
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,508,799 | Website design among different industries | At our Design Agency Design Agentur Form und Zeichen in Graz, we specialize in creating beautiful... | 0 | 2023-06-18T22:34:25 | https://dev.to/christofkarisch/website-design-among-different-industries-5eoi | design, webdev | At our Design Agency [Design Agentur Form und Zeichen in Graz](https://www.formundzeichen.at/), we specialize in creating beautiful websites that are tailored to each industry. In this article, we will showcase some of our client's websites, highlighting the design concepts behind them. Join us as we explore the inspir... | christofkarisch |
1,509,169 | Weekly Roundup 009 (Jun 12) - 🔥Hot Topics🔥 in workplace, sharepoint, and powerplatform | Hey fellow developers! It's @jaloplo, here to give you the latest scoop on what's been happening in... | 22,696 | 2023-06-19T07:49:36 | https://dev.to/jaloplo/weekly-roundup-jun-12-hot-topics-in-workplace-sharepoint-and-powerplatform-4d1d | roundup, workplace, sharepoint, powerplatform | Hey fellow developers! It's @jaloplo, here to give you the latest scoop on what's been happening in the [#workplace](https://dev.to/t/workplace), [#sharepoint](https://dev.to/t/sharepoint), and [#powerplatform](https://dev.to/t/powerplatform) communities. 😎
## [#workplace](https://dev.to/t/workplace)
- [Promising Fu... | jaloplo |
1,510,374 | 🚀 API Maker - i18n Internationalization | ⭐ List of Features ⭐ ✅ Support multiple languages ▸ Internationalization enables you to... | 0 | 2023-10-23T03:31:45 | https://dev.to/apimaker/api-maker-i18n-internationalization-10c0 | ##⭐ List of Features ⭐
✅ Support multiple languages
▸ Internationalization enables you to receive error or response messages in different languages from the API Maker.
✅ x-am-internationalization
▸ To receive a response or error message in a specific language, you have to set the **x-am-internationalization** value... | apimaker | |
1,510,409 | How to Build a Fancy Testimonial Slider with Tailwind CSS and Vue | Live Demo / Download -- Welcome to the third and final part of our series on How to Build... | 23,454 | 2023-06-20T09:01:25 | https://cruip.com/how-to-build-a-fancy-testimonial-slider-with-tailwind-css-and-vue/ | tailwindcss, vue, tutorial, webdev | ####**[Live Demo](https://cruip-tutorials-vue.vercel.app/fancy-testimonials-slider) / [Download](https://github.com/cruip/cruip-tutorials-vue/blob/main/src/components/FancyTestimonialsSlider.vue)**
--
Welcome to the third and final part of our series on **How to Build a Fancy Testimonial Slider with Tailwind CSS**! T... | cruip_com |
1,510,736 | Typescript 5.2 - Using | TypeScript 5.2 is set to introduce a new keyword called 'using', which allows you to dispose of... | 0 | 2023-06-20T12:46:19 | https://dev.to/lingfei1999/typescript-52-using-1o0d | typescript, webdev |
TypeScript 5.2 is set to introduce a new keyword called 'using', which allows you to dispose of resources with a Symbol.dispose function when they go out of scope.
Here's an example of how it works:
```typescript
{
const getResource = () => {
return {
[Symbol.dispose]: () => {
con... | lingfei1999 |
1,510,768 | 50 ChatGPT Prompts for Developers | As you embark on your coding journey armed with these top ChatGPT prompts for developers, remember... | 0 | 2023-06-20T13:33:23 | https://dev.to/mursalfk/50-chatgpt-prompts-for-developers-4bp6 | developer, chatgpt, programming, cheatsheet | As you embark on your coding journey armed with these top ChatGPT prompts for developers, remember that the true magic lies in your creativity and determination. Coding is not just about writing lines of code; it's about solving problems, building solutions, and creating something meaningful. Embrace the challenges, le... | mursalfk |
1,511,355 | Excited to start my Coding Journey! | A post by Jesse Navarette | 0 | 2023-06-21T00:44:09 | https://dev.to/jesse_navarette_b4e40b75b/excited-to-start-my-coding-journey-1lh2 | jesse_navarette_b4e40b75b | ||
1,511,716 | 🚀 API Maker - Git Integration | 👉 Developer accounts ⭐ List of Feature ⭐ ✅ N-number of developer accounts ▸ API Maker... | 0 | 2023-10-20T04:06:52 | https://dev.to/apimaker/api-maker-git-integration-222p | javascript, webdev | ## 👉 Developer accounts
⭐ List of Feature ⭐
✅ N-number of developer accounts
▸ API Maker admin can create multiple developer account, without any limit.
▸ Enables multiple developers to collaborate on a common project with their own accounts.
▸ Each developer account has login credentials with different API paths... | apimaker |
1,511,798 | How Odin AI Helps Employees To Boost Productivity and Time Efficiency | Odin AI | In today’s fast-paced working environment, employees are constantly looking for ways to improve their... | 0 | 2023-06-21T11:02:24 | https://dev.to/getodinai/how-odin-ai-helps-employees-to-boost-productivity-and-time-efficiency-odin-ai-17hf | workplace, programming, promptengineering, ai | In today’s fast-paced working environment, employees are constantly looking for ways to improve their productivity and time efficiency. With Odin AI, an advanced conversational AI tool, achieving these goals has become easier than ever before. In this article, we will discuss the 7 ways in which Odin AI gets the job do... | getodinai |
1,512,380 | AI: how to include AI in software projects | Artificial intelligence is now within everyone's reach. You don't need to be an expert in data... | 0 | 2023-06-21T20:12:37 | https://dev.to/eleonorarocchi/ai-how-to-include-ai-in-software-projects-2ep0 | ai, azure, aws, googlecloud | Artificial intelligence is now within everyone's reach. You don't need to be an expert in data analytics or machine learning to exploit its potential in software projects.
##In which areas to use AI in my software projects.
- Speech Recognition to convert audio into text and to transcribe conversations or voice comma... | eleonorarocchi |
1,512,416 | Data Drift: Understanding and Detecting Changes in Data Distribution | What is Data Drift? Data drift refers to the distributional change between the data used... | 0 | 2023-06-21T20:21:38 | https://dev.to/elldora/data-drift-understanding-and-detecting-changes-in-data-distribution-ne | machinelearning, datadrift, distribution, largedataset | ## What is Data Drift?
`Data drift` refers to the `distributional change` between the data used for training model and the data being send to deployed model. One of the important approaches in machine learning modeling is the **probabilistic modeling**.
> _From **Probabilistic Machine Learning** perspective, we can a... | elldora |
1,512,470 | GPT Engineer: A Generative Pre-trained Transformer for Software Engineering | GPT Engineer: A Generative Pre-trained Transformer for Software Engineering GPT Engineer is a... | 0 | 2023-06-21T21:23:23 | https://dev.to/stackfoss/gpt-engineer-a-generative-pre-trained-transformer-for-software-engineering-17o | opensource, news, stackfoss, chatgpt | ---
title: GPT Engineer: A Generative Pre-trained Transformer for Software Engineering
published: true
date: 2023-06-14 14:18:09 UTC
tags: opensource, news, Stackfoss, Chatgpt
canonical_url:
---
**GPT Engineer: A Generative Pre-trained Transformer for Software Engineering**
GPT Engineer is a generative pre-trained ... | stackfoss |
1,512,966 | Patients With a Condition | LeetCode | MSSQL | The Problem We're given a table called Patients: Column... | 20,410 | 2023-06-28T17:29:00 | https://dev.to/ranggakd/patients-with-a-condition-leetcode-mssql-4lnc | beginners, programming, leetcode, mssql | ## The Problem
We're given a table called `Patients`:
| Column Name | Type |
|--------------|---------|
| patient_id | int |
| patient_name | varchar |
| conditions | varchar |
The `patient_id` is the primary key for this table. The `conditions` field contains zero or more codes separated by spaces. The t... | ranggakd |
1,513,090 | Title: Ehsaas Program: Nurturing Empathy and Social Welfare | Introduction: In a world where poverty and inequality persist as pressing challenges, the Ehsaas... | 0 | 2023-06-22T11:42:35 | https://dev.to/cnfgh547567/title-ehsaas-program-nurturing-empathy-and-social-welfare-4mgi |
Introduction:
In a world where poverty and inequality persist as pressing challenges, the Ehsaas program emerges as a beacon of hope and compassion. Developed with the aim of alleviating poverty and fostering social welfare, Ehsaas stands as a unique initiative that embraces the values of empathy, inclusivity, and hu... | cnfgh547567 | |
1,513,098 | 🚀 API Maker - Auto Increment | ⭐ List of Feature ⭐ ✅ Inbuilt increment ▸ Some databases, such as MongoDB, do not support... | 0 | 2023-10-25T03:24:26 | https://dev.to/apimaker/api-maker-auto-increment-c9h |
⭐ List of Feature ⭐
✅ Inbuilt increment
▸ Some databases, such as MongoDB, do not support auto-incrementing fields. API Maker can provide this functionality for those databases by automatically generating sequential values for each record.
