
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
# BlazingText를 활용한 네이버 영화 리뷰 감성(Sentiment) 이진 분류
*본 노트북 예제는 [DBPedia Ontology Dataset의 텍스트 분류](https://github.com/awslabs/amazon-sagemaker-examples/blob/master/introduction_to_amazon_algorithms/blazingtext_text_classification_dbpedia/blazingtext_text_classification_dbpedia.ipynb) 문서에 기반하여
네이버 영화 리뷰의 텍스트 분류를 수행하는 예제입니다.*
개발자 가이드: https://github.com/awsdocs/amazon-sagemaker-developer-guide/blob/master/doc_source/blazingtext.md
## 개요
텍스트 분류(Text cassification)는 감성 분석(sentiment analysis), 스팸 탐지(spam detection), 해시 태그 예측(hashtag prediction) 등과 같은 다양한 사례들을 해결하는 데 사용될 수 있습니다. BlazingText는 최신 딥러닝 텍스트 분류 알고리즘과 동등한 성능을 달성하면서 멀티 코어 CPU 또는 GPU를 사용하여 몇 분 안에 10억 단어 이상의 모델을 훈련시킬 수 있습니다. BlazingText는 사용자 정의 CUDA 커널을 사용하여 GPU 가속을 활용하도록 FastText 텍스트 분류기를 확장합니다.
본 노트북에서는 네이버 영화 리뷰 데이터의 감성 이진 분류를 BlzaingText로 수행해 보겠습니다. 이 데이터는 총 20만개 리뷰로 구성된 데이터로 영화 리뷰에 대한 텍스트와 레이블(0: 부정, 1: 긍정)으로 구성되어 있습니다.
## Setup
학습 데이터 및 모델 아티팩트(Model Artifact) 저장에 사용될 S3 버킷(bucket) 및 접두사(prefix)는 노트북 인스턴스, 학습 및 호스팅과 같은 리전 내에 있어야 합니다. 버킷을 지정하지 않으면 SageMaker SDK는 동일 리전에서 사전에 정의된 명명 규칙에 따라 기본 버킷을 생성합니다.
데이터에 대한 엑세스 권한을 부여하는 데 사용된 IAM(Identity and Access Management) role ARN(Amazon Resource Name)은 SageMaker Python SDK의 `get_execution_role` 메소드를 사용하여 가져올 수 있습니다.
```
import sagemaker
from sagemaker import get_execution_role
import boto3
import json
sess = sagemaker.Session()
# This is the role that SageMaker would use to leverage AWS resources (S3, CloudWatch) on your behalf
role = get_execution_role()
#print(role)
#bucket = sess.default_bucket()
bucket = '[YOUR-BUCKET]' # Replace with your own bucket name if needed
prefix = 'sagemaker/DEMO-blazingtext-sentiment-analysis' #Replace with the prefix under which you want to store the data if needed
```
## 데이터 준비
https://github.com/e9t/nsmc/ 에 공개된 네이버 영화 리뷰 학습/검증 데이터를 다운로드합니다.<br>
학습 데이터는 총 15만건이며, 검증 데이터는 총 5만건입니다.
```
!wget -nc https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt -P ./data/
!wget -nc https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt -P ./data/
```
## EDA (탐색적 데이터 분석; Exploratory Data Analysis)
간단하게 EDA를 수행해 봅니다. 네이버 영화 리뷰 데이터는 정제가 잘 되어 있는 편이지만, 실제 데이터들은 클래스 불균형(class imbalance)한 데이터도 많고 데이터 정제가 필요한 경우가 많기에 EDA를 통해 데이터의 분포, 통계량 등을 확인하는 것이 좋습니다.
먼저 판다스(pandas)로 학습/검증 데이터를 로드해서 데이터를 확인해 보겠습니다. <br>
`id`는 고유 id 이며, `document`는 영화 리뷰 문장, `label`은 긍정/부정 여부입니다. (긍정: 1, 부정: 0)
```
import pandas as pd
import numpy as np
from wordcloud import WordCloud
train_df = pd.read_csv('./data/ratings_train.txt', header=0, delimiter='\t')
test_df = pd.read_csv('./data/ratings_test.txt', header=0, delimiter='\t')
train_df.head()
```
EDA를 위해 문자 개수 및 단어 개수를 계산합니다.
```
# character count 계산
train_df['char_cnt'] = train_df['document'].astype(str).apply(len)
test_df['char_cnt'] = test_df['document'].astype(str).apply(len)
# word count 계산
train_df['word_cnt'] = train_df['document'].astype(str).apply(lambda x: len(x.split(' ')))
test_df['word_cnt'] = train_df['document'].astype(str).apply(lambda x: len(x.split(' ')))
train_df.head()
```
한글 출력을 위한 설정입니다.
```
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
font_files = fm.findSystemFonts(fontpaths='/usr/share/fonts/nanum', fontext='ttf')
font_list = fm.createFontList(font_files)
fm.fontManager.ttflist.extend(font_list)
mpl.rcParams['font.family'] = 'NanumGothic'
mpl.rc('axes', unicode_minus=False)
mpl.rcParams['font.size'] = 14
```
문자 개수와 단어 개수를 확인해 봅니다.
```
plt.figure(figsize=(12,5))
plt.hist(train_df['char_cnt'], bins=250, alpha=0.5, color='b', label='word')
plt.title('Histogram of Character Count of Naver Movie Review')
plt.xlabel('문자 개수')
plt.figure(figsize=(12,5))
plt.hist(train_df['word_cnt'], bins=75, alpha=0.5, color='b', label='train')
plt.yscale('log', nonposy='clip')
plt.title('Log Histogram of Word Count of Naver Movie Review')
plt.xlabel('단어 개수')
```
워드 클라우드로 자주 등장하는 단어들을 확인합니다. `영화, 진짜, 너무, 정말` 등의 단어들이 많이 사용된 것을 확인할 수 있습니다.
```
%%time
train_review = [row for row in train_df['document'] if type(row) is str]
wordcloud = WordCloud(font_path='/usr/share/fonts/nanum/NanumGothic.ttf').generate(' '.join(train_review))
plt.figure(figsize=(10,6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
```
기본 통계를 확인해 봅니다.
```
def print_basic_stats(df, col_name):
print('===== {} ====='.format(col_name))
print('Maximum: {}'.format(np.max(df[col_name])))
print('Minimum: {}'.format(np.min(df[col_name])))
print('Mean: {:.3f}'.format(np.mean(df[col_name])))
print('Stddev: {:.3f}'.format(np.std(df[col_name])))
print('1st quartile: {}'.format(np.percentile(df[col_name], 25)))
print('Median: {}'.format(np.median(df[col_name])))
print('3rd quartile: {}'.format(np.percentile(df[col_name], 75)))
print_basic_stats(train_df, 'char_cnt')
print_basic_stats(train_df, 'word_cnt')
```
클래스 균형을 확인합니다. 본 데이터는 거의 1:1 비율을 보여주고 있지만, 실제 데이터는 95:5 같은 불균형 데이터들도 많다는 점을 숙지해 주세요.
```
import seaborn as sns
sns.countplot(train_df['label'])
train_df['label'].value_counts()
```
## Data Preprocessing
BlazingText 알고리즘으로 분류 문제를 학습하기 위해서는 말뭉치 데이터의 각 문장의 클래스 레이블 앞에 `__label__`을 접두사로 붙여야 합니다. 변환 예시는 아래를 참조해 주세요.
```
__label__0 아 더빙.. 진짜 짜증나네요 목소리
__label__1 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나
```
또한, 본 노트북에서는 정규식을 활용하여 탭(tab) 문자, 구두점(punctuation) 문자, 한글 문자가 아닌 문자를 제거하는 간단한 전처리를 수행해 보겠습니다.
```
def preprocess_text(corpus_path, output_path):
import re
with open(corpus_path, 'r', encoding='utf-8') as f, \
open(output_path, 'w', encoding='utf-8') as fw:
next(f)
for line in f:
# Remove tab
_, sentence, label = line.strip().split('\t')
# Remove punctuations
sentence = re.sub('[\.\,\(\)\{\}\[\]\`\'\!\?\:\;\-\=]', ' ', sentence)
# Remove non-Korean characters
sentence = re.sub('[^가-힣ㄱ-하-ㅣ\\s]', '', sentence)
if not sentence: continue
fw.writelines('__label__' + label + ' '+ sentence + '\n')
```
#### 학습 데이터 전처리 수행
```
corpus_path = 'data/ratings_train.txt'
output_path = 'data/ratings_train_preprocessd'
preprocess_text(corpus_path, output_path)
!head data/ratings_train_preprocessd -n 5
```
#### 검증 데이터 전처리 수행
```
corpus_path = 'data/ratings_test.txt'
output_path = 'data/ratings_test_preprocessd'
preprocess_text(corpus_path, output_path)
!head data/ratings_test_preprocessd -n 5
```
#### S3 경로 설정
```
train_channel = prefix + '/train'
validation_channel = prefix + '/validation'
sess.upload_data(path='data/ratings_train_preprocessd', bucket=bucket, key_prefix=train_channel)
sess.upload_data(path='data/ratings_test_preprocessd', bucket=bucket, key_prefix=validation_channel)
s3_train_data = 's3://{}/{}'.format(bucket, train_channel)
s3_validation_data = 's3://{}/{}'.format(bucket, validation_channel)
```
모델 아티팩트(Model Artifact)가 저장될 S3의 경로를 설정합니다.
```
s3_output_location = 's3://{}/{}/output'.format(bucket, prefix)
print(s3_train_data, s3_validation_data, s3_output_location)
```
## Training
이제 학습에 필요한 데이터가 준비되었으므로 `sageMaker.estimator.Estimator` 객체를 생성하여 학습을 수행해 봅니다.
```
region_name = boto3.Session().region_name
container = sagemaker.amazon.amazon_estimator.get_image_uri(region_name, "blazingtext", "latest")
print('SageMaker BlazingText 컨테이너 위치: {} ({})'.format(container, region_name))
```
SageMaker BlazingText는 Word2Vec의 원래 구현과 유사하게 네거티브 샘플링(Negative Sampling)을 사용하여 CPU 및 GPU(들)에서 CBOW(Continuous Bag-of-Words) 및 스킵 그램(Skip-gram) 아키텍처를 효율적으로 구현합니다. GPU 구현은 고도로 최적화된 CUDA 커널을 사용합니다. 자세한 내용은 [*BlazingText: Scaling and Accelerating Word2Vec using Multiple GPUs*](https://dl.acm.org/citation.cfm?doid=3146347.3146354)를 참조하세요.
또한, BlazingText는 CBOW 및 스킵 그램 모드로 서브 워드(subwords) 임베딩 학습을 지원합니다. 이를 통해 BlazingText는 out-of-vocabulary(OOV)를 생성할 수 있습니다.
서브 워드 임베딩 학습은 [notebook (text8 데이터셋 서브 워드 임베딩)](https://github.com/awslabs/amazon-sagemaker-examples/blob/master/introduction_to_amazon_algorithms/blazingtext_word2vec_subwords_text8/blazingtext_word2vec_subwords_text8.ipynb)을 참조하세요.
스킵 그램 및 CBOW 외에도 SageMaker BlazingText는 효율적인 미니 배치 및 행렬 연산을 수행하는 "배치 스킵 그램(Batch Skipgram)" 모드도 지원합니다. ([BLAS Level 3 routines](https://software.intel.com/en-us/mkl-developer-reference-fortran-blas-level-3-routines)) 이 모드는 여러 CPU 노드에 걸쳐 분산된 Word2Vec의 학습을 가능하게 하여 보다 빠른 학습이 가능합니다. 자세한 내용은 [*Parallelizing Word2Vec in Shared and Distributed Memory*](https://arxiv.org/pdf/1604.04661.pdf)를 참조하세요.
BlazingText는 텍스트 분류를 위한 교사 학습(supervised learning)도 지원하며, 사용자 지정 CUDA 커널을 사용하여 GPU 가속을 활용하도록 FastText 텍스트 분류기를 확장합니다. 이 모델은 최신 딥러닝 텍스트 분류 알고리즘과 동등한 성능을 달성하면서 멀티 코어 CPU 또는 GPU를 사용하여 몇 분 안에 10억 단어 이상을 학습할 수 있습니다. 자세한 내용은 [알고리즘 설명서](https://docs.aws.amazon.com/sagemaker/latest/dg/blazingtext.html)를 참조하세요.
아래 표는 BlazingText에서 지원하는 모드입니다.
| Modes | cbow (서브워드 학습 지원) | skipgram (서브워드 학습 지원) | batch_skipgram | supervised |
|:----------------------: |:----: |:--------: |:--------------:| :--------------:|
| 단일 CPU 인스턴스 | ✔ | ✔ | ✔ | ✔ |
| 단일 GPU 인스턴스 | ✔ | ✔ | X | ✔ (1 GPU 인스턴스만 지원) |
| 다중 CPU 인스턴스 | X | X | ✔ | X |
```
bt_model = sagemaker.estimator.Estimator(container,
role,
train_instance_count=1,
train_instance_type='ml.c4.2xlarge',
train_volume_size=30,
train_max_run=360000,
input_mode='File',
output_path=s3_output_location,
sagemaker_session=sess)
```
BlazingText 하이퍼파라메터의 자세한 설정 방법은 [이 문서](https://docs.aws.amazon.com/sagemaker/latest/dg/blazingtext_hyperparameters.html)를 참조해 주세요.
```
bt_model.set_hyperparameters(mode="supervised",
epochs=30,
min_count=2,
learning_rate=0.005,
vector_dim=100,
early_stopping=True,
patience=4, # Number of epochs to wait before early stopping if no progress on the validation set is observed
buckets=2000000, # Number of hash buckets to use for word n-grams
min_epochs=5,
word_ngrams=2)
```
학습을 위한 `sagemaker.session.s3_input` 객체를 생성하여 데이터 채널을 알고리즘과 연결합니다.
```
train_data = sagemaker.session.s3_input(s3_train_data, distribution='FullyReplicated',
content_type='text/plain', s3_data_type='S3Prefix')
validation_data = sagemaker.session.s3_input(s3_validation_data, distribution='FullyReplicated',
content_type='text/plain', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data}
```
지금까지 `Estimator` 객체에 대한 하이퍼파라미터를 설정했으며 데이터 채널을 알고리즘과 연결했습니다. 남은 것은 `fit` 메소드로 학습하는 것뿐입니다.<br>
학습에는 몇 가지 단계가 포함됩니다. 먼저 `Estimator` 클래스를 작성하는 동안 요청한 인스턴스가 프로비저닝되고 적절한 라이브러리로 설정됩니다. 그 다음 채널의 데이터가 학습 인스턴스로 다로드되며 이후 학습 작업이 시작됩니다. 데이터 크기에 따라 프로비저닝 및 데이터 다운로드에 시간이 다소 걸리며, 이에 따라 학습 작업에 따른 로그를 확인하는 데 몇 분이 걸립니다.
로그는 `min_epochs`(이 파라메터는 학습에 최소로 필요한 epoch 횟수입니다) 이후 모든 epoch에 대한 검증 데이터의 정확도(accuracy)를 출력합니다.
학습이 완료되면 "작업 완료(Job compelete)" 메시지가 출력됩니다. 학습된 모델은 `Estimator`에서 `output_path`로 설정된 S3 버킷에서 찾을 수 있습니다.
```
bt_model.fit(inputs=data_channels, logs=True)
```
#### Tip
데이터셋이 잘 정제되어 있어 전처리를 거의 수행하지 않았음에도 검증셋에서 비교적 높은 정확도(accuracy)를 보입니다.
이를 baseline으로 잡고 불용어(stopword) 제거, 형태소 분석 등의 전처리와 하이퍼파라메터 튜닝을 통해
좀 더 높은 정확도를 달성할 수 있습니다. 특히, 한국어 데이터의 다운스트림 작업들은 하이퍼파라메터 튜닝보다는 전처리가 훨씬 중요하니 이 점을 유의해 주세요.
## Hosting / Inference
학습을 완료하면 모델을 Amazon SageMaker 실시간 호스팅 엔드포인트(real-time hosted endpoint)로 배포할 수 있고, 이를 통해 모델로부터 추론(inference)을 수행합니다. (추론은 예측; prediction 이라고도 합니다.) 실시간 추론 수행 시 엔드포인트는 계속 가동되어야 하므로, 추론을 위해 저렴한 인스턴스를 선택하시는 것을 권장합니다.
이 과정은 약 10분 정도 소요됩니다.
```
text_classifier = bt_model.deploy(initial_instance_count = 1,instance_type = 'ml.m4.xlarge')
```
#### Use JSON format for inference
BlazingText는 추론을 위한 컨텐츠 유형(content-type)으로 `application/json` 을 지원합니다. 엔드포인트로 전달할 입력 문장은 "**instances**" 키가 반드시 포함되어야 합니다.
```
import nltk
nltk.download('punkt')
sentences = ["재미있게 봤습니다. 제 점수는요 100점 만점에 80점 드리겠습니다.",
"스토리가 너무 단방향이라 재미가 없고 성우 더빙도 그닥이네요..."]
tokenized_sentences = [' '.join(nltk.word_tokenize(sent)) for sent in sentences]
payload = {"instances" : tokenized_sentences}
response = text_classifier.predict(json.dumps(payload))
predictions = json.loads(response)
print(json.dumps(predictions, indent=2))
```
기본적으로는 확률이 가장 높은 예측 결과(top-1 prediction)만 반환합니다. 상위 k개의 예측(top-k prediction)을 얻으려면 `configuration` key에서 `k`를 지정하면 됩니다. 아래 code snippet을 참조해 주세요.
```python
payload = {"instances" : tokenized_sentences,
"configuration": {"k": 2}}
response = text_classifier.predict(json.dumps(payload))
predictions = json.loads(response)
print(json.dumps(predictions, indent=2))
```
## Stop / Close the Endpoint (Optional)
실시간 예측을 제공하기 위해 엔드포인트를 계속 실행할 필요가 없는 경우, 과금을 막기 위해 엔드포인트를 삭제합니다.
```
sess.delete_endpoint(text_classifier.endpoint)
```
| github_jupyter |
Now here's my first deep neural net (multilayer perceptron), I'll use the [MNIST][1] dataset.
[1]:https://en.wikipedia.org/wiki/MNIST_database
```
import tensorflow as tf
import numpy as np
#first get the dataset
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
X_train = mnist.train.images
X_test = mnist.test.images
y_train = mnist.train.labels.astype("int")
y_test = mnist.test.labels.astype("int")
print(X_train)
print(y_train)
#visualization
print(X_train.shape)
```
With that we can see that the mnist dataset is conformed by 55000 images each one containing 784 pixels having a square shape of 28 pixels * 28 pixels
```
#defining our neural net
n_inputs = 784 # MNIST data input (img shape: 28*28)
n_hidden1 = 300 # number of features(neurons) in this layer
n_hidden2 = 100 # number of fatures(neurons) in layer 2
n_outputs = 10 # these are our classes (0-9 digits)
# Placeholders for inputs and outputs
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
def neuron_layer(X, n_neurons, name, activation=None):
with tf.name_scope(name):
n_inputs = int(X.get_shape()[1])
stddev = 2 / np.sqrt(n_inputs)
init = tf.truncated_normal((n_inputs, n_neurons), stddev=stddev)
W = tf.Variable(init, name="weights")
b = tf.Variable(tf.zeros([n_neurons]), name="biases")
z = tf.matmul(X, W) + b
if activation=="relu":
return tf.nn.relu(z)
else:
return z
with tf.name_scope("dnn"):
hidden1 = neuron_layer(X, n_hidden1, "hidden1", activation="relu")
hidden2 = neuron_layer(hidden1, n_hidden2, "hidden2", activation="relu")
logits = neuron_layer(hidden2, n_outputs, "outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,labels= y)
loss = tf.reduce_mean(xentropy, name="loss")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
n_epochs = 47
n_batches = 100
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size )
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={X: mnist.test.images,y: mnist.test.labels})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
save_path = saver.save(sess, "first_neural_net.ckpt")
with tf.Session() as sess:
saver.restore(sess, "my_model_final.ckpt")
X_new_scaled = [...] # some new images (scaled from 0 to 1)
Z = logits.eval(feed_dict={X: X_new_scaled})
y_pred = np.argmax(Z, axis=1)
```
| github_jupyter |
Output: file "de/all_labour.csv"
# Load German labor market statistics
```
from xlrd import open_workbook
import pandas as pd
import numpy as np
book = open_workbook('de/bo-heft-d-0-201506-xlsx.xlsx')
sheet=book.sheet_by_name("SVB - Tabelle I")
# read header values into the list
keys = [sheet.cell(9, col_index).value for col_index in xrange(sheet.ncols)]
keys[0]="Berufsgruppen"
keys[1]="Ingesamt"
keys=keys[:4]
dict_list = []
for row_index in xrange(13, sheet.nrows-3):
d = {keys[col_index]: sheet.cell(row_index, col_index).value
for col_index in xrange(0,4)}
dict_list.append(d)
for i, val in enumerate(dict_list):
dict_list[i]["KldB"]=val["Berufsgruppen"].split(" ",1)[0]
dict_list[i]["Berufsgruppen"]=val["Berufsgruppen"].split(" ",1)[1]
#select only subsub groups
subsubgroups=[]
for i, val in enumerate(dict_list):
if len(dict_list[i]["KldB"]) ==4:
subsubgroups.append(dict_list[i])
subsubgroups_df=pd.DataFrame.from_dict(subsubgroups)
#print soubgroups without values in cells
#subsubgroups_df[~subsubgroups_df[["Frauen","Ingesamt",u'M\xe4nner']].applymap(np.isreal).all(1)]
#dell all 0s
df_all=subsubgroups_df[subsubgroups_df[["Frauen","Ingesamt",u'M\xe4nner']].applymap(np.isreal).all(1)]
print len(df_all)
df_all['Frauen_ratio'] = df_all.Frauen*100/df_all.Ingesamt
df_all.to_csv("de/labourmarket_subgroups.csv", sep='\t', encoding='utf-8')
```
# Read file with profession names (Classificator)
```
book = open_workbook('de/Alphabetisches-Verzeichnis-Berufsbenennungen-Stand12032015.xls')
sheet=book.sheet_by_name("alphabet_Verz_Berufsb")
profession={}
for row_index in xrange(5, sheet.nrows-2):
profession[sheet.cell(row_index, 0).value]=str(int(sheet.cell(row_index, 1).value))\
if str(sheet.cell(row_index, 1).value)[0]!="0" else str(sheet.cell(row_index, 1).value)
```
# Match professions to coresponding profession subgroups
```
import re
k=0
g=0
x=0
profession_1={}
profession_2={}
profession_2_2={}
profession_3_0={}
for i in profession:
if "(e/in)" in i:
j=i.replace("(e/in)","e")
x+=1
elif "(er/in)" in i:
j=i.replace("(er/in)","er")
elif "e/r" in i:
j=i.replace("e/r","er")
elif "mann/-frau" in i:
j=i.replace("mann/-frau","mann")
elif "verk\xe4ufer/in".decode('ISO 8859-16') in i:
j=i.replace("verk\xe4ufer/in".decode('ISO 8859-16'),"verk\xe4ufer".decode('ISO 8859-16'))
elif "keramiker/in" in i:
j=i.replace("keramiker/in","keramiker")
elif "Medientechnologe/-technologin" in i:
j=i.replace("Medientechnologe/-technologin","Medientechnologe")
else:
j=i.replace("er/in","er")
j=re.sub("[*?\(\[].*?[\)\]]", "", j).strip()
if len(j.split("/"))>2:
#print i
k+=1
profession_3_0[j.split("/")[0]]=profession[i]
elif len(j.split("/"))==2:
profession_2[j.split("/")[0].replace("(","").strip()]=profession[i]
if j.split("/")[1][0].isupper():
profession_2_2[re.sub("[*?\(\[].*?[\)\]]", "", j.split("/")[1]).strip()]=profession[i]
else:
g+=1
profession_1[j]=profession[i]
print k,len(profession_3_0),len(profession_2),len(profession_1),g,x
#before addine replace("er/in","er")
print k,len(profession_3_0),len(profession_2),len(profession_1),g,x
import json
def load_simple_json(filename):
with open(filename, 'r') as f:
return json.load(f)
def find_appropriate_prof(page_m,words,profession,profession_2,profession_2_2,profession_1,profession_3_0):
g=0
l=0
s=0
y=0
y1=0
y2=0
yy=0
page_m_index={}
other=[]
for i in page_m:
if i in profession.keys():
page_m_index[i]=profession[i]
elif i in profession_2.keys():
page_m_index[i]=profession_2[i]
elif i in profession_2_2.keys():
page_m_index[i]=profession_2_2[i]
l+=1
elif i in profession_1.keys():
page_m_index[i]=profession_1[i]
s+=1
elif i in profession_3_0.keys():
page_m_index[i]=profession_3_0[i]
elif i.replace(" f\xfcr ".decode('ISO 8859-16'), " - ").replace(" im ", " - ") in profession_1.keys():
page_m_index[i]=profession_1[i.replace(" f\xfcr ".decode('ISO 8859-16'), " - ").replace(" im ", " - ")]
y1+=1
elif i.replace(" f\xfcr ".decode('ISO 8859-16'), " - ").replace(" im ", " - ") in profession_2.keys():
y2+=1
else:
for prof in profession_1:
if i in prof:
y+=1
print i,"=?",prof, profession_1[prof]
for prof in profession_2:
if i in prof:
yy+=1
print "==",i,"=?",prof, profession_2[prof]
g+=1
other.append(i)
#print i
print l,g ,s ,y1,y2,y , yy
return page_m_index,other
```
# Find code of profession for m_page
```
words=load_simple_json('de/occupation_all.json')#{masculine:[[],[feminine]]}
page_m=load_simple_json('de/wiki/m_page.json')
page_m_index,other=find_appropriate_prof(page_m,words,profession,profession_2,profession_2_2,profession_1,profession_3_0)
page_m_index["Kettler"]='28122'
page_m_index["Euromaster"]='26314'
page_m_index["Energieelektroniker"]='26252'
page_m_index["Gehilfe"]='72302'
page_m_index["Krankenpfleger"]='81302'
page_m_index["Mitarbeiter"]='61123'
page_m_index["Geograph"]='42134'
page_m_index["Ordner"]='53112'
page_m_index[u'W\xe4chter']='53112'
page_m_index[u'F\xe4rber']='28101'
page_m_index["Religionslehrer"]='84424'
page_m_index[u'Stoffpr\xfcfer']='41322'
page_m_index["Reiniger"]='54101'
#we ommit Kaufmann,Fachkaufmann, Sachverständiger, Angestellter,
#as of being too broaden or representing only one person in the Labour Markt
other_new=set(other) - set(["Meister","Fachpraktiker","Verwalter",u'Sachverst\xe4ndiger',"Kaufmann","Helfer","Trainer",
"Vertreter","Facharbeiter",u'Angestellter',"Techniker",u'Fachkaufmann',"Werker",
"Fachleiter","Verfahrensmechaniker","Produktionshelfer",
"Energieelektroniker",u'Gehilfe',u'Krankenpfleger',u'Kettler',"Euromaster",
"Mitarbeiter","Geograph","Ordner",u'W\xe4chter',u'F\xe4rber',"Religionslehrer",u'Stoffpr\xfcfer',
"Reiniger"])
print len(other)
print len(other_new)
other_new
manually_retrieved={"Aufzugsmonteur":'25132',
u'Fachangestellter f\xfcr Medien- und Informationsdienste':'73332',
u'Fachverk\xe4ufer im Lebensmittelhandwerk (B\xe4ckerei)':'62312',
u'Fachverk\xe4ufer im Lebensmittelhandwerk (Fleischerei)':'62322',
u'Kraftfahrer':'51311',
u'Masseur und medizinischer Bademeister':'81712',
u'Online-Redakteur':'92413',
u'Produktgestalter Textil':'28112',
u'Produktpr\xfcfer Textil':'28122',
u'Produktveredler Textil':'28142',
u'Pr\xe4sident':'84394',
u'Vorpolierer Schmuck- und Kleinger\xe4teherstellung':'24222',
u'Werkgehilfe Schmuckwarenindustrie, Taschen- und Armbanduhren':'71382'}
for i in manually_retrieved:
page_m_index[i]=manually_retrieved[i]
len(page_m_index),len(page_m)
print "We do not took into account:"
set(page_m)-set(page_m_index.keys())
```
# Masculine_bias
```
page_m=load_simple_json('de/wiki/m_bias.json')
print len(page_m)
words=load_simple_json('de/occupation_all.json')#{masculine:[[],[feminine]]}
m_bias_index,other=find_appropriate_prof(page_m,words,profession,profession_2,profession_2_2,profession_1,profession_3_0)
m_bias_index["Metallformer"]='24142'
m_bias_index["Geograph"]='42134'
m_bias_index["Medienkaufmann"]='92302'
m_bias_index["Gehilfe"]='72302'
m_bias_index[u'Stoffpr\xfcfer']='41322'
m_bias_index[u'Medienberater']='92113'
m_bias_index[u'F\xe4rber']='28101'
m_bias_index["Krankenpfleger"]='81302'
m_bias_index["Mitarbeiter"]='61123'
m_bias_index[u'W\xe4chter']='53112'
m_bias_index["Energieelektroniker"]='26252'
m_bias_index["Religionslehrer"]='84424'
#we ommit Kaufmann,Fachkaufmann, Sachverständiger, Angestellter,
#as of being too broaden or representing only one person in the Labour Markt
other_new=set(other) - set(["Meister","Fachpraktiker",u'Sachverst\xe4ndiger',"Helfer","Trainer",
"Facharbeiter","Verfahrensmechaniker",u'Angestellter',"Techniker",u'Fachkaufmann',
"Kaufmann","Fachleiter","Produktionshelfer",
"Geograph",u'Medienberater',"Medienkaufmann",u'Gehilfe',u'Stoffpr\xfcfer',"Mitarbeiter",
u'W\xe4chter',u'Krankenpfleger',u'F\xe4rber',"Religionslehrer","Energieelektroniker",
"Metallformer"])
print len(other)
print len(other_new)
other_new
manually_retrieved2={"Aufzugsmonteur":'25132',
u'Fachangestellter f\xfcr Medien- und Informationsdienste':'73332',
u'Fachverk\xe4ufer im Lebensmittelhandwerk (B\xe4ckerei)':'62312',
u'Fachverk\xe4ufer im Lebensmittelhandwerk (Fleischerei)':'62322',
u'Film-Regisseur':'94414',
u'Kettengoldschmied':'93522',
u'Kraftfahrer':'51311',
u'Masseur und medizinischer Bademeister':'81712',
u'Online-Redakteur':'92413',
u'Produktgestalter Textil':'28112',
u'Produktpr\xfcfer Textil':'28122',
u'Produktveredler Textil':'28142',
u'Pr\xe4sident':'84394',
u'Vorpolierer Schmuck- und Kleinger\xe4teherstellung':'24222',
u'Werkgehilfe Schmuckwarenindustrie, Taschen- und Armbanduhren':'71382'}
for i in manually_retrieved2:
m_bias_index[i]=manually_retrieved2[i]
len(m_bias_index),len(page_m)
print "We do not took into account:"
set(page_m)-set(m_bias_index.keys())
```
# Femenine
```
page_f=load_simple_json('de/wiki/f_bias.json')
print len(page_f)
words=load_simple_json('de/occupation_all.json')#{masculine:[[],[feminine]]}
f_bias_index,other=find_appropriate_prof(page_f,words,profession,profession_2,profession_2_2,profession_1,profession_3_0)
f_bias_index
```
# Neutral
```
page_n=load_simple_json('de/wiki/n_bias_male_labels.json')
print len(page_n)
words=load_simple_json('de/occupation_all.json')#{masculine:[[],[feminine]]}
n_bias_index,other=find_appropriate_prof(page_n,words,profession,profession_2,profession_2_2,profession_1,profession_3_0)
n_bias_index["Audiodesigner"]='94183'
n_bias_index
page_n_n=load_simple_json('de/wiki/n_bias_n_labels.json')
print len(page_n_n)
words=load_simple_json('de/occupation_all.json')#{masculine:[[],[feminine]]}
n_bias_n_labels_index,other=find_appropriate_prof(page_n_n,words,profession,profession_2,profession_2_2,profession_1,profession_3_0)
print "We do not took into account:"
other
n_bias_n_labels_index
```
# Assign correspondent amount of man/woman from labour market data
```
print "We have:",len(m_bias_index)," inctances."
k=0
m_bias_prop=[]
check=[]
for i in m_bias_index:
for beruf in subsubgroups:
if beruf['KldB']==m_bias_index[i][:4]:
if np.isreal(beruf[u'M\xe4nner']):
m_bias_prop.append({"name":i,
"Berufsgruppe":beruf['Berufsgruppen'],
"KldB":beruf['KldB'],
"KldB5":m_bias_index[i],
"Frauen":float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
u'M\xe4nner':100-float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
"Overall":beruf['Ingesamt']})
check.append(i)
else:
for beruf in dict_list:
if beruf['KldB']==m_bias_index[i][:3]:
if np.isreal(beruf[u'M\xe4nner']):
m_bias_prop.append({"name":i,
"Berufsgruppe":beruf['Berufsgruppen'],
"KldB":beruf['KldB'],
"KldB5":m_bias_index[i],
"Frauen":float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
u'M\xe4nner':100-float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
"Overall":beruf['Ingesamt']})
check.append(i)
break
break
print len(m_bias_prop)
didnot_found=set(m_bias_index.keys())-set(check)
for i in didnot_found:
for beruf in dict_list:
if beruf['KldB']==m_bias_index[i][:2]:
if np.isreal(beruf[u'M\xe4nner']):
m_bias_prop.append({"name":i,
"Berufsgruppe":beruf['Berufsgruppen'],
"KldB":beruf['KldB'],
"KldB5":m_bias_index[i],
"Frauen":float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
u'M\xe4nner':100-float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
"Overall":beruf['Ingesamt']})
check.append(i)
break
didnot_found=set(m_bias_index.keys())-set(check)
print len(m_bias_prop)
print didnot_found
with open("de/m_bias_labour.json","w")as f:
json.dump(m_bias_prop, f, indent=4)
print "We have:",len(f_bias_index)," inctances."
k=0
f_bias_prop=[]
check=[]
for i in f_bias_index:
for beruf in subsubgroups:
if beruf['KldB']==f_bias_index[i][:4]:
if np.isreal(beruf[u'M\xe4nner']):
f_bias_prop.append({"name":i,
"Berufsgruppe":beruf['Berufsgruppen'],
"KldB":beruf['KldB'],
"KldB5":f_bias_index[i],
"Frauen":float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
u'M\xe4nner':100-float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
"Overall":beruf['Ingesamt']})
check.append(i)
break
print len(f_bias_prop)
didnot_found=set(f_bias_index.keys())-set(check)
print didnot_found
with open("de/f_bias_labour.json","w")as f:
json.dump(f_bias_prop, f, indent=4)
print "We have:",len(n_bias_index)," inctances."
k=0
n_bias_prop=[]
check=[]
for i in n_bias_index:
for beruf in subsubgroups:
if beruf['KldB']==n_bias_index[i][:4]:
if np.isreal(beruf[u'M\xe4nner']):
n_bias_prop.append({"name":i,
"Berufsgruppe":beruf['Berufsgruppen'],
"KldB":beruf['KldB'],
"KldB5":n_bias_index[i],
"Frauen":float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
u'M\xe4nner':100-float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
"Overall":beruf['Ingesamt']})
check.append(i)
break
print len(n_bias_prop)
didnot_found=set(n_bias_index.keys())-set(check)
print didnot_found
with open("de/n_bias_labour.json","w")as f:
json.dump(n_bias_prop, f, indent=4)
print "We have:",len(n_bias_n_labels_index)," inctances."
k=0
n_bias_n_labels_index_prop=[]
check=[]
for i in n_bias_n_labels_index:
for beruf in subsubgroups:
if beruf['KldB']==n_bias_n_labels_index[i][:4]:
if np.isreal(beruf[u'M\xe4nner']):
n_bias_n_labels_index_prop.append({"name":i,
"Berufsgruppe":beruf['Berufsgruppen'],
"KldB":beruf['KldB'],
"KldB5":n_bias_n_labels_index[i],
"Frauen":float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
u'M\xe4nner':100-float(beruf["Frauen"]*100)/float(beruf["Ingesamt"]),
"Overall":beruf['Ingesamt']})
check.append(i)
break
print len(n_bias_n_labels_index_prop)
didnot_found=set(n_bias_n_labels_index.keys())-set(check)
print didnot_found
with open("de/n_n_bias_labour.json","w")as f:
json.dump(n_bias_n_labels_index_prop, f, indent=4)
```
# Store all together
```
import json
def load_simple_json(filename):
with open(filename, 'r') as f:
return json.load(f)
words=load_simple_json('de/occupation_all.json')
m_f={i:words[i][1] for i in words}#male:female
f_df=pd.DataFrame.from_dict(f_bias_prop)
n_df=pd.DataFrame.from_dict(n_bias_prop)
n_n_df=pd.DataFrame.from_dict(n_bias_n_labels_index_prop)
m_df=pd.DataFrame.from_dict(m_bias_prop)
all_together = pd.concat([n_df,n_n_df,f_df,m_df],ignore_index=True)
all_together["f_name"]=all_together['name'].map(lambda x: m_f[x] if m_f.has_key(x) else None)
#all_together["other_name"]=all_together['name'].map(lambda x: data. if m_f.has_key(x) else None)
all_together.to_csv("de/all_labour.csv", sep='\t', encoding='utf-8')
all_together#859
```
| github_jupyter |
# Test modules of recognition pipeline
Written by Yujun Lin
## Prepare
import libraries
```
import os
#os.environ['MANTLE_TARGET'] = 'ice40'
from magma import *
set_mantle_target("ice40")
import mantle
import math
from mantle.lattice.ice40 import ROMB, SB_LUT4
from magma.simulator import PythonSimulator
from magma.scope import Scope
from magma.bit_vector import BitVector
```
## Global Settings
```
num_cycles = 16
num_classes = 8
# operand width
N = 16
# number of bits for num_cycles
n = int(math.ceil(math.log2(num_cycles)))
# number of bits for num_classes
b = int(math.ceil(math.log2(num_classes)))
# number of bits for bit counter output
n_bc = int(math.floor(math.log2(N))) + 1
# number of bits for bit counter output accumulator
n_bc_adder = int(math.floor(math.log2(N*num_cycles))) + 1
print('number of bits for num_cycles: %d' % n)
print('number of bits for num_classes: %d' % b)
print('number of bits for bit counter output: %d' % n_bc)
print('number of bits for bit counter output accumulator: %d' % n_bc_adder)
```
## Control module
generate address for weight and image block
`IDX` means the idx-th row of weight matrix
`CYCLE` means the cycle-th block of idx-th row of weight matrix
`CYCLE` also means the cycle-th block of image vector
```
class Controller(Circuit):
name = "Controller"
IO = ['CLK', In(Clock), 'IDX', Out(Bits(b)),
'CYCLE', Out(Bits(n))]
@classmethod
def definition(io):
adder_cycle = mantle.Add(n, cin=False, cout=False)
reg_cycle = mantle.Register(n, has_reset=True)
adder_idx = mantle.Add(b, cin=False, cout=False)
reg_idx = mantle.Register(b, has_ce=True)
wire(io.CLK, reg_cycle.CLK)
wire(io.CLK, reg_idx.CLK)
wire(reg_cycle.O, adder_cycle.I0)
wire(bits(1, n), adder_cycle.I1)
wire(adder_cycle.O, reg_cycle.I)
comparison_cycle = mantle.EQ(n)
wire(reg_cycle.O, comparison_cycle.I0)
wire(bits(num_cycles-1, n), comparison_cycle.I1)
# if cycle-th is the last, then switch to next idx (accumulate idx) and clear cycle
wire(comparison_cycle.O, reg_cycle.RESET)
wire(comparison_cycle.O, reg_idx.CE)
comparison_idx = mantle.EQ(b)
wire(reg_idx.O, comparison_idx.I0)
wire(bits(num_classes-1, b), comparison_idx.I1)
wire(reg_idx.O, adder_idx.I0)
wire(bits(0, b-1), adder_idx.I1[1:])
nand_gate = mantle.NAnd()
wire(comparison_cycle.O, nand_gate.I0)
wire(comparison_idx.O, nand_gate.I1)
# after all idx rows, we stop accumulating idx
wire(nand_gate.O, adder_idx.I1[0])
wire(adder_idx.O, reg_idx.I)
wire(reg_idx.O, io.IDX)
wire(adder_cycle.O, io.CYCLE)
class Test(Circuit):
name = "Test"
IO = ['CLK', In(Clock), 'IDX', Out(Bits(b)), 'CYCLE', Out(Bits(n)),
'CONTROL', Out(Bit)]
@classmethod
def definition(io):
# IF
controller = Controller()
reg_1_cycle = mantle.DefineRegister(n)()
reg_1_control = mantle.DFF(init=1)
wire(io.CLK, controller.CLK)
wire(io.CLK, reg_1_cycle.CLK)
wire(io.CLK, reg_1_control.CLK)
reg_1_idx = controller.IDX
wire(controller.CYCLE, reg_1_cycle.I)
wire(1, reg_1_control.I)
wire(reg_1_idx, io.IDX)
wire(reg_1_cycle.O, io.CYCLE)
wire(reg_1_control.O, io.CONTROL)
simulator = PythonSimulator(Test, clock=Test.CLK)
waveforms = []
for i in range(96):
simulator.step()
simulator.evaluate()
clk = simulator.get_value(Test.CLK)
o = simulator.get_value(Test.IDX)
c = simulator.get_value(Test.CYCLE)
ctl = simulator.get_value(Test.CONTROL)
waveforms.append([clk, ctl] + o + c)
names = ["CLK", "CTL"]
for i in range(n):
names.append("IDX[{}]".format(i))
for i in range(b):
names.append("CYC[{}]".format(i))
from magma.waveform import waveform
waveform(waveforms, names)
```
## ROM module
Test Unit for Rom Reading
```
class TestReadRom(Circuit):
name = "TestReadRom2"
IO = ['IDX', In(Bits(b)), 'CYCLE', In(Bits(n)), 'CLK', In(Clock),
'WEIGHT', Out(Bits(N)), 'IMAGE', Out(Bits(N))]
@classmethod
def definition(io):
weights_list = [1] + [2**16-1]*15 + [3] + [2**16-1]*15 + ([0] + [2**16-1]*15)*((256-32)//16)
weigths_rom = ROMB(weights_list)
lut_list = []
for i in range(N):
lut_list.append(SB_LUT4(LUT_INIT=1))
wire(io.CYCLE, weigths_rom.RADDR[:n])
wire(io.IDX, weigths_rom.RADDR[n:n+b])
if n + b < 8:
wire(bits(0, 8-n-b), weigths_rom.RADDR[n+b:])
wire(1, weigths_rom.RE)
wire(weigths_rom.RDATA, io.WEIGHT)
wire(io.CLK, weigths_rom.RCLK)
for i in range(N):
wire(io.CYCLE, bits([lut_list[i].I0, lut_list[i].I1, lut_list[i].I2, lut_list[i].I3]))
wire(lut_list[i].O, io.IMAGE[i])
class Test(Circuit):
name = "Test"
IO = ['CLK', In(Clock), 'WEIGHT', Out(Bits(N)), 'IMAGE', Out(Bits(N)),
'IDX', Out(Bits(b)), 'CYCLE', Out(Bits(n)), 'CONTROL', Out(Bit)]
@classmethod
def definition(io):
# IF - get cycle_id, label_index_id
controller = Controller()
reg_1_cycle = mantle.DefineRegister(n)()
reg_1_control = mantle.DFF(init=1)
wire(io.CLK, controller.CLK)
wire(io.CLK, reg_1_cycle.CLK)
wire(io.CLK, reg_1_control.CLK)
reg_1_idx = controller.IDX
wire(controller.CYCLE, reg_1_cycle.I)
wire(1, reg_1_control.I)
# RR - get weight block, image block of N bits
readROM = TestReadRom()
wire(reg_1_idx, readROM.IDX)
wire(reg_1_cycle.O, readROM.CYCLE)
reg_2 = mantle.DefineRegister(N + b + n)()
reg_2_control = mantle.DFF()
reg_2_weight = readROM.WEIGHT
wire(io.CLK, reg_2.CLK)
wire(io.CLK, readROM.CLK)
wire(io.CLK, reg_2_control.CLK)
wire(readROM.IMAGE, reg_2.I[:N])
wire(reg_1_idx, reg_2.I[N:N + b])
wire(reg_1_cycle.O, reg_2.I[N + b:])
wire(reg_1_control.O, reg_2_control.I)
wire(reg_2_weight, io.WEIGHT)
wire(reg_2.O[:N], io.IMAGE)
wire(reg_2.O[N:N+b], io.IDX)
wire(reg_2.O[N+b:], io.CYCLE)
wire(reg_2_control.O, io.CONTROL)
simulator = PythonSimulator(Test, clock=Test.CLK)
waveforms = []
for i in range(96):
simulator.step()
simulator.evaluate()
clk = simulator.get_value(Test.CLK)
w = simulator.get_value(Test.WEIGHT)
i = simulator.get_value(Test.IMAGE)
d = simulator.get_value(Test.IDX)
c = simulator.get_value(Test.CYCLE)
ctl = simulator.get_value(Test.CONTROL)
waveforms.append([clk, ctl] + w + i + d + c)
names = ["CLK", "CTL"]
for i in range(N):
names.append("WGT[{}]".format(i))
for i in range(N):
names.append("IMG[{}]".format(i))
for i in range(n):
names.append("IDX[{}]".format(i))
for i in range(b):
names.append("CYC[{}]".format(i))
from magma.waveform import waveform
waveform(waveforms, names)
```
## Pop Count Unit
4/8/16 bit pop count
```
# 4-bit pop count
class BitCounter4(Circuit):
name = "BitCounter4"
IO = ['I', In(Bits(4)), 'O', Out(Bits(3))]
@classmethod
def definition(io):
lut_list = []
lut_list.append(SB_LUT4(LUT_INIT=int('0110100110010110', 2)))
lut_list.append(SB_LUT4(LUT_INIT=int('0111111011101000', 2)))
lut_list.append(SB_LUT4(LUT_INIT=int('1000000000000000', 2)))
for i in range(3):
wire(io.I, bits([lut_list[i].I0, lut_list[i].I1, lut_list[i].I2, lut_list[i].I3]))
wire(lut_list[i].O, io.O[i])
# 8-bit pop count
class BitCounter8(Circuit):
name = "BitCounter8"
IO = ['I', In(Bits(8)), 'O', Out(Bits(4))]
@classmethod
def definition(io):
counter_1 = BitCounter4()
counter_2 = BitCounter4()
wire(io.I[:4], counter_1.I)
wire(io.I[4:], counter_2.I)
adders = [mantle.HalfAdder()] + [mantle.FullAdder() for _ in range(2)]
for i in range(3):
wire(counter_1.O[i], adders[i].I0)
wire(counter_2.O[i], adders[i].I1)
if i > 0:
wire(adders[i-1].COUT, adders[i].CIN)
wire(adders[i].O, io.O[i])
wire(adders[-1].COUT, io.O[-1])
# 16-bit pop count
class BitCounter16(Circuit):
name = 'BitCounter16'
IO = ['I', In(Bits(16)), 'O', Out(Bits(5))]
@classmethod
def definition(io):
counter_1 = BitCounter8()
counter_2 = BitCounter8()
wire(io.I[:8], counter_1.I)
wire(io.I[8:], counter_2.I)
adders = [mantle.HalfAdder()] + [mantle.FullAdder() for _ in range(3)]
for i in range(4):
wire(counter_1.O[i], adders[i].I0)
wire(counter_2.O[i], adders[i].I1)
if i > 0:
wire(adders[i-1].COUT, adders[i].CIN)
wire(adders[i].O, io.O[i])
wire(adders[-1].COUT, io.O[-1])
# pop count
def DefineBitCounter(n):
if n <= 4:
return BitCounter4
elif n <= 8:
return BitCounter8
elif n <= 16:
return BitCounter16
else:
return None
class Test(Circuit):
name = "Test"
IO = ['CLK', In(Clock), 'COUNT', Out(Bits(n_bc_adder)), 'CONTROL', Out(Bit)]
@classmethod
def definition(io):
# IF - get cycle_id, label_index_id
controller = Controller()
reg_1_cycle = mantle.Register(n)
reg_1_control = mantle.DFF(init=1)
wire(io.CLK, controller.CLK)
wire(io.CLK, reg_1_cycle.CLK)
wire(io.CLK, reg_1_control.CLK)
reg_1_idx = controller.IDX
wire(controller.CYCLE, reg_1_cycle.I)
wire(1, reg_1_control.I)
# RR - get weight block, image block of N bits
readROM = TestReadRom()
wire(reg_1_idx, readROM.IDX)
wire(reg_1_cycle.O, readROM.CYCLE)
reg_2 = mantle.Register(N + b + n)
reg_2_control = mantle.DFF()
reg_2_weight = readROM.WEIGHT
wire(io.CLK, reg_2.CLK)
wire(io.CLK, readROM.CLK)
wire(io.CLK, reg_2_control.CLK)
wire(readROM.IMAGE, reg_2.I[:N])
wire(reg_1_idx, reg_2.I[N:N + b])
wire(reg_1_cycle.O, reg_2.I[N + b:])
wire(reg_1_control.O, reg_2_control.I)
# EX - NXOr for multiplication, pop count and accumulate the result for activation
multiplier = mantle.NXOr(height=2, width=N)
bit_counter = DefineBitCounter(N)()
adder = mantle.Add(n_bc_adder, cin=False, cout=False)
mux_for_adder_0 = mantle.Mux(height=2, width=n_bc_adder)
mux_for_adder_1 = mantle.Mux(height=2, width=n_bc_adder)
reg_3_1 = mantle.Register(n_bc_adder)
reg_3_2 = mantle.Register(b + n)
wire(io.CLK, reg_3_1.CLK)
wire(io.CLK, reg_3_2.CLK)
wire(reg_2_weight, multiplier.I0)
wire(reg_2.O[:N], multiplier.I1)
wire(multiplier.O, bit_counter.I)
wire(bits(0, n_bc_adder), mux_for_adder_0.I0)
wire(bit_counter.O, mux_for_adder_0.I1[:n_bc])
if n_bc_adder > n_bc:
wire(bits(0, n_bc_adder - n_bc), mux_for_adder_0.I1[n_bc:])
# only when data read is ready (i.e. control signal is high), accumulate the pop count result
wire(reg_2_control.O, mux_for_adder_0.S)
wire(reg_3_1.O, mux_for_adder_1.I0)
wire(bits(0, n_bc_adder), mux_for_adder_1.I1)
if n == 4:
comparison_3 = SB_LUT4(LUT_INIT=int('0'*15+'1', 2))
wire(reg_2.O[N+b:], bits([comparison_3.I0, comparison_3.I1, comparison_3.I2, comparison_3.I3]))
else:
comparison_3 = mantle.EQ(n)
wire(reg_2.O[N+b:], comparison_3.I0)
wire(bits(0, n), comparison_3.I1)
wire(comparison_3.O, mux_for_adder_1.S)
wire(mux_for_adder_0.O, adder.I0)
wire(mux_for_adder_1.O, adder.I1)
wire(adder.O, reg_3_1.I)
wire(reg_2.O[N:], reg_3_2.I)
wire(reg_3_1.O, io.COUNT)
wire(reg_2_control.O, io.CONTROL)
simulator = PythonSimulator(Test, clock=Test.CLK)
waveforms = []
for i in range(128):
simulator.step()
simulator.evaluate()
clk = simulator.get_value(Test.CLK)
o = simulator.get_value(Test.COUNT)
ctl = simulator.get_value(Test.CONTROL)
waveforms.append([clk, ctl] + o)
names = ["CLK", "CTL"]
for i in range(n_bc_adder):
names.append("COUNT[{}]".format(i))
from magma.waveform import waveform
waveform(waveforms, names)
```
## Classifier Module
using compare operation to decide the final prediction label of image
```
class Classifier(Circuit):
name = "Classifier"
IO = ['I', In(Bits(n_bc_adder)), 'IDX', In(Bits(b)), 'CLK', In(Clock),
'O', Out(Bits(b)), 'M', Out(Bits(n_bc_adder))]
@classmethod
def definition(io):
comparison = mantle.UGT(n_bc_adder)
reg_count = mantle.Register(n_bc_adder, has_ce=True)
reg_idx = mantle.Register(b, has_ce=True)
wire(io.I, comparison.I0)
wire(reg_count.O, comparison.I1)
wire(comparison.O, reg_count.CE)
wire(comparison.O, reg_idx.CE)
wire(io.CLK, reg_count.CLK)
wire(io.CLK, reg_idx.CLK)
wire(io.I, reg_count.I)
wire(io.IDX, reg_idx.I)
wire(reg_idx.O, io.O)
wire(reg_count.O, io.M)
class Test(Circuit):
name = "Test"
IO = ['CLK', In(Clock), 'MAX', Out(Bits(n_bc_adder)),
'IDX', Out(Bits(b)), 'COUNT', Out(Bits(n_bc_adder))]
@classmethod
def definition(io):
# IF - get cycle_id, label_index_id
controller = Controller()
reg_1_cycle = mantle.Register(n)
reg_1_control = mantle.DFF(init=1)
wire(io.CLK, controller.CLK)
wire(io.CLK, reg_1_cycle.CLK)
wire(io.CLK, reg_1_control.CLK)
reg_1_idx = controller.IDX
wire(controller.CYCLE, reg_1_cycle.I)
wire(1, reg_1_control.I)
# RR - get weight block, image block of N bits
readROM = TestReadRom()
wire(reg_1_idx, readROM.IDX)
wire(reg_1_cycle.O, readROM.CYCLE)
reg_2 = mantle.Register(N + b + n)
reg_2_control = mantle.DFF()
reg_2_weight = readROM.WEIGHT
wire(io.CLK, reg_2.CLK)
wire(io.CLK, readROM.CLK)
wire(io.CLK, reg_2_control.CLK)
wire(readROM.IMAGE, reg_2.I[:N])
wire(reg_1_idx, reg_2.I[N:N + b])
wire(reg_1_cycle.O, reg_2.I[N + b:])
wire(reg_1_control.O, reg_2_control.I)
# EX - NXOr for multiplication, pop count and accumulate the result for activation
multiplier = mantle.NXOr(height=2, width=N)
bit_counter = DefineBitCounter(N)()
adder = mantle.Add(n_bc_adder, cin=False, cout=False)
mux_for_adder_0 = mantle.Mux(height=2, width=n_bc_adder)
mux_for_adder_1 = mantle.Mux(height=2, width=n_bc_adder)
reg_3_1 = mantle.Register(n_bc_adder)
reg_3_2 = mantle.Register(b + n)
wire(io.CLK, reg_3_1.CLK)
wire(io.CLK, reg_3_2.CLK)
wire(reg_2_weight, multiplier.I0)
wire(reg_2.O[:N], multiplier.I1)
wire(multiplier.O, bit_counter.I)
wire(bits(0, n_bc_adder), mux_for_adder_0.I0)
wire(bit_counter.O, mux_for_adder_0.I1[:n_bc])
if n_bc_adder > n_bc:
wire(bits(0, n_bc_adder - n_bc), mux_for_adder_0.I1[n_bc:])
# only when data read is ready (i.e. control signal is high), accumulate the pop count result
wire(reg_2_control.O, mux_for_adder_0.S)
wire(reg_3_1.O, mux_for_adder_1.I0)
wire(bits(0, n_bc_adder), mux_for_adder_1.I1)
if n == 4:
comparison_3 = SB_LUT4(LUT_INIT=int('0'*15+'1', 2))
wire(reg_2.O[N+b:], bits([comparison_3.I0, comparison_3.I1, comparison_3.I2, comparison_3.I3]))
else:
comparison_3 = mantle.EQ(n)
wire(reg_2.O[N+b:], comparison_3.I0)
wire(bits(0, n), comparison_3.I1)
wire(comparison_3.O, mux_for_adder_1.S)
wire(mux_for_adder_0.O, adder.I0)
wire(mux_for_adder_1.O, adder.I1)
wire(adder.O, reg_3_1.I)
wire(reg_2.O[N:], reg_3_2.I)
# CF - classify the image
classifier = Classifier()
reg_4 = mantle.Register(n + b)
reg_4_idx = classifier.O
wire(io.CLK, classifier.CLK)
wire(io.CLK, reg_4.CLK)
wire(reg_3_1.O, classifier.I)
wire(reg_3_2.O[:b], classifier.IDX)
wire(reg_3_2.O, reg_4.I)
wire(reg_3_1.O, io.COUNT)
wire(classifier.O, io.IDX)
wire(classifier.M, io.MAX)
simulator = PythonSimulator(Test, clock=Test.CLK)
waveforms = []
for i in range(128):
simulator.step()
simulator.evaluate()
clk = simulator.get_value(Test.CLK)
o = simulator.get_value(Test.IDX)
m = simulator.get_value(Test.MAX)
c = simulator.get_value(Test.COUNT)
waveforms.append([clk] + o + m + c)
names = ["CLK"]
for i in range(b):
names.append("IDX[{}]".format(i))
for i in range(n_bc_adder):
names.append("MAX[{}]".format(i))
for i in range(n_bc_adder):
names.append("CNT[{}]".format(i))
from magma.waveform import waveform
waveform(waveforms, names)
class Classifier(Circuit):
name = "Classifier"
IO = ['I', In(Bits(n_bc_adder)), 'IDX', In(Bits(b)), 'CLK', In(Clock), 'O', Out(Bits(b))]
@classmethod
def definition(io):
comparison = mantle.UGT(n_bc_adder)
reg_count = mantle.Register(n_bc_adder, has_ce=True)
reg_idx = mantle.Register(b, has_ce=True)
wire(io.I, comparison.I0)
wire(reg_count.O, comparison.I1)
wire(comparison.O, reg_count.CE)
wire(comparison.O, reg_idx.CE)
wire(io.CLK, reg_count.CLK)
wire(io.CLK, reg_idx.CLK)
wire(io.I, reg_count.I)
wire(io.IDX, reg_idx.I)
wire(reg_idx.O, io.O)
```
## Pipeline Module
```
class Test(Circuit):
name = "Test"
IO = ['CLK', In(Clock), 'O', Out(Bits(b)), 'IDX', Out(Bits(b))]
@classmethod
def definition(io):
# IF - get cycle_id, label_index_id
controller = Controller()
reg_1_cycle = mantle.Register(n)
reg_1_control = mantle.DFF(init=1)
wire(io.CLK, controller.CLK)
wire(io.CLK, reg_1_cycle.CLK)
wire(io.CLK, reg_1_control.CLK)
reg_1_idx = controller.IDX
wire(controller.CYCLE, reg_1_cycle.I)
wire(1, reg_1_control.I)
# RR - get weight block, image block of N bits
readROM = TestReadRom()
wire(reg_1_idx, readROM.IDX)
wire(reg_1_cycle.O, readROM.CYCLE)
reg_2 = mantle.Register(N + b + n)
reg_2_control = mantle.DFF()
reg_2_weight = readROM.WEIGHT
wire(io.CLK, reg_2.CLK)
wire(io.CLK, readROM.CLK)
wire(io.CLK, reg_2_control.CLK)
wire(readROM.IMAGE, reg_2.I[:N])
wire(reg_1_idx, reg_2.I[N:N + b])
wire(reg_1_cycle.O, reg_2.I[N + b:])
wire(reg_1_control.O, reg_2_control.I)
# EX - NXOr for multiplication, pop count and accumulate the result for activation
multiplier = mantle.NXOr(height=2, width=N)
bit_counter = DefineBitCounter(N)()
adder = mantle.Add(n_bc_adder, cin=False, cout=False)
mux_for_adder_0 = mantle.Mux(height=2, width=n_bc_adder)
mux_for_adder_1 = mantle.Mux(height=2, width=n_bc_adder)
reg_3_1 = mantle.Register(n_bc_adder)
reg_3_2 = mantle.Register(b + n)
wire(io.CLK, reg_3_1.CLK)
wire(io.CLK, reg_3_2.CLK)
wire(reg_2_weight, multiplier.I0)
wire(reg_2.O[:N], multiplier.I1)
wire(multiplier.O, bit_counter.I)
wire(bits(0, n_bc_adder), mux_for_adder_0.I0)
wire(bit_counter.O, mux_for_adder_0.I1[:n_bc])
if n_bc_adder > n_bc:
wire(bits(0, n_bc_adder - n_bc), mux_for_adder_0.I1[n_bc:])
# only when data read is ready (i.e. control signal is high), accumulate the pop count result
wire(reg_2_control.O, mux_for_adder_0.S)
wire(reg_3_1.O, mux_for_adder_1.I0)
wire(bits(0, n_bc_adder), mux_for_adder_1.I1)
if n == 4:
comparison_3 = SB_LUT4(LUT_INIT=int('0'*15+'1', 2))
wire(reg_2.O[N+b:], bits([comparison_3.I0, comparison_3.I1, comparison_3.I2, comparison_3.I3]))
else:
comparison_3 = mantle.EQ(n)
wire(reg_2.O[N+b:], comparison_3.I0)
wire(bits(0, n), comparison_3.I1)
wire(comparison_3.O, mux_for_adder_1.S)
wire(mux_for_adder_0.O, adder.I0)
wire(mux_for_adder_1.O, adder.I1)
wire(adder.O, reg_3_1.I)
wire(reg_2.O[N:], reg_3_2.I)
# CF - classify the image
classifier = Classifier()
reg_4 = mantle.Register(n + b)
reg_4_idx = classifier.O
wire(io.CLK, classifier.CLK)
wire(io.CLK, reg_4.CLK)
wire(reg_3_1.O, classifier.I)
wire(reg_3_2.O[:b], classifier.IDX)
wire(reg_3_2.O, reg_4.I)
# WB - wait to show the result until the end
reg_5 = mantle.Register(b, has_ce=True)
comparison_5_1 = mantle.EQ(b)
comparison_5_2 = mantle.EQ(n)
and_gate = mantle.And()
wire(io.CLK, reg_5.CLK)
wire(reg_4_idx, reg_5.I)
wire(reg_4.O[:b], comparison_5_1.I0)
wire(bits(num_classes - 1, b), comparison_5_1.I1)
wire(reg_4.O[b:], comparison_5_2.I0)
wire(bits(num_cycles - 1, n), comparison_5_2.I1)
wire(comparison_5_1.O, and_gate.I0)
wire(comparison_5_2.O, and_gate.I1)
wire(and_gate.O, reg_5.CE)
wire(reg_5.O, io.O)
wire(classifier.O, io.IDX)
simulator = PythonSimulator(Test, clock=Test.CLK)
waveforms = []
for i in range(300):
simulator.step()
simulator.evaluate()
clk = simulator.get_value(Test.CLK)
o = simulator.get_value(Test.O)
i = simulator.get_value(Test.IDX)
waveforms.append([clk] + o + i)
names = ["CLK"]
for i in range(b):
names.append("O[{}]".format(i))
for i in range(b):
names.append("I[{}]".format(i))
from magma.waveform import waveform
waveform(waveforms, names)
```
| github_jupyter |
```
%pylab
import pandas as pd
import pickle
from scipy.linalg import norm
import cv2 as cv
import os
import importlib
from sklearn.preprocessing import normalize
from skimage.io import imsave, imread
import os
import glob
import argparse
import time
import pickle
import platform
import shutil
import json
import pdb
import numpy as np
import pandas as pd
import cv2 as cv
from skimage.io import imsave
from scipy.stats import entropy
from scipy.linalg import norm
import h5py
from keras.applications.mobilenet_v2 import MobileNetV2
from keras.models import Model, load_model, Sequential
from keras.layers import Input, Dense, Lambda, ZeroPadding2D, LeakyReLU, Flatten, Concatenate, ReLU
from keras.layers.merge import add, subtract
from keras.utils import multi_gpu_model
from keras.utils.data_utils import Sequence
import keras.backend as K
from keras import optimizers
from keras.layers import Conv2D, Conv2DTranspose, Reshape
import keras
from keras.engine.input_layer import InputLayer
from keras.layers import Conv2DTranspose, Reshape, BatchNormalization
cd D:\\topcoder\\face_recog\\src\\space
import sys
sys.path.append('D:\\topcoder\\face_recog\\src')
with open('ref_facial_id_db.pickle', 'rb') as f:
facial_ids = pickle.load(f)
diff_norms = []
for subject_id in facial_ids:
diff_norms.append(norm(facial_ids[1] - facial_ids[subject_id]))
diff_norms = np.asarray(diff_norms)[1:]
diff_norms.min(), diff_norms.max(), diff_norms.mean()
hist(diff_norms, bins=100)
for subject_id_t in list(facial_ids.keys())[:1]:
print(subject_id_t)
diff_norms = []
for subject_id_b in facial_ids:
diff_norms.append(norm(facial_ids[subject_id_t] - facial_ids[subject_id_b]))
diff_norms = np.asarray(diff_norms)
print(diff_norms.min(), diff_norms.max(), diff_norms.mean())
hist(diff_norms, bins=100)
ref_facial_ids = facial_ids
with open("face_vijnana_yolov3_win.json", 'r') as f:
conf = json.load(f)
import face_identification
importlib.reload(face_identification)
fr = face_identification.FaceIdentifier(conf)
fr.model.summary()
dense_layer = fr.model.get_layer('dense1')
dense_layer.input_shape, dense_layer.output_shape
W = dense_layer.get_weights()
len(W)
W[0].shape, W[1].shape
W[0].T.shape
input1 = Input(shape=(64, ))
inv_dense_layer = Dense(fr.model.get_layer('dense1').input_shape[1]
, activation= fr.model.get_layer('dense1').activation
, name='dense1')
x = inv_dense_layer(input1)
inv_dense_layer.input_shape, inv_dense_layer.output_shape
i_W = inv_dense_layer.get_weights()
i_W[0].shape, i_W[1].shape
inv_dense_layer.set_weights((W[0].T, np.random.rand(W[0].shape[0])))
def create_face_reconst_model(self):
"""Create the face reconstruction model."""
if hasattr(self, 'model') != True or isinstance(self.model, Model) != True:
raise ValueError('A valid model instance doesn\'t exist.')
if self.conf['face_vijana_recon_load']:
self.recon_model = load_model('face_vijnana_recon.h5')
return
# Get all layers and extract input layers and output layers.
layers = self.model.layers
input_layers = [layer for layer in layers if isinstance(layer, InputLayer) == True]
output_layer_names = [t.name.split('/')[0] for t in self.model.outputs]
output_layers = [layer for layer in layers if layer.name in output_layer_names]
# Input.
input1 = Input(shape=(int(output_layers[0].output_shape[1]/3), ), name='input1')
x = Lambda(lambda x: K.l2_normalize(x, axis=-1), name='l2_norm_layer')(input1) #?
x = ReLU()(x)
dense_layer = Dense(self.model.get_layer('dense1').input_shape[1]
, activation='linear'
, name='dense1')
x = dense_layer(x)
dense_layer.set_weights((self.model.get_layer('dense1').get_weights()[0].T
, np.random.rand(self.model.get_layer('dense1').get_weights()[0].shape[0])))
# Yolov3.
yolov3 = self.model.get_layer('base')
x = Reshape(yolov3.output_shape[1:])(x)
skip = x #?
# 73 ~ 63.
for i in range(73, 63, -3):
conv_layer = yolov3.get_layer('conv_' + str(i))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
conv_layer = yolov3.get_layer('conv_' + str(i - 1))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i - 1))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
x = subtract([x, skip]) #?
skip = x #?
# 62.
conv_layer = yolov3.get_layer('conv_' + str(62))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, strides=conv_layer.strides
, padding='same'
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(62))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
skip = x
# 60 ~ 38.
for i in range(60, 38, -3):
conv_layer = yolov3.get_layer('conv_' + str(i))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
conv_layer = yolov3.get_layer('conv_' + str(i - 1))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i - 1))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
x = subtract([x, skip]) #?
skip = x #??
# 37.
conv_layer = yolov3.get_layer('conv_' + str(37))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, strides=conv_layer.strides
, padding='same'
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(37))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
skip = x
# 35 ~ 13.
for i in range(35, 13, -3):
conv_layer = yolov3.get_layer('conv_' + str(i))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
conv_layer = yolov3.get_layer('conv_' + str(i - 1))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i - 1))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
#x = subtract([x, skip]) #?
skip = x #?
# 12.
conv_layer = yolov3.get_layer('conv_' + str(12))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, strides=conv_layer.strides
, padding='same'
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(12))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
skip = x
# 10 ~ 6.
for i in range(10, 6, -3):
conv_layer = yolov3.get_layer('conv_' + str(i))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
conv_layer = yolov3.get_layer('conv_' + str(i - 1))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i - 1))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
#x = subtract([x, skip]) #?
skip = x #?
# 5.
conv_layer = yolov3.get_layer('conv_' + str(5))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, strides=conv_layer.strides
, padding='same'
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(5))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
skip = x
# 4 ~ 2.
for i in range(3, 1, -2):
conv_layer = yolov3.get_layer('conv_' + str(i))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
conv_layer = yolov3.get_layer('conv_' + str(i - 1))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same' #?
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(i - 1))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
#x = subtract([x, skip]) #?
skip = x #?
