
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,918,844 | From Idea to Income: Lessons from Startup Founders Who Made $25,000 Monthly | Ever wondered how startup founders achieve significant revenue milestones like $25,000 per month?... | 0 | 2024-07-10T17:46:57 | https://dev.to/resource_bunk/from-idea-to-income-lessons-from-startup-founders-who-made-25000-monthly-304b | startup, sideprojects, saas, marketing | Ever wondered how startup founders achieve significant revenue milestones like $25,000 per month? Learn their secrets in our comprehensive ebook.
Starting a startup is an exhilarating journey filled with uncertainties and challenges. However, what sets successful founders apart is their ability to navigate these chall... | resource_bunk |
1,918,845 | Wireframing in UI/UX | You wanna know? | 0 | 2024-07-10T17:47:12 | https://dev.to/cardendante/wireframing-in-uiux-6e7 | wireframing | You wanna know? | cardendante |
1,918,846 | Why Adding More Developers to a Late Software Project Often Backfires: Understanding Brooks's Law | The statement "Adding manpower to a late software project makes it later" is famously known as... | 0 | 2024-07-10T17:48:51 | https://dev.to/malik_aboshabab_4e478e2e/why-adding-more-developers-to-a-late-software-project-often-backfires-understanding-brookss-law-2h64 | The statement "Adding manpower to a late software project makes it later" is famously known as Brooks's Law, coined by Fred Brooks in his book "The Mythical Man-Month." The principle highlights the inefficiencies and complexities introduced when additional resources are added to a project that is already behind schedul... | malik_aboshabab_4e478e2e | |
1,918,847 | Understanding and Implementing Angular Structural Directives | Angular, a robust framework for building web applications, offers a range of powerful features to... | 0 | 2024-07-10T17:50:22 | https://dev.to/itsshaikhaj/understanding-and-implementing-angular-structural-directives-1i8a | webdev, angular, beginners, tutorial |
Angular, a robust framework for building web applications, offers a range of powerful features to developers. Among these, structural directives stand out as particularly influential. They enable developers to dynamically manipulate the DOM by adding, removing, or replacing elements based on specific conditions or ex... | itsshaikhaj |
1,918,849 | Insights from Founders Who Grew $25,000 Monthly | Explore the strategies and stories behind startup founders who cracked the code to achieving $25,000... | 0 | 2024-07-10T17:50:26 | https://dev.to/resource_bunk/insights-from-founders-who-grew-25000-monthly-2gdp | startup, marketing, tutorial, beginners | Explore the strategies and stories behind startup founders who cracked the code to achieving $25,000 a month in revenue.
Embarking on the journey of entrepreneurship is both exhilarating and daunting. For startup founders aiming to achieve significant revenue milestones like $25,000 per month, strategic decisions and ... | resource_bunk |
1,918,850 | Lessons from $25,000-Monthly Founders | Gain insider knowledge from startup founders who turned visions into profitable realities, earning... | 0 | 2024-07-10T17:52:06 | https://dev.to/resource_bunk/lessons-from-25000-monthly-founders-512o | startup, beginners, tutorial, marketing | Gain insider knowledge from startup founders who turned visions into profitable realities, earning $25,000 monthly and beyond.
Starting a successful startup requires more than just a great idea—it demands strategic decisions, resilience, and a deep understanding of market dynamics. Our latest ebook is a comprehensive ... | resource_bunk |
1,918,851 | Voxel51 Filtered Views Newsletter - July 12, 2024 | Author: Harpreet Sahota (Hacker in Residence at Voxel51) Welcome to Voxel51’s bi-weekly digest of... | 0 | 2024-07-12T14:56:51 | https://voxel51.com/blog/voxel51-filtered-views-newsletter-july-12-2024/ | computervision, machinelearning, datascience, ai | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
Welcome to Voxel51’s bi-weekly digest of the latest trending AI, machine learning and computer vision news, events and resources! [Subscribe to the email version](https://voxel51.com/fil... | jguerrero-voxel51 |
1,918,853 | The "prose" class: my content best friend | The struggle is real Let's be honest: if you're a developer who would rather spend more... | 0 | 2024-07-11T19:34:25 | https://dev.to/karmenatwork/the-prose-class-my-content-best-friend-40l0 | ## The struggle is real
Let's be honest: if you're a developer who would rather spend more time coding the business logic than designing (like me), you celebrated 🎉 big time when CSS frameworks came into our coding lives. I'm sure you have used some of the general-purpose frameworks such as[bootstrap](https://getboot... | karmenatwork | |
1,918,854 | Achieving $25,000 Monthly | Discover the proven strategies and compelling stories behind startup founders who achieved impressive... | 0 | 2024-07-10T17:55:47 | https://dev.to/resource_bunk/achieving-25000-monthly-48dc | beginners, tutorial, productivity, news | Discover the proven strategies and compelling stories behind startup founders who achieved impressive revenue milestones.
Embarking on the journey of entrepreneurship is both thrilling and challenging. For startup founders aiming to achieve significant revenue milestones like $25,000 per month, learning from those who... | resource_bunk |
1,919,484 | How do I print Dymo labels? | Printing Dymo labels involves a few straightforward steps, from setting up your Dymo label printer to... | 0 | 2024-07-11T09:17:50 | https://dev.to/john10114433/how-do-i-print-dymo-labels-39pp | Printing Dymo labels involves a few straightforward steps, from setting up your Dymo label printer to designing and printing your labels. Here’s a step-by-step guide to help you through the process:[dymo 30252 labels](https://betckey.com/collections/hot-sale/products/dymo-30252-compatible-address-and-barcode-labels)
1... | john10114433 | |
1,918,855 | VaultWarden: Dein lokaler Passwortmanager | Vaultwarden bietet eine schlanke, ressourcenschonende und kostenfreie Alternative zu Bitwarden.... | 0 | 2024-07-10T18:00:59 | https://blog.disane.dev/vaultwarden-dein-lokaler-passwortmanager/ | passwortmanager, sicherheit, docker, homelab | Vaultwarden bietet eine schlanke, ressourcenschonende und kostenfreie Alternative zu Bitwarden. Entdecke die Vorteile und erfahre, wie Du Vaultwarden installierst! 🛠️
---
Wenn Du auf der Suche nach einem sicheren ... | disane |
1,918,856 | Guide to $120k Linux Job (Free course link is included) | Don't forget to check the links at the end for the course article. Are you ready to dive deep into... | 0 | 2024-07-10T18:02:39 | https://dev.to/hacker_haii/guide-to-120k-linux-job-free-course-link-in-included-5bg3 | linux, devops, bash, tutorial |
_**Don't forget to check the links at the end for the course article.**_
Are you ready to dive deep into the world of shell scripting and unlock a floodgate of Linux job opportunities? If you're serious about boosting your DevOps career, you can't afford to miss this!
