
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,755,378 | THE PRINT() FUNCTION | By the end of this lesson you should be able to: Describe the print function and its... | 26,360 | 2024-02-08T09:45:14 | https://dev.to/dev123/the-print-function-2ii0 | python, beginners, programming, lesson1 |

## By the end of this lesson you should be able to:
1. Describe the print function and its usage as used in python.
2. Write a simple code using the print function.
3. Avoid common errors associated with the print ... | dev123 |
1,755,398 | AI vs ML: Decoding the Tech Jargon in App Development | I. Hey There, Let's Dive In A. Let's Talk AI (Artificial... | 0 | 2024-02-08T10:02:36 | https://dev.to/sofiamurphy/ai-vs-ml-decoding-the-tech-jargon-in-app-development-40l2 | ai, machinelearning | ## I. Hey There, Let's Dive In
### A. Let's Talk AI (Artificial Intelligence)
Artificial Intelligence, or AI for short, is like the tech whiz kid on the block. It's all about making computers smart, enabling them to do things that usually require a human touch. Think problem-solving, learning, understanding languages... | sofiamurphy |
1,755,415 | A Guide to Updating Your Git Repository After Local Code Changes | Git, a powerful version control system, enables developers to collaborate seamlessly and keep track... | 0 | 2024-02-08T10:34:37 | https://dev.to/nikhilxd/a-guide-to-updating-your-git-repository-after-local-code-changes-3bjj | tutorial, github, devops, productivity | _Git, a powerful version control system, enables developers to collaborate seamlessly and keep track of changes in their projects. However, when you make changes to your code locally, it's crucial to update your Git repository to ensure that your team is on the same page and to avoid conflicts. In this blog post, we'll... | nikhilxd |
1,755,453 | The Specificity Of ::slotted() | The ::slotted() pseudo-element allows you to style elements that are slotted into your web component.... | 0 | 2024-02-08T15:25:48 | https://tomherni.dev/blog/the-specificity-of-slotted/ | css, webcomponents | The `::slotted()` pseudo-element allows you to style elements that are slotted into your web component. But, there is something that may catch you off guard: styles applied with `::slotted()` lose to global styles.
Imagine a website with the following markup:
```html
<style>
p { color: blue } /* (0, 0, 1) */
</styl... | tomherni |
1,755,553 | Transforming Chaos into Order: Incident Management Process, Best Practices, and Steps | Did you realize, only 40% of companies with 100 employees or less have an Incident Response plan in... | 0 | 2024-02-08T12:22:57 | https://dev.to/squadcast/transforming-chaos-into-order-incident-management-process-best-practices-and-steps-1h9g | incident, management, process | Did you realize, only 40% of companies with 100 employees or less have an Incident Response plan in place? Does that include you too? Even if it doesn't, this blog post is for you. Explore the Incident Management processes, best practices and steps so you can compare how your current IR process looks like and if you ne... | squadcastcommunity |
1,755,576 | The Top Generative AI Trends for 2024. | In the landscape of digital transformation, artificial intelligence is evolving at an exponential... | 0 | 2024-02-08T12:44:53 | https://dev.to/xcubelabs/the-top-generative-ai-trends-for-2024-2eg | ai, generativeai, generativeaiusecases, aritficalintelligence | In the landscape of digital transformation, artificial intelligence is evolving at an exponential pace, and within it, Generative AI has emerged as a powerful force. As we move into 2024, it’s essential to stay ahead of the curve and understand the latest trends shaping the landscape of Generative AI. In this comprehen... | xcubelabs |
1,755,587 | The 10 minute mail Solution | The 10 minute mail Solution In today's digital age, the concept of disposable temporary e-mail, often... | 0 | 2024-02-08T13:08:43 | https://dev.to/liuxiao/the-10-minute-mail-solution-2328 | 10minutemail, tempmail, 10minmail, 10minemail | The [10 minute mail](https://10-minutemail.com) Solution
In today's digital age, the concept of disposable temporary e-mail, often referred to as 10 minute mail, has gained popularity for its convenience and security benefits. This article delves into what disposable e-mail is, why one might need a fake e-mail address,... | liuxiao |
1,765,676 | ArgoCD Deployment on RKE2 with Cilium Gateway API | Introduction It has already been a couple of years since the Kubernetes Ingress was... | 0 | 2024-02-19T15:24:34 | https://dev.to/egrosdou/argocd-deployment-on-rke2-with-cilium-gateway-api-412n | kubernetes, opensource, tutorial, argocd | ##Introduction
It has already been a couple of years since the Kubernetes [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) was defined as a “frozen” feature while further development will be added to the [Gateway API](https://gateway-api.sigs.k8s.io/).
After initial exposure to the Cilium G... | egrosdou |
1,765,685 | 100 Days of CSS - Day 1 | Check out this Pen I made! | 0 | 2024-02-19T15:43:49 | https://dev.to/patricknjiru/100-days-of-css-day-1-4661 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Patrick-Njiru/pen/MWxxRxp %} | patricknjiru |
1,765,704 | HostPress: Mehr als nur Hosting – Eine Bewertung | Wenn es darum geht, eine erfolgreiche Website zu betreiben, spielt die Wahl des Hostings eine... | 0 | 2024-02-19T16:30:35 | https://dev.to/j0e/hostpress-mehr-als-nur-hosting-eine-bewertung-2cij | hosting, wordpress | Wenn es darum geht, eine erfolgreiche Website zu betreiben, spielt die Wahl des Hostings eine entscheidende Rolle für die Leistung, die Sicherheit und den Gesamterfolg der Website. Vor allem Premium-WordPress-Hosting bietet eine Reihe von Vorteilen, die auf die besonderen Bedürfnisse von WordPress-Websites zugeschnitte... | j0e |
1,765,747 | A pseudo imperative approach for react confirmation dialogs | Hello, this is the first technical article I am writing since we started developing fouriviere.io;... | 0 | 2024-02-20T16:09:08 | https://dev.to/brainrepo/a-pseudo-imperative-approach-for-react-confirmation-dialogs-3jcn | Hello, this is the first technical article I am writing since we started developing fouriviere.io; for more info about the Fourier project, please visit [fourviere.io](https://www.fourviere.io).
The problem I want to discuss regards the **confirmation modal**; we have a few of them in our most complex flows (e.g., fee... | brainrepo | |
1,766,021 | 📍 OPT-NC agencies on Kaggle | ❔ About OPT-NC has many agencies in New-Caledonia, but getting csv files was not as easy... | 26,496 | 2024-02-21T20:00:48 | https://dev.to/optnc/opt-nc-agencies-on-kaggle-4edd | datascience, opendata, python, showdev | ## ❔ About
OPT-NC has [many agencies in New-Caledonia](https://www.opt.nc/service/l-opt-pres-de-chez-moi-trouver-une-agence), but getting `csv` files was not as easy as that, and if you wanted to use data to build datascience, **you had to achieve manual tasks.**
**👉 The purpose of this post is to show how we recent... | adriens |
1,766,049 | TextMine - AI powered knowledge base for business critical documents | TextMine is an E2E AI-powered knowledge base for your business critical documents, including... | 0 | 2024-02-20T03:25:07 | https://dev.to/textmine/textmine-ai-powered-knowledge-base-for-business-critical-documents-559f | b2b, ai, saas | TextMine is an E2E AI-powered knowledge base for your business critical documents, including invoices, payslips, tender documents, compliance reports, and even contracts. Our platform consolidates everything into a single operational layer to enable proactive decision-making. We provide increased data transparency whil... | textmine |
1,768,103 | Is microservice architecture the best choice | Introduction In recent times I have found a lot of articles criticizing microservice... | 0 | 2024-02-21T16:09:46 | https://dev.to/mommcilo/is-microservice-architecture-the-best-choice-3406 | microservices, modular, architecture | ## Introduction
In recent times I have found a lot of [articles](https://thenewstack.io/year-in-review-was-2023-a-turning-point-for-microservices/) criticizing microservice architecture. It is important to understand when and why to use microservice architecture. This kind of approach increases complexity inside the ... | mommcilo |
1,769,650 | Free newsletter for secure development leaders <3 | The latest edition of Secure Development Leaders is out now and shares three essential ingredients... | 0 | 2024-02-22T23:06:10 | https://dev.to/ladynerd/free-newsletter-for-secure-development-leaders-3-2l95 | security, leadership, news, softwareengineering | The latest edition of Secure Development Leaders is out now and shares three essential ingredients for building security culture in your development team.
