
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,913,685 | Using namespace std :) | A namespace in C++ is a way to organize code into logical groups and prevent name conflicts by... | 0 | 2024-07-16T17:16:49 | https://dev.to/madgan95/using-namespace-std--lo5 | beginners, cpp, basic, c | A namespace in C++ is a way to organize code into logical groups and prevent name conflicts by creating a distinct scope for identifiers such as functions, classes, and variables. It helps in managing libraries and avoiding naming collisions in large projects.
---
# Let's understand this with an analogy:
## The Boo... | madgan95 |
1,914,025 | Implementing ChatGPT for Business Efficiency | Unlock the potential of your business with ChatGPT. Discover how to implement Generative AI to enhance productivity, automate routine tasks, and elevate customer interactions. Learn the strategic steps for seamless AI integration and leverage Dev3loper.ai’s consulting, development, and training services to drive innova... | 0 | 2024-07-15T05:07:46 | https://dev.to/dev3l/implementing-chatgpt-for-business-efficiency-3234 | generativeai, ai, productivity, transformation | ---
title: Implementing ChatGPT for Business Efficiency
published: true
description: Unlock the potential of your business with ChatGPT. Discover how to implement Generative AI to enhance productivity, automate routine tasks, and elevate customer interactions. Learn the strategic steps for seamless AI integration and l... | dev3l |
1,914,224 | Give tech layoffs, how long is it taking to hire devs? | Recently I became curious as to how the job market is for companies hiring developers. I wanted to... | 0 | 2024-07-07T03:41:39 | https://dev.to/brookzerker/give-tech-layoffs-how-long-is-it-taking-to-hire-devs-37n6 | Recently I became curious as to how the job market is for companies hiring developers. I wanted to look into this as I truly believe that it is more cost effective to train devs instead of hiring new ones. But I wanted to gather some data instead of just relying on my feelings (and of course I'm biased too).
My initia... | brookzerker | |
1,914,406 | build a instagram message chat app | Hello, everyone! I have just build a web version of a chat application, similar to the cover image... | 0 | 2024-07-14T08:44:54 | https://dev.to/zwd321081/build-a-instagram-message-chat-app-ibn | javascript, graphql, react, mongodb | Hello, everyone! I have just build a web version of a chat application, similar to the cover image above
You can watch a brief introduction video [youtube](https://youtu.be/S7Zanjrw8v4?si=O_JoZFdD8aPkmBms)
The project consists of both client-side and server-side.
The client-side utilizes [create-vite-app](https://vi... | zwd321081 |
1,914,903 | Implementing Drag-Drop for File Input on the Web. | Drag-drop is one of the most engaging ways of transferring files between windows on a computer. All... | 0 | 2024-07-16T12:17:54 | https://dev.to/ghostaram/implementing-drag-drop-for-file-input-on-the-web-6c | Drag-drop is one of the most engaging ways of transferring files between windows on a computer. All modern file explorers come with this functionality. Browsers also happen to have a default behavior to drag-drop. By default, the browser will try to open a file dropped into it unless it is programmed to do something el... | ghostaram | |
1,915,099 | AWS: RDS IAM database authentication, EKS Pod Identities, and Terraform | We’re preparing to migrate our Backend API database from DynamoDB to AWS RDS with PostgreSQL, and... | 0 | 2024-07-13T09:42:19 | https://rtfm.co.ua/en/aws-rds-iam-database-authentication-eks-pod-identities-and-terraform/ | kubernetes, devops, security, aws | ---
title: AWS: RDS IAM database authentication, EKS Pod Identities, and Terraform
published: true
date: 2024-07-07 22:57:29 UTC
tags: kubernetes,devops,security,aws
canonical_url: https://rtfm.co.ua/en/aws-rds-iam-database-authentication-eks-pod-identities-and-terraform/
---
 | Contents Overview of Azure Virtual Network Steps to Creating Azure Virtual Network ... | 0 | 2024-07-13T04:18:05 | https://dev.to/celestina_odili/create-an-azure-virtual-network-vnet-48fp | virtualnet, azure, tutorial, cloudcomputing | Contents <a name="content"></a>
[Overview of Azure Virtual Network](#overview)
[Steps to Creating Azure Virtual Network
] (#create vnet)
### Overview of Azure Virtual Network <a name="overview"></a>
Azure Virtual Network (VNet) is a versatile and powerful service that provides flexibility, security, and scalability re... | celestina_odili |
1,915,757 | Easily copy any Live website to Figma and then to your App | Picasso was quoted saying “good artists borrow, great artists steal.” I totally agree with this... | 0 | 2024-07-14T13:40:59 | https://dev.to/dellboyan/easily-copy-any-live-website-to-figma-and-then-to-your-app-436d | webdev, javascript, programming, ai | Picasso was quoted saying “good artists borrow, great artists
steal.” I totally agree with this point, I think you should steal whenever there's opportunity to do so easily, and in this post, I'll show you how you can straight up steal any design you want.
I'm just kidding, stealing is wrong and blah blah, we should a... | dellboyan |
1,915,771 | Create a String to Color Helper with Ruby (and Rails) | This article was originally published on Rails Designer. In the latest version (v1) of Rails... | 0 | 2024-07-15T08:00:00 | https://railsdesigner.com/uby-string-to-colors/ | ruby, rails, webdev | This article was originally published on [Rails Designer](https://railsdesigner.com/uby-string-to-colors/).
---
In the [latest version (v1) of Rails Designer](https://railsdesigner/com/) I added a [Chat Messages Component](https://railsdesigner.com/components/chats/).
For one of the provided variants I wanted to hav... | railsdesigner |
1,916,142 | 21 Open Source LLM Projects to Become 10x AI Developer | The time of AI is high especially because of powerful LLMs like GPT-4o and Claude. Today, I'm... | 0 | 2024-07-17T09:00:56 | https://blog.latitude.so/21-open-source-llm-projects/ | programming, opensource, ai, webdev | The time of AI is high especially because of powerful LLMs like GPT-4o and Claude.
Today, I'm covering 21 open source LLM projects that can help you to build something exciting and integrate AI into your project.
As a developer, I can confidently say that AI is not as scary as others make it sound and those who don't... | anmolbaranwal |
1,916,215 | Next-Level Web Applications with On-Device Generative AI: A Look at Google Chrome's Built-In Gemini Nano LLM | Web development is on the brink of a significant transformation with Google Chrome Canary's latest... | 0 | 2024-07-13T18:34:18 | https://dev.to/ptvty/next-level-web-applications-with-on-device-generative-ai-a-look-at-google-chromes-built-in-gemini-nano-llm-4bng | webdev, ai, javascript, a11y | Web development is on the brink of a significant transformation with Google Chrome Canary's latest experimental feature, a new tool called the `window.ai` API, allowing websites to harness the power of on-device generative AI. With Google’s Gemini Nano AI model built into the browser, websites can offer smarter, more p... | ptvty |
1,916,447 | Get Creativity Free Figma Mind Map Template | Are you looking for a versatile and user-friendly tool to create mind maps? Look no further! Sarah... | 0 | 2024-07-13T15:43:00 | https://neattemplate.com/figma-templates/get-creativity-free-figma-mind-map-template | webdev, figma, ui, uidesign | Are you looking for a versatile and user-friendly tool to create mind maps? Look no further! Sarah Elizabeth has designed a free Figma mind map template that will help you organize your thoughts and ideas effectively.
### Why Use a Mind Map?
Mind maps are a powerful visual tool that can enhance your brainstorming sessi... | faisalgg |
1,916,479 | How to Build a Javascript Booking Automation Bot | Introduction I was recently made aware of a waitlist opening up for a new service in my... | 0 | 2024-07-13T20:45:02 | https://dev.to/columk1/how-to-build-a-javascript-booking-automation-bot-32em | webdev, javascript, webscraping, automation | ### Introduction
I was recently made aware of a waitlist opening up for a new service in my local area. I thought it would be a nice exercise to automate the registration process and secure one of the first places on the list.
