
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,712,274 | Complete Object Oriented PHP & MVC 2024 | Welcome to our advanced PHP course on building a custom MVC framework called PHPAdvance!... | 0 | 2023-12-30T06:40:12 | https://dev.to/adeleyeayodeji/complete-object-oriented-php-mvc-2024-34bp | webdev, programming, tutorial, beginners | {% embed https://www.youtube.com/watch?v=Ym4500z9mow %}
Welcome to our advanced PHP course on building a custom MVC framework called PHPAdvance! Throughout this course, we will guide you through the step-by-step process of creating a lightweight MVC framework similar to Laravel but with a smaller footprint.
This open... | adeleyeayodeji |
1,712,298 | Guide to Unlimited Laser Cladding | What Is Laser Cladding? Laser metal deposition, commonly referred to as laser cladding, involves... | 0 | 2023-12-30T07:35:05 | https://dev.to/arhamgbob/guide-to-unlimited-laser-cladding-5c6e | machinelearning | **What Is Laser Cladding?**
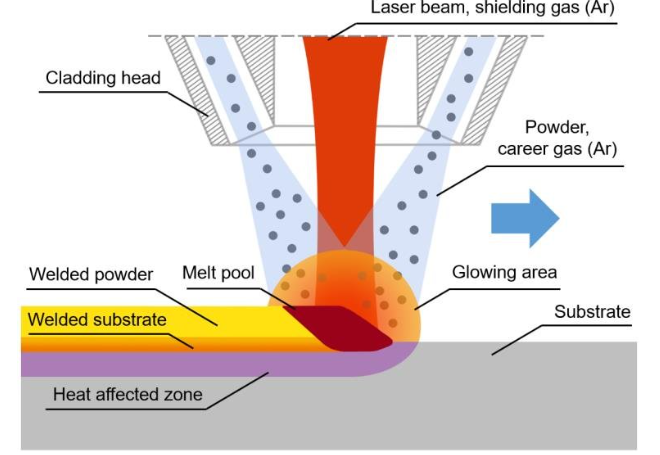
Laser metal deposition, commonly referred to as laser cladding, involves the deposition of one material onto another surface. This is achieved by introducing a metallic powder or wire int... | arhamgbob |
1,712,357 | Lights, Camera, Code: A Blockbuster Streaming Adventure with Golang and Kafka! | Welcome, movie buffs and code enthusiasts! Get ready for a cinematic experience as we embark on a... | 26,068 | 2023-12-30T10:11:57 | https://dev.to/akshitzatakia/lights-camera-code-a-blockbuster-streaming-adventure-with-golang-and-kafka-4562 | streaming, go, kafka, flink | Welcome, movie buffs and code enthusiasts! Get ready for a cinematic experience as we embark on a thrilling adventure into the world of Golang and Kafka. Picture this: a high-tech movie studio where messages flow like scenes in a blockbuster film. Buckle up, grab your popcorn, and let the streaming show begin!

- :file_folder: \MQL5\Scripts\
- :page_facing_up: [WinINet_Test.mq5](https://g... | rabist |
1,713,579 | Viral Paper Tested MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model | 🌟 Welcome to this comprehensive tutorial video where I guide you through the process of installing... | 0 | 2024-01-01T11:17:36 | https://dev.to/furkangozukara/viral-paper-tested-magicanimate-temporally-consistent-human-image-animation-using-diffusion-model-n9c | animation, stablediffusion, ai, animate | 🌟 Welcome to this comprehensive tutorial video where I guide you through the process of installing and using Magic Animate for Temporarily Consistent Human Image Animation using a Diffusion Model, along with other exciting tools like DensePose generator and CodeFormer face restore! 🌟
[MagicAnimate: Temporally Consis... | furkangozukara |
1,713,682 | Closure, Scope and lexical scope simplified | Introduction Kunle is a thief, he stole from Iya Basira jewellery store in Lagos and... | 0 | 2024-01-01T13:30:08 | https://dev.to/ozor/closure-scope-and-lexical-scope-simplified-ado |
## Introduction
Kunle is a thief, he stole from Iya Basira jewellery store in Lagos and managed to escape through the Seme border to Togo. The Nigerian police have been on his trail for some days now, and have gotten an intelligence report of his whereabouts, they traced him to Togo. The Nigerian police cannot enter ... | ozor | |
1,713,692 | Requested URL returned error: 403 | The image below shows a 403 error which means means credentials errors or forbidden (you don’t have... | 0 | 2024-01-01T13:46:58 | https://dev.to/shafia/requested-url-returned-error-403-1pfm | github, git, errors, 403 |
The image below shows a 403 error which means means credentials errors or forbidden (you don’t have permission to push).

## **Solution-1**
**Step-1:** Check if you are pushing the code to your repository
```
g... | shafia |
1,713,742 | Error: (e.g git pull..) before pushing again | The error below takes place when you edit your file directly from github as a result code in local... | 0 | 2024-01-01T14:28:34 | https://dev.to/shafia/error-eg-git-pull-before-pushing-again-kl3 | git, github, errors, gitpull |
The error below takes place when you edit your file directly from github as a result code in local file and file github file does not match.
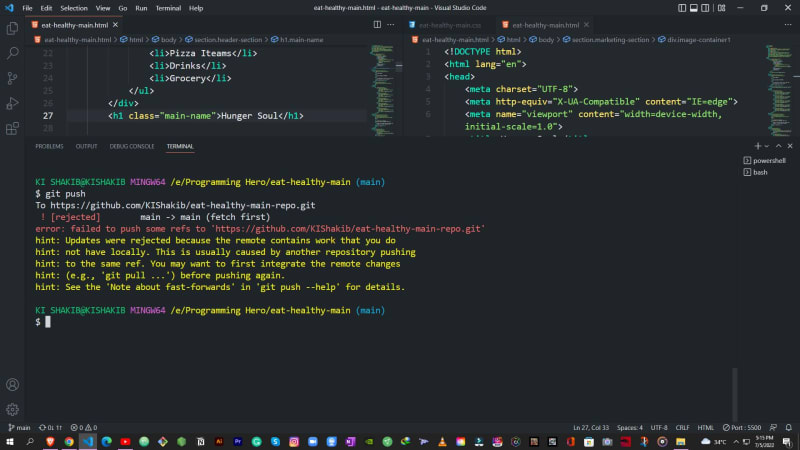
Go to your terminal again and run these commands
**<u>Solution-1</u>**
`... | shafia |
1,713,809 | Agility Accelerator: Scaling Your SaaS with Multi-Tenant Magic | In the realm of SaaS, agility is your golden chariot, propelling you towards growth and market... | 0 | 2024-01-01T16:01:27 | https://dev.to/marufhossain/agility-accelerator-scaling-your-saas-with-multi-tenant-magic-fbg | In the realm of SaaS, agility is your golden chariot, propelling you towards growth and market dominance. But scaling your platform with traditional methods can feel like navigating a labyrinth on a sluggish donkey – slow, cumbersome, and frustrating. Enter the multi-tenant cloud, a potent elixir that transforms your S... | marufhossain | |
1,713,925 | Send fluent bit collected logs to Seq | Here I will setup fluent-bit and seq both with docker and push logs through fluent bit to to seq. I... | 0 | 2024-01-02T20:26:23 | https://github.com/minhaz1217/devops-notes/tree/master/66.%20send%20fluent%20bit%20logs%20into%20seq | devops, fluentbit, seq, docker | Here I will setup fluent-bit and seq both with docker and push logs through fluent bit to to seq.