# 1 ~ 0.
conv_layer = yolov3.get_layer('conv_' + str(1))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, strides=conv_layer.strides
, padding='same'
, use_bias=False
, name=conv_layer.name) #?
norm_layer = yolov3.get_layer('bnorm_' + str(1))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
conv_layer = yolov3.get_layer('conv_' + str(0))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same'
, activation='tanh'
, use_bias=False
, name='output') #?
norm_layer = yolov3.get_layer('bnorm_' + str(0))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
output = deconv_layer(x)
deconv_layer.set_weights(conv_layer.get_weights())
self.recon_model = Model(inputs=[input1], outputs=[output])
self.recon_model.trainable = True
self.recon_model.save('face_vijnana_recon.h5')
create_face_reconst_model(fr)
fr.recon_model.summary()
base = fr.model.get_layer('base')
base.summary()
output = base.outputs[0]
output.value_index
output.consumers()
op = output.op
op
res = op.inputs
res[0], res[1]
op.outputs
add_46 = base.get_layer('add_46')
node = add_46._inbound_nodes
node = node[0]
node.inbound_layers
node.outbound_layer
a = np.array([0, 1, 2])
res1 = np.tile(a, 2)
res2 = np.tile(a, (2, 2))
res3 = np.tile(a, (2, 1, 2))
res1.shape, res2.shape, res3.shape
b = (np.array([[1, 2], [3, 4]]))[..., np.newaxis]
res1 = np.tile(b, (1,10,1))
res1.shape
i_model = Model(inputs=fr.recon_model.input,
outputs=Conv2D(3, 1, padding='same', activation='tanh')(fr.recon_model.get_layer('leaky_re_lu_1').output))
res = np.squeeze(i_model.predict(np.expand_dims(facial_ids[3], axis=0)), axis=0)
figure(figsize=(20,10))
res2 = (res - res.min())*res.std()
imshow(res2)
res.shape, res.min(), res.mean(), res.max(), res.std(), res2.shape, res2.min(), res2.mean(), res2.max(), res2.std()
i_model = Model(inputs=fr.recon_model.input,
outputs=Conv2D(3, 1, padding='same')(fr.recon_model.get_layer('leaky_re_lu_2').output))
res = np.squeeze(i_model.predict(np.expand_dims(facial_ids[3], axis=0)), axis=0)
figure(figsize=(20,10))
res2 = (res - res.min())*4 #*res.std()
imshow(res2)
res.shape, res.min(), res.mean(), res.max(), res.std(), res2.shape, res2.min(), res2.mean(), res2.max(), res2.std()
res
res2
figure(figsize=(20,10))
res3 = res*255
imshow(res3)
# Get all layers and extract input layers and output layers.
layers = fr.model.layers
input_layers = [layer for layer in layers if isinstance(layer, InputLayer) == True]
output_layer_names = [t.name.split('/')[0] for t in fr.model.outputs]
output_layers = [layer for layer in layers if layer.name in output_layer_names]
input1 = Input(shape=(int(output_layers[0].output_shape[1]/3), ), name='input1')
x = Lambda(lambda x: K.l2_normalize(x, axis=-1), name='l2_norm_layer')(input1) #?
x = Dense(fr.model.get_layer('dense1').input_shape[1]
, activation= fr.model.get_layer('dense1').activation
, name='dense1')(x)
yolov3 = fr.model.get_layer('base')
x = Reshape(yolov3.output_shape[1:])(x)
skip = x
skip.shape
x = skip
i = 73
conv_layer = yolov3.get_layer('conv_' + str(i))
deconv_layer = Conv2DTranspose(filters=conv_layer.input_shape[-1]
, kernel_size=conv_layer.kernel_size
, padding='same'
, strides=(2, 2)
, use_bias=False
, name=conv_layer.name) #?
W = conv_layer.get_weights()
W[0].shape
x = deconv_layer(x)
x.shape
W2 = deconv_layer.get_weights()
norm_layer = yolov3.get_layer('bnorm_' + str(i))
inv_norm_layer = BatchNormalization.from_config(norm_layer.get_config())
x = LeakyReLU(alpha=0.1)(x)
x = inv_norm_layer(x)
x = deconv_layer(x)
np.expand_dims(facial_ids[1], axis=0).shape
res = np.squeeze(fr.recon_model.predict(np.expand_dims(facial_ids[3], axis=0)), axis=0)
res.shape, res.min(), res.mean(), res.max()
figure(figsize=(20,10))
imshow(res*255)
tuple([1] + list((2, 3)))
fr.model.loss_functions
res = fr.model.loss_weights
fr.model.losses
base = fr.model.get_layer('base')
base.output_shape[1:]
base.summary()
base.inputs
db = pd.read_csv('subject_image_db.csv')
db = db.iloc[:, 1:]
db_g = db.groupby('subject_id')
subject_ids = db_g.groups.keys()
facial_ids_dict= {}
subject_id = 1
df = db_g.get_group(subject_id)
images = []
for ff in list(df.iloc[:, 1]):
image = imread(os.path.join('subject_faces', ff))
images.append(image/255)
images = np.asarray(images)
facial_ids = fr.fid_extractor.predict(images)
facial_ids_dict[subject_id] = facial_ids
facial_ids.shape
images[0].mean(), images[0].max()
norm(facial_ids[1] - facial_ids[0])
norm(facial_ids[1])
norm(facial_ids[0] - ref_facial_ids[1])
for i in range(facial_ids.shape[1]):
print(facial_ids[0,i], facial_ids[1,i], ref_facial_ids[1][i])
subject_id = 2
df = db_g.get_group(subject_id)
images = []
for ff in list(df.iloc[:, 1]):
image = cv.imread(os.path.join('subject_faces', ff))
r = image[:, :, 0].copy()
g = image[:, :, 1].copy()
b = image[:, :, 2].copy()
image[:, :, 0] = b
image[:, :, 1] = g
image[:, :, 2] = r
images.append(image/255)
images = np.asarray(images)
facial_ids = fr.fid_extractor.predict(images)
facial_ids_dict[subject_id] = facial_ids
facial_ids.shape
for i in range(facial_ids.shape[0]): print(norm(facial_ids[i]))
norm(facial_ids[0] - facial_ids[1])
dists = []
for i in range(facial_ids.shape[0] - 1):
for j in range(i + 1, facial_ids.shape[0]):
dists.append(norm(facial_ids[i] - facial_ids[j]))
dists = np.asarray(dists)
print(dists.min(), dists.max(), dists.mean())
norm(facial_ids_dict[1][0] - facial_ids[1][1])
subject_id = 3
df = db_g.get_group(subject_id)
images = []
for ff in list(df.iloc[:, 1]):
image = imread(os.path.join('subject_faces', ff))
images.append(image/255)
images = np.asarray(images)
facial_ids = fr.fid_extractor.predict(images)
dists = []
for i in range(facial_ids.shape[0] - 1):
for j in range(i + 1, facial_ids.shape[0]):
dists.append(norm(facial_ids[i] - facial_ids[j]))
dists = np.asarray(dists)
print(dists.min(), dists.max(), dists.mean())
image = imread(os.path.join('subject_faces', ff))
imshow(image)
from skimage.io import imread, imsave
from skimage.transform import resize
from skimage.draw import polygon_perimeter, set_color
from PIL import Image, ImageFont, ImageDraw
imageObject = Image.fromarray(image, mode='RGB')
imageDraw = ImageDraw.Draw(imageObject)
font = ImageFont.truetype('arial.ttf', 30)
imageDraw.text((100, 100), 'test', fill=(0,255,0), font=font)
imageDraw.rectangle([10, 10, 50, 50], outline=(0,255,0), width=3)
imshow(np.asarray(imageObject))
res = fr.fid_extractor.predict(image[np.newaxis, ...]/255)
res.shape
norm(res)
b, g, t = cv.split(image)
m_image = cv.merge((b, np.zeros(shape=(416,416), dtype=uint8), np.zeros(shape=(416,416), dtype=uint8)))
ff
image2 = imread(os.path.join('subject_faces', ff))
imshow(image2)
db = pd.read_csv('subject_image_db.csv')
db = db.iloc[:, 1:]
db_g = db.groupby('subject_id')
same_dists = []
diff_dists = []
with h5py.File('subject_facial_ids.h5', 'r') as f:
subject_ids = list(db_g.groups.keys())
# Same face identity pairs.
print('Same face identity pairs.')
for c, subject_id in enumerate(subject_ids):
print(c + 1, '/', len(subject_ids), end='\r')
if subject_id == -1:
continue
# Get face images of a subject id.
df = db_g.get_group(subject_id)
file_names = list(df.iloc[:, 1])
# Check exception.
if len(file_names) < 2: continue
for i in range(len(file_names)):
same_dists.append(norm(ref_facial_ids[subject_id] - f[file_names[i]].value))
print()
# Determine pairs of different face identity randomly.
idxes = range(len(subject_ids))
num_pairs = len(subject_ids) // 2
pairs = np.random.choice(idxes, size=(num_pairs, 2), replace=False)
# Different face identity pairs.b
print('Different face identity pairs.')
for i in range(pairs.shape[0]):
print(i + 1, '/', pairs.shape[0], end='\r')
k = pairs[i, 0]
l = pairs[i, 1]
if subject_ids[k] == -1 or subject_ids[l] == -1:
continue
comp_df = db_g.get_group(subject_ids[l])
comp_file_names = list(comp_df.iloc[:, 1])
for comp_fn in comp_file_names:
diff_dists.append(norm(ref_facial_ids[subject_ids[k]] - f[comp_fn].value))
same_dists = np.asarray(same_dists)
diff_dists = np.asarray(diff_dists)
figure(figsize=(20,10))
hist(same_dists, bins=100)
grid()
figure(figsize=(20,10))
hist(diff_dists, bins=100)
grid()
figure(figsize=(20,10))
hist(same_dists, bins=100)
hist(diff_dists, bins=100)
grid()
for subject_id in list(subject_ids)[:100]:
df = db_g.get_group(subject_id)
images = []
for ff in list(df.iloc[:, 1]):
image = imread(os.path.join('subject_faces', ff))
images.append(image/255)
images = np.asarray(images)
facial_ids = fr.fid_extractor.predict(images)
dists = []
for i in range(facial_ids.shape[0] - 1):
for j in range(i + 1, facial_ids.shape[0]):
dists.append(norm(facial_ids[i] - facial_ids[j]))
dists = np.asarray(dists)
ref_dists = []
for i in range(facial_ids.shape[0]):
ref_dists.append(norm(ref_facial_ids[subject_id] - facial_ids[i]))
ref_dists = np.asarray(ref_dists)
#if len(dists) != 0: print(subject_id, dists.min(), dists.max(), dists.mean())
if len(dists) != 0: print(subject_id, ref_dists.min(), ref_dists.max(), ref_dists.mean())
for subject_id in list(subject_ids)[:100]:
df = db_g.get_group(subject_id)
images = []
for ff in list(df.iloc[:, 1]):
image = imread(os.path.join('subject_faces', ff))
images.append(image/255)
images = np.asarray(images)
facial_ids = fr.fid_extractor.predict(images)
dists = []
for i in range(facial_ids.shape[0]):
for subject_id_p in list(subject_ids)[:100]:
if subject_id_p == subject_id: continue
dists.append(norm(facial_ids[i] - ref_facial_ids[subject_id_p]))
dists = np.asarray(dists)
if len(dists) != 0: print(subject_id, dists.min(), dists.max(), dists.mean())
from keras import backend as K
from keras.layers import Layer, Input, Flatten, Dense
from keras.models import Model
class MyLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
# Create a trainable weight variable for this layer.
self.rbm_weight = self.add_weight(name='rbm_weight'
, shape=(input_shape[1], self.output_dim)
, initializer='uniform' # Which initializer is optimal?
, trainable=True)
self.hidden_bias = self.add_weight(name='rbm_hidden_bias'
, shape=(self.output_dim, )
, initializer='uniform'
, trainable=True)
super(MyLayer, self).build(input_shape) # Be sure to call this at the end
def call(self, x):
return K.sigmoid(K.dot(x, self.rbm_weight) + self.hidden_bias) # Float type?
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
def fit(self, x):
pass
input1 = Input(shape=(100,))
x = MyLayer(10)(input1)
x = Dense(10, activation='softmax')(x)
model = Model(input1, x)
model.compile(optimizer='sgd', loss='categorical_crossentropy')
model.fit(np.random.rand(1,100), np.random.rand(1,10))
import numpy as np
from keras import backend as K
from keras.layers import Layer, Input
from tensorflow.keras import initializers
class RBM(Layer):
"""Restricted Boltzmann Machine based on Keras."""
def __init__(self, hps, output_dim, name=None, **kwargs):
self.hps = hps
self.output_dim = output_dim
self.name = name
super(RBM, self).__init__(**kwargs)
def build(self, input_shape):
self.rbm_weight = self.add_weight(name='rbm_weight'
, shape=(input_shape[1], self.output_dim)
, initializer='uniform' # Which initializer is optimal?
, trainable=True)
self.hidden_bias = self.add_weight(name='rbm_hidden_bias'
, shape=(self.output_dim, )
, initializer='uniform'
, trainable=True)
self.visible_bias = K.variable(initializers.get('uniform')((input_shape[1], ))
, dtype=K.floatx()
, name='rbm_visible_bias')
# Make symbolic computation objects.
# Transform visible units.
self.input_visible = K.placeholder(shape=(None, input_shape[1]), name='input_visible')
self.transform = K.sigmoid(K.dot(self.input_visible, self.rbm_weight) + self.hidden_bias)
self.transform_func = K.function([self.input_visible], [self.transform])
# Transform hidden units.
self.input_hidden = K.placeholder(shape=(None, self.output_dim), name='input_hidden')
self.inv_transform = K.sigmoid(K.dot(self.input_hidden, K.transpose(self.rbm_weight)) + self.visible_bias)
self.inv_transform_func = K.function([self.input_hidden], [self.inv_transform])
super(RBM, self).build(input_shape)
def call(self, x):
return K.sigmoid(K.dot(x, self.rbm_weight) + self.hidden_bias) # Float type?
def transform(self, v):
return self.transform_func(v)
def inv_transform(self, h):
return self.inv_transform_func(h)
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
def fit(self, V, verbose=1):
"""Train RBM with the data V.
Parameters
----------
V : 2d numpy array
Visible data (batch size x input_dim).
verbose : integer
Verbose mode (default, 1).
"""
num_step = V.shape[0] // self.hps['batch_size'] \
if V.shape[0] % self.hps['batch_size'] == 0 else V.shape[0] // self.hps['batch_size'] + 1 # Exception processing?
# Contrastive divergence.
v_pos = self.input_visible
h_pos = self.transform
v_neg = K.cast(K.less(K.random_uniform(shape=(self.hps['batch_size'], V.shape[1]))
, K.sigmoid(K.dot(h_pos, K.transpose(self.rbm_weight)) + self.visible_bias))
, dtype=np.float32)
h_neg = K.sigmoid(K.dot(v_neg, self.rbm_weight) + self.hidden_bias)
update = K.transpose(K.transpose(K.dot(K.transpose(v_pos), h_pos)) \
- K.dot(K.transpose(h_neg), v_neg))
self.rbm_weight_update_func = K.function([self.input_visible],
[K.update_add(self.rbm_weight, self.hps['lr'] * update)])
self.hidden_bias_update_func = K.function([self.input_visible],
[K.update_add(self.hidden_bias, self.hps['lr'] \
* (K.sum(h_pos, axis=0) - K.sum(h_neg, axis=0)))])
self.visible_bias_update_func = K.function([self.input_visible],
[K.update_add(self.visible_bias, self.hps['lr'] \
* (K.sum(v_pos, axis=0) - K.sum(v_neg, axis=0)))])
for k in range(self.hps['epochs']):
if verbose == 1:
print(k, '/', self.hps['epochs'], ' epochs')
for i in range(num_step):
if i == (num_step - 1):
# Contrastive divergence.
v_pos = self.input_visible
h_pos = self.transform
v_neg = K.cast(K.less(K.random_uniform(shape=(V.shape[0] \
- int(i*self.hps['batch_size']), V.shape[1])) #?
, K.sigmoid(K.dot(h_pos, K.transpose(self.rbm_weight)) \
+ self.visible_bias)), dtype=np.float32)
h_neg = K.sigmoid(K.dot(v_neg, self.rbm_weight) + self.hidden_bias)
update = K.transpose(K.transpose(K.dot(K.transpose(v_pos), h_pos)) \
- K.dot(K.transpose(h_neg), v_neg))
self.rbm_weight_update_func = K.function([self.input_visible],
[K.update_add(self.rbm_weight, self.hps['lr'] * update)])
self.hidden_bias_update_func = K.function([self.input_visible],
[K.update_add(self.hidden_bias, self.hps['lr'] \
* (K.sum(h_pos, axis=0) - K.sum(h_neg, axis=0)))])
self.visible_bias_update_func = K.function([self.input_visible],
[K.update_add(self.visible_bias, self.hps['lr'] \
* (K.sum(v_pos, axis=0) - K.sum(v_neg, axis=0)))])
V_batch = [V[int(i*self.hps['batch_size']):V.shape[0]]]
# Train.
self.rbm_weight_update_func(V_batch)
self.hidden_bias_update_func(V_batch)
self.visible_bias_update_func(V_batch)
else:
V_batch = [V[int(i*self.hps['batch_size']):int((i+1)*self.hps['batch_size'])]]
# Train.
self.rbm_weight_update_func(V_batch)
self.hidden_bias_update_func(V_batch)
self.visible_bias_update_func(V_batch)
hps = {}
hps['lr'] = 0.1
hps['batch_size'] = 1
hps['epochs'] = 10
hps['beta_1'] = 0.99
hps['beta_2'] = 0.99
hps['decay'] = 0.0
rbm_layer = RBM(hps, 10)
input1 = Input(shape=(10, 10, 3))
x = Flatten()(input1)
x = rbm_layer(x)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=[input1], outputs=[output])
opt = optimizers.Adam(lr=hps['lr']
, beta_1=hps['beta_1']
, beta_2=hps['beta_2']
, decay=hps['decay'])
model.compile(optimizer=opt, loss='mse')
model.predict(np.random.rand(1,10,10,3))
rbm_layer.fit(np.random.rand(1, 300))
model.fit(np.random.rand(10,10,10,3), np.random.rand(10, 10))
input1 = Input(shape=(10,))
x = Lambda(lambda x: K.l2_normalize(x, axis=1))(input1)
model = Model(input1, x)
res = model.predict(np.random.rand(2,10))
res.shape
norm(res[0])
input1 = Input(shape=(10,))
input2 = Input(shape=(10,))
x = Lambda(lambda x: K.cast(K.less(x[0], x[1]), dtype=float32))([input1, input2])
model = Model(inputs=[input1, input2], outputs=[x])
model.predict([np.random.rand(1,10), np.random.rand(1, 10)])
base = MobileNetV2(include_top = False)
base.summary()
help(input)
res = input('>')
res
print('Score {0: f}'.format(1.8))
hps
import json
res = json.dumps(hps)
res
hps['flag'] = True
res = json.dumps(hps)
res
res = json.loads('{"mode" : "train", "hps" : {"lr" : 0.001, "beta_1" : 0.99, "beta_2" : 0.99, "decay" : 0.0, "epochs" : 1, "batch_size" : 128}, "rbm_hps" : { "lr" : 0.001, "epochs" : 1, "batch_size" : 128}, "nn_arch" : {"output_dim" : 128}, "model_loading": false}')
type(res)
p = np.random.rand(10)
p
sample = np.identity(10)
sample
p = p/p.sum()
res = np.random.multivariate_normal(p, np.identity(10))
res
sol_df = pd.read_csv('d:\\topcoder\\face_recog\\src\\space\\solution.csv', header=None)
res = sol_df.iloc[0]
type(res)
res
sol_df.iloc[0, :]
sol_df.loc[0]
import pandas as pd
import numpy as np
sample = pd.DataFrame([(0, 0, 1), (0, 1, 10), (1, 0, 2), (1, 1, 3)])
sample.sort_values(by=2, ascending=False)
df = sample.iloc[2]
df
df.iloc[2] = 100
sample
res = sample[sample[2] != 100]
res
res_g = res.groupby(2)
res_g.groups.keys()
cd ../src/space
import pdb
import numpy as np
import pandas as pd
class BoundBox:
def __init__(self, xmin, ymin, xmax, ymax
, objness = None
, classes = None
, anchor = None
, subject_id = -1):
self.xmin = xmin
self.ymin = ymin
self.xmax = xmax
self.ymax = ymax
self.objness = objness
self.classes = classes
self.anchor = anchor
self.subject_id = subject_id
self.label = -1
self.score = -1
def get_label(self):
if self.label == -1:
self.label = np.argmax(self.classes)
return self.label
def get_score(self):
if self.score == -1:
self.score = self.classes[self.get_label()]
return np.min([self.score, 1.0])
def get_relative_bb(self, width, height):
left = int(self.xmin/width * 100.)
top = int(self.ymin/height * 100.)
width = int((self.xmax - self.xmin)/width * 100.)
height = int((self.ymax - self.ymin)/height * 100.)
return (left, top, width, height)
def bbox_iou(box1, box2):
intersect_w = _interval_overlap([box1.xmin, box1.xmax], [box2.xmin, box2.xmax])
intersect_h = _interval_overlap([box1.ymin, box1.ymax], [box2.ymin, box2.ymax])
intersect = intersect_w * intersect_h
w1, h1 = box1.xmax-box1.xmin, box1.ymax-box1.ymin
w2, h2 = box2.xmax-box2.xmin, box2.ymax-box2.ymin
union = w1*h1 + w2*h2 - intersect
return float(intersect) / union
def _interval_overlap(interval_a, interval_b):
x1, x2 = interval_a
x3, x4 = interval_b
if x3 < x1:
if x4 < x1:
return 0
else:
return min(x2,x4) - x1
else:
if x2 < x3:
return 0
else:
return min(x2,x4) - x3
sol_path='D:\\topcoder\\face_recog\\resource\\solution_training_fd.csv'
gt_path='D:\\topcoder\\face_recog\\resource\\training.csv'
def evaluate_fd(gt_path, sol_path, iou_th):
# Load ground truth, predicted results and calculate IoU.
sol_df = pd.read_csv(sol_path, header=None)
sol_df = pd.concat([sol_df, pd.DataFrame(np.zeros(shape=(sol_df.shape[0]), dtype=np.float64), columns=[7])], axis=1) # IoU
sol_df.iloc[:, 6] = -1.0
sol_df_g = sol_df.groupby(0) #?
gt_df = pd.read_csv(gt_path)
gt_df = pd.concat([gt_df, pd.DataFrame(np.zeros(shape=(gt_df.shape[0]), dtype=np.float64), columns=[8])], axis=1) # IoU
gt_df.iloc[:, 7] = -1.0
gt_df_g = gt_df.groupby('FILE') #?
for k, image_id in enumerate(list(gt_df_g.groups.keys())):
print(k, '/', len(gt_df_g.groups.keys()), ':', image_id, end='\r')
df = gt_df_g.get_group(image_id)
try:
rel_sol_df = sol_df_g.get_group(image_id)
except KeyError:
continue
gt_ious = {}
for i in range(df.shape[0]):
gt_ious[i] = []
gt_sample = df.iloc[i]
gt_sample_bb = BoundBox(gt_sample[3]
, gt_sample[4]
, gt_sample[3] + gt_sample[5]
, gt_sample[4] + gt_sample[6])
# Check exception.
if rel_sol_df.shape[0] == 0: continue
# Calculate IoUs between a gt region and detected regions
for j in range(rel_sol_df.shape[0]):
rel_sol = rel_sol_df.iloc[j]
rel_sol_bb = BoundBox(rel_sol[1]
, rel_sol[2]
, rel_sol[1] + rel_sol[3]
, rel_sol[2] + rel_sol[4])
iou = bbox_iou(gt_sample_bb, rel_sol_bb)
if iou > 0.: #?
gt_ious[i].append((i, j, iou))
total_gt_ious = []
for i in gt_ious:
total_gt_ious += gt_ious[i]
if len(total_gt_ious) == 0: continue
total_gt_ious_df = pd.DataFrame(total_gt_ious)
# IoU descending order sorting.
total_gt_ious_df = total_gt_ious_df.sort_values(by=2, ascending=False)
# Determine IoU for each detected region.
while total_gt_ious_df.shape[0] != 0: #?
df_p = total_gt_ious_df.iloc[0]
i = int(df_p.iloc[0])
j = int(df_p.iloc[1])
iou = df_p.iloc[2]
#df.iloc[i, -1] = iou
rel_sol_df.iloc[j, -1] = iou
# Remove assigned samples.
total_gt_ious_df = total_gt_ious_df[total_gt_ious_df[0] != i]
total_gt_ious_df = total_gt_ious_df[total_gt_ious_df[1] != j]
if k == 0:
res_df = rel_sol_df
else:
res_df = pd.concat([res_df, rel_sol_df])
# Get the p-r curve.
# Sort the solution in confidence descending order.
res_df = res_df.sort_values(by=5, ascending=False)
ps = []
rs = []
tp_count = 0
count = 0
gt_count = gt_df.shape[0]
for i in range(gt_df.shape[0]):
count +=1
if i < res_df.shape[0] and res_df.iloc[i, 6] >= iou_th:
tp_count += 1
ps.append(tp_count / count)
rs.append(tp_count / gt_count)
ps = np.asarray(ps)
rs = np.asarray(rs)
func = interp1d(rs, ps)
mAP = quad(lambda x: func(x), rs[0], rs[-1])
return (ps, rs, mAP[0])
res_5 = evaluate_fd(gt_path, sol_path, 0.5)
res_5
ps = res_5[0]
rs = res_5[1]
rs.shape
figure(figsize=(20,10))
plot(rs, ps)
grid()
for i in range(10): print(i, end='\r')
rs.max()
rs.min()
from scipy.interpolate import interp1d
from scipy.integrate import quad
func = interp1d(rs, ps)
mAP = quad(lambda x: func(x), rs[0], rs[-1])
mAP
ps_9, rs_9 = evaluate_fd(gt_path, sol_path, 0.9)
func = interp1d(rs_9, ps_9)
quad(lambda x: func(x), rs_9[0], rs_9[-1])
figure(figsize=(20,10))
plot(rs_9, ps_9)
grid()
rs_9.max()
ps_7, rs_7 = evaluate_fd(gt_path, sol_path, 0.7)
figure(figsize=(20,10))
plot(rs_7, ps_7)
grid()
func = interp1d(rs_7, ps_7)
quad(lambda x: func(x), rs_7[0], rs_7[-1])
import h5py
f = h5py.File('sample.h5','w')
top = f.create_group('top')
top['0'] = np.random.rand(10)
top['1'] = np.random.rand(10)
top['0'].shape
top['0'].attrs['id'] = 100
top['0'].attrs['id']
f.close()
ls
f = h5py.File('sample.h5','r')
f.keys()
f.name
for name in f: print(name)
f['top']['0'].value
sample = np.random.rand(10)
sample = sample <= 0.5
sample
sample2 = sample.astype(np.int64)
sample2
sample2.sum()
cd D:\topcoder\\face_recog\src\space
import evaluate
import importlib
importlib.reload(evaluate)
import pandas as pd
sample = pd.DataFrame({'a': range(10), 'b': range(10)})
sample.iloc[0, :]
import h5py
f = h5py.File('p_r_curve.h5', 'r')
iou_ths = np.arange(0.5, 1.0, 0.05)
ps_ls = f['ps_ls'].value
rs_ls = f['rs_ls'].value
mAP_ls = f['mAP_ls'].value
help(legend)
figure(figsize=(20, 10))
for i in range(len(iou_ths)):
plot(rs_ls[i], ps_ls[i], label=str('{0:1.2f}'.format(iou_ths[i])))
title('Precision vs. recall according to IoU threshold.')
xlabel('Recall')
ylabel('Precision')
legend()
grid()
figure(figsize=(20, 10))
plot(mAP_ls, 'o')
plot(mAP_ls)
grid()
mAP_ls
mAP_ls.mean()
input1 = Input(shape=(10,10,3))
x = Lambda(lambda x: K.sigmoid(x[..., 0:2]))(input1)
#x1 = Lambda(lambda x: K.expand_dims(K.sigmoid(x[..., 0:3])))(input1)
#x2 = Lambda(lambda x: K.expand_dims(K.log(x[..., 1])))(input1)
#x3 = Lambda(lambda x: K.expand_dims(K.exp(x[..., 2])))(input1)
#x = Concatenate()([x1, x2, x3])
model = Model(input1, x)
res = model.predict(np.ones(shape=(1,10,10,3)))
res.shape
res
f = h5py.File('face_pairs_dists.h5', 'r')
same_dists = f['sample_dists'].value
diff_dists = f['diff_dists'].value
same_dists.shape
figure(figsize=(20,10))
hist(same_dists, bins=100)
grid()
figure(figsize=(20,10))
hist(diff_dists, bins=100)
grid()
figure(figsize=(20,10))
hist(same_dists, bins=100)
hist(diff_dists, bins=100)
grid()
sample = np.arange(0.1, 1.0, 0.1)
sample
for i in sample: print(i)
f.close()
f = h5py.File('var_far.h5', 'r')
sim_ths = f['sim_ths'].value
vars_p = f['vars'].value
fars_p = f['fars'].value
figure(figsize=(20,10))
plot(fars_p, vars_p)
grid()
f.close()
f = h5py.File('fi_acc.h5', 'r')
accs = f['acc_ls'].value
accs
f.close()
f = h5py.File('face_pairs_dists.h5', 'r')
same_dists = f['same_dists'].value
diff_dists = f['diff_dists'].value
figure(figsize=(20,10))
hist(same_dists, bins=1000)
grid()
figure(figsize=(20,10))
hist(diff_dists, bins=1000)
grid()
figure(figsize=(20,10))
hist(same_dists, bins=1000)
hist(diff_dists, bins=1000)
grid()
36+1+24+6
17+9+9
sample = {'a':10, 'b':20}
hasattr(sample, 'a')
isinstance(None, dict)
'a' in sample.keys()
sample.pop('a')
sample
input1 = Input(shape=(10,10,3))
input2 = Input(shape=(250,))
x1 = Conv2D(filters=10, kernel_size=3, strides=(2, 2), padding='same')(input1)
skip = x1
x1 = Flatten()(x1)
dense_layer = Dense(10)
output1 = dense_layer(x1)
output2 = dense_layer(input2)
model = Model([input1, input2], [output1, output2])
model.compile(optimizer='adam', loss='mse')
model.summary()
x1
skip
model.layers
model.inputs
model.outputs
model.layers[0].name
sample = model.outputs[0]
sample.name.split('/')[0]
model.layers[-2].name
model.layers[0]
isinstance(model.layers[0], keras.engine.input_layer.InputLayer)
layers = model.layers
input_layer1 = layers[1]
input_layer1.input_shape
model.inputs[0].shape
sample = np.random.rand(*[10, 10])
sample.shape
layers.reverse()
layers
layers[0].weights
layer_1 = layers[0]
layer_1.name
layer_1.input_shape
layer_1.output_shape
node_0 = layer_1._inbound_nodes[0]
node_0.input_shapes
node_0.inbound_layers[0].name
node_1 = layer_1._inbound_nodes[1]
node_1.inbound_layers[0].name
W = layer_1.get_weights()
W[0].shape, W[1].shape
layer_1.get_weights()[0].T.shape
layer_1.activation
cW = layers[2].get_weights()
cW[0].shape, cW[1].shape
input2 = Input(shape=(10, ))
inv_layer_1 = Dense(layer_1.input_shape[1])
x_p = inv_layer_1(input2)
inv_layer_1.set_weights([layer_1.get_weights()[0].T, random.rand(250)])
x_p = Reshape((5,5,10))(x_p)
x_p.shape
inv_layer_2 = Conv2DTranspose(filters=3, kernel_size=3, strides=(2,2), padding='same')
x_p = inv_layer_2(x_p)
kW = inv_layer_2.get_weights()
kW[0].shape, kW[1].shape
x_p.shape
inv_model = Model(input2, x_p)
res1 = model.predict(np.random.rand(1,10,10,3))
res1.shape
res1
res2 = inv_model.predict(res1)
res2.shape
np.log2(1024)
2**10
i1 = Input(shape=(10, ))
i2 = Input(shape=(10, ))
res = K.concatenate([i1, i2], axis=-1)
res.shape
input_ph = K.placeholder(shape=(2), dtype='complex128')
x = input_ph*(10 + 10j)
func = K.function([input_ph], [x])
sample = np.expand_dims(np.asarray([1+1j, 2+2j]), axis=0)
sample.shape
func([1+1j, 2+2j])
sample
sample = np.random.rand(10,10,10,3)
res = np.mean(sample, axis=(1, 2), keepdims=True)
res.shape
sample = np.random.rand(10,10,10,3)
res = np.var(sample, axis=1, keepdims=True)
res.shape
res2 = sample - res
res2.shape
fmap_base = 8192 # Overall multiplier for the number of feature maps.
fmap_decay = 1.0 # log2 feature map reduction when doubling the resolution.
fmap_max = 512
def nf(stage):
denorm = pow(2.0, stage * fmap_decay)
return min(int(fmap_base / denorm), fmap_max)
for i in np.arange(18): print(nf(i))
np.log2(1024)
import tensorflow as tf
sess = tf.Session()
sample = tf.placeholder(tf.float32)
x = sample + 1
sess.run(x, feed_dict={sample: np.random.rand(4,5,5,3)})
```
| github_jupyter |
# 11.7 Example: ZIP Code Data (WIP)
<img src="images/fig-11.10.png" alt="Networks" style="width: 560px;"/>
- Net-1: No hidden layer, equivalent to multinomial logistic regression.
- Net-2: One hidden layer, 12 hidden units fully connected.
- Net-3: Two hidden layers locally connected. (3x3 patch
- Net-4: Two hidden layers, locally connected with weight sharing.
- Net-5: Two hidden layers, locally connected, two levels of weight sharing.
```
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
def load_data(path):
df = pd.read_csv(path, delim_whitespace=True, header=None)
df_y = df.pop(0)
return (tf.convert_to_tensor(df.values, dtype=tf.float32),
tf.convert_to_tensor(df_y.values, dtype=tf.int32))
train_x, train_y = load_data('../data/zipcode/zip.train')
test_x, test_y = load_data('../data/zipcode/zip.test')
epochs = 30
from abc import ABC, abstractmethod
class BaseModel(ABC, tf.keras.Model):
def __init__(self):
super(BaseModel, self).__init__()
@abstractmethod
def call(self, x):
pass
def loss(self, x, y):
preds = self(x)
return tf.keras.losses.sparse_categorical_crossentropy(y, preds, from_logits=True)
def grad(self, x, y):
with tf.GradientTape() as tape:
loss_value = self.loss(x, y)
return tape.gradient(loss_value, self.variables)
def accuracy(self, dataset):
accuracy = tf.metrics.Accuracy()
for (x, y) in dataset:
preds = tf.argmax(self(x), axis=1, output_type=tf.int32)
accuracy(preds, y)
return accuracy.result()
def fit(self, x, y, test_x, test_y, epochs = 60, batch_size = 128):
dataset = tf.data.Dataset.from_tensor_slices((x, y)) \
.shuffle(buffer_size=1000) \
.batch(batch_size)
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).batch(batch_size)
train_hist = []
test_hist = []
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for i in range(epochs):
for (x, y) in dataset:
grads = self.grad(x, y)
optimizer.apply_gradients(zip(grads, self.variables))
train_hist.append(self.accuracy(dataset))
test_hist.append(self.accuracy(test_dataset))
return np.array(train_hist), np.array(test_hist)
# Set up plotting
fig = plt.figure(figsize = (12, 6))
train_axes = fig.add_subplot(1, 2, 1)
train_axes.set_title('Train Results')
train_axes.set_xlabel('Epochs')
train_axes.set_ylabel('% Correct on Train Data')
train_axes.set_ylim([60, 100])
test_axes = fig.add_subplot(1, 2, 2)
test_axes.set_title('Test Results')
test_axes.set_xlabel('Epochs')
test_axes.set_ylabel('% Correct on Test Data')
test_axes.set_ylim([60, 100])
def plot_model(model, label, conv=False):
shape = [-1, 16, 16, 1] if conv else [-1, 16*16]
shaped_train_x = tf.reshape(train_x, shape)
shaped_test_x = tf.reshape(test_x, shape)
print(shaped_train_x.shape)
print(shaped_test_x.shape)
epochs_hist = np.arange(1, epochs + 1)
train_hist, test_hist = model.fit(shaped_train_x, train_y,
test_x=shaped_test_x, test_y=test_y,
epochs=epochs)
train_axes.plot(epochs_hist, train_hist * 100, label=label)
train_axes.legend()
test_axes.plot(epochs_hist, test_hist * 100, label=label)
test_axes.legend()
class Net1(BaseModel):
def __init__(self):
super(Net1, self).__init__()
self.layer = tf.keras.layers.Dense(units=10)
def call(self, x):
return self.layer(x)
plot_model(Net1(), 'Net-1')
fig
class Net2(BaseModel):
def __init__(self):
super(Net2, self).__init__()
self.layer1 = tf.keras.layers.Dense(units=12, activation=tf.sigmoid)
self.layer2 = tf.keras.layers.Dense(units=10)
def call(self, x):
out = self.layer1(x)
out = self.layer2(out)
return out
plot_model(Net2(), 'Net-2')
fig
class Net3(BaseModel):
def __init__(self):
super(Net3, self).__init__()
self.layer1 = tf.keras.layers.LocallyConnected2D(1, 2, strides=2, activation='sigmoid')
self.layer2 = tf.keras.layers.LocallyConnected2D(1, 5, activation='sigmoid')
self.layer3 = tf.keras.layers.Flatten()
self.layer4 = tf.keras.layers.Dense(units=10)
def call(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
return out
plot_model(Net3(), 'Net-3', conv=True)
fig
class Net4(BaseModel):
def __init__(self):
super(Net4, self).__init__()
self.layer1 = tf.keras.layers.Conv2D(2, 2, strides=2, activation='sigmoid')
self.layer2 = tf.keras.layers.LocallyConnected2D(1, 5, activation='sigmoid')
self.layer3 = tf.keras.layers.Flatten()
self.layer4 = tf.keras.layers.Dense(units=10)
def call(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
return out
plot_model(Net4(), 'Net-4', conv=True)
fig
class Net5(BaseModel):
def __init__(self):
super(Net5, self).__init__()
self.layer1 = tf.keras.layers.Conv2D(2, 2, strides=2, activation='sigmoid')
self.layer2 = tf.keras.layers.Conv2D(4, 5, activation='sigmoid')
self.layer3 = tf.keras.layers.Flatten()
self.layer4 = tf.keras.layers.Dense(units=10)
def call(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
return out
plot_model(Net5(), 'Net-5', conv=True)
fig
```
| github_jupyter |
## Libraries
```
!pip install numerapi
from numerapi import NumerAPI
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import tensorflow as tf
import os
import random
import glob
import pathlib
import scipy
import time
import datetime
import gc
from sklearn import preprocessing
# visualize
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.style as style
from matplotlib_venn import venn2, venn3
import seaborn as sns
from matplotlib import pyplot
from matplotlib.ticker import ScalarFormatter
import plotly.express as px
sns.set_context("talk")
style.use("seaborn-colorblind")
import warnings
warnings.simplefilter("ignore")
```
## Config
```
today = datetime.datetime.now().strftime("%Y-%m-%d")
today
OUTPUT_DIR = "./"
# Logging is always nice for your experiment:)
def init_logger(log_file="train.log"):
from logging import getLogger, INFO, FileHandler, Formatter, StreamHandler
logger = getLogger(__name__)
logger.setLevel(INFO)
handler1 = StreamHandler()
handler1.setFormatter(Formatter("%(message)s"))
handler2 = FileHandler(filename=log_file)
handler2.setFormatter(Formatter("%(message)s"))
logger.addHandler(handler1)
logger.addHandler(handler2)
return logger
logger = init_logger(log_file=f"{today}.log")
logger.info("Start Logging...")
```
## Check computing environment
```
# check RAM
from psutil import virtual_memory
ram_gb = virtual_memory().total / 1e9
print("Your runtime has {:.1f} gigabytes of available RAM\n".format(ram_gb))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won"t be saved outside of the current session
```
## Fetch data
```
# good features from https://forum.numer.ai/t/feature-selection-with-borutashap/4145
keys = ["era", "data_type", ]
targets = ["target", "target_janet_20", "target_george_20"]
features = [
"feature_unwonted_trusted_fixative",
"feature_introvert_symphysial_assegai",
"feature_jerkwater_eustatic_electrocardiograph",
"feature_canalicular_peeling_lilienthal",
"feature_unvaried_social_bangkok",
"feature_crowning_frustrate_kampala",
"feature_store_apteral_isocheim",
"feature_haziest_lifelike_horseback",
"feature_grandmotherly_circumnavigable_homonymity",
"feature_assenting_darn_arthropod",
"feature_beery_somatologic_elimination",
"feature_cambial_bigoted_bacterioid",
"feature_unaired_operose_lactoprotein",
"feature_moralistic_heartier_typhoid",
"feature_twisty_adequate_minutia",
"feature_unsealed_suffixal_babar",
"feature_planned_superimposed_bend",
"feature_winsome_irreproachable_milkfish",
"feature_flintier_enslaved_borsch",
"feature_agile_unrespited_gaucho",
"feature_glare_factional_assessment",
"feature_slack_calefacient_tableau",
"feature_undivorced_unsatisfying_praetorium",
"feature_silver_handworked_scauper",
"feature_communicatory_unrecommended_velure",
"feature_stylistic_honduran_comprador",
"feature_travelled_semipermeable_perruquier",
"feature_bhutan_imagism_dolerite",
"feature_lofty_acceptable_challenge",
"feature_antichristian_slangiest_idyllist",
"feature_apomictical_motorized_vaporisation",
"feature_buxom_curtained_sienna",
"feature_gullable_sanguine_incongruity",
"feature_unforbidden_highbrow_kafir",
"feature_chuffier_analectic_conchiolin",
"feature_branched_dilatory_sunbelt",
"feature_univalve_abdicant_distrail",
"feature_exorbitant_myeloid_crinkle"
]
logger.info("{:,} Targets: {}".format(len(targets), targets))
logger.info("{:,} Features: {}".format(len(features), features))
```
## NumerAPI
```
# setup API
napi = NumerAPI()
current_round = napi.get_current_round(tournament=8) # tournament 8 is the primary Numerai Tournament
logger.info("NumerAPI is setup!")
```
## Training data
```
%%time
# read in all of the new datas
# tournament data and example predictions change every week so we specify the round in their names
# training and validation data only change periodically, so no need to download them over again every single week
napi.download_dataset("numerai_training_data_int8.parquet", "numerai_training_data_int8.parquet")
training_data = pd.read_parquet("numerai_training_data_int8.parquet")
# already select features and targets
training_data = training_data[keys + features + targets]
# example pred doesn"t exist for training data
training_data["example_pred"] = np.nan
print(training_data.shape)
training_data.head()
```
#### Validation data (and example predictions)
```
%%time
napi.download_dataset("numerai_validation_data_int8.parquet", f"numerai_validation_data_int8.parquet")
validation_data = pd.read_parquet("numerai_validation_data_int8.parquet")
# already select features and targets
validation_data = validation_data[keys + features + targets]
# example prediction
napi.download_dataset("example_validation_predictions.parquet", "example_validation_predictions.parquet")
validation_example_preds = pd.read_parquet("example_validation_predictions.parquet")
validation_data["example_pred"] = validation_example_preds["prediction"].values
print(validation_data.shape)
validation_data.head()
```
#### Tournament data (and example predictions)
```
%%time
# load tournament data
napi.download_dataset("numerai_tournament_data_int8.parquet", f"numerai_tournament_data_int8.parquet")
tournament_data = pd.read_parquet(f"numerai_tournament_data_int8.parquet")
# already select features and targets
tournament_data = tournament_data[keys + features + targets]
# example predictions
napi.download_dataset("example_predictions.parquet", f"example_predictions_{current_round}.parquet")
tournament_example_preds = pd.read_parquet(f"example_predictions_{current_round}.parquet")
tournament_data = tournament_data.merge(
tournament_example_preds
, how="left"
, on="id"
).rename(columns={"prediction": "example_pred"})
print(tournament_data.shape)
tournament_data.head()
```
#### Merge all, only using "good features"
```
%%time
# merge all
feature_df = pd.DataFrame()
for d in [training_data, validation_data, tournament_data]:
feature_df = pd.concat([
feature_df
, d
])
del d
gc.collect()
print(feature_df.shape)
feature_df.head()
# Do we have all the data type?
feature_df["data_type"].value_counts()
```
## EDA (Exploratory Data Analysis)
```
fig, ax = plt.subplots(5, 4, figsize=(20, 20))
ax = ax.flatten()
for i, f in enumerate(np.array(features)[:20]):
feature_df.query("data_type=='validation'")[f].hist(ax=ax[i])
ax[i].set_title(f)
plt.tight_layout()
fig, ax = plt.subplots(1, 3, figsize=(15, 4))
ax = ax.flatten()
for i, f in enumerate(np.array(targets)[:3]):
feature_df.query("data_type=='validation'")[f].hist(ax=ax[i])
ax[i].set_title(f)
plt.tight_layout()
```
## Modeling
#### Define model
```
params = {
"feat_len": len(features)
, "hidden_units": (128, 64, 64)
, "out_dim": len(targets)
, "lr": 0.005
, "batch_size": 4096
, "epochs": 1000
}
# set seed for the reproducibility
def seed_everything(seed : int):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
tf.random.set_seed(seed)
seed_everything(20210901)
# define a multi-layer perceptron model
def create_model(params):
"""Simple multi-layer perceptron
"""
len_feat = params["feat_len"]
hidden_units = params["hidden_units"]
lr = params["lr"]
# input
inputs = tf.keras.Input(shape=(len_feat,), name="num_data")
# Add one or more hidden layers
x = tf.keras.layers.Dense(hidden_units[0], activation="relu")(inputs)
for n_hidden in hidden_units[1:]:
x = tf.keras.layers.Dense(n_hidden, activation="relu")(x)
x = tf.keras.layers.Dropout(0.05)(x)
x = tf.keras.layers.GaussianNoise(0.01)(x)
# output
outs = []
for i in range(params["out_dim"]):
outs.append(tf.keras.layers.Dense(1, activation="linear", name=f"target{i+1}")(x))
# compile
model = tf.keras.Model(inputs=inputs, outputs=outs)
loss = "mse"
loss_weights = [1] * params["out_dim"]
optimizer = tf.keras.optimizers.Adam(learning_rate=lr, decay=lr/100)
model.compile(
loss=loss
, loss_weights=loss_weights
, optimizer=optimizer
, metrics=[]
)
return model
model = create_model(params)
model.summary()
tf.keras.utils.plot_model(model)
```
#### Train
```
# fit model with cross validation
def get_time_series_cross_val_splits(data, cv=3, embargo=4, ERA_COL="era"):
"""Numerai data splitter for cross validation
use embargo = 12 when use target_XXX_60 to avoid potential leakage (target days / 5)
https://github.com/numerai/example-scripts/blob/master/utils.py
"""
all_train_eras = data[ERA_COL].unique()
len_split = len(all_train_eras) // cv
test_splits = [all_train_eras[i * len_split:(i + 1) * len_split] for i in range(cv)]
# fix the last test split to have all the last eras, in case the number of eras wasn"t divisible by cv
test_splits[-1] = np.append(test_splits[-1], all_train_eras[-1])
train_splits = []
for test_split in test_splits:
test_split_max = int(np.max(test_split))
test_split_min = int(np.min(test_split))
# get all of the eras that aren"t in the test split
train_split_not_embargoed = [e for e in all_train_eras if not (test_split_min <= int(e) <= test_split_max)]
# embargo the train split so we have no leakage.
# one era is length 5, so we need to embargo by target_length/5 eras.
# To be consistent for all targets, let"s embargo everything by 60/5 == 12 eras.
train_split = [e for e in train_split_not_embargoed if
abs(int(e) - test_split_max) > embargo and abs(int(e) - test_split_min) > embargo]
train_splits.append(train_split)
# convenient way to iterate over train and test splits
train_test_zip = zip(train_splits, test_splits)
return train_test_zip
# define cross validation splits
ERA_COL = "era"
cv = 3
embargo = 4
train_test_zip = get_time_series_cross_val_splits(
feature_df.query("data_type == 'train'"), cv=cv, embargo=embargo, ERA_COL=ERA_COL
)
# placeholder for each target
for i, t in enumerate(targets):
feature_df[f"pred_{t}"] = 0
# get out of sample training preds via embargoed time series cross validation
print("entering time series cross validation loop")
for fold_id, train_test_split in enumerate(train_test_zip):
# train test split
print(f"doing split {fold_id+1} out of {cv}")
train_split, test_split = train_test_split
# dataset
train_set = {
"X": feature_df.query(f"{ERA_COL} in @train_split")[features].values
, "y": [feature_df.query(f"{ERA_COL} in @train_split")[t].fillna(0.5).values for t in targets]
}
val_set = {
"X": feature_df.query(f"{ERA_COL} in @test_split")[features].values
, "y": [feature_df.query(f"{ERA_COL} in @test_split")[t].fillna(0.5).values for t in targets]
}
print("Train-set shape: {}, valid-set shape: {}".format(
train_set["X"].shape
, val_set["X"].shape
))
# callbacks
es = tf.keras.callbacks.EarlyStopping(
monitor="val_loss", patience=20, verbose=2,
mode="min", restore_best_weights=True)
plateau = tf.keras.callbacks.ReduceLROnPlateau(
monitor="val_loss", factor=0.2, patience=7, verbose=2,
mode="min")
checkpoint_path = f"model_fold{fold_id}.hdf5"
cp_callback = tf.keras.callbacks.ModelCheckpoint(
checkpoint_path,
save_weights_only=True,
verbose=1)
# training
tf.keras.backend.clear_session()
model = create_model(params)
model.fit(
train_set["X"],
train_set["y"],
batch_size=params["batch_size"],
epochs=params["epochs"],
validation_data=(val_set["X"], val_set["y"]),
callbacks=[es, plateau, cp_callback],
verbose=1
)
# inference
preds = model.predict(feature_df.loc[~feature_df["data_type"].isin(["train"]), features].values)
for i, t in enumerate(targets):
feature_df.loc[~feature_df["data_type"].isin(["train"]), f"pred_{t}"] += preds[i].ravel() / cv
```
## Validation score
```
# https://github.com/numerai/example-scripts/blob/master/utils.py
def neutralize(df,
columns,
neutralizers=None,
proportion=1.0,
normalize=True,
era_col="era"):
if neutralizers is None:
neutralizers = []
unique_eras = df[era_col].unique()
computed = []
for u in unique_eras:
df_era = df[df[era_col] == u]
scores = df_era[columns].values
if normalize:
scores2 = []
for x in scores.T:
x = (scipy.stats.rankdata(x, method="ordinal") - .5) / len(x)
x = scipy.stats.norm.ppf(x)
scores2.append(x)
scores = np.array(scores2).T
exposures = df_era[neutralizers].values
scores -= proportion * exposures.dot(
np.linalg.pinv(exposures.astype(np.float32)).dot(scores.astype(np.float32)))
scores /= scores.std(ddof=0)
computed.append(scores)
return pd.DataFrame(np.concatenate(computed),
columns=columns,
index=df.index)
def neutralize_series(series, by, proportion=1.0):
scores = series.values.reshape(-1, 1)
exposures = by.values.reshape(-1, 1)
# this line makes series neutral to a constant column so that it"s centered and for sure gets corr 0 with exposures
exposures = np.hstack(
(exposures,
np.array([np.mean(series)] * len(exposures)).reshape(-1, 1)))
correction = proportion * (exposures.dot(
np.linalg.lstsq(exposures, scores, rcond=None)[0]))
corrected_scores = scores - correction
neutralized = pd.Series(corrected_scores.ravel(), index=series.index)
return neutralized
def unif(df):
x = (df.rank(method="first") - 0.5) / len(df)
return pd.Series(x, index=df.index)
def get_feature_neutral_mean(df, prediction_col, ERA_COL="era", TARGET_COL="target"):
feature_cols = [c for c in df.columns if c.startswith("feature")]
df.loc[:, "neutral_sub"] = neutralize(df, [prediction_col],
feature_cols)[prediction_col]
scores = df.groupby(ERA_COL).apply(
lambda x: (unif(x["neutral_sub"]).corr(x[TARGET_COL]))).mean()
return np.mean(scores)
def fast_score_by_date(df, columns, target, tb=None, era_col="era"):
unique_eras = df[era_col].unique()
computed = []
for u in unique_eras:
df_era = df[df[era_col] == u]
era_pred = np.float64(df_era[columns].values.T)
era_target = np.float64(df_era[target].values.T)
if tb is None:
ccs = np.corrcoef(era_target, era_pred)[0, 1:]
else:
tbidx = np.argsort(era_pred, axis=1)
tbidx = np.concatenate([tbidx[:, :tb], tbidx[:, -tb:]], axis=1)
ccs = [np.corrcoef(era_target[tmpidx], tmppred[tmpidx])[0, 1] for tmpidx, tmppred in zip(tbidx, era_pred)]
ccs = np.array(ccs)
computed.append(ccs)
return pd.DataFrame(np.array(computed), columns=columns, index=df[era_col].unique())
def validation_metrics(validation_data, pred_cols, example_col, fast_mode=False, ERA_COL="era", TARGET_COL="target"):
validation_stats = pd.DataFrame()
feature_cols = [c for c in validation_data if c.startswith("feature_")]
for pred_col in pred_cols:
# Check the per-era correlations on the validation set (out of sample)
validation_correlations = validation_data.groupby(ERA_COL).apply(
lambda d: unif(d[pred_col]).corr(d[TARGET_COL]))
mean = validation_correlations.mean()
std = validation_correlations.std(ddof=0)
sharpe = mean / std
validation_stats.loc["mean", pred_col] = mean
validation_stats.loc["std", pred_col] = std
validation_stats.loc["sharpe", pred_col] = sharpe
rolling_max = (validation_correlations + 1).cumprod().rolling(window=9000, # arbitrarily large
min_periods=1).max()
daily_value = (validation_correlations + 1).cumprod()
max_drawdown = -((rolling_max - daily_value) / rolling_max).max()
validation_stats.loc["max_drawdown", pred_col] = max_drawdown
payout_scores = validation_correlations.clip(-0.25, 0.25)
payout_daily_value = (payout_scores + 1).cumprod()
apy = (
(
(payout_daily_value.dropna().iloc[-1])
** (1 / len(payout_scores))
)
** 49 # 52 weeks of compounding minus 3 for stake compounding lag
- 1
) * 100
validation_stats.loc["apy", pred_col] = apy
if not fast_mode:
# Check the feature exposure of your validation predictions
max_per_era = validation_data.groupby(ERA_COL).apply(
lambda d: d[feature_cols].corrwith(d[pred_col]).abs().max())
max_feature_exposure = max_per_era.mean()
validation_stats.loc["max_feature_exposure", pred_col] = max_feature_exposure
# Check feature neutral mean
feature_neutral_mean = get_feature_neutral_mean(validation_data, pred_col)
validation_stats.loc["feature_neutral_mean", pred_col] = feature_neutral_mean
# Check top and bottom 200 metrics (TB200)
tb200_validation_correlations = fast_score_by_date(
validation_data,
[pred_col],
TARGET_COL,
tb=200,
era_col=ERA_COL
)
tb200_mean = tb200_validation_correlations.mean()[pred_col]
tb200_std = tb200_validation_correlations.std(ddof=0)[pred_col]
tb200_sharpe = mean / std
validation_stats.loc["tb200_mean", pred_col] = tb200_mean
validation_stats.loc["tb200_std", pred_col] = tb200_std
validation_stats.loc["tb200_sharpe", pred_col] = tb200_sharpe
# MMC over validation
mmc_scores = []
corr_scores = []
for _, x in validation_data.groupby(ERA_COL):
series = neutralize_series(unif(x[pred_col]), (x[example_col]))
mmc_scores.append(np.cov(series, x[TARGET_COL])[0, 1] / (0.29 ** 2))
corr_scores.append(unif(x[pred_col]).corr(x[TARGET_COL]))
val_mmc_mean = np.mean(mmc_scores)
val_mmc_std = np.std(mmc_scores)
corr_plus_mmcs = [c + m for c, m in zip(corr_scores, mmc_scores)]
corr_plus_mmc_sharpe = np.mean(corr_plus_mmcs) / np.std(corr_plus_mmcs)
validation_stats.loc["mmc_mean", pred_col] = val_mmc_mean
validation_stats.loc["corr_plus_mmc_sharpe", pred_col] = corr_plus_mmc_sharpe
# Check correlation with example predictions
per_era_corrs = validation_data.groupby(ERA_COL).apply(lambda d: unif(d[pred_col]).corr(unif(d[example_col])))
corr_with_example_preds = per_era_corrs.mean()
validation_stats.loc["corr_with_example_preds", pred_col] = corr_with_example_preds
# .transpose so that stats are columns and the model_name is the row
return validation_stats.transpose()
%%time
# score
pred_cols = [f for f in feature_df.columns if "pred_" in f]
val_scores = validation_metrics(
feature_df.query("data_type == 'validation'"), pred_cols, "example_pred", fast_mode=True,
ERA_COL="era", TARGET_COL="target"
)
# validation scoring results
val_scores.style.background_gradient(cmap="viridis", axis=0)
```
## Upload predictions
```
# drop train, as it is no longer necessary for submission
sub_df = feature_df.query("data_type != 'train'").copy()
del feature_df
gc.collect()
# rank per era for safe ensemble
sub_df[pred_cols + ["example_pred"]] = sub_df.groupby("era").apply(lambda d: d[pred_cols + ["example_pred"]].rank(pct=True))
# ensemble
sub_df["prediction"] = sub_df[pred_cols + ["example_pred"]].mean(axis=1)
# neutralization
# sub_df["prediction"] = neutralize(
# tmp,
# columns=["prediction"],
# neutralizers=features,
# proportion=0.5,
# normalize=True,
# era_col="era"
# )
# scale your prediction from 0 to 1
sub_df["prediction"] = preprocessing.MinMaxScaler().fit_transform(
sub_df["prediction"].values.reshape(-1, 1)
)
# check histogram of target and our prediction
sub_df.query("data_type == 'validation'")["prediction"].hist(color="r", alpha=0.5, label="prediction")
sub_df.query("data_type == 'validation'")["target"].hist(color="k", alpha=0.7, label="target")
plt.legend()
!pip install kaggle_secrets
# my secret API key...;D When you submit your own model prediciton, you need to use yours of course:
# public_id = "Your_numerai_public_id"
# secret_key = "Your_numerai_secret_key"
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
public_id = user_secrets.get_secret("public_id")
secret_key = user_secrets.get_secret("secret_key")
# setup numerapi with authentification for submission
napi = NumerAPI(public_id, secret_key)
model_ids = napi.get_models()
# check submission df
logger.info(sub_df.shape)
sub_df.tail()
# upload
def upload(napi, sub_df, upload_type="diagnostics", slot_name="XXX"):
"""Upload prediction to Numerai
"""
# fetch model slot id
model_slots = napi.get_models()
slot_id = model_slots[slot_name.lower()]
# format submission dataframe
sdf = sub_df.index.to_frame()
sdf["data_type"] = sub_df["data_type"].values
sdf["prediction"] = sub_df["prediction"].values
# upload
if upload_type.lower() == "diagnostics": # diagnostics
sdf.query("data_type == 'validation'")[["id", "prediction"]].to_csv(f"./prediction.csv", index=False)
try:
napi.upload_diagnostics(f"./prediction.csv", model_id=slot_id, )
print(f"{slot_name} submitted for diagnositics!")
except Exception as e:
print(f"{slot_name}: {e}")
else: # predictions for the tournament data
in_data = ["test", "live"]
sdf.query("data_type in @in_data")[["id", "prediction"]].to_csv(f"./prediction.csv", index=False)
try:
napi.upload_predictions("./prediction.csv", model_id=slot_id, version=2)
print(f"{slot_name} submitted for predictions!")
except Exception as e:
print(f"{slot_name}: {e}")
# upload diagnostics
your_model_slot_name = "WHITECAT_01" # use your model slot name, of course
upload(napi, sub_df, upload_type="diagnostics", slot_name=your_model_slot_name)
# upload predictions on test and live
upload(napi, sub_df, upload_type="predictions", slot_name=your_model_slot_name)
```
| github_jupyter |
```
'''
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/bbc-text.csv \
-O ./tmp/nlp/bbc-text.csv
'''
import csv
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import pandas as pd
import json
#Stopwords list from https://github.com/Yoast/YoastSEO.js/blob/develop/src/config/stopwords.js
# Convert it to a Python list and paste it here
stopwords = './tmp/nlp/stopwords.js'
with open(stopwords, 'r') as f:
data = f.read()
obj = data[data.find('[') : data.rfind(']')+1]
jsonObj = json.loads(obj)
stopwords=jsonObj
sentences = []
labels = []
file = pd.read_csv('./tmp/nlp/bbc-text.csv')
file['text'] = file['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stopwords)]))
sentences = file['text'].values.tolist()
labels = file['category'].values.tolist()
print(len(labels))
print(sentences[0])
#Expected output
# 2225
# tv future hands viewers home theatre systems plasma high-definition tvs digital video recorders moving living room way people watch tv will radically different five years time. according expert panel gathered annual consumer electronics show las vegas discuss new technologies will impact one favourite pastimes. us leading trend programmes content will delivered viewers via home networks cable satellite telecoms companies broadband service providers front rooms portable devices. one talked-about technologies ces digital personal video recorders (dvr pvr). set-top boxes like us s tivo uk s sky+ system allow people record store play pause forward wind tv programmes want. essentially technology allows much personalised tv. also built-in high-definition tv sets big business japan us slower take off europe lack high-definition programming. not can people forward wind adverts can also forget abiding network channel schedules putting together a-la-carte entertainment. us networks cable satellite companies worried means terms advertising revenues well brand identity viewer loyalty channels. although us leads technology moment also concern raised europe particularly growing uptake services like sky+. happens today will see nine months years time uk adam hume bbc broadcast s futurologist told bbc news website. likes bbc no issues lost advertising revenue yet. pressing issue moment commercial uk broadcasters brand loyalty important everyone. will talking content brands rather network brands said tim hanlon brand communications firm starcom mediavest. reality broadband connections anybody can producer content. added: challenge now hard promote programme much choice. means said stacey jolna senior vice president tv guide tv group way people find content want watch simplified tv viewers. means networks us terms channels take leaf google s book search engine future instead scheduler help people find want watch. kind channel model might work younger ipod generation used taking control gadgets play them. might not suit everyone panel recognised. older generations comfortable familiar schedules channel brands know getting. perhaps not want much choice put hands mr hanlon suggested. end kids just diapers pushing buttons already - everything possible available said mr hanlon. ultimately consumer will tell market want. 50 000 new gadgets technologies showcased ces many enhancing tv-watching experience. high-definition tv sets everywhere many new models lcd (liquid crystal display) tvs launched dvr capability built instead external boxes. one example launched show humax s 26-inch lcd tv 80-hour tivo dvr dvd recorder. one us s biggest satellite tv companies directtv even launched branded dvr show 100-hours recording capability instant replay search function. set can pause rewind tv 90 hours. microsoft chief bill gates announced pre-show keynote speech partnership tivo called tivotogo means people can play recorded programmes windows pcs mobile devices. reflect increasing trend freeing multimedia people can watch want want.
tokenizer = Tokenizer(oov_token='<OOV>')
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(len(word_index))
# Expected output
# 29714
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding='post')
print(padded[0])
print(padded.shape)
# Expected output
# [ 96 176 1158 ... 0 0 0]
# (2225, 2442)
tokenizer_labels = Tokenizer()
tokenizer_labels.fit_on_texts(labels)
label_word_index = tokenizer_labels.word_index
label_seq = tokenizer_labels.texts_to_sequences(labels)
print(label_seq)
print(label_word_index)
# Expected Output
# [[4], [2], [1], [1], [5], [3], [3], [1], [1], [5], [5], [2], [2], [3], [1], [2], [3], [1], [2], [4], [4], [4], [1], [1], [4], [1], [5], [4], [3], [5], [3], [4], [5], [5], [2], [3], [4], [5], [3], [2], [3], [1], [2], [1], [4], [5], [3], [3], [3], [2], [1], [3], [2], [2], [1], [3], [2], [1], [1], [2], [2], [1], [2], [1], [2], [4], [2], [5], [4], [2], [3], [2], [3], [1], [2], [4], [2], [1], [1], [2], [2], [1], [3], [2], [5], [3], [3], [2], [5], [2], [1], [1], [3], [1], [3], [1], [2], [1], [2], [5], [5], [1], [2], [3], [3], [4], [1], [5], [1], [4], [2], [5], [1], [5], [1], [5], [5], [3], [1], [1], [5], [3], [2], [4], [2], [2], [4], [1], [3], [1], [4], [5], [1], [2], [2], [4], [5], [4], [1], [2], [2], [2], [4], [1], [4], [2], [1], [5], [1], [4], [1], [4], [3], [2], [4], [5], [1], [2], [3], [2], [5], [3], [3], [5], [3], [2], [5], [3], [3], [5], [3], [1], [2], [3], [3], [2], [5], [1], [2], [2], [1], [4], [1], [4], [4], [1], [2], [1], [3], [5], [3], [2], [3], [2], [4], [3], [5], [3], [4], [2], [1], [2], [1], [4], [5], [2], [3], [3], [5], [1], [5], [3], [1], [5], [1], [1], [5], [1], [3], [3], [5], [4], [1], [3], [2], [5], [4], [1], [4], [1], [5], [3], [1], [5], [4], [2], [4], [2], [2], [4], [2], [1], [2], [1], [2], [1], [5], [2], [2], [5], [1], [1], [3], [4], [3], [3], [3], [4], [1], [4], [3], [2], [4], [5], [4], [1], [1], [2], [2], [3], [2], [4], [1], [5], [1], [3], [4], [5], [2], [1], [5], [1], [4], [3], [4], [2], [2], [3], [3], [1], [2], [4], [5], [3], [4], [2], [5], [1], [5], [1], [5], [3], [2], [1], [2], [1], [1], [5], [1], [3], [3], [2], [5], [4], [2], [1], [2], [5], [2], [2], [2], [3], [2], [3], [5], [5], [2], [1], [2], [3], [2], [4], [5], [2], [1], [1], [5], [2], [2], [3], [4], [5], [4], [3], [2], [1], [3], [2], [5], [4], [5], [4], [3], [1], [5], [2], [3], [2], [2], [3], [1], [4], [2], [2], [5], [5], [4], [1], [2], [5], [4], [4], [5], [5], [5], [3], [1], [3], [4], [2], [5], [3], [2], [5], [3], [3], [1], [1], [2], [3], [5], [2], [1], [2], [2], [1], [2], [3], [3], [3], [1], [4], [4], [2], [4], [1], [5], [2], [3], [2], [5], [2], [3], [5], [3], [2], [4], [2], [1], [1], [2], [1], [1], [5], [1], [1], [1], [4], [2], [2], [2], [3], [1], [1], [2], [4], [2], [3], [1], [3], [4], [2], [1], [5], [2], [3], [4], [2], [1], [2], [3], [2], [2], [1], [5], [4], [3], [4], [2], [1], [2], [5], [4], [4], [2], [1], [1], [5], [3], [3], [3], [1], [3], [4], [4], [5], [3], [4], [5], [2], [1], [1], [4], [2], [1], [1], [3], [1], [1], [2], [1], [5], [4], [3], [1], [3], [4], [2], [2], [2], [4], [2], [2], [1], [1], [1], [1], [2], [4], [5], [1], [1], [4], [2], [4], [5], [3], [1], [2], [3], [2], [4], [4], [3], [4], [2], [1], [2], [5], [1], [3], [5], [1], [1], [3], [4], [5], [4], [1], [3], [2], [5], [3], [2], [5], [1], [1], [4], [3], [5], [3], [5], [3], [4], [3], [5], [1], [2], [1], [5], [1], [5], [4], [2], [1], [3], [5], [3], [5], [5], [5], [3], [5], [4], [3], [4], [4], [1], [1], [4], [4], [1], [5], [5], [1], [4], [5], [1], [1], [4], [2], [3], [4], [2], [1], [5], [1], [5], [3], [4], [5], [5], [2], [5], [5], [1], [4], [4], [3], [1], [4], [1], [3], [3], [5], [4], [2], [4], [4], [4], [2], [3], [3], [1], [4], [2], [2], [5], [5], [1], [4], [2], [4], [5], [1], [4], [3], [4], [3], [2], [3], [3], [2], [1], [4], [1], [4], [3], [5], [4], [1], [5], [4], [1], [3], [5], [1], [4], [1], [1], [3], [5], [2], [3], [5], [2], [2], [4], [2], [5], [4], [1], [4], [3], [4], [3], [2], [3], [5], [1], [2], [2], [2], [5], [1], [2], [5], [5], [1], [5], [3], [3], [3], [1], [1], [1], [4], [3], [1], [3], [3], [4], [3], [1], [2], [5], [1], [2], [2], [4], [2], [5], [5], [5], [2], [5], [5], [3], [4], [2], [1], [4], [1], [1], [3], [2], [1], [4], [2], [1], [4], [1], [1], [5], [1], [2], [1], [2], [4], [3], [4], [2], [1], [1], [2], [2], [2], [2], [3], [1], [2], [4], [2], [1], [3], [2], [4], [2], [1], [2], [3], [5], [1], [2], [3], [2], [5], [2], [2], [2], [1], [3], [5], [1], [3], [1], [3], [3], [2], [2], [1], [4], [5], [1], [5], [2], [2], [2], [4], [1], [4], [3], [4], [4], [4], [1], [4], [4], [5], [5], [4], [1], [5], [4], [1], [1], [2], [5], [4], [2], [1], [2], [3], [2], [5], [4], [2], [3], [2], [4], [1], [2], [5], [2], [3], [1], [5], [3], [1], [2], [1], [3], [3], [1], [5], [5], [2], [2], [1], [4], [4], [1], [5], [4], [4], [2], [1], [5], [4], [1], [1], [2], [5], [2], [2], [2], [5], [1], [5], [4], [4], [4], [3], [4], [4], [5], [5], [1], [1], [3], [2], [5], [1], [3], [5], [4], [3], [4], [4], [2], [5], [3], [4], [3], [3], [1], [3], [3], [5], [4], [1], [3], [1], [5], [3], [2], [2], [3], [1], [1], [1], [5], [4], [4], [2], [5], [1], [3], [4], [3], [5], [4], [4], [2], [2], [1], [2], [2], [4], [3], [5], [2], [2], [2], [2], [2], [4], [1], [3], [4], [4], [2], [2], [5], [3], [5], [1], [4], [1], [5], [1], [4], [1], [2], [1], [3], [3], [5], [2], [1], [3], [3], [1], [5], [3], [2], [4], [1], [2], [2], [2], [5], [5], [4], [4], [2], [2], [5], [1], [2], [5], [4], [4], [2], [2], [1], [1], [1], [3], [3], [1], [3], [1], [2], [5], [1], [4], [5], [1], [1], [2], [2], [4], [4], [1], [5], [1], [5], [1], [5], [3], [5], [5], [4], [5], [2], [2], [3], [1], [3], [4], [2], [3], [1], [3], [1], [5], [1], [3], [1], [1], [4], [5], [1], [3], [1], [1], [2], [4], [5], [3], [4], [5], [3], [5], [3], [5], [5], [4], [5], [3], [5], [5], [4], [4], [1], [1], [5], [5], [4], [5], [3], [4], [5], [2], [4], [1], [2], [5], [5], [4], [5], [4], [2], [5], [1], [5], [2], [1], [2], [1], [3], [4], [5], [3], [2], [5], [5], [3], [2], [5], [1], [3], [1], [2], [2], [2], [2], [2], [5], [4], [1], [5], [5], [2], [1], [4], [4], [5], [1], [2], [3], [2], [3], [2], [2], [5], [3], [2], [2], [4], [3], [1], [4], [5], [3], [2], [2], [1], [5], [3], [4], [2], [2], [3], [2], [1], [5], [1], [5], [4], [3], [2], [2], [4], [2], [2], [1], [2], [4], [5], [3], [2], [3], [2], [1], [4], [2], [3], [5], [4], [2], [5], [1], [3], [3], [1], [3], [2], [4], [5], [1], [1], [4], [2], [1], [5], [4], [1], [3], [1], [2], [2], [2], [3], [5], [1], [3], [4], [2], [2], [4], [5], [5], [4], [4], [1], [1], [5], [4], [5], [1], [3], [4], [2], [1], [5], [2], [2], [5], [1], [2], [1], [4], [3], [3], [4], [5], [3], [5], [2], [2], [3], [1], [4], [1], [1], [1], [3], [2], [1], [2], [4], [1], [2], [2], [1], [3], [4], [1], [2], [4], [1], [1], [2], [2], [2], [2], [3], [5], [4], [2], [2], [1], [2], [5], [2], [5], [1], [3], [2], [2], [4], [5], [2], [2], [2], [3], [2], [3], [4], [5], [3], [5], [1], [4], [3], [2], [4], [1], [2], [2], [5], [4], [2], [2], [1], [1], [5], [1], [3], [1], [2], [1], [2], [3], [3], [2], [3], [4], [5], [1], [2], [5], [1], [3], [3], [4], [5], [2], [3], [3], [1], [4], [2], [1], [5], [1], [5], [1], [2], [1], [3], [5], [4], [2], [1], [3], [4], [1], [5], [2], [1], [5], [1], [4], [1], [4], [3], [1], [2], [5], [4], [4], [3], [4], [5], [4], [1], [2], [4], [2], [5], [1], [4], [3], [3], [3], [3], [5], [5], [5], [2], [3], [3], [1], [1], [4], [1], [3], [2], [2], [4], [1], [4], [2], [4], [3], [3], [1], [2], [3], [1], [2], [4], [2], [2], [5], [5], [1], [2], [4], [4], [3], [2], [3], [1], [5], [5], [3], [3], [2], [2], [4], [4], [1], [1], [3], [4], [1], [4], [2], [1], [2], [3], [1], [5], [2], [4], [3], [5], [4], [2], [1], [5], [4], [4], [5], [3], [4], [5], [1], [5], [1], [1], [1], [3], [4], [1], [2], [1], [1], [2], [4], [1], [2], [5], [3], [4], [1], [3], [4], [5], [3], [1], [3], [4], [2], [5], [1], [3], [2], [4], [4], [4], [3], [2], [1], [3], [5], [4], [5], [1], [4], [2], [3], [5], [4], [3], [1], [1], [2], [5], [2], [2], [3], [2], [2], [3], [4], [5], [3], [5], [5], [2], [3], [1], [3], [5], [1], [5], [3], [5], [5], [5], [2], [1], [3], [1], [5], [4], [4], [2], [3], [5], [2], [1], [2], [3], [3], [2], [1], [4], [4], [4], [2], [3], [3], [2], [1], [1], [5], [2], [1], [1], [3], [3], [3], [5], [3], [2], [4], [2], [3], [5], [5], [2], [1], [3], [5], [1], [5], [3], [3], [2], [3], [1], [5], [5], [4], [4], [4], [4], [3], [4], [2], [4], [1], [1], [5], [2], [4], [5], [2], [4], [1], [4], [5], [5], [3], [3], [1], [2], [2], [4], [5], [1], [3], [2], [4], [5], [3], [1], [5], [3], [3], [4], [1], [3], [2], [3], [5], [4], [1], [3], [5], [5], [2], [1], [4], [4], [1], [5], [4], [3], [4], [1], [3], [3], [1], [5], [1], [3], [1], [4], [5], [1], [5], [2], [2], [5], [5], [5], [4], [1], [2], [2], [3], [3], [2], [3], [5], [1], [1], [4], [3], [1], [2], [1], [2], [4], [1], [1], [2], [5], [1], [1], [4], [1], [2], [3], [2], [5], [4], [5], [3], [2], [5], [3], [5], [3], [3], [2], [1], [1], [1], [4], [4], [1], [3], [5], [4], [1], [5], [2], [5], [3], [2], [1], [4], [2], [1], [3], [2], [5], [5], [5], [3], [5], [3], [5], [1], [5], [1], [3], [3], [2], [3], [4], [1], [4], [1], [2], [3], [4], [5], [5], [3], [5], [3], [1], [1], [3], [2], [4], [1], [3], [3], [5], [1], [3], [3], [2], [4], [4], [2], [4], [1], [1], [2], [3], [2], [4], [1], [4], [3], [5], [1], [2], [1], [5], [4], [4], [1], [3], [1], [2], [1], [2], [1], [1], [5], [5], [2], [4], [4], [2], [4], [2], [2], [1], [1], [3], [1], [4], [1], [4], [1], [1], [2], [2], [4], [1], [2], [4], [4], [3], [1], [2], [5], [5], [4], [3], [1], [1], [4], [2], [4], [5], [5], [3], [3], [2], [5], [1], [5], [5], [2], [1], [3], [4], [2], [1], [5], [4], [3], [3], [1], [1], [2], [2], [2], [2], [2], [5], [2], [3], [3], [4], [4], [5], [3], [5], [2], [3], [1], [1], [2], [4], [2], [4], [1], [2], [2], [3], [1], [1], [3], [3], [5], [5], [3], [2], [3], [3], [2], [4], [3], [3], [3], [3], [3], [5], [5], [4], [3], [1], [3], [1], [4], [1], [1], [1], [5], [4], [5], [4], [1], [4], [1], [1], [5], [5], [2], [5], [5], [3], [2], [1], [4], [4], [3], [2], [1], [2], [5], [1], [3], [5], [1], [1], [2], [3], [4], [4], [2], [2], [1], [3], [5], [1], [1], [3], [5], [4], [1], [5], [2], [3], [1], [3], [4], [5], [1], [3], [2], [5], [3], [5], [3], [1], [3], [2], [2], [3], [2], [4], [1], [2], [5], [2], [1], [1], [5], [4], [3], [4], [3], [3], [1], [1], [1], [2], [4], [5], [2], [1], [2], [1], [2], [4], [2], [2], [2], [2], [1], [1], [1], [2], [2], [5], [2], [2], [2], [1], [1], [1], [4], [2], [1], [1], [1], [2], [5], [4], [4], [4], [3], [2], [2], [4], [2], [4], [1], [1], [3], [3], [3], [1], [1], [3], [3], [4], [2], [1], [1], [1], [1], [2], [1], [2], [2], [2], [2], [1], [3], [1], [4], [4], [1], [4], [2], [5], [2], [1], [2], [4], [4], [3], [5], [2], [5], [2], [4], [3], [5], [3], [5], [5], [4], [2], [4], [4], [2], [3], [1], [5], [2], [3], [5], [2], [4], [1], [4], [3], [1], [3], [2], [3], [3], [2], [2], [2], [4], [3], [2], [3], [2], [5], [3], [1], [3], [3], [1], [5], [4], [4], [2], [4], [1], [2], [2], [3], [1], [4], [4], [4], [1], [5], [1], [3], [2], [3], [3], [5], [4], [2], [4], [1], [5], [5], [1], [2], [5], [4], [4], [1], [5], [2], [3], [3], [3], [4], [4], [2], [3], [2], [3], [3], [5], [1], [4], [2], [4], [5], [4], [4], [1], [3], [1], [1], [3], [5], [5], [2], [3], [3], [1], [2], [2], [4], [2], [4], [4], [1], [2], [3], [1], [2], [2], [1], [4], [1], [4], [5], [1], [1], [5], [2], [4], [1], [1], [3], [4], [2], [3], [1], [1], [3], [5], [4], [4], [4], [2], [1], [5], [5], [4], [2], [3], [4], [1], [1], [4], [4], [3], [2], [1], [5], [5], [1], [5], [4], [4], [2], [2], [2], [1], [1], [4], [1], [2], [4], [2], [2], [1], [2], [3], [2], [2], [4], [2], [4], [3], [4], [5], [3], [4], [5], [1], [3], [5], [2], [4], [2], [4], [5], [4], [1], [2], [2], [3], [5], [3], [1]]
# {'sport': 1, 'business': 2, 'politics': 3, 'tech': 4, 'entertainment': 5}
```
| github_jupyter |
# **Finding Lane Lines on the Road**
***
In this project, you will use the tools you learned about in the lesson to identify lane lines on the road. You can develop your pipeline on a series of individual images, and later apply the result to a video stream (really just a series of images). Check out the video clip "raw-lines-example.mp4" (also contained in this repository) to see what the output should look like after using the helper functions below.