#### Registration System
The online form already existed as it was used to register for a n... | columk1 |
1,916,532 | AWS: Kubernetes and Access Management API, the new authentication in EKS | Another cool feature that Amazon showed back at the last re:Invent in November 2023 is changes in... | 0 | 2024-07-13T09:48:39 | https://rtfm.co.ua/en/aws-kubernetes-and-access-management-api-the-new-authentification-in-eks/ | security, kubernetes, aws, devops | ---
title: AWS: Kubernetes and Access Management API, the new authentication in EKS
published: true
date: 2024-07-08 22:17:16 UTC
tags: security,kubernetes,aws,devops
canonical_url: https://rtfm.co.ua/en/aws-kubernetes-and-access-management-api-the-new-authentification-in-eks/
---
 | 4A. Unveiling the Mysteries: Data Exploration (EDA) 🔍 Welcome back to the enchanting halls... | 27,991 | 2024-07-17T06:31:30 | https://dev.to/gerryleonugroho/the-gemikas-magical-guide-to-sorting-hogwarts-students-using-the-decision-tree-algorithm-part-4a-4n3n | machinelearning, ai, harrypotter, python | ## 4A. Unveiling the Mysteries: Data Exploration (EDA) 🔍
Welcome back to the enchanting halls of Hogwarts, dear sorcerers! As we continue our magical journey into the world of data science, it's time to unveil the **mysteries hidden** within our dataset. In this chapter, we'll embark on a series of explorations that ... | gerryleonugroho |
1,916,595 | Stop Phishing by Analyzing the Bait | Phishing is a cybersecurity threat that relies on human error or trust. It's a social engineering attack intent on obtaining information by getting a user to open an email or click on a link. Can I build a tool that could help users to know something about a link before they click on it? | 0 | 2024-07-12T21:10:44 | https://dev.to/rebeccapeltz/stop-phishing-by-analyzing-the-bait-3f0f | cybersecurity, phishing, browserextension | ---
title: Stop Phishing by Analyzing the Bait
published: true
description: Phishing is a cybersecurity threat that relies on human error or trust. It's a social engineering attack intent on obtaining information by getting a user to open an email or click on a link. Can I build a tool that could help users to know s... | rebeccapeltz |
1,916,613 | Gerando embeddings com PHP e ONNX | IA e PHP No campo da inteligência artificial (IA) e processamento de linguagem natural... | 0 | 2024-07-15T21:13:56 | https://dev.to/jonas-elias/gerando-embeddings-com-php-e-onnx-44gk | # IA e PHP
No campo da inteligência artificial (IA) e processamento de linguagem natural (NLP), _embeddings_ são representações matemáticas de palavras, frases ou documentos que capturam seu significado semântico. Esses _embeddings_ são utilizados para aplicações que incluem busca semântica, análise de sentimentos, en... | jonas-elias | |
1,916,645 | God's Vue: An immersive tale (Chapter 2) | Chapter 2: Let There Be Light The Birth of An Instance After laying down the foundation of Eden,... | 0 | 2024-07-14T16:56:31 | https://dev.to/zain725342/gods-vue-an-immersive-tale-chapter-2-2ppp | vue, webdev, javascript, learning | **Chapter 2: Let There Be Light**
**The Birth of An Instance**
After laying down the foundation of Eden, the next step in the developer's journey was to bring light and structure to this nascent world.
With a clear vision in his mind, he placed his fingers on the cosmic keyboard and conjured the `createApp` functio... | zain725342 |
1,917,097 | GitHub Copilot has its quirks | I've been using GitHub Copilot with our production codebase for the last 4 months, and here are some... | 0 | 2024-07-15T14:23:37 | https://dev.to/gauraws/github-copilot-has-its-quirks-34o1 | ai, github, javascript, productivity | I've been using **[GitHub Copilot](https://github.com/features/copilot)** with our production codebase for the last 4 months, and here are some of my thoughts:
**The Good:**
1. **Explains Complex Code**: It’s been great at breaking down tricky code snippets or business logic and explaining them properly.
2. **Unit Te... | gauraws |
1,917,213 | From Requirements to Code: Implementing the Angular E-commerce Product Listing Page | Introduction Welcome back to my series on building a scalable Angular e-commerce... | 28,006 | 2024-07-14T16:25:12 | https://dev.to/cezar-plescan/from-requirements-to-code-implementing-the-angular-e-commerce-product-listing-page-23nn | angular, grid, tutorial, responsivedesign | ## Introduction
Welcome back to my series on building a scalable Angular e-commerce application! In the [previous article](https://dev.to/cezar-plescan/building-an-angular-e-commerce-app-a-step-by-step-guide-to-understanding-and-refining-requirements-hoe), I embarked on the crucial journey of understanding and refinin... | cezar-plescan |
1,917,224 | FHIR crud app using aspnet core 8.0 and sql server | Hi EveryOne! I would like to discuss today, the crud operation for the patient resource using HL7 R4... | 0 | 2024-07-13T11:35:58 | https://dev.to/mannawar/fhir-crud-app-using-aspnet-core-80-and-sql-server-59p1 | microsoft, hl7, sqlserver, apnetcore | Hi EveryOne!
I would like to discuss today, the crud operation for the patient resource using HL7 R4 model using aspnet core and saving of patient data on sql server using EF Core. For modelling of data i have used this package.
Ref- https://www.nuget.org/packages/Hl7.Fhir.R4, https://www.hl7.org/fhir/resource.html#ide... | mannawar |
1,917,269 | REST API Client - Testing a provided API | Introduction This section explains how to test an API application using a Rest API client... | 0 | 2024-07-09T12:14:11 | https://tech.forums.softwareag.com/t/rest-api-client-testing-a-provided-api/268250/1 | api, restapi, adabas | ---
title: REST API Client - Testing a provided API
published: true
date: 2024-06-14 17:41:07 UTC
tags: api, restapi, adabas
canonical_url: https://tech.forums.softwareag.com/t/rest-api-client-testing-a-provided-api/268250/1
---
## Introduction
This section explains how to test an API application using a Rest API ... | techcomm_sag |
1,917,278 | How to activate Adabas as a service in LINUX, if the database has a user exit defined? | Introduction When configuring Adabas as a service in Linux, you may encounter challenges... | 0 | 2024-07-09T12:17:29 | https://tech.forums.softwareag.com/t/how-to-activate-adabas-as-a-service-in-linux-if-the-database-has-a-user-exit-defined/296443/1 | adabas, linux, database, guide | ---
title: How to activate Adabas as a service in LINUX, if the database has a user exit defined?
published: true
date: 2024-06-04 08:52:13 UTC
tags: adabas, linux, database, guide
canonical_url: https://tech.forums.softwareag.com/t/how-to-activate-adabas-as-a-service-in-linux-if-the-database-has-a-user-exit-defined/29... | techcomm_sag |
1,917,507 | Azure Synapse Analytics Security: Access Control | Introduction The assets of a bank are only accessible to some high-ranking officials, and... | 0 | 2024-07-14T12:40:32 | https://dev.to/ayush9892/azure-synapse-analytics-security-access-control-4chl | azure, dataengineering, sqlserver, database | ## Introduction
The assets of a bank are only accessible to some high-ranking officials, and even they don't have access to individual user lockers. These privacy features help build trust among customers. The same goes with in our IT world. Every user wants their sensitive data to be accessible only to themselves, not... | ayush9892 |
1,917,608 | Beginner's Tutorial for CRUD Operations in NodeJS and MongoDB | Introduction CRUD operations stand for Create, Read, Update, and Delete. This procedure... | 0 | 2024-07-16T21:40:48 | https://dev.to/danmusembi/beginners-tutorial-for-crud-operations-in-nodejs-and-mongodb-k7k | webdev, javascript, programming, tutorial | ## Introduction
CRUD operations stand for Create, Read, Update, and Delete. This procedure allows you to work with data from the MongoDB database.
With these four operations, you can create, read, update, and delete data in MongoDB.
