
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,913,022 | Using Async in Ruby on Rails for CSV export | In this article, we'll go over the methods used to achieve async CSV export with Ruby on... | 0 | 2024-07-09T11:10:14 | https://dev.to/mharut/using-async-in-ruby-on-rails-for-csv-export-n69 | csv, ruby, async, webdev | In this article, we'll go over the methods used to achieve async CSV export with Ruby on Rails.
Problem: When a large amount of data is exported and the server is unable to process it quickly after receiving client requests, a timeout error may occasionally occur with CSV exports.
The solution is to move the CSV expo... | mharut |
1,913,076 | Latest Gemini features support in LangChain4j 0.32.0 | LangChain4j 0.32.0 was released yesterday, including my pull requestwith the support for lots of new... | 0 | 2024-07-12T18:31:49 | https://glaforge.dev/posts/2024/07/05/latest-gemini-features-support-in-langchain4j/ | ---
title: Latest Gemini features support in LangChain4j 0.32.0
published: true
date: 2024-07-05 09:53:30 UTC
tags:
canonical_url: https://glaforge.dev/posts/2024/07/05/latest-gemini-features-support-in-langchain4j/
---
[LangChain4j](https://docs.langchain4j.dev/) 0.32.0 was released yesterday, including my [pull req... | glaforge | |
1,913,185 | Which Map Transformation Should I Use? | Map transformation functions find common usage in Android development. They are part of the Kotlin... | 0 | 2024-07-10T10:08:43 | https://darrylbayliss.net/which-map-transformation-should-i-use/ | kotlin, android, androiddev, functional | ---
title: Which Map Transformation Should I Use?
published: true
date: 2024-07-04 05:00:00 UTC
tags: kotlin,android, androiddev, functional
canonical_url: https://darrylbayliss.net/which-map-transformation-should-i-use/
---
Map transformation functions find common usage in Android development. They are part of the [K... | darrylbayliss |
1,913,188 | Getting started with Amazon SageMaker: Building your first machine learning model | This article provides a guide on using Amazon SageMaker to build, train, and deploy a machine... | 0 | 2024-07-08T05:00:00 | https://dev.to/dhoang1905/getting-started-with-amazon-sagemaker-building-your-first-machine-learning-model-2m7n | aws, ai, machinelearning, sagemaker | This article provides a guide on using Amazon SageMaker to build, train, and deploy a machine learning model for predicting house prices using the Ames Housing dataset. It covers the key features of SageMaker, data preprocessing steps, model training, and deployment, and demonstrates how to test the deployed model. The... | dhoang1905 |
1,913,189 | Going Further with Styling | Hey there, welcome back to Learn As You Code: HTML & CSS! Today, we’re diving deeper into the... | 27,613 | 2024-07-08T14:00:00 | https://dev.to/nmiller15/going-further-with-styling-1dnp | html, css, beginners, webdev | Hey there, welcome back to **Learn As You Code: HTML & CSS**! Today, we’re diving deeper into the world of styling. Up until now, we’ve been styling elements directly. But what if you have two `<h2>` elements and want each to look different? Enter CSS selectors!
## Element Selectors
You’re already familiar with these... | nmiller15 |
1,913,274 | Angular Tutorial: Creating a Custom Loading Screen | If you’ve built apps in angular in the past, I’m sure you’ve experienced the blank screen while you... | 0 | 2024-07-12T18:25:31 | https://briantree.se/angular-tutorial-creating-a-custom-loading-screen/angular-tutorial-creating-a-custom-loading-screen/ | angular, angulardevelopers, tutorial, webdev | If you’ve built apps in angular in the past, I’m sure you’ve experienced the blank screen while you wait for the app to be bootstrapped. In smaller applications, it’s not as noticeable but in larger, more complex applications, we may need to wait for a little bit before we see the actual content loaded. And staring at ... | brianmtreese |
1,913,351 | Review: Fifine Ampligame AM6 Condenser Mic | Before we get started, please note that Fifine sent me a microphone for this review. ... | 28,027 | 2024-07-12T03:43:26 | https://www.nickyt.co/blog/review-fifine-ampligame-am6-condenser-mic-714/ | productreview, microphone, livestreaming, contentcreation | Before we get started, please note that Fifine sent me a microphone for this review.
## Packaging
The AM6 comes in a nice box and is very well protected with foam.


Becoming a proficient software developer is a journey that requires dedication, continuous learning, and a passion for problem-solving. In this blog post, we will explore essential strategies and best practices to h... | helloworldttj |
1,913,804 | Make Rust Object Oriented with the dual-trait pattern | Hi! Today I'll tell you about a cool Rust 🦀 trick: dual-trait pattern! It's especially useful when... | 0 | 2024-07-09T05:34:52 | https://dev.to/mslapek/make-rust-object-oriented-with-the-dual-trait-pattern-1kea | rust, architecture, howto, programming | Hi! Today I'll tell you about a cool Rust 🦀 trick: **dual-trait pattern!** It's especially useful when you're dealing with the `dyn` keyword and want to simulate OOP features in Rust.
The key idea is that we'll consider **two perspectives** (dual!) about a trait:
* **implementer** of the trait,
* **user** of the tra... | mslapek |
1,913,869 | Understanding Asynchronous JavaScript: Callbacks, Promises, and Async/Await | Hello and welcome to the first post of the JavaScript: From Novice to Expert Series ! My goal with... | 27,941 | 2024-07-08T01:00:00 | https://dev.to/buildwebcrumbs/understanding-asynchronous-javascript-callbacks-promises-and-asyncawait-cdc | Hello and welcome to the first post of the **JavaScript: From Novice to Expert Series** !
My goal with this series is to review some concepts myself, and while doing so, share my learning to help you learn as well 🌱
. In... | 26,522 | 2024-07-08T15:07:52 | https://dev.to/aws-builders/spring-boot-3-application-on-aws-lambda-part-9-develop-application-with-spring-cloud-function-aws-i1c | java, aws, springboot, serverless | ## Introduction
In the [part 8](https://dev.to/aws-builders/spring-boot-3-application-on-aws-lambda-part-8-introduction-to-spring-cloud-function-99a) we introduced concepts behind Spring Cloud Function (AWS). In this article we'll take a look into how to write AWS Lambda function with Java 21 runtime and Spring Cloud F... | vkazulkin |
1,913,940 | Django: difference between MEDIA_ROOT and STATIC_ROOT | Introduction STATIC_ROOT vs. MEDIA_ROOT In web development, particularly when... | 0 | 2024-07-10T09:10:47 | https://dev.to/doridoro/django-difference-between-mediaroot-and-staticroot-5cb | django | ## Introduction
### `STATIC_ROOT` vs. `MEDIA_ROOT`
In web development, particularly when working with Django, managing assets such as images, videos, CSS, and JavaScript files is a critical component of building a robust and efficient web application. Two key settings in Django, `MEDIA_ROOT` and `STATIC_ROOT`, that o... | doridoro |
1,913,949 | Basic Git and GitHub commands | Learning about version control system is an important part of your developer journey. As I started to... | 0 | 2024-07-09T09:57:13 | https://dev.to/sxryadipta/basic-git-and-github-commands-9jk | webdev, github, git, beginners | Learning about version control system is an important part of your developer journey. As I started to code, one of the first things that I learnt was about Git and GitHub. Straight from the horse’s mouth, “Git is a free and open-source distributed version control system designed to handle everything from small to very ... | sxryadipta |
1,914,052 | What is the Difference between "sequel" and "SQL"? | As you talk to different people, you will hear two different pronunciations of SQL. SQUEL or... | 0 | 2024-07-08T02:50:00 | https://dev.to/thekarlesi/what-is-the-difference-between-sequel-and-sql-oh0 | webdev, beginners, programming, tutorial |

As you talk to different people, you will hear two different pronunciations of SQL. SQUEL or SQL.
What is the correct way? Well, it depends on who you ask, and of course, everybody thinks that their way of pronoun... | thekarlesi |
1,914,069 | JavaScript Decorators and Auto-Accessors | A walkthrough of how to create JavaScript decorators and how using auto-accessors helps improve your... | 27,975 | 2024-07-10T01:30:30 | https://dev.to/frehner/javascript-decorators-and-auto-accessors-437i | javascript, webdev | A walkthrough of how to create JavaScript decorators and how using auto-accessors helps improve your developer experience.
