
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,900,395 | 5 NodeJS Features You Probably Missed | Are you wasting time installing unnecessary libraries and debugging your NodeJS applications the... | 0 | 2024-06-25T17:01:30 | https://dev.to/techvision/5-nodejs-features-you-probably-missed-1i5o |
Are you wasting time installing unnecessary libraries and debugging your NodeJS applications the wrong way? Here are five built-in NodeJS features that can make your life easier and reduce your project's dependencies.
> If you prefer the video version, here is the link 😉
{% embed https://www.youtube.com/watch?v=Ff... | techvision | |
1,900,397 | Cross-Industry Blockchain Integration | 1. Introduction Blockchain technology, initially conceptualized as the underlying... | 27,673 | 2024-06-25T16:59:21 | https://dev.to/rapidinnovation/cross-industry-blockchain-integration-n4p | ## 1\. Introduction
Blockchain technology, initially conceptualized as the underlying framework
for Bitcoin, has evolved far beyond its original purpose. It is now recognized
as a revolutionary technology with the potential to transform various
industries by providing a decentralized, transparent, and secure method of... | rapidinnovation | |
1,900,396 | StarTowerChain successfully obtained seed round investment from three well-known French venture capital companies | According to the latest news, the blockchain project StarTowerChain successfully obtained investment... | 0 | 2024-06-25T16:57:36 | https://startower.fr |
According to the latest news, the blockchain project StarTowerChain successfully obtained investment from three well-known French venture capital companies, Alven Capital, Kima Ventures and Idinvest Partners, in the recent seed round of financing. The total investment reached 5 million euros.
This financing marks tha... | marsbit | |
1,900,394 | CCSP Exam Requirements | The Certified Cloud Security Professional (CCSP) credential, administered by (ISC)², is an... | 0 | 2024-06-25T16:52:33 | https://dev.to/shivamchamoli18/ccsp-exam-requirements-28n5 | ccsp, cloudsecurity, certificationtraining, infosectrain | The Certified Cloud Security Professional (CCSP) credential, administered by (ISC)², is an internationally recognized certification for IT and information security professionals. It demonstrates expertise in cloud security architecture, design, operations, and service orchestration. Achieving the CCSP certification nec... | shivamchamoli18 |
1,900,393 | 🌟 Project 1: Simple Sign-Up Form 🌟 | Hey everyone! I've just completed the first project of my 50 web development projects challenge.... | 0 | 2024-06-25T16:52:04 | https://dev.to/bytesage/project-1-simple-sign-up-form-pe1 | Hey everyone! I've just completed the first project of my 50 web development projects challenge. 🎉
For this project, I created a simple and stylish sign-up form. It features a clean layout, smooth animations, and social media icons for a modern touch. Check out the details below:
## Key Features:
 is a temporary structure installed over sidewalks to protect pedestrians from construction debris, tools, and materials falling from a building undergoing repair, renovation, or demolition. These structures are essential in urban environments wh... | ridge_hillconstruction_d |
1,900,376 | CREATING A VIRTUAL MACHINE USING AZURE CLI | We already established that there are several routes that can be taken to achieve the deployment of... | 27,629 | 2024-06-25T16:23:25 | https://dev.to/aizeon/creating-a-virtual-machine-using-azure-cli-5ec7 | beginners, azure, virtualmachine, tutorial | We already established that there are several routes that can be taken to achieve the deployment of resources and services on Azure.
For today, I will be using the Azure Command Line Interface (CLI) to create a virtual machine on Azure.
## **PREREQUISITE**
- Working computer
- Internet connection
- Microsoft Azure ac... | aizeon |
1,900,374 | DAY 3 PROJECT : VOWEL CHECKER | Elevate Your Writing with the Vowel Checker Application In the world of web development, creating... | 0 | 2024-06-25T16:21:32 | https://dev.to/shrishti_srivastava_/day-3-project-3hd2 | webdev, javascript, beginners, programming | **Elevate Your Writing with the Vowel Checker Application**
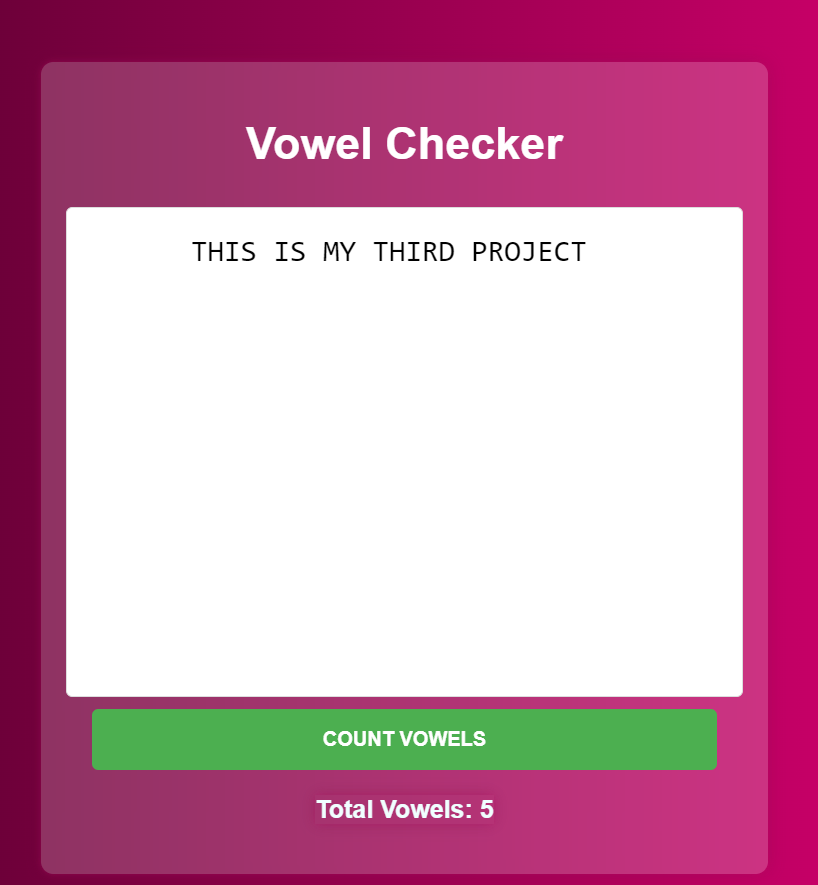
In the world of web development, creating interactive applications is a great way to enhance your skills and provide value to users. One such project tha... | shrishti_srivastava_ |
1,900,373 | The various modules of Digital Marketing. | Digital Marketing Content Marketing: Content marketing focuses on creating and... | 0 | 2024-06-25T16:21:27 | https://dev.to/khushithakuri/the-various-modules-of-digital-marketing-8i0 | digital, marketing, webdev | ## Digital Marketing
1. Content Marketing:
Content marketing focuses on creating and distributing valuable, relevant, consistent content to attract and retain a clearly defined audience. Key aspects include:
Blogging: Regularly publishing articles that provide useful information.