## What is MongoDB
[MongoDB](https://www.mongodb.com/) is a powerful and flexible ... | danmusembi |
1,917,618 | 40 Days Of Kubernetes (14/40) | Day 14/40 Taints and Tolerations in Kubernetes Video Link @piyushsachdeva Git... | 0 | 2024-07-15T17:31:43 | https://dev.to/sina14/40-days-of-kubernetes-1440-m3a | kubernetes, 40daysofkubernetes | ## Day 14/40
# Taints and Tolerations in Kubernetes
[Video Link](https://www.youtube.com/watch?v=nwoS2tK2s6Q)
@piyushsachdeva
[Git Repository](https://github.com/piyushsachdeva/CKA-2024/)
[My Git Repo](https://github.com/sina14/40daysofkubernetes)
We're going to look at `taint` and `toleration`. While a `node` has a... | sina14 |
1,917,900 | Test that forking code! | Originally published on peateasea.de. Not only should the final commit in a pull request patch... | 0 | 2024-07-13T14:45:34 | https://peateasea.de/test-that-forking-code/ | git, bash, python | ---
title: Test that forking code!
published: true
date: 2024-07-08 22:00:00 UTC
tags: Git,Bash,Python
canonical_url: https://peateasea.de/test-that-forking-code/
cover_image: https://peateasea.de/assets/images/git-fork-all-tested.png
---
*Originally published on [peateasea.de](https://peateasea.de/test-that-forking-c... | peateasea |
1,917,982 | Creating a Virtual Network with Two Virtual Machines that can ping each other. | How to create a virtual network that consists of two virtual machines that can communicate with each other. | 0 | 2024-07-12T21:46:36 | https://dev.to/tundeiness/creating-a-virtual-network-with-two-virtual-machines-that-can-ping-each-other-3056 | azure, virtualnetwork, virtualmachines, subnet | ---
title: Creating a Virtual Network with Two Virtual Machines that can ping each other.
published: true
description: How to create a virtual network that consists of two virtual machines that can communicate with each other.
tags: Azure, VirtualNetwork, VirtualMachines, Subnet
cover_image: https://dev-to-uploads.s3.a... | tundeiness |
1,917,993 | Python : Intro | கடந்த 08.07.2024 ஆம் தேதி கணியம் அறக்கட்டளையால் எடுக்கப்பட்ட இணைய வழி பைத்தான் அறிமுக வகுப்பில்... | 0 | 2024-07-13T03:21:30 | https://dev.to/jokergosha/python-intro-3njm | python, coding | கடந்த 08.07.2024 ஆம் தேதி கணியம் அறக்கட்டளையால் எடுக்கப்பட்ட இணைய வழி பைத்தான் அறிமுக வகுப்பில் கலந்து கொண்டேன்.
> பைத்தான் நிரலாக்கம் மொழியானது எளிதில் புரிந்து கொள்ளக்கூடிய வகையில் உள்ளது.
**Applications of Python:**
-Scripting
-to Automate the process for everyday tasks
-Web development
-Data Analysis
-Machine L... | jokergosha |
1,918,266 | Why your Power Platform Setup Needs a Repo | A Repo (repository) is simply a place to store what you develop. Github is probably the most famous... | 20,311 | 2024-07-15T06:18:04 | https://dev.to/wyattdave/why-your-power-platform-setup-needs-a-repo-3eg | powerplatform, powerapps, powerautomate, lowcode | A Repo (repository) is simply a place to store what you develop. Github is probably the most famous repository (though it does more then just that), but there are others like BitBucket, Artificatory and Assembla.
It can be stored as code (editable individual files) or packages (aka artifacts), there are multiple benef... | wyattdave |
1,918,273 | Clean Coding research | Jul 10th Internship journal: Today, I researched about the basic concepts of clean coding, a term... | 28,067 | 2024-07-10T10:33:52 | https://dev.to/dongdiri96/clean-coding-1787 | **Jul 10th Internship journal:**
Today, I researched about the basic concepts of clean coding, a term that refers to the code format with high readability and efficiency. The team could potentially use this introductory information for designing the website we will create. For better understanding, I tried to read Rob... | dongdiri96 | |
1,918,532 | Mastering Application Permissions in SharePoint Embedded | In the previous article, Containers and Files Security in SharePoint Embedded, we explored the power... | 26,993 | 2024-07-16T06:30:00 | https://intranetfromthetrenches.substack.com/p/application-permissions-in-sharepoint-embedded | sharepoint | In the previous article, [Containers and Files Security in SharePoint Embedded](https://intranetfromthetrenches.substack.com/p/containers-files-security-in-sharepoint-embedded), we explored the power of content permissions for controlling access to container data. But security in SharePoint Embedded goes beyond just fi... | jaloplo |
1,918,641 | How having a Data Layer simplified Offline Mode in my frontend app - Part 1 | You're done with a project and the product team comes to you and says: "Hey, I turned off my internet... | 0 | 2024-07-15T14:02:07 | https://dev.to/belgamo/how-having-a-data-layer-simplified-offline-mode-in-my-frontend-app-part-1-5ahc | offline, pwa, data, repository | You're done with a project and the product team comes to you and says: "Hey, I turned off my internet and the app died". You stop for a moment and don't recall seeing this requirement throughout the development. You're afraid because whatever you answer will make them frustrated. Well, there's clearly a lack of communi... | belgamo |
1,918,731 | Infobip Shift returns to Zadar in 2024 – get ready for 3 days of tech innovation and expertise | One of Europe’s premier tech events is returning to Croatia, and for the first time, the event will... | 0 | 2024-07-17T13:05:38 | https://shiftmag.dev/infobip-shift-returns-to-zadar-in-2024-get-ready-for-3-days-of-tech-innovation-and-expertise-3663/ | event, ai, cybersecurity, programming | ---
title: Infobip Shift returns to Zadar in 2024 – get ready for 3 days of tech innovation and expertise
published: true
date: 2024-07-05 09:13:09 UTC
tags: Event,AI,cybersecurity,programming
canonical_url: https://shiftmag.dev/infobip-shift-returns-to-zadar-in-2024-get-ready-for-3-days-of-tech-innovation-and-expertis... | shiftmag |
1,918,813 | 7 Open Source Projects You Should Know - Java Edition ✔️ | Overview Hi everyone 👋🏼 In this article, I'm going to look at seven OSS repository that... | 27,756 | 2024-07-14T06:00:00 | https://domenicotenace.dev/blog/seven-oss-projects-java-edition/ | opensource, github, softwaredevelopment, java | ## Overview
Hi everyone 👋🏼
In this article, I'm going to look at seven OSS repository that you should know written in Java, interesting projects that caught my attention and that I want to share.
Let's start 🤙🏼
---
## 1. [Robolectric](https://robolectric.org/)
Robolectric is a unit testing framework for Android... | dvalin99 |
1,918,816 | Mastering CSS: Understanding the Cascade | Cascading Style Sheets (CSS) is a fundamental technology of the web, allowing developers to control... | 0 | 2024-07-15T13:05:38 | https://mustcode.it/articles/mastering-css-understanding-the-cascade | css, web, webdev |
Cascading Style Sheets (CSS) is a fundamental technology of the web, allowing developers to control the visual presentation of HTML documents. While CSS syntax may seem simple at first glance, the way styles are applied and inherited can be surprisingly complex. Understanding these intricacies is crucial for writing e... | mustapha |
1,918,818 | 40 Days Of Kubernetes (15/40) | Day 15/40 Kubernetes Node Affinity Explained Video Link @piyushsachdeva Git... | 0 | 2024-07-16T15:10:08 | https://dev.to/sina14/40-days-of-kubernetes-1540-1pl4 | kubernetes, 40daysofkubernetes | ## Day 15/40
# Kubernetes Node Affinity Explained
[Video Link](https://www.youtube.com/watch?v=5vimzBRnoDk)
@piyushsachdeva
[Git Repository](https://github.com/piyushsachdeva/CKA-2024/)
[My Git Repo](https://github.com/sina14/40daysofkubernetes)
We're going to understand node `affinity` in `kubernetes` system.

@piyushsachdeva
[Git Repository](https://github.com/piyushsachdeva/CKA-2024/)
[My Git Repo](https://github.com/sina14/40daysofkubernetes)
In this section we're looking to `resource`, `request` and `limit`
which i... | sina14 |
1,918,908 | Top Free Chrome Extensions You Need to Download Today | In today's digital age, having the right tools can make your online experience more productive and... | 0 | 2024-07-15T12:04:31 | https://dev.to/vishnusatheesh/top-free-chrome-extensions-you-need-to-download-today-486k | webdev, beginners, tutorial, productivity | In today's digital age, having the right tools can make your online experience more productive and enjoyable. Whether you're a student, professional, or casual web user, Chrome extensions can help. With so many options, it can be hard to find the best ones. That's why we've made a list of must-have free Chrome extensio... | vishnusatheesh |
1,918,991 | WarpStream Newsletter #4: Data Pipelines, Zero Disks, BYOC and More | Welcome to the fourth issue of the WarpStream newsletter. A lot has happened since our last... | 0 | 2024-07-15T14:09:42 | https://dev.to/warpstream/warpstream-newsletter-4-data-pipelines-zero-disks-byoc-and-more-2ded | dataengineering, apachekafka, datastreaming, warpstream | ---
title: WarpStream Newsletter #4: Data Pipelines, Zero Disks, BYOC and More
published: true
date: 2024-07-10 17:20:40 UTC
tags: dataengineering,apachekafka,datastreaming,warpstream
canonical_url:
---
Welcome to the fourth issue of the WarpStream newsletter. A lot has happened since our last newsletter: we’ve relea... | warpstream |
1,919,089 | Elixir Stream - The way to save resource | Intro When go to Elixir, almost of us use Enum (or for) a lot. Enum with pipe (|>) is... | 0 | 2024-07-16T13:23:56 | https://dev.to/manhvanvu/elixir-stream-the-way-to-save-resource-2ilk | ## Intro
When go to Elixir, almost of us use `Enum` (or `for`) a lot. Enum with pipe (|>) is the best couple, write so easy & clean.