Once you have a result that looks roughly like "raw-lines-example.mp4", you'll need to get creative and try to average and/or extrapolate the line segments you've detected to map out the full extent of the lane lines. You can see an example of the result you're going for in the video "P1_example.mp4". Ultimately, you would like to draw just one line for the left side of the lane, and one for the right.
---
Let's have a look at our first image called 'test_images/solidWhiteRight.jpg'. Run the 2 cells below (hit Shift-Enter or the "play" button above) to display the image.
**Note** If, at any point, you encounter frozen display windows or other confounding issues, you can always start again with a clean slate by going to the "Kernel" menu above and selecting "Restart & Clear Output".
---
**The tools you have are color selection, region of interest selection, grayscaling, Gaussian smoothing, Canny Edge Detection and Hough Tranform line detection. You are also free to explore and try other techniques that were not presented in the lesson. Your goal is piece together a pipeline to detect the line segments in the image, then average/extrapolate them and draw them onto the image for display (as below). Once you have a working pipeline, try it out on the video stream below.**
---
<figure>
<img src="line-segments-example.jpg" width="380" alt="Combined Image" />
<figcaption>
<p></p>
<p style="text-align: center;"> Your output should look something like this (above) after detecting line segments using the helper functions below </p>
</figcaption>
</figure>
<p></p>
<figure>
<img src="laneLines_thirdPass.jpg" width="380" alt="Combined Image" />
<figcaption>
<p></p>
<p style="text-align: center;"> Your goal is to connect/average/extrapolate line segments to get output like this</p>
</figcaption>
</figure>
```
# importing some useful packages
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
import cv2
%matplotlib inline
# calculate running average for line coordinates
def running_average(avg, sample, n=12):
if (avg == 0):
return sample
avg -= avg / n;
avg += sample / n;
return int(avg);
# global variables - need to reset for before each of the video processing
prev_left_line = []
prev_right_line = []
# setting globals
def set_global_prev_left_line(left_line):
global prev_left_line
if prev_left_line and left_line:
x1, y1, x2, y2 = prev_left_line
prev_left_line = (running_average(x1, left_line[0])),(running_average(y1, left_line[1])),(running_average(x2, left_line[2])),(running_average(y2, left_line[3]))
else:
prev_left_line = left_line
def set_global_prev_right_line(right_line):
global prev_right_line
if prev_right_line and right_line:
x1, y1, x2, y2 = prev_right_line
prev_right_line = (running_average(x1, right_line[0])),(running_average(y1, right_line[1])),(running_average(x2, right_line[2])),(running_average(y2, right_line[3]))
else:
prev_right_line = right_line
# reading in an image
image = mpimg.imread('test_images/solidWhiteRight.jpg')
# printing out some stats and plotting
print('This image is:', type(image), 'with dimesions:', image.shape)
plt.imshow(image)
# if you wanted to show a single color channel image called 'gray', for example, call as plt.imshow(gray, cmap='gray')
```
**Some OpenCV functions (beyond those introduced in the lesson) that might be useful for this project are:**
`cv2.inRange()` for color selection
`cv2.fillPoly()` for regions selection
`cv2.line()` to draw lines on an image given endpoints
`cv2.addWeighted()` to coadd / overlay two images
`cv2.cvtColor()` to grayscale or change color
`cv2.imwrite()` to output images to file
`cv2.bitwise_and()` to apply a mask to an image
**Check out the OpenCV documentation to learn about these and discover even more awesome functionality!**
Below are some helper functions to help get you started. They should look familiar from the lesson!
```
import math
def grayscale(img):
"""Applies the Grayscale transform
This will return an image with only one color channel
but NOTE: to see the returned image as grayscale
(assuming your grayscaled image is called 'gray')
you should call plt.imshow(gray, cmap='gray')"""
return cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# Or use BGR2GRAY if you read an image with cv2.imread()
# return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
def canny(img, low_threshold, high_threshold):
"""Applies the Canny transform"""
return cv2.Canny(img, low_threshold, high_threshold)
def gaussian_blur(img, kernel_size):
"""Applies a Gaussian Noise kernel"""
return cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)
def region_of_interest(img, vertices):
"""
Applies an image mask.
Only keeps the region of the image defined by the polygon
formed from `vertices`. The rest of the image is set to black.
"""
#defining a blank mask to start with
mask = np.zeros_like(img)
#defining a 3 channel or 1 channel color to fill the mask with depending on the input image
if len(img.shape) > 2:
channel_count = img.shape[2] # i.e. 3 or 4 depending on your image
ignore_mask_color = (255,) * channel_count
else:
ignore_mask_color = 255
#filling pixels inside the polygon defined by "vertices" with the fill color
cv2.fillPoly(mask, vertices, ignore_mask_color)
#returning the image only where mask pixels are nonzero
masked_image = cv2.bitwise_and(img, mask)
return masked_image
def draw_lines(img, lines, color=[255, 0, 0], thickness=2):
"""
NOTE: this is the function you might want to use as a starting point once you want to
average/extrapolate the line segments you detect to map out the full
extent of the lane (going from the result shown in raw-lines-example.mp4
to that shown in P1_example.mp4).
Think about things like separating line segments by their
slope ((y2-y1)/(x2-x1)) to decide which segments are part of the left
line vs. the right line. Then, you can average the position of each of
the lines and extrapolate to the top and bottom of the lane.
This function draws `lines` with `color` and `thickness`.
Lines are drawn on the image inplace (mutates the image).
If you want to make the lines semi-transparent, think about combining
this function with the weighted_img() function below
"""
for line in lines:
for x1,y1,x2,y2 in line:
cv2.line(img, (x1, y1), (x2, y2), color, thickness)
def average_lines(lines):
line_top = []
line_bottom = []
for line in lines:
for x1,y1,x2,y2 in line:
if y1 < y2:
line_top.append([x1, y1])
line_bottom.append([x2, y2])
else:
line_top.append([x2, y2])
line_bottom.append([x1, y1])
if len(line_top) > 0:
average_top = [ int(np.average([point[0] for point in line_top])), int(np.average([point[1] for point in line_top]))]
else:
average_top = []
if len(line_bottom) > 0:
average_bottom = [ int(np.average([point[0] for point in line_bottom])), int(np.average([point[1] for point in line_bottom]))]
else:
average_bottom = []
return average_top + average_bottom
def segment_hough_lines(lines):
left_lines = []
right_lines = []
# Segment left and right lines based on their slope
for line in lines:
for x1,y1,x2,y2 in line:
slope = (y2 - y1) / (x2 - x1)
if abs(slope) < 0.5:
# skip and continue, if the slope is less than 0.5
continue
if slope >= 0:
right_lines.append(line)
else:
left_lines.append(line)
return right_lines, left_lines
def find_largest_lines(lines):
largest_right_line = []
largest_left_line = []
largest_right_line_length = 0.0
largest_left_line_length = 0.0
# Segment left and right lines based on their slope
for line in lines:
for x1,y1,x2,y2 in line:
slope = (y2 - y1) / (x2 - x1)
if abs(slope) < 0.5:
# skip and continue, if the slope is less than 0.5
continue
line_length = math.hypot(x2 - x1, y2 - y1)
if slope >= 0:
if line_length > largest_right_line_length:
largest_right_line = [x1, y1, x2, y2]
largest_right_line_length = line_length
else:
if line_length > largest_left_line_length:
largest_left_line = [x1, y1, x2, y2]
largest_left_line_length = line_length
return largest_right_line, largest_left_line
def extrapolate_line(line, top_max, bottom_max):
x1, y1, x2, y2 = line
a = np.array([[x1, 1], [x2, 1]])
b = np.array([y1, y2])
m, c = np.linalg.solve(a, b)
# find the extrapolated bottom
y2 = top_max
x2 = int((y2 - c)/m)
# find the extrapolated top
y1 = bottom_max
x1 = int((y1 - c)/m)
return [x1, y1, x2, y2]
def hough_lines(img, rho, theta, threshold, min_line_len, max_line_gap):
"""
`img` should be the output of a Canny transform.
Returns an image with hough lines drawn.
"""
# Image dimensions
img_height = img.shape[0]
img_width = img.shape[1]
lines = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]), minLineLength=min_line_len, maxLineGap=max_line_gap)
line_img = np.zeros((img_height, img_width, 3), dtype=np.uint8)
"""
Approach 1 - Based on largest hough line
"""
"""
# Get largest left/right lines from hough lines
largest_right_line, largest_left_line = find_largest_lines(lines)
# Extrapolate the line to the top and bottom of the region of interest
if largest_right_line:
final_right_line = extrapolate_line(largest_right_line, top_max = int(img_height * 0.6), bottom_max = img_width)
set_global_prev_right_line(final_right_line)
else:
final_right_line = prev_right_line
if largest_left_line:
final_left_line = extrapolate_line(largest_left_line, top_max = int(img_height * 0.6), bottom_max = img_width)
set_global_prev_left_line(final_left_line)
else:
final_left_line = prev_left_line
"""
"""
# Approach 2 - Average the left and right lines
"""
# Segment hough lines
right_lines, left_lines = segment_hough_lines(lines)
# Find average for a line
average_right_line = average_lines(right_lines)
average_left_line = average_lines(left_lines)
# Extrapolate the line to the top and bottom of the region of interest
if average_right_line:
final_right_line = extrapolate_line(average_right_line, top_max = int(img_height * 0.6), bottom_max = img_width)
set_global_prev_right_line(final_right_line)
else:
final_right_line = prev_right_line
if average_left_line:
final_left_line = extrapolate_line(average_left_line, top_max = int(img_height * 0.6), bottom_max = img_width)
set_global_prev_left_line(final_left_line)
else:
final_left_line = prev_left_line
#new_lines = [[final_right_line], [final_left_line]]
new_lines = [[prev_right_line], [prev_left_line]]
draw_lines(line_img, new_lines, thickness=10)
return line_img
# Python 3 has support for cool math symbols.
def weighted_img(img, initial_img, α=0.8, β=1., λ=0.):
"""
`img` is the output of the hough_lines(), An image with lines drawn on it.
Should be a blank image (all black) with lines drawn on it.
`initial_img` should be the image before any processing.
The result image is computed as follows:
initial_img * α + img * β + λ
NOTE: initial_img and img must be the same shape!
"""
return cv2.addWeighted(initial_img, α, img, β, λ)
def process_image(image):
# NOTE: The output you return should be a color image (3 channel) for processing video below
# you should return the final output (image with lines are drawn on lanes)
# Image dimensions
img_height = image.shape[0]
img_width = image.shape[1]
# Step 1: Convert to Grayscale
processed_image = grayscale(image)
# Step 2: Gaussian Blur Transform
kernel_size = 7
processed_image = gaussian_blur(processed_image, kernel_size)
# Step 3: Canny Transform
low_threshold = 100
high_threshold = 200
processed_image = canny(processed_image, low_threshold, high_threshold)
# Step 4: Region of Interest
bottom_left = [100, img_height]
bottom_right = [img_width - 80, img_height]
top_left = [int(0.4 * img_width), int(0.6 * img_height)]
top_right = [int(0.6 * img_width), int(0.6 * img_height)]
processed_image = region_of_interest(processed_image, [np.array([bottom_left, top_left, top_right, bottom_right], dtype=np.int32)])
# Step 5: Hough lines
rho = 1.0
theta = np.pi/180
threshold = 25
min_line_len = 50
max_line_gap = 200
processed_image = hough_lines(img=processed_image, theta=theta, rho=rho, min_line_len=min_line_len, max_line_gap=max_line_gap, threshold=threshold)
# Step 6: Weighted Image
processed_image = weighted_img(img=processed_image, initial_img=image)
return processed_image
img = process_image(mpimg.imread("test_images/solidYellowCurve2.jpg"))
#plt.plot(x, y, 'b--', lw=4)
plt.imshow(img, cmap='gray')
```
## Test on Images
Now you should build your pipeline to work on the images in the directory "test_images"
**You should make sure your pipeline works well on these images before you try the videos.**
run your solution on all test_images and make copies into the test_images directory).
```
import os
test_images_dir = "test_images/"
test_out_dir = "test_output/"
if not os.path.exists(test_out_dir):
os.makedirs(test_out_dir)
for file in os.listdir(test_images_dir):
# Ignore hidden files
if file.startswith('.'):
continue
image = mpimg.imread(test_images_dir + file)
processed_image = process_image(image)
out_file = test_out_dir + file
#cv2.imwrite(out_file, processed_image)
mpimg.imsave(out_file, processed_image)
print('Processed [{0}] -> [{1}]'.format(file, out_file))
print("Done with processing images in {0} folder.".format(test_images_dir))
```
## Test on Videos
You know what's cooler than drawing lanes over images? Drawing lanes over video!
We can test our solution on two provided videos:
`solidWhiteRight.mp4`
`solidYellowLeft.mp4`
```
# Import everything needed to edit/save/watch video clips
from moviepy.editor import VideoFileClip
from IPython.display import HTML
```
Let's try the one with the solid white lane on the right first ...
```
# Reset global variables
set_global_prev_left_line([])
set_global_prev_right_line([])
white_output = 'white.mp4'
clip1 = VideoFileClip("solidWhiteRight.mp4")
white_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!
%time white_clip.write_videofile(white_output, audio=False)
```
Play the video inline, or if you prefer find the video in your filesystem (should be in the same directory) and play it in your video player of choice.
```
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(white_output))
```
**At this point, if you were successful you probably have the Hough line segments drawn onto the road, but what about identifying the full extent of the lane and marking it clearly as in the example video (P1_example.mp4)? Think about defining a line to run the full length of the visible lane based on the line segments you identified with the Hough Transform. Modify your draw_lines function accordingly and try re-running your pipeline.**
Now for the one with the solid yellow lane on the left. This one's more tricky!
```
# Reset global variables
set_global_prev_left_line([])
set_global_prev_right_line([])
yellow_output = 'yellow.mp4'
clip2 = VideoFileClip('solidYellowLeft.mp4')
yellow_clip = clip2.fl_image(process_image)
%time yellow_clip.write_videofile(yellow_output, audio=False)
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(yellow_output))
```
## Reflections
Congratulations on finding the lane lines! As the final step in this project, we would like you to share your thoughts on your lane finding pipeline... specifically, how could you imagine making your algorithm better / more robust? Where will your current algorithm be likely to fail?
Please add your thoughts below, and if you're up for making your pipeline more robust, be sure to scroll down and check out the optional challenge video below!
* Finding lane lines project is a starter project with relatively a simple use case. For a real self-driving car scenarios, finding lane lines need to take care of complex scenarios, real world road conditions, lights and other factors.
* Finding lane lines project doesn't take into consideration of normal driving scenarios, like junctions, signals, lane changes etc.
* Algorithms for finding lane lines project is based on successful canny and hough lines algorithms, any road conditions that may not work well for canny and hough lines requirements/assumptions will have challenges.
* Making the algorithm work for a video (moving car) is much different from making it work for a single image. For video, the algorithm needs to consider prior frames and average the lane lines for smoother lane prediction/projections.
* Tried 2 different approaches, first one based on largest line segment, extrapolating and averaging with prior frames. Second approach was to average both left and right segments, extrapolate and average with prior frames. Haven't found significant difference on the results for the given videos.
* Averaging with prior frames needed to be balanced based on our tests. Noticed that, larger the number of prior frames for average, it affects the average lane line to be off the actual lane line on the frame.
* To have a smooth lane line projection, average lane line to be drawn instead of that frame's lane line.
* Many of the values and parameters could be further adjusted for better results, on the other hand, tuning to specific scenarios may not work well for more challenging scenarios. It would be interesting to find out how to come up with algorithms & parameter values that works well regardless of the road conditions!!
* For example, Optional Challenge video has a few different scenarios on road conditions, with a few frames not having clear lane lines, shadows and turns. Algorithms had to be revised to take into consideration of those conditions.
* Good to start with a simple finding lane line project and move towards more challenging scenarios. Looking forward to upcoming projects!
## Submission
If you're satisfied with your video outputs it's time to submit! Submit this ipython notebook for review.
## Optional Challenge
Try your lane finding pipeline on the video below. Does it still work? Can you figure out a way to make it more robust? If you're up for the challenge, modify your pipeline so it works with this video and submit it along with the rest of your project!
```
# Reset global variables
set_global_prev_left_line([])
set_global_prev_right_line([])
challenge_output = 'extra.mp4'
clip2 = VideoFileClip('challenge.mp4')
challenge_clip = clip2.fl_image(process_image)
%time challenge_clip.write_videofile(challenge_output, audio=False)
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(challenge_output))
```
| github_jupyter |
```
%matplotlib inline
from matplotlib import style
style.use('fivethirtyeight')
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import datetime as dt
```
# Reflect Tables into SQLAlchemy ORM
```
# Python SQL toolkit and Object Relational Mapper
import sqlalchemy
from sqlalchemy.ext.automap import automap_base
from sqlalchemy.orm import Session
from sqlalchemy import create_engine, func
engine = create_engine("sqlite:///hawaii.sqlite")
Base = automap_base()
# reflect an existing database into a new model
Base = automap_base()
# reflect the tables
Base.prepare(engine, reflect=True)
# We can view all of the classes that automap found
Base.classes.keys()
# Save references to each table
Measurement = Base.classes.measurement
Station = Base.classes.station
# Create our session (link) from Python to the DB
session = Session(engine)
```
# Exploratory Climate Analysis
```
# Design a query to retrieve the last 12 months of precipitation data and plot the results.
#Starting from the last data point in the database.
prev_year = dt.date(2017, 8, 23)
# Calculate the date one year from the last date in data set.
prev_year = dt.date(2017, 8, 23) - dt.timedelta(days=365)
# Perform a query to retrieve the data and precipitation scores
results = []
results = session.query(Measurement.date, Measurement.prcp)
#print(results.all())
# Save the query results as a Pandas DataFrame and set the index to the date column
df = pd.DataFrame(results, columns=['date','precipitation'])
df.set_index(df['date'], inplace=True)
#print(df.to_string(index=False))
# Sort the dataframe by date
df = df.sort_index()
#print(df.to_string(index=False))
# Use Pandas Plotting with Matplotlib to plot the data
df.plot()
# Use Pandas to calcualte the summary statistics for the precipitation data
df.describe()
# How many stations are available in this dataset?
session.query(func.count(Station.station)).all()
# What are the most active stations?
# List the stations and the counts in descending order.
session.query(Measurement.station, func.count(Measurement.station)).\
group_by(Measurement.station).order_by(func.count(Measurement.station).desc()).all()
# Using the station id from the previous query, calculate the lowest temperature recorded,
# highest temperature recorded, and average temperature most active station?
session.query(func.min(Measurement.tobs), func.max(Measurement.tobs), func.avg(Measurement.tobs)).\
filter(Measurement.station == 'USC00519281').all()
# Choose the station with the highest number of temperature observations.
# Query the last 12 months of temperature observation data for this station and plot the results as a histogram
results = session.query(Measurement.tobs).\
filter(Measurement.station == 'USC00519281').\
filter(Measurement.date >= prev_year).all()
#print(results)
df = pd.DataFrame(results, columns=['tobs'])
df.plot.hist(bins=12)
plt.tight_layout()
# Write a function called `calc_temps` that will accept start date and end date in the format '%Y-%m-%d'
# and return the minimum, average, and maximum temperatures for that range of dates
```
# Challenge
| github_jupyter |
```
from swat import *
from pprint import pprint
%matplotlib inline
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import ImageGrid
import pandas as pd
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.max_colwidth', 500)
from dlpy.layers import *
from dlpy.applications import *
from dlpy import Model, Sequential
from dlpy.utils import *
from dlpy.splitting import two_way_split
from dlpy.lr_scheduler import *
from dlpy.images import *
from dlpy.image_embedding import *
from dlpy.embedding_model import EmbeddingModel
s = CAS('host_name', port_number)
s.sessionprop.setsessopt(caslib='CASUSER', timeout=31535000)
```
# Build a triplet model using ResNet18 as the base branch
```
#build the base model
resnet18_model = ResNet18_Caffe(s,
width=224,
height=224
,random_flip='HV',
#random_crop='RESIZETHENCROP',
random_mutation='random'
)
# define your own embedding layer with 4 neurons
embedding_layer = Dense(n=4, act='identity')
model_tr = EmbeddingModel.build_embedding_model(resnet18_model, model_table='test_tr',
embedding_model_type='triplet', margin=-3.0,
embedding_layer=embedding_layer)
```
# Train the model with on-the-fly data generation
```
from dlpy.model import Gpu
gpu = Gpu(devices=1)
from dlpy.model import Optimizer, MomentumSolver, AdamSolver
solver = AdamSolver(lr_scheduler=StepLR(learning_rate=0.0001, step_size=4), clip_grad_max = 100, clip_grad_min = -100)
optimizer = Optimizer(algorithm=solver, mini_batch_size=8, log_level=2, max_epochs=8, reg_l2=0.0001)
# In this case, a pre-defined data set is not given.
# When the path option is specified, the fit_embedding_model API will generate the data on-the-fly.
# max_iter defines how many data iterations will be performed
# the returned results contains the training information for each data iteration
# This dataset contains 10680 training images and 3045 testing images
# For training, 4606 images contain the Cat class while 6073 images for Bird
# For testing, 1381 images contain Cat while 1664 images for Bird
# With this on-the-fly data generation, the training images are randomly selected to create the triplets
# max_iter = 15 means this data generation happens 15 times.
# The model will continue being trained with each new data sample set.
# Within the training for a given data sample set, AdamSolver is used and the model is trained with 8 epochs.
res = model_tr.fit_embedding_model(optimizer=optimizer, n_threads=4, gpu=gpu, seed=1234,record_seed=23435,
path='server_side_train_data_location',
n_samples=2048, max_iter=15,
resize_width=224, resize_height=224)
# check the results from the last data iteration
res[-1]
```
# Deploy the model with astore
```
# When model_type='full', the entire model is deployed. However, in many cases,
# We only want to deploy one branch to extract the image features.
# Specifying model_type='branch' will automatically select the first branch as the feature extraction model.
# The generated astore file will be stored at the client path.
# This also returns the generated branch model
branch_model = model_tr.deploy_embedding_model(output_format='astore', model_type='branch',
path='client_side_path')
# Note we generate a fake classification model here
# The output layer does not generate any useful results.
# The features from the EmbeddingLayer_0 layer will be output when deploying the above astore model
branch_model.print_summary()
```
# Test the astore model using clustering
```
# load the generated astore file from the client side into CAS
with open('client_side_path_that_contains_the_astore_file', mode='rb') as file:
fileContent = file.read()
# load the astore action set
s.loadactionset('astore')
# upload it to CAS
store_ = sw.blob(fileContent)
s.astore.upload(rstore=dict(name='test_tr_branch', replace=True),store = store_)
# check the astore information
# note that the useful image embedding columns are
# _LayerAct_53_0_0_0_ to _LayerAct_53_0_0_3_
# these stores 4 numbers as the learned image embedding vector
s.astore.describe(rstore='test_tr_branch')
# load our testing data
my_test_table = ImageTable.load_files(conn=s, path='server_side_test_data_location')
my_test_table.label_freq
my_test_table.show(randomize=True)
# generate the image embedding by calling the astore.score action with one GPU
s.score(rstore = 'test_tr_branch',
table = my_test_table,
nthreads =1,
copyvars=['_filename_0', '_label_'],
options=[dict(name='usegpu', value='1'),
dict(name='NDEVICES', value='1'),
dict(name='DEVICE0', value='0')
],
out = dict(name='astore_score1_branch_gpu', replace=True))
# check the generated image embedding
s.fetch(table='astore_score1_branch_gpu', fetchVars=['_LayerAct_53_0_0_0_', '_LayerAct_53_0_0_0_',
'_LayerAct_53_0_0_1_', '_LayerAct_53_0_0_2_'],
to=5)
# use these generated vectors for clustering
feature_list=[]
for i in range(0, 4):
feature_list.append("_LayerAct_53_0_0_" + str(i) +"_")
s.loadactionset('clustering')
s.kclus(table=dict(name='astore_score1_branch_gpu'),
maxClusters=2, maxIters=100, standardize='std',
inputs=feature_list,
output=dict(casout=dict(name='cluster_results', replace=True),
copyvars=['_filename_0', '_label_']))
# we can get two quite good clusters only using a vector with 4 numbers
# each cluster is only dominated by a single class
s.freq(table=dict(name='cluster_results', groupby='_cluster_id_'), inputs='_label_')
# close the session
s.endsession()
```
| github_jupyter |
# Casamento LGBT no Brasil
*Este notebook contém o projeto final aplicado da disciplina "Análise exploratória de dados", no Master em Jornalismo Dados, Automação e Data Storytelling do Insper, lecionada pelo Prof. André Filipe de Moraes Batista, PhD.*
**Integrantes do grupo:** Gabriela Caesar, Isabela Fleischmann e Thiago Araújo (Grupo GIT).
**Transparência:** o trabalho também está disponível no [GitHub](https://github.com/gabrielacaesar/lgbt_casamento).
**Base de dados escolhida:** casamentos de pessoas do mesmo gênero de 2013 até 2019 (dado mais recente).
**Base de dados complementar:** números de habitantes desagregados por gênero, UF e faixa etária.
**Fonte das bases de dados:** Instituto Brasileiro de Geografia e Estatística (IBGE). Os arquivos brutos [estão salvos aqui](https://github.com/gabrielacaesar/lgbt_casamento/tree/main/data/raw_data).
**Metodologia:** os dados do IBGE estão disponíveis em um formato que dificulta o reaproveitamento para a análise. Por isso, transformamos os dados em [formato "tidy"](https://escoladedados.org/tutoriais/tidy-data-dados-arrumados-e-5-problemas-comuns/) antes de iniciar as análises. Os arquivos tratados [estão salvos aqui](https://github.com/gabrielacaesar/lgbt_casamento/tree/main/data).
## Contexto do assunto
O Brasil tem [mais de 60 mil casais formados por pessoas do mesmo gênero](http://g1.globo.com/brasil/noticia/2011/04/censo-2010-contabiliza-mais-de-60-mil-casais-homossexuais.html), segundo o Censo 2010 - o último realizado no Brasil e divulgado em 2011. Esse número é bastante menor que o de casais formados por pessoas de gêneros diferentes: 37,5 milhões.
Mais de dez anos se passaram. E como está essa situação hoje no Brasil? É inegável que, ao caminhar na Avenida Paulista, em São Paulo, em 2021, vemos mais casais LGBTs do que há 10 anos. O sentimento é que mais pessoas puderam viver histórias homoafetivas nas grandes cidades. Mas será que isso vale para todo o Brasil? E será que a eleição de Jair Bolsonaro impactou esses números?
Além disso, apenas em 2011, o STF julgou legal a união civil de pessoas do mesmo gênero. Em 2013, o Conselho Nacional de Justiça [passou a permitir que todos os cartórios registrassem a união homoafetiva](https://g1.globo.com/distrito-federal/noticia/casamento-gay-no-brasil-completa-4-anos-de-regulamentacao-leia-historias.ghtml).
A orientação sexual é uma informação pessoal e, por isso, há poucos dados sobre isso, já que os órgãos não costumam coletar essa informação. Antes da definição da base, o grupo mapeou diversos dados sobre LGBTs para verificar qual base poderia ter dados de qualidade para tratar o tema.
A base de dados do IBGE, porém, é uma exceção positiva nesse levantamento. Além de ter dados oficiais do Brasil, ela também tem um detalhamento que permite uma ampla análise exploratória para responder a perguntas.
## Perguntas a que queremos responder
1. Quantos casamentos homoafetivos ocorreram no Brasil de 2013 a 2019?
2. Qual foi o ano com mais casamentos? E com menos casamento?
3. Quais foram as estatísticas básicas anuais? E em 2018?
4. Quem casa mais no meio LGBT? Homens ou mulheres?
5. As mulheres também se casam mais considerando os dados anuais?
6. Em qual mês as pessoas mais se casam? E em qual elas menos se casam?
7. Há mais casamentos homoafetivos após a vitória de Jair Bolsonaro, em 28 de outubro de 2018?
8. Em quais estados aconteceram mais casamentos LGBTs em números absolutos? E menos?
9. Em quais regiões do Brasil os casamentos LGBTs mais ocorrem? E menos?
10. Considerando a população adulta, quais estados têm as maiores e menores proporções de casamentos LGBTs?
11. Em um mapa do Brasil, como ficam as taxas de casamentos LGBTS por 100 mil adultos?
12. Considerando a UF e o ano informados pelo usuário, quais são as estatísticas básicas dessa UF e desse ano quanto ao casamento LGBT?
## O que aprendemos com os dados
1. Mais de 40 mil casamentos homoafetivos foram realizados de 2013 a 2019
2. As mulheres definitivamente se casam mais do que os homens
3. 2014 foi o ano em que o número de casamentos de homens quase ultrapassou o de mulheres
4. SP e DF foram as unidades federativas com as maiores taxas de casamentos LGBTs por habitantes adultos;
5. Em números absolutos, SP concentra 41,5% dos casamentos, seguido por RJ (9,3%), MG (7,5%) e SC (5,5%). RR, AC e AP têm os menores números.
6. Estados do Norte e do Nordeste, como MA, TO, PI, AP e AC, aparecem com as menores taxas
7. O Sudeste, região mais populosa do Brasil, também foi a região com mais casamentos
8. O ano com mais casamentos LGBTs foi 2018, seguido por 2019
9. O mês com mais casamentos foi dezembro; e o mês com menos foi abril
10. Os meses próximos à eleição de Jair Bolsonaro foram os picos de casamentos LGBTS
11. Os dados apontam que os casais homoafetivos seguiram [a recomendação da presidente da Comissão Especial da Diversidade Sexual e de Gênero do Conselho Federal da OAB, Maria Berenice Dias](https://g1.globo.com/sp/sao-paulo/noticia/2018/11/07/casamento-lgbt-cresce-25-no-pais-diz-associacao-profissionais-oferecem-servicos-gratuitos-para-celebracoes.ghtml), para os casais procurarem assegurar o matrimônio ainda em 2018.
## 1. Verificação do dataframe
Esta etapa do trabalho se propõe a importar o CSV principal e todas as bibliotecas usadas no Notebook, além de verificar do que esse dataframe é formado antes de responder às perguntas de interesse.
```
# importação das bibliotecas
# %%capture
# !pip install geopandas ## para instalar o geopandas
# import geopandas as gpd
import pandas as pd
import altair as alt
# leitura do CSV como dataframe
lgbt_casamento = pd.read_csv('https://raw.githubusercontent.com/gabrielacaesar/lgbt_casamento/main/data/lgbt_casamento.csv')
# primeiras linhas do nosso dataframe
lgbt_casamento.head()
# últimas linhas do nosso dataframe
lgbt_casamento.tail()
# informações do dataframe, por exemplo: tipo da coluna e número de linhas
lgbt_casamento.info()
# estatísticas das colunas numéricas do dataframe
lgbt_casamento.describe()
# cabeçalho da dataframe
lgbt_casamento.columns
# valores únicos da coluna 'ano' do dataframe
lgbt_casamento['ano'].unique()
# valores únicos da coluna 'mes' do dataframe
lgbt_casamento['mes'].unique()
# valores únicos da coluna 'genero' do dataframe
lgbt_casamento['genero'].unique()
# valores únicos da coluna 'uf' do dataframe
lgbt_casamento['uf'].unique()
# tamanho dos valores únicos da coluna 'uf' do dataframe
len(lgbt_casamento['uf'].unique())
# tamanho dos valores únicos da coluna 'mes' do dataframe
len(lgbt_casamento['mes'].unique())
# tamanho dos valores únicos da coluna 'ano' do dataframe
len(lgbt_casamento['ano'].unique())
# seleciona apenas a coluna 'mes'
lgbt_casamento['mes']
# número de linhas na coluna 'numero'
len(lgbt_casamento['mes'])
# pergunta se aquele campo da coluna 'mes' é NA (ou seja, sem preenchimento)
lgbt_casamento['mes'].isna()
# pergunta se aquele campo da coluna 'numero' é NA (ou seja, sem preenchimento)
lgbt_casamento['numero'].isna()
# número máximo da coluna 'numero'
# ou seja, maior número de casamentos em um mês em uma UF
lgbt_casamento['numero'].max()
# número mínimo da coluna 'numero'
# ou seja, menor número de casamentos em um mês em uma UF
lgbt_casamento['numero'].min()
# média da coluna 'numero'
lgbt_casamento['numero'].mean()
# mediana da coluna 'numero'
lgbt_casamento['numero'].median()
# desvio padrão da coluna 'numero'
lgbt_casamento['numero'].std()
# soma da coluna 'numero'
sum(lgbt_casamento['numero'])
```
## 2. Análise exploratória de dados
Esta etapa do trabalho se propõe a analisar os dados com mais profundida para começar a responder a algumas perguntas formuladas inicialmente. Como o CSV já foi importado e as bibliotecas já foram chamadas anteriormente neste Notebook, isso não precisa ser repetido.
### Quantos casamentos homoafetivos ocorreram no Brasil de 2013 a 2019?
```
# mais de 40 mil casamentos homoafetivos nesse período
lgbt_casamento['numero'].sum()
```
### Qual foi o ano com mais casamentos homoafetivos? E com menos?
```
# 2018 foi o ano com mais casamentos, seguido por 2019
casamento_ano = lgbt_casamento.groupby('ano')['numero'].sum().sort_values(ascending=False).reset_index()
print(casamento_ano)
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/bar_chart_with_highlighted_bar.html
alt.Chart(casamento_ano).mark_bar().encode(
x = alt.X('ano:O', title = 'Ano'),
y = alt.Y('numero', title = 'Nº de casamentos'),
color=alt.condition(
alt.datum.ano == 2018, # destacar com laranka
alt.value('orange'),
alt.value('steelblue')
),
tooltip = ['ano', 'numero']
).properties(title = '2018 é o recorde de casamentos homoafetivos', width=600, height=300).interactive()
```
## Quais foram as estatísticas básicas anuais?
```
# estatísticas básicas por ano e gênero
# ATENÇÃO: as estatísticas (mean, median, std, max e min) se referem a cada mês, e não ao ano completo
lgbt_casamento.groupby(['ano', 'genero']).agg({'numero':['sum', 'mean', 'median', 'std', 'max', 'min']})
```
## Quais foram as estatísticas básicas de 2018?
```
# estatísticas básicas por uf e gênero no ano de 2018
# ATENÇÃO: as estatísticas (mean, median, std, max e min) se referem a cada mês, e não ao ano completo
# Nas mulheres, SP, por exemplo, tem média de 209 casamentos mensais
# e mediana e 130,5
# o mínimo mensal por gênero foi 105; o máximo foi 827
lgbt_casamento.query('ano == 2018').groupby(['genero', 'uf']).agg({'numero':['sum', 'mean', 'median', 'std', 'max', 'min']})
```
### Quem casa mais no meio LGBT? Homens ou mulheres?
```
# as mulheres se casam mais do que os homens
casamento_genero = lgbt_casamento.groupby('genero')['numero'].sum().sort_values(ascending=False).reset_index()
print(casamento_genero)
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/bar_chart_with_highlighted_bar.html
alt.Chart(casamento_genero).mark_bar().encode(
x = alt.X('genero', title = 'Ano'),
y = alt.Y('numero', title = 'Nº de casamentos'),
color=alt.condition(
alt.datum.genero == 'Feminino',
alt.value('orange'),
alt.value('steelblue')
),
tooltip = ['genero', 'numero']
).properties(title = 'Casamentos homoafetivos: mulheres se casam mais do que homens', width=600, height=300).interactive()
```
### As mulheres também se casam mais considerando os dados anuais?
```
# considerando os dados anuais também
# as mulheres se casam mais do que os homens
# apenas em 2014 a diferença foi pequena
casamento_genero_ano = lgbt_casamento.groupby(['ano' , 'genero'])['numero'].sum().reset_index()
print(casamento_genero_ano)
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/line_percent.html
alt.Chart(casamento_genero_ano).mark_line().encode(
x = alt.X('ano:O', title = 'Ano'),
y = alt.Y('numero', title = 'Nº de casamentos'),
color= alt.Color('genero:N', sort = ['Masculino', 'Feminino'], title = 'Gênero'),
tooltip = ['ano', 'numero', 'genero']
).properties(title = '2014 foi o ano com mais proximidade', width=600, height=300).interactive()
```
### Em qual mês as pessoas mais se casam? E menos?
```
# dezembro é o mês com mais casamentos
# abril é o mês com menos casamentos
casamento_mes = lgbt_casamento.groupby(['mes'])['numero'].sum().sort_values(ascending=False).reset_index()
print(casamento_mes)
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/bar_chart_with_highlighted_bar.html
alt.Chart(casamento_mes).mark_bar(point=True).encode(
x = alt.X('mes', title = 'Mês', sort=['Dezembro', 'Novembro', 'Outubro']),
y = alt.Y('numero', title='Número'),
tooltip = ['mes', 'numero'],
color=alt.condition(
alt.datum.mes == 'Dezembro',
alt.value('orange'),
alt.value('steelblue')
),
).properties(
title = 'Dezembro é o mês com mais casamentos homoafetivos', width = 600, height=300).interactive()
```
### Há mais casamentos homoafetivos após a vitória de Jair Bolsonaro, em 28 de outubro de 2018?
```
# observe: dezembro de 2018 foi o mês com mais casamentos
# logo depois, janeiro de 2019, fevereiro de 2019, novembro de 2018...
# todos são meses próximos - e após a eleição de Jair Bolsonaro
casamento_mes_ano = lgbt_casamento.groupby(['mes', 'ano'])['numero'].sum().sort_values(ascending=False).reset_index()
print(casamento_mes_ano)
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/simple_heatmap.html
alt.Chart(casamento_mes_ano).mark_rect().encode(
x = alt.X('mes', title = 'Mês', sort=['Janeiro', 'Fevereiro', 'Março', 'Abril', 'Maio', 'Junho', 'Julho', 'Agosto', 'Setembro', 'Outubro', 'Novembro', 'Dezembro']),
y = alt.Y('ano:O', title = 'Ano'),
color= alt.Color('numero:Q', title = 'Nº de casamentos'),
tooltip = ['mes', 'ano', 'numero'],
).properties(title = 'Dezembro de 2018 foi o pico de casamentos homoafetivos', width=600, height=300)
```
### Em quais estados aconteceram mais casamentos LGBTs em números absolutos? E menos?
```
# mais de 18 mil casamentos foram em SP, seguido pelo RJ e por MG
# SP concentra 41,5% dos casamentos homoafetivos e é também o estado mais populoso do Brasil
# já Roraima, Acre e Amapá aparecem com poucos casamentos e também são pouco populosos
casamento_uf = lgbt_casamento.groupby('uf')['numero'].sum().sort_values(ascending=False).reset_index()
casamento_uf['n_perc'] = (casamento_uf['numero'] / sum(casamento_uf['numero'])) * 100
print(casamento_uf)
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/bar_chart_horizontal.html
alt.Chart(casamento_uf).mark_bar().encode(
x = alt.X('numero', title = 'Nº de casamentos'),
y = alt.Y('uf', sort = ['São Paulo', 'Rio de Janeiro', 'Minas Gerais', 'Santa Catarina'], title = 'UF'),
tooltip = ['uf', 'numero', 'n_perc']
).properties(title = 'Casamento LGBT: estados do Sudeste e do Sul aparecem primeiro no ranking', width=600, height=300)
```
### Em quais regiões do Brasil os casamentos LGBTs mais ocorrem? E menos?
```
# criação de dicionário transformado depois em dataframe com as UFs e as respectivas regiões
uf_norte = {'regiao': ['Norte']*7, 'uf': ["Rondônia","Acre","Amazonas","Roraima", "Pará","Amapá","Tocantins"]}
uf_nordeste = {'regiao': ['Nordeste']*9, 'uf': ["Maranhão","Piauí","Ceará","Rio Grande do Norte","Paraíba","Pernambuco", "Alagoas","Sergipe","Bahia"]}
uf_sudeste = {'regiao': ['Sudeste']*4, 'uf': ["Minas Gerais","Espírito Santo","Rio de Janeiro","São Paulo"]}
uf_sul = {'regiao': ['Sul']*3, 'uf': ["Paraná","Santa Catarina","Rio Grande do Sul"]}
uf_centro_oeste = {'regiao': ['Centro-Oeste']*4, 'uf': ["Mato Grosso do Sul","Mato Grosso","Goiás", "Distrito Federal"]}
regiao_norte = pd.DataFrame(uf_norte)
regiao_nordeste = pd.DataFrame(uf_nordeste)
regiao_sudeste = pd.DataFrame(uf_sudeste)
regiao_sul = pd.DataFrame(uf_sul)
regiao_centro_oeste = pd.DataFrame(uf_centro_oeste)
regioes_uf = pd.concat([regiao_norte, regiao_nordeste, regiao_sudeste, regiao_sul, regiao_centro_oeste])
lgbt_casamento_regioes = lgbt_casamento.merge(regioes_uf, on='uf')
lgbt_casamento_regioes_ano = lgbt_casamento_regioes.groupby(['regiao', 'ano'])['numero'].sum().sort_values(ascending=False).reset_index()
lgbt_casamento_regioes_ano.head()
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/horizontal_stacked_bar_chart.html
alt.Chart(lgbt_casamento_regioes_ano).mark_bar().encode(
x = alt.X('sum(numero)', title = 'Nº de casamentos'),
y = alt.Y('ano', title = 'Ano'),
tooltip = ['regiao', 'numero'],
color = alt.Color('regiao', title = "Região")
).properties(title = 'Sudeste concentra maior número de casamentos homoafetivos', width=600, height=300)
lgbt_casamento_regioes_genero = lgbt_casamento_regioes.groupby(['regiao','genero'])['numero'].sum().reset_index()
lgbt_casamento_regioes_genero.head()
# gráfico para mostrar os dados citados acima
# referência https://altair-viz.github.io/gallery/grouped_bar_chart.html
alt.Chart(lgbt_casamento_regioes_genero).mark_bar().encode(
x = alt.X('genero', title = "Gênero"),
y = alt.Y('numero', title = 'Nº de casamentos'),
color = alt.Color('genero', sort = ['Masculino', 'Feminino'], title = 'Gênero'),
column = alt.Column('regiao:N', title = 'Região'),
tooltip = ['regiao', 'genero', 'numero']
).properties(title = 'Veja, por região, o total de casamentos de 2013 a 2019', width=100)
```
### Considerando a população adulta, quais estados têm as maiores e menores proporções de casamentos LGBTs?
Este trecho da análise depende de alguns cruzamentos para chegarmos ao resultado
```
# arquivo com o nome da uf e a respectiva sigla
sigla_uf = pd.read_csv('https://raw.githubusercontent.com/kelvins/Municipios-Brasileiros/main/csv/estados.csv')
# o arquivo com a população adulta usa a sigla, e não o nome da uf
# por isso, vamos cruzar o dataframe principal com o dataframe acima
# assim, o novo dataframe terá a sigla para criar com o CSV da população adulta
sigla_uf_lgbt_casamento = lgbt_casamento.merge(sigla_uf, how = 'left', left_on = 'uf', right_on = 'nome')
sigla_uf_lgbt_casamento = sigla_uf_lgbt_casamento.drop(['uf_x', 'codigo_uf', 'latitude', 'longitude'], axis=1)
sigla_uf_lgbt_casamento = sigla_uf_lgbt_casamento.rename(columns={'uf_y':'uf', 'nome': 'nome_uf'})
sigla_uf_lgbt_casamento.head(6)
ano_uf_lgbt_casamento = sigla_uf_lgbt_casamento.groupby(['genero', 'ano', 'uf'])['numero'].sum().sort_values(ascending=False)
ano_uf_lgbt_casamento.head(6)
# os dados são do IBGE e tratam das pessoas com 15 anos ou mais
# aqui chamamos esse grupo de 'população adulta'
# para casar no Brasil, a pessoa precisa ter a partir de 16 anos
# mas o grupo etário dessa idade, para o IBGE, é de 15-19 anos
pop_adulta = pd.read_csv('https://raw.githubusercontent.com/gabrielacaesar/lgbt_casamento/main/data/pop_adulta.csv')
# padronizando gênero para ficar igual ao do csv lgbt_casamento
pop_adulta['genero'] = pop_adulta['genero'].replace(['Mulher'],'Feminino').replace(['Homem'],'Masculino')
pop_adulta.head(2)
pop_lgbt_casamento = pd.merge(ano_uf_lgbt_casamento, pop_adulta, how = 'left', on = ['ano', 'genero', 'uf'])
pop_lgbt_casamento.head(5)
### criamos a taxa de casamento lgbt por 100 mil habitantes adultos
pop_lgbt_casamento['tx_pop'] = (pop_lgbt_casamento['numero'] / pop_lgbt_casamento['pop_adulta']) * 100000
pop_lgbt_casamento.sort_values(by = 'tx_pop', ascending=False)
```
### 2019: taxas mais altas e mais baixas, por UF
```
# DF e SP aparecem com destaque, com taxas acima de 10, em 2019
tx_2019 = pop_lgbt_casamento.query('ano == 2019').sort_values(by = 'tx_pop', ascending=False)
tx_2019.head(10)
# MA aparece com destaque, com taxas baixo de 1, em 2019
pop_lgbt_casamento.query('ano == 2019').sort_values(by = 'tx_pop', ascending=True).head(10)
# o gráfico abaixo se refere aos dois dataframes criados acima
# o eixo x tem a taxa de casamentos LGBTs por 100 mil adultos, por gênero, naquele ano
# o eixo y tem o número de casamentos LGBTs, por gênero, naquele ano
# referência https://altair-viz.github.io/gallery/trellis_scatter_plot.html
alt.Chart(tx_2019).mark_point().encode(
x = alt.X('tx_pop:Q', title = 'Nº de casamentos'),
y = alt.Y('numero:Q', title = 'Taxa por 100 mil adultos'),
color = alt.Color('genero', sort = ['Masculino', 'Feminino'], title = 'Gênero'),
tooltip = ['uf', 'genero', 'tx_pop', 'numero', 'pop_adulta']
).properties(title = '2019: Taxa de casamentos LGBTs', width=600, height=300)
```
### 2018: taxas mais altas e mais baixas, por UF
```
# novamente SP e DF aparecem com destaque
tx_2018 = pop_lgbt_casamento.query('ano == 2018').sort_values(by = 'tx_pop', ascending=False)
tx_2018.head(10)
# desta vez, AP, RR, MA e RO têm taxas abaixo de um
pop_lgbt_casamento.query('ano == 2018').sort_values(by = 'tx_pop', ascending=True).head(10)
# o gráfico abaixo se refere aos dois dataframes criados acima
# o eixo x tem a taxa de casamentos LGBTs por 100 mil adultos, por gênero, naquele ano
# o eixo y tem o número de casamentos LGBTs, por gênero, naquele ano
# referência https://altair-viz.github.io/gallery/trellis_scatter_plot.html
alt.Chart(tx_2018).mark_point().encode(
x = alt.X('tx_pop:Q', title = 'Nº de casamentos'),
y = alt.Y('numero:Q', title = 'Taxa por 100 mil adultos'),
color = alt.Color('genero', sort = ['Masculino', 'Feminino'], title = 'Gênero'),
tooltip = ['uf', 'genero', 'tx_pop', 'numero', 'pop_adulta']
).properties(title = '2018: Taxa de casamentos LGBTs', width=600, height=300)
```
### Em um mapa do Brasil, como ficam as taxas de casamentos LGBTS por 100 mil adultos?
#### Observação: para fazer o mapa do Brasil é necessário fazer indicar o caminho para o arquivo "bcim_2016_21_11_2018.gpkg", que pode ser baixado do site do IBGE. Este trecho do mapa não funciona no Colab a princípio, mas sim no Jupyter Notebook.
[Veja este trecho da análise neste Notebook aqui](https://github.com/gabrielacaesar/lgbt_casamento/blob/main/notebooks/gabriela-caesar-analise-de-dados-2out2021-perguntas_2.ipynb).
```
tx_pop_lgbt_casamento = pop_lgbt_casamento.groupby(['ano', 'uf']).agg({'numero': sum,'tx_pop': sum}).reset_index()
tx_pop_lgbt_casamento.head()
print(" --------------------------- \n Bem-vindo/a! \n ---------------------------")
ano_user = int(input("Escolha um ano de 2013 a 2019: \n"))
#print(uf_user)
print(" --------------------------- \n Já vamos calcular! \n ---------------------------")
ano_user_tx_pop_lgbt_casamento = tx_pop_lgbt_casamento.query('ano == @ano_user', engine='python')
ano_user_tx_pop_lgbt_casamento.head()
# referência https://rodrigodutcosky.medium.com/mapas-coropl%C3%A9ticos-com-os-estados-do-brasil-em-python-b9b48c6db585
# baixe o arquivo abaixo no link https://www.ibge.gov.br/geociencias/cartas-e-mapas/bases-cartograficas-continuas/15759-brasil.html?=&t=downloads
# clique em 'bcim' > 'versao2016' > 'geopackage' > 'bcim_2016_21_11_2018.gpkg'
info_ufs = gpd.read_file('bcim_2016_21_11_2018.gpkg', layer = 'lim_unidade_federacao_a')
info_ufs.columns
info_ufs.rename({'sigla':'uf'}, axis = 1, inplace = True)
mapa_br = info_ufs.merge(ano_user_tx_pop_lgbt_casamento, on = 'uf', how = 'left')
#mapa_br[['uf', 'ano', 'numero', 'tx_pop', 'geometry']].head()
%matplotlib inline
mapa_br.plot(column = 'tx_pop',
cmap = 'Blues',
figsize = (10, 6),
legend = True,
edgecolor = 'black')
```
### Considerando a UF e o ano informados pelo usuário, quais são as estatísticas básicas dessa UF e desse ano quanto ao casamento LGBT?
```
sigla_uf_lgbt_casamento = lgbt_casamento.merge(sigla_uf, how = 'left', left_on = 'uf', right_on = 'nome')
sigla_uf_lgbt_casamento.head()
print(" --------------------------- \n Bem-vindo/a! \n ---------------------------")
ano_user = int(input("Escolha um ano de 2013 a 2019: \n"))
uf_user = input("Escolha uma UF. Por exemplo, AC, AL, SP, RJ... \n")
uf_user = uf_user.upper().strip()
#print(uf_user)
print(" --------------------------- \n Já vamos calcular! \n ---------------------------")
# gráfico de linha usando filtro pela UF e pelo ano informados pelo usuário
# referência https://altair-viz.github.io/gallery/line_chart_with_points.html
# obs: tirei a f string por causa da versão antiga no Python neste laptop
alt.Chart(sigla_uf_lgbt_casamento.query('uf_y == @uf_user & ano == @ano_user', engine='python')).mark_line(point=True).encode(
x = alt.X('mes', title = 'Mês', sort=['Janeiro', 'Fevereiro', 'Março']),
y = alt.Y('numero', title='Nº de casamentos'),
color = alt.Color('genero', sort = ['Masculino', 'Feminino'], title = 'Gênero'),
tooltip = ['mes', 'ano', 'genero', 'numero']
).properties(
title = '{}: Casamento LGBTs em {}'.format(uf_user, ano_user),
width = 600, height=300
).interactive()
# boxplot usando filtro pela UF informada pelo usuário
# referência https://altair-viz.github.io/gallery/boxplot.html
# obs: tirei a f string por causa da versão antiga no Python neste laptop
dados_user = sigla_uf_lgbt_casamento.query('uf_y == @uf_user', engine='python')
alt.Chart(dados_user).mark_boxplot(size=80).encode(
x = alt.X('ano:O', title="Ano"),
y = alt.Y('numero', title="Nº de casamentos"),
color = alt.Color('genero', sort = ['Masculino', 'Feminino'], title='Gênero'),
tooltip = ['mes', 'ano', 'genero', 'numero']
).properties(
title={
"text": ['{}: Casamento LGBTs'.format(uf_user)],
"subtitle": ['Mulheres vs. Homens']
},
width=600,
height=300
).interactive()
```
## Muito obrigado/a!
| github_jupyter |
<h1>Batch Transform Using R with Amazon SageMaker</h1>
**Note:** You will need to use R kernel in SageMaker for this notebook.
This sample Notebook describes how to do batch transform to make predictions for an abalone's age, which is measured by the number of rings in the shell. The notebook will use the public [abalone dataset](https://archive.ics.uci.edu/ml/datasets/abalone) hosted by [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php).
You can find more details about SageMaker's Batch Trsnform here:
- [Batch Transform](https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html) using a Transformer
We will use `reticulate` library to interact with SageMaker:
- [`Reticulate` library](https://rstudio.github.io/reticulate/): provides an R interface to use the [Amazon SageMaker Python SDK](https://sagemaker.readthedocs.io/en/latest/index.html) to make API calls to Amazon SageMaker. The `reticulate` package translates between R and Python objects, and Amazon SageMaker provides a serverless data science environment to train and deploy ML models at scale.
Table of Contents:
- [Reticulating the Amazon SageMaker Python SDK](#Reticulating-the-Amazon-SageMaker-Python-SDK)
- [Creating and Accessing the Data Storage](#Creating-and-accessing-the-data-storage)
- [Downloading and Processing the Dataset](#Downloading-and-processing-the-dataset)
- [Preparing the Dataset for Model Training](#Preparing-the-dataset-for-model-training)
- [Creating a SageMaker Estimator](#Creating-a-SageMaker-Estimator)
- [Batch Transform using SageMaker Transformer](#Batch-Transform-using-SageMaker-Transformer)
- [Download the Batch Transform Output](#Download-the-Batch-Transform-Output)
**Note:** The first portion of this notebook focused on data ingestion and preparing the data for model training is inspired by the data preparation section outlined in the ["Using R with Amazon SageMaker"](https://github.com/awslabs/amazon-sagemaker-examples/blob/master/advanced_functionality/r_kernel/using_r_with_amazon_sagemaker.ipynb) notebook on AWS SageMaker Examples Github repository with some modifications.
<h3>Reticulating the Amazon SageMaker Python SDK</h3>
First, load the `reticulate` library and import the `sagemaker` Python module. Once the module is loaded, use the `$` notation in R instead of the `.` notation in Python to use available classes.
```
# Turn warnings off globally
options(warn=-1)
# Install reticulate library and import sagemaker
library(reticulate)
sagemaker <- import('sagemaker')
```
<h3>Creating and Accessing the Data Storage</h3>
The `Session` class provides operations for working with the following [boto3](https://boto3.amazonaws.com/v1/documentation/api/latest/index.html) resources with Amazon SageMaker:
* [S3](https://boto3.readthedocs.io/en/latest/reference/services/s3.html)
* [SageMaker](https://boto3.readthedocs.io/en/latest/reference/services/sagemaker.html)
Let's create an [Amazon Simple Storage Service](https://aws.amazon.com/s3/) bucket for your data.
```
session <- sagemaker$Session()
bucket <- session$default_bucket()
prefix <- 'r-batch-transform'
```
**Note** - The `default_bucket` function creates a unique Amazon S3 bucket with the following name:
`sagemaker-<aws-region-name>-<aws account number>`
Specify the IAM role's [ARN](https://docs.aws.amazon.com/general/latest/gr/aws-arns-and-namespaces.html) to allow Amazon SageMaker to access the Amazon S3 bucket. You can use the same IAM role used to create this Notebook:
```
role_arn <- sagemaker$get_execution_role()
```
<h3>Downloading and Processing the Dataset</h3>
The model uses the [abalone dataset](https://archive.ics.uci.edu/ml/datasets/abalone) from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php). First, download the data and start the [exploratory data analysis](https://en.wikipedia.org/wiki/Exploratory_data_analysis). Use tidyverse packages to read, plot, and transform the data into ML format for Amazon SageMaker:
```
library(readr)
data_file <- 'http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data'
abalone <- read_csv(file = data_file, col_names = FALSE)
names(abalone) <- c('sex', 'length', 'diameter', 'height', 'whole_weight', 'shucked_weight', 'viscera_weight', 'shell_weight', 'rings')
head(abalone)
```
The output above shows that `sex` is a factor data type but is currently a character data type (F is Female, M is male, and I is infant). Change `sex` to a factor and view the statistical summary of the dataset:
```
abalone$sex <- as.factor(abalone$sex)
summary(abalone)
```
The summary above shows that the minimum value for `height` is 0.
Visually explore which abalones have height equal to 0 by plotting the relationship between `rings` and `height` for each value of `sex`:
```
library(ggplot2)
options(repr.plot.width = 5, repr.plot.height = 4)
ggplot(abalone, aes(x = height, y = rings, color = sex)) + geom_point() + geom_jitter()
```
The plot shows multiple outliers: two infant abalones with a height of 0 and a few female and male abalones with greater heights than the rest. Let's filter out the two infant abalones with a height of 0.
```
library(dplyr)
abalone <- abalone %>%
filter(height != 0)
```
<h3>Preparing the Dataset for Model Training</h3>
The model needs three datasets: one for training, testing, and validation. First, convert `sex` into a [dummy variable](https://en.wikipedia.org/wiki/Dummy_variable_(statistics)) and move the target, `rings`, to the first column. Amazon SageMaker algorithm require the target to be in the first column of the dataset.
```
abalone <- abalone %>%
mutate(female = as.integer(ifelse(sex == 'F', 1, 0)),
male = as.integer(ifelse(sex == 'M', 1, 0)),
infant = as.integer(ifelse(sex == 'I', 1, 0))) %>%
select(-sex)
abalone <- abalone %>%
select(rings:infant, length:shell_weight)
head(abalone)
```
Next, sample 70% of the data for training the ML algorithm. Split the remaining 30% into two halves, one for testing and one for validation:
```
abalone_train <- abalone %>%
sample_frac(size = 0.7)
abalone <- anti_join(abalone, abalone_train)
abalone_test <- abalone %>%
sample_frac(size = 0.5)
abalone_valid <- anti_join(abalone, abalone_test)
```
Upload the training and validation data to Amazon S3 so that you can train the model. First, write the training and validation datasets to the local filesystem in .csv format:
Second, upload the two datasets to the Amazon S3 bucket into the `data` key:
```
write_csv(abalone_train, 'abalone_train.csv', col_names = FALSE)
write_csv(abalone_valid, 'abalone_valid.csv', col_names = FALSE)
# Remove target from test
write_csv(abalone_test[-1], 'abalone_test.csv', col_names = FALSE)
s3_train <- session$upload_data(path = 'abalone_train.csv',
bucket = bucket,
key_prefix = paste(prefix,'data', sep = '/'))
s3_valid <- session$upload_data(path = 'abalone_valid.csv',
bucket = bucket,
key_prefix = paste(prefix,'data', sep = '/'))
s3_test <- session$upload_data(path = 'abalone_test.csv',
bucket = bucket,
key_prefix = paste(prefix,'data', sep = '/'))
```
Finally, define the Amazon S3 input types for the Amazon SageMaker algorithm:
```
s3_train_input <- sagemaker$s3_input(s3_data = s3_train,
content_type = 'csv')
s3_valid_input <- sagemaker$s3_input(s3_data = s3_valid,
content_type = 'csv')
```
<hr>
<h3>Creating a SageMaker Estimator</h3>
Amazon SageMaker algorithm are available via a [Docker](https://www.docker.com/) container. To train an [XGBoost](https://en.wikipedia.org/wiki/Xgboost) model, specify the training containers in [Amazon Elastic Container Registry](https://aws.amazon.com/ecr/) (Amazon ECR) for the AWS Region.
```
registry <- sagemaker$amazon$amazon_estimator$registry(session$boto_region_name, algorithm='xgboost')
container <- paste(registry, '/xgboost:latest', sep='')
cat('XGBoost Container Image URL: ', container)
```
Define an Amazon SageMaker [Estimator](http://sagemaker.readthedocs.io/en/latest/estimators.html), which can train any supplied algorithm that has been containerized with Docker. When creating the Estimator, use the following arguments:
* **image_name** - The container image to use for training
* **role** - The Amazon SageMaker service role
* **train_instance_count** - The number of Amazon EC2 instances to use for training
* **train_instance_type** - The type of Amazon EC2 instance to use for training
* **train_volume_size** - The size in GB of the [Amazon Elastic Block Store](https://aws.amazon.com/ebs/) (Amazon EBS) volume to use for storing input data during training
* **train_max_run** - The timeout in seconds for training
* **input_mode** - The input mode that the algorithm supports
* **output_path** - The Amazon S3 location for saving the training results (model artifacts and output files)
* **output_kms_key** - The [AWS Key Management Service](https://aws.amazon.com/kms/) (AWS KMS) key for encrypting the training output
* **base_job_name** - The prefix for the name of the training job
* **sagemaker_session** - The Session object that manages interactions with Amazon SageMaker API
```
# Model artifacts and batch output
s3_output <- paste('s3:/', bucket, prefix,'output', sep = '/')
# Estimator
estimator <- sagemaker$estimator$Estimator(image_name = container,
role = role_arn,
train_instance_count = 1L,
train_instance_type = 'ml.m5.4xlarge',
train_volume_size = 30L,
train_max_run = 3600L,
input_mode = 'File',
output_path = s3_output,
output_kms_key = NULL,
base_job_name = NULL,
sagemaker_session = NULL)
```
**Note** - The equivalent to `None` in Python is `NULL` in R.
Next, we Specify the [XGBoost hyperparameters](https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost_hyperparameters.html) for the estimator.
Once the Estimator and its hyperparamters are specified, you can train (or fit) the estimator.
```
# Set Hyperparameters
estimator$set_hyperparameters(eval_metric='rmse',
objective='reg:linear',
num_round=100L,
rate_drop=0.3,
tweedie_variance_power=1.4)
# Create a training job name
job_name <- paste('sagemaker-r-xgboost', format(Sys.time(), '%H-%M-%S'), sep = '-')
# Define the data channels for train and validation datasets
input_data <- list('train' = s3_train_input,
'validation' = s3_valid_input)
# train the estimator
estimator$fit(inputs = input_data, job_name = job_name)
```
<hr>
<h3> Batch Transform using SageMaker Transformer </h3>
For more details on SageMaker Batch Transform, you can visit this example notebook on [Amazon SageMaker Batch Transform](https://github.com/awslabs/amazon-sagemaker-examples/blob/master/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb).
In many situations, using a deployed model for making inference is not the best option, especially when the goal is not to make online real-time inference but to generate predictions from a trained model on a large dataset. In these situations, using Batch Transform may be more efficient and appropriate.
This section of the notebook explains how to set up the Batch Transform Job and generate predictions.
To do this, we need to identify the batch input data path in S3 and specify where generated predictions will be stored in S3.
```
# Define S3 path for Test data
s3_test_url <- paste('s3:/', bucket, prefix, 'data','abalone_test.csv', sep = '/')
```
Then we create a `Transformer`. [Transformers](https://sagemaker.readthedocs.io/en/stable/transformer.html#transformer) take multiple paramters, including the following. For more details and the complete list visit the [documentation page](https://sagemaker.readthedocs.io/en/stable/transformer.html#transformer).
