
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,693,978 | 30 years of DOOM: new code, new bugs | Today marks the 30th anniversary of the first game in the DOOM series! We couldn't miss the event. To... | 0 | 2023-12-11T06:48:17 | https://dev.to/anogneva/30-years-of-doom-new-code-new-bugs-14ho | cpp, gamedev, doom, programming | Today marks the 30th anniversary of the first game in the DOOM series\! We couldn't miss the event\. To honor the occasion, we decided to see what the code of this legendary game looks like after all these years\.

... | anogneva |
1,693,994 | We value your interest in Write for us or as a guest contributor on this website | We value your interest in Write for us or as a guest contributor on this website. Thank you for... | 0 | 2023-12-11T07:17:00 | https://dev.to/blogest123/we-value-your-interest-in-write-for-us-or-as-a-guest-contributor-on-this-website-38e3 |
We value your interest in Write for us or as a guest contributor on this website. Thank you for visiting Blogest. Let me start by noting that readers find Blogest to be very intriguing since we value quality above quantity. You've come to the right place if you want to establish links to other blogs and contacts with ... | blogest123 | |
1,694,051 | Essential guide to WebSocket authentication | Authenticating WebSocket connections from the browser is a lot trickier than it should be. Cookie... | 0 | 2023-12-13T14:15:46 | https://ably.com/blog/websocket-authentication | webdev, learning, security | Authenticating [WebSocket](https://hubs.la/Q02cBJTh0) connections from the browser is a lot trickier than it should be.
Cookie authentication isn’t suitable for every app, and the [WebSocket browser API](https://developer.mozilla.org/en-US/docs/Web/API/WebSocket) makes it impossible to set an `Authorization` header wi... | bookercodes |
1,694,173 | How to Resolve QuickBooks Error 12007? | QuickBooks Desktop has brought an unprecedented boom to the accounting industry by emphasizing growth... | 0 | 2023-12-11T10:44:51 | https://dev.to/axpertaccounting/how-to-resolve-quickbooks-error-12007-1oo | quickbooquickbookserror12007, axpertaccounting | QuickBooks Desktop has brought an unprecedented boom to the accounting industry by emphasizing growth and efficiency across any business. However, what you should not ignore are the countless errors that sometimes prevent you from working efficiently. The special feature of these QuickBooks errors is that each error ca... | axpertaccounting |
1,694,288 | The History of State Management at CodeSandbox | At CodeSandbox, we run your code in our cloud infrastructure, configure the environment for you and... | 0 | 2023-12-11T13:35:41 | https://codesandbox.io/blog/the-history-of-state-management-at-codesandbox | react, redux, learning, showdev | **At CodeSandbox, we run your code in our cloud infrastructure, configure the environment for you and keep your code always ready, behind a shareable URL. Give it a try with [this Next.js example](/p/sandbox/next-js-fxis37?file=/pages/index.tsx) or [import your GitHub repo](/dashboard?import_repo=true)!**
---
## Code... | christianalfoni |
1,695,577 | Embrace Opportunities: Say Yes to Yourself! 🌟🙌 | A post by Arowolo Wahab Abiodun | 0 | 2023-12-12T11:11:15 | https://dev.to/abbeycity500/embrace-opportunities-say-yes-to-yourself-1m52 | selfdevelopment | abbeycity500 | |
1,696,555 | Choisir le Meilleur Résines CBD sans THC : Bienfaits et Recommandations | Le cannabidiol (CBD) est de plus en plus reconnu pour ses bienfaits potentiels sur la santé, tels que... | 0 | 2023-12-13T09:00:25 | https://dev.to/originecbd/choisir-le-meilleur-resines-cbd-sans-thc-bienfaits-et-recommandations-23mn | Le cannabidiol (CBD) est de plus en plus reconnu pour ses bienfaits potentiels sur la santé, tels que la gestion du stress, le soulagement de la douleur, et la réduction de l'anxiété. Pour ceux qui souhaitent profiter des avantages du CBD sans les effets psychoactifs du tétrahydrocannabinol (THC), choisir la [meilleure... | originecbd | |
1,699,590 | How To Delete Old Image While Updating The Post | The Laravel project can go and run well without touching the older files. For this, you will use the... | 0 | 2023-12-16T06:06:18 | https://dev.to/webfuelcode/how-to-delete-old-image-while-updating-the-post-4cn4 | laravel, tutorial, php | The Laravel project can go and run well without touching the older files. For this, you will use the simple update function and update with the new text entered by the user.
The problem may occur when you grow and have thousands of images and files that are not in use.
The site will take time to load and at this time... | webfuelcode |
1,700,292 | 11 AI Libraries To Make You A Coding Wizard In 2024 | Hey there, coding wizard in the making! Want to add some AI magic to your projects? There are some... | 0 | 2023-12-17T12:19:34 | https://learnn.cc/blogs/11-ai-libraries-to-make-you-a-coding-wizard-in-2024 | ai, webdev, python, library | Hey there, coding wizard in the making! Want to add some AI magic to your projects? There are some amazing AI libraries out there that can make you look like a machine learning master.
🧙♂️In this post, we'll introduce you to 11 of the best AI libraries that every developer should know about. Whether you want to buil... | rahxuls |
1,703,308 | AI in 2024: Art Thrives, Open-Source Battles GPT | If only there were a crystal ball with a chatbot inside. *ChatGPT: Tell us what will happen next in... | 0 | 2023-12-20T06:16:17 | https://dev.to/mindsdb/ai-in-2024-art-thrives-open-source-battles-gpt-2nl6 | gpt, sql, bot, ai | If only there were a crystal ball with a chatbot inside.
**ChatGPT: Tell us what will happen next in AI.
**
Will we all be texting telepathically? Popping popcorn and watching AI-generated movies? (A Marvel movie director says that’ll happen in 2025).
The next best thing to a crystal ball: Polling AI founders, indus... | mindsdbteam |
1,707,832 | Python: the making of Secret Santa | Let's practice with a basic Secret Santa generator in Python. What is Secret... | 8,625 | 2023-12-25T12:45:50 | https://dev.to/spo0q/python-the-making-of-secret-santa-5h2i | python, programming, beginners | Let's practice with a basic Secret Santa generator in Python.
## What is Secret Santa?
Secret Santa is a very popular Christmas tradition. The idea is to exchange very cheap but funny gifts with your colleagues or your friends.
There are three mandatory rules:
- each member is assigned to another member **randomly*... | spo0q |
1,722,795 | Build a 3D Earth Globe Model in Three.js (PS: It's easier than you think) 🌏😱 | Introduction & Demo Hop on a fascinating tutorial as I guide you through the... | 0 | 2024-01-10T05:04:48 | https://dev.to/arjuncodess/build-a-3d-earth-globe-model-in-threejs-ps-its-easier-than-you-think-2pod | webdev, javascript, beginners, tutorial | ## Introduction & Demo
Hop on a fascinating tutorial as I guide you through the surprisingly simple process of building a stunning 3D Earth Globe Model using Three.js.
To begin with, I will explain what WebGL & Three.js is and then we will proceed to the build.
[This](https://earth-globe.vercel.app/) is what you will b... | arjuncodess |
1,723,060 | SC900 Dumps | Practice Time Management: SC900 Dumps to practice time management during the exam. Simulate the exam... | 0 | 2024-01-10T11:03:01 | https://dev.to/sumblefew1966/sc900-dumps-3n4o |
Practice Time Management:
<a href="https://shorturl.at/begx5">SC900 Dumps</a> to practice time management during the exam. Simulate the exam conditions as closely as possible, adhering to the time constraints for each section. This helps in refining your strategy for the actual exam day.
Verify Answers and Seek Clari... | sumblefew1966 | |
1,723,065 | Mobile App Vs Web App: Which Is Best in 2024? | If you want to create an app and you're trying to choose between building a web app or a mobile app,... | 0 | 2024-01-10T11:06:36 | https://dev.to/sparkouttech/mobile-app-vs-web-app-which-is-best-in-2024-3ab8 | webdev, javascript, beginners, programming | If you want to create an app and you're trying to choose between building a web app or a mobile app, you're in the right place.This article offers a clear definition of each of them, along with the main differences, pros, and cons of web apps and mobile apps.
It will also give you a definitive answer on what type of ... | sparkouttech |
1,723,190 | Oracle Performance Tuning: Tips, Tricks and Hidden Secrets | Ever wondered why Oracle Performance Tuning is so thrilling for budding Oracle developers and... | 0 | 2024-01-10T12:35:54 | https://dev.to/dbajamey/oracle-performance-tuning-tips-tricks-and-hidden-secrets-561c | oracle | Ever wondered why Oracle Performance Tuning is so thrilling for budding Oracle developers and DBAs?
The answer lies in the art of transforming a sluggish database into a finely-tuned powerhouse. At first, it might seem as complex as decoding a mad scientist’s experiment.
But fear not!
