
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,836,899 | Finding the Right Balance: Clean Architecture and Entity Framework in Practice | In the world of software development, we often find ourselves grappling with tough decisions about... | 0 | 2024-04-28T21:18:21 | https://dev.to/shahabfar/finding-the-right-balance-clean-architecture-and-entity-framework-in-practice-2bip | cleanarchitecture, entityframework | In the world of software development, we often find ourselves grappling with tough decisions about architecture. One common dilemma is how to integrate Entity Framework, a powerful database tool, within the principles of Clean Architecture.
Clean Architecture is all about creating systems that are easy to test, mainta... | shahabfar |
1,837,260 | Revive Gummies: Unlocking the Natural Power of CBD for Wellness | In recent years, the popularity of CBD products has surged, with consumers seeking natural... | 0 | 2024-04-29T08:26:19 | https://dev.to/nikkisam/revive-gummies-unlocking-the-natural-power-of-cbd-for-wellness-4mga | In recent years, the popularity of CBD products has surged, with consumers seeking natural alternatives to traditional medications for various health concerns. Among these products, CBD-infused gummies have gained significant attention for their convenience, effectiveness, and delicious flavors. One such standout in th... | nikkisam | |
1,837,307 | Maximizing Efficiency with SAP PP: A Comprehensive Guide for Manufacturers | In the dynamic landscape of manufacturing, efficiency is the cornerstone of success. Every production... | 0 | 2024-04-29T09:48:28 | https://dev.to/mylearnnest/maximizing-efficiency-with-sap-pp-a-comprehensive-guide-for-manufacturers-3n90 | In the dynamic landscape of manufacturing, efficiency is the cornerstone of success. Every production process relies on streamlined operations to meet demand, control costs, and stay competitive. [SAP Production Planning (SAP PP)](https://www.sapmasters.in/sap-pp-training-in-bangalore/) stands as a robust solution desi... | mylearnnest | |
1,837,709 | Vite vs Nextjs: Which one is right for you? | Vite and Next.js are both top 5 modern development framework right now. They are both great depending... | 0 | 2024-04-29T16:21:34 | https://dev.to/jenesh/vite-vs-nextjs-which-one-is-right-for-you-53nn | nextjs, vite, webdev, javascript | Vite and Next.js are both top 5 modern development framework right now. They are both great depending on your use case so we’ll discuss 4 areas: Architecture, main features, developer experience and production readiness. After learning about these we’ll have a better idea of which one is best for your project.
[Vite](... | jenesh |
1,838,172 | Find Out How To Buy Or Sell A Home With Jd Puri Realtors | Understanding the Real Estate Market The real estate market is ever-evolving, influenced... | 0 | 2024-04-30T05:54:50 | https://dev.to/jaideeppuri/find-out-how-to-buy-or-sell-a-home-with-jd-puri-realtors-5a2l | jdpurirealtors | ## Understanding the Real Estate Market
The real estate market is ever-evolving, influenced by various factors such as economic conditions, interest rates, and consumer behavior. Understanding these dynamics is crucial whether you're buying or selling a home with [JD Puri Realtors](https://www.quora.com/profile/Jd-Pur... | jaideeppuri |
1,838,260 | Navigating Your Journey with LaGuardia Car Service | Best laguardia car service When you select a means of transport between the cities to undertake your... | 0 | 2024-04-30T07:40:43 | https://dev.to/aakriti0/navigating-your-journey-with-laguardia-car-service-jhj | Best laguardia car service
When you select a means of transport between the cities to undertake your business, or/and leisure mission, the performance of said journey has to be effortless and enjoyable. [best LaGuardia car service](https://laguardiaairportcarservice.com/) is the very source of entrance into New York, ... | aakriti0 | |
1,838,309 | Deploying Forem on Render.com PromptZone.com | The journey of deploying an open-source software platform like forem can be complex and daunting, but... | 0 | 2024-04-30T08:31:03 | https://dev.to/adifsgaid/deploying-forem-on-rendercom-promptzonecom-3721 | forem, deploy, webdev | The journey of deploying an open-source software platform like [forem](https://github.com/forem/forem) can be complex and daunting, but with the right tools and services, it can also be remarkably rewarding. This article details my experience deploying [Forem](https://www.forem.com/), the software behind the [Dev.to](D... | adifsgaid |
1,838,327 | Lockable Store | Lockable Store is a trusted storage service in Dubai, offering self-storage solutions with a team of... | 0 | 2024-04-30T08:50:08 | https://dev.to/lockablestore/lockable-store-m4p | [Lockable Store](https://www.lockablestore.com/) is a trusted storage service in Dubai, offering self-storage solutions with a team of reliable professionals. The company provides secure and affordable self-storage in Dubai with exceptional customer service. The company's offerings are available for both short and long... | lockablestore | |
1,838,334 | Implement React v18 from Scratch Using WASM and Rust - [10] Implement Update for Single Node. | Based on big-react,I am going to implement React v18 core features from scratch using WASM and... | 27,011 | 2024-04-30T08:57:27 | https://dev.to/paradeto/implement-react-v18-from-scratch-using-wasm-and-rust-10-implement-update-for-single-node-jfj | react, webassembly, rust | > Based on [big-react](https://github.com/BetaSu/big-react),I am going to implement React v18 core features from scratch using WASM and Rust.
>
> Code Repository:https://github.com/ParadeTo/big-react-wasm
>
> The tag related to this article:[v10](https://github.com/ParadeTo/big-react-wasm/tree/v10)
The previous artic... | paradeto |
1,838,340 | Dominate China's Business Landscape Harness Success with Ready Mailing Team's China Business Email List | In the fast-paced world of global commerce, China stands as a beacon of opportunity, offering... | 0 | 2024-04-30T09:03:59 | https://dev.to/chinabusiness30/dominate-chinas-business-landscape-harness-success-with-ready-mailing-teams-china-business-email-list-2od | news | In the fast-paced world of global commerce, China stands as a beacon of opportunity, offering boundless potential for businesses willing to seize it. At Ready Mailing Team, we understand that success in China hinges on access to the right contacts. That's why we're proud to introduce our revolutionary solution: the Rea... | chinabusiness30 |
1,838,390 | Integrate Screen Share in JavaScript Video Chat App | 📌 Introduction Integrating screen sharing into your JavaScript video chat app expands... | 0 | 2024-05-06T08:56:59 | https://www.videosdk.live/blog/integrate-screen-share-in-javascript-video-chat-app | javascript | ---
title: Integrate Screen Share in JavaScript Video Chat App
published: true
date: 2024-04-30 09:10:33 UTC
tags: javascript,
canonical_url: https://www.videosdk.live/blog/integrate-screen-share-in-javascript-video-chat-app
---
, which was a basic setup with Golang. In this part, we're setting up our logging in the app.
