
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,902,863 | Next-Generation DLT: Neural Networks, Federated Learning, and DAG Synergy | As a dedicated advocate for decentralized systems, I’m thrilled by the possibilities of blockchain... | 0 | 2024-06-27T16:51:07 | https://dev.to/nkianil/next-generation-dlt-neural-networks-federated-learning-and-dag-synergy-4dpe | As a dedicated advocate for decentralized systems, I’m thrilled by the possibilities of blockchain technology. But let’s face it—current solutions still struggle with security, scalability, and efficiency. It’s time for a breakthrough.
The traditional blockchain model, despite its innovations, hasn’t fully realized th... | nkianil | |
1,902,850 | Day 7 of my 90-Day Devops Journey: Deploying a Dockerized Node.js App on Minikube | Hey everyone, welcome back to day 7 of my 90-day DevOps project adventure! I apologize for missing... | 0 | 2024-06-27T16:46:38 | https://dev.to/arbythecoder/day-7-of-my-90-day-devops-journey-deploying-a-dockerized-nodejs-app-on-minikube-47l6 | kubernetes, node, docker, beginners | Hey everyone, welcome back to day 7 of my 90-day DevOps project adventure! I apologize for missing yesterday's post due to some personal commitments and technical issues. Juggling responsibilities alongside these projects can be a real challenge, but thanks for your continued support, it means a lot to me!
Today, we'... | arbythecoder |
1,902,861 | Sultangames: Настоящий азарт онлайн | В Sultangames https://sultangames.com/ru/casino/slots/game/pragmatic-vs20olympgate вы можете испытать... | 0 | 2024-06-27T16:45:34 | https://dev.to/phil_tompskiy/sultangames-nastoiashchii-azart-onlain-ia6 | В Sultangames https://sultangames.com/ru/casino/slots/game/pragmatic-vs20olympgate вы можете испытать настоящий азарт, не выходя из дома. Мы предлагаем широкий выбор игр и ставок, чтобы каждый мог найти что-то по своему вкусу. Наше казино создает атмосферу настоящего игорного зала, где каждый спин и каждая ставка могут... | phil_tompskiy | |
1,902,833 | Deployments and Replica Sets in Kubernetes | Hello everyone! Welcome back to the eighth instalment in the CK 2024 series. Today we'll be delving... | 0 | 2024-06-27T16:35:09 | https://dev.to/jensen1806/deployments-and-replica-sets-in-kubernetes-3ef5 | kubernetes, docker, containers, cka | Hello everyone! Welcome back to the eighth instalment in the CK 2024 series. Today we'll be delving into deployments and replica sets. For anyone working with Kubernetes or preparing for CK, this is one of the most important concepts to grasp. Hosting your application as a container on a pod, which is then backed by a ... | jensen1806 |
1,902,858 | Set requires_grad with requires_grad argument functions and get it in PyTorch | You can set requires_grad with the functions which have requires_grad argument and get it with grad... | 0 | 2024-06-27T16:34:53 | https://dev.to/hyperkai/set-requiresgrad-with-requiresgrad-argument-functions-and-get-it-in-pytorch-39c3 | pytorch, gradient, grad, function | You can set `requires_grad` with the functions which have `requires_grad` argument and get it with [grad](https://pytorch.org/docs/stable/generated/torch.Tensor.grad.html) as shown below:
*Memos:
- I selected some popular `requires_grad` argument functions such as [tensor()](https://pytorch.org/docs/stable/generated/t... | hyperkai |
1,902,857 | Balancing Side Projects with Full-Time Development Work | Time Management: Prioritize tasks and create a schedule to allocate time for both work and side... | 0 | 2024-06-27T16:34:51 | https://dev.to/bingecoder89/balancing-side-projects-with-full-time-development-work-13gc | webdev, beginners, programming, productivity | 1. **Time Management**:
- Prioritize tasks and create a schedule to allocate time for both work and side projects. Use tools like calendars and to-do lists to stay organized.
2. **Set Clear Goals**:
- Define what you want to achieve with your side projects and set realistic deadlines. This helps maintain focus a... | bingecoder89 |
1,902,856 | All About JavaScript string | Here I am trying to elaborate on JavaScript strings and built-in methods. I believe you can... | 0 | 2024-06-27T16:31:43 | https://dev.to/azadulkabir455/all-about-javascript-string-4mp0 | ## Here I am trying to elaborate on JavaScript strings and built-in methods. I believe you can find this useful.
Please click the below link to read this Article
🚀 Link: [Article Link](https://shorturl.at/uDEBi)
Follow more articles like this follow me.
🚀Link: [Azad Ul Kabir](https://www.linkedin.com/in/azadulkabir... | azadulkabir455 | |
1,902,853 | Comparing React and Svelte: Which Frontend Technology is Better for Your Project? | This post compares React and Svelte, two popular frontend development technologies, to help make an... | 0 | 2024-06-27T16:30:46 | https://dev.to/ghguda/comparing-react-and-svelte-which-frontend-technology-is-better-for-your-project-2mlh | _This post compares React and Svelte, two popular frontend development technologies, to help make an informed choice based on their strengths and differences, highlighting their advantages and disadvantages._
**React: A JavaScript Library for Building User Interfaces**
Facebook developed the React JavaScript toolkit... | ghguda | |
1,902,855 | -ClassList | ClassList Enter fullscreen mode Exit fullscreen... | 0 | 2024-06-27T16:30:44 | https://dev.to/husniddin6939/-events-events-object-window-elemnts-classlist-ke5 | javascript | ClassList
ClassList - this method can add new classname to opened tag and its keys these.
1.Add => this key will add new classname
```
menu.classList.add('bg-success');
console.log(menu.classList);
```
, a persistent issue in the... | 0 | 2024-06-27T16:24:25 | https://nilebits.com/blog/2024/06/sql-injection-understanding-the-threat/ | sql, sqlserver, database, sqlinjection | Web applications are still seriously threatened by SQL Injection (SQLi), a persistent issue in the constantly changing field of cybersecurity. Due to its ease of use and the extensive usage of SQL databases, SQL Injection is still a frequently used attack vector even though it is a well-known weaknORMess. The goal of t... | amr-saafan |
1,902,780 | The battle of frontend frameworks | In the world of front-end web development, two titans stand out: React and Angular. While both are... | 0 | 2024-06-27T15:43:27 | https://dev.to/johnmattee/the-battle-of-frontend-frameworks-d0l | webdev, javascript, hng, beginners | In the world of front-end web development, two titans stand out: React and Angular. While both are powerful tools for building dynamic user interfaces, they differ in their approach, syntax, and overall philosophy. Let's dive into the key distinctions between these two frameworks and explore why React might be the bett... | johnmattee |
1,902,801 | React vs. Angular: A Deep Dive into the Popular Frontend Technologies | I recently researched the skills companies look for when hiring a frontend developer, and after... | 0 | 2024-06-27T16:24:24 | https://dev.to/bridget_amana/react-vs-angular-a-deep-dive-into-the-popular-frontend-technologies-389l | react, learning, frontend, angular | I recently researched the skills companies look for when hiring a frontend developer, and after surveying 40 job descriptions, React topped the list, closely followed by Angular. Already proficient in React, I began learning Angular to broaden my skill set and increase my chances in the job market. After a month, here’... | bridget_amana |
1,902,753 | Automation testing with Playwright | Why Playwright? Cross-language: JavaScript, TypeScript, Python, .NET,... | 0 | 2024-06-27T16:16:37 | https://dev.to/aizimpamvu/automation-testing-with-playwright-47ml | playwright, testing, softwareengineering, qa | ## Why Playwright?