- **model_name** (str) – Name of the SageMaker model being used for the transform job.
- **instance_count** (int) – Number of EC2 instances to use.
- **instance_type** (str) – Type of EC2 instance to use, for example, ‘ml.c4.xlarge’.
- **output_path** (str) – S3 location for saving the transform result. If not specified, results are stored to a default bucket.
- **base_transform_job_name** (str) – Prefix for the transform job when the transform() method launches. If not specified, a default prefix will be generated based on the training image name that was used to train the model associated with the transform job.
- **sagemaker_session** (sagemaker.session.Session) – Session object which manages interactions with Amazon SageMaker APIs and any other AWS services needed. If not specified, the estimator creates one using the default AWS configuration chain.
Once we create a `Transformer` we can transform the batch input.
```
# Define a transformer
transformer <- estimator$transformer(instance_count=1L,
instance_type='ml.m4.xlarge',
output_path = s3_output)
# Do the batch transform
transformer$transform(s3_test_url,
wait = TRUE)
```
<hr>
<h3> Download the Batch Transform Output </h3>
```
# Download the file from S3 using S3Downloader to local SageMaker instance 'batch_output' folder
sagemaker$s3$S3Downloader$download(paste(s3_output,"abalone_test.csv.out",sep = '/'),
"batch_output")
# Read the batch csv from sagemaker local files
library(readr)
predictions <- read_csv(file = 'batch_output/abalone_test.csv.out', col_names = 'predicted_rings')
head(predictions)
```
Column-bind the predicted rings to the test data:
```
# Concatenate predictions and test for comparison
abalone_predictions <- cbind(predicted_rings = predictions,
abalone_test)
# Convert predictions to Integer
abalone_predictions$predicted_rings = as.integer(abalone_predictions$predicted_rings);
head(abalone_predictions)
# Define a function to calculate RMSE
rmse <- function(m, o){
sqrt(mean((m - o)^2))
}
# Calucalte RMSE
abalone_rmse <- rmse(abalone_predictions$rings, abalone_predictions$predicted_rings)
cat('RMSE for Batch Transform: ', round(abalone_rmse, digits = 2))
```
| github_jupyter |
Building Regularized Logistic Rgression
```
import pandas as pd
from sklearn.model_selection import train_test_split
import lightgbm as lgb
import numpy as np
from sklearn import preprocessing
import pickle
from sklearn.model_selection import StratifiedShuffleSplit
#Load the data
with open('test_set.pkl', 'rb') as f:
X_test= pickle.load(f)
with open('train_set.pkl', 'rb') as f:
X_train= pickle.load(f)
with open('ytest.pkl', 'rb') as f:
y_test= pickle.load(f)
with open('ytrain.pkl', 'rb') as f:
y_train= pickle.load(f)
for i in [X_train,X_test]:
i.pop("artist_has_award")
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=2)
X_train_sm, y_train_sm = sm.fit_sample(X_train, y_train['top10'])
print("Number transactions X_train dataset: ", X_train.shape)
print("Number transactions y_train dataset: ", y_train.shape)
print("Number transactions X_test dataset: ", X_test.shape)
print("Number transactions y_test dataset: ", y_test.shape)
print("Number transactions X_train dataset: ", X_train_sm.shape)
print("Number transactions y_train dataset: ", y_train_sm.shape)
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
logreg = LogisticRegression()
logreg.fit(X_train_sm, y_train_sm)
import sklearn.metrics as metrics
a = logreg.predict_proba(X_test)
lr_probs = a[:,1]
print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(logreg.score(X_test, y_test)))
fpr, tpr, threshold = metrics.roc_curve(y_test, lr_probs)
roc_auc = metrics.auc(fpr, tpr)
# method I: plt
import matplotlib.pyplot as plt
%matplotlib inline
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.savefig("Logisticregression")
plt.show()
#Precision over threshold
from sklearn.metrics import precision_recall_curve
# calculate precision-recall curve
precision, recall, thresholds = precision_recall_curve(y_test,lr_probs)
# calculate precision-recall AUC
precision_auc = metrics.auc(recall, precision)
plt.title('Precision Depending on the Threshold')
plt.plot(thresholds, precision[:len(precision)-1], 'b')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('Precision')
plt.xlabel('Threshold')
plt.savefig("PrecisionLogistic")
plt.show()
#Confusion matrix
from sklearn.metrics import confusion_matrix
predictions_matrix = [1 if pred > 0.65 else 0 for pred in lr_probs]
confusion_matrix(y_test,predictions_matrix)
#Boostrapping the precision
from sklearn.utils import resample
df = X_test.copy()
df["top10"] = y_test.values
stats = list()
for i in range(1000):
boot = resample(df, replace=True, n_samples=10000)
boot_y = boot.pop("top10")
boot_pred = logreg.predict_proba(boot)[:,1]
predictions_matrix = [1 if pred > 0.65 else 0 for pred in boot_pred]
precision = (confusion_matrix(boot_y,predictions_matrix)[1][1]) / (confusion_matrix(boot_y,predictions_matrix)[1][1] + confusion_matrix(boot_y,predictions_matrix)[0][1])
stats.append(precision)
# plot scores
plt.hist(stats)
plt.show()
# confidence intervals
alpha = 0.95
p = ((1.0-alpha)/2.0) * 100
lower = max(0.0, np.percentile(stats, p))
p = (alpha+((1.0-alpha)/2.0)) * 100
upper = min(1.0, np.percentile(stats, p))
print('%.1f confidence interval %.1f%% and %.1f%%' % (alpha*100, lower*100, upper*100))
```
| github_jupyter |
# Feature importance method in sci-kit learn (Solution)
We'll get a sense of how feature importance is calculated in sci-kit learn, and also see where it gives results that we wouldn't expect.
Sci-kit learn uses gini impurity to calculate a measure of impurity for each node. Gini impurity, like entropy is a way to measure how "organized" the observations are before and after splitting them using a feature. So there is an impurity measure for each node.
In the formula, freq_{i} is the frequency of label "i". C is the number of unique labels at that node.
$Impurity= \sum_{i=1}^{C} - freq_{i} * (1- freq_{i})$
The node importance in sci-kit learn is calculated as the difference between the gini impurity of the node and the gini impurity of its left and right children. These gini impurities are weighted by the number of data points that reach each node.
$NodeImportance = w_{i} Impurity_{i} - ( w_{left} Impurity_{left} + w_{right} Impurity_{right} )$
The importance of a feature is the importance of the node that it was split on, divided by the sum of all node importances in the tree. You’ll get to practice this in the coding exercise coming up next!
For additional reading, please check out this blog post [The Mathematics of Decision Trees, Random Forest and Feature Importance in Scikit-learn and Spark](https://medium.com/@srnghn/the-mathematics-of-decision-trees-random-forest-and-feature-importance-in-scikit-learn-and-spark-f2861df67e3)
```
import sys
!{sys.executable} -m pip install numpy==1.14.5
!{sys.executable} -m pip install scikit-learn==0.19.1
!{sys.executable} -m pip install graphviz==0.9
import sklearn
from sklearn import tree
import numpy as np
import graphviz
```
## Generate data
We'll generate features and labels that form the "AND" operator. So when feature 0 and feature 1 are both 1, then the label is 1, else the label is 0. The third feature, feature 2, won't have an effect on the label output (it's always zero).
```
"""
Features 0 and 1 form the AND operator
Feature 2 is always zero.
"""
N = 100
M = 3
X = np.zeros((N,M))
X.shape
y = np.zeros(N)
X[:1 * N//4, 1] = 1
X[:N//2, 0] = 1
X[N//2:3 * N//4, 1] = 1
y[:1 * N//4] = 1
# observe the features
X
# observe the labels
y
```
## Train a decision tree
```
model = tree.DecisionTreeClassifier(random_state=0)
model.fit(X, y)
```
## Visualize the trained decision tree
```
dot_data = sklearn.tree.export_graphviz(model, out_file=None, filled=True, rounded=True, special_characters=True)
graph = graphviz.Source(dot_data)
graph
```
## Explore the tree
The [source code for Tree](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/tree/_tree.pyx) has useful comments about attributes in the Tree class. Search for the code that says `cdef class Tree:` for useful comments.
```
# get the Tree object
tree0 = model.tree_
```
## Tree attributes are stored in lists
The tree data are stored in lists. Each node is also assigned an integer 0,1,2...
Each node's value for some attribute is stored at the index location that equals the node's assigned integer.
For example, node 0 is the root node at the top of the tree. There is a list called children_left. Index location 0 contains the left child of node 0.
#### left and right child nodes
```
children_left : array of int, shape [node_count]
children_left[i] holds the node id of the left child of node i.
For leaves, children_left[i] == TREE_LEAF. Otherwise,
children_left[i] > i. This child handles the case where
X[:, feature[i]] <= threshold[i].
children_right : array of int, shape [node_count]
children_right[i] holds the node id of the right child of node i.
For leaves, children_right[i] == TREE_LEAF. Otherwise,
children_right[i] > i. This child handles the case where
X[:, feature[i]] > threshold[i].
```
```
print(f"tree0.children_left: {tree0.children_left}")
print(f"tree0.children_right: {tree0.children_right}")
```
So in this tree, the index positions 0,1,2,3,4 are the numbers for identifying each node in the tree. Node 0 is the root node. Node 1 and 2 are the left and right child of the root node. So in the list children_left, at index 0, we see 1, and for children_right list, at index 0, we see 2.
-1 is used to denote that there is no child for that node. Node 1 has no left or right child, so in the children_left list, at index 1, we see -1. Similarly, in children_right, at index 1, the value is also -1.
#### features used for splitting at each node
```
feature : array of int, shape [node_count]
feature[i] holds the feature to split on, for the internal node i.
```
```
print(f"tree0.feature: {tree0.feature}")
```
The feature 1 is used to split on node 0. Feature 0 is used to split on node 2. The -2 values indicate that these are leaf nodes (no features are used for splitting at those nodes).
#### number of samples in each node
```
n_node_samples : array of int, shape [node_count]
n_node_samples[i] holds the number of training samples reaching node i.
weighted_n_node_samples : array of int, shape [node_count]
weighted_n_node_samples[i] holds the weighted number of training samples
reaching node i.
```
```
print(f"tree0.n_node_samples : {tree0.n_node_samples}")
print(f"tree0.weighted_n_node_samples : {tree0.weighted_n_node_samples}")
```
The weighted_n_node_samples is the same as n_node_samples for decision trees. It's different for random forests where a sub-sample of data points is used in each tree. We'll use weighted_n_node_samples in the code below, but either one works when we're calculating the proportion of samples in a left or right child node relative to their parent node.
## Gini impurity
Gini impurity, like entropy is a way to measure how "organized" the observations are before and after splitting them using a feature. So there is an impurity value calculated for each node.
In the formula, $freq_{i}$ is the frequency of label "i". C is the number of unique labels at that node (C stands for "Class", as in "classifier".
$ \sum_{i}^{C} - freq_{i} * (1- freq_{i})$
```
impurity : array of double, shape [node_count]
impurity[i] holds the impurity (i.e., the value of the splitting
criterion) at node i.
```
What is the impurity if there is a single class (unique label type)?
```
freq0 = 1
impurity = -1 * freq0 * (1 - freq0)
print(f"impurity of a homogenous sample with a single label, is: {impurity}")
```
What is the impurity if there are two classes (two distinct labels), and there are 90% of samples for one label, and 10% for the other?
```
freq1 = 0.9
freq2 = 0.1
impurity = -1 * freq1 * (1 -freq1) + -1 * freq2 * (1 - freq2)
print(f"impurity when 90% are of one label, and 10% are of the other: {impurity}")
```
## Quiz
What is the impurity if there are two classes of label, and there are 50% of samples for one label, and 50% for the other?
```
"""
What is the impurity if there are two classes of label,
and there are 50% of samples for one label, and 50% for the other?
"""
# TODO
freq1 = 0.5
freq2 = 0.5
# TODO
impurity = -1 * freq1 * (1 - freq1) + -1 * freq2 * (1 - freq2)
print(f"impurity when 50% are of one label, and 50% are of the other: {impurity}")
```
## Quiz
Is the impurity larger or smaller (in magnitude) when the samples are dominated by a single class?
Is the impurity larger or smaller (in magnitude) when the frequency of each class is more evenly distributed among classes?
## Answer
The gini impurity is smaller in magnitude (closer to zero) when the samples are dominated by a single class.
The impurity is larger in magnitude (farther from zero) when there is a more even split among labels in the sample.
## Node Importance
The node importance in sklearn is calculated as the difference between the gini impurity of the node and the impurities of its child nodes. These gini impurities are weighted by the number of data points that reach each node.
$NodeImportance = w_{i} Impurity_{i} - ( w_{left} Impurity_{left} + w_{right} Impurity_{right} )$
#### Summary of the node labels
Node 0 is the root node, and its left and right children are 1 and 2.
Node 1 is a leaf node
Node 2 has two children, 3 and 4.
Node 3 is a leaf node
Node 4 is a leaf node
```
# summary of child nodes
print(f"tree0.children_left: {tree0.children_left}")
print(f"tree0.children_right: {tree0.children_right}")
```
Calculate the node importance of the root node, node 0. Its child nodes are 1 and 2
```
ni0 = tree0.weighted_n_node_samples[0] * tree0.impurity[0] - \
( tree0.weighted_n_node_samples[1] * tree0.impurity[1] + \
tree0.weighted_n_node_samples[2] * tree0.impurity[2] )
print(f"Importance of node 0 is {ni0}")
```
## Quiz
Calculate the node importance of node 2. Its left and right child nodes are 3 and 4
```
# TODO
ni2 = tree0.weighted_n_node_samples[2] * tree0.impurity[2] - \
( tree0.weighted_n_node_samples[3] * tree0.impurity[3] + \
tree0.weighted_n_node_samples[4] * tree0.impurity[4] )
print(f"Importance of node 2 is {ni2}")
```
The other nodes are leaf nodes, so there is no decrease in impurity that we can calculate
#### Sum the node importances
Only nodes 0 and node 2 have node importances. The others are leaf nodes, so we don't calculate node importances (there is no feature that is used for splitting at those leaf nodes).
```
# TODO
ni_total = ni0 + ni2
print(f"The sum of node importances is {ni_total}")
```
#### Summary of which feature is used to split at each node
feature 0 was used to split on node 2
feature 1 was used to split on node 0
feature 2 was not used for splitting
```
print(f"tree0.feature: {tree0.feature}")
```
## Quiz: Calculate importance of the features
The importance of a feature is the importance of the node that it was used for splitting, divided by the total node importances. Calculate the importance of feature 0, 1 and 2.
```
# TODO
fi0 = ni2/ni_total
fi1 = ni0/ni_total
fi2 = 0/ni_total
print(f"importance of feature 0: {fi0}")
print(f"importance of feature 1: {fi1}")
print(f"importance of feature 2: {fi2}")
```
## Double check with sklearn
Check out how to use [feature importance](https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier.feature_importances_)
```
# TODO: get feature importances from sci-kit learn
fi0_skl = model.feature_importances_[0]
fi1_skl = model.feature_importances_[1]
fi2_skl = model.feature_importances_[2]
print(f"sklearn importance of feature 0: {fi0_skl}")
print(f"sklearn importance of feature 1: {fi1_skl}")
print(f"sklearn importance of feature 2: {fi2_skl}")
```
## Notice anything odd?
Notice that the data we generated simulates an AND operator. If feature 0 and feature 1 are both 1, then the output is 1, otherwise 0. So, from that perspective, do you think that features 0 and 1 are equally important?
What do you notice about the feature importance calculated in sklearn? Are the features considered equally important according to this calculation?
### Answer
Intuitively, if features 0 and 1 form the AND operator, then it makes sense that they should be equally important in determining the output. The feature importance calculated in sklearn assigns a higher importance to feature 0 compared to feature 1. This is because the tree first splits on feature 1, and then when it splits on feature 0, the labels become cleanly split into respective leaf nodes.
In other words, what we observe is that features which are used to split further down the bottom of the tree are given higher importance, using the gini impurity as a measure.
## Question
If someone tells you that you don't need to understand the algorithm, just how to install the package and call the function, do you agree or disagree with that statement?
## Solution notebook
[Solution notebook](sklearn_feature_importance_solution.ipynb)
| github_jupyter |
# XAI Chatbot
Python Client for Google Dialogflow API V2 <br>
Copyright 2020 Denis Rothman MIT License. See LICENSE.
```
!pip install dialogflow
!pwd
import os
import dialogflow_v2 as dialogflow
from google.api_core.exceptions import InvalidArgument
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] ='['/content/'+YOUR PRIVATE KEY]'#'private_key.json'
DIALOGFLOW_PROJECT_ID = '[YOUR PROJECT ID]' #'[PROJECT_ID]' #Project ID
DIALOGFLOW_LANGUAGE_CODE ='en' #'[LANGUAGE]'
SESSION_ID = '[YOUR PROJECT ID]'
def dialog(our_query):
#session variables
session_client = dialogflow.SessionsClient()
session = session_client.session_path(DIALOGFLOW_PROJECT_ID, SESSION_ID)
# Our query
our_input = dialogflow.types.TextInput(text=our_query, language_code=DIALOGFLOW_LANGUAGE_CODE)
query = dialogflow.types.QueryInput(text=our_input)
# try or raise exceptions
try:
response = session_client.detect_intent(session=session, query_input=query)
except InvalidArgument:
raise
return response.query_result.fulfillment_text
```
# The Bellman equation, Q-learning, based on the Markov decision process(MDP)
## The reward matrix
```
# Markov decision process (MDP) - The Bellman equations adapted to
# Q-learning. Reinforcement learning with the Q action-value(reward) function.
# Copyright 2019 Denis Rothman MIT License. See LICENSE.
import numpy as ql
# R is The Reward Matrix for each state
R = ql.matrix([ [0,0,0,0,1,0],
[0,0,0,1,0,1],
[0,0,100,1,0,0],
[0,1,1,0,1,0],
[1,0,0,1,0,0],
[0,1,0,0,0,0] ])
# Q is the Learning Matrix in which rewards will be learned/stored
Q = ql.matrix(ql.zeros([6,6]))
```
## The learning rate or training penalty
```
# Gamma: It's a form of penalty or uncertainty for learning
# If the value is 1, the rewards would be too high.
# This way the system knows it is learning.
gamma = 0.8
```
## Initial state
```
# agent_s_state. The agent the name of the system calculating
# s is the state the agent is going from and s' the state it's going to
# this state can be random or it can be chosen as long as the rest of the choices
# are not determined. Randomness is part of this stochastic process
agent_s_state = 5
```
## The random choice of the next state
```
# The possible "a" actions when the agent is in a given state
def possible_actions(state):
current_state_row = R[state,]
possible_act = ql.where(current_state_row >0)[1]
return possible_act
# Get available actions in the current state
PossibleAction = possible_actions(agent_s_state)
print(PossibleAction)
# This function chooses at random which action to be performed within the range
# of all the available actions.
def ActionChoice(available_actions_range):
if(sum(PossibleAction)>0):
next_action = int(ql.random.choice(PossibleAction,1))
if(sum(PossibleAction)<=0):
next_action = int(ql.random.choice(5,1))
print(next_action)
return next_action
# Sample next action to be performed
action = ActionChoice(PossibleAction)
```
## The Bellman equation
```
# A version of the Bellman equation for reinforcement learning using the Q function
# This reinforcement algorithm is a memoryless process
# The transition function T from one state to another
# is not in the equation below. T is done by the random choice above
def reward(current_state, action, gamma):
Max_State = ql.where(Q[action,] == ql.max(Q[action,]))[1]
if Max_State.shape[0] > 1:
Max_State = int(ql.random.choice(Max_State, size = 1))
else:
Max_State = int(Max_State)
MaxValue = Q[action, Max_State]
# The Bellman MDP based Q function
Q[current_state, action] = R[current_state, action] + gamma * MaxValue
# Rewarding Q matrix
reward(agent_s_state,action,gamma)
```
## Running the training episodes randomly
```
# Learning over n iterations depending on the convergence of the system
# A convergence function can replace the systematic repeating of the process
# by comparing the sum of the Q matrix to that of Q matrix n-1 in the
# previous episode
for i in range(50000):
current_state = ql.random.randint(0, int(Q.shape[0]))
PossibleAction = possible_actions(current_state)
action = ActionChoice(PossibleAction)
reward(current_state,action,gamma)
# Displaying Q before the norm of Q phase
print("Q :")
print(Q)
# Norm of Q
print("Normed Q :")
print(Q/ql.max(Q)*100)
```
# Improving the program by introducing a decision-making process
```
import random
import numpy as np
# Norm of Q
print("Normed Q :")
print(Q/ql.max(Q)*100)
Qp=Q/ql.max(Q)
import random
import numpy as np
# Norm of Q
print("Normed Q :")
print(Q/ql.max(Q)*100)
Qp=Q/ql.max(Q)
"""# Improving the program by introducing a decision-making process"""
conceptcode=["A","B","C","D","E","F"]
WIP=[0,0,0,0,0,0] # *****
our_query="" # *****
print("Sequences")
maxv=1000
mint=450
maxt=500
#sh=ql.zeros((maxv, 2))
for i in range(0,maxv):
for w in range(0,6):
WIP[w]=random.randint(0,100)
print(WIP)
print("\n")
if(np.sum(WIP)>mint and np.sum(WIP)<maxt):
print(mint,maxt)
print("Alert!", np.sum(WIP))
print("Mention MDP or Bellman in your comment, please")
while our_query !="no" or our_query !="bye":
our_query=input("Enter your comment or question:")
if our_query=="no" or our_query=="bye":
break;
#print(our_query)
vresponse=dialog(our_query)
print(vresponse)
decision=input("Do you want to continue(enter yes) or stop(enter no) to work with your department before letting the program make a decision:")
if(decision=="no"):
break
mint=460
maxt=470
nextc=-1
nextci=-1
origin=ql.random.randint(0,6)
print(" ")
print(conceptcode[int(origin)])
for se in range(0,6):
if(se==0):
po=origin
if(se>0):
po=nextci
for ci in range(0,6):
maxc=Q[po,ci]
maxp=Qp[po,ci]
if(maxc>=nextc):
nextc=maxc
nextp=maxp
nextci=ci
#conceptprob[int(nextci)]=nextp *****
if(nextci==po):
break;
print(conceptcode[int(nextci)])
print("\n")
```
# WEB
[ML Explanation Consult](https://console.dialogflow.com/api-client/demo/embedded/6ba8785d-6b3b-40de-8a2c-fdba7939c220)
[ML Explanation Consult and Share](https://bot.dialogflow.com/6ba8785d-6b3b-40de-8a2c-fdba7939c220)
| github_jupyter |
# Quasi-binomial regression
This notebook demonstrates using custom variance functions and non-binary data
with the quasi-binomial GLM family to perform a regression analysis using
a dependent variable that is a proportion.
The notebook uses the barley leaf blotch data that has been discussed in
several textbooks. See below for one reference:
https://support.sas.com/documentation/cdl/en/statug/63033/HTML/default/viewer.htm#statug_glimmix_sect016.htm
```
import statsmodels.api as sm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from io import StringIO
```
The raw data, expressed as percentages. We will divide by 100
to obtain proportions.
```
raw = StringIO(
"""0.05,0.00,1.25,2.50,5.50,1.00,5.00,5.00,17.50
0.00,0.05,1.25,0.50,1.00,5.00,0.10,10.00,25.00
0.00,0.05,2.50,0.01,6.00,5.00,5.00,5.00,42.50
0.10,0.30,16.60,3.00,1.10,5.00,5.00,5.00,50.00
0.25,0.75,2.50,2.50,2.50,5.00,50.00,25.00,37.50
0.05,0.30,2.50,0.01,8.00,5.00,10.00,75.00,95.00
0.50,3.00,0.00,25.00,16.50,10.00,50.00,50.00,62.50
1.30,7.50,20.00,55.00,29.50,5.00,25.00,75.00,95.00
1.50,1.00,37.50,5.00,20.00,50.00,50.00,75.00,95.00
1.50,12.70,26.25,40.00,43.50,75.00,75.00,75.00,95.00"""
)
```
The regression model is a two-way additive model with
site and variety effects. The data are a full unreplicated
design with 10 rows (sites) and 9 columns (varieties).
```
df = pd.read_csv(raw, header=None)
df = df.melt()
df["site"] = 1 + np.floor(df.index / 10).astype(int)
df["variety"] = 1 + (df.index % 10)
df = df.rename(columns={"value": "blotch"})
df = df.drop("variable", axis=1)
df["blotch"] /= 100
```
Fit the quasi-binomial regression with the standard variance
function.
```
model1 = sm.GLM.from_formula(
"blotch ~ 0 + C(variety) + C(site)", family=sm.families.Binomial(), data=df
)
result1 = model1.fit(scale="X2")
print(result1.summary())
```
The plot below shows that the default variance function is
not capturing the variance structure very well. Also note
that the scale parameter estimate is quite small.
```
plt.clf()
plt.grid(True)
plt.plot(result1.predict(linear=True), result1.resid_pearson, "o")
plt.xlabel("Linear predictor")
plt.ylabel("Residual")
```
An alternative variance function is mu^2 * (1 - mu)^2.
```
class vf(sm.families.varfuncs.VarianceFunction):
def __call__(self, mu):
return mu ** 2 * (1 - mu) ** 2
def deriv(self, mu):
return 2 * mu - 6 * mu ** 2 + 4 * mu ** 3
```
Fit the quasi-binomial regression with the alternative variance
function.
```
bin = sm.families.Binomial()
bin.variance = vf()
model2 = sm.GLM.from_formula("blotch ~ 0 + C(variety) + C(site)", family=bin, data=df)
result2 = model2.fit(scale="X2")
print(result2.summary())
```
With the alternative variance function, the mean/variance relationship
seems to capture the data well, and the estimated scale parameter is
close to 1.
```
plt.clf()
plt.grid(True)
plt.plot(result2.predict(linear=True), result2.resid_pearson, "o")
plt.xlabel("Linear predictor")
plt.ylabel("Residual")
```
| github_jupyter |
```
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import yfinance as yf
import os
# #I have imported and used functions from the previous files uploaded in this repository. Many functions are required
# #for many further implementations and further calculations.
import rolling_stats as rs
import norm_dist as nd
import nature_of_daily_returns as nds
pd.options.display.float_format = '{:.5f}'.format
def get_data_close(symbol):
stock = yf.Ticker(symbol)
df = stock.history(period="max")
return pd.DataFrame(df['Close'])
# def norm_dist_yearwise(symbol, dates, plot=False):
'''
This function first slices out the daterange provided and then uses the first value at the 0th row of the new sliced dataframe as the normalizing value and then
normalizes the entire ditribution based on that and then plots it.
This function accepts the list of stocks and the date range of the required plot.
'''
'''
Sample Run
dates = pd.date_range('2015-01-01','2017-01-01')
print(nd.norm_dist_yearwise('AZPN', dates, True).head())
'''
# def norm_dist(symbol, dates, plot = False):
'''
This function treats the first ever recorded stock price to be the initial value and the rest of the ditribution is accordingly normalized. Then the selected date
range is sliced out and the plot is shown.
This function accepts the list of stocks and the date range of the required plot.
'''
'''
Sample Run
dates =pd.date_range('2015-01-01','2017-01-01')
print(nd.norm_dist('AZPN', dates, True).head())
''''''
# def daily_return(symbol, dates, plot= False):
'''
This function returns or plots the daily returns of a given stock for a given time period.
This function accepts 3 parameters. df - the historic dataframe of the stock, date- the daterange for the plot, plot - a boolean for
whether the user wnats to see the plot or just wants the resulting dataframe.
'''
'''
Sample Run
dates =pd.date_range('2015-01-01','2017-01-01')
print(rs.daily_return('AZPN', dates, True).head())
'''
# def cumulative_return(symbol,dates ,plot=False):
'''
This function calculates the bollinger bands for the given stock in the given time period. These bands are powerful indicators for
making the decision for selling and buying. This should not be your only indicator but it certainly helps to visualize the data and trends.
The upper bound is mean+2*std and the lower bound is mean-2*std. These lines are plotted on the graph along with the prices.
The rolling mean and rolling std is calculated for the past 20 days.
'''
'''
Sample Run
dates =pd.date_range('2015-01-01','2017-01-01')
print(rs.cumulative_return('AZPN', dates, True).head())
'''
# def bollinger_bands(symbol, dates , rolling_range = 20):
'''
This function calculates the bollinger bands for the given stock in the given time period. These bands are powerful indicators for
making the decision for selling and buying. This should not be your only indicator but it certainly helps to visualize the data and trends.
The upper bound is mean+2*std and the lower bound is mean-2*std. These lines are plotted on the graph along with the prices.
The rolling mean and rolling std is calculated for the past 20 days by default but can be changed.
'''
'''
Sample Run
dates =pd.date_range('2016-01-01','2017-01-01')
rs.bollinger_bands("AZPN", dates)
'''
# def plot_hist_with_stats(stocks, dates, m = False, bins = 20):
'''
This function is useful for plotting histograms for one or more than one stock at a time.
This function takes in a list of stock symbols , the range of dates, whether to plot the mean of the stock or not. Default value is False.
This function also takes in the number of bins required in the histogram, the default value is 20.
'''
'''
Sample Run
dates = pd.date_range('2015-01-01','2017-12-31')
nds.plot_hist_with_stats(['AAPL', 'AZPN'], dates)
'''
# def plot_scatter(stocks, dates):
'''
This function takes in a list of pair of stocks between which the alpha and beta is to be found and a line of best fit is to be plotted.
The daily returns of both the stocks are calculated from the function from rolling_stats.py and then graphed against each other. This
function is mainly used to plot any stock against the S&P 500 or Dow Jones Index stocks to get a sens eof how well the stock is
doing with respect to the market and how reactive it is to the market movements.
This function accepts 2 para,eters : stocks - A list of lists of size 2, dates - The daterange for the scatter plot.
'''
'''
Sample run
dates = pd.date_range('2015-01-01','2017-12-31')
nds.plot_scatter([['MSFT', "AZPN"], ['AAPL', 'GOOGL']], dates)
'''
# def portfolio_val(portfolio , comp, dates , val, plot=False):
# '''
# This function takes in
# portfolio : a list of stocks in the portfolio
# comp : a list of composition of the portfolio
# dates : The range of date for which the request is to be observed
# val : The starting value of the portfolio at the start date in the date range
# plot : Whether you want to see the plot of daily returns and price
# This function returns a dataframe that has the value of each stock adjusted ny composition over the daterange, daily returns and
# value of the portfolio, and a stats_dic which has the mean and std of the daily returns and the cumilative return over the
# given date range.
# '''
# df_norm = pd.DataFrame(index = dates)
# for s in portfolio:
# df_temp = nd.norm_dist_yearwise(s, dates)
# df_norm = df_norm.join(df_temp)
# df_norm.dropna(inplace= True)
# df_norm = df_norm*comp*val
# df_norm['Value'] = df_norm.sum(axis=1)
# print(df_norm.head())
# df_daily = rs.daily_return(df_norm, "Value", dates)
# df_daily = (df_norm['Value'][1:]/df_norm['Value'][:-1].values)-1
# df_daily.iloc[0] = 0
# print(df_daily.head())
# portfolio = ['MSFT', 'AZPN', 'NFLX', 'GOOGL']
# composition = [0.4 , 0.4, 0.1, 0.1]
# dates =pd.date_range('2017-01-01','2018-01-01')
# start_val = 1000000
# portfolio_val(portfolio, composition , dates, start_val)
```
| github_jupyter |
# 1.超分大作业
经过这几天的学习,相信大家对GAN已经有了一定的了解了,也在前面的作业中体验过GAN的一些应用了。那现在大家是不是想要升级一下难度,自己动手来训练一个模型呢?
需要自己动手训练的大作业来啦,大作业内容为基于PaddleGAN中的超分模型,实现卡通画超分。
## 1.1 安装PaddleGAN
PaddleGAN的安装目前支持Clone GitHub和Gitee两种方式:
```
# 安装ppgan
# 当前目录在: /home/aistudio/, 这个目录也是左边文件和文件夹所在的目录
# 克隆最新的PaddleGAN仓库到当前目录
# !git clone https://github.com/PaddlePaddle/PaddleGAN.git
# 如果从github下载慢可以从gitee clone:
!git clone https://gitee.com/paddlepaddle/PaddleGAN.git
# 安装Paddle GAN
%cd PaddleGAN/
!pip install -v -e .
```
## 1.2 数据准备
我们为大家准备了处理好的超分数据集[卡通画超分数据集](https://aistudio.baidu.com/aistudio/datasetdetail/80790)
```
# 回到/home/aistudio/下
%cd /home/aistudio
# 解压数据
!unzip -q data/data80790/animeSR.zip -d data/
# 将解压后的数据链接到` /home/aistudio/PaddleGAN/data `目录下
!mv data/animeSR PaddleGAN/data/
```
### 1.2.1 数据集的组成形式
```
PaddleGAN
├── data
├── animeSR
├── train
├── train_X4
├── test
└── test_X4
```
训练数据集包括400张卡通画,其中``` train ```中是高分辨率图像,``` train_X4 ```中是对应的4倍缩小的低分辨率图像。测试数据集包括20张卡通画,其中``` test ```中是高分辨率图像,``` test_X4 ```中是对应的4倍缩小的低分辨率图像。
### 1.2.2 数据可视化
```
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 训练数据统计
train_names = os.listdir('PaddleGAN/data/animeSR/train')
print(f'训练集数据量: {len(train_names)}')
# 测试数据统计
test_names = os.listdir('PaddleGAN/data/animeSR/test')
print(f'测试集数据量: {len(test_names)}')
# 训练数据可视化
img = cv2.imread('PaddleGAN/data/animeSR/train/Anime_1.jpg')
img = img[:,:,::-1]
plt.figure()
plt.imshow(img)
plt.show()
```
## 1.3 选择超分模型
PaddleGAN中提供的超分模型包括RealSR, ESRGAN, LESRCNN, DRN等,详情可见[超分模型](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/super_resolution.md)。
接下来以LESRCNN为例进行演示。
### 1.3.1 修改配置文件
所有模型的配置文件均在``` /home/aistudio/PaddleGAN/configs ```目录下。
找到你需要的模型的配置文件,修改模型参数,一般修改迭代次数,num_workers,batch_size以及数据集路径。有能力的同学也可以尝试修改其他参数,或者基于现有模型进行二次开发,模型代码在``` /home/aistudio/PaddleGAN/ppgan/models ```目录下。
以LESRCNN为例,这里将将配置文件``lesrcnn_psnr_x4_div2k.yaml``中的
参数``total_iters``改为50000
参数``dataset:train:num_workers``改为4
参数``dataset:train:batch_size``改为16
参数``dataset:train:gt_folder``改为data/animeSR/train
参数``dataset:train:lq_folder``改为data/animeSR/train_X4
参数``dataset:test:gt_folder``改为data/animeSR/test
参数``dataset:test:lq_folder``改为data/animeSR/test_X4
## 1.4 训练模型
以LESRCNN为例,运行以下代码训练LESRCNN模型。
如果希望使用其他模型训练,可以修改配置文件名字。
```
%cd /home/aistudio/PaddleGAN/
!python -u tools/main.py --config-file configs/lesrcnn_psnr_x4_div2k.yaml
```
## 1.5 测试模型
以LESRCNN为例,模型训练好后,运行以下代码测试LESRCNN模型。
其中``/home/aistudio/pretrained_model/LESRCNN_PSNR_50000_weight.pdparams``是刚才ESRGAN训练的模型参数,同学们需要换成自己的模型参数。
如果希望使用其他模型测试,可以修改配置文件名字。
```
%cd /home/aistudio/PaddleGAN/
!python tools/main.py --config-file configs/lesrcnn_psnr_x4_div2k.yaml --evaluate-only --load /home/aistudio/pretrained_model/LESRCNN_PSNR_50000_weight.pdparams
```
## 1.6 实验结果展示及模型下载
这里使用LESRCNN模型训练了一个基于PSNR指标的预测模型。
数值结果展示及模型下载
| 方法 | 数据集 | 迭代次数 | 训练时长 | PSNR | SSIM | 模型下载 |
|---|---|---|---|---|---|---|
| LESRCNN_PSNR | 卡通画超分数据集 | 50000 | 2h | 24.9480 | 0.7469 |[LESRCNN_PSNR](./pretrained_model/LESRCNN_PSNR_50000_weight.pdparams)|
可视化
| 低分辨率 | LESRCNN_PSNR | GT |
|---|---|---|
||||
||||
最后效果
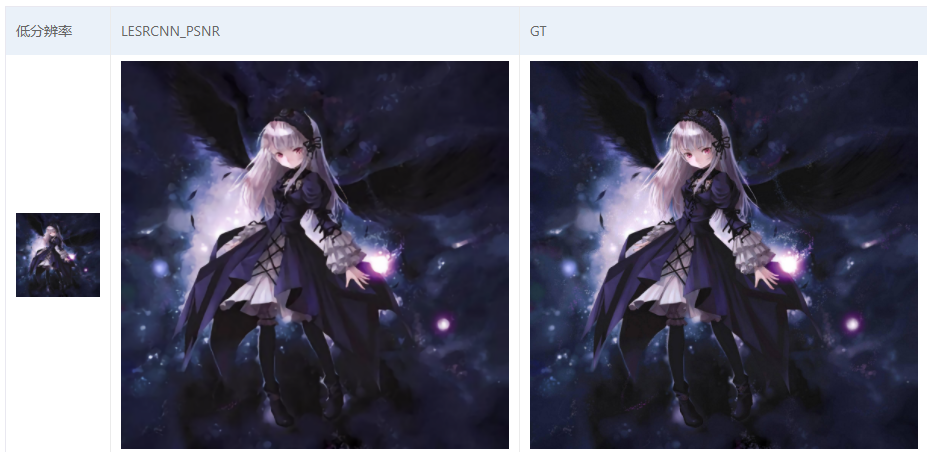

# 2.参考资料
【PaddleGAN的Github地址】:https://github.com/PaddlePaddle/PaddleGAN
【PaddleGAN的Gitee地址】:https://gitee.com/PaddlePaddle/PaddleGAN
【生成对抗网络七日打卡营】课程链接:https://aistudio.baidu.com/aistudio/course/introduce/16651
【生成对抗网络七日打卡营】项目合集:https://aistudio.baidu.com/aistudio/projectdetail/1807841
【图像分割7日打卡营常见问题汇总】
https://aistudio.baidu.com/aistudio/projectdetail/1100155
【PaddlePaddle使用教程】
https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/guides/index_cn.html
【本地安装PaddlePaddle的常见错误】
https://aistudio.baidu.com/aistudio/projectdetail/697227
【API文档】
https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api/index_cn.html
【PaddlePaddle/hapi Github】
https://github.com/PaddlePaddle/hapi
【Github使用】
https://guides.github.com/activities/hello-world/
# 3.个人介绍
> 中南大学 机电工程学院 机械工程专业 2019级 研究生 雷钢
> 百度飞桨官方帮帮团成员
> Github地址:https://github.com/leigangblog
> B站:https://space.bilibili.com/53420969
来AI Studio互关吧,等你哦~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/118783
欢迎大家fork喜欢评论三连,感兴趣的朋友也可互相关注一下啊~
| github_jupyter |
# Generating a Synthetic Dataset for Deep Learning Experiments
<img align="left" width="130" src="https://raw.githubusercontent.com/PacktPublishing/Amazon-SageMaker-Cookbook/master/Extra/cover-small-padded.png"/>
This notebook contains the code to help readers work through one of the recipes of the book [Machine Learning with Amazon SageMaker Cookbook: 80 proven recipes for data scientists and developers to perform ML experiments and deployments](https://www.amazon.com/Machine-Learning-Amazon-SageMaker-Cookbook/dp/1800567030)
### How to do it...
```
import numpy as np
def formula(x):
if x >= -2000:
return x
else:
return -x - 4000
formula(100)
def generate_synthetic_data(n_samples=1000,
start=-5000,
end=5000):
np.random.seed(42)
x = np.random.randint(low=start,
high=end,
size=(n_samples,)).astype(int)
y = np.vectorize(formula)(x) + \
np.random.normal(150, 150, n_samples)
return (x, y)
X, y = generate_synthetic_data()
X[:10]
y[:10]
from matplotlib import pyplot
pyplot.rcParams["figure.figsize"] = (10,8)
pyplot.scatter(X,y,s=1)
pyplot.show()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.2, random_state=0)
print(X_train.shape)
print(X_validation.shape)
print(X_test.shape)
!mkdir -p tmp
import pandas as pd
df_all_data = pd.DataFrame({ 'y': y, 'x': X})
df_all_data.to_csv('tmp/all_data.csv', header=False, index=False)
df_training_data = pd.DataFrame({ 'y': y_train, 'x': X_train})
df_training_data.to_csv('tmp/training_data.csv', header=False, index=False)
df_validation_data = pd.DataFrame({ 'y': y_validation, 'x': X_validation})
df_validation_data.to_csv('tmp/validation_data.csv', header=False, index=False)
df_test_data = pd.DataFrame({ 'y': y_test, 'x': X_test})
df_test_data.to_csv('tmp/test_data.csv', header=False, index=False)
s3_bucket = '<insert s3 bucket name here>'
prefix = "chapter03"
!aws s3 cp tmp/training_data.csv \
s3://{s3_bucket}/{prefix}/synthetic/all_data.csv
!aws s3 cp tmp/training_data.csv \
s3://{s3_bucket}/{prefix}/synthetic/training_data.csv
!aws s3 cp tmp/validation_data.csv \
s3://{s3_bucket}/{prefix}/synthetic/validation_data.csv
!aws s3 cp tmp/test_data.csv \
s3://{s3_bucket}/{prefix}/synthetic/test_data.csv
```
| github_jupyter |
# Regularization for Machine Learning
---
## Getting Started _ Tutorial Demo
This notebook will walk you through all the functions in RegML library
#### Requirments
#### Following libraries are required to use all the functions in RegML library
* Python(>=2.7)-------------------(Of course) If you are able to open this notebook, you already have python
* Numpy(>=1.10.4)---------------For all matrix operations [Numpy](https://pypi.python.org/pypi/numpy) *tested on 1.10.4*
* Matplotlib(>=0.98)--------------For visualization [Matplotlib](https://github.com/matplotlib/matplotlib) *tested on 1.15.1*
* Scipy(>=0.12)-------------------Optional -(If you need to import .mat data files) [Scipy](https://www.scipy.org/install.html) *tested on 0.17.0*
## Contents:
1. Create and Import Dataset
2. Compute Kernel
3. Apply Filter
4. Learn
5. K-Fold Cross Validation
---
## Let's start
```
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import RegML as rg
```
## 1. Create and Import Datasets
Unlike MATLAB, array in python start with index 0,
np.where is same as find function in MATLAB
### Spiral
```
# X,Y,s,w,m = rg.spiral(N=[1000,1000], s = 0.5, wrappings = 'random', m = 'random')
X,Y,_,_,_ = rg.spiral(N=[1000,1000], s = 0.3)
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
plt.show()
```
### Sinusoidal
```
X,Y,s = rg.sinusoidal(N=[5000,5000], s = 0.1)
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
plt.show()
```
### Moons
```
X,Y,s,d,a = rg.moons(N =[1000,1000], s =0.1, d='random', angle = 'random')
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
plt.show()
```
### Gaussian
```
X,Y,nd,m,s = rg.gaussian(N=[1000,1000], ndist = 3, means ='random', sigmas='random')
plt.figure(figsize =(15,5))
plt.subplot(121)
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
# --------With specifications---------------------------
means1 = np.array([[-5, -7],[2, -9],[10, 5],[12,-6]])
sigma1 = np.tile(np.eye(2)* 3, (4, 1))
X, Y, ndist, means, sigmas = rg.gaussian(N=[1000,1000], ndist =2, means = means1, sigmas = sigma1)
plt.subplot(122)
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
plt.show()
```
### Linear
```
X,Y,m,b,s = rg.linear_data(N=[1000,1000], m ='random', b ='random', s =0.1)
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
plt.show()
```
## Alternatively
### you can creat all the above datasets by calling one function "create_datasets"
You can create dataset by passing one of the key words **{MOONS, GAUSSIANS, LINEAR, SINUSOIDAL, SPIRAL'}** to Dtype, uppercase or lowercase and option parameters for correspoding datasets can be pass through **Options** keywords else set **varargin = 'PRESET'** to generate with some default presetting scriptted in code
```
X,Y,Op = rg.create_dataset(N = 1000, Dtype='MOONS', noise =0.1, varargin = 'PRESET')
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
plt.show()
Options = {'s':0.1,'d':np.array([0.6, -0.6])}
X,Y,Op = rg.create_dataset(N = 1000, Dtype='MOONS', noise =0.1, varargin = False,**Options)
plt.plot(X[np.where(Y==1)[0],0],X[np.where(Y==1)[0],1],'.b')
plt.plot(X[np.where(Y==-1)[0],0],X[np.where(Y==-1)[0],1],'.r')
plt.show()
#Options = {'s':0.1,'d':np.array([0.6, -0.6]),'m1':2, 'ndist':3}
```
### LoadMatFiles
```
# if you are sure .mat files has 'x','y','xt','yt' variables use rg.load_Dataset(filePath1)
# Example
filePath1 = '/media/nikb/UB/@UniGe/@Courses/regML2016/Lab1/Lab 1/example_datasets/2moons.mat'
x,y,xt,yt = rg.load_Dataset(filePath1)
print x.shape, y.shape, xt.shape, yt.shape
#------------------------------------------------------------------------------------------------------
# if you are not sure use loadMatFile(filePath1), it will return X,Y and Mat,
# if there are 'X' or 'x' and 'Y' or 'y' variables they will be in X and Y and Mat will return everything in .mat file as
# dictionary from which you can take your dataset
# Example
filePath2 = '/media/nikb/UB/@UniGe/@Courses/regML2016/Lab1/Lab 1/challenge_datasets/one_train.mat'
X,Y,Mat = rg.loadMatFile(filePath2)
print Mat.keys()
X = Mat['one_train']
print X.shape
```
# 2. Compute Kernal
```
x1 = np.random.randint(11, size=(10, 5))
x2 = np.random.randint(11, size=(6, 5))
K1 = rg.kernel(knl = 'lin', kpar = [], X1 =x1, X2 =x2)
K2 = rg.kernel(knl = 'pol', kpar = 3, X1 =x1, X2 =x2)
K3 = rg.kernel(knl = 'gauss', kpar = 0.5, X1 =x1, X2 =x2)
K4 = rg.kernel(knl = 'gauss', kpar = 0.5, X1 =x1, X2 =x1)
print x1
print x2
print K1
print K2
print K3
print K4
plt.matshow(K2)
plt.show()
```
# 3. Applying Filter
### After computing kernal, applying filters
**Regularized least squares (rls), Iterative Landweber (land), Truncated SVD (tsvd), nu-method (nu), Spectral cut-off (cutoff)**
```
x1 = np.random.randint(11, size=(10, 5))
y1 = np.array([-1,-1,-1,-1,-1,1,1,1,1,1]).T
x2 = np.random.randint(11, size=(6, 5))
y2 = np.array([-1,-1,-1,1,1,1]).T
K = rg.kernel(knl = 'lin', kpar = [], X1 =x1, X2 =x1)
print 'Kernal'
print K
print 'RLS---------------'
alpha = rg.rls(K, t_range =[0.1,0.5], y = y1)
print np.around(alpha,3)
print 'TSVD -----------------------'
alpha = rg.tsvd(K,t_range =[0.1,0.5], y =y1)
print np.around(alpha,3)
print 'NU -----------------------'
alpha = rg.nu(K, t_max= 4, y = y1, all_path = False)
print np.around(alpha,3)
print 'LAND -----------------------'
alpha = rg.land(K,t_max =4, y = y1, tau = 2, all_path = True)
print np.around(alpha,3)
print 'CUT-OFF---------------'
alpha = rg.cutoff(K,t_range = 0.1, y = y1)
print np.around(alpha,3)
alpha = rg.cutoff(K,t_range = [0.1,0.5], y = y1)
print np.around(alpha,3)
```
## Spliting test
```
y =2*np.random.randint(2, size=(10, 1))-1
print y.T
sets = rg.splitting(y, k=2, type = 'rand')
print sets
```
# 4. Learn
```
X,y,Op = rg.create_dataset(N = 500, Dtype='MOONS', noise =0.1, varargin = 'PRESET')
Xt,yt,Op = rg.create_dataset(N = 500, Dtype='MOONS', noise =0.1, varargin = 'PRESET')
print 'X, y, Xt, yt.. Training/Testing size'
print X.shape, y.shape, Xt.shape,yt.shape
# ---------------------------Learn---Alpha--------------------------------------
#filt =['rls','land','tsvd','nu','cutoff']
#knl =['lin','poly','gauss']
#kpar =[ [] , int , float ]
print ' '
print 'RLS------Lin---------------'
trange =[1,4]
krnl = 'lin'
filtr ='rls'
kparr =2
alpha,err = rg.learn(knl=krnl, kpar=kparr, filt =filtr, t_range =trange, X = X, y =y, task = 'class')
K = rg.kernel(knl = krnl, kpar = kparr, X1 =Xt, X2 =X)
for i in range(len(alpha)):
y_lrnt = np.dot(K,alpha[i])
errT = rg.learn_error(y_lrnt, yt,'class')
print ' For t :',trange[i]
print ' Training Error: ', err[i], ' Testing Error :' , errT
print ' '
print 'RLS--------Pol-------------'
trange =10
krnl = 'pol'
filtr ='rls'
kparr =2
alpha,err = rg.learn(knl=krnl, kpar=kparr, filt =filtr, t_range =trange, X = X, y =y, task = 'class')
K = rg.kernel(knl = krnl, kpar = kparr, X1 =Xt, X2 =X)
trange = [trange]
for i in range(len(alpha)):
y_lrnt = np.dot(K,alpha[i])
errT = rg.learn_error(y_lrnt, yt,'class')
print ' For t :',trange[i]
print ' Training Error: ', err[i], ' Testing Error :' , errT
print ' '
print 'Land-------------------'
krnl = 'pol'
kparr =2
filtr ='land'
trange = 2
alpha,err = rg.learn(knl=krnl, kpar=kparr, filt =filtr, t_range =trange, X = X, y =y, task = 'class')
K = rg.kernel(knl = krnl, kpar = kparr, X1 =Xt, X2 =X)
for i in range(len(alpha)):
y_lrnt = np.dot(K,alpha[i])
errT = rg.learn_error(y_lrnt, yt,'class')
print ' Training Error: ', err[i], ' Testing Error :' , errT
print ' '
print 'TSVD---------------------'
krnl = 'pol'
kparr =2
filtr ='tsvd'
trange =[0.1,0.2]
alpha,err = rg.learn(knl=krnl, kpar=kparr, filt =filtr, t_range =trange, X = X, y =y, task = 'class')
K = rg.kernel(knl = krnl, kpar = kparr, X1 =Xt, X2 =X)
for i in range(len(alpha)):
y_lrnt = np.dot(K,alpha[i])
errT = rg.learn_error(y_lrnt, yt,'class')
print 'for t :',trange[i]
print ' Training Error: ', err[i], ' Testing Error :' , errT
print ' '
print 'NU---------------------'
krnl = 'gauss'
kparr = rg.autosigma(X, 5)
filtr ='nu'
trange = 4
alpha,err = rg.learn(knl=krnl, kpar=kparr, filt =filtr, t_range =trange, X = X, y =y, task = 'class')
K = rg.kernel(knl = krnl, kpar = kparr, X1 =Xt, X2 =X)
for i in range(len(alpha)):
y_lrnt = np.dot(K,alpha[i])
errT = rg.learn_error(y_lrnt, yt,'class')
print ' Training Error: ', err[i], ' Testing Error :' , errT
```
# 5. KCV K-Fold Cross Validation
```
##-----Dataset
X, Y,_,_,_ = rg.moons(N =[200,200], s =0.1, d=np.array([0.2, -0.2]), angle =0.1)
Xt,Yt,_,_,_ = rg.moons(N =[200,200], s =0.1, d=np.array([0.2, -0.2]), angle =0.1)
plt.plot(X[np.where(Y>=0)[0],0],X[np.where(Y>=0)[0],1],'.b')
plt.plot(X[np.where(Y< 0)[0],0],X[np.where(Y< 0)[0],1],'.r')
plt.show()
# ------------_Choose parametes ----------------------
knl ='gauss'
kpar = rg.autosigma(X,5)
filt ='rls'
trange = [0.1, 0.5 ,1,2,3,4,5] #[1,1.5,5,10] #[0.1,0.3,0.5]#, 0.3, 0.5, 1.0,1.5, 3, 5]
task ='class'
splitype ='seq'
k = 5 # of Splits
#-- KCV---------
t_kcv_idx, avg_err_kcv = rg.kcv(knl,kpar,filt, t_range=trange, X=X, y=Y,k=k, task=task, split_type=splitype)
#print t_kcv_idx, avg_err_kcv
if filt in ['land','nu']:
tval = t_kcv_idx + 1
else:
tval = trange[t_kcv_idx]
alpha, err = rg.learn(knl, kpar, filt, tval, X, Y, task)
index = np.argmin(err)
K = rg.kernel(knl, kpar, X1 =Xt, X2 =X)
y_learnt = np.dot(K,alpha[index])
lrn_error = rg.learn_error(y_learnt,Yt, task)
print 'KCV Error'
print 'Errors : ', avg_err_kcv
print 'Trange : ', trange
print '-------------------------------'
print 'Selected t :', tval
print 'Training Error :', err[index]
print 'Testing Error :', lrn_error
```
| github_jupyter |
```
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import random
import math
import os
SEED = 2222
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
def process_en(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
def process_de(text):
return [tok.text for tok in spacy_de.tokenizer(text)]
Source = Field(tokenize=process_de, init_token='<sos>', eos_token='<eos>', lower=True)
Target = Field(tokenize=process_en, init_token='<sos>', eos_token='<eos>', lower=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'), fields=(Source, Target))
len(train_data),len(valid_data),len(test_data)
Source.build_vocab(train_data, min_freq=2)
Target.build_vocab(train_data, min_freq=2)
BATCH_SIZE = 128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device.type
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data), batch_size=BATCH_SIZE, device=device)
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.input_dim = input_dim
self.emb_dim = emb_dim
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional=True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))#[sent len, batch size]
outputs, hidden = self.rnn(embedded)#[sent len, batch size, emb dim]
#outputs -> [sent len, batch size, hid dim * n directions]
#hidden -> [n layers * n directions, batch size, hid dim]
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)))
#hidden -> [batch size, dec hid dim]
return outputs, hidden
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.vec = nn.Parameter(torch.rand(dec_hid_dim))
def forward(self, hidden, encoder_outputs):
#hidden -> [batch size, dec hid dim]
#encoder_outputs -> [src sent len, batch size, enc hid dim * 2]
batch_size = encoder_outputs.shape[1]
src_len = encoder_outputs.shape[0]
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#hidden -> [batch size, src sent len, dec hid dim]
#encoder_outputs -> [batch size, src sent len, enc hid dim * 2]
association = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
#association -> [batch size, src sent len, dec hid dim]
association = association.permute(0, 2, 1)
#association -> [batch size, dec hid dim, src sent len]
#vec -> [dec hid dim]
vec = self.vec.repeat(batch_size, 1).unsqueeze(1)
#vec -> [batch size, 1, dec hid dim]
attention = torch.bmm(vec, association).squeeze(1)
#attention-> [batch size, src len]
return F.softmax(attention, dim=1)
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.emb_dim = emb_dim
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
#input -> [batch size]
#hidden -> [batch size, dec hid dim]
#encoder_outputs -> [src sent len, batch size, enc hid dim * 2]
input = input.unsqueeze(0)
#input -> [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded -> [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs)
#a -> [batch size, src len]
a = a.unsqueeze(1)
#a -> [batch size, 1, src len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#encoder_outputs -> [batch size, src sent len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
#weighted -> [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
#weighted -> [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim=2)
#rnn_input -> [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
#output -> [sent len, batch size, dec hid dim * n directions]
#hidden -> [n layers * n directions, batch size, dec hid dim]
#output -> [1, batch size, dec hid dim]
#hidden -> [1, batch size, dec hid dim]
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
output = self.out(torch.cat((output, weighted, embedded), dim=1))
#output -> [batch size, output dim]
return output, hidden.squeeze(0)
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
#src->[sent len, batch size]
#trg->[sent len, batch size]
batch_size = trg.shape[1]
max_len = trg.shape[0]
target_voc_size = self.decoder.output_dim
outputs = torch.zeros(max_len, batch_size, target_voc_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[0,:]
for t in range(1, max_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.max(1)[1]
input = (trg[t] if teacher_force else top1)
return outputs
INPUT_DIM = len(Source.vocab)
OUTPUT_DIM = len(Target.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
ENC_HID_DIM = 512
DEC_HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
attn = Attention(ENC_HID_DIM, DEC_HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = Seq2Seq(enc, dec, device).to(device)
model
optimizer = optim.Adam(model.parameters())
pad_idx = Target.vocab.stoi['<pad>']
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
source = batch.src
target = batch.trg#[sent len, batch size]
optimizer.zero_grad()
output = model(source, target)#[sent len, batch size, output dim]
loss = criterion(output[1:].view(-1, output.shape[2]), target[1:].view(-1))
#trg->[(sent len - 1) * batch size]
#output->[(sent len - 1) * batch size, output dim]
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
source = batch.src
target = batch.trg
output = model(source, target, 0)
loss = criterion(output[1:].view(-1, output.shape[2]), target[1:].view(-1))
epoch_loss += loss.item()
return epoch_loss / len(iterator)
DIR = 'models'
MODEL_DIR = os.path.join(DIR, 'seq2seq_model.pt')
N_EPOCHS = 10
CLIP = 10
best_loss = float('inf')
if not os.path.isdir(f'{DIR}'):
os.makedirs(f'{DIR}')
for epoch in range(N_EPOCHS):
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
if valid_loss < best_loss:
best_loss = valid_loss
torch.save(model.state_dict(), MODEL_DIR)
print(f'| Epoch: {epoch+1:03} | Train Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f} | Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f} |')
model.load_state_dict(torch.load(MODEL_DIR))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
```
| github_jupyter |
```
from pylab import *
import numpy as np
import matplotlib, pylab
from dcll.npamlib import plotLIF
from dcll.pytorch_libdcll import *
from dcll.load_dvsgestures_sparse import *
import os
matplotlib.rcParams['text.usetex']=False
matplotlib.rcParams['savefig.dpi']=400.
matplotlib.rcParams['font.size']=14.0
matplotlib.rcParams['figure.figsize']=(5.0,3.5)
matplotlib.rcParams['axes.formatter.limits']=[-10,10]
matplotlib.rcParams['axes.labelsize']= 14.
matplotlib.rcParams['figure.subplot.bottom'] = .2
matplotlib.rcParams['figure.subplot.left'] = .2
def convergence_multiple(dirs, Nlayers=3):
res = np.empty([len(dirs), Nlayers])
pl = [[] for _ in range(len(dirs))]
for k, d in enumerate(dirs):
directory = d
args = np.load(directory+"args.pkl")
testepochs = np.arange(0,args['epochs'],args['testinterval'], dtype='int')
n_iter_test = 1800
iter_test = np.arange(1,n_iter_test+20,20)
Ntests = len(testepochs)
acc_test = np.load(directory+"acc_test.npy")[:Ntests]
N = 288
bs = [args['batchsize'] for i in range(N//args['batchsize'])]
if (N%args['batchsize'])>0:
bs.append(N%args['batchsize'])
weights = np.array(bs)/N
weighted_acc = np.zeros([Ntests,Nlayers],dtype='float')
for i in range(Nlayers):
weighted_acc[:,i] = (acc_test[:,:,i]*weights).sum(axis=1)
for l in range(Nlayers):
x = testepochs*args['batchsize']//1000
y = 1-weighted_acc[:,l]
xm = x.reshape(-1,5).mean(axis=1)
ym = y.reshape(-1,5).mean(axis=1)
res[k,l] = ym[-1]
pl[k].append(ym)
return res, np.array(xm), np.array(pl)
directory = "../Paper_results/dvsgestures/"
args = np.load(os.path.join(directory,"args.pkl"))
testepochs = np.arange(0,args['epochs'],args['testinterval'], dtype='int')
n_iter_test = args['n_iters_test']
iter_test = np.arange(1,n_iter_test+20,20)
Ntests = len(testepochs)
acc_test = np.load(os.path.join(directory,"acc_test.npy"))[:Ntests]
Nlayers = acc_test.shape[-1]
N = 288
bs = [args['batchsize'] for i in range(N//args['batchsize'])]
if (N%args['batchsize'])>0:
bs.append(N%args['batchsize'])
weights = np.array(bs)/N
weighted_acc = np.zeros([Ntests,Nlayers],dtype='float')
for i in range(Nlayers):
weighted_acc[:,i] = (acc_test[:,:,i]*weights).sum(axis=1)
dirs = [directory]
res, xm, ym = convergence_multiple(dirs)
print(res.mean(0))
print(res.std(0))
fig = figure(figsize=(6,4))
ax = subplot(111)
for l in range(3):
ax.plot(xm, 100*ym.mean(axis=0)[l,:], linewidth=3, alpha=.75, label = 'Layer {}'.format(l+1))
ax.set_yticks(np.arange(0,101,10))
ax.grid()
legend()
ax.set_ylabel('Error[%]')
ax.set_xlabel('Training Samples [1000]')
ax.set_ylim([0,80])
tight_layout()
savefig(os.path.join(directory,'convergence_dvs_gestures_small.png'), dpi=300, frameon=False)
fig = figure()
ax = subplot(111)
for l in range(Nlayers):
ax.plot(testepochs*args['batchsize']//1000, (1-weighted_acc[:,l])*100, linewidth=3, alpha=.75, label = 'Layer {}'.format(l+1))
ax.set_yticks(np.arange(0,100*1.1,100*0.1))
ax.grid()
legend()
ax.set_ylabel('Error[%]')
ax.set_xlabel('Training Samples [1000]')
ax.set_ylim([0,60])
tight_layout()
savefig(os.path.join(directory,'convergence_dvs_gestures.png'), dpi=300, frameon=False)
fig = figure(figsize=(6,4))
ax = subplot(111)
for l in range(Nlayers):
x = testepochs*args['batchsize']//1000
y = 1-weighted_acc[:,l]
xm = x.reshape(-1,5).mean(axis=1)
ym = y.reshape(-1,5).mean(axis=1)
ax.plot(xm, 100*ym, linewidth=3, alpha=.75, label = 'Layer {}'.format(l+1))
print(ym[-1])
ax.set_yticks(np.arange(0,100*1.1,100*0.1))
ax.grid()
legend()
ax.set_ylabel('Error[%]')
ax.set_xlabel('Training Samples [1000]')
ax.set_ylim([0,60])
tight_layout()
savefig(os.path.join(directory,'convergence_dvs_gestures_small.png'), dpi=300, frameon=False)
fig = figure(figsize=(5,4))
ax = subplot(111)
for l in range(Nlayers):
x = testepochs*args['batchsize']//1000
y = 1-weighted_acc[:,l]
xm = x.reshape(-1,5).mean(axis=1)
ym = y.reshape(-1,5).mean(axis=1)
ax.plot(xm, 100*ym, linewidth=3, alpha=.75, label = 'Layer {}'.format(l+1))
print(ym[-1])
ax.set_yticks(np.arange(0,1.1*100,0.1*100))
ax.grid()
legend(frameon=False)
ax.set_ylabel('Error[%]', fontsize=18)
ax.set_xlabel('Training Samples [1000]', fontsize=18)
ax.set_ylim([0,80])
ax.set_yticks([0,20,40,60,80], minor=False)
ax.set_yticks([10,30,50,70], minor=True)
ax.xaxis.grid(False, which='major')
ax.yaxis.grid(False, which='major')
ax.yaxis.grid(False, which='minor')
tight_layout()
savefig(directory+'convergence_dvs_gestures_small_largefonts.png', dpi=500, frameon=False)
print(directory+'convergence_dvs_gestures_small_largefonts.png')
voutput = np.load(directory+"doutput4.npy")
soutput = np.load(directory+"doutput1.npy")
soutput = soutput.reshape(soutput.shape[0], -1)
voutput = voutput.reshape(voutput.shape[0], -1)
fig = figure(figsize=[10,5])
ax1, ax2 = plotLIF(voutput[:,0:5],soutput[:,0:20], staggering=1, color='k')
ax2.set_ylabel('Neuron')
ax2.set_xlabel('Time [ms]')
tight_layout()
fig.savefig(directory+'convergence_dvs_gestures_raster.png',dpi = 300)
from tqdm import tqdm
def accuracy_by_vote(pvoutput, labels):
from collections import Counter
pvoutput_ = np.array(pvoutput).T
n = len(pvoutput_)
arr = np.empty(n)
arrl = np.empty(n)
labels_ = labels.argmax(axis=2).T
for i in range(n):
arr[i] = Counter(pvoutput_[i]).most_common(1)[0][0]
arrl[i] = Counter(labels_[i]).most_common(1)[0][0]
return float(np.mean((arr == arrl)))
labels = np.load(directory + "testlabels.npy")
inputrate = np.load(directory + "testinputrate.npy")
accs = [[] for i in range(Nlayers)]
for l in range(Nlayers):
clout = np.load(directory + "clout{}.npy".format(l+1))
for i in tqdm(iter_test):
accs[l].append(accuracy_by_vote(clout[0:i],labels))
from collections import Counter
ct = Counter(clout[:,1])
act = np.zeros(11)
gests = []
for i in range(11):
if i in ct.keys(): act[i] = ct[i]
gests.append(mapping[i])
figure(figsize=(3,3))
barh(range(11), act, align='center', color="#61b861", ecolor='black')
yticks(range(11),gests)
xlabel('$y_3$')
tight_layout()
savefig(directory+'y3_count')
ct
fig = figure()
#ax0 = subplot(211)
ax1 = subplot(111)
#ax0.plot(inputrate[1:], color='k', linewidth=3, alpha=.75)
for l in range(Nlayers):
ax1.plot(iter_test,100*(1-np.array(accs[l])), linewidth=3, alpha=.75, label = "Layer{}".format(l+1))
print(1-accs[l][-1])
ax1.set_ylabel('Error[%]')
ax1.set_xlabel('Sample duration [ms]')
ax1.set_ylim([0,60])
legend()
tight_layout()
savefig(directory+'convergence_dvs_gestures_sampleduration.png')
input_test = np.load(directory + "testinput.npy")
def plot_gestures_imshow(images, labels, nim=11, avg=50, do1h = True, transpose=False):
from matplotlib import colors
import numpy as np
np.random.seed(101)
zvals = np.random.rand(100, 100) * 10
# make a color map of fixed colors
cmap = colors.ListedColormap(['red','black', 'black','green'])
bounds=[-1,-0.1,.1,1]
norm = colors.BoundaryNorm(bounds, cmap.N)
import pylab as plt
plt.figure(figsize = [20,16])
import matplotlib.gridspec as gridspec
if not transpose:
gs = gridspec.GridSpec(images.shape[1]//avg, nim)
else:
gs = gridspec.GridSpec(nim, images.shape[1]//avg)
plt.subplots_adjust(left=0, bottom=0, right=1, top=0.95, wspace=.0, hspace=.04)
if do1h:
categories = labels.argmax(axis=1)
else:
categories = labels
s=[]
for j in range(nim):
for i in range(images.shape[1]//avg):
if not transpose:
ax = plt.subplot(gs[i, j])
else:
ax = plt.subplot(gs[j, i])
on_event = images[j,i*avg:(i*avg+avg),0,:,:].sum(axis=0).T
off_event = -images[j,i*avg:(i*avg+avg),1,:,:].sum(axis=0).T
plt.imshow(on_event+off_event, cmap=cmap, norm=norm, interpolation='nearest')
plt.xticks([])
if i==0:
plt.title(mapping[labels[0,j].argmax()], fontsize=20)
plt.text(3,5,'t={}ms'.format(i*avg),color='white')
plt.yticks([])
s.append(images[j].sum())
print(s)
plot_gestures_imshow(input_test[:100].swapaxes(0,1),labels[:5],nim=5, transpose=True, avg=10)
tight_layout()
savefig(directory+'convergence_dvs_gestures_sample.png')
import numpy as np
from numpy import *
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.patches import FancyArrowPatch
from mpl_toolkits.mplot3d import proj3d
class Arrow3D(FancyArrowPatch):
def __init__(self, xs, ys, zs, *args, **kwargs):
FancyArrowPatch.__init__(self, (0,0), (0,0), *args, **kwargs)
self._verts3d = xs, ys, zs
def draw(self, renderer):
xs3d, ys3d, zs3d = self._verts3d
xs, ys, zs = proj3d.proj_transform(xs3d, ys3d, zs3d, renderer.M)
self.set_positions((xs[0],ys[0]),(xs[1],ys[1]))
FancyArrowPatch.draw(self, renderer)
%matplotlib widget
from mpl_toolkits.mplot3d import Axes3D
inn = np.load(directory+'testinput.npy')
inn0 = inn[:,1,1,:].squeeze()
fig = plt.figure()
ax = plt.axes(projection='3d')
t,x,y = np.where(inn0==1)
col = np.arange(len(t))
jet()
ts = 190
idx = np.where(t==ts)[0]
print(len(idx))
X = np.array([0,32,0,32])
Y = np.array([0,0,32,32])
X, Y = np.meshgrid(X, Y)
ax.plot_surface(X,np.ones_like(Y)*(ts),Y, alpha=.3)
ax.scatter3D(x[idx], t[idx], y[idx], 'filled', color='black', marker='o', alpha=1.0)
ax.scatter3D(x[:idx[0]:1], t[:idx[0]:1], y[:idx[0]:1], 'filled', color='gray', marker='o', alpha=.05)
ax.scatter3D(x[idx[0]:10000:1], t[idx[0]:10000:1], y[idx[0]:10000:1], 'filled', c=col[idx[0]:10000:1], marker='o', alpha=.05)
a = Arrow3D([0, 0], [0, 500],
[33, 33], mutation_scale=20,
lw=3, arrowstyle="-|>", color="k")
ax.view_init(elev=-157, azim=-44)
ax.grid(False)
ax.xaxis.pane.fill = False
ax.zaxis.pane.fill = False
ax.xaxis.set_visible(False)
ax.set_axis_off()
ax.yaxis.set_visible(True)
ax.add_artist(a)
#?ax.text(-15, ts+20, 35, 'Time[ms]')
tight_layout()
savefig(directory+'dvs_3d_plot.png', format='png')
ax.spines
ax.elev
ax.azim
t[10000]
```
| github_jupyter |
```
# Run this cell to mount your Google Drive.
from google.colab import drive
drive.mount("/content/drive", force_remount=True)
```
# [How to train an object detection model easy for free](https://www.dlology.com/blog/how-to-train-an-object-detection-model-easy-for-free/) | DLology Blog
## Configs and Hyperparameters
Support a variety of models, you can find more pretrained model from [Tensorflow detection model zoo: COCO-trained models](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md#coco-trained-models), as well as their pipline config files in [object_detection/samples/configs/](https://github.com/tensorflow/models/tree/master/research/object_detection/samples/configs).