Highlights:
* The importance of education (and why that's not about technology but motivation)
* Why education without empowerment is bad for your security
* The rol... | ladynerd |
1,770,123 | German veteran Cross returns to national team for Euro 2024 | The German national soccer team has called back "Veteran midfielder" Tony Cross 34, Real Madrid, who... | 0 | 2024-02-23T12:08:52 | https://dev.to/slotmachines92/german-veteran-cross-returns-to-national-team-for-euro-2024-4a2p | The German national soccer team has called back "Veteran midfielder" Tony Cross 34, Real Madrid, who announced his retirement from the national team in 2021 in preparation for the 2024 European Football Championship Euro 2024 in his country in June.
"I decided to play for the German national team again from March. Why... | slotmachines92 | |
1,771,477 | CICD pipelines: Application Developers perspective | This blog presents an alternate view of CICD pipelines with an example of AKS build deployment using... | 0 | 2024-02-26T08:36:55 | https://dev.to/abrarmoiz/cicd-pipelines-application-developers-perspective-5dpa | cicd, aks, githubactions |
This blog presents an alternate view of CICD pipelines with an example of AKS build deployment using GitHub actions.
A simplified view of CI pipeline is to allow developers to relate to and make the CICD pipelines more readable and update or fix any issues quickly in the CICD pipeline. The CI pipeline can be conside... | abrarmoiz |
1,771,491 | Zustand EntityAdapter - An EntityAdapter example for Zustand | Hi there! Recently, I came across this amazing library to manage states in React, called Zustand.... | 26,613 | 2024-03-11T12:25:25 | https://dev.to/michaeljota/zustand-entityadapter-an-entityadapter-example-for-zustand-cd2 | javascript, typescript, react, zustand | Hi there! Recently, I came across this amazing library to manage states in React, called Zustand. This library allows you to create simple stores that can be consumed inside the components like a hook. It's simple to learn and use but also very powerful.
## What's Zustand?
Zustand is a state library with a Flux-like... | michaeljota |
1,771,613 | Learning Rust: A clean start | I've decided it's time to learn Rust and in order to keep myself motivated I'm going to keep a record... | 26,565 | 2024-02-26T21:00:00 | https://dev.to/link2twenty/learning-rust-a-clean-start-4eom | rust, learning, beginners | I've decided it's time to learn [Rust](https://www.rust-lang.org/) and in order to keep myself motivated I'm going to keep a record of how the learning is going here.

A little about me; I'm a web developer and have b... | link2twenty |
1,771,683 | PYTHON - DAY 1.1 - my DOODLE | Write a program to choose a CATEGORY from the LIST and get the value for the... | 0 | 2024-02-25T18:56:39 | https://dev.to/technonotes/python-day-11-whz-n-my-mind-2o2k | ### Write a program to choose a CATEGORY from the LIST and get the value for the same.
**_https://api.chucknorris.io/_**
**_https://api.chucknorris.io/jokes/categories_**

**_https://api.chucknorris.io/jokes/random... | technonotes | |
1,772,406 | CDN's: What are they and how they work and why do we need them? | CDN stands for Content Delivery Network. This thing is used, when we create objects in object... | 0 | 2024-02-26T12:44:30 | https://dev.to/swapnilshelke/cdns-what-are-they-and-how-they-work-and-why-do-we-need-them-3a9c | CDN stands for **Content Delivery Network**.
This thing is used, when we create objects in **object store**, that files will obviously exists somewhere in world. So when we upload files to AWS or any cloud provider that file exists somewhere in world. Somewhere in any server for ex: server in USA.
Now suppose, sudde... | swapnilshelke | |
1,771,923 | All things you need to know about Microsoft Power Automate? | PowerApps Mentor | What is Microsoft Power Automate? Microsoft Power Automate is a cloud-based service that allows users... | 0 | 2024-02-26T03:14:02 | https://dev.to/powerapps_mentor/all-things-you-need-to-know-about-microsoft-power-automate-powerapps-mentor-2n2f | microsoft, microsoft365, powerplatform, powerautomate | **What is Microsoft Power Automate?**
Microsoft Power Automate is a cloud-based service that allows users to automate workflows and tasks across various applications and services without writing extensive code. Formerly known as Microsoft Flow, Power Automate offers a user-friendly interface and a wide range of pre-bui... | powerapps_mentor |
1,772,042 | The importance of having a red test first in test driven development | My name is Kazys Račkauskas, and I'm writing about test-driven development. In this blog post, I want... | 0 | 2024-02-26T06:44:14 | https://easytdd.dev/the-importance-of-having-a-red-test-first-in-test-driven-development | tdd, testing, javascript, dotnet | My name is Kazys Račkauskas, and I'm writing about test-driven development. In this blog post, I want to discuss the importance of starting with a red test. The red-green-refactor cycle is a well-known mantra in test-driven development. To recap:
* Red - write a piece of test code for the functionality you want to imp... | easytdd |
1,772,060 | The Amreen Infotech: Best Digital Marketing Agency To Grow Business | The Amreen Infotech emerges as the Best Digital Marketing Agency To Grow Business, specializing in a... | 0 | 2024-02-26T07:04:11 | https://dev.to/amreeninfotech/the-amreen-infotech-best-digital-marketing-agency-to-grow-business-1jh4 | The Amreen Infotech emerges as the [Best Digital Marketing Agency To Grow Business,](https://www.theamreeninfotech.com/) specializing in a diverse array of services including graphic design, SEO, PPC, web development, and more. With a focus on delivering exceptional results, Their expert team crafts tailored strategies... | amreeninfotech | |
1,772,175 | Private Job vs Government Job: A Comprehensive Comparison | Introduction: The choice between pursuing a career in the private sector or opting for a government... | 0 | 2024-02-26T09:40:29 | https://dev.to/saching/private-job-vs-government-job-a-comprehensive-comparison-3h2b | Introduction:
The choice between pursuing a career in the private sector or opting for a government job is a crucial decision that individuals often grapple with. Both paths come with their own set of advantages and challenges, and making an informed decision requires a careful consideration of various factors.
Job S... | saching | |
1,772,203 | Swap Values of Variables Without Temporary Variable : Python challenge 21 | https://youtu.be/ZG-G_WHxZsk | 0 | 2024-02-26T10:13:03 | https://dev.to/ruthrina/swap-values-of-variables-without-temporary-variable-python-challenge-21-3g80 | https://youtu.be/ZG-G_WHxZsk | ruthrina | |
1,772,422 | 🔮 Adobe Redefines Design - Inside Spectrum 2's Visionary Update | Hey everyone ✌️ Here's a quick look at this week's newsletter: 🚀 Your 2024 Boilerplate 🍎 iOS... | 0 | 2024-02-29T12:50:00 | https://dev.to/adam/adobe-redefines-design-inside-spectrum-2s-visionary-update-n59 | design, css, webdev, javascript |
**Hey everyone** ✌️ Here's a quick look at this week's newsletter:
🚀 Your 2024 Boilerplate
🍎 iOS Scrollbar Solved
🐻 Price Pages with Pizzazz
Enjoy this week's edition 👋 - Adam at Unicorn Club.
