
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
761,065 | Game Dev Digest — Issue #103 - Making Things Better | Issue #103 - Making Things Better This article was originally published on... | 4,330 | 2021-07-16T12:20:47 | https://gamedevdigest.com/digests/issue-103-making-things-better.html | gamedev, unity3d, csharp, news | ---
title: Game Dev Digest — Issue #103 - Making Things Better
published: true
date: 2021-07-16 12:20:47 UTC
tags: gamedev,unity,csharp,news
canonical_url: https://gamedevdigest.com/digests/issue-103-making-things-better.html
series: Game Dev Digest - The Newsletter About Unity Game Dev
---
### Issue #103 - Making Things Better
*This article was originally published on [GameDevDigest.com](https://gamedevdigest.com/digests/issue-103-making-things-better.html)*

Short but sweet this week. Some focus on optimization, animation, meshes, shading and more. Enjoy!
---
[**Optimize your mobile game performance: Get expert tips on physics, UI, and audio settings**](https://blog.unity.com/technology/optimize-your-mobile-game-performance-get-expert-tips-on-physics-ui-and-audio-settings) - In this second installment in this series, we’re zooming in on how to improve performance with the UI, physics, and audio settings.
[_Unity_](https://blog.unity.com/technology/optimize-your-mobile-game-performance-get-expert-tips-on-physics-ui-and-audio-settings)
[**Unity Event systems interfaces for Customized GUI behavior**](https://indiewatch.net/2021/02/04/unity-event-systems-interfaces-for-customized-gui-behavior/) - A tutorial for boosting your creativity with the Unity Event Systems Library.
[_indiewatch.net_](https://indiewatch.net/2021/02/04/unity-event-systems-interfaces-for-customized-gui-behavior/)
[**Mesh Deformation in Unity**](https://bronsonzgeb.com/index.php/2021/07/10/mesh-deformation-in-unity/) - In this article, I explore mesh deformation using a custom vertex shader.
[_Bronson Zgeb_](https://bronsonzgeb.com/index.php/2021/07/10/mesh-deformation-in-unity/)
[**ML-Agents plays DodgeBall**](https://blog.unity.com/technology/ml-agents-plays-dodgeball) - Today, we are excited to share a new environment to further demonstrate what ML-Agents can do. DodgeBall is a competitive team vs team shooter-like environment where agents compete in rounds of Elimination or Capture the Flag. The environment is open-source, so be sure to check out the repo.
[_Unity_](https://blog.unity.com/technology/ml-agents-plays-dodgeball)
[**Unity 2021.2.0 Beta 4**](https://unity3d.com/unity/beta/2021.2.0b4) - Unity 2021.2.0 Beta 4 has been released.
[_Unity_](https://unity3d.com/unity/beta/2021.2.0b4)
## Videos
[](https://www.youtube.com/watch?v=lUmRJRrZfGc)
[**Making a Zelda-style Cel Shading Effect in Unity Shader Graph**](https://www.youtube.com/watch?v=lUmRJRrZfGc) - Tons of games use a stylised cel-shading art style to help them stand out graphically, including hits like Zelda: Breath of the Wild, Persona 5 and Okami. In this tutorial, we'll unlock the secrets of cel-shading in Shader Graph by using our own custom lighting and end up with an effect that supports multiple lights!
[_Daniel Ilett_](https://www.youtube.com/watch?v=lUmRJRrZfGc)
[**How to create an AI Bot Race Car Controller in Unity tutorial Part 2 - Avoidance**](https://www.youtube.com/watch?v=5SJ6AAI6Wcs) - This is the 2nd part of our Car AI in Unity from scratch.
[_Pretty Fly Games_](https://www.youtube.com/watch?v=5SJ6AAI6Wcs)
[**Changing Action Maps with Unity's "New" Input System**](https://www.youtube.com/watch?v=T8fG0D2_V5M) - Changing actions maps with Unity's new input system is easy and allows precise control of which inputs are being listened to - switching between a 3rd person controller, vehicle controller or UI buttons. An input manager can provide a static instance of an input action asset as well as centralized control of toggling action maps making implementation easy and error-free.
[_One Wheel Studio_](https://www.youtube.com/watch?v=T8fG0D2_V5M)
[**First Person Controller - Slope Sliding (EP06) [Unity Tutorial]**](https://www.youtube.com/watch?v=jIsHe9ARE70) - Hey guy! In this next instalment of the first person controller series we're going to take a look at fixing one of the flaws in the Unity Character Controller by adding sliding t slope limit parameter. That meaning, if we're on or above the character controllers slope limit, we wont be able to bunny hop or jump our way up it, instead we'll just slide on back down it!
[_Comp-3 Interactive_](https://www.youtube.com/watch?v=jIsHe9ARE70)
[**Animation Retargeting (Unity Tutorial)**](https://www.youtube.com/watch?v=fNgPkuMgWFg) - In this Unity game development tutorial we're going look at how we can make use of animation retargeting in Unity, to use the same animations between different characters.
[_Ketra Games_](https://www.youtube.com/watch?v=fNgPkuMgWFg)
[**DConf 2017 Day 2 Keynote: Things that Matter -- Scott Meyers**](https://www.youtube.com/watch?v=3WBaY61c9sE) - In the 45+ years since Scott Meyers wrote his first program, he’s played many roles: programmer, user, educator, researcher, consultant. Different roles beget different perspectives on software development, and so many perspectives over so much time have led Scott to strong views about the things that really matter. In this presentation, he’ll share what he believes is especially important in software and software development, and he’ll try to convince you to embrace the same ideas he does.
[_The D Language Foundation_](https://www.youtube.com/watch?v=3WBaY61c9sE)
[**How to make a Better Health Bar in Unity : Chip Away Tutorial**](https://www.youtube.com/watch?v=CFASjEuhyf4) - In this Video we will create a better looking health bar for use in your game!
[_Natty Creations_](https://www.youtube.com/watch?v=CFASjEuhyf4)
[**Unity 2D: One Way Platforms**](https://www.youtube.com/watch?v=3Tb-__P_UvU) - Learn how to create 2D one-way platforms in Unity 2020.
[_Root Games_](https://www.youtube.com/watch?v=3Tb-__P_UvU)
[**How to Implement Enemy Abilities/Skills Part 1 | AI Series Part 21 | Unity Tutorial**](https://www.youtube.com/watch?v=faNV-hWu07o) - In this tutorial I show how to set up the foundation for enemies using abilities or skills and implement a basic gap-closing skill - Jump where the enemy AI will jump to the player's location then resume following.
[_LlamAcademy_](https://www.youtube.com/watch?v=faNV-hWu07o)
## Assets
[](https://assetstore.unity.com/summer-sale?aid=1011l8NVc)
[**Smash Hit Summer - Asset Store Sale**](https://assetstore.unity.com/summer-sale?aid=1011l8NVc) - Over the next seven weeks, Unity is launching a series of weekly sales, each with a unique game development theme. Each week, approximately 150 assets will be on sale for 50% off and the assets included will all be great selections to use when making a game highlighted in the weekly theme.
The top assets from one week will carry over into the next week and new assets will be added. The final two weeks of the sale will feature the top assets from the first five weeks, plus an additional set of our most popular assets.
* Week 1: Low-Poly Game - June 22 - June 28
* Week 2: 2D Game - June 29 - July 5
* Week 3: 3D Game - July 6 - July 12
* [Week 4: Fantasy Game - July 13 - July 19](https://assetstore.unity.com/summer-sale?aid=1011l8NVc)
* Week 5: Sci-Fi Game- July 20 - July 26
* Week 6: Dream Project - July 27 - August 9
[_Unity_](https://assetstore.unity.com/summer-sale?aid=1011l8NVc) **Affiliate**
[**Harmony**](https://github.com/pardeike/Harmony) - A library for patching, replacing and decorating .NET and Mono methods during runtime.
[_Andreas Pardeike_](https://github.com/pardeike/Harmony) *Open Source*
[**BMesh for Unity**](https://github.com/eliemichel/BMeshUnity) - This Unity package is a library to make runtime procedural mesh generation as flexible as possible. The mesh structure is similar to the one used in Blender, and a mechanism for adding arbitrary attributes to vertices/edges/loops/faces is available, for instance for people used to Houdini's wrangle nodes.
[_eliemichel_](https://github.com/eliemichel/BMeshUnity) *Open Source*
[**UniMob**](https://github.com/codewriter-packages/UniMob) - Reactive state management for Unity. UniMob is a library that makes state management simple and scalable by transparently applying functional reactive programming. _[also check out [UniMob.UI](https://github.com/codewriter-packages/UniMob.UI)]_
[_codewriter-packages_](https://github.com/codewriter-packages/UniMob) *Open Source*
[**Unity Sparse Voxel Octrees**](https://github.com/BudgetToaster/unity-sparse-voxel-octrees) - A Unity-based method of rendering voxels using Sparse Voxel Octrees as seen in Nvidia's paper: "Efficient Sparse Voxel Octrees – Analysis, Extensions, and Implementation".
[_BudgetToaster_](https://github.com/BudgetToaster/unity-sparse-voxel-octrees) *Open Source*
[**DevLogger**](https://github.com/TheWizardsCode/DevLogger) - DevLogger is a Unity Plugin that helps you keep a DevLog while working on your project.
[_TheWizardsCode_](https://github.com/TheWizardsCode/DevLogger) *Open Source*
[**WooshiiAttributes**](https://github.com/WooshiiDev/WooshiiAttributes) - A growing collection of flexible, powerful Unity attributes.
[_WooshiiDev_](https://github.com/WooshiiDev/WooshiiAttributes) *Open Source*
[**UIElements**](https://github.com/plyoung/UIElements) - Various scripts related to Unity UI Toolkit (UIElements). These are not all plug-and-play but should serve as examples you can adopt for your own needs.
[_plyoung_](https://github.com/plyoung/UIElements) *Open Source*
[**Sound Effects and Audio Bundle**](https://www.humblebundle.com/software/music-sound-effects-for-games-files-content?partner=unity3dreport) - Visuals start a game, great sound finishes them! When creating your next video or game, don’t forget one of the most important senses for immersion; sound. Make whatever you create magic with this bundle of spectacular music and sound effects. Plus, your purchase will support The Michael J. Fox Foundation for Parkinson's Research, WWF, and a charity of your choice!
[_Humble Bundle_](https://www.humblebundle.com/software/music-sound-effects-for-games-files-content?partner=unity3dreport) **Affiliate**
[**Game Dev Arts MegaPack**](https://www.humblebundle.com/software/game-dev-arts-megapack-software?partner=unity3dreport) - Make your game truly magic with these awesome developer assets! Want to add that special spark to your next game creation? Pick up the Game Dev Arts Megapack and enjoy software that puts a wealth of icons, assets, UI frames, characters, and much more at your fingertips! Plus, your purchase will support Cancer Research UK, Save the Children, & a charity of your choice!
[_Humble Bundle_](https://www.humblebundle.com/software/game-dev-arts-megapack-software?partner=unity3dreport) **Affiliate**
## Spotlight
[](https://store.steampowered.com/app/1605320/Unusual_Findings/)
[**Unusual Findings**](https://store.steampowered.com/app/1605320/Unusual_Findings/) - It’s the 80s and the Christmas is coming, Vinny, Nick and Tony are young and their new cable signal descrambler just arrived. That same night while trying to decrypt a pay per view adult channel, they pick up the distress signal of an alien spaceship crash-landing in the woods near their town… Things only get weirder as they realize that the towering alien is killing very specific members of their community!
Explore the world oozing with nostalgia, check the Video Buster Store for clues, challenge other kids at the Laser Llamas Arcades, go learn a new trick at The Emerald Sword comic store, try to get along with the punk looking Lost Boys at their hideout or even dare to ask THE BULL, the quintessential 80s Action hero, for some help!
Follow the story that pays tribute to 80s classics like The Goonies, The Explorers, Monster Squad, The Lost Boys, They Live, Terminator, and Aliens among others and a gameplay that combines mechanics of Point and Clicks masterpieces like Full Throttle with its own unique twist and more.
_[You can [follow development](https://twitter.com/EpicLLamaGames) on Twitter]_
[_Epic Lama_](https://store.steampowered.com/app/1605320/Unusual_Findings/)
---
You can subscribe to the free weekly newsletter on [GameDevDigest.com](https://gamedevdigest.com)
This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.
| gamedevdigest |
761,069 | Tailwind Buttons | Responsive buttons built with Tailwind. Buttons provide predefined styles for multiple button types:... | 0 | 2021-10-13T10:06:46 | https://dev.to/keepcoding/tailwind-buttons-2po | tailwindcss, webdev | Responsive buttons built with Tailwind. Buttons provide predefined styles for multiple button types: outline, rounded, social, floating, fixed, tags, etc.
______
## Installation
#### Quick Start
In order to start using Tailwind simply download our starter.
[DOWNLOAD ZIP STARTER](http://tailwind-elements.com/tw-starter.zip)
Tailwind Elements does not change or add any CSS to the already one from TailwindCSS.
You can directly copy our components into your Tailwind design and they will work straight away.
In some dynamic components (like dropdowns or modals) we add Font Awesome icons and custom JavaScript. However, they do not require any additional installation, all the necessary code is always included in the example and copied to any Tailwind project - it will work.
_______
#### MDB GO
{% youtube RAhugF8NOBs %}
_______
## Customization
##### Regular button
###### HTML
```html
<button
class="bg-purple-500 text-white active:bg-purple-600 font-bold uppercase text-xs px-4 py-2 rounded shadow hover:shadow-md outline-none focus:outline-none mr-1 mb-1 ease-linear transition-all duration-150"
type="button">
Small
</button>
<button
class="bg-purple-500 text-white active:bg-purple-600 font-bold uppercase text-sm px-6 py-3 rounded shadow hover:shadow-lg outline-none focus:outline-none mr-1 mb-1 ease-linear transition-all duration-150"
type="button">
Medium
</button>
<button
class="bg-purple-500 text-white active:bg-purple-600 font-bold uppercase text-base px-8 py-3 rounded shadow-md hover:shadow-lg outline-none focus:outline-none mr-1 mb-1 ease-linear transition-all duration-150"
type="button">
Large
</button>
```
##### Regular button with icon
###### HTML
```html
<!-- Required font awesome -->
<link rel="stylesheet" href="https://use.fontawesome.com/releases/v5.11.2/css/all.css" />
<button
class="bg-purple-500 text-white active:bg-purple-600 font-bold uppercase text-xs px-4 py-2 rounded shadow hover:shadow-md outline-none focus:outline-none mr-1 mb-1 ease-linear transition-all duration-150"
type="button">
<i class="fas fa-gem"></i> Small
</button>
<button
class="bg-purple-500 text-white active:bg-purple-600 font-bold uppercase text-sm px-6 py-3 rounded shadow hover:shadow-lg outline-none focus:outline-none mr-1 mb-1 ease-linear transition-all duration-150"
type="button">
<i class="fas fa-gem"></i> Regular
</button>
<button
class="bg-purple-500 text-white active:bg-purple-600 font-bold uppercase text-base px-8 py-3 rounded shadow-md hover:shadow-lg outline-none focus:outline-none mr-1 mb-1 ease-linear transition-all duration-150"
type="button">
<i class="fas fa-gem"></i> Large
</button>
```
#### You can see more customization examples on the [📄 Buttons documentation page](https://tailwind-elements.com/docs/standard/components/buttons/)
______
## Crucial Resources
Here are the resources that we have prepared to help you work with this component:
1. Read [📄 Buttons documentation page](https://tailwind-elements.com/docs/standard/components/buttons/) <-- start here
2. In to get the most out of your project, you should also get acquainted with other Components options related to Buttons. See the section below to find the list of them.
3. After finishing the project you can publish it with CLI in order to receive [💽 Free hosting (beta)](https://mdbootstrap.com/docs/standard/cli/)
-----
## Related Components options & features
- [Accordion](https://tailwind-elements.com/docs/standard/components/accordion/)
- [Alerts](https://tailwind-elements.com/docs/standard/components/alerts/)
- [Badges](https://tailwind-elements.com/docs/standard/components/badges/)
- [Button group](https://tailwind-elements.com/docs/standard/components/button-group/)
- [Cards](https://tailwind-elements.com/docs/standard/components/cards/)
- [Carousel](https://tailwind-elements.com/docs/standard/components/carousel/)
- [Charts](https://tailwind-elements.com/docs/standard/components/charts/)
- [Chips](https://tailwind-elements.com/docs/standard/components/chips/)
- [Dropdown](https://tailwind-elements.com/docs/standard/components/dropdown/)
- [Gallery](https://tailwind-elements.com/docs/standard/components/gallery/)
- [Headings](https://tailwind-elements.com/docs/standard/components/headings/)
- [Images](https://tailwind-elements.com/docs/standard/components/images/)
- [List group](https://tailwind-elements.com/docs/standard/components/listgroup/)
- [Modal](https://tailwind-elements.com/docs/standard/components/modal/)
- [Paragraphs](https://tailwind-elements.com/docs/standard/components/Paragraphs/)
- [Popover](https://tailwind-elements.com/docs/standard/components/popover/)
- [Progress](https://tailwind-elements.com/docs/standard/components/progress/)
- [Rating](https://tailwind-elements.com/docs/standard/components/rating/)
- [Spinners](https://tailwind-elements.com/docs/standard/components/spinners/)
- [Stepper](https://tailwind-elements.com/docs/standard/components/stepper/)
- [Tables](https://tailwind-elements.com/docs/standard/components/tables/)
- [Template](https://tailwind-elements.com/docs/standard/components/template/)
- [Toast](https://tailwind-elements.com/docs/standard/components/toast/)
- [Tooltip](https://tailwind-elements.com/docs/standard/components/tooltip/)
-----
## Additional resources
Learn web development with our **learning roadmap**:
**[:mortar_board: Start Learning](https://mdbootstrap.com/docs/standard/getting-started/)**
Join our mailing list & receive **exclusive resources** for developers
**[:gift: Get gifts](https://mdbootstrap.com/newsletter/)**
Join our private FB group for **inspiration & community experience**
**[👨👩👧👦 Ask to join](https://www.facebook.com/groups/682245759188413)**
**Support creation of open-source packages** with a STAR on GitHub
[](https://github.com/dawidadach/Tailwind-Elements/)
| keepcoding |
761,269 | Why Astro matters | Next, Nuxt, Gatsby, SvelteKit ... there's been an explosion of frontend application frameworks lately. It's never been a more delightful experience to spin up a new project. What's the point of difference with this one? Why does it 'matter' so much? | 0 | 2021-07-16T16:12:15 | https://dev.to/endymion1818/why-astro-matters-55nj | javascript, react, vue, svelte | ---
title: Why Astro matters
published: true
description: "Next, Nuxt, Gatsby, SvelteKit ... there's been an explosion of frontend application frameworks lately. It's never been a more delightful experience to spin up a new project. What's the point of difference with this one? Why does it 'matter' so much?"
tags: javascript, react, vue, svelte
---
**Next, Nuxt, Gatsby, SvelteKit ... there's been an explosion of frontend application frameworks lately. I've tried many (but not all) of them, and I've got to say, it's never been a more delightful experience to spin up a new project. So much so, that I've got hundreds of unfinished ones lying around everywhere.**
Recently, [Astro](https://astro.build), another new frontend application framework, launched itself on the unsuspecting JavaScript public.
Whilst many of us may have been tempted to say "oh no not another one", this framework really stood out to me.
What's the point of difference with this one? Why does it "matter" so much? Well, consider this:
## 1. Frontend can be one happy family again
Astro could be considered the first frontend "meta framework".
What's one of those then? It's a "set of core interfaces for common services and highly extensible backbone for integrating components [this is already Java thing by the way](https://www.igi-global.com/chapter/java-web-application-frameworks/16864).
Astro is essentially a "bring your own frontend" approach to modern web frameworks. You can use whatever framework (oh, ok "library" then) you know and love, and still spin up a performant app that you can host almost anywhere.
Think about the potential here. Astro could be the place the frontend finally comes together. It no longer matters (as much) what framework you use. Use them all if you like 🤷♂️.
Love Vue? You can love Astro. React? Same. Svelte? You'll find no argument from Astro, because Astro is the glue that underpins how we build websites and applications.
Great, innit? It'll probably never happen but I can dream, can't I?
## 2. Astro pushes the boundaries for every javascript framework*
(* oh, ok library then)
Take a look at this tweet from Evan You, the creator of Vue:
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">I just tried this in a Vite SSRed app and this approach totally works... a plugin can simply remove the script tags for the actual bundle and let petite-vue "sprinkle" the parts.<br><br>aka "Island Architecture" 🏝️ <a href="https://t.co/Oe9KRvFsrd">https://t.co/Oe9KRvFsrd</a> <a href="https://t.co/KV7SvCwyn8">pic.twitter.com/KV7SvCwyn8</a></p>— Evan You (@youyuxi) <a href="https://twitter.com/youyuxi/status/1411405615369539590?ref_src=twsrc%5Etfw">July 3, 2021</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
Is it a coincidence that Vue now can do a similar thing to Astro? did Astro get Evan to start thinking more about this problem? Could the same be said for the other frameworks too?
[Better hydration is something I've been wanting ever since the present generation of frontend application frameworks came out](https://deliciousreverie.co.uk/post/towards-better-rehydration/).
I know the React team have been working on it for a long time. [I even opened (very prematurely it turns out!) this issue on the GatsbyJS repo around 2 years ago](https://github.com/gatsbyjs/gatsby/issues/17993).
React 18's hydration prioritisation is a good step forward, however the whole DOM tree still need to be hydrated. Won't it be great when we need only attach JavaScript generated elements to the DOM when components really need them?!
It would be wonderful to think that partial rehydration could be everywhere, it would certainly level the playing field and even things up a lot [for the next 1 billion web users](https://gomakethings.com/progressive-enhancement-and-the-next-billion-web-users/).
## Check out Astro
If you care about performance (you care right?) please check out this gamechanger. I'm so excited for the potential here.
https://astro.build | endymion1818 |
761,280 | .NET 6: The MOST promising FEATURES 🔥 | Microsoft is putting the batteries and already presents .NET 6 Preview 5. According to what they tell... | 0 | 2021-07-20T15:38:00 | https://www.bytehide.com/blog/dotnet-6-is-here-the-features-that-will-blow-your-mind/ | dotnet, netcore, csharp, dotnet6 | **Microsoft** is putting the batteries and already presents .NET 6 Preview 5. According to what they tell us, they are already in the second half of the **.NET 6** version and they are beginning to teach new features that promise a lot. 🤗
---
## What is .NET? What is it for?
What is .NET in general, is a _Microsoft_ platform to develop Software, covering many operating systems such as **Windows**, **iOS**, **Linux**, **Android** … The main idea of .NET is to be able to develop applications independent of the physical architecture or the operating system in the one that was going to be executed.
Its main advantages are:
* **Decreased** development time
* Use of **predesigned functionalities**
* **Reduction** of development and maintenance cost
* **Simplification** of maintenance
> Okay, I understand. And what is .NET 6? _🤔_
.NET 6 is the new version of .NET _(currently .NET 5)_ that Microsoft promises to release on **November 9** of this year. It brings many improvements and new features compared to .NET 5.
---
## What are .NET 6 new features?
If we speak in general, we can speak from .NET MAUI, through the new implementation of the 64-bit architecture, to Visual Studio 2022 and its function more... 😎 But we are going to explain the most important ones and the ones you should know.
---
### NuGet package validation
Package validation tools will allow **NuGet** library developers to validate that their packages are consistent and well-formed.
Its main characteristics are:
* Validate that there are **no important change**s in the versions
* Validate that the package **has the same set of public APIs** for all specific runtime implementations.
* Determine **applicability gaps in the target framework** or in the execution time.
---
### Workload Enhancements in the .NET SDK
Microsoft reports that it has added new workload commands in .NET 6 to improve administration:
* `dotnet workload search` List the workloads available to install.
* `dotnet workload unistall` Removes the specified workload if you no longer need a workload. It is also a good option to save space.
* `dotnet workload repair` Reinstall all previously installed workloads.
---
### Crossgen2
[Crossgen](https://github.com/dotnet/runtime/blob/main/docs/workflow/building/coreclr/crossgen.md) allows **IL** precompiling into native code as a publishing step. Pre-compiling is primarily beneficial to improve startup. **Crossgen2** is a scratch implementation that is already proving to be a superior platform for code generation innovation.
Here we can see how to enable the pre-compilation with Crossgen2 from the _MSBuild_ properties:
```csharp
<!-- Enable pre-compiling native code (in ready-to-run format) with crossgen2 -->
<PublishReadyToRun>true</PublishReadyToRun>
<!-- Enable generating a composite R2R image -->
<PublishReadyToRunComposite>true</PublishReadyToRunComposite>
```
---
### Windows Forms: The default font
Already with .NET 6 you can set a default font for an `Application.SetDefaultFont`application. Also the pattern it uses is similar to setting high dpi or visual styles. An example:
```csharp
class Program
{
\[STAThread\]
static void Main()
{
Application.SetHighDpiMode(HighDpiMode.SystemAware);
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);\+
Application.SetDefaultFont(new Font(new FontFamily("Microsoft Sans Serif"), 8f));Application.Run(new Form1());
}
}
```
Here are **2 examples** after you set the default font.
Microsoft Sans Serif, 8pt:
Chiller, 12pt:
---
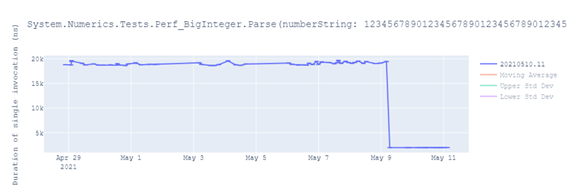
### Performance increase in the BigInteger library
BigIntegers parsing of decimal and hexadecimal strings has been improved. In the following photo you can see improvements of up to **89%**:
---
### SSL 3 support
The .NET crypto APIs support the use of **OpenSSL 3** as the preferred native crypto provider on _Linux_. .NET 6 will use **OpenSSL 3** if available. Otherwise, it will use **OpenSSL 1.x**.
---
### IOS CPU Sampling (SpeedScope)
The graph below shows part of an **iOS** startup _CPU_ sampling session seen in **SpeedScope**:

---
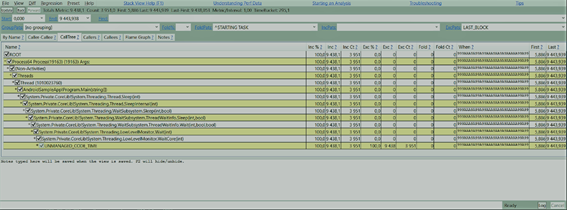
### Android CPU Sampling (PerfView)
The following image shows the **Android** _CPU_ sampling seen in **PerfView**:
---
## .NET 6 Conclusion
This .NET 6 Preview 5 is perhaps the biggest so far of all the ones that have been released in terms of quantity and quality of features. Right now you can try .NET 6 by downloading it from the **Official Web of .NET 6.**
As Microsoft says…
> The future has arrived
With all the tools already announced and all that remain to be shown and released, development will become a much easier, more optimized and more productive task, highly improving the developer experience in their current and future projects.
We would like to know your opinion. Sound good features? Anything you would like them to take out? Leave it in the comments so we can talk about it.😊 | bytehide |
761,289 | Princípio da Responsabilidade Única (SRP) | Neste artigo vou explicar como funciona o Princípio da Responsabilidade Única (SRP) do SOLID e... | 13,664 | 2021-07-16T16:55:06 | https://felipecesar.dev/princ%C3%ADpio-da-responsabilidade-%C3%BAnica-srp | braziliandevs, javascript, programming, architecture | Neste artigo vou explicar como funciona o **Princípio da Responsabilidade Única (SRP)** do **SOLID** e mostrar como aplicá-lo em JavaScript.
## O que é SOLID?
SOLID é um acrônimo de 5 princípios da programação orientada a objetos, são eles:
**[S]**ingle Responsability Principle
**[O]**pen/Closed Principle
**[L]**iskov Substitution Principle
**[I]**nterface Segregation Principle
**[D]**ependency Inversion Principle
Com a aplicação destes princípios podemos obter alguns benefícios, como códigos mais fáceis de manter, adaptar, testar, etc. Além de evitar possíveis problemas como códigos desestruturados, frágeis e duplicados.
## O primeiro princípio
O primeiro princípio do SOLID é o da responsabilidade única ou **SRP**, este princípio define que uma classe deve possuir apenas uma responsabilidade que deve estar totalmente encapsulada dentro dela.
Sua definição formal diz:
> Uma classe deve ter **um, e apenas um**, motivo para ser modificada.
Se uma classe só deve ter um motivo para ser modificada, certamente ela só deve ter uma única responsabilidade.
## Exemplo de violação
Vamos supor que precisamos criar uma classe que faça requisições ao servidor e valide os erros para apresenta-los como um alerta na tela, essa é uma classe que possui mais de uma responsabilidade e claramente viola o SRP. Abaixo segue um exemplo desta classe onde importamos o [SweetAlert2](https://sweetalert2.github.io/) para exibir os alertas de erro:
```javascript
import Swal from 'sweetalert2';
export class HttpClient {
get(url) {
return fetch(url, {
headers: {
Accept: 'application/json'
}
}).then(response => {
if (response.ok) {
return response.json();
} else {
if (response.status == 401) {
Swal({
title: 'Não autorizado',
type: 'error'
});
} else if (response.status == 404) {
Swal({
title: 'Não encontrado',
type: 'warning'
});
} else if (response.status == 500) {
Swal({
title: 'Erro do Servidor Interno',
type: 'error'
});
} else {
Swal({
title: 'Erro desconhecido',
type: 'info'
});
}
}
});
}
}
```
## Resolvendo a violação do SRP
Nesse caso como decidimos importar uma lib para validar o erro antes de que ele seja exibido, podemos separar as responsabilidades em duas classes:
```javascript
import Swal from 'sweetalert2';
export default class ErrorHandler {
static handle(response) {
if (response.status == 401) {
Swal({
title: 'Não autorizado',
type: 'error'
});
} else if (response.status == 404) {
Swal({
title: 'Não encontrado',
type: 'warning'
});
} else if (response.status == 500) {
Swal({
title: 'Erro do Servidor Interno',
type: 'error'
});
} else {
Swal({
title: 'Erro desconhecido',
type: 'info'
});
}
}
}
```
```javascript
import ErrorHandler from './error-handler';
export default class HttpClient {
get(url) {
return fetch(url, {
headers: {
Accept: 'application/json'
}
}).then(response => {
if (response.ok) {
return response.json();
} else {
ErrorHandler.handle(response);
}
});
}
}
```
Dessa forma conseguimos corrigir a violação, dividindo as responsabilidades em classes diferentes.
## Conclusão
Esse é o tipo de princípio que toda aplicação orientada a objetos deve ter, aplicando ele conseguimos criar classes mais coesas e com um acoplamento mais baixo.
Espero que tenham gostado, se tiverem duvidas ou sugestões podem comentar. Abraço! | felipecesr |
761,429 | Tips for creating a good post | [Clique aqui para ler em português] TITLE Write an attention-grabbing headline that will... | 0 | 2021-07-16T19:25:44 | https://dev.to/walternascimentobarroso/tips-for-creating-a-good-post-2bd6 | post, content, tips, article | [[Clique aqui para ler em português]](https://medium.com/walternascimentobarroso-pt/dicas-para-criar-um-bom-post-a5c69143f3d)
## TITLE
Write an attention-grabbing headline that will draw an audience to your text.
## IMAGES
Use an image to reflect what your post means.
some sites with free images:
https://stocksnap.io/
https://www.pexels.com/
Website that searches for free images on other websites https://farejadordeimagens.com.br/
Site to change image dimension
https://www.easy-resize.com/
Website to reduce image weight
https://compressor.io/
## TABLES
Whenever possible, adjust your content in tables, so the information is more organized, by comparison tables.
To help assemble the tables, use the website
https://ozh.github.io/ascii-tables/
## CODES
Whenever you need to put in some code that is too extensive, use some of the tools below:
https://carbon.now.sh/
https://codepen.io/
https://gist.github.com/
## TAGS
Always add tags to your post, so it’s easier to find
## EMOJIS
To convey more feelings and expressions in your posts, use
emojis
http://emojipedia.org/
http://www.iemoji.com/
***
## Thanks for reading!
If you have any questions, complaints or tips, you can leave them here in the comments. I will be happy to answer!
😊😊See you! 😊😊 | walternascimentobarroso |
761,498 | Creando Arte CSS Accesible | El arte y los dibujos CSS no son accesibles por defecto, pero con las técnicas modernas de HTML y CSS, se pueden hacer más cercanos a todo el mundo. | 0 | 2021-07-16T23:13:04 | https://alvaromontoro.com/blog/67979/creating-accessible-css-art#2 | css, a11y, html, spanish | ---
title: Creando Arte CSS Accesible
published: true
description: El arte y los dibujos CSS no son accesibles por defecto, pero con las técnicas modernas de HTML y CSS, se pueden hacer más cercanos a todo el mundo.
tags: css, a11y, html, spanish
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/mduo5hrwmec3ewnhda5l.jpg
canonical_url: https://alvaromontoro.com/blog/67979/creating-accessible-css-art#2
---
> For an English version of this article, visit this other [DEV post](https://dev.to/alvaromontoro/creating-more-accessible-css-art-179n)
El arte y los dibujos CSS ha existido básicamente desde que se creo CSS. Son una manera perfecta de practicar y aprender y son interesantes como retos de programación. Pero tienen un gran problema: el arte CSS no es accesible.
En este post no vamos a ver cómo crear dibujos e ilustraciones en CSS (hay muchos de esos posts). En lugar de eso, nos centraremos en consejos y buenas prácticas para hacer que los dibujos CSS sean más accesibles para todos.
Después de aplicar estas técnicas, tus imágenes en CSS se llevarán mejor con los lectores de pantalla, personas con necesidades específicos de colores, gente con trastornos vestibulares o vértigo... y todo sin impactar negativamente tu arte o tu creatividad. Todos ganan.
Para ver un ejemplo con los consejos de este artículo, [visita esta ilustración CSS](https://codepen.io/alvaromontoro/pen/WNwrPmW). Y sin más preámbulos, vamos a ver las recomendaciones:
1. Identifica el dibujo CSS como una imagen
2. Añade texto alternativo
3. Elige entre dibujar a la perfección o responsivamente
4. Usa elementos HTML semánticos
5. Precaución con las animaciones
6. Respeta las elecciones del colores
7. Especifica la relación de aspecto
## Identifica el dibujo CSS como una imagen
Una de las cosas más importantes es identificar tu arte CSS como una image. Eso se puede hacer añadiendo un [rol ARIA de `img`](https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA/Roles/Role_Img) al contenedor principal del dibujo:
```html
<div role="img">
<!-- HTML de la imagen -->
</div>
```
Al añadir este rol ARIA, las tecnologías de asistencia anunciarán que el contenedor del arte CSS es una imagen cuando lleguen a él.
## Añade texto alternativo
Ahora que los lectores de pantalla anuncian el arte CSS como una imagen, es important proveer una descripción o texto alternativo tal y como lo tendría una imagen normal. Algo equivalente al [atributo `alt`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/img#attr-alt).
Podemos lograr esto al añadir el [atributo `aria-label`](https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA/ARIA_Techniques/Using_the_aria-label_attribute) al dibujo y añadiendo el texto alternativo ahí:
```html
<div aria-label="El texto alternativo iría aquí">
<!-- HTML de la imagen -->
</div>
```
Esto funcionará pero, en el caso improbable (pero posible) de que el CSS no se cargue correctamente, puede no ser suficiente para hacer lo que queremos. Por eso prefiero usar mejor el [atributo `aria-labelledby`](https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA/ARIA_Techniques/Using_the_aria-labelledby_attribute):
```html
<div aria-labelledby="alt-imagen">
<div id="alt-imagen">El texto alternativo va aquí</div>
<!-- HTML de la imagen -->
</div>
```
Esta solución incluye la etiqueta como texto, lo que permite esconderla usando cualquier técnica accesible. Hay muchas posibilidades para ello. Una sencilla se puede encontrar en la [página web de The A11Y Project](https://www.a11yproject.com/posts/2013-01-11-how-to-hide-content/):
```css
#alt-imagen {
clip: rect(0 0 0 0);
clip-path: inset(50%);
height: 1px;
overflow: hidden;
position: absolute;
white-space: nowrap;
width: 1px;
}
```
De este modo, si el CSS no se carga, el texto alternativo se mostrará parecido a como se mostraría el texto alternativo de un `<img />` nativo si la imagen no se carga correctamente en la página.
## Elige entre dibujar a la perfección o responsivamente
Algo **a tener en cuenta antes incluso de empezar a codificar nada**: ¿queremos que el dibujo sea _pixel-perfect_? ¿O queremos que sea algo responsivo y que cambie de tamaño (al coste de que igual no se ve del todo bien)? Por supuesto, las respuesta tendrán consecuencias y decidirán sobre cómo debemos crear el arte CSS.
Si queremos alcanzar resultados perfectos, deberíamos usar [unidades absolutas de medida](https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/Values_and_units#absolute_length_units) como `px`, `cm`, `pt`, etc. De este modo nuestra imagen tendrá un tamaño fijo y no escalará del todo bien (aunque mejor que las imágenes raster ya que lo nuestro será un dibujo vectorial), pero podremos usar cualquier propiedad y valor CSS.
Por otro lado, utilizaremos [unidades relativas de medida](https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/Values_and_units#relative_length_units) como `%`, `vmin`, `em`, etc. si queremos que sea escalable.
Para que sea responsivo debemos tener en cuenta otras consideraciones:
- El resultado será escalable y responsivo... o al menos, tendrá la capacidad de serlo.
- Tendremos que tener cuidado con algunas propiedades CSS que no funcionan bien con algunas unidades relativas (p.e. [`box-shadow`](https://developer.mozilla.org/en-US/docs/Web/CSS/box-shadow) o [`border`](https://developer.mozilla.org/en-US/docs/Web/CSS/border-width)).
- Debemos evitar valores CSS que no usan unidades relativas (p.e. [`clip-path`](https://developer.mozilla.org/en-US/docs/Web/CSS/clip-path) puede tener valores relativos con `polygon()` pero no con `path()`).
No hay nada malo con uno u otro enfoque. Para dibujos artísticos seguramente optemos por escalabilidad, mientras que para cosas más _prácticas_ como iconos o fondos, optar por algo más pixel perfecto será conveniente.
## Usa elementos HTML semánticos
HTML5 provee muchos elementos semánticos. No hace falta usar `<div>` para todas las partes de nuestro dibujo y especialmente no para el contenedor principal. La pregunta debería ser "¿qué elemento HTML debemos usar?"
> Nota del autor: comprendo que mi elección de elementos semánticos puede ser discutible. Intentaré ser lo más neutral/objetivo posible.
Hay un par de elementos que parecen ideales en este caso: [`<article>`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/article) y [`<figure>`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/figure)/[`<figcaption>`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/figcaption). Mientras que el segundo parece una elección obvia, el primero tiene algunas ventajas semánticas, como veremos pronto.
Por un lado, tenemos `<figure>`. Un contenido autónomo con un subtítulo opcional (`<figcaption>`) que puede usarse para el texto alternativo:
```html
<figure aria-labelledby="alt-imagen">
<figcaption id="alt-imagen">Aquí va el texto alternativo</figcaption>
<!-- HTML de la imagen -->
</figure>
```
Esta elección parece venir como un guante para lo que queremos, pero no debemos olvidar `<article>`: una composición completa, autónoma e independiente, con la intención de ser reusada y distribuida. ¡Precisamente lo que es el dibujo CSS!
```html
<article>
<!-- HTML de la imagen -->
</article>
```
¿Qué elemento HTML semántico elegir? Eso dependerá del autor y de cómo quiere que su arte CSS sea presentado a los usuarios.
Alguna gente ha mencionado que no puede haber un `<article>` dentro de otro `<article>`, pero eso no es correcto. [Un artículo puede contener otro artículo](https://html.spec.whatwg.org/multipage/sections.html#the-article-element). Cuando hay artículos anidados, el artículo interior debe estar relacionado con el artículo exterior.
El uso de `<article>` da mucho juego también porque permite una incorporación más natural de otros elementos HTML semánticos como encabezados para el título/texto alternativo de la ilustración, [`<address>`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/address) para el contacto del autor, o [`<time>`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/time) para la fecha de publicación:
```html
<article aria-labelledby="image-alt"
aria-describedby="image-info">
<!-- Todo el `<header>` se escondería de forma accesible -->
<header>
<h2 id="image-alt">Título/Texto alternativo</h2>
<p id="image-info">
<address>
Creado por
<a href="https://twitter.com/alvaro_montoro">
Alvaro Montoro
</a>
</address>
el
<time datetime="2021-06-10">10 de Junio de 2021</time>
</p>
</header>
<!-- HTML de la imagen -->
</article>
```
## Precaución con las animaciones
Algunas veces los dibujos CSS incluyen algún tipo de animación: un perro que mueve la cola, una persona moviéndose y parpadeando, un avión que vuela y da vueltas...
Cuando añadimos animaciones a nuestro arte CSS, debemos tener en cuenta que no a todo el mundo le gusta ver las animaciones o que pueden sufrir de algún trastorno que se vea acentuado por ellas (p.e. [los trastornos vestibulares o el vértigo](https://css-tricks.com/introduction-reduced-motion-media-query/)).
Tenemos que proporcionar algún modo de para las animaciones o reemplazarlas con algo diferente. Para nuestra suerte, CSS ofrece la [media query `prefers-reduced-motion`](https://developer.mozilla.org/en-US/docs/Web/CSS/@media/prefers-reduced-motion) que permite a los desarrolladores hacer precisamente eso.
Por ejemplo, podemos deshabilitar una animación haciendo algo como esto (suponiendo que la clase "animado" está en todos los elementos que se animan):
```css
@media (prefers-reduced-motion) {
.animado {
animation: none;
}
}
```
También tenemos que tener en cuenta que no todas las animaciones son iguales y no todas causarán problemas. **En lugar de cancelar todas las animaciones, podemos plantearnos cambiarlas por otras más apropiadas** o ajustando los tiempos para que no sean tan bruscas.
## Respeta las elecciones del colores
Algunos sistemas operativos permiten a los usuarios seleccionar opciones de accesibilidad y, en algunos casos, CSS puede identificar esos valores usando algunas media queries y propiedades.
Algunos de los métodos que vamos a comentario [no están soportados por los navegadores](https://caniuse.com/?search=forced-colors), pero pueden usarse para mejorar nuestro arte CSS una vez que el soporte esté más extendido.
Las media queries son:
- [`prefers-contrast`](https://developer.mozilla.org/en-US/docs/Web/CSS/@media/prefers-contrast): para indicar si el usuario quiere un contraste más alto o más bajo.
- [`prefers-color-scheme`](https://developer.mozilla.org/en-US/docs/Web/CSS/@media/prefers-color-scheme): para detectar si el usuario prefiere un tema oscuro o claro (muy común para mostrar el modo noche/día.)
- [`forced colors`](https://developer.mozilla.org/en-US/docs/Web/CSS/@media/forced-colors): especifica si un usuario ha elegido una paleta de colores limitada.
```css
@media (prefers-contrast: more) {
/* more: contrastes más altos, bordes, sin transparencias... */
/* less: contrastes de color más bajos */
}
@media (prefers-colors-scheme: dark) {
/* dark: dibujos con más contraste frente a fondos oscuros */
/* light: dibujos con más contraste frente a fondos claros */
}
@media (forced-colors: active) {
/* sobreescribir propiedades como box-shadow, añadir bordes, etc. */
}
```
El uso de [propiedades personalizadas en CSS](https://developer.mozilla.org/en-US/docs/Web/CSS/Using_CSS_custom_properties) (también llamadas variables CSS) hará más fácil el uso de esas media queries ya que sólo habrá que redefinir los valores de las variables.
En casos más extremos, puede que queremos evitar algunas propiedades CSS. Por ejemplo, el valor de `box-shadow` se fuerza a `none` en el modo de colores forzados, y tendríamos que buscar alternativas.
## Especifica la relación de aspecto
Una propiedad más reciente que puede ser útil para crear arte CSS responsivo es [`aspect-ratio`](https://developer.mozilla.org/en-US/docs/Web/CSS/aspect-ratio). Con ella podemos definir la relación de aspecto preferida para la imagen, que el navegador usará para calcular el tamaño y aplicarlo automáticamente:
```css
/* Este dibujo CSS será cuadrado */
#miArteCSS {
aspect-ratio: 1 / 1;
}
/* Este dibujo CSS será el doble de alto que de ancho */
#miArteCSS {
aspect-ratio: 1 / 2;
}
```
Esto es algo muy conveniente para los desarrolladores, pero también tiene un impacto en la accesibilidad porque asegura que nuestros dibujos CSS no se verán estirados o deformados. Y tiene un [buen soporte](https://caniuse.com/?search=aspect-ratio) por parte de los navegadores.
----
Este artículo es una extensión de la presentación que hice durante un meetup de SydCSS. Puedes encontrar el [video en Youtube](https://www.youtube.com/watch?v=bJRETGarbqE&t=2460s).
| alvaromontoro |
761,689 | JS Quiz: Practise Arithmetic Skills | Check out this website I created, where you can practice basic addition, subtraction, multiplication... | 0 | 2021-07-17T05:39:21 | https://dev.to/swatitr06172888/js-quiz-practise-arithmetic-skills-ngh | javascript, beginners, html, css | Check out this website I created, where you can practice basic addition, subtraction, multiplication and division. It is made using pure HTML, CSS and JavaScript. Any suggestions for improvement are most welcome.
Check out the main website here:
[Click to visit sankhya: website to practise mental maths](https://swati-gwc.github.io/sankhya)
Below was the first version of the above website.
{% codepen https://codepen.io/swati_gwc/pen/YzNxdGE %} | swatitr06172888 |
761,767 | Create LANDING PAGE with 3-D Effect | In this article I am going to show you how to add 3-D effects to a Landing Page using HTML, CSS and... | 0 | 2021-07-17T07:50:41 | https://dev.to/rajshreevats/create-landing-page-with-3-d-effect-4136 | html, javascript, css, tutorial | In this article I am going to show you how to add 3-D effects to a Landing Page using __HTML, CSS and JavaScript__. You can add 3-D effects to give your website a _bold navigation_ and also show off your skills of better usability standards. _Unique and beautiful_ effects are what can easily make people stop and take notice, increasing the time they spend on the site.
##Step 1: Create HTML File
This is a basic layout of a landing page, further we are going to add effects using _CSS and JavaScript_.
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>3D Navbar Animation</title>
<link rel="stylesheet" href="style.css" />
</head>
<body>
<div class="container">
<div class="navbar">
<div class="menu">
<h3 class="logo">Rajshree<span>Vats</span></h3>
<div class="hamburger-menu">
<div class="bar"></div>
</div>
</div>
</div>
<div class="main-container">
<div class="main">
<header>
<div class="overlay">
<div class="inner">
<h2 class="title"> Imagination creates reality</h2>
<p>
Hello, This is a sample landing page with 3-D navigation bar.
Created using HTML,CSS and JAVASCRIPT. I hope you like it.
</p>
<button class="btn">Read more</button>
</div>
</div>
</header>
</div>
```
##Step 2: Styling Layout and Hamburger menu
This will style our html elements.
```css
* {
padding: 0;
margin: 0;
box-sizing: border-box;
}
body,
button {
font-family: "Poppins", sans-serif;
}
.container {
min-height: 100vh;
width: 100%;
background-image: url(bg2.png);
overflow-x: hidden;
transform-style: preserve-3d;
}
.navbar {
position: fixed;
top: 0;
left: 0;
width: 100%;
z-index: 10;
height: 3rem;
}
.menu {
max-width: 72rem;
width: 100%;
margin: 0 auto;
padding: 0 2rem;
display: flex;
justify-content: space-between;
align-items: center;
color: #fff;
}
.logo {
font-size: 1.1rem;
font-weight: 600;
text-transform: uppercase;
letter-spacing: 2px;
line-height: 4rem;
}
.logo span {
font-weight: 300;
}
.hamburger-menu {
height: 4rem;
width: 3rem;
cursor: pointer;
display: flex;
align-items: center;
justify-content: flex-end;
}
.bar {
width: 1.9rem;
height: 1.5px;
border-radius: 2px;
background-color: #eee;
transition: 0.5s;
position: relative;
}
.bar:before,
.bar:after {
content: "";
position: absolute;
width: inherit;
height: inherit;
background-color: #eee;
transition: 0.5s;
}
.bar:before {
transform: translateY(-9px);
}
.bar:after {
transform: translateY(9px);
}
.main {
position: relative;
width: 100%;
left: 0;
z-index: 5;
overflow: hidden;
transform-origin: left;
transform-style: preserve-3d;
transition: 0.5s;
}
header {
min-height: 100vh;
width: 100%;
background: url("bg1.png") no-repeat top center / cover;
position: relative;
}
.overlay {
position: absolute;
width: 100%;
height: 100%;
top: 0;
left: 0;
display: flex;
justify-content: center;
align-items: center;
}
.inner {
max-width: 35rem;
text-align: center;
color: #fff;
padding: 0 2rem;
}
.title {
font-size: 2rem;
}
.btn {
margin-top: 1rem;
padding: 0.6rem 1.8rem;
background-color: #1179e7;
border: none;
border-radius: 25px;
color: #fff;
text-transform: uppercase;
cursor: pointer;
text-decoration: none;
}
```
##Step 3 : The Javascript Code
To add __animation__, we need to add a __class__ called __active__ to the container element and remove it every time _hamburger menu_ is clicked on.
```javascript
const hamburger_menu = document.querySelector(".hamburger-menu");
const container = document.querySelector(".container");
hamburger_menu.addEventListener("click", () => {
container.classList.toggle("active");
});
```
##Step 4: Styling __active__ class
After this Let's style the container element and add animation using css -
```css
.container.active .bar {
transform: rotate(360deg);
background-color: transparent;
}
.container.active .bar:before {
transform: translateY(0) rotate(45deg);
}
.container.active .bar:after {
transform: translateY(0) rotate(-45deg);
}
.container.active .main {
animation: main-animation 0.5s ease;
cursor: pointer;
transform: perspective(1300px) rotateY(20deg) translateZ(310px) scale(0.5);
}
@keyframes main-animation {
from {
transform: translate(0);
}
to {
transform: perspective(1300px) rotateY(20deg) translateZ(310px) scale(0.5);
}
}
```
We are done with the 3-D transformation.
####Now, add shadow effect to the image
```css
.shadow {
position: absolute;
width: 100%;
height: 100vh;
top: 0;
left: 0;
transform-style: preserve-3d;
transform-origin: left;
transition: 0.5s;
background-color: white;
}
.shadow.one {
z-index: -1;
opacity: 0.15;
}
.shadow.two {
z-index: -2;
opacity: 0.1;
}
.container.active .shadow.one {
animation: shadow-one 0.6s ease-out;
transform: perspective(1300px) rotateY(20deg) translateZ(215px) scale(0.5);
}
@keyframes shadow-one {
0% {
transform: translate(0);
}
5% {
transform: perspective(1300px) rotateY(20deg) translateZ(310px) scale(0.5);
}
100% {
transform: perspective(1300px) rotateY(20deg) translateZ(215px) scale(0.5);
}
}
.container.active .shadow.two {
animation: shadow-two 0.6s ease-out;
transform: perspective(1300px) rotateY(20deg) translateZ(120px) scale(0.5);
}
@keyframes shadow-two {
0% {
transform: translate(0);
}
20% {
transform: perspective(1300px) rotateY(20deg) translateZ(310px) scale(0.5);
}
100% {
transform: perspective(1300px) rotateY(20deg) translateZ(120px) scale(0.5);
}
}
.container.active .main:hover + .shadow.one {
transform: perspective(1300px) rotateY(20deg) translateZ(230px) scale(0.5);
}
.container.active .main:hover {
transform: perspective(1300px) rotateY(20deg) translateZ(340px) scale(0.5);
}
```
##Step 5: Adding and styling Menu links
```html
<div class="links">
<ul>
<li>
<a href="#" style="--i: 0.05s;">Home</a>
<span> </span>
</li>
<li>
<a href="#" style="--i: 0.1s;">Services</a>
<span> </span>
</li>
<li>
<a href="#" style="--i: 0.15s;">Portfolio</a>
<span> </span>
</li>
<li>
<a href="#" style="--i: 0.2s;">Testimonials</a>
<span> </span>
</li>
<li>
<a href="#" style="--i: 0.25s;"> About</a>
<span> </span>
</li>
<li>
<a href="#" style="--i: 0.3s;"> Contact</a>
<span> </span>
</li>
</ul>
</div>
</div>
```
####Let's __style__ links
```css
.links {
position: absolute;
width: 20%;
right: 2em;
top: 0;
height: 100vh;
z-index: 2;
display: flex;
justify-content: center;
align-items: center;
}
ul {
list-style: none;
}
ul li a .fa{
font-size: 40px;
color:black;
line-height: 80px;
transition: 0.5s;
padding-right: 14px;
}
ul li a{
text-decoration: none;
display:absolute;
display: block;
width:160px;
height:60px;
background:#609aca;
text-align:centre;
padding-left: 20px;
transform: rotate(0deg) skewX(25deg) translate(0,0);
transition: 0.5s;
box-shadow: -20px 20px 10px rgba(0,0,0,3);
}
ul li a:before {
content: '';
position: absolute;
top: 10px;
left: -20px;
height: 100%;
width:20px;
background:#b1b1b1;
transform:0.5s;
transform:rotate(0deg) skewY(-45deg);
}
ul li a:before {
content: '';
position: absolute;
top: 6px;
left: -10px;
height: 100%;
width:10px;
background:#dbe7f0;
transform:0.5s;
transform:rotate(0deg) skewY(-45deg);
}
ul li a:after {
content: '';
position: absolute;
bottom: -10px;
left: -6px;
height: 10px;
width:100%;
background:#dbe7f0;
transform:0.5s;
transform:rotate(0deg) skewX(-45deg);
}
ul li a:hover {
transform:rotate(-30deg) skew(25deg) translate(20px,-15px);
box-shadow: -50px 50px 50px rgba(0,0,0,0);
}
ul li a:hover .fa {
color: #fff;
}
ul li:hover span{
color: #fff;
}
ul li:hover a{
background: #9b154c;
}
ul li:hover a:before{
background: #7B153F;
}
ul li:hover a:after{
background: #9b154c;
}
.links a {
text-decoration: none;
color: black;
padding: 0.7rem 0;
display: flex;
display: block;
font-size: 1.2rem;
font-weight: 200;
text-transform: uppercase;
letter-spacing: 0px;
transition: 0.3s;
opacity: 0;
transform: translateY(10px);
animation: hide 0.5s forwards ease;
}
.links a:hover {
color: #fff;
}
.container.active .links a {
animation: appear 0.5s forwards ease var(--i);
}
```

View the Final Version of this page [here](https://rajshreevats.github.io/3-d-navigation-bar.github.io/)
Hopefully this tutorial was fun and worth your while. Get the full Source Code [here](https://github.com/RajshreeVats/3-d-navigation-bar.github.io) on my [Github](https://github.com/RajshreeVats) __Repo__.
Let's Connect on [LinkedIn](https://www.linkedin.com/in/rajshree-vatsa-6493371b8/) or [Twitter](https://twitter.com/RajshreeVatsa).
| rajshreevats |
761,845 | chemistry tutor | In addition to one-to-one organic chemistry tutoring, I extend my support to the interested students... | 0 | 2021-07-17T10:28:55 | https://dev.to/scopex70932047/chemistry-tutor-2eom | organicchemistrytutor | In addition to one-to-one organic chemistry tutoring, I extend my support to the interested students who are in the need of short and crisp learning material for any organic chemistry topics.
Every year I tutor at least a hundred organic chemistry students from all over the country. Also, I taught organic chemistry topics at the graduate level for other country students who are residing in the USA. Some of the students are from Colorado State University, Georgetown University, Allen University, Augustana University, and few community colleges in the US.
| scopex70932047 |
762,272 | Getting Started with Lodash in JavaScript | Why use lodash It reduces the lines of code significantly Supports common operations... | 0 | 2021-07-17T23:52:12 | https://www.realpythonproject.com/getting-started-with-lodash-in-javascript/ | javascript, programming, codenewbie, computerscience | ### Why use lodash
- It reduces the lines of code significantly
- Supports common operations done on Objects and Arrays
- Supports common operations on strings
- Supports generic functions
- Trusted by other developers. It has [50k+ ⭐️](https://github.com/lodash/lodash) on GitHub
- Well Documented
- You don't need to learn any new syntax or concepts or anything. It uses plain old JavaScript.
### Install lodash
```npm install lodash```
### Accessing values in deeply nested objects
When dealing with API responses, more often than not, the data you'd like to access will be deeply nested.
Consider the following example.

This is a sample response from the [JSON API](https://jsonapi.org/examples/)
If we want to access the title, we could do something like this

This works fine but we made a big assumption:
>> **'deepObject' , 'data' , 'attributes' ,'title' are all defined**.
However, it is possible that any of them might be undefined. This would throw an error. If **'attributes'** is empty or undefined, then **'attributes.title'** would not exist.
Lodash's get function can be used to handle the error gracefully. Below is the syntax
```javascript
_.get(object, path, [defaultValue])
```

In the second console statement, we try to access the element at index 3 in data but this doesn't exist. Therefore 'Value doesn't exist' is printed in the console.
In the third console statement, we try to print the value for **'title'** in **'data[0]'** but **'data[0]'** doesn't have any attribute called **'title'**. Similar to the above case, 'Value doesn't exist' is printed in the console.
### Adding attributes to deeply nested Objects
We will work with the same object we were working with earlier.
If we want to add a new key-value pair for subtitle inside 'attributes', we could do something like this

Again, we made a similar assumption that the entire path is defined. However, if any part of the path is undefined, it will throw an error.
We can use Lodash's set function to handle this error gracefully. Below is the syntax
```javascript
_.set(object, path, value)
```
If the path doesn't exist, it will create the path.

set is an in-place function, i.e it updates the input object. Our new object is below

The second set operation added 3 elements (2 empty elements) to the **'data'** array while the third set operation added an attribute **'subtitle'** to **'data[0]'**
### Check if a path exists
We can use the has function to check if a path exists in an object. Below is the syntax
```javascript
_.has(object, path)
```

### Invert Keys an Values of an object
Lodash's invert function will invert the keys and values. Below is the syntax
```javascript
_.invert(object)
```

### Create an object from another object
If you have a object and want to create an object with some of the keys from the original object, you can use Lodash's pick function. It doesn't add the key and value directly, if the path provided is nested, it will recreate the path as well. If you are confused, refer to the example below
Below is the syntax
```javascript
_.pick(object, [paths])
```
Let's work with the [JSON API](https://jsonapi.org/examples/) response again.

Instead of directly adding title directly, it recreate the path 'data[0].attributes.title'.
### Deep Copy of an Object
The cloneDeep function creates a deep copy of an object

As you can see, the original object remains unchanged.
### Compare Object irrespective of the order of the keys

