
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
358,325 | Turn your server into a Centralize-Git-Repository. | GitHub is Great for Open Source projects, But i don't like GitHub and many other third-party code sto... | 0 | 2020-06-18T21:02:08 | https://dev.to/jswalker_in/turn-your-server-into-a-centralize-git-repository-1p | git, webdev, linux | GitHub is Great for Open Source projects,
But i don't like GitHub and many other third-party code storage systems when it comes to building a Private-Product which is a highly closed-end system.
I believe in "Your-Code-Your-Responsibility".
Don't Transfer Your Responsibility to others or there will be greater consequ... | jswalker_in |
359,175 | Analyzing a DataSet with Unsupervised Learning | Introduction The goal of this article is to show how Unsupervised Learning can be used in... | 0 | 2020-06-20T18:21:59 | https://dev.to/travelleroncode/analyzing-a-dataset-with-unsupervised-learning-31ld | machinelearning, datascience, azure | # Introduction
The goal of this article is to show how Unsupervised Learning can be used in analyzing datasets. This article is a part of the *MSP Developer Stories* initiative by the Microsoft Student Partners (India) program.
# What is Unsupervised Learning ?
Generally, when we talk about Machine Learning, we say ... | travelleroncode |
358,337 | Having inclusive names in docs examples | We want to make the names we use in our docs examples more inclusive from both a gender and a cultura... | 0 | 2020-06-18T21:33:24 | https://dev.to/bravegrape/having-inclusive-names-in-docs-examples-2jo | discuss, inclusion, docs | We want to make the names we use in our docs examples more inclusive from both a gender and a cultural perspective.
We use a [docs-as-code](https://www.writethedocs.org/guide/docs-as-code/) approach to docs so we're interested in automation and scalable approaches.
Is this something you or your team have worked on?
... | bravegrape |
358,557 | Answer: set expandtab in .vimrc not taking effect | answer re: set expandtab in .vimrc no... | 0 | 2020-06-19T01:53:43 | https://dev.to/icy1900/answer-set-expandtab-in-vimrc-not-taking-effect-2pn5 | vim | {% stackoverflow 37962622 %} | icy1900 |
358,632 | React Course Pre-Launch Giveaway | In celebration of our new React course launch (coming soon). Here’s our giveaway challenge to win a... | 0 | 2020-06-19T06:38:49 | https://alterclass.io/blog/react-course-pre-launch-giveaway | react, javascript, alterclass, webdev | In celebration of our new React course launch (coming soon).
Here’s our giveaway challenge to **win a PRO access to the course**.
To enter:
1. Follow us on Twitter [@AlterClassIO](https://twitter.com/AlterClassIO)
2. Retweet the [giveaway post](https://twitter.com/AlterClassIO/status/1273648921181642755?s=20) & tag... | gdangelo |
358,852 |
Solving buffer.readUIntBE is not a function reading a JWKS key with NodeRSA | Recently while trying to read a public key in from a JWKS endpoint I was stumped by an error when imp... | 0 | 2020-06-19T09:10:13 | https://blog.kleeut.com/2020/06/solving-bufferreaduintbe-is-not.html | Recently while trying to read a public key in from a JWKS endpoint I was stumped by an error when importing the public key using [NodeRSA](https://github.com/rzcoder/node-rsa). My code looked like this:
```Typescript
return rsa.importKey(
{
n: Buffer.from(jwksKey.n),
e: jwksKey.e,
},
"compone... | kleeut | |
358,886 | Entry Components Vs Declarations in Angular | Breaking down the differences when you are dealing with Angular components Hi! I am a full... | 0 | 2020-06-19T10:24:08 | https://dev.to/arpan_banerjee7/entry-components-vs-declarations-in-angular-5d | angular, entrycomponents, declarations | ###Breaking down the differences when you are dealing with Angular components
Hi! I am a full stack developer based out of West Bengal, India. I love digging deep into the trickier parts of the technologies. Here is one from my vault. Hope this helps you.
Without further ado, let us dive straight into it.
**For this ... | arpan_banerjee7 |
358,922 | Should programming be taught in schools? | Should programming, logic & algorithms be taught in schools? If so, from what age? What do you t... | 0 | 2020-06-19T11:36:22 | https://dev.to/reece_coombes/should-programming-be-taught-in-schools-19i4 | discuss, education | Should programming, logic & algorithms be taught in schools? If so, from what age?
What do you think? Would this be an unnecessary move or would it help train the next generation of programmers? Share your thoughts in the comments! | reece_coombes |
358,976 | Progressive Web Apps (PWAs): The future of mobile apps | Progressive web apps are continuously gaining momentum in the digital space. PWAs provide the best &a... | 0 | 2020-06-19T13:16:25 | https://dev.to/shanalaggarwal/progressive-web-apps-pwas-the-future-of-mobile-apps-g5i | [Progressive web apps](https://www.techaheadcorp.com/blog/progressive-web-apps/) are continuously gaining momentum in the digital space. PWAs provide the best & combined experience of web and mobile apps to the user. Businesses need it to stay ahead in the competition. If we talk in non-IT language, then it would be wr... | shanalaggarwal | |
359,067 | PlaywrightSharp v0.10 for Firefox is here! | Firefox joined to the PlaywrightSharp family! What can I do with PlaywrightSharp.Firefox?... | 0 | 2020-06-19T17:11:59 | https://www.hardkoded.com/blog/playwright-sharp-firefox-010 | playwright, csharp | ---
title: PlaywrightSharp v0.10 for Firefox is here!
published: true
date: 2020-06-19 00:00:00 UTC
tags: playwright,csharp
canonical_url: https://www.hardkoded.com/blog/playwright-sharp-firefox-010
---

Firefox joined to the PlaywrightSharp family!
... | hardkoded |
359,126 | Java/Spring Twitter Bot | Ah, ye ol' twitter bot... Gotta love them. I've been sat at home for the past couple of months self... | 0 | 2020-06-19T17:35:45 | https://dev.to/goldennoodles/java-spring-twitter-bot-2ceo | java, twitter, spring, bot | Ah, ye ol' twitter bot... Gotta love them.