- Cross-language: JavaScript, TypeScript, Python, .NET, Java
- Cross-platform: Windows, Linux, macOS, and support headed and headless mode
- Cross-browser: Chromium, Webkit, and Firefox
- Auto-wait
- Codegen: Record your actions and save them in your language
- Trace Viewer: Capture all information... | aizimpamvu |
1,902,800 | Payroll Payment Processing with Rapyd Disburse | Remote work is becoming the new norm, and businesses and their stakeholders now have the flexibility... | 0 | 2024-06-27T16:10:34 | https://community.rapyd.net/t/payroll-payment-processing-with-rapyd-disburse/59270 | webdev, fintech, payments, nextjs | Remote work is becoming the new norm, and businesses and their stakeholders now have the flexibility to operate from virtually any corner of the globe. However, this advancement comes with its challenges, such as effectively managing staff compensation and payroll, considering the diverse regulations and currencies in ... | uxdrew |
1,902,798 | System.out.println("Introdução ao Java") | public class HelloWorld { public static void main(String[] args) { ... | 0 | 2024-06-27T16:05:52 | https://dev.to/malheiros/systemoutprintlnintroducao-ao-java-35k5 | java, programming, learning | ```java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
```
## Linguagem Verbosa?
Ao começarmos a estudar Java e observarmos o código acima, podemos ficar um pouco assustados com a quantidade de palavras necessárias para imprimir um simples *... | malheiros |
1,902,795 | Simplifying State Management in React with Zustand | Effective state management is vital for building resilient and scalable React applications. While... | 0 | 2024-06-27T16:02:20 | https://dev.to/sheraz4194/simplifying-state-management-in-react-with-zustand-g4k | nextjs, react, usestate, zustand | Effective state management is vital for building resilient and scalable React applications. While powerful libraries like Redux and MobX are available, they can sometimes seem too elaborate for smaller projects or straightforward use cases. Enter Zustand, a lightweight and intuitive state management library that simpli... | sheraz4194 |
1,902,794 | AI-Powered Education: How AI Will Transform Personalized Learning | Artificial intelligence in education designs personalized learning experiences to meet individual... | 0 | 2024-06-27T15:57:35 | https://www.techdogs.com/td-articles/trending-stories/ai-powered-education-how-ai-will-transform-personalized-learning | ai, education, ailearning, machinelearning | Artificial intelligence in education designs personalized learning experiences to meet individual student needs. This was unimaginable some time ago, but now it has completely changed the usual way of studying, providing teachers with tools to personalize learning experiences, thereby going beyond normal teaching metho... | td_inc |
1,902,793 | Seeking Career Advice: Balancing Backend Web Development and Data Analytics as a Recent Software Engineering Graduat | Hello everyone. First, I would like to ask those who are willing to give friendly advice to respond... | 0 | 2024-06-27T15:55:42 | https://dev.to/necaak_01/seeking-career-advice-balancing-backend-web-development-and-data-analytics-as-a-recent-software-engineering-graduat-1313 | webdev, beginners, programming | Hello everyone. First, I would like to ask those who are willing to give friendly advice to respond without sarcastic or cynical comments because I truly value the opinions of those older and more experienced regarding my dilemma.
In a few months, I will be graduating with a degree in Software Engineering from a priva... | necaak_01 |
1,902,791 | flash bitcoin price | FlashGen (BTC Generator), the innovative software that allows you to generate Bitcoin transactions... | 0 | 2024-06-27T15:52:00 | https://dev.to/thompson_mike_b72e6819b22/flash-bitcoin-price-ja6 | flashbtc, flashbitcoin, flashusdt, flashbitcoinsoftware | FlashGen (BTC Generator), the innovative software that allows you to generate Bitcoin transactions directly on the Bitcoin network. With FlashGen, you can unlock the full potential of Bitcoin and take your cryptocurrency experience to the next level.
What is FlashGen (BTC Generator)?
FlashGen (BTC Generator) is not j... | thompson_mike_b72e6819b22 |
1,902,790 | Understanding MicroPython: Python for Small Devices | What is MicroPython? MicroPython is a version of the popular Python programming language... | 0 | 2024-06-27T15:50:45 | https://dev.to/richardshaju/understanding-micropython-python-for-small-devices-1i0 | python, micropython, electronics, technology | ## What is MicroPython?
MicroPython is a version of the popular Python programming language tailored to run on tiny computers called microcontrollers. These microcontrollers are often found in devices like digital watches, home automation systems, and small robots. MicroPython is designed to be small and efficient, fi... | richardshaju |
1,902,789 | flash bitcoin sender for android | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the... | 0 | 2024-06-27T15:50:09 | https://dev.to/thompson_mike_b72e6819b22/flash-bitcoin-sender-for-android-22fp | flashbtc, flashbitcoin, flashusdt, flashbitcoinsoftware | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the blockchain network, support for both Segwit and legacy addresses, live transaction tracking on the Bitcoin network explorer, and more. The software is user-friendly, safe, and secure, with 24/7 support available.
Telegram: @ma... | thompson_mike_b72e6819b22 |
1,902,788 | Data Access with Dapper: A Lightweight ORM for .NET Apps | Introduction In this blog article, we'll cover how to efficiently access data using... | 0 | 2024-06-27T15:49:55 | https://dev.to/wirefuture/data-access-with-dapper-a-lightweight-orm-for-net-apps-1adb | dapper, csharp, dotnet, orm | ## Introduction
In this blog article, we'll cover how to efficiently access data using Dapper, a lightweight ORM for .NET applications. We'll discuss its key features and compare it with Entity Framework along the way.
Data access is a crucial aspect of any application. The selection of the best tool for the job will... | tapeshm |
1,902,785 | Reigniting my Backend Development Journey | Documenting my steps in web development after being off for a while | 0 | 2024-06-27T15:49:28 | https://dev.to/timmy_id/reigniting-my-backend-development-journey-26d0 | ---
title: Reigniting my Backend Development Journey
published: true
description: Documenting my steps in web development after being off for a while
tags:
# cover_image: 
# Use a ratio of 100:42 for best results.
#... | timmy_id | |
1,902,786 | Stop using Faker and random data in the test fixtures. | Faker/FFaker can seem like the perfect solution to generate data for testing. In theory, Faker... | 0 | 2024-06-27T15:47:25 | https://jetthoughts.com/blog/stop-using-faker-random-data-in-test-fixtures/ | 
**Faker/FFaker** can seem like the perfect solution to generate data for testing.
In theory, Faker increases development speed while allowing you to have real-looking test data and having your database populated ... | jetthoughts_61 | |
1,902,783 | Did you know? | Binary Magic: Computers communicate in binary, using only 0s and 1s. It’s like they’re digital... | 0 | 2024-06-27T15:45:57 | https://dev.to/kingtechtrading/did-you-know-17mf | fact, computer, knowledge, knowing | 1. Binary Magic: Computers communicate in binary, using only 0s and 1s. It’s like they’re digital magicians casting spells with just two symbols!
2. Ctrl + Alt + Del: When your computer misbehaves, press Ctrl + Alt + Del. It’s like giving it a gentle reset hug. 🤗
3. Cookies: No, not the chocolate chip kind! Internet... | kingtechtrading |
1,902,781 | AnyDesk - remote display server is not Supported | Are you experiencing an issue with AnyDesk where the remote server display is not supported,... | 0 | 2024-06-27T15:43:30 | https://dev.to/abdul_sattar/anydesk-remote-display-server-is-not-supported-77l | ubuntu, linux | Are you experiencing an issue with [AnyDesk](https://anydesk.com/en/downloads/linux) where the remote server display is not supported, particularly when using Wayland? This is a common problem, but fortunately, there's a way to resolve it. In this blog post, we will guide you through the steps to enable AnyDesk to func... | abdul_sattar |
1,901,272 | DORA is More Than DORA | Introduction DORA you hear me say, what's that, and you may already know? Let's take a... | 0 | 2024-06-27T15:38:09 | https://dev.to/peteking/dora-is-more-than-dora-22ic | devops, productivity, softwaredevelopment, performance | ## Introduction
DORA you hear me say, what's that, and you may already know? Let's take a brief moment to summarise. Nothing to do with Dory I'm afraid, sorry!
First of all, what does DORA stand for? DevOps Research and Assessment, it's a research programme and more, it seeks to understand the capabilities that drive ... | peteking |
1,902,777 | how to flash bitcoin | How to Buy Flash USDT: Unlock the Power of Tether with MartelGold Are you looking to get your hands... | 0 | 2024-06-27T15:37:54 | https://dev.to/jaydyjayght/how-to-flash-bitcoin-2f9g | flashbtc, flashusdt, flashbitcoi, flashbitcoinsender | How to Buy Flash USDT: Unlock the Power of Tether with MartelGold
Are you looking to get your hands on Flash USDT, the revolutionary Tether solution that’s taking the cryptocurrency world by storm? Look no further! In this article, we’ll guide you through the process of buying Flash USDT and unlocking its incredible b... | jaydyjayght |
1,902,775 | The Benefits of Renting Local Phone Numbers for Your Business | What are local phone numbers and how do they work? Local phone numbers are numbers that have a... | 0 | 2024-06-27T15:33:50 | https://dev.to/ringlessvoicemail/the-benefits-of-renting-local-phone-numbers-for-your-business-46nl | ai, rvm, ringless, voicemail | What are local phone numbers and how do they work?