But we have a trouble when go to process a big list or file for example, all data will processed and passed together to next function this will consume a lot of memory. For this kind of... | manhvanvu | |
1,919,478 | 2.4 A gentle introduction to SvelteKit for Google Cloud developers | Introduction An earlier post in this series (A very gentle introduction to React)... | 0 | 2024-07-16T10:23:16 | https://dev.to/mjoycemilburn/24-a-very-gentle-introduction-to-sveltekit-for-google-cloud-developers-5cfj | sveltekit, javascript, googlecloud, beginners | ---
title: "2.4 A gentle introduction to SvelteKit for Google Cloud developers"
---
### Introduction
An earlier post in this series ([A very gentle introduction to React](https://dev.to/mjoycemilburn/23-a-students-guide-to-firebase-v9-a-very-gentle-introduction-to-reactjs-d67)) introduced readers to the excellent **Re... | mjoycemilburn |
1,919,534 | 19 Microservices Patterns for System Design Interviews | These are the common patterns for Microservice architecture which developer should learn for System Design interviews. | 0 | 2024-07-14T09:36:37 | https://dev.to/somadevtoo/19-microservices-patterns-for-system-design-interviews-3o39 | microservices, softwaredevelopment, systemdesign, programming | ---
title: 19 Microservices Patterns for System Design Interviews
published: true
description: These are the common patterns for Microservice architecture which developer should learn for System Design interviews.
tags: Microservices, softwaredevelopment, systemdesign, programming
# cover_image: https://direct_url_to... | somadevtoo |
1,919,582 | CSS All Tricks and Tips - Part 1 | Index of this Post how to center container How to center container 'San... | 0 | 2024-07-11T10:51:41 | https://dev.to/jaiminbariya/css-all-tricks-and-tips-part-1-1c6d | ## Index of this Post
1. [ how to center container ](#chapter-1)
### How to center container <a name="chapter-1" ></a>
'San Salvador 'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador'San Salvador
```
`print... | jaiminbariya | |
1,919,668 | The Benefits of Caching: Improving Web Performance and Responsiveness | Have you ever visited a website that was slow to load or experienced inconsistent performance?... | 0 | 2024-07-16T07:00:00 | https://devot.team/blog/benefits-of-caching | caching, webdev, programming | Have you ever visited a website that was slow to load or experienced inconsistent performance? Caching can solve these issues and more. In this article, we'll explore caching, how it works, and where it can be applied to improve website performance.
We'll also discuss some common bottlenecks and scenarios where cachin... | ana_klari_e98cbb26da5af3 |
1,919,697 | @let: New feature compiler in Angular 18.1 | Introduction With the arrival of Angular 18.1, this version introduces an exciting new... | 0 | 2024-07-17T09:19:30 | https://dev.to/this-is-angular/let-new-feature-compiler-in-angular-181-jen | angular, news, javascript, webdev | ## Introduction
With the arrival of Angular 18.1, this version introduces an exciting new feature to the compiler: the ability to declare one or more template variables.
How is this feature used, and what are the different use cases?
This article aims to answer.
## The compiler's latest feature: @let
With the late... | nicoss54 |
1,919,795 | Setting up a full-stack MERN (MongoDB, Express, React, Node.js) app for deployment on Vercel. | The MERN stack, comprising MongoDB, Express, React, and Node.js, is one of several technological... | 0 | 2024-07-14T00:17:00 | https://toki-adedapo.com/setting-up-a-full-stack-mern-mongodb-express-react-nodejs-app-for-deployment-on-vercel | serverless, node, react, mongodb | The MERN stack, comprising MongoDB, Express, React, and Node.js, is one of several technological combinations used for building full-stack web applications. Vercel provides a versatile platform capable of deploying a wide range of frameworks and technologies for various project types. While often associated with fronte... | matrix24483 |
1,919,986 | Write spike stories like fairy tales | For more content like this subscribe to the ShiftMag newsletter. _ “Hello, my name is Inigo... | 0 | 2024-07-17T13:05:02 | https://shiftmag.dev/how-to-write-spike-3708/ | softwareengineering, documentation, spike, techicalwriting | ---
title: Write spike stories like fairy tales
published: true
date: 2024-07-11 11:28:23 UTC
tags: SoftwareEngineering,Documentation,spike,techicalwriting
canonical_url: https://shiftmag.dev/how-to-write-spike-3708/
---

_For more con... | shiftmag |
1,920,095 | Getting Started with WordPress: A Step-by-Step Guide to Local Installation | Introduction: 🚀 Welcome to Series 1: Building a Simple WordPress Site! 🚀 In this series, I'll guide... | 28,055 | 2024-07-13T13:49:47 | https://dev.to/anchal_makhijani/getting-started-with-wordpress-a-step-by-step-guide-to-local-installation-3da2 | webdev, learning, opensource | **Introduction:**
🚀 Welcome to Series 1: Building a Simple WordPress Site! 🚀 In this series, I'll guide you through the essential steps to create and manage your very own WordPress website. Whether you're a WordPress newbie or looking to refine your skills, this series will equip you with the knowledge to build a fu... | anchal_makhijani |
1,920,167 | Latency at the Edge with Rust/WebAssembly and Postgres: Part 1 | We have been working on enabling Exograph on WebAssembly. Since we have implemented Exograph using... | 0 | 2024-07-12T01:35:59 | https://exograph.dev/blog/wasm-pg-explorations-1 | postgres, webassembly, rust | ---
title: Latency at the Edge with Rust/WebAssembly and Postgres: Part 1
published: true
date: 2024-06-05 00:00:00 UTC
tags: postgres,wasm,Rust,WebAssembly
canonical_url: https://exograph.dev/blog/wasm-pg-explorations-1
---
We have been working on enabling [Exograph](https://exograph.dev) on [WebAssembly](https://web... | ramnivas |
1,920,168 | Latency at the edge with Rust/WebAssembly and Postgres: Part 2 | In the previous post, we implemented a simple Cloudflare Worker in Rust/WebAssembly connecting to a... | 0 | 2024-07-11T23:12:32 | https://exograph.dev/blog/wasm-pg-explorations-2 | postgres, webassembly, cloudflare, worker | ---
title: Latency at the edge with Rust/WebAssembly and Postgres: Part 2
published: true
date: 2024-06-06 00:00:00 UTC
tags: postgres,WebAssembly,Cloudflare, Worker
canonical_url: https://exograph.dev/blog/wasm-pg-explorations-2
---
In the [previous post](https://exograph.dev/blog/wasm-pg-explorations-1), we implemen... | ramnivas |
1,920,169 | Exograph at the Edge with Cloudflare Workers | We are excited to announce that Exograph can now run as a Cloudflare Worker! This new capability... | 0 | 2024-07-11T20:40:45 | https://exograph.dev/blog/cloudflare-workers | webassembly, cloudflare, workers, edge | ---
title: Exograph at the Edge with Cloudflare Workers
published: true
date: 2024-06-12 00:00:00 UTC
tags: WebAssembly, Cloudflare, Workers, Edge
canonical_url: https://exograph.dev/blog/cloudflare-workers
---
We are excited to announce that Exograph can now run as a [Cloudflare Worker](https://workers.cloudflare.com... | ramnivas |
1,920,170 | GraphQL Server in the Browser using WebAssembly | On the heels of our last feature release, we are excited to announce a new feature: Exograph... | 0 | 2024-07-11T20:28:47 | https://exograph.dev/blog/playground | webassembly, graphql, playground, rust | ---
title: GraphQL Server in the Browser using WebAssembly
published: true
date: 2024-06-18 00:00:00 UTC
tags: WebAssembly,GraphQL,Playground,Rust
canonical_url: https://exograph.dev/blog/playground
---
On the heels of our [last feature release](https://exograph.dev/blog/cloudflare-workers), we are excited to announce... | ramnivas |
1,920,259 | Isolate and Connect Your Applications with Azure Virtual Networks and Subnets (Part 1) | Introduction: Imagine you have a critical application that requires isolation from the public... | 0 | 2024-07-17T21:56:58 | https://dev.to/jimiog/isolate-and-connect-your-applications-with-azure-virtual-networks-and-subnets-part-1-3k70 | azure, cloud, network, security | **Introduction:**
Imagine you have a critical application that requires isolation from the public internet and secure communication with other internal resources. Azure virtual networks and subnets provide the perfect solution to achieve this. We'll guide you through creating virtual networks with peered subnets, enab... | jimiog |
1,920,267 | Package Received | When starting a new job, I tend to enter it cautiously optimistic. I don't consider it a reality... | 0 | 2024-07-12T19:40:13 | https://dev.to/neffcodes/package-received-1815 | webdev, careerdevelopment | When starting a new job, I tend to enter it cautiously optimistic. I don't consider it a reality until I can touch it, literally. Whenever I start a new job, it doesn't hit until I first enter the building or get to my workstation. The same thing happened when I joined the Develop Carolina apprenticeship program as a s... | neffcodes |
1,920,313 | Sharekart | This is a submission for the Wix Studio Challenge . The challenge was to create an innovative... | 0 | 2024-07-12T22:40:17 | https://dev.to/salman2301/sharekart-4i48 | devchallenge, wixstudiochallenge, webdev, javascript | *This is a submission for the [Wix Studio Challenge ](https://dev.to/challenges/wix).*
> The challenge was to create an innovative e-commerce site using Wix Studio and existing Wix API.
