relatively higher opening rate than any other marketing method. But this global pandemic taught all of us an important lesson. You need to differentiate your content to engage with customers even in the hardest times.
When you support your e-mail marketing campaigns with video, you can send special messages to your customer. For example, during the pandemic period, a video can promote your business better. The video-specific to this event can include precautions and hygiene, especially for the service sector.
<b>Decreased Operational Costs</b>
By using the video call SDKs, you can decrease the operational costs of your business. Your sales team no longer needs to have face-to-face meetings with customers in their office. All you need is a video call. This will decrease transportation and other fees.
<b>Engage by Using Webcam</b>
Another way to start a remote sale is by using a webcam to engage with the customers. You will also need a video SDK for this process. However, you might also need some extra properties to live stream.
In this process, the sales team can directly engage with the customers by using their webcam. Instead of face-to-face customer visits, an online visit can be completed within minutes. Thus, your sales team and the customer can save time. Also, the dangers for the disease are minimized by keeping the social distance. When you implement a video sale tool, you can immediately start your remote sale practices.
<b>Support for Multiple Languages</b>
With an integrated subtitle program, you can solve all language problems by using video call SDK integration. Multiple language support is one of the key properties of these tools. You can choose different language subtitles for your videos. Thus, you can easily reach customers living in different countries.
<b>Control the Entire Video Call</b>
These SDKs empower the users by giving control of the conversation. It is possible to mute the video or blur the faces. Also, users can change the background for a more formal look. All of these can be completed with just a few clicks. Your sales team can bring the entire office to their home and connect with your customers and leads. There is no need to leave your home to increase your sales.
<b>Video Call SDK Disadvantages</b>
One of the main video call SDK disadvantages is related to browser incompatibility. Since the majority of these SDKs work on a browser, an older browser version might cause an issue in terms of audio and video quality.
In addition to that, these SDKs require a stable internet connection. All users should have a good and high-speed internet connection to benefit from the best capabilities of a video call SDK. Poor internet connection might lead to lags, disconnection issues and low-quality visuals. | arviatech |
826,214 | How And When to use bind, call, and apply in JavaScript | Call call quite simply lets you substitute a this context when you invoke a function. Calling the... | 0 | 2021-09-16T15:42:30 | https://dev.to/abhi784pat/how-and-when-to-use-bind-call-and-apply-in-javascript-2n5l | javascript | Call
call quite simply lets you substitute a this context when you invoke a function. Calling the .call() method on a function, will immediately invoke that function.
let Person = {
name: "Abhishek Patel",
showname : function(){
return this.name;
}
};
let changename = {
name: "Abhishek"
};
Person.showname; // "Abhishek Patel"
Person.showname.call(changename); // "Abhishek"
When to use call
When you are dealing with an array-like object and want to call an array method.
Apply
The apply() method is used to write methods, which can be used on different objects
let name={
firstname:"Abhishek",
lastname:"Patel
}
let printFullname=function(home,state)
{
console.log(this.firstname+" "+this.lastname+"from"+hometown+","+state
}
printFullname.apply(name,"[Sonepur","Bihar"]) //"Abhishek Patel from Sonepur ,Bihar
so in above function "this" will point to "name" object
we can also apply call function in this way
printFullname.apply(name,"Sonepur","Bihar")
When to use apply
A common use case for apply was to call functions that couldn’t be passed an array of arguments. For example, if you had an array of numbers: let nums = [1,2,3] and you wanted to find the smallest number. You couldn’t just call Math.min(nums) you would instead have to call Math.min.apply(null,nums) to get a minimum.
Bind
Bind creates a new function that will force the "this" inside the function to be the parameter passed to bind().
let name={
firstname:"Abhishek",
lastname:"Patel
}
let printFullname=function(home,state)
{
console.log(this.firstname+" "+this.lastname+"from"+hometown+","+state
}
let printmyname=printFullname.bind(name,"Sonepur","Bihar")
printmyname() //"Abhishek Patel from Sonepur ,Bihar
So,bind will force "this" to point at "name object
When to use
Async stuff
A very common front-end use case for bind is for anything that will happen asynchronously. For example in a callback that needs access to the original this context. This is especially handy in component based frameworks like React.
Further Reading
Call()-https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/call
Apply()-https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/apply
Bind()-https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_objects/Function/bind
| abhi784pat |
829,098 | SAAS Marketing Techniques To Grow Faster In 2021
Your Way To Success | Like every product/service. SaaS products are different. They are intangible. They have intangible... | 0 | 2021-09-17T05:20:01 | https://dev.to/debbiemoran/saas-marketing-techniques-to-grow-faster-in-2021-your-way-to-success-1o8k | saas, saasmarketing, saasmarketingstrategies | Like every product/service. SaaS products are different. They are intangible. They have intangible buyers. They have subscribers like Netflix, who have to pay for their product/ service annually, monthly, or quarterly.
To [increase sales](https://meetanshi.com/blog/magento-2-extensions-to-boost-sales/), they have a few tricks which are by giving annual discounts, showing off customer testimonials, social media promotions, [enhanced customer experience](https://wotnot.io/blog/ecommerce-customer-experience/), demos, [Live chats](https://www.helpcenterapp.com/blog/live-chat-software-benefits/), CTA, set up calls, and Feedback to retain the customer.
Not only this, this industry has its process as it has an intangible audience. So, they have to understand their presentations not through body language but by how they are expressing their views or presenting their questions in an email or call.
Providing Free trials is mostly there in the [SaaS industry] (https://www.peoplehum.com/blog/choosing-the-perfect-saas-partnership-a-checklist). As the audience will get to know what your product is creating value to their biz and how it is helpful in the growth of the biz by saving time/ money.
The free trial should not be too long or short. It should depend upon the complexity of the software.
SAAS Marketing Techniques To Grow Faster In 2021
Your Way To Success
Before knowing the technique one should know what Saas is and how it works. Right?
Like before buying anything we ask for the price of the product.
We all have heard about [SaaS product marketing](https://wotnot.io/blog/top-growth-hacking-strategies-for-saas-companies/)? But how it is different from other marketing channels is the thing to look into. Isn't it?
So, here we will give you the beginners guide For SaaS.
SaaS stands for Software as a service. It is a software licensing tool and a delivery model of a product. This service runs on a subscription basis and is hosted centrally. Like: Microsoft office.
The model involves software delivery by getting access to software with a proper internet connection and a device and removing the time-consuming process of installing and maintaining it.
Example: Netflix, where you chill and watch is an OTT platform which is a SaaS-based product where your service i.e. movies or series. It offers software to [watch licensed videos](https://www.mostlyblogging.com/youtube-shorts-download/) on its platform. It has a zillionth base of subscribers all over the world.
SaaS products are intangible like any tangible product. But attain revenue and profits. They have their selling strategies that differ from company to company.
###What are SaaS conversions?
It is like selling the software that the customer access through an online website or portal which is on a subscription basis which helps the biz and customers to grow their biz with save of time or money or improving their revenues
Since it is a subscription-based price model the customer gets frequent while buying these products as they are part of their growth which is a steady sale of their service.
And also, these products are highly customized. So, you can choose features according to your needs.
But the more expensive your product is, the more stakeholders will be involved which can stretch the process to one month or more. Here are other factors that slow down the SaaS sale cycle :
**1.Complex software:** the more complex the software is, the duration of the cycle will be more. So, in this case, the right prospect should be in the room for the proper and fastened solutions.
**2.New Markets:** if you are selling it to new markets, the cycle may be longer as you’re communicating with them and giving valuable information for the product. But before making them your customer you should educate them properly about the product which will further make them a frequent buyer.
**3.Enterprises:** Selling to these companies would increase the stakeholders but there would be technical and more legal red tapes which would slow down the cycle of sales.
**4.Free Trials:** if offer a free trial, then the length of the trial will naturally add time to the sales cycle. As the customer will utilize the free trial before proceeding with further buying. keeping in mind, the free trial should be short which will give two things: shorten the sales cycle and make the customer buy the service quickly.
The longer the trial, the longer would be the sale cycle which will take time to decide if the customer will buy it or not.
###Fundamentals of SaaS Sales
“Having a repeatable process empowers your sales reps to sell with efficiency and confidence”. The process begins from:
**Prospecting:**Since we are selling it to the tech-savvy audience, we will do [inbound marketing](https://www.yourdigitalresource.com/post/inbound-marketing-strategy-fundamentals) which includes blogs, online posts, email newsletters, whitepapers, etc.
In addition to that, we can do face-to-face interaction with potential buyers which is rare in this SaaS industry.
**Qualifying:** Not all visitors on your website or trial subscribers will buy the product. To know that, there are lead scores which is an automatic way to qualify leads and you will get information and interpret it from your data and assign it with the lead scores from 1 to 10.
Another way is to start a trial is to email them or call them for after-sale service. So, you will get an idea of the status of the buyer.
**Presenting:** Mostly it’s not possible to present in face-to-face interactions in the SaaS industry otherwise we have got it through body language.
Through online mode, presenting would be done through email sequence and frequent follow-ups which will let us know the pain points the way it’s been expressed.
**Handling objectives:** After presenting, prospects have questions and concerns about the product or service. So, you must have known what most of the customers ask and know how to handle the response of the prospect.
**Closing:** At this moment, the prospect becomes your customer. In this stage, we will deliver the final proposal of the product and negotiate with the customer.
**Nurturing:** to retain the SaaS customers excluding customer support which includes training for existing and new customers. Feedback includes reviews, rates, and testimonials.
Part of their happy moments by sending happy birthday, and celebration notes, etc.
###How to increase your SaaS conversions using the right marketing strategy:
**Create strategic trial duration**
Most of the SaaS products have a trial duration. As it is a great way to hook new customers to buy, however, to make it worthwhile, you should plan it strategically.
When the customer has the opportunity to get trials which will help them to know the value of the product in their biz as well as the benefit of your offering.
The trial period should depend on the software. if the software is complex then 14 days or more trials would work. But what if the software is easy to adapt and gives the trial for 30 days?
It would only make the sale cycle long and there would be fewer customers buying the product. As they know every part of your software and will compare with the alternatives of the service. So, it depends on the product.
**Custom/ live setup call**
Many of us don’t know how to set up the software. How did things work? These customers have the priority of how the software will work for them by giving lesser importance to how your products work.
SaaS has the highest conversion from this special technique of Live setup call only. This [CRM](https://close.com/crm/) would help them to achieve their objective related to the product they have taken a trial or purchased.
**Leverage Annual discounts**
Many SaaS products offer annual discounts in exchange for the customer paying the bill all at once in a cheaper amount as compared to paying it every month which attracts customers to attain the service.
While the company gets a sizable influx of cash at a moment and doesn’t get worried about a customer leaving at any moment.
**Automated follow-up**
As you see whenever you log in to the florist website or hospital website. They will ask ‘how may I help you?’ which is an automated way of assisting you.
In the same way, these automated services will help the new customer to assist with the service and product and they have common queries stored which will be solved by the assistant by putting up the questions and shortening the sale cycle.
**Content Marketing**
This is the only way of communication between the buyer and seller. By reading your content, understanding it, and perceiving it makes the buyer come into your contact.
Biz around the globe is using content marketing to reach the audience and generate leads. With consistency, you share the content it will increase its value over time
PPC( pay per click) also generates leads but with valuable content.
So, content marketing is an asset for biz owners while online ads are temporary or rented. Biz around the globe is using content marketing to reach the audience and generate leads. Keeping content quality consistent across [multiple channels](http://litcommerce.com) helps increase brand awareness among your audience.
**Search Engine Optimization (SEO)**
This feature works hand in hand with content marketing by making it discoverable in google, bing, and ranking it in two ways: On-page SEO and off-page SEO.
On-page SEO: This form is under your control. You create content that people search to read. By adding internal links, UI, use of the title, and description.
Off-Page SEO: Mainly, when we hear about SEO, links are the things that click us. But getting the right trusted and authoritative link is what matters! The best way to gain links and shares is by a distribution strategy.
**Google AdWords**
While inbound marketing reduces the spending of Adwords, zillion people are still clicking on the search engine ads per day.
If you don’t want to miss out on these people to generate leads then you should still invest in PPCi.e pay per click
.
PPC is beneficiary as it is scalable, generate leads, and generate the best ROI for your biz
**Pro Tip:** to increases sales, some strategies to take care of is to choose the right model of SaaS, identify the target audience and its value proposition, set prospect qualification criteria, create templates, call scripts, set revenue goals, create a customer support system, and keep track of sales performance metrics that will be effective in rank in the SEO.
| debbiemoran |
829,362 | The OS Data Hub explained: when detail matters | A comprehensive look at what the OS Data Hub is and the APIs that are accessible. Ordnance... | 0 | 2021-09-22T11:36:26 | https://dev.to/charleyglynn/the-os-data-hub-explained-when-detail-matters-5dp3 | ordnancesurvey, webdev, geospatial, tutorial | ###A comprehensive look at what the OS Data Hub is and the APIs that are accessible.
**Ordnance Survey, a data company?**
Fundamentally, Ordnance Survey (OS) is a data company and has been capturing information about Great Britain for almost 230 years. Our original purpose was to create a map in 1801 that would help the military defend and protect the nation. Our aerial imagery techniques helped support surveyors on foot 100 years ago. In the 1940s we were providing an advisory role to international governments on mapping and surveying; and in the 1960s we were mapping government sites.
We’ve developed digital maps of Mars and even used [OS OpenData](https://osdatahub.os.uk/downloads/open?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained) to recreate a map of Great Britain in Minecraft.
[Throughout its history](https://www.ordnancesurvey.co.uk/newsroom/blog/top-10-mapping-moments-in-the-history-of-os?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained), OS has always been at the cutting-edge of location data technology, and its capture and storage. In the early days, surveyors would go out into the wilderness to record waypoints, write them in ledgers and take them back to the office to create an archive of paper maps. However, in the last 50 years, OS has transitioned to capturing and storing this information in digital forms, and as a result, has a huge range of geospatial data about Great Britain that has been included in its data products.
**What is the OS Data Hub?**
[The OS Data Hub](https://osdatahub.os.uk/?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained) is our new platform to serve trusted, authoritative data through new formats to end users. It’s focused on building new efficient ways to access OS data and is a portal for mapping, data, and/or Application Programming Interfaces (APIs).
For those who are not familiar with the term, APIs are services that submit requests to servers and specify the data you want, which is then sent back to you immediately. Think of the restaurant analogy; where you submit your dinner ‘request’ to a server, who will provide this information to the kitchen, who cooks and prepares your order, and then brings your requested order to the table. APIs are essentially important middleware, and programmatically speaking, can reduce technical barriers to entry and the overheads associated with using large, complex datasets.
The OS Data Hub delivers the foundational layer to many geospatial applications. OS makes around 20,000 updates to the database every day. This trusted layer of detailed geospatial data can be pulled into many different use cases including data visualisation, geospatial analysis, and creating business insights. Even within the world of academia, OS data is helping to answer new and interesting geospatial theories.
The data is served through OS APIs in either the British National Grid or Web Mercator standards, and is interoperable with different software and mapping libraries. There are various types of online documentation including [code examples](https://labs.os.uk/public/os-data-hub-examples/?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained) where developers can copy and paste, add in their API keys, and start using OS data within minutes.
The OS Data Hub also has an error reporting tool to feedback about the data, so if you identify errors with the location information, you can report this directly to OS.
**The difference between Open and Premium data**
The signup process provides the technical and pricing information to choose between OS OpenData, Premium and Public Sector plan (Public Sector plan users will need to be a PSGA member).
The OS OpenData plan provides free and unlimited usage but with a data limit determined by the detail. The APIs can be used to view and integrate publicly-accessible datasets and to understand the capabilities of the data within the OS Data Hub. Users can also download the datasets to query offline.
The Premium plan provides access to premium OS datasets where the requests and transactions contain a price. The OS Data Hub provides users free premium data (API transactions) up to £1,000 per month and [information around how much each transaction costs](https://osdatahub.os.uk/plans?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained) so you can estimate the cost based on your usage, to support any budgeting.
The OS Data Hub comes with a dashboard to track progress of API usage. API Projects can help you organise your keys (think of servicing different customers or different websites that you are using) and track the overall usage of the applications you are using OS data on, in more sophisticated ways. Within an API Project you can select several APIs and your key is then directly linked to them all.
**OS Data Hub: the API suite**
OS provides APIs in three broad categories; maps, address data, and geographic features.
**OS Maps API** is a raster tile service that serves maps as PNG images, which are assembled in your browser or GIS. There are two ways to access OS Maps API; Open Geospatial Consortium (OGC) standard web map tile service (WMTS) and ZXY, meaning these maps work with almost all geospatial software and every mapping library. OS Maps API styles are designed and developed by OS cartographers with different features and visual hierarchies.
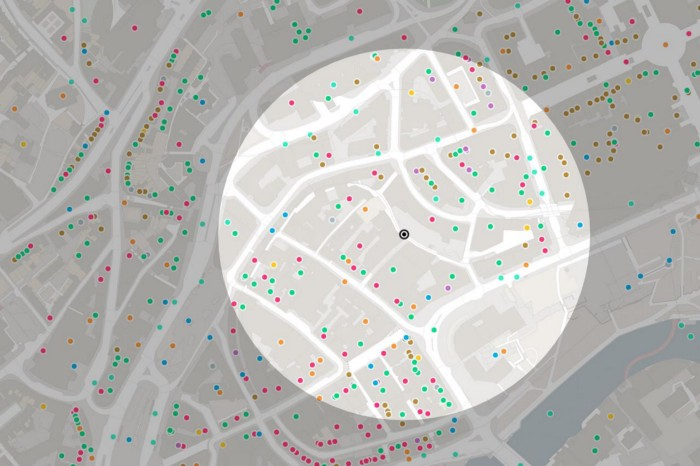
**Using OS APIs for quicker updates**
The OS Maps API is useful for base mapping. For example, the [National Library of Scotland](https://www.ordnancesurvey.co.uk/newsroom/blog/comparing-past-present-new-os-maps-api-layers?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained), which is a repository for historical maps and provides a tool where users can view historical maps and compare them against modern versions. Analysts of The National Library of Scotland originally downloaded large files of OS Maps onto local servers, which meant there could have been gaps of up to two years before updated basemaps were used in their application. Now the analysts have integrated OS Maps API that are connected to OS servers, they are using the most up to date basemaps by only having to change a couple of lines of JavaScript code.
OS Vector Tile API provides an on-demand and quick way to create maps for web and mobile users using OS cartography. The advantage is that vector features are rendered within the browser or client. This means its capable of supporting more interactivity and online experiences and its compatible with common web mapping libraries and increasingly more GIS software. The Vector Tile API is fully customisable not only for individual layers but also individual features.
The Vector Tile API is used with GeoAR.it, an augmented reality company for the environment. It uses vector tiles to create 3D extruded buildings. Every geographic feature can have metadata or attributes that hold relevant details about that feature. Within the Vector Tile API, building footprints have a feature called the building height attribute, a number that represents the height of that building. GeoAR have extruded out the polygons to recreate a 3D model as a city, using the Vector Tile API, to use in this augmented reality environment.
**OS Features API** is used to access the geometries and attribution of OS data. It provides rich geographic vector features in either GeoJSON or GML formats. In addition to the geospatial data (geometries), you receive a set of metadata that is connected to that feature, which are called attributes. In a GIS application, you can examine an attribute table such as address, area, postcodes etc.
The OS Features API provides many data layers, including OS MasterMap Topography Layer. The user specifies the details of the data they need; for example, results that match a building or road, or a spatial query including features that intersect a property. The OS Features API removes overhead of managing and storing the data locally.
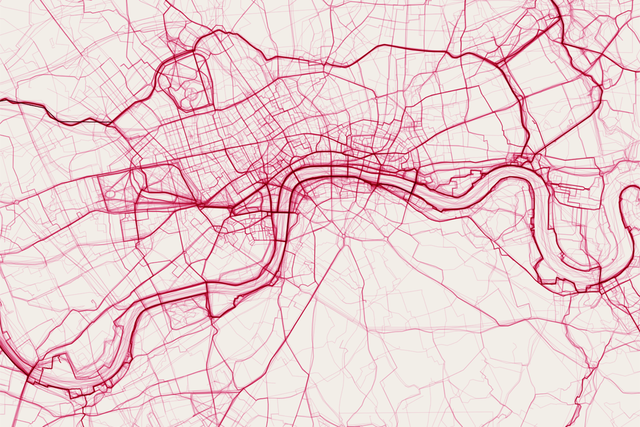
**Achieve detailed location analysis without surveying**
Start-up Balkerne uses OS Features API to conduct location intelligence risk analytics for customers. The data provided via the API helps Balkerne achieve an advanced understanding of which areas of their properties are at risk of natural disasters, such as floods or subsidence. They can perform this location risk analysis, without having to send out surveyors of their own to inspect a given area.
**OS Linked Identifiers API**
Across OS and UK government, a number of geospatial databases store data for several purposes, such as UK highways and Land Registry. Each of these databases require a unique ID to look up the correct data using analytical processes. The community and Government have agreed on providing unique reference numbers that can be attached to a property, street, or topographic feature through its lifecycle. These include the Unique Property Reference Number (UPRN), Unique Street Reference Number (USRN) and OS also provides the Topographic identifier (TOID).
The Linked Identifiers API enables correlation between all these reference points.
OS has individual features associated with their datasets. However, within the Land Registry database, they may have one UPRN that is associated with a single structure. The Linked Identifiers API allows you to query a UPRN and it will correlate and send back all the TOIDs connected to that UPRN. There is no geospatial data returned by the Linked Identifiers API, but it is a way to link between several different database that use multiple reference systems.
**OS Names API** is a free-to-use searchable database to help the user find and verify populated places, cities, roads, and postcodes within Great Britain. To find ‘Southampton’ from the API perspective, when sending a request with the string of ‘Southampton’, it will pull out searches related to that request. Information will include where the location is, its size, and the map view will zoom directly to that location. The OS Names API enables forward and reverse geocoding, and links diverse information such as a statistics or descriptions to locations.
**OS Downloads API** automates the discovery and download of OS OpenData. It enables users to work with bigger datasets, even within the capability of hosting them on their own servers, or to do some country-scale analytics. Users are able to request various coverage areas, metadata, and data format depending on the dataset. From October 2021, it will also include OS premium datasets including OS MasterMap Topography Layer and AddressBase Premium.
**OS Places API and OS Match & Cleanse API** are address APIs and contain AddressBase Premium data. Users can use these APIs for forward and reverse geocoding of detailed address data, which includes a UPRN for linking and sharing. The GeoSearch function allows the user to search for addresses using bounding box, radius, and polygon queries. Both address APIs can save the user time, ensure they capture the correct address details at source, and help minimise errors in their own databases.
**Accessing the OS Data Hub**
Any developers, data scientists, or GIS users can access the OS Data Hub using standard protocols for accessing information over the internet and using the standard format for requesting and retrieving data.
For [web developers](https://labs.os.uk/public/os-data-hub-tutorials/web-development/automated-open-data-download?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained), connect with libraries such as Leaflet, OpenLayers, Mapbox GL JS and ArcGIS for JavaScript. All libraries have, native to their functionality, ways to connect to the OS Data Hub in several standard data formats.
For [data scientists](https://labs.os.uk/public/os-data-hub-tutorials/data-science/price-paid-spatial-distribution?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained), use Python and R libraries, including Geopandas and Jupyter Notebook for fetching data over an http request. This is more around structuring those requests so they comply with how the OS Data Hub APIs are expecting to receive the request and will send the data back.
[GIS analysts](https://labs.os.uk/public/os-data-hub-tutorials/gis-applications/3d-flood-modelling?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained) can use OS APIs to pull the basemaps into their workflows and connect to rich geospatial features directly, along with attribution, for the areas you want to analyse. It’s about using the right data, as and when you need it.
Most trends in software development are due to their ability to do something easier, cheaper, and/or more efficiently. The OS Data Hub encompasses 230 years of mapping and geospatial expertise; it has undertaken and managed the technical GIS burden, in addition to the heritage associated with OS, to allow the developer to use and manage geospatial data through simple and easy-to-access APIs.
**For more information visit [osdatahub.co.uk](https://osdatahub.os.uk/?utm_source=devto&utm_campaign=devrel&utm_content=data-hub-explained).** | charleyglynn |
829,382 | Curious Media lab - DocsBarcelona x Garage Stories | Hello! Sharing this amazing #opencall :) At Garage Stories we are preparing a lab along our... | 0 | 2021-09-17T09:28:57 | https://dev.to/garage__stories/curious-media-lab-docsbarcelona-x-garage-stories-3g0d | design, techtalks, career, challenge | Hello! Sharing this amazing #opencall :)
At Garage Stories we are preparing a lab along our colleagues from #DocsBarcelona to encourage you to work on your first emerging media project (VR/AR/AI) for social impact! Open for creators, artists, filmmakers, storytellers and all sorts of creative minds from all walks of life! 🚀🌍
This year we'll be focusing on these themes:
- conservation of economical balance
- injustices and abuse of power
- the legacy of wars and colonialism
We'll be super excited to have you on board! Please feel free to spread the word!
Curious Media 🕵️♀️📹 - https://www.garagestories.org/curiousmedia
18-21 October, 2021 · 4-day virtual workshop · 6pm-9 CET
Cost: 35 €
Applications open now: https://docs.google.com/forms/d/e/1FAIpQLSeiV1IhWuZVvmgRep3DAXOqfCNA6ZC3suHHGnLA-CHgEDdUKw/viewform | garage__stories |
829,411 | How To Sell Online Fitness Programs | Due to the spread of corona virus, many governments have implemented the rule that gyms, yoga studios... | 0 | 2021-09-17T10:33:46 | https://dev.to/praveene27295/how-to-sell-fitness-programs-online-29c2 | video, videostreaming, streaming, fitness | Due to the spread of corona virus, many governments have implemented the rule that gyms, yoga studios and swimming pools will remain closed for the next 12 months. This has drastically affected gym owners, yoga teachers businesses. So at present, many fitness instructors have started their own online fitness studio, started selling fitness programs online and they have been able to reach more people beyond borders. Many people have moved to an alternative solution that is doing a workout at home by watching fitness videos online. Online Fitness programs have become a trend as many have decided to do work out at home themselves.
Online fitness Studios are Video streaming platforms where fitness instructors perform exercises so that users can watch videos to learn exercises it’s a kind of virtual gym. Through an online fitness studio, you can share workouts, training plans, nutritional diet and health tips and exercise courses. This remains an excellent opportunity for fitness instructors to online fitness as this helps in reaching more people virtually literally from any location.
It’s better to start online fitness programs where you need to build a Video platform with help of a video platforms provider so that people can workout videos at any time, anywhere and on any devices like mobile, laptops and TV. With this online fitness studio, you can train more people without the need of hiring an extra trainer, expanding your training facility and spending more time. So let get into the main topic of how to sell online fitness programs
## How to Start Online Fitness Programs in 4 steps
### 1. Choosing the Business Model
There are two business models: TVOD and SVOD. A business model needs to be chosen depending upon the type of business you run.
**Transactional Video on Demand(TVOD)**: It is a Model where users pay money one time to access the video content permanently or even download it. The transactional model is best when you want to teach a particular topic or exercise, workout routine and even workshop. You can sell a single series of videos as a package such as training plans, exercise, nutritional plans and workout tips. Once the customer bought this video content from you they don’t need to buy it again and they access the content for an entire lifetime
**Advantages**:
* Once the Video product is ready you can sell it for an entire lifetime
* You can sell video products on average between $75 and $100
* You can market your online fitness training business in person and also virtually
* You can even use referrals and affiliate groups to boost your business growth
**Disadvantages**
* Once the product is sold to the particular customer you cannot sell the same product to him again, so you need to find new customers every time to sell the product
* Revenue is not recurring and stable
* More money has to spent in marketing
* It takes more time to create a new video course again
**[Subscription Video on Demand (SVOD)](https://dev.to/praveene27295/7-ways-to-reduce-subscription-churn-59ni)**: It is a model where users have to pay a particular fee monthly or yearly to access an entire library of video content an infinite number of times. If they stop paying the fees, the user loses access. It is the best model for fitness instructors as they want to build a client-based online fitness platform. In this model, the trainer adds and updates videos on these platforms so that users learn and stay updated. Trainers keep on adding multiple exercise videos, nutritional and health tips and different courses from time to time to keep users engaged.
**Advantages**
* Income flow is stable
* You can sell video on an average from $12 to $15
* Recurring income as user renew it monthly or yearly
* Customers remain subscribed for a longer time
* It can be easily promoted online and in-person
**Disadvantages**
* It takes time in creating video content regularly
* Initially, it takes some time to make money
### 2. Planning your content
After selecting the business model and in the next step you have to plan your content of what type of online fitness course you are going to offer and how it looks on a client level.
You need to have a clear picture of what your online fitness program is all about. You need to have some plan before you start training. you need to know your goal before creating video content. You need to have some clear idea about
* What am I going to teach
* How am I going to teach
* What are the important things needed
* What do customers expect from us?
Next is the video content you create,it is what your audience engage and experience it.It is the step how you are going to create an online fitness program for :
* Different intensity of workout from easy to difficult phase
* Different experience levels from beginner to professional
* Training plans
* Health tips
* Workout for particular body parts
It also depends upon how to do you make a video
* Solo or in groups
* Live videos or already recorded content
* Will your course follow logical order or not
It is always better to plan your content before starting off your online fitness course
### 3. Building your own Video Platform
Building your own video platform that is a website and App for mobile remains the face of your online fitness program so through this people will come to know more about fitness courses, pricing and what kind of video is suitable for them. Well developed website is the most important thing to do as there are many **[video platform providers](https://www.flicknexs.com/)** at present that build video platforms for fitness instructors. It is always better to choose a Video platform provider that builds you complete video streaming platforms with important features included such as
* Website and Video player Customization tools.
* Analytics dashboard
* CMS
* Video monetization options
* Different payment options and
* White-label video streaming
* Both on-demand and live streaming capability
With a well-built video platform, you are ready to start and grow your Online fitness program
### 4.Setting up the Pricing Plan
Here comes the most important part as Fitness instructors find it difficult to fix a price for online courses. Most fitness instructors might be knowing the fees for real-time gym sessions but when it comes to online it is better to make market research what other fitness instructs are offering. If prices are too high users will look for other platforms and if prices are too low then the value of your online fitness program goes down. It should be fixed in such a way that it is affordable for all types of users. Set a price at a normal range and then increase it based on customer feedback. Consider giving a free trial for the first week for first-time users. Try to fix a higher price for live and personal training when compared to pre-recorded video content. For the Subscription model, you can sell video on an average from $12 to $15. For the Transaction-based model, You can sell video products on average between $75 and $100
### 5.Marketing Online Fitness Programs
Marketing online fitness programs is a most essential part that needs to be done after building your video platforms can be done through social media channels such as Facebook, Instagram and LinkedIn. You can make it through youtube by releasing short videos or trailers so you gain more traffic to your website. Sending out coupons, promo codes to attract an audience. Conducting referral programs making existing customers refer fitness courses to their family and friends. Setting up a newsletter campaign to retarget the audience who have visited our site. Giving out the free trial for a week to give the new users an experience with our new fitness platform
## Wrapping up
Online Fitness Programs are **[Video-based training platforms](https://www.flicknexs.com/)** where you can easily build, grow your business by reaching more people. It helps in easily selling your product to many people beyond borders to make money provided the content is good and engaging.
| praveene27295 |
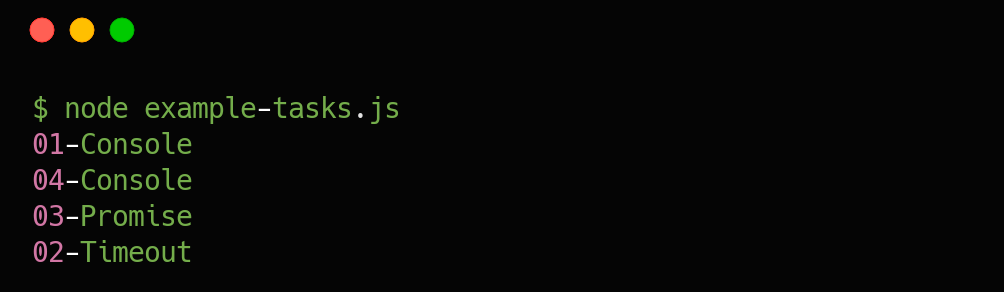
829,583 | Debounce Function in Javascript 🚀 | let count = 0; const debounce = (func, delay) => { let timer; return function(){ ... | 0 | 2021-09-17T11:59:05 | https://dev.to/cagatayunal/debounce-function-in-javascript-47ha | javascript, functional, webdev, debounce | ```javascript
let count = 0;
const debounce = (func, delay) => {
let timer;
return function(){
clearTimeout(timer);
timer = setTimeout(() => {
func();
}, delay);
}
}
let scrollCount = () => {
console.log(count++);
}
scrollCount = debounce(scrollCount, 500);
window.addEventListener('scroll', scrollCount);
``` | cagatayunal |
829,593 | html page | how to ctreate the multpage for the dispaly product details page thanks | 0 | 2021-09-17T12:12:21 | https://dev.to/rakes97/html-page-3ji1 | pagehtml | how to ctreate the multpage for the dispaly product details page
thanks | rakes97 |
829,602 | How to make a simple unread notification animation (ex: with a bell icon) | When building notifications UI elements it is very common to point out when a user has new elements... | 0 | 2021-09-17T12:53:39 | https://dev.to/miralo/how-to-make-a-simple-unread-notification-animation-ex-with-a-bell-icon-4e1i | css, animation, fontawesome, csstrick | When building **notifications UI elements** it is very common to point out when a user has **new elements to read**. This is achieved in most cases with an animation, for example if we have a bell icon we're gonna to make it swing every # seconds.
**Today we're gonna to see this**, you can find a finished example [in this pen](https://codepen.io/Miralo/pen/KKqmVMa).
As usual we're gonna use FontAwesome and, in this case, the SVG format of the "fa-bell" icon (remember to read the [license indications](https://fontawesome.com/license)). So, when we have it's markdown on our page we will add this animation (Courtesy of [Animate.css](https://github.com/animate-css/animate.css/blob/main/source/attention_seekers/swing.css)).
---
### The animation (part 1)
```css
svg {
animation: custom-swing 1s;
-webkit-animation: custom-swing 1s;
animation-iteration-count: infinite;
-webkit-animation-iteration-count: infinite;
}
@keyframes custom-swing {
20% {
transform: rotate3d(0, 0, 1, 15deg);
}
40% {
transform: rotate3d(0, 0, 1, -10deg);
}
60% {
transform: rotate3d(0, 0, 1, 5deg);
}
80% {
transform: rotate3d(0, 0, 1, -5deg);
}
to {
transform: rotate3d(0, 0, 1, 0deg);
}
}
```
The main animation is set, but as you can see it's... too invasive 😜: our bell swings "forever" and fast.
**We need to add some "delay" in the main animation between the swings**, so we will use some Math and logic to get around it.
---
### The animation (2 part)
In few words we need do **edit the keyframe in order to "finish" the animation early**, leaving some "space" as a delay.
At the moment our animation last 1 second, but if we want to our bell swing for 1 second and wait "about" 4 seconds before another one we have to set the animation to 5 seconds.
After this, **we have to "divide" and limit the animation timing to complete in about 1/5 of the total**.
```css
svg {
animation: custom-swing 5s;
-webkit-animation: custom-swing 5s;
animation-iteration-count: infinite;
-webkit-animation-iteration-count: infinite;
}
@keyframes custom-swing {
20% {
transform: rotate3d(0, 0, 1, 15deg);
}
40% {
transform: rotate3d(0, 0, 1, -10deg);
}
60% {
transform: rotate3d(0, 0, 1, 5deg);
}
80% {
transform: rotate3d(0, 0, 1, -5deg);
}
to {
transform: rotate3d(0, 0, 1, 0deg);
}
}
```
Here it is, now we have some delay between the swings, and you can play with duration and percentages as you like to adjust the result!
Photo by <a href="https://unsplash.com/@arturorey?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Arturo Rey</a> on <a href="https://unsplash.com/s/photos/bell?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a> | miralo |
829,816 | How a Shy, Introvert Dev, With Anxiety Issues Spoke at 2 Conferences 🇪🇺. | 8 days, 5 countries, 2 conferences - Dealing with anxiety and networking. Hello beautiful people, in... | 0 | 2021-09-17T16:43:21 | https://blog.eleftheriabatsou.com/how-a-shy-introvert-dev-with-anxiety-issues-spoke-at-2-conferences | conference, publicspeaking, introvert, developer | **8 days, 5 countries, 2 conferences - Dealing with anxiety and networking.**
Hello beautiful people, in this article I’ll describe my last 8 days traveling in Europe and attending as a speaker 2 tech conferences. While we progress I'll share what I learned during these days (tech and non-tech news/advice) as well as some tips about networking and being comfortable around new people (which is something I always struggle with, but I am making my best to improve it).
**Notes:**
*1. I used to travel a lot in conferences all over the world, but then covid happened and I stopped! Maybe the old followers/readers, already know that, but as I usually say, I have 2 passions: my job and traveling. So when these 2 things can be combined you can bet I am a happy girl 😊*
*2. Also, I am fully vaccinated and I take seriously all the health regulations. It's not only about my well-being but also about the people around me. I would never jeopardize their health.*
**Let the journey begin...**
P.S. If you are bored to read, watch the [vlog](https://youtu.be/VBlnjW2Lvgs) 😉.
<a href="http://www.youtube.com/watch?feature=player_embedded&v=VBlnjW2Lvgs" target="_blank"><img src="http://img.youtube.com/vi/VBlnjW2Lvgs/0.jpg" alt="IMAGE ALT TEXT HERE" width="240" height="180" border="10" /></a>
# Day 1 - Monday
## ✈ Greece, Germany and Croatia
I woke up so excited for my journey, everything was ready and planned. I had made my preparation through the weekend (airplane check-in, suitcases, and even some of Monday's work), my flight wasn't until midday so I had some time to work and be productive.
The socializing part started as soon as I arrived at the airport. There was an issue with the online check-in so I had to actually speak to a human for my tickets 😳. I know, I know, for some of you that wouldn't be an issue, or it could even be your pleasure, but I have some anxiety issues even on the smallest things...
I asked the man in the check-in "do you need to see my vaccine ce ce cert certif certification?" I was rumbling so hard, I couldn't prefer the word certification in my own language (certification = πιστοποιητικό), the man laugh but he started to chat with me about other things and that actually made me feel better... Maybe we were chatting for about 7-10' until a huge waiting line had created... (oops, sorry travelers 😊).

The next stop was Munich (Germany 🇩🇪) and right after there Zadar (Croatia 🇭🇷). From Zadar, a taxi driver picked me up and drove me to the hotel. The taxi driver didn't know English so we couldn't communicate... As you can probably understand that was not an issue for me😏.

The hotel was located in an area outside of Zadar and it was one of the best luxurious hotels I have ever been to (more about that later). It was about 7 pm when I took a shower and went alone for a dinner at the hotel's restaurant. As I started to eat a young smiley man approached me, "hi, are you also a speaker? are you this girl?" (pointing at my photo on the conference's website) as I knot my head positively the young man showed his photo on the website too, introduced himself and asked me if he could join me. My heart started to beat faster, not because I didn't like the man, but because, you know, I had to speak with another human😳.

I actually spent the next few hours with this person. He was just one year older than me, a CEO of a company, and a creator of a js framework (let's keep some anonymity, and not get into more details, at least for now). 😁
After dinner, I went to my room, worked for a few more hours, and went for sleeping. 😴
*1st day's thoughts💭 : Could humans be actually pleasant?! The guy from the airport check-in made me feel comfortable and the guy from the dinner kept me company and actually became my companion for the next days!!*
# Day 2: Tuesday
## Conference: [Infobip Shift](https://shift.infobip.com/) - Day 1 of 2 - The day of my talk
The next day started with a nice breakfast near the hotel's pool 🏊 🥐 (I'm telling you dear readers, the hotel was amazing!).
I stayed in my room working until midday when it was time to call an uber and reach the conference's location.

I attended several people's talks and gained some valuable knowledge of tech and coding.
I also gave my talk which was about UX and UI. Everything went great and according to the plan. Weirdly enough when I'm presenting I'm not nervous (I have a trick for that, maybe I could share it on another article... 😊, let me know if you are interested in how to speak to an audience/giving a presentation and not getting a panic attack!! 😁 )

At the venue, I met the dinner-guy who introduced me to his friends/speakers and we became a nice "little" nerd 🤓 and IT gang!! How cool, right?!
At this point, I had checked the conference's website and I knew who were the people that I definitely wanted to meet. These were people like Gift, Ekene, Sébastien, Eduardo, Kent, Nikolas, and more.

Some of those people I was following on social media or I was familiar with their work. Other people seemed very interesting, I loved their talk so I definitely wanted to meet them. As I was surrounded with my cool IT gang it was easier to meet people, they could introduce me to others and if they also didn't know the "others", they were not as anxious as I was (hello extrovert people), so they would just go and speak and I would follow (that's a pretty good approach for meeting new people!)
*2nd day's thoughts💭: Humans have started to seem less terrifying... They like to talk, they like to make jokes and they even want to help you!*

After the conference, I went back to the hotel, worked for a few hours and at night I went for dinner 🍲 in a nice location with my nerd IT gang and we even went for an after-party (come on dear introvert friends, you have to applause me here 👏 👏, I went for both dinner + after party 🎉).
# Day 3: Wednesday
## Conference: [Infobip Shift](https://shift.infobip.com/) - Day 2 of 2 - Networking and meetings
The day started with a nice chilled breakfast ☕ near the pool and continued with work. I only went to the conference venue in the afternoon when I was done with work.
It was time for meetings and networking once again😔.
### 1.The Porche experience 🚙
Let's start with something cool.

**Porche** was one of the sponsors and they wanted a woman in tech to represent them. They liked my talk and my presence and they asked me for some possible collaborations. They took some professional photos with the cars and me (I am waiting for the official photos too... As soon as I get them I’ll share them on Instagram 📸), and they had a professional driver who took me on a fast ride (I can't even describe how insanely beautiful the car and the ride were). For those of you thinking "but where can you drive/run a fast car like Porche safely?", I have an answer: the event was held in Zadar's biggest sports arena. The arena had also a huge parking which was allocated by Porche. Each time only a handful of people could visit at the same time the parking due to safety reasons!
### 2. Being approached by attendees
A few people approached me as they had some questions and queries around my UX and UI talk or they would be interested in potential collaborations. That went well... I only messed up in the end with some emails and phone numbers🤣. See, I m not good with names... And that resulted in sending some messages to the wrong people on WhatsApp!! But I guess these things happen, right?! Or is it only me? (Please say it is not only me, it will make me feel terrible, no kidding😕.)
### 3. The interview
It's not uncommon in a conference to be asked by the organizers to take part in a video that will be used mainly for promoting purposes in their current or upcoming events. Usually, there is someone who will make a few simple questions (hence I call this part "the interview") around the conference and will record the speaker's answers. On the 1st day of the conference the organizer asked me to take part in the video, I said "yes" but then..."hello darkness my old friend" I could not do it... My shyness had returned... So I said "no".
But...the 2nd day, as I was sitting with the cool nerd IT gang and I could watch them doing the interview I decided to give it a chance (that was a nice win 🏆 for my little introvert self), everything went fine!
### 4. The potential collaboration
Since this is work-related I won't get into details. The main point is that I had an online meeting with an "x company" and as we were discussing we realized that on of their developers and I would be at the same conference so now it would be a nice opportunity to meet in real life and discuss some business! That's how I met a fellow developer 😊
### 5. The other speaker, for the other conference
As I mentioned, in the upcoming days I was about to hit another conference in another country. The organizer from the other conference told me about this guy who would be in Croatia and then in Ukraine too (we would be in the same conferences), so I had to meet him! But you know, I'm introvert and shy... How would I do that... At first, I didn't even know who he was...
At the second day of dinner, I asked my cool yet nerdy IT gang if they knew him. Long story short, they found him for me and even the dinner-guy made the introduction as I was too scared for that...
But guess what, it went well! The other-conference-guy was super nice and friendly! And **he's also a writer here at Hashnode**! 😁
Moving on, I had a lovely night with good company 🍻 !
# Day 4: Thursday
## Croatia to Austria 🇦🇹
My day started in the same way. Breakfast 🥐 and work. Later that day I would catch my flight to Vienna, Austria. I reached Vienna and stayed one day there as there was no direct flight to Odesa, Ukraine which was the 2nd conference.

No networking stories this time. I quickly arrived at the hotel. There, I only talked with the hotel receptionist and the host of the hotel's restaurant.
My evening ended with working out and work.
# Day 5: Friday
## Austria to Ukraine 🇺🇦
Another day, another flight 🛬 !
Breakfast in the hotel, a few hours of work, and catching up on a flight!!
This time I landed in Odesa-Ukraine for the conference of **[PyCon](https://pyconodessa.com/en/) Odesa**.

### The "German" organizer
Shall we move on with another **networking story**?!
Did you wonder how a girl from Greece, working occasionally with Javascript and Design, working full time as a community manager at Hashnode, would end up in a Python conference in a little city in Ukraine?
Well, there are 2 points connected to each other. The 1st one is that I simply applied to speak to the conference as I believe my talk is equally important for all kinds of developers... (and that's usually what all speakers do, they apply to conferences...). The 2nd one (and usually the hardest one) is to get an invitation... But... A beautiful sunny morning I received a Twitter DM from an organizer I met a few years ago in Munich, Germany telling me that he is a co-organizer for this conference too and he'd love to have me as a speaker. I specified to him once again that my talk is not related to Python but it would be my pleasure. And just like that, I was in!
Will I have an invitation from the organizer if he didn't know me? I honestly don't know... But I have a suspicion that our old meeting helped.
### Let's go to the accommodation and the venue

The conference venue and the accommodation were in the same location. This is very convenient for the speakers... The only issue was that the location was a bit outside of Odesa and not many taxis were willing to drive you... Thankfully another organizer came and picked me up 😊, he drove me to the venue where I met once again the "German organizer". He introduced me to some lovely girls and fellow speakers (who later became my friends).
I took a few hours to relax and then it was time for dinner and drinks in the city center!

# Day 6: Saturday
## Conference: PyCon Odessa - Day 1 of 2

By now, I m sure you know the drill. Breakfast 🥐 and work! You may be thinking "But Elef, it was Saturday did you have to work?!" and the answer is no... But the thing is I hadn't finished Friday's work and I also wanted to prepare some stuff for Monday that I knew I would be traveling and I wouldn't be able to do.
This time my breakfast wasn't near a pool or at a fancy hotel restaurant but at a terrace with a view of the ocean and the city!
After work, I met my cool gang, a few new speakers and started to attending talks. In the evening, we had a lovely dinner with the crew and the attendees in an open space and we talked about tech and life.
# Day 7: Sunday
## Conference: PyCon Odessa - Day 2 of 2 - The day of my talk

This day started differently... It started with yoga! The speakers and the attendees got together on the building's terrace where we met the yoga instructor and had a lovely short session with her!

We continued with talks, and after lunchtime, it was my turn! I gave once again a talk about UX and UI. I was pleased with it as many people approached me asking for advice.
Since this was the second and last day people were more relaxed and the conference ended up earlier than the previous day.

As a closing party for the organizers and the speakers, we booked ourselves a yacht ⛵ for the afternoon/evening. It was my first time sailing and having so much fun with people that I literally met a couple of days before. Everyone was welcoming and chilled!
*Last day's thoughts💭: Actually those humans who called them shelves developers and advocates are... quite fantastic!*
# Day 8: Monday - Back home 🏠
## Ukraine to Germany to Greece 🇬🇷
As soon as I woke up ☀ , I found the organizers who helped me to find a taxi and get to the airport. At the airport's cafeteria, I did my daily stand-up meeting with the Hashnode team, worked for a few hours, and took my first flight to Berlin. That flight was 2h 30min so I started writing this article!
In Berlin, I had a long layover AND a delay on my flight which actually gave me the time to finish all my work, prepare for the next day, and of course attend Hashnode's Bootcamp!
On the last flight from Berlin to Greece I kept writing this article and I even managed to finish it.
(After writing an article I need some time to review and edit it... Plus in this case, add some photos and edit a video. So although the article was finished on Monday it was published on Thursday.)
# General thoughts 💭
## Could I have created more connections/opportunities?
Of course! You can find opportunities everywhere you just have to know where to look for and be willing to take your risks.
Could I have met more people? Yes.
But on the other hand, I'm glad that I managed to pull this trip of... As a shy, introvert person I'm glad with my progress!

## Thank you... 🙏
At this point I'd like to thank:
- Hashnode for giving me the opportunity to work in a flexible schedule.
- The InfoBip organizers for creating an amazing event.
- The PyCon organizers for creating a truly unique and memorable event.
- All the speakers and the fantastic people who shared freely their knowledge with me (and kept me company).
- And you dear reader. Thank you. I wouldn't be here without your support either on [social](https://instagram.com/elef_in_tech) [media](https://twitter.com/BatsouElef), [YouTube](https://www.youtube.com/c/EleftheriaBatsou), or here at Hashnode! Let me know in the comments if I can do anything to help you too 😊.
Did you actually read the article? If not that's ok, watch the video [here](https://youtu.be/VBlnjW2Lvgs).
<a href="http://www.youtube.com/watch?feature=player_embedded&v=VBlnjW2Lvgs" target="_blank"><img src="http://img.youtube.com/vi/VBlnjW2Lvgs/0.jpg" alt="IMAGE ALT TEXT HERE" width="240" height="180" border="10" /></a>
**************************************
👋Hello, I'm Eleftheria, Community Manager at Hashnode, developer, public speaker, and chocolate lover.
🥰If you liked this post please share.
🍩Would you care about buying me a coffee? You can do it [here](https://www.paypal.com/paypalme/eleftheriabatsou) but If you can't that's ok too!
**************************************
🙏It would be nice to subscribe to my [Youtube](https://www.youtube.com/c/EleftheriaBatsou) channel. It’s free and it helps to create more content.
🌈[Youtube](https://www.youtube.com/c/EleftheriaBatsou) | [Codepen](https://codepen.io/EleftheriaBatsou) | [GitHub](https://github.com/EleftheriaBatsou) | [Twitter](https://twitter.com/BatsouElef) | [Site](http://eleftheriabatsou.com/) | [Instagram](https://www.instagram.com/elef_in_tech) | [LinkedIn](https://www.linkedin.com/in/eleftheriabatsou/)
| eleftheriabatsou |
829,884 | Entendendo o Node.js e seu funcionamento | Introdução Neste artigo, você irá entender o que é o Node.JS, e a sua principal... | 0 | 2021-09-17T23:18:44 | https://dev.to/leonardodesa/entendendo-o-node-js-e-seu-funcionamento-1p9e | node, javascript, programming, tutorial | # Introdução
Neste artigo, você irá entender **o que é o Node.JS**, e a sua principal funcionalidade que é indispensável para qualquer desenvolvedor compreender o funcionamento da linguagem, chamada de **Event Loop**.
# O que é o Node.js
Node.js, ou simplesmente Node, é um software de código aberto baseado no interpretador V8 do Google e que **permite a execução do código javascript do lado do servidor** de forma simples, rápida e performática.
# Interpretador do Node
O Interpretador é um **software especializado que interpreta e executa javascript**. O Node utiliza o Interpretador V8, que tem como proposta acelerar o desempenho de uma aplicação compilando o código Javascript para o formato que a máquina irá entender antes de executá-lo.
# Call Stack
**É uma pilha de eventos**, esses eventos podem ser uma função disparada pelo código. Por isso o event-loop fica monitorando para que, toda vez que uma função for disparada, ele deverá executá-la somente uma coisa por vez.
Vamos ver um exemplo:
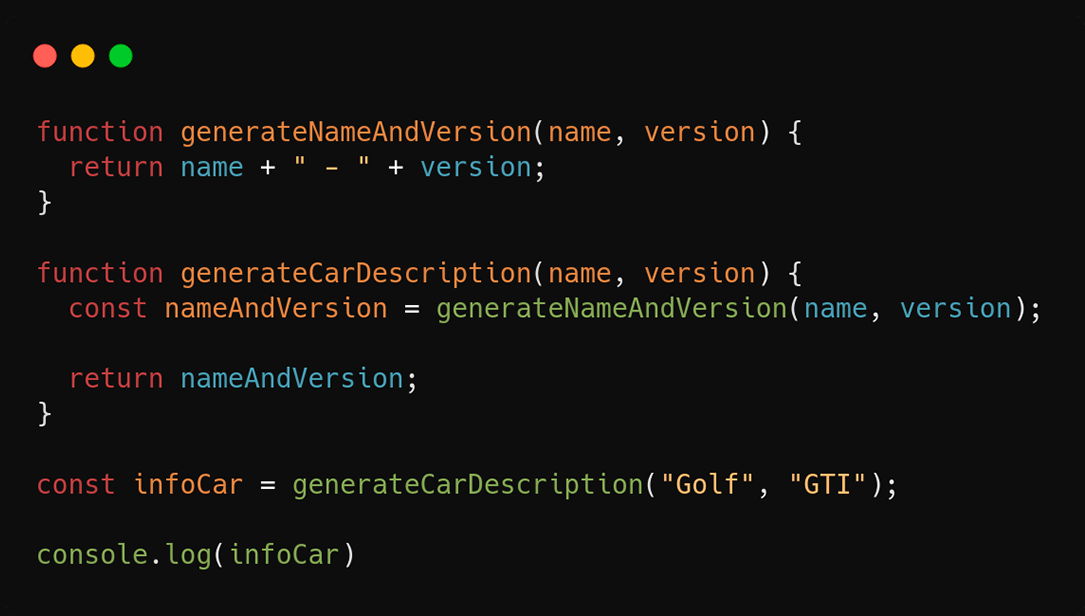
Aqui temos um exemplo bem simples para entendermos como funciona a stack. Basicamente a função **`generateCarDescription`** é chamada recebendo o nome do carro e sua versão, e retorna uma sentença com os parâmetros concatenados. A função **`generateCarDescription`** depende da função **`generateNameAndVersion`**, que é responsável por unir as informações de nome e versão.
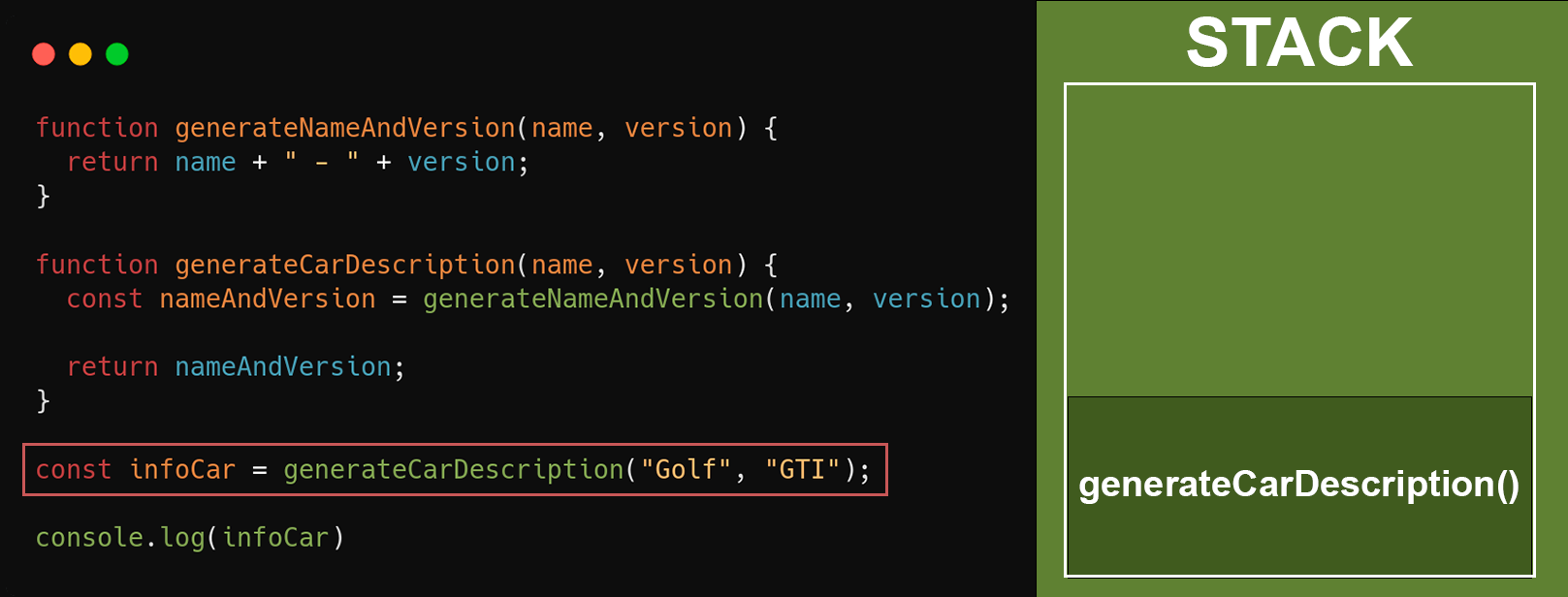
Quando a função **`generateCarDescription`** é invocada, ela depende da função **`generateNameAndVersion`** para atribuir o valor do nome e versão do carro na variável **`nameAndVersion`** e, quando ela for chamada, ela será adicionada na stack como no exemplo abaixo:
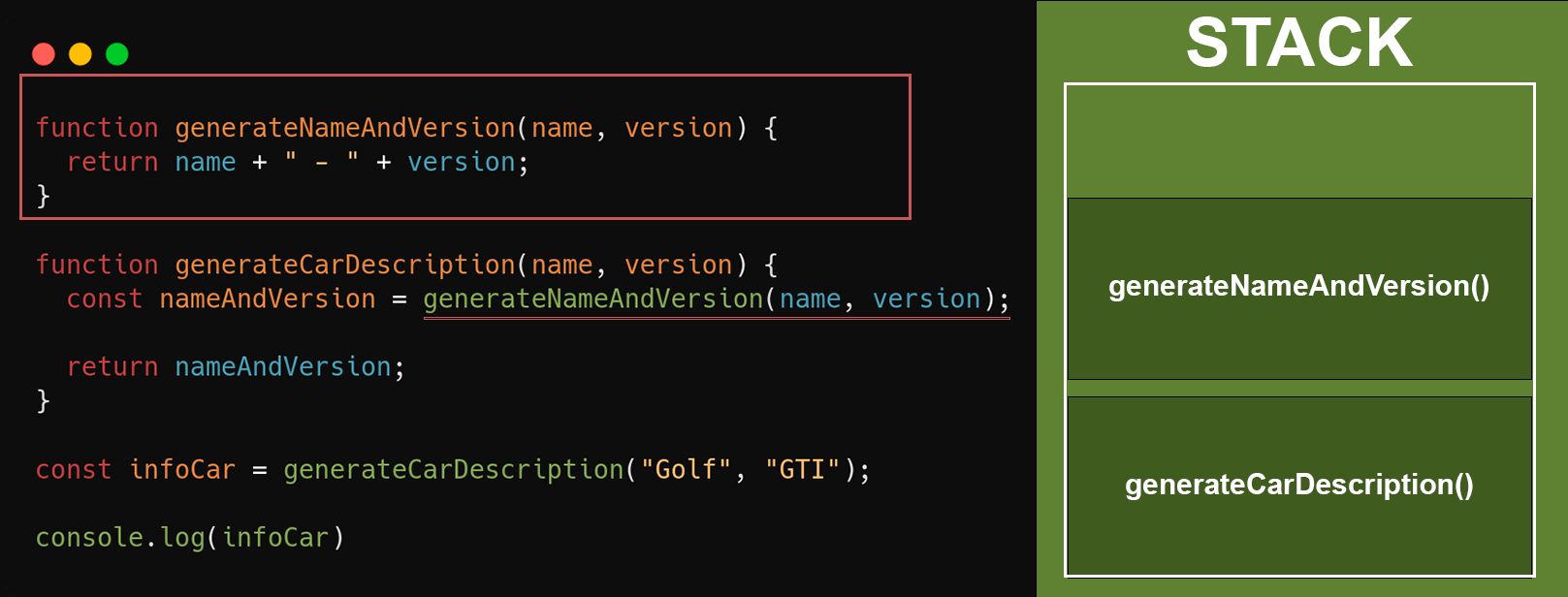
Após a execução da funcão **`generateCarDescription`**, logo em seguida a variável **`nameAndVersion`** irá receber o retorno da função **`generateNameAndVersion`** que foi imediatamente adicionada na stack, até que sua execução finalize e o retorno seja feito. Após o retorno, a stack ficará assim:
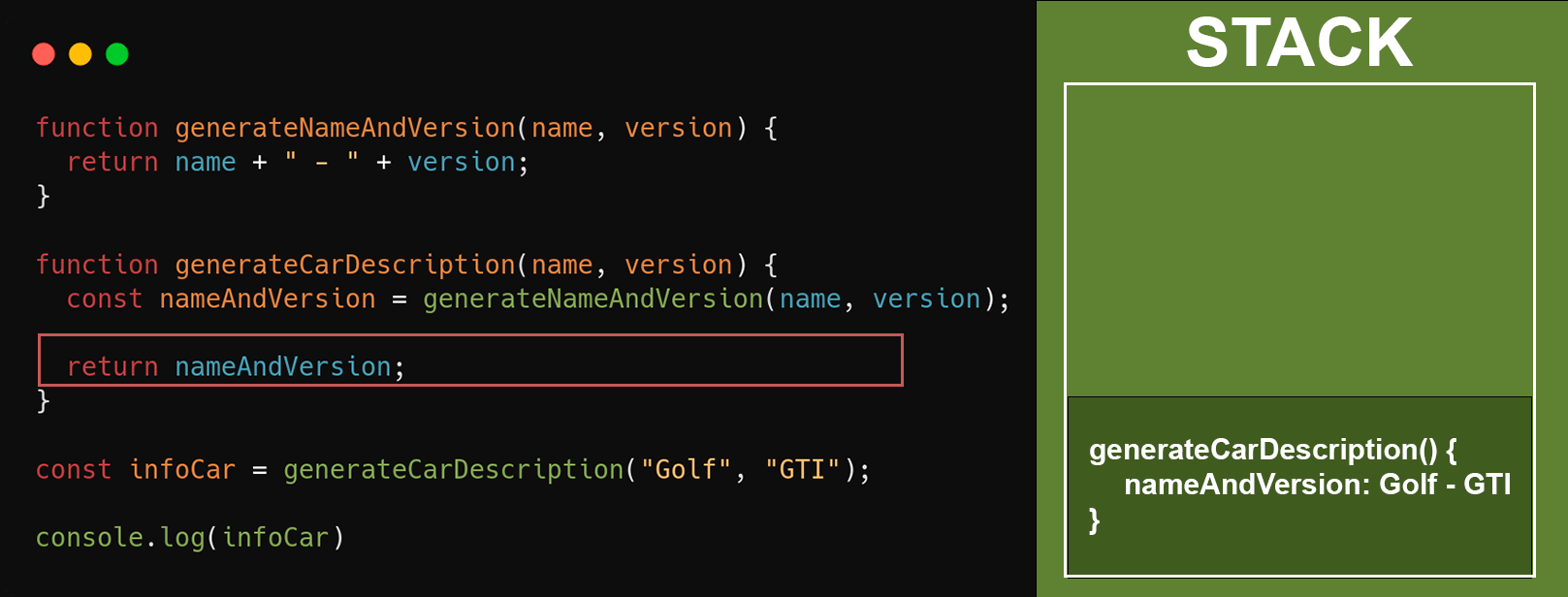
A última etapa será retornar a variável **`nameAndVersion`**, que contém o nome e versão do veículo. Isso não irá alterar em nada na stack. Quando a função `generateCarDescription` terminar, as demais linhas serão executadas. No nosso exemplo será o **`console.log()`** imprimindo a variável **`infoCar`**. E por fim, será adicionado o **`console.log()`** quando tudo acima já estiver sido executado.
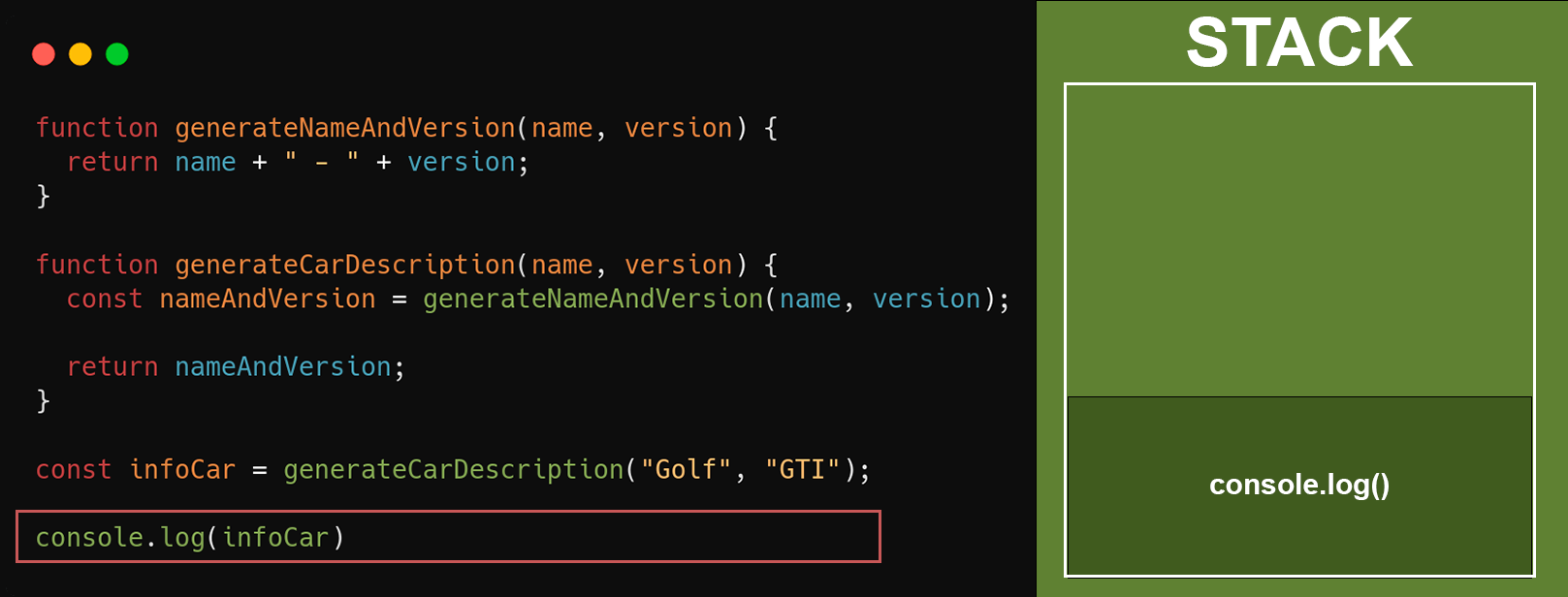
Como a **stack só executa uma função por vez**, de acordo com o tamanho da função e o que será processado, isso irá ocupar mais tempo na stack, fazendo com que as próximas chamadas esperem mais tempo para serem executadas.
# I/O - Operação bloqueante e não bloqueante
I/O se refere, principalmente, à interação com o disco do sistema e a integração com a [libuv](https://libuv.org/).
**Operação bloqueante é a execução do código no processo do Node precisa esperar** até que uma operação seja concluída. Isso acontece porque o event loop é incapaz de continuar executando alguma tarefa, enquanto uma operação bloqueante está sendo executada.
**Todos os métodos I/O na biblioteca padrão do Node tem uma versão assíncrona, que, por definição, são não-bloqueantes**, e aceitam funções de callback. Alguns métodos também têm suas versões bloqueantes, que possuem o sufixo **Sync** no nome. Para maiores Informações sobre I/O, acesse: [I/O](https://nodejs.org/pt-br/docs/guides/blocking-vs-non-blocking/)
# Single-Thread
O Node é uma plataforma orientada a eventos, que utiliza o conceito de thread única para gerenciar a stack. Quem é **single thread é o v8 do Google**, responsável por rodar o código do Node, a stack faz parte do v8, ou seja, ela é single thread, que executa uma função de cada vez.
# Multi-Threading
Para trabalhar com operações paralelas, e obter um ganho de desempenho, o Node e sua stack por si só são incapazes de resolver múltiplas operações ao mesmo tempo, por isso, ele conta com uma lib chamada de [libuv](https://libuv.org/), **que é capaz de gerenciar processos em background de I/O assíncrono não bloqueantes**.
Exemplo de uma função assíncrona sendo executada:
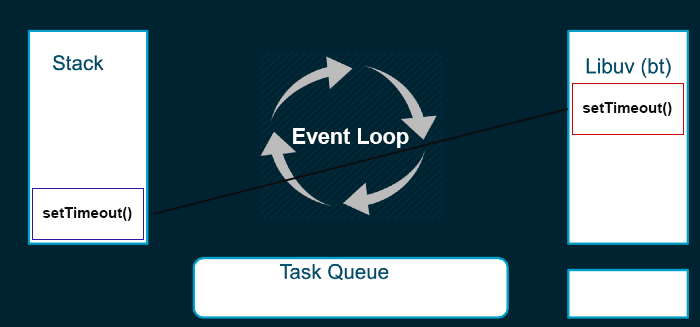
Nesse exemplo, a função **`setTimeout()`** é executada na stack e jogada para uma thread, enquanto ela vai sendo processada e administrada pela libuv. A stack continua executando as próximas funções e, quando terminar o processamento, a função de callback será adicionada na Task Queue para ser processada quando a stack estiver vazia.
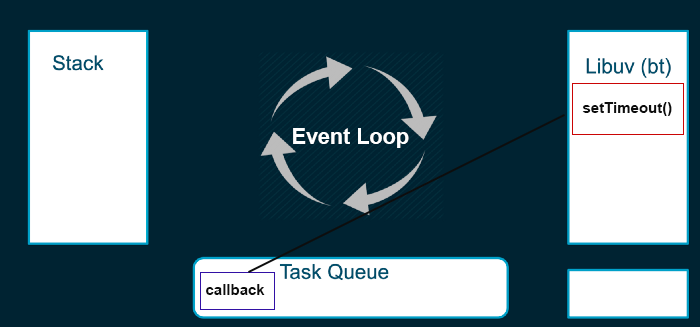
# Task queue
Algumas funções são enviadas para serem executadas em outra thread, permitindo que a stack siga para as próximas funções e não bloqueie nossa aplicação.
Essas funções que são enviadas para outra thread precisam ter um callback, que é uma função que será executada quando a função principal for finalizada.
Os callbacks aguardam a sua vez para serem executados na stack. Enquanto esperam, eles ficam em um lugar chamado de task queue. **Sempre que a thread principal finalizar uma tarefa, o que significa que a stack estará vazia, uma nova tarefa é movida da task queue para a stack, onde será executada**.
Aqui temos um exemplo para facilitar:
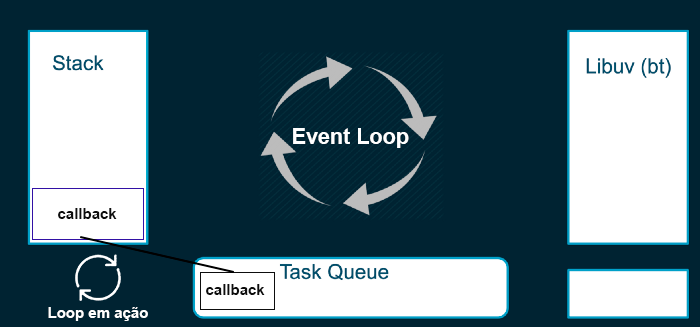
**O Event Loop é responsável por buscar essas tarefas de background, e executá-las na stack**.
# Micro e macro tasks
**O Event Loop é formado por macro tasks e micro tasks**. As macro tasks que serão enfileiradas no background, e que quando forem processadas, terão um callback dentro da task queue que será chamado quando a stack estiver vazia. dentro de cada ciclo, o **event loop irá executar primeiramente as micro tasks** disponíveis. As micro tasks vão sendo processadas, até que a fila de microtask esteja esgotada, assim que todas as chamadas de micro tasks forem feitas, então no próximo ciclo, o callback da macro task que está na task queue será executado. Ou seja, **dentro de um mesmo ciclo, as micro tasks, serão executadas antes das macro tasks**.
# Macro tasks
Vou citar alguns exemplos de funções que se comportam como **macro tasks**: **`setTimeout`**, **`I/O`** e **`setInterval`**.
# Micro tasks
Alguns exemplos conhecidos de **micro tasks** são as **`promises`** e o **`process.nextTick`**. As micro tasks normalmente são tarefas que devem ser executadas rapidamente após alguma ação, ou realizar algo assíncrono sem a necessidade de inserir uma nova task na task queue.
Vamos tentar entender melhor com alguns exemplos, coloquei algumas anotações para facilitar o entendimento:
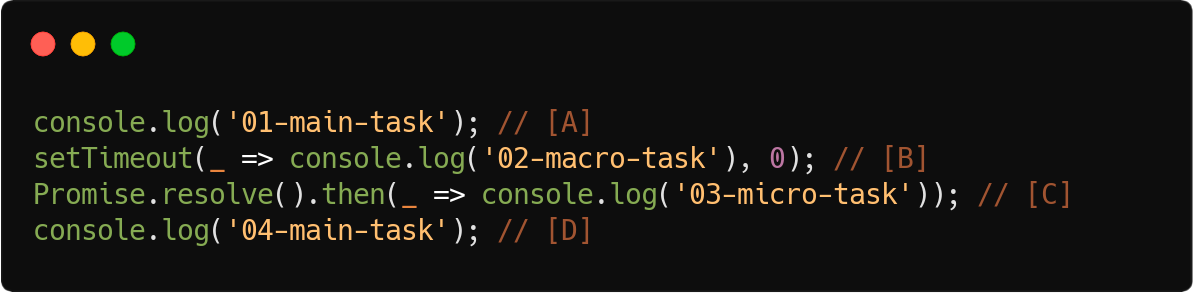
Ao executar o código acima, teremos o seguinte resultado de priorização:
Você deve estar se perguntando o porquê não está sendo executado em ordem, vou tentar explicar com as anotações que fiz no código.
* **[A]**: **Executado diretamente na stack**, dessa forma ele é síncrono, então o restante do código irá aguardar o resultado para ser executado.
* **[B]**: Enfileirado como uma tarefa futura, **prioridade macro task**, será executado apenas no próximo loop.
* **[C]**: Enfileirado como uma tarefa futura, **prioridade micro task**, será executado imediatamente após todas as tarefas/tasks do loop atual e antes do próximo loop.
* **[D]**: **Executado diretamente na stack**, dessa forma ele é síncrono, então o restante do código irá aguardar o resultado para ser executado.
# Conclusão
**Nesse artigo vimos o que é o Node e como ele funciona “por baixo dos panos”**, espero que vocês tenham entendido com clareza e que essa visão ajude vocês a escreverem códigos melhores e de uma maneira que tire maior proveito desse funcionamento. Aconselho também a leitura complementar dos links de referências que irão facilitar o entendimento.
# Links relacionados
https://nodejs.org/pt-br/docs/guides/blocking-vs-non-blocking/
https://imasters.com.br/front-end/node-js-o-que-e-esse-event-loop-afinal
https://fabiojanio.com/2020/03/12/introducao-ao-node-js-single-thread-event-loop-e-mercado/
https://oieduardorabelo.medium.com/javascript-microtasks-e-macrotasks-fac33016de4f
https://www.youtube.com/watch?v=8aGhZQkoFbQ
| leonardodesa |
829,906 | 5 web APIs that add mobile functionality to your project | Written by Chimezie Enyinnaya ✏️ As developers, we frequently use APIs (Application Programming... | 0 | 2021-09-17T18:56:26 | https://blog.logrocket.com/5-web-apis-mobile-functionality/ | mobile | **Written by [Chimezie Enyinnaya](https://blog.logrocket.com/author/chimezieenyinnaya/)** ✏️
As developers, we frequently use APIs (Application Programming Interfaces) to implement complex functionalities easily or create them to abstract complexity. APIs are what allow services to talk to each other and do things like post a Tweet or display a map.
We can classify web APIs into two categories for building client-side web applications:
* [Browser APIs](https://developer.mozilla.org/en-US/docs/Web/API): These are APIs that interface with JavaScript, allowing developers to implement functionalities easily. APIs such as the DOM, Fetch, Audio and Video, WebGL, Notifications and so much more
* Third-party APIs: You’ve probably used one in your project already. These are APIs that are not built into the browser by default. They're provided by companies such as Google, Facebook, Trello, etc. to allow you to access their functionality via JavaScript and use it on your project
Let's go through some of the popular Web APIs:
* Geolocation API: This API allows access to retrieve location information of the host device
* Document Object Model API: The DOM is the API for HTML documents in the sense that it is the interface between your JavaScript program and the HTML document. The [DOM itself has an extensive list of interfaces](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model) such as the `Document` interface, `Window` interface, and so on
* History API: The History API is abstracted in most of the Router implementations. The API enables you to track and modify the browser's URL and history data, as well as access your browsing history through JavaScript
* Canvas API: The Canvas API allows you to display different visual graphics on the page by using a `<canvas>` element, which is useful for HTML games and charts
* Web Animations API: The Web Animations API enables coordinated visual changes on your page. It combines the pros of CSS transitions/animations and JavaScript-based animations.
In this article, I'll be exploring some of my favorite APIs that provide mobile-friendly functionality. This can include anything from social media shares and clipboard operations to contact, speech, and notifications functionalities.
## 5 mobile functionality web APIs for your next project
So far, we've discussed some common APIs that you've made use of directly or indirectly through JavaScript libraries.
In this section, we'll explore five unique APIs that you might need for your next project. These APIs are important because they bring mobile native functionalities to the web.
### Web Share API
This API helps you implement sharing functionality on your websites. It gives that mobile native-sharing feel. It makes it possible to share text, files, and links to other applications on the device.
The Web Share API is accessible through the `navigator.share` method:
```javascript
if (navigator.share) {
navigator.share({
title: 'Logrocket alert here',
text: 'Check out Logrocket',
url: '<https://logrocket.com/>',
})
.then(() => console.log('Successful share'))
.catch((error) => console.log('Error sharing', error));
}
```
The code snippet above exemplifies how to share text using vanilla JavaScript. One important thing to take note of is that you can only invoke this action with the `onclick` event:
```javascript
function Share({ label, text, title }) {
const shareDetails = { title, text };
const handleSharing = async () => {
if (navigator.share) {
try {
await navigator.share(shareDetails).then(() => console.log("Sent"));
} catch (error) {
console.log(`Oops! I couldn't share to the world because: ${error}`);
}
} else {
// fallback code
console.log(
"Web share is currently not supported on this browser. Please provide a callback"
);
}
};
return (
<button onClick={handleSharing}>
<span>{label}</span>
</button>
);
}
```
The code snippet above is a basic example of how to use the API with React to implement sharing options on your app. You can [check out this demo on CodeSandbox](https://3s9r6.csb.app).
As of today, Web Share is not supported by the Chrome desktop browser, but it works on the Android browser.
```html
<template>
<div id="app">
<div v-if="webShareApiSupported" class="refer-wrapper">
<p class="refer-text">
Share your referal code:
<span class="theCode">{{ referralCode }}</span> with a friend and earn
when they sign up
</p>
<button @click="shareNow">Share</button>
</div>
</div>
</template>
<script>
export default {
name: "App",
data() {
return {
referralCode: "Fss4rsc",
};
},
computed: {
webShareApiSupported() {
return navigator.share;
},
},
methods: {
shareNow() {
navigator.share({
title: "Refferal Code",
text: this.referralCode,
});
},
},
};
</script>
```
If you're working with Vue, the code snippet above shows a basic implementation of the Web Share API. [Check the full demo](https://iu4k3.csb.app).
### Contact Picker API
Most mobile apps tend to request access to your contacts or phonebook. This is yet another mobile functionality that's also available on the web.
Let's say you're implementing an airtime recharge feature for a fintech web app. You would want the user to select a contact or multiple contacts. This can be implemented using `navigator.contacts`. It accepts two arguments: `properties`, an array containing the property you want to access, and `options`:
```javascript
const props = ['name', 'tel',];
const opts = { multiple: true };
async function getContacts() {
try {
const contacts = await navigator.contacts.select(props, opts);
handleResults(contacts);
} catch (ex) {
// Handle any errors here.
}
}
```
If you're working with React, you can implement the contact picker feature like this:
```jsx
export default function Contact({ label }) {
const properties = ["name", "tel"];
const options = { multiple: true };
const handleGetContacts = () => {
try {
const contacts = navigator.contacts.select(properties, options);
return contacts;
} catch (ex) {
console.log(ex);
}
};
return (
<>
<button onClick={handleGetContacts}>
<span>{label}</span>
</button>
</>
);
}
```
You can [check the React Contact Picker demo on CodeSandbox.](https://yckot.csb.app)
Working with Vue? You're not left out. This is how you could implement this feature with Vue:
```html
<template>
<div id="app">
<div v-if="contactApiSupported">
<div class="contact-wrapper">
<h4>Select Contacts</h4>
<button @click="pickContact">Select Contact</button>
</div>
</div>
</div>
</template>
<script>
export default {
name: "App",
computed: {
contactApiSupported() {
return "contacts" in navigator && "ContactsManager" in window;
},
},
methods: {
pickContact() {
const properties = ["name", "tel"];
const options = { multiple: true };
try {
const contacts = navigator.contacts.select(properties, options);
return contacts;
} catch (ex) {
console.log(ex);
}
},
},
};
</script>
```
You can [check the Contact Picker demo for Vue on CodeSandbox](https://nyjuh.csb.app).
Note that this API will only work on mobile browsers.
### Clipboard API
Clipboard operations such as copying, cutting, and pasting are some of the most common features in mobile apps. The Clipboard API enables a web user to access the system clipboard and perform basic clipboard operations.
Previously, you could interact with the system clipboard using the DOM `document.execCommand`; some libraries still use this method. However, the modern asynchronous Clipboard API provides access to read and write the clipboard contents directly.
Let's see how it works with JavaScript. Reading from the Clipboard:
```javascript
navigator.clipboard.readText().then(clipText =>
document.getElementById("outbox").innerText = clipText);
```
Writing to the Clipboard:
```javascript
function updateClipboard(newClip) {
navigator.clipboard.writeText(newClip).then(function() {
/* clipboard successfully set */
}, function() {
/* clipboard write failed */
});
}
```
Check out this post if you're trying to [implement the Clipboard API with React](https://blog.logrocket.com/implementing-copy-to-clipboard-in-react-with-clipboard-api/).
For Vue developers, you can implement the copying text with the API like this:
```html
<template>
<div id="app">
<p>Copy this:</p>
<input v-model="code" />
<button v-if="supportCBApi" @click="copyMessage">Copy</button>
<div v-if="message">{{ message }}</div>
</div>
</template>
<script>
export default {
name: "App",
data() {
return {
message: "",
code: "FC Barcelona for ever",
supportCBApi: false,
};
},
created() {
if (navigator.clipboard) {
this.supportCBApi = true;
}
},
methods: {
copyMessage() {
navigator.clipboard
.writeText(this.code)
.then(() => {
console.log("Text is on the clipboard.");
this.message = "Code copied to clipboard.";
})
.catch((err) => console.error(err));
},
},
};
</script>
```
### Web Speech API
Most mobile apps nowadays incorporate speech recognition and text-to-speech features to improve accessibility and user experience. The Web Speech API brings these functionalities to the browser. In this article, we'll just discuss the `SpeechRecognition` interface.
Speech recognition is accessible using the `SpeechRecognition` interface, and it makes use of the default speech recognition system of the device:
```javascript
const SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
const recognition = new SpeechRecognition(); //new SpeechRecognition object
recognition.continuous = false;
recognition.lang = 'en-US';
recognition.interimResults = false;
recognition.onstart = function() {
console.log("Speak into the microphone");
};
recognition.onspeechend = function() {
// when user is done speaking
recognition.stop();
}
// This runs when the speech recognition service returns result
recognition.onresult = function(event) {
var transcript = event.results[0][0].transcript;
var confidence = event.results[0][0].confidence;
};
// start recognition
recognition.start();
```
Source: [MDN Speech Recognition](https://developer.mozilla.org/en-US/docs/Web/API/SpeechRecognition)
Let's go through the code snippet above.
Firstly, we create a speech recognition object by assigning `new SpeechRecognition`. The `SpeechRecognition` object has some properties such as:
* `recognition.continuous`: Listens to a single result (word or phrase) when speech recognition starts. If set to `true`, the `speechRecognition` service keeps listening unless you stop it
* `recognition.lang`: The user's language preference
* `recognition.interimResults`: Returns interim results alongside final results when set to `true`
Also, to get our speech recognition service to work, we need to provide a callback for events such as `onstart`, `onspeechend`, and `onresult`.
* `recognition.onstart`: When a user triggers this event, the speech recognition service starts
* `recognition.onspeechend`: This stops the speech recognition service from running
* `recognition.onresult`: This event is fired once a successful result is received
If you want to implement this in React, go through [this tutorial that shows you how to use the React Speech Recognition Hook for voice assistance](https://blog.logrocket.com/using-the-react-speech-recognition-hook-for-voice-assistance/).
### Notification API
The Web Notification API is often interchanged with the Web Push API, but they differ. The goal of the Notification API is to display information to the user while the Push API allows the service worker to handle push messages from the server even when the device is inactive.
This is now widely used by blogs and web applications to notify users when there’s a change or update to a service. One common use case for this API is when your app is a PWA (progressive web application) and you need the user to refresh the browser to get new updates to the app.
To create a notification, JavaScript has a `Notification` constructor:
```javascript
const message = 'Refresh to get new features';
var notification = new Notification('Savings PWA app', { body: text });
```
You can implement this API with your desired web framework.
## Web APIs that should have widespread support in the future
So far, we've discussed APIs that bring that native mobile feel to the web. A similarity with all those APIs is that they're widely supported by popular modern browsers.
In this section, I'll highlight three APIs that should have widespread support among browsers in the future.
### Screen Wake Lock API
Most apps need access to your device's power status. If you've noticed, mobile apps like YouTube will pause if your screen is locked; some other apps like Spotify will continue playing even if the screen is locked.
On the web, the Screen Wake Lock API allows the developer to control the power state of the device when the web app is running. However, it's not yet supported by Firefox, Safari, and Opera Mini browsers.
### WebXR Device API
Mixed reality is becoming popular nowadays thanks to the likes of Pokemon Go and Google Translate. The [WebXR Device API](https://www.w3.org/TR/webxr/) enables developers to build awesome mixed-reality applications for the web as the range of devices that can support XR keeps on increasing.
Browsers such as Android, Opera, Safari, and Firefox still don't support this API.
### Web NFC API
On mobile devices, NFC helps users make secure transactions and connect with other devices within a certain radius.
On the web, Web NFC will allow sites the ability to read and write to NFC tags when they are in close proximity to the user. So far, it's only supported by Chrome for Android.
## Conclusion
In this article, we discussed Web APIs that add mobile functionality to your project and some other APIs that should have widespread support in the future.
Building for the web means building for all types of users and devices that have access to a web browser. This is why APIs that mimic mobile functionalities are becoming a must for web developers.
---
## [LogRocket](https://logrocket.com/signup/): Full visibility into your web apps

[LogRocket](https://logrocket.com/signup/) is a frontend application monitoring solution that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free](https://logrocket.com/signup/). | mangelosanto |
829,937 | GitLab DevSecOps Report 2021 - Proactively prevent vulnerabilities | Web security or security-aware software development should no longer be a luxury. That's why terms... | 0 | 2021-09-20T10:40:20 | https://cloudogu.com/en/blog/proactive-security | cybersecurity, security, webdev, devsecops | Web security or security-aware software development should no longer be a luxury. That's why terms like DevOps or DevSecOps have become an integral part of our industry. In other words, agile software development that is focused on security is one of the most important approaches to modern development. Or is it?
## What does GitLab's DevSecOps Report 2021 have to say about this?
In it are some very interesting findings for the importance of security in software development:
* 99% of applications contain at least 4 vulnerabilities, 80% even have more than 20.
* More than 90% of participants say that security scans run for more than 3 hours, with about a third running for more than 8 hours.
* For more than two-thirds of participants, it takes more than 4 hours to fix a vulnerability.
These numbers show two things:
* All applications contain vulnerabilities, although automated tests are already used to prevent them.
* It is quite costly to fix vulnerabilities.
In addition, the report shows that a large percentage of companies have already been victims of successful attacks:
* More than 70% have lost critical data.
* Two-thirds have experienced operational disruptions and
* More than 60% have seen negative impacts to their brand.
Based on these serious impacts, we might assume that security is becoming a higher priority. However, nearly 80% of DevOps teams reported just the opposite, saying they were under pressure to shorten release cycles. As a result, more than 50% of organizations reported sometimes skipping security scans to meet deadlines.
## Preventing cyber-attacks and IT vulnerabilities
These results show that companies are in a dilemma: meeting deadlines or repercussions from successful cyber-attacks against themselves or their products. The simple solution to this would be to *simply* value security over new features. But nothing is simple when you constantly must innovate to succeed in today's fast-paced world.
Another solution to the dilemma is to equip development teams with the knowledge and tools to prevent security vulnerabilities from the start, when the code is first written. There are several ways to do this.
### Continuing education in any form to proactively improve IT security.
There are a variety of different offerings in the area of in-person training: Training courses, eLearning, micro-learning, self-study, competitions, etc. Each of these forms of learning has a right to exist, as everyone has different preferences and strengths when it comes to learning. In addition, the different forms of learning have advantages with different levels of prior knowledge. Often a combination is very helpful. For example, in a classic training course, the basics can first be learned, which are then internalized through micro-learning or a competition. The important thing is to <a target="_blank" title="Want developers to code with security awareness? Bring the training to them. | Cloudogu Blog" href="https://cloudogu.com/en/blog/security-learning-strategies">bring the training to the developers</a> and not the other way round.
* Classical **training** courses have, among other things, the advantages that they impart knowledge in a short period of time without distractions and that individual questions and requirements can be addressed. A disadvantage is that they often do not take place directly.
* **eLearning** offers the freedom to work on the learning content at one's own pace, even in between. However, this often leads to the problem that continuing with lessons can easily be lost in the daily work routine alongside other tasks.
* The situation is similar with **micro-learning**, in which learning content is broken down into small modules and ideally integrated into the daily work routine in a context-related manner. An example of this is the Secure Code Warrior plugin for SCM Manager (see below). The contextual integration of learning content has the advantage that the learning units are not in competition with other tasks because they are integrated into the tasks.
* In **self-study** there is no fixed curriculum. This has the advantage that developers only acquire exactly the knowledge they really need. The disadvantage is, that all content must be researched independently.
* At first glance, **competitions** are *only* suitable for deepening existing knowledge. However, they also offer the opportunity to gain new knowledge by working on problems that are new and have to be solved in a creative way.

Learn more about the free tournament <a title="Secure Code Warrior tournament by Cloudogu" href="https://my.cloudogu.com/scw-tournament">here</a>.
### Micro-learning: improving safety through continuous and contextual learning
Contextual learning offers the opportunity to closely integrate practice and theory to improve learning outcomes. For this purpose, suitable learning content, e.g. in the form of micro-learning, is displayed during the processing of tasks. An example of this is the integration of videos and tasks on security vulnerabilities in the code review process.
Through such integrations, learning content is provided exactly when team members are working on tasks with potential security vulnerabilities. An example of this is the Secure Code Warrior plugin for SCM Manager mentioned earlier.
## Conclusion
GitLab's DevSecOps Report 2021 shows that software security, while perceived as an important issue, is prioritized lower than the development of new features in many organizations. This prioritization is unlikely to change much in the future. Therefore, it is necessary to change from a reactive to a proactive approach in order to meet the security requirements while <a target="_blank" title="Is it possible to shorten release cycles and improve security at the same time? | Cloudogu Blog" href="https://dev.to/cloudogu/shorter-release-cycles-through-improved-security-496j">keeping release cycles short</a>. This can be achieved through different types of training. | danielhuchthausen |
841,207 | How to Undo a GIT Commit | Understand the basics of version control Hey, I’m sure I’m not in this case. You know... | 0 | 2021-09-26T15:19:42 | https://medium.com/@redin.gaetan/how-to-undo-a-git-commit-7942cdf6c211 | commit, versioncontrol, git, undo | ---
title: How to Undo a GIT Commit
published: true
date: 2021-09-08 18:03:37 UTC
tags: commit,versioncontrol,git,undo
canonical_url: https://medium.com/@redin.gaetan/how-to-undo-a-git-commit-7942cdf6c211
---
#### Understand the basics of version control

Hey, I’m sure I’m not in this case. You know you make your git add <files>and then your git commit -m "..." But oh no I forgot a file… Well rather than create a second commit, why not just undo the previous one and recreate it?
Here’s a git alias I use every day:
```
alias.undo=reset --soft HEAD^
```
Here’s how to create it:
```
git config --global alias.undo 'reset --soft HEAD^'
```
**Tips** : If you have already pushed your commit into your PR, you will have to use git push -f .
Thanks for reading.
How to undo a commit
Hey, I’m sure I’m not in this case. You know you make your git add <files>and then your git commit -m "..." But oh no I forgot a file… Well rather than create a second commit, why not just undo the previous one and recreate it?
Here’s a git alias I use every day:
```
alias.undo=reset --soft HEAD^
```
Here’s how to create it:
```
git config --global alias.undo 'reset --soft HEAD^'
```
**Tips** : If you have already pushed your commit into your PR, you will have to use git push -f .
Thanks for reading.
### Learn More
- [Install Jest for Angular](https://dev.to/gaetanrdn/jest-and-angular-install-fg3)
- [TypeScript Function Overloads](https://dev.to/gaetanrdn/typescript-function-overloads-2fbd-temp-slug-1069498)
- [Angular for everyone: All about it](https://link.medium.com/SXPQgRn7xjb) | gaetanrdn |
829,979 | Tic-Tac-Toe.py | Try my childhood game I played in elementary with my classmates during class. This is a two player... | 0 | 2021-09-17T21:22:49 | https://dev.to/taimankj/tic-tac-toe-py-4a1 | Try my childhood game I played in elementary with my classmates during class. This is a two player game. Play it with your friends or family. First run 'python3 file-path/tic-tac-toe.py' in the terminal. You will then be prompted to input 'x' or 'o' and press enter for whoever will go first. First player will input the corresponding number to the corresponding space and press enter. Then, the same action will be done by the next player. If the space is taken, the terminal will prompt you that space has been taken and will have to re-enter an authorized number. The game ends when either player has filled a column, row, or diagonal.
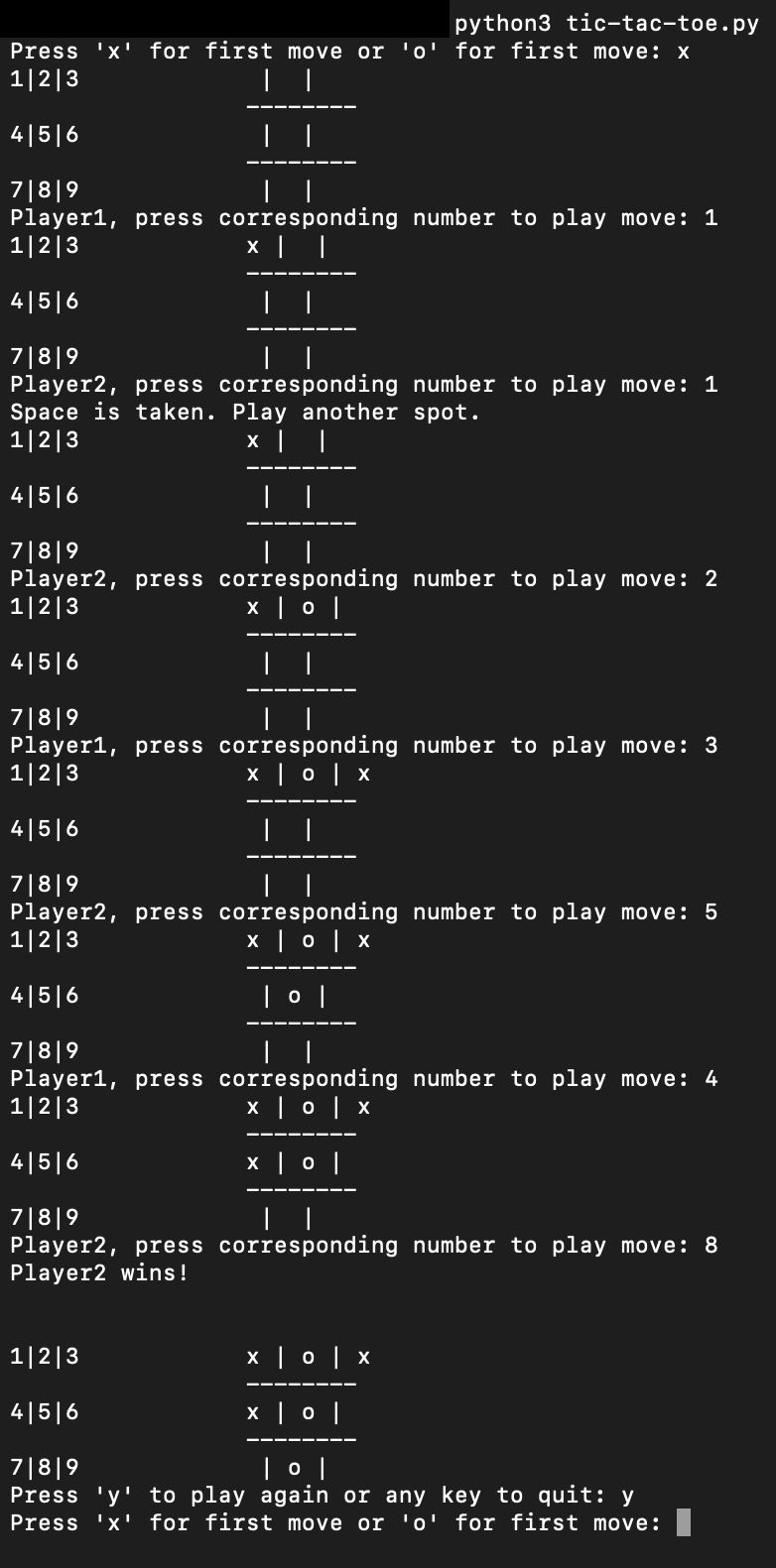
[Tic-Tac-Toe Repository] (https://github.com/taimankj/Tic_Tac_Toe) | taimankj | |
832,038 | HTML tags | s | It is used to indicate a text that is no longer correct, accurate or relevant, and that is usually... | 13,528 | 2021-09-20T06:24:14 | https://dev.to/carlosespada/html-tags-s-acd | html, tags, s | It is used to **indicate a text that is no longer correct, accurate or relevant**, and that is usually rendered with a line through it.
**It is not suitable for indicating edits in a document**, that's what the `<del>` and `<ins>` elements exist for.
The presence of the `<s>` element is not advertised in most screen readers with the default settings. You can force your ad using the `content` property of CSS as well as the `::before` and `::after` pseudo-elements as follows:
```
s::before,
s::after {
clip-path: inset(100%);
clip: rect(1px, 1px, 1px, 1px);
height: 1px;
overflow: hidden;
position: absolute;
white-space: nowrap;
width: 1px;
}
s::before {
content: " [start of stricken text] ";
}
s::after {
content: " [end of stricken text] ";
}
```
Some screen reader users disable content ad to avoid excessive verbosity. So it is important not to abuse this technique, [avoiding using it whenever possible](https://www.tempertemper.net/blog/be-careful-with-strikethrough), except in situations where not knowing that there is a crossed-out content can adversely affect the understanding of the text.
- Type: *inline*
- Self-closing: *No*
- Semantic value: *No*
[Definition and example](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/s) | [Support](https://caniuse.com/mdn-html_elements_s) | carlosespada |
832,678 | How to Extract Email Address from Text using excel VBA? | In this tutorial, we will guide you on how to extract email addresses from text using Excel Office... | 0 | 2021-09-27T07:52:35 | https://geekexcel.com/how-to-extract-email-address-from-text-using-excel-vba/ | toextractemailaddres, vbamacros | ---
title: How to Extract Email Address from Text using excel VBA?
published: true
date: 2021-09-20 09:04:06 UTC
tags: ToExtractEmailAddres,VBAMacros
canonical_url: https://geekexcel.com/how-to-extract-email-address-from-text-using-excel-vba/
---
In this tutorial, we will guide you on how to **extract email addresses from text** using Excel Office VBA. Let’s get them below!! Get an official version of MS Excel from the following link: **[https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)**
## Example
- Firstly, you need to **create a sample data** with more **information in text format**.
<figcaption>Sample data</figcaption>
- In the Excel Worksheet, you have to go to the **Developer Tab.**
- Then, you need to ** ** select the **Visual Basic** option under the **Code** section.
<figcaption>Select Visual Basic</figcaption>
- Now, you have to **copy and paste the code** given below.
```
Function ExtractEmailFromText(s As String) As String Dim AtTheRateSignSymbol As Long Dim i As Long
Dim TempStr As String
Const CharList As String = "[A-Za-z0-9._-]"
AtTheRateSignSymbol = InStr(s, "@")
If AtTheRateSignSymbol = 0 Then
ExtractEmailFromText = ""
Else
TempStr = ""
For i = AtTheRateSignSymbol - 1 To 1 Step -1
If Mid(s, i, 1) Like CharList Then
TempStr = Mid(s, i, 1) & TempStr
Else
Exit For
End If
Next i
If TempStr = "" Then Exit Function
TempStr = TempStr & "@"
For i = AtTheRateSignSymbol + 1 To Len(s)
If Mid(s, i, 1) Like CharList Then
TempStr = TempStr & Mid(s, i, 1)
Else
Exit For
End If
Next i
End If
If Right(TempStr, 1) = "." Then TempStr = _
Left(TempStr, Len(TempStr) - 1)
ExtractEmailFromText = TempStr
End Function
```
- You need to **save the code** by selecting it and then **close the window**.
<figcaption>Save the Code</figcaption>
- Again, you have to go to the **Excel Spreadsheet** , and click on the **Developer Tab**.
- You need to choose the **Macros option** in the Code section.
<figcaption>Choose Macro option</figcaption>
- Now, to get the **output in cell B2** , you have to **use formula** given below.
```
=ExtractEmailFromText(A2)
```
<figcaption>Use Formula</figcaption>
- Finally, you will receive the **output ** in the **Microsoft Excel**.
<figcaption>Output</figcaption>
## End of the Line
We hope that this tutorial gives you guidelines on how to **extract email addresses from text** using Excel Office VBA. Please leave a comment in case of any **queries,** and don’t forget to mention your valuable **suggestions** as well. Thank you so much for Visiting Our Site!! Continue learning on **[Geek Excel](https://geekexcel.com/)!! **Read more on [**Excel Formulas**](https://geekexcel.com/excel-formula/) **!!**
**Further Reference:**
- **[Excel Formulas to Remove File Extension from Filename ~ Simple Tricks!!](https://geekexcel.com/excel-formulas-to-remove-file-extension-from-filename/)**
- **[How to Rename Multiple Files using Macros (VBA) in Excel 365?](https://geekexcel.com/how-to-rename-multiple-files-using-macros-vba-in-excel-365/)**
- **[How to List All Files and Sub-Directories of a Folder in Excel 365?](https://geekexcel.com/how-to-list-all-files-and-sub-directories-of-a-folder-in-excel-365/)**
- **[Split/Save Each Worksheet of One Workbook as Separate Excel/Txt/Csv/Pdf Files in Excel 365!!](https://geekexcel.com/split-save-each-worksheet-of-one-workbook-as-separate-excel-txt-csv-pdf-files-in-excel-365/)**
- **[How to Print Multiple Workbooks/Worksheets from Directories in Excel 365?](https://geekexcel.com/how-to-print-multiple-workbooks-worksheets-from-directories-in-excel-365/)** | excelgeek |
833,133 | Extract, Transform and Load with React & Rails | Learning and going through the steps to ETL data. | 0 | 2021-09-20T21:48:18 | https://dev.to/erinfoox/extract-transform-and-load-with-react-rails-ggp | etl, react, rails, cats | ---
title: Extract, Transform and Load with React & Rails
published: true
description: Learning and going through the steps to ETL data.
tags: ETL, React, Rails, Cats
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/8wcg7wdoop0vmrezfwiq.png
---
You might be thinking, **WFT is ETL and have I been using it all this time?!**
