
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,788,862 | SMTP Relay Service Provider | Empower your email delivery with a trusted smtp relay service provider. Unlock seamless communication... | 0 | 2024-03-13T07:15:03 | https://dev.to/devidrich/smtp-relay-service-provider-2fm2 | smtprelayserviceprovider, smtp, buysmtpserver, smtprelayservices | Empower your email delivery with a trusted **[smtp relay service provider](https://medium.com/@vikaspanache0/boosting-deliverability-the-impact-of-a-reliable-smtp-relay-service-provider-fd71968fd4d4)**. Unlock seamless communication and unparalleled reliability as we streamline your messages to their destination. With ... | devidrich |
1,788,885 | A New Way to Provision Databases on Kubernetes | Need to provide database self-service to internal teams? Can't spare the resources to build and... | 0 | 2024-03-13T07:59:13 | https://dev.to/dbazhenov/a-new-way-to-provision-databases-on-kubernetes-126h | kubernetes, database, opensource, cloudnative | Need to provide database self-service to internal teams? Can't spare the resources to build and maintain your own private DBaaS solution? Sick of cloud DBaaS providers locking you in?
[Percona Everest](https://percona.community/projects/everest/) is a cloud-native database platform to deploy and manage enterprise-gra... | dbazhenov |
1,788,901 | 🤯 150 WebDev Articles to Satisfy Your Curiosity | Image by Freepik This year I started a new series on LinkedIn - "Advanced Links for Frontend". Each... | 0 | 2024-03-13T08:18:49 | https://dev.to/florianrappl/150-articles-to-satisfy-your-curiosity-3c22 | webdev, javascript, css, frontend | *Image by <a href="https://www.freepik.com/free-vector/hand-drawn-web-developers_12063795.htm#query=front%20end%20developer&position=2&from_view=keyword&track=ais&uuid=98351362-efae-41c0-970c-9aa479e41c9a">Freepik</a>*
This year I started a new series on [LinkedIn](https://www.linkedin.com/in/florian-rappl/) - "Advanc... | florianrappl |
1,788,958 | What Is Test Plan: Guidelines And Importance With Examples | OVERVIEW A test plan is a precious written document that describes the testing strategy for a... | 0 | 2024-03-13T09:28:21 | https://dev.to/devanshbhardwaj13/what-is-test-plan-guidelines-and-importance-with-examples-8l8 | testing, softwaredevelopment, software, cloud | OVERVIEW
A **test plan** is a precious written document that describes the [testing strategy](https://www.lambdatest.com/blog/blueprint-for-test-strategy/?utm_source=devto&utm_medium=organic&utm_campaign=mar_13&utm_term=bw&utm_content=blog) for a software or hardware project. It is a document that outlines the scope o... | devanshbhardwaj13 |
1,788,966 | Nebular Express - devlog #4 - This is the end of the beginning | Hi, I started this game for the Minigame a month - FEBRUARY 2024 Game Jam. Unfortunately, I didn’t... | 26,766 | 2024-03-13T09:39:57 | https://dev.to/darkelda/nebular-express-devlog-4-this-is-the-end-of-the-beginning-4kbc | godot, gamedev, development, beginners | Hi,
I started this game for the [Minigame a month - FEBRUARY 2024 Game Jam](https://itch.io/jam/minigame-a-month-february-2024).
Unfortunately, I didn’t finish it on time and I’ve been ranked 88th over 95…
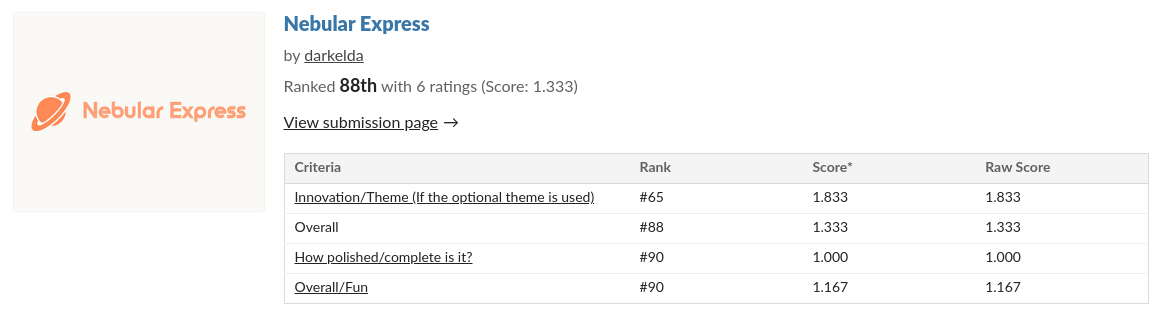
## What wen... | darkelda |
1,788,976 | How To Fix Samsung SSD Not Detected Mac book | In case you’ve got yourself the new samsung SSD T7, T9 etc like myself. you might encounter a problem... | 0 | 2024-03-13T09:46:55 | https://dev.to/lior_amsalem/how-to-fix-samsung-ssd-not-detected-mac-book-4n8j | In case you’ve got yourself the new samsung SSD T7, T9 etc like myself. you might encounter a problem during the initial setup. in the empty SSD you’ll find a setup file for macbook called “SamsungPortableSSD_Setup_Mac_1.0.pkg” that is used to install “samsung portable SSD” application for samsung SSD external device.
... | lior_amsalem | |
1,789,103 | Jenkins Server setup using Terraform | In this project, we are going to setup a Jenkin server using Terraform script. This Terraform script... | 0 | 2024-03-13T11:33:00 | https://dev.to/gbenga700/jenkins-server-setup-using-terraform-2e7o | webdev, devops, git, aws | In this project, we are going to setup a Jenkin server using Terraform script. This Terraform script will spin up an EC2 instance server on AWS with the required tools to run and manage a Jenkins server.
Setting up a Jenkins server on AWS EC2 using Terraform requires a few prerequisites.
• **AWS Account**: You need an ... | gbenga700 |
1,789,114 | The Importance of Automated User Acceptance Testing | User acceptance testing (UAT) is best carried out manually as users will be testing the software... | 0 | 2024-03-13T11:55:48 | https://dev.to/alishahndrsn/the-importance-of-automated-user-acceptance-testing-16i4 | uat, uattesting | User acceptance testing (UAT) is best carried out manually as users will be testing the software product or application in a real-time production environment.
User feedback plays a crucial role in UAT as the value of a product or application is ascertained from a user's perspective. However, in certain scenarios, the... | alishahndrsn |
1,789,158 | VSCode Extensions for 2024 | Are you looking to enhance your coding experience with Visual Studio Code? Look no further! VS Code... | 0 | 2024-03-13T12:42:46 | https://dev.to/himanshudevgupta/vscode-extensions-for-2024-2j3c | vscode, extensions, productivity | Are you looking to enhance your coding experience with Visual Studio Code? Look no further! VS Code offers a plethora of extensions that can supercharge your workflow, streamline tasks, and improve overall productivity. Whether you're a seasoned developer or just starting out, these extensions are sure to make your cod... | himanshudevgupta |
1,789,279 | useRef in react for beginners | UseRef will create a reference of a react element, by using that we can mutate the DOM element or a... | 0 | 2024-03-13T15:12:08 | https://dev.to/uthirabalan/useref-in-react-for-beginners-gmp | react, dom, reacthooks, webdev | UseRef will create a reference of a react element, by using that we can mutate the DOM element or a value that is used across the component. Also, we can store some data and that won’t cause a re-render on update.
