
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
500,517 | How Mandarine Framework could surpass NestJS | Introduction Mandarine is a relatively new typescript framework that runs on Deno. Its obj... | 0 | 2020-10-28T20:49:36 | https://dev.to/andreespirela/how-mandarine-framework-could-surpass-nestjs-13c3 | nestjs, mandarine, typescript, deno | # Introduction
Mandarine is a relatively new typescript framework that runs on [Deno](https://deno.land). Its objective is very simple: to provide as many built-in functionalities as possible for application development.
Mandarine is a ready-for-production framework & one of the few packages that are production-ready,... | andreespirela |
500,541 | Hi, there. I'm having an issue that i really don't understand. | Hi, there. I'm having an issue that i really don't understand. I have noticed that sometimes my compo... | 0 | 2020-10-28T21:47:20 | https://dev.to/sylvastudio/hi-there-i-m-having-an-issue-that-i-really-don-t-understand-1hpc | react, sass, javascript, webdev | Hi, there. I'm having an issue that i really don't understand. I have noticed that sometimes my components that i grouped into a parent component goes against it normal html positioning, the will be stacking on top or behind each components nested together with them within same parent. Please i need help to understand... | sylvastudio |
500,618 | Running a self managed kubernetes cluster on AWS | In this post I want to walk through the steps one needs to take to run a self managed kubernetes clus... | 0 | 2020-10-29T03:01:12 | https://dev.to/pksinghus/running-a-self-managed-kubernetes-cluster-on-aws-mhm | kubernetes, aws, devops | In this post I want to walk through the steps one needs to take to run a self managed kubernetes cluster on AWS. One of the reasons one might want to do it is so that one could run newest version of kubernetes not yet available as a managed service.
We are going to use `kubeadm` to install kubernetes components and us... | pksinghus |
500,789 | HACKTOBERFEST 2020 | About Me Hi! I am Manali Biswas. I am new to the DEV community as I joined it during Hackt... | 0 | 2020-10-29T06:15:23 | https://dev.to/manalibiswas/hacktoberfest-2020-3anm | hacktoberfest | <!-- ✨This template is only meant to get your ideas going, so please feel free to write your own title, structure, and words! ✨ -->
### About Me
Hi! I am Manali Biswas. I am new to the DEV community as I joined it during Hacktoberfest this month. I am a Computer Engineering student at Delhi Technological University. ... | manalibiswas |
503,462 | Back to Basics: Event Delegation | Event Delegation is an old trick to keep your JavaScript DOM enhancements independent of content | 0 | 2020-11-01T14:23:30 | https://dev.to/codepo8/back-to-basics-event-delegation-5742 | javascript, webdev, tricks | ---
title: Back to Basics: Event Delegation
published: true
description: Event Delegation is an old trick to keep your JavaScript DOM enhancements independent of content
tags: javascript, webdevelopment, tricks
cover_image:
---
. Somewhere I coul... | codingknite |
585,009 | Selenium Web Driver Vs Proxies API | The world of web scraping is varied and complex and Proxies API sits at one of the most crucial junct... | 0 | 2021-02-18T09:52:21 | https://proxiesapi.com/blog/selenium-web-driver-vs-proxies-api.html.php | The world of web scraping is varied and complex and Proxies API sits at one of the most crucial junctions. Allowing web scrapers/crawlers to bypass IP blocks by using a single API endpoint to access our 20 million-plus high-speed proxies on rotation.
One of the questions we get frequently is how we are different from s... | proxiesapi | |
503,559 | DuckDB: an embedded DB for data wrangling | Last week, ThoughtWorks released it's latest edition of the Technology Radar. One of the new entries... | 0 | 2020-11-01T19:14:58 | https://dev.to/volkmarr/duckdb-an-embedded-db-for-data-wrangling-4hfm | datascience, sql, python, duckdb | Last week, ThoughtWorks released it's latest edition of the [Technology Radar](https://www.thoughtworks.com/radar/platforms). One of the new entries to the platform section was [DuckDB](https://duckdb.org). This new DB sounded interesting, so I decided to check it out.
# What is DuckDB
ThoughtWorks describes it as
... | volkmarr |
504,059 | Getting my hands dirty with coding !!! | Hi ✨developers ✨, I am 👤 Suraez aka Suraj from Nepal. I am a CS student and passionate about coding a... | 0 | 2020-11-02T11:42:20 | https://dev.to/suraez/getting-my-hands-dirty-with-coding-2il3 | hacktoberfest | Hi ✨developers ✨, I am 👤 Suraez aka Suraj from Nepal. I am a CS student and passionate about coding and programming.I joined DEV 'cause when it came to learning something, there were always articles written by some DEV people with a thorough explanation.So I would also like to share my learnings and learn from other D... | suraez |
504,757 | MY HACKTOBERFEST EXPEREINCE | This was my first Hacktoberfest . Being a fresher, I always thought that my level was not that high f... | 0 | 2020-11-03T03:38:16 | https://dev.to/vishesht27/my-hacktoberfest-expereince-2gbl | hacktoberfest, opensource, github, git | This was my first Hacktoberfest . Being a fresher, I always thought that my level was not that high for clearing this event. But when I started, I started with goal of learning new things and not for completing events.
The things I learned from Hacktoberfest 2020:
1. Git and Github
2. Java
3. Working on issues
... | vishesht27 |
516,266 | Setting Up UFW on Ubuntu Server | UFW (Uncomplicated Firewall) is a program that allows you to internally control ports on your Linux... | 0 | 2020-11-16T12:47:03 | https://bowlerdesign.tech/posts/setting-up-ufw-on-ubuntu-server/ | ---
title: Setting Up UFW on Ubuntu Server
published: true
date: 2019-12-15 11:29:00 UTC
tags:
canonical_url: https://bowlerdesign.tech/posts/setting-up-ufw-on-ubuntu-server/
---

Stats Preview Card Component design from the website Frontend Mentor.
https://www.frontendmentor.io/challenges/stats-preview-card-component-8JqbgoU62
You can see my finished version here:
[Github repo](https://... | aituos |
581,355 | Object-Oriented JavaScript — Object Properties | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-24T21:54:48 | https://thewebdev.info/2020/08/17/object-oriented-javascript%e2%80%8a-%e2%80%8aobject-properties/ | webdev, programming, beginners, javascript | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
JavaScript is partly an object-oriented language.
To learn JavaScript, we got to learn the object-oriented parts of JavaScript.
In this article, we’ll look at o... | aumayeung |
581,730 | Infrastructure as Code: the 5 Questions to Ask before You Start | According to Wikipedia, infrastructure as code (IaC) is the process of managing and provisioning comp... | 0 | 2021-03-15T15:41:42 | https://dev.to/langyizhao/infrastructure-as-code-the-5-questions-to-ask-before-you-start-1i0p | According to Wikipedia, infrastructure as code (IaC) is the process of managing and provisioning computer data centers through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools.
Although I don’t think I can define it any better, I believe that “as code” i... | langyizhao | |
582,210 | 3 Useful Websites Everyone Should Know! 2021 🔥 | https://t.co/vZrZ3XyPqG (Send Notes That Self-Destruct) https://t.co/DSTOyCfqw4 (Username, Domain &... | 0 | 2021-01-25T17:14:09 | https://dev.to/mahmoud38021/3-useful-websites-everyone-should-know-2021-1j0n | html, css, javascript, programming | 1. https://t.co/vZrZ3XyPqG
(Send Notes That Self-Destruct)
2. https://t.co/DSTOyCfqw4
(Username, Domain & Trademark Search.)