I will also show how to setup fluent bit and seq with docker.
## Setup a docker network for the containers
```
docker network create fluent-bit_seq
```
## Setting up Seq
At first setup a hashed password to be used
``... | minhaz1217 |
1,713,928 | Ellipsis in Python | As a Python developer, you may have come across the ellipsis (...) symbol and wondered what it means.... | 25,915 | 2024-01-05T14:00:00 | https://dev.to/julienawonga/ellipsis-in-python-fbd | As a Python developer, you may have come across the ellipsis (...) symbol and wondered what it means. In Python, an ellipsis is a built-in constant that represents a placeholder for code that you will add later. This constant is used in a variety of ways in Python, and in this article, we'll explore some of the common ... | julienawonga | |
1,714,092 | Scraping the full snippet from Google search result | Sometimes, you see truncated text on a Google search result like this (...) . Google doesn't always... | 0 | 2024-01-02T00:28:59 | https://serpapi.com/blog/scraping-the-full-snippet-from-google-search-result/ | webscraping, go | Sometimes, you see truncated text on a Google search result like this (...) . Google doesn't always display the meta description of a website. Sometimes, it gets a snippet of relevant text to the search query, which could truncate the text.

Hey DEV Community,
I hope this message finds you well! 👋
I'm excited to introduce you to Avataryug, a creative avatar design company dedicated to helping app developers like you enhance user experiences.
Why... | avataryug | |
1,714,402 | The Magic of Home Salon Services with Our Exclusive Salon at Home App | Welcome to a world where beauty meets convenience – a realm of glamour and relaxation brought... | 0 | 2024-01-02T07:37:06 | https://dev.to/swagmeesalon/the-magic-of-home-salon-services-with-our-exclusive-salon-at-home-app-39pk |

Welcome to a world where beauty meets convenience – a realm of glamour and relaxation brought directly to your doorstep. Our [salon at home app](https://play.google.com/store/apps/details?id=com.swagmee&pli=1) is no... | swagmeesalon | |
1,714,510 | 10 Tips for Designing and Developing Your Career Roadmap | Embarking on a successful career journey doesn't happen overnight; it requires careful planning,... | 0 | 2024-01-08T01:00:00 | https://quire.io/blog/p/design-career-roadmap.html | Embarking on a successful career journey doesn't happen overnight; it requires careful planning, strategic thinking, and a clear roadmap. Crafting your career path is a dynamic process that involves setting goals, navigating challenges, and staying adaptable to change.
In this blog post, we'll explore 10 essential tip... | brighty_miriam | |
1,743,432 | LangGraph Agents | LangGraph Agents pip install langchain langgraph langchain_openai langchainhub langsmith... | 0 | 2024-01-28T05:48:30 | https://dev.to/jhparmar/langgraph-agents-1jog | **LangGraph Agents**
pip install langchain langgraph
langchain_openai langchainhub langsmith duckduckgo-search beautifulsoup4 gradio
export OPENAI_API_KEY=xxxxxxxxxx
export LANGCHAIN_API_KEY=xxxxxxxxxx
import functools, operator, requests, os, json
from bs4 import BeautifulSoup
from duckduckgo_search import DDGS
... | jhparmar | |
1,714,537 | How to Create a 3D Game in Python and Swap Models (Pizza Toppings Tutorial) | This Python demo uses echo3D's 3D model streaming in combination with Panda3D, a framework for 3D... | 0 | 2024-01-02T10:10:40 | https://dev.to/echo3d/how-to-create-a-3d-game-in-python-and-swap-models-pizza-toppings-tutorial-576b | ai, python, programming, beginners | This Python demo uses [**echo3**D](http://www.echo3d.com)'s 3D model streaming in combination with [**Panda3D**](https://www.panda3d.org/), a framework for 3D rendering and game development in Python. Currently, any .obj or .glb model can be uploaded to the echo3D console and streamed into this app. The app allows you ... | _echo3d_ |
1,714,562 | Real-time Chat application under 5 minutes using NEXTJS and Socket.io | Real-time Chat application under 5 minutes using NEXTJS and Socket.io Let’s start... | 0 | 2024-01-05T16:16:10 | https://dev.to/sarathadhithya/real-time-chat-application-under-2-minutes-using-nextjs-and-socketio-2pj1 | socketio, chatapplication, nextjs, realtimechatapp | ---
title: Real-time Chat application under 5 minutes using NEXTJS and Socket.io
published: true
date: 2023-01-06 13:05:28 UTC
tags: socketio,chatapplication,nextjs,realtimechatapp
canonical_url:
---
## Real-time Chat application under 5 minutes using NEXTJS and Socket.io
### Let’s start the timer,
#### 1. First, ... | sarathadhithya |
1,714,688 | Using BioBERT and Qdrant to Power Semantic Search on Medical Q&A data | Navigating Complex Medical Datasets: Integrating BioBERT's NLP with Qdrant's Vector Database for... | 0 | 2024-01-02T12:57:00 | https://dev.to/shumashah/using-biobert-and-qdrant-to-power-semantic-search-on-medical-qa-data-3f0m | ai, machinelearning, vectordatabase, naturallanguageprocessing | Navigating Complex Medical Datasets: Integrating BioBERT's NLP with Qdrant's Vector Database for Enhanced Semantic Accuracy
 on Unsplash](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/povjx7y40qkuiyak7nxq... | shumashah |
1,714,813 | Unit Testing in NodeJS with Express, TypeScript, Jest and Supertest || Part Three: Writing Unit Tests || A Comprehensive Guide | Welcome back to the third installment of our series on building a powerful API with Node.js, Express,... | 0 | 2024-01-02T14:17:55 | https://dev.to/abeinevincent/unit-testing-in-nodejs-with-express-typescript-jest-part-three-writing-unit-tests-a-comprehensive-guide-3ipj | jest, node, express, unittest | Welcome back to the third installment of our series on building a powerful API with Node.js, Express, and MongoDB and writing unit tests for each line of code! In the previous 2 parts: [part one](https://dev.to/abeinevincent/unit-testing-in-nodejs-with-express-typescript-part-one-environment-setup-24a7) and [part two](... | abeinevincent |
