
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,899,542 | Create an IAM User and Set Up Billing Alerts for Your AWS Account | AWS Identity and Access Management (IAM) is used to enhance security and manage access effectively... | 0 | 2024-06-26T07:27:06 | https://dev.to/ahsan598/aws-iam-cost-management-51ai | aws |

**AWS Identity and Access Management (IAM)** is used to enhance security and manage access effectively in AWS, it's crucial to avoid using the root user account for regular operations due to its broad permissions. Instead,... | ahsan598 |
1,901,016 | Unlocking the Power of Integration with MuleSoft: A Comprehensive Guide | In today's rapidly evolving digital landscape, businesses must stay agile and responsive to... | 0 | 2024-06-26T07:26:14 | https://dev.to/mylearnnest/unlocking-the-power-of-integration-with-mulesoft-a-comprehensive-guide-5e3j | In today's rapidly evolving digital landscape, businesses must stay agile and responsive to ever-changing customer demands and market conditions. One of the critical components to achieving this agility is seamless integration across various applications, systems, and data sources. MuleSoft, a [leading integration plat... | mylearnnest | |
1,901,015 | Can the tip displayed above be configured to modify the background color and text color when hovering a long label? | Title Can the tip displayed above be configured to modify the background color and text... | 0 | 2024-06-26T07:25:50 | https://dev.to/simaq/can-the-tip-displayed-above-be-configured-to-modify-the-background-color-and-text-color-when-hovering-a-long-label-4g19 | vchart, visactor | ---
title: Can the tip displayed above be configured to modify the background color and text color when hovering a long label?
published: true
description:
tags: VChart, visactor
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 07:24 +0000
---
## Titl... | simaq |
1,901,014 | How to remove the axis scale value? | Title How to remove axis scale values? Description How to remove the content... | 0 | 2024-06-26T07:23:50 | https://dev.to/simaq/how-to-remove-the-axis-scale-value-43ob | visactor, vchart | ---
title: How to remove the axis scale value?
published: true
description:
tags: visactor, vchart
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 07:23 +0000
---
## Title
How to remove axis scale values?
## Description
How to remove the con... | simaq |
1,901,013 | How to configure tooltip and legend shape as rectangles with rounded corners | Title How to configure Legend Shape as a rectangle with rounded corners? ... | 0 | 2024-06-26T07:22:03 | https://dev.to/simaq/how-to-configure-tooltip-and-legend-shape-as-rectangles-with-rounded-corners-36mg | visactor, vchart | ---
title: How to configure tooltip and legend shape as rectangles with rounded corners
published: true
description:
tags: visactor, vchart
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 07:21 +0000
---
## Title
How to configure Legend Shape as a ... | simaq |
1,900,245 | Deploy the vLLM Inference Engine to Run Large Language Models (LLM) on Koyeb | vLLM is a high performance and easy-to-use library for running inference workloads. It allows you to... | 0 | 2024-06-26T07:22:00 | https://www.koyeb.com/tutorials/deploy-the-vllm-inference-engine-to-run-large-language-models-llm-on-koyeb | webdev, programming, tutorial, ai | [vLLM](https://github.com/vllm-project/vllm) is a high performance and easy-to-use library for running inference workloads. It allows you to download popular models from [Hugging Face](https://huggingface.co/), run them on local hardware with custom configuration, and serve an OpenAI-compatible API server as an interfa... | alisdairbr |
1,901,012 | The Future of Software Development: How Generative AI is Transforming IT Jobs | The IT industry is no stranger to rapid advancements and transformative technologies. One of the... | 0 | 2024-06-26T07:21:19 | https://dev.to/kiran_raj_r/the-future-of-software-development-how-generative-ai-is-transforming-it-jobs-51jc | The IT industry is no stranger to rapid advancements and transformative technologies. One of the latest game-changers is Generative AI, a branch of artificial intelligence that can create content, code, and even entire software systems autonomously. This technology is poised to revolutionize the roles of software engin... | kiran_raj_r | |
1,901,011 | MEAN OR MERN | i think its time to connect with dev community clarify me one thing MERN OR MEAN. | 0 | 2024-06-26T07:21:00 | https://dev.to/barghava_ramudu_5f5fbceb2/mean-or-mern-117 | i think its time to connect with dev community clarify me one thing
MERN OR MEAN. | barghava_ramudu_5f5fbceb2 | |
1,901,009 | Right-aligned bar chart numeric labels | Title Right-aligned display of bar chart numerical labels Description Display... | 0 | 2024-06-26T07:20:03 | https://dev.to/simaq/right-aligned-bar-chart-numeric-labels-3c06 | visactor, vchart | ---
title: Right-aligned bar chart numeric labels
published: true
description:
tags: visactor, vchart
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 07:19 +0000
---
## Title
Right-aligned display of bar chart numerical labels
## Description
... | simaq |
1,901,008 | George Rosen Smith - Institutional Logic Analyst | George Rosen Smith Investors, analysts 18.06.1959 country: Ireland Graduated from the... | 0 | 2024-06-26T07:18:14 | https://dev.to/mrgsmith/george-rosen-smith-institutional-logic-analyst-567d | George Rosen Smith
Investors, analysts

18.06.1959 country: Ireland
Graduated from the California Institute of Technology in 1978
In 1982, he went to Columbia Business School in the United States to study finance... | mrgsmith | |
1,901,006 | The content displayed in the line chart is currently all selected by default. Is it possible to have a channel inversion | Title The content displayed in the line chart is currently all selected and displayed by... | 0 | 2024-06-26T07:17:12 | https://dev.to/simaq/the-content-displayed-in-the-line-chart-is-currently-all-selected-by-default-is-it-possible-to-have-a-channel-inversion-1p63 | visactor, vchart | ---
title: The content displayed in the line chart is currently all selected by default. Is it possible to have a channel inversion
published: true
description:
tags: visactor, vchart
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 07:16 +0000
---
##... | simaq |
1,886,916 | 4 Ways to Include Comments in JSON | JSON or JavaScript Object Notation is a popular data interchange format used by developers to store... | 0 | 2024-06-13T12:01:18 | https://keploy.io/blog/community/4-ways-to-write-comments-in-json |

JSON or JavaScript Object Notation is a popular data interchange format used by developers to store and exchange data. It's lightweight, easy to read, and easy to parse, making it ideal for various applications. How... | keploy | |
1,901,005 | Boost Customer Engagement: WhatsApp Campaigns Enhanced by Divsly | In today’s digital age, staying connected with your customers is more important than ever. With... | 0 | 2024-06-26T07:16:43 | https://dev.to/divsly/boost-customer-engagement-whatsapp-campaigns-enhanced-by-divsly-59bd | whatsappmarketing, whatsappcampaign, whatsappcampaigns | In today’s digital age, staying connected with your customers is more important than ever. With numerous communication channels available, businesses need to find effective and efficient ways to reach their audience. One of the most powerful tools for this purpose is WhatsApp. Combining this with the capabilities of Di... | divsly |
1,901,004 | How to modify the tag graphic of the tooltip content item | Title How to modify the tag graphic of the tooltip content item? Description I... | 0 | 2024-06-26T07:15:36 | https://dev.to/simaq/how-to-modify-the-tag-graphic-of-the-tooltip-content-item-38pg | visactor, vchart | ---
title: How to modify the tag graphic of the tooltip content item
published: true
description:
tags: visactor, vchart
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 07:14 +0000
---
## Title
How to modify the tag graphic of the tooltip content i... | simaq |
1,901,003 | Linux “ls” Command RHEL 9 | List files using ls with no option ls with no option list files and directories in a bare format... | 0 | 2024-06-26T07:14:15 | https://dev.to/mahir_dasare_333/linux-ls-command-rhel-9-aki | 1. List files using ls with no option
ls with no option list files and directories in a bare format where we won’t be able to view
details like file types, size, modified date and time, permission and links etc.
