
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
866,754 | Introduction to Nodejs and Express | We are going to learn some back end web development using JavaScript. The framework we are going... | 0 | 2021-10-17T17:46:20 | https://dev.to/moreno8423/introduction-to-nodejs-and-express-4pik | javascript, node, webdev, express | 

We are going to learn some back end web development using JavaScript. The framework we are going to learn is very useful for back end web development. That framework is Nodejs. We are also going to use the most popular middleware for Nodejs. That middleware is "Express”. In this tutorial we expect you have some <a href="https://moeslink.com/intro-to-javascript-for-web-development/">JavaScript</a> knowledge. Also some <a href="https://moeslink.com/easy-learn-html/">HTML</a> and <a href="https://moeslink.com/intro-to-css/">CSS</a> for templates and styling purposes. At the end of this tutorial you will have a great foundation to start creating your own applications.
###Introduction###
To start we first need to download Nodejs from its website. Then we proceed to install NodeJs. Once the software is installed, "The Node Package Manager" npm will also be installed.
Once we finish the installation we can check the version of the installed softwares in the terminal. We only need to type the command npm -v && node -v to get the result. If your result is similar to the one we show you below; that means you successfuly installed Nodejs and npm . Otherwise you need to check for installation errors.
```shell
node -v && npm -v
v16.9.1
7.21.1
```
###Creating a Simple server###
It's quite easy to create a simple server with Nodejs. As you may already know, you just need the terminal and a text editor. My favorite text editor is <a href="https://code.visualstudio.com/">Visual Studio Code</a>; but you can use your preferred one. The result is going to be the same. Once we choose our text editor we can create a file and name it app.js. After we create the file we can type the example we see below in our file. Then you will get a result of a route and a console log.
``` javascript
const http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.send('Hello World!');
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
```
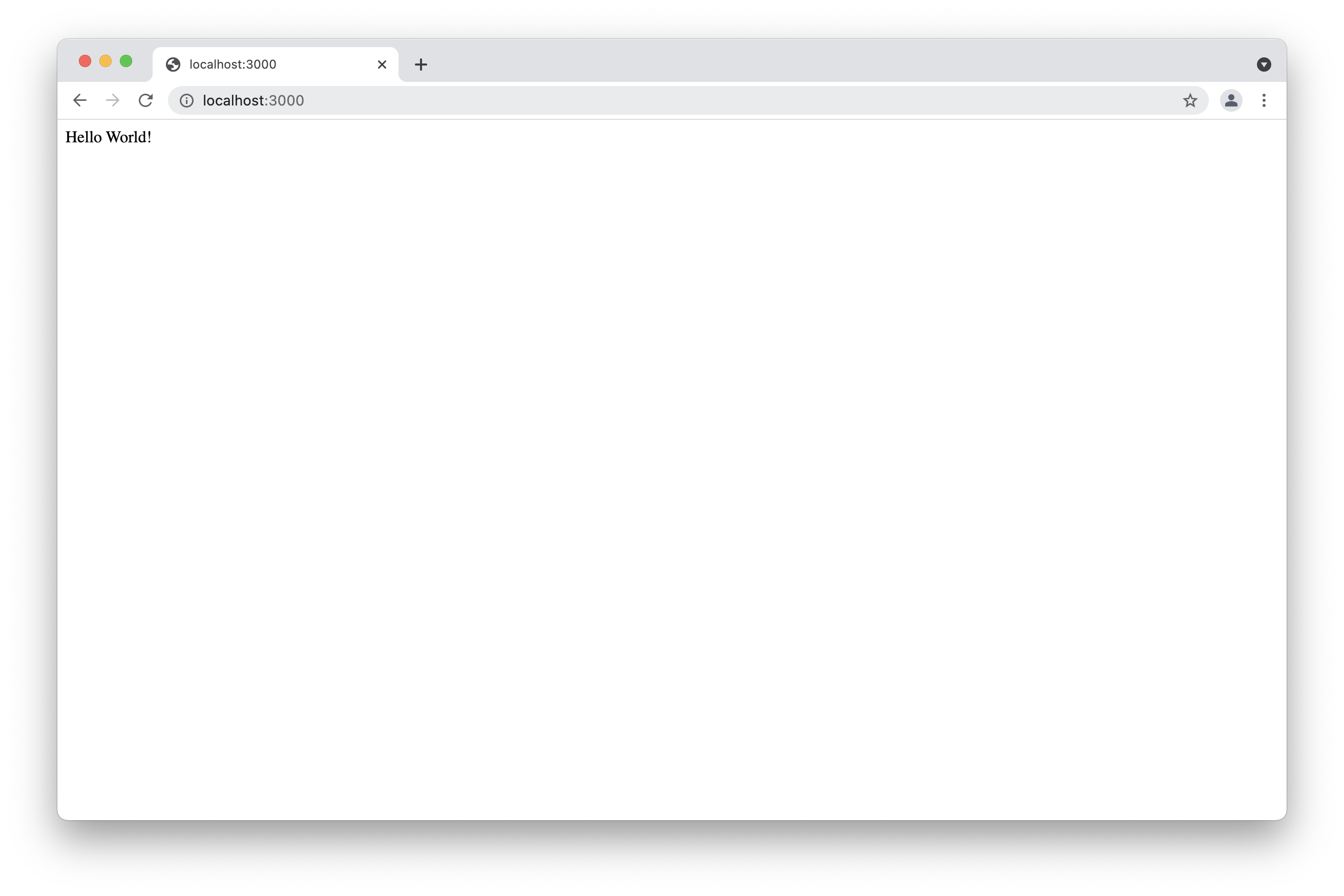
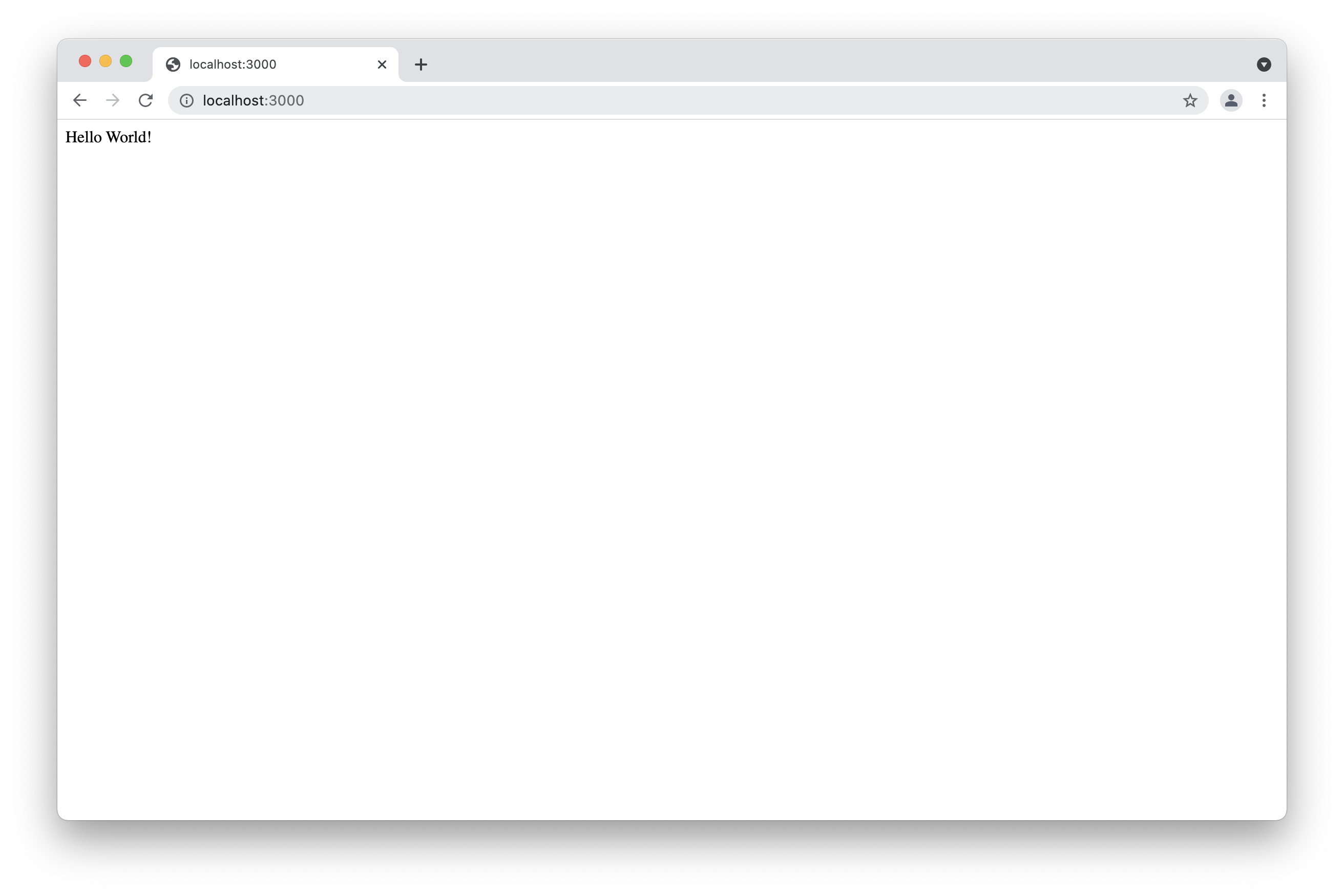
The example above shows how to create a simple server using Nodejs. This example does not use npm. All the used packages are default node packages. As you can see we firstly required the http package to create the route. Then we created a host name and a port. After that we send the status codes and headers. Nodejs Applications listen the port and we get a "Hello World" result in our browser. If you want to see the result, you only need to type in your terminal node app . Then you can go to your favorite browser and type localhost:3000. The result will be similar to the one we show below.
###Introduction to Express###
The example above is the most basic example of a Nodejs server. We can create a lot of things by only using Nodejs; but sometimes it can be tricky. You can see the Nodejs Docs and explore all you can do by only using Nodejs without any additional package. Using only Nodejs can be confusing sometimes. For that reason we have the npm. One of the most popular packages is express, and we are going to learn a lot of express in this tutorial. Let us start learning the express package.
###Installing Express###
When we started this tutorial we set some instructions to install Nodejs and npm. After we installed these softwares we could check their version. In order to install any package we only need to type the command npm install followed by the package name. We can install express as any other package as you can see in the example below.
```shell
npm install express
```
###Creating an Express Application###
To create any Nodejs application using the npm, We first need to create our package.json file. In that package we specify our dependencies and scripts. We can. also specify our dependencies for development as we are going to see below. In order to create the package.json for our application, we need to create a folder with the name of the application we want. We can create the folder in our terminal or manually. After we the folder is created we go to the folder in our terminal and type the command npm init. We can also type the command npm init -y.The example below shows you how the package.json is created.
```shell
npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help init` for definitive documentation on these fields
and exactly what they do.
Use `npm install <pkg>` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
package name: (sample)
version: (1.0.0)
description:
entry point: (index.js) app.js
test command:
git repository:
keywords:
author:
license: (ISC)
About to write to /Users/moe/webapps/node/sample/package.json:
{
"name": "sample",
"version": "1.0.0",
"description": "",
"main": "app.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
Is this OK? (yes) y
```
In the example above you can see how we create the package.json using npm init. We created it and specify everything in the terminal. In case we want to create everything automatically, and then modify it in our text editor. We only need to type the other command that is npm init -y.
###Modifying our Package###
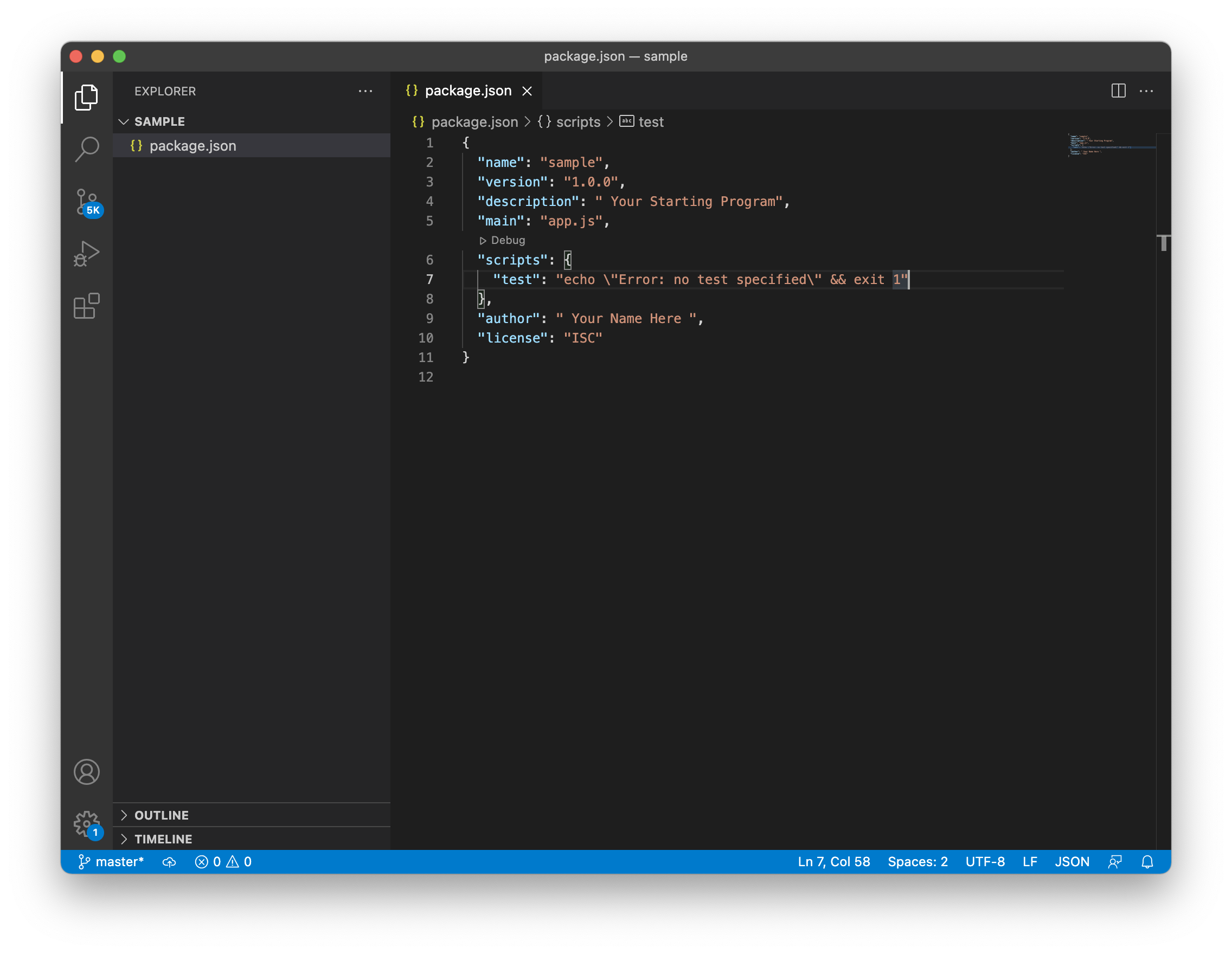
Once we create our package we can modify it using our text editor. No matter if you created it using npm init or npm init -y, the result is similar. You name your application using the name you want. Most times you use the same name we used for our container folder. By default the version is 1.0.0; you are creating a new application. In the description you can add a brief description. The main part is the name of the main file of your application. By default it will be index.js; but I personally name it app.js. You can name it as you want. in the scripts you can type the scripts you are going to use. We are going to explain scripts below. In the author field you can put your name or the name or your company. The image below shows you the package.json using Visual Studio Code.
###Setting Up The Express Application###
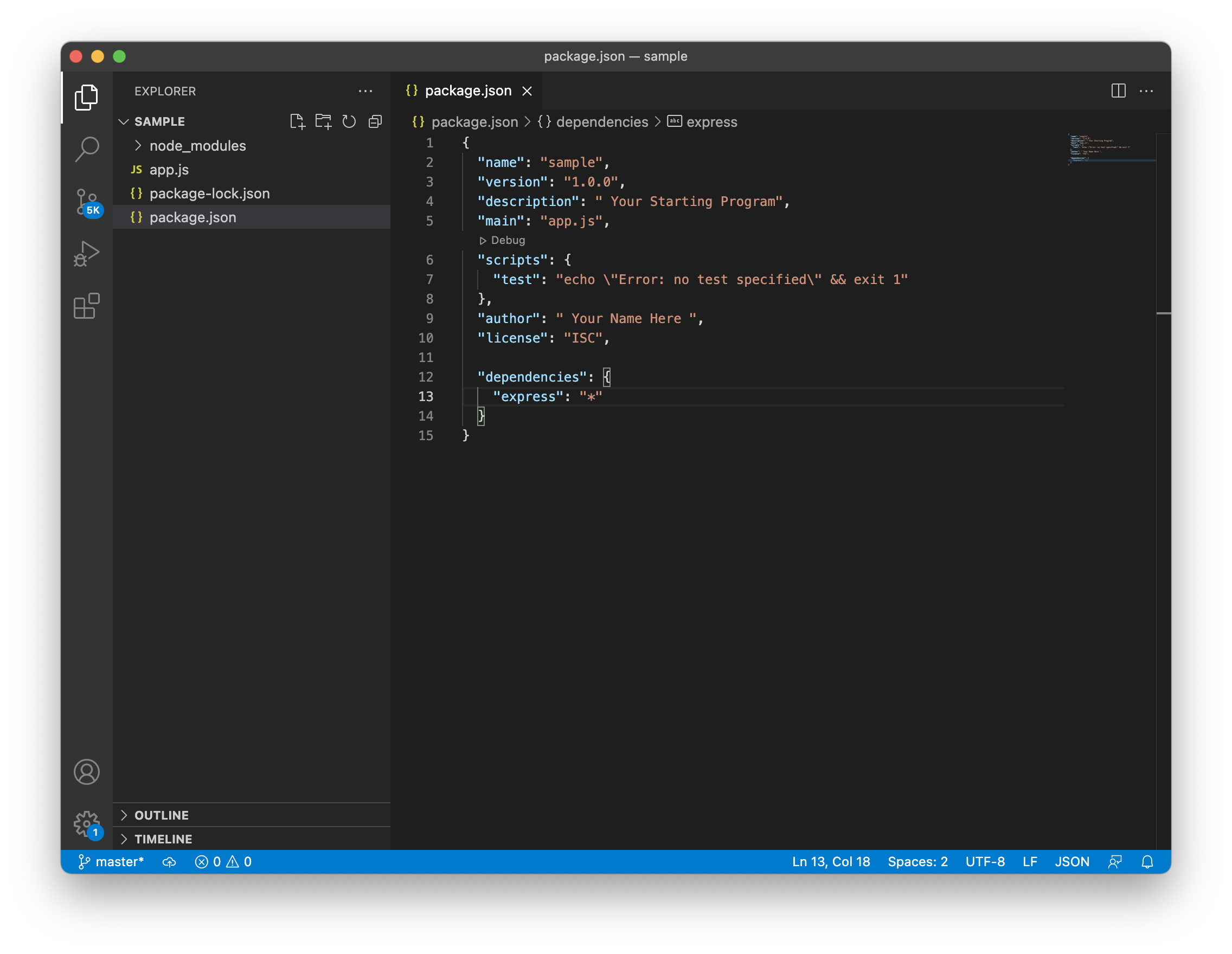
As the package.json specified the name of our application, now we proceed to create it. We said above that default name for any Nodejs application in the package.json is index.js. We can name as we want, and I personally like to name it app.js. In the same folder we create an empty file and name app.js Now we have two files for our application. We also need to install express. We previously showed you how to install express. You only need to go to your terminal and type the command npm install express. That command is going to install the latest version of express in your application. Once express is installed we can check our package.json file and see that another field is added. that field is the dependencies field. and inside is the version of express installed. as we show in the picture below.
```shell
npm install express
```
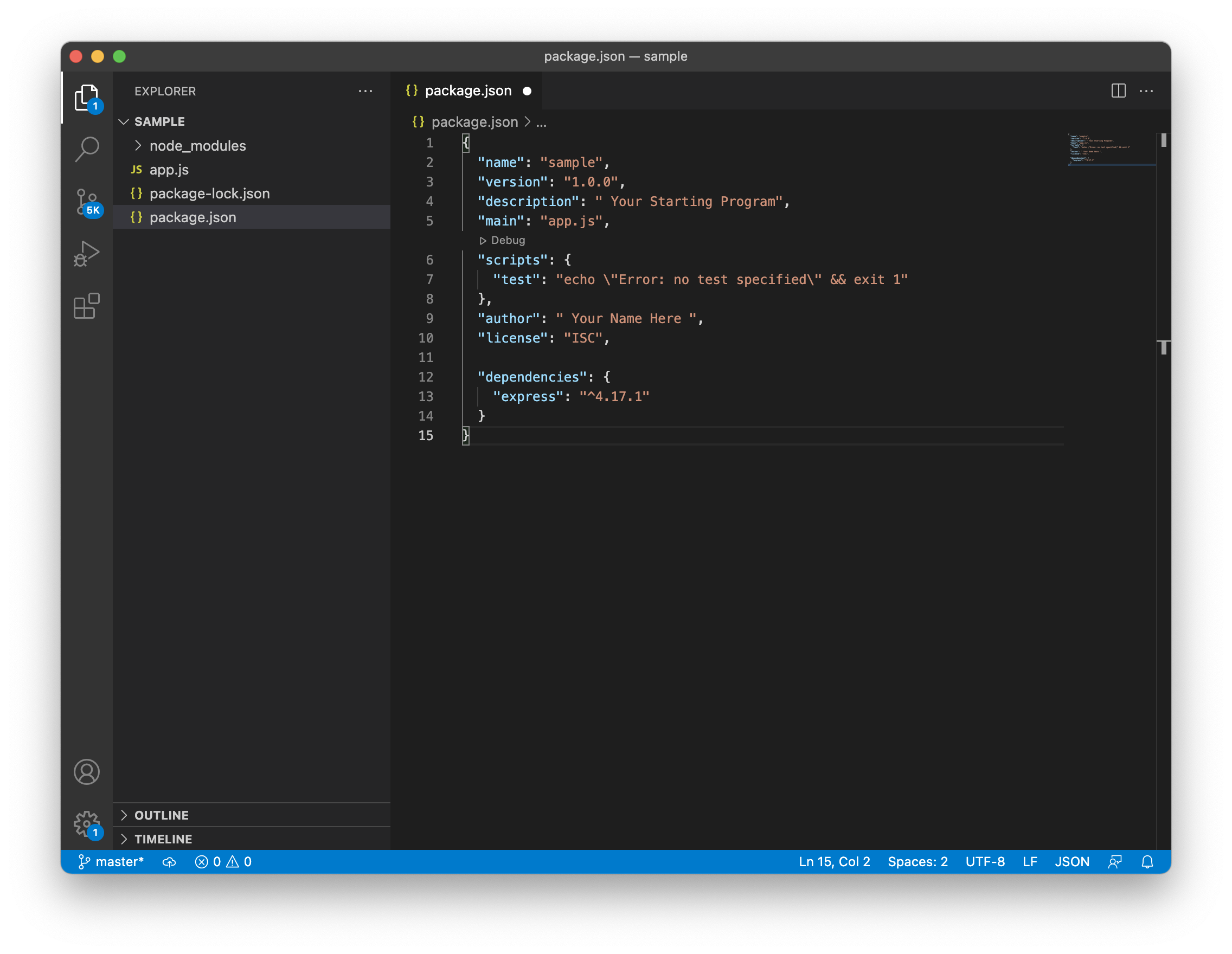
Once we install the first package in this case express, another file will be generated. This file is the package.lock.json. That package describes the exact tree that was generated. That packages also modifies itself when we install more dependencies. We also can create the dependencies field manually in our text editor. We can specify the dependencies we need. Then we type in our terminal npm install. All dependencies will be installed. In case we don't. know the number version of the dependency and we want the latest one. We can type an asterisk * where the number of the version goes. The latest version of the dependency will be installed. Another image below shows you how to do it.
###Creating The Express Application###
After we set everything up in our package.json file and also create the app.js file we can start creating our application. In the app.js file we start importing our packages. As we only have the express package installed. We proceed to import it or required in our app.js creating a variable that import it. To import or require a package we can use the following syntax.
```javascript
import express from 'express'; //ES6 syntax.
let express = require('express');
// Creating the Variable. That is the most used syntax and the one used in this tutorial.
```
After we create the express variable we can create the app. In order to create the app we only use the express variable that we created above as a function. Then we create a variable called app as the one we show below.
``` javascript
let app = express();
```
###Adding a Port for our new Application###
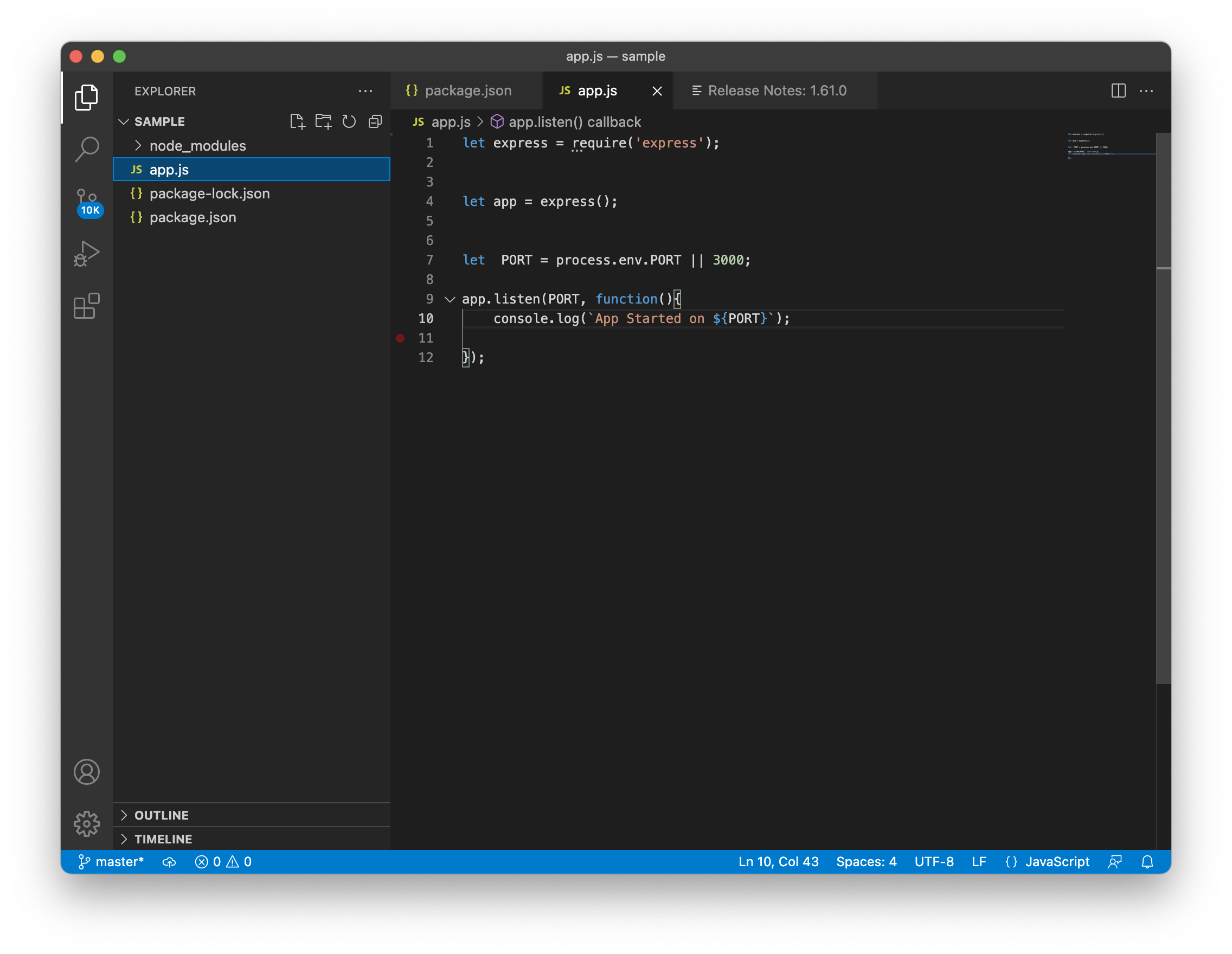
Once we create a new app the app needs to listen to a port. So we can create a variable called port and assign a port number. For development purposes we assign a number; but in order to deploy our application we use the process environment port. After the post creation we can use the listen function and add another callback function to get some results.The example below shows you how to use the process environment port and the number at the same time using a logic OR (||).
```javascript
let PORT = process.env.PORT || 3000;
app.listen(PORT, function(){
console.log(`App Started on ${PORT}`);
// Using Back ticks we can add the variable name to a string using "${}"
});
```
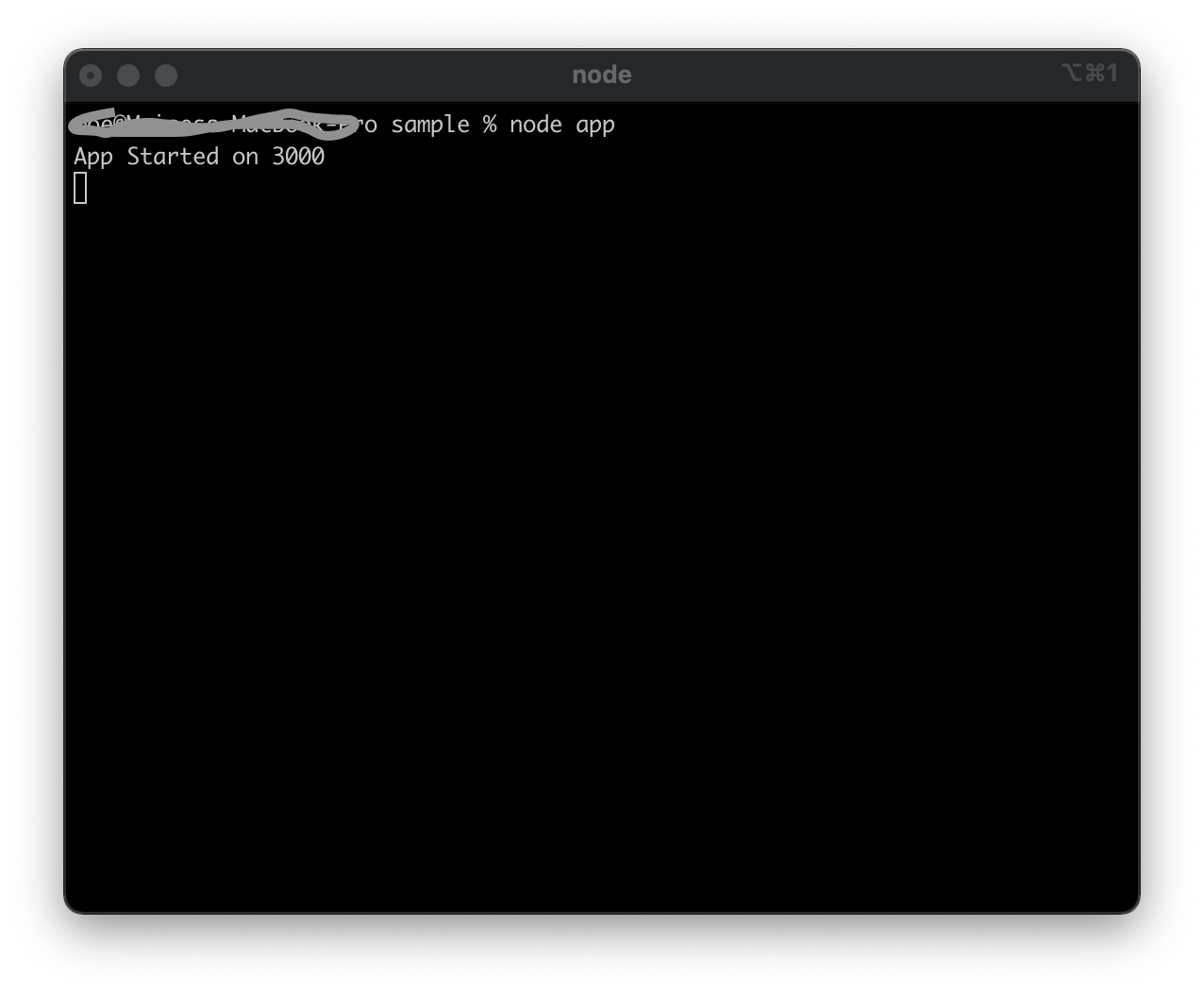
If we followed the same steps we explained here, we created our application. That is a simple application but that is the starting point. In order to run our applications we need to go to our terminal and type node app. Our application will run, and the result will be similar to the one showed in the images below.
###Express Routing###
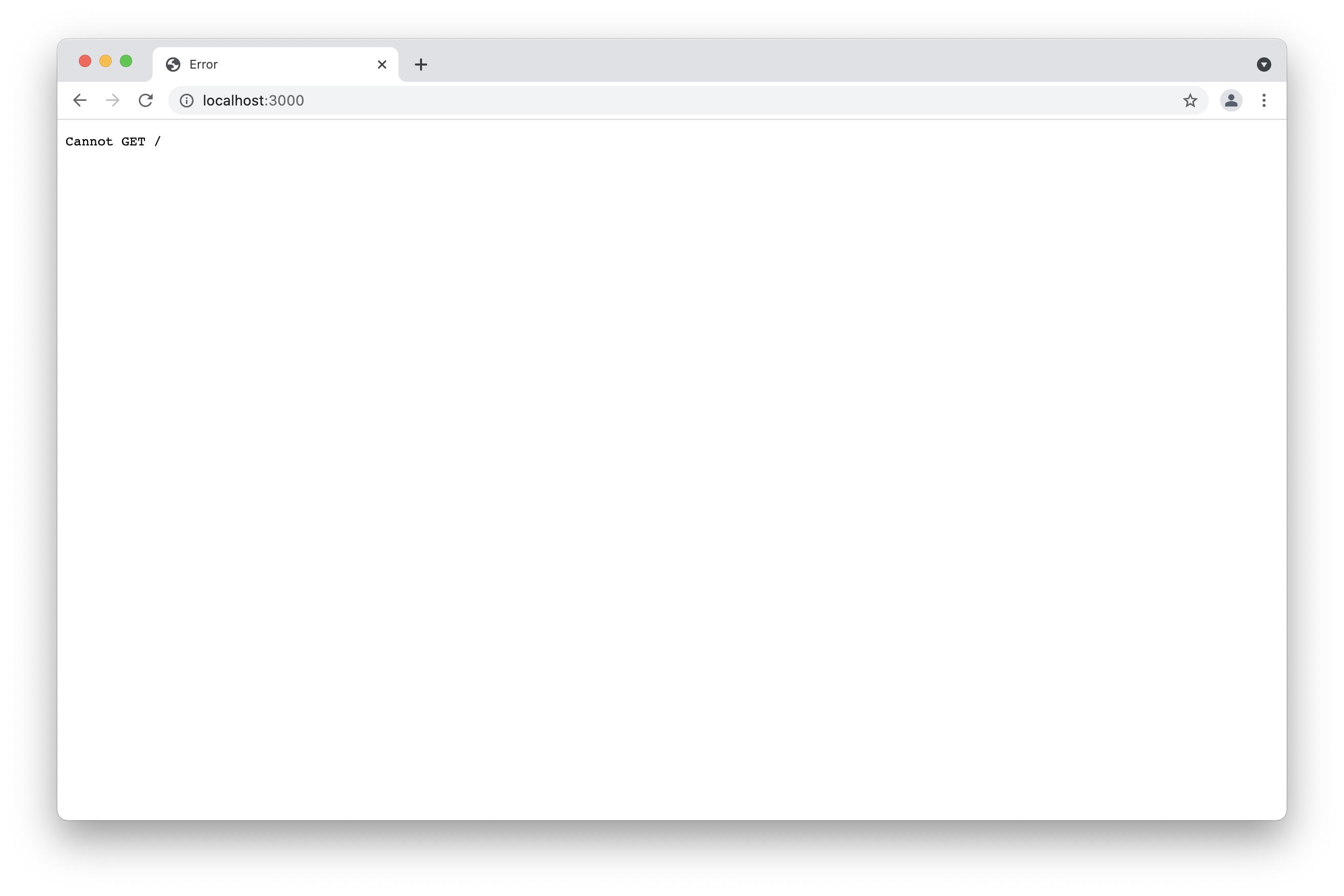
Now that you successfully created your application you can open your browser and go to localhost:3000 and see some results. Well, you can see the application is running; but in the browser you don't have anything. The only result you see in your browser is that the browser cannot get the route. The result is similar to the image below. For that reason we are now going to learn some routing for express applications.
Now it's time to get some routes to our application. In order to add routes we need to apply the HTTP verbs. These verbs are get, post put and delete. In this introduction we are going to use only the get. in a further tutorial we are going to learn how to use all the others. The get method gets the route of the page. the slash symbol( / ) is the home page. We are also going to create some other routes; but let us start with the home route. Most times we start creating routes after the app declaration and before the PORT. If you add the following code to your app you are going to send a Hello World! to the browser.
```javascript
app.get('/', function(req, res){
res.send("Hello World!");
});
```
You can see in the code we added above that we are using the get method as a function. Then we add the home route ('/'). After that we created a callback function with the parameters req and res. These parameters are also Nodejs built in functions. The req parameter requires information, and the res parameter can send information to your browser. You are going to learn deeper about these parameters in a further tutorial. If you added the code to your application your result will be similar to the one we show you below.
###The Express static Public folder###
Now you could send some information to your browser; but that is not the result you want in your application. We can create a static folder where we can put our HTML files. In that folder we can also put our CSS and Javascript files. We can name the folder as we want. Most times we name the folder the public folder. To add the public folder to your app you need to add the following code.
```javascript
app.use(express.static('public')); // Using Express static. The name of the folder is public.
```
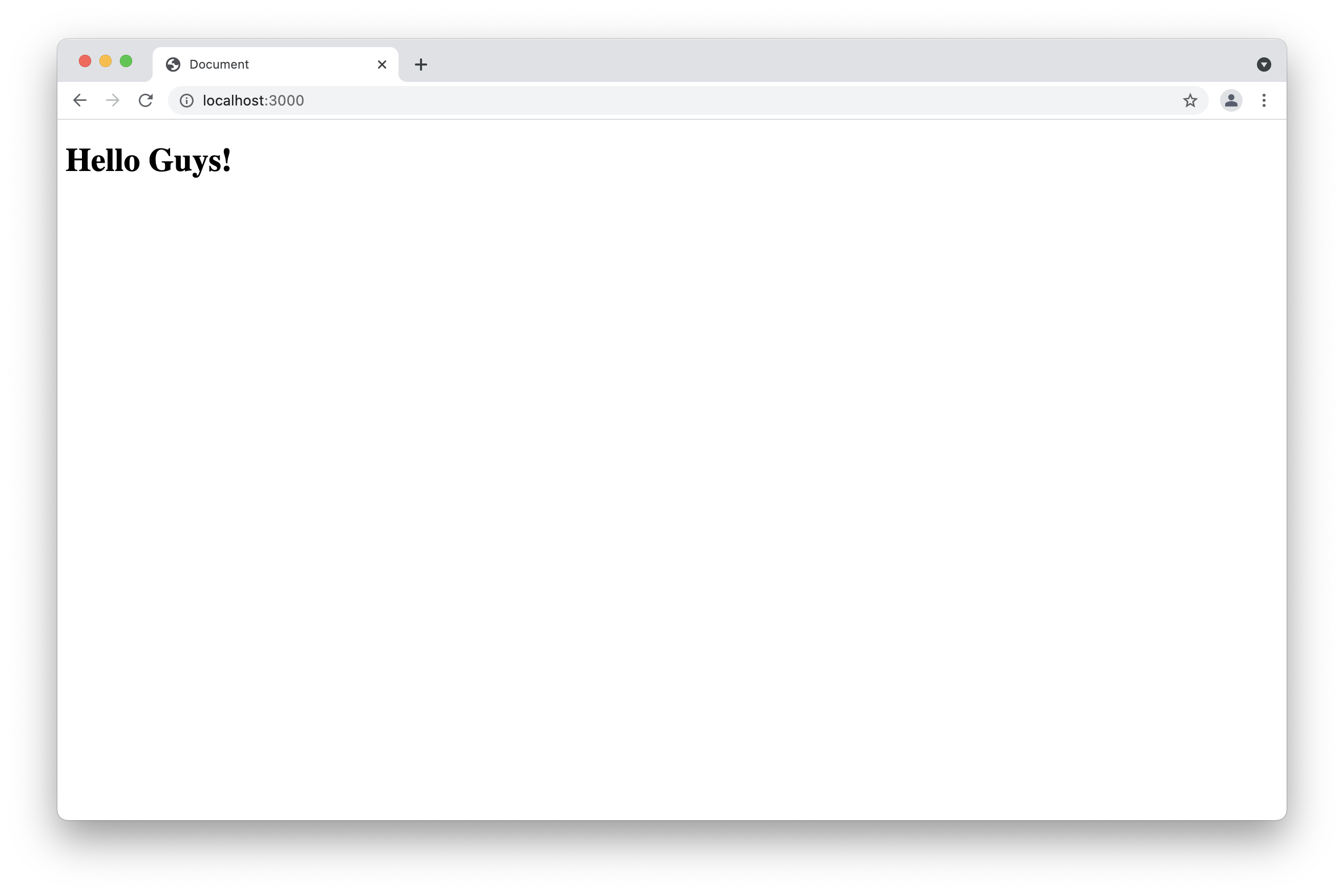
After we create the static folder we can create a file called index.html. By now we are only going to display a "Hello Guys" heading as the result. You can create the html file you want in your html. You only need to name it index.htm so express recognizes the file. now if you reset your application using CTRL+C, and restart it again. Then you go to your browser localhost:3000, and see the new result. ( Make sure you comment out the first route.)
###Installing New Dependencies###
In express applications we can install as many dependencies as we want. We only need to type in our terminal npm install followed by package name. Once we install the package, it will be added to de dependencies in your package.json file. Now let's install one package. In previous examples you saw that you had to reset terminal when you modified your code. This package is going to avoid the need of resetting your application as you add code. This package is<a href="https://nodemon.io"> Nodemon</a>. You only need to type the following command, and your application will be ready.
```shell
npm install nodemon
```
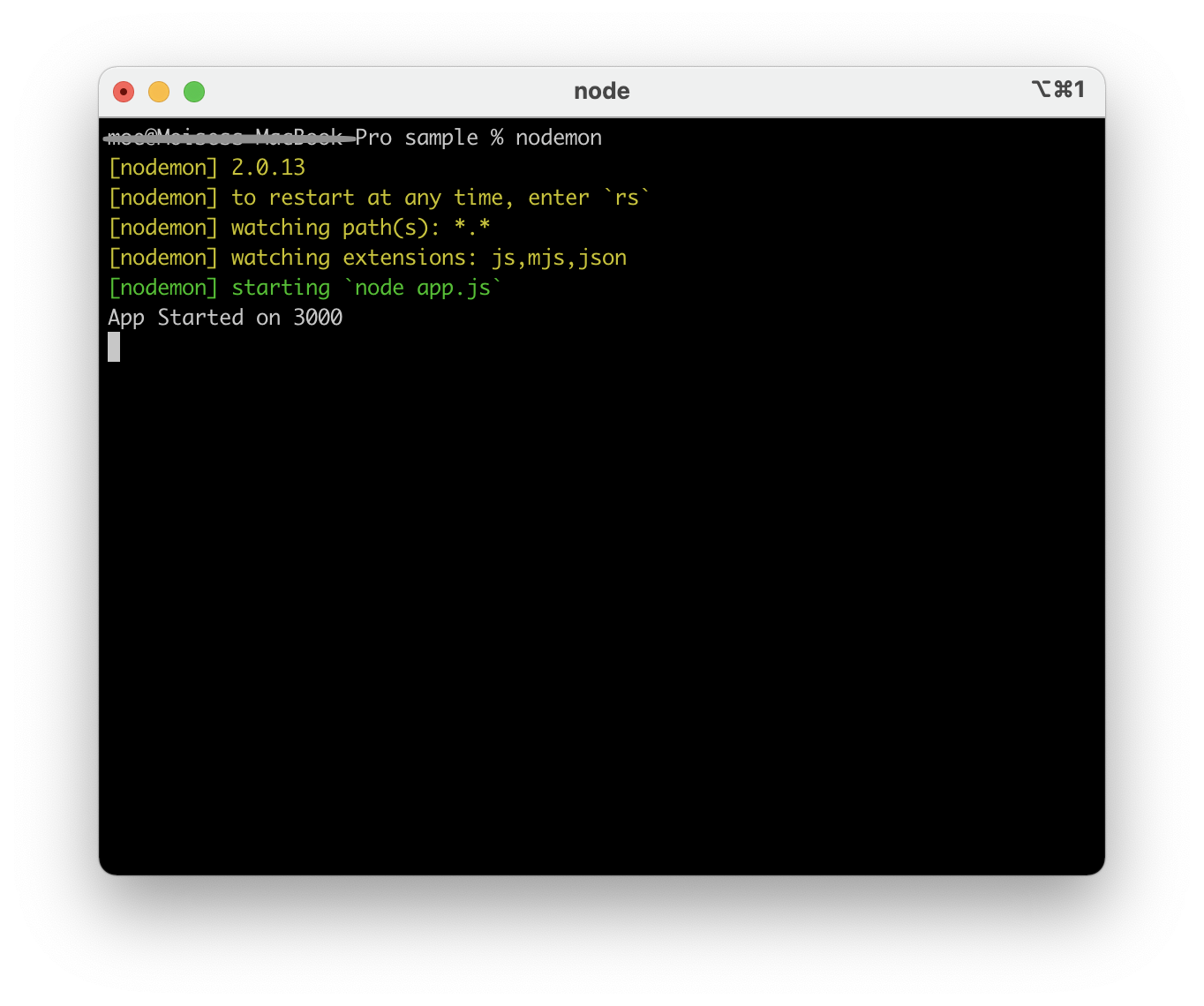
After you installed nodemon, you only need to type nodemon in your terminal in order to use it. Nodemon will reset the application after you add some changes and saved them. In case it does not run on the first try, you need to install the package globally using the following command.
```shell
npm install -g nodemon
OR
sudo npm install -g nodemon
```
###Working with Scripts###
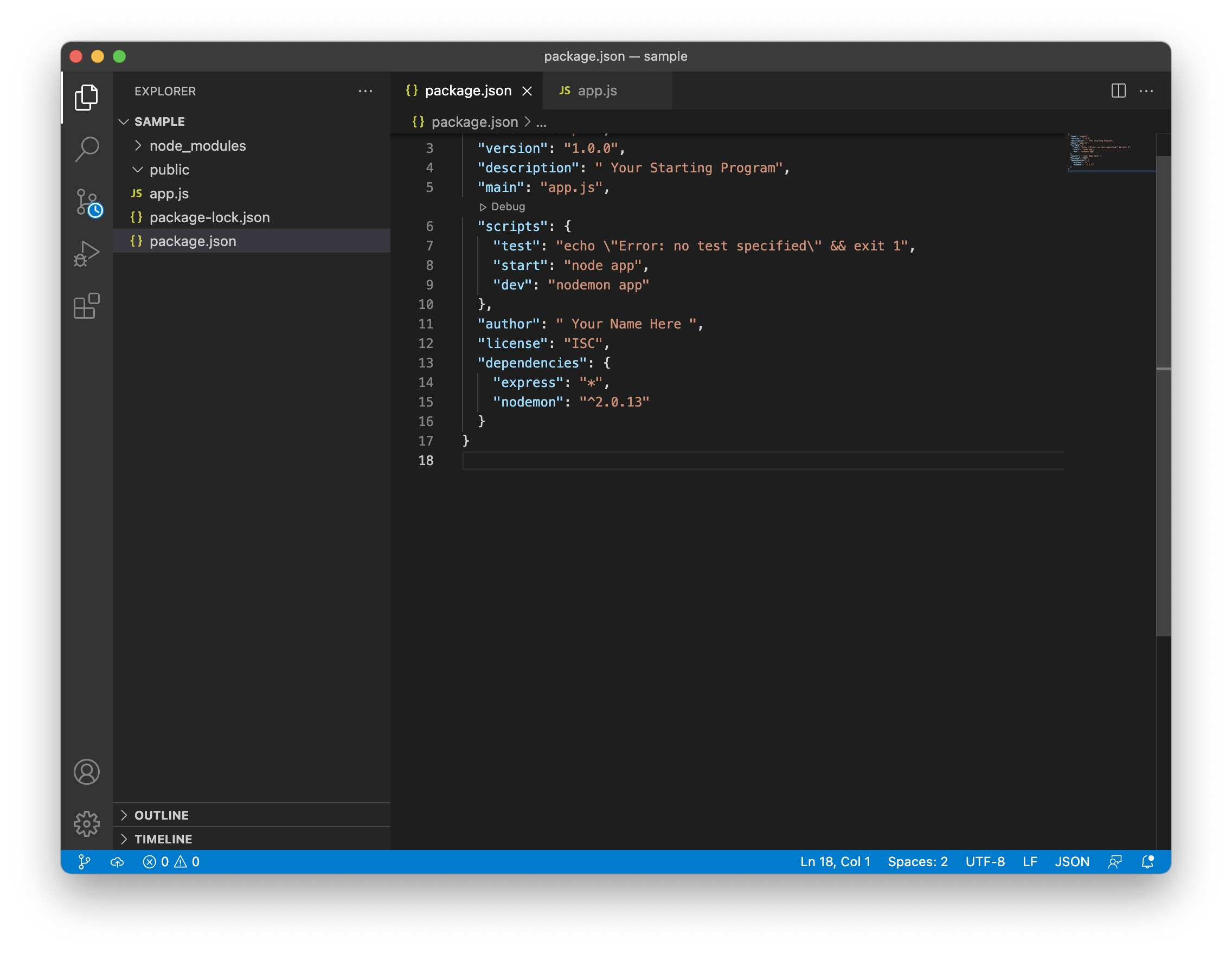
When you first saw your package.json you noted there is a field called scripts. In Nodejs these scripts refer to commands we type in our terminal. They are not like the regular JavaScript scripts. To run any script you created you only need to type the command npm run followed by your script name. When you first create the package.json you can see there is a test script automatically created. Now let us create some scripts for our package.json The first script we are going to create is the start script. Most deployment process environment use the start script by default to start any Nodejs Application. Then we are going to create a dev script in order to use nodemon. The image below shows the modified package.json
```shell
npm start //starts the application
npm run dev // starts the application via nodemon
```
### Express Template Engines###
Besides using plain HTML in the public folder, we can use some view or template engines. That practice is very useful while creating express applications. Express has many view engines such as ejs, jade, handlebars, pug etc. You can see more information about view engines in <a href="https://expressjs.com/en/resources/template-engines.html">their website</a>. My Favorite one is ejs, because that one is similar to HTML. In order to add a view engine to our application, we first proceed to install the package. In this case we install ejs and then set the view engine in our app.js using the app.set() function. After that we can also set a views folder as you can see in the example below.
```shell
npm install ejs
```
``` javascript
app.set('view engine', 'ejs'); //setting ejs as our view engine
app.set('views', 'views'); // setting the views folder
```
After you set the view engine and views folder to your application, you proceed to create the views folder. If you are using a view engine is because you are not going to use the index file that you created in the public folder. You can delete the file and keep the folder for styling and scripts. Now in your views folder you can create a new index file. In that file you use the file extension ejs. The syntax will be similar to HTML. In a further tutorial we are going to show you how to deal with forms and databases using Nodejs and template engines.
###Routes to Views###
The previous section shows how to set a view engine and create the views. In order to see the views in your browser, you need to add routes to your views. That is an easy task in express. When you used the app.get('/') function you also used the res.send() method. In order to display a view from your views folder, you need to change the method to the res.render method. That is going to render the view in your route. The example below shows you how to render a view called index to our home route.
```javascript
app.get('/', function(req, res){
res.render('index');
});
```
###Using the Express Router###
Imagine you have several routes in your app. In express we have pre build router that we can use for these cases. Even if you don't have too many routes, using the router is a good practice. Most times we create another folder called routes for our routes files. After we create the folder we can add as many files as we need. In this case we are creating a file called index.js. In this file we are going to use the pre built express router. Then we can export the file to our app.js file. The example below shows you how to use the express router.
```
let express = require('express');
let router = express.Router();
router.get('/', function(req, res){
res.render('index');
});
module.exports = router;
```
Now we can import the route in our app.js file. We need to make sure we delete the route we had before to avoid errors in our applications. Below you can see how to add the route to the app.js
```javascript
let index = require('./routes/index'); // importing the route from the routes folder
app.use('/', index); Implementing our route with the use() function.
```
As we said before you can use as many routes as you want. We can create another file in our routes folder similar to the one that we created before. We are going to call this file users.js. Then we can import it to our app.js as we can see the other example below.
```javascript
let users = require('./routes/users'); // Importing the users route
app.use('/users', users); // Adding the route to our application.
```
If we add all the changes to the app.js file; the file will be similar to the one we show you in the following image.
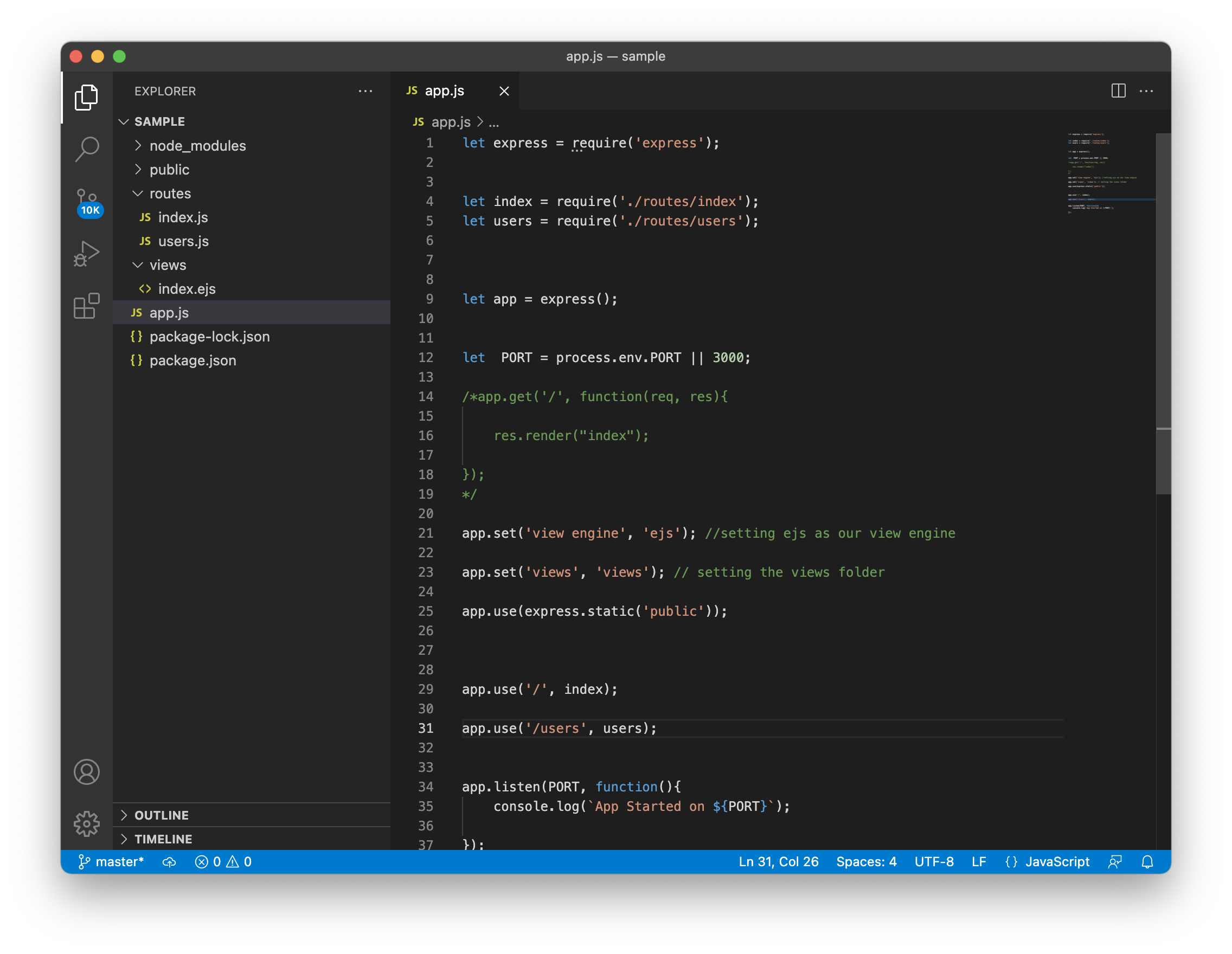
###Express Generator###
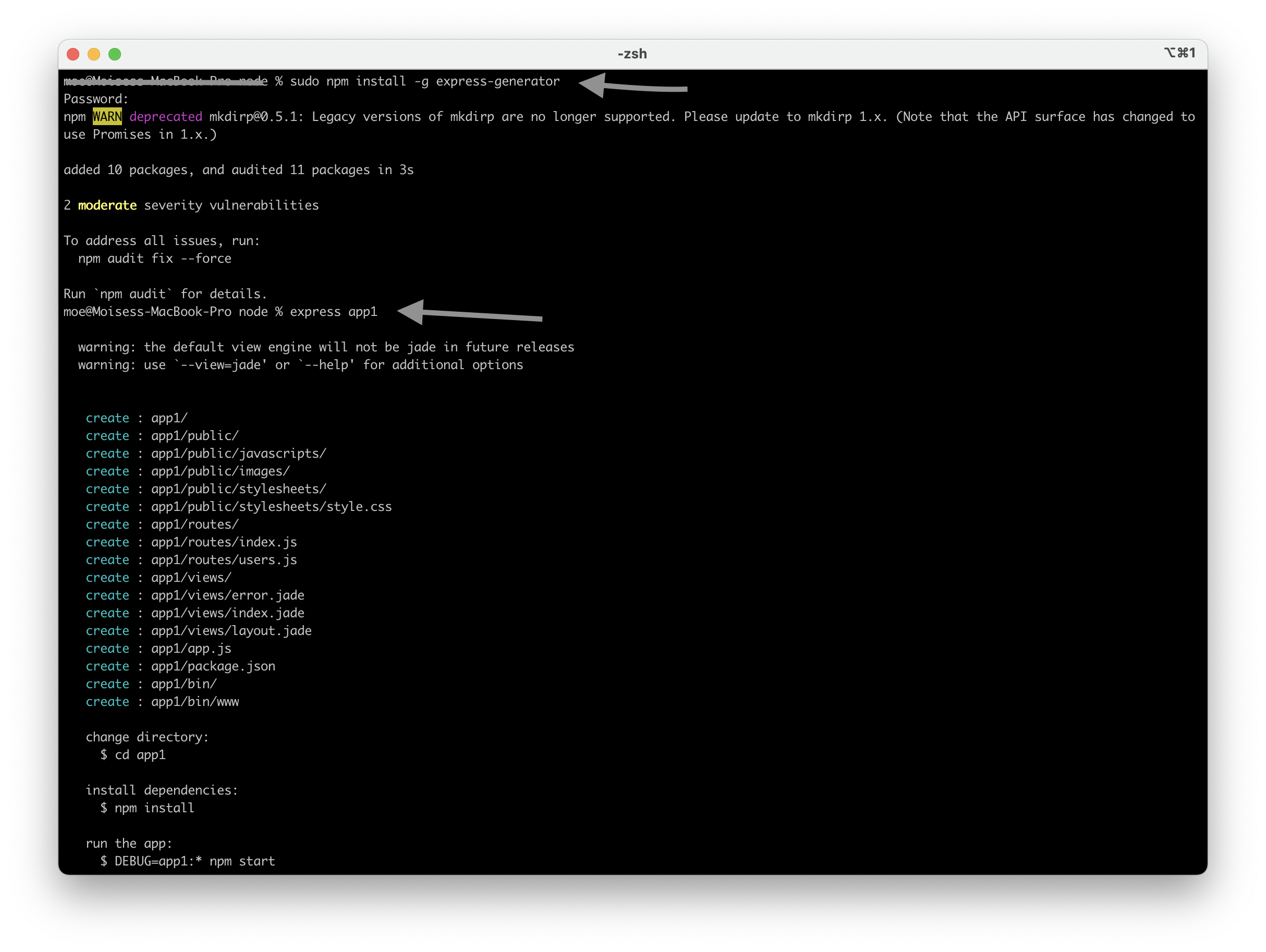
There is a node package called express-generator. That package serves as a shortcut to create an express application. That package will create the package.json, the app.js , and many other required files. It will also add a view engine though we need to install all the dependencies using the npm install command. To use the express generator we first proceed to install it using npm install express-generator. Now we can create an application using express as a command as express app1. Then we install dependencies as we stated before. The application generated with express generator listen port 3000 by default. the image below shows you how to use the express generator.
###Conclusion###
This tutorial is an introduction to Nodejs and Express. We focused more on express because learning a package is a great way to start learning Nodejs and more of its packages. Express is a complete package that we can use to create any application. This is only an introduction to Nodejs and Express. At this time we are working on some others more advance tutorials. Thank you for reading our tutorials, and we hope you learn a lot in this tutorial.
You can find more information about Nodejs in their <a href="https://nodejs.org/en/docs/">Documentation</a>. Also you can find information about express in the <a href="https://expressjs.com/">Express Website</a>. The <a href="https://developer.mozilla.org/en-US/docs/Learn/Server-side/Express_Nodejs">Express MDN </a> also
More at <a href="https://moeslink.com">Moe's Link </a>
| moreno8423 |
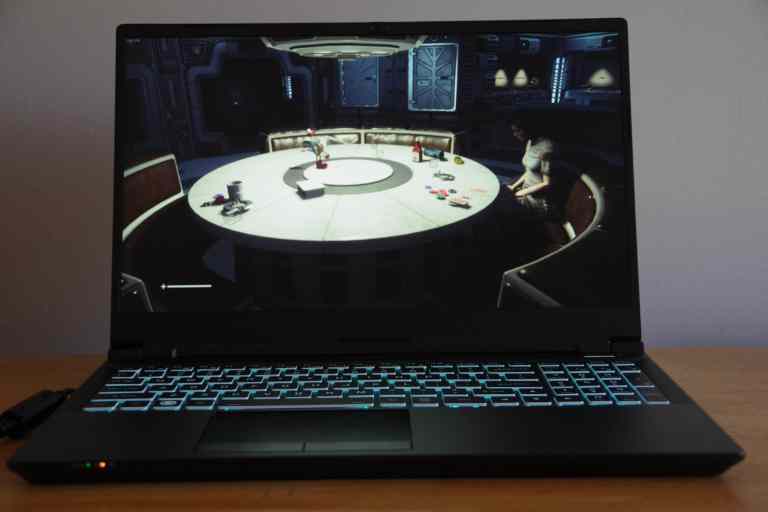
902,464 | Kubuntu Focus M2 Linux Laptop Review | Typically a Linux machine is a mostly do-it-yourself (DIY) endeavor. You’re usually on your own... | 0 | 2021-11-18T23:39:15 | https://techuplife.com/kubuntu-focus-m2-review/ | linux, ubuntu | Typically a Linux machine is a mostly do-it-yourself (DIY) endeavor. You’re usually on your own installing an operating system (OS), regardless of whether you’re using a pre-built machine or custom build. However, there are plenty of off-the-shelf Linux laptops and desktops available. The Kubuntu Focus is an outstanding Linux laptop. It comes with the Ubuntu-based Kubuntu Linux distribution (distro) pre-loaded, boasts an impressive spec sheet, and exceptional build quality. This combination makes is a great choice for programmers, gamers, and anyone switching from Windows or macOS to Linux. But is the [Kubuntu Focus M2](https://kfocus.org/) right for you? Find out in my hands-on review!
What is the Kubuntu Focus M2 – Kubuntu Focus Laptop Overview
------------------------------------------------------------

The [Kubuntu Focus M2](https://kfocus.org/) is a Linux laptop. It ships with the Kubuntu Linux distro pre-installed and, as such, runs Ubuntu with the KDE Plasma Desktop rather than vanilla Ubuntu’s GNOME desktop environment. There’s a 15.6-inch 1080p full high-definition (FHD) 144Hz display.
Under the hood, you’ll find an Intel 11th gen 8-core processor. You can outfit the Kubuntu Focus M2 gen 3 with up to 64GB of 3200MHz RAM, as high as 4TB of NVMe [SSD](https://techuplife.com/what-is-an-ssd/) storage, and up to an NVIDIA GeForce RTX 3080 with a whopping 16GB of GDDR6 video RAM (vRAM).
On the networking side, the Focus M2 sports dual-band 5GHz ac/a/b/g/n/ax Wi-Fi 6, Gigabit Ethernet, and Bluetooth 5.2. Inputs/outputs include a USB 3.0 Type-A, two USB 3.2 Type-A hosts, a 3.5mm audio jack, 3.5mm mic input, HDMI 2.0 port, 40Gbps Thunderbolt USB-C jack, and DisplayPort 1.4.
There’s a sturdy aluminum chassis. Its keyboard features RGB backlighting with over 65,000 different color combinations and 4mm keyboard travel. Pricing starts at $1,945 USD for the Kubuntu Focus M2 gen 3 which gets you an Intel Core i7 11800H, NVIDIA RTX 3060, 16GB of RAM, and 250GB NVMe SSD. You can max the Focus M2 out with the Beast preset which comes with an Intel Core i7 11800H CPU, NVIDIA RTX 3080, 4TB NVMe storage total (2x 2TB NVMe SSDs), and 64GB of RAM.
Kubuntu Focus M2 Specs
----------------------
* CPU: Intel Core i7 11800H
* GPU: Up to NVIDIA GeForce RTX 3080 (choice of GeForce RTX 3060, 3070, 3080)
* RAM: Up to 64GB 3200MHz dual-channel RAM (base 16GB)
* 15.6-inch 1080p 144Hz display
* Aluminium chassis
* RGB backlit keyboard with over 65,000 color combinations
* I/O: 1 x USB 3.0 Type-A, 2 x USB 3.2 Type-A hosts, 1 x 3.5mm audio jack, 1 x 3.5mm mic input, 1 x HDMI 2.0 port, 1 x 40Gbps Thunderbolt USB-C jack, 1 x DisplayPort 1.4
* Networking/communication: Dual-band 5GHz ac/a/b/g/n/ax Wi-Fi 6, Gigabit Ethernet, Bluetooth 5.2, Realtek RTL8168 Gigabit Ethernet jack
[Buy from Kubuntu](https://kfocus.org/)
Kubuntu Focus M2 Review Verdict
-------------------------------
The Kubuntu Focus M2 is an outstanding Linux laptop. I liked that it came with Kubuntu Linux preloaded. Although it’s easy enough to install most Ubuntu and Debian-based Linux distros yourself, I appreciated the ability to fire up the Focus M2 and begin using it right away. Kubuntu is a real treat to use, and several useful apps including the Google Chrome web browser and Steam video game client come preinstalled.
Build quality is excellent. I found the all-metal chassis sturdy and durable. The lid is emblazoned with the Kubuntu logo, and the keyboard includes a super key sporting the Kubuntu logo as well. Keyboard travel at 4mm is great. Writing and editing felt natural. The RGB backlit keyboard was gorgeous, and I enjoyed setting custom colors as well as brightness.

The 1080p FHD 144Hz IPS display boasts fantastic color accuracy along with good viewing angles. Everything from gaming and watching movies to general web browsing looks lovely. My review unit came with an Intel Core i7 11800H CPU, NVIDIA GeForce RTX 3070 GPU, and 16GB of RAM.
In my testing, gaming was buttery smooth for titles such as _Rise of the Tomb Raider_, _Shadow of the Tomb Raider_, and _Alien: Isolation_. Similarly, spinning up Docker instances was blisteringly fast. Therefore, the Kubuntu Focus M2 is a versatile machine that should satisfy a variety of users including gamers, programmers, and system administrators (sysadmins).
I was impressed with the array of different ports. With three USB ports, HDMI and DisplayPort, 3.5mm headphone/mic jacks, Thunderbolt USB-C, and Gigabit Ethernet, there’s generous connectivity. And Wi-Fi 6 alongside Bluetooth 5.2 offer fast wireless networking. The well-ventilated bottom hatch is easy to remove for simple upgrades, a nice touch in an age where laptops are becoming increasingly difficult to open up.
Unfortunately, the metal chassis is a bit of a fingerprint magnet. Additionally, I found the trackpad somewhat small and tough. Since the touchpad isn’t clickable, it took some getting used to. Under full load, the fans do kick in and are slightly noticeable, though this is common to pretty much all gaming laptops. While the Kubuntu Focus does feature switchable graphics, changing between the dedicated GPU and integrated GPU requires restarting the desktop environment. Though that’s a minor convenience, it’s not the end of the world.
Ultimately, the Kubuntu Focus M2 is a superb [Linux](https://techuplife.com/how-to-free-up-more-space-in-boot-on-ubuntu/) laptop. Regardless of whether I was gaming, programming, writing, or simply browsing the web, the Focus was more than up to the task. A few minor quirks don’t detract from the overall excellence of the M2, making it arguably the best Linux laptop on the market.
Kubuntu Focus M2 – Design and Build
-----------------------------------

The Kubuntu Focus M2 features a solidly built aluminum chassis. Its lid includes the Kubuntu logo. Around front, you’ll find a set of status indicator LED lights.

The right-hand side of the laptop includes a pair of USB 3.2 Type-A ports and a Gigabit Ethernet LAN jack.

In back, the Focus M2 sports HDMI 2.0 and DisplayPort 1.4 video outputs. There’s also a barrel jack power connector.

A Kensington lock port, USB 3.0 Type-A, 3.5mm headphone out jack, and 3.5mm mic input grace the left-hand side of the unit.

Underneath, there’s a well-ventilated grille that covers the RAM, NVMe SSD, and cooling fans.
The keyboard boasts great key travel of 4mm. Its RGB led backlighting can easily be customized using a hotkey.

And the keypad is pretty sizable, though not nearly as big as the touchpad on my Razer Blade 15 or Apple’s MacBook Pro.

Construction is stellar all-around. The metal chassis is sturdy, there’s little to no flex to the screen, the keyboard is comfortable to type on, its bottom panel is well-ventilated, and you’ll find ample connection ports.
Kubuntu Focus M2 Gaming Performance
-----------------------------------

Gaming performance is extremely impressive. On my NVIDIA GeForce RTX 3070-equipped system, I clocked an average of around 160 frames per second (FPS) in _Shadow of the Tomb Raider_ at the highest preset in 1080p.

In _Rise of the Tomb Raider_, I averaged about 150 FPS in the highest preset. Visuals were buttery smooth.

Playing _Alien Isolation_ maxed out on ultra, I averaged around 140 frames per second. The Kubuntu Focus churned out gorgeous eyecandy, replicating a lifelike recreation of the Nostromo.

Your experience will vary depending on which GPU you select – the RTX 3060, 3070, or 3080. While the 3080 can handle 4K on ultra or high for most modern AAA titles, the RTX 3070 is best suited to 1080p or 1440p. For Linux gaming, the Kubuntu Focus M2 is a great choice.
**Kubuntu Focus M2 gaming benchmarks:**
* _Alien Isolation_ – 144 FPS average, 1080p ultra
* _Shadow of the Tomb Raider_ – 160 FPS average, 1080p highest preset
* _Rise of the Tomb Raider_– 150 FPS, 1080p average, highest preset
Kubuntu Focus M2 – Software Experience
--------------------------------------

While the Focus M2 delivers wonderful hardware, it’s the software experience that makes this an incredible Linux laptop. Ubuntu and its derivatives tend to be fairly user-friendly on the whole. But Kubuntu takes this to an entirely new level. When you first boot into Kubuntu, there’s a helpful software setup wizard which runs. It walks you through some initial configuration including changing your password, choosing an avatar, and enabling various optional software packages. For instance, Kubuntu prompts you to turn on Dropbox, enable InSync, and turn on the open-source password manager KeePassXC.
Moreover, there’s a helpful list of recommended applications. You can launch this with ease from the taskbar. Suggested [software options](https://techuplife.com/best-linux-media-server-software-options/) include Steam, Kubernetes, Lutris (for playing Windows games with WINE), JetBrains Toolbox, the LibreOffice suite, and more. I appreciated the software wizard and recommended apps list. Although most Linux enthusiasts should have no issue installing different apps, these features make the Kubuntu Focus M2 great for newcomers switching from Windows or macOS to Linux.
Since Kubuntu utilizes the DPKG package manager, downloading apps is pretty fast. The KDE Plasma desktop is an excellent, visually pleasing graphical user interface (GUI). KDE looks similar to Windows for a familiar experience that should ease the transition from a non-Linux OS. The KDE Plasma desktop environment uses few system resources for a snappy experience. Loading up apps and switching windows was seamless.
Privacy Features on the Kubuntu Focus M2
----------------------------------------
The Kubuntu Focus M2 touts a slew of safety and security features. You’ll find full-disk encryption, optional pre-configured YubiKey 5 NFC two-factor authentication (2FA), and a BIOS Trusted Platform Module (TPM) 2.0 disable option. Its YubiKey 5 NFC 2FA support lets you enable hardware-based authentication for bolstered security. There’s even KeePassXC open-source password manager compatibility.
Outside of its robust software security features, the Focus M2 packs hardware security goodies as well. There’s a Kensington lock port for securing your Linux laptop to a desk. And its HD webcam has a physical privacy shutter cover.
**Privacy features:**
* Full-disk encryption
* YubiKey 5 NFC 2FA
* Disable BIOS TPM 2.0
* Kensington lock
* Physical webcam privacy cover
Should You Get the Kubuntu Focus M2 – Who is the Kubuntu Focus M2 For?
----------------------------------------------------------------------
So now on to the real question: Should you get the Kubuntu Focus M2? As a versatile Linux laptop, the Focus is a compelling choice for all sorts of users. Because of its NVIDIA GPU options, the Focus M2 is great for gamers, designers, and video editors. Steam comes preinstalled for gaming. Under the curated apps list, you’ll find Blender for 3D modeling as well as Lutris for running Windows games on Linux with WINE.
Since Linux is an [extremely popular environment for programmers and developers](https://dzone.com/articles/best-linux-distros-for-developers). As such, the Focus M2 is a fantastic choice for devs. Spinning up Docker containers is blisteringly fast, with generally under two-minute install times. That’s mostly because the Focus M2 runs Linux natively, so it eliminates any filesystem emulation layers like you’ll find on macOS or Windows. And there’s a whole host of different programming tools available including Kubernetes, JetBrains Toolbox, IDEs ([integrated development environments](https://dzone.com/articles/best-raspberry-pi-ides)) like IntelliJ or PyCharm, VScode, and more.
Furthermore, with its extremely user-friendly Linux OS in Kubuntu, the Focus M2 is a solid choice for anyone switching from Windows or macOS. Although it’s a full-fledged Linux distro, Kubuntu lets you install apps, run updates, and customize your system without needing to touch the command line much.
**Who is the Kubuntu Focus M2 for:**
* Gamers
* Developers/programmers
* Designers/animators/3D modelers
* Anyone switching from macOS or Windows to Linux
Kubuntu Focus M2 Review – Final Thoughts
----------------------------------------
There’s a lot to love about the Kubuntu Focus M2 third-generation. It offers a spectacular, user-friendly experience that’s suitable for everyone including gamers, programmers, sysadmins, and designers. The pre-loaded Kubuntu Linux OS is easy to use and great for anyone switching from macOS or Windows to Linux. Gaming performance is superb, and many apps for development like Docker benefit from the native Linux environment. With Linux preloaded, the Focus M2 is ready to use out-of-the-box. You can outfit the Focus with outstanding hardware all the way up to an NVIDIA RTX 3080, 4TB of NVMe SSD storage, and 64GB of RAM.
The touchpad is a bit stiff, though I eventually got used to it. While the Focus includes switchable graphics, you’ll have to restart the desktop environment in order to toggle between the high-performance GPU and energy-efficient integrated graphics chip. Although that’s not the end of the world, it’s somewhat cumbersome. Admittedly, the price (beginning at $1,945) is a bit high. However, it’s about in line with premium laptops. For instance, the RTX 30-series Razer Blade 15 starts around $1,700 while the MacBook Pro 14-inch normally starts at $1,999. Thus, the Focus M2’s price tag is aligned with the competition. And for the unparalleled experience of a pre-installed Linux laptop, it’s well worth the cost.
In the end, the Kubuntu Focus is an extraordinary piece of kit. It should satisfy a variety of different needs and makes getting started a breeze. Whether you’re a hardcore gamer, sysadmin, developer, designer, or merely a curious new Linux user, the Kubuntu Focus M2 is a spectacular machine, and arguably the best Linux laptop on the planet.
**Your turn: Which Linux laptops are you using, and what Linux distros are you running?** | mitchellclong |
866,768 | How to make a simple slider component in React | A very common component to use in forms or to receive numeric input with a non-arbitrary range is... | 0 | 2021-10-17T17:12:10 | https://relatablecode.com/how-to-make-a-simple-slider-component-in-react/ | react, slider | ---
title: How to make a simple slider component in React
published: true
date: 2021-10-17 16:53:56 UTC
tags: react,slider
canonical_url: https://relatablecode.com/how-to-make-a-simple-slider-component-in-react/
---

A very common component to use in forms or to receive numeric input with a non-arbitrary range is to use a slider component. However, this can easily be done with some basic HTML and CSS whilst adding some react-y props.
The basic usage can be implemented with a simple HTML Input. Something that is not readily apparent is that an input can be of various types. One of these is of type range.
This is how it looks:
<figcaption>HTML Input type range</figcaption>
Code:
```
<input type="range" />
```
However, while this may fulfill the slider component necessity there are a few things that limit it. We should add some styling and make it so the values of the min and max.
### Styling
Let’s dig into the CSS
```
input[type='range'] {
-webkit-appearance: none;
height: 7px;
background: grey;
border-radius: 5px;
background-image: linear-gradient(#D46A6A, #D46A6A);
background-repeat: no-repeat;
}
```
<figcaption>Bar Styled</figcaption>
This first bit of styling is to target the bar targeting the color and shape:
However it still looks a bit awkward with the circle being of a different color, we can target this portion with a selector: -webkit-slider-thumb
```
input[type='range']::-webkit-slider-thumb {
-webkit-appearance: none;
height: 20px;
width: 20px;
border-radius: 50%;
background: #D46A6A;
cursor: pointer;
box-shadow: 0 0 2px 0 #555;
}
```
<figcaption>Thumb Styled</figcaption>
Simple enough we just make the circle a bit bigger and change the color to match the rest of the component.
However its not very clear what part of the bar is being filled, so let’s change that by changing the track of the slider:
```
input[type="range"]::-webkit-slider-runnable-track {
-webkit-appearance: none;
box-shadow: none;
border: none;
background: transparent;
}
```
But, we also need a way to calculator the current background size of the bar:
```
const [value, setValue] = useState(0);
const MAX = 10;
const getBackgroundSize = () => {
return { backgroundSize: `${(value * 100) / MAX}% 100%` }; };
<input type="range"
min="0"
max={MAX}
onChange={(e) => setValue(e.target.value)}
style={getBackgroundSize()} value={value}
/>
```
Let’s break down a few holes here. When an input is of type you have access to several different properties, two of which are min and max which set the two different ends of the slider.
Essentially we’re just calculating the percentage size of the background color based on the value and possible max value.
<figcaption>Styled Background</figcaption>
### Active Styling
With the bar styled let’s focus on some UX enhancement, with some pseudo-classes we can make the thumb look a bit prettier to the user:
```
input[type="range"]::-webkit-slider-thumb:hover {
box-shadow: #d46a6a50 0px 0px 0px 8px;
}
input[type="range"]::-webkit-slider-thumb:active {
box-shadow: #d46a6a50 0px 0px 0px 11px;
transition: box-shadow 350ms cubic-bezier(0.4, 0, 0.2, 1) 0ms, left 350ms cubic-bezier(0.4, 0, 0.2, 1) 0ms, bottom 350ms cubic-bezier(0.4, 0, 0.2, 1) 0ms;
}
```
As well as adding some transition styling to the thumb itself:
```
input[type="range"]::-webkit-slider-thumb {
// ...other styles;
transition: background 0.3s ease-in-out;
}
```
<img width="100%" style="width:100%" src="https://media.giphy.com/media/tWbIlHfDf4fXYvXHPk/giphy.gif">
And that’s it! Here is a fully working example:
[](https://codesandbox.io/s/react-slider-k868o?fontsize=14&hidenavigation=1&theme=dark)
Do you have a preferred slider component? Let me know in the comments below.
Find more articles at [Relatable Code](https://relatablecode.com)
_Originally published at_ [_https://relatablecode.com_](https://relatablecode.com/how-to-make-a-simple-slider-component-in-react/) _on October 17, 2021._ | diballesteros |
866,944 | Streaming Ethereum Blocks Into bSQL Using Infura and Python | Overview Blockchain data is secure and tamper proof, but when working with blockchain data... | 0 | 2021-11-10T02:05:54 | https://dev.to/cassidymountjoy/streaming-ethereum-blocks-into-bsql-using-infura-and-python-3dl4 | blockchain, python, database, web3 | ##Overview
Blockchain data is secure and tamper proof, but when working with blockchain data in a more traditional environment, let's say a conventional database, it becomes harder to extend these guarantees. Can data be trusted after it has left the blockchain?
By using a less traditional form of DBMS, an immutable database, we can:
- Verify that data hasn't been illicitly changed
- Track all changes made to the system
- Easily access old versions of the system
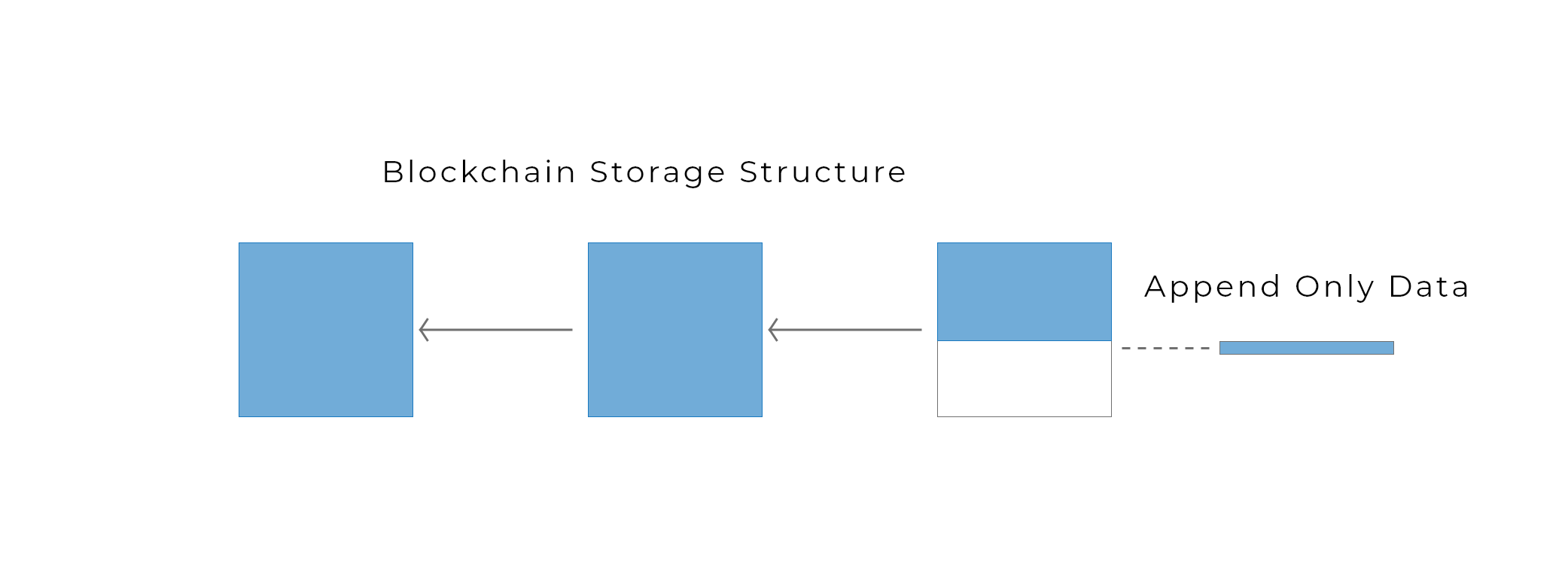
In this tutorial I will be using [Blockpoint's](https://blockpointdb.com/) [bSQL](https://bsql.org/docs/overview), because it's immutable, relational, structured, and has a rich language. The bSQL storage structure is actually very similar to that of a blockchain in that data pages are hashed and linked together. Data is added, never deleted:
---
#Let's Stream Some Ethereum Blocks
We will be using an Infura free trial to access the Ethereum network, Python to filter for new blocks, and bSQL to store blockchain data. In order to do so we will:
- Sign up for a free Infura account and obtain an Ethereum endpoint.
- Create a bSQL account and deploy a free instance.
- Write a python script and start streaming Ethereum blocks to the database.
At any time you can reference the public [repo](https://github.com/blockpointSystems/bsql_eth)
---
##Setting up Infura
Register for a free Infura account [here](https://infura.io/). This will give you access to 100,000 Requests/Day, which is plenty given that this is just a demonstration.
Once you've set up your Infura account, you can access your project ID, it will be needed to connect to Infura using an endpoint and can be found under your project name.
The endpoint for accessing the data will resemble the following:
`https://mainnet.infura.io/v3/your_project_id`
We will use this endpoint when we set up our python application.
---
##Deploying a bSQL instance
The next step is to set up our bSQL instance by:
- Deploying a database using the Blockpoint Portal
- Opening the instance in the IDE
- Creating a database and a blockchain
In order to create a bSQL account you will need an a unique access token, you can get your access token by messaging me directly or joining the [slack](https://join.slack.com/t/bsqlcommunity/shared_invite/zt-169oaigpu-R3W1D5_vc6OyNnKy4thNoA), it's free!
1.) The tutorial for creating an account and deploying your first instance can be found [here](https://www.youtube.com/watch?v=Em8b5qXcQew&list=PLdRS5wHN77gWuG71IvaH4pX7IdfZYGd06). Once completed, a new instance should appear on the blockpoint portal home page.
2.) Once created, navigate to the home page. To open the IDE, click "Open in IDE" and, when prompted, provide your database credentials.
3.) Finally we are going to run a few bSQL commands to finish our set up.
**a.** Create a new database called "eth" by running `CREATE
DATABASE eth;`
**b.** Interact with the newly created database by running `USE
eth;`
Next, we are going to want to configure a single blockchain for capturing Ethereum data. A blockchain is a structured container for storing data in bSQL. Once data has been added to the system, it cannot be removed. For a more comprehensive overview on the blockchain structure read the documentation [here](https://bsql.org/docs/blockchain-overview).
For the sake of keeping this tutorial simple, we are going to use a single *blockchain* called **blocks** to track new blocks added to the Ethereum network. Using a *historical blockchain* we can enforce immutability and check data integrity. Deploy the blockchain by running the following command in the IDE.
```
CREATE BLOCKCHAIN blocks HISTORICAL (
time TIMESTAMP,
number UINT64,
hash STRING SIZE=66,
parent_hash STRING SIZE=66,
nonce STRING SIZE=42,
sha3_uncles STRING SIZE=66,
logs_bloom STRING PACKED SIZE=18000,
transactions_root STRING SIZE=66,
state_root STRING SIZE=66,
receipts_root STRING SIZE=66,
miner STRING SIZE=42,
difficulty FLOAT64,
size_of_block INT64,
extra_data STRING PACKED,
gas_limit INT64,
transaction_count INT64,
base_fee_per_gas INT64
);
```
Congrats on building your first bSQL blockchain! Now let's start adding data.
---
## Setting up your python application.
In order to set up your python applet you will need the following:
- Python downloaded and installed on your computer, I'm using python 3.9.
- A python IDE, I'm using [Pycharm](https://www.jetbrains.com/pycharm/)
- [web3](https://web3py.readthedocs.io/en/stable/) for python
- The bSQL [python bSQL database driver](https://bsql.org/docs/connecting/python-odbc)
Once the follow criteria are met, you can set up a main.py file in your project directory. The code is on [Github](https://github.com/blockpointSystems/bsql_ethk) although it will not work until the above criteria is met and you have deployed an instance.
## Connecting to Infura and bSQL
The first step in our code is to define our connections. You will need to fill out the following fields:
- your Infura project id
- your bSQL username, password and public IP address
```python
infru = "https://mainnet.infura.io/v3/your_project_id" #change me
web3 = Web3(Web3.HTTPProvider(infru))
conn = mdb_bp.driver.connect(
username="your username", #change me
password="your password", #change me
connection_protocol="tcp",
server_address="server address", #change me
server_port=5461,
database_name="eth",
parameters={"interpolateParams": True},
)
```
## Defining our main method
The main method defines a filter for the latest Ethereum block and passes it into our loop that we will define next.
```python
def main():
block_filter = web3.eth.filter('latest')
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(
asyncio.gather(
log_loop(block_filter, 2)))
finally:
# close loop to free up system resources
loop.close()
if __name__ == '__main__':
main()
```
## Defining our Loop
Our loop sleeps for a desired interval, then attempts to pull new entries from the event filter. Every time a new entry is received the event is handled in the `handle_event` function.
```python
async def log_loop(event_filter, poll_interval):
while True:
for PairCreated in event_filter.get_new_entries():
handle_event(web3.eth.get_block(PairCreated))
await asyncio.sleep(poll_interval)
```
## Defining our Event Handling
Time for the database call. Every time a new block is added to the chain, we print to the console and send an insertion statement to the database, inserting block data into **blocks**.
```python
def handle_event(block):
print(block['number'])
conn.exec("INSERT blocks VALUES (" +
"\"" + str(datetime.datetime.utcfromtimestamp(block['timestamp'])) + "\"," +
str(block['number']) + "," +
"\"" + str(block['hash'].hex()) + "\"," +
"\"" + str(block['parentHash'].hex()) + "\"," +
"\"" + str(block['nonce'].hex()) + "\"," +
"\"" + str(block['sha3Uncles'].hex()) + "\"," +
"\"" + str(block['logsBloom'].hex()) + "\"," +
"\"" + str(block['transactionsRoot'].hex()) + "\"," +
"\"" + str(block['stateRoot'].hex()) + "\"," +
"\"" + str(block['receiptsRoot'].hex()) + "\"," +
"\"" + str(block['miner']) + "\"," +
str(block['difficulty']) + "," +
str(block['size']) + "," +
"\"" + str(block['extraData'].hex()) + "\"," +
str(block['gasLimit']) + "," +
str(len(block['transactions'])) + "," +
str(block['baseFeePerGas']) + ")")
```
And that's all the code needed, so give that baby a run.
## Putting it all together
After letting my program run for about an hour, I stopped my script and started to do a little data exploration.
I ran a few queries in the bSQL portal and included them in the [repo](https://github.com/blockpointSystems/bsql_eth/blob/master/example_queries.bsql). You can load this file into the bSQL IDE or write your own queries.
Here's what I came up with:

##Conclusion
There you have it. A fun little script for Ethereum data. There is definitely more to explore when it comes to how the data is pulled and even more queries to write.
Like always, please comment your feedback or any questions you may have.
| cassidymountjoy |
866,985 | ASP.NET Core 6: Minimal APIs y Carter | Introducción El mundo de .NET 6 está a la vuelta de la esquina (al día de hoy está en RC... | 0 | 2021-10-17T21:42:48 | https://dev.to/isaacojeda/aspnet-core-6-minimal-apis-y-carter-3f8k | minimalapis, dotnet, csharp, carter | # Introducción
El mundo de .NET 6 está a la vuelta de la esquina (al día de hoy está en RC 2) y no solo yo estoy emocionado con estos cambios que vienen, si no también el equipo de Carter ya se ha encargado de no quedarse atrás y aprovechar lo nuevo que se viene.
[Carter](https://github.com/CarterCommunity/Carter) en versiones anteriores a .NET 6, nos ofrecían esta forma elegante de modularizar nuestras APIs y olvidarnos por siempre de los controladores y tener una forma simple de crear endpoints. Ahora esto ya lo hace las Minimal APIs pero eso significa que Carter esté muerto.
Para conocer más sobre Minimal APIs podemos ver este [gist](https://www.notion.so/ff1addd02d239d2d26f4648a06158727) de David Flow que simplemente es lo que necesitas para entender todo sobre Minimal APIs.
Otra forma de aprender sobre Minimal APIs es este [repositorio](https://github.com/DamianEdwards/MinimalApiPlayground) de Damian Edwards donde explora toda las funcionalidades con las que se cuenta. Si quieren aprender muy bien Minimal APIs les recomiendo esos dos enlaces.
Te recomiendo seguir este post viendo el código en [GitHub](https://github.com/isaacOjeda/DevToPosts/tree/main/MinimalApis) para una mejor comprensión.
# Carter
Lo que exploraremos en este post es la creación de Minimal APIs con carter con un ejemplo sencillo de catálogo de Productos (as usual).
## ¿Por qué usar Carter?
Que usemos Minimal APIs no significa que nuestra aplicación tiene que ser pequeña. Minimal APIs nace para tener una introducción sencilla a .NET y empezar sin tanto **boilerplate** y **ceremony**.
Carter nos da la posibilidad de modularizar nuestra API de una forma efectiva, utilizando una [arquitectura vertical](https://jimmybogard.com/vertical-slice-architecture/) donde todo nuestro código está partido en **Features,** aunque esto es meramente opcional y no será tema de este post.
> Nota 👀: Muchos de los features que exploraremos en este post no son propias de carter sino de Minimal APIs.
>
También Carter ya nos incluye [FluentValidation](https://github.com/FluentValidation/FluentValidation), que es algo muy importante porque el `ModelState` en Minimal APIs no está disponible. Así que necesitamos alguna forma de validar nuestros modelos. Damian Edwards tiene una [librería](https://github.com/DamianEdwards/MiniValidation) que hace validaciones con Data Annotations, que es un approach válido también, aunque prefiero no decorar los modelos con atributos (y más en este ejemplo que estamos usando directamente los Domain Objects y no DTOs).
## Carter en ASP.NET Core 6
Comenzaremos desde 0, creando un proyecto web vacío con .NET 6 instalado previamente (versión RC 2 para este post).
```bash
dotnet new web -o MinimalApis
```
Y posteriormente instalaremos los siguientes paquetes que incluyen carter y varios de EF Core (revisa mi [GitHub](https://github.com/isaacOjeda/DevToPosts/tree/main/MinimalApis) para ver el ejemplo completo para que no te queden dudas)
```xml
<PackageReference Include="Carter" Version="6.0.0-pre2" />
<PackageReference Include="Microsoft.EntityFrameworkCore" Version="6.0.0-rc.2.21480.5" />
<PackageReference Include="Microsoft.EntityFrameworkCore.InMemory" Version="6.0.0-rc.2.21480.5" />
<PackageReference Include="Swashbuckle.AspNetCore" Version="6.2.3" />
```
> Nota 👀: Recuerda que estamos usando versiones preview y RC de estos paquetes NuGet. Si no te aparecen, hay que decirle a NuGet que incluya paquetes en **pre-release** y si estás leyendo esto después de noviembre, probablemente ya estarás usando las versiones finales.
>
### In Memory Database
Para este ejemplo usaremos la siguiente base de datos con Entity Framework Core que mas adelante la configuraremos para que solo sea en memoria (para fines prácticos).
```csharp
namespace MinimalApis.Api.Entities;
public class Product
{
public Product(string description, double price)
{
Description = description;
Price = price;
}
public int ProductId { get; set; }
public string Description { get; set; }
public double Price { get; set; }
}
```
```csharp
using Microsoft.EntityFrameworkCore;
using MinimalApis.Api.Entities;
namespace MinimalApis.Api.Persistence;
public class MyDbContext : DbContext
{
public MyDbContext(DbContextOptions<MyDbContext> options) : base(options) {}
public DbSet<Product> Products => Set<Product>();
}
```
> Nota 👀: Los nullable reference types han llegado ya por default y es necesario asegurarnos que cualquier tipo de dato por referencia no sea nulo. Esto nos ayudará a que por fin (al menos tratar) eliminemos los `NullReferenceExceptions` que siempre aparecen cuando menos te lo esperas.
>
`Products` lo he guardado en una carpeta **/Entities** y el contexto en **/Persistence**. Realmente esto puede variar según el estilo de cada quien, así que no es relevante por ahora.
### Products Module
Como mencioné antes, Carter nos pide crear módulos en lugar de Controladores. Por lo que guardaré esté módulo dentro de una carpeta **Features/Products**.
La intención de no poner todo junto es poder separar cada Feature según sus componentes relevantes (como Mappers, Validations, Servicios, etc).
```csharp
namespace MinimalApis.Api.Features.Products;
public class ProductsModule : ICarterModule
{
public void AddRoutes(IEndpointRouteBuilder app)
{
// Los endpoints van aquí
}
}
```
Para registrar Endpoints en Minimal APIs tenemos disponible todos los verbos HTTP como lo solemos hacer en Web API (Ejem. `[HttpPost]`, `[HttpGet]`, etc).
Ejemplo.
```csharp
app.MapGet("api/products", () =>
{
// Consultar productos
});
```
Aquí estamos registrando la ruta **api/products** con el verbo `HttpGet`.
### Dependency Injection
Esta es una de las partes un poco extrañas, pero para resolver dependencias (en este caso nuestro `DbContext`) utilizamos los parámetros de la función del Endpoint en lugar del constructor como lo hacíamos antes.
```csharp
app.MapGet("api/products", (MyDbContext context) =>
{
var products = await context.Products
.ToListAsync();
return Results.Ok(products);
});
```
Eso significa que en los parámetros de nuestra función se resuelven dependencias de distintos lados. Como por ejemplo (como ya vimos aquí) del `IServiceCollection` pero también de los datos que se reciben (ejemplo del Body, Headers, Query strings, etc).
Ocurre Model Binding de los datos recibidos por el cliente y también se puede resolver cualquier dependencia desde ahí. Si revisamos los links de Minimal APIs que he puesto más arriba podremos aprender más sobre el tema (ya que para todos es nuevo 😅).
Una versión mejorada y como hice este ejemplo, queda de la siguiente manera.
```csharp
public void AddRoute(IEndpointRouteBuilder app)
{
app.MapGet("api/products", GetProducts)
.Produces<List<Product>>();
}
private static async Task<IResult> GetProducts(MyDbContext context)
{
var products = await context.Products
.ToListAsync();
return Results.Ok(products);
}
```
Aquí ya estamos agregando metadatos al endpoint (con `.Produces<List<Product>>()`) para que librerías como Swagger sepa interpretar y documentar nuestra API.
La clase `Results` cuenta con las posibles respuestas que podemos regresar, así como sucedía con los controladores (que regresábamos un `IActionResult`) aquí regresamos un `IResult` (algo muy similar).
### Problem Details y Validaciones
Una de las cosas que también me gustó de Carter es que ya incluye **FluentValidation**. Y aunque no es algo automático como se podría configurar con MediatR o ASP.NET Web API, es muy sencillo.
Dentro de **Features/Products** puse el siguiente `AbstractValidator`.
```csharp
using FluentValidation;
using MinimalApis.Api.Entities;
namespace MinimalApis.Api.Features.Products
{
public class ProductValidator : AbstractValidator<Product>
{
public ProductValidator()
{
RuleFor(q => q.Description).NotEmpty();
RuleFor(q => q.Price).NotNull();
}
}
}
```
Simplemente estamos estableciendo que los campos son obligatorios, pero aquí se pueden configurar muchas validaciones y es demasiado flexible (en comparación a los `DataAnnotations`).
Nuestro endpoint de creación queda así:
```csharp
using Carter;
using Carter.ModelBinding;
// ... código omitido
public void AddRoutes(IEndpointRouteBuilder app)
{
// ... código omitido
app.MapPost("api/products", CreateProduct)
.Produces<Product>(StatusCodes.Status201Created)
.ProducesValidationProblem()
}
private static async Task<IResult> CreateProduct(HttpRequest req, Product product, MyDbContext context)
{
var result = req.Validate(product);
if (!result.IsValid)
{
return Results.ValidationProblem(result.ToValidationProblems());
}
context.Products.Add(product);
await context.SaveChangesAsync();
return Results.Created($"api/products/{product.ProductId}", product);
}
```
Estamos inyectando 3 cosas en esta función:
- `HttpRequest`. El request actual del `HttpContext` del endpoint
- `Product`. Los datos recibidos en el `[FromBody]` del `[HttpPost]` que viene siendo el entity a crear
- `MyDbContext`. DbContext de EF Core
> Nota 👀: Si el método `Validate` no te aparece, probablemente es por namespaces faltantes.
>
Este endpoint tiene 2 posibles respuestas: un 201 o un 400. Aunque no se está obligado especificarlo, pero con los métodos Produces se especifica eso para que Swagger conozca mejor la API.
Un ejemplo de respuesta de error de validación.
```json
{
"type": "https://tools.ietf.org/html/rfc7231#section-6.5.1",
"title": "One or more validation errors occurred.",
"status": 400,
"errors": {
"Description": [
"'Description' no debería estar vacío."
]
}
}
```
Este formato es un estandar para APIs llamado [Problem Details](https://datatracker.ietf.org/doc/html/rfc7807), este también se usa en los Api Controllers al usar el atributo `[ApiController]` (por si no sabías 😅).
Ejemplo de respuesta exitosa.
```json
{
"productId": 5,
"description": "Product description here.",
"price": 2499.99
}
```
El método `ToValidationProblems` es una extensión de `ValidationResult` de **FluentValidation** para convertirlo en un diccionario agrupado según las propiedades que validaron.
```csharp
using FluentValidation.Results;
namespace MinimalApis.Api.Extensions;
public static class GeneralExtensions
{
public static Dictionary<string, string[]> ToValidationProblems(this ValidationResult result) =>
result.Errors
.GroupBy(e => e.PropertyName, e => e.ErrorMessage)
.ToDictionary(failureGroup => failureGroup.Key, failureGroup => failureGroup.ToArray());
}
```
### Products Module completo
Creo que ya expliqué lo relevante en estos 2 endpoints. Así que `ProductsModule` queda de la siguiente manera.
```csharp
using Carter;
using Carter.ModelBinding;
using Microsoft.EntityFrameworkCore;
using MinimalApis.Api.Entities;
using MinimalApis.Api.Extensions;
using MinimalApis.Api.Persistence;
namespace MinimalApis.Api.Features.Products;
public class ProductsModule : ICarterModule
{
public void AddRoutes(IEndpointRouteBuilder app)
{
app.MapGet("api/products", GetProducts)
.Produces<List<Product>>();
app.MapGet("api/products/{productId}", GetProduct)
.Produces<Product>()
.Produces(StatusCodes.Status404NotFound);
app.MapPost("api/products", CreateProduct)
.Produces<Product>(StatusCodes.Status201Created)
.ProducesValidationProblem();
app.MapPut("api/products/{productId}", UpdateProduct)
.Produces(StatusCodes.Status204NoContent)
.ProducesProblem(StatusCodes.Status404NotFound)
.ProducesValidationProblem();
app.MapDelete("api/products/{productId}", DeleteProduct)
.Produces(StatusCodes.Status204NoContent)
.ProducesProblem(StatusCodes.Status404NotFound);
}
private static async Task<IResult> GetProducts(MyDbContext context)
{
var products = await context.Products
.ToListAsync();
return Results.Ok(products);
}
private static async Task<IResult> GetProduct(int productId, MyDbContext context)
{
var product = await context.Products.FindAsync(productId);
if (product is null)
{
return Results.NotFound();
}
return Results.Ok(product);
}
private static async Task<IResult> CreateProduct(HttpRequest req, Product product, MyDbContext context)
{
var result = req.Validate(product);
if (!result.IsValid)
{
return Results.ValidationProblem(result.ToValidationProblems());
}
context.Products.Add(product);
await context.SaveChangesAsync();
return Results.Created($"api/products/{product.ProductId}", product);
}
private static async Task<IResult> UpdateProduct(
HttpRequest request, MyDbContext context, int productId, Product product)
{
var result = request.Validate(product);
if (!result.IsValid)
{
return Results.ValidationProblem(result.ToValidationProblems());
}
var exists = await context.Products.AnyAsync(q => q.ProductId == productId);
if (!exists)
{
return Results.Problem(
detail: $"El producto con ID {productId} no existe",
statusCode: StatusCodes.Status404NotFound);
}
context.Entry(product).State = EntityState.Modified;
await context.SaveChangesAsync();
return Results.NoContent();
}
private static async Task<IResult> DeleteProduct(int productId, MyDbContext context)
{
var product = await context.Products.FirstOrDefaultAsync(q => q.ProductId == productId);
if (product is null)
{
return Results.Problem(
detail: $"El producto con ID {productId} no existe",
statusCode: StatusCodes.Status404NotFound);
}
context.Remove(product);
await context.SaveChangesAsync();
return Results.NoContent();
}
}
```
## Extensiones (IServiceCollection y WebApplication)
Para dejar un Program.cs más limpio, siempre suelo usar extensiones para agregar la configuración de los middlewares y dependencias.
```csharp
using Microsoft.EntityFrameworkCore;
using Microsoft.OpenApi.Models;
using MinimalApis.Api.Persistence;
namespace MinimalApis.Api.Extensions;
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddSwagger(this IServiceCollection services)
{
services.AddEndpointsApiExplorer();
services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1", new OpenApiInfo()
{
Description = "Minimal API Demo",
Title = "Minimal API Demo",
Version = "v1",
Contact = new OpenApiContact()
{
Name = "Isaac Ojeda",
Url = new Uri("https://github.com/isaacOjeda")
}
});
});
return services;
}
public static IServiceCollection AddPersistence(this IServiceCollection services)
{
services.AddDbContext<MyDbContext>(options =>
options.UseInMemoryDatabase(nameof(MyDbContext)));
return services;
}
}
```
Aquí simplemente estamos creando 2 métodos de extensión para configurar Swagger y el DbContext (en este caso, en memoria).
```csharp
namespace MinimalApis.Api.Extensions;
public static class WebApplicationExtensions
{
public static WebApplication MapSwagger(this WebApplication app)
{
app.UseSwagger();
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "API");
c.RoutePrefix = "api";
});
return app;
}
}
```
Aquí también configuramos Swagger pero ahora su middleware para que tengamos un endpoint de exploración (el json) y la UI para hacer pruebas.
## Integración de todo en Program
Ya tenemos todo listo para por fin correr esta API hecha con Carter
```csharp
using Carter;
using MinimalApis.Api.Extensions;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddSwagger();
builder.Services.AddPersistence();
builder.Services.AddCarter();
var app = builder.Build();
app.MapSwagger();
app.MapCarter();
app.Run();
```
## Probando Swagger
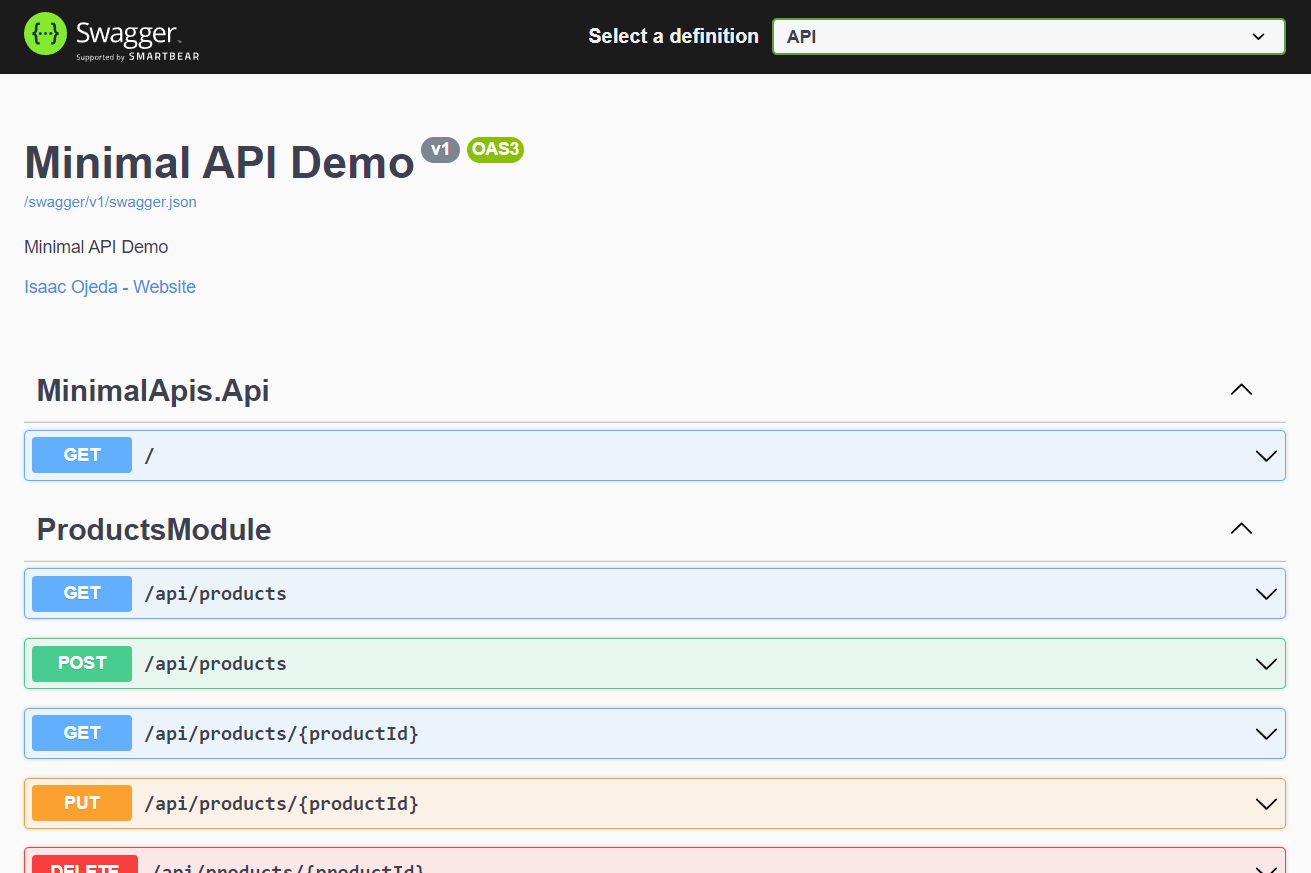
Si ejecutamos `dotnet run` ya podemos explorar la API con Swagger ( o postman si lo prefieres)
# Conclusión
Las Minimal APIs es algo que se necesitaba en .NET. Lenguajes como node con express manejaban este concepto desde siempre, pero poderlo hacer con .NET y toda su plataforma, es perfecto.
Carter existe desde versiones anteriores de .NET Core y buscaba simplificar esto, y su antecessor Nancy.Fx lo ha hecho desde siempre. Hay gente que odia los Controllers 😅.
Es cuestión de gustos, tal vez no todos empiecen a utilizar este approach, pero una buena razón es que por ahora es más rápido.
En un futuro tal vez se construyan más capas sobre Minimal APIs (como carter lo hace) y se vuelvan estandard en los templates que el mismo dotnet ofrecerá, no sé, puede pasar.
Espero que te haya gustado 🖖🏽
Code4Fun 🤓 | isaacojeda |
867,079 | The definitive guide to Accuracy, Precision, and Recall for product developers | TLDR Accuracy tells you how many times the ML model was correct overall. Precision is how... | 0 | 2021-11-29T21:21:28 | https://dev.to/mage_ai/the-definitive-guide-to-accuracy-precision-and-recall-for-product-developers-4ahg | productdevelopment, machinelearning, ai, programming | ### TLDR
Accuracy tells you how many times the ML model was correct overall. Precision is how good the model is at predicting a specific category. Recall tells you how many times the model was able to detect a specific category.
### Outline
1. Introduction
2. Accuracy
3. Precision
4. Recall
5. How to determine if your model is doing well
6. When to use precision or recall
7. Conclusion
## Introduction
Most machine learning (ML) problems fit into 2 groups: [classification and regression](https://m.mage.ai/roadmap-to-ai-ml-sorcerer-supreme-2fc4bdbe89bf). The main metrics used to assess performance of classification models are accuracy, precision, and recall.
<center>_Source: Final Fantasy_</center>
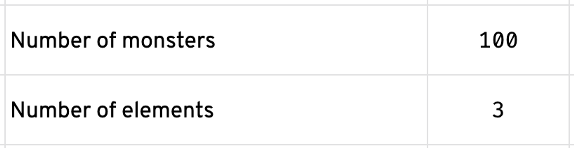
To demonstrate each of these metrics, we’ll use the following example: We’re a mage on a quest to save the villagers from a horde of monsters. There are 100 monsters attacking the village. We’re going to use machine learning to predict what element each monster is weak against. There are 3 possible elements that monsters are weak against: fire, water, and wind.
## Accuracy
After summoning our machine learning model, we approach the village and begin the battle. After hours of intense combat, we are victorious and the villagers are all saved. We sit down by the fire, have a few refreshments (e.g. boba from the local village tea shop), and review how the battle unfolded.
<center>_Magic vs Monsters_</center>
For every monster we fought, our model predicted an element for us to use that would make the monster the weakest possible. Out of 100 predictions, our model predicted the correct element 73 times. Therefore, the accuracy of our model is 73%; 73 correct predictions out of 100 predictions made.

## Precision
Measuring our model’s accuracy told us overall how many times we were correct when predicting a monster’s weakness. However, if we want to know how many times we were correct when predicting a monster was weak against fire, we need to use the precision metric.
<center>_Source: Pokemon_</center>
Let’s say we predicted 30 monsters were weak against fire. At the end of the battle, we saw that of those 30 monsters, 6 of them were actually weak against water and 3 of them were actually weak against wind. That means our precision for predicting fire is 70% (21/30). In other words, we predicted 21 fire weaknesses correctly out of 30 fire predictions.
<center>_Source: Naruto_</center>
After further review of the battle, we predicted 40 monsters were weak against water and 30 monsters were weak against wind. Out of the 40 monsters who we predicted were weak against water, we were correct 28 times resulting in 70% precision (28/40). Out of the 30 monsters who we predicted were weak against wind, we were correct 24 times resulting in 80% precision (24/30).
The following chart is called a confusion matrix:
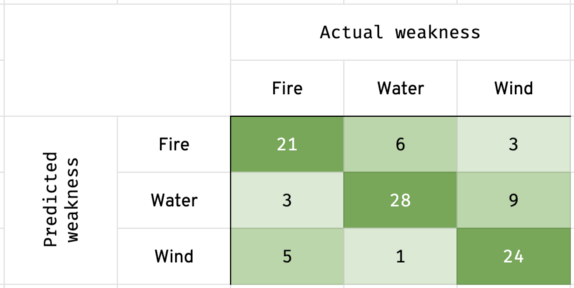
The left y-axis is what was predicted. The top x-axis is what the monster was truly weak against. Look at row 1 and column 2. It’s saying that out of the 30 monsters (21 + 6 + 3) that the model predicted a fire weakness for, 6 of those monsters were actually weak against water.
For more information on how to read a confusion matrix, check out this [article](https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/). Here are 2 helpful images:
<center>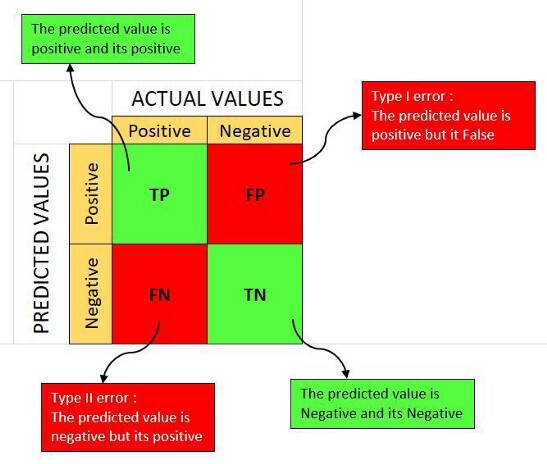_Source: Anuganti Suresh_</center>
<center>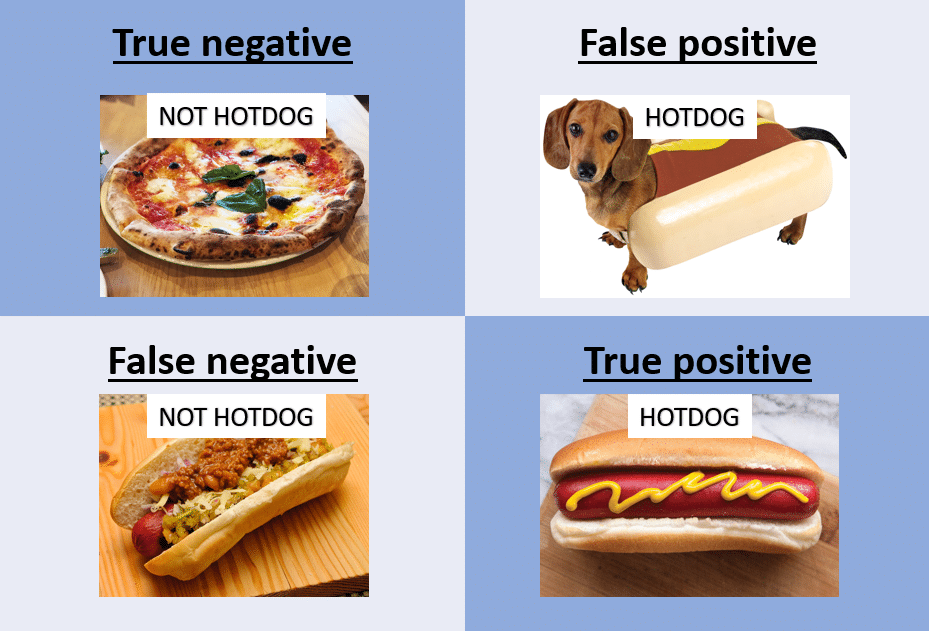_Source: NillsF blog_</center>
## Recall
Now that we know how many times our model predicted correctly overall and how good our model is at predicting a specific weakness (e.g. fire, water, wind), it’s time to find out how good our model is at finding monsters with a particular weakness.
<center>_Source: Avatar: The Last Airbender_</center>
For all the monsters who were actually weak against wind (there are 36 of them), how many did our model find out? Our model found 24 monsters who were weak against wind. That means our model has 67% recall when predicting monsters who are actually weak against wind.

## How to determine if your model is doing well
Before evaluating how good a model is doing, we must establish a baseline score. A baseline score is a value that our model should perform better than. For example, if we have a baseline score of 60% accuracy and our model achieved an accuracy greater than that (e.g. 61%), then the model is good enough to use in real life scenarios (e.g. production environment).
There are many ways to establish a baseline score for your model. In an upcoming tutorial, we’ll show you multiple other methods that can be used.
For our monster weakness prediction model, we’ll use a baseline score method called mode category. This method takes the most abundant weakness category and divides that by the number of predictions. Specifically, more monsters are weak against wind than any other element (only 29 monsters are weak against fire and only 35 monsters are weak against water).
Our baseline accuracy score will be 36% (e.g. 36 monsters weak against wind divided by 100 monsters in total).
<center>_Source: Borat_</center>
Our model had a 73% accuracy score. That is well above the baseline score. We can conclude that our model is performing well.
*Note: you may want to have different baseline scores and use different metrics other than accuracy (e.g. precision, recall, etc) to assess whether your model performed well or not. Depending on your use case, precision or recall may be more important.*
## When to use precision or recall
On our quest to save the village from monsters, our goal was to defeat all the monsters. If we can predict their weakness, we have a higher chance of victory. Therefore, we want a model with the highest accuracy; in other words, a model with the highest chance of predicting the weakness correctly.
However, there are scenarios where you may want a model with higher precision. For example, you may have a fire spell that drains a lot of your energy and you want to use it sparingly. In that case, you’ll want a model that has high precision when predicting a monster is weak against fire. That way, when you use your fire spell, you know with high certainty that the monster is weak against it.
<center>_Source: Lifehack_</center>
The scenario in which you want to choose a model with high recall is when the predicted outcome leads to a critical decision. For example, let’s say we had a model that predicts whether a villager has been poisoned by a monster and needs immediate medical treatment. We want a model that can find every villager that is poisoned even if it incorrectly labels a healthy villager as needing medical treatment. The reason why we want this model to have high recall is because it’s better to give a healthy person unnecessary treatment than to accidentally pass over someone who was poisoned and needs treatment. In other words, better safe than sorry.
## Conclusion
<center>_Accuracy, precision, and recall matters_</center>
Accuracy, precision, and recall are used to measure the performance of a classification machine learning model (there are other metrics for regression models, [read more here](https://m.mage.ai/roadmap-to-ai-ml-sorcerer-supreme-2fc4bdbe89bf)). The metrics alone aren’t enough to determine if your model is usable in real life scenarios. You must establish a baseline score and compare your model’s performance against that baseline score. In a future tutorial, we’ll show you how to assess a regression machine learning model; a model predicting a continuous numerical value (e.g. housing prices, forecasting sales, customer lifetime value, etc). | mage_ai |
867,106 | Completed Hacktoberfest 2021! | I'm glad to say I'm in First 50,000 Participants to earn a T-shirt from Hacktoberfest and also got... | 0 | 2021-10-18T02:32:13 | https://dev.to/saugatrimal/completed-hacktoberfest-2021-1pa9 | hacktoberfest, opensource, github, swags | I'm glad to say I'm in First 50,000 Participants to earn a T-shirt
from Hacktoberfest and also got Hacktoberfest Exclusive badge from Dev.to
Thank You everyone who supports me for this event
| saugatrimal |
867,318 | A malicious user gaining access to your apps can be catastrophic. Here's how a secure SSO could help. | In any enterprise, it is a given that employees will come and go, and many will switch roles within... | 0 | 2021-10-18T07:11:39 | https://dev.to/cloudnowtech/a-malicious-user-gaining-access-to-your-apps-can-be-catastrophic-heres-how-a-secure-sso-could-help-145f | In any enterprise, it is a given that employees will come and go, and many will switch roles within the organization as well. At the same time, the same is true for the applications that the company uses - new apps will be deployed, old ones will be retired, and changes are constant.
What this means is a continuous churn - in identity management for users, and service providers, by means of the SaaS applications in use. Ensuring data and app security across the organization depends heavily on ensuring secure communication between your identity provider and service providers.
Deploying a robust [Single Sign-On (SSO)] (https://www.akku.work/product/single-sign-on.html) solution represents the best answer to this challenge. An SSO allows an enterprise to manage the identities of employees in one place, and delegate access and privileges from there.
Most SaaS providers support [SSO] (https://www.akku.work/product/single-sign-on.html) integration as it is the most efficient route to centralized identity and access management. The [SSO] (https://www.akku.work/product/single-sign-on.html) authentication method also enables users to securely access multiple apps and websites with a single set of credentials, which reduces issues like password fatigue, which boosts security, lowers IT help desk load, and increases organizational efficiency.
**How SSO works**
To get your [SSO] (https://www.akku.work/product/single-sign-on.html) in place, you need to find the right identity provider. The identity provider is essentially a service that securely stores and manages digital identities. An [SSO] (https://www.akku.work/product/single-sign-on.html) works based on a trust relationship between the app and the identity provider.
Organizations establish a trust relationship between an identity provider and their service providers to allow their employees or users to then connect with the resources they need. Such a trust relationship is established by exchanging digital certificates and metadata. The certificate carries secure tokens which contain identity information like email address and password, to authenticate that the request has come from a trusted source and to verify identity.
Although [SSO] (https://www.akku.work/product/single-sign-on.html) can work with as many apps as the organization wants, each must be configured with a unique trust relationship.
**How the Service Provider-Identity Provider relationship works**
Once an identity provider is onboarded, every time a user tries to connect to a service provider, the sign-in request is sent to the central server where the identity provider is hosted. The identity provider validates the credentials and sends back a token. If their identity cannot be verified, the user will be prompted to log into the [SSO] (https://www.akku.work/product/single-sign-on.html) or verify credentials using other methods like a TOTP. Once the identity provider validates the credentials it sends the user a token.
The token confirming the successful authentication is validated by the service provider against the certificate initially configured and shared between service provider and identity provider, after which the user can access the application.
The identity provider verifies the user credentials and sends back an ‘authentication token’ (almost like a temporary ID card) to the service provider. And, of course, all this happens in a fraction of a second.
**Advantages of using [SSO] (https://www.akku.work/product/single-sign-on.html)**
<ul>
<li>Simplifies credentials management for users and admin
<li>Improves speed of app access
<li>Reduces time spent by IT support on recovering passwords
<li>Offers central control of password complexity and [MFA] (https://www.akku.work/product/multi-factor-authentication.html)
<li>Simplifies provisioning and de-provisioning
<li>Secures the system as information moves encrypted across the network
<li>Completely seamless/transparent to the user
<li>Easy to add on new service providers
</ul>
Akku is a powerful [identity and access management solution] (https://www.akku.work/) that can enhance data security, efficiency, and productivity across your corporate network through its robust [SSO feature] (https://www.akku.work/product/single-sign-on.html). If you would like assistance on ensuring secure access for all your users to your organization’s applications, [do get in touch with us] (https://www.akku.work/contact-us.html)..
This blog originally published at [Akku Blog] (https://www.akku.work/blog/). Link to the [original blog] (https://www.akku.work/blog/heres-how-a-secure-sso-could-help/) | cloudnowtech | |
867,509 | Free Image and Video Placeholder
| Hey everyone, Imgsrc.space is the best Placeholder service ever. It's just like searching on google... | 0 | 2021-10-18T10:35:07 | https://dev.to/imgsrcspace/free-image-and-video-placeholder-48o8 | javascript, webdev, html, productivity | Hey everyone,
Imgsrc.space is the best Placeholder service ever. It's just like searching on google images but *you won't even need to leave your coding environment*. We have a vast a library of around **3 million** images and videos, so all you have to do is enter your search term and we will do the rest. Totally free.
[Imgsrc.space](https://imgsrc.space)
#How To Use Our Placeholders?
Well there are 2 ways to use them
1. The easy way - Works everywhere no platform dependence
2. The easier way - Works in your web pages with a js library
##The easy way
###Get a specific image
Just add the search term you want at the end of the url after / and we will deliver it. Simple.
```
https://imgsrc.space/cat
```

###Resizing images
Imgsrc.space can also resize the images for you. To enter your desired dimensions put an "?" at the end of the search term and then your enter your desired height and width. Here "h" stands for height and w stands for width. They must be separated by an &
```
https://imgsrc.space/architecture?h=400&w=400
```

###AutoResizing images
If you only provide a single dimension parameter (i.e only height or width) Imgsrc.Space would automatically resize the other parameters accordingly
```
https://imgsrc.space/paris?h=400
```

###Getting a specific Video
To get a specific image just enter the search word in the image source after a dot and a space followed by an -v
```
https://imgsrc.space/ocean-v
```
[try it](https://imgsrc.space/ocean-v)
##The easier way
If you are writing html pages, then we have a good news, you can use our js library to make things easier.
```
<script src="https://cdn.jsdelivr.net/gh/imgsrc-space/imgsrc.space-js-library/main.js" > </script>
```
Copy and paste the above script tag to the ***TOP*** of your html page (in the head tag), and that's it.
Now to use a image just enter a "dot followed by a space and then your search term ".Here are some examples of what you can do with it:
```
<img src=". cow" >
```
```
<img src=". dog?h=500&w=70" >
```
```
<img src=". sunset?w=700" >
```
```
<video> <source src=". car-v" type="video/mp4"> </video>
```
You can find more details in this [documentation](https://imgsrc.space/documentation.src/index.htm#Using-our-JS-library)
Hope this would save you guys some time. Happy coding 😀👍🏼 | imgsrcspace |
867,534 | Kubernetes Security Checklist 2021 | Photo by Eugene Golovesov on Unsplash October 18 2021 Authentication It is recommended to use an... | 0 | 2021-10-18T10:57:21 | https://dev.to/joseluisp/kubernetes-security-checklist-2021-9j2 | kubernetes, security | Photo by <a href="https://unsplash.com/@eugene_golovesov?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Eugene Golovesov</a> on <a href="https://unsplash.com/t/experimental?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
**October 18 2021**
**Authentication**
- It is recommended to use an IdP server as a provider for user authentication to the Kubernetes API (for example, using [OIDC](https://kubernetes.io/docs/reference/access-authn-authz/authentication/#openid-connect-tokens)) Cluster administrators are advised not to use service account tokens for authentication.
- It is recommended to use a centralized certificate management service to manage certificates within the cluster (for user and service purposes)
- User accounts should be personalized. The names of the service accounts should reflect the purpose access rights of the accounts.
**Authorization**
- For each cluster, a role-based access model should be developed.
- [Role-Based Access Control (RBAC)](https://kubernetes.io/docs/reference/access-authn-authz/rbac/) should be configured for the Kubernetes cluster. Rights need to be assigned within the project namespace based on least privilege and separation of duties ([RBAC-tool](https://github.com/alcideio/rbac-tool))
- All services should have a unique service account with configured RBAC rights.
- Developers should not have access to a production environment without the approval of the security team.
- It is forbidden to use [user impersonation](https://kubernetes.io/docs/reference/access-authn-authz/authentication/#user-impersonation) (the ability to perform actions under other accounts)
- It is forbidden to use anonymous authentication, except for `/healthz`, `/readyz`, `/livez`. Exceptions should be agreed upon with the security team.
- Cluster administrators and maintainers should interact with the cluster API and infrastructure services through privileged access management systems ( [Teleport](https://goteleport.com/docs/kubernetes-access/introduction/), [Boundary](https://www.hashicorp.com/blog/gating-access-to-kubernetes-with-hashicorp-boundary) )
- All information systems should be divided into separate namespaces. It is recommended to avoid the situation when the same maintainer team is responsible for different namespaces
- RBAC Rights should be audited regularly ([KubiScan](https://github.com/cyberark/KubiScan), [Krane](https://github.com/appvia/krane))
**Secure work with secrets**
- Secrets should be stored in third-party storage ([HashiCorp Vault](https://www.vaultproject.io/docs/platform/k8s), [Conjur](https://www.conjur.org/blog/securing-secrets-in-kubernetes/)), or in etcd in encrypted form.
- Secrets should be added to the container using the volumeMount mechanism or the secretKeyRef mechanism. For hiding secrets in source codes, for example, the [sealed-secret](https://github.com/bitnami-labs/sealed-secrets) tool can be used.
**Cluster Configuration Security**
- Use TLS encryption between all cluster components.
- Use Policy engine ([OPA](https://www.openpolicyagent.org/docs/v0.12.2/kubernetes-admission-control/), [Kyverno](https://kyverno.io/))
- The cluster configuration is recommended to comply with [CIS Benchmark](https://www.cisecurity.org/benchmark/kubernetes/) except for [PSP requirements](https://kubernetes.io/blog/2021/04/06/podsecuritypolicy-deprecation-past-present-and-future/)
- It is recommended to use only the latest versions of cluster components ([CVE list](https://www.container-security.site/general_information/container_cve_list.html))
- For services with increased security requirements, it is recommended to use a low-level run-time with a high degree of isolation ([gVisior](https://gvisor.dev/docs/user_guide/quick_start/kubernetes/), [Kata-runtime](https://github.com/kata-containers/documentation/blob/master/how-to/run-kata-with-k8s.md))
- Cluster Configuration should be audited regularly ([Kube-bench](https://github.com/aquasecurity/kube-bench), [Kube-hunter](https://github.com/aquasecurity/kube-hunter), [Kubestriker](https://www.kubestriker.io/))
**Audit and Logging**
- Log all cases of changing access rights in the cluster.
- Log all operations with secrets (including unauthorized access to secrets)
- Log all actions related to the deployment of applications and changes in their configuration.
- Log all cases of changing parameters, system settings, or configuration of the entire cluster (including OS level)
- All registered security events (at the cluster level and application level both) should be sent to the centralized audit logging system (SIEM)
- The audit logging system should be located outside the Kubernetes cluster.
- Build observability and visibility processes in order to understand what is happening in infrastructure and services ([Luntry](https://luntry.com/), [WaveScope](https://github.com/weaveworks/scope))
- Use third-party security monitoring tool on all cluster nodes ([Falco](https://falco.org/), [Sysdig](https://sysdig.com/), [Aqua Enterpise](https://www.aquasec.com/), [NeuVector](https://neuvector.com/), [Prisma Cloud Compute](https://www.paloaltonetworks.com/prisma/cloud))
**Secure OS configuration**
- Host administrators and maintainers should interact with cluster nodes through privileged access management systems (or bastion hosts)
- It is recommended to configure the OS and software following the baseline and standards ([CIS](https://www.cisecurity.org/cis-benchmarks/), [NIST](https://ncp.nist.gov/repository))
- It is recommended to regularly scan packages and configuration for vulnerabilities([OpenSCAP profiles](https://static.open-scap.org/), [Lynis](https://cisofy.com/lynis/))
- It is recommended to regularly update the OS kernel version ([CVEhound](https://github.com/evdenis/cvehound))
**Network Security**
- All namespaces should have NetworkPolicy. Interactions between namespaces should be limited to NetworkPolicy following least privileges principles ([Inspektor Gadget](https://github.com/kinvolk/inspektor-gadget))
- It is recommended to use authentication and authorization between all application microservices ([Istio](https://platform9.com/blog/kubernetes-service-mesh-how-to-set-up-istio/), [Linkerd](https://platform9.com/blog/how-to-set-up-linkerd-as-a-service-mesh-for-platform9-managed-kubernetes/), [Consul](https://www.consul.io/docs/architecture))
- The interfaces of the cluster components and infrastructure tools should not be published on the Internet.
- Infrastructure services, control plane, and data storage should be located in a separate VLAN on isolated nodes.
- External user traffic passing into the cluster should be inspected using WAF.
- It is recommended to separate the cluster nodes interacting with the Internet (DMZ) from the cluster nodes interacting with internal services. Delimitation can be within one cluster, or within two different clusters (DMZ and VLAN)
**Secure configuration of workloads**
- Do not run pods under the [root account](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/) UID 0
- [Set](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-the-security-context-for-a-pod) `runAsUser` parameter for all applications
- [Set](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/) `allowPrivilegeEscalation - false`
- Do not run the [privileged pod](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/) (`privileged: true`)
- It is recommended to [set](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/) `readonlyRootFilesystem - true`
- [Do not](https://kubernetes.io/docs/concepts/policy/pod-security-policy/#host-namespaces) use `hostPID` and `hostIPC`
- [Do not](https://kubernetes.io/docs/concepts/policy/pod-security-policy/#host-namespaces) use `hostNetwork`
- [Do not](https://kubernetes.io/docs/tasks/administer-cluster/sysctl-cluster/) use unsafe system calls (sysctl):
- `kernel.shm *`
- `kernel.msg *`
- `kernel.sem`,
- `fs.mqueue. *`
- [Do not](https://kubernetes.io/docs/concepts/policy/pod-security-policy/#volumes-and-file-systems) use `hostPath`
- [Use](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/) CPU / RAM limits. The values should be the minimum for the containerized application to work
- [Capabilities](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/) should be set according to the principle of least privileges (drop 'ALL', after which all the necessary capacities for the application to work are enumerated, while it is prohibited to use:
- `CAP_FSETID`
- `CAP_SETUID`
- `CAP_SETGID`
- `CAP_SYS_CHROOT`
- `CAP_SYS_PTRACE`
- `CAP_CHOWN`
- `CAP_NET_RAW`
- `CAP_NET_ADMIN`
- `CAP_SYS_ADMIN`
- `CAP_NET_BIND_SERVICE`)
- Do not use the default namespace (`default`)
- The application should have a seccomp, apparmor or selinux profile according to the principles of least privileges ([Udica](https://github.com/containers/udica), [Oci-seccomp-bpf-hook](https://github.com/containers/oci-seccomp-bpf-hook), [Go2seccomp](https://github.com/xfernando/go2seccomp), [Security Profiles Operator](https://github.com/kubernetes-sigs/security-profiles-operator))
- Workload configuration should be audited regularly ([Kics](https://checkmarx.com/product/opensource/kics-open-source-infrastructure-as-code-project/), [Kubeaudit](https://github.com/Shopify/kubeaudit), [Kubescape](https://github.com/armosec/kubescape), [Conftest](https://github.com/open-policy-agent/conftest), [Kubesec](https://github.com/controlplaneio/kubesec), [Checkov](https://github.com/bridgecrewio/checkov))
**Secure image development**
- Do not use `RUN` construct with `sudo`
- `COPY` is required instead of `ADD` instruction.
- Do not use automatic package update via `apt-get upgrade`, `yum update`, `apt-get dist-upgrade`
- It is necessary to explicitly indicate the versions of the installed packages. The SBOM building tools ([Syft](https://github.com/anchore/syft)) can be used to determine the list of packages.
- Do not store sensitive information (passwords, tokens, certificates) in the Dockerfile.
- The composition of the packages in the container image should be minimal enough to work.
- The port range forwarded into the container should be minimal enough to work.
- It is not recommended to install ```wget```, ```curl```, ```netcat``` inside the production application image and container.
- It is recommended to use ```dockerignore``` to prevent putting sensitive information inside the image.
- It is recommended to use a minimum number of layers using a [multi-stage build](https://docs.docker.com/develop/develop-images/multistage-build/)
- It is recommended to use `WORKDIR` as an absolute path. It is not recommended to use `cd` instead of `WORKDIR`
- It is recommended to beware of recursive copying using `COPY . ..`
- It is recommended not to use the `latest` tag
- When downloading packages from the Internet during the build process, it is recommended to check the integrity of these packages.
- Do not run remote control tools in a container
- Based on the results of scanning Docker images, an image signature should be generated, which will be verified before deployment ([Notary, Cosign](https://medium.com/sse-blog/verify-container-image-signatures-in-kubernetes-using-notary-or-cosign-or-both-c25d9e79ec45))
- Dockerfile should be checked during development by automated scanners ([Kics](https://checkmarx.com/product/opensource/kics-open-source-infrastructure-as-code-project/), [Hadolint](https://github.com/hadolint/hadolint), [Conftest](https://github.com/open-policy-agent/conftest))
- All images should be checked in the application lifecycle by automated scanners ([Trivy](https://github.com/aquasecurity/trivy), [Clair](https://github.com/quay/clair), [Grype](https://github.com/anchore/grype))
- Build secure CI and CD as same as suply chain process ([SLSA](https://github.com/slsa-framework/slsa)) | joseluisp |
867,548 | About Git #01 | Let's begin this tutorial with a scenario. Assume that you are a developer who is working on a... | 15,213 | 2021-10-28T04:21:13 | https://dev.to/chathurashmini/about-git-01-56ji | git, tutorial, beginners | Let's begin this tutorial with a scenario. Assume that you are a developer who is working on a project with another bunch of developers as a team. One of the developers in your team adds a new feature to the project. Now some functions which were functioning perfectly well before, gets crashed. What can you do now? This is where version controlling comes to play. They help to keep track of various versions of your code segments and also helps to recover any break downs that happens.
#Version Control Systems (VCS)
Version Control Systems keep track of the changes that we make to our files. We can edit multiple files and treat those files/ collection of edits as a single change. This is commonly known as a **commit**.
There are two categories of version control systems;
1. Centralized VCS
> Here all team members are connected to a central server to get the latest copy of the code and share the changes with others. The issue with this category is the availability of a central point of failure. If server goes offline team members cannot collaborate with each other.
Ex: Subversion, Team foundation server
2. Distributed VCS
> In this category every team member has a copy of the project in the history of his machine. Hence, the snapshots of the project is saved locally to the machine. Even though the central server is offline, synchronization can be done with others.
Ex: Git, Material
#Git
Among various version control systems Git is the most famous one. That is because it is free, open-source, fast, and scalable. It also provides cheap branching and merging facilities. It helps a group of developers to do coding collaboratively without facing issues as it keeps tracks of different versions of the code.
You can use Git via,
* The command line
* Code editors and IDEs
* Graphical User Interfaces
##Installing Git
To check whether you already have git installed in your machine, simply open the command prompt and type the command `git --version`. It will show the git version in your machine, and if it is higher than 2.20, you are good to proceed in this tutorial. If you get an error when you run the above command or if your version is less than 2.20 then you need to install the current version of Git. You can do so by going [to this link](https://git-scm.com/downloads).
##Starting with Git
###Setting Global Configurations
As I have mentioned above, Git keeps track of the things like who made changes and what changes he made. For this we need to add few configurations.
First let git knows who the global user is.
> If you are using Windows you can use Git Bash
`git config --global user.mail "yourmailaddress@example.com"`
`git config --global user.name "your name"`
You can also configure an editor or an IDE. Since I am using Visual Studio, I'm going to set it by following code,
`git config --global core.editor "code --wait"`
You can check all the above configuration information by opening the VScode using following command.
`git config --global -e`
##Creating Repositories
First let's create a new folder and navigate into it using following commands.
`mkdir newFolder`
`cd newFolder`
Now we are to make a git repository. You might be wondering what does Repository mean in Git. It is where all of your software packages and code files are stored.
You should use the following command to create a git repository inside your current folder.
`git init`
This command initializes a new *empty* git repository in your current directory.
Inside your current folder now you have a sub folder named `.git` which is *hidden* for the moment. If you type the command `ls` you cannot see anything. But if you use `ls -a` you can see the hidden `.git` repository. So why this sub folder is hidden? Actually this folder includes information about your project history. It includes directories like branches, info, objects, references, etc. Hence this is not our business but git's to look into it. As we need not to touch this it is hidden from us.
As you created a repository let's add/move any file of your choice into the folder to which you created the git repository before (I added a text file name file1.txt to my current folder 'newFolder'). Now your folder has changed. Previously it was empty, but now it has a file in it. Hence, you need to make git trace this change. To do that you should add the file using the command,
`git add test.py`
Now the file which was only in your local machine is added to the **Staging area(index)**.
>Index is a file maintained by Git that contains all of the information about what files and changes are going to go into your next commit.
If you want to get information on current working tree, you can use `git status`.
And to make a commit which means save the changes you have done, all you need to do is,
`git commit -m 'Commit Message'`
Here add a meaningful commit message stating what you have done related to the new changes.
##Tracking Files
Any Git project consists of three sections;
1. Git Directory: contains the history of all the files and changes that were made
1. Working Tree: contains the current state of the project
2. Staging Area: contains the changes that are marked to be included in the next commit.
Each time you make a commit Git record a new snapshot of the state of your project at that moment. Combination of these snapshots make the history of your project. Files of a project can either be tracked or untracked. Tracked files are part of the snapshots. Untracked are not.
Each track file can be in one of these three stages:
1. Modified: file has changes (adding, modifying, or deleting) which have not yet committed.
1. Staged: files which has changes that are ready to be committed
1. Committed: files whose changes are safely stored in snapshots in git directory.
>To get the current configuration you can use `git config -l`.
>`git log` command will give the commit history.
That's pretty much on starting with Git. For you to know more about staging area, removing files and other things feel free to continue on to the next tutorial. 😃 | chathurashmini |
871,450 | 🚀10 Trending projects on GitHub for web developers - 22nd October 2021 | Trending Projects is available as a weekly newsletter please sign up at Stargazing.dev to ensure you... | 7,129 | 2021-10-22T13:43:05 | https://stargazing.dev/blog/issue/74 | react, javascript, webdev, programming | Trending Projects is available as a weekly newsletter please sign up at [Stargazing.dev](https://stargazing.dev/) to ensure you never miss an issue.
### 1. YoHa
YoHa is a hand tracking engine that is built with the goal of being a versatile solution in practical scenarios where hand tracking is employed to add value to an application.
{% github https://github.com/handtracking-io/yoha %}
---
### 2. Cash
An absurdly small jQuery alternative for modern browsers.
{% github https://github.com/fabiospampinato/cash %}
---
### 3. React Command Palette
WAI-ARIA compliant React command palette like the one in Atom and Sublime
{% github https://github.com/asabaylus/react-command-palette %}
---
### 4. Rowy
Manage Firestore data in a spreadsheet-like UI, write Cloud Functions effortlessly in the browser, and connect to your favorite third party platforms such as SendGrid, Twilio, Algolia, Slack and more.
{% github https://github.com/rowyio/rowy %}
---
### 5. Riju
Extremely fast online playground for every programming language.
{% github https://github.com/raxod502/riju %}
---
### 6. Cromwell CMS
Cromwell CMS is a free open source headless TypeScript CMS for creating lightning-fast websites with React and Next.js. It has a powerful plugin/theming system while providing extensive Admin panel GUI for WordPress-like user experience.
{% github https://github.com/CromwellCMS/Cromwell %}
---
### 7. API Platform
Create REST and GraphQL APIs, scaffold Jamstack webapps, stream changes in real-time.
{% github https://github.com/api-platform/api-platform %}
---
### 8. rx-query
Batteries included fetching library Fetch your data with ease and give your users a better experience
{% github https://github.com/timdeschryver/rx-query %}
---
### 9. Immer
Create the next immutable state by mutating the current one
{% github https://github.com/immerjs/immer %}
---
### 10. React Date Picker
A simple and reusable datepicker component for React
{% github https://github.com/Hacker0x01/react-datepicker %}
---
### Stargazing 📈
#### [Top risers over last 7 days](https://stargazing.dev/?owner=&order=weeklyStarChange&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [JavaScript Algorithms](https://github.com/trekhleb/javascript-algorithms) +1,066 stars
2. [Playwright](https://github.com/microsoft/playwright) +1,036 stars
3. [Public APIs](https://github.com/public-apis/public-apis) +800 stars
4. [Uptime Kuma](https://github.com/louislam/uptime-kuma) +792 stars
5. [Awesome Cheatsheets](https://github.com/LeCoupa/awesome-cheatsheets) +716 stars
#### [Top growth(%) over last 7 days](https://stargazing.dev/?owner=&order=weeklyStarChangePercent&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [Spatial Keyboard Navigation](https://github.com/danilowoz/spatial-keyboard-navigation) +32%
2. [DOM to SVG](https://github.com/felixfbecker/dom-to-svg) +18%
3. [The new css reset](https://github.com/elad2412/the-new-css-reset) +15%
4. [Giscus](https://github.com/giscus/giscus) +14%
5. [ct](https://github.com/csswizardry/ct) +13%
#### [Top risers over last 30 days](https://stargazing.dev/?owner=&order=monthlyStarChange&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [Public APIs](https://github.com/public-apis/public-apis) +5,262 stars
2. [Uptime Kuma](https://github.com/louislam/uptime-kuma) +4,655 stars
3. [JavaScript Algorithms](https://github.com/trekhleb/javascript-algorithms) +3,288 stars
4. [Awesome](https://github.com/sindresorhus/awesome) +3,201 stars
5. [Build your own X](https://github.com/danistefanovic/build-your-own-x) +2,905 stars
#### [Top growth(%) over last 30 days](https://stargazing.dev/?owner=&order=monthlyStarChangePercent&minimumStars=0&search=&reverseOrder=false&moreFilters=false)🔗
1. [Uptime Kuma](https://github.com/louislam/uptime-kuma) +134%
2. [Nice Modal React](https://github.com/eBay/nice-modal-react) +101%
3. [Pico](https://github.com/picocss/pico) +52%
4. [Purity UI Dashboard](https://github.com/creativetimofficial/purity-ui-dashboard) +49%
5. [React Web Editor](https://github.com/CHEWCHEWW/react-web-editor) +43%
For all for the latest rankings please checkout [Stargazing.dev](https://stargazing.dev)
---
Trending Projects is available as a weekly newsletter please sign up at [Stargazing.dev](https://stargazing.dev/) to ensure you never miss an issue.
If you enjoyed this article you can [follow me](https://twitter.com/stargazing_dev) on Twitter where I regularly post about HTML, CSS and JavaScript. | iainfreestone |
873,322 | How to expose LocalHost to internet ? Easy way 📶 | Have you ever wanted to show to your friends your awesome web page, API, etc. But you found that this... | 0 | 2021-10-23T07:31:52 | https://dev.to/jafb321/how-to-expose-localhost-to-internet-easy-way-iok | webdev, programming | Have you ever wanted to show to your friends your awesome web page, API, etc. But you found that this project is running on localhost? 🤔
Well, there is a way to **expose this localhost to the internet** and get an https URL **easy and for free** 😎
For this we can use this app:
### Ngrok
Ngrok give you the ability to expose a specific port of your localhost and share an http/https URL to your friends.
#### How to use
1.- [Download Ngrok here](https://ngrok.com/download) and open it
2.- When you open first time the ngrok.exe it will be installed automaticaly, for use it you have to open a command prompt and type:
**ngrok http _PORT_**
in example, if we want to expose a web page and its server is running on port 8080, we will type:
**ngrok http 8080**