I've been sat at home for the past couple of months self-isolating and have become dreadfully bored.. So why not work on a cool little project? I definitely didn't get super excited and giggled like I was witing my first hello world when the @ItsMelonBot actually posted a t... | goldennoodles |
359,159 | Does Java pass only by value?
| When it comes to Java in calling a method and passing arguments as primitives, there’s no doubt that... | 0 | 2020-06-19T18:59:14 | https://dev.to/vivekworks/does-java-pass-only-by-value-3l7l | java, c, cpp | When it comes to Java in calling a method and passing arguments as primitives, there’s no doubt that it follows the pass by value model. Trouble in understanding comes when dealing with Objects. Since reference types store the address of the object, when reference types are passed as arguments, it’s the memory address ... | vivekworks |
359,244 | What’re the Differences between Software Engineering, Application Lifecycle Management and Project Management? | A post by Franco Scarpa | 0 | 2020-06-19T22:43:35 | https://dev.to/francoscarpa/what-re-the-differences-between-software-engineering-application-lifecycle-management-and-project-management-264a | help, discuss, devops, management | francoscarpa | |
359,330 | Rusty Boy - Week 1: Of Timing and Modes | Hello there! It's been a week since my last report and, as promised, I'm back here with the news of... | 7,308 | 2020-06-22T03:37:35 | https://dev.to/rainbowcookie32/rusty-boy-week-1-of-timing-and-modes-575i | gameboy, emulation, rust | *Hello there!*
It's been a week since my last report and, as promised, I'm back here with the news of the rusty lad. It's been an *interesting* week. Let's jump into it.
#### Monday
I started the week by looking into Dr. Mario and why it wouldn't boot. I haven't seen this one getting to the menu on Rusty-Boy since f... | rainbowcookie32 |
359,418 | Another newsletter for User Interface Frontend Developers | The UI Development Mentoring Newsletter contains a list of exciting and useful articles, tutorials, t... | 0 | 2020-06-20T10:43:46 | https://dev.to/starbist/another-newsletter-for-user-interface-frontend-developers-3oe4 | news, uiweekly, css, career | The UI Development Mentoring Newsletter contains a list of exciting and useful articles, tutorials, tools, apps and everything else related to *user interface frontend development* and *freelancing* and it is sent to your inbox once a week.
Subscribe here: https://mentor.silvestar.codes/reads#newsletter. 🙏 | starbist |
359,648 | SVG Name Animation | Check out the animation which i've created by using SVG | 0 | 2020-06-23T16:56:18 | https://dev.to/caseyanmol/svg-name-animation-25o1 | codepenanimation, svganimation, svg | ---
title: SVG Name Animation
published: true
tags: codepenanimation , svganimation , svg
description: Check out the animation which i've created by using SVG
---
> Check out the cool animation which i've created by using SVG
{% codepen https://codepen.io/caseyanmol/pen/xxZgaZB %}
| caseyanmol |
359,650 | Virtual Environment for Python | Below you learn why need a Python virtual environment and how are you can use it with Python 3 (Why P... | 0 | 2020-06-20T13:01:06 | https://dev.to/importostar/virtual-environment-for-python-dn1 | python | Below you learn why need a **Python virtual environment** and how are you can use it with Python 3 (<a href="https://python-commandments.org/python-2-vs-3/">Why Python 3?</a>).
You should know <a href="https://pythonprogramminglanguage.com/how-to-run/">how to run Python</a> before setting up a virtual environment. If ... | importostar |
359,747 | Bad Security habits to lose | Security is such a vast topic. There are a lot of traps and false beliefs. Since the coronavirus... | 21,638 | 2020-06-20T15:48:50 | https://dev.to/spo0q/bad-security-habits-to-lose-2l7i | security | Security is such a vast topic. There are a lot of traps and false beliefs.
Since the coronavirus crisis, hacking has been increasing, so you got to be prepared.
The good news is that you can significantly mitigate major flaws with simple good practices.
Hackers are looking for vulnerabilities. It's what they do. You'... | spo0q |
359,794 | Create a professional resume in a few minutes (for free). | Having a professional resume is the most important thing when you apply for a job, which depicts your... | 0 | 2020-06-20T17:40:49 | https://dev.to/rakshakannu/create-a-professional-resume-in-a-few-minutes-for-free-28ln | career, googlecloud | Having a professional resume is the most important thing when you apply for a job, which depicts your skills and experiences and could be the deciding factor for getting you shortlisted for the face to face interview out of all the applicants. 😟
Hence, if you don’t have your resume yet, let's start making it. 🥳
Fre... | rakshakannu |
359,878 | Métricas para seu time | Nesse artigo vou apresentar algumas métricas (não todas porque existem muitas), mas talvez as mais co... | 0 | 2020-06-20T21:24:52 | https://dev.to/womakerscode/metricas-para-seu-time-1e04 | Nesse artigo vou apresentar algumas métricas (não todas porque existem muitas), mas talvez as mais conhecidas.
Todas as empresas possuem fluxos de trabalho e devem aprender a administrá-los para direcionar melhor suas ações. As métricas não têm intenção de julgar as pessoas individualmente, mas sim, melhorar o fluxo.
... | abquintino | |
361,781 | Using MQTT on Angular Apps | When you’re building a website that needs to be updated in real-time, your first thought is probably... | 0 | 2020-07-06T08:06:34 | https://bugfender.com/blog/using-mqtt-on-angular-apps/ | angular, javascript, mqtt | ---
title: Using MQTT on Angular Apps
published: true
date: 06/07/2020 08:00 UTC
tags: angular,javascript,js,mqtt
canonical_url: https://bugfender.com/blog/using-mqtt-on-angular-apps/
---
When you’re building a website that needs to be updated in real-time, your first thought is probably to add WebSockets to your appl... | bugfenderapp |
375,159 | How to use git stash effectively | This post was originally posted in the newsletter GitBetter. If you are interested in lev... | 0 | 2020-07-06T07:06:20 | https://gitbetter.substack.com/p/useful-tricks-of-git-stash | git, beginners, programming, tutorial | ---
title: How to use git stash effectively
published: true
tags: git, beginners, programming, tutorial
canonical_url: https://gitbetter.substack.com/p/useful-tricks-of-git-stash
---
 => arr.reduce((a, b) => a ^ b);
```
Always go for functio... | divyajyotiuk |
383,250 | D3.js Creating a Bar Chart from Ground Up | Creating a bar chart is not that difficult, or is it? Today, we are going to dissect the basic... | 0 | 2020-07-05T14:57:06 | https://sahansera.dev/d3-creating-bar-chart-ground-up/ | javascript, d3, beginners | ---
title: D3.js Creating a Bar Chart from Ground Up
published: true
date: 2020-07-05 14:57:00 UTC
tags: javascript, d3, beginners
canonical_url: https://sahansera.dev/d3-creating-bar-chart-ground-up/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/txlv1jxytcjuvs23fx7p.jpg
---
Creating a bar chart is not that d... | sahan |
383,376 | The Eight Buffalo Rule: How to stop writing unreadable code | Eight Buffalo Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo. The eigh... | 0 | 2020-07-05T13:49:21 | https://dev.to/mattpocockuk/the-nine-buffalo-rule-how-to-stop-writing-unreadable-code-2hl4 | beginners, tutorial, codenewbie, learning | # Eight Buffalo
> Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
The eight-buffalo sentence above is commonly cited as the longest grammatically correct sentence you can write with a single word.