### Some Set operations on Arrays
#### Find the elements in array1 but not in array2

#### Find Common elements in two arrays

#### Find the difference between two arrays

### Zip
This is similar to the zip function in Python.

### Get unique elements of an array

Lodash has a bunch of other useful functions, refer to their [documentation](https://lodash.com/docs/4.17.15) for more | rahulbanerjee99 |
773,571 | How to only run a job on a pull request in CircleCI | I wanted a thing to only happen when a pull request is opened. I also wanted to do some cleanup when... | 0 | 2021-07-27T22:00:52 | https://ruarfff.com/circleci-pr-only/ | circleci, pipelines | I wanted a thing to only happen when a pull request is opened. I also wanted to do some cleanup when the pull request is closed. In my last place we used GitHub actions and this was super easy.
Now I am using [CircleCI](https://circleci.com/) and this wasn't so easy.
In this post we will look at how to only run a job on a pull request in CircleCI. There is one major caveat. We also need a way to trigger the job on a pull request. We will look at how to do this with the [CircleCI web api](https://circleci.com/docs/api/v2/).
## Conditionally run a job
There are a few options you can use to only run a job on a pull request in CircleCI. There is the option to
[only ever build on a pull request](https://discuss.circleci.com/t/only-build-pull-requests-not-every-branch/200) but this is all or nothing
i.e. you can never run a build on a branch without opening a pull request.
Another option is, within a job, you can inspect the [environment variables](https://circleci.com/docs/2.0/env-vars/) to see if there is a pull request number like so:
```bash
if [ "${CIRCLE_PULL_REQUEST##*/}" != "" ];then
echo "Is a pull request"
fi
```
This is OK but it would be nice to conditionally run a whole job instead. It is not possible to read environment variables when the pipeline is loaded. It is only possible when a job is run.
To work around this we can use the [circleci/continuation](https://circleci.com/developer/orbs/orb/circleci/continuation) orb.
If you are trying this out, make sure to update your project settings in **Advanced Settings -> Enable dynamic config using setup workflows**.
CircleCI expects all your configuration in one file called `.circleci/config.yml`. The continuation orb takes over as the entry point giving you access to the environment variables and then runs the pipeline using whatever configuration you tell it to.
It's a little bit weird but it works.
This is an example of using the continuation orb to conditionally run a job only on a pull request.
`.circleci/config.yml`
```yaml
setup: true
version: 2.1
orbs:
continuation: circleci/continuation@0.2.0
workflows:
setup:
jobs:
- continuation/continue:
configuration_path: ".circleci/main.yml"
parameters: /home/circleci/params.json
pre-steps:
- run:
command: |
if [ -z "${CIRCLE_PULL_REQUEST##*/}" ]
then
IS_PR=false
else
IS_PR=true
fi
echo '{ "is_pr": '$IS_PR' }' >> /home/circleci/params.json
```
Note, we mentioning PR here but you could do more or less anything to configure your pipeline there. `/home/circleci/params.json` is written to and specified with `parameters: /home/circleci/params.json`.
`.circleci/main.yml`
```yaml
version: 2.1
parameters:
is_pr:
type: boolean
default: false
jobs:
do_something:
docker:
- image: cimg/base:2021.04
steps:
- run:
name: something
command: echo 'You get the picture'
workflows:
version: 2
whence-pr:
when: << pipeline.parameters.is_pr >>
jobs:
- do_something:
name: something
```
We called the file `main.yml` here but it could be any file. You just need to specify it in the parameter called `configuration_path`. [This post](https://circleci.com/blog/building-cicd-pipelines-using-dynamic-config/) also shows another way to generate the configuration on the fly.
Now we have passed the `is_pr` parameter to the pipeline. We can conditionally run things using `when: << pipeline.parameters.is_pr >>`.
There is one major issue with this approach. Our build may have run before a PR (pull request) was ever opened. Opening a PR will not trigger a build in CircleCI.
## Triggering CircleCI pipeline when a pull request is opened
First thing you must do is grab a [CircleCi API token](https://circleci.com/docs/2.0/managing-api-tokens/). A [personal API token](https://app.circleci.com/settings/user/tokens) will do for this example.
You can trigger a pipeline run like so:
```bash
SCM=github
ORG=your-org-here
PROJECT=your-project-here
CIRCLE_BRANCH=a-derived-branch
curl -X POST \
-H "Circle-Token: ${CIRCLE_TOKEN}" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d "{\"branch\":\"${CIRCLE_BRANCH}\"}" \
https://circleci.com/api/v2/project/${SCM}/${ORG}/${PROJECT}/pipeline
```
Hopefully it's clear what values you need to change there. How you will run this bit depends on what tools you have available to you. I was using GitHub and even though we use CircleCI, there are enough free [GitHub Action](https://github.com/features/actions) minutes for me to setup an action like this:
`.github/workflows/pr.yml`
```yaml
name: Trigger Build on PR
on:
pull_request:
types: [opened, reopened]
jobs:
trigger-build:
runs-on: ubuntu-latest
steps:
- name: Trigger CircleCI
env:
CIRCLE_BRANCH: ${{ github.head_ref }}
CIRCLE_TOKEN: ${{ secrets.CIRCLE_TOKEN }}
ORG: your-org-here
PROJECT: your-project-here
run: |
curl -X POST \
-H "Circle-Token: ${CIRCLE_TOKEN}" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d "{\"branch\":\"${CIRCLE_BRANCH}\"}" \
https://circleci.com/api/v2/project/github/${ORG}/${PROJECT}/pipeline
```
This feels like an incredible hack but it works.
## A side note on doing something when a PR is merged
This has nothing to do with CircleCI but if you happen to have access to GitHub actions this might be useful.
`.github/workflows/pr-closed.yml`
```yaml
name: On PR Closed
on:
pull_request:
types: [closed]
jobs:
on-pr-closed:
runs-on: ubuntu-latest
steps:
- name: Print PR number
env:
PR_NUMBER: ${{ github.event.number }}
run: |
echo "${PR_NUMBER}"
```
| ruarfff |
762,584 | A look at PostgreSQL migrations in Node | Data migrations are a common operation for any application with a persistence layer. In this post we... | 0 | 2021-07-27T19:12:27 | https://www.antoniovdlc.me/a-look-at-postgresql-migrations-in-node/ | node, postgres | ---
title: A look at PostgreSQL migrations in Node
published: true
description:
tags: node, postgresql
cover_image: https://images.unsplash.com/photo-1520792699872-64c6ab4e4c3e?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1350&q=80
canonical_url: https://www.antoniovdlc.me/a-look-at-postgresql-migrations-in-node/
---
Data migrations are a common operation for any application with a persistence layer. In this post we will look at how to set a simple data migration on a PostgreSQL database in a Node back-end.
There are already existing libraries that provide the needed level of abstraction to perform data migrations with the above stack, such as [node-pg-migrate](https://www.npmjs.com/package/node-pg-migrate), [postgres-migrations](https://www.npmjs.com/package/postgres-migrations) or [db-migrate](https://www.npmjs.com/package/db-migrate). If you need to run migrations in production, I would encourage using any of those instead of coming up with your own solution.
Yet, let's look at what it takes to build such a library!
---
## Keeping track of migrations
At its core, migrations are just SQL files being executed at most once in a certain order. It is primordial that migrations are only ever run once, and exactly once. To achieve that, we need to keep track of which migrations have already been run when triggering a migration.
As we are already using a persistence layer, one straightforward approach is to use that same persistence layer to keep track of the migrations that have been run. In our case, we can create a `migrations` table in PostgreSQL, which will be updated on every migration run ... and, of course, we will be setting that up using a migration!
`00000001-init-migrations.sql`
```sql
-- Migrations
-- This table will keep a list of migrations that have been run on this database.
--
CREATE TABLE IF NOT EXISTS migrations (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
file TEXT,
created_at TIMESTAMP DEFAULT NOW()
);
```
Some migrations might need to run on certain assumptions (for example, that a table exists). For those cases, we enforce an order for migrations to run. As such, we prefix all migration files with 8 digits.
---
## Writing migrations
As we ideally want to get a working end-to-end system from scratch, the next logical step is to create the needed tables for our application. For example:
`00000002-init-basic-schema.sql`
```sql
-- Users
-- This table will hold the users' information.
CREATE TABLE IF NOT EXISTS users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email TEXT,
created_at TIMESTAMP DEFAULT NOW()
);
-- Settings
-- This table holds all users' settings
CREATE TABLE IF NOT EXISTS settings (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
lang TEXT,
currency TEXT,
user_id UUID REFERENCES users (id),
created_at TIMESTAMP DEFAULT NOW()
);
...
```
With this setup, migrations are just SQL files doing any sort of operation like creating tables, inserting data, deleting columns, adding indexes etc...
`00000003-add-test-data.sql`
```sql
CREATE TABLE IF NOT EXISTS test (
name TEXT
);
INSERT INTO test (name) VALUES ('bonjour'), ('hola'), ('nihao');
```
You might have noticed that we are not supporting "down" migrations. This is by design, as "down" migrations can be thought of as "up" migrations negating a previous migration. In that sense, they are just simply migrations too.
---
## Running migrations
Now for the trickiest part of this exercise, let's see how to run those migration files!
For this section, we will assume we have implemented a similar `getClient()` method as described in https://node-postgres.com/guides/project-structure using [pg](https://www.npmjs.com/package/pg).
The first thing we want to do, is check if there are any outstanding migrations to be run, and if so, read the content of those migrations. To do so, we will introduce a utility function:
```js
async function getOutstandingMigrations(migrations = []) {
const files = await promisify(fs.readdir)(__dirname);
const sql = await Promise.all(
files
.filter((file) => file.split(".")[1] === "sql")
.filter((file) => !migrations.includes(file))
.map(async (file) => ({
file,
query: await promisify(fs.readFile)(`${__dirname}/${file}`, {
encoding: "utf-8",
}),
}))
);
return sql;
}
```
In a nutshell, what this function does is read all files in the current directory and filter out files that don't contain SQL and previously ran migrations. Finally, it reads the content of those files. Note that we are using promisified a few `fs` utility functions to increase the efficiency of this function.
We can now use that function to get all outstanding migrations (i.e. migrations that haven't run yet against the current database) in our `migrate()` function like follows:
```js
async function migrate() {
...
// Check previous migrations
let existingMigrations = [];
try {
let result = await client.query("SELECT * FROM migrations");
existingMigrations = result.rows.map(r => r.file)
} catch {
console.warn("First migration");
}
// Get outstanding migrations
const outstandingMigrations = await getOutstandingMigrations(
existingMigrations
);
...
}
```
Now that we have a list of outstanding migrations, we want to run migrations sequentially in transactions. The order here is important as some migrations might depend on artifacts created in previous migrations. Running each migration in a transaction helps rollback a specific migration if there are any issues.
```js
async function migrate() {
const client = await getClient();
...
try {
// Start transaction
await client.query("BEGIN");
// Run each migration sequentially in a transaction
for (let migration of outstandingMigrations) {
// Run the migration
await client.query(migration.query.toString());
// Keep track of the migration
await client.query("INSERT INTO migrations (file) VALUES ($1)", [
migration.file,
]);
}
// All good, we can commit the transaction
await client.query("COMMIT");
} catch (err) {
// Oops, something went wrong, rollback!
await client.query("ROLLBACK");
} finally {
// Don't forget to release the client!
client.release();
}
}
```
We can now call our `migrate()` function anywhere in our code, like on app start, or in a cron job.
--- | antoniovdlc |
762,589 | AWS EKS With EFS CSI Driver And IRSA Using CDK | AWS EKS With EFS CSI Driver And IRSA Using CDK | 13,481 | 2021-07-18T11:22:21 | https://dev.to/awscommunity-asean/aws-eks-with-efs-csi-driver-and-irsa-using-cdk-dgc | aws, csi, cloudopz, efs | ---
title: AWS EKS With EFS CSI Driver And IRSA Using CDK
published: true
description: AWS EKS With EFS CSI Driver And IRSA Using CDK
tags: aws, csi, cloudopz, efs
cover_image: https://github.com/vumdao/aws-eks-the-hard-way/blob/master/efs-csi/img/cover.jpg?raw=true
series: "AWS EKS The Hard-Way"
---
## Abstract
For multiple pods which need to read/write same data, Amazon Elastic File System (EFS) is the best choice. This post guides you the new way to create and setup EFS on EKS with IAM role for service account using IaC AWS CDK v2
## Table Of Contents
* [What is Amazon Elastic File System?](#What-is-Amazon-Elastic-File-System?)
* [EFS provisioner Architecture](#EFS-provisioner-Architecture)
* [What is Amazon EFS CSI driver?](#What-is-Amazon-EFS-CSI-driver?)
* [Amazon EFS Access Points](#Amazon-EFS-Access-Points)
* [Create EFS Using CDK](#Create-EFS-Using-CDK)
* [Create IAM role for service account for CSI](#-Create-IAM-role-for-service-account-for-CSI)
* [Install EFS CSI using helm](#-Install-EFS-CSI-using-helm)
* [Create storageclass, pv and pvc - Dynamic Provisioning](#-Create-storageclass,-pv-and-pvc---Dynamic-Provisioning)
* [Create storageclass, pv and pvc - EFS Access Points](#-Create-storageclass,-pv-and-pvc---EFS-Access-Points)
* [How to troubleshoot](#-How-to-troubleshoot)
---
## 🚀 **What is Amazon Elastic File System?** <a name="What-is-Amazon-Elastic-File-System?"></a>
- [Amazon Elastic File System (Amazon EFS)](https://www.youtube.com/watch?v=AvgAozsfCrY) provides a simple, scalable, fully managed elastic NFS file system for use with AWS Cloud services and on-premises resources.
## 🚀 **EFS provisioner Architecture** <a name="EFS-provisioner-Architecture"></a>
<p align="center">
<a href="https://dev.to/vumdao">
</br>
<img alt="EFS provisioner Architecture" src="https://github.com/vumdao/aws-eks-the-hard-way/blob/master/efs-csi/img/efs-provisioner-arch.png?raw=true" width="700"/>
</a>
</p>
- The EFS volume at the top of the figure is an AWS-provisioned EFS volume, therefore managed by AWS, separately from Kubernetes. As most of AWS resources are, It will be attached to a VPC, Availability zones and subnets. And it will be protected by security groups.
- This volume can basically be mounted anywhere you can mount volumes using the NFS protocol. So you can mount it on your laptop (considering you configured AWS security groups accordingly), which can be very useful for test or debug purposes. Or you can mount it in Kubernetes. And that’s what will do both the EFS-provisioner (in order to configure sub-volumes inside the EFS volume) and your pods (in order to access the sub-volumes).
- When the EFS provisioner is deployed in Kubernetes, a new StorageClass “efs” is available and managed by this provisioner. You can then create a PVC that references this StorageClass. By doing so, the EFS provisioner will see your PVC and begin to take care of it, by doing the following:
- Create a subdir in the EFS volume, dedicated to this PVC
- Create a PV with the URI of this subdir (Address of the EFS volume + subdir path) and related info that will enable pods to use this subdir as a storage location using NFS protocol
- Bind this PV to the PVC
- Now when a pod is designed to use PVC, it will use the PV’s info in order to connect directly to the EFS volume and use the subdir.
- Ref: https://www.padok.fr/en/blog/efs-provisioner-kubernetes
- Previously, I wrote a post introduce EFS provisoner using `quay.io/external_storage/efs-provisioner:latest` (an OpenShift Container Platform pod that mounts the EFS volume as an NFS share), [read more](https://dev.to/vumdao/eks-persistent-storage-with-efs-amazon-service-14ei).
- In this post, I introduce CSI Driver provisioner
## 🚀 **What is CSI driver?** <a name="What-is-CSI-driver?"></a>
- A [CSI driver](https://kubernetes-csi.github.io/docs/deploying.html) is typically deployed in Kubernetes as two components: a controller component and a per-node component.
- Controller Plugin
- Node plugin
- How the two components works?
## 🚀 **What is Amazon EFS CSI driver?** <a name="What-is-Amazon-EFS-CSI-driver?"></a>
- The [Amazon EFS Container Storage Interface (CSI) driver](https://github.com/kubernetes-sigs/aws-efs-csi-driver) provides a CSI interface that allows Kubernetes clusters running on AWS to manage the lifecycle of Amazon EFS file systems.
- EFS CSI driver supports dynamic provisioning and static provisioning. Currently Dynamic Provisioning creates an access point for each PV. This mean an AWS EFS file system has to be created manually on AWS first and should be provided as an input to the storage class parameter. For static provisioning, AWS EFS file system needs to be created manually on AWS first. After that it can be mounted inside a container as a volume using the driver.
- What is the benefit of using EFS CSI Driver? - [Introducing Amazon EFS CSI dynamic provisioning](https://aws.amazon.com/blogs/containers/introducing-efs-csi-dynamic-provisioning/)
## 🚀 **Amazon EFS Access Points** <a name="Amazon-EFS-Access-Points"></a>
- [Amazon EFS access points](https://docs.aws.amazon.com/efs/latest/ug/efs-access-points.html) are application-specific entry points into an EFS file system that make it easier to manage application access to shared datasets. Access points can enforce a user identity, including the user's POSIX groups, for all file system requests that are made through the access point. Access points can also enforce a different root directory for the file system so that clients can only access data in the specified directory or its subdirectories.
- You can use AWS Identity and Access Management (IAM) policies to enforce that specific applications use a specific access point. By combining IAM policies with access points, you can easily provide secure access to specific datasets for your applications.
---
## We go through the introductions from above, now going to setup.
</br>
## 🚀 **Create EFS Using CDK** <a name="Create-EFS-Using-CDK"></a>
- Note: We need tag `{key='efs.csi.aws.com/cluster', value='true'}` so that later we restrict the IAM permission within this EFS only
```
from constructs import Construct
from eks_statements import EksWorkerRoleStatements
from aws_cdk import (
Stack, Tags, RemovalPolicy,
aws_eks as eks,
aws_ec2 as ec2,
aws_iam as iam,
aws_efs as efs
)
class EksEfsStack(Stack):
def __init__(self, scope: Construct, construct_id: str, env, vpc, **kwargs) -> None:
super().__init__(scope, construct_id, env=env, **kwargs)
efs_sg = ec2.SecurityGroup(
self, 'EfsSG',
vpc=vpc,
description='EKS EFS SG',
security_group_name='eks-efs'
)
efs_sg.add_ingress_rule(ec2.Peer.ipv4('10.3.0.0/16'), ec2.Port.all_traffic(), "EFS VPC access")
Tags.of(efs_sg).add(key='cfn.eks-dev.stack', value='sg-stack')
Tags.of(efs_sg).add(key='Name', value='eks-efs')
Tags.of(efs_sg).add(key='env', value='dev')
file_system = efs.FileSystem(
self, construct_id,
vpc=vpc,
file_system_name='eks-efs',
lifecycle_policy=efs.LifecyclePolicy.AFTER_14_DAYS,
removal_policy=RemovalPolicy.DESTROY,
security_group=efs_sg
)
Tags.of(file_system).add(key='cfn.eks-dev.stack', value='efs-stack')
Tags.of(file_system).add(key='efs.csi.aws.com/cluster', value='true')
Tags.of(file_system).add(key='Name', value='eks-efs')
Tags.of(file_system).add(key='env', value='dev')
```
## 🚀 **Create IAM role for service account for CSI** <a name="Create-IAM-role-for-service-account-for-CSI"></a>
```
...
@staticmethod
def efs_csi_statement():
policy_statement_1 = iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=[
"elasticfilesystem:DescribeAccessPoints",
"elasticfilesystem:DescribeFileSystems"
],
resources=['*'],
conditions={'StringEquals': {"aws:RequestedRegion": "ap-northeast-2"}}
)
policy_statement_2 = iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=[
"elasticfilesystem:CreateAccessPoint",
"elasticfilesystem:DeleteAccessPoint"
],
resources=['*'],
conditions={'StringEquals': {"aws:ResourceTag/efs.csi.aws.com/cluster": "true"}}
)
return [policy_statement_1, policy_statement_2]
```
```
...
# EFS CSI SA
efs_csi_role = iam.Role(
self, 'EfsCSIRole',
role_name='eks-efs-csi-sa',
assumed_by=iam.FederatedPrincipal(
federated=oidc_arn,
assume_role_action='sts:AssumeRoleWithWebIdentity',
conditions={'StringEquals': string_like('kube-system', 'efs-csi-controller-sa')},
)
)
for stm in statement.efs_csi_statement():
efs_csi_role.add_to_policy(stm)
Tags.of(efs_csi_role).add(key='cfn.eks-dev.stack', value='role-stack')
```
## 🚀 **Install EFS CSI using helm** <a name="Install-EFS-CSI-using-helm"></a>
- Use the above service account as external parameter
```
helm repo add aws-efs-csi-driver https://kubernetes-sigs.github.io/aws-efs-csi-driver/
helm repo update
helm upgrade -i aws-efs-csi-driver aws-efs-csi-driver/aws-efs-csi-driver \
--namespace kube-system \
--set serviceAccount.controller.create=false \
--set serviceAccount.controller.name=efs-csi-controller-sa
```
- Annotate IRSA and then rollout restart controllers
```
$ kubectl annotate serviceaccount -n kube-system efs-csi-controller-sa eks.amazonaws.com/role-arn=arn:aws:iam::123456789012:role/eks-efs-csi-sa
serviceaccount/efs-csi-controller-sa annotated
$ kubectl rollout restart deployment -n kube-system efs-csi-controller
deployment.apps/efs-csi-controller restarted
# Check IRSA work
$ kubectl exec -n kube-system efs-csi-controller-6b44dc5977-2w2d6 -- env |grep AWS
AWS_ROLE_ARN=arn:aws:iam::123456789012:role/eks-efs-csi-sa
AWS_WEB_IDENTITY_TOKEN_FILE=/var/run/secrets/eks.amazonaws.com/serviceaccount/token
AWS_DEFAULT_REGION=ap-northeast-2
AWS_REGION=ap-northeast-2
```
- Check CSI
```
[ec2-user@eks-ctl ~]$ kubectl get pod -n kube-system |grep csi
efs-csi-controller-6b44dc5977-2w2d6 3/3 Running 0 18h
efs-csi-controller-6b44dc5977-qtcc6 3/3 Running 0 159m
efs-csi-node-4rn69 3/3 Running 0 17h
efs-csi-node-6zdwg 3/3 Running 0 161m
```
- For understanding IAM Role for service account, [Go to](https://dev.to/vumdao/using-iam-service-account-instead-of-instance-profile-for-eks-pods-262p)
## 🚀 **Create storageclass, pv and pvc - Dynamic Provisioning** <a name="Create-storageclass,-pv-and-pvc---Dynamic-Provisioning"></a>
{% details - storageclass.yaml %}
```
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: efs-sc
provisioner: efs.csi.aws.com
parameters:
provisioningMode: efs-ap
fileSystemId: fs-92107410
directoryPerms: "700"
gidRangeStart: "1000"
gidRangeEnd: "2000"
basePath: "/data"
```
- provisioningMode - The type of volume to be provisioned by efs. Currently, only access point based provisioning is supported efs-ap.
- fileSystemId - The file system under which Access Point is created.
- directoryPerms - Directory Permissions of the root directory created by Access Point.
- gidRangeStart (Optional) - Starting range of Posix Group ID to be applied onto the root directory of the access point. Default value is 50000.
- gidRangeEnd (Optional) - Ending range of Posix Group ID. Default value is 7000000.
- basePath (Optional) - Path on the file system under which access point root directory is created. If path is not provided, access points root directory are created under the root of the file system.
```
apiVersion: v1
kind: Namespace
metadata:
name: storage
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: efs-sc
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: efs-writer
namespace: storage
spec:
containers:
- name: efs-writer
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(date -u) >> /data/out; sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: efs-claim
---
apiVersion: v1
kind: Pod
metadata:
name: efs-reader
namespace: storage
spec:
containers:
- name: efs-reader
image: busybox
command: ["/bin/sh"]
args: ["-c", "while true; do sleep 5; done"]
volumeMounts:
- name: efs-pvc
mountPath: /data
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs-claim
```
{% enddetails %}
- Apply and check
```
$ kubectl get sc efs-sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
efs-sc efs.csi.aws.com Delete Immediate false 2m54s
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
efs-claim Bound pvc-2a7e818f-c513-4b79-a47e-5b9c1a7d26a9 1Gi RWX efs-sc 2m32s
```
- Dynamic Access point is created

- Check read/write pod and ensure pods are located to different nodes to demonstrate EFS strongly
```
$ kubectl get pod -n storage -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
efs-reader 1/1 Running 0 14s 10.3.147.2 ip-10-3-141-203.ap-northeast-2.compute.internal <none> <none>
efs-writer 1/1 Running 0 116s 10.3.235.47 ip-10-3-254-49.ap-northeast-2.compute.internal <none> <none>
$ kubectl exec efs-reader -n storage -- cat /data/out | head -n 2
Fri Jul 16 03:54:49 UTC 2021
Fri Jul 16 03:54:54 UTC 2021
$ kubectl exec efs-writer -n storage -- cat /data/out | head -n 2
Fri Jul 16 03:54:49 UTC 2021
Fri Jul 16 03:54:54 UTC 2021
```
- Ref: https://github.com/kubernetes-sigs/aws-efs-csi-driver/blob/master/examples/kubernetes/dynamic_provisioning/README.md
## 🚀 **Create storageclass, pv and pvc - EFS Access Points** <a name="Create-storageclass,-pv-and-pvc---EFS-Access-Points"></a>
- First create access point using AWS CLI or AWS console, and then get the Access point ID and EFS ID to pass to `volumeHandle: fs-a13cb9c1::fsap-0f9e7568af65cc5bd`

{% details efs-ap.yaml %}
```
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: efs-sc
provisioner: efs.csi.aws.com
---
apiVersion: v1
kind: Namespace
metadata:
name: storage
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: efs-pv
spec:
capacity:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
csi:
driver: efs.csi.aws.com
volumeHandle: fs-a13cb9c1::fsap-0f9e7568af65cc5bd
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: efs-sc
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: efs-writer
namespace: storage
spec:
containers:
- name: efs-writer
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(date -u) >> /data/out; sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: efs-claim
---
apiVersion: v1
kind: Pod
metadata:
name: efs-reader
namespace: storage
spec:
containers:
- name: efs-reader
image: busybox
command: ["/bin/sh"]
args: ["-c", "while true; do sleep 5; done"]
volumeMounts:
- name: efs-pvc
mountPath: /data
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs-claim
```
{% enddetails %}
- Apply the yaml file
```
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
efs-claim Bound efs-pv 1Gi RWX efs-sc 12h
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
efs-pv 1Gi RWX Retain Bound storage/efs-claim efs-sc 12h
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
efs-reader 1/1 Running 0 104s
efs-writer 1/1 Running 0 104s
$ kubectl exec efs-reader -- cat /data/out
Tue Jul 13 05:33:43 UTC 2021
Tue Jul 13 05:33:48 UTC 2021
```
## 🚀 **How to troubleshoot** <a name="How-to-troubleshoot"></a>
- Failed case if we input wrong EFS ID
```
$ kubectl logs -n kube-system -f --tail=100 efs-csi-controller-6b44dc5977-2w2d6 csi-provisioner
E0713 05:50:20.080089 1 event.go:264] Server rejected event '&v1.Event{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"efs-claim.1691439f81a95683", GenerateName:"", Namespace:"storage", SelfLink:"", UID:"", ResourceVersion:"19553746", Generation:0, CreationTimestamp:v1.Time{Time:time.Time{wall:0x0, ext:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]v1.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:"", ManagedFields:[]v1.ManagedFieldsEntry(nil)}, InvolvedObject:v1.ObjectReference{Kind:"PersistentVolumeClaim", Namespace:"storage", Name:"efs-claim", UID:"4c51f212-c828-4a66-a297-31f8d9ebe255", APIVersion:"v1", ResourceVersion:"19553744", FieldPath:""}, Reason:"Provisioning", Message:"External provisioner is provisioning volume for claim \"storage/efs-claim\"", Source:v1.EventSource{Component:"efs.csi.aws.com_ip-10-3-179-184.ap-northeast-2.compute.internal_f7376ef0-1668-4be9-90b5-d18298dc677e", Host:""}, FirstTimestamp:v1.Time{Time:time.Time{wall:0x0, ext:63761752092, loc:(*time.Location)(0x26270e0)}}, LastTimestamp:v1.Time{Time:time.Time{wall:0xc033684704a729f2, ext:68986915168904, loc:(*time.Location)(0x26270e0)}}, Count:8, Type:"Normal", EventTime:v1.MicroTime{Time:time.Time{wall:0x0, ext:0, loc:(*time.Location)(nil)}}, Series:(*v1.EventSeries)(nil), Action:"", Related:(*v1.ObjectReference)(nil), ReportingController:"", ReportingInstance:""}': 'events "efs-claim.1691439f81a95683" is forbidden: User "system:serviceaccount:kube-system:efs-csi-controller-sa" cannot patch resource "events" in API group "" in the namespace "storage"' (will not retry!)
I0713 05:50:20.111457 1 controller.go:1099] Final error received, removing PVC 4c51f212-c828-4a66-a297-31f8d9ebe255 from claims in progress
W0713 05:50:20.111494 1 controller.go:958] Retrying syncing claim "4c51f212-c828-4a66-a297-31f8d9ebe255", failure 7
E0713 05:50:20.111512 1 controller.go:981] error syncing claim "4c51f212-c828-4a66-a297-31f8d9ebe255": failed to provision volume with StorageClass "efs-sc": rpc error: code = InvalidArgument desc = File System does not exist: Resource was not found
I0713 05:50:20.111582 1 event.go:282] Event(v1.ObjectReference{Kind:"PersistentVolumeClaim", Namespace:"storage", Name:"efs-claim", UID:"4c51f212-c828-4a66-a297-31f8d9ebe255", APIVersion:"v1", ResourceVersion:"19553744", FieldPath:""}): type: 'Warning' reason: 'ProvisioningFailed' failed to provision volume with StorageClass "efs-sc": rpc error: code = InvalidArgument desc = File System does not exist: Resource was not found
```
- Success
```
$ kubectl logs -n kube-system -f --tail=100 efs-csi-controller-6b44dc5977-2w2d6 csi-provisioner
I0713 05:53:59.261135 1 controller.go:1332] provision "storage/efs-claim" class "efs-sc": started
I0713 05:53:59.261719 1 event.go:282] Event(v1.ObjectReference{Kind:"PersistentVolumeClaim", Namespace:"storage", Name:"efs-claim", UID:"2a7e818f-c513-4b79-a47e-5b9c1a7d26a9", APIVersion:"v1", ResourceVersion:"19555274", FieldPath:""}): type: 'Normal' reason: 'Provisioning' External provisioner is provisioning volume for claim "storage/efs-claim"
I0713 05:53:59.385168 1 controller.go:838] successfully created PV pvc-2a7e818f-c513-4b79-a47e-5b9c1a7d26a9 for PVC efs-claim and csi volume name fs-a13cb9c1::fsap-0b047e3528a6856ca
I0713 05:53:59.385219 1 controller.go:1439] provision "storage/efs-claim" class "efs-sc": volume "pvc-2a7e818f-c513-4b79-a47e-5b9c1a7d26a9" provisioned
I0713 05:53:59.385244 1 controller.go:1456] provision "storage/efs-claim" class "efs-sc": succeeded
I0713 05:53:59.393941 1 event.go:282] Event(v1.ObjectReference{Kind:"PersistentVolumeClaim", Namespace:"storage", Name:"efs-claim", UID:"2a7e818f-c513-4b79-a47e-5b9c1a7d26a9", APIVersion:"v1", ResourceVersion:"19555274", FieldPath:""}): type: 'Normal' reason: 'ProvisioningSucceeded' Successfully provisioned volume pvc-2a7e818f-c513-4b79-a47e-5b9c1a7d26a9
```
---
{% user vumdao %}
{% github vumdao/vumdao no-readme %}
| vumdao |
762,595 | Pinterest Video Downloader | How to Download Pinterest Videos? pinterestvideodownloader.cc is a free online pinterest video... | 0 | 2021-07-18T11:48:29 | https://dev.to/cooldeveloper314/pinterest-video-downloader-3b73 | pinterestvideodownloader, pinterestvideo, pinterest | <h2>How to Download Pinterest Videos?</h2>
<a href="https://pinterestvideodownloader.cc">pinterestvideodownloader.cc</a> is a free online pinterest video downloader instrument. You can undoubtedly download pinterest recordings from here. Alongside the video, you can likewise download gif and pictures from pinterest. It's anything but a free online video downloader device.
Incidentally, I might want to disclose to you that pinterest is a particularly online media network where individuals from various nations continue to transfer their recordings and pictures for permossion. Yet, <a href="https://pinterest.com">pinterest</a> doesn't give any choice to download recordings. However, you can without much of a stretch download pinterest recordings and pictures with the assistance of Pinterest Video Downloader.
Presently I will disclose to you step to step how you can download pinterest recordings, gif and pictures from your PC, work area, versatile, android or iphone, so how about we go.
<h3>How to Download Pinterest Videos Using Mobile?</h3>
As a matter of first importance, open the pinterest site or application in your portable.
Then, at that point go to the pursuit box and do a video search. Then, at that point you will open the rundown of numerous pinterest recordings.
Then, at that point click on any video you need to download, that video will be open. Assuming you need to download that video, you will see a send name button on that video. You click on it. Then, at that point you will show a duplicate symbol. Tapping on that duplicate symbol will duplicate the connection of your video.
Then, at that point you glue the duplicated connect in the pursuit box of pinterestvideodownloader.cc site, then, at that point click on the download button.
You will get the connection arrangement to download the video, then, at that point you can download your video.
How to Download Pinterest Videos By Computer?
Above all else, you go to the site of pinterest.com. Go to the pursuit box and search recordings there. Then, at that point you will get a rundown of recordings. You can tap on any video according to your decision.
In the wake of tapping the video, your video will be played, presently you need to tap on the send catch of the video. As you can find in the picture underneath.
In the wake of tapping the send button, you will see some menu. Presently you need to tap on the connection interface button and subsequent to tapping on the connection connect button, your video connection will be replicated.
Presently you need to come to pinterest video downloader's site and glue the connection of the replicated video into the inquiry box.
In the wake of sticking the video connect in the pursuit box, you need to tap on the download button, presently you will get the connections of certain recordings to download the video.
Assuming you need to download the video, for this "To download, right-click on the download catch (or tap and hold if utilizing portable) and pick the Save/Download choice."
<h3>Pinterest Video Downloader Features : </h3>
Quick, simple and secure.
No compelling reason to login in your Pinterest account.
You can Download Pinterest Videos, Images and Gif with only a single tick.
Save and download Pinterest recordings in their unique goal and HD Or 720p quality.
<h2>As often as possible Asked Questions </h2>
<h3>What is the organization of downloaded pinterest video? </h3>
Contingent on the accessible nature of the Pinterest video, our Pinterest Video Downloader separates MP4 HD quality video joins. You can decide to download whichever you need.
<h3>Would i be able to Convert Pinterest Video to MP4? </h3>
Indeed, You can undoubtedly change Pinterest Video over to mp4.
<h3>What gadgets are viable? </h3>
Pinterestvideodownloader.cc upholds downloads from Pinterest paying little mind to what gadget or working framework you might be utilizing. Pinterest Video downloading is accessible on iPhones, Android telephones, tables, PCs, and Macs.
<h3>How would I download live Pinterest Videos? </h3>
To download any live Pinterest video, you should delay until the streaming is done, and afterward you can download them actually like different recordings by entering the video connect in the online pinterest video downloader. | cooldeveloper314 |
762,910 | Documenting Express REST APIs with OpenAPI and JSDoc | As usual, this article isn't meant as an in-depth guide, but as a documentation of the what, why,... | 0 | 2021-07-18T21:25:06 | https://dev.to/essentialrandom/documenting-express-rest-apis-with-openapi-and-jsdoc-m68 | express, documentation, javascript, docusaurus | > As usual, this article isn't meant as an in-depth guide, but as a documentation of the what, why, and how of certain architectural choices. If you're trying to achieve the same thing and need help, leave a comment!
### Updates
- **7/20/21:** Added "documenting models" section.
## Goals & Constraints
- To document [BobaBoard](https://www.bobaboard.com)'s REST API.
- Standardize (and document) both the parameters and the responses of various endpoints.
- The documentation should be as close as possible to the source code it describes.
- The documentation should be served through a [docusaurus](https://docusaurus.io/) instance hosted on a different server.
- (Not implemented): Ensuring endpoints conform to the documented API. While we could use [express-openapi-validator](https://github.com/cdimascio/express-openapi-validator/), it doesn't currently support OpenAPI 3.1 ([issue](https://github.com/cdimascio/express-openapi-validator/issues/573))
- *Consideration:* at least at first, we'd like to report the discrepancies without failing the requests. I'm unsure whether this is supported by this library.
## Final Result
### Architecture Flow

### Documentation Page
## How To
### Packages used
- [SwaggerJSDoc](https://www.npmjs.com/package/swagger-jsdoc): to turn JSDocs into the final OpenAPI spec (served at `/open-api.json`).
- [Redocusaurus](https://www.npmjs.com/package/redocusaurus): to embed [Redoc](https://github.com/Redocly/redoc) into Docusaurus. There are other options for documentation, like any OpenAPI/Swagger compatible tool (e.g. [SwaggerUI](https://swagger.io/tools/swagger-ui/)), but Redoc is the nicest feeling one.
### Configuration (Express)
#### OpenAPI Options
These options define the global configuration and settings of your OpenAPI spec. You can find the OpenAPI-specific settings (i.e. the one NOT specific to Redoc) on the [OpenAPI website](https://swagger.io/specification/#oasObject).
```javascript
const options = {
definition: {
openapi: "3.1.0",
info: {
title: "BobaBoard's API documentation.",
version: "0.0.1",
// Note: indenting the description will cause the markdown not to format correctly.
description: `
# Intro
Welcome to the BobaBoard's backend API. This is still a WIP.
# Example Section
This is just to test that sections work. It will be written better later.
`,
contact: {
name: "Ms. Boba",
url: "https://www.bobaboard.com",
email: "ms.boba@bobaboard.com",
},
},
servers: [
{
url: "http://localhost:4200/",
description: "Development server",
},
],
// These are used to group endpoints in the sidebar
tags: [
{
name: "/posts/",
description: "All APIs related to the /posts/ endpoints.",
},
{
name: "/boards/",
description: "All APIs related to the /boards/ endpoints.",
},
{
name: "todo",
description: "APIs whose documentation still needs work.",
},
],
// Special Redoc section to control how tags display in the sidebar.
"x-tagGroups": [
{
name: "general",
tags: ["/posts/", "/boards/"],
},
],
},
// Which paths to parse the API specs from.
apis: ["./types/open-api/*.yaml", "./server/*/routes.ts"],
};
```
#### Documenting Models
OpenAPI specs can contain [a Components section](https://swagger.io/docs/specification/components/) to define reusable models. These are not automatically documented at this stage ([workaround issue](https://github.com/Redocly/redoc/issues/1528)).
To add models documentation, add the following section to your top-level configuration.
```javascript
const options = {
// ...
tags: [
// ...
{
name: "models",
"x-displayName": "Models",
// Note: markdown must not contain spaces after new line.
description: `
## Contribution
<SchemaDefinition schemaRef="#/components/schemas/Contribution" />
## Tags
<SchemaDefinition schemaRef="#/components/schemas/Tags" />
`,
],
"x-tagGroups": [
{
name: "models",
tags: ["models"],
},
]
}
```
### Add the OpenAPI endpoint
Configure the Express server to surface your spec through an `/open-api.json` endpoint. Redocusaurus will use it to retrieve the data to display.
```javascript
import swaggerJsdoc from "swagger-jsdoc";
const specs = swaggerJsdoc(options);
app.get("/open-api.json", (req, res) => {
res.setHeader("Content-Type", "application/json");
res.send(specs);
});
```
### Component Specs
Reusable [types](https://swagger.io/docs/specification/components/) used throughout the documentation.
`/types/open-api/contribution.yaml`
```yaml
# Note the /components/schemas/[component name] hierarchy.
# This is used to refer to these types in the endpoint
# documentation.
components:
schemas:
Contribution:
type: object
properties:
post_id:
type: string
format: uuid
parent_thread_id:
type: string
format: uuid
parent_post_id:
type: string
format: uuid
secret_identity:
$ref: "#/components/schemas/Identity"
required:
- post_id
- parent_thread_id
- secret_identity
```
### Endpoint Documentation
This should be repeated for every API endpoint you wish to document.
```javascript
/**
* @openapi
* posts/{postId}/contribute:
* post:
* summary: Replies to a contribution
* description: Posts a contribution replying to the one with id {postId}.
* tags:
* - /posts/
* - todo
* parameters:
* - name: postId
* in: path
* description: The uuid of the contribution to reply to.
* required: true
* schema:
* type: string
* format: uuid
* responses:
* 403:
* description: User is not authorized to perform the action.
* 200:
* description: The contribution was successfully created.
* content:
* application/json:
* schema:
* type: object
* properties:
* contribution:
* $ref: "#/components/schemas/Contribution"
* description: Finalized details of the contributions just posted.
*/
router.post("/:postId/contribute", isLoggedIn, async (req, res) => {
// The endpoint code
}
```
## Configuration (Docusaurus)
You must update your docusaurus configuration after installing [Redocusaurus](https://www.npmjs.com/package/redocusaurus):
`docusaurus.config.js`:
```javascript
module.exports = {
// other config stuff
// ...
presets: [
// other presets,
[
"redocusaurus",
{
specs: [
{
routePath: "docs/engineering/rest-api/",
// process.env.API_SPEC is used to serve from localhost during development
specUrl:
process.env.API_SPEC ||
"[prod_server_url]/open-api.json",
},
],
theme: {
// See options at https://github.com/Redocly/redoc#redoc-options-object
redocOptions: {
expandSingleSchemaField: true,
expandResponses: "200",
pathInMiddlePanel: true,
requiredPropsFirst: true,
hideHostname: true,
},
},
},
],
],
}
```
| essentialrandom |
762,936 | Architecting Amazon EKS for PCI DSS Compliance Summary | AWS Whitepaper Summary | It was in 2013 when I first heard about PCI DSS compliance after the consecutive and massive... | 0 | 2021-07-19T20:55:42 | https://dev.to/awsmenacommunity/architecting-amazon-eks-for-pci-dss-compliance-summary-20ko | aws, cloudnative, kubernetes, pcidss | 
It was in 2013 when I first heard about PCI DSS compliance after the consecutive and massive credit-card data breaches that happened in the US. I was 16 years old and I was excited to know how the breach happened and what does ‘PCI DSS Compliance’ even mean .Today, with a clearer visual on AWS provided technologies on this subject, I selected this whitepaper to enlighten every curious person about the data security standard for payment cards. This paper, provided by two senior solution architects Arindam Chatterji and Tim Sills, outlines the best practices to configure Amazon Elastic Kubernetes services for AWS Fargate or Amazon Elastic Compute Cloud (Amazon EC2) launch types for Payment Card Industry Data Security Standard (PCI DSS) .It also provides various solutions to mitigate security risks while using the provided AWS services.
This document is dedicated to persons who are involved in projects where AWS is applied for PCI DSS compliance.
#What is Payment Card Industry Data Security Standard (PCI DSS)?
• Provides technical and operational guidance on securing payment card processing environments
• Entities that store, process, or transmit cardholder data (CHD) must be PCI DSS certified ,so they have proven that the followed policies ,procedures, guidelines and best practices to build cardholder data environment (CDE)
#AWS for PCI DSS Compliance
• AWS provided many services that meet PCI DSS Compliance
• AWS Artifact: a central resource for compliance-related information. It can be accessed by companies, on-demand, to reduce compliance efforts .The services provided are containerized by AWS. So companies take advantage of platform independence, deployment speed and resource efficiency.
**PS:** A service listed as PCI DSS compliant doesn’t mean that it makes a customer’s compliant by default.
**PCI DSS compliance status of AWS Services**
• AWS is a Level 1 PCI DSS Service Provider: AWS customers meet easily compliance requirements.
• Any data provided by the customer has :
1. Primary Account Numbers (PAN)
2. Sensitive Authentication Data (SAD)
•The annually updated PCI DSS assessment includes physical security requirements for AWS datacenters.
**AWS Shared Responsibility model**
Security and compliance responsibilities and shared between AWS and the customer.
• AWS : Security , management, control of AWS cloud infrastructure (Hardware ,software, networking and facilities)
• Customer: Security of all the systems components and services provisioned on AWS (included in or connected to the customer’s CDE) like access control ,log settings, encryption , etc
**PS:** The division of responsibilities depends on the AWS service selected by the customer. For example:

**PCI DSS scope determination and validation**
The cardholder data flow determines:
• Applicability of PCI DSS
• Scope of PCI DSS; boundaries and components of CDE
-The customer must have a procedure for PCI DSS scope determination to assure its completeness and to detect changes and violations of the scope.
-Steps that comprise the PCI DSS scope identification are:
**PS:** Customers need to be aware of container configuration parameters through all the phases of a container lifecycle to ensure the satisfaction of the compliance requirements.
#Securing an Amazon EKS Deployment
While architecting a container-based environment for PCI DSS compliance, you have to follow the best practices recommendations for those key topics:
• Network segmentation
• Host and container image hardening
• Data protection
• Restricting user access
• Event logging
• Vulnerability scanning and penetration testing
**Network Segmentation (Requirement N°1):**
PCI DSS doesn’t require network segmentation, but it helps to reduce the scope of the customer’s environment.
• **VPC, subnets and security groups** provide logical isolation of CDE-related resources.

To enforce your VPC’s network policy you can use Calico is an open-source policy engine from Tigera.It works well with Amazon EKS supports extended network policies and can be integrated with service mesh .
• **Security groups** act as a virtual firewall and provide stateful inspection, they restrict communications by IP address, port, and protocol.They are used by Amazon EKS to control the traffic between the Kubernetes control plane and the cluster's worker nodes.
**PS:** It is strongly recommended that you use a dedicated security group for each control plane (one for each cluster).
• Individual AWS accounts for PCI DSS provide the highest level of segmentation boundaries on the AWS platform. Their resources are logically isolated from other accounts.
• To isolate containerized application communications ,you need to :
1) Isolate pods on separate nodes based on the sensitivity of services and isolate CDE workloads in a separate cluster with a dedicated Security group.
2) Use AWS security groups to limit communication between nodes and control plane and external communications.
3) Implement micro-segmentation with Kubernetes network policies and consider the usage of the service mesh, Networking and Cryptography library (NaCI) encryption and Container Network Interfaces (CNIs) to limit and secure communications.
4) Implement a network segmentation and tenant isolation network policy.
**Host and image hardening (Requirement N°2)**
Host and image hardening help to minimize attack vectors by disabling support for vendors for security parameters.In which:
• Customers should create trusted base container images that have been assessed and confirmed to use patched libraries and applications. Use a trusted registry to secure container images, such as Amazon Elastic Container Registry (Amazon ECR). Amazon ECR provides image scanning based upon the Common Vulnerabilities and Exposures (CVEs) database and can identify common software vulnerabilities.
• Container optimized Amazon Machine Image (AMI) contains only essential libraries for deployments. Non-essential services and libraries should be disabled or removed.
• Container builds should be limited and should adopt a model of microservices where a container provides one primary function.
• It is recommended to use special-purpose operating systems (OS) like Bottlerocket that includes a reduced attack surface , a disk image that is verified on boot, and enforced permission boundaries using SELinux.
• Establish configuration standards under the shadow of the industry-accepted system hardening guidelines.
**Data protection (Requirements N°3 and 4)**
This is about the PCI DSS requirement to protect sensitive data in rest and in transit. PCI DSS compliant services and features to assist with these compliance efforts.
*Protect the data in rest:*
Secure all the sensitive stored data of PCI DSS workloads on secure stores or databases NOT on the container host.
• Consider the use of AWS Key Management Service (KMS) to secure encryption key storage, access controls and annual rotation.
• Use AWS Secrets Manager and AWS Systems Manager Parameter Store to secure sensitive data within container build files.
*Protect the data in transit:*
PCI DSS urges the encryption of sensitive data during transmission over open, public networks. Customers are responsible for configuring strong cryptography and security controls.
• Consider a variety of AWS services like Amazon API Gateway and Application Load Balancer
• Encryption in transit for inter-pod communication can also be implemented with a service mesh like AWS App Mesh with support for mTLS.
• Use envelope encryption of Kubernetes secrets in EKS to add a customer-managed layer of encryption for application secrets or user data that is stored within a Kubernetes cluster.
*Other protection measures:*
• Restrict access to authorized personnel(Requirement N°7 and 8), grant least privileges and authenticate with strong authentication requirements that align with the PCI DSS.
• Run containers with non-privileged user accounts and restrict all access to container images.
• Consider disabling the use of the secure shell (SSH) and instead leverage AWS Systems Manager’s Run Command
• Urge that users sign into the Amazon EKS cluster with an IAM identity(either an IAM user or IAM role)
• Create the cluster with a dedicated IAM role which should be regularly audited.
• Make the Amazon EKS Cluster endpoint private.
**Tracking and monitoring access (Requirement N°10)**
This is about the use of event logs to track suspicious activities and even anticipate possible threats. So:
• EKS Cluster audit logs need to be enabled as well as VPC Flow Logs, Amazon CloudWatch and Amazon Kinesis
• CloudWatch dashboard should be configured to monitor and alert on all captured event log activity
• Captured event data have to be stored securely within encrypted Amazon S3 buckets to be analyzed with Amazon Athena and Amazon CloudWatch Logs Insights.
• Amazon GuardDuty provides threat detection .
**Network Intrusion detection(Requirement N°11)**
• Monitoring of all traffic at the perimeter and critical points of the CDE
• Use network inspection options outside of the container host on AWS like :
**Amazon GuardDuty:** a managed service that provides threat detection across multiple AWS data sources to identify threats.
**Amazon VPC Traffic Mirroring:** traditional IDS/IPS solution.
**Virtual IDS/IPS device from the AWS Marketplace:** helps to inspect in transit traffic.You can use a VPC Gateway to route all traffic to on-premises IDS/IPS infrastructure.
**Vulnerability scanning and penetration testing(Requirement N°11.2)**
It aims to test systems and processes regularly to identify and fix vulnerabilities.
• Penetration testing is to be performed on an annual basis and after any significant environmental changes.
• Penetration testing of AWS resources is allowed at any time for certain permitted services in the perimeter of the penetration testing policy .
• PCI DSS Compliance provides guidance and methodologies to perform penetration testing .It depends on customer’s environment.
• When deploying Amazon EKS on Amazon EC2 instances, customers must perform vulnerability scanning of the underlying host.
• Amazon Inspector is a security assessment tool that helps identify vulnerabilities and prioritizes findings by level of severity.
• The Center for Internet Security (CIS) Kubernetes Benchmark provides guidance for Amazon EKS node security configurations.
#Conclusion
AWS provides a convenient infrastructure for customers to address PCI DSS requirements for their containerized workloads. Various security measures are ready to use in order to reduce management complexities for the users.
| dorraelboukari |
763,166 | Temporal - the iPhone of System Design | Temporal ties Orchestration, Event Sourcing, and Workflows-as-Code in one distributed system and it is eating the world. | 0 | 2021-07-19T07:46:12 | https://www.swyx.io/why-temporal | temporal, work, reflections | ---
title: Temporal - the iPhone of System Design
published: true
description: Temporal ties Orchestration, Event Sourcing, and Workflows-as-Code in one distributed system and it is eating the world.
tags: Temporal, Work, Reflections
slug: why-temporal
canonical_url: https://www.swyx.io/why-temporal
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/f4gjemgd6pr1494mmu9g.png
---
> - You can [listen to the audio narrated version here](https://swyx.transistor.fm/episodes/weekend-drop-temporal-the-iphone-of-system-design).
> - I elaborated on these in:
> - [CascadiaJS](https://www.youtube.com/watch?v=WRYozSljSpw) (9 min lightning talk)
> - [React NYC](https://youtu.be/Cxaf8E00GMM) (30min talk)
> - [The MongoDB Podcast](https://mongodb.libsyn.com/ep-93-swyx-learn-in-public-and-temporal) (33min podcast)
> - [The SourceGraph Podcast](https://about.sourcegraph.com/podcast/swyx/) (1h15min podcast)
> - [Complete Intro to Temporal](https://www.youtube.com/watch?v=CeHSmv8oF_4&feature=emb_title) (2h workshop - first 10mins has the "Why Temporal")
I'm excited to finally share why I've joined [Temporal.io](http://temporal.io) as Head of Developer Experience. It's taken me months to precisely pin down why I have been obsessed with Workflows in general and Temporal in particular.
It boils down to 3 core opinions: Orchestration, Event Sourcing, and Workflows-as-Code.
*Target audience: product-focused developers who have some understanding of system design, but limited distributed systems experience and no familiarity with workflow engines. My only goal is to outline Temporal's core design goals and to imply that, if you share these goals, then you will eventually build something like Temporal, as [Mitchell Hashimoto put it](https://temporal.io/#final-quote). I will not explain how it works, how to get started, or even really what Temporal is — that comes later.*
## 30 Second Pitch
The most valuable, mission-critical workloads in any software company are long-running and tie together multiple services.
- **Because this work relies on unreliable networks and systems**:
- You want to standardize timeouts and retries.
- You want offer "reliability on rails" to every team.
- **Because this work is so important**:
- You must never drop any work.
- You must log all progress.
- **Because this work is complex**:
- You want to easily model dynamic asynchronous logic...
- ...and reuse, test, version and migrate it.
**Finally, you want all this to scale**. The same programming model going from small usecases to millions of users without re-platforming. Temporal is the best way to do all this — by writing idiomatic code known as **"workflows"**.
## Requirement 1: Orchestration
Suppose you are executing some business logic that needs to go through System A, then System B, and then System C. Easy enough right?

But:
- System B has rate limiting, so sometimes it fails right away and you're just expected to try again some time later.
- System C goes down a lot — and when it does, it doesn't actively report a failure. Your program is perfectly happy to wait an infinite amount of time and never retry C.
You could deal with B by just looping until you get a successful response, but that ties up compute. Probably the better way is to persist the incomplete task in a database and set a cron job to periodically retry the call.
Dealing with C is similar, but with a twist. You still need B's code to retry the API call, but you also need another (shorter lived, independent) scheduler to place a reasonable timeout on C's execution time since it doesn't report failures when it goes down.

Wiring together queues, timers, databases, and serverless functions just to do retries (just retries!) is a real architecture [recommended by AWS](https://aws.amazon.com/blogs/compute/using-amazon-sqs-dead-letter-queues-to-replay-messages/):
[](https://aws.amazon.com/blogs/compute/using-amazon-sqs-dead-letter-queues-to-replay-messages/)
But imagine doing this *per system*. Pretty soon your architecture looks [like this](https://theburningmonk.com/2017/04/aws-lambda-3-pro-tips-for-working-with-kinesis-streams/):
[](https://theburningmonk.com/2017/04/aws-lambda-3-pro-tips-for-working-with-kinesis-streams/)
Do this often enough and you soon realize that [writing timeouts and retries are really standard production-grade requirements](https://aws.amazon.com/builders-library/timeouts-retries-and-backoff-with-jitter/) when crossing any system boundary, whether you are calling an external API or just a different service owned by your own team.
Instead of writing custom code for timeout and retries for every single service every time, is there a better way? Sure, we could centralize it!

We have just rediscovered the need for **orchestration over choreography**. There are various names for the combined A-B-C system orchestration we are doing — depending who you ask, this is either called a Job Runner, Pipeline, or Workflow.
Honestly, what interests me (more than the deduplication of code) is **the deduplication of infrastructure**. The maintainer of each system **no longer has to provision** the additional infrastructure needed for this stateful, potentially long-running work. This drastically simplifies maintenance — you can shrink your systems down to as small as a single serverless function — and makes it easier to spin up new ones, with the retry and timeout standards you now expect from every production-grade service. Workflow orchestrators are "reliability on rails".
But there's a risk of course — you've just added a centralized dependency to every part of your distributed system. *What if it ALSO goes down?*
## Requirement 2: Event Sourcing
The work that your code does is mission critical. What does that really mean?
- **We cannot drop anything.** All requests to start work must either result in error or success - no "it was supposed to be running but got lost somewhere" mismatch in expectations.
- **During execution, we must be able to resume from any downtime**. If any part of the system goes down, we must be able to pick up where we left off.
- **We need the entire history** of *what* happened *when*, for legal compliance, in case something went wrong, or if we want to analyze metadata across runs.
There are two ways to track all this state. The usual way starts with a simple task queue, and then adds logging:
```jsx
(async function workLoop() {
const nextTask = taskQueue.pop()
await logEvent('starting task:', nextTask.ID)
try {
await doWork(nextTask) // this could fail!
catch (err) {
await logEvent('reverting task:', nextTask.ID, err)
taskQueue.push(nextTask)
}
await logEvent('completed task:', nextTask.ID)
setTimeout(workLoop, 0)
})()
```
But logs-as-afterthought has a bunch of problems.
- The logging is not tightly paired with the queue updates. If it is possible for one to succeed but the other to fail, you either have unreliable logs or dropped work — unacceptable for mission critical work. This could also happen if the central work loop itself goes down while tasks are executing.
- At the local level, you can fix this with batch transactions. Between systems, you can create two-phase commits. But this is a messy business and further bloats your business code with a ton of boilerplate — IF (a big if) you have the discipline to instrument every single state change in your code.
The alternative to logs-as-afterthought is logs-as-truth: If it wasn't logged, it didn't happen. This is also known as **Event Sourcing**. We can always reconstruct current state from an ever-growing list of `eventHistory`:
```jsx
(function workLoop() {
const nextTask = reconcile(eventHistory, workStateMachine)
doWorkAndLogHistory(nextTask, eventHistory) // transactional
setTimeout(workLoop, 0)
})()
```
The next task is strictly determined by comparing the event history to a state machine (provided by the application developer). Work is either done and committed to history, or not at all.
I've handwaved away a lot of heavy lifting done by `reconcile` and `doWorkAndLogHistory`. But this solves a lot of problems:
- Our logs are **always reliable**, since that is the *only* way we determine what to do next.
- We use **transactional guarantees** to ensure that work is either done and tracked, or not at all. There is no "limbo" state — at the worst case, we'd rather retry already-done work with idempotency keys than drop work.
- Since there is no implicit state in the work loop, it can be **restarted easily** on any downtime (or scaled horizontally for high load).
- Finally, with standardized logs in our event history, we can share **observability and debugging tooling** between users.
*You can also make an analogy to the difference between "filename version control" and git — Using event histories as your source of truth is comparable to a git repo that reflects all git commits to date.*
But there's one last problem to deal with - how exactly should the developer specify the full state machine?
## Requirement 3: Workflows-as-Code
The prototypical workflow state machine is a JSON or YAML file listing a sequence of steps. But this abuses configuration formats for expressing code. it doesn't take long before you start adding features like conditional branching, loops, and variables, until you have an underspecified Turing complete "domain specific language" hiding out in your JSON/YAML schema.
```jsx
[
{
"first_step": {
"call": "http.get",
"args": {
"url": "https://www.example.com/callA"
},
"result": "first_result"
}
},
{
"where_to_jump": {
"switch": [
{
"condition": "${first_result.body.SomeField < 10}",
"next": "small"
},
{
"condition": "${first_result.body.SomeField < 100}",
"next": "medium"
}
],
"next": "large"
}
},
{
"small": {
"call": "http.get",
"args": {
"url": "https://www.example.com/SmallFunc"
},
"next": "end"
}
},
{
"medium": {
"call": "http.get",
"args": {
"url": "https://www.example.com/MediumFunc"
},
"next": "end"
}
},
{
"large": {
"call": "http.get",
"args": {
"url": "https://www.example.com/LargeFunc"
},
"next": "end"
}
}
]
```
This example happens to be from [Google](https://github.com/GoogleCloudPlatform/workflows-samples/blob/main/src/step_conditional_jump.workflows.json), but you can compare similar config-driven syntaxes from [Argo](https://github.com/serverlessworkflow/specification/blob/57ed379acdf066c7dd87644b1ec2254f1f350ba6/comparisons/comparison-argo.md), [Amazon](https://states-language.net/spec.html), and [Airflow](https://airflow.apache.org/docs/apache-airflow/stable/tutorial.html#example-pipeline-definition). The bottom line is you ultimately find yourself hand-writing the Abstract Syntax Tree of something you can read much better in code anyway:
```jsx
async function dataPipeline() {
const { body: SomeField } = await httpGet("https://www.example.com/callA")
if (SomeField < 10) {
await httpGet("https://www.example.com/SmallFunc")
} else if (SomeField < 100) {
await httpGet("https://www.example.com/MediumFunc")
} else {
await httpGet("https://www.example.com/BigFunc")
}
}
```
The benefit of using general purpose programming languages to define workflows — Workflows-as-Code — is that you get to **the full set of tooling** that is already available to you as a developer: from IDE autocomplete to linting to syntax highlighting to version control to ecosystem libraries and test frameworks. But perhaps the biggest benefit of all is the reduced need for context switching from your application language to the workflow language. (So much so that you could copy over code and get reliability guarantees with only minor modifications.)
This config-vs-code debate arises in multiple domains: You may have encountered this problem in AWS provisioning (CloudFormation vs CDK/Pulumi) or CI/CD (debugging giant YAML files for your builds). Since you can always write code to interpret any declarative JSON/YAML DSL, the code layer offers a superset of capabilities.
## The Challenge of DIY Solutions
So for our mission critical, long-running work, we've identified three requirements:
1. We want an **orchestration** engine between services.
2. We want to use **event sourcing** to track and resume system state.
3. We want to write all this **with code** rather than config languages.
Respectively, these solve the pain points of reliability boilerplate, implementing observability/recovery, and modeling arbitrary business logic.
If you were to build this on your own:
- You can find an orchestration engine off the shelf, though few have a strong open source backing.
- You'd likely start with a logs-as-afterthought system, and accumulating inconsistencies over time until they are critical enough to warrant a rewrite to a homegrown event sourcing framework with stronger guarantees.
- As you generalize your system for more use cases, you might start off using a JSON/YAML config language, because that is easy to parse. If it were entrenched and large enough, you might create an "as Code" layer just as AWS did with AWS CDK, causing an impedance mismatch until you rip out the underlying declarative layer.
Finally, you'd have to make your system scale for many users (horizontal scaling + load balancing + queueing + routing) and many developers (workload isolation + authentication + authorization + testing + code reuse).
## Temporal as the "iPhone solution"
When [Steve Jobs introduced the iPhone](https://www.youtube.com/watch?v=MnrJzXM7a6o) in 2007, he introduced it as "a widescreen iPod with touch controls, a revolutionary mobile phone, and a breakthrough internet communications device", before stunning the audience: "These are *not* three separate devices. This is **ONE** device."
{% youtube MnrJzXM7a6o %}
This is the potential of Temporal. Temporal has opinions on how to make each piece best-in-class, but the tight integration creates a programming paradigm that is ultimately greater than the sum of its parts:
- You can build a UI that natively understands workflows as potentially infinitely long running business logic, exposing retry status, event history, and code input/outputs.
- You can build workflow migration tooling that verifies that old-but-still-running workflows have been fully accounted for when migrating to new code.
- You can add pluggable persistence so that you are agnostic to what databases or even what cloud you use, helping you be cloud-agnostic.
- You can run polyglot teams — each team can work in their ideal language, and only care about serializable inputs/outputs when calling each other, since event history is language-agnostic.
- There are more possibilities I can't talk about yet.
## The Business Case for Temporal
A fun anecdote about how I got the job: through blogging.
While exploring the serverless ecosystem at Netlify and AWS, I always had the nagging feeling that it was incomplete and that the most valuable work was always "left as an exercise to the reader". The feeling crystallized when I rewatched DHH's 2005 Ruby on Rails demo and realized that there was no way the serverless ecosystem could match up to it. We broke up the monolith to scale it, but there were just too many pieces missing.
I started analyzing cloud computing from a "Jobs to Be Done" framework and wrote two throwaway blogposts called [Cloud Operating Systems and Reconstituting the Monolith](https://gist.github.com/sw-yx/ff8a4f6757286444fa20b43f6b98b205). My ignorant posting led to [an extended comment from a total internet stranger](https://twitter.com/swyx/status/1226747097208295424) telling me all the ways I was wrong. [Lenny Pruss](https://twitter.com/lennypruss?lang=en), who was ALSO reading my blogpost, saw this comment, and got Ryland to join Temporal as Head of Product, and he then turned around and pitched (literally pitched) me to join.
One blogpost, two jobs. [Learn in Public](https://www.swyx.io/LIP) continues to amaze me by the [luck it creates](https://www.swyx.io/create-luck).
Still, why would I quit a comfy, well-paying job at Amazon to work harder for less money at a startup like this?
- **Extraordinary people**. At its core, betting on any startup is betting on the people. The two cofounders of Temporal have been working on variants of this problem for over a decade each at AWS, Microsoft, and Uber. They have attracted an extremely high caliber team around them, with centuries of distributed systems experience. I report to the Head of Product, who is one of the fastest scaling executives Sequoia has ever seen.
- **Extraordinary adoption**. Because it reinvents service orchestration, Temporal (and its predecessor Cadence) is very horizontal by nature. [Descript uses it](https://docs.temporal.io/blog/descript-case-study) for audio transcription, [Snap uses it](https://eng.snap.com/build_a_reliable_system_in_a_microservices_world_at_snap) for ads reporting, [Hashicorp uses it](https://temporal.io/#final-quote) for infrastructure provisioning, [Stripe uses it](https://stripe.com/jobs/listing/infrastructure-engineer-developer-productivity-workflow-engine/2964407) for the workflow engine behind Stripe Capital and Billing, [Coinbase uses it](https://docs.temporal.io/blog/reliable-crypto-transactions-at-coinbase/) for cryptocurrency transactions, [Box uses it](https://docs.temporal.io/blog/Temporal-a-central-brain-for-Box) for file transfer, [Datadog uses it](https://www.youtube.com/watch?v=eWFpl-nzGsY) for CI/CD, [DoorDash uses it](https://doordash.engineering/2020/08/14/workflows-cadence-event-driven-processing/) for delivery creation, [Checkr uses it](https://docs.temporal.io/blog/how-temporal-simplified-checkr-workflows/) for background checks. Within each company, growth is viral; once one team sees successful adoption, dozens more follow suit within a year, all through word of mouth.

- **Extraordinary results**. After migrating, Temporal users report production issues falling from once-a-week to near-zero. Accidental double-spends have been discovered and fixed, saving millions in cold hard cash. Teams report being able to move faster, thanks to testing, code reuse, and standardized reliability. While the value of this is hard to quantify, it is big enough that users organically tell their friends and [list Temporal in their job openings](https://temporal.io/careers#external-jobs).
- **Huge potential market growth**. The main thing you bet on when it comes to Temporal is that its primary competition really is homegrown workflow systems, not other engines like Airflow, AWS Step Functions, and Camunda BPMN. In other words, even though Temporal should gain market share, **the real story is market growth**, driven by the growing microservices movement and developer education around best-in-class orchestration. At AWS and Netlify, I always felt like there was a missing capability in building serverless-first apps — duct-taping functions and cronjobs and databases to do async work — and it all fell into place the moment I saw Temporal. I'm betting that there are many, many people like me, and that I can help Temporal reach them.
- **High potential value capture**. Apart from market share and market growth, any open source project has the additional challenge of value capture, since users can self-host at any time. I mostly subscribe to David Ulevitch's take that [open source SaaS is basically outsourcing ops](https://mobile.twitter.com/swyx/status/1373425786351284228). I haven't talked about [Temporal's underlying architecture](https://docs.temporal.io/blog/workflow-engine-principles) but it has quite a few moving parts and takes a lot of skill and system understanding to operate. For reasons I won't get into, Temporal scales best on Cassandra and that alone is enough to make most want to pay someone else to handle it.
- **Great expansion opportunities**. Temporal is by nature the most direct source of truth on the most valuable, mission critical workflows of any company that adopts it. It can therefore develop the most mission critical dashboard and control panel. Any source of truth also becomes a natural aggregation point for integrations, leaving open the possibility of an internal or third party service marketplace. With the Signals and Queries features, Temporal easily gets data in and out of running workflows, making it an ideal foundation for the sort of human-in-the-loop work for [the API Economy](https://www.swyx.io/api-economy/). Imagine toggling just one line of code to A/B test vendors and APIs, or have Temporal learn while a domain expert manually executes decision processes and take over when it has seen enough. As a "high-code" specialist in reliable workflows, it could be a neutral arms dealer in the "low-code" gold rush, or choose to get into that game itself. If you want to get really wild, the secure distributed execution model of Workflow workers could be facilitated by an [ERC-20 token](https://www.investopedia.com/news/what-erc20-and-what-does-it-mean-ethereum/). (*to be clear... everything listed here is personal speculation and not the company roadmap)*
There is much work to do, though. Temporal Cloud needs a lot of automation and scaling before it becomes generally available. Temporal's UI is in the process of a full rewrite. Temporal's docs need a lot more work to fully explain such a complex system with many use cases. Temporal still doesn't have a production-ready Node.js or Python SDK. And much, much, more to do before Temporal's developer experience becomes accessible to the majority of developers.
## Conclusion: Temporal's Strategy Turn
I've probably exhausted your patience at this point but at least I hope you see that I genuinely think the potential is humongous. *And yet* I'm still understating it.
Temporal today is pitched as "reliability on rails" or as a "workflow-as-code microservices orchestration engine" in the same way that the initial pitch of iPhone led with "a widescreen iPod with touch controls". We do that because it's familiar to things you already know — queues, databases, cronjobs, job runners, data and provisioning pipelines.
But now all my iPhone audio comes from Spotify and Overcast, I barely use the phone functionality, and I'm using the mobile Internet the rest of the time. The equivalent decade-long potential of Temporal is as ambitious as defining an "8th layer" to the [OSI 7 Layer](https://www.swyx.io/osi-layers-coding-careers/) model and reinventing asynchronous programming the way iPhone reinvented smartphones.
Long time readers will recognize this as a "[Strategy Turn](https://www.swyx.io/strategy-turns/)" — the fact that it will happen is a matter of when, not if.
If what I've laid out excites you, take a look at [our open positions](https://temporal.io/careers) (or write in your own!), and [join the mailing list](https://docs.temporal.io/docs/concepts/introduction#mc_embed_signup_scroll)!
## Further Reading
{% youtube WRYozSljSpw %}
- Orchestration
- [Yan Cui's guide to Orchestration vs Choreography](https://theburningmonk.com/2020/08/choreography-vs-orchestration-in-the-land-of-serverless/)
- [InfoQ: Coupling Microservices](https://www.infoq.com/podcasts/design-time-coupling-microservices/) - a non-Temporal focused discussion of Orchestration
- [A Netflix Guide to Microservices](https://www.youtube.com/watch?v=CZ3wIuvmHeM)
- Event Sourcing
- Martin Fowler on [Event Sourcing](https://martinfowler.com/eaaDev/EventSourcing.html)
- Kickstarter's guide to [Event Sourcing](https://kickstarter.engineering/event-sourcing-made-simple-4a2625113224?gi=e356daabcb81)
- Code over Config
- [ACloudGuru's guide to Terraform, CloudFormation, and AWS CDK](https://acloudguru.com/blog/engineering/cloudformation-terraform-or-cdk-guide-to-iac-on-aws)
- [Serverless Workflow's comparison of Workflow specification formats](https://github.com/serverlessworkflow/specification/tree/main/comparisons)
- Temporal
- [Dealing with failure](https://docs.temporal.io/blog/dealing-with-failure/) - when to use Workflows
- [The macro problem with microservices](https://stackoverflow.blog/2020/11/23/the-macro-problem-with-microservices/) - Temporal in context of microservices
- [Designing A Workflow Engine from First Principles](https://docs.temporal.io/blog/workflow-engine-principles/) - Temporal Architecture Principles
- [Writing your first workflow](https://www.youtube.com/watch?v=taKrIWt6KMY&feature=youtu.be) - 20min code video
- [Case studies](https://docs.temporal.io/blog/tags/case-study) and [External Resources](https://docs.temporal.io/docs/external-resources/) from our users | swyx |
772,326 | Remove Items from Arrays with .shift() & .pop() Methods | In this post, we will see "How to Remove Items from an Array". Before going to the main topic, let's... | 13,774 | 2021-07-26T18:32:20 | https://dev.to/swarnaliroy94/remove-items-from-arrays-with-shift-pop-methods-5caf | javascript, beginners, tutorial, webdev | In this post, we will see *"How to Remove Items from an Array"*.
Before going to the main topic, let's remember what we have known earlier. Arrays are *mutable* which means, we can add and remove elements and modify the array. The last post of this series was about *Adding elements to an Array* using *Array.unshift()* & *Array.push()* methods.
In this episode, we can look into two methods, **Array.shift()** & **Array.pop()**, to know how we can remove/delete elements from the *beginning* and the *end* of an existing array respectively.
Both of the methods are nearly *functional opposites* of the methods *.unshift()* & *.push()*. The `key difference` is neither method takes *parameters*, and each only allows an array to be modified by a *single element at a time*. That means, we cannot remove *more than one* element at a time.
### Array.shift() Method
`Array.shift()` method eliminates a single item from the `beginning` of an existing array. A simple *example* of .shift() method is given below:
```js
let fruits = ["Mango", "Orange","Strawberry", "Blueberry"];
let result = fruits.shift();
console.log(result); // output : Mango
console.log(fruits);
// output: ["Orange","Strawberry", "Blueberry"]
```
Notice that, the *result* variable stores the value -- *Mango* that *fruits.shift()* method has removed from the *beginning* of the *fruits* array. The value of the *first index* is eliminated.
We can also discard an *Array* or an *Object* or *both* from the starting of the existing array using `.shift()` method.For example, let's remove an array from the beginning.
```js
let fruits = [
["Grapes","Apples"],"Mango", "Orange",
"Strawberry", "Blueberry"
];
let result = fruits.shift();
console.log(result); //output : [ "Grapes", "Apples"]
console.log(fruits);
//output: ["Mango","Orange","Strawberry", "Blueberry"]
```
Now, let's move on to the next method *Array.pop()*.
### Array.pop() Method
`Array.pop()` method eliminates a single item from the `end` of an existing array. A simple *example* of .shift() method is given below:
```js
let fruits = ["Mango", "Orange","Strawberry", "Blueberry"];
let result = fruits.shift();
console.log(result); // output : Blueberry
console.log(fruits);
// output: ["Mango","Orange","Strawberry"]
```
We can see that, the *result* variable stores the value -- *Blueberry* that *fruits.pop()* method has removed from the *end* of the *fruits* array. The value of the *last index* is eliminated.
Similarly, like `.shift()` method, `.pop()` method can remove an *Array* or an *Object* or *both* from the starting of the existing array using `.pop()` method. Here, we will remove an Object from the end of the array:
```js
let fruits = [
"Mango", "Orange","Strawberry",
"Blueberry",{"P":"Peach","L":"Lemon"}
];
let result = fruits.pop();
console.log(result); //output: { P: 'Peach', L: 'Lemon' }
console.log(fruits);
//output: [ 'Mango', 'Orange', 'Strawberry', 'Blueberry' ]
```
The *last index* was occupying the *Object* and after applying the `.pop()` method to the *fruits* array, the *result* variable stored the *Object* that *fruits.pop()* method has removed from the *end* of the array.
We can use both *.shift()* and *.pop()* method to remove both values of the *first* and *last* indices respectively.
A fine example can be the following one:
```js
let fruits = [[ "Grapes", "Apples"],"Mango",
"Orange","Strawberry", "Blueberry",
{"P":"Peach","L":"Lemon"}];
let shifted = fruits.shift() ;
let popped = fruits.pop();
console.log( shifted , popped );
// [ 'Grapes', 'Apples' ] { P: 'Peach', L: 'Lemon' }
console.log(fruits);
// [ 'Mango', 'Orange', 'Strawberry', 'Blueberry' ]
```
In the above example, the two variables, *shifted* and *popped* deleted the values of the *first index* and *last index* of the *fruits* array and the *output* can be clearly shown in the console.
*Since JavaScript Arrays are Objects, elements can be deleted by using the JavaScript operator "delete" also.* For example:
```js
let fruits = ["Mango", "Orange","Strawberry"]
delete fruits[1];
console.log(fruits); //[ 'Mango', <1 empty item>, 'Strawberry']
```
The *output* changes the *second element* in *fruits* to undefined (<1 empty item>). This may leave some undefined holes in the array.
#####That's why, using `.shift()` and `.pop()` is the best practice.
Now, I want to give my readers a *problem to solve*. Readers can explain their answer in the *discussion section*.
A function, *popShift*, is defined.It takes an array *prob* as an argument and returns a new array. Modify the function, using `.shift()` & `.pop()` methods, to remove the first and last elements of the argument array and assign the removed elements to their corresponding variables, so that the returned array contains their values.
```js
function popShift(prob) {
let shifted; //change code here//
let popped; //change code here//
return [shifted, popped];
}
console.log(popShift(['Problem', 'is', 'not', 'solved']));
```
*The expected output is : [ 'Problem', 'solved' ]*
#### At this point, what if we want to add elements to and remove elements from the middle of an array? That's all we are going to know in the next episode.
| swarnaliroy94 |
772,871 | You don’t need React for building websites | Here’s what I think: if you are building websites, you don’t need React (in most cases). I have been... | 0 | 2021-07-27T08:28:02 | https://www.silvestar.codes/articles/you-don-t-need-react-for-building-websites/ | webdev, javascript, react | Here’s what I think: if you are building websites, you don’t need React (in most cases).
I have been building websites for over nine years now. As I get more experienced, I use fewer libraries and frameworks and rely on good old HTML, CSS, and vanilla JavaScript. I think you should consider doing the same.
## My rant about React
Ever since React came to the stage, I’ve been hearing, reading, and watching how great it is. I had a few attempts to learn it, but I failed every time. It is fair to say that I don’t understand it, so I cannot even rant about its features, shortcomings, or flaws.
What I can rant about is the hype. I mean, it’s not even hype after all these years. It is a necessary evil. Of course, I am exaggerating here, but maybe not.
I feel like 9 out of 10 job ads for a frontend developer mention React.
I don’t get it. Why would I need to use React if I am supposed to work on building websites? Are employers afraid that if you don’t know React that you wouldn’t be able to make a landing page? Would knowing React help you solve any problems when creating a new layout or template? I cannot think of any part of the website that would require React.
All these questions made me realize that I don’t need frameworks for my everyday work.
## There might be a solution
Instead of adding React to every frontend job ad, employers should emphasize HTML, CSS, JavaScript, and accessibility skills. These four amigos are the only thing you need to make websites perform well, achieve a solid SEO score, and allow every user to consume the content.
Brad Frost wrote about [front-of-the-frontend](https://bradfrost.com/blog/post/front-of-the-front-end-and-back-of-the-front-end-web-development/). Chris Coyier wrote about [the great divide](https://css-tricks.com/the-great-divide/). I agree with both of them, but I would make the following distinction: web app developer and website developer.
The web app developer does need React or similar frameworks.
The website developer doesn’t need React or similar frameworks.
Of course, there are exceptions, but I am talking in general here.
I am in a situation where I don’t need to apply to new positions and choose my employer often, but I keep my eye on job ads frequently. I sympathize with developers who are capable of building solid websites but struggle to find a job because of the lack of React skills. I know at least one person who would be thankful if React skill wouldn’t be listed so often — a friend of mine (and my mentee) with whom I share the office these days.
I propose a simple solution: if the job is about building sites, please stop adding React as a required skill unless absolutely necessary. It might be helpful to use the **website** developer term, too.
## Conclusion
Knowing React could only make you a better developer, and I am not saying you shouldn’t learn it. However, I am saying that it is not needed in most cases if your goal is to build websites.
I hope more people would realize how powerful HTML, CSS, and JavaScript are and that these come with the most features that you’ll ever need for building a website. Simpler is usually better.
| starbist |
773,199 | We like speed because our customers need it — check out what we’ve done to make our Chat Widget load quicker | Being ahead of the curve requires much effort — even little tweaks are important for... | 0 | 2021-07-27T14:41:26 | https://dev.to/text/we-like-speed-because-our-customers-need-it-check-out-what-we-ve-done-to-make-our-chat-widget-load-quicker-4aoi | webdev, javascript, showdev | ###Being ahead of the curve requires much effort — even little tweaks are important for delivering a great product. Recently we optimized our Chat Widget to make it faster in terms of page load speed. 🚀
In previous articles, we’ve covered how LiveChat does not slow down websites it's installed on. This time we wanted to optimize the size and loading speed of the widget itself and influence Largest Contentful Paint (LCP), a factor that affects page ranking in Google. Furthermore, our goal was to improve CLS — Cumulative Layout Shift. It's a metric that quantifies how often users experience unexpected layout shifts. The lower the CLS, the more visually stable the page is. Additionally, it helps avoiding unwanted missed interactions from the user perspective, like, for example, a button you want to click which suddenly moves down because something more has loaded and you end up with clicking on another thing.
###What did we do?
In terms of technological development, we introduced a few changes, listed below:
####We split the code.
To make the chat widget appear more quickly, we divided its script into a couple of parts. One part loads automatically with the page and displays the minimized chat widget. The rest of the code loads when the user hovers over the widget.
We got rid of SockJS in favor of a pure WebSocket connection.
Our Chat Widget used to implement SockJS, a wrapper on WebSocket (WS) connections. Ditching it has significantly decreased the Chat Widget loading speed, and its size, as we no longer need to load a third-party library. Consequently, we could cut out the configuration request SockJS used to make to our server, saving additional time.
####We migrated to HTTP/2 from HTTP/1.x.
A small change, but it opened up numerous possibilities for further development. For example, we were finally able to overcome the barrier of making only a single request at a time while having to use multiple TCP connections. With multiple parallel requests and other possibilities to optimize app performance, we look forward to making our chat widget even more swift.
####We’ve been gradually reducing the Chat Widget’s asset size.
In June 2020, our Chat Widget size (measured by Google Lighthouse) was 412KB. Within the first two months, we reduced it to 332KB, but we haven't stopped there. Right now, our chat widget asset size has settled at 256KB. (What a nice number. For now.) Obviously, it has significantly shortened the loading time of the Chat Widget.
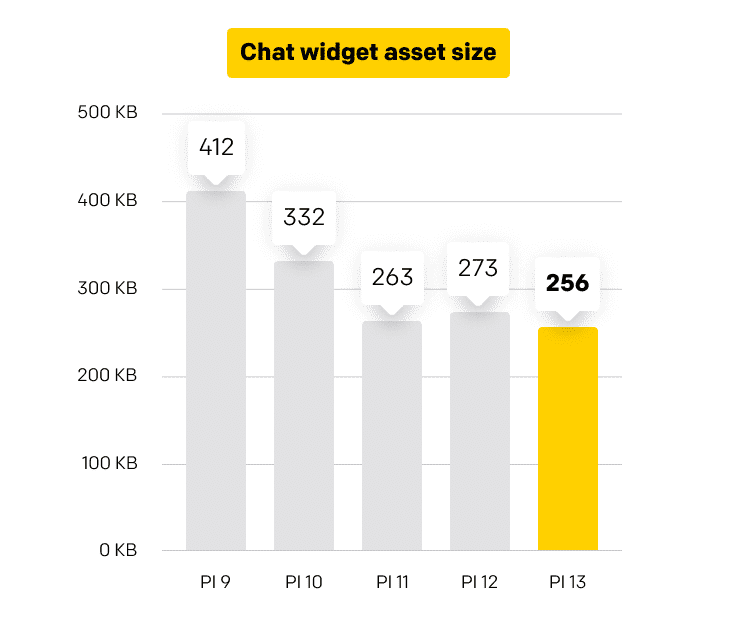
###What was the outcome?
####First marker: FCP/LCP — First/Largest Contentful Paint
FCP, briefly speaking, marks the time the browser needs to display consumable information (text, visuals, etc.). It's much more informative than just First Paint, which measures first render — any render. LCP, on the other hand, measures how long it takes to display the largest element. The less time, the better, and 1.2 seconds is the max. Our LCP result was 252 ms 🔥
####Second marker: CLS — Cumulative Layout Shift
As mentioned before, CLS is a highly user-centric marker that measures the visual stability of the site, an influential factor in terms of user experience. We managed to reduce the CLS impact reported by Google Lighthouse from 0.8 to 0, which translated into lowering the number of CLS issues reported by our customers on the chat.
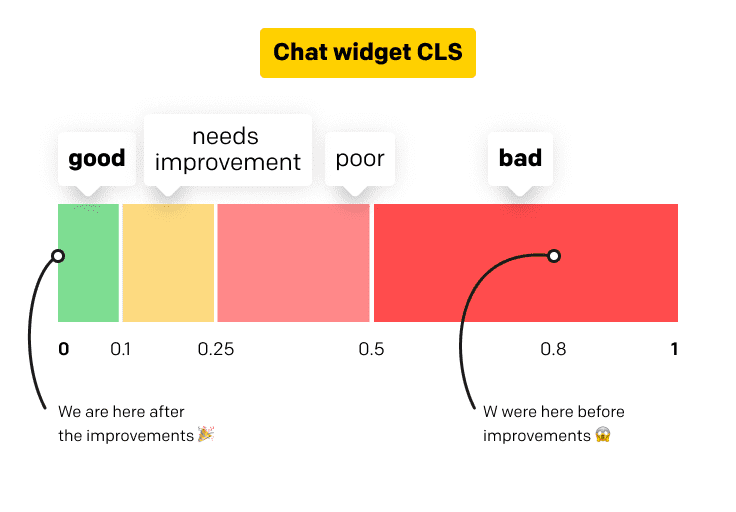
Right now, we are Grade A when measured by GTmetrix. While code splitting and switching to pure WebSockets turned out to be the most effective technological changes, HTTP/2 migration has set us in the right direction for future optimization.
**What do you think about our process? Can you recommend any other ways of optimization when it comes to the size and load speed of the widget?**
| lwardega |
773,231 | GZIP on the Browser | Out of curiosity I created a small demo detailing how you can implement GZIP in the browser, I used... | 0 | 2021-07-27T15:57:20 | https://blog.okikio.dev/gzip-on-the-browser | javascript, webdev, codepen, snippet | ---
title: GZIP on the Browser
published: true
date: 2021-07-27 15:50:12 UTC
tags: javascript, webdev, codepen, snippet
canonical_url: https://blog.okikio.dev/gzip-on-the-browser
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/pl0dt9jbk20cagxet6e1.png
---
Out of curiosity I created a small demo detailing how you can implement GZIP in the browser, I used [`fflate`](https://npmjs.com/fflate) for the GZIP compression, and [`pretty-bytes`](https://npmjs.com/pretty-bytes) to convert bytes into human readable format, the demo is really small but as an example it should be more than good enough. I based it on [bundlejs.com](https://bundlejs.com). Interestingly, I have yet to find a website that lets you see the GZIP size of some random text, all the ones I have found so far expect you to upload a file, the little demo takes a string as an input compresses it, and gives you the final size.
{% codepen https://codepen.io/okikio/pen/ExmQwPM %}
I suggest checking out [bundlejs.com](https://bundlejs.com) it's a specialized for bundling, minifying and compressing js, all locally, right on your browser.
Check out the [product hunt](https://www.producthunt.com/posts/bundle-6) page for [bundlejs.com](https://bundlejs.com). | okikio |
773,578 | The New Leaders of Remote Engineering Event - August 11th | Everyone loves free stuff, right? Even better when that free stuff is both fun and adds value.... | 0 | 2021-07-28T13:55:24 | https://dev.to/linearb/the-new-leaders-of-remote-work-event-august-11th-1og3 | eventdriven, discuss, inthirtyseconds, remotework | Everyone loves free stuff, right?
Even better when that free stuff is both fun and adds value. That’s what Dev Interrupted’s upcoming event - [The New Leaders of Remote Work](https://linearb.io/new-leaders-remote-work-panel/) - is all about. Helping engineering leaders and developers to get the most out of their remote or hybrid work situtions.