So when we run this command, we will get this:
That means we can copy this new URL and paste it on our browser and we could access to our page/api/etc from every pc, as if we were on localhost 😎.
We'll have 2 hours to expose our localhost, but don't worry, when this time get's over, we can re-run ngrok command and it will work again!!
If you liked this tutorial like it and follow me if you want! Thank you for reading
| jafb321 |
873,587 | First impression: Laravel | It's hugely popular. Thousands of stars on GitHub, Podcasts dedicated to it, online courses are... | 0 | 2021-10-28T12:01:17 | https://dev.to/andersbjorkland/first-impression-laravel-1cmh | laravel, php | It's hugely popular. Thousands of stars on GitHub, Podcasts dedicated to it, online courses are teaching it, and I'm yet to give it a shot. That changes today as I explore it and share: my first impressions of Laravel!
>If you rather skip my journey on building my first Laravel-project you can go <a href="#impressions">straight to a summary of my impressions</a>.
## Where to start
There are many places you can go when you want to explore such a popular project as Laravel. There are Laracasts - the dedicated learning platform for everything about Laravel, there are huge swaths of tutorials on YouTube, and blog posts of course. I'll make it easy on my self and get my news straight from the horses mouth: https://laravel.com
### The PHP Framework for Web Artisans
🤔 What are Web Artisans? This is the first question popping up in my head as I visit the official homepage. I get the feeling it is developers that write **clean code**. So it would look like that this framework had this as a focus. *Clean* and *modular* perhaps, with many components ready to be imported into any project I might have.
Reading up on some of the defining features we have:
"dependency injection, an expressive database abstraction layer, queues and scheduled jobs, unit and integration testing, and more."
It looks to me like I won't be terribly lost coming here from Symfony.
I'm off to a good start, so I'll just jump on with the "Get started" documentation.
### Getting started
So an FYI, I'm coding on a laptop running Windows 10. I've got Docker Desktop and WSL 2 for the times I just want to throw some new database engine at a project. *Which is good to have* as we can parse from the installation walkthrough.
The first step to install Laravel (with Docker) is to run the command `curl -s https://laravel.build/example-app | bash`. It took me some Googling to understand that this needs to be run from within WSL. This is a point-deduction for the docs. So here are the actual steps I took:
1. Make sure WSL2 is installed with `wsl -l -v`. I got the following result: ```bash
NAME STATE VERSION
* docker-desktop-data Running 2
docker-desktop Running 2
```
2. Ubuntu is a good WSL dirtro to have. Install it and configure Docker to use it:
a. `wsl --install -d Ubuntu`
b. Open *Docker Desktop* and go into *Settings/Resources/WSL INTEGRATION* and enable *Ubuntu* as an additional distro.
3. Log on to the WSL Ubuntu distro: `wsl -d ubuntu` (You can use PowerShell, Command Prompt or Windows Terminal. I wasn't able to logon from Git Bash for some reason 🤷♂️)
4. From within WSL run `curl -s https://laravel.build/example-app | bash`. This command will now run and create the skeleton of a Larvel project in a new directory *example-app*.
5. Move into the newly created directory: `cd example-app`
6. Then build the docker images with the Laravel-tool *sail* and start the containers: `./vendor/bin/sail up`. At firsts this threw an error at me, so I rebooted my laptop and tried it again from within WSL.
7. The Docker containers are all running. Just check out localhost and there's the proof.
## Can I make a blog out of this?
So everything seems to be working. I've got the Laravel structure in place and Docker containers running - so what can I build with this? For a first project I'm thinking a blog post should be possible. But first I should see what I've got code-wise. Here's the directories I've got in the project.
```
app
bootstrap
config
database
public
resources
routes
storage
tests
vendor
```
For some reason, I love to check out the config alternatives first. Coming from *Symfony* I am thorougly surprised that YAML is nowhere to be found - and it highlights how locked-in I've been with the Symfony fauna. Configurations in Laravel are made within PHP-files, as well as .env. When I look over the configuration PHP-files they seem to serve the same purpose as the *services.yaml* file does in Symfony - a way to make environmental variables available to the app in a predicitive manner. But then again, there's also a *services.php* file for Laravel. And while on this subject - Symfony allows for configuration without any YAML if you prefer it. There's not too much crazy and right now there's nothing I need to change except the title of the project. I'll call it **The Elphant Blog**.
### Outlining The Elephant Blog
My blog would require a few things:
* authentication
* blog post entity
* blog post editor
* blog post listings view
* and the blog post view
Keeping it simple like this, I'm going to have the listings-view serve as the homepage as well. This is the plan, let's see if I can make it through.
### Quick-starting authentication
Browsing the Laravel homepage I find a starter-kit for authentication: *breezer*. I'll try it out and see if it suits my needs.
I run `composer require laravel/breeze --dev` from my regular Windows environment. This install this package as a development dependency. Besides PHP-dependencies, this comes bundled with a few npm-packages as well. There's TailwindCSS, Axios and Laravel-Mix to mention a few. So to get this in order I also need to run `npm install` and `npm run dev` to make a first developer build. I'm almost ready but the documents wants me to update the database schema so I run `php artisan migrate`.
```bash
Illuminate\Database\QueryException
SQLSTATE[HY000] [2002] The requested address is not valid in its context (SQL: select * from infor
mation_schema.tables where table_schema = example_app and table_name = migrations and table_type = '
BASE TABLE')
```
🤔 That doesn't look good. So it would appear that I can't connect to the container for whatever reason. So what would be the solution? Googling shows that some people needed to update their .env with the correct database address: `DB_HOST:0.0.0.0`. Inspecting the MYSQL-container in Docker, this corresponds to the address being used. Running `migrate` again throws the **same error** at me. I did some back and forth, but finally I resolved to move into WSL and run migration through Laravel's *sail* tool. This has the Docker credentials in row: Moving into WSL with `wsl -d ubuntu` from my project folder I run `./vendor/bin/sail artisan migrate`.
> PS, this is provided you have installed PHP and PHP-extensions required in your WSL distro. I hadn't. So within WSL I ran:
> * `sudo add-apt-repository ppa:ondrej/php` to get access to PHP 8.
> * `sudo apt install php8.0 libapache2-mod-php8.0 php8.0-mysql`
> PPS. Running commands through *sail* when you have Docker containers is similar to how I've been doing the same with Symfony and its CLI-tool.
✔ Finally I get access to *register* and *login* pages. Without having to code anything (but debugging my developer environment a bit, which is not the fault of Laravel).
### Creating a Post-entity
Laravel comes with its CLI-tool **artisan**. I've already used it to make database migrations. I suspect that it has, as Symfony's CLI-tool has, a simple way to create entity models. I run `php artisan list` to see what commands are available. Under the key *make* I see something interesting:
```console
make
make:model Create a new Eloquent model class
```
To see what I can do with it I run `php artisan make:model --help`. This shows me arguments and options. A required argument is the name for the model. I can also add options so a controller, factory and migration is created at the same time. Realizing now that migration would require access to a docker container I'm going to continue on by using *sail*. Let's create the model **Post**:
`./vendor/bin/sail artisan make:model Post -cfm`
> The option *c* is to create a Controller. *f* is for a Factory. *m* is for migration.
I now have a basic (*Eloquent**) model, which extends a Model-class. By default every model has columns in a database for auto-incremented primary key, datetime it was updated, and datetime it was created - all without having to be specified in the model.
> **Eloquent* is Laravel's Object Relational Mapper. It serves same purpose as Doctrine does for Symfony.
I want **Post** to have following fields:
* Title
* Summary
* Text
* Slug
So I though I should define these in the class at `./app/Models/Post.php`. But NO. That is not the Eloquent way! It handles its fields rather more dynamically. I can however add these fields and corresponding methods as annotations to make it easier on myself. (Thanks [dotNET](https://stackoverflow.com/questions/51745634/laravel-models-where-are-model-properties/51746287) for clarifying this on StackOverflow).
```php
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Database\Eloquent\Model;
/**
* App\Models\Post
*
* @property int $id
* @property string $title
* @property \Illuminate\Support\Carbon|null $created_at
* @property \Illuminate\Support\Carbon|null $updated_at
* @method static \Illuminate\Database\Eloquent\Builder|\App\Models\Post whereId($value)
* @method static \Illuminate\Database\Eloquent\Builder|\App\Models\Post whereTitle($value)
* @method static \Illuminate\Database\Eloquent\Builder|\App\Models\Post whereCreatedAt($value)
* @method static \Illuminate\Database\Eloquent\Builder|\App\Models\Post whereUpdatedAt($value)
*/
class Post extends Model
{
use HasFactory;
/**
* The model's default values for attributes.
*
* @var array
*/
protected $attributes = [
'title' => '',
'summary' => '',
'slug' => '',
'text' => ''
];
/**
* The attributes that are mass assignable.
*
* @var array
*/
protected $fillable = ['title', 'summary', 'text'];
}
```
I also need to update the migration-file before running it.
```php
// database\migrations\2021_10_24_072240_create_posts_table.php
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreatePostsTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('posts', function (Blueprint $table) {
// Added by default
$table->id();
// Add these function-calls to define the model:
$table->string('title');
$table->text('summary');
$table->text('text');
$table->string('slug');
// Added by default
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('posts');
}
}
```
I've created the model and modified the migration class so the database schema is correctly updated. I can now run the migration: `./vendor/bin/sail artisan migrate`
🐬The way Laravel and Eloquent handles models is a bit different from Symfony and Doctrine. In Symfony I'm used to define entities and through the CLI it will ask me of what each field is called and what type it is. This will then provide information for migration so no manual coding is necessary. My first impression is that the model for Post is simply a placeholder whereas its defining characteristics are handled by the migration-file.
Back to task at hand. The "entity" is done ✔
### Building a **world-class** simple editor
☝ WORLD-CLASS meaning a simple form with a few input fields, and ways to store and fetch the posts. So I start by writing up a form for Laravels templating engine *Blade*. It's reminiscent of Twig but it allows regular PHP in it. Having installed *Breeze* in a previous step, I have access to Tailwind CSS. For this reason I'll be scaffolding the form with the Tailwind utility classes.
```php
<!-- resources\views\posts\_post_form.blade.php -->
<?php $labelClass="flex flex-col w-100"; ?>
<form action="/posts" method="POST" class="p-6">
<h3>Add a Blog Post</h3>
<div class="py-8 flex flex-col gap-4 justify-center max-w-xl m-auto">
<label class="{{ $labelClass }}Title
<input type="text" name="title" required>
</label>
<label class="{{ $labelClass }}">Summary
<textarea name="summary"></textarea>
</label>
<label class="{{ $labelClass }}">Text
<textarea name="text" required></textarea>
</label>
<input class="mt-8 w-40 px-4 py-2 bg-green-600 text-white" type="submit" value="Submit">
</div>
</form>
```
This is a partial template that I'll use from the admin dashboard.
```php
<!-- resources\views\dashboard.blade.php -->
<x-app-layout>
<x-slot name="header">
<h2 class="font-semibold text-xl text-gray-800 leading-tight">
{{ __('Dashboard') }}
</h2>
</x-slot>
<x-slot name="slot">
<div class="py-4">
<div class="max-w-7xl mx-auto sm:px-6 lg:px-8">
<div class="bg-white overflow-hidden shadow-sm sm:rounded-lg">
@include('posts._post_form')
</div>
</div>
</div>
</x-slot>
</x-app-layout>
```
Logging into the dashboard, after registering, I see this:
Next up I need to create a controller to fetch these inputs and store them. Or rather, I need to update the controller that *artisan* already has made for me. Remember that this was created at the same time I created the Post-model. For a first draft I see the need for three methods to this controller:
1. A method to create and store a new post.
2. A method to return an array of posts for a listings page.
3. A method to return a single post for displaying it.
```php
<?php
// app\Http\Controllers\PostController.php
namespace App\Http\Controllers;
use App\Models\Post;
use App\Providers\RouteServiceProvider;
use Illuminate\Http\Request;
use Illuminate\Support\Facades\Auth;
class PostController extends Controller
{
/**
* Return an array of posts to a template.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function index()
{
$posts = Post::all();
return view('posts/post_list', ['posts' => $posts]);
}
/**
* Store a new post in the database.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function store(Request $request)
{
if (!Auth::check()) {
return RouteServiceProvider::HOME;
}
$title = $request->input('title');
$summary = $request->input('summary');
$text = $request->input('text');
$post = new Post();
$post->title = $title;
$post->summary = $summary;
$post->text = $text;
$post->save();
return view('posts/post_view',
[
'title' => $post->getAttribute("title"),
'text' => $post->getAttribute("text"),
'summary' => $post->getAttribute("summary")
]
);
}
/**
* Return a post to a template if one is found.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function view(Request $request)
{
$id = $request->input('id');
$post = Post::where('id', $id)->first();
if (!$post) {
return Redirect('/posts');
}
return view('posts/post_view', ['post' => $post]);
}
}
```
This controller has everything I need right now. Only someone authenticated may create a post and there are methods to retrieve posts in a simple manner. But I'm not quite done yet. I need to add routes for them.
Routes are added in a seperate file `routes\web.php`. I add the following lines:
```php
use App\Http\Controllers\PostController;
Route::post('/posts', [PostController::class, 'store']);
Route::get('/posts', [PostController::class, 'index']);
Route::get('/post', [PostController::class, 'view']);
```
I create a couple of posts and can see that everything is working fine. And that's how we get the **WORLD-CLASS** 👀 editor done ✔
### Listing eloquent posts
Half the work to list the posts are already done. I created a method in the *PostController* that handles this for me. That method returns a view that references a template called `post_list` and passes an array of posts to it. I'll create this now:
```php
<!-- resources\views\posts\post_list.blade.php -->
<x-app-layout>
<x-slot name="header">
<h2 class="font-semibold text-xl text-gray-800 leading-tight">
Blog Posts
</h2>
</x-slot>
<x-slot name="slot">
<div class="sm:px-6 lg:px-8 pb-8 bg-white overflow-hidden shadow-sm">
<div class="flex flex-col gap-4">
@each('posts._post_list_item', $posts, 'post')
</div>
</div>
</x-slot>
</x-app-layout>
```
This template references a *partial*:
```php
<!-- resources\views\posts\_post_list_item.blade.php -->
<div>
<h4 class="font-semibold"><a href="/post?id={{ $post->id }}">{{ $post->title }}</a></h4>
<time class="text-sm">{{ $post->created_at }}</time>
<p>{{ $post->summary }}</p>
</div>
```
The listings page is ready at */posts* ✔
### A *complete* blog
The final piece (disregarding any other fancy functionalities) is to add a blog post view. Again, half the work is already done. There exists a controller handling fetching and returning a view, and a route to it. So now it's time to add the template:
```php
<!-- resources\views\posts\post_view.blade.php -->
<x-app-layout>
<x-slot name="header">
<h2 class="font-semibold text-xl text-gray-800 leading-tight">
{{ $post->title }}
</h2>
<time class="text-sm">{{ $post->created_at }}</time>
</x-slot>
<x-slot name="slot">
<div class="sm:px-6 lg:px-8 pb-8 bg-white overflow-hidden shadow-sm">
<div class="flex flex-col gap-4 max-w-xl">
<p>{{ $post->text }}</p>
</div>
</div>
</x-slot>
</x-app-layout>
```
It's pretty much the same template as the listings page, but this time I'm accessing the text-property instead of the summary. So the final post-view in its glorious form:
## <span id="impressions">My final first impressions 💡</span>
* The Laravel-way is further from the Symfony-way than I thought it would be. No YAML, views are sorted under resources, models can dictate which database to use, and I need to manually configure the migration-files.
* Eloquent is different from Doctrine, but still kind-of easy to use.
* Blade is either the best of two worlds, or the worst. I haven't made up my mind! The templating engine allows me to treat it as just the view. Or, I can spice it up with whole sections of PHP-procedures.
* The documentation was not as thorough as I expected. I thought models would just be the Laravel version of entities. But it's more an apples to oranges comparison - if I haven't completely missed the mark.
* In a weekend in my spare-time I could couble together a simple blogging site in Laravel. That says to me that there might be something to work with here.
I've heard people mention that Symfony would be hard and Laravel easy in comparison to it. I don't agree. Not for something as small-scale as my little project here. But this is coming from having done Symfony for a while and not having done any Laravel at all. | andersbjorkland |
874,607 | Set up .env in react project tips | Found this tips while i'm fetching issue set up .env variable in react project The .env file... | 0 | 2021-10-24T18:54:47 | https://dev.to/devded/set-up-env-in-react-project-tips-3i4g | react, javascript, webdev | Found this tips while i'm fetching issue set up .env variable in react project
- The .env file should be in the root for you application folder. That is one level above your src folder, the same place where you have your package.json
- The variable should be prefixed with `REACT_APP_`
You need to restart the server to reflect the changes in your code.
- You should access the variable in your code like this
`process.env.REACT_APP_SOME_VARIABLE`
- No need to wrap your variable value in single or double quotes.
- Do not put semicolon `;` or comma `,` at the end of each line.
[Source One](https://kiranvj.com/blog/blog/react-environment-variables-not-working/0)
[Source Two](https://stackoverflow.com/questions/53237293/react-evironment-variables-env-return-undefined) | devded |
876,302 | Typesense and React, Typesense an open-source alternative to Algolia and Elasticsearch | Building a custom search into your application can be a deeply technical and expensive endeavour in terms of build hours and license fees. Typesense is aiming to fix those pains with it’s Open-Sourced solution to web search Typesense. | 0 | 2021-10-26T19:05:20 | https://dev.to/mannuelf/typesense-and-react-typesense-an-open-source-alternative-to-algolia-and-elasticsearch-7g6 | javascript, search, react, opensource | ---
title: Typesense and React, Typesense an open-source alternative to Algolia and Elasticsearch
published: true
description: Building a custom search into your application can be a deeply technical and expensive endeavour in terms of build hours and license fees. Typesense is aiming to fix those pains with it’s Open-Sourced solution to web search Typesense.
tags: javascript, search, react, opensource
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/wr9f219um2c8l9bcfs4b.png
---
> original posted in my [blog here.](https://www.mannuelferreira.com/posts/typesense-open-source-alternative-to-algolia-and-elasticsearch)
## What is it
Typesense an open-source alternative to Algolia and Elasticsearch.

## TLDR
> - Show me the code [Click here](https://github.com/mannuelf/typesense-algolia-search-comparison/tree/main/typesense-client)
Otherwise keep reading 🚀
One key feature of any website or web application is the ability to search the data or content within the system. A fast and accurate search experience can improve user experience for you customers.
Building a custom search into your application can be a deeply technical and expensive endeavor in terms of hours and subscription fees. Typesense is aiming to fix those pains with it’s Open-Sourced solution to web search Typesense.
Typesense is a fast typo tolerant search engine boasting a sub-50ms search that feels instant. Typesense is built in C++, it is free to use and deploy on self hosted projects.
## A few notable features include:
### Typo tolerance
Typesense will automatically try to correct your typos. Typo tolerance is configurable on a per field basis.
### Multi-tenant API Keys
Security through API keys, which allows you to restrict access to specific sets of data, not all apps need to have access to all your data.
### Geo search
Filter data using geolocation data to retrieve data within a given radius.
### Federated search
Users are able to search across multiple data sets (collections) in one HTTP request.
Other features include synonyms, tunable ranking, result pinning, filtering and faceting, dynamic sorting, easy high availability and easy version upgrades.
### Client Libraries
Setting up a search experience in your web application is now trivial thanks to the official client libraries available in Ruby, Python, PHP and my personal favourite JavaScript. There are community driven libraries available for GO, C#, Laravel and Symphony. These HTTP libraries allow you to interact with Typesense servers with minimal friction and best practices baked in.
### UI component libraries
If that wasn’t cool enough to further smooth the road, Typesense has UI Component adapters to help you build your UI. The Typesense Instant Search Adapter is based on Algolia open-sourced instantsearch.js. If you have experience with Algolias adapter it makes the switch to Typesense all that much smoother.
### The adapter comes in 4 flavours:
- Instantsearch.js
- react-instantsearch
- vue-instantsearch
- angular-instantsearch
## Demonstration
This demo should run on your localhost only. Have fun 🚀
### Typesense React client
> Fork it [Click here](https://github.com/mannuelf/typesense-algolia-search-comparison/tree/main/typesense-client)
What you will see:
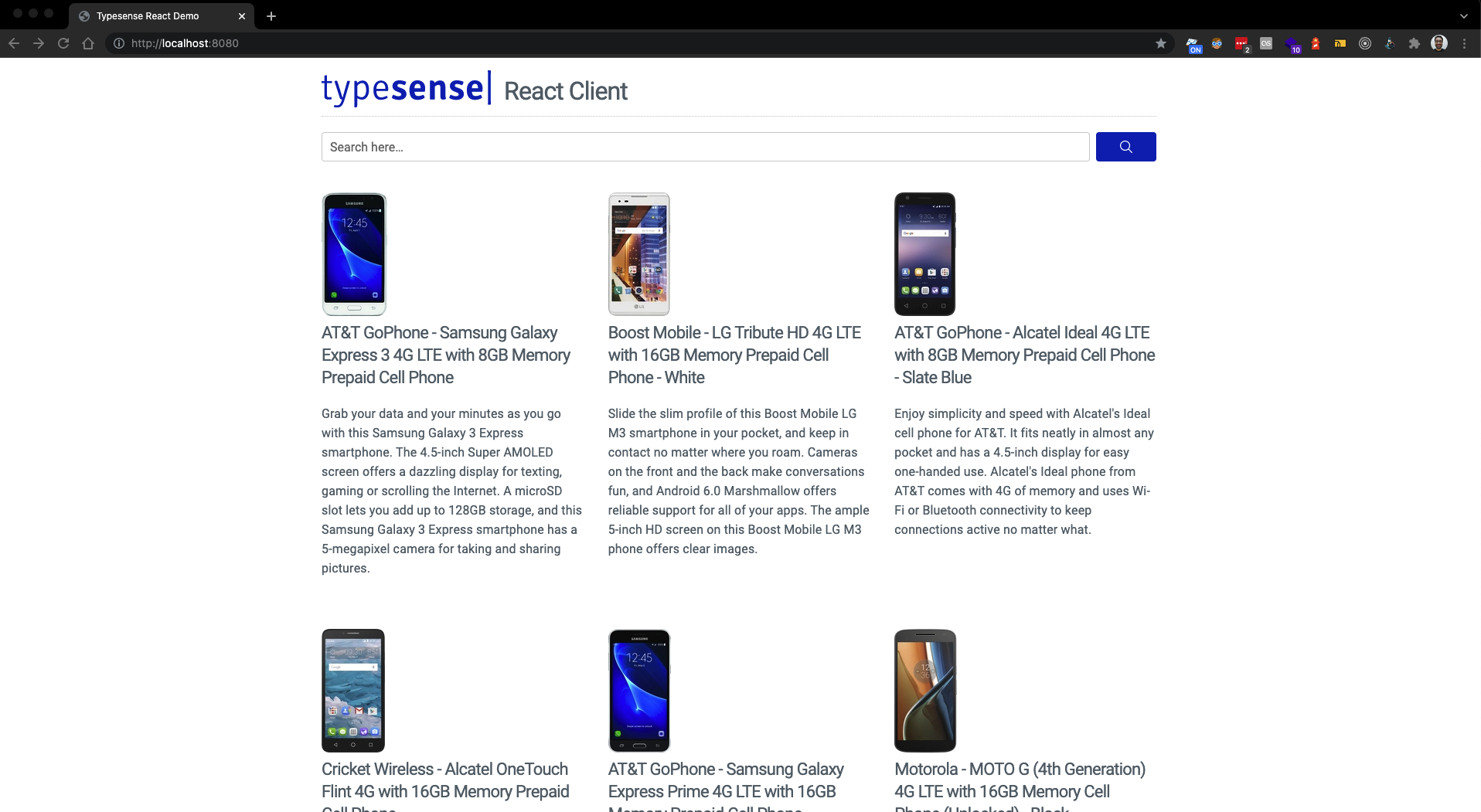
> ✨ Bootstrapped with [Create Snowpack App (CSA)](https://www.snowpack.dev).
### Prerequisites
- [Node.js](https://nodejs.org) using npm or [yarn](https://yarnpkg.com)
- [Docker](https://www.docker.com/get-started)
Use Docker for MAC/Windows etc it's the simplest for this code demo.
### Available Scripts
Run the following scripts in multiple tabs in the order they appear here:
```bash
yarn
```
Yarn, to install all dependencies.
```bash
yarn typesenseServer
```
Pulls down a Typesense Docker image (v0.22.0.rcu6), sets a local data directory, maps it to the container and starts the container. Container is running on port 8180.
```bash
yarn indexer
```
Indexes the demo e-commerce data into Typesense. Thanks to [@jasonbosco](https://github.com/jasonbosco) for this.
> 🚨 Note: environment variables are dangerously set to `process.env.SNOWPACK_PUBLIC_` and should not be deployed to production servers in this demonstration state.
```bash
SNOWPACK_PUBLIC_TYPESENSE_HOST=localhost
SNOWPACK_PUBLIC_TYPESENSE_PORT=8108
SNOWPACK_PUBLIC_TYPESENSE_PROTOCOL=http
SNOWPACK_PUBLIC_TYPESENSE_SEARCH_ONLY_API_KEY=xyz
SNOWPACK_PUBLIC_TYPESENSE_ADMIN_API_KEY=xyz
```
```bash
yarn start
```
Runs the app in the development mode.
Open [http://localhost:8080](http://localhost:8080) to view it in the browser.
The page will reload if you make edits. You will also see any lint errors in the console.
### Snowpack.dev
```bash
yarn build
```
Builds a static copy of your site to the `build/` folder.
Your app is ready to be deployed!
**For the best production performance:** Add a build bundler plugin like [@snowpack/plugin-webpack](https://github.com/snowpackjs/snowpack/tree/main/plugins/plugin-webpack) or [snowpack-plugin-rollup-bundle](https://github.com/ParamagicDev/snowpack-plugin-rollup-bundle) to your `snowpack.config.mjs` config file.
### Links
- [typesense.org](https://typesense.org/)
- [hub.docker.com/r/typesense](https://hub.docker.com/r/typesense/typesense/tags?page=1&ordering=last_updated)
- [producthunt.com/posts/typesense](https://www.producthunt.com/posts/typesense)
### References
- [typesense.org/docs](https://typesense.org/docs/)
### Follow me
[Twitter](https://twitter.com/manidf)
[Website](https://mannuelferreira.com/posts)
| mannuelf |
876,678 | VSM Is The New Way To Measure DevOps | One problem that many managers, engineering leadership, and even engineers themselves have are... | 0 | 2021-10-26T11:29:29 | https://dev.to/thenjdevopsguy/vsm-is-the-new-way-to-measure-devops-2i7c | devops, sre, engineeringleadership, engineeringmanagement | One problem that many managers, engineering leadership, and even engineers themselves have are figuring out how to measure engineering value. It's not like in sales where there are numbers and KPI's to give you an idea about if you're on track or not. With a CICD pipeline, there is no measurement of value. You can't measure how many times it passed or failed because those numbers have nothing to do with providing value.
The best way that everyone on an engineering team, including management/leadership, can see the value gained is by using Value Stream Management (VSM).
In this blog post, you'll learn what VSM is, why it's important, and a few tools to take a look at.
## What is VSM
Let's think of a few things that engineers do (this is by all means not an exhaustive list. I'm just using these as an example):
- Work on tickets via some Kanban board like Jira
- Run CICD pipelines
- Commit and push code to source control repositories
- Lots of troubleshooting
Here's the problem with the list above - there's really no way to measure value in any of those. For example, you can't track how many tickets an engineer completes in Jira and say that they're providing more value than other engineers because a lot of factors go into tickets; one ticket may be harder than another, someone may be new to the team or new to engineering, and it becomes very micro-manager-ish.
More importantly, showing how many tickets someone worked on, how many code pushes someone did, or how many CICD pipelines were run doesn't show technical business value. It doesn't show the CTO or the CIO how an application is coming along. They just see green checkmarks for passed pipelines or red X's for failed pipelines, which is way too black and white, meaning, there isn't enough data by looking at stuff like that.
Value Stream Management (VSM) aims to fix that issue in several different ways, but how?
In today's technologically-driven world, management and leadership care more about software innovation and delivery than ever before. It's at the top of most of their priority lists because quite frankly, software is the primary reason almost all businesses are able to stay in business today. Because of that, management and leadership teams want to see the value provided by the team, just like they want to see sales numbers from the sales team.
VSM, by definition, is a business practice that helps management and leadership teams determine the value of software development and CICD efforts for the organization. The way that they can determine that value is by using VSM platforms and software (more on that later).
## Why is VSM Important
Engineering leadership and management have been micro-managers for years. Assuming that they all don't enjoy it (and I really hope they don't), there's a reason for them being that way. That reason is because it's ridiculously hard to measure value in say, someone testing and troubleshooting one CICD pipeline. For example, an engineer could spend the entire day working on a pipeline. Troubleshooting dependencies that are missing in some Python code, figuring out why builds aren't passing, working with development teams to troubleshoot, spinning up and spinning down test environments, writing and pushing code, all for one pipeline. When a manager who isn't technical or forgot that engineering takes time may look at this and say *how is it possible that it's taking this long? I thought these pipelines were supposed to make us go faster and be more agile* (insert more buzz words here).
If someone, for example, had a VSM tool, they could see what was happening:
- How many code pushes were done for the dependencies in the Python code
- The pipeline analytics
- The tickets being worked on, how long they took, and what was done
The ability to see the analytics of the work vs just seeing one pipeline being worked on for 8 hours at a 50 ft view is critically different.
## VSM Products
Below are a list of VSM products that you can take a look at it to get started on your journey.
- [ConnectALL | Value Stream Management Solutions](https://www.connectall.com/)
- [IBM UrbanCode Velocity](https://www.ibm.com/products/urbancode-velocity)
- [Gitlab Value Stream Management](https://about.gitlab.com/solutions/value-stream-management/) | thenjdevopsguy |
876,722 | Why is HTTP a Stateless Protocol? | "HTTP Protocol is Stateless." This video tutorial will help you understand, what the above... | 0 | 2021-10-26T12:44:39 | https://dev.to/srajangupta__/why-is-http-a-stateless-protocol-2g7i | http, webdev, statelessprotocol, www | {% youtube gxTJPeY26rs %}
"HTTP Protocol is Stateless."
This video tutorial will help you understand, what the above statement means. | srajangupta__ |
876,753 | Designing GraphQL APIs - Best Practices & Learnings from REST API Design | An API Layer As A Contract Paraphrasing Eve Porcello: "a GraphQL API is an agreement... | 0 | 2021-10-26T13:38:05 | https://stepzen.com/blog/designing-graphql-apis-best-practices-and-learnings-from-rest-api-design | graphql, design, architecture, todayilearned | ## An API Layer As A Contract
[Paraphrasing Eve Porcello](https://www.oreilly.com/library/view/learning-graphql/9781492030706/): "a GraphQL API is an agreement between backend and frontend devs."
An API represents the data backend engineers need to provide and the data that frontend developers need to consume. Therefore, in a REST API, the endpoints represent the intersection of these needs.
This can get messy, say, if a backend engineer who is writing the ORM or API provides all the data on a customer to an endpoint and the frontend dev only needs a customer's name for a certain page. This can lead to either data pollution, in which case the frontend developer needs to write unnecessary business logic, or endpoint pollution, in which case the number of endpoints multiplies to the extent that both engineers lose track of the purpose of each endpoint.
GraphQL entered the scene as a way to avoid this type of pollution: ask for what you need, and get it.
And yet, there remains a factor that can multiply complexity: GraphQL queries. Used correctly, they minimize pain, but used incorrectly, they can create confusion and stifle an API layer.
## What makes for a messy GraphQL API layer?
For one, naming convention should remain consistent within the API. If your API returns information on 3 different pet breeds but your naming is inconsistent, it's just not easy to read:
```
catBreedQuery
dog_breed_query
getInfoOnHamsterBreeds
```
Consistency is key for easy reading:
```
cat_breed_query
dog_breed_query
hamster_breed_query
```
Next, meaningless nesting can make for an inconvenient developer experience as well.
For example, wrapping your `users` data unnecessarily in a `data` element:
```
"data" : {
"users" { :
[
{
"username": "Jane Doe"
"id": 1
"joined_at": 12-12-2002
},
{... etc}
]
```
Why not just have the following?
```
"users" : {
[
{
"username": "Jane Doe"
"id": 1
"joined_at": 12-12-2002
},
{...etc}
]
```
These are implementation details, but when we 'zoom out' to the level of the architecture of the API itself, we see another way of creating a cluttered API by using GraphQL queries incorrectly: following the structure of the REST API directly. If you do that, then why have a GraphQL API at all?
To see what I mean, let's pretend we're GraphQL-izing a REST API with three endpoints:
1. https://themovieapi.com/getmoviebyid
2. https://themovieapi.com/getactorsbymovieid
3. https://themovieapi.com/getactorspreviousrolesbyid
The developer wants to enter a movie id, and then get a list of actors with their previous roles.
So, to layer your GraphQL API, you create these queries:
1. `getmoviebyid`
2. `getactorsbymovieid`
3. `getactorspreviousrolesbyid`
This means that the developer must write a lot of frontend business logic. They must first retrieve the results of `getmoviebyid`, then they must use that result in `getactorsbymovieid`, and lastly they must use that result in `getactorspreviousrolesbyid`. Why even use GraphQL in the first place, from the frontend developer's perspective?
This is where a GraphQL API designer can leverage StepZen to create an API that is easily consumed and understood by other developers.
StepZen provides many custom directives to users of its endpoints. One of them, @sequence, [solves this problem](https://stepzen.com/docs/features/executing-queries-in-sequence) within a few lines of code:
```
getActorsPreviousRolesByMovieID(movie_id: String!): MovieType
@sequence(
steps:
[
{query: "getmoviebyid"}
{query: "getactorsbymovieid"}
{query: "getactorspreviousrolesbyid"}
]
)
```
This condenses 3 queries to one-- each `query` in the `steps` argument automagically picks up its parameters from the previous step (while the first uses the parameters entered into the query).
Using these and [other solutions like @materializer](https://stepzen.com/docs/features/linking-types) make connecting APIs with StepZen a matter of a few lines of code in the GraphQL layer, rather than hundreds of lines of business logic in the client.
## An API Layer as Communication
Insofar as an API layer is a contract between developers, it represents a type of static communication between developers.
Much like in the case of software documentation, there are many principles of communication that then apply to API design.
1. Communicate only what is needed.
- Documentation for an npm package needn't explain why a recursive function was needed to build it-- it only needs to explain _how_ to use the package. Similarly, a GraphQL API does not need to make a call for REST endpoint it's layered over, if the API designer makes use of directives like @sequence.
2. Create a smooth entry point.
- Documentation should take the reader clearly from one concept to the next. Similarly, GraphQL queries should create predictable patterns for the developer to follow:
-- allStates
-- statesByName
-- statesByCapital
-- allStateCapitals
-- stateCapitalByName
3. Consider the readability of your API.
- avoid meaningless nesting and inconsistent queries
## Conclusion
GraphQL APIs partially evolved to help clean up messy REST APIs.
But how to redesign a confusing GraphQL API?
Developers can implement a [StepZen GraphQL layer](https://stepzen.com/) using `@sequence` or a similar custom StepZen directive, to craft an API that will smooth out the developer experience.
It might also mean careful renaming of your queries.
Prevention is the best medicine-- patience and forethought in the process of adopting GraphQL, especially since incremental adoption is used at many organizations, can reduce your technical debt in the future.
If you've got questions about anything GraphQL API design, [hit us up on Discord](https://discord.com/invite/9k2VdPn2FR).
| cerchie |
877,123 | 10+ Best Laravel Dev Tools For Faster Development🚀 2024 | Want to boost up your development process while working on a Laravel project? Well, then bookmark... | 0 | 2021-10-26T14:03:45 | https://dev.to/themeselection/10-best-laravel-dev-tools-for-faster-development-4m3j | laravel, webdev, beginners, programming |
Want to boost up your development process while working on a Laravel project? Well, then bookmark this collection of the **best Laravel Dev Tools For Faster development**. Although, before we start the collection, let's know about laravel in short.
It is a framework that is used in many organizations for its high level of security and authentication. It is very easy to learn this language since the syntax of what was there in the language is very simple to understand and use.
## What is Laravel Framework?
[Laravel](https://laravel.com/docs/8.x) is a free and open-source PHP web framework, which is very expressive and has elegant syntax. Laravel is used to design custom software products.
It is a compelling model view controller (MVC) architectural pattern PHP framework, an open-source web application development intended for developers who demand an uncomplicated and rich toolkit to build full-featured web applications.
Laravel makes it effortless for you to produce professional web applications by following refined coding standards and architectural patterns.
[](https://themeselection.com/products/sneat-bootstrap-html-admin-template/)
### What are the benefits of Laravel Framework?
- It provides a convenient environment for automation testing.
- Laravel provides a good level of authorization and authentication.
- It has a very simple and clean API which helps to integrate with the mailing service.
- When there are more technical vulnerabilities laravel can be used to fix them easily
- It provides a very simple and expressive method of routing
- Not only with the mailing services, it can easily integrate with the other tools and helps to deliver fast web applications
- It avails a good level of error and expectation handling
- It can configure and manage scheduled tasks very effectively
**Features:**
- Class Auto-loading
- IOC container
- Migration
- Query Builder
- Artisan Console
- Database Seeding
- Unit-Testing
### What are the Laravel Tools and Packages?
Laravel is one of the most popular applications in the market, which is very easy to learn. This is more popular among the developers because it does not comprise any of the product functionality.
It aims to give many web project functions like integration, authentication, authorization, etc. When you choose a Laravel package and tool, you can actually use them in different ways for accessing databases, performance dependency, and a lot more.
So, Here we have covered some of the best ones to help you speed up your development.
If you are looking for laravel admin templates then you can check the collection of [Laravel admin panel template](https://themeselection.com/laravel-admin-panel-template/).
Now, let's begin...!!

### [Laravel Debugbar](https://github.com/barryvdh/laravel-debugbar)
This is a package to integrate [PHP Debug Bar](http://phpdebugbar.com/) with Laravel. It includes a Service Provider to register the debugbar and attach it to the output. You can publish assets and configure them through Laravel. It bootstraps some Collectors to work with Laravel and implements a couple of custom Data Collectors, specific to Laravel. It is configured to display Redirects and (jQuery) Ajax Requests. (Shown in a dropdown) Read [the documentation](http://phpdebugbar.com/docs/) for more configuration options.
[Laravel Debugbar](https://github.com/barryvdh/laravel-debugbar) is a highly recommended tool for debugging the Laravel application. The tool comes with regularly updated for the latest Laravel versions. The tool is displayed at the bottom of the browser and provides the debug information simultaneously. It also shows the route, and the template which is rendered with the parameters provides detailed information. It allows the developer to add messages.
### [IDE Helper](https://github.com/barryvdh/laravel-ide-helper)

This package generates helper files that enable your IDE to provide accurate autocompletion. Generation is done based on the files in your project, so they are always up-to-date.
### [Laravel Tinker](https://github.com/laravel/tinker)

[Laravel Tinker](https://github.com/laravel/tinker) allows you to interact through a command line with any project that uses the Laravel framework. It allows users to access all the events and objects. Tinker is an optional add-on, so we should manually install it with the Laravel versions after 5.4.
### [Laravel Entrust](https://github.com/Zizaco/entrust)
In Laravel Entrust is a secured process of adding role-based permissions. It has four new tables which include, Role, Role User, Permissions, and Permission Role. The roles are set up under categories at different levels.
### [Laravel Socialite](https://github.com/laravel/socialite)

Laravel Socialite provides an expressive, fluent interface to OAuth authentication with Facebook, Twitter, Google, LinkedIn, GitHub, GitLab, and Bitbucket. It handles almost all of the boilerplate social authentication code you are dreading writing.
[Laravel Socialite](https://github.com/laravel/socialite) enables you to handle OAuth authentication more seamlessly. This tool allows users to log in via social networking sites such as Facebook, LinkedIn, Instagram, Twitter, Google, Bitbucket, etc. This is one of the popular Laravel features that is commonly used in most of the Laravel development.
**Features:**
- It is easy to use
- Contains almost all instance social authentication codes you may need
- Has great community support with a lot of providers
### [Laravel Mix](https://github.com/laravel-mix/laravel-mix)

Laravel Mix provides a clean, fluent API for defining basic [webpack](http://github.com/webpack/webpack) build steps for your applications. Mix supports several common CSS and JavaScript pre-processors.
**Features:**
- Provides a wide API that corresponds to almost all your needs
- Works as a wrapper around Webpack and allows to extend it
- Eliminates all the difficulties associated with setting up and running Webpack
- Works with modern JavaScript tools and frameworks: Vue.JS, React.JS, Preact, TypeScript, Babel, CoffeScript.
- Transpiles and bundles Less, Sass, and Stylus into CSS files
- Supports Browser Sync, Hot Reloading, Assets versioning, and Source Mapping out of the box
### [Sneat Bootstrap 5 HTML Laravel Admin Template](https://themeselection.com/item/sneat-bootstrap-html-laravel-admin-template/) (The Best Laravel Admin Template💥)
[**Sneat Bootstrap 5 HTML Laravel Admin Template**](https://themeselection.com/item/sneat-bootstrap-html-laravel-admin-template/) is the latest developer-friendly & highly customizable [Laravel dashboard](https://themeselection.com/item/category/laravel-admin-templates/). Besides, the highest industry standards are considered to bring you the best laravel bootstrap admin template that is not just fast 🚀 and easy to use, but highly scalable.
In addition, incredibly versatile, the Sneat laravel based [Bootstrap dashboard template](https://themeselection.com/item/category/bootstrap-admin-templates/) also allows you to build any type of web application. For instance, you can create:
- SaaS platforms
- Project management apps
- Ecommerce backends
- CRM systems
- Analytics apps
- Banking apps
- Education apps
- Fitness apps & many more….
Furthermore, you can use this one of the best innovative [**Laravel admin panel template**](https://themeselection.com/item/category/laravel-admin-templates/) to create eye-catching, high-quality, and high-performing Web Applications. Besides, your apps will be completely responsive, ensuring they’ll look stunning and function flawlessly on desktops, tablets, and mobile devices.
**Features:**
- Based on **Bootstrap 5**
- **Laravel 10**
- Integrated **CRUD App**
- **Vertical & Horizontal** layouts
- Default, Bordered & Semi-dark themes
- **Light & Dark** mode support
- **Jetstream** and **ACL Ready**
- **Localization** & **RTL Ready**
- 5 Dashboards, 10 Pre-Designed Apps
- 2 Chart libraries and many more.
[Demo](https://demos.themeselection.com/sneat-bootstrap-html-laravel-admin-template/landing/) [Download](https://themeselection.com/item/sneat-bootstrap-html-laravel-admin-template/)
> For more admin templates check the collection of [Laravel Vue Admin Template Free](https://themeselection.com/10-best-laravel-vue-admin-template-free/).
### [Laravel Websockets](https://github.com/beyondcode/laravel-websockets)
Bring the power of WebSockets to your Laravel application. Drop-in Pusher replacement, SSL support, Laravel Echo support, and a debug dashboard are just some of its features.
**Features:**
- Completely handles WebSockets server-side
- Replaces Pusher and Laravel Echo Server
- Is Ratchet-based, but doesn’t require you to set up Ratchet yourself
- Ships with a real-time Debug Dashboard
- Provides a real-time chart for you to inspect the WebSockets key metrics (peak connections, the number of messages sent, and API messages received)
- Enables to use in multi-tenant applications
- Comes with the pusher message protocol (all the packages you already have that support Pusher will work with Laravel WebSockets too)
- Is compatible with Laravel Echo
- Preserves all the main Pusher features (private and presence channels, Pusher HTTP API)
### [InfyOm Laravel Generator](https://github.com/InfyOmLabs/laravel-generator)

Generate Admin Panels CRUDs and APIs in Minutes with tons of other features and customizations with 3 different themes.
### [Materio Bootstrap 5 Laravel Admin Template](https://themeselection.com/item/materio-bootstrap-laravel-admin-template/)
[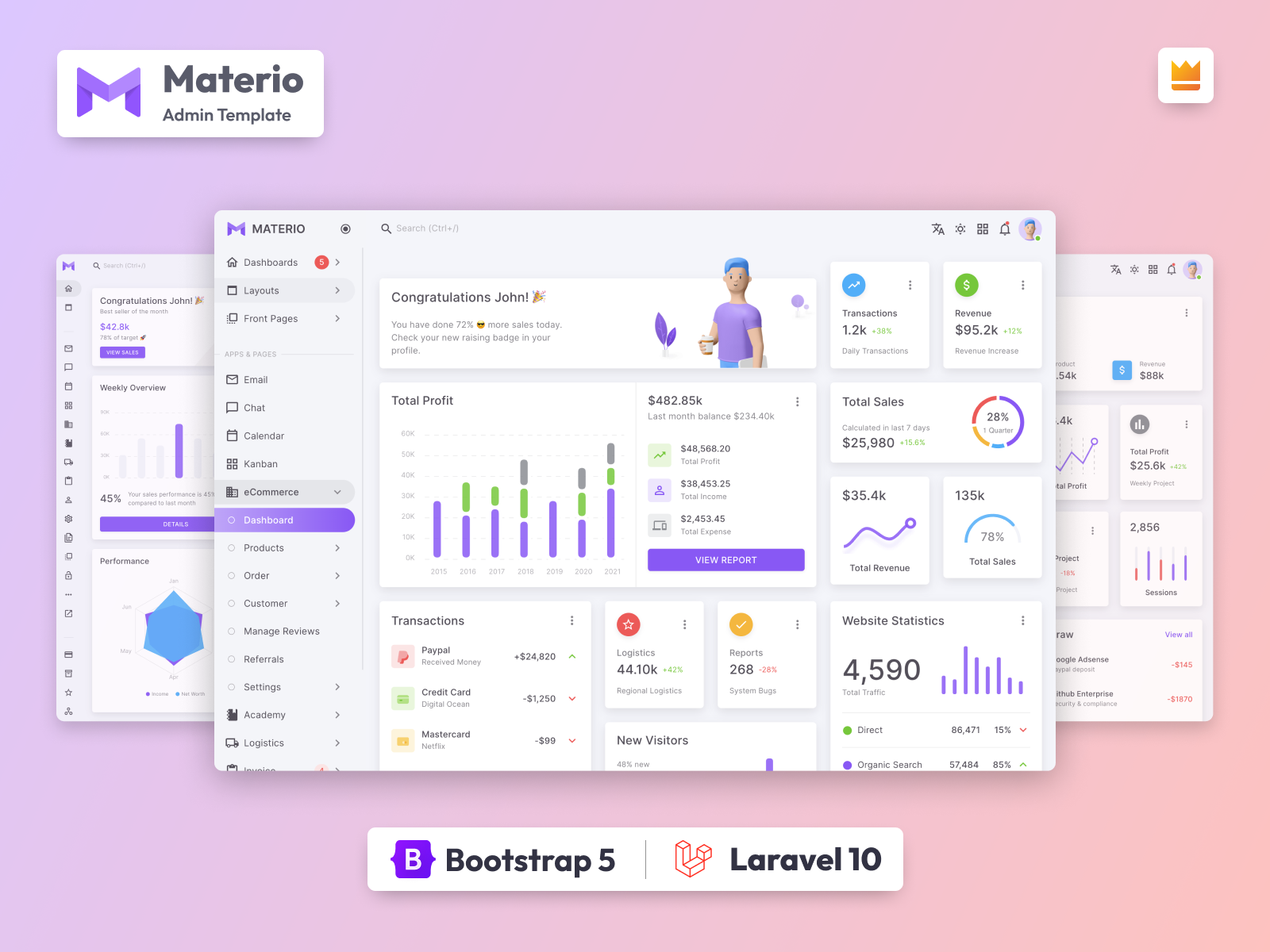](https://themeselection.com/item/materio-bootstrap-laravel-admin-template/)
[**Materio Bootstrap 5 HTML Laravel Admin Template**](https://themeselection.com/item/materio-bootstrap-laravel-admin-template/) is the latest developer-friendly & highly customizable [Laravel Admin dashboard](https://themeselection.com/item/category/laravel-admin-templates/). Besides, the highest industry standards are considered to bring you the best laravel bootstrap admin template that is not just fast🚀and easy to use, but highly scalable.
In addition, incredibly versatile, the Materio laravel based [Bootstrap admin dashboard template](https://themeselection.com/item/category/bootstrap-admin-templates/) also allows you to build any type of web application. For instance, you can create:
- SaaS platforms
- Project management apps
- Ecommerce backends
- CRM systems
- Analytics apps
- Banking apps
- Education apps
- Fitness apps & many more….
Furthermore, you can use this one of the best innovative [**Laravel admin panel template**](https://themeselection.com/item/category/laravel-admin-templates/) to create eye-catching, high-quality, and high-performing Web Applications. Besides, your apps will be completely responsive, ensuring they’ll look stunning and function flawlessly on desktops, tablets, and mobile devices.
**Features:**
- Based on **Bootstrap 5**
- **Laravel 9**
- Integrated **CRUD App**
- **Vertical & Horizontal** layouts
- Default, Bordered & Semi-dark themes
- **Light, Dark & System** mode support
- **Jetstream** and **ACL Ready**
- **Localization** & **RTL Ready**
- **5 Dashboards**
- **10 Prebuilt Apps**
- 2 Chart libraries and many more.
[Demo](https://demos.themeselection.com/materio-bootstrap-html-laravel-admin-template/demo-1/) [Download](https://themeselection.com/item/materio-bootstrap-laravel-admin-template/)
Also, available in [Bootstrap Dashboard Template Free](https://themeselection.com/item/category/bootstrap-admin-templates/) Version.
[](https://themeselection.com/item/materio-bootstrap-html-admin-template/)
And **[Django Dashboard](https://themeselection.com/item/category/django-admin-template/) Version**:
[](https://themeselection.com/item/materio-bootstrap-django-admin-template/)
### [Laravel Passport](https://github.com/laravel/passport)
Laravel Passport is the simplest possible tool for API authentication. It is a full Auth2 server implementation that is very easy to use.
### [Laravel Tenancy](https://github.com/tenancy/multi-tenant)
The unobtrusive Laravel package makes your app multi-tenant. Serving multiple websites, each with one or more hostnames from the same codebase. But with a clear separation of assets, database, and the ability to override logic per tenant.
**Features:**
- Eases the process of development
- Provides a powerful interface to monitor and debug numerous aspects of your app
- Expands the horizons of the development process providing direct access to a wide range of information
- Cuts down bugs and gives ideas on how to improve your application
- Gives a sense of the requests coming into your application. Provides a clear understanding of all the running exceptions, database queries, mail, log entries, cache operations, notifications, and much more
- Collects the information on how long it takes to execute all the necessary commands and queries.
### [Laravel Dusk](https://github.com/laravel/dusk)

Laravel Dusk provides an expressive, easy-to-use browser automation and testing API. By default, Dusk does not require you to install JDK or Selenium on your machine. Instead, Dusk uses a standalone Chromedriver. However, you are free to utilize any other Selenium driver you wish.
If you want to test your application and see how it works from the user’s point of view, try Laravel Dusk. This tool provides automated browser testing with developer-friendly API. Laravel Dusk comes with Chromedriver by default.
**Features:**
- Does not require to install JDK or Selenium (but you are free to use any Selenium driver if you wish)
- Is a powerful tool for the web applications using JavaScript
- Ease the process of testing various clickable elements of your app
- Saves screenshots and browser console outputs of the crushed tests, so you can see what has gone wrong
### [Materio Vuetify VueJS Laravel Admin Template](https://themeselection.com/products/materio-vuetify-vuejs-laravel-admin-template/).
[](https://themeselection.com/products/materio-vuetify-vuejs-laravel-admin-template/)
It is developer-friendly, rich with features, and highly customizable Laravel admin template. Furthermore, you can use this one of the best [laravel admin templates](https://themeselection.com/products/category/laravel-admin-templates/) to create eye-catching, high-quality, and high-performing single-page applications. Materio is also equipped with invaluable features designed to help you create premium-quality apps exactly as you imagine them.
In addition, incredibly versatile, the Materio Vuetify Laravel [Vue admin Panel](https://themeselection.com/item/category/vuejs-admin-templates/) template also allows you to build any type of web applications such as CRM, Analytic apps, Education apps, Fitness Apps, Analytics apps, etc...
**Features:**
- Pure VueJS, No jQuery Dependency
- Created with Vue CLI
- Utilizes Vuex, Vue Router, Webpack
- Code Splitting, Lazy loading
- Carousel (Image Slider)
- Clipboard (Copy to clipboard)
- API-ready JWT Authentication flow
- Access Control (even on CRUD operations)
- Laravel Passport
- Laravel Sanctum
Also, available in **[Nuxt Admin Template](https://themeselection.com/item/category/nuxt-admin-template/)** Free version:
[](https://themeselection.com/item/materio-free-vuetify-nuxtjs-admin-template/)
### [Laravel Packager](https://github.com/Jeroen-G/Laravel-Packager)
This package provides you with a simple tool to set up a new package and it will let you focus on the development of the package instead of the boilerplate
### [Laravel Test Tools](https://chrome.google.com/webstore/detail/laravel-testtools/ddieaepnbjhgcbddafciempnibnfnakl?)
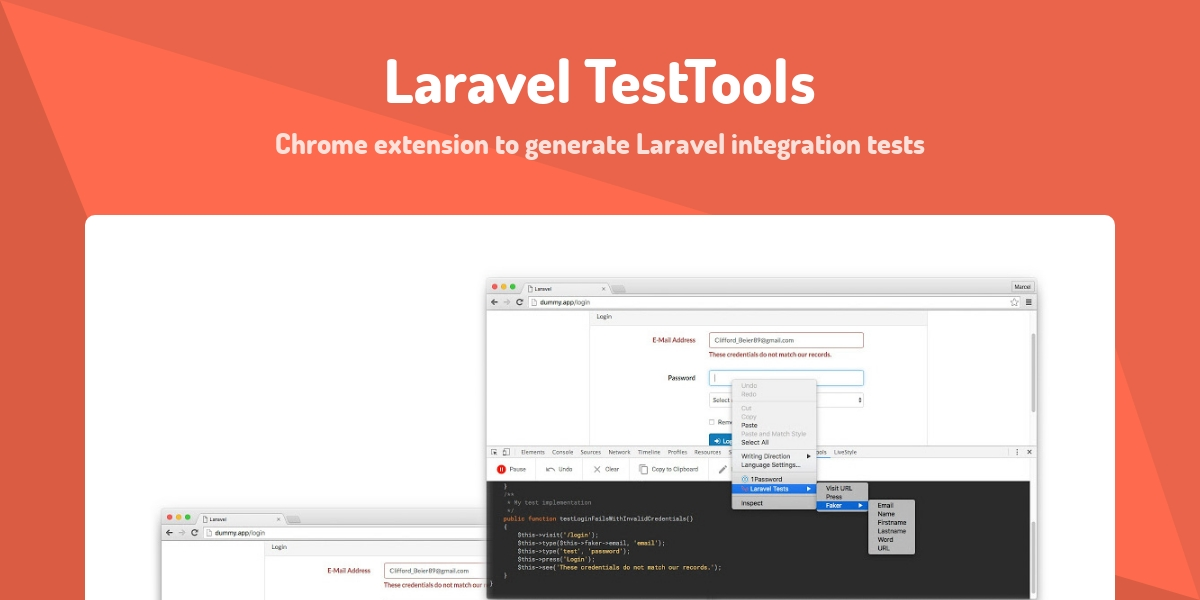
Chrome extension to generate Laravel integration tests while using your app. Create your Laravel integration tests while you surf on your website.
### [PHPStrom](https://www.jetbrains.com/phpstorm/)
PHPStrom is a Smart IDE for Laravel development. It offers multiple features such as Fast and secured refactoring, Smart code navigation, efficient code formatter, and easy debugging, and testing. This IDE will increase the productivity of the developers by debugging the codes faster with consistent performance.
### [Bitbucket](https://bitbucket.org/product)
If you are a developer, you must be quite familiar with GitHub or Bitbucket. Both offer git services, you can choose one depending on your project and the application requisites. Bitbucket is ideal for small enterprise Laravel applications. This helps you avoid sharing the code repositories with a limited number of collaborators. You can also use Bitbucket as a private repository and it’s more flexible.
## Conclusion:
So, this was the collection of the **[best Laravel Dev Tools For Faster development](https://dev.to/theme_selection/10-best-laravel-dev-tools-for-faster-development-4m3j)**. Intention here is to save your time and provide the best dev tools.
Due to its easy deployment and the customized level of integration, many companies want to deploy these Laravel applications in their organization.
Most of the tools mentioned here provide a high level of authority and authentication. Besides, All of them are developer-friendly to use.
So, choose the one according to your needs and requirements. Also, suggest any other laravel tools that you think we should consider in this list.
| theme_selection |
877,133 | Web Scraping: Intercepting XHR Requests | Have you ever tried scraping AJAX websites? Sites full of Javascript and XHR calls? Decipher tons of... | 0 | 2021-10-27T13:25:39 | https://www.zenrows.com/blog/web-scraping-intercepting-xhr-requests | python, webdev, tutorial, beginners | Have you ever tried scraping AJAX websites? Sites full of Javascript and XHR calls? Decipher tons of nested CSS selectors? Or worse, daily changing selector? Maybe you won't need that ever again. Keep on reading, XHR scraping might prove your ultimate solution!
### Prerequisites
For the code to work, you will need [python3 installed](https://www.python.org/downloads/). Some systems have it pre-installed. After that, install Playwright and the browser binaries for Chromium, Firefox, and WebKit.
```bash
pip install playwright
playwright install
```
## Intercept Responses
As we saw in a previous blog post about [blocking resources](https://www.zenrows.com/blog/blocking-resources-in-playwright?utm_source=devto&utm_medium=blog&utm_campaign=xhr_scraping), headless browsers allow request and response inspection. We will use [Playwright](https://playwright.dev/python/) in python for the demo, but it can be done in Javascript or using [Puppeteer](https://github.com/puppeteer/puppeteer).
We can quickly inspect all the responses on a page. As we can see below, the `response` parameter contains the status, URL, and content itself. And that's what we'll be using instead of directly scraping content in the HTML using CSS selectors.
```python
page.on("response", lambda response: print(
"<<", response.status, response.url))
```
## Use case: auction.com
Our first example will be [auction.com](https://www.auction.com/residential/ca/). You might need proxies or a VPN Since it blocks outside of the countries they operate in. Anyway, it might be a problem trying to scrape from your IP since they will ban it eventually. Check out [how to avoid blocking](https://www.zenrows.com/blog/stealth-web-scraping-in-python-avoid-blocking-like-a-ninja?utm_source=devto&utm_medium=blog&utm_campaign=xhr_scraping) if you find any issues.
Here is a basic example of loading the page using Playwright while logging all the responses.
```python
from playwright.sync_api import sync_playwright
url = "https://www.auction.com/residential/ca/"
with sync_playwright() as p:
browser = p.firefox.launch()
page = browser.new_page()
page.on("response", lambda response: print(
"<<", response.status, response.url))
page.goto(url, wait_until="networkidle", timeout=90000)
print(page.content())
page.context.close()
browser.close()
```
`auction.com` will load an HTML skeleton without the content we are after (house prices or auction dates). They will then load several resources such as images, CSS, fonts, and Javascript. If we wanted to save some bandwidth, we could filter out some of those. For now, we're going to focus on the attractive parts.
As we can see in the network tab, almost all relevant content comes from an XHR call to an assets endpoint. Ignoring the rest, we can inspect that call by checking that the response URL contains this string: `if ("v1/search/assets?" in response.url)`.
There is a size and time problem: the page will load tracking and map, which will amount to more than a minute in loading (using proxies) and 130 requests :O. We could do better by blocking certain domains and resources. We were able to do it in under 20 seconds with only 7 loaded resources in our tests. We will leave that as an exercise for you ;)
```curl
<< 407 https://www.auction.com/residential/ca/
<< 200 https://www.auction.com/residential/ca/
<< 200 https://cdn.auction.com/residential/page-assets/styles.d5079a39f6.prod.css
<< 200 https://cdn.auction.com/residential/page-assets/framework.b3b944740c.prod.js
<< 200 https://cdn.cookielaw.org/scripttemplates/otSDKStub.js
<< 200 https://static.hotjar.com/c/hotjar-45084.js?sv=5
<< 200 https://adc-tenbox-prod.imgix.net/resi/propertyImages/no_image_available.v1.jpg
<< 200 https://cdn.mlhdocs.com/rcp_files/auctions/E-19200/photos/thumbnails/2985798-1-G_bigThumb.jpg
# ...
```
For a more straightforward solution, we decided to change to the `wait_for_selector` function. It is not the ideal solution, but we noticed that sometimes the script stops altogether before loading the content. To avoid those cases, we change the waiting method.
While inspecting the results, we saw that the wrapper was there from the skeleton. But each houses' content is not. So we will wait for one of those: `"h4[data-elm-id]"`.
```python
with sync_playwright() as p:
def handle_response(response):
# the endpoint we are insterested in
if ("v1/search/assets?" in response.url):
print(response.json()['result']['assets']['asset'])
# ...
page.on("response", handle_response)
# really long timeout since it gets stuck sometimes
page.goto(url, timeout=120000)
page.wait_for_selector("h4[data-elm-id]", timeout=120000)
```
Here we have the output, with even more info than the interface offers! Everything is clean and nicely formatted 😎
```json
[
{
"item_id": "E192003",
"global_property_id": 2981226,
"property_id": 5444765,
"property_address": "13841 COBBLESTONE CT",
"property_city": "FONTANA",
"property_county": "San Bernardino",
"property_state": "CA",
"property_zip": "92335",
"property_type": "SFR",
"seller_code": "FSH",
"beds": 4,
"baths": 3,
"sqft": 1704,
"lot_size": 0.2,
"latitude": 34.10391,
"longitude": -117.50212,
...
```
We could go a step further and use the pagination to get the whole list, but we'll leave that to you.
## Use case: twitter.com
Another typical case where there is no initial content is [Twitter](https://twitter.com/playwrightweb/status/1396888644019884033). To be able to scrape Twitter, you will undoubtedly need Javascript Rendering. As in the previous case, you could use CSS selectors once the entire content is loaded. But beware, since Twitter classes are dynamic and they will change frequently.
What will most probably remain the same is the API endpoint they use internally to get the main content: `TweetDetail.` In cases like this one, the easiest path is to check the XHR calls in the network tab in devTools and look for some content in each request. It is an excellent example because Twitter can make 20 to 30 JSON or XHR requests per page view.
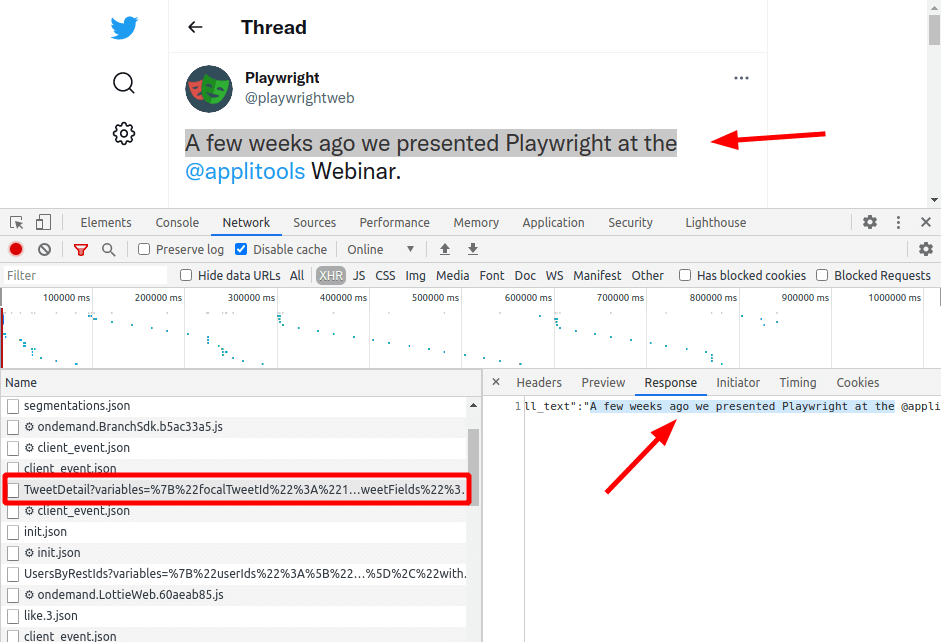
Once we identify the calls and the responses we are interested in, the process will be similar.
```python
import json
from playwright.sync_api import sync_playwright
url = "https://twitter.com/playwrightweb/status/1396888644019884033"
with sync_playwright() as p:
def handle_response(response):
# the endpoint we are insterested in
if ("/TweetDetail?" in response.url):
print(json.dumps(response.json()))
browser = p.firefox.launch()
page = browser.new_page()
page.on("response", handle_response)
page.goto(url, wait_until="networkidle")
page.context.close()
browser.close()
```
The output will be a considerable JSON (80kb) with more content than we asked for. More than ten nested structures until we arrive at the tweet content. The good news is that we can now access favorite, retweet, or reply counts, images, dates, reply tweets with their content, and many more.
## Use case: nseindia.com
Stock markets are an ever-changing source of essential data. Some sites offering this info, such as [the National Stock Exchange of India](https://www.nseindia.com/market-data/live-equity-market), will start with an empty skeleton. After browsing for a few minutes on the site, we see that the market data loads via XHR.
Another common clue is to view the page source and check for content there. If it's not there, it usually means that it will load later, which probably requires XHR requests. And we can intercept those!
Since we are parsing a list, we will loop over it a print only part of the data in a structured way: symbol and price for each entry.
```python
from playwright.sync_api import sync_playwright
url = "https://www.nseindia.com/market-data/live-equity-market"
with sync_playwright() as p:
def handle_response(response):
# the endpoint we are insterested in
if ("equity-stockIndices?" in response.url):
item = response.json()['data'][1]
print(item['symbol'], item['lastPrice'])
browser = p.firefox.launch()
page = browser.new_page()
page.on("response", handle_response)
page.goto(url, wait_until="networkidle")
page.context.close()
browser.close()
# Output:
# NIFTY 50 18125.4
# ICICIBANK 846.75
# AXISBANK 845
# ...
```
As in the previous examples, this is a simplified example. Printing is not the solution to a real-world problem. Instead, each page structure should have a [content extractor and a method to store it](https://www.zenrows.com/blog/mastering-web-scraping-in-python-scaling-to-distributed-crawling?utm_source=devto&utm_medium=blog&utm_campaign=xhr_scraping#custom-parser). And the system should also handle the crawling part independently.
## Conclusion
We'd like you to go with three main points:
1. Inspect the page looking for clean data
2. API endpoints change less often than CSS selectors, and HTML structure
3. Playwright offers more than just Javascript rendering
Even if the extracted data is the same, fail-tolerance and effort in writing the scraper are fundamental factors. The less you have to change them manually, the better.
Apart from XHR requests, there are many other ways to [scrape data beyond selectors](https://www.zenrows.com/blog/mastering-web-scraping-in-python-from-zero-to-hero?utm_source=devto&utm_medium=blog&utm_campaign=xhr_scraping). Not every one of them will work on a given website, but adding them to your toolbelt might help you often.
Thanks for reading! Did you find the content helpful? Please, spread the word and share it. 👈
---
Originally published at [https://www.zenrows.com](https://www.zenrows.com/blog/web-scraping-intercepting-xhr-requests?utm_source=devto&utm_medium=blog&utm_campaign=xhr_scraping) | anderrv |
877,134 | Ruby on Rails will be dead soon! | Yes! I was also surprised and a little bit agitated when I saw similar headlines on tech blogs and... | 0 | 2021-10-26T14:22:41 | https://dev.to/poudyal_rabin/ruby-on-rails-will-be-dead-soon-pab | ruby, rails, webdev, beginners | Yes! I was also surprised and a little bit agitated when I saw similar headlines on tech blogs and magazines few years back. I thought maybe that's right, I don't see much people learning Ruby On Rails these days neither I see much job posts for Rails developer position. Maybe I should learn django? Or maybe I should learn nodejs(express)? If you are also on your early stage of career, these questions must be itching your bones too. And especially, if Rails is the first framework you are working on, you must have been dealing with few more issues too.
For example, people say that Ruby/Rails ecosystem is not really the future because it does not have Machine Learning Capabilities and it is too slow. Some also say that Rails is not that scalable giving the example of Twitter. I also think to some degree that they are right. But should you be worried about it and start learning something else?
Actually you don't need to. If you are learning Rails then you must have shaped your future into being a web developer. So why should you even worry about Machine Learning when you are learning web development? You are worrying then, you are on the wrong path. If you really want to learn both then you can still learn it side by side. What really works according to my experience is that, Rails has the convention over configuration ideology that gives you the bird's eye overview of overall web development ecosystem which you can transfer to any another framework of choice.
A lot of technologies evolve over time but Rails has been there for a while now as a mature framework which has answers to most of the problems faced by web developers. So if you are learning/coding on Rails, then you don't need to worry now. These technologies that have been around for more than decade will take time to die.
Don't forget to share your thoughts too.
Happy Coding! | poudyal_rabin |
877,193 | How To Enable Real-Time Merge Conflict Detection In Android Studio | Ah, the dreaded resolve conflicts popup. You've finished crafting the perfect code, just a quick... | 0 | 2021-10-27T15:38:56 | https://dev.to/gitlive/how-to-enable-real-time-merge-conflict-detection-in-android-studio-ojb | webdev, programming, git, productivity | Ah, the dreaded resolve conflicts popup. You've finished crafting the perfect code, just a quick merge in of master (ahem, main) before you submit your PR, and then... 💥

If only there was an early warning system for merge conflicts so you could be better prepared or even avoid the conflicts in the first place I hear you say? Well if you are an Android Studio user today is your lucky day!
Firstly, you'll need to install and set up GitLive (the latest version requires the Bumblebee Beta version of Android Studio). Then if you right click the gutter on Android Studio, you will see the option to “Show Other's Changes".

It will be disabled if the file open in the editor is not from git or there are no other changes to it from contributors working on other branches (aka you are safe from conflicts). If it's enabled there will be one or more change indicators in the gutter of the editor.

These will show you where your teammates have made changes compared to your version of the file and even update in real-time as you and your teammates are editing.

If you've made a conflicting change you will see the bright red conflict indicator. These conflicts can be uncommitted local changes you have not pushed yet or existing changes on your branch that conflict with your teammates’ changes.
Click your teammate’s icon in the gutter to see the diff between your version and theirs, the branch the offending changes are from, and the issue connected to that branch if there is one.

From this popup you can also cherry-pick your teammate’s change directly from their local version of the file. For simple conflicts this can be a quick way to resolve them as identical changes on different branches will merge cleanly.
Unfortunately, it's not always possible to resolve a conflict straight away but with the early warning, you'll be better prepared, avoiding any nasty surprises at merge time!
Check out [this blog post](https://blog.git.live/gitlive-11.0-Real-time-merge-conflict-detection) or the [GitLive docs](https://docs.git.live/docs/mergeconflicts/) if you want to learn more.
| sunnnygl |
877,205 | Symbolica's Console Newsletter Interview | This week we chatted to Jackson Kelley in the Console newsletter about our open-source symbolic executor. | 0 | 2021-10-26T17:03:27 | https://dev.to/symbolica/symbolicas-console-newsletter-interview-10f2 | showdev, watercooler, githunt | ---
title: Symbolica's Console Newsletter Interview
published: true
description: This week we chatted to Jackson Kelley in the Console newsletter about our open-source symbolic executor.
tags: showdev, watercooler, githunt
cover_image: https://cdn.substack.com/image/fetch/w_1000,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F09e15c36-e7b8-4247-9dbc-81fa9e00d056_720x720.png
---
At [Symbolica](https://www.symbolica.dev) we’re building a cloud-hosted symbolic execution service. Symbolic execution lets you explore every reachable state of your program so that you can write tests without worrying about missing any edge cases. As a bonus we also automatically detect if any states can cause invalid memory access and other undefined behaviours, like divide by zero, without you having to write any additional tests.
The core of our symbolic executor is open source and this week we got to chat with Jackson Kelley for the [latest edition of the Console newsletter](https://console.substack.com/p/console-76) about our project. We talk about our backgrounds and influences and get into the details of some of the technical challenges that we’ve been tackling as we continue to build Symbolica.
{% github Symbolica/Symbolica %}
Each edition of [Console](https://console.substack.com/) is a curated list of interesting open source projects along with an interview of the creators of one of the projects, delivered to your inbox every week. It’s a great way to discover new open source projects and hear from the creators behind the code. If you like open source it’s worth signing up. | choc13 |
877,214 | Djinn CI a simple continuous integration platform | Djinn CI is a simple continuous integration platform that I have been developing in my free time. It... | 0 | 2021-10-26T17:20:34 | https://dev.to/andrewpillar/djinn-ci-a-simple-continuous-integration-platform-1job | showdev, go, ci, tooling | Djinn CI is a simple continuous integration platform that I have been developing in my free time. It has reached the stage where I'm happy enough with its stability to start debuting it to people.
Djinn CI is [open source][0] software, so you can host it on your own infrastructure. There is, however, also a [hosted][1] version that you can pay to use should you not wish to host it yourself. To start using Djinn CI you can either create an account or sign in with GitHub or GitLab.
Detailed below is a list of some of the features on offer in Djinn CI,
* Build objects (files placed inside of a build environment), and build artifacts
* Multi-repository builds
* Cron jobs (repeatable builds on a schedule)
* Namespaces for organizing builds and their resources and for working with collaborators
* Build tagging and auto ref-tagging of builds submitted via push events
* Custom QCOW2 images for builds that use QEMU
* Integrates with GitHub and GitLab
* Namespace webhooks for namespace events
Whilst I am happy with the stability of the software, and it's feature set, there is always room for improvement. So, if you're looking for a new CI tool to use, please check this out, and feel free to reach out to me if you have any questions. You can find my contact details in my profile, via my website or Twitter.
[0]: https://github.com/djinn-ci/djinn
[1]: https://about.djinn-ci.com | andrewpillar |
877,429 | De-Comment Program in C | De-commenting is one of the primary tasks of the C preprocessor. This article demonstrates a... | 0 | 2021-10-26T19:55:24 | https://dev.to/eyuelberga/de-comment-program-in-c-ia4 | c, showdev, programming, systems | De-commenting is one of the primary tasks of the C preprocessor. This article demonstrates a simplified C program to remove comments from source-code.
## DFA Design
The deterministic finite state automaton (DFA) expresses the required de-commenting logic. The DFA is represented using the traditional "labeled ovals and labeled arrows" notation. Each oval represent a state. Each state is given short name with detailed descriptions of the left. Each arrow represent a transition from one state to another. Each arrow is labeled with the single character that causes the transition to occur.

## Usage
```sh
$ ./decomment <file_path>
```
- If the program is run without <file_path> argument, the code to be decommented will be read from the standard input and displayed[decommented code] on the standard output
- If <file_path> argument is given, the code to be decommented will be read form the file and displayed in the standard output.
The full source-code for the project is on GitHub:
{% github eyuelberga/decomment-program-c %}
| eyuelberga |
877,489 | Javascript Object basics | What is an object in JavaScript? Any thing that is not a js primitive is an object. An... | 0 | 2021-10-26T22:52:10 | https://dev.to/jamalmajid/javascript-object-basics-4b5p | javascript, beginners, programming, tutorial | ## What is an object in JavaScript?
> Any thing that is not a js primitive is an object. An object is a collection of keys with there own values or key value pairs. Each value can be of any type.
>
- An object is stored in the heap memory. All javascript objects maintain a reference to it, as opposed to a full copy of it. When checking for object equality, it checks the reference - not the actual value of properties making objects mutable.
## How do you create and object?
Here are three ways we create an object in javaScript are:
1. Object literal
```jsx
// we are literaly typing out our object.
const objectOne = {};
👆🏽
```
2. new Object();
```jsx
// use the js new key word to create a new object.
const objectTwo = new Object();
👆🏽
```
3. Object.create({ })
```jsx
// creates a new object from an existing object.
const objectTwo = Object.create({ });
👆🏽
```
## Properties
- Property is another term used for key value pairs that are stored in an object.
- Names of properties are unique values that can be coerced to a string not including words like `function`, `var`, `return`. The name or key points to a value.
- Property values can be of any type. Including functions witch we call methods.
## Manipulating Properties
### Setting properties can be done at two stages.
- During the creation of our object.
- After the creation of our object.
### Adding properties during its creation
- as of ES6 (ECMAScript 6) we can also use a new short hand for setting properties whos value and name are the same.
```jsx
// in the creation on this object we are declaring its properties.
const anime = {
title: 'naruto',
discription: 'an anime about a ninja who is just trying to be hokage',
isLigit, 'isLigit'
}
const anime = {
title: 'naruto',
discription: 'an anime about a ninja who is just trying to be hokage',
isLigit // ES6 no need to state the value if it is the same as the key
}
```
Two ways of adding properties after its creation
- Dot notation & Bracket notation
Dot notation can only access names or keys that do not stat with a digit or does not include spaces
```jsx
// this works
anime.rating = '100/10';
// this does not
anime.my name = 'Jay';
```
Bracket notation has no problem accessing names or keys that starts with a digit or contains spaces.
```jsx
anime[20] = '100/10'
anime['my name'] = 'Jay';
```
### Getting properties
We can properties in the same way we set them.
```jsx
const anime = anime.title;
console.log(anime) // logs 'naruto'
const anime = anime['title'];
console.log(anime) // logs 'naruto'
```
### Deleting properties.
Object Properties can be deleted using the `delete` keyword.
```jsx
delete anime.title;
``` | jamalmajid |
877,527 | Q&A: How can AI be used in banking? | TLDR The financial services or banking industry is an essential part of our everyday lives... | 0 | 2021-10-26T23:39:51 | https://dev.to/mage_ai/qa-how-can-ai-be-used-in-banking-16p5 | banking, financialservices, ai, finance | ## TLDR
The financial services or banking industry is an essential part of our everyday lives but the institutions who adopt and integrate artificial intelligence (AI) will have a clear advantage for their future business success.
## Outline
* Banking as you know it
* AI use cases today
* Case studies
* Conclusion
## Banking as you know it
Traditionally, banks provided consumers a safe and secure method of saving and storing their money, credit to buy large purchases such as homes and automobiles, and other services such as wealth management. Though the general purpose of banks and financial institutions have remained the same, the way we “bank” has changed significantly within the last few decades.
With the rise of telephone and internet banking in the ’80s and ’90s and now with the disruption of fintechs, we’ve gone from going to a brick and mortar institution or ATM to “pull out cash” to a more cashless society of peer-to-peer (p2p) payments such as [Venmo](https://venmo.com/), [PayPal](https://www.paypal.com/us/home), [Zelle](https://www.zellepay.com/), or [Cash App](https://cash.app/). We can’t forget contactless payments such as [Apple Pay](https://www.apple.com/apple-pay/), [Google Pay](https://pay.google.com/gp/w/u/0/home/signup?sctid=1087184467151157), and [Samsung Pay](https://www.samsung.com/us/samsung-pay/) that may have you wondering if we even need banks at all.
These drastic changes came about with the investment in technology and the ever increasing amount of data. From banks to credit unions to fintechs, they were able to leverage data to improve customer experience; making the process of banking easier and more personalized. According to a recent [Deloitte survey](https://www2.deloitte.com/lu/en/pages/banking-and-securities/articles/future-ai-in-banking.html), 86% of financial services AI adopters say that AI will be very or critically important to their business’s success in the next couple of years. AI has already transformed the banking industry globally in a short span of time. We’ll take a look at some ways AI has impacted and shifted the financial services industry.
## AI use cases today
### Fraud detection
You’re enrolled in it. You could’ve had someone pose as you today and not even know, because AI is protecting you. AI is helping with the fight against money related fraud and scams through fraud detection. It follows the steps of detection, investigation, and then “dealing with it.”
The process stems from an unusual pattern of the payment transaction. Applying AI on your behavioral patterns determines whether the payment is legitimate or not, taking into account frequency of purchase, and location of prior purchases. It’s not about comparing handwriting or signatures, especially in the world of contact-less pay.
In the case that it is flagged as potentially fraud, the bank launches an “investigation” by texting the phone number of the owner’s account. Then, the owner gets a notification to verify whether the transaction is real or illegitimate.
<center>_Only trust verified application notifications not text messages (Source: BofA)_</center>
### Lending
At some point in our lives, we may decide to make some large purchases such as buying a car or home. It’s not uncommon to borrow from a bank to make such purchases under the right terms and circumstances. If you’ve ever applied for a loan, you know how nerve wracking it could be or maybe even frustrating. In the past, the manual verification process of lenders to check transaction history, credit scores, and other factors could take many hours, if not days, to get your approval. AI-based credit decision systems today can analyze consumer transaction data and determine eligibility for the loan in the matter of minutes.
<center>_Can I get an AI-men! (Source: Meme Generator)_</center>
Furthermore, AI is reducing the potential for human error and bias in underwriting and loan origination. Bad underwriting was a huge factor in the ’08 recession. AI companies like [underwrite.ai](https://www.underwrite.ai/) apply machine learning to radically outperform traditional scorecards in both consumer and small business lending while mitigating human errors.
### Risk management
It is common to have an [actuary](https://contingencies.org/the-case-for-the-bank-actuarywhat-is-current-expected-credit-loss-and-how-can-our-profession-help-shine-a-light-on-this-new-and-uncertain-terrain/) at a bank to handle risk management. In other words, determine how to calculate insurance prices and premiums. The occupation generalizes a person’s history, behavior, and other personal private information to forecast the likelihood of what will happen to them in the future.
<center>_In your future, I see… AI_</center>
Similarly, AI can do risk management too. Companies can employ neutral networks to explore an infinite realm of possibilities, given the client’s personal private information.
Conversely, actuaries can use their knowledge to train regression models that make predictions, focusing on forecasting.
### Customer Service
No one enjoys calling the bank to dispute a claim or a credit hold, but everyone has to do it eventually. Have you ever sat down listening to a phone tree? It ruins the customer experience, and is dreadfully slow and emotionally taxing.
<center>_We’ve all been there 😔 (Source: Giphy)_</center>
Banks have multiple legal steps to get consent before processing. This is where AI can shine in banking. Using an AI chatbot to replace a phone tree helps connect customers to their goals faster by recommending relevant questions, answers, and documents.
<center>_Now that’s a 5/5 experience_</center>
## Case studies
### Does Technology Help or Hurt Morale?
The Harvard Business Review tried to tackle this [question](https://hbr.org/2021/07/case-study-will-a-banks-new-technology-help-or-hurt-morale) about banks switching to AI. The results were as they assumed, “no one had time to learn a complicated new system. Some people refused to attend the training. Others brought their laptops to class and worked the entire time.”
Learning a new technology is challenging and can hurt morale, especially if they’re not used to the training topics and have multiple learning spikes. It’s important to develop AI tools that are designed for end users to enjoy, with an onboarding process that builds on the basic foundations of what they currently do. The ideal onboarding process should have employees excited about learning and improving the existing customer service experience.
<center>_It’s as easy as ABC, 123. (Source: Giphy)_</center>
### Shift to No Signature Purchasing
Recently, banks made the [decision](https://www.mybanktracker.com/credit-cards/faq/no-signature-credit-card-purchases-275769) to remove responsibility for signatures. No one reads them, or verifies them with the back of the card, and most customers scribble whatever they like. In the case study, the conclusion for this decision was because “security measures and fraud protection continue to improve making your signature unnecessary.” This is a huge benefit for AI by doing what it should be doing, removing mindless tasks that most don’t want to do, with often a low return on investment. Time spent having a human verify signatures is extra time for people to wait to get to their turn in the line.
<center>_Almost there… (Source: Giphy)_</center>
## Conclusion
Whether you currently work for a financial institution or simply keep your money in one, you know that technology has made the experience on both sides so much better. AI has already made a big impact (customer service, fraud prevention, risk management, automation, etc.) in banking and will have a greater presence in the industry in the near future.

Are you wanting to get started with AI but not sure where to start? [Contact us](mailto:hello@mage.ai) to see if Mage is a good fit for you.
*Co-written by Nathaniel Tjandra and Thomas Chung* | mage_ai |
877,707 | SEEKING: Machine Learning Engineer in Louisville Colorado | Hello, I'm seeking a Machine Learning Engineer for a client of mine in Louisville Colorado. Please... | 0 | 2021-10-27T03:34:11 | https://dev.to/chris_expect/seeking-machine-learning-engineer-in-louisville-colorado-1mbe | machinelearning, python, career, linux | Hello, I'm seeking a Machine Learning Engineer for a client of mine in Louisville Colorado. Please share my post.
Qualifications needed:
Bachelors degree in Computer Science
Relevant qualifications in Machine Learning
2-3 years experience
LIDAR Recognition/Training datasets for object recognition in LIDAR
Unity 3D
Python language Bindings
CUDA programming
OpenCV
Agile / Scrum team environment
JSON Based Restful Web Services
AWS, Docker and Kubernetes
Basic Linux
Must Haves for this position include:
Proven experience using Python with at least one popular AI library (TensorFlow, PyTorch or OpenAI)
Demonstrable capability to use with Keras or Cafe
Experience with Pose Estimation (MediaPipe or OpenPose) for objects (not human pose estimation) and Object recognition with segmentation (not just bounding boxes)
Machine Learning Experience (Model training and tuning, Data preparation, Neural networks for prediction with input data of numerical text, categorical text with high cardinality and numerical text derived from pixel information retrieved through image object recognition and/or segmentation)
Please see this link for the job description: https://loxo.co/job/elngt2r4rpywbfzh?t=1635305569413
Or visit my website: https://expectllc.com | chris_expect |
877,880 | How to make a Memory Matching Card Game with Javascript | Hi Everyone! In this post, I will be showing you how to make a Memory Matching Card Game with HTML,... | 0 | 2021-10-27T06:14:39 | https://dev.to/abhidevelopssuntech/how-to-make-a-memory-matching-card-game-with-javascript-2lna | html, css, javascript, memorymatchgame | Hi Everyone!
In this post, I will be showing you how to make a Memory Matching Card Game with HTML, CSS, and Javascript. If you enjoy this project, please remember to follow me for more cool projects.
Let's get started!
##The HTML User Interface:
```html
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Memory Matching Card Game</title>
<meta name="description" content="">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!--Linking our CSS file-->
<link rel="stylesheet" href="style.css">
<!--Linking Bootstrap Fontawesome-->
<link rel="stylesheet prefetch" href="https://maxcdn.bootstrapcdn.com/font-awesome/4.6.1/css/font-awesome.min.css">
<!--Linking Google Fonts-->
<link rel="stylesheet prefetch" href="https://fonts.googleapis.com/css?family=Coda">
<link rel="stylesheet prefetch" href="https://fonts.googleapis.com/css?family=Gloria+Hallelujah|Permanent+Marker" >
</head>
<body>
<div class="container">
<header>
<h1>Memory Matching Card Game</h1>
</header>
<section class="score-panel">
<ul class="stars">
<li><i class="fa fa-star"></i></li>
<li><i class="fa fa-star"></i></li>
<li><i class="fa fa-star"></i></li>
</ul>
<span class="moves">0</span> Move(s)
<div class="timer">
</div>
<div class="restart" onclick="startGame()">
<i class="fa fa-repeat"></i>
</div>
</section>
<ul class="deck" id="card-deck">
<li class="card" type="diamond">
<i class="fa fa-diamond"></i>
</li>
<li class="card" type="plane">
<i class="fa fa-paper-plane-o"></i>
</li>
<li class="card match" type="anchor">
<i class="fa fa-anchor"></i>
</li>
<li class="card" type="bolt" >
<i class="fa fa-bolt"></i>
</li>
<li class="card" type="cube">
<i class="fa fa-cube"></i>
</li>
<li class="card match" type="anchor">
<i class="fa fa-anchor"></i>
</li>
<li class="card" type="leaf">
<i class="fa fa-leaf"></i>
</li>
<li class="card" type="bicycle">
<i class="fa fa-bicycle"></i>
</li>
<li class="card" type="diamond">
<i class="fa fa-diamond"></i>
</li>
<li class="card" type="bomb">
<i class="fa fa-bomb"></i>
</li>
<li class="card" type="leaf">
<i class="fa fa-leaf"></i>
</li>
<li class="card" type="bomb">
<i class="fa fa-bomb"></i>
</li>
<li class="card open show" type="bolt">
<i class="fa fa-bolt"></i>
</li>
<li class="card" type="bicycle">
<i class="fa fa-bicycle"></i>
</li>
<li class="card" type="plane">
<i class="fa fa-paper-plane-o"></i>
</li>
<li class="card" type="cube">
<i class="fa fa-cube"></i>
</li>
</ul>
<div id="popup1" class="overlay">
<div class="popup">
<h2>Congratulations 🎉</h2>
<a class="close" href="#">×</a>
<div class="content-1">
Congratulations you're a winner 🎉🎉
</div>
<div class="content-2">
<p>You made <span id="finalMove"> </span> moves </p>
<p>in <span id="totalTime"> </span> </p>
<p>Rating: <span id="starRating"></span></p>
</div>
<button id="play-again"onclick="playAgain()">
Play again 😄</a>
</button>
</div>
</div>
</div>
<!--Linking our Javascript File-->
<script src="script.js"></script>
</body>
</html>
```
##Now the CSS to style it:
```css
html {
box-sizing: border-box;
}
*,
*::before,
*::after {
box-sizing: inherit;
}
html,
body {
width: 100%;
height: 100%;
margin: 0;
padding: 0;
}
body {
background: #ffffff;
font-family: 'Permanent Marker', cursive;
font-size: 16px;
}
.container {
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
}
h1 {
font-family: 'Gloria Hallelujah', cursive;
}
/*
* Styles for the deck of cards
*/
.deck {
width: 85%;
background: #716F71;
padding: 1rem;
border-radius: 4px;
box-shadow: 8px 9px 26px 0 rgba(46, 61, 73, 0.5);
display: flex;
flex-wrap: wrap;
justify-content: space-around;
align-items: center;
margin: 0 0 3em;
}
.deck .card {
height: 3.7rem;
width: 3.7rem;
margin: 0.2rem 0.2rem;
background: #141214;;
font-size: 0;
color: #ffffff;
border-radius: 5px;
cursor: pointer;
display: flex;
justify-content: center;
align-items: center;
box-shadow: 5px 2px 20px 0 rgba(46, 61, 73, 0.5);
}
.deck .card.open {
transform: rotateY(0);
background: #02b3e4;
cursor: default;
animation-name: flipInY;
-webkit-backface-visibility: visible !important;
backface-visibility: visible !important;
animation-duration: .75s;
}
.deck .card.show {
font-size: 33px;
}
.deck .card.match {
cursor: default;
background: #E5F720;
font-size: 33px;
animation-name: rubberBand;
-webkit-backface-visibility: visible !important;
backface-visibility: visible !important;
animation-duration: .75s;
}
.deck .card.unmatched {
animation-name: pulse;
-webkit-backface-visibility: visible !important;
backface-visibility: visible !important;
animation-duration: .75s;
background: #e2043b;
}
.deck .card.disabled {
pointer-events: none;
opacity: 0.9;
}
/*
* Styles for the Score Panel
*/
.score-panel {
text-align: left;
margin-bottom: 10px;
}
.score-panel .stars {
margin: 0;
padding: 0;
display: inline-block;
margin: 0 5px 0 0;
}
.score-panel .stars li {
list-style: none;
display: inline-block;
}
.score-panel .restart {
float: right;
cursor: pointer;
}
.fa-star {
color: #FFD700;
}
.timer {
display: inline-block;
margin: 0 1rem;
}
/*
* Styles for congratulations modal
*/
.overlay {
position: fixed;
top: 0;
bottom: 0;
left: 0;
right: 0;
background: rgba(0, 0, 0, 0.7);
transition: opacity 500ms;
visibility: hidden;
opacity: 0;
}
.overlay:target {
visibility: visible;
opacity: 1;
}
.popup {
margin: 70px auto;
padding: 20px;
background: #ffffff;
border-radius: 5px;
width: 85%;
position: relative;
transition: all 5s ease-in-out;
font-family: 'Gloria Hallelujah', cursive;
}
.popup h2 {
margin-top: 0;
color: #333;
font-family: Tahoma, Arial, sans-serif;
}
.popup .close {
position: absolute;
top: 20px;
right: 30px;
transition: all 200ms;
font-size: 30px;
font-weight: bold;
text-decoration: none;
color: #333;
}
.popup .close:hover {
color: #E5F720;
}
.popup .content-1,
.content-2 {
max-height: 30%;
overflow: auto;
text-align: center;
}
.show {
visibility: visible !important;
opacity: 100 !important;
}
#starRating li {
display: inline-block;
}
#play-again {
background-color: #141214;
padding: 0.7rem 1rem;
font-size: 1.1rem;
display: block;
margin: 0 auto;
width: 50%;
font-family: 'Gloria Hallelujah', cursive;
color: #ffffff;
border-radius: 5px;
}
/* animations */
@keyframes flipInY {
from {
transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
animation-timing-function: ease-in;
opacity: 0;
}
40% {
transform: perspective(400px) rotate3d(0, 1, 0, -20deg);
animation-timing-function: ease-in;
}
60% {
transform: perspective(400px) rotate3d(0, 1, 0, 10deg);
opacity: 1;
}
80% {
transform: perspective(400px) rotate3d(0, 1, 0, -5deg);
}
to {
transform: perspective(400px);
}
}
@keyframes rubberBand {
from {
transform: scale3d(1, 1, 1);
}
30% {
transform: scale3d(1.25, 0.75, 1);
}
40% {
transform: scale3d(0.75, 1.25, 1);
}
50% {
transform: scale3d(1.15, 0.85, 1);
}
65% {
transform: scale3d(.95, 1.05, 1);
}
75% {
transform: scale3d(1.05, .95, 1);
}
to {
transform: scale3d(1, 1, 1);
}
}
@keyframes pulse {
from {
transform: scale3d(1, 1, 1);
}
50% {
transform: scale3d(1.2, 1.2, 1.2);
}
to {
transform: scale3d(1, 1, 1);
}
}
/****** Media queries
***************************/
@media (max-width: 320px) {
.deck {
width: 85%;
}
.deck .card {
height: 4.7rem;
width: 4.7rem;
}
}
/* For Tablets and larger screens
****************/
@media (min-width: 768px) {
.container {
font-size: 22px;
}
.deck {
width: 660px;
height: 680px;
}
.deck .card {
height: 125px;
width: 125px;
}
.popup {
width: 60%;
}
}
```
##Next let's add Javascript:
```javascript
// cards array holds all cards
let card = document.getElementsByClassName("card");
let cards = [...card];
// deck of all cards in game
const deck = document.getElementById("card-deck");
// declaring move variable
let moves = 0;
let counter = document.querySelector(".moves");
// declare variables for star icons
const stars = document.querySelectorAll(".fa-star");
// declaring variable of matchedCards
let matchedCard = document.getElementsByClassName("match");
// stars list
let starsList = document.querySelectorAll(".stars li");
// close icon in modal
let closeicon = document.querySelector(".close");
// declare modal
let modal = document.getElementById("popup1")
// array for opened cards
var openedCards = [];
// @description shuffles cards
// @param {array}
// @returns shuffledarray
function shuffle(array) {
var currentIndex = array.length, temporaryValue, randomIndex;
while (currentIndex !== 0) {
randomIndex = Math.floor(Math.random() * currentIndex);
currentIndex -= 1;
temporaryValue = array[currentIndex];
array[currentIndex] = array[randomIndex];
array[randomIndex] = temporaryValue;
}
return array;
};
// @description shuffles cards when page is refreshed / loads
document.body.onload = startGame();
// @description function to start a new play
function startGame(){
// empty the openCards array
openedCards = [];
// shuffle deck
cards = shuffle(cards);
// remove all exisiting classes from each card
for (var i = 0; i < cards.length; i++){
deck.innerHTML = "";
[].forEach.call(cards, function(item) {
deck.appendChild(item);
});
cards[i].classList.remove("show", "open", "match", "disabled");
}
// reset moves
moves = 0;
counter.innerHTML = moves;
// reset rating
for (var i= 0; i < stars.length; i++){
stars[i].style.color = "#FFD700";
stars[i].style.visibility = "visible";
}
//reset timer
second = 0;
minute = 0;
hour = 0;
var timer = document.querySelector(".timer");
timer.innerHTML = "0 mins 0 secs";
clearInterval(interval);
}
// @description toggles open and show class to display cards
var displayCard = function (){
this.classList.toggle("open");
this.classList.toggle("show");
this.classList.toggle("disabled");
};
// @description add opened cards to OpenedCards list and check if cards are match or not
function cardOpen() {
openedCards.push(this);
var len = openedCards.length;
if(len === 2){
moveCounter();
if(openedCards[0].type === openedCards[1].type){
matched();
} else {
unmatched();
}
}
};
// @description when cards match
function matched(){
openedCards[0].classList.add("match", "disabled");
openedCards[1].classList.add("match", "disabled");
openedCards[0].classList.remove("show", "open", "no-event");
openedCards[1].classList.remove("show", "open", "no-event");
openedCards = [];
}
// description when cards don't match
function unmatched(){
openedCards[0].classList.add("unmatched");
openedCards[1].classList.add("unmatched");
disable();
setTimeout(function(){
openedCards[0].classList.remove("show", "open", "no-event","unmatched");
openedCards[1].classList.remove("show", "open", "no-event","unmatched");
enable();
openedCards = [];
},1100);
}
// @description disable cards temporarily
function disable(){
Array.prototype.filter.call(cards, function(card){
card.classList.add('disabled');
});
}
// @description enable cards and disable matched cards
function enable(){
Array.prototype.filter.call(cards, function(card){
card.classList.remove('disabled');
for(var i = 0; i < matchedCard.length; i++){
matchedCard[i].classList.add("disabled");
}
});
}
// @description count player's moves
function moveCounter(){
moves++;
counter.innerHTML = moves;
//start timer on first click
if(moves == 1){
second = 0;
minute = 0;
hour = 0;
startTimer();
}
// setting rates based on moves
if (moves > 8 && moves < 12){
for( i= 0; i < 3; i++){
if(i > 1){
stars[i].style.visibility = "collapse";
}
}
}
else if (moves > 13){
for( i= 0; i < 3; i++){
if(i > 0){
stars[i].style.visibility = "collapse";
}
}
}
}
// @description game timer
var second = 0, minute = 0; hour = 0;
var timer = document.querySelector(".timer");
var interval;
function startTimer(){
interval = setInterval(function(){
timer.innerHTML = minute+"mins "+second+"secs";
second++;
if(second == 60){
minute++;
second=0;
}
if(minute == 60){
hour++;
minute = 0;
}
},1000);
}
// @description congratulations when all cards match, show modal and moves, time and rating
function congratulations(){
if (matchedCard.length == 16){
clearInterval(interval);
finalTime = timer.innerHTML;
// show congratulations modal
modal.classList.add("show");
// declare star rating variable
var starRating = document.querySelector(".stars").innerHTML;
//showing move, rating, time on modal
document.getElementById("finalMove").innerHTML = moves;
document.getElementById("starRating").innerHTML = starRating;
document.getElementById("totalTime").innerHTML = finalTime;
//closeicon on modal
closeModal();
};
}
// @description close icon on modal
function closeModal(){
closeicon.addEventListener("click", function(e){
modal.classList.remove("show");
startGame();
});
}
// @desciption for user to play Again
function playAgain(){
modal.classList.remove("show");
startGame();
}
// loop to add event listeners to each card
for (var i = 0; i < cards.length; i++){
card = cards[i];
card.addEventListener("click", displayCard);
card.addEventListener("click", cardOpen);
card.addEventListener("click",congratulations);
};
```
That's It! You have now successfully made a Memory Matching Card Game with Javascript. I hope you enjoyed!
[Live Demo](https://abhinav-gupta-w3.w3spaces.com/memory-match.html)
[Full Code](https://github.com/Abhi-Develops/memory-match-cards-game.git) | abhidevelopssuntech |
877,904 | k8s the hard way on Centos | Inforamtion Technical Writer Haider Raed Kubernetes The Hard Way This tutorial... | 0 | 2021-10-27T06:39:42 | https://dev.to/haydercyber/k8s-the-hard-way-4nmc | devops, kubernetes, docker, linux |
## Inforamtion ##
Technical Writer [Haider Raed](https://www.linkedin.com/in/haydercyber1)
## Kubernetes The Hard Way ##
This tutorial walks you through setting up Kubernetes the hard way. This guide is not for people looking for a fully automated command to bring up a Kubernetes cluster. If that's you then check out [Google Kubernetes Engine](https://cloud.google.com/kubernetes-engine), or the [Getting Started Guides](https://kubernetes.io/docs/setup). the repo [k8s-the-hard-way](https://github.com/haydercyber/k8s-the-hard-way)
Kubernetes The Hard Way is optimized for learning, which means taking the long route to ensure you understand each task required to bootstrap a Kubernetes cluster.
> The results of this tutorial should not be viewed as production ready, and may receive limited support from the community, but don't let that stop you from learning!
## Target Audience
The target audience for this tutorial is someone planning to support a production Kubernetes cluster and wants to understand how everything fits together.
## Cluster Details
Kubernetes The Hard Way guides you through bootstrapping a highly available Kubernetes cluster with end-to-end encryption between components and RBAC authentication.
* [kubernetes](https://github.com/kubernetes/kubernetes) v1.21.0
* [containerd](https://github.com/containerd/containerd) v1.4.4
* [coredns](https://github.com/coredns/coredns) v1.8.3
* [cni](https://github.com/containernetworking/cni) v0.9.1
* [etcd](https://github.com/etcd-io/etcd) v3.4.15
## Labs
## Prerequisites
- its Need 6 centos vm
- A compatible Linux host. The Kubernetes project provides generic instructions
- 2 GB or more of RAM per machine (any less will leave little room for your apps).
- 2 CPUs or more.
- Full network connectivity between all machines in the cluster (public or private network is fine).
- Unique hostname, MAC address, and product_uuid for every node. See here for more details.
- Swap disabled. You MUST disable swap in order for the kubelet to work properly
> you can see the lab digram in your case you only to change the ip for your machine edit hostname and mapping to your machines ip then add to /etc/hosts
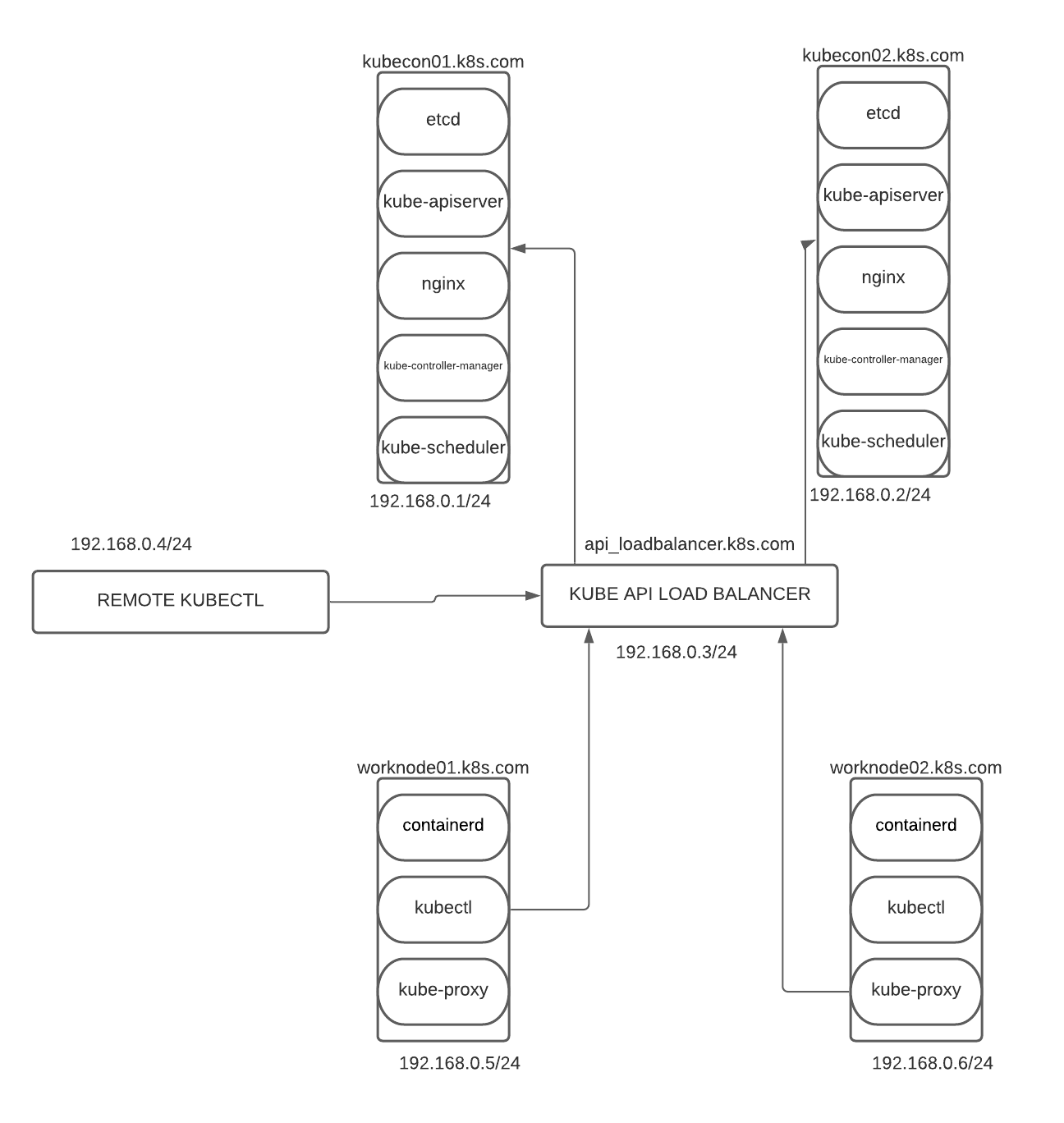
## editing host file
note: the ip will change to your ip range
```
# cat <<EOF>> /etc/hosts
192.168.0.1 kubecon01.k8s.com
192.168.0.2 kubecon02.k8s.com
192.168.0.5 worknode01.k8s.com
192.168.0.6 worknode02.k8s.com
192.168.0.3 api_loadbalancer.k8s.com
EOF
```
## Install Some Package in machine will help you
```
# yum install bash-completion vim telnet -y
```
## make sure the firewalld servies is stop and disabled
```
# systemctl disable --now firewalld
```
## make sure the Selinux is disabled
```
# setenforce 0
# sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
```
## Installing the Client Tools
In this lab you will install the command line utilities required to complete this tutorial: [cfssl](https://github.com/cloudflare/cfssl), [cfssljson](https://github.com/cloudflare/cfssl), and [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl).
in this lissions will work on remote kubectl
## Install CFSSL
The `cfssl` and `cfssljson` command line utilities will be used to provision a [PKI Infrastructure](https://en.wikipedia.org/wiki/Public_key_infrastructure) and generate TLS certificates.
Download and install `cfssl` and `cfssljson`:
```
# wget https://storage.googleapis.com/kubernetes-the-hard-way/cfssl/1.4.1/linux/cfssl
# wget https://storage.googleapis.com/kubernetes-the-hard-way/cfssl/1.4.1/linux/cfssljson
# chmod +x cfssl cfssljson
# sudo mv cfssl cfssljson /usr/local/bin/
```
## Verification
Verify `cfssl` and `cfssljson` version 1.4.1 or higher is installed:
```
cfssl version
```
> output
```
Version: 1.4.1
Runtime: go1.12.12
```
```
cfssljson --version
```
```
Version: 1.4.1
Runtime: go1.12.12
```
## Install kubectl
The `kubectl` command line utility is used to interact with the Kubernetes API Server. Download and install `kubectl` from the official release binaries:
```
# wget https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kubectl
# chmod +x kubectl
# sudo mv kubectl /usr/local/bin/
```
### Verification
Verify `kubectl` version 1.21.0 or higher is installed:
```
# kubectl version --client
```
> output
```
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.0", GitCommit:"cb303e613a121a29364f75cc67d3d580833a7479", GitTreeState:"clean", BuildDate:"2021-04-08T16:31:21Z", GoVersion:"go1.16.1", Compiler:"gc", Platform:"linux/amd64"}
```
# Provisioning a CA and Generating TLS Certificates
In this lab you will provision a [PKI Infrastructure](https://en.wikipedia.org/wiki/Public_key_infrastructure) using CloudFlare's PKI toolkit, [cfssl](https://github.com/cloudflare/cfssl), then use it to bootstrap a Certificate Authority, and generate TLS certificates for the following components: etcd, kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, and kube-proxy.
## Why Do We Need a CA and TLS Certificates?
Note: In this section, we will be provisioning a certificate authority (CA). We will then use the CA to generate several certificates
## Certificates.
are used to confirm (authenticate) identity. They are used to prove that you are who you say you are.
## Certificate Authority
provides the ability to confirm that a certificate is valid. A certificate authority can be used to validate any certificate that was issued using that certificate authority. Kubernetes uses certificates for a variety of security functions, and the different parts of our cluster will validate certificates using the certificate authority. In this section, we will generate all of these certificates and copy the necessary files to the servers that need them.
## What Certificates Do We Need?
- Client Certificates
- These certificates provide client authentication for various users: admin, kubecontroller-manager, kube-proxy, kube-scheduler, and the kubelet client on each worker node.
- Kubernetes API Server Certificate
- This is the TLS certificate for the Kubernetes API.
- Service Account Key Pair
- Kubernetes uses a certificate to sign service account tokens, so we need to provide a certificate for that purpose.
## Provisioning the Certificate Authority
In order to generate the certificates needed by Kubernetes, you must first provision a certificate authority. This lesson will guide you through the process of provisioning a new certificate authority for your Kubernetes cluster. After completing this lesson, you should have a certificate authority, which consists of two files: ca-key.pem and ca.pem
lets create dir that contains all certificates
## Generating Client Certificates
Now that you have provisioned a certificate authority for the Kubernetes cluster, you are ready to begin generating certificates. The first set of certificates you will need to generate consists of the client certificates used by various Kubernetes components. In this lesson, we will generate the following client certificates: admin , kubelet (one for each worker node), kube-controller-manager , kube-proxy , and kube-scheduler . After completing this lesson, you will have the client certificate files which you will need later to set up the cluster. Here are the commands used in the demo. The command blocks surrounded by curly braces can be entered as a single command:
In this lab you will provision a PKI Infrastructure using CloudFlare's PKI toolkit, cfssl, then use it to bootstrap a Certificate Authority, and generate TLS certificates for the following components: etcd, kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, and kube-proxy.
## Certificate Authority
In this section you will provision a Certificate Authority that can be used to generate additional TLS certificates.
Generate the CA configuration file, certificate, and private key:
```
# mkdir k8s
# cd k8s
```
Use this command to generate the certificate authority. Include the opening and closing curly braces to run this entire block as a single command.
```
{
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": ["signing", "key encipherment", "server auth", "client auth"],
"expiry": "8760h"
}
}
}
}
EOF
cat > ca-csr.json <<EOF
{
"CN": "Kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "Kubernetes",
"OU": "CA",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
}
```
Results:
```
ca-key.pem
ca.pem
```
## Client and Server Certificates
In this section you will generate client and server certificates for each Kubernetes component and a client certificate for the Kubernetes `admin` user.
### The Admin Client Certificate
Generate the `admin` client certificate and private key:
```
{
cat > admin-csr.json <<EOF
{
"CN": "admin",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "system:masters",
"OU": "Kubernetes The Hard Way",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
admin-csr.json | cfssljson -bare admin
}
```
Results:
```
admin-key.pem
admin.pem
```
## The Kubelet Client Certificates
Kubernetes uses a [special-purpose authorization mode](https://kubernetes.io/docs/admin/authorization/node/) called Node Authorizer, that specifically authorizes API requests made by [Kubelets](https://kubernetes.io/docs/concepts/overview/components/#kubelet). In order to be authorized by the Node Authorizer, Kubelets must use a credential that identifies them as being in the `system:nodes` group, with a username of `system:node:<nodeName>`. In this section you will create a certificate for each Kubernetes worker node that meets the Node Authorizer requirements.
> Kubelet Client certificates. Be sure to enter your actual machines values for all four of the variables at the top:

```
# WORKER0_HOST=worknode01.k8s.com
# WORKER0_IP=192.168.0.5
# WORKER1_HOST=worknode02.k8s.com
# WORKER1_IP=192.168.0.6
```
```
for instance in worknode01.k8s.com worknode02.k8s.com; do
cat > ${instance}-csr.json <<EOF
{
"CN": "system:node:${instance}",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "system:nodes",
"OU": "Kubernetes The Hard Way",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname=${instance} \
-profile=kubernetes \
${instance}-csr.json | cfssljson -bare ${instance}
done
```
Results:
```
worknode01.k8s.com-key.pem
worknode01.k8s.com.pem
worknode02.k8s.com-key.pem
worknode02.k8s.com.pem
```
### The Controller Manager Client Certificate
Generate the `kube-controller-manager` client certificate and private key:
```
{
cat > kube-controller-manager-csr.json <<EOF
{
"CN": "system:kube-controller-manager",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "system:kube-controller-manager",
"OU": "Kubernetes The Hard Way",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager
}
```
Results:
```
kube-controller-manager-key.pem
kube-controller-manager.pem
```
### The Kube Proxy Client Certificate
Generate the `kube-proxy` client certificate and private key:
```
{
cat > kube-proxy-csr.json <<EOF
{
"CN": "system:kube-proxy",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "system:node-proxier",
"OU": "Kubernetes The Hard Way",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
kube-proxy-csr.json | cfssljson -bare kube-proxy
}
```
Results:
```
kube-proxy-key.pem
kube-proxy.pem
```
### The Scheduler Client Certificate
Generate the `kube-scheduler` client certificate and private key:
```
{
cat > kube-scheduler-csr.json <<EOF
{
"CN": "system:kube-scheduler",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "system:kube-scheduler",
"OU": "Kubernetes The Hard Way",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
kube-scheduler-csr.json | cfssljson -bare kube-scheduler
}
```
Results:
```
kube-scheduler-key.pem
kube-scheduler.pem
```
### The Kubernetes API Server Certificate
The `kubernetes-the-hard-way` static IP address will be included in the list of subject alternative names for the Kubernetes API Server certificate. This will ensure the certificate can be validated by remote clients.
We have generated all of the the client certificates our Kubernetes cluster will need, but we also need a server certificate for the Kubernetes API. In this lesson, we will generate one, signed with all of the hostnames and IPs that may be used later in order to access the Kubernetes API. After completing this lesson, you will have a Kubernetes API server certificate in the form of two files called kubernetes-key.pem and kubernetes.pem .
> Here are the commands used in the demo. Be sure to replace all the placeholder values in CERT_HOSTNAME with their real values from your machines .