On the surface, it looks like nonsense. None of the words communicate any intent. You can't pick out wh... | mattpocockuk |
383,385 | Escaping the tyranny of stack overflow | Hi guys. As someone who has recently entered the world of coding, I have used stack overflow like any... | 0 | 2020-07-05T14:07:39 | https://dev.to/mohammadpishdar/escaping-the-tyranny-of-stack-overflow-56eh | Hi guys. As someone who has recently entered the world of coding, I have used stack overflow like anyone else to ask questions. At first, I was so happy and excited that I'm about to be a member of a community of like-minded people where I can get insights from professionals whenever I need help but it didn't last long... | mohammadpishdar | |
383,511 | When to choose NoSQL over SQL? | The agenda of this blog is simple. We’ll discuss various parameters that we keep in mind while decidi... | 0 | 2020-07-05T17:11:33 | https://dev.to/ombharatiya/when-to-choose-nosql-over-sql-536p | sql, nosql, database, architecture | The agenda of this blog is simple. We’ll discuss various parameters that we keep in mind while deciding a perfect database for our Application Service.
In terms of data engineering, data pressure is the ability of the system to process the amount of data at a reasonable cost or a reasonable time. When one of those dim... | ombharatiya |
383,538 | Tell me what is / why MVC ? | I know, MVC stands for Model View Controller. Its neither a technology nor a programming language. It... | 0 | 2020-07-05T17:58:59 | https://dev.to/manishfoodtechs/tell-me-what-why-mvc-2ggj | help, discuss | I know, MVC stands for Model View Controller. Its neither a technology nor a programming language. Its an architectural pattern commonly used for developing user interfaces that divides an application into three interconnected parts. ...
***Is it necessary? Without it any performance issue?***
| manishfoodtechs |
383,544 | How to create a blog using Laravel and Voyager? | I've just published my very first video course on how to build a blog using Laravel and Voyager. Tur... | 0 | 2020-07-05T18:11:16 | https://dev.to/bobbyiliev/how-to-create-a-blog-using-laravel-and-voyager-jg | laravel, linux, php | I've just published my very first video course on how to build a blog using Laravel and Voyager.
Turned out to be a lot more challenging than I expected!
The quality ended up not as good as I imagined 😅 but was a great learning experience!
I went through the process of setting up a server, installing all of the req... | bobbyiliev |
383,563 | Things I learned while building my side project | Gitify lets you interact with Git from browser extension. | 0 | 2020-07-05T19:25:15 | https://dev.to/akshay090/things-i-learned-while-building-my-side-project-3nil | showdev, github, extension, githunt | ---
title: Things I learned while building my side project
published: true
description: Gitify lets you interact with Git from browser extension.
tags: showdev, github, extension, githunt
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/yyeq8krv82vifcyaymic.png
---
**TLDR :** I build this project called gitify, ... | akshay090 |
397,132 | Minimalist Roadmap to Becoming a Full-Stack Developer | I fear not someone who has practiced 10,000 kicks once, but I fear someone who has practiced one... | 0 | 2020-07-14T12:31:31 | https://dev.to/ericdouglas/minimalist-roadmap-to-becoming-a-full-stack-developer-259b | javascript, react, node, mongodb | > I fear not someone who has practiced 10,000 kicks once, but I fear someone who has practiced one kick 10,000 times.
>
> Bruce Lee
When we are starting to learn about web development, we really struggle to find a clear and feasible path to guide us on this journey.
Although we have a lot of great schools that certai... | ericdouglas |
383,657 | Create React Doc: A Markdown Doc Site Generator For React | Markdown doc site generator for React | 0 | 2020-07-05T19:52:43 | https://dev.to/muyunyun/create-react-doc-write-markdown-site-with-no-build-configuration-hk7 | markdown, blog | ---
title: Create React Doc: A Markdown Doc Site Generator For React
published: true
description: Markdown doc site generator for React
tags: ['markdown', 'blog']
cover_image: https://user-images.githubusercontent.com/19354791/86540722-06202600-bf3a-11ea-9fc0-1d7aa5f11cad.png
---
# Create React Doc
[Create React Doc]... | muyunyun |
383,695 | Create a JavaScript library. Add callbacks | And here is a new part of creating a library of modal windows in JavaScript. This time we are impleme... | 7,207 | 2020-07-07T10:42:03 | https://dev.to/alexandrshy/create-a-javascript-library-add-callbacks-2e64 | javascript, typescript, webdev, tutorial | And here is a new part of creating a library of modal windows in JavaScript. This time we are implementing two small improvements. First, we'll add the ability to use callbacks to the configuration. And secondly, we'll improve the keyboard control. By tradition, I'm sharing a video version with you, for those who want ... | alexandrshy |
383,703 | How to Add a favicon to the site in Rails 6 using Webpacker | In Rails 6, Adding an icon to the HTML tab is very easy with 3 simple steps. 1) Add an image 2) Ref... | 0 | 2020-07-06T00:18:03 | https://dev.to/kattak2k/adding-a-favicon-to-your-site-using-webpacker-in-rails-6-2m2h | ruby, webpack, rails, html | In Rails 6, Adding an icon to the HTML tab is very easy with 3 simple steps.
1) [Add an image](#add)
2) [Reference an image](#reference)
3) [Link an image to HTML head](#link)
For the basic understanding on Webpacker, you may refer the useful guide by Chris Oliver ([Webpacker Setup](https://gorails.com/episodes/u... | kattak2k |
383,709 | AWS 🔒 How to restrict access by IP | Hi there! In today's post, I would like to show you how you can restrict access to your AW... | 0 | 2020-07-05T22:09:38 | http://securityblog.cloud/aws-how-to-restrict-access-by-ip.html | aws, security, iam, policy | ## Hi there!
In today's post, I would like to show you how you can restrict access to your AWS Account. Very often companies use static IP addresses to access the Internet. So if you know that access to your AWS account has to happen from specific IP, why allow it from the whole Internet.