## **Why Shell Scripting?**
Shell scripting is ... | hacker_haii |
1,918,857 | VaultWarden: Your local password manager | Vaultwarden offers a lightweight, resource-efficient and free alternative to Bitwarden. Discover the... | 0 | 2024-07-10T18:03:22 | https://blog.disane.dev/en/vaultwarden-your-local-password-manager/ | passwordmanager, security, docker, homelab | Vaultwarden offers a lightweight, resource-efficient and free alternative to Bitwarden. Discover the advantages and learn how to install Vaultwarden! 🛠️
---
If you're looking for a secure and cost-effective passwo... | disane |
1,918,859 | பைதானில் Data Types | *Data Types: * Numeric int float (decimal numbers) complex numbers Text( strings= collection of... | 0 | 2024-07-10T18:05:12 | https://dev.to/rjagathe/paitaannnil-data-types-30pi | **Data Types:
**
1. Numeric
int
float (decimal numbers)
complex numbers
2. Text( strings= collection of characters,no.,space,etc.,)
denoted within quotes.
3. Boolean
4. None
**Variables and Constants:**
Variable = Containers to hold the values
naming variables ( @,!, etc not to be used)
multiple assignmen... | rjagathe | |
1,918,860 | Platform Engineering Tools: An Overview and Comparison | In the rapidly evolving world of software development, platform engineering has emerged as a crucial... | 0 | 2024-07-10T18:06:56 | https://dev.to/the_real_zan/platform-engineering-tools-an-overview-and-comparison-527d | devops, cloud, webdev, programming | In the rapidly evolving world of software development, platform engineering has emerged as a crucial discipline aimed at optimizing the software development lifecycle (SDLC) and enhancing the developer experience. By constructing internal developer platforms, platform engineering teams strive to streamline processes, r... | the_real_zan |
1,918,861 | 1598. Crawler Log Folder | 1598. Crawler Log Folder Easy The Leetcode file system keeps a log each time some user performs a... | 27,523 | 2024-07-10T18:10:26 | https://dev.to/mdarifulhaque/1598-crawler-log-folder-2l07 | php, leetcode, algorithms, programming | 1598\. Crawler Log Folder
Easy
The Leetcode file system keeps a log each time some user performs a _change folder_ operation.
The operations are described below:
- `"../"` : Move to the parent folder of the current folder. (If you are already in the main folder, **remain in the same folder**).
- `"./"` : Remain in ... | mdarifulhaque |
1,918,862 | How to Learn Blockchain Development: A Step-by-Step Guide | Hello there, and welcome to Dapp Mentors! I'm Darlington Gospel, and today, I want to share some... | 0 | 2024-07-10T18:11:05 | https://dev.to/daltonic/how-to-learn-blockchain-development-a-step-by-step-guide-30ek | webdev, blockchain, web3, programming | Hello there, and welcome to Dapp Mentors! I'm [Darlington Gospel](https://www.linkedin.com/in/darlington-gospel-aa626b125/), and today, I want to share some insights on how to effectively learn blockchain development. Over the years, I've worked on numerous blockchain and smart contract projects, including [**a recent ... | daltonic |
1,918,863 | Join Us For The First Community Smart Contract Challenge With $50,000 In Prizes! | We are thrilled to collaborate with the Stellar Development Foundation to introduce the community to... | 0 | 2024-07-10T18:33:22 | https://dev.to/devteam/join-us-for-the-first-community-smart-contract-challenge-with-50000-in-prizes-41gl | devchallenge, stellarchallenge, web3, blockchain | We are thrilled to collaborate with the [Stellar Development Foundation](https://stellar.org/?utm_campaign=buildbetter) to introduce the community to blockchain technology.
Running through **August 18**, the [Build Better on Stellar: Smart Contract Challenge](https://dev.to/challenges/stellar) provides an opportunity ... | thepracticaldev |
1,918,864 | Weekly Watercooler Thread | This is a general discussion thread about... Whatever. What's new in your life? Hobbies, interests,... | 0 | 2024-07-10T18:11:24 | https://dev.to/ben/weekly-watercooler-thread-1gd1 | watercooler, discuss | This is a general discussion thread about... Whatever. What's new in your life?
Hobbies, interests, games, kids, parents, travel, career updates, whatever.
Let's keep this chat light and positive and see if it can become a nice weekly check-in.
| ben |
1,919,445 | Cloud Risk Management Best Practices | Cloud computing has revolutionized how businesses operate, offering immense computing power and... | 0 | 2024-07-11T08:17:26 | https://www.clouddefense.ai/cloud-risk-management-best-practices/ |

Cloud computing has revolutionized how businesses operate, offering immense computing power and scalability. However, this advancement also introduces significant risks, making cloud risk managem... | clouddefenseai | |
1,918,865 | Setting Sail in Style: A Look at the Latest in Luxury Cruises for 2024 | How can luxury cruise lines innovate their sustainability practices to minimize environmental impact... | 0 | 2024-07-11T03:34:15 | https://dev.to/digital_chaudhary_79/setting-sail-in-style-a-look-at-the-latest-in-luxury-cruises-for-2024-2jai | How can luxury cruise lines innovate their sustainability practices to minimize environmental impact while maintaining the high-end experience their guests expect?
**The Exciting World of Luxury Cruises in 2024: Latest Updates and Highlights**
As the travel industry continues to evolve, luxury cruise lines are steppin... | digital_chaudhary_79 | |
1,918,866 | From Zero to Production: Deploying a Full-Stack Application with Architect | Introduction to Architect's Platform In the fast-paced world of software development,... | 0 | 2024-07-10T18:12:46 | https://dev.to/joswellahwasike/from-zero-to-production-deploying-a-full-stack-application-with-architect-190h | ## Introduction to Architect's Platform
In the fast-paced world of software development, getting your application from conception to production can be a daunting task. Architect simplifies this journey with its continuous delivery platform, enabling developers to create preview, staging, and production environments ef... | joswellahwasike | |
1,918,867 | Typescript Coding Chronicles: Merge Strings Alternately | Problem Statement: You are given two strings word1 and word2. Merge the strings by adding... | 0 | 2024-07-10T18:17:03 | https://dev.to/__zamora__/typescript-coding-chronicles-merge-strings-alternately-5ia | webdev, programming, typescript, javascript | ## Problem Statement:
You are given two strings `word1` and `word2`. Merge the strings by adding letters in alternating order, starting with `word1`. If a string is longer than the other, append the additional letters onto the end of the merged string.