Steps to use UseRef Hook:
step 1: import it from react
step2: declare it as a ref variable
step 3:pass... | uthirabalan |
1,789,287 | The space between the words: tackling generative AI email messages | I started this as a reply to a LinkedIn post by Deane Barker that got me thinking. Then I started it... | 0 | 2024-04-17T16:15:02 | https://jasonstcyr.com/2024/03/13/the-space-between-the-words-tackling-generative-ai-email-messages/ | generativeai | ---
title: The space between the words: tackling generative AI email messages
published: true
date: 2024-03-13 10:54:00 UTC
tags: GenerativeAI
canonical_url: https://jasonstcyr.com/2024/03/13/the-space-between-the-words-tackling-generative-ai-email-messages/
cover_image: https://jasonstcyr.com/wp-content/uploads/2024/0... | jasonstcyr |
1,789,501 | Getting to Work with Kentik NMS | I recently explored why Kentik built and released an all-new network monitoring system (NMS) that... | 0 | 2024-03-13T18:27:17 | https://www.kentik.com/blog/getting-to-work-with-kentik-nms/ | monitoring, observability, snmp, networking | I [recently explored why Kentik](https://www.kentik.com/blog/setting-sail-with-kentik-nms-unified-network-telemetry/) built and released an all-new [network monitoring system (NMS)](https://www.kentik.com/product/network-monitoring-system/) that includes traditional and more modern telemetry collection techniques, such... | adatole |
1,789,545 | Przewodnik dla programistów po inżynierii Prompt i LLM | Dowiedz się, jak przyspieszyć czas tworzenia oprogramowania, korzystając z modułów LLM, takich jak GPT-4. | 0 | 2024-03-13T19:23:03 | https://dev.to/pubnub-pl/przewodnik-dla-programistow-po-inzynierii-prompt-i-llm-2a | Wraz z rozwojem dużych modeli językowych (LLM) i sztucznej inteligencji, takiej jak [ChatGPT](https://chat.openai.com/), programiści mają teraz niezwykle potężnych asystentów AI, którzy mogą pomóc im szybciej kodować i być bardziej produktywnymi. Jednak zwykłe poproszenie LLM o napisanie kodu często skutkuje bezużytecz... | pubnubdevrel | |
1,789,713 | Why I Don't Use AutoMapper in .Net | TL;DR I dislike Automapper as a tool to auto-map objects from one to another. So I performed some... | 0 | 2024-03-14T23:43:54 | https://dev.to/grantdotdev/why-i-dont-use-automapper-in-net-12i6 | dotnet, csharp, tutorial | **TL;DR**
I dislike Automapper as a tool to auto-map objects from one to another. So I performed some benchmark tests around performance and memory usage between AutoMapper and manually mapping an object to a DTO (Data Transfer Object with fewer properties, normally used for API / UI usage).
Results found that the m... | grantdotdev |
1,789,563 | Ein Leitfaden für Entwickler zu Prompt Engineering und LLMs | Erfahren Sie, wie Sie Ihre Entwicklungszeit durch den Einsatz von LLMs wie GPT-4 verkürzen können. | 0 | 2024-03-13T19:41:46 | https://dev.to/pubnub-de/ein-leitfaden-fur-entwickler-zu-prompt-engineering-und-llms-18k6 | Mit dem Aufkommen großer Sprachmodelle (LLMs) und künstlicher Intelligenz wie [ChatGPT](https://chat.openai.com/) stehen Entwicklern jetzt unglaublich leistungsfähige KI-Assistenten zur Verfügung, die ihnen helfen können, schneller zu programmieren und produktiver zu sein. Die einfache Aufforderung an ein LLM, Code zu ... | pubnubdevrel | |
1,789,653 | How to build your AWS infrastructure using CDK | While working on Datalynx I found myself needing to create multiple test environments including... | 0 | 2024-03-13T21:39:10 | https://dev.to/datalynx/how-to-build-your-aws-infrastructure-using-code-and-deploy-your-backend-app-1ic9 | cdk, python, cicd, aws | While working on [Datalynx](https://datalynx.ai/) I found myself needing to create multiple test environments including Production. I started working on the proof-of-concept by building the infrastructure using the AWS console. That was less than ideal and I needed to mentally keep track of all the configurations I set... | rsonsini |
1,789,671 | تصميم واجهات تطبيقات: الجمال والوظائف المتقنة في متناول يديك | تصميم واجهات تطبيقات هو فن يجمع بين الجمال الفني والوظائف المتقنة لإنشاء تجربة مستخدم مذهلة ومرضية.... | 0 | 2024-03-13T22:44:10 | https://dev.to/ridodosaqo/tsmym-wjht-ttbyqt-ljml-wlwzyf-lmtqn-fy-mtnwl-ydyk-2mnf | تصميم واجهات تطبيقات هو فن يجمع بين الجمال الفني والوظائف المتقنة لإنشاء [تجربة مستخدم](https://www.usability.gov/what-and-why/user-experience.html) مذهلة ومرضية. يشير إلى العملية التي يتم من خلالها تصميم العناصر البصرية والتفاعلية لتطبيق الهاتف الذكي أو الويب، مما يجعلها سهلة الاستخدام وجاذبة للمستخدم.
[تصميم واجهات ... | ridodosaqo | |
1,789,676 | Tailwind CSS v4.0 Alpha: A Revolution Unveiled | In a landmark announcement, Tailwind CSS has unveiled the alpha release of its highly anticipated... | 0 | 2024-03-13T23:05:10 | https://dev.to/mitchiemt11/tailwind-css-v40-alpha-a-revolution-unveiled-3g72 | css, web, webdev, news | _In a landmark [announcement](https://tailwindcss.com/blog/tailwindcss-v4-alpha), Tailwind CSS has unveiled the alpha release of its highly anticipated v4.0. This release marks a pivotal moment in web development, introducing groundbreaking features and enhancements poised to reshape the landscape of styling frameworks... | mitchiemt11 |
1,789,680 | Offscreen Rendering | Off-screen rendering or rendering to a texture, plays a crucial role in numerous scenarios within... | 0 | 2024-03-13T23:41:57 | https://dev.to/krjakbrjak/offscreen-rendering-4k1e | rendering, qt, offscreen, cpp | Off-screen rendering or rendering to a texture, plays a crucial role in numerous scenarios within computer graphics and game development:
1. Post-processing Effects: Custom framebuffers are frequently employed to apply post-processing effects such as blur. These effects necessitate rendering the scene into a texture f... | krjakbrjak |
1,789,739 | Snyk users don't have to worry about NVD delays | Learn why NVD delays do not compromise the integrity or efficacy of Snyk's security intelligence, including the Snyk Vulnerability Database. | 0 | 2024-03-14T02:00:26 | https://snyk.io/blog/snyk-users-dont-have-to-worry-about-nvd-delays/ | applicationsecurity | You may have encountered recent discussions and the official notice from NVD (National Vulnerability Database) regarding delays in their analysis process. This [message](https://nvd.nist.gov/general/news) was posted on the February 13:

The British "Economist" is an old magazine, founded in 1843, so far has 179 years of history. #peace#Burma
Every article in this magazine seems to make sense, but many simply cannot stand the scrutiny of time.