## What I Built
**TL;DR:**
The best type of marketing is "Word-of-mouth." I built a site where buyers can post their purchases, all... | salman2301 |
1,920,340 | Securing Data at Rest: The Importance of Encryption and How to Implement It | Introduction Keeping your data safe is essential for any organization to prevent... | 0 | 2024-07-14T17:30:56 | https://dev.to/iamsherif/securing-data-at-rest-the-importance-of-encryption-and-how-to-implement-it-81a | security, serverless, data, dynamodb | ## Introduction
Keeping your data safe is essential for any organization to prevent unauthorized access and breaches. In AWS's shared security responsibility model, customers are responsible for anything they put in the cloud or connect to the cloud, while AWS is responsible for the security of the cloud. For more deta... | iamsherif |
1,920,415 | How to build a Perplexity-like Chatbot in Slack? | TL;DR I spend a lot of time on Slack and often need deep-researched information. For this,... | 0 | 2024-07-16T17:17:09 | https://dev.to/composiodev/how-to-build-a-perplexity-like-chatbot-in-slack-533j | webdev, python, programming, ai | ## TL;DR
I spend a lot of time on Slack and often need deep-researched information. For this, I have to go to Google search and research topics manually, which seems unproductive in the age of AI.
So, I built a Slack chatbot to access the internet and find relevant information with citations, similar to Perplexity.
... | sunilkumrdash |
1,920,465 | Top 6 React Hook Mistakes Beginners Make | The hardest part about learning react is not actually learning how to use react but instead learning... | 0 | 2024-07-14T16:46:04 | https://dev.to/markliu2013/top-6-react-hook-mistakes-beginners-make-1135 | react | The hardest part about learning react is not actually learning how to use react but instead learning how to write good clean react code.
In this article, I will talk about 6 mistakes that I see almost everyone making with the useState and useEffect hook.
## Mistake 1, Using state when you don't need it
The very fir... | markliu2013 |
1,920,504 | Node Docker App | Our Funda is very simple. Just create a simple nodeJs app and dockerize it docker hub😘 ... Step 0:... | 0 | 2024-07-13T05:00:00 | https://dev.to/nisharga_kabir/node-docker-app-2f1e | docker, nodeapp, node, javascript | Our Funda is very simple. Just create a simple nodeJs app and dockerize it docker hub😘 ...
Step 0: create a folder and create a package.json file. and copy these code
```
{
"name": "nodejs-image-demo",
"version": "1.0.0",
"description": "nodejs image demo",
"author": "Nisharga Kabir",
"license": "MIT",
"... | nisharga_kabir |
1,920,615 | Create an API for DataTables with Express | DataTables is a popular jQuery plugin that offers features like pagination, searching, and sorting,... | 0 | 2024-07-15T02:36:26 | https://blog.stackpuz.com/create-an-api-for-datatables-with-express/ | express, datatables | ---
title: Create an API for DataTables with Express
published: true
date: 2024-07-12 08:25:00 UTC
tags: Express,DataTables
canonical_url: https://blog.stackpuz.com/create-an-api-for-datatables-with-express/
---

DataTables is a popular j... | stackpuz |
1,920,788 | Creating API Documentation with Swagger on NodeJS | Introduction Swagger is a popular, simple, and user-friendly tool for creating APIs. Most... | 27,954 | 2024-07-13T03:00:00 | https://howtodevez.blogspot.com/2024/04/creating-api-documentation-with-swagger-on-nodejs.html | node, typescript, beginners, backend | Introduction
------------
**Swagger** is a popular, simple, and user-friendly tool for creating **APIs**. Most backend developers, regardless of the programming languages they use, are familiar with **Swagger**. This article will guide you through creating API documentation using **Swagger** on **Node.js** (specifical... | chauhoangminhnguyen |
1,920,801 | Using MongoDB on Docker | Introduction MongoDB is a widely popular NoSQL database today due to its simplicity and... | 28,046 | 2024-07-15T03:00:00 | https://howtodevez.blogspot.com/2024/04/using-mongodb-on-docker.html | docker, beginners, mongodb, node | Introduction
------------
**MongoDB** is a widely popular **NoSQL** database today due to its simplicity and several advantages over relational databases. Through this guide, you'll learn how to quickly use **MongoDB** within **Docker** without going through many complex installation steps.