Here is a logic schema of how ... | vitali |
384,002 | Data Types In Javascript | There are 3 types of data types in Javascript: primitive and composite and data types. Primitive dat... | 0 | 2020-07-06T02:23:11 | https://dev.to/aidoskashenov/data-types-in-javascript-4ob9 | javascript |
There are 3 types of data types in Javascript: primitive and composite and data types.
Primitive data types are simple types like "Strings", Number, Boolean, _undefined_ and _null_. Composite data are Arrays, Objects and Functions.
Primitive data types are those that can hold only one type of value and cannot be su... | aidoskashenov |
384,230 | How Can You Use Elm to be a Better Front End Programmer? Interview with Richard Feldman | Richard Feldman, the author of "Elm in Action", got interviewed by GOTO about Elm. He said Elm won't... | 0 | 2020-07-06T07:15:30 | https://dev.to/ancatrusca1/how-can-you-use-elm-to-be-a-better-front-end-programmer-interview-with-richard-feldman-39hp | functional, frontend, elm | Richard Feldman, the author of "Elm in Action", got interviewed by [GOTO about Elm](https://gotopia.tech/bookclub/episodes/upgrade-your-frontend-game-be-an-elm-wizard). He said Elm won't take over the world but sure is a fun language to use that compiles in less than 4 seconds and will definitely change your perspectiv... | ancatrusca1 |
384,238 | DEV.to Lookalike App with React | My First Project with React | 0 | 2020-07-06T07:29:34 | https://dev.to/gerwinjonathan/dev-to-lookalike-app-with-react-31ao | react, beginners, api, webdev | ---
title: DEV.to Lookalike App with React
published: true
description: My First Project with React
tags: react, beginners, api, webdev
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0bpm70snj6dmjd4xjcp0.PNG
---
## Introduction
Today, I would like to post my very first project on DEV.to. This project is calle... | gerwinjonathan |
384,275 | 18 Essential Videos That Fundamentally Shaped My Understanding of JavaScript | Learning JavaScript is a wild, tempestuous journey. With so much to learn, it is difficult to keep up with the times. Here are 18 videos I consider to be "essential" in learning JavaScript at a deeper level. Each of these videos once sparked a "eureka moment" within me that ultimately helped in piecing together the Jav... | 7,642 | 2020-07-08T11:29:03 | https://dev.to/somedood/18-essential-videos-that-fundamentally-shaped-my-understanding-of-javascript-3ib | javascript, node, learning | ---
series: "Some Dood\'s Curated List of Essential Learning Materials"
title: "18 Essential Videos That Fundamentally Shaped My Understanding of JavaScript"
published: true
description: "Learning JavaScript is a wild, tempestuous journey. With so much to learn, it is difficult to keep up with the times. Here are 18 vi... | somedood |
384,335 | Pod uses dynamic environment variable | TL; DR This post is build-up on the Merge ConfigMap and Secrets post.It is another use of... | 0 | 2020-07-06T09:06:51 | https://storage-chaos.io/dell-csi-isilon-custom-envvars.html | kubernetes, csi, dell, isilon | ---
title: Pod uses dynamic environment variable
published: true
date: 2020-06-19 07:00:00 UTC
tags: #kubernetes #csi #dell #isilon
canonical_url: https://storage-chaos.io/dell-csi-isilon-custom-envvars.html
---
# TL; DR
This post is build-up on the [Merge ConfigMap and Secrets](/configmap-and-secret.html) post.It is... | coulof |
384,419 | ☄️ How to update version's cache of your package in pkg.go.dev? | Introduction Hi, DEV people! 😉 Sometimes, when you publish a new version of your Go... | 4,444 | 2020-07-06T11:56:27 | https://dev.to/koddr/how-to-update-version-s-cache-of-your-package-in-pkg-go-dev-39ij | go, tutorial, beginners, fiber | ## Introduction
Hi, DEV people! 😉 Sometimes, when you publish a new version of your Go package, [pkg.go.dev](https://pkg.go.dev) may still give away an old version for a long time.
This also means, that if other people are using your package, **not be able** to update to the new version until the cache is updated.
... | koddr |
384,814 | #JulyOT - Getting Started with NVIDIA Jetson Nano: Object Detection | Erik and Paul configure a Jetson Nano device for use with DeepStream SDK using samples provided from NVIDIA. Part 1 of a 5 part series created for #JulyOT - more details @ http://julyot.com | 0 | 2020-07-06T19:05:15 | https://dev.to/azure/julyot-getting-started-with-nvidia-jetson-nano-object-detection-3moe | ai, computervision, nvidia, iot | ---
title: #JulyOT - Getting Started with NVIDIA Jetson Nano: Object Detection
published: true
description: Erik and Paul configure a Jetson Nano device for use with DeepStream SDK using samples provided from NVIDIA. Part 1 of a 5 part series created for #JulyOT - more details @ http://julyot.com
tags: artificialintel... | toolboc |
385,208 | DNS Explained. Introduction/History | Introduction Imagine this scenario. Netflix has a lot of fresh content being released. Yo... | 7,661 | 2020-07-28T16:56:24 | https://dev.to/blake/dns-explained-introduction-history-1an7 | networking, dns, network, domain | # Introduction
Imagine this scenario.
Netflix has a lot of fresh content being released. You decide that you want to watch the next season of [_The Politican_](https://www.netflix.com/title/80241248). So, you open up your favorite browser, type in `netflix.com`, and hit enter. Almost instantly, Netflix's profile sele... | blake |
388,107 | How To Install WordPress on Ubuntu 20.04 with a LAMP Stack | This tutorial is intended for those who desire to install and administer a Wordpress instance on an unmanaged cloud server via the command line. | 0 | 2020-07-08T17:55:44 | https://www.digitalocean.com/community/tutorials/how-to-install-wordpress-on-ubuntu-20-04-with-a-lamp-stack | wordpress, linux, tutorial, cloud | ---
title: How To Install WordPress on Ubuntu 20.04 with a LAMP Stack
published: true
tags: wordpress, linux, tutorial, cloud
description: This tutorial is intended for those who desire to install and administer a Wordpress instance on an unmanaged cloud server via the command line.
canonical_url: https://www.digitalo... | lisaironcutter |
389,432 | Upload your project/files in GitHub using commands | Upload your project/files in GitHub using following commands; Tell the GitHub who are you; $ git c... | 0 | 2020-07-09T10:46:19 | https://dev.to/100rabhcsmc/upload-your-project-files-in-github-using-commands-1hn8 | python, github | Upload your project/files in GitHub using following commands;
Tell the GitHub who are you;
$ git config --global user.email"saurabhchavan052@gmail.com"
$ git config --global user.name"100rabhcsmc"
Lets git ..
