
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,922,832 | Blocking FastAPI Access Logs | Have you ever found your FastAPI deployment cluttered with unnecessary access logs? These logs can... | 0 | 2024-07-14T03:55:08 | https://dev.to/mukulsharma/taming-fastapi-access-logs-3idi | fastapi, python, filter, logs | Have you ever found your FastAPI deployment cluttered with unnecessary access logs? These logs can create more noise than value, obscuring important information. Let's explore a neat trick to selectively block these access logs in FastAPI.

 {
let x: i32 = 5;
let y: u32 = 10;
println!("x = {}, y = {}", x, y);
}
```
### Floating-Point Numbers
**Python:**
```python
pi = 3.14
```
**Rust:**
```rust
fn ... | ahmed__elboshi | |
1,922,836 | Mount share folder in QEMU with same permission as host | Background I would like to share a folder between guest and host in QEMU. File permission... | 0 | 2024-07-14T04:15:32 | https://dev.to/franzwong/mount-share-folder-in-qemu-with-same-permission-as-host-2980 | qemu, 9p | ## Background
I would like to share a folder between guest and host in QEMU. File permission should be the same as the user in host.
## Solution
1\. Create a folder called `shared` in host
```
mkdir -p shared
```
2\. Add a parameter `virtfs` when starting VM with QEMU
```
-virtfs local,path=shared,mount_tag=shar... | franzwong |
1,922,837 | Rust tutorials for Python DEV: if statements | Beginner's Guide to Using if Statements in Rust The if statement in Rust allows you to... | 0 | 2024-07-14T04:16:18 | https://dev.to/ahmed__elboshi/rust-tutorials-for-python-dev-if-statements-170e | # Beginner's Guide to Using `if` Statements in Rust
The `if` statement in Rust allows you to execute code conditionally, depending on whether an expression evaluates to `true` or `false`. This is similar to how `if` statements work in Python, but with some syntax differences.
## Basic `if` Statement
In Python, you m... | ahmed__elboshi | |
1,922,838 | Using Flexbox for Layouts | Introduction In recent years, web design has evolved to focus more on responsive and... | 0 | 2024-07-14T04:17:37 | https://dev.to/tailwine/using-flexbox-for-layouts-4bi3 | sass, scss, css, tailwindcss | ## Introduction
In recent years, web design has evolved to focus more on responsive and flexible layouts. This is where flexbox comes in. Flexbox is a CSS layout model that allows for the creation of flexible and responsive web layouts with ease. It provides developers with a more efficient way to arrange, align, and ... | tailwine |
1,922,839 | Getting Started with Pandas: The Go-To Library for Data Analysis in Python | If you’re new to Python and looking to dive into data analysis, here's one library you’ll want to get... | 0 | 2024-07-14T04:20:00 | https://dev.to/bryan_manuel_ramos/getting-started-with-pandas-the-go-to-library-for-data-analysis-in-python-19hc |
If you’re new to Python and looking to dive into data analysis, here's one library you’ll want to get acquainted with right away: Pandas. This powerful, flexible, and easy-to-use open-source data analysis and manipulation library is a must-have for any data enthusiast. In this blog post, we’ll explore what Pandas is,... | bryan_manuel_ramos | |
1,922,960 | Make Money as a Frontend Developer 🤑 | Career Paths Working for a Company If you choose to work for a company, you can earn a good salary... | 0 | 2024-07-14T07:58:16 | https://dev.to/makemoney2911/make-money-as-a-frontend-developer-2e1b |

Career Paths
Working for a Company
If you choose to work for a company, you can earn a good salary and potentially negotiate higher pay based on your skills and experience.
Freelancing
As a freelance developer, you... | makemoney2911 | |
1,922,874 | Understanding Core Web Vitals: Essential Metrics for Web Performance | In the modern web ecosystem, ensuring optimal user experience is paramount. Core Web Vitals, a set of... | 0 | 2024-07-14T04:23:35 | https://dev.to/mdhassanpatwary/understanding-core-web-vitals-essential-metrics-for-web-performance-33jg | webdev, performance, learning, website | In the modern web ecosystem, ensuring optimal user experience is paramount. Core Web Vitals, a set of specific metrics introduced by Google, serve as critical indicators for assessing the quality of user interaction with a webpage. Understanding and optimizing these metrics can significantly enhance your site's perform... | mdhassanpatwary |
1,922,875 | Buy verified BYBIT account | https://dmhelpshop.com/product/buy-verified-bybit-account/ Buy verified BYBIT account In the... | 0 | 2024-07-14T04:27:49 | https://dev.to/penivet291/buy-verified-bybit-account-88l | webdev, javascript, beginners, programming | https://dmhelpshop.com/product/buy-verified-bybit-account/

Buy verified BYBIT account
In the evolving landscape of cryptocurrency trading, the role of a dependable and protected platform cannot be overstated. Byb... | penivet291 |
1,922,876 | Rust tutorials for Python DEV: Variables and Mutability in Rust | Beginner's Guide to Variables and Mutability in Rust In Rust, the let keyword is used to... | 0 | 2024-07-14T04:28:27 | https://dev.to/ahmed__elboshi/rust-tutorials-for-python-dev-variables-and-mutability-in-rust-4hpf | # Beginner's Guide to Variables and Mutability in Rust
In Rust, the `let` keyword is used to declare variables. When you declare a variable with `let`, you are introducing a new binding (or name) that associates with a value of a particular type.
Here's a detailed explanation of how to assign variables using `let` in... | ahmed__elboshi | |
1,922,877 | Dive into the Fascinating World of Robotics with Prof. D K Pratihar 🤖 | Comprehensive robotics course by an experienced professor from IIT Kharagpur. Learn fundamental concepts, design, kinematics, dynamics, control, and applications of robotics. | 27,844 | 2024-07-14T04:31:51 | https://dev.to/getvm/dive-into-the-fascinating-world-of-robotics-with-prof-d-k-pratihar-7a5 | getvm, programming, freetutorial, universitycourses |
Greetings, fellow robotics enthusiasts! 👋 If you're looking to expand your knowledge and understanding of the captivating field of robotics, I've got the perfect resource for you. Buckle up, because we're about to embark on an exciting journey with Prof. D K Pratihar, an experienced professor from the prestigious Ind... | getvm |
1,922,878 | Buy GitHub Accounts | https://dmhelpshop.com/product/buy-github-accounts/ Buy GitHub Accounts GitHub, a renowned platform... | 0 | 2024-07-14T04:37:28 | https://dev.to/penivet291/buy-github-accounts-be4 | tutorial, react, python, ai | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-github-accounts/\n\n\n\n\nBuy GitHub Accounts\nGitHub, a renowned platform for hosting and collaborating on code, is essential for developers at all levels. With millions of projects worldwide, having a GitHub account is a valuable asset for seasoned programmers and beginners alike. However, the process of creating and managing an account can be complex and time-consuming for some.\n\nThis is where purchasing GitHub accounts becomes advantageous. By buying a GitHub account, individuals can streamline their development journey and access the numerous benefits of the platform efficiently. Whether you are looking to enhance your coding skills or expand your project collaborations, a purchased GitHub account can be a practical solution for optimizing your coding experience.\n\nWhat is GitHub Accounts\nGitHub accounts serve as user profiles on the renowned code hosting platform GitHub, where developers collaborate, track code changes, and manage version control seamlessly. Creating a GitHub account provides users with a platform to exhibit their projects, contribute to diverse endeavors, and engage with the GitHub community. Buy verified BYBIT account\n\nYour GitHub account stands as your virtual identity on the platform, capturing all your interactions, contributions, and project involvement. Embrace the power of GitHub accounts to foster connections, showcase your skills, and enhance your presence in the dynamic world of software development. Buy GitHub Accounts.\n\nCan You Buy GitHub Accounts?\n Rest assured when considering our buy GitHub Accounts service, as we distinguish ourselves from other PVA Account providers by offering 100% Non-Drop PVA Accounts, Permanent PVA Accounts, and Legitimate PVA Accounts. Our dedicated team ensures instant commencement of work upon order placement, guaranteeing a seamless experience for you. Embrace our service without hesitation and revel in its benefits.\n\nGitHub stands as the largest global code repository, playing a pivotal role in the coding world, especially for developers. It serves as the primary hub for exchanging code and engaging in collaborative projects.\n\nHowever, if you find yourself without a GitHub account, you may be missing out on valuable opportunities to share your code, learn from others, and contribute to open-source projects. A GitHub account not only allows you to showcase your coding skills but also enhances your professional network and exposure within the developer community.\n\nAccess To Premium Features\nUnlock a realm of possibilities and boost your productivity by harnessing the full power of Github’s premium features. Enjoy an array of benefits by investing in Github accounts, consolidating access to premium tools under a single subscription and saving costs compared to individual purchases. Buy GitHub Accounts.