## Table of Contents
- [Context and Specification](#context-and-specification)
- [Preface](#preface)
- [Auto-Accessors](#autoaccessors)
- [Creating Decorators](#creating-decorators)
- [A Sim... | frehner |
1,914,121 | Tech Debt: Code Todos Never Get Done? | Let's talk tech debt and code improvements. We've all been on a development team where ToDo comments... | 0 | 2024-07-08T11:56:36 | https://dev.to/grantdotdev/tech-debt-code-todos-never-get-done-2i31 | programming, productivity, discuss, developer | Let's talk tech debt and code improvements. We've all been on a development team where ToDo comments are left in the code, hoping they'll be picked up during downtime when no active tickets need attention.
## Table of Contents
[The Downtime Never Comes](#the-downtime-never-comes)
[How It Is Normally Handled](#how-it-i... | grantdotdev |
1,914,126 | Deploy a Static Website with Route53, CloudFront and AWS Certificate using a Terraform Script | Automation is queen in this side of our world, the more of your work you can automate, the... | 0 | 2024-07-10T13:51:05 | https://dev.to/chigozieco/deploy-a-static-website-with-route53-cloudfront-and-aws-certificate-using-a-terraform-script-25i8 | terraform, aws, devops, automation | Automation is queen in this side of our world, the more of your work you can automate, the better.
The use of Terraform is very necessary for cloud engineers in order to automate deployments of your infrastructure. Terraform is an infrastructure as code tool that lets you define infrastructure resources in human-reada... | chigozieco |
1,914,239 | Ambient Mesh with Istio like a boss! | Why ambient mesh and not sidecar? Ambient mesh uses a shared agent on each Kubernetes... | 28,023 | 2024-07-10T17:59:14 | https://matthewdavis.io/ambient-mesh-with-istio | istio, kubernetes, networking, servicemesh | ## Why ambient mesh and not sidecar?
Ambient mesh uses a shared agent on each Kubernetes node, called a ***ztunnel***. This zero-trust tunnel securely connects and authenticates elements within the mesh, redirecting all traffic through the local ztunnel agent.
This separation allows operators to manage the data plan... | mateothegreat |
1,914,271 | Simple Arduino Framework Photo Frame Implementation with Photos Downloaded from the Internet via DumbDisplay | Simple Arduino Framework Raspberry Pi Pico / ESP32 TFT LCD Photo Frame Implementation with Photos Downloaded from the Internet via DumbDisplay | 0 | 2024-07-08T10:06:04 | https://dev.to/trevorwslee/simple-arduino-framework-photo-frame-implementation-with-photos-downloaded-from-the-internet-via-dumbdisplay-170o | raspberrypipico, esp32, spitftlcd | ---
title: Simple Arduino Framework Photo Frame Implementation with Photos Downloaded from the Internet via DumbDisplay
description: Simple Arduino Framework Raspberry Pi Pico / ESP32 TFT LCD Photo Frame Implementation with Photos Downloaded from the Internet via DumbDisplay
tags: 'raspberrypipico, esp32, spitftlcd'
co... | trevorwslee |
1,914,292 | Mattermost: Free Open-source Alternative to Slack | In today's fast-paced digital world, efficient communication within teams is paramount. Many... | 0 | 2024-07-08T12:21:07 | https://blog.elest.io/mattermost-free-open-source-alternative-to-slack/ | opensourcesoftwares, elestio, mattermost | ---
title: Mattermost: Free Open-source Alternative to Slack
published: true
date: 2024-07-07 03:03:41 UTC
tags: Opensourcesoftwares,Elestio,Mattermost
canonical_url: https://blog.elest.io/mattermost-free-open-source-alternative-to-slack/
cover_image: https://blog.elest.io/content/images/2024/07/mattermost-thumbnail.pn... | kaiwalyakoparkar |
1,914,293 | Part 2: Learning HTML | July 6, 2024 I am working on Codeacademy's HTML Fundamentals Lesson and have learned a few HTML... | 0 | 2024-07-12T03:54:37 | https://dev.to/dgarcia1399/part-2-learning-html-ide | html | July 6, 2024
I am working on Codeacademy's HTML Fundamentals Lesson and have learned a few HTML concepts:
- Start an HTML file with the `<!DOCTYPE html>` declaration. This allows the browser to interpret the file as containing html content and works with the correct version of HTML.
- The next line should contain th... | dgarcia1399 |
1,914,410 | State Management in React: A Beginner's Guide | Introduction State management is a critical concept in React, essential for building... | 0 | 2024-07-10T15:39:32 | https://dev.to/lovishduggal/state-management-in-react-a-beginners-guide-40mg | webdev, javascript, beginners, react | ## Introduction
State management is a critical concept in React, essential for building dynamic and interactive applications. As a junior developer, understanding how to effectively manage state can significantly enhance your ability to create responsive and maintainable React applications. In this blog post, we'll co... | lovishduggal |
1,914,454 | Understanding the Monad Design Pattern | Monads are a powerful concept in functional programming that help manage side effects and maintain... | 0 | 2024-07-11T02:11:27 | https://rmauro.dev/understanding-the-monad-design-pattern/ | javascript, architecture, designpatterns | Monads are a powerful concept in functional programming that help manage side effects and maintain clean, composable code.
In this post, we'll explore the `Maybe` monad design pattern using JavaScript, which is used to handle operations that might fail or return null/undefined.
### What is a Monad?
In simple terms, ... | rmaurodev |
1,914,548 | Concurrency & Async programming in C# | Hello everyone! Today, we're diving into some crucial concepts in C# that will help you write... | 0 | 2024-07-09T10:38:09 | https://dev.to/ipazooki/concurrency-async-programming-in-c-1eda | csharp, tutorial, dotnet, community |
{% embed https://youtu.be/UNLdSsCWIXs %}
Hello everyone! Today, we're diving into some crucial concepts in C# that will help you write more efficient applications. We'll explore processes, threads, concurrency, and asynchronous programming. These topics might seem daunting initially, but don't worry; we'll break them... | ipazooki |
1,914,605 | Announcing Crawlee Python: Now you can use Python to build reliable web crawlers | We launched Crawlee in August 2022 and got an amazing response from the JavaScript community. With... | 0 | 2024-07-09T07:02:41 | https://crawlee.dev/blog/launching-crawlee-python | webdev, python, webscraping, programming |
We launched Crawlee in [August 2022](https://blog.apify.com/announcing-crawlee-the-web-scraping-and-browser-automation-library/) and got an amazing response from the JavaScript community. With many early adopters in its initial days, we got valuable feedback, which gave Crawlee a strong base for its success.
Today, ... | sauain |
1,914,636 | Fighting the imposter syndrome | I recently asked ChatGPT what is the definition of the term "Imposter Syndrome", and I have got the... | 0 | 2024-07-08T17:29:36 | https://eyal-estrin.medium.com/fighting-the-imposter-syndrome-7a0ec53d4e80 | career, careerdevelopment, learning, impostersyndrome |

I recently asked ChatGPT what is the definition of the term "Imposter Syndrome", and I have got the following answer:
*Imposter syndrome refers to feelings of inadequacy and self-doubt that persist despite eviden... | eyalestrin |
1,914,646 | Apple Vision Pro: Redefining Augmented Reality With Cutting-Edge Technology | The Apple Vision Pro has quickly become a standout with its impressive features and presence. The... | 0 | 2024-07-07T20:50:52 | https://dev.to/kwan/apple-vision-pro-redefining-augmented-reality-with-cutting-edge-technology-28gj | apple, applevisionpro, technology | **_The Apple Vision Pro has quickly become a standout with its impressive features and presence. The innovative headset merges virtual reality with the physical world through spatial computing, allowing for seamless and intuitive interactions. In this article, we’ll delve into the key features of Apple Vision Pro as we... | kwan |
1,914,659 | Infinite list loading 🤔, with React Query - useInfiniteQuery hook ! | Sometimes getting all the data in a single API query is worth than getting it in the form of... | 0 | 2024-07-09T03:18:11 | https://dev.to/delisrey/infinite-list-loading-with-react-query-useinfinitequery-hook--19i | react, reactquery, webdev, javascript | Sometimes getting all the data in a single API query is worth than getting it in the form of paginated data, but not in every case what if you need the API to be more optimized and efficient hence implementing a infinite loading kind of a feature from scratch might not only be complicated but also overwhelming if you a... | delisrey |
1,914,735 | Clean Architecture in Node.js: An Approach with TypeScript and Dependency Injection. | A Clean Architecture What is clean architecture and why do we even care about it? The... | 0 | 2024-07-08T14:39:23 | https://dev.to/evangunawan/clean-architecture-in-nodejs-an-approach-with-typescript-and-dependency-injection-16o | node, cleancode, microservices, architecture | ## A Clean Architecture
What is clean architecture and why do we even care about it? The clean architecture approach is a software design pattern and a guideline proposed by Robert C. Martin (Uncle Bob). This architecture urges us to build a cleaner code and more structured code.