**ls**
2. List Files with option -l
Here, ls -l (-l is a character not one) shows file or directory, si... | mahir_dasare_333 | |
1,901,002 | Leveraging Mixins in Ruby on Rails: A Deep Dive | Ruby on Rails is known for its elegance and productivity. One of the powerful tools in Ruby that... | 0 | 2024-06-26T07:13:50 | https://dev.to/afaq_shahid/leveraging-mixins-in-ruby-on-rails-a-deep-dive-5h0a | webdev, ruby, rails, beginners |
Ruby on Rails is known for its elegance and productivity. One of the powerful tools in Ruby that makes Rails development so flexible and clean is Mixins. In this article, we'll explore what Mixins are, how they work, and how you can use them to keep your Rails codebase DRY (Don't Repeat Yourself).
### What are Mixin... | afaq_shahid |
1,901,001 | How the word cloud fills the outer container display | Title How to display a word cloud on top of the outer container? ... | 0 | 2024-06-26T07:13:03 | https://dev.to/simaq/how-the-word-cloud-fills-the-outer-container-display-2f6n | vchart, visactor | ---
title: How the word cloud fills the outer container display
published: true
description:
tags: vchart, visactor
# published_at: 2024-06-26 07:11 +0000
---
## Title
How to display a word cloud on top of the outer container?
## Description
We have a relatively small scene displaying word clouds, hoping to m... | simaq |
1,882,297 | The Basics of WEBPACK | Have you ever run into a problem where you tried to email or send some data to someone and you got a... | 0 | 2024-06-09T19:07:41 | https://dev.to/gagecantrelle/the-basics-of-webpack-2d71 | Have you ever run into a problem where you tried to email or send some data to someone and you got a warning that the data you are trying to send over is too big? What you're trying to send over could be as simple as a 1-minute cute dog/cat video. Well, you are not the only one. Websites can run into similar problems a... | gagecantrelle | |
1,901,000 | 5 Best Websites for Free Jekyll Templates | This is a roundup of the best websites where you can find and download free Jekyll templates. These... | 0 | 2024-06-26T07:12:15 | https://dev.to/devluc/5-websites-for-free-jekyll-themes-and-templates-1gn | webdev, frontend, html, css | This is a roundup of the best websites where you can find and download free Jekyll templates. These high quality items will power up your websites, landing pages, blogs, directories and ecommerce projects.
There are many template creators in the online space. Here is why those mentioned below stand out from the crowd:... | devluc |
1,900,999 | LLD- In Memory Database Python | Problem Statement: The objective is to design and implement an in-memory SQL-like database, which... | 0 | 2024-06-26T07:08:55 | https://dev.to/dipesh_2301_kumar/lld-in-memory-database-python-1e9p | python, lld, systemdesign, solidprinciples | **Problem Statement:**
The objective is to design and implement an in-memory SQL-like database, which should support the following set of operations/functionality:
- It should be possible to create, or delete tables in a database.
- A table definition comprises columns which have types. They can also have constraints.... | dipesh_2301_kumar |
1,900,998 | The Evolution and Impact of Digital Marketing | In the rapidly evolving landscape of business and commerce, digital marketing has emerged as a... | 0 | 2024-06-26T07:06:28 | https://dev.to/mishukseo/the-evolution-and-impact-of-digital-marketing-44d7 |
In the rapidly evolving landscape of business and commerce, [digital marketing](https://dev-mishuk.pantheonsite.io/) has emerged as a transformative force, reshaping how companies connect with their audiences and dri... | mishukseo | |
1,900,997 | Java Script Interview Secret : "console.log([1, 2] + [3, 4])" | I recently wrote an article on Medium about Java Script Secret Check it out to learn more! | 0 | 2024-06-26T07:06:05 | https://dev.to/itsjp/java-script-interview-secret-consolelog1-2-3-4-j55 | javascript, webdev, programming, interview | I recently wrote an article on Medium about [Java Script Secret ](https://medium.com/@robert.clave.official/java-script-interview-secret-console-log-1-2-3-4-48388d783086)
Check it out to learn more! | itsjp |
1,900,996 | MAURITIUS Tour Packages | With I Need Trip | Best Deal | Beaches, sure, however what else could there have been to do in Mauritius? You would have seen the... | 0 | 2024-06-26T07:05:06 | https://dev.to/ineedtrip/mauritius-tour-packages-with-i-need-trip-best-deal-ko9 | Beaches, sure, however what else could there have been to do in Mauritius? You would have seen the ideal palm fringed shoreline in numerous magazines, however a great deal of Mauritius' other magical elements had been presented by the glossy brochures, to such an extent you will be astonished and enamored by this small... | ineedtrip | |
1,900,910 | CodeConductor.AI vs. Microsoft AutoDev: Which Will Transform Your Coding Career? | Undeniably, AI-driven development platforms are reshaping how software is built. While many options... | 0 | 2024-06-26T07:01:56 | https://dev.to/edward_simmons87/codeconductorai-vs-microsoft-autodev-which-will-transform-your-coding-career-46o8 | webdev, ai, softwaredevelopment, softwareengineering |

Undeniably, AI-driven development platforms are reshaping how software is built. While many options exist, [CodeConductor.AI ](https://codeconductor.ai/)and [Microsoft AutoDev ](https://marketplace.visualstudio.com... | edward_simmons87 |
1,900,995 | Taming the Content Chaos: Your One-Stop Shop for Streamlined Brand Management | Do you ever feel like your brand assets are scattered across the digital wilderness? Logos in a dozen... | 0 | 2024-06-26T07:00:46 | https://dev.to/blogsx/taming-the-content-chaos-your-one-stop-shop-for-streamlined-brand-management-e4k | brandmanagement, complyai, digitalassetmanagement | Do you ever feel like your brand assets are scattered across the digital wilderness? Logos in a dozen different formats, marketing materials with outdated fonts, and endless email threads filled with "final, final_v2, final_final..." versions?
**You're not alone.**
Maintaining brand consistency across a multitude of ... | blogsx |
1,901,138 | Exciting News: My Upcoming Book "The Digital Marketer’s Playbook" is about to launch | I am thrilled to share some exciting news about my forthcoming book "The Digital Marketer’s... | 0 | 2024-06-27T22:36:42 | https://diegocarrasco.com/digital-marketers-playbook-launch/ | apress, books, digitalmarketersplay, projects | ---
title: Exciting News: My Upcoming Book "The Digital Marketer’s Playbook" is about to launch
published: true
date: 2024-06-26 07:00:00 UTC
tags: apress,books,digitalmarketersplay,projects
canonical_url: https://diegocarrasco.com/digital-marketers-playbook-launch/
---
**. Boasting exquisite architecture, modern amenities, spacious interiors, and lush green surroundings, this villa offers a perfect blend of elegance and co... | villainnoida87 |
1,900,991 | Exploring Python Task Queue Libraries with Load Test | by Steven Yue | Steven Yue took popular Python Task Queue Libraries and did the load testing. On the benchmarking... | 0 | 2024-06-26T06:57:47 | https://dev.to/tankala/exploring-python-task-queue-libraries-with-load-test-by-steven-yue-5g6e | programming, python, beginners, opensource | Steven Yue took popular Python Task Queue Libraries and did the load testing. On the benchmarking side how they performed and on the usability side how he feels covered in this article.