---
Sponsored by [Webflow](https://go.unicornclub.dev/webflow)
## [Experience the power of code. Without writi... | adam |
1,772,719 | Summarizer Website using MEAN Stack | Introduction: In today's fast-paced world, dealing with information overload is a common... | 0 | 2024-02-26T18:09:34 | https://dev.to/siddheshuncodes/summarizer-website-using-mean-stack-5hbj | webdev, javascript, programming, tutorial | ## **Introduction:**
In today's fast-paced world, dealing with information overload is a common challenge. Picture having a tool that swiftly summarizes lengthy articles, allowing you to grasp the main points without spending excessive time reading. In this article, we'll walk you through the process of crafting a S... | siddheshuncodes |
1,772,896 | HOW TO USE EOS HYPERION HISTORY NODE | docs.google.com | 0 | 2024-02-26T21:13:02 | https://docs.google.com/document/d/e/2PACX-1vQwi6xYSFoVMWJHYZe5K5JhZajgC3xVyRDYli41Zz0LO1KIrIuA7rrPyjGBQEI16YtJ37Ur7AEO6iCW/pub | {% embed https://docs.google.com/document/d/e/2PACX-1vQwi6xYSFoVMWJHYZe5K5JhZajgC3xVyRDYli41Zz0LO1KIrIuA7rrPyjGBQEI16YtJ37Ur7AEO6iCW/pub %} | ebuka | |
1,772,919 | Understanding AWS Storage: S3 vs. EBS – Use Cases | Introduction Amazon Web Services (AWS) provides a comprehensive suite of cloud storage solutions,... | 26,581 | 2024-02-26T21:51:40 | https://dev.to/nwhitmont/understanding-aws-storage-s3-vs-ebs-use-cases-2jpa | aws, s3, ebs, cloud | **Introduction**
Amazon Web Services (AWS) provides a comprehensive suite of cloud storage solutions, each tailored for specific purposes. Among these, AWS S3 (Simple Storage Service) and AWS EBS (Elastic Block Store) are two of the most widely used. While both are powerful storage technologies, understanding their fu... | nwhitmont |
1,773,082 | 🚀 Unleashing the Power of AWS Lambda for Image Compression in Laravel Application 🚀 | Hey Dev community! 👋 Today, let's explore the magic of AWS Lambda and seamlessly integrate it into a... | 0 | 2024-02-27T04:18:08 | https://dev.to/anwarsr/unleashing-the-power-of-aws-lambda-for-image-compression-in-laravel-application-27fi | lamda, aws, serverless, laravel | Hey Dev community! 👋 Today, let's explore the magic of AWS Lambda and seamlessly integrate it into a Laravel application for uploading raw images to S3 and compressing them on the fly! 🖼️💡
**Step 1: Set Up Your Laravel Application**
Ensure you have a Laravel project up and running. If not, use Composer to create a... | anwarsr |
1,773,151 | Cloudinary to s3 bucket db changes | If you have a database collection that has url field , containing cloudinary or any cloud based... | 0 | 2024-02-27T06:02:14 | https://dev.to/chetan_2708/cloudinary-to-s3-bucket-db-changes-3mp6 | webdev, javascript, node, mongodb | If you have a database collection that has url field , containing cloudinary or any cloud based platform links and you want to shift/ migrate the urls specifically to s3 bucket then you can use this script.
```
query = { $regex: /^https:\/\/res\.cloudinary\.com/i }
const urls = await Audio.find(query).toArra... | chetan_2708 |
1,773,162 | Unleashing the Power of Edge Computing: A Technical Deep Dive | Introduction: In the ever-evolving landscape of computing, edge computing has emerged as a... | 0 | 2024-02-27T06:16:31 | https://dev.to/vikasverma/unleashing-the-power-of-edge-computing-a-technical-deep-dive-8ei | **Introduction**:
In the ever-evolving landscape of computing, edge computing has emerged as a transformative paradigm, promising to revolutionize how we process and analyze data. Unlike traditional cloud computing models that centralize data processing in remote data centers, edge computing distributes computing resou... | vikasverma | |
1,773,685 | Find & Replace in whole folder or all files | Streamlining Code Editing: VS Code and Online Tools for Find & Replace In the world of... | 0 | 2024-02-27T13:47:49 | https://dev.to/sh20raj/find-replace-in-whole-folder-or-all-files-1fo3 | abotwrotethis |
# Streamlining Code Editing: VS Code and Online Tools for Find & Replace
In the world of software development, efficiency and precision are paramount. When working with large codebases, making widespread changes while maintaining accuracy is a challenge. This article explores how the powerful features of Visual Studi... | sh20raj |
1,773,797 | Mautic Open Startup Report #9 - December 2023 | Key points This month has seen a growth in memberships, however we have not met the target... | 0 | 2024-02-27T15:53:22 | https://dev.to/mautic/mautic-open-startup-report-9-december-2023-475e | mautic, opensource, openstartup, marketingautomation | ## Key points
This month has seen a growth in memberships, however we have not met the target we set for our end-of-year financial goals, being just under $38,000 short. The year end saw us with a positive balance of just under $68,000 across our various projects on Open Collective. Greater focus will need to paid to ... | rcheesley |
1,773,819 | Regain Bladder Control: The Latest Treatments for Urinary Incontinence | Do you find yourself constantly worrying about unexpected leaks or feeling embarrassed by your lack... | 0 | 2024-02-27T16:06:21 | https://dev.to/forlooks/regain-bladder-control-the-latest-treatments-for-urinary-incontinence-144j | Do you find yourself constantly worrying about unexpected leaks or feeling embarrassed by your lack of bladder control? Urinary incontinence is a common condition that affects millions of people worldwide, and it can significantly impact your quality of life. The good news is that advancements in medical technology hav... | forlooks | |
1,774,086 | Building a WebSocket Chatroom using Golang and Spread the PubSub Library | We are trying to build a websocket based chatroom. There are two excellent examples of websocket... | 0 | 2024-03-07T13:15:06 | https://dev.to/egemengol/building-a-websocket-chatroom-using-golang-and-spread-the-pubsub-library-2n03 | We are trying to build a websocket based chatroom.
There are two excellent examples of websocket based chatrooms already, let's go over them.
---
[nhooyr/websocket example](https://github.com/nhooyr/websocket/blob/master/internal/examples/chat/chat.go)
The server struct holds a set of subscriber structs, each consi... | egemengol | |
1,774,327 | AI and the future of web and mobile development | AI boom is real this time, unlike many years ago. As a web and mobile developer, I’d like to share... | 0 | 2024-02-28T01:09:53 | https://dev.to/eddiekimdev/ai-and-the-future-of-web-and-mobile-development-2moo | AI boom is real this time, unlike many years ago.
As a web and mobile developer, I’d like to share my prediction for AI and the future development of web and mobile applications.
The LLM-based ChatGPT really changed the way people interact with machines these days. Before the ChatGPT, we use browser for the web, oper... | eddiekimdev | |
1,774,464 | winvnes | Nha cai ca cuoc game online dinh cao nhat moi thoi dai, tai winvn co rat nhieu tro choi nhu: the... | 0 | 2024-02-28T04:26:21 | https://dev.to/winvnes/winvnes-10ce | Nha cai ca cuoc game online dinh cao nhat moi thoi dai, tai winvn co rat nhieu tro choi nhu: the thao, ban ca, no hu, casino, gam bai, da ga, co tuong...vv...