1,714,947 | Rust Learning Note: async/await and Stream | This article is a summary of Chapter 4.11.4 of Rust Course (course.rs/) The Lifecycle of async If... | 25,784 | 2024-01-02T16:37:24 | https://raineyang.hashnode.dev/rust-learning-note-asyncawait-and-stream | rust, learning, asyncawait, stream | This article is a summary of Chapter 4.11.4 of Rust Course (course.rs/)
**The Lifecycle of async**
If an async function has reference type parameters, the parameter it refers to must life longer than the Future the function returns. For instance, the code below would throw an error since the variable x only lives ins... | raineyanguoft |
1,715,241 | Avoid Getting Stuck Inside of Your Garage - Garage Door Company in Pittsburgh, PA and Surrounding Areas | People ignore their garage door until it malfunctions. The largest moving object in your house, the... | 0 | 2024-01-02T21:06:52 | https://dev.to/liveyourblog1/avoid-getting-stuck-inside-of-your-garage-garage-door-company-in-pittsburgh-pa-and-surrounding-areas-k2e | news | People ignore their garage door until it malfunctions. The largest moving object in your house, the garage door, may be frightful if it's broken and won't open. Usually, when you need your garage door to function the most is when you discover that it has turned on you. The worst-case scenario is that your garage door w... | liveyourblog1 |
1,715,455 | Mastering Advanced Spring Data Specifications within Spring Data Repositories for Complex Queries in Spring Boot | Greetings, fellow developers! Today, we're delving into the intricate world of Spring Data... | 0 | 2024-01-05T19:00:00 | https://dev.to/dinaessam/mastering-advanced-spring-data-specifications-within-spring-data-repositories-for-complex-queries-in-spring-boot-28m7 | java, springboot | Greetings, fellow developers! Today, we're delving into the intricate world of Spring Data Specifications within the Spring Boot framework. Join us on this exploration as we uncover the prowess of Specifications in crafting advanced and complex queries within Spring Data Repositories. Let's dive deeper into the realm o... | dinaessam |
1,715,658 | Hello dev.to! | Hi! After signing up, I am excited to write my first blog post with the goal of enhancing my skills... | 0 | 2024-01-03T09:03:02 | https://dev.to/ruccess/hello-devto-428l | beginners, webdev | Hi!
After signing up, I am excited to write my first blog post with the goal of enhancing my skills as a developer.
dev.to에 처음으로 글 써본다... 맞는 블로그를 찾지 못해 정착하지 못한 나로서는 여긴 잘 맞을지 모르겠다 열심히 써보면 되지 않을까?
| ruccess |
1,715,699 | AI powered video summarizer with Amazon Bedrock and Anthropic’s Claude | At times, I find myself wanting to quickly get a summary of a video or capture the key points of a... | 0 | 2024-01-03T10:55:25 | https://levelup.gitconnected.com/ai-powered-video-summarizer-with-amazon-bedrock-and-anthropics-claude-9f1832f397dc | bedrock, claude, generativeai, serverless |  on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/6942/0*u1aoh6IkniSqBqg8)
At times, I find myself wanting to quickly get a summary of a video or capture the k... | zied |
1,715,742 | GIT Workflow | Terdapat empat metode yang saya ketahui dalam penggunaan Git, beberapa diantaranya adalah sebagai... | 0 | 2024-01-03T10:23:19 | https://dev.to/lanamaulanna/git-workflow-kda | Terdapat empat metode yang saya ketahui dalam penggunaan Git, beberapa diantaranya adalah sebagai berikut:
1. Centralized Workflow
2. Feature Branch Workflow
3. Gitflow Workflow
4. Forking Workflow
Ketika saya baru bergabung di perusahaan, alur kerja Git yang digunakan adalah Centralized Workflow. Selang beberapa bula... | lanamaulanna | |
1,715,837 | How to Pay Gas Fees for Users of Your dApp: Meta Transactions on Tezos | This tutorial introduces Meta transactions on Tezos and covers how to use the Gas Station API to... | 0 | 2024-01-03T12:06:20 | https://dev.to/debosthefirst/how-to-pay-gas-fees-for-users-of-your-dapp-meta-transactions-on-tezos-po5 | tezos, web3, gas, metatransactions | This tutorial introduces Meta transactions on Tezos and covers how to use the Gas Station API to cover gas fees for dApp users.
To onboard the next billion users on Web3, simplifying user onboarding and improving the user experience of dApps (decentralized applications) is extremely important.
 | alright as promised yesterday I’m going to try making the Random Number Generator HTML again today... | 0 | 2024-01-24T11:17:53 | https://dev.to/gregor_schafroth/daily-code-48-random-number-1-100-python-and-javascript-3-2oik | beginners, daily, javascript | alright as promised yesterday I’m going to try making the Random Number Generator HTML again today without looking up anything or using any ChatGPT. I already solved that for Python yesterday, so now it’s just JS left
# My Code
Tadaa! Turns out this time I was able to solve it fully on my own!
```html
<!DOCTYPE html... | gregor_schafroth |
1,740,053 | What Mr. Robot Teaches Us About Bugs | Sometimes, we act as if bugs just appear in our code by themselves, but we all know that's not true.... | 0 | 2024-01-24T12:04:41 | https://dev.to/rodri-oliveira-dev/what-mr-robot-teaches-us-about-bugs-3hnm | programming | Sometimes, we act as if bugs just appear in our code by themselves, but we all know that's not true. The errors in my code were written by me. I didn't mean to write them. I didn't want to write them. But I did anyway.
I remember when I first read Al Shalloway referring to a bug as 'code that he had written' and it st... | rodri-oliveira-dev |
1,740,060 | Why Flutter BLoC is Loved and Popular by the Developers? | 𝗦𝗲𝗽𝗮𝗿𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝗖𝗼𝗻𝗰𝗲𝗿𝗻𝘀: Flutter BLoC allows for the separation of business logic and UI. This means... | 0 | 2024-01-24T12:09:27 | https://dev.to/amrazzam31/why-flutter-bloc-is-loved-and-popular-by-the-developers-1632 | flutter, dart, bloc, statemanagement | - 𝗦𝗲𝗽𝗮𝗿𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝗖𝗼𝗻𝗰𝗲𝗿𝗻𝘀: Flutter BLoC allows for the separation of business logic and UI. This means that developers can focus on implementing the business logic in the BLoC without worrying about the UI, and vice versa.