✅ isAutoIncrementByAM
▸ To enable this feature, the user only has to set the ... | apimaker | |
1,513,161 | Bootstrap! | Ah so yes, I finally gained extra progress in this whole journey. I started the section of Bootstrap... | 0 | 2023-06-22T12:51:23 | https://dev.to/doyinaluko/bootstrap-1a70 | bootstrap, css, html, developer | Ah so yes, I finally gained extra progress in this whole journey. I started the section of Bootstrap properly some days back after spending so much time understanding how to use Bootstrap! I honestly can`t believe it took me close to two months to find my way into Bootstrap. I hope the developers out there will forgive... | doyinaluko |
1,513,271 | 5 Reasons Why You Should Containerize | Containerization has turned into a de facto practice of software development. But some businesses are... | 0 | 2023-06-22T14:31:31 | https://blog.dyrector.io/2023-06-21-why-containerize/ | containers, docker, kubernetes, podman | **Containerization has turned into a de facto practice of software development. But some businesses are still hesitant to jump on the hype train. Learn about the 5 reasons why organizations containerize, and how the practice improves the development of applications on any scale.**
---
## #1: Containers Are Simple for... | gerimate |
1,513,661 | A Beginner's Guide to the useReducer Hook in React.js | React.js is a popular JavaScript library for building user interfaces, and it provides several hooks... | 0 | 2023-06-22T19:14:16 | https://dev.to/gaurbprajapati/a-beginners-guide-to-the-usereducer-hook-in-reactjs-5cp6 | webdev, javascript, react, frontend |
React.js is a popular JavaScript library for building user interfaces, and it provides several hooks that simplify state management. One of the most powerful hooks is `useReducer`, which offers a predictable way to manage complex state logic within a React component. In this tutorial, we will explore the code example ... | gaurbprajapati |
1,514,703 | Automating Code Formatting with Bash and Prettier | Code formatting can be a tedious and time-consuming task, but it’s also an essential part of... | 0 | 2023-06-23T17:09:37 | https://dev.to/mazenadel19/automating-code-formatting-with-bash-and-prettier-1ddm | productivity, softwaredevelopment, programming, webdev | ---
title: Automating Code Formatting with Bash and Prettier
published: true
date: 2023-06-22 21:36:27 UTC
tags: productivity,softwaredevelopment,programming,webdevelopment
canonical_url:
---

Code formatting can be a tedious and time-consumin... | mazenadel19 |
1,515,744 | Why Are There So Many Snapshot Tables in BI Systems? | There is a phenomenon that in BI systems of some big organizations there are a lot of snapshot tables... | 0 | 2023-06-24T23:55:35 | https://dev.to/jbx1279/why-are-there-so-many-snapshot-tables-in-bi-systems-4llo | database, bigdata, sql, programming | There is a phenomenon that in BI systems of some big organizations there are a lot of snapshot tables in their data warehouses. Take the BI system of a certain transaction business as an example. There are the huge transaction details table stored as a number of segment tables by month, and some tables that are not ver... | jbx1279 |
1,517,384 | How to build a LLM powered carbon footprint analysis app | In this post I am going to showcase how you can build an app that analyzes the carbon footprint of... | 0 | 2023-06-27T06:54:09 | https://codesphere.com/articles/llm-powered-carbon-footprint-app | tutorial, largelanguagemodels, ai, carbonfootprint | ---
title: How to build a LLM powered carbon footprint analysis app
published: true
date: 2023-06-26 13:03:07 UTC
tags: Tutorial,largelanguagemodels,AI,Carbonfootprint
canonical_url: https://codesphere.com/articles/llm-powered-carbon-footprint-app
---
. And AppMap is at the cutting edge, creati... | ghamelin |
1,520,766 | Building a Serverless Program with AWS Lambda, DynamoDB, and SQS | Introduction: Serverless computing has revolutionized the way we develop and deploy... | 0 | 2023-06-29T17:48:06 | https://dev.to/vedvaghela/building-a-serverless-program-with-aws-lambda-dynamodb-and-sqs-2p8c | aws, serverless, dynamodb, lambda | ## **Introduction:**
Serverless computing has revolutionized the way we develop and deploy applications, offering scalability, cost-efficiency, and simplified management. In this blog, we'll explore how to build a serverless program using AWS Lambda, DynamoDB, and SQS (Simple Queue Service). By leveraging these powerfu... | vedvaghela |
1,521,168 | NSX-T 3.2 and NSX ALB (Avi) Deployment Error - "Controller is not reachable. {0}" | Note: This feature has been deprecated by VMware NSX-T 3.2 has been released, and has a ton of... | 0 | 2023-07-04T15:30:45 | https://blog.engyak.co/2021/12/nsx-t-32-and-nsx-alb-avi-deployment/ | ---
title: NSX-T 3.2 and NSX ALB (Avi) Deployment Error - "Controller is not reachable. {0}"
published: true
date: 2021-12-23 06:00:00 UTC
tags:
canonical_url: https://blog.engyak.co/2021/12/nsx-t-32-and-nsx-alb-avi-deployment/
---
**Note: This feature has been [deprecated by VMware](https://kb.vmware.com/s/article/8... | ngschmidt | |
1,521,497 | Mastering Pytest: An Introduction to Python Testing | Introduction Welcome to the first installment of our blog series on pytest—an incredible testing... | 23,569 | 2023-06-30T02:44:41 | https://dev.to/bshadmehr/mastering-pytest-an-introduction-to-python-testing-2gpd | Introduction
Welcome to the first installment of our blog series on pytest—an incredible testing framework for Python developers. Testing is a crucial aspect of software development, and pytest offers a simple yet powerful approach to writing and executing tests. In this blog post, we'll lay the foundation for masteri... | bshadmehr | |
1,522,361 | Infrastructure as Code: Managing Docker Containers using AWS DevOps Tools | Introduction: In the world of modern software development, managing infrastructure has... | 0 | 2023-06-30T18:17:56 | https://dev.to/ukemzyskywalker/infrastructure-as-code-managing-docker-containers-using-aws-devops-tools-1oc4 | devops, docker, aws, containers | ### Introduction:
In the world of modern software development, managing infrastructure has become a critical aspect of the DevOps lifecycle. Infrastructure as Code (IaC) has emerged as a best practice that allows developers to define and manage their infrastructure using code.