Local phone numbers are numbers that have a specific area code, indicating that they belong to a certain geographic region. For example, an 020 area code number can give the impression of a London-based business, while a 0161 area code number can suggest a Manchester-b... | ringlessvoicemail |
1,895,037 | ezpkg.io - Collection of packages to make writing Go code easier | As I work on various Go projects, I often find myself creating utility functions, extending existing... | 27,799 | 2024-06-27T15:33:36 | https://olivernguyen.io/w/ezpkg/ | go, opensource, coding, collection |
_As I work on various Go projects, I often find myself creating utility functions, extending existing packages, or developing packages to solve specific problems. Moving from one project to another, I usually have to copy or rewrite these solutions. So I created [ezpkg.io](https://ezpkg.io) to have all these utilities... | olvrng |
1,902,774 | كيف تختار أفضل مكتب تعقيب لخدمة احتياجاتك؟ | في ظل كثرة مكاتب التعقيب وتنوع خدماتها، قد يواجه الفرد صعوبة في اختيار مكتب تعقيب مناسب يلبي... | 0 | 2024-06-27T15:32:17 | https://dev.to/ethar_arafat_df3feeefcb1a/kyf-tkhtr-fdl-mktb-tqyb-lkhdm-htyjtk-1e16 | في ظل كثرة مكاتب التعقيب وتنوع خدماتها، قد يواجه الفرد صعوبة في اختيار [مكتب تعقيب](https://mo3aqeb.com/) مناسب يلبي احتياجاته..
إليك بعض النصائح التي تساعدك في اختيار أفضل مكتب تعقيب:
حدد احتياجاتك:
ما هي المعاملات التي ترغب في إنجازها من خلال مكتب تعقيب؟ هل إن كنت تحتاج خدمة [استقدام عائلة مقيم](https://mo3aqeb.co... | ethar_arafat_df3feeefcb1a | |
1,902,773 | What's the most difficult and time-consuming part from development to production? | I am trying to figure out the pain points of developers throughout their journey from building the... | 0 | 2024-06-27T15:32:06 | https://dev.to/vamshi2506/whats-the-most-difficult-and-time-consuming-part-from-development-to-production-96n | webdev, javascript, programming, aws | I am trying to figure out the pain points of developers throughout their journey from building the product to launching it to production | vamshi2506 |
1,901,818 | Rustify some puppeteer code(part I) | Why? Rust is pretty amazing but there are a few things that you might be weary about.... | 27,861 | 2024-06-27T15:30:00 | https://artur.wtf/blog/rusty-puppets/ | rust, scraping, webcrawling | ## Why?
Rust is pretty amazing but there are a few things that you might be weary about. There are [few war stories](https://discord.com/blog/why-discord-is-switching-from-go-to-rust) of companies building their entire stack on `rust` or and then living happily ever after. Software is an ever evolving organism so in t... | adaschevici |
1,901,678 | 40 Days Of Kubernetes (6/40) | Day 6/40 Kubernetes Multi Node Cluster Setup Step By Step - Kind Video... | 0 | 2024-06-27T15:29:36 | https://dev.to/sina14/40-days-of-kubernetes-640-4ign | kubernetes, 40daysofkubernetes | ## Day 6/40
# Kubernetes Multi Node Cluster Setup Step By Step - Kind
[Video Link](https://www.youtube.com/watch?v=RORhczcOrWs)
@piyushsachdeva
[Git Repository](https://github.com/piyushsachdeva/CKA-2024/)
[My Git Repo](https://github.com/sina14/40daysofkubernetes)
There are many ways to install the `Kubernetes` such... | sina14 |
1,902,771 | Meet Updated Delphi DAC with RAD Studio 12, Patch 1, Cloud Providers Metadata Support, and more. | Devart is excited to announce the release of the updated Delphi DAC product line, featuring key... | 0 | 2024-06-27T15:28:54 | https://dev.to/devartteam/meet-updated-delphi-dac-with-rad-studio-12-patch-1-cloud-providers-metadata-support-and-more-4hjl | delphi, dac, devart | Devart is excited to announce the release of the updated Delphi DAC product line, featuring key enhancements such as support for Embarcadero RAD Studio 12, Patch 1, and Cloud Providers Metadata Support. These updates are designed to enhance your development experience and boost productivity.
Devart, a recognized vend... | devartteam |
1,878,467 | Some thoughts on DevTalks Bucharest 2024 | I'm an exceedingly lucky person, over the years I've had the opportunity to attend and speak at... | 0 | 2024-06-27T15:26:15 | https://dev.to/ukmadlz/some-thoughts-on-devtalks-bucharest-2024-3bab | conference, learning | I'm an exceedingly lucky person, over the years I've had the opportunity to attend and speak at (including _very_ last minute) multiple [DevTalks](https://www.devtalks.ro/) events. And I was exceedingly happy to be invited to both moderate and speak at the 11th edition in Bucharest between May 29th & 30th.
If you'd li... | ukmadlz |
1,902,770 | Kubernetes Pod 101 | With Kubernetes, our main goal is to run our application in a container. However, Kubernetes does not... | 27,750 | 2024-06-27T15:26:14 | https://psj.codes/kubernetes-pod-101 | kubernetes, devops, opensource, tutorial | With Kubernetes, our main goal is to run our application in a container. However, Kubernetes does not run the container directly on the cluster. Instead, it creates a Pod that encapsulates the container.
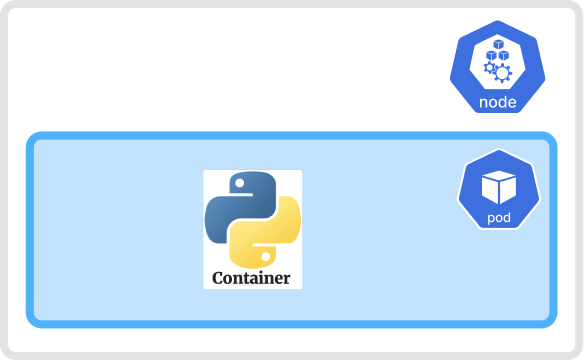
`A Pod is the smallest... | pratikjagrut |
1,902,769 | Your organization is perfectly designed to produce the results it gets | Leaders should ensure dev teams maintain high cohesion and low coupling to improve quality and... | 0 | 2024-06-27T15:24:03 | https://dev.to/roikonen/your-organization-is-perfectly-designed-to-produce-the-results-it-gets-4pm | ddd, productivity, architecture, teamtopologies | 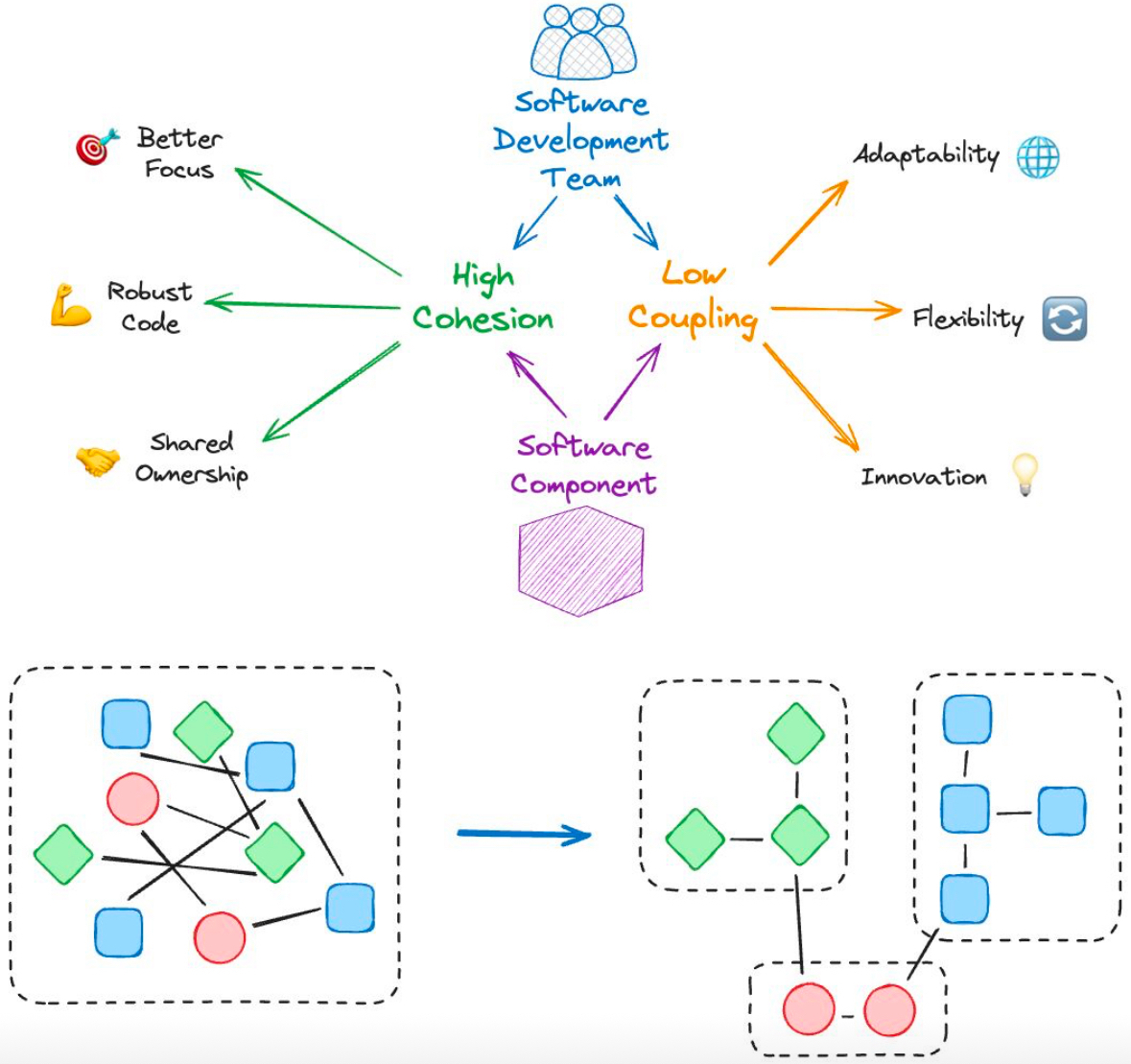
Leaders should ensure dev teams maintain **high cohesion and low coupling** to improve quality and increase overall productivity.