### Example 1:
- Input: `word1 = "abc"`, `word2 = "pqr"`
- Output:... | __zamora__ |
1,918,868 | Identifying 🤖 AI Articles? | Generative AI articles seem to be common now and detecting them can be difficult. I even found an... | 0 | 2024-07-10T23:13:41 | https://dev.to/oculus42/identifying-ai-articles-2olj | webdev, discuss, ai | Generative AI articles seem to be common now and detecting them can be difficult. I even found an AI-generated article about detecting AI-generated articles. It was created by an AI-based SEO service, which I am not linking it because I do not think it should receive more SEO benefit. This article is mostly my thoughts... | oculus42 |
1,918,898 | Chart of the Week: Creating a WPF Range Bar Chart to Visualize the Hearing Range of Living Beings | TL;DR: The human hearing range spans from 20 Hz to 20 kHz. Similarly, we’ll visualize the hearing... | 0 | 2024-07-11T16:55:14 | https://www.syncfusion.com/blogs/post/wpf-range-bar-chart-hearing-range | wpf, chart, desktop, datavisualization | ---
title: Chart of the Week: Creating a WPF Range Bar Chart to Visualize the Hearing Range of Living Beings
published: true
date: 2024-07-10 14:39:37 UTC
tags: wpf, chart, desktop, datavisualization
canonical_url: https://www.syncfusion.com/blogs/post/wpf-range-bar-chart-hearing-range
cover_image: https://dev-to-uploa... | jollenmoyani |
1,918,899 | Typescript Coding Chronicles: Greatest Common Divisor of Strings | Problem Statement: For two strings s and t, we say "t divides s" if and only if s = t + t... | 0 | 2024-07-10T18:22:46 | https://dev.to/__zamora__/typescript-coding-chronicles-greatest-common-divisor-of-strings-3ko6 | typescript, webdev, programming, javascript | ## Problem Statement:
For two strings `s` and `t`, we say "t divides s" if and only if `s = t + t + t + ... + t + t` (i.e., `t` is concatenated with itself one or more times).
Given two strings `str1` and `str2`, return the largest string `x` such that `x` divides both `str1` and `str2`.
### Example 1:
- Input: `str1... | __zamora__ |
1,918,900 | Session Handling with the PRG pattern and Flashing | In our previous project, returning a view directly from the POST request when validation failed was... | 0 | 2024-07-10T18:23:51 | https://dev.to/ghulam_mujtaba_247/session-handling-with-the-prg-pattern-and-flashing-1jog | webdev, beginners, programming, php | In our previous project, returning a view directly from the POST request when validation failed was not the best approach.
## The Problem
When a user submits a login form with invalid data, the form displays error messages and redirects the user to the login page. However, if the user refreshes the page or navigates ... | ghulam_mujtaba_247 |
1,918,902 | Share to PWA from mobile | If you have a website that can be installed as a PWA on your mobile device it has also the ability to... | 0 | 2024-07-10T18:35:37 | https://www.koffeinfrei.org/2023/11/19/share-to-pwa-from-mobile/ | webdev, javascript, pwa, mobile | If you have a website that can be installed as a [PWA](https://developer.mozilla.org/en-US/docs/Web/Progressive_web_apps) on your mobile device it has also the ability to receive data from the "share to" functionality on mobile phones. Depending on what you're trying to do you don't need to create a native app.
This a... | koffeinfrei |
1,918,903 | 18 Projects Announced as part of XRPL Accelerator First Launch Cohort | The XRPL Accelerator - Launch Program is dedicated to nurturing innovation and the development of... | 0 | 2024-07-10T18:35:45 | https://dev.to/ripplexdev/18-projects-announced-as-part-of-xrpl-accelerator-first-launch-cohort-3eb0 | The [XRPL Accelerator - Launch Program](https://xrplaccelerator.org/) is dedicated to nurturing innovation and the development of financial use cases on the XRP Ledger (XRPL). The initiative continues to support entrepreneurs and builders looking to scale their projects on the XRP Ledger and we are excited to announce ... | sopvictori | |
1,918,907 | HIRE A HACKER | The cryptocurrency market has seen a surge in demand for recovery assistance services. As more people... | 0 | 2024-07-10T18:44:06 | https://dev.to/evelyn_amelia_c116fc28b42/hire-a-hacker-4h1n | The cryptocurrency market has seen a surge in demand for recovery assistance services. As more people enter the exciting yet unpredictable world of cryptocurrency, the need for specialized help in recovering lost investments has become increasingly apparent. And that's where INTELLIGENCE CYBER WIZARD comes into play - ... | evelyn_amelia_c116fc28b42 | |
1,918,909 | What is the most direct cause of customer loyalty | This Blog was Originally Posted to Churnfree Blog We all know various factors to retain customers but... | 0 | 2024-07-10T18:49:50 | https://churnfree.com/blog/what-is-the-most-direct-cause-of-customer-loyalty/ | churnfree, saaschurn, customerloyalty, customerchurn | **This Blog was Originally Posted to [Churnfree Blog](https://churnfree.com/blog/what-is-the-most-direct-cause-of-customer-loyalty/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Content_distribution)**
We all know various factors to retain customers but what is the most direct cause of customer loyalty? What is th... | churnfree |
1,918,911 | How to Find Salesforce Certified Tableau CRM and Einstein Discovery Consultant | Why Do You Need a Salesforce Certified Tableau CRM and Einstein Discovery Consultant? AI... | 0 | 2024-07-10T18:52:15 | https://www.sfapps.info/salesforce-certified-tableau-and-einstein-consultant/ | blog, howto | ---
title: How to Find Salesforce Certified Tableau CRM and Einstein Discovery Consultant
published: true
date: 2024-07-10 18:46:25 UTC
tags: Blog,HowTo
canonical_url: https://www.sfapps.info/salesforce-certified-tableau-and-einstein-consultant/
---
## Why Do You Need a Salesforce Certified Tableau CRM and Einstein Di... | doriansabitov |
1,918,912 | HIRE A HACKER | The cryptocurrency market has seen a surge in demand for recovery assistance services. As more people... | 0 | 2024-07-10T18:54:49 | https://dev.to/evelyn_amelia_c116fc28b42/hire-a-hacker-353o | The cryptocurrency market has seen a surge in demand for recovery assistance services. As more people enter the exciting yet unpredictable world of cryptocurrency, the need for specialized help in recovering lost investments has become increasingly apparent. And that's where INTELLIGENCE CYBER WIZARD comes into play - ... | evelyn_amelia_c116fc28b42 | |
1,918,913 | What’s New in .NET 9 Preview 6: Comprehensive Overview | On July 9th, 2024, Microsoft released .NET 9 Preview 6, featuring significant updates and... | 0 | 2024-07-10T18:59:43 | https://dev.to/3a5abi/whats-new-in-net-9-preview-6-comprehensive-overview-5b9f | csharp, dotnet, devtoys | On July 9th, 2024, Microsoft released .NET 9 Preview 6, featuring significant updates and enhancements across the framework. Key highlights include:
---
## Runtime Updates:
- ARM64 Code Generation: Improved data loading/storing, enhancing execution time.