If you're an engineer, you probably have done some form of ETL. I never realized I was extracting, transforming and loading data throughout my career until researching it recently. I also, need to get better at it and the best way I know how is by researching, practice and writing about it.
I'm still working on learning it with more complicated data structures and data transformations, but I wanted to break it down to the beginning to make sure I understand it each step of the way. But with cats added.
## What is ETL?
**ETL** = Extract, Transform, Load
ETL is a series of steps to move data from one location to another. When doing this, it transforms the data structure before it is loaded from its source to its new destination. In more words, it is a process you can use to help plan and execute the movement of data that you need.
## Why use ETL?
I'm sure there are several answers to this question. For me, using it breaks down the steps of gathering and retrieving data. It also forces you to understand the shape of the data, what data you need, and how eventually you want it to look before rendering it in your app, browser or database.
A more fancier definition for why we use it: Data from different sources can be pulled together and restructured to a standardized format.
Let's walk through each step of extracting, transforming and loading data with React and Rails.
## Extract - PLAN IT
Extract, is all about planning for the transforming. There are 3 steps or questions to ask yourself to find the answers needed in order to move on to the next step, transform.
1. Where is the data that I need?
* Get it locally from your routes file?
* From another endpoint or 3rd party API like
the Spotify API?
* For our example, we will use hardcoded
code found in our controller.
```
def cats
render json: {
cats: [ # Cat.all
{
name: "Maya",
color: "calico",
rating: "perfect",
owners: [
"Mark"
]
},
{
name: "Sully",
color: "seal bicolor",
rating: "perfect",
owners: [
"Erin"
]
}
]
}
end
```
2. What specific information do I need from that data?"
* Decide what data to extract
* **In our example, let's extract the
colors of the cats. So we want to
return only the colors.**
3. What should I use to retrieve that data?
* Query/retrieve the data
* A fetch request with JS on the frontend?
* A `Net::HTTP` with Ruby?
* **For our example, we will use `request`
which is a custom little thing we built
internally. It is build off JS fetch.**
This `handleGet` function is the main way we will extract and receive the data we need.
```
async function handleGet() {
const response = await request("/some-cool-route/cats") // built off js fetch, so this is a GET request
console.log("handleGet", response)
}
```
And our console log, would look like this:
## Transform - DO IT
Now that we have learned where the data is (in a method within the controller), what part of it we need (the cat's colors) and how to retrieve the data (a fetch GET request using an internal tool we use) we can now start changing the data to the shape we want. We can restructure it, rename it, remove things we don't need and even add values.
1. What should the data structure look like?
* Since our example is small, we are looking
_only_ to return the cat's colors. We don't
need the name, rating or owners.
* We would want our transformed data to
look like this if we were to console log it.
We can transform the cats array, to return only the cat colors by creating a function that takes the data (cat's array) and returns a new data structure (an array of cat colors).
With our data in a method in our controller, let's look at our react component that will render the page.
This is were we can create a transform function `transformColors()` that will return an array of each cat's color: ["calico", "seal bicolor"]
```
function transformColors(cats) {
return cats.map(cat => cat.color)
}
```
## Load / Render - SHOW IT
1. Where should the data then be loaded or rendered?
* Add it to the database or display it to the
user
* In some situations, you may be adding this
new array of cat colors to your database.
* I mostly work with rendering the data to
the page with React components, so let's see it all play out that way.
Here is the react component rendering our new transformed data.
```
import React, { useState } from "react"
import { request } from "react-rb" // internal tool by CK
export default function Meow() {
const [cats, setCats] = useState([])
const [colors, setColors] = useState([])
async function handleGet() {
// EXTRACT
const response = await request("/some-cool-route/cats") // built off js fetch, so this is a GET request
setCats(response.data.cats)
const transformCatColors = transformColors(response.data.cats)
setColors(transformCatColors)
}
return (
<div className="m-8">
<button onClick={handleGet}>Get cat colors 🐈 🐈⬛</button>
// LOAD/RENDER
<div>{colors}</div>
</div>
)
}
// TRANSFORM
function transformColors(cats) {
return cats.map(cat => <div key={cat.color}>{cat.color}</div>)
}
```
Let's recap. We have **Extracted** the data from our controller using a fetch request. We then **Transformed** that data to return only the cat colors with our `transformColors()` function. And finally, we can **Load/Render** it to the page in our React component in the JSX.
Here's a gif it it all working! It is not pretty, but hopefully you get the idea.

Hopefully this small example helps explain ETL just a little but more!
A big shoutout to my coworker [Mark M.](https://twitter.com/mtmdev_) for helping me grasp this concept even further and for setting up this awesome cat example. | erinfoox |
840,660 | Matt's Tidbits #101 - How to write a good bug report | This week I have a story to share about filing bug reports -why they're important, and what makes a... | 2,397 | 2021-09-28T14:13:34 | https://medium.com/@matthew-b-groves/matts-tidbits-101-how-to-write-a-good-bug-report-818ab8994ada | mattstidbits, android, opensource, tidbittuesday | This week I have a story to share about filing bug reports -why they're important, and what makes a "good" one. [Last time, (sorry for the delay between posts!) I wrote about some Teams-related tips.](https://medium.com/nerd-for-tech/matts-tidbits-100-all-about-teams-856771e938de)
I've written several tidbits before where I file a bug report, but I have an exciting update to share - one of the bugs I filed has recently been fixed as a direct result of my report!!
[In February of 2020 I wrote about a bug](https://matthew-b-groves.medium.com/matts-tidbits-56-be-careful-with-jvmoverloads-165d87581820) I had discovered where Android Studio's "quick fix" suggestion for Kotlin-based classes that derive from Android view components dangerously auto-generate a constructor with the @JvmOverloads annotation which causes the default style/theme properties to be ignored.
The report describing the bug is here: https://issuetracker.google.com/issues/149986188
What's the lesson to be learned here? Aside from my original caution around using @JvmOverloads, what I would like to impart this time is around how to write a good bug report. This is really one of the key differences between the bugs that get fixed and the ones that get ignored.
So, what goes into a good bug report?
1. A clear description of the problem - if people can't understand what you're talking about, it will be disregarded very early on in the process. The trick is to be very precise about what the issue is, with a sufficient level of detail - as a developer, I've seen bug reports that say "<X> doesn't work" - that's not good enough. Also try to specify exactly what versions of all components you are using (Android Studio, Kotlin, libraries, phone make/model, OS, etc.), and if you can, do a little extra testing to determine and be able to explain what configurations may be impacted by this issue.
2. An easily reproducible test case - it's one thing to understand what the problem is, but you can greatly boost the likelihood of your issue being addressed if you do a little extra work to put together a sample project that clearly demonstrates the issue. Don't just upload a copy of your entire project - the smaller/simpler an example you can provide, the better.
3. A description of what the expected behavior should be - if the person investigating your bug has followed you through the first 2 items above, but you haven't spelled out what you think should happen, your bug may not get worked on - they may believe that it "functions as designed". This is where you can use some persuasive/logical arguments to clearly explain why the current behavior is wrong, and what it should do instead.
4. Double-check your bug report for errors (logical errors, missing information, typos, poor grammar, etc.) If there are bugs in your bug report, it's not going to be taken as seriously - so be sure to double-check it for errors, and try to write it in a professional tone. Using full sentences with proper capitalization, etc. eliminates the hurdle of the person reading it possibly concluding that you don't know what you're talking about.
5. Publicize the issue and get other people on board - the more people who are clearly affected by the issue, the more highly it will be prioritized. So, once you have submitted the issue, share it as broadly as you are able - tell your coworkers past & current and ask them to do the same, and consider writing an article about it to increase its visibility.
Follow the above steps, and with any luck, your issue will be resolved! The quality of especially open source projects increasingly relies on members of the community reporting the issues they're experiencing. And, if it seems like your bug is taking a long time to be fixed, consider trying to resolve it yourself! Open source projects often have limited developer resources, so if you provide a solid fix for the issue yourself (or at least have done some research into the cause and provide a suggestion for how to fix it), this can be another helpful boost towards getting the issue resolved.
Finally, note that the above suggestions don't just apply to external bug reports - these same strategies can be used to supercharge your internal bug reports as well!
For reference, here are two other Android Studio bugs I have filed previously which have also been resolved (both of these indirectly, but it can still be helpful the project's developers to provide additional data points):
https://issuetracker.google.com/issues/131403382
https://issuetracker.google.com/issues/143971679
---
Interested in working with me in the awesome Digital Products team here at Accenture? We have several open roles, including:
- [Mobile Developer #1 (Northeast locations)](https://www.accenture.com/us-en/careers/jobdetails?id=00960587_en&title=Native+Mobile+Developer)
- [Mobile Developer #2 (Northeast locations)](https://www.accenture.com/us-en/careers/jobdetails?id=00960583_en&title=Mobile+Developer)
- [Engineering Director (Boston or Philadelphia)](https://www.accenture.com/us-en/careers/jobdetails?id=00983613_en&title=Engineering+Director)
- [Senior iOS Developer (Southern locations)](https://www.accenture.com/us-en/careers/jobdetails?id=R00036232_en&title=Senior+iOS+Developer)
- [Android Mobile Developer (Southern locations)](https://www.accenture.com/us-en/careers/jobdetails?id=R00027147_en&title=Android+Mobile+Developer)
- [iOS Mobile Development Lead (Southern Locations)](https://www.accenture.com/us-en/careers/jobdetails?id=R00027113_en&title=iOS+Mobile+Development+Lead)
---
Do you have other suggestions for how to write a good bug report? Let me know in the comments below! | mpeng3 |
841,231 | 25 Top Google Cloud Services that YOU should know! | I just left the Cloud Azure zone and I just arrived at the Google Cloud zone. I wonder what I will... | 0 | 2021-09-26T15:51:20 | https://dev.to/howtoubuntu/25-top-google-cloud-services-that-you-should-know-4bb9 | I just left the Cloud Azure zone and I just arrived at the Google Cloud zone. I wonder what I will find in this area!
---
I just found the Compute section, I wonder what we can find!
---
# 1. Compute Engine
Compute Engine offers always-encrypted local solid-state drive (SSD) block storage. Local SSDs are physically attached to the server that hosts the virtual machine instance for very high input/output operations per second (IOPS) and very low latency compared to persistent disks.
---
# 2. Kubernetes Engine
Google Kubernetes Engine (GKE) provides a managed environment for deploying, managing, and scaling your containerized applications using Google infrastructure. The GKE environment consists of multiple machines (specifically, Compute Engine instances) grouped together to form a cluster.
---
# 3. VMWare Engine
Google Cloud VMware Engine is a fully managed service that lets you run the VMware platform in Google Cloud. Google manages the infrastructure, networking, and management services so that you can use the VMware platform efficiently and securely.
---
I just found something really cool! I wonder what the `Serverless` Section has!
---
# 4. Cloud Run
Cloud Run is a managed compute platform that enables you to run containers that are invocable via requests or events. Cloud Run is serverless: it abstracts away all infrastructure management, so you can focus on what matters most — building great applications.
---
# 5. Cloud Functions
Cloud Functions is a lightweight compute solution for developers to create single-purpose, stand-alone functions that respond to Cloud events without the need to manage a server or runtime environment.
---
# 6. App Engine
App Engine is a fully managed, serverless platform for developing and hosting web applications at scale. You can choose from several popular languages, libraries, and frameworks to develop your apps, and then let App Engine take care of provisioning servers and scaling your app instances based on demand.
---
Man, this trip is getting BETTER and BETTER by the seconds! I just found the Storage Section!
---
# 7. Filestore
Filestore instances are fully managed NFS (Network File System) file servers on Google Cloud for use with applications running on Compute Engine virtual machines (VMs) instances or Google Kubernetes Engine clusters. Not sure which storage product is right for you?
---
# 8. Cloud Storage
Cloud Storage allows world-wide storage and retrieval of any amount of data at any time. You can use Cloud Storage for a range of scenarios including serving website content, storing data for archival and disaster recovery, or distributing large data objects to users via direct download.
---
# 9. Storage Transfer
Storage Transfer Service allows you to quickly import online data into Cloud Storage. You can also set up a repeating schedule for transferring data, as well as transfer data within Cloud Storage, from one bucket to another.
---
I need to store and data, lets find the DataBase section.
---
# 10. BigTable
Cloud Bigtable is Google's fully managed NoSQL Big Data database service. It's the same database that powers many core Google services, including Search, Analytics, Maps, and Gmail.
---
# 11. Firestore
Firestore in Datastore mode is a NoSQL document database built for automatic scaling, high performance, and ease of application development.
---
# 12. DataBase Migration
Database Migration Service makes it easier for you to migrate your data to Google Cloud. This service helps you lift and shift your MySQL and PostgreSQL workloads into Cloud SQL.
---
# 13. Cloud SQL
Cloud SQL is a fully-managed database service that helps you set up, maintain, manage, and administer your relational databases on Google Cloud Platform.
---
I need to renovate my house, where are the tools needed. Let me find the tools section
---
# 14. Cloud Run on Anthos
Cloud Run for Anthos provides a flexible serverless development platform in your Anthos environment. Cloud Run for Anthos is powered by Knative, an open source project that supports serverless workloads on Kubernetes.
---
# 15. Endpoints
Endpoints is an API management system that helps you secure, monitor, analyze, and set quotas on your APIs using the same infrastructure Google uses for its own APIs. After you deploy your API to Endpoints, you can use the Cloud Endpoints Portal to create a developer portal, a website that users of your API can access to view documentation and interact with your API.
---
# 16. Apigee
You have data, you have services, and you want to develop new business solutions quickly, both internally and externally. With Apigee, you can build API proxies—RESTful, HTTP-based APIs that interact with your services. With easy-to-use APIs, developers can be more productive, increasing your speed to market.
---
I really want now to make a robot with some AI! I just found the AI section!
---
# 17. Vertex Ai
Vertex AI brings AutoML and AI Platform together into a unified API, client library, and user interface. With Vertex AI, both AutoML training and custom training are available options. Whichever option you choose for training, you can save models, deploy models and request predictions with Vertex AI.
---
# 18. Speech-To-Text
Speech-to-Text enables easy integration of Google speech recognition technologies into developer applications. Send audio and receive a text transcription from the Speech-to-Text API service.
---
# 19. Talent Solution
Transform your job search capabilities with Cloud Talent Solution, designed to support enterprise talent acquisition technology and evolve with your growing needs. This AI solution provides candidates and employers with an enhanced talent acquisition experience!
---
Its getting late outside, lets finish up with my last operation! The operation section!
---
# 20. Monitoring
Cloud Monitoring collects metrics, events, and metadata from Google Cloud, Amazon Web Services (AWS), hosted uptime probes, and application instrumentation. Using the BindPlane service, you can also collect this data from over 150 common application components, on-premise systems, and hybrid cloud systems.
---
# 21. Debugger
Cloud Debugger is a feature of Google Cloud Platform that lets you inspect the state of an application, at any code location, without stopping or slowing down the running app. Cloud Debugger makes it easier to view the application state without adding logging statements.
---
Ok ok fine. Just 4 more I promise. The last will be networking!
---
# 22. VPC Network
A Virtual Private Cloud (VPC) network is a virtual version of a physical network, implemented inside of Google's production network, using Andromeda. A VPC network provides the following:
---
# 23. Hybrid Connectivity
Hybrid Connectivity allows you to easily create a VPN/Interconnect/Cloud Routers/Network Connectivity Center using Hybrid Connectivity!
---
# 24. Network Sercutity
Security policies let you control access to your Google Cloud Platform resources at your network's edge. You have the 2 following options: Cloud Armor (Which helps protect(s) your applications and websites against denial of service and web attacks.) and SSL Policies (SSL policies give you the ability to control the features of SSL that your SSL proxy or HTTPS load balancer negotiates. In this document, the term "SSL" refers to both the SSL and TLS protocols.)
---
# 25. Network Intelligence
Network Intelligence Center provides unmatched visibility into your network in the cloud along with proactive network verification. Centralized monitoring cuts down troubleshooting time and effort, increases network security, and improves the overall user experience.
---
## If you found this usful then please comment and follow me! Also check out [my website where I also post everything from here](https://howtoubuntu.xyz) | howtoubuntu | |
841,448 | Safe and simple AWS credential management for your Symfony/PHP application | Introduction If you have a Symfony/PHP application which needs to connect to AWS and use... | 0 | 2021-10-10T16:15:04 | https://dev.to/nikolastojilj12/safe-and-simple-aws-credential-management-for-your-symfony-php-application-29i | webdev, devops, aws, php | ## Introduction
If you have a Symfony/PHP application which needs to connect to AWS and use some of its services (S3, Secrets Manager,...) and you want to avoid pushing credentials to your Git repository or revealing them to any third party (ex. deployment, testing or code review tools), then follow this guide.
This guide will show you how to quickly and safely integrate AWS authentication both on your local development environment and on the server, both on bare metal and by using Docker.
Note that this is all available on the official AWS Documentation portal... scattered across multiple pages and documentation sections and buried in walls of text.
## AWS SDK for PHP
[AWS SDK for PHP](https://aws.amazon.com/sdk-for-php/) (install in your project with `composer require aws/aws-sdk-php`) is a library which you'll use the most when working with AWS services in your PHP application. The SDK has several built-in method for connecting to AWS and authenticating your application - you only need to know how best to use it.
---
## Local development environment - bare metal
Steps:
- Install AWS CLI;
- Configure AWS CLI;
- AWS SDK for PHP will pick up credentials stored in `~/.aws` directory and automatically use them.
### Step 1. Install AWS CLI
#### Windows - default installation method
- Download the installer from https://awscli.amazonaws.com/AWSCLIV2.msi and run it.
#### Windows - Scoop (my preferred method)
Scoop is a Windows package manager which provides many CLI tools, including those from Linux. If you don't know about it and would like to know more, check out my article on Scoop: [Using Scoop and Cmder to make PHP development on Windows bearable](https://dev.to/nikolastojilj12/using-scoop-and-cmder-to-make-php-development-on-windows-bearable-8pd)
Install AWS CLI with:
```bash
scoop install aws
```
#### Other operating systems
Follow the official guide for your operating system at: https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-install.html
### Step 2. Configure AWS CLI
Run:
```bash
aws configure
```
and complete the questions from the prompt. This will store your AWS login credentials to your user's `~/.aws` directory.
When your application tries to use AWS SDK, the SDK will automatically look whether credentials are stored in this directory and will try to use them.
---
## Local development environment - Docker
Steps:
- Add `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables to `.env.local` file;
- AWS SDK for PHP will pick them up and use them to connect to AWS services from your Docker container.
Apart from reading credentials from the `~/.aws` directory, AWS SDK for PHP supports reading credentials from the mentioned environment variables.
If you're running your application in Docker locally, open the `.env.local` file and add `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables to it (of course, fill the values with your AWS access key ID and AWS secret access key).
Symfony's `.env.local` file is excluded from Git by default, so these values will not leave your computer.
---
## Server - AWS EC2
You don't need to configure anything. EC2 instances can connect to other AWS services by default by using AWS metadata service to retrieve credentials from an IAM role.
---
## Server - non-AWS bare metal server
If you are running your Symfony application on a server which is not hosted on AWS:
- Open terminal and open `ssh` connection to your server;
- Download and install AWS CLI on your server. Guide: https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2-linux.html#cliv2-linux-install ;
- Run `aws configure` and add your credentials. They will be stored on the server in your user's `~/.aws` directory;
- Make sure that a user on your server which has PHP execution rights (for example: apache) has access to the `.aws` directory;
- AWS SDK for PHP will pick up credentials stored in `~/.aws` directory and use them to connect to AWS services.
---
## Server - Dockerized environment on AWS
Steps:
- Use the `AWS_CONTAINER_CREDENTIALS_RELATIVE_URI` environment variable during `docker build`;
- Add `AWS_CONTAINER_CREDENTIALS_RELATIVE_URI` argument to your `Dockerfile`;
### Step 1. Add `AWS_CONTAINER_CREDENTIALS_RELATIVE_URI` in `docker build`
Open your project's `buildspec.yml` file and edit the `docker build` to include `AWS_CONTAINER_CREDENTIALS_RELATIVE_URI` environment variable. It should look something like this:
```yaml
phases:
build:
commands:
...
docker build --build-arg AWS_CONTAINER_CREDENTIALS_RELATIVE_URI=$AWS_CONTAINER_CREDENTIALS_RELATIVE_URI -t myapp:latest .
```
### Step 2. Add an argument to your `Dockerfile`
Open your project's `Dockerfile` and add `AWS_CONTAINER_CREDENTIALS_RELATIVE_URI` argument before the first `RUN` command:
```
ARG AWS_CONTAINER_CREDENTIALS_RELATIVE_URI
```
AWS SDK for PHP will handle the rest. The app in your Docker container can now connect to AWS services by using AWS metadata service to retrieve credentials from an IAM role.
---
## Server - Dockerized environment outside of AWS
To be completely honest, I didn't have an opportunity to work on this setup directly. Having that in mind, let's proceed.
The method of integrating AWS credentials in this case really depends on your CI/CD pipeline and tools. By reading this article you probably already have an idea how to add credentials to a Dockerized server environment, but here's some of the options anyway:
#### Option 1. - AWS CLI + Docker volume
Just like a bare metal non-AWS server (described above), you can open an `ssh` session to your server and install/configure AWS CLI on the server. You can then add a Docker volume pointing to `~/.aws` directory on the server which will transfer credentials into the container.
#### Option 2. - Use `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables
This option is based on the same method as the local Dockerized environment.
Depending on your CI/CD pipeline and tools, you might consider using `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables. Of course, you have to make sure that no third-party *server* has access to these values. If you are controlling your own CI/CD pipeline, for example by using a self-hosted GitLab instance, you can add these values in it.
#### Note: You can't use `AWS_CONTAINER_CREDENTIALS_RELATIVE_URI`
`AWS_CONTAINER_CREDENTIALS_RELATIVE_URI` is populated by AWS services (ECS and CodeBuild). Using this environment variable makes sense when you are deploying using AWS CodeBuild, but if you are building and deploying outside of AWS, then it's not available to you.
---
## Conclusion
You should now have an idea on how to set up your environment(s) so that your project can use AWS services securely without exposing credentials.
Let me know in the comments if you have a more elegant solution.
| nikolastojilj12 |
841,481 | Week 1/Google PM Specialization | Hey all, Recently I've started the second course of Project Management specialization created by... | 0 | 2021-09-26T20:25:59 | https://dev.to/hananekacemi/week-1-google-pm-specialization-4pdm | management, projectmanager, googlecourse, coursera | Hey all,
Recently I've started the second course of Project Management specialization created by Google and titled : **Project Initiation : Starting a successful project**. I decided to post my notes here as a memo.
#Week 1 :
## Initiation phase of the project life cycle :
Among Project Manager responsibilities during the project initiation phase we find:
1. Identify goals and resources based on initial discussion with stakeholders
2. Ask the right questions to stakeholders, perform research
3. Document the key component of the project.
Getting in the same page with the stakeholders, by clarifying the goals of the project, will save a lot of time and extra work for everyone throughout the project.
It's a crucial phase, because it determines how well the goals will be met, and it ensures that the benefits will outweigh the cost of the project.
## Key component of project initiation :
The key component to concider during the initiation phase are :
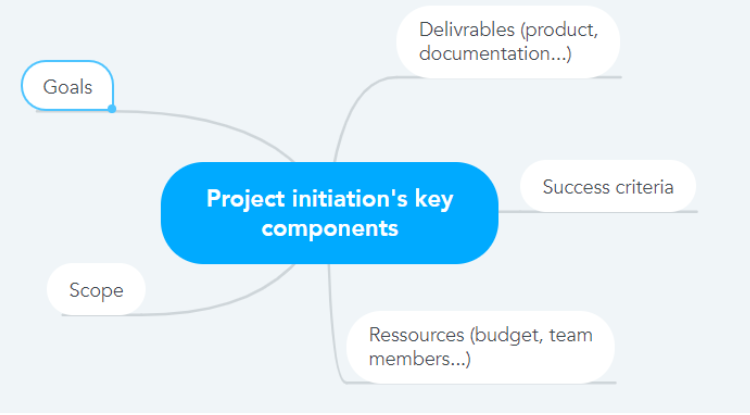
Once key components established, you need to create a project charter, the document that contain all project details to review with stakeholders in order to get their approval so you can start with the planning stage.
Next, I will write about cost-benefit analysis and its importance in project management.
Have a nice day all :)
| hananekacemi |
841,497 | A step-by-step guide for building a startup (or 'The four steps to epiphany' mini-summary) | Quite a lot of people have heard "The lean startup" book and movement. But fewer people have heard... | 0 | 2021-09-26T21:34:53 | https://www.rockandnull.com/a-step-by-step-guide-for-building-a-startup-or-the-four-steps-to-epiphany-mini-summary/ | business, bookreview | ---
title: A step-by-step guide for building a startup (or 'The four steps to epiphany' mini-summary)
published: true
date: 2021-09-26 21:31:19 UTC
tags: Business,Bookreview
canonical_url: https://www.rockandnull.com/a-step-by-step-guide-for-building-a-startup-or-the-four-steps-to-epiphany-mini-summary/
---

Quite a lot of people have heard "[The lean startup](https://smile.amazon.com/The-Lean-Startup-Eric-Ries-audiobook/dp/B005MM7HY8/)" book and movement. But fewer people have heard about "[The four steps to epiphany](https://smile.amazon.com/Four-Steps-Epiphany-Successful-Strategies/dp/1119690358/)". This was the inspiration for the lean startup way of thinking and worth a read.
The main premise of the book is that building a startup is not a mysterious process that no one knows how works. The author claims that after building and advising a few startups, clear patterns had emerged that if followed can give "structure" to the journey of building a startup.
Traditional companies follow what is known as the product development model: Concept -> Product Development -> Alpha/Beta Test -> Launch. Although this works great for companies that are doing something more "conventional", it's not a good model for "innovative" startups. Instead, a 4 step customer-centric and feedback-centric approach is proposed by the author that incorporates early feedback before actually building anything.
## Step 1: Customer discovery
Every business starts with an idea, a hypothesis that must hold for the company to be successful. This is the step where you **clearly define** and then test the **problem, product, and customer hypotheses**.
First, write down the mission of your company, that incorporates the problem assumption (i.e. the problem that your potential customers have and you will solve).
Then you need to test:
- this problem exists that
- the potential product can solve the problem
- that customers are willing to pay for your solution
You will do this by getting out of your office and comfort zone and talk to potential customers. Because this is easier said than done, check out other resources on [how to talk to potential customers](https://dev.to/mavris/a-practical-guide-for-talking-to-customers-or-the-mom-test-mini-summary-1aln-temp-slug-6192743).
Remember that the aim of this step is not to sell anything. It's to verify your assumptions.
## Step 2: Customer validation
Ok, so you validated the problem exists and the solution can work. Now you don't need to just sell. You need to figure out a **repeatable and scalable sales process**.
You will do this by working out your value proposition: a clear message on why someone will choose your product.
You will sell to early adopters/visionaries: they know they have a problem and they tried (hopefully unsuccessfully) to solve it themselves. They are open to accepting for a solution (or a superior solution). Get their feedback and improve your positioning.
Don't confuse the selling to early adopters with give-aways. You need to get actual orders to verify that you have a sales process.
> Would you deploy the product if it was free?
>
> Asking this question reveals the extent to which customers find the product valuable.
>
> If the customer is willing to use the product if it were free, continue by asking, “Actually I cannot give it away for free. I will need to charge $1 million for it. Would you buy it?” The customer might reply, “There is no way I will pay more than $250 000 for it.” You have just discovered how much they think the product is worth to them.
>
> [...]
>
> This leads to the observation that products should be sold, and not given free, to beta customers so that a realistic, replicable sales roadmap can be developed.
If you are happy with the results of this step, proceed. Otherwise, back to step 1.
## Step 3: Customer creation
Now you will need to execute that plan you created in step 2. There's no marketing team and no sales team. The entire company is executing the plan until you get to the next step.
Depending on the **type of market** you are trying to enter (i.e. existing market, resegmenting, new market), you will have different goals (e.g. getting marketing share, or, educating customers). Don't forget to **position** your startup according to your market type (e.g. do not go for "brand awareness" in a new market - no one knows what you are doing).
> There are four different types of startups, defined by market type:
> - Startups entering an existing market. For example, a new brand of pizza
> - Startups creating an entirely new market. For example, a pizza flavoured meal replacement.
> - Startups that want to re-segment an existing market as a low-cost entrant. For example, discounts for bulk buys.
> - Startups that want to re-segment an existing market as a niche player. For example, organic pizzas.
>
> Launching a product into an existing market has the advantage of existing customers but faces greater competition. A product in a new market has no competitors, but there are no well-defined and known customers either. Growth in an existing market could be a linear upward path, while in new markets it will take a few years before steady growth kicks in, when the product becomes mainstream.
>
> Therefore, customer education is the focus in new markets, while branding and positioning will be important in existing markets.
## Step 4: Company building
This is for **converting the small startup** (where everyone is doing everything) into a proper **company** (with specialized departments).
Clearly craft each department mission and goal. This easy-to-digest mission should be understoodby everyone in the department, not just the leadership (e.g. asking a salesman what it the missions department should not be "to sell").
Create a culture of information gathering and analyzing. All the "superstar" employees should be groomed and positioned as models and coached within the organization.
Hopefully, this was a useful and quick summary of the Four steps to epiphany. If you have the time, it's worth a read! | rockandnull |
841,503 | Embedded System | What is an Embedded System? Embedded System is the integration of actuators, sensors and also... | 0 | 2021-09-26T22:04:57 | https://dev.to/maazeez/embedded-system-8fe | What is an Embedded System?
Embedded System is the integration of actuators, sensors and also intelligence with the support of a system to give a more versatile, robust output.
Microcontroller
A microcontroller is a chip that contains :
1. CPU
2. RAM
3. ROM
4. FLASH
This chip functions as the brain of an embedded system. It is built in such a way that it can process a lot of activities together and give a robust output.
We can use a microcontroller:
1. when Intelligence is required.
2. It is less expensive than all other components.
3. It breaks down complexity in embedded systems, e.t.c.
When we do not use a microcontroller:
1. little or no intelligence.
2. Slow response, e.t.c.
We have different examples of microcontrollers, the most common one we have today is the arduino. The Arduino is a multitasking microcontroller. It is designed not only for technicians but also for other people like artists. It is designed for hobbies. It is also used to create simple circuits.
We have different types of Arduino, for example:
1. Arduino Uno
2. Arduino Mega
3. Arduino Nano
4. Arduino Micro e.t.c
In the Arduino, we have different pins on it. The two types of pins we have are:
1. Digital pins/GPIO
2. Analogue pins
Digital pins/GPIO:
- General Purpose Input and Output.
- Can be used as digital input or output.
- Each pin is uniquely assignable.
- "Analogue" (PWM) output are:3,5,6,9,10,11.
- Analogue pins 0-5 can also be used as GPIO pins.
Arduino shield
Shields are the things that can connect up to your Arduino.
AbdulMalik Abdulazeez is 14 and an upcoming Embedded Systems Engineer at IQ Academy Bodija Ibadan. Kindly support my work [here](https://ko-fi.com/abdulazeezmalik201)
Edited by [Ahmidat Gbadegesin](https://linkedin.com/)
Ahmidat Gbadegesin is a School Admin 2 and Student Manager at [IQ Academy Ibadan.](https://iqacademyibadan.com) | maazeez | |
841,584 | Web Components Update | Work Done So Far Throughout the weeks of understanding web components, there has been tons... | 15,902 | 2021-09-26T23:55:25 | https://dev.to/coltone37/web-components-update-1g85 | ##Work Done So Far
Throughout the weeks of understanding web components, there has been tons of new functions and coding techniques that were introduced to me since my last semester. We have started using our open-wc boilerplate to introduce our first project, creating a CTA Button. For the first week, our group has produced a not-so-pleasant-looking button, yet is the starting point into building something better. So far, our button has the functions of hovering, disabling, focusing, and activation, so far following all the necessary guidelines. HTML, CSS, and JS are the languages I have enjoyed learning and improving on so far this semester.
##Easy Parts
So far, the button has been pretty straight forward with functionality and being visually appealing. Being able to design in CSS with our button and give it the professional look and functions has been "easy enough" with the help of examples and in-class walkthroughs. Although, there has been some challenges.
##Difficulties
Some difficulties we have faced are mostly with GitHub, with the merging and pulling of different people's code. We have resolved most of our issues so far from talking in person with one another and getting our code on the same level. Other than that, the button project has been smooth.
##What I've learned
I have learned to closely follow examples and code walkthroughs in class, as well as trying to get as much of a head-start as you can. We have been given the opportunity to have our code reviewed and improved so much, by just working ahead. It is awesome to have a great instructor who sees hard-work being done and giving all students the opportunity to progress their learning and code skills by working ahead on assignments and projects.
Our Repo: https://github.com/TheKodingKrab/cta-button/tree/main/CEEK | coltone37 | |
841,594 | Development of a Button Web Component: Our Progress | Progress to Date In terms of the progress made by my teammate and I, we have come a very... | 15,890 | 2021-09-27T01:18:20 | https://dev.to/nro337/development-of-a-button-web-component-our-progress-40hb | ## Progress to Date
In terms of the progress made by my teammate and I, we have come a very long way from 4-5 weeks ago when we were first introduced to Lit and Web Components. To date, we have been able to create a Call to Action (CTA) button extended from [this](https://teuxdeux.com/) example we found on Teuxdeux's homepage. We started out by constructing a very basic button composed of a `<button>` nested in an `<a>` tag, and were able to grow our visual API to support various CSS styling designs. We have developed distinct visual and funtional support for four main button states: hover, focus, active, and disabled. We have tested for accessibility concerns regarding tab order and are continuing to leverage Storybook to investigate color contrast and support for other theming styles like our "dark" mode. Finally, out button uses some cool CSS transitions and rotations to allow out button to feel more animated and interactive. This is done when the user is hovering to dissipate to a transparent background while having our caret icon spin 90 degrees.
## Difficulties Along the Way
My teammate and I certainly faced a few difficulties along the way, as is common for any new learning process. There were a few nuances within LitElement that took some additional research and instructor clarification to truthfully understand how certain functions should be used. Things like the Shadowroot, the `<slot>` tag, reflecting properties in the constructor, and using bindings like `@click` just did not really click with me initially. I am used to vanilla JS where these do not exist, so wrapping my head around where the Shadowroot lies in the DOM Tree and why it is so awesome definitely took some time. Now that I have a better understanding of why reflecting properties makes data binding a breeze, it has helped situate me in my current development style as well.
## TIL
After really digging deep over the past few weeks into Web Components and Lit, it really has come down to one major theme for me: **Accessibility is King**.
There is really no reason that anyone from major corporations to small start-up could not prioritize their online websites and products following an accessibility-first mindset. While there is an initial learning curve, web components make it incredibly straight forward and explicit in order to handle events, select attributes, and ultimately leverage the CSS cascade to meet the varying needs of my group's button. For myself, I think the idea that you have the power to influence any and all component states and properties was a really humbling fact to understand once I could comprehend it. For example, working to have the same stylistic behavior appear both when a user hovers over the button as well as when it receives tab focus was a fact I wouldn't have thought about coming in. But now that I understand why this consistency is preferable, I find myself motivated to apply this notion elsewhere in my code. Another big realization I came to is the true value in writing succinct and logical code. Things like consistent CSS variable naming and carring those styles dynamically through different button properties and states is crucial for the readability of one's code. This is definitely something I need to work on further, but the division of styles, properties, and the rendering of the component make it *very* easy to comprehend how a component works if the logic is succinct.
Here's a link to our Button if you are interested! https://github.com/table-in-the-corner/invisi-button | nro337 | |
841,608 | What is REST | REST is a term that’s referred to a lot in programming. So, what is REST? It stands for... | 0 | 2021-09-27T02:54:05 | https://dev.to/liz_p/what-is-rest-1pgh | REST is a term that’s referred to a lot in programming. So, what is REST? It stands for REpresentational State Transfer. Ok, huh? [REST is an architectural style for providing standards between computer systems on the web, making it easier for systems to communicate with each other.](https://www.codecademy.com/articles/what-is-rest)
Still confused? Basically, it boils down to a fairly simple explanation, REST is a standardized way that web apps should structure and name their URLS. It [has gained a lot of popularity in recent years due to its simplicity and scalability.] (https://www.freecodecamp.org/news/benefits-of-rest/)
Ok, but maybe this concept's still a little hazy. Totally understandable. There are 4 basic HTTP verbs that are used to interact with resources.
`www.mysite.com` (example site)
`www.mysite.com/results` (results is my resource in this example)
**1) GET**- retrieves the resources and displays the result
`www.mysite.com/results` (all results)
`www.mysite.com/results/1` (single result retrieved by ID)
**2) POST**- creates a new resource
**3) PUT**- updates a single resource by ID
**4) DELETE**- deletes a single resource by ID
The below [image](https://miro.medium.com/max/1494/1*LraiNuIhwGGVb9nLmvuAIA.png) explains the HTTP methods and each CRUD action (Create, Read, Update and Destroy) well.
By using RESTful conventions it makes things clear and predictable. Thanks for reading! | liz_p | |
841,609 | Progress Update: Button Web Component | Since starting the development of a call-to-action (CTA) button for IST 402, I have encountered quite... | 0 | 2021-09-27T01:52:41 | https://dev.to/dronk6/progress-update-button-web-component-4p02 | Since starting the development of a call-to-action (CTA) button for IST 402, I have encountered quite a few challenges while learning a lot about open web components and LitElement. My partner and I chose to develop a CTA button modeled after a circular button on an e-commerce clothing site, which would act as a building block for learning about atomic web design.
#### Progress
Thus far, my partner and I have created the button component itself, linked it, and have completed a lot of the responsive CSS behavior for the button itself. This includes resizing the button when different text is inserted into it, as well as changes in state when it is hovered over and focused on. We plan to also create behavior for "active" and "disabled" states, and are currently working on these. In addition, we've added optional icon support that features conditional rendering, allowing for the creation and removal of an icon in our button from the "inspect" tab of a browser. We have began working on our button's dark mode behavior as well, designing a way for dark mode to be initiated within the button's tag.
> Here is the repository that exhibits our progress thus far: [circle-button-ad Repository] (https://github.com/3B4B/circle-button-ad)
#### Challenges
Building a responsive, reusable circular button is hard. As the lead developer in my partner team, I learned this very quickly and figured out my knowledge of CSS was *not great* almost immediately. That said, lots of browsing CSS on overly-specific sites has led to me learning a lot more about it than I assumed I would when starting this button. I can proudly say I know more about styling a button than I did when I started this assignment.
As web components are something I've never extensively worked with until now, this also presented a learning curve. LitElement seemed intuitive when I was using a hello-world boilerplate, but getting familiar with its inner workings took more time than I'd like to admit. This isn't a shortcoming of the structure so much as it is my lack of experience with it. As I've continued to work in the directory structure that our web component is set up, I've become more familiar with it and feel that my understanding of our button has gotten much better. For instance, learning how the demo folder's index.html file interacts with my JavaScript file in my src folder has allowed me to vastly improve the way I visually test the functionality of our button--and increase its customizability.
| dronk6 | |
841,640 | Create a Netflix clone from Scratch: JavaScript PHP + MySQL Day 63 | Netflix provides streaming movies and TV shows to over 75 million subscribers across the globe.... | 0 | 2021-09-27T03:30:48 | https://dev.to/cglikpo/create-a-netflix-clone-from-scratch-javascript-php-mysql-day-63-1n0p | php, javascript, webdev, tutorial | Netflix provides streaming movies and TV shows to over 75 million subscribers across
the globe. Customers can watch as many shows/ movies as they want as long as they are
connected to the internet for a monthly subscription fee of about ten dollars. Netflix produces
original content and also pays for the rights to stream feature films and shows.
In this video,we will be Making our first ajax call
{% youtube mIKK5mm1E94 %}
If you like my work, please consider
[](https://www.buymeacoffee.com/cglikpo)
so that I can bring more projects, more articles for you
If you want to learn more about Web Development, feel free to [follow me on Youtube!](https://www.youtube.com/c/ChristopherGlikpo) | cglikpo |
841,783 | State Management | State management and how it can be handled in Javascript frameworks | 0 | 2021-09-27T05:19:07 | https://dev.to/sunitha_nair/state-management-19b2 | designpatterns, angular, javascript | ---
title: "State Management"
published: true
author : "Sunitha Premakumaran"
description : "State management and how it can be handled in Javascript frameworks"
tags : [
"designpatterns",
"Angular",
"Javascript"
]
---
I am sure you have heard about state management when it comes to developing enterprise applications. Let’s get started with the concept by understanding what it means for us and how it helps us build a Reactive application. This blog will focus on how to maintain state in Angular applications but the concepts are the same for all the component based frameworks including React and Vue Js.
## What is State management?
`State` in application is the single source of truth containing the user contexts or other global information. Let us consider the scenario where you wanna build an application which will use login functionality. Let’s say you have multiple components using the login information to display the information about the login like Login name, email and your avatar, when you update any of these information you want all the components capture and reflect this change. With state management you can handle this change and make sure that the data is available from a single place for consumption that components can rely on and use in a reusable and structured way.
## State management libraries for Javascript
There are a lot of libraries for State management for Javascript frameworks. Most of these libraries use the Redux pattern to manage the state. The most used frameworks use RxJs pattern in their implementation as RxJs strongly promotes Reactive programming for applications. NgRx is one such framework for State management for Angular applications.
## Components of State management
### Store
This component takes care of all the input and output operations concerned with the application state. The below snippet defines a way to handle State for a Todo application.
```
export interface TodoState {
todos: string[];
loading?: boolean;
}
```
### Action
Actions are how the change is transpiled. The below snippet is an example of using actions from `ngrx/store` that is defined to handle the particular case of adding a todo. This action has to dispached to store when an end user is trying to perform an action.
```
import { Action } from '@ngrx/store';
export class PostTodo implements Action {
readonly type = 'POST_TODO';
payload: string;
constructor(payload: string) {
this.payload = payload;
}
}
```
### Effects
Effect is the way to handle javascript’s asynchronous code like invoking http requests and such. The following snippet is an example for a Side Effect for a Http post that will be triggered once the `PostTodo` action is dispached as a result of change in UI.
```
@Effect() todoPersist = this.actions$.pipe(
ofType('POST_TODO'),
switchMap((payload: string) => {
return this.http.post(
'https://demo9257915.mockable.io/todos',
{
payload: payload
}
).pipe(
map((data: string) => {
return new AddTodo(data);
}),
catchError(error => {
return of(null);
})
)
})
);
```
### Reducer
This is a javascript function that makes a copy of state and makes changes and returns new state along with old state since changes made in the application have to be immutable.
```
export function todoReducer(state = initialState, action: TodoType) {
switch (action.type) {
case 'ADDED_TODO': {
return {
...state,
todos: [
...state.todos,
action.payload
]
}
};
case 'POST_TODO': {
return {
...state,
loading: true
};
};
}
}
```
### Selector
Selector is used to subscribe specific changes to your state change and update the UI depending on the change. The following snippet subscribes to added todos and updates the UI accordingly after the server creates a todo.
```
ngOnInit() {
//Observable for the key todoList, subscribed value using async pipe in component template
this.store.select('todoList').subscribe(data => {
this.array = data.todos;
});
}
```
### Summary
While state management in your application gives you the leverage to handle reads and updates to your application data it also adds a lot of complexity if your Single page application is small in size. For cases with small applications it is better to handle your application state using RxJs alone. A complete working of managing state using NgRx in angular applications can be found [here](https://github.com/sunitha-premakumaran/ngrx-angular-demo).
| sunitha_nair |
841,790 | Alexander Zingman talks on Agro Deal | Alexander Zingman, Zimbabwe’s honorary ambassador, said the $ 58 million agreement between the two... | 0 | 2021-09-27T05:28:56 | https://dev.to/charllouiss/alexander-zingman-talks-on-agro-deal-1oi0 | Alexander Zingman, Zimbabwe’s honorary ambassador, said the $ 58 million agreement between the two countries would transform Zimbabwe’s agriculture. The first batch of high-tech farms has been set up in the Valley, including 20 July, including 100 tractors and 52 farmers, while it is expected in December.
Alexander Zingman said, “This agreement brings the knowledge of Belarus to Zimbabwe’s agriculture and engineering.
Read more here : https://www.tmcnet.com/usubmit/-alexander-zingman-says-belarus-agriculture-deal-will-boost-/2020/06/25/9174623.htm | charllouiss | |
841,842 | Modern Companies Need a Customer Data Platform. Should You Build or Buy? | "Before RudderStack, I tried to build customer data pipelines inside a large enterprise using... | 0 | 2021-09-27T07:26:14 | https://rudderstack.com/blog/build-or-buy-lessons-from-ten-years-building-customer-data-pipelines | cdp, customerdata, rudderstack, datawarehouse | "Before RudderStack, I tried to build customer data pipelines inside a large enterprise using homegrown and vendor solutions. This article summarizes what I learned both building and buying customer data pipelines over the last ten years and how I would approach the challenge today."
- Soumyadeb Mitra
A major initiative for all modern companies is aligning every team around driving a better experience for their users or customers across every touchpoint. This makes sense: happy, loyal users increase usage, business growth, and ultimately revenue.
Creating powerful experiences for each user, especially when it comes to use case personalization, is easier said than done.
To drive great experiences across every team and technology, you must:
- Collect every touchpoint each customer has with your business
- Unify that data in a centralized, accessible repository
- Enrich and deliver that data to every downstream tool (product, marketing, data science, sales, etc.)
Overlooking any of these measures makes eliminating bad user experiences nearly impossible. Your marketing and product teams will continue to send email promotions for products your customers have already bought, and data science won't be able to produce models that increase lifetime value.
With customer expectations higher than ever, failing to unify and activate your customer data means slower growth and higher churn.
The Big Decision: Build or Buy?
-------------------------------
As a technical leader supporting data-driven growth initiatives, your biggest decision regarding customer data pipelines is whether or not to buy a solution from a vendor or work with your engineering team to build your own.
I'm an engineer by trade, and before starting RudderStack, I spent years at a large enterprise trying to unify and activate customer data with both homegrown and vendor pipeline solutions.
Over the last two years, I've worked with 20+ engineers to build customer data pipeline solutions, and based on those ten years of experience, here's why I think trying to build your solution is a mistake.
The Challenges I Faced in Building
----------------------------------
As engineers, we like to build things. Also, in many cases, the idea of building things has advantages. In my previous role at an enterprise company, building our own customer data pipelines seemed like a more tailored and less expensive choice for our needs, especially because we had the engineering talent.
As is often the case, though, the idea of building something is different from reality. Here are the things I wish I considered before going down the build path:
### Scaling is a Challenge
One of the characteristics of customer data is that initial use cases always seem manageable (send page view data to marketing, feature usage to product, etc.), but the more data you have, the more use cases you enable. This is a virtuous cycle that can be very powerful for teams, such as marketing and product, but from a technical standpoint, your initial set of requirements rarely reflects the system's long-term needs at scale.
Ultimately, you want to track *every* action your users take, from clicks to searches to transactions. That event volume for even a mid-sized B2C company can easily get into millions of events per day.
First, building any system to handle that scale isn't trivial from a collection and processing standpoint, and because the data is driving actual experiences, latency can cause major problems.
Event volume peaks are another major issue. Planning for average usage is one thing, but the system needs to handle significant spikes in volume without any additional configuration or infrastructure management. (Otherwise, the engineering team is always putting out fires whenever the business has a big event like a sale, peak season, etc.).
If you don't build the system for efficiency at scale from the outset, costs can also become a major problem.
Managing these considerations while ensuring low latency and minimal performance overhead almost always means engineering resources are being used to collect and route data instead of working on the actual product and product-related infrastructure.
### Building and Managing Data Source Integrations is an Annoying, Never-Ending Problem
Customer data is spread across multiple different data sources. Think about even a simple business with one website and one app:
- Website
- App
- Cloud tools
- Payment/transaction data
- Messaging data (email, push, SMS)
- Advertising data (Google, Facebook, etc.)
- Cloud apps (CRM, marketing automation, etc.)
Building integrations for every data source is not only a huge amount of work but requires knowledge of a diverse set of programming languages, libraries, and application architectures. Worse yet, the integrations are constantly evolving with new features and API versions.
Another major challenge is that there are different categories of pipelines. Event data comes from the website and app and needs to be delivered in real-time, but customer data from cloud sources is often tabular and needs to be loaded in batches.
Keeping an engineering team motivated to keep messy integrations up to date is a huge challenge, not to mention concerns around the value of using expensive, smart resources to maintain base-line functionality.
### Unifying Data Isn't as Easy as Dumping Customer Events Into Your Data Warehouse / Data Lake.
At face value, it doesn't seem hard to take an event stream and dump it into a data warehouse, such as BigQuery or Snowflake, or a data lake (or "lakehouse"), such as Databricks Delta Lake.
Well, it turns out that it is hard. You must:
- Handle millions of events per hour while managing warehouse performance and cost
- Manage schema changes as your event structures change (which happens all of the time with customer data)
- Dedupe events
- Maintain event ordering
- Automatically handle failures (during warehouse maintenance, for example)
There are other challenges, but even that small list shows you how complex the actual architecture is.
### Every Downstream Team Wants Data Integrated Into Their Tools Too
Even though it is the customer data stack's central piece, the warehouse isn't the only destination where you need to send your event stream. Every downstream team wants customer data in their tools.
For example, your product team will want event stream data in analytics tools such as Amplitude or Mixpanel. The marketing team will want those events in Google Analytics, and Marketo and the data science team will want it delivered to their infrastructure.
As I said above, managing these integrations is a full-time engineering function.
More importantly, event stream connections (source-destination) aren't the only pipeline you have to manage. Downstream teams are increasingly requiring data enriched in the warehouse for use cases like lead scoring, win-back campaigns for customers likely to churn, and maintaining a single view of the customer in each tool. Building pipelines from your warehouse to each downstream tool is a significant engineering problem in and of itself.
### Dealing With Privacy Regulations is Complex When There are so Many Sources and Destinations
As an engineer, the last thing you want to deal with is figuring out how to suppress or delete all records related to a user from your warehouse or cloud destinations because your legal team requires it.
Not only is the exercise hard and boring, but deciding to build that functionality into your internal pipeline product significantly increases the complexity and extends the project into building internal tooling.
Unfortunately, you don't have a choice on this one---in the era of GDPR, CCPA, and other regulatory measures being put in place, non-compliance can lead to millions of dollars of fines.
### The Complexity of Error Handling Scales With the Number of Integrations
Normally you would think about error handling in the context of the integrations themselves (sources and destinations). However, after dealing with the actual problem, I learned that it deserves its mention.
The summary is that error handling is hard. Think about it: any of your sources, destinations, or warehouses can be down for any length of time. (Keep in mind many tools, like the warehouse, are sources *and* destinations!)
The reality is that your system needs to ensure you don't lose events in any circumstance and maintain the event order for future delivery when there is a problem.
The Challenges I Faced With Buying
----------------------------------
If you know that building isn't the right path (which I discovered the hard way), should you buy a vendor solution? Well, I tried that too, and there were problems.
### It's Not Just Vendor Lock-in Anymore; it's Data Lock-in
Data lock-in is a huge problem. Sure, a vendor can give you a CSV dump or API access to all of your data if you ask. Still, their systems are fundamentally designed to store a copy of your data, which inherently means you are tied not only to their features but are limited in your ability to leverage the data fully.
Vendors who store data leverage it to drive a few specific features well, but that never serves every need you have to fill for downstream teams. For example, pipelines built for enterprise-scale don't enable real-time use cases, while pipelines that serve marketing teams fail when ingesting tabular data from cloud sources. Neither serves data science well.
Lastly, and this is a personal pet peeve, paying a vendor to store a copy of data you're already storing in your warehouse is an unnecessary cost in an already expensive system.
### Most Vendors Don't Support Complex Customer Data Stacks.
As I mentioned above, the modern customer data stack is far more complex than an event stream and cloud tools. You need to ingest tabular data. You need to deliver enriched data from your warehouse and interact with data from internal systems behind a firewall, all while dealing with privacy requirements from InfoSec.
Central management would be great, but buying a solution for each part of the pipeline means managing multiple vendors. Also, there are challenges of varying data formats and system-wide control for both data governance. Furthermore, it isn't easy to suffice even more complex needs such as identity resolution.
### The Cost Outweighs the Benefits
Ironically, when you look at the cost that many vendors charge, it increases the attractiveness of building your solution.
When a vendor manages both the processing *and* storage of your customer data, they up-charge you on their costs. Even for a moderately sized business (a few million users or a few billion events per month), to operationalize the tool, the cost could be $250,000 - $500,000 annually plus all of your internal costs.
Building yourself has massive hidden internal costs, but paying a vendor half a million dollars a year is a hard investment to justify, especially when it takes a while to get results.
What I Would do Today: Implement Warehouse-First Customer Data Pipelines
------------------------------------------------------------------------
Given the difficulties I experienced trying to build pipelines internally and the pitfalls and costs that come with buying a solution off the shelf, I'm fully convinced that the right solution is actually the best of both worlds. This requires what I call a "warehouse-first" approach, and it's the foundation of RudderStack's solution for customer data pipelines.
A [warehouse-first](https://rudderstack.com/blog/step-by-step-guide-how-to-set-up-a-warehouse-first-cdp-on-snowflake-using-rudderstack/) approach puts your owned infrastructure (warehouse, systems, etc.) at the center of the stack, so you own and have full control over all your data but *outsources* the parts that don't make sense to build with internal engineering resources. Importantly, warehouse-first pipelines don't store any data; they ingest, process, and deliver it.
Said another way, warehouse-first customer data pipelines allow you to build an integrated customer data lake *on your warehouse*. You don't have to build the plethora of source and destination integrations or deal with peak volume or error handling. Instead, you retain full control over your data and the flexibility to enable any possible use case.
There are many benefits to the warehouse-first approach, but here are the top 3 based on my experience:
- You can build for any use case: Instead of being limited to vendor-specific use cases, owning your data with flexible pipelines means you can enable all sorts of valuable use cases. You own everything, from driving real-time personalization on your website to delivering enriched lead profiles from your warehouse to your sales team.
- You can deliver better data products: If you have flexible schemas, event stream pipelines, tabular pipelines, and warehouse → SaaS pipelines managed for you, your team can leverage the power of unified data in your warehouse to build creative and valuable data products for the entire company (instead of building and managing infrastructure).
- You don't have to deal with vendor security concerns: Because your warehouse is the central repository for data and the vendor doesn't store any data, you can eliminate most security concerns common among 3rd-party vendors who store your customer data.
- You can decrease costs: Quite simply, you don't have to pay a vendor a premium to store data that already lives in your warehouse.
I Built RudderStack to Make it Easier For You to Build Better Customer Data Pipelines.
--------------------------------------------------------------------------------------
RudderStack was built from the beginning with the warehouse-first approach in mind. We don't store any customer data, solve the headache of managing integrations and provide the infrastructure for the different types of customer data pipelines required by the modern stack (learn more about [Event Stream](https://resources.rudderstack.com/rudderstack-cloud), [Cloud Extract](https://rudderstack.com/blog/rudderstack-cloud-extract-makes-cloud-to-warehouse-pipelines-easy), and [Warehouse Actions](https://rudderstack.com/blog/rudderstack-warehouse-actions-unlocks-the-data-in-your-warehouse)).
Sign up for Free and Start Sending Data
---------------------------------------
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app. [Get started](https://app.rudderlabs.com/signup?type=freetrial). | teamrudderstack |
841,873 | How to build Serverless API with database using AWS CDK | Serverless gives us tremendous opportunities to ship new digital products faster at no cost in the... | 15,067 | 2021-09-27T08:09:18 | https://dev.to/grenguar/how-to-build-serverless-api-with-database-using-aws-cdk-4i2d | serverless, aws, api, devops | _Serverless gives us tremendous opportunities to ship new digital products faster at no cost in the beginning. The most classical way of using serverless is to have API backed by AWS Lambdas. This blog will guide the provision and deployment of an application using AWS CDK version 2. However, when I have started implementing it, issues started to appear. I would tell about them while depicting the process and code. Serverless will give the ability to have a full API setup for free._
First of all, what are we building? It will be an API Gateway backed by AWS Lambdas. They will be reading and writing items to the DynamoDB table. So, here we are, creating the CRUD with REST API. One can find the GitHub repository [here](https://github.com/Grenguar/aws-cdk-api-workshop).
```API Gateway -> AWS Lambda -> DynamoDB```
Reading is great for many things. So our items will be books! The model will be like that:
```json
{
"title": "name of the book>",
"author": "<author of the book>",
"yearPublished": "<published year of the book>",
"isbn": "<universal identifier of the book>"
}
```
## Implementation
In this demo application, we are using Dynamo DB. It is a NoSQL database where AWS manages infrastructure. It is working like a magic spell with the Lambda functions. This app will do classic CRUD operations.
```typescript
import { DocumentClient } from 'aws-sdk/clients/dynamodb';
import { Book } from '../models/book';
import uuid from 'uuid';
const dynamo = new DocumentClient();
export async function create(table: string, book: Book) {
const params = {
TableName: table,
Item: {
id: uuid.v4(),
...book
}
}
const dbResponse = await dynamo.put(params).promise();
return params.Item;
}
```
The start will be related to the writing items to the table. Typescript allows having a strongly typed object. The only thing which will be great to have as unique as possible is UUID. In this case, getting a book by the ID will be straightforward. The deleting operation will be very similar.
```typescript
export async function get(table: string, id: string) {
const params = {
TableName: table,
Key: {
id
}
};
const dbResponse = await dynamo.get(params).promise();
return dbResponse.Item;
}
export async function deleteItem(table: string, id: string) {
const params = {
TableName: table,
Key: {
id
}
}
await dynamo.delete(params).promise();
}
```
It would be great also to check the created items. Here I am using the 'Scan' operation, which goes through the whole table. For demo purposes, this should be enough. Whenever possible, one should use 'Query.'
```typescript
export async function list(table: string): Promise<DocumentClient.ItemList> {
const params = {
TableName: table,
}
const dbResponse = await dynamo.scan(params).promise();
if (dbResponse.Items) {
return dbResponse.Items;
}
throw new Error('Cannot get all books');
}
```
The most complicated request is to update the book from the database. It needs to have parameters and values to edit.
```typescript
export async function update(table: string, id: string, book: Book) {
const params = {
TableName: table,
Key: {
id,
},
ExpressionAttributeValues: {
':title': book.title,
':author': book.author,
':yearPublished': book.yearPublished,
':isbn': book.isbn
},
UpdateExpression: 'SET title = :title, ' +
'author = :author, yearPublished = :yearPublished, isbn = :isbn',
ReturnValues: 'UPDATED_NEW',
}
await dynamo.update(params).promise();
}
```
Dependency injection is the first complication that is happening with lambdas. If one packs it to the AWS by using CDK or CloudFormation, there will be no dependencies. I am using typescript in the project, so in theory, running will create a working js file:
```bash
npm i -D typescript
tsc init
tsc
```
However, it is not so straightforward. There are two issues here:
- packing additional files with functionality because having Lambda with the implementation inside one file is a bad practice
- packing external dependencies. In our case, it will be UUID one.
I tried to pack just src/functions/create. Running Lambda will give that:
That is why the next logical step will be to find out how to pack Lambda code together with dependencies and don't upload 100 Mb of node_modules. I decided to use webpack for that. It does the job right and will allow running just this command after installation: `webpack`
Lambdas' main handler functions will be as simple as calling the DynamoDB file with the needed operations. For example, creating the item would be like that.
```typescript
import { APIGatewayProxyEventV2, Callback, Context } from 'aws-lambda';
import { create } from '../connectors/dynamo-db-connector';
export async function handler (event: APIGatewayProxyEventV2, context: Context, callback: Callback) {
if (typeof event.body === 'string') {
const bookItem = JSON.parse(event.body);
const createBook = await create(process.env.table as string, bookItem);
const response = {
statusCode: 201,
}
callback(null, response);
}
callback(null, {
statusCode: 400,
body: JSON.stringify('Request body is empty!')
});
}
```
One could find handlers for other operations in the [repository](https://github.com/Grenguar/aws-cdk-api-workshop/tree/main/src/functions).
## Infrastructure
As previously mentioned, CDK will be in charge of the infrastructure provisioning. I will be using just one stack with DynamoDB, 5 Lambdas, Rest API, permissions for table connections, and integrations for endpoints. We will put the infrastructure application in a separate folder <root>/infra.
To create DynamoDB with Lambda calling it, one will need ready-made typed constructs for DynamoDB, Lambda, and permissions. The code is situated one level above, so it is essential to put it like this. The good thing here is that CDK will error when one calls the template's 'synthesizing' with the wrong parameters. After that, Lambda will need a permission to put an item to DynamoDB. One could do this by adding one line of code.
```typescript
const dynamoTable = new ddb.Table(this, 'BookTable', {
tableName: 'BookStorage',
readCapacity: 1,
writeCapacity: 1,
partitionKey: {
name: 'id',
type: ddb.AttributeType.STRING,
},
})
const createBookFunction = new lambda.Function(this, 'CreateHandler', {
runtime: lambda.Runtime.NODEJS_14_X,
code: lambda.Code.fromAsset('../code'),
handler: 'create.handler',
environment: {
table: dynamoTable.tableName
},
logRetention: RetentionDays.ONE_WEEK
});
dynamoTable.grant(createBookFunction, 'dynamodb:PutItem')
```
After that, the function could be attached to the API. First, we are initializing RestAPI. Then, we add a resource to root for having a path like POST <api-root>/.
```typescript
const api = new apigw.RestApi(this, `BookAPI`, {
restApiName: `book-rest-api`,
});
const mainPath = api.root.addResource('books');
const createBookIntegration = new apigw.LambdaIntegration(createBookFunction);
mainPath.addMethod('POST', createBookIntegration);
```
The steps shown in this section will be repeated for other endpoints also. The best part comes when one can see that lambda creation is the same but with different parameters. CDK could wrap it into the function for saving space and having reusable code for provisioning handlers.
## Testing endpoints
After the manipulations mentioned in the previous sections, we can try out the API mentioned in this article. Let's start with the list of all books. The result should be empty.
```bash
curl --location --request GET 'https://<api-id>.execute-api.<region>.amazonaws.com/prod/books'
RESPONSE:
Status: 200
[]
```
After that, let's create a couple of books.
```bash
curl --location --request POST 'https://<api-id>.execute-api.<region>.amazonaws.com/prod/books' \
--header 'Content-Type: application/json' \
--data-raw '{
"title": "Life of PI",
"author": "Yann Martel",
"yearPublished": "2000",
"isbn": "0-676-97376-0"
}'
RESPONSE:
Status: 201
```
And one more:
```bash
curl --location --request POST 'https://<api-id>.execute-api.<region>.amazonaws.com/prod/books' \
--header 'Content-Type: application/json' \
--data-raw '{
"title": "Simulacra and Simulation",
"author": "Jean Baudrillard",
"yearPublished": "0-472-06521-1",
"isbn": "0-676-97376-0"
}'
RESPONSE:
Status: 201
```
Now we can call a list to make sure that all the books are in their places.
```bash
curl --location --request GET 'https://<api-id>.execute-api.<region>.amazonaws.com/prod/books'
RESPONSE:
Status: 200
[{
"isbn": "0-676-97376-0",
"id": "617d6b3e-ce6d-4e8d-a10f-05d6703ad7ac",
"yearPublished": "2000",
"title": "Life of PI",
"author": "Yann Martel"
}, {
"isbn": "0-676-97376-0",
"id": "2a8251ee-73ee-4717-8f6f-0f11dd2b861f",
"yearPublished": "0-472-06521-1",
"title": "Simulacra and Simulation",
"author": "Jean Baudrillard"
}]
```
Lambda added the books, and a listing is also working. However, there is an error in the database. I noticed that 'Life of PI' was published in 2001 and not in 2000. So, we need to call the update endpoint.
```bash
curl --location --request PUT 'https://y55xcv8jmc.execute-api.eu-west-1.amazonaws.com/prod/books/617d6b3e-ce6d-4e8d-a10f-05d6703ad7ac' \
--header 'Content-Type: application/json' \
--data-raw '{
"isbn": "0-676-97376-0",
"yearPublished": "2001",
"title": "Life of PI",
"author": "Yann Martel"
}'
Status: 200
```
Another list call will show that the book was successfully updated.
```bash
[{
"isbn": "0-676-97376-0",
"id": "617d6b3e-ce6d-4e8d-a10f-05d6703ad7ac",
"yearPublished": "2001",
"author": "Yann Martel",
"title": "Life of PI"
}, {
"isbn": "0-676-97376-0",
"id": "2a8251ee-73ee-4717-8f6f-0f11dd2b861f",
"yearPublished": "0-472-06521-1",
"title": "Simulacra and Simulation",
"author": "Jean Baudrillard"
}]
```
Let's delete one of the books by calling the DELETE endpoint.
```bash
curl --location --request DELETE 'https://<api-id>.execute-api.<region>.amazonaws.com/prod/books/2a8251ee-73ee-4717-8f6f-0f11dd2b861f'
Status: 200
```
After calling it multiple times with different ids, one will get empty response for the list of books. This is what we are expecting here.
---
In this article, I showed how to deploy Serverless API with the NoSQL Database using AWS Lambda, DynamoDB, and API Gateway deployed by CDK. Lambdas have all permissions for CRUD operations. This can be a sample project for a more complicated setup. Also, I was using the webpack to have all the node dependencies in place. The future work will include the CodePipeline for CI/CD connected to the GitHub hook. Thanks for reading this article!
_Want to learn more about AWS, Serverless, and CDK? Subscribe to my blog where I am posting about these topics on a regular basis._
| grenguar |
842,068 | How can I allow users to use a Google account for sign-in without a GMS phone? | If users have not installed GMS on their phones, they cannot directly sign in to your app using a... | 0 | 2021-09-27T09:20:22 | https://dev.to/devwithzachary/how-can-i-allow-users-to-use-a-google-account-for-sign-in-without-a-gms-phone-421i | android, gms, login | If users have not installed GMS on their phones, they cannot directly sign in to your app using a Google account. In this case, you can let them sign in to your app in web mode by obtaining the access token for sign-in authentication from Google. The procedure is as follows:
Sign in to the Google Play Console, click Credentials, and create an OAuth 2.0 client ID with Type set to Web application.
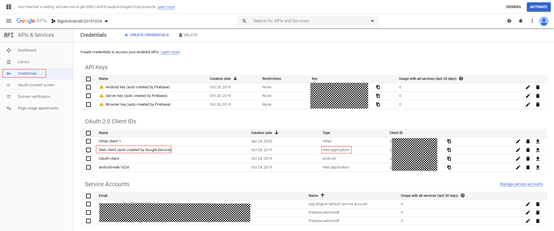
Go to the settings page and find Client ID and Client secret on the right side of the page, which are needed for integrating Google sign-in. Add a URI of the page to be displayed after the web sign-in is complete to Authorized redirect URIs.
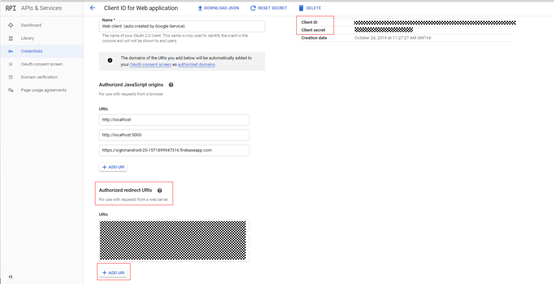
When users want to sign in with their Google accounts, the web page domain name that is https://accounts.google.com/o/oauth2/v2/auth, query should be opened. Add the following parameters to it.
* client_id - **Required** - The client ID for your application. You can find this value in the API Console Credentials page.
* redirect_uri - **Required** - Determines where the API server redirects the user after the user completes the authorization flow. The value must exactly match one of the authorized redirect URIs for the OAuth 2.0 client, which you configured in your client's API Console Credentials page. If this value doesn't match an authorized redirect URI for the provided client_id you will get a redirect_uri_mismatch error.
Note that the http or https scheme, case, and trailing slash ('/') must all match.
* response_type - **Required** - Determines whether the Google OAuth 2.0 endpoint returns an authorization code.
Set the parameter value to code for web server applications.
* scope - **Required** - A space-delimited list of scopes that identify the resources that your application could access on the user's behalf. These values inform the consent screen that Google displays to the user.
Scopes enable your application to only request access to the resources that it needs while also enabling users to control the amount of access that they grant to your application. Thus, there is an inverse relationship between the number of scopes requested and the likelihood of obtaining user consent.
We recommend that your application request access to authorization scopes in context whenever possible. By requesting access to user data in context, via incremental authorization, you help users to more easily understand why your application needs the access it is requesting.
* access_type - **Recommended** - Indicates whether your application can refresh access tokens when the user is not present at the browser. Valid parameter values are online, which is the default value, and offline.
Set the value to offline if your application needs to refresh access tokens when the user is not present at the browser. This is the method of refreshing access tokens described later in this document. This value instructs the Google authorization server to return a refresh token and an access token the first time that your application exchanges an authorization code for tokens.
* state - **Recommended** - Specifies any string value that your application uses to maintain state between your authorization request and the authorization server's response. The server returns the exact value that you send as a name=value pair in the URL fragment identifier (#) of the redirect_uri after the user consents to or denies your application's access request.
You can use this parameter for several purposes, such as directing the user to the correct resource in your application, sending nonces, and mitigating cross-site request forgery. Since your redirect_uri can be guessed, using a state value can increase your assurance that an incoming connection is the result of an authentication request. If you generate a random string or encode the hash of a cookie or another value that captures the client's state, you can validate the response to additionally ensure that the request and response originated in the same browser, providing protection against attacks such as cross-site request forgery. See the OpenID Connect documentation for an example of how to create and confirm a state token.
* include_granted_scopes - **Optional** - Enables applications to use incremental authorization to request access to additional scopes in context. If you set this parameter's value to true and the authorization request is granted, then the new access token will also cover any scopes to which the user previously granted the application access. See the incremental authorization section for examples.
* login_hint - **Optional** - If your application knows which user is trying to authenticate, it can use this parameter to provide a hint to the Google Authentication Server. The server uses the hint to simplify the login flow either by prefilling the email field in the sign-in form or by selecting the appropriate multi-login session.
Set the parameter value to an email address or sub identifier, which is equivalent to the user's Google ID.
* prompt - **Optional** - A space-delimited, case-sensitive list of prompts to present the user. If you don't specify this parameter, the user will be prompted only the first time your project requests access.
Possible values are:
none Do not display any authentication or consent screens. Must not be specified with other values.
consent Prompt the user for consent.
select_account Prompt the user to select an account.
Examples
{% gist https://gist.github.com/devwithzachary/cfc22b8001abce44fadcc1a7d764e127 %}
**redirect_uri** is the URI we configured in step 2.
When the web page we generated in step 3 is opened, the Google account sign-in page is displayed. Once users are signed in, they will be redirected to the URI we set for redirect_uri. You should save the code value that clings to this domain name.
Example:
{% gist https://gist.github.com/devwithzachary/0d893dbd984e01c9e7f0d82ef6c6fc64 %}
In this case, the **code** value is as follows:
4%2FzAFyRfnDjPJKLRlkcZCedy-P6GpYbmAPpOvbmeUwXCfv0lXkUWjjHRXGtrwpoordursX2wfKShoGakKbLGzS4Ac
After obtaining the code value, send an HTTP request to https://oauth2.googleapis.com/token to obtain the value of access_token required for AppGallery Connect authentication.
The parameters are as follows.
* client_id - The client ID obtained from the API Console Credentials page.
* client_secret - The client secret obtained from the API Console Credentials page.
* code - The authorization code returned from the initial request.
* grant_type - As defined in the OAuth 2.0 specification, this field must contain a value of authorization_code.
* redirect_uri - One of the redirect URIs listed for your project in the API Console Credentials page for the given client_id.
Example:
{% gist https://gist.github.com/devwithzachary/3879c92e800eb6f93a81985313d4b8f3 %}
The return result of the request carries the **access_token** you need.
Example of the return result:
{% gist https://gist.github.com/devwithzachary/3444556ec95a6f4ba6835b52691d5631 %}
6. Use the token to pass the AppGallery Connect authentication.
Sample code
{% gist https://gist.github.com/devwithzachary/cba392d2aa60fb83d4cafb48d32f2e36 %}
References
1. [Create a client ID on Google Play Console](https://developers.google.com/identity/protocols/oauth2/web-server#creatingclient)
2. [Sign in to AppGallery Connect with a Google account](https://developer.huawei.com/consumer/en/doc/development/AppGallery-connect-Guides/agc-auth-android-hwaccount-0000001053532656#h2-1577179637846)
| devwithzachary |
842,124 | 7 Most Common Web Design Mistakes and Some Ideas to Avoid Them | According to Ranolia's January 2018 Web Server Survey, there are over 1.8 billion websites on the... | 0 | 2021-09-27T10:52:11 | https://dev.to/ranoliaventures/7-most-common-web-design-mistakes-and-some-ideas-to-avoid-them-10hk | webdesignmistakes | According to Ranolia's January 2018 Web Server Survey, there are over 1.8 billion websites on the internet. The internet appears to be a congested zone of websites, all vying for the attention of people and Google.
However, there is another intriguing thing to consider here: the majority of these websites receive very few visitors. Now, this can work in your favour as well as against you. For starters, you understand that by creating a fantastic website and performing other critical actions, you may increase the number of people who see your work.
Furthermore, you will have less rivalry because the bulk of people do not receive any user views. However, this also indicates that your chances of being one of those people are high. After all, how would you attract users if they couldn't?
But let's not be pessimistic. There are a number of things you can do to boost your Google rating and attract more people to your website. Good site design is one of the most important of these criteria.
While there are various things you can do to improve your site design, avoiding common web design blunders is the most important. So, without further ado, let's get down to business:
1. Difficult navigation
A golden guideline of web design is to create an easy-to-use online navigation pattern. A tangled web for a navigation bar may confuse your users, resulting in poor website usability and fewer visitors.
Furthermore, poor navigation may lead the user to believe that the section he seeks does not exist. As a result, he can leave your website. Furthermore, drop-down menus compel a person to make many choices, which can be inconvenient. The following step is self-evident. The user navigates away from the website.
What can you do to stay away from it?
To begin, if you only have a few sections, avoid drop-down menus. Second, remember that consumers expect the horizontal navigation bar to be visible at the top of the page.
As a result, follow the user's expectations when designing your website. Users also pay more attention to the navigation bar's first and last items. As a result, save these areas for crucial information like contact information.
2. Unappealing colour scheme
Poor site design colours are an automatic turn off for visitors, who can depart in seconds as a result. According to studies, it takes a person 90 seconds to form an opinion on a product.
About 62-90 percent of this opinion is influenced only by the product's colour. If you visualise this product as your website, you'll quickly realise how important colour is in attracting people.
What can you do to make sure you don't make colour mistakes?
In this section, you'll need to know about colour psychology in order to improve your website design skills. The colour blue, for example, aids in the development of trust. Red, on the other hand, denotes zeal.
The colours you choose are determined by the purpose of your website. Additionally, utilise three distinct colours in the required amounts of 60%, 30%, and 10%. If you're confused by all of this, it's better to get assistance from <b><a href="https://www.ranoliaventures.com/us/custom-web-design-company/">custom web design company</a></b>.
3. There isn't a clear call to action (CTA)
One of the most common blunders in web design is failing to include a call to action (CTA). A call to action (CTA) is a persuasive command connected to a button or a link. It encourages people to take action by telling them what to do. In essence, a clear CTA gives the site visitor direction.
Although the language of a CTA is vital, the design of the CTA is even more critical. For example, if the colour of the CTA button matches the rest of the website's colour scheme, your users will not notice it. As a result, you must avoid committing a web design error here.
What can you do to ensure that the CTA is correct?
A CTA that adheres to good user experience should focus on telling the user three things: what to do, where to go, and how to feel. So, what, where, and how are the three fundamental foundations of an ideal CTA.
All of these concerns should be addressed in the CTA you create. Furthermore, you must pay attention to the colour of your CTA to ensure that it shines out and attracts the attention of your readers.
4. Using an excessive number of fonts
Using too many fonts is another big web design blunder. It's difficult to resist the desire to utilise various fonts or even upload your own font when creating your first site design.
The reader, on the other hand, becomes perplexed. Furthermore, the text size is important. If you want your website to be easier to read, make sure the font size isn't too small. This can cause users' eyes to strain. Users have the time to read about 28% of the words on your website in a single visit on average. As a result, ensure sure the font is readable.
How can you avoid making a mistake when it comes to web design fonts?
On your website, use no more than two fonts. Choose a fancy or bold font for the headlines and a simple font for the body of the material. Avoid using a typeface that is overly ornate or difficult to read.
5. The location of the contact information is difficult to locate.
According to Vendasta, 65% of viewers are interested in reading a company's contact information. As a result, if your website design does not clearly display your contact information, you will be at a significant disadvantage.
The easiest solution is to include a "contact us" page in the navigation bar so that users don't have to go out of their way to find your contact information. Provide as many ways for your users to reach you as feasible, including email, phone number, email address, and a submission form.
How can you avoid making such a blunder?
Add a contact page to the navigation bar, as previously indicated. Your phone number can also be shown in the header and footer sections. For example, include the phrase "call for a free quote today: 999-444-5555."
Only enter your digits in the header and footer sections if you find this promotional or sales-y. This is one of the most effective strategies to reduce user effort and increase user convenience.
6. A clumsy web design
Visitors may be turned off by a cluttered design. There are two primary causes for this. To begin with, a cluttered design is unappealing to the user's eye. Second, consumers want to be able to find information fast on the internet.
A cluttered web page, on the other hand, does not serve this objective. Minimalist designs, on the other hand, assist in achieving this goal. There should just be a few tabs on your menu. This makes it simple for a user to locate and access the information he requires.
What can you do to make your website less crowded?
Consider what you can remove from your website rather than what you can add. Additionally, provide a lot of whitespace in your design to give it some breathing room. Users will be able to concentrate better as a result of this.
It's also critical that you maintain your consistency. Any abrupt changes in the colour scheme, sidebar locations, or layout should be avoided. Minor differences are fine, but your visitor should not feel as if he has landed on a separate website after visiting one of your pages.
7. Design that isn't mobile-friendly
Finally, if your website is not responsive to mobile devices, you may lose points. Mobile traffic accounted for 52.4 percent of all traffic in the third quarter of 2018. Customers use their computers and mobile devices to browse websites on a regular basis.
As a result, people expect your web design to be consistent. Furthermore, 57 percent of consumers said they will not suggest a firm with a poorly designed mobile site, according to statistics. Furthermore, if the target website is not effectively built for mobile devices, 40% of consumers will transfer to a competitor's site.
What can you do to avoid this problem in the future?
Don't create two websites, one for desktops and the other for mobile devices. Because Google dislikes duplicate material, owning two websites will get you into serious trouble with the search engine behemoth.
Instead, for responsive web design, employ adaptable images and layouts. Use a font size of at least 14 pixels. This may appear to be a large font, but it is preferable to forcing your users to zoom in to read your material. Also, on your website, use high-resolution photographs. Because the latest mobile devices have high-definition screens, employing low-resolution photos will result in your mobile visitors seeing low-resolution, pixelated graphics.
To sum it up
To summarise, it is quite easy for you to make web design mistakes. However, you can always fix the problem by either avoiding mistakes in the first place or addressing them as soon as your website is online. | ranoliaventures |
842,490 | How to send money on emails using "MOMP Network" | Greetings everyone, Brief about "MOMP" "MOMP" (Money Over Mail Protocol) provides a... | 0 | 2021-09-27T16:33:34 | https://dev.to/genievot/how-to-send-money-on-emails-using-momp-network-57m6 | momp, mompnetwork, cryptography, cryptocurrency | ---
title: How to send money on emails using "MOMP Network"
published: true
description:
tags: momp, mompnetwork, cryptography, cryptocurrency
cover_image: https://res.cloudinary.com/dpnrocxf9/image/upload/v1632741142/momp%20network/send%20money%20tutorial/1.png
---
Greetings everyone,
## Brief about "MOMP"
"MOMP" (Money Over Mail Protocol) provides a mechanism for sending money to email addresses on top of decentralized network. MOMP itself is a set of rules (Protocol) originally created by "[Jeevanjot Singh](https://www.linkedin.com/in/jeevanjot-singh/)" and currently implemented by [momp.network](https://momp.network). Learn more about "MOMP" from the [document](https://github.com/genievot/momp-network-document/blob/main/Momp%20protocol%20document%2024-SEP-2021.pdf)
## Process for sending money using "MOMP Network"
> You need a supported web wallet to perform any operation at momp.network, Currently supported wallet is **Superhero** and you can add it on your browser from extension marketplace, For e.g. [Chrome browser wallet extension](https://chrome.google.com/webstore/detail/superhero/mnhmmkepfddpifjkamaligfeemcbhdne)
### First Steps:
- Go to https://www.momp.network/#/ and look for permissions. If you are agree then approve the access from your wallet for momp network.