\n\nCultivating a thriving Github profile demands dedication and perseverance, involving continuous code contributions, active collaboration with peers, and diligent repository management. Elevate your development journey by embracing these premium features and optimizing your workflow for success on Github.\n\nGitHub private repository limits\nFor those of you who actively develop and utilize GitHub for managing your personal coding projects, consider the storage limitations that may impact your workflow. GitHub’s free accounts, which currently allow for up to three personal repositories, may prove stifling if your coding demands surpass this threshold. In such cases, upgrading to a dedicated buy GitHub account emerges as a viable remedy.\n\nTransitioning to a paid GitHub account not only increases repository limits but also grants a myriad of advantages, including unlimited collaborators access, as well as premium functionalities like GitHub Pages and GitHub Actions. Thus, if your involvement in personal projects confronts space constraints, transitioning to a paid account can seamlessly accommodate your expanding requirements.\n\nGitHub Organization Account\nWhen managing a team of developers, leveraging a GitHub organization account proves invaluable. This account enables the creation of a unified workspace where team members can seamlessly collaborate on code, offering exclusive features beyond personal accounts like the ability to edit someone else’s repository. Buy GitHub Accounts.\n\nEstablishing an organization account is easily achieved by visiting github.com and selecting the “Create an organization” option, wherein you define a name and configure basic settings. Once set up, you can promptly add team members and kickstart collaborative project work efficiently.\n\nTypes Of GitHub Accounts\nInvesting in a GitHub account (PVA) offers access to exclusive services typically reserved for established accounts, such as beta testing programs, early access to features, and participation in special GitHub initiatives, broadening your range of functionality.\n\nBy purchasing a GitHub account, you contribute to a more secure and reliable environment on the GitHub platform. A bought GitHub account (PVA) allows for swift account recovery solutions in case of account-related problems or unexpected events, guaranteeing prompt access restoration to minimize any disruptions to your workflow.\n\nAs a developer utilizing GitHub to handle your code repositories for personal projects, the matter of personal storage limits may be of significance to you. Presently, GitHub’s complimentary accounts are constrained to three personal repositories. Buy GitHub Accounts.\n\nShould your requirements surpass this restriction, transitioning to a dedicated GitHub account stands as the remedy. Apart from elevated repository limits, upgraded GitHub accounts provide numerous advantages, including access to unlimited collaborators and premium functionalities like GitHub Pages and GitHub Actions.\n\nThis ensures that if your undertakings encompass personal projects and you find yourself approaching storage boundaries, you have viable options to effectively manage and expand your development endeavors. Buy GitHub Accounts.\n\nWhy are GitHub accounts important?\nGitHub accounts serve as a crucial tool for anyone seeking to establish a presence in the tech industry. Regardless of your experience level, possessing a GitHub account equates to owning a professional online portfolio that highlights your skills and ventures to potential employers or collaborators.\n\nThrough GitHub, individuals can exhibit their coding proficiency and projects, fostering the display of expertise in multiple programming languages and technologies. This not only aids in establishing credibility as a developer but also enables prospective employers to evaluate your capabilities and suitability for their team effectively. Buy GitHub Accounts.\n\nBy maintaining an active GitHub account, you can effectively demonstrate a profound dedication to your field of expertise. Employers are profoundly impressed by individuals who exhibit a robust GitHub profile, as it signifies a genuine enthusiasm for coding and a willingness to devote significant time and energy to refining their abilities.\n\nThrough consistent project sharing and involvement in open source projects, you have the opportunity to showcase your unwavering commitment to enhancing your capabilities and fostering a constructive influence within the technology community. Buy GitHub Accounts.\n\nConclusion\nFor developers utilizing GitHub to host their code repositories, exploring ways to leverage coding skills for monetization may lead to questions about selling buy GitHub accounts, a practice that is indeed permissible. However, it is crucial to be mindful of pertinent details before proceeding. Buy GitHub Accounts.\n\nNotably, GitHub provides two distinct account types: personal and organizational. Personal accounts offer free access with genuine public storage, in contrast to organizational accounts. Before delving into selling a GitHub account, understanding these distinctions is essential for effective decision-making and navigating the platform’s diverse features.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | penivet291 |
1,922,879 | Getting Answers Quickly | Video Tutorials Q: I want to start web development but I don't know how to start. A:... | 0 | 2024-07-16T13:30:00 | https://dev.to/ijay/frequently-asked-questions-1boh | beginners, webdev, resources | ## Video Tutorials
- **Q:** I want to start web development but I don't know how to start.
**A:** Starting your journey into web development doesn't have to be difficult. Many developers learn on their own without formal education. According to Stack Overflow, less than half of all developers have a computer science ... | ijay |
1,922,881 | I'm from Nicaragua,fjmv25 | Hi, community community engagement Android and Python so amazing July 13th 2024 | 0 | 2024-07-14T04:55:14 | https://dev.to/fjmurillov_3743_5322b0771/im-from-nicaraguafjmv25-2jf6 | Hi, community
community engagement Android and Python
so amazing
July 13th 2024 | fjmurillov_3743_5322b0771 | |
1,922,882 | hstack() and column_stack() in PyTorch | Buy Me a Coffee☕ *Memos: My post explains stack(). My post explains vstack() and dstack(). My... | 0 | 2024-07-14T04:59:21 | https://dev.to/hyperkai/hstack-and-columnstack-in-pytorch-2mfb | pytorch, hstack, columnstack, function | [Buy Me a Coffee](ko-fi.com/superkai)☕
*Memos:
- [My post](https://dev.to/hyperkai/stack-in-pytorch-1bp1) explains [stack()](https://pytorch.org/docs/stable/generated/torch.stack.html).
- [My post](https://dev.to/hyperkai/vstack-and-dstack-in-pytorch-58ml) explains [vstack()](https://pytorch.org/docs/stable/generated/... | hyperkai |
1,922,884 | vstack() and dstack() in PyTorch | Buy Me a Coffee☕ *Memos: My post explains stack(). My post explains hstack() and... | 0 | 2024-07-14T05:06:26 | https://dev.to/hyperkai/vstack-and-dstack-in-pytorch-58ml | pytorch, vstack, dstack, function | [Buy Me a Coffee](ko-fi.com/superkai)☕
*Memos:
- [My post](https://dev.to/hyperkai/stack-in-pytorch-1bp1) explains [stack()](https://pytorch.org/docs/stable/generated/torch.stack.html).
- [My post](https://dev.to/hyperkai/hstack-and-columnstack-in-pytorch-2mfb) explains [hstack()](https://pytorch.org/docs/stable/gener... | hyperkai |
1,922,885 | Lasso Regression, Regression: Supervised Machine Learning | Lasso Regression Lasso regression, or Least Absolute Shrinkage and Selection Operator, is... | 0 | 2024-07-14T06:46:57 | https://dev.to/harshm03/lasso-regression-regression-supervised-machine-learning-2jk7 | machinelearning, datascience, python, tutorial | ### Lasso Regression
Lasso regression, or Least Absolute Shrinkage and Selection Operator, is a type of linear regression that includes a penalty term in the loss function to enforce both regularization and variable selection. This method can shrink some coefficients to zero, effectively selecting a simpler model that... | harshm03 |
1,922,887 | 🌟 Tech Landscape : Revolutionized by Unleashing the Power of Serverless Computing 🌟 | Introduction It's essential to keep up with technology developments in the fast-paced... | 0 | 2024-07-14T05:12:00 | https://dev.to/vivekranjansahoo/tech-landscape-revolutionized-by-unleashing-the-power-of-serverless-computing-4f64 | serverless, cloudcomputing, development, programming | ## Introduction
It's essential to keep up with technology developments in the fast-paced field of software development. Serverless computing is one of the most revolutionary ideas to emerge in recent years. Serverless computing, despite its somewhat deceptive moniker, abstracts away server management rather than doing ... | vivekranjansahoo |
1,922,888 | How to Connect to an EC2 Instance in a Private Subnet | Prerequisites Before you start, ensure you have the following: An EC2 instance running... | 0 | 2024-07-14T05:15:16 | https://dev.to/aktran321/how-to-connect-to-an-ec2-instance-in-a-private-subnet-13cm | ## Prerequisites
Before you start, ensure you have the following:
- An EC2 instance running in a private subnet.
- AWS Systems Manager (SSM) Agent installed and running on the instance.
- An IAM role attached to the instance with the necessary permissions to use SSM.
- AWS CLI configured on your local machine.