Video Marketing: Creating engaging vi... | khushithakuri |
1,900,375 | Super Club Net: Libro de Introducción a HTML, CSS y JS | Una pequeña y amena introducción a las tecnologías para desarrollo web | 0 | 2024-06-25T16:12:00 | https://dev.to/javascriptchile/super-club-net-libro-de-introduccion-a-html-css-y-js-32hc | javascript, html, css, chile | ---
title: Super Club Net: Libro de Introducción a HTML, CSS y JS
published: true
description: Una pequeña y amena introducción a las tecnologías para desarrollo web
tags: javascript, html, css, chile
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/docfxqv0c1t0zxbgqb0i.jpg
# Use a ratio of 100:42 ... | clsource |
1,900,138 | How AppMap Navie solved the SWE bench AI coding challenge | AppMap Navie is an AI coding assistant that you can use directly in your VSCode or JetBrains code... | 27,856 | 2024-06-25T16:11:31 | https://dev.to/appmap/how-appmap-navie-solved-the-swe-bench-ai-coding-challenge-20an | ai, vscode, llm, python | [AppMap Navie](https://appmap.io/product/appmap-navie.html) is an AI coding assistant that you can use directly in your VSCode or JetBrains code editor.
[SWE Bench](https://www.swebench.com/) is a benchmark from Princeton University that assesses AI language models and agents on their ability to solve real-world softw... | kgilpin |
1,900,119 | Refactoring fix_encoding | I've been writing about Unicode on Twitter over the last week, and specifically handling Unicode in... | 0 | 2024-06-25T16:10:21 | https://dev.to/mdchaney/refactoring-fixencoding-1d34 | ruby, unicode | I've been writing about Unicode on Twitter over the last week, and specifically handling Unicode in Ruby. Ruby has robust Unicode support, along with robust support for the older code pages.
In my work in the music publishing industry I have to write code to process all manner of spreadsheets, typically in the form o... | mdchaney |
1,900,364 | Generating photos by IA | Is generating photos with AI that easy? What do you ask for the bot to bring the photos you want? I... | 0 | 2024-06-25T16:08:46 | https://dev.to/epi2024/generating-photos-by-ia-2ppb | webdev, beginners, javascript | Is generating photos with AI that easy? What do you ask for the bot to bring the photos you want? I asked for meta AI to give me several photos now I wonder if those photos are already existing on some servers or not. I want something to generate for my blog website or instagram for educational purposes. Please help ho... | epi2024 |
1,900,363 | Revolutionizing Healthcare: Salesforce's AI Solutions Combat Physician Burnout | The Crisis: Physician Burnout The medical field is experiencing a crisis. Physician... | 27,673 | 2024-06-25T16:08:33 | https://dev.to/rapidinnovation/revolutionizing-healthcare-salesforces-ai-solutions-combat-physician-burnout-3n6e | ## The Crisis: Physician Burnout
The medical field is experiencing a crisis. Physician burnout is a major
barrier to providing the best possible care for patients, even while medical
innovations continue to push boundaries. An alarming picture is painted by a
recent Athenahealth poll, which found that 64% of doctors f... | rapidinnovation | |
1,898,922 | Exploring the CSS display property: A deep dive | Written by Ibadehin Mojeed✏️ HTML elements typically follow the standard flow layout — also called... | 0 | 2024-06-25T16:07:18 | https://blog.logrocket.com/exploring-css-display-property | css, webdev | **Written by [Ibadehin Mojeed](https://blog.logrocket.com/author/ibadehinmojeed/)✏️**
HTML elements typically follow the standard flow layout — also called “normal flow” — and naturally arrange themselves on the page. In this flow layout, some elements expand to fill their entire parent container and stack vertically,... | leemeganj |
1,899,361 | Utilizando o Git e o GitHub para anotar seus estudos | Olá, meus amores. Tudo bem com vocês? Hoje eu vim aqui compartilhar um dos métodos que eu utilizo... | 0 | 2024-06-25T16:00:00 | https://larissaabreu.dev/utilizando-git-e-github-para-anotar-seus-estudos/ | git, github, learning, braziliandevs | Olá, meus amores. Tudo bem com vocês? Hoje eu vim aqui compartilhar um dos métodos que eu utilizo para estudar. É um método que eu gosto bastante e qualquer pessoa pode aderir (mesmo que você não seja uma pessoa desenvolvedora).
Primeiramente vamos conhecer o que é <a href="https://git-scm.com" target="_blank" aria-la... | thesweetlari |
1,900,362 | CREATING A VIRTUAL MACHINE ON AZURE USING POWERSHELL | There are several routes that can be taken to achieve the deployment of resources and services on... | 27,629 | 2024-06-25T16:05:30 | https://dev.to/aizeon/creating-a-virtual-machine-on-azure-using-powershell-1jj1 | beginners, azure, virtualmachine, tutorial | There are several routes that can be taken to achieve the deployment of resources and services on Azure. Whether it be through clicking and selecting resources directly on Azure portal or using scripting tools like PowerShell, Windows PowerShell or Command Prompt.