- After you approve, The basic information starts to load in the background and you will receive a notification once it's loaded. It may take some time depending on the current network response time.
> You can start filling the information on the stepper fields until data loads.
<p align="center">
<img src="https://res.cloudinary.com/dpnrocxf9/image/upload/v1632741141/momp%20network/send%20money%20tutorial/2.png" alt="Momp network"/>
</p>
### After that:
- You can fill the details, e.g.
> On first step's first field you can add **your Name or Email**. If you add your email then you will receive a copy of the email that will be sent to the receiver.
- Click on "send" and check for confirmation logo appeared by your wallet. If you agree then you can proceed to confirm and this will send the money from the smart contract to the verified email address's public key and an email will be delivered to the receiver's email address of transaction.


> If the email is not verified then the money will remain on smart contract and an email will be sent to the sender with an option to verify their email on the network (without exposing their email address) and claim their money into their personal wallet.
**Notes:**
- In this process neither sender nor receiver will ever need to expose their email on the public blockchain network.
- If you had sent money to wrong email addresss that cannot be verified then you can claim your money back after expiration date. You can read more on claiming back your unclaimed amount here (To be updated)...
Learn more about this protocol from this [document (AKA white paper)](https://github.com/genievot/momp-network-document/blob/main/Momp%20protocol%20document%2024-SEP-2021.pdf)
### Links
- Visit [Website](https://momp.network)
- Join MOMP Network on [Discord](https://discord.gg/grsA7QUZhJ)
- Follow on [twitter](https://twitter.com/genievot)
- Learn about current offers available on MOMP Network [in this post](https://forum.aeternity.com/t/money-over-mail-protocol-momp/10066) (Updated frequently)
| genievot |
842,601 | How to include Flutter module as a React Native package | Integrate Flutter module to React Native app as a npm package | 23,825 | 2021-09-27T21:21:34 | https://dev.to/mazhnik/how-to-include-flutter-module-as-a-react-native-package-5b00 | flutter, reactnative, ios, android | ---
title: How to include Flutter module as a React Native package
description: Integrate Flutter module to React Native app as a npm package
published: true
date: 2021-09-27 19:31:37 UTC
tags: flutter,reactnative,ios,android
series: "How to include Flutter module as a React Native package"
cover_image: https://cdn-images-1.medium.com/max/1024/1*DbzQqC3z1ZAU1eyAggv7Sg.png
---
It’s sometimes not practical to rewrite your entire application in Flutter all at once. In such case, Flutter can be seamlessly integrated into your existing application as a library or module. While there are numerous resources discussing the utilization of React Native's code in Flutter, there appears to be a dearth of information on the inverse scenario, that is, incorporating Flutter code into a React Native application. In this article series, I'll delve into the process of integrating a Flutter module as a React Native npm package.
Topics covered in the article series:
Article 1: **How to include Flutter module as a React Native package** (current)
- Step-by-step guide for setting up a Flutter module as an npm package in a React Native app.
- Launching Flutter screen from the React Native app on Android and iOS platforms.
[Article 2: **Render Flutter module alongside React Native components**](https://dev.to/mazhnik/render-flutter-module-alongside-react-native-components-gk9)
- Rendering Flutter module alongside React Native components for a seamless integration on Web, iOS, and Android platforms.
Article 3: TBD
- Establishing communication between Flutter and React Native.
Even if this article positioned as a guide for React Native developers, here also presented the best way (in my opinion) to use Flutter app as an iOS CocoaPods dependency.
In this article we will try to minimize the number of references on the Flutter + React Native package (required to install it) from the host React Native app.
Let's try to implement a solution for this as simple as possible.
This article requires some basic knowledge of React Native and Flutter.
**Full source code can be found** [**on GitHub**](https://github.com/p-mazhnik/rn-package-flutter)**.**
<hr />
### Prerequisites
- **Flutter** ≥ 2.5.1, **Node** ≥ 14;
using these versions is recommended, but not required.
- AndroidStudio;
XCode, CocoaPods ≥ **1.11.0** (this version is important)
### Getting Started
- Initialize host RN (React Native) project:
```shell
$ npx react-native init ReactNativeApp
```
- Create Flutter module:
```shell
$ flutter create -t module --org com.example flutter_module_rn
```
- Initialize RN package in the newly created `flutter_module_rn` directory:
> Note that this command will overwrite `.gitignore` and `README.md` files
```shell
$ npx create-react-native-module flutter_module_rn --package-name flutter-module-rn
```
Let's make following modifications in `flutter_module_rn` directory:
- rename `ios` directory to `ios-rn`, `android` to `android-rn`.
We need this to separate our RN-wrapper files from Flutter code.
- add `react-native.config.js` file with the reference to new paths:
```js
module.exports = {
dependency: {
platforms: {
android: {
sourceDir: './android-rn/',
},
},
},
};
```
> I also made some changes to the `android-rn/build.gradle` file and `package.json` (update some versions) and rename `flutter_module_rn.podspec` file to `FlutterModuleRn.podspec`, to use more standard naming for iOS dependencies. These changes are not important.
- Add this package to our host app's (ReactNativeApp) `package.json`:
```json
"flutter-module-rn": "file:../flutter_module_rn"
```
Note that we don't need to install it yet.
<hr />
Now we are ready to start implementing Flutter+RN integration through the native code.
### Android integration 🤖
#### Build local repository
To setup Android integration we will follow [Option A from Flutter official guide](https://flutter.dev/docs/development/add-to-app/android/project-setup#option-a---depend-on-the-android-archive-aar)
and build our Flutter library as a generic local Maven repository composed of AARs and POMs artifacts.
This way we can build the host app (`ReactNativeApp` in our case) without installing the Flutter SDK — this is important, because we don't want our package's RN users to install Flutter.
Therefore, let's build AAR artifacts:
```shell
$ flutter build aar
```
We run this command in `flutter_module_rn` directory. This command creates a local Maven repository in `build/host/outputs/repo`.
In the console we can see instructions to integrate, let's follow them with some modifications:
- Open `flutter_module_rn/android-rn/build.gradle`
- Ensure you have the repositories configured, otherwise add them:
```kotlin
repositories {
maven {
url "$rootDir/../build/host/outputs/repo"
}
maven {
url "https://storage.googleapis.com/download.flutter.io"
}
}
```
- Add our Flutter module dependencies:
```kotlin
dependencies {
debugImplementation 'com.example.flutter_module_rn:flutter_debug:1.0'
profileImplementation 'com.example.flutter_module_rn:flutter_profile:1.0'
releaseImplementation 'com.example.flutter_module_rn:flutter_release:1.0'
//noinspection GradleDynamicVersion
implementation 'com.facebook.react:react-native:+' // From node_modules
}
```
- Add the `profile` build type:
```kotlin
android {
buildTypes {
profile {
initWith debug
}
}
}
```
- Open `ReactNativeApp/android/build.gradle` and add repositories as in
step 2:
```kotlin
repositories {
maven {
url "$rootDir/../node_modules/flutter-module-rn/build/host/outputs/repo"
}
maven {
url "https://storage.googleapis.com/download.flutter.io"
}
}
```
We need to duplicate repositories in host app because of the following issue:
[3rd party maven dependency in react-native npm module](https://stackoverflow.com/questions/65089494/3rd-party-maven-dependency-in-react-native-npm-module)
**This is the first place where we need to reference our RN package anywhere other than in `package.json`!**
If anyone knows how to avoid this, please post your solution in comments. PRs to the repository are welcome as well 🙂
#### Adding a Flutter screen to an Android app
Following [the official Flutter tutorial](https://flutter.dev/docs/development/add-to-app/android/add-flutter-screen),
let's add FlutterActivity to `flutter_module_rn/android-rn/src/main/AndroidManifest.xml`:
> It will be easier if you open `android-rn` directory in Android Studio
```xml
<!-- AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.reactlibrary">
<application>
<activity
android:name="io.flutter.embedding.android.FlutterActivity"
android:configChanges="orientation|keyboardHidden|keyboard|screenSize|locale|layoutDirection|fontScale|screenLayout|density|uiMode"
android:hardwareAccelerated="true"
android:windowSoftInputMode="adjustResize"
/>
</application>
</manifest>
```
Package's Android Manifest will be merged with the host's Manifest during gradle build.
Now let's replace `sampleMethod` in `flutter_module_rn/android-rn/src/main/java/com/reactlibrary/FlutterModuleRnModule.java` with the `startFlutterActivity` function:
```java
@ReactMethod
public void startFlutterActivity(String stringArgument, int numberArgument, Callback callback) {
Activity currentActivity = reactContext.getCurrentActivity();
// we can pass arguments to the Intent
currentActivity.startActivity(
FlutterActivity.createDefaultIntent(currentActivity)
);
callback.invoke("Received numberArgument: " + numberArgument + " stringArgument: " + stringArgument);
}
```
This function does exactly what its name says — starts FlutterActivity.
Finally, we can make changes to the host app, ReactNativeApp:
```js
import FlutterModuleRn from 'flutter-module-rn';
const startFlutterScreen = () => {
// call native function
FlutterModuleRn.startFlutterActivity('', 0, (text: string) => {
console.log(text);
});
};
...
<Button title={'Start Flutter Screen'} onPress={startFlutterScreen} />
```
Now we can run `yarn && yarn android` in `ReactNativeApp`.
If you did everything right then you should see that Flutter screen is opened successfully 🎉
> I was need to resolve Java OutOfMemory Error. To fix this, change memory settings — uncomment line 13 in `ReactNativeApp/android/gradle.properties`:
> `org.gradle.jvmargs=-Xmx2048m -XX:MaxPermSize=512m -XX:+HeapDumpOnOutOfMemoryError -Dfile.encoding=UTF-8`
<hr/>
In this article we consider Android integration using FlutterActivity. In Android we can integrate Flutter module using Fragments as well, but this will require some extra steps. You can check out the following articles as a start point:
- [Adding a Flutter Fragment to an Android app](https://flutter.dev/docs/development/add-to-app/android/add-flutter-fragment)
- [Rendering Native Android Fragments in React Native](https://stefan-majiros.com/blog/native-android-fragments-in-react-native/)
<hr/>
### iOS integration 📱
According to [the official Flutter tutorial](https://flutter.dev/docs/development/add-to-app/ios/project-setup#option-a---embed-with-cocoapods-and-the-flutter-sdk), there are only two ways to embed Flutter in your existing application:
1. Use the CocoaPods dependency manager and installed Flutter SDK. (They marked this way as _Recommended_)
2. Create frameworks for the Flutter engine, your compiled Dart code, and all Flutter plugins. Manually embed the frameworks, and update your existing application's build settings in Xcode.
We don't want our React Native developers to install Flutter SDK in order to use the package, thus let's take a look at the second option. I was immediately confused by the phrase
"**Manually** embed the frameworks", because each Flutter dependency with the iOS platform code will produce its own framework:
```
Flutter/
├── Debug/
│ ├── Flutter.xcframework
│ ├── App.xcframework
│ ├── FlutterPluginRegistrant.xcframework (only if you have plugins with iOS platform code)
│ └── example_plugin.xcframework (each plugin is a separate framework)
```
It means that we will need to manually add frameworks to our host React Native app each time we add new Flutter dependency with the iOS code to the package. This will be very inconvenient for users of our package.
In addition, Flutter has an important warning, saying that plugins might produce **static or dynamic frameworks**. Static frameworks should be linked on, but never embedded:
"If you embed a static framework into your application, your application is not publishable to the App Store and fails with a **Found an unexpected Mach-O header code** archive error".
This means that for each framework we will need to manually determine if the framework is static or not 👎
It takes a lot of actions, doesn't it? We definitely should find a way to fix this.
#### Build frameworks
- As a first step, we are going to add Flutter dependencies in our package in order to test integration with different types of frameworks:
```shell
$ flutter pub add url_launcher
```
- As a second step, let's build iOS frameworks:
```shell
$ flutter build ios-framework --cocoapods
```
As a result, **static** `FlutterPluginRegistrant` framework will be added, and `url_launcher` package will produce **dynamic** `url_launcher` framework.
We have different frameworks for Debug and Release configurations as well, and we can't use Release frameworks for the Debug configuration and vice versa.
Therefore, we need to find a way to automatically link frameworks, depending on the configuration.
#### Achieve automatic embedding
React Native use CocoaPods to install iOS dependencies, and it has a `[CP] Embed Pods Frameworks` build phase in XCode.
CocoaPods can automatically determine if the framework is static or dynamic. Then let's use flutter module's iOS frameworks as an CocoaPods package.
- In CocoaPods we can't define pod configuration ("Debug" or "Release") in `podspec` file
([https://github.com/CocoaPods/CocoaPods/issues/2847](https://github.com/CocoaPods/CocoaPods/issues/2847) and [https://github.com/CocoaPods/CocoaPods/issues/6338](https://github.com/CocoaPods/CocoaPods/issues/6338)),
so we will need to reference our CocoaPods packages directly in our host ReactNativeApp `Podfile`.
To simplify this reference, we can create `ruby` function in `flutter_module_rn/ios-rn/pods.rb`:
```ruby
require 'json'
def use_flutter_module_rn! (options={})
package = JSON.parse(File.read(File.join(__dir__, "../package.json")))
packageName = package['name']
prefix = options[:path] ||= "../node_modules/#{packageName}"
pod 'Flutter', :podspec => "#{prefix}/build/ios/framework/Release/Flutter.podspec"
pod 'FlutterModuleFrameworks-Debug',
:configuration => 'Debug',
:podspec => "#{prefix}/ios-rn/Podspecs/FlutterModuleRn-Debug.podspec"
pod 'FlutterModuleFrameworks-Release',
:configuration => 'Release',
:podspec => "#{prefix}/ios-rn/Podspecs/FlutterModuleRn-Release.podspec"
end
```
And we should call this function in our React Native app:
```ruby
require_relative '../node_modules/flutter-module-rn/ios-rn/pods'
...
use_flutter_module_rn!()
```
**This is the second place where we need to reference our RN package in the source code.** Again, if anyone knows how to avoid this, please post your solution in comments.
- Now we need to define podspecs for each configuration:
```ruby
require 'json'
package = JSON.parse(File.read(File.join(__dir__, '../../package.json')))
Pod::Spec.new do |s|
s.name = "FlutterModuleFrameworks-Debug"
s.summary = 'FlutterModuleFrameworks'
s.description = package['description']
s.license = package['license']
s.homepage = package['homepage']
s.version = package['version']
s.source = { :http => "file:///#{__dir__}/../../build/ios/framework/Debug.zip"}
# You can reference sources as a git repository instead:
# s.source = { :git => "https://github.com/p-mazhnik/rn-package-flutter.git", :tag => 'some tag' }
s.authors = { package['author']['name'] => package['author']['url'] }
s.preserve_paths = "**/*.xcframework"
s.pod_target_xcconfig = { 'DEFINES_MODULE' => 'YES' }
s.platforms = { :ios => "11.0" }
s.swift_version = '5.0'
s.source_files = "**/*.{swift,h,m}"
s.vendored_frameworks = '**/*.xcframework'
s.xcconfig = { 'FRAMEWORK_SEARCH_PATHS' => "'${PODS_ROOT}/FlutterModuleFrameworks-Debug'"}
s.requires_arc = true
end
```
> Here we're facing with [CocoaPods limitation](https://github.com/CocoaPods/cocoapods-packager/issues/216) — we can't define local directory in the
> `source` property. But usually you will reference remote git repository instead of local directory.
> Workaround for local directories: we can reference `zip` archives, then we will need to add our flutter build artifacts to zip archives:
> `$ cd ./build/ios/framework && zip -r Debug.zip Debug && zip -r Release.zip Release && find . -name "*.xcframework" -type d -exec rm -rf {} \;`
> This script will zip and remove Debug and Release directories (tested on MacOS).
The similar code will be for the "Release" configuration.
Moreover, we need to specify our dependencies in `FlutterModuleRn.podspec` in order to be able to use dependencies in module iOS code:
```ruby
s.dependency "Flutter"
s.dependency "FlutterModuleFrameworks-Debug"
s.dependency "FlutterModuleFrameworks-Release"
```
With this setup our frameworks will be embedded to the host app automatically by CocoaPods.
#### Adding a Flutter screen to an iOS app
At this step we can start writing iOS code.
> Before moving on: it is better to read the documentation on [the Flutter integration guide for iOS](https://flutter.dev/docs/development/add-to-app/ios/add-flutter-screen) first.
We are going to modify `flutter_module_rn/ios-rn/FlutterModuleRn.{h,m}` files:
{% gist https://gist.github.com/p-mazhnik/547e4779a48e979fd58e0785abfe20d7 %}
This code was partially taken from Flutter integration guide. This code initializes `FlutterEngine` and starts `FlutterViewController`.
> The `FlutterEngine` serves as a host to the Dart VM and your Flutter runtime, and the `FlutterViewController` attaches to a `FlutterEngine` to pass UIKit input events into Flutter and to display frames rendered by the `FlutterEngine`.
> [Source](https://flutter.dev/docs/development/add-to-app/ios/add-flutter-screen?tab=engine-objective-c-tab#start-a-flutterengine-and-flutterviewcontroller)
Note that we can provide `flutterEngine` from host app's `AppDelegate` file using `initWithFlutterEngine` function.
We may need this if we want to share instance between different modules, but this is not required — we can initialize `flutterEngine` in `FlutterViewController` implicitly or initialize it in our module's `init` function
Now we can install dependencies:
`cd ios && yarn upgrade flutter-module-rn && pod install`,
and then open `ReactNativeApp/ios/ReactNativeApp.xcworkspace` file in XCode and run our app.
If you did everything right then you should see that Flutter screen is opened 🎉
<figcaption>iOS app</figcaption>
### Conclusion
In conclusion, I want to show resulting installation instructions for our Flutter+React Native package:
```shell
$ yarn add flutter-module-rn
```
#### Android
Add following repositories to your android/build.gradle file:
```kotlin
repositories {
maven {
url "$rootDir/../node_modules/<package-name>/build/host/outputs/repo"
}
maven {
url "https://storage.googleapis.com/download.flutter.io"
}
}
```
#### iOS
- Add following to your Podfile:
```ruby
require_relative '../node_modules/<package-name>/ios-rn/pods'
…
target 'ReactNativeApp' do
…
use_flutter_module_rn!()
…
end
```
- Run `cd ios && pod install`
<hr />
Looks quite simple, what do you think? Our package's users don't need to install Flutter SDK, changes in our package do not require changes on their part. All complex integration processes are done implicitly using auto-linking features from both React Native and CocoaPods. Of course, due to several limitations, we cannot fully automate adding a package. Hopefully these issues will be resolved in the future.
**Like it if you find this article helpful**. Please consider giving the GitHub repository a star ⭐️
**Full source code for this article can be found [on GitHub](https://github.com/p-mazhnik/rn-package-flutter).**
Your feedback and engagement mean a lot to me, so please share any suggestions or recommendations in the comments or, even better, as a GitHub issue. If you encounter any difficulties, please don't hesitate to reach out 🙂
**Thank you for reading!**
<hr />
This article was inspired by the work we do at **Aktiv Learning** (acquired by TopHat).
Aktiv Learning builds mobile-first teaching and assessment tools for college STEM courses. If you want to build cool stuff with us, check out some of our [job openings](https://tophat.com/company/work-with-us/)!
[Aktiv Learning - aktivate Student Engagement in STEM](https://aktiv.com/)
| mazhnik |
842,789 | DRC Survey III: DevRel Career Stages and Salaries | Career Stages We’ve plotted career stages and salary below, since we thought it was something... | 14,809 | 2021-09-27T23:12:14 | https://dev.to/bffjossy/drc-survey-iii-devrel-career-stages-and-salaries-3859 | <div class="entry-content">
<h2>Career Stages </h2>
<p>We’ve plotted career stages and salary below, since we thought it was something people would appreciate. We didn’t find any major surprises in the data, but it’s good practice to check for the unexpected (i.e some other result).<br><br>It would appear that once a worker has “enough” compensation, it becomes much harder to know how the package stacks up. All the medians of the people above Neutral stack atop each other. It’s possible this suggests a struggle to understand the difference between “Mildly Well Compensated” up through “Extremely Well Compensated”, but we don’t know for sure.<br></p>
<p>Sometimes it’s difficult to understand why we’re getting compensated more. If we get more uncertain in our worth as salary rises, then it’s helpful to see what causes those rises. One obvious candidate is career stage:<br></p>
<h4>Career level and salary</h4>
<figure class="wp-block-image"><img src="https://lh4.googleusercontent.com/M5P596jpK1PItYA_26SXtw5scUPn7aFaSHfTnUh-XtX9qbtp_clX5QxlDeKQH1j6IruJ_zzcTk5xjotPncJCO7VCMqPFKms4k-qXfHH9OvO5d_gC-cark8ypuEGmBnHcLIP72thO=s0" alt=""></figure>
<p>This plot is solid, and expected in terms of its progression. It supports the hypothesis that salary rises with experience. However, it doesn’t help us understand the variation in higher salaries we see in “Compensation.”<br></p>
<p>“Career Level” is a somewhat vague term, so let’s go deeper. We asked about both years of expertise in DevRel work, and also the years in the current company. That suggests a place to look. First, let’s examine years of experience:<br></p>
<h4>Salary, time in field, and time at current company</h4>
<figure class="wp-block-image"><img src="https://lh5.googleusercontent.com/8pnxG_uwxkQAH3Ho2cyqvBX1A_TlmUr3ww4RBe3Ovme-4jwj7KD4VslZia4BuPVFgQ0uCRyEFV4FcKgAk7buSRTZdeOSg487jZadFhkzkCqVvEkZa03IskpvjC1EFGO-fCjeK3q3=s0" alt=""></figure>
<p>The right plot is not hugely informative – “Years at Company” alone isn’t telling us much. The left plot suggests a trend of around $6000 increase for each year of DevRel expertise, but there’s a catch!<br></p>
<p>People tend to gain more money as they gain experience. What we really want to do is compare people who stay in one job to people who move around – both are gaining “years” on the left plot, but one keeps resetting to “0” years on the right plot with each job move.<br></p>
<p>So, we built a model using both variables. Visualising such models is difficult – we have more than one “y-axis”, and we want to understand the effect of both things, but 3D plots are difficult to read clearly. However, we can compare two <strong><em>purely hypothetical</em></strong>scenarios – one where a person stays at the same company for twelve years, and one where they move companies every three years:<br></p>
<h4>Modeling job strategy: Salary, while staying or remaining at company</h4>
<figure class="wp-block-image"><img src="https://lh5.googleusercontent.com/uX2Lh_URoBzVFOEnHSsU-Las94cmGhc67GDB8dCzmPwUC96PVodEhqr-EAV9RUzbia02Ot8FlRqmXH13lfahHvnSM2fBf3j7t7aAIaIbp1KzsShqDL-bYpBZogGCOI7W8hc5Wplj=s0" alt=""></figure>
<p>The lower line (all circles) shows the person who stays at Company 1 for twelve years. The upper line (with different shapes) shows the person who hops from company to company.<br></p>
<p>We’ve omitted the uncertainty (it’s quite large, as the sample is small), but a trend is apparent. In this hypothetical model, while the effect starts off small, there’s a noticeable salary jump after each job hop, and person 2 ends up earning ~$15,000 more after twelve years. In other words, seniority matters, but in this model staying in one place does indeed lead to decreased raises. (This is a <a href="https://www.forbes.com/sites/jackkelly/2019/07/26/a-new-study-concludes-that-it-literally-pays-to-switch-jobs-right-now/">well-researched effect</a>, but it’s nice to find it in our data too).<br></p>
<p>This is a good explanation for some of the variation seen in the Compensation and Perceived Fairness plot – some people will feel well compensated because of how their career shook out, and others will have less satisfaction with their package.</p>
</div>
######[TABLE OF CONTENTS](https://dev.to/bffjossy/2021-devrel-salary-survey-results-table-of-contents-43fe)
>[Introduction](https://dev.to/bffjossy/devrel-collective-2021-salary-survey-introduction-40j8)
>[Pt. 1](https://dev.to/bffjossy/drc-survey-i-devrel-salaries-specializations-by-country-2m3) | [Pt. 2](https://dev.to/bffjossy/drc-salary-ii-devrel-salaries-fair-compensation-aie) | [Pt. 3](https://dev.to/bffjossy/drc-survey-iii-devrel-career-stages-and-salaries-3859) | [Pt. 4](https://dev.to/bffjossy/drc-survey-iv-devrel-job-titles-and-salaries-oon) | [Pt. 5](https://dev.to/bffjossy/drc-survey-v-devrel-salaries-and-gender-3i4g) | [Pt. 6](https://dev.to/bffjossy/drc-survey-vi-devrel-salaries-and-ethnicity-29on) | [Pt. 7](https://dev.to/bffjossy/drc-survey-vii-devrel-salaries-and-sexual-orientation-55cd) | [Pt. 8](https://dev.to/bffjossy/drc-survey-vii-devrel-coders-devrel-managers-and-salary-15j)
>[Conclusion and Takeaways](https://dev.to/bffjossy/drc-survey-ix-devrel-salary-takeaways-2021-3lp1)
>[Appendix A:](https://dev.to/bffjossy/drc-survey-appendix-a-other-plots-company-size-trading-status-and-regional-spread-569b) | [Appendix B:] (https://dev.to/bffjossy/drc-survey-appendix-b-devrel-salary-survey-questions-2ajm)
##### SPECIAL THANKS TO OUR DATA SCIENTIST, GREG SUTCLIFFE
##### Greg Sutcliffe has been working in community management for a decade, and is currently the Principal Data Scientist for the Ansible Community. He's interested in how appropriate use of data can inform the development and governance of communities, especially with regards to open source projects. He also likes cooking. | bffjossy | |
843,469 | Using Doppler in Serverless Applications | Summary Secrets management is a core part of any application development as it helps keep... | 0 | 2021-09-28T04:27:33 | https://dev.to/isaacthajunior/using-doppler-in-serverless-applications-13bn | ##Summary
Secrets management is a core part of any application development as it helps keep secrets safe and ensures that you can control how and when your secrets are stored. Secret management might be tough for any developer as it requires broader security controls and a coordinated process for managing all types of secrets. Doppler was created to manage your secrets. In this tutorial, we will learn how to manage secrets in serverless applications using Doppler.
##Goals
In this tutorial, you will learn how to build a simple serverless application. We’ll then set up our project with Doppler to store these secret keys instead of using the native .env file. At the end of this tutorial you will learn how Doppler can be used to store all your secrets credentials.
##What are Serverless applications?
Serverless applications are cloud native applications that run without having us manage servers. they also have service integrations that are built in so that we can put our focus into building our applications instead of configuring it and thinking about servers. Serverless applications scale automatically as needed and respond to change faster.
##What are secrets?
Simply put, secrets are sets of sensitive information that unlocks protected resources and are used to authenticate privileged users. They are also known as digital authentication credentials. Passwords are a well-known example, but there are APIs, SSH keys, private certificates, etc. These secrets are fundamental to an application's productivity. Still, they can cause huge risks if not handled properly, and that is why you need a secret manager to help remove these risks. This is where [Doppler](https://www.doppler.com/) comes in.
##ENV files and why you should stop using it
A .env file is a simple configuration file used for customizing and controlling app environment variables. Simply put, it is used to keep secrets out of source code and has been used and is still used by developers today. Inasmuch as it has served us in the past and is still serving us, you should not use them again for storing confidential information.
One of the reasons is that .env files breaks down during updates and branch merging. Another is that it is hard to track access because the domain where they are stored is completely available.
One other reason is that managing .env files is time consuming and error prone if done manually which might give rise to misconfiguration.
These reasons are why you need a fully automated secret manager like [Doppler](https://www.doppler.com/).
##What is Doppler?
According to its [documentation](https://docs.doppler.com/docs/enclave-guide),
Doppler's secure and scalable Universal Secrets Manager seeks to make developers lives easier by removing the need for env files, hardcoded secrets, and copy-pasted credentials.
The Doppler CLI provides easy access to secrets in every environment from local development to production and a single dashboard makes it easy for teams to centrally manage app configuration for any application, platform, and cloud provider.
Doppler works for every language with a steadily growing list of integrations and to get started, choose your type of adventure. Whether you want to create your first project or install the Doppler CLI, you have come to the right place.
Doppler provides a safe and secure place for developers to store secrets, thereby doing away with hardcoded secrets and .env files, which have a very high risk of your secrets getting exposed or accessed by unauthorized parties. Doppler also removes the human element and automates the secret management process.
Doppler also has its CLI that makes it easier to install, authenticate and run your applications in a few clicks. Doppler groups secrets together by application in its dashboard so that access is served when the application starts.
Doppler also makes it easier for users to integrate directly from most major cloud platforms like Heroku, Netlify, and other secret managers.
##Setting up a Serverless application
In this section, readers will learn how to manage app secrets in a serverless application using Doppler.
In the image above, we have our serverless application. We need to get our secret keys from FaunaDB to store them in our secret manager.
Then we navigated to the security tab, and there we got the secret key which we will use for our application, as we will see from the image below:
##Setting up Doppler
Before we start saving our secrets on Doppler, we first have to create an account. Then we create a workplace that we can save with any name we want. Our workplace should look like the image below:
##Creating our serverless project
We will create our project on Doppler by navigating to the create project card when setting up our workspace. Then we will add the details of our projects, and the results should look like the image below if done correctly:
After we have created our application, we will then navigate to the dev environment. Then we will store our secret from Fauna in the secrets card, which should look like the image below if done correctly.
##Conclusion
We have successfully set up Doppler for a serverless application to secure our apps secrets. We have drastically reduced risks by doing away with .env files.
With this article, serverless teams can now learn how to use Doppler for building serverless apps. First, using our serverless application, we connected it to FaunaDB for our secret keys. Next, we then stored the said keys using Doppler instead of the traditional .env file. Readers can find the code used in this tutorial [here](https://github.com/IkehAkinyemi/serverless-ui-project), you can also learn more about Doppler [here](https://docs.doppler.com/docs).
| isaacthajunior | |
843,476 | JS Boilerplates Comparison | Here, I will discuss a set of four boilerplates, created for one each of the following JavaScript... | 15,359 | 2021-09-30T00:37:25 | https://dev.to/ngyaboi/js-boilerplates-comparison-51e0 | Here, I will discuss a set of four boilerplates, created for one each of the following JavaScript libraries: React, Angular, Vue.js, and StencilJS. A boilerplate, for those who don't know, is a basic template that can be used to build a project from.
My process for finding my Angular boilerplate was using the web to look for one that is hosted on GitHub. Unlike looking for Vue.js or especially React boilerplates, there is no _de facto_ standard boilerplate available, but rather several smaller user-generated boilerplates which do not guarantee that they work well. The installation was straightforward, which involved installing dependencies using npm, which I didn't expect to take as long as it actually did considering how stripped-down the end boilerplate is.
The React boiler chosen was created by Max Stoiber, and is by far the most popular React boiler on GitHub. It's individual components are divvied into their own files and folders all contained within the app/components folder. The components are easy to follow.
The StencilJS boiler is a Storybook boiler that had an absurd number of vulnerabilities that had to be audited when installing npm. It is very barebones with few in the way of interactive components.
The Vue.js boiler is the Vue CLI as provided by vuejs.org. required running `npm run build` followed by `serve -s dist` to start up as opposed to `npm start` with Angular, React, and Stencil. It is very simple with a handful of links and text, and the components are quite simple.
For me, the React boilerplate had the most to work with, the most straight-forward code, and had by far the most hassle-free setup.
The link to our cloned boilerplates is here: https://github.com/Viable-Slime/BoilerPlate | ngyaboi | |
843,658 | Animation In Flutter : AnimatedAlign | As a developer, animation becomes an important part of your app development workflow. To make your... | 0 | 2021-09-28T06:27:08 | https://dev.to/redstar25/animation-in-flutter-animatedalign-m5f | flutter, dart, animation, programming | * As a developer, animation becomes an important part of your app development workflow. To make your app memorable, you might want to create cool animations in your application.
* Animation makes a huge difference in user engagement. It is a powerful tool for grabbing user's attention and making the app's UI more friendly to use.
* Animation is the process of creating a visual illusion of motion, with the help of elements such as images or videos. It is such a wonderful technique that allows you to convey your message with emotion and feeling.
* Animation is one of the integral parts that make Flutter such a powerful framework. It helps us to create apps that not only look fantastic but feel natural and seamless as well.
* In this series, I'm going to explain different in-built animation widgets like AnimatedAlign, AnimatedContainer, AnimatedOpacity, AnimatedWidget, AnimatedModalBarrier, etc.
* In this article, I've explained the AnimatedAlign widget. Which is used to animate the position.
Read Full Article [Here](https://dhruvnakum.xyz/animation-in-flutter-animatedalign) | redstar25 |
843,776 | Picking your tech stack - Canonic vs Strapi | Introduction Canonic and Strapi are often compared as direct competitors. However, the two... | 0 | 2021-09-28T13:01:09 | https://dev.to/canonic/picking-your-tech-stack-canonic-vs-strapi-1b44 | ## Introduction
Canonic and Strapi are often compared as direct competitors. However, the two are quite different in terms of intended usage & audience. This article aims to highlight these differences from an unbiased perspective and help *you choose* the perfect tool for *your particular use case.*

