
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,898,512 | Custom hooks: How and why to create them | Custom Hooks: How and Why to Create Them In the realm of modern React development, custom... | 0 | 2024-06-26T04:50:53 | https://dev.to/sumit_01/custom-hooks-how-and-why-to-create-th-4ip3 | javascript, react, webdev, tutorial | ### Custom Hooks: How and Why to Create Them
In the realm of modern React development, custom hooks have emerged as a powerful tool for encapsulating and reusing logic across components. They provide a way to abstract complex logic into reusable functions, enhancing code readability, maintainability, and scalability. ... | sumit_01 |
1,900,853 | Ocean Golf Car Rental | Ocean Golf Car Rental Address: 4317 N Ocean Dr, Lauderdale-By-The-Sea, FL 33308 Phone: (954)... | 0 | 2024-06-26T04:49:57 | https://dev.to/shellyeuthanc/ocean-golf-car-rental-5g4g | golf, carts, florida | Ocean Golf Car Rental
Address: 4317 N Ocean Dr, Lauderdale-By-The-Sea, FL 33308
Phone: (954) 500-5400
Email: info@oceangolfcarrental.com
Website: https://oceangolfcarrental.com
GMB Profile: https://www.google.com/maps?cid=7309250063377317658
Ocean Golf Car Rental, nestled at 4317 N Ocean Dr, Lauderdale-By-The-Sea, FL ... | shellyeuthanc |
1,900,849 | Provide private storage for internal company documents in Azure | The first step is to create a storage account for the internal private company documents. To do this,... | 0 | 2024-06-26T04:49:09 | https://dev.to/bdporomon/provide-shared-file-storage-for-the-company-offices-in-azure-59j9 | webdev, beginners, programming, devops | The first step is to create a storage account for the internal private company documents. To do this, search for and select Storage accounts. Click create. Select the Resource group that was created in the previous lab. Name the storage account. Select Review + Create, and then Create the storage account. Once the stor... | bdporomon |
1,900,852 | Personalizing the Shopping Experience with Salesforce Commerce Cloud | Personalization has become a crucial element for thriving in the competitive e-commerce industry.... | 0 | 2024-06-26T04:48:54 | https://dev.to/janiferterisa/personalizing-the-shopping-experience-with-salesforce-commerce-cloud-2mei | sfcc, salesforce, ecommerce, sfra |

Personalization has become a crucial element for thriving in the competitive e-commerce industry. And this is achieved by [Salesforce Commerce Cloud](https://absyz.com/salesforce-commerce-cloud/... | janiferterisa |
1,900,851 | Dive into App Development with FlutterFlow | The world of mobile apps is booming, but the process of creating one can seem daunting, especially... | 0 | 2024-06-26T04:48:39 | https://dev.to/epakconsultant/dive-into-app-development-with-flutterflow-3mia | The world of mobile apps is booming, but the process of creating one can seem daunting, especially for those without coding expertise. Here's where FlutterFlow steps in, offering a revolutionary approach to app development.
What is FlutterFlow?
FlutterFlow is a visual development platform built on the robust Flutter ... | epakconsultant | |
1,900,850 | Top 10 ES6 Features that Every Developer Should know | JavaScript is one of the most widely-used programming languages in the world, and its popularity... | 0 | 2024-06-26T04:48:11 | https://dev.to/sagor_cnits_73eb557b53820/i-just-test-my-frist-blog-for-my-portfolio-177n | javascript, beginners, programming | JavaScript is one of the most widely-used programming languages in the world, and its popularity continues to grow. ES6, also known as ECMAScript 2015, introduced many new and exciting features to the JavaScript language. In this blog, we'll take a look at 10 advanced ES6 features that every JavaScript developer should... | sagor_cnits_73eb557b53820 |
1,900,366 | 🚀 Understanding the V8 Engine: Optimizing JavaScript for Peak Performance | The V8 engine is the powerhouse behind JavaScript execution in Google Chrome and Node.js. Developed... | 0 | 2024-06-26T04:45:00 | https://dev.to/parthchovatiya/understanding-the-v8-engine-optimizing-javascript-for-peak-performance-1c9b | javascript, webdev, learning, development | The V8 engine is the powerhouse behind JavaScript execution in Google Chrome and Node.js. Developed by Google, V8 compiles JavaScript directly to native machine code, providing high performance and efficiency. In this article, we'll explore the inner workings of the V8 engine and share advanced techniques to optimize y... | parthchovatiya |
1,900,848 | My Journey with Backlog Refinement Cards - Optimizing Collaboration with Stakeholders | Hi everyone, I wanted to share a game-changer I recently discovered in our collaboration — Backlog... | 0 | 2024-06-26T04:41:42 | https://dev.to/nihyo/my-journey-with-backlog-refinement-cards-optimizing-collaboration-with-stakeholders-1i53 | opensource, agile, gamification, scrum |
Hi everyone,
I wanted to share a game-changer I recently discovered in our collaboration — Backlog Refinement Cards. These cards have transformed the way my team and I approach backlog refinement, turning what was once a chaotic process into a structured, collaborative, and efficient system.
 tool generally associated with managing cloud... | 0 | 2024-06-26T04:25:28 | https://spacelift.io/blog/terraform-on-premise | Terraform is a popular infrastructure as code (IaC) tool generally associated with managing cloud infrastructure, but its capabilities extend far beyond the cloud. It is versatile enough to use in on-premises environments, VCS providers, Kubernetes, and more.
##Can you use Terraform on-premise?
Terraform works with t... | spacelift_team | |
1,900,842 | ChatGPT - AI Textgenerator | Artificiell intelligens (AI) har transformerat hur vi skapar och använder textbaserat innehåll. Ett... | 0 | 2024-06-26T04:25:17 | https://dev.to/chatgptsvenskaio/chatgpt-ai-textgenerator-5102 | chatgpt, svenska, gratis | Artificiell intelligens (AI) har transformerat hur vi skapar och använder textbaserat innehåll. Ett av de mest imponerande exemplen på denna teknologiska utveckling är ChatGPT, en avancerad textgenerator utvecklad av OpenAI. ChatGPT erbjuder användare möjligheten att generera högkvalitativ text på begäran, vilket öppna... | chatgptsvenskaio |
1,900,805 | Padronização de Respostas de Erro em APIs com RFC-9457: Implementando no Spring Framework | No desenvolvimento de APIs, a clareza e consistência na comunicação de erros são cruciais para a... | 0 | 2024-06-26T04:24:40 | https://dev.to/diegobrandao/padronizacao-de-respostas-de-erro-em-apis-com-rfc-9457-implementando-no-spring-framework-4kk0 | java, errors, api, spring | No desenvolvimento de APIs, a clareza e consistência na comunicação de erros são cruciais para a eficiência e a experiência positiva dos desenvolvedores.
Imagine uma situação onde, ao integrar com uma API, você recebe mensagens de erro confusas ou inconsistentes, dificultando a identificação e correção dos problemas.... | diegobrandao |
1,900,841 | The Rise of No-Code Platforms: Threat or Opportunity? | Democratization of Development: No-code platforms empower non-technical users to create... | 0 | 2024-06-26T04:22:25 | https://dev.to/bingecoder89/the-rise-of-no-code-platforms-threat-or-opportunity-3of4 | webdev, beginners, programming, tutorial | 1. **Democratization of Development**: No-code platforms empower non-technical users to create applications, reducing the dependency on skilled developers and promoting innovation across various domains.