So why do we care about it, why is it ... | evangunawan |
1,914,752 | Destiny or Coincidence: Based on Shannon Perry s Experiment. | TL;DR: I developed a project to determine if you have ever crossed paths with ‘that’ person before... | 26,735 | 2024-07-11T00:50:12 | https://chriisduran.medium.com/destiny-or-coincidence-based-on-shannon-perry-s-experiment-d43da0ac5529 | python, javascript, replit, codepen | **TL;DR:** I developed a project to determine if you have ever crossed paths with ‘that’ person before meeting them in your life based on your mobile.
## Background
I often read [Xataka](https://www.xataka.com/privacidad/cuantas-veces-coincidiste-tu-pareja-antes-conocerla-asi-se-pueden-usar-datos-google-maps-para-desc... | chriisduran |
1,914,908 | Understanding self-assumption and scoped-down policy in AWS IAM | AWS IAM is a fundamental service for all 200+ AWS services, as it enables interaction with AWS... | 0 | 2024-07-08T21:13:55 | https://dev.to/aws-builders/understanding-self-assumption-and-scoped-down-policy-in-aws-iam-2io | aws, iam, security, githubactions | AWS IAM is a fundamental service for all 200+ AWS services, as it enables interaction with AWS principals. An AWS IAM role consists of two components: a policy and a trust relationship. The trust relationship handles authentication, while the policy is for authorization.
.ONG using server-side redirects, but Google... | 0 | 2024-07-08T09:03:56 | https://chi.miantiao.me/posts/google-safe-browsing-alternative/ | google, cloudflare, safebrowsing, zerotrust | ---
title: How to Replace Google Safe Browsing with Cloudflare Zero Trust
published: true
date: 2024-07-07 14:48:53 UTC
tags: Google,Cloudflare,SafeBrowsing,ZeroTrust
canonical_url: https://chi.miantiao.me/posts/google-safe-browsing-alternative/
---
So, get this, right? I built the first version of [L(O\*62).ONG](http... | ccbikai |
1,914,902 | It's time to ditch the complicated and slow Python setup | A guide and tutorial on Rye | 0 | 2024-07-11T14:03:06 | https://dev.to/assertnotnull/its-time-to-ditch-the-complicated-and-slow-python-setup-5ee8 | python | ---
title: It's time to ditch the complicated and slow Python setup
published: true
description: A guide and tutorial on Rye
tags: python
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-07-07 19:20 +0000
---
At my work I was faced with a complicated instal... | assertnotnull |
1,915,061 | 4 Database tips for Java Developers 💡 | Introduction 🔍 Understanding databases is essential for Java developers, as they... | 0 | 2024-07-08T00:18:44 | https://dev.to/joaomarques/4-database-tips-for-java-developers-2hg9 | ### Introduction
🔍 Understanding databases is essential for Java developers, as they frequently handle critical data such as user information, past actions, application settings, and feature flags. As applications expand, databases must scale to meet performance demands and ensure efficient data management. For insig... | joaomarques | |
1,915,068 | (JavaScript Proxy vs Object.define Property) Vue.js dagi reaktivlikni ortida nima turadi va qanday ishlaydi ? | Assalamu alaykum! ahli O'zbek Vue community! Keling bugun Vue.js da reaktivlik qanday ishlaydi ,... | 0 | 2024-07-08T00:20:53 | https://dev.to/mukhriddinweb/vuejs-dagi-reaktivlikni-ortida-nima-turadi-va-qanday-ishlaydi--p4g | javascript, vue, nuxt, mukhriddinweb |

Assalamu alaykum! ahli O'zbek Vue community! Keling bugun Vue.js da reaktivlik qanday ishlaydi , minde sizlarga tushuntirsam :)
Bismillah!
Hamma gap **JavaScriptda** , ya'ni `Object.defineProperty` va `Proxy` Ja... | mukhriddinweb |
1,915,069 | Building Flexible and Maintainable Go-Lang Apps | In software development, Dependency Injection (DI) is one of the fundamental principles that help... | 0 | 2024-07-08T00:26:19 | https://dev.to/dyaksaa_/building-flexible-and-maintainable-go-lang-apps-56kn | webdev, go, programming, tutorial | In software development, Dependency Injection (DI) is one of the fundamental principles that help build flexible and maintainable applications. In this article, we will discuss the use of Dependency Injection in Go-Lang and how the Wire tool can help us configure dependencies easily.
**What is Dependency Injection?**
... | dyaksaa_ |
1,915,070 | Deploying a windows 11 VM, Windows Server & a Linux VM | Step 1: To access the Azure portal, we must provide our login credentials which includes our username... | 0 | 2024-07-08T01:43:30 | https://dev.to/bdporomon/deploying-a-windows-11-vm-windows-server-a-linux-vm-1m9b | webdev, beginners, programming, devops | Step 1: To access the Azure portal, we must provide our login credentials which includes our username and password.
Step 2: In the "Search resources, services and docs" field, type and click “virtual machines”.
Step 3: Click the “Create” button to start the virtual machine creation process then Create a virtual machine... | bdporomon |
1,915,071 | Exploring Advanced Features of TypeScript | Introduction: TypeScript is a superset of JavaScript that offers advanced features and advantages to... | 0 | 2024-07-08T00:34:52 | https://dev.to/kartikmehta8/exploring-advanced-features-of-typescript-807 | Introduction:
TypeScript is a superset of JavaScript that offers advanced features and advantages to enhance the development experience. It provides static typing, interfaces, classes, and other features to help developers write more robust and error-free code. In this article, we will explore some of the advanced fea... | kartikmehta8 | |
1,915,073 | Vue3 da ( ref va reactive) farqi | Vue3-daref va reactive hook-larini tanlashda qaysi biri qulayroq ekanligini aniqlashda, ularning... | 0 | 2024-07-08T00:53:30 | https://dev.to/mukhriddinweb/vue3-da-ref-va-reactive-farqi-1bme | vue, javascript, php, mukhriddinweb | **Vue3-da**`ref` va `reactive` hook-larini tanlashda qaysi biri qulayroq ekanligini aniqlashda, ularning farqlarini va qanday holatlarda foydalanishni tushunish kerak . Har ikkala hook ham reaktiv ma'lumotlar yaratish uchun ishlatiladi, lekin ularning ishlash usuli va qo'llanilishi jichcha farq qiladi.