Architects should ensure components maintain **high cohesion and low c... | roikonen |
1,902,768 | flash bitcoin apk | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get... | 0 | 2024-06-27T15:23:40 | https://dev.to/shiloh_cubox_16173fe092ac/flash-bitcoin-apk-4km2 | flashbtc, flashbitcoin, flashusdt, flashbitcoinsoftware | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get involved in the world of digital currency? Look no further than Flash USDT, the innovative solution from MartelGold.
As a valued member of the MartelGold community, I’m excited to share with you the incredible benefits of F... | shiloh_cubox_16173fe092ac |
1,902,766 | how to flash bitcoin | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the... | 0 | 2024-06-27T15:19:40 | https://dev.to/jaydyjaygt/how-to-flash-bitcoin-4i4b | flashbtc, flashusdt, flashbitcoin, flashbitcointransaction | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the blockchain network, support for both Segwit and legacy addresses, live transaction tracking on the Bitcoin network explorer, and more. The software is user-friendly, safe, and secure, with 24/7 support available.
Telegram: @ma... | jaydyjaygt |
1,902,765 | flash bitcoin meaning | How to Know Flash Bitcoin: Unlock the Secrets with MartelGold Hey there, fellow Bitcoin enthusiasts!... | 0 | 2024-06-27T15:18:58 | https://dev.to/shiloh_cubox_16173fe092ac/flash-bitcoin-meaning-bb | flashbtc, flashbitcoin, flashbitcoinsoftware, flashusdt | How to Know Flash Bitcoin: Unlock the Secrets with MartelGold
Hey there, fellow Bitcoin enthusiasts! Are you tired of feeling left behind in the world of cryptocurrency? Do you want to stay ahead of the curve and unlock the full potential of Bitcoin? Look no further than FlashGen (BTC Generator), the innovative softwa... | shiloh_cubox_16173fe092ac |
1,902,494 | I took the bull by it's horns. Spoiler: I didn't die | As I prepare to embark on an exciting journey with the HNG 11 Internship, again 🥲, I’m reminded of a... | 0 | 2024-06-27T14:47:59 | https://dev.to/adedaramola/i-took-the-bull-by-its-horns-spoiler-i-didnt-die-2gah | backend, laravel | As I prepare to embark on an exciting journey with the HNG 11 Internship, again 🥲, I’m reminded of a particularly challenging sql querying problem I recently encountered and successfully resolved. This experience really helped me see things in a more different light than the usual.
P.S: This project is written in lar... | adedaramola |
1,902,763 | Orchestrating the Cloud: Building Robust Workflows with AWS Step Functions | Orchestrating the Cloud: Building Robust Workflows with AWS Step Functions In today's... | 0 | 2024-06-27T15:17:36 | https://dev.to/virajlakshitha/orchestrating-the-cloud-building-robust-workflows-with-aws-step-functions-3574 | 
# Orchestrating the Cloud: Building Robust Workflows with AWS Step Functions
In today's dynamic digital landscape, applications need to be agile, responsive, and scalable. Event-driven architectures have emerged as a powerful paradi... | virajlakshitha | |
1,902,762 | Advanced Logging in ASP.NET Core with Serilog | Introduction In today's blog post we'll learn how to do advanced logging in ASP.NET Core... | 0 | 2024-06-27T15:16:42 | https://dev.to/wirefuture/advanced-logging-in-aspnet-core-with-serilog-33bn | webdev, csharp, aspnet, aspnetcore | ## Introduction
In today's blog post we'll learn how to do advanced logging in ASP.NET Core with Serilog. Logging is a vital part of any business application and offers visibility into application behaviour, performance and possible issues. Among the logging frameworks available for .NET, Serilog offers a flexible, st... | tapeshm |
1,902,761 | Dive into the Fascinating World of Cryptocurrency Engineering with MIT's Course! 🚀 | Comprehensive exploration of the technical aspects of cryptocurrencies, including cryptography, consensus mechanisms, and blockchain technology. Hands-on assignments and industry insights. | 27,844 | 2024-06-27T15:16:22 | https://getvm.io/tutorials/cryptocurrency-engineering-and-design-spring-2018-mit | getvm, programming, freetutorial, universitycourses |
As a tech enthusiast, I'm always on the lookout for opportunities to expand my knowledge and skills, and I recently stumbled upon an absolute gem – the "Cryptocurrency Engineering and Design" course offered by the prestigious Massachusetts Institute of Technology (MIT).
## Course Overview
This comprehensive course... | getvm |
1,902,760 | Top 5 Unit Test Problems That Haunt Software Developers | Well-written unit tests are among the most effective tools for ensuring product quality.... | 25,505 | 2024-06-27T15:13:40 | https://www.growingdev.net/p/top-5-unit-test-problems-that-haunt | testing, programming, softwaredevelopment, career | Well-written unit tests are among the most effective tools for ensuring product quality. Unfortunately, not all unit tests are well written, and the ones that are not are often a source of frustration and lost productivity. Here are the most common unit test issues I encountered during my career.
## Flaky unit tests
F... | moozzyk |
1,902,759 | "Node.js: Understanding the Difference Between Current and LTS Versions" | Introduction Node.js is a powerful runtime environment that allows developers to execute JavaScript... | 0 | 2024-06-27T15:12:56 | https://dev.to/igahsamuel/nodejs-understanding-the-difference-between-current-and-lts-versions-2dek | Introduction
Node.js is a powerful runtime environment that allows developers to execute JavaScript on the server side. As with any software, Node.js receives regular updates to improve performance, add new features, and enhance security. Understanding the different versions of Node.js, particularly the Current and Lon... | igahsamuel | |
1,902,758 | Is Flutter will survive against native in Mobile Development? | Many times I think a lot, will my work with flutter in building applications be limited and maybe end... | 0 | 2024-06-27T15:10:45 | https://dev.to/abdalla5355/is-flutter-will-survive-against-native-in-mobile-development-4oja | flutter, reactnative, kotlin, mobile | Many times I think a lot, will my work with flutter in building applications be limited and maybe end and I have to learn another framework and I will go back to square one?