For today, I will be using the PowerShell application ... | aizeon |
1,900,361 | 1038. Binary Search Tree to Greater Sum Tree | 1038. Binary Search Tree to Greater Sum Tree Medium Given the root of a Binary Search Tree (BST),... | 27,523 | 2024-06-25T16:03:38 | https://dev.to/mdarifulhaque/1038-binary-search-tree-to-greater-sum-tree-20hb | php, leetcode, algorithms, programming | 1038\. Binary Search Tree to Greater Sum Tree
Medium
Given the `root` of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST.
As a reminder, _a binary search tree_ is a tree that ... | mdarifulhaque |
1,900,360 | Introducing Multi-Player Car Parking Game! 🚗 | Get ready to test your parking skills with friends in our exciting new Multi-Player Car Parking game!... | 0 | 2024-06-25T16:00:45 | https://dev.to/katobhi/introducing-multi-player-car-parking-game-2p19 |
Get ready to test your parking skills with friends in our exciting new Multi-Player Car Parking game! Challenge your buddies, compete for the best parking spots, and prove who’s the ultimate parking master.
**Features:
**
**Real-Time Multiplayer:** Park alongside your friends and see who can snag the best spot.
Diver... | katobhi | |
1,900,359 | Getting "Start a Power Apps trial" when using Canvas with Dataverse even with a premium license. | I have a project built with Canvas that connects with Dataverse. When accessing the published... | 0 | 2024-06-25T16:00:42 | https://dev.to/r1l/getting-start-a-power-apps-trial-when-using-canvas-with-dataverse-even-with-a-premium-license-552b | I have a project built with Canvas that connects with Dataverse. When accessing the published linked, it brings up a "Start a Power Apps trial". It was confirmed that we have premium license. It does not prompt with other combination: canvas with sharepoint, model with dataverse.
[](
 I try to explain step-by-step how to build an API focused on operations using many symfony features such as tagged iterators, service configurators, firewalls, voters, symfo... | icolomina |
1,900,368 | Bootcamp De Blockchain Developer Gratuito Da DIO | A DIO, em parceria com a Binance, oferece o bootcamp gratuito “Coding The Future Binance – Blockchain... | 0 | 2024-06-28T13:38:14 | https://guiadeti.com.br/bootcamp-blockchain-developer-gratuito-dio/ | bootcamps, blockchain, criptomoedas, cursosgratuitos | ---
title: Bootcamp De Blockchain Developer Gratuito Da DIO
published: true
date: 2024-06-25 15:53:15 UTC
tags: Bootcamps,blockchain,criptomoedas,cursosgratuitos
canonical_url: https://guiadeti.com.br/bootcamp-blockchain-developer-gratuito-dio/
---
A DIO, em parceria com a Binance, oferece o bootcamp gratuito “Coding ... | guiadeti |
1,900,354 | Kalos by Stratus10: The All-in-One Cloud Management Platform | Stratus10 Cloud Computing Services is an Amazon Web Services (AWS) Advanced Consulting Partner... | 0 | 2024-06-25T15:48:21 | https://dev.to/oscar_moncada_9be1af0b050/kalos-by-stratus10-the-all-in-one-cloud-management-platform-3eee | Stratus10 Cloud Computing Services is an Amazon Web Services (AWS) Advanced Consulting Partner helping organizations migrate to the cloud or if they’re already on AWS we help implement best practices. Our core competencies are cloud migration, application modernization, DevOps and DevSecOps, CI/CD pipelines, Windows Se... | oscar_moncada_9be1af0b050 | |
1,900,353 | Typescript newbie can't get Vue app to see his Type. | Hello, everyone. I am developing a Vue 3 app with Vuetify 3 and Pinia. I'm functional on all of those... | 0 | 2024-06-25T15:47:44 | https://dev.to/franklee/typescript-newbie-cant-get-vue-app-to-see-his-type-588g | typescript, vue | Hello, everyone. I am developing a Vue 3 app with Vuetify 3 and Pinia. I'm functional on all of those but far from massively experienced with them. I'm trying to add Typescript to the mix because I'm quite excited about the good things Typescript does with respect to type safety.
My app, especially the main Pinia sto... | franklee |
1,900,352 | Manipulating Elements | Changing Content innerHTML: Gets or sets the HTML content inside an... | 0 | 2024-06-25T15:38:17 | https://dev.to/__khojiakbar__/manipulating-elements-1m5g | dom, javascript, manipulation | ## Changing Content
- **innerHTML:** Gets or sets the HTML content inside an element.
```
element.innerHTML = '<p>New Content</p>';
```
- **textContent:** Gets or sets the text content of an element.
```
element.textContent = 'New Text';
```
- **innerText:** Similar to textContent but takes into account CSS styling.... | __khojiakbar__ |
1,900,351 | Why are marketing strategies important for running a business? | In today's competitive business landscape, effective marketing strategies are indispensable for... | 0 | 2024-06-25T15:37:26 | https://dev.to/richamishra/why-are-marketing-strategies-important-for-running-a-business-1ald | marketing, business, startup | In today's competitive business landscape, effective marketing strategies are indispensable for success. From enhancing brand visibility to driving sales and fostering customer loyalty, these strategies play a pivotal role in shaping a company's growth trajectory. By strategically reaching and engaging target audiences... | richamishra |
1,900,350 | Object reference not set to an instance of an object | I'm pretty new to C# coming from a VB.Net environment. This error message isn't new to me, however,... | 0 | 2024-06-25T15:37:22 | https://dev.to/blakemckenna/object-reference-not-set-to-an-instance-of-an-object-3c58 | I'm pretty new to C# coming from a VB.Net environment. This error message isn't new to me, however, in this context, I'm really not sure why this is happening. I've created a datasource with several tables which each table is connected to a ListBox control via a DataAdapter. If I comment out the line in error, the prog... | blakemckenna | |
1,900,349 | Serving different routes depending the port webserver serves my applciation in laravel. | Dude check this out: How I resolve... | 0 | 2024-06-25T15:35:30 | https://dev.to/pcmagas/serving-different-routes-depending-the-port-webserver-serves-my-applciation-in-laravel-5fi9 | howto, laravel, php | Dude check this out:
{% stackoverflow 78668284 %}
I managed to serve a same application with different routes depending the port that webserver serves the application. | pcmagas |
1,900,348 | Sass II - Funciones avanzadas | Sass II Operador & El operador & en SASS es un operador de... | 0 | 2024-06-25T15:34:20 | https://dev.to/fernandomoyano/sass-ii-funciones-avanzadas-14m | spanish | # Sass II
---
## Operador &
---
El operador **&** en SASS es un operador de referencia que se utiliza para hacer referencia al selector actual dentro de una regla anidada. Es especialmente útil para aplicar estilos a pseudo-clases, pseudo-elementos, y combinadores, así como para anidar selectores complejos de maner... | fernandomoyano |
1,900,347 | I would like to get comments on Adaptive Playback Speed, which I developed to reduce video freezes. | Greetings everyone, I would like to get your comments about the video player that will work with the... | 0 | 2024-06-25T15:32:06 | https://dev.to/ahmetilhn/i-would-like-to-get-comments-on-adaptive-playback-speed-which-i-developed-to-reduce-video-freezes-4n8i | javascript, react, vue, webdev | Greetings everyone, I would like to get your comments about the video player that will work with the Adaptive Streaming and Adaptive Playback Speed approaches I am working on.