The m... | mnshe | |
1,790,006 | Add giscus comments and i18n to Docusaurus | Goal This post is detailed description of adding giscus and i18n to website built by... | 0 | 2024-03-14T07:40:23 | https://dev.to/chenyuannew/add-giscus-comments-and-i18n-to-docusaurus-ka9 | docusaurus, tutorial, frontend, giscus | ## Goal
This post is detailed description of adding [giscus](https://giscus.app/) and i18n to website built by [Docusaurus](https://docusaurus.io/).
## Add giscus comments feature
### Preparations
- Enable discussion feature for your website's **public** github repo, it can be done in repo's `Settings/General/Featu... | chenyuannew |
1,790,019 | Maximizing Returns: The Impact of Personalization on Your Email Marketing Approach | In today's digital landscape, where competition for consumer attention is fierce, effective email... | 0 | 2024-03-14T07:58:05 | https://dev.to/divsly/maximizing-returns-the-impact-of-personalization-on-your-email-marketing-approach-2nhe | email, emailmarketing, emailmarketingcampaigns | In today's digital landscape, where competition for consumer attention is fierce, effective email marketing is essential for businesses looking to stand out and drive meaningful engagement. While traditional email blasts may have once sufficed, the modern consumer expects personalized, relevant content tailored to thei... | divsly |
1,790,069 | Exploring Python: Everything is an Object | ID and Type: In Python, every object has an identity (id) and a type. The id uniquely identifies each... | 0 | 2024-03-14T09:21:10 | https://dev.to/bestverie/exploring-python-everything-is-an-object-549j | python, programming, object, opensource | **ID and Type:**
In Python, every object has an identity (`id`) and a type. The `id` uniquely identifies each object, acting as its address in memory. This means that even basic data types like integers, strings, and lists are treated as objects in Python.
##### Example of getting ID and type of an object
```
x = 42
... | bestverie |
1,790,085 | Stress-Testing Your Mental Health: Recognizing Signs You Need a Break | This post was developed via a partnership with BetterHelp. As a developer, you're a pro at analyzing... | 0 | 2024-03-14T09:39:44 | https://dev.to/asifsidiq/stress-testing-your-mental-health-recognizing-signs-you-need-a-break-od9 | mentalhealth, healthydebate, singleresponsibility, stress | This post was developed via a partnership with BetterHelp.
As a developer, you're a pro at analyzing code and finding the glitches that can cause major headaches. But what about checking in with those personal "programs" running in the background — your mental health?
Sometimes, even the most dedicated devs need to... | asifsidiq |
1,790,094 | Unit testing redux toolkit slices | Recently, I worked on an application where I chose redux toolkit slices over the traditional way of... | 0 | 2024-03-14T10:24:19 | https://dev.to/ujjavala/unit-testing-redux-toolkit-slices-4g7d | unittest, redux, webdev, jest | Recently, I worked on an application where I chose redux toolkit [slices](https://redux-toolkit.js.org/api/createSlice) over the traditional way of redux state management (reducer logic, action creators, and action types spread across separate files) and interestingly enough, there were not many resources that explaine... | ujjavala |
1,790,163 | Generative AI Development Solutions | Introduction Generative AI represents a revolutionary leap forward in artificial... | 0 | 2024-03-14T11:54:42 | https://dev.to/binaryinformatics/generative-ai-development-solutions-3amm | generativeai, ai, aidevelopment, binaryinformatics | ## Introduction
Generative AI represents a revolutionary leap forward in artificial intelligence capabilities. Powered by deep learning techniques like neural networks, generative AI can create brand new content, designs, and more from scratch. Unlike previous AI systems focused on analysis, generative AI can actively... | binaryinformatics |
1,790,410 | test | test | 0 | 2024-03-14T13:39:36 | https://dev.to/programci42/test-4deb | test | programci42 | |
1,834,380 | Hello world | Hello everyone! | 0 | 2024-04-25T18:06:08 | https://dev.to/shubhsk/hello-world-3cdb | webdev, javascript, python, genai | Hello everyone! | shubhsk |
1,790,426 | Error: unable to run private channel using Pusher in Laravel 10 | Error: unable to run private channel using... | 0 | 2024-03-14T14:15:58 | https://dev.to/hilmi/error-unable-to-run-private-channel-using-pusher-in-laravel-10-551g | {% stackoverflow 78152277 %} | hilmi | |
1,790,466 | ReductStore v1.9.0 Released | We are pleased to announce the release of the latest minor version of ReductStore, 1.9.0. ReductStore... | 0 | 2024-03-14T15:20:08 | https://www.reduct.store/blog/news/reductstore-9-released | news, database, reductstore | We are pleased to announce the release of the latest minor version of [**ReductStore**](https://www.reduct.store/), [**1.9.0**](https://github.com/reductstore/reductstore/releases/tag/v1.9.0). ReductStore is a time series database designed for storing and managing large amounts of blob data.
To download the latest rel... | atimin |
1,790,490 | Portfolio Website / Bible App - Devlog #9 | Accomplished: Configured a MySQL database with free hosting services. Securely connected to the... | 0 | 2024-03-14T15:52:37 | https://dev.to/ashray_sam/portfolio-website-bible-app-devlog-9-4gh3 | webdev, react, learning, sql | Accomplished:
- Configured a MySQL database with free hosting services.
- Securely connected to the database from local Spring Boot application.
To Do:
- Implement responsive design.
- Integrate a "Contact Me" section with social icons.
- Incorporate project listings to showcase relevant work.
Next Steps:
Deploy b... | ashray_sam |
1,790,522 | FAST WINDOWS | La rentrée 2023 et les réseaux sociaux riches en évènements avec Whatsapp et Facebook nous ont permis... | 0 | 2024-03-14T16:26:28 | https://dev.to/longjumpingfile/fast-windows-4dho | codepen | <p>La rentrée 2023 et les réseaux sociaux riches en évènements avec Whatsapp et Facebook nous ont permis de concrétiser nos activitées notamment l' obtention d' un stage qui valide l' expérience professionnelle pour un élève du Lycée Scientifique du Carré Sénart et un étudiant inscrit en BTS privé pour un examen.</p>
... | longjumpingfile |
1,799,340 | Spin up command-line Ubuntu VMs in (almost) seconds | Sometimes, you need a clean and disposable Linux environment to test configuration changes, try out... | 0 | 2024-03-23T11:09:52 | https://www.paleblueapps.com/rockandnull/spin-up-ubuntu-vms-multipass/ | infra | ---
title: Spin up command-line Ubuntu VMs in (almost) seconds
published: true
date: 2024-03-23 11:09:13 UTC
tags: Infra
canonical_url: https://www.paleblueapps.com/rockandnull/spin-up-ubuntu-vms-multipass/
---
https://g.co/kgs/kfawyMn | ishakhatun |
1,808,812 | Discover Reliable Acer Service Centre Near You | Experience peace of mind with Acer Service Centre's comprehensive solutions for your Acer devices.... | 0 | 2024-04-02T09:47:13 | https://dev.to/bajrangwaghmare08/discover-reliable-acer-service-centre-near-you-4975 |

Experience peace of mind with Acer Service Centre's comprehensive solutions for your Acer devices. From software issues to hardware resolve, our technicians handle it all with precision and care. Call Us: +91-951... | bajrangwaghmare08 | |
1,809,021 | How to Create OTP Input with Resend CountDown Timer in Livewire using Alphinejs and TailwindCss | If you're working with Laravel Livewire and need to create an OTP Input. Here is how to create a OTP... | 0 | 2024-04-02T13:27:58 | https://dev.to/andychukse/how-to-create-otp-input-with-resend-countdown-timer-in-livewire-using-alphinejs-and-tailwindcss-4d9i | otp, alphinejs, tailwindcss, livewire | If you're working with Laravel Livewire and need to create an OTP Input. Here is how to create a OTP input with a count down timer that has a resend button using Alphine.js and TailwindCss.