$ git init
$ git add -A#adding file
$git commit -m "your commit"
$git remote ... | 100rabhcsmc |
389,950 | Is there cheese down that hole? | I have a good friend who has a saying: “Is there cheese down that hole?” It’s of course a literal re... | 0 | 2020-07-09T16:31:01 | https://dev.to/thinkster/is-there-cheese-down-that-hole-38fk | impact, webdev, productivity, change | I have a good friend who has a saying: “Is there cheese down that hole?”
It’s of course a literal reference to mice looking for cheese down a hole, but it’s also a reference to questioning whether a course of action has the potential for a valuable result we actually want.
So many times in our lives, we are simply re... | josepheames |
391,579 | How to get more people to join your Discord community by adding an invite widget to your README | Inspired by shields.io, we've created a service that generates SVG images that mimic Discord's invite... | 0 | 2020-07-10T15:01:54 | https://dev.to/pedrofracassi/how-to-get-more-people-to-join-your-discord-community-by-adding-an-invite-widget-to-your-readme-9ne | showdev, github | Inspired by shields.io, we've created a service that generates SVG images that mimic Discord's invite widgets, shown on the app when you send an invite link to a chat. Adding these to your README is an easy way to get more people interested in joining your community!
These look really cool on your repository README, o... | pedrofracassi |
394,225 | Imperative and declarative programming | Nowadays, programming has become the main routine for people inserted in the technology market. Wheth... | 0 | 2020-07-12T13:24:59 | https://dev.to/aryclenio/imperative-and-declarative-programming-2b2a | productivity, javascript, codequality, declarative | Nowadays, programming has become the main routine for people inserted in the technology market. Whether in front-end, back-end programming, data science, microcontrollers, among others.
Many of us view programming as a kind of order, where you tell the computer what you want, using codes, and it will return it to you ... | aryclenio |
394,638 | Jest mocking strategies | This post was last updated on July 12, 2020. Always refer to library documentation for the most updat... | 0 | 2020-07-13T01:14:15 | https://www.mercedesbernard.com/blog/jest-mocking-strategies/ | javascript, jest, testing, mocking | _This post was last updated on July 12, 2020. Always refer to library documentation for the most updated information._
_Note: this post assumes familiarity with Jest and mocking. If you want to learn more, take a look at [the Jest docs](https://jestjs.io/docs/en/mock-functions) first_ 🙂
## Table of contents
1. [ES6 ... | mercedes |
395,649 | Váš sken dorazil... | ... a je to HTML! Slovo "[EXTERNAL]" do předmětu automaticky vkládá Office 365, aby byl uživatel n... | 0 | 2020-07-13T11:02:50 | https://dev.to/rhybnik/vas-sken-dorazil-161a | ... a je to HTML!
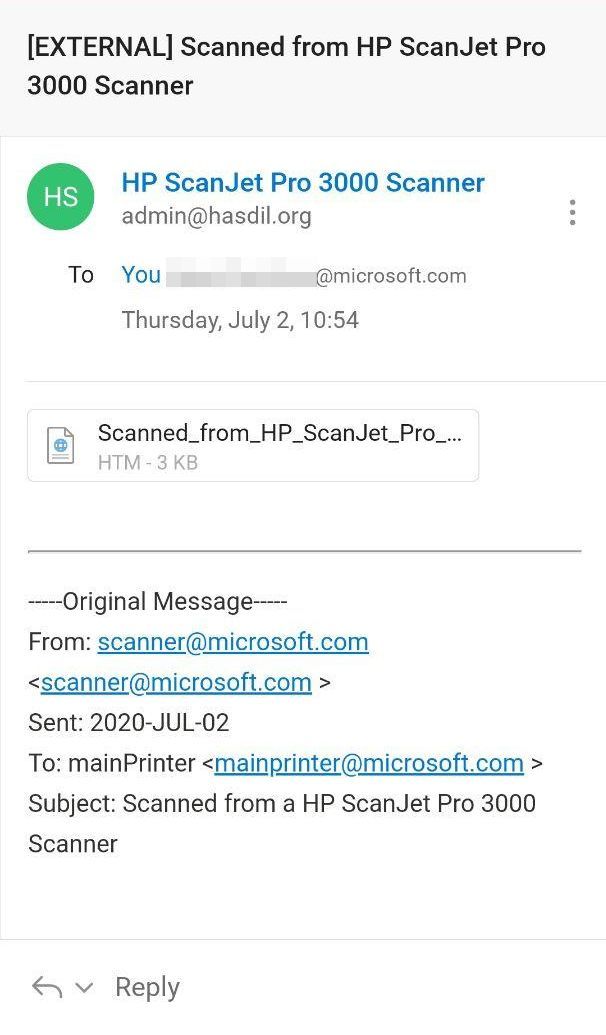
Slovo "[EXTERNAL]" do předmětu automaticky vkládá Office 365, aby byl uživatel na pozoru. Standardně jej tam ale nenajdete, tak ho budeme ignorovat.
V tomto případě je zajímavá hlavně technika zvýšení důvěryhodnos... | rhybnik | |
395,830 | Hello World! | A “Hello World!” program is often used as a simplistic introduction to programming languages, as it’s... | 0 | 2020-07-13T14:17:34 | https://blog.ganeshagrawal.com/hello-world-ckcex0voq002t9as1cfbpe1vg | A **“Hello World!”** program is often used as a simplistic introduction to programming languages, as it’s generally quite self-explanatory, and simple enough that even those with little or no programming experience can understand its function. However, do not mistake its simplicity for a lack of utility. The program ne... | ganeshagrawal | |
396,019 | JavaScript: Type Conversion | To Binary JavaScript has two boolean values: true and false. But, it also treats certain v... | 7,685 | 2020-07-13T16:33:41 | https://dev.to/bhagatparwinder/javascript-type-conversion-14eg | javascript, codenewbie, tricks | ## To Binary
JavaScript has two boolean values: `true` and `false`. But, it also treats certain values as `truthy` or `falsy`. All values are `truthy` except `0`, `null`, `undefined`, `""`, `false`, and `NaN`.