3. https://t.co/XdiEPd7TXO
(Take beautiful, high-resolution screen captures of websites.) | mahmoud38021 |
582,503 | How to use TypeScript with GraphQL | GraphQL is a powerful query language that allows you to build flexible APIs. It lets you define a... | 10,984 | 2021-01-25T22:01:27 | https://www.takeshape.io/articles/how-to-use-typescript-with-graphql/ | tutorial, webdev, javascript, graphql | ---
title: How to use TypeScript with GraphQL
published: true
description:
series: TypeScript + GraphQL + TypeGraphQL
tags: tutorial, webdev, javascript, graphql
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/s2t6cb5wgfsrdk1d4sw7.png
canonical_url: https://www.takeshape.io/articles/how-to-use-typescript-with-g... | ibrahima92 |
582,674 | Vue Router 4–Scroll Behavior | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-25T23:30:42 | https://thewebdev.info/2020/08/22/vue-router-4-scroll-behavior/ | vue, webdev, programming, javascript | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
**Vue Router 4 is in beta and it’s subject to change.**
To build a single page app easily, we got to add routing so that URLs will be mapped to components that a... | aumayeung |
792,269 | Introduction to Python | Python is a programming language created by Guido van Rossum and it was released in 1991. The... | 0 | 2021-08-15T09:17:00 | https://dev.to/kamula/introduction-to-python-3m9k | python, git | 
Python is a programming language created by Guido van Rossum and it was released in 1991.
The language is used in
- Server side web development using frameworks like [Django](https://www.djangoproject.com/) or [Flask](https://... | kamula |
583,204 | Eryn - React Native Template | Always starting a project with React Native leads me to make some changes and make choices on how it... | 0 | 2021-01-26T15:55:04 | https://caian.dev/posts/eryn-react-native-template/ | reactnative, react, mobile | Always starting a project with React Native leads me to make some changes and make choices on how it should be structured. In general, I think in:
- Directories Structure
- Common Libraries
- Libraries Configuration
Even tho some choices can vary between projects, some of them are constant. I noticed then that I coul... | caiangums |
583,221 | javascript return? | return quirks, is this just js thingy? | 0 | 2021-01-26T15:23:50 | https://dev.to/johndoesup/javascript-return-4p00 | help | ---
title: javascript return?
published: true
description: return quirks, is this just js thingy?
tags: #help
//cover_image: https://direct_url_to_image.jpg
---
```js
function e(){
return 4, false;
}
e()
// e () -> false
function f() {
return 4 + 4, true;
}
f()
// f() -> true
```
Shouldn't I expect it to return ... | johndoesup |
583,293 | Show console outputs based on environment | A project can be beautiful from the outside, but if the browser console is full of messy outputs it w... | 0 | 2021-01-26T18:02:36 | https://giuliachiola.dev/posts/show-console-outputs-based-on-environment/ | javascript | A project can be beautiful from the outside, but if the browser console is full of messy outputs it will immediately seem confusing and carelessly 😅
## Using the local storange + custom script
In this script we:
- assign the `window.console` to a custom variable named `consoleWrap`
- create a "state" variable `devMo... | giulia_chiola |
583,636 | JavaScript Best Practices - Returns, scopes, and if statements | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-27T00:01:44 | https://thewebdev.info/2020/07/18/javascript-best-practices-returns-scopes-and-if-statements/ | webdev, programming, javascript, codequality | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
JavaScript is a very forgiving language. It’s easy to write code that runs but has mistakes in it.
In this article, we’ll look at returning values in certain call... | aumayeung |
583,978 | How to Install Java & Set Environment Variables | In this course, we will study the How to Install Java and how to Set Environment Variables in java an... | 0 | 2021-01-27T10:51:21 | https://dev.to/alimammiya/how-to-install-java-set-environment-variables-42j3 | java, beginners, tutorial, programming | <p>In this course, we will study the <a href="https://usemynotes.com/how-to-install-java/">How to Install Java</a> and how to Set Environment Variables in java and Installation of Java in Windows Operating System</p>
<h2>How to install Java?</h2>
<p>Java is supported in many platforms like Windows, Linux, Solaris, etc.... | alimammiya |
640,658 | Setting Up Webpack for ReScript | As much as I strongly prefer ES6 modules, using them with ReScript (formerly BuckleScript / ReasonML)... | 0 | 2021-03-24T15:25:51 | https://webbureaucrat.gitlab.io/articles/setting-up-webpack-for-rescript/ | bucklescript, reason, rescript, webpack | ---
title: Setting Up Webpack for ReScript
published: true
date: 2021-03-20 00:00:00 UTC
tags: ["bucklescript", "reasonml", "rescript", "webpack"]
canonical_url: https://webbureaucrat.gitlab.io/articles/setting-up-webpack-for-rescript/
---
As much as I _strongly_ prefer ES6 modules, using them with ReScript ([formerly... | webbureaucrat |
583,994 | Bitcoin T shirt | Hi, I offer you a Classic “The Bitcoin Family” T-Shirt design in black. Let everyone know that you ac... | 0 | 2021-01-27T11:05:37 | https://dev.to/dwieroneto/bitcoin-t-shirt-4m54 | tshirt | Hi, I offer you a Classic “The Bitcoin Family” T-Shirt design in black. Let everyone know that you accept in BTC. This is best T-shirt quality, thick cotton material.
100% Cotton material
High-quality screenprint
Slim-fit ==> Grap Yours Here ==>https://www.bonfire.com/the-bitcoin-family/ | dwieroneto |
584,253 | ReScript: Adding new actions to an existing useReducer | Previously we updated a React component to use the useReducer hook in rescript-react. In this post, w... | 11,015 | 2021-01-27T18:04:08 | https://willcodefor.beer/posts/compiler-help-when-updating-variants-in-rescript/ | rescript, react | [Previously](https://dev.to/believer/rescript-using-usereducer-in-reasonreact-bin) we updated a React component to use the `useReducer` hook in rescript-react. In this post, we'll add a couple of new actions to our reducer and see how the compiler helps us with adding these new features.
```rescript
type action = Togg... | believer |
584,267 | Ant Design component customization and bundle optimization | Easily replace original components with your custom wrappers and efficiently decrease bundle size. St... | 0 | 2021-01-30T14:57:09 | https://dev.to/kopivan/ant-design-component-customization-and-bundle-optimization-5c2j | typescript, javascript, programming | Easily replace original components with your custom wrappers and efficiently decrease bundle size. Step-by-step tutorial with React, TypeScript, Styled-Components.
____
I’m Ivan Kopenkov, a front-end developer. In this article, I will tell you about the approaches I have used for the UI library component customization.... | kopivan |
584,427 | Swimm Live Demo | Get Beta Access at Swimm's first Live Demo Event. Join Swimm with your team to create and access unl... | 0 | 2021-01-27T19:42:02 | https://dev.to/omerr/swimm-live-demo-32pn | tutorial, devtool, documentation, opensource | Get Beta Access at Swimm's first Live Demo Event.
Join Swimm with your team to create and access unlimited tutorials coupled with your repository, or enjoy complimentary tutorials contributed by the community.
https://www.eventbrite.com/e/swimm-live-demo-version-035-tickets-137414651923
Swimm makes development more ... | omerr |
584,489 | Iniciando mi camino con Python | Mi nombre es Wilson, de 40 años que para muchos es muy viejo pero yo todavía no siento esa edad. Esto... | 0 | 2021-01-27T20:58:30 | https://dev.to/wilgutl/iniciando-mi-camino-con-python-11c5 | python, beginners, 100daysofcode | Mi nombre es Wilson, de 40 años que para muchos es muy viejo pero yo todavía no siento esa edad. Estoy finalizando en la universidad la carrera de ingeniería de software. La verdad son muchas cosas básicas que enseñan pero poco que quede como conocimiento consciente.