## Ste... | aktran321 | |
1,922,892 | A list of lists in Python | Python Tip: Creating a List of Lists When creating a list of lists in Python, it's important to... | 0 | 2024-07-14T05:30:20 | https://dev.to/siddharth_singhtanwar_6a/a-list-of-lists-in-python-20e1 | learnpython, coding, programming | **Python Tip: Creating a List of Lists**
When creating a list of lists in Python, it's important to understand how list multiplication works.
Using:
```
m = [[]] * 7
```
creates seven references to the same list. Modifying one list will affect all others because they reference the same object.
Instead, use list com... | siddharth_singhtanwar_6a |
1,922,893 | Certifications to Kickstart Your Career in Reverse Engineering and Malware Analysis with C++ and Python | Introduction The world of cybersecurity is continuously evolving, with new threats... | 0 | 2024-07-14T05:30:58 | https://dev.to/adityabhuyan/certifications-to-kickstart-your-career-in-reverse-engineering-and-malware-analysis-with-c-and-python-50kh | reverseengineering, malware, certification, career |

Introduction
------------
The world of cybersecurity is continuously evolving, with new threats emerging daily. Reverse engineering and malware analysis are critical components in the battle against these threat... | adityabhuyan |
1,922,945 | Introduction to Delegates | Hi there! Delegates, Funcs, and Actions are all C# words, and are used extensively... | 28,089 | 2024-07-17T08:37:14 | https://dev.to/rasheedmozaffar/introduction-to-delegates-pdm | csharp, dotnet, tutorial, beginners | ## Hi there!
**Delegates**, **Funcs**, and **Actions** are all **C#** words, and are used extensively throughout the language, the frameworks you use, and in almost every project you're going to work on, you'll encounter them in one form or another, so what are they, why are they used, what's their benefit, and what ar... | rasheedmozaffar |
1,922,894 | The Comprehensive Guide to Workshop Manuals PDF | In the realm of vehicle maintenance and repair, having access to accurate and detailed information is... | 0 | 2024-07-14T05:31:20 | https://dev.to/repw21m/the-comprehensive-guide-to-workshop-manuals-pdf-3leh | In the realm of vehicle maintenance and repair, having access to accurate and detailed information is crucial. Workshop manuals PDF are invaluable resources that provide step-by-step guidance on servicing, repairing, and maintaining various vehicles. This guide will delve into everything you need to know about **[works... | repw21m | |
1,922,895 | Detailed Explanation of the QUIC Protocol: The Next-Generation Internet Transport Layer Protocol | 1. Introduction With the rapid development of internet technology, the design and... | 0 | 2024-07-14T05:35:19 | https://dev.to/happyer/detailed-explanation-of-the-quic-protocol-the-next-generation-internet-transport-layer-protocol-37d0 | network, development, quic, ai | ## 1. Introduction
With the rapid development of internet technology, the design and optimization of network transport layer protocols have become increasingly important. The QUIC protocol, as an emerging transport layer protocol proposed by Google, has garnered widespread attention and research in recent years. QUIC ... | happyer |
1,922,897 | Empathetic Product Story For Readability | There was some interest on the last product post so I figure I follow up with some clarification on... | 0 | 2024-07-14T05:00:00 | https://dev.to/theholyspirit/empathetic-product-story-for-readability-2e0e | product, engineering, leadership | There was some interest on the last product post so I figure I follow up with some clarification on some of the ideas.
---
**Empathetic Product Story For Readability** is a formal proposal of user story. It contains 3 stories of user journeys for the proposed new context.
For information on the interesting formatti... | theholyspirit |
1,922,898 | My Wins of Week 🌟 [14/07/24] | Ahhhh...⚡ This week has been full of exciting developments, achievements & Ups and Down. I... | 27,912 | 2024-07-14T06:32:57 | https://dev.to/developedbyjk/my-wins-of-week-140724-3798 | weeklywins, weeklyretro, 100daysofcode |

<br>
<br>
> _Ahhhh...⚡
This week has been full of exciting developments, achievements & Ups and Down. I would like to share my wins with you all. Let's dive in!_ 🌊
---
### 🎯 Coding this week #100daysofcode

In the burgeoning landscape of web application development, choosing the right database is crucial. For developers, especially those in the initial stages of their projects, cost is a significant factor. Fortuna... | adityabhuyan |
1,922,901 | Revolutionizing Voice Control Integration with Sista AI | Experience the power of voicebots with Sista AI. Transform user interactions today! 🚀 | 0 | 2024-07-14T05:45:37 | https://dev.to/sista-ai/revolutionizing-voice-control-integration-with-sista-ai-3ol9 | ai, react, javascript, typescript | <h2>Enhancing User Experiences with Sista AI</h2><p>Voice user interfaces are reshaping technology interactions and enhancing user experiences. In React apps, integrating voice commands can significantly improve accessibility and engagement. **Sista AI** revolutionizes app interactions with its AI voice assistant, tran... | sista-ai |
1,922,902 | A Simple Python Tkinter-based Ollama GUI with no external dependencies | Hello everyone, I would like to share with you ollama-gui - a lightweight, Tkinter-based python GUI... | 0 | 2024-07-14T06:08:35 | https://github.com/chyok/ollama-gui | ollama, python, tkinter, llm | Hello everyone, I would like to share with you [ollama-gui](https://github.com/chyok/ollama-gui) - a lightweight, Tkinter-based python GUI for the Ollama.
## Overview
The project is very simple, with no other dependencies, and can be run in a single file.

Migrating legacy systems to modern full stack architectures is a complex, multifaceted endeavor that many organizations face as they seek to leverage the benefits of contemporary technologies. Legacy systems, often... | adityabhuyan |
1,922,904 | Understanding Serverless Architecture and Its Impact on Full Stack Development | Introduction Serverless architecture is a revolutionary paradigm in cloud computing that... | 0 | 2024-07-14T06:05:49 | https://dev.to/adityabhuyan/understanding-serverless-architecture-and-its-impact-on-full-stack-development-2f0l | fullstack, serverless |

### Introduction
Serverless architecture is a revolutionary paradigm in cloud computing that has transformed how developers build and deploy applications. Contrary to its name, serverless computing does involve ser... | adityabhuyan |
1,922,906 | Securing the AWS Infrastructure | Introduction Securing AWS resource infrastructure involves robust IAM (Identity and Access... | 0 | 2024-07-14T11:19:26 | https://dev.to/hrmnjm/securing-the-aws-infrastructure-4n58 | aws, security, vulnerabilities, vpc | ### Introduction
Securing AWS resource infrastructure involves robust IAM (Identity and Access Management), encryption, and continuous monitoring, along with configuring secure VPCs, subnets, and managing ports. I will now discuss and demonstrate a few methods by which we can protect the AWS infrastructure from malicio... | hrmnjm |
1,922,907 | PHP cheat sheet covering essential syntax and functions | Here's a comprehensive PHP cheat sheet covering essential syntax and functions: ... | 0 | 2024-07-14T06:15:13 | https://dev.to/devabdul/php-cheat-sheet-covering-essential-syntax-and-functions-33e1 | webdev, php, laravel, beginners | Here's a comprehensive PHP cheat sheet covering essential syntax and functions:
### Basics
```php
<?php
// Single-line comment
/*
Multi-line comment
*/
// Variables
$variable_name = "Value"; // String
$number = 123; // Integer
$float = 12.34; // Float
$boolean = true; // Boolean
... | devabdul |
1,922,908 | Ten Drops: A Python Pygame-CE Game Inspired by Splash Back | I would like to introduce my pygame project, Ten Drops - a fun and addictive water droplet game built... | 0 | 2024-07-14T06:16:02 | https://github.com/chyok/ten-drops | python, pygame, gamedev | I would like to introduce my pygame project, [Ten Drops](https://github.com/chyok/ten-drops) - a fun and addictive water droplet game built using Pygame-CE. This game is a loving tribute to the classic Flash game "Splash Back," reimagined for modern platforms.