2. **Rapid Prototyping**: These platforms enable quick creation and testing of ideas, significantly accelerating th... | bingecoder89 |
1,900,837 | Exploring MB WhatsApp: The Enhanced Messaging Experience | In the world of instant messaging, WhatsApp stands out as one of the most widely used platforms... | 0 | 2024-06-26T04:18:50 | https://dev.to/downloadmbwhatsapp/exploring-mb-whatsapp-the-enhanced-messaging-experience-5a7b | mb, mbwhatsapp, androidapk, webdev | In the world of instant messaging, WhatsApp stands out as one of the most widely used platforms globally. Its simple interface, reliable service, and comprehensive features have made it a staple for personal and professional communication. However, for users seeking more customization and advanced features, modified ve... | downloadmbwhatsapp |
1,900,835 | Sopplayer Integration: HTML5 Stylish Video Player | Sopplayer Integration: HTML5 Stylish Video Player Sopplayer is a modern, feature-rich HTML5 video... | 0 | 2024-06-26T04:16:58 | https://dev.to/sh20raj/sopplayer-integration-html5-stylish-video-player-4foa | html5videoplayer, javascript | **Sopplayer Integration: HTML5 Stylish Video Player**
Sopplayer is a modern, feature-rich HTML5 video player designed to enhance the visual and interactive experience of video playback on web pages. It is compatible across various devices and browsers, supporting multiple video formats. Here’s a detailed guide on inte... | sh20raj |
1,900,834 | 📢 Introducing Hookform-field: Simplify Your Form Management in React! 🚀 | I am thrilled to share the release of Hookform-field, a package designed to enhance the form-handling... | 0 | 2024-06-26T04:13:06 | https://dev.to/duongductrong/introducing-hookform-field-simplify-your-form-management-in-react-3gah | I am thrilled to share the release of Hookform-field, a package designed to enhance the form-handling experience in React applications. Built on top of the popular react-hook-form library, Hookform-field brings type safety, strong reusability, and ease of use to custom-form components. 🌟
## Features
- **Type-safe:** ... | duongductrong | |
1,900,439 | Understanding Linux Permissions and Ownership | Linux is a powerful operating system, and one of its core features is its robust permissions and... | 0 | 2024-06-26T04:02:08 | https://dev.to/mesonu/understanding-linux-permissions-and-ownership-39kg | linux, webdev, programming, devops | Linux is a powerful operating system, and one of its core features is its robust permissions and ownership model. Understanding how to manage these permissions and ownership is crucial for maintaining system security and ensuring proper access control. In this blog post, we'll break down Linux permissions and ownership... | mesonu |
1,900,833 | Troubleshooting Heap Memory Errors in Sitecore XM Cloud Next.js Projects | Heap memory errors can be a daunting issue to face, especially when working on complex projects like... | 0 | 2024-06-26T03:59:20 | https://dev.to/sebasab/troubleshooting-heap-memory-errors-in-sitecore-xm-cloud-nextjs-projects-bl6 | Heap memory errors can be a daunting issue to face, especially when working on complex projects like those involving Sitecore XM Cloud with Next.js. These errors often stem from memory leaks, inefficient code, or large data processing tasks that exhaust the available memory. In this blog post, we'll focus on practical ... | sebasab | |
1,900,832 | Tech Industry Insights: A Comprehensive Guide to Enterprise Software Development Workflow Example | To summarize and provide a more structured overview of enterprise software development, let's break... | 0 | 2024-06-26T03:58:40 | https://dev.to/vyan/enterprise-software-development-a-comprehensive-workflow-overview-example-2jfn | webdev, beginners, react, development | To summarize and provide a more structured overview of enterprise software development, let's break down the process into key stages and roles. This will help in understanding how a team of developers collaborates to build, integrate, test, and deploy software. Here's an organized walkthrough of the process:
### Key R... | vyan |
1,900,436 | Essential Linux Commands for Daily Use as a Developer | As a software developer, mastering Linux commands can significantly enhance your productivity and... | 0 | 2024-06-26T03:58:33 | https://dev.to/mesonu/essential-linux-commands-for-daily-use-as-a-developer-3l0l | programming, learning, development, linux | As a software developer, mastering Linux commands can significantly enhance your productivity and streamline your workflow. Whether you're managing files, navigating directories, or automating tasks, Linux offers a robust set of commands that are invaluable for daily use. In this blog post, we'll cover some of the most... | mesonu |
1,900,831 | KMP Libraries | Do we have any repo for getting all the libraries built in KMP for ease in development? | 0 | 2024-06-26T03:45:43 | https://dev.to/saroj_khanal_e98ddbafdd66/kmp-libraries-7k2 | Do we have any repo for getting all the libraries built in KMP for ease in development? | saroj_khanal_e98ddbafdd66 | |
1,900,830 | Uploading Files to Amazon S3 in a Next.js Application Using AWS SDK v3 | Uploading Files to Amazon S3 in a Next.js Application Using AWS SDK v3 In this tutorial,... | 0 | 2024-06-26T03:44:02 | https://dev.to/sh20raj/uploading-files-to-amazon-s3-in-a-nextjs-application-using-aws-sdk-v3-21a2 | nextjs, javascript, aws, awsfileuploadingnodejs | # Uploading Files to Amazon S3 in a Next.js Application Using AWS SDK v3
In this tutorial, we will walk through how to upload files to Amazon S3 in a Next.js application using the AWS SDK for JavaScript (v3). We will ensure that the files are served securely over HTTPS using the appropriate URL format.
## Prerequisit... | sh20raj |
1,900,828 | Understanding Closures in JS (with Examples and Analogies) | [Video version of the post] : https://www.youtube.com/watch?v=UCk7XcAG_Cs Today, in this post, I’ll... | 0 | 2024-06-26T03:43:00 | https://dev.to/itric/understanding-closures-in-js-with-examples-and-analogies-1i35 | javascript, beginners, learning | [Video version of the post] : https://www.youtube.com/watch?v=UCk7XcAG_Cs
Today, in this post, I’ll be going talk about closures in js, my archnemesis 🤥
The things that I will be covering in this post, are listed in content’s overview:
Content’s Overview:
1. Starting analogy
2. What is a Closure?
3. How Closures W... | itric |
1,900,804 | How to create a Node.js web server with cPanel | Welcome to this article, where I guide you on creating your own Node.js Express web server with... | 0 | 2024-06-26T03:39:53 | https://dev.to/_briannw/how-to-create-a-nodejs-web-server-with-cpanel-21lb | webdev, beginners, tutorial, cpanel | Welcome to this article, where I guide you on creating your own Node.js Express web server with [cPanel](https://cpanel.net/). This guide will apply for most domain registrars which offer hosting services with cPanel, such as [Namecheap](https://www.namecheap.com/hosting/shared/) or [Hostgator](https://www.hostgator.co... | _briannw |
1,890,539 | Closures in JS 🔒 | TL/DR: Closures are a synthetic inner delimiter that has access to its parent's scope, even after the... | 0 | 2024-06-26T03:38:46 | https://dev.to/bibschan/closures-in-js-1gik | javascript, webdev, career, tutorial |
_**TL/DR:**
Closures are a synthetic inner delimiter that has access to its parent's scope, even after the parent function has finished executing._
Not clear? I didn't get it either. Read along partner!
---
## 🔒 Closures 🔒
Ah, closures. Sounds pretty straight forward... whatever's inside the curly braces right?!... | bibschan |
1,900,827 | Understanding NPM and NVM: Essential Tools for Node.js Development | 📚 Introduction: In the world of Node.js development, two tools stand out as essential for... | 0 | 2024-06-26T03:38:14 | https://dev.to/dipakahirav/understanding-npm-and-nvm-essential-tools-for-nodejs-development-3j56 | node, npm, nvm | ### 📚 Introduction:
In the world of Node.js development, two tools stand out as essential for managing packages and Node.js versions: NPM (Node Package Manager) and NVM (Node Version Manager). This blog post will delve into what these tools are, their version details, and how they work together to create a smooth deve... | dipakahirav |
1,900,826 | Mastering Chemistry | Learning Chemistry is an online understanding software designed to simply help pupils successfully... | 0 | 2024-06-26T03:37:49 | https://dev.to/yajeda9403/mastering-chemistry-3coh | Learning Chemistry is an online understanding software designed to simply help pupils successfully examine and understand chemistry concepts.