#### Design the Input Field
The code below creates a single input field for entering a single number. The number of fields depend... | andychukse |
1,809,024 | What Does a Scrum Master Do? Your Essential Breakdown | Tired of projects feeling like a constant uphill battle? Scrum Masters can change that! 🚀 In my new... | 0 | 2024-04-02T13:39:38 | https://dev.to/codewithnazam/what-does-a-scrum-master-do-your-essential-breakdown-c27 | scrum, agile, teams, development | Tired of projects feeling like a constant uphill battle? Scrum Masters can change that! 🚀
In my new article, get the inside scoop on:
**What Scrum Masters actually do**
**How they boost team motivation**
**Why they're the key to delivering projects on time and on budget**
Check it out! 👇 {% embed https://codewith... | codewithnazam |
1,809,600 | Water Bottle Caps Manufacturers In Bangalore | In Bangalore, a bustling hub of industry and innovation in India, water bottle caps manufacturers... | 0 | 2024-04-03T04:17:33 | https://dev.to/vvachanpolymer/water-bottle-caps-manufacturers-in-bangalore-5157 | bottlecaps, manufacturers | In Bangalore, a bustling hub of industry and innovation in India, water bottle caps manufacturers play a crucial role in supplying the beverage industry with high-quality caps for bottled water and other beverages. With a growing population and increasing demand for packaged drinking water, the manufacturers in Bangalo... | vvachanpolymer |
1,809,665 | NATURAL OLD MINER DIAMONDS HALO RING ROUND CUT | Title: Embrace Vintage Elegance with the Natural Halo Ring: Old Miner Diamonds Round Cut Unveil the... | 0 | 2024-04-03T06:20:54 | https://dev.to/olivia19244475/natural-old-miner-diamonds-halo-ring-round-cut-1e24 |
Title: Embrace Vintage Elegance with the Natural Halo Ring: Old Miner Diamonds Round Cut
Unveil the timeless allure of vintage elegance with our [Natural Halo Ring](https://harrychadent.co.uk/collections/rings/produ... | olivia19244475 | |
1,809,680 | Buy Negative Google Reviews | https://usashopit.com/product/buy-negative-google-reviews/ Buy Negative Google Reviews Negative... | 0 | 2024-04-03T06:39:39 | https://dev.to/soloke5708/buy-negative-google-reviews-4kki | devops, css, aws, ai | https://usashopit.com/product/buy-negative-google-reviews/

Buy Negative Google Reviews
Negative reviews on Google are detrimental critiques that expose customers’ unfavorable experiences with a business. These revi... | soloke5708 |
1,809,761 | The Race Against Time: Delivering Quality Code Quickly | In the ever-evolving landscape of software development, the balance between speed and quality is a... | 0 | 2024-04-03T07:33:29 | https://dev.to/nitin-rachabathuni/the-race-against-time-delivering-quality-code-quickly-3pji | webdev, javascript, programming, devops | In the ever-evolving landscape of software development, the balance between speed and quality is a tightrope walk every developer faces. The demand for rapid delivery often collides with the need for high-quality code, leading to the critical question: how can we accelerate development without compromising on quality? ... | nitin-rachabathuni |
1,809,791 | How to create a blog using Golang | After getting fed up with React, SPAs, and Javascript around 2021 I decided to re-write my personal... | 0 | 2024-04-03T08:21:03 | https://mortenvistisen.com/posts/how-to-create-a-blog-using-golang | go, tutorial, beginners, howto | After getting fed up with React, SPAs, and Javascript around 2021 I decided to re-write my personal webpage in Rust and wrote an [article](https://mortenvistisen.com/posts/how-to-build-a-simple-blog-using-rust) on how you could build a simple blog, purely using Rust. It ended up becoming one of my most popular articles... | mbv-labs |
1,835,975 | Buy Verified Stripe Accounts-22 | Buy Verified Stripe Accounts , with details including Name, Address, Email, Phone, Bank Name, Routing... | 0 | 2024-04-27T09:14:48 | https://dev.to/verifiedstripe11/buy-verified-stripe-accounts-22-36m1 | [Buy Verified Stripe Accounts](https://smmshopes.com/product/buy-verified-stripe-accounts/) , with details including Name, Address, Email, Phone, Bank Name, Routing Number, and Account Number. These details are all verified and 100% valid. You can also customize them to suit your needs.
Our accounts are secure and com... | verifiedstripe11 | |
1,809,850 | How Mobile Apps Enhance Fleet Management Efficiency: The Best Trends | Did you know that as of a recent study, nearly 80% of fleet management companies are now adapting... | 0 | 2024-04-03T09:28:53 | https://dev.to/fleetstakes/how-mobile-apps-enhance-fleet-management-efficiency-the-best-trends-5en0 | mobile, application, webdev, programming | Did you know that as of a recent study, nearly 80% of fleet management companies are now adapting some form of mobile app technology to enhance their operations?
Fleet management is compelled to innovate and adapt more than ever before. The need for this unparalleled change? Mobile app technology. Equipped with advan... | fleetstakes |
1,809,894 | Surpresa e agradecimento pelos 1,000 seguidores em cerca de meio mês após o registro. | Relatório e agradecimento Tenho solicitações no final. Por favor, leia esta página para... | 0 | 2024-04-05T03:00:00 | https://dev.to/zmsoft/surpresa-e-agradecimento-pelos-1000-seguidores-em-cerca-de-meio-mes-apos-o-registro-3mec | android, google, developers, news | ## Relatório e agradecimento
Tenho solicitações no final.
Por favor, leia esta página para todos, quer você esteja interessado em desenvolvimento Android ou não.
Olá, eu sou o zmsoft.
Registrei-me no dev.to em 16 de março de 2024.
Já faz cerca de meio mês que me registrei e estou muito feliz em anunciar que tenho mais... | zmsoft |
1,809,952 | Top 3 questions people ask about Larafast | People ask a lot of questions about Larafast, I've chosen the top 3 of them to clarify. 1. Is it... | 0 | 2024-04-03T11:46:57 | https://dev.to/karakhanyans/top-3-questions-people-ask-about-larafast-4a05 | People ask a lot of questions about Larafast, I've chosen the top 3 of them to clarify.