---
Excited to share my plans for the next 6 months! 🎉
I will be dedicating this time to learning and building projects, focusing on enhancing my skills and bringing innovative ideas to life. As I dive deeper in... | satyam_kumar_550219cfcffd | |
1,922,935 | My rails performance tips compilation | This serves as a compilation of rails performance tips I posted on Twitter. This is an ongoing work.... | 0 | 2024-07-14T06:43:11 | https://dev.to/haseebeqx/my-rails-performance-tips-compilation-4dhd | rails | ---
title: My rails performance tips compilation
published: true
description:
tags: #rails
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-07-14 06:32 +0000
---
This serves as a compilation of rails performance tips I posted on Twitter. This is an ongoing w... | haseebeqx |
1,922,937 | Python : Print() method | Day 1- Hi, Everyone Today I learned about the print() method Print () is the simplest used to... | 0 | 2024-07-14T06:53:40 | https://dev.to/ishwariya_ishu0708_3e5224/python-print-method-12hh | python, programming, method | Day 1-
Hi, Everyone
Today I learned about the print() method
Print () is the simplest used to display a string or a number. Here are some basic examples:
```python
print("Hello world")
```
| ishwariya_ishu0708_3e5224 |
1,922,938 | 🌟 JavaScript Learning Journey: Two Weeks of Progress! 🌟 | Over the past two weeks, I've been diving deep into JavaScript, and I'm excited to share my progress... | 0 | 2024-07-14T06:51:18 | https://dev.to/nitin_kumar_8d95be7485e37/javascript-learning-journey-two-weeks-of-progress-2iio | Over the past two weeks, I've been diving deep into JavaScript, and I'm excited to share my progress with you all! 🎉
🔍 Here's what I've been working on:
Fundamentals of JavaScript:
Understanding variables, data types, and operators.
Learning about control structures like loops and conditionals.
Functions and Scope... | nitin_kumar_8d95be7485e37 | |
1,922,939 | Day 13 of 100 Days of Code | Sat, Jul 13, 2024 Today I began the last Codecademy lesson of the first course, Responsive Design.... | 0 | 2024-07-14T06:59:38 | https://dev.to/jacobsternx/day-13-of-100-days-of-code-2lda | 100daysofcode, webdev, javascript, beginners | Sat, Jul 13, 2024
Today I began the last Codecademy lesson of the first course, Responsive Design. Now that all course material is new for me, my focus going forward will be on learning rather than hitting targets. I may not make JavaScript by Monday, but I'm going to responsively design my way to JavaScript as soon a... | jacobsternx |
1,922,940 | Unveiling the World in 3D: Exploring Point Clouds and Ouster's LiDAR Technology | The world around us is brimming with intricate details. Capturing these details in a way that... | 0 | 2024-07-14T07:12:45 | https://dev.to/epakconsultant/unveiling-the-world-in-3d-exploring-point-clouds-and-ousters-lidar-technology-1igj | lidar | The world around us is brimming with intricate details. Capturing these details in a way that transcends traditional 2D representations has become increasingly important. This is where point clouds and LiDAR (Light Detection and Ranging) technology come into play. Let's delve into the fascinating world of point clouds ... | epakconsultant |
1,922,941 | Vivaldi Browser: Must-have extensions for developers | Having the right tools can help a lot in web development. Vivaldi is flexible and customizable, which... | 0 | 2024-07-14T07:19:25 | https://dev.to/qostya/vivaldi-browser-must-have-extensions-for-developers-30f4 | webdev, devex, browser, productivity | Having the right tools can help a lot in web development. Vivaldi is flexible and customizable, which makes it a good choice for developers who want to work better.
### **Getting to know the Vivaldi browser: A developer's best friend**
Vivaldi is a simple and user-friendly browser with many features for developers. I... | qostya |
1,922,942 | K Nearest Neighbors Regression, Regression: Supervised Machine Learning | k-Nearest Neighbors Regression Definition and Purpose k-Nearest Neighbors... | 0 | 2024-07-14T07:23:23 | https://dev.to/harshm03/k-nearest-neighbors-regression-regression-supervised-machine-learning-283e | machinelearning, datascience, python, tutorial | ### k-Nearest Neighbors Regression
#### Definition and Purpose
**k-Nearest Neighbors (k-NN)** regression is a non-parametric, instance-based learning algorithm used in machine learning to predict continuous output values based on the values of the nearest neighbors in the feature space. It estimates the output for a n... | harshm03 |
1,922,943 | Building Your Smart Home: A Guide to OpenHAB and Raspberry Pi | Imagine a home that seamlessly responds to your needs, a place where lights adjust automatically,... | 0 | 2024-07-14T07:24:29 | https://dev.to/epakconsultant/building-your-smart-home-a-guide-to-openhab-and-raspberry-pi-7f3 | openhab, raspberrypi | Imagine a home that seamlessly responds to your needs, a place where lights adjust automatically, thermostats adapt to your preferences, and devices work in harmony. This is the magic of smart home automation, and with OpenHAB and a Raspberry Pi, you can transform your living space into a connected haven. This guide eq... | epakconsultant |
1,922,944 | How to write release note with LLM agents | TL;DR This blog shows how to simplify the process of writing release notes using... | 0 | 2024-07-14T07:29:47 | https://dev.to/littlelittlecloud/how-to-write-release-note-with-llm-agents-57no | llm, ai, dotnet, github | ## TL;DR
This blog shows how to simplify the process of writing release notes using `issue-helper` and `gpt` agent in [Agent ChatRoom](https://github.com/LittleLittleCloud/Agent-ChatRoom). The `issue-helper` pulls issues in a milestone and `gpt` generates a release note based on these issues.
## What is Agent ChatRoom... | littlelittlecloud |
1,922,946 | Flitter vs D3.js: Revolutionizing Data Visualization for the Web | In the world of web-based data visualization, D3.js has long been the go-to library for developers.... | 0 | 2024-07-14T07:33:46 | https://dev.to/moondaeseung/flitter-vs-d3js-revolutionizing-data-visualization-for-the-web-2f7h | In the world of web-based data visualization, D3.js has long been the go-to library for developers. However, Flitter is changing the game, offering a fresh approach that addresses many of the challenges developers face with D3. Let's explore why Flitter is becoming the preferred choice for modern data visualization pro... | moondaeseung | |
1,922,947 | Bridging the Gap: Communicating with Leadshine Servo Drivers using Modbus RTU on Raspberry Pi | The world of industrial automation hinges on seamless communication between devices. This guide... | 0 | 2024-07-14T07:34:28 | https://dev.to/epakconsultant/bridging-the-gap-communicating-with-leadshine-servo-drivers-using-modbus-rtu-on-raspberry-pi-2nfo | raspberrypi | The world of industrial automation hinges on seamless communication between devices. This guide empowers you to establish communication between Leadshine servo drivers and a Raspberry Pi using the Modbus RTU protocol, unlocking control and monitoring capabilities for your projects.
Understanding the Players:
- Leadsh... | epakconsultant |
1,922,948 | 4 ways to iterate over “objects” in javascript | In javascript object contain the key value pair properties and iterating over object is different... | 0 | 2024-07-14T07:35:16 | https://dev.to/sagar7170/4-ways-to-iterate-over-objects-in-javascript-1e8p | javascript, web, beginners | In javascript object contain the key value pair properties and iterating over object is different from arrays . Objects can be iterated using for...in loops and Object.keys(), Object.values(), and Object.entries(). Let’s see how you can use each method:
**1. using `for...in` method**
```
const person = {
name: '... | sagar7170 |
1,922,949 | Comprendre le Makefile (Exemple avec langage C). | Un Makefile est un fichier utilisé par l'outil make pour automatiser la compilation de programmes.... | 28,059 | 2024-07-14T07:37:37 | https://dev.to/ashcript/comprendre-le-makefile-exemple-avec-le-langage-c-47n9 | makefile, c | Un Makefile est un fichier utilisé par l'outil `make` pour automatiser la compilation de programmes. Voici les règles standards et les bonnes pratiques pour rédiger un Makefile efficace :
### Structure de Base d'un Makefile
1. **Cible (Target)** : Ce que tu veux construire (ex. un fichier exécutable).
2. **Prérequis ... | ashcript |
1,922,953 | BetterPic | AI Headshots | Forget expensive, complicated photoshoots. Get your professional headshots on the go, with 10... | 0 | 2024-07-14T07:41:20 | https://dev.to/betterpic/betterpic-ai-headshots-2aoc | aiheadshot, imagegenerator | > Forget expensive, complicated photoshoots. Get your professional headshots on the go, with 10 selfies/casual photos in less than an hour. High-quality customer service, top data privacy, and a clear money-back guarantee policy. [GET YOURS TODAY!](http://www.betterpic.io/ )
You need some studio-quality (4K) headshots... | betterpic |
1,922,954 | Unleashing Creativity: Exploring Raspberry Pi LED Programming | The humble LED, a ubiquitous light-emitting diode, transforms into a vibrant canvas for creative... | 0 | 2024-07-14T07:41:24 | https://dev.to/epakconsultant/unleashing-creativity-exploring-raspberry-pi-led-programming-2il1 | The humble LED, a ubiquitous light-emitting diode, transforms into a vibrant canvas for creative coding with a Raspberry Pi. This guide delves into the world of Raspberry Pi LED programming, empowering you to control LEDs, create dazzling light patterns, and embark on interactive projects.