We can switch values between true and false using the negation operator `!`. This conversion also converts t... | bhagatparwinder |
396,222 | Easy Deployment Setup With Bitbucket and AWS ECS | Deploy to AWS ECS via Bitbucket | 0 | 2020-07-13T17:57:00 | https://dev.to/olaoluwa98/easy-deployment-setup-with-bitbucket-and-aws-ecs-46ac | deployment, aws, bitbucket, docker | ---
title: "Easy Deployment Setup With Bitbucket and AWS ECS"
published: true
description: "Deploy to AWS ECS via Bitbucket"
tags: [Deployment,AWS,Bitbucket,Docker]
---
Deployment is one of the most important parts of product development and launch. The better the deployment process is the faster it is. There are many... | olaoluwa98 |
396,223 | The 7 Most Popular DEV Posts from the Past Week | A round up of the most-read and most-loved contributions from the community this past week. | 0 | 2020-07-14T15:48:52 | https://dev.to/devteam/the-7-most-popular-dev-posts-from-the-past-week-3m5 | top7 | ---
title: The 7 Most Popular DEV Posts from the Past Week
published: true
description: A round up of the most-read and most-loved contributions from the community this past week.
tags: icymi
cover_image: https://thepracticaldev.s3.amazonaws.com/i/sfwcvweirpf2qka2lg2b.png
---
_Every Tuesday we round up the previous wee... | jess |
396,395 | Javascript way to go / Guide / Something | Heeeey, this is the first time Im writting here. Sorry for my broken english. My name is Ernesto, I... | 0 | 2020-07-13T20:06:47 | https://dev.to/skullflowerss/javascript-way-to-go-guide-something-465j | javascript, beginners, tutorial | 
Heeeey, this is the first time Im writting here. Sorry for my broken english.
My name is Ernesto, I am from Mexico City and I started coding few years ago.
When I was in college I started learning Java and C++, only the basic things. Dat... | skullflowerss |
396,673 | Day 43 : #100DaysofCode - The Amazing Faker Gem | If you are relatively new to code and learning all about Ruby and Ruby on Rails, then you most likely... | 7,070 | 2020-07-14T02:45:09 | https://dev.to/sincerelybrittany/day-43-100daysofcode-the-amazing-faker-gem-2d28 | 100daysofcode, codenewbie | If you are relatively new to code and learning all about Ruby and Ruby on Rails, then you most likely have experience or heard of the ``seed.rb`` file. The file allows us to create objects/ data and add it to our database. In general, you would run ``rails db:seed`` or ``rake db:seed`` AFTER running your migration. Tod... | sincerelybrittany |
399,730 | Java OOP Cheatsheet | I will be exploring Java OOP concepts with relevant real-life examples as well as the coding... | 0 | 2020-07-16T06:58:50 | https://dev.to/sivantha96/java-oop-cheatsheet-3ph1 | java, jvm | I will be exploring Java OOP concepts with relevant real-life examples as well as the coding examples. So let us get started.
Here is the order that I am going to discuss each OOP concept.
[1. Encapsulation](#encapsulation)
[2. Inheritance](#inheritance)
[3. Polumorphism](#polymorphism)
[2. Abstraction](#abstraction... | sivantha96 |
396,822 | Hi ! Help Needed to remove custom Domain on GitHub pages | Hi!, someone who are familiar with GitHub. Please help me. I added a custom domain to use GitHub page... | 0 | 2020-07-14T06:23:29 | https://dev.to/ajaydaram/hi-help-needed-to-remove-custom-domain-on-github-pages-ai8 | Hi!,
someone who are familiar with GitHub. Please help me. I added a custom domain to use GitHub pages. Now I decided to remove but I don't know how to do it. The problem is this:
when i created dummysite.github.io to publish, it is always pointing to www.dummysitesz.com.
How to remove the custom domain? | ajaydaram | |
396,959 | Testing a Nuxt.js application using WebdriverIO | Recently WebdriverIO has been added in Nuxt.js create-nuxt-app scaffolding tool as a test framework o... | 0 | 2020-07-14T16:11:31 | https://dev.to/astagi/testing-a-nuxt-js-application-using-webdriverio-1215 | vue, javascript, nuxt, tutorial | Recently [WebdriverIO](https://webdriver.io/) has been added in [Nuxt.js create-nuxt-app scaffolding tool](https://github.com/nuxt/create-nuxt-app) as a test framework option to provide end to end browser and mobile automation testing.
In this tutorial you'll learn how to test a Nuxt.js app with WebdriverIO following... | astagi |
396,981 | Developers From India | Do you want to extend your team of developers? Just drop a line of your requirements and we will give... | 0 | 2020-07-14T09:24:24 | https://dev.to/bijinazeez/developers-from-india-2bmp | Do you want to extend your team of developers? Just drop a line of your requirements and we will give you an opportunity to hire web developers or app developers that are the best fit for your needs. Our only goal is to establish an engagement model that takes care of all your development needs, while you concentrate o... | bijinazeez | |
397,123 | How do you identify "over-engineering"? | How do you spot over-engineering as it is happening, how do you communicate around this issue? | 0 | 2020-07-14T12:12:39 | https://dev.to/ben/how-do-you-identify-over-engineering-1oad | discuss, codequality | How do you spot over-engineering as it is happening, how do you communicate around this issue? | ben |
397,124 | TOP 2 New APIs in Chromium | 1- Screen Wake Lock API Supported in Chrome 83+ This API helps to prevent de... | 0 | 2020-07-14T12:14:08 | https://dev.to/sharadcodes/top-2-new-apis-in-browsers-4eog | webdev | ## 1- Screen Wake Lock API
### Supported in
* **Chrome 83+**
This API helps to prevent devices from dimming, locking or turning off the screen when your web application needs to keep running.
## 2- Web NFC
### Supported in
* **Chrome 79+**
* **Chrome for Android 80+**
* **Edge 79+**
* **Opera 66+**
Can only be e... | sharadcodes |
397,258 | What is Dev Community business model? | I did't find anything through that a revenue can be generated. But still servers need money to keep r... | 0 | 2020-07-14T13:50:10 | https://dev.to/milindsingh/what-is-dev-community-business-model-2dmg | I did't find anything through that a revenue can be generated. But still servers need money to keep running.
How it happens here? | milindsingh | |
397,288 | Using CSS Modules with create-react-app | Starting a new React project used to be a complicated process that involved setting up a build system... | 0 | 2020-07-14T14:22:46 | https://dev.to/0x96f/using-css-modules-with-create-react-app-22hd | react, css, beginners, javascript | Starting a new React project used to be a complicated process that involved setting up a build system, a code transpiler to convert modern JS code to code that is readable by all browsers, and a base directory structure. Create-react-app offers a modern build setup that comes pre-configured with everything we need to s... | 0x96f |
397,298 | NextJS + TypeScript + TailwindCSS + Storybook project setup | TUTORIAL BASED ON STORYBOOK v5, ON v6 EVERYTHING STORYBOOK-RELATED WORKS OUT OF THE BOX! Following... | 0 | 2020-07-14T15:15:04 | https://stackrant.com/posts/nextjs-typescript-tailwindcss-storybook-project-setup | nextjs, typescript, tailwindcss, storybook | > TUTORIAL BASED ON STORYBOOK v5, ON v6 EVERYTHING STORYBOOK-RELATED WORKS OUT OF THE BOX!