[Mastering Chemistry]([url=https://oneclickinfohub.blogspot.com/]Mastering Chemistry[/url]
)
| yajeda9403 | |
1,900,822 | Hadoop FS Shell Expunge: Optimizing HDFS Storage with Ease | Welcome to our exciting lab set in an interstellar base where you play the role of a skilled intergalactic communicator. In this scenario, you are tasked with managing the Hadoop HDFS using the FS Shell expunge command to maintain data integrity and optimize storage utilization. Your mission is to ensure the efficient ... | 27,774 | 2024-06-26T03:24:23 | https://labex.io/tutorials/hadoop-hadoop-fs-shell-expunge-271869 | hadoop, coding, programming, tutorial |
## Introduction
Welcome to our exciting lab set in an interstellar base where you play the role of a skilled intergalactic communicator. In this scenario, you are tasked with managing the Hadoop HDFS using the FS Shell expunge command to maintain data integrity and optimize storage utilization. Your mission is to ens... | labby |
1,900,821 | My first day in school. | Today i am so happy to going first time in school 🤫. | 0 | 2024-06-26T03:20:40 | https://dev.to/usman_ali_developer/my-first-day-in-school-ipo | Today i am so happy to going first time in school 🤫. | usman_ali_developer | |
1,900,813 | George Rosen Smith - Exploring Financial Strategies and Trends | George Rosen Smith: Exploring Financial Strategies and Trends Mr George Rosen Smith, a prominent name... | 0 | 2024-06-26T03:16:03 | https://dev.to/globalinsightn/george-rosen-smith-exploring-financial-strategies-and-trends-4ho4 | georgerosensmith | **George Rosen Smith: Exploring Financial Strategies and Trends**
Mr George Rosen Smith, a prominent name in the financial industry, with his vast experience and excellent teaching ability, has become a dual identity in the financial field: an excellent financial analyst and a highly acclaimed financial lecturer.
From ... | globalinsightn |
1,900,812 | Exploring Toca Life Mod APK: A New Dimension to Interactive Play | The world of mobile gaming has seen a significant transformation with the advent of interactive and... | 0 | 2024-06-26T03:14:59 | https://dev.to/toca_lifeworld_c58049db2/exploring-toca-life-mod-apk-a-new-dimension-to-interactive-play-302m | toca, tocamodapk, android, gamedev | The world of mobile gaming has seen a significant transformation with the advent of interactive and **[educational games](https://tocalifeworldsapk.com/blog/is-toca-boca-educational/)**. One such series that has captured the hearts of children and parents alike is the Toca Life series. Developed by Toca Boca, these gam... | toca_lifeworld_c58049db2 |
1,899,823 | Random Thoughts #1 | It sucks. I've made my Dev.to to improve my writing and help document stuff I've learned. Days pass... | 0 | 2024-06-26T03:11:28 | https://dev.to/isaiahwp/random-thoughts-1-3p4j | learning, webdev, javascript, gamedev | It sucks. I've made my Dev.to to improve my writing and help document stuff I've learned. Days pass by, my account is still barren. So here I am, taking my first step.
It's still hard though. My thoughts are resisting to be turned into written form. I do know this will get easier as long as I keep doing it. I sincerel... | isaiahwp |
1,900,811 | Unlocking Innovation with AWS Bedrock: Your Gateway to Generative AI | Unlocking Innovation with AWS Bedrock: Your Gateway to Generative AI The world of... | 0 | 2024-06-26T03:11:00 | https://dev.to/virajlakshitha/unlocking-innovation-with-aws-bedrock-your-gateway-to-generative-ai-3485 | 
# Unlocking Innovation with AWS Bedrock: Your Gateway to Generative AI
The world of technology is no stranger to rapid evolution, and at the forefront of this exciting frontier is the realm of artificial intelligence. Within this do... | virajlakshitha | |
1,900,809 | Understanding Upstream and Downstream: A Simple Guide | Upstream in Linux distributions: Fedora openSUSE OpenShift Downstream in Linux... | 0 | 2024-06-26T03:04:24 | https://dev.to/mahir_dasare_333/understanding-upstream-and-downstream-a-simple-guide-144j | linux, linuxadministration, downstream, upstream | Upstream in Linux distributions:
- Fedora
- openSUSE
- OpenShift
Downstream in Linux distributions:
- Red Hat
- ORACLE
- SUSE
Upstream:
In open-source software development, "upstream" refers to the original source or the primary development branch of a project. It's where the original developers and maintainers wor... | mahir_dasare_333 |
1,900,792 | Ultimate Guide to Mastering JavaScript Object Methods | JavaScript is a versatile language, and objects are a fundamental part of its architecture.... | 0 | 2024-06-26T02:58:00 | https://raajaryan.tech/ultimate-guide-to-mastering-javascript-object-methods | javascript, beginners, tutorial, learning | [](https://buymeacoffee.com/dk119819)
JavaScript is a versatile language, and objects are a fundamental part of its architecture. Mastering object methods is crucial for any JavaScript dev... | raajaryan |
1,897,905 | My Journey to My First Hackathon | Ever spent hours huddled with friends, brainstorming ideas for a new app or a website? Imagine that... | 0 | 2024-06-26T02:54:56 | https://dev.to/anshul_bhartiya_37e68ba7b/my-journey-to-my-first-hackathon-5970 | hackathon, programming, career, javascript | Ever spent hours huddled with friends, brainstorming ideas for a new app or a website? Imagine that energy, that collaborative spirit, multiplied by a hundred, fueled by gallons of coffee and the pressure of a ticking clock. That, in a nutshell, is a hackathon!
## How Fate Landed Me in My First Hackathon:
Fresh out o... | anshul_bhartiya_37e68ba7b |
1,900,802 | How to Determine API Slow Downs, Part 2 | A long time ago I wrote an article on how to determine that an API is slowing down using simple... | 0 | 2024-06-26T02:24:44 | https://dev.to/lazypro/how-to-determine-api-slow-downs-part-2-433 | machinelearning, python, devops, testing | A long time ago I wrote an article on [how to determine that an API is slowing down](https://medium.com/better-programming/how-to-know-api-is-slowing-down-2957b9e1341d) using simple statistics known as linear regression.

In the conclusion of that article, it was men... | lazypro |
1,900,798 | Sustainable Aviation Fuel – a Path Toward the Future | ✈️ Sustainable Aviation Fuel (SAF) is a sustainable aviation fuel produced from sustainable... | 0 | 2024-06-26T02:15:50 | https://dev.to/sarah_eitta30/sustainable-aviation-fuel-a-path-toward-the-future-36k1 | discuss, news, algorithms, beginners | ✈️ Sustainable Aviation Fuel
(SAF) is a sustainable aviation fuel produced from sustainable feedstocks and is very similar in its chemistry to conventional fossil-based jet fuel.
.
Using SAF, greenhouse gas emissio... | sarah_eitta30 |
1,900,795 | Outdoor LED display: Using technology to improve the city's grade | With the continuous advancement of LED display technology, LED display screens have gradually become... | 0 | 2024-06-26T02:05:03 | https://dev.to/sostrondylan/outdoor-led-display-using-technology-to-improve-the-citys-grade-4dpb | outdoor, led, display | With the continuous advancement of LED display technology, [LED display screens](https://sostron.com/products/ares-outdoor-led-display/) have gradually become popular and spread across every corner of the city, affecting our urban construction. Whether it is the large-screen LED advertisements that can be seen when you... | sostrondylan |
1,900,794 | Finding and fixing exposed hardcoded secrets in your GitHub project with Snyk | In this blog, we'll show how you can use Snyk to locate hardcoded secrets and credentials and then refactor our code to use Doppler to store those secrets instead. | 0 | 2024-06-26T02:00:42 | https://snyk.io/blog/fixing-exposed-hardcoded-secrets/ | codesecurity, javascript, node | Snyk is an excellent tool for spotting project vulnerabilities, including hardcoded secrets. In this blog, we'll show how you can use Snyk to locate hardcoded secrets and credentials and then refactor our code to use Doppler to store those secrets instead. We'll use the open source Snyk goof project as a reference Node... | snyk_sec |
1,900,793 | How to Quickly Drive Traffic to Your Website | Hello, everyone! Website traffic is key to success. Whether you're a startup or an experienced... | 0 | 2024-06-26T01:58:56 | https://dev.to/juddiy/how-to-quickly-drive-traffic-to-your-website-2dlp | seo, website, learning | Hello, everyone! Website traffic is key to success. Whether you're a startup or an experienced business owner, attracting more visitors to your site is crucial. So, how can you quickly drive traffic to your website? Here are some practical strategies and tips to help you boost your website's traffic rapidly.