The video player I mentioned slows down the buffer flow in the video buffer zone when the internet speed is low and increases the time until ... | ahmetilhn |
1,900,346 | Embracing Digital Twins Technology - Key Considerations, Challenges, and Critical Enablers | Digital Twins technology has emerged as a transformative force in various industries, providing a... | 0 | 2024-06-25T15:30:43 | https://victorleungtw.com/2024/06/25/digital-twins/ | digitaltwins, analytics, iot, ai | Digital Twins technology has emerged as a transformative force in various industries, providing a virtual representation of physical systems that uses real-time data to simulate performance, behavior, and interactions. This blog post delves into the considerations for adopting Digital Twins technology, the challenges a... | victorleungtw |
1,900,345 | LeetCode Day 17 Binary Tree Part 7 | 701. Insert into a Binary Search Tree You are given the root node of a binary search tree... | 0 | 2024-06-25T15:28:40 | https://dev.to/flame_chan_llll/leetcode-day-17-binary-tree-part-7-1emk | leetcode, java, algorithms, datastructures | # 701. Insert into a Binary Search Tree
You are given the root node of a binary search tree (BST) and a value to insert into the tree. Return the root node of the BST after the insertion. It is guaranteed that the new value does not exist in the original BST.
Notice that there may exist multiple valid ways for the ins... | flame_chan_llll |
1,900,343 | Unlocking Affordable Storage Magic: Our Journey with Uploadthing! 🚀✨ | I was working on a project where we have to store PDFs in a storage bucket or any storage solution.... | 0 | 2024-06-25T15:27:59 | https://dev.to/shu12388y/unlocking-affordable-storage-magic-our-journey-with-uploadthing-41ma | webdev, javascript, aws, nextjs | I was working on a project where we have to store PDFs in a storage bucket or any storage solution. Initially, we were storing the PDFs in an AWS S3 bucket so that users could easily access the content of the PDFs. However, as we know, the pricing of the S3 bucket is high.🔥.
So, we are looking for some good alternati... | shu12388y |
1,900,342 | Need help setting up multiline parsers. | I have setup a multiline parser in my fluentbit.conf have tried the multiline parser with a base... | 0 | 2024-06-25T15:25:58 | https://dev.to/prem_sharma_3a951c400b378/need-help-setting-up-multiline-parsers-3ali | fluentbit, help | I have setup a multiline parser in my fluentbit.conf have tried the multiline parser with a base config on local cli and it seems to work there however when i add the parser to my production config the final optput is not taking the lines. below is my configuration that is not working. what am i missing
configs i tried... | prem_sharma_3a951c400b378 |
1,900,144 | Generating logos with GPT and text-to-image AI models (Stable Diffusion V2, V3, SDXL) | In this quick tutorial, we will create a no-code AI agent for generating logos using Aiflowly.com. ... | 0 | 2024-06-25T15:24:29 | https://dev.to/appbaza/generating-logos-with-gpt-and-text-to-image-ai-models-stable-diffusion-v2-v2-and-sdxl-3dpe | ai, agent, llm, nocode | In this quick tutorial, we will create a no-code AI agent for generating logos using [Aiflowly.com](https://www.aiflowly.com/).
# Workflow
Our AI agent will be able to:
1. Read short user input for a logo topic.
2. Pass it to text-to-text AI mode (we will use OpenAI's GPT models) and generate an advanced prompt for ... | appbaza |
1,892,980 | Implementing an Interceptor for RestClient (Java + Spring Boot) | Hello, everyone! Today, I'll be showing you a straightforward way to set up an interceptor in the new... | 0 | 2024-06-25T15:23:33 | https://dev.to/felipejansendev/implementing-an-interceptor-for-restclient-java-spring-boot-3h75 | java, spring, springboot | Hello, everyone! Today, I'll be showing you a straightforward way to set up an interceptor in the new RestClient class of the Spring Framework.
1º) First, let's create our project. We'll keep it simple, just for study purposes.

# Real-Time Stream Processing with AWS Lambda and Kinesis: Building Real-Time Analytics Pipelines
In today's data-driven world, businesses need to process and analyze data in real time to gain insights and make timely decisions. Rea... | virajlakshitha | |
1,900,244 | DEjango twilio mms fowarding | I have a small web page for my pigeon club. I use Twilio to send 1 direction messages. I want to be... | 0 | 2024-06-25T15:09:26 | https://dev.to/tim_bennett_d721431c8295a/dejango-twilio-mms-fowarding-309b | I have a small web page for my pigeon club. I use Twilio to send 1 direction messages. I want to be able to send a pic to the Twilio number and forward to multiple numbers. I can receive the message but do not know how to forward the image from my message. Any help would be great.