Following is a simple guide to get up and running with the NextJS+TypeScript+TailwindCSS+Storybook combination, a task which took me a lot more time than I originally estimated, due to the unexpected lack of specific guides on h... | hood |
397,652 | Beautiful World of Monads | Practical Introduction to Monads for Java Developers | 0 | 2020-07-14T17:43:09 | https://dev.to/siy/beautiful-world-of-mondas-2cd6 | java, beginners, tutorial | ---
title: Beautiful World of Monads
published: true
description: Practical Introduction to Monads for Java Developers
tags: #java #beginners #tutorial
//cover_image: https://direct_url_to_image.jpg
---
Let me start with disclaimer. Explanation below in no way pretends to be precise or absolutely accurate from the poi... | siy |
398,213 | What does the terms front-end and back-end cover? (opinions) | For example, whenever I hear the term front-end I think about sketching, design, color theory, UI/UX,... | 0 | 2020-07-15T01:32:45 | https://dev.to/jouo/what-does-the-terms-front-end-and-back-end-cover-opinions-3ja7 | discuss | For example, whenever I hear the term **front-end** I think about sketching, design, color theory, UI/UX, coding...
For **back-end**: databases, coding, algorithms, devops, systems...
My definitions could be completely wrong, but that's just how I personally perceive them.
How do **you** perceive those two terms? :) | jouo |
426,642 | The story of how I got into web dev... | Hey everyone, my name is Nazanin but my online friends call me Zani lol I saw people sharing their st... | 0 | 2020-08-13T17:00:52 | https://dev.to/nazanin_ashrafi/the-story-of-how-i-got-into-web-dev-3ff1 | webdev, watercooler, codenewbie | Hey everyone, my name is Nazanin but my online friends call me Zani lol
I saw people sharing their stories and how they got into coding so i thought I'd do the same
Here we go :
Coding was never my passion, hell i didn't even know what it is. I never knew what I liked or what I wanna do, The only thing I knew was th... | nazanin_ashrafi |
398,282 | ES6 Modules: How to use import and export in JavaScript | ES6 provides the ability to split JavaScript into multiple files (modules). Modules can then be expo... | 0 | 2020-07-15T03:32:42 | https://dev.to/michaelburrows/es6-modules-how-to-use-import-and-export-in-javascript-1op5 | javascript, tutorial | ES6 provides the ability to split JavaScript into multiple files (modules).
Modules can then be exported and imported as required into other files.
The biggest benefit of modules is they help keep large amounts of JavaScript organised.
To better understand how modules work let’s create a simple project with followin... | michaelburrows |
398,408 | Instagram Data Scraper | Wrote and program that allows you to see the total likes and comments of a public user, plus the numb... | 0 | 2020-07-15T06:28:53 | https://dev.to/nenwam/instagram-data-scraper-4b2b | webdev, database, entertainment | Wrote and program that allows you to see the total likes and comments of a public user, plus the number of likes on each post
https://cranky-yonath-059111.netlify.app/ | nenwam |
398,542 | Effective Object Usage Examples in JavaScript | In this article, I try to suggest effective solutions with objects in JavaScript for common use cases... | 0 | 2020-07-15T10:18:00 | https://dev.to/halilcanozcelik/javascript-objects-in-use-1e12 | javascript, computerscience, webdev, tutorial | In this article, I try to suggest effective solutions with objects in JavaScript for common use cases in the real world.
### Objects instead of array search
Using objects in an array search decreases the time complexity of your solution in quite a lot of cases. Let’s continue explaining with examples:
```js
function f... | halilcanozcelik |
398,845 | Next.js - the future of React? | A short overview of probably most versatile framework for React | 0 | 2020-07-24T11:50:48 | https://dev.to/dotintegral/next-js-the-future-of-react-21nb | nextjs, react, javascript, typescript | ---
title: Next.js - the future of React?
published: true
description: A short overview of probably most versatile framework for React
tags: nextjs, react, javascript, typescript
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/kh3ntlg6dnemjeaz531z.png
---
React and Angular are probably the most popular, competi... | dotintegral |
398,974 | .NET CIL interpreter in F# | I've prepared compact .NET CIL interpreter called Fint in pure F# for NskDotNet Meetup #6. It can ru... | 0 | 2020-07-15T15:30:42 | https://dev.to/sergeyt/net-cil-interpreter-in-f-31fl | dotnet, functional | I've prepared compact [.NET CIL](https://en.wikipedia.org/wiki/Common_Intermediate_Language) interpreter called [Fint](https://github.com/sergeyt/fint) in pure F# for [NskDotNet Meetup #6](https://www.meetup.com/NskDotNet/events/265652338/).
It can run C# programs with the following features at this point:
- all contr... | sergeyt |
427,123 | 16 Underused Web Platform Features | What follows is a list of APIs and features that are uncommon to see in the wild, but have use cases... | 0 | 2020-08-14T00:56:22 | https://dev.to/robbiegm/16-underused-web-platform-features-3k90 | webdev, javascript | What follows is a list of APIs and features that are uncommon to see in the wild, but have use cases nonetheless and the potential to greatly improve the experience your users have while visiting your website. Each feature below has a link to a demo so you can try it out in your browser. Without further ado...
[**App ... | robbiegm |
399,030 | A quick start base for python developers looking to build AI based chat apps | Today, We will learn how to set up a base for a Python based AI chatbot using the MACHAAO + RASA Samp... | 0 | 2020-07-15T16:02:04 | https://dev.to/unixguru2k/a-quick-start-base-for-python-developers-looking-to-build-ai-based-chat-apps-1n7h | machinelearning, python, tutorial | Today, We will learn how to set up a base for a Python based AI chatbot using the MACHAAO + RASA Sample Chatbot Template.
So, I have chosen the above mentioned chatbot template because it is easy to learn, build, deploy, monetise, integrate and manage.
We will require ngrok (optional) secure introspect-able tunnels t... | unixguru2k |
399,162 | Jersey Configuration with Spring | Hey All!... This is my first post in this platform ,So be soft in the comment section. In this post... | 0 | 2020-07-15T17:49:14 | https://dev.to/vinayhegde2013/jersey-configuration-with-spring-4514 | java, spring, jersey | Hey All!...