### `ref`
####... | mukhriddinweb |
1,915,074 | Mastering Multithreading in C Programming: A Deep Dive with In-Depth Explanations and Advanced Concepts | Introduction: Multithreading in C programming enables developers to harness the full... | 0 | 2024-07-08T01:06:39 | https://dev.to/vivekyadav200988/mastering-multithreading-in-c-programming-a-deep-dive-with-in-depth-explanations-and-advanced-concepts-245g | multithreading, posix, c, embedded | ## Introduction:
Multithreading in C programming enables developers to harness the full potential of modern multicore processors, facilitating concurrent execution of tasks within a single process. This comprehensive guide explores fundamental multithreading concepts, synchronization mechanisms, and advanced topics, p... | vivekyadav200988 |
1,915,075 | Understanding Blocking and Non-blocking Sockets in C Programming: A Comprehensive Guide | Introduction: In the realm of network programming with C, mastering the intricacies of... | 0 | 2024-07-08T01:11:02 | https://dev.to/vivekyadav200988/understanding-blocking-and-non-blocking-sockets-in-c-programming-a-comprehensive-guide-2ien | ## Introduction:
In the realm of network programming with C, mastering the intricacies of socket operations is paramount. Among the fundamental concepts in this domain are blocking and non-blocking sockets, which significantly influence the behavior and performance of networked applications. In this comprehensive guid... | vivekyadav200988 | |
1,915,076 | Working on Something You Hate for 7 Years - How to Escape a Professional Crisis | Have you ever found yourself with a feeling of emptiness, feeling some kind of melancholy that you... | 0 | 2024-07-08T01:13:08 | https://dev.to/juanemilio31323/working-on-something-you-hate-for-7-years-how-to-escape-a-professional-crisis-5892 | career, help, productivity, learning | Have you ever found yourself with a feeling of emptiness, feeling some kind of melancholy that you can't explain? If the answer is yes, let me tell you that I have felt it too, and it hasn't been easy to turn it off. In this post, I want to share the personal and professional crisis that I'm going through and the thing... | juanemilio31323 |
1,915,093 | Invalid Date in Safari | Hello everyone, Today, I encountered a weird bug that only appears in the Safari browser. It works... | 0 | 2024-07-08T01:43:13 | https://dev.to/deni_sugiarto_1a01ad7c3fb/invalid-date-in-safari-4ff6 | safari, webdev, javascript, programming | Hello everyone,
Today, I encountered a weird bug that only appears in the Safari browser. It works fine in other browsers. After debugging the code in Safari, I found that filtering data by date was resulting in an empty array. I have been using dayjs as my date library for formatting and filtering.
Here is the sourc... | deni_sugiarto_1a01ad7c3fb |
1,915,095 | HackerRank 3 Months Preparation Kit(JavaScript) - Plus Minus | Given an array of integers, calculate the ratios of its elements that are positive, negative, and... | 0 | 2024-07-08T01:52:07 | https://dev.to/saiteja_amshala_035a7d7f1/hackerrank-3-months-preparation-kit-plus-minus-3cgn | webdev, javascript, beginners, learning | Given an array of integers, calculate the ratios of its elements that are positive, negative, and zero. Print the decimal value of each fraction on a new line with _6_ places after the decimal.
Note: This challenge introduces precision problems. The test cases are scaled to six decimal places, though answers with absol... | saiteja_amshala_035a7d7f1 |
1,915,096 | A new beginning | Hi, Good morning This is umaganesh and I am much thrilled to learn python through my native language... | 0 | 2024-07-08T01:56:32 | https://dev.to/yuga/a-new-beginning-3glf | python | Hi, Good morning
This is umaganesh and I am much thrilled to learn python through my native language thanks for kaniyam foundation. | yuga |
1,915,097 | Concatenate Column Values and Perform Grouping & Aggregation | Problem description & analysis: In the table below, the 1st column is person’s name, and the... | 0 | 2024-07-08T02:16:29 | https://dev.to/judith677/concatenate-column-values-and-perform-grouping-aggregation-3b3 | programming, beginners, tutorial, productivity | **Problem description & analysis**:
In the table below, the 1st column is person’s name, and the multiple columns after it are items they purchased. There are people who sometimes buy multiple same items in one purchase and who place multiple orders at different times.
 has been a feature in React since v16.6.0. Despite this, I... | 0 | 2024-07-08T03:32:03 | https://www.bbss.dev/posts/react-learn-suspense/ | react, javascript | ---
title: Learn Suspense by Building a Suspense-Enabled Library
published: true
tags: react, javascript
canonical_url: https://www.bbss.dev/posts/react-learn-suspense/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/zoqblkosiwbgexh5jbh8.png
---
Suspense (along with concurrent rendering) has bee... | vezyank |
1,915,101 | Get 24% Off Nexa N20000 Disposable Vape – 20,000 Puffs of Pure Bliss! | Experience unparalleled vaping satisfaction with the Nexa N20000 Disposable Vape, now at an... | 0 | 2024-07-08T02:27:02 | https://dev.to/vapenear/get-24-off-nexa-n20000-disposable-vape-20000-puffs-of-pure-bliss-1dld | Experience unparalleled vaping satisfaction with the Nexa N20000 Disposable Vape, now at an incredible 24% off at [VapeNear](https://vapenear.com/nexa-n20000-disposable-vape-20000-puffs.html)! Enjoy 20,000 puffs of premium flavor and convenience. Don't miss out on this limited-time offer – elevate your vaping experienc... | vapenear | |
1,915,103 | ChatGPT Portugues: A Revolução da IA em Língua Portuguesa | Nos últimos anos, a inteligência artificial (IA) tem transformado a maneira como interagimos com a... | 0 | 2024-07-08T02:30:46 | https://dev.to/chatgpt_portugues_15d9d13/chatgpt-portugues-a-revolucao-da-ia-em-lingua-portuguesa-35n9 | chatgpt | Nos últimos anos, a inteligência artificial (IA) tem transformado a maneira como interagimos com a tecnologia. Um dos exemplos mais notáveis dessa transformação é o ChatGPT, um modelo de linguagem desenvolvido pela OpenAI. Com o crescente interesse e necessidade de conteúdos em português, surge o ChatGPT Portugues, uma... | chatgpt_portugues_15d9d13 |
1,915,104 | Transparent LED display: Leading the new modern vision | Introduction With its unique visual effects and application flexibility, transparent LED display is... | 0 | 2024-07-08T02:34:07 | https://dev.to/sostrondylan/transparent-led-display-leading-the-new-modern-vision-245o | transparent, led, display | Introduction
With its unique visual effects and application flexibility, [transparent LED display](https://sostron.com/products/crystal-transparent-led-screen/) is gradually changing our perception of traditional display technology. This article will explore the innovative application of transparent LED display in dif... | sostrondylan |
1,915,107 | How to Build a Data Collection System (Fast & Easy) | Build a Data Collection System in 3 Easy Steps In this guide, we outline the steps necessary to... | 0 | 2024-07-08T02:40:41 | https://five.co/blog/how-to-build-a-data-collection-system/ | database, datascience, mysql, development | <!-- wp:heading -->
<h2 class="wp-block-heading">Build a Data Collection System in 3 Easy Steps</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In this guide, we outline the steps necessary to build and launch a data collection system using Five’s rapid application development environment.</p>
<!-- /wp:paragraph --... | domfive |
1,915,108 | Thiết kế Website Tại Bình Phước Tối Ưu Chi Phí | Đối với các doanh nghiệp tại Bình Phước, việc sở hữu một website ấn tượng, tối ưu hóa về mặt SEO và... | 0 | 2024-07-08T02:47:07 | https://dev.to/terus_technique/thiet-ke-website-tai-binh-phuoc-toi-uu-chi-phi-377j | website, digitalmarketing, seo, terus |
Đối với các doanh nghiệp tại Bình Phước, việc sở hữu một website ấn tượng, tối ưu hóa về mặt SEO và có khả năng mang lại lượng khách hàng tiềm năng là vô cùng cần thiết.