#### 1. *... | juddiy |
1,899,322 | Terraform Basics | Infrastructure as Code (IaC) tools allow you to manage infrastructure with configuration files rather... | 0 | 2024-06-26T01:48:11 | https://dev.to/sanjaikumar2311/terraform-basics-1d2j | terraform | Infrastructure as Code (IaC) tools allow you to manage infrastructure with configuration files rather than through a graphical user interface.Terraform is HashiCorp's infrastructure as code tool.HashiCorp's is the company that develop the terraform.It describes the desired end-state for your infrastructure, in contrast... | sanjaikumar2311 |
1,895,546 | Amazon S3 Storage Classes | Amazon S3 offers a variety of storage classes to meet to different use cases, data access patterns,... | 0 | 2024-06-26T01:46:55 | https://dev.to/sachithmayantha/amazon-s3-storage-classes-1kjn | aws | ---
title: Amazon S3 Storage Classes
published: true
description:
tags: aws
cover_image: https://media.licdn.com/dms/image/D5612AQEbWwOGMJNE2w/article-cover_image-shrink_720_1280/0/1661347299570?e=2147483647&v=beta&t=BuXtmQHoyf1OJ4DK1HrzrUwl6U_34OWhuO4p5aKajNE
# Use a ratio of 100:42 for best results.
# published_at: ... | sachithmayantha |
1,900,790 | Ultimate Guide to Mastering JavaScript Array Methods | Arrays are fundamental data structures in JavaScript that allow us to store and manipulate... | 0 | 2024-06-26T01:41:41 | https://raajaryan.tech/javascript-array-method | javascript, beginners, tutorial, opensource | [](https://buymeacoffee.com/dk119819)
Arrays are fundamental data structures in JavaScript that allow us to store and manipulate collections of data. JavaScript provides a plethora of met... | raajaryan |
1,900,789 | SQLynx,A Cloud-native SQL Editor tool,Supports on-premises deployment | SQLynx is a powerful and user-friendly web-based database management tool, natively supporting both... | 0 | 2024-06-26T01:31:05 | https://dev.to/concerate/sqlynxa-cloud-native-sql-editor-toolsupports-on-premises-deployment-4375 | SQLynx is a powerful and user-friendly web-based database management tool, natively supporting both individual and enterprise users. It is designed to simplify database management and operations.
Key Features
1. User-Friendly Interface:
Intuitive web interface for quick onboarding and operation.
Drag-and-drop functio... | concerate | |
1,900,788 | Creating a nextjs chat app for learning to integrate sockets | Hi everyone in this post I will share with everyone my personal experience building a chat... | 0 | 2024-06-26T01:22:57 | https://dev.to/caresle/creating-a-nextjs-chat-app-for-learning-to-integrate-sockets-34af | nextjs, sockets, personal, webdev | Hi everyone in this post I will share with everyone my personal experience building a chat application in nextjs. To practice websockets integration.
## Why are you building this app?
I have been having troubles implementing sockets on a nextjs base application, so I wanted to build an app that was really focus on th... | caresle |
1,900,787 | Ilya Sutskever's Vision: Safe Superintelligent AI | In a recent discussion, Ilya Sutskever, the prominent deep learning computer scientist and co-founder... | 0 | 2024-06-26T01:22:34 | https://dev.to/frtechy/ilya-sutskevers-vision-safe-superintelligent-ai-17n2 | ai, machinelearning, interview, chatgpt | In a recent discussion, Ilya Sutskever, the prominent deep learning computer scientist and co-founder of OpenAI, shared insights into his long-held conviction about the potential of large neural networks, the path to Artificial General Intelligence (AGI), and the crucial issues surrounding AI safety.
### The Convicti... | frtechy |
1,900,700 | How to Customize GitHub Profile: Part 2 | Welcome back to the second part of my series on customizing your GitHub profile! In this part, we'll... | 0 | 2024-06-26T01:18:04 | https://dev.to/ryoichihomma/how-to-customize-your-github-profile-part-2-32g2 | github, githubprofile, githubportfolio, git | Welcome back to the second part of my series on customizing your GitHub profile! In this part, we'll cover how to effectively showcase your social media links and media section, followed by highlighting your tech stack. These sections help visitors quickly understand your skills, interests, and how to connect with you.... | ryoichihomma |
1,900,706 | Essential DevOps Principles for Beginners | In the rapidly evolving world of software development, DevOps has emerged as a critical methodology... | 0 | 2024-06-26T01:17:28 | https://dev.to/iaadidev/essential-devops-principles-for-beginners-14on | devops, practice, beginners, guide | In the rapidly evolving world of software development, DevOps has emerged as a critical methodology for ensuring efficient and reliable software delivery. But what exactly does good DevOps look like? If you're new to the concept, let's break it down by exploring the key principles, practices, and cultural elements that... | iaadidev |
1,900,703 | SQL Server Query Utilities | Search tables SELECT c.name AS 'ColumnName', ... | 0 | 2024-06-26T01:05:02 | https://dev.to/romerodias/sql-server-utilities-3m53 |
## Search tables
```sql
SELECT c.name AS 'ColumnName',
(SCHEMA_NAME(t.schema_id) + '.' + t.name) AS 'TableName'
FROM sys.columns c
JOIN sys.tables t ON c.object_id = t.object_id
WHERE c.name LIKE '%ColumnName%'
ORDER BY TableName
,ColumnName;
``` | romerodias | |
1,900,701 | Voguer | Voguer is the largest maritime experience portal in Brazil. Find the ideal boat for any occasion on... | 0 | 2024-06-26T00:49:35 | https://dev.to/heverton_rodrigues/voguer-jjo | Voguer is the largest maritime experience portal in Brazil. Find the ideal boat for any occasion on our rental platform or offer your yacht for charter.
See our website [https://www.voguer.com.br](https://www.voguer.com.br)
See our blog [https://news.voguer.com.br](https://news.voguer.com.br) | heverton_rodrigues | |
1,900,640 | Why AI Won’t Replace Programmers, Probably | AI will doom us all! Or not? Artificial Intelligence (AI) has taken the world by storm.... | 0 | 2024-06-26T00:47:00 | https://dev.to/salladshooter/why-ai-wont-replace-programmers-probably-bj7 | programming, ai, discuss | ## AI will doom us all! Or not?

Artificial Intelligence (AI) has taken the world by storm. New developments seem to pop up overnight. Programming seems like it will get replaced by AI, as it i... | salladshooter |
1,900,699 | How to create an SSL certificate with Let’s Encrypt | In this concise tutorial, I will cover how you can set up a trusted SSL certificate for free with... | 0 | 2024-06-26T00:42:17 | https://dev.to/_briannw/how-to-create-an-ssl-certificate-with-lets-encrypt-5e5e | ssl, certbot, letsencrypt, webdev | In this concise tutorial, I will cover how you can set up a trusted SSL certificate for free with Let’s Encrypt. SSL certificates are crucial for any website, because they encrypt data transmitted between the server and the user’s browser, helping ensure privacy and security. They also validate the website’s security, ... | _briannw |
1,900,697 | How to accept Cash App payments on your Node.js web server without Cash App Pay! | Hello there! Welcome to this concise Node.js tutorial where I will guide you through integrating Cash... | 0 | 2024-06-26T00:35:20 | https://dev.to/_briannw/how-to-accept-cash-app-payments-on-your-nodejs-web-server-without-cash-app-pay-1k7g | node, webdev, javascript | Hello there! Welcome to this concise Node.js tutorial where I will guide you through integrating Cash App payments into your Node.js website without relying on Stripe, Cash App Pay, or any other payment processing platforms. The best part? No SSN or ID verification is required to handle the payments!