This blog post will explore how AWS DevO... | ukemzyskywalker |
1,522,374 | Answer: Text search across multiple MS Word documents | answer re: Text search across multiple MS... | 0 | 2023-06-30T18:28:59 | https://dev.to/oscarsun72/answer-text-search-across-multiple-ms-word-documents-3m7l | {% stackoverflow 76591343 %} | oscarsun72 | |
1,522,801 | Chơi tài xỉu trực tuyến tại Sunwin – Đánh bài, giải trí, kiếm tiền thả ga | https://sunwinnews.com/ là một trang web cung cấp các dịch vụ casino trực tuyến✔️ bao gồm cả chơi tài... | 0 | 2023-07-01T07:27:19 | https://dev.to/sunwinnewscom/choi-tai-xiu-truc-tuyen-tai-sunwin-danh-bai-giai-tri-kiem-tien-tha-ga-528i | https://sunwinnews.com/ là một trang web cung cấp các dịch vụ casino trực tuyến✔️ bao gồm cả chơi tài xỉu✔️ Với Sunwin✔️ bạn sẽ được trải nghiệm những trò chơi đỉnh cao cùng các tính năng công nghệ tiên tiến nhất✔️✔️✔️
https://peatix.com/user/18007672
https://matters.town/@sunwinnewscom
https://matters.town/@sunwinnews... | sunwinnewscom | |
1,523,020 | Exploring Web3 and the Sephron Blockchain: Building a Decentralized Future | Introduction: Web3 and blockchain technology have emerged as revolutionary forces that are... | 0 | 2023-07-01T12:33:24 | https://dev.to/deven16082003/exploring-web3-and-the-sephron-blockchain-building-a-decentralized-future-3fa0 | Introduction:
Web3 and blockchain technology have emerged as revolutionary forces that are transforming various industries and redefining how we interact, transact, and collaborate online. One intriguing project in the realm of Web3 is Sephron, a blockchain platform that aims to create a decentralized ecosystem. In thi... | deven16082003 | |
1,524,579 | Process of Trademark Renewal in India | Step 1: Application Filing Submit a renewal application in Form TM-R to the Trademark... | 0 | 2023-07-03T10:19:14 | https://dev.to/gaurikaverma89/process-of-trademark-renewal-in-india-1lm3 | trademarkrenewalprocess, trademarkrenewal, trademarkregistration, trademarkregistrationinindia | Step 1: Application Filing
- Submit a renewal application in Form TM-R to the Trademark Registry.
- Include details such as the trademark registration number, current status, and applicant's contact information.
Step 2: Verification and Examination
- The Registry verifies the application and examines the trademark ... | gaurikaverma89 |
1,524,752 | Introducing Memphis.dev Cloud: Empowering Developers with the Next Generation of Streaming | Event processing innovator Memphis.dev today introduced Memphis Cloud to enable a full serverless... | 0 | 2023-07-03T13:30:37 | https://memphis.dev/blog/introducing-memphis-dev-cloud-empowering-developers-with-the-next-generation-of-streaming/ |
Event processing innovator Memphis.dev today introduced Memphis Cloud to enable a full serverless experience for massive scale event streaming and processing, and announced it had secured $5.58 million in seed funding co-led by Angular Ventures and boldstart ventures, with participation from JFrog co-founder and CTO F... | atrifsik | |
1,525,531 | Lets build a simple interpreter from scratch in python, pt.11: Parser | Simple parser in Python... | 0 | 2023-07-04T06:17:43 | https://dev.to/smadev/lets-build-a-simple-interpreter-from-scratch-in-python-pt11-parser-1c0o | python, programming, interpreter | {% embed https://m.youtube.com/watch?v=ioaC-YmZZHE %} | smadev |
1,527,237 | JavaScript Web APIs Series: Introduction | When talking about technology in the context of software and especially web and internet... | 23,677 | 2023-07-07T18:37:28 | https://olodocoder.hashnode.dev/javascript-web-apis-series-introduction | javascript, webdev, api, programming | When talking about technology in the context of software and especially web and internet applications, it is safe to say that Application Programming Interfaces, commonly known as APIs, are one of the most essential tools that enable developers to build useful and functional applications because they allow things that ... | olodocoder |
1,564,697 | pgBackRest: PostgreSQL S3 backups | This tutorial explains how to backup PostgreSQL database using pgBackRest and S3. ... | 0 | 2023-08-10T11:48:37 | https://bun.uptrace.dev/postgres/pgbackrest-s3-backups.html | postgres, s3 | This tutorial explains how to backup PostgreSQL database using [pgBackRest](https://pgbackrest.org/) and S3.
## Introduction
pgBackRest is a modern PostgreSQL Backup & Restore solution that has all the features you may ever need:
- Parallel backup and restore.
- Full, differential, and incremental backups.
- Delta r... | vmihailenco |
1,573,571 | The Relevance of C in Building Efficient Operating Systems | Harnessing C’s Power: The Unrivaled Choice for Operating System Development ... | 0 | 2023-08-20T00:05:34 | https://dev.to/eztosin/the-relevance-of-c-in-building-efficient-operating-systems-995 | c | ## Harnessing C’s Power: The Unrivaled Choice for Operating System Development
## Introduction
The creation of a simple, yet powerful tool remains one of the most remarkable innovations the world has ever beheld. This innovation carries the weight of the computing world, revolutionizing how we interact ... | eztosin |
1,600,637 | Defending your castle: Raising walls versus detecting intruders | When defending your digital assets in 2023, building a moat and a drawbridge might not be the first... | 0 | 2023-09-14T20:28:43 | https://blog.gitguardian.com/defending-your-castle-raising-walls-versus-detecting-intruders/ | cybersecurity, breach, defense, security | When defending your digital assets in 2023, building a moat and a drawbridge might not be the first thing you think about. You probably wouldn't base your defensive posture on tech like trap doors or guard towers. However, there is a reason these methods have been employed for hundreds of years; they worked, at least w... | dwayne_mcdaniel |
1,633,742 | Expedition logbook: Journey into the world of stable diffusion | This will be a summarization on a high level of my experience and some related learnings from a hobby... | 0 | 2023-11-03T16:56:18 | https://dev.to/charliefoxtrot/expedition-logbook-journey-into-the-world-of-stable-diffusion-104n | writing, learning, stablediffusion, showdev | This will be a summarization on a high level of my experience and some related learnings from a hobby project trying to generate images with stable diffusion in the cloud.
## Intro: Preface & vision
I had previously played around a bit with generating images using Dall-E 2 and similar solutions using some free credits... | malcolmerikssonfoxtrot |
1,634,847 | Build serverless applications with AWS CDK | Serverless computing is becoming an increasingly popular way to develop and deploy applications.... | 0 | 2023-11-23T10:28:00 | https://blog.mikaeels.com/build-serverless-applications-with-aws-cdk | aws, awscdk, cdk, serverless | ---
title: Build serverless applications with AWS CDK
published: true
date: 2023-02-15 15:51:13 UTC
tags: #aws #awscdk #cdk #serverless
canonical_url: https://blog.mikaeels.com/build-serverless-applications-with-aws-cdk
---

##### Prerequisites
🎯 AWS account
🎯 Github account
🎯 Nodejs installed on your local machi... | drsimplegraffiti |
1,634,284 | Sloan's Inbox: Considering a career change from coding to graphic design, any advice? | Hey friends! Sloan, DEV Moderator and resident mascot, back with another question submitted by a DEV... | 22,731 | 2023-10-26T16:00:00 | https://dev.to/devteam/sloans-inbox-considering-a-career-change-from-coding-to-graphic-design-any-advice-565n | discuss, career, design | Hey friends! Sloan, DEV Moderator and resident mascot, back with another question submitted by a DEV community member. 🦥
For those unfamiliar with the series, this is another installment of Sloan's Inbox. You all send in your questions, I ask them on your behalf anonymously, and the community leaves comments to offer... | sloan |
1,634,330 | GIT Merge Conflict | How to Resolve Git Merge Conflicts Hello, Upon completion of my journey as a beginner software... | 0 | 2023-10-13T23:28:26 | https://dev.to/zdededg97/git-merge-conflict-3ig3 | github, merge, beginners |
**How to Resolve Git Merge Conflicts**
Hello, Upon completion of my journey as a beginner software developer and, like many before me,I encountered the seemingly daunting world of Git merge conflicts. At first, it felt overwhelming, but guess what? It wasn't as scary as it sounded! Let me share my experience with you... | zdededg97 |
1,634,557 | Determining the Ideal Length of a Research Paper: Guidelines and Considerations | The length of a research paper is a critical aspect of academic writing, and it often leaves students... | 0 | 2023-10-14T09:30:39 | https://dev.to/mikkejames/determining-the-ideal-length-of-a-research-paper-guidelines-and-considerations-o47 |
The length of a research paper is a critical aspect of academic writing, and it often leaves students and researchers pondering questions such as, "[How long should a research paper be](https://studyfy.com/blog/how-long-should-a-research-paper-be)?" and "What is the optimal length for each section?"