Join us from **9am-10am PST on August 11th** for another great panel discussion with:
* Darren Murph Head of Remote at GitLab & Guinness World Record Holder as the most prolific blogger ever
* Lawrence Mandel Director of Engineering at Shopify & Hockey Enthusiast
* Shweta Saraf Director of Engineering at Equinix & Plato Mentor
* And the Panda himself, Chris Downard VP of Engineering at GigSmart
Dan Lines, COO of LinearB, will be moderating a discussion with our guests on how they lead their teams remotely, how the current workplace is changing, and what's next as the pandemic continues to change.
Want to learn from the new leaders of remote work? Then this livestreamed Dev Interrupted Panel is the event for you.
[Register here](https://linearb.io/new-leaders-remote-work-panel/?__hstc=75672842.ea2a35812d5192739a119c7ab37040a0.1624488310794.1627418140391.1627422268722.36&__hssc=75672842.9.1627422268722&__hsfp=1224415886)
We're excited for the future and very thankful to have you on this journey with us. You can always reach me for feedback (or site bug reports!) via our developer Discord community or on our Twitter.
Thanks for everything -
Conor Bronsdon
Community & Content Lead, Dev Interrupted
*If you haven't already joined the best developer discord out there, WYD?*
Look, I know we talk about it a lot but we love our developer discord community. With over 1400 members, the Dev Interrupted Discord Community is the best place for Engineering Leaders to engage in daily conversation. No salespeople allowed. [Join the community](https://discord.gg/devinterrupted) | conorbronsdon |
773,681 | JavaScript ES6 keyed collections | Introduction With Data Structures we can store, organize, order and handle data. We need... | 0 | 2021-08-02T14:52:32 | https://dev.to/guilhermegules/javascript-es6-keyed-collections-544n | javascript, algorithms, webdev, programming | ## Introduction
With Data Structures we can store, organize, order and handle data. We need to understand how and when use determinate structures.
JavaScript has some built-in structures introduced on es6 version, even though these data structures have some time of existence has many developers has doubt about how to use them, today I wanna try to clarify the information about these.
## Map
Map is an object and works as a common object, the major difference between them is because map lets you work with internal functions to make the insertion, deletion or get one element with a more simplistic form.
Also, Map only permit a unique key with diferents values. So if I create a map like this:
```
const map = new Map();
map.set('first', 1);
console.log(map.get('first')); // 1
map.set('first', 100);
console.log(map.get('first')); // 100
console.log(map.size); // 1
```
We can note the value is changed but only one key as stored on our Map.
Map is iterable, so we can use a for..of or for each to iterate through our structure and make operations there.
```
const map = new Map();
map.set('first', 1);
map.set('second', 2);
for(let item of map) {
console.log(item);
}
for(let [key, value] of map.entries()) {
console.log(key, value);
}
for(let key of map.keys()) {
console.log(key);
}
for(let value of map.values()) {
console.log(value);
}
map.forEach((item, key) => {
console.log(key, item);
});
```
With `for...of` each iteration return an array like this `[key, value]`, with `forEach` on each we have three parameters, first the value, them the key and finally the map itself.
### Why/When use Map?
We wanna use Map structure when it's necessary to keep control of information about the object, and we need to keep keys unique, also Map has a simple usage, so it's simple to get used to using.
## WeakMap
WeakMap is a collection of key/value in which keys are weakly referenced.
Because keys are weakly referenced, they cannot be enumerated, so we can't iterate them like Map and cannot obtain the keys.
We can use WeakMaps like this:
```
const weakMap = new WeakMap();
const value1 = {};
const value2 = function(){};
const value3 = "I'm the third value";
const value4 = { foo: 'foo' };
const value5 = { key: 'foo' };
weakMap.set(value1, value2);
console.log(weakMap.has(value3)); // false
console.log(weakMap.get(value1)); // Returns the value based on key, in this case function() {}
weakMap.delete(value1);
weakMap.set(value5, value4);
console.log(weakMap.get(value5)); // Using a object that already in memory, we can access the position
weakMap.set({ myKey: 'myKey' }, {value: 1});
console.log(weakMap.get({ myKey: 'myKey' })); // Will return undefined, because the object on function call is one and the object on the set function is another
```
_Note: We can't use primitives values like keys with WeakMaps_
### Why/When use WeakMap?
Some use cases for WeakMaps, [here](https://stackoverflow.com/questions/29413222/what-are-the-actual-uses-of-es6-weakmap) have some discussion on the topic, here I will put some tests and my understandings about the data structure:
- When we need to handle some private data and do not want to iterate that data, only getting the specific property, WeakMap can be a good choice.
## Set
Sets are collections that permits the storage of any type of unique values. With sets we can avoid duplicate data, remembering that objects references can be added like a new value too.
We can use Sets like that:
```
const set = new Set();
set.add(1); // set [1]
set.add(5); // set [1, 5]
set.add(5); // 5 already was been setted, so set [1, 5]
const object = { foo: 'foo', bar: 'bar' };
set.add(object);
set.add({ foo: 'foo', bar: 'bar' }); // This object will be added because is another reference
```
It's possible check if a value was inserted in our Set:
```
const set = new Set();
set.add(1);
set.has(1); // true
set.has(5); // false
```
Also we can check the size of Sets:
```
const set = new Set();
set.add(1);
set.add(5);
set.add(10);
console.log(set.size) // 3
set.delete(10); // Removes 10 from our set
console.log(set.size); // 2
```
Like Maps, Sets can also be iterated:
```
const set = new Set();
set.add(1);
set.add("text");
set.add({foo: 'bar', bar: 'foo'});
for(let item of set) {
console.log(item);
}
// Keys will have the inserted values
for (let item of set.keys()) {
console.log(item)
}
/**
* key and values are the same here
*/
for (let [key, value] of set.entries()) {
console.log(key);
console.log(value);
}
```
Using spread operator we can create a copy of a Set and use as an array:
```
const set = new Set();
set.add(1);
set.add("text");
set.add({foo: 'bar', bar: 'foo'});
const setToArray = [...set];
setToArray.forEach(item => {
console.log(item);
});
```
### Why/When use Set?
We would like to use Sets when it's necessary to keep unique values without the need to use key/value on our structure. For that Sets are the best choice because they will keep the consistency of our data.
_Note: it's valid to think about the objects references example because even though you pass the same object to the set, it will be saved because are different references._
## WeakSet
WeakSet objects permit you to store weakly held objects. Like as Set collection, WeakSet will permits each object occurrence only once.
**What the difference of WeakSet and Set?** WeakSet only accepts objects, so they cannot contain any values like Sets. Another difference is like the WeakMap, WeakSet has weak references of the objects they held, if no other references of an object store exist this object can be garbage collected. Last but not less important, the WeekMap collection cannot be enumerable.
In the [documentation](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/WeakSet) have an interesting example about the usage of that structure.
Simple example of using WeakSet:
```
const weakSet = new WeakSet();
const foo = {};
const bar = {};
weakSet.add(foo);
weakSet.add(bar);
console.log(weakSet.has(foo)); // true
console.log(weakSet.has(bar)); // true
weakSet.delete(foo);
console.log(weakSet.has(foo)); // false
console.log(weakSet.has(bar)); // true
console.log(weakSet.has({})); // false because is another reference
```
## Useful links:
- Key equality is based on the [sameValueZero](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Equality_comparisons_and_sameness#same-value-zero_equality) algorithm
- [Keyed collections](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Keyed_collections)
- [Standard built-in objects](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects) | guilhermegules |
773,690 | LeetCode 300. Longest Increasing Subsequence
(javascript solution) | Description: Given an integer array nums, return the length of the longest strictly... | 0 | 2021-07-28T01:56:30 | https://dev.to/cod3pineapple/leetcode-300-longest-increasing-subsequence-javascript-solution-m3o | algorithms, javascript | ###Description:
Given an integer array nums, return the length of the longest strictly increasing subsequence.
A subsequence is a sequence that can be derived from an array by deleting some or no elements without changing the order of the remaining elements. For example, [3,6,2,7] is a subsequence of the array [0,3,1,6,2,2,7].
###Solution:
Time Complexity : O(n^2)
Space Complexity: O(n)
```javascript
// Dynamic programming
var lengthOfLIS = function (nums) {
// Create dp array
const dp = Array.from(nums, () => 1);
// Max subsequence length
let max = 1
// Check all increasing subsequences up to the current ith number in nums
for (let i = 1; i < nums.length; i++) {
// Keep track of subsequence length in the dp array
for (let j = 0; j < i; j++) {
// Only change dp value if the numbers are increasing
if (nums[i] > nums[j]) {
// Set the value to be the larget subsequence length
dp[i] = Math.max(dp[i], dp[j] + 1)
// Check if this subsequence is the largest
max = Math.max(dp[i], max)
}
}
}
return max;
};
``` | cod3pineapple |
774,076 | How to do it FAST & FREE? : Design to Responsive Web Code | In usual Responsive Webpage developing way, Developers are required to convert Design file they adapt... | 0 | 2021-07-30T09:26:16 | https://dev.to/jacksonchill2/how-to-do-it-fast-free-design-to-responsive-web-code-fbb | html, css, react, webdev | In usual Responsive Webpage developing way, Developers are required to convert Design file they adapt from Designer, and have to learn the language to convert design's element into Responsive.
To conclude, it required some extra costs to learn and complete a simple developing stage.
Yes, a SIMPLE developing stage. Because there is simple substitute solution.
Very recently, a few low-code tools have been successfully developed to improve Developers' workflow. But most of the tools never really get enough exposure and trust, mostly because doesn't sounds persuasive enough.
I'm also one who never really believe in this at first. But ever since I give it try...... it might sounds cliche, but, it really changed my original workflow.

***A FAST & FREE tool***
Been using a Responsive Developing tool called pxCode (www.pxcode.io) lately. What surprised me the most is that it allows me to simply skipped the coding & handoff stage, and with just instinctive visual editing steps, I can complete a well-structured Responsive Webpage.
I first encounter this tool across YouTube, and this general introduction video caught my attention to give it a try. It introduced some major functions within 4 mins, which I strongly recommend watching.
{% youtube RF48QP2rbNc %}
*3 Major Editing Steps:*
1. Split to Sections
2. Analyze Group
3. Smart Responsive
-
**Split to Sections**

First, [Split to Sections]. In this stage, you can simply & instinctively split your design into sections, in order to have a better and clearer editing interface.
**Analyze Group**
In [Analyze Group]. The ultimate target is to turn all the ‘Buggy Group’ into ‘Well-Structured’ mode.

While [Analyze Group] is the core editing part, it uses four main steps to complete, which are ‘Suggestion’, ‘Clean Up’, ‘Boundary’ & ‘Layout’. Most of the time, pxCode will suggests the possible next editing steps for you.
What you have to do here, is to simply decide the options it provided. For Instance, when you’re into ‘Suggestion’ stage, you'll need to judge if the suggestion is suitable, by clicking [Group It] or [Reject].

In general designs, it was completed by three layers, which are ‘Foreground’, ‘Main Content’, and ‘Background’. Therefore, you'll need to separate them by applying settings for each. It helps maintaining a clean HTML structure.
Lastly, is to apply [Flex Row], [Flex Column], or [Keep as Group] to each content's element, which also affects directly to the HTML structure. Then, pick the main child item in order to enlarge with the content.
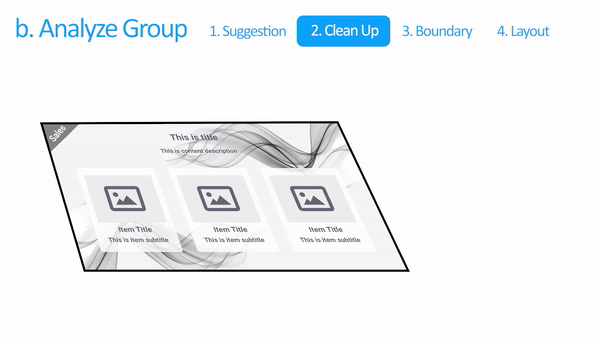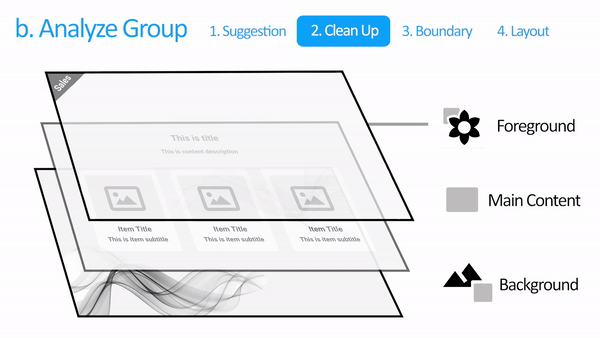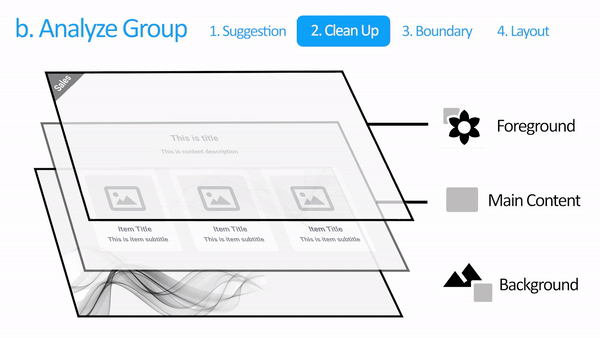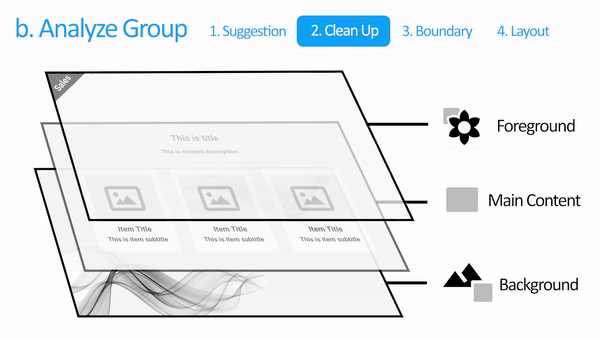
**Smart Responsive**
It is the final step of pxCode editing. When you complete all the suggestions and received a ‘Congratulations’ badge, pxCode will suggest to apply ‘Lucky Guess’.
It will intelligently apply all the suitable numbers for your responsive content, from ‘Margin’, ‘Text’ and ‘Flex’. Therefore, you can make a decent CSS layout while your design can smoothly respond in any resolutions.
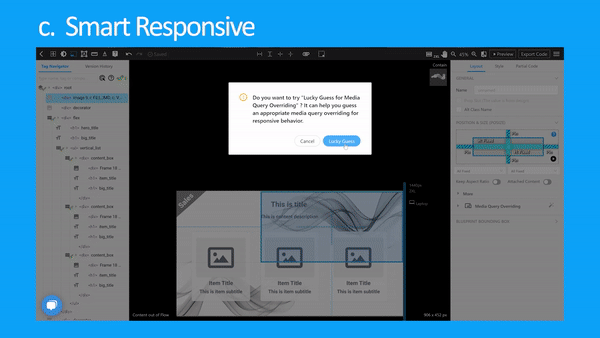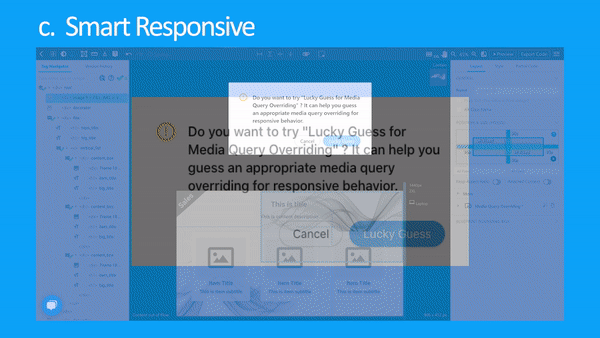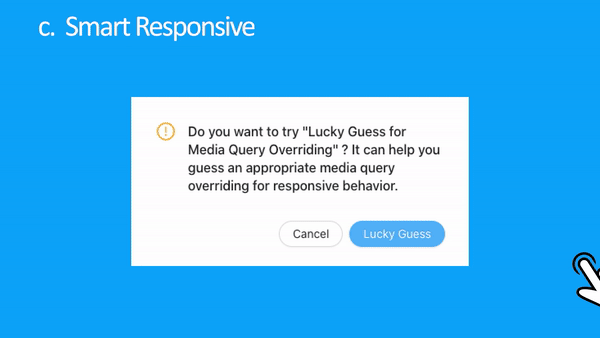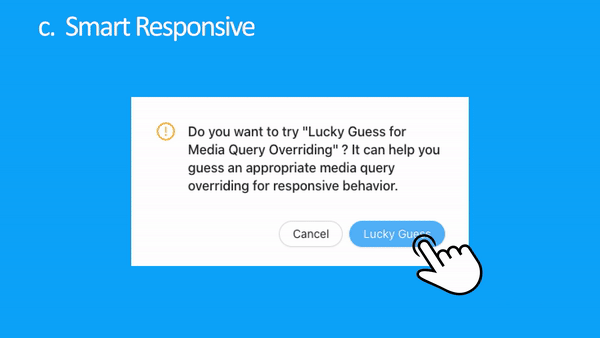
***Give it a TRY***
I've been enjoying this tool to convert my usual Design to Web workflow, and still discovering more of the features from it at the moment, as they still have plenty to do on the instructions.
But I personally looking forward for it to be more profound in the future. At the moment, the tool is unbelievable but completely FREE! not sure will it make any subscriptions fee, but why not try it now?

【Here are the tutorial of pxCode I found】:
YouTube: https://www.youtube.com/channel/UCi-NJnon0ROgyX2xdO9y-QA
Medium: https://medium.com/pxcode | jacksonchill2 |
774,182 | Experience of Web Development Internship at LetsGrowMore Community | Hello everyone, I'm elated to share that I've successfully completed the web Development Internship... | 0 | 2021-07-28T13:13:28 | https://dev.to/bhuvaneshwari05/experience-of-web-development-internship-at-letsgrowmore-community-5d05 | css, html, javascript, react | Hello everyone, I'm elated to share that I've successfully completed the web Development Internship at LetsGrowMore by completing the Task-1 and Task-2.
**Task-1 :** Single-Page Website
**Technologies used :** HTML,CSS,javascript
**Code Editor :** Visual Studio Code
**Github Link :** https://github.com/Bhuvaneshwari05/LGMVIP-WebDev
**Task-1 Experience:**
I have learnt HTML,CSS and javascript for designing this website. I have learnt so many new things about CSS and its purposes. This Internship helped me to know more about javascript. I faced issues in coding for alignment of pictures and in using some other css attributes. It was a great learning experience. I have learnt how to sort out my issues. This website has no database linked in it for responsive data storage. It is a simple website that will let you know about the theme of website when you click on the responsive button that I have designed.
**Task-2 :**Web Application Using Create-React-App
**Technologies Used :**HTML,React js,Javascript,CSS
**Code Editor :**CodeSandBox
**Github Link :** https://github.com/Sasirekha-123/LGMVIP-WebDev
**Task-2 Experience:**
I have learnt React JS to complete this Web Application. In this I have used HTML,CSS to design the layout and the responsive part is made of React js. I have used API link to fetch the data and to display. This is a simple web application to display the users of brand while clicking in the get users button. It was a great learing experience. On the whole I have learnt React js completely while doing this task.
**Conclusion:**
I thank Mr.Aman Kesarwani and LetsGrowMore for giving me this opportunity to work on the projects based on Web Development. Through this Internship I have learnt and gained a lot of practical knowledge in the field of Web Development.
To know more about LetsGrowMore Internships visit the site
https://letsgrowmore.in/ and https://letsgrowmore.in/vip/ | bhuvaneshwari05 |
774,299 | Using C# Source Generators to Generate Data Transfer Objects (DTOs) – Part 2 | In part 1, I created a very basic DTO generator that could only work with primitive types. In this... | 0 | 2021-07-30T06:34:28 | https://amanagrawal.blog/2021/07/28/using-c-sharp-source-generators-to-generate-dtos-part2/ | csharp, sourcegenerators, developerproductivity, automation | ---
title: Using C# Source Generators to Generate Data Transfer Objects (DTOs) – Part 2
published: true
date: 2021-07-28 10:00:00 UTC
tags: csharp,sourcegenerators,developerproductivity,automation
canonical_url: https://amanagrawal.blog/2021/07/28/using-c-sharp-source-generators-to-generate-dtos-part2/
---
In [part 1](https://dev.to/coolblue/using-c-source-generators-to-generate-data-transfer-objects-dtos-5gbl), I created a very basic DTO generator that could only work with primitive types. In this final and very looong part, I will try and extend it to be more useful by supporting generic types, complex types and generating mapping methods.
First though I am going to tackle the mapping extension methods because that can enhance the usability of the current generator quite a bit with minimal work (ye’ old 80/20 rule). What I am after is something that looks like this:
{% gist https://gist.github.com/explorer14/35054dfc2cd8812fbb9259a724739cbf %}
This may not be uncommon for a mapping method, I have written tons of mappers like this and from experience I can say unequivocally, they never get much smarter than this with the exception of, null input handling. There shouldn’t be any smarts in the DTOs or the mappers anyway, its an anti-pattern and a design smell because DTOs are only meant as data vessels that get serialised over the network. Nothing more!
To keep things clean, I will remove the code that I had already written for the basic generator and simply add code to the end:
{% gist https://gist.github.com/explorer14/e3d5f76c8180cdb5bcecba55f1556aa8 %}
Much of the code should be pretty self-explanatory, I am simply generating a static class with an extension method in to convert from the domain entity to the DTO but let’s unpack:
1. I am all for contextual names for classes and functions etc, but in this case if I just give the class the name `EntityExtensions` or something along those lines, then the names will clash with the other extension classes that I will create for other complex types later on. Its possible to put all extension methods in one class but for now, I’d rather keep them per DTO. The impact on compilation should be minimal so there is little incentive to bung them all in one class. Therefore, I am just going to append a “-” stripped Guid to the class name so they are all unique.
2. Next I will define the signature of the extension method which accepts an instance of the domain entity type and returns an instance of DTO type. The `TypeDeclarationSyntax` instance will give me the name of the domain entity type I am creating the extension method on.
3. Then I am going to loop over all the property members of the current domain entity type and add assignment statements that copy values from domain entity property and into the corresponding DTO property. Once again, this is driven by convention as opposed to configuration i.e. the property on the DTOs are assumed to be the same name and type as the corresponding properties in the corresponding domain entities. This will ensure type safety and keep the generation code simple.
4. Finally, I close out the method, class and namespace. Note that I am adding the extension class and methods to the same namespace as that of the DTO for simplicity reasons.
Once this is done, I will build the solution and inspect my consuming app `ConsoleApp9` for any generated code and sure enough, I see it (if the build succeeded):
[](https://codequirksnrants.files.wordpress.com/2021/07/image-2.png)
Note that I didn’t have to restart Visual Studio for these changes to reflect. Turns out if you create a new source generator i.e. for the first time and do a build, VS picks it up. Its only any subsequent changes you might make to the types or the generated code that it needs to be restarted for.
The generated code also looks like its correct, if you can build its a good indicator that the code is syntactically correct otherwise the original build would have failed if I had made a typo whilst generating code.
[](https://codequirksnrants.files.wordpress.com/2021/07/image-5.png)
I can easily show this, I will fudge up a semi-colon in the `return` statement and **re-build** the solution (normal build will not throw up errors):
[](https://codequirksnrants.files.wordpress.com/2021/07/image-3.png)
But when I go to the generated entity, the semi-colon is still there!!🤔 Of course, I need to restart VS to see that, don’t I? 💡🤦♂️
[](https://codequirksnrants.files.wordpress.com/2021/07/image-4.png)
Now I can start using this mapper from my consumer app because the `ToDto` extension method just magically appears (_that’s not to say I don’t need to import the `ConsoleApp9.Domain.Dtos` namespace where all this generated code lives, I absolutely do_ _but I will let Re-sharper and/or intellisense help me do that_!):
[](https://codequirksnrants.files.wordpress.com/2021/07/image-6.png)
Just to make sure it works as well as it looks, I will simply JSON-ify the DTO (_the ultimate destiny for almost all DTOs anyway_) and dump it on the console:
[](https://codequirksnrants.files.wordpress.com/2021/07/image-7.png)
Looks like it!
So far so good! I’ve got the basic DTO and mapper working but I am not out of the woods yet. Say now the domain asks me to record an employee’s address, for this I will create a value type `Address` and add a nullable property of that type to the `Employee` domain entity (its not required to have a home address right from the start, an employee can always add their home address once they have a permanent place to stay):
{% gist https://gist.github.com/explorer14/479cc1b790b0ba61fc5c7155d6c35cb2 %}
I will just do a quick re-build at this stage to see what the generator outputs (if anything):
[](https://codequirksnrants.files.wordpress.com/2021/07/image-11.png)<figcaption> The new types have been added! so, yay! </figcaption>
But if I open the EmployeeDto class, at first blush everything seems fine! But there are two problems both highlighted in orange:
[](https://codequirksnrants.files.wordpress.com/2021/07/image-12.png)
1. The DTO mis-identified the type of the `HomeAddress` property as `Address` as opposed to `AddressDto`?, and
2. The mapping function is directly assigning the entity property to the DTO property which will not work since the type is a complex type and will need to be further converted to DTO. Due to the mis-identification of the property type in problem 1, the build also didn’t fail because the mapper is assigning the property of an assignable type i.e. `Address?`.
To fix these I essentially need to:
a. Detect if the type of the domain entity property being evaluated is a complex type or not.
b. If its complex type, then 1) Use `AddressDto?` as the property type (for nullable types) instead of `Address`? 2) instead of directly assigning (as I had been doing thus far), invoke the corresponding ToDto() method on the domain entity property. This will convert `Address` to `AddressDto` for e.g. Otherwise, do what I am doing currently because the property is not a complex type.
For determining if the type is a complex type or not, I will be using the semantic model exposed by `GeneratorExecutionContext` because the semantic model is the one that contains information on what things _mean_ for e.g. if something is a reference type and a class etc. which is what I need to find out. I will modify the BuildDtoProperty() method and add two convenience extension methods as shown in the gist below:
{% gist https://gist.github.com/explorer14/f68a03cbb9cfee64ae4b887926e1c528 %}
As it turns out this semantic information about properties lives inside the semantic model as `ISymbol` instances and for properties more specifically in `IPropertySymbol` instances and exposes type information. The `IsOfTypeClass` method, checks to see if the property type is a reference type, its kind is `class` and the property type must be within the same namespace as the original namespace. This last one is important i.e. both DTO types should be in the same namespace, this means no external types are allowed because it will be hard to be certain if that type is controlled by the client application or not, hence might be difficult to decorate with custom attributes and appropriately convert to a DTO. For e.g. if I create a `String` property in my domain entity, without this check, the generator will create a property of type `StringDto` which makes no sense since `String` is a .NET CLR type, not a custom domain type and is therefore not controlled by the consuming application.
The `IsOfTypeStruct` method is mostly the same except for checking to see if the type is a `struct` value. If either of these is true, then I want to suffix the original type name in the property with the word “Dto” to reference the DTO class. Whilst at it, I will also take care of nullable types as well! It would appear that **IPropertySymbol.Type.Name** excludes the “?” from the nullable types, **IPropertySymbol.Type.ToDisplayString()** includes it. The former is useful for complex type because I need to suffix “Dto” for the DTO property whilst the latter will work for primitive types because the type name can go into the DTO verbatim. Using display string for complex type could result in the type name looking like: `Address?Dto?` which is syntactically wrong and will fail to compile.
>  Lot of this code is trial and error. Exploring the Roslyn syntax/semantics API can help in understanding which types contain what information but good ol’ trial and error is less painful than trying to debug the source generator. Its doable by calling `Debugger.Attach` in the `Initialize` method but I’ve found that it tends to create a vicious debug cycle where VS prompts the UAC dialog everytime something causes the debugger to run for e.g. any time you change anything in the code. Dismissing that dialog half a dozen times everytime you alter a single letter in code is a NIGHTMARE so I wouldn’t recommend that approach!
Finally, I will change the mapper generation to include the ToDto invocation against any complex type properties. This is straightforward since it builds on the work already done above. For this I will modify the member loop in the main Execute method to do the same complex type vs primitive type check, and for complex type I will append the null coalescing operator and “ToDto()” suffix at the end (to make it null safe):
{% gist https://gist.github.com/explorer14/fadf91e64acc38f82920687d92efc178 %}
Build the solution to generate the updated code:
[](https://codequirksnrants.files.wordpress.com/2021/07/image-15.png)<figcaption>That’s more like it!</figcaption>
And now run the consumer app to make sure that its all working:
[](https://codequirksnrants.files.wordpress.com/2021/07/image-14.png)<figcaption>And the serialised version of the DTO agrees!</figcaption>
If the address was never set, the serialised value will simply be `null` but the app won’t crash due to a null-ref exception like it would have done if I hadn’t made the dto conversion null safe for nullable types.
Finally the domain is asking me to change the Employee definition to keep a track of all the assets an employee has been issued by the company for e.g. business phones, laptops etc.
To accommodate this request I will make 2 changes to the domain model:
1. Create 2 new value types called `CompanyAsset` and `AssetCode`, in the domain and decorate them with the `GenerateMappedDto` attribute. An asset MUST have a code associated with it. This is just to see how code gen will work with nested complex types, domain modeling is outside the scope of this blog series.
2. Add an `IReadOnlyCollection<CompanyAsset>` property calls `AssetsAllocated` and expose a method on the `Employee` class to add assets to the collection when they are allocated to our employee. So now the entity class looks like:
{% gist https://gist.github.com/explorer14/bc06243d52e59cc894a4ea315d9fb33c %}
I’ll be able to build on the work done so far for much of the remaining challenge but generic types still need to be handled properly, more specifically generic collection types as in this case. If I were to build the code in its current form, the generic collection property(ies) will have the same problem of mis-identified types. So to address this what I want to do is: a) add a DTO property with type `IReadOnlyCollection<CompanyAssetDto>` b) Invoke the `ToDto()` method on each item of this collection in the mapper extension and so on down.
The challenge now is to detect if the property type is a generic type and suffix all **complex type arguments** with “Dto” so, `IReadOnlyCollection<CompanyAsset>` will become `IReadOnlyCollection<CompanyAssetDto>`.
> !!! You are now entering messy, hacky code territory!!! 
Turns out this is a ~~little~~ quite a bit more difficult to achieve using the semantic model alone so I will also use the syntactic model (_please read the inline comments in code to get some idea of what the hell is happening_):
{% gist https://gist.github.com/explorer14/22287c9d65ad2d6d588597a383ead6dd %}
The way I figured which syntax types I need to use, is with this little nifty tool called _Syntax Visualizer_. You can install this if you modify your VS installation to add the _.NET Compiler Platform SDK_ workload, via the _Visual Studio Installer_ app. The way this works is by simply clicking on the type in your code that you want to visualise and the visualiser will automatically refresh and open up the corresponding node in the syntax tree:
[](https://codequirksnrants.files.wordpress.com/2021/07/image-18.png)<figcaption>What I am interested in is the <code>TypeArgumentList</code> node of the <code>GenericNameSyntax</code> node for this property</figcaption>
Basically it comes down to which types in the type argument list should have the Dto suffix and which shouldn’t. All custom types i.e. the ones defined in the **Domain.Dtos** namespace, need a Dto suffix whereas all .NET types, don’t. In the `BuildTypeName()` method, the `INamedTypeSymbol::TypeArguments` will carry all type arguments listed on the generic type whereas the node under consideration only refers to one type at a time, so I’ve got to do a “lookup” and then determine if the type in the type argument list is custom or not and then return appropriately suffixed DTO type names.
[](https://codequirksnrants.files.wordpress.com/2021/07/image-16.png)<figcaption>Ok! Property type name sorted, onto the mapper method…</figcaption>
This is getting hackier (or at least uglier) by the minute because I am focussing on getting it to work first, I will eventually put a more cleaned-up version of the code up on Github but for now I will highlight the chunk that fixes the conversion methods for properties with generic collection types.
{% gist https://gist.github.com/explorer14/5b1fdc19b519035c83b27c999669ad26 %}
Essentially, if the generic type argument is a primitive type then conversion is basically direct assignment from entity to DTO. But if any type argument is a custom type, then I will attach the “ToDto()” call to the assignment to convert from the entity type to DTO type. I am also making an assumption about the entity and the DTO, that is generic type arguments are only used with collection types like the ones I mentioned previously (so no `Task<T>` in domain entities for e.g.). Therefore if I find generic types with complex types as arguments, then I will also generate extension methods to convert a collection of entity types to a collection of DTO types:
{% gist https://gist.github.com/explorer14/fe20f96082c7396c21aeca260f95307b %}
I am having to handle Dictionaries differently because they have 2 type arguments as opposed to just one and either TKey or TValue could be a custom type. I still have to fix this bit (_hence the 🤷♂️_) but at this stage I am wondering if this whole thing is worth it in the first place? I mean just look at the code so far!! Horribly unreadable mess!
Anyway, this results in the `EmployeeDto` class that also has extension methods to convert collection type properties in the domain entity to their DTO counterpart:
[](https://codequirksnrants.files.wordpress.com/2021/07/image-19.png)<figcaption>Finally!</figcaption>
…
HOLY CRAP! _That_ was a _lot_! Am I done though? For this particular source generator, I think yes. What’s “outstanding” i.e. is niggling at the back of my mind ? Well, a couple of things at least:
1. Putting DTOs closer to where they are used: _currently the code puts the generated DTOs within the sub-namespace within the domain and this could be a bit of problem because DTOs serve a different purpose than domain entities so they should be colocated with the thing that uses them. In this case, it should be the host project_ _for e.g. web api etc. I’ve not yet found a way to put the generated code in a custom location or if its even possible. If it is, then custom namespace could be passed to the attribute which the generator could use but at the moment I am not sure._
2. Performance profiling of the build with and without source generation: _To be perfectly honest, in my sample scenario, I didn’t notice a whole lot of build slowdowns. A couple of seconds to do a clean build doesn’t sound a whole lot, of course this is going to be solution dependent. Given a large enough solution and dog slow build machine, things could change._ _The source generator’s Execute method itself takes < 20 ms on my laptop_ _when doing builds inside Visual Studio_ _(I’ve added a little bit of timing code that roughly measures this)_
3. Testability of source generators: _Because throughout this entire exercise my focus was on exploration and trying to see what’s possible, I didn’t really TDD it (sue me! Its perfectly fine to not write tests when you are exploring/sketching because you don’t know how will it pan out!)_ _I will tackle testing in a later post_ _(accompanied by a fully refactored version of the code)_, _assuming I haven’t given up on this problem by then!_ _By the [looks](https://github.com/dotnet/roslyn/blob/main/docs/features/source-generators.cookbook.md#unit-testing-of-generators)of things, this might be possible I will have to see._
4. Debuggability of source generators: _One way to debug source generator will be to output another .cs file with logs written out as C# comments. The process of emitting this is no different than what I have shown here. Key thing to remember, the `hintName` argument in the `context.AddSource(...)` should be whatever you want to name the generated .cs file and the encoding MUST be UTF8, don’t let the optionality of that parameter fool you. F5 debugging of source generators is horrible like I have already mentioned in a preceding section._
5. Some edge case domain entity structures might not be covered by the current generator or might not produce the correct output: _In order to keep the generator relatively simple and not have it do too much, I would keep special customisations out of it. So no ability to inject custom behaviour into the DTOs and/or extensions._
6. Ignoring properties that I don’t want mapped: _This is fairly straightforward to do and can be achieved by decorating such properties with another custom attribute may be [ExcludeFromMapping_] _or something_. _I might do this by the time you read this post._
7. Un-mapping DTOs: i.e. if you don’t want an entity to be mapped to a DTO anymore, just remove the `GenerateMappedDto` attribute from the class and the generator will not generate code for it thereby effectively removing it. The generated code doesn’t get checked into the source control, so no harm either way.
## Conclusion
I do see the value of source generators in affording productivity gains with regards to repetitive tasks that developers do that don’t change from one to the next all that much. For e.g. generating mapping code like the one I have shown in these posts, the canonical example of automatically generating implementations for interfaces for e.g. stubs etc and another one that I would like to try out : auto-generating tests for a public API, although this might also mean somehow auto-generating the whole test project and then generating test code _into_ that project.
I find it a bit limiting that only new code could be created but existing code couldn’t be modified, although I can see where they are coming from on this. Allowing source generators to modify engineer written code can be risky due to potential flakiness and stability risks.
I also find limited debugging options a real pain and the fact that I have to restart VS multiple times to see the changes reflect but I am hoping these are just teething problems because VS Code is a lot better experience however, it doesn’t have the capability of showing the generated code so its a bit like flying blind.
Discovering the Roslyn syntax APIs with trial and error is quite time consuming but tools like Syntax Tree Visualiser help and once you’ve used the APIs you get some sense of what you need to use and then its just a matter of Ctrl + . exploration to find the right method/property to invoke.
Anyway, this has been fun, the code is on [GitHub](https://github.com/explorer14/SourceGenerators)!
_Header image [source](https://developers.redhat.com/blog/2021/04/27/some-more-c-9)_ | explorer14 |
774,384 | Build a React App with Authorization and Authentication | June 27, 2024: This blog post uses Amplify Gen 1, if you're starting a new Amplify app I recommend... | 0 | 2021-08-02T14:42:41 | https://welearncode.com/auth-react/ | javascript, react, aws | ---
title: Build a React App with Authorization and Authentication
published: true
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/p8j12k5aovf9owl4rplm.jpg
tags: javascript, react, aws
canonical_url: https://welearncode.com/auth-react/
---
> **June 27, 2024:** This blog post uses Amplify Gen 1, if you're starting a new Amplify app I recommend trying out [Gen 2](https://dev.to/aws/introducing-a-new-fullstack-typescript-dx-for-aws-1ap9)!
In this tutorial, we'll be talking about authorization and how to implement it with AWS Amplify's DataStore. First, let's get on the same page with what authorization and authentication are:
**Authorization** - Different users have different actions that they can perform. **Authentication** - making sure someone is who they say they are, for example through making them enter a password.
**Please note that I work as a Developer Advocate on the AWS Amplify team, if you have any feedback or questions about it, please reach out to me or ask on our discord - discord.gg/amplify!**
{% youtube U5Ls-RspRv8 %}
This tutorial will be bypassing teaching React and AWS Amplify - check out [this React tutorial](https://welearncode.com/beginners-guide-react/) and [this Amplify Admin UI tutorial](https://welearncode.com/intro-amplify-admin-ui/) if you're new to either. You'll also need to know [React Router](https://reactrouter.com/).
I created a repo with some [starter code](https://github.com/aspittel/react-authorization) in order to get to the relevant pieces of the tutorial. Go ahead and clone it down if you want to follow along. Run `npm i` within the cloned directory to get all the needed packages installed.
We'll be building a blogging platform with a frontend and backend authentication system with admin roles and certain actions restricted to content's creators. We'll first have blogs -- similar to Medium publications or Blogger blogs. Only admin users will be able to create new blogs, though anybody can view a list of the blogs. Blogs will have posts within them that anyone can view, but only the person who created the blog will be able to update or delete blogs.
## Create a Blog using the Admin UI
First, we'll need to create the data models for our app. You can go to [the Amplify Sandbox](https://sandbox.amplifyapp.com/getting-started) in order to get started. We'll create two models, a Blog and a Post. The Blog will be a publication that has a collection of Posts attached to it. The Blog will just have a name, and then Blog will have a title, and content. All fields will be strings, I also made name and title required fields. There will also be a 1:n relationship between the two models.
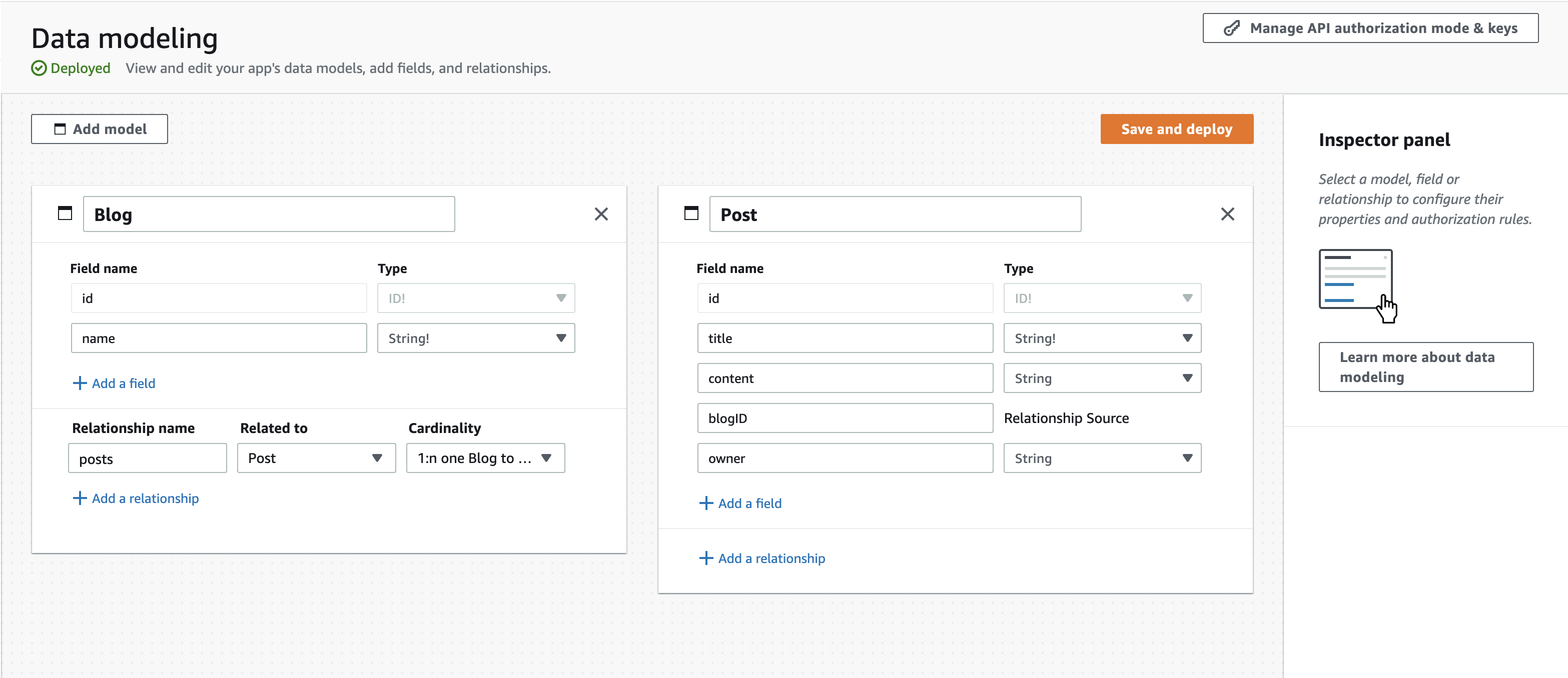
Now, go ahead and deploy your data models by following the guided process the Admin UI offers. Once it deploys, go into the Admin UI and create a few blogs and a few posts.
Then, we'll add authentication. In the Admin UI, click on "Authentication" tab and then configure auth. I deployed with the default options.
Once your authentication is deployed, add in authorization rules. First, click on the Blog model and on the right-hand panel, configure authorization. Uncheck create, update, and delete from under "Anyone authenticated with API Key can..." -- we'll allow anyone to view a blog but only admins to mutate them. Then, click the add an authorization rule dropdown. From here click "Create new" under "Specific Group", and name your group "admin". Allow admin users to perform all actions.
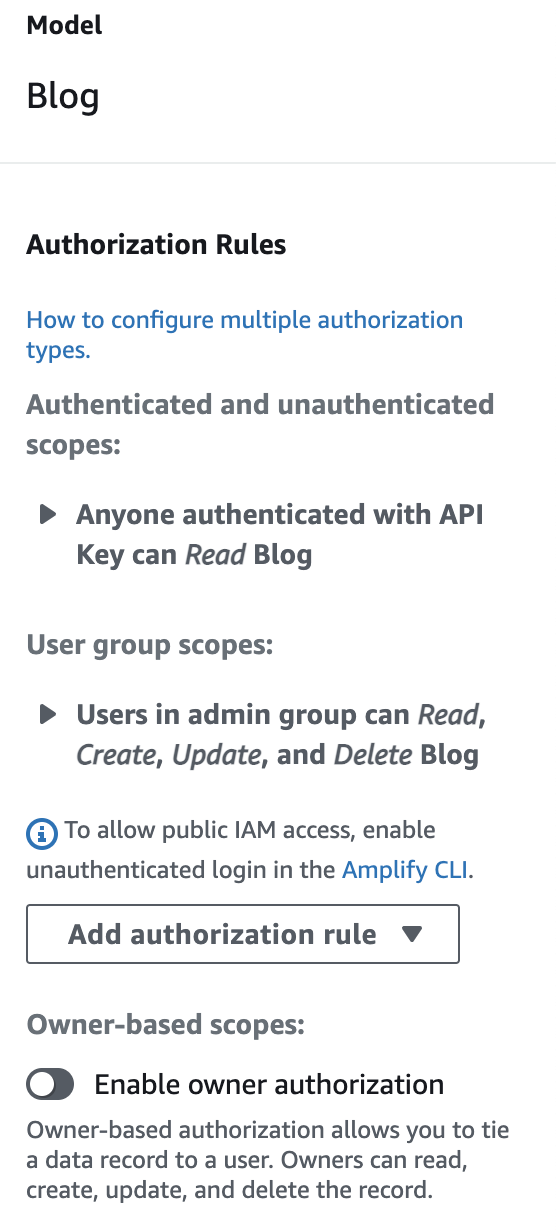
Now we'll configure authorization for posts. Select that model, and again change the permissions for "Anyone authenticated with API Key" to "Read" a post. Then toggle the "Enable owner authorization" to the on state. Under "Deny other authenticated users to perform these operations on an owner’s record:" select "Update" and "Delete" -- we want anyone to be able to read a post, but only the post's owner should be able to mutate existing posts. We also need to allow someone to be able to create posts! Under "add authorization rule" and then "Any signed-in users authenticated using" and then choose "Cognito".
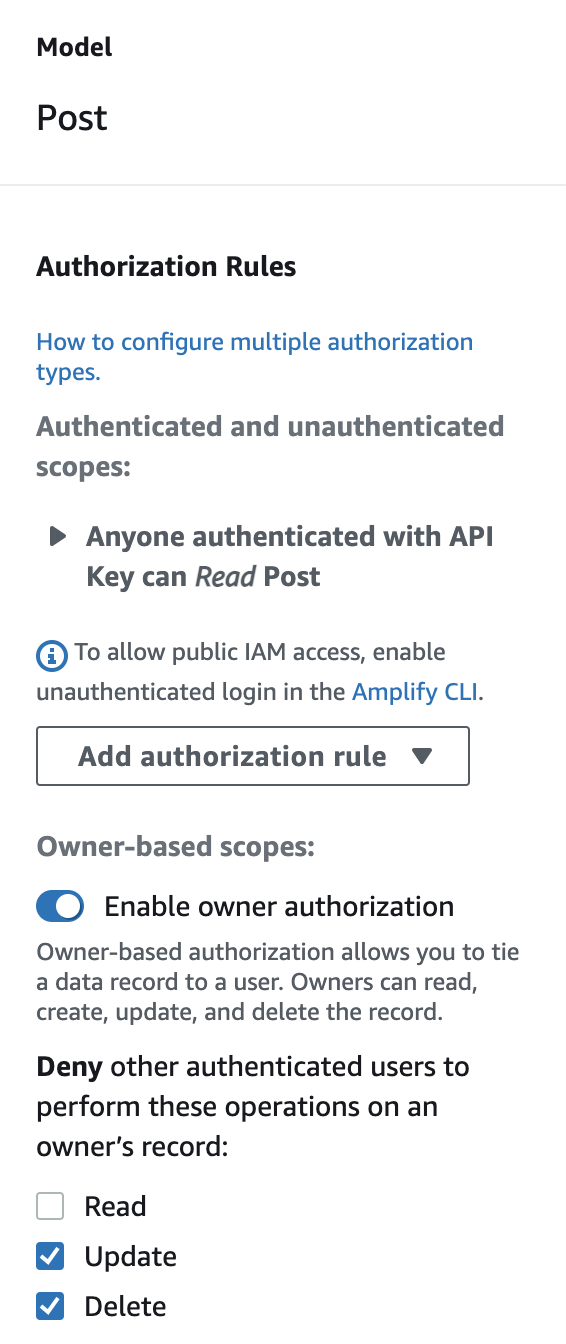
Back in your code's directory, run Amplify pull with your app id -- you can find this command under "local setup instructions" in the Admin UI. If you're not using the cloned repository from above, install the Amplify JavaScript and React libraries.
```sh
$ npm i aws-amplify @aws-amplify/ui-react
```
You'll also need to configure Amplify in your `index.js` file so that your frontend is linked to your Amplify configuration. You'll also need to configure multi-auth within this step.
```js
import Amplify, { AuthModeStrategyType } from 'aws-amplify'
import awsconfig from './aws-exports'
Amplify.configure({
...awsconfig,
DataStore: {
authModeStrategyType: AuthModeStrategyType.MULTI_AUTH
}
})
```
## Implement Authentication
First, we'll need to implement authentication for our site so that users can log in and different accounts can perform different actions. I created a `<SignIn>` component with a route to it. Then, add the `withAuthenticator` higher order component to implement a user authentication flow!
```diff
// SignIn.js
import { withAuthenticator } from '@aws-amplify/ui-react'
import React from 'react'
import { Link } from 'react-router-dom'
function SignIn () {
return (
<div>
<h1>Hello!</h1>
<Link to='/'>home</Link>
</div>
)
}
+ export default withAuthenticator(SignIn)
```
Then, we'll load all the blogs on to the home page of the app. I'm starting with the following code that will implement different routes for my app. If you're using the cloned boilerplate, you'll already have this in your code. You'll also want to create React components for `BlogPage`, `PostPage`, and `BlogCreate` -- these can just be empty components for now.
```js
import './App.css'
import { Auth } from 'aws-amplify'
import { DataStore } from '@aws-amplify/datastore'
import { useEffect, useState } from 'react'
import { Switch, Route, Link } from 'react-router-dom'
import BlogPage from './BlogPage'
import PostPage from './PostPage'
import BlogCreate from './BlogCreate'
import SignIn from './SignIn'
import { Blog } from './models'
function App () {
const [blogs, setBlogs] = useState([])
return (
<div className='App'>
<Switch>
<Route path='/sign-in'>
<SignIn />
</Route>
<Route path='/blog/create'>
<BlogCreate isAdmin={isAdmin} />
</Route>
<Route path='/blog/:name'>
<BlogPage user={user} />
</Route>
<Route path='/post/:name'>
<PostPage user={user} />
</Route>
<Route path='/' exact>
<h1>Blogs</h1>
{blogs.map(blog => (
<Link to={`/blog/${blog.name}`} key={blog.id}>
<h2>{blog.name}</h2>
</Link>
))}
</Route>
</Switch>
</div>
)
}
export default App
```
In the `<App>` component, first import the `Blog` model.
```js
import { Blog } from './models'
```
Then, create a `useEffect` which will be used to pull data to that component.
```js
// create a state variable for the blogs to be stored in
const [blogs, setBlogs] = useState([])
useEffect(() => {
const getData = async () => {
try {
// query for all blog posts, then store them in state
const blogData = await DataStore.query(Blog)
setBlogs(blogData)
} catch (err) {
console.error(err)
}
}
getData()
}, [])
```
Then, we'll want to fetch the current user if there is one. We'll also want to check and see if that user is an admin.
```diff
const [blogs, setBlogs] = useState([])
+ const [isAdmin, setIsAdmin] = useState(false)
+ const [user, setUser] = useState({})
useEffect(() => {w
const getData = async () => {
try {
const blogData = await DataStore.query(Blog)
setBlogs(blogData)
// fetch the current signed in user
+ const user = await Auth.currentAuthenticatedUser()
// check to see if they're a member of the admin user group
+ setIsAdmin(user.signInUserSession.accessToken.payload['cognito:groups'].includes('admin'))
+ setUser(user)
} catch (err) {
console.error(err)
}
}
getData()
}, [])
```
Finally, we'll want to render different information depending if the user is signed in or not. First, if the user is signed in, we'll want to show a sign out button. If they're logged out, we'll want to give them a link to the sign in form. We can do this with the following ternary:
```js
{user.attributes
? <button onClick={async () => await Auth.signOut()}>Sign Out</button>
: <Link to='/sign-in'>Sign In</Link>}
```
You can also add this snippet to make it so that admin users have a link to create a new blog.
```js
{isAdmin && <Link to='/blog/create'>Create a Blog</Link>}
```
I added both lines to the home route for my site.
```diff
<Route path='/' exact>
<h1>Blogs</h1>
+ {user.attributes
+ ? <button onClick={async () => await Auth.signOut()}>Sign Out</button>
+ : <Link to='/sign-in'>Sign In</Link>}
+ {isAdmin && <Link to='/blog/create'>Create a Blog</Link>}
{blogs.map(blog => (
<Link to={`/blog/${blog.name}`} key={blog.id}>
<h2>{blog.name}</h2>
</Link>
))}
</Route>
```
Here is the [completed code](https://github.com/aspittel/react-authorization/blob/finished/src/App.js) for the App component.
## Blog Page
Now, we'll implement the component that shows one blog. We'll first query to get the blog's information, then get the posts attached to it. In my app, I used React Router to create blog detail pages for each blog that follow the url pattern `/blog/:blogName`. I'll then use the `:blogName` to get all of that blog's information.
I'll start with a page that renders each post. I'll also add a button to create a new post, but only if there's a user:
```js
import { DataStore } from 'aws-amplify'
import { useEffect, useState } from 'react'
import { useParams, Link } from 'react-router-dom'
import { Post, Blog } from './models'
export default function BlogPage ({ user }) {
const { name } = useParams()
const createPost = async () => {
}
return (
<div>
<h1>{name}</h1>
{user && <button onClick={createPost}>create new post</button>}
{
posts.map(post => (
<h2 key={post.id}>
<Link to={`/post/${post.title}`}>
{post.title}
</Link>
</h2>)
)
}
</div>
)
}
```
Then, I'll add this `useEffect` in order to load all the posts.
```js
// body of BlogPage component inside BlogPage.js
const [blog, setBlog] = useState({})
const [posts, setPosts] = useState([])
useEffect(() => {
const getData = async () => {
// find the blog whose name equals the one in the url
const data = await DataStore.query(Blog, p => p.name('eq', name))
setBlog(data[0].id)
// find all the posts whose blogID matches the above post's id
const posts = await DataStore.query(Post, p => p.blogID('eq', data[0].id))
setPosts(posts)
}
getData()
}, [])
```
Let's also add functionality to the "create new post" button that allows you to create a new post on click! The owner field will autopopulate with the current logged in user.
```js
const createPost = async () => {
const title = window.prompt('title')
const content = window.prompt('content')
const newPost = await DataStore.save(new Post({
title,
content,
blogID: blog.id
}))
}
```
[Final code](https://github.com/aspittel/react-authorization/blob/finished/src/BlogPage.js) for the BlogPage component.
## Blog Create
Let's also make it so that people can create a new blog. Inside of the `<BlogCreate>` component. First, create a standard React form that will allow a user to create a new blog.
```js
import { DataStore } from 'aws-amplify'
import { useState } from 'react'
import { Blog } from './models'
export default function BlogCreate ({ isAdmin }) {
const [name, setName] = useState('')
const createBlog = async e => {
e.preventDefault()
}
return (
<form onSubmit={createBlog}>
<h2>Create a Blog</h2>
<label htmlFor='name'>Name</label>
<input type='text' id='name' onChange={e => setName(e.target.value)} />
<input type='submit' value='create' />
</form>
)
}
```
Now, implement the `createBlog` function by adding the following:
```js
const createBlog = async e => {
e.preventDefault()
// create a new blog instance and save it to DataStore
const newBlog = await DataStore.save(new Blog({
name
}))
console.log(newBlog)
}
```
Finally, add a conditional around the form - we only want to render it if the user is an admin!
```js
if (!isAdmin) {
return <h2>You aren't allowed on this page!</h2>
} else {
return (
<form>
...
</form>
)
}
```
Here's [this component](https://github.com/aspittel/react-authorization/blob/finished/src/PostPage.js) all together.
## Post Page
Last component to implement! This one's the post detail page. We'll implement an edit form so that content owners can edit their posts. First, create a React form for the post. We'll again use React Router to send the name of the post to the component.
```js
import { DataStore } from 'aws-amplify'
import { useEffect, useState } from 'react'
import { useParams, Link } from 'react-router-dom'
import { Post } from './models'
export default function PostPage ({ user }) {
const { name } = useParams()
const [post, setPost] = useState([])
const [title, setTitle] = useState('')
const [content, setContent] = useState('')
const handleSubmit = async e => {
e.preventDefault()
}
return (
<div>
<h1>{name}</h1>
<form onSubmit={handleSubmit}>
<label>Title</label>
<input type='text' value={title} onChange={e => setTitle(e.target.value)} />
<label>Content</label>
<input type='text' value={content} onChange={e => setContent(e.target.value)} />
<input type='submit' value='update' />
</form>
</div>
)
}
```
Then we'll create a `useEffect` that will get the information about the post from DataStore and render it in the form. Note that this won't work well if you have two posts with the same name! In a larger-scale app you'd want to have some differentiator in the urls for each post.
```js
useEffect(() => {
const getData = async () => {
const posts = await DataStore.query(Post, p => p.title('eq', name))
setPost(posts[0])
setTitle(posts[0].title)
setContent(posts[0].content)
}
getData()
}, [])
```
Then, we'll need to implement the handleSubmit. We'll want to copy the original post, update the needed attributes and save them to DataStore.
```js
const handleSubmit = async e => {
e.preventDefault()
await DataStore.save(Post.copyOf(post, updated => {
updated.title = title
updated.content = content
}))
}
```
Finally, within the `return`, we'll only want to render the form if the user owns the post. Outside the form, add the following conditional to only render it if the post owner is that user! Amplify automatically creates the owner field for us. Every time that you create a new post, it will be populated for you too!
```js
{user.attributes && (post.owner === user.attributes.email) && (
<form onSubmit={handleSubmit}>
...
</form>
)}
```
Here's the component's [final code](https://github.com/aspittel/react-authorization/blob/finished/src/PostPage.js).
## Conclusion
In this post, we use Amplify's DataStore multi-auth to implement different permissions based on the user's role and ownership of content. You could keep extending this with more forms, styling, and data rendering. I'd love to hear your thoughts on this app and this new Amplify feature! | aspittel |
774,387 | What is the full form of CID? | The Full-Form of CID | Meaning, History, FAQs| Latest Update 2021 The full form of CID is Criminal... | 0 | 2021-07-28T15:24:16 | https://dev.to/gotechmantra/what-is-the-full-form-of-cid-10h3 | The Full-Form of CID | Meaning, History, FAQs| Latest Update 2021
The full form of CID is Criminal Investigation Department. It is a branch of the police department inducted with the task of carrying out investigations, inquiries and other related detective jobs relating to a crime committed.
The criminal investigations by police personnel wearing plainclothes in India is a very ancient system first modernized by Chanakya (also known as Kautilya) and applied in the Mauryan Kingdom some 2350 years ago. The Mughal Emperors further modernized the CID.
Also Read:
[file:///sdcard/](https://techcrazee.com/file-sdcard/)
[filmy4wap tech](https://techcrazee.com/filmy4wap-movie-download-website/)
[moviezwap](https://techcrazee.com/moviezwap/)
[4movierulz](https://gotechmantra.com/4movierulz/)
[Technology Write for us](https://www.flipupdates.com/write-for-us/)
[Technology Write for us](https://dailytechquest.com/write-for-us/)
[content://com.android.browser.home/](https://dailytechquest.com/content-com-android-browser-home/)
[Technology Write for us](https://dailytechhunt.com/write-for-us/)
[4movierulz](https://techkalture.com/4movierulz/)
[tamilrockers proxy](https://www.webtechmantra.com/tamilrockers-proxy/)
[mis webmail](https://www.webtechmantra.com/mis-webmail/)
[solarmovie](https://techkalture.com/top-best-solarmovie-alternatives/)
[bts full form](https://techcrazee.com/bts/)
[cid full form](https://techkalture.com/cid/)
[tmc full form](https://techkalture.com/full-form-of-tmc/)
[movierulz.vpn](https://www.webtechmantra.com/movierulz-vpn/)
| gotechmantra | |
774,665 | My journey through the world of Web development with Datastax | At the beginning of this summer, I completed my first year of study at the Faculty of Liberal Arts... | 0 | 2021-07-29T00:08:35 | https://dev.to/darbian/my-journey-through-the-world-of-web-development-with-datastax-1l42 | datastax, programming, beginners, webdev | At the beginning of this summer, I completed my first year of study at the Faculty of Liberal Arts and Sciences, and the biggest fear was the feeling that *I was not good enough*. Not good enough to compete with purposeful Computer Science students to apply for an internship in an IT company. I independently choose what kind of knowledge I will receive during training and around me are mainly students of creative directions: philosophers, writers, directors, musicians, film critics, and so on. For the whole year, I managed to get acquainted with only one student who, like me, chose Computer Science and Artificial Intelligence. This creates for me a feeling of vacuum, isolation, a sense of uncertainty, where to develop in the IT world, **what exactly I need**.

This summer, I realized that I didn't want to waste my free months just on TV shows, parties, etc. In June, I started reading several books, and basically finished studying them in 2 weeks. First, I read *"Code Complete"* written by Steve McConnell and I totally recommend getting acquainted with this work to everyone who is just starting to dive into the world of development and programming, because the book helps to understand the basic principles of both the structure of the architecture of languages and the product, and programming in general. My second book was *"100 Things Every Designer Needs to Know About People"* by Susan M. Weinschenk. I also recommend reading it, because it sets out really useful things for those who are even indirectly involved in creating applications or interfaces for users.