**To begin accept... | _briannw |
1,900,683 | WebRTC in WebView in IOS | This article was originally written on the Metered Blog: WebRTC in WebView in IOS In this article we... | 0 | 2024-06-26T00:33:34 | https://www.metered.ca/blog/webrtc-in-webview-in-ios/ | webdev, ios, javascript, beginners | This article was originally written on the Metered Blog: [WebRTC in WebView in IOS](https://www.metered.ca/blog/webrtc-in-webview-in-ios/)
In this article we are going to learn about how to implement WebRTC in WebView for IOS
## Implementing WebRTC in IOS WebView
Let us create a simple app with WebRTC enables and in... | alakkadshaw |
1,900,696 | Understanding Cross-Site Scripting (XSS) Attacks and Prevention | Introduction Cross-Site Scripting (XSS) is a type of security vulnerability in web... | 0 | 2024-06-26T00:32:34 | https://dev.to/kartikmehta8/understanding-cross-site-scripting-xss-attacks-and-prevention-c59 | javascript, beginners, programming, tutorial | ## Introduction
Cross-Site Scripting (XSS) is a type of security vulnerability in web applications, where attackers inject malicious scripts into seemingly harmless websites. These scripts can then be executed by unsuspecting users, leading to a range of consequences from data theft to website defacement. It is a prev... | kartikmehta8 |
1,900,695 | Action Transformers: Revolutionizing AI Capabilities | 1. Introduction The realm of artificial intelligence (AI) is ever-evolving, with... | 27,673 | 2024-06-26T00:28:19 | https://dev.to/rapidinnovation/action-transformers-revolutionizing-ai-capabilities-dck | ## 1\. Introduction
The realm of artificial intelligence (AI) is ever-evolving, with new
technologies and methodologies emerging at a rapid pace. Among these, the
development of Action Transformers represents a significant leap forward in
making AI systems more dynamic and interactive.
## 2\. What is Action Transform... | rapidinnovation | |
1,857,854 | Estratégias de cache | Cache Strategies | Estratégias de armazenamento em cache; write-through, read-through, lazy loading e... | 0 | 2024-06-26T00:20:24 | https://dev.to/jonasbarros/estrategias-de-cache-cache-strategies-klk | redis, elasticsearch, aws, programming | #### Estratégias de armazenamento em cache; write-through, read-through, lazy loading e TTL
**Write-Through:** Essa estratégia é utilizada quando precisamos de consistência dos dados entre o meu banco de dados primário (SQL) e o cache. Para sua implementação correta, precisamos adicionar os dados no cache em todos os ... | jonasbarros |
1,900,684 | How to Write your First C++ Program on the Raspberry Pi Pico | Welcome to this comprehensive tutorial on setting up, building, and flashing a C++ project for... | 0 | 2024-06-26T00:13:45 | https://dev.to/shilleh/how-to-write-your-first-c-program-on-the-raspberry-pi-pico-25h2 | raspberrypi, sdk, programming, cpp | {% embed https://www.youtube.com/watch?v=fqgeUPL7Z6M %}
Welcome to this comprehensive tutorial on setting up, building, and flashing a C++ project for the Raspberry Pi Pico W on macOS. The Raspberry Pi Pico W is a powerful microcontroller board based on the RP2040 microcontroller, featuring dual-core ARM Cortex-M0+ pr... | shilleh |
1,900,682 | Artisan – The Command-Line Interface Included with Laravel | 👋 Introduction So, you’ve stumbled across the term “Artisan” in the mystical world of... | 27,882 | 2024-06-26T00:05:27 | https://n3rdnerd.com/artisan-the-command-line-interface-included-with-laravel/ | laravel, webdev, programming, learning | ## 👋 Introduction
So, you’ve stumbled across the term “Artisan” in the mystical world of Laravel, and you’re wondering if it’s a blacksmith’s workshop or a crafty beer. Spoiler alert: It’s neither! Artisan is the command-line interface (CLI) that ships with Laravel, a wildly popular PHP framework. Picture it as a Swis... | n3rdnerd |
1,812,680 | Welcome Thread - v282 | Leave a comment below to introduce yourself! You can talk about what brought you here, what... | 0 | 2024-06-26T00:00:00 | https://dev.to/devteam/welcome-thread-v282-1ca9 | welcome | ---
published_at : 2024-06-26 00:00 +0000
---

---
1. Leave a comment below to introduce yourself! You can talk about what brought you here, what you're learning, or just a fun fact ab... | sloan |
1,900,678 | How to Conquer Imposter Syndrome | It's been about 20 days, and I've been very busy with my college assignments. But on the side, I... | 0 | 2024-06-25T23:36:03 | https://dev.to/aniiketpal/how-to-conquer-imposter-syndrome-1fpg | webdev, javascript, beginners, programming | It's been about 20 days, and I've been very busy with my college assignments. But on the side, I managed to finish the basics of web development and tried to get back into coding by creating a few small projects. However, I encountered a significant challenge: imposter syndrome. I kept comparing myself to many younger ... | aniiketpal |
1,900,681 | Explain in 5 Levels of Difficulty: Bitcoin | Bitcoin is here to stay TL;DR: I will explain Bitcoin in five levels to different audiences. ... | 21,134 | 2024-06-25T23:59:39 | https://maximilianocontieri.com/explain-in-5-levels-of-difficulty-bitcoin | bitcoin, blockchain, cryptocurrency, explainlikeimfive | *Bitcoin is here to stay*
> TL;DR: I will explain Bitcoin in five levels to different audiences.
# Child
Bitcoin is like coins you can use on the internet.
Imagine having coins in a video game that you can exchange for goods.
You can purchase candies, save them for later, or trade your Bitcoin like fantasy coins.
... | mcsee |
1,894,121 | The Magical World of Machine Learning at Hogwarts (Part #4) | Greetings, young wizards and witches! 🧙♂️✨ Today, we embark on the fourth journey in our magical... | 0 | 2024-06-25T23:58:37 | https://dev.to/gerryleonugroho/the-magical-world-of-machine-learning-at-hogwarts-part-4-2g0e | algorithms, ai, machinelearning, beginners | Greetings, young **wizards** and **witches**! 🧙♂️✨ Today, we embark on the fourth journey in our **magical series**, where the fascinating world of machine learning intertwines with the mystical charms of Hogwarts. I, Professor Gerry Leo Nugroho, invite you to discover the secrets behind two extraordinary areas of ma... | gerryleonugroho |
1,900,680 | Eloquent – Laravel’s ORM for Seamless Database Interactions | 👋 Introduction Eloquent, Laravel’s Object-Relational Mapping (ORM) system, is designed to make... | 27,882 | 2024-06-25T23:54:24 | https://n3rdnerd.com/eloquent-laravels-orm-for-seamless-database-interactions/ | laravel, webdev, programming, framework | > 👋 Introduction
Eloquent, Laravel’s Object-Relational Mapping (ORM) system, is designed to make database interactions smooth as butter, even for those who break into a cold sweat at the sight of SQL queries. With its expressive syntax and powerful capabilities, Eloquent enables developers to wrangle databases with a ... | n3rdnerd |
1,887,407 | Entendendo Polling: Técnicas, Implementações e Alternativas para Comunicação em Tempo Real | Requisições feitas por pooling, ou polling (a palavra correta em inglês), referem-se a uma técnica de... | 0 | 2024-06-25T23:53:00 | https://dev.to/vitorrios1001/entendendo-polling-tecnicas-implementacoes-e-alternativas-para-comunicacao-em-tempo-real-3d8n | pooling, react, javascript, webdev | Requisições feitas por pooling, ou **polling** (a palavra correta em inglês), referem-se a uma técnica de comunicação onde um cliente solicita regularmente ou em intervalos regulares informações de um servidor. O objetivo do polling é verificar se há novos dados ou atualizações disponíveis no servidor. Esta abordagem é... | vitorrios1001 |
942,652 | Building a parser combinator: basic parsers 1. | In the previous post, an implementation of the parser class have been introduced, and in this post... | 16,110 | 2024-06-25T20:34:16 | https://dev.to/0xc0der/building-a-parser-combinator-basic-parsers-1-1jgh | javascript, parser, parsercombinator | In the previous post, an implementation of the parser class have been introduced, and in this post will be about some basic parsers.