- 𝗖𝗼𝗱𝗲 𝗥𝗲𝘂𝘀𝗮𝗯𝗶𝗹𝗶𝘁𝘆: With Flutter BLoC, developers can create r... | amrazzam31 |
1,744,216 | Is the DSA matter in Fullstack Development if yes how much ? | A post by Rsgcv | 0 | 2024-01-29T04:35:56 | https://dev.to/bhingarde8/is-the-dsa-matter-in-fullstack-development-if-yes-how-much--31d2 | bhingarde8 | ||
1,740,069 | Decoding Cryptocurrency and Navigating the Developer's Realm | In today's fast-paced financial landscape, the emergence of digital currency is beginning a new era,... | 0 | 2024-01-24T12:17:06 | https://dev.to/shridhargv/decoding-cryptocurrency-and-navigating-the-developers-realm-949 | cpp, cryptoappdevelopmentwithcpp, cryptocurrency, apirequest | In today's fast-paced financial landscape, the emergence of digital currency is beginning a new era, reshaping our understanding and utilization of money. Beyond the familiar names of Bitcoin and Ethereum, there are over 9,000 cryptocurrencies, each contributing to the evolving narrative of decentralized finance. But w... | shridhargv |
1,740,137 | Best Practices for Effective Software Testing in Agile Development | Introduction: In the fast-paced world of Agile development, where rapid iterations and continuous... | 0 | 2024-01-24T13:11:31 | https://dev.to/talenttinaapi/best-practices-for-effective-software-testing-in-agile-development-i7n | softwaretesting, testing, qaengineering, softwareqaengineering | **Introduction:**
In the fast-paced world of Agile development, where rapid iterations and continuous delivery are the norm, the role of Software Quality Assurance (QA) has become more critical than ever. Effective software testing is essential to ensure that the product meets both functional and non-functional require... | talenttinaapi |
1,740,183 | Unlocking the Potential of Containerization Tools in DevOps: A Comprehensive Guide | Introduction: In the ever-evolving realm of software sorcery, where the wizards of development and... | 0 | 2024-01-24T14:18:57 | https://dev.to/kingkunte_/exploring-containerization-tools-in-devops-3edk | devops, kubernetes, docker | **Introduction:**
In the ever-evolving realm of software sorcery, where the wizards of development and the alchemists of operations converge, there's a mystical art known as containerization. It's the secret potion, the magical key that unlocks the door to a world where applications dance seamlessly across different l... | kingkunte_ |
1,740,215 | NestJs 환경 설정, 2024-01-24 | cmd 또는 VScode 터미널에 입력(PowerShell 안됨) npm i -g @nestjs/cli Enter fullscreen mode ... | 0 | 2024-01-24T14:52:43 | https://dev.to/sunj/nestjs-hwangyeong-seoljeong-2024-01-24-50p0 | nestjs |
cmd 또는 VScode 터미널에 입력(PowerShell 안됨)
```
npm i -g @nestjs/cli
``` | sunj |
1,755,609 | The continued rise of Handheld Gaming | My very first handheld game was probably the ring toss game… But in all seriousness it was my... | 0 | 2024-02-08T14:19:39 | https://dev.to/deusinmachina/the-continued-rise-of-handheld-gaming-5hkf | gaming |

My very first handheld game was probably the ring toss game… But in all seriousness it was my fathers Game Boy in the late 90s. I distinctly remember playing Star Wars and I don’t think I ever beat it.
![Origi... | deusinmachina |
1,740,302 | Getting Started with TypeScript: A Comprehensive Guide | Introduction TypeScript is a superset of JavaScript that brings static typing to the... | 0 | 2024-01-29T08:21:35 | https://dev.to/jps27cse/getting-started-with-typescript-a-comprehensive-guide-1djm | typescript, react, webdev, javascript | ## Introduction
TypeScript is a superset of JavaScript that brings static typing to the language. Developed by Microsoft, it aims to enhance the development experience by catching errors during development rather than at runtime. TypeScript code is transpiled to JavaScript, making it compatible with all JavaScript env... | jps27cse |
1,740,320 | Hashes and Symbols | Codecademy Cheatsheet Ruby Symbols In Ruby, symbols are immutable names primarily used as hash keys... | 0 | 2024-01-24T17:28:34 | https://dev.to/aizatibraimova/hashes-and-symbols-p4m | _Codecademy Cheatsheet_
**Ruby Symbols**
In Ruby, _symbols_ are immutable names primarily used as hash keys or for referencing method names.
```
my_bologna = {
:first_name => "Oscar",
:second_name => "Meyer",
:slices => 12
}
puts my_bologna[:second_name] # => Meyer
```
<u>_Symbol Syntax_</u>
Symbols always s... | aizatibraimova | |
1,740,578 | Hosting your static website in S3 by leveraging cloudfront | S3 as a service can be linked from on-premise and other cloud services like Amazon Ec2 a computing... | 0 | 2024-01-27T17:48:13 | https://dev.to/gathungu/s3-breakdown-3koc | aws | S3 as a service can be linked from on-premise and other cloud services like Amazon Ec2 a computing services that allows to 'rent' servers in AWS. We will be hosting a static website in s3, this does not require compute
Before we setup the environment we need to understand that when adapting to cloud we should have a ... | gathungu |
1,740,652 | Enhancing CX: Building a DataMotion-Powered Message Center Widget for React (Part 1) | Introduction For any business, efficient and secure communication isn't just beneficial —... | 0 | 2024-03-01T15:18:31 | https://dev.to/janellephalon/enhancing-cx-building-a-datamotion-powered-message-center-widget-for-react-part-1-3nak | ## Introduction
For any business, efficient and secure communication isn't just beneficial — it's essential. In this guide, we're focusing on creating a widget that centralizes your message management, offering a clear view of your inbox within your dashboard. While today we're honing in on efficiently accessing messa... | janellephalon | |
1,740,762 | Boost Team Productivity with AI Presentation Maker for Meetings" | In the fast-paced world of business, effective communication is pivotal to success. One of the key... | 0 | 2024-01-25T04:38:17 | https://dev.to/team-meeting-presentation/boost-team-productivity-with-ai-presentation-maker-for-meetings-4g83 | teammeetingpresentati | In the fast-paced world of business, effective communication is pivotal to success. One of the key components of communication within a professional setting is the ability to deliver compelling presentations. Whether it's a sales pitch, a project update, or a strategic plan, presentations play a crucial role in conveyi... | team-meeting-presentation |
1,740,850 | Revolutionizing Sports with AI: A Deep Dive into Sports App Development | In the ever-evolving landscape of sports, technology has become a game-changer, and the integration... | 0 | 2024-01-25T06:43:40 | https://dev.to/sofiamurphy/revolutionizing-sports-with-ai-a-deep-dive-into-sports-app-development-4p29 | ai, app, sportappdevelopment | In the ever-evolving landscape of sports, technology has become a game-changer, and the integration of Artificial Intelligence (AI) into sports app development has marked a new era. As athletes strive for peak performance and fans demand immersive experiences, AI emerges as the catalyst for transforming the way we enga... | sofiamurphy |
1,740,945 | Keep AWS Costs down: 5 steps to start with on your infrastructure | Leveraging built-in tools like Cost Optimization Hub, Cost Explorer, Compute Optimizer and others. | 0 | 2024-01-25T08:53:29 | https://dev.to/mkdev/keep-aws-costs-down-5-steps-to-start-with-on-your-infrastructure-3ng6 | aws, costs, infrastructure | ---
title: Keep AWS Costs down: 5 steps to start with on your infrastructure
published: true
description: Leveraging built-in tools like Cost Optimization Hub, Cost Explorer, Compute Optimizer and others.