`@csrf_exempt
def mms_reply(self... | tim_bennett_d721431c8295a | |
1,900,243 | Mastering Python’s re Module: A Comprehensive Guide to Regular Expressions | by Gaurav Kumar | Regular expressions are a powerful tool for matching patterns in the text which can be used for data... | 0 | 2024-06-25T15:09:03 | https://dev.to/tankala/mastering-pythons-re-module-a-comprehensive-guide-to-regular-expressions-by-gaurav-kumar-30i4 | webdev, beginners, programming, python | Regular expressions are a powerful tool for matching patterns in the text which can be used for data validation, text processing and many other places. Gaurav Kumar covered Python's re module and also about Regular expressions extensively in this article.
{% embed https://gaurav-adarshi.medium.com/mastering-pythons-re... | tankala |
423,629 | NodeJs + GraphQL Courses | Somebody knows an advanced NodeJs course with GraphQL ? | 0 | 2020-08-10T11:48:41 | https://dev.to/mb3n/nodejs-graphql-courses-3p6m | javascript, typescript, node, graphql | Somebody knows an advanced NodeJs course with GraphQL ? | mb3n |
1,900,242 | LMDX: Language Model-based Document Information Extraction and Localization | LMDX: Language Model-based Document Information Extraction and Localization | 0 | 2024-06-25T15:02:11 | https://aimodels.fyi/papers/arxiv/lmdx-language-model-based-document-information-extraction | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LMDX: Language Model-based Document Information Extraction and Localization](https://aimodels.fyi/papers/arxiv/lmdx-language-model-based-document-information-extraction). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi ne... | mikeyoung44 |
1,900,241 | Large language models surpass human experts in predicting neuroscience results | Large language models surpass human experts in predicting neuroscience results | 0 | 2024-06-25T15:01:37 | https://aimodels.fyi/papers/arxiv/large-language-models-surpass-human-experts-predicting | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Large language models surpass human experts in predicting neuroscience results](https://aimodels.fyi/papers/arxiv/large-language-models-surpass-human-experts-predicting). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi ne... | mikeyoung44 |
1,900,240 | Chain-of-Thought Unfaithfulness as Disguised Accuracy | Chain-of-Thought Unfaithfulness as Disguised Accuracy | 0 | 2024-06-25T15:01:02 | https://aimodels.fyi/papers/arxiv/chain-thought-unfaithfulness-as-disguised-accuracy | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Chain-of-Thought Unfaithfulness as Disguised Accuracy](https://aimodels.fyi/papers/arxiv/chain-thought-unfaithfulness-as-disguised-accuracy). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.su... | mikeyoung44 |
1,900,239 | EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models | EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models | 0 | 2024-06-25T15:00:28 | https://aimodels.fyi/papers/arxiv/easyedit-easy-to-use-knowledge-editing-framework | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models](https://aimodels.fyi/papers/arxiv/easyedit-easy-to-use-knowledge-editing-framework). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslett... | mikeyoung44 |
1,900,238 | The Impact of Reasoning Step Length on Large Language Models | The Impact of Reasoning Step Length on Large Language Models | 0 | 2024-06-25T14:59:53 | https://aimodels.fyi/papers/arxiv/impact-reasoning-step-length-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [The Impact of Reasoning Step Length on Large Language Models](https://aimodels.fyi/papers/arxiv/impact-reasoning-step-length-large-language-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimo... | mikeyoung44 |
1,900,237 | Codedex.io Project 1 - HTML | Hiya! Documenting the journey! Here is my first project with Codedex program for HTML. 📝... | 0 | 2024-06-25T14:59:45 | https://dev.to/jade0x/codedexio-project-1-html-2i4n | learning, html, coding | **Hiya!**
Documenting the journey! Here is my first project with Codedex program for HTML.
## 📝 The Project
I created a restaurant menu webpage using HTML. Here are the guidelines:
### Final Project
Congratulations on finishing all of the chapters in The Origins I: HTML! Now let’s use the skills we’ve gained thr... | jade0x |
1,900,236 | JavaFX In Action with Christopher Schnick about XPipe, an app to manage all your servers | In the next video in this "JFX In Action" series, I talked with Christopher Schnick about... | 27,855 | 2024-06-25T14:59:40 | https://webtechie.be/post/2024-06-18-jfxinaction-christopher-schnick/ | java, javafx, interview, ui | In the next video in this "JFX In Action" series, I talked with Christopher Schnick about XPipe.
{% embed https://www.youtube.com/watch?v=mZV1OJ23d2c %}
## About Christopher Schnick
Christopher is a software engineer with experience in the Java ecosystem and desktop application development. He is passionate about de... | fdelporte |
1,900,235 | Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning | Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning | 0 | 2024-06-25T14:59:18 | https://aimodels.fyi/papers/arxiv/q-improving-multi-step-reasoning-llms-deliberative | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning](https://aimodels.fyi/papers/arxiv/q-improving-multi-step-reasoning-llms-deliberative). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](ht... | mikeyoung44 |
1,900,188 | Congrats to our first Computer Science Challenge Winners! | Woohoo! It’s time to announce the winners of the Computer Science Challenge. We challenged you all... | 0 | 2024-06-25T14:58:57 | https://dev.to/devteam/congrats-to-our-first-computer-science-challenge-winners-2mg2 | devchallenge, cschallenge, computerscience, beginners | Woohoo! It’s time to announce the winners of the [Computer Science Challenge](https://dev.to/challenges/cs).