Strapi positions itself as a developer first open-source headless CMS platform; essentially trying to make content management & subsequent development faster and easier. Canonic, on the other hand, positions itself as a low-code backend development platform trying to take care of all your backend requirements in a single place. The two platforms are, therefore, positioned differently which should give you a clear indication of the requirement each platform is trying to fulfil.
-----------
## Pre Requisites
### Strapi requires certain softwares to be pre-installed.
Strapi requires three softwares to be pre-installed on your computer before you can use the platform. These are Node.js, Npm/Yarn and a database (SQLite, PostgreSQL, MySQL, etc). As Strapi is "developer-first", these softwares do have a certain learning curve to them (if you're not a developer) on top of the minimal learning curve of the platform itself. However, the well maintained Docs section or [these video tutorials](https://www.youtube.com/watch?v=yH6cQRRWNFI) can help you get started in no time.
Post the installation of the pre-requisites, you can get your Strapi Dashboard up and running!
### Canonic requires no pre-requisites.
Canonic does not have any pre-requisites. Since **Canonic is a web app**, it can be accessed through any internet browser, removing the need to switch between applications. Everything created on the platform remains on the platform itself; therefore making it a complete backend development tool.
The only learning curve here is of the platform itself which can be navigated through by reading the documentation or completing the onboarding.
Canonic dashboard.
For anyone without substantial development experience, Strapi might be a little overwhelming to get started with, in comparison to Canonic. However, if you are a fully-fledged developer, there is a good chance that you already have the Strapi pre-requisites installed on your computer and can get your project up & running in no time.
---
## Hosting & Security
### Strapi projects are self-hosted.
Strapi projects are self-hosted which means that the data is hosted on your computer or your server(s). They do have a Cloud Server functionality coming soon; the dates of which haven't yet been released.
Due to the projects being self-hosted, there lies a hidden pre-requisite to use Strapi in terms of DevOps / deployment experience as well as the knowledge of hosting your server.
### Canonic projects are serverless backends.
Canonic, on the other hand, is a cloud-based platform with a server-less architecture. The projects are serverless backends securely hosted on the AWS platform and your data is securely saved on your database; reducing the risk of losing data and allowing you to scale without worrying about the stability (in case of higher traffic or other such cases).
There is no hidden requirement of DevOps experience to use Canonic.
---
## Platform
Both platforms utilise graphical interfaces. However, due to the differences in product orientation, the way data is represented varies immensely.
### Strapi uses a list-based view to make content management faster.
Strapi uses a list-based view to show the CMS collection types (essentially folders or elements of your database). This is helpful while maintaining a large number of entries as Strapi is more focused on content management as a platform.
### Canonic uses a graphical node-based representation for your database.
Canonic, on the other hand, differs completely. It uses a graph-like view to help see your database structure more clearly. With each table having separate nodes for fields, one can see the entire data structure in a single glance.
Therefore, a database with many fields of varying field types becomes faster to identify on Canonic as it is inherently a visual interface. The same can become a little difficult on Strapi.
An instance of this is to see what fields in a table are of the "linked" type in a database. Visual interfaces can afford signifiers, which in this case, Canonic provides with the help of a dotted line to signify a linked table. Therefore, time to locate specific fields is reduced on Canonic's visual interface while the same can become a little tedious on Strapi.
Linked table types (or Relational Fields on Strapi).
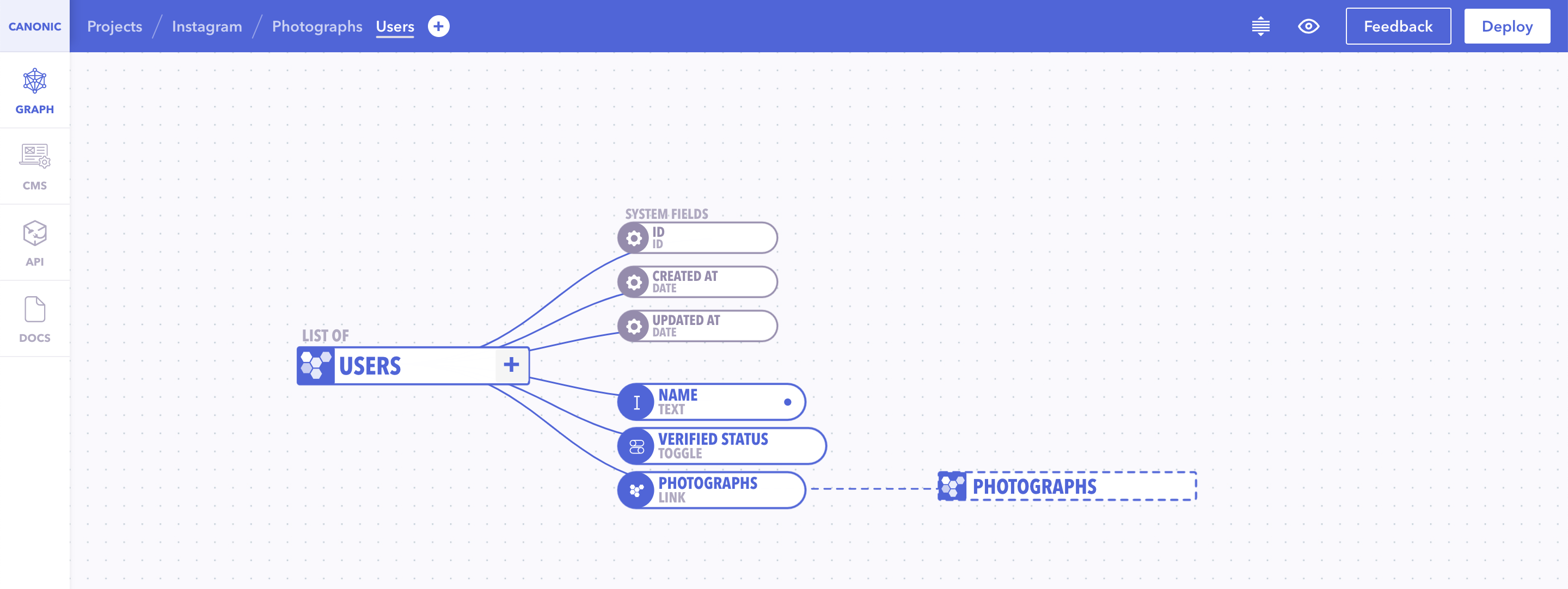
Linked field types on Canonic on the graph-view use a dotted line and show what table the field is linked to.
---
## APIs
Both platforms offer auto-generated CRUD APIs with the added functionality of adding custom-coded business logic and creating your own APIs. However, here is where a major difference lies between both platforms.
### Strapi uses a plugin to view APIs and is editable through your code editor.
Strapi provides you with a list of APIs by using a plugin built into the platform called Swagger. Since Strapi is developer-first, any modification/creation of APIs has to be done via your code editor. To aid this process, Strapi autogenerates folders inside your preferred code editor where you can meddle around with the APIs.
The APIs documented on Swagger show up like this:
API List on Swagger.
The APIs are then incorporated inside your code editor, as shown below:
Strapi autogenerates folders directly inside your code editor.
### Canonic allows you to create/modify APIs all in one place.
Canonic works a little differently. Even though the platform has an [SDK](https://canonic.dev/features/sdk?utm_campaign=canonicvsstrapi) to integrate your project directly into your code editor, the true power of the platform lies in the platform itself. Canonic is essentially a one-stop platform for all backend requirements. Your database, CMS, APIs and documentation exists in one place: on the Canonic web app.
Each API and subsequent trigger/webhook is seen as an endpoint, again in a similar node-like structure. This makes it easy to see webhooks and APIs in logic blocks. However, this preference can be quite subjective.
---
The documentation for the APIs exist on the platform itself, as shown below in the screenshot:
Another point to highlight is that Canonic allows you to create complex workflows straight from the platform itself which you would otherwise have to write in code on Strapi or other headless CMS platforms.
Therefore, the difference between the platforms also lies in the requirement of DevOps experience. While Strapi requires you to build out your APIs inside your code editor, Canonic allows you to do the same on the platform itself along with the added functionality of creating complex workflows and triggers; all on a visual interface. Custom business logic has to be written in code for both platforms.
## Pricing
Both platforms feature a free forever plan along with several paid options. However, because of the difference in functionality and what each platform has to offer, there are differences in pricing options.
### Strapi is an open-source platform and has a "free forever" plan.
Strapi's free forever plan allows you to have a self-hosted Strapi project with unlimited CMS entries and API Calls with 3 default roles. The paid plans offer features to scale up your project with more custom roles and support.

### Canonic features a freemium plan.
Canonic's free plan allows you to create 3 projects with one additional collaborator and 5000 requests a day. Paid pricing plans allow more API calls and CMS entries.
---
## Conclusion
Based on the points above, it becomes evident that Canonic and Strapi are quite different in terms of positioning and what they're striving to do.
If you are a developer with knowledge about backend systems and DevOps, Strapi integrates into your workflow more easily. It sits inside your code editor; leaving you to dabble between your Strapi CMS and frontend framework straight from your code editor.
With Canonic, your entire backend system is in one single place complete with your database, CMS, APIs and documentation. This can be created regardless of development experience, making it a better choice for people who lack the knowledge or resources required to create a backend. While Canonic also allows you to use SDKs and incorporate your project with your frontend framework, the true power of the platform lies in the relative ease and rapid speed with which you can make a backend on the Canonic web app.
The next major point of differentiation is hosting. Strapi allows you to self-host your project which means that the data is only with you (your server) and not on any other place on the internet. Canonic, on the other hand, hosts your backend for you and you can even select the region of deployment. Therefore, API response time is faster and the risk of losing your data becomes next to impossible. A serverless backend also removes the hindrance of unstable systems as you scale up your backend, accommodating higher API calls and CMS entries.
Finally, the preference of Strapi over Canonic or vice-versa largely depends on your specific use case. If you are looking for a developer-first content management tool, look no further than Strapi. However, if you're looking for a fully-fledged low-code backend development tool, regardless of your development experience, Canonic might be a better fit for you.
I hope this clarifies some of the confusion surrounding the similarity & differences between the two platforms. Let us know which one would you prefer and why in the comments below. Godspeed to your backends and you!
---
| tanisha | |
843,900 | How to create a Postman Collection from OpenAPI Docs | In the previous article of this series, we learned how to create the documentation for your API using... | 0 | 2021-10-02T15:55:41 | https://www.victorgarciar.com/how-to-create-a-postman-collection-from-openapi-docs | postman, api, openapi | ---
title: How to create a Postman Collection from OpenAPI Docs
published: true
date: 2021-09-28 09:39:10 UTC
tags: postman, apis, openapi
canonical_url: https://www.victorgarciar.com/how-to-create-a-postman-collection-from-openapi-docs
cover_image: https://www.victorgarciar.com/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1632822726221%2FhLDHGnhX7.png%3Fw%3D1600%26h%3D840%26fit%3Dcrop%26crop%3Dentropy%26auto%3Dcompress%2Cformat%26format%3Dwebp&w=1920&q=75
---
In the [previous article of this series](https://www.victorgarciar.com/api-documentation-with-openapi), we learned how to create the documentation for your API using OpenAPI.
If you didn't check it out, what are you waiting for !?!? 😁😁
Today we will see in this brief tutorial how to create a [Postman](https://www.postman.com) collection from this documentation.
* * *
## Download API docs
> We have different ways to download the YAML file containing the documentation. It depends on how we stored it.
### Swagger Editor
Swagger Editor stores the status of your last edition. Yet, if you have to delete information from your browser, all your progress may be lost! 🆘🆘
Swagger Editor is an excellent tool for fast edition and linting your files. However, if the documentation is large and will take you days, then use editors like Notepad++, Gedit, or VSCode to write it.
To download the API documentation file from Swagger Editor, we have to click on: `Edit`-> `Save as YAML`

The browser will download an `openapi.yaml` file.
### SwaggerHub
Swagger Hub stores the information on their servers. There is nothing to worry about here 🤗 To download it, we have to click on our API project.
Once we are editing our project, we have to click on `Export` -> `Download API` -> `YAML Resolved`.