{% embed https://stevenyue.com/blogs/exploring-python-task-queue-libraries-with-load-test %} | tankala |
1,900,990 | Scop in Javascript. | JavaScript, renowned for its versatility, stands as a pivotal language in the realm of web... | 0 | 2024-06-26T06:57:26 | https://dev.to/sagor_cnits_73eb557b53820/scop-in-javascript-11ci | javascript, beginners, programming |
JavaScript, renowned for its versatility, stands as a pivotal language in the realm of web development. Core to its essence lies the concept of scope, delineating the reach of variables, functions, and objects within a codebase. In this discourse, we delve into the nuanced dimensions of scope in JavaScript, encapsulat... | sagor_cnits_73eb557b53820 |
1,901,134 | Kubernetes: containers, and the “lost” SIGTERM signals | We have an API service with Gunicorn in Kubernetes that periodically returns 502, 503, 504... | 0 | 2024-07-07T11:20:49 | https://rtfm.co.ua/en/kubernetes-containers-and-the-lost-sigterm-signals/ | linux, kubernetes, devops, todayilearned | ---
title: Kubernetes: containers, and the “lost” SIGTERM signals
published: true
date: 2024-06-26 06:54:26 UTC
tags: linux,kubernetes,devops,todayilearned
canonical_url: https://rtfm.co.ua/en/kubernetes-containers-and-the-lost-sigterm-signals/
---
. This means that the transition of an electron from the valence band to the conduction band (or vic... | electricalvolt |
1,900,987 | Unmasking Negative SEO Attacks: How to Identify and Mitigate Online Reputation Damage | In today's digital age, search engine optimization (SEO) plays a crucial role in online reputation... | 0 | 2024-06-26T06:53:41 | https://dev.to/soulilutionitfirmusa/unmasking-negative-seo-attacks-how-to-identify-and-mitigate-online-reputation-damage-318i | In today's digital age, search engine optimization (SEO) plays a crucial role in online reputation management. A strong SEO strategy ensures your website appears prominently in search results, driving traffic and building brand awareness. However, there exists a malicious counterpart to SEO: Negative SEO. Negative SEO ... | soulilutionitfirmusa | |
1,900,985 | business | In the modern landscape, business operates as a multifaceted entity, encompassing a vast array of... | 0 | 2024-06-26T06:52:42 | https://dev.to/nelohor44/business-3abj | business, webdev, javascript, beginners | In the modern landscape, business operates as a multifaceted entity, encompassing a vast array of activities that drive economies, shape societies, and influence everyday life. At its core, business involves the exchange of goods or services for profit, but this simple definition belies the complexity and dynamism inhe... | nelohor44 |
1,900,982 | How to create a search input with Tailwind CSS and JavaScript | Today we're going to create a search input with Tailwind CSS and JavaScript. Just like the previous... | 0 | 2024-06-26T06:44:52 | https://dev.to/mike_andreuzza/how-to-create-a-search-input-with-tailwind-css-and-javascript-4iom | javascript, tailwindcss, tutorial | Today we're going to create a search input with Tailwind CSS and JavaScript. Just like the previous tutorial with Alpinejs, we'll use the same structure and we'll add some JavaScript to make it interactive.
[See it live and get the code](https://lexingtonthemes.com/tutorials/how-to-create-a-search-input-with-tailwind-c... | mike_andreuzza |
1,900,980 | Mbbs consultancy in Hyderabad | Navigating Your MBBS Journey with the Best Consultancy in Hyderabad Embarking on the journey to... | 0 | 2024-06-26T06:43:09 | https://dev.to/sales_aakrutisolutions_/mbbs-consultancy-in-hyderabad-521l |
**[Navigating Your MBBS Journey with the Best Consultancy in Hyderabad](https://vietmbbs.com/)**
Embarking on the journey to becoming a doctor is a monumental decision, one that requires meticulous planning, immense dedication, and the right guidance. For many aspiring medical students in Hyderabad, the process of se... | sales_aakrutisolutions_ | |
1,900,979 | smooth stack lawsuit | Smoothstack, a tech talent and training company, recently found itself embroiled in a lawsuit that... | 0 | 2024-06-26T06:42:56 | https://dev.to/nelohor44/smooth-stack-lawsuit-3agd | lawsuit | Smoothstack, a tech talent and training company, recently found itself embroiled in a lawsuit that has garnered significant attention. The core of the lawsuit revolves around allegations from former employees who claim that Smoothstack's employment practices were not only unfair but potentially unlawful. These employee... | nelohor44 |
1,900,977 | There is no excuse to not start improving accessibility | In my three years of working on accessibility as a front-end developer I have heard quite a few... | 0 | 2024-06-26T06:31:37 | https://dev.to/pancompany/there-is-no-excuse-to-not-start-improving-accessibility-50hj | a11y | In my three years of working on accessibility as a front-end developer I have heard quite a few misconceptions about accessibility: “Improving accessibility is the developers' responsibility”, “It costs a lot of time and effort to improve accessibility” or “Accessibility is not a top priority because not a lot of disab... | lavendelana |
1,900,975 | Watercooler Wednesday | General discussion thread about... Whatever. What's new in your life? Hobbies, interests, games,... | 0 | 2024-06-26T06:30:07 | https://dev.to/ben/watercooler-wednesday-4mm9 | watercooler | General discussion thread about... Whatever. What's new in your life?
Hobbies, interests, games, kids, parents, travel, career, whatever.
Let's keep this chat light and positive and see if it can become a nice weekly check-in. | ben |
1,871,915 | Boletín AWS Open Source, June Edition | Bienvenidos a una nueva edición del boletín de AWS Open Source. Con el verano a la vuelta de la... | 0 | 2024-06-26T06:30:00 | https://dev.to/aws-espanol/boletin-aws-open-source-june-edition-3go3 | opensource, cybersecurity, developers, awsespanol | Bienvenidos a una nueva edición del boletín de AWS Open Source. Con el verano a la vuelta de la esquina, muchos podréis disfrutar de unas merecidas vacaciones, y es el momento perfecto para conocer nuevas herramientas y soluciones.
En esta edición, exploraremos herramientas de pentesting específicas para AWS. Aprende... | iaasgeek |
1,900,974 | What is Yatter ai And how he help in our daily life? | I'm Yatter AI, an advanced Telegram assistant built by Infokey Technology Pvt. Ltd. in New Delhi. I'm... | 0 | 2024-06-26T06:26:25 | https://dev.to/sachin_singh_93e21cc2028e/what-is-yatter-ai-and-how-he-help-in-our-daily-life-520o | I'm [Yatter AI](https://yatter.in/), an advanced Telegram assistant built by Infokey Technology Pvt. Ltd. in New Delhi. I'm designed to make your life easier by providing quick and precise information on various topics.
Here are some ways I can help in your daily life:
1. **Voice Message Processing**: I can transcrib... | sachin_singh_93e21cc2028e | |
1,900,973 | Mastering the Virtual DOM in JavaScript: Your Gateway to Efficient UI Updates 🚀 | Hey Devs and Upcoming Devs! 👩💻👨💻 Ever felt bogged down by sluggish UI updates? The Virtual DOM... | 0 | 2024-06-26T06:25:20 | https://dev.to/gadekar_sachin/mastering-the-virtual-dom-in-javascript-your-gateway-to-efficient-ui-updates-3eda | virtualmachine | Hey Devs and Upcoming Devs! 👩💻👨💻
Ever felt bogged down by sluggish UI updates? The **Virtual DOM** might be your knight in shining armor! 🛡️✨ Let's dive into how this game-changing concept can optimize your front-end development.
**What is the Virtual DOM?**
The Virtual DOM is a lightweight copy of the actual... | gadekar_sachin |
1,900,972 | Arduino 8bit-CPU | Hey there!, i've build something that you can call as a*CLI based 8-bit CPU processor!* Let me... | 0 | 2024-06-26T06:23:16 | https://dev.to/programmer-ayush/arduino-8bit-cpu-1721 | Hey there!,
i've build something that you can call as a**CLI based 8-bit CPU processor!**
Let me explain you how it works!