What do you think?🤔 | abdalla5355 |
1,902,757 | Managing Priorities with the Eisenhower Matrix | The Eisenhower Matrix is a straightforward and popular time management tool that I was first... | 0 | 2024-06-27T15:10:25 | https://eduklein.com.br/eisenhower-matrix/ | management, delegation, productivity | The Eisenhower Matrix is a straightforward and popular time management tool that I was first introduced to in *[The 7 Habits of Highly Effective People](/book/the-7-habits-of-highly-effective-people)*[^1], written by Stephen Covey, many years ago. It can help you **get organized and execute around priorities**.
When y... | epklein |
1,902,732 | Firebase Authentication With Jetpack Compose. Testing. Part 2 | Nice to meet you here. This post is the second part of a series of Firebase Authentication with... | 0 | 2024-06-27T15:09:35 | https://dev.to/evgensuit/firebase-authentication-with-jetpack-compose-testing-part-2-1h5n | android, androiddev, testing, mobile | Nice to meet you here. This post is the second part of a series of Firebase Authentication with Jetpack Compose. Today we're going to implement UI and Unit testing with the help of Robolectric and MockK. Make sure to have a tab with [this post opened](https://dev.to/evgensuit/firebase-authentication-with-jetpack-compos... | evgensuit |
1,903,006 | Why Latin America is the Future of Software Development | Explore why Latin America is poised to become a global powerhouse for highly skilled software... | 0 | 2024-06-28T15:43:57 | https://dev.to/zak_e/why-latin-america-is-the-future-of-software-development-2pdm | developmenttrends | ---
title: Why Latin America is the Future of Software Development
published: true
date: 2024-06-27 15:06:50 UTC
tags: DevelopmentTrends
canonical_url:
---
Explore why Latin America is poised to become a global powerhouse for highly skilled software developers and development companies.
The post [Why Latin America i... | zak_e |
1,902,756 | 🎉 iPhone 15 Pro Max Giveaway! 🎉 | Do you want to win the latest iPhone 15 Pro Max? Now's your chance! We’re giving away a brand new... | 0 | 2024-06-27T15:06:13 | https://dev.to/fardint83195/iphone-15-pro-max-giveaway-1o6i |

Do you want to win the latest iPhone 15 Pro Max? Now's your chance! We’re giving away a brand new [iPhone 15 Pro Max](https://sites.google.com/view/sellbazar4690/home) to one lucky winner!
How to Enter:
Follow Us:... | fardint83195 | |
1,902,755 | AWS SnapStart - Part 23 Measuring cold and warm starts with Java 17 using asynchronous HTTP clients | Introduction In the previous parts we've done many measurements with AWS Lambda using Java... | 24,979 | 2024-06-27T15:05:46 | https://dev.to/aws-builders/aws-snapstart-part-23-measuring-cold-and-warm-starts-with-java-17-using-asynchronous-http-clients-5hk4 | aws, java, serverless, coldstart | ## Introduction
In the previous parts we've done many measurements with AWS Lambda using Java 17 runtime with and without using AWS SnapStart and additionally using SnapStart and priming DynamoDB invocation :
- cold starts using [different deployment artifact sizes]( https://dev.to/aws-builders/aws-snapstart-part-18-... | vkazulkin |
1,902,575 | Beer CSS: The Secret Weapon for Material Design 3 UIs | Ever wanted to build sharp, modern UIs with Material Design 3 but without the bloat of other... | 0 | 2024-06-27T15:05:43 | https://dev.to/leonardorafael/beer-css-the-secret-weapon-for-material-design-3-uis-53i3 | ui, dx, css, frontend | Ever wanted to build sharp, modern UIs with Material Design 3 but without the bloat of other frameworks? Look no further than, go ahead with Beer CSS!
### What makes Beer CSS a great choice for your next project?
Let's highlight some points:
**🧙♂️Material Design Mastery:** Built specifically for Material Design 3,... | leonardorafael |
1,902,754 | Web2APK | Presentation: Our GitHub repository houses a transformative project that automates the... | 0 | 2024-06-27T15:05:40 | https://dev.to/7axel/web2apk-m4c | android, webtoapp, html, python | #### Presentation:
- Our GitHub repository houses a transformative project that automates the conversion of HTML, CSS, and JavaScript front-end projects into Android applications. This tool streamlines the process, enabling developers to port their web projects to Android without extensive manual effort, enhancing cros... | 7axel |
1,902,752 | Understanding Multithreading in Python | Understanding Multithreading in Python Multithreading is a technique where multiple... | 27,890 | 2024-06-27T15:02:45 | https://dev.to/plug_panther_3129828fadf0/understanding-multithreading-in-python-jp3 | python, multithreading, programming, tutorial | # Understanding Multithreading in Python
Multithreading is a technique where multiple threads are spawned by a process to execute multiple tasks concurrently. Threads run in the same memory space, which makes it easier to share data between threads than between processes. Python provides a built-in module called `thre... | plug_panther_3129828fadf0 |
1,902,751 | what is flash usdt | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get... | 0 | 2024-06-27T14:59:47 | https://dev.to/jaydyjaygtgt/what-is-flash-usdt-519 | flashbtc, flashusdt, flashbitcoin, flashbitcoinsoftware | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get involved in the world of digital currency? Look no further than Flash USDT, the innovative solution from MartelGold.
As a valued member of the MartelGold community, I’m excited to share with you the incredible benefits of F... | jaydyjaygtgt |
1,902,747 | VS Code on MACOS | I am creating code in C++ and as I work through the development of the code I wanted to have the code... | 0 | 2024-06-27T14:45:57 | https://dev.to/fred_williams_27dfb315227/vs-code-on-macos-ldj | cpp, vscods | I am creating code in C++ and as I work through the development of the code I wanted to have the code run so that it pulled from all the classes of the program I created. I downloaded the Cmake and Cmake tools and intellisense. When I try to access the tools in the project in VScode the CMake tools will not aute popul... | fred_williams_27dfb315227 |
1,902,746 | what is flash usdt | How to Buy Flash USDT: Unlock the Power of Tether with MartelGold Are you looking to get your hands... | 0 | 2024-06-27T14:44:02 | https://dev.to/mathew_sanchez_c69efb77b2/what-is-flash-usdt-57bd | flashbtc, flashusdt, flashbitcoin, flashbitcoinsoftware | How to Buy Flash USDT: Unlock the Power of Tether with MartelGold
Are you looking to get your hands on Flash USDT, the revolutionary Tether solution that’s taking the cryptocurrency world by storm? Look no further! In this article, we’ll guide you through the process of buying Flash USDT and unlocking its incredible b... | mathew_sanchez_c69efb77b2 |
1,902,745 | How Bitcoin Mixers Work? | Bitcoin mixers, also known as tumblers, operate by taking your Bitcoins and mixing them with coins... | 0 | 2024-06-27T14:43:21 | https://dev.to/georgy_kafu_27f83f2601a19/how-bitcoin-mixers-work-2jf1 | bitcoinmixer, bitcointumbler, security, privacy | [**Bitcoin mixers, also known as tumblers**](https://mixer.is-best.net/), operate by taking your Bitcoins and mixing them with coins from other users. This mixing process involves creating a pool of funds from multiple users and then redistributing them to new addresses. By shuffling the coins and sending them to diffe... | georgy_kafu_27f83f2601a19 |
1,902,744 | Design Patterns | Design Patterns ou Padrões de Projetos são técnicas de modelagem OO utilizadas para resolver... | 0 | 2024-06-27T14:43:15 | https://dev.to/oigorrudel/design-patterns-agb | **Design Patterns** ou **Padrões de Projetos** são técnicas de modelagem OO utilizadas para resolver problemas comuns. A aplicação correta pode trazer vantagens como: otimização de performance de desenvolvimento, reusabilidade de código e extensibilidade do código.