tags: aws, costs, infrastructure
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best re... | mkdev_me |
1,741,051 | AI on the Hunt: Revolutionizing the Recruiting Landscape | The world of recruitment is undergoing a seismic shift, with artificial intelligence (AI) emerging as... | 0 | 2024-01-25T11:13:46 | https://dev.to/airecruiter/ai-on-the-hunt-revolutionizing-the-recruiting-landscape-5cpj | The world of recruitment is undergoing a seismic shift, with artificial intelligence (AI) emerging as a game-changer. No longer relegated to science fiction, AI is rapidly transforming how we identify, attract, and hire top talent. But is this a robotic takeover of the HR department, or a powerful tool waiting to be ha... | airecruiter | |
1,741,133 | Desarrollo de un algoritmo anti-envenenamiento de sistemas de IA | He desarrollado CIBRAtool, una herramienta de #ciberseguridad aplicada a la #IA para evitar el... | 0 | 2024-01-25T11:58:54 | https://dev.to/gcjordi/desarrollo-de-un-algoritmo-anti-envenenamiento-de-sistemas-de-ia-4hl8 | cybersecurity, ai, robotics, computervision | He desarrollado **CIBRAtool**, una herramienta de #ciberseguridad aplicada a la #IA para evitar el envenenamiento de datasets de imágenes en entrenamiento o inferencia, aquí el artículo técnico explicativo:
---
## **Desarrollo de un sistema algoritmo avanzado anti-envenenamiento de sistemas de IA centrados en la visi... | gcjordi |
1,741,409 | From Novice to Pro in 14 Days: My Journey to AWS MLOps Certification | Introduction In the dynamic world of cloud computing and machine learning, integrating ML... | 0 | 2024-01-25T16:39:08 | https://dev.to/devopsadventurer/from-novice-to-pro-in-14-days-my-journey-to-aws-mlops-certification-3ca | aws, beginners, devops, learning | ###**Introduction**
In the dynamic world of cloud computing and machine learning, integrating ML into operational processes is increasingly crucial. The AWS MLOps certification is a benchmark of excellence for professionals at all levels in DevOps and ML. My journey to earning this certification in a mere 14 days was ... | devopsadventurer |
1,741,448 | 10 essential tools if you are a web developer | 1.CSS Gradient A simple tool to visualize gradients and generate CSS for them. 2.JSON Placeholder A... | 0 | 2024-01-25T17:33:29 | https://dev.to/dev_abdulhaseeb/10-essential-tools-if-you-are-a-web-developer-9pm | webdev, javascript, beginners, programming | 1.CSS Gradient
A simple tool to visualize gradients and generate CSS for them.
2.JSON Placeholder
A JSON API to return dummy data
3. Color Contrast Checker
Check contrast ratio between foreground and background colors.
4.Better PLaceholder
API to return placeholder images
5.Can I USe
Check how well a particular web... | dev_abdulhaseeb |
1,741,456 | Aggregation Pipeline in MongoDB and the use of $match and $group operator (Part 2) | Hello and welcome back readers, sorry for the delay in this second part of the MongoDB Aggregation... | 0 | 2024-01-25T17:54:54 | https://dev.to/ganeshyadav3142/aggregation-pipeline-in-mongodb-and-the-use-of-match-and-group-operator-part-2-18gg | webdev, mongodb, beginners, javascript | Hello and welcome back readers, sorry for the delay in this second part of the MongoDB Aggregation Pipeline series, where we are going to explore the power of the Aggregation Pipeline provided by MongoDB to make a developer's life easy.
If you are new to this article, I would like you to check the first part of the se... | ganeshyadav3142 |
1,741,556 | (Part 2/2) FullStory Digital Analytics: Convert Results of Analysis to Product Requirements | In this podcast, Krish explores the process of digital analysis and how to take the analysis forward.... | 0 | 2024-01-25T21:10:33 | https://dev.to/vpalania/part-22-fullstory-digital-analytics-convert-results-of-analysis-to-product-requirements-3oa | In this podcast, Krish explores the process of digital analysis and how to take the analysis forward. He discusses different approaches to analyzing product usage, including general product usage analysis, client-specific product usage analysis, feature-specific product usage analysis, ad hoc analysis, and usage patter... | vpalania | |
1,741,788 | I built a task management and to-do list app for your goals | I built a task management and to-do list app that helps you prioritize your tasks toward your goals.... | 0 | 2024-01-26T04:00:25 | https://dev.to/tanhenggek/i-built-a-task-management-and-to-do-list-app-that-helps-you-prioritize-your-tasks-toward-your-goals-33co | productivity | I built a task management and to-do list app that helps you prioritize your tasks toward your goals.
It helps me focus on what matters and make conscious decision in my daily tasks. I hope it’s useful to you too. It’s currently in V1. I will add more features and integrations in the coming weeks.