This basic CPU made using Arduino Uno has EEPROM storage ,
this pc has Maximum Storage of 1KB EEPROM , You can plug an extrenal eeprom emeory for more storage ,
moreover it has a gps module and blu... | programmer-ayush | |
1,900,922 | I am looking for new role | I'm a passionate fullstack web engineer from China, where I spend my days turning caffeine into code... | 0 | 2024-06-26T06:20:11 | https://dev.to/william_jin_a67c15000737b/i-am-looking-for-new-role-2k0a | I'm a passionate fullstack web engineer from China, where I spend my days turning caffeine into code and my nights dreaming of seamless user interfaces. With a love for both front-end and back-end development, I thrive on creating solutions that are both functional and beautiful.
When I'm not wrestling with code, you ... | william_jin_a67c15000737b | |
1,900,906 | Wizard Communication: Leading the Way in IT Excellence in Kolkata | Your Trusted Partner for Custom Software Development, Web and Mobile Applications, Digital Marketing,... | 0 | 2024-06-26T06:09:37 | https://dev.to/wizard111/wizard-communication-leading-the-way-in-it-excellence-in-kolkata-5575 |
Your Trusted Partner for Custom Software Development, Web and Mobile Applications, Digital Marketing, and IT Consulting
In the bustling city of Kolkata, a place where tradition seamlessly blends with modernity, one company has made its mark as a leader in the IT industry—Wizard Communication. Renowned for its innova... | wizard111 | |
1,900,921 | iPad Screen Repair Newcastle | iPad Screen Repair Newcastle specializes in restoring your iPad's screen to pristine condition... | 0 | 2024-06-26T06:19:57 | https://dev.to/iphonemate/ipad-screen-repair-newcastle-5gb4 |
iPad Screen Repair Newcastle specializes in restoring your iPad's screen to pristine condition quickly and affordably. Whether your screen is cracked, shattered, or malfunctioning, their expert technicians provide expert repair services using only high-quality replacement parts. With a focus on customer satisfaction, ... | iphonemate | |
1,900,920 | AI in Software Development | Let's discuss the future of developers in the era of AI: How do you think AI will transform software... | 0 | 2024-06-26T06:18:44 | https://dev.to/jottyjohn/ai-in-software-development-5c31 | discuss, ai, coding, career | Let's discuss the future of developers in the era of AI: How do you think AI will transform software development, and what new roles and skills might emerge for developers? | jottyjohn |
1,900,919 | Maha Kumbh 2025: Exotic India Tours | The Maha Kumbh Mela, set to take place in Prayagraj (formerly Allahabad) in 2025, is an extraordinary... | 0 | 2024-06-26T06:18:04 | https://dev.to/exoticindiatours/maha-kumbh-2025-exotic-india-tours-4aj4 | The Maha Kumbh Mela, set to take place in Prayagraj (formerly Allahabad) in 2025, is an extraordinary event that draws millions of pilgrims and curious travelers from around the world. At ExoticIndiaTours.com, we're excited to offer you the opportunity to experience this awe-inspiring gathering firsthand.
The Maha Kumb... | exoticindiatours | |
1,900,918 | Understanding HTTP Status Codes: A Comprehensive Guide | Introduction HTTP (Hypertext Transfer Protocol) status codes are standardized codes that the web... | 0 | 2024-06-26T06:17:17 | https://dev.to/keploy/understanding-http-status-codes-a-comprehensive-guide-2iai | webdev, beginners, programming, tutorial |

Introduction
HTTP (Hypertext Transfer Protocol) status codes are standardized codes that the web server returns to the client (usually a web browser) to indicate the result of the client's request. These codes are e... | keploy |
1,900,917 | JavaFX In Action with Robert Ladstätter about LogoRRR, a cross-platform log analysis tool | In the next video in this "JFX In Action" series, I talked with Robert Ladstätter about LogoRRR, an... | 27,855 | 2024-06-26T06:16:56 | https://webtechie.be/post/2024-06-26-jfxinaction-robert-ladstatter/ | java, scala, javafx, ui | In the next video in this "JFX In Action" series, I talked with Robert Ladstätter about LogoRRR, an application written with Scala and JavaFX.
{% embed https://www.youtube.com/watch?v=2y8aK_t--gM %}
## About Robert Ladstätter
Robert is Team Lead at NEXTSENSE Worldwide and develops software with Scala and JavaFX. You... | fdelporte |
1,900,916 | Enhancing Transparency, Security, and Efficiency in ModeSpray with Tenderly | In the fast-paced world of decentralized applications (DApps) and smart contracts, transparency,... | 0 | 2024-06-26T06:16:45 | https://dev.to/wolfcito/enhancing-transparency-security-and-efficiency-in-modespray-with-tenderly-3h7n | modenetwork, tenderly, alerts | In the fast-paced world of decentralized applications (DApps) and smart contracts, transparency, security, and efficiency are fundamental pillars. These elements not only ensure the proper functioning of smart contracts but also strengthen the trust of users and developers in the blockchain ecosystem. In this article, ... | wolfcito |
1,900,915 | Enhancing Transparency, Security, and Efficiency in ModeSpray with Tenderly | In the fast-paced world of decentralized applications (DApps) and smart contracts, transparency,... | 0 | 2024-06-26T06:16:45 | https://dev.to/wolfcito/enhancing-transparency-security-and-efficiency-in-modespray-with-tenderly-232d | In the fast-paced world of decentralized applications (DApps) and smart contracts, transparency, security, and efficiency are fundamental pillars. These elements not only ensure the proper functioning of smart contracts but also strengthen the trust of users and developers in the blockchain ecosystem. In this article, ... | wolfcito | |
1,900,914 | iPhone Repairs Newcastle | iPhone Repairs Newcastle offers comprehensive solutions for all your iPhone repair needs, ensuring... | 0 | 2024-06-26T06:16:22 | https://dev.to/iphonemate/iphone-repairs-newcastle-2k03 |
iPhone Repairs Newcastle offers comprehensive solutions for all your iPhone repair needs, ensuring fast and reliable service. Whether you're dealing with a cracked screen, water damage, battery issues, or software glitches, their skilled technicians are equipped to diagnose and fix the problem efficiently. Using top-q... | iphonemate | |
1,900,913 | Mobile Phone Screen Replacement Melbourne | Mobile Phone Screen Replacement Melbourne specializes in providing high-quality screen replacement... | 0 | 2024-06-26T06:13:51 | https://dev.to/iphonemate/mobile-phone-screen-replacement-melbourne-10ke | Mobile Phone Screen Replacement Melbourne specializes in providing high-quality screen replacement services for various mobile phone models. Whether you have a cracked, shattered, or malfunctioning screen, their experienced technicians offer prompt and reliable solutions to restore your device to its original condition... | iphonemate | |