- Code Layout: Optimized basic block ordering for better perfor... | 3a5abi |
1,918,938 | Why InstaPro APK? Get It from Where? | Instapro APK is a modified version of the official Instagram app for Android devices. It is not... | 0 | 2024-07-10T19:49:04 | https://dev.to/fg_tbcentre_f9dbfc5489f0/why-instapro-apk-get-it-from-where-113a | instapro, apk, app | [Instapro APK](https://appinstapro.com/) is a modified version of the official Instagram app for Android devices. It is not available on the Google Play Store and must be downloaded from third-party sources. This modded version offers additional features and functionalities that are not available in the official Instag... | fg_tbcentre_f9dbfc5489f0 |
1,918,914 | 8 Reasons Why You Need an APIToolkit | Your website is a dynamic entity. A lot happens on a daily basis; hundreds or more API requests are... | 0 | 2024-07-10T19:07:04 | https://dev.to/irhose/8-reasons-why-you-need-an-apitoolkit-34ch | api, devops, webdev, programming | Your website is a dynamic entity. A lot happens on a daily basis; hundreds or more API requests are sent regularly which makes monitoring the integrity of each call a demanding task.
Data shows that even the most reputable developer playgrounds like Discord and Slack have experienced downtime due to APIs breaking. The... | irhose |
1,918,915 | Hello | Hello I am Melissa. I am currently studying Software Development at City Colleges of Chicago. A... | 0 | 2024-07-10T19:11:46 | https://dev.to/martinez415/hello-288i | Hello I am Melissa. I am currently studying Software Development at City Colleges of Chicago. A recent thing I learned is how to create a static website on render.com | martinez415 | |
1,918,917 | benefits of parcel as a bundler | benefits of parcel dev tools HMR - hot modules replacement --->> how - by using... | 0 | 2024-07-10T19:12:37 | https://dev.to/anurag_singh_2jz/benefits-of-parcel-as-a-bundler-1fbi | systemdesign, webdev, javascript, programming | ## benefits of parcel
- dev tools
- HMR - hot modules replacement <basically refreshes the file as we save the file>
--->> how - by using file watching algorithms made in c++ which keep track of your code and as soon as
you try to save the file it refreshes the server with new code
- local server <ht... | anurag_singh_2jz |
1,918,918 | How to publish Docker images to AWS ECR | ABOUT ECS ECS - Elastic Container Service is to containers what EC2 is to virtual... | 0 | 2024-07-10T19:15:42 | https://dev.to/justplegend/how-to-publish-docker-images-to-aws-ecr-1n8p | ###ABOUT ECS
ECS - Elastic Container Service is to containers what EC2 is to virtual machines. ECS have to modes:
1. EC2 mode which uses EC2 instances as container hosts (you can see this inside your aws account).
2. FARGATE MODE - this is serverless way of running docker containers where AWS manage the container ... | justplegend | |
1,918,919 | Exploring the Impact of DefiLlama in Shaping the Landscape of Decentralized Finance | As the modern digital sphere continues to evolve, the advantages of a particular platform in this... | 0 | 2024-07-10T19:18:43 | https://dev.to/defillama545/exploring-the-impact-of-defillama-in-shaping-the-landscape-of-decentralized-finance-2on9 | cryptocurrency, ethereum, blockchain, web3 |
As the modern digital sphere continues to evolve, the advantages of a particular platform in this rapidly changing economy become increasingly important. One such platform, known synonymously as DefiLlama, has solidified its niche within the landscape of Dispersed Financial systems. This innovative and rapidly growin... | defillama545 |
1,918,921 | Unlocking the Power of Decentralized Finance with Essential DeFi Tracking Tools | The Importance of DeFi Tracking Tools Join us as we venture into an integral aspect of the crypto... | 0 | 2024-07-10T19:20:33 | https://dev.to/defillama545/unlocking-the-power-of-decentralized-finance-with-essential-defi-tracking-tools-3eb1 | cryptocurrency, ethereum, blockchain, defillama |
- The Importance of DeFi Tracking Tools
Join us as we venture into an integral aspect of the crypto finance sphere, one that is often overlooked despite its crucial role. Monitoring the crypto stage isn't just about watching the values rise and fall, it involves considerably more to guarantee that your virtual asset... | defillama545 |
1,918,923 | Discover Advanced Facial Tightening Treatments for a Youthful Glow | Discover advanced facial tightening treatments designed to rejuvenate your skin and reveal a youthful... | 0 | 2024-07-10T19:27:09 | https://dev.to/beverlythorp1/discover-advanced-facial-tightening-treatments-for-a-youthful-glow-4oc9 | Discover advanced facial tightening treatments designed to rejuvenate your skin and reveal a youthful glow. Experience the latest in non-invasive technology for a firmer, radiant complexion.
[Facial Vaughan](https://bfancy.ca/facial-vaughan/
. They specialise in providing strategic defence and expert advice tailored to your case. Whether it's speeding, DUI, or traffic... | motoringlawyers | |
1,918,926 | Understanding DeFi - Unraveling the Role of Blockchain Technology in Decentralized Finance | How DeFi Works: The Use of Blockchain Technology Delve deeply into the progressive sphere of modern... | 0 | 2024-07-10T19:35:31 | https://dev.to/defillama3/understanding-defi-unraveling-the-role-of-blockchain-technology-in-decentralized-finance-3e69 | cryptocurrency, ethereum, web3, web | How DeFi Works: The Use of Blockchain Technology
Delve deeply into the progressive sphere of modern monetary solutions through a fine-grained exploration of decentralized financial (DeFi) protocols, guided by this comprehensive elucidation. Uncover the wonders of this game-changing domain that employs cryptographic le... | defillama3 |
1,918,927 | Discover and Understand the World of DeFi through a Comprehensive Guide on DefiLlama | Have you ever pondered the essence of DefiLlama? Surely the notion has spurred your interest and... | 0 | 2024-07-10T19:36:47 | https://dev.to/defillama3/discover-and-understand-the-world-of-defi-through-a-comprehensive-guide-on-defillama-48il | cryptocurrency, ethereum, web3, blockchain | Have you ever pondered the essence of DefiLlama? Surely the notion has spurred your interest and tickled your curious mind. A fusion of innovation, technology and finance, DefiLlama stands as a beacon leading the way towards the realm of decentralised finance. In essence, it brings the future to your fingertips.