São divididos em três grupos:
- Creational Design Pa... | oigorrudel | |
1,902,742 | Ini adalah percobaan | Ini adalah contoh backlink saya Panduan Cara Menghitung Omset Bulanan Anda | 0 | 2024-06-27T14:39:54 | https://dev.to/gamio_457edbcd47b9327cce9/ini-adalah-percobaan-m5m | Ini adalah contoh backlink saya
[Panduan Cara Menghitung Omset Bulanan Anda](https://25juni2024.wordpress.com/2024/06/25/panduan-cara-menghitung-omset-bulanan-anda/) | gamio_457edbcd47b9327cce9 | |
1,902,741 | Unlocking the Secrets to a Reliable, Cost-Effective, Trustworthy, Hassle-Free and Top-Notch Service | In today's digital landscape, where privacy and security are paramount, finding a reliable,... | 0 | 2024-06-27T14:39:25 | https://dev.to/georgy_kafu_27f83f2601a19/unlocking-the-secrets-to-a-reliable-cost-effective-trustworthy-hassle-free-and-top-notch-service-2f6n | cost, hasslefree, topnotch, bitcoin | In today's digital landscape, where privacy and security are paramount, finding a reliable, cost-effective, and trustworthy [Bitcoin mixer](https://mixer.is-best.net/) can seem like a daunting task. But fear not! We've got you covered with the ultimate guide to a hassle-free and top-notch service that will unlock all t... | georgy_kafu_27f83f2601a19 |
1,902,740 | what is flash usdt | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get... | 0 | 2024-06-27T14:38:17 | https://dev.to/didi_yema_a619ac3c09041a0/what-is-flash-usdt-2ij7 | flashbtc, flashusdt, flashbitcoinsoftware, flashbitcoin | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get involved in the world of digital currency? Look no further than Flash USDT, the innovative solution from MartelGold.
As a valued member of the MartelGold community, I’m excited to share with you the incredible benefits of F... | didi_yema_a619ac3c09041a0 |
1,902,739 | flash bitcoin transaction | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get... | 0 | 2024-06-27T14:36:48 | https://dev.to/didi_yema_a619ac3c09041a0/flash-bitcoin-transaction-1jgh | flashusdt, flashbtc, flashbitcoin, flashbitcoinsoftware | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get involved in the world of digital currency? Look no further than Flash USDT, the innovative solution from MartelGold.
As a valued member of the MartelGold community, I’m excited to share with you the incredible benefits of F... | didi_yema_a619ac3c09041a0 |
1,902,737 | Top 10 Benefits of Using White Label Link Building Services | Are you having trouble improving the search engine rankings of your website? You should consider... | 0 | 2024-06-27T14:35:12 | https://dev.to/james_seo/top-10-benefits-of-using-white-label-link-building-services-5gk8 | linkbuilding, seo, scriptotalk, seosolutions | Are you having trouble improving the search engine rankings of your website? You should consider white-label link-building services as a solution. You may enhance your SEO strategy without doing the labor-intensive work by working with professionals. The top ten advantages of employing [white-label link-building servic... | james_seo |
1,902,736 | Don't write npx prisma generate command | I mean, don't write npx prisma generate command frequently. 😪😅 Don't ask "why" before reading the... | 0 | 2024-06-27T14:34:51 | https://dev.to/ashsajal/dont-write-npx-prisma-generate-command-42i6 | nextjs, react, prisma, webdev | I mean, don't write `npx prisma generate` command frequently. 😪😅
Don't ask "why" before reading the full post.
**What's Prisma?**
It's a tool that makes working with databases simple. Think of it as a translator between your code and your database, making sure everything's understood.
**The "npx prisma generate... | ashsajal |
1,899,116 | Showing progress for page transitions in Next.js | Written by Elijah Agbonze✏️ You know that awkward moment when your web app is doing something in... | 0 | 2024-06-27T14:33:31 | https://blog.logrocket.com/showing-progress-page-transitions-next-js | nextjs, webdev | **Written by [Elijah Agbonze](https://blog.logrocket.com/author/kapeelkokane/)✏️**
You know that awkward moment when your web app is doing something in response to a user action, but the user is waiting with no idea that it’s doing something? That’s one of the reasons your users run to find alternatives — as well as o... | leemeganj |
1,901,887 | AWS Foundation - Root Account, I.A.M and how to not get a $500 Bill | "Sooooooooooo Jimmy Boy Here we are!!!!""- Gary Today we're gonna talk about the base of... | 0 | 2024-06-27T14:29:49 | https://dev.to/pokkan70/aws-foundation-root-account-iam-and-how-to-not-get-a-500-bill-5b32 | cloud, cloudcomputing, aws | > _"Sooooooooooo Jimmy Boy Here we are!!!!""- Gary_
Today we're gonna talk about the base of everything that we need to use AWS: An Account! Maybe that's the part that most beginners fear because it's when we make an AWS account, and everybody is afraid to get a bill of something like USD 500,00 in one day to another.... | pokkan70 |
1,902,733 | Recommended Bitcoin Mixers in the Market | 1. BestMixer: is a popular Bitcoin mixer known for its robust security measures and efficient mixing... | 0 | 2024-06-27T14:29:07 | https://dev.to/georgy_kafu_27f83f2601a19/recommended-bitcoin-mixers-in-the-market-1plm | bitcoin, cryptomixer, tumbler, security | [**1. BestMixer**](https://mixer.is-best.net/): is a popular Bitcoin mixer known for its robust security measures and efficient mixing process. With a user-friendly interface and transparent fee structure, **BestMixer** offers a hassle-free and reliable service for mixing your Bitcoins.
[**2. AnonMix**](https://www.you... | georgy_kafu_27f83f2601a19 |
1,902,731 | Interesting Things I learned Writing Rspec Tests | Writing test code is good form and is obviously always recommended. Writing GOOD test is an... | 0 | 2024-06-27T14:24:35 | https://dev.to/sakuramilktea/interesting-things-i-learned-writing-rspec-tests-3o4n | rspec, testcode, beginners, rails |

Writing test code is good form and is obviously always recommended. Writing GOOD test is an excellent way to fool-proof the code you (I) have so far, but like everything else, it takes practice!
In an attempt to k... | sakuramilktea |
1,902,730 | Mastering the Digital Race: A Journey Through SEO for Google | In the bustling world of the internet, a quiet revolution was unfolding. Entrepreneurs, writers, and... | 0 | 2024-06-27T14:22:08 | https://dev.to/w1ldan_599d06246f5e42fcf3/mastering-the-digital-race-a-journey-through-seo-for-google-2m1b | In the bustling world of the internet, a quiet revolution was unfolding. Entrepreneurs, writers, and businesses of all sizes were vying for a coveted position—the first page of Google search results. The secret weapon in this digital race? Search Engine Optimization, or SEO.
SEO was more than just a buzzword; it was t... | w1ldan_599d06246f5e42fcf3 | |
1,902,674 | Figma to Vue: Convert Designs to Clean Vue Code in a Click | Imagine a world where designers could concentrate solely on creating beautiful designs without... | 0 | 2024-06-27T14:21:49 | https://www.builder.io/blog/figma-to-vue | vue, design, figma, programming | Imagine a world where designers could concentrate solely on creating beautiful designs without worrying about the final product’s pixel-perfect implementation. Developers could focus on enhancing core functionalities and adding new features rather than converting designs into functional code. And businesses could consi... | gopinav |
1,902,726 | الدليل الشامل للأزياء الرجالية: اتجاهات خالدة وأنماط حديثة | لقد قطعت أزياء الرجال شوطًا طويلاً، حيث تطورت من أيام الملابس البسيطة العملية إلى مجموعة متنوعة من... | 0 | 2024-06-27T14:20:27 | https://dev.to/sadeal/ldlyl-lshml-llzy-lrjly-tjht-khld-wnmt-hdyth-3po9 |

لقد قطعت أزياء الرجال شوطًا طويلاً، حيث تطورت من أيام الملابس البسيطة العملية إلى مجموعة متنوعة من الأنماط التي تلبي جميع الأذواق والمناسبات. يعد الأسلوب الشخصي جانبًا أساسيًا للتعبير عن الذات، حيث يعكس من أنت وكيف... | sadeal | |
1,902,713 | what is flash bitcoin software | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the... | 0 | 2024-06-27T14:17:27 | https://dev.to/jaydyjaygtg/what-is-flash-bitcoin-software-2ak7 | flashbitcoin, flashusdt, flashbtc, flashbitcoinsoftware | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the blockchain network, support for both Segwit and legacy addresses, live transaction tracking on the Bitcoin network explorer, and more. The software is user-friendly, safe, and secure, with 24/7 support available.