Note that before starting,... | chauhoangminhnguyen |
1,921,773 | 获客霸屏机器人 | 全球获客活粉采集软件,获客群发工具,获客霸屏机器人 了解相关软件请登录 http://www.vst.tw... | 0 | 2024-07-12T23:24:53 | https://dev.to/qmmc_sqru_40a68d5c587d92e/huo-ke-ba-ping-ji-qi-ren-19e2 |
全球获客活粉采集软件,获客群发工具,获客霸屏机器人
了解相关软件请登录 http://www.vst.tw
获客活粉采集软件是当今数字营销领域中的一种重要工具,它们为企业提供了强大的能力来吸引、获取和管理潜在客户的信息。无论是传统企业还是新兴的在线业务,都可以通过这些软件有效地扩展其客户基础和市场份额。
1. 获客活粉采集软件的定义和作用
获客活粉采集软件是指一类专门用于从互联网上收集潜在客户信息的工具。它们通过自动化或半自动化的方式,搜索并收集与企业产品或服务相关的信息,如电子邮件地址、社交媒体账号、联系电话等。这些软件不仅帮助企业建立客户数据库,还能够进行客户细分和管理,为营销和销售团队提供精准的目标群... | qmmc_sqru_40a68d5c587d92e | |
1,920,804 | A New Open Source Platform for people to share their links of Favorite content over the internet | I have Created an open source Platform where a user can share the links of their favorite content... | 0 | 2024-07-13T07:08:57 | https://dev.to/emdadr/a-new-open-source-platform-for-people-to-share-their-links-of-favorite-content-over-the-internet-1hm2 | webdev, opensource, dotnet, csharp | I have Created an open source Platform where a user can share the links of their favorite content over like (Insat reels, TikTok, Youtube vids, Facebook posts, Twitter/X Tweet/Post, Sub-Reddits, anything)
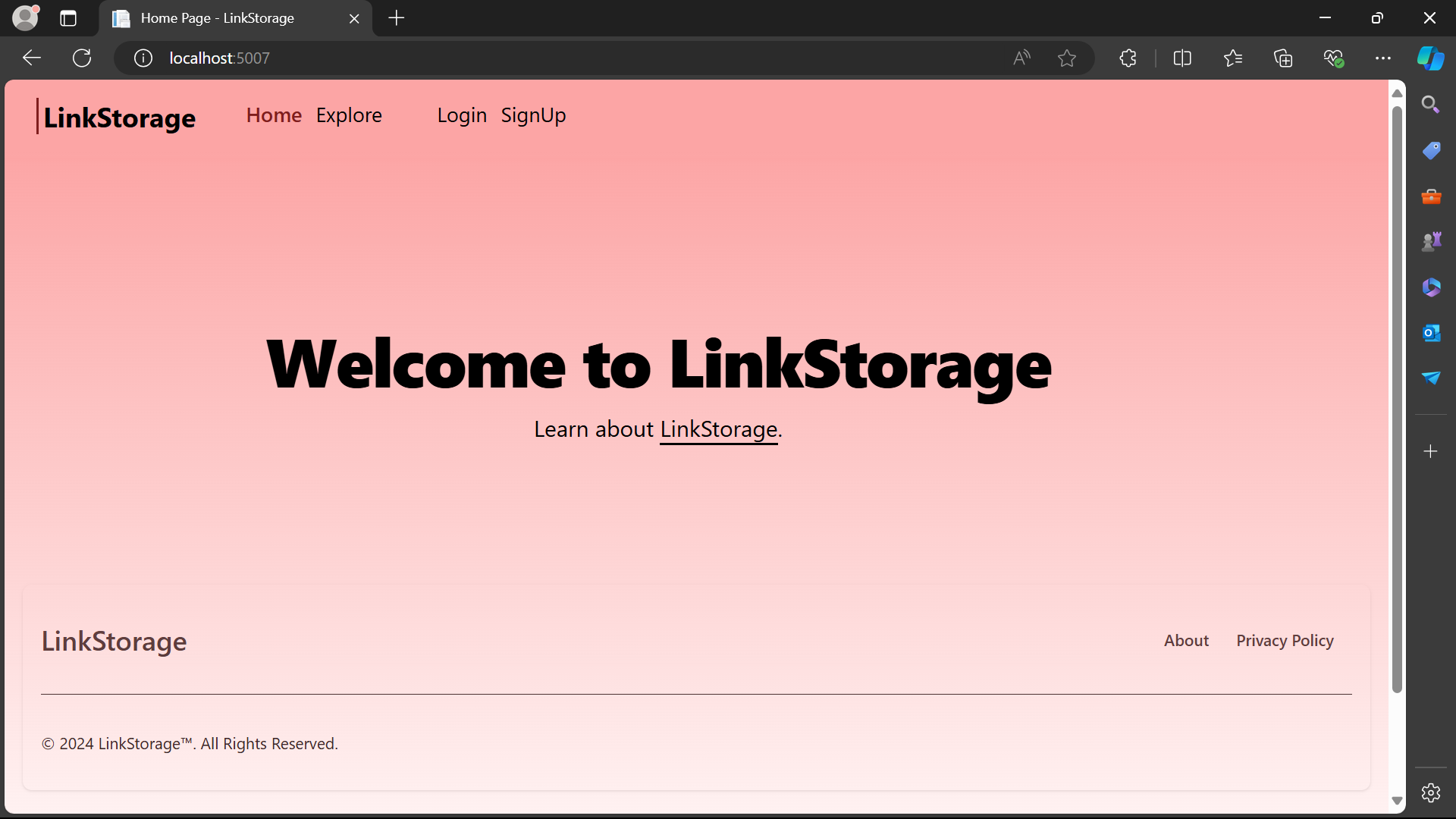
--------------... | emdadr |
1,920,805 | Mastering Text Extraction from Multi-Page PDFs Using OCR API: A Step-by-Step Guide | Introduction Optical Character Recognition (OCR) technology has transformed the way we... | 0 | 2024-07-15T10:58:50 | https://dev.to/api4ai/mastering-text-extraction-from-multi-page-pdfs-using-ocr-api-a-step-by-step-guide-amm | ocr, textrecognition, pdf, ai | #Introduction
Optical Character Recognition (OCR) technology has transformed the way we manage and process documents. OCR enables computers to convert various types of documents, such as scanned paper documents, PDF files, or images taken by a digital camera, into editable and searchable data. By identifying the text ... | taranamurtuzova |
1,920,821 | Practicing with Google Cloud Platform - Google Kubernetes Engine to deploy nginx | Introduction This article provides simple step-by-step instructions for those who are new... | 28,047 | 2024-07-17T03:00:00 | https://howtodevez.blogspot.com/2024/04/practicing-with-google-cloud-platform-google-kubernetes-engine-to-deploy-nginx.html | kubernetes, gcp, beginners, devops | Introduction
------------
This article provides simple step-by-step instructions for those who are new to **Google Cloud Platform (GCP)** and **Google Kubernetes Engine (GKE)**.
I'll guide you through using **GKE** to create clusters and deploy **nginx**.
The instructions below will primarily use **gcloud** and **ku... | chauhoangminhnguyen |
1,920,845 | RTX A6000 vs RTX 4090: Which GPU Is Right for You? | Introduction Nvidia leads with its RTX series, featuring the top-notch GPUs RTX A6000 and... | 0 | 2024-07-12T21:30:00 | https://blogs.novita.ai/rtx-a6000-vs-rtx-4090-which-gpu-is-right-for-you/ | webdev, gpu | ## **Introduction**
Nvidia leads with its RTX series, featuring the top-notch GPUs RTX A6000 and RTX 4090 for professionals and gamers. Today, the blog will break down their features, performance, design, and energy efficiency to help you choose the best one that may fit your needs. We will explore key features, perfo... | novita_ai |
1,920,871 | Generate cube image panorama | Introduction In today's digital age, high-quality panorama images are becoming... | 0 | 2024-07-17T04:41:19 | https://dev.to/nmthangdn2000/cut-cube-image-panorama-3gmn | threejs, panorama, view360 | # Introduction
In today's digital age, high-quality panorama images are becoming increasingly popular in fields like tourism, real estate, and interior design. However, the manual process of cropping cube panorama images can be time-consuming and prone to errors, which may affect the image quality when uploaded to the... | nmthangdn2000 |
1,920,901 | pip Trends Newsletter | 13-Jul-2024 | This week's pip Trends newsletter is out. Interesting stuff by Stuart Ellis, Gonçalo Valério, Martin... | 0 | 2024-07-13T03:30:00 | https://dev.to/tankala/pip-trends-newsletter-13-jul-2024-3gch | programming, python, opensource, news | This week's pip Trends newsletter is out. Interesting stuff by Stuart Ellis, Gonçalo Valério, Martin Heinz, Himani Bansal & Ebo Jackson are covered this week
{% embed https://newsletter.piptrends.com/p/modern-good-practices-for-python %} | tankala |
1,920,933 | Make Your Business Grow with Volusion Integration | In the ever-evolving world of eСommerce, integrating software and apps with various shopping... | 0 | 2024-07-16T06:04:28 | https://dev.to/api2cartofficial/make-your-business-grow-with-volusion-integration-5han | volusion, integration, ecommerce, saas | In the ever-evolving world of eСommerce, integrating software and apps with various shopping platforms is critical to success. With Volusion integration development, your path to eСommerce success will be more precise and achievable than ever.
This article explores the benefits and processes of Volusion Integration, pr... | api2cartofficial |
1,921,030 | Baby Steps in Tech | Transitioning into tech can be overwhelming, from choosing a programming language to getting the... | 0 | 2024-07-12T20:29:11 | https://dev.to/udeze/baby-steps-in-tech-4fo6 | programming, beginners, tutorial, productivity | Transitioning into tech can be overwhelming, from choosing a programming language to getting the right resources, meeting the right mentors, and being in the right communities. Tech is an ever-evolving and robust field with plenty of room for you and me to make a career out of it.
>
_“The only way to discover the lim... | udeze |
1,921,154 | Making a HTTP server in Go | I've stumbled upon Codecrafters a while ago, and the idea really caught my attention. Making real... | 0 | 2024-07-15T12:44:57 | https://dev.to/enzoenrico/making-a-http-server-in-go-1gpo | go, codenewbie, codecrafters, backend | I've stumbled upon [Codecrafters](https://codecrafters.io/) a while ago, and the idea really caught my attention. Making real world projects to learn, instead of following tutorials is everything I could've asked for when I was getting started, so just so I don't let the opportunity get away, I'm following their free p... | enzoenrico |
1,921,156 | Day 3: Data types and variables in python 🧡 | You do not need to specify which data you assigning to variable. It is smart⛓ enough to recognize... | 0 | 2024-07-17T05:08:09 | https://dev.to/aryan015/day-3-data-types-and-variables-in-python-3e3j | 100daysofcode, python, javascript, java | You do not need to specify which data you assigning to variable. It is smart⛓ enough to recognize which datatype you are holding.