Envis... | defillama3 |
1,918,928 | Satta Matka | Get Fastest Satta Matka Result For Kalyan Matka And Other Matka Market Visit SattaMatka777 Now | 0 | 2024-07-10T19:39:16 | https://dev.to/satta_matka_777/satta-matka-4kk3 | sattamatka, matka, satta, dpboss | Get Fastest Satta Matka Result For Kalyan Matka And Other Matka Market
Visit [SattaMatka777](https://sattamatka777.in) Now | satta_matka_777 |
1,918,929 | Mastering Dependency Management with Architect: Tips and Best Practices | Liquid syntax error: 'raw' tag was never closed | 0 | 2024-07-10T19:39:22 | https://dev.to/joswellahwasike/mastering-dependency-management-with-architect-tips-and-best-practices-5bjk | In today’s software development landscape, managing dependencies effectively is crucial for building reliable and scalable applications. This task becomes even more complex in cloud environments where applications often rely on a multitude of services, APIs, and databases. Architect, with its robust dependency-aware fe... | joswellahwasike | |
1,918,931 | Mastering Dependency Management with Architect: Tips and Best Practices | Liquid syntax error: 'raw' tag was never closed | 0 | 2024-07-10T19:39:23 | https://dev.to/joswellahwasike/mastering-dependency-management-with-architect-tips-and-best-practices-2ooi | In today’s software development landscape, managing dependencies effectively is crucial for building reliable and scalable applications. This task becomes even more complex in cloud environments where applications often rely on a multitude of services, APIs, and databases. Architect, with its robust dependency-aware fe... | joswellahwasike | |
1,918,932 | The Struggles of Making Games | How gamedev is complicated | 0 | 2024-07-10T19:47:07 | https://dev.to/shinspiegel/the-struggles-of-making-games-32hp | gamedev, godot | ---
title: The Struggles of Making Games
published: true
description: How gamedev is complicated
tags: gamedev, godot
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-07-10 18:35 +0000
---
Ok, I'll try to write this post in both [portuguese](#pt) and [englis... | shinspiegel |
1,918,933 | Dpboss Matka Result For Kalyan Matka | Sattamatka.gg Is one Of The most Popular website for Dpboss Matka Result also Get Kalyan matka Chart... | 0 | 2024-07-10T19:43:29 | https://dev.to/satta_matka_777/dpboss-matka-result-for-kalyan-matka-1f1k | sattamatka | Sattamatka.gg Is one Of The most Popular website for [Dpboss](https://sattamatka.gg/) Matka Result
also Get Kalyan matka Chart Fully Free. | satta_matka_777 |
1,918,934 | Typescript Coding Chronicles: Kids With the Greatest Number of Candies | Problem Statement: There are n kids with candies. You are given an integer array candies,... | 0 | 2024-07-10T19:44:16 | https://dev.to/__zamora__/typescript-coding-chronicles-kids-with-the-greatest-number-of-candies-5h57 | webdev, javascript, programming, typescript | ## Problem Statement:
There are `n` kids with candies. You are given an integer array `candies`, where each `candies[i]` represents the number of candies the `i`-th kid has, and an integer `extraCandies`, denoting the number of extra candies that you have.
Return a boolean array `result` of length `n`, where `result[i... | __zamora__ |
1,918,935 | Tutorial: SwiftUI Character Limit in a TextField | Here is a simple, but handy tutorial for limiting the number of characters in a TextField. I use this... | 0 | 2024-07-10T23:07:10 | https://dev.to/troyhusted/tutorial-swiftui-character-limit-in-a-textfield-2f1i | swiftui, swift, textfield | Here is a simple, but handy tutorial for limiting the number of characters in a TextField. I use this in my app [Recitation](https://www.recitation-app.com/) to limit the number of characters that the user can have for different tags.
Validated for Swift Version 5.9
## Step 1: Combine & Just()
```
import Combine
```... | troyhusted |
1,918,936 | Sugar Wax Haven | Address: 3030 S Rural Rd Suite 107a, Tempe, AZ 85282 Country - United States Phone: (623)... | 0 | 2024-07-10T19:47:21 | https://dev.to/sugar_waxhaven_7b4e3632e/sugar-wax-haven-aki | Address:
3030 S Rural Rd Suite 107a, Tempe, AZ 85282
Country - United States
Phone:
(623) 287-6139
Email:
sugarwaxhavenbacklink@gmail.com
Website:
https://sugarwaxhaven.com/
| sugar_waxhaven_7b4e3632e | |
1,918,937 | 100+ FREE Resources Every Web Developer Must Try | In this post, I’ll share 100+ free web development resources including APIs,hosting platforms,cheat... | 0 | 2024-07-10T19:48:18 | https://dev.to/agunwachidiebelecalistus/100-free-resources-every-web-developer-must-try-47ln | webdev, beginners, javascript, css | In this post, I’ll share 100+ free web development resources including APIs,hosting platforms,cheat sheets,icons,templates,fonts, color resources,learning platforms, CSS games,code editors and JavaScript animation libraries.
Let’s jump right into it!
**FREE Resources to Learn Web Development** 🔥
**Websites**
.[free... | agunwachidiebelecalistus |
1,918,939 | Awnings San Diego | Address: 9252 Miramar Rd, San Diego, CA 92126, United States Phone: (877)... | 0 | 2024-07-10T19:49:58 | https://dev.to/awnings_sandiego_ebca2c9/awnings-san-diego-262j | Address:
9252 Miramar Rd, San Diego, CA 92126, United States
Phone:
(877) 391-0499
Website
https://awningsandiego.com/
| awnings_sandiego_ebca2c9 | |
1,918,940 | "Innovative Ecosystem for AI-Powered Art and NFTs" | "Empowering artists and developers with AI, blockchain, and web development... | 0 | 2024-07-10T19:50:44 | https://dev.to/nexusplus/innovative-ecosystem-for-ai-powered-art-and-nfts-2g36 | sacrediamondgeometrynfts, nfts, blockchain, polygon | "Empowering artists and developers with AI, blockchain, and web development tools."
Introduction
We're excited to introduce our groundbreaking project, an innovative ecosystem designed to merge AI-powered art generation, blockchain technology, and web development tools.
Our platform aims to empower artists, develope... | nexusplus |
1,918,941 | Exploring AI Agents: Autonomous Helpers Transforming Our World | Artificial Intelligence (AI) is transforming our world in remarkable ways, with AI agents being at... | 0 | 2024-07-10T19:56:41 | https://dev.to/savagenewcanaan/exploring-ai-agents-autonomous-helpers-transforming-our-world-6g | <p style="text-align: justify;">Artificial Intelligence (AI) is transforming our world in remarkable ways, with AI agents being at the forefront of this technological revolution. But what exactly are AI agents, and how do they function? In this article, we'll delve into the fundamentals of AI agents, their types, appli... | savagenewcanaan | |
1,918,942 | JavaScript Basics: Understanding Syntax and Structure | JavaScript Basics: Understanding Syntax and Structure Welcome back to our "JavaScript: From Novice... | 27,941 | 2024-07-11T09:00:00 | https://dev.to/buildwebcrumbs/javascript-basics-understanding-syntax-and-structure-5d9b | javascript, beginners, programming, codenewbie |
JavaScript Basics: Understanding Syntax and Structure
Welcome back to our "JavaScript: From Novice to Expert" series!
Today, we’re diving into the core of JavaScript—its syntax and structure. Understanding these basics is super important for any developer starting out.