THE [ORIGINAL POST](https://edulixir.com/2024/05/17/golang-logging-configuration-with-zap-practical-imple... | ronnymedina |
1,857,098 | TFT LCD Display Applications: From Wearables to Home Appliances | screenshot-1715645179664.png TFT LCD Display Applications: Making Life More Convenient TFT LCD... | 0 | 2024-05-18T01:24:02 | https://dev.to/jer_win_bad86b29df116649d/tft-lcd-display-applications-from-wearables-to-home-appliances-310m | lcd |
screenshot-1715645179664.png
TFT LCD Display Applications: Making Life More Convenient
TFT LCD displays may not be something that you're familiar with, but chances are that you have encountered them at some point in your life. These displays are coming to be more and more prevalent in numerous products, ranging fro... | jer_win_bad86b29df116649d |
1,857,313 | Understanding OK Win Platform | OK Win is a popular online gaming platform that offers users the chance to win big prizes through... | 0 | 2024-05-18T06:35:16 | https://dev.to/ryjghnjfygh/understanding-ok-win-platform-hbb | OK Win is a popular online gaming platform that offers users the chance to win big prizes through various games and contests. Whether you are a seasoned gamer or a newcomer, OK Win provides an exciting and rewarding experience. In this article, we will explore the key features of OK Win, tips for maximizing your chance... | ryjghnjfygh | |
1,857,346 | Extracting Words from Scanned Books: A Step-by-Step Tutorial with Python and OpenCV | Our video tutorial will show you how to extract individual words from scanned book pages, giving you... | 0 | 2024-05-18T07:15:37 | https://dev.to/feitgemel/extracting-words-from-scanned-books-a-step-by-step-tutorial-with-python-and-opencv-4p95 | python, opencv |

Our video tutorial will show you how to extract individual words from scanned book pages, giving you the code you need to extract the required text from any book.
We'll walk you through the entire process, from con... | feitgemel |
1,857,443 | Elevate Your WordPress Site: Building Custom Plugins | Introduction: In the expansive realm of WordPress, customization is king. While themes offer a great... | 0 | 2024-05-24T12:30:00 | https://dev.to/nitin-rachabathuni/elevate-your-wordpress-site-building-custom-plugins-ihp | Introduction:
In the expansive realm of WordPress, customization is king. While themes offer a great starting point, true flexibility often requires diving into the world of plugins. These plugins can extend functionality, streamline processes, and tailor your site to your exact specifications. But what if you can't fi... | nitin-rachabathuni | |
1,857,519 | Type Hinting and Annotations in Python: Improving Code Readability and Understanding | Python is a popular and powerful programming language known for its dynamic typing, where variable... | 0 | 2024-05-18T10:46:16 | https://dev.to/myexamcloud/type-hinting-and-annotations-in-python-improving-code-readability-and-understanding-49jj | python, programming, software, coding | Python is a popular and powerful programming language known for its dynamic typing, where variable types are inferred at runtime. While this allows for flexibility, it can make code more difficult to understand in a collaborative setting.
To address this issue, Python introduced type hinting and annotations. This allo... | myexamcloud |
1,857,549 | How Can Sports Betting Software Help You Win More Bets? | In the fast-paced world of sports betting, success often hinges on having the right tools at your... | 0 | 2024-05-18T11:39:23 | https://dev.to/mathewc/how-can-sports-betting-software-help-you-win-more-bets-5e2f | webdev, softwaredevelopment, programming | In the fast-paced world of sports betting, success often hinges on having the right tools at your disposal. With the advent of advanced technologies, sports betting software has become a crucial asset for both casual bettors and professionals. This software not only simplifies the betting process but also provides stra... | mathewc |
1,857,615 | Advancing Nursing Practice: Mastering Strategies for NURS FPX | Embarking on the journey of nursing education is a transformative experience, where nurses hone their... | 0 | 2024-05-18T13:51:12 | https://dev.to/ryanhiggs/advancing-nursing-practice-mastering-strategies-for-nurs-fpx-4aag | tutorial, discuss, design, interview |
Embarking on the journey of nursing education is a transformative experience, where nurses hone their skills and knowledge to elevate their practice to new heights. In this guide, "Advancing Nursing Practice: Mastering Strategies for NURS FPX", we delve into essential strategies and insights to empower nurses as they ... | ryanhiggs |
1,857,628 | Works, don't touch it? Or never ending optimization game? | I've built a photo sharing app https://www.wisaw.com. I use it on my iPhone all the time, and it... | 0 | 2024-05-18T15:09:24 | https://dev.to/dmitryame/works-dont-touch-it-or-never-ending-optimization-game-1aoo | javascript, performance, optimization | ---
title: Works, don't touch it? Or never ending optimization game?
published: true
description:
tags: JavaScript, Performance, Optimization
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ac6oms24akf8ojerfvm8.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-18 14:05 +0000
... | dmitryame |
1,858,057 | frvr ai game century fight 2060 done by:nassim haddad | Hello again dear developers i'm going to share with you today my game that was created using ai the... | 0 | 2024-05-19T04:14:26 | https://dev.to/nassim_haddad_4fdd304a846/frvr-ai-game-century-fight-2060-done-bynassim-haddad-1amg | gamedev, ai | Hello again dear developers i'm going to share with you today my game that was created using ai the link will be provided to test it out (https://beta.frvr.ai/@njnjnj/play/M-sixgc6MS?utm_medium=share&utm_source=link) if you guys like my game and published content you can also suppourt my work through this link by copy... | nassim_haddad_4fdd304a846 |
1,858,289 | Terratest vs Terraform/OpenTofu Test: In-Depth Comparison | The release of Terraform and OpenTofu 1.6 brought with it the general availability of the Terraform... | 0 | 2024-05-20T12:56:00 | https://www.env0.com/blog/terratest-vs-terraform-opentofu-test-in-depth-comparison | terraform, devops, testing, infrastructureascode | The release of [Terraform](https://www.env0.com/blog/what-is-terraform-cli) and [OpenTofu](https://www.env0.com/blog/opentofu-the-open-source-terraform-alternative) 1.6 brought with it the general availability of the Terraform Test Framework. This framework allows you to write unit and integration tests for your [Terra... | env0team |
1,858,342 | How I went from failing every interview to a job at Amazon | Originally posted here I studied computer science at Stanford. You probably would’ve expected me to... | 0 | 2024-05-19T14:28:59 | https://dev.to/alex420/how-i-went-from-failing-every-interview-to-a-job-at-amazon-3h5b | interview, recruiting, jobs, programming | Originally posted [here](https://sites.google.com/view/jobs2k24/home)
I studied computer science at Stanford. You probably would’ve expected me to be swimming in job offers. In my sophomore year and first-half of junior year, I got a lot of interviews, and I failed every single one of them. And not in a, “this person ... | alex420 |
1,858,347 | Go Lang Cheatsheet | Table of Contents Getting Started Basic Syntax Data Types Control... | 27,438 | 2024-05-19T14:47:38 | https://dev.to/syedmuhammadaliraza/go-lang-cheatsheet-31d8 | go, webdev, programming, development |
### Table of Contents
1. **Getting Started**
2. **Basic Syntax**
3. **Data Types**
4. **Control Structures**
5. **Functions**
6. **Structs and Interfaces**
7. **Concurrency**
### 1. Installation
To install Go, download it from the [official website](https://golang.org/dl/) and follow the installation instructions f... | syedmuhammadaliraza |
1,858,922 | Building an Elearning Course Creator with Streamlit and Lyzr Automata | In the rapidly evolving landscape of education and professional development, the demand for tailored,... | 0 | 2024-05-20T06:54:57 | https://dev.to/harshitlyzr/building-an-elearning-course-creator-with-streamlit-and-lyzr-automata-55im | In the rapidly evolving landscape of education and professional development, the demand for tailored, high-quality Elearning courses has surged. Educational institutions, businesses, and individual educators are striving to create engaging and effective online courses that cater to specific audiences. However, the proc... | harshitlyzr | |
1,859,475 | Introduction to Database Connectivity with Go (SQL and NoSQL) | Introduction to Database Connectivity with Go (SQL and NoSQL) Whether you are building a... | 0 | 2024-05-20T15:10:03 | https://dev.to/romulogatto/introduction-to-database-connectivity-with-go-sql-and-nosql-2jp9 | # Introduction to Database Connectivity with Go (SQL and NoSQL)
Whether you are building a simple web application or a complex enterprise system, the ability to connect to databases is essential. In this guide, we will explore how to connect and interact with both SQL and NoSQL databases using GoLang.