> The answer to ... | mikkejames | |
1,634,705 | 1. Hello World! | Nice to meet you! Happy to have finally signed up to DEV. My name is Manoj Kumar, a beginner... | 0 | 2023-10-14T13:35:45 | https://dev.to/emanoj/1-hello-world-3bin | Nice to meet you!
Happy to have finally signed up to DEV.
My name is Manoj Kumar, a beginner student in coding. A very late starter in this field but I hope I can study and use it well. Not hiding the fact that I am nervous: _will I understand the subject matter? Will I be good at it? Will I enjoy it?_
I am working ... | emanoj | |
1,634,858 | ADD A DISK, INITIALIZE IT AND MAKE IT USEABLE IN AZURE | Step 1: After you have launched your virtual machine, come back to your Azure portal and click on... | 0 | 2023-10-14T16:08:34 | https://dev.to/jeffderick/how-to-add-a-disk-initialize-it-and-make-it-useable-55ac | devops, azure, beginners, cloudcomputing | **Step 1:** After you have launched your virtual machine, come back to your Azure portal and click on **DISK**
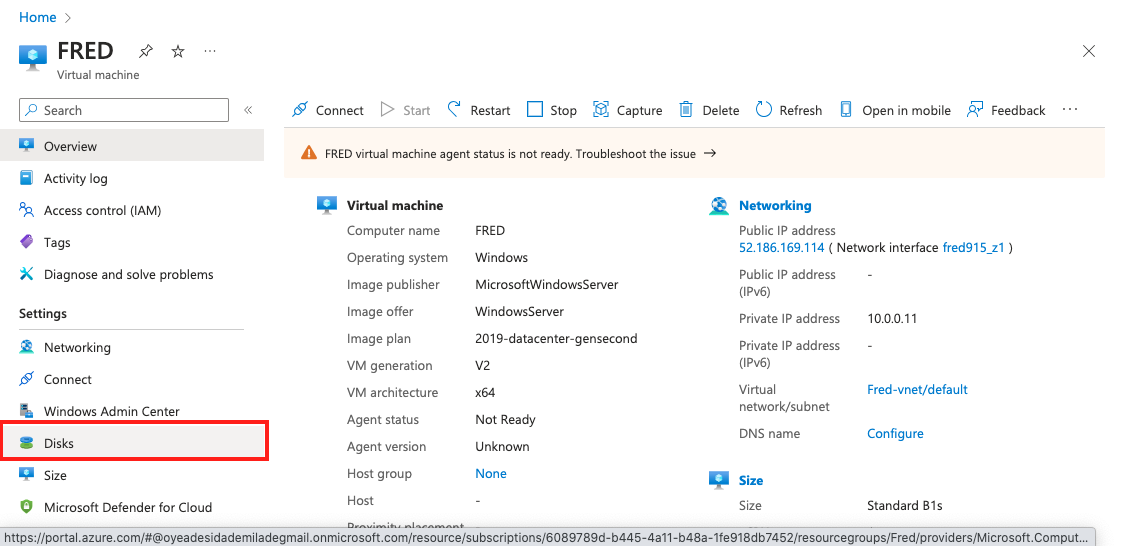
**Step 2:** Scroll down and click on **create and attach a new disk**
: Install manually | Summary Apache Maven is a popular open source software to build and manage projects of... | 25,038 | 2023-10-15T04:00:17 | https://scqr.net/en/blog/2023/10/15/maven-on-java-21-and-devuan-5-debian-12-install-manually/index.html | maven, java, openjdk, devuan | ## Summary
[Apache](https://apache.org/) [Maven](https://maven.apache.org/) is a popular open source software to build and manage projects of [Java](https://dev.java/) (and also other programming languages), licensed under [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0).
With [Devuan](https://www.devuan.org... | nabbisen |
1,635,224 | My Hacktoberfest 2023 Experience | Intro I’m excited to share with you my experience of participating in this year's... | 24,880 | 2023-10-15T08:57:40 | https://dev.to/_eduard26/my-hacktoberfest-2023-experience-47b0 | hack23contributor, hacktoberfest23, opensource, github | ### Intro
I’m excited to share with you my experience of participating in this year's Hacktoberfest. In this post, I will talk about the highs and lows, the growth, and the benefits of contributing to open source projects during this month.
### Highs and Lows
One of the biggest highs for me was discovering and contrib... | _eduard26 |
1,638,072 | hola | A post by tamij12 | 0 | 2023-10-18T02:39:03 | https://dev.to/tamij12/hola-4bkn | tamij12 | ||
1,639,039 | Serving Tasks Efficiently: Understanding P-Limit In Javascript | You are at a busy restaurant. There’s just so many tables available, and there’s a large queue of... | 0 | 2023-10-18T18:24:35 | https://dev.to/doziestar/serving-tasks-efficiently-understanding-p-limit-in-javascript-4m0m | javascript, concurrency, beginners, advanced | ---
title: Serving Tasks Efficiently: Understanding P-Limit In Javascript
published: true
date: 2023-10-18 17:30:35 UTC
tags: javascript,concurrency,beginner,advanced
canonical_url:
---

You are at a busy restaurant. There’s just so many table... | doziestar |
1,671,155 | Hi! I'm new here.. | I’m Ryan VerWey, a mid-level developer with a burgeoning passion in the fields of web development and... | 0 | 2023-11-19T04:12:57 | https://dev.to/rverwey/hi-im-new-here-2069 | webdev, powerplatform, newdev, beginners | I’m Ryan VerWey, a mid-level developer with a burgeoning passion in the fields of web development and UI/UX design. With my roots firmly planted in SharePoint and Microsoft Power Platform, I've decided to venture into the dynamic world of web development and the creative realm of UI/UX design.