If the parsing process broke down to it's simplest components, a pattern will be found in these components that represent the simplest operations the parser can do, then they can be com... | 0xc0der |
1,900,677 | Framework – A platform for developing software applications. | 👋 Introduction Welcome, weary traveler of the digital realm, to this humorously... | 0 | 2024-06-25T23:33:21 | https://n3rdnerd.com/framework-a-platform-for-developing-software-applications-2/ | framework, webdev, beginners, programming | ## 👋 Introduction
Welcome, weary traveler of the digital realm, to this humorously high-quality glossar entry on the mystical concept known as a "framework." Imagine a place where code whispers sweet nothings to your development environment, where bugs hide in terror, and where you, the developer, wield power like a c... | n3rdnerd |
1,900,676 | [Game of Purpose] Day 38 | Today I played around with dropping granades. I decided to ditch dangling granade with... | 27,434 | 2024-06-25T23:31:13 | https://dev.to/humberd/game-of-purpose-day-38-4j39 | gamedev | Today I played around with dropping granades. I decided to ditch dangling granade with PhysicsConstraint for now, because it caused many problems, such as:
* granade's weight impacted drones flying and I didn't know to to fix it
* granade hitting a ground with a force with rotation also applied it to a drone making i... | humberd |
1,900,675 | I built a template for the retro vibes | Easy UI Diaries | Free Templates Part-2 | I built a template for the retro vibes using React, Next.js, Tailwind CSS, Magic UI. Shadcn UI, and... | 0 | 2024-06-25T23:26:12 | https://dev.to/darkinventor/i-built-a-template-for-the-retro-vibes-easy-ui-diaries-free-templates-part-2-2if2 | webdev, javascript, design, website | I built a template for the retro vibes using React, Next.js, Tailwind CSS, Magic UI. Shadcn UI, and Framer Motion.
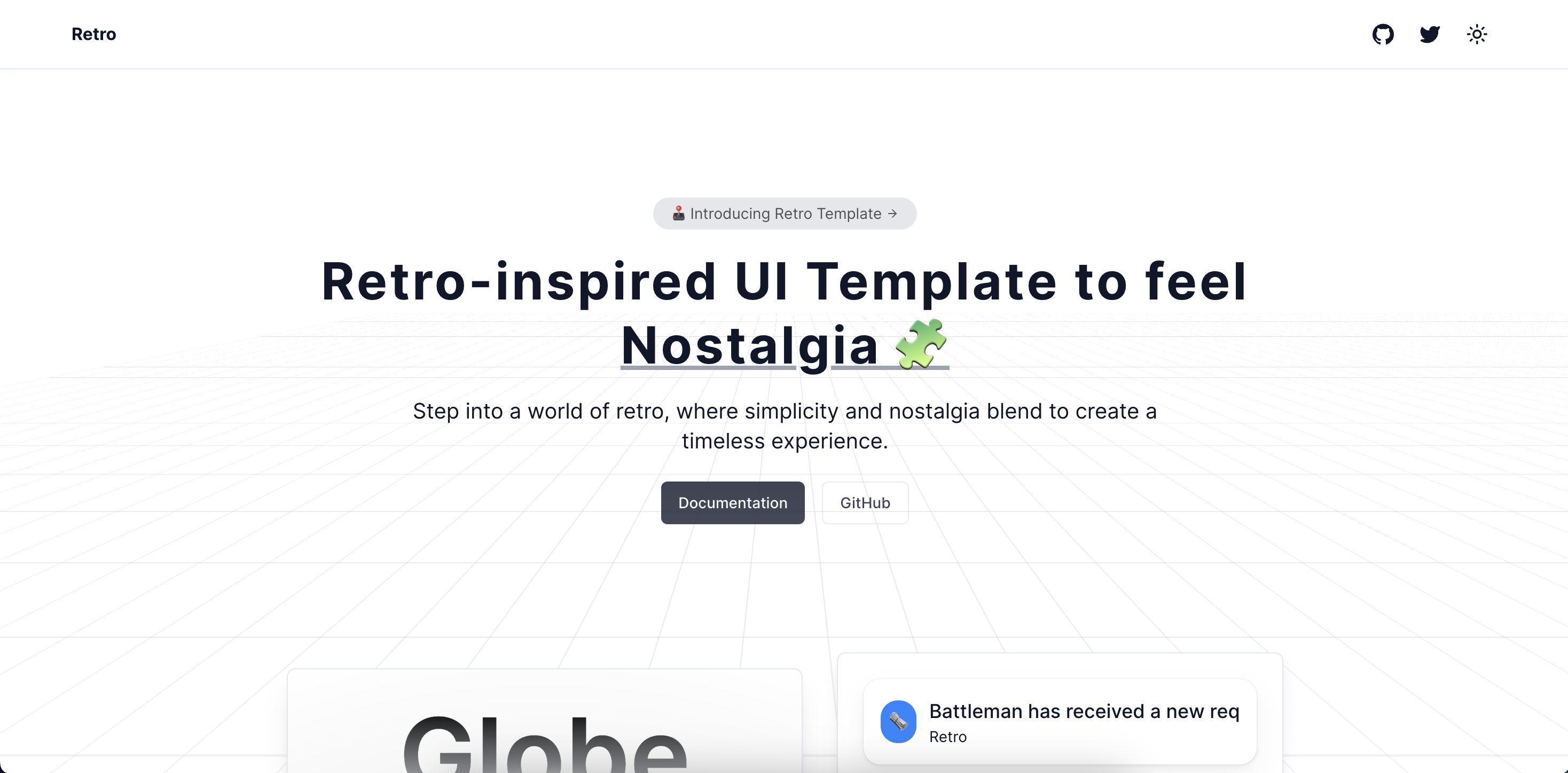
If you are someone who likes retro animations its for you.
Here’s why this template will b... | darkinventor |
1,899,505 | Node.js Walkthrough: Build a Simple Event-Driven Application with Kafka | Have you ever wondered how some of your favorite apps handle real-time updates? Live sports scores,... | 0 | 2024-06-25T23:24:38 | https://dzone.com/articles/nodejs-walkthrough-build-a-simple-event-driven-app | kafka, eventdriven, node, tutorial | Have you ever wondered how some of your favorite apps handle real-time updates? Live sports scores, stock market tickers, or even social media notifications — they all rely on event-driven architecture (EDA) to process data instantly. EDA is like having a conversation where every new piece of information triggers an im... | alvinslee |
1,900,672 | DOM – Document Object Model. | 👋 Introduction Welcome to the world of the Document Object Model, or DOM, where web pages... | 0 | 2024-06-25T23:19:29 | https://n3rdnerd.com/dom-document-object-model-2/ | dom, html, javascript, beginners | ## 👋 Introduction
Welcome to the world of the Document Object Model, or DOM, where web pages come alive with more than just words and pictures. Get ready to dive into the structure that turns static HTML documents into dynamic, interactive experiences. Sit back, grab some popcorn 🍿, and let’s hit the road!