Dia Chi: 1067 D. La Thanh, Lang Thuong, Ba Dinh, Ha Noi, Viet Nam
Email: winvnes@gmail.com
Website: https://winvn.es/
Dien Thoai: (+63)9663292132
#winvn #winvn_c... | winvnes | |
1,774,501 | The Art of Data Migration to commercetools | Introduction Data migration is a critical step for businesses transitioning to cloud-based commerce... | 0 | 2024-02-28T05:59:12 | https://dev.to/nitin-rachabathuni/the-art-of-data-migration-to-commercetools-57c8 | Introduction
Data migration is a critical step for businesses transitioning to cloud-based commerce platforms like commercetools. This process involves moving data from legacy systems or other e-commerce platforms to commercetools, ensuring that the integrity, functionality, and performance of the data are maintained ... | nitin-rachabathuni | |
1,774,536 | Alkaline water has a higher pH level | Health Center Network | Quench your thirst and rejuvenate your body with our Alkaline Water Plant. Through an 8-stage... | 0 | 2024-02-28T06:58:17 | https://dev.to/healthcenternetwork/alkaline-water-has-a-higher-ph-level-health-center-network-3fp7 | alkalinewater, healthandwellness, waterpurifier, alkalinewaterionize | Quench your thirst and rejuvenate your body with our [Alkaline Water Plant](https://www.healthcenternetwork.in/). Through an 8-stage purification process, our water ionizer optimizes pH levels, ensuring clean and refreshing hydration. Experience the benefits of alkaline water and elev

In the rapidly evolving landscape of modern visitor systems, the power of instant host notifications stands out as a game-changer, revolutionizing the way organizations manage and enhance their visitor experiences.... | innomaintcmms |
1,774,879 | "Shedding Pounds: Your Ultimate Guide to Effective Weight Loss Strategies" | Fitspresso Coffee Loophole is a huge industry. That was how to double your effectiveness with... | 0 | 2024-02-28T11:59:43 | https://dev.to/healthinfor31/shedding-pounds-your-ultimate-guide-to-effective-weight-loss-strategies-33en | webdev | Fitspresso Coffee Loophole is a huge industry. That was how to double your effectiveness with Fitspresso Coffee Loophole. Where can mavens receive attractive Fitspresso Coffee Loophole hand-outs? In any respect, I won't explain to you how to use Fitspresso Coffee Loophole. This is how to stop being bothered about somet... | healthinfor31 |
1,774,990 | Top 3 Elixir books that will make you love Elixir even more | Introduction: Beyond the basics I've been using Elixir for about 2 years now and so far I... | 0 | 2024-02-28T12:44:12 | https://dev.to/hoonweedev/top-3-elixir-books-that-will-make-you-love-elixir-even-more-2bi6 | elixir, phoenix, books, concurrency | ## Introduction: Beyond the basics
I've been using Elixir for about 2 years now and so far I can confidently say that it's one of the most practical languages I've ever used. It has a lot of features that make it a joy to work with. It's a functional language, it's concurrent, it's distributed, it's fault-tolerant, an... | hoonweedev |
1,775,072 | Is Hosting on Netlify Going to Bankrupt you? | On Tuesday, February 27, I was casually browsing Reddit, as I often do, when I stumbled on a slightly... | 0 | 2024-02-28T15:00:00 | https://wheresbaldo.dev/tech/netlify/is-hosting-on-netlify-going-to-bankrupt-you | netlify, hosting, webdev, discuss | On Tuesday, February 27, I was casually browsing Reddit, as I often do, when I stumbled on a slightly alarming post in the **r/webdev** subreddit. The post was titled "Netlify just sent me a $104K bill for a simple static site".
You can read [the full post here on Reddit](https://www.reddit.com/r/webdev/comments/1b14b... | mlaposta |
1,775,150 | A Love Letter to the Underrepresented in Tech | Dear "Underrepresented," In my dreams, you are fully represented - unabashedly you. Never need to... | 26,618 | 2024-03-01T12:58:28 | https://dev.to/abbeyperini/a-love-letter-to-the-underrepresented-in-tech-4jj3 | wecoded, inclusion, career, writing | Dear "Underrepresented,"
In my dreams, you are fully represented - unabashedly you. Never need to watch what you say or how you say it. Never asked to be less or more. Never told what you can and can't. Never told what you want and don't want.
I see the way you wake up every morning and draw on that inner well of st... | abbeyperini |
1,775,396 | What are you learning about this weekend? 🧠 | Howdy! 🤠 Hope you're weekend is going well. Whether you're sharpening your JS skills, making PRs to... | 0 | 2024-03-09T12:30:00 | https://dev.to/devteam/what-are-you-learning-about-this-weekend-183o | learning, beginners, discuss | Howdy! 🤠
Hope you're weekend is going well.
Whether you're sharpening your [JS](https://dev.to/t/javascript) skills, making PRs to [your OSS repo of choice](https://github.com/forem/forem) 😉, sprucing up your portfolio, or [writing a new post](https://dev.to/new) here on DEV, we'd like to hear about it.
Learn some... | michaeltharrington |
1,775,568 | Just a simple Songs API using Spring Reactive with Functional Endpoints, Docker and MongoDB | Blocking is a feature of classic servlet-based web frameworks like Spring MVC. Introduced in Spring... | 0 | 2024-02-29T00:55:13 | https://dev.to/daasrattale/just-a-simple-songs-api-using-spring-reactive-with-functional-endpoints-docker-and-mongodb-2hp7 | spring, java, docker, mongodb | Blocking is a feature of classic servlet-based web frameworks like Spring MVC. Introduced in Spring 5, Spring WebFlux is a reactive framework that operates on servers like **Netty** and is completely non-blocking.
Two programming paradigms are supported by Spring WebFlux. Annotations (Aspect Oriented Programming) and ... | daasrattale |
1,775,619 | Mastering Test Data Management: A Strategic Approach | To commence effective test data management, you must first comprehend your testing project’s... | 0 | 2024-02-29T02:49:33 | https://asurascanss.com/mastering-test-data-management/ | test, data, management | 
To commence effective test data management, you must first comprehend your testing project’s specific data requirements: these needs can vary significantly. Thus–given their crucial nature; it is imperative to invest... | rohitbhandari102 |
1,775,686 | Engenharia Reversa: Primeiro Contato - Parte 1 | Você vai praticar engenharia reversa pela primeira vez. "Engenharia reversa", na área de T.I.... | 0 | 2024-03-17T15:22:02 | https://dev.to/ryan_gozlyngg/engenharia-reversa-primeiro-contato-parte-1-2gih | braziliandevs, tutorial, beginners, debugging | Você vai praticar engenharia reversa pela primeira vez.
"Engenharia reversa", na área de T.I. refere-se à engenharia reversa de software, que, a grosso modo, é a prática de entender o funcionamento de um software alheio, "nos mínimos detalhes".
Esse tutorial é uma breve introdução ao uso do **debugger x64dbg**, que é ... | ryan_gozlyngg |
1,775,705 | Avoid These Pitfalls: A Programmer's Guide to Career Success | In the world of programming, success isn't just about writing great code; it's also about avoiding... | 0 | 2024-02-29T04:21:04 | https://www.youtube.com/watch?v=8utVaB4MMwo | programming, beginners, career | In the world of programming, success isn't just about writing great code; it's also about avoiding common pitfalls that can derail your career. Let's explore some key things programmers should avoid for a brighter professional future.
## Neglecting Soft Skills
While technical skills are important, don't overlook the v... | aslisachin |
1,775,706 | AWS cross account access (switch role) | In this tutorial we will switch role delegated to access a resources in different AWS accounts. You... | 0 | 2024-03-11T01:07:10 | https://dev.to/aws-builders/aws-cross-account-access-switch-role-3bn | aws, iam, iamrole | In this tutorial we will switch role delegated to access a resources in different AWS accounts. You share resources in one account with users in a different account. By setting up cross-account access in this way, you don't have to create individual IAM users in each account.