This article is your guide, tur... | dbajamey |
1,723,204 | pydroid | firstly, a big hi. i'm new here. does anyone use (or have used) pydroid3? after the last android... | 0 | 2024-01-10T12:52:53 | https://dev.to/anorieni/pydroid-3cl7 | firstly, a big hi. i'm new here.
does anyone use (or have used) pydroid3? after the last android update, it started acting funny. it doesn't find, nor can it install requests. anyone knows what is this about? thanks | anorieni | |
1,723,229 | Webinar: Shift-Left: Accelerating Quality Assurance in Agile Environments [Experience (XP) Series] | Agile methodologies guide teams to deliver high-quality products efficiently and quickly in the... | 0 | 2024-01-10T13:18:45 | https://dev.to/yashbansal651/webinar-shift-left-accelerating-quality-assurance-in-agile-environments-experience-xp-series-369 | Agile methodologies guide teams to deliver high-quality products efficiently and quickly in the ever-changing software industry. As the demand for rapid innovation increases, QA in the Agile process becomes pivotal. Therefore, by implementing the shift-left concept, quality assurance tasks are moved earlier in the deve... | yashbansal651 | |
1,723,388 | Growing Up with Disney: The Influence on Child Development | For over a century, children have grown up in Disney's charming world, where creativity knows no... | 0 | 2024-01-10T15:38:43 | https://dev.to/huxley133/growing-up-with-disney-the-influence-on-child-development-297b | media, learning, marketing | For over a century, children have grown up in Disney's charming world, where creativity knows no limitations. From the inception of the early Disney Brothers studio in October 1923 to its current status as a media giant, Disney's impact on young minds is indisputable. Some critics have expressed their concerns, saying ... | huxley133 |
1,723,486 | A IA vai nos substituir? | Você acabou de começar no mundo da programação e, ao mesmo tempo que lê notícias de vagas em... | 0 | 2024-01-10T20:44:42 | https://dev.to/giovannibayerlein/ia-vai-nos-substituir-4nc1 | <p>Você acabou de começar no mundo da programação e, ao mesmo tempo que lê notícias de vagas em abundância, também vê profissionais já consolidados abrindo discussões sobre um futuro incerto e sombrio onde as IAs tomarão todos os empregos.</p>
<p>Você então começa a pesquisar o assunto e se depara com diversos materiai... | giovannibayerlein | |
1,723,527 | Ibuprofeno.py💊| #48: Explica este código Python | Explica este código Python Dificultad: Básico ## Reto #48 lista_1 =... | 25,824 | 2024-02-07T14:23:40 | https://dev.to/duxtech/ibuprofenopy-48-explica-este-codigo-python-20h4 | python, spanish, learning, beginners | ## **<center>Explica este código Python</center>**
#### <center>**Dificultad:** <mark>Básico</mark></center>
```py
## Reto #48
lista_1 = ["item1", "item2"]
lista_2 = []
lista_3 = ["item3", "item4"]
print(lista_1 + lista_2 + lista_3)
```
👉 **A.** `['item1', 'item2', [], 'item3', 'item4']`
👉 **B.** `['item1', 'item2... | duxtech |
1,723,592 | Frost warning with Home Assistant 🥶 | Do you have a garden and want to be notified when winter is coming? I'll show you how easy it is... | 0 | 2024-01-10T19:02:58 | https://blog.disane.dev/en/frost-warning-with-home-assistant/ | Do you have a garden and want to be notified when winter is coming? I'll show you how easy it is 🏡
---
Every garden owner will know the problem: _Winter is coming._
... | 0 | 2024-01-11T07:30:19 | https://dev.to/ojasvi/how-to-choosing-the-right-seo-services-for-you-in-2024-24j2 | seo, searchengine, webdev | In the ever-evolving digital landscape of 2024, the importance of Search Engine Optimization (SEO) cannot be overstated. With businesses vying for online visibility and a higher ranking on search engine results pages (SERPs), selecting the Right SEO services is crucial for success. This guide will walk you through key ... | ojasvi |
1,724,088 | natural herbs | All type of pure herbs are available | 0 | 2024-01-11T07:33:19 | https://dev.to/newpansari/natural-herbs-2cn6 | _All type of pure herbs are available_ | newpansari | |
1,724,248 | DevOps Certification Online | In the dynamic landscape of IT and software development, the adoption of DevOps practices has become... | 0 | 2024-01-11T10:39:24 | https://dev.to/leoanthony/devops-certification-online-1a11 | devops, azure, aws | In the dynamic landscape of IT and software development, the adoption of DevOps practices has become a driving force behind innovation and efficiency. As organizations increasingly prioritize this transformative approach, the demand for skilled DevOps professionals has surged. To validate and showcase your proficiency ... | leoanthony |
1,724,256 | Navigating the DevOps Landscape: A Comprehensive Insight into the Modern Software Development Role | In the rapidly evolving world of software development, DevOps professionals stand at the forefront,... | 0 | 2024-01-11T10:50:24 | https://dev.to/annajade1234/navigating-the-devops-landscape-a-comprehensive-insight-into-the-modern-software-development-role-id2 | In the rapidly evolving world of software development, DevOps professionals stand at the forefront, orchestrating seamless workflows and optimizing processes. The DevOps role is a dynamic and collaborative journey that demands a unique blend of technical prowess and interpersonal skills. This exploration delves into th... | annajade1234 | |
1,724,386 | Unleashing the Power of SEO in Lichfield: Choosing the Right SEO Company | In the digital age, establishing a strong online presence is crucial for businesses of all sizes. As... | 0 | 2024-01-11T12:37:02 | https://dev.to/nautilusmarketing/unleashing-the-power-of-seo-in-lichfield-choosing-the-right-seo-company-cn3 | In the digital age, establishing a strong online presence is crucial for businesses of all sizes. As more consumers turn to the internet to discover products and services, the importance of search engine optimization (SEO) cannot be overstated. For businesses in Lichfield, a thriving city with a rich history and a grow... | nautilusmarketing | |
1,724,406 | Vonage Developer Newsletter - December 2023 | Hi! Welcome to our December Newsletter! This month marks an exciting period with the launch of our... | 0 | 2024-01-11T13:01:30 | https://dev.to/vonagedev/vonage-developer-newsletter-december-2023-1gpj | api, vonage, tutorial, news | Hi!
Welcome to our December Newsletter! This month marks an exciting period with the launch of our newest product: Conversations for Salesforce. Enjoy the latest updates and tutorials on all things Vonage Communications APIs. Get ready for an exciting 2024 with events kicking off in January. We hope this season brings... | danielaf |
1,724,860 | Jam Aims to be a QA's Best Friend | (And a developers too) Jam is a browser extension that allows you to create the perfect bug report... | 0 | 2024-01-11T22:06:35 | https://www.bradbodine.dev/posts/jam-aims-to-be-a-qas-best-friend | webdev, qa, management | (And a developers too)
Jam is a browser extension that allows you to create the perfect bug report in just one click.
The goal of Jam is to make bug reporting faster for QA's, faster for developers, and overall pain and frustration free.
Imagine how bugs are reported at a company. The bug finder, many times a QA, cr... | bradbodine-dev |
1,724,901 | How to Delete Files in Python | Photo by Robert Linder on Unsplash Like, lots and lots of files... I work as a web developer... | 0 | 2024-01-17T20:00:00 | https://dev.to/margaretincali/how-to-delete-files-in-python-1g7b | python, programming, beginners | <figcaption>Photo by <a href="https://unsplash.com/@rwlinder?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Robert Linder</a> on <a href="https://unsplash.com/photos/a-row-of-trash-cans-sitting-next-to-a-brick-wall-JLoE-DntHtY?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Unsp... | margaretincali |
1,724,918 | TDD is cheaper | A nod to a recent article from Tim Ottinger with an additional conclusion | 0 | 2024-01-11T23:47:00 | https://dev.to/mbjelac/tdd-is-cheaper-3i6a | tdd | ---
title: TDD is cheaper
published: true
description: A nod to a recent article from Tim Ottinger with an additional conclusion