The books helped me to understand how many things I do not know and that the university will not give me all the knowledge that I can, and most importantly, I want to get. Once, while flipping through the Instagram feed, I accidentally came across an advertisement for workshops from **Datastax**. Usually, I scroll through such stories and do not pay attention to them, but for some reason, this ad has become an exception. Having registered a week before the start, I continued to do my own business, but I did not forget that a series of *workshops* was waiting for me. I realized that I need more practice, more opportunities to try out various technologies, and Datastax helped me with this. In July, I managed to create my own clones of **Tik Tok** and **Netflix**, and this was a pleasant surprise for me, since there is no such modern approach at the university.

A series of workshops took place over three weeks, each week it was necessary to pass homework and hone skills in practice. Datastax supports each participant and really shows an individual approach, checks the created applications, and gives advice. at the same time, they have **a wide community in Discord**, where everyone can ask a question and get an answer from professionals. My favorite workshop was the creation of *Tik Tok*, I don't even know why, because all three were beautiful. At the end of each broadcast, there was a short game in the quiz format, and Datastax gave **memorable gifts** to the three fastest and most erudite participants. I really like such a warm attitude and support from the company.
The workshops were limited in time and lasted about two to three hours each, so they did not talk in too much detail about creating an application or using certain language constructs. Nevertheless, the team answered absolutely all questions during the broadcast and even stayed for about an hour after the workshop to answer questions and support the audience. Moreover, in the files with the homework, **Datastax** offered to additionally watch a video and create an application from *Ania Kubów*, a web developer who describes in detail the stages of creating Tik Tok and Netflix clones and also helps to manipulate objects more deeply inside.
{% youtube IATOicvih5A %}
A series of workshops helped me learn a lot of new things and honestly, I still don't understand why Datastax is so kind. The company uses *NoSQL databases such as* **Cassandra** and helps participants of workshops understand their basics, which was a pleasant surprise for me and even inspired me to learn more about them and about Cloud Storage Technologies. I am extremely glad that I had such an opportunity to participate in **the summer series of workshops** and I understand that I will recommend every opportunity that **Datastax** offers, because it is really worth it.
 | darbian |
774,965 | PortokaLive - An opensource experimental platform for broadcasting live stream | 🎉🎉🎉 After years of procrastinating on working on this project, I'm finally proud to launch this... | 0 | 2021-07-29T06:04:22 | https://dev.to/m3yevn/portokalive-an-opensource-experimental-platform-for-broadcasting-live-stream-4b8j | portokalive, portoka, live, react | 🎉🎉🎉 After years of procrastinating on working on this project, I'm finally proud to launch this platform PortokaLive to public. Hooray! Here's the link
- Web ( https://portokalive.vercel.app/ )
- Mobile ( https://play.google.com/store/apps/details?id=com.portokalive)
# 🌞 How it started (The origin)
PortokaLive was started off as a coding challenge by one of the company that I was interviewing back in 2019. The company requested me to showcase my coding ability and asked to create a proof-of-concept POC application which can do a live-streaming between Mobile Application and Web.
Since I'm proficient in Javascript, I've done my research and found that https://www.npmjs.com/package/node-media-server (Node Media Server) is a viable option for me to use to implement this kind of feature.
I've checked out their code, forked and changed some styling/navigation to the react-native application which will do the recording and broadcasting as well as the node-media-server using rtmp protocol.
There are lots of tutorials online on how to play the live stream in React web using videojs. Luckily, node-media-server provide option to play the video in flv format which directly suits our needs.
Eventually, after 2 or 3 days of self hackathon, the suite of Mobile Client, Web Client, Media Server and Auth API server written in node.js are completed and demonstrated to them. Anyway, I ended up not accepting their offer and this POC project was left behind as a byproduct hanging in my repository.
# 💙 Rebranding to another name
When it was created it was given the company's name and logo, which is in Orange and white color theme. Considering to rebrand this project, I've decided to just stick to the original theme and also give the name as "OrangeLive" which I thought was pretty good. However, after searching on the Google, it seems that the name was taken by another company leading me to change it into something else. I tried to use Google Translate to search other names of Orange in other languages.
Finally, I found out Orange in Greek language is called `Portokali`.
https://translate.google.com/?sl=el&tl=en&text=%CF%80%CE%BF%CF%81%CF%84%CE%BF%CE%BA%CE%AC%CE%BB%CE%B9&op=translate&hl=en
And fortunately, I can omit the "L" and "I" of the `Live` word if I merged them together. So, there it goes. "PortokaLive"
# 📚 Tech Stack
The tech stack was initially a rush because I just want to quickly completed in a few days so I just went for my comfort stack which is
1. React for Web UI
2. Bootstrap for Web theme
3. Node.JS (Typescript) for API
4. ReactNative for Mobile
5. Ui Kitten for Mobile theme
There was a change in media server because media server with rtmp support cannot be deployed on any free backend hosting. (Or maybe at least I don't know, Give a comment below if you know how to 😉)
Therefore, I changed it to using api.video(https://api.video) freemium which is great except the part they put watermark if you want to use it without paying premium charges.
api.video came with a cool REST api and iframe web player which makes my life easier so that I do not need to develop all the wrappers around it.
# 💅 Illustration Design
To put some aesthetic design in my app, I've used Undraw's free illustrations which are not only attractive but also accurately designed to the context.
Please checkout https://undraw.co/ (❤️ Super cool illustration pack!)
# Conclusion
Disclaimer of this application is that it is not meant for production or public use but anyone who are interested in these tech stack can checkout and learn from it for educational purpose.
Stay safe and Thanks for the read! 🙇♂️🙇♂️
Author: Kevin Moe Myint Myat
https://kevinmoemyintmyat.gitlab.io
| m3yevn |
775,024 | I made a website that makes articles appear like a Twitter thread | Link: threadRoll So long ago, I came across a product called Thread Reader App, that unrolls Twitter... | 0 | 2021-07-29T07:55:06 | https://dev.to/kunal/i-made-a-website-that-makes-articles-appear-like-a-twitter-thread-12pp | twitter, react, nextjs, node | Link: [threadRoll](https://threadroll.app)
So long ago, I came across a product called Thread Reader App, that unrolls Twitter threads into a article format. So this, is exactly the opposite of that.
But why?
I have been asking myself the same question for weeks while I was making this. Basically, people read really long threads in Twitter. So they are habitual to reading them like that, and may find it nostalgic to read everything that way.
This was made completely from scratch using this tech stack:
```
React.js [Next.js], Node.js [Express.js], Auth0 [Authentication]
Deployed on: Vercel [Frontend] and Railway [Backend]
```
Features:
- Custom Article Links
- Save Articles
- Curated Article Recommendations
- Share them with others
- Theme switching
Hope you like it. Any feedback is appreciated in the comments! | kunal |
775,218 | How I helped improve Angular Console | How I helped improve Angular Console. By doing GraphQL the right way. | 0 | 2021-07-29T09:51:40 | https://the-guild.dev/blog/improved-angular-console | angular, console | > This article was published on Friday, November 30, 2018 by [Kamil Kisiela](https://twitter.com/kamilkisiela) @ [The Guild Blog](https://the-guild.dev/)
## By Doing GraphQL RightDid you know that **Angular Console** uses **GraphQL** under the hood? I want to tell about how it
used it and how I helped to improve it because that might be useful for people trying to implement
GraphQL in their applications, both on client and server.> [Angular Console](http://angularconsole.com) is a user interface for Angular CLI created by
> [Nrwl](http://medium.com/nrwl), widely used in Angular Community.
>
> I will link to the PRs I've made to Angular Console throughout the article, so you could see
> everything I recommend in practice.After reading
[the announcement](https://blog.nrwl.io/angular-console-the-ui-for-the-angular-cli-a5d0924240b7) of
**Angular Console** I got very excited about the tool and immediately decided to explore the
codebase. I noticed **Electron** and that the project is based on **Angular CLI** and Nrwl's **NX**.That's super cool but what I found the most interesting was *GraphQL*.As a freelancer, I work on daily basis with [The Guild](/). Most of our projects are built with
GraphQL. Throughout the 3 years of adopting it, our team **tested practices and developed open
source tools that helped to improve our workflow**.So when I saw the first implementation, I thought it would be nice to share some ideas and implement
some code that might help to improve the GraphQL part of Angular Console.***## Apollo Angular as the GraphQL ClientI was hoping to find [**Apollo Angular**](https://github.com/apollographql/apollo-angular) as one of
dependencies. I might be a bit bias as the author of that library but our team used it in all of our
angular based projects with huge success.> KLM and AirFrance runs on Apollo AngularOkay, but just like in REST, you don't need sophisticated tools to communicate with the API. Simple
`fetch` or Angular's `HttpClient` is far enough. Why then the GraphQL client?Having a client, like Apollo, allows you to easily execute GraphQL operations and by having a cache
layer, fetched data stays consistent across all components. Dhaivat Pandya explains it well in his
[*“Why you might want a GraphQL client*](https://blog.apollographql.com/why-you-might-want-a-graphql-client-e864050f789c)*”
post*.Apollo has a comprehensive [documentation](https://apollographql.com/docs/angular) that covers a lot
of use cases, and I highly recommend to read it.***## Using DI to Create ApolloAngular Console used an old way of initializing Apollo. In one of the recent versions of Apollo
Angular I introduced `APOLLO_OPTIONS`, an InjectionToken that provides a configuration object to
Apollo service. The old API caused an issue with a race condition where a service tried to use
Apollo before it got created.https://github.com/nrwl/nx-console/pull/158That was the first, very small PR. Next PR brought more changes and was focused only on the server.## Apollo Server 2.0I replaced `express-graphql` with a more complete solution, Apollo Server. This move helped to
improve developer experience by having a **built-in support for GraphQL Subscription**, file
uploading and error handling. I'm pretty sure the team behind Angular Console have plans to take
advantage of it and implement subscriptions in the app, for example to replace currently used
polling technique.## Schema Definition LanguageSDL, in short, is a syntax that allows to define GraphQL Schema, so instead of using GraphQL's API,
you simply write everything as string.For example, using `GraphQLObjectType` might look like this:```ts
new GraphQLObjectType({
name: 'Post',
fields: {
id: {
type: GraphQLString
},
text: {
type: GraphQLString
}
}
})
```with Schema Definition Language:```graphql
type Post {
id: String
text: String
}
```In my opinion, it's more convenient and way more intuitive to work with.## Keeping Resolve Functions Separated from SDLIn our projects, we try to group resolvers by GraphQL type and have them nearby the corresponding
schema definition.Having both, type definition and resolve functions in the `GraphQLObjectType` looks like that:```ts
new GraphQLObjectType({
name: 'Post',
fields: {
id: {
type: GraphQLString,
resolve: parent => parent._id
},
text: {
type: GraphQLString,
resolve: parent => parent.content
}
}
})
```I personally think it was a good choice because it forces developers to write logical part right
next to type definition. The problem is, the bigger types the more confusing it gets. Also keeping
resolvers as standalone functions makes them easier to test.With Schema Definition Language, it's looks way better.```ts
const PostType = gql`
type Post {
id: String
text: String
}
`
const Post = {
id: parent => parent._id,
text: parent => parent.content
}
```Here are the relevant changes that I've mentioned above, that allowed me to introduce something
really interesting in the next PR.https://github.com/nrwl/nx-console/pull/175Apollo Server 2.0 Latest Apollo Angular refactoring — moved files under /api directory used SDL
instead of classes from…github.com')## Strongly Typed ResolversWe love [TypeScript](https://typescriptlang.org), and we saw an opportunity to take our GraphQL
servers to the next level. Instead of having `any` or defining interfaces for each resolver by hand,
we decided to take advantage of one of our tools, called
[GraphQL Code Generator](https://graphql-code-generator.com) (thanks Dotan Simha for creating it).In short, it's a tool to generate pretty much any piece of code, based on a GraphQL Schema. We use
it a lot, mostly for types (server and client) but also to create MongoDB models, introspection
files, Angular components and more.In Angular Console, I used the TypeScript plugins to generate types for a schema and also for
GraphQL Resolvers. It's one of the pieces that makes your code even more strongly typed, from end to
end.Here's how it might look like.```ts
import { PostResolvers } from './generated-types'
const Post: PostResolvers.Resolvers = {
id: parent => parent._id,
text: parent => parent.content
}
``````ts
export interface PostParent {
_id: string
content: string
}
```If you want to take a look at the changes and read about GraphQL Code Generator:https://github.com/nrwl/nx-console/pull/185We recently released another new version of the GraphQL Code Generator that fixed a lot of issues,
introduced a feature called Mappers, made signatures of resolve functions more strict and handles
multiple results in parallel.https://github.com/nrwl/nx-console/pull/413The GraphQL Code Generator is one powerful beast that enables any kind of code generation based just
on GraphQL Schema (you can create your own custom generation templates).# Named OperationsGraphQL in most cases allows to use a shorthand syntax but putting a type and a name of an operation
is very useful, simply for debugging and logging. It's easier to track down a failed operation,
because it's no longer anonymous and by keeping all names unique you're able to take advantage of
any tool or service. One tool I described in the next chapter.## Strongly Typed Operations and Code GenerationFetching data with Apollo Angular, requires few steps:* Import `Apollo` service
* Inject the service in a component
* Define GraphQL operation
* Wrap the operation with the `gql` tag
* Call `Apollo.watchQuery` with the operation
* Get an `Observable` with dataThat's a lot, and in order to have everything strongly typed you even have to define extra
interfaces that are specific for each operation.```typescript
import { Apollo } from 'apollo-angular'
import gql from 'graphql-tag'
interface Post {
id: string
text: string
}
interface PostQuery {
post: Post
}
@Component({
/*...*/
})
export class PostComponent {
@Input() postId: string
post: Observable<Post>
constructor(private apollo: Apollo) {}
ngOnInit() {
this.post = this.apollo
.watchQuery<PostQuery>({
query: gql`
query getPost($id: String!) {
post(id: $id) {
id
text
}
}
`,
variables: {
id: this.postId
}
})
.valueChanges.pipe(map(result => result.data.post))
}
}
```I wanted to share with Angular Console, something that we use and what helped to improve our
workflow.One interesting thing that we're able to achieve is the
[`apollo-angular` code-generator plugin](https://graphql-code-generator.com/docs/plugins/typescript-apollo-angular).Its main purpose is to generate strongly typed services for each GraphQL operation. Take a look at
the following scientific visualization:<Video src="/medium/f55951c146120a5fc45fa19066b8b6dd.webm" title="This is how magic happens." />Given the example I previously used, this is how it might look like with Apollo Angular plugin now.* Write a query in a `.graphql` file
* Run the codegen *(has watch mode)*
* Use a **fully typed generated Angular service** directly in your component```graphql
query getPost($id: String!) {
post(id: $id) {
id
text
}
}
``````typescript
import { GetPostGQL, Post } from './generated/graphql';
@Component({...})
export class PostComponent {
@Input() postId: string;
post: Observable<Post>;
constructor(
private getPostGQL: GetPostGQL
) {}
ngOnInit() {
this.post = this.getPostGQL
.watch({ id: this.postId })
.valueChanges
.pipe(
map(result => result.data.post)
);
}
}
```As you can see, we no longer use Apollo service directly (it's used under the hood) and every
operation has now strongly typed API.It wouldn't be possible without introducing this new API. I highly recommend to read an article
linked below, it explains what it is and how it could be used with the codegen./blog/apollo-angular-12I also prepared an explanation video that might help you to learn step by step, what code generation
is and how to use it in a project.<Video src="https://youtube.com/embed/KGBPODrjtKA" title="GraphQL Code Generator - Angular Apollo Template" />Here is the relevant PR introducing this change into Angular Console:https://github.com/nrwl/nx-console/pull/219***https://github.com/nrwl/nx-console/pull/263## SummaryGraphQL is a very useful and fast growing technology. It helps with so many different use cases of
developing applications, large and small. But don't forget that the ecosystem of GraphQL is huge and
there are a lot of extra tools and best practices that might make it even more useful!I hope this post was helpful for you to learn about some handy things in GraphQL.
| theguild_ |
775,289 | Introduction to Control Flow and Functions in Python. | CONTROL FLOW What is control Flow? A program's control flow is the order in... | 0 | 2021-07-30T16:53:35 | https://dev.to/phylis/introduction-to-control-flow-and-functions-in-python-41cc | datascience, machinelearning, python, programming | ## CONTROL FLOW
######What is control Flow?
* A program's control flow is the order in which the program's code executes.
* The control flow of a Python program is regulated by conditional statements, loops, and function calls.
######Python if Statement
You use the if statement to execute a block of code based on a specified condition.
The syntax of the if statement is as follows:
```python
if condition:
if-block
```
The if statement checks the condition first.
If the condition evaluates to True, it executes the statements in the if-block. Otherwise, it ignores the statements.
Example
```python
marks = input('Enter your score:')
if int(marks) >= 40:
print("You have passed")
```
Output
```
Enter your score:46
You have passed
```
######Python if…else statement
Used when you want to perform an action when a condition is True and another action when the condition is False.
Here is the syntax
```python
if condition:
if-block;
else:
else-block;
```
* From the above syntax, the if...else will execute the if-block if the condition evaluates to True. Otherwise, it’ll execute the else-block.
An example to illustrate how to use the if...else statement:
```python
marks = input('Enter your score:')
if int(age) >= 40:
print("You have passed.")
else:
print("You have failed.")
```
######Python if…elif…else statement
It is used to check multiple conditions and perform an action accordingly.
The elif stands for else if.
Here is the syntax:
```python
if if-condition:
if-block
elif elif-condition1:
elif-block1
elif elif-condition2:
elif-block2
...
else:
else-block
```
* The elif statement allows you to check multiple expressions for **true** and execute a block of code as soon as one of the conditions evaluates to **true**.
* If no condition evaluates to **true**, the if...elif...else statement executes the statement in the **else** branch.
Example
```python
marks = input('Enter your score:')
your_marks = int(marks)
if your_marks >= 70:
print("Your grade is A")
elif your_marks >= 60:
print("Your grade is B")
else:
print("null")
```
Output
```python
Enter your score:70
Your grade is A
```
######Python for Loop
To execute a block of code multiple times in programming you use **for loop**
Here is the syntax:
```python
for index in range(n):
statement
```
* In this syntax, the *index* is called a **loop counter**. And *n* is the number of times that the loop will execute the statement.
* The range() is a built-in function in Python that generates a sequence of numbers: 0,1, 2, …n-1.
Example
```python
for index in range(5):
print(index)
```
Output
```python
0
1
2
3
4
```
**Specifying the starting value for the sequence**
The range() function allows you to specify the starting number like this:
```
range(start,stop)
```
Example
```python
for index in range(1, 4):
print(index)
```
Output
```python
1
2
3
4
```
**Specifying the increment for the sequence**
By default, the range(start, stop) increases the start value by one in each loop iteration.
To specify increment sequence, use the following syntax:
```
range(start, stop, step)
```
The following example shows all odd numbers from 0 to 10:
```python
for index in range(0, 11, 2):
print(index)
```
output
```python
0
2
4
6
8
10
```
**Using Python for loop to calculate the sum of a sequence**
The following example uses the for loop statement to calculate the sum of numbers from 1 to 50:
```python
sum = 0
for num in range(51):
sum += num
print(sum)
```
Output
```python
1275
```
######Python while Loop
Python while statement allows you to execute a code block repeatedly as long as a condition is True
Here is the syntax:
```python
while condition:
body
```
* The condition is an expression that evaluates to a Boolean value, either True or False.
* The while statement checks the condition at the beginning of each iteration and executes the body as long as the condition is True.
An example that uses a while statement to show 5 numbers from 0 to 4 to the screen:
```python
max = 5
counter = 0
while counter < max:
print(counter)
counter += 1
```
Output
```python
0
1
2
3
4
```
######Python break Statement
* Break statement in python is used to terminate a for loop and a while loop prematurely regardless of the conditional results.
Example:
```python
for index in range(0, 11):
print(index)
if index == 3:
break
```
Output
```python
0
1
2
3
```
**FUNCTIONS IN PYTHON**
A **function** is a block of organized, reusable code that is used to perform a single, related action.
####Defining a Function
Here are simple rules to define a function in Python.
* Function blocks begin with the keyword **def** followed by the function name and parentheses ( ( ) ).
* Any input parameters or arguments should be placed within these parentheses. You can also define parameters inside these parentheses.
* The code block within every function starts with a colon (:) and is indented.
* The statement return [expression] exits a function, optionally passing back an expression to the caller. A return statement with no arguments is the same as return None.
#####Syntax
```python
def functionname( parameters ):
"function_docstring"
function_suite
return [expression]
```
######Calling a Function
When you want to use a function, you just need to call it. A function call instructs Python to execute the code inside the function.
######Returning a value
A function can perform a task like the greet() function. Or it can return a value. The value that a function returns is called a **return value**.
To return a value from a function, you use the return statement inside the function body.
######Function Parameters and Arguments
Parameter and argument can be used for the same thing but from functions perspectives;
* A **parameter** is the variable listed inside the parentheses in the function definition.
* An **argument** is the value that are sent to the function when it is called.
From this example;
```python
def addNumbers(a, b):
sum =a + b
print("The sum is " ,sum)
addNumbers(2,5)
```
* We have a function called addNumbers which contains two values inside the parenthesis, a, and b. These two values are called parameters.
* We have passed two values along with the function 2 and 5. These values are called arguments.
######Python functions with multiple parameters
A function can have zero, one, or multiple parameters.
The following example defines a function called sum() that calculates the sum of two numbers:
```python
def sum(a, b):
return a + b
total = sum(1,20)
print(total)
```
output
```python
21
```
In the above example, the sum() function has two parameters a and b, and returns the sum of them. Use commas to separate multiple parameters.
######Types of Arguments in Python Function Definition
* Default arguments.
* Keyword arguments.
* Positional arguments.
* Arbitrary positional arguments.
* Arbitrary keyword arguments
######Python Recursive Functions
* A **recursive function** is a function that calls itself and always has condition that stops calling itself.
######Where do we use recursive functions in programming?
* To divide a big problem that’s difficult to solve into smaller problems that are easier-to-solve.
* In data structures and algorithms like trees, graphs, and binary searches.
**Recursive Function Examples**
1.Count Down to Zero
* countdown()takes a positive number as an argument and prints the numbers from the specified argument down to zero:
def countdown(n):
```python
def countdown(n):
print(n)
if n == 0:
return # Terminate recursion
else:
countdown(n - 1) # Recursive call
countdown(5)
```
Output
```python
5
4
3
2
1
0
```
2.Calculating the sum of a sequence
Recursive functions makes a code shorter and readable.
Suppose we want to calculate the sum of sequence from 1 to n instead of using **for loop with range() function** we can use recursive function.
```python
def sum(n):
if n > 0:
return n + sum(n - 1)
return 0
result = sum(100)
print(result)
```
######Python Lambda Expressions
A lambda function is a small anonymous function that can take any number of arguments, but can only have one expression.
Syntax
```python
lambda arguments : expression
```
Examples:
```python
def times(n):
return lambda x: x * n
double = times(2)
result = double(2)
print(result)
result = double(3)
print(result)
```
From the above example times() function returns a function which is a lambda expression.
######Python Decorators.
* A **decorator** is a design pattern in Python that allows a user to add new functionality to an existing object without modifying its structure.
* Decorators are usually called before the definition of a function you want to decorate.
Here is a simple syntax for a basic python decorator
```python
def my_decorator_func(func):
def wrapper_func():
# Do something before the function.
func()
# Do something after the function.
return wrapper_func
```
To use a decorator ,you attach it to a function like you see in the code below.
```python
@my_decorator_func
def my_func():
pass
```
| phylis |
775,423 | Simple Text Effects Using CSS | Here is a list of few text effects created using CSS, they are simple, I think it will be good for... | 0 | 2021-07-29T13:44:55 | https://dev.to/kiranrajvjd/simple-text-effects-using-css-3dgp | css, webdev, beginners, codenewbie | Here is a list of few text effects created using CSS, they are simple, I think it will be good for beginners.
[Text Effect 1] (https://codepen.io/kiran-r-raj/pen/PomQRwR)
{% codepen https://codepen.io/kiran-r-raj/pen/PomQRwR default-tab=result,css %}
[Text Effect 2](https://codepen.io/kiran-r-raj/pen/eYWVVoq)
{% codepen https://codepen.io/kiran-r-raj/pen/eYWVVoq default-tab=result %}
[Text Effect 3](https://codepen.io/kiran-r-raj/pen/OJmQQwO)
{% codepen https://codepen.io/kiran-r-raj/pen/OJmQQwO default-tab=result %}
[Text Effect 4](https://codepen.io/kiran-r-raj/pen/oNWEEdb)
{% codepen https://codepen.io/kiran-r-raj/pen/oNWEEdb default-tab=result %}
[Text Effect 5](https://codepen.io/kiran-r-raj/pen/GRmQQJq)
{% codepen https://codepen.io/kiran-r-raj/pen/GRmQQJq default-tab=result %}
[Text Effect 6](https://codepen.io/kiran-r-raj/pen/jOmZYvm)
{% codepen https://codepen.io/kiran-r-raj/pen/jOmZYvm default-tab=result %}
[Text Effect 7](https://codepen.io/kiran-r-raj/pen/QWvaPwE)
{% codepen https://codepen.io/kiran-r-raj/pen/QWvaPwE default-tab=result %}
[Text Effect 8](https://codepen.io/kiran-r-raj/pen/poPpYmE)
{% codepen https://codepen.io/kiran-r-raj/pen/poPpYmE default-tab=result %}
Hope it will be useful. | kiranrajvjd |
775,936 | Improving EventBridge Schema Discovery | In my previous post, Evaluating AWS EventBridge Schema Discovery I used AWS Schema Registry with... | 0 | 2021-07-30T01:47:52 | https://matt.martz.codes/improving-eventbridge-schema-discovery | serverless, aws | In my previous post, [Evaluating AWS EventBridge Schema Discovery](https://matt.martz.codes/evaluating-aws-eventbridge-schema-discovery) I used [AWS Schema Registry with Event Discovery](https://aws.amazon.com/blogs/compute/introducing-amazon-eventbridge-schema-registry-and-discovery-in-preview/) and tried out a 3rd party project called [EventBridge Atlas](https://github.com/boyney123/eventbridge-atlas) to generate documentation.
It was fairly successful but required a lot of manual action to keep the docs up to date... and you and I both know that wouldn't happen in practice. EventBridge Atlas was neat, but ultimately it just pulled the schema registry as-is and then parsed it into multiple formats (when only one is really necessary).
So in this part I'll cut out the middleman and just parse straight into [AsyncAPI](https://www.asyncapi.com/) format, which was my preferred format from the ones EB Atlas parsed into.
# Architecture and Setup
[The code is here](https://github.com/martzcodes/inquisitor)
In part 1 I learned that the default EventBus for an account receives events anytime a Schema is created or updated to the EventBridge Schema Registry. From there we can trigger a lambda function and process the schema.
Building onto my previous code, I'll create the target function, add a policy to it that allows it to read the schemas and grant it access to DynamoDB. Then I'll create the rule to subscribe to `aws.schemas` events which are the create/update events for the schema registry.
```typescript
const targetFunction = new NodejsFunction(this, 'targetFunction', {
functionName: `${this.stackName}targetFunction`,
...lambdaProps,
entry: `${__dirname}/target.ts`,
memorySize: 1024,
timeout: Duration.seconds(60),
environment: {
API_BUCKET: inquisitorApiBucket.bucketName,
INQUISITOR_BUS: bus.eventBusArn,
},
});
const schemaPolicy = new PolicyStatement({
effect: Effect.ALLOW,
actions: [
'schemas:*',
],
resources: [
`arn:aws:schemas:${this.region}:${this.account}:registry/*`,
`arn:aws:schemas:${this.region}:${this.account}:schema/*`,
],
});
targetFunction.addToRolePolicy(schemaPolicy);
table.grantReadWriteData(targetFunction);
inquisitorApiBucket.grantReadWrite(targetFunction);
const rule = new Rule(this, 'schemaRule', {
description: 'This is a rule for schema events...',
eventPattern: {
source: ['aws.schemas'],
},
});
rule.addTarget(new LambdaFunction(targetFunction));
```
One thing Schema Registry doesn't do is infer optional parameters. If the first time it processes an event there's a property called "something" and the next time "something" isn't there... the 2nd version of the schema will be as if "something" never existed. That wouldn't be optimal if you're trying to export TypeScript types / interfaces for the schema. You could also argue the Best Practice is to NOT have optional parameters in your events and to just emit variations of the detail-types... and you'd probably be right.

To fix that we'll store the schemas (and the AsyncAPI Spec) in DynamoDB and improve them over time. That's what the `target.ts` lambda function does. It receives the `aws.schemas` event, downloads the OpenAPI v3 flavor of the schema that was updated, and then merges it into the AsyncAPI Spec that's already stored in DynamoDB.
# Great, so our work is done now, right?
Not quite. I want to host the actual documentation portion. I decided to both store the AsyncAPI Spec in DynamoDB and also to save it as a yaml file to a public s3 bucket*... but I'd still like to have a UI to look at it with.
[AsyncAPI has a react project](https://github.com/asyncapi/asyncapi-react/tree/next) which is essentially what their "playground" uses. Use the Next branch... trust me.
It doesn't have to be rebuilt ever really... the way I have it set up is it just makes an http request to s3 and downloads the yaml file from there. This is actually a little overkill... it'd be easy enough to spin up a RestAPI and get the same spec via API request instead of s3... but it doesn't hurt for demo purposes so I decided to keep it.
To add a frontend to an existing projen project you can extend the `.projenrc.js` file. All you have to do is add a subproject via projen and it will install everything necessary in a subdirectory in the project. Pretty neat.
```js
const frontendProject = new web.ReactTypeScriptProject({
defaultReleaseBranch: 'main',
outdir: 'frontend',
parent: project,
name: 'cdk-s3-website',
deps: ['@asyncapi/react-component@v1.0.0-next.14', 'axios'],
jest: false,
});
frontendProject.setScript('test', 'npx projen test -- --passWithNoTests');
frontendProject.synth();
```
I also had to update the build script for the parent project `project.setScript('build', 'cd frontend && npm run build && cd .. && npx projen build');`.
This creates the react app, but doesn't actually deploy it anywhere. Fortunately that is as simple as adding a bucket and BucketDeployment:
```typescript
const siteBucket = new Bucket(this, 'SiteBucket', {
websiteIndexDocument: 'index.html',
websiteErrorDocument: 'error.html',
publicReadAccess: true,
cors: [
{
allowedMethods: [HttpMethods.GET, HttpMethods.HEAD],
allowedOrigins: ['*'],
allowedHeaders: ['*'],
exposedHeaders: ['ETag', 'x-amz-meta-custom-header', 'Authorization', 'Content-Type', 'Accept'],
},
],
removalPolicy: RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
// Deploy site contents to S3 bucket
new BucketDeployment(this, 'BucketDeployment', {
sources: [Source.asset('./frontend/build')],
destinationBucket: siteBucket,
});
```
So now, when I run `npx projen deploy` it deploys all the automation needed to self-generate EventBridge Schema documentation. It looks like this:
[You can see this in action here.](https://playground.asyncapi.io/?load=https://raw.githubusercontent.com/martzcodes/inquisitor/main/latest.yml)
There is still an inherent ~5 minute delay for the Schema Registry to process the events and this is observable from both the AWS Console and the `aws.schemas` events.
One more thing worth mentioning... Schema Registry won't create a new Schema Version for an event with the same properties that comes from a different detail-type... which I *suppose* is nice? but it doesn't help with the observability / traceability I was hoping to get out of this.
# What's Next?
As I started this "series" I thought this was only going to be a two-parter... but as I delved deeper into what this could do I was quickly overwhelmed with possibilities.

Part 3 will still be generating an npm package with the TypeScript interfaces inferred from the AsyncAPI. The schemas are stored in JSONSchema format and there are several code generators that can go from JSONSchema / OpenAPI Schema -> TypeScript. It will probably use an event to trigger a CodeBuild pipeline.
The AsyncAPI React App is *very* extensible. Which is good because there are definitely gaps in my current approach. There's definitely a need for the occasional manual override in the schemas. In my code I used the schema `description` properties to store stringified JSON with things like "first seen" / "last seen"... but it could also be used for overrides.
Right now any time an event gets processed by Schema Registry whatever fields are present are marked as "required" and if old properties aren't there they just cease to exist. My lambda counters that by merging the old with the new... but I can definitely see cases where I'd need to go in and say... "this property was a mistake... get rid of it" or "this should always be required". Also if there are any errant events that pass through the bus (dev events / misplaced rules / whatever) and I need to remove an entire message type... that would be nice to adjust.
In these cases, npm version-wise, I think removing messages would be a major version change... while removing / updating properties would be minor version changes. The existing already code bumps the patch version with every update (which should be backwards compatible).
So Part 4 (and/or 5) could be adding the Rest/Http API and the corresponding React App changes to edit those things.
| martzcodes |
775,970 | Deploying a NestJS application with PostgreSQL database and react frontend on Heroku | Recently, we ported the ToolJet server from Ruby on Rails to NestJS, ToolJet can be deployed to... | 0 | 2021-07-30T03:43:15 | https://dev.to/navaneethpk/deploying-a-nestjs-application-with-postgresql-database-and-react-frontend-on-heroku-3ce | nestjs, react, heroku, typeorm | Recently, we ported the [ToolJet](https://github.com/ToolJet/ToolJet) server from Ruby on Rails to NestJS, ToolJet can be deployed to Heroku using the one-click deployment feature of Heroku. ToolJet server is built using Nest.js with TypeORM as the ORM and PostgreSQL as the database. This article will explain how to deploy a NestJS API application on Heroku using the one-click deployment feature of Heroku.
Many of our users deploy the frontend and backend separately, the backend might be deployed on Heroku/K8S/EC2 while the frontend is served from Firebase/Netlify/etc. The first part of this guide explains how to deploy a NestJS API to Heroku and the last part explains how to deploy the frontend too.
###1) Create app.json file in the root directory of your repository
```json
{
"name": "ToolJet",
"description": "ToolJet is an open-source low-code framework to build and deploy internal tools.",
"website": "https://tooljet.io/",
"repository": "https://github.com/tooljet/tooljet",
"logo": "https://app.tooljet.io/assets/images/logo.svg",
"success_url": "/",
"scripts":{
"predeploy": "npm install && npm run build"
},
"env": {
"NODE_ENV": {
"description": "Environment [production/development]",
"value": "production"
}
},
"formation": {
"web": {
"quantity": 1
}
},
"image": "heroku/nodejs",
"addons": ["heroku-postgresql"],
"buildpacks": [
{
"url": "heroku/nodejs"
}
]
}
```
Environment variables, add-ons, buildpacks and other information about the app needs to be added to the app.json file. More details about the app.json manifest can be found [here](https://devcenter.heroku.com/articles/app-json-schema#stack).
Using the predeploy hook, we are installing the npm packages required for the application and then build the application. `npm run build` runs the nest build command. More details about nest build can be found [here](https://docs.nestjs.com/cli/usages#nest-build).We have also added `heroku-postgresql` to the addons so that a Postgres database will be provisioned by Heroku.
###2) Listen to the port assigned by Heroku
Heroku dynamically assigns a port for your app. We need to make sure that the application is listening to requests on the port assigned by Heroku. Modify the `main.ts` file to listen to the port assigned by Heroku and fallback to 3000. We also need to set 0.0.0.0 as the binding address.
```app.listen(parseInt(process.env.PORT, '0.0.0.0') || 3000);```
Note: you will come across the following error if the application is listening on a different port. Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch
###3) Configuring TypeORM to use Postgres database provisioned by Heroku
Add the following options to your `ormconfig(.json/.ts/.js)` file.
```
url: process.env.DATABASE_URL,
ssl: { rejectUnauthorized: false }
```
`DATABASE_URL` config variable is added to your app's environment if a Postgres resource is provisioned for your app. Without setting the `rejectUnauthorizedoption` as false, Error: self signed certificate will be thrown by the application (the reason is explained [here](https://stackoverflow.com/questions/61097695/self-signed-certificate-error-during-query-the-heroku-hosted-postgres-database)).
###4) Procfile
Add `web: npm run start:prod` as a new line to Procfile. We are assuming that the start:prod script is defined in package.json as `NODE_ENV=production node dist/src/main`. TypeORM migrations can be run after every release.
Add `release: npm run typeorm migration:run` as a new line to your Procfile. The Procfile will now look like this:
```
web: npm run start:prod
release: npm run typeorm migration:run
```
###5) Deploy!
You can visit https://heroku.com/deploy?template=https://github.com/your-organization/your-repository/tree/your-branch to deploy the application using the one-click deployment feature of Heroku.
If you want to deploy just NestJS API on Heroku, you can stop reading this guide. If you want to deploy the frontend too to Heroku, please continue.
In the following steps, we will explain how to make NestJS serve a React single page application. We are assuming that the React application lives under the frontend directory.
###1) Install serve-static NestJS plugin
```bash
npm install --save @nestjs/serve-static
```
###2) Modify AppModule
Add this to the imports.
```typescript
ServeStaticModule.forRoot({
rootPath: join(__dirname, '../../../', 'frontend/build'),
}),
```
### 3) Routing
Now the NestJS will serve index.html in the build directory of the frontend. This can be a problem when there are similar routes on the frontend and backend. For example, if the frontend application's path for users page is /users and the path to fetch users from the backend is also the same, NestJS will not serve the static files for that path. To solve this issue, let's add a prefix to the backend endpoints.
```javascript
app.setGlobalPrefix('api');
```
This line needs to be added to `main.ts` to make sure the path for all API requests starts with api. For example: http://localhost/api/users.
###4) Build the frontend while deploying to Heroku
We need to build the frontend for production to generate the build folder.
```json
"scripts": {
"build": "npm --prefix frontend install && NODE_ENV=production npm --prefix frontend run build && npm --prefix server install && NODE_ENV=production npm --prefix server run build",
"deploy": "cp -a frontend/build/. public/",
"heroku-postbuild": "npm run build && npm run deploy",
"heroku-prebuild": "npm --prefix frontend install && npm --prefix server install "
}
```
Add this to the package.json on the root directory of the repository.
###5) Deploy!
You can visit https://heroku.com/deploy?template=https://github.com/your-organization/your-repository/tree/your-branch to deploy the application using the one-click deployment feature of Heroku.
We would love you to check out ToolJet on GitHub: https://github.com/ToolJet/ToolJet/
| navaneethpk |
776,208 | Introducing Tomorrow - A New Look for Code Editor | Introduction Visual Studio Code is by far one of the most popular code editors for web,... | 0 | 2021-07-30T07:38:05 | https://blog.suhailkakar.com/introducing-tomorrow-a-new-look-for-code-editor | javascript, vscode, programming, codenewbie |
### Introduction
Visual Studio Code is by far one of the most popular code editors for web, mobile, and hardware developers. More than 2,600,000 people use VS Code every month, up by over 160% in the last year.
A week ago I have created my own theme ( [ **Tomorrow**](https://marketplace.visualstudio.com/items?itemName=suhailkakar.tomorrow) ), This theme was inspired by One Dark Pro and Material Theme.
### Installation
1. Open **Extensions** sidebar panel in VS Code. `View → Extensions`
2. Search for `Tomorrow` - find the one by **Suhail Kakar**
3. Click **Install** to install it.
4. Code > Preferences > Color Theme > **Tomorrow**
### Recommended Settings
If you want to give the same look as the above picture for your Code Editor you need to paste the below code into your VS Code Settings JSON
```json
{
"editor.fontSize": 17,
"editor.fontWeight": "500",
"editor.fontLigatures": true,
"editor.lineHeight": 35,
"editor.tabSize": 2,
"editor.lineNumbers": "off",
"editor.renderIndentGuides": false,
"editor.renderWhitespace": "none",
"editor.renderControlCharacters": false,
"editor.minimap.enabled": false,
"workbench.colorTheme": "Tomorrow Theme",
"tabnine.experimentalAutoImports": true,
"editor.smoothScrolling": true,
"editor.mouseWheelScrollSensitivity": 2,
"editor.scrollBeyondLastLine": true,
"editor.cursorStyle": "block",
"editor.cursorBlinking": "phase",
"editor.cursorSmoothCaretAnimation": true,
"editor.cursorWidth": 2,
"explorer.openEditors.visible": 0,
"explorer.confirmDelete": false,
"explorer.decorations.badges": false,
"problems.decorations.enabled": false,
"workbench.sideBar.location": "left",
"window.zoomLevel": 1,
"window.menuBarVisibility": "toggle",
"workbench.statusBar.visible": true,
"workbench.activityBar.visible": true,
"terminal.integrated.cursorStyle": "block",
"terminal.integrated.cursorBlinking": true,
"terminal.integrated.fontWeight": "500",
"code-runner.runInTerminal": true,
"editor.formatOnSave": true,
"workbench.startupEditor": "none",
"editor.detectIndentation": true,
"editor.insertSpaces": false,
"terminal.integrated.rendererType": "dom",
"window.compositionAttribute": "acrylic",
"editor.fontFamily": "'Cascadia Code', 'monospace', monospace, 'Droid Sans Fallback'",
}
```
### Font
**Cascadia Code** font is recommended, This font was created by Microsoft and available publicly on GitHub. You can download the font [here](https://github.com/microsoft/cascadia-code/releases)
### Conclusion
If you like this theme, be sure to give it a start ⭐ on [Github](https://github.com/suhailkakar/Tomorrow-Theme). I hope you found this article helpful. If you need any help please let me know in the comment section
Let's connect on [Twitter](https://twitter.com/suhailkakar) and [LinkedIn](https://www.linkedin.com/in/suhailkakar/)
👋 Thanks for reading, See you next time
| suhailkakar |
776,260 | Learning to code | There are lots of free resources available to start learning coding online. Here are some to get you... | 0 | 2021-07-30T09:11:37 | https://dev.to/theproductivecoder/learning-to-code-1fkh | webdev, beginners, javascript, html | There are lots of free resources available to start learning coding online.
Here are some to get you started.
<ol>
Learning to code:
<li>
<a href="#w3schools">W3Schools</a>
</li>
<li>
<a href="#freecodecamp">FreeCodeCamp</a>
</li>
Taking it further:
<li>
<a href="#javatpoint">JavaTpoint</a>
</li>
<li>
<a href="#geeksforgeeks">GeeksforGeeks</a>
</li>
<li>
<a href="#devcommunity">DEV Community</a>
</li>
Testing your knowledge:
<li>
<a href="#leetcode">LeetCode</a>
</li>
<li>
<a href="#hackerrank">HackerRank</a>
</li>
<li>
<a href="#linkedin">LinkedIn</a>
</li>
Asking for help:
<li>
<a href="#stackoverflow">StackOverflow</a>
</li>
Extra:
<li>
<a href="#udemy">Udemy</a>
</li>
</ol>
<h2>Learning to code:</h2>
<p id="w3schools"><a href="https://www.w3schools.com/" target="_blank">1. W3Schools</a></p>
<p>Reference website to learn about web technologies online. Learn about HTML, CSS, JavaScript, Python, SQL and much more.
It also has a built in editor so you can play around with code without leaving the site.</p>
<p id="freecodecamp"><a href="https://www.freecodecamp.org/" target="_blank">2. FreeCodeCamp</a></p>
<p>An interactive web development learning platform. Learn about HTML5, CSS, JavaScript, Python, Algorithms, Data Structures, Node, jQuery, React, Python and much more.
Also gives you a certification after completing a course.</p>
<h2>Taking it further:</h2>
<p id="javatpoint"><a href="https://www.javatpoint.com/" target="_blank">3. JavaTpoint</a></p>
<p>Read up on subjects like digital marketing, functional programming, AI, testing and much more.</p>
<p id="geeksforgeeks"><a href="https://www.geeksforgeeks.org/" target="_blank">4. GeeksforGeeks</a></p>
<p>Well explained articles related to computer science and programming.</p>
<p id="devcommunity"><a href="https://dev.to/" target="_blank">5. DEV Community</a></p>
<p>This site. =)</p>
<h2>Test your knowledge:</h2>
<p id="leetcode"><a href="https://leetcode.com/" target="_blank">6. LeetCode</a></p>
<p>Try programming puzzles and get scored on runtime and memory usage.</p>
<p id="hackerrank"><a href="https://www.hackerrank.com/" target="_blank">7. HackerRank</a></p>
<p>Programming puzzles with certifications for topics like CSS, JavaScript, Problem Solving and much more.</p>
<p id="linkedin"><a href="https://www.linkedin.com/" target="_blank">8. Linkedin</a></p>
<p>LinkedIn is not only for looking for a new job, but also has a section where you can test your skills in several categories like Front End Development.</p>
<h2>Need help:</h2>
<p id="stackoverflow"><a href="https://stackoverflow.com/" target="_blank">9. StackOverflow</a></p>
<p>Question and answer website for programmers. When you get stuck, this is the next step after Googling.</p>
<h2>Extra:</h2>
<p id="udemy"><a href="https://www.udemy.com/" target="_blank">10. Udemy</a></p>
<p>The only paid alternative in the list, Udemy is a course provider with videos on most topics.
Some courses can be expensive, but most of them are available for a recurring discount of around €12.</p>
<p>Hopefully some of these will be of use to you.</p>
| theproductivecoder |
776,270 | Connect your Hackathon to your Favorite Apps | TAIKAI is able to integrate with your favorite apps to automate workflows and build engaging... | 0 | 2021-07-30T09:46:55 | https://taikai.network/en/blog/connect-to-your-favorite-apps | hackathon, sass, architecture | TAIKAI is able to integrate with your favorite apps to automate workflows and build engaging experiences that will leverage your hackathon to a different level.
{% youtube 5OUOMJ0M0Fw %}
As a digital platform where our main goal is to foster innovation and as a customer-centric company, we are always trying to find novel ways to make our hackathon platform a global standard on the SaaS ecosystem.
In order to achieve that remarkable goal, it is essential for our platform to interact with other traditional applications that our customers are using on a daily basis to increase their productivity.
Apart from **productivity** gains, the integration with other applications allows us to extend our functionalities by allowing the hackathon organizers to create data automation and engagement flows that as a consequence will increment the audience interaction and simplify processes.
The **automation** also saves you time by taking on some of your more mindless, repetitive tasks and helps you stay organized by making sure information is transferred accurately between your main event participants.
These tailored engagement loops allow without too much hassle to be connected with participants, mentors, and jury on a more frequent basis by delivering them the most up-to-date information generated during the event, as an example, notify a jury when there is a new project submitted.
## Let's Connect TAIKAI to the outside world 🤝
Taking all the feedback that we collected from previous hackathon events, we decided that it was crucial to our future to allow our customers to create their own customized automations and engagement loops and give them some freedom to tailor an outstanding experience for their hackathons.
Apart from the level of customization that these integrations allowed us to achieve, this new capability allows our development team to focus their efforts on features that bring more value to our users since the customizations required for some hackathon events can be crafted by someone without coding skills.
During the last month, the TAIKAI team made a significant update on their platform to allow any hackathon organizer to customize the delivery of events generated on the platform to external services like **Zappier**, **n8n**, **Automate**, **IFTTT**, automation providers, or customized web services developed by organizers.
These events, generated by the interaction of the users with our platform, are propagated in real time with contextualized information that could be used to automate workflows. Some of the events that are currently propagated to external services are:
* Participant Registration
* Jury Registration
* New Project Submission
* Hackathon Step Change
* Project Submission Update
* Voting Submitted
* Challenge Update Published
* ...
Imagine the possibilities that you can bring to the table when you have the freedom to connect the data generated on your hackathon with a set of integrations provided by these no-code platforms.🤩
Imagine the possibilities that you can bring to the table when you have the freedom to connect the data generated on your hackathon with a set of integrations provided by these no-code platforms.🤩
You don’t need to hire a developer, any person with no code skills can design workflows that fit the hackathon needs just by connecting and assembling some pieces.
It is just like Legos. 😲
In the meantime we have prepared a list of recipes and examples that you can incorporate in your event just by using TAIKAI at your hackathon event:
* **Twitter, Slack, Discords Bot** - Create a bot that will publish the main hackathon updates, new submissions or inform the participants that a new deadline is approaching.
* **Follow the Hackathon Voting** - Gather all the votes and deliver streamlined voting reports or realtime charts to your most important event stakeholders.
* **Fill a Spreadsheet** - Fill a spreadsheet with all projects, all votes, and all actions that take place throughout the hackathon.
* **Create calendar events** - Create calendar events to notify a participant about a deadline.
* **Create SMS or push notifications** - Push mobile notifications to participants, mentors, jury, and organizers when any particular event happens on the platform.
## Better Connected than Alone 👫
{% wikipedia https://en.wikipedia.org/wiki/composability %} **Composability** leads inevitably toward more choice, and better user experiences, making it easier to use, or adapting it to new use cases requested by our customers to create delightful online hackathons.
Technology and innovation are progressing at a huge pace, and this growth shows no signs of slowing down, so we are preparing the ground for the future. A future where the TAIKAI platform could be interconnected and talk with a myriad of tools that are created today and tomorrow.
We don't imagine a future where TAIKAI works alone to provide you a full hackathon experience, we imagine a world where a hackathon platform can talk with external APIs and services to deliver an outstanding and customized service that matches your needs.
## Conclusion
Organizing a successful hackathon is a challenging effort and without the right tools could be a daunting task for organizations with limited resources and time. By using the right platform and by automating your most important processes you can significantly reduce the amount of time wasted performing data processing and organizing information. In the end, you could spend more time interacting and engaging with your hackathon audience.
TAIKAI makes it possible to automate most of these time-consuming tasks by allowing you to design flows with NoCode platforms like **Zapier**, **n8n**, **Microsoft Logic Apps**, **Automate.io**, or even design your own customized solutions.
Sounds good right 🤩
[Talk with us today](https://taikai.network/organizations), we can help you to design an amazing experience and take your hackathon to the next level. 👌
With [TAIKAI](https://taikai.network) the sky is always the limit 🚀
**PS: In the upcoming months we will prepare some tutorials and recipes that will help you create amazing automations for your hackathon.**
| heldervasc |
776,353 | Custom React + TailwindCSS Calendar Component | Hey there, If you need a custom calendar for your React app, that's light (built without any... | 0 | 2021-07-30T10:34:20 | https://blog.daliborbelic.com/custom-react-tailwindcss-calendar-component | ---
title: Custom React + TailwindCSS Calendar Component
published: true
date: 2021-07-30 10:25:00 UTC
tags:
canonical_url: https://blog.daliborbelic.com/custom-react-tailwindcss-calendar-component
---
Hey there,
If you need a custom calendar for your React app, that's light (built without any external code), you came across the right blog post! Check out the custom calendar I coded with React and TailwindCSS.
### [Live demo](https://custom-calendar.netlify.app/)
[GH repo](https://github.com/daliboru/calendar). P.S. If you like it, give it a star :)
Happy coding,
Dalibor | daliboru | |
776,427 | Ensuring Risk-free Dynamics AX to Dynamics 365 F&O Migration with Continuous Test Automation | Organizations that are looking to migrate from Dynamics AX (on-premise) to Microsoft Dynamics 365... | 0 | 2021-07-30T12:11:19 | https://dev.to/opkey_ssts/ensuring-risk-free-dynamics-ax-to-dynamics-365-f-o-migration-with-continuous-test-automation-81b | Organizations that are looking to migrate from Dynamics AX (on-premise) to Microsoft Dynamics 365 Finance & Operations (D365 F&O) need to understand that it is much more than a simple technology transition. Apart from feeling worried about the business continuity, business users, owners, & IT heads must be pondering how to keep up with tight migration timelines and budgets. Since the incorporation of testing in SDLC is something that greatly influences software delivery, organizations that get stuck in migration projects need to realize the importance of automation to deliver software more rapidly and with fewer errors.
In this article, we’ll discuss how introducing “continuous delivery” & “continuous testing” in Dynamics AX migration can help you achieve your project timelines and budgets.
<B>Challenges that hold you back in Dynamics 365 migration initiative</B>
<B>Customizations:</B> <a href="https://www.opkey.com/ms-dynamics/">Microsoft Dynamics AX</a> is a complex web application that can be customized easily to meet business requirements. While migrating to D365 F&O, business users need to understand how functions and processes interacting with AX today may get impacted. Furthermore, they want to analyze the impact on the organization as a whole due to migration.
<B>Integration:</B> Dynamics AX can be integrated seamlessly with Office 365, EDI, 3PL, & other third-party applications. It may not be necessary that these integrations work in the new cloud environment. Only, end-to-end integration testing can ensure that whether or not integrations are working as expected.
<B>Workflow Approvals:</B> The cloud environment of Dynamics 365 Finance & Operations can be configured rather than customized. So, enterprises need to embrace some standard processes, and workflows. So, key workflow approvals and critical reports need to be validated to ensure business continuity in the cloud.
<B>Update Adoption Readiness:</B> Post live, enterprises need to prepare for continuous adoption of frequent application updates (Wave 1 & Wave 2). Microsoft updates constantly affect business processes with changes. So, enterprises need to prepare to accommodate updates.
<B>Your way ahead towards Continuous Testing</B>
Test automation acts as the “sole source of truth” for all changes that occur throughout the MSD system, enabling effective launch planning and delivery. Quality is “shifted left” to an earlier stage in the development life cycle, where problems are quickly identified through automated analysis. The result is less rework, shorter cycle times, and faster and more secure automatic deployment of the entire system.
<B>Continuous Testing:</B> <a href="https://www.opkey.com/"> continuous test automation </a> makes the job of building MS Dynamics systems in the cloud and manage them alongside on-premise systems is much easier, which means a cheaper transition and fewer interruptions after go-live.
<B>Automated Change Management:</B> Automated change management makes the infrastructure transparent. Users just don’t need to worry about what hosted where, and the dynamic nature of cloud-based environments, where systems can be easily added or removed, fits without increasing complexity or risk.
<B>Script-free Regression Testing:</B> Regression testing is a big problem here too. Although certain parts of your system can be optimized to take advantage of the cloud, there will be a lot of unchanged functionality that just needs to keep working as it did before. The right kind of automated, regression test ensures you can be confident of your move to the cloud that will have no unexpected consequences.
<B>Conclusion</B>
Thus, continuous testing approach expedite your migration process while protecting your apps from getting crashed or issues like server downtime. Furthermore, continuous testing prepares you to embrace continuous innovation that you get as frequent application updates (Wave 1 & Wave 2). You can easily embrace these updates to improve your business processes.
<B>Tittle:</B> Ensuring Risk-free Dynamics AX to Dynamics 365 F&O Migration with Continuous Test Automation
<B>Description:</B>In this article, we’ll discuss how introducing “continuous delivery” & “continuous testing” in Dynamics AX migration can help you achieve your project timelines and budgets.
<B>Canonical Url:</B> https://www.opkey.com/blog/ensuring-risk-free-dynamics-ax-to-dynamics-365-fo-migration-with-continuous-test-automation/ | opkey_ssts | |
776,466 | AWS DynamoDB – Introduction, Use Cases & Case Study | AWS DynamoDB is a fast, flexible, NoSQL database service for all applications that need consistent... | 0 | 2021-07-30T12:49:23 | https://www.sndkcorp.com/aws-dynamodb-introduction-use-cases-case-study/ | aws, dynamodb | **AWS DynamoDB** is a fast, flexible, NoSQL database service for all applications that need consistent latency, in milliseconds, at any scale. It is a fully-managed database service that takes care of operational reliability, hardware or software provisioning, data partition, data recovery, security, built-in fault tolerance and is suitable for mobile, web, gaming, ad tech, IoT etc. Also, you don’t have to worry about patching and updating databases to the latest version.
DynamoDB handles more than one trillion requests per day, and more than 100,000 AWS customers use DynamoDB. To get started with your organization’s cloud migration and cloud computing journey, contact [SNDK Corp](https://www.sndkcorp.com/), your most trusted AWS consulting partner with rich experience in serving customers in their journey to the cloud.
##When to use DynamoDB?##
When you have unstructured data and need a scalable database that is fast and reliable, DynamoDB is the best choice. It is the auto scale database for modern apps that needs high performance, higher throughput, lower latency, reduced cost of ownership, to make your life easier. [SNDK Corp](https://www.sndkcorp.com/), a renowned cloud service provider offers cloud monitoring and [cloud migration](https://www.sndkcorp.com/cloud-services/7-reasons-to-migrate-your-business-to-cloud) services as well as tools under the cloud computing services that help customers in driving and improving their productivity, output and performance – whether it’s a new cloud application or an existing application needing to be migrated.
##Scaling high-velocity use cases with DynamoDB##
Many of the world’s fastest-growing businesses such as Lyft, Airbnb, Redfin as well as enterprises such as Samsung, Toyota, and Capital One depend on the scale and performance of DynamoDB to support their mission-critical workloads.
No matter which sector your enterprise belongs with, you can always scale your database to cloud using DynamoDB. Let’s look at some of the common use cases across different sectors where DynamoDB proves to be an effective solution. For more details on scaling your enterprise database to cloud, read about [SNDK Corp cloud computing services](https://www.sndkcorp.com/cloud-computing-services/).
<table style="width:100%">
<tr>
<th>Sector</th>
<th>Commpon Use Cases</th>
</tr>
<tr>
<td><b>Ad Tech</b></td>
<td>User profile stores in RTB and ad targeting
<br>User events, clickstreams, and impressions data store</br>
<br>Metadata stores for assets</br>
<br>Popular-item caches</br></td>
</tr>
<tr>
<td><b>Retail</b></td>
<td><br>Shopping carts</br>
<br>Workflow engines</br>
<br>Inventory tracking and fulfilment</br>
<br>Customer profiles and accounts</br></td>
</tr>
<tr>
<td><b>Banking and Finance</b></td>
<td><br>User transactions</br>
<br>Event-driven transaction processing</br>
<br>Fraud detection</br>
<br>Mainframe offloading and change data capture</br></td>
</tr>
<tr>
<td><b>Media and entertainment</b></td>
<td><br>Media metadata stores</br>
<br>User data stores</br>
<br>Digital rights management data stores</br></td>
</tr>
<tr>
<td><b>Gaming</b></td>
<td><br>Game states</br>
<br>Player data stores</br>
<br>Player session history data stores</br>
<br>Leaderboard</br></td>
</tr>
<tr>
<td><b>Software and internet</b></td>
<td><br>User content metadata stores</br>
<br>Relationship graph data stores</br>
<br>Metadata caches</br>
<br>Ride-tracking data stores</br>
<br>User, vehicle, and driver data stores</br>
<br>User vocabulary data stores</br></td>
</tr>
</table>
##Serverless IoT##
Out of the box, the AWS IoT console gives you your own searchable device registry with access to the device state and information about device shadows. You can enhance and customize the service using [Lambda](https://aws.amazon.com/lambda/) and [DynamoDB](https://aws.amazon.com/dynamodb/) to build a serverless backend with a customizable device database that can be used to store useful information about the devices as well as helping to track what devices are activated with an activation code if required. For queries related to how you can leverage DynamoDB for your organization, contact [SNDK Corp](https://www.sndkcorp.com/).
##Case study: Unlocking opportunities with AWS DynamoDB##
As companies in banking and finance build more cloud-native applications, they usefully managed services to increase agility, reduce time to market, and minimize operational overhead. **Vanguard** is a financial services company that started a cloud construction team to set up a lab architecture, allowing the team to experiment and innovate with any kind of open-source software within an enterprise-grade security architecture setup. By having a multitude of servers and applications, users can access any open-source application and marketplace and work on managing and automating user transactions, event-driven transaction processing, fraud detection, using a sandbox or live environment.
Many companies in the retail space use common DynamoDB design patterns. Being free from scaling concerns and the operational burden is a key competitive advantage and an enabler for high-velocity, extreme-scaled events such as **Amazon Prime Day**, whose magnitudes are difficult to forecast. Scaling up and down allows these customers to pay only for the capacity they need and keeps precious technical resources focused on innovation rather than operations.

One key commonality among software companies and many other DynamoDB customers is the ability to accommodate extreme concurrency, request rates, and spikes in traffic.
**Netflix** uses DynamoDB to run A/B testing that builds personalized streaming experiences for its 125+ million customers. To make your enterprise cloud journey a success, contact [SNDK Corp](https://www.sndkcorp.com/), your most trusted AWS consulting partner.
**Duolingo**, an online language learning site, uses DynamoDB to store 31 billion items on their online learning site. With courses provided in 80 languages, 24000 read units/second and 3300 write units/second. This is a read-heavy application, and DynamoDB is the perfect choice for a storage database.
**Also Read: [Amazon Connect – The Future of Call Centers: Features & Use Cases](https://www.sndkcorp.com/blog/amazon-connect-features-and-use-cases/)**
##Summing Up##
By leveraging the power of the [AWS DynamoDB](https://www.sndkcorp.com/cloud-computing-services/), you can take advantage of the seamless integration between your enterprise applications, by managing your database using the cloud. Storage database powered by Amazon DynamoDB helps to manage and scale your growing user base and accompanied data, thus unlocking numerous opportunities to grow your business! | sndkcorp |
776,522 | Beating TimSort at Merging | Here is a problem. You are tasked with improving the hot loop of a Python program: maybe it is an... | 0 | 2021-07-30T14:49:40 | https://earthly.dev/blog/python-timsort-merge/ | python, computerscience, cpp, opensource | ---
title: Beating TimSort at Merging
published: true
description:
tags: python, computerscience, cpp, opensource
cover_image: https://earthly.dev/blog/generated/assets/images/python-timsort-merge/header-1200-75e74e4c2.webp
canonical_url: https://earthly.dev/blog/python-timsort-merge/
---
Here is a problem. You are tasked with improving the hot loop of a Python program: maybe it is an in-memory sequential index of some sort. The slow part is the updating, where you are adding a new sorted list of items to the already sorted index. You need to combine two sorted lists and keep the result sorted. How do you do that update?
Yes, this sounds like a LeetCode problem, and maybe in the real-world you would reach for some existing [sorted set](https://docs.oracle.com/javase/8/docs/api/java/util/SortedSet.html) [data structure](http://www.cplusplus.com/reference/set/set/), but if you were working with python lists, you might do something like this[^1]:
``` Python
def merge_sorted_lists(l1, l2):
sorted_list = []
while (l1 and l2):
if (l1[0] <= l2[0]): # Compare both heads
item = l1.pop(0) # Pop from the head
sorted_list.append(item)
else:
item = l2.pop(0)
sorted_list.append(item)
# Add the remaining of the lists
sorted_list.extend(l1 if l1 else l2)
return sorted_list
```
Python has a built-in method in [`heapq.merge`](https://github.com/python/cpython/blob/3.7/Lib/heapq.py#L314) that does this. It takes advantage of the fact that our lists are already sorted, so we can get a new sorted list linear time rather than the `n*log(n)` time it would take for combining and sorting two unsorted lists.
Imagine my surprise then when I saw this performance graph from Stack Overflow:

Sorting the list is faster than just merging the list in almost all cases! That doesn't sound right, but I checked it, and it's true. As Stack Overflow user [JFS](https://stackoverflow.com/users/4279/jfs) puts it:
> Long story short, unless `len(l1 + l2)` >= 1,000,000 use sort
The reason sort beats merge in most cases is because of a man named Tim Peters.
## TimSort
Python's `list.sort` is the original implementation of a hybrid sorting algorithm called TimSort, named after its author, [Tim](https://github.com/python/cpython/commit/92f81f2e63b5eaa6d748d51a10e32108517bf3bf#diff-6d09fc0f0b57214c2e3a838d366425836c296fa931fe9dc430f604b7e3950c29) Peters.
> \[Here is\] stable, natural merge sort, modestly called
Timsort (hey, I earned it <wink>). It has supernatural performance on many
kinds of partially ordered arrays (less than lg(N!) comparisons needed, and
as few as N-1), yet as fast as Python's previous highly tuned sample sort
hybrid on random arrays.
<figcaption>Tim Peters explaining TimSort</figcaption>
Timsort is designed to find runs of sequential numbers and merge them together:
> The main routine marches over the array once, left to right,
alternately identifying the next run, then merging it into the previous
runs "intelligently". Everything else is complication for speed, and some
hard-won measure of memory efficiency.
This is why `(x + y).sort()` can be surprisingly fast: once it finds the sequential runs of numbers, it functions like our merge algorithm: combining the two sorted lists in linear time.
Timsort does have to do extra work, though. It needs to do a pass over the data to find these sequential runs, and `heapq.merge` knows where the runs are ahead of time. Timsort overcomes this disadvantage by being written in C rather than Python. Or as ShawdowRanger on Stack Overflow explains it:
> CPython's `list.sort` is implemented in C (avoiding interpreter overhead), while `heapq.merge` is mostly implemented in Python, and optimizes for the "many iterables" case in a way that slows the "two iterables" case.
This means that if I drop down to C and write a C extension I should be able to beat Timsort. This turned out to be easier than I thought it would be[^2].
## The C Extension
The bulk of the C Extension, whose performance I'm going to cover in a minute, is just the pop the stack algorithm discussed before, but using an index to point to the head of the stack ([full version](https://github.com/earthly/pymerge/blob/main/merge.c)):
``` c
//New List
PyObject* mergedList = PyList_New( n1 + n2 );
for( i = 0;; ) {
elem1 = PyList_GetItem( listObj1, i1 );
elem2 = PyList_GetItem( listObj2, i2 );
result = PyObject_RichCompareBool(v, w, Py_LT);
switch( result ) {
// List1 has smallest, Pop from list 1
case 1:
PyList_SetItem( mergedList, i++, elem1 );
i1++;
break;
case 0:
// List2 has smallest, Pop from list 2
PyList_SetItem( mergedList, i++, elem2 );
i2++;
break;
}
if( i2 >= n2 || i1 >= n1 )) {
//One list is empty, add remainder of other list to result
...
break;
}
}
return mergedList;
```
<figcaption>C merge</figcaption>
The nice thing about C extensions in Python is that they are easy to use. Once compiled, I can just `import merge` and use my new merge method:
``` Python
import merge
# create some sorted lists
a = list(range(-100, 1700))
b = list(range(1400, 1800))
# merge them
merge.merge(a, b)
```
## Testing It
Testing my new merge with a list of integers and floats, we can see that we are beating Timsort, especially for long lists:
``` Python
import merge
import timeit
a = list(range(-100, 1700))
b = [0.1] + list(range(1400, 1800))
def merge_test():
m1 = merge.merge(a, b)
def sort_test():
m2 = a + b
m2.sort()
sort_time = timeit.timeit("sort_test()", setup="from __main__ import sort_test", number=100000)
merge_time = timeit.timeit("merge_test()", setup="from __main__ import merge_test",number=100000)
print(f'timsort took {sort_time} seconds')
print(f'merge took {merge_time} seconds')
```
``` bash
timsort took 3.9523325259999997 seconds
merge took 3.0547665259999994 seconds
```
Graphing the performance we get this:
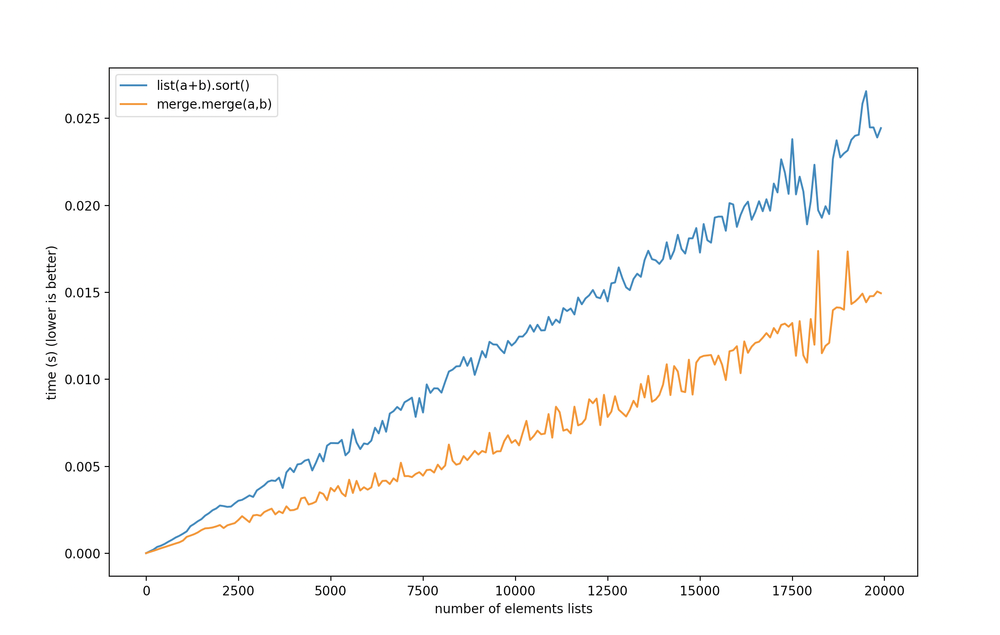
<figcaption>We are beating Timsort with our merge</figcaption>
</div>
But if we switch to a list of only integers `sort` is beating us for small lists and even on big lists our performance improvement is thin at best:

<figcaption>With lists of all `int` or all `float` we lose our advantage.</figcaption>
What is going on here?
## Timsort's Special Comparisons
It turns out that Timsort has some extra tricks up its sleeves in the case of a list of integers. In that initial pass over the list, it checks the types of the elements, and if they are all uniform it tries to use a cheaper comparison operation.
Specifically, if your list is all [longs](https://github.com/python/cpython/blob/main/Objects/listobject.c#L2085), [floats](https://github.com/python/cpython/blob/main/Objects/listobject.c#L2113), or [Latin strings](https://github.com/python/cpython/blob/main/Objects/listobject.c#L2061) Timsort will save a lot of cycles on the comparison operations.
Learning from Timsort we can bring in these comparison operations ourselves. We don't want to do a full pass over the list, or we will lose our advantage, so we can just specialize our merge by offering separate calls for longs, floats, and Latin alphabet strings like so:
``` c
//Default comparison
PyObject* merge( PyObject*, PyObject* );
//Compare assuming ints
PyObject* merge_int( PyObject*, PyObject* );
//Compare assuming floats
PyObject* merge_float( PyObject*, PyObject* );
//Compare assuming latin
PyObject* merge_latin( PyObject*, PyObject* )
```
<figcaption>merge.h</figcaption>
## Beating TimSort
Doing that, we now can finally beat Timsort at merging sorted lists, not just when the list is a heterogeneous mix of elements, but also when it's all integers, or floating-point numbers, or one byte per char strings.