**1. Is it scalable and customizable?**
Yes, Larafast is a normal Laravel application, with pre-built features and components. It can be scaled and customized, and every Laravel package compatible with the boilerplate version (cur... | karakhanyans | |
1,820,668 | TypeScript Tip #1: forEach vs for loop | While working on a typescript project, it is recommended to enable noUncheckedIndexedAccess for safer... | 0 | 2024-04-14T02:41:01 | https://dev.to/tusharshahi/typescript-tip-1-foreach-vs-for-loop-56og | typescript, webdev, programming, beginners | While working on a typescript project, it is recommended to enable [`noUncheckedIndexedAccess`](https://www.typescriptlang.org/tsconfig/noUncheckedIndexedAccess.html) for safer object access.
The difference it makes can be summarised below:
```
const obj : Record<string,number[]> = {};
obj.nonExistentKey.push(2);
``... | tusharshahi |
1,823,508 | My First Open Source Contribution | Introduction I was involved in a program through CodeDay and my university that paired... | 0 | 2024-04-15T16:28:57 | https://dev.to/jaredscarr/my-first-open-source-contribution-3j07 | opensource | ### Introduction
I was involved in a program through [CodeDay](https://www.codeday.org/) and my university that paired myself, and two other team members, with a mentor that would guide us through an open-source contribution to a project hosted on GitHub. I have worked in software for about 3 years, but I had never co... | jaredscarr |
1,826,053 | Python's MAP/FILTER/REDUCE: Streamlining Data Manipulation in Seconds | Introduction: Python offers powerful built-in functions for working with collections of data: MAP,... | 0 | 2024-04-17T19:30:16 | https://dev.to/sk_rajibul_9ce58a68c43bb5/pythons-mapfilterreduce-streamlining-data-manipulation-in-seconds-34e5 | python, programming, development, developer |
Introduction:
Python offers powerful built-in functions for working with collections of data: MAP, FILTER, and REDUCE. In just 30 seconds, let's dive into what these functions do and how they can simplify your code.
## MAP:
The map function takes in 1) a function and 2) an iterable. The purpose of the function is to ... | sk_rajibul_9ce58a68c43bb5 |
1,826,094 | Ripple's CEO Shares Optimistic Crypto Market Prediction: Details | Brad Garlinghouse expects the crypto market to double in size, totalling $5 trillion by the... | 0 | 2024-04-17T21:07:14 | https://dev.to/endeo/ripples-ceo-shares-optimistic-crypto-market-prediction-details-dcp | webdev, javascript, web3, blockchain | #### Brad Garlinghouse expects the crypto market to double in size, totalling $5 trillion by the end of 2024. This is larger than the market cap of Amazon and Microsoft combined.
The CEO of Ripple blockchain, Brad Garlinghouse, [claimed](https://www.cnbc.com/2024/04/08/ripple-ceo-crypto-market-to-double-in-size-to-5-... | endeo |
1,826,367 | Angular 15 Dynamic Dialog with angular material | Live demo https://stackblitz.com/github/maag070208/NgDynamicDialog ... | 0 | 2024-04-18T06:05:49 | https://dev.to/maag070208/angular-15-dynamic-dialog-with-angular-material-339p | ## Live demo
https://stackblitz.com/github/maag070208/NgDynamicDialog
## Agenda
- Angular installation
- Create a angular project with specific version
- Installation of angular material
- Primeflex installation
- Create dialog atom component
- Create dialog service
- Create the components to be called from th... | maag070208 | |
1,826,419 | ✍️Testing in Storybook | Introduction Storybook provides an environment where you can build components in... | 27,134 | 2024-04-18T07:12:55 | https://dev.to/algoorgoal/testing-in-storybook-378c | webdev, testing, frontend | ## Introduction
Storybook provides an environment where you can build components in isolation, and checking edge case UI states became easier with Storybook. What's more, you can write tests in Storybook. Also, testing environment comes with zero configuration. Aren't you excited? In this post, I will talk about what ... | algoorgoal |
1,826,423 | How to create a scroll to top button with Tailwind CSS and Alpinejs | In this tutorial, we'll be creating a scroll to top button using Tailwind CSS and Alpine.js. Read... | 0 | 2024-04-18T07:18:43 | https://dev.to/mike_andreuzza/how-to-create-a-scroll-to-top-button-with-tailwind-css-and-alpinejs-1hoj | tutorial, tailwindcss, alpinejs, webdev | In this tutorial, we'll be creating a scroll to top button using Tailwind CSS and Alpine.js.
[Read the article See it live and get the code](https://lexingtonthemes.com/tutorials/how-to-create-a-scroll-to-top-button-with-tailwind-css-and-alpinejs/)
| mike_andreuzza |
1,827,203 | Node.js itself is not single-threaded. | Node.js itself is not single-threaded. Node.js developers often confuse the main single-threaded... | 0 | 2024-04-18T19:09:59 | https://dev.to/nowaliraza/nodejs-itself-is-not-single-threaded-5aib | node, javascript, backend, webdev | Node.js itself is not single-threaded.
Node.js developers often confuse the main single-threaded event loop with Node.js entirely.
When a Node.js app is running, it automatically creates 4 threads under the worker pool for blocking tasks.
So at any given time, there are at least five threads.
This worker pool is ma... | nowaliraza |
1,827,426 | Simplificando sua Internacionalização | Fala Devs, blz? Semanas atrás escrevi um artigo mostrando uma maneira de internacionalizarmos nosso... | 0 | 2024-04-19T02:03:01 | https://dev.to/flutterbrasil/simplificando-sua-internacionalizacao-4nif |
Fala Devs, blz? Semanas atrás escrevi um artigo mostrando uma maneira de internacionalizarmos nosso aplicativo utilizando o package flutter_localization, confesso que esta maneira ficou um pouco avançada e um pouco complicada.
Mas graças a comunidade Flutter, principalmente aqui em terras tupiniquins, sempre vão surg... | toshiossada | |
1,827,530 | Nuget support will make Selenium coding simpler! | 🚀 Hello programming community! Today, I am pleased to introduce and share my new NuGet package... | 0 | 2024-04-19T03:46:35 | https://dev.to/vinzh05/nuget-support-will-make-selenium-coding-simpler-2n6m | webdev, csharp, selenium, automation | 🚀 Hello programming community! Today, I am pleased to introduce and share my new NuGet package designed to support Selenium in C#. 🎯
🔧 This package makes writing automated test scripts faster and easier than ever! From quick setups to visually writing test cases, everything is simplified to save time and enhance yo... | vinzh05 |
1,827,666 | Famous Bakery in Delhi | Enjoy the delicious foods of Delhi's most famous bakery, The Signature Bakery by Halwaivala in... | 0 | 2024-04-19T08:16:45 | https://dev.to/halwaivala/famous-bakery-in-delhi-1jcg | bakery, delhi | Enjoy the delicious foods of Delhi's most famous bakery, The Signature Bakery by Halwaivala in Naraina. Enjoy an arrangement of sensations made with the best ingredients, from gorgeous cakes and tempting pastries to savory pizzas and delightful pasta. Whether you want cookies, bread, or a culinary masterpiece, our bake... | halwaivala |
1,828,086 | Working with Modules and Packages | Working with Modules and Packages One of the key strengths of Python is its extensive... | 0 | 2024-04-19T15:10:03 | https://dev.to/romulogatto/working-with-modules-and-packages-2b1e | # Working with Modules and Packages
One of the key strengths of Python is its extensive library of modules and packages. These pre-written code blocks allow you to easily add functionality to your programs without having to reinvent the wheel. In this guide, we will explore how to work with modules and packages in Pyt... | romulogatto | |
1,828,989 | Rewrites are a symptom of bad initial engineering | I was prone to this problem at the beginning of my career, I would want to rewrite everything from... | 0 | 2024-04-20T16:25:45 | https://dev.to/shailennaidoo/rewrites-are-a-symptom-of-bad-initial-engineering-4nfl | softwareengineering, beginners, discuss, learning | I was prone to this problem at the beginning of my career, I would want to rewrite everything from the ground-up if I got this chance or I felt that the initial implementation did not "scale" well.