1,900,912 | FlashGet Cast: Effortless Screen Mirroring for iPhone, Android, Mac, and Windows | Nowadays, More increasing demand for stable connections and different devices information sharing.... | 0 | 2024-06-26T06:12:49 | https://dev.to/jackcer/flashget-cast-effortless-screen-mirroring-for-iphone-android-mac-and-windows-2njb | flashgetcast, screenmirroring | Nowadays, More increasing demand for stable connections and different devices information sharing. Whatever in company meeting room, classroom or home, mirroring screen function always can improve work efficiency, collaboration and entertainment significantly. **[FlashGet Cast](https://cast.flashget.com/)** tools supp... | jackcer |
1,900,911 | The experience is next-level | I love the thrill of this live casino games! There's something electric about playing blackjack or... | 0 | 2024-06-26T06:12:41 | https://dev.to/franksinatra/the-experience-is-next-level-4l0m | experience, games | I love the thrill of this [live casino games](https://ninlay.com/en/live-casino)! There's something electric about playing blackjack or roulette with a live dealer from the comfort of your own home. At ninlay, the experience is next-level. The dealers are professional and engaging, and the HD streaming quality makes yo... | franksinatra |
1,900,909 | HTML to PDF API | HTML to PDF API Overview API Name: HTML to PDF API URL Path:... | 0 | 2024-06-26T06:11:40 | https://dev.to/gugudata/html-to-pdf-api-5e04 | # HTML to PDF API

## Overview
**API Name:** HTML to PDF
**API URL Path:** `/v1/imagerecognition/html2pdf`
**Request Method:** POST
**Description:** Supports converting web pages to PDF
**Test URL:** [API Demo](https://a... | gugudata | |
1,900,908 | Mobile Phone Repairs Newcastle | Mobile phone repair Newcastle offers reliable and efficient services to cater to all your smartphone... | 0 | 2024-06-26T06:10:43 | https://dev.to/iphonemate/mobile-phone-repairs-newcastle-54o5 | Mobile phone repair Newcastle offers reliable and efficient services to cater to all your smartphone needs. Whether you've cracked your screen, need a battery replacement, or require software troubleshooting, their skilled technicians ensure prompt and professional repairs. With a focus on customer satisfaction, [Mobil... | iphonemate | |
1,900,907 | dezbro | Дезинсекция от насекомых - одно из основных направлений деятельности «Братьев Карбофосовых». Мы... | 0 | 2024-06-26T06:10:17 | https://dev.to/dezbro2/dezbro-5d58 | [Дезинсекция от насекомых](https://dezbro.ru/) - одно из основных направлений деятельности «Братьев Карбофосовых». Мы эффективно боремся с муравьями, клопами, тараканами и другими вредителями, обеспечивая безопасность и комфорт вашего жилища. Наши специалисты по уничтожению тараканов проведут детальную оценку ситуации ... | dezbro2 | |
1,900,905 | Advanced Digital Marketing Training in Dehradun | Are you ready to master the art of online branding and advertising? Join the best digital marketing... | 0 | 2024-06-26T06:08:48 | https://dev.to/arman_nair/advanced-digital-marketing-training-in-dehradun-3hbd | digitalmarketingcourse, digital, hashtagaademydehradun | Are you ready to master the art of online branding and advertising? Join the [best digital marketing course in Dehradun](https://www.hashtagdigitalmarketing.in/)! From SEO to social media strategies, PPC, and video editing, our comprehensive curriculum covers it all. Gain hands-on experience with industry experts and u... | arman_nair |
1,900,904 | The Classic Allure of a Real Leather Jacket | A real leather jacket is an enduring investment in quality and elegance, not merely a piece of... | 0 | 2024-06-26T06:04:57 | https://dev.to/louise_martin_5c7175f2b2b/the-classic-allure-of-a-real-leather-jacket-5hij | fashion, leatherjackets, taylorjon, realleatherjackets | A [real leather jacket](https://taylorjon.com/
) is an enduring investment in quality and elegance, not merely a piece of apparel. A real leather jacket, valued for its longevity and timeless style, is an essential piece of clothing that every closet needs.
## The Legitimacy of Real Leather
A real leather jacket's ... | louise_martin_5c7175f2b2b |
1,900,889 | Server-Side Pagination with Express.js and MongoDB | Introduction When working with large datasets, various techniques are employed to optimize... | 0 | 2024-06-26T06:04:18 | https://dev.to/michaelikoko/server-side-pagination-with-expressjs-and-mongodb-3g5i | express, mongodb, backend, javascript |
### Introduction
When working with large datasets, various techniques are employed to optimize queries, enhance user experience, and improve performance. One of those techniques is Pagination. Pagination involves dividing large datasets into smaller, manageable subsets.
Pagination can be implemented in two ways:
* *... | michaelikoko |
1,900,903 | Introducing a New Laravel Package DumpTable for Seamless Migrations | Introduction In the dynamic world of web development, managing databases efficiently is... | 0 | 2024-06-26T06:04:07 | https://dev.to/armanrahman/introducing-a-new-laravel-package-dumptable-for-seamless-migrations-51lb | dumptable, laravelpackage, armanrahman, helloarman | ## Introduction
In the dynamic world of web development, managing databases efficiently is crucial. Laravel, one of the most popular PHP frameworks, provides a robust migration system to handle database schema changes. However, updating migrations often means altering entire tables, which can result in data loss in ot... | armanrahman |
1,900,902 | Tips for Educators: Using Moss Stanford to Promote Academic Integrity in Coding Classes | Worried about students copying code in your programming class? You're not alone! Moss Stanford, a... | 0 | 2024-06-26T06:00:31 | https://dev.to/codequiry/tips-for-educators-using-moss-stanford-to-promote-academic-integrity-in-coding-classes-455m | moss, mossplagiarismchecker, codequiry, codeplagiarism | Worried about students copying code in your programming class? You're not alone! Moss Stanford, a code similarity checker, can be a helpful tool, but it requires a bit of know-how.
Here are some simple tips to make [Moss Stanford](https://codequiry.com/moss/measure-of-software-similarity) your ally in promoting academ... | codequiry |
1,899,806 | Next.js 14: App with OpenAI API Integration | Introduction In today's digital landscape, AI-powered applications are becoming... | 26,489 | 2024-06-26T06:00:00 | https://dev.to/wadizaatour/nextjs-14-app-with-openai-api-integration-293k |
## Introduction
In today's digital landscape, AI-powered applications are becoming increasingly popular. In this tutorial, we'll explore how to build a web application using Next.js and React, while seamlessly integrating the OpenAI API. By the end, you'll have a powerful app that leverages AI capabilities for gener... | wadizaatour | |
1,900,901 | Why single sign-on (SSO) is better | Single sign-on (SSO) is a great way to simplify the authentication model and improve the user... | 0 | 2024-06-26T05:57:49 | https://blog.logto.io/sso-is-better/ | webdev, security, opensource, identity | Single sign-on (SSO) is a great way to simplify the authentication model and improve the user experience for every app. Here's why.