```
# If you forked the repository, you can replace the link.
repo_url = 'https://github.com/fuadkhairi/object_detection_demo'
# Number of training steps.
num_steps = 200000 # 200000
# Number of evaluation steps.
num_eval_steps = 50
MODELS_CONFIG = {
'ssd_mobilenet_v2': {
'model_name': 'ssd_mobilenet_v2_coco_2018_03_29',
'pipeline_file': 'ssd_mobilenet_v2_coco.config',
'batch_size': 12
},
'faster_rcnn_inception_v2': {
'model_name': 'faster_rcnn_inception_v2_coco_2018_01_28',
'pipeline_file': 'faster_rcnn_inception_v2_pets.config',
'batch_size': 12
},
'rfcn_resnet101': {
'model_name': 'rfcn_resnet101_coco_2018_01_28',
'pipeline_file': 'rfcn_resnet101_pets.config',
'batch_size': 8
}
}
# Pick the model you want to use
# Select a model in `MODELS_CONFIG`.
selected_model = 'faster_rcnn_inception_v2'
# Name of the object detection model to use.
MODEL = MODELS_CONFIG[selected_model]['model_name']
# Name of the pipline file in tensorflow object detection API.
pipeline_file = MODELS_CONFIG[selected_model]['pipeline_file']
# Training batch size fits in Colabe's Tesla K80 GPU memory for selected model.
batch_size = MODELS_CONFIG[selected_model]['batch_size']
```
## Clone the `object_detection_demo` repository or your fork.
```
import os
%cd /content
repo_dir_path = os.path.abspath(os.path.join('.', os.path.basename(repo_url)))
!git clone {repo_url}
%cd {repo_dir_path}
!git pull
```
## Install required packages
```
%cd /content
!git clone --quiet https://github.com/tensorflow/models.git
!apt-get install -qq protobuf-compiler python-pil python-lxml python-tk
!pip install -q Cython contextlib2 pillow lxml matplotlib
!pip install -q pycocotools
%cd /content/models/research
!protoc object_detection/protos/*.proto --python_out=.
import os
os.environ['PYTHONPATH'] += ':/content/models/research/:/content/models/research/slim/'
!python object_detection/builders/model_builder_test.py
```
## Prepare `tfrecord` files
Use the following scripts to generate the `tfrecord` files.
```bash
# Convert train folder annotation xml files to a single csv file,
# generate the `label_map.pbtxt` file to `data/` directory as well.
python xml_to_csv.py -i data/images/train -o data/annotations/train_labels.csv -l data/annotations
# Convert test folder annotation xml files to a single csv.
python xml_to_csv.py -i data/images/test -o data/annotations/test_labels.csv
# Generate `train.record`
python generate_tfrecord.py --csv_input=data/annotations/train_labels.csv --output_path=data/annotations/train.record --img_path=data/images/train --label_map data/annotations/label_map.pbtxt
# Generate `test.record`
python generate_tfrecord.py --csv_input=data/annotations/test_labels.csv --output_path=data/annotations/test.record --img_path=data/images/test --label_map data/annotations/label_map.pbtxt
```
```
%cd {repo_dir_path}
# Convert train folder annotation xml files to a single csv file,
# generate the `label_map.pbtxt` file to `data/` directory as well.
!python xml_to_csv.py -i data/images/train -o data/annotations/train_labels.csv -l data/annotations
# Convert test folder annotation xml files to a single csv.
!python xml_to_csv.py -i data/images/test -o data/annotations/test_labels.csv
# Generate `train.record`
!python generate_tfrecord.py --csv_input=data/annotations/train_labels.csv --output_path=data/annotations/train.record --img_path=data/images/train --label_map data/annotations/label_map.pbtxt
# Generate `test.record`
!python generate_tfrecord.py --csv_input=data/annotations/test_labels.csv --output_path=data/annotations/test.record --img_path=data/images/test --label_map data/annotations/label_map.pbtxt
test_record_fname = '/content/object_detection_demo/data/annotations/test.record'
train_record_fname = '/content/object_detection_demo/data/annotations/train.record'
label_map_pbtxt_fname = '/content/object_detection_demo/data/annotations/label_map.pbtxt'
```
## Download base model
```
%cd /content/models/research
import os
import shutil
import glob
import urllib.request
import tarfile
MODEL_FILE = MODEL + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
DEST_DIR = '/content/models/research/pretrained_model'
if not (os.path.exists(MODEL_FILE)):
urllib.request.urlretrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar = tarfile.open(MODEL_FILE)
tar.extractall()
tar.close()
os.remove(MODEL_FILE)
if (os.path.exists(DEST_DIR)):
shutil.rmtree(DEST_DIR)
os.rename(MODEL, DEST_DIR)
!echo {DEST_DIR}
!ls -alh {DEST_DIR}
fine_tune_checkpoint = os.path.join(DEST_DIR, "model.ckpt")
fine_tune_checkpoint
```
## Configuring a Training Pipeline
```
import os
pipeline_fname = os.path.join('/content/models/research/object_detection/samples/configs/', pipeline_file)
assert os.path.isfile(pipeline_fname), '`{}` not exist'.format(pipeline_fname)
def get_num_classes(pbtxt_fname):
from object_detection.utils import label_map_util
label_map = label_map_util.load_labelmap(pbtxt_fname)
categories = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=90, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
return len(category_index.keys())
import re
num_classes = get_num_classes(label_map_pbtxt_fname)
with open(pipeline_fname) as f:
s = f.read()
with open(pipeline_fname, 'w') as f:
# fine_tune_checkpoint
s = re.sub('fine_tune_checkpoint: ".*?"',
'fine_tune_checkpoint: "{}"'.format(fine_tune_checkpoint), s)
# tfrecord files train and test.
s = re.sub(
'(input_path: ".*?)(train.record)(.*?")', 'input_path: "{}"'.format(train_record_fname), s)
s = re.sub(
'(input_path: ".*?)(val.record)(.*?")', 'input_path: "{}"'.format(test_record_fname), s)
# label_map_path
s = re.sub(
'label_map_path: ".*?"', 'label_map_path: "{}"'.format(label_map_pbtxt_fname), s)
# Set training batch_size.
s = re.sub('batch_size: [0-9]+',
'batch_size: {}'.format(batch_size), s)
# Set training steps, num_steps
s = re.sub('num_steps: [0-9]+',
'num_steps: {}'.format(num_steps), s)
# Set number of classes num_classes.
s = re.sub('num_classes: [0-9]+',
'num_classes: {}'.format(num_classes), s)
f.write(s)
!cat {pipeline_fname}
model_dir = 'training/'
# Optionally remove content in output model directory to fresh start.
!rm -rf {model_dir}
os.makedirs(model_dir, exist_ok=True)
# if use my drive
model_dir = '/content/drive/"My Drive"/training/'
```
## Run Tensorboard(Optional)
```
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip -o ngrok-stable-linux-amd64.zip
LOG_DIR = model_dir
get_ipython().system_raw(
'tensorboard --logdir {} --host 0.0.0.0 --port 6006 &'
.format(LOG_DIR)
)
get_ipython().system_raw('./ngrok http 6006 &')
```
### Get Tensorboard link
```
! curl -s http://localhost:4040/api/tunnels | python3 -c \
"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
```
## Train the model
```
!python /content/models/research/object_detection/model_main.py \
--pipeline_config_path={pipeline_fname} \
--model_dir={model_dir} \
--alsologtostderr \
--num_train_steps={num_steps} \
--num_eval_steps={num_eval_steps}
!ls {model_dir}
# Legacy way of training(also works).
# !python /content/models/research/object_detection/legacy/train.py --logtostderr --train_dir={model_dir} --pipeline_config_path={pipeline_fname}
```
## Exporting a Trained Inference Graph
Once your training job is complete, you need to extract the newly trained inference graph, which will be later used to perform the object detection. This can be done as follows:
```
# if use my drive
'/content/object_detection_demo/models'
import re
import numpy as np
output_directory = '/content/object_detection_demo/models53k'
lst = os.listdir('/content/drive/My Drive/training/')
lst = [l for l in lst if 'model.ckpt-' in l and '.meta' in l]
steps=np.array([int(re.findall('\d+', l)[0]) for l in lst])
last_model = lst[steps.argmax()].replace('.meta', '')
last_model_path = os.path.join('/content/drive/"My Drive"/training/', last_model)
print(last_model_path)
!python /content/models/research/object_detection/export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path={pipeline_fname} \
--output_directory={output_directory} \
--trained_checkpoint_prefix={last_model_path}
!ls {output_directory}
```
## Download the model `.pb` file
```
import os
pb_fname = os.path.join(os.path.abspath(output_directory), "frozen_inference_graph.pb")
assert os.path.isfile(pb_fname), '`{}` not exist'.format(pb_fname)
!ls -alh {pb_fname}
```
### Option1 : upload the `.pb` file to your Google Drive
Then download it from your Google Drive to local file system.
During this step, you will be prompted to enter the token.
```
# Install the PyDrive wrapper & import libraries.
# This only needs to be done once in a notebook.
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Authenticate and create the PyDrive client.
# This only needs to be done once in a notebook.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
fname = os.path.basename(pb_fname)
# Create & upload a text file.
uploaded = drive.CreateFile({'title': fname})
uploaded.SetContentFile(pb_fname)
uploaded.Upload()
print('Uploaded file with ID {}'.format(uploaded.get('id')))
```
### Option2 : Download the `.pb` file directly to your local file system
This method may not be stable when downloading large files like the model `.pb` file. Try **option 1** instead if not working.
```
from google.colab import files
files.download(pb_fname)
```
### Download the `label_map.pbtxt` file
```
from google.colab import files
files.download(label_map_pbtxt_fname)
```
### Download the modified pipline file
If you plan to use OpenVINO toolkit to convert the `.pb` file to inference faster on Intel's hardware (CPU/GPU, Movidius, etc.)
```
files.download(pipeline_fname)
# !tar cfz fine_tuned_model.tar.gz fine_tuned_model
# from google.colab import files
# files.download('fine_tuned_model.tar.gz')
```
## Run inference test
Test with images in repository `object_detection_demo/test` directory.
```
repo_dir_path
import os
import glob
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = '/content/object_detection_demo/models53k/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = '/content/object_detection_demo/data/annotations/label_map.pbtxt'
# If you want to test the code with your images, just add images files to the PATH_TO_TEST_IMAGES_DIR.
PATH_TO_TEST_IMAGES_DIR = os.path.join(repo_dir_path, "test")
assert os.path.isfile(pb_fname)
assert os.path.isfile(PATH_TO_LABELS)
TEST_IMAGE_PATHS = glob.glob(os.path.join(PATH_TO_TEST_IMAGES_DIR, "*.*"))
assert len(TEST_IMAGE_PATHS) > 0, 'No image found in `{}`.'.format(PATH_TO_TEST_IMAGES_DIR)
print(TEST_IMAGE_PATHS)
%cd /content/models/research/object_detection
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
# This is needed to display the images.
%matplotlib inline
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=num_classes, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {
output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(
tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(
tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(
tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [
real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [
real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(
output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
```
| github_jupyter |
# "Deploying demo projects to Heroku"
> "How to get your shiny new model into a working demo"
- toc: true
- badges: true
- comments: true
- categories: [Misc]
```
#hide
from IPython.display import Image as IPImage
def url_image(url):
display(IPImage(url=url))
def local_image(fn):
display(IPImage(filename=fn))
```
> Note: Since posting this I've turned it into the [Heroku deployment guide](https://course.fast.ai/deployment_heroku) in the official fast.ai course notes, so you really only need to read one or the other.
<br>
So you’ve created a deep learning model and it can understand the difference between different breeds of dog or different Hemsworth brothers. Awesome.
Now what? There are various options for deploying some kind of working demo.
Some people want to put a lot of effort into very beautifully presented standards compliant ajax enabled websites and mobile apps. That’s fine, I’m not knocking it, but life is short and personally I just want somewhere I can upload my notebook so I can go “LOOK I MADE A THING AND IT’S REALLY COOL!!”
[Heroku](http://heroku.com/) combined with [Voila](https://voila.readthedocs.io/en/stable/index.html) is perfect for me. Voila renders Jupyter notebooks as web pages and Heroku is a lovely free service which lets me just throw my notebooks at it. Heroku also scales as you grow so you can start free and work your way up if you want to host something serious on it. (You can also use Heroku for proper websites if you prefer, google away).
If you take a look at [the repo](https://github.com/joedockrill/heroku) for [my demo site](https://joedockrill.herokuapp.com/voila/render/default.ipynb) on Heroku, you’ll see:
- Procfile – what to do when the heroku application starts
- requirements.txt – modules you need
- Some .ipynb notebooks
**Procfile** – mine looks like this:
```
web: voila –port=$PORT –no-browser –enable_nbextensions=True
```
If you add notebook.ipynb to the end of that string then Voila will display that notebook when the app starts **but** you can *only* display that notebook and if you try to link to any others you’ll get an http error. I want to use this for multiple demos so I don’t specify a notebook, but if you go to the root of the app at [joedockrill.herokuapp.com](https://joedockrill.herokuapp.com/) then you’ll be greeted with a rather unattractive list of files.
```
#hide_input
local_image("voila.jpg")
```
Hopefully you can tell from the rather unattractive list of files where I’m headed with this. I use `default.ipynb` as a homepage to list all the demos on the website; It just means having to explicitly link to [joedockrill.herokuapp.com/voila/render/default.ipynb](https://joedockrill.herokuapp.com/voila/render/default.ipynb) which isn’t the biggest pain in the world.
**requirements.txt** is for all the modules you need. do not do pip installs in your notebook. Heroku builds an image with everything you need **once** when you deploy, then just copies it onto a server when someone runs the app.
Once you have your repo in place you just need to
- Create an account on Heroku
- Connect it to your github
- Choose the repo
- Choose between automatic deploys when the repo changes or manual deploys when you press the button
Two things to keep in mind. First, there is a maximum compiled “slug size” for your app image and it’s 500MB. If you intend to deploy multiple demos with large model files then keep the pickles on Google Drive or something similar and load them from there. You also need to make sure that you use the CPU versions of Pytorch because the GPU ones are massive by comparison. (See my [requirements.txt](https://raw.githubusercontent.com/joedockrill/heroku/master/requirements.txt) file).
The other issue (related to the first) is that Voila runs **all** the code in your notebook before it renders that part of the UI. That’s an issue when you have to load a model export across the intertubes. You’ll see in the clown classifier that the markdown cell at the top displays right away so I waffle and talk about the demo and make excuses and hope that it’s rendered the rest of the UI by the time you finish reading.
I haven’t yet found a way around this and believe me I’ve tried. I even tried downloading the model from drive on a worker thread so my foreground would complete and render the UI before the download started. It works fine in Colab but Voila didn’t like it, and somehow still managed to wait until the background thread had completed before rendering anything. It was like trying to make VB5 behave itself with multi-threading APIs. I gave up.
Don’t get me wrong though, Voila and Heroku are both lovely and I highly recommend giving them a go. If there's a better option for a quick demo project, I haven't found it yet.
| github_jupyter |
```
# HIDDEN
import sys
sys.path.insert(0, "/Users/blankjul/workspace/pyrecorder")
from IPython.display import display, HTML, Image
from base64 import b64encode
def display(fname):
extension = fname.split(".")[-1]
if extension == "gif":
gif = open(fname,'rb').read()
return Image(b64encode(gif),embed=True)
elif extension == "mp4" or extension == "webm":
from IPython.display import HTML, display
video = open(fname,'rb').read()
data = "data:video/mp4;base64," + b64encode(video).decode()
html = """
<div align="middle">
<video controls>
<source src="%s" type="video/%s">
</video>
</div>
"""
return display(HTML(data=html % (data, extension)))
elif fname.endswith("html"):
return HTML(filename=fname)
```
# pyrecorder

**Github:** https://github.com/anyoptimization/pyrecorder
## Installation
The framework is available at the PyPi Repository:
## Matplotlib
Please note that the example below are using the `vp80` codec to create a video which can be played in a browser and also this documentation. Nevertheless, without specifing the codec `mp4v` is used by default.
### Video
```
import numpy as np
import matplotlib.pyplot as plt
from pyrecorder.recorder import Recorder
from pyrecorder.writers.video import Video
from pyrecorder.converters.matplotlib import Matplotlib
# create a writer that takes the
writer = Video("example.webm", codec='vp80')
# use the with statement to close the recorder when done
with Recorder(writer) as rec:
# use black background for this plot
plt.style.use('dark_background')
# record 10 different snapshots
for t in range(50, 500, 5):
a = np.arange(t) * 0.1
plt.plot(a * np.sin(a), a * np.cos(a))
plt.xlim(-50, 50)
plt.ylim(-50, 50)
plt.axis('off')
# use the record to store the current plot
rec.record()
# revert to default settings for other plots
plt.style.use('default')
```
When the code has finished, the video has been written to the specified filename `example.mp4`. Let us look what has been recorded:
```
display("example.webm")
```
For this example the default settings have been used and the global drawing space of Matplotlib is recorded. Let us look at another example with a few modifications:
```
import numpy as np
import matplotlib.pyplot as plt
from pyrecorder.recorder import Recorder
from pyrecorder.writers.video import Video
from pyrecorder.converters.matplotlib import Matplotlib
# initialize the converter which is creates an image when `record()` is called
converter = Matplotlib(dpi=120)
writer = Video("example2.webm", codec='vp80')
rec = Recorder(writer, converter=converter)
for t in range(10):
# let us create a local figure object with two sub figures
fig, (ax1, ax2) = plt.subplots(2, figsize=(3, 4))
X = np.random.random((100, 2))
ax1.scatter(X[:, 0], X[:, 1], color="green")
X = np.random.random((100, 2))
ax2.scatter(X[:, 0], X[:, 1], color="red")
# fix the size of figure and legends
fig.tight_layout()
# take a snapshot the specific figure object with the recorder
rec.record(fig=fig)
rec.close()
display("example2.webm")
```
### GIF
```
import matplotlib.pyplot as plt
import numpy as np
from pyrecorder.recorder import Recorder
from pyrecorder.writers.gif import GIF
with Recorder(GIF("example.gif", duration=0.2)) as rec:
for t in range(0, 200, 5):
x = np.linspace(0, 4, 100)
y = np.sin(2 * np.pi * (x - 0.01 * t))
plt.plot(x, y)
rec.record()
```

## Contact
| github_jupyter |
# Cleaning up WikiData Query Results
There are several issues with WikiData queries, one of the biggest is that some queries for different Node types will yield some of the same nodes. These need to be reconciled before continuing (1 node type for one ID).
***Warning*** The cleanup pipeline is a result of my queries to WikiData at the time that I performed them. As WikiData is constantaly changing, on future runs, changes may need to be peformed to get this notebook to complete successfully. I've outlined all decisions made to resolve conflicts in a way that hopefully allows future conflicts to be similarly resolved
```
# Make issue for script
import pandas as pd
from pathlib import Path
from data_tools import combine_nodes_and_edges
from data_tools.df_processing import combine_group_cols_on_char, split_col
from data_tools.wiki import xref_to_wd_item, get_curi_xrefs
from data_tools.plotting import count_plot_h
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
# New line recommended by notebook
from tqdm.autonotebook import tqdm
prev_dir = Path('../results/').resolve()
nodes = pd.read_csv(prev_dir.joinpath('nodes.csv'), dtype=str)
edges = pd.read_csv(prev_dir.joinpath('edges.csv'), dtype=str)
```
# Reconcile Nodes
```
drop_idx = []
new_nodes = []
new_edges = []
# adjust?
duped_ids = nodes[nodes['id'].duplicated(keep=False)].sort_values('id')
duped_ids['id'].nunique()
dup_type_map = duped_ids.groupby('id')['label'].apply(lambda x: ', '.join(sorted(list(x)))).to_dict()
duped_ids['duped_types'] = duped_ids['id'].map(dup_type_map)
dup_frac = duped_ids['duped_types'].value_counts() / duped_ids['duped_types'].value_counts().max()
count_plot_h(duped_ids['duped_types'].value_counts() // 2)
# 1,180 nodes showing up in both disease and phenotype node type
## Why not have the nodes show up among all, why compare between two?
# need all this to ensure consistent ordering each time notebook is run...
dt = (duped_ids['duped_types'].value_counts()
.to_frame()
.reset_index()
.sort_values(['duped_types', 'index'], ascending=(True, True))['index']
.tolist())
# Keep a consistent order for future iterations...
dt = ['Anatomy, Disease',
'Cellular Component, Phenotype',
'Disease, Gene',
'Disease, Taxon',
'Anatomy, Phenotype',
'Compound, Gene',
'Biological Process, Phenotype',
'Anatomy, Cellular Component',
'Biological Process, Disease',
'Compound, Protein',
'Biological Process, Molecular Function',
'Biological Process, Pathway',
'Disease, Phenotype']
# Check that all show
print(dt[0:13])
dti = iter(dt)
# Add more documentation later
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
# No show for these, why?
## Working after increasing limit on compounds -- maybe there weren't connections?
### More compounds mean more likely to show up as duplicate
### How to classify if something is a disease vs phenotype, and how to compute
#### If everything is assigned as Disease (Disease, Phenotype) ==> if we flip, do we get same downstream result in algorithm?
##### If different, then look into (biologically, contextually) metric for what's better?
```
This is a Disease, but it is located in anatomy...
```
xid = duped_ids.query('duped_types == @this_dup and label == "Anatomy"')['xrefs'].values[0]
qid = xref_to_wd_item(nodes, xid, always_list=True)
nodes.query('id in @qid')
```
No other WD items have that UBERON identifier. Drop the Anatomy, but add a new edge
```
def xrefs_to_new_nodes(combined_nodes, new_names=None):
add_nodes = combined_nodes[['xrefs', 'name', 'label']].rename(columns={'xrefs': 'id'}).copy()
if new_names is not None:
add_nodes['name'] = new_names
return add_nodes
def xrefs_to_new_edges(combined_nodes, start_col, end_col, semmantics):
# ensure we've got a dataframe (single index will return series)
if type(combined_nodes) == pd.Series:
combined_nodes = combined_nodes.to_frame().T
add_edges = combined_nodes[['xrefs', 'id']].rename(columns={start_col: 'start_id', end_col: 'end_id'}).copy()
add_edges['type'] = semmantics
add_edges['dsrc_type'] = 'computed'
add_edges['comp_type'] = 'split'
return add_edges.loc[:, ['start_id','end_id','type','dsrc_type','comp_type']]
def combine_xrefs_and_set_label(combined_nodes, label):
add_nodes = combine_group_cols_on_char(combined_nodes, ['id'], ['xrefs'], prog=False)
add_nodes['label'] = label
add_nodes = add_nodes.drop('duped_types', axis=1)
return add_nodes
# Prepare to drop the bad edge
to_drop = [duped_ids.query('duped_types == @this_dup and label == "Anatomy"').index.values[0]]
drop_idx += to_drop
# Add the new node
add_node = xrefs_to_new_nodes(duped_ids.loc[to_drop], 'Pupillary membrane')
new_nodes.append(add_node)
# And add the edge
add_edge = xrefs_to_new_edges(duped_ids.loc[to_drop], 'id', 'xrefs', 'localized_to')
new_edges.append(add_edge)
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
While a valid phenotype, seems ot have more incommon with the cell component...
```
this_drop = duped_ids.query('duped_types == @this_dup').index.tolist()
drop_idx += this_drop
new_nodes.append(combine_xrefs_and_set_label(duped_ids.loc[this_drop], 'Cellular Component'))
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
This is a Gene... look for this MONDO ID elsewhere...
```
xid = duped_ids.query('duped_types == @this_dup and label == "Disease"')['xrefs'].values[0]
xid = [x for x in xid.split('|') if x.startswith('MONDO:')][0]
mondo_ids = xref_to_wd_item(nodes, xid, always_list=True)
nodes.query('id in @mondo_ids')
```
The Disease already exists, prepare to drop and ensure that the edge between the two exists
```
to_drop = duped_ids.query('duped_types == @this_dup and label == "Disease"').index.values[0]
drop_idx.append(to_drop)
sid, eid = nodes.query('id in @mondo_ids')['id'].unique()
edges.query('(start_id == @sid and end_id == @eid) or (start_id == @eid and end_id == @sid)')
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
HPV infection is not a taxon, but rather a disease. It has a cause of ... hpv
```
drop_idx += duped_ids.query('duped_types == @this_dup and label == "Taxon"').index.tolist()
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
Both well annotated, but seeming more like anatomy nodes... will keep the xrefs
```
this_drop = duped_ids.query('duped_types == @this_dup').index.tolist()
drop_idx += this_drop
new_nodes.append(combine_xrefs_and_set_label(duped_ids.loc[this_drop], 'Anatomy'))
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
Two compounds with no xrefs... Just drop the compound version
```
drop_idx = drop_idx + duped_ids.query('duped_types == @this_dup and label == "Compound"').index.tolist()
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
Phenotypes and biological Processes... GO is a really tight annotaiton system, so don't really want to remove... will keep the pheno annotations...
```
this_drop = duped_ids.query('duped_types == @this_dup').index.tolist()
drop_idx += this_drop
new_nodes.append(combine_xrefs_and_set_label(duped_ids.loc[this_drop], 'Biological Process'))
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
These are all Cell Component Terms... `myelin` and `climbing fiber` have proper uberon annotations, but the remainder are either xref'd to a (close but) incorrect term, or xref to obsolete UBERON terms.
```
# Get rid of the conflicting nodes
this_drop = duped_ids.query('duped_types == @this_dup and label == "Anatomy"').index.tolist()
drop_idx = drop_idx + this_drop
# Keep the two ok nodes
keep_xrefs = duped_ids.loc[this_drop].query('name in {!r}'.format(['myelin', 'climbing fiber']))
add_nodes = xrefs_to_new_nodes(keep_xrefs)
new_nodes.append(add_nodes)
# Add links between the two concepts
add_edges = xrefs_to_new_edges(keep_xrefs, 'id', 'xrefs', 'localized_to')
new_edges.append(add_edge)
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
Definitely instances of both.. need to split into Biological Processes and Diseases
```
this_drop = duped_ids.query('duped_types == @this_dup and label == "Biological Process"').index.tolist()
drop_idx = drop_idx + this_drop
new_nodes.append(xrefs_to_new_nodes(duped_ids.loc[this_drop]))
new_edges.append(xrefs_to_new_edges(duped_ids.loc[this_drop], 'xrefs', 'id', 'causes'))
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
These are all Polypeptides... However, they have numerous chemical annotations...
```
this_drop = duped_ids.query('duped_types == @this_dup').index.tolist()
drop_idx += this_drop
new_nodes.append(combine_xrefs_and_set_label(duped_ids.loc[this_drop], 'Protein'))
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
These are all obsolete terms. Drop em all.
```
drop_idx = drop_idx + duped_ids.query('duped_types == @this_dup').index.tolist()
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
These pathways have no Xrefs, so we will keep them as GO biological Processes.
```
qr = duped_ids.query('duped_types == @this_dup')
drop_idx = drop_idx + qr[qr['xrefs'].isnull()].index.tolist()
this_dup = next(dti)
duped_ids.query('duped_types == @this_dup')
```
### Disease and Phenotype...
Too many to do any kind of a blanket merge... We will:
1. Convert those with an HPO id but no DOID to a Phenotype
2. Covert those with no HPO id but with a DOID to a Disease
3. See how many have both...
#### Conflicts with no Disease Xref
```
pheno_dis = duped_ids.query('duped_types == @this_dup').copy()
qr = pheno_dis.query('label == "Disease"')
no_d_xref = qr[qr['xrefs'].isnull()]['id'].tolist()
duped_ids.query('id in @no_d_xref')
this_drop = duped_ids.query('id in @no_d_xref').index.tolist()
drop_idx += this_drop
pheno_dis = pheno_dis.drop(this_drop)
new_nodes.append(combine_xrefs_and_set_label(duped_ids.loc[this_drop], 'Phenotype'))
```
Mostly bad have no xrefs, 2 with phenotypes. I think we can safely merge these to phenotypes
#### Conflicts with no Pheno Xref
```
qr = pheno_dis.query('label == "Phenotype"')
no_p_xref = qr[qr['xrefs'].isnull()]['id'].tolist()
duped_ids.query('id in @no_p_xref')
```
gummatous syphilis is a Disease, but the acroparesthesia appears to be a Phenotype
```
this_drop = duped_ids.query('id in @no_p_xref').index.tolist()
drop_idx += this_drop
new_nodes.append(duped_ids.loc[this_drop].query('name == "gummatous syphilis" and label == "Disease"'))
new_nodes.append(duped_ids.loc[this_drop].query('name == "acroparesthesia" and label == "Phenotype"'))
pheno_dis = pheno_dis.drop(this_drop)
```
#### Now for conflicts with no HPO xref
```
qr = pheno_dis.query('label == "Phenotype"').dropna(subset=['xrefs'])
no_hpo_xref = qr[~qr['xrefs'].str.contains('HP:')]['id'].tolist()
duped_ids.query('id in @no_hpo_xref')
```
`corneal damage` is a phenotype, remainder can be classified as a disease.
```
this_drop = duped_ids.query('id in @no_hpo_xref').index.tolist()
drop_idx += this_drop
new_nodes.append(duped_ids.loc[this_drop].query('name == "corneal damage" and label == "Phenotype"'))
new_nodes.append(combine_xrefs_and_set_label(duped_ids.loc[this_drop].query('name != "corneal damage"'), 'Disease'))
pheno_dis = pheno_dis.drop(this_drop)
```
#### Conflicts with no DO xref
```
qr = pheno_dis.query('label == "Disease"').dropna(subset=['xrefs'])
no_doid_xref = qr[~qr['xrefs'].str.contains('DOID:')]['id'].tolist()
duped_ids.query('id in @no_doid_xref')
```
Lots of examples here... This small smattering looks like Primarily phenotypes...
Lets take a bigger sample to make sure
```
duped_ids.query('id in @no_doid_xref').drop_duplicates(subset=['id']).sample(40)
```
Lots of HPO Xrefs on these, most look like phenotypes, so we will coerce them all to phenotypes, while maintaining the original Xref
```
this_drop = duped_ids.query('id in @no_doid_xref').index.tolist()
drop_idx += this_drop
new_nodes.append(combine_xrefs_and_set_label(duped_ids.loc[this_drop], 'Phenotype'))
pheno_dis = pheno_dis.drop(this_drop)
```
What's left should have both DO and HPO xref identifiers
```
pheno_dis
```
Still 900 confilcts... all we can do here is split the concepts.
We'll keep the cannonical wikidata item as a Disease, and make new phenotypes with the HPO Xrefs...
```
pheno_nodes = get_curi_xrefs(pheno_dis.query('label == "Phenotype"'), 'HP')
pheno_nodes = pheno_nodes.merge(pheno_dis.query('label == "Phenotype"'), how='left', on='id', suffixes=('', '_old'))
xrefs = pheno_nodes['xrefs_old']
# Remove the hpo xref from the nodes
xrefs = split_col(xrefs, '|').apply(lambda x: [r for r in x if not r.startswith('HP:')]).apply(lambda x: '|'.join(x))
add_nodes = xrefs_to_new_nodes(pheno_nodes)
add_nodes['xrefs'] = xrefs
# Add the Pheno and disease nodes
new_nodes.append(add_nodes.replace('', float('nan')))
new_nodes.append(pheno_dis.query('label == "Disease"'))
# Add the Disease to pheno edges
new_edges.append(xrefs_to_new_edges(pheno_nodes, 'id', 'xrefs', 'presents'))
drop_idx += pheno_dis.index.tolist()
```
## Putting it all back together
```
nodes = nodes.drop(drop_idx)
nodes = pd.concat([nodes]+new_nodes, sort=False, ignore_index=True).drop('duped_types', axis=1)
nodes
edges = pd.concat([edges]+new_edges, sort=False, ignore_index=True)
edges
```
## Cleaning Up Edges
Some of the Edge Queryies we were less specific about how we defined node types... So we may have some IDs that don't appear in any of the nodes. We need to remove these.
```
print('{:,}'.format(len(edges)))
node_ids = nodes['id'].unique()
edges = edges.query('start_id in @node_ids and end_id in @node_ids')
print('{:,}'.format(len(edges)))
edges = edges.drop_duplicates(subset=['start_id', 'end_id', 'type'])
print('{:,}'.format(len(edges)))
count_plot_h(edges['dsrc_type'])
count_plot_h(edges['comp_type'])
count_plot_h(edges['type'])
count_plot_h(nodes['label'])
combo = combine_nodes_and_edges(nodes, edges)
meta_edges = combo['start_label'] + '_' + combo['type'] + '_' + combo['end_label']
meta_edges.nunique()
count_plot_h(meta_edges.value_counts().head(10))
count_plot_h(meta_edges.value_counts().head(20).tail(10))
count_plot_h(meta_edges.value_counts().head(30).tail(10))
count_plot_h(meta_edges.value_counts().head(40).tail(10))
count_plot_h(meta_edges.value_counts().tail(6))
```
Many of the low count metaedges are either mistakes, or otherwise useless noisy edges:
Compound to protein edges are ok as they will later be changed to simplied semmantics:
One other should be examined:
- Disease Presents Diseases
This edge is of diseases that are also likely phenotypes, so we should have the proper phenotype in place instead of the disease
For now we will drop these edges...
```
drop_me = ['Protein_enables_Biological Process', 'Phenotype_subclass_of_Phenotype', 'Phenotype_subclass_of_Disease',
'Disease_subclass_of_Phenotype', 'Phenotype_presents_Disease', 'Protein_involved_in_Molecular Function',
'Cellular Component_subclass_of_Cellular Component', 'Phenotype_presents_Phenotype',
'Protein_agonist_Protein', 'Protein_involved_in_Cellular Component', 'Protein_involved_in_Disease',
'Gene_associated_with_Gene', 'Gene_subclass_of_Gene', 'Disease_causes_Disease']
new_drop_index = meta_edges.rename('me').to_frame().query('me in @drop_me').index
len(new_drop_index)
```
### Now examine the Likely Disease Phenotype Edges...
```
dis_pheno_idx = combo.query('start_label == "Disease" and end_label == "Disease" and type != "subclass_of"').index
combo.loc[dis_pheno_idx].head(20)
likely_phenos = combo.loc[dis_pheno_idx]['end_id']
pheno_names = nodes.query('id in @likely_phenos')['name']
pheno_ids = nodes.query('name in @pheno_names and label == "Phenotype"')['id']
pheno_map = combo.query('start_label == "Disease" and end_id in @pheno_ids').set_index('start_id')['end_id'].to_dict()
edges.loc[dis_pheno_idx, 'end_id'] = edges.loc[dis_pheno_idx]['end_id'].map(pheno_map)
edges.loc[dis_pheno_idx]
edges = edges.drop(new_drop_index)
edges = edges.dropna(subset=['end_id'])
combo = combine_nodes_and_edges(nodes, edges)
meta_edges = combo['start_label'] + '_' + combo['type'] + '_' + combo['end_label']
meta_edges.nunique()
plt.figure(figsize=(8,12))
count_plot_h(meta_edges)
```
## Save out Resultant Edges
```
out_dir = Path('../results/')
out_dir.mkdir(parents=True, exist_ok=True)
nodes.to_csv(out_dir.joinpath('01c_nodes.csv'), index=False)
edges.to_csv(out_dir.joinpath('01c_edges.csv'), index=False)
```
| github_jupyter |
```
from google.colab import drive
drive.mount('/content/drive')
import tensorflow as tf
import keras
import matplotlib.pyplot as plt
import re
import numpy as np
import os
import pandas
# PARAMETERS CAN BE CHANGED HERE WITHOUT MESSING WITH THE CODE
kmersize=5
modelout=4**kmersize
"""
this function provides information about the array
"""
def array_inspect(x):
print ("shape=",(x.shape),"len=",len(x),"ndim=",x.ndim,"size=",x.size,"dtype=",x.dtype)
x_train=np.load("/content/drive/My Drive/Colab Notebooks/tensorflow_basecaller/datasets/x_train.npy")
model=tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(64, activation=tf.nn.relu)) # uses 128 neurons and is a feed forward rectilinear relu
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(1024, activation=tf.nn.relu))
model.add(tf.keras.layers.Dropout(0.2))
#model.add(tf.keras.layers.Dense(512, activation=tf.nn.relu)) # do the same thig for hidden layer 2
#model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(modelout, activation=tf.nn.softmax)) # output layer with number of classifications (256) use softmax for output distribution
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
checkpoint_path = "/content/drive/My Drive/Colab Notebooks/tensorflow_basecaller/training_7mer/jochum/jochum_cp1.ckpt"
checkpoint_dir = os.path.dirname(checkpoint_path)
checkpoint = tf.keras.callbacks.ModelCheckpoint(checkpoint_path, monitor='loss',
verbose=1,
save_weights_only=True,
save_best_only=True,
period = 10,
mode='min')
callbacks_list = [checkpoint]
#model.load_weights(checkpoint_path)
x_val = x_train[0:800000]
partial_x_train = x_train[800000:]
y_val = y_train[0:800000]
partial_y_train = y_train[800000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=100,
validation_data=(x_val, y_val),
batch_size=30000,
verbose=1,
callbacks = callbacks_list)
model.summary()
results = model.evaluate(x_train, y_train)
print(results)
min_pred = 0
max_pred = min_pred+100
preds = model.predict(x_train[min_pred:max_pred])
concat_reads = ''
concat_ref = ''
for arr in preds:
concat_reads += str(dict2[np.argmax(arr)])
for arr in y_train[min_pred:max_pred]:
concat_ref += str(dict2[arr])
read_len = len(concat_reads)
accurate = 0
for i in range(0,read_len):
if concat_reads[i] == concat_ref[i]:
accurate+=1
ret_arr = [concat_reads, concat_ref]
print(ret_arr)
history_dict = history.history
history_dict.keys()
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
```
| github_jupyter |
# PyMongo
Start the MongoDB server before running
- On Windows, click on the application to run the server
- On Mac, run ```brew services start mongodb-community@4.2``` (depending on what version you have downloaded)
```
import pymongo
# create client connection to database
client = pymongo.MongoClient("localhost", 27017)
# client = pymongo.MongoClient('127.0.0.1', 27017)
# create database
library = client["library"]
# create collection
books = library["books"]
# insert document
# document = { "_id":1, "book_title":"Tom's adventures"}
# document = { "_id":2, "book_title":"Mary's happy day"}
# x = collection.insert_one(document)
# print(x.inserted_id)
# query documents
results = books.find({})
print(results) # returns a cursor object
for result in results:
print(result) # empty database currently
# close client connection
client.close()
```
# NoSQL
- Optional fields
- Different field types
## Load Data into Database
### Define schema (dynamic, so it can be changed)
```
{"uid": STRING,
"book_title" STRING,
"subject": STRING,
"summary": STRING,
"author_name": STRING,
"published": STRING,
"language": STRING}
```
```
import csv
data_link = "Datasets/data.gov.sg/national-library-board-read-singapore-short-stories/national-library-board-read-short-story.csv"
with open (data_link, "r") as data_file:
# csv allows easy reading of data files with defined delimiter
file_data = csv.reader(data_file, delimiter=",") # returns a csv object
file_data = [data for data in file_data]
# print(file_data[0])
# fields:
# ['uid', 'book_title', 'subject', 'summary', 'original_publisher',
# 'digital_publisher', 'format', 'language', 'copyright', 'author_name',
# 'published', 'resource_url', 'cover', 'thumbnail']
books_data = [] # store all data as an array of dictionaries
for i in range (1, len(file_data)): # skip initial header row
data = file_data[i]
books_data.append({
"_id": data[0],
"book_title": data[1],
"subject": data[2],
"summary": data[3],
"author_name": data[9],
"published": int(data[10]),
"language": data[7]
})
print(books_data[0])
```
# CRUD: Create, Read, Update, Delete
### C - create/insert
### R - read/select/query
### U - update/edit
### D - delete/remove
## CREATE (INSERT)
```
import pymongo
# create client connection to database
client = pymongo.MongoClient("localhost", 27017)
# client = pymongo.MongoClient('127.0.0.1', 27017)
# get database
library = client["library"]
# get collection
books = library["books"]
# load data into collection
books.insert_many(books_data)
print("Inserted successfully!")
print("-" * 50)
# query documents
results = books.find({}).limit(2) # limit(n) returns first n items
print(results) # returns a cursor object
for result in results:
print(result) # empty database currently
# close client connection
client.close()
```
## READ (QUERY)
```
# NoSQL
# - optional fields
# - different field types
import pymongo
import json
# load / loads
# dump / dumps
# create connection
client = pymongo.MongoClient('localhost', 27017)
# create database
library = client["library"]
# create collection
books = library["books"] # equivalent to table in SQL
print("Querying all data...")
query = {}
fields = {"book_title": 1, "language": 1} # fields that we want to return (leave it empty to return all fields)
results = books.find(query, fields).limit(2)
for result in results:
print(result)
print("-" * 50)
print("Sorting all data by year published...")
query = {}
fields = {"book_title": 1,
"language": 1,
"published": 1} # fields that we want to return (leave it empty to return all fields)
results = books.find(query, fields).sort("published", pymongo.ASCENDING).limit(5) # sort in ascending order
for result in results:
print(result)
print("-" * 50)
print("Getting all data where year published >= 2013...")
query = {"published": {"$gte": 2013}} # gte (>=), gt (>), lte (<=), lt (<)
fields = {"book_title": 1,
"language": 1,
"published": 1} # fields that we want to return (leave it empty to return all fields)
results = books.find(query, fields).limit(2)
for result in results:
print(result)
print("-" * 50)
print("Getting all data where length of book_title <= 10...")
length = 10
query = {"$where": f"this.book_title.length <= {length}"} # use f-string for easy formatting
fields = {"book_title": 1,
"language": 1} # fields that we want to return (leave it empty to return all fields)
results = books.find(query, fields).limit(5)
for result in results:
print(result)
print("-" * 50)
print("Getting all data where length of book_title <= 10 AND language is English...")
length = 10
query = {"$and": [{"$where": f"this.book_title.length <= {length}"}, {"language": "eng"}]}
fields = {"book_title": 1,
"language": 1} # fields that we want to return (leave it empty to return all fields)
results = books.find(query, fields).limit(5)
for result in results:
print(result)
print("-" * 50)
print("Getting all data where subject is 'Under One Sky' OR language is Malay...")
length = 10
query = {"$or": [{"subject": "Under One Sky"}, {"language": "may"}]}
fields = {"book_title": 1,
"language": 1,
"subject": 1} # fields that we want to return (leave it empty to return all fields)
results = books.find(query, fields).limit(5)
for result in results:
print(result)
print("-" * 50)
# close connection
client.close()
```
## UPDATE (SET)
```
# programming style
##- meaningful identifier names
##- appropriate comments
##- appropriate white space (blank lines, indentation, spaces)
# import module
import pymongo
# create connection to MongoDB server
# localhost = 127.0.0.1
client = pymongo.MongoClient("localhost", 27017)
# get database
library = client["library"]
# get collection
books = library["books"]
# insert into collection
# {"uid": STRING,
# "book_title" STRING,
# "subject": STRING,
# "summary": STRING,
# "author_name": STRING,
# "published": STRING,
# "language": STRING}
# automatically assigned unique _id if not set
# dynamic schema and data type
documents = [
{"_id": 234, "book_title": "Father Night", "author_name": "Kurt",
"publisher": "APress", "page_count": 433, "published": "2018"},
{"_id": 134, "book_title": "Mother Night", "author_name": ["Kurt", "Dan"],
"publisher": "APress", "published": "2015"},
{"_id": 334, "book_title": "Programming C## 6.0", "author_name": ["Andrew", "Dan"],
"page_count": 300, "published": "2000"},
{"_id": 534, "book_title": "Introduction to Python",
"publisher": "MPH", "published": "1999"},
{"_id": 434, "book_title": "Travel with Dogs", "author_name": "Andy",
"publisher": "APress", "page_count": 100, "published": "2017"}
]
books.insert_many(documents)
print("Inserted successfully!")
# close connection
client.close()
# programming style
##- meaningful identifier names
##- appropriate comments
##- appropriate white space (blank lines, indentation, spaces)
# import module
import pymongo
# create connection to MongoDB server
# localhost = 127.0.0.1
client = pymongo.MongoClient("localhost", 27017)
# get database
library = client["library"]
# get collection
books = library["books"]
print("Get title, author for books published in 2015")
criteria = {"published": "2015"}
docs = books.find(criteria, {"book_title": 1, "author_name": 1})
for doc in docs:
print(doc)
print("-" * 50)
print("Get books where 100 <= page_count < 400")
criteria = {"$and": [{"page_count": { "$gte": 100 }}, {"page_count": { "$lt": 400 }}]}
# criteria = {"page_count": {"$gte":100, "$lt":400}}
docs = books.find(criteria)
for doc in docs:
print(doc)
print("-" * 50)
print("Update page_count for documents without page_count to 'Less Than 100 Pages'")
criteria = {"page_count": {"$exists": False}}
new_value = {"$set": {"page_count": "Less Than 100 Pages"}}
books.update_many(criteria, new_value)
docs = books.find().limit(5)
for doc in docs:
print(doc)
print("-" * 50)
# close connection
client.close()
```
## DELETE
```
# programming style
##- meaningful identifier names
##- appropriate comments
##- appropriate white space (blank lines, indentation, spaces)
# import module
import pymongo
# create connection to MongoDB server
# localhost = 127.0.0.1
client = pymongo.MongoClient("localhost", 27017)
# get database
library = client["library"]
# get collection
books = library["books"]
print("Delete documents with 'Less Than 100 Pages'")
criteria = {"page_count": "Less Than 100 Pages"}
initial_count = books.count_documents(criteria)
books.delete_one(criteria) # delete one
final_count = books.count_documents(criteria)
docs = books.find(criteria)
print(f"There were initially {initial_count} documents, but now there are {final_count} documents matching the criteria.")
print("-" * 50)
# close connection
client.close()
# programming style
##- meaningful identifier names
##- appropriate comments
##- appropriate white space (blank lines, indentation, spaces)
# import module
import pymongo
# create connection to MongoDB server
# localhost = 127.0.0.1
client = pymongo.MongoClient("localhost", 27017)
# get database
library = client["library"]
# get collection
books = library["books"]
print("Delete all documents with subject 'Under One Sky'")
criteria = {"subject": "Under One Sky"}
initial_count = books.count_documents(criteria)
books.delete_many(criteria) # delete all matching
final_count = books.count_documents(criteria)
docs = books.find(criteria)
print(f"There were initially {initial_count} documents, but now there are {final_count} documents matching the criteria.")
print("-" * 50)
# close connection
client.close()
# programming style
##- meaningful identifier names
##- appropriate comments
##- appropriate white space (blank lines, indentation, spaces)
# import module
import pymongo
# create connection to MongoDB server
# localhost = 127.0.0.1
client = pymongo.MongoClient("localhost", 27017)
# get database
library = client["library"]
# get collection
books = library["books"]
# delete colleciton
library.drop_collection(books)
print("Removed books collection!")
client.drop_database(library)
print("Removed library database!")
# close connection
client.close()
```
| github_jupyter |
# Notebook for generating training data distribution and configuring Fairness
This notebook analyzes training data and outputs a JSON which contains information related to data distribution and fairness configuration. In order to use this notebook you need to do the following:
1. Read the training data into a pandas dataframe called "data_df". There is sample code below to show how this can be done if the training data is in IBM Cloud Object Storage.
2. Edit the below cells and provide the training data and fairness configuration information.
3. Run the notebook. It will generate a JSON and a download link for the JSON will be present at the very end of the notebook.
4. Download the JSON by clicking on the link and upload it in the IBM AI OpenScale GUI.
If you have multiple models (deployments), you will have to repeat the above steps for each model (deployment).
**Note:** Please restart the kernel after executing below cell
```
!pip install pandas
!pip install ibm-cos-sdk
!pip install numpy
!pip install scikit-learn==0.20.2
!pip install pyspark
!pip install lime
!pip install --upgrade ibm-watson-openscale
!pip install ibm-wos-utils==2.1.1
```
# Read training data into a pandas data frame
The first thing that you need to do is to read the training data into a pandas dataframe called "data_df". Given below is sample code for doing this if the training data is in IBM Cloud Object Storage. Please edit the below cell and make changes so that you can read your training data from the location where it is stored. Please ensure that the training data is present in a data frame called "data_df".
*Note: Pandas' read\_csv method converts the columns to its data types. If you want the column type to not be interpreted, specify the dtype param to read_csv method in this cell. More on this method [here](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html)*
*Note: By default NA values will be dropped while computing training data distribution and training the drift archive. Please ensure to handle the NA values during Pandas' read\_csv method*
```
# ----------------------------------------------------------------------------------------------------
# IBM Confidential
# OCO Source Materials
# 5900-A3Q, 5737-H76
# Copyright IBM Corp. 2018, 2021
# The source code for this Notebook is not published or other-wise divested of its trade
# secrets, irrespective of what has been deposited with the U.S.Copyright Office.
# ----------------------------------------------------------------------------------------------------
VERSION = "5.0.1"
# code to read file in COS to pandas dataframe object
import sys
import types
import pandas as pd
from ibm_botocore.client import Config
import ibm_boto3
def __iter__(self): return 0
api_key = "<API Key>"
resource_instance_id = "crn:v1:bluemix:public:cloud-object-storage:global:a/111111aaa1a111aa11d111111aa11111:22b22bbb-b22b-22bb-2b22-22b22bB22b2b::"
auth_endpoint = "https://iam.ng.bluemix.net/oidc/token"
service_endpoint = "https://s3-api.dal-us-geo.objectstorage.softlayer.net"
bucket = "<Bucket Name>"
file_name= "<File Name>"
cos_client = ibm_boto3.client(service_name='s3',
ibm_api_key_id=api_key,
ibm_auth_endpoint=auth_endpoint,
config=Config(signature_version='oauth'),
endpoint_url=service_endpoint)
body = cos_client.get_object(Bucket=bucket,Key=file_name)['Body']
# add missing __iter__ method, so pandas accepts body as file-like object
if not hasattr(body, "__iter__"): body.__iter__ = types.MethodType( __iter__, body )
data_df = pd.read_csv(body)
data_df.head()
#Print columns from data frams
#print("column names:{}".format(list(data_df.columns.values)))
# Uncomment following 2 lines if you want to read training data from local CSV file when running through local Jupyter notebook
#data_df = pd.read_csv("<FULLPATH_TO_CSV_FILE>")
#data_df.head()
```
# Select the services for which configuration information needs to be generated
This notebook has support to generaton configuration information related to fairness , explainability and drift service. The below can be used by the user to control service specific configuration information.
Details of the service speicifc flags available:
- enable_fairness : Flag to allow generation of fairness specific data distribution needed for configuration
- enable_explainability : Flag to allow generation of explainability specific information
- enable_drift: Flag to allow generation of drift detection model needed by drift service
service_configuration_support = { <br>
"enable_fairness": True,
"enable_explainability": True,
"enable_drift": False
}
```
service_configuration_support = {
"enable_fairness": True,
"enable_explainability": True,
"enable_drift": False
}
```
# Training Data and Fairness Configuration Information
Please provide information about the training data which is used to train the model. In order to explain the configuration better, let us first consider an example of a Loan Processing Model which is trying to predict whether a person should get a loan or not. The training data for such a model will potentially contain the following columns: Credit_History, Monthly_salary, Applicant_Age, Loan_amount, Gender, Marital_status, Approval. The "Approval" column contains the target field (label column or class label) and it can have the following values: "Loan Granted", "Loan Denied" or "Loan Partially Granted". In this model we would like to ensure that the model is not biased against Gender=Female or Gender=Transgender. We would also like to ensure that the model is not biased against the age group 15 to 30 years or age group 61 to 120 years.
For the above model, the configuration information that we need to provide is:
- class_label: This is the name of the column in the training data dataframe (data_df) which contains the target field (also known as label column or the class label). For the Loan Processing Model it would be "Approval".
- feature_columns: This is a comma separated list of column names which contain the feature column names (in the training data dataframe data_df). For the Loan Processing model this would be: ["Credit_History", "Monthly_salary", "Applicant_Age", "Loan_amount", "Gender", "Marital_status"]
- categorical_columns: The list of column names (in data_df) which contain categorical values. This should also include those columns which originally contained categorical values and have now been converted to numeric values. E.g., in the Loan Processing Model, the Marital_status column originally could have values: Single, Married, Divorced, Separated, Widowed. These could have been converted to numeric values as follows: Single -> 0, Married -> 1, Divorced -> 2, Separated -> 3 and Widowed -> 4. Thus the training data will have numeric values. Please identify such columns as categorical. Thus the list of categorical columns for the Loan Processing Model will be Credit_History, Gender and Marital_status.
For the Loan Processing Model, this information will be provided as follows:
training_data_info = { <br>
"class_label": "Approval",
"feature_columns": ["Credit_History", "Monthly_salary", "Applicant_Age", "Loan_amount", "Gender", "Marital_status"],
"categorical_columns": ["Credit_History","Gender","Marital_status"]
}
**Note:** Please note that categorical columns selected should be subset of feature columns. If there are no categorical columns among the feature columns selected , please set "categorical_columns as [] or None"
Please edit the next cell and provide the above information for your model.
```
training_data_info = {
"class_label": "<EDIT THIS>",
"feature_columns": ["<EDIT THIS>"],
"categorical_columns": ["<EDIT THIS>"]
}
```
# Specify the Model Type
In the next cell, specify the type of your model. If your model is a binary classification model, then set the type to "binary". If it is a multi-class classifier then set the type to "multiclass". If it is a regression model (e.g., Linear Regression), then set it to "regression".
```
#Set model_type. Acceptable values are:["binary","multiclass","regression"]
model_type = "binary"
#model_type = "multiclass"
#model_type = "regression"
```
# Specify the Fairness Configuration
You need to provide the following information for the fairness configuration:
- fairness_attributes: These are the attributes on which you wish to monitor fairness. In the Loan Processing Model, we wanted to ensure that the model is not baised against people of specific age group and people belonging to a specific gender. Hence "Applicant_Age" and "Gender" will be the fairness attributes for the Loan Processing Model.
- With Indirect Bias support, you can also monitor protected attributes for fairness. The protected attributes are those attributes which are present in the training data but are not used to train the model. For example, sensitive attributes like gender, race, age may be present in training data but are not used for training. To check if there exists indirect bias with respect to some protected attribute due to possible correlation with some feature column, it can be specified in fairness configuration.
- type: The data type of the fairness attribute (e.g., float or int or double)
- minority: The minority group for which we want to ensure that the model is not biased. For the Loan Processing Model we wanted to ensure that the model is not biased against people in the age group 15 to 30 years & 61 to 120 years as well as people with Gender = Female or Gender = Transgender. Hence the minority group for the fairness attribute "Applicant_Age" will be [15,30] and [61,120] and the minority group for fairness attribute "Gender" will be: "Female", "Transgender".
- majority: The majority group for which the model might be biased towards. For the Loan Processing Model, the majority group for the fairness attribute "Applicant_Age" will be [31,60], i.e., all the ages except the minority group. For the fairness attribute "Gender" the majority group will be: "Male".
- threshold: The fairness threshold beyond which the Model is considered to be biased. For the Loan Processing Model, let us say that the Bank is willing to tolerate the fact that Female and Transgender applicants will get upto 20% lesser approved loans than Males. However, if the percentage is more than 20% then the Loan Processing Model will be considered biased. E.g., if the percentage of approved loans for Female or Transgender applicants is say 25% lesser than those approved for Male applicants then the Model is to be considered as acting in a biased manner. Thus for this scenario, the Fairness threshold will be 80 (100-20) (this is represented as a value normalized to 1, i.e., 0.8).
The fairness attributes for Loan Processing Model will be specified as:
fairness_attributes = [
{
"feature": "Applicant_Age",
"type" : "int",
"majority": [ [31,60] ],
"minority": [ [15, 30], [61,120] ],
"threshold" : 0.8
},
{
"feature": "Gender",
"type" : "string",
"majority": ["Male"],
"minority": ["Female", "Transgender"],
"threshold" : 0.8
}
]
Please edit the next cell and provide the fairness configuration for your model.
```
fairness_attributes = [{
"type" : "<DATA_TYPE>", #data type of the column eg: float or int or double
"feature": "<COLUMN_NAME>",
"majority": [
[X, Y] # range of values for column eg: [31, 45] for int or [31.4, 45.1] for float
],
"minority": [
[A, B], # range of values for column eg: [10, 15] for int or [10.5, 15.5] for float
[C, D] # range of values for column eg: [80, 100] for int or [80.0, 99.9] for float
],
"threshold": <VALUE> #such that 0<VALUE<=1. eg: 0.8
}]
```
# Specify the Favorable and Unfavorable class values
The second part of fairness configuration is about the favourable and unfavourable class values. Recall that in the case of Loan Processing Model, the target field (label column or class label) can have the following values: "Loan Granted", "Loan Denied" and "Loan Partially Granted". Out of these values "Loan Granted" and "Loan Partially Granted" can be considered as being favorable and "Loan Denied" is unfavorable. In other words in order to measure fairness, we need to know the target field values which can be considered as being favourable and those values which can be considered as unfavourable.
For the Loan Prediction Model, the values can be specified as follows:
parameters = {
"favourable_class" : [ "Loan Granted", "Loan Partially Granted" ],
"unfavourable_class": [ "Loan Denied" ]
}
In case of a regression models, the favourable and unfavourable classes will be ranges. For example, for a model which predicts medicine dosage, the favorable outcome could be between 80 ml to 120 ml or between 5 ml to 20 ml whereas unfavorable outcome will be values between 21 ml to 79ml. For such a model, the favorable and unfavorable values will be specified as follows:
parameters = {
"favourable_class" : [ [5, 20], [80, 120] ],
"unfavourable_class": [ [21, 79] ]
}
Please edit the next cell to provide information about your model.
```
# For classification models use the below.
parameters = {
"favourable_class" : [ "<EDIT THIS>", "<EDIT THIS>" ],
"unfavourable_class": [ "<EDIT THIS>" ]
}
# For regression models use the below. Delete the entry which is not required.
parameters = {
"favourable_class" : [ [<EDIT THIS>, <EDIT THIS>], [<EDIT THIS>,<EDIT THIS>] ],
"unfavourable_class": [ [<EDIT THIS>, <EDIT THIS>] ]
}
```
# Specify the number of records which should be processed for Fairness
The final piece of information that needs to be provided is the number of records (min_records) that should be used for computing the fairness. Fairness checks runs hourly. If min_records is set to 5000, then every hour fairness checking will pick up the last 5000 records which were sent to the model for scoring and compute the fairness on those 5000 records. Please note that fairness computation will not start till the time that 5000 records are sent to the model for scoring.
If we set the value of "min_records" to a small number, then fairness computation will get influenced by the scoring requests sent to the model in the recent past. In other words, the model might be flagged as being biased if it is acting in a biased manner on the last few records, but overall it might not be acting in a biased manner. On the other hand, if the "min_records" is set to a very large number, then we will not be able to catch model bias quickly. Hence the value of min_records should be set such that it is neither too small or too large.
Please updated the next cell to specify a value for min_records.
```
# min_records = <Minimum number of records to be considered for preforming scoring>
min_records = <EDIT THIS>
```
# End of Input
You need not edit anything beyond this point. Run the notebook and go to the very last cell. There will be a link to download the JSON file (called: "Download training data distribution JSON file"). Download the file and upload it using the IBM AI OpenScale GUI.
*Note: drop_na parameter of TrainingStats object should be set to 'False' if NA values are taken care while reading the training data in the above cells*
```
from ibm_watson_openscale.utils.training_stats import TrainingStats
enable_explainability = service_configuration_support.get('enable_explainability')
enable_fairness = service_configuration_support.get('enable_fairness')
if enable_explainability or enable_fairness:
fairness_inputs = None
if enable_fairness:
fairness_inputs = {
"fairness_attributes": fairness_attributes,
"min_records" : min_records,
"favourable_class" : parameters["favourable_class"],
"unfavourable_class": parameters["unfavourable_class"]
}
input_parameters = {
"label_column": training_data_info["class_label"],
"feature_columns": training_data_info["feature_columns"],
"categorical_columns": training_data_info["categorical_columns"],
"fairness_inputs": fairness_inputs,
"problem_type" : model_type
}
training_stats = TrainingStats(data_df,input_parameters, explain=enable_explainability, fairness=enable_fairness, drop_na=True)
config_json = training_stats.get_training_statistics()
config_json["notebook_version"] = VERSION
#print(config_json)
```
### Indirect Bias
In case of Indirect bias i.e if protected attributes(the sensitive attributes like race, gender etc which are present in the training data but are not used to train the model) are being monitored for fairness:
- Bias service identifies correlations between the protected attribute and model features. Correlated attributes are also known as proxy features.
- Existence of correlations with model features can result in indirect bias w.r.t protected attribute even though it is not used to train the model.
- Highly correlated attributes based on their correlation strength are considered while computing bias for a given protected attribute.
The following cell identifies if user has configured protected attribute for fairness by checking the feature, non-feature columns and the fairness configuration. If protected attribute/s are configured then it identifies correlations and stores it in the fairness configuration.
```
# Checking if protected attributes are configured for fairness monitoring. If yes, then computing correlation information for each meta-field and updating it in the fairness configuration
if enable_fairness:
fairness_configuration = config_json.get('fairness_configuration')
training_columns = data_df.columns.tolist()
label_column = training_data_info.get('class_label')
training_columns.remove(label_column)
feature_columns = training_data_info.get('feature_columns')
non_feature_columns = list(set(training_columns) - set(feature_columns))
if non_feature_columns is not None and len(non_feature_columns) > 0:
protected_attributes = []
fairness_attributes_list = [attribute.get('feature') for attribute in fairness_attributes]
for col in non_feature_columns:
if col in fairness_attributes_list:
protected_attributes.append(col)
if len(protected_attributes) > 0:
from ibm_watson_openscale.utils.indirect_bias_processor import IndirectBiasProcessor
fairness_configuration = IndirectBiasProcessor().get_correlated_attributes(data_df, fairness_configuration, feature_columns, protected_attributes, label_column)
import json
print("Finished generating training distribution data")
# Create a file download link
import base64
from IPython.display import HTML
def create_download_link( title = "Download training data distribution JSON file", filename = "training_distribution.json"):
if enable_explainability or enable_fairness:
output_json = json.dumps(config_json, indent=2)
b64 = base64.b64encode(output_json.encode())
payload = b64.decode()
html = '<a download="{filename}" href="data:text/json;base64,{payload}" target="_blank">{title}</a>'
html = html.format(payload=payload,title=title,filename=filename)
return HTML(html)
else:
print('No download link generated as fairness/explainability services are disabled.')
create_download_link()
```
# Drift detection model generation
Please update the score function which will be used forgenerating drift detection model which will used for drift detection . This might take sometime to generate model and time taken depends on the training dataset size. The output of the score function should be a 2 arrays 1. Array of model prediction 2. Array of probabilities
- User is expected to make sure that the data type of the "class label" column selected and the prediction column are same . For eg : If class label is numeric , the prediction array should also be numeric
- Each entry of a probability array should have all the probabities of the unique class lable .
For eg: If the model_type=multiclass and unique class labels are A, B, C, D . Each entry in the probability array should be a array of size 4 . Eg : [ [0.50,0.30,0.10,0.10] ,[0.40,0.20,0.30,0.10]...]
**Note:**
- *User is expected to add "score" method , which should output prediction column array and probability column array.*
- *The data type of the label column and prediction column should be same . User needs to make sure that label column and prediction column array should have the same unique class labels*
- **Please update the score function below with the help of templates documented [here](https://github.com/IBM-Watson/aios-data-distribution/blob/master/Score%20function%20templates%20for%20drift%20detection.md)**
```
#Update score function
# def score(training_data_frame){
# <Fill in the template using the score function templates provided>
# }
#Generate drift detection model
from ibm_wos_utils.drift.drift_trainer import DriftTrainer
enable_drift = service_configuration_support.get('enable_drift')
if enable_drift:
drift_detection_input = {
"feature_columns":training_data_info.get('feature_columns'),
"categorical_columns":training_data_info.get('categorical_columns'),
"label_column": training_data_info.get('class_label'),
"problem_type": model_type
}
drift_trainer = DriftTrainer(data_df,drift_detection_input)
if model_type != "regression":
#Note: batch_size can be customized by user as per the training data size
drift_trainer.generate_drift_detection_model(score,batch_size=data_df.shape[0])
#Note:
# - Two column constraints are not computed beyond two_column_learner_limit(default set to 200)
# - Categorical columns with large (determined by categorical_unique_threshold; default > 0.8) number of unique values relative to total rows in the column are discarded.
#User can adjust the value depending on the requirement
drift_trainer.learn_constraints(two_column_learner_limit=200, categorical_unique_threshold=0.8)
drift_trainer.create_archive()
#Generate a download link for drift detection model
from IPython.display import HTML
import base64
import io
def create_download_link_for_ddm( title = "Download Drift detection model", filename = "drift_detection_model.tar.gz"):
#Retains stats information
if enable_drift:
with open(filename,'rb') as file:
ddm = file.read()
b64 = base64.b64encode(ddm)
payload = b64.decode()
html = '<a download="{filename}" href="data:text/json;base64,{payload}" target="_blank">{title}</a>'
html = html.format(payload=payload,title=title,filename=filename)
return HTML(html)
else:
print("Drift Detection is not enabled. Please enable and rerun the notebook")
create_download_link_for_ddm()
```
| github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Distributed training with Keras
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/tutorials/distribute/keras"><img src="https://www.tensorflow.org/images/tf_logo_32px.png" />View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/distribute/keras.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/docs/blob/master/site/en/tutorials/distribute/keras.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/distribute/keras.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Download notebook</a>
</td>
</table>
## Overview
The `tf.distribute.Strategy` API provides an abstraction for distributing your training
across multiple processing units. The goal is to allow users to enable distributed training using existing models and training code, with minimal changes.
This tutorial uses the `tf.distribute.MirroredStrategy`, which
does in-graph replication with synchronous training on many GPUs on one machine.
Essentially, it copies all of the model's variables to each processor.
Then, it uses [all-reduce](http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/) to combine the gradients from all processors and applies the combined value to all copies of the model.
`MirroredStrategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distributed_training.ipynb).
### Keras API
This example uses the `tf.keras` API to build the model and training loop. For custom training loops, see the [tf.distribute.Strategy with training loops](training_loops.ipynb) tutorial.
## Import dependencies
```
from __future__ import absolute_import, division, print_function, unicode_literals
# Import TensorFlow and TensorFlow Datasets
try:
!pip install tf-nightly
except Exception:
pass
import tensorflow_datasets as tfds
import tensorflow as tf
tfds.disable_progress_bar()
import os
print(tf.__version__)
```
## Download the dataset
Download the MNIST dataset and load it from [TensorFlow Datasets](https://www.tensorflow.org/datasets). This returns a dataset in `tf.data` format.
Setting `with_info` to `True` includes the metadata for the entire dataset, which is being saved here to `info`.
Among other things, this metadata object includes the number of train and test examples.
```
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
```
## Define distribution strategy
Create a `MirroredStrategy` object. This will handle distribution, and provides a context manager (`tf.distribute.MirroredStrategy.scope`) to build your model inside.
```
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
```
## Setup input pipeline
When training a model with multiple GPUs, you can use the extra computing power effectively by increasing the batch size. In general, use the largest batch size that fits the GPU memory, and tune the learning rate accordingly.
```
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
```
Pixel values, which are 0-255, [have to be normalized to the 0-1 range](https://en.wikipedia.org/wiki/Feature_scaling). Define this scale in a function.
```
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
```
Apply this function to the training and test data, shuffle the training data, and [batch it for training](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#batch). Notice we are also keeping an in-memory cache of the training data to improve performance.
```
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
```
## Create the model
Create and compile the Keras model in the context of `strategy.scope`.
```
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
```
## Define the callbacks
The callbacks used here are:
* *TensorBoard*: This callback writes a log for TensorBoard which allows you to visualize the graphs.
* *Model Checkpoint*: This callback saves the model after every epoch.
* *Learning Rate Scheduler*: Using this callback, you can schedule the learning rate to change after every epoch/batch.
For illustrative purposes, add a print callback to display the *learning rate* in the notebook.
```
# Define the checkpoint directory to store the checkpoints
checkpoint_dir = './training_checkpoints'
# Name of the checkpoint files
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Callback for printing the LR at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
```
## Train and evaluate
Now, train the model in the usual way, calling `fit` on the model and passing in the dataset created at the beginning of the tutorial. This step is the same whether you are distributing the training or not.
```
model.fit(train_dataset, epochs=12, callbacks=callbacks)
```
As you can see below, the checkpoints are getting saved.
```
# check the checkpoint directory
!ls {checkpoint_dir}
```
To see how the model perform, load the latest checkpoint and call `evaluate` on the test data.
Call `evaluate` as before using appropriate datasets.
```
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
```
To see the output, you can download and view the TensorBoard logs at the terminal.
```
$ tensorboard --logdir=path/to/log-directory
```
```
!ls -sh ./logs
```
## Export to SavedModel
Export the graph and the variables to the platform-agnostic SavedModel format. After your model is saved, you can load it with or without the scope.
```
path = 'saved_model/'
model.save(path, save_format='tf')
```
Load the model without `strategy.scope`.
```
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
```
Load the model with `strategy.scope`.
```
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
```
### Examples and Tutorials
Here are some examples for using distribution strategy with keras fit/compile:
1. [Transformer](https://github.com/tensorflow/models/blob/master/official/nlp/transformer/transformer_main.py) example trained using `tf.distribute.MirroredStrategy`
2. [NCF](https://github.com/tensorflow/models/blob/master/official/recommendation/ncf_keras_main.py) example trained using `tf.distribute.MirroredStrategy`.
More examples listed in the [Distribution strategy guide](../../guide/distributed_training.ipynb#examples_and_tutorials)
## Next steps
* Read the [distribution strategy guide](../../guide/distributed_training.ipynb).
* Read the [Distributed Training with Custom Training Loops](training_loops.ipynb) tutorial.
Note: `tf.distribute.Strategy` is actively under development and we will be adding more examples and tutorials in the near future. Please give it a try. We welcome your feedback via [issues on GitHub](https://github.com/tensorflow/tensorflow/issues/new).
| github_jupyter |
## Select galaxies (for the LSLGA) from G<18 Gaia sources
The goal of this notebook is to develop a set of cuts that we can use to find galaxies which will otherwise be "forced PSF" in DR9.