We challenged you all to explain a computer science concept in 256 characters or less. In return, we got to see all the different ways creativity was stretched when explaining concepts such as recursion, big o ... | thepracticaldev |
1,900,234 | Efficient LLM inference solution on Intel GPU | Efficient LLM inference solution on Intel GPU | 0 | 2024-06-25T14:58:44 | https://aimodels.fyi/papers/arxiv/efficient-llm-inference-solution-intel-gpu | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Efficient LLM inference solution on Intel GPU](https://aimodels.fyi/papers/arxiv/efficient-llm-inference-solution-intel-gpu). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or f... | mikeyoung44 |
1,900,233 | A Survey on In-context Learning | A Survey on In-context Learning | 0 | 2024-06-25T14:58:09 | https://aimodels.fyi/papers/arxiv/survey-context-learning | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [A Survey on In-context Learning](https://aimodels.fyi/papers/arxiv/survey-context-learning). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twi... | mikeyoung44 |
1,900,232 | JavaFX In Action with Daniel Zimmermann about JavaFX and Kotlin | For the second video in this "JFX In Action" series, I talked to Daniel Zimmermann. He got my... | 27,855 | 2024-06-25T14:57:50 | https://webtechie.be/post/2024-06-12-jfxinaction-daniel-zimmermann/ | java, javafx, kotlin, interview | For the second video in this "JFX In Action" series, I talked to Daniel Zimmermann. He got my attention when he recently tweeted: ["To your dismay I have to tell you I write all my desktop applications using Kotlin and JavaFX"](https://x.com/DystopianSnow/status/1793140611773554938). Why is he a big Kotlin AND JavaFX f... | fdelporte |
1,900,231 | Jellyfish: A Large Language Model for Data Preprocessing | Jellyfish: A Large Language Model for Data Preprocessing | 0 | 2024-06-25T14:57:35 | https://aimodels.fyi/papers/arxiv/jellyfish-large-language-model-data-preprocessing | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Jellyfish: A Large Language Model for Data Preprocessing](https://aimodels.fyi/papers/arxiv/jellyfish-large-language-model-data-preprocessing). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.... | mikeyoung44 |
1,900,230 | Building a Static Website with Terraform: Step-by-Step Guide | Creating and hosting a static website has never been easier with the power of Infrastructure as Code... | 0 | 2024-06-25T14:57:17 | https://dev.to/kaviya_kathirvelu_0505/building-a-static-website-with-terraform-step-by-step-guide-38c6 | aws, cloudcomputing, awscloudclubs | Creating and hosting a static website has never been easier with the power of Infrastructure as Code (IaC) and cloud services. In this guide, we'll walk you through setting up a static website using Terraform to manage AWS resources. You'll learn how to automate the creation of an S3 bucket, configure it for static web... | kaviya_kathirvelu_0505 |
1,900,229 | Where there's a will there's a way: ChatGPT is used more for science in countries where it is prohibited | Where there's a will there's a way: ChatGPT is used more for science in countries where it is prohibited | 0 | 2024-06-25T14:57:00 | https://aimodels.fyi/papers/arxiv/where-theres-will-theres-way-chatgpt-is | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Where there's a will there's a way: ChatGPT is used more for science in countries where it is prohibited](https://aimodels.fyi/papers/arxiv/where-theres-will-theres-way-chatgpt-is). If you like these kinds of analysis, you should subscribe to the [AImo... | mikeyoung44 |
1,900,228 | Transcendence: Generative Models Can Outperform The Experts That Train Them | Transcendence: Generative Models Can Outperform The Experts That Train Them | 0 | 2024-06-25T14:56:26 | https://aimodels.fyi/papers/arxiv/transcendence-generative-models-can-outperform-experts-that | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Transcendence: Generative Models Can Outperform The Experts That Train Them](https://aimodels.fyi/papers/arxiv/transcendence-generative-models-can-outperform-experts-that). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi ... | mikeyoung44 |
1,900,227 | MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data | MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data | 0 | 2024-06-25T14:55:51 | https://aimodels.fyi/papers/arxiv/mindeye2-shared-subject-models-enable-fmri-to | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data](https://aimodels.fyi/papers/arxiv/mindeye2-shared-subject-models-enable-fmri-to). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https... | mikeyoung44 |
1,900,226 | JavaFX In Action with Pedro Duque Vieira, aka Duke, about Hero, PDFSam, FXThemes, FXComponents,... | People who follow me know I have a big love for JavaFX. It’s my go-to for every desktop user... | 27,855 | 2024-06-25T14:55:44 | https://webtechie.be/post/2024-06-05-jfxinaction-pedro-duque-vieira-duke/ | java, javafx, interview, ui | People who follow me know I have a big love for JavaFX. It’s my go-to for every desktop user interface application I build. I love the simplicity of quickly creating an app that makes full use of the “Java powers” to build both multi-threaded “backend services” combined with a beautiful-looking UI into one executable. ... | fdelporte |
1,900,225 | Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models | Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models | 0 | 2024-06-25T14:55:17 | https://aimodels.fyi/papers/arxiv/self-play-fine-tuning-converts-weak-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models](https://aimodels.fyi/papers/arxiv/self-play-fine-tuning-converts-weak-language). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](h... | mikeyoung44 |
1,900,224 | How Susceptible are Large Language Models to Ideological Manipulation? | How Susceptible are Large Language Models to Ideological Manipulation? | 0 | 2024-06-25T14:54:42 | https://aimodels.fyi/papers/arxiv/how-susceptible-are-large-language-models-to | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [How Susceptible are Large Language Models to Ideological Manipulation?](https://aimodels.fyi/papers/arxiv/how-susceptible-are-large-language-models-to). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://... | mikeyoung44 |
1,900,223 | Hello everyone, I am looking for someone who needs to learn English in return for teaching me frontend development. | MY email - kbondar649@gmail.com MY discord - .k.i.r.i.l.l. (If you haven't found any account or not... | 0 | 2024-06-25T14:54:38 | https://dev.to/kirill_bondar_d460b050a31/hello-everyone-i-am-looking-for-someone-who-needs-to-learn-english-in-return-for-teaching-me-frontend-development-4anp | MY email - kbondar649@gmail.com
MY discord - .k.i.r.i.l.l. (If you haven't found any account or not sure, just email me) | kirill_bondar_d460b050a31 | |