Terus tự tin là một công ty chuyên về thiết... | terus_technique |
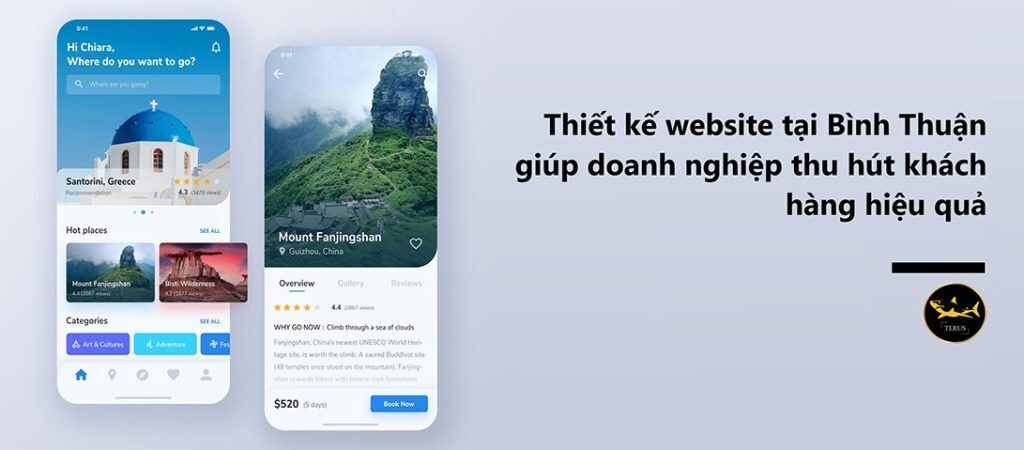
1,915,109 | Thiết kế Website Tại Bình Thuận Thu Hút | Trong thời đại số hóa ngày nay, sở hữu một website chuyên nghiệp đóng vai trò then chốt trong việc... | 0 | 2024-07-08T02:49:44 | https://dev.to/terus_technique/thiet-ke-website-tai-binh-thuan-thu-hut-2di6 | website, digitalmarketing, seo, terus |
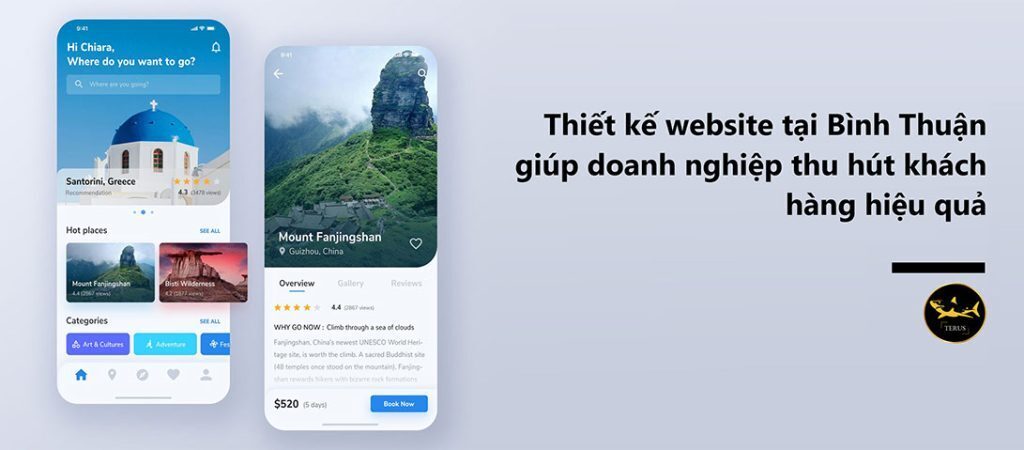
Trong thời đại số hóa ngày nay, sở hữu một website chuyên nghiệp đóng vai trò then chốt trong việc thúc đẩy sự phát triển của doanh nghiệp. Đặc biệt đối với các công ty tại Bình Thuận, thiết kế website là một giải p... | terus_technique |
1,915,110 | debouncing and throttling in javascript simplified by aryan | These jargon is nothing but ways to improve javascript❤ performance. Debounce Debounce is... | 0 | 2024-07-08T02:50:02 | https://dev.to/aryan015/debouncing-and-throttling-in-javascript-simplified-by-aryan-492e | javascript, react, webdev, programming | These jargon is nothing but ways to improve javascript❤ performance.
## Debounce
Debounce is improved version of throttle. `beware` that it will only run when cursor stops running, might miss some important inputs. If you move the cursor within second then it will reset the cursor.
snippet.js
```js
let interval;
functi... | aryan015 |
1,915,111 | Thiết kế Website Tại Cà Mau Chuyên Nghiệp | Khi doanh nghiệp muốn xây dựng một website tại Cà Mau, việc xác định đúng nhu cầu là bước quan trọng... | 0 | 2024-07-08T02:52:57 | https://dev.to/terus_technique/thiet-ke-website-tai-ca-mau-chuyen-nghiep-kp5 | website, digitalmarketing, seo, terus |

Khi doanh nghiệp muốn xây dựng một website tại Cà Mau, việc xác định đúng nhu cầu là bước quan trọng đầu tiên. Doanh nghiệp cần hiểu rõ mục tiêu kinh doanh, mục đích tiếp thị, mục tiêu công nghệ và mục tiêu tài chín... | terus_technique |
1,915,112 | Simple Guide to Learning SEO Without Tech Experience | SEO (Search Engine Optimization) is super important for your website's success. Don't worry if you're... | 0 | 2024-07-08T02:53:16 | https://dev.to/juddiy/simple-guide-to-learning-seo-without-tech-experience-1ign | website, seo, learning | SEO (Search Engine Optimization) is super important for your website's success. Don't worry if you're not a tech guru—you can still grasp and use SEO to boost your site's ranking and visibility in search engines with these easy methods:
1. **Learn the Basics**: Understanding the fundamental concepts of SEO is the firs... | juddiy |
1,915,113 | Thiết kế Website Tại Cao Bằng Tăng Doanh Thu | Dịch vụ thiết kế website chuyên nghiệp tại Cao Bằng sẽ mang lại nhiều lợi ích cho doanh nghiệp. Đầu... | 0 | 2024-07-08T02:55:54 | https://dev.to/terus_technique/thiet-ke-website-tai-cao-bang-tang-doanh-thu-2nm5 | website, digitalmarketing, seo, terus |

[Dịch vụ thiết kế website chuyên nghiệp tại Cao Bằng](https://terusvn.com/thiet-ke-website-tai-hcm/) sẽ mang lại nhiều lợi ích cho doanh nghiệp. Đầu tiên, nó sẽ là nơi cung cấp nguồn thông tin hữu ích và đáng tin cậ... | terus_technique |
1,915,114 | Stay Updated with PHP/Laravel: Weekly News Summary (01/07/2024–07/07/2024) | Intro: Check out this insightful summary of PHP Laravel Weekly News for the week of July 1st to July... | 0 | 2024-07-08T02:57:34 | https://poovarasu.dev/php-laravel-weekly-news-summary-01-07-2024-to-07-07-2024/ | php, laravel | **Intro**: Check out this insightful summary of PHP Laravel Weekly News for the week of July 1st to July 7th, 2024. Stay updated with the latest developments, releases, and community updates in the PHP Laravel ecosystem.
**Key Points:**
- 🚀 New String Helpers and ServeCommand Improvements in Laravel 11.14: Releases i... | poovarasu |
1,915,115 | Thiết kế Website Tại Đắk Lắk Đầy Đủ Chức Năng | Một website chuyên nghiệp mang lại nhiều lợi ích cho doanh nghiệp. Thứ nhất, nó giúp tăng tính... | 0 | 2024-07-08T02:59:12 | https://dev.to/terus_technique/thiet-ke-website-tai-dak-lak-day-du-chuc-nang-2c5 | website, digitalmarketing, seo, terus |
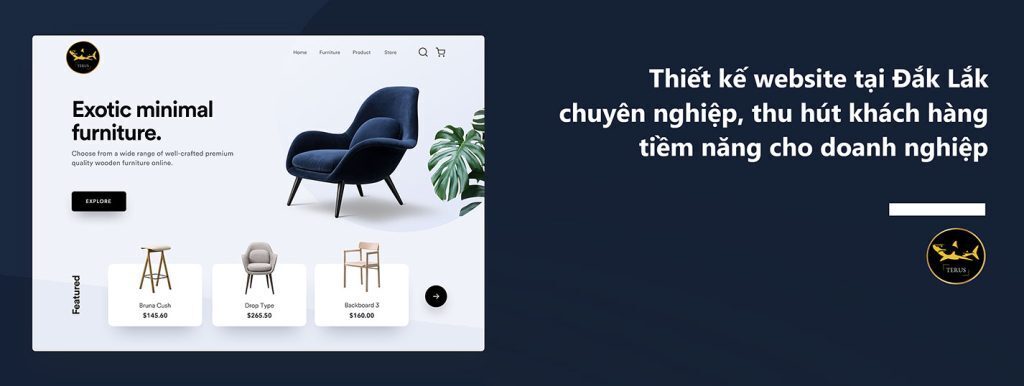
Một website chuyên nghiệp mang lại nhiều lợi ích cho doanh nghiệp.
Thứ nhất, nó giúp tăng tính chuyên nghiệp và uy tín của thương hiệu, khẳng định vị thế của doanh nghiệp trong mắt khách hàng.