My journey into this new... | rverwey |
1,639,713 | A minimal setup for a high availability service using Cloud Run | In this blog post, I will explain what is needed to set up a web service that runs in multiple GCP... | 0 | 2023-10-19T11:58:31 | https://xebia.com/blog/a-minimal-setup-for-a-high-availability-service-using-cloud-run/ | cloud, googlecloudplatform, terraform | ---
title: A minimal setup for a high availability service using Cloud Run
published: true
date: 2022-01-11 14:16:13 UTC
tags: Cloud,GoogleCloudPlatform,Terraform
canonical_url: https://xebia.com/blog/a-minimal-setup-for-a-high-availability-service-using-cloud-run/
---
In this blog post, I will explain what is needed ... | christerbeke |
1,640,646 | What's new in .NET 8? - New Features Unveiled | DOT NET is a prominent platform for custom software development chosen mostly by large-scale IT... | 0 | 2023-10-20T08:19:34 | https://www.ifourtechnolab.com/blog/what-s-new-in-net-8-new-features-unveiled | dotnet, webdev, programming, tutorial | DOT NET is a prominent platform for [custom software development](https://www.ifourtechnolab.com/custom-software-development-company) chosen mostly by large-scale IT giants. According to statistics, there are more than 307,590 developers working in the United States, and the number is growing every day. These figures e... | ifourtechnolab |
1,643,980 | 15 Reasons to Use Custom Neon Signs to Decorate Your Gaming Room | Setting up equipment is only one aspect of designing the optimal gaming space; you also need to... | 0 | 2023-10-23T19:01:57 | https://dev.to/hammadtanveer100/15-reasons-to-use-custom-neon-signs-to-decorate-your-gaming-room-4jnb | Setting up equipment is only one aspect of designing the optimal gaming space; you also need to create an environment that captures your enthusiasm for gaming. In this endeavor, Custom Neon Signs have come to light as an eye-catching method of transforming your gaming room into a world of excitement and individuality. ... | hammadtanveer100 | |
1,644,835 | Game "Black_Jack" in Python | The game "Black_Jack" is one of the game projects on the "Codecademy" course "Computer Science". I... | 0 | 2023-10-24T15:07:20 | https://dev.to/nikola71/game-blackjack-in-python-4o20 | The game "Black_Jack" is one of the game projects on the "Codecademy" course "Computer Science". I enclosed that game project on my GitHub account "https://github.com/NikolaPopovic71". | nikola71 | |
1,658,014 | JavaScript topics for learning react | Learning React in 2023 requires a solid understanding of various JavaScript concepts, as React is a... | 0 | 2023-11-06T07:23:51 | https://dev.to/rowsanali/javascript-topics-for-learning-react-2ao6 | webdev, javascript, react, beginners | Learning React in 2023 requires a solid understanding of various JavaScript concepts, as React is a JavaScript framework for building user interfaces. Here are some of the essential JavaScript topics you should be comfortable with before diving into React:
[Follow me on X](https://bit.ly/3SinH8E)
1. **Callback Functi... | rowsanali |
1,658,198 | GPT-4 Vs Zephyr 7b Beta: Which One Should You Use? 2023 | "zephyr 7b beta" is a fine-tuned version of the mode"Mistral" developed by the Hugging Face H4 team... | 0 | 2023-11-06T11:03:22 | https://dev.to/tarikkaoutar/gpt-4-vs-zephyr-7b-beta-which-one-should-you-use-2023-4n7c | gpt4, langchain, llamaindex, datascience | "zephyr 7b beta" is a fine-tuned version of the mode"Mistral" developed by the Hugging Face H4 team that performs similarly to the previous Chat Llama 70B model in multiple benchmark tests and even better results in "MT Bench''. and is more accurate than Meta's LLama 2
Full Article on My [HomePage](https://quickaituto... | tarikkaoutar |
1,658,224 | Efficient HP Device Support: Resolving Printer, ToucHPad, and Laptop Keyboard Issues Hassle-Free | In the ever-evolving world of technology, having reliable support for your devices is crucial. When... | 0 | 2023-11-06T11:33:15 | https://dev.to/contactphonenumber/efficient-hp-device-support-resolving-printer-touchpad-and-laptop-keyboard-issues-hassle-free-1pe8 | In the ever-evolving world of technology, having reliable support for your devices is crucial. When it comes to <a href="https://www.contact-phone-number.com/hp-support/">HP printers support</a>, our dedicated team of professionals is committed to providing top-notch solutions for all your printer-related concerns. But... | contactphonenumber | |
1,658,327 | Unlocking the World of International Job Listings: A Node.js and Puppeteer Web Scraping Project🚀 | Introduction Job hunting can be a daunting task, especially with countless job platforms... | 0 | 2023-11-06T13:32:17 | https://dev.to/dcerverizzo/unlocking-the-world-of-international-job-listings-a-nodejs-and-puppeteer-web-scraping-project-297m | node, puppeteer, scraper, beginners | ---
title:Unlocking the World of International Job Listings: A Node.js and Puppeteer Web Scraping Project🚀
published: true
description:
tags: #nodejs #puppeteer #scraper #beginner
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/6l67d1gk58r68qtfq4k1.png
---
## Introduction
Job hunting can be a ... | dcerverizzo |
1,658,374 | # Setting up Impression Tracking with Rails using the Impressionist Gem | Impression tracking is a valuable feature for many web applications as it allows you to keep a count... | 0 | 2023-11-06T13:24:12 | https://dev.to/bhartee_sahare/-setting-up-impression-tracking-with-rails-using-the-impressionist-gem-53oc | Impression tracking is a valuable feature for many web applications as it allows you to keep a count of how many times a specific resource, like a post or a page, has been viewed. In this blog post, we will walk through the process of setting up impression tracking in a Ruby on Rails application using the Impressionist... | bhartee_sahare | |
1,669,013 | Project Euler #4 - Two-Headed Monster | Project Euler Series This is a 4th post of ongoing series based on Project Euler. You can check out... | 0 | 2023-11-16T19:57:33 | https://dev.to/fangcode/project-euler-4-two-headed-monster-a56 | kotlin, projecteuler, programming, beginners | > **Project Euler Series**
>
> This is a 4th post of ongoing series based on [Project Euler](https://projecteuler.net/).
> You can check out the previous post [here](https://dev.to/fangcode/project-euler-3-to-sieve-or-not-to-sieve-29f0).
>
> **Disclaimer**
>
> This blogpost provides solution to the 4th problem from Pro... | fangcode |
1,658,437 | Resizing Your Installed Linux Partition: A Step-by-Step Guide | Resizing your Linux partition can be a bit tricky, especially for new users, especially when you're... | 0 | 2023-11-06T14:46:12 | https://dev.to/deri_kurniawan/how-to-resize-your-linux-partition-p63 | linux, tutorial, beginners | Resizing your Linux partition can be a bit tricky, especially for new users, especially when you're using a dual-boot setup. To make it clear and concise, here's an updated step-by-step guide using Ubuntu as an example.
Please note that if you're not using Ubuntu, the specific Linux distribution mentioned in this guid... | deri_kurniawan |
1,658,667 | How to automate an image-based captcha solution in JavaScript | This article describes how to automate image-based captcha solving in JavaScript using Puppeteer and... | 0 | 2023-11-06T18:18:27 | https://dev.to/dzmitry/how-to-automate-an-image-based-captcha-solution-in-javascript-5925 | javascript, captcha, 2captcha, puppeteer | This article describes how to automate image-based captcha solving in JavaScript using [Puppeteer](https://pptr.dev/) and the [2captcha](https://2captcha.com/) service. [Puppeteer](https://pptr.dev/) is a Node.js library used for automation. [2captcha](https://2captcha.com/) is a service used to solve captchas. To inte... | dzmitry |
1,658,690 | First Open Source Contribution 🧑💻 | Intro This October was my first Open Source contribution and I am glad to part of it. I've... | 0 | 2023-11-06T19:13:33 | https://dev.to/judesan/first-open-source-contribution-o55 | hack23contributor | <!-- ✨This template is only meant to get your ideas going, so please feel free to write your own title, structure, and words! ✨ -->
### Intro
<!-- Share a bit about yourself as a contributor. Is this your first Hacktoberfest, or have you contributed to others? Feel free to embed your GitHub account by using {% embed L... | judesan |
1,658,981 | ⤴️How to build a Midjourney API with Nest.js 🚀 | TL;DR In this post I will show you the architecture of building an unofficial Midjourney... | 0 | 2023-11-29T10:59:17 | https://dev.to/confidentai/how-to-build-unofficial-midjourney-api-with-nestjs-1lnd | javascript, midjourney, api, nestjs | ## TL;DR
In this post I will show you the architecture of building an unofficial Midjourney API with Typescript and Nest.js.