## Connecting t... | romulogatto | |
1,860,018 | Enhance Your Efficiency with These 13 Cursor Extensions | Here are 13 extensions that have proven to be quite beneficial 1. Prettier: An indispensable tool... | 0 | 2024-05-21T06:07:45 | https://dev.to/tuner9696/enhance-your-efficiency-with-these-13-cursor-extensions-4p54 | Here are 13 extensions that have proven to be quite beneficial
**1. Prettier:** An indispensable tool for JavaScript developers, Prettier automatically formats your code, ensuring a consistent style across your project.
**2. Auto Close Tag:** This extension automatically adds a closing tag when you type an opening HT... | tuner9696 | |
1,860,179 | AWS RDS Tutorial | Please have a look at this first:... | 0 | 2024-05-22T07:28:49 | https://dev.to/duyhung___/aws-rds-tutorial-3aha | Please have a look at this first: https://dev.to/hungrushb/amazon-rds-create-database-deep-dive-2m8j
# I. Preparation
### Create VPC
1 . Create a simple VPC with name **labRDS**. Keep everything as default and create.
... | 0 | 2024-05-21T10:40:32 | https://dev.to/saumya27/experience-the-future-smart-home-technology-and-ai-agency-1j8p | ai, chatgpt, aws, devops | **CPGChat** refers to an AI-powered chatbot solution tailored for the Consumer Packaged Goods (CPG) industry. These chatbots are designed to enhance customer engagement, streamline operations, and provide valuable insights to businesses in the CPG sector. Here’s an overview of what CPGChat entails, including its featur... | saumya27 |
1,860,349 | Website Design and Development Compa | A strong online presence is crucial for businesses to thrive in today's digital age. A well-designed... | 0 | 2024-05-21T11:50:02 | https://dev.to/akanksha_mall_3394babcd79/website-design-and-development-compa-4o2i | A strong online presence is crucial for businesses to thrive in today's digital age. A well-designed website is key to success.
If you are looking for a reliable and professional website design and development company in Delhi, Rishikesh, Meerut, or Dehradun, you've come to the right place.
In this article, we will... | akanksha_mall_3394babcd79 | |
70,825 | Observables, Side-effects, and Subscriptions | Exploring examples in idiomatic uses of Observables | 0 | 2018-12-25T23:16:17 | https://blog.eyas.sh/2018/12/observables-side-effects-and-subscriptions/ | reactivex, observable, reactiveprogramming, functional | ---
title: Observables, Side-effects, and Subscriptions
published: true
description: Exploring examples in idiomatic uses of Observables
tags: reactivex, observable, reactive programming, fp
canonical_url: https://blog.eyas.sh/2018/12/observables-side-effects-and-subscriptions/
---
My previous articles on [using `Asyn... | eyassh |
1,860,359 | Understanding AWS Control Tower: Part 2 - Implementation and Deployment | Introduction Welcome back to part two of our series on understanding AWS Control Tower. In part one,... | 0 | 2024-05-21T11:57:39 | https://dev.to/aminabrhm4/understanding-aws-control-tower-part-2-implementation-and-deployment-hdk | cloudmanagement, controltower, cloudgovernance, multiaccount | **Introduction**
Welcome back to part two of our series on understanding AWS Control Tower. In part one, we discussed how AWS Control Tower simplifies the management of multi-account AWS environments, addressing challenges like inconsistent security policies. We also explored its core features, including landing zones... | aminabrhm4 |
1,860,650 | GPT-4 passes most of the 297 written Polish Board Certification Examinations | GPT-4 passes most of the 297 written Polish Board Certification Examinations | 0 | 2024-05-21T15:39:45 | https://aimodels.fyi/papers/arxiv/gpt-4-passes-most-297-written-polish | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [GPT-4 passes most of the 297 written Polish Board Certification Examinations](https://aimodels.fyi/papers/arxiv/gpt-4-passes-most-297-written-polish). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://ai... | mikeyoung44 |
1,861,224 | Accessible DeFi Experience: MIMI Leading the Low-Barrier Financial Revolution | In the rapid development of blockchain technology and cryptocurrencies, decentralized finance (DeFi)... | 0 | 2024-05-22T05:47:58 | https://dev.to/mimi_official/accessible-defi-experience-mimi-leading-the-low-barrier-financial-revolution-3mon |
In the rapid development of blockchain technology and cryptocurrencies, decentralized finance (DeFi) is emerging as an innovative financial model that is gradually transforming the global financial ecosystem. However... | mimi_official | |
1,861,271 | JavaScript Function , First Class function / First Class Citizen in JavaScript | What is a Function in JavaScript? In JavaScript, a function is a block of code designed to perform a... | 0 | 2024-05-22T06:32:09 | https://dev.to/pervez/javascript-function-first-class-function-first-class-citizen-in-javascript-55i8 | **What is a Function in JavaScript?**
In JavaScript, a function is a block of code designed to perform a particular task. A function is executed when "something" invokes it (calls it).
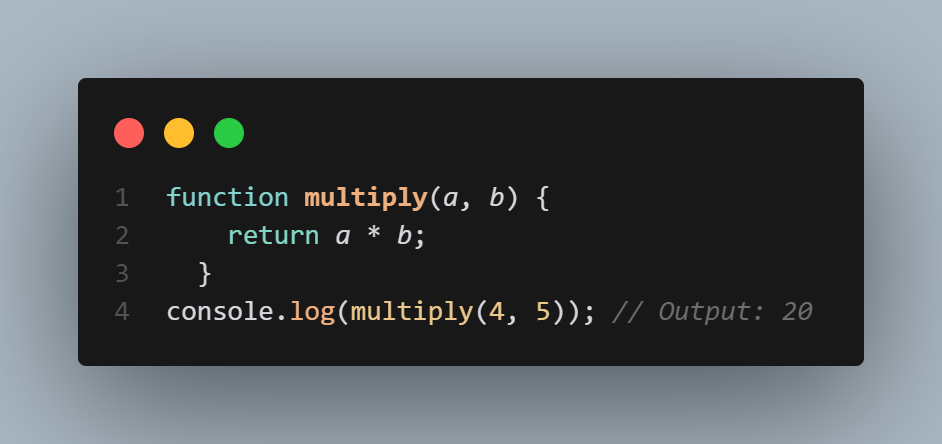
**What is an Anonymous Functi... | pervez | |
1,861,351 | Create a Heart Shaped Animation with CSS3 | Introduction Creating a personalized love confession page can be a fun and heartfelt way... | 0 | 2024-05-22T08:02:45 | https://dev.to/markyu/create-a-heart-shaped-animation-with-html5-css3-and-javascript-1pjh | html, css, codepen, animation | ### Introduction
Creating a personalized love confession page can be a fun and heartfelt way to express your feelings. By using HTML5, CSS3 animations, and a touch of JavaScript, you can create a beautiful page with an animated heart effect. In this tutorial, we will walk you through a simple example to get you starte... | markyu |
1,861,356 | Artificial Intelligence vs Mobile App Development | Recently, artificial intelligence has been a popular term in the business and technology sectors.... | 0 | 2024-05-22T08:15:54 | https://dev.to/owais121/5-ways-artificial-intelligence-will-disrupt-mobile-app-development-in-2024-3j2o | mobileappdevelopment, webdev, programming, ai | Recently, artificial intelligence has been a popular term in the business and technology sectors. This ground-breaking revolution is causing waves across a variety of industries. In the [field of app development](https://khired.com/solutions/mobile-application-development/), it's worthwhile to investigate the possibili... | owais121 |
1,861,453 | Web Worker in React: A step-by-step guide | Understanding web worker in React is entirely dependent on the idea of JavaScript’s code execution.... | 0 | 2024-05-22T09:43:16 | https://dev.to/ifourtechnolab/web-worker-in-react-a-step-by-step-guide-156a | webworker, react, reactwebworker, webdev | Understanding [web worker in React](https://www.ifourtechnolab.com/blog/how-to-use-web-workers-in-reactjs-a-step-by-step-guide) is entirely dependent on the idea of JavaScript’s code execution. So, before you begin, you should understand how JavaScript code is executed.