As I progressed in my career I started to realize that rewriting your application is a symptom of bad initial engineering... | shailennaidoo |
1,829,157 | Feedback on RazorOps CI/CD | What is RazorOps CICD? Learn More : https://razorops.com/?utm_source=dev.to... | 0 | 2024-04-20T21:17:51 | https://dev.to/madhuk/feedback-on-razorops-cicd-3n2n |
**What is RazorOps CICD?**
**Learn More :** https://razorops.com/?utm_source=dev.to
**Features:**
**User-Friendly Interface:** RazorOps offers an intuitive and user-friendly interface, making it easy for... | madhuk | |
1,829,288 | เว็บโฮสติ้งเป็นหัวใจสำคัญของเว็บไซต์ใดๆ | สิ่งที่ทำให้ผู้ให้บริการที่เชื่อถือได้เหล่านี้แตกต่างออกไปคือความมุ่งมั่นอย่างแน่วแน่ต่อความน่าเชื่อถ... | 0 | 2024-04-21T05:10:01 | https://dev.to/thaidatahosting23/ewbohstingepnhawaicchsamkhaykhngewbaichtaid-648 | สิ่งที่ทำให้ผู้ให้บริการที่เชื่อถือได้เหล่านี้แตกต่างออกไปคือความมุ่งมั่นอย่างแน่วแน่ต่อความน่าเชื่อถือ พวกเขาลงทุนในศูนย์ข้อมูลล้ำสมัยที่ติดตั้งระบบสำรองเพื่อให้มั่นใจถึงเวลาทำงานสูงสุดและลดความเสี่ยงของการหยุดชะงักของบริการ ความน่าเชื่อถือนี้เป็นสิ่งจำเป็นสำหรับธุรกิจที่ไม่สามารถให้เว็บไซต์ของตนไม่สามารถเข้าถึงได้ เน... | thaidatahosting23 | |
1,829,531 | White Label Virtual Assistants: Redefining Outsourcing in the Digital Era | Modern businesses must adapt quickly in the face of digitization to remain competitive, streamline... | 0 | 2024-04-21T11:40:19 | https://dev.to/jennifer12345/white-label-virtual-assistants-redefining-outsourcing-in-the-digital-era-20h | Modern businesses must adapt quickly in the face of digitization to remain competitive, streamline operations, improve efficiencies, and stay nimble in a digital economy. One solution that has gained significant traction recently is white-label virtual assistants (WLVAs). These remote professionals offer administrative... | jennifer12345 | |
1,829,606 | Women's Cute Sloth Animal T-Shirt - Limited Edition | Cute Sloth Animal T-shirt: A Perfect Blend of Comfort and Style Are you a sloth enthusiast or... | 0 | 2024-04-21T14:47:54 | https://dev.to/frafashion/womens-cute-sloth-animal-t-shirt-limited-edition-1l1p | tshirt, tutorial, react, programming | Cute Sloth Animal T-shirt: A Perfect Blend of Comfort and Style

Are you a sloth enthusiast or simply love adorable animal-themed apparel? Look no further! Our Cute Sloth Animal T-shirt (Design ID: CM_SPQNM9H) combin... | frafashion |
1,829,721 | Getting Started with C# Records | Introduction to C# Records C# 9.0 introduced a new type of class in called record. Record... | 0 | 2024-04-21T18:13:22 | https://antondevtips.com/blog/getting-started-with-csharp-records | programming, csharp, dotnet | ---
canonical_url: https://antondevtips.com/blog/getting-started-with-csharp-records
---
## Introduction to C# Records
C# 9.0 introduced a new type of class in called **record**.
Record is a reference type that offers immutability and equality comparison out of the box.
There are 2 forms of defining a record: a c... | antonmartyniuk |
1,829,794 | Optimizing PostgreSQL Performance: Navigating the Use of Bind Variables in Version 16 | In PostgreSQL, the use of bind variables, also known as parameterized queries or prepared statements,... | 0 | 2024-04-21T19:38:05 | https://dev.to/shiviyer/optimizing-postgresql-performance-navigating-the-use-of-bind-variables-in-version-16-2ehk | postgres, sql, dba, mysql | In PostgreSQL, the use of bind variables, also known as parameterized queries or prepared statements, is a common practice to execute SQL queries more efficiently and securely by separating the query structure from the data values. These variables help prevent SQL injection attacks and can improve performance by allowi... | shiviyer |
1,829,801 | 8 Things I Wish I Understood Earlier In My Career | Our lives and careers are journeys, so we should expect that we’ll be learning for the duration we’re... | 0 | 2024-04-22T16:00:00 | https://www.devleader.ca/2024/04/15/8-things-i-wish-i-understood-earlier-in-my-career/ | career, learning, codenewbie, writing | Our lives and careers are journeys, so we should expect that we’ll be learning for the duration we’re on this planet. As long as we’re moving forward in life, we have experiences to learn from. When I reflect on my career, there are a lot of lessons that I wish I could have taught myself early on. While I can’t talk to... | devleader |
1,830,026 | Hi , Still new | I'm thrilled to make my first post in the dev community, where I look forward to learning new things... | 0 | 2024-04-22T05:11:30 | https://dev.to/mayank6787/hi-still-new-1555 | webdev, newstart | I'm thrilled to make my first post in the dev community, where I look forward to learning new things and exploring diverse groups. | mayank6787 |
1,830,278 | Prophecy of Redux: State Management in Large React Apps | In the mystical realm of large-scale React applications, managing state becomes a saga of complexity... | 27,083 | 2024-04-22T11:00:00 | https://dev.to/kigazon/prophecy-of-redux-state-management-in-large-react-apps-49d5 | react, webdev, javascript, intermediate | In the mystical realm of large-scale React applications, managing state becomes a saga of complexity and cunning. Redux, the revered oracle of state management, emerges as the protagonist in this tale, offering a robust solution to tame the sprawling state of enterprise-level applications. This extensive guide explores... | kigazon |
1,830,437 | Decision Table Testing | Decision table testing is black box testing. It’s one of the testing techniques. Used to test systems... | 0 | 2024-04-22T12:29:26 | https://dev.to/gayu99/decision-table-testing-10ei | Decision table testing is black box testing. It’s one of the testing techniques. Used to test systems or systems that involve complex business logic with multiple inputs and conditions.