- Access AWS console
- Open Identity and A... | olawde |
1,775,715 | Posca Markers: A Comprehensive Guide to Mastering Fine Art | In the dynamic realm of digital art and non-fungible tokens (NFTs), Bermuda Unicorn stands as a... | 0 | 2024-02-29T04:44:14 | https://dev.to/jackjones9354/posca-markers-a-comprehensive-guide-to-mastering-fine-art-4ip8 |

In the dynamic realm of digital art and non-fungible tokens (NFTs), Bermuda Unicorn stands as a beacon of creativity and innovation. Among its diverse offerings, Posca Markers NFT emerges as a standout piece within... | jackjones9354 | |
1,775,745 | Enhancing Your Experience with WP-Events Manager: Insights and Suggestions | Dear Community, I hope this message finds you well. As someone who passionately teaches Salsa Dance... | 0 | 2024-02-29T05:55:28 | https://dev.to/paulpreibisch/before-you-buy-wp-events-manager-these-3-things-need-to-be-improved-d7p | Dear Community,
I hope this message finds you well. As someone who passionately teaches Salsa Dance in a picturesque beach town in Mexico, I've embarked on a journey that bridges cultures and continents. My unique path—from a Canadian learning Latin dance in Korea, to sharing these vibrant rhythms with both tourists a... | paulpreibisch | |
1,775,771 | Fortifying Your WordPress Arsenal: Essential Strategies for Securing Custom Plugins | WordPress is undeniably one of the most popular content management systems (CMS) globally, powering... | 0 | 2024-02-29T06:51:17 | https://dev.to/jamesmartindev/fortifying-your-wordpress-arsenal-essential-strategies-for-securing-custom-plugins-2mph | wordpress, javascript, programming, devops | WordPress is undeniably one of the most popular content management systems (CMS) globally, powering millions of websites across diverse industries. Its flexibility and ease of use make it a top choice for businesses and individuals alike. However, with great popularity comes great risk, particularly concerning security... | jamesmartindev |
1,776,004 | Cloud Computing 2024: Explore the Future Today! | Stay earlier of the curve in 2024 with our whole analysis of the modern-day-day dispositions,... | 0 | 2024-02-29T11:53:49 | https://dev.to/ecfdataus/cloud-computing-2024-explore-the-future-today-clh | devops, azure, azureai, cloudcomputing | Stay earlier of the curve in 2024 with our whole analysis of the modern-day-day dispositions, possibilities and traumatic situations in cloud computing! Our blog “[Cloud Computing 2024: Key Trends and Challenges](https://www.ecfdata.com/cloud-computing-key-trends-and-challenges/)” delves deeper into the evolution of cl... | ecfdataus |
1,776,034 | Maximizing Business Potential with AWS Serverless | Imagine if building apps were as easy as snapping your fingers – that's the magic of serverless... | 0 | 2024-02-29T12:38:46 | https://dev.to/krunalbhimani/maximizing-business-potential-with-aws-serverless-1n30 | serverless, cloudcomputing, aws, lambda | Imagine if building apps were as easy as snapping your fingers – that's the magic of serverless computing. It takes all the hassle out of managing servers, so developers can focus solely on writing awesome code. One of the big players in this game is Amazon Web Services (AWS), offering a suite of tools that promise to ... | krunalbhimani |
1,776,185 | Exploring Pkl: Apple's Fresh Approach to Configuration Languages | In a digital epoch where the only constant is change, Apple introduces Pkl—pronounced "Pickle"-a new... | 0 | 2024-02-29T14:20:00 | https://configu.com/blog/exploring-pkl-apples-fresh-approach-to-configuration-languages/ | devops, programming, opensource, configuration | In a digital epoch where the only constant is change, Apple introduces Pkl—pronounced "Pickle"-a new entrant in the dynamic landscape of software development. With an eye towards addressing some of the longstanding issues in configuration management, Pkl trying to bring forward concepts of programmability, scalability,... | rannn505 |
1,776,285 | Introduction to Cannabis Tincture Boxes | Introduction to Cannabis Tincture Boxes In the ever-expanding market of cannabis products, packaging... | 0 | 2024-02-29T16:35:40 | https://dev.to/bobbieschwartz/introduction-to-cannabis-tincture-boxes-m3o | coutom, boxes, wholesale, webdev | <p><strong>Introduction to Cannabis Tincture Boxes</strong></p>
<p>In the ever-expanding market of cannabis products, packaging plays a pivotal role in not only preserving the quality of the product but also in catching the consumer's eye. Among various packaging solutions, <a href="https://thepremierpackaging.com/cann... | bobbieschwartz |
1,776,610 | Building for sustainability: Dashboards | As the software industry increases its focus on environmental, social, and wider sustainability... | 0 | 2024-02-29T22:52:16 | https://newrelic.com/blog/best-practices/building-esg-sustainability-dashboards?utm_source=devto&utm_medium=community&utm_campaign=global-fy24-q4-esg-blog | devops, tutorial, productivity, monitoring | As the software industry increases its focus on environmental, social, and wider sustainability practices, there’s been a rise in new reporting regulations. Regulations like the EU’s Due Diligence proposal put the onus on large and medium companies to identify, prevent, or mitigate damaging environmental and human righ... | frivolouis |
1,776,926 | Transforming Ideas into Action Collaborating with an IoT App Development Company 2024 | Introduction to IoT App Development The Internet of Things (IoT) refers to the ever-growing network... | 0 | 2024-03-01T08:31:16 | https://dev.to/dhwanil/transforming-ideas-into-action-collaborating-with-an-iot-app-development-company-2024-58pg | iotdevelopment, iotapps, iot, appdevelopment |

Introduction to IoT App Development
The Internet of Things (IoT) refers to the ever-growing network of physical devices embedded with sensors, software, and other technologies that enable them to collect and exchang... | dhwanil |
1,777,056 | Kafka와 RabbitMQ: 적합한 메시징 브로커 선택하기 | Kafka와 RabbitMQ 메시지 브로커 아키텍처, 성능 및 사용 사례 비교 | 0 | 2024-03-01T09:48:45 | https://dev.to/pubnub-ko/kafkawa-rabbitmq-jeoghabhan-mesijing-beurokeo-seontaeghagi-16bb | [이벤트 중심 아키텍처의](https://www.pubnub.com/solutions/edge-message-bus/) 역동적인 세계에서 효율적이고 확장 가능한 커뮤니케이션을 위해서는 올바른 메시징 브로커를 선택하는 것이 중요합니다. 가장 인기 있는 두 가지 경쟁자로는 각각 장단점이 있는 Kafka와 RabbitMQ가 있습니다. 비슷한 용도로 사용되지만 아키텍처, 성능 특성 및 사용 사례는 서로 다릅니다. 이 블로그 게시물에서는 아키텍처 차이점과 성능 비교를 자세히 살펴보고, 의사 결정 과정을 탐색하는 데 도움이 될 수 있도록 Kafka와 RabbitMQ의 몇 가지 ... | pubnubdevrel | |
1,777,060 | Kafka vs. RabbitMQ: Die Wahl des richtigen Messaging-Brokers | Ein Vergleich von Kafka und RabbitMQ Message Broker Architektur, Leistung und Anwendungsfällen | 0 | 2024-03-01T09:53:46 | https://dev.to/pubnub-de/kafka-vs-rabbitmq-die-wahl-des-richtigen-messaging-brokers-164a | In der dynamischen Welt der [ereignisgesteuerten Architekturen](https://www.pubnub.com/solutions/edge-message-bus/) ist die Wahl des richtigen Messaging-Brokers entscheidend für eine effiziente und skalierbare Kommunikation. Zwei der beliebtesten Konkurrenten sind Kafka und RabbitMQ, die jeweils ihre Stärken und Schwäc... | pubnubdevrel | |
1,777,155 | Unlock Your Potential with a Podcast Clip Maker | In today's digital landscape, podcasts have become a powerful medium for sharing ideas, stories, and... | 0 | 2024-03-01T12:31:41 | https://dev.to/devtripath94447/unlock-your-potential-with-a-podcast-clip-maker-27d3 | productivity, discuss, ai, architecture | In today's digital landscape, podcasts have become a powerful medium for sharing ideas, stories, and expertise. As a content creator, tapping into this platform can significantly expand your reach and impact. However, with the proliferation of podcasts, standing out from the crowd can be a challenge. This is where a [p... | devtripath94447 |
1,777,331 | Day 11: Introduction to React Hooks | Introduction Welcome to Day 11 of our 30-day blog series on React.js! Today, we'll explore React... | 26,617 | 2024-03-01T14:29:59 | https://dev.to/pdhavalm/day-11-introduction-to-react-hooks-211m | react, reactjsdevelopment, reactnative, javascript | **Introduction**
Welcome to Day 11 of our 30-day blog series on React.js! Today, we'll explore React Hooks, a powerful feature introduced in React 16.8 for adding state and other React features to functional components. Hooks provide a more concise and flexible way to write components compared to class components.