```
# CERT_HOSTNAME=10.32.0.1,<controller node 1 Private IP>,<controller node 1 hostname>,<controller node 2 Private IP>,<controller node 2 hostname>,<API load balancer Private IP>,<API load balancer hostname>,127.0.0.1,localhost,kubernetes.default
```
```
CERT_HOSTNAME=10.32.0.1,192.168.0.1,kubecon01.k8s.com,192.168.0.2,kubecon02.k8s.com,192.168.0.3,api_loadbalancer.k8s.com,127.0.0.1,localhost,kubernetes.default
```
Generate the Kubernetes API Server certificate and private key:
```
{
cat > kubernetes-csr.json <<EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "Kubernetes",
"OU": "Kubernetes The Hard Way",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname=${CERT_HOSTNAME} \
-profile=kubernetes \
kubernetes-csr.json | cfssljson -bare kubernetes
}
```
> The Kubernetes API server is automatically assigned the `kubernetes` internal dns name, which will be linked to the first IP address (`10.32.0.1`) from the address range (`10.32.0.0/24`) reserved for internal cluster services during the [control plane bootstrapping](07-bootstrapping-kubernetes-controllers.md#configure-the-kubernetes-api-server) lab.
Results:
```
kubernetes-key.pem
kubernetes.pem
```
Kubernetes provides the ability for service accounts to authenticate using tokens. It uses a key-pair to provide signatures for those tokens. In this lesson, we will generate a certificate that will be used as that key-pair. After completing this lesson, you will have a certificate ready to be used as a service account key-pair in the form of two files: service-account-key.pem and service-account.pem . Here are the commands used
## The Service Account Key Pair
The Kubernetes Controller Manager leverages a key pair to generate and sign service account tokens as described in the [managing service accounts](https://kubernetes.io/docs/admin/service-accounts-admin/) documentation.
Generate the `service-account` certificate and private key:
```
{
cat > service-account-csr.json <<EOF
{
"CN": "service-accounts",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "Portland",
"O": "Kubernetes",
"OU": "Kubernetes The Hard Way",
"ST": "Oregon"
}
]
}
EOF
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
service-account-csr.json | cfssljson -bare service-account
}
```
Results:
```
service-account-key.pem
service-account.pem
```
## Distribute the Client and Server Certificates
Copy the appropriate certificates and private keys to each worker instance:
Now that all of the necessary certificates have been generated, we need to move the files onto the appropriate servers. In this lesson, we will copy the necessary certificate files to each of our cloud servers. After completing this lesson, your controller and worker nodes should each have the certificate files which they need. Here are the commands used in the demo. Be sure to replace the placeholders with the actual values from from your cloud servers. Move certificate files to the worker nodes:
```
# scp ca.pem $WORKER0_HOST-key.pem $WORKER0_HOST.pem root@$WORKER0_HOST:~/
# scp ca.pem $WORKER1_HOST-key.pem $WORKER1_HOST.pem root@$WORKER1_HOST:~/
```
Move certificate files to the controller nodes:
```
# scp ca.pem ca-key.pem kubernetes-key.pem kubernetes.pem service-account-key.pem service-account.pem root@kubecon01.k8s.com:~/
# scp ca.pem ca-key.pem kubernetes-key.pem kubernetes.pem service-account-key.pem service-account.pem root@kubecon02.k8s.com:~/
```
# Generating Kubernetes Configuration Files for Authentication
In this lab you will generate [Kubernetes configuration files](https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/), also known as kubeconfigs, which enable Kubernetes clients to locate and authenticate to the Kubernetes API Servers.
## What Are Kubeconfigs and Why Do We Need Them?
- Kubeconfigs
- A Kubernetes configuration file, or kubeconfig, is a file that stores “information about clusters, users, namespaces, and authentication mechanisms.” It contains the configuration data needed to connect to and interact with one or more Kubernetes clusters. You can find more information about kubeconfigs in the Kubernetes documentation: [Kubernetes configuration files](https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/), Kubeconfigs contain information such as
- The location of the cluster you want to connect to
- What user you want to authenticate as
- Data needed in order to authenticate, such as tokens or client certificates
- You can even define multiple contexts in a kubeconfig file, allowing you to easily switch between multiple clusters.
## Why Do We Need Kubeconfigs?
- How to Generate a Kubeconfig
- Kubeconfigs can be generated using kubectl
```
# kubectl config set-cluster // set up the configuration for the location of the cluster.
```
```
# kubectl config set-credentials // set the username and client certificate that will be used to authenticate.
```
```
# kubectl config set-context default // set up the default context
```
```
# kubectl config use-context default // set the current context to the configuration we provided
```
## What Kubeconfigs Do We Need to Generate?
- We will need several Kubeconfig files for various components of the Kubernetes cluster:
- Kubelet(one for each worker node)
- Kube-proxy
- Kube-controller-manager
- Kube-scheduler
- Admin
- The next step in building a Kubernetes cluster the hard way is to generate kubeconfigs which will be used by the various services that will make up the cluster. In this lesson, we will generate these kubeconfigs. After completing this lesson, you should have a set of kubeconfigs which you will need later in order to configure the Kubernetes cluster. Here are the commands used in the demo. Be sure to replace the placeholders with actual values from your machine . Create an environment variable to store the address of the Kubernetes API, and set it to the IP of your load balancer
> in our digram the ip for loadblancer is 192.168.0.3 you can see blow

```
# KUBERNETES_PUBLIC_ADDRESS=192.168.0.3
```
## Client Authentication Configs
In this section you will generate kubeconfig files for the `controller manager`, `kubelet`, `kube-proxy`, and `scheduler` clients and the `admin` user.
### The kubelet Kubernetes Configuration File
When generating kubeconfig files for Kubelets the client certificate matching the Kubelet's node name must be used. This will ensure Kubelets are properly authorized by the Kubernetes [Node Authorizer](https://kubernetes.io/docs/admin/authorization/node/).
> The following commands must be run in the same directory used to generate the SSL certificates during the [Generating TLS Certificates](04-certificate-authority.md) lab.
Generate a kubeconfig file for each worker node:
```
for instance in worknode01.k8s.com worknode02.k8s.com; do
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=https://${KUBERNETES_PUBLIC_ADDRESS}:6443 \
--kubeconfig=${instance}.kubeconfig
kubectl config set-credentials system:node:${instance} \
--client-certificate=${instance}.pem \
--client-key=${instance}-key.pem \
--embed-certs=true \
--kubeconfig=${instance}.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:node:${instance} \
--kubeconfig=${instance}.kubeconfig
kubectl config use-context default --kubeconfig=${instance}.kubeconfig
done
```
Results:
```
worknode01.k8s.com.kubeconfig
worknode02.k8s.com.kubeconfig
```
### The kube-proxy Kubernetes Configuration File
Generate a kubeconfig file for the `kube-proxy` service:
```
{
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=https://${KUBERNETES_PUBLIC_ADDRESS}:6443 \
--kubeconfig=kube-proxy.kubeconfig
kubectl config set-credentials system:kube-proxy \
--client-certificate=kube-proxy.pem \
--client-key=kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
}
```
Results:
```
kube-proxy.kubeconfig
```
### The kube-controller-manager Kubernetes Configuration File
Generate a kubeconfig file for the `kube-controller-manager` service:
```
{
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=https://127.0.0.1:6443 \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=kube-controller-manager.pem \
--client-key=kube-controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:kube-controller-manager \
--kubeconfig=kube-controller-manager.kubeconfig
kubectl config use-context default --kubeconfig=kube-controller-manager.kubeconfig
}
```
Results:
```
kube-controller-manager.kubeconfig
```
### The kube-scheduler Kubernetes Configuration File
Generate a kubeconfig file for the `kube-scheduler` service:
```
{
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=https://127.0.0.1:6443 \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config set-credentials system:kube-scheduler \
--client-certificate=kube-scheduler.pem \
--client-key=kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=system:kube-scheduler \
--kubeconfig=kube-scheduler.kubeconfig
kubectl config use-context default --kubeconfig=kube-scheduler.kubeconfig
}
```
Results:
```
kube-scheduler.kubeconfig
```
### The admin Kubernetes Configuration File
Generate a kubeconfig file for the `admin` user:
```
{
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=https://127.0.0.1:6443 \
--kubeconfig=admin.kubeconfig
kubectl config set-credentials admin \
--client-certificate=admin.pem \
--client-key=admin-key.pem \
--embed-certs=true \
--kubeconfig=admin.kubeconfig
kubectl config set-context default \
--cluster=kubernetes-the-hard-way \
--user=admin \
--kubeconfig=admin.kubeconfig
kubectl config use-context default --kubeconfig=admin.kubeconfig
}
```
Results:
```
admin.kubeconfig
```
## Distribute the Kubernetes Configuration Files
Copy the appropriate `kubelet` and `kube-proxy` kubeconfig files to each worker instance:
```
for instance in worknode01.k8s.com worknode02.k8s.com; do
scp ${instance}.kubeconfig kube-proxy.kubeconfig ${instance}:~/
done
```
Copy the appropriate `kube-controller-manager` and `kube-scheduler` kubeconfig files to each controller instance:
```
for instance in kubecon01.k8s.com kubecon02.k8s.com; do
scp admin.kubeconfig kube-controller-manager.kubeconfig kube-scheduler.kubeconfig ${instance}:~/
done
```
# Generating the Data Encryption Config and Key
Kubernetes stores a variety of data including cluster state, application configurations, and secrets. Kubernetes supports the ability to [encrypt](https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data) cluster data at rest.
In this lab you will generate an encryption key and an [encryption config](https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/#understanding-the-encryption-at-rest-configuration) suitable for encrypting Kubernetes Secrets.
## What Ist he Kubernetes Data Encryption Config?
- Kubernetes Secret Encryption
- Kubernetes supports the ability to encrypt secret data at rest. This means that secrets are encrypted so that they are never stored on disc in plain text. This feature is important for security, but in order to use it we need to provide Kubernetes with an encryption key. We will generate an encryption key and put it into a configuration file. We will then copy that file to our Kubernetes controller servers.
- In order to make use of Kubernetes' ability to encrypt sensitive data at rest, you need to provide Kubernetes with an encrpytion key using a data encryption config file. This lesson walks you through the process of creating a encryption key and storing it in the necessary file, as well as showing how to copy that file to your Kubernetes controllers. After completing this lesson, you should have a valid Kubernetes data encryption config file, and there should be a copy of that file on each of your Kubernetes controller servers.
## The Encryption Key
Here are the commands used in the demo. Generate the Kubernetes Data encrpytion config file containing the encrpytion key
Generate an encryption key:
```
ENCRYPTION_KEY=$(head -c 32 /dev/urandom | base64)
```
## The Encryption Config File
Create the `encryption-config.yaml` encryption config file:
```
cat > encryption-config.yaml <<EOF
kind: EncryptionConfig
apiVersion: v1
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: ${ENCRYPTION_KEY}
- identity: {}
EOF
```
## Distribute the Kubernetes Encryption Config
Copy the `encryption-config.yaml` encryption config file to each controller instance:
```
for instance in kubecon01.k8s.com kubecon02.k8s.com; do
scp encryption-config.yaml ${instance}:~/
done
```
# Bootstrapping the etcd Cluster
Kubernetes components are stateless and store cluster state in [etcd](https://github.com/etcd-io/etcd). In this lab you will bootstrap a three node etcd cluster and configure it for high availability and secure remote access.
## What Is etcd?
“etcd is a distributed key value store that provides a reliable way to store data across a cluster of machines.” [etcd](https://coreos.com/etcd/) etcd provides a way to store data across a distributed cluster of machines and make sure the data is synchronized across all machines. You can find more information, as well as the etcd source code, in the etcd GitHub repository [etcd](https://github.com/etcd-io/etcd)
## How Is etcd Used in Kubernetes?
Kubernetes uses etcd to store all of its internal data about cluster state. This data needs to be stored, but it also needs to be reliably synchronized across all controller nodes in the cluster. etcd fulfills that purpose. We will need to install etcd on each of our Kubernetes controller nodes and create an etcd cluster that includes all of those controller nodes. You can find more information on managing an etcd cluster for Kubernetes here [k8setcd](https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/)
## Creating the etcd Cluster
Before you can stand up controllers for a Kubernetes cluster, you must first build an etcd cluster across your Kubernetes control nodes. This lesson provides a demonstration of how to set up an etcd cluster in preparation for bootstrapping Kubernetes. After completing this lesson, you should have a working etcd cluster that consists of your Kubernetes control nodes. Here are the commands used in the demo (note that these have to be run on both controller servers, with a few differences between them):
### Download and Install the etcd Binaries
Download the official etcd release binaries from the [etcd](https://github.com/etcd-io/etcd) GitHub project:
```
wget "https://github.com/etcd-io/etcd/releases/download/v3.4.15/etcd-v3.4.15-linux-amd64.tar.gz"
```
Extract and install the `etcd` server and the `etcdctl` command line utility:
```
# tar -xvf etcd-v3.4.15-linux-amd64.tar.gz
# mv etcd-v3.4.15-linux-amd64/etcd* /usr/local/bin/
```
### Configure the etcd Server
```
# mkdir -p /etc/etcd /var/lib/etcd
# chmod 700 /var/lib/etcd
# cp ca.pem kubernetes-key.pem kubernetes.pem /etc/etcd/
```
Set up the following environment variables.
```
# ETCD_NAME=$(hostname -s)
# INTERNAL_IP=$(/sbin/ip -o -4 addr list eth0 | awk '{print $4}' | cut -d/ -f1)
```
Set up the following environment variables. Be sure you replace all of the with their corresponding real values:
> you can see the lab digram in your case you only to change the ip for varaible

```
# CONTROLLER0_IP=192.168.0.1
# CONTROLLER0_host=kubecon01
# CONTROLLER1_IP=192.168.0.2
# CONTROLLER1_host=kubecon02
```
Create the `etcd.service` systemd unit file:
```
cat <<EOF | sudo tee /etc/systemd/system/etcd.service
[Unit]
Description=etcd
Documentation=https://github.com/coreos
[Service]
Type=notify
ExecStart=/usr/local/bin/etcd \\
--name ${ETCD_NAME} \\
--cert-file=/etc/etcd/kubernetes.pem \\
--key-file=/etc/etcd/kubernetes-key.pem \\
--peer-cert-file=/etc/etcd/kubernetes.pem \\
--peer-key-file=/etc/etcd/kubernetes-key.pem \\
--trusted-ca-file=/etc/etcd/ca.pem \\
--peer-trusted-ca-file=/etc/etcd/ca.pem \\
--peer-client-cert-auth \\
--client-cert-auth \\
--initial-advertise-peer-urls https://${INTERNAL_IP}:2380 \\
--listen-peer-urls https://${INTERNAL_IP}:2380 \\
--listen-client-urls https://${INTERNAL_IP}:2379,https://127.0.0.1:2379 \\
--advertise-client-urls https://${INTERNAL_IP}:2379 \\
--initial-cluster-token etcd-cluster-0 \\
--initial-cluster ${CONTROLLER0_host}=https://${CONTROLLER0_IP}:2380,${CONTROLLER1_host}=https://${CONTROLLER1_IP}:2380 \\
--initial-cluster-state new \\
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
```
### Start the etcd Server
```
# systemctl daemon-reload
# systemctl enable etcd
# systemctl start etcd
```
> Remember to run the above commands on each controller node: `kubecon01`, `kubecon02` .
## Verification
List the etcd cluster members:
```
sudo ETCDCTL_API=3 etcdctl member list \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/etcd/ca.pem \
--cert=/etc/etcd/kubernetes.pem \
--key=/etc/etcd/kubernetes-key.pem
```
> output
```
19e6cf768d9d542e, started, kubecon02, https://192.168.0.2:2380, https://192.168.0.2:2379, false
508e54ff346cdb88, started, kubecon01, https://192.168.0.1:2380, https://192.168.0.1:2379, false
```
# Bootstrapping the Kubernetes Control Plane
In this lab you will bootstrap the Kubernetes control plane across three compute instances and configure it for high availability. You will also create an external load balancer that exposes the Kubernetes API Servers to remote clients. The following components will be installed on each node: Kubernetes API Server, Scheduler, and Controller Manager.
## Prerequisites
The commands in this lab must be run on each controller instance: `kubecon01`, `kubecon02`
## Provision the Kubernetes Control Plane
The first step in bootstrapping a new Kubernetes control plane is to install the necessary binaries on the controller servers. We will walk through the process of downloading and installing the binaries on both Kubernetes controllers. This will prepare your environment for the lessons that follow, in which we will configure these binaries to run as systemd services. You can install the control plane binaries on each control node like this
```
# mkdir -p /etc/kubernetes/config
```
### Download and Install the Kubernetes Controller Binaries
Download the official Kubernetes release binaries
```
# wget "https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kube-apiserver" \
"https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kube-controller-manager" \
"https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kube-scheduler" \
"https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kubectl"
```
Lets change the permission to be executable
```
# chmod +x kube-apiserver kube-controller-manager kube-scheduler kubectl
```
Lets mv binary to /usr/local/bin
```
# mv kube-apiserver kube-controller-manager kube-scheduler kubectl /usr/local/bin/
```
### Configure the Kubernetes API Server
The Kubernetes API server provides the primary interface for the Kubernetes control plane and the cluster as a whole. When you interact with Kubernetes, you are nearly always doing it through the Kubernetes API server. This lesson will guide you through the process of configuring the kube-apiserver service on your two Kubernetes control nodes. After completing this lesson, you should have a systemd unit set up to run kube-apiserver as a service on each Kubernetes control node. You can configure the Kubernetes API server like so
```
# mkdir -p /var/lib/kubernetes/
# mv ca.pem ca-key.pem kubernetes-key.pem kubernetes.pem \
service-account-key.pem service-account.pem \
encryption-config.yaml /var/lib/kubernetes/
```
Set some environment variables that will be used to create the systemd unit file. Make sure you replace the placeholders with their actual values
```
# INTERNAL_IP=$(/sbin/ip -o -4 addr list eth0 | awk '{print $4}' | cut -d/ -f1)
# CONTROLLER0_IP=192.168.0.1
# KUBERNETES_PUBLIC_ADDRESS=$(/sbin/ip -o -4 addr list eth0 | awk '{print $4}' | cut -d/ -f1)
# CONTROLLER1_IP=192.168.0.2
```
Generate the kube-apiserver unit file for systemd :
```
# cat <<EOF | sudo tee /etc/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
ExecStart=/usr/local/bin/kube-apiserver \\
--advertise-address=${INTERNAL_IP} \\
--allow-privileged=true \\
--apiserver-count=3 \\
--audit-log-maxage=30 \\
--audit-log-maxbackup=3 \\
--audit-log-maxsize=100 \\
--audit-log-path=/var/log/audit.log \\
--authorization-mode=Node,RBAC \\
--bind-address=0.0.0.0 \\
--client-ca-file=/var/lib/kubernetes/ca.pem \\
--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \\
--etcd-cafile=/var/lib/kubernetes/ca.pem \\
--etcd-certfile=/var/lib/kubernetes/kubernetes.pem \\
--etcd-keyfile=/var/lib/kubernetes/kubernetes-key.pem \\
--etcd-servers=https://${CONTROLLER0_IP}:2379,https://${CONTROLLER1_IP}:2379 \\
--event-ttl=1h \\
--encryption-provider-config=/var/lib/kubernetes/encryption-config.yaml \\
--kubelet-certificate-authority=/var/lib/kubernetes/ca.pem \\
--kubelet-client-certificate=/var/lib/kubernetes/kubernetes.pem \\
--kubelet-client-key=/var/lib/kubernetes/kubernetes-key.pem \\
--service-account-key-file=/var/lib/kubernetes/service-account.pem \\
--service-account-signing-key-file=/var/lib/kubernetes/service-account-key.pem \\
--service-account-issuer=https://${KUBERNETES_PUBLIC_ADDRESS}:6443 \\
--service-cluster-ip-range=10.32.0.0/24 \\
--service-node-port-range=30000-32767 \\
--tls-cert-file=/var/lib/kubernetes/kubernetes.pem \\
--tls-private-key-file=/var/lib/kubernetes/kubernetes-key.pem \\
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
```
### Configure the Kubernetes Controller Manager
Move the `kube-controller-manager` kubeconfig into place:
```
sudo mv kube-controller-manager.kubeconfig /var/lib/kubernetes/
```
Create the `kube-controller-manager.service` systemd unit file:
```
cat <<EOF | sudo tee /etc/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
ExecStart=/usr/local/bin/kube-controller-manager \\
--bind-address=0.0.0.0 \\
--cluster-cidr=10.200.0.0/16 \\
--cluster-name=kubernetes \\
--cluster-signing-cert-file=/var/lib/kubernetes/ca.pem \\
--cluster-signing-key-file=/var/lib/kubernetes/ca-key.pem \\
--kubeconfig=/var/lib/kubernetes/kube-controller-manager.kubeconfig \\
--leader-elect=true \\
--root-ca-file=/var/lib/kubernetes/ca.pem \\
--service-account-private-key-file=/var/lib/kubernetes/service-account-key.pem \\
--service-cluster-ip-range=10.32.0.0/24 \\
--use-service-account-credentials=true \\
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
```
### Configure the Kubernetes Scheduler
Move the `kube-scheduler` kubeconfig into place:
```
sudo mv kube-scheduler.kubeconfig /var/lib/kubernetes/
```
Create the `kube-scheduler.yaml` configuration file:
```
cat <<EOF | sudo tee /etc/kubernetes/config/kube-scheduler.yaml
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: "/var/lib/kubernetes/kube-scheduler.kubeconfig"
leaderElection:
leaderElect: true
EOF
```
Create the `kube-scheduler.service` systemd unit file:
```
cat <<EOF | sudo tee /etc/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
ExecStart=/usr/local/bin/kube-scheduler \\
--config=/etc/kubernetes/config/kube-scheduler.yaml \\
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
```
### Start the Controller Services
```
# systemctl daemon-reload
# systemctl enable kube-apiserver kube-controller-manager kube-scheduler
# systemctl start kube-apiserver kube-controller-manager kube-scheduler
```
> Allow up to 10 seconds for the Kubernetes API Server to fully initialize.
### Enable HTTP Health Checks
- Why Do We Need to Enable HTTP Health Checks?
- In Kelsey Hightower’s original Kubernetes the Hard Way guide, he uses a Good Cloud Platform (GCP) load balancer. The load balancer needs to be able to perform health checks against the Kubernetes API to measure the health status of API nodes. The GCP load balancer cannot easily perform health checks over HTTPS, so the guide instructs us to set up a proxy server to allow these health checks to be performed over HTTP. Since we are using Nginx as our load balancer, we don’t actually need to do this, but it will be good practice for us. This exercise will help you understand the methods used in the original guide.
- Part of Kelsey Hightower's original Kubernetes the Hard Way guide involves setting up an nginx proxy on each controller to provide access to
- the Kubernetes API /healthz endpoint over http This lesson explains the reasoning behind the inclusion of that step and guides you through
- the process of implementing the http /healthz proxy. You can set up a basic nginx proxy for the healthz endpoint by first installing nginx"
> The `/healthz` API server endpoint does not require authentication by default.
Install a basic web server to handle HTTP health checks:
```
# yum install epel-release nginx -y
```
Create an nginx configuration for the health check proxy:
```
cat > /etc/nginx/conf.d/kubernetes.default.svc.cluster.local.conf <<EOF
server {
listen 80;
server_name kubernetes.default.svc.cluster.local;
location /healthz {
proxy_pass https://127.0.0.1:6443/healthz;
proxy_ssl_trusted_certificate /var/lib/kubernetes/ca.pem;
}
}
EOF
```
Started and enabled nginx
```
# systemctl enable --now nginx
```
### Verification
```
kubectl cluster-info --kubeconfig admin.kubeconfig
```
```
Kubernetes control plane is running at https://127.0.0.1:6443
```
Test the nginx HTTP health check proxy:
```
curl -H "Host: kubernetes.default.svc.cluster.local" -i http://127.0.0.1/healthz
```
```
HTTP/1.1 200 OK
Server: nginx/1.18.0 (Ubuntu)
Date: Sun, 02 May 2021 04:19:29 GMT
Content-Type: text/plain; charset=utf-8
Content-Length: 2
Connection: keep-alive
Cache-Control: no-cache, private
X-Content-Type-Options: nosniff
X-Kubernetes-Pf-Flowschema-Uid: c43f32eb-e038-457f-9474-571d43e5c325
X-Kubernetes-Pf-Prioritylevel-Uid: 8ba5908f-5569-4330-80fd-c643e7512366
ok
```
> Remember to run the above commands on each controller node: `kubecon01`, `kubecon02`
## RBAC for Kubelet Authorization
One of the necessary steps in setting up a new Kubernetes cluster from scratch is to assign permissions that allow the Kubernetes API to access various functionality within the worker kubelets. This lesson guides you through the process of creating a ClusterRole and binding it to the kubernetes user so that those permissions will be in place. After completing this lesson, your cluster will have the necessary role-based access control configuration to allow the cluster's API to access kubelet functionality such as logs and metrics. You can configure RBAC for kubelet authorization with these commands. Note that these commands only need to be run on one control node. Create a role with the necessary permissions
In this section you will configure RBAC permissions to allow the Kubernetes API Server to access the Kubelet API on each worker node. Access to the Kubelet API is required for retrieving metrics, logs, and executing commands in pods.
> This tutorial sets the Kubelet `--authorization-mode` flag to `Webhook`. Webhook mode uses the [SubjectAccessReview](https://kubernetes.io/docs/admin/authorization/#checking-api-access) API to determine authorization.
The commands in this section will effect the entire cluster and only need to be run once from one of the controller nodes.
Create the `system:kube-apiserver-to-kubelet` [ClusterRole](https://kubernetes.io/docs/admin/authorization/rbac/#role-and-clusterrole) with permissions to access the Kubelet API and perform most common tasks associated with managing pods:
```
cat <<EOF | kubectl apply --kubeconfig admin.kubeconfig -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
verbs:
- "*"
EOF
```
The Kubernetes API Server authenticates to the Kubelet as the `kubernetes` user using the client certificate as defined by the `--kubelet-client-certificate` flag.
Bind the `system:kube-apiserver-to-kubelet` ClusterRole to the `kubernetes` user:
```
cat <<EOF | kubectl apply --kubeconfig admin.kubeconfig -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
EOF
```
### Setting up a Kube API Frontend Load Balancer
In order to achieve redundancy for your Kubernetes cluster, you will need to load balance usage of the Kubernetes API across multiple control nodes. In this lesson, you will learn how to create a simple nginx server to perform this balancing. After completing this lesson, you will be able to interact with both control nodes of your kubernetes cluster using the nginx load balancer. Here are the commands you can use to set up the nginx load balancer. Run these on the server that you have designated as your load balancer server:
```
# ssh root@192.168.0.3
```
Note will use stream module for nginx for easy wiil create a docker image that contain the all moudle config first lets install docker
```
# yum install -y yum-utils
# yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# yum-config-manager --enable docker-ce-nightly
# yum install docker-ce docker-ce-cli containerd.io -y
# systemctl enable --now docker
```
### Config the Loadbalancer
Now will create the dir for image to configure all image nassry
```
# mkdir nginx && cd nginx
```
Set up some environment variables for the lead balancer config file:
```
# CONTROLLER0_IP=192.168.0.1
# CONTROLLER1_IP=192.168.0.2
```
Create the load balancer nginx config file
```
# cat << EOF | sudo tee k8s.conf
stream {
upstream kubernetes {
least_conn;
server $CONTROLLER0_IP:6443;
server $CONTROLLER1_IP:6443;
}
server {
listen 6443;
listen 443;
proxy_pass kubernetes;
}
}
EOF
```
Lets create a nginx config
```
# cat << EOF | tee nginx.conf
user www-data;
worker_processes auto;
pid /run/nginx.pid;
events {
worker_connections 768;
# multi_accept on;
}
http {
##
# Basic Settings
##
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
# server_tokens off;
# server_names_hash_bucket_size 64;
# server_name_in_redirect off;
include /etc/nginx/mime.types;
default_type application/octet-stream;
##
# SSL Settings
##
ssl_protocols TLSv1 TLSv1.1 TLSv1.2; # Dropping SSLv3, ref: POODLE
ssl_prefer_server_ciphers on;
##
# Logging Settings
##
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
##
# Gzip Settings
##
gzip on;
gzip_disable "msie6";
# gzip_vary on;
# gzip_proxied any;
# gzip_comp_level 6;
# gzip_buffers 16 8k;
# gzip_http_version 1.1;
# gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript;
##
# Virtual Host Configs
##
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
#mail {
# # See sample authentication script at:
# # http://wiki.nginx.org/ImapAuthenticateWithApachePhpScript
#
# # auth_http localhost/auth.php;
# # pop3_capabilities "TOP" "USER";
# # imap_capabilities "IMAP4rev1" "UIDPLUS";
#
# server {
# listen localhost:110;
# protocol pop3;
# proxy on;
# }
#
# server {
# listen localhost:143;
# protocol imap;
# proxy on;
# }
#}
include /etc/nginx/tcpconf.d/*;
EOF
```
Lets create a Dockerfile
```
# cat << EOF | tee Dockerfile
FROM ubuntu:16.04
RUN apt-get update -y && apt-get upgrade -y && apt-get install -y nginx && mkdir -p /etc/nginx/tcpconf.d
RUN rm -rf /etc/nginx/nginx.conf
ADD nginx.conf /etc/nginx/
ADD k8s.conf /etc/nginx/tcpconf.d/
CMD ["nginx", "-g", "daemon off;"]
EOF
```
Lets build and run docker
```
# docker build -t nginx .
# docker run -d --network host --name nginx --restart unless-stopped nginx
```
Make a HTTP request for the Kubernetes version info:
```
curl --cacert ca.pem https://${KUBERNETES_PUBLIC_ADDRESS}:6443/version
```
> output
```
{
"major": "1",
"minor": "21",
"gitVersion": "v1.21.0",
"gitCommit": "cb303e613a121a29364f75cc67d3d580833a7479",
"gitTreeState": "clean",
"buildDate": "2021-04-08T16:25:06Z",
"goVersion": "go1.16.1",
"compiler": "gc",
"platform": "linux/amd64"
}
```
# Bootstrapping the Kubernetes Worker Nodes
In this lab you will bootstrap three Kubernetes worker nodes. The following components will be installed on each node: [runc](https://github.com/opencontainers/runc), [container networking plugins](https://github.com/containernetworking/cni), [containerd](https://github.com/containerd/containerd), [kubelet](https://kubernetes.io/docs/admin/kubelet), and [kube-proxy](https://kubernetes.io/docs/concepts/cluster-administration/proxies).
### What Are the Kubernetes Worker Nodes?
Kubernetes worker nodes are responsible for the actual work of running container applications managed by Kubernetes. “The Kubernetes node has the services necessary to run application containers and be managed from the master systems.” You can find more information about Kubernetes worker nodes in the Kubernetes documentation:
### Kubernetes Worker Node Components
Each Kubernetes worker node consists of the following components
- Kubelet
- Controls each worker node, providing the APIs that are used by the control plane to manage nodes and pods, and interacts with the container runtime to manage containers
- Kube-proxy
- Manages iptables rules on the node to provide virtual network access to pods.
- Container runtime
- Downloads images and runs containers. Two examples of container runtimes are Docker and containerd (Kubernetes the Hard Way uses containerd)
### Prerequisites
The commands in this lab must be run on each worker instance: `worknode01`, `worknode01`
## Provisioning a Kubernetes Worker Node
Install the OS dependencies:
```
# yum install socat conntrack ipset -y
```
> The socat binary enables support for the `kubectl port-forward` command.
### Disable Swap
By default the kubelet will fail to start if [swap](https://help.ubuntu.com/community/SwapFaq) is enabled. It is [recommended](https://github.com/kubernetes/kubernetes/issues/7294) that swap be disabled to ensure Kubernetes can provide proper resource allocation and quality of service.
Verify if swap is enabled:
```
sudo swapon --show
```
If output is empthy then swap is not enabled. If swap is enabled run the following command to disable swap immediately:
```
# swapoff -a
# sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
```
### Download and Install Worker Binaries
```
# wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.21.0/crictl-v1.21.0-linux-amd64.tar.gz \
https://github.com/opencontainers/runc/releases/download/v1.0.0-rc93/runc.amd64 \
https://github.com/containernetworking/plugins/releases/download/v0.9.1/cni-plugins-linux-amd64-v0.9.1.tgz \
https://github.com/containerd/containerd/releases/download/v1.4.4/containerd-1.4.4-linux-amd64.tar.gz \
https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kubectl \
https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kube-proxy \
https://storage.googleapis.com/kubernetes-release/release/v1.21.0/bin/linux/amd64/kubelet
```
Create the installation directories:
```
# mkdir -p \
/etc/cni/net.d \
/opt/cni/bin \
/var/lib/kubelet \
/var/lib/kube-proxy \
/var/lib/kubernetes \
/var/run/kubernetes
```
Install the worker binaries:
```
# mkdir containerd
# tar -xvf crictl-v1.21.0-linux-amd64.tar.gz
# tar -xvf containerd-1.4.4-linux-amd64.tar.gz -C containerd
# tar -xvf cni-plugins-linux-amd64-v0.9.1.tgz -C /opt/cni/bin/
# mv runc.amd64 runc
# chmod +x crictl kubectl kube-proxy kubelet runc
# mv crictl kubectl kube-proxy kubelet runc /usr/local/bin/
# mv containerd/bin/* /bin/
```
### Configure containerd
Create the containerd configuration file:
```
# mkdir -p /etc/containerd/
# cat << EOF | sudo tee /etc/containerd/config.toml
[plugins]
[plugins.cri.containerd]
snapshotter = "overlayfs"
[plugins.cri.containerd.default_runtime]
runtime_type = "io.containerd.runtime.v1.linux"
runtime_engine = "/usr/local/bin/runc"
runtime_root = ""
EOF
```
Create the `containerd.service` systemd unit file:
```
cat <<EOF | sudo tee /etc/systemd/system/containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target
[Service]
ExecStartPre=/sbin/modprobe overlay
ExecStart=/bin/containerd
Restart=always
RestartSec=5
Delegate=yes
KillMode=process
OOMScoreAdjust=-999
LimitNOFILE=1048576
LimitNPROC=infinity
LimitCORE=infinity
[Install]
WantedBy=multi-user.target
EOF
```
### Configure the Kubelet
Kubelet is the Kubernetes agent which runs on each worker node. Acting as a middleman between the Kubernetes control plane and the underlying container runtime, it coordinates the running of containers on the worker node. In this lesson, we will configure our systemd service for kubelet. After completing this lesson, you should have a systemd service configured and ready to run on each worker node. You can configure the kubelet service like so. Run these commands on both worker nodes. Set a HOSTNAME environment variable that will be used to generate your config files. Make sure you set the HOSTNAME appropriately for each worker node:
```
# mv ${HOSTNAME}-key.pem ${HOSTNAME}.pem /var/lib/kubelet/
# mv ${HOSTNAME}.kubeconfig /var/lib/kubelet/kubeconfig
# mv ca.pem /var/lib/kubernetes/
```
Create the `kubelet-config.yaml` configuration file:
```
# cat <<EOF | sudo tee /var/lib/kubelet/kubelet-config.yaml
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
enabled: true
x509:
clientCAFile: "/var/lib/kubernetes/ca.pem"
authorization:
mode: Webhook
clusterDomain: "cluster.local"
clusterDNS:
- "10.32.0.10"
runtimeRequestTimeout: "15m"
tlsCertFile: "/var/lib/kubelet/${HOSTNAME}.pem"
tlsPrivateKeyFile: "/var/lib/kubelet/${HOSTNAME}-key.pem"
EOF
```
Create the `kubelet.service` systemd unit file:
```
cat <<EOF | sudo tee /etc/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
After=containerd.service
Requires=containerd.service
[Service]
ExecStart=/usr/local/bin/kubelet \\
--config=/var/lib/kubelet/kubelet-config.yaml \\
--container-runtime=remote \\
--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock \\
--image-pull-progress-deadline=2m \\
--kubeconfig=/var/lib/kubelet/kubeconfig \\
--network-plugin=cni \\
--register-node=true \\
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
```
### Configure the Kubernetes Proxy
Kube-proxy is an important component of each Kubernetes worker node. It is responsible for providing network routing to support Kubernetes networking components. In this lesson, we will configure our kube-proxy systemd service. Since this is the last of the three worker node services that we need to configure, we will also go ahead and start all of our worker node services once we're done. Finally, we will complete some steps to verify that our cluster is set up properly and functioning as expected so far. After completing this lesson, you should have two Kubernetes worker nodes up and running, and they should be able to successfully register themselves with the cluster. You can configure the kube-proxy service like so. Run these commands on both worker nodes:
```
# mv kube-proxy.kubeconfig /var/lib/kube-proxy/kubeconfig
```
Create the `kube-proxy-config.yaml` configuration file:
```
# cat <<EOF | sudo tee /var/lib/kube-proxy/kube-proxy-config.yaml
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
clientConnection:
kubeconfig: "/var/lib/kube-proxy/kubeconfig"
mode: "iptables"
clusterCIDR: "10.200.0.0/16"
EOF
```
Create the `kube-proxy.service` systemd unit file:
```
# cat <<EOF | sudo tee /etc/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Kube Proxy
Documentation=https://github.com/kubernetes/kubernetes
[Service]
ExecStart=/usr/local/bin/kube-proxy \\
--config=/var/lib/kube-proxy/kube-proxy-config.yaml
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
```
Start the Worker Services
```
# systemctl daemon-reload
# systemctl enable containerd kubelet kube-proxy
# systemctl start containerd kubelet kube-proxy
```
## Verification
Finally, verify that both workers have registered themselves with the cluster. Log in to one of your control nodes and run this:
First should we create a dir in both of controller nodes
will crate dir for kubectl to containe the certificate and config
```
# mkdir -p $HOME/.kube
# cp -i admin.kubeconfig $HOME/.kube/config
# chown $(id -u):$(id -g) $HOME/.kube/config
# kubectl get nodes
```
> output
```
NAME STATUS ROLES AGE VERSION
worknode01.k8s.com NotReady <none> 5m28s v1.21.0
worknode02.k8s.com NotReady <none> 5m31s v1.21.0
```
> dotnot wary about `NotReady` because in networking will fix this issues
# Configuring kubectl for Remote Access
In this lab you will generate a kubeconfig file for the `kubectl` command line utility based on the `admin` user credentials.
### What Is Kubectl?
Kubectl
- is the Kubernetes command line tool. It allows us to interact with Kubernetes clusters from the command line.
We will set up kubectl to allow remote access from our machine in order to manage the cluster remotely. To do this, we will generate a local kubeconfig that will authenticate as the admin user and access the Kubernetes API through the load balancer.
In this lab you will generate a kubeconfig file for the kubectl command line utility based on the admin user credentials.
Run the commands in this lab from the same directory used to generate the admin client certificates.
There are a few steps to configuring a local kubectl installation for managing a remote cluster. This lesson will guide you through that process. After completing this lesson, you should have a local kubectl installation that is capable of running kubectl commands against your remote Kubernetes cluster. In a separate shell, open up an ssh tunnel to port 6443 on your Kubernetes API load balancer:
The Admin Kubernetes Configuration File
Each kubeconfig requires a Kubernetes API Server to connect to. To support high availability the IP address assigned to the external load balancer fronting the Kubernetes API Servers will be used.
Generate a kubeconfig file suitable for authenticating as the admin user:
Lets configure the
```
# cd /k8s
# mkdir -p $HOME/.kube
# cp -i admin.kubeconfig $HOME/.kube/config
# chown $(id -u):$(id -g) $HOME/.kube/config
# KUBERNETES_PUBLIC_ADDRESS=192.168.0.3
```
## The Admin Kubernetes Configuration File
Each kubeconfig requires a Kubernetes API Server to connect to. To support high availability the IP address assigned to the external load balancer fronting the Kubernetes API Servers will be used.
Generate a kubeconfig file suitable for authenticating as the `admin` user:
```
{
kubectl config set-cluster kubernetes-the-hard-way \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=https://${KUBERNETES_PUBLIC_ADDRESS}:6443
kubectl config set-credentials admin \
--client-certificate=admin.pem \
--client-key=admin-key.pem
kubectl config set-context kubernetes-the-hard-way \
--cluster=kubernetes-the-hard-way \
--user=admin
kubectl config use-context kubernetes-the-hard-way
}
```
## Verification
Check the version of the remote Kubernetes cluster:
```
kubectl version
```
> output
```
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.0", GitCommit:"cb303e613a121a29364f75cc67d3d580833a7479", GitTreeState:"clean", BuildDate:"2021-04-08T16:31:21Z", GoVersion:"go1.16.1", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.0", GitCommit:"cb303e613a121a29364f75cc67d3d580833a7479", GitTreeState:"clean", BuildDate:"2021-04-08T16:25:06Z", GoVersion:"go1.16.1", Compiler:"gc", Platform:"linux/amd64"}
```
List the nodes in the remote Kubernetes cluster:
```
kubectl get nodes
```
> output
```
NAME STATUS ROLES AGE VERSION
worknode01.k8s.com NotReady <none> 5m28s v1.21.0
worknode02.k8s.com NotReady <none> 5m31s v1.21.0
```
> dotnot wary about `NotReady` because in networking will fix this issues
# Provisioning Pod Network Routes
In this lab you will use [calico ](https://docs.projectcalico.org/getting-started/kubernetes/)
> There are [other ways](https://kubernetes.io/docs/concepts/cluster-administration/networking/#how-to-achieve-this) to implement the Kubernetes networking model.
### The Kubernetes Networking Model
- What Problems Does the Networking Model Solve?
- How will containers communicate with each other?
- What if the containers are on different hosts (worker nodes)?
- How will containers communicate with services?
- How will containers be assigned unique IP addresses? What port(s) will be used?
### The Docker Model
Docker allows containers to communicate with one another using a virtual network bridge configured on the host. Each host has its own virtual network serving all of the containers on that host. But what about containers on different hosts? We have to proxy traffic from the host to the containers, making sure no two containers use the same port on a host. The Kubernetes networking model was created in response to the Docker model. It was designed to improve on some of the limitations of the Docker model
### The Kubernetes Networking Model
- One virtual network for the whole cluster.
- Each pod has a unique IP within the cluster.
- Each service has a unique IP that is in a different range than pod IPs.
### Cluster Network Architecture
Some Important CIDR ranges:
- Cluster CIDR
- IP range used to assign IPs to pods in the cluster. In this course, we’ll be using a cluster CIDR of 10.200.0.0/16
- Service Cluster IP Range
- IP range for services in the cluster. This should not overlap with the cluster CIDR range! In this course, our service cluster IP range is 10.32.0.0/24.
- Pod CIDR
- IP range for pods on a specific worker node. This range should fall within the cluster CIDR but not overlap with the pod CIDR of any other worker node. In this course, our networking plugin will automatically handle IP allocation to nodes, so we do not need to manually set a pod CIDR.
### Install Calico Networking on Kubernetes
We will be using calico Net to implement networking in our Kubernetes cluster.
We are now ready to set up networking in our Kubernetes cluster. This lesson guides you through the process of installing Weave Net in the cluster. It also shows you how to test your cluster network to make sure that everything is working as expected so far. After completing this lesson, you should have a functioning cluster network within your Kubernetes cluster. You can configure Weave Net like this: First, log in to both worker nodes and enable IP forwarding
```
# sysctl net.ipv4.conf.all.forwarding=1
# echo "net.ipv4.conf.all.forwarding=1" | sudo tee -a /etc/sysctl.conf
```
login in remote kubectl then install clico
```
# kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
```
> note it take between 10 to 15 min to be up
Now calico Net is installed, but we need to test our network to make sure everything is working. First, make sure the calico Net pods are up and running:
```
# kubectl get pods -n kube-system
```
### Verification
Next, we want to test that pods can connect to each other and that they can connect to services. We will set up two Nginx pods and a service for those two pods. Then, we will create a busybox pod and use it to test connectivity to both Nginx pods and the service. First, create an Nginx deployment with 2 replicas:
```
# cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
EOFnginx.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
run: nginx
replicas: 2
template:
metadata:
labels:
run: nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
```
Next, create a service for that deployment so that we can test connectivity to services as well:
```
# kubectl expose deployment/nginx
```
Now let's start up another pod. We will use this pod to test our networking. We will test whether we can connect to the other pods and services from this pod.
```
# kubectl run busybox --image=radial/busyboxplus:curl --command -- sleep 3600
# POD_NAME=$(kubectl get pods -l run=busybox -o jsonpath="{.items[0].metadata.name}")
```
Now let's get the IP addresses of our two Nginx pods:
```
# kubectl get ep nginx
```
Now let's make sure the busybox pod can connect to the Nginx pods on both of those IP addresses
```
# kubectl exec $POD_NAME -- curl <first nginx pod IP address>
# kubectl exec $POD_NAME -- curl <second nginx pod IP address>
```
Both commands should return some HTML with the title "Welcome to Nginx!" This means that we can successfully connect to other pods. Now let's verify that we can connect to services.
```
# kubectl get svc
```
Let's see if we can access the service from the busybox pod!
```
# kubectl exec $POD_NAME -- curl <nginx service IP address>
```
This should also return HTML with the title "Welcome to Nginx!" This means that we have successfully reached the Nginx service from inside a pod and that our networking configuration is working!
Now that we have networking set up in the cluster, we need to clean up the objects that were created in order to test the networking. These object could get in the way or become confusing in later lessons, so it is a good idea to remove them from the cluster before proceeding. After completing this lesson, your networking should still be in place, but the pods and services that were used to test it will be cleaned up.
```
# kubectl get deploy
# kubectl delete deployment nginx
# kubectl delete svc nginx
# kubectl delete pod busybox
```
### DNS in a Kubernetes Pod Network
- Provides a DNS service to be used by pods within the network.
- Configures containers to use the DNS service to perform DNS lookups for example
- You can access services using DNS names assigned to them.
- You can access other pods using DNS names
# Deploying the DNS Cluster Add-on
In this lab you will deploy the [DNS add-on](https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/) which provides DNS based service discovery, backed by [CoreDNS](https://coredns.io/), to applications running inside the Kubernetes cluster.
Deploying the DNS Cluster Add-on
In this lab you will deploy the DNS add-on which provides DNS based service discovery, backed by CoreDNS, to applications running inside the Kubernetes cluster.
The DNS Cluster Add-on
## The DNS Cluster Add-on
Deploy the `coredns` cluster add-on:
```
kubectl apply -f https://storage.googleapis.com/kubernetes-the-hard-way/coredns-1.8.yaml
```
> output
```
serviceaccount/coredns created
clusterrole.rbac.authorization.k8s.io/system:coredns created
clusterrolebinding.rbac.authorization.k8s.io/system:coredns created
configmap/coredns created
deployment.apps/coredns created
service/kube-dns created
```
List the pods created by the `kube-dns` deployment:
```
kubectl get pods -l k8s-app=kube-dns -n kube-system
```
it take 3 min then the pods will up
> output
```
coredns-8494f9c688-j97h2 1/1 Running 5 3m31s
coredns-8494f9c688-wjn4n 1/1 Running 1 3m31s
```
## Verification
Create a `busybox` deployment:
```
kubectl run busybox --image=busybox:1.28 --command -- sleep 3600
```
List the pod created by the `busybox` deployment:
```
kubectl get pods -l run=busybox
```
> output
```
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 0 3s
```
Retrieve the full name of the `busybox` pod:
```
POD_NAME=$(kubectl get pods -l run=busybox -o jsonpath="{.items[0].metadata.name}")
```
Execute a DNS lookup for the `kubernetes` service inside the `busybox` pod:
```
kubectl exec -ti $POD_NAME -- nslookup kubernetes
```
> output
```
Server: 10.32.0.10
Address 1: 10.32.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.32.0.1 kubernetes.default.svc.cluster.local
```
## Smoke Test
In this lab you will complete a series of tasks to ensure your Kubernetes cluster is functioning correctly.
Now we want to run some basic smoke tests to make sure everything in our cluster is working correctly. We will test the following features:
- Data encryption
- Deployments
- Port forwarding
- Logs
- Exec
- Services
- Untrusted workloads
## Data Encryption
In this section you will verify the ability to [encrypt secret data at rest](https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/#verifying-that-data-is-encrypted).
Create a generic secret:
- Goal:
- Verify that we can encrypt secret data at rest.
- Strategy:
- Create a generic secret in the cluster.
- Dump the raw data from etcd and verify that it is encrypted
we set up a data encryption config to allow Kubernetes to encrypt sensitive data. In this lesson, we will smoke test that functionality by creating some secret data and verifying that it is stored in an encrypted format in etcd. After completing this lesson, you will have verified that your cluster can successfully encrypt sensitive data
```
kubectl create secret generic kubernetes-the-hard-way \
--from-literal="mykey=mydata"
```
Print a hexdump of the `kubernetes-the-hard-way` secret stored in etcd:
Log in to one of your controller servers, and get the raw data for the test secret from etcd
```
# ETCDCTL_API=3 etcdctl get \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/etcd/ca.pem \
--cert=/etc/etcd/kubernetes.pem \
--key=/etc/etcd/kubernetes-key.pem\
/registry/secrets/default/kubernetes-the-hard-way | hexdump -C
```
> output
```
00000000 2f 72 65 67 69 73 74 72 79 2f 73 65 63 72 65 74 |/registry/secret|
00000010 73 2f 64 65 66 61 75 6c 74 2f 6b 75 62 65 72 6e |s/default/kubern|
00000020 65 74 65 73 2d 74 68 65 2d 68 61 72 64 2d 77 61 |etes-the-hard-wa|
00000030 79 0a 6b 38 73 3a 65 6e 63 3a 61 65 73 63 62 63 |y.k8s:enc:aescbc|
00000040 3a 76 31 3a 6b 65 79 31 3a ea 5f 64 1f 22 63 ac |:v1:key1:._d."c.|
00000050 e5 a0 2d 7f 1e cd e3 03 64 a0 8e 7f cf 58 db 50 |..-.....d....X.P|
00000060 d7 d0 12 a1 31 2e 72 53 e3 51 de 31 53 96 d7 3f |....1.rS.Q.1S..?|
00000070 71 f5 e3 3f 07 bc 33 56 55 ed 9c 67 6a 91 77 18 |q..?..3VU..gj.w.|
00000080 52 bb ad 61 64 76 43 df 00 b5 aa 7e 8e cb 16 e9 |R..advC....~....|
00000090 9b 5a 21 04 49 37 63 a5 6c df 09 b7 2b 5c 96 69 |.Z!.I7c.l...+\.i|
000000a0 02 03 42 02 93 7d 42 57 c9 8d 28 2d 1c 9d dd 2b |..B..}BW..(-...+|
000000b0 a3 69 fa ca c8 8f a0 0e 66 c8 5b 5a 40 29 80 0d |.i......f.[Z@)..|
000000c0 06 c3 56 87 27 ba d2 19 a6 b0 e6 b5 70 b3 18 02 |..V.'.......p...|
000000d0 69 ed ae b1 4d 03 be 92 08 9e 20 62 41 cd e6 a4 |i...M..... bA...|
000000e0 8c e0 fd b0 5f 44 11 a1 e0 99 a4 61 71 b2 c2 98 |...._D.....aq...|
000000f0 b1 f3 bf 48 a5 26 11 8c 9e 4e 12 7a 81 f4 20 11 |...H.&...N.z.. .|
00000100 05 0d db 62 82 53 2c d9 71 0d 9f af d7 e2 b6 94 |...b.S,.q.......|
00000110 4c 67 98 2e 66 21 77 5e ea 4d f5 23 6c d4 4b 56 |Lg..f!w^.M.#l.KV|
00000120 58 a7 f1 3b 23 8d 5b 45 14 2c 05 3a a9 90 95 a4 |X..;#.[E.,.:....|
00000130 9a 5f 06 cc 42 65 b3 31 d8 9c 78 a9 f1 da a2 81 |._..Be.1..x.....|
00000140 5a a6 f6 d8 7c 2e 8c 13 f0 30 b1 25 ab 6e bb 2f |Z...|....0.%.n./|
00000150 cd 7f fd 44 98 64 97 9b 31 0a |...D.d..1.|
0000015a
```
The etcd key should be prefixed with `k8s:enc:aescbc:v1:key1`, which indicates the `aescbc` provider was used to encrypt the data with the `key1` encryption key.
### Deployments
- Goal:
- Verify that we can create a deployment and that it can successfully create pods.
- Strategy:
- Create a simple deployment.
- Verify that the deployment successfully creates a pod
Deployments are one of the powerful orchestration tools offered by Kubernetes. In this lesson, we will make sure that deployments are working in our cluster. We will verify that we can create a deployment, and that the deployment is able to successfully stand up a new pod and container.
In this section you will verify the ability to create and manage [Deployments](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/).
Create a deployment for the [nginx](https://nginx.org/en/) web server:
```
kubectl create deployment nginx --image=nginx
```
List the pod created by the `nginx` deployment:
```
kubectl get pods -l app=nginx
```
> output
```
nginx-6799fc88d8-vtz4c 1/1 Running 0 21s
```
### Port Forwarding
- Goal:
- Verify that we can use port forwarding to access pods remotely
- Strategy:
- Use kubectl port-forward to set up port forwarding for an Nginx pod
- Access the pod remotely with curl.
In this section you will verify the ability to access applications remotely using [port forwarding](https://kubernetes.io/docs/tasks/access-application-cluster/port-forward-access-application-cluster/).
Retrieve the full name of the `nginx` pod:
```
POD_NAME=$(kubectl get pods -l app=nginx -o jsonpath="{.items[0].metadata.name}")
```
Forward port `8080` on your local machine to port `80` of the `nginx` pod:
```
kubectl port-forward $POD_NAME 8080:80
```
> output
```
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
```
In a new terminal make an HTTP request using the forwarding address:
```
curl --head http://127.0.0.1:8080
```
> output
```
HTTP/1.1 200 OK
Server: nginx/1.19.10
Date: Sun, 02 May 2021 05:29:25 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 13 Apr 2021 15:13:59 GMT
Connection: keep-alive
ETag: "6075b537-264"
Accept-Ranges: bytes
```
Switch back to the previous terminal and stop the port forwarding to the `nginx` pod:
```
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
Handling connection for 8080
^C
```
### Logs
- Goal:
- Verify that we can get container logs with kubectl logs.
- Strategy:
- Get the logs from the Nginx pod container.
When managing a cluster, it is often necessary to access container logs to check their health and diagnose issues. Kubernetes offers access to container logs via the kubectl logs command. In this lesson, In this section you will verify the ability to [retrieve container logs](https://kubernetes.io/docs/concepts/cluster-administration/logging/).
Print the `nginx` pod logs:
```
kubectl logs $POD_NAME
```
> output
```
2021/10/26 18:07:29 [notice] 1#1: start worker processes
2021/10/26 18:07:29 [notice] 1#1: start worker process 30
2021/10/26 18:07:29 [notice] 1#1: start worker process 31
127.0.0.1 - - [26/Oct/2021:18:20:44 +0000] "HEAD / HTTP/1.1" 200 0 "-" "curl/7.29.0" "-"
```
### Exec
- Goal:
- Verify that we can run commands in a container with kubectl exec
- Strategy:
- Use kubectl exec to run a command in the Nginx pod container.
The kubectl exec command is a powerful management tool that allows us to run commands inside of Kubernetes-managed containers. In order to verify that our cluster is set up correctly, we need to make sure that kubectl exec is working.
In this section you will verify the ability to [execute commands in a container](https://kubernetes.io/docs/tasks/debug-application-cluster/get-shell-running-container/#running-individual-commands-in-a-container).
Print the nginx version by executing the `nginx -v` command in the `nginx` container:
```
kubectl exec -ti $POD_NAME -- nginx -v
```
> output
```
nginx version: nginx/1.21.3
```
## Services
- Goal:
- Verify that we can create and access services.
- Verify that we can run an untrusted workload under gVisor (runsc)
- Strategy:
- Create a NodePort service to expose the Nginx deployment.
- Access the service remotely using the NodePort.
- Run a pod as an untrusted workload.
- Log in to the worker node that is running the pod and verify that its container is running using runsc.
In order to make sure that the cluster is set up correctly, we need to ensure that services can be created and accessed appropriately. In this lesson, we will smoke test our cluster's ability to create and access services by creating a simple testing service, and accessing it using a node port. If we can successfully create the service and use it to access our nginx pod, then we will know that our cluster is able to correctly handle services!
In this section you will verify the ability to expose applications using a [Service](https://kubernetes.io/docs/concepts/services-networking/service/).
Expose the `nginx` deployment using a [NodePort](https://kubernetes.io/docs/concepts/services-networking/service/#type-nodeport) service:
```
kubectl expose deployment nginx --port 80 --type NodePort
```
Retrieve the node port assigned to the `nginx` service:
```
NODE_PORT=$(kubectl get svc nginx \
--output=jsonpath='{range .spec.ports[0]}{.nodePort}')
```
Make an HTTP request using the external IP address and the `nginx` node port:
```
curl -I http://${EXTERNAL_IP}:${NODE_PORT}
```
> output
```
HTTP/1.1 200 OK
Server: nginx/1.19.10
Date: Sun, 02 May 2021 05:31:52 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 13 Apr 2021 15:13:59 GMT
Connection: keep-alive
ETag: "6075b537-264"
Accept-Ranges: bytes
```
# Cleaning Up
In this lab you will delete the compute resources created during this tutorial.
Now that we have finished smoke testing the cluster, it is a good idea to clean up the objects that we created for testing. In this lesson, we will spend a moment removing the objects that were created in our cluster in order to perform the smoke testing
```
# kubectl delete secret kubernetes-the-hard-way
# kubectl delete svc nginx
# kubectl delete deployment nginx
```
| haydercyber |
877,976 | Why bother with TDD? | Disclaimer : I am still very much learning about best practices and clean code so all... | 0 | 2021-10-27T08:34:36 | https://dev.to/ephieo/why-bother-with-tdd-5mn | tdd, testing, beginners, ruby |
### Disclaimer :
I am still very much learning about best
practices and clean code so all views shared are personal to me and where I currently am in my coding journey.
Testing. Ever since I started embarking on my coding journey, testing has been nothing to me other than a nemesis that I avoided at all costs. Delegating the task of testing was always easy up until now because you don't have to look too far in a project for green tick addicts that equate testing to pure joy and happiness.
### What is TDD?
TDD stands for 'Test Drive Development'. [TDD](https://en.wikipedia.org/wiki/Test-driven_development) is a software development process that involves writing failing tests before you actually write any fully developed software and continuously testing the software against all tests cases. TDD is a popular alternative to writing software and then testing later.
### Why implement TDD in your work ?
I would say that TDD is the code equivalent to cleaning as you go in the kitchen compared to cleaning the kitchen after a very messy Christmas dinner. TDD is more effective in forming the habit of caring about your code and the effects it leaves behind. It doesn't really matter if your code works when you don't know if it will break or even worse you have no clue when your code will break.
I'm an apprentice at 8th Light and currently entering my second month at the company. I was tasked with building a tic tac toe (noughts & crosses) CLI game in ruby. The aim of the project wasn't to get the game working but to challenge me to learn another language while learning how to implement TDD.
I started building my app while using both Ruby and Rspec for the first time. I had experiences with classes but it definitely wasn't a strong point for me. This challenged me to learn a more object oriented approach to programming while thinking about how to implement unit and integration tests.
### What are unit and integration tests ?
Unit testing is the process of testing a unit. In programming that unit is most often a function or the smallest amount of code you can isolate in a codebase. Integration testing pretty much does what is says on the label. Integration tests help test the flow of an application forming tests for where units of software are connected together. Therefore you are testing how your software integrates and how it combines different functionalities.
## Advantages of TDD ?
- You only write code that's needed.
- Modular design.
- High Test Coverage.
- Easier to maintain code.
- Easier to refactor.
- Easier Debugging.
## Disadvantages of TDD ?
- Slow process.
- Writing test before your software takes time, even straight forward implementations will take a little longer.
- It takes a team.
- TDD becomes pointless if only one person on a team implements it. TDD influences the planning of code so a team approach is necessary to plan and implement code in that manner. There is no point cleaning the kitchen when five other people are making a mess and never cleaning.
- Tests need t be maintained when code is changed.
- Similar to the slow process of writing tests it also then takes more time to maintain said tests.
So is TDD for you ? If it's not that's understandable because it definitely wasn't for me and right now with a failing test in front of me I'm reconsidering this conclusion. I joke.
Overall my experience with TDD has been good the only downside being the effort it requires, I personally think it pays off in the end. Currently my greatest benefit from TDD has been Thinking through why I actually want or need to write a specific piece of code. TDD has helped me cut down on repeated and redundant code.
### Resources :
- [Advantages and disadvantages of Test Driven Development (TDD)](https://www.geeksforgeeks.org/advantages-and-disadvantages-of-test-driven-development-tdd/)
- [What is unit testing?](https://smartbear.com/learn/automated-testing/what-is-unit-testing/) | ephieo |
878,168 | HTML tags | input | It is used to create interactive controls for web-based forms in order to accept data from the... | 13,528 | 2021-11-02T07:25:33 | https://dev.to/carlosespada/html-tags-input-5h9g | html, tags, input | It is used to **create interactive controls for web-based forms in order to accept data from the user**.
A wide variety of types of input data and control widgets are available, depending on the device and [user agent](https://developer.mozilla.org/en-US/docs/Glossary/User_agent).
The <input> element can be displayed in several ways, depending on the `type` attribute. If this attribute is not specified, the default type adopted is `text`.
The different input types are as follows:
* `button`: a push button with no default behavior displaying the value of the `value` attribute, empty by default.
* `checkbox`: a check box allowing single values to be selected/deselected.
* `color`: a control for specifying a color. Opens a color picker when active in supporting browsers.
* `date`: a control for entering a date (year, month, and day, with no time). Opens a date picker or numeric wheels for year, month, day when active in supporting browsers.
* `datetime-local`: a control for entering a date and time, with no time zone. Opens a date picker or numeric wheels for date- and time-components when active in supporting browsers.
* `email`: a field for editing an email address. Looks like a text input, but has validation parameters and relevant keyboard in supporting browsers and devices with dynamic keyboards.
* `file`: a control that lets the user select a file. Use the `accept` attribute to define the types of files that the control can select.
* `hidden`: a control that is not displayed but whose value is submitted to the server.
* `image`: a graphical submit button. Displays an image defined by the `src` attribute. The `alt` attribute displays if the image `src` is missing.
* `month`: a control for entering a month and year, with no time zone.
* `number`: a control for entering a number. Displays a spinner and adds default validation when supported. Displays a numeric keypad in some devices with dynamic keypads.
* `password`: a single-line text field whose value is obscured. Will alert user if site is not secure.
* `radio`: a radio button, allowing a single value to be selected out of multiple choices with the same `name` attribute value.
* `range`: a control for entering a number whose exact value is not important. Displays as a range widget defaulting to the middle value. Used in conjunction `min` and `max` to define the range of acceptable values.
* `reset`: a button that resets the contents of the form to default values. Not recommended.
* `search`: a single-line text field for entering search strings. Line-breaks are automatically removed from the input value. May include a delete icon in supporting browsers that can be used to clear the field. Displays a search icon instead of enter key on some devices with dynamic keypads.
* `submit`: a button that submits the form.
* `tel`: a control for entering a telephone number. Displays a telephone keypad in some devices with dynamic keypads.
* `text`: the default value. A single-line text field. Line-breaks are automatically removed from the input value.
* `time`: a control for entering a time value with no time zone.
* `url`: a field for entering a URL. Looks like a `text` input, but has validation parameters and relevant keyboard in supporting browsers and devices with dynamic keyboards.
* `week`: a control for entering a date consisting of a week-year number and a week number with no time zone.
Since every `<input>` element, regardless of type, is based on the [HTMLInputElement](https://developer.mozilla.org/en-US/docs/Web/API/HTMLInputElement) interface, they technically share the exact same set of attributes. However, in reality, most attributes have an effect on only a specific subset of input types. In addition, the way some attributes impact an input depends on the input type, impacting different input types in different ways.
### accept
Valid for the `file` input type only, defines which file types are selectable in a file upload control.
### alt
Valid for the `image` button only, provides alternative text for the image, displaying the value of the attribute if the image `src` is missing or otherwise fails to load. Required for accessibility.
### autocomplete
Takes as its value a [space-separated string](https://developer.mozilla.org/en-US/docs/Web/HTML/Attributes/autocomplete#values) that describes what, if any, type of autocomplete functionality the input should provide. A typical implementation of autocomplete recalls previous values entered in the same input field or a browser integrating with a device's contacts list to autocomplete email addresses in an `email` input field.
It has no effect on input types that do not return numeric or text data, being valid for all input types except `checkbox`, `file`, `radio` or any of the button types.
### autofocus
A Boolean attribute which, if present, indicates that the input should automatically have focus when the page has finished loading (or when the `<dialog>` containing the element has been displayed).
An element with the `autofocus` attribute may gain focus before the `DOMContentLoaded` event is fired.
No more than one element in the document may have the `autofocus attribute`. If put on more than one element, the first one with the attribute receives focus.
It cannot be used on inputs of type `hidden`, since hidden inputs cannot be focused.
**Automatically focusing a form control can confuse** visually-impaired people using screen-reading technology and people with cognitive impairments. When `autofocus` is assigned, screen-readers "teleport" their user to the form control without warning them beforehand.
**Use careful consideration for accessibility** when applying the `autofocus` attribute. Automatically focusing on a control can cause the page to scroll on load. The focus can also cause dynamic keyboards to display on some touch devices. While a screen reader will announce the label of the form control receiving focus, the screen reader will not announce anything before the label, and the sighted user on a small device will equally miss the context created by the preceding content.
### capture
Valid for the `file` input type only, defines which media—microphone, video or camera—should be used to capture a new file for upload with file upload control in supporting scenarios.
### checked
Valid for both `radio` and `checkbox` types, is a Boolean attribute. If present on a `radio` type, it indicates that the radio button is the currently selected one in the group of same-named radio buttons. If present on a `checkbox` type, it indicates that the checkbox is checked by default (when the page loads).
It does not indicate whether this checkbox is currently checked: if the checkbox’s state is changed, this content attribute does not reflect the change (only the [HTMLInputElement’s checked IDL attribute](https://developer.mozilla.org/en-US/docs/Web/API/HTMLInputElement) is updated.)
Unlike other input controls, a checkboxes and radio buttons value are only included in the submitted data if they are currently checked. If they are, the name and the value of the checked controls are submitted with the form as part of a name/value pair. If not, they aren't listed in the form data at all.
The default value for checkboxes and radio buttons is `on`.
### dirname
Valid for `text` and `search` input types only, enables the submission of the directionality of the element. When included, the form control will submit with two name/value pairs: the first being the `name` and `value`, the second being the value of the `dirname` as the name with the value of `ltr` or `rtl` being set by the browser.
```
<form action="page.html" method="post">
<label>Fruit: <input type="text" name="fruit" dirname="fruit.dir" value="cherry"></label>
<input type="submit"/>
</form>
<!-- page.html?fruit=cherry&fruit.dir=ltr -->
```
When the form above is submitted, the input cause both the name/value pair of `fruit=cherry` and the dirname/direction pair of `fruit.dir=ltr` to be sent.
### disabled
A Boolean attribute which, if present, indicates that the user should not be able to interact with the input. Disabled inputs are typically rendered with a dimmer color or using some other form of indication that the field is not available for use.
Specifically, disabled inputs do not receive the `click` event, and disabled inputs are not submitted with the form.
Although not required by the specification, Firefox will by default persist the dynamic disabled state of an `<input>` across page loads. Use the `autocomplete` attribute to control this feature.
### form
A string specifying the `<form>` element with which the input is associated (that is, its form owner). This string's value, if present, must match the `id` of a `<form>` element in the same document. If this attribute isn't specified, the `<input>` element is associated with the nearest containing form, if any.
The `form` attribute lets you place an input anywhere in the document but have it included with a form elsewhere in the document.
An input can only be associated with one form.
### formaction
Valid for the `image` and `submit` input types only. It is a string indicating the URL to which to submit the data. This takes precedence over the action attribute on the `<form>` element that owns the `<input>`.
### formenctype
Valid for the `image` and `submit` input types only. It is a string that identifies the encoding method to use when submitting the form data to the server. There are three permitted values:
* `application/x-www-form-urlencoded`: the default value, sends the form data as a string after URL encoding the text using an algorithm such as [encodeURI()](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/encodeURI).
* `multipart/form-data`: uses the [FormData API](https://developer.mozilla.org/en-US/docs/Web/API/FormData) to manage the data, allowing for files to be submitted to the server. You must use this encoding type if your form includes any `<input>` elements of type `file` (`<input type="file">`).
* `text/plain`: plain text; mostly useful only for debugging, so you can easily see the data that's to be submitted.
If specified, the value of the `formenctype` attribute overrides the owning form's `action` attribute.
### formmethod
Valid for the `image` and `submit` input types only. IT is a string indicating the HTTP method to use when submitting the form's data; this value overrides any method attribute given on the owning form. Permitted values are:
* `get`: a URL is constructed by starting with the URL given by the `formaction` or action attribute, appending a question mark (`?`) character, then appending the form's data, encoded as described by `formenctype` or the form's `enctype` attribute. This URL is then sent to the server using an HTTP `get` request. This method works well for simple forms that contain only ASCII characters and have no side effects. This is the default value.
* `post`: the form's data is included in the body of the request that is sent to the URL given by the `formaction` or `action` attribute using an HTTP `post` method. This method supports complex data and file attachments.
* `dialog`: this method is used to indicate that the button closes the dialog with which the input is associated, and does not transmit the form data at all.
### formnovalidate
Valid for the `image` and `submit` input types only. It is a Boolean attribute which, if present, specifies that the form should not be validated before submission to the server. This overrides the value of the `novalidate` attribute on the element's owning form.
### formtarget
Valid for the `image` and `submit` input types only. It is a string which specifies a name or keyword that indicates where to display the response received after submitting the form. The string must be the name of a browsing context (that is, a tab, window, or `<iframe>`. A value specified here overrides any `target given by the `target` attribute on the `<form>` that owns this input.
In addition to the actual names of tabs, windows, or inline frames, there are a few special keywords that can be used:
* `_self`: loads the response into the same browsing context as the one that contains the form. This will replace the current document with the received data. This is the default value used if none is specified.
* `_blank`: loads the response into a new, unnamed, browsing context. This is typically a new tab in the same window as the current document, but may differ depending on the configuration of the user agent.
* `_parent`: loads the response into the parent browsing context of the current one. If there is no parent context, this behaves the same as `_self`.
* `_top`: loads the response into the top-level browsing context; this is the browsing context that is the topmost ancestor of the current context. If the current context is the topmost context, this behaves the same as `_self`.
### height
Valid for the `image` input button only, is the height of the image file to display to represent the graphical submit button.
### id
Global attribute valid for all elements, including all the input types, it defines a unique identifier (ID) which must be unique in the whole document. Its purpose is to identify the element when linking. The value is used as the value of the `<label>`'s `for` attribute to link the label with the form control.
### inputmode
Global value valid for all elements, it provides a hint to browsers as to the type of virtual keyboard configuration to use when editing this element or its contents. Values include `decimal`, `email`, `none`, `numeric`, `search`, `tel`, `text` and `url`.
### list
The value given to the list attribute should be the `id` of a `<datalist>` element located in the same document. The `<datalist>` provides a list of predefined values to suggest to the user for this input. Any values in the list that are not compatible with the `type` are not included in the suggested options. The values provided are suggestions, not requirements: users can select from this predefined list or provide a different value.
It is valid for all input types except `checkbox`, `file`, `hidden`, `password`, `radio` or any of the button types.
Depending on the browser, the user may see a custom color palette suggested, tic marks along a range, or even a input that opens like a `<select>` but allows for non-listed values.
### max
Valid for `date`, `datetime-local`, `month`, `number`, `range`, `time` and `week`, it defines the greatest value in the range of permitted values. If the value entered into the element exceeds this, the element fails [constraint validation](https://developer.mozilla.org/en-US/docs/Web/Guide/HTML/Constraint_validation). If the value of the `max` attribute isn't a number, then the element has no maximum value.
There is a special case: if the data type is periodic (such as for dates or times), the value of `max` may be lower than the value of `min`, which indicates that the range may wrap around; for example, this allows you to specify a time range from 10 PM to 4 AM.
### maxlength
Valid for `email`, `password`, `search`, `tel`, `text` and `url`, it defines the maximum number of characters (as UTF-16 code units) the user can enter into the field. This must be an integer value `0` or higher. If no `maxlength` is specified, or an invalid value is specified, the field has no maximum length. This value must also be greater than or equal to the value of `minlength`.
The input will fail [constraint validation](https://developer.mozilla.org/en-US/docs/Web/Guide/HTML/Constraint_validation) if the length of the text entered into the field is greater than `maxlength` UTF-16 code units long. By default, browsers prevent users from entering more characters than allowed by the `maxlength` attribute.
### min
Valid for `date`, `datetime-local`, `month`, `number`, `range`, `time` and `week`, it defines the most negative value in the range of permitted values. If the value entered into the element is less than this this, the element fails [constraint validation](https://developer.mozilla.org/en-US/docs/Web/Guide/HTML/Constraint_validation). If the value of the `min` attribute isn't a number, then the element has no minimum value.
This value must be less than or equal to the value of the `max` attribute. If the `min` attribute is present but is not specified or is invalid, no `min` value is applied. If the `min` attribute is valid and a non-empty value is less than the minimum allowed by the `min` attribute, constraint validation will prevent form submission.
There is a special case: if the data type is periodic (such as for dates or times), the value of `max` may be lower than the value of `min`, which indicates that the range may wrap around; for example, this allows you to specify a time range from 10 PM to 4 AM.
### minlength
Valid for `email`, `password`, `search`, `tel`, `text` and `url`, it defines the minimum number of characters (as UTF-16 code units) the user can enter into the entry field. This must be an non-negative integer value smaller than or equal to the value specified by `maxlength`. If no `minlength` is specified, or an invalid value is specified, the input has no minimum length.
The input will fail [constraint validation](https://developer.mozilla.org/en-US/docs/Web/Guide/HTML/Constraint_validation) if the length of the text entered into the field is fewer than `minlength` UTF-16 code units long, preventing form submission.
### multiple
A Boolean attribute which, if set, means the user can enter comma separated email addresses in the `email` widget or can choose more than one file with the `file` input.
### name
A string specifying a name for the input control. This name is submitted along with the control's value when the form data is submitted.
Consider the `name` a required attribute (even though it's not). If an input has no `name` specified, or `name` is empty, the input's value **is not submitted with the form** (disabled controls, unchecked radio buttons, unchecked checkboxes and reset buttons are also not sent).
There are two special cases:
* `_charset_`: if used as the `name` of an `<input>` element of type `hidden`, the input's value is automatically set by the user agent to the character encoding being used to submit the form.
* `isindex`: for historical reasons, the name `isindex` is not allowed.
The `name` attribute creates a unique behavior for radio buttons: only one radio button in a same-named group of radio buttons can be checked at a time. Selecting any radio button in that group automatically deselects any currently-selected radio button in the same group. The value of that one checked radio button is sent along with the name if the form is submitted,
Avoid giving form elements a `name` that corresponds to a built-in property of the form, since you would then override the predefined property or method with this reference to the corresponding input.
### pattern
Valid for `password`, `tel` and `text`. When specified, is a regular expression that the input's value must match in order for the value to pass [constraint validation](https://developer.mozilla.org/en-US/docs/Web/Guide/HTML/Constraint_validation). It must be a valid JavaScript regular expression, as used by the [RegExp](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp) type; the `'u'` flag is specified when compiling the regular expression, so that the pattern is treated as a sequence of Unicode code points, instead of as ASCII. No forward slashes should be specified around the pattern text.
If the `pattern` attribute is present but is not specified or is invalid, no regular expression is applied and this attribute is ignored completely. If the `pattern` attribute is valid and a non-empty value does not match the pattern, constraint validation will prevent form submission.
If using the `pattern` attribute, **inform the user about the expected format** by including explanatory text nearby. You can also include a title attribute to explain what the requirements are to match the pattern; most browsers will display this title as a tooltip. The visible explanation is required for accessibility. The tooltip is an enhancement.
### placeholder
Valid for `password`, `search`, `tel`, `text` and `url`, is a string that provides a brief hint to the user as to what kind of information is expected in the field. It should be a word or short phrase that provides a hint as to the expected type of data, rather than an explanation or prompt. The text must not include carriage returns or line feeds. So for example if a field is expected to capture a user's first name, and its label is "First Name", a suitable placeholder might be "e.g. Fausto".
It should **never be required to understand your forms**. It is not a label, and should not be used as a substitute, because it isn't. The placeholder is used to provide a hint as to what an inputted value should look like, not an explanation or prompt.
Not only is the placeholder not accessible to screen readers, but once the user enters any text into the form control, or if the form control already has a value, the placeholder disappears. Browsers with automatic page translation features may skip over attributes when translating, meaning the placeholder may not get translated.
Don't use the `placeholder` attribute if you can avoid it. If you need to label an `<input>` element, use the `<label>` element.
### readonly
A Boolean attribute which, if present, indicates that the user should not be able to edit the value of the input. The readonly attribute is supported by the `date`, `datetime-local`, `email`, `month`, `number`, `password`, `search`, `tel`, `text`, `time`, `url` and `week` input types.
### required
A Boolean attribute which, if present, indicates that the user must specify a value for the input before the owning form can be submitted. The required attribute is supported by
the `checkbox`, `date`, `datetime-local`, `email`, `file`, `month`, `number`, `password`, `radio`, `search`, `tel`, `text`, `time`, `url` and `week` input types.
### size
Valid for `email`, `password`, `tel`, `text` and `url` input types only. Specifies how much of the input is shown. Basically creates same result as setting CSS `width` property with a few specialities. The actual unit of the value depends on the input type. For `password` and `text`, it is a number of characters (or `em` units) with a default value of `20`, and for others, it is pixels. CSS width takes precedence over `size` attribute.
Interactive elements such as form input should provide an area large enough that it is easy to activate them. This helps a variety of people, including people with motor control issues and people using non-precise forms of input such as a stylus or fingers. A minimum interactive size of 44×44 [CSS pixels](https://www.w3.org/TR/WCAG21/#dfn-css-pixels) is recommended.
### src
Valid for the `image` input button only, is a string specifying the URL of the image file to display to represent the graphical submit button.
### step
Valid for the numeric input types, including `number`, date/time input types and `range`, the step attribute is a number that specifies the granularity that the value must adhere to.
If not explicitly included:
* `step` defaults to `1` for `number` and `range`.
* For the date/time input types, `step` is expressed in seconds, with the default step being `60` seconds. The step scale factor is `1000` (which converts the seconds to milliseconds, as used in other algorithms).
The value must be a positive number—integer or float—or the special value any, which means no stepping is implied, and any value is allowed (barring other constraints, such as `min` and `max`).
If `any` is not explicity set, valid values for the `number`, date/time input types and `range` input types are equal to the basis for stepping — the `min` value and increments of the step value, up to the `max` value, if specified.
For example, if you have `<input type="number" min="10" step="2">`, then any even integer, `10` or greater, is valid. If omitted, <input type="number">, any integer is valid, but floats (like `4.2`) are not valid, because step defaults to `1`. For `4.2` to be valid, step would have had to be set to `any`, `0.1`, `0.2`, or any the `min` value would have had to be a number ending in `.2`, such as `<input type="number" min="-5.2">`.
When the data entered by the user doesn't adhere to the stepping configuration, the value is considered invalid in contraint validation and will match the `:invalid` pseudoclass.
### tabindex
Global attribute valid for all elements, including all the input types, an integer attribute indicating if the element can take input focus (is focusable), if it should participate to sequential keyboard navigation. As all input types except for input of type `hidden` are focusable, this attribute should not be used on form controls, because doing so would require the management of the focus order for all elements within the document with the risk of harming usability and accessibility if done incorrectly.
### title
Global attribute valid for all elements, including all input types, containing a text representing advisory information related to the element it belongs to. Such information can typically, but not necessarily, be presented to the user as a tooltip. The title **should NOT be used as the primary explanation** of the purpose of the form control. Instead, use the `<label>` element with a `for` attribute set to the form control's `id` attribute.
### type
A string specifying the type of control to render. If omitted (or an unknown value is specified), the input type `text` is used, creating a plaintext input field.
### value
The input control's value. When specified in the HTML, this is the initial value, and from then on it can be altered or retrieved at any time using JavaScript to access the respective `HTMLInputElement` object's `value` property. The `value` attribute is always optional, though should be considered mandatory for `checkbox`, `hidden` and `radio`.
### width
Valid for the `image` input button only, is the width of the image file to display to represent the graphical submit button.
Inputs, being replaced elements, have a **few features not applicable to non form elements**. There are CSS selectors that can specification target form controls based on their UI features, also known as **UI pseudo-classes**. The input element can also be targeted by type with attribute selectors. There are some properties that are especially useful as well.
* `:blank`: `<input>` and `<textarea>` elements that currently have no value.
* `:checked`: matches `checkbox` and `radio` input types that are currently checked (and the `<option>` in a `<select>` that is currently selected).
* `:default`: form elements that are the default in a group of related elements. Matches `checkbox` and `radio` input types that were checked on page load or render.
* `:disabled`: any currently disabled element that has an enabled state, meaning it otherwise could be activated (selected, clicked on, typed into, etc.) or accept focus were it not disabled.
* `:enabled`: any currently enabled element that can be activated (selected, clicked on, typed into, etc.) or accept focus and also has a disabled state, in which it can't be activated or accept focus.
* `:indeterminate`: `checkbox` elements whose indeterminate property is set to `true` by JavaScript, radio elements, when all radio buttons with the same name value in the form are unchecked, and `<progress>` elements in an indeterminate state.
* `:in-range`: a non-empty input whose current value is within the range limits specified by the `min` and `max` attributes and the `step`.
* `:invalid`: form controls that have constraint validation applied and are currently not valid. Matches a form control whose value doesn't match the constraints set on it by its attributes, such as `max`, `pattern`, `required` and `step`.
* `:optional`: `<input>`, `<select>` or `<textarea>` element that does NOT have the `required` attribute set on it. Does not match elements that can't be required.
* `:out-of-range`: a non-empty input whose current value is NOT within the range limits specified by the `min` and `max` attributes or does not adher to the `step` constraint.
* `:placeholder-shown`: element that is currently displaying placeholder text, including `<input>` and `<textarea>` elements with the `placeholder` attribute present that has, as of yet, no value.
* `:read-only`: element not editable by the user.
* `:read-write`: element that is editable by the user.
* `:required`: `<input>`, `<select>` or `<textarea>` element that has the `required` attribute set on it. Only matches elements that can be required. The attribute included on a non-requirable element will not make for a match.
* `:user-invalid`: similar to `:invalid`, but is activated on blur. Matches invalid input but only after the user interaction, such as by focusing on the control, leaving the control, or attempting to submit the form containing the invalid control.
* `:valid`: form controls that can have constraint validation applied and are currently valid.
In addition to using CSS to style inputs based on the `:valid` or `:invalid` UI states based on the current state of each input, the browser provides for client-side validation on (attempted) form submission. On form submission, if there is a form control that fails constraint validation, supporting browsers will display an error message on the first invalid form control; displaying a default message based on the error type, or a message set by you.
If a form control doesn't have the `required` attribute, no value, or an empty string, is not invalid.
We can set limits on what values we accept, and supporting browsers will natively validate these form values and alert the user if there is a mistake when the form is submitted.
**Always validate input constraints both client side and server side**. Constraint validation doesn't remove the need for validation on the server side. Invalid values can still be sent by older browsers or by bad actors.
By default, the appearance of placeholder text is a translucent or light gray. The `::placeholder` pseudo-element is the input's placeholder text. It can be styled with a limited subset of CSS properties, the same as that applied to the `::first-line` pseudo-element.
The `appearance` property enables the displaying of (almost) any element as a platform-native style based on the operating system's theme as well as the removal of any platform-native styling with the none value. You could make a `<div>` look like a radio button with div `{appearance: radio;}` or a `radio` look like a `checkbox` with `[type="checkbox] {appearance: checkbox;}`, but don't. Setting `appearance: none` removes platform native borders, but not functionality.
A property specific to text entry-related elements is the CSS `caret-color` property, which lets you set the color used to draw the text input caret.
In certain cases (typically involving non-textual inputs and specialized interfaces), the `<input>` element is a [replaced element](https://developer.mozilla.org/en-US/docs/Web/CSS/Replaced_element). When it is, the position and size of the element's size and positioning within its frame can be adjusted using the CSS `object-position` and `object-fit` properties.
- Type: *inline-block*
- Self-closing: *No*
- Semantic value: *No*
[Definition and example](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input) | [Support](https://caniuse.com/mdn-html_elements_input) | carlosespada |
878,214 | Pattern Matching in C# for Beginners | Pattern matching in C# helps developers handle control flows with variables and types that are not... | 0 | 2021-10-27T11:58:54 | https://www.syncfusion.com/blogs/post/pattern-matching-in-c-for-beginners.aspx | csharp, dotnet, productivity | ---
title: Pattern Matching in C# for Beginners
published: true
date: 2021-10-27 10:00:32 UTC
tags: csharp, dotnet, productivity
canonical_url: https://www.syncfusion.com/blogs/post/pattern-matching-in-c-for-beginners.aspx
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/hvo7xox7ce09yf2m9z7z.png
---
Pattern matching in [C#](https://en.wikipedia.org/wiki/C_Sharp_(programming_language) "Link to Wikipedia page for C Sharp language") helps developers handle control flows with variables and types that are not linked by a hierarchy of inheritance. Pattern matching was implemented in C# 7.0 to add power to the existing language operators and statements. Since then, pattern matching capabilities have been expanded in every major C# version.
You can perform pattern matching on any type of data, including your own, although primitives still need to align with **if** / **else**. Also, pattern matching will extract expression values.
In this blog, we will briefly discuss some of the pattern matching features.
## The is type pattern expression
The **is** type expression tests the compatibility of an object with a given type.**is** type pattern matching in C# enables the use of type in a control flow, and the logic used is type-driven versus literal value.
Consider the following code example. The code defines three classes: Mathematics, Science, and English.
```csharp
public class Mathematics
{
public double Score { get; set; }
public string GetSubjectDetails() => "Mathematics class";
}
public class Science
{
public double Score { get; set; }
public string GetSubjectDetails() => "Science class";
}
public class English
{
public double Score { get; set; }
public string GetSubjectDetails() => "English class";
}
```
You can now code against a subject type using the **is** type. The following code snippet provides an example.
```csharp
public static string GetSubjectDetails (object subject)
{
if (subject is English e)
return e.GetSubjectDetails ();
if (subject is Science s)
return s.GetSubjectDetails ();
if (subject is Mathematics m)
return m.GetSubjectDetails ();
throw new ArgumentException("unsupported subject type", nameof(subject));
}
```
The **is** expression checks the variable and assigns it to a new type of variable that is suitable. The**is** type expression works with both the value and the type of reference.
## Switch statements
Instead of a fixed value, the **switch** case statement pattern improves case blocks by allowing us to compare the switch value with different values returned by an expression.
We can do this with a **when** / **case** expression to check a value and perform some action based on the condition check.
```csharp
public static string GetSubjectScore(object subject)
{
switch (subject)
{
case Mathematics m when m.Score >= 90:
//Go to the grade calculation.
case Science s:
//Get the subject details.
case var sub when (sub.Equals(100)):
//Got the centum.
case null:
//Code logic go here.
default:
throw new ArgumentException("Unsupported subject type", nameof(subject));
}
}
```
You can see case statements for null, default, type check, conditions, and the use of conditions without type check ( **case var** ) in the example above. Because **case var** can also match **null** , we put it below **case null** to prevent that from occurring.
Only constants were allowed by the classic **switch** argument. In pattern matching, the order of pattern cases matters due to the dynamic conditions.
Switch expressions were added in C# 8.0. A switch expression is a short approach to return a particular result based on another value. We don’t require the case keywords in switch expressions. The arrow ( **=>** ) takes the place of the colon ( **:** ). The **\_** (underscore) replaces the keyword **default**.
The following code snippet calculates a subject score by using **switch** expressions.
```csharp
var (score1, score2, option) = (50, 40, “+”);
var score = option switch
{
“+” => score1 + score2,
“-” => score1 - score2,
_ => 0
};
Console.WriteLine("Score Details: " + score);
```
## Relational and logical patterns
The **C# 9** version provides support to relational and logical patterns.
They allow the use of relational operators **<** , **>**, **<=**, and **>=**. Use the **to** keyword to express a range in relational patterns.
Logic operators such as **and**, **or**, and **not** can be used.
Using relational and logical patterns, the following code displays the subject grade.
```csharp
var subjectScore = 90;
var grade = subjectScore switch
{
100 => “Grade O”,
>= 90 and <= 99 => “Grade A”,
75 to 89 => “Grade B”,
> 60 => “Grade C”
};
Console.WriteLine("Subject Grade: " + grade);
```
## Conclusion
We have looked at C#’s support for pattern matching in this blog post. Pattern matching works with any data type. It provides a more concise syntax for testing expressions and taking action when an expression matches. Try out these pattern matching concepts in C# and enhance your productivity!
Syncfusion has over 1,600 components and frameworks for [.NET MAUI(Preview)](https://www.syncfusion.com/maui-controls "Link to .NET MAUI UI controls"), [WinForms](https://www.syncfusion.com/winforms-ui-controls "Link to WinForms UI Controls"), [WPF](https://www.syncfusion.com/wpf-ui-controls "Link to WPF UI Controls"), [WinUI](https://www.syncfusion.com/winui-controls "Link to WinUI Controls"), ASP.NET ([Web Forms](https://www.syncfusion.com/jquery/aspnet-web-forms-ui-controls "Link to ASP.NET Web Forms UI Controls"), [MVC](https://www.syncfusion.com/aspnet-mvc-ui-controls "Link to ASP.NET MVC UI Controls"), [Core](https://www.syncfusion.com/aspnet-core-ui-controls "Link to ASP.NET Core UI Controls")), [UWP](https://www.syncfusion.com/uwp-ui-controls "Link to UWP UI Controls"), [Xamarin](https://www.syncfusion.com/xamarin-ui-controls/ "Link to Xamarin UI Controls"), [Flutter](https://www.syncfusion.com/flutter-widgets "Link to Flutter UI Controls"), [JavaScript](https://www.syncfusion.com/javascript-ui-controls "Link to JavaScript UI Controls"), [Angular](https://www.syncfusion.com/angular-ui-components "Link to Angular UI Controls"), [Blazor](https://www.syncfusion.com/blazor-components "Link to Blazor UI Controls"), [Vue](https://www.syncfusion.com/vue-ui-components "Link to Vue UI Controls"), and [React](https://www.syncfusion.com/react-ui-components "Link to React UI Controls"). Use them to boost your application development speed.
If you have any concerns or need any clarification, please mention them in the comments section below. You can also reach us through our [support forums](https://www.syncfusion.com/forums "Link to the Syncfusion support forum"), [Direct-Trac](https://www.syncfusion.com/support/directtrac/ "Link to the Syncfusion support system Direct Trac"), or [feedback portal](https://www.syncfusion.com/feedback/ "Link to Syncfusion Feedback Portal").
## Related blogs
- [Add, Remove, Extract, and Replace Images in PDF using C#](https://dev.to/syncfusion/add-remove-extract-and-replace-images-in-pdf-using-c-480i "Link to Add, Remove, Extract, and Replace Images in PDF using C# blog")
- [4 Features Every Developer Must Know in C# 9.0](https://dev.to/karthickramasamy08/4-features-every-developer-must-know-in-c-9-0-5bpe-temp-slug-9388860 "Link to 4 Features Every Developer Must Know in C# 9.0 blog")
- [Understanding C# Anonymous Types](https://dev.to/karthickramasamy08/understanding-c-anonymous-types-2c66-temp-slug-4931589 "Link to Understanding C# Anonymous Types blog")
- [Create ZUGFeRD-Compliant PDF Invoice in C#](https://www.syncfusion.com/blogs/post/create-zugferd-compliant-pdf-invoices-in-c.aspx "Link to Create ZUGFeRD-Compliant PDF Invoice in C# blog") | sureshmohan |
878,223 | Middleware in NextJS 12 - What are they and how to get started with them | Yesterday, we had the NextJS Conf and we got a lot of new things. NextJS 12 has been released and it... | 0 | 2021-10-27T11:32:00 | https://blog.anishde.dev/middleware-in-nextjs-12-what-are-they-and-how-to-get-started-with-them | nextjs | Yesterday, we had the [NextJS Conf](https://nextjs.org/conf) and we got a lot of new things. [NextJS 12](https://nextjs.org/blog/next-12) has been released and it has got a ton of new and exciting features. One of these features is [middleware in NextJS](https://nextjs.org/docs/middleware) so let us see how it works with an example.
# What is NextJS Middleware?
Middleware are simple pieces of code that allows one to modify the response to a request even before it is completed. We can rewrite, redirect, add headers or even stream HTML based on the user's request.
> This definition is from the [NextJS Middleware Docs](https://nextjs.org/docs/middleware)
# Getting Started with NextJS 12
I am going to do everything in [Replit](https://replit.com/) for this example. You can also follow along with me on this tutorial.
The Repl - https://replit.com/@AnishDe12020/NextJS-12-Middleware
Creating a NextJS project with `create-next-app` will give us a project with NextJS 11 set up (as of 27th October 2021) so, firstly, we need to upgrade to NextJS 12.
With NPM -
```
npm install next@latest
```
With Yarn -
```
yarn add next@latest
```
## A simple middleware
Now, to add middleware, we need to make a `_middleware.js` file in our pages directory. Note that you can also add middleware files in sub-directories in the pages directory to make it run after the top-level middleware file. You can refer to the [NextJS Middleware Execution Order Documentation](https://nextjs.org/docs/middleware#execution-order) for more information.
Now let us write a simple middleware function -
```js
const middleware = (req, ev) => {
return new Response(req.ua.os.name);
};
export default middleware;
```
This will show the operating system of the user on the page. We were streaming HTML to the user but now let us see how we can rewrite routes under the hood.
## A middleware that rewrites the route under the hood
First, we will create a new file called `[os].js` and copy in the `index.js` code into there, just replacing the function name.
`[os].js` -
```js
import Head from 'next/head'
import Image from 'next/image'
import styles from '../styles/Home.module.css'
export default function Home() {
return (
<div className={styles.container}>
<Head>
<title>Create Next App</title>
<meta name="description" content="Generated by create next app" />
<link rel="icon" href="/favicon.ico" />
</Head>
<main className={styles.main}>
<h1 className={styles.title}>
Welcome to <a href="https://nextjs.org">Next.js!</a>
</h1>
</main>
<footer className={styles.footer}>
<a
href="https://vercel.com?utm_source=create-next-app&utm_medium=default-template&utm_campaign=create-next-app"
target="_blank"
rel="noopener noreferrer"
>
Powered by Vercel
and Replit
</a>
</footer>
</div>
)
}
```
Now let us go back to our `_middleware.js` file and make some changes. First we will import `NextResponse`
```js
import {NextResponse} from "next/server"
```
Now, let us store the user's operating system in a variable
```js
const os = req.ua.os.name
```
Now, we can rewrite the URL to the new route we created and that is where `NextResponse` comes in.
```js
return NextResponse.rewrite(`/${os}`) // This return is necessary
```
This is how out `_middleware.js` files should look now -
```js
import {NextResponse} from "next/server"
const middleware = (req, ev) => {
const os = req.ua.os.name
return NextResponse.rewrite(`/${os}`)
};
export default middleware;
```
Now let us import Next Router in our new route
```js
import {useRouter} from "next/router"
```
As this is a react hook, we need to create a new instance of the NextJS router inside of the function being returned.
```js
const router = useRouter()
```
We can get the operating system of the user from the URL parameter we rewrote earlier in the middleware
```js
const os = router.query.os
```
At last, let us show the user what operating system they are using
```js
<h1 className={styles.title}>
You are using the {os} operating system
</h1>
```
At last this is how are `[os].js` should look like -
```js
import Head from 'next/head'
import Image from 'next/image'
import styles from '../styles/Home.module.css'
import {useRouter} from "next/router"
export default function Os() {
const router = useRouter()
const os = router.query.os
return (
<div className={styles.container}>
<Head>
<title>Create Next App</title>
<meta name="description" content="Generated by create next app" />
<link rel="icon" href="/favicon.ico" />
</Head>
<main className={styles.main}>
<h1 className={styles.title}>
You are using the {os} operating system
</h1>
</main>
<footer className={styles.footer}>
<a
href="https://vercel.com?utm_source=create-next-app&utm_medium=default-template&utm_campaign=create-next-app"
target="_blank"
rel="noopener noreferrer"
>
Powered by Vercel
and Replit
</a>
</footer>
</div>
)
}
```
Now if we visit the home page, we should see this (note that I had removed some of the nextjs boilerplate code) -
I can emulate the browser user agent using the browser dev tools and we get a different result for the operating system -
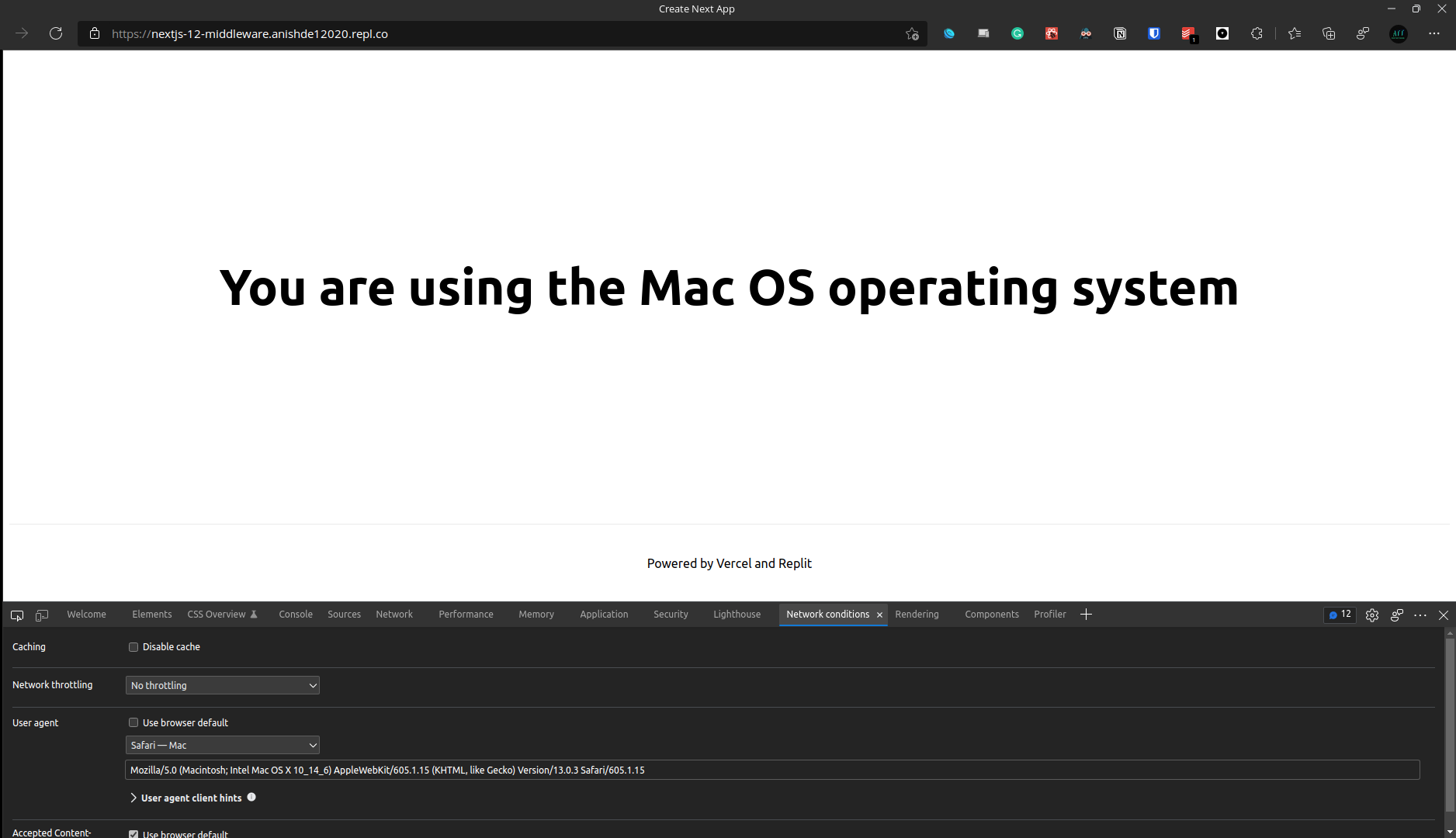
Now, note that the URL is `https://nextjs-12-middleware.anishde12020.repl.co/` and not `https://nextjs-12-middleware.anishde12020.repl.co/Linux` or `https://nextjs-12-middleware.anishde12020.repl.co/Mac Os`. This is because, we are re-writing the request in the middleware and hence there is no change on the client side.
## How does NextJS middleware work under the hood?
NextJS middleware make use of [Vercel's Edge Functions](https://vercel.com/features/edge-functions) which run on the [V8 Engine](https://v8.dev/). The V8 Engine is a javascript engine written in C++ and is maintained by Google. It is considerably faster than running NodeJS on a virtual machine or a container and Vercel claims these edge functions to be instantaneous.
### Limitations of edge functions
Some NodeJS APIs are not available with middleware (as they are edge functions) such as the filesystem API. Also, some NodeJS modules won't work as only modules which have implemented ES Modules and do not use any native NodeJS APIs are allowed. For more information, see [here](https://nextjs.org/docs/api-reference/edge-runtime)
# Wrapping Up
So far, we have seen the power of middleware and how this is going to be a huge feature for developers. Things like serving localized sites, providing region-based discounts, authentication, bot detection and much more can be done quickly and easily by using middleware.
The team at Vercel has also put together many examples using middleware. Check them out [here](https://vercel.com/features/edge-functions#examples)
That is it for this post, feel free to leave down a comment below and you can also reach out to me on [Twitter](https://twitter.com/AnishDe12020)
| anishde12020 |
878,229 | Where should i start from? | {Use the questions/pointers below to guide your post — don't forget to delete the placeholder... | 0 | 2021-10-27T11:36:24 | https://dev.to/deathrangerr/where-should-i-start-from-16l1 | help | {Use the questions/pointers below to guide your post — don't forget to delete the placeholder text!}
What is your question/issue (provide as much detail as possible)?
Hi Everyone, I love opensource community and tools, but keeping that aside i have no idea where to start or what should i do to become a member of opensource community, same goes with github hacktoberfest
What technologies are you using?
I have been working on deployments for devops projects
What were you expecting to happen?
Just want to be a member of opensource community as an regular contributor
What is actually happening?
I just look around people who are same as me are doing alot out there
What have you already tried/thought about?
I have thought about contributing to some opensource projects but i get stuck, like what should i do..
Please try to avoid very broad "How do I make x" questions, unless you have used Google and there are no tutorials on the subject.
#help #hacktoberfest | deathrangerr |
878,269 | 5 Useful Non Technical Skills when you Hire iPhone App Developers | If you wish to hire iPhone apps programmer for your mobile app, you must seek these nontechnical... | 0 | 2021-10-27T11:59:02 | https://dev.to/technobyt/5-useful-non-technical-skills-when-you-hire-iphone-app-developers-3c9e | <div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p style="text-align: justify;">If you wish to hire iPhone apps programmer for your mobile app, you must seek these nontechnical skills in your developers.</p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><strong>Java & Other Coding methodology</strong></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p>Java & Other Coding methodology is a project management technique which involves self-organizing and crosses-functional teams. It’s an iPhone app development life-cycle model which is a combination of iterative and incremental process centered on customer satisfaction. Java development requires continuous interaction and feedback from the customer. An iPhone app developer must have experience of working in a Java development environment to be able effectively to cater to the requirements of the client.</p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><strong>Communication</strong></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p>A good iPhone app developer must have good verbal and written communication skills. It’s important for an iPhone developer to communicate the understanding, challenges and approach related to the project internally as well as with the client. It becomes all the more important for the iPhone app developer to prepare technical documentation for nontechnical co-workers and clients.</p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><strong>Collaboration</strong></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p>An iPhone app developer must be a team player to synergize working in a collaborative environment. An iPhone app developer will have to cooperate and coordinate with other developers as well as designers. Being a team player aids the swift and effective development of the project. An iPhone app development team player will help and motivate other team members to perform at the benchmark levels.</p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><strong>Business Knowledge</strong></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p>An iPhone App developer must have sound knowledge of the iPhone app development business environment of the industry for which the app is developed. If an app is being developed for the hospitality industry and the iPhone app developer is unaware of the fact that the industry demands premium customer experience, he would not be able to cater to the needs of iPhone mobile app users. Having updated information on the business aspects of a mobile app will help an iPhone app developer to consult the customer on which features to include in the app for a sustainable revenue stream.</p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><strong>Passion</strong></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p>Passion towards work motivates the iPhone app developer to go the extra mile for customer satisfaction. A passionate individual would take ownership of the work and perform at exceeding expectation level. Passion is the key differentiator between just another iPhone app developer and an exception iPhone app Programmer.</p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><strong>Positive about </strong><a href="https://www.prnewswire.com/news-releases/oem-controls-harnesses-the-power-of-iot-for-their-data-delivery-devices-by-partnering-with-hokuapps-to-automate-fuel-consumption-tracking-and-improve-roi-for-their-customers-301341179.html" target="_blank"><strong>HokuAPPS</strong></a></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><a href="https://www.prnewswire.com/news-releases/hokuapps---the-engine-for-roofing-southwests-growth-to-us-national-prominence-301189609.html" target="_blank">HokuApps</a>is the fastest growing rapid application development platform that empowers organizations to develop innovative technology solutions incredibly fast. Our <a href="https://www.hokuapps.com/products/rapid-application-development-platform/" target="_blank">rapid application development platform</a> has enhanced mobile and data integration capabilities to enable companies to speedily deploy mobile and web applications. We empower organizations to usher in their digital transformation journey to better engage with customers, partners, and employees.</p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><strong>Few More Success Stories about HokuApps:</strong></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><a href="https://markets.businessinsider.com/news/stocks/hokuapps-facilitates-c2c-selling-as-a-new-retail-avenue-for-de-longhi-group-1029794089" target="_blank">HokuApps Facilitates C2C Selling as a New Retail Avenue for De'Longhi Group</a></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><a href="https://apnews.com/press-release/marketers-media/virus-outbreak-business-technology-media-asia-edb10f1a116c6b31c26525602890ef94" target="_blank">HokuApps Creates an Effective Solution for The Severely Hit Events Business During the Pandemic</a></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section" style="text-align: justify;">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p><a href="https://finance.yahoo.com/news/hokuapps-creates-engaging-platform-sdi-010000612.html?guccounter=1&guce_referrer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS8&guce_referrer_sig=AQAAAMUo7Fz3A9kPhGcLY0sRR08tUsTqs_8Hf9_sed9jGF2--FoZ7k87CY_tZfb5Hq4HgAZJs8IDSG_Kl7tcMvgGcSJyueoN1yf4AKyruvTvtjPJHMEF8OOa9I2T0C7c4GuVp1CT8uPtVGRJfG4nGXsLJOTWah8c3BUwXDpL1JlP5v4Q" target="_blank">HokuApps Creates Engaging Platform for SDI Academy Helping Migrants to Cope with the COVID-19 Induced Isolation</a></p>
</div>
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div class="s-component-content s-font-body">
<p style="text-align: justify;"><a href="https://www.accesswire.com/611718/HokuApps-Digitalizes-Mentoring-Framework-for-Early-Childhood-Educators-at-Busy-Bees" target="_blank">HokuApps Digitalizes Mentoring Framework for Early Childhood Educators at Busy Bees</a></p>
</div> | technobyt | |
878,310 | Intigriti 1021 - XSS Challenge Writeup | Halloween came with an awesome XSS Challenge by Intigriti, and I'm here to present the solution I... | 0 | 2021-11-01T12:35:16 | https://dev.to/therealbrenu/intigriti-1021-xss-challenge-writeup-253m | security, progamming, javascript, ctf | Halloween came with an awesome XSS Challenge by Intigriti, and I'm here to present the solution I found for this. Hope you like it :bat:
## :detective: In-Depth Analysis
Reading the content of the page, at the first glance, it tells us that there is a query parameter called `html`, which is capable of define partially what's displayed to the user. When we define, for example, a ``<h1>`` tag to this parameter, we are going to get returned a page with this tag being reflected, which is already an HTML injection. From now on, we will be working to make it become an XSS.

### :see_no_evil: Oops, CSP
If we simply try to inject something like `<script>alert(document.domain);</script>`, this script tag will be reflected, but the code itself will not be executed. Why? Well, if we look at the head of the page, we are going to find something interesting:
```<meta http-equiv="Content-Security-Policy" content="default-src 'none'; script-src 'unsafe-eval' 'strict-dynamic' 'nonce-random'; style-src 'nonce-random'">```
This meta tag tells us that the page has a CSP, which will not let any random script be executed. Also, it's possible to see, from the script-src policies, that 'strict-dynamic' was defined, which means that generally a script will only be trusted if it comes with a trusted one-use token (nonce).
But there is an exception to the strict-dynamic rule. It allows JavaScript code to be executed if it's being created by using the function `document.createElement("script")`, and by the way, if we look a little bit further at the page source, we are going to find this section of code:
### :construction: Managing to work with the DOM
When we don't pay enough attention to the code, we might think that it's just needed to insert something like `alert(document.domain)` to the `xss` parameter on the URL, but if you do so, you won't get any alert popping out, because what's truthfully being inserted to the script tag is: `)]}'alert(document.domain)`. Something like that will never be executed, because it returns an error from JavaScript right on the first character.
Paying a little bit more attention to the previous section of code, this specific piece is important:

Now, we know that we have to create a tag with an id "intigriti", and also that this tag needs to, somehow, unbreak the `)]}'` that we have seen. The second part its actually pretty easy to think of, because it ends with a simple quotation mark, and if we open it before, every other character will be considered part of the string, so the solution for this would be something like `a='`, but we have to apply this on the context of an HTML tag, resulting in `<div><diva='>`. Remember that Intigriti Jr's INTERNAL HTML is what is parsed, and not the element itself, that's the reason for the external div.
The other part is the one who takes more effort. If we simply try to add `<div id="intigriti"><div><diva='></diva='></div></div>` to the `html` parameter, as you can see on the picture below, we will have these tags inside of the DOM but inside `<div>` and `<h1>` tags, and waaaay too far from being the last element of the body, which is what is want:
So, in order to trigger an alert, we have to figure out a way of go outside this `<div><h1></h1></div>` pair and a way of making the next divs fit inside our payload `<div id="intigriti"><div><diva='></diva='></div></div>`. One possibility is to trick the browser by inserting unopened/unclosed tags, so it tries and fails to fix it.
### :checkered_flag: Getting there
For getting outside of the `<div><h1></h1></div>` pair, all we have to do is insert `</h1></div>` before our friends `<div id="intigriti">`, `<div>` and `<diva='>`, resulting in:

Now we have to make everything that originally goes next `</h1></div><div id="intigriti"><div><diva='></diva='></div></div>`, fit inside our structure so it becomes the last element of the body. Just by leaving the DIVs unclosed, like `</h1></div><div id="intigriti"><div><diva='>`, we will have as result that all the divs that goes after our payload instantly fit inside `<div id="intigriti">`, which is great but not our final goal.
Finally, by adding a `<div>` tag and leaving it unclosed at the end of our payload, everything will fit inside our `<diva='></diva='>` tags, and also, if we look at the generated script tag, we will find something REALLY insteresting:
`<script type="text/javascript">a= '>)]}' null</script>`
This means that all the weird characters were turned into a string called "a", and we just have to insert our alert onto the `xss` parameter. This would result on the final payload:
``https://challenge-1021.intigriti.io/challenge/challenge.php?html=</h1></div><div id=intigriti><div><diva='><div>&xss=;alert(document.domain)``
And from this payload right down below, I was able to trick our fictional villain 1337Witch69 :hugs:
[Happy Ending](https://challenge-1021.intigriti.io/challenge/challenge.php?html=%3C/h1%3E%3C/div%3E%3Cdiv%20id=intigriti%3E%3Cdiv%3E%3Cdiva=%27%3E%3Cdiv%3E&xss=%3Bwindow.top.history.pushState%28%27%27%2C%27%27%2C%27%2Fhappy-ending%27%29%3Bdocument.body.style.backgroundColor%3D%60%234C59A8%60%3Bdocument.body.innerHTML%3D%60%3Ch1%20id%3D%22title%22%3EHappy%20Ending%3Cbr%2F%3E%3Cbr%2F%3E%F0%9F%A4%8D%3C%2Fh1%3E%60%3Bdocument.getElementById%28%22title%22%29.style.color%3D%60%23FFFFFF%60%3Bdocument.getElementById%28%22title%22%29.style.textShadow%20%3D%20%222px%202px%202px%20rgba%280%2C0%2C0%2C0.2%29%22%3B)
### Thank you for taking your time :hugs: | therealbrenu |
878,328 | Use pipeline instead of pipe | Stream data is very common in Nodejs. There is a module called Stream which provides an API for... | 0 | 2021-10-27T13:57:21 | https://dev.to/yenyih/use-pipeline-instead-of-pipe-4gl3 | node, javascript, programming | Stream data is very common in Nodejs. There is a module called [Stream](https://nodejs.org/api/stream.html#stream_stream) which provides an API for implementing the stream interface. Streams make for quite a handy abstraction, and there's a lot you can do with them - as an example, let's take a look at **_stream.pipe()_**, the method used to take a readable stream and connect it to a writeable stream.
A very common use for **_stream.pipe()_** is file stream.
```
const fs = require("fs");
let readStream = fs.createReadStream("./myDataInput.txt");
let writeStream = fs.createWriteStream("./myDataOutput.txt");
readStream.pipe(writeStream);
```
Above is a simple example shows that we use **_pipe_** to transfer the data from the read stream to the write stream.
However there is a problem when using the standard source.pipe(destination). Source will not be destroyed if the destination emits close or an error. You are not able to provide a callback to tell when then pipe has finished.
To solve this problem, we can use **pipeline** which introduced in Nodejs 10.x or later version. If you are using Nodejs 8.x or earlier, you can use [pump](https://github.com/mafintosh/pump).
```
const { pipeline } = require('stream');
let readStream = fs.createReadStream("./myDataInput.txt");
let writeStream = fs.createWriteStream("./myDataOutput.txt");
pipeline(readStream, writeStream, error => {
if (error) {
console.error(error);
} else {
console.info("Pipeline Successful")
}
});
```

---
##That's it~🎉
##Thank you for reading
you may also read [Backpressuring in Streams](https://nodejs.org/en/docs/guides/backpressuring-in-streams/) which explains more detail on why you should use pipeline. | yenyih |
878,331 | How to make a Tik Tak Toe Game (With Html, Css And Js) | Hello, readers welcome to my new blog and today I am going to tell you how to make a Tic Tac Toe game... | 0 | 2021-10-29T08:24:54 | https://dev.to/codeflix/how-to-make-a-tik-tak-toe-game-with-html-css-and-js-2972 | javascript, programming, tutorial, beginners | Hello, readers welcome to my new blog and today I am going to tell you how to make a Tic Tac Toe game in Html, Css and Javascript .
As you know that Tic tac toe is a multiplayer game and the players of this game have to position their marks(sign) so that they can construct a continuous line of three cells or boxes vertically, horizontally, or diagonally. An opponent can stop a win by blocking the end of the opponent’s line.
In our program or design [Tic Tac Toe Game], at first, on the webpage, there is a selection box with the game title and two buttons which are labeled as “Player(X)” and “Player(O)”. Users must select one option or button to continue the game. If the user selects the X then the bot will be O and if the user selects the O then the bot will be X.
Once the user selects one of them, the selection box will disappear and the playboard is visible. There are the player names at the top in the playboard section and it indicates or shows whose turn is now. At the center of the webpage, there is a tic tac toe play area with nine square boxes. Once you click on the particular box then there is visible a sign or icon which you have chosen on the selection box.
Once you click on any box then after a couple of seconds the bot will automatically select the box which is not selected by you or the bot before, and the opposite icon is visible there means if your icon is X then the bot will have O. Once a match is won by someone, the playboard section will be hidden and the result box appears with the winner sign or icon and a replay button.
If no one wins the match and all nine-box selected then again the playboard section is hidden and the result box appears with “Match has been drawn text” and a replay button. Once you click on the replay button, the current page reloads and you can play again.
###How To Make it A Search Box In Vanilla Javascript YouTube Preview
[####Preivew](https://youtu.be/GnJcV6t2jTg)
###How To Make it A Search Box In Vanilla Javascript Code On YouTube
####Now let's not waste anymore time and get started.
##Html
As you know The HyperText Markup Language, or HTML is the standard markup language for documents designed to be displayed in a web browser. It can be assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.
Web browsers receive HTML documents from a web server or from local storage and render the documents into multimedia web pages. HTML describes the structure of a web page semantically and originally included cues for the appearance of the document.
HTML elements are the building blocks of HTML pages. With HTML constructs, images and other objects such as interactive forms may be embedded into the rendered page. HTML provides a means to create structured documents by denoting structural semantics for text such as headings, paragraphs, lists, links, quotes and other items. HTML elements are delineated by tags, written using angle brackets. Tags such asand directly introduce content into the page. Other tags such as
surround and provide information about document text and may include other tags as sub-elements. Browsers do not display the HTML tags, but use them to interpret the content of the page.
##Source Code
The source code is given below please read and do it carefully any
mistake can generate wrong results.
##Step 1
Make a file named index.html and write the following code.
Basic code with link to css.
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Tic Tac Toe Game | Codeflix</title>
<link rel="stylesheet" href="style.css">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css"/>
</head>
<body>
```
##Step 2
This is the front page's html.
```
<!-- select box -->
<div class="select-box">
<header>Tic Tac Toe</header>
<div class="content">
<div class="title">Select which you want to be?</div>
<div class="options">
<button class="playerX">Player (X)</button>
<button class="playerO">Player (O)</button>
</div>
<div class="credit">Created By <a href="https://dev.to/codeflix/how-to-make-a-glassorphism-calculator-dhk" target="_blank">Codeflix</a></div>
</div>
</div>
```
##Step 3
Code to tell which player's chance it is.
```
<!-- playboard section -->
<div class="play-board">
<div class="details">
<div class="players">
<span class="Xturn">X's Turn</span>
<span class="Oturn">O's Turn</span>
<div class="slider"></div>
</div>
</div>
```
##Step 4
Code for playing area.
```
<div class="play-area">
<section>
<span class="box1"></span>
<span class="box2"></span>
<span class="box3"></span>
</section>
<section>
<span class="box4"></span>
<span class="box5"></span>
<span class="box6"></span>
</section>
<section>
<span class="box7"></span>
<span class="box8"></span>
<span class="box9"></span>
</section>
</div>
</div>
```
##Step 5
Replay button and link to javascript file.
```
<!-- result box -->
<div class="result-box">
<div class="won-text"></div>
<div class="btn"><button>Replay</button></div>
</div>
<script src="script.js"></script>
</body>
</html>
```
##Css
CSS is designed to enable the separation of presentation and content, including layout, colors, and fonts. This separation can improve content accessibility, provide more flexibility and control in the specification of presentation characteristics, enable multiple web pages to share formatting by specifying the relevant CSS in a separate .css file which reduces complexity and repetition in the structural content as well as enabling the .css file to be cached to improve the page load speed between the pages that share the file and its formatting.
Separation of formatting and content also makes it feasible to present the same markup page in different styles for different rendering methods, such as on-screen, in print, by voice (via speech-based browser or screen reader), and on Braille-based tactile devices. CSS also has rules for alternate formatting if
the content is accessed on a mobile device.
## Css Source Code
##Step 1
Make a css file named style.css
This code represents selection, body, about box, header, title, button and player's css code.
```
@import url('https://fonts.googleapis.com/css2?family=Poppins:wght@200;300;400;500;600;700&display=swap');
*{
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Poppins', sans-serif;
}
::selection{
color: #fff;
background:#56baed;
}
body{
background:#56baed;
}
.select-box, .play-board, .result-box{
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
transition: all 0.3s ease;
}
.select-box{
background: #fff;
padding: 20px 25px 25px;
border-radius: 5px;
max-width: 400px;
width: 100%;
}
.select-box.hide{
opacity: 0;
pointer-events: none;
}
.select-box header{
font-size: 30px;
font-weight: 600;
padding-bottom: 10px;
border-bottom: 1px solid lightgrey;
}
.select-box .title{
font-size: 22px;
font-weight: 500;
margin: 20px 0;
}
.select-box .options{
display: flex;
width: 100%;
}
.options button{
width: 100%;
font-size: 20px;
font-weight: 500;
padding: 10px 0;
border: none;
background: #56baed;
border-radius: 5px;
color: #fff;
outline: none;
cursor: pointer;
transition: all 0.3s ease;
}
.options button:hover,
.btn button:hover{
transform: scale(0.96);
}
.options button.playerX{
margin-right: 5px;
}
.options button.playerO{
margin-left: 5px;
}
```
##Step 2
This code represents animation, credit ,details , players , victory text.
```
.select-box .credit{
text-align: center;
margin-top: 20px;
font-size: 18px;
font-weight: 500;
}
.select-box .credit a{
color: #56baed;
text-decoration: none;
}
.select-box .credit a:hover{
text-decoration: underline;
}
.play-board{
opacity: 0;
pointer-events: none;
transform: translate(-50%, -50%) scale(0.9);
}
.play-board.show{
opacity: 1;
pointer-events: auto;
transform: translate(-50%, -50%) scale(1);
}
.play-board .details{
padding: 7px;
border-radius: 5px;
background: #fff;
}
.play-board .players{
width: 100%;
display: flex;
position: relative;
justify-content: space-between;
}
.players span{
position: relative;
z-index: 2;
color: #56baed;
font-size: 20px;
font-weight: 500;
padding: 10px 0;
width: 100%;
text-align: center;
cursor: default;
user-select: none;
transition: all 0.3 ease;
}
.players.active span:first-child{
color: #fff;
}
.players.active span:last-child{
color: #56baed;
}
.players span:first-child{
color: #fff;
}
.players .slider{
position: absolute;
top: 0;
left: 0;
width: 50%;
height: 100%;
background: #56baed;
border-radius: 5px;
transition: all 0.3s ease;
}
.players.active .slider{
left: 50%;
}
.players.active span:first-child{
color: #56baed;
}
.players.active span:nth-child(2){
color: #fff;
}
.players.active .slider{
left: 50%;
}
.play-area{
margin-top: 20px;
}
.play-area section{
display: flex;
margin-bottom: 1px;
}
.play-area section span{
display: block;
height: 90px;
width: 90px;
margin: 2px;
color: #56baed;
font-size: 40px;
line-height: 80px;
text-align: center;
border-radius: 5px;
background: #fff;
}
.result-box{
padding: 25px 20px;
border-radius: 5px;
max-width: 400px;
width: 100%;
opacity: 0;
text-align: center;
background: #fff;
pointer-events: none;
transform: translate(-50%, -50%) scale(0.9);
}
.result-box.show{
opacity: 1;
pointer-events: auto;
transform: translate(-50%, -50%) scale(1);
}
.result-box .won-text{
font-size: 30px;
font-weight: 500;
display: flex;
justify-content: center;
}
.result-box .won-text p{
font-weight: 600;
margin: 0 5px;
}
.result-box .btn{
width: 100%;
margin-top: 25px;
display: flex;
justify-content: center;
}
.btn button{
font-size: 18px;
font-weight: 500;
padding: 8px 20px;
border: none;
background: #56baed;
border-radius: 5px;
color: #fff;
outline: none;
cursor: pointer;
transition: all 0.3s ease;
}
```
##JavaScript
JavaScript , often abbreviated as JS, is a programming language that conforms to the ECMAScript specification. JavaScript is high-level, often just-in-time compiled and multi-paradigm. It has curly-bracket syntax, dynamic typing, prototype-based object-orientation and first-class functions.
Alongside HTML and CSS, JavaScript is one of the core technologies of the World Wide Web. Over 97% of websites use it client-side for web page behavior, often incorporating third-party libraries.Most web browsers have a dedicated JavaScript engine to execute the code on the user's device.
As a multi-paradigm language, JavaScript supports event-driven, functional, and imperative programming styles. It has application programming interfaces (APIs) for working with text, dates, regular expressions, standard data structures, and the Document Object Model (DOM).
The ECMAScript standard does not include any input/output (I/O), such as networking, storage, or graphics facilities. In practice, the web browser or other runtime system provides JavaScript APIs for I/O. JavaScript engines were originally used only in web browsers, but they are now core components of other software systems, most notably servers and a variety of applications.
Although there are similarities between JavaScript and Java, including language name, syntax, and respective standard libraries, the two languages are distinct and differ greatly in
design.
## JavaScript Source Code
Firstly make a file named script.js.
##Source Code
I've tried to explain each JavaScript line....Hope you'll understand
##Step 1
Code of all required elements Such as:- Player, Win-Text , Result-Box, Buttons ect
```
const selectBox = document.querySelector(".select-box"),
selectBtnX = selectBox.querySelector(".options .playerX"),
selectBtnO = selectBox.querySelector(".options .playerO"),
playBoard = document.querySelector(".play-board"),
players = document.querySelector(".players"),
allBox = document.querySelectorAll("section span"),
resultBox = document.querySelector(".result-box"),
wonText = resultBox.querySelector(".won-text"),
replayBtn = resultBox.querySelector("button");
```
##Step 2
This code means once window loaded and the player selected his/her team then hide select team box and show the playboard section
```
window.onload = ()=>{
for (let i = 0; i < allBox.length; i++) {
allBox[i].setAttribute("onclick", "clickedBox(this)");
}
}
selectBtnX.onclick = ()=>{
selectBox.classList.add("hide");
playBoard.classList.add("show");
}
```
##Step 3
The first line of code tells the computer the icon playerX
(fas fa-times is the class named fountausome cross icon)
and the second line represents the icon of PlayerO
(far fa-circle is the class name fountausome circle icon)
#####let playerSign = "X";
this is a global variable beacuse we've used this variable inside multiple functions
#####let runBot = true;
this also a global variable with boolen value..we used this variable to stop the bot once match won by someone or drawn
```
let playerXIcon = "fas fa-times";
let playerOIcon = "far fa-circle";
let playerSign = "X";
let runBot = true;
```
##Step 4
This tells the computer that if player choose O then change playerSign to O in the next line we are adding circle icon tag inside user clicked element/box.
In seventh line of code we have added active class in players.
In tenth line of code we have are
adding cross icon tag inside user clicked element/box.Last line of code we have added active class in player.
```
function clickedBox(element){
if(players.classList.contains("player")){
playerSign = "O";
element.innerHTML = `<i class="${playerOIcon}"></i>`;
players.classList.remove("active");
element.setAttribute("id", playerSign);
}else{
element.innerHTML = `<i class="${playerXIcon}"></i>`;
element.setAttribute("id", playerSign);
players.classList.add("active");
}
```
##Step 5
The fist line of code tells the computer that once user have selected any box then that box can'be clicked again. Forth line of code tells the computer that add pointerEvents none to playboard so user can't immediately click on any other box until bot select.
The eigth line of code tells the computer that generating random number so bot will randomly delay to select unselected box.
###Tip- There are some comments pasting with the comments won't generate wrong results.
```
selectWinner( );
element.style.pointerEvents = "none";
playBoard.style.pointerEvents = "none";
let randomTimeDelay = ((Math.random() * 1000) + 200).toFixed();
setTimeout(()=>{
bot(runBot);
}, randomTimeDelay); //passing random delay value
}
// bot auto select function
function bot(){
let array = []; //creating empty array...we'll store unclicked boxes index
if(runBot){ //if runBot is true
playerSign = "O"; //change the playerSign to O so if player has chosen X then bot will O
for (let i = 0; i < allBox.length; i++) {
if(allBox[i].childElementCount == 0){ //if the box/span has no children means <i> tag
array.push(i); //inserting unclicked boxes number/index inside array
}
}
```
##Step 6
The firt line of code tells the computer that getting random index from array ,so bot will select random unselected box.
The forth line of code tells the computer that if player has chosen O then bot will X. In the fifth and sixth line we are adding cross icon tag inside bot selected element. In the line-no 21 we have added pointerEvents auto in playboard so user can again click on box.
playerSign = "X"; //if player has chosen X then bot will be O right then we change the playerSign again to X so user will X because above we have changed the playerSign to O for bot.
###Tip- There are some comments pasting with the comments won't generate wrong results.
```
let randomBox = array[Math.floor(Math.random() * array.length)];
if(array.length > 0){ //if array length is greater than 0
if(players.classList.contains("player")){
playerSign = "X";
allBox[randomBox].innerHTML = `<i class="${playerXIcon}"></i>`; //adding cross icon tag inside bot selected element
allBox[randomBox].setAttribute("id", playerSign); //set id attribute in span/box with player choosen sign
players.classList.add("active"); //add active class in players
}else{
allBox[randomBox].innerHTML = `<i class="${playerOIcon}"></i>`; //adding circle icon tag inside bot selected element
players.classList.remove("active"); //remove active class in players
allBox[randomBox].setAttribute("id", playerSign); //set id attribute in span/box with player choosen sign
}
selectWinner(); //calling selectWinner function
}
allBox[randomBox].style.pointerEvents = "none"; //once bot select any box then user can't click on that box
playBoard.style.pointerEvents = "auto"; //
}
}
function getIdVal(classname){
return document.querySelector(".box" + classname).id; //return id value
}
function checkIdSign(val1, val2, val3, sign){ //checking all id value is equal to sign (X or O) or not if yes then return true
if(getIdVal(val1) == sign && getIdVal(val2) == sign && getIdVal(val3) == sign){
return true;
}
}
function selectWinner(){ //if the one of following winning combination match then select the winner
if(checkIdSign(1,2,3,playerSign) || checkIdSign(4,5,6, playerSign) || checkIdSign(7,8,9, playerSign) || checkIdSign(1,4,7, playerSign) || checkIdSign(2,5,8, playerSign) || checkIdSign(3,6,9, playerSign) || checkIdSign(1,5,9, playerSign) || checkIdSign(3,5,7, playerSign)){
runBot = false; //passing the false boolen value to runBot so bot won't run again
bot(runBot); //calling bot function
setTimeout(()=>{ //after match won by someone then hide the playboard and show the result box after 700ms
resultBox.classList.add("show");
playBoard.classList.remove("show");
}, 700); //1s = 1000ms
wonText.innerHTML = `Player <p>${playerSign}</p> won the game!`; //displaying winning text with passing playerSign (X or O)
}else{ //if all boxes/element have id value and still no one win then draw the match
if(getIdVal(1) != "" && getIdVal(2) != "" && getIdVal(3) != "" && getIdVal(4) != "" && getIdVal(5) != "" && getIdVal(6) != "" && getIdVal(7) != "" && getIdVal(8) != "" && getIdVal(9) != ""){
runBot = false; //passing the false boolen value to runBot so bot won't run again
bot(runBot); //calling bot function
setTimeout(()=>{ //after match drawn then hide the playboard and show the result box after 700ms
resultBox.classList.add("show");
playBoard.classList.remove("show");
}, 700); //1s = 1000ms
wonText.textContent = "Match has been drawn!"; //displaying draw match text
}
}
}
replayBtn.onclick = ()=>{
window.location.reload(); //reload the current page on replay button click
}
```
####Hi, Everyone hope you have learnt how to make a Tic Tac Toe game in JavaScript and please support me by subscribing my channel codeflix- [Codeflix](https://youtu.be/GnJcV6t2jTg)
Join my classes - Class Code-764co6g Class Link- [Join My Classes](https://classroom.google.com/c/NDE5MDU2MDYzOTcw?cjc=764co6g)
| codeflix |
878,342 | OOPs in JavaScript - Deeper Into Objects & Dunder Proto | In this post, originally published here we shall dive a bit deeper into nature of objects, and cover... | 0 | 2021-10-27T14:18:17 | https://dev.to/vinoo/oops-in-javascript-deeper-into-objects-dunder-proto-53g3 | javascript, webdev, programming | > In this post, originally published [here](https://ivinoop.hashnode.dev/oops-in-javascript-what-is-dunder-proto) we shall dive a bit deeper into nature of objects, and cover the Dunder Proto concept.
> This post is part of the [Advanced JavaScript series](https://ivinoop.hashnode.dev/series/javascript-advanced) where I try to explain essential advanced JS concepts in a simple manner.
### Nature of Objects
Consider the below object -
```js
let details = {
name: 'Richard Hendricks',
company: 'Pied Piper',
};
```
In the above object, if we try to access the property `company`, it is possible since `company` is an existing property of the `details` object.
However, the below snippet would return `undefined` -
```js
console.log(details.designation); //undefined
```
This is because there is no property named `designation` inside `details`. This is exactly how we would expect an object to behave.
However, take a look at the example below -
```js
let arr = [1, 2, 4, 5, 7];
console.log(arr.map( () => 21 );
```
The output would be as below -
But `map()` is not a method inside `arr`. So how is this being computed and where is this coming from?
### Dunder Proto `__proto__`
Inside every object in JavaScript lies a special property called `Dunder Proto`. The name is coined due to the way this object is represented - `__proto__` (accompanied by double underscore on both sides of the word `proto`).
As we can see in the above image, the object `arr` (and basically every object you create in JS), has the `[[Prototype]]:Array` property, inside which lies `__proto__`. If we expand this `[[Prototype]]: Array` property in our example, we should be able to see `__proto__`, which in turn contains a huge list of methods like `every`, `forEach`, `map`, `splice`, etc.
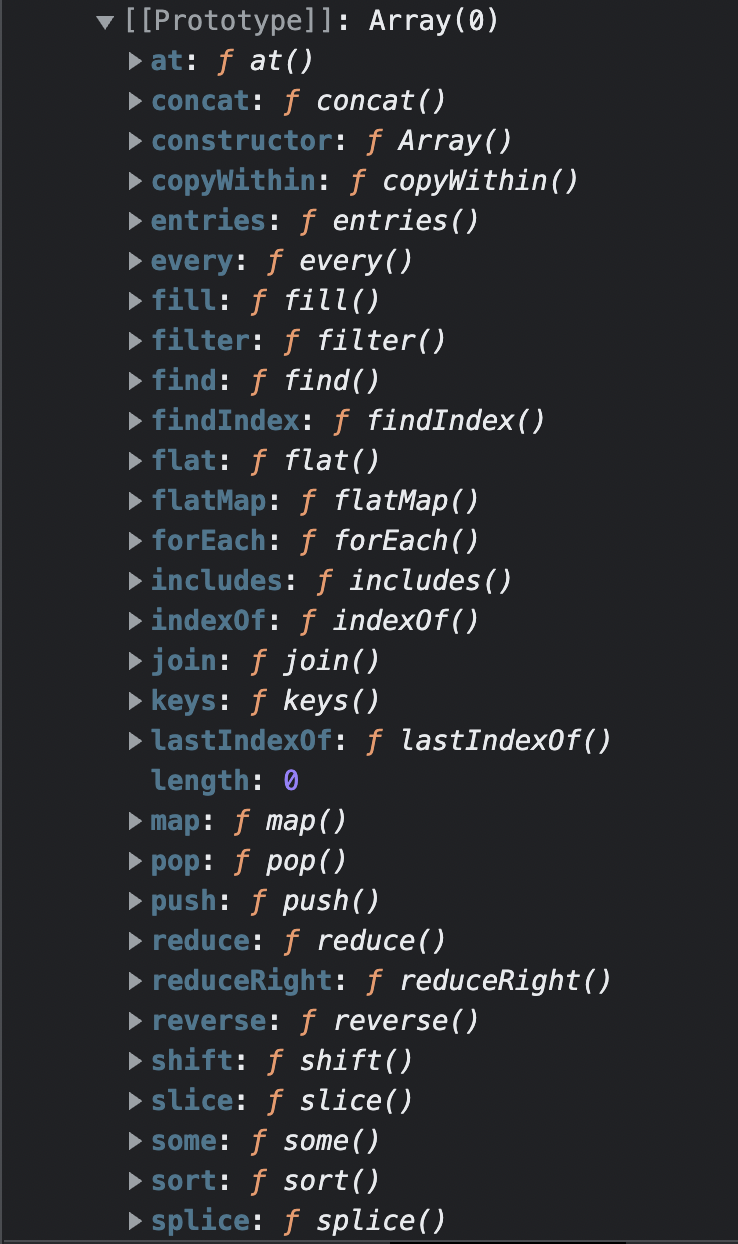
The point to be noted here is that each object we create has a different set of key-value pairs in the `__proto__` property.
Whenever we try to call/access a property that does not exist in the defined object, the JS engine goes down the `__proto__` chain (or a rabbit 🐇 hole), to search for that property. In the above case, we tried to compute the `map()` method on an array (which is an object), and it went down the `__proto__` chain to look for the same.
This is how the hidden nature of object allows for all array, object, and string methods to be carried out.
Since `__proto__` is a special property of an object, it can be accessed as well. Suppose you want to add a new property under `__proto__` to the `details` object above, this is how to do it -
```js
details.__proto__.alertMsg = function () {
alert(`Hello Dunder Proto => __proto__`);
}
```
This function is now added to the `__proto__` property as can be seen below -
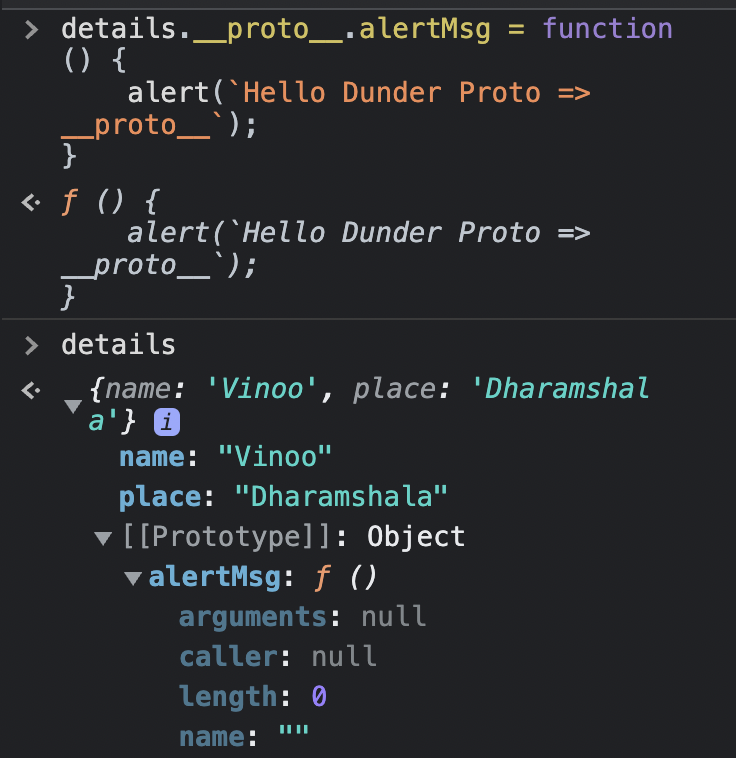
---
We learnt a hidden nature of objects in JavaScript, and the basics of Dunder Proto. In the next post, we shall learn about why and where Dunder Proto can be used to make our code more efficient.
Until next time! 🙌 | vinoo |
878,349 | How to Design and Implement a Top-Notch Test Automation Strategy | Every new software, method, or tool comes with certain growing pains and takes some time to get... | 0 | 2021-10-31T04:30:31 | https://www.katalon.com/resources-center/blog/automation-test-strategy/ | testautomation, automationtesting, testing, automation | ---
title: How to Design and Implement a Top-Notch Test Automation Strategy
published: true
date: 2021-10-27 13:06:22 UTC
tags: TestAutomation, automationtesting, testing, automation
canonical_url: https://www.katalon.com/resources-center/blog/automation-test-strategy/
---

Every new software, method, or tool comes with certain growing pains and takes some time to get used to, although it’s almost always worth the adoption effort, a major part of which is testing.
Test automation dramatically improves your processes, saves you time and resources, and ultimately leads to higher-quality software. But you can’t just jump into it and expect the automation to produce the results you want. You need a clear strategy in place if you want your releases to go smoothly.
This article explains how to design and implement a top-notch test automation strategy so that your testing efforts are fully worth it and your software quality reflects a well-thought-out plan that enables you to fully optimize your product _before_ your customers start to use it.
## **I Don’t Have a Strategy—What Can Go Wrong?**

First off, let’s discuss what happens if you don’t have a test automation strategy. Not having a test automation strategy is something that’s been, er, _tested_ many times already in the real world, so we have a pretty good idea of what happens without test automation strategies in place.
### **1. Inability to show business value**
When teams look to implement a new test automation or other solution, such as performance testing or browser-based testing, quite often they don’t bother to take the time up front to examine the business reasons for doing it. Yes—the tech is cool. Yes—it’s something that will potentially help the business. But if you don’t take time to tie that into real business value, you run the very high risk of the project getting canceled—or not even approved in the first place—for lack of demonstrating ROI or potential ROI.
### **2. Lack of vision**
Without a plan of action, it’s very tough to have a vision. Automation projects tend to pivot. You may need to bring in a new application to automate as part of your framework, or potentially even switch the framework technology itself. If you don’t know what your original vision was, it’s very easy to end up postponing or scrapping the project when faced with a glitch. With a vision, you have a documented way to assess the bigger pivoting questions that come up and act on them accordingly.
### **3. Technology efficiency loss**
Without a clear test automation strategy, you also run the risk of choosing the wrong testing automation technology for your project, in what we call “technology efficiency loss”. Your test automation technology needs to match the application you’re building. If you don’t take the time to write that down and have a strategy around that, you will likely wind up trying to shoehorn technology into a solution for which it shouldn’t be used.
### **4. Being unprepared for the “testing squeeze”**
Agile development processes were supposed to have done away with testing squeezes by now, but we all know that hasn’t happened. Testing squeezes are still very much a reality of software development, and given that they’re still happening, you need a test automation strategy in place to decide on what to cut first. Which scripts should you cut? What was the most important thing to test? What was tied to business value? Without understanding that or having something like that in the strategy, you’re left scrambling to decide what to cut and where to look, and often you will just end up cutting everything—removing it all to worry about it later.
## **What is a Test Automation Strategy?**

Now that you know you need a test automation strategy, let’s define what a test automation strategy actually is.
Simply put, a test automation strategy is a microcosm of your larger testing strategy. A lot of the same techniques you followed to develop and build your overall testing strategy will be the same for your testing automation strategy. Accordingly, your test automation strategy should sit on the same level as your other system and performance testing because you’re using a lot of the same data points to drive toward the answer of what to automate, how to automate it, and which technology makes the most sense to use.
In short, a test automation strategy lives inside your larger testing strategy and uses the same kinds of processes and tools to determine who you’re testing for, what the users do, what the testers do, what the developers are doing, and all of the associated metrics.
## **What’s the Purpose of a Test Automation Strategy?**

You may still be wondering about the true purpose of a test automation strategy. What’s the goal?
First and foremost it’s to **_inform_** on the risk, capabilities, and functionality and arrive at a reliable, repeatable process of informing on those things.
Second, it’s a way to **_communicate_** your goals and plans.
It’s also a _ **discussion** starter_ that can sometimes be a springboard for a new proof-of-concept or a new technology to bring into your company.
Finally, it’s an _ **auditing tool** _ that allows you to go back and look at what you planned to do and compare it against what was actually done.
## **What Does a Test Automation Strategy Look Like?**
Don’t worry about format. It doesn’t need to be a 70-page Word doc. It can be a living document such as a [mind map](https://en.wikipedia.org/wiki/Mind_map). In fact, mind maps work quite well for test automation strategies. You can start with ideas or rough sketches as a way to lead into the bigger test automation strategy document that you build out over time. But again, format should be the least of your concerns.
_( Maybe you want to take the_ [_Tester’s Checklist_](https://www.katalon.com/resources-center/blog/test-automation-best-practices/) _too!)_
## **Steps to Start Creating a Test Automation Strategy**
Now that you understand the value, purpose, and look of a test automation strategy, let’s dive into the actual steps to get started on one.
### **Step 1: Define your high business value tests**
The first step is to define what’s most important to test by defining what we call the “high business value tests” – ie, the flows that could potentially cause the business to fail if they stopped working. Consider [Knight Capital Group](https://en.wikipedia.org/wiki/Knight_Capital_Group), the trading company that went from fully functional to belly up in just 45 minutes and lost $485 million due to the failure of a single software book (ie, a high business value test that wasn’t considered). Be sure to work with your business to understand what your high business value tests are because it will allow you to understand if the solution you’re proposing fits your critical scenarios. It will also help you demonstrate true business value with your automation framework, which will dovetail nicely into the ROI conversations.
### **Step 2: Identify your risk**
A key part of any test automation strategy is knowing what to test first and what to test last. You should use a risk-based approach to determine this testing automation priority. You can determine the risk, or priority, of each thing you want to test by figuring out its business impact and adding that to the probability of it failing. Obviously, the things with the highest business impact and highest probability of failure should be highest on your priority list, while the things with the lowest business impact and lowest probability of failure should be at the bottom. This will also help quite a lot with the aforementioned testing squeeze and knowing what you want to cut first.
### **Step 3: Understand your technology, tools, and resources**
You need to understand how your overall testing automation solution will affect your overall environment. Do you have the proper accounts to run this? Do you have the proper environmental access? Do you have the right libraries and APIs and other pieces you may need to have your testing automation solution talk to your applications? You need to have a robust working solution that you can easily build into your overall framework without bogging anything down or creating broken or fragile tests.
**_Recommended:_** [How to select Automation Testing Tools?](https://www.katalon.com/resources-center/blog/automation-testing-tool-strategy/)
### **Step 4: Make sure your data is good**
A lot of test automation projects fail due to data failures. What if you could ensure the data is correct right at the start using another script in your automation framework or by running pre-scripts to validate or load the data, thereby saving you hours and hours of rewriting or redoing your tests? For each release and big framework iteration, you should deeply examine how you’re handling your data, how you’re storing your data, where your data is coming from, what your retry logic is, and if you have to worry about masking or de-identifying data.
### **Step 5: Define your DevSecOps**
A lot of testers can now work directly with Jenkins servers or other build-and-deploy tools, so you need to define that in your testing automation strategy.
You need to ask:
- Where is the code stored?
- How are you deploying it?
- What environments are you running it on and are they safe?
- Are the libraries and open source code you’re using secure?
You need to be doing some level of security scanning and have a process for how that scanning is done for your test automation framework.
### **Step 6: Consider your testing environment**
There are a lot of things to document around environmental conditions. Do you need certain tokens or VPNs? Do you need a launch box? How does that work and where does that live and who is responsible for it? How is the patching done on those systems? You need to document all of this, as it will also help greatly with onboarding new testers to your organization and getting the logins set up. In short, you need to understand where your code is running at all times and have it fully documented.
### ** Step 7: Tag your tests**
Having the ability to tag your tests and group them logically will allow you to say, “It doesn’t matter whether we have 20,000 or 50,000 test automation scripts because I know these are for my check-out, these are for my login, these are for smoke tests, etc…” If you don’t have those tags in place, you may be left doing a lot of groundwork trying to figure out the purpose of certain tests and figuring out which tests to run. Set a tagging agreement right up front to ensure consistent tagging and regular updates of the most commonly used tags.
### **Step 8: Look for testing efficiencies**
As you do more and more testing, you can start to apply the same testing logic in different areas to create efficiencies and shave off testing time and resources. For example, if you’re doing the same thing with the unit testing, manual testing, and automation testing, you probably don’t need three people running the exact same test. You can save a lot of time by fully understanding your overall testing automation strategy, all the way from the unit test down to the UI test.
### **Step 9: Embrace agile tools **
Embrace your agile and DevOps tools and really work on your documentation. Your testing automation strategy should become a living document that’s updated and reviewed each sprint to make sure you’re sticking to your visions and goals. Embrace this process and use cloud-based tools such as GitHub to make it a success. That said, you don’t need to document _everything_. You should, however, have regular check-ins and micro-strategy sessions.
**[Video] Katalon x PNSQC: Test Automation Strategy: Insider Practices & Secrets ** [here](https://youtu.be/ViXflAclG-A)
## **Tying it all Together**
**Remember** : the main thing you want to accomplish with your test automation strategy is to focus on your goals and communication and not your format. How will you deliver value? What is your overall technology goal? How is it affecting the people in your organization and your environments?
Also—be sure to win the support of your business partners, product owners, and project managers, because they’re the ones who are going to support you when the testing squeeze comes. As long as they understand your strategy, they’ll trust you to make the decisions on what needs to be cut and what doesn’t.
Finally, use your testing automation strategy as a basis for investing in the right technologies and growing your business through innovation—because, after all, that’s what this is all about, right? Growth, innovation, and not having to go in reverse.
**_Read more: [Automation Testing 101](https://www.katalon.com/resources-center/blog/what-is-automation-testing/)_**
The post [Implement Test Automation Strategy](https://www.katalon.com/resources-center/blog/automation-test-strategy/) appeared first on [Katalon Solution](https://www.katalon.com). | testingnews1 |
878,604 | Kubernetes Secrets... | A post by jmbharathram | 0 | 2021-10-27T15:31:31 | https://dev.to/jmbharathram/kubernetes-secrets-44lm | devops, kubernetes | {% youtube -VORdmSiYmc %} | jmbharathram |
878,635 | demo version of roulette online | Hello everyone. Have you ever played online roulette? I would like to try playing the demo version of... | 0 | 2021-10-27T16:28:36 | https://dev.to/milana678/demo-version-of-roulette-online-50lo | Hello everyone. Have you ever played online roulette? I would like to try playing the demo version of roulette in order to understand how to play roulette in general. I think this is a very interesting experience. | milana678 | |
878,648 | Communicate interface inheritance omission with type definition | You can easily tell members about inheritance omissions using TypeScript type definitions.You can... | 0 | 2021-10-27T17:04:51 | https://dev.to/activeguild/communicate-inheritance-leaks-with-typescript-2k41 | typescript | You can easily tell members about inheritance omissions using TypeScript type definitions.You can check the sample introduced [here](https://www.typescriptlang.org/play?#code/JYOwLgpgTgZghgYwgAgMIFcDOYD2BbAUSihymQG8AoZG5aEqAfgC4LraO8JNM4BzCM2xRQfADTsONBDgAmg4aIkcAvpTWVQkWIhQAlbgAccITCiocs0Vhak0QcLq0Ug+k5Go1gAnoZQBBAAUASWQAXmQAHgAVOgAPSBBZTGR0EABrEBwAdxAAPgAKKAgARxZkAxL0bjAASmRKMLzkWIgEiCSUjGx8IgZkRhbkVgBybtxCYlJkLWh4JBmQAAtoYDA4EAXiquBi2RHKSjbjKDBkGVMzuENgViDQiIL6prYOYrB0KBAKFWQ4FI23nUhwu2GQeDgoHCyCe4WatmkJjBxUwxlMKAi12AkQMqKREEKtQA3MDKBDQE8iUA).
Suppose you have the following type definition:
```ts
interface CustomError {
error?: {
message:string,
code:string,
}
}
interface Response {
user: {
name: string
}
}
type API = <T extends unknown>(req?: Request) => T
```
Response needs to inherit from CustomError, but you can't understand it without reading the type definition carefully.
In such a case, I will tell you the technique to easily tell the user.
Add a message prompting inheritance to the type definition.
```ts
type API = <T extends unknown>(req?: Request)
=> T extends CustomError
? T : 'CustomError interface inheritance required'
```
The user can notice because a message prompting inheritance is displayed in the response when using.
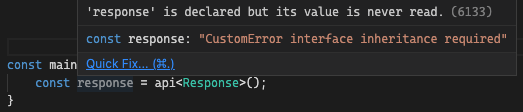
I don't think it's the intended use, Maybe you should know it as one technique. | activeguild |
878,710 | Cache API Integration with HydratedBLoC in Flutter (Source Codes Included) | Introduction 🎉 BLoC stands for Business Logic Controller. It was created by Google and... | 0 | 2021-10-27T19:25:15 | https://dev.to/imransefat/cache-api-integration-with-hydratedbloc-in-flutter-source-codes-included-42kg | flutter, api, bloc, cache | #Introduction 🎉
<br />
BLoC stands for Business Logic Controller. It was created by Google and introduced at Google I/O 2018. It is made based on Streams and Reactive Programming.
<br />
I can assure you that every intermediate-level Flutter developer in their development lifetime heard about Bloc or maybe tried to learn bloc. Bloc is one of the most popular state management choices among developers because it has rich documentation and is well maintained. But yes, there are some downsides as well, for example, a lot of boilerplate codes.
<br />
We will implement API integration at first, then persist the state so that when the user closes the app, it can maintain the state or load the data from the local device saved from the last API call to put it simply.
<br />
Note that after we kill the app, it starts right back where it left off. In addition, after it has loaded the previous (cached) state, the app requests the latest API data and updates seamlessly. Let’s get started!
<br />
<br />

<br />
#Steps 👣
####1. Configuring the Flutter Project
####2. Add the datamodel
####3. Creating the bloc
####4. Creating the bloc state and event
####5. Creating the Bloc Repository
####6. Implementing the bloc
<br />
<br />

<br />
#1. Configuring the Flutter project ⚙️
Let’s add the necessary packages that we’re going to use throughout the application.
Copy the dependencies to your Pubspec.yaml file. I am using the latest version available now at this moment.
{% gist https://gist.github.com/ImranSefat/417eb1acf77716cb6d79df140b699c8c %}
Then we need to install it with:
```
flutter packages get
```
You will get to understand everything as we go ahead.
<br />

<br />
#2. Add the datamodel 📳
We will implement the “FREETOGAME API”. For this, we have to make a datamodel of the API’s response. I have used the following website to make the datamodel class. It’s pretty easy, copy the JSON response and paste it on the website. The website will generate a class for you.
<br />
> Website Link: https://ashamp.github.io/jsonToDartModel/
> Don’t forget to tick the Null Safety checkbox!
<br />
{% gist https://gist.github.com/ImranSefat/a95d9f3eb4ad8620db497d35cb3a23d9 %}
<br />
Another datamodel that will contain the list of the games refers to the code below.
<br />
{% gist https://gist.github.com/ImranSefat/0a6a5e766dc9df5d85d70e4455a53c5e %}
<br />
The above code will show you some errors, as you can see that the 5th line contains a code that indicates that this file is part of another file that needs to be generated. Another thing, look at the 7th line, it is indicating that we will serialize so that we can save the response for later use.
<br/>
Open a terminal and run the below code.
> flutter packages pub run build_runner build
<br />

<br />
#3. Creating the bloc
<br />
{% gist https://gist.github.com/ImranSefat/e8031cdd341726688ea89d00cb755df2 %}
<br />
It contains the logic behind the main bloc. Now we have to make the event and state as well.
<br />

<br />
#4. Creating the bloc state and event
{% gist https://gist.github.com/ImranSefat/e8031cdd341726688ea89d00cb755df2 %}
<br />
There can be three(3) states.
1. Game list is loading -> GamelistLoading
2. Game list loaded -> GamelistLoaded
3. Game list cannot be loaded -> GamelistError
<br />

<br />
#5. Creating the Bloc Repository👾
{% gist https://gist.github.com/ImranSefat/f01ffbb344d00da417eb490cc67dab02 %}
We are calling the API using the HTTP package form from this file or class.
<br />

<br />
#6. Implementing the bloc🛠
{% gist https://gist.github.com/ImranSefat/2902f72681f51fc91bd6bbbbaee40d18 %}
<br/>
This portion contains the UI and the Bloc implementation. You can check the main function. It is instantiating the hydrated bloc in the temporary directory.
Note that after we kill the app it starts right back where it left off. In addition, after it has loaded the previous (cached) state, the app requests the latest API data and updates seamlessly.
<br />
<br />
#Congratulations! 🎊
You just integrated an API with HydratedBloc that has Caching.
<br />

<br />
<br />
<br />
#Contact Me🌎
YouTube Channel: [Coding with Imran](https://www.youtube.com/c/CodingwithImran)
Twitter: [@ImranSefat](https://twitter.com/ImranSefat)
LinkedIn: [MD. Al Imran Sefat](https://www.linkedin.com/in/imransefat/)
Facebook Page: [Coding with Imran](https://www.facebook.com/CodingWithImran)
| imransefat |
878,770 | Producing the MVP vs Becoming the MVP | As web developers we can all agree that most of us enjoy programming because it allows us to build... | 0 | 2021-10-27T19:32:03 | https://dev.to/adammoore_dev/being-the-mvp-vs-making-the-mvp-19m6 | beginners, react, advice, focus |
As web developers we can all agree that most of us enjoy programming because it allows us to build beautiful, dynamic, applications from practically nothing but a keyboard, monitor and an internet connection. Lets face it, typing a few lines of code and getting visual confirmation almost instantaneously is pretty cool! On the other hand, with this great power comes great responsibility, most of us are learning these skills constantly to become employed either as a freelancer or as part of a team of other developers --both of which do carry some responsibility. This is where being the MVP and making the MVP are two different hurdles that all of us will have to overcome. Personally in just the first few phases of Flatiron's Bootcamp I have come face to face with this challenge on many occasions.
What do I mean by MVP and MVP, are they not the same? Letter wise, yes. Acronym wise, absolutely not. Becoming the Most Valuable Player on your team (even a team of one as a freelancer) and making the Minimum Viable Product are vastly different when it comes to setting out project goals and achieving your deliverables for a client, employer, or your instructor. Personally, I have succumbed to the allure of wanting to code 15-30 different ideas all at once and make the next epic web page the internet has ever seen...for a project that had 3-5 deliverables required to satisfy expectations. Those deliverables are the Minimum Viable Product, and are nonnegotiable.
The urge to become the MVP of your team can be challenging to resist. When it comes to road mapping towards the deliverables and trying to finesse solutions to code bugs along the way, ideas are great. However, a lot of ideas in the beginning, paired with excitement for a project, can lead to you and your team spending precious time coding the 'many' instead of coding the 'few'(main deliverables). Its been my experience that the best course of action is to write out what you need (the minimum viable product). Once that is clear to everyone involved, a wire frame --or drawing-- of the components that will render the content, data, and functionality in your app to meet the the core deliverables can act as your road map. This is not to say that brainstorming ways to accomplish the MVP goes without some creativity; coding is a learned art where many paths can lead to the same goal. New and seasoned programmers just need to strive for and meet the goals set by the MVP first, then the framing and additional goals can be accomplished.
An individual or team that meets the standards as the minimum of their goals first, then stretches them with new ideas and creative thoughts are the real MVPs. They all just have to...

| adammoore_dev |
879,372 | Working together is the best -- the guide to happy embedding | What is the embedded model? Companies need specialists. And specialists often do their... | 0 | 2021-11-16T05:47:19 | https://www.rubick.com/embedded-model/ | leadership, management, agile | ---
title: Working together is the best -- the guide to happy embedding
published: true
date: 2021-10-27 00:00:00 UTC
tags: leadership, management, agile
canonical_url: https://www.rubick.com/embedded-model/
---
### What is the embedded model?
Companies need specialists. And specialists often do their work with people outside their department. For example, all these specialties work with software engineers:
- Designers
- Product managers
- Site reliability engineers (SREs)
- Quality engineers (QA)
- Application security engineers
- and Architects
Specialists often apply the most leverage when they work next to engineers. For example, an SRE might help a team improve their monitoring. They might help even more if they help the team to understand how to do monitoring themselves. A designer might work side by side with an engineering team. They design future features, and collaborate on current features.
One way to structure this relationship is by _embedding_ these experts on teams. They still report back to a home team of specialists, but spend almost all their time on another team. This is the Embedded Model of coordination.
Sometimes you might embed an expert on several teams. Or you might embed them in an organization. For example, you can embed a QA engineer with a Director. This director will have several teams they support. The QA engineer can then help improve quality across this organization. When doing so, they might focus on the top priority project. Or they might rotate between teams.
### When to embed
- **Embedding can be one of the best coordination models to use.** It is appropriate when you want specialists to collaborate within a team. I like embedding designers, product managers, sometimes SREs, sometimes architects, and sometimes QA.
Embedding can be the easiest way to add specialist skills. In some organizations, you are not “allowed” to hire specialists into your organization. For example, an engineering leader can’t hire a designer into their team. Embedding allows you to get around this. See later in this post for a discussion on this.
- **The embedded person’s work should be mostly aligned with the existing team**. It only makes sense to use embedding if you need collaboration. Embedding increases context, collaboration, and relationships within the team.
- **You can only embed up until a maximum team size.** If the team already has eight or nine people on it, you need to split the team, or not embed. This count includes other embedded people.
The embedded model scales well with the growth in teams. Each new team gets a new member. It does reduce the maximum team size by one. A rule of thumb is that the specialist team member should add more value than a generalist would.
- **You are tying company investment to be proportional to the growth of these teams**. That can be good, or bad. Many supporting organizations should grow slower than the growth of teams. They need to become more efficient over time. Other specialists should grow at exactly the same rate as engineering. Embedding makes the most sense when the growth should be at the same rate. Embedding makes these growth plans part of the structure of the organization. If you know every product team needs a product designer, then that is a good thing. You know that the plan will account for those hires.
Sometimes specialist teams should grow slower. For example, a security team should grow slower than a proportion to engineering. They won’t achieve this goal with embedding, so other approaches might make better sense. You can still use embedding, but it should be temporary.
### Hints to embedding well
- **You may need a central team**. It’s common to need a centralized team even while embedding. This team is usually small.
For example, a design organization might embed, but have a central team or two. This central team can work on a design system, or design research.
An SRE organization might have a central SRE team as well. This team can work on standardized tooling, and provide reliability information. (See my upcoming post on objective experts). This works together with embedding.
This sort of pairing is natural. You may or may not need it to start. But you usually end up needing both.
- **Support the home team too**. Embeds maintain split allegiances. Embeds need support on both teams. Some people tend to make stronger attachments on their work team. Other people tend to make stronger attachments with their home team.
Encourage embeds to view their work team as their primary team. But don’t neglect the home team. Home teams can share practices and information among specialists. They act as a Community of Practice that can spread expertise throughout the company.
- **Don’t shift people around too frequently**. Part of the value of these long-term pairings is you build relationships and context. It is expensive to move people because it breaks these connections. Most embedded organizations tend to move people more than they should. It can be frustrating to have embeds on your team if you can’t rely on them to stay. Yet it is tempting for the embed’s manager to move people around. They want to react to changing needs, and sometimes there aren’t enough people to go around. This can be a source of friction.
- **Negotiate how it works and take care onboarding**. A new embedded person has a more complex situation than new employees do. They have another manager, and things outside your team they may be paying attention to. Kick off the relationship with explicit conversations. Spend twice the care you would with onboarding a generalist employee.
Gus Shaffer offers this advice: “One thing that I found helpful when embedding staff engineers was to conduct a standard Kick-off process with a Statement of Work as output. Early on I learned the hard way that leaving success criteria loose leads to lingering engagements / disappointment / confusion.”
- **Be clear who directs their work**. When negotiating an embedded situation, decide who directs their work. It can cause problems if both the home and work team managers assign work. This makes their output less predictable. Even worse than that, it causes surprises because it seems predictable until it isn’t. This can make it hard to depend on the embedded person.
- **Clarify what type of work they’ll be doing**. Another thing to be specific about is the type of work you’re expecting them to do. For example, is the SRE joining the team to do operational work? Or are they there to help the team get better at operational work?
Many companies focus on cross training and [T-shaped people](https://jchyip.medium.com/why-t-shaped-people-e8706198e437). They do this to create more flexible teams. And they see value in spreading that skillset within the team. If you can, make it explicit that the specialist won’t do all the work. The goal is for them to help the team get better at that type of work. This won’t always make sense. Team members can’t internalize every specialty.
- **Good role definition can help clarify expectations**. Develop role definitions. Review expectations when they join the team. This will help both them and the team know what to expect.
- **Maintain good communication between managers**. If you’re the manager of the embedded person, check in with the manager of the team your person works with. Set up a regular cadence for checking in. It’s good customer service, and it’s also vital so you can offer good feedback and coaching to your direct report.
For the embedded person, they are living in a sort of matrix-managed world. Although they don’t have two managers, in practice it can feel that way. They attend two sets of meetings. And their manager isn’t seeing their work.
As a manager of an embedded team, make sure you have a way to assess your team members’ work and coach them. They need career development and support like any other employee.
- **Be careful of meeting load**. Embeds will often have a higher meeting burden than other individual contributors. The easiest way to handle this is to keep their home commitments light.
- **Watch out for embedding with multiple teams**. Embeds with multiple teams have an even more complex situation. They have three or more teams they’re a part of, and they have a lot of relationships and complexity to navigate. It’s usually best to pair them with the organization’s leader. That way, the org leader can direct their work. This can help simplify some of the complexity they’re dealing with.
When you don’t align an embed with an org leader, it can get complicated. When a reorg occurs, you’ll have to do your own reorganization. Even if less optimal, keep your organizational design aligned with the embed’s organization. I’ve seen reorganizations with three separate hierarchies. It was a complete mess.
### Embedded versus other coordination models
**Single threaded owner: why embed when you could hire that skill directly on to the team?**
One way to handle embedding is to take it even further and actually put the embedded person on the team. This has a lot of advantages, and some disadvantages as well. I wrote up an experience report on this model in[The Single Threaded Owner model](https://www.rubick.com/implementing-amazons-single-threaded-owner-model/). See it for more details. It’s arguably a better approach. You should combine it with a strong Community of Practice (post forthcoming). You also need good role definition and career ladders.
Usually, you won’t have the latitude to do this. The designers will need to be on the design team. If they aren’t serving you well, you may consider hiring a designer onto your team. A sneaky way to handle this is to hire an engineer who has a design background or who is design-focused. Doing this as an organization can be difficult, so it’s often a one-off approach.
**Merged group: let’s do DevOps!**
You can combine departments that historically passed work between each other. The classic version of this is to combine developers and operators. Eliminating the departments and having them on the same team improves flow. This approach is like the [Single Threaded Owner model](https://www.rubick.com/implementing-amazons-single-threaded-owner-model/), but less extreme. You’re not doing it for every specialty, but one.
This has similar tradeoffs, so read the STO model post for details.
**Service provider: have them come to you instead?**
I generally prefer embedding to a [service provider](https://www.rubick.com/service-provider-model/) approach. Most service providers lack the context and relationships to collaborate with teams.
Prefer the Service provider model when you want to scale your organization slower than the organization you’re serving. It’s also preferable if you offer a service where you don’t need much context from the team you’re serving.
**Liaison: I don’t need to actually WORK with them, just want to spy on them**
If you’re just gaining context from them, you don’t need a full blown embedding regime. Just use a [liaison](https://www.rubick.com/liaison-model/), and attend their meetings. Make your home team your main team.
**Rotation: when context is less important, or you want to share the burden**
If context is less important, a rotation may be preferable. This doesn’t build as deep of connections between people, or ease communication as much. But it does share the burden, so it can be useful if parts of where you serve are really hard work or are uninteresting. Some teams may also enjoy the variety of a rotation. Stay tuned for a post on this.
**Objective expert: give the central team leverage!**
When pairing the embedded model with a small centralized team, it can be useful to have the central team use the Objective expert approach. A reliability organization might have a central SRE group that is in charge of reporting on reliability for the organization, broken down by team. This can drive a lot of work in other teams. I love this approach, and will write more on it soon.
### Coordination models
Embedded is just one of many [coordination models](https://www.rubick.com/coordination-models/). Coordination models give you a menu of choices to choose from when solving your inter-team coordination issues.
### Feedback
See anything I missed? Disagree with this? Please let me know your thoughts!
Also, I blog about these topics at https://www.rubick.com
### Thank you
[Gus Shaffer](https://www.linkedin.com/in/gusshaffer/) provided a lot of feedback on an earlier version of this post, and had some good suggestions on how to embed effectively.
Image by [PublicDomainPictures](https://pixabay.com/users/publicdomainpictures-14/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=17109) from [Pixabay](https://pixabay.com/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=17109) | jade_rubick_4c243cdc3ad05 |
879,377 | Simple Script To Send Emails In Python | Emails are, nowadays, a common way of formal communication, which is also good for the transfer of... | 0 | 2021-10-28T06:02:57 | https://dev.to/visheshdvivedi/simple-script-to-send-emails-in-python-11ee | python, programming, tutorial, beginners | [](https://1.bp.blogspot.com/-NlhES-ojmpE/YR1NQnS04KI/AAAAAAAAAeA/S22tLiOAdaMIEjtTZhQ-Pxw15cTZ9_JKQCLcBGAsYHQ/s1280/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2BEmails.png)
[Emails](https://en.wikipedia.org/wiki/Email) are, nowadays, a common way of formal communication, which is also good for the transfer of files easily from person to person. Almost every person who has some identity over the internet, or simply uses it, has an email ID of his own, be it [Gmail](https://en.wikipedia.org/wiki/Gmail) or [outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook).
Now of all the awesome stuff that can be done in python, one of those is to be able to send or receive [emails](https://en.wikipedia.org/wiki/Email). Python programming
libraries can be used to send mails or to list all the mails within your email account. You can also perform some basic actions, like marking the mail as read, using python.
And in this blog, I am gonna show you, how you can do this yourself.
**About Mail Servers**
[](https://1.bp.blogspot.com/-alQJy_Z_noE/YR1NmQV9u_I/AAAAAAAAAeI/fQ1lEWQGBB0tapeGv5XBTTOx8-1PeBuDgCLcBGAsYHQ/s2997/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2BSMTP%2Band%2BIMAP%2BMail%2BServers.jpg)
Before we start with the coding part, you need to have some basic
information about mails and mail servers.
Mail servers are basically servers that are used to manage [emails](https://en.wikipedia.org/wiki/Email), [Outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook), [Gmail](https://en.wikipedia.org/wiki/Gmail), Yahoo, Hotmail, etc. have their own mail servers that manage their mail services. Mail servers can further be classified into two categories;
**SMTP Server**
SMTP stands for [Simple Mail Transfer Protocol](https://en.wikipedia.org/wiki/Simple_Mail_Transfer_Protocol).This server is responsible for sending or transferring mail from server to server i.e. whenever you send a mail to someone, you typically make use of the SMTP server.
**IMAP Server**
IMAP stands for [Internet Message Access Protocol](https://en.wikipedia.org/wiki/Internet_Message_Access_Protocol).This server is responsible for storing and listing mails from your server i.e. whenever you open your [Gmail](https://en.wikipedia.org/wiki/Gmail) or [Outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook), you typically make use of the IMAP server.
**SSL and TLS**
There are two types of encryption protocols used for
[emails](https://en.wikipedia.org/wiki/Email), SSL ([Secure Socket Layer](https://en.wikipedia.org/wiki/Transport_Layer_Security#SSL_1.0,_2.0,_and_3.0)) and TLS ([Transport Layer Security](https://en.wikipedia.org/wiki/Transport_Layer_Security)).
Whenever you will connect to any mail server, you will connect through one of these protocols. Each protocol has its port assigned to the server.
TLS - port 587
SSL - port 465
Although [Gmail](https://en.wikipedia.org/wiki/Gmail) and [Outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook) server support both these protocols, we are gonna use only TLS protocol in this post for simplicity.
**Sending Mails using Python**
[](https://1.bp.blogspot.com/-lkyurw5VAtI/YR1OAnZAUaI/AAAAAAAAAeQ/xbT0ZOWMRNIDmzKLnDOs_dvsuakk7G_KACLcBGAsYHQ/s1280/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2BSending%2Bmails%2Busing%2Bpython.png)
Now that we are clear about mail servers, let's create our first script to send mail using python
**Installing the library**
[](https://1.bp.blogspot.com/-eeDjAGu_aLA/YR1OWkDQwxI/AAAAAAAAAeY/wo06MeFGVRgWl3OiRFFy3239_XEkmz7OgCLcBGAsYHQ/s2048/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bpython%2Blibrary%2Bto%2Bsend%2Bmails.jpg)
We will be using the smtplib library of python to send [Gmail](https://en.wikipedia.org/wiki/Gmail) or [Outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook) mail. This library comes built-in in python, so you don't need to download it from elsewhere.
**Creating the script**
Here's how the script would look like
[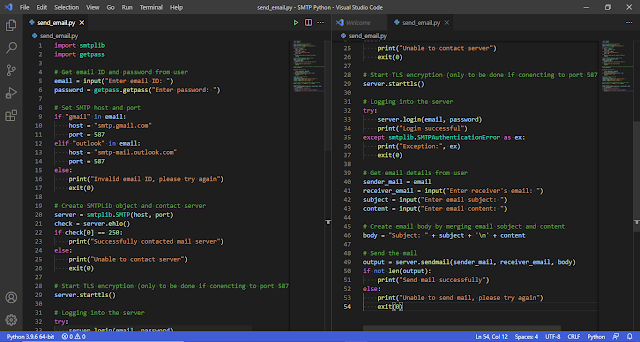](https://1.bp.blogspot.com/-uHUX2Nso6uQ/YR1OxolUNqI/AAAAAAAAAeg/DRGyTX_tZjEaH6XIUj5f0AXftEiu3lMzwCLcBGAsYHQ/s1366/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bpython%2Bscript%2Bto%2Bsend%2Bmails.PNG)
The script may look complicated, but we will go line-by-line to discuss each function and class of the script and understand its use
[](https://1.bp.blogspot.com/-z-rc47TPTEQ/YR1PQRCKI7I/AAAAAAAAAeo/oVF72gI7pvwPB4ERR23uN8TSpmqs0fV3wCLcBGAsYHQ/s152/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bimport%2Blibraries.png)
The script starts with importing smtplib and getpass library. We are using the getpass library so that we can retrieve the password from the
user.
[](https://1.bp.blogspot.com/-wDGAtsEE83s/YR1Q8BOJQnI/AAAAAAAAAew/KQnYH71cEcEZy7RAVeQtFhQ8NzL6XHocACLcBGAsYHQ/s403/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bemail%2Band%2Bpassword.PNG)
After that, we ask the user to enter the credentials for their mail account, which will be used to send the mail. We use getpass to ask the user for the password. Since we are using getpass, the password that the user will enter will not be displayed on the screen but will be saved within the variable.
[](https://1.bp.blogspot.com/--nIYKydzfNo/YR1RNf-1UKI/AAAAAAAAAe4/LAX8PHAS4Gkmd9wrcu40gA2g0i-dlq8DgCLcBGAsYHQ/s434/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bset%2Bhost%2Band%2Bport.PNG)
In the next step, we set up the SMTP server host and port to be used. If the entered email ID is a [Gmail](https://en.wikipedia.org/wiki/Gmail) account, the host will be set to [Gmail](https://en.wikipedia.org/wiki/Gmail) SMTP server, or else if it is [Outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook), the ost
will be set to [Outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook) SMTP server.
We set the port to 587 as we had discussed above within the 'SSL and TLS heading. In case if the entered email ID cannot be identified as [Gmail](https://en.wikipedia.org/wiki/Gmail) or
[Outlook](https://en.wikipedia.org/wiki/Microsoft_Outlook), the script will give an error message and exit.
[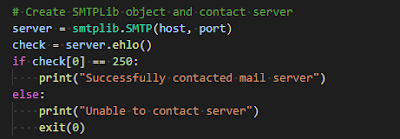](https://1.bp.blogspot.com/-cUFEIlwJ1yM/YR1RXHQteoI/AAAAAAAAAe8/S_Q-rUbNlAE4Llw-Pd9gMuPfMJJ4GPnWQCLcBGAsYHQ/s461/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bsmtplib.SMTP%2Bclass%2Bobject.PNG)
In the next step, we will create the SMTP class object, which will be used to perform the actions. We create an object of smtplib.SMTP class and save the object by the name 'server'. The class object requires two parameters, the hostname, and the port.
Once we have created the object, we call the ehlo() function of the class object, which is basically used to send a greeting message to the mail server. This step is crucial, as not performing this step may cause problems in communicating with the mail server.
[](https://1.bp.blogspot.com/-QAltlFCcouA/YR1Rf9sAzmI/AAAAAAAAAfE/Yvr9_HpdvDsV6sc37BErPvIo9P6SgJk5QCLcBGAsYHQ/s537/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bstart%2Btls%2Bencryption.png)
After receiving a successful response from the server, we call the starttls() function to start TLS encryption. This step is only required for TLS connection and not for SSL connection.
[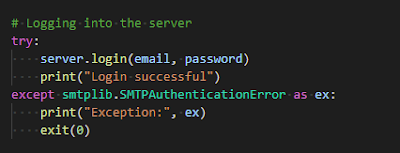](https://1.bp.blogspot.com/-o88SInWtQ6Q/YR1R4HZC88I/AAAAAAAAAfU/nEAcbcKHrzoRjv4qOHB-FNbkqiPMRB8aQCLcBGAsYHQ/s426/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Blogin%2Bto%2Bmail%2Bserver.PNG)
After this, we call the login() function to log in to the mail account. The function requires two parameters, the email ID and the password, which we had retrieved from the user.
[](https://1.bp.blogspot.com/-E0rbx8h68ME/YR1R_gXFJTI/AAAAAAAAAfc/ASO4-kqbgCs0EaiAzU0HQGZS9iUK_umsACLcBGAsYHQ/s458/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bget%2Bemail%2Bcontent.PNG)
Once we have successfully logged in, we ask the user for the receiver's email ID, mail's subject, and mail body.
[](https://1.bp.blogspot.com/-eytSNF_SFSs/YR1SHvioJfI/AAAAAAAAAfg/I1r1aQfn-SMukMEHE9V36aZY_yrOU8eEwCLcBGAsYHQ/s495/Simple%2BScript%2BTo%2BSend%2BEmails%2BIn%2BPython%2B-%2Bsend%2Bmail.PNG)
And finally, we call the sendmail() function and pass three parameters, sender mail ID, receiver mail ID, and the mail body (created by merging mail subject and mail content).
Here is the full code
import smtplib
import getpass
# Get email ID and password from user
email = input("Enter email ID: ")
password = getpass.getpass("Enter password: ")
# Set SMTP host and port
if "gmail" in email:
host = "smtp.gmail.com"
port = 587
elif "outlook" in email:
host = "smtp-mail.outlook.com"
port = 587
else:
print("Invalid email ID, please try again")
exit(0)
# Create SMTPLib object and contact server
server = smtplib.SMTP(host, port)
check = server.ehlo()
if check[0] == 250:
print("Successfully contacted mail server")
else:
print("Unable to contact server")
exit(0)
# Start TLS encryption (only to be done if conencting to port 587 i.e. TLS)
server.starttls()
# Logging into the server
try:
server.login(email, password)
print("Login successful")
except smtplib.SMTPAuthenticationError as ex:
print("Exception:", ex)
exit(0)
# Get email details from user
sender_mail = email
receiver_email = input("Enter receiver's email: ")
subject = input("Enter email subject: ")
content = input("Enter email content: ")
# Create email body by merging emails object and content
body = "Subject: " + subject + '\n' + content
# Send the mail
output = server.sendmail(sender_mail, receiver_email, body)
if not len(output):
print("Send mail successfully")
else:
print("Unable to send mail, please try again")
exit(0)
And that's it, you have successfully sent a mail through python
**Conclusion**
In this blog, I have only covered sending mail through python. I will soon create another blog that will deal with accessing email from accounts by contacting the IMAP servers using python.
Hope you liked this blog
Stay safe, stay blessed, and thanks for reading.
| visheshdvivedi |
879,386 | Share Components across Front Ends frameworks using Nx and Web Components Part 2 | Create a Web Component library and use it across your Front-end frameworks - Part 2 | 0 | 2021-10-28T06:22:52 | https://crocsx.hashnode.dev/share-components-across-front-ends-frameworks-using-nx-and-web-components-part-2 | webdev, nx, webcomponents, frontend | ---
published: true
title: "Share Components across Front Ends frameworks using Nx and Web Components Part 2"
cover_image: "https://raw.githubusercontent.com/Crocsx/dev.to/main/blog-posts/share-component-across-front-end-framework-using-nx-and-web-component/assets/Cover.png"
description: "Create a Web Component library and use it across your Front-end frameworks - Part 2"
tags: webdev, nx, webcomponents, frontend
canonical_url: "https://crocsx.hashnode.dev/share-components-across-front-ends-frameworks-using-nx-and-web-components-part-2"
---
This is the second of three Part Guides:
- [Part 1 - Project Setup and Introduction to Web Component](https://crocsx.hashnode.dev/share-components-across-front-ends-frameworks-using-nx-and-web-components)
- [Part 2 - Add Custom Style and Property Binding](https://crocsx.hashnode.dev/share-components-across-front-ends-frameworks-using-nx-and-web-components-part-2)
- [Part 3 - Output Event and Allow Retrocompatibility.](https://crocsx.hashnode.dev/share-components-across-front-ends-frameworks-using-nx-and-web-components-part-3)
## Part 2 - Add Custom Style and Property Binding
In part one, we introduced Web Components, what they are and how to use them. We also created and set up an Nx workspace with an Angular and React project alongside a shared Web Components library. We created a custom element that "listens" to the attribute `title` and changed the `DOM` content accordingly. In this second part, we are going further by styling and assigning properties to our Web Components.
### 1. Style our Web Component
Our Web Component works, but they are very flat at the moment. It would be great to add some CSS to it. You may want to add a CSS class to our title and create a global stylesheet with some rules, and it would work. But the idea behind Web Components is creating fully independent elements that are auto-sufficient and do not require anything from the "outside". Adding a global CSS class would affect every element on our page and quickly turn into a gigantic file full of rules.
Hopefully, Web Components allow us to use [Shadow DOM](https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_shadow_DOM), which makes us able to keep the markup structure, style, and behavior hidden and separate from other code on the page. Thanks to it, elements will not clash, and the code will be kept simple and clean.
Let's head back to our library (set up in part one) and edit our title component (or create a new title element).
If you still have what we worked on, it should look like this (I removed the logs) :
```
export class DemoTitleElement extends HTMLElement {
public static observedAttributes = ['title'];
attributeChangedCallback(name: string, old: string, value: string) {
this.innerHTML = `<h1>Welcome From ${this.title}!</h1>`;
}
}
customElements.define('demo-title', DemoTitleElement);
```
In the above example, we just replaced the entire HTML inside our element for every update on our attribute `title`:
```
attributeChangedCallback(name: string, old: string, value: string) {
this.innerHTML = `<h1>Welcome From ${this.title}!</h1>`;
}
```
As you may know, this method doesn't allow us to append some `<style>` tag. Therefore, we are unable to create new styles unless we manually write a class and add some global rules. Also, this approach is pretty poor in performance, as we recreate all the content for every change of our attribute. It would be great to have some kind of template...
Well, it turns out there is [template](Using templates and slots - Web Components | MDN (mozilla.org)) element that would suit our need! Templates are not rendered in the DOM, but can still be referenced via Javascript. We can then clone this template inside our Shadow DOM once and access it across our components.
Let's create one outside of our component class and assign the styles we like.
```
const template = document.createElement('template');
template.innerHTML = `<style>
h1 {
color: red;
}
</style>
<h1>Welcome From <span id="title"></span>!</h1>`;
```
You will notice I added a `span` with an `id` where we would like to write the dynamic title. It will come in handy for updating our DOM without having to recreate the template entirely.
Now in our Component `constructor`, attach a Shadow DOM, and append our template to it.
```
export class DemoTitleColoredElement extends HTMLElement {
public static observedAttributes = ['title'];
constructor() {
super();
this.attachShadow({ mode: 'open' });
this.shadowRoot.appendChild(template.content.cloneNode(true));
}
}
```
Here is what we added
- `super` will call the `constructor` of `HTMLElement`
- `attachShadow`attaches a shadow DOM tree to the specified element and returns a reference to its ShadowRoot. There can be two different `encapsulation modes`. `open` means elements of the shadow root are accessible from JavaScript outside the root while `closed` Denies access to the node(s) of a closed shadow root from JavaScript outside
- `this.shadowRoot.appendChild` we are adding our template to the shadow Root and using `template.content.cloneNode(true)` we are cloning all the DOM element we defined in the template.
Now, this is much better; our template is cloned once and will be available through `shadowRoot` inside the component.
When the attribute change, we can now update what interests us inside the template. As we only care about the `title` attribute, we can simply add the following.
```
attributeChangedCallback() {
this.shadowRoot.getElementById('title').innerHTML = this.title;
}
```
We should end up with a component similar to this :
```
const template = document.createElement('template');
template.innerHTML = `<style>
h1 {
color: red;
}
</style>
<h1>Welcome From <span id="title"></span>!</h1>`;
export class DemoTitleColoredElement extends HTMLElement {
public static observedAttributes = ['title'];
constructor() {
super();
this.attachShadow({ mode: 'open' });
this.shadowRoot.appendChild(template.content.cloneNode(true));
}
attributeChangedCallback() {
this.shadowRoot.getElementById('title').innerHTML = this.title;
}
}
customElements.define('demo-title-colored', DemoTitleColoredElement);
```
Nice! Remember to add this new element to your library's export and try it on your Angular and/or React project. I added the old title we created previously and the new one on the bottom. What we expect to see is our old title to remain Black, while our new title should be Red (and do not affect `h1` outside of it)
```
<demo-title [title]="'Angular'"></demo-title>
<demo-title-colored [title]="'Angular'"></demo-title-colored>
```

AWESOME! Our style is applied only to our Component!
## 2. Passing object to Web Components
One common thing we would like to do is pass objects to our Web Component, and not just simple strings.
Since Web Component `attributeChangedCallback` and `observedAttributes` works exclusively with `attribute`, a possible solution would be to stringify objects and pass them via the attribute [`data-*`](https://developer.mozilla.org/en-US/docs/Learn/HTML/Howto/Use_data_attributes) and our HTML would remain valid.
Let's try this first, we are going to pass a person `object` to our Web Component and simply display that person's name.
### 2.1 Passing objects via attributes
In our library, create a new element that will observe a custom attribute named `data-person`
```
export class DemoObjectElement extends HTMLElement {
public static observedAttributes = ['data-person'];
attributeChangedCallback(name: string, old: string, value: string) {
console.log(`Attribute ${name} value:`, value);
}
}
customElements.define('demo-object', DemoObjectElement);
```
Add this new element to your library's exports, and let's first use it in Angular.
Inside `app.component.ts` create this object :
```
person = {
firstName: 'Jack',
lastName: 'Doe'
}
```
Move to the `app.component.html` add and assign our object to our web component. You have to specify Angular to use `attribute` by prefixing our binding with `attr.person`
```
<demo-object [attr.data-person]="person"></demo-object>
```
You will see that our Web Component log will look like this :
> Attribute data-person value: [object Object]
Which is not what we want... To receive the entire object, we will need to use `JSON.stringify` first and then `JSON.parse`...
Update our Angular `app.component.ts` with the following line :
```
JSON = JSON;
```
and the template
```
<demo-object [data-person]="JSON.stringify(person)"></demo-object>
```
You can also update our Web Component log to display the value as an `object`
```
console.log(`Attribute ${name} value:`, JSON.parse(value));
```
It will now display our object as expected :
> Attribute data-person value: {"firstName":"Jack","lastName":"Doe"}
For React, it is very similar. Open `app.tsx` and just add the following :
```
return (
<div className={styles.app}>
<demo-object dataPerson={JSON.stringify(person)}/>/>
</div>
);
```
Since our Web Components are "natives" HTML elements, just assigning `dataPerson` will change the attribute `data-person`.
Passing objects as attributes is enough in some cases where we just want to assign small objects. But ideally, we do not wish to pollute attributes, and worst, assign objects that will need to be stringified and parsed at every change. What about passing things as properties instead? Well, we can, but it is a bit harder.
### 2.2 Passing Object via Properties
To allow our Web Component to receive properties, we first need to change a few things in the code. Web Components lifecycle works with `attributes` so we are required to manually detect property changes, and call our method ourselves. Additionally, as stated in the last part, Web Components are consumed like basic HTML, therefor passing property to HTML elements varies depending on the framework we use.
While we are at changes, let's also display the person's name and not just log it. Create a template in our component to do so.
```
const template = document.createElement('template');
template.innerHTML = `
<style>
.name {
font-weight: bold;
}
</style>
<p>
<span class="name">first name</span>
<span id="firstName"></span>
</p>
<p>
<span class="name">last name</span>
<span id="lastName"></span>
</p>`;
```
Let's now change our component code. Assuming I would like to pass a property named `person` to my Web Component. If we do all like we are used to doing until now, we would be doing the following.
```
export class DemoProfileElement extends HTMLElement {
public static observedAttributes = ['person'];
constructor() {
super();
this.attachShadow({ mode: 'open' });
this.shadowRoot.appendChild(template.content.cloneNode(true));
}
attributeChangedCallback() {
this.update(this.person);
}
update(person: {firstName: string, lastName: string}) {
this.shadowRoot.getElementById('firstName').innerHTML = person.firstName;
this.shadowRoot.getElementById('lastName').innerHTML = person.lastName;
}
}
customElements.define('demo-profile', DemoProfileElement);
```
But as your Typescript might tell, `person` is not an HTML attribute, so `this.person` is not defined. Additionally, the `attributeChangedCallback` will never be called since `observedAttributes = ['person'];` can't observe attributes that do not exist.
To fix this and make it work, we need to forget about what we did until now and implement our way to detect changes, like if we were coding a simple Typescript Class. You can try to fix it by yourself or just scroll for the solution.
We going to need a property in our class I chose `_person`, and a `get/set` that will assign to that property
```
export class DemoProfileElement extends HTMLElement {
_person = {
firstName: '',
lastName: '',
};
get person(){
return this._person
}
set person(value: {firstName: string, lastName: string}){
this._person = value;
this.update(this._person);
}
constructor() {
super();
this.attachShadow({ mode: 'open' });
this.shadowRoot.appendChild(template.content.cloneNode(true));
}
update(person: {firstName: string, lastName: string}) {
this.shadowRoot.getElementById('firstName').innerHTML = person.firstName;
this.shadowRoot.getElementById('lastName').innerHTML = person.lastName;
}
}
customElements.define('demo-profile', DemoProfileElement);
```
Yes, we just use a get/set to check when the property is updated and update our DOM accordingly.
Let's try this in Angular, but before, don't forget to add this new element to your library's export!
When passing Input to a component, Angular will assign it as a property of that element. It makes things simple for us, as we do not need to change much.
In your Angular app, just add this line :
```
<demo-profile [person]="person"></demo-profile>
```
And that's it!

Let's head to React, where things are a bit different. React pass props as JSX Attributes, and therefore, simply doing `<demo-profile person={person} />` will not work. We need to treat our Web Component as what it is, an HTML Element. So, get the reference and assign to it the property.
In your React app, add a Reference to our component, and after initialization, assigns the `person` property to our Web Component :
```
import { DemoCounterElement, DemoProfileElement } from '@demo-shared/demo-library';
export function App() {
const person = {
firstName: 'Jack',
lastName: 'Doe'
}
const profile = useRef<DemoProfileElement>(null);
useEffect(function () {
if(profile.current) {
profile.current.person = person
}
}, []);
return (
<div className={styles.app}>
<demo-profile ref={counter}/>
</div>
);
```
This is all also for React; start the project, and you will see the same result!

Great, we did almost all we would like to do, but there are still some things we might want to add.
In the last part, we will add some custom events to be dispatched in our Web Component and add polyfill to use our component on old browsers.
You can find the entire repo here :
[https://github.com/Crocsx](https://github.com/Crocsx/dev.to/tree/main/blog-posts/share-component-across-front-end-framework-using-nx-and-web-component/exemple/demo-shared)
Found a Typo or some problem?
If you’ve found a typo, a sentence that could be improved, or anything else that should be updated on this blog post, you can access it through a git repository and make a pull request. Please go directly to https://github.com/Crocsx/dev.to and open a new pull request with your changes. | crocsx |
879,465 | What Is Terraform CDK? - Terraform code in JavaScript | What is Terraform🤔? Terraform is an open-source infrastructure as a code software tool... | 0 | 2021-10-28T14:16:10 | https://www.thegogamicblog.xyz/introduction-to-terraform-cdk/ | terraform, typescript, python, csharp | ### What is Terraform🤔?
[Terraform](https://www.terraform.io/) is an **open-source** infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. It was developed by [HashiCorp](https://www.hashicorp.com/)
### What is Terraform CDK?
[Terraform CDK](https://github.com/hashicorp/terraform-cdk) is a tool developed by terraform developers which allows you to write your infrastructure in your favorite language
- It supports TypeScript, Python, C#, Go(Beta), and Java Currently.
### Getting started 😃
Before we get started install cdktf-cli by running `npm i -g cdktf-cli@latest` and then run `cdktf init` to initialize a broiler code for you. Choose the language and name as your choice. For this instance, I will be using typescript.

Let's add AWS providers and try to make an EC2 Instance. There are some prebuilt providers like the following for typescript. So in this case we install the AWS provider by running `npm i @cdktf/provider-aws`

If in case you are using any other language then you can add your providers to the **terraformProviders** field in the cdktf.json file and run `cdktf get` to install the constructs and convert them to your native language
{% gist https://gist.github.com/raghavmri/d9a4f6c441e885b369727bb57764cad8 %}
Here's my Typescript Code
{% gist https://gist.github.com/raghavmri/ee0d2321868277ffd170716c83c9588c
%}
Running `cdktf synth` will create a directory called **cdktf.out** where you will have your stack named folder which contains the terraform files.
Now you can run `terraform init` & `terraform plan` to initialize terraform and review your infrastructure resources and if you want to go ahead and apply the changes run `terraform apply`
### Notes
- You must have to terraform installed in order for cdktf to work. You can Download the latest version by visiting this [link](https://www.terraform.io/downloads.html)
- If you guys want me write the same for other language do let me know in the comment section below.
### Video Reference
{% youtube fgLkbNZQOh0 %}
| raghavmri |
879,488 | REACH LANGUAGE BASICS | Reach is a programming language that has been designed to work on POSIX systems with make, Docker and... | 0 | 2021-10-28T09:15:46 | https://dev.to/watiriroyalty/reach-language-basics-3lg3 | blockchain, programming, devjournal | Reach is a programming language that has been designed to work on POSIX systems with make, Docker and Docker Compose installed.
In my case, I am operating on Linux OS. The first thing that I had to do was make sure that I created a directory where I am going to install the necessary files. To do this, I used the command $ mkdir reach.
To run Reach in your project repository you can run the following command : $ curl https://docs.reach.sh/reach -o reach ; chmod +x reach. Run this command within the new directory that you just created. In this case (reach).
To initialize a new Reach project, you can run the command $ reach init or $ ./reach init . This creates a template which contains an index.rsh & a index.mjs file.
Once you have prepared your code and are now ready to run the program, you can go ahead and execute the command $ reach run or $./reach run.
What happens when this command is run is that your program is compiled with reach, a docker image is build. This image depends on the Reach Javascript standard library. A container that is based on that particular image is executed while connected to the network.
You can halt all dockerized Reach apps and devnets by running the command $ ./reach down.
To create templated Dockerfile and package.json files for a simple Reach app use the command $ ./reach scaffold.
To execute a simple react app ,especially for frontend, use the command $ ./reach react. This command assumes that the frontend React JS program is named index.js and the reach program is called index.rsh.
To execute a private Reach devnet, you can use the command $ ./reach devnet. The option --await-background is supported and runs in the background and awaits availability.
The command $ ./reach docker-reset kills and removes all docker containers.
You can upgrade your reach installation by executing $./reach upgrade
Additionally, you can update your docker images by executing the command $ ./reach update.
To check the version on reach that you currently have installed you can run the command $./reach version.
To see the exact version of Reach Docker images that you are using, you can run the command $./reach hashes.
| watiriroyalty |
879,686 | PHP Interfaces | Interfaces Interfaces allow you to create code which specifies which methods a class must... | 15,218 | 2021-10-28T11:16:27 | https://dev.to/bazeng/interfaces-261d | php, programming, tutorial | ###Interfaces
Interfaces allow you to create code which specifies which methods a class must implement, without any of the methods having their contents defined. Interfaces can be used in different classes this is referred as **Polymorphism.**
Interfaces are almost like abstract classes , difference being:
- all methods must be public in an interface unlike in an abstract class where they can be `protected` or `public`
- interfaces are declared with the `interface` keyword
- classes can inherit from other classes but still use interfaces unlike abstract classes
Its however important to note all interface methods are abstract without the `abstract` keyword
To use an interface, a class must use the `implements` keyword. See example below:
```
<?php
interface Vehicle{
public function typeOfFuel();
}
class Lorry implements Vehicle{
public function typeOfFuel(){
echo "I use Diesel";
}
}
class Sedan implements Vehicle{
public function typeOfFuel(){
echo "I use Petrol";
}
}
class Hatchback implements Vehicle{
public function typeOfFuel(){
echo "I use electricity";
}
}
$lorry = new Lorry();
$lorry->typeOfFuel();
echo "\n";
$sedan = new Sedan();
$sedan->typeOfFuel();
echo "\n";
$hatchBack = new Hatchback();
$hatchBack->typeOfFuel();
``` | bazeng |
879,778 | Set Your First Alias Command in Mac Terminal(+ z command) | Setting aliases can help you type more efficiently and work faster. In this article, I will explain... | 0 | 2021-10-28T15:21:13 | https://dev.to/shoki/set-your-first-alias-command-in-mac-terminal-z-command-1m8l | linux, beginners, git, bash | Setting aliases can help you type more efficiently and work faster. In this article, I will explain what aliases are and how to set them from the beginning. And finally, I will introduce some aliases that will help you in your coding life.
## Purpose
1. Understand what an alias is
2. Set your first alias and use it
3. Custom some other useful aliases
In the following, I will use the term "terminal" regardless of the type of shell, assuming a UNIX-like OS environment such as Mac or Linux.
## 1. What an alias is
As it turns out, aliases are like shortcut keys in the terminal.
Just like `command+x` to cut text and `command+v` to paste on Macbook, the terminal also has shortcuts.
For example, `git branch` is one of the most common commands to see what branch you are on. However, typing `git branch` every time is a bit tedious, isn't it? So, if you create an alias, you can use the git branch command just by typing `gb`.
## 2. Set your first alias and use it
### Step1. Open your .zshrc file
First, open the terminal, and type
```vim ~/.zshrc```
Then, you may see something and you may not find any in the file.
### Step2. Learn a bit about commands in Vim.
If you are knowledgeable about vim commands, you can skip this step.
Vim is one of the editors, just like Visual Studio Code, and by typing commands, you can change modes and perform operations such as editing and saving.
Followings are common commands in Vim editor:
```javascript
i
// Insert mode: Start editing from where the cursor is
```
This is one of the most commonly used commands for changing.
```javascript
esc
// Exit insert mode:Pressing Esc key will exit insert mode.
```
```javascript
dd
// Delete and copy the line containing the cursor
```
```javascript
$
// Move the cursor to the end of the line.
```
```javascript
p
// Paste the copied content after the cursor position
```
```javascript
:wq
// Save your edits and then close Vim.
// If you don't save your edits, :q works.
```
There are much more commands to edit in Vim, and you can search others if you are interested in.
### Step3. Write an alias
For now, I will show you how you can write an alias for your terminal command.
Basically, you can register an alias in the file you just created with `alias name = "command to execute"`.
For example, if you want to make an alias of `clear` command, which will clean your terminal, you just write `alias c="clear"` in insert mode. Then press the `esc` key, and enter `:wq` to save and close Vim.
### Step4. Apply the change and use the alias
To apply your changes, you need the command `source ~/.zshrc`.
After applying the changes with the command, you can now use `c` to `clear` in your terminal.
Of course, you can also customize other commands to be as short as you like.
## 3. Custom some other useful aliases
Now that you know how to create aliases, let's list some aliases that will speed up your work.
```
alias g="g"
alias cm="commit -m"
alias gb="git branch"
alias gbD="git branch -D"
alias st="git status"
alias gp="git pull"
alias gs="git switch"
alias gpo="git push origin"
alias ..="cd ../"
alias ....="cd ../../"
alias ......="cd ../../../"
alias ni="npm i"
```
## Bonus Tier z command
z command is a tool that saves the history of directory names that were once moved by `cd`, and moves to the directory by simply typing part of the directory name.
Moves by cd will be saved in ~/.zshrc, and you will be able to move to any directory there at once.
For example, once you move the directory `myFile`, the directory name is stored in ~/.zshrc. After that, you can access to `myFile` directory wherever you are by `z myFile`. (Only `z myF` also works.)
**Install z command**
```terminal
brew install z
```
```terminal
vim ~/.zshrc
```
type `i` to change to insert mode
```./zshrc
# z
. `brew --prefix`/etc/profile.d/z.sh
```
Press `esc` key, and type `:wq` to save and quit.
Then, `source ~/.zshrc` to apply the change.
Now, you can use z command.
## Summary
Setting aliases are very helpful for your work.
Why don't you make more aliases for commands frequently using to improve your work efficiency? | shoki |
879,786 | Text translation application | I have created a text translation application . It supports 16 languages this time. Have a look on it... | 0 | 2021-10-28T14:21:54 | https://dev.to/shamaz332/text-translation-application-3lm9 | javascript, programming, react, gatsby | I have created a text translation application . It supports 16 languages this time. Have a look on it . I have used Gatsby while developing this application. Please have a look my article in medium i will appreciate your feedback.
<a href="https://shamazsaeed.medium.com/text-translation-application-in-gatsbyjs-d92065fd3fea">https://shamazsaeed.medium.com/text-translation-application-in-gatsbyjs-d92065fd3fea</a> | shamaz332 |
880,024 | Svelte with Vite and TailwindCSS | What is Tailwind CSS? Tailwind CSS is a utility-first CSS framework with classes that can... | 0 | 2021-10-28T16:09:38 | https://eternaldev.com/blog/svelte-with-vite-and-tailwindcss | svelte | ---
title: Svelte with Vite and TailwindCSS
published: true
date:
tags: svelte
canonical_url: https://eternaldev.com/blog/svelte-with-vite-and-tailwindcss
cover_image: https://www.eternaldev.com/static/97a2100e3efae3ff5d3b5afec8840bc7/aa1b3/svelte.webp
---
## What is Tailwind CSS?
Tailwind CSS is a utility-first CSS framework with classes that can be composed to build UI. They provide easy classes to replace the CSS you will be writing. You can add multiple CSS classes which are documented in the tailwind website and create the design which you want. This removes the need for coming up with clear names for your CSS class and trying your best to reuse them in your projects.
[TailwindCSS website](https://tailwindcss.com/) contains good documentation of their different classes and how to use them
## Setting up Svelte with Vite
You can create a new project with Svelte and vite by following this guide posted earlier. You should find details on why to use Vite and how to setup the Svelte project with ease.
[https://www.eternaldev.com/blog/build-and-deploy-apps-with-svelte-and-vite/](https://www.eternaldev.com/blog/build-and-deploy-apps-with-svelte-and-vite/)
## Adding TailwindCSS
There are different ways to add TailwindCSS to svelte apps.
1. Svelte with Rollup - If you would like to configure the Tailwind in Svelte which uses Rollup, you can check out the other tutorial like [this](https://css-tricks.com/how-to-use-tailwind-on-a-svelte-site/)
2. Svelte with Vite - You can follow this tutorial to setup TailwindCSS with Svelte and Vite
## What is Svelte Add
Svelte add is a community project to easily add integrations and other functionality to Svelte apps. So you can use this to easily add the TailwindCSS to your Svelte and Vite powered apps. Note that this will work for Vite-powered Svelte apps and SvelteKit.
**Note: This method is recommended for projects you are just freshly initialized. Existing projects may face some issues.**
If you are interested in finding more about other integrations, check out the [Github project](https://github.com/svelte-add)
## Running the Svelte Add command
Go to the root of your project directory and run the following command
```bash
npx svelte-add@latest tailwindcss
```
This command will do a lot of configuration for you. After running the command you can install the new package which are added from this process
```
npm install
```
## Start using TailwindCSS
Once the above steps are completed, you can start using the tailwind CSS in your Svelte app.
Let's build something with our newfound Tailwind CSS power. Instead of the regular todo application, let's build the activity feed from GitHub.
[](/static/106cd4b48e9824064978b83824da9290/350de/gihub_reference.png)
Create a new model.ts file for storing the data in Typescript
```ts
export interface ActivityContent {
profileName: string;
profileUrl: string;
time: string;
repo: Repository
}
interface Repository {
name: string;
url: string;
description: string;
language: string;
stars: number;
updatedDate: string;
}
```
Create a new svelte file and call it ActivityItem.svelte
```ts
<script type="ts">
import type { ActivityContent } from "src/models";
import logo from "../assets/svelte.png";
var activityContent: ActivityContent = {
profileName: "profile2",
profileUrl: "https://github.com/eternaldevgames",
time: "4 days ago",
repo: {
name: "eternaldevgames/svelte-projects",
url: "https://github.com/eternaldevgames/svelte-projects",
description: "This Repository contains multiple svelte project to learn",
language: "Svelte",
stars: 2,
updatedDate: "Oct 15",
},
};
</script>
<div class="p-3 m-3">
<div class="flex flex-row items-center">
<img class="h-8 w-8 rounded-full bg-gray-200" src={logo} alt="hero" />
<h4 class="p-2">
<a href={activityContent.profileUrl}>{activityContent.profileName}</a>
started the repo
<a href={activityContent.repo.url}>{activityContent.repo.name}</a>
</h4>
<p class="text-gray-500 text-sm">{activityContent.time}</p>
</div>
<div class="ml-8 p-5 rounded-lg bg-white border border-black">
<a class="text-lg" href={activityContent.repo.url}
>{activityContent.repo.name}</a
>
<p>{activityContent.repo.description}</p>
<div class="flex flex-row items-center mt-4">
<div class="w-3 h-3 bg-red-600 rounded-full ml-1 mr-1" />
<p class="mr-5">{activityContent.repo.language}</p>
<img
src="https://img.icons8.com/material-outlined/24/000000/star--v2.png"
alt="star"
/>
<p class="ml-1 mr-5">{activityContent.repo.stars}</p>
<p class="mr-5">Updated {activityContent.repo.updatedDate}</p>
</div>
</div>
</div>
```
Here is the result
[](/static/a205776e12bae4ce66e91264d92171a6/d61c2/tailwind1.png)
## Breakdown of TailwindCSS classes
Since we have all the components styles with Tailwind classes, we will breakdown on some of the important classes which will help you in the next project
```ts
<div class="p-3 m-3">
```
`p-3` refers to the padding on all the sides. The number 3 represents how much padding is added.
```ts
padding: 0.75rem;
```
Similarly, `m-3` refers to adding the margin on all the sides.
```ts
<img class="h-8 w-8 rounded-full bg-gray-200" src={logo} alt="hero" />
```
For the image, we can add the height and width using `h-8` and `w-8`
`rounded-full` can be used to create circles. So it is useful in creating circle avatars for the profile picture.
`bg-gray-200` is used to add background color to the element. The cool thing here is you can replace gray-200 with any color of your choice and it gets set as a background color.
```ts
<p class="text-gray-500 text-sm">{activityContent.time}</p>
```
`text-gray-500` is used to set the font color of the element.
```ts
<div class="ml-8 p-5 rounded-lg bg-white border border-black">
```
`border` is used to add border of 1px
`border-black` is used to add the border-color as black
```ts
<div class="flex flex-row items-center mt-4">
```
`flex` is used to set the display to flex
`flex-row` is used to set the flex-direction to row
`items-center` is used to set the align-items property to center
TailwindCSS has a really good docs site if you want to learn more about the classes used
[https://tailwindcss.com/docs](https://tailwindcss.com/docs)
## Summary
You can see that it is easier to add CSS styles without defining a separate class for each element. This method is a lot faster than adding individual classes but you will have to learn the different classes of TailwindCSS to create content faster.
Join our Discord - [https://discord.gg/AUjrcK6eep](https://discord.gg/AUjrcK6eep) and let's have a discussion there | eternal_dev |
898,338 | Code Smell 102 - Arrow Code | Code Smell 102 - Arrow Code Nested IFs and Elses are very hard to read and test TL;DR: Avoid... | 9,470 | 2021-11-15T03:04:25 | https://maximilianocontieri.com/code-smell-102-arrow-code | oop, javascript, cleancode, refactoring | Code Smell 102 - Arrow Code
*Nested IFs and Elses are very hard to read and test*
> TL;DR: Avoid nested IFs. Even Better: Avoid ALL IFs
# Problems
- Readability
# Solutions
1. Extract Method
2. Combine Boolean Conditions
3. Remove accidental IFs
# Context
In procedural code, it is very common to see complex nested ifs. This is more related to scripting than object-oriented programming.
# Sample Code
## Wrong
[Gist Url]: # (https://gist.github.com/mcsee/0313b55715cf050e4eadb80e7b0ffad2)
```javascript
if (actualIndex < totalItems)
{
if (product[actualIndex].Name.Contains("arrow"))
{
do
{
if (product[actualIndex].price == null)
{
// handle no price
}
else
{
if (!(product[actualIndex].priceIsCurrent()))
{
// add price
}
else
{
if (!hasDiscount)
{
// handle discount
}
else
{
// etc
}
}
}
actualIndex++;
}
while (actualIndex < totalCounf && totalPrice < wallet.money);
}
else
actualIndex++;
}
return actualIndex;
}
```
## Right
[Gist Url]: # (https://gist.github.com/mcsee/a01fc3411e8aff647a2ff0812f313318)
```javascript
foreach (products as currentProduct)
addPriceIfDefined(currentProduct)
addPriceIfDefined()
{
//Several extracts
}
```
# Detection
[X] Automatic
Since many linters can parse trees we can check on compile-time for nesting levels.
# Tags
- Readability
- Complexity
# Conclusion
Following [uncle bob's advice](https://learning.oreilly.com/library/view/97-things-every/9780596809515/ch08.html), we should leave the code cleaner than we found it.
Refactoring this problem is easy.
# Relations
{% post https://dev.to/mcsee/code-smell-78-callback-hell-287f %}
{% post https://dev.to/mcsee/code-smell-03-functions-are-too-long-4hji %}
{% post https://dev.to/mcsee/code-smell-36-switch-case-elseif-else-if-statements-h6c %}
# More Info
- [C2 Wiki](http://wiki.c2.com/?ArrowAntiPattern)
- [Flattening Arrow Code](https://blog.codinghorror.com/flattening-arrow-code/)
* * *
> The purpose of software engineering is to control complexity, not to create it.
_Pamela Zave_
{% post https://dev.to/mcsee/software-engineering-great-quotes-26ci %}
* * *
This article is part of the CodeSmell Series.
{% post https://dev.to/mcsee/how-to-find-the-stinky-parts-of-your-code-1dbc %} | mcsee |
898,380 | Third week TaskForce 4.0 BootCamp | Hello folks, it's been a while; I hope you are doing great and safe. Today's top is essential in... | 0 | 2021-11-15T05:04:42 | https://dev.to/habaumugisha1/third-week-taskforce-40-bootcamp-3p1o | codeofafrica, awesomitylab, taskforce | Hello folks, it's been a while; I hope you are doing great and safe.
Today's top is essential in software development, which is database design. In software development, we need to store data for future use in data analysis and decision making. For keeping and retrieving our data, we should prepare where we will keep it conveniently.