By the end of this article, you'll be familiar... | pachicodes |
1,918,943 | Mastering Dependency Management with Architect: Tips and Best Practices | In today’s software development landscape, managing dependencies effectively is crucial for building... | 0 | 2024-07-10T19:59:57 | https://dev.to/joswellahwasike/mastering-dependency-management-with-architect-tips-and-best-practices-1j17 | In today’s software development landscape, managing dependencies effectively is crucial for building reliable and scalable applications. This task becomes even more complex in cloud environments where applications often rely on a multitude of services, APIs, and databases. Architect, with its robust dependency-aware fe... | joswellahwasike | |
1,918,944 | Mastering Dependency Management with Architect: Tips and Best Practices | In today’s software development landscape, managing dependencies effectively is crucial for building... | 0 | 2024-07-10T19:59:58 | https://dev.to/joswellahwasike/mastering-dependency-management-with-architect-tips-and-best-practices-3m29 | In today’s software development landscape, managing dependencies effectively is crucial for building reliable and scalable applications. This task becomes even more complex in cloud environments where applications often rely on a multitude of services, APIs, and databases. Architect, with its robust dependency-aware fe... | joswellahwasike | |
1,918,945 | Typescript Coding Chronicles: Can Place Flowers | Problem Statement: You have a long flowerbed in which some of the plots are planted, and... | 0 | 2024-07-10T20:02:03 | https://dev.to/__zamora__/typescript-coding-chronicles-can-place-flowers-4mhb | webdev, javascript, programming, typescript | ## Problem Statement:
You have a long flowerbed in which some of the plots are planted, and some are not. However, flowers cannot be planted in adjacent plots.
Given an integer array `flowerbed` containing 0's and 1's, where 0 means empty and 1 means not empty, and an integer `n`, return `true` if `n` new flowers can ... | __zamora__ |
1,918,946 | How to Invoke AWS Lambda Functions from Amazon SQS Message | To invoke AWS Lambda functions from an Amazon SQS (Simple Queue Service) message, you need to... | 0 | 2024-07-10T20:06:02 | https://dev.to/albine_peter_c2ffb10b422f/how-to-invoke-aws-lambda-functions-from-amazon-sqs-message-1npg | aws, cloud, architecture, cloudcomputing |
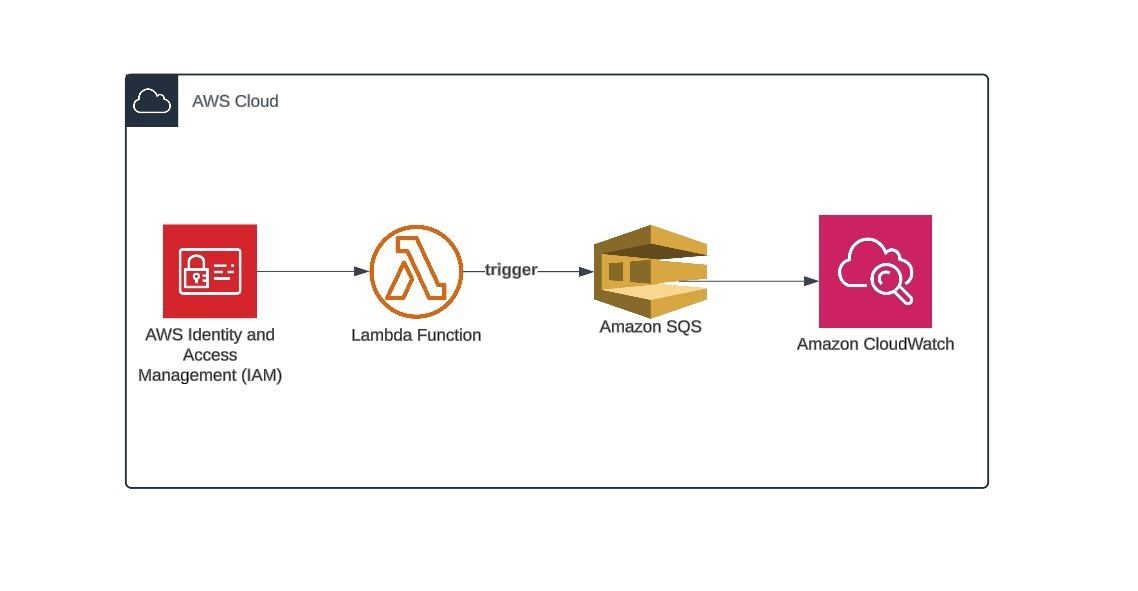
**To invoke AWS Lambda functions from an Amazon SQS (Simple Queue Service) message, you need to create an event source mapping that connects the SQS queue to the Lambda function.**
**I have used this code :**
impo... | albine_peter_c2ffb10b422f |
1,918,947 | Typescript Coding Chronicles: Reverse Vowels of a String | Problem Statement: Given a string s, reverse only all the vowels in the string and return... | 0 | 2024-07-10T20:12:09 | https://dev.to/__zamora__/typescript-coding-chronicles-reverse-vowels-of-a-string-2c9p | webdev, javascript, programming, typescript | ## Problem Statement:
Given a string `s`, reverse only all the vowels in the string and return it.
The vowels are 'a', 'e', 'i', 'o', and 'u', and they can appear in both lower and upper cases, more than once.
### Example 1:
- Input: `s = "hello"`
- Output: `"holle"`
### Example 2:
- Input: `s = "leetcode"`
- Output... | __zamora__ |
1,918,997 | Slack chatGPT AI bot | Features OpenAI chatGPT bot for Slack app mostly used in corporate This bot is another... | 0 | 2024-07-10T20:41:40 | https://dev.to/nitinkumar30/slack-chatgpt-ai-bot-2aoc | aitools, slackchatbot, chatgpt, aibot | ## Features
> 1. OpenAI chatGPT bot for [Slack app](https://app.slack.com/) mostly used in corporate
> 2. This bot is another app to be used as a chatGPT integrated there
> 3. .env file for all generated tokens
---
## Working

United Constructors, Inc. is a family-inspired company. The family business of construction started generations ago with grandpa building his own house. Cash’s father, Jerry, started serving the Bay Area doing kit... | unitedconstructors | |
1,918,995 | Implementando Transactional Outbox com Go, DynamoDB, MongoDB, Kafka e RabbitMq | Introdução O padrão Transactional Outbox é uma solução de arquitetura que ajuda a garantir a... | 0 | 2024-07-10T22:26:06 | https://dev.to/ederfmatos/implementando-transactional-outbox-com-go-dynamodb-e-mongodb-1kn3 | microservices, dynamodb, mongodb, transactionaloutbox |
**Introdução**
O padrão Transactional Outbox é uma solução de arquitetura que ajuda a garantir a consistência de dados entre um banco de dados e um sistema de mensageria. Ele é especialmente útil em sistemas distribuídos onde é necessário garantir que uma mensagem seja enviada somente se a transação do banco de dados... | ederfmatos |
1,918,996 | Properties and attributes in Python | When writing code in Python there are many different functions you can write. In these functions you... | 0 | 2024-07-11T19:17:30 | https://dev.to/spencer_adler_880da14d230/properties-and-attributes-in-python-39aj | python, properties, attributes | When writing code in Python there are many different functions you can write. In these functions you can create attributes and property.