[Mastering Drone PCB Design ... | epakconsultant | |
1,922,955 | Slider Component - JavaScript & CSS | Pada kesempatan kali ini kita akan praktik membuat slider, slider bisa berisi image maupun text... | 0 | 2024-07-14T07:42:05 | https://dev.to/boibolang/slider-component-javascript-css-1oai | Pada kesempatan kali ini kita akan praktik membuat slider, slider bisa berisi image maupun text nantinya disesuaikan dengan kebutuhan. Idenya adalah dengan menyiapkan image maupun text yang akan dijadikan slide, kemudian terdapat button sebagai navigasi kiri-kanan, nantinya kita juga bisa menggunakan arrow keyboard mau... | boibolang | |
1,922,956 | Sunday memes ? | share memes @brunopicolo @tomasz_badowiec_1810be404 @muzzu45 @syedmuhammadaliraza @kinval... | 0 | 2024-07-14T07:45:25 | https://dev.to/chaopas/sunday-memes--ogo | memes, sunday | share memes
@brunopicolo @tomasz_badowiec_1810be404 @muzzu45 @syedmuhammadaliraza @kinval @ali_wazeer_ddab516ecaae1d @m-alikhizar | chaopas |
1,922,957 | Crafting Modern Web APIs with Django and Django REST Framework: A Comprehensive Guide | Introduction In the interconnected world of the internet, much of our online activities... | 0 | 2024-07-14T07:53:33 | https://www.developerchronicles.com/crafting-modern-web-apis-with-django-and-django-rest-framework-a-comprehensive-guide | django, api, restapi, python | ### Introduction
In the interconnected world of the internet, much of our online activities depend on the seamless interaction of multiple computers through APIs (Application Programming Interfaces). These APIs define the communication protocols between computers, and in the realm of web development, RESTful APIs (Rep... | terrancoder |
1,922,959 | Unlocking the Power of Amazon S3 | Amazon Simple Storage Service (S3) is a scalable cloud storage solution designed for storing and... | 0 | 2024-07-14T07:55:21 | https://dev.to/noorscript/unlocking-the-power-of-amazon-s3-571k | aws, cloudcomputing, learning |
Amazon Simple Storage Service (S3) is a scalable cloud storage solution designed for storing and managing data. In this post, I’ll provide an overview of S3 buckets, which are essential components for organizing and accessing data in S3. You’ll learn about their features, how to create them, and best practices for u... | noorscript |
1,922,961 | Creating Accessible Web Forms: A Beginner's Guide 🎉 | In today’s digital world, accessibility is a critical aspect of web development. Accessible web forms... | 0 | 2024-07-14T07:58:55 | https://dev.to/soham1300/creating-accessible-web-forms-a-beginners-guide-349c | In today’s digital world, accessibility is a critical aspect of web development. Accessible web forms ensure that all users, including those with disabilities, can interact with your website effectively. Think of it as opening the door wide instead of leaving it cracked! 🚪✨
-> Introduction to Web Accessibility
Web ac... | soham1300 | |
1,922,970 | Infamous Guitars: Wix Studio 'Make an Offer' eCommerce Website using Wix Velo | This is a submission for the Wix Studio Challenge . What I Built Visit Site 'Make an... | 0 | 2024-07-14T08:21:05 | https://dev.to/phoedesign/infamous-guitars-wix-studio-make-an-offer-ecommerce-website-using-wix-velo-2jln | devchallenge, wixstudiochallenge, webdev, javascript | *This is a submission for the [Wix Studio Challenge ](https://dev.to/challenges/wix).*
## What I Built
[Visit Site](https://phoedesign.wixstudio.io/infamous-guitars)
'Make an Offer' eCommerce website with an immersive user audio experience. This fictional store 'Infamous Guitar' sells authenticated guitars and memorab... | phoedesign |
1,922,972 | ✨Top 9 Open-Source Hidden Gems🤯 | Hello Devs👋 In this article I will be sharing some amazing open-source projects I've found that can... | 0 | 2024-07-14T14:48:36 | https://dev.to/dev_kiran/top-9-open-source-hidden-gems-56d9 | webdev, opensource, productivity, programming | Hello Devs👋
In this article I will be sharing some amazing open-source projects I've found that can really save your time and help you. You should give a shot.🔥
> ✨Open-source projects rely on **community support** 🙏, so consider exploring these projects and **star**ring these repositories to contribute to their g... | dev_kiran |
1,922,974 | Welcome to BlackCardCoin 🚀 | JOIN the BlackCardCoin revolution and stand a chance to win a share of our $1 million cash reward... | 0 | 2024-07-14T08:24:18 | https://dev.to/blackcardcoin/welcome-to-blackcardcoin-5e00 | JOIN the BlackCardCoin revolution and stand a chance to win a share of our $1 million cash reward pool! As we gear up for our grand prize drawing on December 12, 2024, your engagement and XP accumulation on our platform could lead you to significant rewards.
Here's how our reward system works:
Each XP point you earn ... | blackcardcoin | |
1,922,975 | 🚀 BlackCardCoin Big Announcement: 01.07.2024 🚀 | Dear BlackCardCoin Community, Today, 01.07.2024, is a milestone in BlackCardCoin history! We are... | 0 | 2024-07-14T08:29:12 | https://dev.to/blackcardcoin/blackcardcoin-big-announcement-01072024-4i8l | Dear BlackCardCoin Community,
Today, 01.07.2024, is a milestone in BlackCardCoin history! We are excited to share our success story, the big steps we've taken, and our future plans. Here are the details:
🔥 Token Burn and Lock on New Contract 🔥
On our New Token Contract: https://bscscan.com/token/0x450593Bf7f2d7E55... | blackcardcoin | |
1,922,977 | Top Free APIs Every Developer Should Know About | Top Free APIs Every Developer Should Know About In the world of software development, APIs... | 0 | 2024-07-14T08:37:03 | https://dev.to/sh20raj/top-free-apis-every-developer-should-know-about-4do1 | api, javascript, webdev, beginners |
### Top Free APIs Every Developer Should Know About
In the world of software development, APIs (Application Programming Interfaces) are essential for integrating various functionalities into applications. Here’s a curated list of top free APIs categorized by their functionality:
#### 1. **Weather APIs**
- **Open... | sh20raj |
1,922,978 | Top Free APIs Every Developer Should Know About | Top Free APIs Every Developer Should Know About In the world of software development, APIs... | 0 | 2024-07-14T08:37:03 | https://codexdindia.blogspot.com/2024/07/top-free-apis-every-developer-should.html | api, javascript, webdev, beginners |
### Top Free APIs Every Developer Should Know About
In the world of software development, APIs (Application Programming Interfaces) are essential for integrating various functionalities into applications. Here’s a curated list of top free APIs categorized by their functionality:
Know More In Detail :- https://codex... | sh20raj |
1,922,979 | Day 30 of 30 of JavaScript | Hey reader👋 Hope you are doing well😊 First of all I would like to congratulate you as you have made... | 0 | 2024-07-15T07:15:55 | https://dev.to/akshat0610/day-30-of-30-of-javascript-50fn | webdev, javascript, beginners, tutorial | Hey reader👋 Hope you are doing well😊
First of all I would like to congratulate you as you have made it to this post🎉. This is the last blog of our JavaScript tutorial🥳.
In the last post we have talked about JSON. In this post we are going to discuss about some important concepts.
So let's get started🔥
## JS Web A... | akshat0610 |
1,922,981 | Terabox online video downloader | Queries Solved :- Terabox direct download Terabox online video downloader Terabox link video... | 0 | 2024-07-14T08:45:48 | https://t.me/terasop_bot?? | terabox, teraboxdownload, teraboxdownloader | >

Queries Solved :-
Terabox direct download
Terabox online video downloader
Terabox link video downloader online
How to download Terabox link video without app
Terabox-downloader github
Terabox downloader online ... | banmyaccount |
1,922,982 | Golang WebRTC. Como usar Pion 🌐Remote Controller | ¿ Porqué debería elegir Go para crear una aplicación WebRTC 🤷♂️? WebRTC y Go es una... | 0 | 2024-07-14T08:47:02 | https://dev.to/piterweb/golang-webrtc-como-usar-pion-remote-controller-5d8e | webdev, webrtc, go, spanish | ## ¿ Porqué debería elegir Go para crear una aplicación WebRTC 🤷♂️?