When it comes to database design, it means data security in a database and easy access, removing data redundancy or repeating of the data, because it can increase the cost for data, as a developer should minimize the cost but increase the efficiency of the database's application.
In database design consists of many things. According to its definition, it is a collection of steps that help create, implement, and maintain data in a database's system. The main goal of database design is to produce physical and logical models of structures of a database system.
ERD stands for Entity Relationship Diagram. ERD is a diagram that displays the relationship of entity sets stored in a database; ERD will help us determine a good database design by showing the entity, relationship, and attributes within a particular database.
An entity in a database is a thing, person, place, unit, object or any item about which the data should be captured and stored in the form of properties, workflow and tables.
A relationship is it shows how the tables will share the data between them. It shows which table has a foreign key from another table and which cardinality, like many-to-many, many-to-one, and one-to-one.
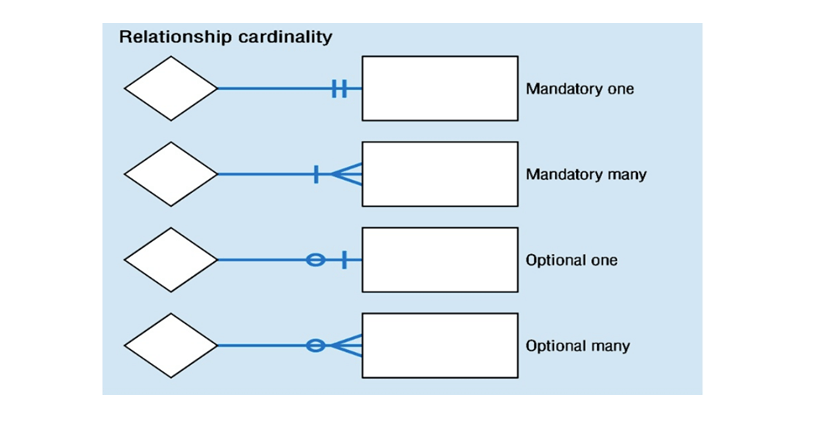
In ERD, we determine which are strong and weak entities according to their relationship associated in a database; a strong entity is the one whose existence does not depend on any other entity in a schema. While a weak entity is an entity that cannot be identified uniquely by its attributes alone; therefore, it must use a foreign key in conjunction with its attributes to create a primary key.
As we have seen above, before diving into coding, first spend your time designing a database to save future database useability.
Thank you, #AwesomityLab, #taskForce, and #CodeOfAfrica, for helping me to know this excellent concept you provided to me.
Thank you folks for reading; let's wait next week for what will come with us.
| habaumugisha1 |
898,559 | Let's Build Express Server. Beginners Guide | What Is Express Js? Express Js Is Web Framework For Node.js Where To Use Express... | 0 | 2021-11-15T09:53:52 | https://dev.to/shreyanshsheth/lets-build-express-server-beginners-guide-3od1 | javascript, webdev, beginners, node | ## What Is Express Js?
Express Js Is Web Framework For Node.js
## Where To Use Express Js
- Most Popular Use Of Express Js In the Current Time Is To Create Web Apis.
- Also Some People Are Using To Create Full-stack Web App With using Pug, Ejs, Or Basic HTML
> here we are going to create a simple API to understand concepts of express
## Getting Started
### Requirements
- You need Node.js Installed In Your System. You can download node.js from [Node.js](https://nodejs.org/en/)
- Open New Directory And Write This command to initialize a new project.
` npm init -y`
-Now install express as dependencies for your project
`npm install express`
## Create basic hello world API
1. Create index.js file and import express js & initialize the app

2. Create an endpoint
>in simple term endpoint is a path where you are getting expected data
`/users return all users`
`/products returns all products`
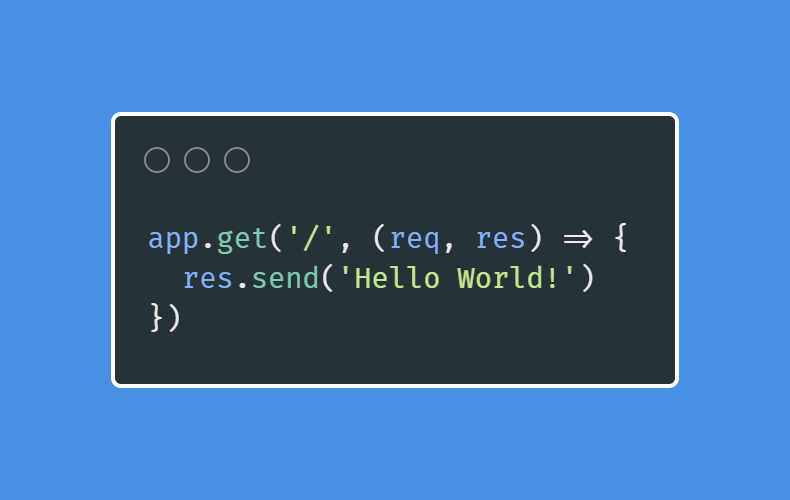
here we have created endpoint `/` where we are sending hello world as a response.
3 Open a port for connections

4. Run application
> write `node index.js` to start the application
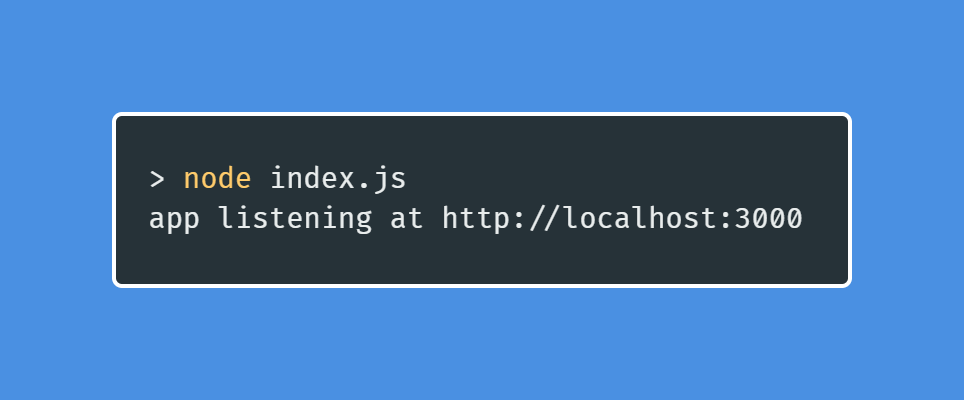
5. open localhost:3000 on browser
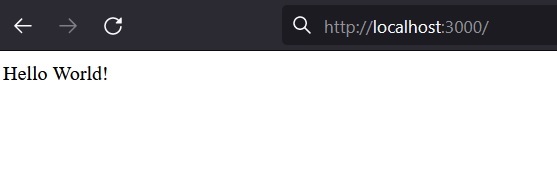
#hooray you made it 🥳
### what now
now try to render Html. try to create forms & process data using any database.
> find material online and create your own express apps.
| shreyanshsheth |
898,819 | Microsoft Learn Student Ambassador Program | What Is Microsoft Learn Student Ambassadors Program? Microsoft Learn Student Ambassador... | 0 | 2021-11-15T14:58:24 | https://dev.to/seths10/microsoft-learn-student-ambassador-program-2hnk | microsoft, beginners, javascript, career | ### What Is Microsoft Learn Student Ambassadors Program?
**Microsoft Learn Student Ambassador** program is aimed at bringing students all over the world who has interest in technology together. These students get the opportunity to connect and interact with others on topics they are passionate about (mostly Microsoft Technologies). Also, they are able to organize events to teach each other various tech stacks.

###Application Requirements
* You must be **16** years or older.
* You must be enrolled in an accredited academic institution(eg: **college**, **university**).
* You must not be a Microsoft or Government employee.
* You need to at least have some basic knowledge in coding.
###Why Should You Join?
There are a lot of benefits for joining this amazing program. A few of them are listed below:
* Free Swag Box from Microsoft
* Access to Microsoft 365
* Access to TechSmith products(i.e Camtasia and Snagit)
* Name.com voucher
* Azure credits
* LinkedIn Learning Voucher
>NOTE: Some of these benefits are given to you based on the milestone you have achieved.

###How Do I Apply Then?
To apply, Use this Link: [Apply for MLSA](https://studentambassadors.microsoft.com/)
####Steps Involved:
1. Login or Create a new Microsoft account. After that, Click o **Apply Now**.

2. Read all the Terms and Conditions. Once you are done with the conformation, Click on Next to move to the **Personal Information** section.

Here, you will fill the fields with information about yourself (i.e your Name, Gender, Date of Birth, etc)
3. Now move onto the **Academic Institution** section, Enter the required information about your academic institution. After that, Let's go to the **Written Sample** section.

4. The **Written Sample** section is one of the most important section. Here you will talk about why you want to be a part of the program, how you will get students to attend your events and also how you will teach technical concepts to beginners. This helps the recruiters to see how valuable and passionate you can be to the program.

> NOTE: For one of the **3** questions, you will have to produce a video presentation of yourself explaining that particular topic you have chosen.
5. When you are done with that, move to the **social media** section. Here, as the name indicate, you will provide links to your social media accounts including LinkedIn, twitter, Instagram, Stack Overflow, etc. If you have written an article about any tech product you can provide a link to it. You can also provide links to your portfolio website if you have one.
>NOTE: This section is also very important because your online presence, projects and other amazing stuffs you have been will be viewed.

6. Finally, Now move to the Final Section (**Additional Information**), Provide any other information about yourself (it can be achievements or personal stuffs about you) that you think the recruiters need to know about you.
I hope that this was helpful to you. If you have any questions, please drop it in the comment section below and I will make sure to answer all questions you have. Also, you can connect with me on:
Twitter: https://twitter.com/set_addo
LinkedIn: https://linkedin/in/seth-addo-034327190
Thanks For Reading | seths10 |
898,830 | Tim Sort. | Tim sort is a hybrid, stable sorting algorithm which uses insertion sort to sort small blocks and... | 0 | 2021-11-15T15:36:05 | https://dev.to/hagarbarakatt/tim-sort-3d4b | programming, python, algorithms | **Tim sort** is a hybrid, stable sorting algorithm which uses insertion sort to sort small blocks and then merge them using merge function of merge sort, the idea is that insertion sort is typically faster for small arrays.
It is used by sort built-in functions used in python and java languages.
Technically, **Tim sort** was implemented in 2002 by Tim Peters in to be used in Python.
##How it works:
1. An array is divided to number of blocks known as ***Runs,*** the size of a ***Run*** is either 32 or 64 depending on the size of the array, if the size of an array is less than the **run** then the whole array is sorted just by using insertion sort.
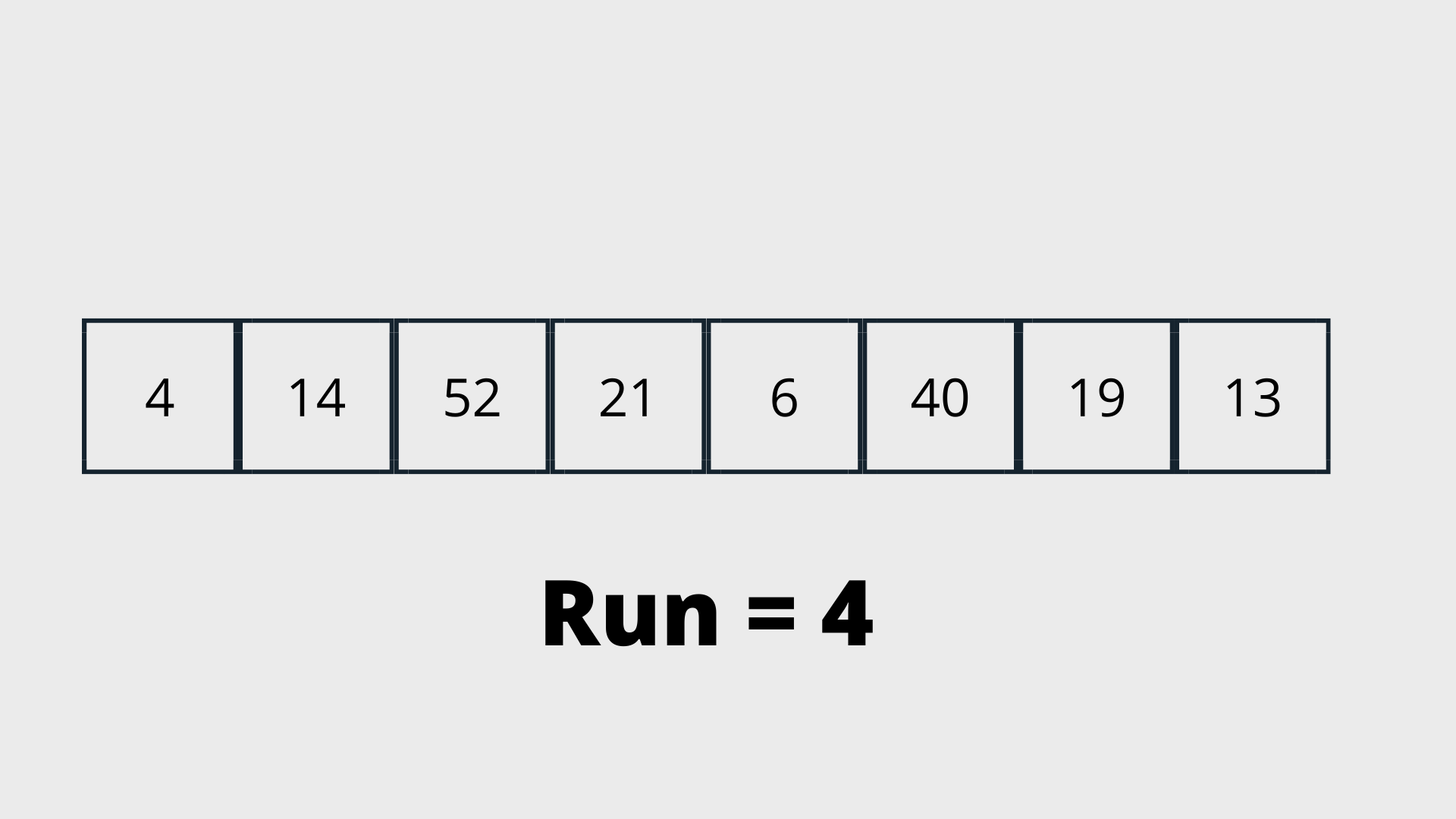
2. Sort each **run** using insertion sort.
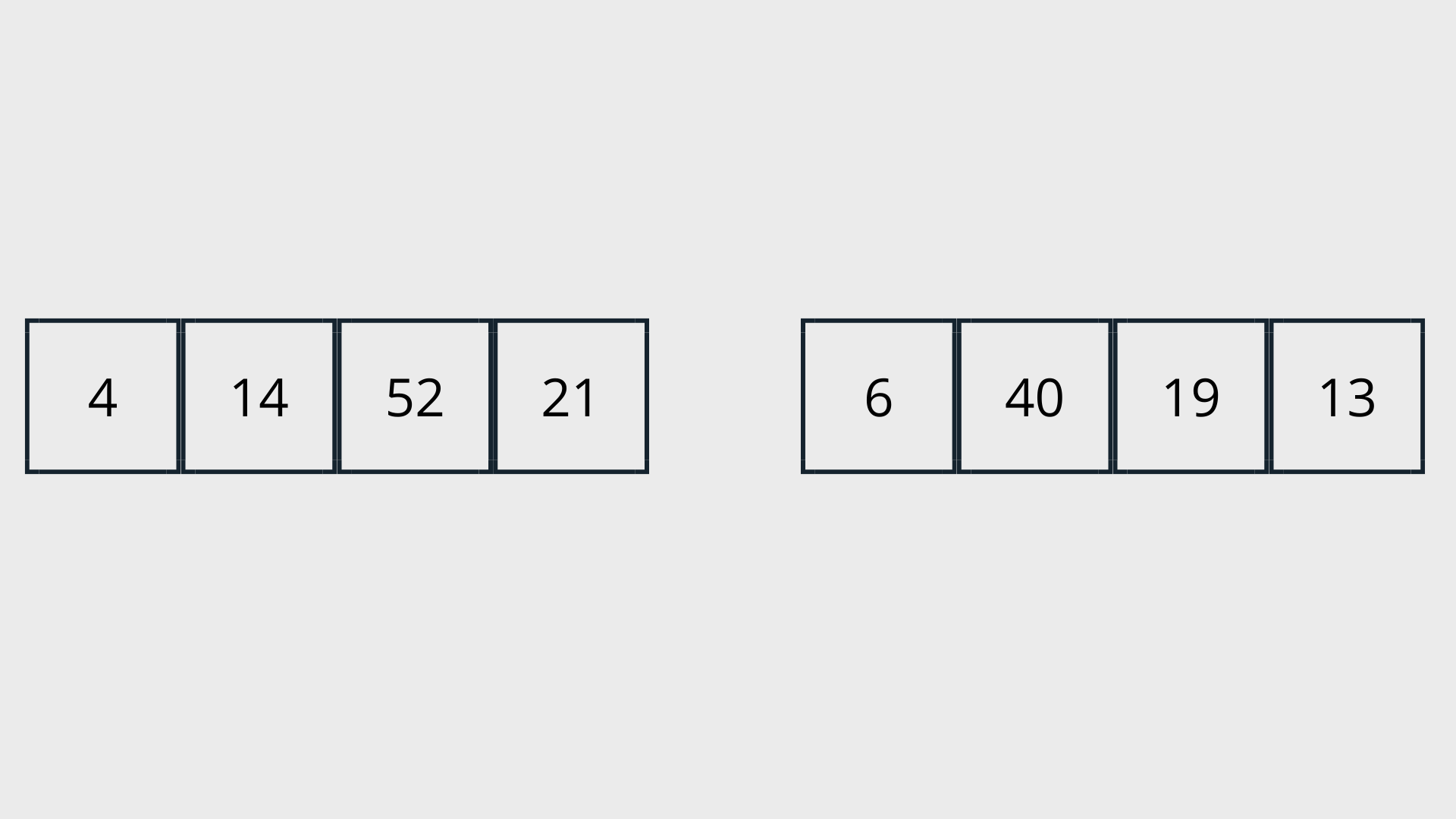
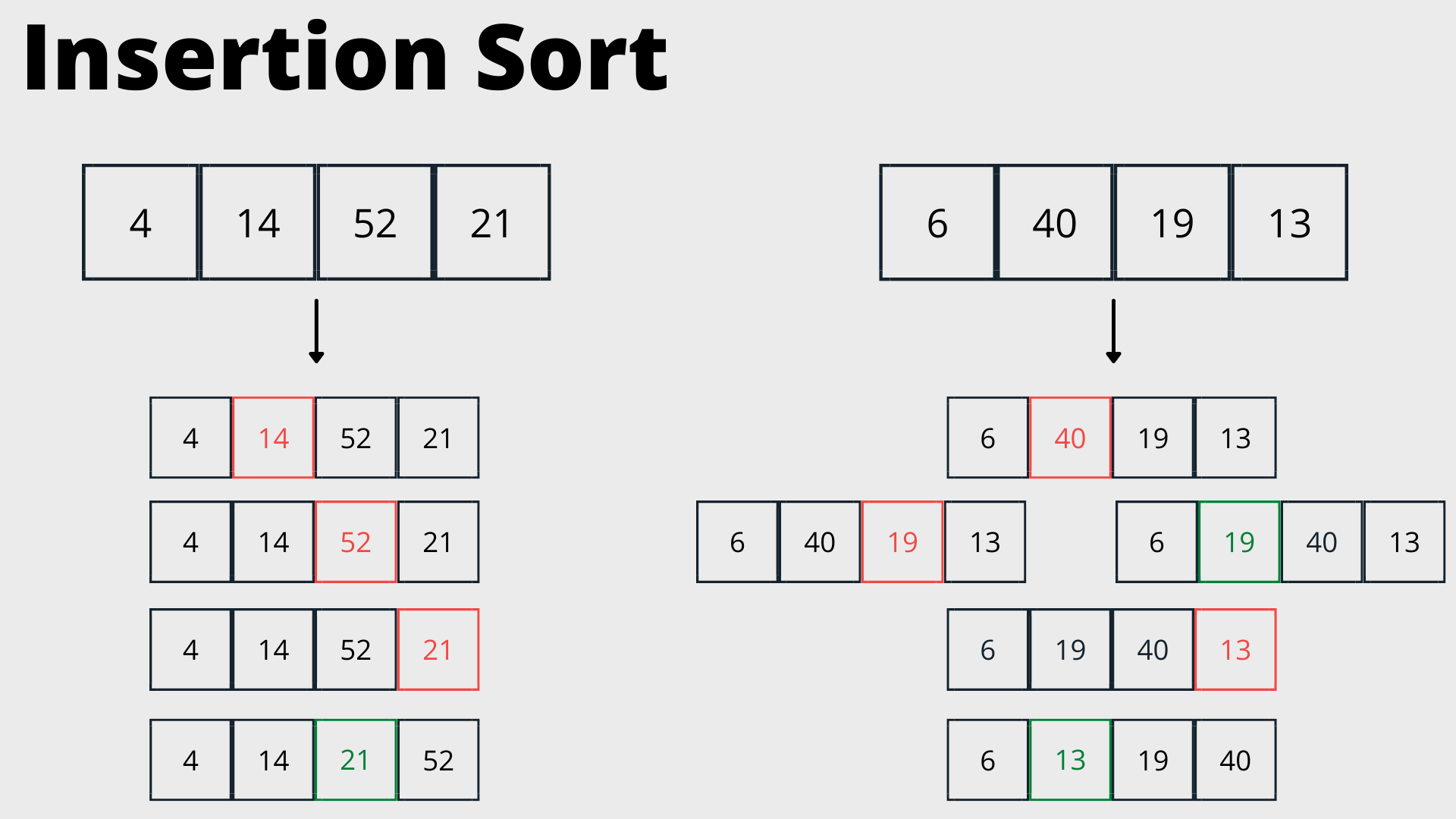
3. Merge sorted **run** using merge function of merge sort.
4. Double the size of merged subarray after each iteration.
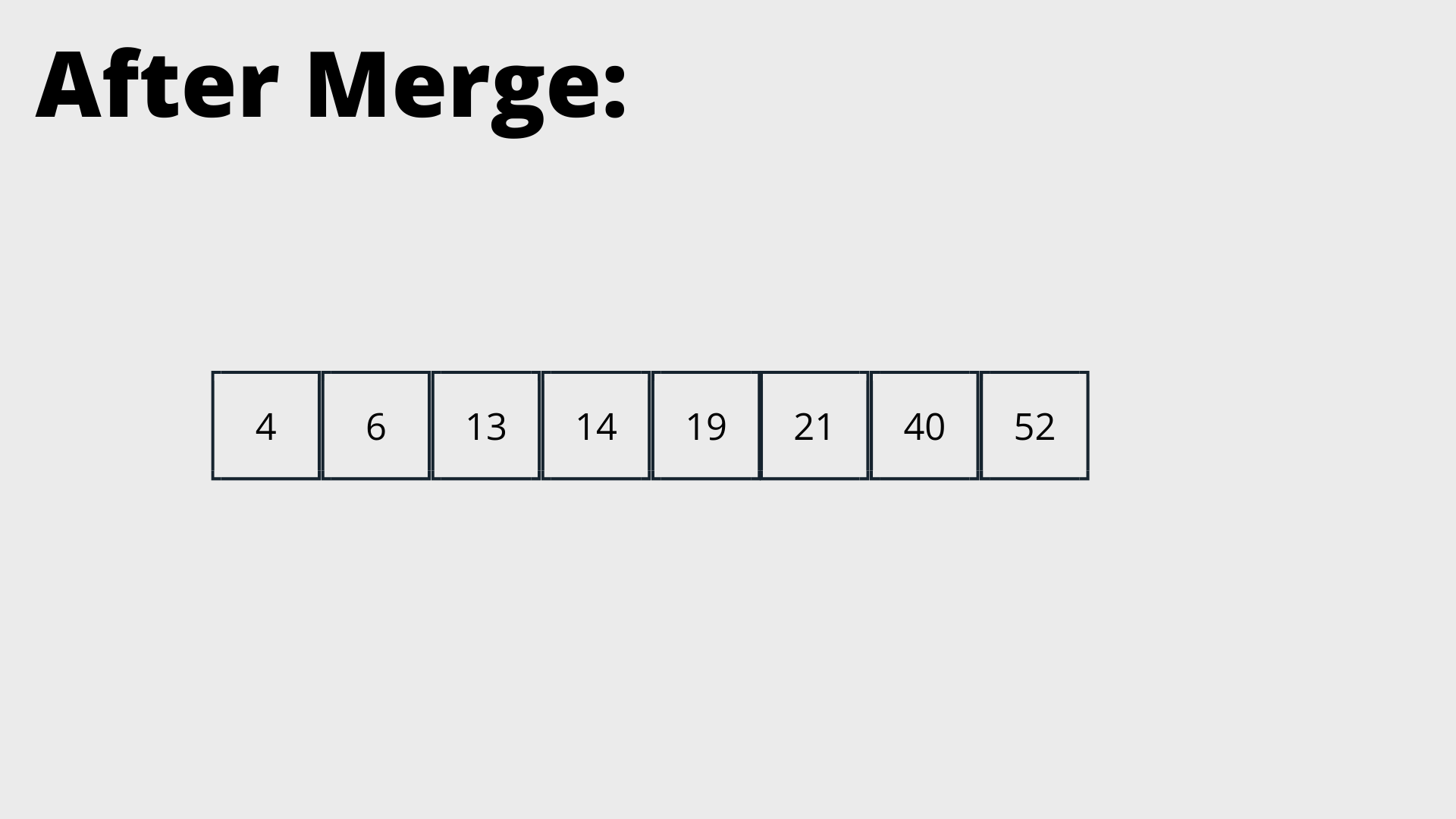
##What's minimum run?
Minimum run is the smallest size of each **run**, ***minimum run*** shouldn't be:
- too big as insertion sort is faster with small array.
- too small so that it will give more number of runs that will be merged through merge function of merge sort.
For better results make sure that size of subarrays **size of array/minimum run** is of power of 2 as merge function of merge sort performs better with this case.
```python
minrun = 32
def min_run(n):
run = 0
while n >= minrun:
run |= n & 1
n >>= 1
return n + run
def insertion_sort(arr, left, right):
for i in range(left + 1, right + 1):
j = i
while j > left and arr[j] < arr[j - 1]:
arr[j], arr[j - 1] = arr[j - 1], arr[j]
j -= 1
def merge(arr, left, mid, right):
len_arr1, len_arr2 = mid - left + 1, right - mid
left_arr, right_arr = [],[]
for i in range(0, len_arr1):
left_arr.append(arr[left + i])
for i in range(0, len_arr2):
right_arr.append(arr[mid + 1 + i])
i, j, k = 0, 0, left
while i < len_arr1 and j < len_arr2:
if left_arr[i] <= right_arr[j]:
arr[k] = left_arr[i]
i += 1
else:
arr[k] = right_arr[j]
j += 1
k += 1
while i < len_arr1:
arr[k] = left_arr[i]
i += 1
k += 1
while j < len_arr2:
arr[k] = right_arr[j]
j += 1
k += 1
def tim_sort(arr):
minimum_run = min_run(len(arr))
for start in range(0, len(arr), minimum_run):
end = min(start + minimum_run - 1, len(arr) - 1)
insertion_sort(arr, start, end)
size = minimum_run
while size < len(arr):
for left in range(0, len(arr), 2 * size):
mid = min(len(arr) - 1, left + size - 1)
right = min(left + 2 * size -1, n - 1)
merge(arr, left, mid, right)
size = 2 * size
array = [4, 14, 52, 21, 6, 40, 19, 13]
print("Array:")
print(array)
tim_sort(array)
print("Sorted Array:")
print(array)
```
###Complexity:
####Time Complexity:
Complexity | value
--- | ---
*Best* | **O(n)**
*Average* | **O(n log n)**
*Worst* | **O(n log n)**
#####Best Case: **O(n)**
- Happens when the array is already sorted.
#####Worst Case: **O(n log n)**
- Happens when the array is sorted in reverse order.
####Space Complexity: **O(n)**
| hagarbarakatt |
898,847 | The Glue That Binds Forms Together | Monster makes it quick and easy to create forms. | 15,528 | 2021-11-15T22:49:47 | https://dev.to/schukai/the-glue-that-binds-forms-together-3b01 | javascript, forms, webdev, webdesign | ---
title: The Glue That Binds Forms Together
published: true
description: Monster makes it quick and easy to create forms.
tags: javascript, forms, webdev, webdesign
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/v5fdketexdca35zqlqhs.png
series: Manage Forms with Monster
---
The first two parts were about the on-board tools that HTML and Javascript provide for developing great forms. Now let's get to the missing parts.
## The glue
However, besides these great capabilities that the browser already offers, there are still a few small parts missing to make a form perfect. Among others, the data storage, the sending of the data and the processing of the server response.
These can, as always, be closed with custom javascript. There are already many great extensions, plug-ins and code samples to implement the missing parts.
Why did we decide to develop our own solution for the missing parts? The simple and rational answer is that none of the solutions meet our requirements 100%. The less rational answer is that we can do it and have a lot of fun developing Monster.
Here we have a normal simple form.
<br><br>

<br><br>
So what do we need? First, a way to load data from a data source, then a way to display this data in the form, and finally to submit the form again.
## Custom elements
We decided to use custom elements as the basis for our form. On the one hand we find the technology impressive and on the other hand we can encapsulate the functionality well.
We use the CustomElement class from the Monster library for our form. As tag name we use the tag `monster-form`.
```javascript
class Form extends CustomElement {
static getTag() {
return "monster-form"
}
}
```
For data storage we use the Javascript Proxy object, which we extended with some tape. We call the object ProxyObserver.
The data itself comes via a `DataSource` object from the Monster library.
The finished class can be found in the Monster Form NPM Repos `@schukai/component-form`.
Besides the `CustomElement` we also use the ProxyObserver and the Updater class. This allows us to react to changes in the data.
Now we can include the form in an HTML page.
```html
<monster-form
data-monster-datasource="restapi"
data-monster-datasource-arguments="">
<input name="fieldIID"
id="fieldIID"
data-monster-bind="path:iid"
data-monster-attributes="value path:iid">
<!-- more fields -->
</monster-form>
```
As far as here follows more ...
## References
- [developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy)
- [npmjs.com/package/@schukai/component-form](https://www.npmjs.com/package/@schukai/component-form)
- [monsterjs.org/en/doc/1.24.0/Monster.DOM.CustomControl.html](https://monsterjs.org/en/doc/1.24.0/Monster.DOM.CustomControl.html)
- [monsterjs.org/en/doc/components/form/1.7.0/](https://monsterjs.org/en/doc/components/form/1.7.0/)
- [developer.mozilla.org/en-US/docs/Web/Web_Components/Using_custom_elements](https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_custom_elements)
| volker_schukai |
899,033 | kedro catalog create | I use kedro catalog create to boost my productivity by automatically generating yaml catalog entries... | 0 | 2021-11-15T17:36:18 | https://dev.to/waylonwalker/kedro-catalog-create-3d2d | kedro, python | ---
templateKey: blog-post
tags: ['kedro', 'python']
title: kedro catalog create
published: true
---
I use `kedro catalog create` to boost my productivity by automatically
generating yaml catalog entries for me. It will create new yaml files for each
pipeline, fill in missiing catalog entries, and respect already existing
catalog entries. It will reformat the file, and sort it based on catalog key.
{% youtube _22ELT4kja4 %}
https://waylonwalker.com/what-is-kedro/
> 👆 Unsure what kedro is? Check out this post.
## Running Kedro Catalog Create
The command to ensure there are catalog entries for every dataset in the passed
in pipeline.
``` bash
kedro catalog create --pipeline history_nodes
```
* Create's new yaml file, if needed
* Fills in new dataset entries with the default dataset
* Keeps existing datasets untouched
* it will reformat your yaml file a bit
* default sorting will be applied
* empty newlines will be removed
## CONF_ROOT
Kedro will respect your `CONF_ROOT` settings when it creates a new catalog
file, or looks for existing catalog files. You can change the location of your
configuration files by editing your `CONF_ROOT` variable in your projects.
`settings.py`.
``` python
# settings.py
# default settings
CONF_ROOT = "conf"
# I like to package my configuration
CONF_ROOT = str(Path(__file__).parent / "conf")
```
> I prefer to keep my configuration packaged inside of my project. This is
> partly due to how my team operates and deploys pipelines.
## File Location
The `kedro catalog create` command will look for a `yaml` file based on the
name of the pipeline (`CONF_ROOT/catalog/<pipeline-name>.yml`). If it does not
find one it will create one and make entries for each dataset in the pipeline.
It will not look in all of your existing catalog files for entries, only the
one in the exact file for your pipeline. If you are going to use this command
its important that you follow this pattern or copy what it generates into your
own catalog file of choice.
> ⚠️ It will not look in all of your existing catalog files for entries, only the
one in the exact file for your pipeline.
## MemoryDataSet's
When you run `kedro catalog create` you get `MemoryDataSet`, that's it. As of
`0.17.4` its hard coded into the library and not configurable.
``` yaml
range12:
type: MemoryDataSet
```
## Your free to use what you want though
Let's switch this dataset over to a `pandas.CSVDataSet` so that the file gets
stored and we can pick up and read the file without re-running the whole
pipeline.
``` yaml
range12:
type: pandas.CSVDataSet
filepath: data/range12.csv
```
## Continue adding nodes
As we work we will keep adding nodes to our kedro pipeline, in this case we
added another node that created a dataset called `range13`.
``` bash
kedro catalog create --pipeline history_nodes
```
After telling kedro to create new catalog entries for us we will see that it
left our `range12` entry alone and created `range13` for us.
``` yaml
range12:
type: pandas.CSVDataSet
filepath: data/range12.csv
range13:
type: MemoryDataSet
```
## Formatting is not worthwhile
If we decide this is too cramped for us we could add some space between
datasets. The next time we run `kedro catalog create` empty lines will be
removed.
``` yaml
range12:
type: pandas.CSVDataSet
range13:
type: MemoryDataSet
```
## Continuing to work
If we coninue adding new nodes, and tell kedro to create catalog entries again,
all of our effort given to formatting will be lost. I wouldn't worry about it
unless you have an autoformatter that you can run on your yaml files. The
productivity gains in an semi-automated catalog are worth it.
``` yaml
range12:
type: pandas.CSVDataSet
filepath: data/range12.csv
range121:
type: MemoryDataSet
range13:
type: MemoryDataSet
```
## Sorting Order
Notice the sorting order in the last entry, `range121` comes before `range13`.
This is all based on how pythons `yaml.safe_dump` works, kedro has set the
`default_flow_style` to `False`. You can see where they write your file in the
source code currently
[here](https://github.com/quantumblacklabs/kedro/blob/master/kedro/framework/cli/catalog.py#L202)
| waylonwalker |
899,250 | ใช้คำสั่ง docker บน Ubuntu โดยไม่ต้องใช้ sudo | หลังจากลง Docker บน Ubuntu แล้วนั่นเราจะใช้งานมันได้เราต้องใช้สิทธิ์ root ซึ่งต้องสั่ง docker โดยใช้... | 0 | 2021-11-16T00:56:26 | https://dev.to/iporsut/aichkhamsang-docker-bn-ubuntu-odyaimtngaich-sudo-3f1h | docker, ubuntu | หลังจากลง Docker บน Ubuntu แล้วนั่นเราจะใช้งานมันได้เราต้องใช้สิทธิ์ root ซึ่งต้องสั่ง docker โดยใช้ sudo เช่น `sudo docker ps`
แต่ถ้าเราอยากสั่งโดยไม่ต้องใช้ sudo ก็สามารถทำได้โดยเพิ่ม user ของเราเข้าไปใช้ usergroup ที่ชื่อว่า `docker` ด้วยคำสั่งแบบนี้
```
sudo usermod -aG docker $USER
```
หลังจากนั้น logout แล้ว login อีกที (ถ้าไม่ได้ก็จัดการ restart OS อีกรอบ) เราก็สามารถสั่งคำสั่ง `docker` ด้วย user เราเองโดยไม่ต้องใช้สิทธิ์ root ผ่าน sudo อีกแล้ว เช่น
```
docker run hello-world
```
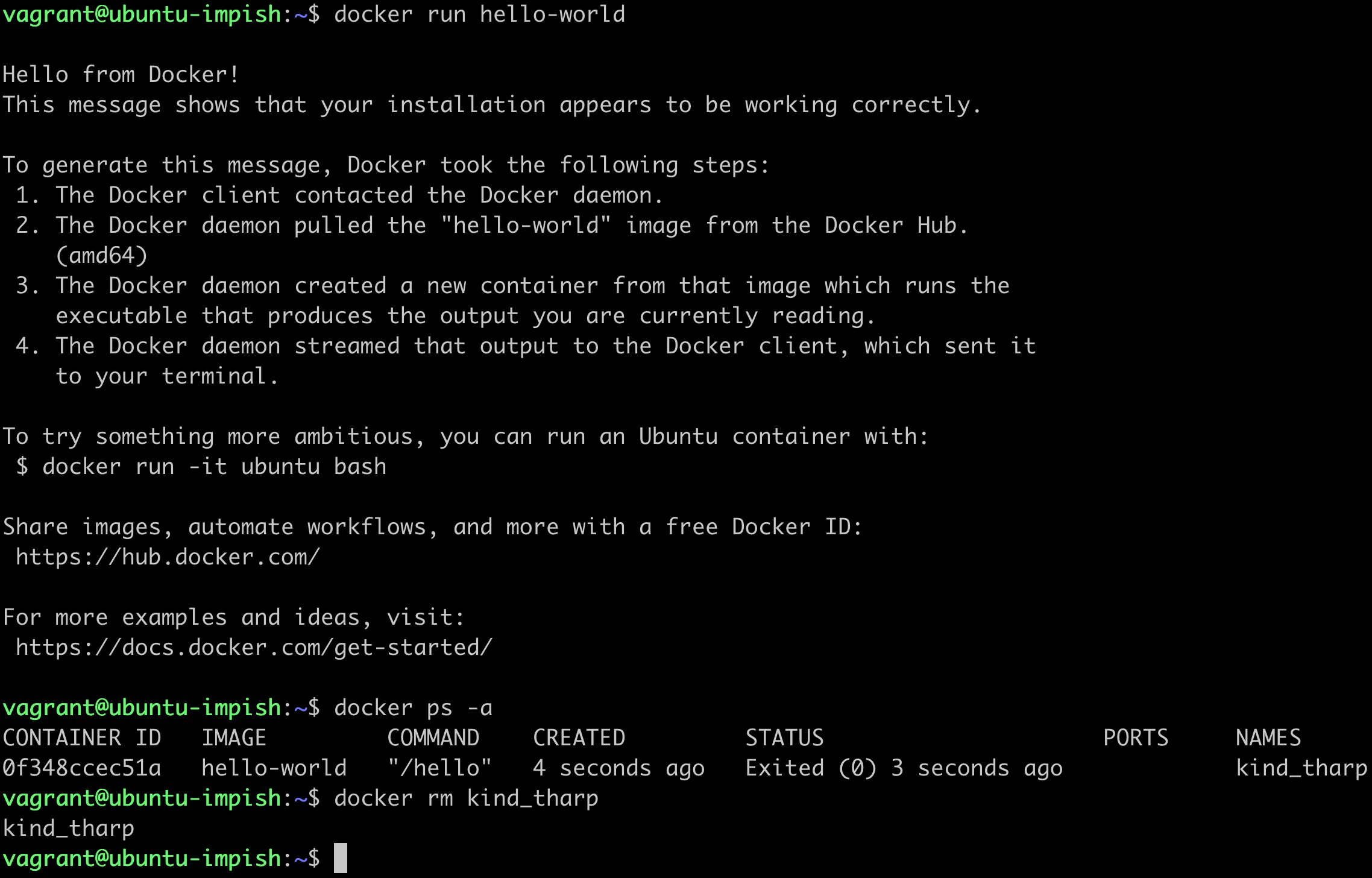
อ้างอิง: https://docs.docker.com/engine/install/linux-postinstall/ | iporsut |
899,338 | Microsoft Learn Student Ambassador Program | What Is Microsoft Learn Student Ambassadors Program? Microsoft Learn Student Ambassador... | 0 | 2021-11-16T03:37:01 | https://dev.to/aniketmishra/microsoft-learn-student-ambassador-program-36e | microsoft, beginners, programming, azure | ## What Is Microsoft Learn Student Ambassadors Program?
Microsoft Learn Student Ambassador program is aimed at bringing students all over the world who has interest in technology together. These students get the opportunity to connect and interact with others on topics they are passionate about (mostly Microsoft Technologies). Also, they are able to organize events to teach each other various tech stacks.