**W... | pdhavalm |
1,777,345 | webMethods.io Integration processing excel file | Introduction This article explains how the excel input file can be processed using out of... | 0 | 2024-03-01T14:56:16 | https://tech.forums.softwareag.com/t/webmethods-io-integration-processing-excel-file/291726 | webmethods, integration, excel, connectors | ---
title: webMethods.io Integration processing excel file
published: true
date: 2024-02-19 11:07:55 UTC
tags: webMethods, integration, excel, connectors
canonical_url: https://tech.forums.softwareag.com/t/webmethods-io-integration-processing-excel-file/291726
---
## Introduction
This article explains how the excel i... | techcomm_sag |
1,777,393 | Creating S3 Buckets using CloudFormation via AWS CLI | Whether you're setting up a new stack using CloudFormation or trying to decipher an existing stack,... | 0 | 2024-03-01T23:21:21 | https://dev.to/gritcoding/creating-s3-buckets-using-cloudformation-via-aws-cli-1c1b | cloudformation, s3 | Whether you're setting up a new stack using CloudFormation or trying to decipher an existing stack, understanding CloudFormation syntax is crucial for building, updating, and maintaining AWS resources effectively. In this tutorial, we'll learn by doing. We're going to create two S3 buckets using CloudFormation through ... | gritcoding |
1,777,418 | LEGO 3D Coordinates | The Grid Dimensions Length (X): The number of blocks you can place in a row. Width (Y):... | 0 | 2024-03-01T16:38:06 | https://dev.to/sagordondev/lego-3d-coordinates-4ndp | python, programming, tutorial, beginners | ### The Grid Dimensions
- **Length (X)**: The number of blocks you can place in a row.
- **Width (Y)**: The number of blocks you can place in a column, perpendicular to the row.
- **Height (Z)**: The number of layers of blocks you can stack on top of each other.
Imagine you have a LEGO base that's 1 block wide, 1 bloc... | sagordondev |
1,777,457 | Ao infinito e além | Hoje, vamos falar um pouco sobre o impossível que está apenas na sua cabeça e os limites que você... | 0 | 2024-03-01T17:30:46 | https://dev.to/ujs74wiop6/ao-infinito-e-alem-2iof | career, pgrowth | Hoje, vamos falar um pouco sobre o impossível que está apenas na sua cabeça e os limites que você mesmo coloca sobre si.
Há algum tempo, comecei a tomar alguns cuidados com a minha saúde mental no trabalho e nos estudos, pois, para atingir a longevidade na minha carreira que pretendo, preciso me preocupar com esses as... | ujs74wiop6 |
1,777,611 | Importance of Data Structures in Computer Science. | Introduction: Data Structures refer to the organization and storage of data to facilitate efficient... | 0 | 2024-03-01T19:54:02 | https://dev.to/nsanju0413/importance-of-data-structures-in-computer-science-4055 | datastructures, dsa, programming, beginners | **Introduction:**
> Data Structures refer to the organization and storage of data to facilitate efficient access and modification. Algorithms, on the other hand, are step-by-step procedures or formulas for solving computational problems. Together, they form the bedrock of computer science, influencing the way programm... | nsanju0413 |
1,777,619 | Journey from 82289ms to 975ms: Optimizing a Heavy Query in .NET Core | Introduction: The Quest for Speed Unveiling the Challenge: A 82289ms Monster Analyzing the Culprit:... | 0 | 2024-03-01T20:14:28 | https://dev.to/emadkhanqai/journey-from-82289ms-to-975ms-optimizing-a-heavy-query-in-net-core-4k8j | programming, refactoring | 1. Introduction: The Quest for Speed
2. Unveiling the Challenge: A 82289ms Monster
3. Analyzing the Culprit: Understanding the Code
4. The Road to Optimization: Strategies Employed
5. Refactored Elegance: Witnessing the Transformation
6. Lessons Learned: Insights and Reflections
7. Conclusion: From Struggle to Success
... | emadkhanqai |
1,777,635 | Estimate the read time of an article without any library in JavaScript. | In this article, we'll embark on a journey to craft a JavaScript function to help us estimate the... | 0 | 2024-03-01T20:56:19 | https://dev.to/lennyaiko/estimate-the-read-time-of-an-article-without-any-library-in-javascript-2k4e | javascript, webdev, tutorial, beginners | In this article, we'll embark on a journey to craft a JavaScript function to help us estimate the read time of an article. You will dabble with a little bit of regex to help you strip your content clean for proper estimation. Keep in mind that since this is pure JavaScript, it works across the stack (front-end and back... | lennyaiko |
1,777,833 | Evolving Skills: What Developers Need to Succeed in 2024 and Beyond | Introduction: In the rapidly evolving landscape of technology, staying ahead of the curve is... | 0 | 2024-03-02T04:54:28 | https://dev.to/pdhavalm/evolving-skills-what-developers-need-to-succeed-in-2024-and-beyond-2ok4 | xrdev2024, microservices, blockchain, iot | **Introduction**:
In the rapidly evolving landscape of technology, staying ahead of the curve is essential for developers. As we stride into 2024, the demand for new skills and expertise continues to grow. In this blog, we'll explore the crucial skills that developers need to succeed in 2024 and beyond.
1. **Quantum C... | pdhavalm |
1,777,898 | Strengthening Salah through Nazra Quran | Salah is a crucial component of Islamic theology because it provides a direct channel of... | 0 | 2024-03-02T06:40:44 | https://dev.to/equranekareem/strengthening-salah-through-nazra-quran-55oj | qurancourse, onlinequran, onlinenazara | Salah is a crucial component of Islamic theology because it provides a direct channel of communication between believers and the Almighty. Salah can be made even more potent by using Nazra Quran, which is reciting the Quran during prayers. This promotes elevation and a strong spiritual bond. Using the rich legacy of th... | equranekareem |
1,777,966 | Building a Container-Optimized VM Template with Ignition on Proxmox 8.x | Learn how to create a versatile VM template with Proxmox 8.x for your Kubernetes infrastructure using openSUSE MicroOS, customized with Ignition for seamless deployment and management. Follow step-by-step instructions to download the system image, configure the template, and ensure compatibility with Proxmox features. | 0 | 2024-03-02T10:22:21 | https://dev.to/sdeseille/building-a-container-optimized-vm-template-with-ignition-on-proxmox-8x-356p | proxmox, ignition, chatgpt, tutorial | ---
title: Building a Container-Optimized VM Template with Ignition on Proxmox 8.x
published: true
description: Learn how to create a versatile VM template with Proxmox 8.x for your Kubernetes infrastructure using openSUSE MicroOS, customized with Ignition for seamless deployment and management. Follow step-by-step ins... | sdeseille |
1,778,037 | Streamlining Your Next.js Projects with Supabase and Drizzle ORM | This guide showcases how to build an efficient application using Supabase for data handling,... | 0 | 2024-03-02T10:50:17 | https://dev.to/musebe/streamlining-your-nextjs-projects-with-supabase-and-drizzle-orm-4gam | ---
title: Streamlining Your Next.js Projects with Supabase and Drizzle ORM
published: true
description:
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-02-29 06:55 +0000
---
This guide showcases how to build an efficient application using Supabase ... | musebe | |
1,778,038 | Memory Handling in Java | Before diving into memory management of java one must know java has primitive datatypes and more... | 0 | 2024-03-04T13:19:15 | https://dev.to/coderatul/memory-handling-in-java-jc6 | java, programming, computerscience, learning | > Before diving into memory management of java one must know java has primitive datatypes and more complex objects (reference types)
- Primitive type
- refference type
> Java has no concept of pointers and java only has pass by value, there is nothing like pass by reference in java
---
### primitives
- Primitive typ... | coderatul |
1,778,065 | Supercharge Your Website Search with Google's PSE! | Hey developers! Let's talk about enhancing your website's user experience with a powerful search bar.... | 0 | 2024-03-02T12:09:34 | https://dev.to/beginnerdeveloper/supercharge-your-website-search-with-googles-pse-2a0h | webdev, google, search, javascript | Hey developers! Let's talk about enhancing your website's user experience with a powerful search bar. Today, we're diving into Google's Programmable Search Engine (PSE).