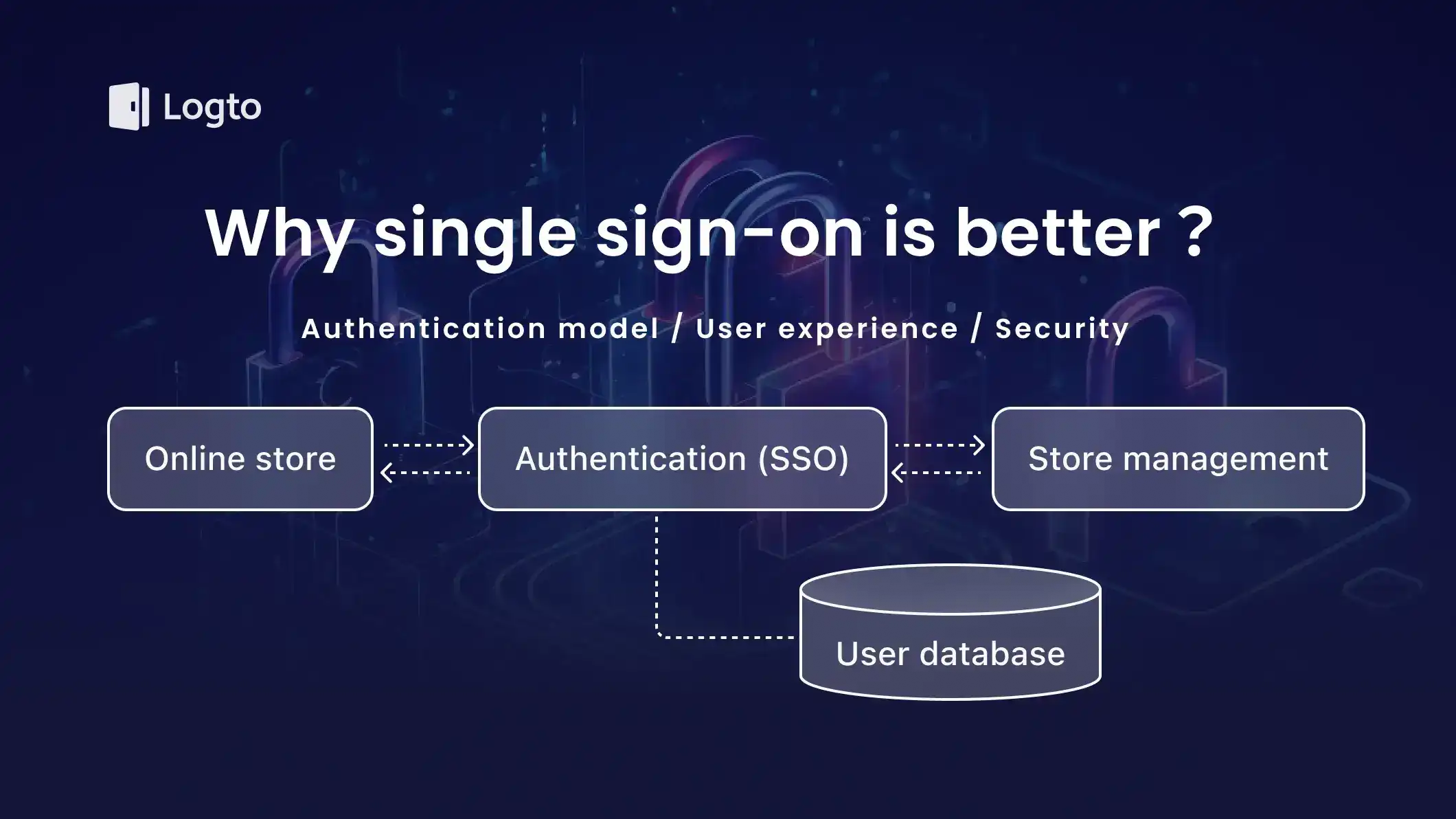
Single sign-on (SSO) is a technology that allows users to authenticate once and acc... | palomino |
1,899,492 | Instant Navigation con Speculation Rules API | Uno de las fantasías de todo frontend es que la navegación entre las diferentes partes de nuestra web... | 0 | 2024-06-26T05:54:45 | https://dev.to/dezkareid/instant-navigation-con-speculation-rules-api-1dnc | webdev, webperf, javascript, frontend | Uno de las fantasías de todo frontend es que la navegación entre las diferentes partes de nuestra web sea instantanea como si de alguna manera la web estuviera lista para la página a la que queremos acceder.
El browser nos ofrece mecanismos como los [resource hints](https://web.dev/learn/performance/resource-hints) pa... | dezkareid |
1,900,900 | Benefits of Playing Big Daddy Game | The "Big Daddy Game" is a popular online game that has captured the hearts of many gamers. With its... | 0 | 2024-06-26T05:53:49 | https://dev.to/hfjhjf/benefits-of-playing-big-daddy-game-4fm1 | The "Big Daddy Game" is a popular online game that has captured the hearts of many gamers. With its engaging gameplay, vibrant graphics, and strategic elements, it provides endless hours of entertainment. This game is designed for players of all skill levels, making it accessible and enjoyable for everyone. In this art... | hfjhjf | |
1,900,899 | Integrating a VS Code Like Editor in NextJS | Code Snippet Sharing App Series | Welcome back to our Code Snippet Sharing App series! In this video, we take a significant step... | 27,859 | 2024-06-26T05:53:16 | https://dev.to/gkhan205/integrating-a-vs-code-like-editor-in-nextjs-code-snippet-sharing-app-series-5fnc | nextjs, webdev, javascript, beginners | Welcome back to our Code Snippet Sharing App series! In this video, we take a significant step forward by integrating a VS Code-like editor into our NextJS application. This powerful feature will greatly enhance the user experience, allowing for seamless code writing and editing within our app.
In this video, you'll l... | gkhan205 |
1,900,898 | Unlocking the Potential of P2P Crypto Exchange Development | In the rapidly evolving world of cryptocurrencies, P2P (Peer-to-Peer) crypto exchanges have emerged... | 0 | 2024-06-26T05:53:09 | https://dev.to/kala12/unlocking-the-potential-of-p2p-crypto-exchange-development-3h46 | In the rapidly evolving world of cryptocurrencies, P2P (Peer-to-Peer) crypto exchanges have emerged as a revolutionary way to trade digital assets. Unlike traditional exchanges, P2P platforms connect buyers and sellers directly, facilitating transactions without intermediaries. This article explores the potential for t... | kala12 | |
423,797 | Road to Vim Mastery Day 2 | this post is continuation to road to mastery day 1. if you are vim beginner like me, i recommend you... | 0 | 2020-08-10T14:40:57 | https://dev.to/cosmospilot/road-to-vim-mastery-day-2-3ai4 | vim, codenewbie | *this post is continuation to [road to mastery day 1](https://dev.to/justcallmezed/road-to-vim-mastery-day-1-39d8).*
if you are vim beginner like me, i recommend you to go practice at VimGenius website daily.
In the previous post we discussed about basic commands and navigational keys in vim.
In this post we will di... | cosmospilot |
1,900,862 | Retrieve satellite earth observation images easily with QGIS JAXA Earth API Plugin | Abstract Climate is changing rapidly, and these changes must be monitored continuously,... | 0 | 2024-06-26T05:52:58 | https://dev.to/mierune/retrieve-satellite-earth-observation-images-easily-with-qgis-jaxa-earth-api-plugin-1e7j | qgis, satellite, climatechange, foss4g | ## Abstract
Climate is changing rapidly, and these changes must be monitored continuously, especially with satellite observations.
The Japan Aerospace Exploration Agency (JAXA) publishes Earth observation images, such as temperature, precipitation amount, vegetation, etc., which can be retrieved using the JAXA Ear... | bordoray |
1,900,897 | What Role Do Freight Forwarders Play In Shipment Registration? | In shipment registration, the freight forwarders are responsible for ensuring that the shipment takes... | 0 | 2024-06-26T05:52:37 | https://dev.to/prasanth_m_dcc6e8ac627c42/what-role-do-freight-forwarders-play-in-shipment-registration-3ac1 | productivity, career, discuss, news | In shipment registration, the freight forwarders are responsible for ensuring that the shipment takes place from one destination to another. Their warehousing, certification, and customs law skills position them as important allies for exporters. This article discusses different aspects of the participation of freight ... | prasanth_m_dcc6e8ac627c42 |
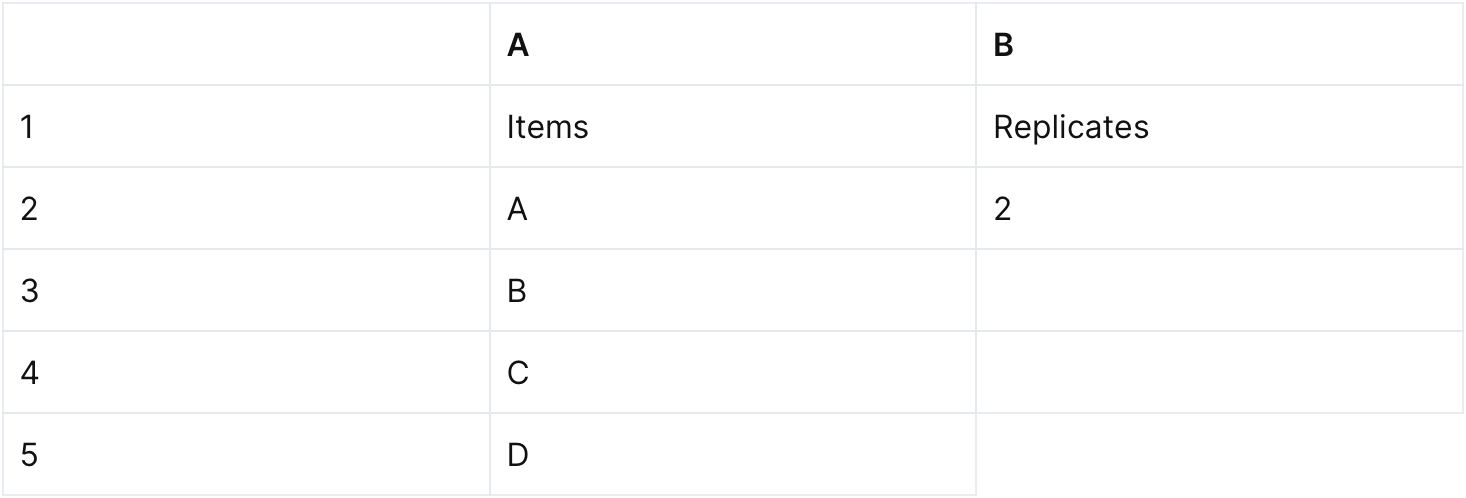
1,900,896 | In Excel, Re-arrange A Sequence N Times Randomly | Problem description & analysis: Column A is a random sequence. Cell B2 contains the parameter... | 0 | 2024-06-26T05:52:14 | https://dev.to/judith677/in-excel-re-arrange-a-sequence-n-times-randomly-3g0d | tutorial, productivity, beginners, programming | **Problem description & analysis**:
Column A is a random sequence. Cell B2 contains the parameter that represents the number of times of re-arranging members of the sequence.