This is my first post in this platform ,So be soft in the comment section. In this post I am going to tell how to configure Jersey with Spring.
Have you ever wondered how to configure Jersey in the Spring project?. Didn’t find the exact solution for that?. If Yes, you are in the right place. I assume you ... | vinayhegde2013 |
399,180 | CS50 Week 2 - Arrays in C | This post is edited from my original blog post. Find it, and other posts by me on kewbish.github.io/b... | 7,459 | 2020-07-16T18:48:18 | https://kewbish.github.io/blog/posts/200709/ | This post is edited from my [original blog post](https://kewbish.github.io/blog/posts/200709/). Find it, and other posts by me on [kewbish.github.io/blog](https://kewbish.github.io/blog/).
# Introduction
And now, our *third* week of CS50! This week, we went over arrays, but also spent a lot of time on CLI / terminal t... | kewbish | |
399,324 | Melhores Alternativas Gratuitas para o Photoshop – 2020 | O Adobe Photoshop é um dos melhores programas disponíveis para design, seu preço porém pode ser desan... | 0 | 2020-07-16T04:28:09 | https://marquesfernandes.com/melhores-alternativas-gratuitas-para-o-photoshop-2020/ | design, gimp, inkscape, photoshop | ---
title: Melhores Alternativas Gratuitas para o Photoshop – 2020
published: true
date: 2020-07-14 19:27:26 UTC
tags: Design,gimp,inkscape,photoshop
canonical_url: https://marquesfernandes.com/melhores-alternativas-gratuitas-para-o-photoshop-2020/
---
O Adobe Photoshop é um dos melhores programas disponíveis para des... | shadowlik |
399,396 | Have you ever felt that multiple screens do more harm than good sometimes? | Common sense says that more screens equals more productivity but I've just realized that on low focus... | 0 | 2020-07-15T22:04:53 | https://dev.to/vtrpldn/have-you-ever-felt-that-multiple-screens-do-more-harm-than-good-sometimes-4hnl | watercooler | Common sense says that more screens equals more productivity but I've just realized that on low focus days like today, having a spare screen actually makes me less productive.
What do you think about it? | vtrpldn |
399,876 | Free Product-Market Fit consultancy (30 mins) | Are you having problems finding a product-market fit for your app or have questions about fundraising... | 0 | 2020-07-16T09:01:22 | https://dev.to/gdi3d/free-product-market-fit-consultancy-30-mins-40mf | startup, tips, developer | Are you having problems finding a product-market fit for your app or have questions about fundraising or how to do customer discovery?
You can have a free one-to-one consultancy session call with one of the volunteers of GetAdvice
https://getadvice.github.io/warren.fauvel.html
Disclaimer: I'm the guy behind GetAdvic... | gdi3d |
399,903 | Send data between tabs with JavaScript | Did you know you can send information between open browser tabs using JavaScript? Let's say your... | 0 | 2020-07-16T10:13:47 | https://dev.to/dcodeyt/send-data-between-tabs-with-javascript-2oa | javascript, webdev, tutorial | Did you know you can send information between open browser tabs using JavaScript?
Let's say your user is viewing your site with multiple tabs and something happens one tab which you want to react to on the other tabs - you can do this using the [Broadcast Channel API](https://developer.mozilla.org/en-US/docs/Web/API/B... | dcodeyt |
399,998 | Let’s Write an IPython Extension the Hard Way | I love IPython. I love using it, I love writing about it, I love taking pictures with its core contri... | 0 | 2020-07-16T17:19:39 | https://switowski.com/blog/lets-write-ipython-extension | python, ipython | ---
title: Let’s Write an IPython Extension the Hard Way
date: 2020-07-16 00:00:00 UTC
tags: Python, IPython
canonical_url: https://switowski.com/blog/lets-write-ipython-extension
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/izf3dv9dp6qee4eorj20.jpg
published: true
---
I love IPython. I love using it, I love... | switowski |
400,147 | My First Programming Project | Leading up to my first project, I was feeling anxious, nervous and excited at the same time. It’s cra... | 0 | 2020-07-16T12:00:02 | https://dev.to/mindful_developer/my-first-programming-project-2elk | ruby, cli | Leading up to my first project, I was feeling anxious, nervous and excited at the same time. It’s crazy to this that a month ago I had no coding background, and now I’m tasked with creating a project based off the knowledge I’ve learned in the past month. I felt that I could do it and was excited to put my knowledge to... | mindful_developer |
400,203 | What are your best meeting hacks? 👨🏻💼🚀 | I've been thinking a lot about meetings recently. So many of us are stuck with unproductive meetings... | 0 | 2020-07-16T13:29:25 | https://dev.to/xenoxdev/what-are-your-best-meeting-hacks-5ckl | discuss, watercooler, productivity | I've been thinking a lot about meetings recently. So many of us are stuck with unproductive meetings day in and day out. So I wrote a post about it on Medium today and shared my best tips on how to make meetings productive.
You can find the post here!
[" by Luis Augusto, where he explained why `position: fixed` is an inferior way of sticking headers.
{% post https://dev.to/luisaugusto/stop-using-fixed-... | pavelloz |
400,937 | Seeing Sound with Amit Nambiar | Sharing a passion project of visualizing audio in 3D, talking through the assumptions, limitations, and challenges. | 0 | 2020-07-23T11:52:46 | https://dev.to/amitlzkpa/seeing-sound-with-amit-nambiar-18ik | codeland, audio, visualization | ---
title: Seeing Sound with Amit Nambiar
published: true
description: Sharing a passion project of visualizing audio in 3D, talking through the assumptions, limitations, and challenges.
tags: codeland, audio, visualization
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/dw8xm7m8ycvafjwfaqtr.png
---
Hey, ... | amitlzkpa |
401,094 | UML: Vantagens e Desvantagens | Estudar UML é sempre um jogo de perguntas e respostas para a profissão de desenvolvedor, por um ponto... | 0 | 2020-07-16T22:16:45 | https://dev.to/marcialwushu/uml-vantagens-e-desvantagens-4bnd | uml, braziliandevs | Estudar UML é sempre um jogo de perguntas e respostas para a profissão de desenvolvedor, por um ponto de vista, ela é uma estrutura padrão no ensino acadêmico superior e nos é mostrada como algo essencial e indispensável para a modelagem e arquitetura do software a ser desenhado, por outro ponto de vista, temos opiniõ... | marcialwushu |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.