## Application Requirements
You must be 16 years or older.
You must be enrolled in an accredited academic institution(eg: college, university).
You must not be a Microsoft or Government employee.
You need to at least have some basic knowledge in coding.
## Why Should You Join?
There are a lot of benefits for joining this amazing program. A few of them are listed below:
Free Swag Box from Microsoft
Access to Microsoft 365
Access to TechSmith products(i.e Camtasia and Snagit)
Name.com voucher
Azure credits
LinkedIn Learning Voucher
Free access to one or more Microsoft Certification voucher and more.
**NOTE**: Some of these benefits are given to you based on the milestone you have achieved.
## Apply Here
To apply, Use this Link: [Apply for MLSA](https://studentambassadors.microsoft.com/)
I hope that this was helpful to you. If you have any questions, please drop it in the comment section below and I will make sure to answer all questions you have. Also, you can connect with me on:
[Twitter](https://twitter.com/aniketmishra0)
[LinkedIn](https://linkedin/in/aniketmishra0) | aniketmishra |
899,343 | Setup Passport functionality in Laravel | First of all install laravel new project by composer composer create-project laravel/laravel... | 0 | 2021-11-16T03:50:43 | https://easycodesardar.blogspot.com/2021/11/Setup%20Passport%20functionality%20in%20Laravel.html | laravel, passport, php, mysql |
First of all install laravel new project by composer
composer create-project laravel/laravel laraERP
Important: please add namespace inside RouteServiceProvider
protected $namespace = 'App\Http\Controllers';
Now, install passport functionality inside our laravel project
composer require laravel/passport
Read more: https://easycodesardar.blogspot.com/2021/11/Setup%20Passport%20functionality%20in%20Laravel.html | hardeepcoder |
901,884 | Oklahoma Secretary of State Business Search | Welcome to the page that is going to talk all about the Oklahoma Secretary of State business search.... | 0 | 2021-11-23T13:30:49 | https://cobaltintelligence.com/blog/oklahoma-secretary-of-state-business-search/ | secretaryofstate, oklahomasecrtaryofst | ---
title: Oklahoma Secretary of State Business Search
published: true
date: 2021-11-18 14:14:23 UTC
tags: SecretaryofState,oklahomasecrtaryofst,secretaryofstate
canonical_url: https://cobaltintelligence.com/blog/oklahoma-secretary-of-state-business-search/
---
Welcome to the page that is going to talk all about the Oklahoma Secretary of State business search. First point. Should Secretary of State be capitalized? I do not know.
The Oklahoma Secretary of State entity search will allow you to search for LLCs, corporations, partnerships, or any other entity that is registered with the state of Oklahoma. Here is the [official search page](https://www.sos.ok.gov/corp/corpInquiryFind.aspx).
If you want a way to search for a business in any state, please feel free to use our [verify a business tool here](https://cobaltintelligence.com/verify-a-business), free of charge. It looks a little like this. It allows you to also easily copy and download the data.
[](https://i0.wp.com/cobaltintelligence.com/blog/wp-content/uploads/2021/11/image-9.png?ssl=1)
## Oklahoma Secretary of State Entity Search
[](https://i2.wp.com/cobaltintelligence.com/blog/wp-content/uploads/2021/11/image-10.png?ssl=1)
Using the Oklahoma Secretary of State business search The advanced search may not look as fancy as other states but it does allow to do quite a bit, including search by active status, check business name availability, and search by individual name.
Making my search for “pizza” with active businesses only took 2.32 seconds. Not too bad. Here’s the list.
[](https://i0.wp.com/cobaltintelligence.com/blog/wp-content/uploads/2021/11/image-11.png?ssl=1)
Classic information here. Entity type, status, and registered agent. I find it interesting here that it has a “Name Type” field. I’m not sure what that means. I haven’t ever seen it return anything other than “Tradename”.
Clicking the filing number takes us into the details page. It is one of the more sparse details page.
[](https://i2.wp.com/cobaltintelligence.com/blog/wp-content/uploads/2021/11/image-12.png?ssl=1)
This business is supposedly active but you can see above it has an “OTC Suspension”. I believe this means that the business is currently active and in good status with the Oklahoma Secretary of State but is not in good shape with the Oklahoma Tax Commission.
## Order Documents?
I clicked in to order documents to see what it would take. It asked for my name and email address and then the documents I wanted. Looks like they charge per document. Ouch.

Does something with a charge quality as public under the Freedom of Information Act? I don’t know. I’m sure it started as an administration fee but with this kind of thing being easily fully automated, I wonder how applicable it is.
## Search by Person Name Weirdness
Searching by person name is an interesting one in Oklahoma. You can do it but the person’s name isn’t visible on the details page. So you end up with a situation like this:
[](https://i1.wp.com/cobaltintelligence.com/blog/wp-content/uploads/2021/11/image-14.png?ssl=1)
The owner/officer of this company is “Rosa Anguiano Garcia” but that name doesn’t show up anywhere on the details page. You can see the registered agent name but it is definitely not Rosa.
## Extra Credit
So you can find out businesses owned by an individual but if you are looking at that same business later, you will not know that they own that business. Registered agent is sometimes the primary officer/owner but it certainly does not have to be.
For all of my power users out there. You can access any of this business data via API. This can be handy for things like:
- Business verification
- KYC/KYB (know your business) anti-money laundering
- Business credit check
- Finding business owner information
It’s as simple as this:
```
let url = `https://apigateway.cobaltintelligence.com/v1/search?searchQuery=${encodeURIComponent(businessName)}&state=${state}`;
const axiosResponse = await axios.get(url, {
headers: {
'x-api-key': this.apiKey
}
});
return axiosResponse.data;
```
[Get a free Secretary of State API key here](https://cobaltintelligence.com/secretary-of-state).
Want know how to do some web scraping of the Oklahoma Secretary of State, here’s a helpful video.
<iframe loading="lazy" width="560" height="315" src="https://www.youtube.com/embed/MHvNFVhFlMk" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
And if you are looking to learn how to get newly registered businesses with the state of Oklahoma, here it is:
<iframe loading="lazy" title="Getting newly registered businesses in Oklahoma" width="640" height="360" src="https://www.youtube.com/embed/7W1423DIJ2Q?feature=oembed" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
The post [Oklahoma Secretary of State Business Search](https://cobaltintelligence.com/blog/oklahoma-secretary-of-state-business-search/) appeared first on [Cobalt Intelligence](https://cobaltintelligence.com/blog). | aarmora |
899,366 | Automated testing for staging Apps | I have developed a process to update the pull request status based on staging app deployment using... | 0 | 2021-11-16T05:41:30 | https://dev.to/suryasr007/test-for-staging-apps-1b3 | ci, heroku, reviewapp, actionshackathon21 | I have developed a process to update the pull request status based on staging app deployment using Github Actions and Heroku API.
Entire journey and workflow can be found here: https://niteo.co/blog/staging-like-its-2020
The journey consists of:
* A simple custom [GitHub Action](https://github.com/marketplace/actions/heroku-review-app-deployment-status) for small & medium projects. It takes care of all the burden.
* A bit complex process for larger projects which can be helpful in reducing unnecessary costs. | suryasr007 |
899,401 | Node v17.0.1 bug | Error encountered when running yarn start, npm start. Probably caused by issue with webpack digital... | 0 | 2022-08-03T13:52:44 | https://dev.to/blu3fire89/node-v1701-bug-146o | react, javascript, node | 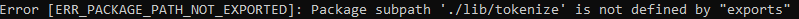
Error encountered when running yarn start, npm start.
Probably caused by issue with webpack [digital envelope routines::unsupported](https://github.com/webpack/webpack/issues/14532).
A quick fix is configuring package.json script.
<pre>
"start": "react-scripts --openssl-legacy-provider start"
</pre> | blu3fire89 |
899,595 | How to start career in Salesforce Administration | Why Salesforce I would not say it's main Salesforce yet in addition its solid and enhanced... | 0 | 2021-11-16T08:33:53 | https://dev.to/harmanj62642137/how-to-start-career-in-salesforce-administration-1o5m | salesforce | #Why Salesforce
I would not say it's main Salesforce yet in addition its solid and enhanced local area. A huge number of experts are there to help and guide around the world. You would get an incredible stage to show your ability, difficult work, and contribution. When you stand out enough to be noticed, numerous enrollment specialists will move toward you for [learning salesforce administration](https://www.janbasktraining.com/online-salesforce-training).
A brilliant illustration of what I will talk about a friend.We can get engaged in the Salesforce people group during school days, heading out many miles to go to a Salesforce engineer bunch meet, and write Salesforce books.We can likewise be featured straight by [Salesforce](https://admin.salesforce.com/blog/2019/nine-ways-to-get-started-in-the-salesforce-ecosystem-as-a-salesforce-administrator#:~:text=Nine%20Ways%20to%20Get%20Started%20in%20the%20Salesforce,a%20job%20in%20the%20Salesforce%20ecosystem.%20More%20items) in one of their webinars.
#What might it take
Not a solitary penny, indeed you might procure in the course of landing position. Relax, it is not noticed or I won't get compensated straightforwardly or in a roundabout way by anybody on ideas.
Everything necessary is commitment, difficult work, and faith in yourself. What's more, more than everything, your "Understanding". Persistence is unpleasant, however, its natural product is sweet. You may get disappointed that your companions are landing positions and procuring great compensation. Accept yourself, continue to look through positions, and attempt underneath strategy.
As I would like to think, joining classes to learn Salesforce won't help you. Bosses don't care a lot regarding which courses you have finished, instructing classes "Authentication of Completion" are useless.
#Genuine approach
Get to know any OOP language and its ideas (Preferably Java).
Learn HTML5, CSS, and JavaScript essentials and the best asset are W3Schools.
Not compulsory, but rather it will give you some benefit by learning one of the JavaScript structures like JQuery.
[Trailhead](https://admin.salesforce.com/blog/2019/nine-ways-to-get-started-in-the-salesforce-ecosystem-as-a-salesforce-administrator#:~:text=Nine%20Ways%20to%20Get%20Started%20in%20the%20Salesforce,a%20job%20in%20the%20Salesforce%20ecosystem.%20More%20items)
This item is a reason, I said that we needn't bother with any paid training to comprehend the essentials of Salesforce. Trailhead is the creative stage from Salesforce, where the client can find out with regards to various modules at self speed. Why is it unique? At the end of modules, there are involved activities that should be finished in your engineer organization and they will be approved by the trailhead. Assuming there is any blunder, it will be shown. When you procure any identification, share it on Twitter, you're connected in profile, and show your mastery. There are various paths (courses) to learning Salesforce like Admin, Advanced Admin, Developer, and so forth…
#Topcoder
Presently, the subsequent stage is to join the "Topcoder" people group. Topcoder people group is one of the realized stages to deal with Salesforce projects. The venture will be posted in Topcoder and individuals can present their answers. If your answer is chosen, it will be granted by the sum in dollars. Before winning your first undertaking, you might have to vie for some tasks without winning any way you will get the hang of during that time. Try not to think it's a trick, read it yourself. My companion and Salesforce MVP Kartik is additionally very notable and victor of different entries. I'm not giving its opinion of cake yet not feasible. Your point isn't winning yet learning. At first for freshers, it is exceptionally intense yet you can see the code of different submitters and gain from them in case you can't think of an arrangement for learning salesforce administration.
Stackexchange, #Askforce, IRC, Community, and Developer discussion
Visit Stackexchange, Salesforce people group, and designer gathering every day and attempt to address questions. On the off chance that you don't know the reply, gain from others' reply. You would be astounded by the speed and detail of replies by donors. It's like getting exceptional help from an administration liberated from cost.
If you can attempt to continue to screen the #askforce hashtag on Twitter. You can help and get a reply from here also. There is an IRC channel accessible too assuming you need to utilize it in #learning salesforce administration
[Salesforce Developer](https://admin.salesforce.com/blog/2019/nine-ways-to-get-started-in-the-salesforce-ecosystem-as-a-salesforce-administrator#:~:text=Nine%20Ways%20to%20Get%20Started%20in%20the%20Salesforce,a%20job%20in%20the%20Salesforce%20ecosystem.%20More%20items) #and User gatherings
There are week after week, fortnightly, and month-to-month gatherings in User gatherings and Developer bunches all around the world. Attempt to see as the closest one and begin working together and contributing if conceivable.
#Inspiration factor
Procuring focuses and status by responding to inquiries on designer gathering, stack-trade, and finishing trailhead identifications you can quantify yourself day by day or week by week premise. More you work, the more focus, regard and perceivability will be procured.
#Certifications
When you get sufficient experience and ability in Salesforce, go for Salesforce Certifications. Start with Admin and afterward Developer certification.
#Update Curriculum Vitae
Whenever you are known in the local area, put a reference of your Stack trade, designer gathering. trailhead public profiles, designer or client bunch name where you are part and donor.
#The anticipated course of events
"There is no alternate way to progress". It's not exceptionally simple but rather surely a great shot to attempt. On the off chance that you as of now have a programming foundation, it would take around 7-8 months or 9-10 months with practically no earlier programming information.
#Consider the possibility that this doesn't work
"Information is power". You will in any case learn HTML5, CSS, JavaScript, OOP and that information can be utilized in some other innovation, work, or even in site designing. Keep in mind, "No Pain, No Gain". You want to invest every one of your amounts of energy, to get a dream job.
| harmanj62642137 |
899,679 | Bug Severity vs Priority, or How to Manage Defect Fixing | Bug severity and bug priority are two closely related notions. Still, these are two different terms... | 0 | 2021-11-16T11:50:50 | https://dev.to/qamadness/bug-severity-vs-priority-or-how-to-manage-defect-fixing-ge4 | testing, qa, qualityassurance, development | Bug severity and bug priority are two closely related notions. Still, these are two different terms describing slightly different sides of a defect. It is essential to distinguish severity and priority for everyone engaged in the development process. A clear understanding of the difference makes it easier to find the best answer to the question “What to fix first?” that can cause tension between QA engineers, developers, and stakeholders. Hopefully, this article will explain the basics and help to clear the air.
##What Is Bug Severity?##
Bug severity is the extent of the impact a particular defect has on the software under test. The higher effect this defect has on the overall functionality or performance, the higher the severity level is.
###Levels of Bug Severity###
* **Blocker (S1)**. Such an error makes it impossible to proceed with using or testing the software. For instance, it shuts an application down.
* **Critical (S2)**. It is an incorrect functioning of a particular area of business-critical software functionality, like unsuccessful installation or failure of its main features.
* **Major (S3)**. An error has a significant impact on an application, but other inputs and parts of the system remain functional, so you can still use it.
* **Minor (S4)**. A defect is confusing or causes undesirable behavior but doesn’t affect user experience significantly. Many UI bugs belong here.
* **Low/Trivial (S5)**. A bug doesn’t affect the functionality or isn’t evident. It can be a problem with third-party apps, grammar or spelling mistakes, etc.
##What Is Bug Priority?
Bug priority is a way to decide in what order the defects will be fixed. The higher the priority is, the sooner a development team is going to look into the problem. Very often, bug priority is determined by its severity. Well, it is reasonable to start fixing with blockers rather than minor defects.
###Levels of Bug Priority
* **High (P1)**. The defect is critical to the product and has to be resolved as soon as possible.
* **Medium (P2)**. The error doesn’t require urgent resolution and can be fixed during the usual course of activities – for example, during the next sprint.
* **Low (P3)**. The bug isn’t serious, so it can be resolved after the critical defects are fixed or not fixed at all.
Based on these, we can also classify fixes per their timing:
* **Hotfix**. If a defect has a high impact on a user and business performance, it is essential to fix it as soon as possible. For instance, if an installation fails or a user cannot register/sign in, a team should fix these issues immediately.
* **Upcoming release**. If bugs are troubling but don’t affect the core functionality, a team doesn’t need to go with a hotfix. For example, a broken layout is confusing, but it doesn’t interfere with actual functionality. It is okay to add this fix to a pool of the tasks for the nearest update.
* **Later sprints**. If problems aren’t severe and there’s no pressure from a user’s or business side, the bugs go to a backlog and are resolved sometime during the upcoming sprints. It is a common scenario of dealing with typos and minor compatibility issues.
##Do We Need Both Severity and Priority?
Basically, the severity and priority both describe the level of criticality of a defect. Seemingly, the priority should entirely depend on the severity. It sounds reasonable to determine the order of fixing defects based on their criticality. However, it is more complicated.
Severity reflects a possible impact of a defect on a user. Therefore, a QA team assigns severity to each defect. Since QA specialists study a system to evaluate it from a user’s viewpoint, they can tell how bad it is broken.
Priority establishes the order in which developers will fix bugs. It is up to a person in charge – Product Owner, Project Manager, Business Analyst, etc. – to finalize this order. Defect severity is one of the criteria used for determining the priority, but not always the defining one. Stakeholders decide on the priority with a bigger picture in mind. They always have to consider business implications.
So yes, we need both priority and severity. Though closely related, these two criteria aren’t always interdependent. Severity doesn’t necessarily determine priority. As a result, these terms are usually operated by different groups of specialists participating in software development.
###How to Assign Bug Severity?
To determine the degree of severity of a defect, QA engineers identify how frequently it occurs and to what extent it influences the functionality. It is significant to consider both parameters.
Let’s say we’ve got an incorrect size of specification icons on all product pages and overlapping buttons on two popular products. These are both examples of the broken layout. However, the icons only look displeasing, while a problem with buttons disables purchasing functionality. The nature of these defects is similar, but their levels of severity vary.
###How to Assign Bug Priority?
If you a) have to decide on bug priority but aren’t sure how to do it correctly or b) are a QA specialist exasperated by the way the detected bugs have been prioritized, here are a few questions that will help you understand this process better:
* How many users does a bug affect?
* What functionality is affected?
* On what devices and OS does a bug occur?
* Is there a decrease in activity because of this defect?
* Does the company start losing money because of it?
* Is users’ trust or a company’s image affected?
* Does this software issue carry legal implications?
As you can see, there’s more to this issue than severity. It is essential to pay attention to business data, too.
###Different Severity and Priority Combinations
Here’s one more illustrative example of why we need both severity and priority. The combination of these two bug attributes can be different.
* **A high severity with a high priority:** a user cannot log in to the account. There’s no need for long explanations, right?
* **A low severity with a low priority:** design of a rarely visited section doesn’t match the recently updated website design. It often happens after rebranding, and some pages can wait for updates for months.
* **A low severity with a high priority:** broken layout or typos on the top-visited pages. These things don’t affect functionality, but they can affect user’s perception of a brand and, thus, satisfaction rates and even revenue.
* **A high severity with a low priority:** layout doesn’t fully load in older versions of legacy browsers. Though the entire application is affected, if only a few users access the website via these browsers, fixing these issues will not be of high importance.
##Bug Severity and Priority: The Friction
So what actually causes tension and conflicts? A development team might be confused when there’s a mismatch in expectations regarding severity and priority. In some cases, each party is sure they have more reasons to advise on the priority of a certain issue. However, it is only for stakeholders to decide.
If a QA engineer or a developer believes the priority should be different, they should address an issue calmly. It would be great if a person in charge of the decision should share their reasons for assigning a particular priority. And vice versa, if a stakeholder doesn’t understand why a particular issue has the assigned severity, they should ask for clarification.
So the conflict comes from a human factor. When a team works towards a common goal, which is releasing the best product possible, everyone can become a little too excited. Transparent communication is what helps to avoid suchlike situations. Still, each specialist should understand the hierarchy of the development process and read the situation. In other words, just do your job well and know when it is reasonable to ask for clarifications.
##To Sum Up
Severity and priority are parameters operated by different teams. However, severity is one of the key factors for prioritizing a defect. A project leader is the one to consider both and make a decision. The best you can do is remember the difference between bug severity and priority and don’t use these terms interchangeably. Another piece of advice would be to pay attention to the roles and responsibilities each member of the team has. QA engineers should back up the development with their expertise in product quality research, while analysts and managers make sure that each decision is based on business goals and with a bigger picture in mind. | qamadness |
900,624 | The Ternary operator with React! | Hey fellow creators, The Ternary operator is a great way to do some conditional rendering with... | 0 | 2021-11-18T11:56:10 | https://dev.to/ziratsu/the-ternary-operator-with-react-3b9c | html, css, react, tutorial | Hey **fellow creators**,
The **Ternary operator** is a great way to do some conditional rendering with React! Let's learn how to do that.
If you prefer to watch the video **version**, it's right here :
{%youtube kAg66VPdsCc%}
##1. What is the Ternary operator?
Let's say we have this code :
```react
import "./App.css";
function App() {
const toggle = 1;
return (
<div className="container">
</div>
)
}
```
We can execute a console.log to see how a ternary operator works.
```react
console.log(toggle ? "true" : "false");
```
Then in the console you will have "true", since toggle is not null or undefined.
Great, so let's now use the power of the ternary operator combined with React !
##2. Let's implement some state
Let's import the hook *useState* from React:
```react
import {useState} from 'React'
```
and create the state:
```react
function App() {
const [toggle, setToggle] = useState(false);
return (
<div className="container">
</div>
)
}
```
We'll start the state with *false*, and then add a button to trigger the change in the state :
```react
return (
<div className="container">
<button>Toggle</button>
</div>
)
```
Now let's add the function which will reverse the value of toggle every time you click on the button:
```react
const toggleFunc = () => {
setToggle(!toggle)
}
```
Obviously you now need to add that function to the button:
```react
<button onClick={toggleFunc}>Toggle</button>
```
In order to see the change in state, you can add a *console.log* beneath the *toggleFunc()*:
```react
const toggleFunc = () => {
setToggle(!toggle)
}
console.log("Update")
```
Now you can see that every time you click on the button, it re-enders your component and changes the value from false to true!
##3. Use the Ternary operator to go from one classname to another!
Here's a recap of the code you have for now:
```react
import {useState} from 'React'
import "./App.css";
function App() {
const [toggle, setToggle] = useState(false);
const toggleFunc = () => {
setToggle(!toggle)
}
console.log("Update")
return (
<div className="container">
<button onClick={toggleFunc}>Toggle</button>
</div>
)
}
```
Now, modify the className of the div that contains the button with a ternary operator:
```react
<div className={toggle ? "container salmon" : "container"}>
<button onClick={toggleFunc}>Toggle</button>
</div>
```
If the toggle is false, then the background of the container will be dark, if it's true then it'll turn salmon.
It's pretty simple, but is actually really useful, especially if you want to use animations, interactions or even to show or hide some content!
##4. You can also render some CSS!
You can also modify the height of your div for example:
```react
<div
className={toggle ? "container salmon" : "container"}
style={{height: toggle ? "400px" : "200px"}}
>
<button onClick={toggleFunc}>Toggle</button>
</div>
```
##5. The same goes for some text.
Let's add a const to toggle the text of a title that you'll then add in the *div*:
```react
const txt = toggle ? "Lorem" : "Ipsum"
```
```react
<div
className={toggle ? "container salmon" : "container"}
style={{height: toggle ? "400px" : "200px"}}
>
<button onClick={toggleFunc}>Toggle</button>
<h1>{txt}</h1>
</div>
```
As before, you'll see that the text changes!
You can now see how useful the **Ternary operator** can be with React!
Come and take a look at my **Youtube channel**: https://www.youtube.com/c/TheWebSchool
*Have fun looking at my other tutorials!*
Enzo. | ziratsu |
899,873 | Root cause analysis for enterprise & SMB infrastructure. Feedback is appreciated! | For the past few months, my team worked hard on developing our new incident root cause solution -... | 0 | 2021-11-16T14:25:01 | https://dev.to/soniabelokur/root-cause-analysis-for-enterprise-smb-infrastructure-feedback-is-appreciated-1o3e | monitoring, devops, machinelearning, serverless | For the past few months, my team worked hard on developing our new incident root cause solution - Incident Timeline.
InsightCat launched the Incident Timeline, the root cause analysis solution developed for IT experts who manage, view, and investigate software incidents. The solution is implemented in the InsightCat platform to provide IT specialists with automated root cause analysis, downtime details, and behavior.
Incident Timeline allows you to:
📷 Obtain root cause analyze
📷 Surface relevant insights
📷 Enhance observability
Check out InsightCat's new update below and see how it works in practice or you can register to InsightCat and try Incident Timeline for free.
Any feedback is appreciated, don't hesitate to share it in the comment section :)
InsightCat registration: https://portal.insightcat.com/register
Website: https://insightcat.com/
| soniabelokur |
899,913 | Easy way to exclude files during git add | Every day we use the "git add" command a lot to add our changes to the index for new commits, but... | 0 | 2021-11-16T16:00:58 | https://kodewithchirag.com/easy-way-to-exclude-files-during-git-add | git, webdev, tutorial, productivity | Every day we use the **"git add"** command a lot to add our changes to the index for new commits, but have you ever wondered how we can add all the changed files with some files excluded during the execution of this command (not with .gitignore)? If the answer is yes, then this article will help you to understand how certain files can be excluded during the git add command.
## TLDR; command to exclude specific file
```
git add -A ':!<file_path>'
```
## Problem
One day I was put in a situation where I need to add some files for my new commit but I also need to exclude a few files during that execution and those files will get added later on once my work is done on those.
**One way to do this is to hit the below command**
```
git add <file_path> <file_path> ... <file_path>
```
Basically, If I have done changes to under 13 files and wanted to exclude only 3 files from those, that means 10 files need to be added with the git add command, then I have to copy all those 10 files path and paste it to the terminal manually and it will have become little bit tedious task. Let’s look at the example.
```
git add Dockerfile \
README.md \
nest-cli.json \
package-lock.json \
package.json \
src/app.controller.spec.ts \
src/app.controller.ts \
src/app.module.ts \
src/app.service.ts \
src/main.ts
```
After this command, you can now check for the staged files by hitting.
```
git status
```
## Solution
But what if this process can be done inversely🤔? Like instead of passing 10 files paths I could just pass 3 files path, 👀 yes you heard it right this can be possible with git add with the below example.
```
git add -A ':!.eslintrc.js' ':!.gitignore' ':!.prettierrc'
```
And now when you hit **git status** it will show all 10 files added to the index apart from the 3 excluded files. It's like a **NOT (!) operator** under the git add path option.
> Hope you enjoyed this content, please share your thoughts under comment and also get in touch with me on [Twitter](https://twitter.com/KodeWithChirag).
| kodewithchirag |
899,925 | [git] find semantic version tags | Sure, you could use grep/sed, but can it be done with glob(7)? Supply a pattern to git describe or... | 0 | 2021-11-16T16:28:19 | https://dev.to/stavxyz/git-find-semantic-version-tags-4ob6 | glob, git, semantic | Sure, you could use grep/sed, but can it be done with `glob(7)`? Supply a pattern to `git describe` or `git tag` to print the matching tags.
```
git tag --list 'v[[:digit:]]*[\.][[:digit:]]*[\.][[:digit:]]*'
```
Maybe there's a better way 🤷🏼.
## Why?
In a ci/cd environment, I wanted to be able to build and publish new releases of a binary if and when the latest commit has a semantic version tag attached.
| stavxyz |
899,985 | Synchronous vs Asynchronous Callbacks | This article was originally published at... | 0 | 2021-11-16T17:33:21 | https://maximorlov.com/synchronous-vs-asynchronous-callbacks/ | javascript, webdev, beginners, codenewbie | *This article was originally published at https://maximorlov.com/synchronous-vs-asynchronous-callbacks/*
Asynchronous code in JavaScript can be confusing at best, and at worst, preventing you from landing your first job or implementing an urgent feature at work.
Just when you think you understand a program's execution order, you stumble upon asynchronous code that executes out of order and leaves you utterly confused.
To understand how asynchronous code works, it's important to know the difference between synchronous and asynchronous callbacks and be able to recognize them in your code.
Before we dive in, let's do a refresher on callback functions. If you already know what callback functions are, feel free to skip to the next section.
## What is a callback function?
A callback function is a function passed as an *argument* to another function in order to be called from *inside* that function. This may sound confusing, so let's look at some code:
```js
function printToConsole(greeting) {
console.log(greeting);
}
function getGreeting(name, cb) {
cb(`Hello ${name}!`);
}
getGreeting('Maxim', printToConsole); // Hello Maxim!
```
In the above example, the function `printToConsole` is passed as an argument to `getGreeting`. Inside `getGreeting`, we call `printToConsole` with a string which is then printed to the console. Because we pass `printToConsole` to a function to be called from inside that function, we can say that `printToConsole` is a callback function.
In practice, callback functions are often initialized anonymously and inlined in the function call. The following example is equivalent to the one above:
```js
function getGreeting(name, cb) {
cb(`Hello ${name}!`);
}
getGreeting('Maxim', (greeting) => {
console.log(greeting);
}); // Hello Maxim!
```
The difference is that `printToConsole` is now an anonymous callback function. Nonetheless, it's still a callback function!
Here's another example you may be familiar with:
```js
function multiplyByTwo(num) {
return num * 2;
}
const result = [1, 2, 3, 4].map(multiplyByTwo);
console.log(result); // [2, 4, 6, 8]
```
Here, `multiplyByTwo` is a callback function because we pass it as an argument to `.map()`, which then runs the function with each item in the array.
Similar to the previous example, we can write `multiplyByTwo` inline as an anonymous callback function:
```js
const result = [1, 2, 3, 4].map((num) => {
return num * 2;
});
console.log(result); // [2, 4, 6, 8]
```
## Order of execution
All the callbacks we've seen so far are synchronous. Before we discuss asynchronous callbacks, let's have a look at the program's order of execution first.
In what order do you think the following console.log statements are printed?
```js
console.log('start');
function getGreeting(name, cb) {
cb(`Hello ${name}!`);
}
console.log('before getGreeting');
getGreeting('Maxim', (greeting) => {
console.log(greeting);
});
console.log('end');
```
If your answer was:
```shell-session
start
before getGreeting
Hello Maxim!
end
```
You got it right! The program starts at the top and executes each line sequentially as it goes to the bottom. We do a mental jump up and down when we call `getGreeting` to go to the function's definition and then back to execute the callback function, but otherwise, nothing weird is happening.
## Asynchronous Callbacks
Now let's have a look at asynchronous callbacks by converting `getGreeting` to run asynchronously:
```js
console.log('start');
function getGreetingAsync(name, cb) {
setTimeout(() => {
cb(`Hello ${name}!`);
}, 0);
}
console.log('before getGreetingAsync');
getGreetingAsync('Maxim', (greeting) => {
console.log(greeting);
});
console.log('end');
```
In what order do you think the console.log statements are printed this time around?
Go ahead, I'll wait.
.
.
.
.
.
.
.
.
.
.
The right answer is:
```shell-session
start
before getGreetingAsync
end
Hello Maxim!
```
With the addition of setTimeout, we're *deferring* execution of the callback function to a later point in time. The callback function will run only *after* the program has finished executing the code from top to bottom (even if the delay is 0ms).
The main difference between synchronous and asynchronous callbacks is that **synchronous callbacks are executed immediately, whereas the execution of asynchronous callbacks is deferred to a later point in time**.
This may be confusing at first, especially if you're coming from synchronous languages like PHP, Ruby or Java. To understand what's going on in the background, have a look at [how the event loop works](https://maximorlov.com/javascript-event-loop-talk/).
## How can you tell if a callback is synchronous or asynchronous?
Whether a callback is executed synchronously or asynchronously depends on the function which calls it. If the function is asynchronous, then the callback is asynchronous too.
Asynchronous functions are usually the ones that do a network request, wait for an I/O operation (like a mouse click), interact with the filesystem or send a query to a database. What these functions have in common is that they interact with something *outside* the current program and your application is left *waiting* until a response comes back.
Conversely, synchronous callbacks are executed within the program's current context and there's no interaction with the outside world. You'll find synchronous callbacks in functional programming where, for example, the callback is called for each item in a collection (eg. `.filter()`, `.map()`, `.reduce()` etc.). Most prototype methods in the JavaScript language are synchronous.
If you're not sure whether a callback function is executed synchronously or asynchronously, you can add console.log statements inside and after the callback and see which one is printed first.
## Learn how to write asynchronous code in Node.js
Write clean and easy to read asynchronous code in Node.js with this **FREE 5-day email course**.
Visual explanations will teach you how to decompose asynchronous code into individual parts and put them back together using a modern async/await approach. Moreover, with **30+ real-world exercises** you'll transform knowledge into a practical skill that will make you a better developer.

👉 [**Get Lesson 1 now**](https://maximorlov.com/refactoring-callbacks-course/) | maximization |
900,158 | El [Nuevo] estado de CSS en Angular | Artículo original de Angular Blog por Emma Twersky en inglés aquí: Han pasado algunos años desde la... | 0 | 2021-11-16T21:31:51 | https://dev.to/macaoblog/el-nuevo-estado-de-css-en-angular-4089 | css, webdev, angular, news | Artículo original de [Angular Blog](https://blog.angular.io/) por [Emma Twersky](https://medium.com/@emmatwersky_24094) en inglés [aquí:](https://blog.angular.io/the-new-state-of-css-in-angular-bec011715ee6)
Han pasado algunos años desde la última vez que cubrimos CSS en el blog de Angular,¡y han sucedido muchas cosas desde entonces!
En esta publicación, veremos las nuevas funciones web que afectan la forma en que definimos el estilo en nuestras aplicaciones Angular.
##Usando @use en Lugar de @import
En 2019,[Sass](https://sass-lang.com/) introdujo un nuevo sistema de módulos, incluida una migración de ``@import`` a ``@use``. Al cambiar a la [sintaxis](https://sass-lang.com/documentation/at-rules/use)``@use``, podemos determinar más fácilmente qué CSS no se utiliza y reducir el tamaño de la salida CSS compilada. Esto hace que sea imposible extraer inadvertidamente dependencias transitivas. Cada módulo se incluye solo una vez, sin importar cuántas veces se carguen esos estilos.
Angular Material v12 incluyó una migración del uso de ``@import`` a ``@use`` para todas las importaciones en los estilos Angular Material Sass. Esta refactorización de nuestra Superficie de API de personalización es más fácil de entender y leer, lo que ayuda a los desarrolladores a aprovechar mejor este nuevo sistema de módulos. Esta migración tiene lugar en los scripts incluidos en ``ng update``. Un ejemplo de este cambio está en cómo definimos un tema de Angular Material :
```css
// El estilo de Angular Material se importa como 'mat'.
@use '@angular/material' as mat;// 'mat' namespace is referenced.
// Se hace referencia al espacio de nombre "mat".
$my-primary: mat.define-palette(mat.$indigo-palette, 500);
$my-accent: mat.define-palette(mat.$pink-palette, A200, A100, A400);
```
Ahora hacemos uso de la introducción de espacios de nombres para definir el núcleo``'@angular/material'`` como ``mat``, luego accedemos a variables como ``mat.$indigo-palette``. Si profundizamos en el código fuente, somos más intencionales sobre qué variables se ``@forward-ed`` (reenvían) para el acceso público a fin de guiar a los usuarios hacia un estilo más limpio.
Consulte la [documentación de temas Angular Material](https://material.angular.io/guide/theming) recientemente reescrita para ver cómo ``@use`` y esta migración simplifican la aplicación de temas los componentes.
##Habilitación de conceptos CSS modernos
Angular v13 eliminó el soporte para IE11 después de una solicitud exitosa de comentarios, lo que hace posible que Angular adopte un estilo web moderno como CSS Grid, propiedades lógicas CSS, CSS calc (), :: hover y más. Puedes esperar que la librería de Angular Material comience a usar estas funciones, y te alentamos a que también lo hagas.
Si tienes curiosidad por mejorar tus habilidades de CSS modernas, te recomiendo encarecidamente el curso Learn CSS de web.dev como una excelente manera de aprender o pulir tus conocimientos de CSS.
##¡Comienza a usar variables CSS!
La eliminación de la compatibilidad con IE11 allana el camino para algo que me entusiasma mucho: las variables CSS, también conocidas como propiedades personalizadas de CSS. Piense en ello como la definición de una superficie de API que los desarrolladores pueden usar para personalizar estilos. Puede proporcionar un conjunto de propiedades abiertas para guiar el tamaño de los márgenes o una gama de variables de color y permitir que los desarrolladores las consuman y anulen.
Imagina una librería que incluye un botón para compartir con un estilo personalizado:
```css
:root {
--primary: pink;
--accent: blue;
}
.share-button {
background-color: var(--primary);
color: var(--accent);
}
```
Luego, un usuario puede implementar un estilo limpio usando variables CSS en el ámbito en el que este componente de librería se usa para reasignar los colores primarios y de realce, y ver estos cambios visuales reflejados en su uso del botón de compartir:
```css
:root {
--primary: green;
--accent: purple;
}
```
##El futuro de los estilos predominantes
Las variables CSS abren la puerta a API's bien compatibles para la personalización de componentes, lo que permite a los desarrolladores alejarse de las anulaciones de CSS y ``::ng-deep``.
Recomendamos introducir variables personalizadas en sus librerías y dependencias con el fin de crear una superficie de API para personalizar librerías sin la necesidad de ``::ng-deep``. La implementación de variables personalizadas permite a los desarrolladores tener más control sobre su estilo y proporcionar una ruta lejos de las invalidaciones de CSS y ``::ng-deep``.
##Variables CSS en Angular Material
Estamos explorando las variables CSS para abrir la superficie de API para personalización de Material y admitir una mayor individualización de los componentes Angular Material como parte de la expansión de los sistemas de personalización de Material Design.
Te Interesa este proyecto? ¿Sobreescribes de manera personalizada Angular Material en tu proyecto? Me encantaría saber más sobre tu experiencia con la personalización de temas de Angular Material. Ponte en contacto con nuestro equipo por [correo electrónico](mailto:devrel@angular.io).
##El CLI de Angular puede ayudarte a diseñar
###Inline Sass en componentes
v12 introdujo la opción de usar Sass en línea en tus componentes Angular. El CLI ahora tiene una opción para proporcionar un ``inlineStyleLanguage`` y compila Sass directamente desde sus componentes Angular en el estilo. Esto es útil para los desarrolladores que utilizan componentes de un solo archivo o que desean agregar pequeñas cantidades de estilo dentro de sus archivos de componentes.
Para usar Sass, deberá especificar el idioma en sus configuraciones de compilación de ``angular.json``:
```json
{ "projects": {
"architect": {
"build": {
"options": {
"styles": [
"src/styles.scss"
],
"inlineStyleLanguage": "scss",
...
```
¡Ahora puedes escribir Sass en tus @Componentes!
```typescript
import { Component } from '@angular/core';@Component({
selector: 'app-root,
template: '<h1>v12 has inline Sass!</h1>',
styles: [`
$neon: #cf0;
@mixin background ($color: #fff) {
background: $color;
}
h1 {@include background($neon)}
`]
}) export class AppComponent {}
```
## Tailwind y otros PostCSS
Angular v11.2 agregó soporte nativo para ejecutar TailwindCSS PostCSS con Angular CLI.
Para habilitar TailwindCSS, ``ng update``(actualice) a v11.2 + y luego:
1. Instale con ``yarn add -D tailwindcss``
2. Cree un archivo de configuración TailwindCSS en el espacio de trabajo o en la raíz del proyecto.
```javascript
// tailwind.config.js
module.exports = {
purge: [],
darkMode: false, // or 'media' or 'class'
theme: {
extend: {},
},
variants: {
extend: {},
},
plugins: [],
}
```
##Inlining CSS crítico (Critical CSS inlining)
Angular v12 también introdujo Critical CSS Inlining para ayudar a garantizar que las aplicaciones Angular entreguen las mejores métricas de Core Web Vital posibles. Puede obtener más información sobre la inserción de recursos en el [canal de Angular en YouTube](https://www.youtube.com/watch?v=yOpy9UMQG-Y). ¡Este es un gran ejemplo de cómo Angular está a la vanguardia del rendimiento web!
***¡Gracias por seguir haciendo de la web un lugar más elegante con Angular! ¿Qué nueva caracteristica de estilo te entusiasma más?*** | antoniocardenas |
900,186 | Why is `this` a pointer and not an rvalue reference in C++? | What was the thought behind making this a pointer of T, instead of T&&? | 0 | 2021-11-16T22:32:46 | https://dev.to/baenencalin/why-is-this-a-pointer-and-not-an-rvalue-reference-in-c-33a7 | cpp, discuss, watercooler | What was the thought behind making `this` a pointer of `T`, instead of `T&&`? | baenencalin |
900,307 | I must be stupid | I follow tutorials for everything to do with programming and computers, but I can't seem to get... | 0 | 2021-11-17T02:02:15 | https://dev.to/craftyminer1971/i-must-be-stupid-jaf | beginners, programming, tailwindcss, vscode | I follow tutorials for everything to do with programming and computers, but I can't seem to get anywhere with them, and when I see just one error, I have the tendency to give up trying any further.
So, I am begging for assistance on the most basic of levels, if possible. PLEASE someone, anyone, tell me like I'm 5 years old, how do you install tailwindcss into VS Code?
I just followed the steps of a tutorial for this process from 9/21, and things seemed to be going well, until things didn't for me (which seems to be the case for every single tutorial I've followed in the past)
| craftyminer1971 |
900,313 | How to set default object parameter in Javascript | Hello Devs, Do you find any error when you set the default object as parameter? Let's talk about... | 0 | 2021-11-19T06:14:00 | https://dev.to/sajidurshajib/how-to-set-default-object-parameter-in-javascript-587c | Hello Devs,
Do you find any error when you set the default object as parameter? Let's talk about it.
```javascript
const fullName = ({fname, lname})=> {
console.log(fname + ' ' + lname)
}
fullName({fname:'Sajidur', lname:'Rahman')
//your@console:~$ Sajidur Rahman
```
I Guess you already know what's going on in this simple function. In this topic this is our demo function.
```javascript
const fullName = ({fname='Jhon', lname='Doe'})=> {
console.log(fname + ' ' + lname)
}
fullName({fname='Sajidur'})
//your@console:~$ Sajidur Doe
```
This parameter is an object where we set 2 properties with default value. If we don't pass any of the property, then default property will use. We pass only `fname` that's why default `lname` use.
```javascript
const fullName = ({fname='Jhon', lname='Doe'})=> {
console.log(fname + ' ' + lname)
}
fullName()
//your@console:~$ TypeError: Cannot read property 'fname' of undefined
```
If we don't pass any parameter, then we will find this error. But why? We set default parameter right?
No, we didn't. We just set the default property value of an object. That object is our actual parameter.
```javascript
const fullName = ({fname='Jhon', lname='Doe'} = {})=> {
console.log(fname + ' ' + lname)
}
fullName()
//your@console:~$ Jhon Doe
```
Now set a default parameter as an empty object `{fname='Jhon', lname='Doe'} = {}`. Now it works, but why? Let's talk about it step by step.
1. This whole object `{fname='Jhon', lname='Doe'}` is a single parameter. For this parameter default parameter value is `{}`. When the parameter is undefined that time this `{}` empty object will appear.
2. Now we have empty object. But we already set some default properties with value for empty object right? `fname='Jhon', lname='Doe'` Those properties now appear here with their default value.
So Dev, I hope you understand and find the solution if you stuck on this issue. | sajidurshajib | |
900,402 | 1.2 WordPress Smart Coding Tips | Schedule Event / scheduled tasks | Normally in WordPress plugin development, we declare a scheduled event like the... | 0 | 2021-11-17T16:11:42 | https://dev.to/plugin-master/12-wordpress-smart-coding-tips-schedule-event-5hig | wordpress, pluginmaster, wordpressplugidevelopment |

Normally in WordPress plugin development, we declare a scheduled event like the following.
```php
register_activation_hook( __FILE__, 'my_plugin_activation_event' );
function my_plugin_activation_event() {
if ( ! wp_next_scheduled( 'my_plugin_activation_event' ) ) {
wp_schedule_event( time(), 'daily', 'my_plugin_activation_event' );
}
}
register_deactivation_hook( __FILE__, 'my_plugin_deactivation_event' );
function my_plugin_deactivation_event() {
wp_clear_scheduled_hook( 'my_plugin_deactivation_event' );
}
```
We use this type of code in many places.
### Problem is that - This code is not re-usable.
## We can create a class for reuse.
Let's Start
1. Create a class or global functions file
a. First create a class name <code>Schedule</code>
```php
namespace MyPlugin\Utilities;
class Scheduler {
}
```
b. Then add a method name <code>add</code>
```php
public static function add( $hook, $callback, $recurrence = 'daily', $start_time = null ) {
if ( ! wp_next_scheduled( $hook ) ) {
if(!$start_time) $start_time = time();
wp_schedule_event( $start_time, $recurrence, $hook );
}
add_action( $hook, $callback );
}
```
** <code>$hook</code>: hook name for the event.
** <code>$callback</code>: callback function or array for add action of our event hook.
** <code>$recurrence</code>: How often the event should subsequently recur. See wp_get_schedules() for accepted values. Default id 'daily'
** <code> $start_time</code>: event first starting time. You can pass your desired time.
c. Then we need to remove/clean our event.
For that let's create a method for removing events.
```php
public static function delete($hook){
wp_clear_scheduled_hook($hook);
}
```
### Uses
```php
Schedule::add('my-custom-schedule-event', [$this, 'event_handler']);
Schedule::delete('my-custom-schedule-event');
```
## OR you can create global functions as like previous methods.
[AL EMRAN](https://alemran.me)
[Github](https://github.com/emrancu)
For Creating Awesome Structured PSR Based Plugin:
[PluginMaster, a WordPress plugin development framework](https://dev.to/plugin-master)
| emrancu |
900,446 | Adding Continuous Integration - GitHub Actions | Continuous Integration In order to avoid breaking the code in the main branch, I added the... | 0 | 2021-11-18T19:14:15 | https://dev.to/minhhang107/adding-continuous-integration-github-actions-n1m | opensource, osd600 | ### Continuous Integration
In order to avoid breaking the code in the main branch, I added the Continuous Integration to the GitHub workflow. In this workflow, I want it to run on `node ver 14.x` whenever there's push or a pull request to the `main` branch. There are 2 actions I wanted to include:
- a clean install of all dependencies: `npm ci`
- a full test run: `npm test`
The `yml` file would look like this:
```
name: Node.js CI
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [14.x]
steps:
- uses: actions/checkout@v2
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v2
with:
node-version: ${{ matrix.node-version }}
cache: 'npm'
- run: npm ci
- run: npm test
```
After setting it up myself, I found that CI is not too hard to use and it also brings lots of conveniences as it can quickly detect if a push or pull request might contain a potential error.
### Adding more tests to another project
This week, I also created some test cases for another [repo](https://github.com/lyu4321/jellybean). Adding tests for someone else's code is no doubt for difficult than working on my own code. I had to understand the logic of the code and try to figure out what each function is supposed to do in order to find all possible scenarios.
For Leyang's [project](https://github.com/lyu4321/jellybean), I found that `getHtlmlTitleBody()` was not tested yet so I decided to contribute some tests to it. This function accepts the content of the file as a string and a boolean indicating whether it's a text file or not, it then returns an object with 2 properties: title and body.
```c
const getHtmlTitleBody = (file, isTxt) => {
let html = {
title: '',
body: '',
};
let tempTitle = file.match(/^.+(\r?\n\r?\n\r?\n)/);
if (tempTitle) {
html.title = tempTitle[0].trim();
}
if (isTxt) {
html.body = file
.split(/\r?\n\r?\n/)
.map((para) => {
if (para == html.title) {
return `<h1>${para.replace(/\r?\n/, ' ')}</h1>\n`;
} else {
return `<p>${para.replace(/\r?\n/, ' ')}</p>\n`;
}
})
.join('');
} else {
let md = new markdownit();
html.body = md.render(
file.substring(html.title.length).trim()
);
}
return html;
};
```
After investigating the function carefully, I came up with 3 scenarios to test:
- a text file input with title
- a text file input without title
- a markdown input file
The details of the tests can be found [here](https://github.com/lyu4321/jellybean/pull/32/files).
| minhhang107 |
900,625 | Why micro front-ends are the way forward in modernizing application user interfaces | It is a misconception that microservices are only used for the back-end development of apps. The fact... | 0 | 2021-11-17T10:33:59 | https://dev.to/cloudnowtech/why-micro-front-ends-are-the-way-forward-in-modernizing-application-user-interfaces-3b0 | It is a misconception that microservices are only used for the back-end development of apps. The fact is that microservices are the way forward for front-end development as well, because, like with the back-end, they fragment front-end monoliths into smaller, more manageable components. This increases the efficiency of the development process, makes the UI more maintainable, and makes the deployment of individual features independent.
**Web developer Cam Jackson [defines micro front-ends] (https://martinfowler.com/articles/micro-frontends.html) as "An architectural style where independently deliverable frontend applications are composed into a greater whole".**
Micro front-ends are becoming an increasingly widely adopted trend for building web-based applications, and are already in use by leading enterprises including Ikea, Starbucks, and Spotify.
**Why are companies modularizing their front-ends with microservices?**
There are a number of reasons for this shift - here are a few important use cases for this approach.
**1. To convert existing apps into a progressive or responsive web applications**
Using micro front-ends can represent an easier way to modify the existing code as the approach democratizes development and deployment.
**2. To manage multiple teams and complex front-end needs for large organizations**
A monolithic front-end would mean slow forward progress, while micro front-ends reduce cross-team dependency, thereby speeding things up.
**3. To scale development**
With a modularized front-end, testing and deployment become more efficient without affecting the entire [application development.] (https://www.cloudnowtech.com/application-development-services.html)
**4. To use new or different languages**
In legacy applications with monolithic architecture, integration with new languages may not be possible because they may have dependencies beyond what meets the eye. This needs comprehensive decoupling into microservices in order to adopt new languages. This is seamlessly achieved with micro front-ends.
**In the words of software developer Martin Fowler, "Micro front-ends push you to be explicit and deliberate about how data and events flow between different parts of the application, which is something that we should have been doing anyway!"**
**Let’s get to the benefits of micro front-ends**
**1. Code maintenance is easier**
As the codebase for each micro front-end is smaller, it’s almost as if developers are working on mini apps, where each team will be responsible for specific micro-apps right from database to user interface.
Additionally, one component of the app can be deployed, and different teams can re-use it as well as the code for it. These individual codebases are easier to manage and mitigate the risk of complexities from accidental coupling.
**2. Micro front-ends are tech agnostic**
The architecture of micro front-ends is independent of technology. That means you can use any language of your preference - whether PHP, Python, or any JavaScript like Node, Angular, Vue, etc. - without worrying about deployment, upgrades, or updates.
**3. They are easily scalable**
Moving from a monolith architecture to microservices can help you upgrade incrementally with teams working independently. This makes the app more scalable because if there is a bug-fix or upgrade on one part of the front-end, it can be made on that part alone, without disrupting the functioning of the rest of the application.
**Are there downsides?**
Yes, there are a few.
**1. Real-world testing**
Complex testing of the application as a whole can get a little complicated and it may be harder to get a complete picture of the application. While each front-end mini app can be tested in isolation, getting a real-world user test is tougher.
**2. Ensuring standard quality across micro front-ends**
The deployment, assembly, and configuration process for each micro front-end will be different, so it can get challenging to keep all developers working to the same standards to ensure a high-quality user experience is delivered.
While these two downsides do represent genuine challenges, they also have clear solutions. For instance, defining and implementing the right testing use cases during the course of the user acceptance testing (UAT) sprints can help address testing concerns. And with a well-oiled Agile process followed through the development process, adherence to quality standards across the team can be ensured as well.
As with micro back-ends, the tremendous benefits that micro front-ends offer in terms of ability to scale, maintain and upgrade the front-end of an application far outweigh the increased complexity that they bring, especially for larger organizations.
Micro front-ends are not just a new buzzword. They are an important tool enabling large enterprises to provide enhanced customer experiences. If you are looking to maintain a competitive edge and propel your brand forward, give [CloudNow a call today.] (https://www.cloudnowtech.com/contact-us.html)
This blog originally published at [CloudNow Blog] (https://www.cloudnowtech.com/blog/). Link to the [original blog] (https://www.cloudnowtech.com/blog/why-micro-front-ends-are-the-way-forward-in-modernizing-application-user-interfaces/) | cloudnowtech | |
900,917 | Hello, World! | Hello DEV, this is my first post | 15,553 | 2021-11-17T14:12:15 | https://dev.to/rgard90/hello-world-ddl | discuss | Hello DEV, this is my first post | rgard90 |
900,947 | Get Excited and Keep Pushing Through with Rizél Scarlett | Relicans host Pachi Parra talks to Developer Advocate at GitHub, Rizél Scarlett, about coming to... | 0 | 2021-11-17T14:54:09 | https://dev.to/therubyrep/get-excited-and-keep-pushing-through-with-rizel-scarlett-1ddo | codenewbie, beginners, career, webdev | [Relicans](https://therelicans.com) host [Pachi Parra](https://twitter.com/pachicodes) talks to Developer Advocate at [GitHub](https://github.com), [Rizél Scarlett](https://twitter.com/blackgirlbytes), about coming to America as an undocumented immigrant, the biggest barriers she encountered when getting into tech, and the learning curve when going from coder to DevRel.
Should you find a burning need to share your thoughts or rants about the show, please spray them at devrel@newrelic.com. While you're going to all the trouble of shipping us some bytes, please consider taking a moment to let us know what you'd like to hear on the show in the future. Despite the all-caps flaming you will receive in response, please know that we are sincerely interested in your feedback; we aim to appease. Follow us on the Twitters: [@LaunchiesShow](https://twitter.com/LaunchiesShow).
{% podcast https://dev.to/launchies/get-excited-and-keep-pushing-through-with-rizel-scarlett %}
Jonan Scheffler: Hello and welcome to [Launchies](https://twitter.com/LaunchiesShow), proudly brought to you by New Relic's Developer Relations team, [The Relicans](https://therelicans.com). The Launchies podcast is about supporting new developers and telling their stories and helping you make the next step in what we certainly hope is a very long and healthy career in software. You can find the show notes for this episode along with all of The Relicans podcasts on [developer.newrelic.com/podcasts](developer.newrelic.com/podcasts). We're so glad you're here. Enjoy the show.
Pachi Parra: Hello and welcome to [Launchies](https://twitter.com/Launchies), a podcast for newbies, developers with non-traditional backgrounds, and career-switchers. I am [Pachi](https://twitter.com/pachicodes), and I'm a DevRel Engineer at [New Relic](https://newrelic.com). And I'll be your host for today. Today I have here with me [Rizél Scarlett](https://twitter.com/blackgirlbytes), and she's a Developer Advocate at [GitHub](https://github.com). Because of her undocumented status, she pivoted her career plans from psychology to tech. And she now helps lots of people in tech.
She attended a non-profit coding bootcamp with her boyfriend, now husband. And after landing in tech, she discovered her passion for helping others to get into tech. So she also works as a software engineer implementing a number of projects, including AutoTranslate at [Hi Marley](https://www.himarley.com/), which allows non-native English speakers to communicate with insurance operators, which is awesome. Welcome.
Rizél Scarlett: Thank you so much. I'm happy to be here.
Pachi: I'm glad you're here. How are you doing today?
Rizél: I'm doing pretty good. Like we were just saying, it's a busy Monday, but I'm settling in.
Pachi: Yeah, I feel like Mondays are just the days you have to just get everything done. So for the rest of the week, you can relax a little.
Rizél: Relax, yeah. [laughs]
Pachi: So I always like to start asking when did you first get interested in tech? Because lots of people I feel like they never, especially women (And I see that you are an immigrant, and I am too.), we don't even consider tech as a thing we can do until later in life. It's not like Americans that in high school, they have programming classes. That was mind-boggling when I learned that. So, when did you first realize that okay, I can work with tech and that it's awesome?
Rizél: At first, it was never an option to me, just like you're saying. I was always into writing, and English, and stuff like that. And I just didn't consider myself as someone in tech. That seemed like people that wore hoodies, and they're just always typing. So I was like, that's not me.
Pachi: [chuckles]
Rizél: But I ended up having to make the pivot when I was in college and studying psychology. And I realized I don't have enough money to continue going to college. And I was like, oh my gosh, I'm 18, and I made a bad choice of just going off to college without any money. And I can't continue for the next semester. So I ended up going back to live with my parents; they were in Boston. And I started trying to figure out, like, okay, I need to brainstorm a couple of things.
Because on top of that, I was undocumented, so I wouldn't get financial aid. But I still wanted to go to college. So eventually, I think that same year I had gotten approval for DACA, which is something that is called Deferred Action for Childhood Arrivals. And it allows undocumented immigrants to be able to work, and it expires every two years. So every two years, you got to pay money again.
Pachi: Is that a Boston thing?
Rizél: No, it's a United States thing. Obama instated it. It's only if you came to America undocumented and your parents brought you.
Pachi: Oh, okay.
Rizél: Yeah, that's the only way. And you had to have a certain amount of years and all that. So I was like, okay, but then these next two years, I need to be able to get a degree or something like that that I can actually use. I was like, I don't want to do psychology anymore because if I do two years, I will still be in the same place, no money, no nothing. And for psychology, you got to go for your grad degree. So what I ended up doing is I googled, and Google was like, if you go into tech, you can get an associate and be able to make money, and I was like, okay.
Pachi: Go for it.
Rizél: Yeah. So in community college, I studied computer information systems, and I started working as a help desk technician. And that's when I started hearing people talk about software engineering. I was a help desk technician at [HubSpot](https://www.hubspot.com/), and everyone's like, "Yeah, I'm coding," dah, dah, dah. I'm like, oh, what's that? So it looked really cool. And that's when I decided to sign up for a free coding bootcamp called [Resilient Coders](https://www.resilientcoders.org/) that's located in Boston. And that's how I found out about it and decided to learn to code.
Pachi: That's awesome. That's really awesome. And I just wanted to tell people who are listening that if you want to stay in the West with a student visa, you have to pay the whole thing and have the money in your account. I feel like lots of Americans don't know how hard it is to stay legally in the U.S.
Rizél: Yes.
Pachi: You have to have the money for the whole course, and you cannot work. You cannot legally work in the U.S. while you have a student visa. So basically, you can only come to the U.S. for college if you're very rich.
Rizél: Yeah, that's the thing. A lot of people think it's easy. They're like, "Just do the legal route." And my parents didn't even know when they brought me here that it will cause this much trouble. [laughs]
Pachi: I was undocumented for like five years. And people were just like, oh, why don't you just get legal? And I'm like, [laughs] why haven't I thought of that? And I feel like Americans don't know their migration laws. So just so you hear, it's very difficult to be legal in the U.S. to get the documents. For the work visa, you have to be a unicorn. The company has to prove that this person cannot find... anyone else. So it's not "Just go get a visa."
Rizél: It's not easy. [laughter] And it's very expensive.
Pachi: Yes. And I wanted to make this point because when I was looking for listings, they said, "Hey, why don't you just do that?" Because it's not an option. [laughs] I ended up marrying, and that was, for me, the only thing.
Rizél: Option, yeah.
Pachi: But yes, I'm glad you went through that to do coding in school. And after you finished your coding school...that's a silly question, and I know the answer, but I like to ask it. Did you feel ready for your first job after that? [laughs]
Rizél: Not fully ready. [Resilient Coders](https://www.resilientcoders.org/) is a super, super good coding bootcamp. They taught me a lot, but I was still nervous. I was still like, I don't really know what it's going to be like. [laughs] And the interviews, there's so much data structures and algorithms. And I'm like, you see that I'm a bootcamp grad. Why would I know something that computer --
Pachi: Yeah. I still can't do that.
Rizél: [laughs] I'm like, this is too much. So I didn't feel ready. But I just decided to jump in and just apply to a bunch of jobs because I wanted money.
Pachi: And how long did it take you after the bootcamp to get your first job?
Rizél: I got an internship before the bootcamp ended. So I'm always overly ambitious, I guess. So maybe some people waited until the bootcamp ended. But I knew the bootcamp was starting to end, and I applied for a job, interviewed, and I got it and started right after.
Pachi: That's great.
Rizél: Yeah, thank you.
Pachi: You just got it. I always say you're not the person to judge. The interviewer or director is going to say if you're good or not.
Rizél: Exactly. I will say I cried after my first interview, though. It was like a simple question, and I was so scared, and then I just cried. [laughs]
Pachi: It is too much. And the interview is usually...I don't know about the one you did, but especially the technical part, they're not very realistic. And nothing prepares for it. [laughs]
Rizél: They're not realistic at all. [laughs]
Pachi: And so you did the internship. Did you get a job after that, or you had the first job after that?
Rizél: So I did an internship at a company called [Formlabs](https://formlabs.com/), and it's like a 3D printing startup. And then, after that, I already had another internship lined up at this company called [Veson Nautical](https://veson.com/). And I ended up staying there and going full time.
Pachi: Oh, that's good.
Rizél: I have had multiple jobs.
Pachi: How long had it been before you got your first job?
Rizél: Oh, that's a good question. I think I graduated from my coding bootcamp in April 2018. So I had started that internship sometime in April 2018. And then the full-time role I started maybe October or September 2018.
Pachi: And you have been here since.
Rizél: Yeah. [laughs]
Pachi: And now you're a developer advocate at [GitHub](https://github.com/).
Rizél: Yeah, I am. I'm a junior developer advocate. [laughs]
Pachi: How did that happen?
Rizél: I've been interested in developer advocacy for a while because, like I mentioned to you before I discovered tech, I was really into writing and stuff like that. When I was little, I was like, I want to be an author or something. I was very into writing, and I was like, man, I wish there was a way for me to work and be able to blog and code like still have that balance. And I started finding out, like, oh my gosh, there are people who do that, and they do technical talks. I'm like, that's cool.
I started applying to some places, but they were looking for more senior people. And then I also got experience teaching women of color to code and creating the curriculum and stuff like that at this program called [G{Code}](https://www.thegcodehouse.com/). So that made me even want to do developer advocacy even more. I was like, this is awesome; getting to teach, create content, write, and just learn in public is really great for me.
So I saw a [GitHub](https://github.com/) post on Twitter that they were looking for a junior developer advocate. And they were like, yeah; you don't...they didn't have really strong requirements or anything like that. It was just like, you want to learn in public. You already know how to code and stuff like that. And I was like, okay, I'll apply. And I went through the interview process, and they hired me.
Pachi: Awesome. Congrats. And that was quite recently, right? Because I think I remember seeing you announcing your job on Twitter.
Rizél: Yeah, that was very recent. This is my third week.
Pachi: Oh. How do you like it so far?
Rizél: I love it. It's so fun. People are already reaching out to me about doing talks or writing for their blog. And I feel like it's just a good balance of being able to continue to code but then also do other stuff that I'm passionate about.
Pachi: Yeah, it's really fun. I really love it. I'm doing this podcast, and it's my work. Yay. [laughter] So you talked about [G{Code}](https://www.thegcodehouse.com/). So that's a place specifically for women and non-binary people to learn to code?
Rizél: Yes.
Pachi: That's really awesome. So you say you work there helping with the curriculum, but you also give classes there.
Rizél: Yeah. So essentially, it's a team of three of us. The founder created this idea. Basically, she wanted to purchase the house in a town in Boston that's historically black but starting to get heavily gentrified. And the idea was to house women of color there who are struggling with housing insecurity and also teach them to code. But it needs a lot of renovation. So in the meantime of renovating, me and another woman that works there, Bailey, we came up with the idea of, like, let's do online sessions. So yeah, what that turned into is me creating the curriculum and then me sometimes teaching. But I found a couple of other people who could also teach that way. I'm not burnt out.
Pachi: That's such an awesome project, not only teaching you to code but having this space. Because, again, people assume that they can just go to a college or a coding bootcamp. But if you don't have a safe space, you cannot think about it.
Rizél: Exactly. It's like you need to have shelter. You need to have food. You need to have those basic needs met before you can go into learning to code because it's not really useful when people are like, "Oh yeah, I don't have money. I'm struggling." And everybody is like, "Oh, why don't you learn to code." It's like, they have other stuff to focus on. They can't just be coding.
Pachi: Yeah. People are like that. "Why don't you just code hard enough?" And now when you don't even have everything just to start on. Like when you're working, and you just feel a little hunger, and you don't have a snack, you already cannot concentrate. [laughs]
Rizél: Yeah, you will not be able to absorb the information
Pachi: It is very important. I love that. So since you got into tech and it has been almost three years, especially in the beginning, what do you think were the biggest barriers you encountered? I feel like being an immigrant, and everything is hard enough already. But for you, like in the beginning especially, what were the worst things?
Rizél: I feel like getting comfortable with asking questions and knowing when to ask and how many. Because I would sometimes be like, okay, I don't want to ask because everyone seems like they know what they're doing. Or sometimes, when I would ask, there were some teams that I was on that were a little toxic. Some teams, everyone would be like, "Oh yeah, ready to help you." But some people would just be rolling their eyes when I asked for help, so then I just felt like I had to just sit there and just keep my head down. So that was definitely a struggle for me.
Pachi: Yeah. I feel like asking for help is hard. So when you do it, and the person is not responsive, it just breaks it.
Rizél: [laughs] It made me have a lot of [imposter syndrome](https://en.wikipedia.org/wiki/Impostor_syndrome). But I realized, okay, maybe I need to change the way I ask questions. So I'll just be like, here are all the things I tried. Here's where I'm at. Please help me here. And I got a little bit more responses that way.
Pachi: Yeah, I feel like it's very common. It's a mix of we need help, but we don't know what we're doing. But I don't want people to know that we don't know. [laughter] That's funny because when I was looking for my front-end job, this person liked me but she didn't have space. "I am thinking about hiring a part-time DevRel. Do you have an interest in DevRel?" And I didn't know what DevRel was. But I didn't want to ask her and say, "I don't know," because what if it's something that everybody should know? So I just googled it very quickly and said, "I never thought about that, but I would be interested in trying it out." [laughs] I just didn't want to say, "No."
Rizél: [laughs] That's the perfect way to answer.
Pachi: And I said, "Yes, I haven't considered that, but I'll try it out."
[laughter]
Rizél: I love it.
Pachi: So just ask for help, people. If you don't know something, just say it. It's the best thing. My brother has been my mentor, and he used to say to me that if he explains something to me and I don't understand, that was his fault because as a mentor, as a senior person, he should be able to explain that in a way that makes sense. And that was like, hey, it's not my fault I don't understand, and I will get there eventually.
Rizél: Yeah, I'm still learning that today. And I always tell people at [G{Code}](https://www.thegcodehouse.com/) too. I'm like, "Definitely interrupt and say you don't know what we're talking about because there's no point in us to keep on going, and you guys are lost." [laughs]
Pachi: And the secret is nobody knows what they're doing.
Rizél: Yeah, exactly. I told them that too. I'm like, listen; there are mentors here that are senior engineers. They don't know stuff. I'm like; I worked with people who are senior engineers. They don't know CSS. It's crazy. You have an advantage. You know CSS. You know the little stuff. [laughs]
Pachi: If you can align this div, you're ahead of so many people in life, seriously. [laughter] So ... learn.
Rizél: Exactly. [laughs]
Pachi: I always tell people the hardest thing in computer science is aligning things. Because CSS does what CSS wants to do.
Rizél: [laughs]
Pachi: It's not like your function that behaves the way you tell it to behave. CSS is like; I don't want to be there. I want to go here. But I love CSS; I do. [laughter]
Rizél: Yeah, with JavaScript or other languages, you're like, I want to get the data. You tell it to get the data; it gives it back to you, whatever. But with CSS, like you're saying, you're like, flex display, flex-direction column. And you're like, it’s not changing.
Pachi: You just try everything. Sometimes something is going to work eventually. Maybe you just forgot a semicolon, and that was the whole thing.
Rizél: Yeah. I hate when that happens.
Pachi: Yeah, this happens too often. [laughter] But anyways, you have been in your new job for three weeks. How has been the learning curve? In your first job, you were only coding, and now you're coding, too, but you don't have a product to deploy on Friday. Don't deploy on Friday, people. So, how has it been?
Rizél: It's definitely new. I'm feeling very positive about it so far, though. Usually, I get a first ticket, and they're like, deploy to production. But now it's kind of more autonomous of like, okay if you want to post a blog, you can. Do you want to do a talk? You can. I'm like, wow. I think I like how much opportunities there are. And I really like how [GitHub](https://github.com/) because they're remote-first; they do a good job at communicating and finding information and stuff like that. So they have everything compiled, and I'm just reading through it. It's a firehose of information, but it's useful. And I've been trying to pace myself so I don't feel overwhelmed.
Pachi: That's good. That's the thing about the DevRel job. It's so flexible in what we can do. That was true for me in the beginning. I want to do everything. [laughs] I'm going to do this YouTube video, and I'm going to write this tutorial. And I'm going to stream, and then I'm going to go to Instagram. And I was like, I can't do everything. Okay, I'm doing too much. [laughs] Slow down.
Rizél: Yeah, I'm hoping I pace myself.
Pachi: And I feel like lots of people in this already used to write these things, content creation as a hobby, not as a job. And when it turns into your job, you're like, wow, that's my job. I used to do that. Is this still my job? Did I work? The other thing that I used to ask my manager a lot was, "Did I work today? I streamed this thing, and I wrote this blog post. Did I work today?" And he's like, "Yes, you worked."
Rizél: [laughs] That's so true because I was feeling...I'm like, this is too good to be true. I'm on Twitter. I'm writing a blog post. This is fun for me, [laughs] but I'm not sure if I'm working. But yeah, like you said, it is working.
Pachi: You're working. And another I'm not going to forget is I was on vacation, and before bed, I just went on my phone, and I was scrolling Twitter. And then I saw a post about DevRel, and then I tagged my manager. I don't remember what it was about, but it was interesting. And he's like, "Pachi, you're in DevRel, so Twitter is work, and you're on vacation."
[laughter]
Rizél: And he's like, "Log out."
Pachi: I'm like, oh, I didn't think like that. Because normally, we are developers, so even if you’re on Twitter, tweeting is –
Rizél: Part of it, yeah. [laughs]
Pachi: Seriously, people, who would have thought? But yes, even if we're having fun, we might not even realize that we do tend to work too much. And then we are having fun, but our bodies are catching up. And then you're going to burn out, and you don't even know why.
Rizél: Yeah. I'm like, I don't know how much is too much work or what's going to burn me out. So I'm trying to pace myself, but I'm also excited. People are like, "Want to do the talk at [All Things Open](https://2021.allthingsopen.org/)? Want to do a talk here?" I'm like, "Okay, yeah. Let's see what you're organizing."
Pachi: I totally know how you feel. I say that. I still do so many things. What helped, though, for me is I have a rigid, not a schedule, but I don't work before 9:00, and I avoid working after 5:00. Even if I'm excited to write a blog post and it's like 5:00, I stop [laughs] because I can go forever.
Rizél: Yeah, I need to do that.
Pachi: And especially because sometimes when you just stop and you sit there thinking, we don't feel productive because you're just thinking. But your brain is working so hard. So you might not feel like you're working, but your brain is working.
Rizél: I didn't think of that. That's so true, yeah. My brain is working overtime. I definitely have the...like you're saying, after 5:00, I'll be like, oh, I could just like finish this really quickly. So that's a good tip. It's a common tip but a good reminder.
Pachi: Yeah, and I just feel with DevRel it's more true because, like I said, I don't know about you, but I'm guessing you used to write blog posts for fun. And your brain's like, I don't even know if you're working. And it's very easy to overwork yourself, especially in the beginning because you're so excited. I'm doing this thing, and it's so cool. I'm helping people, and I'm coding this fun thing.
Rizél: Yeah, that's so true.
Pachi: Your brain is like, yeah, I'm taking tabs of everything you're doing. [laughs]
Rizél: Oh gosh. Yeah, I'm going to try to keep and be aware of that. It's like this is the first time people...I write blog posts. I try to do talks, and now everybody's excited about me doing these. They're reaching out while before I was reaching out, and I'm like, "Please accept my talk." So yeah, I'll try to pace myself. [laughs]
Pachi: I know it's very hard because you want to say yes to everything. You want to do everything. So you want to say yes to everything. Like this week, I had a talk with you today. I'm going to be giving a talk in the [GitHub](https://github.com/) meetup tomorrow, and then I have a conference talk on Saturday. It doesn't feel like much, but all the prep work for that...and I'm an introvert, so all the emotional time I need for that. [laughs] It's like an hour of work that people see, but all the prep is like 10 hours. [laughs]
Rizél: Yeah, for real. [laughs] Just writing out the slides and practicing and stuff like that it's a lot
Pachi: Yes, and then to keep worrying about the design of the slides. Are they cute enough? It's not too weird. Just keep it professional. [laughter] And the colors.
Rizél: Yeah, oh my God. Okay, I thought I was the only one. [laughs]
Pachi: Oh no. Half the time making a slide is making sure you change the color palette because I never really -- [laughter]
Rizél: Oh my goodness.
Pachi: But I'm just so excited for you because I was where you were six months ago, so I totally understand you. [laughs]
Rizél: Wow.
Pachi: I started this job in...no, it was a little more. We started in December. But it was my first job with DevRel, and I was like, yay. I'm still saying yes to too much stuff.
Rizél: Congrats. I didn't realize it was so recent.
Pachi: This year just feels weird because it's September already. How did that happen? But it feels like I started yesterday, but it has been more.
Rizél: Yeah. You've been there for like, maybe 9 or 10 months.
Pachi: Yeah, almost.
Rizél: Wow, oh my God. Okay.
Pachi: [chuckles] But yes, I'm just loving that, and now there is a podcast about you, and you're just talking about like...Get yourself a podcast, people, just talking. We're friends now. And my cat is here. You can't see him, but he's here. Hey, hey. This is the other thing about --
Rizél: Great cat. So cute. [laughs]
Pachi: This is the home office thing. He's like, it's petting time. He's like, hey, stop working and just pet me.
Rizél: [laughs]
Pachi: Yeah, it didn’t happen. And he's just clicking on the file that had the things. But yes, so what are you more excited about? I know you have all these people reaching out to find out if you can talk now. But is there something you're more excited about? What in your job description when you saw you're going to do that were you like, yes!
Rizél: I think in the interview that I had...I've talked a lot about focusing on early-career developers. And I think that's where my focus is going to be since more of my team is a little bit more senior. And they'll be advocating more to people who are more senior in their career. And I think I'm excited about that because I'm very passionate about making sure early-career developers have a good experience, making sure they feel empowered, and the ability for them to learn in public. I think I'm most excited about helping build that out at [GitHub](https://github.com/), making sure that early-career developers know where to go, know what to do, and feel empowered while coding. That's my most exciting thing because I wish that was more available to me when I first started out as an engineer.
Pachi: Definitely. And that's so important that I always comment about, like, my team, too, the other people are mostly seniors, and I'm the early career, me and [Danny](https://twitter.com/muydanny). And I always comment how...because you haven't been a developer for too long, you forget how to talk the simple beginner language. Even if you try, you have been doing that for too long; it’s so natural that you cannot explain with simple words like, what is an array, for example. You just over-complicate everything because in your brain, that is set.
So I think it's so important to have somebody that's going to focus on people that are starting because you just got into the area. It's fresh in your brain. So you'll know how to break things down and say, "Hey, this is what it is," and with words that are real words, not technical words. It really matters. It's really, really important.
Rizél: Yeah, I agree. Because even if you think about...similar to computer scientists like how mathematicians are, if someone tries to teach someone one plus one, that seems so easy to us. [laughs] One plus one is two. But you're a little kid. You're not going to pick that up. So you have to be able to remember what it was like to be at that elementary stage and use visuals or use something more applicable that they'll be able to put into.
Pachi: Definitely, and it's good to keep that in mind, and that is not only for developer advocates but for people in general. After you do something too much, you just forget how to explain it. And it could really make a lot of difference for somebody that is learning. It can make or break you sometimes because sometimes you're just so frustrated with learning. Like, you cannot find documentation about X thing that makes sense to you, then you feel that you're dumb, then you feel like it's your fault, but it's not.
Rizél: Yeah, exactly.
Pachi: But it is so exciting. And what are you looking forward to? Is there an event happening or a talk?
Rizél: Yeah, I'm going to talk at [CodeLand Conference](https://codelandconf.com/). I'm just going to do a little five-minute talk, though. And then [GitHub Univers(ity)](https://education.github.com/) is coming up in October. I don't know what I'm going to be doing. But my manager said to keep my calendar open because I might be doing something. So I'm curious to see. I've never been on the side of being in [GitHub](https://github.com/) while [GitHub Univers(ity)](https://education.github.com/) is happening.
Pachi: That's awesome.
Rizél: Yeah. So I'm looking forward to those. And there are a couple of other conferences I think [All Things Open](https://2021.allthingsopen.org/) where I'm going to be talking about contributing to open source. And [Pulumi](https://www.pulumi.com/) is having a [Cloud Engineering Summit](https://www.pulumi.com/cloud-engineering-summit/), and they recently reached out to me.
Pachi: Oh. Look at you; you’re; people going everywhere now.
Rizél: Yeah, I'm so excited. I'm like, yay, people are reaching out. And I feel like those conferences...I'm very into open source, very into early-career developers, and cloud engineering, and stuff like that. So I'm very excited to be part of those.
Pachi: So, as a person that works in [GitHub](https://github.com/) and loves open source and [Hacktoberfest](https://hacktoberfest.digitalocean.com/) is coming soon, what is your advice for people who want to start contributing to open source but they're scared? Because open source can be scary.
Rizél: Yeah, for real. I actually just wrote a blog post about how scared I was because I will go into the codebase, and I'll be like, what is going on here? Or the documentation will be outdated, and I will just give up because I'm like, I just spent an hour trying to figure this out, [laughs] and now I realize this doesn't work.
But I will say some of my advice is one, try to join their...usually, open-source projects have a [Slack](https://slack.com/) or a [Discord](https://discord.com/) or something like that. Try to join that and introduce yourself. That way, you will feel more comfortable knowing who to reach out to and ask questions to because they might be aware that their documentation is not up to date. And they might be able to better lead you and be like, "Oh, this is a good ticket to pick up." Also, looking for good first issues.
And then another thing is pacing yourself. I keep talking about that. I used to get so overwhelmed. I would jump into a project, pick up an issue, try to install my environment, and I'll be like, oh my gosh, what's going on? I think just doing it on day one, and you're like, all right, I'm going to just read the documentation today. Then tomorrow, I'm going to set up my environment. Then the next day, I will explore the codebase figure out what's making what happen. And then, after that, pick up an issue. I think pacing yourself like that is really helpful and less scary [laughs], if that makes any sense.
Pachi: Yes, it does. It's like these kinds of things; giving the first step is the hardest part. After you're over that, things get a bit easier. But the first step is really scary, especially because you're exposing yourself and your code to other people's judgment. But next month is going to be fun because of [Hacktoberfest](https://hacktoberfest.digitalocean.com/).
Rizél: I know. [chuckles]
Pachi: Anyways.
Rizél: I'm super excited for that.
Pachi: Yeah, I can't imagine how exciting it is to work at [GitHub](https://github.com) in October. [laughs] And you talk a lot about people starting. My last question for you...it's not a question. Like, what is your best advice for people starting? What would you have liked somebody to have stopped you and told you, even before you started studying, like when you were still considering working in tech?
Rizél: That's a good question. I will say it's okay...I feel like this is a common theme of what we've been talking about, too, just knowing it's okay that you don't know things. It's okay that you're not sure what software engineering is or product management or DevRel or whatever. But the good thing is Google has the answers. And there are so many resources for you to find those answers. There are people and communities for you to join and reach out to from the beginning of your tech career or just exploring to like...when you're actually in the job, you're not going to know all the answers, and that's okay. Keep pushing through. Use the fact that you don't know something as an opportunity for growth. Don't be like, oh my gosh, I don't know it. I feel sad. Be like, oh my gosh, here's something I don't know. That means I'm going to get to learn something and know something. Get excited about it.
Pachi: That's a good mindset because it's very easy to be like, I don't that. I suck. I don't know what I'm doing. And like, hey, I don't know this. There's something new to learn. Yay.
Rizél: Exactly. [laughs]
Pachi: And that's going to happen in your entire career. It doesn't matter where you hide. [laughs]
Rizél: Yeah, especially in tech.
Pachi: Especially in tech, seriously.
Rizél: [laughs]
Pachi: Things just change so quickly. And there's always some new things, some new meme. And you have to keep up.
Rizél: [laughs] Yap.
Pachi: [laughs] I love that, though. I do.
Rizél: Me too. It's fun. It's so fun, and you're never bored. That's one thing I can say; you're never bored.
Pachi: You're definitely never bored. Those are the questions I had for you today. Thank you so much for coming to talk with me. I had so much fun.
Rizél: Yeah, of course. Thank you. Thanks for interviewing me.
Pachi: And where can people find you online?
Rizél: Yeah, you can find me on Twitter [@blackgirlbytes](https://twitter.com/blackgirlbytes). You can also find my blog at [blackgirlbytes.dev](https://blackgirlbytes.dev/). Basically, anywhere just look up [blackgirlbytes](https://www.google.com/search?q=blackgirlbytes&oq=blackgirlbytes&aqs=chrome..69i57j69i60l2.580j0j4&sourceid=chrome&ie=UTF-8), and I'll be there.
Pachi: I love that. It makes life much easier. [laughs] Okay, so that was it for today. Thank you for listening. This was [Launchies](https://twitter.com/LaunchiesShow). And have a great rest of your day, People.
Jonan: Thank you so much for joining us. We really appreciate it. You can find the show notes for this episode along with all of the rest of The Relicans podcasts on [therelicans.com](https://therelicans.com). In fact, most anything The Relicans get up to online will be on that site. We'll see you next week. Take care. | therubyrep |
900,959 | 01 Text Field | Building 🚧 Dock-UI: Custom Tailwind CSS components for H010SPACE | Every since I was introduced to Tailwind CSS - A utility-first CSS framework - I have wanted to... | 15,554 | 2021-11-18T15:55:16 | https://dev.to/shecodez/building-dock-ui-custom-tailwind-css-components-for-h010space-1-text-fields-28dj | tailwindcss, css | > Every since I was introduced to Tailwind CSS - A utility-first CSS framework - I have wanted to build my own flavor of custom UI components with it. Even with so many wonderful UI component frameworks and libraries out there, some may have a few component styles I like, but none have all and only the components I like / find useful.
> So, I have decided to document building a complete set of my own custom components called Dock-UI.
While H010SPACE is in development, the only accessible page for awhile will be the landing page which has one main element, a sign up `<form />` for the mailing list with a email `<input />` and submit `<button />`.
**So, first up we're building an `<input />` with [Tailwind CSS](https://tailwindcss.com/)**.
Of all the frameworks and libraries I've seen so far, my favorite style for `<input />` is by [Material Design](https://material.io/components/text-fields). Today we'll build the Material Design Filled Text field with Tailwind CSS.
*Note: I usually use [Windi CSS](https://windicss.org/) instead of Tailwind CSS for the speed ⚡, but the classes work the exact same for both.*
Starting with the foundation we have:
```
<input type="email" placeholder="E-Mail" class="border" />
```
Now that we have the base lets style it up. According to Material Design the [anatomy](https://material.io/components/text-fields#anatomy) of a text field consists of:
1. Container
2. Leading icon (optional)
3. Label text
4. Input text
5. Trailing icon (optional)
6. Activation indicator
7. Helper text (optional)
```
<div>
<label for="email">E-Mail</label>
<input type="email" name="email" class="border" />
</div>
```
For simplicity I've left out the *optional* bits.
**TL;DR** the finished code is right below take it, use it, and modify the crap 💩 out of it. A brief explanation of the code will follow if you want to stick around for it.
**HTML**
```
<div class="d-textfield relative bg-black bg-opacity-10 px-4 pt-5 pb-1.5 rounded-t border-b border-black border-opacity-40">
<input type="email" name="email" placeholder=" " class="block bg-transparent w-full appearance-none focus:outline-none text-sm" />
<label for="email" class="absolute top-0 transform translate-y-1/2 duration-300">E-Mail</label>
</div>
```
**SCSS**
```
.d-textfield:focus-within {
border-bottom: 2px solid blue;
background-color: rgba(0,0,0, 0.20) !important;
& input {
caret-color: blue;
}
& label {
color: blue;
}
}
.d-textfield label {
z-index: -1;
}
.d-textfield input:focus-within ~ label,
.d-textfield input:not(:placeholder-shown) ~ label {
//@apply transform scale-75 -translate-y-6;
transform: translate(-0.4em) scale(0.74);
}
```
{% codepen https://codepen.io/shecodez/pen/zYdyXOK %}
Part of the beauty of Tailwind CSS is that the utility classes make it pretty clear what's going on. Plus because you can extend tailwind the SCSS can be made even shorter.
For example we can change the border color when the input is focused using the pseudo-class `focus-within`. We can enable the focus-within variant in Tailwind for `borderColor` by adding it in the `tailwind.config.js` or `windi.config.js` under the variants section:
**tailwind.config.js** / **windi.config.js**
```
variants: {
borderColor: ['responsive', 'hover', 'focus', 'focus-within'],
}
```
Then we can add the `focus-within:border-blue-500` class to the input container `<div />` to change the border color on focus and remove the `.d-textfield:focus-within { border-bottom: 2px solid blue; }` from the SCSS.
The same thing could be done with the negative `z-index` for the `<label />`. Just extend the Tailwind theme to generate a negative z-index for you:
**tailwind.config.js** / **windi.config.js**
```
theme: {
extend: {
zIndex: {
"-1": "-1",
},
},
}
```
With that you can add the class `-z-1` to the `<label />`, and remove `.d-textfield label { z-index: -1; }` from the SCSS.
And with that we've completed our first dock-ui component. Of course it's very basic right now but I leave the upgrades for you and future me. 😊
Thanks for reading! 🖖 | shecodez |
901,219 | Algorithm Series - Insertion Sort | Photo by Dee @ Copper and Wild on Unsplash This is a quick tutorial on the Insertion Sort algorithm... | 0 | 2021-11-17T21:11:13 | http://tatyanacelovsky.com/algorithm_series_-_insertion_sort | algorithms | ---
title: Algorithm Series - Insertion Sort
published: true
date: 2021-11-17 16:00:00 UTC
tags: Algorithms
canonical_url: http://tatyanacelovsky.com/algorithm_series_-_insertion_sort
---
 Photo by [Dee @ Copper and Wild](https://unsplash.com/@copperandwild) on [Unsplash](https://unsplash.com/)
_This is a quick tutorial on the Insertion Sort algorithm and its implementation in Javascript._
### What is Insertion Sort Algorithm
Insertion Sort is a [sorting algorithm](%5Bhttps://en.wikipedia.org/wiki/Sorting_algorithm%5D(https://en.wikipedia.org/wiki/Sorting_algorithm)) that places the element in its appropriate place based on the sorting order. A good example of Insertion Sort is sorting cards held in your hands during a card game.
Let’s take a look at Insertion Sort when trying to sort the elements of an array in an ascending order:
1. Assume that the first element of the array is property sorted;
2. Store the second element of the array in a `key`;
3. Compare `key` to the first element - if `key` is smaller that the first element, then `key` is placed in front of the first element;
4. Store the next unsorted element of the array in a `key`;
5. Compare `key` to the sorted element and place it in the appropriate place with respect to the sorted elements based on whether `key` is smaller or greater than each of the sorted elements;
6. Continue with steps 4 and 5 until all elements of the array are sorted.
The array is sorted when all the unsorted elements are placed in their correct positions.
### Insertion Sort Code in Javascript
Let’s take a look at the code for the Insertion Sort algorithm described above (ascending order):
{% gist https://gist.github.com/tcelovsky/8c8d41a80c6d9525b69b7daeaf1c4b12.js %}
Let’s take a look at the code for the Insertion Sort algorithm described above (ascending order):
### Insertion Sort and Big-O
Insertion Sort compares the adjacent elements, hence, the number of comparisons is:
(n-1) + (n-2) + (n-3) +…..+ 1 = n(n-1)/2
This nearly equals to n2, therefore Big-O is O(n²) or quadratic time. We can also deduce this from observing the code: insertion sort requires two loops, therefore Big-O is expected to be O(n²).
### Conclusion
Insertion Sort inserts each element of the array in its appropriate place based on whether the array is being sorted in ascending or descending order. It is a simple way to sort a list when complexity does not matter and the list that needs sorting is short.
### Resources
[Insertion Sort Algorithm gist](https://gist.github.com/tcelovsky/4c7b1b5a852adacf13ba7a3604000f79)
[Let’s Talk About Big-O](https://dev.to/tcelovsky/let-s-talk-about-big-o-2ah9) | tcelovsky |
901,229 | Conceptos básicos de Docker | Docker te permite construir, distribuir y ejecutar cualquier app en cualquier lugar, mediante... | 0 | 2021-11-18T20:44:10 | https://dev.to/tris460/iniciando-con-docker-2lfi | docker, beginners, linux | Docker te permite construir, distribuir y ejecutar cualquier app en cualquier lugar, mediante contenedores.
Para poder usarlo debes ingresar a https://www.docker.com/ y descargar 'Docker desktop' y crear una cuenta en DockerHub.
### Conceptos importantes
- Contenedores: Dónde va a correr la app, sirve para poder compartir las imágenes con otros servidores, computadoras, etc. Es una agrupación de procesos aislados del sistema, es decir, como si se estuviera corriendo una máquina virtual en tu computadora, pero mucho mejor.
- Imágenes: Es la encapsulación del contenedor a compartir, lo que tú creas para que otros usuarios lo usen.
- Volúmenes de datos: Archivos del sistema, pueden ser archivos, carpetas, imágenes, etc.
- Redes: Permiten la comunicación entre servidores, son conexiones básicamente.
### Comandos importantes
+ **docker login** Inicia sesión en DockerHub para poder usar el código que ya está escrito y compartir tu código.
+ **docker run `<contenedor>`** Ejecuta el contenedor.
* `--name <nombre>` Le asigna un nombre al contenedor.
* `--mount src=<nombre_volumen>,dst=<ruta_contenedor>` Asigna un volumen al contenedor, como `-v`.
* `-i` Abre el modo interactivo.
* `-t` Ejecuta su terminal.
* `-d` Lo ejecuta en segundo plano.
* `-p <puerto_local>:<puerto_contenedor>` Expone un puerto del contenedor para acceder en la máquina local.
* `-v <ruta_local>:<ruta_contenedor>` Copia todos la data de la ruta del contenedor en la ruta local especificada. Crea un volumen.
* `--rm` Cuando se cierra el contenedor, se elimina.
* `--env <nombre_variable>=<valor>` Define una variable de entorno.
* `--scale <nombre_contenedor>=<número>` Crea 'n' instancias del contenedor
* `--memory <cantidad_memoria>` Limita el uso de memoria.
+ **docker ps** Lista los contenedores activos y su información.
* `-a` Muestra también los contenedores inactivos.
* `-q` Muestra solo los ID de los contenedores.
* `-l` Muestra solo la información del último proceso.
+ **docker inspect `<id_contenedor | nombre_contenedor>`** Muestra información más completa sobre el contenedor dado su ID o nombre.
* `--format '{{<atributo>.<propiedad>}}'` Retorna solo la información solicitada.
+ **docker rename `<actual> <nuevo>`** Cambia el nombre de un contenedor.
+ **docker rm `<id_contenedor | nombre_contenedor>`** Elimina el contenedor seleccionado.
* `-f` Fuerza el borrado.
+ **docker container prune** Elimina todos los contenedores.
+ **docker exec `<nombre_contenedor>`** Conectar con un contenedor que ya está corriendo.
+ **docker stop `<nombre_contenedor>`** Mata un proceso.
+ **docker logs** Muestra los logs.
* `-f` Se queda esperando a que lleguen más logs.
* `--tail <número>` Muestra los últimos 'n' logs.
+ **docker tag `<nombre_contenedor> <nuevo_nombre_contenedor>`** Renombra la etiqueta del contenedor.
+ **docker history `<nombre_contenedor>`** Muestra los cambios hechos al contenedor.
+ **docker system prune** Borra todo lo que este inactivo.
+ **docker stats** Ver los recursos que está consumiendo el contenedor.
+ **docker volume ls** Lista los volúmenes activos.
+ **docker volume create `<nombre_volumen>`** Crea un volumen.
+ **docker volume prune** Borra los volúmenes inactivos.
+ **docker cp `<archivo> <nombre_contenedor>:<ruta_local>`** Copia un archivo del contenedor a la ruta local asignada
+ **docker cp `<nombre_contenedor>:/<directorio> <ruta_local>`** Copia un directorio desde el contenedor.
+ **docker image ls** Lista las imágenes.
+ **docker pull <nombre_contenedor>:<versión?>** Trae la imagen desde DockerHub.
+ **docker build `<nombre_contenedor>` .** Construye una imagen.
* `-t` Agrega una etiqueta a la imagen.
+ **docker push `<nombre_contenedor>`** Publica el contenedor en DockerHub.
+ **docker network ls** Muestra las redes existentes.
+ **docker network create `<nombre_red>`** Crea una red.
* `--attachable` Permite que cualquiera se conecte a la red.
+ **docker network inspect `<nombre_red>`** Muestra información de esa red.
+ **docker network connect `<nombre_red> <nombre_contenedor>`** Conecta un contenedor a una red.
+ **docker network prune** Elimina todas las redes que no estén siendo usadas.
+ **docker-compose up** Corre todo lo que definimos en el archivo docker-compose.yml (redes, servicios, contenedores, etc).
* `-d` Lo corre en segundo plano.
+ **docker-compose ps** Muestra los contenedores activos.
+ **docker-componse logs** Muestra los logs de los servicios/contenedores.
* `-f` Muestra los logs conforme llegan.
* `<nombre_contenedor>` Muestra los logs de solo ese servicio.
+ **docker-compose down** Apaga los contenedores y elimina todo lo que tenga que ver con ellos.
+ **docker-compose build `<nombre_contenedor>`** Construye una imagen a partir de los archivos que tiene en disco, basandose en el archivo docker-compose.yml.
### Dockerfile
Es un archivo de texto plano con instrucciones necesarias para crear una imagen.
Una estructura básica puede ser:
```
FROM node:12 //En qué se basa
COPY [".", "/usr/src/"] //Copia archivos
WORKDIR /usr/src/ //Cambia de directorio (como cd)
RUN npm install //Corre este comando
EXPOSE 3000 //Expone el puerto para usarlo en local
CMD ["node", "index.js"] //Comando a ejecutar cuando se corra el contenedor
```
### Docker Compose
Permite escribir en un archivo lo que queremos que Docker realice sin usar los comandos. El archivo es docker-compose.yml. Es parecido a un archivo JSON, aquí importa el tabulado, es decir que si no pones el espaciado correcto, la aplicación no funcionará.
Ejemplo:
```
version: "3.8" //Versión de DockerCompose
services: //Componentes a ejecutarse
app: //Servicio
image: ubuntu //Imagen en la que se va a basar el contenedor
environment: //Define las variables de entorno
MONGO_URL: "mongodb://db:27017/test"
depends_on: //Servicios que deben existir para que funcione
- db
ports: //Puertos a exponer y en que puerto
-"3000:3000"
-"2000-20003:2000" //Expone un rango de puertos
volumes: //Define un volumen
-.:/usr/src/ //De dónde toma los datos y en dónde los guarda
build: . // Dónde va a construir la app
db:
image: mongo
command: npx nodemon index.js //Qué comando se ejecutará
```
### Docker Compose Override
Este archivo es como docker-compose.yml pero para cuando queremos trabajar en nuestro local sin hacer cambios que puedan afectar al resto del equipo.
No podemos dejar vacío este archivo, ya que puede generar errores.
Podríamos poner solo `version: "3.8"` para que funcione, ya que 'hereda' los datos de docker-compose.yml, si hay líneas repetidas, el archivo docker-componse.override.yml lo sobrescribe.
Es aconsejable no sobrescribir los puertos, sino dejarlos solo en un archivo, esto para evitar errores.
### Docker Ignore
Aquí definimos los archivos que no serán tomados en cuenta para realizar el build. El archivo se llama: .dockerignore.
Su sintaxis es:
```
*.log
.dockerignore
.git
Dockerfile
```
| tris460 |
901,236 | Decoding CBOR with PureScript | Decoding CBOR with PureScript | 0 | 2021-11-17T22:07:38 | https://dev.to/reactormonk/decoding-cbor-with-purescript-2afl | cbor, purescript | ---
title: Decoding CBOR with PureScript
published: true
description: Decoding CBOR with PureScript
tags: #cbor #purescript
//cover_image: https://direct_url_to_image.jpg
---
If you want to decode cbor data from PureScript, there's `cborg`, which works just fine... if you use `useMaps` to deal with the `Error: CBOR decode error: non-string keys not supported (got number)` errors. Afterwards you have javascript `Map`s, which can't be decoded with argonaut. I use this code as workaround:
```javascript
const toObject = function(cbor) {
if (cbor instanceof Map) {
var obj = {}
cbor.forEach(function(value, key) {
obj[key.toString()] = toObject(value);
});
return obj;
} else {
if (cbor instanceof Array) {
return cbor.map(ob => toObject(ob));
} else {
if (cbor instanceof Object) {
var obj = {}
cbor.forEach(function(value, key) {
obj[key.toString()] = toObject(value);
});
return obj;
} else {
return cbor
}
}
}
}
```
After that, you can decode the tags as string keys, e.g.
```purescript
decodeJson cbor :: _ { "1" :: Int }
```
| reactormonk |
901,523 | Deeper Into this In JavaScript | In a previous article, we saw how to use this keyword with objects. In this post, we shall dive... | 0 | 2021-11-18T07:49:04 | https://dev.to/vinoo/deeper-into-this-in-javascript-4lil | javascript, webdev, programming | In a [previous article](https://dev.to/vinoo/oops-in-javascript-intro-to-creating-objects-and-this-keyword-2bi), we saw how to use `this` keyword with objects. In this post, we shall dive deeper into different bindings of `this` that we will encounter when dealing with it in functions. Bindings mean the different ways `this` behaves in different contexts in a function.
### 1. Default Binding
Consider the following example -
```js
function defaultThis() {
console.log(this);
alert(`Welcome ${this.username}`);
}
defaultThis();
```
Since there is no `username` variable declared or defined, `this` keyword gets the default binding - it references the global `Window` object here, as can be seen below -