Thứ hai, website ... | terus_technique |
1,915,116 | WebCheck: Find out what hackers know about your site | There are times when you would like to know what all these hackers know about your site that you may... | 0 | 2024-07-08T03:00:22 | https://dev.to/tkouleris/webcheck-find-out-what-hackers-know-about-your-site-1elj | web, security | There are times when you would like to know what all these hackers know about your site that you may be unaware of. So you open 5-6 tools on your computer, you open sites in your browser that can help you, but finally you lose yourself between applications and data which you try to put in a logical order.
But don't be... | tkouleris |
1,915,117 | Stay Updated with Python/FastAPI/Django: Weekly News Summary (01/07/2024–07/07/2024) | Intro: Check out this insightful summary of Python/FastAPI/Django Weekly News for the week of July... | 0 | 2024-07-09T03:00:00 | https://poovarasu.dev/python-fastapi-django-weekly-news-summary-01-07-2024-to-07-07-2024/ | python, fastapi, django, flask | **Intro:** Check out this insightful summary of Python/FastAPI/Django Weekly News for the week of July 1st to July 7th, 2024. Stay updated with the latest developments, releases, and community updates in the Python ecosystem.
**Key Points:**
🐍 Python News Roundup: NumPy and Polars release new major versions, impactin... | poovarasu |
1,915,118 | Thiết kế Website Tại Đắk Nông Chuyên Nghiệp Uy Tín | Lý do các doanh nghiệp cần thiết kế website tại Đắk Nông: Tăng tính chuyên nghiệp và độ tin cậy của... | 0 | 2024-07-08T03:02:07 | https://dev.to/terus_technique/thiet-ke-website-tai-dak-nong-chuyen-nghiep-uy-tin-bjj | website, digitalmarketing, seo, terus |
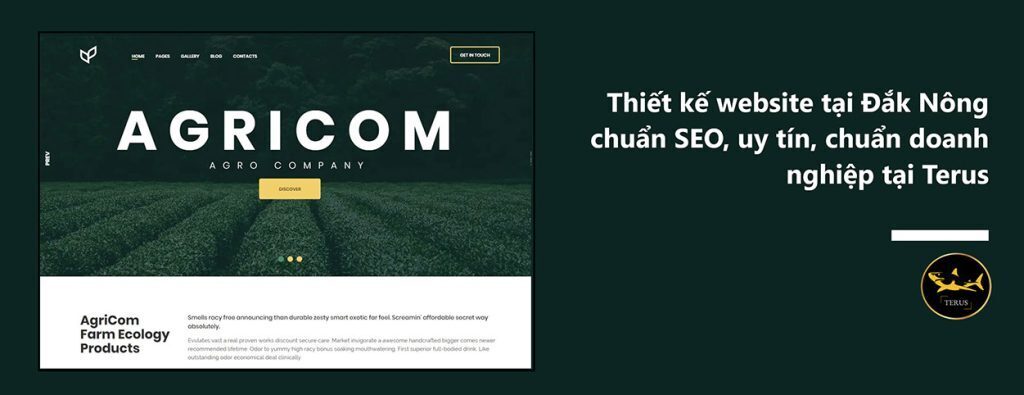
Lý do các doanh nghiệp cần thiết kế website tại Đắk Nông:
Tăng tính chuyên nghiệp và độ tin cậy của thương hiệu: Một website chuyên nghiệp với thiết kế đẹp mắt và nội dung chất lượng sẽ tạo ấn tượng tốt với khách h... | terus_technique |
1,915,119 | Thiết kế Website Tại Điện Biên Độc Đáo, Thu Hút | Lý do các doanh nghiệp cần thiết kế website tại Điện Biên Nâng cao hiệu quả hoạt động kinh doanh:... | 0 | 2024-07-08T03:04:34 | https://dev.to/terus_technique/thiet-ke-website-tai-dien-bien-doc-dao-thu-hut-21ih | website, digitalmarketing, seo, terus |
Lý do các doanh nghiệp cần thiết kế website tại Điện Biên
Nâng cao hiệu quả hoạt động kinh doanh: Một website chuyên nghiệp không chỉ là công cụ quảng bá, tiếp thị hiệu quả mà còn là kênh để doanh nghiệp tương tác,... | terus_technique |
1,915,121 | Mengenal GPXSlot: Platform Slot Online Terpercaya | Dalam era digital saat ini, perjudian online telah menjadi bagian tak terpisahkan dari kehidupan... | 0 | 2024-07-08T03:07:20 | https://dev.to/gpxslot/mengenal-gpxslot-platform-slot-online-terpercaya-1lnp | gpxslot, linkaltgpxslot, slotgacor | Dalam era digital saat ini, perjudian online telah menjadi bagian tak terpisahkan dari kehidupan banyak orang di seluruh dunia. Salah satu jenis perjudian online yang populer adalah permainan slot. Dengan perkembangan teknologi, semakin banyak platform judi online bermunculan, salah satunya adalah [GPXSlot](https://gpx... | gpxslot |
1,915,122 | Thiết kế Website Tại Đồng Tháp Chuẩn UI/ UX | Trong thời đại số hóa như hiện nay, việc sở hữu một website chuyên nghiệp đóng vai trò rất quan... | 0 | 2024-07-08T03:07:42 | https://dev.to/terus_technique/thiet-ke-website-tai-dong-thap-chuan-ui-ux-2l1g | website, digitalmarketing, seo, terus |
Trong thời đại số hóa như hiện nay, việc sở hữu một website chuyên nghiệp đóng vai trò rất quan trọng đối với các doanh nghiệp tại Đồng Tháp. Một website có thể giúp doanh nghiệp quảng bá sản phẩm, dịch vụ, tăng tín... | terus_technique |
1,915,123 | Thiết kế Website Tại Gia Lai Tiêu Chuẩn 2024 | Trong thời đại ngày nay, sở hữu trang thiết kế website chuyên nghiệp và hiện đại không chỉ là một... | 0 | 2024-07-08T03:10:36 | https://dev.to/terus_technique/thiet-ke-website-tai-gia-lai-tieu-chuan-2024-1efk | website, digitalmarketing, seo, terus |

Trong thời đại ngày nay, [sở hữu trang thiết kế website chuyên nghiệp và hiện đại](https://terusvn.com/thiet-ke-website-tai-hcm/) không chỉ là một lựa chọn mà còn là một nhu cầu cấp thiết đối với các doanh nghiệp tạ... | terus_technique |
1,915,124 | Best and Good Solution | Weekly lessons from a Software Engineer: — Working in an Agile Software Development team for a... | 0 | 2024-07-08T03:13:14 | https://dev.to/rodonguyen/best-and-good-solution-236e | Weekly lessons from a Software Engineer:
—
Working in an Agile Software Development team for a while, I realised that the best solution is not always the best thing for business.
The business owner (BO) may not care how well the code is written or if the architecture is well designed for the future.
Sometimes, ... | rodonguyen | |
1,915,125 | Mastering Regular Expressions: A Comprehensive Journey | The article is about a comprehensive collection of 8 free programming learning resources from GetVM.io, all focused on the topic of regular expressions. It covers a wide range of topics, including the fundamentals of regular expression matching, efficient algorithms for regular expression matching, building custom regu... | 27,985 | 2024-07-08T03:14:38 | https://dev.to/getvm/mastering-regular-expressions-a-comprehensive-journey-2pgg | getvm, programming, freetutorial, collection |
Are you ready to dive deep into the world of regular expressions and unlock the power of pattern matching? 🔍 This collection of tutorials from GetVM.io offers a comprehensive exploration of the fundamental concepts, practical applications, and advanced techniques behind this essential programming tool.