You might want to g... | tanhenggek |
1,741,838 | winvnbz | WinVN – Dia diem nha cai hap dan voi da dang cac the loai ca cuoc game bai slot game cuoc the thao ma... | 0 | 2024-01-26T06:05:47 | https://dev.to/winvnbz/winvnbz-243p | WinVN – Dia diem nha cai hap dan voi da dang cac the loai ca cuoc game bai slot game cuoc the thao ma dam bao se dap ung nhung nhu cau giai tri cua ho
Dia Chi: 83A Nguyen Thai Son Phuong 4 Go Vap Thanh pho Ho Chi Minh Viet Nam
Email: winvnbz@gmail.com
Website: https://winvn.bz
Dien Thoai: (+63 ) 9628363765
#winvn #nhac... | winvnbz | |
1,741,930 | Tips To Optimize Your Website For Better Performance | 🚀 Unlock Peak Performance for Your Website! 🌐💻 In the digital landscape, a high-performing website... | 0 | 2024-01-26T08:45:19 | https://dev.to/eddieadams/tips-to-optimize-your-website-for-better-performance-a81 | seo, design, javascript, webdev | 🚀 Unlock Peak Performance for Your Website! 🌐💻
In the digital landscape, a high-performing website is key to success. Here are some tips to optimize your site for better performance and user satisfaction. 🌟🔧
**🚀 Key Optimization Tips:**
**💨 Page Loading Speed:** Optimize images, leverage browser caching, and ... | eddieadams |
1,742,008 | Celebrating Data Privacy International Day! | The National Cybersecurity Alliance (NCA) has themed Data Privacy Day 2024 as "Take Control of Your... | 0 | 2024-01-28T14:26:51 | https://dev.to/cnatsopoulou/celebrating-data-privacy-international-day-11o5 | cybersecurity, security, data, privacy | _The [National Cybersecurity Alliance](https://staysafeonline.org/) (NCA) has themed Data Privacy Day 2024 as "Take Control of Your Data"._
As we commemorate Data Privacy Day, a global initiative dedicated to raising awareness about the importance of safeguarding private information, we recognize the increasing need f... | cnatsopoulou |
1,742,137 | ABEND dump #8 | Welcome to the ABEND dump, the issue where I share the most interesting content I’ve been reading,... | 19,725 | 2024-01-26T13:57:43 | https://bitmaybewise.substack.com/p/abend-dump-8 | news, programming | Welcome to the ABEND dump, the issue where I share the most interesting content I’ve been reading, listening to, and watching lately.
Want to check the previous issue? Read it here:
{% embed https://dev.to/bitmaybewise/abend-dump-7-4ine %}
---
## [Write Like You Talk](https://www.paulgraham.com/talk.html)
> Here'... | bitmaybewise |
1,742,177 | Creating a Countdown Timer with Vue.js | Service Level Agreements (SLAs) often come with strict timelines, and having a visual representation... | 0 | 2024-01-27T10:46:56 | https://dev.to/ayowandeapp/creating-a-countdown-timer-with-vuejs-21nm | javascript, tutorial, vue, beginners | Service Level Agreements (SLAs) often come with strict timelines, and having a visual representation of the time remaining can be crucial. In this post, we'll explore how to implement a countdown timer in Vue.js to display the remaining time for SLAs.
**Step 1: Set Up Your Vue Component**
```
<template>
<div>
<... | ayowandeapp |
1,742,180 | Simplifying API Calls with Refit in ASP.NET Core | Refit is a library in ASP.NET Core that simplifies the process of making HTTP requests to RESTful... | 0 | 2024-01-26T15:13:31 | https://dev.to/mohammadkarimi/simplifying-api-calls-with-refit-in-aspnet-core-f6 | dotnet, refit, aspdotnet, dotnetcore | Refit is a library in ASP.NET Core that simplifies the process of making HTTP requests to RESTful APIs. It allows you to define your API interfaces as C# interfaces and then use them as if they were local methods. This makes it easier to work with APIs in a type-safe manner. Here's a guide to help you get started on wr... | mohammadkarimi |
1,742,261 | Kotlin Design Patterns: Simplifying the Traditional Solutions (plus: Simplifying the Singleton Pattern) | Kotlin Design Patterns: Simplifying the Singleton Pattern The Singleton pattern is a... | 26,674 | 2024-01-26T17:06:07 | https://fugisawa.com/kotlin-design-patterns-simplifying-the-traditional-solutions-plus-simplifying-the-singleton-pattern/ | kotlin, backend, designpatterns, java | ## Kotlin Design Patterns: Simplifying the Singleton Pattern
The Singleton pattern is a design pattern that ensures a class has only one instance, while providing a global point of access to it. This pattern is used when exactly one object is needed to coordinate actions across the system.
This is useful in scenarios... | lucasfugisawa |
1,742,571 | ChatCraft Adventures #3 | This week I've been getting more involved in ChatCraft's development. This is what I've done so... | 26,549 | 2024-01-27T03:57:00 | https://dev.to/rjwignar/chatcraft-adventures-3-4lng | This week I've been getting more involved in ChatCraft's development.
This is what I've done so far.
## How I've been using ChatCraft
To identify improvements or potential new features for ChatCraft I've been playing around with ChatCraft. Sometimes I ask ChatCraft to generate random code, but I've also found it help... | rjwignar | |
1,742,657 | Choosing the Right Gazebo Design: | Choosing the right gazeboconstruction design involves considering various factors, including your... | 0 | 2024-01-27T04:53:23 | https://dev.to/kaali33/choosing-the-right-gazebo-design-4j6k | Choosing the right[ gazeboconstruction](http://gazeboconstructions.com/) design involves considering various factors, including your personal preferences, the surrounding landscape, intended use, and the architectural style of your home. Here are some key considerations to help you select the ideal gazebo design:
Purp... | kaali33 | |
1,742,677 | How Facebook Keeps Millions of Servers Synced 🕰️⏰ | If youre running a distributed system, its incredibly important to keep the system clocks of the... | 0 | 2024-01-27T05:34:28 | https://devangtomar.hashnode.dev/how-facebook-keeps-millions-of-servers-synced-efb88f-6d6ebd519963 | facebook, softwaredesign, architecture, systemdesign | ---
title: How Facebook Keeps Millions of Servers Synced 🕰️⏰
published: true
date: 2024-01-26 05:31:44 UTC
tags: facebook, softwaredesign, architecture, systemdesign
canonical_url: https://devangtomar.hashnode.dev/how-facebook-keeps-millions-of-servers-synced-efb88f-6d6ebd519963
---
If youre running a distributed sys... | devangtomar |
1,742,788 | Sheikh Zayed Road Dubai | The neighborhood along Sheikh Zayed Road Dubai has been renamed after the Burj Khalifa, Dubai Road... | 0 | 2024-01-27T09:10:30 | https://dev.to/dubaigpt/sheikh-zayed-road-dubai-267l | The neighborhood along [Sheikh Zayed Road Dubai](https://blog.dubaigpt.com/sheikh-zayed-road-dubai-28-neighbourhoods-renamed/
) has been renamed after the Burj Khalifa, Dubai Road Naming Committee, a novel approach to road naming is unfolding. | dubaigpt | |
1,742,797 | Buy Commercial Kitchen Equipment Online | Bakery & Catering equipment | Buy online commercial kitchen equipment for bakery, catering, cloud kitchen and restaurants. Ovens,... | 0 | 2024-01-27T09:38:59 | https://dev.to/akashroy/buy-commercial-kitchen-equipment-online-bakery-catering-equipment-4ija | kitchen, bakerymachiene, commercialkitchenequipment |

Buy online **[commercial kitchen equipment](https://restolane.com/)** for bakery, catering, cloud kitchen and restaurants. Ovens, mixers, slicers, fryers, grillers and more.