### 2. Implicit Binding
This binding is created by the behaviour of the function. Let's take an example to understand -
```js
let hobbit = {
name: 'Bilbo',
welcome() {
alert(`Hello ` + this.name);
}
}
hobbit.welcome();
```
The output would be as exptected -
Here, since there is an object that calls the function `welcome()`, `this` implicitly refers to the object inside the function.
### 3. Explicit Binding
Explicit binding means to explicitly bind the value of `this` to any specific object.
There are 3 methods to implement explicit binding -
* `call()`
Consider the code snippet we used above in Implicit Binding - the property `name` and method `welcome` are both defined inside the object `hobbit`. This makes the binding for `this` fairly..implicit 🌝. What if the object is separate from a method? Consider the snippet below -
```js
function welcome() {
alert(`Welcome ${this.name}`);
}
let hobbit = {
name: 'Frodo'
}
welcome(); // Welcome
welcome.call(hobbit); // Welcome Frodo
```
The first function call `welcome()` has no reference to an object, so it would not return anything in the alert statement after `Welcome`.
The second function call is where we have accessed the object with the `call` method. This means that we are specifying to the browser to assign the object `hobbit` being passed as parameter to `this` using `call` method.
Another use case for `call` is that we can pass parameters to signify the value for `this` along with arguments for the function. Example -
```js
function foo(spellOne, spellTwo) {
alert(`${this.name} cast the spells ${spellOne} and ${spellTwo}`);
}
let wizard = {
name: 'Ron Weasley'
};
foo.call(wizard, 'Expelliarmus', 'Slugulus Eructo');
```
Here, the function `foo` is called with the `call` method and the object `wizard` is passed as the first argument which automatically gets assigned to `this` in the function, along with the rest of the arguments. Note that the first argument always gets assigned to `this`.
The output is as below -

But there is a drawback for this use case. What if there are tens of arguments to be passed for multiple objects? Very cumbersome 😕 We have the next binding method to improve usability a little better.
* `apply()`
Take a look at this snippet -
```js
function foo(spellOne, spellTwo) {
alert(`${this.name} cast the spells ${spellOne} and ${spellTwo}`);
}
let wizard = {
name: 'Ron Weasley'
};
foo.apply(wizard, ['Expelliarmus', 'Slugulus Eructo']);
```
The format is the same, except that instead of `call`, we use the method `apply`, and instead of passing the arguments one after the other, we just wrap them in an array. The output remains the same.
* `bind()`
The `bind()` method creates a new function which when invoked, assigns the provided values to `this`.
Take a look at the snippet below -
```js
function foo(spellOne, spellTwo) {
alert(`${this.name} cast the spells ${spellOne} and ${spellTwo}`);
}
let wizard = {
name: 'Ron Weasley'
};
let castSpell = foo.bind(wizard, 'Expelliarmus', 'Slugulus Eructo');
castSpell();
```
Here, we are using `bind()` to be referenced by the variable `castSpell`, which can then be invoked as a normal function call.
The advantages of using `bind()` are that -
- We are explicitly binding the `foo()` method to the instance `castSpell` such that `this` of `foo()` is now bound to `castSpell`
- Even though the `wizard` object does not have `castSpell` as its property, because we are using `bind()`, `wizard` now recognises `castSpell` as its method
`bind()` returns a new function reference that we can call anytime we want in future.
### 4. new Binding
`new` binding is used specifically for constructor functions. Take a look below -
```js
function Wizard(name, spell) {
this.name = name;
this.spell = spell;
this.intro = function() {
if(this.name === 'Hermione') {
alert(`The witch ${this.name} cast the spell ${this.spell}`);
} else {
alert(`The wizard ${this.name} cast the spell ${this.spell}`);
}
}
}
let hermione = new Wizard('Hermione', 'Occulus Reparo');
let ronald = new Wizard('Ronald', 'Slugulus Erecto');
```
Constructor functions are special functions that are used to create new objects. The use of `new` keyword means that we are creating a new object (or instance) of the (constructor) function.
Whenever `new` is used before any constructor function (name with the Capitalized convention followed), the JS engine undertands that `this` inside the function will always point to the empty object created by `new`.
### 5. HTML Element Event Binding
`this` can be used to bind the values of specific events or elements in HTML.
Take a look at this example -
```html
<button
class ="this-one"
onclick="console.log(this)">
this One
</button>
```
In this case, `this` will always bind itself to the element where the event happened; in this case, the `this-one` class button.
The output will be as below -
Now take a look at this snippet -
```html
<button
class ="this-two"
onclick="this.style.backgroundColor='orange'">
this Two
</button>
```
Here, `this` is again bound to the button with the class `this-two`, and the `onclick` event happens only on that specific button.
Output -
How about when we call a function within the element?
```js
<button
class ="this-three"
onclick="changeColor()">
this Three
</button>
<script>
function changeColor() {
console.log(this);
}
</script>
```
Note that we are calling the `console.log()` function along with `this`.
So, the value of `this` is as below -

Here, `this` points to the global `Window` object. We can see that Default Binding occurs here since the function `changeColor()` is called without a prefix.
---
`this` is definitely strange. However, the use cases provide us with flexibility to use objects effectively. | vinoo |
901,673 | Share Local Laravel Project with IP address | Use Laravel's artisan for it which is Very simple php artisan serve --host 192.168.1.101 --port... | 0 | 2021-11-18T09:50:20 | https://dev.to/krixnaas/share-local-laravel-project-with-ip-address-5aln | Use Laravel's artisan for it which is Very simple
```
php artisan serve --host 192.168.1.101 --port 80
```
Now from other computers, you can type: http://192.168.1.101:80
Note Do not forget to replace the IP with your own local one. That's it.
| krixnaas | |
901,790 | What is random.shuffle() method in python? How to use it? | In this blog, we will explore the random.shuffle method in python, and implement this method in our... | 15,405 | 2021-11-18T13:53:24 | https://dev.to/vaarun_sinha/what-is-randomshuffle-method-in-python-how-to-use-it-57o5 | python, beginners, projects | In this blog, we will explore the random.shuffle method in python, and implement this method in our password generator project.
**So Let's Get Started!**
What is the random.shuffle method?
Basically the random.shuffle methods takes in a list like:
[1, 2, 3, 4, 5, 6, 7, 8, 9] and shuffles it like: 2, 1, 5, 6, 8, 9, 4, 7, 3].
Run this code to know more:
{%replit @vaarunSinha/Random-Shuffle-Method %}
**Let's implement this in our own project!**
In the previous blog, we had a problem:
>Now if we print/generate the password every time ,there is a
predictable format, first numbers then special etc..
So for that first let's convert the password into a list:
```python
password = list(numPart + spPart + smallPart + bigPart)
random.shuffle(password)
password_str = ''.join(password)
return password_str
```
This is the final code for a basic password generator!
{%replit @vaarunSinha/Password-Generator-with-secrets-module %}
**So stay tuned!**
**Happy Coding!**
| vaarun_sinha |
901,886 | Artificial Intelligence Technology: AI Trends That Matter for Business | According to 2020’s McKinsey Global Survey on artificial intelligence (AI), in 2020 more than 50% of... | 0 | 2021-11-18T14:31:59 | https://dev.to/oleksiitsymbal/artificial-intelligence-technology-ai-trends-that-matter-for-business-2a8e | ai, machinelearning, security, gans | According to 2020’s McKinsey Global [Survey](https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/global-survey-the-state-of-ai-in-2020) on artificial intelligence (AI), in 2020 more than 50% of companies have adopted AI in at least one business unit or function, so we witness the emergence of new AI trends. Organizations apply AI tools to generate more value, increase revenue and customer loyalty. AI leading companies invest at least 20% of their earnings before interest and taxes (EBIT) in AI. This figure may increase as COVID-19 is accelerating digitization. Lockdowns resulted in a massive surge of online activity and an intensive AI adoption in business, education, administration, social interaction, etc.
This article aims to overview new and current AI trends that emerged in 2020 and are still increasing in 2021. Based on trends, companies can make projections of the AI future in 2022 and successfully mitigate risks. Saying AI, we mean neural networks, machine learning, deep learning, computer vision, and other [subfields](https://www.g2.com/articles/artificial-intelligence-terms) of Artificial Intelligence.
[Image credit](https://unsplash.com/photos/s4dfrh7hdDU)
##AI Adoption Trends
AI Adoption level differs depending on the industry. Using the data mentioned in the McKinsey Global Survey on AI, we can highlight four leading sectors: high-tech, telecom, automotive, assembly.
Companies apply AI for service operations, service or product design, advertising, and sales. Regarding investments, the area of drug discovery and development received the highest amount of money — in 2020, the total sum of investments exceeded 13.8 billion dollars, 4.5-fold higher than the year before.
AI drives the highest revenue growth if applied in inventory and parts optimization, pricing and promotion, customer-service analytics, sales, and demand forecasting. Use cases that reported cost decrease are related to optimization of talent management, contact-center automation, and warehouse automation.
##AI Technology Trends
In 2021 and the following years, AI will be leveraged to simplify operations and make them more efficient. Businesses should try to benefit from the commercial application of Artificial Intelligence through improving IT infrastructure and data management. But not each deployed AI model could be useful for companies and appropriate for performance monitoring. We’ll focus on AI trends 2021-2022 that are likely to become mainstream.
##Trend 1. AI for Security & Surveillance
AI techniques have already been applied to face recognition, voice identification, and video analysis. These techniques form the best combo for surveillance and biometric authentication. So, in 2021, we can foresee the intensive exploitation of AI in video surveillance.
Artificial Intelligence is beneficial for a flexible setup of security systems. Previously, engineers spent a lot of time configuring the system because it was activated when a specific number of pixels on a screen changed. So, there were too many false alarms. These alarms were caused by falling leaves or a running animal. Thanks to AI, the security system identifies objects, which contributes to a more flexible setup.
[](https://www.youtube.com/watch?v=X7_ojlEXnWc)
AI in video surveillance can detect suspicious activity by focusing on abnormal behavior patterns, not faces. This ability enables creating more secure spaces, both public and private, through identifying potential threats. Such AI-driven video solutions could be also useful for logistics, retail, and manufacturing.
Another niche that provides promising perspectives for the AI application is voice recognition. Technologies related to voice recognition are able to determine the identity. By identity, we mean the age of a person, gender, and emotional state. The principles on which voice recognition for surveillance is based can be the same as in the case of Alexa or [Google Assistant](https://voicebot.ai/2020/11/16/google-demonstrates-new-speech-recognition-model-for-mobile-use/). A feature that is suitable for security and surveillance is a built-in anti-spoofing model that detects synthesized and recorded voice.
One of the most crucial technologies for security is biometric face recognition. Different malicious applications try to trick security systems by providing fake photos instead of real images. To defend against such cases, multiple anti-spoofing techniques are presently being developed and used at large scale.
[](https://www.youtube.com/watch?v=uIIE1p3c188)
##Trend 2. AI in real-time video processing
The challenge for processing of real-time video streams is handling data pipelines. Engineers aim to ensure accuracy and minimize latency of video processing. And AI solutions can help to achieve this goal.
To implement an AI-based approach in live video processing, we need a pre-trained neural network model, a cloud infrastructure, and a software layer for applying user scenarios. Processing speed is crucial for real-time streaming, so all these components should be tightly integrated. For faster processing, we can parallelize processes or improve algorithms. Processes parallelization is achieved through file splitting or using a pipeline approach. This pipeline architecture is the best choice since it doesn’t decrease a model’s accuracy and allows for use of an AI algorithm to process video in real-time without any complexities. Also, for pipeline architecture, it’s possible to apply additional effects implying face detection and blurring. You can find more information on the subject in our article dedicated to AI in real-time video processing.
[](https://www.youtube.com/watch?v=ykJ9pQuyh2k)
Modern real-time stream processing is inextricably linked to the application of background removal and blur. The demand for these tools has increased because of COVID-19 contribution to the emergence and popularization of new trends in video conferencing. And these trends will be actively developed because, according to [GlobeNewswire](https://www.globenewswire.com/en/news-release/2021/06/21/2250123/28124/en/Video-Conferencing-Market-Global-Forecast-2021-to-2026-Impressive-Growth-at-a-CAGR-of-19-7-Expected.html), the global video conferencing market is expected to grow from USD 9.2 billion in 2021 to USD 22.5 billion by 2026.
There are different ways to develop tools for background removal and blur in a real-time video. The challenge is to design a model capable of separating a person in the frame from the background. The neural network that is able to carry out such a task could be based on existing models like BodyPix, MediaPipe, or PixelLib. When the model is chosen, the challenge remains for its integration with an appropriate framework and organizing the optimal execution process through the application of WebAssembly, WebGL, or WebGPU.
##Trend 3. Generative AI for content creation & chatbots
Modern AI models are able to generate text, audio, images in a very high quality, almost indistinguishable from non-synthetic real data.
At the heart of text generation stands Natural Language Processing (NLP). Rapid advances in NLP have led to the emergence of language models. For instance, BERT model is being successfully used by Google and Microsoft to complement their search engines.
How else does the development of technologies related to NLP boost companies? First of all, combining NLP and AI tools allows the creation of chatbots. According to [Business Insider](https://www.businessinsider.com/chatbot-market-stats-trends?op=1), the chatbot market is expected to reach USD 9.4 billion in 2024, so let’s emphasize the ways businesses benefit from AI-driven chatbots implementation.
Chatbot tries to understand the intentions of people, instead of just performing standard commands. Companies working in different areas use the AI-driven chatbot to provide their clients or users with human-level communication. Applications of chatbots are widely observed in the following business domains : healthcare, banking, marketing, travel and hospitality.
AI-driven chatbots help to automate admin tasks. For instance, in healthcare they reduce the amount of manual work. Here, chatbots help to organize appointments, send reminders related to taking meds, and provide patients with answers to queries. In other areas, chatbots are introduced to deliver targeted messages, improve customer engagement and support, and provide users with personalized offers.
Besides chatbots, NLP lies at the heart of other cutting-edge technological solutions. One of the examples is NLP text generation that can be used in business applications. An NLP-based Question Generation system presented in the video below is used in a secure authentication process.
[](https://www.youtube.com/watch?v=dvWbgvgnPE4)
The recent arrival of the GPT-3 model allows AI engineers to generate an average of [4.5 billion words](https://openai.com/blog/gpt-3-apps/) per day. This will allow a tremendous range of downstream applications of AI for both socially useful and less useful purposes. It is also causing researchers to invest in technologies for detecting generative models. Note that in 2021-2022 we will witness the arrival of GPT-4 — “artificially generally intelligent AI”.
Coming back to Generative AI, we want to pay attention to GANs, or Generative Adversarial Networks, that are now capable of creating images indistinguishable from human-produced ones. That could be images of [non-existent people](https://thispersondoesnotexist.com), animals, objects, as well as other types of media, such as audio and text. Now is the best moment to implement GANs gaining from their abilities because they can model real data distributions and learn helpful representations for improving the AI pipelines, securing data, finding anomalies, and adapting to specific real-world cases.
##Trend 4. AI-driven QA and inspection
The most remarkable branch of Computer Vision is AI inspection. In recent years, this direction has been prospering because of the increasing accuracy and performance. Companies started to invest both computational and financial resources to develop сomputer vision systems at a faster rate. The intensive development of AI inspection is also connected with a rapid progress in the domain of object detection in video frames.
[](https://www.youtube.com/watch?v=UY6xbrcViVw)
Automated inspection in manufacturing implies the analysis of products in terms of their compliance with quality standards. The methodology is also applied to equipment monitoring.
Here are few use cases of AI inspection:
* Detecting defects of products on the assembly line
* Identifying defects of mechanical and car body parts
* Baggage screening and aircraft maintenance
* Inspections of nuclear power stations
* Use cases of AI inspection
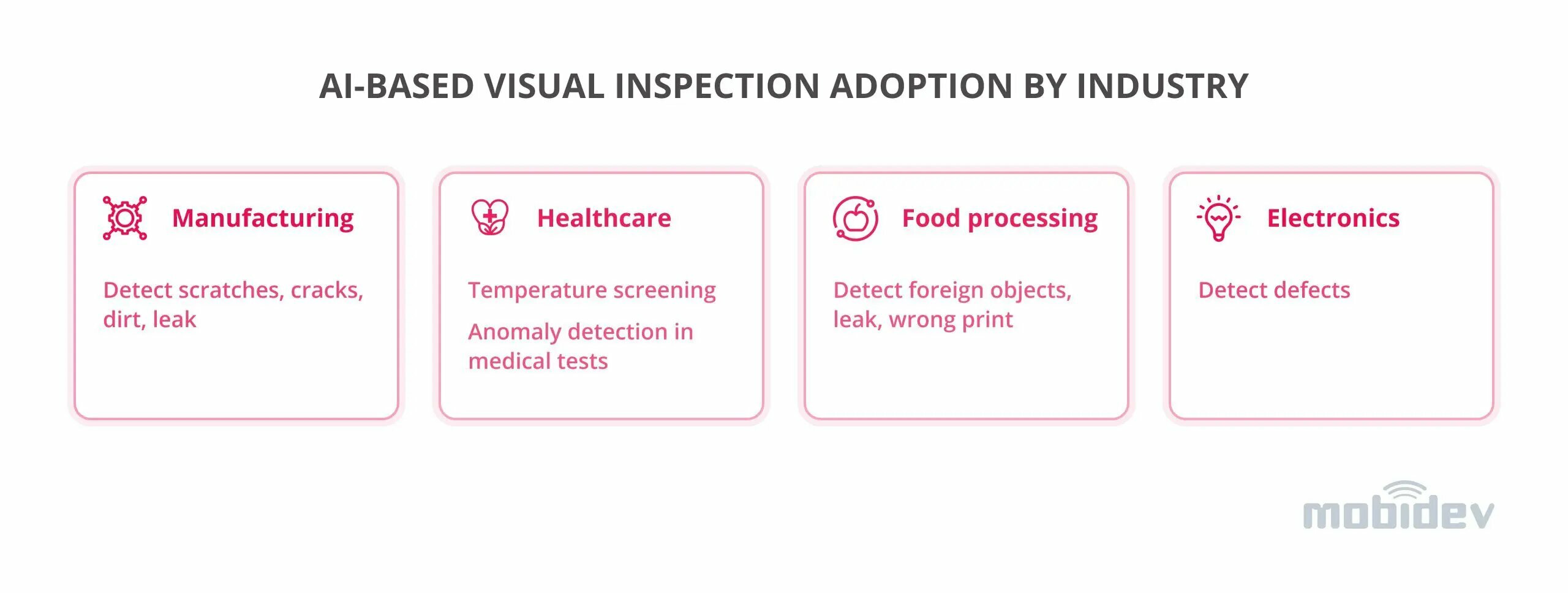
##Trend 5. Game-changing AI breakthroughs in healthcare
The next trend related to the implementation of AI in the healthcare industry has been intensively discussed over recent years. Scientists use AI models and computer vision algorithms in the fight against COVID-19, including areas like pandemic detection, vaccine development, drug discovery, thermal screening, facial recognition with masks, and analyzing CT scans.
To counteract the spread of COVID-19, AI models can detect and analyze potential threats and make accurate predictions. Also, AI helps to develop vaccines by identifying crucial components that make them efficient.
AI-driven solutions may be applied as an efficient tool in The Internet of Medical Things and for handling confidentiality issues specific to the healthcare industry. If we systematize use cases of AI in healthcare, it becomes clear that they are united by one aim – to ensure that the patient is diagnosed quickly and accurately.
##Trend 6. No-code AI platforms in at least three areas
No-code AI platforms have enabled even small companies to apply powerful technologies that were previously available only to large enterprises. Let’s find out why such platforms are a key AI trend for businesses in 2021.
Developing AI models from scratch requires time expenditure and relevant experience. Adoption of the no-code AI platform simplifies the task because it reduces the entry barrier. The advantages are:
* Fast implementation — compared with writing code from scratch, working with data, and debugging, time saving reaches 90%.
* The lower cost of development — through automation, the businesses eliminated the need for large data science teams.
* Ease of use — drag-and-drop functionality simplifies software development and enables the creation of apps without coding.
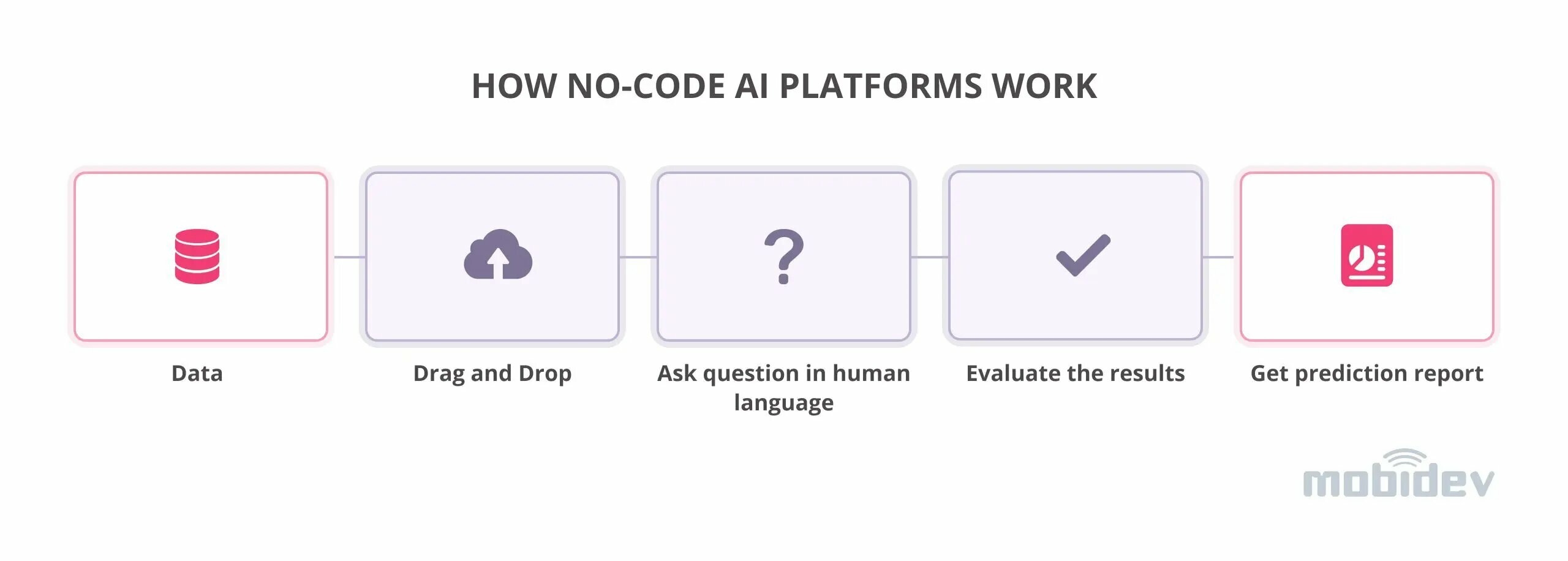
No-code AI platforms are in demand in healthcare, financial sector, and marketing — though produced solutions couldn’t be highly customized. Among the most sought-after no-code AI platforms, you can find Google Cloud Auto ML, Google ML Kit, Runaway AI, CreateML, MakeML, SuperAnnotate, etc.
Enterprise-sized companies, as well as mid-size businesses, leverage no-code platforms for software solutions aiming at image classification, recognizing poses and sounds, and object detection.
##Trend 7. Diversity in AI##
The lack of [diversity in AI](https://www.turing.ac.uk/about-us/equality-diversity-and-inclusion/women-data-science-and-ai) can contribute to the emergence of racial and gender biases. By diversity, we mean a variety of people who develop AI models. According to [NYU’s research](https://ainowinstitute.org/discriminatingsystems.pdf), 80% of professors involved in AI development are men, and only 10% of researchers who work with Artificial Intelligence at Google are women. The same research shows that not even 5% of staff at Google, Facebook, and Microsoft are Black workers.
The number of female graduates of AI PhD programs and computer science faculties has remained at a low level for a long time. But the need for diversity in AI should influence this situation, which is one of the emerging trends. Moreover, women in AI can make big decisions influencing the development and implementation of AI systems. So, if you want to know more about females in AI, read the article dedicated to the brilliant career path of an [AI engineer](https://jaxenter.com/women-in-tech-taranenko-174188.html) at MobiDev.
##Evolution and Future of AI
Trends show that the future of Artificial Intelligence is promising because AI solutions are becoming commonplace. Autonomous cars, robots and sensors for predictive analysis in manufacturing, virtual assistants in healthcare, NLP for reports in media, virtual educational tutors, AI assistants, and chatbots that can replace humans in customer service — all these AI-powered solutions are moving forward with huge steps.
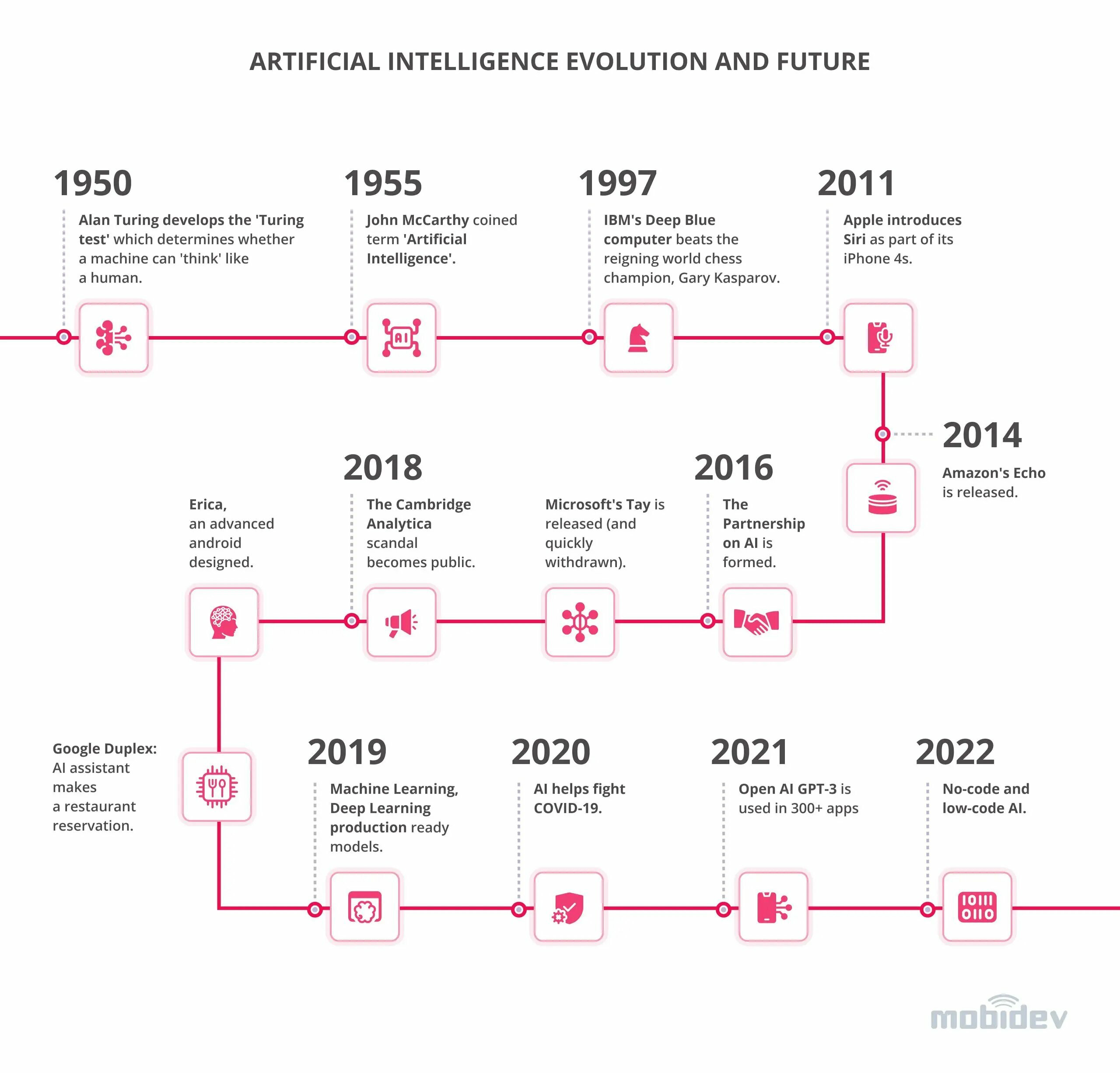
| oleksiitsymbal |
902,218 | How to handle a daily stand-up | Ah! The famous stand-ups! The daily meetings you have with your team to talk about what you did the... | 0 | 2021-11-18T15:42:21 | https://thetrendycoder.com/how-to-handle-a-daily-stand-up/ | agile, standup, tutorial, career | Ah! The famous stand-ups! The daily meetings you have with your team to talk about what you did the day before and what you are planning to do today. An important step if your team is following the Agile methodology.
The issue that can happen when you have to talk during a stand-up is either you have nothing to say, and you could look like you didn’t do any work. Or you could talk too much when it’s not the purpose of a stand-up. I have a few years of experience with stand-ups. I’ll give you some tips to help you be efficient and not look like a fool.
## Surprisingly I like stand-ups
I used to be very shy during my childhood. Even though I got very confident, I am still the kind of person not crazy about talking in front of a lot of people. If I have to do it, I will of course. However, if it’s not mandatory I will not take my chance.
Nevertheless, I never had any problems talking with my team during our daily stand-ups. I will even say, I like this moment with the team. I even don’t feel good when the stand-up is canceled. I feel that something in my day is missing. As if I didn’t share this important moment with the team, I couldn’t share with them my achievements or struggles. It’s like when you are used to journaling on a daily basis, if you miss a day, you don’t feel good.
## Most importantly : Get prepared
The easiest thing is to prepare a small sticky note with bullet points, so you don’t forget any of the things you did. It basically takes only about a minute to go through the things you did and write them down. You don’t need to tell in detail what you did, just mention the things you worked on, and the status: are you done with the task, or still working on it. You can mention if you encountered any problems or if you need any help from the team. Then talk about what you are going to work on later on today. If you don’t have any idea about that, ask the team if they need any help. And most of all, RELAX! You are just talking to your team, you don’t have to be stressed or under pressure. Be yourself and chill out.
## What to do if you’re not ready
If you didn’t prepare for the meeting, no worries, it happens. Try to remember what you did, if you don’t have a lot to say, try to ask questions about problems you encountered. Explain the problem, how you tried to solve it and ask for advice. Usually, developers are really supportive, they will do their best to help. You need to show that you are involved, it might not be your day, you have a lot on your plate and couldn’t get prepared. Nevertheless, you are still a good element of the team. Above all, be honest, you can tell them it’s not your day, you didn’t do much because you got stuck on this and that.
## Careful! Things not to do
One very important piece of advice: don’t lie! It won’t help you on the job to use lies to show that you are a hard worker. More so if it is based on lies. Also, don’t overestimate what you could do.
When you talk about what you are going to do next in the day don’t say I’m going to “try” doing this. We don’t try. We do. So if you think you’re not going to make it, lower your objective into something you are sure you can do. Or specify that you are going to start working on this task, and you may need the help of a colleague because it’s not a topic you are comfortable with.
I will summarize below the Do and Don’t, hoping this could benefit you.
### **DO**
- Prepare a sticky note with bullet points
- List the tasks you worked on and their status (Done, WIP, Paused…)
- Explain your issues and ask for advice/help
- Tell what you are planning to do next
- Set clear and reachable goals
- Offer your help if you are free
### **DON'T**
- Give too many details about what you did
- Lie
- Overestimate your capacities
- Say “I’m going to try doing this”
Now you have some keys to help you handle a daily stand-up. Follow these steps and don’t forget to have fun! | thetrendycoder |
902,298 | Create a React App (Video) | Hi guys! Ok so in many of my tutorials related to react JS, I have not mentioned how to get started... | 0 | 2021-11-18T19:29:55 | https://dev.to/salehmubashar/create-a-react-app-video-4fcj | javascript, beginners, tutorial, react | Hi guys!
Ok so in many of my tutorials related to react JS, I have not mentioned how to get started with React JS or how to create a react app.
If you want to learn how to create an application in react js and follow along with my tutorials you can watch the below video in which I tell step-by-step how to create a react app and the commands needed.
{% youtube zLiMsF0UlpI %}
###Commands Used in terminal
These are the commands I used in the VS code terminal in the video.
* Create a new app (replace appname with any name but make sure it is letters only and does not begin with uppercase)
```
npx create-react-app appname
```
* Change directory
```
cd directoryname
```
* Open your app or run it in the browser.
```
npm start
```
-----------------------------------------------------------------
I hope you all found the video useful.
Check out my other [tutorials](https://turbofuture.com/computers/React-and-Firebase-A-complete-tutorial-Part-1) on [hubpages](https://hubpages.com/@salehmubashar).
Also follow me on [twitter](https://twitter.com/SyntaxE85827144).
> Like my work? Buy me a coffee!
<a href="https://www.buymeacoffee.com/salehmubashar" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>
Until next time,
Cheers :)
| salehmubashar |
902,429 | The Art of Functions | Section 2: Functions ⚙ Wondering, what's up with this weird ancient art? Well, they help... | 15,575 | 2021-11-18T21:32:50 | https://dev.to/snehangsude/the-art-of-functions-2njg | python, codenewbie, beginners, tutorial | ## Section 2: Functions ⚙
Wondering, what's up with this weird ancient art? Well, they help portray how civilization evolved much like how we learned to evolve our ways to talk to machines. Like us humans divided our society to do specific tasks say carpenters to work with wood, barbers to trim our hairs, similarly, we can ask machines to work specifically on something or take a specific action when some work is given. As an example imagine, when we wake up, we follow the below step -
**Get your bed done > Brush your teeth > Wash your face > Dry your face**
For machines, these are described as functions. To understand what a function is imagine a set of instructions that needs to be done when something happens.
Now you might think why do we need to have functions? It's simple, however much we like to abuse **Ctrl+C** & **Ctrl+V** it's not a good practice to have repeatable code. Instead, every time you have to do the same action, you can simply call the function to make it work.
## Fundamentals of Functions
In Python, there are two kinds of functions - **Built-in functions** and **User-defined functions**. We will talk about Built-in functions in a later post.
Today, we will discuss the three kinds of **User-defined functions**, let's start with the basic one. To write any function we need to have a few important things in mind -
- A function should always start with `def` word
- The `def` will be followed by the name of the function, recommended in all lower case
- The name of the function is followed by a parenthesis and colon `():`, denoting the end of defining a function
- Any lines inside the function should be indented to work under the function call.
- Optional requirement, a docstring can be added right below the function.
Here's how it would look like. 👇
<img src='https://s3.amazonaws.com/revue/items/images/011/289/911/original/Function__2301.png?1632427737' alt='An example of Python Function'>
Now the important takeaway from here is how a function when defined doesn't do anything, which means that it would be defined inside the variable `wake_up` when you run the file, however, you would need to call it to make sure it does what you have asked it to do. You can call it by writing the unique name of the function you have defined, followed by the parenthesis.
Here, I've asked it to print ***I woke up at 8 AM***
Before we jump into understanding the other two types of functions and when to use them, we need to understand two important concepts:
- **Parameters** - Parameters are something that your function can take and work with, inside the function. Think of it as a variable inside a function that can take inputs or can be optional too.
- **Arguments** - Arguments are the values that you would assign to your parameter when calling the function. Think of it as assigning a value to the pre-defined parameters. Arguments are again defined into two groups:
1. **Positional Arguments** - Arguments that are called into functions based on the positions of the paraments.
2. **Keyword Arguments** - Arguments that are called into functions using the same keyword that is used to define the parameters.
As we have grasped the basic idea of Parameters and Arguments let's dive into the next type of function *drum-roll* -
## Functions with inputs 👇
<img src="https://s3.amazonaws.com/revue/items/images/011/290/173/original/Function__2302.png?1632429172" alt='An example of Python function with input'>
Here, we can see that `wake_up` has two parameters `time` & `meridian`. You can see that `time` requires a value however `meridian` has a pre-assigned value of a string `'AM'`, which means that the meridian is optional for you to assign. Here's how you can call this function:
**Calling the function with only the required data -**
- <u>*Positional argument*</u>: `wake_up(12)` --> This will print ***I woke up at 12 AM***
- <u>*Keyword argument*</u>: `wake_up(time=12)` --> This will also print ***I woke up at 12 AM***
*Here, the 12 gets assigned to the time variable whereas the meridian uses the 'AM' as the default value.*
**Calling the function with both data -**
- <u>*Positional argument*</u>: `wake_up(12, 'PM')` --> This will print ***I woke up at 12 PM***
- <u>*Keyword argument*</u>: `wake_up(meridian='PM', time=12)` --> This will print ***I woke up at 12 PM***
*Here, the 12 gets assigned to the time variable and the meridian gets assigned to the 'PM' value. This is one of the benefits of using keyword variables as it doesn't require the position of arguments to match the position of parameters.*
<u>**Note**</u>: Changing the positional argument `wake_up('PM', 12)` would print --> ***I woke up at PM 12***
## Functions with inputs and outputs 👇
<img src="https://s3.amazonaws.com/revue/items/images/011/291/108/original/Function__2303.png?1632434550" alt="An example of Python function with output">
This is probably the most used kind of function and is really handy to work with. Almost every rule stays the same from when we defined the Fundamentals of Functions apart from the addition of one:
1. As this gives us an output a command `return` is added at the end which allocates the output to a variable outside the function which can then be re-used.
<u>**Note:**</u> Anything after the command `return` would be ignored by the console as the function would immediately end and allocate the value.
**Calling the function with positional argument -**
`returned_value = add(2, 3)` --> This doesn't print any value but instead allocated the variable `returned_value` with `5`.
Try this out and see, how the print statement is absolutely ignored by the console.
**Calling the function with keyword argument -**
`returned_value = add(number1 = 6, number2 = 3)` --> This too doesn't print any value but instead allocated the variable `returned_value` with `9`.
## Conclusion
We have now understood the types of functions that we can write to help us talk to machines efficiently, without having to repeat ourselves. However, sometimes, we speak in languages our machines have a hard time understanding, those are bugs or errors in our code.
Here are a few common ones for you to catch:
1. Missing an argument, if your function has parameters would pop a `TypeError`
2. Writing a Keyword argument before a Positional argument would result in `SyntaxError`
3. Any line of code after the `return` command on the same indentation level would be ignored.
Here's an image that summarizes how functions are triggered and how they work.
<img src="https://s3.amazonaws.com/revue/items/images/011/291/499/original/Params.PNG?1632437863" alt="An example of how functions work">
1. The code starts execution from the arrow tail and follows its head
2. When it hits the star
3. It jumps to see the function under the name of `sum`
4. Executes everything inside the function taking the arguments to replace the parameters
5. Hits the `return` statement
6. Allocates the value of the local variable `num` to the global variable `addition`
That's it for Functions! Next, we will talk about more advanced function usages. Hope this has helped you understand how functions work & what exactly happens under the hood making our lives easier. If you have any interesting suggestions or feedbacks, feel free to connect with me on <a href="https://twitter.com/__xSpace">Twitter</a>. I also have a newsletter, which I send out every week Thursday. You can subscribe it <a href="https://www.getrevue.co/profile/xSpace/">here</a>.
I hope this message finds you in good health! | snehangsude |
902,436 | Part 3 - Routing & Preferences: The Developer's Guide To Building Notification Systems | Your CTO handed you a project to revamp or build your product’s notification system recently. You... | 15,170 | 2021-11-18T22:21:41 | https://dev.to/courier/the-developers-guide-to-building-notification-systems-part-3-routing-preferences-3g27 | startup, operations, programming, devops | Your CTO handed you a project to revamp or build your product’s notification system recently. You realized the complexity of this project around the same time as you discovered that there’s not a lot of information online on how to do it. Companies like LinkedIn, Uber, and Slack have large teams of over 25 employees working just on notifications, but smaller companies like yours don’t have that luxury. So how can you meet the same level of quality with a team of one? This is the third post in our series on how you, a developer, can build or improve the best notification system for your company. It follows the first post about identifying [user requirements](https://www.courier.com/blog/the-developers-guide-user-requirements) and designing with [scalability and reliability](https://www.courier.com/blog/scalability-and-reliability) in mind. In this piece, we will learn about setting up routing and preferences.
Notifications serve a range of purposes, from delivering news to providing crucial security alerts that require immediate attention. A reliable notification system both enables valuable interactions between an organization and its customers and prospects and also drives user engagement. These systems combine software engineering with the art of marketing to the right people at the right time.
Building a service capable of dynamically routing notifications and managing preferences is vital to any notification system. But if you’ve never built a system like this, it might be difficult to figure out what the requirements are and where the edge cases lie.
In this article, you’ll learn invaluable points to consider when building your own routing service. You’ll understand the requirements for multi-channel support and in choosing the right API providers. You’ll also learn how to design user preferences so that you can make the most out of each message.
## Multi-channel support: a necessity
Let’s say that you have just built a web-based application. The first channel that you’ll use to connect with your users is likely email because of how ubiquitous it is. However, with the diversification of channels and depending on your use case, email might not be the most efficient notification channel for you. Compared to other channels, emails typically have a low delivery rate, a low open rate, and a high time to open rate. It’s not uncommon for people to take a full day to even notice your email. If your email gets to the user, it might take awhile before they open it, if at all.
To engage with your users more effectively, you’ll want to support channels across a broad range of systems not limited to any one application or device. It’s vital to understand not only which channels are most relevant for you but also for your users. If you opt to use Telegram and your users don’t have it, it won’t be a very useful channel to interact with them. Multi-channel support is also vital because while you might pick appropriate channels today, you won’t know which channels you will need to support in the future. Typically, the more appropriate channels you support, the higher the chances of intersecting with applications your users actually use now and in the future.
## Choosing notification channels and providers
You’ll have to select relevant channels and appropriate providers for each channel. For example, two core providers for mobile push notifications are [Apple Push Notification Service (APNs)](https://developer.apple.com/library/archive/documentation/NetworkingInternet/Conceptual/RemoteNotificationsPG/APNSOverview.html#//apple_ref/doc/uid/TP40008194-CH8-SW1) and [Firebase Cloud Messaging (FCM)](https://firebase.google.com/docs/cloud-messaging). APNs only supports Apple devices while Firebase supports both Android and iOS as well as Chrome web apps.
In the world of email providers, SendGrid, Mailgun, and Postmark are all popular but there are hundreds more. All email APIs differ in what they offer, both in supported functionality and API flexibility. Some providers, like Mailgun, only support transactional emails triggered by user activity. Other providers, like SendGrid and Sendinblue, offer both transactional and marketing emails. If your company opts for a provider that can handle both, you’ll still want to separate the traffic sources, by using different email addresses or domains, to aid email deliverability. If you only have one domain for sending both types of emails and the domain gets flagged as spam, your critical transactional emails will also be affected. Whichever provider you choose, you’ll still want to meticulously verify your DKIM, SPF, and DMARC checks, and domain and IP blacklisting using your own tools or a site like [Mail-Tester](https://www.mail-tester.com/).
Making requests and receiving responses also differs with each email API provider. Some providers, like Amazon SES, require the developer to [handle sending attachments](https://www.courier.com/blog/send-email-attachments-aws-s3), while others, like Mailgun, [provide fields in the API schema](https://documentation.mailgun.com/en/latest/api-sending.html#sending) for including attachment files directly.
There are minute variances in formatting HTTPS requests. The maximum payload sizes range from 10MB with Amazon SES API and up to 50MB with Postmark. There are also differences between the rate limits for requests.
In terms of API responses, Amazon SES [provides](https://docs.aws.amazon.com/ses/latest/APIReference-V2/API_SendEmail.html) a message identifier when an email is sent successfully through the API, but, for example, SendGrid [returns an empty response](https://docs.sendgrid.com/api-reference/mail-send/mail-send) in that situation. The HTTP response codes also differ slightly depending on the provider. For example, AWS SES uses the response code [200](https://docs.aws.amazon.com/ses/latest/APIReference-V2/API_SendEmail.html#API_SendEmail_Errors) for successful email send operations, while Sendinblue uses [201](https://developers.sendinblue.com/reference/sendtransacemail), and SendGrid uses [202](https://docs.sendgrid.com/api-reference/mail-send/mail-send#responses).
No matter which provider you end up choosing, don’t build your application solely to fit *their* logic and specifications. If you do so, it will be much more difficult to change providers in the future as you’ll have to overhaul your backend. It’s crucial to invest in a layer of abstraction based on your own paradigm.
## Dynamically routing notifications between channels
How do you determine which channels to use and when? Just because you’re able to use email, SMS and mobile push doesn’t mean that you should use all of them simultaneously, since doing so carries a high risk of annoying your users. This is where you begin to formulate an algorithm to route messages between the different channels and the different providers within each channel. The algorithm needs to be robust to handle delivery failures and other errors. For example, if the user hasn’t engaged with a push notification after a day, do you resend it or use email instead?
You can begin constructing the algorithm using basic criteria. For example, if there is no phone number, eliminate SMS as an option for that user. If email is the primary channel, opting to send at 10 a.m. or 1 p.m. local time typically improves read rates. If the user is present or active in the app, consider sending an in-app push notification instead of an email. Finally, and especially important, get your user’s preferences for how and when they want to be contacted and integrate these preferences into your routing service.
## Adding user preferences to your system
Once you’ve got your channels, providers, and routing algorithm figured out, you need to think about providing users with granular control over notification preferences instead of just a binary opt-in/opt-out switch.
Consider this: if you only allow opting in to or out of all notifications at once, your users might unsubscribe from all your communications because they find one specific notification annoying. As a result, you will lose out on valuable user engagement.
With granular control over preferences, a user identifies exactly how and when they hear from you. If a user doesn’t like email but wants SMS messages (not common, but possible!), they can adjust their preferences and keep the SMS line of communication open. Every enabled notification channel is another opportunity to engage the user in a way that’s productive for them. From the end user’s perspective, it’s empowering to control how and when they are contacted.
Note that for some channels, the user’s preferences should be ignored. For instance, two-factor authentication should go to SMS or mobile push regardless of the user’s preference for email. The possibility to override the default logic should be incorporated into your algorithm while you are designing your routing engine.
If you want to take user engagement further, allow users to opt-in/opt-out of specific channels, frequency, timing and topics. You can allow them to set up their preferences based on time of day, frequency per period, or to specify more than one email address. You can give them the option to receive transactional, digest emails, daily newsletters, or only the critical ones. You can also allow them to redirect their notifications to another address, for example if the user is out of office.
Granular preferences also extend past the dominion of developers and the user’s experience. Granularity of consent is becoming part of privacy [compliance laws in Europe](https://edpb.europa.eu/sites/default/files/files/file1/edpb_guidelines_202005_consent_en.pdf) and in the [state of California](https://src.bna.com/MVJ?utm_source=ANT&utm_medium=ANP) and might follow elsewhere in the future. Separately, granular preferences are an extremely advantageous analytical tool for the marketing team to improve brand strategy and personalization efforts. Is there a particular channel or topic that seems to be more popular? That information can be highly helpful to pivot in line with your users and grow your company.
## Tips for future-proof maintenance
When you’re starting with notifications for a new product, there is nothing wrong with sticking to one channel and one provider. The most important principle to keep in mind is to design your notification system so that you can expand it in the future. You should leave the door open to include more providers when you need them.
Don’t assume that **API paradigms** are the same for each provider or notification type. For example, you want to send an email, and if delivery fails to send a push notification instead. But you won’t get a 400 HTTP response from the email provider in case of failure. The provider will retry your email over a couple of days. Instead, you’ll want to include [webhooks](https://docs.github.com/en/developers/webhooks-and-events/webhooks/about-webhooks) or queues to notify you of the failure, and you’ll need to track the state of the message here. If you make blanket assumptions about how API calls work or how errors are returned, you’ll have trouble adapting to a different paradigm in the future. Instead, you can add a layer of abstraction on top of the API.
It’s also invaluable to **centralize the way you call the provider APIs**. If you spread out calls to an API throughout your code base, it will be more difficult to integrate other channels or API providers in the future. Let’s say you’re starting with email and [AWS SES](https://docs.courier.com/docs/setup-email-using-aws-ses) as the provider. In two years’ time, you might decide to integrate mobile push notifications as well. What might that look like? The incurred technical debt will include scouring the code base for all instances of calls to the AWS SES API before you can integrate mobile push as an additional channel. But with centralized calls, you’ll have more consistent, cleaner, and reusable code as you grow.
## How many notification channels should you have?
Typically, having three or four channels that are relevant to your product is an ideal scenario for a mature product. When you intersect channels with the preferences and availability of users, you create higher levels of complexity for your algorithm. Offering many channels for notifications might become too complex to maintain. But offering too few channels might harm your chances of interacting with users since some channels might not be viable for all users. For instance, you might decide to offer email and push notifications. But if a user didn’t download your product, your interaction with them is limited only to email.
## Best technologies for routing and preferences engines
It ultimately pays to choose technologies that will be a good fit for your routing and preferences needs. There will be a great deal of [asynchronous programming](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Asynchronous/Concepts), as the routing service will often be waiting to receive responses for each function. You’ll want to pick a language or a framework that allows you to respond to async events at scale.
The routing service also involves considerable state tracking, as most of the routing will depend on waiting on a response for each notification before changing state. The routing service will also need to be re-activated every time it receives a response from a provider and will need to determine if the notification was sent successfully or if it has to pursue next steps. See the example below of how a notification function’s state might be tracked.
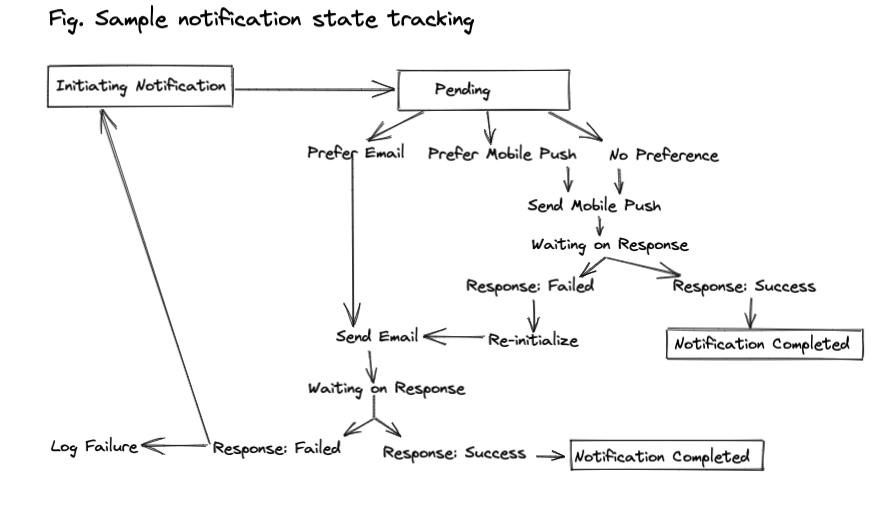
At Courier, we use [AWS Lambda](https://aws.amazon.com/lambda/). Since our usage tends to come in bursts, serverless technology allows us to adjust and scale for changes in demand throughout each day as well as handle asynchronous operations efficiently.
## Don’t forget: compliance in notification routing
When creating your own routing and preferences service, you will need to ensure that whichever channels you implement are fully compliant with applicable laws. For example, there are legal mandates on how users may be contacted or how they can unsubscribe from contact.
For commercial email messages, the [CAN-SPAM Act](https://www.ftc.gov/sites/default/files/documents/cases/2007/11/canspam.pdf) of 2003 is a federal United States law that spells out distinct rules and gives recipients a way to stop all contact. Penalties can cost as much as $16,000 per email in violation. This law also outlines requirements such as not using misleading header information or subject lines, identifying ads, and telling recipients how they can opt out of all future email from you. The opt-out process itself is strictly regulated.
For SMS, the United States [Telephone Consumer Protection Act (TCPA)](https://www.fdic.gov/resources/supervision-and-examinations/consumer-compliance-examination-manual/documents/8/viii-5-1.pdf) of 1991 sets forth rules against telemarketing and SMS marketing. Under this law, businesses cannot send messages to a recipient without their consent. This consent needs to be explicit and documented. The consent is also twofold: recipients need to consent to receiving SMS marketing messages and they need to consent to receiving them on their mobile device. Recipients need to be provided a description of what they are subscribing to, how many messages they should expect, a link to the terms and conditions of the privacy policy, and instructions on how to opt-out.
In California especially, the [California Consumer Privacy Act (CCPA)](https://leginfo.legislature.ca.gov/faces/codes_displayText.xhtml?division=3.&part=4.&lawCode=CIV&title=1.81.5) of 2018 provides additional rights for California residents only. These rights include the right to know which information a company has collected about them and how it’s used as well as the right to delete it or to opt-out of the sale of this information. Information that qualifies under the consumers’ right-to-know includes names, email addresses, products purchased, browsing history, geolocation information, fingerprints, and anything else that can be used to infer preferences. Should a consumer request this information, the company has to share the preceding 12 months of records, and also include sources of this information and with whom it was shared and why. In 2020, [California Privacy Rights Act (CPRA)](https://src.bna.com/MVJ?utm_source=ANT&utm_medium=ANP) of 2020 amended the CCPA. The CRPA provides further consumer rights to limit the use and disclosure of their personal information.
Other countries have their own compliance laws for businesses reaching out to leads and customers. Canada has its [Anti-Spam Legislation (CASL)](https://laws-lois.justice.gc.ca/eng/acts/E-1.6/index.html). The European Union has the [General Data Protection Regulation (GDPR)](https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679) which now also covers granularity of consent. The United Kingdom has its own regulations along with the GDPR, the [Privacy and Electronic Communications Regulations (PECR)](https://www.legislation.gov.uk/uksi/2003/2426/pdfs/uksi_20032426_en.pdf) and [Data Protection Act](https://www.legislation.gov.uk/ukpga/2018/12/contents/enacted).
Compliance itself needs to be integrated at the developer level. Providers, like SendGrid, don’t know what you’re sending. It’s up to the developer to ensure that all applicable compliance laws are followed for their choice of channels.
## Conclusion
Building a notification system into a product is not for everyone. The process is time-consuming, complex, and expensive. The level of notification customizability and routing options you decide to implement will ultimately dictate a preference for either maximizing user engagement or optimizing cost. A startup with a product that hasn’t yet found its product-market fit has to focus on finding early customers and getting their feedback. But established companies with a proven customer base will have concerns related to more complex routing logic, future-proofing and compliance. This would require more functionality and higher maintenance costs.
This piece taught us about the necessity of sending data for notifications to the right people, at the right frequency, at the right time and how this can be done through routing and customized preferences. Tune in for the next post in this series to learn about observability and analytics to monitor the functioning and performance of your in-house notifications system. To stay in the loop about the upcoming content, subscribe below or follow us [@trycourier](https://twitter.com/trycourier?lang=en)! | artsarescis |
902,486 | Guide to model training: Part 3 — Estimating your missing data | TLDR Oftentimes when collecting consumer data, there are times when you’re unable to... | 0 | 2021-11-19T00:59:11 | https://dev.to/mage_ai/guide-to-model-training-part-3-estimating-your-missing-data-5h90 | deved, machinelearning, modeltraining, mage | ## TLDR
Oftentimes when collecting consumer data, there are times when you’re unable to retrieve all the data. Instead of having a lack of data ruin your results, you’ll want to “guestimate” what the data should be.
## Outline
* Recap
* Before we begin
* What does impute mean?
* 3 ways to impute
* Impute in Pandas
* Next step
## Recap
In the [last section](https://www.mage.ai/blog/scaling-numerical-data), we completed scaling categorical and numerical data so that all of our data is scaled properly. The higher ups want a list of past customers to target for our sales campaign, so we’re given new data that shows the history of how past customers interacted with our past 4 promotional emails.
<center>_Big sales are coming soon!_</center>
Using the new data, our goal is to build a model for the remarketing campaign. There’s just one small problem. Code embedded in the marketing campaign email contained bugs, leaving us unable to identify what actions the people who clicked the email took. The bug occurs every 5 emails, but was patched by the 2nd wave of emails. In this section, we’ll go over imputing, a technique used to fill in unknown results.
<center>_Bugs poke holes in my data (Source: [Pest Control](https://assets.website-files.com/577717ef3dcedd7133bc0ac5/58b95ce05d75b92f63032310_silverfish-damage.jpg))_</center>
## Before we begin
This guide will use the [big_data](https://app.box.com/s/ktd1t87fl925hjxkzsclp1343eq822f1) dataset along with the new, [promo](https://app.box.com/s/ybntbd8uibb2fzo61ljy1960bxpntozq) dataset. It is recommended to read our guide on transforming data, using [filters](https://www.mage.ai/blog/surfing-through-dataframes), and [groups](https://www.mage.ai/blog/product-developers-guide-to-getting-started-with-ai-pt3-terraforming-dataframes), to understand this section. Additionally, start reading from [part 1](https://www.mage.ai/blog/qualitative-data), to understand all the different data types we’ll be working with and how we got to this point.
## What does impute mean?
Impute is a technique used to fill in the missing information when given a dataset. When you impute, you use existing data to create references to missing data. Through imputing, data scientists are able to repair or patch parts of the data to give back its meaning. The quality of the data depends on how you handle imputing the data. The more complex a method is, the better the results. I’ll be showing 3 methods that are straightforward and easy for beginners, but do note that there are more out there that utilize other forms of AI, such as deep learning.
## 3 ways to impute
To get started, let’s think about what kind of references we can use in the data. The simplest and the most common method is by filling in the missing value with the value with the most occurences. Another method is by computing the average and storing the value there. Finally, the 3rd utilizes a mix of both methods, it checks the closest values to the term, then averages it.
### Mean average value
Similarly, for mean average inputting, we calculate the average value out of all values in a column and then change the null values with the average value. Note that since this is an average, it will only work for numerical data and not categorical data, as categories are a classifier and not a count. In the case of a categorical variable, use a different method.
<center>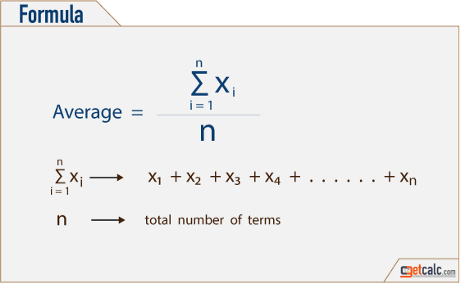_Take the sum and divide by the total (Source: [getcalc](https://getcalc.com/formula/math/average.png))_</center>
### Most frequent value
To calculate the most frequent value, first we search for the value that appears the most. Then we find all occurrences of the value and replace it with the most common value. A downside to this approach is that, since the value that is most common is used, it tends to skew data by adding bias towards the majority.
<center>_The hand of bias tips the scales (Source: Global Government Forum)_</center>
### K-Nearest Neighbors
K-Nearest Neighbors (KNN) is an algorithm that computes the closest “k” values in the graph. In imputation we’ll utilize this algorithm to determine a more accurate method that combines the best of both prior methods. Similar to taking the average, it takes into account portions of the dataset, but it only compares values nearby, resulting in less bias and more accuracy. Instead of repeating the most frequent value, it takes into consideration the other values, and constructs a graph to visit each neighborhood, or set of data points. However, since it is a brute force method that visits every value, it takes a long amount of time to run as the datasets grow larger.
<center>_KNN graph (Source: [Towards Data Science](https://towardsdatascience.com/6-different-ways-to-compensate-for-missing-values-data-imputation-with-examples-6022d9ca0779))_</center>
## Impute in Pandas
First, we identify what type of data the promotional data we’re imputing is. By the looks of it, the value represents whether a user accepted the email campaign. In this case it’s a categorical variable, which represents the categories of “did accept” and “didn’t accept”.
As a result, we cannot apply the mean average method and will use the most frequent value and K-nearest-neighbors to impute the **AcceptedCmp1** in the promo dataset. Most frequent and mean average can be calculated using a [SimpleImputer](https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html#sklearn.impute.SimpleImputer), but we’ll be using Pandas to show the basic steps taken.
### Most frequent
Using Pandas, along with grouping the values into True, False, and None, we can find the most frequently used of the 1s and 0s then set the NaN values to be equal. First, to find the count, we group the data to be 0 or 1 and take the count using **size**.

Next, we’ll use fillna to replace the values with 0. Previously, NaN couldn’t be an integer, so we also convert the float back to int, since true/false values should be 0 or 1.

Taking a look at the output, we now have this as our final dataset.
The breakdown can be found again by grouping and taking the **size**.

### K-Nearest Neighbors
The algorithm of K-Nearest Neighbors is more complex and it visits each and every point. In this case, we’ll leverage the **KNNImputer** function from SciKit Learn.
Start by importing the functions we’ll be using, then select a value for “k”. This will determine the depth of the graph, and larger values will increase the time.
Since there are 2240 rows, we’ll pick a k value of 3 which is the floor of log(2240). I chose this arbitrarily by taking the log, since the function grows exponentially. Please note there may be better ways to determine the k value, which is better learned through trial and error.

Next, we can take our imputer, and apply it to our promo dataframe.

<center>_Upon inspection, we notice that some values aren’t exactly 1 or 0, but are in between._</center>
We’ll take an extra step to round off, so “maybe” values become strictly “yes” or “no”.

## Next Step
KNN was able to give more accurate results, but this doesn’t mean that the choices were correct. With such a big difference between accepted or not, using the most frequent value can save time compared to using the KNN. On the other hand, when you value accuracy and are dealing with smaller datasets or have a lot of time, KNNs will pick values in the middle of actual and frequent. Now that we’ve prepared all our data, we are now ready to begin training models. In the next series, we’ll look at how to train machine learning models for our remarketing use case. We’ll go deeper into what a model means, metrics, and answer the big question, which users should be part of the remarketing campaign?

| mage_ai |
902,492 | What to do if you're a bottleneck | Jackson is a go-to person when it comes to MongoDB. You have a problem — you go to Jackson. He’s an... | 0 | 2021-11-19T11:14:14 | https://evgenii.info/bottleneck | productivity, leadership, teamwork | ---
title: What to do if you're a bottleneck
published: true
date: 2021-11-19 11:12:58 UTC
tags: productivity,leadership,teamwork
canonical_url: https://evgenii.info/bottleneck
---
Jackson is a go-to person when it comes to MongoDB.
You have a problem — you go to Jackson. He’s an expert. Of course, you can go to anyone else – it’s a free world. You can go to Molly if you want. But you know what Molly would recommend, don’t you? She’ll tell you to ask Jackson, that overworked guy with a giant todo list.
Let’s talk about what to do if you ended up being a Jackson and need a way out.
## What kind of a bottleneck are you?
There are two different kinds of overworked Jacksons: knowledge bottlenecks and expertise bottlenecks.
Knowledge bottlenecks are the ones who answer questions:
* _Who owns Payment API?_
* _Which database has client emails?_
* _When is our next release?_
If you're one of those, write documentation. Sorry for such trivial advice, but boring problems need boring solutions.
It's worth writing docs even if people don't read them. Sounds stupid, but it will serve as your second brain from where you can quickly copy answers.
> Watch out for an urge to share your screen and demonstrate something. It's always better to record a video (or a gif) and share it instead – this way, you will be able to reuse it later.
That was all about knowledge bottlenecks.
Expertise bottlenecks are trickier. They don't just answer questions — they solve problems:
* _This program crashes for Netherlands users._
* _My DB query is slow._
* _Our photo gallery page leaks memory._
This situation is much more complicated because you need more experts to share the load. But unfortunately, there are no books or tutorials you could give to somebody and turn them into an expert – they need to build the expertise themselves. And it takes time.
But how to accelerate the process?
## Limited opportunities
If someone wants to learn how to play the guitar, they need to practice playing the guitar. Likewise, if one wants to learn how to fix memory leaks, they need to fix memory leaks.
The tricky part is there are much more opportunities to play the guitar than memory leaks to fix. They don't happen every day.
Zoom out now and look where you ended up: people call you whenever a challenging problem arises because nobody else has a similar experience. And nobody else has a similar experience because you solve all the challenging problems. A chicken and egg situation.
## Growing new experts
The naive advice would be to stop doing what you're doing so that others can practice and build necessary expertise in time. But, unfortunately, it's overly utopian – a few companies have the luxury of accumulating unsolved problems while their best specialist sits idle and waits for new experts to emerge.
But I'm not saying it's impossible – there is a way to grow new experts without slowing down the process. Here it is:
1. Pick **one** successor to mentor. _Learning opportunities are scarce resource, so resist the temptation to pick more than one._
2. Redirect all requests to this person.
_Need help? Ping Nelson, he knows this stuff._
3. Be available for this person.
_Answer all their questions as soon as possible, pair program or pair debug when necessary._
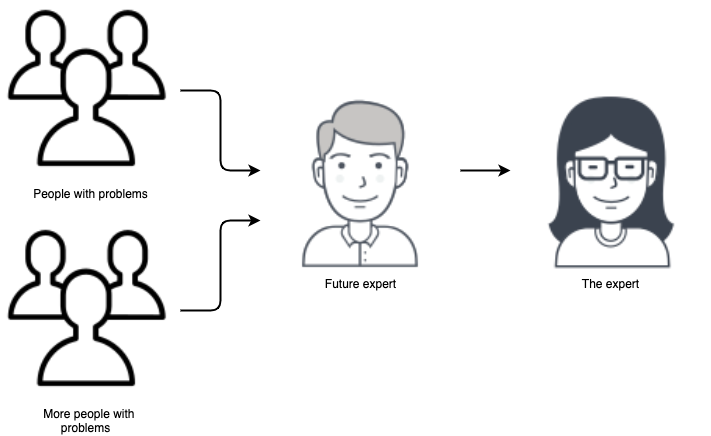
It works because:
1. The company will not slow down in critical situations – if the time is tight, the mentoree can ask you for help.
2. You can tune your involvement depending on the circumstances to manage risks and guide the learning.
3. This person starts earning credibility from day one, solving real problems with your invisible help.
In the beginning, be prepared to play broken telephone answering proxied questions:
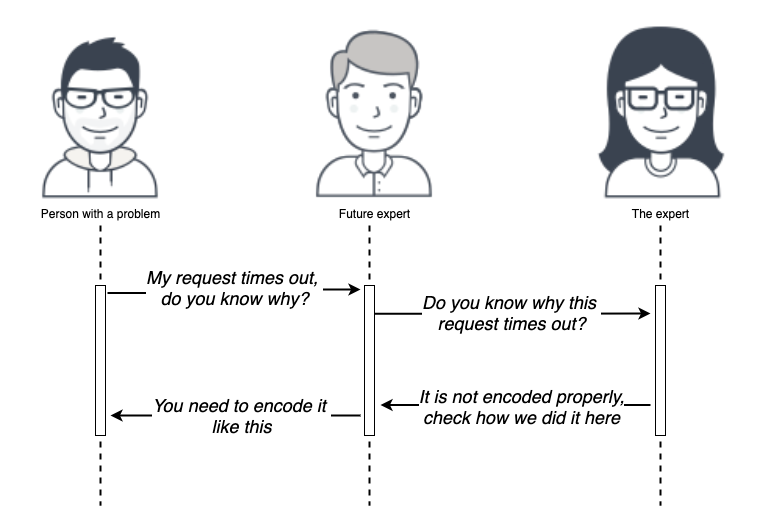
It may look like a waste of time, but it's far from it. Yes, the future expert acts as a proxy, but they learn about the domain. Even if it's a proxy, it's a caching proxy:
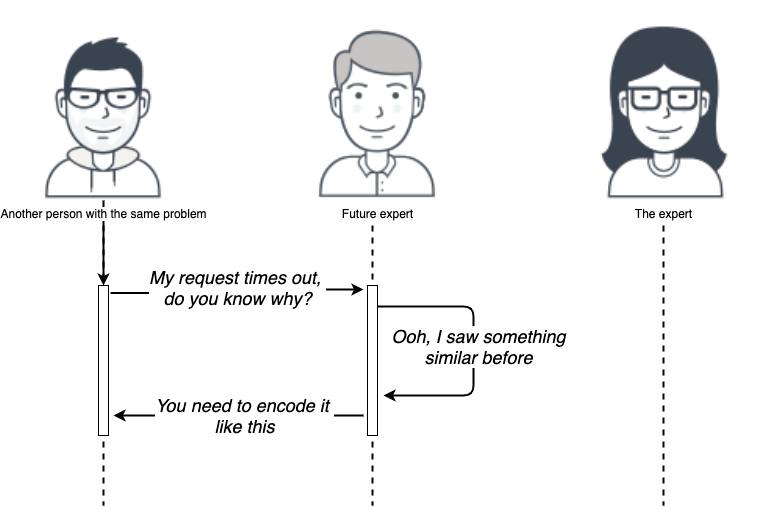
As their experience grows, they will start asking more complex questions:
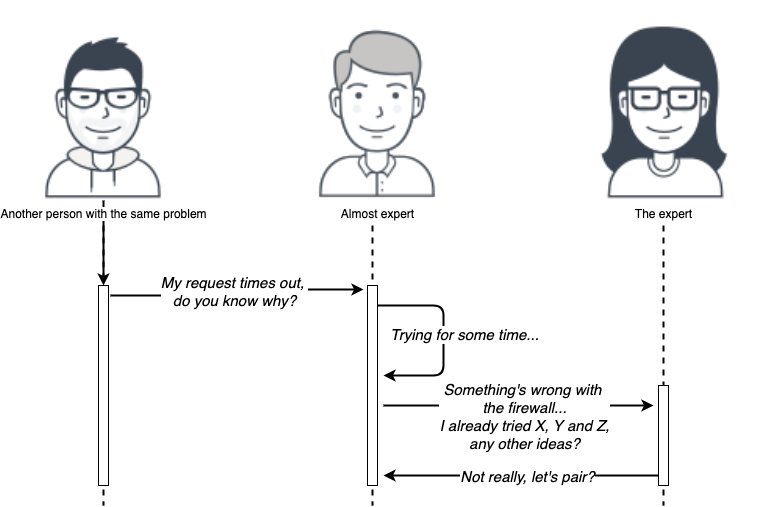
This is the point where you can return to your expert's duties, which you now can split with another person:
* * *
This is a cross-post from [Resilient Systems](https://www.getrevue.co/profile/elergy) – a newsletter about strategic software engineering. | _elergy_ |
902,494 | Product Manager vs. Product Owner [and the Product-minded Software Engineer] | In this article, I clarify the differences and similarities between Product Manager and Product... | 0 | 2021-11-20T00:30:18 | https://dev.to/brunodasilva/product-manager-vs-product-owner-and-the-product-minded-software-engineer-eh3 | product, management, software | In this article, I clarify the differences and similarities between Product Manager and Product Owner. Also, I take the chance to briefly talk about the importance of the product mindset in software engineers.
All right, let's jump into the first part.
## Product Manager vs. Product Owner
Product Owner (PO) is one of the process roles in Scrum. [Scrum](https://scrumguides.org/) is a process framework for developing and sustaining complex products. Let's look at how Scrum defines the PO role:
> A Product Owner orders the work for a complex problem into a Product Backlog.
Typically, only one person is playing the PO role at a time in a Scrum team. The concept of a "complex problem" is vaguely defined in the sentence above from the Scrum Guide and I think this is intentional since the Scrum framework can be applied to all sorts of problems. And they go on:
> The Product Owner is accountable for maximizing the value of the product resulting from the work of the Scrum Team. How this is done may vary widely across organizations, Scrum Teams, and individuals.
> The Product Owner is also accountable for effective Product Backlog management, which includes:
> * Developing and explicitly communicating the Product Goal;
> * Creating and clearly communicating Product Backlog items;
> * Ordering Product Backlog items; and,
> * Ensuring that the Product Backlog is transparent, visible and understood.
> The Product Owner may do the above work or may delegate the responsibility to others. Regardless, the Product Owner remains accountable.
> For Product Owners to succeed, the entire organization must respect their decisions. These decisions are visible in the content and ordering of the Product Backlog, and through the inspectable Increment at the Sprint Review.
> The Product Owner is one person, not a committee. The Product Owner may represent the needs of many stakeholders in the Product Backlog. Those wanting to change the Product Backlog can do so by trying to convince the Product Owner.
In summary, as many people say, the PO is the voice of the stakeholder. The PO is supposed to bridge the gap between the problem domain and the rest of the Scrum team working on a solution. That's the only way they can maximize the value of the product (as the definition suggests).
Well... All of it is in the context of the Scrum framework. The PO role is a particular Scrum terminology. Strictly speaking, outside Scrum, people do not use this term very often. And my hypothesis is that his happens for two main reasons. First, there has been more emphasis on the backlog management and grooming pieces of the PO role rather than the "maximize the value of the product" piece of the PO responsibility. Second, in order to maximize the value of the product, people need to go way beyond the team backlog scope. And that's when the concept of Product Management comes into play.
> Product management is a career, not just a role you play on a team. The product manager deeply understands both the business and the customer to identify the right opportunities to produce value -- *Escaping the Build Trap by Melissa Perri.*
Generally, a Product Manager talks to customers to understand their crucial pain points, gather requirements, and test ideas to further explore potential solutions. PMs may also collect and analyze telemetry data to draw conclusions about existing products and features. PMs also communicate "in different languages" with various people such as engineers, UI/UX designers, researchers, marketing, sales, etc. PMs create product roadmaps and manage backlog items together with engineering teams. PMs work with business and engineering counterparts to define metrics, analyze data, and assess whether the product is going in the right direction by delivering value to the organization. Another essential skill in PMs is the capacity to drive conversations and influence others without authority. Ultimately, PMs should keep the team focused on the why (Why are we building this product, and what outcome will it produce?).
The above paragraph summarizes some of the most important PM responsibilities, and there is probably more depending on the organization. As you may have noticed, these responsibilities associated with the product management job are not explicitly defined as the PO role in the Scrum framework. Indeed, PM is a full-time job, whereas PO is specifically a role in a Scrum team.
If you are a Product Manager and your team follows the Scrum framework, we can tell you play the PO role in the team. But not all PMs are POs, simply because not everyone follows the Scrum framework.
Here's the confusion now.
> *Hey, Bruno, I've heard someone saying they're a PO in a team that does not follow Scrum. They follow whatever agile practices they find applicable to their context. Are they mistakenly applying the terminology?*
My short answer is Yes, they are applying the wrong terminology. As discussed, PO emerged as a Scrum term and with a scope clearly defined in the Scrum framework.
> *Bruno, in this new project, the other developers working with me will continue as developers while I volunteered to be a PO, since we don't have anyone else in the company to be a PO in this project and I know the domain well. Can I consider myself a PM, too?*
Tricky question. Without much additional context, I'd say No, you're not a PM. In this case, you're a developer working temporarily as PO in a project. You may be a developer at times and switch to play the PO role at other times. Still, your job is not a full-time Product Manager. This experience may lead you to become a full-time PM, though.
All in all, we cannot control how people apply those terms in the field. At the end of the day, people are not committing a crime by calling PMs as POs and vice-versa. Moreover, some buzzwords come and go over time, and we never know to what extent practitioners will adhere to specific terms in the field. Some years from now, the chances are that new terms will apply to the Product Management area, and this article may even become obsolete. For now, you can consider the general term as PM, while PO is the specific terminology for the "product person" in the specific context of a Scrum team. That's also why you see Product Manager as the job title in many job ads when organizations look for "product people."
Well... And if you are a software engineer, and you want to stand out in the crowd and deliver significant value to your users, try to develop the product mindset in you.
### The Product-minded Software Engineer
While you can simply define PMs as those responsible for defining the "what" and the "why" in software products, software engineers are sometimes defined as the deeply technical people that are specialized in hacking out solutions (the "how") to solve end-user problems. And this is not largely wrong. Many successful software engineers, in their careers, do not develop a product mindset that makes them connect well with the value proposition of the solutions they implement. However, more and more, the industry needs engineers capable of reducing the gap between the problem domain and the solution domain and understanding the impact of their solutions and fine-grained design decisions on the business as a whole.
This is what we call "Product-minded Software Engineers." These are engineers that work close to the product vision and give inputs to the roadmap. They also make an effort to understand why product decisions are made, how people use the product and often endeavor to actively make product decisions.
Throughout their career, product-minded engineers find more flexibility in either switching to a product management career or moving up on the engineering career ladder by showing the product-awareness capacity in their work. Whether in big tech-companies building world-class products or startups developing highly innovative ideas, product-minded engineers usually help organizations take teams to a new level of impact.
From a management perspective, these are the engineers you like to work with to shorten the gap between the problem and solution spaces and ultimately deliver value to users and businesses in a more productive fashion at a lower friction.
If you want to read more about product-minded engineers, check [this article](https://blog.pragmaticengineer.com/the-product-minded-engineer/) from an experienced ex-engineering manager at Uber.
If you want to discuss anything related to this content, please drop me a line on Twitter [(@BrunoDaSilvaSE)](https://twitter.com/BrunoDaSilvaSE) or a comment below.
I welcome your feedback! | brunodasilva |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.