<figcaption>merge vs TimSort for `int`.</figcaption>

<figcaption>merge vs TimSort for `float`.</figcaption>

<figcaption>merge vs TimSort for Latin alphabet strings.</figcaption>

<figcaption>merge vs TimSort for everything without a specialized compare.</figcaption>
The default `merge` beats Timsort for heterogeneous lists, and the specialized versions are there for when you have uniform types in your list, and you need to go fast.
## TimSort Is Good
There, I have beat Timsort for merging sorting lists, although I had to pull in some code from TimSort itself to get here. I'm not sure how valuable this is: if you need to go fast, you might not choose Python, but it was a fun learning project.
Also, I learned that dropping down to C isn't as scary as it sounds. The build steps are a bit more involved, but with the included [Earthfile](https://github.com/earthly/pymerge/blob/main/Earthfile), the build is a one-liner and works cross-platform. You can find the code [on GitHub](https://github.com/earthly/pymerge) and an intro to [Earthly](https://earthly.dev/) on this very site, and with that example, you can build your own C extension reasonably quickly.
The surprising thing, though, is how good Timsort still is. It wasn't designed for merging sorted lists but for sorting real-world data. It turns out real-world data is often partially sorted, just like our use case.
Timsort on partially sorted data shows us where Big O notation can misinform us. If your input always keeps you near the median or best-case performance, then the worst-case performance doesn't matter much. It's no wonder then that since its first creation, Timsort has spread from Python to JavaScript, Swift, and Rust. Thank you, Tim Peters!
[^1]: Practically, you might not want to use pop, but just track an index of where the head of the stack should be, like the C code shown later.
[^2]: It was easier because my teammate Alex has experience writing C extensions for Python, so by the time I had found the Python header files, Alex had already put together a prototype solution. | adamgordonbell |
776,524 | What are DLTs and how they differ from Blockchain
| surely you are already more than familiar with Bitcoin and Blockchain technology as a result of all... | 0 | 2021-07-30T14:54:16 | https://dev.to/eatzillaapp/what-are-dlts-and-how-they-differ-from-blockchain-1ea7 | blockchain, cryptocurrency | surely you are already more than familiar with Bitcoin and Blockchain technology as a result of all the noise generated earlier this year. However, you may not know the “twin” brother of the Blockchain, DLT ( Distributed Ledger Technology). In this post we tell you what DLTs are and how they differ from Blockchain .
What are DLTs and what is their meaning
Distributed Ledger Technology (DLT) or distributed ledger technologies are a set of technologies that allow us to design a system structure that allows it to function as a NOT centralized database . This means that there is no central computer or server that stores the information, making it a more secure system (the database cannot be “hacked” as there is no central computer to attack).
Now, not all DLT systems have to be fully decentralized. We can find a complete decentralization (without a control nucleus), distributed (one or several control nuclei, together with several support nodes), or federated (where the local nuclei have great autonomy). Access to these systems can be public or private, taking into account the level of security that you want to apply to the system.
Differences between DLT and Blockchain
If you are wondering what differences exist between a DLT system and a blockchain system, it is completely legitimate. We can say that DLT technologies are the largest category of Blockchain. This means that ALL blockchain networks are DLT technologies but not all DLTs are blockchain technology.
To give you an example we could say that DLT is the category “sports” and Blockchain is the “football”. As you can see, soccer is within the sports category but not all sports have to be soccer.
For its part, Blockchain development services or Blockchain technology is a system whose operation depends on generating blocks where information is stored. These blocks are then linked to each other generating the well-known chain of blocks. This chain ends up generating a linked and non-modifiable record of the information that has been stored in these blocks.
Both DLT networks and blockchain networks use protocols of the P2P or peer-to-peer type , which guarantees that the security and immutability standards are very high. And just as in DLTs there are different degrees of decentralization (complete, distributed or federated), in blockchain networks the exact same thing happens.
In short, a DLT network enables the secure operation of a decentralized digital database and where distributed networks eliminate the need for a central authority to control manipulation.
How DLT works
DLT allows all information to be stored safely and accurately using cryptography. It can be accessed through “keys” and cryptographic signatures . Once the information is stored, it becomes an immutable database and is governed by the rules of the network.
The Distributed Ledger Technology are not entirely new, many organizations and companies maintain their databases “separate” in different locations. This guarantees them a minimum degree of decentralization, however, each location is typically in a central connected system that makes them vulnerable to cyber attacks and local problems.
The very nature of a DLT makes them immune to cybercrime, as all copies stored on the network must be attacked at the same time for the attack to be successful.
In addition, the simultaneous (peer-to-peer) exchange and update of records makes the entire process much faster, more efficient, and cheaper.
Potential and the future of DLT
DLTs have great potential to revolutionize the way governments, institutions, and corporations work. It can assist governments with tax collection, issuance of passports, property and licenses, and disbursement of Social Security benefits, as well as voting procedures.
This technology is changing the way many industries work such as finance , music and entertainment, art, supply chains of various commodities and more.
The benefits of Blockchain and DLT technology
The potential applications of both technologies is, quite simply, immense. You may think that they are simply databases but what is truly innovative about them is that they allow us to have a greater degree of transparency, efficiency and automation.
We are going to review some of the applications that DLT has by field
1 # Financial systems
You have probably heard the applications of decentralized technologies, blockchain and cryptocurrencies like Bitcoin. And it is that financial systems were one of the first cases of use of this type of technology and have allowed us to build a new payment system that is safer and more accessible to the world.
2 # Cybersecurity
Although it seems that finance is the field with the greatest application of these technologies, it is actually cybersecurity. Remember that one of the most interesting characteristics of these technologies is the potential they have to build secure networks with different degrees of decentralization.
3 # Supply chain and logistics
One of the sectors in which decentralized technologies can cause greater disruption is in logistics and the supply chain. Especially in those logistics processes in which there is a high number of intermediaries. With this technology we can generate and create systems that adjust to the complex realities of logistics processes.
One of the best examples is the TradeLens system, a system designed by Maersk in collaboration with IBM that allows optimizing processes in marine logistics and international trade.
4 # Health
Finally, one of the most relevant areas pending disruption is the health system. An area with great potential for the development of decentralized technologies.
One of the challenges is to develop a distributed system where hospitals are able to store information safely and are quite accessible.
With such a system, for example, the data could only be read or modified by the hospital in question. Something only possible if your access credentials or private keys are used. Of the rest, no one could access or affect those systems. In case something happens, it would be enough to restart the systems, resynchronize and start working again.
In addition to this, the level of auditing and access to patient medical data is granular. That is, you can create systems that only give access to very specific pieces of information if you want. | eatzillaapp |
776,525 | The "new" blunder in JavaScript | No, I am not even talking about why JavaScript tries to replicate classical inheritance. As much as... | 0 | 2021-07-30T16:00:37 | https://dev.to/mayankav/the-new-blunder-in-javascript-1lee | javascript, programming, react, webdev | No, I am not even talking about why JavaScript tries to replicate classical inheritance. As much as that is an easy target on JavaScript, lets leave that upto anti evangelists. Just pondering over the **"new"** keyword in isolation is what I aim for right now. [Do we know all the possible ways of creating objects in JavaScript](https://codepen.io/mayankav/pen/zYwZOZJ)? Assuming that we do, two of the four ways available to us, make use of the **"new"** operator. The first one being **constructor functions** and yes you guessed it, **ES6 classes**.
When I talk of classes, I am somehow driven by my conscience to talk about all the problems classical inheritance brings along but for now I will hold on to the **"new"** keyword. The question you should ask is, why did we feel the need to have **"new"**, when we could actually use object literals in the first place? I mean, there must be some benefit of saying **new SomeFunction()** over your old pal **{ }**. Make a guess. Did someone say **"creating similar objects"**? So when you have a class **"YourClass"** with [class fields](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes/Public_class_fields) **"x"** and **"y"** and then when you say **"new YourClass(1,2)"**, you're assured that everytime you do a **"new"** object creation you will get a similar object, right? We can do that using **object concatenation** or **factory functions** but alright, not bad. What else? Maybe it also feels way simpler, no? So far so good. Smart people probably won't even talk about classes and constuctor functions, leave alone the **"new"** operator. [Smart people will do whatever they want](https://medium.com/javascript-scene/common-misconceptions-about-inheritance-in-javascript-d5d9bab29b0a#:~:text=Smart%20people%20will%20do%20whatever%20they%20want.). I personally don't favor using classes but that only makes sense when everything is under my control. Being a part of some team, that's not always the case. We need to deal with code whether we like it or not. Assuming that the **"new"** operator makes it intuitive for you specially when you're coming from OOP, can you figure out the difference here?
```javascript
new Date(); // Fri Jul 30 2021 20:08:55 GMT+0530 (India Standard Time)
new Date; // Fri Jul 30 2021 20:08:55 GMT+0530 (India Standard Time)
Date(); // "Fri Jul 30 2021 20:08:55 GMT+0530 (India Standard Time)"
```
Is **Date** a class, a constructor function or a factory function? If you don't know what a **factory function** is, its just another normal function that returns an object. So, if a function explicitly returns an object and is apparently not a constructor function, you can call it an object factory function. So what do you think Date in JavaScript is? I'll leave that on you to experiment with. If you can't reckon, think of how **"new String()"** & **"String()"** behave. The former gives you a new object whereas simply calling **String(..)** over some primitive does cast the value's type to string. The question is how do you define a function that can be safely called with and without the **"new"** operator? A factory function returns you the same object irrespective of whether you call it with or without a **"new"** operator. A constructor function on the other hand unless and until called with a **"new"** prefix returns undefined.
```javascript
function factoryFn(x, y) {
const obj = {};
obj.x = x;
obj.y = y;
return obj;
}
function ConstructorFn(x, y) {
this.x = x;
this.y = y;
}
console.log(factoryFn(1, 2)); // {x:1, y:2}
console.log(new factoryFn(1, 2)); // {x:1, y:2}
console.log(ConstructorFn(1, 2)); // undefined
console.log(new ConstructorFn(1, 2)); // {x:1, y:2}
```
<center><h6>[Try on Codepen](https://codepen.io/mayankav/pen/VwbxmEY)</h6></center><br>
Now, I am kind of more interested in the **constructor function**. Notice that when you simply call your constructor function without the **"new"** keyword, it returns undefined? Visibly so because there's nothing to return. Interestingly, unless you're in strict mode, you've now also created properties **"x"** and **"y"** on the global object. I understand, there's hardly someone in the wild who'd instantiate a constructor function without **"new"**. Anyway, we know how a constructor function otherwise implicitly returns "this" ([an anonymous object created using the "new" keyword](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/new#:~:text=Creates%20a%20blank%2C%20plain%20JavaScript%20object.)). What if I put a blunt **return statement** right inside the constuctor function? Take a look.
```javascript
function ConstructorFn(x, y) {
this.x = x;
this.y = y;
return new String('a blunder');
}
function AnotherConstructorFn(x, y) {
this.x = x;
this.y = y;
return "not a blunder";
}
console.log(new ConstructorFn(1,2)); // "a blunder"
console.log(new AnotherConstructorFn(1,2)); // {x:1, y:2}
```
<center><h6>[Try on Codepen](https://codepen.io/mayankav/pen/WNjJRNz)</h6></center><br>
Uncannily, if you return an object or an array, it seems to block the implicit nature of the constructor function that returns the **"this"** object, upon being instantiated with the **"new"** operator whereas returning an atomic string makes no difference as such. How do you think it is possible to make a constructor function work safe without the **"new"** operator? Why would you even want to do that? Well, you may have your own reasons, I just want to prevent the users of my constructor function from mistakenly trying to invoke it without the **"new"** operator. I know you can simply use an ES6 class but for some reason I want to stick to the old functions style and yes I am not using the strict mode as well. Strict mode inside the function can alert you from creating implicit globals.
```javascript
function StrictConstructor() {
if(this.constructor === StrictConstructor) {
this.x = 1;
this.y = 2;
} else {
throw new Error("StrictConstructor should only be instantiated with 'new' operator")
}
}
console.log(new StrictConstructor()); // {x:1, y:2}
StrictConstructor(); // Error
```
<center><h6>[Try on Codepen](https://codepen.io/mayankav/pen/xxdWoxx)</h6></center><br>
So the conditional filter we used to throw the error depends on how the **"new"** operator creates a new object and assigns it a constructor under the hood. If you want to get deep into this you should definitely go check out the [MDN reference](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/new#:~:text=Creates%20a%20blank%2C%20plain%20JavaScript%20object.) and then [my last blog post](https://dev.to/mayankav/javascript-inside-story-more-about-prototypes-and-inheritance-3a9l). As a matter of fact, instead of throwing an error you can even return an object to eliminate the need of calling the function using **"new"** like so:
```javascript
function StrictConstructor() {
if(this.constructor === StrictConstructor) {
this.x = 1;
this.y = 2;
} else {
return new StrictConstructor();
}
}
console.log(new StrictConstructor()); // {x:1, y:2}
console.log(StrictConstructor()); // {x:1, y:2}
```
<hr>
##Conclusion
For a while, if you forget about JavaScript, its not very intuitive to instantiate functions with the **"new"** operator. Probably that's why we name our constructor functions in [PascalCase](). Due to the fact that the **"new"** operator and constructor functions may behave eerie at times (specially when you forget the **"new"** operator), you can choose a combination of options from the available list to keep your code safe from surprises.
1. An ES6 class shall help you spot when someone forgets the **"new"** keyword, by throwing an error
2. Following the convention of naming constructor functions in Pascal.
3. Placing a check within your constructor function to either throw an error on skipping the **"new"** operator or to silently fix the implicit behavior of the constructor function.
##Originally Posted Here -
https://mayankav.webflow.io/blog/the-new-blunder-in-javascript | mayankav |
776,689 | Handy tools for your next Flutter project | 1: scrcpy: Control Android devices connected on USB ... | 0 | 2021-07-30T15:40:38 | https://dev.to/luckeyelijah/handy-tools-for-your-next-flutter-project-1gg2 | mobile, flutter, tools, dart | ## 1: `scrcpy`: Control Android devices connected on USB
{% github Genymobile/scrcpy no-readme %}
I've been using this tool for demoing, side-by-side mock-ups to screen, and getting emulator-like experience on a physical device's performance, easier screenshots, etc. This has been one the most useful tools for an Android developing experience for flutter developers.
## 2: Mockoon: Create mock APIs in seconds
{% github mockoon/mockoon no-readme %}
A simple, intuitive, local web service environment that will have you setting up API calls faster than the Firebase local emulator. This one is a favorite for viewing logs, creating routes on uncaught requests, and multiple environments.
## 3: Lefthook for linting and analysis before pushing and committing
{% github evilmartians/lefthook no-readme %}
Execute custom commands triggered by git actions. In my opinion it is much simpler than using traditional local git hooks.
```yaml
# On `git commit` lefthook will run `flutter format` and `flutter test`.
pre-commit:
commands:
flutter-format:
glob: "*.dart"
run: flutter format {staged_files}
flutter-test:
glob: "*.dart"
run: flutter test
```
## 4: Mason: Create and consume reusable templates
{% github felangel/mason no-readme %}
> Mason allows developers to create and consume reusable templates called bricks.
This tooling feels similar to snippets, but allows you bulk-create your project's boiler plate code.
## 5: Flutter DevTools - Network & Flutter Inspector
[Network](https://flutter.dev/docs/development/tools/devtools/network) & [Flutter Inspector](https://flutter.dev/docs/development/tools/devtools/inspector) are the two most useful tools in my utility belt. The network tools is extremely helpful in determining how many calls are being made for service and ensuring the data in the channel is formatting and not being mutated unknowingly. The Flutter Inspector is handy for exploring your widget tree. Two handy uses from the inspector are the "Select widget mode" for quickly finding a UI component and the the "Debug paint" for getting layout and sizing just right with Flutter's [flex-like](https://api.flutter.dev/flutter/widgets/Flex-class.html) widgets.
These may seem obvious to some but many new developers don't take advantage of these two immensely helpful utilities (and along with the rest of the DevTools Suite)!
## 6: Add user snippets live templates to your editor
The two primary code editors for the Flutter developer are Visual Studio Code and Android Studio/IntelliJ IDEAs. Many extension/plugins are offered on these platforms that include snippets and live templates, but sometimes these pieces of code don't fulfill your needs. You are able to create your own with each of the platforms. See the below pages to et more information for you prefer editor:
- [Snippets in Visual Studio Code](https://code.visualstudio.com/docs/editor/userdefinedsnippets)
- [Live templates in IntelliJ IDEA](https://www.jetbrains.com/help/idea/creating-and-editing-live-templates.html) | luckeyelijah |
776,924 | Build a Trading Bot with Cassandre Spring Boot Starter | A trading bot is a computer program that can automatically place orders to a market or exchange... | 0 | 2021-07-30T19:55:44 | https://dev.to/straumat/build-a-trading-bot-with-cassandre-spring-boot-starter-3m99 | spring, trading, cryptocurrency | A trading bot is a computer program that can automatically place orders to a market or exchange without the need for human intervention.
In this tutorial, we'll use [Cassandre](https://www.baeldung.com/cassandre-spring-boot-trading-bot) to create a simple crypto trading bot that will generate positions when we think it’s the best moment. | straumat |
776,927 | GitLab as your Continuous Deployment one-stop shop | This week, I want to take a break from my Start Rust series and focus on a different subject. I've... | 0 | 2021-08-01T16:33:17 | https://blog.frankel.ch/gitlab-continuous-deployment-one-stop-shop/ | devops, gitlab, continuousdeployment, docker | This week, I want to take a break from my Start Rust series and focus on a different subject. I've already written about [my blogging stack](https://blog.frankel.ch/my-blogging-stack-publishing-process/) in detail.
However, I didn't touch into one facet, and that facet is how I generate the static pages from Jekyll. As I describe in the blog post, I've included quite a couple of customizations. Some of them require external dependencies, such as:
* A <abbr title="Java Runtime Environment">JRE</abbr> for PlantUML diagrams generation
* The _graphviz_ package for the same reason
* etc.
All in all, it means that I require a fully configured system. I solved this problem by using containerization, namely Docker. Within the `Dockerfile`, I'm able to install all required dependencies. Then, in my GitLab build file, I can reference this image and benefit from all its capabilities.
```yaml
image: registry.gitlab.com/nfrankel/nfrankel.gitlab.io:latest
# ...
```
## Updating, the hard way
Jekyll is built on top of Ruby. Shared libraries in Ruby are known as _gems_. I'm using a few of them, along with the Jekyll gem itself. As a long-time Maven user, I searched for the equivalent dependency management utility in the Ruby world and stumbled upon [Bundler](https://bundler.io/):
> Bundler provides a consistent environment for Ruby projects by tracking and installing the exact gems and versions needed.
Bundler rests on a `Gemfile` file. It's similar to npm's `package.json`. When you execute `bundle install`, it creates a `Gemfile.lock` with the latest gems' version; with `bundle update`, it updates them.
So far, this is how my update process looked like:
1. Update the gems to their latest version
2. Build the Docker image on my laptop
3. Upload the image to my project's GitLab registry
4. Commit the change to the lock file
5. Push
6. In turn, that triggers the build on GitLab and deploys my site on GitLab Pages.
It has several drawbacks:
* It requires Docker on my laptop. Granted, I have it already, but not everybody is happy with that
* The build takes time, as well as CPU time
* The image takes up storage. I can clean it up, but it's an additional waste of my time.
* It clogs my network. As my upload speed is very limited, I cannot do anything that involves the Internet when I'm uploading.
## Updating, the smart way
I recently stumbled upon the excellent [series of GitLab cheatsheets](https://dev.to/jphi_baconnais/series/12928). In the [6<sup>th</sup> part](https://dev.to/zenika/gitlabcheatsheet-6-registry-2bjo), the author mentions [Kaniko](https://github.com/GoogleContainerTools/kaniko):
>kaniko is a tool to build container images from a Dockerfile, inside a container or Kubernetes cluster.
>
>kaniko doesn't depend on a Docker daemon and executes each command within a Dockerfile completely in userspace. This enables building container images in environments that can't easily or securely run a Docker daemon, such as a standard Kubernetes cluster.
>
>kaniko is meant to be run as an image: `gcr.io/kaniko-project/executor`.
It means that you can move the Docker image build part to the build process itself. The new process becomes:
So far, this is how my update process looked like:
1. Update the gems to their latest version
2. Commit the change to the lock file
3. Push
4. Enjoy!
To achieve that, I had to browse through the documentation quite intensively. I also moved the build file to the "new" syntax. Here's the new version:
```yaml
stages:
- image # 1
- deploy # 1
build: # 2
stage: image # 3
image:
name: gcr.io/kaniko-project/executor:debug # 4
entrypoint: [""] # 5
script:
- mkdir -p /kaniko/.docker
- echo "{\"auths\":{\"$CI_REGISTRY\":{\"auth\":\"$(echo -n ${CI_REGISTRY_USER}:${CI_REGISTRY_PASSWORD} | base64)\"}}}" > /kaniko/.docker/config.json # 6
- /kaniko/executor --context $CI_PROJECT_DIR --dockerfile $CI_PROJECT_DIR/Dockerfile --destination $CI_REGISTRY_IMAGE:$CI_COMMIT_TAG # 7
only:
refs:
- master
changes:
- Gemfile.lock # 8
pages: # 2
stage: deploy # 3
image:
name: registry.gitlab.com/nfrankel/nfrankel.gitlab.io:latest # 9
# ...
```
1. Define the _stages_. Stages are ordered: here, `image` runs before `deploy`.
2. Define the _jobs_
3. A job is associated with a stage. For the record, jobs associated with the same stage run in parallel.
4. Use the `debug` flavor of the Kaniko Docker image. While it's not necessary, this image logs what it's doing to improve debugging if something goes wrong.
5. Reset the `entrypoint`
6. Create the credentials file used by Kaniko to push to the Docker registry in the next line
7. Build the image using the provided `Dockerfile` and push it to the project's Docker registry. Note that GitLab passes all environment variables used here
8. Run this job only if the `Gemfile.lock` file has been changed
9. Generate the static site using the previously generated image
## Conclusion
This post shows how one could offload the Docker part of your build pipeline from your local machine to GitLab using the Kaniko image. It saves on time and resources. The only regret I have is that I should have done it much earlier as I'm a huge proponent of automation.
I miss one last step: schedule a job that updates dependencies and creates a _merge request_ _à la_ Dependabot.
**To go further:**
* [GitLab Cheatsheet Series](https://dev.to/jphi_baconnais/series/12928)
* [Use kaniko to build Docker images](https://docs.gitlab.com/ee/ci/docker/using_kaniko.html)
* [Keyword reference for the .gitlab-ci.yml file](https://docs.gitlab.com/ee/ci/yaml/)
* [Least Privilege Container Builds with Kaniko on GitLab](https://www.youtube.com/watch?v=d96ybcELpFs)
* [GitLab's predefined variables reference](https://docs.gitlab.com/ee/ci/variables/predefined_variables.html)
_Originally published at [A Java Geek](https://blog.frankel.ch/gitlab-continuous-deployment-one-stop-shop/) on August 1<sup>st</sup>, 2021_ | nfrankel |
777,007 | Use Advanced MySQL Operations to Analyze Python Web Scraper Data
| Prerequisites To follow this tutorial, you should have the following: Python 3.7 or... | 0 | 2021-07-30T21:44:51 | https://arctype.com/blog/mysql-advanced-queries | mysql, guide | 
## Prerequisites
To follow this tutorial, you should have the following:
- Python 3.7 or newer.
- [Arctype](https://arctype.com)
- Basic understanding of SQL.
- A text editor.
### Installing the required libraries
The libraries required for this tutorial are as follows:
- numpy — fundamental package for scientific computing with Python
- pandas — library providing high-performance, easy-to-use data structures, and data analysis tools
- requests — is the only Non-GMO HTTP library for Python, safe for human consumption. (love this line from official docs :D)
- BeautifulSoup — a Python library for pulling data out of HTML and XML files.
To install the libraries required for this tutorial, run the following commands below:
```
pip install numpy
pip install pandas
pip install requests
pip install bs4
```
## Building the Python Web Scraper
Now that we have all the required libraries installed let’s get to building our web scraper.
### Importing the Python libraries
```
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import json
```
### Carrying Out Site Research
The first step in any web scraping project is researching the web page you want to scrape and learn how it works. That is critical to finding where to get the data from the site. For this tutorial, we'll be using http://understat.com.

We can see on the home page that the site has data for six European leagues. However, we will be extracting data for just the top 5 leagues(teams excluding RFPL).

We can also notice that data on the site starts from 2014/2015 to 2020/2021. Let’s create variables to handle only the data we require.
```
# create urls for all seasons of all leagues
base_url = 'https://understat.com/league'
leagues = ['La_liga', 'EPL', 'Bundesliga', 'Serie_A', 'Ligue_1']
seasons = ['2016', '2017', '2018', '2019', '2020']
```
The next step is to figure out where the data on the web page is stored. To do so, open Developer Tools in Chrome, navigate to the Network tab, locate the data file (in this example, 2018), and select the “Response” tab. After executing requests, this is what we'll get.

After looking through the web page's content, we discovered that the data is saved beneath the "script" element in the `teamsData` variable and is JSON encoded. As a result, we'll need to track down this tag, extract JSON from it, and convert it to a Python-readable data structure.

### Decoding the JSON Data with Python
```
season_data = dict()
for season in seasons:
url = base_url+'/'+league+'/'+season
res = requests.get(url)
soup = BeautifulSoup(res.content, "lxml")
# Based on the structure of the webpage, I found that data is in the JSON variable, under <script> tags
scripts = soup.find_all('script')
string_with_json_obj = ''
# Find data for teams
for el in scripts:
if 'teamsData' in str(el):
string_with_json_obj = str(el).strip()
# strip unnecessary symbols and get only JSON data
ind_start = string_with_json_obj.index("('")+2
ind_end = string_with_json_obj.index("')")
json_data = string_with_json_obj[ind_start:ind_end]
json_data = json_data.encode('utf8').decode('unicode_escape')
#print(json_data)
```
After running the python code above, you should get a bunch of data that we’ve cleaned up.
### Understanding the Scraper Data
When we start looking at the data, we realize it's a dictionary of dictionaries with three keys: id, title, and history. Ids are also used as keys in the dictionary's initial layer.
Therefore, we can deduce that history has information on every match a team has played in its own league (League Cup or Champions League games are not included).
After reviewing the first layer dictionary, we can begin to compile a list of team names.
```
# Get teams and their relevant ids and put them into separate dictionary
teams = {}
for id in data.keys():
teams[id] = data[id]['title']
```
We see that column names frequently appear; therefore, we put them in a separate list. Also, look at how the sample values appear.
```
columns = []
# Check the sample of values per each column
values = []
for id in data.keys():
columns = list(data[id]['history'][0].keys())
values = list(data[id]['history'][0].values())
break
```
Now let’s get data for all teams. Uncomment the print statement in the code below to print the data to your console.
```
# Getting data for all teams
dataframes = {}
for id, team in teams.items():
teams_data = []
for row in data[id]['history']:
teams_data.append(list(row.values()))
df = pd.DataFrame(teams_data, columns=columns)
dataframes[team] = df
# print('Added data for {}.'.format(team))
```
After you have completed this code, we will have a dictionary of DataFrames with the key being the team's name and the value being the DataFrame containing all of the team's games.
### Manipulating the Data Table
When we look at the DataFrame content, we can see that metrics like PPDA and OPPDA (ppda and ppda allowed) are represented as total sums of attacking/defensive actions.
However, they are shown as coefficients in the original table. Let's clean that up.
```
for team, df in dataframes.items():
dataframes[team]['ppda_coef'] = dataframes[team]['ppda'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)
dataframes[team]['oppda_coef'] = dataframes[team]['ppda_allowed'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)
```
We now have all of our numbers, but for every game. The totals for the team are what we require. Let's look at the columns we need to add up. To do so, we returned to the original table on the website and discovered that all measures should be added together, with only PPDA and OPPDA remaining as means in the end. First, let’s define the columns we need to sum and mean.
```
cols_to_sum = ['xG', 'xGA', 'npxG', 'npxGA', 'deep', 'deep_allowed', 'scored', 'missed', 'xpts', 'wins', 'draws', 'loses', 'pts', 'npxGD']
cols_to_mean = ['ppda_coef', 'oppda_coef']
```
Finally, let’s calculate the totals and means.
```
for team, df in dataframes.items():
sum_data = pd.DataFrame(df[cols_to_sum].sum()).transpose()
mean_data = pd.DataFrame(df[cols_to_mean].mean()).transpose()
final_df = sum_data.join(mean_data)
final_df['team'] = team
final_df['matches'] = len(df)
frames.append(final_df)
full_stat = pd.concat(frames)
full_stat = full_stat[['team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'npxG', 'xGA', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts']]
full_stat.sort_values('pts', ascending=False, inplace=True)
full_stat.reset_index(inplace=True, drop=True)
full_stat['position'] = range(1,len(full_stat)+1)
full_stat['xG_diff'] = full_stat['xG'] - full_stat['scored']
full_stat['xGA_diff'] = full_stat['xGA'] - full_stat['missed']
full_stat['xpts_diff'] = full_stat['xpts'] - full_stat['pts']
cols_to_int = ['wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'deep', 'deep_allowed']
full_stat[cols_to_int] = full_stat[cols_to_int].astype(int)
```
In the code above, we reordered columns for better readability, sorted rows based on points, reset the index, and added column ‘position’.
We also added the differences between the expected metrics and real metrics.
Lastly, we converted the floats to integers where appropriate.
### Beautifying the Final Output of the Dataframe
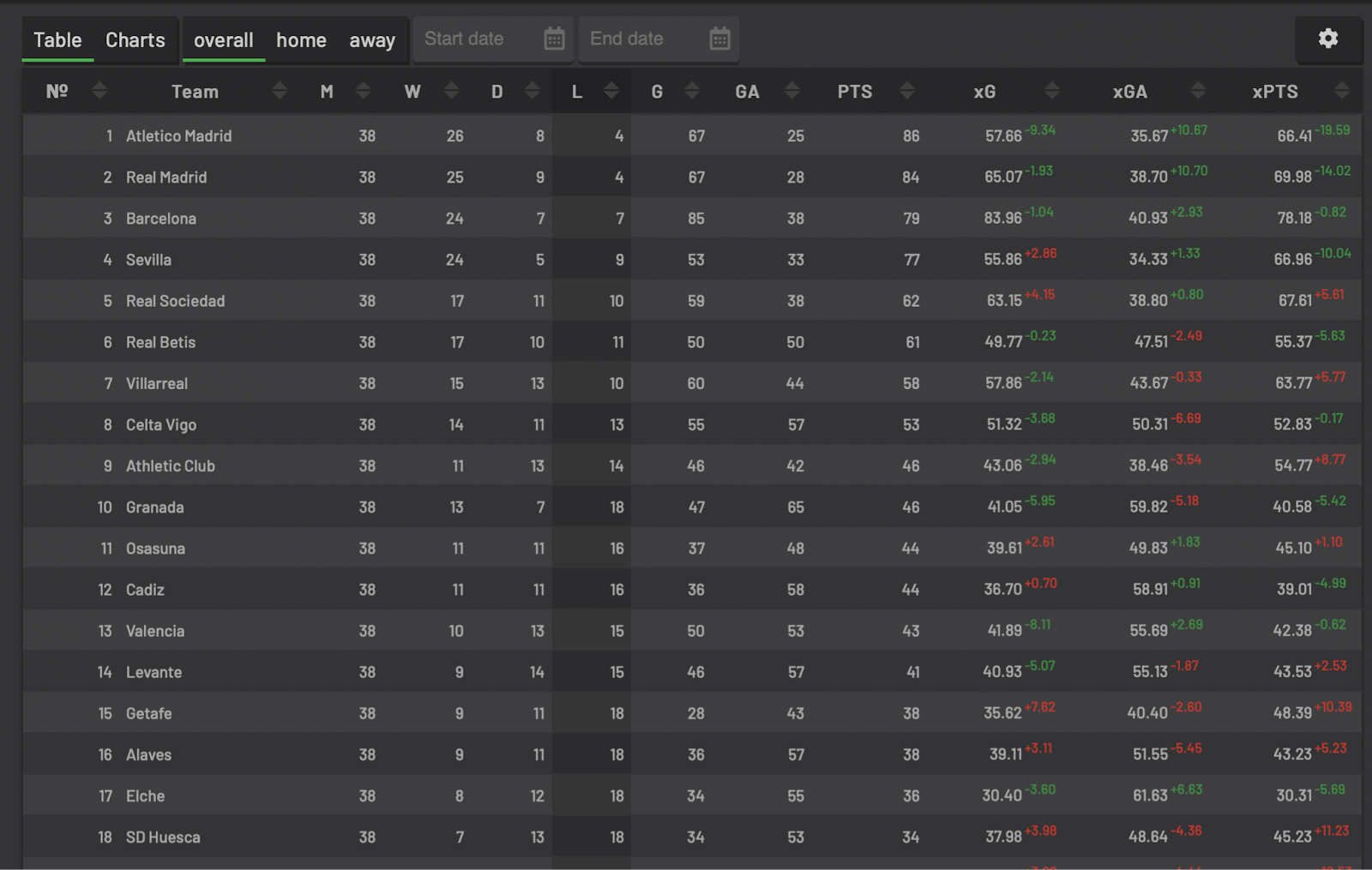
Finally, let’s beautify our data to become similar to the site data in the image above. To do this, run the python code below.
```
python
col_order = ['position', 'team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'xG_diff', 'npxG', 'xGA', 'xGA_diff', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts', 'xpts_diff']
full_stat = full_stat[col_order]
full_stat = full_stat.set_index('position')
# print(full_stat.head(20))
```
To print a part of the beautified data, uncomment the print statement in the code above.
### Compiling the Final Python Data Aggregator Code
To get all the data, we need to loop through all the leagues and seasons then manipulate it to be exportable as a CSV file.
```
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import json
# create urls for all seasons of all leagues
base_url = 'https://understat.com/league'
leagues = ['La_liga', 'EPL', 'Bundesliga', 'Serie_A', 'Ligue_1']
seasons = ['2016', '2017', '2018', '2019', '2020']
full_data = dict()
for league in leagues:
season_data = dict()
for season in seasons:
url = base_url+'/'+league+'/'+season
res = requests.get(url)
soup = BeautifulSoup(res.content, "lxml")
# Based on the structure of the webpage, I found that data is in the JSON variable, under <script> tags
scripts = soup.find_all('script')
string_with_json_obj = ''
# Find data for teams
for el in scripts:
if 'teamsData' in str(el):
string_with_json_obj = str(el).strip()
# print(string_with_json_obj)
# strip unnecessary symbols and get only JSON data
ind_start = string_with_json_obj.index("('")+2
ind_end = string_with_json_obj.index("')")
json_data = string_with_json_obj[ind_start:ind_end]
json_data = json_data.encode('utf8').decode('unicode_escape')
# convert JSON data into Python dictionary
data = json.loads(json_data)
# Get teams and their relevant ids and put them into separate dictionary
teams = {}
for id in data.keys():
teams[id] = data[id]['title']
# EDA to get a feeling of how the JSON is structured
# Column names are all the same, so we just use first element
columns = []
# Check the sample of values per each column
values = []
for id in data.keys():
columns = list(data[id]['history'][0].keys())
values = list(data[id]['history'][0].values())
break
# Getting data for all teams
dataframes = {}
for id, team in teams.items():
teams_data = []
for row in data[id]['history']:
teams_data.append(list(row.values()))
df = pd.DataFrame(teams_data, columns=columns)
dataframes[team] = df
# print('Added data for {}.'.format(team))
for team, df in dataframes.items():
dataframes[team]['ppda_coef'] = dataframes[team]['ppda'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)
dataframes[team]['oppda_coef'] = dataframes[team]['ppda_allowed'].apply(lambda x: x['att']/x['def'] if x['def'] != 0 else 0)
cols_to_sum = ['xG', 'xGA', 'npxG', 'npxGA', 'deep', 'deep_allowed', 'scored', 'missed', 'xpts', 'wins', 'draws', 'loses', 'pts', 'npxGD']
cols_to_mean = ['ppda_coef', 'oppda_coef']
frames = []
for team, df in dataframes.items():
sum_data = pd.DataFrame(df[cols_to_sum].sum()).transpose()
mean_data = pd.DataFrame(df[cols_to_mean].mean()).transpose()
final_df = sum_data.join(mean_data)
final_df['team'] = team
final_df['matches'] = len(df)
frames.append(final_df)
full_stat = pd.concat(frames)
full_stat = full_stat[['team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'npxG', 'xGA', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts']]
full_stat.sort_values('pts', ascending=False, inplace=True)
full_stat.reset_index(inplace=True, drop=True)
full_stat['position'] = range(1,len(full_stat)+1)
full_stat['xG_diff'] = full_stat['xG'] - full_stat['scored']
full_stat['xGA_diff'] = full_stat['xGA'] - full_stat['missed']
full_stat['xpts_diff'] = full_stat['xpts'] - full_stat['pts']
cols_to_int = ['wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'deep', 'deep_allowed']
full_stat[cols_to_int] = full_stat[cols_to_int].astype(int)
col_order = ['position', 'team', 'matches', 'wins', 'draws', 'loses', 'scored', 'missed', 'pts', 'xG', 'xG_diff', 'npxG', 'xGA', 'xGA_diff', 'npxGA', 'npxGD', 'ppda_coef', 'oppda_coef', 'deep', 'deep_allowed', 'xpts', 'xpts_diff']
full_stat = full_stat[col_order]
full_stat = full_stat.set_index('position')
# print(full_stat.head(20))
season_data[season] = full_stat
df_season = pd.concat(season_data)
full_data[league] = df_season
```
To analyze our data in Arctype, we need to export the data to a CSV file. To do this, copy and paste the code below.
```
python
data = pd.concat(full_data)
data.to_csv('understat.com.csv')
```
## Analyzing Scraper Data with MySQL
Now that we have a clean CSV file containing our soccer data, let's create some visualizations. First, we'll need to import the CSV file into a MySQL table.
### Importing CSV Data into MySQL
To use the data we extracted, we need to import the CSV data as a table in our database. To do this, follow the steps below:
**Step 1**
In the database menu, click on the three-dotted icon and select “Import Table”. Click on “accept” to accept the schema.
**Step 2**
Enter table name as “soccer_data”, then rename the first two columns to “league” and “year”. Leave all other settings and click the “Import CSV” button, as seen in the image below.

After following the steps above, the “soccer_data” table should be populated with data from the CSV file, as seen in the image below.
Now that we have imported our data stored in a CSV file, we can compare various data and visualize them on data charts.
### Use Dynamic SQL to Create a Pivot Table and Bar Chart
We will be analyzing scored and missed shots data for one league across all years in order to calculate each team's **shots per goal** ratio. The perfect league to run this analysis on is the “Bundesliga” as they are a league known for taking many outside-the-box shots.
**Creating a Shots-Per-Goal Pivot Table**
For this visualization, we're going to need our results in a pivot-style table with a unique column for each season in the dataset. This is the basic logic of our query:
```
SELECT
year,
SUM(
CASE
WHEN year = '2020' THEN (scored + missed) / scored
ELSE NULL
END
) AS `2020 Season`
FROM
soccer_data
WHERE
league = 'Bundesliga'
GROUP BY
team
ORDER BY
team;
```
This way, the shots-per-goal ratio of each team in the 2020 season is outputted in a column called `2020 Season`. But what if we want five separate columns doing the same thing for five seasons? Of course, we can define each one manually, or we can use `GROUP CONCAT()` and user variables to do this dynamically. The only dynamic component of our query is the season columns in our `SELECT` statement, so let's start by `SELECT`ing this query string into a variable (@sql).
```
SELECT
GROUP_CONCAT(
DISTINCT CONCAT(
'SUM(case when year = ''',
year,
''' then (scored + missed) / scored ELSE NULL END) AS `',
year,
' Season`'
)
ORDER BY
year ASC
) INTO @sql
FROM
soccer_data;
```
Here, `DISTINCT CONCAT()` is generating a `SUM(CASE WHEN year=...)` column definition for each distinct value in the `year` column of our table. If you want to see the exact output, simply add `SELECT @sql`; on a new line and execute the query.
Now that we have the dynamic portion of our query string, we just need to add in everything else around it like this:
```
SET
@sql = CONCAT(
'WITH pivot_data AS (SELECT team, ',
@sql,
'FROM understat_com
WHERE league=''Bundesliga''
GROUP BY team
ORDER BY team)
SELECT *
FROM pivot_data
WHERE `2019 Season` IS NOT NULL
AND `2020 Season` IS NOT NULL;'
);
```
Finally, we just need to prepare an SQL statement from the string in @sql and execute it:
```
PREPARE stmt FROM @sql;
EXECUTE stmt;
```
Run, rename and save the entire query above.
**Visualizing The Goal-per-Shot Ratio with a Bar Chart**
An excellent way to visualize the query above is using a bar chart. Use the `team` column for the x-axis and each of our `Season` columns for the y-axis. This should yield a bar chart like the one below:

### Create a 'Top 5 vs. The Rest' Pie Chart Using CTEs
We will be analyzing data for one league from different years in order to compare **the total wins of the top five teams against the rest of the league**. The perfect league to run this analysis on is the “Serie A” as they record many wins.
**How to Separate the Top 5 Teams using a WITH Statement**
For this visualization, we essentially want our query results to look like this:
| team | wins |
|------|------|
|Team 1 | 100|
|Team 2 | 90|
|Team 3 |80 |
|Team 4 |70|
|Team 5 |60|
|Others | 120|
With this in mind, we'll focus first on the rows for the top five teams:
```
WITH top5 AS(
SELECT
team,
SUM(wins) as wins
FROM
soccer_data
WHERE
league='Serie_A'
GROUP BY
1
ORDER BY
2 DESC
LIMIT 5
)
SELECT * FROM top5
```
Here, we're using a WITH clause to create a Common Table Expression (CTE) called `top5` with the team name and total wins for the top 5 teams. Then, we're selecting everything in `top5`.
Now that we have the top five teams, let's use UNION to add the rest:
```
UNION
SELECT
'Other' as team,
SUM(wins) as wins
FROM
soccer_data
WHERE
league='Serie_A'
AND team NOT IN (SELECT team FROM top5)
```
Run, rename and save the entire query above.
**Visualizing Top 5 vs. The Rest with a Pie Chart**
An excellent way to visualize the query above is using a pie chart. Use the `team` column for 'category' and `wins` for 'values'. After adding the columns, we should have a pie chart like the one in the image below. As you can see, the top five teams comprise close to 50% of wins in the Serie A league:

### Comparing Win-Loss Ratios with CTEs and Dynamic SQL
For this query, we'll be using CTEs and dynamic SQL to compare the win-loss ratios of top three teams in Serie A to all other teams. We'll want our result set to look something like this:
| year | team 1 | team 2 | team 3 | other |
|------|--------|--------|--------|--------|
|2016 | value| value| value| value|
|2017 | value| value| value| value|
|2018| value| value| value| value|
|2019| value| value| value| value|
|2020| value| value| value| value|
The fundamental query logic should look something like this:
```
SELECT
year,
MAX(CASE
WHEN team = 'team1' THEN wins / losses
ELSE NULL
END) AS `team 1`
AVG(CASE
WHEN team NOT in ('team1','team2','team3') THEN wins / losses
ELSE NULL
END) AS `other`
FROM
soccer_stats
WHERE
league = 'Serie_A'
GROUP BY
team
```
Of course, this won't quite work without some MySQL magic.
**Separating the Top 3 Teams**
First things first, let's separate our top three teams using a CTE:
```
WITH top3 AS(
SELECT
team,
AVG(wins / loses) as wins_to_losses
FROM
soccer_data
WHERE
league = 'Serie_A'
GROUP BY
team
ORDER BY
2 DESC
LIMIT
3
)
```
**Generating Dynamic SQL Strings inside a CTE**
Because each of these teams will need its own column, we'll need to use dynamic SQL to generate some special CASE statements. We'll also need to generate a CASE statement for our 'Other' column. For this, we'll use dynamic SQL inside a CTE:
```
variable_definitions AS(
SELECT
(
GROUP_CONCAT(
CONCAT(
'''',
team,
''''
)
)
) as team_names,
(
GROUP_CONCAT(
DISTINCT CONCAT(
'MAX(case when team = ''',
team,
''' then wins / loses ELSE NULL END) AS `',
team,
'`'
)
)
) as column_definitions
FROM top3
)
```
Next, let's take the `team_names` and `column_definitions` strings and `INSERT` them into variables:
```
SELECT
team_names,
column_definitions
INTO
@teams,
@sql
FROM
variable_definitions;
```
At this point, we should have a list of the top three teams in string format saved to `@teams` and our column case statements for the top three teams saved to `@sql`. We just have to build the final query:
```
SET
@sql = CONCAT(
'SELECT year, ',
@sql,
', AVG(CASE WHEN team NOT IN (',
@teams,
') THEN wins / loses ELSE NULL END) AS `Others` ',
'FROM soccer_data WHERE league = ''Serie_A'' GROUP BY year;'
);
prepare stmt FROM @sql;
EXECUTE stmt;
```
You can find the query in full at the bottom of this article.
**Visualizing Win-Loss-Ratio with an Area Chart**
An excellent way to visualize the query above is using an area chart. To create this area chart, use `year` for the x-axis and all other columns for the y-axis. Your chart should look something like this:

Because we're using dynamic SQL, we can easily add more team columns by changing `LIMIT 3` in the `top3` CTE to `LIMIT 5`:

## Conclusion
In this article, you learned how to extract sports data with python from a website and use advanced MySQL operations to analyze and visualize it with [Arctype](https://www.arctype.com/). In addition, you saw how easy it is to run SQL queries on your database using Arctype and got the chance to explore some of its core features and functionalities.
The source code of the python script, the CSV file, and other data are available on [Github](https://github.com/Chukslord1/ARCTYPE_SPORTS_WEBSCRAPPER). If you have any questions, don't hesitate to contact me on Twitter: [@LordChuks3](https://twitter.com/LordChuks3).
**Final SQL Query:**
```
WITH top3 AS(
SELECT
team,
AVG(wins / loses) as wins_to_losses
FROM
soccer_data
WHERE
league = 'Serie_A'
GROUP BY
team
ORDER BY
2 DESC
LIMIT
3
), variable_definitions AS(
SELECT
(GROUP_CONCAT(CONCAT('''', team, ''''))) as team_names,
(
GROUP_CONCAT(
DISTINCT CONCAT(
'MAX(case when team = ''',
team,
''' then wins / loses ELSE NULL END) AS `',
team,
'`'
)
)
) as column_definitions
FROM
top3
)
SELECT
team_names,
column_definitions
INTO
@teams,
@sql
FROM
variable_definitions;
SET
@sql = CONCAT(
'SELECT year, ',
@sql,
', AVG(CASE WHEN team NOT IN (',
@teams,
') THEN wins / loses ELSE NULL END) AS `Others` ',
'FROM soccer_data WHERE league = ''Serie_A'' GROUP BY year;'
);
prepare stmt FROM @sql;
EXECUTE stmt;
``` | rettx |
777,028 | Algorithms Scripting Notes and Examples: Part 4 | 7:45 AM Trying to do my studies early in the morning and some in the afternoon. In order for me to... | 0 | 2021-08-20T20:36:48 | https://dev.to/rthefounding/algorithms-scripting-notes-and-examples-part-4-29ln | javascript, beginners, algorithms, devops | * 7:45 AM Trying to do my studies early in the morning and some in the afternoon. In order for me to become who I wanna be I need to continue not giving up no matter how hard.
* Anyways moving on. Now Today we're figuring out how to return the sum of all odd Fibonacci Numbers that are less than or equal to `num`.
* Basically its just every additional number in the sequence is the sum of the previous numbers. Ex: the first two numbers in the Fibonacci sequence starts with 1 and 1. After it should be followed by 2, 3, 5, 8, and so forth.
* For example, `sum(10)` should return `10` because all odd Fibonacci numbers less than or equal to `10` are 1, 1, 3, and 5.
```
function sum(num) {
return num;
}
sum(4); // this should return 5 because all odd Fibonacci numbers less than or equal to `4` are 1, 1, 3
```
* Answer:
```
function sum(num) {
let sequence = [0, 1]
let count = sequence[sequence.length - 2] + sequence[sequence.length - 1];
while (count <= num) {
sequence.push(count);
count = sequence[sequence.length - 2] + sequence[sequence.length - 1];
}
let sumOfAllOdds = 0
sequence.forEach(function(num) {
if (num % 2 != 0) {
sumOfAllOdds += num;
}
});
return sumOfAllOdds;
}
console.log(sum(4)); // want to return 5 because that's the sum of all odd Fibonacci numbers [ 1, 1, 3];
```
#### Alright onto the next one! This time they want us to check return the sum of all prime numbers that are less than or equal to num.
* If you don't know what a prime number is, basically it's a whole number greater than 1 with exactly two divisors: 1 and itself. For example, 2 is a prime number because it is only divisible by 1 and 2. While something like 4 is not because it is divisible by 1, 2 and 4.
* Now lets rewrite `SumOfAllPrimes` so it returns the sum of all prime numbers that are less than or equal to num.
```
function sumOfAllPrimes(num) {
return num;
}
sumOfAll(10);
```
* Answer:
```
function sumOfAllPrimes(num) {
function isPrime(num) {
for (let x = 2; x < num; x++) {
if (num % x === 0) {
return false;
}
}
return true;
}
let range = []
for (let i = 2; i <= num; i++) {
if (isPrime(i)) {
range.push(i)
}
}
return range.reduce((a, b) => a + b)
}
console.log(sumOfAllPrimes(10)); // will display 17 because 2 + 5 + 10 = 17
// Recommended (reduce with default value)
// Array.prototype.reduce can be used to iterate through the array, adding the current element value to the sum of the previous element values.
// console.log(
// [1, 2, 3, 4].reduce((a, b) => a + b, 0)
// )
// console.log(
// [].reduce((a, b) => a + b, 0)
// )
// a prime number can only return false - your code --> "if num % x ===0 { return false}" if it % 1 OR ITSELF. But you put x start from 2, so it won't check 1. then u put "x < num" so it won't check itself
``` | rthefounding |
777,182 | setgrsg | CREATE TABLE employee ( id int(11) NOT NULL PRIMARY KEY AUTO_INCREMENT, emp_name varchar(70) NOT... | 0 | 2021-07-31T04:09:14 | https://dev.to/mauryapiyush713/setgrsg-hch | python, laravel | CREATE TABLE `employee` (
`id` int(11) NOT NULL PRIMARY KEY AUTO_INCREMENT,
`emp_name` varchar(70) NOT NULL,
`gender` varchar(10) NOT NULL,
`date_of_join` date NOT NULL,
`email` varchar(80) NOT NULL,
`timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
) | mauryapiyush713 |
777,367 | Flutter create a search bar for a list view | In this article, we'll learn how to add a search bar to a list view. This is a common practice as we... | 0 | 2021-07-31T08:05:50 | https://daily-dev-tips.com/posts/flutter-create-a-search-bar-for-a-list-view/ | flutter, dart | In this article, we'll learn how to add a search bar to a list view. This is a common practice as we can have long lists. It can be super helpful to have a search bar on top.
The end result for this article will look like this:

As a starting point, I'm using the [Flutter anime app](https://daily-dev-tips.com/posts/top-anime-shows-flutter-app/) we build before.
This app already has a list view and data assigned to it, so we can focus on adding the search bar.
## Adding a search bar in the Flutter UI
Let's wrap our existing list view into a column layout to have the input field above it.
```dart
body: Column(
mainAxisSize: MainAxisSize.max,
mainAxisAlignment: MainAxisAlignment.start,
crossAxisAlignment: CrossAxisAlignment.start,
children: [
SizedBox(height: 10),
Padding(
padding: const EdgeInsets.symmetric(horizontal: 15.0),
child: TextField(
onChanged: (value) {
setState(() {
searchString = value.toLowerCase();
});
},
decoration: InputDecoration(
labelText: 'Search',
suffixIcon: Icon(Icons.search),
),
),
),
SizedBox(height: 10),
Expanded(
child: FutureBuilder(
// Our existing list code
),
),
],
)
```
As you can see, I wrapped the body in a column to have multiple children rendered.
Next, I've added some sized boxes for space between the search bar.
The search bar itself is a text field with an onChanged function.
In our case, it will save the value into a searchString variable.
I save the value in lowercase. This makes it more versatile to search with.
Let's also add the search string variable so that part is finished.
```dart
String searchString = "";
```
So by now, if we run our code, we have a search bar above our list. When we type something in this search, it's saved to this search string.
## Implementing the search query
Now for a static list, we could choose to have a duplicated array to search from.
However, since we are using the future builder, we don't have the data before, so we can't compare it with a search list.
However, we can modify our builder to render items based on the search string conditionally.
Since the state is being changed every time we type a letter, the list is also re-evaluated.
Let's change the return function of the builder.
```dart
itemBuilder: (BuildContext context, int index) {
return snapshot.data![index].title
.toLowerCase()
.contains(searchString)
? ListTile(
// List tile widget data
)
: Container();
},
separatorBuilder: (BuildContext context, int index) {
return snapshot.data![index].title
.toLowerCase()
.contains(searchString)
? Divider()
: Container();
},
```
So inside the item builder, we evaluate if that item's title matches our search string by using the contains query.
This makes it a partial match, so we can also search for a word in the middle of the title.
The partial match works like this:
```dart
return condition ? true return : false return;
```
If this match returns true, we return a list tile. Else we return an empty container.
Since we used a separator builder, we also need to add this code to the separator builder. Else we would get empty dividers.
And with that, we can now search in our list view.
If you are looking for the complete code example, you can find it in this [GitHub repo](https://github.com/rebelchris/flutter/tree/feature/list-search).
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
777,437 | Retrospectives or postmortems? | A couple of months ago during a workshop presentation on the topic of getting started with DevOps, I... | 0 | 2021-08-02T08:33:48 | https://jhall.io/archive/2021/07/31/retrospectives-or-postmortems/ | retrospectives, postmortem, devops | ---
title: Retrospectives or postmortems?
published: true
date: 2021-07-31 00:00:00 UTC
tags: retrospectives,postmortem,devops
canonical_url: https://jhall.io/archive/2021/07/31/retrospectives-or-postmortems/
---
A couple of months ago during a workshop presentation on the topic of [getting started with DevOps](https://jhall.io/archive/2021/07/30/where-to-start-with-devops/), I was asked an interesting question:
> Is it easier to start with retrospectives, or with postmortems?
The two serve distinct, although related, purposes. Retrospectives exist to encourage regular [retrospection](https://jhall.io/archive/2021/04/22/are-retrospectives-required/), whereas postmortems serve to understand root causes of incidents and prevent future reoccurences. So naturally, most teams will want to do both.
But if your team is doing neither, which is easier to start with?
If your team is open to it, by all means, start doing retrospectives regularly (monthly or biweekly). But if this doesn’t work, or you sense resistance, then starting with postmortems could make good sense. Here are some reasons:
1. Postmortems are _timely_. They ideally happen the day after a major incident has been resolved. This means everyone still has the incident, and its resolution, fresh on mind, and are generally in the mood to prevent such an incident from recurring.
2. Postmortems are _focused_. Each postmortem focuses on a single incident, and its proximate causes. This leads to focused discussion in a way that retrospectives may not.
3. Postmortems are _blameless_. Of course, your retrospectives, and indeed entire company culture, ought to be blameless, too. But if this is not already part of your culture, starting this tradition in isolation can be easier.
4. Postmortems can gracefully turn into retrospectives. Every postmortem requires follow-up. If your team is ready for it, you can easily turn your first postmortem followup into your first retrospective. After addressing the old business from the postmortem, leave the meeting open for other areas of improvement.
If your team could use some help implementing effective blameless postmortems, I’d love to help. [Reach out](https://jhall.io/contact/) and let’s discuss your needs.
* * *
_If you enjoyed this message, [subscribe](https://jhall.io/daily) to <u>The Daily Commit</u> to get future messages to your inbox._ | jhall |
777,581 | Blurry image backgrounds like on Instagram | A JavaScript/CSS prototype to automatically generate blurred background images from the image source... | 0 | 2021-07-31T14:48:33 | https://dev.to/typo3freelancer/blurry-image-backgrounds-like-on-instagram-4bel | codepen, css, javascript, instagram | A JavaScript/CSS prototype to automatically generate blurred background images from the image source of the original image. The img tag just has to be packed into a container. The rest is done by JavaScript and CSS filters.
TIP: If you use Twitter Bootstrap 5, you can also use the ratio classes (.ratio, .ratio-16x9) for the image container (.image-container).
{% codepen https://codepen.io/typo3-freelancer/pen/ExmLBJP %}
NOTE: If you want to use this code for a live website, please add more CSS rules and better responsive handling ;-) It's not perfectly done yet!
## Your Feedback is appreciated!
What do you think about this approach? Would you do it the same way? What would you do better in the current code? Just write it in the comments! | typo3freelancer |
777,748 | Browser and React onChange event: The conundrum | The Problem Sometimes I think we all are so inclined towards Javascript frameworks or... | 0 | 2021-08-01T17:24:20 | https://dev.to/kpulkit29/browser-and-react-onchange-event-the-conundrum-4ke7 | javascript, webdev, react, html | ##The Problem
Sometimes I think we all are so inclined towards Javascript frameworks or libraries that we don't pay attention to how things work natively. Recently when I was debugging an issue about input tag's **onchange** event, I was startled when the callback function was not being called on changing the input value. Well, React triggers onChange whenever one changes the input value. Coming from React I just assumed that such things would work the same in vanilla Javascript 😔 😔 . **The way browser fires the onchange event is different.**
###Javascript onchange
Coming from React it's easy to fall into the trap. But let's understand some events the browser fires when one interacts with the input tag
* onfocus - Fired when the user sets focus on the element
* onblur - Opposite of onfocus. Fired when an element loses focus
* onchange - (the most interesting one 😅). Unlike React, the browser fires onchange event after focus from input element is taken off. So when focus is set on an input element and something is typed, onchange won't be fired until and unless the input element is out of focus.
When an element is out of focus, the browser assumes that the user is done making the change(probably the reason why onchange is fired late).
Let's see this in action. Check out the JS part here and open your console to see what is logged.
**Note that onchange is fired only when input is out of focus**
{% codepen https://codepen.io/pulkit29/pen/QWvxwrW %}
###Question for the readers 🧐
I am not too sure as to why in the above example onblur callback is fired after the onchange callback. We know now that onchange is fired when the element is out of focus. Know the reason?? Please comment down below.
###React onChange
Apart from the camel case difference the way React onChange handler works is also pretty different. It gets triggered whenever one makes a change in the input element value.
I tried to create something like React onChange. Let's have a look (not saying that this is how it works exactly).
{% jsfiddle https://jsfiddle.net/kpulkit29/pg7ew9kv/31/ js,html,result %}
* I had attached my custom onChange callback to the element.
* Using setter/getter to get the previously entered value and compare it with the latest one.
* Additionally attached a keyup event listener to get hold of the latest value
* Notice that the custom onChange handler gets triggered everytime a change is made.
Bye Bye !! 👋👋 Hope there were takeaways.
####Let's connect
[Linkedin](https://www.linkedin.com/in/pulkit291/)
[Twitter](https://twitter.com/kpulkit29)
[Github](https://github.com/kpulkit29) | kpulkit29 |
777,814 | How to use React to generate your own OpenGraph images | This article was originally posted on my personal website. In this blog post, I want to show you... | 0 | 2021-07-31T20:11:00 | https://dominik.sumer.dev/blog/how-to-use-react-to-generate-og-images | react, playwright, opengraph, image | *This article was originally posted on my [personal website](https://dominik.sumer.dev/blog/how-to-use-react-to-generate-og-images).*
---
In this blog post, I want to show you how you can generate an OpenGraph image out of your React component. Personally, I love this approach, because I can leverage my frontend development skills to generate dynamic images (actually not only OpenGraph images).
As already stated in the title, I am going to use React to generate the image, but the approach can probably be easily transferred to other Frontend Frameworks too, so I hope you also find it helpful although you're not into React!
# Using Puppeteer / Playwright
The first building stone for this approach is to use a browser automation framework like Puppeteer or Playwright. Both are very similar feature-wise and also API-wise so there shouldn't be many differences between them. Today I am going to use Playwright.
Both of the mentioned frameworks can be used to automate a (headless) browser. You can write scripts to navigate to specific websites and scrape them or do other fancy stuff. And for the generation of our OG images, we're leveraging the power to take screenshots of websites. 🙌
Check out the following snippet:
```ts
import * as playwright from 'playwright-aws-lambda';
const width = 1200;
const height = 630;
const browser = await playwright.launchChromium({ headless: true });
const page = await browser.newPage({
viewport: {
width,
height,
},
});
const imageBuffer = await page.screenshot({
type: 'jpeg',
clip: {
x: 0,
y: 0,
width,
height,
},
});
await browser.close();
```
With these few lines we:
1. Fire up a headless chrome browser
2. Open a new tab with the given viewport (I chose 1200x630 because it is the most common og image size)
3. Take a screenshot of it - you can choose between PNG or JPEG and with JPEG you can even specify the quality of the image
4. Close the browser
That's pretty neat, isn't it? But yeah, we're now just generating a plain white og image - so how can we use React to design a dynamic image of our desire? 😄
# Leverage the power of React
Imagine we have the following component which we want to use to render our og image:
```tsx
interface Props {
title: string;
}
export const OgImage = ({ title }: Props) => {
return <div style={{ color: 'red', fontSize: '60px' }}>{title}</div>;
};
```
It's a very simple component, perfect for our example. It takes a title as a prop and renders it as a red text. Let's tell playwright that we want to render it onto our page.
First we're creating an instance of our React Component passing our desired title as prop:
```ts
const el = createElement(OgImage, {
title: 'This is a test title',
});
```
And then we're leveraging the power of React server side rendering. We're rendering it as static HTML markup:
```ts
const body = renderToStaticMarkup(el);
```
Additionally we add a utility function to render our basic HTML structure:
```ts
const baseCSS = `*{box-sizing:border-box}body{margin:0;font-family:system-ui,sans-serif}`;
const getHtmlData = ({ body }: { body: string }) => {
const html = `<!DOCTYPE html>
<head>
<meta charset="utf-8"><style>${baseCSS}</style>
</head>
<body style="display:inline-block">
${body}
</body>
</html>`;
return html;
};
```
And now we tell playwright, right after opening the new page in the browser, that our generated HTML should be set as the content of the page:
```ts
const html = getHtmlData({
body,
});
await page.setContent(html);
```
Voilá now we're rendering our own React component with playwright and taking a screenshot of it. 🥳 From here your imagination knows no boundaries. Just style your og image like you're used to style your frontend applications and use as many dynamic parameters as you need.
## Using ChakraUI
I love to use ChakraUI to style my web applications. Since I switched to ChakraUI I would never want to style my React applications differently. Therefore I also wanted to use ChakraUI to generate my og images.
To achieve this you also need to include the `<ChakraProvider>` into your OgImage component so that you can access all of the functionality.
# Deploying it as a serverless function
Basically, you could use this technique to generate images of your React component however you want. E.g. as a Node.js script that generates some images with the given arguments. But with this blog post, I am specifically mentioning og images, which are being fetched when a bot crawls your website.
I am using [Next.js](https://nextjs.org/) to write my React applications and my plan was to actually generate those og images while building my project. Next.js creates static sites for my blog posts and I wanted to create the static og image once the static site is created and then just serve it as static asset. But I didn't get this working on [Vercel](https://vercel.com/) as I ran into memory limits during the build process.
So then I went for the second-best approach which came into my mind: deploy it as a serverless function (in my case a Next.js API route) which is called with dynamic parameters.
It's basically just a GET call that takes my dynamic parameters, renders the og image with playwright, and returns it as response. That's how I am rendering the og images for my blog posts here. 😄
You can find the source of this og image generation [right here](https://github.com/dsumer/portfolio/blob/master/src/pages/api/og-image.ts).
And [this is the API](https://dominik.sumer.dev/api/og-image?title=How%20to%20integrate%20Gumroad%20as%20a%20payment%20provider%20for%20your%20SaaS&slug=/blog/how-to-integrate-gumroad-as-payment-provider-for-your-saas&date=June%2030%2C%202021&rt=8%20min%20read) where those og images are located / being generated on the fly.
# Conclusion
I hope this blog post was somehow helpful to and maybe it could spark some ideas about how you can use this technique to generate some awesome images. If you have further questions, please don't hesitate to [shoot me a DM on Twitter](https://twitter.com/messages/compose?recipient_id=798465058061881344), cheers!
| dominiksumer |
777,888 | Why I Love Prince Of Persia | I've always found Prince of Persia a fascinating game. I still play it from start to finish every now... | 0 | 2021-08-03T01:08:09 | https://dev.to/tehsis/why-i-love-prince-of-persia-46c3 | gamedev | I've always found Prince of Persia a fascinating game. I still play it from start to finish every now and then. If you do the math twice a year ends up adding up.
I refuse to believe that the reason behind this is that it's among the firsts (if not the first) game I have ever played.
I also think a fundamental skill for a game designer is to understand how the games we love have been able to generate the sensations we feel when we play it and, most important, why they are fun.
In this post, I'll analyze this masterpiece, from the point of view of the player and focusing on the sensations it generates without going deep into details.
## Disclaimer
The analysis I make here is not free of nostalgia.
While this game has many ports I think the definitive version is the DOS version, using the EGA color mode and the PC internal speakers. The screenshots used on the article came from this version.
Now, let's start.
## Story

The plot of the game is extremely simple:
> Jaffar, the Sultan's Grand Vizier wants the throne and for that, he needs to marry the Sultan's young daughter. He casts a spell over the princess and she has to marry Jaffar or die. Only "the brave youth she loves" can save her, but he's a prisoner in the castle's dungeons.
And for a good period of my youth, this was basically "save the princess from the evil one". Since rarely I kept all the intro through the end (also, I've been playing this game since before I was able to read and English is not even my mother tongue)
For all it matters, the story gives us purpose: to rescue the princess. But also plays with our anxiety: we know that eventually we will fight Jaffar and get to the princess before the hour runs out.
Both aspects are equally important, exploring the castle is fun, but we also need to be in line with our mission. This tension came into play at different points in the game. Even when this is in most aspects a linear game, you feel all the time that there's a lot to explore. Though most of the time, diverging from the main path will lead you to death ends (though sometimes you'll get rewarded by increasing your max health)
## Visuals
We are talking of a game released in 1989 for a machine that was not intended for video games and developed by a small team yet it has its own identity and does a great job setting the atmosphere. The first three levels, the dungeons, makes you feel locked up and afraid. You can feel the darkness and loneliness our young hero might be feeling. Then you discover a much more colorful area, that resembles more the characteristics of the princess's room seen during the intro. This alternation provides a well received freshness just went the visuals might start to feel monotonous.
The character animation requires its own paragraph of course as it feels extremely _real_ (and it is, since it was made from recordings of the author's brother performing the movements) and provides a delightful feedback to the player actions. I always lost a couple of seconds just making the character slide from one side to the other.
## Game Mechanics
These are less simpler than the history but not by far if you compare it with most games from today.

You can move left or right either running by default or walking when pressing a key. You can also jump straight or forward and combine the running with the jump.
You also have the _combat mode_ which involves a sword and has a few actions: attack, move right or left, guard or sheath the sword.
Some combats are avoidable if you are clever enough. Well, maybe not too clever, but it's truly rewarding when you make a guard fall into a cliff or get locked behind a door.
Potions deserves a note aside: most of them will just heal you others will damage you and a few will increase your life meter. There are only two of them that have special effects: the one that makes you fall slower and avoid a certain death and the one that inverts the screen and controls.
This is certainly another important aspect of the game: It does not repeat itself, which leads me to the next section.
## Music
I've kept music for the last since normally it is something I overlook. But turns out the music in this game (and sound effects in general) are as subtle as any other aspect of the game: There's the main theme, the music for completing a level, the tune played when you die, the one used when you kill a guard and the one played when you drink the fall-slowered potion on level 7.
At any moment the music distracts you as the game doesn't really have a background music. As we discussed for the visuals, the music sets the atmosphere. The absence of music during most of the gameplay adds to the loneliness created by the visuals and helps to empathize with particular events.
There's one particular tune that makes me shiver and it's a great example of this: On level 4, when you find the mirror, you find yourself shocked and intrigued. It's actually scary when you cross it and the shadow guy appears for the first time. After completing the level, you start hearing the classic end level music... but it suddenly gets cut and an upbeat tune is heard, emphasizing the disturbing moment you have just witnessed.
## Game events
In every section, we have talked about how each aspect of the games helps to set the tone of the game and how they are wisely used to create an atmosphere or emphasize the _Events_ in the game.
I call Events to those _specific moments_ that appear on each level.