**Example**: Correct user name and password; the user will be redirected to the home screen; if any input is invalid, an error messag... | gayu99 | |
1,830,455 | Self-Care for ADHD Learners: Prioritizing Well-Being in Your Learning Journey (5/12) | Introduction: Welcome back to our 12-part series dedicated to supporting ADHD learners and... | 27,224 | 2024-04-22T12:52:45 | https://dev.to/techtobe101/self-care-for-adhd-learners-prioritizing-well-being-in-your-learning-journey-512-301k | adhd, techtobe101, selfcare, studytips | ## Introduction:
Welcome back to our 12-part series dedicated to supporting ADHD learners and individuals with similar learning differences. In this article, we'll explore the importance of self-care and strategies for prioritizing your mental and physical well-being amidst the challenges of academia.
## Understanding... | techtobe101 |
1,830,528 | Let's Build a Unique Tech YouTube Channel Together - Share Your Ideas and Be Part of the Journey! | Introduction Are you passionate about technology and love discovering new content? Join me... | 0 | 2024-04-22T14:32:43 | https://dev.to/huseyn0w/lets-build-a-unique-tech-youtube-channel-together-share-your-ideas-and-be-part-of-the-journey-2i93 | community, discuss, career, help | ### Introduction
Are you passionate about technology and love discovering new content? Join me as we create a one-of-a-kind Tech YouTube channel tailored by the tech community, for the tech community! Your insights are not only welcomed but essential.
### Why Your Voice Matters
In a world brimming with tech gurus an... | huseyn0w |
1,830,760 | Cloud Resume Challenge | Transitioning to the Cloud: My Journey with Azure Hey everyone! My name is Evan Dolatowski... | 0 | 2024-04-23T00:45:03 | https://dev.to/gnarlylasagna/cloud-resume-challenge-2jik | cicd, githubactions, azure, serverless |
# Transitioning to the Cloud: My Journey with Azure
Hey everyone! My name is Evan Dolatowski from Houston, Texas, and I’m a Full Stack developer. I'm currently working towards transitioning to the Cloud industry. The realization of an important gap in my knowledge and the adventure of educating myself more deeply abo... | gnarlylasagna |
1,830,915 | Get Unique Elements in a Python List | In Python we can get the unique elements from a list by converting it to a set with set(). Sets are a... | 0 | 2024-04-29T23:51:26 | https://nelson.cloud/get-unique-elements-in-a-python-list/ | python, beginners | ---
title: Get Unique Elements in a Python List
published: true
date: 2024-04-22 00:00:00 UTC
tags: python, beginners
canonical_url: https://nelson.cloud/get-unique-elements-in-a-python-list/
---
In Python we can get the unique elements from a list by converting it to a set with `set()`. Sets are a [collection of **un... | nelsonfigueroa |
1,830,947 | Leveraging Mob Programming for Knowledge Sharing and Instant Code Review | Hey fellow developers, Let's talk about a powerful practice that not only fosters collaboration but... | 0 | 2024-04-22T22:24:57 | https://dev.to/ivan-klimenkov/leveraging-mob-programming-for-knowledge-sharing-and-instant-code-review-23g9 | Hey fellow developers,
Let's talk about a powerful practice that not only fosters collaboration but also accelerates knowledge sharing and ensures instant code review: Mob Programming. In an era where teamwork and efficiency are paramount, Mob Programming emerges as a potent strategy for software development teams.
*... | ivan-klimenkov | |
1,831,091 | Crafting Reliable Web Apps: Embracing Offline Accessibility with Service Workers | Ever experienced the frustration of a web app crashing due to a lost network connection? Discover how... | 0 | 2024-04-23T04:22:56 | https://dev.to/sangeetha/crafting-reliable-web-apps-embracing-offline-accessibility-with-service-workers-3if1 |
Ever experienced the frustration of a web app crashing due to a lost network connection? Discover how Service Workers can revolutionize your web applications, ensuring they remain functional even offline. Accompanied by video demonstrations, witness the transformation from a traditional web app to one empowered by Ser... | sangeetha | |
1,831,125 | Conflict Resolution Training | Conflict is an inevitable part of human interaction, whether in personal relationships, professional... | 0 | 2024-04-23T05:51:52 | https://dev.to/maheshmahe3286/conflict-resolution-training-3f49 | education, training, certification, conflict |
Conflict is an inevitable part of human interaction, whether in personal relationships, professional settings, or within communities. However, unresolved conflicts can lead to misunderstandings, tension, and even escalation into more significant issues. That's where conflict resolution training comes into play. By equ... | maheshmahe3286 |
1,831,134 | From AI to AR: The Latest Technologies Reshaping the Retail Landscape | The retail industry has come a long way since its humble beginnings as small, local shops. With the... | 0 | 2024-04-23T06:02:14 | https://dev.to/sageit/from-ai-to-ar-the-latest-technologies-reshaping-the-retail-landscape-2be0 | ai, automation, cloud, devops | The retail industry has come a long way since its humble beginnings as small, local shops. With the rise of globalization and technological advancements, retailers have had to adapt to keep up with changing customer demands and market trends. Today, the retail industry is more competitive than ever, with customers expe... | sageit |
1,831,139 | Step-by-Step Guide: Installing Jenkins on Docker | 🚀 Excited about DevOps automation? Learn how to set up Jenkins on Docker for seamless CI/CD... | 0 | 2024-04-23T06:08:11 | https://dev.to/shubhthakre/step-by-step-guide-installing-jenkins-on-docker-en7 |
🚀 Excited about DevOps automation? Learn how to set up Jenkins on Docker for seamless CI/CD workflows! 🛠️
## Prerequisites :
Before we begin, ensure you have the following prerequisites:
- Docker installed on your machine
- Basic familiarity with Docker commands
- Internet connectivity to pull Docker images
🔹 St... | shubhthakre | |
1,831,293 | How to Manage Usage Limits in Colab for Optimal Performance | Optimize performance in Colab by managing usage limits effectively. Learn how to navigate usage... | 0 | 2024-04-23T09:30:00 | https://dev.to/novita_ai/how-to-manage-usage-limits-in-colab-for-optimal-performance-5bnb | ai, stablediffusion, colab | Optimize performance in Colab by managing usage limits effectively. Learn how to navigate usage limits in colab on our blog.
## Key Highlights
- Understand the usage limits of Google Colab and how they can impact your machine learning projects.
- Discover common usage limits and their implications.