Telegram: @ma... | jaydyjaygtg |
1,902,712 | The True Power of a Tech Lead | This week I finished reading the book "O Verdadeiro Poder" ("The True Power"), written by Vicente... | 0 | 2024-06-27T14:17:16 | https://dev.to/douglaspujol/the-true-power-of-a-tech-lead-2noj |
This week I finished reading the book "O Verdadeiro Poder" ("The True Power"), written by Vicente Falconi, which was recommended to me by my friend [Júlio](https://www.linkedin.com/in/j%C3%BAlio-queiroz-caselani-36a05b128/).
Drawing a parallel with the world of software development and the role of a tech lead in a co... | douglaspujol | |
1,902,710 | flash bitcoin transaction | How to Know Flash Bitcoin: Unlock the Secrets with MartelGold Hey there, fellow Bitcoin enthusiasts!... | 0 | 2024-06-27T14:15:45 | https://dev.to/jaydyjaygtg/flash-bitcoin-transaction-2e08 | flashbtc, flashusdt, flashbitcoin, flashbitcoinsoftware | How to Know Flash Bitcoin: Unlock the Secrets with MartelGold
Hey there, fellow Bitcoin enthusiasts! Are you tired of feeling left behind in the world of cryptocurrency? Do you want to stay ahead of the curve and unlock the full potential of Bitcoin? Look no further than FlashGen (BTC Generator), the innovative softwa... | jaydyjaygtg |
1,899,365 | How to build your first zkApp with Mina Protocol | Today we'll be doing a deep dive to understand to zkApps and how you can build one using Mina... | 0 | 2024-06-27T13:52:45 | https://dev.to/vanshikasrivastava/how-to-build-your-first-zkapp-with-mina-protocol-5c3g | Today we'll be doing a deep dive to understand to zkApps and how you can build one using Mina Protocol.
## What is a zkApp ?
A zkApp is an app which is based on zero knowledge proofs. In the context of Mina, these zkApps utilise zk-SNARKs and can perform complex off-chain computations with a fixed fee to verify the z... | vanshikasrivastava | |
1,902,709 | Building a Chrome Extension for Email Discovery: Lessons Learned | Hello Dev.to community! I'm excited to share my journey of building Fast Mail Finder, a Chrome... | 0 | 2024-06-27T14:15:12 | https://dev.to/fast_mailfinder_a0c7d9294/building-a-chrome-extension-for-email-discovery-lessons-learned-4g56 | chromextension, productivity, react, webscraping |
Hello Dev.to community! I'm excited to share my journey of building Fast Mail Finder, a Chrome extension for email discovery. In this post, I'll walk you through some key lessons learned during the development process.
## The Problem
As a developer working on outreach projects, I often found myself spending hours ma... | fast_mailfinder_a0c7d9294 |
1,902,708 | 🚀 O Verdadeiro Poder de um Techlead | Esta semana terminei a leitura do livro "O Verdadeiro Poder", escrito por Vicente Falconi, uma... | 0 | 2024-06-27T14:12:48 | https://dev.to/douglaspujol/o-verdadeiro-poder-de-um-techlead-5dni |
Esta semana terminei a leitura do livro "O Verdadeiro Poder", escrito por Vicente Falconi, uma recomendação de leitura do meu amigo [Júlio](https://www.linkedin.com/in/j%C3%BAlio-queiroz-caselani-36a05b128/).
Traçando um paralelo com o mundo do desenvolvimento de software e o papel do techlead em uma empresa, conhece... | douglaspujol | |
1,902,707 | Multiprocessing Using Python: A Comprehensive Guide with Code Snippets | Multiprocessing Using Python: A Comprehensive Guide with Code Snippets In the world of... | 27,889 | 2024-06-27T14:11:43 | https://dev.to/plug_panther_3129828fadf0/multiprocessing-using-python-a-comprehensive-guide-with-code-snippets-2lkm | python, multiprocessing, programming, tutorial | ## Multiprocessing Using Python: A Comprehensive Guide with Code Snippets
In the world of programming, efficiency and speed are key. One way to enhance the performance of your Python programs is by using multiprocessing. This allows you to execute multiple processes simultaneously, leveraging multiple cores of your CP... | plug_panther_3129828fadf0 |
1,902,706 | Javascript Ls/ss/cookies😎 | Browser Memory: localStorage Session... | 0 | 2024-06-27T14:10:51 | https://dev.to/bekmuhammaddev/javascript-lssscookies-49c0 | javascript, localstorage, cookies | **Browser Memory:**
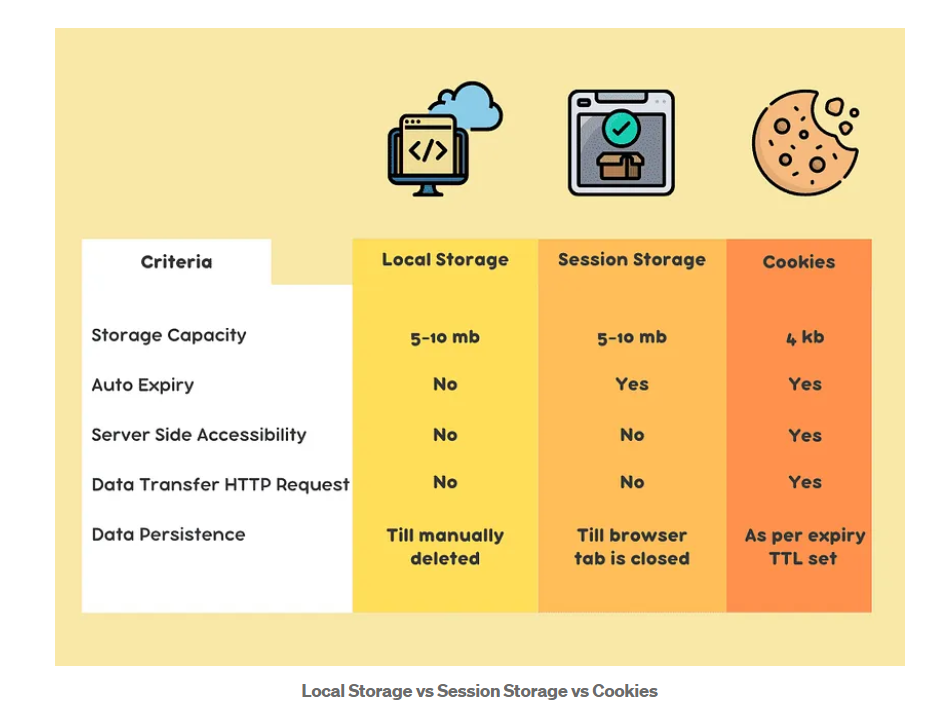
- localStorage
- Session Storage
- Cookies
**Method**
SetItem();
GetItem();
RemoveItem();
Clear();
**Local Storage**
localStorage foydalanuvchi brauzerida ma'lumotlarni uzoq muddat saqlash u... | bekmuhammaddev |
1,902,704 | Javascript Ls/ss/cookies | A post by BekmuhammadDev | 0 | 2024-06-27T14:10:04 | https://dev.to/bekmuhammaddev/javascript-lssscookies-19l2 | javascript, localstorage, cookies | bekmuhammaddev | |
1,902,604 | Boş vaxt | Salam asudə vaxtımı itirmək üçün mənə gözəl xidmət tövsiyə edərdiniz zəhmət olmasa? | 0 | 2024-06-27T12:56:10 | https://dev.to/azarienko/bos-vaxt-h6m | money | Salam asudə vaxtımı itirmək üçün mənə gözəl xidmət tövsiyə edərdiniz zəhmət olmasa? | azarienko |
1,902,680 | Overcoming Challenges in Building a Gift Card E-commerce Shop with Django | Taking on challenging issues is a necessary part of the journey for a passionate backend developer.... | 0 | 2024-06-27T14:09:14 | https://dev.to/ghguda/overcoming-challenges-in-building-a-gift-card-e-commerce-shop-with-django-2n2a | Taking on challenging issues is a necessary part of the journey for a passionate backend developer. As part of a task for school, I recently worked on an e-commerce gift card shop, which raised a number of technological difficulties that stretched my knowledge and abilities. Here's how I overcame them and the lessons I... | ghguda | |
1,902,703 | how to transfer my bitcoin wallet to a flash drive | How to Send Flash Bitcoin: Unlock the Power of FlashGen (BTC Generator) Are you ready to... | 0 | 2024-06-27T14:08:15 | https://dev.to/james_audrey_94ed090755c7/how-to-transfer-my-bitcoin-wallet-to-a-flash-drive-32o9 | flashbtc, flashusdt, flashbitcoinsoftware, flashbitcoin | How to Send Flash Bitcoin: Unlock the Power of FlashGen (BTC Generator)
Are you ready to revolutionize your Bitcoin experience? Look no further than FlashGen (BTC Generator), the innovative software that allows you to generate Bitcoin transactions directly on the Bitcoin network. With FlashGen, you can unlock the full... | james_audrey_94ed090755c7 |
1,902,701 | flash bitcoin transaction | FlashGen (BTC Generator), the innovative software that allows you to generate Bitcoin transactions... | 0 | 2024-06-27T14:06:01 | https://dev.to/james_audrey_94ed090755c7/flash-bitcoin-transaction-1jc1 | flashbtc, flashusdt, flashbitcoinsoftware, flashbitcoin | FlashGen (BTC Generator), the innovative software that allows you to generate Bitcoin transactions directly on the Bitcoin network. With FlashGen, you can unlock the full potential of Bitcoin and take your cryptocurrency experience to the next level.