We need to rearrange column A N times.
!... | judith677 |
1,900,895 | GBase 8a Implementation Guide: Performance Optimization | 1. Hardware Configuration Recommendations CPU Ensure the BIOS settings are in... | 0 | 2024-06-26T05:50:30 | https://dev.to/congcong/gbase-8a-implementation-guide-performance-optimization-1flj | database | ## 1. Hardware Configuration Recommendations
### CPU
Ensure the BIOS settings are in non-power-saving mode to prevent the CPU from throttling. For servers using Intel CPUs that are not deployed in a multi-instance environment, it is recommended to disable the `vm.zone_reclaim_mode` parameter. To disable the NUMA param... | congcong |
1,899,999 | Type vs Interface | In TypeScript development, choosing between type and interface can be confusing. Both are essential... | 27,852 | 2024-06-26T05:34:26 | https://dev.to/023prashantsharma/type-vs-interface-41a0 | typescript, beginners, webdev | In TypeScript development, choosing between type and interface can be confusing. Both are essential for defining object shapes and types, but knowing when to use each can be tricky.
Developers often wonder: When should I use `type` instead of `interface`?
How can I extend existing types? What about defining complex ty... | 023prashantsharma |
1,900,891 | Unlock Your Coding Potential with "Data Structures and Algorithms" 🔑 | Comprehensive course on data structures and algorithms, taught by an experienced professor at the University of Florida. Covers fundamental topics, emphasizes problem-solving, and prepares students for technical interviews. | 27,844 | 2024-06-26T05:45:24 | https://getvm.io/tutorials/cop-3530-data-structures-and-algorithms-prof-sahni-ufl | getvm, programming, freetutorial, universitycourses |
As a computer science enthusiast, I recently stumbled upon an incredible resource that has completely transformed my understanding of data structures and algorithms. Introducing the "Data Structures and Algorithms" course, taught by the esteemed Professor Sahni at the University of Florida. 🎓
## Course Overview
Th... | getvm |
1,900,890 | Best IT Recruitment Agency in Noida | Explore the Best IT Recruitment Agency in Noida with TalentOnLease. We address the industry's... | 0 | 2024-06-26T05:43:11 | https://dev.to/talentonlease01/best-it-recruitment-agency-in-noida-kap | recruitment | Explore the Best **[IT Recruitment Agency](https://talentonlease.com/)** in Noida with TalentOnLease. We address the industry's technical talent deficit by connecting clients and partners through a collaborative platform. Our vast network of IT Services and Solution providers guarantees top-tier technical competence fo... | talentonlease01 |
1,900,886 | Top Node.js Backend Frameworks for 2024 | As the backbone of modern web applications, backend frameworks play a critical role in the... | 0 | 2024-06-26T05:41:10 | https://devtoys.io/2024/06/25/top-node-js-backend-frameworks-for-2024/ | webdev, node, javascript, devtoys | ---
canonical_url: https://devtoys.io/2024/06/25/top-node-js-backend-frameworks-for-2024/
---
As the backbone of modern web applications, backend frameworks play a critical role in the efficiency, scalability, and maintainability of your projects. Node.js, known for its non-blocking, event-driven architecture, has bec... | 3a5abi |
1,900,888 | OpenAI Will Terminate Its Services in China: A Comprehensive Analysis | According to the political policies in some countries, they are not allowed to use ChatGPT. Now,... | 0 | 2024-06-26T05:39:31 | https://dev.to/derek-compdf/openai-will-terminate-its-services-in-china-a-comprehensive-analysis-257d | chatgpt, ai, openai | According to the political policies in some countries, they are not allowed to use ChatGPT. Now, OpenAI will block the API traffic from those countries like China. This abrupt shift leaves a significant void in the Chinese AI landscape, given OpenAI’s contributions to natural language processing and artificial intellig... | derek-compdf |
1,900,887 | e-commerce marketplace management services in delhi | Delhi is home to a number of businesses that provide [ee-commerce marketplace management services].... | 0 | 2024-06-26T05:37:47 | https://dev.to/reftonbia6/e-commerce-marketplace-management-services-in-delhi-541m | ecommerce, marketplace, amazon, programming | Delhi is home to a number of businesses that provide [ee-commerce marketplace management services]. (urhttps://reftonbia.com/l)These[ organization])s offer a variety of services to assist companies in selling their goods on different e-commerce sites such as Amazon, Flipkart, Myntra, and so on. Some of the main service... | reftonbia6 |
1,900,885 | I built a tool to turn YouTube into a learning platform | Hey Dev.to! I wanted to share with you a milestone I reached - launching my web app, NoteTube. I... | 0 | 2024-06-26T05:33:50 | https://dev.to/kentokana/i-built-a-tool-to-turn-youtube-into-a-learning-platform-167m | webdev, saas, solopreneur, buildinpublic | Hey Dev.to!
I wanted to share with you a milestone I reached - launching my web app, [NoteTube](https://notetube.app).
I started building this app because I wanted a tool that will shorten the onboarding sessions to teach new hires the tech stack that we use. I figured that YouTube content can do 90% of the teaching... | kentokana |
1,900,884 | Maven Project Setup Guide | Step-by-Step Guide to Creating a Maven Project Using Maven Archetype You can create a new Maven... | 0 | 2024-06-26T05:32:27 | https://dev.to/amit_singh_bisht/maven-project-setup-guide-24po |

Step-by-Step Guide to Creating a Maven Project
Using Maven Archetype
You can create a new Maven project by running the following command:
```
mvn archetype:generate
```
This command will prompt you to enter various de... | amit_singh_bisht | |
1,900,883 | Zeeve RaaS Partners with PandaSea for the Launch of their OP Stack Powered Layer2 chain | We are delighted to announce our partnership with PandaSea as their chosen Rollups-as-a-Service... | 0 | 2024-06-26T05:26:26 | https://www.zeeve.io/blog/zeeve-raas-partners-with-pandasea-for-the-launch-of-their-op-stack-powered-layer2-chain/ | announcement, pandasea, rollup | <p>We are delighted to announce our partnership with <a href="https://pandasea.io/">PandaSea</a> as their chosen <a href="https://www.zeeve.io/rollups/">Rollups-as-a-Service provider</a> for the new L2 OP chain built with the <a href="https://www.zeeve.io/appchains/optimistic-rollups/">OP Stack</a>. We warmly welcome t... | zeeve |
1,900,882 | VibeTabs: Customize Your Browser for Every Task | Hello everyone, I’m excited to share with you my latest Chrome extension, VibeTabs! As a web... | 0 | 2024-06-26T05:23:45 | https://dev.to/luciandev/vibetabs-customize-your-browser-for-every-task-19i9 | extensions, webdev, javascript, productivity | Hello everyone,
I’m excited to share with you my latest Chrome extension, VibeTabs! As a web developer, I often find myself juggling multiple tasks, each requiring different sets of tabs and resources. That’s why I created VibeTabs – to make switching between different browsing setups as seamless as possible.