I think this is the best format to do so. JSON will be valid as well, although I find YAML easier to edit.
* * *
## Import it to Postman
Now, go on and open Postman. If you don't have it, you can download it from [this link](https://www.postman.com/downloads/).
We are going to select the `APIs` tab.
Then let's click on `Import` and select the OpenAPI docs file. Confirm that you want the Collection to act as `Documentation`
If you check the APIs section, the definition of your OpenAPI Documentation should appear.

Moreover, the generated collection will appear in the `Collections` tab. You should see something like this:

## Create a Mock Server in Swaggerhub
> Do you have a server to make requests to? NO? LET'S MOCK IT THEN!
Before testing our API, we have to create a _Mock Server_ to make requests to! To do so, we are going to take advantage of the _Integrations_ available at SwaggerHub.
Click on your API name inside the editor and delete `Integrations` tab.

Then, add new integration and select `API Auto Mocking`
Set your API name to whatever you want. In this case, I defined `Idea API`.

Now the integration is completed. We have our mock server up and running! The address has the following format:
`https://virtserver.swaggerhub.com/<owner>/<api-name>/<version>`
In my case, this results in `https://virtserver.swaggerhub.com/victorgarciar/idea-api/1.0.0`
* * *
## Test!
> You can't say "It works!" if you haven't tested it yourself
Let's go back to our Postman Collection and set the "baseUrl" variable to the URL of our mock server.
Click on the Collection's name and select the `Variables` tab. You will have a variable there named "baseUrl" as mentioned. Delete the current value and paste your mock server URL!

Now we have everything set up! Go to one of the requests and send it. You should see something like this:
Of course, results will make no sense since we are using a mock server. Don't forget!
* * *
## Summary
In this article, I hope you have learned:
- Downloading your API docs
- Importing it to Postman
- Creating a mock server in SwaggerHub
- Test your API with a mock server

I am HONOURED if you have reached this point. Thanks a lot for reading 💙
Hopefully, I was able to explain how to import OpenAPI docs to Postman and create a Mock Server in SwaggerHub to test it!
Reach out on [Twitter](https://twitter.com/VictorGarciaDev) to find more valuable content or just chatting!
🐦 @victorgarciadev
😼 https://github.com/victorgrubio
## References
- [Previous Article of the Series](https://www.victorgarciar.com/api-documentation-with-openapi)
- [OpenAPI Documentation](https://swagger.io/docs/specification/about/)
- [SwaggerHub Integrations](https://support.smartbear.com/swaggerhub/docs/integrations/api-auto-mocking.html)
Thanks and Keep It Up! 🦾🦾 | victorgarciadev |
843,905 | Creating a reusable layout in Next.js | Yesterday we added a menu to our Next.js application. However, this was hardcoded on one page. Today... | 0 | 2021-09-28T10:46:43 | https://daily-dev-tips.com/posts/creating-a-reusable-layout-in-nextjs/ | nextjs, react | Yesterday we [added a menu to our Next.js application](https://daily-dev-tips.com/posts/retrieving-the-primary-wordpress-menu-in-nextjs/). However, this was hardcoded on one page.
Today we'll take a look at how we can introduce a layout component to have a shared layout for our menu on each page.
## Creating the layout component
Create a file called `layout.js` in the `components` folder.
This file will act as the main layout. In our case, it will render the header and the children for each page.
```js
import Header from './Header';
export default function Layout({children, menu}) {
return (
<>
<Header menuItems={menu} />
<main>{children}</main>
</>
);
}
```
The children are passed through our main page, the `_app.js`, and we will pass the `menu` variable, so we'll have a look at how that works next.
## Retrieving the menu items
Before we go there, let's see how we can retrieve the menu items in one place instead of doing it per page.
For this, we need to open the `_app.js` file. Here we can add a function called `getInitialProps`.
This function can be used to retrieve the menu and eventually pass it to our layout.
```js
import {getPrimaryMenu} from '../lib/api';
MyApp.getInitialProps = async () => {
const menuItems = await getPrimaryMenu();
return {menuItems};
};
```
## Passing items to the layout component
Let's see how we can now make sure the layout is used everywhere and pass the menu items.
Let's first add the layout to our `_app.js` file.
```js
import Layout from '../components/Layout';
function MyApp({Component, pageProps}) {
return (
<Layout>
<Component {...pageProps} />
</Layout>
);
}
```
To access the menu items, we have to add them to the `MyApp` function.
```js
function MyApp({Component, pageProps, menuItems}) {
return (
<Layout menu={menuItems}>
<Component {...pageProps} />
</Layout>
);
}
```
And with this, we have a fully functional universal layout.
- `_app` loads the menu and passes it to our layout component
- `layout` works as the main layout and renders the header
If we now run our application, we can see the menu work on all pages automatically.

You can find the complete code on [GitHub](https://github.com/rebelchris/next-tailwind/tree/layout).
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
843,984 | How to Create a Sensible Take-Home Coding Test | Tech assessment is an essential part of developer hiring. Take-home challenges seem a convenient... | 0 | 2021-09-28T11:03:18 | https://devskills.co/blog/how-to-create-a-sensible-take-home-coding-test | career, tutorial, programming | Tech assessment is an essential part of developer hiring. Take-home challenges seem a convenient option to assess tech skills because they are asynchronous and remove candidate's stress.
However, overlooking some fundamental aspects might lead to never completed tests, lots of time wasted on both sides, and bias when assessing candidates' results.
In this post, we'll cover the basic rules for ensuring that your take-home tests achieve their primary goal, i.e., identifying if someone has the necessary tech skills required for the job.
## Problem
The main challenge with take-home tests is that people have to do them outside working hours. So you have to deal with the following constraints:
- Candidates are short on time. So they might not complete your take-home test.
- Take-home tests require a longer feedback loop. So given your candidates are in several interview processes, you might lose them to someone else.
## Is There a Solution?
I have some bad news for you: unfortunately, there is no silver bullet to ensure that all your candidates will complete your take-home test and that you'll have enough time to select the best ones.
However, if you follow the ground rules below, it'll significantly increase your chances of getting the most out of your take-home coding tests.
### Define a Concise Challenge Scope
First, define the main assessment objective and make your exercise revolve around it. The following questions should help you:
- What experience levels do we target?
- What tech skills do we want to assess?
- Do we only want to screen candidates or do a full tech assessment?
- What competencies can we assess automatically using auto-tests, and when would we need a manual code review?
Second, create a clear task description. Here's an example of the structure I stick to that has been working well so far:
- Introduction - provides a general description of the task.
- Getting started instructions - helps the candidate get started fast (e.g., describes the setup, how to run tests, describes external dependencies, etc.).
- Expectations - describes what the candidate should focus on.
- Way to get help - describes how to proceed in case the candidate gets stuck.
- Time estimate - helps the candidate plan their time before starting working on the task.
Here is an example of how it could look:

Third, provide auto-tests that the candidate can run locally to help them ensure they built what you wanted them to.

Once your candidate volumes have grown, you can also use the auto-test results to vet your candidates with no developer effort on your side.
### Reduce Friction
Stick to the process developers use every day:
- Instead of sharing your take-home challenge as an email/Word doc/ zip file/, use a Git repository (ideally, use GitHub as most developers already have an account there).
- Instead of asking them to send you an email when they are ready, tell them to create a Pull Request.
- To avoid lost emails, ask them to create a ticket (e.g., GitHub issue) on their repository instead whenever they experience a problem.
- Pre-upload a project template (or templates if you expect submissions in multiple tech stacks) so that your candidates don't waste time setting everything up from scratch. Feel free to use [this upload script](https://docs.devskills.co/collections/85-the-interview-process/articles/342-importing-challenge-boilerplate) that has support for lots of tech stacks.
### Define a Standardized Code Review Scorecard
Because we're all humans, it's easy to slide into the bias-land when code reviewing someone's work.
To ensure no bias creeps in, create a code review scorecard that includes the following:
- The scoring rules. Here's one way to define it:

- Define scoring criteria per evaluated area. Here's an example of how it could look:

### Embrace Continuous Improvement
Likely your take-home challenges will have some sharp edges in the beginning. What's worse is that not all your candidates will be vocal about it.
To ensure that your take-home challenges are up to standard, use this 2-step rule:
- Add the following to the challenge criteria: "Describe one thing you'd improve about this coding task".
- Once there is a good suggestion, implement it right away.
Following this rule will save your tech interviewing team hours of future process revamping.
## In Closing
Developer hiring is hard. But it doesn't have to be terrible. Following the take-home interview principles above will already put you well beyond most of the hiring processes out there.
Is there a good principle not described in this post? Don't hesitate to share it below in the comments. | fenske |
844,010 | How to Reduce Memory Bloat in Ruby | The issue of memory bloat in Ruby applications is a topic of frequent discussion. In this post, we... | 0 | 2021-09-28T12:01:16 | https://blog.appsignal.com/2021/09/21/how-to-reduce-memory-bloat-in-ruby.html | The issue of memory bloat in Ruby applications is a topic of frequent discussion. In this post, we will look at how Ruby memory management can go wrong, and what you can do to prevent your Ruby application from blowing up.
First, we need to understand what bloat means in the context of an application’s memory.
Let's dive in!
## What Is Memory Bloat in Ruby?
Memory bloat is when your application’s memory usage increases all of a sudden without an apparent explanation. This increase may or may not be quick, but in most cases, it becomes continuous. It is different from a memory leak, which results from multiple executions taking place over some time.
Memory bloat can be one of the worst things to happen to your Ruby application in production. However, it is avoidable if you take proper measures. For example, if you notice a spike in your application’s memory usage, it is best to check for signs of memory bloat before troubleshooting other issues.
Before we explore how to diagnose and fix memory bloat, let’s take a quick walkthrough of Ruby’s memory architecture.
## Ruby's Memory Structure
Ruby's memory usage revolves around specific elements that manage the judicious use of available system resources. These elements include the Ruby language, host operating system, and the system kernel.
Apart from these, the garbage collection process also plays a vital role in determining how Ruby memory is managed and reused.
## Ruby Heap Pages and Memory Slots
The Ruby language organizes objects into segments called heap pages. The entire heap space (available memory) is divided into used and empty sections. These heap pages are further split into equal-sized slots, which allow one unit-sized object each.
When allocating memory to a new object, Ruby first looks in the used heap space for free slots. If none are found, it allocates a new heap page from the empty section.
Memory slots are small memory locations, each nearly 40 bytes in size. The data that overflows out of these slots is stored in a different area outside the heap page and each slot stores a pointer to the external information.
A system’s memory allocator makes all allocations in the Ruby runtime environment, including heap pages and external data pointers.
## Operating System Memory Allocation in Ruby
Memory allocation calls made by the Ruby language are handled and responded to by the host operating system’s memory allocator.
Usually, the memory allocator consists of a group of C functions, namely _malloc_, _calloc_, _realloc_, and _free_. Let’s quickly take a look at each:
- **Malloc**: Malloc stands for memory allocation, and it is used to allocate free memory to objects. It takes in the size of the memory to be allocated and returns a pointer to the starting index of the allocated memory block.
- **Calloc**: Calloc stands for contiguous allocation, and it allows the Ruby language to allocate consecutive blocks of memory. It is beneficial when allocating object arrays of known length.
- **Realloc**: Realloc stands for re-allocation, and it allows the language to re-allocate memory with a new size.
- **Free**: Free is used to clear out pre-allocated sets of memory locations. It takes in a pointer to the starting index of the memory block that has to be freed.
## Garbage Collection in Ruby
The garbage collection process of a language runtime dramatically affects how well it utilizes its available memory.
Ruby happens to have pretty advanced garbage collection that uses all of the above-described API methods to optimize application memory consumption at all times.
An interesting fact about the garbage collection process in Ruby is that it halts the complete application! This ensures that no new object allocation happens during garbage collection. Because of this, your garbage collection routine should be infrequent and as quick as possible.
## Two Common Causes of Memory Bloat in Ruby
This section will discuss two of the most significant reasons why memory bloats occur in Ruby: fragmentation and slow release.
## Memory Fragmentation
Memory fragmentation is when object allocations in memory are scattered all over, reducing the number of contiguous chunks of free memory. Memory can't be allocated to objects without contiguous blocks, even if more than enough free memory is available on the disk. This problem can occur in any programming language or environment, and each language has its methods for solving the issue.
Fragmentation can occur at two different levels: the language’s level and the memory allocator’s level. Let’s take a look at both of these in detail.
## Fragmentation at the Ruby Level
Fragmentation at the language level occurs due to the design of the garbage collection process. The garbage collection process marks a Ruby heap page slot as free, allowing reuse of that slot to allocate another object in the memory. If a complete Ruby heap page consists of only free slots, then that heap page can be released to the memory allocator for reuse.
But what if a tiny number of slots are not marked free on a heap? It will not be released back to the memory allocator. Now, think about the many slots in various heap pages simultaneously allocated and freed by garbage collection. It is improbable for entire heap pages to be released at once. Even though the garbage collection process frees memory, it can't be reused by the memory allocator since memory blocks partially occupy it.
## Fragmentation at the Memory Allocator Level
The memory allocator itself faces a similar problem: it has to release OS heaps once they are all entirely free. But it is improbable that an entire OS heap can be freed at once considering the random nature of the garbage collection process.
The memory allocator also provisions OS heaps from system memory for an application’s use. It will simply move to provision new OS heaps, even if the existing heaps have enough free memory to satisfy the application’s memory requirements. This is the perfect recipe for a spike in the memory metrics of an application.
## Slow Release
Another important cause of memory bloat in Ruby is a slow release of freed memory back to the system. In this situation, memory is freed much more slowly than the rate at which new memory blocks are allocated to objects. While this is not a conventional or a rookie issue to solve, it intensely affects memory bloat — even more so than fragmentation!
Upon investigating the memory allocator’s source, it turns out that the allocator is designed to release OS pages just at the end of OS heaps, and even then, only very occasionally. This is probably for performance reasons, but it can backfire and be counter-productive.
## How to Fix Ruby Memory Bloat
Now that we know what causes Ruby’s memory to bloat, let’s take a look at how you can fix these issues and improve your app's performance through defragmentation and trimming.
## Fix Ruby Memory Bloat with Defragmentation
Fragmentation happens due to the design of garbage collection, and there isn't much you can do to fix it. However, there are a few steps that you can follow to reduce the chances of ending up with a fragmented memory disk:
- If you declare a reference to an object that uses a considerable amount of memory, make sure you free it manually when its job is done.
- Try to declare all of your static object allocations in one big block. This will put all your permanent classes, objects, and other data on the same heap pages. Later, when you play around with dynamic allocations, you won’t have to worry about the static heap pages.
- If possible, try to do large dynamic allocations at the *beginning* of your code. This will put them close to your bigger static allocation memory blocks and will keep the rest of your memory clean.
- If you use a small and rarely cleared cache, it is better to group it with permanent static allocation in the beginning. You can even consider removing it altogether to improve your app’s memory management.
- Use [jemalloc](https://github.com/jemalloc/jemalloc) instead of the standard glibc memory allocator. This small tweak can bring down your Ruby memory consumption [by up to four times](https://www.mikeperham.com/2018/04/25/taming-rails-memory-bloat/). The only caveat here is that it might not be compatible in all environments, so be sure to test your app thoroughly before rolling into production.
## Trimming to Fix Ruby Memory Bloat
You need to override the garbage collection process and release memory more often to fix slow memory release. There is an API that can do this called _malloc_trim_. All you need to do is modify Ruby to call this function during the garbage collection process.
Here’s the modified Ruby 2.6 code that calls _malloc_trim_ in gc.c function `gc_start`:
```c
gc_prof_timer_start(objspace);
{
gc_marks(objspace, do_full_mark);
// BEGIN MODIFICATION
if (do_full_mark)
{
malloc_trim(0);
}
// END MODIFICATION
}
gc_prof_timer_stop(objspace);
```
*Note:* This is not recommended in production applications as it can make your app unstable. However, it comes in handy when slow memory release causes major hits to your performance, and you are ready to try out any solution.
## Wrap-up and Next Steps
Memory bloats are tricky to identify and even more challenging to fix.
This article looked at two significant reasons behind memory bloats in Ruby apps — fragmentation and slow release — and two fixes: defragmentation and trimming.
You must keep a constant eye on your app’s metrics to identify an impending bloat incident and fix it before it takes your app down.
I hope that I've helped you take some steps towards fixing memory bloat in your Ruby application.
**P.S. If you'd like to read Ruby Magic posts as soon as they get off the press, [subscribe to our Ruby Magic newsletter and never miss a single post](https://blog.appsignal.com/#ruby-magic)!**
*Kumar Harsh is an up-and-coming software developer by craft. He is a spirited writer who puts together content around popular web technologies like Ruby and JavaScript. You can find out more about him [through his website](https://kumarharsh.me/) and [follow him on Twitter](https://twitter.com/krharsh17).* | krharsh17 | |
844,017 | Frontend Mentor: 3-Column Preview Card Component | Frontend Mentor is one of the popular platforms for improving your frontend development skills. This... | 4,635 | 2021-09-28T12:20:55 | https://dev.to/w3hubs/frontend-mentor-3-column-preview-card-component-1ac3 | css, html, webdev, codenewbie | Frontend Mentor is one of the popular platforms for improving your frontend development skills. This website has frontend challenges for a developer who is given JPEG design files for mobile & desktop layouts.
This challenge is category-wise for Newbie to Guru sort options. This completes this challenge we have to use only HTML and CSS. Also in this challenge, they provide us a starter file with images and a color list. This is fully responsive for mobile views as well as tables views.
Make it yours now by using it, downloading it, and please share it. we will design more elements for you. Also, we are submitting this repository on Github.
[Source Code](https://w3hubs.com/frontend-mentor-3-column-preview-card-component/) | w3hubs |
844,037 | Best Online Software Documentation Tools of 2021 | Software documentation tools are very important for the process of software development. It acts as a... | 0 | 2021-09-28T12:47:34 | https://aviyel.com/post/807/best-online-software-documentation-tools-of-2021 | opensource, softwaretools, documentation | Software documentation tools are very important for the process of software development. It acts as a guide to building software, determines the workflow processes and overall usage of the software.
<center>  </center>
# Software documentation
Software documentation is a long and tedious procedure, but an important one to keep your software project on track. Let’s first go through the guidelines you need to follow for the documentation and learn how it will benefit you.
<center>
 Image Source: kinsta.com
</center>
## Guidelines to follow through
1. Reader’s View: Documentation should be curated from a reader’s point of view. This makes the reader understand the documentation and work on it better.
2. Unambiguous: Documentation should be unambiguous, clear, precise, and to the point.
3. Repetition: Documentation should not include any repetition. It should be concise.
4. Standardized: Documentation should be in the standard industry format.
5. Updated: Avoid having pending things be added to the document. Your documentation should be up to date with the recent changes.
6. Redundancy: Documents that are outdated should be removed after finalizing all added content parts. This will just keep the final document consisting of all required information.
<center>
 Image Source: kinsta.com
</center>
## 10 best online software documentation tools in the market
**1. Github**
The open source software documentation tool, Github is a community for the developers to manage their projects, put up codes, review them and also build software. Using Github pages and Wiki features, one can maintain software documentation in an effective manner. Github can also convert your repositories and documents into websites that you can further host. This will let you put up your projects, documents, or even portfolios.
**2. Docz**
My favorite of all the tools is Docz. It is an amazing documentation generator and allows users to write interactive documents using your React components. Additionally, you can have a coding playground for your components. That’s where you can modify, view and even share it with others. People can view your documentation live, see the changes and also copy the code snippets for their projects.
Docz lets you create live-reloading, SEO-friendly, and production-ready, customizable documentation sites. You can customize its look, behavior, or pattern according to your preferences.
### Why Docz is my favourite tool?
1. Zero-configuration: The unnecessary steps are cut down, skipping the confusing building steps. Also, build your own customizable sites with a single, click command.
2. Easy to learn: Docz is one user-friendly documentation tool. Even beginners can start incorporating their codes with Docz.
3. Blazing fast: Increased performance speed, making it faster, reliable, and convenient to work with.
4. Customization made easy: You can customize template, process workflow and create something productive out of your thoughts using the simple method component shadowing. This will definitely make your page stand out.
5. MDX based: MDX is basically Markdown+JSX. MDX makes it easier to import components and use them. It incorporates some of the best industry standards used for code writing. This definitely speeds up the process of documentation workflow.
6. Powered by Gatsby: Allows you to leverage GatsbyJS's enormous ecosystem of plugins and tools. Docz is completely built using GatsbyJS.
7. Pluggable: Adding additional functionalities to your application is made easy using plugins without making any change in your code. GatsbyJS and Docz plugins together makes your documentation attractive and shareable.
8. Typescript support: Docz offers Native TypeScript support for TSX components and generates documentation from your prop types and comments. Typescript builds all the exported Docz components.
Docz’s optimized, fast development experience and speedy build times make it stand apart. The document settings let the developer enrich their document with metadata used for the generation of the documentation site. Also, there are built-in properties for Docz extensible for the creation of new templates or themes, by editing different properties. These customized properties can be set on Docz’s document settings and they will be automatically parsed to the newer documents.
Creating plugins is another area where Docz stands out. Plugins let you modify processes, default configurations, and create hooks for build and render. So this turns out to be the perfect place for integrating all the other tools with Docz. Just a simple createPlugin method lets you create a new plugin in Docz.
**3. Read The Docs**
It’s a free software documentation tool and mostly works like Github. You can create as much open source material as you wish. However, you’ll have to pay to keep your documentation private. Read the Docs doesn't work well if you are building something for your company or organization since you would want to keep your internal project private. You can import documentation from any version control, be it, Git, Subversion, or Bazaar. Also, whenever you commit your code, webhooks will build the document automatically.
***To continue reading more about the other open-source documentation tools and it's effectiveness and also learn more about software documentation and perks of using it, read my complete article [here](https://aviyel.com/post/807/best-online-software-documentation-tools-of-2021) .***
<hr></hr>
Feel free to connect with me on [LinkedIn](https://www.linkedin.com/in/bhumikhokhani/) | [Twitter](https://twitter.com/bhumikhokhani)
<br>
>
If you like my work, you can extend your support by buying me a ☕. Thank you!
<a href="https://www.buymeacoffee.com/bhumikhokhani"><img src="https://img.buymeacoffee.com/button-api/?text=Buy me a coffee&emoji=&slug=bhumikhokhani&button_colour=FF5F5F&font_colour=ffffff&font_family=Cookie&outline_colour=000000&coffee_colour=FFDD00"></a>
| bhumikhokhani |
844,042 | Persistent routes | Hi, everyone. I'm sure you know, route management in an enterprise project is a tricky task. Enum... | 0 | 2021-09-28T12:56:16 | https://dev.to/qodunpob/persistent-routes-1ga5 | frontend, typescript | Hi, everyone. I'm sure you know, route management in an enterprise project is a tricky task. Enum (typescript data structure) is often used to keep them persistent. But enum itself doesn't solve all problems while we handle the route concatenation. Let's take a look at an example.
Suppose we have three levels of nesting routes:
```typescript
enum ROOT_ROUTES {
CATALOG = 'catalog',
ABOUT = 'about',
SUPPORT = 'support',
}
enum CATALOG_ROUTES {
CATEGORY = 'category',
ITEM = 'item',
CART = 'cart'
}
enum CATEGORY_ROUTES {
TOP = 'top',
SALES = 'sales',
ALL = 'all'
}
```
Then, in order to assemble the full route, we have to correctly concatenate all the intermediate values:
```typescript
const topCategoryRoute = `/${ROOT_ROUTES.CATALOG}/${CATALOG_ROUTES.CATEGORY}/${CATEGORY_ROUTES.TOP}`;
```
It's a very bad idea to keep it just as it is. I'm sure you don't do that. It's easy to overlook any nesting level. And if similar code starts to appear in several places of project, we violate the DRY principle. It will also lead to problems in the future when we want to change the navigation.
The situation looks better when we add global constants with the routes already concatenated:
```typescript
const rootRoutes: { [key in keyof typeof ROOT_ROUTES]: string } = {
CATALOG: `/${ROOT_ROUTES.CATALOG}`,
ABOUT: `/${ROOT_ROUTES.ABOUT}`,
SUPPORT: `/${ROOT_ROUTES.SUPPORT}`
}
const catalogRoutes: { [key in keyof typeof CATALOG_ROUTES]: string } = {
CATEGORY: `${rootRoutes.CATALOG}/${CATALOG_ROUTES.CATEGORY}`,
ITEM: `${rootRoutes.CATALOG}/${CATALOG_ROUTES.ITEM}`,
CART: `${rootRoutes.CATALOG}/${CATALOG_ROUTES.CART}`
}
// It's terribly tedious even just to write this example.
// Let's move on to the final part.
```
And even so, we are not immune to mistakes.
Let's try to automate the process to get rid of the routine and reduce the human factor. I started to think not from what I can do, but from what I want to get.
Suppose we already have `rootRoutes` with a signature corresponding to `ROOT_ROUTES`. I would like the `rootRoutes` properties to behave like primitive values in operations, but at the same time have a method for the subsequent concatenation of routes. Something like that (TDD in action):
```typescript
// https://nodejs.org/api/assert.html#assert_assert_strictequal_actual_expected_message
assert.strictEqual(`${rootRoutes.CATALOG}`, '/catalog')
const catalogRoutes = rootRoutes.CATALOG.concatRoutes(CATALOG_ROUTES);
assert.strictEqual(`${catalogRoutes.CATEGORY}`, '/catalog/category');
```
The implementation of the [`[Symbol.toPrimitive]` method](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/toPrimitive) in the class will help us achieve this.
Final result:
```typescript
class Route {
constructor(private _value: string) {}
[Symbol.toPrimitive]() {
return this._value;
}
concatRoutes<R extends Record<string, string>, K extends keyof R>(routes: R) {
return Object.fromEntries(
Object.entries(routes).map(([key, value]) => [key, new Route(`${this._value}/${value}`)])
) as { [key in K]: Route };
}
}
const rootRoutes = new Route('').concatRoutes(ROOT_ROUTES);
```
Thank you for reading. Please share, how do you manage routes in your project? | qodunpob |
844,081 | Functional Programming inside OOP? It’s possible with Python | I'm sharing my EuroPython 2021 talk today. Please enjoy! | 0 | 2021-09-28T14:30:59 | https://dev.to/po5i/functional-programming-inside-oop-it-s-possible-with-python-1m04 | python, community, conference, talk | I'm sharing my [EuroPython 2021 talk](https://ep2021.europython.eu/talks/5SQrJC4-functional-programming-inside-oop-its-possible-with-python/) today.
Please enjoy!
{% youtube 43yNp4D2UKo %} | po5i |
844,195 | Vue 3 Composition API migration from Vue 2 SFC | Quick introduction to help migrate from the Vue 2 options API to Vue 3's Composition API. | 0 | 2021-09-30T13:01:19 | https://terabytetiger.com/lessons/moving-from-vue-2-to-vue-3-composition-api/ | vue | ---
title: Vue 3 Composition API migration from Vue 2 SFC
published: true
description: Quick introduction to help migrate from the Vue 2 options API to Vue 3's Composition API.
tags: vue
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/wmcn6sr9qm5j8mhgt2vx.png
canonical_url: https://terabytetiger.com/lessons/moving-from-vue-2-to-vue-3-composition-api/
---
Since Gridsome recently hinted that it would be [considering Vite + Vue 3 with the 1.0 release](https://twitter.com/gridsome/status/1436343468717191172), I've started poking around the [Vue 3 docs](https://v3.vuejs.org/) to start figuring out this fancy new composition API. Specifically the [Vue 2 to 3 migration guide](https://v3.vuejs.org/guide/migration/introduction.html) is where I started. While this does a great job at highlighting breaking changes and addressing those, it doesn't really highlight transitioning Single File Components from V2's Option API to V3's Composition API (at least not in a way that I could easily process).
This is me creating my own cheat sheet to hopefully help me with the transition.
## What is script setup?
With the release of Vue 3, the big new feature that everyone is talking about is the composition API, which includes a function called `setup()` which is kind of like a rollup of the script export from V2 Single File Components (e.g. props, data, methods, etc...).
As the Vue team does, they realize that in most scenarios, you'll be needing to type out `setup(props, context) { //component stuff// }` and created a nice syntactic sugar and allow you to use `<script setup>`. For the purposes of this post, I'm going to be using `<script setup>` because that's how I intend to write 99%+ of my components (and is [the recommended way to write new SFC components](https://github.com/vuejs/rfcs/discussions/378#discussioncomment-1197332)).
## How to convert my data function to the Vue 3 Composition API?
With the Composition API if we want something to be reactive, we declare it as a variable (let or const) and use `ref()`. to declare that value as reactive (Other variables can be declared and used within the script tag also, they just don't get the coolio Vue features).
So instead of having:
```vue
<!-- Vue 2.x -->
<script>
export default {
data() {
return {
messageToUser: "Hello, welcome to our app! 👋🏻",
buttonClicks: 0,
}
}
}
</script>
```
We have:
```vue
<!-- Vue 3 Composition API -->
<script setup>
// We need to import the Vue Functions we need:
import { ref } from "vue";
const messageToUser = ref("Hello, welcome to our app! 👋🏻");
const buttonClicks = ref(0);
// Note that ref() creates an object and you can use
// variable.value to refer to the value in your <script setup>
// {{ buttonClicks }} will still work like in Vue 2
// in our <template>
console.log(buttonClicks.value)
// logs 0 to the console
</script>
```
> Note that `ref()` creates an object and you can use `variable.value` to refer to the value in your `<script setup>`, but `{{ buttonClicks }}` will still work like in Vue 2 in our `<template>`.
## How do I use props in the Vue 3 Composition API?
Within script setup, a function called `defineProps()` can be used in two ways to create . Consider the following Component call:
```vue
<!-- Vue 2.x or 3.X -->
<!-- Parent Component Reference to child component-->
<template>
<Component msg="Hello World!" :start="4"/>
</template>
```
And how we would use props in Vue 2.X:
```vue
<!-- Vue 2.x -->
<!-- Child Component -->
<script>
export default {
props: [ "msg", "start"]
}
</script>
```
In Vue 3, we can define our props using `defineProps()` like this if we don't need to reference them for any JavaScript:
```vue
<script setup>
defineProps({
msg: String,
start: Number
})
</script>
<!-- This is now usable as {{ msg }} in our template as in Vue 2! -->
```
But if we want to create a reactive value `count` that starts at our `start` prop value we can do:
```vue
<script setup>
const props = defineProps({
msg: String,
start: Number
})
const count = ref(props.start)
// Updating count will be covered shortly in the methods section 😄
</script>
<!-- {{ msg }} is still usable in our template as in Vue 2! -->
```
**If you aren't using `<script setup>` make sure you look into the difference between `toRef()` and `toRefs()` [in the docs](https://v3.vuejs.org/guide/composition-api-setup.html#props)**
## Where do my methods go in the Vue 3 Composition API?
Similar to our data function, the methods object is no more! Now we can declare our functions as a `const` and call it the same as in Vue 2.X!
In Vue 2 we would use:
```vue
<!-- Vue 2.X -->
<!-- Child Component -->
<template>
<div>
<h1> {{msg}} </h1>
<button type="button" @click="doubleCount()">
count is: {{ count }}
</button>
</div>
</template>
<script>
export default {
props: ["msg", "start"],
methods: {
doubleCount: function() {
this.count = this.count * 2;
}
}
}
</script>
```
In Vue 3 we can do:
```vue
<template>
<!-- Note that we don't need the wrapper div! -->
<!-- Vue 3 auto fragments for us! -->
<h1> {{msg}} </h1>
<button type="button" @click="doubleCount()">
count is: {{ count }}
</button>
</template>
<script setup>
import {ref} from "vue";
const props = defineProps({
msg: String,
start: Number,
});
const count = ref(props.start);
const doubleCount = () => {
return count.value * 2
}
</script>
```
## How do I use computed values in the Vue 3 Composition API?
Similar to how we can now use `ref()` to define a variable as reactive, we can use a new `computed()` function to define a variable as a computed value.
Consider if we wanted to show users what the new count value would be before they clicked the button.
In both Vue 2.X and Vue 3 we can update our child component's template to be:
```vue
<!-- Vue 2.X or Vue 3 Child Component -->
<template>
<!-- In Vue 3 the wrapper div is optional -->
<div>
<h1>{{ msg }}</h1>
<button type="button" @click="doubleCount()">
count is: {{ count }}
</button>
<p>
If you click the multiply button,
the new value will be {{ futureValue }}
</p>
</div>
</template>
```
In Vue 2.X our script will look like this:
```vue
<!-- Vue 2.X Child Component -->
<script>
export default {
props: ["msg", "start"],
data() {
return {
count: 0,
};
},
methods: {
doubleCount: function() {
this.count = this.count * 2;
},
},
mounted() {
this.count = this.start;
},
computed: {
futureValue: function() {
return this.count * 2;
},
},
};
</script>
```
And in Vue 3 our script will look like this:
```vue
<!-- Vue 3 Child Component -->
<script setup>
import { ref, computed } from "vue";
const props = defineProps({
msg: String,
start: Number,
});
const count = ref(props.start);
const doubleCount = () => {
count.value = count.value * 2;
};
const futureValue = computed(() => count.value * 2);
</script>
``` | terabytetiger |
844,369 | Replacing ZEN - Part 1 - Introduction | Index to Articles Hi All I am an avid user of ZEN for over 10 years now and it works for... | 0 | 2021-09-28T18:01:50 | https://community.intersystems.com/post/replacing-zen-part-1-introduction | fronted, zen, json, angular | <p style="text-align: center;">
<a href="https://community.intersystems.com/post/replacing-zen-index-articles">Index to Articles</a>
</p>
Hi All
I am an avid user of ZEN for over 10 years now and it works for me.
But it seems that Intersystems are no longer actively developing it (or ZEN Mojo), the only published reference to this is [here](https://community.intersystems.com/post/intersystems-iris-data-platform-201810-release#comment-43716)
<p style="margin-left: 40px;">
<em>As an aside, Intersystems makes fine products (I have been using the technology for 35 years) and has great support BUT they are not good at being open with their product road map/retirement plans. This is very embarrassing to me when talking with my end user clients.</em>
</p>
So I am looking at how to replace ZEN - this is not a short term project, at one client I have over 800 ZEN pages.
And it's such a shame as ZEN works and, most importantly, I and the team know how to make it "sing and dance".
I work in back office business apps so do not need some of the fancy stuff that is the modern web;
* **Responsive pages** - nope my users work on PC's only - having the page layout jump around would be confusing
* **Band width** - not a problem -my clients will all have good/excellent connectivity
* **Cross browser/device** - not so important - I can design for a subset and insist on that
* **Synchronous XHTTP** - Is crucial for me - if a user posts an invoice (say) I want them to see the result and not be clicking elsewhere
* **Back button, bookmarking and general navigation** - don't want this - there is a business process flow that I need to insist on - it makes no sense to me to go back to a display a record that has just been deleted
* **Fancy transitions** - not really, my users are in front of a screen most of the day - using these would be tiring on the eyes
Also as a developer I want to have:-
* **Longevity of the development environment** - I have seen many web development tool kits be the favourite of the month/year only to be discontinued after a short time.
* **Minimise the development stack** - with ZEN you have COS, HTML, CSS, JS, XSLT (for FOP but I have got round having to learn that) more than enough. I want to devote my intellectual effort to the business processes not learning the latest buzz technology.
So I have all of these in ZEN, and to re-iterate we know how to do make it "sing and dance"
However.....
I need to have a strategy to replace ZEN over the coming years.
<p style="margin-left: 40px;">
<em>Let me give you a real example of the issue with ZEN....<br />Recently I needed to implement (for the first time) printing bar charts - no problem, use the ZEN reporting chart component. Spent 2 days trying to make it work - looking at the code in the component I could see that the programming for css styling was just not finished (comments in the code 'TBD' (To Be Done)). I could have attempted to sub-class and make it work, but instead did some Googling and found chart.js (open source) got the first chart up and running in 1/2 day and the second took only a couple of hours.</em>
</p>
Some principles:-
* **Decoupling** the web UI development from the back end is the way forward.
* **Communication** between font and back end via JSON.
* **Leverage the ecosystem** (where appropriate) there's a wealth of stuff out there.
* **Incremental development** ideally I would like to find a strategy that allows me to have a single UI that runs the existing ZEN pages and the New UI together - this would allow me to develop new business modules in the New that work seamlessly with the Old. Also to move the Old to the New one by one over a period of time.
* **Programmatic Conversion** of the ZEN page definitions to the New. This should be possible (at least to some high %) by scanning the globals ^oddDEF and ^oddCOM (%Dictionary.* classes) parse the XML/COS/JS and create definitions for the new.
So I plan this to be a series of articles documenting the journey.
Hopefully I will be able to find time to keep it going
Peter
<p style="text-align: center;">
<a href="https://community.intersystems.com/post/replacing-zen-index-articles">Index to Articles</a>
</p> | intersystemsdev |
844,607 | Working with Python Jupyter Notebooks and MS Graph in VS Code | Lately I find myself falling in love with Python more and more. It's simple, fast and super powerful.... | 0 | 2021-09-28T20:59:21 | https://dev.to/425show/working-with-python-jupyter-notebooks-and-ms-graph-in-vs-code-4oog | Lately I find myself falling in love with Python more and more. It's simple, fast and super powerful. I know I'm late to the game but you know the saying: "better late than never" :)
Since Python is my go-to language these days, I decided to use it to automate one of the mundane and tricky parts of working with Azure AD - creating an App Registration for app authentication. Every time you need to implement authentication and authorization in your applications, be it a web app, api, desktop, mobile etc, you need to register an app, or possibly multiple apps in Azure AD. This is how you create the 1:1 relationship between your code and Azure AD and where you also configure api permissions, flows etc. This can get tricky since there are multiple steps and missing one can break things. What if there was a way to automate all that and avoid human errors?
Enter the world of MS Graph and Jupyter Notebooks.
## Set up your environment
You'll need to install the latest [Python](https://www.python.org/downloads/). I'm using Python 3.9.x and since I'm late to the game, I'm happy to avoid the whole 2v3 debacle. Straight to Python 3!
In VS Code, you also want to install the following extensions:
- [Python](https://marketplace.visualstudio.com/items?itemName=ms-python.python)
- [Jupyter](https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter)
- [Jupyter Keymap](https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter-keymap)
- [Pylance](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance)
##Create the project
Crate a new directory and open it in VS Code. Here, we're going to create our Python virtual environment and install our dependencies. To create and activate a virtual environment, type the following commands:
PS - I'm working on Windows so the commands are slightly different
```
python -m venv .venv
.venv/scripts/activate.ps1
```
Next, we'll create a `requirements.txt` file and add the following dependencies/packages
```
ipykernel>=6.4.1
msgraph-core>=0.2.2
azure-identity>=1.6.1
```
Use this command to install the dependencies
```
pip install -r requirements.txt
```
If you get prompted to upgrade your `pip` to stop being pestered every time you run the pip command, now is a good time. In your terminal, type the following:
```
<path to your current directory>\.venv\scripts\python.exe -m pip install --upgrade pip
```
Finally, we can use the command palette to create a new Jupyter Notebook
## Let's write some MS Graph code
To automate the Azure AD App Registration code, we can use MS Graph - the one API to rule them all! But before we write any code, we first need to.... register an app in Azure AD. Confused? I'm sure you are but let me break it down for you. To interact with Azure AD we need to be in an authenticated context. We need a way to authenticate as a user and consent to the right permissions so that we can programmatically configure Azure AD. And for this to happen, we need an App Registration.
I have created a multitenant app registration so if you have the right permissions, you should be able to sign in with your own organizational account and run the notebook. However, if you need to create your own App Registration, then these are the steps:
1. Open the browswer and navigate to your Azure AD Portal
2. Navigate to App Registrations
3. Create a new App Registration
4. Navigate to the Authentication tab
5. Add a new Platform
6. Select Desktop and Mobile
7. Set the Redirect Uri to Custom -> `http://localhost`
8. Save everything
9. From the Overview tab, copy the Client ID
And now we can write some code :)
In the first code segment of our Jupyter Notebook, we'll initialize our Graph client and set some variables to use later. Something that you may notice is that MS Graph now relies on the `Azure.Identity` library, which is part of the Azure SDKs, for authenticating and acquiring tokens which is super neat!
```
from azure.identity import InteractiveBrowserCredential
from msgraph.core import GraphClient
import uuid
import json
browser_credential = InteractiveBrowserCredential(client_id='7537790f-b619-4d30-a804-1c6b8b7f1523')
graph_client = GraphClient(credential=browser_credential)
scopes = ['Application.ReadWrite.All', 'User.Read']
```
On the next code segment, we'll create an API App Registration and set a custom API permission. Client apps should use this scope to call our API in the future.
```
apiAppName='automation - Python API'
apiIdentifier = f"api://{uuid.uuid4()}"
permissionId = f"{uuid.uuid4()}";
body = {
'displayName': apiAppName,
'identifierUris': [
apiIdentifier
],
'api': {
'acceptMappedClaims': None,
'knownClientApplications': [],
'requestedAccessTokenVersion': 2,
'oauth2PermissionScopes': [
{
'id': permissionId,
'adminConsentDescription':'access the api as a reader',
'adminConsentDisplayName':'access the api as a reader',
'isEnabled': True,
'type': 'User',
'userConsentDescription': 'access the api as a reader',
'userConsentDisplayName': 'access the api as a reader',
'value':'api.read'
}],
'preAuthorizedApplications':[]
}
}
result = graph_client.post('/applications',
data=json.dumps(body),
headers={'Content-Type': 'application/json'}
)
appJson = json.dumps(result.json())
application = json.loads(appJson)
response = graph_client.get('/organization')
tenantJson = json.dumps(response.json())
tenant = json.loads(tenantJson)
print(f"Client Id: {application['appId']}")
print(f"Domain: {application['publisherDomain']}")
print(f"Tenant Id: {tenant['value'][0]['id']}")
```
For your example, you'll have to change the `ApiAppName` and `ApiPermission` variable values to make them meaningful to you and you're ready to go!
## Show me teh c0dez
If you want to grab the Notebook and run it on your end, check out the [GitHub repo](https://github.com/425show/PythonInteractiveGraphSample) | christosmatskas | |
844,663 | Google No Longer Values Our Privacy and Security | As a tech person, I've always been observing small details, such as what personal information those... | 14,803 | 2021-09-29T00:27:50 | https://dev.to/mosbat/google-no-longer-values-our-privacy-and-security-23a7 | security, privacy, cybersecurity, freedom | As a tech person, I've always been observing small details, such as what personal information those services force us users to input and what not. I remember in the past when it was possible to create an email address within a few minutes, and you did not have to worry about your personal or private information being compromised because many services at that time didn't actually require you to disclose personal information, same as today.
Frankly speaking, I have nothing to hide as a person; but since I'm a liberal person, I take those things very seriously.
The way how Google contradict themselves makes me laugh sometimes.
When you go Incognito mode (because why not), Google will keep harassing you with the captcha sometimes till you give up or go back to your regular browser session with all the cookies stored.
I know that Google uses machine learning and that counts several risk factors, I don't need a lecture on that. However, I could interpret Google saying "We don't like it when we cannot collect your information".
Google is not just no longer valuing our privacy by bullying people for using incognito but also our security in a sense that Google themselves with their highly paid Devs, they couldn't stop a data breach that took place in 2018 via Google+. That means, if you're signed in via your Google accounts and doing your Googling while you're logged in, everything you search for and/or view can be stolen and misused in the wrong hands. Now, I'm not talking about how Google is already doing the same with Ads, but rather the question I'm trying here to raise, why we are not free to do our work without Google collecting our information?
I know you can tell me, "It's the price of using their service without paying money".
What worries me even more is that before, it was possible to create a new email on Google (Gmail) without providing personal information such as a phone number. However, this is no longer possible, you cannot simply create an email or an account without them collecting your personal information.
Finally, comes the question, is the internet still free or are the tech giants going to be deciding what we can learn and what we cannot about the world; is our freedom tied to corporations and their hidden agreements for surveillance. Do we need to be careful with typing certain keywords that they don't like or keywords that contain sensitive information about us, without doing 100s of risk calculations on whether Google will have a breach? Lots of questions can be asked.
While Google's browser product "Chrome" is the dominant browser today, we can feel that Google has begun taking the world for granted and doesn't mind controlling our lives, either directly or indirectly, with their algorithms.
According to Statista.com, the total number of active Gmail users, as of 2018, is around 1.5 billion. That means, Google knows a lot of personal information about 1.5 billion users across the world. That is more than Europe and Americas combined.(https://www.statista.com/statistics/432390/active-gmail-users/).
As Devs, we are committed into making our world better, and so I want both Devs and non-Devs to take a brave stand, to be bold and say "No" to those practices. There are several other services available that "Promise" that they are different or better, such as https://duckduckgo.com/ that is a lot more flexible and a bit more user-friendly since you don't have to push lots of accept buttons to do a quick search while you're shopping or in the middle of the road and need to find information about an address. | mosbat |
844,800 | Top 5 BEST Front End Web Development Tools In 2021 | Web Development Tools help developers to work with a variety of technologies. It should be able to... | 0 | 2021-09-29T04:01:04 | https://dev.to/designveloper/top-5-best-front-end-web-development-tools-in-2021-1c9e | webdev, news, devops | Web Development Tools help developers to work with a variety of technologies.
It should be able to provide faster mobile development at lower costs, and allow them in creating responsive designs which will improve the online browsing experience for users as well as facilitate improved SEO through front end web development tools like these ones that are scalable.
Moreover, choosing wisely can save you money on maintenance needs down the line!

## Pros and Cons While Choosing The Technology Stack
Technology is changing all the time, and there are new technologies available for every project.
However you should always choose a technology according to what your current needs dictate instead of choosing one because it was used in another successful project or on competitors' websites- no matter how good those previous experiences were!
## List Of The Top Web Development Tools
### 1.Chrome DevTools
Chrome is the ultimate [web app development tool](https://www.designveloper.com/blog/top-10-web-development-companies-vietnam/) for any web developer. With all these amazing features, you’ll be able to browse your site and make changes on-the fly with ease!
You can view messages from anywhere in chrome by clicking warnings or errors that pop up when things go wrong--no need to hunt down different windows or tabs; it's right there before us at almost every turn of this browser extension.
Chrome DevTools also has an optimization feature which helps speed up load times so our users don't get frustrated quickly while browsing pages like yours as well!
### 2.GitHub
As a professional software developer, you know how important it is to harness all of your resources and utilize every tool at the disposal.
One such resource that can greatly enhance productivity in any development environment—GitHub!
Not only does this platform provide project management tools but also allows developers access over code review processes for their projects from anywhere on whichever device they choose-even if its not connected via network connection or internet service provider (ISP).
### 3.JQuery
With this JavaScript library, you can quickly and easily manipulate the DOM tree of any HTML document. It also has event handling features as well as animation capabilities that make working with web forms even more convenient!
### 4.Bootstrap
Bootstrap is the front-end component library that will let you develop with HTML, CSS and JS. It's used in developing responsive mobile first projects on web applications to be developed by using this toolkit for Bootstraps' open source project template.
### 5.Sketch
With Sketch, you can create a timeline animation in no time and with ease. It’s easy to use for beginners because of its intuitive interface that provides all the necessary tools needed at once!
The site offers hundreds-of plugins so your design will never look boring or outdated again - Plus it supports MacOS too which means even more creative opportunities await those who invest into learning how this program works best.
## Conclusion
In order to ensure the success of a project, it's important that you are well equipped with all your tools. This includes web development software and I hope this article will help guide in-depth reviews on some great options!
We at [Designveloper](https://www.designveloper.com/) want to provide you with the best web development tools available. We've spent 22 Hours, cross-referencing top 13 popular and reliable sources on a weekly basis in order find out which ones are worth your time investment for online success! | designveloper |
844,841 | How can you differentiate between Array and LinkedList? | Hey Everyone, As I am posting some DSA related stuff on Twitter & LinkedIn using Python for few... | 0 | 2021-09-29T05:52:15 | https://payalsasmal.hashnode.dev/how-can-you-differentiate-between-array-and-linkedlist | python, datastructures, algorithms, django | Hey Everyone, As I am posting some DSA related stuff on [Twitter](https://twitter.com/payalsasmal) & [LinkedIn](https://www.linkedin.com/in/payalsasmal/) using Python for few days it made me realize that let's write an article for everyone. Here you go.....
## What is Array?
Array is a data structure that stores the same type of data in memory i.e you can't have multiple data types in an array.
Array elements store contiguously in memory location.
### Syntax:
array(data_type, value_list)
### Example:
Here "i" is the data type code. Check below the common data types used for the array module.
## What is LinkedList?
LinkedList is the collection of nodes that stores dynamically/randomly in memory. Node has two parts **data** and **link**, **data** is the value store in a node and **link** holds the address of the next node.
## Array 🆚 LinkedList
There are so many differences between Array and LinkedList. pointed few of them using examples in below
👉 **As we already discussed below point in Array and LinkedList definition:-**
🔸Array stores elements contiguously in the memory location.
🔸LinkedList nodes stores dynamically/randomly in memory.
See the below pic for a better understanding 👇
👉 **Cost of accessing an element:-**
🔸**Array**: In the below picture, you can see elements are stored and base addresses are assigned for each element.
These base addresses are contiguous for the array i.e 400, 401, 402..... 406,407.
So, if you know the base address of an element in an array, then you can get the base address of any element in an array.
To get the address of an element you just need to perform a simple operation that's it.
So accessing the elements of an array's cost is **O(1)**.
🔸**LinkedList**: As we discussed above LinkedList is a collection of Nodes and that is a collection of two sub-parts i.e., one part contains elements and another one contains the address of the next node.
So if you want to access an element in a linked list, you have to know the first element address which is called **Head** here.
If you want to access the 4th node, have to traverse from the first node.
Accessing the last node, you have to traverse all the nodes.
So Average time complexity to access an element in LinkedList is **O(n)**.
We can conclude that for accessing an element, **Array is the best choice than LinkedList.**
👉 **Cost of Inserting the element at the beginning:-**
🔸**Array**: If we are adding an element at the beginning, we need to shift other elements to the right to create the space in the first position.
if n numbers of elements are present in the array, the time complexity will be equal to the size of the array i.e., **O(n)**.
🔸**LinkedList**: If we need to add a node at the beginning, we don't move any elements anywhere, just create a new node and add the address of the first node to the new node.
This is an easy way to add an element at the beginning. We can say this is just a constant time i.e., **O(1).**
We can conclude here, for inserting an element at the beginning **LinkedList is the best choice than Array.**
👉 **Cost of Inserting the element at the end:-**
🔸**Array**: If the array has space, we can insert an element at the end using the array index. In this case, it has constant time complexity i.e **O(1)**.
But If the array is full then we have to copy the array to the new array. So, the time complexity is **O(n)**.
🔸**LinkedList**: If we talk about LinkedList, we have to find the head then we can find the last node.
So, we are searching the whole LinkedList to find out the last node to insert an element.
So time complexity is **O(n)**.
👉 **Cost of Inserting the element at the middle:-**
🔸**Array**: If the array has space, insert an element at the middle of the array and moving other elements to the right side of the array.
So the time complexity is **O(n).**
🔸**LinkedList**: If you want to insert an element at LinkedList, you have to traverse from head to that position.
So, the time complexity is equal to the size of LinkedList elements i.e **O(n)**.
Based on the above discussion you can choose one or another one of your requirements.
Thank you so much for reading my article. Hope you understood the differences between Array and LinkedList. 😊 | payalsasmal |
845,063 | 15 Challenges Faced by Web Scraping Tools | Web scraping has become a well-known topic among individuals who have a high demand for big data. An... | 0 | 2021-09-29T08:01:24 | https://dev.to/rlogical/15-challenges-faced-by-web-scraping-tools-4f57 | html, privacy, security, management | Web scraping has become a well-known topic among individuals who have a high demand for big data. An increasing number of folks tend to extract data from various sites for prospering their business. Unfortunately, people find it difficult to obtain data due to several challenges that creep up while performing web scraping. Here, we have mentioned some of those challenges in detail.
1.Changes in the structure of websites
Structural changes are made to several websites at times for providing a superior UX. This can be a challenging task for the scrapers who might have been set up for some specific designs initially. Consequently, they won’t be capable of functioning properly once some modifications are made. Even when there is a trivial alteration, it is essential to set up web scrapers and the changes made to the web pages. It will be possible to fix these types of problems by monitoring them constantly and adjusting on time.
2.Bot access
Before starting any target website, it will be a good idea to verify whether it allows for scraping. You might request the web owner to provide you with permission to scrape if you find that it doesn’t allow for scraping through its robots.txt, and while doing so, you ought to explain your scraping purposes and requirements. Try to come across an alternative site having similar info in case the owner does not agree.
3.IP blocking
It will be possible to prevent web scrapers from gaining access to a site’s information by the process of IP blocking. On most occasions, it occurs when many requests are detected by a site from an identical IP address. The website must limit its access to break down the process of scraping or ban the IP. You will come across many IP proxy services that you can include with automatic scrapers, thus avoiding this type of blocking.
4.Different HTML coding
While dealing with extremely large websites consisting of many pages, such as e-Commerce, be prepared to encounter the challenge of various pages featuring different HTML coding. This sort of threat is quite common if the development process lasted for quite some time and the coding team had been altered forcibly. In this case, it will be imperative to set the parsers accordingly for each page and modified if needed. The fix for this will be to scan the whole website to figure out any difference in the coding and take any action as needed.
5.Challenge of resolving captchas
Perhaps you have come across captcha requests on lots of web pages used to separate human beings from crawling tools by using logical tasks or requesting the user to enter the characters displayed. At present, special open-source tools have made it simple to solve captchas, and you will also come across several crawling services developed for passing this check. For instance, one might find it quite tough to pass these captchas on certain Chinese websites, and you will come across specialist <a href="https://www.rlogical.com/web-data-scraping-services-data-extraction-outsourcing/">data scraping services</a> that will be able to get the job done manually.
6.Data management and data warehousing
Lots of information will be generated by web scraping at a scale. Furthermore, this data will be used by many individuals if you happen to be a part of a large team. Therefore, it will be a good idea if you can manage the data efficiently. Unfortunately, this aspect is overlooked by the majority of the companies attempting the extraction of large-scale data. Searching, querying, and filtering, plus exporting this information, will become time-consuming and quite hectic in case the data warehousing infrastructure is not built properly. As a result, it is imperative for the data warehousing infrastructure to be scalable, fault-tolerant, as well as secure for massive extraction of data. The quality of this data warehousing system happens to be a deal-breaker in certain business-critical cases where it is essential to have real-time processing. As a result, lots of options are available at present ranging from BigQuery to Snowflake.
7.Anti-scraping technology
Several websites actively use powerful anti-scraping technologies that will prevent all types of web scraping endeavors. One remarkable example of this happens to be LinkedIn. These websites use dynamic coding algorithms for preventing bot access and implementing IP blocking techniques even though one sticks to the legitimate practices of the data extraction services. Plenty of money and time will be required for developing a technical solution for working around these types of anti-scraping technologies. Companies functioning in web scraping are going to imitate the behavior of humans for getting around anti-scraping technologies
8.Legal challenges
An extremely delicate challenge in web scraping comes from legal issues. Even though it is legitimate, there is a restriction on the commercial use of extracted data. It will depend on the type and situation of data you are extracting and how you will use it. In case you want to know more about the pain points associated with web scraping legality, you can take the help of the Internet.
9.Professional safeguard utilizing Akamai and Imperva
These two are responsible for providing professional protection services. They are known to offer bot detection services as well as solutions for the auto- replacement of content. One can distinguish between web crawlers and human visitors by using bot detection, which helps to safeguard the web pages from any parsing info. However, professional web scrapers can simulate the behavior of humans flawlessly. Outwitting anti-scraping traps is also feasible by making use of genuine and registered accounts or mobile gadgets. The information scraped might be displayed in a mirror image when it comes to an auto substitution of the content. Otherwise, the text might be created in hieroglyphics font. It will be feasible to remove this issue with the help of timely checking and special tools.
10.Honeypot traps
This is a kind of trap put on the page by the website owner for catching scrapers. These can be links that are visible to scrapers despite being invisible to human beings. Once any scraper is trapped, the information (for example, IP address) can be used by the website for blocking that particular scraper.
11.Unstable or slow load speed
If a website receives an excessive number of requests, it might respond slowly or fail to load. This problem will not be encountered when humans browse the site since they simply need to load the page again and wait for the site to recover. However, scraping might be broken up since the scraper does not know how to deal with these types of emergencies.
12.Login requirement
You might be required to log in first by some information that is protected. Once your credentials have been submitted, your browser will automatically be appending the cookie value to multiple requests made by you. The website understands that you happen to be the identical person who had logged in previously. Therefore, make certain that cookies have been dispatched with the requests when a login is required by scraping websites.
13.Dynamic content
Many websites apply AJAX for updating dynamic web content. Examples happen to be infinite scrolling, lazy loading images, and showing more information by clicking a button using AJAX calls. Users will view more information on these types of websites, although it will not be possible for scrapers.
14.Data quality challenge
It is a fact that data accuracy is of high importance when it comes to web parsing. For instance, it may not be possible for the texting fields to be filled in properly or extracted information to match a predefined template. To ensure data quality, it will be imperative to run a test and verify each phrase and field before saving. While some tests will be performed automatically, there are certain cases when the assessment has to be performed manually.
15.Balancing time for scraping
The performance of the site can be affected by big data web scraping. Therefore, it is essential to balance the stripping time to prevent any possibility of overloading. The only solution to make accurate estimations for figuring out the time limits will be testing what is required to do by verifying the endurance of the site before beginning data extraction.
Learn more here: https://thenewsify.com/technology/15-challenges-faced-by-web-scraping-tools/
| rlogical |
845,101 | 1st post | jknfvewjvcnel | 0 | 2021-10-16T17:44:41 | https://dev.to/sajal0208/1st-post-3cff | jknfvewjvcnel | sajal0208 | |
845,106 | React Browser Cache Data for My Site | i am updating my data through content management system . for caching m using cloudflare , cloudflare... | 0 | 2021-09-29T09:16:58 | https://dev.to/deveshwebdunia/react-browser-cache-data-for-my-site-22gm | i am updating my data through content management system . for caching m using cloudflare , cloudflare purging data properly m analysing in network tab . but at the frontend i need to hard refresh to get updated data. api is updating but frontend not. | deveshwebdunia | |
845,166 | 9 VSCODE EXTENSIONS YOU MUST HAVE | 1. PRETTIER Prettier is an opinionated code formatter that enforces a consistent style by parsing... | 0 | 2021-09-29T10:47:30 | https://dev.to/aaditya9899/beginners-vscode-extensions-you-must-have-11d6 | vscode, webdev, github, codenewbie | **1. PRETTIER**
Prettier is an opinionated code formatter that enforces a consistent style by parsing your code and reprinting it with its own rules that take the maximum line length into account, wrapping code when necessary.
Benefits: Having consistent formatting and styling across your
code can save a lot of time, especially when collaborating with other developers.