Hace muchos años he querido hacer parte del gremio... | wilgutl |
584,541 | Better Perl with subroutine signatures and type validation | Did you know that you could increase the readability and reliability of your Perl code with one featu... | 0 | 2021-01-27T22:30:47 | https://phoenixtrap.com/2021/01/27/better-perl-with-subroutine-signatures-and-type-validation/ | perl, programming, signatures, types | Did you know that you could increase the readability and reliability of your Perl code with one feature? I'm talking about subroutine signatures: the ability to declare what arguments, and in some cases what types of arguments, your functions and methods take.
Most Perl programmers know about the [`@_`](https://perldo... | mjgardner |
584,550 | Overcoming Impostor Syndrome | It’s been over 4months since I promised I was going to write about how I overcame Impostor syndrome.... | 0 | 2021-01-28T07:43:49 | https://dev.to/dammyton/overcoming-impostor-syndrome-33oe | impostorsyndrome | It’s been over 4months since I promised I was going to write about how I overcame Impostor syndrome. I’m so sorry it came late.
>But right within me i knew I was nervous and fighting impostor syndrome. "Impostor syndrome sucks"... Thanks to Segun Onilude(A friend), who adviced me and his advice did helped. I would def... | dammyton |
584,566 | Back to Basics: Operators, Operators, Operators | This series discusses the building blocks of JavaScript. Whether you're new to the language, you're p... | 10,733 | 2021-01-28T00:14:09 | https://dev.to/alisabaj/back-to-basics-operators-operators-operators-3l3h | javascript, operators, beginners, technicalinterviews | This series discusses the building blocks of JavaScript. Whether you're new to the language, you're preparing for a technical interview, or you're hoping to brush up on some key JS concepts, this series is for you.
Today's post is about operators. In this post, I'll go over some of the most common operators you'll com... | alisabaj |
584,595 | Convolutional Sequence to Sequence | Recurrent neural networks (RNNs) with LSTM or GRU units are the most prevalent tools for NLP research... | 0 | 2021-01-28T00:36:51 | https://dev.to/divyarkamat/convolutional-sequence-to-sequence-4i5l | Recurrent neural networks (RNNs) with LSTM or GRU units are the most prevalent tools for NLP researchers, and provide state of the art results on many different NLP tasks, including language modeling (LM), neural machine translation (NMT), sentiment analysis, and so on. However, a major drawback of RNNs is that since e... | divyarkamat | |
584,783 | Using React 17 in the angular 11 gives the error React is not defined when makes prod build but working fine in dev build. | Hi I am following this URL to integrate React in angular https://medium.com/@zacky_14189/embedding-re... | 0 | 2021-01-28T07:02:27 | https://dev.to/sumitkumar151294/using-react-17-in-the-angular-11-gives-the-error-react-is-not-defined-when-makes-prod-build-but-working-fine-in-dev-build-gfo | Hi I am following this URL to integrate React in angular https://medium.com/@zacky_14189/embedding-react-components-in-angular-the-easy-way-60f796b68aef
But when I make production build then in the browser console I got the error
main.597a58e09c20f4baf37b.js:1 ERROR ReferenceError: React is not defined
at e.rende... | sumitkumar151294 | |
585,029 | Moving forward with Previous | In this series, I'm documenting my experiences with attempting to write and execute a machine learnin... | 10,975 | 2021-01-28T12:55:29 | https://dev.to/goyder/moving-forward-with-previous-3bc4 | python, machinelearning, retro | In this series, I'm documenting my experiences with attempting to write and execute a machine learning program in Python 1.6 on a NeXT hardware emulator running NeXTSTEP.
As I outlined in the first article, my motivations carrying out this project are basically:
* Curiosity
* Interest in picking up technical skills
... | goyder |
585,238 | Difference between 'extends' and 'implements' in TypeScript | Today, a friend ask about the difference between extends and implements. class Media { format: s... | 0 | 2021-01-28T15:45:09 | https://dev.to/danywalls/difference-between-extends-and-implements-in-typescript-32i0 | typescript, oop | Today, a friend ask about the difference between `extends` and `implements`.
```typescript
class Media {
format: string;
}
class Video extends Media {}
class Image implements Media {}
```
The short answer for him was:
extends: The class get all these methods and properties from the parent, so you don't have to imp... | danywalls |
585,311 | AWS CloudFormation Templates: Getting Started. Available Now | I'm excited to announce a new course is available now in the Pluralsight library, The AWS CloudFor... | 0 | 2021-01-28T17:23:44 | https://dev.to/distinctlyminty/aws-cloudformation-templates-getting-started-available-now-5fg3 | I'm excited to announce a new course is available now in the Pluralsight library,
The AWS CloudFormation Templates: Getting Started course shows you step by step how you can use CloudFormation Templates to codify your infrastructure, providing you with a single source of truth and allowing you to automate the deploy... | distinctlyminty | |
585,545 | Passing Arguments into Svelte Actions | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-28T21:37:21 | https://thewebdev.info/2020/05/15/passing-arguments-into-svelte-actions/ | webdev, programming, javascript, svelte | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
Svelte is an up and coming front end framework for developing front end web apps.
It’s simple to use and lets us create results fast.
In this article, we’ll look... | aumayeung |
585,555 | Sharing Code Between Svelte Component Instances with Module Context | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-28T21:40:52 | https://thewebdev.info/2020/08/10/sharing-code-between-svelte-component-instances-with-module-context/ | svelte, webdev, programming, javascript | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
Svelte is an up and coming front end framework for developing front end web apps.
It’s simple to use and lets us create results fast.
In this article, we’ll loo... | aumayeung |
585,575 | Browser extension - Setup and test | I just published a new extension on Chrome and Firefox that allows anyone to run Code Tours from the... | 10,972 | 2021-01-29T15:56:35 | https://dev.to/qmenoret/browser-extension-setup-and-test-2kbc | javascript, typescript, extension | I just published a new extension on Chrome and Firefox that allows anyone to run Code Tours from the Github UI. More information about Code Tours and the extension in this blog post.