1,900,222 | Large Language Models Are Zero-Shot Time Series Forecasters | Large Language Models Are Zero-Shot Time Series Forecasters | 0 | 2024-06-25T14:54:08 | https://aimodels.fyi/papers/arxiv/large-language-models-are-zero-shot-time | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Large Language Models Are Zero-Shot Time Series Forecasters](https://aimodels.fyi/papers/arxiv/large-language-models-are-zero-shot-time). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substa... | mikeyoung44 |
1,900,221 | SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages | SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages | 0 | 2024-06-25T14:53:33 | https://aimodels.fyi/papers/arxiv/seacrowd-multilingual-multimodal-data-hub-benchmark-suite | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages](https://aimodels.fyi/papers/arxiv/seacrowd-multilingual-multimodal-data-hub-benchmark-suite). If you like these kinds of analysis, you should subscribe to t... | mikeyoung44 |
1,900,220 | Is the System Message Really Important to Jailbreaks in Large Language Models? | Is the System Message Really Important to Jailbreaks in Large Language Models? | 0 | 2024-06-25T14:52:59 | https://aimodels.fyi/papers/arxiv/is-system-message-really-important-to-jailbreaks | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Is the System Message Really Important to Jailbreaks in Large Language Models?](https://aimodels.fyi/papers/arxiv/is-system-message-really-important-to-jailbreaks). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslett... | mikeyoung44 |
343,096 | FizzBuzz Typescript & SOLID Principles | FizzBuzz Typescript & SOLID Principles | 0 | 2020-05-24T22:30:39 | https://dev.to/st0ik/fizzbuzz-typescript-solid-principles-4e6f | fizzbuzz, interview, typescript, solid | ---
title: FizzBuzz Typescript & SOLID Principles
published: true
description: FizzBuzz Typescript & SOLID Principles
tags: #fizzbuzz #interview #typescript #solid
---
**"FizzBuzz"** is a well-known programming assignment, often used as a little test to see if a candidate for a programming job could manage to implement... | st0ik |
1,900,219 | From dotenv to dotenvx: Next Generation Config Management | The day after July 4th 🇺🇸, I wrote dotenv's first commit and released version 0.0.1 on npm. It looked... | 0 | 2024-06-25T14:52:48 | https://dotenvx.com/blog/2024/06/24/dotenvx-next-generation-config-management.html | dotenv, node | The day after July 4th 🇺🇸, I wrote [dotenv's first commit](https://github.com/motdotla/dotenv/commit/71dabbf27b699fcb7a04714709cecfc6e78892b9) and released [version 0.0.1 on npm](https://www.npmjs.com/package/dotenv/v/0.0.1). It looked like this.
<img src="https://github.com/dotenvx/dotenvx/assets/3848/632a3bf4-50f4... | dotenv |
1,900,218 | Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models | Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models | 0 | 2024-06-25T14:52:24 | https://aimodels.fyi/papers/arxiv/sycophancy-to-subterfuge-investigating-reward-tampering-large | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models](https://aimodels.fyi/papers/arxiv/sycophancy-to-subterfuge-investigating-reward-tampering-large). If you like these kinds of analysis, you should subscribe to the [AImod... | mikeyoung44 |
1,900,217 | Refusal in Language Models Is Mediated by a Single Direction | Refusal in Language Models Is Mediated by a Single Direction | 0 | 2024-06-25T14:51:49 | https://aimodels.fyi/papers/arxiv/refusal-language-models-is-mediated-by-single | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Refusal in Language Models Is Mediated by a Single Direction](https://aimodels.fyi/papers/arxiv/refusal-language-models-is-mediated-by-single). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.... | mikeyoung44 |
1,900,216 | Transformers are Multi-State RNNs | Transformers are Multi-State RNNs | 0 | 2024-06-25T14:51:13 | https://aimodels.fyi/papers/arxiv/transformers-are-multi-state-rnns | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Transformers are Multi-State RNNs](https://aimodels.fyi/papers/arxiv/transformers-are-multi-state-rnns). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter]... | mikeyoung44 |
1,900,215 | Python Essentials: A Speedy Introduction | Are you ready to dive into the exciting world of Artificial Intelligence and Machine Learning but... | 0 | 2024-06-25T14:51:02 | https://dev.to/mubbashir10/python-essentials-a-speedy-introduction-3ie1 | python, machinelearning, ai, beginners | Are you ready to dive into the exciting world of Artificial Intelligence and Machine Learning but need a quick introduction to Python first? This crash course is here to help! In this article, we'll cover the basics of Python programming to get you up to speed quickly. Whether you're new to programming or just need a r... | mubbashir10 |
1,900,214 | Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation | Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation | 0 | 2024-06-25T14:50:38 | https://aimodels.fyi/papers/arxiv/joint-audio-symbolic-conditioning-temporally-controlled-text | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation](https://aimodels.fyi/papers/arxiv/joint-audio-symbolic-conditioning-temporally-controlled-text). If you like these kinds of analysis, you should subscribe to the ... | mikeyoung44 |
1,900,213 | A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges | A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges | 0 | 2024-06-25T14:50:03 | https://aimodels.fyi/papers/arxiv/survey-large-language-models-financial-applications-progress | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges](https://aimodels.fyi/papers/arxiv/survey-large-language-models-financial-applications-progress). If you like these kinds of analysis, you should subscribe... | mikeyoung44 |
1,900,212 | How Do Humans Write Code? Large Models Do It the Same Way Too | How Do Humans Write Code? Large Models Do It the Same Way Too | 0 | 2024-06-25T14:49:28 | https://aimodels.fyi/papers/arxiv/how-do-humans-write-code-large-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [How Do Humans Write Code? Large Models Do It the Same Way Too](https://aimodels.fyi/papers/arxiv/how-do-humans-write-code-large-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substac... | mikeyoung44 |
1,900,211 | i Build a Cli Tool like Shadcn for Nextjs😅 | So let's Start 👇 and don't Forget to "💖🦄🔥". Hello👋 Developers! Welcome to My Another Blog... | 0 | 2024-06-25T14:49:23 | https://dev.to/random_ti/i-build-a-cli-tool-like-shadcn-for-nextjs-29e0 | webdev, javascript, beginners, programming | 
So let's Start 👇 and don't Forget to "💖🦄🔥".
Hello👋 **Developers**! Welcome to My Another Blog Post.
In this blog post, Its me you friend [Md Taqui Imam](https://mdtaquiimam.vercel.app) and i want to tell you about my la... | random_ti |
1,900,129 | String methods in JavaScript.! part(2) | 11.concat() Ikta yoki birnechta qatorlarni birlashtirish uchun ishlatiladi.! let fName_ =... | 0 | 2024-06-25T13:59:24 | https://dev.to/samandarhodiev/string-methods-in-javascript-part2-12hc |
11.<u>**`concat()`**</u>
Ikta yoki birnechta qatorlarni birlashtirish uchun ishlatiladi.!