JavaScript is single-threaded in nature. That is... | ifourtechnolab |
1,861,572 | My Cleaners: Your Trusted Choice for the Best Dry Cleaners in Varanasi | In the vibrant streets of Varanasi, where tradition dances with modernity, stands a beacon of garment... | 0 | 2024-05-22T11:35:02 | https://dev.to/sunny_kumar_977fafbe9bc42/my-cleaners-your-trusted-choice-for-the-best-dry-cleaners-in-varanasi-32k8 | In the vibrant streets of Varanasi, where tradition dances with modernity, stands a beacon of garment care excellence – My Cleaners. Renowned as the city's premier dry cleaning establishment, My Cleaners has earned the trust and loyalty of Varanasi's residents through its unwavering commitment to quality, reliability, ... | sunny_kumar_977fafbe9bc42 | |
1,862,332 | Top 10 Trends in BDD Testing 2024 | Behavior-driven development (BDD) has revolutionized software testing by fostering clear... | 0 | 2024-05-23T04:13:26 | https://dev.to/ngocninh123/top-10-trends-in-bdd-testing-2024-2l30 | testing, trends | Behavior-driven development (BDD) has revolutionized software testing by fostering clear communication and collaboration between development teams and stakeholders.
The emergence of new BDD testing tools and platforms can further amplify the benefits they bring, as they promise to revolutionize collaboration between ... | ngocninh123 |
1,862,379 | Embracing the Style Web: Exploring the World of SP5DER Clothing | Embracing the Style Web: Exploring the World of SP5DER Clothing At sp5der clothing, we're not just... | 0 | 2024-05-23T04:47:36 | https://dev.to/larrypage/embracing-the-style-web-exploring-the-world-of-sp5der-clothing-h1a | Embracing the Style Web: Exploring the World of SP5DER Clothing
At sp5der clothing, we're not just about clothing; we're about crafting an experience, a lifestyle that transcends the ordinary. From the threads we choose to the intricate designs we create, every aspect of sp5der clothing is a testament to our commitme... | larrypage | |
1,862,496 | Programación asincrónica en Javascript | JavaScript, al ser un lenguaje de un solo subproceso, solo puede procesar una tarea a la vez. Esto... | 0 | 2024-05-23T18:55:31 | https://dev.to/w4ll-3/programacion-asincronica-en-javascript-46c5 | javascript, node, react, asynchronous | JavaScript, al ser un lenguaje de un solo subproceso, solo puede procesar una tarea a la vez. Esto puede provocar largos tiempos de espera para tareas complejas, ya que el script no podrá ejecutar ninguna otra tarea hasta que termine la actual. Para abordar este problema, JavaScript ofrece programación asincrónica, per... | w4ll-3 |
1,863,520 | Unlock TikTok Shop Success: Proven Strategies to Get Your Products Approved and Selling | Embarking on the journey to get your items approved and uploaded on TikTok Shop can be a rewarding... | 0 | 2024-05-24T03:53:13 | https://dev.to/epakconsultant/unlock-tiktok-shop-success-proven-strategies-to-get-your-products-approved-and-selling-17dd | tiktok | Embarking on the journey to get your items approved and uploaded on TikTok Shop can be a rewarding yet challenging process. Understanding the intricacies of TikTok's approval guidelines, optimizing product listings, creating compelling videos, and leveraging various features are essential steps in achieving success on ... | epakconsultant |
1,864,173 | New shell scripting language, a new tablet, and in-product messaging | Amber, a programming language that compiles to BASH The slippery slope of in-product... | 0 | 2024-05-24T16:15:26 | https://dev.to/rudolfolah/new-shell-scripting-language-a-new-tablet-and-in-product-messaging-5g5h | bash, ipad, product, marketing | * [Amber, a programming language that compiles to BASH](https://amber-lang.com/)
* [The slippery slope of in-product messaging
](https://matthewstrom.com/writing/wayfinding/)
* [Daylight Computer, an alternative to Kindle and iPad?](https://daylightcomputer.com/product)
## Shell scripting times a million
[Amber is a n... | rudolfolah |
1,866,002 | ChatGPT and how it is a great learning tool | Hello everybody👋! In this article I would like to show you my process in learning a new technology... | 0 | 2024-05-27T01:00:13 | https://dev.to/slydragonn/chatgpt-and-how-it-is-a-great-learning-tool-1pk2 | chatgpt, learning, webdev, beginners | **Hello everybody👋!**
In this article I would like to show you my process in learning a new technology with ChatGPT, which without a doubt nowadays is one of the best tools for learning, specifically I am learning to create desktop applications with electron.js since I want to focus more on a web stack, so let's star... | slydragonn |
1,866,128 | Rails: Switches Serializer according to STI Type | Introduction Hello, here is Tamura. Suppose you have model data of multiple types using... | 27,526 | 2024-05-28T14:00:00 | https://dev.to/weseek-inc/rails-switches-serializer-according-to-sti-type-4pc7 | rails, ruby, programming | ## Introduction
Hello, here is Tamura.
Suppose you have model data of multiple types using STI and want to mix and return them in a single API endpoint. In this case, you would like to switch the serializer according to the STI type.
In this article, I will show you how to do this.
## Issue
Suppose the following cl... | weseek-inc |
1,867,434 | Create more of WordPress Gutenberg | Hey Is this Repo all has to be offered from Wordpress.org Community? 📌 Ref Link:... | 0 | 2024-05-28T09:21:45 | https://dev.to/akehsanz/create-more-of-wordpress-gutenberg-56fp | javascript, wordpress, wordpressblockthemes, wordpressgutenberg | Hey
Is this Repo all has to be offered from Wordpress.org Community?
📌
Ref Link: https://wordpress.org/gutenberg/ | akehsanz |
1,868,352 | Dummy ticket for visa | Does one need a visa? You are unable to purchase a ticket because you do not have specific travel... | 0 | 2024-05-29T03:03:32 | https://dev.to/onlineodt/dummy-ticket-for-visa-5fl5 | dummyticket, dummyplaneticket | Does one need a visa? You are unable to purchase a ticket because you do not have specific travel dates.