{% link https://dev.to/doctolib/run-code-tours-without-leaving-github-1dj3 %}
I thought it would be nice to write a series about how yo... | qmenoret |
585,733 | Working with Docker and other unix-things on Windows like on macOS or Linux | Install WSL 2 Install Ubuntu (or other distro) into WSL Place your project files in Linux inside WSL... | 0 | 2021-01-29T04:14:38 | https://dev.to/grawl/working-with-docker-and-other-unix-things-on-windows-like-on-macos-or-linux-4o6p | windows, wsl, docker, jetbrains | 1. [Install WSL 2](https://docs.microsoft.com/en-us/windows/wsl/install-win10)
1. [Install Ubuntu (or other distro) into WSL](https://docs.microsoft.com/en-us/windows/wsl/install-win10#step-6---install-your-linux-distribution-of-choice)
1. Place your project files in Linux inside WSL using path like `\\wsl$\Ubuntu\home... | grawl |
585,740 | 3 Software Engineering podcasts you must subscribe to now | Software Engineering podcasts have been my companion for a long time. I have listened to software eng... | 0 | 2021-01-29T04:22:22 | https://geshan.com.np/blog/2020/09/software-engineering-podcasts-you-must-subscribe-to/ | podcast, webdev | Software Engineering podcasts have been my companion for a long time. I have listened to software engineer podcasts for more than a [decade](https://geshan.com.np/blog/2009/02/3-drupal-podcasts-you-must-be-fool-to/). Software Engineering podcasts give you the latest news and views in a great format that is equally easy... | geshan |
585,747 | Let's Git It | At one point a codenewbie, I found myself thoroughly confused by git commands, how to use them, when... | 0 | 2021-01-29T17:08:26 | https://dev.to/gabbinguyen/let-s-git-it-13m6 | git, codenewbie, beginners | At one point a codenewbie, I found myself thoroughly confused by git commands, how to use them, when to use them, and so on. While there's many online resources outlining the commands, most of what I found wasn't 'beginner-friendly' or robust enough for my liking. In short, the documentation confused me even more. It s... | gabbinguyen |
585,881 | Most Common Mistakes To Avoid During Website Redesigning | Websites are the visual representation of your business and are not only a medium to reach a large nu... | 0 | 2021-01-29T06:38:00 | https://dev.to/ltdsolace/most-common-mistakes-to-avoid-during-website-redesigning-1l61 | webdev | Websites are the visual representation of your business and are not only a medium to reach a large number of users, but they also provide credibility and trust of your users for business. This is a main reason of why entrepreneurs come to the web designing company to seek professional help and get their website designe... | ltdsolace |
586,002 | so amazing to be part of this group | A post by Selunati | 0 | 2021-01-29T09:56:04 | https://dev.to/selunati/so-amazing-to-be-part-of-this-group-378g | selunati | ||
586,034 | Container v0.1 Released - with Attributes Injection | https://github.com/apexpl/container/ A lightweight, straight forward dependency injection container... | 0 | 2021-01-29T11:35:43 | https://dev.to/apexpl/container-v0-1-released-with-attributes-injection-2gn6 | php | ERROR: type should be string, got "\nhttps://github.com/apexpl/container/\n\nA lightweight, straight forward dependency injection container that simply works, and works well. Supports config file and all standard injection methods -- constructor, setter, annotation, plus also attributes. Also includes a `Di` wrapper class that allows container methods to be accessed statically for greater simplicity and efficiency.\n" | apexpl |
586,158 | The must listen Podcast If you are a CEO | Business wars is amazing podcast series. In which the host David Brown discusses the business strateg... | 0 | 2021-01-29T14:35:37 | https://dev.to/alimemonzx/the-must-listen-podcast-if-you-are-a-ceo-5h93 | podcast, leadership, watercooler | Business wars is amazing podcast series. In which the host David Brown discusses the business strategies and competition between the biggest business in the world.
The best series so far for me was Netflix vs Blockbuster. Blockbuster's was the pioneer in movie rental business. In 2000 Netflix offered Blockbuster a par... | alimemonzx |
586,217 | Scilla - Recon | Scilla is a recon tool. It's a CLI tool for collecting dns records, directories, subdomains and open... | 0 | 2021-01-29T15:40:00 | https://dev.to/edoardottt/scilla-recon-1ald | github, go, security, recon | Scilla is a recon tool. It's a CLI tool for collecting dns records, directories, subdomains and open ports giving a single domain.
https://github.com/edoardottt/scilla | edoardottt |
586,476 | Azure Calling Functions | Your frontend is able to call an Azure Function using any type of HTTP Request. Simply ensure that... | 0 | 2021-02-09T22:31:57 | https://dev.to/jwp/azure-calling-functions-3c45 | Your frontend is able to call an Azure Function using any type of HTTP Request.
Simply ensure that the function name is preceded with the segment /api/ as shown here:
```json
https://xyz.azurewebsites.net/
api/Function1'
```
However to get this to work, the Function application's CORS configuration must include th... | jwp | |
665,432 | Lessons learned from Junior to Senior Developer | Lessons Learned from Junior to Senior Developer | 0 | 2021-05-18T19:54:12 | https://dev.to/vincentntang/lessons-learned-from-junior-to-senior-developer-2dob | ---
title: Lessons learned from Junior to Senior Developer
published: true
description: Lessons Learned from Junior to Senior Developer
tags:
//cover_image: https://direct_url_to_image.jpg
---
3 years ago, I decided to change careers and become a software developer. I had no formal training in software development an... | vincentntang | |
586,797 | Project 41 of 100 - Writing Responsive CSS in JSX | Hey! I'm on a mission to make 100 React.js projects ending March 8th. Please follow my dev.to profile... | 0 | 2021-01-30T07:26:54 | https://dev.to/jameshubert_com/project-41-of-100-writing-responsive-css-in-jsx-2me6 | react, 100daysofcode, javascript | *Hey! I'm on a mission to make 100 React.js projects ending March 8th. Please follow my dev.to profile or my [twitter](https://www.twitter.com/jwhubert91) for updates and feel free to reach out if you have questions. Thanks for your support!*
Link to today's deployed app: [Link](https://www.dolcesdollhouse.com/)
Link ... | jameshubert_com |
586,858 | Excel Formulas to Find the Reverse VLOOKUP Value ~ Clear-Cut Example | Normally, the Excel VLOOKUP function searches the values from left to right in the table. Have you ev... | 0 | 2021-02-08T10:27:29 | https://geekexcel.com/excel-formulas-reverse-vlookup/ | excelformula, excelformulas | ---
title: Excel Formulas to Find the Reverse VLOOKUP Value ~ Clear-Cut Example
published: true
date: 2021-01-30 09:11:33 UTC
tags: ExcelFormula,Excelformulas
canonical_url: https://geekexcel.com/excel-formulas-reverse-vlookup/
---
Normally, the Excel **[VLOOKUP function](https://geekexcel.com/how-to-use-excel-vlookup... | excelgeek |
587,853 | Deploying An Asp.Net WebApi and MySql DataBase Container to Kubernetes (Part-2)-Deployment | Read Part 1 Setting up Kubernetes and Kubernetes Dashboard using Docker Desktop. In this article, we... | 0 | 2021-01-31T14:26:13 | https://dev.to/gbengelebs/deploying-an-asp-net-webapi-and-mysql-database-container-to-kubernetes-part-2-deployment-3g82 | docker, kubernetes, csharp, mysql | Read Part 1 [Setting up Kubernetes and Kubernetes Dashboard using Docker Desktop](https://dev.to/gbengelebs/deploying-an-asp-net-webapi-and-mysql-database-container-to-kubernetes-part-1-setup-1ll9). In this article, we will be deploying a WebApi and MySql Database to Kubernetes. To understand the process, here is a vi... | gbengelebs |
591,806 | Go to ~base install in ubuntu | I relalized that there is no free space in my root parition. I installed a lot of stuff with a lot of... | 0 | 2021-02-04T09:17:20 | https://dev.to/bodnarlajos/go-to-base-install-in-ubuntu-3k4j | ubuntu | I relalized that there is no free space in my root parition. I installed a lot of stuff with a lot of libraries but there are became unnecessary now.
What you can do with it ?
I tried to remove all packages what was installed after the first booting.