## What is PSE?
PSE is a free service that empowers you to integrate a custom search engine directly into your website. It utilizes Google Search's t... | beginnerdeveloper |
1,778,069 | Dynamic AWS IAM Policies | We maintain a CloudFormation custom resource provider for Amazon Connect. The provider has grown... | 0 | 2024-03-02T12:27:50 | https://bliskavka.com/2024/03/02/dynamic-iam-policies/ | aws, cdk, iam, security | We maintain a CloudFormation custom resource provider for Amazon Connect. The provider has grown organically, and as new features were added, the default role policy has become large.
The provider can do simple low-security tasks like `associateLambda`, or complex tasks like `createInstance`, which requires access to ... | ibliskavka |
1,778,074 | 4 facets of API monitoring you should implement | Introduction Issues with APIs often have the potential to cause major disruptions to... | 0 | 2024-03-02T12:37:23 | https://apitally.io/blog/four-facets-of-api-monitoring-you-should-implement | api, monitoring, webdev | ## Introduction
Issues with APIs often have the potential to cause major disruptions to businesses. Proactive API monitoring is therefore essential for tech professionals who are responsible for maintaining the integrity and performance of business-critical APIs.
In this blog post we'll take an in-depth look at the f... | simongurcke |
1,778,082 | How to: Replace Rollup.js with Vite ⚡️ | For me, it was once again time to take care of a project that I haven't worked on for almost a year.... | 0 | 2024-03-02T12:49:23 | https://thr0n.github.io/how-to-replace-rollup-js-with-vite | webdev, frontend, svelte, vite | For me, it was once again time to take care of a project that I haven't worked on for almost a year. As we can see in the output below (the package.json was analyzed using [npm-check-updates](https://www.npmjs.com/package/npm-check-updates)), the project still uses rollup.js and many libraries have become outdated in t... | thr0n |
1,778,149 | What is JavaScript? | JavaScript, often abbreviated JS, is a programming language that is one of the core technologies of... | 0 | 2024-03-02T14:42:14 | https://dev.to/lav-01/what-is-javascript-5glm | javascript, beginners | JavaScript, often abbreviated JS, is a programming language that is one of the core technologies of the World Wide Web, alongside HTML and CSS. It lets us add interactivity to pages e.g. you might have seen sliders, alerts, click interactions, popups, etc on different websites — all of that is built using JavaScript. A... | lav-01 |
1,778,256 | Error monitoring and bug triage: Whose job is it? | The invisible and thankless work of determining the right things to fix | 0 | 2024-03-02T16:23:42 | https://jenchan.biz/blog/error-monitoring-and-bug-triage | bugs, agile, career, discuss | ---
title: Error monitoring and bug triage: Whose job is it?
published: true
description: The invisible and thankless work of determining the right things to fix
tags: bugs, agile, career, discuss
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/4q6lgxl65gnm32cwjk3s.png
# Use a ratio of 100:42 for ... | jenc |
1,778,302 | React Strict DOM package | Hi Dev's After the React team announcement to all the improvements that React v19 will bring,... | 0 | 2024-03-02T18:49:44 | https://dev.to/ricardogesteves/react-strict-dom-package-1og1 | webdev, react, javascript, news | Hi Dev's
After the React team announcement to all the improvements that React v19 will bring, including the awesome introduction of a compiler. The React team is working on a truly exciting package that I believe is worth your time.
In the dynamic landscape of web and native application development, achieving cross-p... | ricardogesteves |
1,778,426 | Uncovering Generative Artificial Intelligence and LLMs: A Brief Introduction | With the popularization of tools such as ChatGPT, Google Bard (currently Gemini), and other similar applications, which generate responses based on what the user asks, the machinery behind these innovations also came to light. | 0 | 2024-03-02T23:00:20 | https://dev.to/yuricosta/uncovering-generative-artificial-intelligence-and-llms-a-brief-introduction-4ge2 | gpt4, generativeai, llm, largelanguagemodels | ---
title: Uncovering Generative Artificial Intelligence and LLMs: A Brief Introduction
published: true
description: With the popularization of tools such as ChatGPT, Google Bard (currently Gemini), and other similar applications, which generate responses based on what the user asks, the machinery behind these innovati... | yuricosta |
1,778,521 | A simple tip to find hidden gems in Shodan | Shodan is a well-known recon tool, but in larger scopes, it has so many results that it’s hard to... | 0 | 2024-03-03T03:55:28 | https://dev.to/menna/a-simple-tip-to-find-hidden-gems-in-shodan-2c92 | security, infosec, cybersecurity | Shodan is a well-known recon tool, but in larger scopes, it has so many results that it’s hard to find something useful without navigating through all the results pages.