The definition of attributes are variables that belong to an object. The definition of properties are attributes that are controlled by methods.
An example of attributes and propert... | spencer_adler_880da14d230 |
1,918,998 | How to install the most recent Python in your Synology diskstation | Synology, the taiwanese manufacturer of the best NASes in the world, deliveres its devices with a... | 0 | 2024-07-10T20:50:35 | https://codehouse.digfish.org/how-to-install-the-most-recent-python-in-your-synology-diskstation/ | python, anaconda, synology, nas | Synology, the taiwanese manufacturer of the best NASes in the world, deliveres its devices with a [RTD1619B](https://gadgetversus.com/processor/realtek-rtd1619b-specs/) processor, which is based the in ARM-64 architecture (also known as aarch64). I possess a [NAS DS223j](https://www.synology.com/en-br/products/DS223j#s... | digfish |
1,918,999 | Journey of Streamlining Oncall and Incident Management | For many engineering and operations teams, being available when needed is essential to... | 0 | 2024-07-12T07:30:44 | https://dev.to/pagerlyio/journey-of-streamlining-oncall-and-incident-management-3043 | oncall, devops, incident, sre |
For many engineering and operations teams, being available when needed is essential to maintaining the dependability and availability of their services. One of the main responsibilities is to assist in meeting different SLAs. The key principles of on-call work are discussed in this article along with real-world ... | falitjain |
1,919,000 | Validated forms with useFetcher in Remix | Build a custom "useFetcherForm" hook to easily handle fetcher requests. Interacting with the... | 0 | 2024-07-10T21:05:15 | https://blog.sjdonado.com/validated-forms-with-usefetcher-in-remix | remix, react, typescript | > Build a custom "useFetcherForm" hook to easily handle fetcher requests.
Interacting with the server without using `window.navigation` significantly improves the user experience. E.g: Login forms within a dialog box or modal, optimistic UI forms or submitting multiple forms within a complex view.
If you are not fami... | sjdonado |
1,919,001 | shadcn-ui/ui codebase analysis: How does shadcn-ui CLI work? — Part 2.10 | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the... | 0 | 2024-07-10T21:06:46 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-does-shadcn-ui-cli-work-part-210-3j60 | opensource, shadcnui, nextjs, node | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the shadcn-ui/ui CLI.
In part 2.9, we looked at getRegistryStyles function, fetchRegistry function and stylesSchema.
In this article, we will understand the below concepts:
1. getRegistryBaseColors function
2. prompts
3... | ramunarasinga |
1,919,003 | CLOUD COMPUTING THE NEW ERA OF SERVERS. | Cloud computing is one of the fundamentals in any business operation, personal life routines given... | 0 | 2024-07-10T22:56:50 | https://dev.to/emmanuel_adodoadjie/cloud-computing-the-new-era-of-servers-222p |
Cloud computing is one of the fundamentals in any business operation, personal life routines given how quickly our digital world's landscape has changed. Cloud computing allows the deployment of different types of software applications without in-depth knowledge but demand short term access to dynamic resources ove... | emmanuel_adodoadjie | |
1,919,016 | Os Principais Pontos para uma Documentação Técnica de Negócios com Arquitetura de Sistemas | Percebo que muitos profissionais tem dificuldade em como estruturar ou desenvolver uma boa... | 0 | 2024-07-10T21:24:17 | https://dev.to/annamatias/desvendando-os-segredos-os-principais-pontos-para-uma-documentacao-tecnica-de-negocios-com-arquitetura-de-sistemas-5blj | programming, learning, documentation, dataengineering | Percebo que muitos profissionais tem dificuldade em como estruturar ou desenvolver uma boa documentação técnica. É imprescindível documentar os processos de negócios e suas regras, além de descrever como o técnico se alinha a cada processo de negócio. Não deixar de incluir quais são as ferramentas/frameworks utilizados... | annamatias |
1,919,017 | Most In-Demand Programming Languages in Europe and Worldwide: A Discussion | 🌍 What programming languages do you think are most in demand in Europe and worldwide? 💬 Share your... | 0 | 2024-07-10T21:27:23 | https://dev.to/burakboduroglu/most-in-demand-programming-languages-in-europe-and-worldwide-a-discussion-1jdf | beginners, career, discuss, programming | 🌍 What programming languages do you think are most in demand in Europe and worldwide?
💬 Share your thoughts and experiences in the comments!
🤔 We’re curious to hear your perspectives on which languages are leading the job market and why they are so sought after.
📊📱💻 Whether it's for web development, mobile ap... | burakboduroglu |
1,919,018 | Do you know these 4 API monitoring pillars? | API observability and monitoring go beyond technical details, requiring an understanding of API... | 0 | 2024-07-10T21:29:26 | https://dev.to/ehikioya/do-you-know-these-4-api-monitoring-pillars-3796 | API observability and monitoring go beyond technical details, requiring an understanding of API health and performance for optimal software experiences.
## Four pillars underpin API observability
**Logs:** Detailed records of API interactions, essential for troubleshooting and understanding user behavior.
**Metrics:... | ehikioya | |
1,919,019 | What Makes Golden Doodles Special | Golden Doodles Kissimmee are a cross between a Golden Retriever and a Poodle. This combination brings... | 0 | 2024-07-10T21:31:17 | https://dev.to/aronwilliam/what-makes-golden-doodles-special-16j | [Golden Doodles Kissimmee](https://g.page/r/CSIjnm8znrUHEAE) are a cross between a Golden Retriever and a Poodle. This combination brings together the best traits of both breeds, resulting in a dog that is not only friendly and affectionate but also intelligent and easy to train. Here are some reasons why Golden Doodle... | aronwilliam | |
1,919,020 | Total Madness #1: Async/Await | In the last episode (which is also the first episode, lol) we explored a bit of the world of... | 0 | 2024-07-10T21:36:37 | https://dev.to/gmelodie/total-madness-1-asyncawait-1omk | rust, async, futures, concurrency | In the last episode (which is also the first episode, lol) we explored a bit of the world of concurrency by talking about locks. I mean, we didn't use the word "concurrent" explicitly, but effectively that's what we were talking about.
> Concurrency means multiple computations are happening at the same time.
>
> [MIT]... | gmelodie |
1,919,021 | Made a new logo for Place! | Hopefully when Place 2 is finished, mobile support will be a LOT better, it's completely disabled... | 0 | 2024-07-10T21:33:10 | https://dev.to/aud/made-a-new-logo-for-place-40l4 | Hopefully when Place 2 is finished, mobile support will be a LOT better, it's completely disabled right now.