WebRTC y Go es una combinación poderosa, puedes desplegar pequeños binarios en cualquier sistema operativo soportado por el compilador de Go. Y por el hecho de ser compilado acostumbra ser más rápido que muchos otros lenguajes, así que es ideal si q... | piterweb |
1,922,985 | Easily Use Selenium with AWS Lambda | In this tutorial, I will guide you through the process of running Selenium with ChromeDriver... | 0 | 2024-07-14T08:52:25 | https://dev.to/shilleh/easily-use-selenium-with-aws-lambda-lml | aws, python, pip, programming | {% embed https://www.youtube.com/watch?v=8XBkm9DD6Ic %}
In this tutorial, I will guide you through the process of running Selenium with ChromeDriver inside an AWS Lambda function. This setup is useful for automating web scraping tasks, testing web applications, or performing any browser automation tasks on the cloud. ... | shilleh |
1,922,986 | Queen Problem Solution and Analysis—Part 1 | This post describes my fun project to solve the Queen problem in multiple languages and compare their... | 0 | 2024-07-14T09:00:23 | https://dev.to/dragondive/queen-problem-solution-and-analysis-part-1-3nh1 | cpp, crosslanguagecomparison, python, rust |
---
layout: post
title: "Queen Problem Solution and Analysis—Part 1"
comments: true
share: true
published: true
tags:
- cpp
- CrossLanguageComparison
- python
- rust
---
This post describes my fun project to solve the [Queen problem](https://en.wikipedia.org/wiki/Eight_queens_puzzle) in multiple languages and... | dragondive |
1,922,987 | Unlocking the Power of Modern CSS Color Functions: History, Uses, and Practical Applications | CSS color functions provide developers with a robust toolkit for defining and manipulating colors in... | 0 | 2024-07-14T08:59:33 | https://dev.to/mdhassanpatwary/unlocking-the-power-of-modern-css-color-functions-history-uses-and-practical-applications-3j2a | webdev, productivity, css, learning | CSS color functions provide developers with a robust toolkit for defining and manipulating colors in web design. These functions offer flexibility and precision, allowing you to create dynamic and visually appealing designs. This article will delve into the history of CSS color functions, the issues they aim to solve, ... | mdhassanpatwary |
1,922,988 | Building JWT Auth Chaining with FastAPI and Python | In this article, we'll explore how to implement JWT (JSON Web Token) authentication in a FastAPI... | 0 | 2024-07-14T09:09:24 | https://dev.to/rishisharma/building-jwt-auth-chaining-with-fastapi-and-python-11hn | python, fastapi, jwt, security | In this article, we'll explore how to implement JWT (JSON Web Token) authentication in a FastAPI application. We'll cover everything from setting up the project to securing endpoints with JWT. By the end, you'll have a fully functional authentication system with chained JWT verification.
- JSON Web Token
- Setting Up ... | rishisharma |
1,922,989 | How to make Animation in Css? | Introduction Today I will tell you how to make animation. We will see all the necessary... | 0 | 2024-07-14T10:53:32 | https://dev.to/lakshita_kumawat/how-to-make-animation-in-css-1f97 | animation, css, tutorial | ## Introduction
Today I will tell you how to make animation. We will see all the necessary animation property in this post. You can get the code on my [github](https://github.com/Lakshita-Kumawat/Animation-Tutorial). So Let's Get Started!!
## Animation
Animation are the property use to enhance the look of the website.... | lakshita_kumawat |
1,923,030 | Creating a Smooth Transitioning Dialog Component in React (Part 1/4) | Part 1: Setting Up the Basic Dialog Component with Minimise/Expand Functionality Welcome... | 0 | 2024-07-14T10:31:15 | https://dev.to/copet80/creating-a-smooth-transitioning-dialog-component-in-react-part-14-7nd | javascript, reactjsdevelopment, react, css | ## Part 1: Setting Up the Basic Dialog Component with Minimise/Expand Functionality
Welcome to the first part of my four-part series on creating a responsive dialog component in React. In this series, I'll explore different approaches to achieve smooth animation transitions while maintaining the dialog's fluid dimensi... | copet80 |
1,923,031 | Discovering Dash: The Framework for Interactive Web Applications in Python | In the constantly evolving world of data science and data analysis, the ability to visualize and... | 0 | 2024-07-14T09:30:15 | https://dev.to/moubarakmohame4/discovering-dash-the-framework-for-interactive-web-applications-in-python-50gi | data, beginners, analyst, python | In the constantly evolving world of data science and data analysis, the ability to visualize and interact with data in real-time has become indispensable. Dash, an open-source framework developed by Plotly, perfectly meets this need. Designed for data scientists, analysts, and engineers, Dash enables the creation of in... | moubarakmohame4 |
1,923,033 | Algorithm Complexity with Go — Linear Time Complexity O(n) | Algorithm Complexity with Go — Linear Time Complexity O(n) Today, we will focus on... | 0 | 2024-07-14T09:33:53 | https://medium.com/@kstntn.lsnk/algorithm-complexity-with-go-linear-time-complexity-o-n-eaee7558f225 | go, softwareengineering, algorithms, programming | ---
title: Algorithm Complexity with Go — Linear Time Complexity O(n)
published: true
date: 2024-07-14 09:13:10 UTC
tags: go,softwareengineering,algorithms,programming
canonical_url: https://medium.com/@kstntn.lsnk/algorithm-complexity-with-go-linear-time-complexity-o-n-eaee7558f225
---
### Algorithm Complexity with G... | kostiantyn_lysenko_5a13a9 |
1,923,034 | Run of Queries in Amazon Timestream Database for LiveAnalytics | “ I have checked the documents of AWS to run the queries in amazon timestream database for... | 0 | 2024-07-14T09:35:04 | https://dev.to/aws-builders/run-of-queries-in-amazon-timestream-database-for-liveanalytics-23p2 | aws, amazontimestream, amazons3, sns | “ I have checked the documents of AWS to run the queries in amazon timestream database for liveanalytics. Amazon timestream service provides a query editor where we can directly select the database and table created in timestream db and be able to run the queries in it. Pricing of the solution depends on usage of times... | bhatnagargargee |
1,923,036 | Makefile - .h - .c exemple. | Voici la structure du projet avec l'exemple sans bibliothèque statique en premier, suivi de l'exemple... | 0 | 2024-07-14T09:36:27 | https://dev.to/ashcript/makefile-h-c-exemple-2m9 | makefile, c | Voici la structure du projet avec l'exemple sans bibliothèque statique en premier, suivi de l'exemple avec bibliothèque statique.
### Structure du Projet
```
/mon_projet
├── Makefile
├── utils.h
├── utils.c
└── main.c
```
### Exemple 1 : Sans bibliothèque statique
#### 1. Fichier d'en-tête : `utils.h`
```c
#ifndef... | ashcript |
1,923,037 | ハロー ワールド | <!DOCTYPE... | 0 | 2024-07-14T09:36:39 | https://dev.to/shizuka_takahashi235/haro-warudo-18pk | ```css
<!DOCTYPE html>
<html>
<head>
<title></title>
</head>
<body
<p></p>