**2.Bracket Pair Colorizer**
This extension allows matching brackets to be identified with colors. The user can define which characters to match, and which colors to use. As our functions get more complex, it becomes more challenging to keep track of opening and closing brackets such as parentheses and curly braces.
**3.Project Dashboard**
VSCode Project Dashboard is a Visual Studio Code extension that lets you organize your projects in a speed-dial like manner. Pin your frequently visited folders, files, and SSH remotes onto a dashboard to access them quickly.
**4.Community Material Theme**
The most epic theme meets Visual Studio Code. The community maintained version of Material Theme with ”legacy" color schemes you love!
This project is community-maintained and the source is encrypted. If you want to maintain it and ship new fixes, ask to become a maintainer so you’ll have full access to the repository.

**5.Material Icon Theme**
The most epic file icon theme for Visual Studio Code.

**6.GitLens — Git supercharged**
Supercharge the Git capabilities built into Visual Studio Code — Visualize code authorship at a glance via Git blame annotations and code lens, seamlessly navigate and explore Git repositories, gain valuable insights via powerful comparison commands, and so much more

**7.Peacock**
Subtly change the workspace color of your workspace. Ideal when you have multiple VS Code instances and you want to quickly identify which is which.
**8.Live Server**
Live server launches a local development server with a live reload feature for both static and dynamic pages. Every time you save your code you’ll automatically see the changes reflected in your browser.

**9.Thunder Client**
Thunder Client is a lightweight Rest API Client Extension for Visual Studio Code, hand-crafted by Ranga Vadhineni with simple and clean design. Personally, its a perfect alternative of POSTMAN for someone like me who love simple UI, plus its in-built with VsCode saving me from hassle of switching tabs.
Thanks Ranga Vadhineni.

_-> Feel free to add more useful Extensions in the comment section below._
| aaditya9899 |
863,474 | Release Notes 10.14 - Advanced Filters and Stability Improvements | We're excited to present you with the latest release of Syntropy Stack. Our team has been tailoring... | 0 | 2021-10-14T11:41:20 | https://dev.to/syntropystack/release-notes-1014-advanced-filters-and-stability-improvements-pf3 | devops, networking, filters, release | We're excited to present you with the latest release of Syntropy Stack. Our team has been tailoring the product to better align with upcoming features, and we hope these aesthetic and functional updates will also improve your Syntropy Stack experience today.
> We released Advanced Filters allowing you to filter network results by one or multiple criteria and included additional stability and performance improvements.
---
As we progress our technology and grow the ecosystem, we listen closely to our community to integrate the tools and to build blocks that matter. If you have any feedback or ideas, let’s talk on [Discord](https://discord.gg/UYDyHwk5gN).
> **Syntropy Stack** is free to use.
> **[Access the platform here!](https://platform.syntropystack.com/?utm_source=devto&utm_medium=devto&utm_campaign=release0921)**
---
## Syntropy Stack
### New Features
#### Advanced Network Filtering
You can now use Advanced Filters to quickly filter your endpoints by one or multiple criteria. It is particularly helpful when you are managing networks with hundreds or thousands of endpoints and services. To use Advanced Filters, navigate to the network view and click on a filters icon on the top left corner.
You can add as many filters as you want and filter by any of the following (Endpoint with connections, Endpoint, Endpoint Type, Agent version, Tag, Provider, Location, Connection status, Origin)
Filters have conditions such as (“**any of**”, “**is none of**”) to filter the network results. In the last step, you can choose from a range of options that vary based on the filter you chose. For example, see options for “**Endpoint**” and “**Connection Status**” filters below:
Currently, you can only use the “**AND**” connector in advanced filters.
---
## Improvements
* Search queries now only return results from the filtered-out set of items.
* Removed the graph rehydration when the user navigates outside the graph borders.
* Search bar contents are now cleared when the user moves between different Network sections.
* Endpoint statuses are now displayed in the connection table and the endpoint management sidebar.
* Pending connection status is now unclickable while the Analytics data is being populated.
* Made visual improvements of the Network graph & Analytics section.
* Connection latencies to display in a fixed ‘n.nn’ format.
---
## Fixes
* Fixed bugs that occur when removing agent tokens.
* Fixed a bug causing the selected log level to show too many entries.
* Fixed a bug causing the search bar to jump up when the user selects an item.
* Fixed a bug causing a quick search in the map view to hide all of the nodes.
* Made multiple other minor fixes.
If you like the new updates and improvements, we are looking forward to hearing your feedback on Twitter or Discord.
---
## Get Started
Get started with Syntropy Stack with our three minute [quick start video](https://vimeo.com/499558754), or follow the [documentation](https://docs.syntropystack.com) for more details. Use Syntropy Stack to streamline your container and multi-cloud deployments and automate network orchestration.
## Get Involved
Our community helps us identify the right problems to solve for our users. Whether you’re an active user of one of our products or just getting started, [join our community on Discord](https://discord.com/invite/HxW6DbUeMn)! We love to foster communication among developers. Also don’t hesitate to send us a message if you have feedback or need assistance. We're happy to help! | omranic |
863,496 | Stop using if else | Recently, I had a take home assignment for a front end role, and I had to make a sort of Dashboard. I... | 0 | 2021-10-14T12:34:45 | https://dev.to/rjitsu/stop-using-if-else-264o | javascript, webdev, oop, tutorial |
Recently, I had a take home assignment for a front end role, and I had to make a sort of Dashboard. I thought I did everything right, but I was rejected, partly on my carelessness, and also due to my code. I was using too many if/else statements everywhere! And I didn't know any better. But now I do, and I'm here to share that with you.
Most of us use if/else and switch statements whenever there is some conditional logic to handle. Although it might be a good idea to do that for one or two conditions here and there, using multiple if else statements chained together or big switch statements will make your code look very ugly, less readable and error prone.
```js
function whoIsThis(character) {
if (character.toLowerCase() === 'naruto') {
return `Hokage`
} else if (character.toLowerCase() === 'sasuke') {
return `Konoha's Strongest Ninja`
} else if (character.toLowerCase() === 'isshiki') {
return `Otsutsuki being`
} else if (character.toLowerCase() === 'boruto') {
return `Naruto and Hinata's son`
}
}
whoIsThis('')
```
You see that we are repeating ourselves many times by writing multiple console.logs and if statements.
But there's an Object-Oriented way of doing this, and that is by using Objects.
Instead of writing if else blocks we just define an object which has the values we use in comparisons as keys, and the values we return as values of the objects, like so:
```js
function whoIsThis(character) {
const listOfCharacters = {
'naruto': `Hokage`,
'sasuke': `Konoha's Strongest Ninja`,
'isshiki': `Otsutsuki being`,
'boruto': `Naruto and Hinata's son`
}
return listOfCharacters[character] ?? `Please provide a valid character name`
}
```
By using objects, we were able to make a sort of dictionary to look up to, and not use multiple if-else statements.
We can also make this better by using the **Map** object instead of using an object. Maps are different from normal objects:
- They remember the original order of insertion
- Unlike objects, we can use any type of data as key/value, not just strings, numbers and symbols.
```js
function whoIsThis(character){
const mapOfCharacters = new Map([
['naruto', `Hokage`],
['sasuke', `Konoha's Strongest Ninja`],
['isshiki', `Otsutsuki being`],
['boruto', `Naruto and Hinata's son`]
])
return mapOfCharacters.get(character) ?? `Please provide a valid character name`
}
```
Thanks for reading this short article, if you liked it, you can support my work at https://www.buymeacoffee.com/rishavjadon
| rjitsu |
863,546 | Why Django For Backend Than PHP(Laravel) | The topic really interested me in Quora as developers from both groups defended their tools. Before... | 14,930 | 2021-10-14T13:48:00 | https://techmaniac649449135.wordpress.com/2021/10/14/why-django-for-backend-than-php/ | beginners, python, programming | The topic really interested me in Quora as developers from both groups defended their tools. Before developing a system, you must select the best tools to use. Have in mind the effects of each, both the advantages and disadvantages.
Don’t be too choosy. Each tool was created for a specific purpose. What you might accomplish with PHP might or might not happen with Django. But both are server languages. I have never touched PHP because of the negative talks from people. But from the compilation I have made, here is my reason why I would rather work with Django than PHP.
Easier Integration with AI, DS, and ML projects
Of course, we are living in the world of AI where people are developing projects using artificial intelligence. Machine learning technology is trending daily. Since the most common language used is Python, it becomes easier to integrate with that application. Django as a python framework makes the work look much simpler than you might work with PHP.
Security
Many people have abandoned the use of WordPress because they have a PHP backend. The language has leaked and is most of the time prone to hackers. Django comes with strong built-in security. This is a rare case where you will hear about a leak in the Django server application
Django is easier to Learn
Yes, both PHP and Python are easier to understand when you dedicate your maximum time to them. Python syntax is much easier to read and understand. While in a rush for server language, opt to pick python Django. If you have the basics of python, it will be much simpler.
Django is faster than PHP
Python is powerful in general. So it can be used for complex projects, with its numerous libraries. It’s faster when developing a site and also the running time. If you are new to server language, kindly work with Django. But when it comes to deployment, things turn out different. I would rather advise you to stick to what you have been doing if you ever worked with PHP. Django calls upon a specific environment in order to run.
Time management
If you want to build a web application quickly and deploy it, then Django might be your best choice. Although you might face a variety of problems, that is common to almost everyone. Are you comfortable using Django, then come solve problems as fast as possible?
Handle complex tasks
This is an attribute related to the vast community of python Django. The framework keeps growing daily as new packages are added. Python is a memory efficient language that takes up less space.
Although the comparison might sound biased, the fact remain we can’t compare Django with PHP. One is a framework while the php is programming language. However, both can build awesome backend servers. Have a tool then dig deeper to understand what it can do.
All the same, AI projects are the most popular technologies. This means Django will have space to exist in the coming years. | techmaniacc |
863,633 | A bash solution for docker and iptables conflict | If you’ve ever tried to setup firewall rules on the same machine where docker daemon is running you... | 0 | 2021-10-14T15:14:30 | https://dev.to/garutilorenzo/a-bash-solution-for-docker-and-iptables-conflict-5gac | docker, firewall, iptables, linux | If you’ve ever tried to setup firewall rules on the same machine where docker daemon is running you may have noticed that docker (by default) manipulate your iptables chains.
If you want the full control of your iptables rules this might be a problem.
### Docker and iptables
Docker is utilizing the iptables "nat" to resolve packets from and to its containers and "filter" for isolation purposes, by default docker creates some chains in your iptables setup:
```
sudo iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy DROP)
target prot opt source destination
DOCKER-USER all -- anywhere anywhere
DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
DOCKER all -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT all -- anywhere anywhere
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain DOCKER (1 references)
target prot opt source destination
Chain DOCKER-INGRESS (0 references)
target prot opt source destination
Chain DOCKER-ISOLATION-STAGE-1 (1 references)
target prot opt source destination
DOCKER-ISOLATION-STAGE-2 all -- anywhere anywhere
RETURN all -- anywhere anywhere
Chain DOCKER-ISOLATION-STAGE-2 (1 references)
target prot opt source destination
DROP all -- anywhere anywhere
RETURN all -- anywhere anywhere
Chain DOCKER-USER (1 references)
target prot opt source destination
RETURN all -- anywhere anywhere
```
now for example we have the need to expose our nginx container to the world:
```
docker run --name some-nginx -d -p 8080:80 nginx:latest
47a12adff13aa7609020a1aa0863b0dff192fbcf29507788a594e8b098ffe47a
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
47a12adff13a nginx:latest "/docker-entrypoint.…" 27 seconds ago Up 24 seconds 0.0.0.0:8080->80/tcp, :::8080->80/tcp some-nginx
```
and now we can reach our nginx default page:
```
curl -v http://192.168.25.200:8080
* Trying 192.168.25.200:8080...
* TCP_NODELAY set
* Connected to 192.168.25.200 (192.168.25.200) port 8080 (#0)
> GET / HTTP/1.1
> Host: 192.168.25.200:8080
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: nginx/1.21.1
< Date: Thu, 14 Oct 2021 10:31:38 GMT
< Content-Type: text/html
< Content-Length: 612
< Last-Modified: Tue, 06 Jul 2021 14:59:17 GMT
< Connection: keep-alive
< ETag: "60e46fc5-264"
< Accept-Ranges: bytes
<
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
...
* Connection #0 to host 192.168.25.200 left intact
```
**NOTE** the connection test is made using an external machine, not the same machine where the docker container is running.
The "magic" iptables rules added also allow our containers to reach the outside world:
```
docker run --rm nginx curl ipinfo.io/ip
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 15 100 15 0 0 94 0 --:--:-- --:--:-- --:--:-- 94
1.2.3.4
```
Now check what happened to our iptables rules:
```
iptables -L
...
Chain DOCKER (1 references)
target prot opt source destination
ACCEPT tcp -- anywhere 172.17.0.2 tcp dpt:http
...
```
a new rule is appeared, but is not the only rule added to our chains.
To get a more detailed view of our iptables chain we can dump the full iptables rules with *iptables-save*:
```
# Generated by iptables-save v1.8.4 on Thu Oct 14 12:32:46 2021
*mangle
:PREROUTING ACCEPT [33102:3022248]
:INPUT ACCEPT [33102:3022248]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [32349:12119113]
:POSTROUTING ACCEPT [32357:12120329]
COMMIT
# Completed on Thu Oct 14 12:32:46 2021
# Generated by iptables-save v1.8.4 on Thu Oct 14 12:32:46 2021
*nat
:PREROUTING ACCEPT [1:78]
:INPUT ACCEPT [1:78]
:OUTPUT ACCEPT [13:1118]
:POSTROUTING ACCEPT [13:1118]
:DOCKER - [0:0]
:DOCKER-INGRESS - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80
COMMIT
# Completed on Thu Oct 14 12:32:46 2021
# Generated by iptables-save v1.8.4 on Thu Oct 14 12:32:46 2021
*filter
:INPUT ACCEPT [4758:361293]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [4622:357552]
:DOCKER - [0:0]
:DOCKER-INGRESS - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Thu Oct 14 12:32:46 2021
```
in our dump we can see some other rules added by docker:
**DOCKER-INGRESS (nat table)**
```
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80
```
**DOCKER-USER (filter table)**
```
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
```
to explore in detail how iptables and docker work:
* Docker [docs](https://docs.docker.com/network/iptables/)
* Docker forum [question](https://forums.docker.com/t/understanding-iptables-rules-added-by-docker/77210)
* [gist](https://gist.github.com/x-yuri/abf90a18895c62f8d4c9e4c0f7a5c188) from x-yuri
* argus-sec.com [post](https://argus-sec.com/docker-networking-behind-the-scenes/)
### The problem
But what happen if we stop and restart our firewall?
```
systemctl stop ufw|firewalld # <- the service (ufw or firewalld) may change from distro to distro
systemctl stop ufw|firewalld
curl -v http://192.168.25.200:8080
* Trying 192.168.25.200:8080...
* TCP_NODELAY set
docker run --rm nginx curl ipinfo.io/ip
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:06 --:--:-- 0
```
we can see that:
* our container is not reachable from the outside world
* our container is not able to reach internet
### The solution
The [solution](https://github.com/garutilorenzo/iptables-docker) for this problem is a simple bash script (combined to an awk script) to manage our iptables rules.
In short the script parse the output of the *iptables-save* command and preserve a set of chains. The chains preserved are:
for table nat:
* POSTROUTING
* PREROUTING
* DOCKER
* DOCKER-INGRESS
* OUTPUT
for table filter:
* FORWARD
* DOCKER-ISOLATION-STAGE-1
* DOCKER-ISOLATION-STAGE-2
* DOCKER
* DOCKER-INGRESS
* DOCKER-USER
### Install iptables-docker
The first step is to clone [this](https://github.com/garutilorenzo/iptables-docker) repository
#### Local install (sh)
**NOTE** this kind of install use a static file (src/iptables-docker.sh). By default **only** ssh access to local machine is allowd. To allow specific traffic you have to edit manually this file with your own rules:
```
# Other firewall rules
# insert here your firewall rules
$IPT -A INPUT -p tcp --dport 1234 -m state --state NEW -s 0.0.0.0/0 -j ACCEPT
```
**NOTE2** if you use a swarm cluster uncomment the lines under *Swarm mode - uncomment to enable swarm access (adjust source lan)* and adjust your LAN subnet
To install iptables-docker on a local machine, clone [this](https://github.com/garutilorenzo/iptables-docker) repository and run *sudo sh install.sh*
```
sudo sh install.sh
Set iptables to iptables-legacy
Disable ufw,firewalld
Synchronizing state of ufw.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install disable ufw
Failed to stop firewalld.service: Unit firewalld.service not loaded.
Failed to disable unit: Unit file firewalld.service does not exist.
Install iptables-docker.sh
Create systemd unit
Enable iptables-docker.service
Created symlink /etc/systemd/system/multi-user.target.wants/iptables-docker.service → /etc/systemd/system/iptables-docker.service.
start iptables-docker.service
```
#### Automated install (ansible)
You can also use ansible to deploy iptables-docker everywhere. To do this adjust the settings under group_vars/main.yml.
| Label | Default | Description |
| ------- | ------- | ----------- |
| `docker_preserve` | `yes` | Preserve docker iptables rules |
| `swarm_enabled` | `no` | Tells to ansible to open the required ports for the swarm cluster |
| `ebable_icmp_messages` | `yes` | Enable response to ping requests |
| `swarm_cidr` | `192.168.1.0/24` | Local docker swarm subnet |
| `ssh_allow_cidr` | `0.0.0.0/0` | SSH alloed subnet (default everywhere) |
| `iptables_allow_rules` | `[]` | List of dict to dynamically open ports. Each dict has the following key: desc, proto, from, port. See group_vars/all.yml for examples |
| `iptables_docker_uninstall` | `no` | Uninstall iptables-docker |
Now create the inventory (hosts.ini file) or use an inline inventory and run the playbook:
```
ansible-playbook -i hosts.ini site.yml
```
### Usage
To start the service use:
```
sudo systemctl start iptables-docker
or
sudo iptables-docker.sh start
```
To stop the srevice use:
```
sudo systemctl stop iptables-docker
or
sudo iptables-docker.sh stop
```
### Test iptables-docker
Now if you turn off the firewall with *sudo systemctl stop iptables-docker* and if you check the iptable-save output, you will see that the docker rules are still there:
```
sudo iptables-save
# Generated by iptables-save v1.8.4 on Thu Oct 14 15:52:30 2021
*mangle
:PREROUTING ACCEPT [346:23349]
:INPUT ACCEPT [346:23349]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [340:24333]
:POSTROUTING ACCEPT [340:24333]
COMMIT
# Completed on Thu Oct 14 15:52:30 2021
# Generated by iptables-save v1.8.4 on Thu Oct 14 15:52:30 2021
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:DOCKER - [0:0]
:DOCKER-INGRESS - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80
COMMIT
# Completed on Thu Oct 14 15:52:30 2021
# Generated by iptables-save v1.8.4 on Thu Oct 14 15:52:30 2021
*filter
:INPUT ACCEPT [357:24327]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [355:26075]
:DOCKER - [0:0]
:DOCKER-INGRESS - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Thu Oct 14 15:52:30 2021
```
our container is still accesible form the outside:
```
curl -v http://192.168.25.200:8080
* Trying 192.168.25.200:8080...
* TCP_NODELAY set
* Connected to 192.168.25.200 (192.168.25.200) port 8080 (#0)
> GET / HTTP/1.1
> Host: 192.168.25.200:8080
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: nginx/1.21.1
< Date: Thu, 14 Oct 2021 13:53:33 GMT
< Content-Type: text/html
< Content-Length: 612
< Last-Modified: Tue, 06 Jul 2021 14:59:17 GMT
< Connection: keep-alive
< ETag: "60e46fc5-264"
< Accept-Ranges: bytes
```
and our container can reach internet:
```
docker run --rm nginx curl ipinfo.io/ip
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 15 100 15 0 0 94 0 --:--:-- --:--:-- --:--:-- 94
my-public-ip-address
```
### Important notes
Before install iptables-docker please read this notes:
* both local instal and ansible install configure your system to use **iptables-legacy**
* by default **only** port 22 is allowed
* ufw and firewalld will be permanently **disabled**
* filtering on all docker interfaces is disabled
Docker interfaces are:
* vethXXXXXX interfaces
* br-XXXXXXXXXXX interfaces
* docker0 interface
* docker_gwbridge interface
### Extending iptables-docker
You can extend or modify iptables-docker by editing:
* src/iptables-docker.sh for the local install (sh)
* roles/iptables-docker/templates/iptables-docker.sh.j2 template file for the automated install (ansible)
### Uninstall
#### Local install (sh)
Run uninstall.sh
#### Automated install (ansible)
set the variable "iptables_docker_uninstall" to "yes" into group_vars/all.yml and run the playbook. | garutilorenzo |
863,859 | Choosing a future career as a programmer | Hello guys! My name is Olim and as you know I want to explain to choose your future horizon as a... | 0 | 2021-10-14T16:54:32 | https://dev.to/olimsadullaev/choosing-future-career-as-a-programmer-3b33 | Hello guys! My name is Olim and as you know I want to explain to choose your future horizon as a programmer. You may have different options like IOS, Android, Web developer and maybe .Net developer.
Actually, what is .Net developer? .Net is a free, open-source, cross-platform for building many different types of applications. Moreover, you can build web, mobile, desktop, games.
What about programming language?
Do not worry C# is armor for your applications and Object-Oriented Language as well as it is easy to learn compared to C++.
All information taken from (https://dotnet.microsoft.com/).
| olimsadullaev | |
863,866 | SPO600 - Lab 2 | Hey guys, to whoever's reading this, here's some context. This is my 2nd lab for my course SPO600... | 0 | 2021-10-14T17:16:12 | https://dev.to/hyporos/spo600-lab-2-59nl | Hey guys, to whoever's reading this, here's some context.
This is my 2nd lab for my course SPO600 (open source development). This lab involves assembly language, specifically 6502.
```
lda #$00 ; set a pointer at $40 to point to $0200
sta $40
lda #$02
sta $41
lda #$05 ; green color
ldy #$00 ; set index to 0
top:
sta ($40), y ; set first y pixel to green
iny ; increment y
cpy #$20 ; stop when it hits y20
bne top
sta $41 ; point at last page
ldy #$e0 ; set index to last row
lda #$06 ; blue color
bottom:
sta ($40), y ; set pixel to blue
iny ; increment y
bne bottom
left_right:
lda #$07 ; yellow color
sta ($40), y ; set pixel to yellow
tya ; transfer y to a
clc ; clear carry
adc #$1f ; add with carry
tay ; transfer a to y
lda #$04 ; purple color
sta ($40), y ; set pixel to purple
iny ; increment y
bne left_right
inc $41 ; increment page
ldx $41 ; get current page number
cpx #$06 ; compare with 6
bne left_right ; continue until done all pages
```
This is the result produced:

I gained a lot of experience into assembly language from this lab. It was very difficult at first but the more I looked into it, the simpler it got.
| hyporos | |
863,893 | Control Flow in JavaScript: Loops | This article is part of my Control Flow in JavaScript Series. In this article, we will be discussing... | 0 | 2021-10-14T18:07:10 | https://dev.to/pszponder/control-flow-in-javascript-loops-26bd | javascript, beginners, programming, webdev | This article is part of my Control Flow in JavaScript Series.
In this article, we will be discussing loops.
# Why do we need loops?
Very often in code, you will find yourself in the situation where you need to perform a particular task or tasks repeatedly.
Let's say that you want to print to the console the numbers 1 though 10. One way to do that would be the following:
```js
console.log(1);
console.log(2);
console.log(3);
console.log(4);
console.log(5);
console.log(6);
console.log(7);
console.log(8);
console.log(9);
console.log(10);
```
Ok, that's only 10 lines of code, that's not that bad you may say. What if instead of printing the numbers 1 through 10, you were asked to print the number 1 through 1000! Do you really want to type out 1000 `console.log()` statements? Instead of writing 1000 lines, we can implement the following loop for example:
```js
// Print out the numbers 1 through 1000 to the console
for (let i = 0; i < 1000; i++) {
console.log(i);
}
```
Loops enable a program to repeat a piece of code for a specified (or unspecified) amount of time.
# Loop Basics
All 3 of the standard loops (for, while, and do-while) need 3 things to run correctly:
1. An iterator / initial condition.
2. A condition to evaluate to true or false to determine whether or not the loop should run. Typically, this condition is associated with the iterator / initial condition.
3. A way to increment the iterator / initial condition.
## for loops:
The `for` loop is the most often used loop out of all 3 of the standard loops.
Here is the syntax:
```
for (iterator; condition; incrementIterator) {
// Code in for block goes here
// This code will only execute if the condition
// evaluates to true
}
```
Let's look at an example of a for loop and step though what is happening:
```js
// Initialize an array
let myArray = ["a", "b", "c", "d", "e"];
// Loop through the array and print each element
for (let i = 0; i < myArray.length; i++) {
console.log(myArray[i]);
}
// The above loop prints out
// a
// b
// c
// d
// e
// This console.log() will run after the for loop has
// completed printing out all of the elements in the
// array
console.log("For loop ended");
```
1. When the for loop is run for the 1st time, the iterator is set to 0.
2. The condition is then checked and since 0 is less than myArray.length (5), the condition evaluates to `true`.
3. Since the condition evaluated to `true`, then the code inside the for loop is run once and the first element in the array is printed to the console.
4. After the code inside the loop has executed once, the iterator is incremented from 0 to 1 by `i++`.
5. After this, the condition is checked again, since 1 is less than the length of the array, the code inside the for loop is run once again and the 2nd value of the array is printed to the console.
6. After the code runs a second time, the iterator is again increased by 1 so now its value is 2.
7. The loop of checking the condition, running the code and incrementing the iterator is repeated until the iterator is incremented to the length of the array which is 5. At this point, the condition is no longer true since 5 < 5 is `false`. This results in the for loop terminating and moving to the next set of code which is `console.log("For loop ended")`;
## while loops:
Unlike for loops, while loops have their iterator initialized outside of the while loop declaration. Also different from the for loop, the incrementing of the iterator does not happen automatically, instead it needs to be specifically declared within the while loop code block, otherwise, the iterator will not increment and the while loop will keep looping forever. This is called an `infinite loop condition`. This should be avoided as once you get into an infinite loop, you cannot break out of it from within the code, you will have to manually close or quit out of your program.
Here is the syntax for a while loop:
```js
let iterator = someValue;
while (condition) {
// Code goes here
// If we don't increment the iterator here, our
// loop will probably keep going to infinity
iterator++;
}
```
**NOTE**: Technically, you don't need an iterator in order to use a while (or a do...while) loop. However, if you don't use an iterator, you need to have some other way of ensuring that the condition in your while loop eventually evaluates to false, otherwise you will end up with an infinite loop. Instead of using an iterator, you can have an if condition inside your loop that checks if a flag is a certain value and if it is, change the condition in the while loop to evaluate to false.
```js
// Initialize variable to be printed (and decremented) in loop
let n = 5;
// Initialize flag to be used in while loop evaluation
let flag = true;
// Loop while flag evaluates to true
while (flag) {
// Log values to console
console.log("Flag is true");
console.log(n);
n--; // Decrement n
// Condition that flips flag to false and ends
// execution of while loop
if (n < -5) {
console.log("Flag is false");
flag = false;
}
}
/* CODE OUTPUT:
Flag is true
5
Flag is true
4
Flag is true
3
Flag is true
2
Flag is true
1
Flag is true
0
Flag is true
-1
Flag is true
-2
Flag is true
-3
Flag is true
-4
Flag is true
-5
Flag is false
*/
```
Now let's see an example where we loop through an array and print all it's values:
```js
// Initialize an array
let myArray = ["a", "b", "c", "d", "e"];
// Set an iterator with an initial value
// for the while loop
let i = 0;
// Loop through the array and print each element
while (i < myArray.length) {
// Log the current element in the array to the console
console.log(myArray[i]);
// Increment the iterator
i++;
}
// The above loop prints out
// a
// b
// c
// d
// e
// This console.log() will run after the loop has
// completed printing out all of the elements in the
// array
console.log("while loop ended");
```
1. In the example above, we initialize the iterator outside of the while loop and set it's value to 0.
2. The while loop checks the condition which is `i < myArray.length` and since `i` is currently 0, the loop will run and print the 1st element in the array as well as increment the iterator which is declared outside the loop.
3. This is then repeated with the condition of the while loop being checked before the code inside runs.
4. Once the iterator inside the while loop is incremented to a value 5 which is the same as the length of the array,the condition on the while loop will no longer be `true` and the while loop will exit and move to the next set of instructions which is to `console.log("while loop ended")`.
## do...while loops:
Do while loops are very similar to while loops except the checking of the condition happens after the contents inside the loop are executed. This ensures that even if the condition inside the while loop will evaluate to `false` right away, the contents inside the loop will run once before the loop exits due to the condition evaluating to `false`.
Syntax of a `do...while` loop:
```js
// Initialize an iterator which will be used to control
// how many times the loop will run.
let iterator = someValue;
// Run the code inside the do code block
do {
// Code goes here
// If we don't increment the iterator here, our
// loop will probably keep going to infinity
iterator++;
// check the condition evaluates to true
// before going back and running the code again
// inside the do loop
} while (condition);
```
Example of do...while loop:
```js
// Initialize an array
let myArray = ["a", "b", "c", "d", "e"];
// Set an iterator with an initial value
// for the do...while loop
let i = 0;
// Loop through the array and print each element
do {
// Log the current element in the array to the console
console.log(myArray[i]);
// Increment the iterator
i++;
} while (i < myArray.length);
// The above loop prints out
// a
// b
// c
// d
// e
// This console.log() will run after the loop has
// completed printing out all of the elements in the
// array
console.log("do...while loop ended");
```
1. Here, the iterator is also declared outside of the loop and initialized to a starting value of 0.
2. The code inside the `do...while` loop is run and the iterator is incremented by 1.
3. The condition in the while loop is then checked. Since 1 is less than the length of the array, the code in the do portion of the loop is run once again.
4. This cycle of checking the condition and running the code inside the do block is repeated until the condition inside of the while loop is no longer true. At this point, the `do...while` loop exits and the next section of code is run which is the `console.log("do...while loop ended")`.
# Skipping Iterations and Escaping Out of Loops:
## break:
The break statement in JavaScript is used inside a loop to prematurely break out of the loop. These are typically found in `if` statements and used to aid in the control of the loop.
A particularly useful use for the `break` statement is to break out of an infinite while loop.
If a `break` statement is found inside a nested (loop within a loop) loop, then the `break` statement only forces JavaScript to break out of the inner-most loop containing the break statement.
Examples of using the break statement:
```js
for (let i = 0; i < 10; i++) {
console.log(i);
if (i === 3) {
break;
}
}
console.log("printing outside for loop");
/*
Output of code above
0
1
2
3
printing outside for loop
*/
for (let i = 0; i < 5; i++) {
console.log("Printing i:", i);
for (let j = 0; j < 5; j++) {
if (j > 3) {
break;
}
console.log("Printing j:", j);
}
}
/*
Output of Nested For Loop:
Printing i: 0
Printing j: 0
Printing j: 1
Printing j: 2
Printing j: 3
Printing i: 1
Printing j: 0
Printing j: 1
Printing j: 2
Printing j: 3
Printing i: 2
Printing j: 0
Printing j: 1
Printing j: 2
Printing j: 3
Printing i: 3
Printing j: 0
Printing j: 1
Printing j: 2
Printing j: 3
Printing i: 4
Printing j: 0
Printing j: 1
Printing j: 2
Printing j: 3
*/
// You can also use the break statement to break out of an infinite while loop
let counter = 0;
while (true) {
console.log(counter);
counter++;
if (counter > 5) {
break;
}
}
/*
Output of while loop:
0
1
2
3
4
5
*/
```
## continue:
The `continue` statement works similarly to to the `break` statement except that instead of completely breaking out of the loop containing the `continue` statement, `continue` just forces the current loop to start its next iteration, while skipping any additional statements below the `continue` statement.
More specifically, when the `continue` statement is executed, there are 2 possibilities that occur depending on the type of loop the statement is located in:
- For a `while` loop, `continue` forces the loop to proceed with its next iteration.
- For a `for` loop, `continue` forces the loop to update the current iterator and then proceed with the next iteration.
Also similar to the `break` statement, `continue` only works on the inner-most loop which contains the `continue` statement.
```js
for (let i = 0; i < 5; i++) {
if (i === 3) {
continue;
}
console.log(i);
}
console.log("printing outside for loop");
/*
Notice how the value of 3 is not printed. This is because
the if statement triggers and the continue causes
the console.log(i) to get skipped and the next iteration
proceeds.
Output of code above:
0
1
2
4
printing outside for loop
*/
for (let i = 0; i < 5; i++) {
console.log("Printing i:", i);
for (let j = 0; j < 5; j++) {
if (j === 2) {
continue;
}
console.log("Printing j:", j);
}
}
/*
NOTE: Notice how the number 2 is not being printed
inside the nested for loop. This is because of the
continue statement.
Output of Nested For Loop:
Printing i: 0
Printing j: 0
Printing j: 1
Printing j: 3
Printing j: 4
Printing i: 1
Printing j: 0
Printing j: 1
Printing j: 3
Printing j: 4
Printing i: 2
Printing j: 0
Printing j: 1
Printing j: 3
Printing j: 4
Printing i: 3
Printing j: 0
Printing j: 1
Printing j: 3
Printing j: 4
Printing i: 4
Printing j: 0
Printing j: 1
Printing j: 3
Printing j: 4
*/
```
# Looping through Iterables and Objects in JS with for...of and for...in loops:
## for...of loops:
`for...of` loops are a shorthand way to write a for loop to iterate over all elements in an iterable object. `strings`, `arrays`, `maps` and `sets` are examples of iterable objects in JavaScript. Elements in an array-like object such as a `NodeList` can also be accessed using `for...of`.
When using a `for...of` loop, the iterator which is declared inside the conditional statement of the loop takes on the value of the current element in the iterable being evaluated.
```js
let myArray = ["a", "b", "c", "d", "e"];
for (let letter of myArray) {
console.log(letter);
}
/*
Output from for...of array
a
b
c
d
e
*/
```
## for...in loops:
`for...in` loops iterate through properties in an object, specifically their keys.
```js
let myObject = {
firstName: "John",
lastName: "Doe",
age: 50,
};
for (let property in myObject) {
console.log(`${property}: ${myObject[property]}`);
}
/*
Output from the for...in loop
firstName: John
lastName: Doe
age: 50
*/
```
**NOTE:** While it is possible to use the `for...in` loop to iterate over an array, please only use `for...in` loops to iterate over object properties. `for...in` loops will not necessarily iterate over the array in a specific order.
# References
- [MDN - for](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for)
- [MDN - while](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/while)
- [MDN - do...while](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/do...while)
- [MDN - continue](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/continue)
- [MDN - break](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/break)
- [MDN - Built-in iterables](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols#built-in_iterables)
- [MDN - for...of](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for...of)
- [MDN - for...in](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for...in)
| pszponder |
863,949 | Arquitetura Hexagonal... É arquitetura? É hexagonal? | Nas últimas semanas estou vendo algumas discussões relacionadas a confirmação da arquitetura... | 0 | 2021-10-14T20:01:32 | https://diegoborgs.com.br/blog/arquitetura-hexagonal-%C3%A9-arquitetura-%C3%A9-hexagonal | architecture | Nas últimas semanas estou vendo algumas discussões relacionadas a confirmação da arquitetura hexagonal e outros modelos como DDD como arquitetura ou não. Acredito que a discussão é bem válida, e achei pertinente dar meus 2 centavos sobre o assunto. Diferente de alguns outros posts, acredito que o conteúdo desse é mais um ponto de vista do que uma resposta definitiva sobre o assunto, portanto cabe a você que lê, guardar aquilo que faz sentido.
Só para contextualizar, a arquitetura hexagonal consiste em dividir a aplicação em camadas separando o código em categorias diferentes (são geralmente usadas as camadas de infraestrutura, aplicação e domínio). Ela é baseada no famoso desenho da arquitetura de cebola ou arquitetura em camadas muito usado para representar a Clean Architecture” ou no bom português “Arquitetura Limpa”, mas é chamada arquitetura hexagonal por causa dos primeiros desenhos usados em sua representação.
Leia o artigo na íntegra no meu (blog)[https://diegoborgs.com.br/blog/arquitetura-hexagonal-%C3%A9-arquitetura-%C3%A9-hexagonal]. | eudiegoborgs |
864,098 | Handling Twilio Events Part 1: PG Notify | Sequin gives developers a secondary source of truth for their data. Instead of making GET requests to... | 0 | 2021-10-14T22:08:39 | https://blog.sequin.io/using-pg-notify-with-twilio | elixir, postgres, twilio, programming | [Sequin](https://sequin.io/sources/twilio) gives developers a _secondary source of truth_ for their data. Instead of making GET requests to fetch data or keep your local copy of data in sync, you can rely on Sequin to handle that for you in real-time.
We recently added support for Twilio. With our Twilio sync, it takes just a couple clicks to have all your messages, phone calls, and call recordings synced to a `twilio` schema in your database as they are sent and received.
While this second source of truth is powerful, Twilio is the most event-oriented platform we've integrated with. Often, developers want to handle inbound text messages or phone calls _right away_, like by having their app respond to a text. With Sequin, new text messages will be synced straight to your database. This gives you a reliable source to query from. But in contrast to a webhook, by default your own code will not be invoked when you receive a new text.
We're exploring different ways to attach events to our sync process. The simplest way is using **PG Notify**. In this post, we'll explore how this might work.
To do so, we'll build an SMS service where a group of people can manage a list of tasks over text message:
1. Texting in a string of text adds it to the global list.
2. Texting the number `1` or `ls` will send back the current list. Each text entry is numbered, eg:
```plain
1. clean rackets
2. order more pickle balls
3. make court reservations for saturday
```
3. Texting `del [num]` will delete the entry listed at `[num]`
For simplicity, we're going to have just one global list in this app. But a real-world implementation would allow users to invite certain members (phone numbers) to participate in their list.
This post showcases both the Postgres code for triggering notifications as well as Elixir code to handle those notifications. If you don't know Elixir, context is given around code blocks to help you get the gist.
> We won't cover every line of code or command needed to get a functioning version of this app. However, if you're following along and want help, feel free to [reach out](founders@sequin.io) if you get stuck!
## Setup the sync
We're using [Twilio](https://www.twilio.com/) to send and receive text messages, which offers a free trial. After signing up, spin up a sync to your database with [Sequin](https://app.sequin.io/signup) by supplying your API key:

Sequin's Twilio sync polls for changes to Twilio every couple seconds, meaning your database is always up-to-date.
Instead of using Twilio's webhooks to subscribe to new texts, we'll use PG Notify. However, Twilio needs to call _some_ endpoint when new texts come in, otherwise it won't handle them. It's a bit of a hack, but on the page where you configure the webhooks for your Twilio Phone Number, you can just have Twilio make a GET request to our homepage:
```
GET https://sequin.io
```