You can start with the ubuntu manifest file which one is contains the... | bodnarlajos |
592,348 | Responsive Navigation Menu for 2021🎖️|| CSS JS | Let's Build a Responsive Navigation Hamburger Menu in 2021 from Scratch for both desktop & mobile... | 0 | 2021-02-13T21:58:09 | https://dev.to/joyshaheb/responsive-navigation-menu-for-2021-css-js-34pk | css, beginners, tutorial, javascript | Let's Build a Responsive Navigation Hamburger Menu in 2021 from Scratch for both desktop & mobile screen🎖️
# Table of Contents -
* [Codepen](#level-1)
* [Setup](#level-2)
* [HTML](#level-3)
* [SCSS](#level-4)
* [JavaScript](#level-5)
* [Conclusion](#level-6)
# Codepen <a name="level-1"></a>
{% co... | joyshaheb |
597,511 | Running distributed k6 tests on Kubernetes | 📖What you will learn What the operator pattern is and when it is useful Deploying the k6... | 0 | 2021-02-11T11:38:12 | https://k6.io/blog/running-distributed-tests-on-k8s | performance, cloud, testing, kubernetes | ---
title: Running distributed k6 tests on Kubernetes
published: true
date: 2021-02-11 00:00:00 UTC
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/tqbj0asgy45ip9owh711.png
canonical_url: https://k6.io/blog/running-distributed-tests-on-k8s
tags: #performance #cloud #testing #kubernetes
---
> ### 📖What you will... | simme |
602,107 | Reactive Forms And Form Validation In Angular With Example | This tutorial we are learn how to create Reactive Forms And Form Validation In Angular With Example v... | 0 | 2021-02-13T03:55:26 | https://dev.to/robertlook/reactive-forms-and-form-validation-in-angular-with-example-5062 | angular, node | This tutorial we are learn how to create Reactive Forms And Form Validation In Angular With Example very simply form see below:
provides a model-driven approach to handling form inputs value change over time. In this form reactive form, we need to import "ReactiveFormsModule" from the angular forms library. We will use... | robertlook |
602,111 | Github Search and BLoC | In case it helped :) Website: https://web.flatteredwithflutter.com/#/ We will cover briefly... | 0 | 2021-02-13T04:36:35 | https://dev.to/aseemwangoo/github-search-and-bloc-3gpi | computerscience, productivity, programming, flutter | *In case it helped :)*
<a href="https://www.buymeacoffee.com/aseemwangoo" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png" alt="Pass Me A Coffee!!" style="height: 41px !important;width: 174px !important;box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;-webki... | aseemwangoo |
602,167 | Thinking About Writing As A Means Of Livelihood | In this post, I muse over some of the thinking I've been doing lately about what it'll take for me to write fulltime and to figure ways out to have automatic passive income. | 0 | 2021-02-13T06:48:39 | https://arihantverma.com/posts/2021/01/23/thinking-about-writing-as-means-of-livelihood/ | writing, passingincome, stories, essay | ---
title: Thinking About Writing As A Means Of Livelihood
published: true
description: In this post, I muse over some of the thinking I've been doing lately about what it'll take for me to write fulltime and to figure ways out to have automatic passive income.
tags: ["writing", "passingincome", "stories", "essay"]
co... | arihantverma |
602,445 | My javascript / tech / web development newsletter for 13-02-2021 is out! | A roundup of all the best javascript, tech and web development links posted to my linkblog in the past week | 0 | 2021-02-13T13:37:50 | https://dev.to/mjgs/my-javascript-tech-web-development-newsletter-for-13-02-2021-is-out-130i | javascript, tech, webdev, discuss | ---
title: My javascript / tech / web development newsletter for 13-02-2021 is out!
published: true
description: A roundup of all the best javascript, tech and web development links posted to my linkblog in the past week
tags: javascript, tech, webdev, discuss
---
In this week’s edition:
Governments, DevOps CI/CD, Gam... | mjgs |
602,491 | Top 12 libraries for NextJS, React apps and React Native apps for i18n and react localization | Best i18n libraries for React web, React Native, Expo and all other React apps. Check how to react localization should look like. | 0 | 2021-02-13T16:17:09 | https://simplelocalize.io/blog/posts/the-most-popular-react-localization-libraries/ | javascript, react, typescript | ---
title: Top 12 libraries for NextJS, React apps and React Native apps for i18n and react localization
published: true
description: "Best i18n libraries for React web, React Native, Expo and all other React apps. Check how to react localization should look like."
tags: [javascript, react, typescript]
cover_image: ht... | jpomykala |
602,583 | Vuetify and MDB | Both Vuetify and MDB implement the Material Design Design Language. Whereas Vuetify implements Materi... | 0 | 2021-02-24T12:38:57 | https://drmsite.blogspot.com/2021/02/vuetify-and-mdb.html | css, html, javascript, thoughts | ---
title: Vuetify and MDB
published: true
date: 2021-02-13 14:18:00 UTC
tags: CSS,HTML,JavaScript,Thoughts
canonical_url: https://drmsite.blogspot.com/2021/02/vuetify-and-mdb.html
---
Both [Vuetify](https://vuetifyjs.com/en/) and [MDB](https://mdbootstrap.com) implement the Material Design Design Language. Whereas Vu... | mouseannoying |
602,701 | How to verify school email addresses in Node.js | In this post, we look at how school email addresses can be verified easily and quickly in Node.js. T... | 0 | 2021-02-13T17:50:14 | https://www.marvinschopf.com/2021/02/how-to-verify-school-email-addresses-in-node-js/ | node, javascript, howto, tutorial | **In this post, we look at how school email addresses can be verified easily and quickly in Node.js.**
This is especially useful when a service wants to give certain perks or benefits to students or teachers. Often this is done using paid enterprise service providers, but in the vast majority of cases, verification ca... | marvinschopf |
602,826 | Create self signed certificates for Kubernetes using cert-manager | Install Cert manager in Kubernetes Read this for up-to-date instructions: https://cert-man... | 0 | 2021-02-13T21:37:22 | https://dev.to/amritanshupandey/create-self-signed-certificates-for-kubernetes-using-cert-manager-403n | kubernetes | ## Install Cert manager in Kubernetes
Read this for up-to-date instructions: https://cert-manager.io/docs/installation/kubernetes/
```bash
# Kubernetes 1.16+
$ kubectl apply —validate=false -f https://github.com/jetstack/cert-manager/releases/download/v1.0.2/cert-manager.yaml
```
## Create a keypair secret
In this ... | amritanshupandey |
602,896 | Animated Sonar Screen - CSS Only | Old ship styled sonar screen built with CSS only. Animated rotary effect which hides and reveals ship... | 0 | 2021-02-13T22:26:55 | https://dev.to/nikolab/animated-sonar-screen-css-only-3p9f | codepen, css, animation, frontend | <p>Old ship styled sonar screen built with CSS only. Animated rotary effect which hides and reveals ships is built with conic-gradient() function so it only works in Chrome/Firefox. </p>
{% codepen https://codepen.io/nikolab/pen/poNEgKW %}
<p>Feel free to comment, fork, upgrade and use for any purpose.</p>
If yo... | nikolab |
603,102 | What are CSS Variables? | CSS Variables is a big win for Front-end Developers. It brings the power of variable to CSS, which re... | 0 | 2021-02-14T04:27:38 | https://dev.to/rahxuls/what-are-css-variables-1p1h | webdev, css, programming, codenewbie | CSS Variables is a big win for Front-end Developers. It brings the power of variable to CSS, which results in less repetition, better readability and more flexibility.
---
In this example below, it's much better to create a variable for the `#ff6f69` colour then repeating it.