As a company, Restolane is dedicated to... | akashroy |
1,742,819 | Develop Your Next Mobile App with React Native | Are you looking to develop your next mobile app? Look no further than React. With React, you can... | 0 | 2024-01-27T10:32:37 | https://dev.to/dotpotit/develop-your-next-mobile-app-with-react-native-4i1p | appdevelopment, webdev, react, reactnative |
Are you looking to develop your next mobile app? Look no further than React. With React, you can create dynamic and interactive applications that run seamlessly across devices. Its component-based architecture and virtual DOM make it a powerful and efficient tool for building user interfaces.
Advantages of Using R... | dotpotit |
1,742,915 | Best Body Massager Machine India | In the hustle and bustle of modern life, stress and tension often find a home in our bodies. A good... | 0 | 2024-01-27T12:55:56 | https://dev.to/annat/best-body-massager-machine-india-9da | In the hustle and bustle of modern life, stress and tension often find a home in our bodies. A good body massager can be the key to unlocking relaxation and relieving muscle fatigue. Whether you're seeking relief from a long day at work or looking to enhance your overall well-being, we present a guide to the best body ... | annat | |
1,742,916 | Query Performance - Data Masking | Note: This is Problem Statement Solution Introduction This case study revolves around... | 0 | 2024-02-06T05:38:34 | https://dev.to/lokesh-g/query-performance-data-masking-3aj | anonymize, datamasking, database, dataswapping | > **Note: This is Problem Statement Solution**
## Introduction
This case study revolves around the optimization of an anonymization process for a large database within our system. The original script was observed to be significantly time-consuming, taking approximately **22+** **hours** to execute on larger databases... | lokesh-g |
1,742,931 | Why Javascript has to be slower than C++ | The primary reason is that javascript is an interpreted language Interpreted vs Compiled... | 0 | 2024-01-27T13:17:03 | https://dev.to/codeparrot/why-javascript-has-to-be-slower-than-c-4inj | javascript, programming, performance, webdev | The primary reason is that javascript is an interpreted language
## Interpreted vs Compiled languages
JavaScript is an interpreted language, meaning the code is executed line-by-line by an interpreter at runtime. In contrast, C++ is a compiled language, where the source code is translated into machine code before exe... | royaljain |
1,742,954 | Brushing Up on Linear Regression in Python: Theory to Practice | Having completed an extensive machine learning course, I've noticed that my memory of the material is... | 0 | 2024-02-01T11:23:59 | https://dev.to/esakik/re-learn-linear-regression-in-python-from-theory-to-practice-277m | machinelearning, python, ai, datascience | Having completed an extensive machine learning course, I've noticed that my memory of the material is starting to diminish. To address this, I've made the decision to write a series of articles.
## Introduction
Assuming the x-axis represents age and the y-axis indicates income, it appears possible to somehow express ... | esakik |
1,742,999 | AI-Powered Snapchat Stories: Convert Instagram Videos with Ease | In the realm of social media, the seamless transition of content across platforms is crucial for... | 0 | 2024-01-27T15:29:14 | https://dev.to/instagram-to-snapchat/ai-powered-snapchat-stories-convert-instagram-videos-with-ease-4i74 | webdev, javascript, beginners, programming | In the realm of social media, the seamless transition of content across platforms is crucial for maintaining a strong online presence. Simplified Clips introduces an innovative solution for content creators: the AI-Powered Snapchat Stories feature. This tool facilitates the effortless conversion of Instagram videos to ... | instagram-to-snapchat |
1,743,110 | Conversational Excellence: Unleashing the Power of AI Chatbots with Consultopia.ai | In the dynamic landscape of digital communication, the emergence of AI chatbots has revolutionized... | 0 | 2024-01-27T18:02:33 | https://dev.to/janzaib121/conversational-excellence-unleashing-the-power-of-ai-chatbots-with-consultopiaai-1d6f | ai | In the dynamic landscape of digital communication, the emergence of AI chatbots has revolutionized the way businesses interact with their audience. At the forefront of this transformative wave is Consultopia.ai, a company dedicated to elevating conversational experiences through cutting-edge AI technology. This article... | janzaib121 |
1,743,118 | Recent Fossil Findings Reveal a Pivotal Chapter in Evolution | In the epic tale of Earth's evolution, researchers from Curtin University have unearthed a... | 0 | 2024-01-27T18:16:53 | https://dev.to/lilyanakarim/recent-fossil-findings-reveal-a-pivotal-chapter-in-evolution-20mb | In the epic tale of Earth's evolution, researchers from Curtin University have unearthed a captivating chapter, delving into the mysteries of [ancient multicellular fossils](https://hubtales.com/2024/01/16/journey-through-time-recent-fossil-findings-reveal-a-pivotal-chapter-in-evolution/
) dating back an astonishing 56... | lilyanakarim | |
1,743,176 | 7 | Sure, I can help you understand these codes. They are written in JavaScript, a programming language... | 0 | 2024-01-27T19:23:35 | https://dev.to/pooyaalamdari/7-22fp | Sure, I can help you understand these codes. They are written in **JavaScript**, a programming language that can run on both the browser and the server. These codes are part of a web application that uses **Express.js**, a framework that simplifies Node.js web server APIs and adds new features¹²³.
Let me explain each ... | pooyaalamdari | |
1,743,195 | Can spring boot be used for front end rendering as well ? | Everyone knows that Spring boot might be the most popular framework to build powerful backend... | 0 | 2024-01-27T20:29:47 | https://dev.to/engineeringexpert/can-spring-boot-be-used-for-front-end-rendering-as-well--47lk | ai, llm | Everyone knows that Spring boot might be the most popular framework to build powerful backend services. However can it be also used for front ends ?
The short answer appears to be yes.