## PG Notify
> The code in this section is largely adapted from the wonderful article [How to use LISTEN and NOTIFY PostgreSQL commands in Elixir](https://blog.lelonek.me/listen-and-notify-postgresql-commands-in-elixir-187c49597851) by [Kamil Lelonek](https://medium.com/@KamilLelonek).
Sequin will sync changes in Twilio's API right to your database. In our case, text messages will be synced to the `message` table inside the schema `twilio`.
But our requirements for this app are event-oriented. We want to respond to text messages right away, as they come in.
We could have a worker that polls the `message` table for changes. Perhaps every tick, it polls the `message` table with an incrementing `inserted_at` cursor to see if there's anything new to handle. But for fun, and for illustrative purposes, we'll use PG Notify in this project.
Each Postgres notification includes a _name_ and a _payload_. The _name_ is the event name. You can send a notification using the `pg_notify()` function like this:
```sql
select pg_notify('new_message', '{"body": "clean rackets", "from": "+12135550000"}');
```
For our application, we want to publish new notifications based on inserts into the `twilio.message` table. When Sequin sees a new message at Twilio's `/Messages.json` endpoint, it will insert that message into our database. We can use a _Postgres trigger_ that executes a function that creates a notification whenever this happens.
We'll ignore _updates_ to messages for now. In Twilio, the only time we'll see updates for messages is when the delivery `status` has changed (from eg `sent` to `delivered`). (In a more robust production application, we might want to monitor these events for delivery failures.)
#### Notify function
Here's what the function that creates the notification will look like:
```sql
create or replace function notify_new_message()
returns trigger
as $$
begin
perform
pg_notify('new_message', json_build_object('operation', tg_op, 'message', row_to_json(new))::text);
return new;
end;
$$
language plpgsql;
```
Everything around the `BEGIN/END` block is standard syntax to declare a Postgres function. Our function is called `notify_new_message()`. The name of the notification is `new_message`. In `json_build_object()`, we define a JSON object with two properties: `operation` and `message`. `operation` is set to the special variable `TG_OP`, which in our case will always be `'INSERT'`. Then `message` will contain the full message row that was just inserted (the special variable `NEW` inside a trigger function body).
Notifications are cast to `text`. But here's what they will look like as parsed JSON:
```js
{
"operation": "INSERT",
"record": {
"account_id": "ACc96f9",
"api_version": "2010-04-01",
"body": "pickup jersey from cleaners ",
"date_created": "2021-09-27T15:29:34",
"date_sent": "2021-09-27T15:29:35",
"date_updated": "2021-09-27T15:29:35",
"deleted": false,
"direction": "inbound",
"error_code": null,
"error_message": null,
"from": "+12135551111",
"id": "SMbdac6",
"messaging_service_id": null,
"num_media": 0,
"num_segments": 1,
"price": null,
"price_unit": "USD",
"status": "received",
"to": "+12135550000",
"uri": "/2010-04-01/Accounts/ACc96f9d47739a/Messages/SMbdac623.json"
}
}
```
#### The after insert trigger
Now, we just need to invoke our notify function after messages are created in the database:
```sql
create trigger new_message
after insert
on twilio.message
for each row
execute procedure notify_new_message()
```
Our notify function is written and it's connected to an `after insert` trigger on `message`. Now it's time to subscribe to this notification from Elixir.
## The Elixir subscription
If you want the complete starting point for a brand new app that uses PG Notify, I recommend you check out [this article](https://blog.lelonek.me/listen-and-notify-postgresql-commands-in-elixir-187c49597851).
Touching on the highlights: First, you need to ensure that your app subscribes to the `new_message` event on boot. One way to do this is to create a new GenServer that invokes `Postgrex.Notifications.listen/2` inside its `init`.
Below is an Elixir GenServer declaration. A _GenServer_ in Elixir is a process that can send and receive messages. In our case, our GenServer will subscribe to notifications from Postgres. We'll first see how to subscribe to these notifications, then we'll see how to handle them.
If you're not familiar with Elixir, gloss over the methods `child_spec/1` and `start_link/1` – these are standard for a GenServer:
```elixir
defmodule SmsBot.Listener do
use GenServer
def child_spec(opts) do
%{
id: __MODULE__,
start: {__MODULE__, :start_link, [opts]}
}
end
def start_link(opts \\ []),
do: GenServer.start_link(__MODULE__, opts)
def init(opts) do
with {:ok, _pid, _ref} <- setup_listener("new_message") do
{:ok, opts}
else
error -> {:stop, error}
end
end
defp setup_listener(event_name) do
with {:ok, pid} <- Postgrex.Notifications.start_link(SmsBot.Repo.config()),
{:ok, ref} <- Postgrex.Notifications.listen(pid, event_name) do
{:ok, pid, ref}
end
end
```
The important part is inside `init/1`, which is invoked when this process is booted. That calls `setup_listener/1`, which tells Postgres (via the `Postgrex` library), that our process would like to receive notifications for all `"new_message"` events.
To get the connection details for `Postgrex.Notifications.start_link/1`, we're using the `config/0` function on an Ecto repo (common in Phoenix apps).
Now, just add this new GenServer to your child spec in your `Application`:
```elixir
defp children do
[
SmsBot.Listener
]
end
```
If we were to boot the app, we'd now have a GenServer listening for notifications. But we still need to handle those notifications.
Postgrex.Notifications will send notifications to our GenServer as regular process messages. That means we can handle them with `handle_info/2`:
```elixir
defmodule SmsBox.Listener do
@impl true
def handle_info({:notification, _pid, _ref, "new_message", payload}, _state) do
with {:ok, data} <- Jason.decode(payload, keys: :atoms) do
data
|> inspect()
|> Logger.info()
{:noreply, :event_handled}
else
error -> {:stop, error, []}
end
end
end
```
The event name is `"new_message"` and the payload is the stringified JSON object from our `notify_new_message()` function.
If we booted our server and sent an SMS in, we'd see an insert notification like the one above printed to the console.
With notifications flowing from inserts through Elixir, we're almost ready to write our app's handler code. We just need to add one more construct to our data model.
## Creating `list_item`
The `message` table will contain an append-only list of all messages flowing through Twilio. For managing lists in our app, we'll want to group messages in a separate table. In the short run, this will allow users to remove messages from the list. In the long run, this is the construct we'd use to isolate lists between groups of phone numbers. We'd add a `list` table then group `list_items` under that table.
Here's the declaration for the `list_item` table:
```sql
create table list_item (
id serial not null,
message_id text references message (id)
);
```
## Handling inbound SMS messages
We'll use this handler to route the incoming SMS notification to one of three functions, depending on the command. We'll rewrite the body of `handle_info/2` and extract the logic out to a new function `handle_message/1`:
```elixir
defmodule SmsBot.Listener do
@impl true
def handle_info({:notification, _pid, _ref, "new_message", payload}, _state) do
with {:ok, data} <- Jason.decode(payload, keys: :atoms) do
handle_message(data[:message])
{:noreply, :event_handled}
else
error -> {:stop, error, []}
end
end
defp handle_message(%{ direction: "inbound" }) do
message = data[:message]
message_body =
data[:message][:body]
|> String.trim_leading()
|> String.trim_trailing()
case message_body do
body when body in ["1", "ls"] ->
hande_list(message)
"del " <> num ->
num = String.to_integer(num)
handle_delete(message, num)
_body ->
handle_add(message)
end
end
defp handle_message(_outbound_message) do
:ok
end
end
```
Inside `handle_message/1`, we first normalize the inbound message by trimming trailing and leading whitespace. Then we use a `case` statement to direct the message to the appropriate sub-handler:
- If the message was a `1` or `ls`, then we know the user wants to list all list items so far.
- If the message matches `del [num]`, then they want to delete a list item.
- Otherwise, we'll create a new list item for the message.
> Note: A production app would want to do way more inbound text normalization.
Note that we only want to handle messages that have `direction="inbound"`. Twilio will also record all of our _outbound_ messages (replies to the users), which will in turn trigger PG Notifications. We just ignore those.
Here's what each of those handler functions might look like. Note that this assumes we've setup an Ecto repo for list items, called `ListItem`.
First, we define a helper function that lists all list items in the database, with a corresponding index. These indexes will be used when displaying the list, to both number the list and to allow the user to delete items:
```elixir
defp list_messages_with_indexes do
ListItem
|> SmsBot.Repo.all()
|> SmsBot.Repo.preload(:message)
|> Enum.map(fn item -> item.message.body end)
|> Enum.with_index(1)
end
```
The result of calling this function will be a list that looks like this:
```elixir
[
{1, "clean rackets"},
{2, "order more pickle balls"},
{3, "make court reservations for saturday"}
]
```
We'll use this helper function in a couple places in our handler functions:
```elixir
defmodule SmsBot.Listener do
# ...
defp handle_list(message) do
messages =
list_messages_with_indexes()
|> Enum.map(fn {idx, msg} -> "#{idx}. #{msg}" end)
|> Enum.join("\n")
outgoing_body = "Here's the list:\n#{messages}"
send_sms(message.from, outgoing_body)
end
defp handle_delete(message, del_idx) do
to_delete =
ListItem
|> SmsBot.Repo.all()
|> Enum.with_index(1)
|> Enum.find(fn {idx, msg} -> idx == del_idx end)
if to_delete do
with {:ok, _li} <- SmsBot.Repo.delete(to_delete) do
send_sms(message.from, "Item deleted")
end
else
send_sms(message.from, "Error: No entry for #{del_idx}")
end
end
defp handle_add(message) do
changeset = Ecto.Changeset.cast(%ListItem{}, %{ message_id: message.id })
with {:ok, _li} <- SmsBot.Repo.create(changeset) do
send_sms(message.from, "Item added")
handle_list(message)
else
err ->
Logger.error(err)
send_sms(message.from, "Something went wrong.")
end
end
end
```
Digging in to how each of these functions work is beyond the scope of this tutorial. But touching on the highlights:
- We assume the implementation of `send_sms/2`, which makes an API call to send a message via Twilio. This expects a phone number as the first argument and a message body as the second. Note that all messages are sent to `message.from`, or the sender of the message we are handling.
- Our ordering/indexing of list items is simple. We just generate the indexes on the fly, relying on insertion order to keep the list stable.
- The `message` table is a read-only table that reflects our Twilio data, kept in-sync by Sequin. By creating the `list_item` table, we are maintaining our domain-specific data (list items) elsewhere. That gives us the freedom to e.g. delete list items, while preserving the full record of messages sent and received by Twilio.
## Wrapping up
PG Notify is a great way to trigger events around your sync process. It's well-supported among programming languages, quick to setup, and doesn't require any other tools outside of Postgres (like eg Kafka).
Using Sequin as the backbone of our Twilio integration offers us a foundation that is both easy to build on and scalable. Our app – like many apps built with Twilio – relies on a historical record of all text messages received. Retrieving that text message history via Twilio every time we needed it would be inefficient. Having the data readily available in a database alleviates the need for polling or handling webhooks.
However, using PG Notify here has some big limitations:
- If your app is down (no listeners), _events are not buffered anywhere_. After broadcast, events disappear immediately. This means even if you're down for just a few seconds, you could miss text messages that you need to respond to.
- There are no retries. If your notification handler in your code has a bug, or hits a temporary error (Twilio is unable to process your outgoing text), the event will be lost.
All this means that PG Notify is best used in production _in collaboration with_ some type of database polling process. For example, in this application, we could store a cursor somewhere, `last_message_processed`. As we process messages, we increment the cursor. If our app restarts, we use the cursor to "catch up" on any messages we may have missed before subscribing to the notify stream for new ones.
At Sequin, we're brainstorming other ways to trigger events around your sync. If there's anything you'd love to see here, let us know! Otherwise, stay tuned. | thisisgoldman |
864,102 | The future of Jamstack is Less JS! | Yang Zhang hosted a Jamstack session where he discussed the functions of Plasmic, a visual builder... | 0 | 2021-10-14T22:24:09 | https://dev.to/prestonlacasse/the-future-of-jamstack-is-less-js-1o13 | javascript, jamstack, webdev, tutorial | Yang Zhang hosted a Jamstack session where he discussed the functions of Plasmic, a visual builder that can plug into your own code base similar to a headless CMS but has a no-code page builder that allows you to style landing pages the way you want.
A little before knowledge we dive in! I signed up for the Jamstack Conf 2021 but had no idea what Jamstack was or even did for that matter. So before listening into a few sessions, I did some research on Jamstack and here's what I learned. Jamstack is an architecture that builds on many of the existing frameworks and workflows that developers use today. Jamstack allows you to build beautiful website easier with JavaScript frameworks, Static Site Generators, Headless CMSs, and CDNs.
Back to what I learned. One concept I learned while listening to Yang speak was the term "Streaming Render". So how rendering works is you fetch all the data you need to render the page, your render the full page, than you send the result out to the browser. This can take some time as different data takes less/more time to render. Streaming render allows your to mark certain parts of your page as lazy loaded and a place holder is rendered instead, and the server will continue to render the rest of the page. This cuts back on the render time.
As someone who know the basics of coding web based projects. My main question on these topics would be, how do these frameworks and software affect the average developer? With all these new programs that allow most everyday users to create a project without any prior coding knowledge, how does this affect developers and the field?
In conclusion I was very pleased to attend Yang Zhang's session on Plasmic. Plasmic uses all the best practices around images, text, etc. like streaming rendering, API's, plugins, etc. All in all a great learning experience where I was able to further my knowledge in web development.
| prestonlacasse |
864,120 | Week3 SPO600 Math Problem Solving | Hello everyone, welcome back to the 4th week of SPO600(Software Portability and Optimization)... | 0 | 2021-10-15T00:19:20 | https://dev.to/qzhang125/week4-spo666-13mj | Hello everyone, welcome back to the 4th week of SPO600(Software Portability and Optimization) reflection and extra exploration blog! In this blog, I'm going to use 6502 assembly language to do some math problems.
In 6502 assembly language, we use [ADC(add with carry)](https://wiki.cdot.senecacollege.ca/wiki/6502_Math#Addition) and [SBC(subtract with carry)](https://wiki.cdot.senecacollege.ca/wiki/6502_Math#Subtraction) to add and subtract the value which is stored in the accumulator.
With the basic ideology, let's create a simple program to calculate numbers.
```
LDY #$05 ;Load Y register with 40 in hexadecimal
SEC ;Set carry flag
TYA ;Transfer Y register to the accumulator
SBC #$02 ;Do the subtraction 2
CLC ;Clear carry flag
ADC #$01
TAY ;Transfer the A register to Y
```
In this simple program, we load a number 5 to the Y register in hex decimal. For subtraction, we have to use the SEC to set up a carry flag. Next, we transfer the value which is stored in Y to the accumulator for processing calculation. Afterwards, we subtract carry 2 to the number in the accumulator, then CLC is used to clear the flag for the addition with carry 1. Lastly we transfer the result from the accumulator to the Y register. In this little program we simply do a 5-2+1 calculation by using assembly language. As we expected, the answer is 4 in the Y register!
My thoughts about the math problem in the assembly world. Personally, I start the programming with a high level programming language, creating a program to do the calculation above is the easiest thing for me. But in assembly language, numbers are stored in registers. If we want to access them and modify the number we have to set them into the accumulator, then create or clear carry flags for addition or subtraction. It shows the property of a low-level programming language which has to actually access the memory by the programmer every single time during the programming.
| qzhang125 | |
864,253 | Array en PHP | Declarar un array vacío //Sintaxis con array()... | 0 | 2021-10-15T20:33:17 | https://dev.to/marcodeev/array-en-php-48gf | 
### Declarar un array vacío
```php
//Sintaxis con array()
$lista_de_series=array();
//Sintaxis short array valida a partir de PHP 5.4
$lista_de_series=[];
```
### Declarar un array con elementos
```php
//Sintaxis con array()
$lista_de_series=array('El juego del calamar','Cobra kay','Love, Death and Robots','Sweet Tooth');
//Sintaxis short array
$lista_de_series=['El juego del calamar','Cobra kay','Love, Death and Robots','Sweet Tooth'];
```
[Ver ejemplo 1](https://onecompiler.com/php/3xeh47dpq)
### Acceder a un elemento de un array simple
```php
$indice=3;
echo $lista_de_series[$indice];
```
### Declarar un array asociativo con elementos
```php
//Sintaxis con array()
$jugador=array('nombre'=>'Lionel',
'apellido'=>'Messi',
'nacionalidad'=>'Argentina',
'edad'=>34);
//Sintaxis short array
$jugador=['nombre'=>'Lionel',
'apellido'=>'Messi',
'nacionalidad'=>'Argentina',
'edad'=>34];
```
### Acceder a un elemento de un array asociativo con claves
```php
//Sintaxis con array()
echo $jugador['nombre'];
```
[Ver ejemplo 2](https://onecompiler.com/php/3xeh4ng5h)
### Acceder a un elemento de un array asociativo con claves
```php
//Sintaxis con array()
echo $jugador['nombre'];
```
[Ver ejemplo 2](https://onecompiler.com/php/3xeh4ng5h)
### Agregar elementos a un array
PHP nos proporciona la funcion array_push() para agregar elementos a un array
Sintaxis: array_push($array, $elemento);
También es posible agregar mas de un elemento
array_push($array, $elemento1,$elemento2,$elemento3,$elemento4);
```php
$lista_de_series=array('El juego del calamar','Cobra kay','Love, Death and Robots','Sweet Tooth');
array_push($lista_de_series,'La casa de papel');
array_push($lista_de_series,'Sweet Home','De yakuza a amo de casa');
FIN
DEL
POST
```
[Ver ejemplo 3](https://onecompiler.com/php/3xeh8fake)
| marcodeev | |
864,277 | Learn with me:Apple's Swift
Variables and Constants | Hey guys,Welcome to 2nd part of Learn With Me:Apple's Swift.In previous tutorial you learned how to... | 0 | 2021-10-15T06:43:37 | https://dev.to/thisisanshgupta/learn-with-meapples-swift-528p | programming, swift, ios, tutorial | Hey guys,Welcome to 2nd part of Learn With Me:Apple's Swift.In previous tutorial you learned how to write Hello World in Swift and in this tutorial we are going to learn about Variables and Constants in Swift.I will highly recommend to read the first part of Swift tutorial [here](https://dev.to/thisisanshgupta/learn-with-meapples-swift-o21).So let's get started.
#Variables
In programming,variable is a storage area to store data.For eg:
```swift
var name="Swift"
```
Here **name** is a variable storing "Swift".
#Declaring Variables in Swift
In Swift,variables are declared using **var** keyword.
For example,
```swift
var name:String
var id:Int
```
Here,
•name is a variable of type String. Meaning, it can only store textual values.
•id is a variable of Int type. Meaning, it can only store integer values.
You can assign values to a variable using **=** operator.
```swift
var name:String
name="Swift"
print("My favorite programming language is:",name)
```
**Output**
```
My favorite programming language is:Swift
```
**Note:**You can also assign a variable directly without the type annotation.
For example,
```swift
var name="Swift"
```
#Constants in Swift
A constant is a special type of variable whose value cannot be changed. A constant is declared using **let** keyword.For example,
```swift
let name="John Doe"
print(name)
```
**Output**
```
John Doe
```
If you'll try to change the value of **name** then you will get an error.For example,
```swift
let name="John Doe"
name="Jonathan"
print(name)
```
**Output**
```
error: cannot assign to value: 'name' is a 'let' constant
```
**Note:**You cannot declare constant without initializing it.
#Conclusion
Thanks for reading.I hope it will help you a lot in achieving your dreams.And in next part we are going to learn about Literals in Swift.
| thisisanshgupta |
865,122 | My Hacktoberfest2021 Journey | Hacktoberfest 2021 ~ Women In Tech App/API creation ~ A Web Dev's... | 0 | 2021-11-01T00:49:24 | https://dev.to/kwing25/my-hacktoberfest2021-journey-4cc5 | hacktoberfest, womenintech, devops | ## Hacktoberfest 2021 ~ Women In Tech App/API creation ~ A Web Dev's Reflection
[Hacktoberfest2021](https://hacktoberfest.digitalocean.com/)
{% github kwing25/Women-Who-ve-Changed-Tech no-readme%}
‣[The Project](#the-project) ‣[The Beginning](#the-beginning) ‣[The Future](#the-future) ‣[Being a Maintainer](#being-a-maintainer) ‣[Women In Tech](#women-in-tech) ‣[Thanks](#thanks) ‣[See more](#see-more)
This was my 1st time being a Contrbutor & Maintainer in Hactoberfest. I'm a new Bootcamp Grad & Developer and this event was a great opportunity to contribute to Open Source Projects.
### The Project
Looking at the many open source projects I decided I wanted to do more than just contribute. For a while, I've wanted to do a Female Tech Pioneers Web API/React App after noticing that there aren't many sources online of just Females in Tech. I decided to start a project that would build the foundation of an all-Women Tech & STEM Pioneer API and Website. I wanted to have multiple contributors building a list of Female Tech Individuals. It's been surprising to see the number of people Contributing to the list. I didn't think that there would be many people who would see the Repo and it's been incredible working with people all over the world 🌎.
#### The Beginning
I started with the goal of developing a simple Front End [React JS](https://reactjs.org/) and a JSON & Yaml File for the API List. Creating the basic structure of the site I used [Sass/SCSS](https://sass-lang.com/) for Styling, [Bootstrap](https://getbootstrap.com/) for Structure, and [npm packages](https://www.npmjs.com/) (Font Awesome, React-Scroll-Motion). For the API Development I used [Postman](postman.com).
#### The Future
This project is just in its infancy and I plan on developing this into a full Web API using REST & React.js as the main technologies. Having multiple Collaborators & Contributors will help to the project's development. ***[Contribute☞](https://github.com/kwing25/Women-Who-ve-Changed-Tech)***
#### Being a Maintainer
Being a maintainer on a repo can be very rewarding but also involves a lot of work. [GitHub](https://docs.github.com/) & GitLab make Devops/Repo Management accessible for users and is vital for open source collaboration. *Issues, Docs, PR's, Tracking, Actions, Projects, Etc.*. One of the most important things I've learned is that having strong connections & communication with other collaborators can make a huge difference in a project.
---
### Women in Tech
My experience as a Woman in the Tech Industry has come with challenges. I started out taking Computer Networking courses and wanted to get certifications in IT and Security. There were very few women in these classes and sometimes I was the only one. I never let this stop me from going into this field and I don't want this to stop any other woman from pursuing a career in tech. But I had to learn and grow more confident in myself. Amy Hood the CFO of Microsoft put this feeling into good words-<br>
<i>"Every job I took, I was deeply uncomfortable in terms of feeling unqualified. Every step, every risk I took, built confidence."</i><br>
When you love a certain field and are passionate about it you can achieve about anything (usually easier said than done). There are so many talented women in the Tech Industry and so many that have made a lasting impact. My ultimate goal for this project is to document women in Tech and make sure there remembered in Tech history.
---
#### Thanks
👏 Many great Contributors on this project. <i>See the list ☞ github.com/kwing25/Women-Who-ve-Changed-Tech/graphs/contributors</i>
#### See more
Contact-
[](https://github.com/kwing25)
[](https://www.linkedin.com/in/kendrawing/)
---
<i>[Ada Lovelace](https://www.britannica.com/biography/Ada-Lovelace) was my first entry to the list. ✦ Known as the 1st Computer Programmer. Ada was brilliant in Mathematics & Computing. She lived in the 1800s and is still remembered today for her contributions in this field. </i><br><img src="https://cdn.britannica.com/22/23622-050-E60DC899/Ada-King-countess-Lovelace-Alfred-Edward-Chalon-circa-1838.jpg" width="105px" alt="profile">
```json
{
"id": "1",
"name": "Ada Lovelace",
"known_for": "First Computer Programmer",
"Bio": {
"Summary": "The daughter of famed poet Lord Byron, Augusta Ada Byron, Countess of Lovelace — better known as \"Ada Lovelace\" — showed her gift for mathematics at an early age. She translated an article on an invention by Charles Babbage, and added her own comments. Because she introduced many computer concepts, Lovelace is considered the first computer programmer"
}
{
"Fields": [
{
"Computing": [
"Programming",
"Algorithms"
]
}
],
"Legacy": "Lovelace's contributions to the field of computer science were not discovered until the 1950s. Her notes were reintroduced to the world by B.V. Bowden, who republished them in 'Faster Than Thought - A Symposium on Digital Computing Machines'. Since then, Ada has received many posthumous honors for her work.",
}
```
---
| kwing25 |
864,278 | Receiving an error for a while... | ./src/Redux/Reducer/rootReducer.js Attempted import error: 'combineReducer' is not exported from... | 0 | 2021-10-15T05:30:52 | https://dev.to/bharatsharma77/receiving-an-error-for-a-while-25cd | javascript, react | ./src/Redux/Reducer/rootReducer.js
Attempted import error: 'combineReducer' is not exported from 'redux'. | bharatsharma77 |
864,473 | Types of html inputs | There are lot of html syntaxs for allowing inputs in our projects. 2day let take them one after the... | 0 | 2021-10-15T09:31:54 | https://dev.to/ezekiel8807/types-of-html-inputs-ahh | There are lot of **html** syntaxs for allowing inputs in our projects.
2day let take them one after the other for better understanding..
### Text input
```html
<input type="text">
```
#### _input_:
Input are reserved word in html enclosed with the opening and closing tag (< >).
#### _type_:
Type is one of html attributes in html, they are generally use specify the type of input needed.
#### _text_:
Text is one of type_value for the input attribute **_Type_**. It's use for getting input data in form of strings or characters.
** **
### Number input
```html
<input type="number">
```
#### _number_:
Number is one of type_value for the input attribute **_Type_**. It's use for getting input data in form of numbers.
** **
### Email input
```html
<input type="email">
```
#### _email_:
Email is also one of type_value for the input attribute **_Type_**. It's use for getting email address. Other input aside a correct email address throw error.
** **
### Button
```html
<input type="button">
```
#### _button_:
Button is also one of type_value for the input attribute **_Type_**. It's use for creating buttons
** **
### Password input
```html
<input type="password">
```
#### _password_:
Password is also one of type_value for the input attribute **_Type_**. It help to hide sensitive data.
** **
### Option input
```html
<input type="radio">
```
```html
<input type="checkbox">
```
```html
<input type="range">
```
#### _radio, checkbox and range_:
They are type_value for the input attribute **_Type_**. It's use for getting multiple data at a time.
** **
### Color input
```html
<input type="color">
```
#### _color_:
Color is also one of type_value for the input attribute **_Type_**. It's use to get color value.
** **
### Url input
```html
<input type="url">
```
#### _url_:
Url is also one of type_value for the input attribute **_Type_**. It's use for getting url as input data.
** **
### Date input
```html
<input type="date">
```
#### _date_:
Date is one of type_value for the input attribute **_Type_**. It's use for getting date as input from a form.
** **
### Media input
```html
<input type="image">
```
```html
<input type="file">
```
#### _image and file_:
These are also type_value for the input attribute **_Type_**. They are use for getting media data such as;
* Music file
* Image file
* Document e.t.c
| ezekiel8807 | |
864,557 | | import * as Localization from "expo-localization" | | solution : yarn add expo-localization | 0 | 2021-10-15T11:01:34 | https://dev.to/hafdiahmed/-import-as-localization-from-expo-localization--133o | react, javascript, reactnative, android | solution : yarn add expo-localization
| hafdiahmed |
864,594 | docker basics ubuntu | table of content : Mysql configuration Docker Network Using ipv6 docker compose ... | 0 | 2021-10-23T10:58:07 | https://dev.to/karenpanahi/docker-basics-ubuntu-2ch5 | ## table of content :
* [ Mysql configuration](#chapter-1)
* [ Docker Network ](#chapter-5)
* [ Using ipv6 ](#chapter-6)
* [ docker compose ](#chapter-9)
* [ docker data persistence and file management](#chapter-10)
### Mysql docker conf <a name='chapter-1'></a>
https://phoenixnap.com/kb/mysql-docker-container
mysql
https://docker-curriculum.com/#webapps-with-docker
https://www.tutorialspoint.com/docker/
# tut:
benefits :
no environmental configuration needed on the server Exept
Docker Runtime
if we use the same app but different versions they will use the same port ,how does that work??
-the containers use the same port but the port that the host binds to them are different for example redis:latest & redis:4.6 both use port 6379 but the ports that host assigned to them are different (i.e 3000 & 3001)
but you have to use the host port for each container :
>>>someApp://localhost:3000
>>>someApp://localhost:3001
but if you dont specify the ports while runnuig the container ,it would be unreachable for other apps so :
sudo docker run -p<hostPort>:<applicationPort>
sudo docker run -p6000:6379
postgres:version
if not specified
for example: postgres:9.6
sudo docker -d :detached mode
# some basic commands
sudo docker logs containerId
if you want to give container a name:
sudo docker docker run -p6000:6379 --name <containerName> <imageName>
docker run --name heshmat redis
$ lists the processes running within a container.
docker top container options
$ Display a live stream of container(s) resource usage statistics.
docker stats options container
$ applying limitations:
docker container run -d --name testContainer
--cpu-shares 512 --memory 128M -p 8080:80 nginx
$ if you have an existing container you can update it by:
docker container update --cpu-shares 512 ...
for debugging:
sudo docker -it containerId /bin/bash
start &run :
run creates new
start restarts already made container
sudo docker image
sudo docker run
sudo docker pull
sudo docker run -it packageName /bin/bash
in the above command we have:
-it which runs the <package>(centOs) in interactive mode
/bin/bash which runs bash shell once packageName(centOs) is running
TAG − This is used to logically tag images.
Image ID − This is used to uniquely identify the image.
sudo docker rmi ImageId #removing an image
sudo docker images -q #just ids !
sudo docker inspect ImageName # returns bunch of info about the ImageName
sudo docker run -it busybox sh
interactive mode with
docker container prune #this deletes all stopped containers .
the ps cmd is abbr of process status and is available inside a container
-f ,--filter :filter output based on the condition provided
(here is -f status=exited)
--quiet ,-q :just the id's
--all ,-a :running and stopped containers
sudo docker rm $(sudo docker ps -a -q -f status=exited)
##### the dollar sign pass the output of the other cmd to previous
sudo docker run --rm prakhar1989/static-site
$# the --rm deletes the container after it has been exited
sudo docker run -d -P --name static-site prakhar1989/static-site
$#-P (capital p) publish all exposed ports to random ports.
$#-D :run the docker on debug mode
$#-
docker port static-site
output >>>
80/tcp -> 0.0.0.0:32769
443/tcp -> 0.0.0.0:32768
### containers
sudo docker top containerId
$ this shows the running process
sudo docker stop containerId
docker rm containerId
sudo docker stats containerId
sudo docker kill containerId
sudo docker pause conatainerID
sudo docker unpause containerId
### making Dockerfile :
$# specifying the base image
FROM python:3
$# set a directory for the app
WORKDIR /usr/src/app
$# copy all the files to the container
COPY . .
$# install dependencies
RUN pip install --no-cache-dir -r requirements.txt
the next thing wew need to specify is the port number that needs to be exposed.since flaskis runnig on port 5000 thats what we will indicate .
EXPOSE 5000
then we write the command for running the application :
CMD ["python","./app.py"]
# building the image:
docker build -t <yourUserName>/<yourAppName> .
(the period at last is important )
### Docker network <a name='chapter-5'></a>
#### user-defined network:
```
docker network create <networkName>
docker network rm <networkName>
```
__disconnect the containers to the network you want
to remove__
## connect a container to a user-defined network
```
docker create --name my-nginx \
--network my-net \
--publish 8080:80 \
nginx:latest
```
to connect a running container to userdef network:
```
docker network connect <networkName> <containerName>
docker network connect my-net my-container
docker network disconnect myNet myContainer
```
the above command connect/disconnect an already existing container to an already existing network
\
### Using ipv6 <a name='chapter-6'></a>
you have to enable the option on the docker daemon and reload its configuration before assigning any kind of network to it.
## enable forwarding from docCont to the outside world
By default, traffic from containers connected to the default bridge network is not forwarded to the outside world. To enable forwarding, you need to change two settings. These are not Docker commands and they affect the Docker host’s kernel.
1.configure linux kernel to allow IP forwarding
```
sysctl net.ipv4.conf.all.forwarding=1
```
2. change policy for iptables FORWARD form DROP to ACCEPT
```
sudo iptables -P FORWARD ACCEPT
```
#### ATTENTION: these settings do not persist across a reboot so ,you may need to add them to a start-up script .
## overlay networks
The overlay network driver creates a distributed network among multiple Docker daemon hosts
Start the registry automatically
If you want to use the registry as part of your permanent infrastructure, you should set it to restart automatically when Docker restarts or if it exits. This example uses the --restart always flag to set a restart policy for the registry.
$
Tag the image as localhost:5000/my-ubuntu. This creates an additional tag for the existing image. When the first part of the tag is a hostname and port, Docker interprets this as the location of a registry, when pushing.
# DATA manging in docker
1-use Data Volumes
docker volume --help
2-Mount host directory (bind mounts)
-the bind mount or volume writes the data to the host filesystem as tmpfs mount write the data into host memory .
-Volumes are stored in a part of the host filesystem which is managed by Docker (/var/lib/docker/volumes/ on Linux). Non-Docker processes should not modify this part of the filesystem. Volumes are the best way to persist data in Docker.
-Bind mounts may be stored anywhere on the host system. They may even be important system files or directories. Non-Docker processes on the Docker host or a Docker container can modify them at any time.
# Use data Volume :
create a data volume:
docker volume create my-vol
view all data volumes:
docker volume ls
inspect a data volume :
docker volume inspect my-vol
--mount
docker run -d \
--name=nginxtest \
--mount source=nginx-
vol,destination=/usr/share/nginx/html \
nginx:latest
volumes arent controled by docker meaning that if you delete a container the volume is still there. for deletion :
docker volume rm my-vol
unknown or tangling volumes are a mess .get rid of them by:
docker volume prune
$ docker run -d -P \
--name web \
# -v /src/webapp:/opt/webapp \
--mount type=bind, source=/src/webapp,target=/opt/webapp
training/webapp \
python app.py
The above command to load the host /src/webapp directory into a container /opt/webapp directory. --mount parameter throws an error if the local directory does not exist.
--mount also can mount a single data volume.
You can also set readonly volume as --mount source=nginx-vol,destination=/usr/share/nginx/html,readonly.
# Docker network configuration
https://jstobigdata.com/docker-network-configuration/
-p is used to specify hostPort:containerPor .
-P Is used to map any port which is between 49000 to 49900 into the container open network port.
for seeing the port :
sudo docker port containerName
use this format for port specification:
docker run -d -p <hostPort:theContainerPort>
you can use this to run the command:
curl localhost:<theTargetPort>
curl localhost: 5000
random:
docker run -d -p 80.674.839.82:5000:5000
you can specify it to use udp ,but the default is tcp:
docker run -dp localhost:port:port/udp container ....
Docker network configuration – docker allows network services for externally accessing containers and container interconnections. There are also open source network management tools for docker. Make sure you have a good understanding of the ecosystem before reading this article, check out the introduction.
Will be using docker network to establish a connection, I do not recommend using --link (if you are already using it, please stop).
Copy
1
docker network create -d bridge my-bridge-nwk
-d – Parameter is used to specify the docker network types, as explained above, bridge, overlay, macvlan and etc.
Container connection
Run 2 containers and connect them using the new bridge my-bridge-nwk.
Copy
docker run -it --rm --name busybox1 --network my-bridge-nwk busybox sh
1
docker run -it --rm --name busybox1 --network my-bridge-nwk busybox sh
Open another terminal and run the below code,
Copy
docker run -it --rm --name busybox2 --network my-bridge-nwk busybox sh
docker run -it --rm --name busybox2 --network my-bridge-nwk busybox sh
1
docker run -it --rm --name busybox2 --network my-bridge-nwk busybox sh
If both the above code was sucessful, try pinging one container from another, like ping busybox2 from busybox1.
/ # ping busybox2
NOTE: For multi containers that need to connect to each other,Docker-Compose is recommanded.
# Edit network configuration file
Docker 1.2.0 onwards, it is possible to edit the container’s /etc/hosts, /etc/hostnameand and /etc/resolv.conffiles.
### Docker Compose <a name="chapter-9"></a>
helpful url:
https://docs.linuxserver.io/general/docker-compose
#### sample docker-compose.yml file :
```
version: "2.1"
services:
heimdall:
image: linuxserver/heimdall
container_name: heimdall
volumes:
- /home/user/appdata/heimdall:/config
environment:
- PUID=1000
- PGID=1000
- TZ=Europe/London
ports:
- 80:80
- 443:443
restart: unless-stopped
nginx:
image: linuxserver/nginx
container_name: nginx
environment:
- PUID=1000
- PGID=1000
- TZ=Europe/London
volumes:
- /home/user/appdata/nginx:/config
ports:
- 81:80
- 444:443
restart: unless-stopped
mariadb:
image: linuxserver/mariadb
container_name: mariadb
environment:
- PUID=1000
- PGID=1000
- MYSQL_ROOT_PASSWORD=ROOT_ACCESS_PASSWORD
- TZ=Europe/London
volumes:
- /home/user/appdata/mariadb:/config
ports:
- 3306:3306
restart: unless-stopped
```
you can simply run :
```
docker-compose up -d
```
from within the same folder and the heimdall image will be automatically pulled, and a container will be created and started.
## docker-compose example
helpful url:
https://docs.docker.com/compose/gettingstarted/
1-create a directory
2-create an app.py in the dir with this context :
```python
import time
import redis
from flask import Flask
app = Flask(__name__)
cache = redis.Redis(host='redis', port=6379)
def get_hit_count():
retries = 5
while True:
try:
return cache.incr('hits')
except redis.exceptions.ConnectionError as exc:
if retries == 0:
raise exc
retries -= 1
time.sleep(0.5)
@app.route('/')
def hello():
count = get_hit_count()
return 'Hello World! I have been seen {} times.\n'.format(count)
```
3-create a file requirements.txt in your project directory and paste this :
```
flask
redis
```
### Docker data persistence and file management <a name='chapter-10'></a>
## docker volumes
docker volumes are handled by docker and therefore independent of both directory structure and OS of the host machine.when we use volume , a new directory is created within docker's storage dir on the host machine. and docker manages that directory's contents.
##### Use cases
if you want your data to be fully managed by docker and accessed only through docker containers, volumes are the right choice.
if you need full control of the storage and plan on allowing other processes besides Docker to access or modify the storage layer ,bind mounts could be the right choice but you have to consider the security risks explained here.
##### Getting started using volumes
the docker daemon store data within the docker directory
/var/lib/docker/volumes/...
Let’s say you want to create a PostgreSQL container, and you are interested in persisting the data. Start with a folder called postgres in :
```
$HOME/docker/volumes/postgres
docker run --rm --name postgres-db -e POSTGRES_PASSWORD=password --mount type=volume,source=$HOME/docker/volumes/postgres,target=/var/lib/postgresql/data -p 2000:5432 -d postgres
```
Alternately, here is the same command using the shorthand flag -v:
```
docker run --rm --name postgres-db -e POSTGRES_PASSWORD=password --v $HOME/docker/volumes/postgres:/var/lib/postgresql/data -p 2000:5432 -d postgres
```
? | karenpanahi | |
864,778 | A simple CSS Grid System | sc-css-grid-system Simple CSS grid system component built with styled component for react.... | 0 | 2021-10-15T15:11:46 | https://dev.to/madeelahsan/a-simple-css-grid-system-5a5i | css, react, javascript | # sc-css-grid-system
Simple CSS grid system component built with styled component for react.
sc-css-grid-system utilizes the power of CSS grid and styled-components to easily create responsive grids.
## key features
1. responsive breakpoint xs,sm,md,lg,xl
2. responsive gutter/gap option
3. really easy to use
### Responsive Grid Example:
```javascript
import {Grid} from 'sc-css-grid-system';
function CssGridSystem() {
return (
<Grid xs={2} sm={3} md={4} lg={6} xl={12} gap={30}>
<div>1</div>
<div>2</div>
<div>3</div>
<div>4</div>
<div>5</div>
<div>6</div>
<div>7</div>
<div>8</div>
<div>9</div>
<div>10</div>
<div>11</div>
<div>12</div>
</Grid>
);
}
```
render as:

###for complete documentation and demo:
[Github repo](https://github.com/madeelahsan/sc-css-grid-system)
### NPM
[SC-CSS-Grid-System](https://www.npmjs.com/package/sc-css-grid-system)
| madeelahsan |
864,794 | Ultimate Markdown Cheatsheet | Ultimate Markdown Cheat Sheet Table of contents Standard... | 0 | 2021-10-15T14:56:55 | https://dev.to/bgoonz/ultimate-markdown-cheatsheet-1o1e | # Ultimate Markdown Cheat Sheet
## Table of contents
- [Standard features](#standard-features)
* [Headings](#headings)
* [Paragraphs](#paragraphs)
* [Breaks](#breaks)
* [Horizontal Rule](#horizontal-rule)
* [Emphasis](#emphasis)
+ [Bold](#bold)
+ [Italics](#italics)
* [Blockquotes](#blockquotes)
* [Lists](#lists)
+ [Unordered](#unordered)
+ [Ordered](#ordered)
+ [Time-saving Tip](#time-saving-tip)
* [Code](#code)
+ [Inline code](#inline-code)
+ ["Fenced" code block](#fenced-code-block)
+ [Indented code](#indented-code)
+ [Syntax highlighting](#syntax-highlighting)
* [Links](#links)
+ [Autolinks](#autolinks)
+ [Inline links](#inline-links)
+ [Link titles](#link-titles)
+ [Named Anchors](#named-anchors)
* [Images](#images)
* [Raw HTML](#raw-html)
* [Escaping with backslashes](#escaping-with-backslashes)
- [Non-standard features](#non-standard-features)
* [Strikethrough](#strikethrough)
* [Todo List](#todo-list)
* [Tables](#tables)
+ [Aligning cells](#aligning-cells)
* [Footnotes](#footnotes)
+ [Inline footnotes](#inline-footnotes)
* [Additional Information](#additional-information)
+ [What is markdown?](#what-is-markdown)
+ [Other Resources](#other-resources)
+ [Contributing](#contributing)
<br>
<br>
# Standard features
The following markdown features are defined by the [CommonMark][] standard, and are generally supported by all markdown parsers and editors.
## Headings
Headings from `h1` through `h6` are constructed with a `#` for each level:
```
# h1 Heading
## h2 Heading
### h3 Heading
#### h4 Heading
##### h5 Heading
###### h6 Heading
```
Renders to this HTML:
```html
<h1>h1 Heading</h1>
<h2>h2 Heading</h2>
<h3>h3 Heading</h3>
<h4>h4 Heading</h4>
<h5>h5 Heading</h5>
<h6>h6 Heading</h6>
```
Which looks like this in the browser:
# h1 Heading
## h2 Heading
### h3 Heading
#### h4 Heading
##### h5 Heading
###### h6 Heading
**A note about "Setext" Headings**
Note that this document only describes [ATX headings](https://spec.commonmark.org/0.28/#atx-headings), as it is the preferred syntax for writing headings. However, the CommonMark specification also describes [Setext headings](https://spec.commonmark.org/0.28/#setext-headings), a heading format that is denoted by a line of dashes or equal signes following the heading. It's recommended by the author of this guide that you use only ATX headings, as they are easier to write and read in text editors, and are less likeley to conflict with other syntaxes and demarcations from language extensions.
<br>
<br>
## Paragraphs
Body copy written as normal plain-text will be wrapped with `<p></p>` tags in the rendered HTML.
So this:
```
Lorem ipsum dolor sit amet, graecis denique ei vel, at duo primis mandamus. Et legere ocurreret pri, animal tacimates complectitur ad cum. Cu eum inermis inimicus efficiendi. Labore officiis his ex, soluta officiis concludaturque ei qui, vide sensibus vim ad.
```
Renders to this HTML:
```html
<p>Lorem ipsum dolor sit amet, graecis denique ei vel, at duo primis mandamus. Et legere ocurreret pri, animal tacimates complectitur ad cum. Cu eum inermis inimicus efficiendi. Labore officiis his ex, soluta officiis concludaturque ei qui, vide sensibus vim ad.</p>
```
<br>
<br>
## Breaks
You can use multiple consecutive newline characters (`\n`) to create extra spacing between sections in a markdown document. However, if you need to ensure that extra newlines are not collapsed, you can use as many HTML `<br>` elements as you want.
## Horizontal Rule
The HTML `<hr>` element is for creating a "thematic break" between paragraph-level elements. In markdown, you can use of the following for this purpose:
* `___`: three consecutive underscores
* `---`: three consecutive dashes
* `***`: three consecutive asterisks
Renders to:
___
---
***
<br>
<br>
## Emphasis
### Bold
For emphasizing a snippet of text with a heavier font-weight.
The following snippet of text is **rendered as bold text**.
```
**rendered as bold text**
```
renders to:
**rendered as bold text**
and this HTML
```html
<strong>rendered as bold text</strong>
```
### Italics
For emphasizing a snippet of text with italics.
The following snippet of text is _rendered as italicized text_.
```
_rendered as italicized text_
```
renders to:
_rendered as italicized text_
and this HTML:
```html
<em>rendered as italicized text</em>
```
## Blockquotes
Used for defining a section of quoting text from another source, within your document.
To create a blockquote, use `>` before any text you want to quote.
```
> Lorem ipsum dolor sit amet, consectetur adipiscing elit. Integer posuere erat a ante
```
Renders to:
> Lorem ipsum dolor sit amet, consectetur adipiscing elit. Integer posuere erat a ante.
And the generated HTML from a markdown parser might look something like this:
```html
<blockquote>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Integer posuere erat a ante.</p>
</blockquote>
```
Blockquotes can also be nested:
```
> Donec massa lacus, ultricies a ullamcorper in, fermentum sed augue.
Nunc augue augue, aliquam non hendrerit ac, commodo vel nisi.
>> Sed adipiscing elit vitae augue consectetur a gravida nunc vehicula. Donec auctor
odio non est accumsan facilisis. Aliquam id turpis in dolor tincidunt mollis ac eu diam.
>>> Donec massa lacus, ultricies a ullamcorper in, fermentum sed augue.
Nunc augue augue, aliquam non hendrerit ac, commodo vel nisi.
```
Renders to:
> Donec massa lacus, ultricies a ullamcorper in, fermentum sed augue.
Nunc augue augue, aliquam non hendrerit ac, commodo vel nisi.
>> Sed adipiscing elit vitae augue consectetur a gravida nunc vehicula. Donec auctor
odio non est accumsan facilisis. Aliquam id turpis in dolor tincidunt mollis ac eu diam.
>>> Donec massa lacus, ultricies a ullamcorper in, fermentum sed augue.
Nunc augue augue, aliquam non hendrerit ac, commodo vel nisi.
<br>
<br>
## Lists
### Unordered Lists
A list of items in which the order of the items does not explicitly matter.
You may use any of the following symbols to denote bullets for each list item:
```
* valid bullet
- valid bullet
+ valid bullet
```
For example
```
+ Lorem ipsum dolor sit amet
+ Consectetur adipiscing elit
+ Integer molestie lorem at massa
+ Facilisis in pretium nisl aliquet
+ Nulla volutpat aliquam velit
- Phasellus iaculis neque
- Purus sodales ultricies
- Vestibulum laoreet porttitor sem
- Ac tristique libero volutpat at
+ Faucibus porta lacus fringilla vel
+ Aenean sit amet erat nunc
+ Eget porttitor lorem
```
Renders to:
+ Lorem ipsum dolor sit amet
+ Consectetur adipiscing elit
+ Integer molestie lorem at massa
+ Facilisis in pretium nisl aliquet
+ Nulla volutpat aliquam velit
- Phasellus iaculis neque
- Purus sodales ultricies
- Vestibulum laoreet porttitor sem
- Ac tristique libero volutpat at
+ Faucibus porta lacus fringilla vel
+ Aenean sit amet erat nunc
+ Eget porttitor lorem
And this HTML
```html
<ul>
<li>Lorem ipsum dolor sit amet</li>
<li>Consectetur adipiscing elit</li>
<li>Integer molestie lorem at massa</li>
<li>Facilisis in pretium nisl aliquet</li>
<li>Nulla volutpat aliquam velit
<ul>
<li>Phasellus iaculis neque</li>
<li>Purus sodales ultricies</li>
<li>Vestibulum laoreet porttitor sem</li>
<li>Ac tristique libero volutpat at</li>
</ul>
</li>
<li>Faucibus porta lacus fringilla vel</li>
<li>Aenean sit amet erat nunc</li>
<li>Eget porttitor lorem</li>
</ul>
```
### Ordered Lists
A list of items in which the order of items does explicitly matter.
```
1. Lorem ipsum dolor sit amet
2. Consectetur adipiscing elit
3. Integer molestie lorem at massa
4. Facilisis in pretium nisl aliquet
5. Nulla volutpat aliquam velit
6. Faucibus porta lacus fringilla vel
7. Aenean sit amet erat nunc
8. Eget porttitor lorem
```
Renders to:
1. Lorem ipsum dolor sit amet
2. Consectetur adipiscing elit
3. Integer molestie lorem at massa
4. Facilisis in pretium nisl aliquet
5. Nulla volutpat aliquam velit
6. Faucibus porta lacus fringilla vel
7. Aenean sit amet erat nunc
8. Eget porttitor lorem
And this HTML:
```html
<ol>
<li>Lorem ipsum dolor sit amet</li>
<li>Consectetur adipiscing elit</li>
<li>Integer molestie lorem at massa</li>
<li>Facilisis in pretium nisl aliquet</li>
<li>Nulla volutpat aliquam velit</li>
<li>Faucibus porta lacus fringilla vel</li>
<li>Aenean sit amet erat nunc</li>
<li>Eget porttitor lorem</li>
</ol>
```
### Time-saving Tip!
Sometimes lists change, and when they do it's a pain to re-order all of the numbers. Markdown solves this problem by allowing you to simply use `1.` before each item in the list.
For example:
```
1. Lorem ipsum dolor sit amet
1. Consectetur adipiscing elit
1. Integer molestie lorem at massa
1. Facilisis in pretium nisl aliquet
1. Nulla volutpat aliquam velit
1. Faucibus porta lacus fringilla vel
1. Aenean sit amet erat nunc
1. Eget porttitor lorem
```
Automatically re-numbers the items and renders to:
1. Lorem ipsum dolor sit amet
2. Consectetur adipiscing elit
3. Integer molestie lorem at massa
4. Facilisis in pretium nisl aliquet
5. Nulla volutpat aliquam velit
6. Faucibus porta lacus fringilla vel
7. Aenean sit amet erat nunc
8. Eget porttitor lorem
<br>
<br>
## Code
### Inline code
Wrap inline snippets of code with a single backtick: <code>`</code>.
For example, to show `<div></div>` inline with other text, just wrap it in backticks.
```html
For example, to show `<div></div>` inline with other text, just wrap it in backticks.
```
### "Fenced" code block
Three consecutive backticks, referred to as "code fences", are used to denote multiple lines of code: <code>```</code>.
For example, this:
<pre>
```html
Example text here...
```
</pre>
Renders to something like this in HTML:
```html
<pre>
<p>Example text here...</p>
</pre>
```
And appears like this when viewed in a browser:
```
Example text here...
```
### Indented code
You may also indent several lines of code by at least four spaces, but this is not recommended as it is harder to read, harder to maintain, and doesn't support syntax highlighting.
Example:
```
// Some comments
line 1 of code
line 2 of code
line 3 of code
```
// Some comments
line 1 of code
line 2 of code
line 3 of code
### Syntax highlighting
Various markdown parsers, such as [remarkable](https://github.com/jonschlinkert/remarkable), support syntax highlighting with fenced code blocks. To activate the correct styling for the language inside the code block, simply add the file extension of the language you want to use directly after the first code "fence": <code>```js</code>, and syntax highlighting will automatically be applied in the rendered HTML (if supported by the parser). For example, to apply syntax highlighting to JavaScript code:
<pre>
```js
grunt.initConfig({
assemble: {
options: {
assets: 'docs/assets',
data: 'src/data/*.{json,yml}',
helpers: 'src/custom-helpers.js',
partials: ['src/partials/**/*.{hbs,md}']
},
pages: {
options: {
layout: 'default.hbs'
},
files: {
'./': ['src/templates/pages/index.hbs']
}
}
}
});
```
</pre>
Which renders to:
```js
grunt.initConfig({
assemble: {
options: {
assets: 'docs/assets',
data: 'src/data/*.{json,yml}',
helpers: 'src/custom-helpers.js',
partials: ['src/partials/**/*.{hbs,md}']
},
pages: {
options: {
layout: 'default.hbs'
},
files: {
'./': ['src/templates/pages/index.hbs']
}
}
}
});
```
And this complicated HTML is an example of what might be generated by the markdown parser, when syntax highlighting is applied by a library like [highlight.js](https://highlightjs.org/):
```xml
<div class="highlight"><pre><span class="nx">grunt</span><span class="p">.</span><span class="nx">initConfig</span><span class="p">({</span>
<span class="nx">assemble</span><span class="o">:</span> <span class="p">{</span>
<span class="nx">options</span><span class="o">:</span> <span class="p">{</span>
<span class="nx">assets</span><span class="o">:</span> <span class="s1">'docs/assets'</span><span class="p">,</span>
<span class="nx">data</span><span class="o">:</span> <span class="s1">'src/data/*.{json,yml}'</span><span class="p">,</span>
<span class="nx">helpers</span><span class="o">:</span> <span class="s1">'src/custom-helpers.js'</span><span class="p">,</span>
<span class="nx">partials</span><span class="o">:</span> <span class="p">[</span><span class="s1">'src/partials/**/*.{hbs,md}'</span><span class="p">]</span>
<span class="p">},</span>
<span class="nx">pages</span><span class="o">:</span> <span class="p">{</span>
<span class="nx">options</span><span class="o">:</span> <span class="p">{</span>
<span class="nx">layout</span><span class="o">:</span> <span class="s1">'default.hbs'</span>
<span class="p">},</span>
<span class="nx">files</span><span class="o">:</span> <span class="p">{</span>
<span class="s1">'./'</span><span class="o">:</span> <span class="p">[</span><span class="s1">'src/templates/pages/index.hbs'</span><span class="p">]</span>
<span class="p">}</span>
<span class="p">}</span>
<span class="p">}</span>
<span class="p">});</span>
</pre></div>
```
<br>
<br>
## Links
### Autolinks
Autolinks are absolute URIs and email addresses inside `<` and `>`. They are parsed as links, where the URI or email address itself is used as the link's label.
```
<http://foo.bar.baz>
```
Renders to:
<http://foo.bar.baz>
URIs or email addresses that are not wrapped in angle brackets are not recognized as valid autolinks by markdown parsers.
### Inline links
```
[Assemble](http://assemble.io)
```
Renders to (hover over the link, there is no tooltip):
[Assemble](http://assemble.io)
HTML:
```html
<a href="http://assemble.io">Assemble</a>
```
### Link titles
```
[Assemble](https://github.com/assemble/ "Visit Assemble!")
```
Renders to (hover over the link, there should be a tooltip):
[Assemble](https://github.com/assemble/ "Visit Assemble!")
HTML:
```html
<a href="https://github.com/assemble/" title="Visit Assemble!">Assemble</a>
```
### Named Anchors
Named anchors enable you to jump to the specified anchor point on the same page.
For example, the following "chapter" links:
```
# Table of Contents
* [Chapter 1](#chapter-1)
* [Chapter 2](#chapter-2)
* [Chapter 3](#chapter-3)
```
...will jump to these sections:
```
## Chapter 1 <a name="chapter-1"></a>
Content for chapter one.
## Chapter 2 <a name="chapter-2"></a>
Content for chapter one.
## Chapter 3 <a name="chapter-3"></a>
Content for chapter one.
```
**Anchor placement**
Note that placement of achors is arbitrary, you can put them anywhere you want, not just in headings. This makes adding cross-references easy when writing markdown.
<br>
<br>
## Images
Images have a similar syntax to links but include a preceding exclamation point.
```