---
#... | guybuildingai |
1,659,347 | Easily Bind SQLite Data to .NET MAUI ListView and Perform CRUD Actions | In this blog, we’ll see how to bind and populate data from an SQLite database in the Syncfusion .NET... | 0 | 2023-11-10T04:20:30 | https://www.syncfusion.com/blogs/post/sqlite-data-to-net-maui-listview.aspx | dotnetmaui, crud, mobile, sqlite | ---
title: Easily Bind SQLite Data to .NET MAUI ListView and Perform CRUD Actions
published: true
date: 2023-11-07 11:12:18 UTC
tags: dotnetmaui, crud, mobile, sqlite
canonical_url: https://www.syncfusion.com/blogs/post/sqlite-data-to-net-maui-listview.aspx
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/a... | jollenmoyani |
1,659,754 | Running Open Source Models locally with a TAURI GUI | I've always been a fan of the Ollama Project. Recently, I created a simple web UI for it. It was... | 0 | 2023-11-07T18:07:23 | https://dev.to/akintunde102/running-open-source-models-locally-with-a-tauri-gui-2i62 | ollama, llama, ai, tauri |
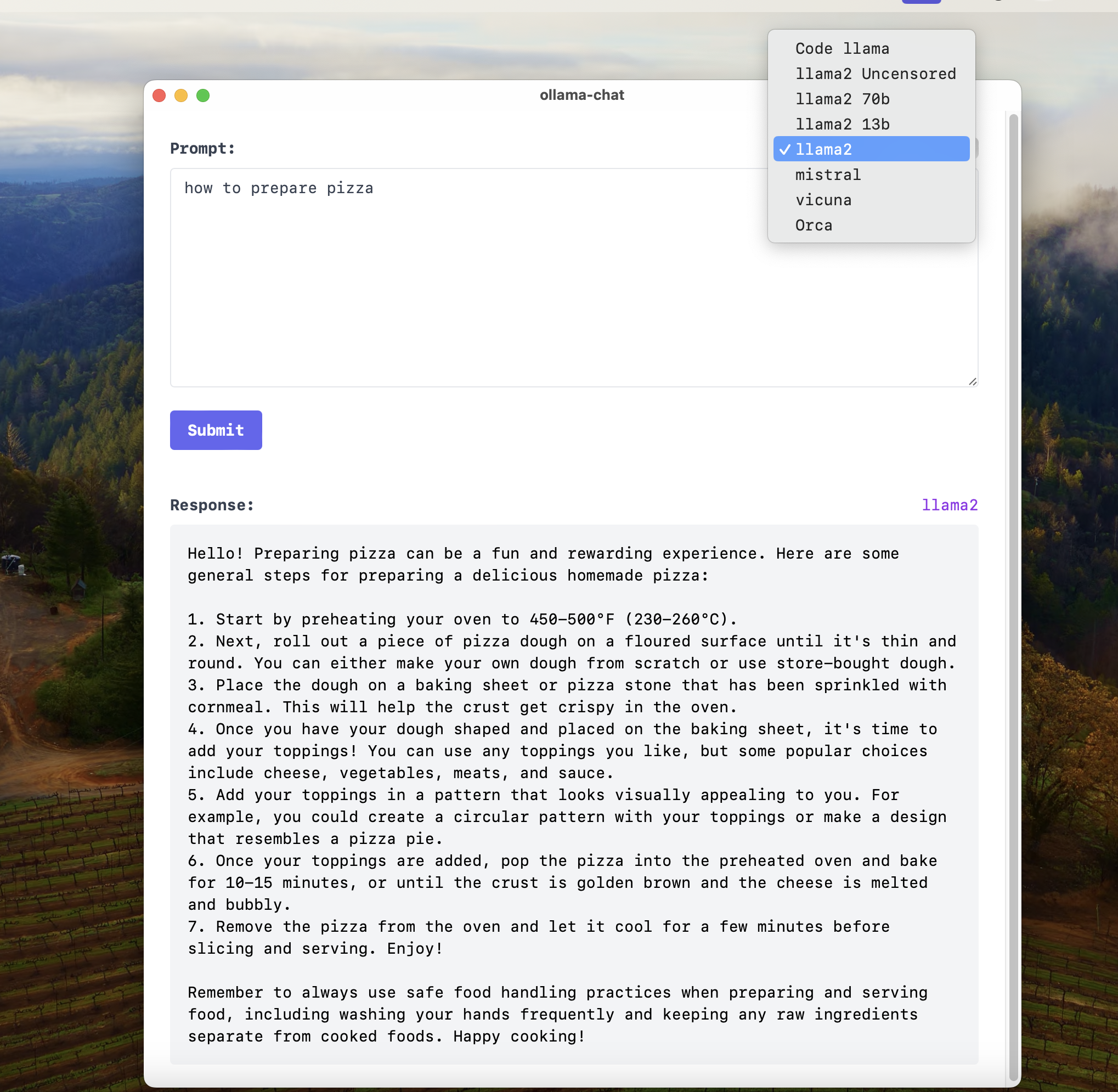
I've always been a fan of the [Ollama Project](https://ollama.ai).
Recently, I created a simple web UI for it. It was just a slap-together of react codes.
I've also developed a desktop application with improved feature... | akintunde102 |
1,659,827 | Exploring HTTP Requests in Flutter | I'm excited to share insights into the world of HTTP requests in Flutter and how they play a vital... | 0 | 2023-11-08T02:30:00 | https://raman04.hashnode.dev/exploring-http-requests-in-flutter | api, flutter, programming, beginners | I'm excited to share insights into the world of HTTP requests in Flutter and how they play a vital role in mobile app development. Before diving into practical examples, I'd like to direct your attention to a couple of resources that can complement and expand your understanding of this topic.
I've created a YouTube vi... | raman04byte |
1,659,831 | Money pattern in PHP: the problem | Introduction When we work with numbers, we may face moments when we lose precision, maybe... | 25,302 | 2023-11-15T09:00:00 | https://dev.to/rubenrubiob/money-pattern-in-php-the-problem-334a | php, designpatterns, money, number | ## Introduction
When we work with numbers, we may face moments when we lose precision, maybe because the number is gigantic or maybe because it has infinite decimals. The problem is representing infinite numbers in a finite system; no matter how much memory you have, it will always be finite. This number representatio... | rubenrubiob |
1,659,967 | JavaScript Beast on the Block | Hello world... If you are looking to learn from an expert... And take your programming to the next... | 0 | 2023-11-07T22:02:30 | https://dev.to/erasmuskotoka/javascript-beast-on-the-block-4n30 | Hello world...
If you are looking to learn from an expert...
And take your programming to the next level...
Or in search of someone to take on your programming projects...
Then look no further because I am the Programming Beast on the block.
I am about to reshape the future with code one line at a time.
I am know... | erasmuskotoka | |
1,660,062 | Realizando ataques de força bruta em containers docker usando hydra | Neste post iremos entender como usar a ferramenta hydra para ataques de força bruta e de dicionário... | 0 | 2023-11-20T22:40:13 | https://dev.to/cancio/testando-o-hydra-com-o-docker-3ceg | hydra, docker, kali, linux | Neste post iremos entender como usar a ferramenta hydra para ataques de força bruta e de dicionário através de um site ou de um computador para outro. Podemos entender por definição:
> Um **ataque de dicionário** é um ataque às senhas que **usa palavras ou frases comuns encontradas em dicionários para comprometer cred... | cancio |
1,660,118 | Neuromorphic Computing: A Comprehensive Guide | Introduction Neuromorphic computing is an intriguing and fast expanding area that... | 0 | 2023-11-08T04:06:57 | https://dev.to/adityapratapbh1/neuromorphic-computing-a-comprehensive-guide-1885 | computing, neuromorphic |
[](https://cloudnativejourney.files.wordpress.com/2023/11/pexels-photo-1714208.jpeg?w=1024 "Computing")
Introduction
------------
Neuromorphic computing is an intriguing and fast expanding area that create... | adityapratapbh1 |
1,660,199 | Understanding parts of URL | Understanding parts of an URL In the context of web development, the URL path refers to... | 0 | 2023-11-08T05:31:52 | https://dev.to/tanmaycode/understanding-parts-of-url-1n1g | webdev, javascript, programming, beginners | ### Understanding parts of an URL
In the context of web development, the URL path refers to the part of the URL that comes after the domain name and includes various parameters and components. These parameters are used to provide additional information to the server or to specify certain resources or actions. Here are... | tanmaycode |
1,660,301 | @iaminebriki at Hacktoberfest ✨ | This year was first time I participate to Hacktoberfest and It's been such a nice experience! ... | 0 | 2023-11-08T07:32:19 | https://dev.to/iaminebriki/iaminebriki-at-hacktoberfest-11i1 | hack23contributor, hacktoberfest23, hacktoberfest, opensource | This year was first time I participate to Hacktoberfest and It's been such a nice experience!