You can apply for a visa in this case using a fake ticket. Since it provides all the information required for visa filing, it is feasible to submit it. You will incur significant losses if your application for a vis... | onlineodt |
1,868,620 | Ubuntu热点问题 | 最近从公司出来了,自己电脑重新启动,升级到Ubuntu24.04LTS, 目前基本稳定。使用过程中碰到一个需求,需要开启热点供手机联网。虽然是最新版本LTS,... | 0 | 2024-05-29T07:10:16 | https://dev.to/shouhua_57/ubunture-dian-wen-ti-lpf | hotspot, ubuntu, proxy | 最近从公司出来了,自己电脑重新启动,升级到Ubuntu24.04LTS, 目前基本稳定。使用过程中碰到一个需求,需要开启热点供手机联网。虽然是最新版本LTS, 其他版本应该也能使用。下面就遇到的问题整理下。
1. 开启热点注意点
开启热点不能使用wifi, 所以如果要开启热点上网需要使用有线连接,以前使用MAC有类似经历,所以这个对我不是问题。
2. 笔记本网络正常,开启热点正常,手机能连上,但是显示“无网络连接”
这个在网上找了半天答案,发现是由于防火墙问题,~~临时打开防火墙就好,完事后开启就好~~。
**经过网友提醒,ufw可以不用关闭,添加相关ufw策略就好,主要是运行无线网卡数据进入,物理网卡可以路由数据,因为无线网卡数... | shouhua_57 |
1,868,851 | Unlocking the Potential of SAP Production Planning (SAP PP) for Efficient Manufacturing | In the fast-paced world of manufacturing, efficiency and precision are crucial for staying... | 0 | 2024-05-29T10:27:33 | https://dev.to/mylearnnest/unlocking-the-potential-of-sap-production-planning-sap-pp-for-efficient-manufacturing-1aki | In the fast-paced world of manufacturing, efficiency and precision are crucial for staying competitive. [SAP Production Planning (SAP PP)](https://www.sapmasters.in/sap-pp-training-in-bangalore/) is a vital component of the SAP ERP system designed to streamline production processes and ensure optimal use of resources. ... | mylearnnest | |
1,868,986 | What is in PHP-FPM configuration file? | Hi I'm Tak Fukushima, Software Engineer. This article, I'll write PHP-FPM configuration file. I... | 0 | 2024-05-29T14:10:54 | https://dev.to/takahiro_82jp/what-is-in-php-fpm-configuration-file-2na6 | php, phpfpm, laravel | Hi I'm Tak Fukushima, Software Engineer.
This article, I'll write PHP-FPM configuration file.
I often use PHP-FPM with Nginx, they say unix domain socket connection.
I frequently modify PHP-FPM configuration file that time.
But first time it is difficult to read this file.
So Let me explain.
### Condition
* use Ubunt... | takahiro_82jp |
1,869,536 | Vue.js 101: Mastering Computed Properties and Watchers for Reactive Data | In Vue.js, computed properties and watchers are powerful tools for managing and reacting to reactive... | 0 | 2024-05-29T19:27:27 | https://dev.to/delia_code/vuejs-101-mastering-computed-properties-and-watchers-for-reactive-data-18mb | javascript, beginners, tutorial, vue | In Vue.js, computed properties and watchers are powerful tools for managing and reacting to reactive data. Understanding these features is essential for building efficient and responsive Vue.js applications. In this article, we'll explore computed properties and watchers in detail, from beginner to advanced examples, u... | delia_code |
1,870,062 | The Best Share Market Apps For This Year | The stock market, with its potential for wealth creation and opportunities, continues to draw... | 0 | 2024-05-30T07:42:55 | https://dev.to/sanjay_raghuvanshi_/the-best-share-market-apps-for-this-year-4odh | The stock market, with its potential for wealth creation and opportunities, continues to draw investors in the ever-changing environment of Indian finance. It's now easier than ever to access the stock market thanks to the development of mobile technologies. Because they offer real-time data, research tools, and fricti... | sanjay_raghuvanshi_ | |
1,870,739 | Design e Arquitetura de Software: Entendendo Suas Funções e Desafios no Desenvolvimento | Bom, estou começando a ler o excelente livro Arquitetura Limpa: o Guia do Artesão Para Estrutura e... | 0 | 2024-05-30T19:54:51 | https://dev.to/mathsena/design-e-arquitetura-de-software-entendendo-suas-funcoes-e-desafios-no-desenvolvimento-3b6e | cleancode, design |
Bom, estou começando a ler o excelente livro Arquitetura Limpa: o Guia do Artesão Para Estrutura e Design de Software escrito pelo autor Robert C. Martin, então por isso resolvi escrever um pouco sobre alguns temas importantes que são descritos na obra.
Começamos com um assunto importante, que é a diferença entre Des... | mathsena |
1,872,204 | How to setup an Apache server on Ubuntu 22.04.4 LTS with Virtual hosting | Apache is a popular open source web server that is widely used to host web pages. In this... | 0 | 2024-05-31T15:45:40 | https://dev.to/oyololatoni/how-to-setup-an-apache-server-on-ubuntu-22044-lts-with-virtual-hosting-1mnm | apache, devops, ubuntu, selfhosting |

Apache is a popular open source web server that is widely used to host web pages.
In this tutorial, you’ll be creating a virtual host environment to run multiple websites with Apache on your Ubuntu 22.04.4 LTS server allowing you to add seve... | oyololatoni |
1,873,422 | Способы установки Node.js | Способы установки Node.js Node.js — это популярная платформа для разработки серверных приложений, и... | 0 | 2024-06-02T03:02:35 | https://dev.to/mibii/sposoby-ustanovki-nodejs-1dme | node | Способы установки Node.js
Node.js — это популярная платформа для разработки серверных приложений, и для многих разработчиков важно знать, как правильно установить и управлять версиями Node.js. Давайте рассмотрим основные способы установки Node.js.
Установка из репозитория
Наиболее распространенный способ установки Nod... | mibii |
1,875,717 | How to Integrate Firebase in NestJS for Notifications 🚀 | Introduction NestJS is a powerful Node.js framework for building efficient server-side... | 27,583 | 2024-06-03T18:30:00 | https://dev.to/shahharsh/how-to-integrate-firebase-in-nestjs-for-notifications-gik | firebase, nestjs, notification, android | #### Introduction
NestJS is a powerful Node.js framework for building efficient server-side applications, while Firebase offers tools like Firebase Cloud Messaging (FCM) for sending notifications. Integrating Firebase with NestJS allows you to send real-time notifications easily.
#### Prerequisites
Make sure you hav... | shahharsh |
1,876,278 | Boost MongoDB Performance: Motor Client vs PyMongo - Which is Faster? | Once I was tasked with improving the database and general app operations of backend services which... | 0 | 2024-06-04T06:55:55 | https://www.developertimeline.io/scalable-database-operations | webdev, mongodb, python |
Once I was tasked with improving the database and general app operations of backend services which are using MongoDB as their main database.
These services were part of huge infrastructure where millions of messages coming through the queues and needed to be processed based on the message actions. That means tons of... | thedevtimeline |
1,876,600 | Simplifying Transformer Blocks | Simplifying Transformer Blocks | 0 | 2024-06-04T12:22:29 | https://aimodels.fyi/papers/arxiv/simplifying-transformer-blocks | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Simplifying Transformer Blocks](https://aimodels.fyi/papers/arxiv/simplifying-transformer-blocks). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https... | mikeyoung44 |
1,877,070 | OpenID Connect Flows: From Implicit to Authorization Code with PKCE & BFF | Introduction This article will review the principles behind various OpenID Connect (OIDC)... | 0 | 2024-06-04T19:49:23 | https://dev.to/alexey-abblix/openid-connect-flows-from-implicit-to-authorization-code-with-pkce-bff-4ke8 | authentication, security, oauth2, webdev | ## Introduction
This article will review the principles behind various OpenID Connect (OIDC) authentication flows, from the simplest to the most modern, highlighting the vulnerabilities present in each.
We will explore each of the following OpenID Connect flows in detail:
Frontend-only implementations:
- **Implicit ... | alexey-abblix |
1,880,140 | Can a line chart be segmented? | Title Can a line chart be segmented? Description In vchart, is it possible to... | 0 | 2024-06-07T08:53:48 | https://dev.to/neuqzxy/can-a-line-chart-be-segmented-1l5k | # Title
Can a line chart be segmented?