 - KisFlow-Golang Stream Real-Time Computing - Flow Parallel Operation | Github: https://github.com/aceld/kis-flow Document:... | 0 | 2024-07-08T03:15:34 | https://dev.to/aceld/case-i-kisflow-golang-stream-real-time-computing-flow-parallel-operation-364m | go | <img width="150px" src="https://github.com/aceld/kis-flow/assets/7778936/8729d750-897c-4ba3-98b4-c346188d034e" />
Github: https://github.com/aceld/kis-flow
Document: https://github.com/aceld/kis-flow/wiki
---
[Part1-OverView](https://dev.to/aceld/part-1-golang-framework-hands-on-kisflow-streaming-computing-framework... | aceld |
1,915,127 | Thiết kế Website Tại Hà Giang Đẹp Mắt | Lợi ích của việc thiết kế website tại Hà Giang chuẩn SEO Cầu nối giữa công ty và khách hàng: Một... | 0 | 2024-07-08T03:16:09 | https://dev.to/terus_technique/thiet-ke-website-tai-ha-giang-dep-mat-34po | website, digitalmarketing, seo, terus |

Lợi ích của việc thiết kế website tại Hà Giang chuẩn SEO
Cầu nối giữa công ty và khách hàng: Một website chuyên nghiệp sẽ là cầu nối hiệu quả, giúp khách hàng dễ dàng tìm kiếm, tiếp cận và tương tác với doanh nghiệ... | terus_technique |
1,915,161 | Leetcode Day 7: Remove Duplicated from Sorted Array Explained | The problem is as follows: Given an integer array nums sorted in non-decreasing order, remove the... | 0 | 2024-07-08T03:25:02 | https://dev.to/simona-cancian/leetcode-day-7-remove-duplicated-from-sorted-array-explained-3oe | leetcode, python, beginners, codenewbie | **The problem is as follows:**
Given an integer array `nums` sorted in non-decreasing order, remove the duplicates in-place such that each unique element appears only once. The relative order of the elements should be kept the same. Then return t_he number of unique elements in `nums`_.
Consider the number of unique ... | simona-cancian |
1,915,162 | How to Install MySQL on Linux/UNIX and Windows | MySQL is one of the most popular open-source relational database management systems (RDBMS). It is developed, distributed, and supported by Oracle Corporation. MySQL is used by many database-driven web applications, including Drupal, Joomla, phpBB, and WordPress. It is also used by many popular websites, including Face... | 27,755 | 2024-07-08T03:25:24 | https://dev.to/labex/how-to-install-mysql-on-linuxunix-and-windows-nfm | mysql, coding, programming, tutorial |
## Introduction

This article covers the following tech skills:
... | labby |
1,915,163 | OAuth em aplicações SPA / Mobile (PKCE extension) | Em diversas implementações OAuth / OpenID Connect nos deparamos com o uso de clientes confidenciais... | 0 | 2024-07-08T03:25:46 | https://dev.to/erick_tmr/oauth-em-aplicacoes-spa-mobile-pkce-extension-iao | security, webdev, mobile, oauth | Em diversas implementações OAuth / OpenID Connect nos deparamos com o uso de clientes confidenciais (clientes registrados que possuem um par `client_id` e `client_secret`), porém, em aplicações client-side, como SPAs e apps mobile, é impossível garantir a confidencialidade do `client_secret`. Portanto, torna-se necessá... | erick_tmr |
1,915,164 | Как мы принимали новичка на должность дизайнера | Наша компания, ABC Design, всегда славилась тем, что мы находим самых талантливых и креативных людей.... | 0 | 2024-07-08T03:28:53 | https://dev.to/abcsultan/kak-my-prinimali-novichka-na-dolzhnost-dizainiera-3l4k | Наша компания, ABC Design, всегда славилась тем, что мы находим самых талантливых и креативных людей. Если хотите ознакомиться с нашими услугами: https://abc-design.uz/. Но вот однажды решили мы принять нового дизайнера. Да не простого, а самого что ни на есть гениального! Провели несколько собеседований, отсмотрели то... | abcsultan | |
1,915,165 | Open-Source Website Directory System AigoTools, Deploy Your Website Directory Site with One Click! | I have open-sourced a website directory system on GitHub that can automatically generate website... | 0 | 2024-07-08T03:37:29 | https://dev.to/someu/open-source-website-directory-system-aigotools-deploy-your-website-directory-site-with-one-click-235l | opensource, nextjs, nestjs | I have open-sourced a website directory system on GitHub that can automatically generate website information — AigoTools. By simply inputting the address of the websites to be included, the system can automatically take screenshots of the websites, crawl the website information, and process this information through a l... | someu |
1,915,166 | Dynamic Typing vs. Static Typing: Which is Better? | Introduction In programming languages, typing systems dictate how variables are defined and used. Two... | 0 | 2024-07-08T03:32:41 | https://dev.to/test_automation/dynamic-typing-vs-static-typing-which-is-better-553a | **Introduction**
In programming languages, typing systems dictate how variables are defined and used. Two prominent typing systems are Dynamic Typing and Static Typing. Each approach has distinct advantages and considerations, depending on the requirements of the project and the preferences of the development team. In ... | test_automation | |
1,915,167 | 3D Venn Diagram Chess Game | Check out this Pen I made! | 0 | 2024-07-08T03:34:29 | https://dev.to/dan52242644dan/3d-venn-diagram-chess-game-pea | codepen, javascript, css, html | Check out this Pen I made!
{% codepen https://codepen.io/Dancodepen-io/pen/mdZdWLZ %} | dan52242644dan |
1,915,169 | Thiết kế Website Tại Hà Nội Tối Ưu Giao Diện | Hà Nội được đánh giá là thành phố đang phát triển nhanh, thu hút nhiều nguồn đầu tư. Để vươn lên dẫn... | 0 | 2024-07-08T03:41:28 | https://dev.to/terus_technique/thiet-ke-website-tai-ha-noi-toi-uu-giao-dien-27k4 | website, digitalmarketing, seo, terus |

Hà Nội được đánh giá là thành phố đang phát triển nhanh, thu hút nhiều nguồn đầu tư. Để vươn lên dẫn đầu và tạo ra lợi ích kinh doanh cho các doanh nghiệp lớn và nhỏ, bạn cần có trang web của riêng mình.
Những lợi... | terus_technique |
1,915,170 | Elevate Loyalty: Minting Polygon-Based Rewards with Wix Backend Events | This is a submission for the Wix Studio Challenge . What I Built I've developed an... | 0 | 2024-07-08T03:41:32 | https://dev.to/ubinix_warun/elevate-loyalty-minting-polygon-based-rewards-with-wix-backend-events-k2l | devchallenge, wixstudiochallenge, webdev, javascript | *This is a submission for the [Wix Studio Challenge ](https://dev.to/challenges/wix).*
## What I Built
I've developed an innovative loyalty program platform using Wix Studio and Velo (Service Plugins). This platform incentivizes user engagement and fosters brand loyalty through:
- Polygon-Based Rewards: Users earn lo... | ubinix_warun |
1,915,171 | Round Two: Enhancing the Ollama Cluster | Re-cap Just over three weeks ago I wrote a post titled: Setting Up an Ollama + Open-WebUI... | 0 | 2024-07-08T03:43:01 | https://www.saltyoldgeek.com/posts/ollama-cluster-part-ii/ | ollama, openwebui, hardware, troubleshooting | ## Re-cap
Just over three weeks ago I wrote a post titled: [Setting Up an Ollama + Open-WebUI Cluster](https://www.saltyoldgeek.com/posts/ollama-cluster-part-i/?utm_source=internal), where I went over my first experiment in creating a entry barrier node for what was to become an Ollama cluster. In short, I could see t... | blacknight318 |
1,915,173 | Top 6 video downloader: Use yt-dlp for pornhub video downloader | In this article, we will explore some top-rated Pornhub video downloader options for Windows, Mac,... | 0 | 2024-07-08T03:44:23 | https://dev.to/cris_dejohn_ec017df54c2b4/top-6-video-downloader-use-yt-dlp-for-pornhub-video-downloader-cl | python, video, downloader | In this article, we will explore some top-rated [Pornhub video downloader](https://go2keep.com/) options for Windows, Mac, Android and direct browser use. We'll look at their key features, supported formats and ideal scenarios for each. Guidelines around legal personal downloading will also be covered. Finally, various... | cris_dejohn_ec017df54c2b4 |
1,915,174 | The React useRef Hook: Not Just for DOM Elements | In this post, we'll cover what the useRef hook is, some examples of how it can be used, and when you... | 26,157 | 2024-07-08T04:38:17 | https://dev.to/opensauced/the-react-useref-hook-not-just-for-html-elements-3cf3 | react, javascript, webdev | In this post, we'll cover what the `useRef` hook is, some examples of how it can be used, and when you shouldn't use it.