Anyway, the new logo is available on the beta site, [here!](https://beta.placepixel.online/)
Have fun!
 | Hospedar um site Django completo pode ser um desafio, especialmente ao optar por plataformas... | 0 | 2024-07-12T18:24:17 | https://dev.to/aghastygd/hospede-seu-site-django-com-arquivos-estaticos-na-vercel-gratuitamente-novo-metodo-339p | tutorial, vercel, django, python | Hospedar um site Django completo pode ser um desafio, especialmente ao optar por plataformas gratuitas. No entanto, com a Vercel, você pode configurar seu site para ser hospedado sem custo algum 💸 , e com os arquivos estáticos funcionando corretamente utilizando esse novo método sem erros 🤩.
Neste tutorial, você será... | aghastygd |
1,919,027 | 18 Métodos de Arrays em JavaScript que Você Deveria Saber | Os arrays são uma parte essencial da programação em JavaScript, proporcionando uma maneira poderosa... | 0 | 2024-07-10T21:56:36 | https://josafa.com.br/blog/18-metodos-de-array-em-javascript-que-voce-deveria-saber/ | javascript, programming, braziliandevs | Os arrays são uma parte essencial da programação em JavaScript, proporcionando uma maneira poderosa de armazenar e manipular coleções de dados. Neste artigo, vamos explorar dezoito métodos fundamentais de arrays que todo programador JavaScript deveria conhecer para escrever código mais eficiente e claro.
## 1. Push
O... | josafamarengo |
1,919,028 | AI for System Design and Architecture Documentation | Learn how AI transforms system design and architecture with insights from Multiplayer's CTO. Explore new tools and collaborative features for developers. | 25,852 | 2024-07-10T22:02:59 | https://codingcat.dev/podcast/ai-for-system-design-and-architecture-documentation | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/ai-for-system-design-and-architecture-documentation
{% youtube https://youtu.be/BLIPiA6P4kc %}
## Introduction and Welcome
* **Introduction of Guests and Sponsors:** The host welcomes the audience to the Coding Cat.dev podcast, sponsored by Cloudinary and Algolia, and introdu... | codercatdev |
1,919,029 | 30 things I wish I could go back and tell my junior engineer self👇 | Consistency is more important than inconsistent hustling Anyone can learn software engineering, keep... | 0 | 2024-07-10T22:03:48 | https://dev.to/msnmongare/30-things-i-wish-i-could-go-back-and-tell-my-junior-engineer-self-5ae | webdev, beginners, programming, tutorial | - Consistency is more important than inconsistent hustling
- Anyone can learn software engineering, keep going
- Join a team where others are growing
- Take on challenging projects that will stretch you
- Freelancing is a business, you have to be good at coding and running a business
- Drive the screen while screen sh... | msnmongare |
1,919,032 | Casting to the Same-Sized Unsigned Type | Given an integral expression, how to cast it to an unsigned type of the same size. | 0 | 2024-07-10T23:08:33 | https://dev.to/pauljlucas/casting-to-the-same-sized-unsigned-type-1kd3 | c | ---
title: Casting to the Same-Sized Unsigned Type
published: true
description: Given an integral expression, how to cast it to an unsigned type of the same size.
tags: #c
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-07-10 21:47 +0000
---
## Introduction... | pauljlucas |
1,919,033 | [Game of Purpose] Day 53 | Today I finally made the animation work. It turns out that I had to check the "Use Acceleration for... | 27,434 | 2024-07-10T22:14:17 | https://dev.to/humberd/game-of-purpose-day-53-1j96 | gamedev | Today I finally made the animation work. It turns out that I had to check the "Use Acceleration for Paths" checkbox on a Character Movement component. Reading its description I assume Animation Class assigns proper animation: Stand/Walk/Run depending on how much it accelerates.

You can invite it [here!](https://discord.com/oauth2/authorize?client_id=1260712345106382880)
Use /set... | aud | |
1,919,044 | Foremost ที่ไม่ใช่ นม | ในการทำงานทางด้าน Computer Forensics นั้น มีเครื่องมือด้วยกันหลายตัว หนึ่งในนั้น คือ Foremost... | 0 | 2024-07-10T22:39:24 | https://dev.to/iyosnu/foremost-thiiaimaich-nm-217d | security, forensic, datacarving, foremost | ในการทำงานทางด้าน Computer Forensics นั้น มีเครื่องมือด้วยกันหลายตัว หนึ่งในนั้น คือ Foremost ซึ่งจัดได้ว่าเป็น tool ที่ ใช้ง่าย และใช้กันอย่างแพร่หลาย ดังนั้น จึงนำเครื่องมือตัวนี้มาแนะนำให้รู้จัก และ อธิบายถึงการใช้งาน เพื่อให้ได้รู้จักเครื่องมือที่มีประโยชน์ และ ยังไม่เสียค่าใช้จ่ายอีกด้วย
Foremost เป็นเครื่องมือตั... | iyosnu |
1,919,045 | Awesome ("must have" links to recourses ) | Awesome Lists on GitHub are curated lists of resources and tools related to a specific topic or area.... | 0 | 2024-07-10T22:44:50 | https://dev.to/mibii/awesome-must-have-links-to-recourses--1o6o | musthave | Awesome Lists on GitHub are curated lists of resources and tools related to a specific topic or area. They are created and maintained by the GitHub community and often serve as a comprehensive and well-organized collection of useful resources for developers, data scientists, system administrators, etc. Awesome lists co... | mibii |
1,919,046 | Day 988 : So Good | liner notes: Professional : Got up super early to sit in on a talk prep session. Then I went back... | 0 | 2024-07-10T22:47:09 | https://dev.to/dwane/day-988-so-good-3jdi | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Got up super early to sit in on a talk prep session. Then I went back to sleep. Woke up a couple of hours later and got to work. Responded to some community questions. Worked on the refactor of a project. Sat in another talk prep session. After that, I had another meeting. For the rest o... | dwane |
1,919,047 | useFormState(useActionState) | I introduce "useFormState" which is new hook in React19. Now this hook is called "useActionState" as... | 0 | 2024-07-11T12:19:01 | https://dev.to/makoto0825/useformstateuseactionstate-642 | webdev, react, nextjs | I introduce "useFormState" which is new hook in React19. Now this hook is called "useActionState" as another name.
**Note**: The official React reference says that "useFormState" will change to "useActionState". It is expected that useFormState will no longer be available in the near future.
## What is "useFormState"... | makoto0825 |
1,919,180 | The 7 Best Canned Ham of 2024 | Is canned ham good for you? Canned ham can be a convenient and long-lasting food option, but whether... | 0 | 2024-07-11T03:09:24 | https://dev.to/chien_bui_8ed10263e2f8ebb/the-7-best-canned-ham-of-2024-b5p | Is canned ham good for you?
Canned ham can be a convenient and long-lasting food option, but whether it is good for you depends on several factors, including its nutritional content, ingredients, and how it fits into your overall diet. Here are some points to consider:
Nutritional Content
Protein: Canned ham is a goo... | chien_bui_8ed10263e2f8ebb |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.