```css
/*THE OLD WAY */
#title {
... | rahxuls |
603,404 | useHug: Creating custom React Hooks 🥰 | Learn how to pull behaviors out of components and into custom hooks with React | 0 | 2021-02-14T15:16:01 | https://dev.to/headwayio/usehug-creating-custom-react-hooks-1edc | react, webdev, javascript | ---
title: useHug: Creating custom React Hooks 🥰
published: true
description: Learn how to pull behaviors out of components and into custom hooks with React
tags: react, webdev, javascript
//cover_image: https://direct_url_to_image.jpg
---
Building custom hooks is a great way to encapsulate behaviors and reuse them t... | chrisheld927 |
603,457 | linux command tips | liste of linux commande i user thid week | 0 | 2021-12-10T17:38:32 | https://dev.to/fredlag/linux-command-tips-4l36 | ---
title: linux command tips
published: true
description: liste of linux commande i user thid week
tags:
//cover_image: https://direct_url_to_image.jpg
---
Hi all, my second post on dev not an original post but i will describe here what's linux command i have used last week.
## CTRL+r command
This command help m... | fredlag | |
603,696 | How to build a Quiz Game in Python | Hello everyone, today we are going to create a fun Quiz Game in python. How does it work?... | 11,147 | 2021-02-14T18:34:32 | https://dev.to/mindninjax/how-to-build-a-quiz-game-in-python-10ik | python, tutorial, beginners, codenewbie | Hello everyone, today we are going to create a fun **Quiz Game in python**.
## How does it work?
Our quiz game will be asking questions to the player to which player has to reply with the right answer. Each question will have 3 attempts. If the player fails to answer the question within 3 attempts then the game will ... | mindninjax |
603,780 | Node Worker Service - Youtube GIF Maker Using Next.js, Node and RabbitMQ | Hello everyone, This Article is the third part of the series Youtube GIF Maker Using Next.js, Node an... | 11,201 | 2021-02-14T22:15:44 | https://dev.to/ragrag/node-worker-service-youtube-gif-maker-using-next-js-node-and-rabbitmq-2g51 | webdev, node, react, javascript | Hello everyone,
This Article is the third part of the series Youtube GIF Maker Using Next.js, Node and RabbitMQ.
In this article we will dive into building the worker service of our Youtube to GIF converter. This Article will contain some code snippets but the whole project can be accessed [on github](https://github.c... | ragrag |
603,891 | Validation using schematron in java by example | We write a simple example in java to run a validation using Schematron. The framework Schematron is a way to do easy validation of XML documents and create output that is easily readable by someone working with these documents. | 0 | 2021-03-01T04:44:17 | https://dev.to/kalaspuffar/validation-using-schematron-in-java-by-example-4om6 | ---
title: Validation using schematron in java by example
published: true
description: We write a simple example in java to run a validation using Schematron. The framework Schematron is a way to do easy validation of XML documents and create output that is easily readable by someone working with these documents.
tags:... | kalaspuffar | |
603,911 | Being RESTful Is Not Always Best For The User | The RESTful convention has been invaluable regarding creating a consistency in the internet allowing... | 0 | 2021-02-15T01:16:31 | https://dev.to/davidnnussbaum/being-restful-is-not-always-best-for-the-user-13p0 | ruby, sinatra, rest | The RESTful convention has been invaluable regarding creating a consistency in the internet allowing for improved communication. However, as with most things in life, there are exceptions. My project involved having a page on which people can enter their medical histories and subjective reports. It would not be conveni... | davidnnussbaum |
603,930 | I want to know weather a fresher learn Java(hibernate, spring) or python(django) | A post by AKHIL | 0 | 2021-02-15T03:01:45 | https://dev.to/a4akhil007/i-want-to-know-weather-a-fresher-learn-java-hibernate-spring-or-python-django-38co | beginners, career, webdev | a4akhil007 | |
604,097 | Introduction to AWS and AWS Compute Services | I spent over a week reading about cloud deployment models and service models, AWS compute services, i... | 0 | 2021-02-15T04:31:16 | https://dev.to/aws-builders/introduction-to-aws-and-aws-compute-services-2dh4 | aws, awscomputeservices, security, cloud | <!-- wp:paragraph -->
<p>I spent over a week reading <strong>about cloud deployment models and service models, AWS compute services, its security and compliance.</strong> I have started with explaining what do you mean by cloud and it's benefits. </p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3><strong>... | hridyeshbisht |
604,313 | Perl programmers are Mandalorians | The Perl programmers were a clan-based cultural group that was composed of members from multiple sp... | 0 | 2021-02-16T17:53:44 | https://dev.to/thibaultduponchelle/perl-programmers-are-mandalorians-l0b | perl, mandalorians | 
***The Perl programmers were a clan-based cultural group that was composed of members from multiple species all bound by a common culture, creed, and code. They originated on the planet Unix in the Outer Rim Territories and had... | thibaultduponchelle |
604,382 | Cleanup your Azure DevOps Service Principals | We’ve all been there, out of convenience you auto generate a service principal to connect a Azure Dev... | 0 | 2021-02-15T12:03:19 | https://jamescook.dev/cleanup-azure-devops-service-principals | azure, devops, cloud, security | We’ve all been there, out of convenience you auto generate a service principal to connect a Azure DevOps project to your Azure subscriptions. As long as IAM (Identity and Access Management) is configured correctly within your subscription, it’s so easy to just click, create, go and never look back. However, there can b... | officialcookj |
604,387 | Weekly Challenge 100 | Challenge 100 TASK #1 › Fun Time The task You are given a time (12 hour / 24 h... | 0 | 2021-02-15T12:12:40 | https://dev.to/simongreennet/weekly-challenge-100-4lf6 | perl, perlweeklychallenge | [Challenge 100](https://perlweeklychallenge.org/blog/perl-weekly-challenge-100/)
# TASK #1 › Fun Time
## The task
You are given a time (12 hour / 24 hour).
Write a script to convert the given time from 12 hour format to 24 hour format and vice versa.
Ideally we expect a one-liner.
## My solution
Let's start with... | simongreennet |
604,517 | MaiD: Hackable newsfeed reader with Postman. | How much time do you spend reading stuff on the internet?? If your answer is 'A lot' then MaiD is th... | 0 | 2021-02-15T13:48:12 | https://dev.to/nirmaljuluru/maid-hackable-newsfeed-reader-with-postman-2o6i | javascript | **How much time do you spend reading stuff on the internet??**
If your answer is *'A lot'* then MaiD is the solution you need.
**MaiD?**
if you are thinking, what the fluff is MaiD? then let me simplify it for you.
*MaiD = Mail in your feeD*
Before you read the rest of the article, this is how a feed looks like: ... | nirmaljuluru |
605,261 | Web Font Loading & The Status Quo | Let's start with the obvious: there's lots of great posts out there on font loading (which all tend... | 0 | 2021-02-18T01:31:06 | https://whistlr.info/2021/font-loading/ | javascript, html, font, webfonts | ---
title: Web Font Loading & The Status Quo
published: true
date: 2021-02-16 00:00:00 UTC
tags: javascript, html, font, webfonts
canonical_url: https://whistlr.info/2021/font-loading/
---
Let's start with the obvious: there's lots of great posts out there on font loading (which all tend to be 27 pages long for some r... | samthor |
605,450 | Web Scraping Yahoo Cryptocurrency Indices using Python
| The aim of this article is to get you started on real-world problem solving while keeping it super... | 0 | 2021-07-23T17:35:28 | https://proxiesapi.com/blog/Web-Scraping-Yahoo-Cryptocurrency-Indices-using-Python.php | The aim of this article is to get you started on real-world problem solving while keeping it super simple so you get familiar and get practical results as fast as possible.