The Events in the game are used as plot devices to move the _story_ forward. Once again, the subtlety on how they are used is the trick here. No Event lasts more than a few seconds and they rarely block the player, they just "happen". If the game was made today, most likely you will get a cut scene for each one of them. Though here you will just continue moving while hearing a particular tone or participating in it.
Each of these Events makes their corresponding level unique. They normally add their own mechanic to the game and are used only once. They surely disrupt you the first time you play the game and make you wonder what's ahead.
Just for reference, let's make a quick summary of them:
Level 1: Get the sword.
Level 2: No events.
Level 3: The Skeleton.
Level 4: The mirror and the shadow.
Level 5: The shadow steals a healing bottle.
Level 6: The Fat Guard and The shadow closes a door making you fall to the dungeons.
Level 7: The floating potion.
Level 8: The passive guard and the mice.
Level 9: The inverse-control potion.
Level 10: No events.
Level 11: The ceiling collapses as you go.
Level 12: Encounter with the shadow.
Level 12+: Fight with Jaffar.
Level 13: Rescue the princess.
## Summary
Overall, I think the subtlety each element used in the game is what makes this game a masterpiece. The simple story gives you a purpose, the visuals and the music sets a tone of a thriller that gets you engaged, the mechanics provide the fun and the events make the game to not be repetitive and keep you attached to it until the end.