```

or
```

```

Like links, Images also have a footnote style syntax
```
![Alt text][id]
```
![Alt text][id]
With a reference later in the document defining the URL location:
[id]: http://octodex.github.com/images/dojocat.jpg "The Dojocat"
```
[id]: http://octodex.github.com/images/dojocat.jpg "The Dojocat"
```
## Raw HTML
Any text between `<` and `>` that looks like an HTML tag will be parsed as a raw HTML tag and rendered to HTML without escaping.
_(Note that markdown parsers do not attempt to validate your HTML)._
Example:
```
**Visit <a href="https://github.com">Jon Schlinkert's GitHub Profile</a>.**
```
Renders to:
**Visit <a href="https://github.com">Jon Schlinkert's GitHub Profile</a>.**
## Escaping with backslashes
Any ASCII punctuation character may be escaped using a single backslash.
Example:
```
\*this is not italic*
```
Renders to:
\*this is not italic*
# Non-standard features
The following markdown features are not defined by the [CommonMark][] specification, but they are commonly supported by markdown parsers and editors, as well as sites like GitHub and GitLab.
## Strikethrough
In GitHub Flavored Markdown (GFM) you can do strickthroughs.
```
~~Strike through this text.~~
```
Which renders to:
~~Strike through this text.~~
<br>
<br>
### Todo List
```
- [ ] Lorem ipsum dolor sit amet
- [ ] Consectetur adipiscing elit
- [ ] Integer molestie lorem at massa
```
Renders to:
- [ ] Lorem ipsum dolor sit amet
- [ ] Consectetur adipiscing elit
- [ ] Integer molestie lorem at massa
**Links in todo lists**
```
- [ ] [foo](#bar)
- [ ] [baz](#qux)
- [ ] [fez](#faz)
```
Renders to:
- [ ] [foo](#bar)
- [ ] [baz](#qux)
- [ ] [fez](#faz)
<br>
<br>
## Tables
Tables are created by adding pipes as dividers between each cell, and by adding a line of dashes (also separated by bars) beneath the header _(this line of dashes is required)_.
- pipes do not need to be vertically aligned.
- pipes on the left and right sides of the table are sometimes optional
- three or more dashes must be used for each cell in the _separator_ row (between the table header and body)
- the left and right pipes are optional with some markdown parsers
Example:
```
| Option | Description |
| --- | --- |
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
```
Renders to:
| Option | Description |
| --- | --- |
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
And this HTML:
```html
<table>
<tr>
<th>Option</th>
<th>Description</th>
</tr>
<tr>
<td>data</td>
<td>path to data files to supply the data that will be passed into templates.</td>
</tr>
<tr>
<td>engine</td>
<td>engine to be used for processing templates. Handlebars is the default.</td>
</tr>
<tr>
<td>ext</td>
<td>extension to be used for dest files.</td>
</tr>
</table>
```
### Aligning cells
**Center text in a column**
To center the text in a column, add a colon to the middle of the dashes in the row beneath the header.
```
| Option | Description |
| -:- | -:- |
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
```
| Option | Description |
| -:- | -:- |
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
**Right-align the text in a column**
To right-align the text in a column, add a colon to the middle of the dashes in the row beneath the header.
```
| Option | Description |
| --: | --:|
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
```
Renders to:
| Option | Description |
| --: | --:|
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
<br>
<br>
## Footnotes
> Markdown footnotes are not officially suppored by the [CommonMark][] specification. However, the feature is supported by [remarkable][] and other markdown parsers, and it's very useful when available.
Markdown footnotes are denoted by an opening square bracket, followed by a caret, followed by a number and a closing square bracket: `[^1]`.
```
This is some text[^1] with a footnote reference link.
```
The accompanying text for the footnote can be added elsewhere in the document using the following syntax:
```
[^1]: "This is a footnote"
```
When rendered to HTML, footnotes are "stacked" by the markdown parser at the bottom of the file, in the order in which the footnotes were defined.
### Inline footnotes
Some markdown parsers like [Remarkable][remarkable] also support inline footnotes. Inline footnotes are written using the following syntax: `[^2 "This is an inline footnote"]`.
<br>
<br>
## Additional Information
### What is markdown?
> Markdown is "a plain text format for writing structured documents, based on formatting conventions from email and usenet" -- [CommonMark][]
Sites like GitHub and Stackoverflow have popularized the use markdown as a plain-text alternative to traditional text editors, for writing things like documentation and comments.
### Other Resources
- [We've been trained to make paper](https://ben.balter.com/2012/10/19/we-ve-been-trained-to-make-paper/) - A great blog post about why markdown frees us from the shackles of proprietary formats imposed by bloated word processors, such as Microsoft Word.
- [CommonMark](https://commonmark.org/) - "A strongly defined, highly compatible specification of Markdown" | bgoonz | |
865,148 | What Does It Mean For GraphQL To Be A Runtime, Anyway? | Note: This article assumes a basic familiarity with GraphQL as a query language. GraphQL.org defines... | 0 | 2021-10-15T19:40:14 | https://stepzen.com/blog/what-does-it-mean-for-graphql-to-be-a-runtime | graphql, architecture, discuss, runtime | _Note: This article assumes a basic familiarity with [GraphQL as a query language](https://graphql.org/)._
[GraphQL.org](https://graphql.org/) defines GraphQL as
> ... a query language for APIs and a runtime for fulfilling those queries with your existing data.
Most resources focus on how to use GraphQL as a query language. But what does it mean for GraphQL to be a runtime?
Let's start with the fundamentals and review the definition of a runtime.
## What Is a Runtime?
It's important to note that there are [two meanings of 'runtime'](https://davidxiang.com/2021/02/26/what-is-a-runtime-environment/) broadly present in the tech vernacular.
The first is: the time during which your program executes. That's not what we're talking about in this blog post.
The second meaning, which we are going to focus on, refers to the _environment_ in which your program executes. It's good to note that the runtime is determined by [the GraphQL spec](https://spec.graphql.org/June2018/), which sets a global standard for GraphQL implementation between developers.
When you create a GraphQL query, you expect a response. You get a response because of the way the GraphQL runtime executes your request. The runtime's higher level of abstraction is what allows us to use GraphQL at all.
If this all feels a bit abstract, consider [JavaScript's runtime environments](https://www.codecademy.com/articles/introduction-to-javascript-runtime-environments). The browser's runtime environment allows you to write frontend applications in JavaScript. You can call methods on the window object, like `window.alert()`. On the otherhand, node's runtime environment allows you to execute backend applications in JavaScript and access objects like `process.env`. Similarly, when you write a GraphQL query, GraphQL's runtime is at work.
We'll get into the nitty gritty of GraphQL's runtime in particular next.
## How GraphQL Is a Runtime
The GraphQL spec, as a set of rules that delineates GraphQL conventions, has a lot of details, so I've condensed the logic a bit in my summary.
First, a request for execution includes some information. It _must_ include a document with an _OperationDefinition_ and optionally a _FragmentDefinition_, and there may be multiple instances of those. Beyond that, it may include the name of the operation in the document to execute and the variable values in the operation. The request also must know what the root type (`query myQuery`, e.g.) is.
We zoom out even further for the next step, in which GraphQL will validate the request, and coerce any variables (if present).
Now the GraphQL runtime identifies whether the operation is a query, mutation, or subscription.
Subscriptions trigger event streams and return response streams, while mutations and queries return ordered maps containing data and errors.
The selection sets of fields inside operations undergo a process through which they are [executed either normally or serially](https://spec.graphql.org/June2018/#sec-Executing-Selection-Sets). The runtime determines the field collection, and then the [field execution](https://spec.graphql.org/June2018/#sec-Executing-Fields), which is complete when each field has been coerced, and its values resolved and completed.
These values, along with any errors that may be thrown, form the response.
## How StepZen Works with GraphQL as a Runtime
StepZen's engineers work with GraphQL as a runtime to create new features in GraphQL as a query language.
Take, for example, StepZen's custom `@materializer` directive. `@materializer` combines data from two types into one, allowing you to [martial data from multiple different backends](/docs/features/linking-types), _and_ multiple different _types_ of backends. StepZen has a selection walker implementation that allows `@materializer` to resolve the correct fields for the query.
To accomplish the same thing without StepZen, you'd would have to spend time writing custom resolvers to call the backend service correctly.
By adding a custom directive like `@materializer`, you can give your frontend developers the ability to retrieve data from, say, your PostGreSQL database and your CMS's REST API in a single query. Adding a GraphQL layer can be a complex undertaking, but StepZen simplifies it by polishing the runtime with things like custom directives and [scalar types](/docs/design-a-graphql-schema/custom-scalars).
Since StepZen considers GraphQL both as a query language and as a runtime, we are able to leverage GraphQL queries powerfully, which saves you valuable time when it comes to using GraphQL as a query language.
| cerchie |
865,364 | Emailing a user when they are assigned a case using Power Automate | Requirement - When a user is assigned a case, alert them on their personal email. This can be... | 0 | 2021-10-16T01:29:52 | https://waiholiu.blogspot.com/2021/10/alerting-user-when-they-are-assigned.html | dynamics365, powerautomate, powerplatform | ---
title: Emailing a user when they are assigned a case using Power Automate
published: true
date: 2021-10-11 11:50:00 UTC
tags: Dynamics365,PowerAutomate,PowerPlatform
canonical_url: https://waiholiu.blogspot.com/2021/10/alerting-user-when-they-are-assigned.html
---
Requirement - When a user is assigned a case, alert them on their personal email.
This can be accomplished using a Power Automate flow
#### Prerequisite
- This is done within a Power Apps environment with Dynamics 365 Customer Service (but arguably this will work for any table and not just the Case table)
- Create a cloud flow with a service account that has access to the DataVerse and ability to send email
#### Step 1 - Trigger when assigned user changes
| [](https://lh3.googleusercontent.com/-zhMjhYbxr8Y/YWQjaZrp6KI/AAAAAAACb0w/-pV-EWeOi1k_0_1Vwv1JpOPhU2bLjYbdQCLcBGAsYHQ/image.png) |
| This trigger will only be triggered when ownerid field changes
|
#### Step 2 - Identify the Assigner and Assigned user
[](https://lh3.googleusercontent.com/-Cxp0mNaMvYw/YWQj7IRS3AI/AAAAAAACb04/TSuKxy5Rh70K337WCgVRcMd8v218JEmGACLcBGAsYHQ/image.png)
#### Step 3 - Check if the Assigned user actually has a personal email
[](https://lh3.googleusercontent.com/-TGwuAGr5Mjs/YWQkMVyZodI/AAAAAAACb1A/Xvre_iylxDAeavdwBJGTi2YoeJj2_U6CgCLcBGAsYHQ/image.png)
#### Step 4 - If so, then send them an email
[](https://lh3.googleusercontent.com/-kAroUPEE9u4/YWQkamY_VtI/AAAAAAACb1E/gvfgu9sDkTcDNhDVInhezjJRfVdQ5ex2ACLcBGAsYHQ/image.png)
All of the fields populated in the email you'll be able to find from the steps above. The one thing is Domain Name - this is an environment variable I've created so that this solution will work as I migrate it through the various environments up to production. | diskdrive |
865,368 | Open Source: Rewriting git history(amend/rebase) | It's Friday which means... it's Blog Time! So many due dates!🙉 This week, I would like to introduce... | 0 | 2021-10-16T02:48:34 | https://dev.to/okimotomizuho/open-source-rewriting-git-historyamendrebase-ada | opensource, javascript, github, git | It's Friday which means... it's Blog Time! So many due dates!:hear_no_evil:
This week, I would like to introduce how to refactor my Static Site Generator(SSG) project, and also what I did for practice by using git amend and rebase.
## Refactoring my SSG
Refactoring means not changing code, but making existing code easier to read, maintain, and more modular.
In fact, my SSG project had a lot of duplication, and there were a number of conditional templates, which was very inconvenient when adding new features and maintenance.
Link: [my SSG project repo](https://github.com/MizuhoOkimoto/pajama-ssg)
### What I did
1. Added a yargsConfig.js file to keep yargs separates from the main js file.
2. Added a tempGenerator.js file and created a function to avoid redundancy in the main js file.
3. Replaced the code to call the function created in step2 in the pajama-ssg.js (main) file.
### My redundancy code
```
var language = argv.l?argv.l:"en-CA";
if (argv.s == undefined) {
var template = `
<!doctype html>
<html lang="${language}">
<head>
<meta charset="utf-8">
<link rel="stylesheet" type="text/css" href="please_add_your_css_path" />
<title>${title}</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
${titleName}
${text}
</body>
</html>`;
} else {
var template = `
<!doctype html>
<html lang="${language}">
<head>
<meta charset="utf-8">
<link rel="stylesheet" type="text/css" href="${argv.s}" />
<title>${title}</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
${titleName}
${text}
</body>
</html>`;
}
```
I had this code for each condition (This is when a user enter '-l' as an argument, so I had 3 more...)
### My new function
```
module.exports = tempGenerate = (argv_s, argv_l, title, titleName="", text) => {
let style = argv_s ? `<link rel="stylesheet" type="text/css" href="${argv_s}" />` : `<link rel="stylesheet" type="text/css" href="please_add_your_css_path" />`;
let lang = argv_l ? `<html lang="${argv_l}">`: `<html lang="en-CA">`;
let titleLine = title ? `<title>${title}</title>` : "";
var template = `
<!doctype html>
${lang}
<head>
<meta charset="utf-8">
${style}
${titleLine}
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
${titleName}
${text}
</body>
</html>`;
return template;
}
```
With this one function, I was able to remove the duplicate template in the main ssg and replace it with a single line of code to call the function.
## Creating a branch for refactoring and committing
### Before working on refactoring
Before I started, I made sure if I had everything from GitHub and it was up-to-date.
`$git checkout main`
`$git pull origin main`
I created a branch for refactoring.
`$ git checkout -b refactoring`
### Testing and Committing
When I successfully added files and the function, I made a commit every time.
Added files:
`$ git add <fileName>`
Made 4 commits:
`$ git commit -m "Add yargsConfig file"`
### After committing, before pushing
Time to rebase!
`$ git rebase -i`
I used squash and melded into previous commit. Below is what I did and the display on the terminal:
I changed from 'pick' to 's' and 'squash' to squashing!
```
pick 563d8dd Add yargsConfig file
s 0922645 Add a function and make tempGenerator
squash 48b0fd0 replace code to call function
# Rebase 04a71d5..48b0fd0 onto 04a71d5 (3 commands)
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
# x, exec <command> = run command (the rest of the line) using shell
# b, break = stop here (continue rebase later with 'git rebase --continue')
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
# t, reset <label> = reset HEAD to a label
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# . create a merge commit using the original merge commit's
# . message (or the oneline, if no original merge commit was
# . specified). Use -c <commit> to reword the commit message.
# These lines can be re-ordered; they are executed from top to bottom.
# If you remove a line here THAT COMMIT WILL BE LOST.
```
When I saved, I used Ctrl+o and exit with Ctrl+x.
It successfully rebased and git created a new commit!
```sh
pick 9a1ea54 Add yargsConfig file
Rebase 04a71d5..9a1ea54 onto 04a71d5 (1 command)
```
### Practicing amend
I could change my commit message by using `$ git commit --amend`.
Also, I learned `$git --amend --no-edit` command from my professor. This is where I want to update the previous commit to add/change something, but don't want to change the commit message (--no-edit means leave the commit message as it is).
### Ready to merge!
I went back to my main branch, and I merged and pushed this refactoring!
## Conclusion
I focused on getting rid of the 4 templates in my main js file to improve my project. I had many conditions based on the user input (if a user use -i or -s or -l or none). However, implementing a function made it easier to read since I added a condition in the separate file.
Rebasing and amending are very powerful and useful, and every time I learn about Git, I find it's very interesting. One of my goals through this course is becoming a Git master, so I hope I'm getting close to it!:mage::star2:
(Photo by Hello I'm Nik on Unsplash)
| okimotomizuho |
865,469 | Integrating Cryptocurrency as a Payment Option with API | Continuous evolvement of cryptocurrency as a means of payment drives the need for multicurrency... | 14,820 | 2021-10-16T17:13:00 | https://dev.to/omolade11/integrating-cryptocurrency-as-a-payment-option-with-api-31f8 | cryptocurrency, javascript, api, payment | Continuous evolvement of cryptocurrency as a means of payment drives the need for multicurrency payment options on payment gateways. In this article, @tkings and I will be sharing a great solution that works for implementing cryptocurrency payment with API.
An example of how you can implement cryptocurrency in your project using CoinForBarter is below:
Sending an API post request to https://api.coinforbarter.com/v1/payments with the required payload will generate a payment object that you can work with.
Example in javascript using axios is shown below
```
/**
*
* @returns a CoinForBarter payment object
*/
const createPaymentObject = async () => {
try {
const url = "https://api.coinforbarter.com/v1/payments";
const requestPayload = {
txRef: "RX1",
amount: 10,
currency: "BTC",
currencies: [],
meta: {
consumer_id: 23,
},
customer: "example@gmail.com",
customerPhoneNumber: "+234xxxxxx",
customerFullName: "John Doe",
};
const secretKey = "xxxxxxxxxxxxxxxxxxx";
const headers = {
Authorization: `Bearer ${secretKey}`,
};
const { data } = await axios.post(url, requestPayload, { headers });
return data;
} catch (error) {
// console.log(error)
}
};
```
You will receive a response like below
```
{
"status": "success",
"data": {
"payment": {
"id": "613a1067500d0f0020adf882",
"_id": "613a1067500d0f0020adf882",
"status": "in progress",
"description": "Payment from Dayne_OKon@gmail.com",
"txRef": "hrgyuur743784",
"redirectUrl": "",
"amount": 0,
"nairaValue": 0,
"dollarValue": 0,
"baseAmount": 0.01,
"baseCurrency": "BTC",
"currencies": [
"BTC",
"DOGE",
"ETH",
"USDT",
"USDC",
"BUSD",
"DAI",
"PAX",
"BCH",
"WBTC"
],
"expiresBy": 0,
"transactionFees": 0,
"totalDue": 0,
"customer": "Dayne_OKon@gmail.com",
"customerDetails": {
"email": "Dayne_OKon@gmail.com",
"fullName": ""
},
"addressSentFrom": [],
"transactionTimeLog": [
{
"time": "2021–09–09T13: 47: 19.098Z",
"type": "event",
"event": "Started transaction"
}
],
"isCurrencyLocked": false,
"createdAt": "2021–09–09T13: 47: 19.100Z"
},
"url": "https: //coinforbarter-checkout.herokuapp.com/v1/api-pay/6109aa97-ad5bab00–1b913f89–613a1067–500d0f00–20adf882"
},
"message": "payment created"
}
```
There are two modes in which this payment object can be used to process a full payment,
• CoinForBarter hosted.
• Self hosted.
###CoinForBarter Hosted
You can simply redirect your customer to the `data.url` field to complete the payment. This is referred to as the CoinForBarter Standard. You can read more from the [CoinForBarter Standard Documentation](https://developers.coinforbarter.com/docs/integration-options-coinforbarter-standard/).
It will open a payment gateway like below for the customer to complete the payment.
You can provide a redirectUrl to the request payload to redirect the customer to that url when the payment ends.
You can also provide a [webhook as seen here](https://developers.coinforbarter.com/docs/overview-webhook/).
###Self Hosted
For the self hosted, you can have your own interface shown to the customer all through the payment process.
The payment process has the following cycle.
- Select currency and network
- Lock currency
- Get address and amount the customer is to pay with from selected currency.
An example is shown below using Javascript axios
```
/**
*
* @param {string} paymentId the payment id gotten from data.id
* @param {string} currency the selected currency to process the payment in eg BTC
* @param {string} network the selected blockchain network of the currency eg. BEP20
* @returns an updated payment object containing extra information based on selected currency and network
*/
const setCurrency = async (paymentId, currency, network) => {
try {
const url = `https://api.coinforbarter.com/v1/payments/${paymentId}/currency/set/${currency}/${network}`;
const secretKey = "xxxxxxxxxxxxxxxxxxx";
const headers = {
Authorization: `Bearer ${secretKey}`,
};
const { data } = await axios.patch(url, {}, { headers });
return data;
} catch (error) {
// console.log(error)
}
};
```
A list of [supported currencies and their networks to choose from can be found here](https://developers.coinforbarter.com/docs/overview-introduction/).
After selecting a currency, the returned payload will look like below
```
{
"status": "success",
"data": {
"id": "60d461fe6410f43ce05be378",
"status": "in progress",
"description": "Payment from Jody_Wolff21@hotmail.com",
"txRef": "hrgyuur743784",
"fee": 0.00030047,
"currency": "BTC",
"currencyNetwork": "bitcoin",
"amount": 0.01030047,
"baseAmount": 0.01,
"baseCurrency": "BTC",
"currencies": [],
"transactionFees": 0,
"totalDue": 0,
"customer": "Jody_Wolff21@hotmail.com",
"customerDetails": {
"email": "Jody_Wolff21@hotmail.com"
},
"addressInformation": {
"address": "19xqUGJ5Keo1LjDfatShxfHcKQT6HV24x3",
"network": "bitcoin",
"id": "60c7ca61ef2a380a447ed864"
},
"addressSentFrom": [],
"transactionTimeLog": [
{
"time": "2021–06–24T10:44:14.787Z",
"type": "event",
"event": "Started transaction"
},
{
"time": "2021–06–24T10:44:54.905Z",
"type": "event",
"event": "set currency to BTC, bitcoin"
},
{
"time": "2021–06–24T10:45:40.482Z",
"type": "event",
"event": "locked currency"
}
],
"isCurrencyLocked": true,
"createdAt": "2021–06–24T10:44:14.788Z"
},
"message": "currency locked"
}
```
The object above contains `data.currency` and `data.currencyNetwork`. This confirms that a currency has been selected.
`data.amount` is the amount to be paid now in the selected currency.
The next step will be to confirm that the transaction is to be made in our selected currency.
An example is below
```
/**
*
* @param {string} paymentId paymentId the payment id gotten from data.id
* @returns an updated payment object containing extra information based on the locked currency and network
*/
const lockCurrency = async (paymentId) => {
try {
const url = `https://api.coinforbarter.com/v1/payments/${paymentId}/currency/lock`;
const secretKey = "xxxxxxxxxxxxxxxxxxx";
const headers = {
Authorization: `Bearer ${secretKey}`,
};
const { data } = await axios.patch(url, {}, { headers });
return data;
} catch (error) {
// console.log(error)
}
};
```
The data returned above is similar to this
```
{
"status": "success",
"data": {
"id": "60d461fe6410f43ce05be378",
"status": "in progress",
"description": "Payment from Jody_Wolff21@hotmail.com",
"txRef": "hrgyuur743784",
"fee": 0.00030047,
"currency": "BTC",
"currencyNetwork": "bitcoin",
"amount": 0.01030047,
"baseAmount": 0.01,
"baseCurrency": "BTC",
"currencies": [],
"transactionFees": 0,
"totalDue": 0,
"customer": "Jody_Wolff21@hotmail.com",
"customerDetails": {
"email": "Jody_Wolff21@hotmail.com"
},
"addressInformation": {
"address": "19xqUGJ5Keo1LjDfatShxfHcKQT6HV24x3",
"network": "bitcoin",
"id": "60c7ca61ef2a380a447ed864"
},
"addressSentFrom": [],
"transactionTimeLog": [
{
"time": "2021–06–24T10: 44: 14.787Z",
"type": "event",
"event": "Started transaction"
},
{
"time": "2021–06–24T10: 44: 54.905Z",
"type": "event",
"event": "set currency to BTC, bitcoin"
},
{
"time": "2021–06–24T10: 45: 40.482Z",
"type": "event",
"event": "locked currency"
}
],
"isCurrencyLocked": false,
"createdAt": "2021–06–24T10: 44: 14.788Z"
},
"message": "currency locked"
}
```
The object above contains `data.isCurrencyLocked` This confirms that the transaction has been locked for the selected currency.
`data.addressInformation` shows the address and network the amount is to be sent to.
The final step is to get notified and verify when a payment has been received.
You can use the CoinForBarter Webhooks to get notified.
Then verify the transaction by checking the `data.amountReceived` to be equal to `data.amount` with the following endpoint.
```
/**
*
* @param {string} paymentId paymentId paymentId the payment id gotten from data.id
* @returns the present state of the payment object
*/
const verifyPayment = async (paymentId) => {
try {
const url = `https://api.coinforbarter.com/v1/payments/${paymentId}`;
const secretKey = "xxxxxxxxxxxxxxxxxxx";
const headers = {
Authorization: `Bearer ${secretKey}`,
};
const { data } = await axios.patch(url, {}, { headers });
return data;
} catch (error) {
// console.log(error)
}
};
```
You can get your secret key on your [CoinForBarter's](https://coinforbarter.com/) dashboard.
You can also use the `data.status` to be `success` if payment was successful, `error` if payment failed, `inProgress` if payment is in progress or `cancelled` if payment was cancelled.
In this article, we learnt how to integrate cryptocurrency as a payment option with APIs. @tkings and I wrote it. We previously wrote about how to implement cryptocurrency as a means of payment using [html](https://dev.to/omolade11/integrating-cryptocurrency-as-a-payment-option-html-352i) and [javascript](https://dev.to/omolade11/integrating-cryptocurrency-as-a-payment-option-javascript-1jad). In the future, we will be writing on implementing it using React and React Native. We will appreciate your comments, and if you have any questions, do not hesitate to hit either [Kingsley](https://twitter.com/tkings_) or [me](https://twitter.com/OmoladeEkpeni) up on Twitter. | omolade11 |
865,500 | $IOTX one off the kind | Introduction to $IOTX The IoTeX Network is fueled by the native IOTX token. In addition to... | 0 | 2021-10-16T05:58:20 | https://dev.to/fariztiger/iotx-one-off-the-kind-484m |
**Introduction to $IOTX**
The IoTeX Network is fueled by the native IOTX token. In addition to representing fractional ownership of the IoTeX Network, IOTX has multiple uses (or “utility”) to enable trusted and transparent interactions between various stakeholders, including users, Delegates, developers, and service providers. The IOTX token is the lifeblood of the IoTeX protocol and instills economic and reputational incentives to ensure the IoTeX Network is governed/maintained in a decentralized fashion.
IoTeX stakeholders can spend, stake, and/or burn IOTX in order to access network resources. As the utility of IOTX grows, the demand and value of IOTX will also grow, providing continued incentives for network participants to maintain and grow the network. As such, IOTX tokenomics are designed to balance incentives across multiple types of stakeholders:
Users pay for DApps/services and stake/vote for Delegates with IOTXDevelopers power their devices/DApps and incentives via IOTXDelegates stake IOTX in order to be eligible to produce blocksService Providers offer services to devices/DApps, paid in IOTX | fariztiger | |
865,609 | Push Docker image to Azure Container Registry | If you are already familiar with Docker and Docker Hub then in this post I’d like to introduce the... | 0 | 2021-10-16T07:36:02 | https://dev.to/theromie/push-docker-image-to-azure-container-registry-3d7c | azure, docker, node, vue | If you are already familiar with Docker and Docker Hub then in this post I’d like to introduce the Azure Container Registry which is an alternative to the well-known Docker Hub.
**Things required before starting:**
1. Docker Desktop
2. Azure CLI
3. Azure Account
In order to start with Azure Container Registry, you need an Azure account which you can create easily with FREE Credits and also ACR is a very cheap service. Once you logged into Azure, Navigate to Azure Container Registry by clicking on **New --> Search --> type Azure Container Registry**. After that create a new ACR by filling in all details you want to add but make sure you enable admin access. After Two or three minutes your ACR will be created.
Once you created a resource navigate Access Keys to get the Login server, Username, and password which is required for the command line push your local Docker image to ACR.
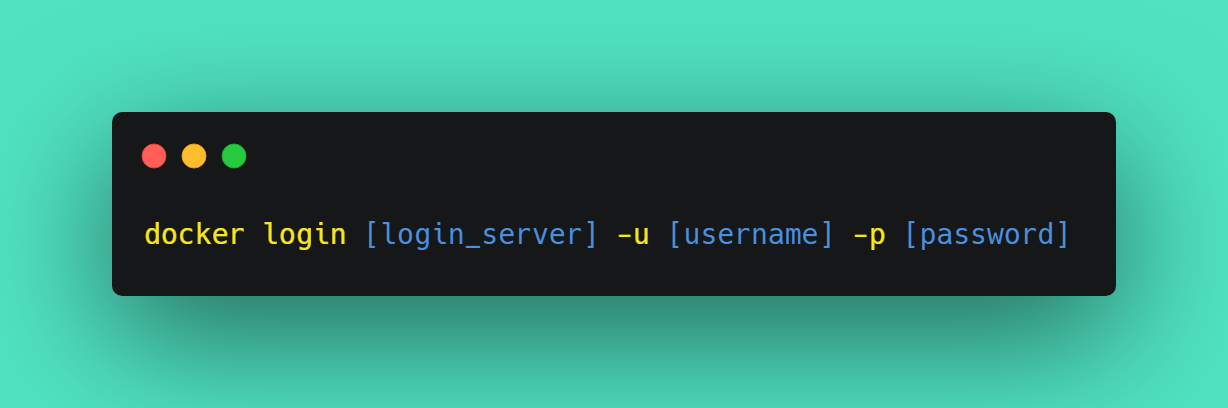
Type Above fig command and replace [login-server] with your ACR resource EG: **firstapp.azureacr.io** [username] with firstapp and [password] with the hash password. Once completed, you should see Login succeeded! Message. After this you need to build your docker image with this command
```
docker build –f ./Dockerfile . –t node_vue_app
```
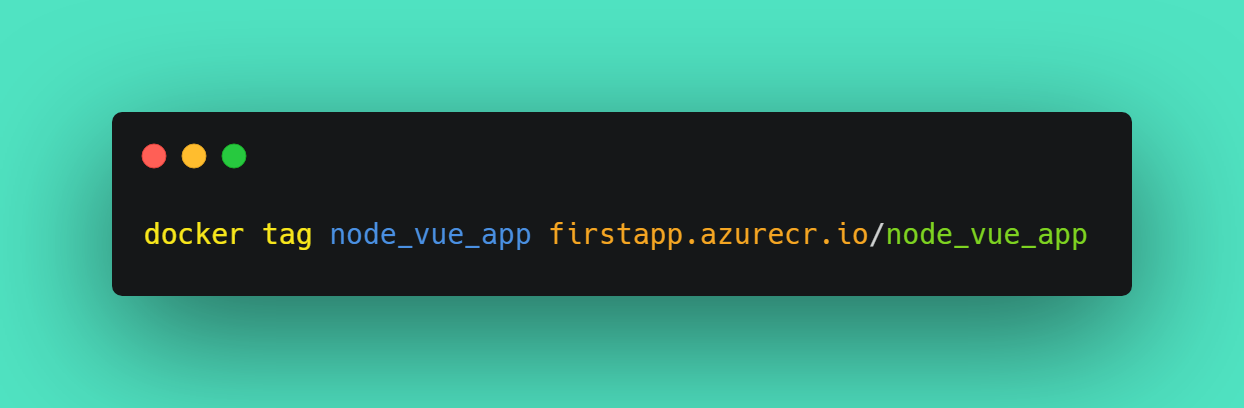
Final step is to push your local Docker image to ACR. Follow below image command to push. Keep in mind though that these repositories are private by default, which means that you have to perform authentication first.
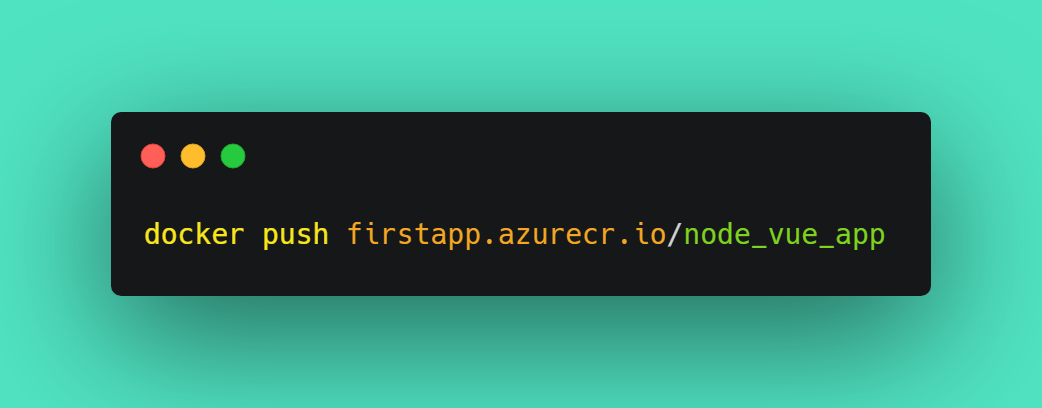
And that’s it. You can make use of this container registry just like you used. In Part 2 we will see how we can deploy same thing using CI/CD with GitHub Workflow
| theromie |
865,620 | 21 Binary Tree Coding Questions for Java Developers | Frequently asked binary tree based coding problem from Java interviews. | 0 | 2021-10-16T08:17:47 | https://dev.to/javinpaul/21-binary-tree-coding-questions-for-java-developers-325o | java, programming, algorithms, coding | ---
title: 21 Binary Tree Coding Questions for Java Developers
published: true
description: Frequently asked binary tree based coding problem from Java interviews.
tags: java, programming, algorithms, coding
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/6eqdglvvzak748l1xkvq.jpeg
---
*Disclosure: This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.*
Hello devs, I have been sharing a lot of resources about programming job interviews like the [books](https://medium.com/javarevisited/10-best-books-for-data-structure-and-algorithms-for-beginners-in-java-c-c-and-python-5e3d9b478eb1), [courses](https://medium.com/hackernoon/10-data-structure-algorithms-and-programming-courses-to-crack-any-coding-interview-e1c50b30b927), and some interview questions on the [software design](https://medium.com/javarevisited/25-software-design-interview-questions-to-crack-any-programming-and-technical-interviews-4b8237942db0) and data structures like an [array](https://javarevisited.blogspot.com/2015/06/top-20-array-interview-questions-and-answers.html#axzz5dCg1cNYo), [string](https://medium.com/javarevisited/top-21-string-programming-interview-questions-for-beginners-and-experienced-developers-56037048de45), and [linked list](https://medium.com/javarevisited/top-20-linked-list-coding-problems-from-technical-interviews-90b64d2df093).
So far, we have looked at only the **linear data structures**, like an array and linked list, but all information in the real world cannot be represented in a linear fashion, and that's where tree data structure helps.
A tree data structure is a hierarchical data structure that allows you to store hierarchical data like a family tree or office hierarchy. Depending on how you store data, there are different types of trees, such as a [binary tree](http://javarevisited.blogspot.sg/2016/07/binary-tree-preorder-traversal-in-java-using-recursion-iteration-example.html), where each node has, at most, two child nodes.
Along with its close cousin [binary search tree](http://javarevisited.blogspot.sg/2017/04/recursive-binary-search-algorithm-in-java-example.html), it's also one of the most popular tree data structures. Therefore, you will find a lot of questions based on them, such as how to traverse them, count nodes, find depth, and check if they are balanced or not.
**A key point to solving binary tree questions is a strong knowledge of theory,** like what is the size or depth of the binary tree, what is a leaf, and what is a node, as well as an understanding of the popular traversing algorithms, like pre-order, post-order, and in-order traversal.
If you are not familiar with these concepts then I strongly suggest you to first go through a comprehensive data structure and algorithm course like[**Data Structures and Algorithms: Deep Dive Using Java**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fdata-structures-and-algorithms-deep-dive-using-java%2F) which explains essential data structure in detail. It's also very affordable as you can purchase this course on just $9.9 on crazy Udemy sales which happen every now and then.
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fdata-structures-and-algorithms-deep-dive-using-java%2F)
## Top 21 Binary Tree Based Coding Problems for Interviews
Now that you know how to solve binary tree-based coding problem using [recursion](https://www.educative.io/courses/recursion-for-coding-interviews-in-java?affiliate_id=5073518643380224) and some tips about solving tree-based coding problems, here is a list of popular binary tree-based coding questions from software engineer or developer job interviews:
1. **What is the difference between binary and binary search trees? (answer)**
A Binary Tree is a basic structure with a simple rule that no parent must have more than 2 children whereas the Binary Search Tree is a variant of the binary tree following a particular order with which the nodes should be organized. In binary search tree, values of nodes on left sub tree are less than or equal to root and values of nods on right sub trees are greater than or equal to root.
2. **What is a self-balanced tree? (answer)**
Self-Balancing Binary Search Trees are height-balanced binary search trees that automatically keeps height as small as possible when insertion or deletion happens. Hence, for self-balancing BSTs, the minimum height must always be log₂(n) rounded down. In other word, A tree is balanced if, for every node in the tree, the height of its right and left subtrees differs by at most 1
3. **What is the AVL Tree? (answer)**
An AVL tree is a self-balancing binary search tree. It was the first such data structure to be invented. In an AVL tree, the heights of the two child subtrees of any node differ by at most one; if at any time they differ by more than one, rebalancing is done to restore this property
4. **How do you perform an inorder traversal in a given binary tree? (**[**solution**](http://www.java67.com/2016/08/binary-tree-inorder-traversal-in-java.html)**)**
5. **How do you print all nodes of a given binary tree using inorder traversal without recursion? (**[**solution**](http://www.java67.com/2016/08/binary-tree-inorder-traversal-in-java.html)**)**
6. **How do you implement a postorder traversal algorithm? (**[**solution**](http://www.java67.com/2016/10/binary-tree-post-order-traversal-in.html)**)**
7. **How do you traverse a binary tree in postorder traversal without recursion? (**[**solution**]
(http://www.java67.com/2017/05/binary-tree-post-order-traversal-in-java-without-recursion.html)**)**
8. **How are all leaves of a binary search tree printed? (**[**solution**](http://www.java67.com/2016/09/how-to-print-all-leaf-nodes-of-binary-tree-in-java.html)**)**
9. **How do you count a number of leaf nodes in a given binary tree? (**[**solution**]
(http://javarevisited.blogspot.sg/2016/12/how-to-count-number-of-leaf-nodes-in-java-recursive-iterative-algorithm.html)**)**
10. **How do you perform a binary search in a given array? (**[**solution**](http://javarevisited.blogspot.sg/2015/10/how-to-implement-binary-search-tree-in-java-example.html#axzz4wnEtnNB3)**)**
11. **How do you convert a given binary tree to double linked list in Java? (solution)**
12. **Write a program to find a depth of a given binary tree in Java? (solution)**
13. **How is a binary search tree implemented? (**[**solution**](http://javarevisited.blogspot.com/2015/10/how-to-implement-binary-search-tree-in-java-example.html#axzz4wnEtnNB3)**)**
14. **How do you perform preorder traversal in a given binary tree? (**[**solution**](http://javarevisited.blogspot.com/2016/07/binary-tree-preorder-traversal-in-java-using-recursion-iteration-example.html#axzz5ArdIFI7y)**)**
15. **How do you traverse a given binary tree in preorder without recursion? (**[**solution**](http://www.java67.com/2016/07/binary-tree-preorder-traversal-in-java-without-recursion.html)**)**
16. **You have given a BST, where two nodes are swapped? How do you recover the original BST? (solution)**
17. **How do you convert a binary tree to a binary search tree in Java? (solution)**
18. **Find the largest BST subtree of a given binary tree in Java? (solution)**
19. **Write a Java program to connect nodes at the same level as a binary tree? (solution)**
20. **What is a Trie data structure? (answer)**
A trie is an ordered data structure, a type of search tree used to store associative data structures. It is also referred to as a Radix tree or Prefix tree.
21. **What is the difference between the Binary tree and Trie?**
Unlike a binary search tree, nodes in the trie do not store their associated key. Instead, a node's position in the trie defines the key with which it is associated. This distributes the value of each key across the data structure, and means that not every node necessarily has an associated value.
These are some of the most popular binary tree-based questions asked on Programming job interviews. You can solve them to become comfortable with tree-based problems.
If you feel that your understanding of binary tree coding is inadequate and you can't solve these questions on your own, I suggest you go back and pick a good data structure and algorithm courses like [**Easy to Advanced Data Structures**](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fintroduction-to-data-structures%2F) by William Fiset, a former Google engineer, and former **ACM-ICPC world** finalist to refresh your knowledge about the binary tree and binary search tree.
[](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fcourse%2Fintroduction-to-data-structures%2F)
If you need some more recommendations, here is my list of useful [data structure algorithm books](http://javarevisited.blogspot.sg/2015/07/5-data-structure-and-algorithm-books-best-must-read.html) and [courses](http://javarevisited.blogspot.sg/2018/01/top-5-free-data-structure-and-algorithm-courses-java--c-programmers.html) to start with.
###Now You're One step closer to the Coding Interview
These are some of the most common questions about binary tree data structure form coding interviews that help you to do really well in your interview.
I have also shared a lot of [data structure questions](https://codeburst.io/100-coding-interview-questions-for-programmers-b1cf74885fb7) on my [blog](http://java67.com/), so if you are really interested, you can always go there and search for them.
These **common coding, data structure, and algorithm questions** are the ones you need to know to successfully interview with any company, big or small, for any level of programming job.
If you are looking for a programming or software development job in 2021, you can start your preparation with this [list of coding questions](https://medium.com/javarevisited/50-data-structure-and-algorithms-interview-questions-for-programmers-b4b1ac61f5b0).
This list provides good topics to prepare and also helps assess your preparation to find out your areas of strength and weakness.
Good knowledge of data structure and algorithms is important for success in coding interviews and that's where you should focus most of your attention.
#### Further Learning*
Here are some resources to level up your algorithms and coding skills for interviews:
[Grokking the Coding Interview: Patterns for Coding Questions](https://www.educative.io/collection/5668639101419520/5671464854355968?affiliate_id=5073518643380224)
[Data Structures and Algorithms: Deep Dive Using Java](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fdata-structures-and-algorithms-deep-dive-using-java%2F)
[Data Structure and Algorithms Analysis --- Job Interview](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fdata-structure-and-algorithms-analysis%2F)
[Algorithms and Data Structure Part1 and 2](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fads-part1)
[Data Structures in Java: An Interview Refresher](https://www.educative.io/collection/5642554087309312/5724822843686912?affiliate_id=5073518643380224)
[Grokking Dynamic Programming Patterns for Coding Interviews](https://www.educative.io/collection/5668639101419520/5633779737559040?affiliate_id=5073518643380224)
#### Other **Data Structure and Algorithms Resources** you may like
- 75+ Coding Problems from Interviews ([questions](http://www.java67.com/2018/05/top-75-programming-interview-questions-answers.html))
- 10 Free Courses to learn Data Structure and Algorithms ([courses](http://www.java67.com/2019/02/top-10-free-algorithms-and-data.html))
- 10 Books to Prepare Technical Programming/Coding Job Interviews ([books](http://www.java67.com/2017/06/10-books-to-prepare-technical-coding-job-interviews.html))
- 10 Courses to Prepare for Programming Job Interviews ([courses](http://javarevisited.blogspot.sg/2018/02/10-courses-to-prepare-for-programming-job-interviews.html))
- 100+ Data Structure and Algorithms Interview Questions ([questions](http://www.java67.com/2018/06/data-structure-and-algorithm-interview-questions-programmers.html))
- My favorite Free Algorithms and Data Structure Courses on FreeCodeCamp ([courses](https://medium.freecodecamp.org/these-are-the-best-free-courses-to-learn-data-structures-and-algorithms-in-depth-4d52f0d6b35a?sk=15709c9f6c9b4bfc639b3b7a1f9b3ef5))
- 30+ linked list interview questions with a solution ([linked list](https://javarevisited.blogspot.com/2017/07/top-10-linked-list-coding-questions-and.html))
- 30+ array-based interview questions for programmers ([array](https://javarevisited.blogspot.com/2015/06/top-20-array-interview-questions-and-answers.html))
- 40 Object Oriented Programming questions ([tips](https://javarevisited.blogspot.com/2020/05/object-oriented-programming-questions-answers.html#axzz6vwZEctyQ))
- 5 Free Courses to learn Algorithms in-depth ([courses](https://javarevisited.blogspot.com/2018/01/top-5-free-data-structure-and-algorithm-courses-java--c-programmers.html))
- 10 Algorithms books every Programmer should read ([books](http://www.java67.com/2015/09/top-10-algorithm-books-every-programmer-read-learn.html))
- Top 5 Data Structure and Algorithms Courses for Programmers ([courses](https://javarevisited.blogspot.com/2018/11/top-5-data-structures-and-algorithm-online-courses.html#axzz5YFaOvjsh))
#### Closing Notes
Thanks, You made it to the end of the article ... Good luck with your programming interview! It's certainly not going to be easy, but by following this roadmap and guide, you are one step closer to becoming a Software Developer.
If you like this article, then please share it with your friends and colleagues, and don't forget to follow [javinpaul](https://twitter.com/javinpaul) on Twitter!
>P.S. --- If you need some FREE resources, you can check out this list of [free data structure and algorithm courses](https://medium.com/javarevisited/top-10-free-data-structure-and-algorithms-courses-for-beginners-best-of-lot-ad807cc55f7a) to start your preparation.
| javinpaul |
865,630 | Stage 4: Optional chaining | Motivation When looking for a property value that's deep in a tree-like structure, one often has to... | 14,968 | 2021-10-17T14:58:19 | https://dev.to/zaidrehman/stage-4-optional-chaining-212h | javascript, webdev, programming | **Motivation**
When looking for a property value that's deep in a tree-like structure, one often has to check whether intermediate nodes exist or not like below
const street = user.address && user.address.street;
Also, many API return either an object or null/undefined, and one may want to extract a property from the result only when it is not null
const fooInput = myForm.querySelector('input[name=foo]')
const fooValue = fooInput ? fooInput.value : undefined
The Optional Chaining Operator allows a developer to handle many of those cases without repeating themselves and/or assigning intermediate results in temporary variables:
var street = user.address?.street
var fooValue = myForm.querySelector('input[name=foo]')?.value
The call variant of Optional Chaining is useful for dealing with interfaces that have optional methods
iterator.return?.() // manually close an iterator
or with methods not universally implemented
if (myForm.checkValidity?.() === false) { // skip the test in older web browsers
// form validation fails
return;
}
**Syntax**
The Optional Chaining operator is spelled ?.. It may appear in three positions:
obj?.prop // optional static property access
obj?.[expr] // optional dynamic property access
func?.(...args) // optional function or method call
**Semantics**
If the operand at the left-hand side of the `?.` operator evaluates to undefined or null, the expression evaluates to undefined. Otherwise the targeted property access, method or function call is triggered normally.
a?.b // undefined if `a` is null/undefined, `a.b` otherwise.
a == null ? undefined : a.b
a?.[x] // undefined if `a` is null/undefined, `a[x]` otherwise.
a == null ? undefined : a[x]
a?.b() // undefined if `a` is null/undefined
a == null ? undefined : a.b() // throws a TypeError if `a.b` is not a function
// otherwise, evaluates to `a.b()`
a?.() // undefined if `a` is null/undefined
a == null ? undefined : a() // throws a TypeError if `a` is neither null/undefined, nor a function
// invokes the function `a` otherwise
**Short-circuiting**
a?.[++x] // `x` is incremented if and only if `a` is not null/undefined
a == null ? undefined : a[++x]
**Stacking**
a?.b[3].c?.(x).d
a == null ? undefined : a.b[3].c == null ? undefined : a.b[3].c(x).d
// (as always, except that `a` and `a.b[3].c` are evaluated only once)
**Optional deletion**
delete a?.b
a == null ? true : delete a.b
| zaidrehman |
865,654 | Principles of Object-oriented programming | Object-oriented programming has been the most popular programming paradigm for over two decades. It... | 0 | 2021-10-16T14:27:09 | https://dev.to/abh1navv/principles-of-object-oriented-programming-51k1 | oop, beginners, programming, codenewbie | Object-oriented programming has been the most popular programming paradigm for over two decades. It is build on the idea that problems can be broken down in terms of the objects required to solve it.
Let's have a look into the core principles around the object-oriented programming paradigm.
## Building blocks of OOP
### Objects
Objects are entities which have certain attributes and provide some services.
In programming terms attributes are data held by the object in variables and services are the methods of the object that are accessible from outside.
A Car is an object. Its attributes are its engine, color, model, seats, etc. while its service is to help people travel.
### Class
Class is based on the idea of "type". It provides a template for defining similar objects and an interface for interacting with the object's services and data.
In OOP, each object will belong to a class which defines its characteristics and behaviour. Objects, also called as instances of a class, are created, stored and utilized as per the template defined by their class.
## Principles
### Encapsulation
The object's data and its capabilities are bundled together. And as we already know, they are defined in a class.
- The class provides an interface for other objects to interact with instances of that class. The point to note about the interface is that it does not need to reveal everything about the object.
- Some capabilities and data are internal to the object. They are not for the outside world to know or use.
This can be understood in terms of a capsule which is consumed from the outside. It has a composition of medicines inside but they cannot be taken separately.
### Abstraction
Focus on "what" can solve your problem and not on "how" it solves it. More specifically, find the objects which can solve your problem and use their relevant services.
Objects communicate by calling each other's services to get the job done. At no point does one object need to know the specifics of how the other object is implementing the services.
Abstraction and Encapsulation work together to ensure that implementation details of an object are hidden from the external world.
For e.g. a Car is an encapsulated unit. It will not tell you what each of its parts are made of and what material was used to create them. However, it will provide you with some abstracted functionalities.
You can press the accelerator and it will increase your speed without you knowing how it increases the speed or what parts are involved in the process.
### Inheritance
At its core, inheritance is a technique for code reuse.
- Inheritance allows a class (*subclass*) to build on top of another class (*superclass*).
- The subclass will have all the properties of its superclass and should be able to perform all the services provided by the superclass.
- In addition it can define/update a few properties and services of its own.
Sometimes objects required to solve problems will follow a uniform interface but will differ in implementation details. In such cases, inheritance is useful to help in avoiding repetition of code that will remain the same.
A stricter and recommended use case of inheritance is subtyping where we state that if a subclass object "is-a" and "behaves-as-a" superclass object, only then the inheritance is valid.
A Car is a class. Additionally, cars can be of several subtypes. A SUV is also a Car and a LUV is a Car too because they will both have all the attributes of .
If we were defining SUV and LUV as classes, it would make sense to make them inherit the class of Car.
### Polymorphism
Polymorphism is the ability to behave differently in different situations.
- This is achieved using a technique called "Late Binding". The code to be executed is determined at runtime.
- From another perspective, the object or method to be used is determined at runtime.
- This helps in making the code "decoupled" - not tied strongly with objects of a specific type.
---
| abh1navv |
865,664 | find factorial with recursion | def factorial(n): if n <= 1: return 1 else: return n * (factorial(n -... | 0 | 2021-10-16T10:41:30 | https://dev.to/s_belote_dev/find-factorial-with-recursion-32a | python | ```python
def factorial(n):
if n <= 1:
return 1
else:
return n * (factorial(n - 1))
print(factorial(21))
``` | s_belote_dev |
865,959 | How And Where To Buy BullPerks (BLP) – An Easy Step By Step Guide | The total value of the crypto market is expected to reach $23.3 Billion by 2023, according to... | 0 | 2021-10-16T17:26:27 | https://dev.to/gashihk/how-and-where-to-buy-bullperks-blp-an-easy-step-by-step-guide-4p4m | blockchain, startup, tutorial, writing | The total value of the crypto market is expected to reach $23.3 Billion by 2023, **[according to TechJury](https://techjury.net/blog/cryptocurrency-statistics/#gref)**. Crypto launchpads play a crucial role in this fast industry development.
Most of today’s decentralized launchpads have a high entry and have become private member clubs after their token decreased. BullPerks stands out from them offering low entry for retail investors and access to early-stage crypto projects.
What is BullPerks and what are the BLP tokens? Where and how to buy it? Keep on reading this step-by-step guide to know more about it!
## What is BullPerks?

**BullPerks** is the fairest and most community-oriented **[decentralized launchpad](https://bullperks.com/)** that helps impactful crypto projects raise funds and offer safety for retail investors.
BullPerks offers two types of deals: Venture Capital (VC) and Initial DEX Offerings (IDO). The company works with startups from various industries, such as decentralized finance (DeFi), NFT, gaming, metaverse, and much more.
## Unique features

The problem with Traditional VCs (and a lot of other decentralized VCs in the market today), is that getting access to seed or private sales is quite challenging. In fact, you should have an exclusive membership (that costs fortunes) or be in close connection with the members of the platform to participate in the deals.
Unlike the majority of crypto launchpads, BullPerks offers low-entry and access to early-stage deals for retail investors. These are other features that make BullPerks stand out in the market.
1. BullPerks is the most community-focused platform
2. Incredibly high ROI rates from the projects
3. Completely transparent and fully decentralized system
4. Fair tier-based system and FCFS model in place
5. User-friendly platform
6. Affordable options even for users with lower investment plans.
## How and where to buy BLP tokens

### Buying BLP on Bitmart
**1. Register on BitMart**
First, register on **[BitMart](https://www.bitmart.com)**. Write down your email address or phone number and press the button **“Get Started.”** Next, you will be asked to provide a password and verify the account through email or phone.
**2. Buy USDT with fiat money on BitMart**
Before you can go on and trade BLPs, you will need to make sure you have enough USDT for the transaction. In case you don’t, you can buy crypto with fiat directly on the Bitmart exchange.

First, you will need to click on **Buy & Sell**.
Next, write down the amount of **USDT** you want to purchase and click on **Buy**.
After you click **Buy**, choose the payment method.
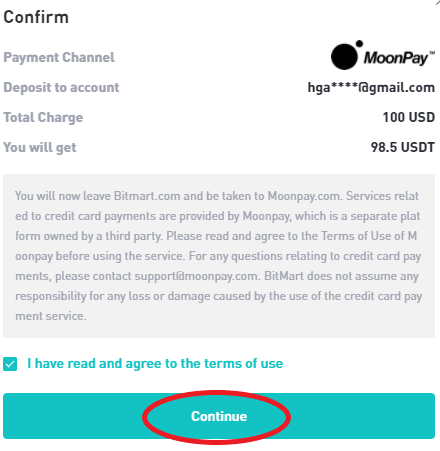
If you have read and agreed to the terms of use, press **Continue**. Next, you will be redirected to your **MoonPay** or **Simplex** account. You will have to complete the payment there.
**3. Buy BLPs**
Once you purchase **USDTs**, you can buy **BLPs** on BitMart. To do so, simply go to the homepage and click **Trade**.
Next, head over to the top-right corner and search for **BLP** in the search bar.
Type the number of BLPs you want to buy and **confirm** your transaction. You just bought your BullPerks (BLP) tokens!
### Buying BLP on Pancakeswap
Another way you can buy BLPs is through **PancakeSwap**, a decentralized exchange (DEX) based on Binance Smart Chain (BSC) Network. It is a fast and inexpensive alternative to Ethereum. Similar to the well-known UniSwap DeFi protocol, PancakeSwap allows users to trade between crypto-assets through user-generated liquidity pools.
To purchase BLPs, go to the **[PancakeSwap website](https://pancakeswap.finance/swap)**.
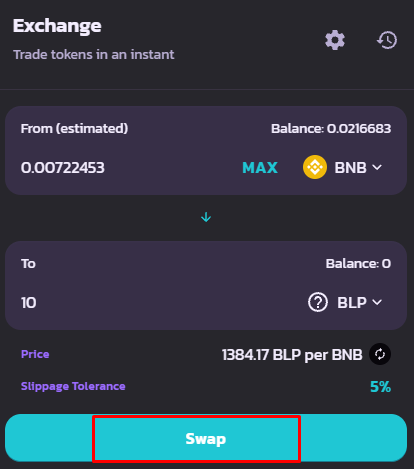
Next, write down the number of BLP tokens you want to buy and choose the crypto asset you want to pay with. Click **Swap**.
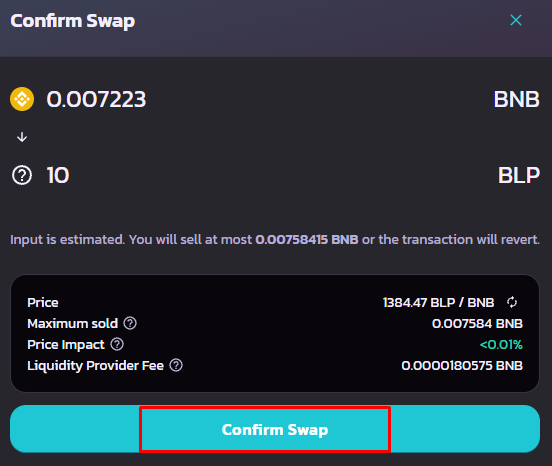
Check your details once again and press **“Confirm Swap.”**
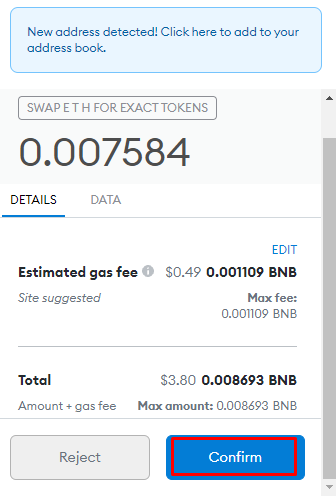
Now, confirm the transaction in your MetaMask wallet.
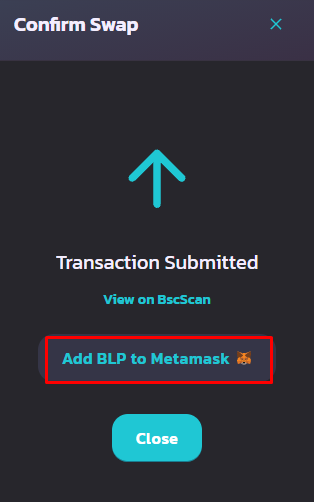
Once your transaction is complete, make sure to add BLP tokens to your MetaMask. You can do it by clicking “**Add BLP to MetaMask.**” And you will have the BLP on your Metamask wallet!
## Conclusion
The crypto world is on a bullish run. Crypto launchpads have become even more popular in recent times since they offer people the chance to make high returns from private or public sales.
BullPerks has brought the concept of decentralized VCs and launchpads to a new level. The transparency and dedication to their community say a lot about what the future may hold for this project in the crypto world.
| gashihk |
866,077 | Rails templates with docker | Starting new rails apps has never been easier for me. Here's why and how. Before... | 0 | 2021-10-16T17:58:28 | https://www.ananunesdasilva.com/posts/rails-templates-with-docker | docker, rails | Starting new rails apps has never been easier for me. Here's why and how.
## Before docker
You know when you want to start a new app, but you end up losing too much time setting it up, and solving issues with the dependencies on your machine? And after a while, you want to start another new project, only to find yourself going through the same steps and pains, to a point where you almost lose interest?
I've always wanted to find a way to start a new project on my machine, seamlessly. No hassle, just plug and play. But I never found a solution for that until I started using docker. Being able to start a rails project in under 5 minutes has given me back the joy of working on side projects and exploring new things.
## After docker
So, recently I've decided to put together simple docker based templates with the tools I generally work with on a rails project:
- [rails with postgres] (https://github.com/anansilva/docker-rails-postgres-template)
- [rails api with postgres] (https://github.com/anansilva/docker-rails-api-postgres-template)
- [rails api with mysql] (https://github.com/anansilva/docker-rails-api-mysql-template)
- [rails api with postgres and rspec] (https://github.com/anansilva/docker-rails-api-postgres-rspec-tempate)
Using [github templates](https://docs.github.com/pt/repositories/creating-and-managing-repositories/creating-a-template-repository) I can easily create new repositories based on a chosen template, clone it to my machine, run some `docker-compose` commands documented in the project's README, and voilà!
These templates are mostly based on the official docker [quickstart tutorial for rails](https://docs.docker.com/samples/rails/). They are currently set for ruby 3 and rails 6 but the beauty of docker is that you can go ahead and easily change them to whatever version you like, without the need to have anything installed on your computer. The same goes for postgres, mysql or whatever other tools you might add to these templates.
I'll be adding more as I start new rails apps with different toolsets that might be helpful in the future. For instance, I've currently started a new rails app with sidekiq and since I use sidekiq often, I know it's a good candidate for a template. I'll not create templates for all possible combinations of tools but mostly for those that involve adding containers, networking, or installing other dependencies. The idea is to save time with cumbersome configurations.
I'm happy to get feedback on these, feel free to use them, adapt them to your needs or just take some ideas to start your own. If you're fairly new to docker like me, I recommend you build your own from scratch. You'll learn a lot about docker and docker tools.
 | anakbns |
866,082 | Machine Learning in Artificial Intelligence 💯 | Introduction Hello everyone! In this article, we look into about machine... | 0 | 2021-10-16T18:26:59 | https://dev.to/deepakguptacoder/machine-learning-in-artificial-intelligence-35cm | machinelearning, webdev, showdev, webpack |
#Introduction
####Hello everyone!
In this article, we look into about machine learning in Artificial intelligence
We are using Artificial intelligence in our daily life I will tell you that Machine learning how it work and how many types we are see all the step in this article it's help you to grow and build your knowledge.
Machine learning is a subset of AI,and it's provide the static ( Statistics )Method and there algorithm and enable to machine and computers learning ,the program to change in any case Machine Learning is utilized in various applications, ranging from automating.
##What is Machine learning ?
Machine Learning provides many different techniques and algorithms to make the computer learn Machine learning uses a massive amount of structured and semi-structured data so that a machine learning model can generate accurate result or give predictions based on that data. Also it's called (ML)Machine learning enables a computer system to make predictions or take some decisions using historical data without being explicitly programmed.
##Types Of Machine Learning
There are Three types of Machine learning
1.Supervised Learning
2.Unsupervised Learning
3.Reinforcement Learning
###Supervised Learning
Supervised learning is typically done in the context of classification, when we want to map input to output labels, or regression.
Supervised learning (SL) is the machine learning task of learning a function that maps an input to an output based on example input-output pairs.
###Unsupervised Learning
Unsupervised learning is a type of machine learning in which the algorithm is not provided with any pre-assigned labels or scores for the training data.
Advantages of unsupervised learning include a minimal workload to prepare and audit the training set, in contrast to supervised learning techniques where a considerable amount.
###Reinforcement Learning
Reinforcement learning is a machine learning training method based.It enables an agent to learn through the consequences of actions in a specific environment.
example, types of reinforcement might include praise, getting out of unwanted work, token rewards ,etc.
#####It's the some of the basis points of the machine learning I will also provide the machine learning and there platform is also giving in my last article. You can check there and learn about the machine learning.
.
.
.
###Conclusion
####I hope you found this article useful, if you need any help please let me know in the comment section.💯
| deepakguptacoder |
866,102 | From Jobless to FAANG - My three year journey | Disclaimer: this post is all about my personal experience, only representing my point of view, take... | 0 | 2021-10-16T18:59:13 | https://blog.nate-lin.com/posts/from-jobless-to-faang-my-three-year-journey-zbnr | career, faang |
> Disclaimer: this post is all about my personal experience, only representing my point of view, take it with a grain of salt.
About three years ago, I was graduating from college with a CS degree. Dreaming of going to U.S. to study, I gave up the opportunity of attending graduate program without entrance exam at my school. Unfortunately, I wasn't able to get into any U.S schools. Not only didn't I prepare for job interviews, I also missed all on-campus hiring event as well as new grad hiring time window of most companies.
At the point, I was fresh out of the college and jobless, possibly the most painful time of my life. I made some changes to my plan and tried to take an exam to get in another graduate school at my country because there's a pandemic going on and studying abroad seems impossible. Somehow I failed the exam. I was hopeless and desperately trying my best to find a job to get by.
After a plethora of interviews, I was fortunate enough to land a job at Ericsson. However, I was hired through a vendor so the pay and benefits are terrible. I had no choice but to learn on the job. I never wrote much javascript at school and it took me a long time to understand the mechanics of async and await.
Once I got the hang of it. I began creating side projects on GitHub. At first the projects are pretty simple: a REST api with jwt authentication and authorization, a single page made from react or vue, or a CMS with some CRUD functions. I was never satisfied with my work and always trying to explore and improve. I began learning typescript, learning advanced react usage, learning graphQL. I was also writing my learnings down as I progress. [My most popular blog post](https://dev.to/llldar/migrate-to-typescript-the-advance-guide-1df6) had more than 10k views and is still at the first page of `migrate to typescript` google search result to this day. [My toy react hook library](https://www.npmjs.com/package/react-use-hoverintent) also have thousands of download per week. Like all the developers, I'm also obsessed with creating my own blogging system. From markdown engine to database design, I was in from every aspect of my blogging system. My blog have gone through three major version change, reflecting my skill up. Going from `ASP.NET Core+ JQuery + Bootstrap` to `ASP.NET Core + React + Component Library` to `Node.js + React + components written myself`. Looking at my blog now, I can say that it came a long way.
Having a lot of side projects is not you gold ticket to FAANG though, There's also leetcode grind like everyone else. The only difference might be when I was practicing problems, I will first try to understand the mechanism of this type of problems, then I take the problem to strengthen my impression.
Then these's the interview, There's 6 rounds of technical interviews and some of them might even in 1AM due to timezone differences. I would just talk about projects at my previous companies and then solve some leetcode problems, not being able to find the optimal solution is fine, but you have to at least provide a promising solution.
After what feels like a century, I finally got the offer from Microsoft. To be honest, I didn't believe I would got into Microsoft at all and would never dream of getting into FAANG three years ago. Using GitHub, npm, typescript and vscode almost everyday, I'm quite impressed by the products that Microsoft was building. I'm really looking forward to take on new challenges at Microsoft. | natelindev |
866,117 | Release0.2 week two | I have had experience about how to search Hacktoberfest issue, so I found the appropriate issue very... | 0 | 2021-10-16T20:04:18 | https://dev.to/yodacanada/release02-week-two-366o | I have had experience about how to search Hacktoberfest issue, so I found the appropriate issue very soon. The Second Hacktoberest issue is about "String Metadata Extraction", and it is more difficult than the first one. The project named [Nirjas] (https://github.com/fossology/Nirjas). This project focus on extracting the comments and source code out of your file(s). The extracted comments can be processed in various ways to detect licenses, generate documentation, process info, etc.
### The issue
The [issue](https://github.com/fossology/Nirjas/issues/36) named "String Metadata Extraction". The problem is that in code files there are variables which are assigned with the strings. Extraction of it can be simply done using the same process of regex.
foo = "This is a string".
Nirjas is currently extracting several type of metadata including the SLOC, Comments. This can be a separate output metadata with only assigned string extractions.
### How to do
**First**, I studied the code structure and understood the functions meaning. Then I authored a new function according to a similar function in this project.
**Second**, the point of the new function is about the regular expression. I had some regular expression experience in recent weeks. However, it is too complicated, so I need a tool to test it. I found an extension named "Regex Previewer", and it help me to find a right regular expression.
**Third**, Interact with the project owner and revise the code repeatedly according to their opinions.
### Reflection
1. Regular expression is very useful, but it is also complicated. We will continue to learn it in the coming weeks.
2. Be patient! This project have sever owners and they have different style. They will put forward different requirements to improve a function, and sometimes their opinions are not clear. I need to keep good communication to clarify what needs to be modified. I have learned a lot in this process.
3. I want to introduce my method which search the project. I used the advanced search, and choose "With this many forks <50 "in Repositories options part. It is very helpful for me to search for issues at my level. | yodacanada | |
866,400 | Learn Simple HTML5(First Article), Beginner level | What is an HTML? HTML (Hyper Text MarkUp language), which we use to define the basic... | 0 | 2021-10-17T04:59:40 | https://dev.to/abdulmoiz8994/learn-simple-htmlfirst-article-beginner-level-1i37 | html, beginners, programming | ## What is an HTML?
- HTML (Hyper Text MarkUp language), which we use to define the basic structure of the web pages. Like The contents where we have some paragraphs, bullets points, data table forms, images,videos and map etc.
- The HTML Tags Contains machine-readable information about the metadata of the Document, like title, script, style, etc.
### what is MetaData?
- The simplest Definition is that the data describes the data is called metadata.Like the tag of <html> </html> element also contain metadata in its head tag which also describes the data like style title, the script is metadata of HTML
### what head tag holds between the opening and Closing Tag?
- I will also cover, about opening and closing tags below in the document.The Head tag holds the Information about the machine-understandable data, not for human-readable,but for humans html provides use some tags which we use in browser tab and provide some extra information about the website as well.
### What is an Element?
- I will to explain about the element through an example?
```
<p>This is a content </p>
This is an complete Example of an Element
```
- There are some pre-defined key words in HTML such as ```p```which tells us about the Paragraph ,same like `h1` which represents heading.There are many other pre-defined key words as well. I will provide the link to learn more about the element and tags name at the end of this article.
- We have Two opening angle brackets `<p>`
- In between of tags we have the content .```This is an Enclosed text content <p> This is an content</p>```
we can write whatever we want in between of opening & close brackets.
- The two closing angle Brackets and slash ```</p>```.
### Attribute
-The element can contain an attribute where we store extra information about the element which does not appear on the web page, we use attributes for different reasons just like, the class for styling, id attribute, `<p class="para">moiz </p>`, this is an attribute.
### Nested Elements
-In HTML we have nested elements as well, we can make the elements and we can make another elements inside of it, `<p>Moiz JS<strong>Dev</strong> <p>`
###### Important Note:
-we need to remember that, when we make the nested element and after the opening tag then we must make the closing tag before the parent Closing tag.
###Empty Elements
- Empty Elements are those elements are those elements which are not contain any content `<img/>` , but this tag accepts and we also called the self-closing tag `<img src="Path of Image" alt="Meaning full Message"/>`
The Link of Elements:`https://developer.mozilla.org/en-US/docs/Web/HTML/Element`
Message:
If Someone see some wrong thing which should be correct then feel free to contact me on LinkedIn or twitter
LinkedIn: `https://www.linkedin.com/in/abdul-moiz-8b84361b2/`
Twitter: `https://twitter.com/Abdulmoiz8994`
| abdulmoiz8994 |
866,415 | How do you become a writer? 7 steps. | What do you have to do to become a writer? The short answer: writing. The long answer: reading, being... | 0 | 2021-10-17T07:16:56 | https://dev.to/johnsmithgeek/how-do-you-become-a-writer-7-steps-cmi | beginners, career, motivation, writing | What do you have to do to become a writer? The short answer: writing. The long answer: reading, being insecure, sitting still (ergo: working), being rejected, looking critically at your own work and submitting it to a publisher.
1. Read and Learn
The best writers are readers. They learn when they read (for pleasure) and are genuinely interested in stories. Here are five books by writers about writing that you can start with, but also read what you feel like yourself.
2. Be insecure
Hey? Shouldn't you be very firm as a writer? New. In general, it is a good sign if you are insecure about your own work: you realize that you do not know everything and that there is still a lot to learn. Knowing more?
3. Sit still (and work)
As a writer you have to have guts. My solution to sitting still is to start moving when I'm not writing or pausing .
4. You must exhibit 'writer behavior'
You are a writer when you write and eventually finish a book, for example. To write you need three things:
Motivation
Trigger
Power (such as a computer and time)
Are you missing an element? Then you get stuck. For example, when you lack motivation and you have new ideas every time, but do not bring anything to realization. Learn more about this behavioral model and how to make sure you become a writer with these elements .
5. You must be rejected
Rejection is part of writing. You learn from it. There is no writer whose work is all good and 100% accepted. Especially if you're just starting to write. That doesn't make getting rejected any easier. I found a way to collect rejection, learn from it, and grow into a debut writer.
6. Be critical of your work
Really good writing is a result of rewriting. That's where the story gets taut and where everything comes together. A few tips to look at your writing with a fresh, critical eye . And know: deleting hurts, and for this reason.
7. Send your manuscript to a publisher
If you want to become a published writer, at some point you have to send your book to a publishing house . It is important that your manuscript looks good and that you may have a good writer's resume.
For more info: https://www.outreachway.com/ | johnsmithgeek |
866,547 | React Developer Roadmap | React Developer Roadmap will help you to start your react learning path in an organized way. You can... | 0 | 2021-10-17T11:21:57 | https://dev.to/codingtute/react-developer-roadmap-227 | react, javascript, webdev, reactnative | [React Developer Roadmap](https://codingtute.com/react-developer-roadmap) will help you to start your react learning path in an organized way.
You can find more useful developer content at [codingtute](https://codingtute.com) and follow [facebook](https://www.facebook.com/codingtute) page for latest updates
| codingtute |
866,733 | Using replace() and replaceAll() in JavaScript | In this tutorial, we're going to see how to use the methods replace() and replaceAll() in... | 0 | 2021-10-17T15:49:11 | https://dev.to/vladymir01/using-replace-and-replaceall-in-javascript-102e | javascript, string, beginners, webdev | In this tutorial, we're going to see how to use the methods replace() and replaceAll() in javascript.
Both methods are part of the String object. that means you can invoke them on strings. Let's start with replace().
The replace() method can be used to search from a string, a specific character or a substring that matches a pattern that you provide in order to replace it by another character or a new substring. The method takes 2 arguments, the first one will be the pattern and the second one will be the newsubstring.
```javascript
replace('pattern','newsubstring');
```
The pattern can be a string or a regular expression.
let's put an example:
```javascript
let str = 'cars are fast';
let newstr = str.replace('cars', 'planes');
console.log(newstr);
//the output will be:planes are fast
```
There are 2 important points to mention:
First, the method return a new string, it doesn't modify the original one.
```javascript
let str = 'cars are fast';
let newstr = str.replace('cars', 'planes');
console.log(newstr);
//the output will be:planes are fast
console.log(str); // str is still: cars are fast
```
Second, when the pattern is a string it will return the first occurence it finds.
```javascript
let str = 'cars are fast but, some cars are really fast';
let newstr = str.replace('cars', 'planes');
console.log(newstr);
/**
* The output will be:
* planes are fast but, some cars are really fast
*/
```
Now, let's see with a regular expression
```javascript
let str = 'cars are fast but, some cars are really fast';
let newstr = str.replace(/cars/g, 'planes');
console.log(newstr);
/**
* The output will be:
* planes are fast but, some planes are really fast
*/
```
The letter g in the regular expression is for global, it makes the function searches for all the occurence.
For more details about how to use regular expression visit [this guide](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions).
For the replaceAll(), as the name suggest it will look for all the occurence that match the pattern to replace them by the newsubstring. And as the replace(), it will return a new string with the changes.
```javascript
let str = 'cars are fast but, some cars are really fast';
let newstr = str.replaceAll('cars', 'planes');
console.log(newstr);
/**
* The output will be:
* planes are fast but, some planes are really fast
*/
```
I hope this will help you have a quick understanding of how to use replace() and replaceAll() in JavaScript.
| vladymir01 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.