https://youtu.be/vGUO6klO9O4 | proxiesapi | |
605,627 | JavaScript Interview Question #38: Can you add multiple arrays in JavaScript? | Can you add multiple arrays in JavaScript? What’s the output? . . . . . . . . . . . .... | 11,099 | 2021-05-06T11:40:55 | https://learn.coderslang.com/js-test-38-adding-3-arrays-of-integers/ | javascript, beginners, codenewbie, webdev | 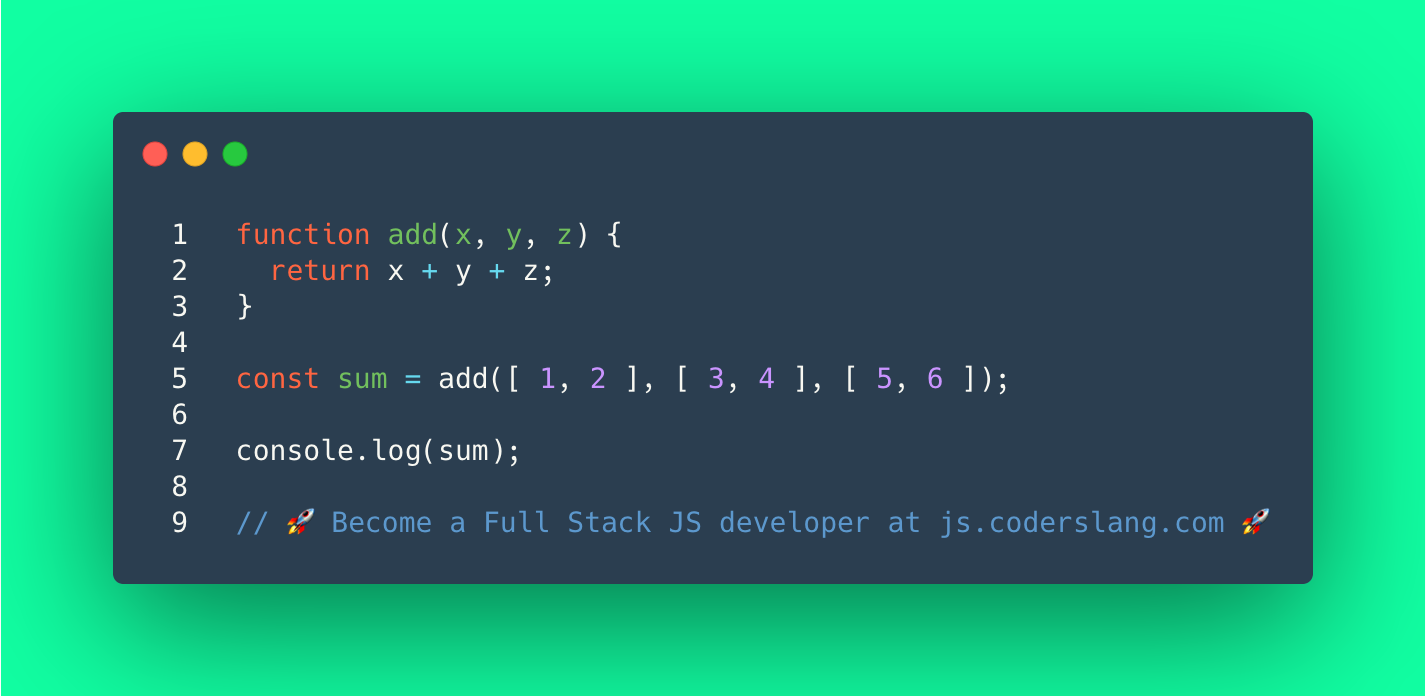
Can you add multiple arrays in JavaScript? What’s the output?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
The function `add(x, y, z)` applies the `+` operator to the provided arguments. Or, simply put, adds them up.
In line 5 we provide it with 3 a... | coderslang |
605,959 | Get JSON Data from API Call and pass it to component as a parameter | I have a URL that I am returning Json data, that is need to pass as a parameter to react component, t... | 0 | 2021-02-16T15:46:06 | https://dev.to/asp1979/get-json-data-from-api-call-and-pass-it-to-component-as-a-parameter-d7h | fetch, apicall, jsondata, passingparametertocomponent | I have a URL that I am returning Json data, that is need to pass as a parameter to react component, that component is: https://rsuitejs.com/components/multi-cascader
and here is my code:
fetch('http://ABCServer/LabMag/Home/GetCategories')
.then(response => response.json())
.then(json => console.log(json));
... | asp1979 |
606,116 | Install a Haskell compiler on Macbook with chip M1 | Hi everyone! I struggled with this after getting my new macbook (Apple Silicon (arm64) based macs),... | 0 | 2021-02-16T19:13:25 | https://dev.to/raquelhn/install-a-haskell-compiler-on-macbook-with-chip-m1-50k1 | haskell, programming | Hi everyone!
I struggled with this after getting my new macbook (Apple Silicon (arm64) based macs), the instructions can be very confusing for a newbie so I thought a post would be useful. I followed the instructions of Moritz Angerman @angerman_io
The first step is to open terminal and install rossetta 2:
/usr/sb... | raquelhn |
606,226 | dev.to bug with creating a new post | I was going to file a bug on GitHub, but as a non-contributor, I wasn't sure if that would be more co... | 0 | 2021-02-16T20:16:46 | https://dev.to/jasterix/dev-to-bug-with-creating-a-new-post-3809 | bug, help | I was going to file a bug on GitHub, but as a non-contributor, I wasn't sure if that would be more counterproductive.
**Issue**: The title field to create a new post is shorter than font
**Description**: The title field when you create a new post is too short and cuts off the text. This makes it impossible to see wha... | jasterix |
607,799 | Know The Web: HTTP Cookie 🍪 | In this post, we are going to learn about Cookie certainly not the edible one. We'll discuss cookie p... | 11,371 | 2021-02-17T12:55:21 | https://souvikinator.netlify.app/blog/web-cookies/ | webdev, httpcookie, javascript, security | In this post, we are going to learn about Cookie certainly not the edible one. We'll discuss **cookie properties** and **security stuff** related to HTTP cookies, also **create cookie** on the way so make sure that you and your patience grab milk and cookie, enjoy the post.
## Cookie Time!
While using Facebook, Insta... | souvikinator |
607,255 | GameDevHQ Intensive Training Week 01 / Week 08 [Day 2] | I will honestly lie if I tell you that today was easy. For the second day of week 1, personally, it... | 0 | 2021-02-17T00:06:19 | https://dev.to/rehtsestudio/gamedevhq-intensive-training-week-01-week-08-day-2-1124 | unity3d, gamedev | I will honestly lie if I tell you that today was easy. For the second day of week 1, personally, it took me a while to figure it out.
Today's task was to create the spawn manager, where we need to control the spawning of the enemy and to optimize with an object pooling from the beginning.
Spawn Manager
Create star... | rehtsestudio |
607,511 | Pengenalan Bootstrap | Bootstrap merupakan framework CSS yang menyediakan class dan komponen yang siap dipakai, sehingga kit... | 0 | 2021-02-17T06:29:03 | https://dev.to/syhn/pengenalan-bootstrap-2p58 | Bootstrap merupakan framework CSS yang menyediakan class dan komponen yang siap dipakai, sehingga kita tidak perlu menulis kode CSS dari nol, cukup hanya memanggil class yang telah disediakan oleh Bootstrap
| syhn | |
607,639 | How to Deploy your Website using Vercel | Hey Guys! Previously, I made a blog on how to deploy your website to GitHub Pages. If you... | 11,411 | 2021-02-17T09:38:21 | https://dev.to/therickedge/how-to-deploy-your-website-using-vercel-4499 | deploy, vercel, programming, coding | ## Hey Guys!