- Explore strategi... | novita_ai |
1,831,329 | Adding Speech Navigation To A Website | by Sarah Okolo As technology evolves, so do the methods of interaction with websites. One such... | 0 | 2024-04-24T14:23:19 | https://blog.openreplay.com/adding-speech-navigation-to-a-website/ | by [Sarah Okolo](https://blog.openreplay.com/authors/sarah-okolo)
<blockquote><em>
As technology evolves, so do the methods of interaction with websites. One such advancement is the integration of speech navigation, allowing users to interact with web content hands-free using their voice. JavaScript's [Web Speech ... | asayerio_techblog | |
1,831,347 | Why Youngsters are Choosing Digital Marketing as a Career Option? | Digital marketing is in huge demand these days. If you are just starting out you might be thinking... | 0 | 2024-04-23T08:30:39 | https://dev.to/redapplelearning/why-youngsters-are-choosing-digital-marketing-as-a-career-option-5285 | digitalmarketing, seo, digitalmarketingcourse, redapplelearning | Digital marketing is in huge demand these days. If you are just starting out you might be thinking about the reasons for choosing digital marketing as a career option. Digital marketing is a strategy that’s different from other marketing strategies because it isn’t just about traditional advertising. Digital marketing ... | redapplelearning |
1,831,380 | Software Testing as a Debugging Tool | The Intersection of Debugging and Testing Unit Tests Integration Tests Coverage The Debug-Fix... | 20,817 | 2024-04-23T15:00:00 | https://debugagent.com/software-testing-as-a-debugging-tool | - [The Intersection of Debugging and Testing](#the-intersection-of-debugging-and-testing)
* [Unit Tests](#unit-tests)
* [Integration Tests](#integration-tests)
* [Coverage](#coverage)
- [The Debug-Fix Cycle](#the-debugfix-cycle)
- [Composing Tests with Debuggers](#composing-tests-with-debuggers)
- [Test-Driven... | codenameone | |
1,831,451 | Doge Dreams: Experts Predict 700% Surge in Dogecoin Value – Is $1 Within Reach? | Dogecoin Prediction: Analysts Bullish on DOGE's Future Dogecoin (DOGE) has proven its resilience... | 0 | 2024-04-23T10:20:46 | https://dev.to/cryptoalerts/doge-dreams-experts-predict-700-surge-in-dogecoin-value-is-1-within-reach-4k74 | cryptocurrency, dogecoin, bitcoin | [Dogecoin Prediction](https://coinpedia.org/price-prediction/dogecoin-price-analysis/): Analysts Bullish on DOGE's Future
Dogecoin (DOGE) has proven its resilience once again, with a 2.5% price uptick in the last 24 hours, reaching $0.1607 in trading value. Analysts like Altcoin Sherpa and Ali Martinez have recently s... | cryptoalerts |
1,831,541 | Discovering Georgia: A Traveler's Paradise | Georgia, located at the crossroads of Europe and Asia, is a country blessed with stunning natural... | 0 | 2024-04-23T12:02:17 | https://dev.to/travejars/discovering-georgia-a-travelers-paradise-mpa | Georgia, located at the crossroads of Europe and Asia, is a country blessed with stunning natural landscapes, rich history, and vibrant culture. Here are some [Place To Visit In Georgia](https://www.travejar.com/attractions/places-to-visit-in-georgia)
Tbilisi:
The capital city of Georgia, Tbilisi, is a dynamic blend o... | travejars | |
1,831,685 | Exploring the Role of Bioculture Manufacturers in Modern Biotechnology | Bioculture manufacturers play a crucial role in advancing modern biotechnology, providing essential... | 0 | 2024-04-23T12:35:51 | https://dev.to/ecolagro/exploring-the-role-of-bioculture-manufacturers-in-modern-biotechnology-33e6 | bioculturemanufacturer, biocultureforetp | Bioculture manufacturers play a crucial role in advancing modern biotechnology, providing essential resources and expertise to support research, development, and production in various industries. Let's delve into the multifaceted role of **[bioculture manufacturers](https://ecolagro.com/bio-culture-for-etp-stp-manufact... | ecolagro |
1,831,710 | Top 10 Most Common P&C Insurance Mistakes & How to Avoid Them | Do you know P&C insurance helps protect your assets? Yes, many businesses prefer this insurance... | 0 | 2024-04-23T12:42:24 | https://dev.to/fbspl/top-10-most-common-pc-insurance-mistakes-how-to-avoid-them-5pb | insurance, outsourcing, fbspl, bpo |

Do you know P&C insurance helps protect your assets? Yes, many businesses prefer this insurance because it helps against unforeseen circumstances. It protects assets like your house and belongings and offers liabi... | fbspl |
1,831,834 | The Thrilling World of Horse Racing: Where Speed, Skill, and Tradition Collide | In the realm of sports, maxichevalcom few events capture the imagination and excitement of... | 0 | 2024-04-23T15:13:21 | https://dev.to/stories-blogs/the-thrilling-world-of-horse-racing-where-speed-skill-and-tradition-collide-4pfa | In the realm of sports, **[maxichevalcom](https://maxicheval.com/)** few events capture the imagination and excitement of spectators quite like horse racing. From the thundering hooves pounding against the track to the heart-stopping finishes at the wire, horse racing embodies the essence of athleticism, competition, ... | stories-blogs | |
1,831,848 | Join the BitNest Community: A Hub for Crypto Enthusiasts | A post by xin yang | 0 | 2024-04-23T15:23:45 | https://dev.to/bitneestejhon/join-the-bitnest-community-a-hub-for-crypto-enthusiasts-748 |
 | bitneestejhon | |
1,832,246 | 📦 Put dev dependencies in tools.go | TL;DR: Use a tools.go file with //go:build tools to list import _ "github.com/octocat/somedevtool" to... | 0 | 2024-04-24T00:42:20 | https://dev.to/jcbhmr/put-dev-dependencies-in-toolsgo-9e6 | go, todayilearned, todayisearched | **TL;DR:** Use a `tools.go` file with `//go:build tools` to list `import _ "github.com/octocat/somedevtool"` to stop `go mod tidy` from removing them.
```go
//go:build tools
package tools
import (
_ "github.com/melbahja/got/cmd/got"
_ "github.com/arkady-emelyanov/go-shellparse"
)
```
<sup>💡 `go mod tidy` doesn't... | jcbhmr |
1,832,266 | Python 新手在找尋套件時的選擇困境 | 選擇困難 在 Python... | 0 | 2024-04-24T02:06:47 | https://dev.to/neilskilltree/python-xin-shou-zai-zhao-xun-tao-jian-shi-de-xuan-ze-kun-jing-m34 | python, programming, coding, beginners | ## 選擇困難
在 Python 的世界中,選擇合適的套件可能是一場挑戰,尤其對於新手來說。
首先他們會面臨到的困難是不知道該使用什麼關鍵字來進行精準快速的搜尋;其次,由於缺乏特定領域的背景知識,他們可能會誤解說明文件的內容,誤認為某個套件非常適合自己的需求,或者反過來,錯過最適合的選擇。
## 案例研究:Flask
我們以 Flask 為例,它是一個建立網站的工具,專門負責網站的幕後工作,雖然小巧但擴充性強。
以下是 Flask 開發小組於 PyPI 上的套件描述:
 is the second PTE Writing task, which asks you to read an essay topic and write a response in between 200 and 300 words. The [PTE Write Essay](https://edutrainex.com/blog/pte-write-essay-template-and-sample-topics/) task comes after the Summarize Written Text questions in... | edutrainexpte | |
1,833,414 | XDebug with WP-Setup | Introduction WP Setup has been updated to version 1.1.0, introducing Xdebug support and... | 27,179 | 2024-04-24T23:11:16 | https://dev.to/lucascarvalhopl/xdebug-with-wp-setup-1hkg | wordpress, news, php, testing | ## Introduction
WP Setup has been updated to version 1.1.0, introducing [Xdebug](https://xdebug.org/) support and allowing for easy generation of test coverage reports.
Additionally, some small fixes and improvements were made, such as using the [adm-zip](https://www.npmjs.com/package/adm-zip) library instead of [unz... | lucascarvalhopl |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.