## 👨💻 ... | n3rdnerd |
1,900,671 | JavaScript – A programming language used for web development. | 👋 Introduction Welcome, dear reader, to the rollercoaster ride that is JavaScript. Whether... | 0 | 2024-06-25T23:12:15 | https://n3rdnerd.com/json-javascript-object/-notation | javascript, webdev, beginners, learning | ## 👋 Introduction
Welcome, dear reader, to the rollercoaster ride that is JavaScript. Whether you’re a seasoned coder or someone who thinks JavaScript is what Harry Potter uses to conjure his Patronus, this glossary entry is for you. JavaScript is like the Swiss Army knife of the web—versatile, indispensable, and occa... | n3rdnerd |
1,900,670 | CSS – Cascading Style Sheets. | 👋 Introduction Welcome to the wacky, wonderful world of CSS – Cascading Style Sheets! Can... | 0 | 2024-06-25T23:03:03 | https://n3rdnerd.com/css-cascading-style-sheets-2/ | css, beginners, learning | ## 👋 Introduction
Welcome to the wacky, wonderful world of CSS – Cascading Style Sheets! Can you imagine a website without any styling? Yikes! It would be like eating spaghetti without sauce: bland, messy, and utterly unappetizing. CSS is the magical sauce that turns plain HTML into a feast for the eyes. But wait! The... | n3rdnerd |
1,900,669 | The Journey to Financial Freedom: Lessons from Felix | We've all dreamed of reaching financial freedom - having enough money to live comfortably without the... | 0 | 2024-06-25T22:52:09 | https://dev.to/devmercy/the-journey-to-financial-freedom-lessons-from-felix-469k | tutorial, productivity, opensource, career | We've all dreamed of reaching financial freedom - having enough money to live comfortably without the constraints of a regular 9-5 job. For most people though, that dream seems elusive. But what if I told you the story of mine, a woman who achieved financial independence in her 30s through diligent savings and smart in... | devmercy |
1,900,665 | Guía completa para crear y configurar Azure Cosmos DB con Terraform | En esta guía detallada, aprenderás a crear y configurar una cuenta de Azure Cosmos DB utilizando... | 0 | 2024-06-25T22:46:50 | https://danieljsaldana.dev/guia-completa-para-crear-y-configurar-azure-cosmos-db-con-terraform/ | azure, terraform, cosmodb, spanish | ---
title: Guía completa para crear y configurar Azure Cosmos DB con Terraform
published: true
tags: Azure, Terraform, Cosmodb, Spanish
canonical_url: https://danieljsaldana.dev/guia-completa-para-crear-y-configurar-azure-cosmos-db-con-terraform/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/706... | danieljsaldana |
1,900,666 | 5 Major SEO Website Mistakes That Ruin 87% Businesses 💰 | Top Website Mistakes That Ruin Businesses So you really want to know the most important... | 0 | 2024-06-25T22:46:49 | https://dev.to/davedolls/5-major-seo-website-mistakes-that-ruin-87-businesses-2n4 | website, webdesign, web3, webdev | ## Top Website Mistakes That Ruin Businesses
So you really want to know the most important website mistakes that ruin businesses!!
Cool, that's what I'll be explaining to you today
My name is Ani David and this is my niche so It's likely I know better..
It’s mind-blowing to know that nearly 38% of people will stop e... | davedolls |
1,900,664 | JSON – JavaScript Object Notation | Introduction Ah, JSON. If you’ve been dabbling in web development or any sort of data... | 0 | 2024-06-25T22:39:24 | https://n3rdnerd.com/json-javascript-object-notation/ | json | ## Introduction
Ah, JSON. If you’ve been dabbling in web development or any sort of data interchange format, chances are you’ve encountered this delightful little acronym and thought, "What in the world is this?" Fear not, dear reader, because we’re about to embark on a wild and whimsical ride to demystify JSON. Buckle... | n3rdnerd |
1,900,663 | 🚀 Connecting to Databases with Node.js: MongoDB and Mongoose 🌐 | Dive into the world with your instructor #KOToka by learning Node.js and supercharge your... | 0 | 2024-06-25T22:32:15 | https://dev.to/erasmuskotoka/connecting-to-databases-with-nodejs-mongodb-and-mongoose-2bdd |
Dive into the world with your instructor #KOToka by learning Node.js and supercharge your applications by connecting to MongoDB using Mongoose!
📡🛠️ Mongoose provides a powerful and flexible way to interact with MongoDB, making data management a breeze.
Why MongoDB? 🌟
- Scalable and Flexible: Perfect for handli... | erasmuskotoka | |
1,900,662 | How I making my career transition and why? | Just a note before I started: I'm from Brazil, I speak Portuguese, and I'm learning how communicate... | 0 | 2024-06-25T22:23:20 | https://dev.to/devmarianasouza/how-i-making-my-career-transition-and-why-17i0 | beginners, careertransition, career | Just a note before I started: I'm from Brazil, I speak Portuguese, and I'm learning how communicate with the rest of the world with English, so, i'ts for pratice, take easy with me and my beginner english. Thanks, let's go!
## The career of technology _always_ been in my radar!
As soon as I finished my high school, ... | devmarianasouza |
1,900,661 | Day 978 : Rain | liner notes: Professional : Not a bad day. Had a bunch of meetings. Helped out with some community... | 0 | 2024-06-25T22:23:05 | https://dev.to/dwane/day-978-rain-pd6 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Not a bad day. Had a bunch of meetings. Helped out with some community questions and created a project to try and figure some stuff out. Worked on a blog post.
- Personal : Last night, I went through some tracks for the radio show. Did some more research on a project. I worked on the lo... | dwane |
1,900,645 | Resourcely founder-led in person or virtual hands-on workshop | Join Resourcely for a free founder-led in person or virtual hands-on workshop. Learn how easy it is... | 0 | 2024-06-25T22:10:06 | https://dev.to/resourcely/resourcely-founder-led-in-person-or-virtual-hands-on-workshop-1o46 | devops, beginners, learning, security | Join Resourcely for a free founder-led in person or virtual hands-on workshop.
Learn how easy it is to enable cloud infrastructure paved roads to prevent misconfigurations for your organization.
In this session, you’ll learn how to:
✅ Navigate Resourcely user interface, and connection options.
✅ Integrate your SSO ... | ryan_devops |
1,900,646 | non vbv bin | 400022 US VISA DEBIT CLASSIC NAVY F.C.U. 401105 US VISA DEBIT CLASSIC PENTAGON F.C.U. 401154 US... | 0 | 2024-06-25T22:10:00 | https://dev.to/kelvin_walker_659dab40902/non-vbv-bin-2l1k | 400022 US VISA DEBIT CLASSIC NAVY F.C.U.
401105 US VISA DEBIT CLASSIC PENTAGON F.C.U.
401154 US VISA DEBIT CLASSIC VYSTAR C.U.
402203 US VISA DEBIT CLASSIC NORTHWEST SAVINGS BANK
[non vbv bin](https://benumbcvvshop.com/list-of-best-non-vbv-bins-for-carding/)
402944 US VISA DEBIT CLASSIC TD BANK, N.A.
406095 US V... | kelvin_walker_659dab40902 | |
1,899,173 | Effortless GraphQL in Next.js: Elevate Your DX with Codegen and more | Introduction GraphQL endpoints are gaining popularity for their flexibility, efficient... | 0 | 2024-06-25T22:02:25 | https://dev.to/ptvty/effortless-graphql-in-nextjs-elevate-your-dx-with-codegen-and-more-58l5 | graphql, nextjs, typescript, webdev | ## Introduction
GraphQL endpoints are gaining popularity for their flexibility, efficient data fetching, and strongly typed schema. Putting these powers in hands of API consumers will elevate the Developer Experience (DX) and leads to building robust and maintainable applications. Combining Next.js, GraphQL, and TypeS... | ptvty |
1,900,643 | SEO Strategies for Single Page Applications (Insights and Best Practices) | Hi everyone! I'm exploring the SEO implications of Single Page Applications. Could you share your... | 0 | 2024-06-25T22:00:30 | https://dev.to/fatima_tl_af275ccfc7f998e/seo-strategies-for-single-page-applications-insights-and-best-practices-17n4 | discuss | Hi everyone! I'm exploring the SEO implications of Single Page Applications. Could you share your experiences or insights on how SPAs affect search engine indexing and crawling? What strategies have you found effective in ensuring SPAs are SEO-friendly, especially compared to Multi-Page Applications?