Previously, I made a blog on how to deploy your website to GitHub Pages.
If you did not check that out yet, check it out over <a href = "https://dev.to/code2rithik/how-to-deploy-your-website-using-github-pages-34hc">here</a>
But this time, we are Deploying our website using Vercel.
### 1. First, create... | therickedge |
607,656 | Assembly: Embedded Resource elenco e lettura | 🔥 Assembly: Embedded Resource elenco e lettura ❓ Step0: cosa sono le Embedded Resource? Sviluppare... | 0 | 2021-02-17T10:15:12 | https://dev.to/devandreacarratta/assembly-embedded-resource-elenco-e-lettura-4cj9 | assembly, embeddedresource, streamreader, devandreacarratta | 🔥 Assembly: Embedded Resource elenco e lettura
❓ Step0: cosa sono le Embedded Resource?
Sviluppare in C# mi ha sempre portato ad utilizzare le Embedded Resource e devo dire che senza di loro la vita dello sviluppatore non sarebbe interessante come ora.
Nell'articolo verra' spiegato come ...
1️⃣ Come adeguo il mio... | devandreacarratta |
607,790 | Step into Your Customers’ Shoes to Build Impactful SaaS Apps | Before you get started with your next SaaS project, make sure you put yourself into your customers’ p... | 0 | 2021-02-17T12:30:04 | https://dev.to/chirag191094/step-into-your-customers-shoes-to-build-impactful-saas-apps-2eh6 | Before you get started with your next SaaS project, make sure you put yourself into your customers’ place as that will help you envision and better understand what exactly is required. In this article, I will talk about the various aspects of SaaS app development. Let’s begin with the introduction of SaaS first.
![S... | chirag191094 | |
607,800 | 前端判斷網頁是不是webview開啟 | 第一次使用不太熟悉 用了找到的code不過依然判斷不了 function isWebview() { var useragent = navigator.userAgent; va... | 0 | 2021-02-17T13:01:11 | https://dev.to/douknowccy/webview-32fg | 第一次使用不太熟悉
用了找到的code不過依然判斷不了
```javascript
function isWebview() {
var useragent = navigator.userAgent;
var rules = [
"WebView",
"webview",
"(iPhone|iPod|iPad)(?!.*Safari/)",
"Android.*(wv|.0.0.0)",
];
var regex = new RegExp(`(${rules.join("|")})`, "ig");
return Boolean(userag... | douknowccy | |
607,947 | Anomaly Detection For IoT Using Open Distro For ElasticSearch | This post is the third in series on using the AWS ecosystem for IoT applications. Previously, we int... | 0 | 2021-02-17T15:23:12 | https://dev.to/tejpochiraju/anomaly-detection-for-iot-using-open-distro-for-elasticsearch-14kj | ios, aws, elasticsearch, machinelearning | > This post is the third in series on using the AWS ecosystem for IoT applications. Previously, we integrated AWS IoT with [Timestream /Quicksight](https://iotready.co/blog/metal-to-alerts-with-aws-iot-timestream-quicksight/) and [ElasticSearch/Kibana](https://iotready.co/blog/metal-to-alerts-with-aws-iot-elasticsearch... | tejpochiraju |
608,120 | CSS animation-delay Property | The CSS animation-delay property is used to specify the delay for the start of an animation. This is... | 0 | 2021-02-19T06:59:15 | https://sharepointanchor.com/learn-css/css-animation-delay-property/ | learncss, cssa | ---
title: CSS animation-delay Property
published: true
date: 2021-02-17 11:59:25 UTC
tags: LearnCSS,CSSA
canonical_url: https://sharepointanchor.com/learn-css/css-animation-delay-property/
---
The [CSS](https://sharepointanchor.com/learn-css/ "CSS") animation-delay property is used to **specify the delay for the star... | anchorshare |
608,140 | Multi-account AWS environments with superwerker | Managing and securing multiple AWS accounts gets complex. superwerker is a free and open-source... | 0 | 2021-02-17T16:33:34 | https://sbstjn.com/blog/superwerker-aws-multi-account-environment/ | aws, cloud, opensource, github | Managing and securing multiple AWS accounts gets complex. [superwerker](https://superwerker.cloud) is a free and open-source solution to automate the setup and management of your multi-account AWS environments. Based on our experiences at [superluminar](https://superluminar.io/), we teamed up with [kreuzwerker](https:/... | sbstjn |
608,177 | Day 4 | Day 4/100 of #100DaysOfCode scroll-animation | Codewars | Node.js Hours coded: 3.2 Lines of code: 2... | 11,311 | 2021-02-17T17:31:46 | https://www.linkedin.com/feed/update/urn:li:activity:6767854732536115201/ | 100daysofcode | Day 4/100 of #100DaysOfCode
scroll-animation | Codewars | Node.js
Hours coded: 3.2
Lines of code: 246
Keystrokes: 3666
1. Completed the "scroll-animation" project. It's part of the "50 Projects in 50 Days" Udemy Course.
Technology: HTML, CSS, JavaScript DOM
2. I tried to solve the "(4kyu) Next bigger number with... | rb_wahid |
608,207 | React - how to create dynamic table | Hello Coders! 👋 😊 In this article, I would like to show you how to create a dynamic table... | 0 | 2021-02-17T18:51:21 | https://dirask.com/posts/How-to-create-customized-dynamic-table-in-React-pqa53p | react, javascript, webdev, html | ###Hello Coders! 👋 😊
In this article, I would like to show you how to create a dynamic table in React.
__Before we start__, I would highly recommend you to check out __runnable examples__ for the solution on our website:
[How to create customized dynamic table in React](https://dirask.com/posts/How-to-create-customi... | diraskreact |
608,221 | The Top 3 Office 365 Backup And Recovery Solutions | Having a comprehensive and customizable Office 365 backup and recovery solution is increasingly impor... | 0 | 2021-02-17T19:13:03 | https://dev.to/hugholssen/the-top-3-office-365-backup-and-recovery-solutions-42hf | recovery, office365, backup, microsoft |
Having a comprehensive and customizable <a href="https://vmarena.com/altaro-office-365-backup-solution/">Office 365 backup</a> and recovery solution is increasingly important for Office 365 clients.
Backup and recovery solutions capture a copy of a file, database, or even an entire computer at a given time and save t... | hugholssen |
610,509 | Why Programmers don't make money? | I am not aware of anything in your mind, but if you are reading this post, you probably don’t agree w... | 0 | 2021-02-18T06:49:48 | https://dev.to/songa1/why-programmers-don-t-make-money-3kal | earnmoneyprogramming, programming, programmersdontmakemoney, problemsolving | I am not aware of anything in your mind, but if you are reading this post, you probably don’t agree with me. Right? And I know that it would be hard for many people to believe this but if you’re going to read this to the end, you will understand what I mean.
When I started programming, I was very curious. I knew nothi... | songa1 |
610,679 | Mathematical Calculator | Dealing with math homework statistics seems to be a daunting task though; It has its benefits that sh... | 0 | 2021-02-18T11:04:15 | https://dev.to/jinjohn38/mathematical-calculator-mme | Dealing with math homework statistics seems to be a daunting task though; It has its benefits that should help you a lot. The first is that you are able to prepare and further improve your problem-solving skills, and another thing is that by doing your maths with homework, you will be able to continually be exposed to ... | jinjohn38 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.