tags: TDD
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/pjbdtumt89coqtshfpmh.png
# Use a ratio of 100:42 for best results.
published_at: 2024-01-11 23:47 +0000
---
Co... | mbjelac |
1,724,950 | Machine Learning | JavaScript is a programming language that is heavily use in the tech industry. As the tech industry... | 0 | 2024-01-12T00:42:17 | https://dev.to/tiffanyman19/machine-learning-gci | machinelearning, ai, javascript, programming | JavaScript is a programming language that is heavily use in the tech industry. As the tech industry evolves, new trends emerge. One is artificial intelligence, or machine learning. Machine learning, an application of AI, is the process of using models of data to help a program/computer without direct instructions. That... | tiffanyman19 |
1,724,985 | Module Federation in Next.js 14 | Introduction Next.js 14 brings to the table the innovative feature of Module Federation,... | 0 | 2024-01-12T02:06:24 | https://dev.to/lexyerresta/module-federation-in-nextjs-14-13il | webdev, javascript, react, nextjs | ## Introduction
Next.js 14 brings to the table the innovative feature of Module Federation, revolutionizing the way developers approach code sharing and the construction of microfrontend architectures. This article aims to dissect the concept of Module Federation within the Next.js framework, unraveling its impact on c... | lexyerresta |
206,078 | dssdf | A post by isaac calderon | 3,281 | 2019-11-15T21:00:57 | https://app.clickfunnels.com/for_domain/8746876545684864645465468468468hgygu.clickfunnels.com/webinar-registration-page33596330?updated_at=f4a0ace58b63c33c9ccdf1a153d3a210v2&track=0&preview=true | icm654987 | ||
1,724,996 | How to insert a countdown screen in the video that is the same length as the video? | Step 1: Open the software and click where the arrow points to import the video clip. Step 2: Click... | 0 | 2024-01-12T03:17:44 | https://dev.to/shenmuxingjing/how-to-insert-a-countdown-screen-in-the-video-that-is-the-same-length-as-the-video-2nni |
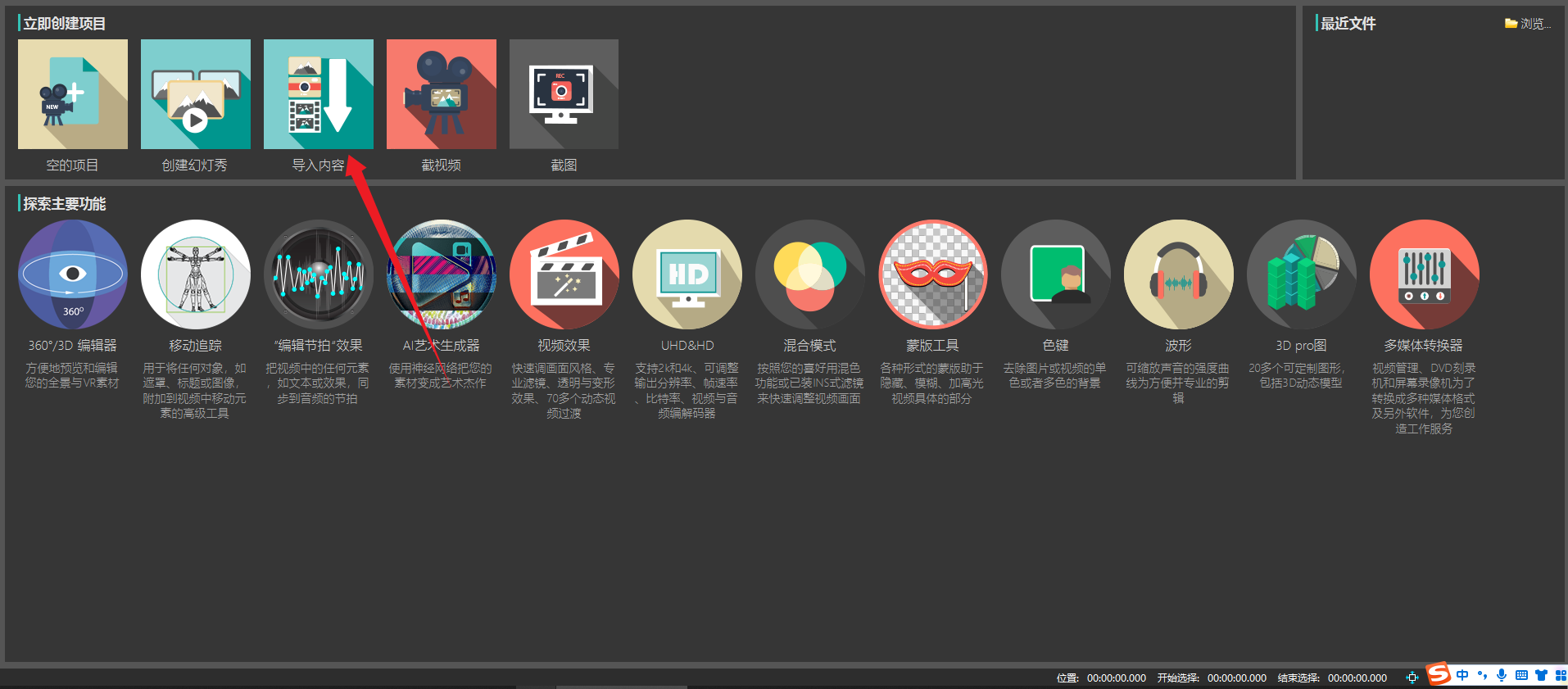
Step 1: Open the software and click where the arrow points to import the video clip.
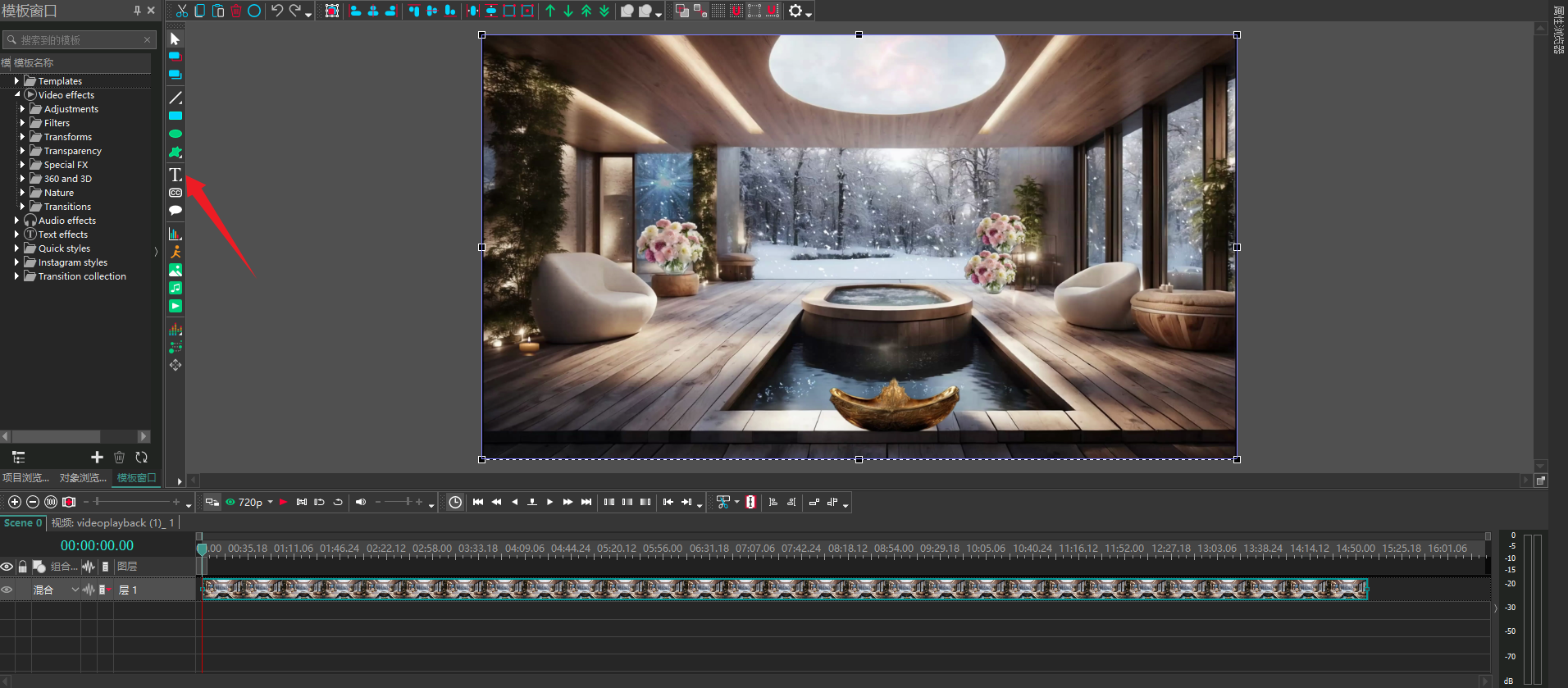
Step 2: Click the counter... | shenmuxingjing | |
1,725,110 | Exploring Next.js Plugins and Middleware | Introduction Next.js, a popular React framework, is known for its flexibility and... | 0 | 2024-01-12T06:10:23 | https://dev.to/lexyerresta/exploring-nextjs-plugins-and-middleware-4am3 | webdev, javascript, react, nextjs | ## Introduction
Next.js, a popular React framework, is known for its flexibility and extensibility, partly due to its rich ecosystem of plugins and middleware. This article aims to explore these enhancements, highlighting how they can significantly extend the functionality and efficiency of Next.js applications. By und... | lexyerresta |
1,725,129 | What Are Top Benefits of Automating Project Management Processes? | Time is of the essence in project management. No wonder project managers are constantly looking for... | 0 | 2024-01-12T06:36:11 | https://dev.to/rafikke_lion/what-are-top-benefits-of-automating-project-management-processes-2c8 | automation | Time is of the essence in project management. No wonder project managers are constantly looking for ways to optimize their workflow and increase productivity.
One solution that has gained popularity in recent years is the use of [automation through project management tools](https://monday.com/blog/project-management/a... | rafikke_lion |
1,725,333 | Hello, dev.to Community! 🚀 | Hey everyone! I just joined Dev.to. This post is to say hello to everyone. I'm here writing under... | 0 | 2024-01-12T10:34:04 | https://dev.to/1geek/hello-devto-community-9j | welcome, welcomenote | Hey **everyone**!
I just joined Dev.to. This post is to say hello to everyone. I'm here writing under the name @1geek . I am a developer, excited about AI, development, game development, and tech.
🌐 Let's build something great together! Share your insights, ask questions, or just drop a comment to say hello. I can't... | 1geek |
1,725,368 | 🌟 5 secret TypeScript repos the top 1% of devs LOVE 🔥 | Hi there 👋 For this week's analysis, we found 5 TypeScript repos adored by the top 1% of... | 0 | 2024-01-12T11:25:07 | https://dev.to/quira/5-secret-typescript-repos-the-top-1-of-devs-love-38eh | typescript, javascript, webdev, programming | Hi there 👋
For this week's analysis, we found **5 TypeScript repos adored by the top 1% of developers**.
Ready to check them out?