[Spring boot can be used for front ends but its key strength is backend development](https://www.frontendeng.dev/blog/35-spring-boot... | engineeringexpert |
1,743,201 | Como eu criei um servidor de PalWorld na AWS com start por bot no Discord — Parte 2 | Na primeira parte, ensinei como criar uma máquina virtual na AWS e instalar um servidor de Palworld.... | 0 | 2024-01-27T20:50:05 | https://dev.to/andarilhoz/como-eu-criei-um-servidor-de-palworld-na-aws-com-start-por-bot-no-discord-parte-2-7ce | programming, devops, aws, gamedev | Na primeira parte, ensinei como criar uma máquina virtual na AWS e instalar um servidor de Palworld. Porém, ainda precisamos resolver a questão da máquina ficar ligada o tempo todo, uma forma de permitir que qualquer pessoa inicie o servidor a partir do Discord e também ter acesso ao IP do server.
## Desligando a máqu... | andarilhoz |
1,743,264 | Getting Started with Natural Language Toolkit (NLTK) | Introduction NLTK (Natural Language Toolkit), one of the most popular libraries in Python... | 0 | 2024-01-27T22:22:19 | https://dev.to/mahmoudrasmyfathy1/getting-started-with-natural-language-toolkit-nltk-3eok | nlp, llm | # Introduction
NLTK (Natural Language Toolkit), one of the most popular libraries in Python for working with human language data (i.e., text). This tutorial will guide you through the installation process, basic concepts, and some key functionalities of NLTK.
> [Link for the Notebook](https://github.com/mahmoudrasmyf... | mahmoudrasmyfathy1 |
1,743,271 | Speech-to-Text Discord bot written in Go | As part of my personal journey to learn Go, I've decided to rewrite one of my open source projects in... | 0 | 2024-01-27T22:42:16 | https://dev.to/codr/speech-to-text-discord-bot-written-in-go-eih | go, discord, ai, productivity | As part of my personal journey to learn Go, I've decided to rewrite one of my open source projects in GoLang.
The project is a standalone (offline) speech-to-text bot for Discord. Basically it transcribes everything you say in a voice channel. This is useful if you want to have custom voice commands (eg. while gaming)... | codr |
1,743,364 | How To Customize WordPress Website? | I started a new blog site created on WordPress. Now website customization is difficult to me like... | 0 | 2024-01-28T03:20:46 | https://dev.to/jenni007/how-to-customize-wordpress-website-1ng5 | webdev, themes, wordpress, tutorial | I started a new blog site created on WordPress. Now website customization is difficult to me like themes, customize themes and more and I do not know how to do it. Anyone here or give me suggestions "How Can I customize my theme?". My website is [apkworldx](www.apkworldx.com) you can check it and give me suggestions. | jenni007 |
1,743,454 | Crew AI Travel Agents | Crew AI Travel Agents git clone https://github.com/joaomdmoura/crewAI-examples cd crewAI-examples cd... | 0 | 2024-01-28T06:23:01 | https://dev.to/jhparmar/crew-ai-travel-agents-8dl | **Crew AI Travel Agents**
git clone https://github.com/joaomdmoura/crewAI-examples
cd crewAI-examples
cd trip_planner
conda create -n crewai python=3.11 -y
conda activate crewai
pip install poetry platformdirs
poetry install --no-root
poetry run python main.py | jhparmar | |
1,743,479 | RAG with ChromaDB + Llama Index + Ollama + CSV | *RAG with ChromaDB + Llama Index + Ollama + CSV * curl https://ollama.ai/install.sh | sh ollama... | 0 | 2024-01-28T07:23:20 | https://dev.to/jhparmar/rag-with-chromadb-llama-index-ollama-csv-23f7 | **RAG with ChromaDB + Llama Index + Ollama + CSV **
curl https://ollama.ai/install.sh | sh
ollama serve
ollama run mixtral
pip install llama-index torch transformers chromadb
Section 1:
# Import modules
from llama_index.llms import Ollama
from pathlib import Path
import chromadb
from llama_index import VectorStore... | jhparmar | |
1,743,495 | Matching Any character (Using the dot (.))| Regular Expressions for the Absolute Beginner | In this video, we look at how we can match every single character within text. we achieve this by... | 0 | 2024-01-28T07:48:17 | https://dev.to/jod35/matching-any-character-using-the-dot-regular-expressions-for-the-absolute-beginner-3pae | regex, programming, tutorial, basics | In this video, we look at how we can match every single character within text. we achieve this by using the dot character. The dot (.) allows us to construct regular expressions that match only a single character. In regular expressions, the dot (.) matches any single character except for a new line. It's like a wildc... | jod35 |
1,743,507 | Unlocking Data Analysis Efficiency: A Guide to PivotTables and Data Cleaning Functions | In the dynamic world of data analysis, mastering tools like PivotTables and data cleaning functions... | 0 | 2024-01-28T08:12:17 | https://dev.to/tinapyp/unlocking-data-analysis-efficiency-a-guide-to-pivottables-and-data-cleaning-functions-40f8 | tutorial, data, analytics | In the dynamic world of data analysis, mastering tools like PivotTables and data cleaning functions is crucial for deriving meaningful insights from your datasets. Whether you're a seasoned analyst or just stepping into the world of data, understanding how to leverage these tools can significantly enhance your efficien... | tinapyp |
1,761,789 | 6 Best Tubi Tv Alternatives 2024 | In the realm of free streaming services, Tubi stands as a popular choice for entertainment... | 0 | 2024-02-15T04:29:09 | https://dev.to/siddiquelab/6-best-tubi-tv-alternatives-2024-3kf | tubitv, softcodeon, alternratives, webdev | In the realm of free streaming services, Tubi stands as a popular choice for entertainment enthusiasts. However, if you're looking to expand your horizons and explore other options beyond Tubi, there are several noteworthy alternatives available. Let's delve into six of the best alternatives that offer compelling featu... | siddiquelab |
1,743,594 | Memory leak detection in modern frontend app | One of the challenges when building a single-page application (SPA) like dev.to or an app where users... | 0 | 2024-01-28T11:32:58 | https://dev.to/shcheglov/graphql-non-standard-way-of-selecting-a-client-library-5bid | javascript, react, performance | One of the challenges when building a single-page application (SPA) like dev.to or an app where users have standart session more than **10 minutes**, is testing for memory leaks at a large scale. Manual testing, finding and analyzing memory leaks can be time-consuming and inefficient, especially when there are a large ... | shcheglov |
1,743,595 | Tracking redirects on Cloudflare with Google Analytics | I recently came across this interesting problem of wanting to track URL redirects with Google... | 0 | 2024-01-28T11:59:32 | https://dev.to/allentv/tracking-redirects-on-cloudflare-with-google-analytics-3bfi | webdev, cloudcomputing, analytics, edgecomputing | I recently came across this interesting problem of wanting to track URL redirects with Google Analytics on Cloudflare and it got me spending some time into investigating how things work and a potential solution.
Before I explain my solution, let me provide some context on the problem. I am working on a side project th... | allentv |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.