We will understand data type and variables hand to hand.
## python variables
Variable in programming(in general) is nothing but a value that can be used multiple times in your code.
syntax... | aryan015 |
1,921,161 | Measuring and minimizing latency in a Kafka Sink Connector | Kafka is often chosen as a solution for realtime data streaming because it is highly scalable,... | 0 | 2024-07-17T07:51:44 | https://ably.com/blog/optimizing-kafka-sink-connector-latency | latency, kafka, webdev, news | Kafka is often chosen as a solution for realtime data streaming because it is highly scalable, fault-tolerant, and can operate with low latency even under high load. This has made it popular for companies in the fan engagement space, and where transactional data is used (e.g. betting) as low latency ensures that action... | ttypic |
1,921,175 | Integrating Cypress with CI/CD Pipelines: A Step-by-Step Guide | Introduction Continuous Integration (CI) and Continuous Deployment (CD) are essential... | 0 | 2024-07-13T05:17:46 | https://dev.to/aswani25/integrating-cypress-with-cicd-pipelines-a-step-by-step-guide-1kck | webdev, javascript, testing, cypress | ## Introduction
Continuous Integration (CI) and Continuous Deployment (CD) are essential practices in modern software development. They ensure that code changes are automatically tested and deployed, leading to faster development cycles and higher quality software. Cypress, a powerful end-to-end testing framework, can ... | aswani25 |
1,921,178 | A Guide to Master JavaScript-Objects | Objects are a fundamental part of JavaScript, serving as the backbone for storing and managing data.... | 28,049 | 2024-07-15T13:09:00 | https://dev.to/imsushant12/a-guide-to-master-javascript-objects-362b | webdev, javascript, beginners, programming | Objects are a fundamental part of JavaScript, serving as the backbone for storing and managing data. An object is a collection of properties, and each property is an association between a key (or name) and a value. Understanding how to create, manipulate, and utilize objects is crucial for any JavaScript developer. In ... | imsushant12 |
1,921,199 | How to add a scrollbar to Syncfusion Flutter Charts | TL;DR: Learn to add scrollbars to Syncfusion Flutter Charts using the Range Slider and Range Selector... | 0 | 2024-07-17T16:14:02 | https://www.syncfusion.com/blogs/post/adding-scrollbar-in-flutter-charts | flutter, chart, mobile, desktop | ---
title: How to add a scrollbar to Syncfusion Flutter Charts
published: true
date: 2024-07-12 09:46:37 UTC
tags: flutter, chart, mobile, desktop
canonical_url: https://www.syncfusion.com/blogs/post/adding-scrollbar-in-flutter-charts
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/tmxcitsew4651of... | jollenmoyani |
1,921,266 | My Cloud Resume Challenge | Here's my shot at the Cloud Resume Challenge... | 0 | 2024-07-15T14:13:46 | https://dev.to/anthony_coughlin_f0ae1698/my-cloud-resume-challenge-j4p | Here's my shot at the Cloud Resume Challenge https://cloudresumechallenge.dev/docs/the-challenge/aws/
I managed to complete the challenge after 2 weeks, well, if I'm completely honest I did not take the AWS Cloud Practitioner certification but plan to get that in the future. I'm a QA Manager by trade, but have got qui... | anthony_coughlin_f0ae1698 | |
1,921,304 | Creating An Azure virtual Network with Subnets | Outline Step 1: Introduction Step 2: Log in to Azure Portal Step 3: Create a Virtual Network Step 4:... | 0 | 2024-07-12T20:55:01 | https://dev.to/mabis12/creating-azure-virtual-network-with-subnets-1ei0 | networking, azure, virtualsubnets, cloudcomputing | **Outline**
Step 1: Introduction
Step 2: Log in to Azure Portal
Step 3: Create a Virtual Network
Step 4: Configure the Basics Tab
Step 5: Configure IP Addresses Tab
Step 6: Configure Subnet
Step 7: Create Virtual Network
Step 8: Verification of Azure Virtual Network with subnets
**Step 1: Introduction**
An Azure Virtu... | mabis12 |
1,921,356 | Differences Between Edge Stack and Emissary: A Breakdown | One of our new segments, Community Corner, features weekly deep dives into common questions we get in... | 0 | 2024-07-15T06:00:00 | https://www.getambassador.io/blog/differences-edge-stack-emissary | edge, apigateway, emissary, api | One of our new segments, Community Corner, features weekly deep dives into common questions we get in our Community across our products: [Edge Stack](https://www.getambassador.io/products/edge-stack/api-gateway), [Telepresence](https://www.getambassador.io/products/telepresence), and [Blackbird](https://www.getambassad... | getambassador2024 |
1,921,374 | How to optimize your MERN workflow with a solid architecture | We've probably encountered a MERN stack project on the internet that was perhaps the messiest thing... | 0 | 2024-07-12T20:06:41 | https://dev.to/fullstackdev/optimize-your-mern-workflow-with-a-solid-architecture-37p4 | webdev, javascript, programming, architecture | We've probably encountered a MERN stack project on the internet that was perhaps the messiest thing we've seen. Where everything was crammed into one single file. Where the front-end and back-end logic were squeezed together, files and variables have random names, making the codebase hard to explore and no error handli... | fullstackdev |
1,921,396 | What's In The Box? | Welcome back! We’re diving into the CSS Box-Model, a rite of passage for any web developer. Let’s... | 27,613 | 2024-07-15T14:00:00 | https://dev.to/nmiller15/whats-in-the-box-4nh0 | html, css, webdev, beginners |

Welcome back! We’re diving into the CSS Box-Model, a rite of passage for any web developer. Let’s see: "What's in the Box!?"
---
## The Content Box
In web styling, **everything is in a box**. So far, we’... | nmiller15 |
1,921,397 | How to Install TypeScript and write your first program | TypeScript has become a popular choice for many developers due to its strong typing and excellent... | 28,050 | 2024-07-13T06:05:00 | https://dev.to/jakaria/how-to-install-typescript-and-write-your-first-program-1fj4 | webdev, typescript, programming, learning | TypeScript has become a popular choice for many developers due to its strong typing and excellent tooling support. In this guide, we'll walk you through installing TypeScript and writing your first TypeScript program.
#### Step 1: Install Node.js and npm
Before installing TypeScript, you need to have Node.js and npm (... | jakaria |
1,921,400 | Once You Touch It, You Own It! | While working for my last client, we needed to extend an existing feature. We had to import an Excel... | 27,567 | 2024-07-15T05:00:00 | https://canro91.github.io/2024/02/05/LessonsOnAFinishedProject/ | career, softwareengineering, beginners, projectmanagement | While working for my last client, we needed to extend an existing feature.
We had to import an Excel file with a list of guests into a group event. Think of importing all the guests to a wedding reception at a hotel.
> "You only have to add your changes to this existing component. It's already working."
That was wha... | canro91 |
1,921,413 | Adding Web Scraping and Google Search to AWS Bedrock Agents | Motivation After all of the AWS product announcements at the NYC Summit last week, I... | 0 | 2024-07-17T17:27:07 | https://dev.to/b-d055/adding-web-scraping-and-google-search-to-aws-bedrock-agents-55a8 | docker, typescript, aws, ai | ## Motivation
After all of the [AWS product announcements](https://aws.amazon.com/events/summits/new-york/) at the NYC Summit last week, I wanted to start testing out AWS Bedrock Agents more thoroughly for myself. Something clients often ask for is the ability for their LLM workflows to have access to the web.