## What is useRef?
The `useRef` hook creates a reference object that holds a mutable value, stored in its [current](https://react.dev/reference/react/useRef#referencing-a-value-with-a-ref) property... | nickytonline |
1,915,175 | how to overcome 413 error code in | I am using react and express for my application , i am uploading camera file using js api and then... | 0 | 2024-07-08T03:47:30 | https://dev.to/mohammed_mubeen/how-to-overcome-413-error-code-in-3gmi | I am using react and express for my application , i am uploading camera file using js api and then upload pdf , png file in a single payload object but it has 413 error how to overcome from this issue | mohammed_mubeen | |
1,915,178 | Thiết kế Website Tại Hà Tĩnh Phù Hợp Mọi Ngành Nghề | Ngày nay, Internet bao trùm mọi lĩnh vực. Việc tìm kiếm thông tin trên Internet hay mua bán, kinh... | 0 | 2024-07-08T03:51:49 | https://dev.to/terus_technique/thiet-ke-website-tai-ha-tinh-phu-hop-moi-nganh-nghe-4bab | website, digitalmarketing, seo, terus |

Ngày nay, Internet bao trùm mọi lĩnh vực. Việc tìm kiếm thông tin trên Internet hay mua bán, kinh doanh trực tuyến không còn xa lạ với mọi người, không chỉ ở Hà Tĩnh mà còn ở tất cả các nơi khác. Doanh nghiệp muốn t... | terus_technique |
1,915,180 | Self-Hosting Perplexica and Ollama | Perplexica and Ollama Setup Are you in the self-hosted camp, enjoying Ollama, and... | 0 | 2024-07-08T03:57:59 | https://www.saltyoldgeek.com/posts/perplexica-with-ollama/ | ollama, perplexica, perplexityai | ## Perplexica and Ollama Setup
Are you in the self-hosted camp, enjoying Ollama, and wondering when we'd have something like Perplexity AI but local, and maybe a bit more secure? I had been keeping an eye out when I came across an article on [MARKTECHPOST](https://www.marktechpost.com/2024/06/09/perplexica-the-open-so... | blacknight318 |
1,915,181 | Rendering Modes Explained | In this article, we will explore the different rendering modes for a web application, commonly seen... | 0 | 2024-07-10T14:02:04 | https://dev.to/andresilva-cc/rendering-modes-explained-2711 | webdev, javascript, frontend | In this article, we will explore the different **rendering modes** for a web application, commonly seen in meta-frameworks like **Next.js** and **Nuxt**. Understanding these modes is **crucial** for developers seeking to **optimize performance** and **user experience**.
For demonstration purposes, we will use a projec... | andresilva-cc |
1,915,182 | 4 Essential UI Design Tips That Will Transform Your Interfaces | Starting from scratch Starting a new design completely from the ground up can be a... | 0 | 2024-07-08T03:59:56 | https://dev.to/syedumaircodes/4-essential-ui-design-tips-that-will-transform-your-interfaces-5e5p | beginners, ux, ui, productivity | ## Starting from scratch
Starting a new design completely from the ground up can be a challenging task, if you don't have the complete requirements or haven't decided on the features that your product will have.
Figure out the main components of your product first and then get to designing. If you spend time designing... | syedumaircodes |
1,915,183 | Thiết kế Website Tại Hải Dương Chuyên Nghiệp | Dịch vụ thiết kế website chuyên nghiệp và hiện đại không chỉ là một công cụ để quảng bá thương... | 0 | 2024-07-08T04:00:04 | https://dev.to/terus_technique/thiet-ke-website-tai-hai-duong-chuyen-nghiep-2koj | website, digitalmarketing, seo, terus |
[Dịch vụ thiết kế website chuyên nghiệp và hiện đại](https://terusvn.com/thiet-ke-website-tai-hcm/) không chỉ là một công cụ để quảng bá thương hiệu, sản phẩm và dịch vụ, mà còn là một kênh tiếp cận khách hàng tiềm... | terus_technique |
1,915,184 | Thiết kế Website Tại Hải Phòng Chất Lượng Cao | Lợi ích của việc thiết kế website tại Hải Phòng chuẩn SEO Cầu nối giữa công ty và khách hàng: Một... | 0 | 2024-07-08T04:02:21 | https://dev.to/terus_technique/thiet-ke-website-tai-hai-phong-chat-luong-cao-1d1o | website, digitalmarketing, seo, terus |
Lợi ích của việc thiết kế website tại Hải Phòng chuẩn SEO
Cầu nối giữa công ty và khách hàng: Một website chuyên nghiệp sẽ là cầu nối hiệu quả, giúp khách hàng dễ dàng tìm kiếm, tiếp cận và tương tác với doanh nghi... | terus_technique |
1,915,185 | SEO Offpage là gì | SEO Offpage, hay còn gọi là SEO Offsite, là một kỹ thuật tối ưu hóa các yếu tố ngoài trang web nhằm... | 0 | 2024-07-08T04:06:47 | https://dev.to/khoahocseoimta1/seo-offpage-la-gi-3ckj | khoahocseoimta, daotaoseoimta, daotaoseotphcm, seooffpage | SEO Offpage, hay còn gọi là SEO Offsite, là một kỹ thuật tối ưu hóa các yếu tố ngoài trang web nhằm nâng cao thứ hạng trên trang kết quả tìm kiếm (SERP). Các yếu tố chính bao gồm:
Xây dựng liên kết ngoài (backlink): Tạo ra các liên kết chất lượng từ các trang web uy tín trỏ về trang web của bạn, giúp tăng cường độ tin ... | khoahocseoimta1 |
1,915,186 | Developing a GROWI Plug-in (Template Edition) | Explain the procedure for developing a GROWI plug-in. This is as much as we know, as we have not yet grasped the whole process, but please use it as a reference during development. | 0 | 2024-07-08T04:07:38 | https://dev.to/goofmint/developing-a-growi-plug-in-template-edition-40jp | opensource, growi, markdown | ---
title: Developing a GROWI Plug-in (Template Edition)
published: true
description: Explain the procedure for developing a GROWI plug-in. This is as much as we know, as we have not yet grasped the whole process, but please use it as a reference during development.
tags:
- OSS
- GROWI
- Markdown
# cover_image: ... | goofmint |
1,915,187 | Demystifying Volatility: Calculating the Relative Volatility Index (RVI) for Crypto Trading | Volatility – the lifeblood of any crypto market – can be a double-edged sword. While it presents... | 0 | 2024-07-08T04:10:09 | https://dev.to/epakconsultant/demystifying-volatility-calculating-the-relative-volatility-index-rvi-for-crypto-trading-5ea7 | trading | Volatility – the lifeblood of any crypto market – can be a double-edged sword. While it presents opportunities for profit, it also carries significant risk. The Relative Volatility Index (RVI) emerges as a valuable tool for crypto traders, offering insights into a cryptocurrency's relative volatility and potentially g... | epakconsultant |
1,915,188 | How to add Stripe payment functionality to Next.js App | How to add Stripe payment functionality using the Next.js App Router: 1. Set Up Your... | 0 | 2024-07-08T04:12:59 | https://article.shade.cool/p/34 | webdev, javascript, beginners, programming | How to add Stripe payment functionality using the Next.js App Router:
{% youtube https://youtu.be/cE4PzMonikc?si=Xr2sxJt53lMpyjD4 %}
### 1. **Set Up Your Stripe Account**
- Sign up at [stripe.com](https://stripe.com).
- Complete the setup process including adding business details and bank account.
### 2. **... | sh20raj |
1,915,189 | Navigating Crypto's Choppy Waters: Understanding Risk with Historical Volatility (HV) | The cryptocurrency market, with its dynamic price swings, can be both thrilling and treacherous.... | 0 | 2024-07-08T04:13:04 | https://dev.to/epakconsultant/navigating-cryptos-choppy-waters-understanding-risk-with-historical-volatility-hv-1505 | trading | The cryptocurrency market, with its dynamic price swings, can be both thrilling and treacherous. Investors and traders rely on various tools to navigate this volatility, and Historical Volatility (HV) emerges as a crucial metric for risk assessment. This article dives into HV, how it compares to the Relative Volatility... | epakconsultant |
1,915,190 | Python | Python is an high-level interpreter and object oriented programming language used for various... | 0 | 2024-07-08T04:15:03 | https://dev.to/arokya_naresh_178a488116e/python-2d7e | python, beginners | Python is an high-level interpreter and object oriented programming language used for various applications
It have standard library
| arokya_naresh_178a488116e |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.