Before running this notebook, some preparatory work needs to be done to generate a set of sweep catalogs containing *just* *G<18* Gaia stars. The details are documented in `/global/cfs/cdirs/desi/users/ioannis/lslga-from-gaia/README`, but briefly, we select ~22M Gaia point sources using the following cuts:
```
BRICK_PRIMARY == True &
GAIA_PHOT_G_MEAN_MAG > 0 &
GAIA_PHOT_G_MEAN_MAG < 18 &
GAIA_ASTROMETRIC_EXCESS_NOISE < 10**0.5 &
(MASKBITS & 0x2) == 0 &
(MASKBITS & 0x2000) == 0 &
FLUX_R > 0 &
FLUX_W1 > 0 &
ALLMASK_G == 0
ALLMASK_R == 0
ALLMASK_z == 0
NOBS_G > 0
NOBS_R > 0
NOBS_Z > 0
```
Once that's done, this notebook can be run.
```
import os, pdb
import fitsio
import numpy as np
import matplotlib.pyplot as plt
from glob import glob
from astropy.table import vstack, Table
from astrometry.libkd.spherematch import match_radec
import seaborn as sns
sns.set(context='talk', style='ticks', font_scale=1.4)
%matplotlib inline
dr8dir = '/global/project/projectdirs/cosmo/data/legacysurvey/dr8/'
outdir = '/global/project/projectdirs/desi/users/ioannis/lslga-from-gaia'
```
#### Read the SDSS training sample.
Train our selection using the set of spectroscopically confirmed SDSS galaxies which would otherwise be forced PSF.
```
def read_gaia_psf_sdss(clobber=False):
outfile = os.path.join(outdir, 'dr8-gaia-psf-sdss.fits')
if os.path.isfile(outfile) and not clobber:
out = Table.read(outfile)
print('Read {} galaxies from {}'.format(len(out), outfile))
else:
sdss = fitsio.read('/global/cfs/cdirs/cosmo/work/sdss/cats/specObj-dr14.fits')
out = []
for region in ('north', 'south'):
print('Working on {}'.format(region))
ext = fitsio.read(os.path.join(dr8dir, region, 'external',
'survey-dr8-{}-specObj-dr14.fits'.format(region)))
keep = np.where((ext['GAIA_PHOT_G_MEAN_MAG'] > 0) *
(ext['GAIA_PHOT_G_MEAN_MAG'] < 18) *
(ext['GAIA_ASTROMETRIC_EXCESS_NOISE'] < 10.**0.5) *
(ext['FLUX_W1'] > 0) *
(ext['FLUX_R'] > 0) *
((sdss['PRIMTARGET'] & 2**6) != 0) *
(sdss['Z'] > 0.001) * (sdss['Z'] < 1) *
(sdss['ZWARNING'] == 0))[0]
if len(keep) > 0:
out.append(Table(ext[keep]))
out = vstack(out)
out.write(outfile, overwrite=True)
return out
%time specz = read_gaia_psf_sdss(clobber=False)
#m1, m2, _ = match_radec(specz['RA'], specz['DEC'], specz['RA'], specz['DEC'], 1/3600, nearest=False)
#print(len(m1), len(specz))
#ext = fitsio.read(os.path.join(dr8dir, 'north', 'external', 'survey-dr8-north-specObj-dr14.fits'))
#m1, m2, _ = match_radec(ext['RA'], ext['DEC'], ext['RA'], ext['DEC'], 1/3600, nearest=False)
#print(len(m1), len(ext))
```
#### Next, assemble the full catalog of forced-PSF Gaia sources from DR8.
Merge the sweeps together that were generated using `/global/cfs/cdirs/desi/users/ioannis/lslga-from-gaia/build-gaia-psf`. For DR8 this step takes approximately 7 minutes to generate it for the first time, or roughly 45 seconds to read it in.
```
def read_gaia_psf(clobber=False):
outfile = os.path.join(outdir, 'dr8-gaia-psf.fits')
if os.path.isfile(outfile) and not clobber:
out = Table(fitsio.read(outfile))
print('Read {} objects from {}'.format(len(out), outfile))
else:
out = []
for region in ['north', 'south']:
print('Working on {}'.format(region))
sweepdir = os.path.join(outdir, 'sweep-{}-gaia'.format(region))
catfile = glob(os.path.join(sweepdir, 'sweep*.fits'))
for ii, ff in enumerate(catfile):
if ii % 50 == 0:
print('{} / {}'.format(ii, len(catfile)))
cc = fitsio.read(ff)
if len(cc) > 0:
out.append(Table(cc))
out = vstack(out)
print('Writing {} objects to {}'.format(len(out), outfile))
out.write(outfile, overwrite=True)
return out
%time cat = read_gaia_psf(clobber=True)
```
### Make some plots and develop the selection.
```
def getmags(cat):
gmag = cat['GAIA_PHOT_G_MEAN_MAG']
bp = cat['GAIA_PHOT_BP_MEAN_MAG']
rp = cat['GAIA_PHOT_RP_MEAN_MAG']
rmag = 22.5-2.5*np.log10(cat['FLUX_R'])
Wmag = 22.5-2.5*np.log10(cat['FLUX_W1'])
resid = cat['APFLUX_RESID_R'][:, 5]/10**(-0.4*(gmag-22.5))
#resid = cat['APFLUX_RESID_R'][:, 7]/cat['FLUX_R']
chi2 = cat['RCHISQ_R']
return gmag-Wmag, bp-rp, resid, chi2
gW, bprp, resid, chi2 = getmags(cat)
sgW, sbprp, sresid, schi2 = getmags(specz)
xlim, ylim = (-0.3, 4), (0, 3.5)
# north cuts
#x0, x1, x2, x3 = (0.2, 0.2, 0.55, 5.0)
#y0, y1, y2, y3 = ( _, 1.7, 1.0, 1.0)
# north/south
x0, x1, x2, x3 = (0.25, 0.25, 0.55, 5.0)
y0, y1, y2, y3 = ( _, 1.7, 1.2, 1.2)
c1 = np.polyfit([x1, x2], [y1, y2], 1)
c2 = np.polyfit([x2, x3], [y2, y3], 1)
print('Cut 1: x>{:.2f}'.format(x0))
print('Cut 2: y>{:.4f}x + {:.4f}'.format(c1[0], c1[1]))
print('Cut 3: y>{:.2f}'.format(c2[0]))
#print(c1, c2)
J = np.where((resid > x0) * (gW > np.polyval(c1, resid)) * (gW > np.polyval(c2, resid)))[0]
I = np.where((sresid > x0) * (sgW > np.polyval(c1, sresid)) * (sgW > np.polyval(c2, sresid)))[0]
print('Selected SDSS-specz galaxies: N={}/{} ({:.4f}%)'.format(len(I), len(specz), 100*len(I)/len(specz)))
print('Candidate LSLGA-Gaia galaxies: N={}/{} ({:.4f}%)'.format(len(J), len(cat), 100*len(J)/len(cat)))
#print(len(J), len(cat), len(J)/len(cat))
fig, ax = plt.subplots(figsize=(12, 10))
ax.hexbin(resid, gW, mincnt=3, cmap='Greys_r',
extent=np.hstack((xlim, ylim)))
ax.scatter(resid[J], gW[J], s=10, marker='s', alpha=0.7,
label='Candidate galaxies (N={})'.format(len(J)))
ax.scatter(sresid, sgW, s=15, marker='o', alpha=0.7,
label='SDSS-specz (N={})'.format(len(specz)))
ax.plot([x0, x0], [y1, ylim[1]], color='red', lw=2)
ax.plot([x1, x2], [y1, y2], color='red', lw=2)
ax.plot([x2, x3], [y2, y3], color='red', lw=2)
ax.set_xlim(xlim)
ax.set_ylim(ylim)
ax.set_xlabel(r'Residual Aperture $r$ Flux (7" diameter) / Gaia $G$ flux')
ax.set_ylabel(r'$G - W_{1}$ (mag)')
#_ = ax.set_title(r'$0 < G < 18$ & AEN $< 10^{0.5}$')
ax.text(0.93, 0.9, r'$0 < G < 18$ & AEN $< 10^{0.5}$',
ha='right', va='bottom', transform=ax.transAxes,
fontsize=20)
hh, ll = ax.get_legend_handles_labels()
#print(ll)
ax.legend(hh[1:], ll[1:], loc='lower right', fontsize=18)
fig.subplots_adjust(left=0.13, bottom=0.12, top=0.95)
pngfile = os.path.join(outdir, 'dr8-gaia-psf-galaxies.png')
print('Writing {}'.format(pngfile))
fig.savefig(pngfile)
```
Might as well add all the SDSS galaxies to the output sample, irrespective of where they lie.
```
K = []
for brickid in set(specz['BRICKID']):
W = np.where(brickid == specz['BRICKID'])[0]
for ww in W:
K.append(np.where((cat['BRICKID'] == brickid) * (cat['OBJID'] == specz['OBJID'][ww]))[0])
K = np.unique(np.hstack(K))
print('Matched {} unique galaxies from the parent SDSS-Gaia sample.'.format(len(K)))
Jfinal = np.unique(np.hstack((J, K)))
print('Original sample = {}, final sample = {}'.format(len(J), len(Jfinal)))
#m1, m2, _ = match_radec(cat['RA'][J], cat['DEC'][J], specz['RA'], specz['DEC'], 1/3600.0, nearest=True)
#missed = np.delete(np.arange(len(specz)), m2)
#print('Selected SDSS galaxies {}/{}, missing {}.'.format(len(m2), len(specz), len(missed)))
#k1, k2, _ = match_radec(cat['RA'], cat['DEC'], specz['RA'][missed], specz['DEC'][missed],
# 1/3600.0, nearest=True)
#print('Found {}/{} of the missed SDSS galaxies.'.format(len(k2), len(missed)))
# check
#m1, m2, _ = match_radec(cat['RA'][Jfinal], cat['DEC'][Jfinal], specz['RA'], specz['DEC'], 2/3600.0, nearest=True)
#print(len(m2), len(specz))
#missed = np.delete(np.arange(len(specz)), m2)
#specz[missed]
#assert(len(m2)==len(specz))
for ra, dec in zip(cat['RA'][Jfinal[:500]], cat['DEC'][Jfinal[:500]]):
if dec < 30:
print(ra, dec)
# We get this broadline QSO now!!
# http://legacysurvey.org/viewer-dev?ra=178.6654&dec=34.8714&layer=dr8-resid&zoom=14&lslga&masks-dr9&spectra
#match_radec(cat['RA'][Jfinal], cat['DEC'][Jfinal], 178.6654, 34.8714, 1/3600, nearest=True)
```
#### Write out.
```
outfile = os.path.join(outdir, 'dr8-gaia-psf-galaxies.fits')
print('Writing {} galaxies to {}'.format(len(Jfinal), outfile))
cat[Jfinal].write(outfile, overwrite=True)
```
| github_jupyter |
# Find stellar parameters from measured frequencies
This notebook finds stellar parameters from measured frequencies. Provided all dependencies are installed, it should work right out of the box.
First import some things
```
%matplotlib inline
import random
import h5py
import numpy as np
import sys
import os
from tqdm import tqdm_notebook as tqdm
import tflearn
import tensorflow as tf
import math
import json
import matplotlib as mpl
import matplotlib.pyplot as plt
from IPython.display import clear_output
```
### Set up the network architecture and load the model
```
def calc_distance(predictions, targets, inputs):
return tf.nn.l2_loss(tf.subtract(predictions, targets), name='l2')
net = tflearn.input_data(shape=[None, 8])
net = tflearn.batch_normalization(net)
net = tflearn.fully_connected(net, 500, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 500, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 500, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 500, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 500, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 500, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 5000, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 5000, activation='relu', regularizer='L2')
net = tflearn.fully_connected(net, 5000, activation='tanh', regularizer='L2')
net = tflearn.fully_connected(net, 1, activation='linear', regularizer='L2')
net = tflearn.regression(net, metric=None, loss='mean_square')
model = tflearn.DNN(net, checkpoint_path='./model_checkpoints')
# model.load('./models/run_star_8.tflearn')
model.load('./models/dnn.tflearn')
```
### Set the lower and upper bound from the data
This sets the initial random sampling box, these are the limits from the grid
```
bound_low = [2., 0.012, 0.68, 0.01, 1, 0.01]
bound_high = [20., 0.02, 0.72, 0.05, 1000, 0.72]
```
### Define functions for the genetic algorithm
```
# Set up random sampling and particle filter functions
def random_sample():
return [[np.random.uniform(bound_low[i], bound_high[i]) for i in range(len(bound_low))] for x in range(settings["initial_iteration_size"])]
def gauss_sample(seeds, i, spread):
def bound(low, high, value):
return max(low, min(high, value))
def gauss_sample_single(seed):
return [
bound(bound_low[i], bound_high[i], np.random.normal(seed[i], seed[i]*spread))
for i in range(len(seed) - 1)
]
return [gauss_sample_single(random.choice(seeds)) for x in range(settings['iteration_size'])]
```
### Define the loss function
Please don't touch this
```
def calculate_point(point):
inputs = []
for l in range(3):
for n_pg in range(-50, 6):
inputs.append(point + [l] + [n_pg])
outputs = model.predict(inputs)
return outputs
def get_point_index(l, n_pg):
return 56*l + n_pg + 50
def get_error(y1, y2):
return (y1-y2)**2
# Set up function to determine error of a point
def point_error(points, verbose = False):
global model
errors = []
if verbose == True:
best_list = []
for point in tqdm(points):
# Append l and n_pg to all points
y_pred = calculate_point(point)
y_true = star['data']
if star['settings']['match_mode'] == 'relative':
min_err = math.inf
# Only with fixed l and relative but fixed n_pg
# Take min and max n_pg values to scan around
min_n_pg = -50
if 'min_n_pg' in star['settings']:
min_n_pg = star['settings']['min_n_pg']
max_n_pg = 5
if 'max_n_pg' in star['settings']:
max_n_pg = star['settings']['max_n_pg']
max_n_pg = max_n_pg - y_true[-1]['n_pg']
# Calculate least error
for n_pg_idx in range(min_n_pg, max_n_pg):
current_error = 0
for y in y_true:
if type(y['l']).__name__ == 'int':
point_index = get_point_index(y['l'], n_pg_idx+y['n_pg'])
current_error += get_error(y_pred[point_index], y['freq'])
else:
min_l_err = math.inf
for l in y['l']:
point_index = get_point_index(l, n_pg_idx+y['n_pg'])
current_l_error = get_error(y_pred[point_index], y['freq'])
if current_l_error < min_l_err:
min_l_err = current_l_error
current_error += min_l_err
if current_error < min_err:
min_err = current_error
best_n_pg_idx = n_pg_idx
if verbose == True:
best_list.append(best_n_pg_idx)
point_error = min_err
else:
# Exact match: calculate error for all star samples independently
point_error = 0
max_n_pg = 5
if 'max_n_pg' in star['settings']:
max_n_pg = star['settings']['max_n_pg']
prev_n_pg = [max_n_pg, max_n_pg]
for idx, y in enumerate(y_true):
# Exact match
if 'l' in y and 'n_pg' in y:
if type(y['l']).__name__ == 'int':
n_pg = y['n_pg']
if n_pg == 'prev':
n_pg = prev_n_pg[y['l'] - 1]
point_index = get_point_index(y['l'], n_pg)
point_error += get_error(y_pred[point_index], y['freq'])
prev_l = y['l']
prev_n_pg = n_pg
if verbose == True:
best_list.append([prev_l, prev_n_pg])
else:
min_err = math.inf
for l in y['l']:
point_index = get_point_index(l, y['n_pg'])
current_error = get_error(y_pred[point_index], y['freq'])
if current_error < min_err:
min_err = current_error
prev_l = l
prev_n_pg[l - 1] = y['n_pg']
point_error += min_err
if verbose == True:
best_list.append([prev_l, prev_n_pg])
elif 'l' in y and 'n_pg_max' in y:
min_n_pg = -50
if 'min_n_pg' in star['settings']:
min_n_pg = star['settings']['min_n_pg']
n_pg_min = min_n_pg + len(y_true)-1 - idx
if 'n_pn_min' in y:
n_pg_min = y['n_pg_min']
if type(y['l']).__name__ == 'int':
# Get the max n_pg
n_pg_max = y['n_pg_max']
if (n_pg_max == 'prev'):
n_pg_max = prev_n_pg[y['l'] - 1]
min_err = math.inf
for n_pg in range(n_pg_min, n_pg_max):
point_index = get_point_index(y['l'], n_pg)
current_error = get_error(y_pred[point_index], y['freq'])
if current_error < min_err:
min_err = current_error
prev_l_x = y['l']
prev_n_pg_x = n_pg
prev_l = prev_l_x
prev_n_pg[prev_l_x - 1] = prev_n_pg_x
point_error += min_err
if verbose == True:
best_list.append([prev_l, prev_n_pg[prev_l - 1]])
else:
min_err = math.inf
for l in y['l']:
# Get the max n_pg
n_pg_max = y['n_pg_max']
if (n_pg_max == 'prev'):
n_pg_max = prev_n_pg[l - 1]
for n_pg in range(n_pg_min, n_pg_max):
point_index = get_point_index(l, n_pg)
current_error = get_error(y_pred[point_index], y['freq'])
if current_error < min_err:
min_err = current_error
prev_l_x = l
prev_n_pg_x = n_pg
prev_l = prev_l_x
prev_n_pg[prev_l_x - 1] = prev_n_pg_x
point_error += min_err
if verbose == True:
best_list.append([prev_l, prev_n_pg[prev_l - 1]])
else:
print("Could not parse", y)
point_error /= len(star['data'])
errors.append(point_error)
if verbose == True:
return np.array(errors), best_list
return np.array(errors)
```
### Define plotting function
```
def create_plot(Data, save_to_disk = False):
fig = plt.figure(figsize=(30,20))
plt.rc('text', usetex=True)
def add_plot(fig, fig_key, x, y, x_label, c_label):
ax = fig.add_subplot(3,3,fig_key)
ax.scatter(Data[:,x], Data[:,y])
ax.set_xlabel(x_label, size=25)
ax.set_yscale('log')
ax.set_ylabel(c_label, size=25)
axes = fig.gca()
ax.xaxis.set_tick_params(labelsize=25)
ax.yaxis.set_tick_params(labelsize=25)
axes.set_xlim([np.min(Data[:,x]), np.max(Data[:,x])])
axes.set_ylim([np.min(Data[:,y])/1.2, np.max(Data[:,y])*1.2])
add_plot(fig, 1, 0, 6, r'$M (M_\odot)$', r'$\chi^2$')
add_plot(fig, 2, 3, 6, r'$f_{\rm ov}$', r'$\chi^2$')
add_plot(fig, 3, 1, 6, 'Z', r'$\chi^2$')
add_plot(fig, 4, 5, 6, r'$X_c$', r'$\chi^2$')
add_plot(fig, 5, 4, 6, r'$D_{\rm mix} (cm^2\,s^{-1}$', r'$\chi^2$')
add_plot(fig, 6, 2, 6, r'X', r'$\chi^2$')
if save_to_disk == True:
fig.savefig('./stars/results/'+star['settings']['filename']+'.pdf', pad_inches=0, bbox_inches='tight')
print("Saved to disk")
else:
clear_output()
fig.show()
plt.pause(0.0001)
def create_plot2(Data, Data2, save_to_disk = False):
fig = plt.figure(figsize=(30,20))
plt.rc('text', usetex=True)
def add_plot(fig, fig_key, x, y, x_label, c_label):
ax = fig.add_subplot(3,3,fig_key)
ax.scatter(Data[:,x], Data[:,y], alpha=0.5, c='#cccccc')
ax.scatter(Data2[:,x], Data2[:,y], alpha=0.5)
ax.set_xlabel(x_label, size=25)
ax.set_yscale('log')
ax.set_ylabel(c_label, size=25)
axes = fig.gca()
ax.xaxis.set_tick_params(labelsize=25)
ax.yaxis.set_tick_params(labelsize=25)
axes.set_xlim([np.min(Data[:,x]), np.max(Data[:,x])])
axes.set_ylim([np.min(Data[:,y])/1.2, np.max(Data[:,y])*1.2])
add_plot(fig, 1, 0, 6, r'$M (M_\odot)$', r'$\chi^2$')
add_plot(fig, 2, 3, 6, r'$f_{\rm ov}$', r'$\chi^2$')
add_plot(fig, 3, 1, 6, 'Z', r'$\chi^2$')
add_plot(fig, 4, 5, 6, r'$X_c$', r'$\chi^2$')
add_plot(fig, 5, 4, 6, r'$D_{\rm mix} (cm^2\,s^{-1})$', r'$\chi^2$')
add_plot(fig, 6, 2, 6, r'X', r'$\chi^2$')
if save_to_disk == True:
fig.savefig('./stars/results/'+star['settings']['filename']+'.pdf', pad_inches=0, bbox_inches='tight')
fig.savefig('./stars/results/'+star['settings']['filename']+'.png', pad_inches=0, bbox_inches='tight')
print("Saved to disk")
else:
clear_output()
fig.show()
plt.pause(0.0001)
```
### Run genetic algorithm on specific star
The JSON structure should be fairly straightforward. The settings can be left alone or changed if you want to run the genetic algorithm longer or shorter.
```
for starname in ['star-1', 'star-2', 'star-3', 'star-5', 'star-6', 'star-7']:
star = json.load(open('./stars/'+starname+'.json'))
settings = {
"initial_iteration_size": 5000,
"iteration_size": 2000,
"iteration_count": 20, # In this setup, the total number of iterations is 3*iteration_count to optimize around the found minima.
"active_points": 200
}
iteration_num=1
result_list_big = np.empty((0, 7))
for i in tqdm(range(3*settings['iteration_count'])):
if (i == 0):
sample = random_sample()
elif i < settings['iteration_count']:
sample = gauss_sample(result_list_big[:settings['active_points']], i, 0.4)
elif i < settings['iteration_count']*2:
sample = gauss_sample(result_list_big[:settings['active_points']], i, 0.1)
else:
sample = gauss_sample(result_list_big[:settings['active_points']], i, 0.01)
errors = point_error(sample)
errors = np.array(errors).reshape(len(errors), 1)
result = np.hstack((np.array(sample), errors))
result_list_big = np.vstack((result_list_big, result))
result_list_big = np.array(sorted(result_list_big, key=lambda row: row[-1]))
settings = {
"initial_iteration_size": 1000,
"iteration_size": 100,
"iteration_count": 10, # In this setup, the total number of iterations is 3*iteration_count to optimize around the found minima.
"active_points": 10
}
iteration_num=1
result_list_small = np.empty((0, 7))
for i in tqdm(range(3*settings['iteration_count'])):
if (i == 0):
sample = random_sample()
elif i < settings['iteration_count']:
sample = gauss_sample(result_list_small[:settings['active_points']], i, 0.4)
elif i < settings['iteration_count']*2:
sample = gauss_sample(result_list_small[:settings['active_points']], i, 0.1)
else:
sample = gauss_sample(result_list_small[:settings['active_points']], i, 0.01)
errors = point_error(sample)
errors = np.array(errors).reshape(len(errors), 1)
result = np.hstack((np.array(sample), errors))
result_list_small = np.vstack((result_list_small, result))
result_list_small = np.array(sorted(result_list_small, key=lambda row: row[-1]))
print("Done")
print(result_list_big.shape)
print(result_list_small.shape)
# Plot and write results file
create_plot2(result_list_big, result_list_small, True)
inputs = [result_list_big.tolist()[0][:-1]]
errors = point_error(inputs, True)
text_file = open("./stars/results/"+star['settings']['filename']+".txt", "w")
text_file.write("Best point big:\n")
text_file.write("M: %s\n" % inputs[0][0])
text_file.write("Z: %s\n" % inputs[0][1])
text_file.write("Xi: %s\n" % inputs[0][2])
text_file.write("ov: %s\n" % inputs[0][3])
text_file.write("D: %s\n" % inputs[0][4])
text_file.write("center_h1: %s\n" % inputs[0][5])
text_file.write("Best point has error: %s\n\n" % errors[0][0][0])
inputs = [result_list_small.tolist()[0][:-1]]
errors = point_error(inputs, True)
text_file.write("Best point small:\n")
text_file.write("M: %s\n" % inputs[0][0])
text_file.write("Z: %s\n" % inputs[0][1])
text_file.write("Xi: %s\n" % inputs[0][2])
text_file.write("ov: %s\n" % inputs[0][3])
text_file.write("D: %s\n" % inputs[0][4])
text_file.write("center_h1: %s\n" % inputs[0][5])
text_file.write("Best point has error: %s" % errors[0][0][0])
if star['settings']['match_mode'] == 'relative':
text_file.write("\nn_pg absolute index: %s" % errors[1][0])
else:
text_file.write("\nfreq, l, n_pg value table:\n")
for i in range(len(star['data'])):
text_file.write("%s %s %s\n" % (star['data'][i]['freq'], *(errors[1][i])))
text_file.close()
```
| github_jupyter |
TSG035 - Spark History logs
===========================
Description
-----------
Steps
-----
### Parameters
```
import re
tail_lines = 500
pod = None # All
container='hadoop-livy-sparkhistory'
log_files = [ "/var/log/supervisor/log/sparkhistory*" ]
expressions_to_analyze = [
re.compile(".{23} WARN "),
re.compile(".{23} ERROR ")
]
log_analyzer_rules = []
```
### Instantiate Kubernetes client
```
# Instantiate the Python Kubernetes client into 'api' variable
import os
from IPython.display import Markdown
try:
from kubernetes import client, config
from kubernetes.stream import stream
except ImportError:
# Install the Kubernetes module
import sys
!{sys.executable} -m pip install kubernetes
try:
from kubernetes import client, config
from kubernetes.stream import stream
except ImportError:
display(Markdown(f'HINT: Use [SOP059 - Install Kubernetes Python module](../install/sop059-install-kubernetes-module.ipynb) to resolve this issue.'))
raise
if "KUBERNETES_SERVICE_PORT" in os.environ and "KUBERNETES_SERVICE_HOST" in os.environ:
config.load_incluster_config()
else:
try:
config.load_kube_config()
except:
display(Markdown(f'HINT: Use [TSG118 - Configure Kubernetes config](../repair/tsg118-configure-kube-config.ipynb) to resolve this issue.'))
raise
api = client.CoreV1Api()
print('Kubernetes client instantiated')
```
### Get the namespace for the big data cluster
Get the namespace of the Big Data Cluster from the Kuberenetes API.
**NOTE:**
If there is more than one Big Data Cluster in the target Kubernetes
cluster, then either:
- set \[0\] to the correct value for the big data cluster.
- set the environment variable AZDATA\_NAMESPACE, before starting
Azure Data Studio.
```
# Place Kubernetes namespace name for BDC into 'namespace' variable
if "AZDATA_NAMESPACE" in os.environ:
namespace = os.environ["AZDATA_NAMESPACE"]
else:
try:
namespace = api.list_namespace(label_selector='MSSQL_CLUSTER').items[0].metadata.name
except IndexError:
from IPython.display import Markdown
display(Markdown(f'HINT: Use [TSG081 - Get namespaces (Kubernetes)](../monitor-k8s/tsg081-get-kubernetes-namespaces.ipynb) to resolve this issue.'))
display(Markdown(f'HINT: Use [TSG010 - Get configuration contexts](../monitor-k8s/tsg010-get-kubernetes-contexts.ipynb) to resolve this issue.'))
display(Markdown(f'HINT: Use [SOP011 - Set kubernetes configuration context](../common/sop011-set-kubernetes-context.ipynb) to resolve this issue.'))
raise
print('The kubernetes namespace for your big data cluster is: ' + namespace)
```
### Get tail for log
```
# Display the last 'tail_lines' of files in 'log_files' list
pods = api.list_namespaced_pod(namespace)
entries_for_analysis = []
for p in pods.items:
if pod is None or p.metadata.name == pod:
for c in p.spec.containers:
if container is None or c.name == container:
for log_file in log_files:
print (f"- LOGS: '{log_file}' for CONTAINER: '{c.name}' in POD: '{p.metadata.name}'")
try:
output = stream(api.connect_get_namespaced_pod_exec, p.metadata.name, namespace, command=['/bin/sh', '-c', f'tail -n {tail_lines} {log_file}'], container=c.name, stderr=True, stdout=True)
except Exception:
print (f"FAILED to get LOGS for CONTAINER: {c.name} in POD: {p.metadata.name}")
else:
for line in output.split('\n'):
for expression in expressions_to_analyze:
if expression.match(line):
entries_for_analysis.append(line)
print(line)
print("")
print(f"{len(entries_for_analysis)} log entries found for further analysis.")
```
### Analyze log entries and suggest relevant Troubleshooting Guides
```
# Analyze log entries and suggest further relevant troubleshooting guides
from IPython.display import Markdown
print(f"Applying the following {len(log_analyzer_rules)} rules to {len(entries_for_analysis)} log entries for analysis, looking for HINTs to further troubleshooting.")
print(log_analyzer_rules)
hints = 0
if len(log_analyzer_rules) > 0:
for entry in entries_for_analysis:
for rule in log_analyzer_rules:
if entry.find(rule[0]) != -1:
print (entry)
display(Markdown(f'HINT: Use [{rule[2]}]({rule[3]}) to resolve this issue.'))
hints = hints + 1
print("")
print(f"{len(entries_for_analysis)} log entries analyzed (using {len(log_analyzer_rules)} rules). {hints} further troubleshooting hints made inline.")
print("Notebook execution is complete.")
```
| github_jupyter |
## _*Using Qiskit Aqua for stable-set problems*_
This Qiskit Aqua Optimization notebook demonstrates how to use the VQE algorithm to compute the maximum stable set of a given graph.
The problem is defined as follows. Given a graph $G = (V,E)$, we want to compute $S \subseteq V$ such that there do not exist $i, j \in S : (i, j) \in E$, and $|S|$ is maximized. In other words, we are looking for a maximum cardinality set of mutually non-adjacent vertices.
The graph provided as an input is used first to generate an Ising Hamiltonian, which is then passed as an input to VQE. As a reference, this notebook also computes the maximum stable set using the Exact Eigensolver classical algorithm and the solver embedded in the commercial IBM CPLEX product (if it is available in the system and the user has followed the necessary configuration steps in order for Qiskit Aqua to find it). Please refer to the Qiskit Aqua Optimization documentation for installation and configuration details for CPLEX.
```
import numpy as np
from qiskit.aqua import Operator, run_algorithm
from qiskit.aqua.translators.ising import stable_set
from qiskit.aqua.input import EnergyInput
from qiskit.aqua.algorithms.classical.cplex.cplex_ising import CPLEX_Ising
from qiskit import Aer
```
Here an Operator instance is created for our Hamiltonian. In this case the Paulis are from an Ising Hamiltonian of the maximum stable set problem (expressed in minimization form). We load a small instance of the maximum stable set problem.
```
w = stable_set.parse_gset_format('sample.maxcut')
qubitOp, offset = stable_set.get_stable_set_qubitops(w)
algo_input = EnergyInput(qubitOp)
```
We also offer a function to generate a random graph as a input.
```
if True:
np.random.seed(8123179)
w = stable_set.random_graph(5, edge_prob=0.5)
qubitOp, offset = stable_set.get_stable_set_qubitops(w)
algo_input.qubit_op = qubitOp
print(w)
```
Here we test for the presence of algorithms we want to use in this notebook. If Aqua is installed correctly `ExactEigensolver` and `VQE` will always be found. `CPLEX.Ising` is dependent on IBM CPLEX being installed (see introduction above). CPLEX is *not required* but if installed then this notebook will demonstrate the `CPLEX.Ising` algorithm , that uses CPLEX, to compute stable set as well.
```
to_be_tested_algos = ['ExactEigensolver', 'CPLEX.Ising', 'VQE']
print(to_be_tested_algos)
```
We can now use the Operator without regard to how it was created. First we need to prepare the configuration params to invoke the algorithm. Here we will use the ExactEigensolver first to return the smallest eigenvalue. Backend is not required since this is computed classically not using quantum computation. We then add in the qubitOp Operator in dictionary format. Now the complete params can be passed to the algorithm and run. The result is a dictionary.
```
algorithm_cfg = {
'name': 'ExactEigensolver',
}
params = {
'problem': {'name': 'ising'},
'algorithm': algorithm_cfg
}
result = run_algorithm(params,algo_input)
x = stable_set.sample_most_likely(result['eigvecs'][0])
print('energy:', result['energy'])
print('stable set objective:', result['energy'] + offset)
print('solution:', stable_set.get_graph_solution(x))
print('solution objective and feasibility:', stable_set.stable_set_value(x, w))
```
*Note*: IBM CPLEX is an _optional_ installation addition for Aqua. If installed then the Aqua CPLEX.Ising algorithm will be able to be used. If not, then solving this problem using this particular algorithm will simply be skipped.
We change the configuration parameters to solve it with the CPLEX backend. The CPLEX backend can deal with a particular type of Hamiltonian called Ising Hamiltonian, which consists of only Pauli Z at most second order and can be used for combinatorial optimization problems that can be formulated as quadratic unconstrained binary optimization problems, such as the stable set problem. Note that we may obtain a different solution - but if the objective value is the same as above, the solution will be optimal.
```
cplex_installed = True
try:
CPLEX_Ising.check_pluggable_valid()
except Exception as e:
cplex_installed = False
if cplex_installed:
algorithm_cfg = {
'name': 'CPLEX.Ising',
'display': 0
}
params = {
'problem': {'name': 'ising'},
'algorithm': algorithm_cfg
}
result = run_algorithm(params, algo_input)
x_dict = result['x_sol']
print('energy:', result['energy'])
print('time:', result['eval_time'])
print('stable set objective:', result['energy'] + offset)
x = np.array([x_dict[i] for i in sorted(x_dict.keys())])
print('solution:', stable_set.get_graph_solution(x))
print('solution objective and feasibility:', stable_set.stable_set_value(x, w))
```
Now we want VQE and so change it and add its other configuration parameters. VQE also needs and optimizer and variational form. While we can omit them from the dictionary, such that defaults are used, here we specify them explicitly so we can set their parameters as we desire.
```
algorithm_cfg = {
'name': 'VQE',
'operator_mode': 'matrix'
}
optimizer_cfg = {
'name': 'L_BFGS_B',
'maxfun': 2000
}
var_form_cfg = {
'name': 'RYRZ',
'depth': 3,
'entanglement': 'linear'
}
params = {
'problem': {'name': 'ising'},
'algorithm': algorithm_cfg,
'optimizer': optimizer_cfg,
'variational_form': var_form_cfg
}
backend = Aer.get_backend('statevector_simulator')
result = run_algorithm(params, algo_input, backend=backend)
x = stable_set.sample_most_likely(result['eigvecs'][0])
print('energy:', result['energy'])
print('time:', result['eval_time'])
print('stable set objective:', result['energy'] + offset)
print('solution:', stable_set.get_graph_solution(x))
print('solution objective and feasibility:', stable_set.stable_set_value(x, w))
```
| github_jupyter |
<a href="https://colab.research.google.com/github/cxbxmxcx/EvolutionaryDeepLearning/blob/main/EDL_3_1_OneMax_DEAP.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
Original Source: https://github.com/DEAP/deap/blob/master/examples/ga/onemax_numpy.py
DEAP is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
DEAP is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with DEAP. If not, see <http://www.gnu.org/licenses/>.
```
#@title Install DEAP
!pip install deap --quiet
#@title Imports
import random
import numpy
from deap import algorithms
from deap import base
from deap import creator
from deap import tools
#@title Setup Fitness Criteria
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", numpy.ndarray, fitness=creator.FitnessMax)
#@title Open the Toolbox
toolbox = base.Toolbox()
toolbox.register("attr_bool", random.randint, 0, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_bool, n=100)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
#@title Define a Fitness Function
def evalOneMax(individual):
return sum(individual),
#@title Define a Crossover Function
def cxTwoPointCopy(ind1, ind2):
"""Execute a two points crossover with copy on the input individuals. The
copy is required because the slicing in numpy returns a view of the data,
which leads to a self overwritting in the swap operation. It prevents
::
>>> import numpy
>>> a = numpy.array((1,2,3,4))
>>> b = numpy.array((5,6,7,8))
>>> a[1:3], b[1:3] = b[1:3], a[1:3]
>>> print(a)
[1 6 7 4]
>>> print(b)
[5 6 7 8]
"""
size = len(ind1)
cxpoint1 = random.randint(1, size)
cxpoint2 = random.randint(1, size - 1)
if cxpoint2 >= cxpoint1:
cxpoint2 += 1
else: # Swap the two cx points
cxpoint1, cxpoint2 = cxpoint2, cxpoint1
ind1[cxpoint1:cxpoint2], ind2[cxpoint1:cxpoint2] \
= ind2[cxpoint1:cxpoint2].copy(), ind1[cxpoint1:cxpoint2].copy()
return ind1, ind2
#@title Add Genetic Operators to Toolbox
toolbox.register("evaluate", evalOneMax)
toolbox.register("mate", cxTwoPointCopy)
toolbox.register("mutate", tools.mutFlipBit, indpb=0.05)
toolbox.register("select", tools.selTournament, tournsize=3)
#@title Run the Evolution
random.seed(64)
pop = toolbox.population(n=300)
# Numpy equality function (operators.eq) between two arrays returns the
# equality element wise, which raises an exception in the if similar()
# check of the hall of fame. Using a different equality function like
# numpy.array_equal or numpy.allclose solve this issue.
hof = tools.HallOfFame(1, similar=numpy.array_equal)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean)
stats.register("std", numpy.std)
stats.register("min", numpy.min)
stats.register("max", numpy.max)
algorithms.eaSimple(pop, toolbox, cxpb=0.5, mutpb=0.2, ngen=40, stats=stats,
halloffame=hof,verbose=None)
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import tracktor as tr
import cv2
import sys
import scipy.signal
from scipy.optimize import linear_sum_assignment
from scipy.spatial.distance import cdist
```
## Global parameters
This cell (below) enlists user-defined parameters
```
# colours is a vector of BGR values which are used to identify individuals in the video
# since we only have one individual, the program will only use the first element from this array i.e. (0,0,255) - red
# number of elements in colours should be greater than n_inds (THIS IS NECESSARY FOR VISUALISATION ONLY)
n_inds = 1
colours = [(0,0,255),(0,255,255),(255,0,255),(255,255,255),(255,255,0),(255,0,0),(0,255,0),(0,0,0)]
# this is the block_size and offset used for adaptive thresholding (block_size should always be odd)
# these values are critical for tracking performance
block_size = 1201
offset = 100
# the scaling parameter can be used to speed up tracking if video resolution is too high (use value 0-1)
scaling = 1.0
# minimum area and maximum area occupied by the animal in number of pixels
# this parameter is used to get rid of other objects in view that might be hard to threshold out but are differently sized
min_area = 1000
max_area = 10000
# mot determines whether the tracker is being used in noisy conditions to track a single object or for multi-object
# using this will enable k-means clustering to force n_inds number of animals
mot = False
# name of source video and paths
video = 'tractor_video'
input_vidpath = '/mnt/ssd1/Documents/Vivek/tracktor/videos/' + video + '.mp4'
output_vidpath = '/mnt/ssd1/Documents/Vivek/tracktor/output/' + video + '_tracked.mp4'
output_filepath = '/mnt/ssd1/Documents/Vivek/tracktor/output/' + video + '_tracked.csv'
codec = 'DIVX' # try other codecs if the default doesn't work ('DIVX', 'avc1', 'XVID') note: this list is non-exhaustive
## Open video
cap = cv2.VideoCapture(input_vidpath)
if cap.isOpened() == False:
sys.exit('Video file cannot be read! Please check input_vidpath to ensure it is correctly pointing to the video file')
## Video writer class to output video with contour and centroid of tracked object(s)
# make sure the frame size matches size of array 'final'
fourcc = cv2.VideoWriter_fourcc(*codec)
output_framesize = (int(cap.read()[1].shape[1]*scaling),int(cap.read()[1].shape[0]*scaling))
out = cv2.VideoWriter(filename = output_vidpath, fourcc = fourcc, fps = 30.0, frameSize = output_framesize, isColor = True)
## Individual location(s) measured in the last and current step
meas_last = list(np.zeros((n_inds,2)))
meas_now = list(np.zeros((n_inds,2)))
last = 0
df = []
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
this = cap.get(1)
if ret == True:
frame = cv2.resize(frame, None, fx = scaling, fy = scaling, interpolation = cv2.INTER_LINEAR)
redch = frame[...,2]
redch = 255-redch
redch = redch[...,np.newaxis]
frame_red = np.concatenate((redch, redch, redch), axis=2)
thresh = tr.colour_to_thresh(frame_red, block_size, offset)
final, contours, meas_last, meas_now = tr.detect_and_draw_contours(frame, thresh, meas_last, meas_now, min_area, max_area)
row_ind, col_ind = tr.hungarian_algorithm(meas_last, meas_now)
final, meas_now, df = tr.reorder_and_draw(final, colours, n_inds, col_ind, meas_now, df, mot, this)
# Create output dataframe
for i in range(n_inds):
df.append([this, meas_now[i][0], meas_now[i][1]])
# Display the resulting frame
out.write(final)
cv2.imshow('frame', final)
if cv2.waitKey(1) == 27:
break
if last >= this:
break
last = this
## Write positions to file
df = pd.DataFrame(np.matrix(df), columns = ['frame','pos_x','pos_y'])
df.to_csv(output_filepath, sep=',')
## When everything done, release the capture
cap.release()
out.release()
cv2.destroyAllWindows()
cv2.waitKey(1)
```
| github_jupyter |
# Recurrent Neural Network in TensorFlow
Credits: Forked from [TensorFlow-Examples](https://github.com/aymericdamien/TensorFlow-Examples) by Aymeric Damien
## Setup
Refer to the [setup instructions](http://nbviewer.ipython.org/github/donnemartin/data-science-ipython-notebooks/blob/master/deep-learning/tensor-flow-examples/Setup_TensorFlow.md)
```
# Import MINST data
import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
import tensorflow as tf
from tensorflow.models.rnn import rnn, rnn_cell
import numpy as np
'''
To classify images using a reccurent neural network, we consider every image row as a sequence of pixels.
Because MNIST image shape is 28*28px, we will then handle 28 sequences of 28 steps for every sample.
'''
# Parameters
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10
# Network Parameters
n_input = 28 # MNIST data input (img shape: 28*28)
n_steps = 28 # timesteps
n_hidden = 128 # hidden layer num of features
n_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_steps, n_input])
istate = tf.placeholder("float", [None, 2*n_hidden]) #state & cell => 2x n_hidden
y = tf.placeholder("float", [None, n_classes])
# Define weights
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # Hidden layer weights
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
def RNN(_X, _istate, _weights, _biases):
# input shape: (batch_size, n_steps, n_input)
_X = tf.transpose(_X, [1, 0, 2]) # permute n_steps and batch_size
# Reshape to prepare input to hidden activation
_X = tf.reshape(_X, [-1, n_input]) # (n_steps*batch_size, n_input)
# Linear activation
_X = tf.matmul(_X, _weights['hidden']) + _biases['hidden']
# Define a lstm cell with tensorflow
lstm_cell = rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0)
# Split data because rnn cell needs a list of inputs for the RNN inner loop
_X = tf.split(0, n_steps, _X) # n_steps * (batch_size, n_hidden)
# Get lstm cell output
outputs, states = rnn.rnn(lstm_cell, _X, initial_state=_istate)
# Linear activation
# Get inner loop last output
return tf.matmul(outputs[-1], _weights['out']) + _biases['out']
pred = RNN(x, istate, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) # Softmax loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Reshape data to get 28 seq of 28 elements
batch_xs = batch_xs.reshape((batch_size, n_steps, n_input))
# Fit training using batch data
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2*n_hidden))})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2*n_hidden))})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2*n_hidden))})
print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + \
", Training Accuracy= " + "{:.5f}".format(acc)
step += 1
print "Optimization Finished!"
# Calculate accuracy for 256 mnist test images
test_len = 256
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label,
istate: np.zeros((test_len, 2*n_hidden))})
```
| github_jupyter |
```
import pandas as pd
import os.path
root_path = os.path.dirname(os.getcwd())
# Import food inspection data
inspections = pd.read_csv(os.path.join(root_path, "DATA/food_inspections.csv"))
# Generate column names
critical_columns = [("v_" + str(num)) for num in range(1, 15)]
serious_columns = [("v_" + str(num)) for num in range(15, 30)]
minor_columns = [("v_" + str(num)) for num in range(30, 45)]
minor_columns.append("v_70")
columns = critical_columns + serious_columns + minor_columns
# Split violations into binary values for each violation
def split_violations(violations):
values_row = pd.Series([])
if type(violations) == str:
violations = violations.split(' | ')
for violation in violations:
index = "v_" + violation.split('.')[0]
values_row[index] = 1
return values_row
# 5 mins
values_data = inspections.violations.apply(split_violations)
# Ensure no missing columns, fill NaN
values = pd.DataFrame(values_data, columns=columns).fillna(0)
values['inspection_id'] = inspections.inspection_id
# Count violations
counts = pd.DataFrame({
"critical_count": values[critical_columns].sum(axis=1),
"serious_count": values[serious_columns].sum(axis=1),
"minor_count": values[minor_columns].sum(axis=1)
})
counts['inspection_id'] = inspections.inspection_id
titles = pd.DataFrame({
"v_1": "Approved food sources (1)",
"v_2": "Hot/cold storage facilities (2)",
"v_3": "Hot/cold storage temp. (3)",
"v_4": "Contaminant protection (4)",
"v_5": "No sick handlers (5)",
"v_6": "Proper hand washing (6)",
"v_7": "Proper utensil washing (7)",
"v_8": "Proper sanitizing solution (8)",
"v_9": "Hot/cold water supply (9)",
"v_10": "Waste water disposal (10)",
"v_11": "Adequate toilet facilities (11)",
"v_12": "Adequate hand washing facilities (12)",
"v_13": "Control of rodents, other pests (13)",
"v_14": "Correct serious violations (14)",
"v_15": "No re-served food (15)",
"v_16": "Protection from contamination (16)",
"v_17": "Proper thawing (17)",
"v_18": "Pest control, associated areas (18)",
"v_19": "Proper garbage area (19)",
"v_20": "Proper garbage storage (20)",
"v_21": "Oversight of hazardous food (21)",
"v_22": "Dishwasher maintenance (22)",
"v_23": "Scrape before washing (23)",
"v_24": "Proper dishwashers (24)",
"v_25": "Minimize toxic materials (25)",
"v_26": "Adequate customer toilets (26)",
"v_27": "Supplied toilet facilities (27)",
"v_28": "Visible inspection report (28)",
"v_29": "Correct minor violations (29)",
"v_30": "Labelled containers (30)",
"v_31": "Sterile utensils (31)",
"v_32": "Clean, maintain equipment (32)",
"v_33": "Clean, sanitize utensils (33)",
"v_34": "Clean, maintain floor (34)",
"v_35": "Maintain walls & ceiling (35)",
"v_36": "Proper lighting (36)",
"v_37": "Toilet rooms vented (37)",
"v_38": "Proper venting, plumbing (38)",
"v_39": "Linen, clothing storage (39)",
"v_40": "Proper thermometers (40)",
"v_41": "Clean facilities, store supplies (41)",
"v_42": "Ice handling, hairnets, clothes (42)",
"v_43": "Ice equipment storage (43)",
"v_44": "Restrict prep area traffic (44)",
"v_70": "Restrict smoking (70)"
}, index=[0])
import os.path
root_path = os.path.dirname(os.getcwd())
# Save results
values.to_csv(os.path.join(root_path, "DATA/violation_values.csv"), index=False)
counts.to_csv(os.path.join(root_path, "DATA/violation_counts.csv"), index=False)
titles.to_csv(os.path.join(root_path, "DATA/violation_titles.csv"), index=False)
```
| github_jupyter |
# WordRank wrapper tutorial on Lee Corpus
WordRank is a new word embedding algorithm which captures the semantic similarities in a text data well. See this [notebook](https://github.com/RaRe-Technologies/gensim/blob/develop/docs/notebooks/Wordrank_comparisons.ipynb) for it's comparisons to other popular embedding models. This tutorial will serve as a guide to use the WordRank wrapper in gensim. You need to install [WordRank](https://bitbucket.org/shihaoji/wordrank) before proceeding with this tutorial.
# Train model
We'll use [Lee corpus](https://github.com/RaRe-Technologies/gensim/blob/develop/gensim/test/test_data/lee.cor) for training which is already available in gensim. Now for Wordrank, two parameters `dump_period` and `iter` needs to be in sync as it dumps the embedding file with the start of next iteration. For example, if you want results after 10 iterations, you need to use `iter=11` and `dump_period` can be anything that gives mod 0 with resulting iteration, in this case 2 or 5.
```
from gensim.models.wrappers import Wordrank
wr_path = 'wordrank' # path to Wordrank directory
out_dir = 'model' # name of output directory to save data to
data = '../../gensim/test/test_data/lee.cor' # sample corpus
model = Wordrank.train(wr_path, data, out_dir, iter=11, dump_period=5)
```
Now, you can use any of the Keyed Vector function in gensim, on this model for further tasks. For example,
```
model.most_similar('President')
model.similarity('President', 'military')
```
As Wordrank provides two sets of embeddings, the word and context embedding, you can obtain their addition by setting ensemble parameter to 1 in the train method.
# Save and Load models
In case, you have trained the model yourself using demo scripts in Wordrank, you can then simply load the embedding files in gensim.
Also, Wordrank doesn't return the embeddings sorted according to the word frequency in corpus, so you can use the sorted_vocab parameter in the load method. But for that, you need to provide the vocabulary file generated in the 'matrix.toy' directory(if you used default names in demo) where all the metadata is stored.
```
wr_word_embedding = 'wordrank.words'
vocab_file = 'vocab.txt'
model = Wordrank.load_wordrank_model(wr_word_embedding, vocab_file, sorted_vocab=1)
```
If you want to load the ensemble embedding, you similarly need to provide the context embedding file and set ensemble to 1 in `load_wordrank_model` method.
```
wr_context_file = 'wordrank.contexts'
model = Wordrank.load_wordrank_model(wr_word_embedding, vocab_file, wr_context_file, sorted_vocab=1, ensemble=1)
```
You can save these sorted embeddings using the standard gensim methods.
```
from tempfile import mkstemp
fs, temp_path = mkstemp("gensim_temp") # creates a temp file
model.save(temp_path) # save the model
```
# Evaluating models
Now that the embeddings are loaded in Word2Vec format and sorted according to the word frequencies in corpus, you can use the evaluations provided by gensim on this model.
For example, it can be evaluated on following Word Analogies and Word Similarity benchmarks.
```
word_analogies_file = 'datasets/questions-words.txt'
model.accuracy(word_analogies_file)
word_similarity_file = 'datasets/ws-353.txt'
model.evaluate_word_pairs(word_similarity_file)
```
These methods take an [optional parameter](http://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Word2Vec.accuracy) restrict_vocab which limits which test examples are to be considered.
The results here don't look good because the training corpus is very small. To get meaningful results one needs to train on 500k+ words.
# Conclusion
We learned to use Wordrank wrapper on a sample corpus and also how to directly load the Wordrank embedding files in gensim. Once loaded, you can use the standard gensim methods on this embedding.
| github_jupyter |
```
# Let printing work the same in Python 2 and 3
from __future__ import print_function
```
# Matplotlib
## Introduction
Matplotlib is a library for producing publication-quality figures. mpl (for short) was designed from the beginning to serve two purposes:
1. allow for interactive, cross-platform control of figures and plots
2. make it easy to produce static raster or vector graphics files without the need for any GUIs.
Furthermore, mpl -- much like Python itself -- gives the developer complete control over the appearance of their plots, while still being very usable through a powerful defaults system.
## Online Documentation
The [matplotlib.org](http://matplotlib.org) project website is the primary online resource for the library's documentation. It contains the [example galleries](https://matplotlib.org/gallery/index.html), [FAQs](http://matplotlib.org/faq/index.html), [API documentation](http://matplotlib.org/api/index.html), and [tutorials](https://matplotlib.org/tutorials/index.html).
## Gallery
Many users of Matplotlib are often faced with the question, "I want to make a figure that has X with Y in the same figure, but it needs to look like Z". Good luck getting an answer from a web search with that query! This is why the [gallery](https://matplotlib.org/gallery/index.html) is so useful, because it showcases the variety of ways one can make figures. Browse through the gallery, click on any figure that has pieces of what you want to see and the code that generated it. Soon enough, you will be like a chef, mixing and matching components to produce your masterpiece!
As always, if you have a new and interesting plot that demonstrates a feature of Matplotlib, feel free to submit a concise, well-commented version of the code for inclusion in the gallery.
## Mailing Lists, StackOverflow, and gitter
When you are just simply stuck, and cannot figure out how to get something to work, or just need some hints on how to get started, you will find much of the community at the matplotlib-users [mailing list](https://mail.python.org/mailman/listinfo/matplotlib-users). This mailing list is an excellent resource of information with many friendly members who just love to help out newcomers. We love plots, so an image showing what is wrong often gets the quickest responses.
Another community resource is [StackOverflow](http://stackoverflow.com/questions/tagged/matplotlib), so if you need to build up karma points, submit your questions here, and help others out too!
We are also on [Gitter](https://gitter.im/matplotlib/matplotlib).
## Github repository
### Location
[Matplotlib](https://github.com/matplotlib) is hosted by GitHub.
### Bug Reports and feature requests
So, you think you found a bug? Or maybe you think some feature is just too difficult to use? Or missing altogether? Submit your bug reports [here](https://github.com/matplotlib/matplotlib/issues) at Matplotlib's issue tracker. We even have a process for submitting and discussing Matplotlib Enhancement Proposals ([MEPs](https://matplotlib.org/devel/MEP/index.html)).
# Quick note on "backends" and Jupyter notebooks
Matplotlib has multiple "backends" that handle converting Matplotlib's in-memory representation of your plot into the colorful output you can look at. This is done either by writing files (e.g., png, svg, pdf) that you can use an external tool to look at or by embedding into your GUI toolkit of choice (Qt, Tk, Wx, etc).
To check what backend Matplotlib is currently using:
```
import matplotlib
print(matplotlib.__version__)
print(matplotlib.get_backend())
```
If you are working interactively at an (I)python prompt, the GUI framework is not critical (mostly aesthetic) however when working in Jupyter we need to pick a backend that integrates with Jupyter (javascript) framework.
To select the backend use ``matplotlib.use("backend_name")``, in this case we want ``'nbagg'``
```
matplotlib.use('nbagg')
print(matplotlib.get_backend())
```
which must be done *before* you `import matplotlib.pyplot as plt`.
You can also set the backend via an 'ipython magic' ``%matplotlib backend_name``. In addition to setting the backend, the magic also calls `plt.ion()`, which puts Matplotlib in 'interacitve mode' (the inverse is `plt.ioff()`). In 'interactive mode' figures are shown (injected into the web page in the notebook) as soon as they are created. Otherwise, figures are not shown until you explicitly call `plt.show()`.
In these tutorials we will mostly work in non-interactive mode for better control of when
figures are shown in the notebooks.
This also better mimics the behavior you can expect in regular python scripts.
# On with the show!
Matplotlib is a large project and can seem daunting at first. However, by learning the components, it should begin to feel much smaller and more approachable.
## Anatomy of a "Plot"
People use "plot" to mean many different things. Here, we'll be using a consistent terminology (mirrored by the names of the underlying classes, etc):
<img src="images/figure_axes_axis_labeled.png">
The ``Figure`` is the top-level container in this hierarchy. It is the overall window/page that everything is drawn on. You can have multiple independent figures and ``Figure``s can contain multiple ``Axes``.
Most plotting ocurs on an ``Axes``. The axes is effectively the area that we plot data on and any ticks/labels/etc associated with it. Usually we'll set up an Axes with a call to ``subplot`` (which places Axes on a regular grid), so in most cases, ``Axes`` and ``Subplot`` are synonymous.
Each ``Axes`` has an ``XAxis`` and a ``YAxis``. These contain the ticks, tick locations, labels, etc. In this tutorial, we'll mostly control ticks, tick labels, and data limits through other mechanisms, so we won't touch the individual ``Axis`` part of things all that much. However, it is worth mentioning here to explain where the term ``Axes`` comes from.
## Getting Started
In this tutorial, we'll use the following import statements. These abbreviations are semi-standardized, and most tutorials, other scientific python code that you'll find elsewhere will use them as well.
```
import numpy as np
import matplotlib.pyplot as plt
```
### Figures
Now let's create a figure...
```
fig = plt.figure(facecolor=(1, 0, 0, .1)) # red background to see where the figure is
```
Awww, nothing happened! This is because by default mpl will not show anything until told to do so, as we mentioned earlier in the "backend" discussion.
Instead, we'll need to call ``plt.show()``
```
plt.show()
```
Great, a blank figure! Not terribly useful yet.
However, while we're on the topic, you can control the size of the figure through the ``figsize`` argument, which expects a tuple of ``(width, height)`` in inches.
A really useful utility function is [`figaspect`](https://matplotlib.org/api/_as_gen/matplotlib.figure.figaspect.html?highlight=figaspect#matplotlib.figure.figaspect)
```
# Twice as tall as it is wide:
fig = plt.figure(figsize=plt.figaspect(2.0), facecolor=(1, 0, 0, .1))
plt.show()
```
# Axes
All plotting is done with respect to an [`Axes`](http://matplotlib.org/api/axes_api.html#matplotlib.axes.Axes). An *Axes* is made up of [`Axis`](http://matplotlib.org/api/axis_api.html#matplotlib.axis.Axis) objects and many other things. An *Axes* object must belong to a *Figure* (and only one *Figure*). Most commands you will ever issue will be with respect to this *Axes* object.
Typically, you'll set up a `Figure`, and then add an `Axes` to it.
You can use `fig.add_axes`, but in most cases, you'll find that adding a subplot will fit your needs perfectly. (Again a "subplot" is just an axes on a grid system.)
```
fig = plt.figure()
ax = fig.add_subplot(111) # We'll explain the "111" later. Basically, 1 row and 1 column.
ax.set(xlim=[0.5, 4.5], ylim=[-2, 8], title='An Example Axes',
ylabel='Y-Axis', xlabel='X-Axis')
plt.show()
```
Notice the call to ``set``. Matplotlib's objects typically have lots of "explicit setters" -- in other words, functions that start with ``set_<something>`` and control a particular option.
To demonstrate this (and as an example of IPython's tab-completion), try typing `ax.set_` in a code cell, then hit the `<Tab>` key. You'll see a long list of `Axes` methods that start with `set`.
For example, we could have written the third line above as:
```
ax.set_xlim([0.5, 4.5])
ax.set_ylim([-2, 8])
ax.set_title('A Different Example Axes Title')
ax.set_ylabel('Y-Axis (changed)')
ax.set_xlabel('X-Axis (changed)')
plt.show()
```
Clearly this can get repitive quickly. Therefore, Matplotlib's `set` method can be very handy. It takes each kwarg you pass it and tries to call the corresponding "setter". For example, `foo.set(bar='blah')` would call `foo.set_bar('blah')`.
Note that the `set` method doesn't just apply to `Axes`; it applies to more-or-less all matplotlib objects.
However, there are cases where you'll want to use things like `ax.set_xlabel('Some Label', size=25)` to control other options for a particular function.
## Basic Plotting
Most plotting happens on an `Axes`. Therefore, if you're plotting something on an axes, then you'll use one of its methods.
We'll talk about different plotting methods in more depth in the next section. For now, let's focus on two methods: `plot` and `scatter`.
`plot` draws points with lines connecting them. `scatter` draws unconnected points, optionally scaled or colored by additional variables.
As a basic example:
```
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot([1, 2, 3, 4], [10, 20, 25, 30], color='lightblue', linewidth=3)
ax.scatter([0.3, 3.8, 1.2, 2.5], [11, 25, 9, 26], c=[1, 2, 3, 5], marker='^')
ax.set_xlim(0.5, 4.5)
plt.show()
```
## Axes methods vs. pyplot
Interestingly, just about all methods of an *Axes* object exist as a function in the *pyplot* module (and vice-versa). For example, when calling `plt.xlim(1, 10)`, *pyplot* calls `ax.set_xlim(1, 10)` on whichever *Axes* is "current". Here is an equivalent version of the above example using just pyplot.
```
plt.plot([1, 2, 3, 4], [10, 20, 25, 30], color='lightblue', linewidth=3)
plt.scatter([0.3, 3.8, 1.2, 2.5], [11, 25, 9, 26], c=[1, 2, 3, 5], marker='^')
plt.xlim(0.5, 4.5)
plt.show()
```
That is a bit terser and has fewer local varialbes, so, why will most of my examples not follow the pyplot approach? Because [PEP20](http://www.python.org/dev/peps/pep-0020/) "The Zen of Python" says:
"Explicit is better than implicit"
While very simple plots, with short scripts would benefit from the conciseness of the pyplot implicit approach, when doing more complicated plots, or working within larger scripts, you will want to explicitly pass around the *Axes* and/or *Figure* object to operate upon.
The advantage of keeping which axes we're working with very clear in our code will become more obvious when we start to have multiple axes in one figure.
### Multiple Axes
We've mentioned before that a figure can have more than one `Axes` on it. If you want your axes to be on a regular grid system, then it's easiest to use `plt.subplots(...)` to create a figure and add the axes to it automatically.
For example:
```
fig, axes = plt.subplots(nrows=2, ncols=2)
plt.show()
```
`plt.subplots(...)` created a new figure and added 4 subplots to it. The `axes` object that was returned is a 2D numpy object array. Each item in the array is one of the subplots. They're laid out as you see them on the figure.
Therefore, when we want to work with one of these axes, we can index the `axes` array and use that item's methods.
For example:
```
fig, axes = plt.subplots(nrows=2, ncols=2)
axes[0,0].set(title='Upper Left')
axes[0,1].set(title='Upper Right')
axes[1,0].set(title='Lower Left')
axes[1,1].set(title='Lower Right')
# To iterate over all items in a multidimensional numpy array, use the `flat` attribute
for ax in axes.flat:
# Remove all xticks and yticks...
ax.set(xticks=[], yticks=[])
plt.show()
```
One really nice thing about `plt.subplots()` is that when it's called with no arguments, it creates a new figure with a single subplot.
Any time you see something like
```
fig = plt.figure()
ax = fig.add_subplot(111)
```
You can replace it with:
```
fig, ax = plt.subplots()
```
We'll be using that approach for the rest of the examples. It's much cleaner.
However, keep in mind that we're still creating a figure and adding axes to it. When we start making plot layouts that can't be described by `subplots`, we'll go back to creating the figure first and then adding axes to it one-by-one.
Quick Exercise: Exercise 1.1
--------------
Let's use some of what we've been talking about. Can you reproduce this figure?
<img src="images/exercise_1-1.png">
Here's the data and some code to get you started.
```
# %load exercises/1.1-subplots_and_basic_plotting.py
import numpy as np
import matplotlib.pyplot as plt
# Try to reproduce the figure shown in images/exercise_1-1.png
# Our data...
x = np.linspace(0, 10, 100)
y1, y2, y3 = np.cos(x), np.cos(x + 1), np.cos(x + 2)
names = ['Signal 1', 'Signal 2', 'Signal 3']
# Can you figure out what to do next to plot x vs y1, y2, and y3 on one figure?
import numpy as np
import matplotlib.pyplot as plt
# Try to reproduce the figure shown in images/exercise_1-1.png
# Our data...
x = np.linspace(0, 10, 100)
y1, y2, y3 = np.cos(x), np.cos(x + 1), np.cos(x + 2)
names = ['Signal 1', 'Signal 2', 'Signal 3']
# Can you figure out what to do next to plot x vs y1, y2, and y3 on one figure?
```
| github_jupyter |
```
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn import metrics
%matplotlib inline
```
# Load data
```
y_score_30_rf = pd.read_csv("plot metric/y_score_30_rf.csv",header = None)
y_score_1y_rf = pd.read_csv("plot metric/y_score_1y_rf.csv",header = None)
y_score_30_linreg = pd.read_csv("plot metric/y_score_30_linreg.csv",header = None)
y_score_1y_linreg = pd.read_csv("plot metric/y_score_1y_linreg.csv",header = None)
y_score_30_logreg = pd.read_csv("plot metric/y_score_30_logreg.csv",header = None)
y_score_1y_logreg = pd.read_csv("plot metric/y_score_1y_logreg.csv",header = None)
y_score_30_simple = pd.read_csv("plot metric/y_score_30_simple.csv")
y_score_1y_simple = pd.read_csv("plot metric/y_score_1y_simple.csv")
y_score_30_vgg = pd.read_csv("plot metric/y_score_30_vgg.csv")
y_score_1y_vgg = pd.read_csv("plot metric/y_score_1y_vgg.csv")
y_score_30_GNB = pd.read_csv("plot metric/y_score_30_GNB.csv",header = None)
y_score_1y_GNB = pd.read_csv("plot metric/y_score_1y_GNB.csv",header = None)
y_score_30_xgtree = pd.read_csv("plot metric/y_score_30_xgboost.csv",header = None)
y_score_1y_xgtree = pd.read_csv("plot metric/y_score_1y_xgboost.csv",header = None)
y_score_30_kNN = pd.read_csv("plot metric/y_score_30_kNN.csv",header = None)
y_score_1y_kNN = pd.read_csv("plot metric/y_score_1y_kNN.csv",header = None)
test_1y = pd.read_csv("data_pp_test_1y.csv")
test_30 = pd.read_csv("data_pp_test_30d.csv")
y_test_1y = test_1y['one_year']
y_test_30 = test_30['thirty_days']
```
# Plot ROC of different models predicting 1 year mortality.
```
def plot_ROC(fpr, tpr, auc,name='', title = 'ROC curve'):
sns.set_style('whitegrid')
# plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr, tpr, label='{}: (AUC = {:.3f})'.format(name,auc))
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title(title)
plt.legend(loc='best')
plt.rcParams.update({'font.size': 18})
# plt.show()
pass
plt.rcParams.update({'font.size': 18})
plt.figure(figsize=(16,12))
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_vgg)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'VGG')
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_simple)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Simple CNN')
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_linreg)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Linear Reg')
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_logreg)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Logistic Reg')
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_kNN)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'kNN')
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_GNB)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'GNB')
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_xgtree)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'xgtree')
fpr, tpr, thresholds = metrics.roc_curve(y_test_1y, y_score_1y_rf)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Random Forest',title = 'ROC of different model predicting 1 year mortality')
```
# Plot ROC of different models predicting 30 day mortality.
```
plt.figure(figsize=(16,12))
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_vgg)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'VGG')
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_simple)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Simple CNN')
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_linreg)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Linear Reg')
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_logreg)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Logistic Reg')
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_kNN)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'kNN')
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_GNB)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'GNB')
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_xgtree)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'xgtree')
fpr, tpr, thresholds = metrics.roc_curve(y_test_30, y_score_30_rf)
auc = metrics.auc(fpr, tpr)
plot_ROC(fpr, tpr, auc,name = 'Random Forest',title = 'ROC of different model predicting 30 day mortality')
```
# Plot Precision-Recall Curve of different models predicting 1 year mortality.
```
def plot_PRC(precision, recall, ap, name = '',title= 'Precision-Recall Curve'):
sns.set_style('whitegrid')
# plt.figure()
plt.plot(recall, precision, lw=2, label='{}: (AUC = {:.4f})'.format(name,ap))
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title(title)
plt.legend(loc='lower left')
plt.rcParams.update({'font.size': 18})
return
plt.figure(figsize=(16,12))
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_vgg)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_vgg)
plot_PRC(precision, recall, average_precision,name = 'VGG')
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_simple)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_simple)
plot_PRC(precision, recall, average_precision,name = 'Simple CNN')
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_logreg)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_logreg)
plot_PRC(precision, recall, average_precision,name = 'Logistic Reg')
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_linreg)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_linreg)
plot_PRC(precision, recall, average_precision,name = 'Linear Reg')
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_kNN)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_kNN)
plot_PRC(precision, recall, average_precision,name = 'kNN')
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_GNB)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_GNB)
plot_PRC(precision, recall, average_precision,name = 'GNB')
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_xgtree)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_xgtree)
plot_PRC(precision, recall, average_precision,name = 'xgtree')
precision, recall, _ = metrics.precision_recall_curve(y_test_1y, y_score_1y_rf)
average_precision = metrics.average_precision_score(y_test_1y, y_score_1y_rf)
plot_PRC(precision, recall, average_precision,name = 'Random Forest',title = 'Precision-Recall Curve of different model predicting 1 year mortality')
```
# Plot Precision-Recall Curve of different models predicting 30 day mortality.
```
plt.figure(figsize=(16,12))
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_vgg)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_vgg)
plot_PRC(precision, recall, average_precision,name = 'VGG')
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_simple)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_simple)
plot_PRC(precision, recall, average_precision,name = 'Simple CNN')
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_logreg)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_logreg)
plot_PRC(precision, recall, average_precision,name = 'Logistic Reg')
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_linreg)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_linreg)
plot_PRC(precision, recall, average_precision,name = 'Linear Reg')
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_kNN)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_kNN)
plot_PRC(precision, recall, average_precision,name = 'kNN')
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_GNB)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_GNB)
plot_PRC(precision, recall, average_precision,name = 'GNB')
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_xgtree)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_xgtree)
plot_PRC(precision, recall, average_precision,name = 'xgtree')
precision, recall, _ = metrics.precision_recall_curve(y_test_30, y_score_30_rf)
average_precision = metrics.average_precision_score(y_test_30, y_score_30_rf)
plot_PRC(precision, recall, average_precision,name = 'Random Forest',title = 'Precision-Recall Curve of different model predicting 30 day mortality')
```
# Confusion matrix
```
def probability_to_label(probabilities, threshold=0.5):
probabilities = list(probabilities)
th = threshold
predictions = [1 if i > th else 0 for i in probabilities]
return predictions
def plot_cm(y_test, y_score, title='Confusion Matrix', cmap=plt.cm.Blues):
y_pred = probability_to_label(y_score, threshold=0.5)
sns.set_style('white')
cm = metrics.confusion_matrix(y_test, y_pred)
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] # normarlize
from sklearn.utils.multiclass import unique_labels
classes = unique_labels(y_test, y_pred)
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=cmap)
ax.figure.colorbar(im, ax=ax)
# We want to show all ticks...
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
# ... and label them with the respective list entries
xticklabels=classes, yticklabels=classes,
title=title,
ylabel='True label',
xlabel='Predicted label')
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
plt.rcParams.update({'font.size': 10})
# Loop over data dimensions and create text annotations.
fmt = '.2f'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], fmt),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
y_pred_1y_vgg = probability_to_label(y_score_1y_vgg.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_vgg,title = 'Confusion Matrix of VGG for 1 year')
y_pred_1y_rf = probability_to_label(y_score_1y_rf.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_rf,title = 'Confusion Matrix of Random Forest for 1 year')
y_pred_1y_simple = probability_to_label(y_score_1y_simple.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_simple,title = 'Confusion Matrix of CNN for 1 year')
y_pred_1y_linreg = probability_to_label(y_score_1y_linreg.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_linreg,title = 'Confusion Matrix of Linear Regression for 1 year')
y_pred_1y_logreg = probability_to_label(y_score_1y_logreg.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_logreg,title = 'Confusion Matrix of Logistic Regression for 1 year')
y_pred_1y_kNN = probability_to_label(y_score_1y_kNN.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_kNN,title = 'Confusion Matrix of k-NN for 1 year')
y_pred_1y_GNB = probability_to_label(y_score_1y_GNB.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_GNB,title = 'Confusion Matrix of GNB for 1 year')
y_pred_1y_xgtree = probability_to_label(y_score_1y_xgtree.values, threshold=0.5)
plot_cm(y_test_1y, y_pred_1y_xgtree,title = 'Confusion Matrix of xgtree for 1 year')
y_pred_30_vgg = probability_to_label(y_score_30_vgg.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_vgg,title = 'Confusion Matrix of VGG for 30 days')
y_pred_30_rf = probability_to_label(y_score_30_rf.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_rf,title = 'Confusion Matrix of Random Forest for 30 days')
y_pred_30_simple = probability_to_label(y_score_30_simple.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_simple,title = 'Confusion Matrix of CNN for 30 days')
y_pred_30_linreg = probability_to_label(y_score_30_linreg.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_linreg,title = 'Confusion Matrix of Linear Regression for 30 days')
y_pred_30_logreg = probability_to_label(y_score_30_logreg.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_logreg,title = 'Confusion Matrix of Logistic Regression for 30 days')
y_pred_30_kNN = probability_to_label(y_score_30_kNN.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_kNN,title = 'Confusion Matrix of k-NN for 30 days')
y_pred_30_GNB = probability_to_label(y_score_30_GNB.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_GNB,title = 'Confusion Matrix of GNB for 30 days')
y_pred_30_xgtree = probability_to_label(y_score_30_xgtree.values, threshold=0.5)
plot_cm(y_test_30, y_pred_30_xgtree,title = 'Confusion Matrix of xgtree for 30 days')
```
| github_jupyter |
# About this file
This file takes all of the files that have been normalized, and writes them in a new `responses-{date}.csv` file. Since the results file is not saved in version control, it will create a different response file each day. Again, this is only because we don't want to commit private data into version control.