All things considered, Prince of Persia is a perfect example on how a few elements can be used to create a cohesive experience that, wisely used, provides a simple linear game yet with a lot of re playable value.
If you want to talk about game development, game design or just games in general, please reach me out to @tehsis on Twitter.
For more game development content, follow @alidionstudios so you don't miss out our next publication.
Now, I'll type the magic words, and play some PoP.
```
C:\> prince ega
````
| tehsis |
778,046 | Functional Programming in Ruby – State | Ruby is, by nature, an Object Oriented language. It also takes a lot of hints from Functional... | 10,895 | 2021-08-01T03:47:37 | https://dev.to/baweaver/functional-programming-in-ruby-state-13p2 | ruby, functional | Ruby is, by nature, an Object Oriented language. It also takes a lot of hints from Functional languages like Lisp.
Contrary to popular opinion, Functional Programming is not an opposite pole on the spectrum. It’s another way of thinking about the same problems that can be very beneficial to Ruby programmers.
Truth be told, you’re probably already using a lot of Functional concepts. You don’t have to get all the way to Haskell, Scala, or other languages to get the benefits either.
The purpose of this series is to cover Functional Programming in a more pragmatic light as it pertains to Ruby programmers. That means that some concepts will not be rigorous proofs or truly pure ivory FP, and that’s fine.
We’ll focus on examples you can use to make your programs better today.
With that, let’s take a look at our first subject: State.
> This series is a partial rewrite and update of [my own series on Medium on Functional Programming](https://medium.com/@baweaver/functional-programming-in-ruby-state-5e55d40b4e67). It has been modernized and updated a bit.
## Functional Programming and State
One of the prime concepts of Functional Programming is immutable state. In Ruby it may not be entirely practical to forego it altogether, but the concept is still exceptionally valuable to us.
By foregoing state, we make our applications easier to reason about and test. The secret is that you don’t entirely need to forego it to get some of these benefits, and that's what we need to keep in mind with Ruby: there are always tradeoffs.
### Defining State
So what is state exactly? State is the data that flows through your program, and the concept of immutable state means that once it’s set it’s set. No changing it.
```ruby
x = 5
x += 2 # Mutation of state!
```
That especially applies to methods:
```ruby
def remove(array, item)
array.reject! { |v| v == item }
end
array = [1,2,3]
remove(array, 1)
# => [2, 3]
array
# => [2, 3]
```
By performing that action, we’ve mutated the array we passed in. Now imagine we have two or three more functions which also mutate the array and we get into a bit of an issue. In general it's not great to mutate data that's passed into your function.
A pure function is one that does not mutate its inputs:
```ruby
def remove(array, item)
array.reject { |v| v == item }
end
array = [1,2,3]
remove(array, 1)
# => [2, 3]
array
# => [1, 2, 3]
```
It’s slower, but it’s much easier to predict that this is going to return us a new array. Every time I give it input A, it gives me back result B.
### Has That Ever Really Happened?
Problem is, one can preach all day on the merits of pure functions, but until you find yourself in a situation where it bites you the benefits may not be readily apparent.
There was one time in Javascript where I’d used `reverse` to test the output of a game board. It would look fine, but when I added one more `reverse` to it all of my tests broke!
What gives?
Well, as it turned out the `reverse` function was mutating my board.
It took me longer than I want to admit here how long it took me to realize this was happening, but mutation can have subtle cascading effects on your program unless you keep it under control.
That’s the secret though, you don’t have to exclusively avoid it, you just need to manage it in such a way that it’s very clear when and where mutations happen.
> In Ruby, frequently state mutations are indicated with `!` as a suffix. Not always, though, because methods like `concat` break those rules so keep an eye out.
### Isolate State
One method of dealing with state is to keep it in the box. A pure function might look something like this:
```ruby
def add(a, b)
a + b
end
```
When given the same inputs, it will *always* give us back the same outputs. That’s handy, but there are ways to hide tricks from it.
```ruby
def count_by(array, &fn)
array.each_with_object(Hash.new(0)) { |v, h|
h[fn.call(v)] += 1
}
end
count_by([1,2,3], &:even?)
# => {false=>2, true=>1}
```
> **Note**: Newer versions of Ruby have the `tally` function which would be used like this to get a similar result: `[1, 2, 3].map(&:even?).tally`
Strictly speaking, we’re mutating that hash for each and every value in the array. Not so strictly speaking, when given the same input we get back the exact same output.
Does that make it functionally pure? No. What we’ve done here is created isolated state that’s only present inside our function. Nothing on the outside knows about what we’re doing to the hash inside the function, and in Ruby this is an acceptable compromise.
The problem is though, isolate state still requires that functions do one and only one thing.
### Single Responsibility and IO State
Functions should do one and only one thing.
I’ve seen this type of pattern very commonly in newer programmers code:
```ruby
class RubyClub
attr_reader :members
def initialize
@members = []
end
def add_member
print "Member name: "
member = gets.chomp
@members << member
puts "Added member!"
end
end
```
The problem here is that we’re conflating a lot of things in one function:
* Asking a user for a member name
* Getting that name
* Adding a member
* Notifying the user we added a member
That’s not the concern of our class, it only needs to know how to add a member, anything else is outside the scope of that method.
At first this seems harmless, as you’re only really getting input and outputting at the end. The problems we run into are that `gets` is going to pause the test, waiting for input, and `puts` is going to return `nil` afterwards.
How would we test such a thing?
```ruby
describe '#add_member' do
before do
$stdin = StringIO.new("Havenwood\n")
end
after do
$stdin = STDIN
end
it 'adds a member' do
ruby_club = RubyClub.new
ruby_club.add_member
expect(ruby_club.members).to eq(['Havenwood'])
end
end
```
That’s a lot of code. We have to intercept `STDIN` (standard input) to make it work which makes our test code a lot harder to read as well.
Take a look at a more focused implementation, the only concern it has is that it gets a new member as input and returns all the members as output.
```ruby
class RubyClub
attr_reader :members
def initialize
@members = []
end
def add_member(member)
@members << member
end
end
```
All we need to test now is this:
```ruby
describe '#add_member' do
it 'adds a member' do
ruby_club = RubyClub.new
expect(ruby_club.add_member('Havenwood')).to eq(['Havenwood'])
end
end
```
It’s abstracted from the concern of dealing with `IO` (`puts`, `gets`), another form of state.
Now let’s say that your Ruby Club has to also run with a CLI, or maybe load results from a file. How do you refactor it to work? Your current class is conflated with the idea that it has to get input and deal with output.
This adds up to very brittle tests and code that are going to give you problems over time.
### Static State
Another common pattern is to abstract data into constants. This alone isn’t a bad idea, but can result in your classes and methods being effectively hardcoded to work in one way.
Consider the following:
```ruby
class SampleLoader
SAMPLES_DIR = '/samples/ruby_samples'
def initialize
@loaded_samples = {}
end
def load_sample(name)
@loaded_samples[name] ||= File.read("#{SAMPLES_DIR}/#{name}")
end
end
```
It’s great as long as you’re only concerned with that specific directory, but what if we need to make a sample loader for `elixir_samples` or `rust_samples`? We have a problem. Our constant has become a piece of static state we cannot change.
The solution is to use an idea called injection. We inject the prerequisite knowledge into the class instead of hardcoding the value in a constant:
```ruby
class SampleLoader
def initialize(base_path)
@base_path = base_path
@loaded_samples = {}
end
def load_sample(name)
@loaded_samples[name] ||= File.read("#{@base_path}/#{name}")
end
end
```
Now our sample loader really doesn’t care where it gets samples from, as long as that file exists somewhere on the disk. Granted there are potential risks with caching as well, but that’s an exercise left to the reader.
A way to cheat this is by using default values, set to a constant, but for some this may be a bit to implicit. Use wisely:
```ruby
class SampleLoader
SAMPLES_DIR = '/samples/ruby_samples'
def initialize(base_path: SAMPLES_DIR)
@base_path = base_path
@loaded_samples = {}
end
def load_sample(name)
@loaded_samples[name] ||= File.read("#{@base_path}/#{name}")
end
end
```
### IO State — Reading Files
Let’s say your Ruby Club has an idea of loading members. We remembered to not statically code paths this time:
```ruby
class RubyClub
def initialize
@members = []
end
def add_member(member)
@members << member
end
def load_members(path)
JSON.parse(File.read(path)).each do |m|
@members << m
end
end
end
```
The problem this round is that we’re relying on the fact that the members file is not only a file, but also in a `JSON` format. It makes our loader very inflexible.
We’ve become entangled in another type of IO state: we’re too concerned with how we load data into our club.
Say you wanted to switch it out with a database like `SQLite`, or maybe even just use `YAML ` instead. That’s a very hard task with the code like it is.
Some solutions to this problem I see from newer developers are to make multiple “loaders” to deal with different types of inputs. What if it’s none of the concern of our club in the first place?
If we extract the entire concept of loading members, we could have code like this instead:
```ruby
class RubyClub
attr_reader :members
def initialize(members = [])
@members = members
end
def add_members(*members)
@members.concat(members)
end
end
new_members = YAML.load(File.read('data.yml'))
RubyClub.new(new_members)
```
### Wait, isn’t this just Separation of Concerns?
The fun thing about OO and FP is that a lot of the same concepts can apply, they just tend to have different names. They may not be exact overlaps, but a lot of what you learn from a Functional language may feel very familiar from best practices in a more Imperative style language.
In a lot of ways, keeping state under control is an exercise in separation of concerns. Pure functions coupled with this can make exceptionally flexible and robust code that is easier to test, reason about, and extend.
A common point of confusion is that Functional Programming is an entirely new and independent paradigm from Object Oriented Programming, when in fact they share quite a few ideas, and often times are more complimentary than some would like to admit.
## Wrapping Up
State in Ruby may not be entirely pure, but by keeping it under control your programs will be substantially easier to work with later. In programming, that’s everything.
You’ll be reading and upgrading code far more than you’re outright writing it, so the more you do to write it flexibly from the start the easier it will be to read and work with later on.
As I mentioned earlier, this course will be more focused on pragmatic usages of Functional Programming as they relate to Ruby. We could focus on an entire derived Lambda Calculus scheme and make a truly pure program, but it would be slow and incredibly tedious.
That said, it’s also fun to play with on occasion just to see how it works. If that’s of interest this is a great book on the subject:
[Understanding Computation](http://shop.oreilly.com/product/0636920025481.do)
If you want to keep exploring that rabbit hole, Raganwald does a lot to delight here:
[Kestrels, Quirky Birds, and Hopeless Egocentricity](https://leanpub.com/combinators)
As always, enjoy! | baweaver |
778,179 | Creating Tabs component in Vue 3 | Hi! In this post we are going to walk through how to create a Tabs component in Vue 3. The main aim... | 0 | 2021-08-01T09:42:32 | https://dev.to/zafaralam/creating-tabs-component-in-vue-3-hio | vue, typescript, firstpost | Hi! In this post we are going to walk through how to create a **Tabs** component in Vue 3.
The main aim for this post is for me to get started with writing posts and giving back to the wonderful open source community. If you find this helpful please share and like the post. Also please send you feedback on what could be improved for future posts.
You can access the [Demo](https://modest-pare-7a44fc.netlify.app/) for the sample app.
You can access the full code of the component and sample app {% github zafaralam/vue3-tabs no-readme %}
Enough of small talk, lets get to business. We are going to start with creating a blank project using **Vite** for **Vue 3** project. You can read more about getting started with **[Vite](https://vitejs.dev/guide/#scaffolding-your-first-vite-project)** at the docs.
We are going to use typescript for this sample project.
```shell
$ yarn create vite tabs-example --template vue-ts
```
Next, we are going to install the dependencies and run the project.
```shell
$ yarn
# once the above command completes run the project with the below command
$yarn dev
```
You can access a basic Vue 3 app in you browser using `http://localhost:3000/` and it should look like the below screenshot.
Your project folder structure should look.
```
├───node_modules
├───public
│ └───favicon.ico
├───src
│ ├───App.vue
│ ├───main.ts
│ ├───shims-vue.d.ts
│ ├───vite-env.d.ts
│ ├───assets
│ │ └──logo.png
│ └───components
│ └──HelloWorld.vue
├───.gitignore
├───index.html
├───package.json
├───README.md
├───tsconfig.json
├───vite.config.js
└───yarn.lock
```
Next, we will remove all the code within the _App.vue_ file under the _src_ folder and replace it with the below.
**App.vue**
```vue
<script lang="ts">
import { defineComponent } from "vue";
export default defineComponent({
name: "App",
components: {},
});
</script>
<template>
<div class="tabs-example">
<h1>This is a <b>Tabs</b> example project with Vue 3 and Typescript</h1>
</div>
</template>
<style>
#app {
font-family: Avenir, Helvetica, Arial, sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
</style>
```
Now, we can create a new file under the _src/components_ folder called **Tabs.vue**. We are going to use scss for our styles so we need a `sass` dependency for our project. You can install it by
```shell
yarn add sass
```
**Note**: you will need to stop and start the dev server again `yarn dev`
Now add the following code to the _Tabs.vue_ file we created earlier.
The component also registers an event listener for keyboard events and can tabs can be changed using `Ctrl + [Tab number]` e.g.`Ctrl + 1`
**Tabs.vue**
```vue
<script lang="ts">
import {
defineComponent,
onMounted,
onBeforeUnmount,
ref,
watch,
toRefs,
h,
VNode,
computed,
onBeforeUpdate,
} from "vue";
interface IProps {
defaultIndex: number;
resetTabs: boolean;
position: string;
direction: string;
reverse: boolean;
}
export default defineComponent({
name: "Tabs",
props: {
defaultIndex: {
default: 0,
type: Number,
},
resetTabs: {
type: Boolean,
default: false,
},
direction: {
type: String,
default: "horizontal",
validator(value: string) {
return ["horizontal", "vertical"].includes(value);
},
},
position: {
type: String,
default: "left",
validator(value: string) {
return ["left", "start", "end", "center"].includes(value);
},
},
reverse: {
type: Boolean,
required: false,
default: false,
},
},
emits: {
tabChanged(index: number) {
return index !== undefined || index !== null;
},
},
setup(props: IProps, { emit, slots, attrs }) {
const { defaultIndex, resetTabs, position, direction, reverse } =
toRefs(props);
const selectedIndex = ref(0);
const tabs = ref<Array<any>>([]);
const _tabItems = ref<any[]>([]);
const onTabKeyDown = (e: KeyboardEvent) => {
if (e.ctrlKey || e.metaKey) {
if (parseInt(e.key) - 1 in tabs.value) {
e.preventDefault();
switchTab(e, parseInt(e.key) - 1, tabs.value[parseInt(e.key) - 1]);
}
}
};
const reset = () => {
selectedIndex.value = 0;
};
const switchTab = (_: any, index: number, isDisabled: boolean) => {
if (!isDisabled) {
selectedIndex.value = index;
emit("tabChanged", index);
}
};
onMounted(() => {
getTabItems();
document.addEventListener("keydown", onTabKeyDown);
});
onBeforeUnmount(() => {
document.removeEventListener("keydown", onTabKeyDown);
});
watch(defaultIndex, (newValue, oldValue) => {
if (newValue !== selectedIndex.value) {
selectedIndex.value = newValue;
}
});
watch(resetTabs, (newValue, oldValue) => {
if (newValue === true) reset();
});
onBeforeUpdate(() => {
getTabItems();
});
const getTabItems = () => {
_tabItems.value.splice(0, _tabItems.value.length);
(slots as any).default().forEach((component: any) => {
if (component.type.name && component.type.name === "Tab") {
_tabItems.value.push(component);
} else {
component.children.forEach((cComp: any) => {
if (cComp.type.name && cComp.type.name === "Tab") {
_tabItems.value.push(cComp);
}
});
}
});
};
const getTitleSlotContent = (titleSlot: string): any => {
let slotContent: any = null;
let shouldSkip = false;
(slots as any).default().forEach((item: any) => {
if (shouldSkip) {
return;
}
if (item.type === "template" && item.props.name === titleSlot) {
slotContent = item.children;
shouldSkip = true;
} else {
if (item.children.length) {
item.children.forEach((cItem: any) => {
if (shouldSkip) {
return;
}
if (cItem.props.name === titleSlot) {
slotContent = cItem.children;
shouldSkip = true;
}
});
}
}
});
return slotContent === null ? [] : slotContent;
};
const tabToDisplay = computed(() => {
return _tabItems.value.map((item, idx) => {
return h(
"div",
{
class: "tab",
style: `display: ${selectedIndex.value == idx ? "block" : "none"}`,
},
item
);
});
// return h("div", { class: "tab" }, _tabItems.value[selectedIndex.value]);
});
return () => {
const tabList: Array<VNode> = [];
_tabItems.value.forEach((tab: VNode, index: number) => {
const _tabProps = tab.props as {
title?: string;
"title-slot"?: string;
disabled?: boolean | string;
};
const titleContent = _tabProps["title-slot"]
? getTitleSlotContent(_tabProps["title-slot"])
: _tabProps.title;
const isDisabled =
_tabProps.disabled === true || _tabProps.disabled === "";
tabs.value[index] = isDisabled;
tabList.push(
h(
"li",
{
class: "tab-list__item",
tabIndex: "0",
role: "tabItem",
"aria-selected": selectedIndex.value === index ? "true" : "false",
"aria-disabled": isDisabled ? "true" : "false",
onClick: (e: MouseEvent) => {
switchTab(e, index, isDisabled);
},
},
titleContent
)
);
});
return h(
"div",
{
class: `tabs ${direction.value} ${reverse.value ? "reverse" : ""}`,
role: "tabs",
},
[
h(
"ul",
{ class: `tab-list ${position.value}`, role: "tabList" },
tabList
),
...tabToDisplay.value,
]
);
};
},
});
</script>
<style lang="scss">
:root {
--primary-color: #4313aa;
--border-color: #e2e2e2;
--disabled-text-color: #999;
}
.tabs {
display: grid;
grid-template-columns: 1fr;
.tab-list {
list-style: none;
display: flex;
padding-left: 0;
border-bottom: 1px solid var(--border-color);
&.center {
justify-content: center;
}
&.end {
justify-content: flex-end;
}
&__item {
padding: 8px 10px;
cursor: pointer;
user-select: none;
transition: border 0.3s ease-in-out;
position: relative;
bottom: -1px;
text-transform: uppercase;
font-size: 0.85rem;
letter-spacing: 0.05rem;
&:not(:first-child) {
margin-left: 10px;
}
&[aria-selected="true"] {
border-bottom: 2px solid var(--primary-color);
font-weight: 700;
color: var(--primary-color);
}
&[aria-disabled="true"] {
cursor: not-allowed;
color: var(--disabled-text-color);
}
}
}
&.horizontal {
&.reverse {
.tab-list {
grid-row: 2;
border: none;
border-top: 1px solid var(--border-color);
}
}
}
&.vertical {
grid-template-columns: auto 1fr;
gap: 1rem;
.tab-list {
flex-direction: column;
border-bottom: none;
border-right: 1px solid var(--border-color);
&__item {
margin-left: 0;
border-radius: 0;
&[aria-selected="true"] {
border: none;
border-left: 2px solid var(--primary-color);
}
}
}
&.reverse {
grid-template-columns: 1fr auto;
.tab-list {
grid-column: 2;
border: none;
border-left: 1px solid var(--border-color);
}
.tab {
grid-row: 1;
grid-column: 1;
}
}
}
}
</style>
```
Next we are going to use our newly created components. All examples can be see in the _App.vue_ file. Here I'm going to show you some example use cases.
### Example 1
This is the most basic way to use the Tabs component. The tab list will be show at the top and the names of the tabs are derived from the title prop of each Tab component.
```html
<tabs>
<tab title="Tab 1">
<h3>This is Tab 1</h3>
</tab>
<tab title="Tab 2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
```
### Example 2
This example shows that the tab list items can be fully customized with there own icons if required.
```html
<tabs>
<template name="config">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<tab title-slot="config">
<h3>This is a config tab</h3>
</tab>
<tab title="Tab 2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
```
### Example 3
This example shows that the tab list items can be displayed at the bottom using the **reverse** prop on the Tabs component.
```html
<tabs reverse>
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
```
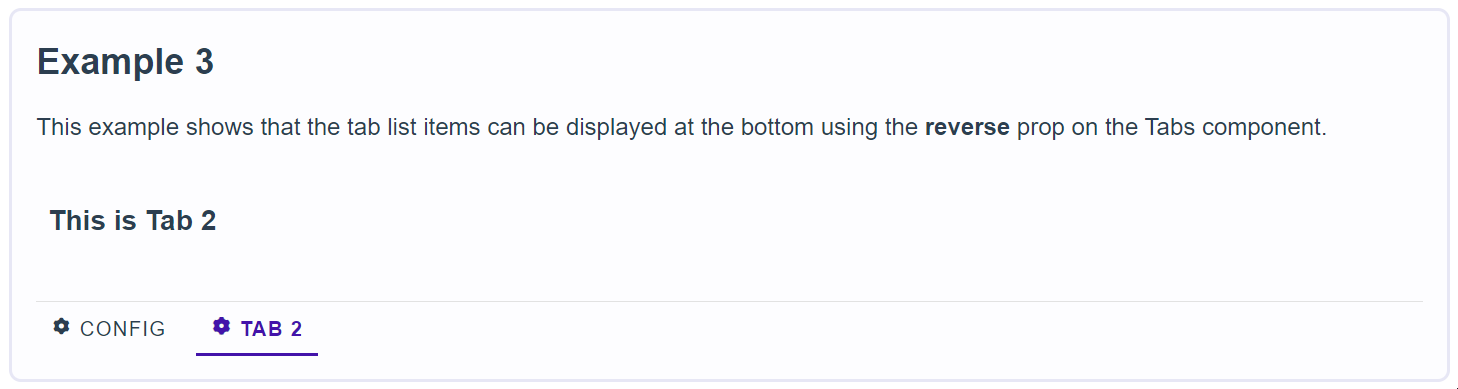
### Example 4
This example shows that the tab list can be shown vertically by using the **direction** prop on the Tabs component.
```html
<tabs direction="vertical">
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
```
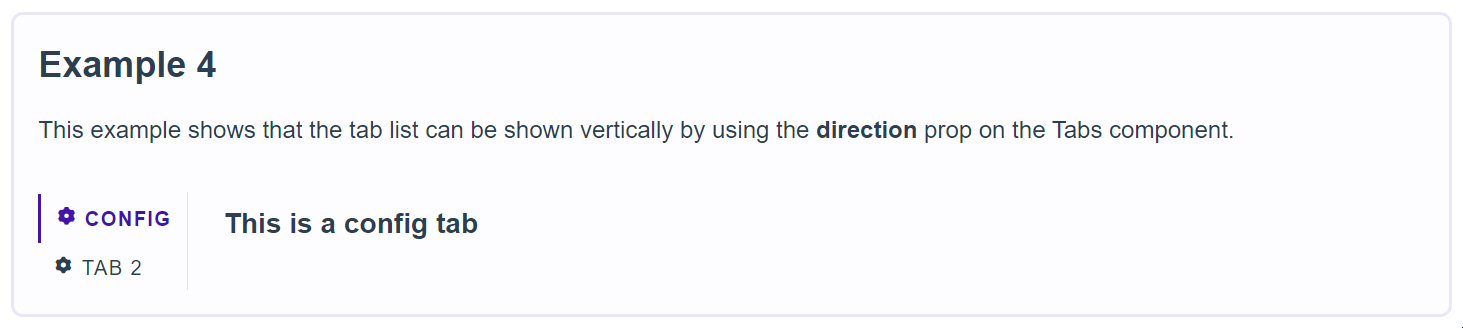
### Example 5
This example shows that the tab list can be shown in the center or end by using the **position** prop on the Tabs component.
```html
<tabs position="center">
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
```
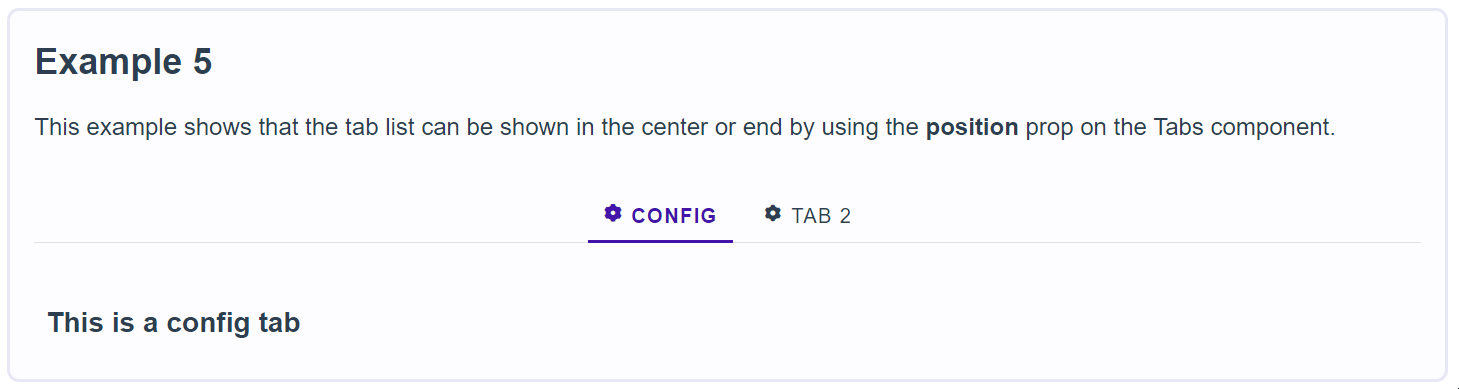
### Example 6
This example shows that the tab list can be shown in the center or end by using the **position** prop on the Tabs component.
```html
<tabs position="end">
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
```
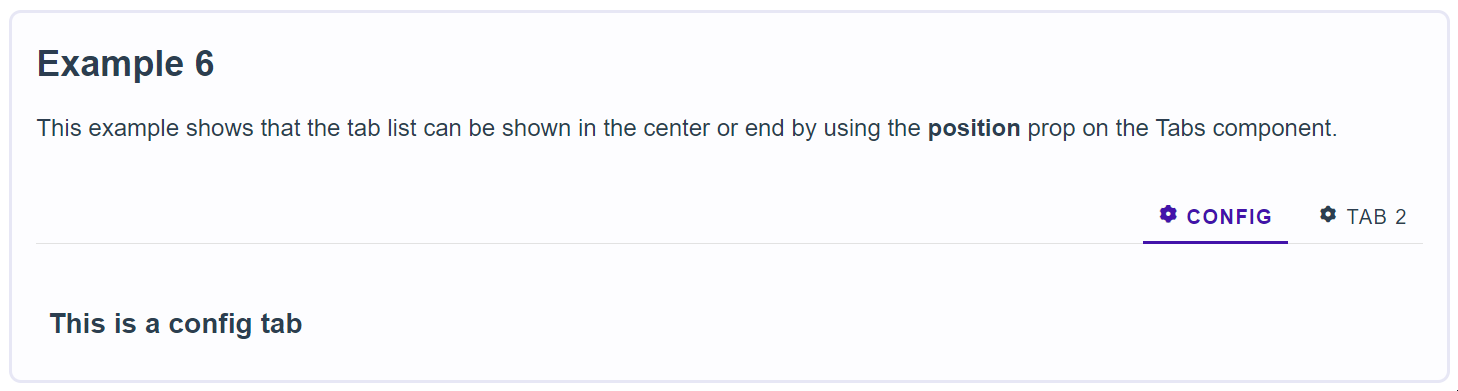
**Have a look at the html in App.vue file for examples 7 and 8 for dynamically generating the tabs**
**App.vue**
```vue
<script lang="ts">
import { defineComponent } from "vue";
import Tabs from "./components/Tabs.vue";
import Tab from "./components/Tab.vue";
export default defineComponent({
name: "App",
components: { Tabs, Tab },
});
</script>
<template>
<h1>This is a <b>Tabs</b> example project with Vue 3 and Typescript</h1>
<div class="tabs-example">
<div class="example example-1">
<h2>Example 1</h2>
<p>
This is the most basic way to use the Tabs component. The tab list will
be show at the top and the names of the tabs are derived from the title
prop of each Tab component.
</p>
<tabs class="Tab-exp1">
<tab title="Tab 1">
<h3>This is Tab 1</h3>
</tab>
<tab title="Tab 2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
</div>
<div class="example example-2">
<h2>Example 2</h2>
<p>
This example shows that the tab list items can be fully customized with
there own icons if required.
</p>
<tabs>
<template name="config">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<tab title-slot="config">
<h3>This is a config tab</h3>
</tab>
<tab title="Tab 2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
</div>
<div class="example example-3">
<h2>Example 3</h2>
<p>
This example shows that the tab list items can be displayed at the
bottom using the <b>reverse</b> prop on the Tabs component.
</p>
<tabs reverse>
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
</div>
<div class="example example-4">
<h2>Example 4</h2>
<p>
This example shows that the tab list can be shown vertically by using
the <b>direction</b> prop on the Tabs component.
</p>
<tabs direction="vertical">
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
</div>
<div class="example example-5">
<h2>Example 5</h2>
<p>
This example shows that the tab list can be shown in the center or end
by using the <b>position</b> prop on the Tabs component.
</p>
<tabs position="center">
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
</div>
<div class="example example-6">
<h2>Example 6</h2>
<p>
This example shows that the tab list can be shown in the center or end
by using the <b>position</b> prop on the Tabs component.
</p>
<tabs position="end">
<template name="tab1">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Config
</div>
</template>
<template name="tab2">
<div class="tab-title">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab 2
</div>
</template>
<tab title-slot="tab1">
<h3>This is a config tab</h3>
</tab>
<tab title-slot="tab2">
<h3>This is Tab 2</h3>
</tab>
</tabs>
</div>
<div class="example example-7">
<h2>Example 7</h2>
<p>
This example shows a list of tabs generated from an array. This can be
used to dynamically generate the tabs
</p>
<tabs>
<tab v-for="(i, idx) in dynamicTabs" :key="idx" :title="`Tab ${i}`">
<h3>This is Tab {{ i }}</h3>
</tab>
</tabs>
</div>
<div class="example example-8">
<h2>Example 8</h2>
<p>
This example shows a list of tabs generated from an array. This can be
used to dynamically generate the tabs
</p>
<tabs>
<template v-for="(i, idx) in dynamicTabs" :key="idx">
<div class="tab-title" :name="`tab-exp7-${i}`">
<i class="ri-settings-3-fill" aria-hidden="true"></i>
Tab {{ i }}
</div>
</template>
<tab
v-for="(i, idx) in dynamicTabs"
:key="idx"
:title-slot="`tab-exp7-${i}`"
>
<h3>This is Tab {{ i }}</h3>
</tab>
</tabs>
</div>
</div>
</template>
<style lang="scss">
#app {
font-family: Avenir, Helvetica, Arial, sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
color: #2c3e50;
text-align: center;
margin-top: 4px;
}
.tabs-example {
display: grid;
place-items: center;
text-align: left;
.example {
width: 80%;
padding: 0 1rem;
border-radius: 8px;
background: #fdfdff;
border: 2px solid #e7e7f5;
margin-block-end: 1rem;
}
}
</style>
```
As you can see the component can be used in a multitude of ways depending on the need of your app.
I know that the component can be improved and more functionality can be added or improved, so please send in your feedback. Also I will be packaging this component so you can directly use it your own apps without having to write it yourself but I wanted to show you a way of creating dynamic components for your app.
You can access the full code of the component and sample app {% github zafaralam/vue3-tabs no-readme %}
Thanks for reading and happy coding!!!
| zafaralam |
778,192 | How newcomers can avoid and prevent unwanted charges on their AWS accounts | Lately I saw many posts and tweets about people racking up moderate to huge bills on AWS without... | 0 | 2021-08-01T08:31:19 | https://dev.to/aws-builders/how-newcomers-can-avoid-and-prevent-unwanted-charges-on-their-aws-accounts-5425 |
Lately I saw many posts and tweets about people racking up moderate to huge bills on AWS without realizing it, a lot of heated discussions, but nothing on how to mitigate those problems. So I have decided to share my experience and my tools to make sure you won't end up owning 80.000$ to AWS.
Take in consideration that this is a "starter kit", the more your usage grows the more sophisticated methods you will have to adopt, but as a starting point is enough.
I would say there are two categories when it comes to this matter:
- Costs control
- Security
# Costs control
Costs control is just the act of monitoring your current and forecasted bill and make sure it won't exceed your expectation and budget.
We can monitor costs through:
- Budget and alerts
- General view of all the resources deployed
- Daily cost notification
### Budget
**The first thing you should do after you sign up for an AWS account is setting up the budget alters**. If you are lazy but you still want to avoid huge bills, this is the only thing you should do.
Navigate to [AWS budget](https://console.aws.amazon.com/billing/home#/budgets#/home) with your root account, click on *create budget*, select *Cost budget*, here you can setup your costs, after that click on *configure threshold.
*Here I usually suggest to have two thresholds, one with *Actual* and the other with *Forecasted *costs, in this way you can have a visibility on your current and future bill.
**Remember to insert your email under *****Set up notifications****.*
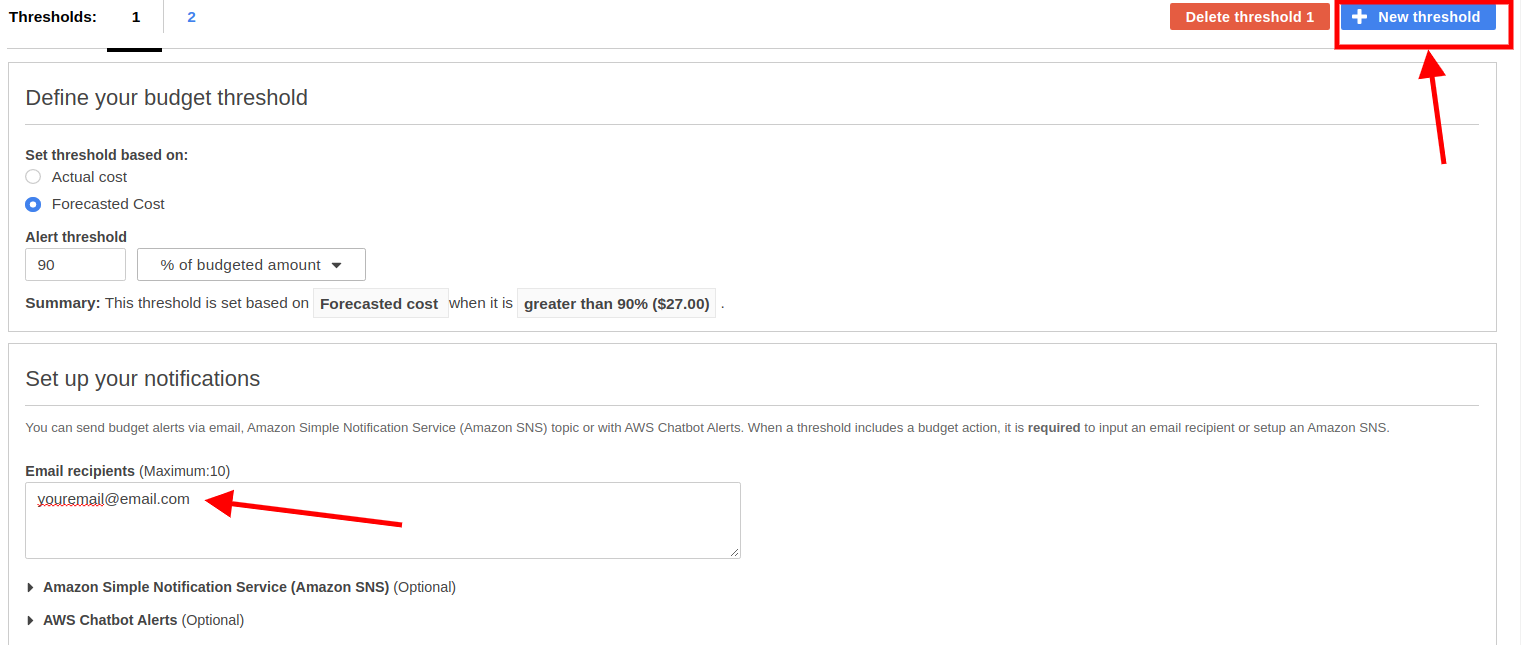
You can check [this video tutorial](https://www.youtube.com/watch?v=fvz0cphjHjg) for more detailed instructions.
### General view
So, did you spin up a super computer cluster in some obscure region and forgot it about it?
There is a little "trick" to search for all the deployed resources in one place, it is called [AWS Resource Groups and tag editor](https://docs.aws.amazon.com/ARG/), probably it is not meant for searching resources, but you can use it for this purpose.
Navigate to the AWS Console *Resource Groups and Tag editor* and from here you can access the [tag editor](https://console.aws.amazon.com/resource-groups/tag-editor/find-resources?region=us-east-1), select *All regions* and if needed *Resources types *(For example: <code>AWS::EC2::Instace</code>)*, *then press *Search resources. *
Remember this works only at account level, if you have multi-account setup you will have to switch role and repeat the same thing.
### Daily costs notifications
This is more of an optional step, but sometimes budgets might be not enough, at least in my opinion.
**Budgets, in fact,** **only alert you when the threshold is breached or it is forecasted to be breached**.
What I usually do, is to have a lambda that gets triggered every day and sends me an SNS notification directly to my inbox with both the forecasted and total current bill; in this way I can check if there have been any abnormality and immediately take action.
Just recently I have decide to open source it and make it available in the [Serverless Application Repository](https://serverlessrepo.aws.amazon.com/applications/ap-southeast-1/164102481775/periodic-costs-notification). To start using it you just need to deploy it into your account, feel free to propose new features or open a new issue if you find any in the [github repository](https://github.com/hirvitek/aws-tools/tree/master/periodicCostsNotification).
# Security
Security can also have a big impact on costs.
What can happen If a malicious actor can access your account? Well you know, credit card, bitcoin mining, DDOS attacks, etc...
- Avoid accidentally pushing credentials to public repository
- Activate Multi-factor authentication
- Periodically rotate passwords and IAM credentials
- Restrict the <code>AdministratorAccess</code> policy
### Avoid pushing credentials to public repository or share them
This is the scariest thing that can happen to us, if you push credentials to a public repository chances are that in few minutes some bot will discover and grab them.
Let's face it, it might happens, and the remediation is fairly simple.
One of the tool I am using is [git-secrets by awslabs](https://github.com/awslabs/git-secrets).
This tool will install a pre-commit hook that will make your commit fail if it recognize a particular patter, like aws credentials secret keys, in your committed files.
### Multi-factor authentication
This should be another must and done immediately after sign up.
**You should activate Multi-factor authentication** for both root account and any IAM user account you create.
You can read more [here](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa.html). You can use the Google Authenticator app, however these days I prefer using my [YubiKey](https://www.yubico.com/).
### Passwords rotation
**I highly suggest periodic password rotation.** You can simply enable password expiration in IAM password policy, in this way you will be forced to periodically change it. Navigate to your [IAM account settings](https://console.aws.amazon.com/iam/home#/account_settings) and check *Password Policy*, check the *Enable password expiration* and set the expiration you desire.
Here you can also enforce some password requirements.
### IAM credentials rotation
**You should periodically rotate your local AWS keys**.
This is often very overlooked, I saw personal credentials active for years and never deleted or inactivated when a member leaves.
Changing IAM credentials regularly should be a must in any organization, it reduces the impact if the key become compromised.
The process to rotate the credentials [requires some steps](https://aws.amazon.com/blogs/security/how-to-rotate-access-keys-for-iam-users/):
1. Create a second access keys pair
2. Download those keys
3. Substitute them from your <code>~/.aws/credentials </code>file
4. Deactivate the previous access keys
5. Test that everything is working
6. Delete the old keys
But we can automate this process using the AWS SDK or API.
This is why I have built a small go utility that **helps you rotate local credentials called **[**LocalKeyRotation**](https://github.com/hirvitek/aws-tools/tree/master/localKeyRotation), not much fantasy in naming, but it does the job.
You can simply run the command or create an [anacron job](https://man7.org/linux/man-pages/man8/anacron.8.html) to run it periodically.
Feel free to suggest any feature or open a new issue if you find any.
Alternatively, if you are using [aws-vault](https://github.com/99designs/aws-vault), you can use their [rotate feature](https://github.com/99designs/aws-vault/blob/master/USAGE.md#rotating-credentials)
### Limit IAM permission
**Note: do not create access keys for your root account, instead create a IAM user with limited permission and then create the access keys for that user. **
This is a more of an advanced topic, but nonetheless useful.
After you have created your first IAM user, instead of giving him <code>AdministratorAccess</code>, you can make a custom policy using IAM conditions; you can read more about [IAM condition here](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html).
One thing I would do is to limit the regions in which you can provision resources:
```
"Condition": {
"StringEquals": {
"aws:RequestedRegion": "us-east-1"
}
}
```
Since a lot of services have regional quotas, for example the base limit of EC2 instances per region is 20, this could somehow tamper the effect of compromised credentials.
You can also limit the type of instances size you can deploy:
```
"Condition": {
"ForAnyValue:StringNotLike": {
"ec2:InstanceType": [
"*.nano",
"*.small",
"*.micro"
]
}
}
```
You can also limit the resources you can work with:
```
{
"Effect": "Allow",
"Action": [
"sns:*",
"s3:*",
"cloudwatch:*",
"apigateway:*",
"lambda:*",
"dynamodb:*"
],
"Resource": "*"
}
}
```
In this way you will make sure nothing else can be deployed other than those services listed in the actions.
So your custom policy could be something like this:
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*",
"Condition": {
"StringEquals": {
"aws:RequestedRegion": "us-east-1"
},
"ForAnyValue:StringNotLike": {
"ec2:InstanceType": [
"*.nano",
"*.small",
"*.micro"
]
}
}
}
]
}
```
## Conclusion
I really hope this post can help someone getting started on AWS without getting unwanted nasty surprises, always be vigilant, AWS is not a toy and money is money.
Cheers!
| matteogioioso | |
778,398 | Ninth-week check in for PSF, GSoC 2021 | Hi! This is my ninth post of my GSoC 2021 series 😃 This week I did 3 things. I fixed some details... | 0 | 2021-08-18T20:59:00 | https://dev.to/leocumpli21/ninth-week-check-in-for-psf-gsoc-2021-329a | gsoc, python | Hi! This is my ninth post of my GSoC 2021 series :smiley:
This week I did 3 things.
1. I fixed some details of my third milestone PRs. Also, I added the final exercise that was missing in the second challenge. This was pretty straightforward.
2. I reviewed the PRs of the other students.
3. I had to research about `pytest-vcr`, a <cite>plugin for managing VCR.py cassettes</cite>, and to implement it in 2 tests of the project. See its docs [here](https://pytest-vcr.readthedocs.io/en/latest/)
To implement `pytest-vcr`correctly, I needed to undestand what a decorator is, and what it does, because to use `pytest-vcr` tools I had to add decorators to the tests functions. In a nutshell, this was necessary for a couple of tests that make API calls because sometimes this APIs are not active. What `pytest-vcr` does is that the fisrt time a test is run, the request to a web page is made, and a `.yaml` file is generated with the information of that request. Next time the same test is run, there will not be a web request. Instead, the data will be returned from the `.yaml` file. This not only speeds up the tests, but makes them less error prone.
This week, I can't say I got stuck somewhere, because I didn't. However, I took more time than expected in the `pytest-vcr` thing.
| leocumpli21 |
778,570 | Top 100+ Startup Directories And Resources to Launch your Product And Optimize Traffic | When you are building a Startup, marketing plays a very crucial role which helps you to find your... | 0 | 2021-08-01T20:10:59 | https://www.boxpiper.com/posts/top-startup-directories-resources | startup, marketing, productivity | When you are building a Startup, marketing plays a very crucial role which helps you to find your true tribes, early adopters and customers that pays for your Product.
{% youtube bNpx7gpSqbY %}
Bill Gross has founded a lot of start-ups and he found one factor that stands out from the others — and surprised even him.
To do so, you need to promote your product and market it to gain visibility. The best way to do so is to promote in all the available active Communities, Startup Directories, Reddit and submit it to Press, which can bring in initial traction, customer's feedback, and may get a chance to gain early press coverage.
Currently, we have a lot of available options but only a few of them can maximize the return of your time. Therefore, we have consolidated the lists of directories and resources that you shouldn’t miss.
## Startup Directories and Communities
1. https://news.ycombinator.com/
2. https://www.producthunt.com/
3. https://www.f6s.com/startups
4. https://www.gartner.com/en/digital-markets
5. https://stackshare.io/create-stack/new-company
6. https://www.indiehackers.com/contribute
7. https://www.webdesignernews.com/
8. https://inc42.com/startup-submission/
9. https://www.uplabs.com/submit
10. https://www.designernews.co/
11. https://dev.to/
12. https://www.makerpad.co/
13. https://sidebar.io/
14. https://sideprojects.net/
15. https://dribbble.com/
16. https://index.co/
17. https://www.productmanagerhq.com/join-the-community/
18. https://www.behance.net/
19. https://www.geekwire.com/startup-spotlight-apply/
20. https://www.g2crowd.com/products/new
21. https://hello.webwide.io/
22. https://growingpage.com/
23. https://www.instructables.com/
24. https://broadwise.org/
25. https://nextbigwhat.com/
26. https://saasified.co/
27. https://betapage.co/
28. https://betalist.com/
29. https://www.betabound.com/
30. https://wip.chat/
31. https://www.sideprojectors.com/#/
32. https://launched.io/
33. https://alternativeto.net/
34. https://digg.com/submit-link
35. https://getmakerlog.com/
36. https://startuptracker.io/
37. https://startupsgalaxy.com/
38. https://www.promoteproject.com/
39. https://apprater.net/
40. https://www.webwiki.com/
41. https://startupbuffer.com/
42. https://launchlister.com/
43. https://www.startupinspire.com/
44. https://startupstash.com/
45. https://www.crazyaboutstartups.com
46. https://startuplift.com/submit-your-startup/
47. https://www.thestartupinc.com/
48. https://vator.tv/
49. https://www.startupcosts.co/
50. https://www.allstartups.info/Startups/Submit
51. https://startupresources.io/add-resource/
52. https://www.snapmunk.com/submit-your-startup/
53. https://appsumo.com/partners/apply/
54. http://capterra.com/
55. http://angel.co/
56. http://launchingnext.com/
57. http://startuptunes.com/
58. https://www.springwise.com/
59. http://feedmyapp.com/
60. http://erlibird.com/
61. http://webmenu.org/
62. http://gust.com/
63. http://webgeek.ph/
64. http://www.killerstartups.com/
65. http://upload.cnet.com/
66. http://business-software.com/
67. http://g2link.com/
68. http://vbprofiles.com/
69. http://launch.it/
70. http://startupli.st/
71. http://randomstartup.org/
72. https://thestartuppitch.com/
73. http://listly.com/
74. https://remote.tools/
## Communities - Reddit
1. https://www.reddit.com/r/Entrepreneur/
2. https://www.reddit.com/r/IMadeThis/
3. https://www.reddit.com/r/ladybusiness/
4. https://www.reddit.com/r/roastmystartup/
5. http://reddit.com/r/sideproject/
6. https://www.reddit.com/r/smallbusiness/
7. https://www.reddit.com/r/startups/
8. https://www.reddit.com/r/alphaandbetausers/
9. https://www.reddit.com/r/design_critiques/
10. https://www.reddit.com/r/productivity/
11. https://www.reddit.com/r/indiebiz/
12. https://www.reddit.com/r/growmybusiness/
13. https://www.reddit.com/r/shamelessplug/
14. https://www.reddit.com/r/coupons/
## Press submissions
1. https://mashable.com/submit/
1. https://techcrunch.com/pages/tips/
1. https://www.makeuseof.com/contact/
1. https://www.netted.net/contact-us/
1. https://www.techradar.com/news/about-us
1. https://www.engadget.com/about/tips/
1. https://www.wired.com/about/feedback/
1. https://www.gizmodo.com.au/contact/
1. https://pando.com/
1. https://readwrite.com/contact/
1. https://slate.com/
1. http://startupdope.com/submit-news/
1. https://www.theguardian.com/info/2013/may/26/contact-guardian-australia
1. https://www.forbes.com/contact/#56977f2e7de2
1. https://techli.com/contact/
1. https://www.superbcrew.com/about/
1. https://www.appvita.com/#
1. http://feedmystartup.com/contact-us/
1. https://smash.vc/contact/
1. https://www.redmondpie.com/about/
1. http://techfaster.com/contact-us/
1. https://www.theregister.co.uk/about/company/contact/
1. https://www.techinasia.com/about
1. https://startupbeat.com/startup-beat-featured-startup-pitch-guidelines/
1. https://www.thetechblock.com/contact-tim/
## Ending Note
In a Startup, product building is one part of a bigger problem. The next is to find your niche. It’s always recommended to take the best leverage of all the available directories, and resources. You may find some are free as well. Nothing better than saving your bucks. Try to be a little cautious before using the paid resources because not everyone can deliver as per your expectation. Due diligence is always recommended.
{% youtube kzVvjKLdAbk %}
| boxpiperapp |
778,596 | Build in Public: Versatilist Portfolio with Ghost | So I'm rebuilding my portfolio to be more of a versatilist, personal brand hub. I'll be building this... | 0 | 2021-08-01T21:28:45 | https://dev.to/madebyporter/build-in-public-versatilist-portfolio-with-ghost-1bnf | jamstack, ghost, middleman, portfolio | So I'm rebuilding my portfolio to be more of a versatilist, personal brand hub. I'll be building this portfolio in public. It's different from the typical portfolio/agency sites as I'll be up to the challenge of fulfilling these goals:
- Showcase all my specializations on one site, keeping it simple, and without it scaring away certain audiences
- Build a massive database of all my work, that can use tagging to show everything, just one discipline, free stuff or paid stuff behind a pay wall
- Get it up quickly and then build in public, adding features and pages along the way
## What's a Versatilist?
Before I continue, you're probably like, "What the hell is a versatilist?". Well let me explain:
A versatilist is a person who specializes in multiple disciplines. This is different from a Generalist, who just has experience in multiple disciplines, but usually has no proven work to show for it.
Generalists tend to just learn just enough to hire someone else to build it. They may go as far as use a novice or no-code solution just to get by. For example, a generalist might code in JS, but all their work is in Codepen as a prototype. So they'll hire a specialist to code their product or use a no-code solution.
### Macro Versatlist
There's two types of versatilists and you can be both if you have the work to show for it. A macro–versatilist would be how I work. I'm a Business Founder, Product/Web Designer, Web Developer, Music Producer & Photographer. I've spent more than 10 years in each discipline, learning the software, the theories & the fundamentals.
### Micro Versatilist
A micro versatilist example would be a full–stack developer that specializes in multiple languages like JS, Python, Ruby, C#, HTML & CSS; or a full–stack designer specializing in Graphic Design, Web Design, Product Design & 3D Design. Of course having public proof such as work being used by many people helps certify those specialties.
So now you know what a versatilist is. Let's talk about the portfolio.
## The Portfolio
My work is currently at madebyporter.com. I built the portfolio using Ruby Middleman, which is one of the OG static website generators. I started using Middleman back in 2014. It's been great, but now I have other features that Middleman would have a hard time with.
### The Vision
My vision is to build multiple streams of residual income using my portfolio site. So some of the features I need includes subscription memberships for content I want to sell such as access to my music database, special blog posts, etc. So far I'm looking at Ghost for the answer.
My main hope is that I can implement custom fields for Ghost. This would allow me to create a music database in Ghost and display all the music on a custom page as a database. Same with the photos. Then also have a portfolio database for past design work, public blog for free reading, etc.
### The Structure
Im thinking the structure would look like this (work in progress):
- Home or /
- A better linktree page displaying most recent posts and links to important projects, services, etc.
- The only way you can get to the discipline landing pages
- Once on a discipline landing page, you have to click back (and maybe the logo) to go back home to get to other discipline landing pages. If you're on the design page, you can't get to the photo page unless you click home > photos.
- /design
- Static landing page I will send to potential design clients
- Portfolio DB (/design/{project_slug}
- Blog posts tagged "design, free"
- /music
- Static landing page I will send to potential music clients
- Showcase my past music projects {/music/project_slug}
- Showcase free beats to use
- Sales page to signup for music db membership
- Database will hide behind membership (/music/database/{track_slug}
- Database will have music player to allow for streaming right from page
- You can also download music for usage in film/commercials/music
- Blog posts tagged "music, free"
- /photo
- Static landing page I will send to potential photography clients
- Will showcase photo work (/photo/{project_slug})
- May have a membership db if there's enough demand for stock photography (ala a decentralized unsplash)
- Display blog posts tagged "photography, free"
- /library
- Dynamic page, to be used as an archive, but cool looking
- Posts of links from my Raindrop.io bookmarks, curated for my portfolio. I currently have something like this at [Think Versa](https://thinkversa.com) but I want to move everything to one place to build brand awareness and make it easy to update. This will also be the easiest way for me to generate content between bigger posts.
- A collection of all my design, music, and photo projects
- Blog articles for design, music and photography to share tips and tricks
- Free stuff for design, music and photography like design assets, free beats, free photos of patterns
- Hopefully I can feed these posts to their perspective landing pages so I can provide some free value to potential clients and not just "sell, sell, sell".
I will build the templates from scratch using HTML and SCSS. Maybe I can see about using SLIM or something similar for pre-processing the HTML. I'm designing everything in Figma, and you can view that [here](https://www.figma.com/file/ITKp0WQjmIfnwQO1yGMq9p/MBP2021?node-id=305%3A454). I'm thinking, just build the finish wireframes as is and launch. Then improve from there by adding UI & animation until it looks like a site that can be on [Awwwards.com](https://awwwards.com).
## Build in Public Conclusion
This will serve as a "build in public" page with updates. Of course if you have any suggestions or links to other ways I can build this, please feel free to hit the comments. If you think I can build this solution better in Gatsby, VuePress, etc, let me know. I tend to start as an extreme maximalist, then start the deduction process until I have a minimalist MVP to work with. Some pages will probably launch later, so higher priority on landing pages that has higher demand, such as the design and library pages.
Also, I wrote this from my head and published immediately because I'm so busy that this would stay as a draft if I went through a traditional writing process, so this article is a "write in public" post, lol. Any suggestions would be great, just be nice.
That's all for now. Will update with a more structured game plan once I'm ready to code.
Best,
Porter
| madebyporter |
778,650 | Hooks | This post has been backlogged for a few days. Nearly all of it was written this past Sunday... | 0 | 2021-08-04T05:02:34 | https://dev.to/zbretz/hooks-i29 | *This post has been backlogged for a few days. Nearly all of it was written this past Sunday (8/1).*
In this post:
- [Intro](#re-factoring-the-refactor)
- [Infinite Loops and *useEffect* dependencies](#infinite-loops-and-useeffect-dependencies)
###Refactoring the refactor
I set off this morning to refactor some sparse front-end code. My goal was to turn a class based, stateful component, into a hook-equipped, functional component. While I didn't necessarily expect it to take much time - the fact that it ate away into the early afternoon didn't shock me. What *did* come as a surprise was that I ended up refactoring a significant element of my first refactor, bringing it back around to resemble its earlier state. It was a winding process, but I learned quite a bit while navigating hooks, routes, and the React *way*.
###Infinite Loops and *useEffect* dependencies
After the initial class/state -> functional/hook conversion looked up-to-form (the result of which follows this sentence), I ran a test by refreshing the browser, hoping that the transformation would be seamless.
```javascript
//index.jsx
<Router>
<Switch>
<Route path="/all" exact component={Feed} />
<Route path="/:user/feed" exact component={Feed} />
<Route path="/:user/post/:post_id " exact component={(props) => <Post {...props}/>} />
</Switch>
</Router>
//feed.jsx
componentDidMount(){
const path = this.props.match.path
if (path === "/all"){
httpHandler.getFeedAllUsers((err, data)=>{
this.setState({postData:data})
})
} else if (path === "/:user/feed"){
const user = this.props.match.params.user
httpHandler.getFeedOneUser(user, (err, data)=>{
this.setState({postData:data})
})
}
}
```
Instead what I saw was an infinite loop of 'get' calls being made by the `useEffect` hook. Essentially the cycle looked like this (this is, my 100% faulty understanding):
1. Call `useEffect`
2. Call data
3. Render component (which triggers 'useEffect')
4. Call `useEffect`
5. repeat
How to break this cycle? First, I did a bit of reading to understand the problem. [This post](https://blog.bitsrc.io/fetching-data-in-react-using-hooks-c6fdd71cb24a) does a great job of explaining the issue and the solution.
What I needed to do was give React a change to observe - a change that would trigger `useEffect`. Without it, useEffect would only be called when Feed was mounted. And since Feed isn't re-mounted by a changed url, it doesn't call the data-fetcher that creates the state change that renders the correct data from the new url. Essentially I was facing the opposite of an infinite loop - a loop I couldn't get *into*. There was no call to the data-fetcher inside of that function.
What I landed on was using a prop to indicate that the feed being requested had changed. From one of 'user posts' or 'all posts' to the other. Passing that prop as a **dependency** into useEffect would signal - on a change - to useEffect to fetch fresh data.
The resulting `<Route/>` component looked like this:
```javascript
<Route path="/all" render={(props)=>(<Feed {...props} feedView={'all'}/>)} />
```
---
Now as I type this, I wonder if I could have just passed in a Router parameter like 'path' as a dependency. Were that to work, I could avoid that re-refactor I performed and go back to the simpler refactor that passed only a component into the `<Route/>` as a prop. Compare the above code snippet to this:
```javascript
<Route path="/all" component={Feed} />
```
Way simpler.
| zbretz | |
778,664 | Accenture - June + July 2021 | Cross posted on mitchinson.dev What I've been doing at Accenture for the month of June + July. Took... | 0 | 2021-08-01T23:23:32 | https://dev.to/bmitchinson/accenture-june-july-2021-2957 |
_Cross posted on [mitchinson.dev](https://mitchinson.dev/pillar/june-july-21/)_
What I've been doing at [Accenture](https://www.accenture.com/us-en/insights/industry-x-index) for the month of June + July.
Took a break in between jobs during the month of May. Did some contracting to deploy a small node server + corresponding frontend in AWS Beanstalk.
## What I've worked on
- Managed deployments in multiple AWS k9s environments with Terraform
- Introduction to elixir
- Learning how to work in an [open source organization](https://github.com/Datastillery)
- Presented on code review standards + practices
- Utilized the Helm Terraform provider to manage helm deployments in k9s
- Configured Strimzi to deploy a kafka cluster
- Pair Programming in a remote environment. We typically pair for 4+ hours a day.
- Deploying Prometheus and Grafana alongside our data pipeline using public helm charts
- Combining several of our teams custom helm charts into one configurable mono chart
- Coming up with fun + not awkward bonding activities for our team to participate in despite our distance from one another
## What I'd like to improve
- Learning so much technology has left me feeling burnt out when I could be taking on new cards / tech debt. I'd like to more effectively use my time when not actively pairing.
- Making new cards when discovering potential improvements
- Continue to practice creating very organized and condensed technical presentations
| bmitchinson | |
793,430 | ...My Holy Grail in HNGi8 internship.🎯 | HNGi8 is back like it never left. I couldn't help myself to wait for this virtual coding... | 0 | 2021-08-16T10:51:30 | https://dev.to/murithijoshua/my-holy-grail-in-hngi8-internship-174j | hng, internship, computerscience, zuri | >**HNGi8 is back like it never left.**
I couldn't help myself to wait for this virtual coding internship. I have been fascinated by the intense coding atmosphere, the adrenaline spikes and coffee nights behind the screen.For code wannabes you know this feeling.
**Intro to HNG**
HNG Internship is a long running, large scale virtual internship for people learning to code and design. It focuses on the post-training phase, and creates a virtual work environment for participants.It's easier when said than done, entry is free and you can enroll [here](https://internship.zuri.team). for more about info go through this [site](https://training.zuri.team)
##### My objective during this internship
As I move from one stage to another am looking forward to :
* identify new ways to ship quality code
* add on my existing knowledge on software development most importantly on backend
part
* Test my ability to meet deadline and enforce on time management skill
* form teams,create solutions and finally form life transformative networks
* Lastly, I am looking forward to a really good time.
>Tutorial Section
Here are some beginner friendly tutorials to get you started.
**Figma tutorial** [here is link to Gary Simon, he is really good at figma](https://www.youtube.com/watch?v=3q3FV65ZrUs)
**Git tutorial Link** [here is a great tutorial by programming by mosh](https://www.youtube.com/watch?v=8JJ101D3knE)
**python**[here is the best tutorial for a beginner who wants to get started with python](https://docs.python.org/3/tutorial/)
| murithijoshua |
793,449 | Documentation Guide for developer | As a developer, we always underestimate the power of the documentation. We (developers) always... | 0 | 2021-10-04T06:32:08 | https://hellonehha.hashnode.dev/documentation-guide-for-developers-cksie1jh7050pvps1bnrgf7vh | As a developer, we always underestimate the power of the documentation. We (developers) always underestimate the power of the documentation. As a result, we focus more on the code than thinking about the documentation.
Moving to the EM role, I learned the importance of documentation. I have seen that this is one of the many things which differentiate a process-oriented team/work/company from a chaos-oriented one.
>> Documentation required 10-20% time effort, but the impact or use of it is big or immense
*Eg: how many times does a new member join the team and you end up repeating the same things - product, code, process, setting up system & code?. If you document all this, then you can save time as well as this would come in handy every time any developer, product, a person requires a quick overview of your code-bases*
Another example is how often the developers move around and you end up asking - *"Oh!! the developer who wrote the code has left and we are not sure why we took this approach".*
❓❓ I can keep going on and on with an example. But this blog is about **what to document**?
## 📝 What to document?
It is common to be unclear about what to document. Well as a developer you can document:
### 1. Feature and approaches
You can start documenting the approaches, LLD, HLD of the solution of the feature. You can add:
- different solutions
- prefer a solution with reasons
- detailed design of the solution
- dependencies
- APIs contracts
- any trade-offs
- LLD (Low-Level Design)
- HLD (High-Level Design)
👉 [developer-story-template.md](https://github.com/Neha/documentation/blob/master/developer-story-template.md)
### 2. Knowledge sharing
This is one of the most underrated at work. Document the knowledge sharing. It could have:
- Early review of any tech
- Anything you learned
- A bug you fixed
- A feature we should have
- A complex feature
👉 [knowledge-sharing-template.md](https://github.com/Neha/documentation/blob/master/knowledge-sharing-template.md)
### 3. Code guidelines
If you are a lead, Senior developer, or Engineering Manager then this is 1st documentation you should have.
Code guidelines are helpful for the new devs joining the team, set a bar, and most important reduce the code-review comments (logical comments will stay). After a few revisions, you will see the value in this documentation. We can automate the code guidelines in the project by using CI/CD, linters, and npm packages will help you in automating quite a few things.
👉 [code-guidelines-template.md](https://github.com/Neha/documentation/blob/master/code-guidelines-template.md)
### 4. Checklist
One constant thing in every project (small/big) is missing something while doing the code deployment. I would say it is a must to have a checklist of the things to take care of before doing deployment or going Live.
👉 [checklist-template.md](https://github.com/Neha/documentation/blob/master/checklist-template.md)
### 5. API Contracts
One of the common ways of working is in collaboration with the APIs. Though it is expected that the API team must be documenting their contracts if they are not then you should suggest them to do. Eg: [Stripe](https://stripe.com/docs/api), [PayPal](https://developer.paypal.com/docs/api/overview/)
This should happen from Day-0. Again, the outline would be just like a developer conversation:
- Problem
- Suggestions
- Solutions pros & cons
- trade-offs
- challenges
- feedback
👉 [Sample Template](https://github.com/Neha/documentation/blob/master/api_template.md)
### 6. Dependencies
While working on the big/large-scale projects or any size of the project it is common to have dependencies on the different teams, code such as APIs, attribute(s), backend, DevOps, etc. I would say it is MUST document the dependencies of your code-base and project.
Your future self and your team will be thankful to you 😊
👉 [dependencies_template.md](https://github.com/Neha/documentation/blob/master/dependencies_template.md)
>> As an Engineering Manager, allow developers an opportunity to try the different features to know the code-base. The most common problem I have seen is that the new developer is not aware of the code's dependencies. Documentation such as this would be super helpful. Also, This is also an opportunity for developers to push their code to quality by reviewing the dependencies, and if there is something the developer can fix something.
### 7. Sprint Milestones, celebrations, retrospect, and reviews
As a senior developer, tech lead, or Engineering manager block time in your team and at the end of your sprint present sprint milestones, review, and celebrate. Yes, we do have JIRA, yes, we do have the scrum but as a developer doing a playback (playback of the work done in the last sprint) is important.
Why? it is an opportunity to appreciate the good work, celebrate the milestones, and reflect back on mistakes and retrospect.
This document could be a reference when a team wants to see how far we have come, what we have delivered, and milestones achieved.
👉 [sprint-review.md](https://github.com/Neha/documentation/blob/master/sprint-review.md)
### 8. Cookbooks
A cookbook is a beautiful way to set the standard guidelines across organizations from the engineering side. For example, a cookbook could have the performance guide, metrics, measurement of front-end apps, back-end, API.
A cookbook is a 'black book' for your developers to see the area to focus on, what is expected, how to achieve, etc.
As a tech lead or engineering manager , investing time in the Cook Book is a good investment. The cookbook helps the developers what is expected from their contribution to the product/project, how the review of their work will be done or how would be measure. Eg: Accessibility should be at least AA level. If a developer's code is meeting that then it is a concern. Similarly, these cookbooks would help in quantifying the quality of the code.
### 9. Brag Document
A brag document is a personal document that every developer should maintain. This document will have all the things you have achieved - small/big. Basically, everything which created an impact - code, tech discussion, mentoring, hiring, tech talk, etc.
At the time of your yearly review, you can refer to this document to look back at your progress, share with your leads, or whenever you feel low you can just go through this doc to reflect back.
### 9. Project Starter Guide
Create a project starter guide for your project. This document will reduce the repetitive work/meetings/communication. This document could covers:
- Summary of your project
- Team structure
- Product/Project walkthrough
- WOW (way of working)
- Code walkthrough
- Tools and Applications required
- Escalation Process
- and anything which is required in your project
- HLD (High-Level Design)
## 📇 Where to document?
- Wiki (GitHub)
- confluences (Atlassian)
- Drive (any Google, One Drive)
- or a shared folder with readme(s), or doc(s)
## 🔄 Is it a one-time effort?
Well, a few documents would be just a 1-time effort but a lot of the documentation needs to be updated from time to time as you will move ahead or your project.
>> How to make it automated? Well, fortunately, a few things can't be automated. Yes, I said, fortunately...The reason is: a lot of documents depend on the developer's experience. No harm in doing the manual effort. But there are a few tools that can be used - [JSDocs](https://www.npmjs.com/package/jsdoc-to-markdown)
*Thank you [@iamshadmirza](https://twitter.com/iamshadmirza), [@nchiarora](https://twitter.com/nchiarora), [@rahulrana_95](https://twitter.com/rahulrana_95),[@prasadsunny1](https://twitter.com/prasadsunny1),[@PKodmad](https://twitter.com/PKodmad),[@izshreyansh](https://twitter.com/izshreyansh) for reviewing and providing valuable feedback.*
Happy Learning!!
| hellonehha | |
793,564 | The Easiest Way to Enable Tls 1.2 and Disable Cipher suits without troubles | Both SSL and TLS are cryptographic protocols designed to secure communications over a network .... | 0 | 2021-08-16T12:00:37 | https://dev.to/mellaithy0/the-easiest-way-to-enable-tls-1-2-and-disable-cipher-suits-without-troubles-3dj | security, aws, cloud | Both SSL and TLS are cryptographic protocols designed to secure communications over a network . Mainly we Have To Enable TLS 1.2 ONLY and Disable Old Versions of TLS.
I'm Using AWS windows server 2019 EC2 Virtual Machine
and here are steps depending on personal experiment after many many tries and reading articles and watching videos
Here are the easiest way to patch security issues
1-First You Have To Enable TLS 1.2
*Note Run PowerShell as Administrator and Run the following
```
New-Item 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Server' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Server' -name 'Enabled' -value '1' -PropertyType 'DWord' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Server' -name 'DisabledByDefault' -value 0 -PropertyType 'DWord' -Force | Out-Null
New-Item 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Client' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Client' -name 'Enabled' -value '1' -PropertyType 'DWord' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.2\Client' -name 'DisabledByDefault' -value 0 -PropertyType 'DWord' -Force | Out-Null
```
2-Disable TLS 1.0
```
New-Item 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.0\Server' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.0\Server' -name 'Enabled' -value '0' -PropertyType 'DWord' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.0\Server' -name 'DisabledByDefault' -value 1 -PropertyType 'DWord' -Force | Out-Null
New-Item 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.0\Client' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.0\Client' -name 'Enabled' -value '0' -PropertyType 'DWord' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.0\Client' -name 'DisabledByDefault' -value 1 -PropertyType 'DWord' -Force | Out-Null
```
3-Disable TLS 1.1
```
New-Item 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.1\Server' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.1\Server' -name 'Enabled' -value '0' -PropertyType 'DWord' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.1\Server' -name 'DisabledByDefault' -value 1 -PropertyType 'DWord' -Force | Out-Null
New-Item 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.1\Client' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.1\Client' -name 'Enabled' -value '0' -PropertyType 'DWord' -Force | Out-Null
New-ItemProperty -path 'HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols\TLS 1.1\Client' -name 'DisabledByDefault' -value 1 -PropertyType 'DWord' -Force | Out-Null
```
4- How to Disable Weak Ciphers:
we have to Disable Every Weak Cipher found in Testing Report
for example from [Link](https://www.ssllabs.com/ssltest) we can generate Security report for HTTPS Domain and check
Cipher Suites section to find out **Weak Ciphers**
For Example i found those 2 weak ciphers
TLS_DHE_RSA_WITH_AES_256_CBC_SHA
TLS_DHE_RSA_WITH_AES_128_CBC_SHA
Using the following Command you can Easily Disable Weak cipher
through powershell as Administrator
```
Disable-TlsCipherSuite -Name "TLS_DHE_RSA_WITH_AES_256_CBC_SHA"
Disable-TlsCipherSuite -Name "TLS_DHE_RSA_WITH_AES_128_CBC_SHA"
```
**Important**
You can also use this site [Link](https://tls.imirhil.fr/)
Sometimes you Find in security report ((DES3)) as Critical Cipher
so here how to Disable it
First open registry
Follow this path (HKLM:\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL)
Add new Key Rename to **RC4 1288/128**
Then add new DWORD 32 bit >> Rename to **Enabled** and Value is **0**
Add new Key Rename to **Triple Des 168**
Then add new DWORD 32 bit >> Rename to **Enabled** and Value is **0**
**Important Note**
You have to **Restart** windows machine after you finish those stpes
**Concluding**
Get rid of old protocols, cipher suites and hashing algorithms in your Hybrid Identity implementation, so they cannot be used to negotiate the security of the connections down.
| mellaithy0 |
793,574 | DynamoDB in 15 minutes | DynamoDB is a fully managed NoSQL database offering by AWS. It seems simple on the surface, but is... | 0 | 2021-08-16T14:17:38 | https://aws-blog.de/2021/03/dynamodb-in-15-minutes.html | aws, cloud, dynamodb, database | DynamoDB is a fully managed NoSQL database offering by AWS. It seems simple on the surface, but is also easy to misunderstand. In this post I introduce some of the basics that are required to understand DynamoDB and how it's intended to be used. We'll first take a look at the data structures inside DynamoDB, then talk about reading and writing to the database and also cover different kinds of indexes and access patterns before we move on to talking about performance and cost. We'll end with a mention of some additional features and then come to a conclusion.
Since I intend to keep the scope of this manageable, I won't go into too much detail on all of the features. That's what the documentation and the other references I'll mention in the end are for.
## Data structures
Data in DynamoDB is organized in tables, which sounds just like tables in relational databases, but they're different. Tables contain items that may have completely different attributes from one another. There is an exception though and that relates to how data is accessed. In DynamoDB you primarily access data on the basis of its primary key attributes and as a result of that, the attributes that make up the primary key are required for all items.

The primary key is what **uniquely identifies an item in the table** and it's either a single attribute on an item (the partition key) or a composite primary key, which means that there is a combination of two attributes (partition key and sort key) that identify an item uniquely. Let's look at some examples.
This example shows a table that has only a partition key as its primary key. That means whenever we want to efficiently get an item from the table, we have to know its partition key. Here you can also see that a single table can contain items with different structures.

It's more common to have a composite primary key on a table, which you can see below. This allows for different and more flexible query patterns. Items that share the same partition key value are called an **item collection**. The items in a collection can still be different entities.
At this point I'd like to point out a few things about the table above. You can see that it uses generic names for the partition and sort key attribute (PK and SK) and this is done on purpose. When modelling data in DynamoDB we often try to put as many different entities into a single table as possible. Since these entities are identified by different underlying attributes, it's less confusing to have generic attribute names. You can also see, that the values in the Key-Attributes are duplicated. The number behind the `ISBN#` sort key is also a separate attribute, same with the author's name. This makes serialization and deserialization easier.
Putting all (or at least most) entities in a single table is the aptly named *Single-Table-Design* pattern. To enable working with such a table, each item has a `type` attribute that we use to distinguish the different entities. This makes deserialization more convenient. Another effect of the single table design can be observed in the key attributes. The actual values like "J. R. R. Tolkien" or "Stephen King" have a prefix. This prefix acts as a namespace - it allows us to separate entities with the same key value but different type and helps to avoid key collisions inside of our table.
Let's now talk about the different ways we can get data into and out of DynamoDB.
## Reading and Writing data
The options to write to DynamoDB are essentially limited to four API-calls:
- `PutItem` - Create or replace an item in a table
- `BatchPutItem` - Same as `PutItem` but allows you to batch operations together to reduce the number of network requests
- `UpdateItem` - Create a new item or update attributes on an existing item
- `DeleteItem` - Delete a single item based on its primary key attributes
The details of these calls aren't very interesting right now, let's focus on reading data. For this we have a selection of another four API-Calls:
- `GetItem` - retrieve a single item based on the values of its **primary key attributes**
- `BatchGetItem` - group multiple `GetItem` calls in a batch to reduce the amount of network requests
- `Query` - get an **item collection** (all items with the same partition key) or filter in an item collections based on the sort key
- `Scan` - the equivalent of a table scan: access **every item** in a table and filter based on arbitrary attributes
The `Scan` operation is by far the slowest and most expensive, since it scans the whole table, so we try to avoid it at all cost.
We want to rely only on `GetItem` (and potentially `BatchGetItem`) and `Query` to fetch our data, because they are very fast operations. Let's visualize how these operations work.
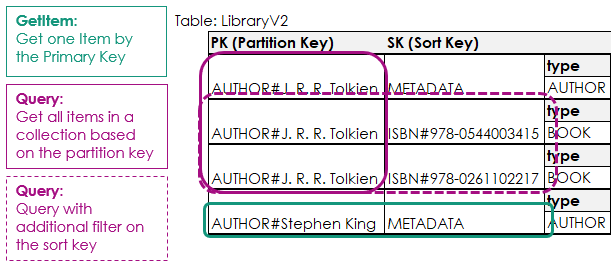
When we call `GetItem` we need to specify **all** primary key attributes to fetch exactly one item. That means we need to know the partition and sort key in advance. Getting the green item in Python can be achieved like this:
```python
import boto3
def get_author_by_name(author_name: str) -> dict:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.get_item(
Key={
"PK": f"AUTHOR#{author_name}",
"SK": "METADATA"
}
)
return response["Item"]
if __name__ == "__main__":
print(get_author_by_name("Stephen King"))
```
As you can see, I've specified both the partition and the sort key to uniquely identify an item. This API call is very efficient and will result in single-digit millisecond response times no matter how much data is in our table. Let's take a look at a query example - in this case one that gets all author information:
```python
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_all_author_information(author_name: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.query(
KeyConditionExpression=conditions.Key("PK").eq(f"AUTHOR#{author_name}")
)
return response["Items"]
if __name__ == "__main__":
print(get_all_author_information("J. R. R. Tolkien"))
```
This function essentially returns the whole item collection of the author. It's equivalent to the violet query in the picture.
We can also add conditions on the sort key, which makes the `Query` operation quite powerful. Here's an example to fetch all books that an author wrote:
```python
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_books_by_author(author_name: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.query(
KeyConditionExpression=conditions.Key("PK").eq(f"AUTHOR#{author_name}") \
& conditions.Key("SK").begins_with("ISBN")
)
return response["Items"]
if __name__ == "__main__":
print(get_books_by_author("J. R. R. Tolkien"))
```
I'm using the ampersand `&` to chain the conditions. The `begins_with` is one of the conditions supported to filter on the sort key - others are listed in the [documentation](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GettingStarted.Python.04.html).
## Indexes
So far you've seen me use different ways to fetch data from our table. All of these have been using attributes from the primary key. What if we want to select data based on an attribute that's not part of the primary key? This is where things get interesting. In a traditional relational database you'd just add a different `WHERE` condition to your query in order to fetch the data. In DynamoDB there is the `Scan` operation you can use to select data based on arbitrary attributes, but it shares a similar problem as a where condition on unoptimized table in a relational database: **it's slow and expensive**.
To make things faster in a relational database we add an index to a column and in DynamoDB we can do something similar. Indexes are very common in computer science. They're secondary data structures that let you quickly locate data in a [b-tree](https://en.wikipedia.org/wiki/B-tree). We've already been using an index in the background - the primary index, which is made up of the primary key attributes. Fortunately that's not the only index DynamoDB supports - we can add secondary indexes to our table which come in two varieties:
- The **local secondary index** (LSI) allows us to specify a different sort key on a table. In this case the partition key stays identical, but the sort key can change. LSIs have to be specified when we create a table and share the underlying performance characteristics of the table. When we create a local secondary index we also limit the size of each individual item collection to 10GB.
- The **global secondary index** (GSI) is more flexible, it allows us to create a different partition and sort key on a table whenever we want. It doesn't share the read/write throughput of the underlying table and doesn't limit our collection size. This will create a copy of our table with the different key schema in the background and replicate changes in the primary table asynchronously to this one.
Secondary indexes in DynamoDB are **read only** and only allow for eventually consistent reads. The only API calls they support are `Query` and `Scan` - all other rely on the primary index. In practice you'll see a lot more GSIs than LSIs, because they're more flexible.
How can these help us? Suppose we want to be able to select a book by it's ISBN. If we take a look at our table so far, we notice that the ISBN is listed as a key attribute, which seems good at first glance. Unfortunately it's the sort key. This means in order to **quickly** retrieve a book, we'd need to know it's author as well as the ISBN for it (`Scan` isn't practical with larger tables).
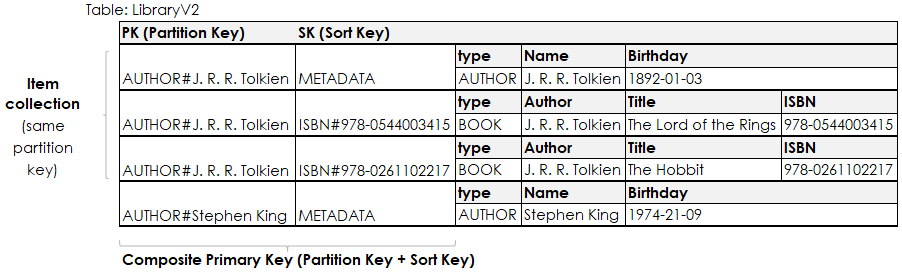
The way our table is layed out at the moment doesn't really work well for us, let's add a secondary index to help us answer the query. The modified table is displayed below and has additional attributes that make up the global secondary index. I've added the attributes `GSI1PK` as the partition key for the global secondary index and `GSI1SK` as the sort key. The index itself is just named `GSI1`. The attribute names that make up the index are very generic again, this allows us to use the GSI for multiple query patterns. You can also see, that the GSI attributes are only filled for the book entities so far. Only items that have the relevant attributes set are projected into the index, that means I couldn't use the index to query for the author entities at the moment. This is what's called a **sparse index**. Sparse indexes have benefits from a financial perspective, because the costs associated with them are lower.
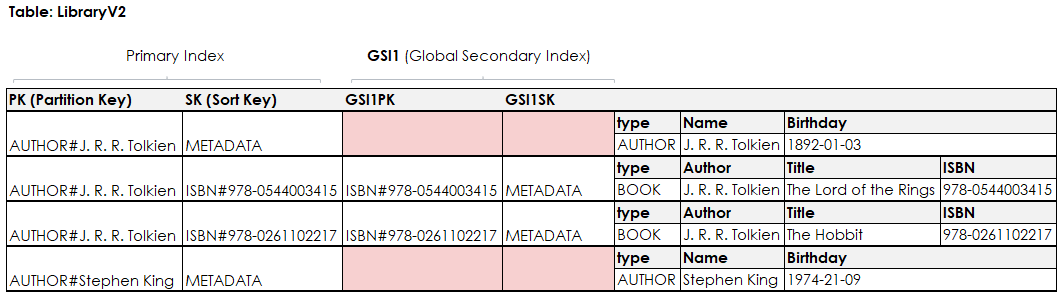
Back to our original question - *how can we use this to fetch a book by its ISBN?* That's now very easy, we can just use the `Query` API to do that, as the next code sample shows. It's very similar to a regular query, we just use different key attributes and specify the `IndexName` attribute to define which index to use (there can be multiple indexes on a table).
```python
import boto3
import boto3.dynamodb.conditions as conditions
def get_book_by_isbn(isbn: str) -> dict:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.query(
KeyConditionExpression=conditions.Key("GSI1PK").eq(f"ISBN#{isbn}") \
& conditions.Key("GSI1SK").eq("METADATA"),
IndexName="GSI1"
)
return response["Items"][0]
if __name__ == "__main__":
print(get_book_by_isbn("978-0544003415"))
```
You might wonder why `GSI1` has a sort key that seems to be set to the static value `METADATA` for all items. To implement this specific query pattern "Get a book by its ISBN", a global secondary index with only a primary key would have been sufficient. I still went with a partition and sort key, because it's common to overload a secondary index. This means you create a secondary index that not only fulfills one, but more than one query patterns. In these cases it's very useful to have a partition and sort key available. By setting the sort key to a static value, we basically tell the system that there's only going to be one of these items.
This has been an example on how you can use a global secondary index to enable different query patterns on our dataset. There are many more access patterns that can be modeled this way, but those will have to wait for future posts.
Let's now talk about something different: performance and cost.
## Performance & Cost
So far I've shown you some things about DynamoDBs data model and APIs but we haven't talked about what makes it perform so well and how that relates to cost. DynamoDB has a few factors that influence performance and cost, which you can control:
- Data model
- Amount of data
- Read throughput
- Write throughput
**The data model you implement has a major impact on performance.** If you set it up in a way that it relies on scan operations, it won't hurt you too much with tiny databases, but it will be terrible at scale. Aside from `Scan` all DynamoDB operations are designed to be quick at essentially any scale. That however requires you to design your data model in a way that let's you take advantage of that.
The amount of data has a limited influence on performance, which may even be negligible if you design your data model well. In combination with read and write throughput it may have an influence under certain conditions, but that would be a symptom of a poorly designed data model. The amount of data is a cost component - data in DynamoDB is billed per GB per month (around $0.25 - $0.37 depending on your region). Keep in mind that global secondary indexes are a separate table under the hood, that come with their own storage costs. This should be a motivation to use sparse indexes.
Whenever your read from or write to your table you consume what's called read and write capacity units (RCU/WCU). These RCUs or WCUs are how you configure the throughput your table is able to handle and there are two options you can do this with:
- **Provisioned Capacity:** You specify the amount of RCUs/WCUs for your table and that's all there is. If you use more throughput than you have provisioned, you'll get a `ProvisionedThroughputExceeded` exception. This can be integrated with AutoScaling to respond to changes in demand. This billing model is fairly well predictable.
- **On-Demand Capacity:** DynamoDB will automatically scale the RCUs and WCUs for you, but individual RCUs and WCUs are a little bit more expensive. You're billed for the amount of RCUs/WCUs you use. This mode is really nice when you get started and don't know your load patterns yet or you have very spiky access patterns.
A general recommendation is to start with on-demand capacity mode, observe the amount of consumed capacity and once the app is fairly stable switch to provisioned capacity with Auto Scaling. You should be aware that secondary indexes differ in the way they use the capacity. Local secondary indexes share the capacity with the underlying base table whereas global secondary indexes have their own capacity settings.
Since this is supposed to be a short introduction to DynamoDB we don't have time to go over all the details, but there are nevertheless some features I'd like to briefly mention.
## Additional features
DynamoDB offers many other useful features. Here are a few I'd like to mention:
- **DynamoDB Streams** allow you perform change-data-capture (CDC) on your DynamoDB table and respond to updates in your table using Lambda functions. You can also pipe these changes into a Kinesis data stream.
- **Transactions** allow you to do all-or-nothing operations across different items.
- **DynamoDB Global Tables** is a feature that allows you to create Multi-Region Multi-Master setups across the globe with minimal latency.
- **PartiQL** is a query language designed by AWS that's similar to SQL and can be used across different NoSQL offerings.
- **DAX** or the DynamoDB Accelerator is an in-memory write-through cache in front of DynamoDB if you need microsecond response times.
## Conclusion
We have looked at a few key aspects of DynamoDB that should give you a good basic understanding of the service and will help you with further research. First we discussed tables, items, keys and item collections, which are the basic building blocks of DynamoDB. Then we moved on to the API calls you use to fetch and manipulate data in the tables before moving on to the two types of secondary indexes. Performance and cost were also aspects we've discussed and in the end I mentioned a few other key features.
If you want to play around with the tables I've mentioned in this post, you can find the code for that on [github](https://github.com/MauriceBrg/aws-blog.de-projects/blob/master/dynamodb-intro/library_example.py).
Thank you for your time, I hope you gained something from this article. If you have questions, feedback or want to get in touch to discuss projects, feel free to reach out to me over the social media I've listed in my bio below.
— Maurice
## Additional Ressources
Here is a list of additional resources you might want to check out. I can highly recommend anything done by Rick Houlihan.
The DynamoDB book is also very well written and a great resource if you want to do a deep dive. If you're curious about the techniques that make DynamoDB work, the talk by Jaso Sorensen is a good resource.
<!-- - [AWS re:Invent 2017: [REPEAT] Advanced Design Patterns for Amazon DynamoDB (DAT403-R)](https://www.youtube.com/watch?v=jzeKPKpucS0) - by Rick Houlihan -->
- [dynamodbbook.com](https://www.dynamodbbook.com/) - _The_ book about DynamoDB by Alex DeBrie
- [dynamodbguide.com](https://www.dynamodbguide.com/)
- [AWS re:Invent 2018: Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database (DAT321)](https://www.youtube.com/watch?v=yvBR71D0nAQ) - by Jaso Sorensen
- [AWS re:Invent 2018: Amazon DynamoDB Deep Dive: Advanced Design Patterns for DynamoDB (DAT401)](https://www.youtube.com/watch?v=HaEPXoXVf2k) - by Rick Houlihan
- [AWS re:Invent 2019: Data modeling with Amazon DynamoDB (CMY304)](https://www.youtube.com/watch?v=DIQVJqiSUkE) - by Alex DeBrie
- [AWS re:Invent 2019: [REPEAT 1] Amazon DynamoDB deep dive: Advanced design patterns (DAT403-R1)](https://www.youtube.com/watch?v=6yqfmXiZTlM) - by Rick Houlihan
---
I first published this post on [our company blog](https://aws-blog.de/2021/03/dynamodb-in-15-minutes.html) in march. | mauricebrg |
793,596 | Useful resources for FRP. | https://easyfirmwarez.com/ | 0 | 2021-08-16T13:02:11 | https://dev.to/jasmimejaw/useful-resources-for-frp-35i5 | https://easyfirmwarez.com/ | jasmimejaw | |
793,754 | HNGi8 Goals | Tech has always been a thing of pleasure for me, many a time I imagine how things come to be, who... | 0 | 2021-08-16T14:51:46 | https://dev.to/godsfavour_williams/hngi8-goals-1p2p | Tech has always been a thing of pleasure for me, many a time I imagine how things come to be, who thought of this, how and what does it take to become a solution specialist using tech. As a tech-savvy individual, I started my journey to become a Techie as it's commonly called, in the **Frontend Development** track at **HNGi8**.
**HNGi8**, organized by [The Zuri Team](https://internship.zuri.team/) is a fast-growing remote internship for people who seek to learn a new skill in the tech industry or sharpen their already known skill and is held annually for a period of 8weeks. The internship focuses on giving interns the experience of of a working environment where they make collaborations, build a working community and also solve problems within a set deadline.
My goals at the end of this **8th edition** of the internship is to boost my experience level, become part of the community and possibly gain employment.
The Zuri Team has a [Youtube channel](https://www.youtube.com/channel/UCCZYGgIn2X1I8mortBJ5UUw) with a lot of resource materials for both beginners and those who are advanced in the field. A few of the materials includes [Introduction to Figma](https://www.youtube.com/watch?v=1MbQaYCCzzI), a beginner tutorial guide for designers, an [Introduction to git](https://www.youtube.com/watch?v=dI_CUlVKrFw), Introduction to [HTML](https://www.youtube.com/watch?v=xpfF6V2zobM) and [CSS](https://www.youtube.com/watch?v=Y49F9FDbrF0) and of course, [JavaScript](https://www.youtube.com/watch?v=wf9E3UUZgsw).
I am keen about this internship and I hope to make it to the finals. | godsfavour_williams | |
793,797 | Hng Internship 8 | Hey there! I personally decided to spend the last half of the year on self improvement since i'm... | 0 | 2021-08-16T15:53:28 | https://dev.to/mubaracktahir/hng-internship-8-583h | Hey there!
I personally decided to spend the last half of the year on self improvement since i'm idle at the moment. So, I stumbled upon [HNG](https://zuri.team). [HNG](https://zuri.team) is a community that offers internship to people who are willing to improve their skill in any area. Although, this offer covers for both techie and non techie people. As for me, A correct techie guy who's ready to spend the next six to eight weeks on self improvement immediately leverage on this awesome opportunity. So, for the next six to eight weeks, I will be improving my self in my field which is mobile development. By the end of the eight week i should be better in the following field
- Modularising Apps
- Project Management
- Writing Maintainable Code
- Proficient in Git & GitHub
- Improve in kotlin Programing
### Links To Tutorials
- [Figma tutorial for beiginners](https://youtu.be/FTFaQWZBqQ8)
- [Git tutorial for beginners](https://youtu.be/8JJ101D3knE)
- [Kotline tutorial for intermediate Developers](https://www.youtube.com/watch?v=wuiT4T_LJQo&t=43s)
| mubaracktahir | |
793,822 | Getting Started with React Hooks and React Data Grid in 5 minutes | In previous blog posts we have shown how to use classes in React: get started in 5 minutes and... | 0 | 2021-09-27T09:03:29 | https://blog.ag-grid.com/getting-started-with-react-hooks-and-ag-grid-in-5-minutes/ | react, tutorial, aggrid | ---
title: Getting Started with React Hooks and React Data Grid in 5 minutes
published: true
date: 2021-08-16 13:30:04 UTC
tags: React,Tutorial, aggrid
canonical_url: https://blog.ag-grid.com/getting-started-with-react-hooks-and-ag-grid-in-5-minutes/
---
In previous blog posts we have shown how to use classes in React: [get started in 5 minutes](https://blog.ag-grid.com/react-get-started-with-react-grid-in-5-minutes/) and [customising react data grid](https://blog.ag-grid.com/learn-to-customize-react-grid-in-less-than-10-minutes/), in this post we will cover Getting Started using Hooks and how to optimise components which use the React Data Grid.
Hooks let us use [React features from functions](https://reactjs.org/docs/hooks-overview.html) so you won't see any classes in this Getting Started Guide.
- [Video Tutorial](#video-tutorial)
- [Example Code](#example-code)
- [Creating Project From Scratch](#creating-project-from-scratch)
- [Create a Grid Component](#create-a-grid-component)
- [carsgrid.js](#carsgrid.js)
- [In Cell Editing](#in-cell-editing)
- [Sorting and Filtering](#sorting-and-filtering)
- [Data Grid Pagination](#data-grid-pagination)
- [Optimising React Data Grid for Hooks](#optimising-react-data-grid-for-hooks)
- [Column Definitions as Objects](#column-definitions-as-objects)
- [Reducing Rendering by Memoizing](#reducing-rendering-by-memoizing)
- [Learn More React Data Grid](#learn-more-react-data-grid)
## Video Tutorial
{% youtube VIieyjYQ1KE %}
## Example Code
If you want to run the example from this blog post then you can find the repository on Github:
- download examples repo from [react-data-grid](https://github.com/ag-grid/react-data-grid)
Then run the example in the `getting-started-5-mins-hooks` directory:
```
cd getting-started-5-mins-hooks
npm install
npm start
```
## Creating Project From Scratch
Since this is a getting started post I'll summarise the absolute basic steps to getting started, I assume you have npm installed.
- use npx create-react-app to create the project
```
npx create-react-app getting-started-5-mins-hooks
```
- change directory into the project
```
cd getting-started-5-mins-hooks
```
- install AG Grid and the AG React Library
```
npm install --save ag-grid-community ag-grid-react
```
- then start the project running so we can view it in a browser
```
npm start
```
### Create a Grid Component
Rather than add all the code into my `App.js` I'm going to create a component to render data using AG Grid. I'll use our basic cars data set so I'll amend my `App.js` to us a `CarsGrid`.
```
function App() {
return (
<CarsGrid />
);
}
```
I'll write my `CarsGrid` in a `carsgrid.js` file and import it.
```
import {CarsGrid} from `./carsgrid`
```
### carsgrid.js
The content of `carsgrid.js` is as basic as it gets.
I import the `React` and AG Grid features I will use:
```
import React, {useState} from 'react';
import {AgGridColumn, AgGridReact} from 'ag-grid-react';
import 'ag-grid-community/dist/styles/ag-grid.css';
import 'ag-grid-community/dist/styles/ag-theme-alpine.css';
```
Then I will create the data that I will load into the grid. Initially I'll create this as a simple array and we'll consider alternatives later in the post.
```
const InitialRowData = [
{make: "Toyota", model: "Celica", price: 35000},
{make: "Ford", model: "Mondeo", price: 32000},
{make: "Porsche", model: "Boxter", price: 72000}
];
```
Finally I'll create a JavaScript function for my React Component which:
- sets the data to render use state as `rowData`
- returns the JSX that renders data using AG Grid.
```
export function CarsGrid() {
// set to default data
const [rowData, setRowData] = useState(InitialRowData);
return (
<div className="ag-theme-alpine" style={{height: 400, width: 600}}>
<AgGridReact
defaultColDef={{sortable: true, filter: true }}
pagination={true}
rowData={rowData}
>
<AgGridColumn field="make"></AgGridColumn>
<AgGridColumn field="model"></AgGridColumn>
<AgGridColumn field="price" editable={true}></AgGridColumn>
</AgGridReact>
</div>
)
};
```
This gives me a very basic grid that will render the data.
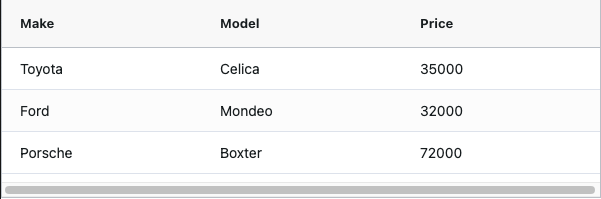
Since AG Grid offers a lot of features out of the box, I'll enable some of those like:
- in cell editing
- sorting
- filtering
- pagination
### In Cell Editing
To enable a cell as editable, I change the column definition to have an additional attribute: `editable={true}`
e.g.
```
<AgGridColumn field="price" editable={true}></AgGridColumn>
```
This will make the price cells editable.
### Sorting and Filtering
To make a column sortable or filterable I again add an attribute to the column e.g.
- Sortable
- `<AgGridColumn field="make" sortable={true}></AgGridColumn>`
- Filterable
- `<AgGridColumn field="model" filter={true}></AgGridColumn>`
I can control each column via individual attributes.
But I'd rather configure all the columns to be sortable and filterable at the same time, and I can do that by adding a default column definition on the grid itself.
```
<AgGridReact
defaultColDef={{sortable: true, filter: true }}
```
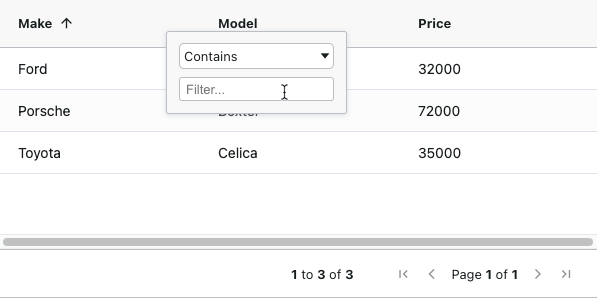
### Data Grid Pagination
If I want to add pagination to the grid then I can enable this with a single attribute on the grid `pagination={true}`.
```
<AgGridReact
defaultColDef={{sortable: true, filter: true }}
pagination={true}
```
But, there is really no point in having a pagination, sorting and filtering on a grid with such a small amount of data.
As soon as I load data into the grid we can then see some of the benefits of using a React Data Grid like AG Grid.
```
React.useEffect(() => {
fetch('https://www.ag-grid.com/example-assets/row-data.json')
.then(result => result.json())
.then(rowData => setRowData(rowData))
}, []);
```
By loading a lot of data into the grid we can see that:
- the grid maintains is position on the page
- pagination and rendering happens automatically
- sorting and filtering are fast with no additional programming required
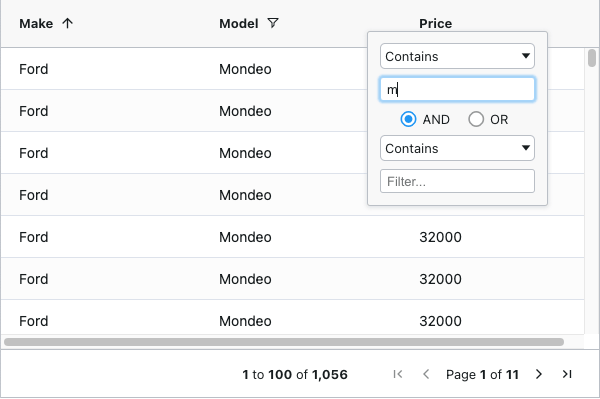
There is another feature that we get free with AG Grid.
If I amend the initial state to be unassigned, then AG Grid will display a `loading...` message while we load data into the grid from the server.
```
const [rowData, setRowData] = useState();
```
## Optimising React Data Grid for Hooks
At this point the blog post has covered most of the same ground as the [class based getting started post](https://blog.ag-grid.com/react-get-started-with-react-grid-in-5-minutes/).
We should learn a few ways to optimise the component:
- make it easier to amend by using state and objects
- reduce rendering cycles
### Column Definitions as Objects
At the moment our grid has the column definitions defined declaratively:
```
<AgGridColumn field="make"></AgGridColumn>
<AgGridColumn field="model"></AgGridColumn>
<AgGridColumn field="price" editable={true}></AgGridColumn>
```
This reduces the flexibility available to me to customise the grid at run time.
If I want to adjust the column definitions then I would be better off setting them as objects via state.
```
const [colDefs, setColDefs] = useState([
{field: 'make'},
{field: 'model'},
{field: 'price', editable: 'true'},
]);
```
And amending my grid to use the state.
```
<AgGridReact
defaultColDef={{sortable: true, filter: true }}
pagination={true}
rowData={rowData}
columnDefs={colDefs}>
</AgGridReact>
```
This way I can add or remove columns from the state, or adjust their attributes to make them editable or have custom rendering, and the component would automatically re-render to accomodate the changes to the state.
This way our complete intial functional component using hooks looks as follows:
```
import React, {useState} from 'react';
import {AgGridColumn, AgGridReact} from 'ag-grid-react';
import 'ag-grid-community/dist/styles/ag-grid.css';
import 'ag-grid-community/dist/styles/ag-theme-alpine.css';
export function CarsGrid() {
const [rowData, setRowData] = useState();
const [colDefs, setColDefs] = useState([
{field: 'make'},
{field: 'model'},
{field: 'price', editable: 'true'},
]);
React.useEffect(() => {
fetch('https://www.ag-grid.com/example-assets/row-data.json')
.then(result => result.json())
.then(rowData => setRowData(rowData))
}, []);
return (
<div className="ag-theme-alpine" style={{height: 400, width: 600}}>
<AgGridReact
defaultColDef={{sortable: true, filter: true }}
pagination={true}
rowData={rowData}
columnDefs={colDefs}
>
</AgGridReact>
</div>
)
};
```
### Reducing Rendering by Memoizing
If we didn't want to update the column definitions at run time, that doesn't mean we should go back to declarative definitions.
We still make the code easier to maintain longer term by using objects. But we should memoize them to make sure we don't unnecessarily add more render cycles than we need to.
The AG Grid React Data Grid is already well optmised for rendering, but in typical real world usage, we will wrap AG Grid in our own components for common styling and configuration.
I would memoize the `colDefs` as follows:
```
const colDefs = useMemo( ()=> [
{field: 'make'},
{field: 'model'},
{field: 'price', editable: 'true'},
], []);
```
The Column Definitions are constant and won't trigger a re-render should the parent component change.
## Learn More React Data Grid
We have a longer [Getting started guide in our documentation](https://www.ag-grid.com/react-grid/getting-started/) which also covers selection, grouping and changing themes.
We also have some React examples to study which [show more use cases of AG Grid](https://blog.ag-grid.com/react-data-grid-example-projects/).
The code for this post is in the [react-data-grid](https://github.com/ag-grid/react-data-grid) repo in the `getting-started-5-mins-hooks` folder.
<!--kg-card-end: markdown--> | eviltester |
793,979 | Help me to figure out pattern | Hi, I have an array of Fibonacci numbers up to (10 power 6) and a lot of Queries that ranges from L... | 0 | 2021-08-16T16:55:02 | https://dev.to/elmoogym/help-me-to-figure-out-pattern-ica | help, cpp | Hi, I have an array of Fibonacci numbers up to (10 power 6) and a lot of Queries that ranges from L to R, these ranges are not indices but Fibonacci number, I wanna calculate number of even and odd numbers in these range, Is there a fast method to get this instead of take a loop from beginning range to end in these whole queries ?
Example :
2
2 21
3 13 | elmoogym |
794,068 | Part 2: Sneak peek at Kotlin | This post is the second part of the course,... | 0 | 2021-08-16T17:30:59 | https://dev.to/clint22/part-2-sneak-peek-at-kotlin-1maa | android, kotlin, tutorial, codenewbie | This post is the second part of the course,
(https://dev.to/clint22/part-1-why-should-you-learn-android-development-or-programming-in-general-5a8i)
Before we start, think about this. Was it necessary for Google to endorse Kotlin as the first-class language for Android? Was Java incapable of becoming a modern programming language? Or, is Kotlin that Android-friendly? I would say it’s a combination of both. When I started to learn Android development in college ( 2012 ), things were pretty different. As is the case of the programming language, there was no official IDE available for Android. We had to lease “Eclipse IDE” for developing Android apps but, its primary purpose was to build Java applications. So, when Jetbrains created Android Studio on top of the popular IntelliJ IDEA software, everything soon changed for the good.

Suddenly, Android Developers have an IDE they can call their own. We were not second-class citizens anymore. But, still, Java was used as the primary programming language for Android. Honestly, I was okay with it. I didn’t know I wanted to code in another language until I started coding in Kotlin. Oh, I forgot to mention one thing, it was Jetbrains that developed Kotlin. Google announced Kotlin as the first choice language for Android in Google I/O 2017. I’m still getting goosebumps thinking about that unveiling. For me, it was a breath of fresh air and a chance to master this newly developed language.

**Why Kotlin is a good option for us Android Developers?**
One thing I noticed early about Kotlin is that it is concise. We can reduce a large chunk of code if we write it in Kotlin when comparing with Java. Our codebases were starting to look a bit cleaner. There were Extension functions, Data classes, Lambdas, Primary constructors and Secondary constructors, etc.
They introduced type inference. It was such a blessing. We don’t have to mention the data type of a variable when we declare it. The Kotlin compiler will automatically find out its type. Also, we don’t have to add a semicolon ( ; ) at the end of each line of code like Java.
Eg:
Kotlin with type inference. We don’t have to mention the data type here. Kotlin compiler already assumed that the data type is an integer.
```val sum = 10```
The same line of code using Java. We have to mention the data type as an integer. If not, the compiler will throw an error.
```int sum = 10;```
Kotlin is interoperable with Java. That means you don’t have to delete or modify your existing Java classes in an Android project to use Kotlin. You can call Kotlin classes from a Java class and vice-versa. This increased the adoption rate considerably. Apps with millions of users started using Kotlin in no time. Because, they were guaranteed that, it will not interfere with their existing Java classes.
NullPointerException or the billion-dollar mistake.

There is a huge probability that you must have dealt with a null pointer exception at least once in your career. And, chances are, you must have used Java as the programming language. Java is notorious for Null pointer exceptions.
The NullPointerException (NPE) occurs when you declare a variable but did not create an object and assign it to the variable before trying to use the contents of the variable (called dereferencing).
Kotlin is handling this pitfall in the programming world much gracefully. In Kotlin, all variables are considered non-null by default. This means the IDE itself will remind you if you forgot to assign an object to the variable you have just created.
We will look deep into all the above-mentioned features in the upcoming sections. Don’t fret if you couldn’t understand much now. You can always come back here once you deal with all of them during our coding sessions.
Before you go, let’s just code at least a “Hello World.” Then, you can tell your friends that I taught you something and all 😋.

Go to https://play.kotlinlang.org/ and replace it with the below code.
```fun main() {
println("Hello World")
}```
And press the play button.
You can use this compiler if you ever want to try out some basic stuff. You don’t have to install any huge-sized IDEs for that purpose. This is more than enough.
A small exercise for you now. Try to change the code in such a way that it must print your first name and age. You should store the value of name and age in two different variables as well. The result should be something like this,
Clint 27
I know we didn’t learn much about the variables today. But, do some research and see if you can get the result. Always keep this in mind, “All good programmers are exceptionally good at Googling stuff.” If you do find the correct answer, reply with the code in the comments. I’ll be happy to cheer for you. 🥳 If you couldn’t find the answer, no problem. Please comment on that as well, We can correct it together.
Hope you had a great today and we all learned something new and useful. In the next chapter, we will see how to install the JDK and Android Studio. I’m super excited. 😉 Please make sure you are following me on [LinkedIn](https://www.linkedin.com/in/clint-paul-2504bba7/), [Medium](https://clintpaul.medium.com/), [GitHub](https://github.com/clint22), [Twitter](https://twitter.com/dev_duct_tape), or [buy me a coffee](https://www.buymeacoffee.com/clintpaul_dev).
The article was originally posted at [clintpauldev.com](https://clintpauldev.com/part-2-sneak-peek-at-kotlin/)
| clint22 |
794,070 | React Design Patterns: Generating User-configured UI Using The Visitor Pattern | I had a problem in my React app: I needed to render a form with multiple inputs of multiple types:... | 0 | 2021-08-16T17:55:10 | https://www.arahansen.com/react-design-patterns-generating-user-configured-ui-using-the-visitor-pattern/ | react, javascript, algorithms | ---
tags: react, javascript, algorithms
---
I had a problem in my React app: I needed to render a form with multiple inputs of multiple types: date fields, number fields, dropdowns: the usual suspects.
But here's the kicker: similar to form builders like SureveyMonkey or Typeform, users need to be able to design these forms themselves and configure them to include whatever fields they need.
How do I go about this? Users won't be writing React themselves so I need a data model that describes their form's configuration. While data structures and algorithms are not typically my strong-suit, what I landed on is what I came to realize is the Visitor Pattern but implemented with React components.
## What is the visitor pattern?
The [Wikipedia page for the visitor pattern](https://en.wikipedia.org/wiki/Visitor_pattern) describes the visitor pattern as __"a way of separating an algorithm from an object structure on which it operates".__ Another way to put this is it changes how an object or code works without needing to modify the object itself.
These sorts of computer science topics go over my head without seeing actual use cases for the concept. So let's briefly explore the visitor pattern using a real-world use case.
[Babel](https://babeljs.io/) is a great practical example of the visitor pattern in action. Babel operates on Abstract Syntax Trees (ASTs) and transforms your code by **visiting** various nodes (eg, blocks of text) in your source code.
Here is a minimal hello world example of how Babel uses the visitor pattern to transform your code:
```js
// source.js
const hello = "world"
const goodbye = "mars"
// babel-transform.js
export default function () {
return {
visitor: {
Identifier(path) {
path.node.name = path.node.name.split('').reverse().join('')
}
}
}
}
// output.js
const olleh = "world"
const eybdoog = "mars"
```
You can play with this example yourself [here](https://astexplorer.net/#/gist/4eb83c0722f63c31492c7fb69d4f7d20/a4b3b0c9428af4046b5feeb05792b02eb03fcc15).
By implementing the Visitor Pattern, Babel **visits** each `Identifier` token within `source.js`. In the above example, the `Identifier` tokens are the variable names `hello` and `goodbye`.
When Babel finds an `Identifier`, it hands things over to our transformation code and lets us decide how we want to transform the token. Here, we reverse the variable string and assign the result as the new name for the variable. But we could modify the code however we want.
This is powerful because Babel does all the heavy lifting to parse the source code, figure out what type of token is where, etc. Babel just checks in with us whenever it finds a token type we care about (eg, `Identifier`) and asks what we want to do about it. We don't have to know how Babel works and Babel doesn't care what we do in our visitor function.
## The Visitor Pattern In React
Now we know what the visitor pattern looks like as a general-purpose algorithm, how do we leverage it in React to implement configurable UIs?
Well, in this React app I'm building, I mentioned I would need a data model that describes a user's configured custom form. Let's call this the form's `schema`.
Each field in this schema has several attributes like:
- **Field type.** eg, dropdown, date, number, etc
- **Label.** What data the field represents. eg, First name, Birthdate, etc.
- **Required.** Whether or not the field is mandatory for the form.
The schema could also include other customization options but let's start with these.
We also need to be able to enforce the order in which each field shows up. To do that, we can put each field into an array.
Putting that all together, here's an example schema we could use for a form with three fields:
```js
const schema = [
{
label: "Name",
required: true,
fieldType: "Text",
},
{
label: "Birthdate",
required: true,
fieldType: "Date",
},
{
label: "Number of Pets",
required: false,
fieldType: "Number",
},
]
```
## The Simple But Limited Approach
How might we go about rendering this in React? A straight-forward solution might look something like this:
```jsx
function Form({ schema }) {
return schema.map((field) => {
switch (field.fieldType) {
case "Text":
return <input type="text" />
case "Date":
return <input type="date" />
case "Number":
return <input type="number" />
default:
return null
}
})
}
```
This is already looking a bit like the visitor pattern like we saw with Babel. And, this could probably scale decently for a lot of basic forms!
However, this approach is missing the key aspect of the visitor pattern: it doesn't allow customization without modifying the implementation.
For example, maybe we want to be able to re-use this schema for other use cases like a profile view, we would have to extend our `Form` component to capture both use-cases.
## The Customizable Visitor Pattern Approach
Let's formalize our usage of the visitor pattern to enable full customization of our `schema` rendering without needing to modify the `Form` implementation:
```js
const defaultComponents = {
Text: () => <input type="text" />,
Date: () => <input type="date" />,
Number: () => <input type="number" />
}
function ViewGenerator({ schema, components }) {
const mergedComponents = {
...defaultComponents,
...components,
}
return schema.map((field) => {
return mergedComponents[field.fieldType](field);
});
}
```
This new `ViewGenerator` component achieves the same thing `Form` was doing before: it takes in a `schema` and renders `input` elements based on `fieldType`. However, we've extracted each component type out of the switch statement and into a `components` map.
This change means we can still leverage the default behavior of `ViewGenerator` to render a form (which would use `defaultComponents`). But, if we wanted to change how `schema` is rendered we don't have to modify `ViewGenerator` at all!
Instead, we can create a new `components` map that defines our new behavior. Here's how that might look:
```jsx
const data = {
name: "John",
birthdate: "1992-02-01",
numPets: 2
}
const profileViewComponents = {
Text: ({ label, name }) => (
<div>
<p>{label}</p>
<p>{data[name]}</p>
</div>
),
Date: ({ label, name }) => (
<div>
<p>{label}</p>
<p>{data[name]}</p>
</div>
),
Number: ({ label, name }) => (
<div>
<p>{label}</p>
<p>{data[name]}</p>
</div>
)
}
function ProfileView({ schema }) {
return (
<ViewGenerator
schema={schema}
components={profileViewComponents}
/>
)
}
```
`ViewGenerator` maps over the schema and blindly calls each of the functions in `profileViewComponents` as it comes across them in the `schema`.
`ViewGenerator` doesn't care what we do in that function, and our functions don't have to care about how `ViewGenerator` is parsing the schema. The `components` prop is a powerful concept that leverages the visitor pattern to lets us customize how the schema is interpreted without needing to think about how the schema is parsed.
## Extending The Framework
Our app has a new requirement for these user-configured forms: users want to be able to group input fields into sections and collapse content to hide them.
Now that we have a framework for implementing basic user-configured forms, how would we extend this framework to enable these new capabilities while still keeping our schema and view decoupled?
To start, we could add a `Section` component to our `components` map:
```jsx
const components = {
Section: ({ label }) => (
<details>
<summary>{label}</summary>
{/* grouped fields go here? */}
</details>
)
}
```
But we don't have a good way of identifying which fields are related to our `Section`. One solution might be to add a `sectionId` to each field, then map over them to collect into our `Section`. But that requires parsing our schema which is supposed to be the `ViewGenerator`'s job!
Another option would be to extend the `ViewGenerator` framework to include a concept of child elements; similar to the `children` prop in React. Here's what that schema might look like:
```jsx
const schema = [
{
label: "Personal Details",
fieldType: "Section",
children: [
{
label: "Name",
fieldType: "Text",
},
{
label: "Birthdate",
fieldType: "Date",
},
],
},
{
label: "Favorites",
fieldType: "Section",
children: [
{
label: "Favorite Movie",
fieldType: "Text",
},
],
},
]
```
Our schema is starting to look like a React tree! If we were to write out the jsx for a form version of this schema it would look like this:
```jsx
function Form() {
return (
<>
<details>
<summary>Personal Details</summary>
<label>
Name
<input type="text" />
</label>
<label>
Birthdate
<input type="date" />
</label>
</details>
<details>
<summary>Favorites</summary>
<label>
Favorite Movies
<input type="text" />
</label>
</details>
</>
)
}
```
Now let's update the `ViewGenerator` framework to support this new `children` concept and enable us to generate the jsx above:
```jsx
function ViewGenerator({ schema, components }) {
const mergedComponents = {
...defaultComponents,
...components,
}
return schema.map((field) => {
const children = field.children ? (
<ViewGenerator
schema={field.children}
components={mergedComponents}
/>
) : null
return mergedComponents[field.fieldType]({ ...field, children });
})
}
```
Notice how `children` is just another instance of `ViewGenerator` with the schema prop set as the parent schema's `children` property. If we wanted we could nest `children` props as deep as we want just like normal jsx. Recursion! It's turtles`ViewGenerator` all the way down.
`children` is now a React node that is passed to our `components` function map and use like so:
```jsx
const components = {
Section: ({ label, children }) => (
<details>
<summary>{label}</summary>
{children}
</details>
)
}
```
`Section` is returning the pre-rendered `children` and it doesn't have to care how `children` are rendered because the `ViewGenerator` component is handling that.
You can play with the final solution on codesandbox:
[](https://codesandbox.io/s/view-generator-demo-svn3z?fontsize=14&hidenavigation=1&theme=dark)
## Conclusion
Nothing is new in software. New ideas are just old ideas with a hat on. As we see in the example above, it doesn't take much code to implement the visitor pattern in React. But as a concept, it unlocks powerful patterns for rendering configuration-driven UIs.
While this article covered building a configurable "form generator" component, this pattern could be applicable for many situations where you need configuration (aka, schema) driven UI.
I would love to see what use-cases you come up with for your own `ViewGenerator` framework. [Hit me up on twitter](https://twitter.com/arahansen)! I'd love to see what you build.
## Additional Resources
- [react-jsonschema-form](https://github.com/rjsf-team/react-jsonschema-form) is a React library that generates forms based on a [json-schema](https://json-schema.org/) and uses concepts very similar to the ones introduced here
- If you want to learn more about Babel plugins, the [Babel plugin handbook](https://github.com/jamiebuilds/babel-handbook/blob/master/translations/en/plugin-handbook.md#visitors) by Jamie Kyle is a great resource for walking through a practical application of the visitor pattern.
- This [Tutorial on the visitor pattern in JavaScript](https://www.youtube.com/watch?v=x-Gx0Ym1Di0) shows a brief example of the visitor pattern with just vanilla JavaScript.
| arahansen |
794,114 | Organizing TypeScript code using namespaces | Written by Emmanuel John ✏️ Introduction With the use of third-party libraries in... | 0 | 2021-08-16T19:46:48 | https://blog.logrocket.com/organizing-typescript-code-using-namespaces | typescript, webdev | **Written by [Emmanuel John] (https://blog.logrocket.com/author/emmanueljohn/)** ✏️
## Introduction
With the use of third-party libraries in enterprise software increasing, we often encounter the problem of polluted global namespaces, causing name collision between components in the global namespace. Therefore, we need to organize blocks of code using namespaces so that variables, objects, and classes are uniquely identified.
In this article, we will discuss namespaces, when you'll need them, and how to use them to enhance the organization of your TypeScript code.
### Prerequisites
* Knowledge of TypeScript
* Familiarity with JavaScript
## What are namespaces?
Namespaces are paradigm of organizing code so that variables, functions, interfaces, or classes are grouped together within a local scope in order to avoid naming conflicts between components in the global scope. This is one of the most common strategies to reduce global scope pollution.
While [modules](https://blog.logrocket.com/organize-code-in-typescript-using-modules/) are also used for code organization, namespaces are easy to use for simple implementations. Modules offer some additional benefits like strong code isolation, strong support for bundling, re-exporting of components, and renaming of components that namespaces do not offer.
## Why do we need namespaces?
Namespaces have these advantages:
* Code reusability — The importance of namespaces for code reusability cannot be understated
* Bloated global scope — Namespaces reduce the amount of code in the global scope, making it less bloated
* Third-party libraries — With the increasing number of websites depending on third-party libraries, it's important to safeguard your code using namespaces to prevent same-name conflicts between your code and the third-party libraries
* Distributed development — With distributed development becoming popular, pollution is almost unavoidable because it’s a lot easier for developers to use common variable or class names. This results in name collision and pollution of the global scope
## Design considerations using namespaces
### Implicit dependency order
Using namespaces while working with some external libraries will require an implicit implementation of dependency between your code and these libraries. This results in the stress of managing the dependencies yourself so that they are loaded correctly, because the dependencies can be error-prone.
If you find yourself in such a situation, using modules will save you the stress.
### Node.js applications
For [Node.js applications, modules are recommended](https://blog.logrocket.com/how-to-use-ecmascript-modules-with-node-js/) over namespaces since modules are the de facto standard for encapsulation and code organization in Node.
### Non-JavaScript content import
Modules are recommended over namespaces when dealing with non-JavaScript content since some module loaders such as SystemJS and AMD allow non-JavaScript content to be imported.
### Legacy code
When working with a codebase that is no longer engineered but continually patched, using namespaces is recommended over modules.
Also, namespaces come in handy when porting old JavaScript code.
## Exploring namespaces in TypeScript
Now that we have a shared understanding of what TypeScript namespaces are and why we need them, we can take a deeper dive into how to use them.
Given that TypeScript is a superset of JavaScript, it derives its namespace concept from JavaScript.
By default, JavaScript has no provision for namespacing because we have to implement namespaces using IIFE (Immediately Invoked Function Expression):
```javascript
var Vehicle;
(function (Vehicle) {
let name = "car";
})(Vehicle || (Vehicle = {}));
```
This is so much code for defining a namespace. Meanwhile, TypeScript does things differently.
### Single-file namespacing
In TypeScript, namespaces are defined using the `namespace` keyword followed by a name of choice.
A single TypeScript file can have as many namespaces as needed:
```typescript
namespace Vehicle {}
namespace Animal {}
```
As we can see, TypeScript namespaces are a piece of syntactic cake compared to our JavaScript implementation of namespaces using the IIFE.
Functions, variables, and classes can be defined inside a namespace as follows:
```typescript
namespace Vehicle {
const name = "Toyota"
function getName () {
return `${name}`
}
}
namespace Animal {
const name = "Panda"
function getName () {
return `${name}`
}
}
```
The above code allows us to use the same variable and function name without collision.
### Accessing functions, variables, objects, and classes outside a namespace
In order to access functions or classes outside their namespaces, the `export` keyword must be added before the function or class name as follows:
```typescript
namespace Vehicle {
const name = "Toyota"
export function getName () {
return `${name}`
}
}
```
Notice that we had to omit the `export` keyword with the variable because it should not be accessible outside the namespace.
Now, we can access the `getName` function as follows:
```typescript
Vehicle.getName() //Toyota
```
### Organizing code using nested namespaces
TypeScript allows us to organize our code using nested namespaces.
We can create nested namespaces as follows:
```typescript
namespace TransportMeans {
export namespace Vehicle {
const name = "Toyota"
export function getName () {
return `${name}`
}
}
}
```
Notice the `export` keyword before the `Vehicle` namespace. This allows the namespace to be accessible outside of the `TransportMeans` namespace.
We can also perform deep nesting of namespaces.
Our nested namespaces can be accessed as follows:
```typescript
TransporMeans.Vehicle.getName() // Toyota
```
### The namespace alias
For deeply nested namespaces, the namespace alias comes in handy to keep things clean.
Namespace aliases are defined using the import keyword as follows:
```typescript
import carName= TransporMeans.Vehicle;
carName.getName(); //Toyota
```
### Multi-file namespacing
Namespaces can be shared across multiple TypeScript files. This is made possible by the `reference` tag.
Considering the following:
```typescript
//constant.ts
export const name = "Toyota"
//vehicle.ts
<reference path = "constant.ts" />
export namespace Vehicle {
export function getName () {
return `${name}`
}
}
```
Here, we had to reference the `constant.ts` file in order to access `name`:
```typescript
//index.ts
<reference path = "constant.ts" />
<reference path = "vehicle.ts" />
Vehicle.getName() // Toyota
```
Notice how we started our references with the highest-level namespace. This is how to handle references in multi-file interfaces. TypeScript will use this order when compiling the files.
We can instruct the compiler to compile our multi-file TypeScript code into a single JavaScript file with the following command:
```
tsc --outFile index.js index.ts
```
With this command, the TypeScript compiler will produce a single JavaScript file called `index.js`.
## Conclusion
In order to build scalable and reusable TypeScript applications, TypeScript namespaces are handy because they improve the organization and structure of our application.
In this article, we’ve been able to explore namespaces, when you need them, and how to implement them. Check out [TypeScript Handbook: Namespaces](https://www.typescriptlang.org/docs/handbook/namespaces.html) for more information about namespaces.
---
## [LogRocket] (https://logrocket.com/signup/): Full visibility into your web apps
[![LogRocket Dashboard Free Trial Banner] (https://blog.logrocket.com/wp-content/uploads/2017/03/1d0cd-1s_rmyo6nbrasp-xtvbaxfg.png)](https://logrocket.com/signup/)
[LogRocket] (https://logrocket.com/signup/) is a frontend application monitoring solution that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free] (https://logrocket.com/signup/). | mangelosanto |
794,246 | Using Terraform (IaC) to automate your Kubernetes Clusters and Apps | Introduction – Why My goal for this project was to find a way to deploy a new cluster in... | 0 | 2021-08-17T07:04:55 | https://vzilla.co.uk/vzilla-blog/using-terraform-iac-to-automate-your-kubernetes-clusters-and-apps | kubernetes, devops, iac | ---
title: Using Terraform (IaC) to automate your Kubernetes Clusters and Apps
published: true
date: 2021-08-16 17:01:11 UTC
tags: Kubernetes, DevOps, IAC
canonical_url: https://vzilla.co.uk/vzilla-blog/using-terraform-iac-to-automate-your-kubernetes-clusters-and-apps
---
# Introduction – Why
My goal for this project was to find a way to deploy a new cluster in AWS, Microsoft Azure and Google. I am constantly spinning up and down Kubernetes clusters and running through scenarios for content creation and just learning scenarios.
I have written several blogs talking about creating managed Kubernetes clusters in the three big clouds and some other options more recently. But I wanted to go one step further and wanted to automate the creation and removal of these environments for demo purposes.
The goal is to make it simple to not only create these clusters using Terraform from Hashicorp but to then also have a very easy way to deploy Kasten K10 as well to each of the clusters.
The purpose is to cover those on demand demo environments which deploys with one command and then allows me to rip it all down as well.
You can find the raw code here; I have however been conscious of creating readme.md files throughout the repository as maybe only certain areas will be of interest.
[https://github.com/MichaelCade/tf\_k8deploy](https://github.com/MichaelCade/tf_k8deploy)
# Walkthrough one example
I figured it would or might be useful to also walk through how to use at least one of these public clouds terraform scripts. For this demo we are going to use the GKE option.
## Prerequisites
On our workstation first we need the [Google Cloud Platform account](https://console.cloud.google.com/), we also need the [gcloud sdk](https://cloud.google.com/sdk/docs/install) to be configured on our system, finally we need [kubectl](https://kubernetes.io/docs/tasks/tools/) each of these options are not OS constrained so if you are running Linux, Windows or MacOS you are good to go here.
I have also documented the steps for Google Cloud Platform specifically [here](https://dev.to/michaelcade1/getting-started-with-google-kubernetes-service-gke-554i).
before we get into the walkthrough we are also going to need to install Terraform on our system, once again this will have you covered across Linux, Windows and MacOS. This resource should help get you going with [Terraform](https://learn.hashicorp.com/tutorials/terraform/install-cli).
The first step is making sure you have gcloud configured correctly as per the section above and the link that dives into the step by step on authenticating to your GCP account. We then want to get our code downloaded from the following, be sure to have this located in your common location for code.
git clone https://github.com/MichaelCade/tf\_k8deploy.git
You will notice that this contains the deployment steps for AWS EKS, Microsoft AKS and GKE for this walkthrough we are only interested in GKE, but you are more than welcome obviously to explore the other folders, we will also cover the helm folder later in the walkthrough.
Let’s navigate to the GKE folder with the following command:
cd learn-terraform-provision-gke-cluster
I am using Visual Studio Code for my IDE so now we are into our folder you can run the following command to open the folder in VSCode
code .
You can check through the .tf files in the folder now and start to see what is going to be created, if you are new to terraform then I suggest you walking through the following to understand what is happening at each step before making specific changes to your [deployment](https://learn.hashicorp.com/tutorials/terraform/gke?in=terraform/kubernetes).
The one folder that you need to update before anything will work is the terraform.tfvars this needs to contain your project ID and your region. You should change the region accordingly to where you would like everything to be deployed. You can get your project ID by running the following command
gcloud config get-value project
Once you have updated your file above, we can then get provisioning our cluster, simple stuff so far even if you are new to terraform. Back in your terminal that is in the GKE folder you should run the following command: this command will download the required providers.
terraform init
We can now go ahead and deploy our new GKE cluster along with a dedicated VPC away from any existing infrastructure you have in your Google Cloud Platform. Run the following and type in yes if you are happy to proceed at the prompt
terraform apply
Once you have hit enter after saying “yes” it will start deploying your new GKE cluster. You can go through and check beforehand what this is going to deploy, this script will deploy a new GKE regional cluster and this can be explained [here](https://cloud.google.com/kubernetes-engine/docs/how-to/creating-a-regional-cluster). I do have a plan to also add a zonal cluster option to the scripts here or if someone has already created it then please share.
After around 10 minutes possibly shorter you will have created your GKE cluster. For us to connect though we need to download the configuration for kubectl on our local machine to connect to the cluster. We can do this using the following command.
gcloud container clusters get-credentials $(terraform output -raw kubernetes\_cluster\_name) –region $(terraform output -raw region)
Once you have ran the above you can also confirm you have access by using the following confirmation command of checking your hosts.
kubectl get nodes
From the above command you should see 6 nodes in a ready state, this is because we have deployed 2 nodes in each zone of the region. You can also check the context with the following command to confirm you are indeed in the correct configuration.
kubectl config get-contexts
This will be useful later when we come to remove the cluster and we want to also remove the context and cluster from our kubectl configuration.
At this stage we have a GKE cluster up and running and even this might be useful to some people but in the next section I want to add the functionality of deploying an application using the helm provider so that I can show and demonstrate the functionality of the application.
# Helm deployment of Kasten K10 and example
As I mentioned the above gets us a fast way to deploy a new cluster without affecting our existing infrastructure, my use case here is to quickly spin up an environment for demos but also a fast way to destroy or get rid of the environment I created.
In this example I want to be able to deploy Kasten K10 which is a tool that provides the ability to protect your applications within Kubernetes.
In the git repository we downloaded earlier you should be able to navigate to the helm folder and within the folder you will see three additional folders and depending on your deployment of Kubernetes will determine the folder you choose.
Before we continue, I will also highlight that in each of the Kubernetes deployment folders you will find a similar file to GKE\_Instructions.md which walks through step by step including the helm deployment of your application.
In your helm folder and then in our case the Google GKE folder you will see two files, kasten.tf and main.tf
Now that we are in our terminal, we should again issue the following command to download the required providers.
terraform init
The next command along with your approval “yes” will go ahead and firstly create a namespace called “kasten-io” and then proceed to deploy from the helm chart the latest release version of Kasten K10. You can also add additional helm chart values to the kasten.tf file if you have specific requirements, you will see this to be the case in the other options for the other public cloud deployments.
terraform apply
You can follow the progress of the deployment by running the following command
kubectl get pods –n kasten-io –w
When all pods are up and running you can also run the following to get the public IP of the Kasten K10 dashboard as we set this with our helm chart option within kasten.tf
kubectl get svc –n kasten-io
You can then take this DNS / IP address and add to your browser to connect to your instance of Kasten K10
[https://IP](https://IP) Address/k10/#
Because we don’t want this now accessible to the world, we must obtain our token authentication that we also defined in our helm chart variables. [You can follow this post to get that secret information](https://dev.to/michaelcade1/building-the-home-lab-kubernetes-playground-part-10-57kc).
# Deleting your cluster or application
Ok so we are now at the stage where we might want to get rid of things or at least roll back to pre-Kasten K10 being deployed. It is easy to get things removed or reverted, we can run the following command from the helm folder to remove the Kasten deployment and namespace. Again, this is going to prompt you for a yes to continue.
terraform destroy
Let’s then say we are also done with the cluster as well, we can run the following command, for this to work you need to navigate to the first folder where we ran terraform apply the first time to create the cluster. This time I am going to share a faster way without the requirement to type in yes to make any of the terraform apply or destroy commands do what you want.
terraform destroy –auto-approve
So far so good? But we still have that kubectl context for the cluster, we can run the following command to get the cluster and context name.
kubectl config get-contexts
Then it’s a case of running the following to delete the context
kubectl config delete-context <context name>
And then the following to delete the cluster
Kubectl config delete-cluster <cluster name>
I do hope this was useful and I am also open to improving this workflow or adding additional features, my initial thoughts are for better and faster ways to demo I should also deploy a data service such as MySQL and add some data to it and automate the creation of backup policies etc. | michaelcade1 |
794,261 | How To Fix the Health Issues Associated With the Engineering Lifestyle | Table of Content Musculoskeletal issues Visual impairment Mental stress Poor food... | 0 | 2021-08-16T22:00:11 | https://www.ltvco.com/engineering/health-implications-engineer-lifestyle/ | diet, fitness, health, engineering | ## Table of Content
- [Musculoskeletal issues](#musculoskeletal-issues)
- [Visual impairment](#visual-impairment)
- [Mental stress](#mental-stress)
- [Poor food decisions](#poor-food-decisions)
- [Changes you can make](#changes-you-can-make)
---
As software engineers, we spend most of our day in front of a computer, usually sitting in a chair for eight hours until we go home. At home, we will probably also sit for most of the night, whether we're watching TV, working on a personal project or just browsing the web. The job just doesn't require much physical activity, aside from walking to meetings, the bathroom or the pantry to make a snack. The mental stress of the job also paves the way for overeating and snacking, increasing the risk of obesity.
The software engineering lifestyle isn't necessarily glamorous, and can definitely be unhealthy. However, for every risk of prolonged sitting, there are remediations that can reduce their impact.
---
## Musculoskeletal issues <a name="musculoskeletal-issues"></a>
Most people don't think about the time spent in a chair until faced with an ailment, such as lower back pain or a stiff neck. However, it's easy to miss the forest for the trees. Let's say you dropped something and you leaned over to pick it up, causing you to tweak your back. The impulse is to blame that one action, but in reality years of compensating for bad posture meant something had to give eventually.
If you imagine your co-workers right now, you'll probably picture them hunched over their desks staring at their screens. On your commute home, you'll see people head down on their phones whether they're standing or sitting. Technology is changing the way we connect with people, but it's also changing our bodies.
If you were to count the time you spend sitting in a chair, it would probably be about 11 hours - nearly 70% of most people's waking hours. Some people exercise after work, but unfortunately 1–2 hours of exercise will not reverse the potentially harmful effects of being sedentary for the other 23 hours.
Poor posture can cause Postural Kyphosis and it can have detrimental effects ([adult kyphosis](https://www.umms.org/ummc/health-services/orthopedics/services/spine/patient-guides/adult-kyphosis?__cf_chl_jschl_tk__=pmd_a3ff403e6ca9005a2ef0c2a879be685f5420d018-1629150031-0-gqNtZGzNAnijcnBszQiO)). Every inch that you hold your head forward while slouching adds 10 pounds of pressure on your spine. The rounded-forward position of flexion causes your shoulders and neck muscle to become adaptively stiff.
Over time, the cultivated stiffness can compromise your ability to straighten your spine. This rounded back can also compromise your ability to breathe fully and efficiently. This mechanical obstruction makes your body breathe in short, shallow breaths, which triggers the state of fight or flight. This releases stress hormones that will compromise your ability to get back to a relaxed state (Starrett, 2016).
---
## Visual impairment <a name="visual-impairment">
Staring at a computer screen all day also may cause retinal damage. Computer screens and digital devices emit blue light. The short high energy wavelength flickers and creates a glare that decreases visual contrast and may be one of the reasons for eye strain, headaches, and mental fatigue are associated with prolonged screen exposure ([Blue Light Exposed](http://www.bluelightexposed.com/#where-is-blue-light-found)).
You blink less when you are concentrated on a screen, which can cause irritation and dry eyes (["Blue Light and Your Eyes"](https://preventblindness.org/blue-light-and-your-eyes/#:~:text=Fatigue,%20dry%20eyes,%20bad%20lighting,lead%20to%20damaged%20retinal%20cells.)). Blue light with wavelengths between 415 nm and 455 nm are closely related to eye damaging diseases such as dry eye, cataracts, and age-related macular degeneration ([Zhao et al., 2018](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6288536/)).
We should decrease screen time and take frequent breaks, and eyeglasses that block blue light might also help. Consider talking to an eye professional to see how they can protect your eyes.
---
## Mental stress <a name="mental-streess">
In addition to the physical complications of the software engineer life, there are also mental ones. Sometimes, when stuck on a bug, you may get frustrated and stressed out. Stress activates the fight or flight response in your body, increasing your heart rate and adrenaline. Cortisol, a stress hormone, can cause fat to build up on your abdomen (["Study: Stress May Cause Excess Abdominal Fat in Otherwise Slender Women"](https://news.yale.edu/2000/09/22/study-stress-may-cause-excess-abdominal-fat-otherwise-slender-women)).
Stress on the mind might also cause disruptions in sleep. Software engineers tend to be on the computer all day, so the blue light from the computer screen makes it harder to fall asleep. The high energy blue light inhibits melatonin secretion, and enhances adrenocortical hormone production, which will destroy the hormonal balance and affect sleep quality. Your body follows the circadian rhythm, and sunlight affects your internal body clock ([Chang, et al., 2014](https://pubmed.ncbi.nlm.nih.gov/25535358/)).
---
## Poor food decisions <a name="poor-food-decisions">
When concentrating deeply on solutions to work through a code problem, the last thing you want to do is prepare a healthy meal. When the body is stressed, it wants to be comforted, so food consumption is a common stress relief. High-calorie, low-nutrient snacks are often convenient to grab since they usually come in packaged form.
You may find yourself reaching for some chocolate in the snack closet when you become stressed about something. Ingesting sweets provides a small dopamine release into your body for immediate comfort but it also raises your insulin levels, making your body less sensitive to insulin, which can lead to diabetes if it becomes chronic. Excess sugars get stored as fat in your body, leading to weight gain (Taubes, 2011). When comforting carbohydrates such as cookies and chips are easily accessible because they're prepackaged and require no work to prepare, it is easy to overeat. Unfortunately, most of the prepackaged foods you see are full of added sugar. Sugar elicits addiction-like cravings and can even become even more addictive than cocaine, according to a study on rats (Ahmed, et al., 2013).
It's not a surprise when excessive eating combined with a sedentary lifestyle will result in more than just weight gain. Sitting too much doesn't just shorten lives, the Centers of Disease Control reports that we are spending 75 cents of every health-care dollar on chronic conditions linked to sedentary behavior such as obesity, diabetes, and heart disease. If we made small changes to be more active, it could reduce the amount of money spent for these diseases that exist due to lifestyle decisions.
---
## Changes you can make <a name="changes-you-can-make">
As you can see, having a desk job causes many stresses on the body and the mind. But it's never too late to fix a problem, as hopeless it may seem. A few key changes can mean the difference between a healthy, active life or one of prolonged discomfort.
---
### Desk ergonomics
The first step is to notice when you slouch at your desk. When you start to feel neck pain, imagine a piece of string at the crown of your head is being pulled up. That will relieve some tension.
Sitting properly at your desk will mitigate some of the stressors. When you take a seat on your chair, your legs should bend at a 90 degree angle with your feet flat on the floor. If you are short, you need to lower your chair or get a footrest. You also shouldn't be reaching too far for your keyboard and mouse, because that will make you hunch forward.
Your monitor should be high enough that the top is level with your eyes, allowing you to maintain a neutral posture. Putting your monitor too high will cause you to look up, which may cause you to slouch. Being mindful of keeping your back straight is a hard endeavor in itself, but remember that small changes can turn into lifelong habits with consistency.
One solution to prolonged sitting is to get a standing desk, as it's an easy way to be a little more active and a positive investment in your health. Personally, I've noticed that over time I got fatigued faster when I was standing at events or happy hours and attributed this to the fact that I sit all day long. I couldn't stand for long periods when I did get a standing desk, either. My body had to get adjusted to the new changes of standing, because my muscles were weak from not using them. Standing can also help increase mobility.
---
### Fitness and stretching
Strengthening your back muscles can also help; a stronger back is naturally more capable of supporting your torso. Research suggests that those who work out a lot might slouch less. A long-term study of children found that targeted athletic training seemed to improve body posture from adolescence to adulthood ([Ludwig et al., 2018](https://medium.com/r?url=https%3A%2F%2Fwww.ncbi.nlm.nih.gov%2Fpmc%2Farticles%2FPMC6277893%2F))
Remember to take regular breaks and do some stretching. As we sit, hip flexors and the hamstrings become shorter, tighter and less flexible (Farrar, 2019). Stretching your hips will help relieve the tightness. Maintaining is the key here, it is far easier to do maintenance than to fix something that's broken. Taking breaks also allows your brain to take a rest and come back with a better perspective on tackling your coding problem. You are not a machine.