# Description
In vchart, is it possible to segment a line chart if there is a point that you do not want to display?
 plays a vital role in ensuring your website ranks high on search engines, driving organic traffic and potential customers to your site. Hiring an SEO agency can be a game-changer for your business, but ... | tdigitalguru1 |
1,889,238 | Shift-Left Testing: A Testing Methodology to Maximize Efficiency | Software development is ever-growing, and agility and speed are paramount to ensure quick delivery... | 0 | 2024-06-15T04:50:06 | https://dev.to/elle_richard_232/shift-left-testing-a-testing-methodology-to-maximize-efficiency-39in | testing, software, programming, productivity | Software development is ever-growing, and agility and speed are paramount to ensure quick delivery time. In this fast-paced environment, continuous testing has emerged as a game changer. By integrating the testing cycle into the entire software delivery lifecycle organizations can ensure that the applications meet the ... | elle_richard_232 |
1,890,711 | JS, form 동작 막기 | const $form = document.querySelecotr('form'); $form.addEventListener("submit", (event) => { //... | 0 | 2024-06-17T02:15:33 | https://dev.to/sunj/js-form-dongjag-maggi-59bp | javascript | ```
const $form = document.querySelecotr('form');
$form.addEventListener("submit", (event) => {
// 동작(이벤트)을 실행하지 못하게 막는 메서드입니다.
event.preventDefault();
console.log(event.target);
});
```
_참조 : https://gurtn.tistory.com/206_
| sunj |
1,891,320 | Why do we have const enums in Typescript? | Typescript usually has two schools of thought—enums and unions—with strong supporters on both sides... | 0 | 2024-06-17T13:33:22 | https://www.allthingstypescript.dev/p/why-do-we-have-const-enums-in-typescript | webdev, javascript, typescript, tutorial | Typescript usually has two schools of thought—enums and unions—with strong supporters on both sides of the argument. In today's issue, I want to avoid that debate and focus solely on Enums, specifically a different, lesser-known version of enums: const enums.
Before we go any further, let’s briefly talk about what enu... | mainawycliffe |
1,893,762 | What are High-Level Programming Languages? Really, what are they? | I was sitting on nails as the Hungarian says, meaning I couldn’t wait to write about High-level... | 0 | 2024-06-19T15:10:38 | https://dev.to/zoltan_fehervari_52b16d1d/what-are-high-level-programming-languages-really-what-are-they-1gng | highlevelprogramminglanguages, programming, programminglanguages | I was sitting on nails as the Hungarian says, meaning I couldn’t wait to write about High-level programming languages (HLPLs)!
They are designed to be easily readable and understood by humans, providing a higher degree of abstraction from the underlying hardware. These languages simplify the programming process by usi... | zoltan_fehervari_52b16d1d |
1,894,049 | Distributed Google Maps scraping | Introduction In this post, I will show you how you can utilize the power of Kubernetes to scrape data... | 0 | 2024-06-19T20:29:01 | https://blog.gkomninos.com/distributed-google-maps-scraping | webscraping, googlemapsscraper, googlemapscrawler, go | ---
title: Distributed Google Maps scraping
published: true
date: 2023-05-14 15:10:45 UTC
tags: webscraping,GoogleMapsScraper,googlemapscrawler,golang
canonical_url: https://blog.gkomninos.com/distributed-google-maps-scraping
---
Introduction In this post, I will show you how you can utilize the power of Kubernetes to... | gosom |
1,901,053 | Introducing Thin: The App for Rapid, Concise Content Sharing | Hello dev.to community, I'm excited to introduce Thin, an app designed to revolutionize how you... | 0 | 2024-06-26T08:21:00 | https://dev.to/frulow/introducing-thin-the-app-for-rapid-concise-content-sharing-9pp | react, reactnative, javascript, productivity | Hello dev.to community,
I'm excited to introduce Thin, an app designed to revolutionize how you consume and share content. Whether you’re looking to share a digest of your latest blog post or quickly read up on various topics, Thin makes it easy and efficient.
## Why Thin?
Thin is all about brevity and convenience. ... | frulow |
1,902,122 | Animated Video Production: A Comprehensive Guide | Introduction to Animated Video Production Animated video production has become a pivotal tool in... | 0 | 2024-06-27T05:50:27 | https://dev.to/releb55973/animated-video-production-a-comprehensive-guide-9f9 | **Introduction to Animated Video Production**
Animated video production has become a pivotal tool in modern communication, marketing, and entertainment. With its ability to simplify complex ideas and captivate audiences, animation offers a unique way to convey messages effectively. Whether for educational content, adve... | releb55973 | |
1,902,782 | Next.js Vs React.Js: What you need to know | React and NextJS are tools becoming more popular this days, with a lot of similarities, and people... | 0 | 2024-06-28T09:39:13 | https://dev.to/mikeya-yo/nextjs-vs-reactjs-what-you-need-to-know-319k | javascript, webdev, react, nextjs | React and NextJS are tools becoming more popular this days, with a lot of similarities, and people often ask what are the diffences between this two and which one should i use?
Before we can talk about the differences between this two we need to first understand what exactly they are.
## React
React is a frontend lib... | mikeya-yo |
1,903,469 | C# IEnumerables | Key Points: What is IEnumerable? IEnumerable is an interface in C# that... | 0 | 2024-06-28T02:54:53 | https://dev.to/jsdevelopermano/c-ienumerables-2bbi | ## Key Points:
### What is IEnumerable?
- `IEnumerable` is an interface in C# that allows you to iterate over a collection of items.
- It is found in the `System.Collections` namespace for non-generic collections and `System.Collections.Generic` namespace for generic collections.
### Methods and Properties
- The pr... | jsdevelopermano | |
1,903,473 | Operadores em Java | Tipos de Operadores Aritméticos: Realizam operações matemáticas básicas. Bitwise: Operam sobre... | 0 | 2024-06-28T02:47:59 | https://dev.to/devsjavagirls/operadores-em-java-2ced | java |
**Tipos de Operadores**
**Aritméticos:**
- Realizam operações matemáticas básicas.