To ensure that data never gets lost, we can also maintan this git project inside of a Dropbox/Drive. This is to prevent loss of any work in case the files get accidentally deleted.
```
from functools import partial
import numpy as np
import pandas as pd
import re
import random
import json
import datetime
import os
import constants
# Configure any settings
pd.set_option('display.max_columns', None)
# Declare any constants
raw_file = '../private/results-04-10.csv' # REPLACE THIS WITH THE MOST EXISTING DATA SET FILEPATH
results_directory = '../private/' # Path where we'll create the data set with the normalized columns
normalized_rows_directory = '../private/rows/' # Path with the normalized rows
indices_directory = '../private/indices/'
df = pd.read_csv(raw_file)
df.columns = constants.columns
# Grabs the metadata file given a filename, and returns the shuffled indices
def read_indices(filename):
with open(indices_directory + filename, 'r') as f:
metadata = json.loads(f.read())
return metadata['order']
# Returns a list of all of the rows values
def read_normalized_rows(filename):
if not os.path.isfile(normalized_rows_directory + filename):
return None
df = pd.read_csv(normalized_rows_directory + filename)
return df[df.columns[1]].tolist()
# Place each row into its original location
def unshuffle_rows(rows, indices):
buffer = [None] * len(indices)
for i, index in enumerate(indices):
buffer[index] = rows[i]
return buffer
row_count = df.shape[0]
for col in constants.columns_to_normalize:
# Read the normalized rows
rows_filename = col + '.csv'
normalized_rows = read_normalized_rows(rows_filename)
# File doesn't exist
if normalized_rows is None:
continue
# Read the private indices
indices_filename = col + '.json'
indices = read_indices(indices_filename)
# Unshuffle the rows
column_data = unshuffle_rows(normalized_rows, indices)
# Save it inside the dataframe
df[col] = column_data
now = datetime.datetime.now()
formatted_date = now.strftime("%m-%d")
df.to_csv(results_directory + 'results-' + formatted_date + '.csv', index=False)
```
| github_jupyter |
```
from __future__ import print_function
from p3d_model_offset_fyq import *
import torch
model=P3D199_offset(pretrained=False,num_classes=400)
print (model)
# we have pretrained data: 'p3d_rgb_199.checkpoint.pth.tar'
model=P3D199_offset(pretrained=False,num_classes=400)
model=model.cuda()
data=torch.autograd.Variable(torch.rand(10,3,16,160,160)).cuda()
out=model(data)
print(out.size(),out)
from PIL import Image
import torchvision.transforms as transforms
image_path='/home/hl/Desktop/lovelyqian/CV_Learning/UCF101_jpg/ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/image_00001.jpg'
img=Image.open(image_path)
img.show()
transform = transforms.Compose([
transforms.RandomCrop(160), #size
# transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) #nedd to calculute
])
transformed_img=transform(img)
img.close()
print (transformed_img) #range [0,1]
from skimage import io, color, exposure
from skimage.transform import resize
import numpy as np
image_path='/home/hl/Desktop/lovelyqian/CV_Learning/UCF101_jpg/ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01/image_00025.jpg'
image=resize(io.imread(image_path),output_shape=(160,160),preserve_range= True) #240,320,3--160,160,3
io.imshow(image.astype(np.uint8))
io.show()
image =image.transpose(2, 0, 1) #3,160,160
image= torch.from_numpy(image) #range[0,255]
print (image)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result1_fyq_readimage2_size8_lr0_001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result2_fyq_readimage2_size8_lr0_001_videoM_mome0_9.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result3_fyq_lr0_0001_lr_00001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result4_fyq_author_lr0_0001_lr0_00001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result5_conv_s_author_lr0_0001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr[0:7185],index=np.arange(7186))
s.plot()
plt.show()
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result6_fyq_conv_s_author_lr0_0001_lr0_00001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result6_fyq_conv_s_author_lr0_0001_lr0_00001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result7_fyq_conv_s_author_lr0_00001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result8_fyq_author_lr0_0001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result9_fyq_comv_T_author_lr0_0001.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('/home/hl/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S/result10_p3d.txt',delimiter=':')
print (data.shape)
lossstr=data.iloc[:,1]
print (lossstr.shape)
s=pd.Series(lossstr,index=np.arange(lossstr.shape[0]))
s.plot()
plt.show()
```
| github_jupyter |
# Dependencies
```
import os
import random
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import class_weight
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, cohen_kappa_score
from keras import backend as K
from keras.models import Model
from keras import optimizers, applications
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, Callback
from keras.layers import Dense, Dropout, GlobalAveragePooling2D, Input
# Set seeds to make the experiment more reproducible.
from tensorflow import set_random_seed
def seed_everything(seed=0):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
set_random_seed(0)
seed_everything()
%matplotlib inline
sns.set(style="whitegrid")
warnings.filterwarnings("ignore")
```
# Load data
```
train = pd.read_csv('../input/aptos2019-blindness-detection/train.csv')
test = pd.read_csv('../input/aptos2019-blindness-detection/test.csv')
print('Number of train samples: ', train.shape[0])
print('Number of test samples: ', test.shape[0])
# Preprocecss data
train["id_code"] = train["id_code"].apply(lambda x: x + ".png")
test["id_code"] = test["id_code"].apply(lambda x: x + ".png")
train['diagnosis'] = train['diagnosis'].astype('str')
display(train.head())
```
# Model parameters
```
# Model parameters
BATCH_SIZE = 8
EPOCHS = 30
WARMUP_EPOCHS = 2
LEARNING_RATE = 1e-4
WARMUP_LEARNING_RATE = 1e-3
HEIGHT = 512
WIDTH = 512
CANAL = 3
N_CLASSES = train['diagnosis'].nunique()
ES_PATIENCE = 5
RLROP_PATIENCE = 3
DECAY_DROP = 0.5
def kappa(y_true, y_pred, n_classes=5):
y_trues = K.cast(K.argmax(y_true), K.floatx())
y_preds = K.cast(K.argmax(y_pred), K.floatx())
n_samples = K.cast(K.shape(y_true)[0], K.floatx())
distance = K.sum(K.abs(y_trues - y_preds))
max_distance = n_classes - 1
kappa_score = 1 - ((distance**2) / (n_samples * (max_distance**2)))
return kappa_score
```
# Train test split
```
X_train, X_val = train_test_split(train, test_size=0.25, random_state=0)
```
# Data generator
```
train_datagen=ImageDataGenerator(rescale=1./255,
zca_whitening=True,
fill_mode='reflect',
horizontal_flip=True,
vertical_flip=True)
train_generator=train_datagen.flow_from_dataframe(
dataframe=X_train,
directory="../input/aptos2019-blindness-detection/train_images/",
x_col="id_code",
y_col="diagnosis",
batch_size=BATCH_SIZE,
class_mode="categorical",
target_size=(HEIGHT, WIDTH))
valid_generator=train_datagen.flow_from_dataframe(
dataframe=X_val,
directory="../input/aptos2019-blindness-detection/train_images/",
x_col="id_code",
y_col="diagnosis",
batch_size=BATCH_SIZE,
class_mode="categorical",
target_size=(HEIGHT, WIDTH))
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_dataframe(
dataframe=test,
directory = "../input/aptos2019-blindness-detection/test_images/",
x_col="id_code",
target_size=(HEIGHT, WIDTH),
batch_size=1,
shuffle=False,
class_mode=None)
```
# Model
```
def create_model(input_shape, n_out):
input_tensor = Input(shape=input_shape)
base_model = applications.ResNet50(weights=None,
include_top=False,
input_tensor=input_tensor)
base_model.load_weights('../input/resnet50/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5')
x = GlobalAveragePooling2D()(base_model.output)
x = Dropout(0.5)(x)
x = Dense(2048, activation='relu')(x)
x = Dropout(0.5)(x)
final_output = Dense(n_out, activation='softmax', name='final_output')(x)
model = Model(input_tensor, final_output)
return model
model = create_model(input_shape=(HEIGHT, WIDTH, CANAL), n_out=N_CLASSES)
for layer in model.layers:
layer.trainable = False
for i in range(-5, 0):
model.layers[i].trainable = True
class_weights = class_weight.compute_class_weight('balanced', np.unique(train['diagnosis'].astype('int').values), train['diagnosis'].astype('int').values)
metric_list = ["accuracy", kappa]
optimizer = optimizers.Adam(lr=WARMUP_LEARNING_RATE)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=metric_list)
model.summary()
```
# Train top layers
```
STEP_SIZE_TRAIN = train_generator.n//train_generator.batch_size
STEP_SIZE_VALID = valid_generator.n//valid_generator.batch_size
history_warmup = model.fit_generator(generator=train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=valid_generator,
validation_steps=STEP_SIZE_VALID,
epochs=WARMUP_EPOCHS,
class_weight=class_weights,
verbose=1).history
```
# Fine-tune the complete model
```
for layer in model.layers:
layer.trainable = True
es = EarlyStopping(monitor='val_loss', mode='min', patience=ES_PATIENCE, restore_best_weights=True, verbose=1)
rlrop = ReduceLROnPlateau(monitor='val_loss', mode='min', patience=RLROP_PATIENCE, factor=DECAY_DROP, min_lr=1e-6, verbose=1)
callback_list = [es, rlrop]
optimizer = optimizers.Adam(lr=LEARNING_RATE)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=metric_list)
model.summary()
history_finetunning = model.fit_generator(generator=train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=valid_generator,
validation_steps=STEP_SIZE_VALID,
epochs=EPOCHS,
callbacks=callback_list,
class_weight=class_weights,
verbose=1).history
```
# Model loss graph
```
history = {'loss': history_warmup['loss'] + history_finetunning['loss'],
'val_loss': history_warmup['val_loss'] + history_finetunning['val_loss'],
'acc': history_warmup['acc'] + history_finetunning['acc'],
'val_acc': history_warmup['val_acc'] + history_finetunning['val_acc'],
'kappa': history_warmup['kappa'] + history_finetunning['kappa'],
'val_kappa': history_warmup['val_kappa'] + history_finetunning['val_kappa']}
sns.set_style("whitegrid")
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, sharex='col', figsize=(20, 18))
ax1.plot(history['loss'], label='Train loss')
ax1.plot(history['val_loss'], label='Validation loss')
ax1.legend(loc='best')
ax1.set_title('Loss')
ax2.plot(history['acc'], label='Train accuracy')
ax2.plot(history['val_acc'], label='Validation accuracy')
ax2.legend(loc='best')
ax2.set_title('Accuracy')
ax3.plot(history['kappa'], label='Train kappa')
ax3.plot(history['val_kappa'], label='Validation kappa')
ax3.legend(loc='best')
ax3.set_title('Kappa')
plt.xlabel('Epochs')
sns.despine()
plt.show()
```
# Model Evaluation
```
lastFullTrainPred = np.empty((0, N_CLASSES))
lastFullTrainLabels = np.empty((0, N_CLASSES))
lastFullValPred = np.empty((0, N_CLASSES))
lastFullValLabels = np.empty((0, N_CLASSES))
for i in range(STEP_SIZE_TRAIN+1):
im, lbl = next(train_generator)
scores = model.predict(im, batch_size=train_generator.batch_size)
lastFullTrainPred = np.append(lastFullTrainPred, scores, axis=0)
lastFullTrainLabels = np.append(lastFullTrainLabels, lbl, axis=0)
for i in range(STEP_SIZE_VALID+1):
im, lbl = next(valid_generator)
scores = model.predict(im, batch_size=valid_generator.batch_size)
lastFullValPred = np.append(lastFullValPred, scores, axis=0)
lastFullValLabels = np.append(lastFullValLabels, lbl, axis=0)
```
# Threshold optimization
```
def find_best_fixed_threshold(preds, targs, do_plot=True):
best_thr_list = [0 for i in range(preds.shape[1])]
for index in reversed(range(1, preds.shape[1])):
score = []
thrs = np.arange(0, 1, 0.01)
for thr in thrs:
preds_thr = [index if x[index] > thr else np.argmax(x) for x in preds]
score.append(cohen_kappa_score(targs, preds_thr))
score = np.array(score)
pm = score.argmax()
best_thr, best_score = thrs[pm], score[pm].item()
best_thr_list[index] = best_thr
print(f'thr={best_thr:.3f}', f'F2={best_score:.3f}')
if do_plot:
plt.plot(thrs, score)
plt.vlines(x=best_thr, ymin=score.min(), ymax=score.max())
plt.text(best_thr+0.03, best_score-0.01, ('Kappa[%s]=%.3f'%(index, best_score)), fontsize=14);
plt.show()
return best_thr_list
lastFullComPred = np.concatenate((lastFullTrainPred, lastFullValPred))
lastFullComLabels = np.concatenate((lastFullTrainLabels, lastFullValLabels))
complete_labels = [np.argmax(label) for label in lastFullComLabels]
threshold_list = find_best_fixed_threshold(lastFullComPred, complete_labels, do_plot=True)
threshold_list[0] = 0 # In last instance assign label 0
train_preds = [np.argmax(pred) for pred in lastFullTrainPred]
train_labels = [np.argmax(label) for label in lastFullTrainLabels]
validation_preds = [np.argmax(pred) for pred in lastFullValPred]
validation_labels = [np.argmax(label) for label in lastFullValLabels]
train_preds_opt = [0 for i in range(lastFullTrainPred.shape[0])]
for idx, thr in enumerate(threshold_list):
for idx2, pred in enumerate(lastFullTrainPred):
if pred[idx] > thr:
train_preds_opt[idx2] = idx
validation_preds_opt = [0 for i in range(lastFullValPred.shape[0])]
for idx, thr in enumerate(threshold_list):
for idx2, pred in enumerate(lastFullValPred):
if pred[idx] > thr:
validation_preds_opt[idx2] = idx
```
## Confusion Matrix
```
fig, (ax1, ax2) = plt.subplots(1, 2, sharex='col', figsize=(24, 7))
labels = ['0 - No DR', '1 - Mild', '2 - Moderate', '3 - Severe', '4 - Proliferative DR']
train_cnf_matrix = confusion_matrix(train_labels, train_preds)
validation_cnf_matrix = confusion_matrix(validation_labels, validation_preds)
train_cnf_matrix_norm = train_cnf_matrix.astype('float') / train_cnf_matrix.sum(axis=1)[:, np.newaxis]
validation_cnf_matrix_norm = validation_cnf_matrix.astype('float') / validation_cnf_matrix.sum(axis=1)[:, np.newaxis]
train_df_cm = pd.DataFrame(train_cnf_matrix_norm, index=labels, columns=labels)
validation_df_cm = pd.DataFrame(validation_cnf_matrix_norm, index=labels, columns=labels)
sns.heatmap(train_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax1).set_title('Train')
sns.heatmap(validation_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax2).set_title('Validation')
plt.show()
fig, (ax1, ax2) = plt.subplots(1, 2, sharex='col', figsize=(24, 7))
labels = ['0 - No DR', '1 - Mild', '2 - Moderate', '3 - Severe', '4 - Proliferative DR']
train_cnf_matrix = confusion_matrix(train_labels, train_preds_opt)
validation_cnf_matrix = confusion_matrix(validation_labels, validation_preds_opt)
train_cnf_matrix_norm = train_cnf_matrix.astype('float') / train_cnf_matrix.sum(axis=1)[:, np.newaxis]
validation_cnf_matrix_norm = validation_cnf_matrix.astype('float') / validation_cnf_matrix.sum(axis=1)[:, np.newaxis]
train_df_cm = pd.DataFrame(train_cnf_matrix_norm, index=labels, columns=labels)
validation_df_cm = pd.DataFrame(validation_cnf_matrix_norm, index=labels, columns=labels)
sns.heatmap(train_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax1).set_title('Train optimized')
sns.heatmap(validation_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax2).set_title('Validation optimized')
plt.show()
```
## Quadratic Weighted Kappa
```
print("Train Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds, train_labels, weights='quadratic'))
print("Validation Cohen Kappa score: %.3f" % cohen_kappa_score(validation_preds, validation_labels, weights='quadratic'))
print("Complete set Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds+validation_preds, train_labels+validation_labels, weights='quadratic'))
print("Train optimized Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds_opt, train_labels, weights='quadratic'))
print("Validation optimized Cohen Kappa score: %.3f" % cohen_kappa_score(validation_preds_opt, validation_labels, weights='quadratic'))
print("Complete optimized set Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds_opt+validation_preds_opt, train_labels+validation_labels, weights='quadratic'))
```
# Apply model to test set and output predictions
```
test_generator.reset()
STEP_SIZE_TEST = test_generator.n//test_generator.batch_size
preds = model.predict_generator(test_generator, steps=STEP_SIZE_TEST)
predictions = [np.argmax(pred) for pred in preds]
predictions_opt = [0 for i in range(preds.shape[0])]
for idx, thr in enumerate(threshold_list):
for idx2, pred in enumerate(preds):
if pred[idx] > thr:
predictions_opt[idx2] = idx
filenames = test_generator.filenames
results = pd.DataFrame({'id_code':filenames, 'diagnosis':predictions})
results['id_code'] = results['id_code'].map(lambda x: str(x)[:-4])
results_opt = pd.DataFrame({'id_code':filenames, 'diagnosis':predictions_opt})
results_opt['id_code'] = results_opt['id_code'].map(lambda x: str(x)[:-4])
```
# Predictions class distribution
```
fig, (ax1, ax2) = plt.subplots(1, 2, sharex='col', figsize=(24, 8.7))
sns.countplot(x="diagnosis", data=results, palette="GnBu_d", ax=ax1)
sns.countplot(x="diagnosis", data=results_opt, palette="GnBu_d", ax=ax2)
sns.despine()
plt.show()
val_kappa = cohen_kappa_score(validation_preds, validation_labels, weights='quadratic')
val_opt_kappa = cohen_kappa_score(validation_preds_opt, validation_labels, weights='quadratic')
if val_kappa > val_opt_kappa:
results_name = 'submission.csv'
results_opt_name = 'submission_opt.csv'
else:
results_name = 'submission_norm.csv'
results_opt_name = 'submission.csv'
results.to_csv(results_name, index=False)
results.head(10)
results_opt.to_csv(results_opt_name, index=False)
results_opt.head(10)
```
| github_jupyter |
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn import metrics
# from mlxtend.plotting import plot_decision_regions
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from ast import literal_eval
import warnings
import numpy as np
from collections import OrderedDict
from lob_data_utils import lob, db_result, model, roc_results
from lob_data_utils.svm_calculation import lob_svm
import os
sns.set_style('whitegrid')
warnings.filterwarnings('ignore')
data_length = 10000
r = 1.0
s = 1.0
stocks = list(roc_results.result_cv_10000.keys())
def get_mean_scores(scores: dict) -> dict:
mean_scores = {}
for k, v in scores.items():
mean_scores[k] = np.mean(v)
return mean_scores
def get_score_for_clf(clf, df_test):
x_test = df_test[['queue_imbalance']]
y_test = df_test['mid_price_indicator'].values
return model.test_model(clf, x_test, y_test)
def get_logistic_regression(stock, data_length):
df, df_test = lob.load_prepared_data(
stock, data_dir='../gaussian_filter/data', cv=False, length=data_length)
clf = LogisticRegression()
train_x = df[['queue_imbalance']]
scores = model.validate_model(clf, train_x, df['mid_price_indicator'])
res = {
**get_mean_scores(scores),
'stock': stock,
'kernel': 'logistic',
}
test_scores = get_score_for_clf(clf, df_test)
return {**res, **test_scores}
df_res = pd.DataFrame()
for stock in stocks:
#pd.read_csv('svm_features_{}_len{}_r{}_s{}.csv'.format(stock, data_length, r, s))
filename = 'svm_pca_only_gdf_{}_len{}_r{}_s{}.csv'.format(stock, data_length, r, s)
if os.path.exists(filename):
df_res = df_res.append(pd.read_csv(filename))
#df_res.drop(columns=['Unnamed: 0'], inplace=True)
columns = ['C', 'f1', 'features', 'gamma', 'kappa',
'matthews', 'roc_auc', 'stock',
'test_f1', 'test_kappa', 'test_matthews', 'test_roc_auc']
df_res[columns].sort_values(by='matthews', ascending=False).groupby('stock').head(1)
log_res = []
for stock in stocks:
log_res.append(get_logistic_regression(stock, data_length))
df_log_res = pd.DataFrame(log_res)
df_log_res['stock'] = df_log_res['stock'].values.astype(np.int)
df_log_res.index = df_log_res['stock'].values.astype(np.int)
df_gdf_best = df_res[columns].sort_values(by='test_matthews', ascending=False).groupby('stock').head(1)
df_gdf_best['stock'] = df_gdf_best['stock'].values.astype(np.int)
df_gdf_best.index = df_gdf_best['stock'].values.astype(np.int)
df_all = pd.merge(df_gdf_best, df_log_res, on='stock', suffixes=['_svm', '_log'])
all_columns = [ 'features', 'matthews_svm', 'matthews_log', 'test_matthews_svm', 'test_matthews_log',
'roc_auc_svm', 'roc_auc_log', 'test_roc_auc_svm', 'test_roc_auc_log', 'stock',
'f1_svm', 'f1_log', 'test_f1_svm', 'test_f1_log', 'stock']
df_all[all_columns]
len(df_all[df_all['matthews_svm'] > df_all['matthews_log']][all_columns]), len(df_all)
len(df_all[df_all['roc_auc_svm'] > df_all['roc_auc_log']][all_columns]), len(df_all)
df_all[df_all['test_matthews_svm'] < df_all['test_matthews_log']][all_columns]
df_all[df_all['test_roc_auc_svm'] < df_all['test_roc_auc_log']][all_columns]
df_all[df_all['matthews_svm'] < df_all['matthews_log']]['features'].value_counts()
df_all[df_all['matthews_svm'] > df_all['matthews_log']]['features'].value_counts()
```
| github_jupyter |
```
START = '20160229000000'
FINISH = '20160605000000'
# imports
import matplotlib.pyplot as plt
import matplotlib
# necessary for the plot to appear in a Jupyter
%matplotlib inline
# Control the default size of figures in this Jupyter
%pylab inline
matplotlib.rcParams['figure.figsize'] = (20.0, 10.0)
import numpy as np
from sqlalchemy import create_engine
from sqlalchemy import inspect, select, MetaData, and_
import datetime
import pandas as pd
#SQLALCHEMY
db_uri = 'postgresql://ostap:12345@localhost:5432/msft'
engine = create_engine(db_uri)
conn = engine.connect()
inspector = inspect(engine)
# Get table information
meta = MetaData(engine,reflect=True)
table = meta.tables['news']
#print(inspector.get_table_names())
#print(inspector.get_columns('news'))
select_st = select([table.c.DATE, table.c.TONE, table.c.DOCUMENTIDENTIFIER, table.c.SOURCECOMMONNAME, table.c.GCAM]).where(and_(table.c.DATE < FINISH , table.c.DATE > START))
res = conn.execute(select_st).fetchall()
news = dict()
news['date'] = [datetime.datetime.strptime(el[0], '%Y%m%d%H%M%S') for el in res if '.' not in el[0]]
sents = [el[1] for el in res if '.' not in el[0]]
conn.close()
sent = [x.split(',') for x in sents]
news['tone'] = [float(el[0]) for el in sent]
news['positive'] = [float(el[1]) for el in sent]
news['negative'] = [float(el[2]) for el in sent]
news['polarity'] = [float(el[3]) for el in sent]
news['activ_den'] = [float(el[4]) for el in sent]
news['self_den'] = [float(el[5]) for el in sent]
news['source'] = [el[2] for el in res if '.' not in el[0]]
news['agency'] = [el[3] for el in res if '.' not in el[0]]
news['words'] = [el[4] for el in res if '.' not in el[0]]
del res
TONE = pd.DataFrame.from_dict(news)
TONE = TONE.sort_values(by=['date'])
TONE = TONE[['date', 'tone', 'positive', 'negative', 'polarity', 'activ_den', 'self_den', 'source', 'agency', 'words']]
TONE = TONE.reset_index(drop=True)
print(len(TONE))
TONE.head()
TONE.corr()
```
## Price Tone Correlation
```
intraday = pd.read_csv('/home/ostapkharysh/Documents/bachelor_thesis/CONVERTING/stocks/ET/MSFTReturn.csv')
intraday['date'] = pd.to_datetime(intraday['date'])
period_df = intraday[(intraday['date'] > START ) & (intraday['date'] < FINISH)]
period_df.head()
```
### Merging Stock return and Tonality
```
start = datetime.datetime.strptime(START, '%Y%m%d%H%M%S') #2016-02-01
finish = datetime.datetime.strptime(FINISH, '%Y%m%d%H%M%S')
step = datetime.timedelta(minutes=15)
t = start
TIME = list()
while t < finish:
TIME.append(t)
t+=step
#selecting only 15 minute price periods
period_df = period_df[pd.to_datetime(period_df['date'].values).minute % 15 == 0]
period_df = period_df.reset_index(drop=True)
# filling gaps with NONE
lack_p = set(TIME) - set(period_df['date'])
for el in lack_p:
period_df = period_df.append({'date': el, 'fin_return': np.nan}, ignore_index = True)
lack_t = set(TIME) - set(TONE['date'])
for el in lack_t:
TONE = TONE.append({'date': el, 'tone': np.nan, 'positive': np.nan,
'negative': np.nan, 'polarity' : np.nan,
'activ_den': np.nan,
'self_den' : np.nan}, ignore_index = True)
# sorting by date
period_df = period_df.sort_values(by=['date'])
TONE = TONE.sort_values(by=['date'])
period_df = period_df.reset_index(drop=True)
TONE = TONE.reset_index(drop=True)
# ACTUAL MERGE
TONE['fin_return']=TONE[['date']].merge(period_df,how='left').fin_return
TONE.head()
```
### Financial filtering
```
# Data types that should be included in news to be considered financial
GCAM_most = ['c18.59', 'c18.60', 'c18.61', 'c18.63', 'c18.154','c18.286', 'c18.287', 'c18.288']
GCAM = ['c18.59', 'c18.60', 'c18.61', 'c18.63', 'c18.154','c18.286', 'c18.287', 'c18.288', 'c1.2', 'c2.45',
'c2.58', 'c4.1', 'c4.16', 'c9.853', 'c16.47', 'c16.60', 'c18.36',
'c18.42', 'c18.47', 'c18.53', 'c18.54', 'c18.62', 'c18.178',
'c18.187', 'c18.188', 'c18.189', 'c18.213', 'c18.214', 'c18.215', 'c18.218',
'c18.219', 'c18.223', 'c18.225', 'c18.246', 'c18.247', 'c18.248', 'c18.258',
'c18.272', 'c18.279', 'c18.280', 'c18.289', 'c18.290', 'c18.292', 'c18.293', 'c18.294', 'c18.307', 'c18.332',
'c18.335']
# greedy qualifier whether the news is financial
fin = list()
for el in TONE.words:
dec = False
for tp in GCAM_most:
try:
if tp in el:
dec = True
except TypeError:
pass
fin.append(dec)
TONE['financial'] = fin
TONE = TONE.reset_index(drop=True)
TONE.head()
TONE.corr()
TONE[TONE.financial==True].corr()
print(len(TONE[['tone']]))
TONE[['tone']].plot()
print(len(TONE[TONE.financial==True][['tone']]))
TONE[TONE.financial==True][['tone']].plot()
fin_TONE = TONE[TONE.financial==True]
fin_TONE = fin_TONE[['date', 'tone', 'positive', 'negative', 'polarity',
'activ_den', 'self_den', 'source', 'agency', 'fin_return']].reset_index(drop=True)
```
### Page Rank Prioritization
```
prior_TONE = pd.DataFrame(columns=fin_TONE.columns)
prior_TONE.columns
RANK = pd.read_csv('/home/ostapkharysh/Documents/bt_data/news_rank/agency_rank.csv')
TYPE = 'pr_val' # 'harmonicc_val' or 'pr_val' available for ranking
AGENCIES =[
'abcnews.com',
'wsj.com',
'bloomberg.com',
'cnbc.com',
'cnn.com',
'ft.com',
'financialpost.com',
'nytimes.com',
'bbc.co.uk',
'businessinsider.com',
'economist.com',
'foxnews.com',
'ap.org',
'google.com',
'aljazeera.com',
'theguardian.com',
'reuters.com']
def set_weights(agencies, ranking):
score = list()
#bound = 0.000049 if ranking=='pr_val' else 17259954.0
for ag in agencies:
#if ag in AGENCIES:
pos = RANK[RANK.host_rev==ag][ranking].values # news source
pos = float(pos) if pos else 0
#score.append(pos) if pos >= bound else score.append(0)
score.append(pos)
#else:
# score.append(0)
#print('score')
#print(score)
weights_list = [el/sum(score) for el in score] # prioritization (weighting) of news agencies
weights_list = [0 if math.isnan(x) else x for x in weights_list]
glob_weight = sum(score)/sum(RANK[ranking]) #подумати
#print('weight')
#print(weights_list, glob_weight)
return weights_list, glob_weight
def prioritize(quarter_news=None, ranking=None): # 'harmonicc_val' also available for ranking
generalized = dict((el,0) for el in quarter_news) # dict of 15 minute weighted outcome
del generalized['agency'], generalized['source']
weights = set_weights([news[8] for news in quarter_news.values], ranking=ranking) #
for idx, el in enumerate(quarter_news.values):
generalized['tone'] += float(el[1]) * weights[0][idx]
generalized['positive'] += float(el[2]) * weights[0][idx]
generalized['negative'] += float(el[3]) * weights[0][idx]
generalized['polarity'] += float(el[4]) * weights[0][idx]
generalized['activ_den'] += float(el[5]) * weights[0][idx]
generalized['self_den'] += float(el[6]) * weights[0][idx]
generalized['fin_return'] = quarter_news.fin_return.values[0]
generalized['date'] = quarter_news.date.values[0]
generalized['weight'] = weights[1]
return generalized
rankedData = pd.DataFrame(columns=['date', 'tone', 'positive', 'negative', 'polarity',
'activ_den', 'self_den', 'fin_return', 'weight'])
for el in TIME[1:]:
data = fin_TONE[fin_TONE.date==el]
if not pd.isnull(data.tone).all():
data = prioritize(data, TYPE)
rankedData = rankedData.append(data, ignore_index=True)
else:
#print("tut")
rankedData = rankedData.append({'date': el}, ignore_index=True)
rankedData[["tone", "negative", "polarity", "positive", "self_den", "activ_den"]] = rankedData[["tone", "negative", "polarity", "positive", "self_den", "activ_den"]].fillna(0)
rankedData.head()
rankedData[1:].to_csv("/home/ostapkharysh/Documents/bt_data/DescriptiveFebruary29June05_2016/ET/MSFT/PR1.csv", index=False)
RANK.head()
RANK[RANK.pr_pos==500].pr_val
RANK[RANK.harmonicc_pos==500].harmonicc_val
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from matplotlib import pyplot as plt
%matplotlib inline
```
# load mosaic data
```
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=10, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=10, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
foreground_classes = {'plane', 'car', 'bird'}
#foreground_classes = {'bird', 'cat', 'deer'}
background_classes = {'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'}
#background_classes = {'plane', 'car', 'dog', 'frog', 'horse','ship', 'truck'}
fg1,fg2,fg3 = 0,1,2
dataiter = iter(trainloader)
background_data=[]
background_label=[]
foreground_data=[]
foreground_label=[]
batch_size=10
for i in range(5000):
images, labels = dataiter.next()
for j in range(batch_size):
if(classes[labels[j]] in background_classes):
img = images[j].tolist()
background_data.append(img)
background_label.append(labels[j])
else:
img = images[j].tolist()
foreground_data.append(img)
foreground_label.append(labels[j])
foreground_data = torch.tensor(foreground_data)
foreground_label = torch.tensor(foreground_label)
background_data = torch.tensor(background_data)
background_label = torch.tensor(background_label)
def create_mosaic_img(bg_idx,fg_idx,fg):
"""
bg_idx : list of indexes of background_data[] to be used as background images in mosaic
fg_idx : index of image to be used as foreground image from foreground data
fg : at what position/index foreground image has to be stored out of 0-8
"""
image_list=[]
j=0
for i in range(9):
if i != fg:
image_list.append(background_data[bg_idx[j]])#.type("torch.DoubleTensor"))
j+=1
else:
image_list.append(foreground_data[fg_idx])#.type("torch.DoubleTensor"))
label = foreground_label[fg_idx]-fg1 # minus 7 because our fore ground classes are 7,8,9 but we have to store it as 0,1,2
#image_list = np.concatenate(image_list ,axis=0)
image_list = torch.stack(image_list)
return image_list,label
desired_num = 30000
mosaic_list_of_images =[] # list of mosaic images, each mosaic image is saved as list of 9 images
fore_idx =[] # list of indexes at which foreground image is present in a mosaic image i.e from 0 to 9
mosaic_label=[] # label of mosaic image = foreground class present in that mosaic
for i in range(desired_num):
np.random.seed(i)
bg_idx = np.random.randint(0,35000,8)
fg_idx = np.random.randint(0,15000)
fg = np.random.randint(0,9)
fore_idx.append(fg)
image_list,label = create_mosaic_img(bg_idx,fg_idx,fg)
mosaic_list_of_images.append(image_list)
mosaic_label.append(label)
class MosaicDataset(Dataset):
"""MosaicDataset dataset."""
def __init__(self, mosaic_list_of_images, mosaic_label, fore_idx):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.mosaic = mosaic_list_of_images
self.label = mosaic_label
self.fore_idx = fore_idx
def __len__(self):
return len(self.label)
def __getitem__(self, idx):
return self.mosaic[idx] , self.label[idx], self.fore_idx[idx]
batch = 250
msd = MosaicDataset(mosaic_list_of_images, mosaic_label , fore_idx)
train_loader = DataLoader( msd,batch_size= batch ,shuffle=True)
test_images =[] #list of mosaic images, each mosaic image is saved as laist of 9 images
fore_idx_test =[] #list of indexes at which foreground image is present in a mosaic image
test_label=[] # label of mosaic image = foreground class present in that mosaic
for i in range(10000):
np.random.seed(i+30000)
bg_idx = np.random.randint(0,35000,8)
fg_idx = np.random.randint(0,15000)
fg = np.random.randint(0,9)
fore_idx_test.append(fg)
image_list,label = create_mosaic_img(bg_idx,fg_idx,fg)
test_images.append(image_list)
test_label.append(label)
test_data = MosaicDataset(test_images,test_label,fore_idx_test)
test_loader = DataLoader( test_data,batch_size= batch ,shuffle=False)
```
# models
```
class Module1(nn.Module):
def __init__(self):
super(Module1, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
self.fc4 = nn.Linear(10,1)
def forward(self, z):
x = torch.zeros([batch,9],dtype=torch.float64)
y = torch.zeros([batch,3, 32,32], dtype=torch.float64)
x,y = x.to("cuda"),y.to("cuda")
for i in range(9):
x[:,i] = self.helper(z[:,i])[:,0]
x = F.softmax(x,dim=1) # alphas
x1 = x[:,0]
torch.mul(x1[:,None,None,None],z[:,0])
for i in range(9):
x1 = x[:,i]
y = y + torch.mul(x1[:,None,None,None],z[:,i])
return y , x
def helper(self,x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
class Module2(nn.Module):
def __init__(self):
super(Module2, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
self.fc4 = nn.Linear(10,3)
def forward(self,y): #z batch of list of 9 images
y1 = self.pool(F.relu(self.conv1(y)))
y1 = self.pool(F.relu(self.conv2(y1)))
y1 = y1.view(-1, 16 * 5 * 5)
y1 = F.relu(self.fc1(y1))
y1 = F.relu(self.fc2(y1))
y1 = F.relu(self.fc3(y1))
y1 = self.fc4(y1)
return y1
torch.manual_seed(1234)
where_net = Module1().double()
where_net = where_net.to("cuda")
# print(net.parameters)
torch.manual_seed(1234)
what_net = Module2().double()
what_net = what_net.to("cuda")
def calculate_attn_loss(dataloader,what,where,criter):
what.eval()
where.eval()
r_loss = 0
alphas = []
lbls = []
pred = []
fidices = []
correct = 0
tot = 0
with torch.no_grad():
for i, data in enumerate(dataloader, 0):
inputs, labels,fidx = data
lbls.append(labels)
fidices.append(fidx)
inputs = inputs.double()
inputs, labels = inputs.to("cuda"),labels.to("cuda")
avg,alpha = where(inputs)
outputs = what(avg)
_, predicted = torch.max(outputs.data, 1)
correct += sum(predicted == labels)
tot += len(predicted)
pred.append(predicted.cpu().numpy())
alphas.append(alpha.cpu().numpy())
loss = criter(outputs, labels)
r_loss += loss.item()
alphas = np.concatenate(alphas,axis=0)
pred = np.concatenate(pred,axis=0)
lbls = np.concatenate(lbls,axis=0)
fidices = np.concatenate(fidices,axis=0)
#print(alphas.shape,pred.shape,lbls.shape,fidices.shape)
analysis = analyse_data(alphas,lbls,pred,fidices)
return r_loss/i,analysis,correct.item(),tot,correct.item()/tot
def analyse_data(alphas,lbls,predicted,f_idx):
'''
analysis data is created here
'''
batch = len(predicted)
amth,alth,ftpt,ffpt,ftpf,ffpf = 0,0,0,0,0,0
for j in range (batch):
focus = np.argmax(alphas[j])
if(alphas[j][focus] >= 0.5):
amth +=1
else:
alth +=1
if(focus == f_idx[j] and predicted[j] == lbls[j]):
ftpt += 1
elif(focus != f_idx[j] and predicted[j] == lbls[j]):
ffpt +=1
elif(focus == f_idx[j] and predicted[j] != lbls[j]):
ftpf +=1
elif(focus != f_idx[j] and predicted[j] != lbls[j]):
ffpf +=1
#print(sum(predicted==lbls),ftpt+ffpt)
return [ftpt,ffpt,ftpf,ffpf,amth,alth]
```
# training
```
# instantiate optimizer
optimizer_where = optim.RMSprop(where_net.parameters(),lr =0.001)#,nesterov=True)
optimizer_what = optim.RMSprop(what_net.parameters(), lr=0.001)#,nesterov=True)
scheduler_where = optim.lr_scheduler.ReduceLROnPlateau(optimizer_where, mode='min', factor=0.5, patience=2,min_lr=5e-5,verbose=True)
scheduler_what = optim.lr_scheduler.ReduceLROnPlateau(optimizer_what, mode='min', factor=0.5, patience=2,min_lr=5e-5, verbose=True)
criterion = nn.CrossEntropyLoss()
acti = []
analysis_data_tr = []
analysis_data_tst = []
loss_curi_tr = []
loss_curi_tst = []
epochs = 100
every_what_epoch = 1
# calculate zeroth epoch loss and FTPT values
running_loss,anlys_data,correct,total,accuracy = calculate_attn_loss(train_loader,what_net,where_net,criterion)
print('training epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(0,running_loss,correct,total,accuracy))
loss_curi_tr.append(running_loss)
analysis_data_tr.append(anlys_data)
running_loss,anlys_data,correct,total,accuracy = calculate_attn_loss(test_loader,what_net,where_net,criterion)
print('test epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(0,running_loss,correct,total,accuracy))
loss_curi_tst.append(running_loss)
analysis_data_tst.append(anlys_data)
# training starts
for epoch in range(epochs): # loop over the dataset multiple times
ep_lossi = []
running_loss = 0.0
what_net.train()
where_net.train()
if ((epoch) % (every_what_epoch*2) ) <= every_what_epoch-1 :
print(epoch+1,"updating what_net, where_net is freezed")
print("--"*40)
elif ((epoch) % (every_what_epoch*2)) > every_what_epoch-1 :
print(epoch+1,"updating where_net, what_net is freezed")
print("--"*40)
for i, data in enumerate(train_loader, 0):
# get the inputs
inputs, labels,_ = data
inputs = inputs.double()
inputs, labels = inputs.to("cuda"),labels.to("cuda")
# zero the parameter gradients
optimizer_where.zero_grad()
optimizer_what.zero_grad()
# forward + backward + optimize
avg, alpha = where_net(inputs)
outputs = what_net(avg)
loss = criterion(outputs, labels)
# print statistics
running_loss += loss.item()
loss.backward()
if ((epoch) % (every_what_epoch*2) ) <= every_what_epoch-1 :
optimizer_what.step()
elif ( (epoch) % (every_what_epoch*2)) > every_what_epoch-1 :
optimizer_where.step()
running_loss_tr,anls_data,correct,total,accuracy = calculate_attn_loss(train_loader,what_net,where_net,criterion)
analysis_data_tr.append(anls_data)
loss_curi_tr.append(running_loss_tr) #loss per epoch
print('training epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(epoch+1,running_loss_tr,correct,total,accuracy))
running_loss_tst,anls_data,correct,total,accuracy = calculate_attn_loss(test_loader,what_net,where_net,criterion)
analysis_data_tst.append(anls_data)
loss_curi_tst.append(running_loss_tst) #loss per epoch
print('test epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(epoch+1,running_loss_tst,correct,total,accuracy))
if running_loss_tr<=0.05:
break
if ((epoch) % (every_what_epoch*2) ) <= every_what_epoch-1 :
scheduler_what.step(running_loss_tst)
elif ( (epoch) % (every_what_epoch*2)) > every_what_epoch-1 :
scheduler_where.step(running_loss_tst)
print('Finished Training run ')
analysis_data_tr = np.array(analysis_data_tr)
analysis_data_tst = np.array(analysis_data_tst)
fig = plt.figure(figsize = (12,8))
#vline_list = np.arange(every_what_epoch, epoch + every_what_epoch, every_what_epoch)
# train_loss = np.random.randn(340)
# test_loss = np.random.randn(340)
epoch_list = np.arange(0, epoch+2)
plt.plot(epoch_list,loss_curi_tr, label='train_loss')
plt.plot(epoch_list,loss_curi_tst, label='test_loss')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("CE Loss")
#plt.vlines(vline_list,min(min(loss_curi_tr),min(loss_curi_tst)), max(max(loss_curi_tst),max(loss_curi_tr)),linestyles='dotted')
plt.title("train loss vs test loss")
plt.show()
fig.savefig("train_test_loss_plot.pdf")
analysis_data_tr
analysis_data_tr = np.array(analysis_data_tr)
analysis_data_tst = np.array(analysis_data_tst)
columns = ["epochs", "argmax > 0.5" ,"argmax < 0.5", "focus_true_pred_true", "focus_false_pred_true", "focus_true_pred_false", "focus_false_pred_false" ]
df_train = pd.DataFrame()
df_test = pd.DataFrame()
df_train[columns[0]] = np.arange(0,epoch+2)
df_train[columns[1]] = analysis_data_tr[:,-2]
df_train[columns[2]] = analysis_data_tr[:,-1]
df_train[columns[3]] = analysis_data_tr[:,0]
df_train[columns[4]] = analysis_data_tr[:,1]
df_train[columns[5]] = analysis_data_tr[:,2]
df_train[columns[6]] = analysis_data_tr[:,3]
df_test[columns[0]] = np.arange(0,epoch+2)
df_test[columns[1]] = analysis_data_tst[:,-2]
df_test[columns[2]] = analysis_data_tst[:,-1]
df_test[columns[3]] = analysis_data_tst[:,0]
df_test[columns[4]] = analysis_data_tst[:,1]
df_test[columns[5]] = analysis_data_tst[:,2]
df_test[columns[6]] = analysis_data_tst[:,3]
df_train
df_test
plt.figure(figsize=(12,12))
plt.plot(df_train[columns[0]],df_train[columns[1]], label='argmax > 0.5')
plt.plot(df_train[columns[0]],df_train[columns[2]], label='argmax < 0.5')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("training data")
plt.title("On Training set")
#plt.vlines(vline_list,min(min(df_train[columns[1]]),min(df_train[columns[2]])), max(max(df_train[columns[1]]),max(df_train[columns[2]])),linestyles='dotted')
plt.show()
plt.figure(figsize=(12,12))
plt.plot(df_train[columns[0]],df_train[columns[3]], label ="focus_true_pred_true ")
plt.plot(df_train[columns[0]],df_train[columns[4]], label ="focus_false_pred_true ")
plt.plot(df_train[columns[0]],df_train[columns[5]], label ="focus_true_pred_false ")
plt.plot(df_train[columns[0]],df_train[columns[6]], label ="focus_false_pred_false ")
plt.title("On Training set")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("training data")
#plt.vlines(vline_list,min(min(df_train[columns[3]]),min(df_train[columns[4]]),min(df_train[columns[5]]),min(df_train[columns[6]])), max(max(df_train[columns[3]]),max(df_train[columns[4]]),max(df_train[columns[5]]),max(df_train[columns[6]])),linestyles='dotted')
plt.show()
plt.figure(figsize=(12,12))
plt.plot(df_test[columns[0]],df_test[columns[1]], label='argmax > 0.5')
plt.plot(df_test[columns[0]],df_test[columns[2]], label='argmax < 0.5')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("training data")
plt.title("On Training set")
#plt.vlines(vline_list,min(min(df_test[columns[1]]),min(df_test[columns[2]])), max(max(df_test[columns[1]]),max(df_test[columns[2]])),linestyles='dotted')
plt.show()
plt.figure(figsize=(12,12))
plt.plot(df_test[columns[0]],df_test[columns[3]], label ="focus_true_pred_true ")
plt.plot(df_test[columns[0]],df_test[columns[4]], label ="focus_false_pred_true ")
plt.plot(df_test[columns[0]],df_test[columns[5]], label ="focus_true_pred_false ")
plt.plot(df_test[columns[0]],df_test[columns[6]], label ="focus_false_pred_false ")
plt.title("On Training set")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("training data")
#plt.vlines(vline_list,min(min(df_test[columns[3]]),min(df_test[columns[4]]),min(df_test[columns[5]]),min(df_test[columns[6]])), max(max(df_test[columns[3]]),max(df_test[columns[4]]),max(df_test[columns[5]]),max(df_test[columns[6]])),linestyles='dotted')
plt.show()
```
| github_jupyter |
```
#%matplotlib notebook
#DEFAULT_FIGSIZE = (8, 6)
%matplotlib inline
DEFAULT_FIGSIZE = (12, 8)
import numpy as np
import scipy.signal
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
from phobos.constants import sa
import plot_sim as ps
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = DEFAULT_FIGSIZE
log = ps.ProcessedRecord('logs/multisine.pb.cobs.gz')
# calculate upper and lower masses
accel = scipy.signal.savgol_filter(log.measured_steer_angle, 101, 3, 2, 0.001)
torque1 = log.kistler_sensor_torque
torque2 = -torque1 + log.kollmorgen_applied_torque
m1 = np.linalg.lstsq(accel.reshape((-1, 1)), torque1.reshape((-1, 1)))[0][0][0]
print('least-squares fit for upper inertia {} kg-m^2'.format(m1))
m2 = np.linalg.lstsq(accel.reshape((-1, 1)), torque2.reshape((-1, 1)))[0][0][0]
print('least-squares fit for lower inertia {} kg-m^2'.format(m2))
color = sns.color_palette('Paired', 12)[1::2]
plt.close('all')
fig, ax = plt.subplots(3, 1, sharex=True)
ax[0].plot(log.t, accel,
color=color[0],
label='accel')
ax[0].legend()
ax[1].plot(log.t, accel * m1,
color=color[1], linestyle='--',
label='m1*a')
ax[1].plot(log.t, torque1,
color=color[2],
label='sensor torque')
ax[1].legend()
ax[2].plot(log.t, accel * m2,
color=color[1], linestyle='--',
label='m2*a')
ax[2].plot(log.t, torque2,
color=color[2],
label='-(sensor torque) + acuator torque')
ax[2].legend()
plt.show()
log = ps.ProcessedRecord('logs/2018-02-09T16h46m40sZ.pb.cobs.gz')
m1 = sa.UPPER_ASSEMBLY_INERTIA
m2 = sa.LOWER_ASSEMBLY_INERTIA
# reduce amount of data plotted
index = slice(20*1000, 100*1000)
t = log.t[index]
sensor_torque = log.kistler_sensor_torque[index]
motor_torque = log.kollmorgen_applied_torque[index]
accel = scipy.signal.savgol_filter(
log.measured_steer_angle[index], 101, 3, 2, 0.001)
inertia_torque_accel = m1*accel
steer_torque_accel = -sensor_torque + inertia_torque_accel
inertia_torque_motor = m1/m2*(-sensor_torque + motor_torque)
steer_torque_motor = -sensor_torque + inertia_torque_motor
color = sns.color_palette('Paired', 12)
fig, ax = plt.subplots()
ax.plot(t, sensor_torque,
color=color[0], label='sensor torque')
ax.plot(t, -sensor_torque,
color=color[1], label='-(sensor torque)')
ax.plot(t, motor_torque,
color=color[2], label='motor torque')
ax.plot(t, inertia_torque_accel,
color=color[4], label='inertia torque (accel)')
ax.plot(t, inertia_torque_motor,
color=color[8], label='inertia torque (motor)')
ax.plot(t, steer_torque_accel,
color=color[5], label='steer torque (accel)')
ax.plot(t, steer_torque_motor,
color=color[9], label='steer torque (motor)')
ax.legend()
plt.show()
```
| github_jupyter |
**Chapter 09**
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
```
# 4
```
np.random.seed(131)
x_1 = np.random.normal(0,1,100)
x_2 = 3 * x_1*x_1 + 4 + np.random.normal(0,1,100)
indices = np.random.choice(100, 50, replace=False)
x_2[indices] += 6
X = np.vstack((x_1,x_2)).T
y = np.full((100,1),1.0)
y[indices] = -1.0
for idx, y_value in enumerate(y):
if y_value == 1.0:
plt.scatter([X[idx,0]],[X[idx,1]],c='b',marker='+')
else:
plt.scatter([X[idx,0]],[X[idx,1]],c='g', marker='*')
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
y = y.reshape(100,)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4)
# use polynoimal kernel
poly_svc = SVC(kernel='poly')
poly_svc.fit(X_train, y_train)
poly_pred = poly_svc.predict(X_test)
print('polynomial kernel test data score: ', accuracy_score(poly_pred, y_test))
# use rbf kernel
rbf_svc = SVC(kernel='rbf')
rbf_svc.fit(X_train, y_train)
rbf_pred = rbf_svc.predict(X_test)
print('rbf kernel test dataset score: ', accuracy_score(rbf_pred, y_test))
```
# 5
## 5(a)
```
x1 = np.random.uniform(0,1,500) - 0.5
x2 = np.random.uniform(0,1,500) - 0.5
y =1*(x1*x1 - x2*x2>0)
```
## 5(b)
```
plt.scatter(x1[y==0],x2[y==0], c='r', marker='+')
plt.scatter(x1[y==1],x2[y==1], c='g', marker='*')
```
## 5(c,d)
```
from sklearn.linear_model import LogisticRegression
X = np.vstack((x1,x2)).T
lr = LogisticRegression()
lr.fit(X, y)
y_pred = lr.predict(X)
plt.scatter(X[y_pred==0,0],X[y_pred==0,1],c='r', marker='+')
plt.scatter(X[y_pred==1,0],X[y_pred==1,1],c='g', marker='*')
```
## 5 (e,f)
```
X_new = np.vstack((
np.power(X[:,0],2),
np.power(X[:,1],2),
X[:,0] * X[:,1])).T
lr = LogisticRegression()
lr.fit(X_new, y)
y_pred = lr.predict(X_new)
plt.scatter(X[y_pred==0,0],X[y_pred==0,1],c='r', marker='+')
plt.scatter(X[y_pred==1,0],X[y_pred==1,1],c='g', marker='*')
```
## 6(g)
```
from sklearn.svm import LinearSVC
linear_svc = LinearSVC()
linear_svc.fit(X,y)
y_pred = linear_svc.predict(X)
plt.scatter(X[y_pred==0,0],X[y_pred==0,1],c='r', marker='+')
plt.scatter(X[y_pred==1,0],X[y_pred==1,1],c='g', marker='*')
```
## 6(h)
```
rbf_svc = SVC(kernel='rbf')
rbf_svc.fit(X, y)
y_pred = rbf_svc.predict(X)
plt.scatter(X[y_pred==0,0],X[y_pred==0,1],c='r', marker='+')
plt.scatter(X[y_pred==1,0],X[y_pred==1,1],c='g', marker='*')
```
# 6
Pass
# 7
```
auto_file_path = '../data/Auto'
autos = pd.read_table(auto_file_path,sep='\s+',na_values='?')
autos=autos.dropna()
autos.head()
```
## 7(a)
```
mpg_median = np.median(autos['mpg'])
autos['mpg_status'] = [1 if item >= mpg_median else 0 for item in autos['mpg']]
autos.head()
```
## 7(b)
```
from pandas.tools.plotting import scatter_matrix
fig, ax = plt.subplots(figsize=(15, 15))
scatter_matrix(autos,ax=ax);
```
## 7(c)
```
from sklearn.cross_validation import cross_val_score
X = autos[['displacement','horsepower','weight','acceleration']].values
y = autos['mpg_status'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
Cs = [1,10,50,100,500,1000]
scores = []
for c in Cs:
clf = LinearSVC(C=c)
score = cross_val_score(clf, X_train, y_train, cv=5)
scores.append(score.mean())
plt.plot(Cs,scores)
clf = LinearSVC(C=500)
clf.fit(X_train,y_train)
pred = clf.predict(X_test)
print('test data set score: ', accuracy_score(pred, y_test))
```
## 7(c,d)
```
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.svm import SVC
# set the parameter by cross-validation
tuned_parameters = [
{
'kernel':['rbf'],
'gamma':[1e-3,1e-4],
'C':[1,10,100,1000]
},
{
'kernel':['poly'],
'C':[1,10,100,1000]
}
]
scores = ['precision', 'recall']
for score in scores:
clf = GridSearchCV(SVC(C=1), tuned_parameters,cv=5,
scoring='%s_macro' % score)
clf.fit(X_train, y_train)
print("Best parameters set found on development set:")
print(clf.best_params_)
```
# 8
```
oj_file_path = '../data/OJ.csv'
oj = pd.read_csv(oj_file_path, index_col=0)
oj.head()
```
## 8(a)
```
oj.columns
df_X = oj[['WeekofPurchase', 'StoreID', 'PriceCH', 'PriceMM', 'DiscCH',
'DiscMM', 'SpecialCH', 'SpecialMM', 'LoyalCH', 'SalePriceMM',
'SalePriceCH', 'PriceDiff', 'Store7', 'PctDiscMM', 'PctDiscCH',
'ListPriceDiff', 'STORE']]
df_X = pd.get_dummies(df_X, prefix=['Store'])
df_X.head()
X = df_X[['WeekofPurchase', 'StoreID', 'PriceCH', 'PriceMM', 'DiscCH',
'DiscMM', 'SpecialCH', 'SpecialMM', 'LoyalCH', 'SalePriceMM',
'SalePriceCH', 'PriceDiff', 'Store_No','Store_Yes', 'PctDiscMM', 'PctDiscCH',
'ListPriceDiff', 'STORE']].values
y = oj['Purchase'].values
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=(y.shape[0]-800)/y.shape[0])
```
## 8(b)
```
from sklearn.svm import SVC
clf = SVC(C=0.01,kernel='linear')
clf.fit(X_train, y_train)
```
## 8(c)
```
from sklearn.metrics import accuracy_score
train_pred = clf.predict(X_train)
print(accuracy_score(train_pred, y_train))
test_pred = clf.predict(X_test)
print(accuracy_score(test_pred, y_test))
```
## 8(d)
```
from sklearn.cross_validation import cross_val_score
Cs = np.linspace(0.1,10, 10)
scores = []
for c in Cs:
clf = SVC(C=c, kernel='linear')
score = cross_val_score(clf,X_train,y_train,cv=5)
scores.append(score.mean())
plt.plot(Cs,scores)
```
## 8(e)
```
clf = SVC(C=3,kernel='linear')
clf.fit(X_train, y_train)
pred_train = clf.predict(X_train)
print('train data set score: ', accuracy_score(pred_train, y_train))
pred_test = clf.predict(X_test)
print('test data set score: ', accuracy_score(pred_test, y_test))
```
## 8(f)
```
Cs = np.linspace(0.1,10, 10)
scores = []
for c in Cs:
clf = SVC(C=c, kernel='rbf')
score = cross_val_score(clf,X_train,y_train,cv=5)
scores.append(score.mean())
plt.plot(Cs,scores)
clf = SVC(C=10,kernel='rbf')
clf.fit(X_train, y_train)
pred_train = clf.predict(X_train)
print('train data set score: ', accuracy_score(pred_train, y_train))
pred_test = clf.predict(X_test)
print('test data set score: ', accuracy_score(pred_test, y_test))
```
## 8(g)
```
Cs = np.linspace(0.1,10, 10)
scores = []
for c in Cs:
clf = SVC(C=c, kernel='poly', degree=2)
score = cross_val_score(clf,X_train,y_train,cv=5)
scores.append(score.mean())
plt.plot(Cs,scores)
```
| github_jupyter |
# How to use ERA5 in zarr format
Zarr is a new storage format which, thanks to its simple yet well-designed specification, makes large datasets easily accessible to distributed computing. In Zarr datasets, the arrays are divided into chunks and compressed. These individual chunks can be stored as files on a filesystem or as objects in a cloud storage bucket. The metadata are stored in lightweight .json files. Zarr works well on both local filesystems and cloud-based object stores. Existing datasets can easily be converted to zarr via xarray’s zarr functions.
In this example we show how to use zarr format from S3 shared by Planet OS. When data is read in, we show some easy operations with the data.
```
%matplotlib notebook
import xarray as xr
import datetime
import numpy as np
from dask.distributed import LocalCluster, Client
import s3fs
import cartopy.crs as ccrs
import boto3
```
First we look into the era5-pds bucket zarr folder to find out what variables are available. Assuming that all the variables are available for all the years, we look into a random year-month data.
```
bucket = 'era5-pds'
#Make sure you provide / in the end
prefix = 'zarr/2008/01/data/'
client = boto3.client('s3')
result = client.list_objects(Bucket=bucket, Prefix=prefix, Delimiter='/')
for o in result.get('CommonPrefixes'):
print (o.get('Prefix'))
client = Client()
client
fs = s3fs.S3FileSystem(anon=False)
```
Here we define some functions to read in zarr data.
```
def inc_mon(indate):
if indate.month < 12:
return datetime.datetime(indate.year, indate.month+1, 1)
else:
return datetime.datetime(indate.year+1, 1, 1)
def gen_d_range(start, end):
rr = []
while start <= end:
rr.append(start)
start = inc_mon(start)
return rr
def get_z(dtime,var):
f_zarr = 'era5-pds/zarr/{year}/{month:02d}/data/{var}.zarr/'.format(year=dtime.year, month=dtime.month,var=var)
return xr.open_zarr(s3fs.S3Map(f_zarr, s3=fs))
def gen_zarr_range(start, end,var):
return [get_z(tt,var) for tt in gen_d_range(start, end)]
```
This is where we read in the data. We need to define the time range and variable name. In this example, we also choose to select only the area over Australia.
```
%%time
tmp_a = gen_zarr_range(datetime.datetime(1979,1,1), datetime.datetime(2020,3,31),'air_temperature_at_2_metres')
tmp_all = xr.concat(tmp_a, dim='time0')
tmp = tmp_all.air_temperature_at_2_metres.sel(lon=slice(110,160),lat=slice(-10,-45)) - 272.15
```
Here we read in an other variable. This time only for a month as we want to use it only for masking.
```
sea_data = gen_zarr_range(datetime.datetime(2018,1,1), datetime.datetime(2018,1,1),'sea_surface_temperature')
sea_data_all = xr.concat(sea_data, dim='time0').sea_surface_temperature.sel(lon=slice(110,160),lat=slice(-10,-45))
```
We decided to use sea surface temperature data for making a sea-land mask.
```
sea_data_all0 = sea_data_all[0].values
mask = np.isnan(sea_data_all0)
```
Mask out the data over the sea. To find out average temepratures over the land, it is important to mask out data over the ocean.
```
tmp_masked = tmp.where(mask)
tmp_mean = tmp_masked.mean('time0').compute()
```
Now we plot the all time (1980-2019) average temperature over Australia. This time we decided to use only xarray plotting tools.
```
ax = plt.axes(projection=ccrs.Orthographic(130, -20))
tmp_mean.plot.contourf(ax=ax, transform=ccrs.PlateCarree())
ax.set_global()
ax.coastlines();
plt.draw()
```
Now we are finding out yearly average temperature over the Australia land area.
```
yearly_tmp_AU = tmp_masked.groupby('time0.year').mean('time0').mean(dim=['lon','lat'])
f, ax = plt.subplots(1, 1)
yearly_tmp_AU.plot.line();
plt.draw()
```
In conclusion, this was the easy example on how to use zarr data. We were reading in 39 years of global data with 1 hour temporal coverage. Proceeded some operations on this data like selecting out only needed area and computing averages. Zarr makes large amount of data processing much faster than it used to be.
| github_jupyter |
# TensorFlow Tutorial #02
# Convolutional Neural Network
by [Magnus Erik Hvass Pedersen](http://www.hvass-labs.org/)
/ [GitHub](https://github.com/Hvass-Labs/TensorFlow-Tutorials) / [Videos on YouTube](https://www.youtube.com/playlist?list=PL9Hr9sNUjfsmEu1ZniY0XpHSzl5uihcXZ)
## Introduction
The previous tutorial showed that a simple linear model had about 91% classification accuracy for recognizing hand-written digits in the MNIST data-set.
In this tutorial we will implement a simple Convolutional Neural Network in TensorFlow which has a classification accuracy of about 99%, or more if you make some of the suggested exercises.
Convolutional Networks work by moving small filters across the input image. This means the filters are re-used for recognizing patterns throughout the entire input image. This makes the Convolutional Networks much more powerful than Fully-Connected networks with the same number of variables. This in turn makes the Convolutional Networks faster to train.
You should be familiar with basic linear algebra, Python and the Jupyter Notebook editor. Beginners to TensorFlow may also want to study the first tutorial before proceeding to this one.
## Flowchart
The following chart shows roughly how the data flows in the Convolutional Neural Network that is implemented below.

The input image is processed in the first convolutional layer using the filter-weights. This results in 16 new images, one for each filter in the convolutional layer. The images are also down-sampled so the image resolution is decreased from 28x28 to 14x14.
These 16 smaller images are then processed in the second convolutional layer. We need filter-weights for each of these 16 channels, and we need filter-weights for each output channel of this layer. There are 36 output channels so there are a total of 16 x 36 = 576 filters in the second convolutional layer. The resulting images are down-sampled again to 7x7 pixels.
The output of the second convolutional layer is 36 images of 7x7 pixels each. These are then flattened to a single vector of length 7 x 7 x 36 = 1764, which is used as the input to a fully-connected layer with 128 neurons (or elements). This feeds into another fully-connected layer with 10 neurons, one for each of the classes, which is used to determine the class of the image, that is, which number is depicted in the image.
The convolutional filters are initially chosen at random, so the classification is done randomly. The error between the predicted and true class of the input image is measured as the so-called cross-entropy. The optimizer then automatically propagates this error back through the Convolutional Network using the chain-rule of differentiation and updates the filter-weights so as to improve the classification error. This is done iteratively thousands of times until the classification error is sufficiently low.
These particular filter-weights and intermediate images are the results of one optimization run and may look different if you re-run this Notebook.
Note that the computation in TensorFlow is actually done on a batch of images instead of a single image, which makes the computation more efficient. This means the flowchart actually has one more data-dimension when implemented in TensorFlow.
## Convolutional Layer
The following chart shows the basic idea of processing an image in the first convolutional layer. The input image depicts the number 7 and four copies of the image are shown here, so we can see more clearly how the filter is being moved to different positions of the image. For each position of the filter, the dot-product is being calculated between the filter and the image pixels under the filter, which results in a single pixel in the output image. So moving the filter across the entire input image results in a new image being generated.
The red filter-weights means that the filter has a positive reaction to black pixels in the input image, while blue pixels means the filter has a negative reaction to black pixels.
In this case it appears that the filter recognizes the horizontal line of the 7-digit, as can be seen from its stronger reaction to that line in the output image.

The step-size for moving the filter across the input is called the stride. There is a stride for moving the filter horizontally (x-axis) and another stride for moving vertically (y-axis).
In the source-code below, the stride is set to 1 in both directions, which means the filter starts in the upper left corner of the input image and is being moved 1 pixel to the right in each step. When the filter reaches the end of the image to the right, then the filter is moved back to the left side and 1 pixel down the image. This continues until the filter has reached the lower right corner of the input image and the entire output image has been generated.
When the filter reaches the end of the right-side as well as the bottom of the input image, then it can be padded with zeroes (white pixels). This causes the output image to be of the exact same dimension as the input image.
Furthermore, the output of the convolution may be passed through a so-called Rectified Linear Unit (ReLU), which merely ensures that the output is positive because negative values are set to zero. The output may also be down-sampled by so-called max-pooling, which considers small windows of 2x2 pixels and only keeps the largest of those pixels. This halves the resolution of the input image e.g. from 28x28 to 14x14 pixels.
Note that the second convolutional layer is more complicated because it takes 16 input channels. We want a separate filter for each input channel, so we need 16 filters instead of just one. Furthermore, we want 36 output channels from the second convolutional layer, so in total we need 16 x 36 = 576 filters for the second convolutional layer. It can be a bit challenging to understand how this works.
## Imports
```
%matplotlib inline
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from sklearn.metrics import confusion_matrix
import time
from datetime import timedelta
import datetime
import math
import os
from scipy import ndimage
#import test4 as tst
```
This was developed using Python 3.6.1 (Anaconda) and TensorFlow version:
```
tf.__version__
```
## Configuration of Neural Network
The configuration of the Convolutional Neural Network is defined here for convenience, so you can easily find and change these numbers and re-run the Notebook.
```
# Convolutional Layer 1.
filter_size1 = 5 # Convolution filters are 5 x 5 pixels.
num_filters1 = 16 # There are 16 of these filters.
# Convolutional Layer 2.
filter_size2 = 5 # Convolution filters are 5 x 5 pixels.
num_filters2 = 36 # There are 36 of these filters.
# Fully-connected layer.
fc_size = 128 # Number of neurons in fully-connected layer.
```
## Load Data
The MNIST data-set is about 12 MB and will be downloaded automatically if it is not located in the given path.
```
a = datetime.datetime.now()
from tensorflow.examples.tutorials.mnist import input_data
data = input_data.read_data_sets('data/MNIST/', one_hot=True)
b = datetime.datetime.now()
c = b-a
print(c.microseconds)
```
The MNIST data-set has now been loaded and consists of 70,000 images and associated labels (i.e. classifications of the images). The data-set is split into 3 mutually exclusive sub-sets. We will only use the training and test-sets in this tutorial.
```
print("Size of:")
print("- Training-set:\t\t{}".format(len(data.train.labels)))
print("- Test-set:\t\t{}".format(len(data.test.labels)))
print("- Validation-set:\t{}".format(len(data.validation.labels)))
```
The class-labels are One-Hot encoded, which means that each label is a vector with 10 elements, all of which are zero except for one element. The index of this one element is the class-number, that is, the digit shown in the associated image. We also need the class-numbers as integers for the test-set, so we calculate it now.
```
data.test.cls = np.argmax(data.test.labels, axis=1)
```
## Data Dimensions
The data dimensions are used in several places in the source-code below. They are defined once so we can use these variables instead of numbers throughout the source-code below.
```
# We know that MNIST images are 28 pixels in each dimension.
img_size = 28
# Images are stored in one-dimensional arrays of this length.
img_size_flat = img_size * img_size
# Tuple with height and width of images used to reshape arrays.
img_shape = (img_size, img_size)
# Number of colour channels for the images: 1 channel for gray-scale.
num_channels = 1
# Number of classes, one class for each of 10 digits.
num_classes = 10
```
### Helper-function for plotting images
Function used to plot 9 images in a 3x3 grid, and writing the true and predicted classes below each image.
```
def plot_images(images, cls_true, cls_pred=None):
assert len(images) == len(cls_true) == 9
# Create figure with 3x3 sub-plots.
fig, axes = plt.subplots(3, 3)
fig.subplots_adjust(hspace=0.3, wspace=0.3)
for i, ax in enumerate(axes.flat):
# Plot image.
ax.imshow(images[i].reshape(img_shape), cmap='binary')
# Show true and predicted classes.
if cls_pred is None:
xlabel = "True: {0}".format(cls_true[i])
else:
xlabel = "True: {0}, Pred: {1}".format(cls_true[i], cls_pred[i])
# Show the classes as the label on the x-axis.
ax.set_xlabel(xlabel)
# Remove ticks from the plot.
ax.set_xticks([])
ax.set_yticks([])
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
```
### Plot a few images to see if data is correct
```
# Get the first images from the test-set.
images = data.test.images[0:9]
# Get the true classes for those images.
cls_true = data.test.cls[0:9]
# Plot the images and labels using our helper-function above.
plot_images(images=images, cls_true=cls_true)
print(images[0])
```
## TensorFlow Graph
The entire purpose of TensorFlow is to have a so-called computational graph that can be executed much more efficiently than if the same calculations were to be performed directly in Python. TensorFlow can be more efficient than NumPy because TensorFlow knows the entire computation graph that must be executed, while NumPy only knows the computation of a single mathematical operation at a time.