---
# How do we identify the "top 1%" of devs? 🔎
At Quira, we rank devel... | fernandezbaptiste |
1,725,386 | Easy Guide to Creating Smart Chatbots with Langchain & GPT-4 | Introduction Langchain is a dynamic Python library revolutionizing natural language... | 0 | 2024-01-12T12:17:50 | https://dev.to/zanepearton/easy-guide-to-creating-smart-chatbots-with-langchain-gpt-4-i5c | webdev, tutorial, ai, python | ###Introduction
Langchain is a dynamic Python library revolutionizing natural language processing, text embedding, document indexing, and information retrieval. Seamlessly integrated with OpenAI's GPT-4, it provides developers with a powerful toolkit. This guide explores Langchain's conversational retrieval model imp... | zanepearton |
1,725,585 | Dissolving with Dignity: Compassionate and Strategic Divorce Guidance in New Jersey | In the challenging landscape of divorce, finding a supportive and strategic guide is essential for... | 0 | 2024-01-12T15:14:20 | https://dev.to/morrisoelliott/dissolving-with-dignity-compassionate-and-strategic-divorce-guidance-in-new-jersey-3j7j |

In the challenging landscape of divorce, finding a supportive and strategic guide is essential for navigating the complex legal terrain. If you're contemplating divorce in New Jersey, you're not alone in seeking com... | morrisoelliott | |
1,725,817 | Pare de culpar e comece a resolver | Para de culpar e comece a resolver... Culpar a si, culpar os outros, justificar cada erro de maneira... | 0 | 2024-01-12T18:48:04 | https://dev.to/lincolixavier/para-de-culpar-e-comece-a-resolver-bgm | career, softskills, discuss, softwareengineering |
_Para de culpar e comece a resolver..._
_Culpar a si, culpar os outros, justificar cada erro de maneira extensa é tiro certeiro pro fracasso tanto pra sua carreira quanto pro seu time atual._
A resolução de problemas é uma habilidade essencial para se destacar no ambiente de trabalho. Um profissional de sucesso não ... | lincolixavier |
1,725,889 | virapanel | I want to introduce a site in the field of sandwich panels ساندویچ پانل سقفی ساندویچ پانل... | 0 | 2024-01-12T21:10:22 | https://dev.to/virapanel/virapanel-h64 | I want to introduce a site in the field of sandwich panels
[ساندویچ پانل سقفی
](https://virapanel.com/sandwich-panel-ceiling/)
[ساندویچ پانل دیواری
](https://virapanel.com/what-is-a-wall-panel-sandwich/)
[قیمت ساندویچ پانل
](https://virapanel.com/sandwich-panel-price/)
[ساندویچ پانل](https://virapanel.com/) | virapanel | |
1,725,922 | What am I? | What am I I am a researcher at heart. Nobody pays me to do research, though. Yet I don’t... | 0 | 2024-01-13T01:27:54 | https://siran.github.io/writing/2023/12/28/what-am-i.html | ---
title: What am I?
published: true
date: 2023-12-28 00:00:00 UTC
tags:
canonical_url: https://siran.github.io/writing/2023/12/28/what-am-i.html
---
# What am I
I am a researcher at heart.
Nobody pays me to do research, though.
Yet I don’t think I want to do anything else. Even improvising music is a type of inn... | anrodriguez | |
1,725,991 | Categorizing Tasks into Five Groups (Bite-size Article) | Introduction I've previously written articles on task management, but as we step into the... | 0 | 2024-01-12T23:28:23 | https://dev.to/koshirok096/categorizing-tasks-into-five-groups-bite-size-article-26o3 | productivity | #Introduction
I've [previously written articles](https://dev.to/koshirok096/how-i-make-daily-task-list-with-logseq-126p) on task management, but as we step into the new year, I'm revisiting my approach to make it more productive and comfortable. While it's not set in stone yet, at this moment, I'm considering refining ... | koshirok096 |
1,726,001 | Diving Into Python's Lambda Functions | Introduction Lambda functions, also known as anonymous functions, are a powerful tool in... | 0 | 2024-01-13T00:30:48 | https://dev.to/kartikmehta8/diving-into-pythons-lambda-functions-2fp2 | python, beginners, programming, tutorial | ## Introduction
Lambda functions, also known as anonymous functions, are a powerful tool in Python for creating small, one-line functions without a formal name. In this article, we will dive into the world of lambda functions in Python and explore their advantages, disadvantages, and features.
## Advantages
One of t... | kartikmehta8 |
1,726,111 | Modules Status Update | New Year, New Challenges, New Possibilities As we step into the year 2024, the Puppet... | 0 | 2024-01-13T18:28:55 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-01-12-modules-status-update/ | puppet, community | ---
title: Modules Status Update
published: true
date: 2024-01-12 00:00:00 UTC
tags: puppet, community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-01-12-modules-status-update/
---
## New Year, New Challenges, New Possibilities
As we step into the year 2024, the Puppet Module... | puppetdevx |
1,726,124 | New tool: sln-items-sync for Visual Studio solution folders | How and why I created sln-items-sync - a dotnet tool to generate SolutionItems from filesystem... | 0 | 2024-01-13T23:19:28 | https://timwise.co.uk/2024/01/13/new-tool-sln-items-sync-for-visual-studio-solution-folders/ | ---
title: New tool: sln-items-sync for Visual Studio solution folders
published: true
date: 2024-01-13 00:00:00 UTC
tags:
canonical_url: https://timwise.co.uk/2024/01/13/new-tool-sln-items-sync-for-visual-studio-solution-folders/
---
How and why I created `sln-items-sync` - a `dotnet tool` to generate SolutionItems ... | timabell | |
1,726,323 | AI APIs: Feedback required | Hi there, We have released a bunch of APIs dealing with images and documents. I am really looking... | 0 | 2024-01-13T11:52:39 | https://dev.to/nikoldimit/ai-apis-feedback-required-g31 | Hi there,
We have released a bunch of APIs dealing with images and documents. I am really looking for people with experience in API development and testing to let me know if they find them useful (hopefully) and what use cases they can think of that would make these APIs shine.
thanks!
have a look here: https://apy... | nikoldimit | |
1,726,603 | Review code | Review code là gì? Review code là một hoạt động quan trọng trong quá trình phát triển... | 0 | 2024-01-28T03:42:06 | https://anhtuank7c.dev/blog/review-code | reviewcode, softwaredevelopment, codequality, qualitycontrol | 
## Review code là gì?
Review code là một hoạt động quan trọng trong quá trình phát triển phần mềm, nơi các đồng nghiệp kiểm tra và đánh giá chéo mã code của nhau.
## Vì sao cần review code?
Việc con người gây ra l... | anhtuank7c |
1,726,647 | I trained a Web Component GPT, but it is not perfect | It is January 2024 We can now create our own GPTs trained with an instruction set. I spent a whole... | 0 | 2024-01-13T21:14:41 | https://dev.to/dannyengelman/i-trained-a-web-component-gpt-but-it-is-not-perfect-2i5f | webcomponents, javascript, dom, frontend | It is January 2024
We can now create our own GPTs trained with an instruction set.
I spent _a whole day_ writing instructions what code GPT should and should not create as JavaScript Web Component output
It still is far from perfect.
But this is getting close to what I expect my students to write.
https://chatgpt-w... | dannyengelman |
1,726,863 | Audiaire – Plugins Bundle (Windows) Download | Discover a world of sonic possibilities with the Audiaire Plugins Bundle for Windows, available now... | 0 | 2024-01-14T09:08:18 | https://dev.to/premiumplugins/audiaire-plugins-bundle-windows-download-42e0 | musicmakers, windowsmusicsoftware, audioproduction, windowssoftware | Discover a world of sonic possibilities with the Audiaire Plugins Bundle for Windows, available now on our site **[Pluginsforest.com](https://telegra.ph/Audiaire--Plugins-Bundle-Windows-Download-01-14)**. Elevate your music production to new heights with this comprehensive collection of cutting-edge audio plugins desig... | premiumplugins |
1,726,872 | Essential Linux Commands for Storage Monitoring | Introduction A fundamental aspect of Linux system administration is managing disk space... | 0 | 2024-01-14T10:08:12 | https://dev.to/duroemmanuel/essential-linux-commands-for-storage-monitoring-1bl5 | ## Introduction
A fundamental aspect of Linux system administration is managing disk space effectively. Understanding how to gauge and monitor available disk space is crucial for maintaining system performance and ensuring the seamless operation of applications.
**In this tutorial, we'll delve into four valuable Linux ... | duroemmanuel | |
1,727,202 | The Art of code understanding: Going beyond copy and paste practices in Programming | In the fast-paced world of programming, the ability to understand code swiftly is a valuable skill... | 0 | 2024-01-14T16:27:43 | https://dev.to/igbodi/the-art-of-code-understanding-going-beyond-copy-and-paste-practices-in-programming-1fdn | programming, codenewbie, webdev |
In the fast-paced world of programming, the ability to understand code swiftly is a valuable skill that can set you apart as a proficient developer. While copy-pasting code snippets may seem like a shortcut to getting things done, it's essential to recognize that true mastery of programming requires a deeper understan... | igbodi |
1,727,220 | BEST BITCOIN RECOVERY SERVICE TO RECOVER SCAMMED BITCOIN HIRE / ADWARE RECOVERY SPECIALIST | Losing $40,000 is a gut-wrenching experience. The pit in your stomach, the sleepless nights, the... | 0 | 2024-01-14T17:18:01 | https://dev.to/eriannaesfahani/best-bitcoin-recovery-service-to-recover-scammed-bitcoin-hire-adware-recovery-specialist-lj5 | Losing $40,000 is a gut-wrenching experience. The pit in your stomach, the sleepless nights, the constant replaying of "what if" scenarios – it's a storm of emotions that can leave you feeling helpless. My own foray into this financial nightmare unfolded when I fell victim to an elaborate online scam. $40,000, gone. Ju... | eriannaesfahani | |
1,727,253 | How can you learn to code and get a job? | If you want to learn how to code, you don't need a fancy degree or certificate – just grab a computer... | 0 | 2024-01-14T17:35:53 | https://dev.to/horsecoder/how-can-you-learn-to-code-and-get-a-job-4mc4 | programming, career, learning, beginners | If you want to learn how to code, you don't need a fancy degree or certificate – just grab a computer and get online.