### Intro
I am a Machine learning Engineer and freelancer interested in the intersection of AI and Healthcare (Medical Imaging specifically).
I've been interested in Open-source for a while now but didn't know where exactly ... | iaminebriki |
1,660,464 | Why is WordPress Popular? | WordPress is a popular and widely-used Content Management System (CMS) for several reasons that... | 0 | 2023-11-08T11:12:18 | https://dev.to/pogo_themes/why-is-wordpress-popular-3jl9 | wordpress, seo, cms, beginners | WordPress is a popular and widely-used Content Management System (CMS) for several reasons that contribute to its reputation as one of the best CMS options. However, it's important to note that what makes WordPress the "best" CMS can be subjective and depends on your specific needs and preferences.
Here are some of t... | pogo_themes |
1,660,661 | Stop using Lambda Layers (use this instead) | This post is also available on YouTube: Lambda layers are a special packaging mechanism provided... | 0 | 2023-11-08T13:38:26 | https://aaronstuyvenberg.com/posts/why-you-should-not-use-lambda-layers | aws, lambda, webdev, programming | This post is also available on YouTube:
{% embed https://www.youtube.com/embed/Y4EJPIpqmuk?si=tzscV5es_MaXigPs %}
[Lambda layers](https://docs.aws.amazon.com/lambda/latest/dg/chapter-layers.html) are a special packaging mechanism provided by AWS Lambda to manage dependencies for zip-based Lambda functions. Layers them... | astuyve |
1,673,201 | Day 21 OOPS | I spent the day studying OOPS. | 0 | 2023-11-21T06:29:09 | https://dev.to/harshaart/day-21-oops-95e | I spent the day studying OOPS. | harshaart | |
1,660,923 | Angular @for | Angular has released the new '@IF' block syntax similar to Javascript How does this... | 0 | 2023-11-08T17:30:28 | https://dev.to/dionisd/angular-for-ad4 | angular, angular17, typescript | ## Angular has released the new '@IF' block syntax similar to Javascript
How does this work?
`@For`
> Similar to JavaScript’s `for...of` loops, Angular provides the `@for` block for rendering repeated elements.
 { super(...args); })... | 0 | 2023-11-08T17:49:53 | https://dev.to/jayakantharun/i-am-facing-an-error-while-integrating-mongoose-with-elysia-3oj4 | bunjs, elysia | error looks like this :
MongooseServerSelectionError:
1 | (function (...args) { super(...args); }) ^ MongooseServerSelectionError: Failed to connect code: "undefined" at new MongooseError (:1:32) at new MongooseServerSelectionError (:1:32) at _handleConnectionErrors (/home/jka_583/Projects/bun_project_1/backend/node... | jayakantharun |
1,661,046 | Cracking the Code: Understanding and Developing the NLP Core of Contexto.me Using GloVe Technique | What is contexto.me game? Contexto.me game play Contexto.me is a compelling linguistic... | 0 | 2023-11-08T21:21:58 | https://dev.to/estevesegura/cracking-the-code-understanding-and-developing-the-nlp-core-of-contextome-using-glove-technique-40oi | ## What is contexto.me game?

Contexto.me game play **Contexto.me** is a compelling linguistic game, taking inspiration from **Semantle.com**, that harnesses the power of semantic distances in language. The obje... | estevesegura | |
1,661,293 | Retrieving Implementation Contract Addresses from Proxy Contracts in EVM Networks | Proxy patterns, such as Transparent and UUPS (Universal Upgradeable Proxy Standard), are critical in... | 0 | 2023-11-09T02:07:46 | https://dev.to/mister_g/retrieving-implementation-contract-addresses-from-proxy-contracts-in-evm-networks-38fm | solidity, web3, javascript, webdev | Proxy patterns, such as Transparent and UUPS (Universal Upgradeable Proxy Standard), are critical in the upgradeable design of smart contracts. However, discerning the implementation contract address from a proxy through block explorers can be challenging. This article aims to instruct developers on extracting this inf... | mister_g |
1,661,373 | Unlocking the Power of Open Source: How to Get Involved and Why It Matters | Open source is the pulse of the modern software ecosystem. From tiny libraries to operating system... | 0 | 2023-11-09T05:17:33 | https://dev.to/opensign/unlocking-the-power-of-open-source-how-to-get-involved-and-why-it-matters-2b68 | webdev, javascript, beginners, opensource | Open source is the pulse of the modern software ecosystem. From tiny libraries to operating system behemoths, open-source projects drive innovation and keep the digital world spinning. If you're a developer who hasn't yet plunged into the open-source pool, you're missing out on an ocean of opportunities. In this post, ... | alexopensource |
1,661,398 | Deadlock in Operating System | Introduction Deadlock is a critical problem in programs and operating systems. It happens... | 24,699 | 2023-11-09T05:36:18 | https://dev.to/syedmuhammadaliraza/deadlock-in-operating-system-30e2 | computerscience, softwareengineering, operatingsystem, deadlock | # Introduction
Deadlock is a critical problem in programs and operating systems. It happens when two or more processes or threads cannot continue because they are waiting for each other to release a resource. In this article, we will explore the concept of deadlock, its causes, prevention strategies, and various resol... | syedmuhammadaliraza |
1,661,544 | Is Duolingo the right tool for learning? | I'd been using Duolingo for learning German for 1-2 months. Was it the right tool for learning new... | 0 | 2023-11-09T08:42:01 | https://dev.to/apetryla/is-duolingo-the-right-tool-for-learning-53aj | learning, discuss, productivity, career | I'd been using Duolingo for learning German for 1-2 months. Was it the right tool for learning new language? Not for me!
Duolingo doesn't take advantage of spaced repetition. I got sick and tired of successfully answering the same word for 15 lessons and then not seeing that word ever again. In total I did 2.5 units, ... | apetryla |
1,661,775 | The only thing you need to master React! (from my 5 years of experience) | I've been working in and around React since the time it got popular. I've dug in every corner of it,... | 0 | 2023-11-11T14:52:32 | https://dev.to/goodgit/the-only-thing-you-need-to-master-react-from-my-5-years-of-experience-1i6o | react, webdev, javascript, programming | I've been working in and around React since the time it got popular. I've dug in every corner of it, from reading the source code to creating my own libraries to simplify the mess React can create at times.
But this was all possible because of one thing I did, and even to this date, I continue to do it when I want to ... | brainspoof |
1,662,292 | I have made 100+ CSS-only Ribbon Shapes | The Perfect Collection 🎀 | It's time for another collection! After the loaders, the hover effects, and the background patterns,... | 0 | 2023-11-13T10:37:12 | https://dev.to/afif/i-have-made-100-css-only-ribbon-shapes-the-perfect-collection-4374 | css, webdev, beginners, showdev | It's time for another collection! After [the loaders](https://dev.to/afif/css-loaderscom-the-biggest-collection-of-loading-animations-more-than-500--23jg), [the hover effects](https://dev.to/afif/100-underline-overlay-animation-the-ultimate-css-collection-4p40), and [the background patterns](https://dev.to/afif/i-creat... | afif |
1,662,390 | A classic Snake game built using React.js, HTML Canvas, and TypeScript | Snake Game 🐍 A classic Snake game built using React.js, HTML Canvas, and... | 0 | 2023-11-10T08:58:59 | https://reactjsexample.com/a-classic-snake-game-built-using-react-js-html-canvas-and-typescript/ | games | ---
title: A classic Snake game built using React.js, HTML Canvas, and TypeScript
published: true
date: 2023-11-10 00:56:00 UTC
tags: Games
canonical_url: https://reactjsexample.com/a-classic-snake-game-built-using-react-js-html-canvas-and-typescript/
---
# Snake Game 🐍
 YouTube downloader & MP3 converter is a simple tool to download any video from
YouTube and many other similar services in an easy, fast streaming app for music and app
Download the latest version of Snaptube YouTube downloader & MP3 converter for Android. | snaptubeapps |
1,662,831 | Transitioning from Lunr.js to Minisearch.js | As I embarked on weeks five and six of my Google Summer of Code (GSoC) project, a pivotal shift took... | 26,962 | 2023-11-10T11:49:32 | https://dev.to/hetarth02/transitioning-from-lunrjs-to-minisearchjs-36aa | opensource, gsoc, julialang, devjournal | As I embarked on weeks five and six of my Google Summer of Code (GSoC) project, a pivotal shift took place in client-side searching. To optimize the initial load times, I transitioned from using Lunr.js to Minisearch.js. This change brought about a host of improvements and refinements that made a more efficient search ... | hetarth02 |
1,662,983 | Unit Test | Jest I used Jest to add unit tests in my typescript project, which is straight-forward and... | 0 | 2023-11-10T14:57:17 | https://dev.to/seogjun/unit-test-4jmp | ### Jest
I used `Jest` to add unit tests in my typescript project, which is straight-forward and I used to work with `Jest` before, I felt it was handy.