**Bitwise:** Operam sobre bits.
**Relacionais:** Comparam valores.
**Lógicos:** Realizam operações lógicas.
**Operadores Aritméticos**
**Operadores Básicos:**
+ Adição
- Subtração
* Multiplicação
/ Divisão
% Módulo (resto da divisão... | devsjavagirls |
1,903,493 | Unlocking Cloud Networking Potential: A Deep Dive into AWS VPC | Unlocking Cloud Networking Potential: A Deep Dive into AWS VPC ... | 0 | 2024-06-28T03:10:50 | https://dev.to/virajlakshitha/unlocking-cloud-networking-potential-a-deep-dive-into-aws-vpc-4eo1 | 
# Unlocking Cloud Networking Potential: A Deep Dive into AWS VPC
### Introduction
The cloud revolution hinges on flexibility and scalability. Amazon Virtual Private Cloud (VPC) empowers businesses to build and manage their own pr... | virajlakshitha | |
1,903,718 | virtual address for gst registration | A virtual office in Jaipur with “Virtual States GST” will make your business stand out. We have... | 0 | 2024-06-28T07:11:32 | https://dev.to/manojkumararvian_9f54148/virtual-address-for-gst-registration-6ao | A virtual office in Jaipur with “Virtual States GST” will make your business stand out. We have reliable virtual office plans, that suit your business environment. We provide the best help solution for today’s fast-moving, versatile business environment. Our proficient experts will you to open your office without takin... | manojkumararvian_9f54148 | |
1,904,493 | Using Past Performance Information Retrieval System PPIRS to Showcase Your Track Record | Discover how to leverage the Past Performance Information Retrieval System (PPIRS) to display and enhance your professional track record effectively. | 0 | 2024-06-28T16:36:39 | https://www.govcon.me/blog/using_past_performance_information_retrieval_system_ppirs_to_showcase_your_track_record | technology, innovation, ppirs, performancemanagement | # Using Past Performance Information Retrieval System (PPIRS) to Showcase Your Track Record
In today’s fast-evolving professional landscape, standing out requires more than just sheer talent and a strong work ethic. Enter the Past Performance Information Retrieval System (PPIRS)—a game-changer in performance managemen... | quantumcybersolution |
1,905,876 | Understanding The Use Of Context API In React JS | React JS, known for its efficient and flexible JavaScript library for building user interfaces, often... | 0 | 2024-06-29T17:56:46 | https://reacttonext.com/context-api-react-js/ | reactjsdevelopment, frontend, react, webdev | React JS, known for its efficient and flexible JavaScript library for building user interfaces, often requires sharing data between components without passing props at every level. This is where the Context API in React JS comes into play. The Context API enables the seamless transmission of data through the component ... | shrikant9907 |
1,906,820 | Unsupervised Learning: Unveiling the Hidden Secrets in Your Data | Imagine walking into a room full of people, but none of them have name tags. Unsupervised learning is... | 0 | 2024-06-30T18:04:07 | https://dev.to/abhinav_yadav_554cab962bb/unsupervised-learning-unveiling-the-hidden-secrets-in-your-data-g82 | beginners, ai, machinelearning, datascience | Imagine walking into a room full of people, but none of them have name tags. Unsupervised learning is like being tasked with organising them into groups based on what you see. Unlike supervised learning where we have labeled data, here we're on our own to find hidden patterns and structures.
## Table Of Content
- Int... | abhinav_yadav_554cab962bb |
1,907,172 | Microsoft Azure Migration Challenges & Solutions In 2024 | If you are reading this article, you might be interested in migrating your system to Microsoft Azure.... | 0 | 2024-07-01T05:32:47 | https://dev.to/priya_raimagiya_c204c9e90/microsoft-azure-migration-challenges-solutions-in-2024-161c | azure, azuremigration, migrationchallenges, azuresolutions |
If you are reading this article, you might be interested in migrating your system to Microsoft Azure. This decision might leave you with several questions and doubts, one of which might be about the challenges of migrating to the cloud!
These questions are not wrong—as you prepare to migrate your legacy infrast... | priya_raimagiya_c204c9e90 |
1,907,681 | ASTRO JS | WEB DEV | Hello my fellow web developers, today i will be starting a small series about astro js which is a new... | 0 | 2024-07-01T12:38:35 | https://dev.to/shubhamtiwari909/astro-js-web-dev-15fp | html, webdev, javascript, beginners | Hello my fellow web developers, today i will be starting a small series about astro js which is a new framework just like NEXT JS and if you know about next js, the learning curve could be very easy and straight forward.
Let's get started...
## Table of Contents
- [What is Astro JS](#intro)
- [Some of the key feature... | shubhamtiwari909 |
1,907,750 | SQL Course: One-to-one Relationships and Inner Joins. | In this chapter, we will set up a user and a profile table and create a one-to-one relationship... | 27,924 | 2024-07-01T17:28:37 | https://dev.to/emanuelgustafzon/sql-course-one-to-one-relationships-and-inner-joins-4e9g | sql | In this chapter, we will set up a user and a profile table and create a one-to-one relationship between them.
A user can create a `user` with a username and password and then create a `profile` with a profile image and bio. A user can only have one profile and a profile can only be related to one user. That is why it... | emanuelgustafzon |
1,908,503 | RouterInput in Angular v16 | Introduction: Angular v16 has recently been released, bringing along a range of new... | 0 | 2024-07-02T06:52:41 | https://dev.to/sanjaisak/routerinput-in-angular-v16-p8j | webdev, angular, javascript | ## **Introduction:**
Angular v16 has recently been released, bringing along a range of new features aimed at enhancing the developer experience. One of these exciting features is RouterInput, which allows developers to retrieve route information through inputs. In this blog post, we will explore how RouterInput can be ... | sanjaisak |
1,908,625 | Streamlining Tariff Classification for Seamless Customs Declarations | As developers, efficiency is key. Here’s how accurate Ai in tariff classification can simplify your... | 0 | 2024-07-02T08:30:23 | https://dev.to/john_hall/streamlining-tariff-classification-for-seamless-customs-declarations-1587 | ai, productivity, learning, software | As developers, efficiency is key. Here’s how accurate Ai in tariff classification can simplify your customs processes and boost your international trade operations.
## Why Tariff Classification Matters
The [Harmonised System (HS)](https://www.icustoms.ai/blogs/hs-code/) is used globally by over 200 countries, coverin... | john_hall |
1,908,686 | 1. Series introduction | In this series I will explain principles of vim and neovim, and it is complementary to another series... | 27,946 | 2024-07-03T09:34:44 | https://dev.to/stroiman/series-introduction-2o3n | neovim, vim | In this series I will explain principles of vim and neovim, and it is complementary to another series where I rebuild my configuration from scratch.
When I reach a new vim concept, in my configuration that I think could benefit need explaining in depth, I will add an article to this series about that concept.
Note on... | stroiman |
1,909,233 | Configurando pipeline com github actions para um projeto React | Fazia tempo que não configurava um serviço de ci/cd e esses dias fui fazer isso no github usando o... | 0 | 2024-07-02T17:33:24 | https://dev.to/mayconbalves/configurando-pipeline-com-github-actions-para-um-projeto-react-lj4 |

Fazia tempo que não configurava um serviço de ci/cd e esses dias fui fazer isso no github usando o github actions e percebi ser bem simples, e podemos fazer várias rotinas, é bem legal, mesmo se você estiver traba... | mayconbalves | |
1,909,249 | Conversão de tipos | Conversão de tipos em atribuições É comum atribuir um tipo de variável a outro em... | 0 | 2024-07-02T20:48:29 | https://dev.to/devsjavagirls/conversao-de-tipos-127g | java | **Conversão de tipos em atribuições**
- É comum atribuir um tipo de variável a outro em programação.
Exemplo: atribuir um valor int a uma variável float.