Your input will g... | fatima_tl_af275ccfc7f998e |
1,854,428 | Dev: IoT | An IoT (Internet of Things) Developer is a professional responsible for designing, developing, and... | 27,373 | 2024-06-25T22:00:00 | https://dev.to/r4nd3l/dev-iot-16do | iot, developer | An **IoT (Internet of Things) Developer** is a professional responsible for designing, developing, and implementing software and hardware solutions for IoT devices and systems. Here's a detailed description of the role:
1. **Understanding of IoT Ecosystem:**
- IoT Developers have a deep understanding of the IoT eco... | r4nd3l |
1,899,487 | Understanding the @DependsOn Annotation in Spring | Introduction to the @DependsOn Annotation This annotation tells Spring that the bean... | 27,602 | 2024-06-25T22:00:00 | https://springmasteryhub.com/2024/06/25/understanding-the-dependson-annotation-in-spring/ | java, springboot, spring, programming |
## Introduction to the `@DependsOn` Annotation
This annotation tells Spring that the bean marked with this annotation should be created after the beans that it depends on are initialized.
You can specify the beans you need to be created first in the `@DependsOn` annotation parameters.
This annotation is used when a... | tiuwill |
1,900,642 | K.I.S.S. - Why I moved my main site from Drupal to Grav CMS | In case you don't know, K.I.S.S. stands for Keep. It. Simple. Stupid. (And not a shit rock band from... | 0 | 2024-06-25T21:58:10 | https://symfonystation.mobileatom.net/drupal-grav-cms | drupal, gravcms, twig, markdown | **In case you don't know, K.I.S.S. stands for Keep. It. Simple. Stupid. (And not a shit rock band from Detroit).**
And I am sure you do know building content-oriented websites today is an overcomplicated clusterfuck.
But there is a content management system that makes it easier and simpler. And this is especially tru... | reubenwalker64 |
1,900,637 | Code joke (may contain bugs) | if ($you_want == "My body" && $you_think == "I'm sexy") { echo '🎶 Come on, sugar, let me... | 0 | 2024-06-25T21:56:10 | https://dev.to/snook/code-joke-1lf2 | jokes | ```
if ($you_want == "My body" && $you_think == "I'm sexy")
{
echo '🎶 Come on, sugar, let me know. 🎶';
}
``` | snook |
1,900,641 | API – Application Programming Interface | Introduction Welcome, dear reader, to the fascinating world of APIs! 🎉 If you’ve ever... | 0 | 2024-06-25T21:53:45 | https://n3rdnerd.com/api-application-programming-interface | api | ## Introduction
Welcome, dear reader, to the fascinating world of APIs! 🎉 If you’ve ever wondered how different software applications chat with each other, you’ve come to the right place. An API is like the magical translator that makes sure everyone gets along, much like a universal remote that controls all your devi... | n3rdnerd |
1,897,060 | 2.1 Tente isso - Qual é a distância do relâmpago? | Crie um programa que calcula a que distância, em pés, um ouvinte está da queda de um relâmpago. O som... | 0 | 2024-06-25T21:43:20 | https://dev.to/devsjavagirls/21-tente-isso-qual-e-a-distancia-do-relampago-19db | java | Crie um programa que calcula a que distância, em pés, um ouvinte está da queda de um relâmpago. O som viaja a aproximadamente 1.100 pés por segundo pelo ar. Logo, conhecer o intervalo entre o momento em que você viu um relâmpago e o momento em que o som o alcançou lhe permitirá calcular a distância do relâmpago. Para e... | devsjavagirls |
1,897,059 | 2 - Tipos de dados | - Por que os tipos de dados são importantes Java é uma linguagem fortemente tipada, ou seja, cada... | 0 | 2024-06-25T21:42:58 | https://dev.to/devsjavagirls/2-tipos-de-dados-25i0 | java | **- Por que os tipos de dados são importantes**
Java é uma linguagem fortemente tipada, ou seja, cada variável e expressão tem um tipo específico, que define o conjunto de valores que a variável pode armazenar e as operações que podem ser realizadas com ela.
Não há o conceito de uma variável “sem tipo” em Java.
O t... | devsjavagirls |
1,900,638 | Flask: The basics! | Welcome back SE nerds!! I'm back with another blog to talk about everything you'll need to know about... | 0 | 2024-06-25T21:42:07 | https://dev.to/trippl/flask-the-basics-gng | python, flask, softwareengineering, students | Welcome back SE nerds!! I'm back with another blog to talk about everything you'll need to know about Python Flask! Flask is an awesome addition to being a full-stack developer, bringing the backend dynamics and the next step to put the frontend and backend together!
This first thing you should be familiar with is an ... | trippl |
1,900,635 | Why B2C Auth is Fundamentally Broken | Introduction In 2024, traditional B2C authentication methods are fundamentally flawed.... | 0 | 2024-06-25T21:38:21 | https://dev.to/corbado/why-b2c-auth-is-fundamentally-broken-3fpb | authentication, cybersecurity, webdev, passkeys | ## Introduction
In 2024, traditional B2C authentication methods are fundamentally flawed. Despite the widespread adoption of [Multi-Factor Authentication (MFA)](https://www.corbado.com/blog/invisible-mfa) and [password management solutions](https://www.corbado.com/blog/passkeys-vs-password-managers), security breaches ... | vdelitz |
1,900,634 | Why B2C Auth is Fundamentally Broken | Introduction In 2024, traditional B2C authentication methods are fundamentally flawed.... | 0 | 2024-06-25T21:38:21 | https://dev.to/corbado/why-b2c-auth-is-fundamentally-broken-3akf | authentication, cybersecurity, webdev, passkeys | ## Introduction
In 2024, traditional B2C authentication methods are fundamentally flawed. Despite the widespread adoption of [Multi-Factor Authentication (MFA)](https://www.corbado.com/blog/invisible-mfa) and [password management solutions](https://www.corbado.com/blog/passkeys-vs-password-managers), security breaches ... | vdelitz |
1,900,632 | "From Classroom to Clinical: How Writing Services Support Nursing Students" | The path from the classroom to the clinical nursing nurse writing services education environment... | 0 | 2024-06-25T21:36:40 | https://dev.to/nursewritingservices/from-classroom-to-clinical-how-writing-services-support-nursing-students-393p | seo | The path from the classroom to the clinical nursing [nurse writing services](https://nursewritingservices.com/) education environment in nursing education is both challenging and rewarding. Nursing students must master a vast array of knowledge, develop critical thinking skills, and demonstrate competence in clinica... | nursewritingservices |
1,900,630 | Memory Allocations in Rust | Introduction Welcome to this in-depth tutorial on memory allocations in Rust. As a... | 0 | 2024-06-25T21:24:39 | https://dev.to/gritmax/memory-allocations-in-rust-3m7l | rust, tutorial |
## Introduction
Welcome to this in-depth tutorial on memory allocations in Rust. As a developer, understanding how Rust manages memory is crucial for writing efficient and safe programs. This guide is the result of analysing several expert sources to provide you with a comprehensive overview of memory management, not... | gritmax |
1,900,615 | Cloud Migration Services: Your Roadmap to a Scalable, Cost-Effective IT Future | Why Cloud Migration is Essential for Your Business Growth? Cloud migration is no longer a luxury;... | 0 | 2024-06-25T21:17:07 | https://dev.to/unicloud/cloud-migration-services-your-roadmap-to-a-scalable-cost-effective-it-future-44f9 | cloud | Why Cloud Migration is Essential for Your Business Growth?
Cloud migration is no longer a luxury; it's a strategic imperative for businesses seeking to thrive in the digital age. By shifting your applications, data, and infrastructure to the cloud, you unlock a world of benefits, including enhanced scalability, reduced... | unicloud |
1,900,614 | Add liquid tag for podcasters.spotify.com | I was hoping that I would be able to add this player to dev.to, or at least add the audio from the... | 0 | 2024-06-25T21:14:08 | https://dev.to/codercatdev/add-liquid-tag-for-podcastersspotifycom-3o34 | discuss | ---
title: Add liquid tag for podcasters.spotify.com
published: true
tags: discuss
---
I was hoping that I would be able to add this player to dev.to, or at least add the audio from the RSS feed.
## Embed
```
<iframe src="https://podcasters.spotify.com/pod/show/codingcatdev/embed/episodes/4-13---Firebase-Security-Ru... | codercatdev |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.