_Here's a simple PLAN that works:_
1. Stick with one course until you finish it. Don't hop around. Do your <u>homework</u> before picking your course.
2. Every morning, spend 90 minutes learning. Af... | codewithshahan |
1,727,265 | iOS and Android devs, how do you create all sizes of icon for AppStore? | I have a solution that generates all sizes required with just one click. Would be interested to know... | 0 | 2024-01-14T17:48:00 | https://dev.to/lksngy/ios-and-android-devs-how-do-you-create-all-sizes-of-icon-for-appstore-f55 | ios, mobile, android | I have a solution that generates all sizes required with just one click. Would be interested to know how do you handle it now.
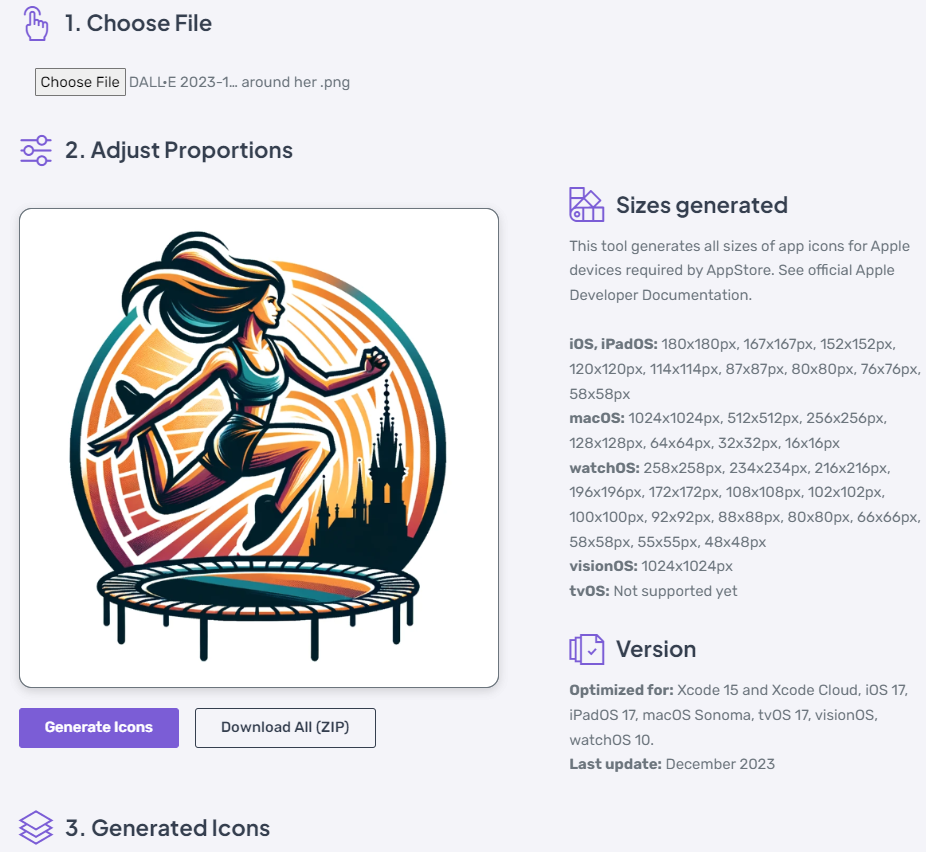
 object and turn it into a <abbr title=... | chasm |
1,727,475 | Git Branch Naming Strategies | Good branch naming in Git is essential for effective project management. This post explores the types... | 0 | 2024-01-15T01:11:36 | https://dev.to/marmariadev/git-branch-naming-strategies-enhancing-software-project-management-5a6a | webdev, programming, git, github | Good branch naming in Git is essential for effective project management. This post explores the types of branches in Git and offers tips for naming them effectively.
## 1. Main Branches
- `main` or `master`: This is the main branch where the source code reflects the current production state.
- `develop` or `dev`: In ... | marmariadev |
1,727,794 | Demystifying Regular Expressions: A Beginner's Guide 🧩 | Regular expressions, often referred to as regex or regexp, are powerful tools for string manipulation and pattern matching in various programming languages. In this article, we'll unravel the basics of regex, providing a foundation for understanding and utilizing this essential skill in your coding endeavors. | 0 | 2024-02-19T18:00:00 | https://dev.to/amatisse/demystifying-regular-expressions-a-beginners-guide-5a06 | tutorial, regex, regular, expression | ---
title: Demystifying Regular Expressions: A Beginner's Guide 🧩
published: true
description: Regular expressions, often referred to as regex or regexp, are powerful tools for string manipulation and pattern matching in various programming languages. In this article, we'll unravel the basics of regex, providing a fou... | amatisse |
1,727,824 | What's Gateway API and how to deploy on AWS? | Co-author: @coangha21 Gateway API is recently standing out to be a promising project that will... | 0 | 2024-01-15T09:15:44 | https://dev.to/haintkit/whats-gateway-api-and-how-to-deploy-on-aws-3ma1 | gatewayapi, kubernetes, aws, vpclattice | Co-author: @coangha21
Gateway API is recently standing out to be a promising project that will change the way we manage traffic in Kubernetes. It is looking forward to being the next generation of APIs used for Ingress, Load Balancing, and Service Mesh functionalities. In today's blog, we will discuss what Gateway AP... | haintkit |
1,728,066 | Navigating the Seas: A Deep Dive into the World of Ships | Ships have been pivotal throughout history, shaping the course of nations and connecting cultures. In... | 0 | 2024-01-15T11:59:51 | https://dev.to/ukazer21/navigating-the-seas-a-deep-dive-into-the-world-of-ships-2p98 | webdev, beginners, tutorial, react | Ships have been pivotal throughout history, shaping the course of nations and connecting cultures. In this article, we embark on a journey through the historical significance of ships and the ever-evolving landscape of shipbuilding technology.
**_[read more](https://aitechai.blogspot.com/2024/01/navigating-seas-deep-di... | ukazer21 |
1,728,398 | Digital Foundations: Exploring the Criteria for Lucknow's Best Web Development Company | In the digital age, a robust online presence is the cornerstone of success for businesses. Lucknow,... | 0 | 2024-01-15T17:49:35 | https://dev.to/csalabs/digital-foundations-exploring-the-criteria-for-lucknows-best-web-development-company-54d | webdevlopmentcompanyinlucknow, webdev, webdesigning |
In the digital age, a robust online presence is the cornerstone of success for businesses. Lucknow, with its burgeoning tech scene, hosts a plethora of web development companies. Let's delve into the essential criteria that define the **[best web development company in Lucknow](https://www.deviantart.com/csalabs/art/B... | csalabs |
1,728,167 | Docker Security Best Practices: Safeguarding Containers with Privileges, Capabilities, and Resource Management | Docker has revolutionized the way we deploy and manage applications, providing a lightweight and... | 0 | 2024-06-02T09:06:50 | https://dev.to/ajeetraina/docker-security-best-practices-safeguarding-containers-with-privileges-capabilities-and-resource-management-2dk1 | Docker has revolutionized the way we deploy and manage applications, providing a lightweight and portable solution for containerization. However, with great power comes great responsibility, especially when it comes to security. In this blog post, we will explore key Docker security best practices related to privileges... | ajeetraina | |
1,728,229 | 1 of 90 days to learning to become a better dev. | I am freelancer web dev, front-end developer with small experiences in the work field as finding... | 0 | 2024-01-15T15:12:03 | https://dev.to/markhov234/1-of-90-days-to-learning-to-become-a-better-dev-57gb | I am freelancer web dev, front-end developer with small experiences in the work field as finding something as a junior can be challenging. So as i am trying to reach my dream that is to be a web-dev or a full-stack developer, i thought learning DevOps could help me personally and professionally.
**What is DevOps** : ... | markhov234 | |
1,728,262 | API Guide to Setup OTP SMS Verification | Requirements If you want to send OTP SMS or enable SMS verification, you need to Register... | 0 | 2024-01-15T15:52:37 | https://dev.to/alinaj/api-guide-to-setup-otp-sms-verification-4ck2 | otp, sms, smsverification | ## Requirements
If you want to send OTP SMS or enable [SMS verification][1], you need to Register and [create an account with Verify Now][2] console.messagecentral.com/signUp Have a valid balance in your account to send OTPs.