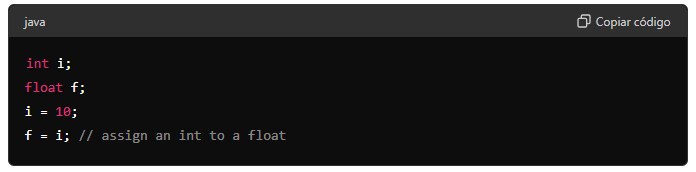
- Quando tipos compatíveis são combinados em uma atribuição... | devsjavagirls |
70,647 | Automating GitHub tasks with Node-RED | How to build easy-to-use workflows on Node-RED to automate GitHub tasks | 0 | 2018-12-23T22:01:38 | https://dev.to/webhookrelay/automating-github-tasks-with-node-red-3cgc | javascript, nodered, devops, productivity | ---
title: Automating GitHub tasks with Node-RED
published: true
description: How to build easy-to-use workflows on Node-RED to automate GitHub tasks
tags: javascript, node-red, devops, productivity
---
## Some background
While majority of the [Node-RED](https://nodered.org/) community seems to be interested... | krusenas |
1,909,704 | Embrace the Richness of India: Drape Yourself in a Lambani Embroidery Saree | Introduction: India is a land of rich cultural heritage, and one way to embrace its richness is by... | 0 | 2024-07-03T05:48:42 | https://dev.to/tittibha/embrace-the-richness-of-india-drape-yourself-in-a-lambani-embroidery-saree-377h | saree, fashion | <h2 class="AnswerParser_ChrpVTwoAnswerParserH2__sR11m">Introduction:</h2>
<p><span class="ReactMarkdownParser_ChrpVTwoTextContainer__ThA7z" data-testid="youchat-text">India is a land of rich cultural heritage, and one way to embrace its richness is by adorning yourself in a <strong><a href="https://tittibha.in/product/... | tittibha |
1,910,152 | The Differences Between EntityFramework .Add and .AddAsync | Introduction Entity Framework is a popular Object-Relational Mapper (ORM) for .NET, which... | 0 | 2024-07-03T15:25:01 | https://dev.to/tkarropoulos/the-differences-between-entityframework-add-and-addasync-2koo | csharp, softwaredevelopment, entityframework | ### Introduction
Entity Framework is a popular Object-Relational Mapper (ORM) for .NET, which allow us to better interact with a database using .NET objects. One of the fundamental operations we are using all of us that interact with databases is adding new entities. In this article I will try to explain the two method... | tkarropoulos |
1,910,427 | Automating Linux User Creation with a Bash Script | A Practical Script for SysOps Engineers In the SysOps engineer world, automation is key,... | 0 | 2024-07-03T21:47:31 | https://dev.to/sipsdaoracle/automating-linux-user-creation-with-a-bash-script-1fc2 | linux, bash, devops, hng |
## A Practical Script for SysOps Engineers
In the SysOps engineer world, automation is key, especially for repetitive tasks that save valuable time and ensure consistency. As a SysOps engineer, knowing how to write robust and efficient scripts along with strong Linux skills, boosts productivity and gives you a better... | sipsdaoracle |
1,910,429 | # 🌳 Dive into Decision Trees: A Fun Guide! 🌳 | Hey there, fellow data enthusiasts! 👋 Are you ready to dive into the world of Decision Trees? 🌲 Let's... | 0 | 2024-07-03T16:35:51 | https://dev.to/aviralgarg05/-dive-into-decision-trees-a-fun-guide-590l | ai, python, tensorflow, machinelearning | Hey there, fellow data enthusiasts! 👋 Are you ready to dive into the world of Decision Trees? 🌲 Let's make it interactive and fun with emojis! 🎉
## What is a Decision Tree? 🤔
A Decision Tree is like a flowchart that helps us make decisions based on data. Each node represents a decision point, and the branches sho... | aviralgarg05 |
34,247 | iOS remote debugging - a how-to guide | find out how to enable iOS remote debugging in Xcode and debug apps on remote iOS devices. | 0 | 2018-06-06T12:06:03 | https://dev.to/rickey_oak/ios-remote-debugging---a-how-to-guide-2onh | iosdebug, debugiosapp, remotedebugios, debugiosappondevice | ---
title: iOS remote debugging - a how-to guide
published: true
description: find out how to enable iOS remote debugging in Xcode and debug apps on remote iOS devices.
tags: ios debug, debug ios app, remote debug ios, debug ios app on device
---
# iOS remote debugging - a how-to guide
When it comes to testi... | rickey_oak |
54,150 | Which language would you want to see take over the world? | Let's imagine for a second that we live in a world where all programming languages are equally suited... | 0 | 2018-10-09T06:36:05 | https://dev.to/avalander/which-language-would-you-want-to-see-take-over-the-world-492 | discuss, languages, programming | ---
title: Which language would you want to see take over the world?
published: true
description:
tags: discuss, languages, programming
cover_image: https://images.unsplash.com/photo-1459478309853-2c33a60058e7?ixlib=rb-0.3.5&ixid=eyJhcHBfaWQiOjEyMDd9&s=ba9893452f120b4af8ffe3b3f9475e7f&auto=format&fit=crop&w=750&q... | avalander |
57,071 | 6 MSSQL Interview Questions for Experienced | Sharing 6 MSSQL Interview Questions for Experienced | 0 | 2018-10-25T17:31:51 | https://dev.to/sharadtricks/6-mssql-interview-questions-for-experienced-bdm | mssql, interview, questions | ---
title: 6 MSSQL Interview Questions for Experienced
published: true
description: Sharing 6 MSSQL Interview Questions for Experienced
tags: MSSQL, Interview, Questions
---
##1. How to shrink a database in Mssql?
In MSSQl you can shrink database by using SQL Server Management Studio or Transact-SQL.We have de... | sharadtricks |
68,690 | Friday hack: Suspense, Concurrent mode and lazy to load locales for i18n | I have a small series of posts about Lingui. I implemented all i18n related features. And I want to a... | 125 | 2018-12-15T04:13:02 | https://dev.to/stereobooster/friday-hack-suspense-concurrent-mode-and-lazy-to-load-locales-for-i18n-hgg | react, javascript, i18n | ---
title: Friday hack: Suspense, Concurrent mode and lazy to load locales for i18n
published: true
description:
tags: [react, js, i18n]
cover_image: https://thepracticaldev.s3.amazonaws.com/i/qz8jv655155c37byozj0.jpg
series: i18n of React with Lingui.js
---
I have a small series of posts about Lingui. I imp... | stereobooster |
70,337 | Build a Basic Website with ASP.NET MVC and Angular | This tutorial walks you through building a basic website with ASP.NET MVC and Angular. | 0 | 2019-11-21T19:17:53 | https://developer.okta.com/blog/2018/12/21/build-basic-web-app-with-mvc-angular | dotnet, angular, tutorial, webdev | ---
title: Build a Basic Website with ASP.NET MVC and Angular
published: true
description: This tutorial walks you through building a basic website with ASP.NET MVC and Angular.
tags: dotnet, angular, tutorial, webdev
canonical_url: https://developer.okta.com/blog/2018/12/21/build-basic-web-app-with-mvc-angular
---
AS... | oktadev_77 |
70,530 | How do you DEV.to? | I am new to the community and curious how others are using it. | 0 | 2018-12-26T04:14:36 | https://dev.to/therealdanvega/how-do-you-devto-1i7m | discuss | ---
title: How do you DEV.to?
published: true
description: I am new to the community and curious how others are using it.
tags: discuss
---

I recently joined the DEV.to community and I am curious how each of you are using the pl... | therealdanvega |
70,842 | Install and Update Solidity(solc) in Mac | You can install and update solc: brew update brew upgrade brew tap ethereum/ethereum brew install s... | 0 | 2018-12-26T06:16:03 | https://dev.to/sot528/install-and-update-soliditysolc-in-mac-n8i | solidity, ethereum, solc | ---
title: Install and Update Solidity(solc) in Mac
published: true
description:
tags: solidity,ethereum,solc
---
You can install and update solc:
```bash
brew update
brew upgrade
brew tap ethereum/ethereum
brew install solidity
brew link --overwrite solidity
```
# Errors
If you got the error be... | sot528 |
71,013 | Java 8 lambdas: 101 | Java 8 lambdas starter for absolute beginners. | 0 | 2018-12-27T08:41:28 | https://dev.to/shriyog/java-8-lambdas-101-1ah3 | java, java8, lambda, beginners | ---
title: Java 8 lambdas: 101
published: true
description: Java 8 lambdas starter for absolute beginners.
tags: java, java8, lambda, beginners
---
All you need is 5 minutes to grok the Lambda expressions introduced in Java 8. This post acts as a starter by quickly demonstrating how lambdas are super cool in re... | shriyog |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.