## What... | luciandev |
1,900,880 | data scientist course in mumbai | Are you looking for the best Data Scientist course in Mumbai To boost your career, 360DigiTMG is the... | 0 | 2024-06-26T05:21:38 | https://dev.to/yarava_sreenivas_3cb0124c/data-scientist-course-in-mumbai-13n3 |

Are you looking for the best [Data Scientist course in Mumbai](https://360digitmg.com/india/mumbai/data-science-certification-course-training-institute) To boost your career, 360DigiTMG is the right place for you. A... | yarava_sreenivas_3cb0124c | |
1,900,867 | Becoming a 1% Better MERN Stack Developer Every Day | Introduction As a MERN stack developer, continuous improvement is crucial to staying ahead in the... | 0 | 2024-06-26T05:19:45 | https://raajaryan.tech/becoming-a-1-better-mern-stack-developer-every-day | node, react, 100daysofcode, beginners | [](https://buymeacoffee.com/dk119819)
**Introduction**
As a MERN stack developer, continuous improvement is crucial to staying ahead in the fast-paced tech industry. Small, consistent ef... | raajaryan |
1,900,866 | How to Dynamically Generate and Decode a QR Code with NodeJs | In today's digital age, QR (Quick Response) codes have become vital for bridging the gap between the... | 0 | 2024-06-26T05:16:29 | https://dev.to/codegirl0101/how-to-dynamically-generate-and-decode-a-qr-code-with-nodejs-3310 | tutorial, node, qrcode, webdev | In today's digital age, QR (Quick Response) codes have become vital for bridging the gap between the physical and digital domains. They provide a range of applications, covering everything from payment and verification to smooth information exchange. Node.js, a popular JavaScript runtime environment, allows developers ... | codegirl0101 |
1,900,865 | How we're trying to make our PHP devs efficient also with Golang | For the quick background presentation (👋), I'm a backend / platform engineer, I work in a company... | 0 | 2024-06-26T05:14:26 | https://dev.to/ekkinox/how-were-trying-to-make-our-php-devs-efficient-also-with-golang-1ef4 | go, php, opensource, backend | For the quick background presentation (:wave:), I'm a backend / platform engineer, I work in a company with a monolithic PHP (Laravel) main application.
We're in the journey to split it in smaller services or to move some recurring logic as sidecars. And for this, we noticed that the best choice **was not always PHP**... | ekkinox |
1,900,863 | Top 20 React.JS interview questions. | As a React developer, it is important to have a solid understanding of the framework's key concepts... | 0 | 2024-06-26T05:10:34 | https://dev.to/sagor_cnits_73eb557b53820/top-20-reactjs-interview-questions-o0f | javascript, react, interview, node | As a React developer, it is important to have a solid understanding of the framework's key concepts and principles. With this in mind, I have put together a list of 20 important questions that every React developer should know, whether they are interviewing for a job or just looking to improve their skills.
Before div... | sagor_cnits_73eb557b53820 |
1,900,856 | Unleash the Power of the Edge: Exploring Supabase Edge Functions | In today's fast-paced world, application performance is paramount. Supabase Edge Functions emerge as... | 0 | 2024-06-26T04:59:19 | https://dev.to/epakconsultant/unleash-the-power-of-the-edge-exploring-supabase-edge-functions-57ga | supabase | In today's fast-paced world, application performance is paramount. Supabase Edge Functions emerge as a game-changer, empowering developers to bring logic and processing power closer to users. This article delves into the world of Supabase Edge Functions, exploring their capabilities and how they can enhance your applic... | epakconsultant |
1,900,861 | Several recommended practices for writing good asynchronous JavaScript code | Introduction Asynchronous programming in JavaScript is crucial for building efficient and... | 0 | 2024-06-26T05:04:36 | https://dev.to/safdarali/several-recommended-practices-for-writing-good-asynchronous-javascript-code-1oc1 | webdev, javascript, async, programming | ## Introduction
Asynchronous programming in JavaScript is crucial for building efficient and responsive web applications. However, improper use of asynchronous constructs can lead to performance issues and hard-to-debug errors. Here are several best practices to help you write better asynchronous JavaScript code.
## ... | safdarali |
1,900,860 | 5 Best Practices for Responsive Web Design | One of the major shifts in the web development industry is the move towards responsive web design.... | 0 | 2024-06-26T05:04:35 | https://dev.to/joywinter90/5-best-practices-for-responsive-web-design-1k40 | webdev, devops, design, php | One of the major shifts in the web development industry is the move towards responsive web design. With a wide array of devices used by consumers nowadays, designing websites to consider multiple devices has become necessary.
Websites need to adapt to various devices and display sizes while providing an optimal user e... | joywinter90 |
1,900,859 | Demystifying OAuth 2.0: A Guide to Secure User Authentication | In today's interconnected world, applications often rely on user data from external sources. OAuth... | 0 | 2024-06-26T05:03:24 | https://dev.to/epakconsultant/demystifying-oauth-20-a-guide-to-secure-user-authentication-1iaa | oauth | In today's interconnected world, applications often rely on user data from external sources. OAuth 2.0 emerges as a secure and standardized protocol for authorization, allowing users to grant access to their information without sharing their credentials directly. This article unpacks the core concepts of OAuth 2.0 and ... | epakconsultant |
1,900,858 | How to Create a Web Form in 3 Steps | Create a Web Form Using Five's Online Web Form Generator In this article, we explain the three steps... | 0 | 2024-06-26T05:02:27 | https://five.co/blog/how-to-create-a-web-form-in-3-steps/ | webdev, form, database, data | <!-- wp:heading -->
<h2 class="wp-block-heading">Create a Web Form Using Five's Online Web Form Generator</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In this article, we explain the three steps required to build and launch a web form using Five's rapid application development environment. </p>
<!-- /wp:paragrap... | domfive |
1,900,857 | How to Save Image with Multer | Introduction There is usually a user image-saving feature in any web app with user login... | 0 | 2024-06-26T05:00:49 | https://dev.to/md_enayeturrahman_2560e3/how-to-save-image-with-multer-j74 | ### Introduction
- There is usually a user image-saving feature in any web app with user login functionality. The flow is as follows: We receive the user image from the front end through the request body. We use Multer at the backend to save the file in a temporary folder on the server. From the folder, we save the i... | md_enayeturrahman_2560e3 | |
1,900,855 | Delving into the World of Dart: A Versatile Language for Modern App Development | In the ever-evolving landscape of programming languages, Dart stands out as a powerful and versatile... | 0 | 2024-06-26T04:54:44 | https://dev.to/epakconsultant/delving-into-the-world-of-dart-a-versatile-language-for-modern-app-development-17gd | dart | In the ever-evolving landscape of programming languages, Dart stands out as a powerful and versatile option for building modern applications. Developed by Google, Dart boasts a unique blend of features that cater to developers of all levels. Whether you're a seasoned coder or just starting your programming journey, Dar... | epakconsultant |
1,900,854 | Django AllAuth Chapter 1 - The All-in-one solution for Auth in Django | After some experimentation in previous articles, now we will build some useful apps with Django. And... | 0 | 2024-06-26T04:52:53 | https://dev.to/doctorserone/django-allauth-chapter-1-the-all-in-one-solution-for-auth-in-django-1dog | django, python, allauth | After some experimentation in previous articles, now we will build some useful apps with Django. And one of the most important aspects of any web app is the user authentication. Django has a pretty useful authentication mechanism, but in this series of articles we will explore a full authentication package: Django AllA... | doctorserone |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.