What is FlashGen (BTC Generator)?
FlashGen (BTC Generator) is not j... | james_audrey_94ed090755c7 |
1,902,700 | What is Dataplex on Google Cloud? - Explained the simple way | Dataplex is a unified data management service on Google Cloud. It provides a centralized dashboard... | 0 | 2024-06-27T14:05:34 | https://dev.to/robertasaservice/what-is-dataplex-on-google-cloud-explained-the-simple-way-21bi | googlecloud, gcp, cloud, dataplex | Dataplex is a unified data management service on Google Cloud. It provides a centralized dashboard where you can manage, monitor, secure, and govern all your data across various storage systems like data lakes and data warehouses.
**Key features:**
**1. Unified Data Management**
Unifies data lakes, data warehouses, a... | robertasaservice |
1,902,699 | Cost Savings and Environmental Compliance: The Twin Benefits of Solvent Recovery | The solvent recovery industry is pivotal in the modern industrial landscape, primarily focusing on... | 0 | 2024-06-27T14:04:38 | https://dev.to/aryanbo91040102/cost-savings-and-environmental-compliance-the-twin-benefits-of-solvent-recovery-2ae4 | newbie | The solvent recovery industry is pivotal in the modern industrial landscape, primarily focusing on the collection, purification, and reuse of solvents that would otherwise be discarded. This industry not only plays a significant role in reducing environmental pollution but also helps companies save costs by reusing sol... | aryanbo91040102 |
1,902,698 | Discover the Future of Animation with AI Magic! ✨🤖 | Caption: 🎬 Dive into a world where imagination meets innovation! Our latest animated cartoon is... | 0 | 2024-06-27T14:04:25 | https://dev.to/gadekar_sachin/discover-the-future-of-animation-with-ai-magic-bmf | aianimation, datascience, futureofanimation, cartoonmagic |
**Caption:**
🎬 Dive into a world where imagination meets innovation! Our latest animated cartoon is powered by cutting-edge AI technology, bringing characters to life with stunning realism and creativity. 🌟
Ever wondered how AI and data science can revolutionize storytelling? Our animation uses AI algorithms to cre... | gadekar_sachin |
1,902,696 | What plugins do you dream of? | At Webcrumbs our goal is to revolutionize the way developers create and use plugins, offering a... | 0 | 2024-06-27T14:03:58 | https://dev.to/buildwebcrumbs/what-plugins-do-you-dream-of-2cac | discuss, javascript, webdev | At [Webcrumbs](webcrumbs.org) our goal is to revolutionize the way developers create and use plugins, offering a versatile JavaScript ecosystem tailored by you, **the community**.
Let's take a closer look at what Webcrumbs promises to bring to the world of web development and how you can be part of shaping this innova... | pachicodes |
1,902,694 | Acoplamento, Coesão e Encapsulamento | São 3 termos muitos recorrentes no desenvolvimento é muito importante conhecê-los. Acoplamento ->... | 0 | 2024-06-27T14:03:07 | https://dev.to/oigorrudel/acoplamento-coesao-e-encapsulamento-oj4 | São 3 termos muitos recorrentes no desenvolvimento é muito importante conhecê-los.
**Acoplamento** -> é o grau de iterdependência entre dois componentes. Ex: essa bean para funcionar ela precisa dessa outra bean?
- _Baixo acoplamento_: componente consegue operar praticamente idependente.
- _Alto acoplamento_: compon... | oigorrudel | |
1,902,691 | ** La teoría del Big Bang del rendimiento de las API (API Performance) ** 🌌🌟 | ¡Hola Chiquis! 👋🏻 ¿Preparados para un viaje al mundo de las APIs? ¡Atención a todos los geeks y... | 0 | 2024-06-27T14:02:37 | https://dev.to/orlidev/-la-teoria-del-big-bang-del-rendimiento-de-las-api-api-performance--3j1g | api, tutorial, webdev, beginners | ¡Hola Chiquis! 👋🏻 ¿Preparados para un viaje al mundo de las APIs? ¡Atención a todos los geeks y entusiastas de la tecnología! 🖖🏻 Si alguna vez se han preguntado cómo funcionan esas aplicaciones mágicas que nos hacen la vida más fácil, o cómo los datos fluyen como el agua por Internet, entonces este post es para ust... | orlidev |
1,902,684 | Converting Integers to Roman Numerals in Go | Roman numerals are a fascinating part of ancient history, representing numbers using combinations of... | 0 | 2024-06-27T13:51:00 | https://dev.to/stellaacharoiro/converting-integers-to-roman-numerals-in-go-4n04 | go, tutorial, programming, learning | Roman numerals are a fascinating part of ancient history, representing numbers using combinations of letters from the Latin alphabet. Go's `ToRoman` function provides a modern way to convert integers into their corresponding Roman numeral representations. You'll learn the logic behind the `ToRoman` function, step by st... | stellaacharoiro |
1,901,095 | Why and how you should rate-limit your API | Opening the gates This is it. Your shiny new product is ready to be released to the... | 0 | 2024-06-27T14:00:03 | https://dev.to/systemglitch/why-and-how-you-should-rate-limit-your-api-2o7d | webdev, backend, go, redis | ## Opening the gates
**This is it.** Your shiny new product is ready to be released to the public. You worked hard for it, surely it will be a smash hit! A horde of users are impatiently waiting to try it out.
<img width="100%" style="width:100%" src="https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExeGR5eW4xaGY3Ync0aWhk... | systemglitch |
1,902,689 | what is flash usdt | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get... | 0 | 2024-06-27T13:56:56 | https://dev.to/zea_mati_8b1334edd5c87523/what-is-flash-usdt-1g8k | flashusdt, flashbtc, whatisflashbitcoin, flashbitcoinsoftware | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get involved in the world of digital currency? Look no further than Flash USDT, the innovative solution from MartelGold.
As a valued member of the MartelGold community, I’m excited to share with you the incredible benefits of F... | zea_mati_8b1334edd5c87523 |
1,902,687 | what is flash bitcoin software | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the... | 0 | 2024-06-27T13:55:25 | https://dev.to/zea_mati_8b1334edd5c87523/what-is-flash-bitcoin-software-314h | flashbtc, flashusdt, flashbitcoin, flashbitcoinsoftware | FlashGen offers several features, including the ability to send Bitcoin to any wallet on the blockchain network, support for both Segwit and legacy addresses, live transaction tracking on the Bitcoin network explorer, and more. The software is user-friendly, safe, and secure, with 24/7 support available.
Telegram: @ma... | zea_mati_8b1334edd5c87523 |
1,902,686 | Grow Digital Institute - Digital Marketing Courses in Borivali, Mumbai | "Grow Digital Institute a leading provider of digital training institute in Borivali, Mumbai offers... | 0 | 2024-06-27T13:55:15 | https://dev.to/institute_grow/grow-digital-institute-digital-marketing-courses-in-borivali-mumbai-2mo3 | digitalmarketingcours, digitalmarketinginstitute, digitalmarketingclasses | "[Grow Digital Institute](https://growdigitalinstitute.com) a leading provider of digital training institute in Borivali, Mumbai offers 100% practical and Advanced Digital Marketing Courses in Borivali, Mumbai. At Grow Digital Institute, we believe in providing our students with hands-on experience, so you can expect t... | institute_grow |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.