</body>
</html>
```
#beginner | shizuka_takahashi235 | |
1,923,038 | How to Win Free Apple Gift Cards | https://www.linkedin.com/pulse/free-target-gift-card-2024-new-claim-now-gift-github-zeqfc https://www... | 0 | 2024-07-14T09:39:23 | https://dev.to/lotuslusa/how-to-win-free-apple-gift-cards-58h2 | https://www.linkedin.com/pulse/free-target-gift-card-2024-new-claim-now-gift-github-zeqfc
https://www.linkedin.com/pulse/100-safe-target-gift-card-free-unlimited-2024-gift-github-kgejc
https://www.linkedin.com/pulse/claim-free-starbucks-gift-card-100-safe-2024-gift-github-arkfc
https://www.linkedin.com/pulse/starbucks-... | lotuslusa | |
1,923,039 | Recreating History: Building a Windows 98 Disk Defrag Simulator with Modern Web Tech | Hey fellow devs! I'm Dennis Morello, a Senior Frontend Engineer with a passion for both... | 0 | 2024-07-14T09:41:54 | https://dev.to/morellodev/recreating-history-building-a-windows-98-disk-defrag-simulator-with-modern-web-tech-34bc | webdev, react, nextjs, tailwindcss | 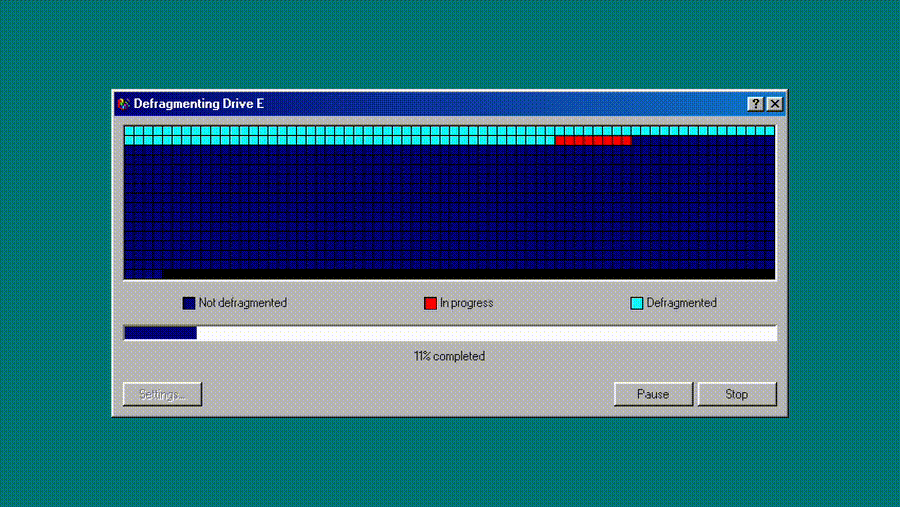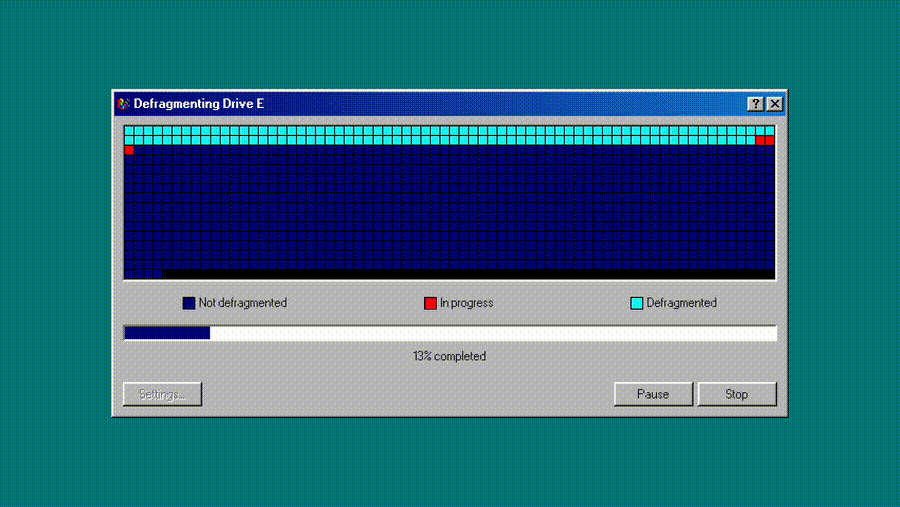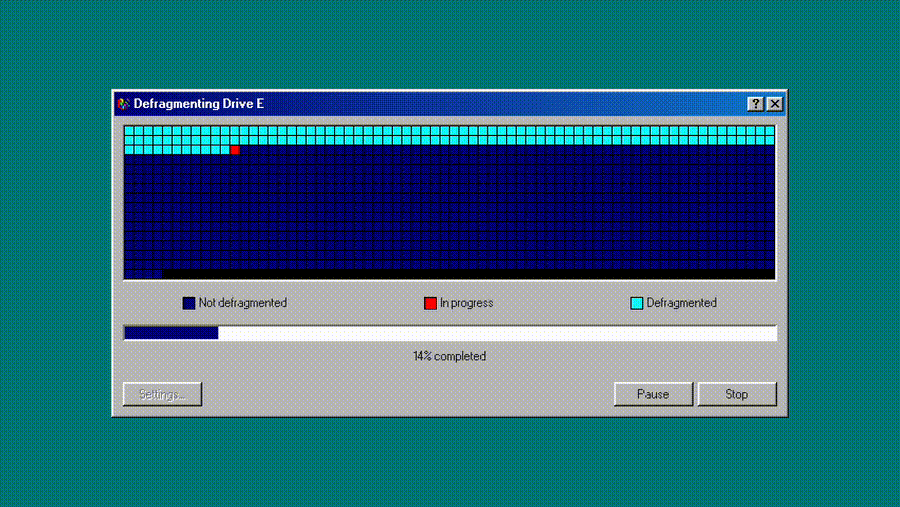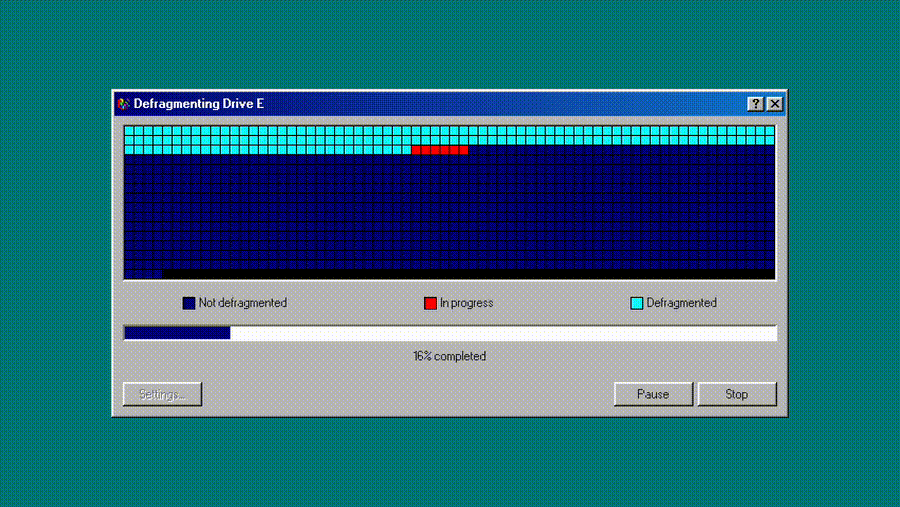
Hey fellow devs! I'm Dennis Morello, a Senior Frontend Engineer with a passion for both cutting-edge web technologies and retro computing. I'm excited to share my latest projec... | morellodev |
1,923,040 | Roadmap belajar Keamanan Siber | 1. Dasar-dasar Keterampilan TI - Keterampilan dasar komputer - Dasar jaringan komputer -... | 0 | 2024-07-14T09:42:00 | https://dev.to/nabirecybersecurity/roadmap-belajar-keamanan-siber-4plo | **1. Dasar-dasar Keterampilan TI**
- Keterampilan dasar komputer
- Dasar jaringan komputer
- Komponen Perangkat Keras Komputer
**2. Jaringan Komputer**
- Model-model OSI
- Topologi Jaringan
- Protokol Umum dan penggunaannya
- IPv4 DAN IPv6
- Dasar dari Subnetting
**3. Keterampilan dan Pengetahuan Keamanan**
... | putrakoteka | |
1,923,041 | 🇩🇪 Grundlegende SQL-Befehle für Einsteiger | Einführung in SQL und Datenbanken Wie im letzten Eintrag erwähnt sind Datenbanken aus der... | 27,970 | 2024-07-14T14:00:00 | https://informatik-ninja.de/tutorials/grundlegende-sql-befehle | german, sql, database, beginners |
## Einführung in SQL und Datenbanken
Wie im letzten Eintrag erwähnt sind Datenbanken aus der heutigen Zeit nicht mehr wegzudenken. SQL *(Structured Query Language)* ist dabei die Basis für Datenbank Manipulationen und Abfragen. Egal ob Datenbankadministrator, oder Web-/Softwareentwickler, Kenntnisse in SQL sind unerl... | informatik-ninja |
1,923,042 | The Importance of Interoperability in Healthcare Systems | Interoperability in healthcare systems is a critical aspect that enables different healthcare... | 0 | 2024-07-14T09:58:30 | https://dev.to/edwardsykes099/the-importance-of-interoperability-in-healthcare-systems-24bd | healthcaredevelopment, appdevelopment, softwaredevelopment, technology | Interoperability in healthcare systems is a critical aspect that enables different healthcare information systems to communicate, exchange data, and use the information that has been exchanged. This ability to share and make use of data across different systems is crucial for improving patient care, enhancing operation... | edwardsykes099 |
1,923,043 | Steps to Create Custom Product Attributes Programmatically in Magento 2 | In the realm of e-commerce, customization is key to standing out in the crowd. Magento 2 offers a... | 0 | 2024-07-14T10:04:08 | https://dev.to/augmetic/steps-to-create-custom-product-attributes-programmatically-in-magento-2-32i6 | In the realm of e-commerce, customization is key to standing out in the crowd. Magento 2 offers a robust platform for creating custom product attributes enabling merchants to organize product information effectively. While it's common to create these attributes through the admin panel there's another method worth explo... | augmetic | |
1,923,044 | Enhance Your Site with a Magento Website Audit Checklist 2024 | Are you ready to take your e-commerce website to the next level in 2024? Whether you're a small... | 0 | 2024-07-14T10:06:48 | https://dev.to/augmetic/enhance-your-site-with-a-magento-website-audit-checklist-2024-4jih | magneto, websiteaudit, websitechecklist | Are you ready to take your e-commerce website to the next level in 2024? Whether you're a small business just starting out or an enterprise looking to optimize your online presence, ensuring your Magento website is running smoothly is crucial for success. In today's competitive online market, a comprehensive website au... | augmetic |
1,923,045 | PrintAI - A Print on Demand E-com website powered with Wix and AI | This is a submission for the Wix Studio Challenge . What I Built We’ve innovatively... | 0 | 2024-07-14T11:00:43 | https://dev.to/dhairya_chheda/printai-a-print-on-demand-e-com-website-powered-with-wix-and-ai-538l | devchallenge, wixstudiochallenge, webdev, javascript | *This is a submission for the [Wix Studio Challenge ](https://dev.to/challenges/wix).*
## What I Built
<!-- Share an overview about your project. -->
We’ve innovatively combined print-on-demand with AI to create a custom product configurator. This advanced solution allows users to enter a prompt and choose from four d... | dhairya_chheda |
1,923,046 | Partnering with the Professionals | In the realm of your digital footprint, settling for mediocrity is simply not an option. In a world... | 0 | 2024-07-14T10:08:06 | https://dev.to/augmetic/partnering-with-the-professionals-3nnn | In the realm of your digital footprint, settling for mediocrity is simply not an option. In a world where first impressions are paramount, your online platform must be meticulously curated to captivate your audience and mirror the eminence of your brand. But such excellence isn't a serendipitous outcome; it's a product... | augmetic | |
1,923,047 | Augmented Reality (AR) Is Fostering The Mobile App Development Scope | Augmented Reality (AR) Is Fostering The Mobile App Development Scope The realm of mobile application... | 0 | 2024-07-14T10:09:14 | https://dev.to/augmetic/augmented-reality-ar-is-fostering-the-mobile-app-development-scope-48l4 | Augmented Reality (AR) Is Fostering The Mobile App Development Scope
The realm of mobile application development offers extensive possibilities in tandem with cutting-edge technologies like Artificial Intelligence (AI), Augmented Reality/Virtual Reality (AR/VR), Internet of Things (IoT), Blockchain, and more. Among t... | augmetic | |
1,923,048 | Mobile Compatibility Testing: A Comprehensive Guide | Ensuring your app works perfectly across different devices is essential for success in the current... | 0 | 2024-07-14T10:10:26 | https://dev.to/jamescantor38/mobile-compatibility-testing-a-comprehensive-guide-54d7 | mobilecompatibilitytesting, testgrid | Ensuring your app works perfectly across different devices is essential for success in the current diverse mobile landscape. That’s where mobile compatibility testing plays a role.