You can use the test credits during integration to verify our services or test our [SMS verifi... | alinaj |
1,728,357 | 6 Amazing Headers for Freelancer/Agency Website | Design link : https://www.figma.com/community/file/1328662399939962106 Design link :... | 25,911 | 2024-01-15T16:58:44 | https://www.figma.com/community/file/1328662399939962106 | webdev, beginners, design, react |
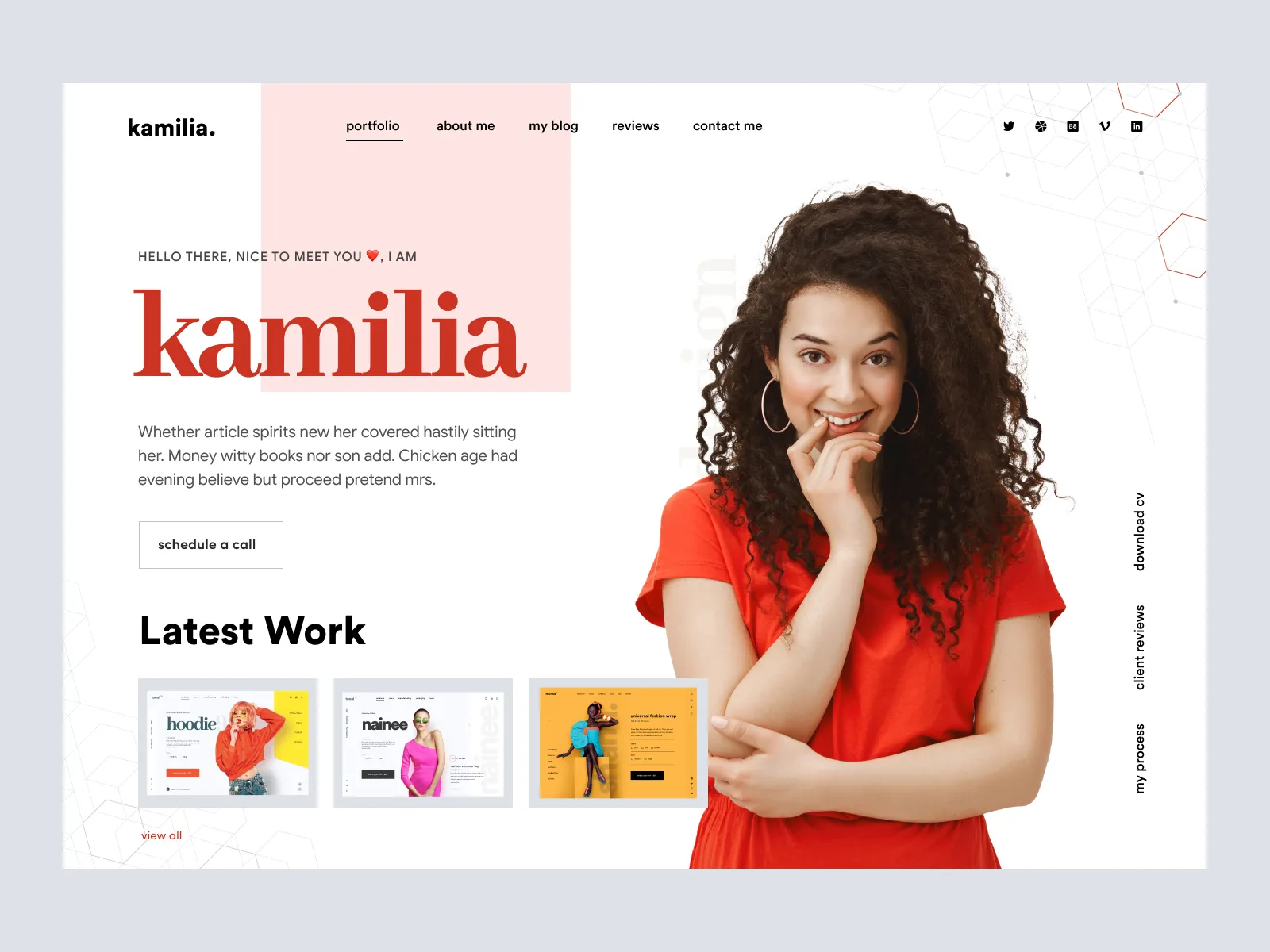
1. Design link : https://www.figma.com/community/file/1328662399939962106
---
2. Design link : https://ww... | codingcss |
1,798,357 | Tuning system performance | Sistem Penyetelan Administrator sistem dapat mengoptimalkan kinerja sistem dengan menyesuaikan... | 0 | 2024-03-23T04:08:11 | https://dev.to/mhmmdrafii/tuning-system-performance-2o31 | ramadhanbersamaredhat | **Sistem Penyetelan**
Administrator sistem dapat mengoptimalkan kinerja sistem dengan menyesuaikan berbagai pengaturan perangkat berdasarkan berbagai beban kerja kasus penggunaan. Daemon tunedmenerapkan penyesuaian penyetelan baik secara statis maupun dinamis, menggunakan profil penyetelan yang mencerminkan persyarata... | mhmmdrafii |
1,728,467 | How to Build a Stepper Component in React 🤔 ? | What is Stepper Component in React ? The Stepper component enables the user to create a... | 0 | 2024-01-15T19:46:03 | https://dev.to/nonish/how-to-build-a-stepper-component-in-react--3495 | react, scss, stepper, machinecoding | ## What is Stepper Component in React ?
- The Stepper component enables the user to create a sequence of logical steps that visualises progress.
- It could also be used for navigation purposes.
#### Key Features
- **Display Modes**—The various display modes allow you to configure the step layout and type.
- **Linear ... | nonish |
1,728,512 | BITCOIN AND CRYPTO RECOVERY COMPANY | I’m highly recommending SpyWeb Cyber Security Service for your Bitcoin, crypto, and digital assets... | 0 | 2024-01-15T20:45:18 | https://dev.to/garci/bitcoin-and-crypto-recovery-company-4odi | I’m highly recommending SpyWeb Cyber Security Service for your Bitcoin, crypto, and digital assets recovery. This company was able to help me recover all my crypto that was stolen from me in less than 72 hours. It is very important to carry out enough research about the crypto market before investing in it, I was one o... | garci | |
1,728,566 | Curso De Front-End Gratuito E Online Da Alura | Explore e aprimore suas habilidades em Front-end através de um projeto prático. Em cinco aulas... | 0 | 2024-01-27T02:05:24 | https://guiadeti.com.br/curso-front-end-gratuito-online-alura/ | cursogratuito, cursosgratuitos, desenvolvimento, frontend | ---
title: Curso De Front-End Gratuito E Online Da Alura
published: true
date: 2024-01-15 18:34:15 UTC
tags: CursoGratuito,cursosgratuitos,desenvolvimento,frontend
canonical_url: https://guiadeti.com.br/curso-front-end-gratuito-online-alura/
---
Explore e aprimore suas habilidades em Front-end através de um projeto pr... | guiadeti |
1,728,624 | Now is the opportunity to be part of an exceptional technology community | Now is the opportunity to be part of an exceptional technology community Global community! If you... | 0 | 2024-01-15T23:50:02 | https://dev.to/basel5001/now-is-the-opportunity-to-be-part-of-an-exceptional-technology-community-d8g | Now is the opportunity to be part of an exceptional technology community Global community!
If you want to explore and be part of this technological community, join the hashtag#awscommunitybuilders AWS Community Builder program and delve into the world of technology, innovation, and individual cooperation.
In additi... | basel5001 | |
1,728,646 | How to Create and Use a Custom ResultMatcher for Date Testing with MockMvc | In this tutorial, you will learn how to create a custom ResultMatcher for MockMvc, to suit your... | 0 | 2024-01-17T12:00:00 | https://springmasteryhub.com/2024/01/17/how-to-create-and-use-a-custom-resultmatcher-for-date-testing-with-mockmvc/ | tutorial, java, testing, spring |
In this tutorial, you will learn how to create a custom ResultMatcher for MockMvc, to suit your project needs.
Imagine you are testing an API and the response contains a date. And you want to check if the response date is valid.
So you have a test assertion that checks for an exact date and time. But for some reason... | tiuwill |
1,728,782 | Choosing the Right Coverall Color: More Than Aesthetics, It's About Safety | Introduction: When it comes to personal protective equipment (PPE), the color of coveralls may seem... | 0 | 2024-01-16T05:05:19 | https://dev.to/sim_chanda/choosing-the-right-coverall-color-more-than-aesthetics-its-about-safety-ej9 | coverallsmarket, marketsteategy, markettrends, marketinsights |

Introduction:
When it comes to personal protective equipment (PPE), the color of coveralls may seem such as a minor consideration compared to factors such as material and fit. However, the choice of coverall color... | sim_chanda |
1,728,792 | 2024 AWS Community Builders Application Form is now live | Hi All, I am happy to share you all, I hope it will be good news for the aws cloud community... | 0 | 2024-01-16T05:38:07 | https://dev.to/santhakumar_munuswamy/2024-aws-community-builders-application-form-is-now-live-53d7 | aws, awscommunitybuilders, ai, machinelearning | Hi All,
I am happy to share you all, I hope it will be good news for the aws cloud community peoples and it is a time to apply for the aws community builders program.
What is AWS Community Builders?