Deskbound Guidelines, from *Deskbound (Starrett, 2016)*
1. Reduce optional sitting in your life.
2. For every 30 minutes that you are deskbound, move for at least 2 minutes.
3. Prioritize position and mechanics whenever you can.
4. Perform 10 to 15 minutes of daily maintenance on your body.
---
### Reframing food choices
Start noticing when you get stressed out and how you react to it. It's important to be in tune with your body so you can understand your impulses. When you realize what's actually happening, you can make better choices.
Instead of reaching for chocolate, opt for a healthier snack like fruit, nuts, eggs, yogurt, etc. Eating fewer carbohydrates will also help avoid weight gain, because carbohydrates (particularly simple, processed ones) are what prompts the body to release insulin, in turn signaling the fat cells to intake and store the excess calories.
Make healthy foods more easily available by choosing low carb alternatives, or pack your own snack bags that are full of nutrients. Surprise, your co-worker just bought a box of donuts for everyone, and that triggers your sweet tooth. It's not a matter of ignoring your craving, you should just plan to eat half a donut instead of a full one. That should curb your cravings and still not over indulge in sugar.
When you slowly decrease your carbohydrate intake, you will crave them less. The idea is to increase the portion of protein and vegetables and decrease the amount of carbohydrates. Some people choose to eventually remove all unnecessary added sugars from their diet.
Sitting in front of a computer while eating your lunch isn't a great idea either. People tend to overeat when they're not mindful of what they're eating and how much they're eating. It is important to eat slowly so that your stomach can signal to your brain that it is full. Don't worry about having leftovers, you can always eat that as a snack later. Having nutritious food is better than eating unneeded calories.
---
### Practicing mindfulness
Social activities such as taking walks with your co-workers to get coffee or just enjoy the sunshine can help relieve some stress. Shows like "Silicon Valley" and "Mr.Robot" portray programmers as socially awkward, but you don't have to fit the stereotype.
Spending your whole life talking to a computer isn't particularly healthy because humans are social creatures. We need positive social interactions to thrive and not burn out. Especially during the current COVID-19 pandemic, it can be refreshing to talk to another human being, even if it is through a happy hour with your team on Google Hangouts.
Consider including meditation in your daily life. Meditation will help with keeping calm and curb your impulses to reach for a candy bar every time you feel stressed. It may also help you sleep better, as it did for me when I revisited the same relaxed state before I drifted away to sleep.
At LTV, we have meditation sessions every day, and attending them made me see an improvement in my mental well-being. I was able to take some time out to relieve some stress, and it improved my productivity afterwards.
There was a time that I was overwhelmed with the sheer amount of broken specs that I had to go through for our Rails upgrades, and I went to meditate in the middle of the day. It was like magic; I felt instant mental clarity and I realized that my mind felt fuzzy before that. I was able to go through specs faster and more logically afterwards because I took some time out of my day to meditate. The rewards are long lasting and greater than you think.
Keeping a healthy lifestyle, staying in tune with your own feelings and impulses, and becoming more active during the day will help you become a healthier software engineer. Health is more important than anything else. Don't let the ergonomic and mental aspects of the job inhibit your ability to live your best life. Stay healthy!
---
Interested in working with us? Have a look at our [careers page](https://www.ltvco.com/careers/) and reach out to us if you would like to be a part of our team!
---

| ltvengineering |
794,300 | Made a little node app that lets your Discord bot track crypto prices | I would love your feedback. The idea is to update the bot's nickname periodically with crypto price.... | 0 | 2021-08-16T23:52:32 | https://dev.to/nazareth/made-a-little-node-app-that-lets-your-discord-bot-track-crypto-prices-4i1n | node, crypto, discord, bot | I would love your feedback. The idea is to update the bot's nickname periodically with crypto price. Here's a demo:
https://github.com/Omar-Aziz/KryptoBOT
| nazareth |
794,341 | Create a voice recorder with React | When we develop a web app we can think browsers like a swiss knifes, these include a bunch of... | 0 | 2021-08-17T01:56:10 | https://dev.to/jleonardo007/create-a-voice-recorder-with-react-32j6 | programming, webdev, react, javascript |
When we develop a web app we can think browsers like a swiss knifes, these include a bunch of utilities (APIs), one of them is get media devices access through `mediaDevices` API from the `navigator` object, this allows to devs create features related with the user media devices, this features migth be create voice notes, like Whatsapp Web does.
Today we're gonna create an app that records the user's voice and then saves the recorded voice on an `<audio>` tag will be played later, this app looks like this

Apart `mediaDevices` API we require
* `MediaRecorder` constructor, this creates a recorder object from the requested media device through `mediaDevices.getUserMedia()` method.
* `Blob` constructor, this one allows create a blob object from the data adquired from `MediaRecorder` instance.
* `URL.createObjectURL(blob)` method, this creates a URL, the URL contains the data (voice) create previously from the `Blob` instance and it is gonna be use like `<audio src=URL/`.
If you don't understand, don't worry, I'll explain you below. First, look at the `<App/>` component.
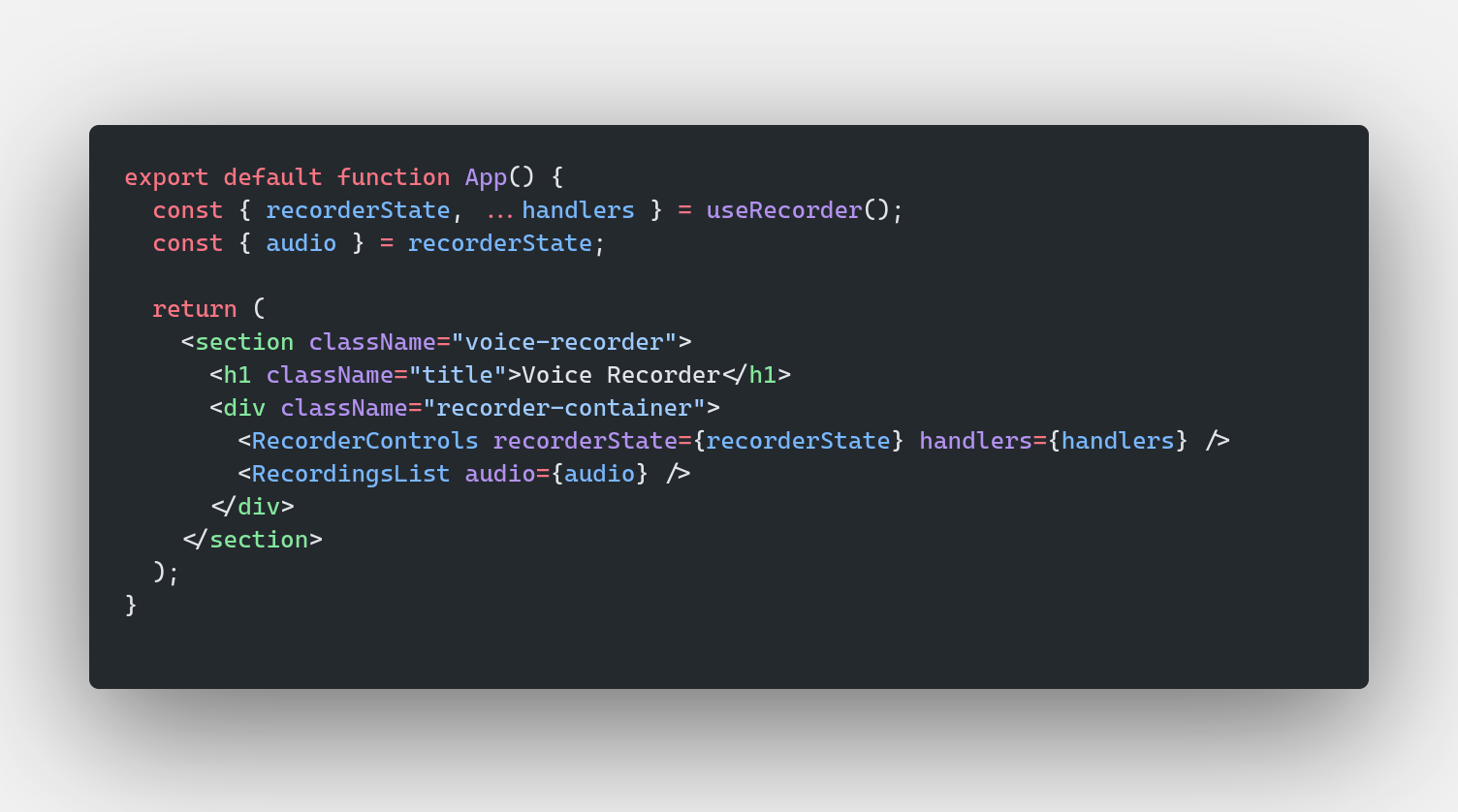
`<App/>` consumes a custom hook that provides the recorderState and several handlers. If you don't know how to use a custom hook I share with you a [post](https://dev.to/jleonardo007/keep-your-react-components-clean-with-custom-hooks-j74) about this.
The recorderState is like this:
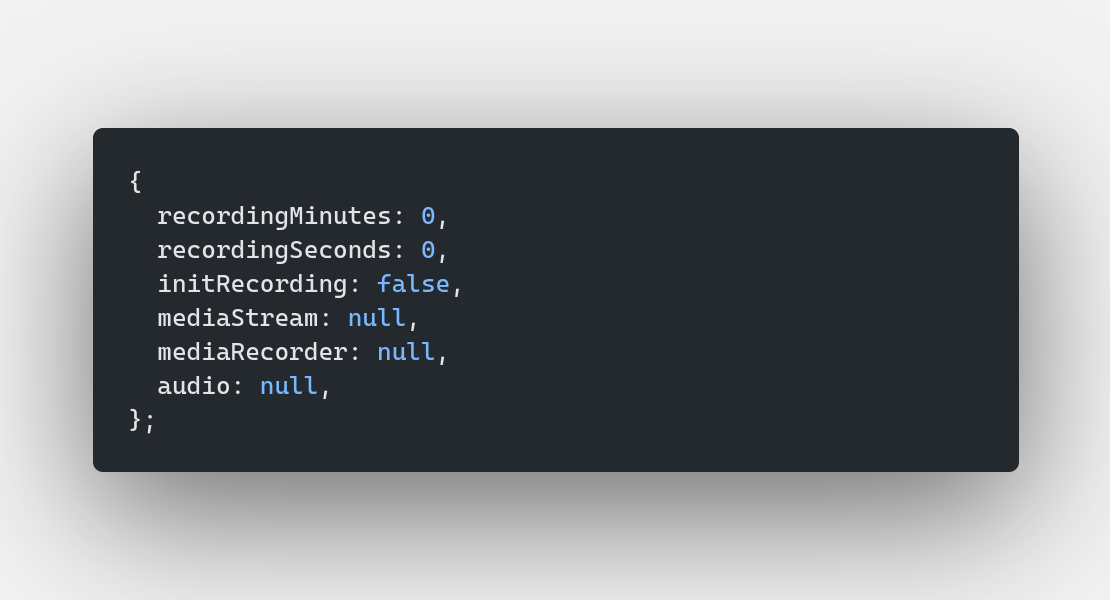
* `recordingMinutes` and `recordingSeconds` are use to show the recording time and `initRecording` initializates the recorder.
* The other parts of the state, `mediaStream` will be the media device provide by `mediaDevices.getUserMedia()` and `mediaRecorder` will be the instance of `MediaRecorder`, `audio` will be the URL mentioned previously.
`mediaStream` is set by the handler `startRecording`
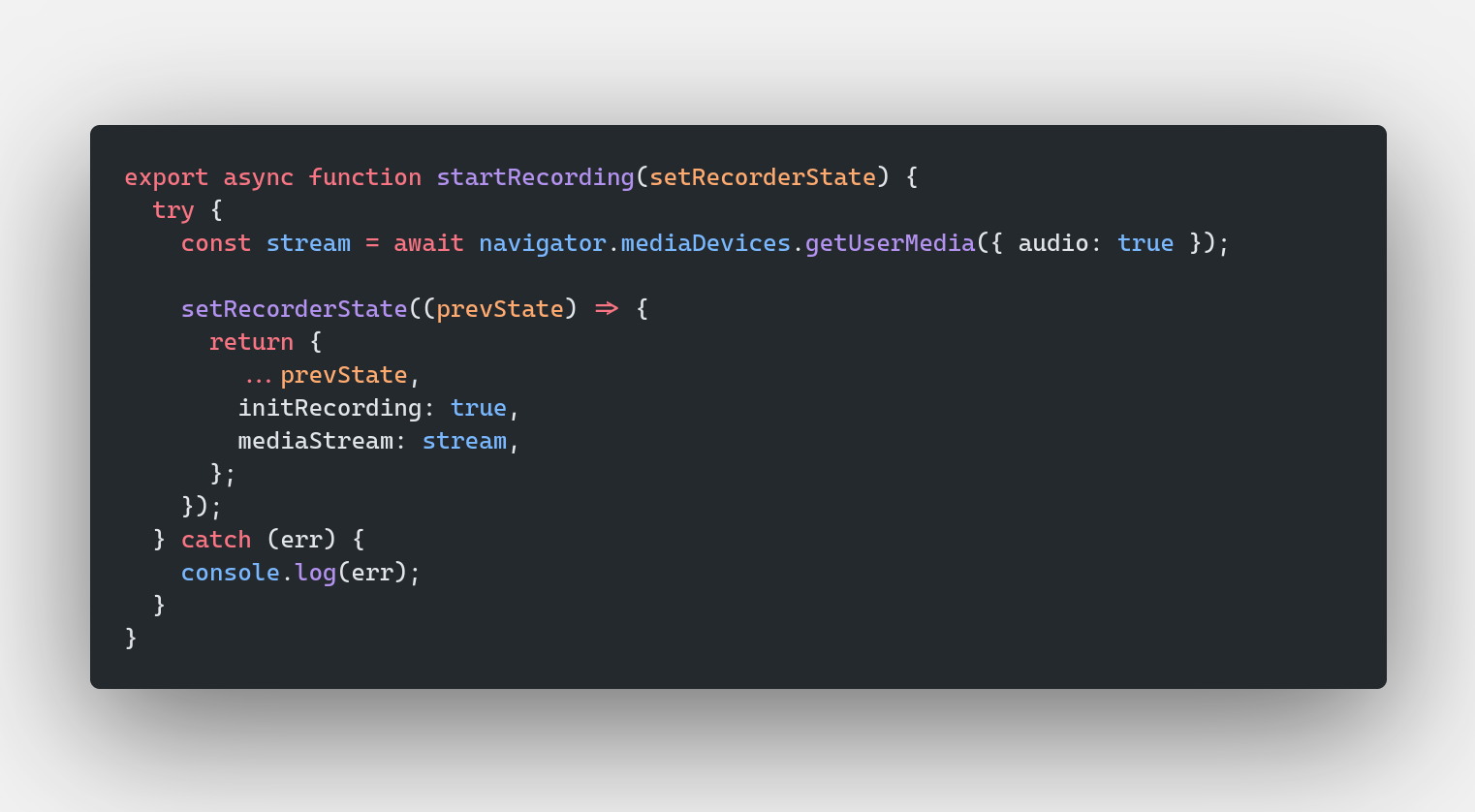
After set the `mediaStream`, `MediaRecorder` instance is created
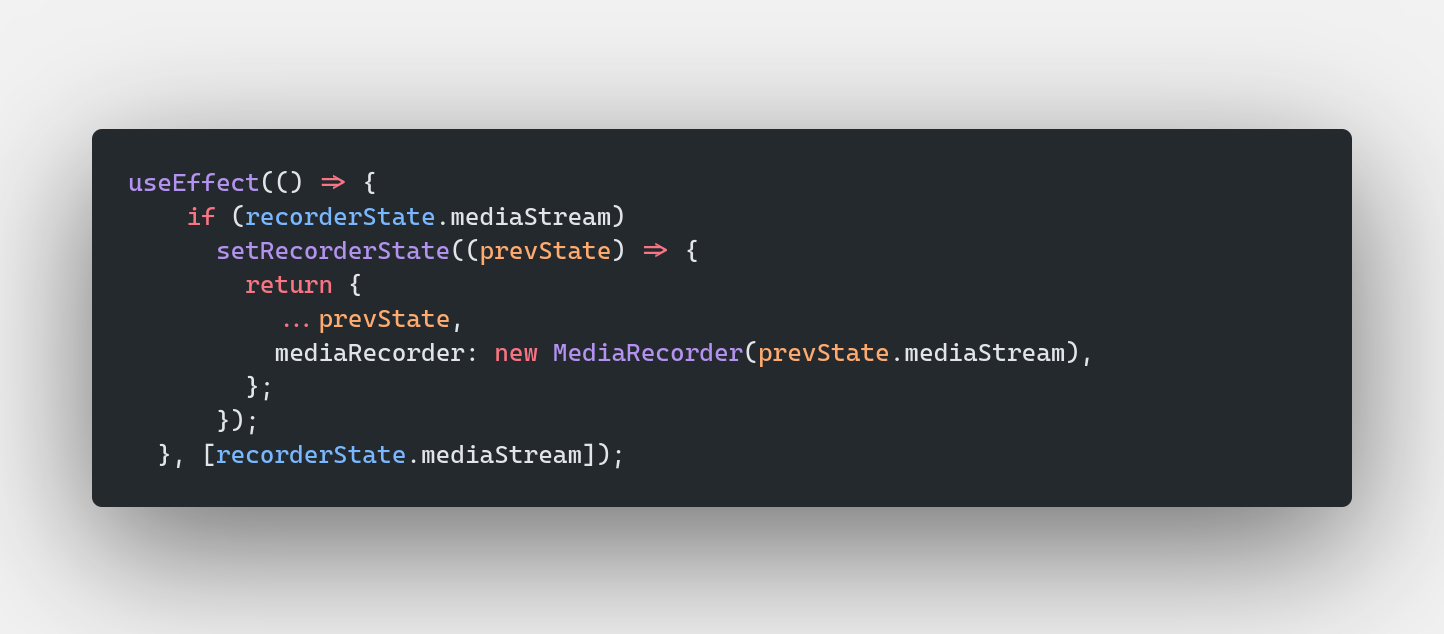
Then `audio` is set

To adquire the voice and create the audio `mediaRecorder` needs create two event listeners `ondataavailable` and `onstop` the first one gets chunks of the voice and pushes it to the array `chunks` and the second one is use to create the blob through `chunks` then audio is created. The stop event is fired by `saveRecording` handler or the effect cleanup function, the cleanup function is called when recording is cancel.
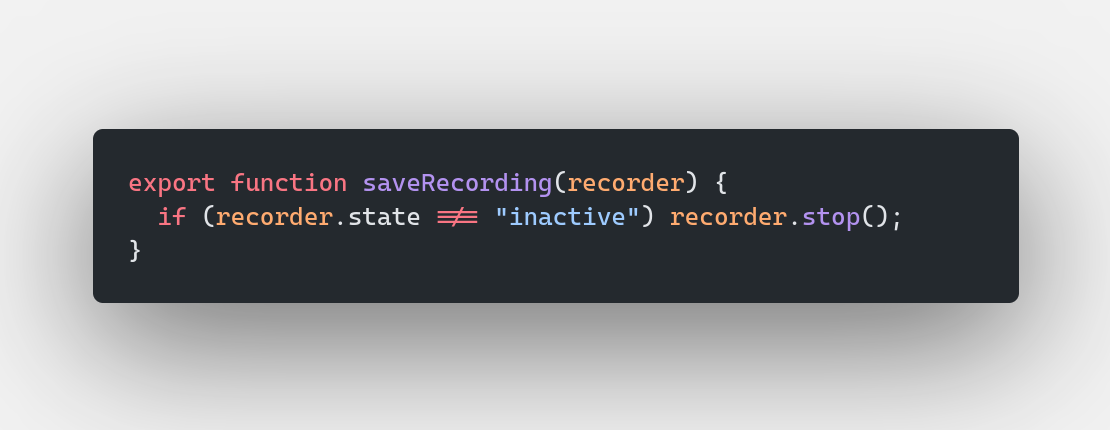
Now take a look at the components `<RecorderControls/>` and `<RecordingsList/>`.
**`<RecorderControls/>`**
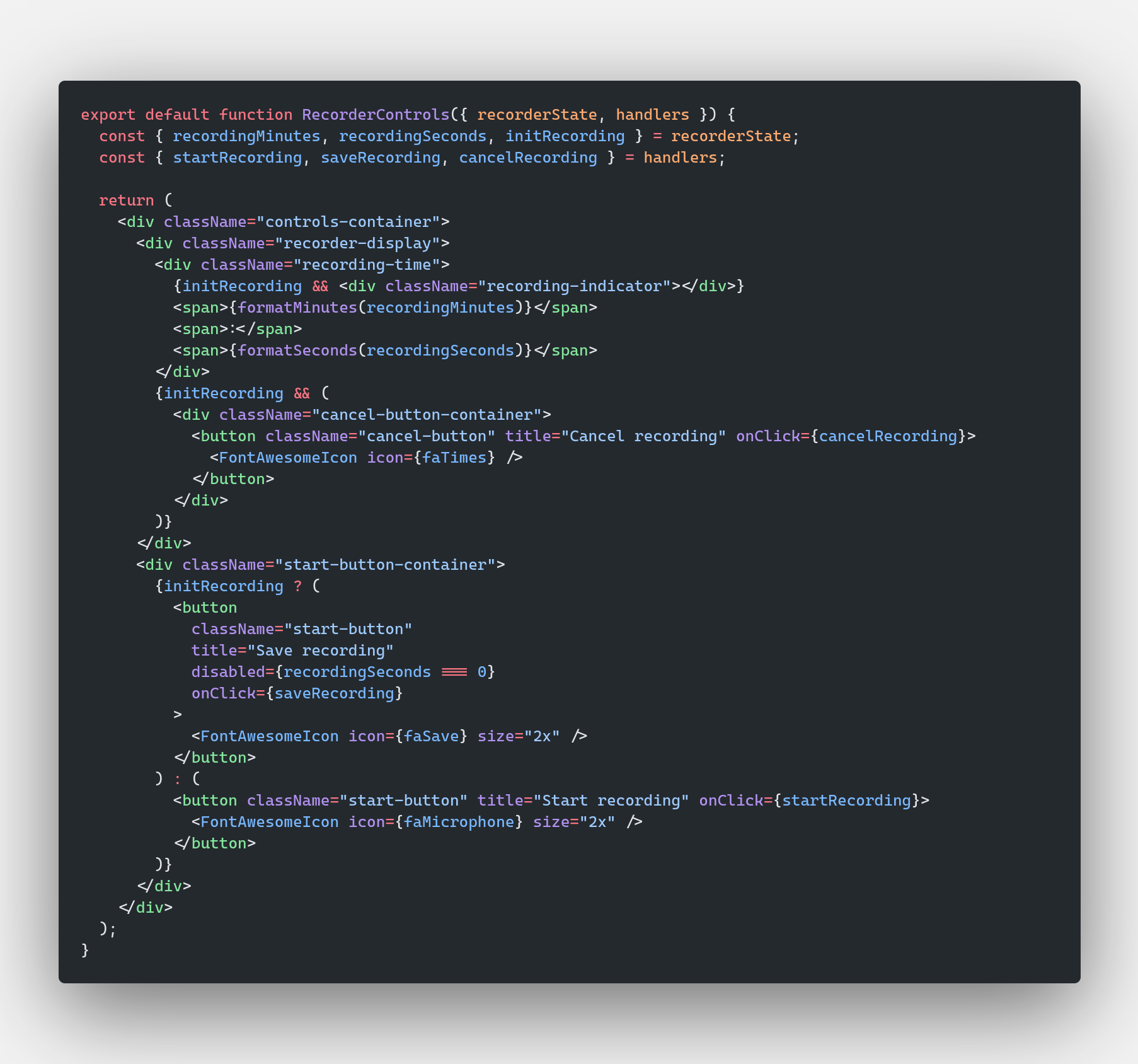
`<RecorderControls/>` have the prop handlers and this is used by the jsx
**`<RecordingsList/>`**
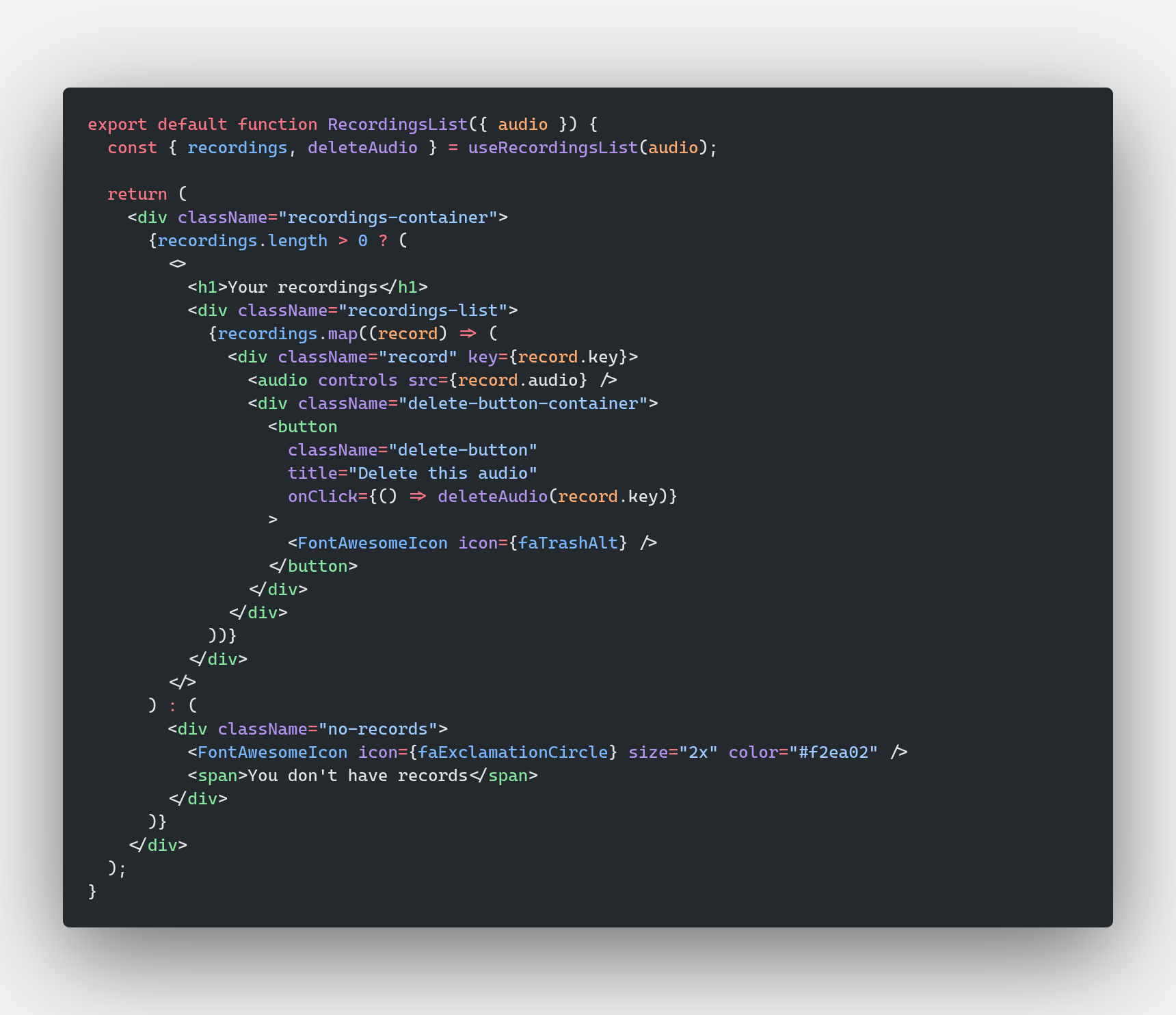
`<RecordingsList/>` receives `audio` and consumes a custom hook that pushes the audio created previously.
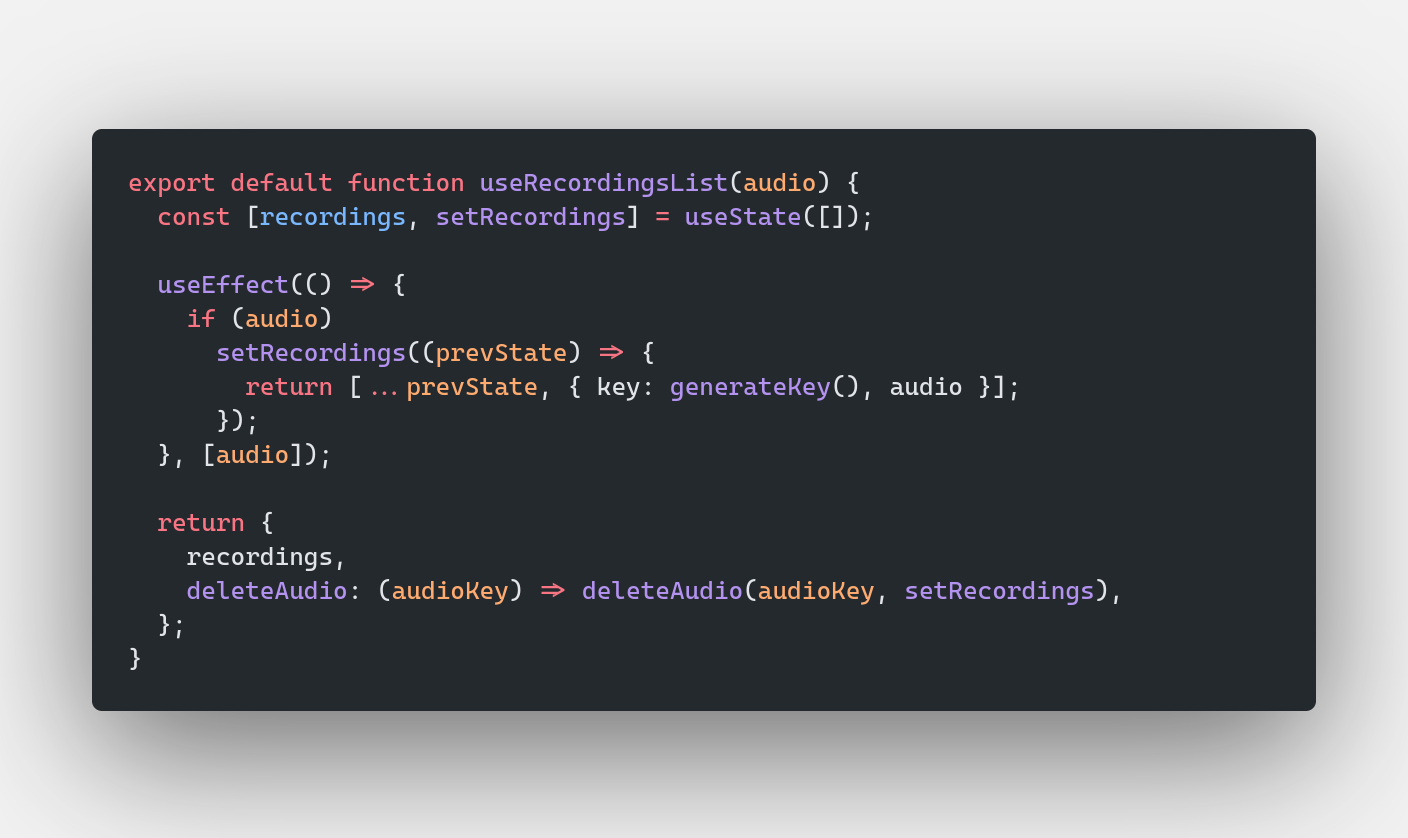
The handler `deleteAudio` is like this
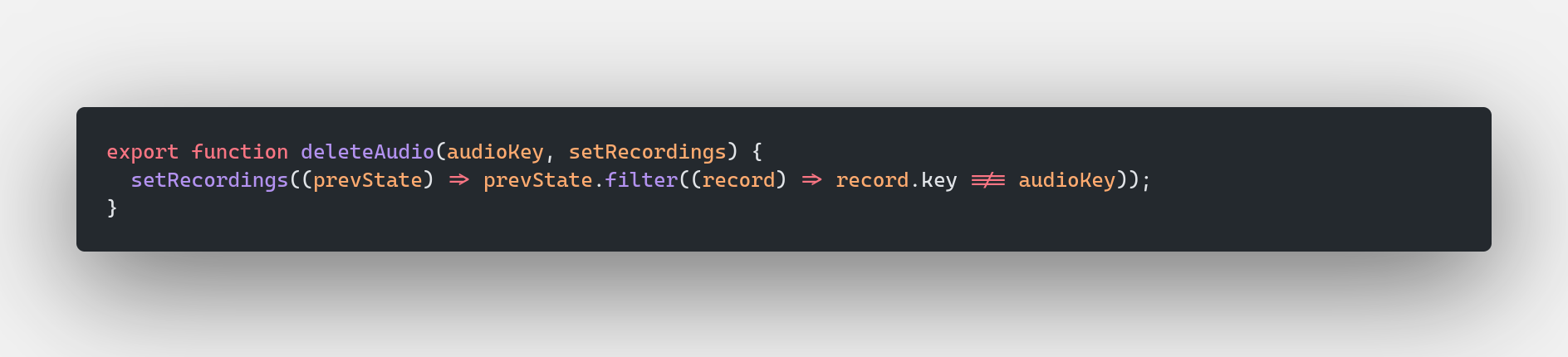
And that's it! With React we can make use of `useEffect` to access the user devices and create related features.
## Final Notes
* You can find the source code [here](https://github.com/jleonardo007/voice-recorder-example)
* The Typescript version [here](https://github.com/jleonardo007/voice-recorder-ts-version) | jleonardo007 |
794,496 | Create a Netflix clone from Scratch: JavaScript PHP + MySQL Day 22 | Netflix provides streaming movies and TV shows to over 75 million subscribers across the globe.... | 0 | 2021-08-17T04:03:38 | https://dev.to/cglikpo/create-a-netflix-clone-from-scratch-javascript-php-mysql-day-22-4j39 | php, javascript, webdev, tutorial | Netflix provides streaming movies and TV shows to over 75 million subscribers across
the globe. Customers can watch as many shows/ movies as they want as long as they are
connected to the internet for a monthly subscription fee of about ten dollars. Netflix produces
original content and also pays for the rights to stream feature films and shows.
In this video,we will be setting up verification page
{% youtube owFkYPbFDIs %}
In this video,we will be creating userData method
{% youtube s3Zt97Wrdzk %}
In this video,we will be Testing for PHPMailer
{% youtube 4q9qOP28Wyc %}
If you like my work, please consider
[](https://www.buymeacoffee.com/cglikpo)
so that I can bring more projects, more articles for you
If you want to learn more about Web Development, feel free to [follow me on Youtube!](https://www.youtube.com/c/ChristopherGlikpo) | cglikpo |
794,509 | Hi, my name is Yemisi. I’m a Software Engineer! | Not so great a title? Don’t get bored yet, keep reading with me. Smiles As you can guess already, my... | 0 | 2021-08-17T04:50:39 | https://dev.to/yemmyade/hi-my-name-is-yemisi-i-m-a-software-engineer-3l3i | Not so great a title? Don’t get bored yet, keep reading with me. Smiles
As you can guess already, my name is Yemisi Adesanya, I girl whose interest in Software Engineering was aroused by an introduction to HTML class. Like the dream of almost every young child in West Africa, Nigeria, you should relate when I say I wanted to become a Medical Doctor, therefore I had no hesitation in choosing Science Class when the time came for diversion in Secondary School.
But lo and behold, I found myself studying Computer Science in a Federal polytechnic in Nigeria. Devastated? Yes, I was. I see no potential in the Course because I had no proper orientation and I would always thought I would end up been a typist, so far as I knew back then Computer was use for typing. To cut the long story very short, in my second year during my National Diploma days, we had an introductory class to HTML. Oh finally, I could only thank God for placing me in this path, I saw a whole lot of possibilities, potentials, curiosity and knowledge opened up to me without been sat down and given a prep talk. I knew I was in the right path and I was going to do everything it takes to maximize this path to it full potentials.
Moving forward, a whole lot of training process has contributed to my growth as a Software Engineer and HNG Internship is about to become part of the success story. I decided to apply for HNG Internship by Zuri because I have heard a lot of stories about the internship, how it has helped a lot of Software Engineers achieve their goals of broadening their Software Engineering skills and Knowledge, also how it has helped build a network of Software Engineers for them and I hope to achieving the same goal, in addition to this I hope to build fully functional Front-end Applications using React and Redux for State Management at the end of the 8 weeks intensive training .
Do you want to learn more about HNG Internship? Visit https://internship.zuri.team.
Perhaps just like me, you are curious but don’t know where to start from. Check out the following video tutorials it will give you the head start you need.
{% youtube pQN-pnXPaVg %} https://youtu.be/pQN-pnXPaVg a beginner friendly HTML tutorial.
{% youtube g6rQFP9zCAM %} https://youtu.be/g6rQFP9zCAM a tutorial on Figma.
{% youtube SWYqp7iY_Tc %} an introductory tutorial to Git .
{% youtube W6NZfCO5SIk %} a beginner friendly Javascript tutorial.
Ever since I started this journey, I had always yarn for a day I would introduce myself as the title above. Stories of how I worked my way to this current stage, would be shared later. Until I come your way again. My name is Yemisi, I’m a Software Engineer!
| yemmyade | |
794,795 | Learning with Self-Help | Let's start with introductions. Hi, I'm John Phillips. I'm an aspiring web developer. Like everyone... | 0 | 2021-08-17T12:36:00 | https://dev.to/john_k_phillips/learning-with-self-help-o3d | learning, discuss, webdev, motivation | Let's start with introductions.
Hi, I'm John Phillips.
I'm an aspiring web developer.
Like everyone else, I have many flaws, I embrace, resent and blame them. I'm not ashamed to discuss my "failures", or my "flaws", consequently the creation of this post.
*So, let's get started...*
## My thoughts on "self-help".
I've always **HATED** self-help advice, still do actually.
##### Why?
* Harmful Advice. ✅
* Empty Promises. ✅
* Egotistical Writers. ✅
Now, this is a stern belief, I know, so why have I found my success in learning and believe it's an incredible approach to learning?
---
### Failures
I've failed at too many things in life, *of course due to my
own self-loathing*. I struggle to continue working on topics I believed I wanted to understand.
I had attempted web development several times over the course of a decade, and I'll say again, due to my **OWN** self-loathing, decided to stop trying.
---
#### The Blame
A few years had passed, blaming my 'compulsive nature' to abandon everything I work on, I found it easy to pick up and ditch projects...
Of course, this blame game was an issue, it was an excuse that many of us make, taking pity on our-self's, temporarily making us feel good.
#### The Resentment
I resented my 'compulsive nature' and refused to learn anything else, believing it just wasn't my 'destiny' to be educated, successful or even happy.
This was starting to become a problem.
##### Embracing My Flaws
On the 12th of August, 2020. I decided to stop self-loathing and actually solve this "problem" because that's all it was, a problem that required solving.
I wanted to become a developer, however; I knew that this wasn't going to come to fruition unless I **fixed** this problem I have.
I delved into books, guides, blogs, videos you name it, attempting to solve this 'problem' and after a few months, I made progress.
---
### The Problem
This "advice" had given me a quick fix, these self-help guru's would talk about their stories of success, never actually explaining the pain, sacrifice and stress they took to get to their goals; hell, perhaps they fluked their success, but, this isn't going to happen, not to me, you or perhaps anyone else reading this.
Following and believing in this advice was ruining my progress, my self-worth and my confidence. Blindly following these Guru's was just irresponsible and stupid, to be blunt.
---
### The Fix
> What pain do you want in your life?
This was a quote from a [book](https://www.audible.co.uk/pd/The-Subtle-Art-of-Not-Giving-a-F-ck-Audiobook/B01MG9416Z?source_code=M2M30DFT1BkSH101514006S&ipRedirectOverride=true&gclid=Cj0KCQjwvO2IBhCzARIsALw3ASp_st7hoPC00_Y4jynGH35DVg7X1v3wHkSIHS5S98Px5RgfDtb07DEaArk-EALw_wcB&gclsrc=aw.ds) published [by Mark Manson.](https://twitter.com/IAmMarkManson?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor)
Mark is like the Ghost of Christmas. Brutally telling you how it is and not what you'd like it to be.
This particular quote caught my attention, and I believe this is how I've failed and if you feel the same way, perhaps you are too.
Mark explains that in life, everything has a sacrifice. Simply put; A house needs **repairs**, A job comes with **stress** and a relationship requires **work**.
Undoubtedly, you're happy to go through these 'pains' and that's exactly why you're untroubled by the thought of them; likewise with learning.
I believe this is a great philosophy to follow. So far, It hasn't failed me, I am happy to go through the pain and struggles of being a developer and that's exactly why I'm still here; rather it is the pain I enjoy that has allowed me to continue my fight.
---
### Wrapping Up My Points
Ok... My points? This perhaps dragged on for far too long; however, I want to show you that what you're going through is common, especially for beginners, I still struggle even now, a year later.
Following blindly to one guru is a waste of your time and effort, ensure you **filter** the useful quotes and information that tailors to you.
Self-help Guru's that try and give you a boost of encouragement are mostly doing what we call in retail 'customer satisfaction'.
Don't fall into the same pitfalls I did and receive a burst of motivation.
Solving your own personal issues is crucial to learning, if you find yourself continuing to blame a particular 'feature' of your character, then find a solution for it.
*Easier said that done, for sure, I still struggle to this day, but after a year of struggles, my problem has become more of an asset and hence, embracing it.*
---
NOTE: Re-reading this, I planned on leaving it unpublished; however, I will post it regardless of how I feel in hopes that it motivates someone to do something of similar nature.
*P.S This is my first blog, It's probably flawed, messy and not well structured. But, It's an attempt and something I aim to get better at.*
Thanks for reading. Best of luck learning.
| john_k_phillips |
794,801 | How to make object iterable | In order to be iterable, an object must implement the @@iterator method. This means that the object... | 0 | 2021-08-17T11:30:03 | https://dev.to/afozbek/how-to-make-object-iterable-1jl2 | iterable, generators, javascript | In order to be iterable, an object must implement the @@iterator method. This means that the object (or one of the objects up its prototype chain) must have a property with a Symbol.iterator key.
If you want to create your own iterable object here is how you can do it.
```jsx
const iterable = {
*[Symbol.iterator]() {
yield 1;
yield 2;
yield 3;
}
}
for (let value of iterable) {
console.log(value);
}
// 1
// 2
// 3
```
## Links
- [Iterators & Generators](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Iterators_and_Generators) | afozbek |
795,031 | Entering into the Web-Dev World | Hi I am Rittik and I am still quite new to this development world. I came to know about web-dev when... | 0 | 2021-08-17T14:47:43 | https://dev.to/rittikghosh/entering-into-the-web-dev-world-1ah5 | beginners, webdev | Hi I am Rittik and I am still quite new to this development world. I came to know about web-dev when I was in my 8th semester when I was doing my internship with a fin-tech start-up. ( Yes, Of course I am an engineer but I took instrumentation as my branch i.e. not CS). Before that I always was scared to code and I had a stigma attached to it that it's too damn difficult.
I couldn't be more wrong. Coding is not difficult it just requires patience and persistence. I started with JAVA learned the semantics did some problems but I couldn't see the visible output, nothing being created was visible and then came the web-dev with its HTML,CSS and javaScript to rescue me. That is the beauty of web-dev, whatever you learn in web-dev you can implement it, develop it and see it building in front your eyes and it's just magnificent.
I stated with HTML the skeleton of the web and gave it around 5 days. I learned about the HTML tags and about how they are placed and used in a website. The id and class attributes for each tag along with attributes like type, placeholder etc gave me an idea about how to modify a simple tag and make it more descriptive and elaborate.
For eg. the label tag can be grouped with the input tag so that the browser can understand for which input it has been placed.
```
<label for="dob">Date Of Birth</label>
<input id="dob" type="date" />
```
Next I stated learning about the CSS - "the one that makes it all beautiful". Using the id's, class and tags we can target specific elements of the HTML in the website and change the way they look. It is one of the things that you would want to be perfect but there is always one element that goes out of alignment but it's worth all the efforts.
For eg. you can change the heading colour, it's size and it's positioning all with the help of CSS.
```
.heading{
font-size:3rem,
color:red,
font-weight:bold
}
```
The logic to the website comes from the javaScript and hence, it's called the brains of the website (Don't think that there are any similarities between java and javaScript, it's the same as that of a car and a carpenter). This is the scripting language that is mostly being used by everyone in world and why not it's astonishing what one can achieve using this language. It can detect each and everything that you do while you are in a particular website and it can change the CSS depending upon your action.
The field is vast and I am still to learn many things from frameworks to databases but I am really liking it and hope my journey to become a fullstack remains as exucting as it is now. | rittikghosh |
795,082 | HNGi8 x I4G 2021 INTERNSHIP PERSONAL MISSION STATEMENT | The HNG Internship is a large-scale remote mentoring program that seeks to onboard aspiring software... | 0 | 2021-08-17T16:06:17 | https://dev.to/tabsspaces/hngi8-x-i4g-2021-internship-personal-mission-statement-38kd | The HNG Internship is a large-scale remote mentoring program that seeks to onboard aspiring software developers, designers, and entrepreneurs over a period of three months into intensive, rigorous, technical processes designed to help its participants hit the ground running in their chosen tracks upon its conclusion.
Currently in its 8th iteration, this initiative is spearheaded by Hotels.ng CEO, Mark Essien, in partnership with notable tech personalities and companies around the globe, and will be offering a total of five tracks: UI/UX Design, Front-end, Back-end, Mobile, and Entrepreneurial to its participants.
Having joined the Back-end track, my mission is to accomplish the following:
- Significantly ramp up my technical ability
- Build enduring relationships with my mentors and fellow interns
- Gain exposure to adjacent tech domains
If you are interested in knowing more about this opportunity, here are some helpful links:
https://zuri.team, https://internship.zuri.team or https://training.zuri.team.
In addition, you might find the tutorial links below useful if you're just getting your feet wet in the field of web development:
Figma introductory tutorial
https://youtu.be/g6rQFP9zCAM
Github introductory tutorial
https://youtu.be/g6rQFP9zCAM
HTML/CSS introductory tutorial
https://youtu.be/kMT54MPz9oE
Python introductory tutorial
https://www.youtube.com/watch?v=rfscVS0vtbw
| tabsspaces | |
806,447 | Infra as code, pipelines and hidden patterns | This article is archived and not maintained. It mostly contains notes and unorganized thought about... | 0 | 2021-08-28T17:19:58 | https://dev.to/sbelzile/infra-as-code-pipelines-and-hidden-patterns-36j6 | This article is archived and not maintained. It mostly contains notes and unorganized thought about the subject. Read it at your own risks.
I rarely find articles about implementation patterns and technicalities of infrastructure as code, and build and deployment pipelines other than basic tool usage. In fact, most articles I can find on the web about infra as code and devops are about the benefits of adopting such practices and rarely aimed at users of these practices.
This article aims at creating a record of patterns and/or practices that I often encourage when writing infrastructure as code and deployment pipelines.
If you read this and:
- know of other similar resources,
- have and encourage other similar practices,
- think something is missing,
please contribute by adding a comment, I am interested to hear about these things.
## Using stack outputs in other stacks
It is possible to reference the output of other deployment stacks and use it as input in another stack.
Example: Let's say we have a project split in 2: a front-end and a backend. The backend will create some resources that the front-end also needs to reference. What often do is creating secrets in the front-end build/deployment pipeline and referencing the value of these secrets in our code.
This is a manual step that can be removed. To do so:
- Define these values as output of the backend stack
- Reference the backend stack from the front-end stack
- Use the outputs of the backend stack in the front-end stack
How to do this with:
- [Pulumi](https://www.pulumi.com/docs/intro/concepts/stack/#stackreferences)
- [Terraform](https://www.terraform.io/docs/language/state/remote-state-data.html)
## Isolating the base infrastructure from the application specific infrastructure
Key principle: speed
There are multiple ways to organize infrastructure as code. A lot of projects keep the infra definition as close to the code as possible. It is a practice I endorse: related things should be as close as possible from each other as possible. However, this will result in a slow deployment time.
This slow deployment time is caused by the deployment pipeline always validating the whole infrastructure. Problem is: once it's been built, the infrastructure rarely changes.
To optimize deployment speed, isolate the base blocks of the infra and only build/deploy the pieces that need to be rebuilt/redeployed in the application part of your code.
Ex:
- In a front-end repository, only push file to an already existing S3 bucket.
- Keep Cognito, databases creation, API Gateway, etc. in an infrastructure stack. Only deploy your lambdas/containers from the backend repository
## Automation of projects and privileges
You can keep track of your repositories/repository accesses with infrastructure as code. This is an easy way to centralize the resources your company uses, control your company code policies (example: at least one approval before you can merge to master) and control who can access what.
## Artifact based deployments
Key principles: speed, reproducibility
Keep your build and deployment pipelines separate. Do not rebuild your docker image, React project on every deployment. Your build pipeline should build a docker image and store it in an image registry, or compile and bundle your JS files. Your deployment pipeline should use the resulting artifacts and deploy them with runtime variables to the runtime environments.
## Interesting Resources
- [Common Patterns of Infrastructure as Code Architecture](https://spacelift.io/blog/iac-architecture-patterns-terragrunt) | sbelzile | |
795,096 | Introduction to Pointers | Introduction A pointer is a memory address. Think of a pointer like a bookmark. A bookmark... | 0 | 2021-08-18T01:30:41 | https://dev.to/iamjajuan/introduction-to-pointers-116f | cpp | ## Introduction
A pointer is a memory address. Think of a pointer like a bookmark. A bookmark references a page in a book. A pointer references an address in memory that holds a particular value: string, integer, Boolean, etc. The purpose of pointers is to create data structures such as arrays or graphs. In this post, you will learn how to declare a pointer variable and pointer operations.
## Declaring Pointer Variables In C++
Declaring a pointer in C++ is the same as declaring a regular variable, except adding an asterisk behind the variable like the following example.
```
int* x;
```
## Pointer Operations
To turn a variable into reference, you would need to use the address-of operator (&). Applying the address-of operator to variable y would convert it to a pointer like the example below.
```
int y = 100;
cout << "Memory Address " << &y << " Value " << y;
//Memory Address 0x7ffe4aa8a4bc Value 100
```
If you would like to convert a pointer to a regular variable, you need to use the dereference operator (*) like the example below.
```
int y = 100;
int *x = &y;
cout << "Memory Address " << x << " Value " << *x;
//Memory Address 0x7fffa5778f94 Value 100
```
In the example above pointer x points to variable y. The variables hold the same memory address. If the value of x would have change, so does y. Refer to the example below.
```
int y = 100;
int *x = &y;
*x = 200;
cout << "Value " << y;
//Value 200
```
| iamjajuan |
795,142 | My HNG Goals | Just got accepted into the HNG internship last week which makes me so excited since I didn't complete... | 0 | 2021-08-17T16:53:40 | https://dev.to/yhugoh/my-hng-goals-h8n | hng, internship | Just got accepted into the HNG internship last week which makes me so excited since I didn't complete last year's edition.
My programming journey has been filled with so many ups and downs and trying to stay motivated can be a daunting task and that's where HNG internship comes into play.
You must be wondering what HNG is, HNG internship is a 3-month remote internship designed to find and develop the most talented software developers. This program involves a lot of team collaborations, real world projects and networking with brilliant people.
Newcomers can join the program [here](https://internship.zuri.team)
My main aim in participating in this internship program is to improve on my skills, learn more about applications of various technologies. And I also see this as an opportunity to build resume worthy projects and improve on my collaborative skill.
If you are trying to get your programming journey started, you can follow the links below.
For Design using Figma: [Figma](https://youtu.be/Gu1so3pz4bA)
HTML: [HTML](https://html.spec.whatwg.org/)
GIT tutorial: [Git](https://git-scm.com/docs/gittutorial)
JavaScript: [JS](https://www.youtube.com/watch?v=hdI2bqOjy3c)
Node Js: [Node](https://youtu.be/Oe421EPjeBE)
If you would like to know about this internship, you can click on any of the following links: https://zuri.team or https://internship.zuri.team or https://training.zuri.team. | yhugoh |
795,281 | #100daysofcode [Day - 07] {Weekly Project - 01} | 100daysofcode [Day - 07] {Weekly Project - 01} Today I've made a one-page website using... | 0 | 2021-08-17T17:51:54 | https://dev.to/alsiam/100daysofcode-day-07-weekly-project-01-19ie | webdev, beginners, programming | #100daysofcode [Day - 07] {Weekly Project - 01}
Today I've made a one-page website using bootstrap. you can get details about bikes & also can buy the bike.
still updating the site...!
live preview: https://bike-palace.netlify.app
#javascript #programming #webdevelopement | alsiam |
795,389 | C++ Programming Solutions — Encrypt String | Today we will give you the C++ Programming Solution of Encrypting a String. We are going to encrypt a... | 0 | 2021-08-17T19:34:46 | https://dev.to/hecodesit/c-programming-solutions-encrypt-string-8mm | cpp, cprogramming, coding, codingsolutions | Today we will give you the C++ Programming Solution of Encrypting a String. We are going to encrypt a simple String in C++. The Coding Problem and its Solution are below.
Question
Kathy is a scientist who is developing a machine that creates 5-character long string code. She prefers to encrypt the strings rather than save them as they are. She’s requested you to create software that would accept a 5-character string as input and encrypt it in the format she’s provided.
You must look for the letters in the odd locations of the string and, if they are vowels, you must replace them with _ (underscore).
Example
“hecod” should be “h_c_d”.
“progr” should be “progr”. because odd locations are not vowels.
To Get The Answer Visit https://hecodesit.com/c-programming-solutions-encrypt-string/ | hecodesit |
795,503 | How to use the POISSON.DIST function in Excel office 365? | POISSON.DIST function built-in statistical function returns the probability for the POISSON... | 0 | 2021-08-23T06:17:09 | https://geekexcel.com/how-to-use-the-poisson-dist-function-in-excel-office-365/ | tousethepoissondistf, excel, excelfunctions | ---
title: How to use the POISSON.DIST function in Excel office 365?
published: true
date: 2021-08-17 18:06:57 UTC
tags: ToUseThePOISSONDISTF,Excel,ExcelFunctions
canonical_url: https://geekexcel.com/how-to-use-the-poisson-dist-function-in-excel-office-365/
---
**POISSON.DIST** function **built-in statistical function** returns the **probability for the POISSON distribution**. It takes the 2 arguments with the type of distribution function. Here, we will show the formulas to **use the POISSON.DIST Function In Excel Office 365**. Let’s jump into this article!! Get an official version of ** MS Excel** from the following link: [https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)
## POISSON.DIST Function syntax
```
=POISSON.DIST(x, exp_mean, cumulative)
```
**Syntax Explanation:**
- **x** : **number of events**.
- **exp\_mean** : **expected average or mean value** for the event.
- **cumulative** : **logical value** that determines the form of the function. If **cumulative is TRUE,** **POISSON.DIST returns the cumulative distribution function** ; if **FALSE** , it returns the **probability density function**.
## Example
- Firstly, you need to **create the sample data** with **x number of events** and **expected mean**.
<figcaption>Sample data</figcaption>
- Then, you have to calculate the **cumulative for the POISSON distribution** function.
- Now, you need to use the following **formula** given below.
```
=POISSON.DIST ( B2, B3, FALSE)
```
<figcaption>Cumulative distribution</figcaption>
- After that, you can find out the **probability value for the POISSON distribution** function for the **value at least 5** following the **same parameters** with the formula shown below.
```
=POISSON.DIST ( B2, B3, TRUE)
```
<figcaption>Probability mass distribution</figcaption>
**NOTE:**
- The POISSON.DIST Function only works with **numbers**.
- If any **argument** other than **cumulative is non-numeric** , the function **returns #VALUE! error**.
- The **function returns #NUM! Error**.
- If argument x < 0
- If argument exp\_mean < 0
- Then, the **argument x** event is **truncated to integers if not**.
- Now, the **cumulative argument** can be used with **boolean numbers** (0 and 1) or (FALSE or TRUE).
- After that, the **value in decimal** and **value in percentage id** the same value in Excel and **convert the value to percentage** , if required.
- Finally, you can **feed the arguments** to the **function** directly or using the **cell reference,** as explained in the example.
## Verdict
We hope that this short tutorial gives you guidelines to **use the POISSON.DIST Function In Excel Office 365. ** Please leave a comment in case of any **queries,** and don’t forget to mention your valuable **suggestions** as well. Thank you so much for Visiting Our Site!! Continue learning on **[Geek Excel](https://geekexcel.com/)!! **Read more on [**Excel Formulas**](https://geekexcel.com/excel-formula/) **!!**
**Read Next:**
- **[Excel Formulas to Calculate the Cumulative Loan Interest ~ Easily!!](https://geekexcel.com/excel-formulas-to-calculate-the-cumulative-loan-interest-easily/)**
- **[Formulas to Calculate the Cumulative Loan Principal Payments!!](https://geekexcel.com/excel-formulas-to-calculate-the-cumulative-loan-principal-payments/)**
- **[How to Find the Last Column of Data in Excel Office 365?](https://geekexcel.com/how-to-find-the-last-column-of-data-in-excel-office-365/)** | excelgeek |
795,727 | Overview of Syncfusion Flutter UI Widgets and File Format Packages | Get an overview of Syncfusion's Flutter UI widgets and File Format packages. Flutter is Google’s... | 0 | 2021-08-18T04:04:08 | https://dev.to/syncfusion/overview-of-syncfusion-flutter-ui-widgets-and-file-format-packages-5hhn | flutter, dart, webdev, mobile | Get an overview of Syncfusion's [Flutter UI widgets](https://www.syncfusion.com/flutter-widgets) and File Format packages.
Flutter is Google’s mobile app development SDK that has widgets and tools for creating natively compiled cross-platform mobile and web applications from a single code base. Developed in Dart code from scratch, the Essential Widgets for Flutter include beautifully crafted widgets like [DataGrid](https://www.syncfusion.com/flutter-widgets/flutter-datagrid), [Chart](https://www.syncfusion.com/flutter-widgets/flutter-charts), [Calendar](https://www.syncfusion.com/flutter-widgets/flutter-calendar), [Maps](https://www.syncfusion.com/flutter-widgets/flutter-maps), [Radial Gauge](https://www.syncfusion.com/flutter-widgets/flutter-radial-gauge), [PDF](https://www.syncfusion.com/flutter-widgets/pdf-library), [XlsIO ](https://www.syncfusion.com/flutter-widgets/excel-library)and many more.
This video explains how to go through the tutorial videos, system requirements to use Syncfusion flutter widgets, supported platforms, where to download Syncfusion flutter packages, and how to contact the Syncfusion Support team.
{% youtube FwUSJtv-3NY %} | techguy |
795,768 | I was misguided by the network policy of the office when I try to determine whether the target port of target server is open | I wish the access to 3306 port of the target server was blocked from the internet, but when I test it... | 0 | 2021-08-18T06:02:08 | https://dev.to/icy1900/i-was-misguided-by-the-network-policy-of-the-office-when-i-try-to-determine-whether-the-target-port-of-target-server-is-open-en1 | troubleshooting | I wish the access to 3306 port of the target server was blocked from the internet, but when I test it from my computer and a server in the test environment, it shows the port was open, the test by my co-worker in the other office shows the opposite result. I find out that I change the port to number that definitely have no service use it, or change the ip that may not been owned by a server on the internet, the result is still open, I realise that the network policy of my work place is nothing like I've been used to. | icy1900 |
795,777 | Vue.js - How I call a method in a component from outside the component in Vue 2 | Calling a method in a component outside that component is something we have to do sometimes. But how... | 0 | 2021-08-18T06:43:31 | https://dev.to/jannickholmdk/vue-js-how-to-call-a-method-in-a-component-from-outside-the-component-3c81 | vue, webdev, javascript | Calling a method in a component outside that component is something we have to do sometimes. But how exactly can we do that? Are there multiple ways? What is the best practice?
In this article, I try to answer these questions, show you how i like to do it and give some code examples on how you can implement some of my favorite methods in your Vue app.
Alright let’s get started.
# 1. Using Event Bus
Using an event bus is one way to do it. The event bus can be used in most scenarios: sibling-to-sibling, cousin-to-cousin, parent-to-child, child-to-parent. When it comes to the event bus i would recommend that you use in the case of calling a method in a sibling-to-sibling or cousin-to-cousin scenario, why? Because i do believe that there is other more convenient ways for the other scenarios.
### What is an event bus?
Essentially an event bus is a Vue.js instance that can emit events in one component, and then listen and react to the emitted event in another component.
There are two ways of implementing an event bus in your project:
#### 1. Implementing the event bus as an instance property
An instance property explained in one sentence is a property (or variable) that you wanna make available global for all your components without polluting the global scope.
Okay, that all sounds really cool and all but how do I set it up in my app? Great question, it’s actually fairly simple once you got the hang of it.
```
import Vue from 'vue';
Vue.prototype.$eventBus = new Vue();
```
And you can then access it anywhere in your app like this:
```
this.$eventBus
```
Implementing the event bus as an ES6 module
The other way of implementing an event bus is as an ES6 module. Now it might sound scary at first but stay with me here, it is actually not that difficult and can be done in only a few lines of code.
First, we need to create the ES6 module. So let’s do that:
1. Start by creating a new file in your project called event-bus.js.
2. Then add the following code to the same file:
```
import Vue from 'vue';
const EventBus = new Vue();
export default EventBus;
```
As might have already noticed this is very similar to the instance property. We are creating a variable and then exporting the variable so that we can use it in our app.
Tada!! now we have created an ES6 module. See that wasn’t that bad.
Now, all we have to do is import it to the components that we want to use it in and we’ll import it like this:
```
<script>
import EventBus from './event-bus.js'
export default {
...
}
</script>
```
When we have implemented the event bus in our app we can then emit an event in one of our components like this:
```
<script>
export default {
methods: {
callMethodInChildComponent() {
//As an instance property
this.$eventBus.$emit("callMethodInChild");
//As an ES6 module.
EventBus.$emit("callMethodInChild");
},
},
};
</script>
```
And then in the other component we listen for the event and then executing the method like this:
```
<script>
export default {
mounted() {
//As an instance property
this.$eventBus.$on("callMethodInChild", () => {
this.methodInChild();
});
//As an ES6 module
EventBus.$on("callMethodInChild", () => {
this.methodInChild();
});
},
methods: {
methodInChild() {
//Execute code
},
},
};
</script>
```
## 2. Using $refs
Using the $refs property is a great and simple way of calling a components method from the parent component so to reference the before mentioned scenarios this would be the parent-to-child scenario.
### What are $refs property and how do we use it?
The $refs property is used to reference DOM elements in the Vue instance’s templates.
To use the $refs property assign a reference ID to the child component you want to reference using the ref attribute. For example:
```
<template>
<child-component ref="childComponent"></child-component>
</template>
```
Now we can access the child components methods and then call the method directly from the parent component like this:
```
<script>
export default {
methods: {
callMethodInChildComponent() {
this.$refs.childComponent.methodInChild();
},
},
};
</script>
```
## 3. The good old $emit
The $emit property is the last way of calling a components method outside the component that I will show you in this article.
The scenario for using the $emit property would be when you want to call a method in a parent component from the child component also what I call the child-to-parent scenario.
### What is the $emit property and how do we use it?
The $emit property is used for emitting a custom event from our child component and we can then listen for the same custom event in our parent component.
The $emit property unlike components and props, event names don’t provide any automatic case transformation. Instead, the name of an emitted event must exactly match the name used to listen to that event. For example, if emitting a camelCased event name like “updateItem”, listening to the kebab-cased version “update-item” will have no effect.
Emitting the event in the child component:
```
<script>
export default {
methods: {
callMethodInParentComponent() {
this.$emit("callMethodInParent");
},
},
};
</script>
```
Listening for the event in the parent component:
```
<template>
<child-component v-on:callMethodInParent="callMethodInParent">
</child-component>
</template>
```
# Conclusion
So now that I have shown you some of my favorite ways of calling a components method outside of the component, You might still sit with one question. What is the best practice? And thats completely understandable because i didn’t really answer the question and here is why:
There isn’t one right way to do it since some of the methods mentioned above only work in specific scenarios and therefore the best practice depends so much more than just some guy in an article picking one for you. It depends on what relation does your component have to the component that you want to call the method from, and of course what do you prefer or what is already used in the project your working on.
I hope that you learned something new or maybe this article brought you closer to deciding on which method you want to use for calling a components method outside the component in your project.
If you have any questions put in the comments and i will do my very best to answer, this also applies if you have a fourth (or maybe even a fifth) way of calling a components method outside that component, put it down in the comments so that we can all learn from each other. | jannickholmdk |
795,820 | JavaScript Form Validation and CSS Neumorphism (Video Tutorial) | In the following tutorial we are going to cover JavaScript Client Side Form Validation, CSS... | 0 | 2021-08-18T08:25:32 | https://dev.to/chaoocharles/javascript-form-validation-and-css-neumorphism-video-tutorial-4chb | javascript, css, html, webdev | In the following tutorial we are going to cover JavaScript Client Side Form Validation, CSS Neumorphism and Show/Hide Password.
The source code is available here: https://github.com/chaoocharles/javascript-projects
##The Video Tutorial
{% youtube QPRTgsTkM1k %} | chaoocharles |
806,705 | How to create an institutional Gmail email? | Currently there are many people who are looking for how to create Gmail institutional mail,... | 0 | 2021-08-29T01:47:18 | https://dev.to/giancar58876391/how-to-create-an-institutional-gmail-email-349m | github, googlecloud, webdev, wordpress | Currently there are many people who are looking for how to create Gmail institutional mail, especially because it brings benefits for educational institutions.
Universal Web Peru, puts at your disposal the steps to activate and create institutional emails in Gmail. Therefore, you must first have a domain and hosting to get your email for your college or university, without further ado let's start.
Steps to create an institutional email in Gmail
Now in order to know the steps to create an institutional Gmail email, you must follow the following steps:
Sign in to your Gmail account.
On the main page go to "Settings" and select the nice display density.
Click on the "Accounts" tab.
Click on "Add a POP3 email account of your property".
A new tab will appear, there you must write the address you want to configure and click on "Next".
The form must be completed verbatim. Then, the word "mail" must be entered followed by the domain of the specific institution or company. And ready!
Universal Web has advisors to help you buy your institutional Gmail and activate it. Therefore, write to us at WhatsApp to help you buy institutional Gmail emails.
That is why creating institutional Gmail emails is very simple and uncomplicated. It is important to mention that a verification email will be sent to the account that was configured in order to confirm and activate it.
Advantages of creating institutional email Gmail
It is surprising the multiple modifications that Gmail has so that its users have many facilities. In addition, there are options that can work very well for work or study activities, especially in a digitization stage. https://webuniversal.pe/cableado-estructurado/
Google Meet
Google Meet is one more Google g-suite application. therefore, it is used by teachers, administrators and students through different devices with internet access using the institutional account.
Zoom
Zoom is a calling and video conferencing tools. Ideal for virtual meetings and classes in times of a pandemic. In addition, this application can include up to 1000 participants in a video call.
Gsuite
In an educational context, it is best to turn to G. Suite for education that Gmail offers and do it through it.
That is why creating an institutional Gmail email is so simple, in reality the steps are few and it is really useful. therefore, the ideal way to obtain results through an online medium. | giancar58876391 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.