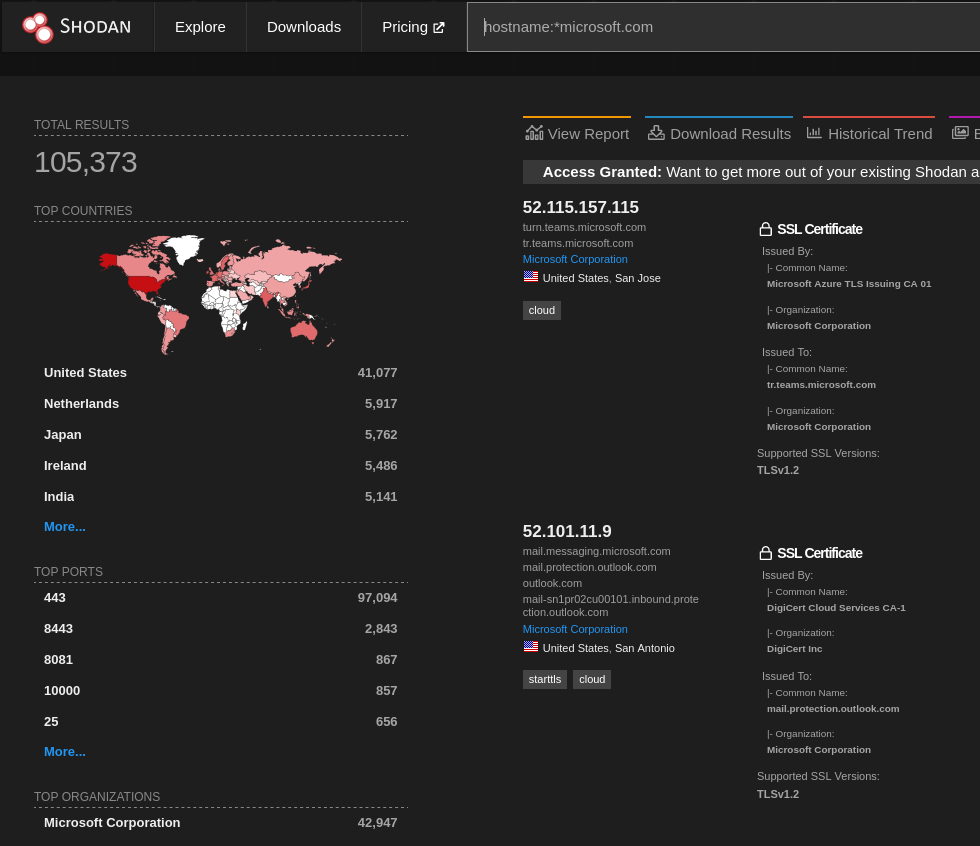
In this image searching for hostnames from ... | menna |
1,778,552 | The Magic of Reactivity and Data Binding in Native JavaScript | Reactivity: The Secret Sauce of the Web To put it simply, reactivity means that when you... | 0 | 2024-03-03T05:56:17 | https://oatta.codes/notes/the-magic-of-reactivity-and-data-binding-in-native-javascript | javascript, vue, react, svelte | ## **Reactivity: The Secret Sauce of the Web**
To put it simply, reactivity means that when you update a piece of data or a variable, every part of your webpage that uses or displays that data updates in real time. This automatic synchronization between the data and the UI elements ensures that your webpage always sho... | omaratta212 |
1,778,683 | What You See is What You Get - Building a Verifiable Enclave Image | Table of Contents 1. Obstacle of proofing TEE 1.1. Image digest is... | 0 | 2024-03-03T10:30:06 | https://blog.richardfan.xyz/2024/03/03/what-you-see-is-what-you-get-building-a-verifiable-enclave-image.html | aws, nitroenclaves, sigstore, supplychainsecurity | ## Table of Contents
1. [Obstacle of proofing TEE](#obstacle-of-proofing-tee)
1.1. [Image digest is meaningless](#image-digest-is-meaningless)
1.2. [Stable image digest is difficult](#stable-image-digest-is-difficult)
2. [Solution - T... | richardfan1126 |
1,791,030 | What is the relevance of software testing? | Testing is useful to identify errors in development and compare actual outcome with expected outcome... | 0 | 2024-03-15T06:31:41 | https://dev.to/david3dev/what-is-the-relevance-of-software-testing-3g4g | Testing is useful to identify errors in development and compare actual outcome with expected outcome to make sure product quality before deliver to client. | david3dev | |
1,778,752 | How Do I Get a Refund From Microsoft Store? | Microsoft continues to improve its user experience and customer satisfaction. According to user... | 0 | 2024-03-03T11:24:50 | https://dev.to/subrato525/how-do-i-get-a-refund-from-microsoft-store-13kl | Microsoft continues to improve its user experience and customer satisfaction. According to user feedback, they have improved cancellation procedures and refund policies. It is a sign that they are committed to providing great service. Microsoft Store refund requests are often confusing, even though it is easy to buy ap... | subrato525 | |
1,778,827 | Learning web development is hard | console.log(Learning web development is hard) Yup, you read it right. Learning web... | 0 | 2024-03-03T14:12:55 | https://dev.to/pietrell/learning-web-development-is-hard-44cj | webdev, javascript, beginners, programming | ## `console.log(Learning web development is hard)`
Yup, you read it right. Learning web development is hard and that's a fact. Not only web development, but in fact everything that's worth learning takes time. For example cooking, if you want to be a good chef, you have to spend lots of time in the kitchen. Same is for... | pietrell |
1,778,885 | Training LLMs Taking Too Much Time? Technique you need to know to train it faster | The Challenges of Training LLMs: Lots of Time and Resources Suppose you want to train a... | 0 | 2024-03-03T15:48:23 | https://dev.to/hexmos/training-llms-taking-too-much-time-technique-you-need-to-know-to-train-it-faster-3k8d | llms, ai, llama2, machinelearning | #### The Challenges of Training LLMs: Lots of Time and Resources
Suppose you want to train a **Large Language Model(LLM)**, which can understand and produce human-like text. You want to input questions related to your organization and get answers from it.
The problem is that the LLM doesn't know your organization, It... | rijultp |
1,778,904 | What is the currying function | Currying is the process of taking a function with multiple arguments and turning it into a sequence... | 0 | 2024-03-03T16:12:37 | https://dev.to/lav-01/what-is-the-currying-function-3kpi | Currying is the process of taking a function with multiple arguments and turning it into a sequence of functions each with only a single argument. Currying is named after a mathematician Haskell Curry. By applying currying, an n-ary function turns into a unary function.
Let's take an example of n-ary function and how ... | lav-01 | |
1,778,969 | CSS tips to avoid bad UX | I believe CSS is a powerful tool to make perfect UX. I'm here to share my tips for unfortunate... | 0 | 2024-03-03T17:18:56 | https://dev.to/melnik909/css-tips-to-avoid-bad-ux-2b40 | css, webdev | I believe CSS is a powerful tool to make perfect UX. I'm here to share my tips for unfortunate mistakes.
If you like it you'll get more [by subscribing to my newsletter](https://cssisntmagic.substack.com).
## Please, stop using resize: none
We used to use resize: none to disable textarea resizing. We end up textarea... | melnik909 |
1,779,000 | ➡️Whats next❓Der erste Schritt in die Welt der Nullen und Einsen | Die Suche nach dem richtigen Ausbildungsbetrieb kann eine aufregende, aber auch herausfordernde Zeit... | 0 | 2024-03-03T18:46:55 | https://dev.to/codingwerkstatt/whats-nextder-erste-schritt-in-die-welt-der-nullen-und-einsen-470i | fachinformatiker, ausbildung, beginners, ausbildungsbetrieb | Die Suche nach dem richtigen Ausbildungsbetrieb kann eine aufregende, aber auch herausfordernde Zeit sein. Als ich mich damals auf die Suche nach einem Ausbildungsplatz machte, war ich zunächst etwas überfordert. Ich bewarb mich relativ spät auf verschiedene offene Stellen und hoffte auf eine Rückmeldung. Glücklicherwe... | codingwerkstatt |
1,779,298 | All Time Best Figma Plugins | Figma is a browser-based interface and design application that can help you design and prototype and... | 0 | 2024-03-04T04:59:52 | https://dev.to/chandankumarpanigrahi/all-time-best-figma-plugins-2j2o | figma, ux, ui, plugins | **Figma** is a browser-based interface and design application that can help you design and prototype and can be used to generate code for your application. It is likely the **leading interface design tool on the market** right now and has features that support teams throughout every step of the design process.
If you ... | chandankumarpanigrahi |
1,779,352 | Embrace Luxury Living: Discover M3M Antalya Hills | Title: Embrace Luxury Living: Discover M3M Antalya Hills Situated in the bustling metropolis of... | 0 | 2024-03-04T06:25:24 | https://dev.to/comingkeysss/embrace-luxury-living-discover-m3m-antalya-hills-5ebl | m3m, gurugram, comingkeys, antalyahills | Title: Embrace Luxury Living: Discover M3M Antalya Hills

Situated in the bustling metropolis of Gurugram, where elegance and refinement collide, [M3M Antalya Hills](https://m3m-newlaunch.in/) towers as a testament t... | comingkeysss |
1,779,401 | SOLID Principle in NextJS using Typescript | SOLID is an acronym for five key principles of object-oriented programming that aim to improve the... | 0 | 2024-03-04T11:46:20 | https://dev.to/fajarriv/solid-principle-in-nextjs-using-typescript-3l3k | webdev, typescript, nextjs, solidprinciples | SOLID is an acronym for five key principles of object-oriented programming that aim to improve the readability, maintainability, extensibility, and testability of code. However, SOLID principles are not limited to object-oriented programming that uses classes. They can also be applied to other paradigms, such as functi... | fajarriv |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.