The AWS Community Builders program offers technical resources, education, and networking opportunities to AWS technica... | santhakumar_munuswamy |
1,728,835 | Vue Basis: Navigating Through Your App with Vue Router | Check this post in my web notes Unlocking the full potential of your Vue.js projects involves... | 0 | 2024-01-16T06:56:53 | https://webcraft-notes.com/blog/vue-basis-navigating-through-your-app-with | vue, webdev, beginners, tutorial |

> Check [this post](https://webcraft-notes.com/blog/vue-basis-navigating-through-your-app-with) in [my web notes](https://webcraft-notes.com/)
Unlocking the full potential of your Vue.js ... | webcraft-notes |
1,728,915 | assertTrue() in Java: A Complete Tutorial | Assertions are an important part of the automation testing process, ensuring the software functions... | 0 | 2024-01-16T07:53:47 | https://www.lambdatest.com/blog/asserttrue-in-java/ | asserttrue, javascript, automationtesting, softwaretesting | Assertions are an important part of the automation testing process, ensuring the software functions as anticipated. If it is not working as desired, the tests have to be marked as failure and need to be halted to make the necessary investigation for the failure.
An assertion statement helps to test the assumption abou... | faisalkhatri123 |
1,729,429 | Buy Google 5 Star Reviews | https://dmhelpshop.com/product/buy-google-5-star-reviews/ Buy Google 5 Star Reviews Reviews... | 0 | 2024-01-16T09:20:10 | https://dev.to/ronrobinsonofficeal/buy-google-5-star-reviews-9 | programming, react, python, tutorial | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-google-5-star-reviews/\n\n\nBuy Google 5 Star Reviews\nReviews represent the opinions of experienced customers who have utilized services or purchased products from various online or offline markets. These reviews convey customer demands and opinions, and ratings are assigned based on the quality of the products or services and the overall user experience. Google serves as an excellent platform for customers to leave reviews since the majority of users engage with it organically. When you purchase Buy Google 5 Star Reviews, you have the potential to influence a large number of people either positively or negatively. Positive reviews can attract customers to purchase your products, while negative reviews can deter potential customers.\n\nIf you choose to Buy Google 5 Star Reviews, people will be more inclined to consider your products. However, it is important to recognize that reviews can have both positive and negative impacts on your business. Therefore, take the time to determine which type of reviews you wish to acquire. Our experience indicates that purchasing Buy Google 5 Star Reviews can engage and connect you with a wide audience. By purchasing positive reviews, you can enhance your business profile and attract online traffic. Additionally, it is advisable to seek reviews from reputable platforms, including social media, to maintain a positive flow. We are an experienced and reliable service provider, highly knowledgeable about the impacts of reviews. Hence, we recommend purchasing verified Google reviews and ensuring their stability and non-gropability.\n\nLet us now briefly examine the direct and indirect benefits of reviews:\nReviews have the power to enhance your business profile, influencing users at an affordable cost.\nTo attract customers, consider purchasing only positive reviews, while negative reviews can be acquired to undermine your competitors. Collect negative reports on your opponents and present them as evidence.\nIf you receive negative reviews, view them as an opportunity to understand user reactions, make improvements to your products and services, and keep up with current trends.\nBy earning the trust and loyalty of customers, you can control the market value of your products. Therefore, it is essential to buy online reviews, including Buy Google 5 Star Reviews.\nReviews serve as the captivating fragrance that entices previous customers to return repeatedly.\nPositive customer opinions expressed through reviews can help you expand your business globally and achieve profitability and credibility.\nWhen you purchase positive Buy Google 5 Star Reviews, they effectively communicate the history of your company or the quality of your individual products.\nReviews act as a collective voice representing potential customers, boosting your business to amazing heights.\nNow, let’s delve into a comprehensive understanding of reviews and how they function:\nGoogle, with its significant organic user base, stands out as the premier platform for customers to leave reviews. When you purchase Buy Google 5 Star Reviews , you have the power to positively influence a vast number of individuals. Reviews are essentially written submissions by users that provide detailed insights into a company, its products, services, and other relevant aspects based on their personal experiences. In today’s business landscape, it is crucial for every business owner to consider buying verified Buy Google 5 Star Reviews, both positive and negative, in order to reap various benefits.\n\nSince both positive and negative reviews have an impact on online businesses and trading activities, it is important to determine which type of reviews align with your objectives. If your aim is to influence potential customers online and attract organic traffic, then investing in positive Buy Google 5 Star Reviews is recommended. However, it is crucial to prioritize security and only purchase verified Google reviews. On the other hand, if you wish to acquire negative Google reviews, it is advisable to first gather relevant feedback and reviews.\n\nWhy are Google reviews considered the best tool to attract customers?\nGoogle, being the leading search engine and the largest source of potential and organic customers, is highly valued by business owners. Many business owners choose to purchase Google reviews to enhance their business profiles and also sell them to third parties. Without reviews, it is challenging to reach a large customer base globally or locally. Therefore, it is crucial to consider buying positive Buy Google 5 Star Reviews from reliable sources. When you invest in Buy Google 5 Star Reviews for your business, you can expect a significant influx of potential customers, as these reviews act as a pheromone, attracting audiences towards your products and services. Every business owner aims to maximize sales and attract a substantial customer base, and purchasing Buy Google 5 Star Reviews is a strategic move.\n\nAccording to online business analysts and economists, trust and affection are the essential factors that determine whether people will work with you or do business with you. However, there are additional crucial factors to consider, such as establishing effective communication systems, providing 24/7 customer support, and maintaining product quality to engage online audiences. If any of these rules are broken, it can lead to a negative impact on your business. Therefore, obtaining positive reviews is vital for the success of an online business. To attract a large customer base, it is necessary to purchase Buy Google 5 Star Reviews for both local and international markets. Additionally, buying reviews from other platforms can further boost your business profile.\n\nWhat are the benefits of purchasing reviews online?\nIn today’s fast-paced world, the impact of new technologies and IT sectors is remarkable. Compared to the past, conducting business has become significantly easier, but it is also highly competitive. To reach a global customer base, businesses must increase their presence on social media platforms as they provide the easiest way to generate organic traffic. Numerous surveys have shown that the majority of online buyers carefully read customer opinions and reviews before making purchase decisions. In fact, the percentage of customers who rely on these reviews is close to 97%. Considering these statistics, it becomes evident why we recommend buying reviews online. In an increasingly rule-based world, it is essential to take effective steps to ensure a smooth online business journey.\n\nBuy Google 5 Star Reviews\nMany people purchase reviews online from various sources and witness unique progress. Reviews serve as powerful tools to instill customer trust, influence their decision-making, and bring positive vibes to your business. Making a single mistake in this regard can lead to a significant collapse of your business. Therefore, it is crucial to focus on improving product quality, quantity, communication networks, facilities, and providing the utmost support to your customers.\n\nReviews reflect customer demands, opinions, and ratings based on their experiences with your products or services. If you purchase Buy Google 5-star reviews, it will undoubtedly attract more people to consider your offerings. Google is the ideal platform for customers to leave reviews due to its extensive organic user involvement. Therefore, investing in Buy Google 5 Star Reviews can significantly influence a large number of people in a positive way.\n\nHow to generate google reviews on my business profile?\nFocus on delivering high-quality customer service in every interaction with your customers. By creating positive experiences for them, you increase the likelihood of receiving reviews. These reviews will not only help to build loyalty among your customers but also encourage them to spread the word about your exceptional service. It is crucial to strive to meet customer needs and exceed their expectations in order to elicit positive feedback. If you are interested in purchasing affordable Google reviews, we offer that service.\n\nOnce you have established a strong rapport with your customers through the provision of quality service, kindly request them to share their experiences on Google voluntarily. You can provide them with a direct link or clear instructions on how to leave a review. If possible, offering them a written script can simplify the process for them. Additionally, we offer the option to buy online reviews from us at a reasonable price, with a 100% replacement and cash back guarantee.\n\nIt is essential to reply or respond to the customer opinions left as reviews promptly. Make it easy for customers to leave reviews by prominently displaying review options on your website and social media profiles. Furthermore, consider offering incentives to customers who assist you by leaving reviews, such as providing them with better service at a discounted price.\n\nAlternatively, if you are interested in generating verified Buy Google 5 Star Reviews for your website, you can quickly reach out to dmhelpshop.com. Our team of experts is readily available to help you purchase verified Google reviews at cost-effective prices.\n\nNow, let’s discuss how Google reviews work and the value they add.\nAccording to research conducted by various platforms in the field of online marketing, users tend to engage with reviews that they perceive as authentic. Once a review is submitted, it undergoes a moderation process to ensure compliance with Google’s content guidelines. Another study reveals that many individuals rely on reviews to inform their purchasing decisions. By purchasing online reviews from a trustworthy source, you can significantly enhance your business’s reputation in a short period of time.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | ronrobinsonofficeal |
1,731,106 | Technical Writing Guidelines to Create AI-Friendly Content | The widespread adoption of artificial intelligence is fundamentally changing how people engage with... | 0 | 2024-01-16T10:22:32 | https://dev.to/ragavi_document360/technical-writing-guidelines-to-create-ai-friendly-content-k8k | The widespread adoption of artificial intelligence is fundamentally changing how people engage with information. Technological advancements, including Generative AI tools like ChatGPT and Bard, are reshaping the behaviors of content consumers. This shift is characterized by the following patterns:
- Increased efficien... | ragavi_document360 | |
1,731,117 | React Forms: Controlled and Uncontrolled Components. | React provides developers with two main approaches to handling form data: controlled and uncontrolled... | 0 | 2024-01-16T10:36:41 | https://dev.to/delaquash/react-forms-controlled-and-uncontrolled-components-3kcm | webdev, react, javascript, frontend | React provides developers with two main approaches to handling form data: controlled and uncontrolled forms. In most cases, the recommended method by the React teams for forms are the controlled method, although the uncontrolled method is still valid, it gives less flexibility compared to the controlled form.