### What is Jest?
Jest is a JavaScript testing framework designed to ensure correctness of any JavaScript codebase.
### Jest with Typescript
#### Prerequisite
```ba... | seogjun | |
1,663,029 | Digital Empire: Mobile App Development in New York | Energize your business with cutting-edge app development services in New York's vibrant and dynamic... | 0 | 2023-11-10T15:56:59 | https://dev.to/martindye/digital-empire-mobile-app-development-in-new-york-7ed | Energize your business with cutting-edge [app development services in New York](https://www.technbrains.com/locations/mobile-app-development-new-york/)'s vibrant and dynamic landscape, tailored to redefine your digital presence.
**Reach Out To Us**
Email: contact@technbrains.com
Call: 833-888-8370
**Social Links**
... | martindye | |
1,663,404 | Unit Testing | This week, my focus in the development of Learn2Blog centred on implementing unit testing, a crucial... | 0 | 2023-11-11T01:21:11 | https://dev.to/yousefmajidi/unit-testing-1l1o | opensource, beginners, testing, dotnet | This week, my focus in the development of [Learn2Blog](https://github.com/Yousef-Majidi/Learn2Blog) centred on implementing unit testing, a crucial aspect of ensuring the reliability and stability of the project. In this blog post, I'll delve into the significance of unit testing and touch upon the broader concept of e... | yousefmajidi |
1,663,482 | Implementing a Testing Framework | This week I managed to add a testing framework to my open source project, TILerator. Since it's a... | 0 | 2023-11-11T03:04:38 | https://dev.to/mismathh/implementing-a-testing-framework-2m0p | beginners, opensource, javascript, testing | This week I managed to add a testing framework to my open source project, [TILerator](https://github.com/mismathh/TILerator). Since it's a JavaScript project, I decided to use [Jest](https://jestjs.io/) as my testing framework.
<h2>What is Jest?</h2>
Jest is a JavaScript testing framework developed by Facebook, and is... | mismathh |
1,663,563 | Python - Use Hash Tables (Dictionaries) for Fast Data Retrieval | Hash tables, often implemented as dictionaries in Python, are a fundamental data structure for... | 0 | 2023-11-24T15:30:00 | https://dev.to/theramoliya/python-use-hash-tables-dictionaries-for-fast-data-retrieval-1oom | python, programming, beginners, tutorial | Hash tables, often implemented as dictionaries in Python, are a fundamental data structure for efficiently storing and retrieving data. They provide constant-time average-case lookup, insertion, and deletion operations, making them valuable for various applications. Here's an example:
```python
def count_elements(arr)... | theramoliya |
1,663,802 | Data Engineering for Beginners: A Step-by-Step Guide | Introduction The data age has come with challenges that require innovations and the... | 0 | 2023-11-11T12:39:25 | https://dev.to/allan_ouko/data-engineering-for-beginners-a-step-by-step-guide-1o9p | ## Introduction
The data age has come with challenges that require innovations and the development of existing technological services to handle huge amounts of data. Data from various sources also require faster processing to make it available for different use cases. Therefore, data engineering has become part of the... | allan_ouko | |
1,663,813 | EP 5 - Conditionals and Booleans | So interesting lesson where we touch again on string interpolation and introduce booleans and... | 0 | 2023-11-11T13:18:28 | https://dev.to/kostanovak/ep-5-conditionals-and-booleans-488 | interpolation, conditionals, php | So interesting lesson where we touch again on string interpolation and introduce booleans and conditionals.
I solved task myself first by including conditional logic inside h1 like this:
```PHP
<body>
<?php
$name = "Dark Matter";
$read = true;
?>
<h1>
<?php
if ($read){
echo "You have read $name";
}else {
echo "Y... | kostanovak |
1,663,852 | Making Utility App Development a Breeze with Tech Experts | In today's digital world, finding a friend who can simplify Utility App Development is like striking... | 0 | 2023-11-11T14:33:50 | https://dev.to/asadbashir/making-utility-app-development-a-breeze-with-tech-experts-53n | In today's digital world, finding a friend who can simplify Utility App Development is like striking gold. Lucky for you, we have the wizards of simplicity, your go-to Tech Experts. Let's take a walk through their easy solutions, making Utility App Development a walk in the park.
## Tech Experts Unveiled: Simplifying ... | asadbashir | |
1,663,858 | AppSec and DevSecOps: part 1 - metrics, statistics, challenges, state of the industry | Intro We can hear quite often that cybersecurity in a companies with low maturity is... | 0 | 2023-11-11T15:59:59 | https://dev.to/d3one/appsec-and-devsecops-part-1-metrics-statistics-challenges-state-of-the-industry-3fg3 | security | # **Intro**
We can hear quite often that cybersecurity in a companies with low maturity is expensive and it make a questions about what benefits it brings to the business. Why does a development need AppSec\DevSecOps specialists? Why is the cost of fixing a code defect at the design level cheaper than at the developme... | d3one |
1,663,997 | React কেন বর্তমানে বেশি জনপ্রিয়? | May 29, 2013, প্রথম রিলিজ হওয়ার পরেও React বর্তমানে বেশি জনপ্রিয় UI লাইব্রেরি। অত্যন্ত জনপ্রিয়... | 0 | 2023-11-11T18:18:24 | https://dev.to/samiulalimsaad/react-ken-brtmaane-beshi-jnpriyy-4k1f | react, javascript, programming | May 29, 2013, প্রথম রিলিজ হওয়ার পরেও React বর্তমানে বেশি জনপ্রিয় UI লাইব্রেরি। অত্যন্ত জনপ্রিয় হওয়ার হওয়ার বেশ কয়েকটি কারণ রয়েছে। এই কারণগুলির মধ্যে রয়েছে:
**Performance**: React শুধুমাত্র সেই অংশগুলিকে পুনরায় রেন্ডার করে যা প্রয়োজন, যা ওয়েব অ্যাপ্লিকেশনগুলিকে আরও fast এবং আরও efficient করে তোলে।
**Comm... | samiulalimsaad |
1,664,279 | API Explained to a 5 year old kid LITERALLY! | Disclaimer This is a blog to explain topics in a funny way and I don't intend to hurt... | 0 | 2023-11-12T05:04:42 | https://dev.to/maiommhoon/api-explained-to-a-5-year-old-kid-literally-5306 | api, webdev, beginners | ## Disclaimer
**This is a blog to explain topics in a funny way and I don't intend to hurt anyone's feelings**
## Introduction
What is an API? Well, it's Application programming interface.
(*gasp*) F**k that a huge word! No problem we will calmly ask google.
![Image description](https://dev-to-uploads.s3.amazonaws.co... | maiommhoon |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.