There ... | b-d055 |
1,921,416 | Yet another attempt to get better at chess | Do you recall that golden period when your chess rating skyrocketed? When you were effortlessly... | 0 | 2024-07-15T03:50:33 | https://dev.to/mrdimosthenis/yet-another-attempt-to-get-better-at-chess-5fjm | chess, devtools | Do you recall that golden period when your chess rating skyrocketed? When you were effortlessly conquering opponents who seemed invincible? It felt like you could defeat anyone with just a little extra focus on the next game. Perhaps you even believed that your rating would continue to soar indefinitely. You may have e... | mrdimosthenis |
1,921,420 | Mastering Image Optimization and Utilization in Web Development | Images are integral to web development, significantly enhancing the visual appeal and user experience... | 0 | 2024-07-13T03:12:06 | https://dev.to/mdhassanpatwary/mastering-image-optimization-and-utilization-in-web-development-317a | webdev, learning, productivity, html | Images are integral to web development, significantly enhancing the visual appeal and user experience of websites. However, improper use of images can lead to performance issues, slow loading times, and a poor user experience. This guide will delve into various aspects of using images in web development, covering attri... | mdhassanpatwary |
1,921,460 | Building Your First Use Case With Clean Architecture | This is a question I often hear: how do I design my use case with Clean Architecture? I understand... | 0 | 2024-07-16T16:09:10 | https://www.milanjovanovic.tech/blog/building-your-first-use-case-with-clean-architecture | cleanarchitecture, usecases, dotnet, mediatr | ---
title: Building Your First Use Case With Clean Architecture
published: true
date: 2024-07-13 00:00:00 UTC
tags: cleanarchitecture,usecases,dotnet,mediatr
canonical_url: https://www.milanjovanovic.tech/blog/building-your-first-use-case-with-clean-architecture
cover_image: https://dev-to-uploads.s3.amazonaws.com/uplo... | milanjovanovictech |
1,921,462 | How to Enable Static Content Service in IIS in Windows 11? | Static Content Service in Internet Information Services: The Static Content Service in... | 0 | 2024-07-17T16:01:19 | https://winsides.com/enable-static-content-service-iis-windows-11/ | tips, beginners, tutorials, windows11 | ---
title: How to Enable Static Content Service in IIS in Windows 11?
published: true
date: 2024-07-05 15:55:00 UTC
tags: tips,beginners,tutorials,windows11
canonical_url: https://winsides.com/enable-static-content-service-iis-windows-11/
cover_image: https://winsides.com/wp-content/uploads/2024/01/Enable-Static-Conten... | vigneshwaran_vijayakumar |
1,921,495 | Exploring TypeScript: A Comprehensive Guide | TypeScript enhances JavaScript by adding static types, which can improve code quality and development... | 28,050 | 2024-07-13T05:25:00 | https://dev.to/jakaria/exploring-typescript-a-comprehensive-guide-36nk | typescript, programming, webdev, learning | TypeScript enhances JavaScript by adding static types, which can improve code quality and development efficiency. This guide covers key TypeScript features including data types, objects, optional and literal types, functions, spread and rest operators, destructuring, type aliases, union and intersection types, ternary ... | jakaria |
1,921,497 | BUTLER MACHINE EXPLOIT WALKTHROUGH | This walkthrough will showcase a creative approach in exploiting a windows machine named butler and... | 0 | 2024-07-13T00:03:01 | https://dev.to/babsarena/butler-machine-exploit-walkthrough-5cfb | This walkthrough will showcase a creative approach in exploiting a windows machine named butler and gaining access on the machine.
After successfully setting up your butler windows machine, use the following details to login to the machine.
**butler: JeNkIn5@44
administrator: A%rc!BcA!**
We can login using the admi... | babsarena | |
1,921,505 | Usando PAM no Linux | O que é? Bem, vamos primeiro falar sobre o que são os PAM, Plugglable Autentication... | 0 | 2024-07-12T21:00:23 | https://dev.to/rafaelbonilha/usando-pam-no-linux-lp4 | linux, security, logicapps, systems | #O que é?
Bem, vamos primeiro falar sobre o que são os **PAM**, **Plugglable Autentication Modules** que são um conjunto de bibliotecas usadas para fazer autenticação, gerenciamento de contas, controle de recursos dos usuários no sistema, em adição ao tradicional sistema de acesso baseado em usuários/grupos, isto é, p... | rafaelbonilha |
1,921,523 | JavaScript to TypeScript in React-Native Development | TypeScript in React Native: My Journey from Confusion to Clarity After a year of working... | 0 | 2024-07-16T16:55:14 | https://dev.to/rafi_barides_faa6677ba16d/javascript-to-typescript-in-react-native-development-4hd7 | typescript, reactnative, mobile | ## TypeScript in React Native: My Journey from Confusion to Clarity
After a year of working with JavaScript, I was encouraged to learn TypeScript as I embarked on my mobile development journey. Having a solid foundation in React made the transition to React Native smoother. However, TypeScript introduces a new level o... | rafi_barides_faa6677ba16d |
1,921,535 | Deploying a Django App to Kubernetes with Amazon ECR and EKS | Today, I'll be deploying a simple Django App to practice using Docker and Kubernetes. I have a... | 0 | 2024-07-12T20:37:48 | https://dev.to/aktran321/deploying-a-django-app-to-kubernetes-with-amazon-ecr-and-eks-3736 | Today, I'll be deploying a simple Django App to practice using Docker and Kubernetes.
I have a simple setup.
A directory with cloned git repo and a virtual environment.
![Image description](https://dev-to-uplo... | aktran321 | |
1,921,541 | Your First Programming Language: A Strategic Guide for Beginners | In today's tech-driven world, there seems to be an overwhelming number of programming languages to... | 0 | 2024-07-12T20:08:27 | https://dev.to/sharoztanveer/your-first-programming-language-a-strategic-guide-for-beginners-29ka | programming, softwareengineering, python, c | In today's tech-driven world, there seems to be an overwhelming number of programming languages to choose from. This article aims to simplify your journey into programming by guiding you on which languages to learn and in what order, ensuring you learn to program as efficiently as possible.
As technology permeates eve... | sharoztanveer |
1,921,544 | growing linkedin using aws learnings? | is it a good idea to share your day to day learning about aws on linkedin? like growing your linkedin... | 0 | 2024-07-12T19:04:25 | https://dev.to/newjourney_95874cd87b2724/growing-linkedin-using-aws-learnings-4kke | aws, learning, cloudcomputing, cloudpractitioner | is it a good idea to share your day to day learning about aws on linkedin? like growing your linkedin account instead of writing articles?
| newjourney_95874cd87b2724 |
1,921,545 | ТОП-10 самых легких песен караоке в Москве | Одним из самых любимых и веселых развлечений современной молодежи и не только, можно смело назвать... | 0 | 2024-07-12T19:05:28 | https://dev.to/sevencode/top-10-samykh-lieghkikh-piesien-karaokie-v-moskvie-1ecd | Одним из самых любимых и веселых развлечений современной молодежи и не только, можно смело назвать караоке. Именно здесь, компании друзей, влюбленные парочки, родные люди могут насладиться общением, отдохнуть душой и телом. Даже если вы считаете, что пение совершенно не ваша сильная сторона. Есть несколько беспроигрышн... | sevencode | |
1,921,546 | 发防封号助手,获客霸屏工具 | 纸飞机营销获客系统,获客群发防封号助手,获客霸屏工具 了解相关软件请登录 http://www.vst.tw... | 0 | 2024-07-12T19:07:18 | https://dev.to/qagv_mfot_30e81d81bdc3b1a/fa-fang-feng-hao-zhu-shou-huo-ke-ba-ping-gong-ju-8a7 |
纸飞机营销获客系统,获客群发防封号助手,获客霸屏工具
了解相关软件请登录 http://www.vst.tw
纸飞机营销获客系统,重新定义数字营销的新篇章
在当今这个信息爆炸的时代,纸飞机营销获客系统以其独特的魅力和高效的性能,成为了众多企业争相追捧的营销利器。该系统通过精准定位目标客户群体,利用大数据和人工智能技术,实现营销信息的精准推送,帮助企业快速获客并提升品牌影响力。
纸飞机营销获客系统的特点在于其高度的智能化和个性化。它能够根据用户的浏览历史、购买行为等多维度数据,为用户画像,从而推送更符合其兴趣和需求的营销信息。这种个性化的推送方式,不仅提高了用户的点击率和转化率,还增强了用户对企业品牌的认知度和好... | qagv_mfot_30e81d81bdc3b1a | |
1,921,547 | Производство напитков СТМ под вашим брендом | Производство напитков под собственным брендом может иметь несколько преимуществ: Уникальность... | 0 | 2024-07-12T19:07:21 | https://dev.to/sevencode/proizvodstvo-napitkov-stm-pod-vashim-briendom-1hj6 | Производство напитков под собственным брендом может иметь несколько преимуществ:
1. Уникальность продукта: Вы сможете создать уникальные рецептуры и вкусы, которые отличаются от того, что предлагается другими брендами. Это позволит вам выделиться на рынке и привлечь внимание потребителей.
2. Контроль качества: При пр... | sevencode |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.