## Contr... | delaquash |
1,731,188 | DIY Customization: Transform Your Plain Sweatshirt into a Fashion Statement | Are you tired of wearing plain and boring sweatshirts? Do you want to stand out from the crowd and... | 0 | 2024-01-16T12:09:11 | https://dev.to/isrealwelch/diy-customization-transform-your-plain-sweatshirt-into-a-fashion-statement-3i4p | Are you tired of wearing plain and boring sweatshirts? Do you want to stand out from the crowd and make a fashion statement? Look no further! In this blog post, we will guide you through the process of transforming your plain **[sweatshirt](https://www.meant2bekids.com/)** into a unique and stylish piece that will turn... | isrealwelch | |
1,731,270 | Legacy Electrical : Electrician Nottingham and EICR Nottingham | When it comes to electrical requirements, Legacy Electrical stands out as the definitive choice,... | 0 | 2024-01-16T12:57:21 | https://dev.to/business123/legacy-electrical-electrician-nottingham-and-eicr-nottingham-466a | eicr, electrical | When it comes to electrical requirements, Legacy Electrical stands out as the definitive choice, excelling in Electrician services in Nottingham and EICR services. Our highly skilled professionals are dedicated to providing top electrical solutions, emphasizing safety, compliance, and efficiency.
Why Choose Legacy[ El... | business123 |
1,731,356 | 7 Alternatywy dla interfejsów API REST | Siedem alternatyw REST, które musisz znać i najczęstsze przypadki użycia, które wspierają ich użycie w terenie. | 0 | 2024-01-16T14:22:18 | https://dev.to/pubnub-pl/7-alternatywy-dla-interfejsow-api-rest-b28 | Representational State Transfer (REST) to styl architektoniczny i protokół do tworzenia usług internetowych. Jest to popularne podejście do projektowania interfejsów programowania aplikacji internetowych (API), ponieważ kładzie nacisk na skalowalność, prostotę i możliwość modyfikacji.
W przeciwieństwie do ścisłych ram... | pubnubdevrel | |
1,731,386 | Troubleshoot Windows Server 2012 Arc-enabled servers not receiving updates | If your Windows Server 2012 servers that are Arc-enabled to receive their Extended Security Updates... | 0 | 2024-01-16T15:08:41 | https://www.techielass.com/troubleshoot-windows-server-2012-arc-enabled-servers-not-receiving-updates/ | azure, windows | 
If your Windows Server 2012 servers that are [Arc-enabled](https://www.techielass.com/tags/azure-arc) to recei... | techielass |
1,731,420 | Decoding the Myth of 'Junior' in DevOps and SRE: Navigating Challenges and Cultivating Expertise | In my view, assigning roles such as 'Junior DevOps' and 'Junior SRE (Site Reliability Engineer)'... | 0 | 2024-01-16T15:38:01 | https://dev.to/edersonbrilhante/decoding-the-myth-of-junior-in-devops-and-sre-navigating-challenges-and-cultivating-expertise-4bmk | beginners, devops, discuss, career | In my view, assigning roles such as **'Junior DevOps'** and **'Junior SRE (Site Reliability Engineer)'** seems impractical, reminiscent of labeling someone an **'Entry-Level Software Architect.'**
## Navigating the intricate landscape
Navigating the intricate landscape of DevOps and SRE demands proficiency in **codin... | edersonbrilhante |
1,731,425 | Desvendando a Certificação Amazon Practitioner 2024: Um Relato e Dicas de Estudo | Um pouco sobre mim: Meu nome é Hudson, sou desenvolvedor frontend e Mobile na OPEN... | 0 | 2024-01-19T03:41:00 | https://dev.to/hudson3384/desvendando-a-certificacao-amazon-practitioner-2024-um-relato-e-dicas-de-estudo-b1m | aws, programming, certification, linux |
## Um pouco sobre mim:
Meu nome é Hudson, sou desenvolvedor frontend e Mobile na OPEN Datacenter, e busco compartilhar conhecimentos sobre minha área e aquelas em que tenho interesse em atuar. Estudo áreas como backend, DevOps, Linux e automações.
## O que é o Amazon Practitioner:
O Amazon Practitioner é uma certi... | hudson3384 |
1,731,452 | INTRODUCTION TO DEVREL | The practice of developing a mutually advantageous connection between software engineers and... | 0 | 2024-01-16T16:11:54 | https://dev.to/mgorretti/introduction-to-devrel-53gg | The practice of developing a mutually advantageous connection between software engineers and organizations is known as developer relations, or DevRel.
Put another way, it's a set of techniques and approaches that assist businesses in improving their collaboration with software engineers. What developer relations teams... | mgorretti | |
1,731,661 | Showcase on LinkedIn | Would you like to showcase your favorite piece of work on linkedIn ? Have a look at the below video... | 0 | 2024-01-16T19:49:51 | https://dev.to/tanmaybanerjee/showcase-on-linkedin-21k2 | linkedin, showcase, skills | Would you like to showcase your favorite piece of work on linkedIn ?
Have a look at the below video and support for more such info!
[](https://www.youtube.com/watch?v=MQiypu7kAPE) | tanmaybanerjee |
1,731,688 | Your Best Guide to Becoming a Developer Advocate | Developer Advocate, Developer Success, Developer Experience, Developer Evangelist, Developer... | 0 | 2024-01-16T22:04:24 | https://dev.to/arshadayvid/your-best-guide-to-becoming-a-developer-advocate-1ij3 | devrel, discuss, beginners, tutorial | Developer Advocate, Developer Success, Developer Experience, Developer Evangelist, Developer Community Manager, Developer Programs Engineer, etc, are relatively new job titles that have been flying around within the tech ecosystem for some time now. What exactly do these job titles mean? Do they all mean the same thing... | arshadayvid |
1,731,706 | AdQure Copywriting Services (ACS) | AdQure offers marketing solutions that empower service providers and small- to medium-sized business... | 0 | 2024-01-16T21:03:07 | https://dev.to/adqure/adqure-copywriting-services-acs-d2b | webdev, marketing, advertising, seo | AdQure offers marketing solutions that empower service providers and small- to medium-sized business owners to establish themselves as leaders in their respective industries and to grow their internet presence.
| adqure |
1,731,828 | 9 ways to improve how you ship software | 10x developers are real, and there’s more than one way to be a 10x developer. Perhaps the most... | 0 | 2024-01-16T23:58:12 | https://www.flightcontrol.dev/blog/9-ways-to-improve-how-you-ship-software | webdev, devops, programming, engineering |
10x developers are real, and there’s more than one way to be a 10x developer.
Perhaps the most approachable is to make 10 other people 10% more productive.
In this article, I cover things to improve your individual and team productivity. This is valuable to your company, so it will likely help level up your career.... | flybayer |
1,731,868 | REACT COMPONENTS | INTRODUCTION In React, components are like building blocks of a webpage. They are small,... | 0 | 2024-01-17T01:50:00 | https://dev.to/pearlodi/react-components-3oa2 | beginners, react, webdev, programming | ## INTRODUCTION
In React, components are like building blocks of a webpage. They are small, reusable pieces of code that handle specific tasks. Each component is responsible for a particular part of the user interface, making it easier to manage and organize the overall structure of a web application. For example, you ... | pearlodi |
1,731,982 | Learn PHP | Although php language seems to be dying, it is still used by many companies and is widely popular... | 0 | 2024-01-17T04:30:17 | https://dev.to/sagarkattel/learn-php-2ace | Although php language seems to be dying, it is still used by many companies and is widely popular among the legacy codebases of many large companies. It was the language that give rise to the current web development field. Learning PHP can also help you alot in your carrier. I guess these motivation is enough for you g... | sagarkattel | |
1,732,123 | Creating a Custom Abstract User Model in Django | Django provides a default user model that is suitable for most projects. However, as the project... | 0 | 2024-01-17T05:47:11 | https://dev.to/arindam-sahoo/creating-a-custom-abstract-user-model-in-django-p24 | django, python, user, model | Django provides a default user model that is suitable for most projects. However, as the project scales, a customized approach is often required. This guide will demonstrate how to create a custom abstract user model in Django, providing greater flexibility and customization options. This comprehensive tutorial will ta... | arindam-sahoo |
1,732,183 | Boostaro™ Supplement | OFFICIAL WEBSITE - Only $49/Bottle Today | Boostaro has emerged as a robust and natural solution within the competitive landscape of sexual... | 0 | 2024-01-17T07:05:52 | https://dev.to/boostaro/boostaro-supplement-official-website-only-49bottle-today-kpf | healthydebate, sexual, support, supplement | **[Boostaro](https://www.boost-aro.com/)** has emerged as a robust and natural solution within the competitive landscape of sexual health supplements, addressing a range of male sexual health concerns. This powerful supplement takes pride in its ability to enhance sexual drive and improve the quality of erections throu... | boostaro |
1,732,188 | Information Overload and Chasing the trends Can Ruin Your Life: | Information Overload and Chasing the trends Can Ruin Your Life: Zayn and Dawood, were... | 0 | 2024-01-17T07:11:47 | https://dev.to/dev_abdulhaseeb/information-overload-and-chasing-the-trends-can-ruin-your-life-jjl | webdev, beginners, programming, productivity |

## Information Overload and Chasing the trends Can Ruin Your Life:
Zayn and Dawood, were good friends they went to same school lived in the same neighbour hood in a metropolitan city, and when the time came th... | dev_abdulhaseeb |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.