Mobile compatibility testing is critical in developing mobile applications, ensuring that an app performs well across various devices, oper... | jamescantor38 |
1,923,049 | What are the Benefits of Machine Learning in Business | What are the Benefits of Machine Learning in Business? In the dynamic landscape of modern business,... | 0 | 2024-07-14T10:10:34 | https://dev.to/augmetic/what-are-the-benefits-of-machine-learning-in-business-i2g | What are the Benefits of Machine Learning in Business?
In the dynamic landscape of modern business, staying ahead of the curve is not just a luxury; it's a necessity. One technological marvel that has reshaped the business landscape is Machine Learning.
Understanding Website Security
From predicting customer beha... | augmetic | |
1,923,050 | Decolonize The Internet | It is the unfortunate fact that almost all of the social media tech companies are colluding with... | 0 | 2024-07-14T10:14:37 | https://dev.to/mosbat/decolonize-the-internet-1mf | censorship, internet, decolonizetheinternet, meta | It is the unfortunate fact that almost all of the social media tech companies are colluding with state actors in order to censor free speech at mass scale.
They can no longer hide behind the logos and pretend that it's company policy!
The internet has become colonized where you have no freedom of what you write,post ... | mosbat |
1,923,052 | Online Image Processing Tools | Image processing involves altering the look of an image to improve its aesthetic information for... | 0 | 2024-07-14T10:23:12 | https://dev.to/saiwa/online-image-processing-tools-49eg |
Image processing involves altering the look of an image to improve its aesthetic information for human understanding or enhance its utility for unsupervised computer perception. Digital image processing, a subset of electronics, converts a picture into an array of small integers called pixels. These pixels represent p... | saiwa | |
1,923,055 | My Experience Learning TypeScript | So, I had my fill of JavaScript and thought, "Why not torture myself with TypeScript?”. To get... | 0 | 2024-07-14T10:25:44 | https://dev.to/bridget_amana/my-experience-learning-typescript-1jn0 | typescript, frontend, beginners, webdev | So, I had my fill of JavaScript and thought, "Why not torture myself with TypeScript?”. To get started, I dug into the official TypeScript documentation but later stumbled upon this gem of a tutorial: [TypeScript Tutorial](https://www.typescripttutorial.net/). A friend also recommended some YouTube videos too which I w... | bridget_amana |
1,923,059 | AWS UG Deep Talk: Summary of key points from an in-depth conversation with nine Chinese IT practitioners | Danny Chan speaking AI topic in AWS User Group (Shen Zhen, China) on 2024-07-06 More Photos of AWS... | 0 | 2024-07-14T12:10:00 | https://dev.to/aws-builders/aws-ug-deep-talk-summary-of-key-points-from-an-in-depth-conversation-with-nine-chinese-it-practitioners-27ma | _**Danny Chan**_ speaking AI topic in AWS User Group (Shen Zhen, China) on 2024-07-06
[More Photos of AWS COMMUNITY DAY in Shen Zhen](https://m.alltuu.com/album/... | kennc | |
1,923,060 | Unlock Your App's Potential with Expert React Native Development Services | In today's digital age, having a mobile app is no longer a luxury but a necessity for businesses... | 0 | 2024-07-14T10:43:38 | https://dev.to/john127/unlock-your-apps-potential-with-expert-react-native-development-services-n6e |

In today's digital age, having a mobile app is no longer a luxury but a necessity for businesses looking to stay competitive. As consumer behavior increasingly leans towards mobile usage, ensuring that your app stan... | john127 | |
1,923,061 | The Struggles of Manual Project Timeline Visualization | As a project manager, I often face the daunting task of visualizing project timelines. Creating... | 0 | 2024-07-14T10:55:47 | https://dev.to/xuho/the-struggles-of-manual-project-timeline-visualization-f9k | sideprojects, management, startup, buildinpublic |

As a project manager, I often face the daunting task of visualizing project timelines. Creating Gantt charts manually from extensive task lists is not only time-consuming but also prone to errors. Here are some co... | xuho |
1,923,065 | Elevate Your eCommerce Experience: Discover VeloShop an Innovative Wix-Powered Platform! | This is a submission for the Wix Studio Challenge . What I Built Wix Website :... | 0 | 2024-07-14T13:57:03 | https://dev.to/dailydev/elevate-your-ecommerce-experience-discover-veloshop-an-innovative-wix-powered-platform-4jf5 | devchallenge, wixstudiochallenge, webdev, javascript |
*This is a submission for the [Wix Studio Challenge ](https://dev.to/challenges/wix).*
## What I Built
Wix Website : https://adixander07.wixstudio.io/veloshop/login
Login Credentials:
Email: nostalgicsatoshi7@imcourageous.com
Password: test
**If you wish to see all functionalities of VeloShop try to see the Bottle ... | dailydev |
1,923,066 | Tailwind Catalyst: Getting Started with Tailwind's React Toolkit | What is Tailwind Catalyst? Tailwind Catalyst is a powerful toolkit designed to streamline... | 0 | 2024-07-14T11:11:13 | https://codeparrot.ai/blogs/tailwind-catalyst-getting-started-with-tailwinds-react-toolkit | tailwindcss, catalyst, react, toolkit |
## What is Tailwind Catalyst?
Tailwind Catalyst is a powerful toolkit designed to streamline the integration of Tailwind CSS with React applications. Functioning as a link between React components and Tailwind's utility-first CSS framework, it makes the process easier. Tailwind Catalyst offers pre-built components, t... | harshalranjhani |
1,923,091 | Alpha Wolf Gear - Adventure Sports eCom on Wix Studio | This is a submission for the Wix Studio Challenge . What I Built I created an innovative... | 0 | 2024-07-14T11:20:51 | https://dev.to/maveristic/alpha-wolf-gear-adventure-sports-ecom-on-wix-studio-17d5 | devchallenge, wixstudiochallenge, webdev, javascript | *This is a submission for the [Wix Studio Challenge ](https://dev.to/challenges/wix).*
## **What I Built**
I created an innovative and interactive eCommerce experience using Wix Studio. The project includes several features designed to enhance the user experience on an eCommerce platform. These features include a dyn... | maveristic |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.