```
let fName_ = 'samandar';
let lName_ = 'hodiev';
let l_f_Name_ = fName_.concat( lName_);
console.log(l_f_Name_);
//natija - samandarhodiev
```
12.<u>**`trim()`**</u>
Ushbu metod string elementining boshlanish va tugash qi... | samandarhodiev | |
1,900,210 | Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models | Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models | 0 | 2024-06-25T14:48:54 | https://aimodels.fyi/papers/arxiv/large-legal-fictions-profiling-legal-hallucinations-large | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models](https://aimodels.fyi/papers/arxiv/large-legal-fictions-profiling-legal-hallucinations-large). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi ... | mikeyoung44 |
1,900,209 | Evaluating the Performance of ChatGPT for Spam Email Detection | Evaluating the Performance of ChatGPT for Spam Email Detection | 0 | 2024-06-25T14:48:19 | https://aimodels.fyi/papers/arxiv/evaluating-performance-chatgpt-spam-email-detection | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Evaluating the Performance of ChatGPT for Spam Email Detection](https://aimodels.fyi/papers/arxiv/evaluating-performance-chatgpt-spam-email-detection). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://a... | mikeyoung44 |
1,900,208 | Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning | Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning | 0 | 2024-06-25T14:47:45 | https://aimodels.fyi/papers/arxiv/optimized-feature-generation-tabular-data-via-llms | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning](https://aimodels.fyi/papers/arxiv/optimized-feature-generation-tabular-data-via-llms). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi n... | mikeyoung44 |
1,900,207 | DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer | DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer | 0 | 2024-06-25T14:47:11 | https://aimodels.fyi/papers/arxiv/ditto-tts-efficient-scalable-zero-shot-text | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer](https://aimodels.fyi/papers/arxiv/ditto-tts-efficient-scalable-zero-shot-text). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsle... | mikeyoung44 |
1,900,175 | State-Compute Replication: Parallelizing High-Speed Stateful Packet Processing | State-Compute Replication: Parallelizing High-Speed Stateful Packet Processing | 0 | 2024-06-25T14:29:20 | https://aimodels.fyi/papers/arxiv/state-compute-replication-parallelizing-high-speed-stateful | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [State-Compute Replication: Parallelizing High-Speed Stateful Packet Processing](https://aimodels.fyi/papers/arxiv/state-compute-replication-parallelizing-high-speed-stateful). If you like these kinds of analysis, you should subscribe to the [AImodels.f... | mikeyoung44 |
1,900,206 | Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data | Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data | 0 | 2024-06-25T14:46:36 | https://aimodels.fyi/papers/arxiv/connecting-dots-llms-can-infer-verbalize-latent | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data](https://aimodels.fyi/papers/arxiv/connecting-dots-llms-can-infer-verbalize-latent). If you like these kinds of analysis, you should subscribe to the [AImod... | mikeyoung44 |
1,900,205 | LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing | LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing | 0 | 2024-06-25T14:46:01 | https://aimodels.fyi/papers/arxiv/llamafuzz-large-language-model-enhanced-greybox-fuzzing | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing](https://aimodels.fyi/papers/arxiv/llamafuzz-large-language-model-enhanced-greybox-fuzzing). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aim... | mikeyoung44 |
1,900,204 | TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners | TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners | 0 | 2024-06-25T14:45:27 | https://aimodels.fyi/papers/arxiv/trip-pal-travel-planning-guarantees-by-combining | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners](https://aimodels.fyi/papers/arxiv/trip-pal-travel-planning-guarantees-by-combining). If you like these kinds of analysis, you should subscribe to the [... | mikeyoung44 |
1,900,203 | Direct Home Services | Direct Home Services, your trusted HVAC contractor in Durham CT, offers top-notch heating,... | 0 | 2024-06-25T14:45:19 | https://dev.to/directhomeservices/direct-home-services-4acc |

Direct Home Services, your trusted HVAC contractor in Durham CT, offers top-notch heating, ventilation, and air conditioning solutions. With our team of skilled technicians, we specialize in providing efficient HVA... | directhomeservices | |
1,900,202 | An Image is Worth 32 Tokens for Reconstruction and Generation | An Image is Worth 32 Tokens for Reconstruction and Generation | 0 | 2024-06-25T14:44:52 | https://aimodels.fyi/papers/arxiv/image-is-worth-32-tokens-reconstruction-generation | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [An Image is Worth 32 Tokens for Reconstruction and Generation](https://aimodels.fyi/papers/arxiv/image-is-worth-32-tokens-reconstruction-generation). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aim... | mikeyoung44 |
1,900,201 | garak: A Framework for Security Probing Large Language Models | garak: A Framework for Security Probing Large Language Models | 0 | 2024-06-25T14:44:17 | https://aimodels.fyi/papers/arxiv/garak-framework-security-probing-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [garak: A Framework for Security Probing Large Language Models](https://aimodels.fyi/papers/arxiv/garak-framework-security-probing-large-language-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https:/... | mikeyoung44 |
1,900,200 | Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews | Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews | 0 | 2024-06-25T14:43:43 | https://aimodels.fyi/papers/arxiv/monitoring-ai-modified-content-at-scale-case | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews](https://aimodels.fyi/papers/arxiv/monitoring-ai-modified-content-at-scale-case). If you like these kinds of analysis, you should subscribe to ... | mikeyoung44 |
1,900,199 | Exploitation Business: Leveraging Information Asymmetry | Exploitation Business: Leveraging Information Asymmetry | 0 | 2024-06-25T14:43:08 | https://aimodels.fyi/papers/arxiv/exploitation-business-leveraging-information-asymmetry | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Exploitation Business: Leveraging Information Asymmetry](https://aimodels.fyi/papers/arxiv/exploitation-business-leveraging-information-asymmetry). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimod... | mikeyoung44 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.