TensorFlow can also automatically calculate the gradients that are needed to optimize the variables of the graph so as to make the model perform better. This is because the graph is a combination of simple mathematical expressions so the gradient of the entire graph can be calculated using the chain-rule for derivatives.
TensorFlow can also take advantage of multi-core CPUs as well as GPUs - and Google has even built special chips just for TensorFlow which are called TPUs (Tensor Processing Units) and are even faster than GPUs.
A TensorFlow graph consists of the following parts which will be detailed below:
* Placeholder variables used for inputting data to the graph.
* Variables that are going to be optimized so as to make the convolutional network perform better.
* The mathematical formulas for the convolutional network.
* A cost measure that can be used to guide the optimization of the variables.
* An optimization method which updates the variables.
In addition, the TensorFlow graph may also contain various debugging statements e.g. for logging data to be displayed using TensorBoard, which is not covered in this tutorial.
### Helper-functions for creating new variables
Functions for creating new TensorFlow variables in the given shape and initializing them with random values. Note that the initialization is not actually done at this point, it is merely being defined in the TensorFlow graph.
```
def new_weights(shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.05))
def new_biases(length):
return tf.Variable(tf.constant(0.05, shape=[length]))
```
### Helper-function for creating a new Convolutional Layer
This function creates a new convolutional layer in the computational graph for TensorFlow. Nothing is actually calculated here, we are just adding the mathematical formulas to the TensorFlow graph.
It is assumed that the input is a 4-dim tensor with the following dimensions:
1. Image number.
2. Y-axis of each image.
3. X-axis of each image.
4. Channels of each image.
Note that the input channels may either be colour-channels, or it may be filter-channels if the input is produced from a previous convolutional layer.
The output is another 4-dim tensor with the following dimensions:
1. Image number, same as input.
2. Y-axis of each image. If 2x2 pooling is used, then the height and width of the input images is divided by 2.
3. X-axis of each image. Ditto.
4. Channels produced by the convolutional filters.
```
def new_conv_layer(input, # The previous layer.
num_input_channels, # Num. channels in prev. layer.
filter_size, # Width and height of each filter.
num_filters,): # Use 2x2 max-pooling.
# Shape of the filter-weights for the convolution.
# This format is determined by the TensorFlow API.
shape = [filter_size, filter_size, num_input_channels, num_filters]
# Create new weights aka. filters with the given shape.
weights = new_weights(shape=shape)
# Create new biases, one for each filter.
biases = new_biases(length=num_filters)
# Create the TensorFlow operation for convolution.
# Note the strides are set to 1 in all dimensions.
# The first and last stride must always be 1,
# because the first is for the image-number and
# the last is for the input-channel.
# But e.g. strides=[1, 2, 2, 1] would mean that the filter
# is moved 2 pixels across the x- and y-axis of the image.
# The padding is set to 'SAME' which means the input image
# is padded with zeroes so the size of the output is the same.
layer = tf.nn.conv2d(input=input,
filter=weights,
strides=[1, 1, 1, 1],
padding='SAME')
#layerConvOut = layer
# Add the biases to the results of the convolution.
# A bias-value is added to each filter-channel.
#layer += biases
return layer, weights, biases
def pooling_relu(input, # The previous layer.
use_pooling=True): # Use 2x2 max-pooling.
# Use pooling to down-sample the image resolution?
if use_pooling:
# This is 2x2 max-pooling, which means that we
# consider 2x2 windows and select the largest value
# in each window. Then we move 2 pixels to the next window.
layer = tf.nn.max_pool(value=input,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
# Rectified Linear Unit (ReLU).
# It calculates max(x, 0) for each input pixel x.
# This adds some non-linearity to the formula and allows us
# to learn more complicated functions.
layer = tf.nn.relu(layer)
# Note that ReLU is normally executed before the pooling,
# but since relu(max_pool(x)) == max_pool(relu(x)) we can
# save 75% of the relu-operations by max-pooling first.
# We return both the resulting layer and the filter-weights
# because we will plot the weights later.
return layer
```
### Helper-function for flattening a layer
A convolutional layer produces an output tensor with 4 dimensions. We will add fully-connected layers after the convolution layers, so we need to reduce the 4-dim tensor to 2-dim which can be used as input to the fully-connected layer.
```
def flatten_layer(layer):
# Get the shape of the input layer.
layer_shape = layer.get_shape()
# The shape of the input layer is assumed to be:
# layer_shape == [num_images, img_height, img_width, num_channels]
# The number of features is: img_height * img_width * num_channels
# We can use a function from TensorFlow to calculate this.
num_features = layer_shape[1:4].num_elements()
# Reshape the layer to [num_images, num_features].
# Note that we just set the size of the second dimension
# to num_features and the size of the first dimension to -1
# which means the size in that dimension is calculated
# so the total size of the tensor is unchanged from the reshaping.
layer_flat = tf.reshape(layer, [-1, num_features])
# The shape of the flattened layer is now:
# [num_images, img_height * img_width * num_channels]
# Return both the flattened layer and the number of features.
return layer_flat, num_features
```
### Helper-function for creating a new Fully-Connected Layer
This function creates a new fully-connected layer in the computational graph for TensorFlow. Nothing is actually calculated here, we are just adding the mathematical formulas to the TensorFlow graph.
It is assumed that the input is a 2-dim tensor of shape `[num_images, num_inputs]`. The output is a 2-dim tensor of shape `[num_images, num_outputs]`.
```
def new_fc_layer(input, # The previous layer.
num_inputs, # Num. inputs from prev. layer.
num_outputs, # Num. outputs.
use_relu=True): # Use Rectified Linear Unit (ReLU)?
# Create new weights and biases.
weights = new_weights(shape=[num_inputs, num_outputs])
biases = new_biases(length=num_outputs)
# Calculate the layer as the matrix multiplication of
# the input and weights, and then add the bias-values.
layer = tf.matmul(input, weights) + biases
# Use ReLU?
if use_relu:
layer = tf.nn.relu(layer)
return layer,weights
```
### Placeholder variables
Placeholder variables serve as the input to the TensorFlow computational graph that we may change each time we execute the graph. We call this feeding the placeholder variables and it is demonstrated further below.
First we define the placeholder variable for the input images. This allows us to change the images that are input to the TensorFlow graph. This is a so-called tensor, which just means that it is a multi-dimensional vector or matrix. The data-type is set to `float32` and the shape is set to `[None, img_size_flat]`, where `None` means that the tensor may hold an arbitrary number of images with each image being a vector of length `img_size_flat`.
```
x = tf.placeholder(tf.float32, shape=[None, img_size_flat], name='x')
```
The convolutional layers expect `x` to be encoded as a 4-dim tensor so we have to reshape it so its shape is instead `[num_images, img_height, img_width, num_channels]`. Note that `img_height == img_width == img_size` and `num_images` can be inferred automatically by using -1 for the size of the first dimension. So the reshape operation is:
```
x_image = tf.reshape(x, [-1, img_size, img_size, num_channels])
```
Next we have the placeholder variable for the true labels associated with the images that were input in the placeholder variable `x`. The shape of this placeholder variable is `[None, num_classes]` which means it may hold an arbitrary number of labels and each label is a vector of length `num_classes` which is 10 in this case.
```
y_true = tf.placeholder(tf.float32, shape=[None, num_classes], name='y_true')
```
We could also have a placeholder variable for the class-number, but we will instead calculate it using argmax. Note that this is a TensorFlow operator so nothing is calculated at this point.
```
y_true_cls = tf.argmax(y_true, axis=1)
```
### Convolutional Layer 1
Create the first convolutional layer. It takes `x_image` as input and creates `num_filters1` different filters, each having width and height equal to `filter_size1`. Finally we wish to down-sample the image so it is half the size by using 2x2 max-pooling.
```
layer_conv1, weights_conv1,biases_conv1 = \
new_conv_layer(input=x_image,
num_input_channels=num_channels,
filter_size=filter_size1,
num_filters=num_filters1)
```
### Add Biases
```
layer_conv1_biases = layer_conv1 + biases_conv1
```
### Pooling Relu Convolution Layer 1
```
layer_conv1_pool_relu = pooling_relu(input = layer_conv1_biases,use_pooling=True)
```
Check the shape of the tensor that will be output by the convolutional layer. It is (?, 14, 14, 16) which means that there is an arbitrary number of images (this is the ?), each image is 14 pixels wide and 14 pixels high, and there are 16 different channels, one channel for each of the filters.
```
x_image
```
### Convolutional Layer 2
Create the second convolutional layer, which takes as input the output from the first convolutional layer. The number of input channels corresponds to the number of filters in the first convolutional layer.
```
layer_conv2, weights_conv2,biases_conv2 = \
new_conv_layer(input=layer_conv1_pool_relu,
num_input_channels=num_filters1,
filter_size=filter_size2,
num_filters=num_filters2)
```
### Adding Biases
```
layer_conv2_biases = layer_conv2 + biases_conv2
```
### Pooling Relu Convolution Layer 2
```
layer_conv2_pool_relu = pooling_relu(input = layer_conv2_biases,use_pooling=True)
```
Check the shape of the tensor that will be output from this convolutional layer. The shape is (?, 7, 7, 36) where the ? again means that there is an arbitrary number of images, with each image having width and height of 7 pixels, and there are 36 channels, one for each filter.
```
layer_conv2[1][:,:,1][:,:]
weights_conv2
```
### Flatten Layer
The convolutional layers output 4-dim tensors. We now wish to use these as input in a fully-connected network, which requires for the tensors to be reshaped or flattened to 2-dim tensors.
```
layer_flat, num_features = flatten_layer(layer_conv2_pool_relu)
```
Check that the tensors now have shape (?, 1764) which means there's an arbitrary number of images which have been flattened to vectors of length 1764 each. Note that 1764 = 7 x 7 x 36.
```
layer_flat
num_features
```
### Fully-Connected Layer 1
Add a fully-connected layer to the network. The input is the flattened layer from the previous convolution. The number of neurons or nodes in the fully-connected layer is `fc_size`. ReLU is used so we can learn non-linear relations.
```
layer_fc1,weights_fc1 = new_fc_layer(input=layer_flat,
num_inputs=num_features,
num_outputs=fc_size,
use_relu=True)
```
Check that the output of the fully-connected layer is a tensor with shape (?, 128) where the ? means there is an arbitrary number of images and `fc_size` == 128.
```
layer_fc1
```
### Fully-Connected Layer 2
Add another fully-connected layer that outputs vectors of length 10 for determining which of the 10 classes the input image belongs to. Note that ReLU is not used in this layer.
```
layer_fc2,weights_fc2 = new_fc_layer(input=layer_fc1,
num_inputs=fc_size,
num_outputs=num_classes,
use_relu=False)
layer_fc2.shape
```
### Predicted Class
The second fully-connected layer estimates how likely it is that the input image belongs to each of the 10 classes. However, these estimates are a bit rough and difficult to interpret because the numbers may be very small or large, so we want to normalize them so that each element is limited between zero and one and the 10 elements sum to one. This is calculated using the so-called softmax function and the result is stored in `y_pred`.
```
y_pred = tf.nn.softmax(layer_fc2)
print(y_pred)
```
The class-number is the index of the largest element.
```
y_pred_cls = tf.argmax(y_pred, axis=1)
```
### Cost-function to be optimized
To make the model better at classifying the input images, we must somehow change the variables for all the network layers. To do this we first need to know how well the model currently performs by comparing the predicted output of the model `y_pred` to the desired output `y_true`.
The cross-entropy is a performance measure used in classification. The cross-entropy is a continuous function that is always positive and if the predicted output of the model exactly matches the desired output then the cross-entropy equals zero. The goal of optimization is therefore to minimize the cross-entropy so it gets as close to zero as possible by changing the variables of the network layers.
TensorFlow has a built-in function for calculating the cross-entropy. Note that the function calculates the softmax internally so we must use the output of `layer_fc2` directly rather than `y_pred` which has already had the softmax applied.
```
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=layer_fc2,
labels=y_true)
```
We have now calculated the cross-entropy for each of the image classifications so we have a measure of how well the model performs on each image individually. But in order to use the cross-entropy to guide the optimization of the model's variables we need a single scalar value, so we simply take the average of the cross-entropy for all the image classifications.
```
cost = tf.reduce_mean(cross_entropy)
```
### Optimization Method
Now that we have a cost measure that must be minimized, we can then create an optimizer. In this case it is the `AdamOptimizer` which is an advanced form of Gradient Descent.
Note that optimization is not performed at this point. In fact, nothing is calculated at all, we just add the optimizer-object to the TensorFlow graph for later execution.
```
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost)
```
### Performance Measures
We need a few more performance measures to display the progress to the user.
This is a vector of booleans whether the predicted class equals the true class of each image.
```
correct_prediction = tf.equal(y_pred_cls, y_true_cls)
```
This calculates the classification accuracy by first type-casting the vector of booleans to floats, so that False becomes 0 and True becomes 1, and then calculating the average of these numbers.
```
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
```
## TensorFlow Run
### Create TensorFlow session
Once the TensorFlow graph has been created, we have to create a TensorFlow session which is used to execute the graph.
```
session = tf.Session()
```
### Save Session
```
saver = tf.train.Saver()
save_dir = 'checkpoints_lenetMinst/'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_path = os.path.join(save_dir, 'best_validation')
```
### Restore saved session
```
try:
print("Trying to restore last checkpoint ...")
# Use TensorFlow to find the latest checkpoint - if any.
last_chk_path = tf.train.latest_checkpoint(checkpoint_dir=save_dir)
# Try and load the data in the checkpoint.
saver.restore(session, save_path=last_chk_path)
# If we get to this point, the checkpoint was successfully loaded.
print("Restored checkpoint from:", last_chk_path)
except:
# If the above failed for some reason, simply
# initialize all the variables for the TensorFlow graph.
print("Failed to restore checkpoint. Initializing variables instead.")
session.run(tf.global_variables_initializer())
```
### Initialize variables
The variables for `weights` and `biases` must be initialized before we start optimizing them.
```
session.run(tf.global_variables_initializer())
```
### Helper-function to perform optimization iterations
There are 55,000 images in the training-set. It takes a long time to calculate the gradient of the model using all these images. We therefore only use a small batch of images in each iteration of the optimizer.
If your computer crashes or becomes very slow because you run out of RAM, then you may try and lower this number, but you may then need to perform more optimization iterations.
```
train_batch_size = 64
```
Function for performing a number of optimization iterations so as to gradually improve the variables of the network layers. In each iteration, a new batch of data is selected from the training-set and then TensorFlow executes the optimizer using those training samples. The progress is printed every 100 iterations.
```
# Counter for total number of iterations performed so far.
total_iterations = 0
def optimize(num_iterations):
# Ensure we update the global variable rather than a local copy.
global total_iterations
# Start-time used for printing time-usage below.
start_time = time.time()
for i in range(total_iterations,
total_iterations + num_iterations):
# Get a batch of training examples.
# x_batch now holds a batch of images and
# y_true_batch are the true labels for those images.
x_batch, y_true_batch = data.train.next_batch(train_batch_size)
# Put the batch into a dict with the proper names
# for placeholder variables in the TensorFlow graph.
feed_dict_train = {x: x_batch,
y_true: y_true_batch}
# Run the optimizer using this batch of training data.
# TensorFlow assigns the variables in feed_dict_train
# to the placeholder variables and then runs the optimizer.
session.run(optimizer, feed_dict=feed_dict_train)
# Print status every 100 iterations.
if i % 100 == 0:
# Calculate the accuracy on the training-set.
acc = session.run(accuracy, feed_dict=feed_dict_train)
# Message for printing.
msg = "Optimization Iteration: {0:>6}, Training Accuracy: {1:>6.1%}"
# Print it.
print(msg.format(i + 1, acc))
if (total_iterations % 1000 == 0) or (i == num_iterations - 1):
# Save all variables of the TensorFlow graph to a
# checkpoint. Append the global_step counter
# to the filename so we save the last several checkpoints.
saver.save(session,
save_path=save_path,
global_step = total_iterations)
print("Saved checkpoint.")
total_iterations += 1
# Update the total number of iterations performed.
#total_iterations += num_iterations
# Ending time.
end_time = time.time()
# Difference between start and end-times.
time_dif = end_time - start_time
# Print the time-usage.
print("Time usage: " + str(timedelta(seconds=int(round(time_dif)))))
```
### Helper-function to plot example errors
Function for plotting examples of images from the test-set that have been mis-classified.
```
def plot_example_errors(cls_pred, correct):
# This function is called from print_test_accuracy() below.
# cls_pred is an array of the predicted class-number for
# all images in the test-set.
# correct is a boolean array whether the predicted class
# is equal to the true class for each image in the test-set.
# Negate the boolean array.
incorrect = (correct == False)
# Get the images from the test-set that have been
# incorrectly classified.
images = data.test.images[incorrect]
# Get the predicted classes for those images.
cls_pred = cls_pred[incorrect]
# Get the true classes for those images.
cls_true = data.test.cls[incorrect]
# Plot the first 9 images.
plot_images(images=images[0:9],
cls_true=cls_true[0:9],
cls_pred=cls_pred[0:9])
```
### Helper-function to plot confusion matrix
```
def plot_confusion_matrix(cls_pred):
# This is called from print_test_accuracy() below.
# cls_pred is an array of the predicted class-number for
# all images in the test-set.
# Get the true classifications for the test-set.
cls_true = data.test.cls
# Get the confusion matrix using sklearn.
cm = confusion_matrix(y_true=cls_true,
y_pred=cls_pred)
# Print the confusion matrix as text.
print(cm)
# Plot the confusion matrix as an image.
plt.matshow(cm)
# Make various adjustments to the plot.
plt.colorbar()
tick_marks = np.arange(num_classes)
plt.xticks(tick_marks, range(num_classes))
plt.yticks(tick_marks, range(num_classes))
plt.xlabel('Predicted')
plt.ylabel('True')
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
```
### Helper-function for showing the performance
Function for printing the classification accuracy on the test-set.
It takes a while to compute the classification for all the images in the test-set, that's why the results are re-used by calling the above functions directly from this function, so the classifications don't have to be recalculated by each function.
Note that this function can use a lot of computer memory, which is why the test-set is split into smaller batches. If you have little RAM in your computer and it crashes, then you can try and lower the batch-size.
```
# Split the test-set into smaller batches of this size.
test_batch_size = 256
def print_test_accuracy(show_example_errors=False,
show_confusion_matrix=False):
# Number of images in the test-set.
num_test = len(data.test.images)
# Allocate an array for the predicted classes which
# will be calculated in batches and filled into this array.
cls_pred = np.zeros(shape=num_test, dtype=np.int)
# Now calculate the predicted classes for the batches.
# We will just iterate through all the batches.
# There might be a more clever and Pythonic way of doing this.
# The starting index for the next batch is denoted i.
i = 0
while i < num_test:
# The ending index for the next batch is denoted j.
j = min(i + test_batch_size, num_test)
# Get the images from the test-set between index i and j.
images = data.test.images[i:j, :]
# Get the associated labels.
labels = data.test.labels[i:j, :]
# Create a feed-dict with these images and labels.
feed_dict = {x: images,
y_true: labels}
# Calculate the predicted class using TensorFlow.
cls_pred[i:j] = session.run(y_pred_cls, feed_dict=feed_dict)
# Set the start-index for the next batch to the
# end-index of the current batch.
i = j
# Convenience variable for the true class-numbers of the test-set.
cls_true = data.test.cls
# Create a boolean array whether each image is correctly classified.
correct = (cls_true == cls_pred)
# Calculate the number of correctly classified images.
# When summing a boolean array, False means 0 and True means 1.
correct_sum = correct.sum()
# Classification accuracy is the number of correctly classified
# images divided by the total number of images in the test-set.
acc = float(correct_sum) / num_test
# Print the accuracy.
msg = "Accuracy on Test-Set: {0:.1%} ({1} / {2})"
print(msg.format(acc, correct_sum, num_test))
# Plot some examples of mis-classifications, if desired.
if show_example_errors:
print("Example errors:")
plot_example_errors(cls_pred=cls_pred, correct=correct)
# Plot the confusion matrix, if desired.
if show_confusion_matrix:
print("Confusion Matrix:")
plot_confusion_matrix(cls_pred=cls_pred)
```
## Performance before any optimization
The accuracy on the test-set is very low because the model variables have only been initialized and not optimized at all, so it just classifies the images randomly.
```
print_test_accuracy()
```
## Performance after 1 optimization iteration
The classification accuracy does not improve much from just 1 optimization iteration, because the learning-rate for the optimizer is set very low.
```
optimize(num_iterations=1)
a = time.time()
print_test_accuracy()
b = time.time()
c = b-a
print(c)
```
## Performance after 100 optimization iterations
After 100 optimization iterations, the model has significantly improved its classification accuracy.
```
optimize(num_iterations=99) # We already performed 1 iteration above.
print_test_accuracy(show_example_errors=True)
```
## Performance after 1000 optimization iterations
After 1000 optimization iterations, the model has greatly increased its accuracy on the test-set to more than 90%.
```
optimize(num_iterations=900) # We performed 100 iterations above.
print_test_accuracy(show_example_errors=True)
total_iterations
```
## Performance after 10,000 optimization iterations
After 10,000 optimization iterations, the model has a classification accuracy on the test-set of about 99%.
```
optimize(num_iterations=9000) # We performed 1000 iterations above.
print_test_accuracy(show_example_errors=True,
show_confusion_matrix=True)
```
## Store the original weights
```
w_conv1_original = session.run(weights_conv1)
w_conv2_original = session.run(weights_conv2)
w_fc1_original = session.run(weights_fc1)
w_fc2_original = session.run(weights_fc2)
w_fc1_original.shape
wOrigConv = [w_conv1_original,w_conv2_original]
wOrigFc = [w_fc1_original]
w_conv1_original[:,:,0,1]
w_conv2_original[:,:,15,35]
```
## Restore Original Weights
```
def restoreWeights():
for wIdx in range(0,len(weightsConvMat)):
assign_op = weightsConvMat[wIdx].assign(wOrigConv[wIdx])
session.run(assign_op)
for wIdx in range(0,len(weightsFcMat)):
assign_op = weightsFcMat[wIdx].assign(wOrigFc[wIdx])
session.run(assign_op)
restoreWeights()
```
## Create list of weights_conv and assign to alternate varialbles
# This is the point of contraption where we will re run from each time in order to calculate our ME values
```
weightsConvMat = [weights_conv1,weights_conv2]
weightsFcMat = [weights_fc1]
wConv1 = session.run(weights_conv1)
wConv2 = session.run(weights_conv2)
wFc1 = session.run(weights_fc1)
wFc2 = session.run(weights_fc2)
wConv = [wConv1,wConv2]
wFc = [wFc2]
wConv[1].shape
```
## Create List that will hold the difference between 2 filters
```
wDiffConv = [] + wOrigConv
wDiffFc = [] + wOrigFc
```
## Create Alternate Filters
### Negative values to zero
```
def roundToZeroFilter(wtListConv,wtListFc):
num = len(wtListConv)
for wtMat in wtListConv:
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
numChnls = shape[2]
numFilters = shape[3]
for c in range(0,numChnls):
for i in range(0,numFilters):
for j in range(0,xlen):
for k in range(0,ylen):
if wtMat[j,k,c,i] < 0:
wtMat[j,k,c,i] = 0#float('%.5f'%(w[j,k,0,i]))
for wtMat in wtListFc:
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
for i in range(0,xlen):
j=0
while j<ylen:
if wtMat[i,j] < 0:
wtMat[i,j] = 0
j=j+1;
#roundToZeroFilter(w)
```
### Centroid based averaging filter
```
def centroidFilter(wtListConv,wtListFc):
num = len(wtListConv)
for wtMat in wtListConv:
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
numChnls = shape[2]
numFilters = shape[3]
for c in range(0,numChnls):
for i in range(0,numFilters):
for j in range(0,xlen,2):
for k in range(0,ylen,2):
first = wtMat[j,k,c,i]
if j+1 < xlen:
second = wtMat[j+1,k,c,i]
else:
second = 0
if k+1 < xlen:
third = wtMat[j,k+1,c,i]
else:
third = 0
if j+1 < xlen and k+1 < ylen:
forth = wtMat[j+1,k+1,c,i]
else:
forth = 0
total = 0.0
total = float(first + second + third + forth)
total /= 4
wtMat[j,k,c,i] = total
if j+1 < xlen:
wtMat[j+1,k,c,i] = total
if k+1 < xlen:
wtMat[j,k+1,c,i] = total
if j+1 < xlen and k+1 < ylen:
wtMat[j+1,k+1,c,i] = total
#if wtMat[j,k,0,i] < 0:
# wtMat[j,k,0,i] = 0#float('%.5f'%(w[j,k,0,i]))
for wtMat in wtListFc:
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
for i in range(0,xlen):
j=0
while j<ylen:
first = wtMat[i,j]
second = wtMat[i,j+1]
avg = (first+second)/2
wtMat[i,j] = avg
wtMat[i,j+1] = avg
j = j+2
#centroidFilter(w)
```
### Truncating the decimal
```
def truncateFilter(wtListConv,wtListFc):
num = len(wtListConv)
for wtMat in wtListConv:
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
numChnls = shape[2]
numFilters = shape[3]
for c in range(0,numChnls):
for i in range(0,numFilters):
for j in range(0,xlen):
for k in range(0,ylen):
wtMat[j,k,c,i] = float('%.5f'%(wtMat[j,k,c,i]))
for wtMat in wtListFc:
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
for i in range(0,xlen):
j=0
while j<ylen:
wtMat[i,j]=float('%.5f'%(wtMat[i,j]))
j=j+1;
#truncateFilter(w)
def borderFilter(wtListConv):
for wtMat in wtListConv:
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
numChnls = shape[2]
numFilters = shape[3]
for c in range(0,numChnls):
for i in range(0,numFilters):
for j in range(0, xlen):
for k in range(0,ylen):
if(k%4 == 0 or j%4 == 0):
wtMat[j,k,c,i] = 0
#centroidFilter(wConv,wFc)
#truncateFilter(w)
wFc
wConv[0][:,:,0,0]
```
## Testing and Assigning the alternate filters
```
def assignFilters(wConv,wFc):
for wIdx in range(0,len(weightsConvMat)):
assign_op = weightsConvMat[wIdx].assign(wConv[wIdx])
session.run(assign_op)
for wIdx in range(0,len(weightsFcMat)):
assign_op = weightsFcMat[wIdx].assign(wFc[wIdx])
session.run(assign_op)
# a = time.time()
# print_test_accuracy()
# b = time.time()
# c = b-a
# print(c)
assignFilters(wConv,wOrigFc)
a = time.time()
print_test_accuracy()
b = time.time()
c = b-a
print(c)
```
## Multiplication Error
### Loading Image Data
```
def loadValues(numImg):
#numImg = 100
image1 = data.test.images[0:numImg]
feed_dict = {x: image1}
values_conv1 = session.run(layer_conv1, feed_dict=feed_dict)
values_conv2 = session.run(layer_conv2, feed_dict=feed_dict)
values_fc1 = session.run(layer_fc1, feed_dict=feed_dict)
valuesConvMat = [values_conv1,values_conv2]
valuesFcMat = [values_fc1]
return valuesConvMat, valuesFcMat,numImg
```
### Calculating ME for Conv Layer
```
def calculateConvME(valuesMat):
shape = valuesMat.shape
valMat = valuesMat
numFilters = shape[3]
means = np.zeros(numFilters)
meanSum = np.zeros(numFilters)
for nImg in range(0,numImg):
meanSum = meanSum + means
for i in range(0,numFilters):
result = valMat[nImg,:,:,i]
result_sum = np.sum(result)
means[i] = result_sum
average = [x / numImg for x in meanSum]
averageSorted = np.sort(average)
return average, averageSorted
def calculateFCME(valuesMat):
shape = valuesMat.shape
valMat = valuesMat
numFilters = shape[1]
print(valMat)
means = np.zeros(numFilters)
meanSum = np.zeros(numFilters)
for nImg in range(0,numImg):
meanSum = meanSum + means
for i in range(0,numFilters):
result = valMat[nImg,i]
result_sum = np.sum(result)
means[i] = result_sum
average = [x / numImg for x in meanSum]
averageSorted = np.sort(average)
return average, averageSorted
def plotME(ME):
ypos = np.arange(len(ME))
y = ME
plt.bar(ypos,y,align='center')
```
### Filter Policy (20% of the Top filters)
```
def newApproxFilters(ME,wConvNew,wOrigConv):
sortedME = np.sort(ME)
length = len(ME)
thresh = (int)(length*0.8)
threshVal = sortedME[thresh]
shape = wConvNew.shape
numChnls = shape[2]
numFilters = shape[3]
for i in range(0,numFilters):
if ME[i] >= threshVal:
wConvNew[:,:,:,i] = wOrigConv[:,:,:,i]
```
### Subtracting the two filters
```
for i in range(len(wConv)):
wDiffConv[i] = np.absolute(wOrigConv[i] - wConv[i])
for i in range(len(wFc)):
wDiffFc[i] = np.absolute(wOrigFc[i] - wFc[i])
weightsConvMat[0].shape
wFc
```
### Assign the values and Calculate the ME
```
centroidFilter(wConv, wFc)
wFc
assignFilters(wConv,wOrigFc)
assign_op = weightsConvMat[0].assign(wDiffConv[0])
session.run(assign_op)
valuesConvMat,valuesFcMat,numImg = loadValues(100)
MEConv1,MEConv1Sorted = calculateConvME(valuesConvMat[0])
MEFullyConnected1, MEFullyConnected1Sorted = calculateFCME(valuesFcMat[0])
assignFilters(wConv,wOrigFc)
assign_op = weightsConvMat[1].assign(wDiffConv[1])
session.run(assign_op)
valuesConvMat,valuesFcMat,numImg = loadValues(100)
MEConv2,MEConv2Sorted = calculateConvME(valuesConvMat[1])
##MEFullyConnected2, MEFullyConnected2Sorted = calculateFCME(valuesFcMat[1])
MEConvMat = [MEConv1, MEConv2]
MEFullyConnectedMat = [MEFullyConnected1]
##centroidFilter(wConv,wFc)
thisLength = len(MEFullyConnectedMat[0])
thisLength
printingFCME = [] + MEFullyConnectedMat
printingFCME = MEFullyConnectedMat[0]
printingFCME.sort()
printingFCME
plotME(printingFCME)
plotME(MEConvMatBorder[0])
plotME(MEConvMatTruncate[0])
plotME(MEConvMatRTZ[0])
MEConvMatCBA = []+ MEFullyConnectedMat #ME values for CBA
MEConvMatBorder = []+ MEFullyConnectedMat #ME values for Border
MEConvMatTruncate = []+ MEFullyConnectedMat #ME values for Truncate
MEConvMatRTZ = []+ MEFullyConnectedMat #ME values for Truncate
```
### Filter Policy implementation
```
wConvNew = [] + wConv
newApproxFilters(MEConv1,wConvNew[0],wOrigConv[0])
newApproxFilters(MEConv2,wConvNew[1],wOrigConv[1])
assign_op = weightsConvMat[0].assign(wConvNew[0])
session.run(assign_op)
assign_op = weightsConvMat[1].assign(wConvNew[1])
session.run(assign_op)
wConvNewCBA = [] + wConvNew #New filter values for CBA
wConvNewBorder = [] + wConvNew #New filter values for Border
wConvNewTruncate = [] + wConvNew #New filter values for Border
wConvNewRTZ = [] + wConvNew #New filter values for Border
wConvArr1 = [wConvNewCBA[0], wConvNewBorder[0], wConvNewTruncate[0],wConvNewRTZ[0]]
wConvArr11 = [wConvNewCBA[0], wConvNewBorder[0]]
len(wConvArr1)
wConvArr2 = [wConvNewCBA[1], wConvNewBorder[1], wConvNewTruncate[1],wConvNewRTZ[1]]
wConvArr22 = [wConvNewCBA[1], wConvNewBorder[1]]
```
## Checksum Calculation
```
wOrigConv[1].shape
def calculateCheckSum(wtMat,wOrig):
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
numChnls = shape[2]
numFilters = shape[3]
means = np.zeros((xlen,ylen,numChnls))
meanAvg = np.zeros((xlen,ylen,numChnls))
for c in range(0,numChnls):
for i in range(0,numFilters):
means[:,:,c] += np.absolute(wtMat[:,:,c,i]-wOrig[:,:,c,i])
meanAvg = np.float32( means/ numFilters)
return meanAvg
def calculateWeightedCheckSum(wtMat,wOrig,MEConv):
shape = wtMat.shape
xlen = shape[0]
ylen = shape[1]
numChnls = shape[2]
numFilters = shape[3]
means = np.zeros((xlen,ylen,numChnls))
meanAvg = np.zeros((xlen,ylen,numChnls))
for c in range(0,numChnls):
for i in range(0,numFilters):
means[:,:,c] += np.absolute(wtMat[:,:,c,i]-wOrig[:,:,c,i])*MEConv[i]
meanAvg = np.float32( means/ numFilters)
return meanAvg
checkCBA_1 = calculateCheckSum(wConv[0],wOrigConv[0])
checkCBA_2 = calculateCheckSum(wConv[1],wOrigConv[1])
checkBorder_1 = calculateCheckSum(wConv[0],wOrigConv[0])
checkRTZ_1[0]
checkBorder_2 = calculateCheckSum(wConv[1],wOrigConv[1])
checkTruncate_1 = calculateCheckSum(wConv[0],wOrigConv[0])
checkTruncate_2 = calculateCheckSum(wConv[1],wOrigConv[1])
checkRTZ_1 = calculateCheckSum(wConv[0],wOrigConv[0])
checkRTZ_2 = calculateCheckSum(wConv[1],wOrigConv[1])
img = np.reshape(image1[10],[img_size,img_size])
kernel = meanAvgOrig - meanAvgConv1
result = ndimage.correlate(img,kernel,mode = 'constant',cval = 0.0)
checkConv1 = [checkCBA_1,checkBorder_1, checkTruncate_1, checkRTZ_1]
checkConv11 = [checkCBA_1,checkBorder_1]
checkConv2 = [checkCBA_2,checkBorder_2, checkTruncate_2, checkRTZ_2]
checkConv22 = [checkCBA_2,checkBorder_2]
```
## Selecting Filter During Testing
```
imageTest = data.test.images[0]
feed_dict_test = {x: imageTest}
#Run throuh checksum list
imgTest = np.reshape(imageTest,[img_size,img_size])
kernel = meanAvgOrig - meanAvgConv1
result = ndimage.correlate(img,kernel,mode = 'constant',cval = 0.0)
#minimum checksum
checkSumOut = np.sum(result)
#assign weigths
assignFilters(wConv,wOrigFc)
#Output of first layer
val_out1 = session.run(layer_con1_pool_relu, feed_dict=feed_dict)
#calculate chekcsum for second layer
imageTest = data.train.images[1000:1010]
xAxis = []
yAxisCB = []
yAxisR20 = []
yAxisBA = []
for i in range(0,len(imageTest)):
feed_dict_test = {x: [imageTest[i]]}
imgTest = np.reshape(imageTest[i],[img_size,img_size])
checkSumOut = []
for chckSum in checkConv1:
kernel = chckSum[:,:,0]
result = ndimage.correlate(imgTest,kernel,mode = 'constant',cval = 0.0)
#minimum checksum
checkSumOut.append(np.sum(result))
minSum = 1000000000
indx = -1
iterV = 0
for chckSumVal in checkSumOut:
if minSum > chckSumVal:
minSum = chckSumVal
indx = iterV
iterV += 1
#Assigning 20% filter LAYER 1
#print("layr1:",indx,"sumMin:",checkSumOut)
xAxis.append(i)
yAxisCB.append(checkSumOut[0])
yAxisR20.append(checkSumOut[3])
yAxisBA.append(checkSumOut[1])
assign_op = weightsConvMat[0].assign(wConvArr1[indx])
session.run(assign_op)
val_out1 = session.run(layer_conv1_pool_relu, feed_dict=feed_dict_test)
#print(val_out1.shape)
shapeT = val_out1.shape
#input_4d = tf.reshape(val_out1,[shapeT[0], shapeT[1], shapeT[2],1 ] )
layr2Sum = []
for chckSum in checkConv2:
input_4d = tf.expand_dims(chckSum,3)
checkSumOut2 = tf.nn.conv2d(input=np.float32(val_out1),
filter=input_4d,
strides=[1, 1, 1, 1],
padding='SAME')
abc = session.run(checkSumOut2)
layr2Sum.append(np.sum(abc))
minSum = 1000000000
itr = 0
indx = -1
for chckSumVal in layr2Sum:
if minSum > chckSumVal:
minSum = chckSumVal
indx = itr
itr += 1
#print("layer2:",indx,"minSum:",layr2Sum)
#print("\n")
assign_op = weightsConvMat[1].assign(wConvArr2[indx])
session.run(assign_op)
#print_test_accuracy()
plt.plot(xAxis,yAxisCB,color='red')
plt.plot(xAxis,yAxisR20,color='green')
plt.plot(xAxis,yAxisBA,color='blue')
plt.show()
checkConv11[][:,:,0]
imageTest = data.test.images[0:100]
feed_dict_test = {x: [imageTest[0]]}
imgTest = np.reshape(imageTest[0],[img_size,img_size])
print(imgTest.shape)
checkSumOut = []
#for chckSum in checkConv1:
kernel = checkConv1[0][:,:,0]
print(kernel.shape)
result = ndimage.correlate(imgTest,kernel,mode = 'constant',cval = 0.0)
def assignFilterSP(wConv):
assign_op = weightsConvMat[0].assign(wConv)
session.run(assign_op)
temp = session.run(checkSumOut2)
print(np.sum(temp))
```
## Visualization of Weights and Layers
In trying to understand why the convolutional neural network can recognize handwritten digits, we will now visualize the weights of the convolutional filters and the resulting output images.
### Helper-function for plotting convolutional weights
```
def plot_conv_weights(weights, input_channel=0):
# Assume weights are TensorFlow ops for 4-dim variables
# e.g. weights_conv1 or weights_conv2.
# Retrieve the values of the weight-variables from TensorFlow.
# A feed-dict is not necessary because nothing is calculated.
w = session.run(weights)
# Get the lowest and highest values for the weights.
# This is used to correct the colour intensity across
# the images so they can be compared with each other.
w_min = np.min(w)
w_max = np.max(w)
# Number of filters used in the conv. layer.
num_filters = w.shape[3]
# Number of grids to plot.
# Rounded-up, square-root of the number of filters.
num_grids = math.ceil(math.sqrt(num_filters))
# Create figure with a grid of sub-plots.
fig, axes = plt.subplots(num_grids, num_grids)
# Plot all the filter-weights.
for i, ax in enumerate(axes.flat):
# Only plot the valid filter-weights.
if i<num_filters:
# Get the weights for the i'th filter of the input channel.
# See new_conv_layer() for details on the format
# of this 4-dim tensor.
img = w[:, :, input_channel, i]
# Plot image.
ax.imshow(img, vmin=w_min, vmax=w_max,
interpolation='nearest', cmap='seismic')
# Remove ticks from the plot.
ax.set_xticks([])
ax.set_yticks([])
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
```
### Helper-function for plotting the output of a convolutional layer
```
def plot_conv_layer(layer, image):
# Assume layer is a TensorFlow op that outputs a 4-dim tensor
# which is the output of a convolutional layer,
# e.g. layer_conv1 or layer_conv2.
# Create a feed-dict containing just one image.
# Note that we don't need to feed y_true because it is
# not used in this calculation.
feed_dict = {x: [image]}
# Calculate and retrieve the output values of the layer
# when inputting that image.
values = session.run(layer, feed_dict=feed_dict)
# Number of filters used in the conv. layer.
num_filters = values.shape[3]
# Number of grids to plot.
# Rounded-up, square-root of the number of filters.
num_grids = math.ceil(math.sqrt(num_filters))
# Create figure with a grid of sub-plots.
fig, axes = plt.subplots(num_grids, num_grids)
# Plot the output images of all the filters.
for i, ax in enumerate(axes.flat):
# Only plot the images for valid filters.
if i<num_filters:
# Get the output image of using the i'th filter.
# See new_conv_layer() for details on the format
# of this 4-dim tensor.
img = values[0, :, :, i]
# Plot image.
ax.imshow(img, interpolation='nearest', cmap='binary')
# Remove ticks from the plot.
ax.set_xticks([])
ax.set_yticks([])
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
```
### Input Images
Helper-function for plotting an image.
```
def plot_image(image):
plt.imshow(image.reshape(img_shape),
interpolation='nearest',
cmap='binary')
plt.show()
```
Plot an image from the test-set which will be used as an example below.
```
image1 = data.test.images[200]
plot_image(image1)
```
Plot another example image from the test-set.
```
image2 = data.test.images[23]
plot_image(image2)
image2.shape
```
### Convolution Layer 1
Now plot the filter-weights for the first convolutional layer.
Note that positive weights are red and negative weights are blue.
```
plot_conv_weights(weights=weights_conv1)
```
Applying each of these convolutional filters to the first input image gives the following output images, which are then used as input to the second convolutional layer. Note that these images are down-sampled to 14 x 14 pixels which is half the resolution of the original input image.
```
plot_conv_layer(layer=layer_conv2_pool_relu, image=image1)
```
The following images are the results of applying the convolutional filters to the second image.
```
plot_conv_layer(layer=layer_conv1_pool_relu, image=image2)
```
It is difficult to see from these images what the purpose of the convolutional filters might be. It appears that they have merely created several variations of the input image, as if light was shining from different angles and casting shadows in the image.
### Convolution Layer 2
Now plot the filter-weights for the second convolutional layer.
There are 16 output channels from the first conv-layer, which means there are 16 input channels to the second conv-layer. The second conv-layer has a set of filter-weights for each of its input channels. We start by plotting the filter-weigths for the first channel.
Note again that positive weights are red and negative weights are blue.
```
plot_conv_weights(weights=weights_conv2, input_channel=0)
```
There are 16 input channels to the second convolutional layer, so we can make another 15 plots of filter-weights like this. We just make one more with the filter-weights for the second channel.
```
plot_conv_weights(weights=weights_conv2, input_channel=1)
```
It can be difficult to understand and keep track of how these filters are applied because of the high dimensionality.
Applying these convolutional filters to the images that were ouput from the first conv-layer gives the following images.
Note that these are down-sampled yet again to 7 x 7 pixels which is half the resolution of the images from the first conv-layer.
```
#plot_conv_layer(layer=layer_conv1, image=image1)
```
And these are the results of applying the filter-weights to the second image.
```
plot_conv_layer(layer=layer_conv2, image=image2)
```
From these images, it looks like the second convolutional layer might detect lines and patterns in the input images, which are less sensitive to local variations in the original input images.
These images are then flattened and input to the fully-connected layer, but that is not shown here.
### Close TensorFlow Session
We are now done using TensorFlow, so we close the session to release its resources.
```
# This has been commented out in case you want to modify and experiment
# with the Notebook without having to restart it.
#session.close()
```
## Conclusion
We have seen that a Convolutional Neural Network works much better at recognizing hand-written digits than the simple linear model in Tutorial #01. The Convolutional Network gets a classification accuracy of about 99%, or even more if you make some adjustments, compared to only 91% for the simple linear model.
However, the Convolutional Network is also much more complicated to implement, and it is not obvious from looking at the filter-weights why it works and why it sometimes fails.
So we would like an easier way to program Convolutional Neural Networks and we would also like a better way of visualizing their inner workings.
## Exercises
These are a few suggestions for exercises that may help improve your skills with TensorFlow. It is important to get hands-on experience with TensorFlow in order to learn how to use it properly.
You may want to backup this Notebook before making any changes.
* Do you get the exact same results if you run the Notebook multiple times without changing any parameters? What are the sources of randomness?
* Run another 10,000 optimization iterations. Are the results better?
* Change the learning-rate for the optimizer.
* Change the configuration of the layers, such as the number of convolutional filters, the size of those filters, the number of neurons in the fully-connected layer, etc.
* Add a so-called drop-out layer after the fully-connected layer. Note that the drop-out probability should be zero when calculating the classification accuracy, so you will need a placeholder variable for this probability.
* Change the order of ReLU and max-pooling in the convolutional layer. Does it calculate the same thing? What is the fastest way of computing it? How many calculations are saved? Does it also work for Sigmoid-functions and average-pooling?
* Add one or more convolutional and fully-connected layers. Does it help performance?
* What is the smallest possible configuration that still gives good results?
* Try using ReLU in the last fully-connected layer. Does the performance change? Why?
* Try not using pooling in the convolutional layers. Does it change the classification accuracy and training time?
* Try using a 2x2 stride in the convolution instead of max-pooling? What is the difference?
* Remake the program yourself without looking too much at this source-code.
* Explain to a friend how the program works.
## License (MIT)
Copyright (c) 2016 by [Magnus Erik Hvass Pedersen](http://www.hvass-labs.org/)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| github_jupyter |
```
import matplotlib.pyplot as plt
import os
import pandas as pd
import numpy as np
from tqdm import tqdm
import pickle
# preprocessing functions
def one_hot (sentence):
vocabulary = ['а','б','в','г','д','е','ё','ж','з','и','й','к','л','м','н','о','п','р','с','т','у','ф','х','ц','ч','ш','щ','ъ','ы','ь','э','ю','я',
'А','Б','В','Г','Д','Е','Ё','Ж','З','И','Й','К','Л','М','Н','О','П','Р','С','Т','У','Ф','Х','Ц','Ч','Ш','Щ','Ъ','Ы','Ь','Э','Ю','Я',
'!','@','#','$','%','^','&','*','(',')',':',';','/',',','.','%','№','?','~','-','+','=',' ',
'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z',
'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']
result = np.zeros((1,len(vocabulary)))
for char in sentence:
if char in vocabulary:
vector = np.zeros((1,len(vocabulary)))
vector[0, vocabulary.index(char)] = 1
result = np.concatenate((result, vector))
result = np.delete(result, (0), axis=0)
#encoded = one_hot(sentence)
num_of_lett = 300
if len(result)<num_of_lett:
result = np.concatenate((result, np.zeros((num_of_lett-result.shape[0],result.shape[1]))))
if len(result)>num_of_lett:
result = result[:num_of_lett,:]
return result
def char_to_vocab (sentence):
vocabulary = ['а','б','в','г','д','е','ё','ж','з','и','й','к','л','м','н','о','п','р','с','т','у','ф','х','ц','ч','ш','щ','ъ','ы','ь','э','ю','я',
'А','Б','В','Г','Д','Е','Ё','Ж','З','И','Й','К','Л','М','Н','О','П','Р','С','Т','У','Ф','Х','Ц','Ч','Ш','Щ','Ъ','Ы','Ь','Э','Ю','Я',
'!','@','#','$','%','^','&','*','(',')',':',';','/',',','.','%','№','?','~','-','+','=',' ',
'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z',
'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']
result = []
for char in sentence:
if char in vocabulary:
result.append(vocabulary.index(char)+1)
result = np.array(result)
#encoded = one_hot(sentence)
num_of_lett = 300
if len(result)<num_of_lett:
result = np.concatenate((result, np.zeros(num_of_lett-result.shape[0])))
if len(result)>num_of_lett:
result = result[:num_of_lett]
return list(result)
#char_to_vocab(X_train[1])
#X_train[0]
data = pd.read_csv('Dataset/dataset_raw.csv')
plt.hist(data.likes,bins = 150)
plt.show()
data.likes.mean()
data[data.likes < 10000].
data.likes = data.likes/data.likes.max()
pic_names = os.listdir('Dataset/images/')
msk = np.random.rand(len(pic_names)) < 0.8
train_names = np.array(pic_names)[msk]
val_names = np.array(pic_names)[~msk]
msk = np.random.rand(len(val_names)) < 0.5
test_names = val_names[msk]
val_names = val_names[~msk]
print(train_names.shape)
print(val_names.shape)
print(test_names.shape)
#data_lett = pd.read_csv('Dataset/dataset_raw.csv')
X = data.texts.values
#np.isnan(np.nan)
X_test = []
y_test = []
id_test = []
for name in test_names:
cache = data.iloc[int(name[:-4])]
if type(cache.texts) == type('a'):
id_test.append(name)
X_test.append(cache.texts)
y_test.append(cache.likes)
X_val = []
y_val = []
id_val = []
for name in val_names:
cache = data.iloc[int(name[:-4])]
if type(cache.texts) == type('a'):
id_val.append(name)
X_val.append(cache.texts)
y_val.append(cache.likes)
X_train = []
y_train = []
id_train = []
for name in train_names:
cache = data.iloc[int(name[:-4])]
if type(cache.texts) == type('a'):
id_train.append(name)
X_train.append(cache.texts)
y_train.append(cache.likes)
print('train dataset: '+str(len(id_train)))
print('val dataset: '+str(len(id_val)))
print('test dataset: '+str(len(id_test)))
# X_ = []
# y_ = []
# for i in range(len(X)):
# if type(X[i])==type('a'):
# X_.append(X[i])
# y_.append(y[i])
# print(len(X_))
# print(len(y_))
len_X =[]
for i in X:
len_X.append(len(i))
plt.hist(len_X, bins =100)
plt.show()
X_train_encoded = []
for sentence in tqdm(X_train):
X_train_encoded.append(char_to_vocab(sentence))
#X_train_encoded = np.array(X_train_encoded)
X_val_encoded = []
for sentence in tqdm(X_val):
X_val_encoded.append(char_to_vocab(sentence))
#X_val_encoded = np.array(X_val_encoded)
X_test_encoded = []
for sentence in tqdm(X_test):
X_test_encoded.append(char_to_vocab(sentence))
#X_test_encoded = np.array(X_test_encoded)
X_val_encoded
data_test = {'id':id_test, 'texts':X_test, 'likes':y_test}
dataset_test = pd.DataFrame(data_test)
with open ('Dataset/dataset_test.pkl', 'wb') as f:
pickle.dump(dataset_test, f)
#dataset_test.to_csv('Dataset/dataset_test.csv', encoding='utf-8')
data_val = {'id':id_val, 'texts':X_val, 'likes':y_val}
dataset_val = pd.DataFrame(data_val)
with open ('Dataset/dataset_val.pkl', 'wb') as f:
pickle.dump(dataset_val, f)
#dataset_val.to_csv('Dataset/dataset_val.csv',encoding='utf-8')
data_train = {'id':id_train, 'texts':X_train, 'likes':y_train}
dataset_train = pd.DataFrame(data_train)
with open ('Dataset/dataset_train.pkl', 'wb') as f:
pickle.dump(dataset_train, f)
#dataset_train.to_csv('Dataset/dataset_train.csv',encoding='utf-8')
dataset_train.texts.values[0]
```
| github_jupyter |
```
import os
import matplotlib.pyplot as plt
import numpy as np
import shutil
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.python.feature_column import feature_column
print(tf.__version__)
```
## 1. Define Parameters
```
class FLAGS():
pass
FLAGS.model_dir = './trained_models'
FLAGS.data_dir = './mnist_data'
FLAGS.model_name = 'auto-encoder-03'
FLAGS.batch_size = 100
FLAGS.encoder_hidden_units = [50]
FLAGS.learning_rate = 0.01
FLAGS.l2_reg = 0.0001
FLAGS.noise_level = 0.0
FLAGS.dropout_rate = 0.1
FLAGS.resume_training = False
FLAGS.max_steps = 10000
FLAGS.eval_steps = 100
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
```
## 2. Define Input Pipeline
```
def generate_input_fn(mnist_data,
mode=tf.estimator.ModeKeys.EVAL,
batch_size=1):
def input_fn():
if mode == tf.estimator.ModeKeys.EVAL:
images = mnist.validation.images
labels = images
elif mode == tf.estimator.ModeKeys.TRAIN:
images = mnist.train.images
labels = images
else:
assert(False)
is_shuffle = (mode == tf.estimator.ModeKeys.TRAIN)
return tf.estimator.inputs.numpy_input_fn(
batch_size=batch_size,
shuffle=is_shuffle,
x={'images': images},
y=labels)
return input_fn()
```
## 3. Define Features
```
def get_feature_columns():
feature_columns = {
'images': tf.feature_column.numeric_column('images', (784,))
}
return feature_columns
```
## 4. Define a Custom Estimator
```
def get_estimator(run_config, hparams):
def _model_fn(features, labels, mode, params):
encoder_hidden_units = params.encoder_hidden_units
decoder_hidden_units = encoder_hidden_units
# Remove a middle unit if length of encoder hidden units exceeds 1.
if len(encoder_hidden_units) > 1:
decoder_hidden_units.reverse()
decoder_hidden_units.pop(0)
output_layer_size = 784
l2_regularizer = tf.contrib.layers.l2_regularizer(scale=params.l2_reg)
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
with tf.name_scope('input'):
feature_columns = list(get_feature_columns().values())
input_layer = tf.feature_column.input_layer(
features=features, feature_columns=feature_columns)
with tf.name_scope('noisy_input'):
# Adding Gaussian Noise to input layer
noisy_input_layer = input_layer + (
params.noise_level * tf.random_normal(tf.shape(input_layer)))
# Dropout layer
dropout_layer = tf.layers.dropout(
inputs=noisy_input_layer, rate=params.dropout_rate, training=is_training)
with tf.name_scope('encoder'):
# Encoder layers stack
encoding_hidden_layers = tf.contrib.layers.stack(
inputs=dropout_layer,
layer=tf.contrib.layers.fully_connected,
stack_args=encoder_hidden_units,
weights_regularizer = l2_regularizer,
activation_fn=tf.nn.relu)
with tf.name_scope('decoder'):
# Decoder layers stack
decoding_hidden_layers = tf.contrib.layers.stack(
inputs=encoding_hidden_layers,
layer=tf.contrib.layers.fully_connected,
stack_args=decoder_hidden_units,
weights_regularizer=l2_regularizer,
activation_fn=tf.nn.relu)
# Output (reconstructured) layer
output_layer = tf.layers.dense(inputs=decoding_hidden_layers,
units=output_layer_size,
activation=None)
# Encoding output (i.e., extracted features) reshaped
encoding_output = tf.squeeze(encoding_hidden_layers)
# Reconstruction output reshaped (for loss calculation)
reconstruction_output = tf.squeeze(output_layer)
# Provide an estimator spec for `ModeKeys.PREDICT`.
if mode == tf.estimator.ModeKeys.PREDICT:
# Convert predicted_indices back into strings.
predictions = {
'encoding': encoding_output,
'reconstruction': reconstruction_output,
}
export_outputs = {
'predict': tf.estimator.export.PredictOutput(predictions)
}
# Provide an estimator spec for `ModeKeys.PREDICT` modes.
return tf.estimator.EstimatorSpec(
mode, predictions=predictions, export_outputs=export_outputs)
with tf.name_scope('loss'):
# Define loss based on reconstruction and regularization.
loss = tf.losses.mean_squared_error(tf.squeeze(input_layer),
reconstruction_output)
loss = loss + tf.losses.get_regularization_loss()
# Create optimizer
optimizer = tf.train.AdamOptimizer(params.learning_rate)
# Create training operation
train_op = optimizer.minimize(loss=loss,
global_step=tf.train.get_global_step())
# Calculate root mean squared error as additional metric.
eval_metric_ops = {
'rmse': tf.metrics.root_mean_squared_error(tf.squeeze(input_layer),
reconstruction_output)
}
# Provide an estimator spec for `ModeKeys.EVAL` and `ModeKeys.TRAIN` modes.
estimator_spec = tf.estimator.EstimatorSpec(mode=mode,
loss=loss,
train_op=train_op,
eval_metric_ops=eval_metric_ops)
return estimator_spec
return tf.estimator.Estimator(model_fn=_model_fn, params=hparams, config=run_config)
```
## 5. Define Serving Function
```
def serving_input_fn():
receiver_tensor = {'images': tf.placeholder(shape=[None, 784], dtype=tf.float32)}
features = receiver_tensor
return tf.estimator.export.ServingInputReceiver(features, receiver_tensor)
```
## 6. Train, Evaluate and Export a Model
```
run_config = tf.estimator.RunConfig(
model_dir=os.path.join(FLAGS.model_dir, FLAGS.model_name),
save_checkpoints_steps=1000,
#save_checkpoints_secs=None,
keep_checkpoint_max=5,
tf_random_seed=19851211
)
hparams = tf.contrib.training.HParams(
batch_size=FLAGS.batch_size,
encoder_hidden_units=FLAGS.encoder_hidden_units,
learning_rate=FLAGS.learning_rate,
l2_reg=FLAGS.l2_reg,
noise_level=FLAGS.noise_level,
dropout_rate=FLAGS.dropout_rate)
estimator = get_estimator(run_config, hparams)
train_spec = tf.estimator.TrainSpec(
input_fn=generate_input_fn(mnist,
mode=tf.estimator.ModeKeys.TRAIN,
batch_size=FLAGS.batch_size),
max_steps=FLAGS.max_steps, hooks=None)
exporter = tf.estimator.LatestExporter(
name='Servo',
serving_input_receiver_fn=serving_input_fn,
exports_to_keep=5)
eval_spec = tf.estimator.EvalSpec(
input_fn=generate_input_fn(mnist,
mode=tf.estimator.ModeKeys.TRAIN,
batch_size=FLAGS.batch_size),
steps=FLAGS.eval_steps, exporters=exporter)
if not FLAGS.resume_training:
print('Removing previous artifacts...')
shutil.rmtree(os.path.join(FLAGS.model_dir, FLAGS.model_name), ignore_errors=True)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
```
## 6. Load an Exported Model and Make Prediction
```
export_dir = os.path.join(FLAGS.model_dir, FLAGS.model_name, 'export/Servo/')
saved_model_dir = os.path.join(export_dir, os.listdir(export_dir)[-1])
predictor_fn = tf.contrib.predictor.from_saved_model(
export_dir = saved_model_dir,
signature_def_key='predict')
output = predictor_fn({'images': mnist.test.images})
%matplotlib inline
x = np.random.randint(len(mnist.test.images))
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10,4))
ax1.set_title('original image')
ax1.imshow(mnist.test.images[x].reshape(28,28))
ax2.set_title('reconstructured image')
ax2.imshow(output['reconstruction'][x].reshape(28,28))
plt.show()
```
| github_jupyter |
---
_You are currently looking at **version 1.5** of this notebook. To download notebooks and datafiles, as well as get help on Jupyter notebooks in the Coursera platform, visit the [Jupyter Notebook FAQ](https://www.coursera.org/learn/python-data-analysis/resources/0dhYG) course resource._
---
# Assignment 3 - More Pandas
This assignment requires more individual learning then the last one did - you are encouraged to check out the [pandas documentation](http://pandas.pydata.org/pandas-docs/stable/) to find functions or methods you might not have used yet, or ask questions on [Stack Overflow](http://stackoverflow.com/) and tag them as pandas and python related. And of course, the discussion forums are open for interaction with your peers and the course staff.
### Question 1 (20%)
Load the energy data from the file `Energy Indicators.xls`, which is a list of indicators of [energy supply and renewable electricity production](Energy%20Indicators.xls) from the [United Nations](http://unstats.un.org/unsd/environment/excel_file_tables/2013/Energy%20Indicators.xls) for the year 2013, and should be put into a DataFrame with the variable name of **energy**.
Keep in mind that this is an Excel file, and not a comma separated values file. Also, make sure to exclude the footer and header information from the datafile. The first two columns are unneccessary, so you should get rid of them, and you should change the column labels so that the columns are:
`['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable']`
Convert `Energy Supply` to gigajoules (there are 1,000,000 gigajoules in a petajoule). For all countries which have missing data (e.g. data with "...") make sure this is reflected as `np.NaN` values.
Rename the following list of countries (for use in later questions):
```"Republic of Korea": "South Korea",
"United States of America": "United States",
"United Kingdom of Great Britain and Northern Ireland": "United Kingdom",
"China, Hong Kong Special Administrative Region": "Hong Kong"```
There are also several countries with numbers and/or parenthesis in their name. Be sure to remove these,
e.g.
`'Bolivia (Plurinational State of)'` should be `'Bolivia'`,
`'Switzerland17'` should be `'Switzerland'`.
<br>
Next, load the GDP data from the file `world_bank.csv`, which is a csv containing countries' GDP from 1960 to 2015 from [World Bank](http://data.worldbank.org/indicator/NY.GDP.MKTP.CD). Call this DataFrame **GDP**.
Make sure to skip the header, and rename the following list of countries:
```"Korea, Rep.": "South Korea",
"Iran, Islamic Rep.": "Iran",
"Hong Kong SAR, China": "Hong Kong"```
<br>
Finally, load the [Sciamgo Journal and Country Rank data for Energy Engineering and Power Technology](http://www.scimagojr.com/countryrank.php?category=2102) from the file `scimagojr-3.xlsx`, which ranks countries based on their journal contributions in the aforementioned area. Call this DataFrame **ScimEn**.
Join the three datasets: GDP, Energy, and ScimEn into a new dataset (using the intersection of country names). Use only the last 10 years (2006-2015) of GDP data and only the top 15 countries by Scimagojr 'Rank' (Rank 1 through 15).
The index of this DataFrame should be the name of the country, and the columns should be ['Rank', 'Documents', 'Citable documents', 'Citations', 'Self-citations',
'Citations per document', 'H index', 'Energy Supply',
'Energy Supply per Capita', '% Renewable', '2006', '2007', '2008',
'2009', '2010', '2011', '2012', '2013', '2014', '2015'].
*This function should return a DataFrame with 20 columns and 15 entries.*
```
def answer_one():
import pandas as pd
import numpy as np
x = pd.ExcelFile('Energy Indicators.xls')
energy = x.parse(skiprows=17, skip_footer=(38)) # SKip the rows & footer
energy = energy[['Unnamed: 1','Petajoules','Gigajoules','%']]
# Set the column names
energy.columns = ['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable']
energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']] = energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']].replace('...',np.NaN).apply(pd.to_numeric)
# For converting Energy Supply to gigajoules
energy['Energy Supply'] = energy['Energy Supply'] * 1000000
# Rename the following list of countries
energy['Country'] = energy['Country'].replace({'China, Hong Kong Special Administrative Region':'Hong Kong','United Kingdom of Great Britain and Northern Ireland':'United Kingdom','Republic of Korea':'South Korea','United States of America':'United States','Iran (Islamic Republic of)':'Iran'})
energy['Country'] = energy['Country'].str.replace(r" \(.*\)","")
GDP = pd.read_csv('world_bank.csv',skiprows=4)
GDP['Country Name'] = GDP['Country Name'].replace('Korea, Rep.', 'South Korea')
GDP['Country Name'] = GDP['Country Name'].replace('Iran, Islamic Rep.', 'Iran')
GDP['Country Name'] = GDP['Country Name'].replace('Hong Kong SAR, China', 'Hong Kong')
GDP = GDP[['Country Name','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']]
GDP.columns = ['Country','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']
ScimEn = pd.read_excel(io='scimagojr-3.xlsx')
ScimEn_m = ScimEn[:15] # For 15 entries
# Merge sci & energy
df = pd.merge(ScimEn_m, energy, how='inner', left_on='Country', right_on='Country')
# Merge sci energy & GDP
final_df = pd.merge(df, GDP, how='inner', left_on='Country', right_on='Country')
final_df = final_df.set_index('Country')
#print(len(final_df))
return final_df
answer_one()
```
### Question 2 (6.6%)
The previous question joined three datasets then reduced this to just the top 15 entries. When you joined the datasets, but before you reduced this to the top 15 items, how many entries did you lose?
*This function should return a single number.*
```
%%HTML
<svg width="800" height="300">
<circle cx="150" cy="180" r="80" fill-opacity="0.2" stroke="black" stroke-width="2" fill="blue" />
<circle cx="200" cy="100" r="80" fill-opacity="0.2" stroke="black" stroke-width="2" fill="red" />
<circle cx="100" cy="100" r="80" fill-opacity="0.2" stroke="black" stroke-width="2" fill="green" />
<line x1="150" y1="125" x2="300" y2="150" stroke="black" stroke-width="2" fill="black" stroke-dasharray="5,3"/>
<text x="300" y="165" font-family="Verdana" font-size="35">Everything but this!</text>
</svg>
def answer_two():
import pandas as pd
import numpy as np
x = pd.ExcelFile('Energy Indicators.xls')
energy = x.parse(skiprows=17, skip_footer=(38)) # SKip the rows & footer
energy = energy[['Unnamed: 1','Petajoules','Gigajoules','%']]
# Set the column names
energy.columns = ['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable']
energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']] = energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']].replace('...',np.NaN).apply(pd.to_numeric)
# For converting Energy Supply to gigajoules
energy['Energy Supply'] = energy['Energy Supply'] * 1000000
# Rename the following list of countries
energy['Country'] = energy['Country'].replace({'China, Hong Kong Special Administrative Region':'Hong Kong','United Kingdom of Great Britain and Northern Ireland':'United Kingdom','Republic of Korea':'South Korea','United States of America':'United States','Iran (Islamic Republic of)':'Iran'})
energy['Country'] = energy['Country'].str.replace(r" \(.*\)","")
GDP = pd.read_csv('world_bank.csv',skiprows=4)
GDP['Country Name'] = GDP['Country Name'].replace('Korea, Rep.', 'South Korea')
GDP['Country Name'] = GDP['Country Name'].replace('Iran, Islamic Rep.', 'Iran')
GDP['Country Name'] = GDP['Country Name'].replace('Hong Kong SAR, China', 'Hong Kong')
GDP = GDP[['Country Name','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']]
GDP.columns = ['Country','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']
ScimEn = pd.read_excel(io='scimagojr-3.xlsx')
ScimEn_m = ScimEn[:15] # For 15 entries
# Merge sci & energy
df = pd.merge(ScimEn_m, energy, how='inner', left_on='Country', right_on='Country')
# Merge sci energy & GDP
final_df = pd.merge(df, GDP, how='inner', left_on='Country', right_on='Country')
final_df = final_df.set_index('Country')
# Merge sci & energy
df2 = pd.merge(ScimEn_m, energy, how='outer', left_on='Country', right_on='Country')
# Merge sci energy & GDP
final_df2 = pd.merge(df, GDP, how='outer', left_on='Country', right_on='Country')
final_df2 = final_df2.set_index('Country')
print(len(final_df))
print(len(final_df2))
return 156
answer_two()
```
## Answer the following questions in the context of only the top 15 countries by Scimagojr Rank (aka the DataFrame returned by `answer_one()`)
### Question 3 (6.6%)
What is the average GDP over the last 10 years for each country? (exclude missing values from this calculation.)
*This function should return a Series named `avgGDP` with 15 countries and their average GDP sorted in descending order.*
```
def answer_three():
Top15 = answer_one()
avgGDP = Top15[['2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']].mean(axis=1).rename('avgGDP').sort_values(ascending=False)
return avgGDP
answer_three()
```
### Question 4 (6.6%)
By how much had the GDP changed over the 10 year span for the country with the 6th largest average GDP?
*This function should return a single number.*
```
def answer_four():
import pandas as pd
Top15 = answer_one()
ans = Top15[Top15['Rank'] == 4]['2015'] - Top15[Top15['Rank'] == 4]['2006']
return pd.to_numeric(ans)[0]
answer_four()
```
### Question 5 (6.6%)
What is the mean `Energy Supply per Capita`?
*This function should return a single number.*
```
def answer_five():
Top15 = answer_one()
ans = Top15['Energy Supply per Capita'].mean()
return ans
answer_five()
```
### Question 6 (6.6%)
What country has the maximum % Renewable and what is the percentage?
*This function should return a tuple with the name of the country and the percentage.*
```
def answer_six():
Top15 = answer_one()
ans = Top15[ Top15['% Renewable'] == max(Top15['% Renewable']) ]
return (ans.index.tolist()[0], ans['% Renewable'].tolist()[0])
answer_six()
```
### Question 7 (6.6%)
Create a new column that is the ratio of Self-Citations to Total Citations.
What is the maximum value for this new column, and what country has the highest ratio?
*This function should return a tuple with the name of the country and the ratio.*
```
def answer_seven():
Top15 = answer_one()
# Created col of citation ratio
Top15['Citation Ratio'] = Top15['Self-citations'] / Top15['Citations']
# Same as the above query
ans = Top15[Top15['Citation Ratio'] == max(Top15['Citation Ratio'])]
return (ans.index.tolist()[0], ans['Citation Ratio'].tolist()[0])
answer_seven()
```
### Question 8 (6.6%)
Create a column that estimates the population using Energy Supply and Energy Supply per capita.
What is the third most populous country according to this estimate?
*This function should return a single string value.*
```
def answer_eight():
Top15 = answer_one()
Top15['Population'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15['Population'] = Top15['Population'].sort_values(ascending=False)
#print(Top15['Population'])
return Top15.sort_values(by = 'Population', ascending = False).iloc[2].name
answer_eight()
```
### Question 9 (6.6%)
Create a column that estimates the number of citable documents per person.
What is the correlation between the number of citable documents per capita and the energy supply per capita? Use the `.corr()` method, (Pearson's correlation).
*This function should return a single number.*
*(Optional: Use the built-in function `plot9()` to visualize the relationship between Energy Supply per Capita vs. Citable docs per Capita)*
```
def answer_nine():
Top15 = answer_one()
Top15['PopEst'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15['Citable docs per Capita'] = Top15['Citable documents'] / Top15['PopEst']
return Top15['Citable docs per Capita'].corr(Top15['Energy Supply per Capita'])
answer_nine()
def plot9():
import matplotlib as plt
%matplotlib inline
Top15 = answer_one()
Top15['PopEst'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15['Citable docs per Capita'] = Top15['Citable documents'] / Top15['PopEst']
Top15.plot(x='Citable docs per Capita', y='Energy Supply per Capita', kind='scatter', xlim=[0, 0.0006])
#plot9() # Be sure to comment out plot9() before submitting the assignment!
```
### Question 10 (6.6%)
Create a new column with a 1 if the country's % Renewable value is at or above the median for all countries in the top 15, and a 0 if the country's % Renewable value is below the median.
*This function should return a series named `HighRenew` whose index is the country name sorted in ascending order of rank.*
```
def answer_ten():
Top15 = answer_one()
Top15['HighRenew'] = [1 if x >= Top15['% Renewable'].median() else 0 for x in Top15['% Renewable']]
return Top15['HighRenew']
answer_ten()
```
### Question 11 (6.6%)
Use the following dictionary to group the Countries by Continent, then create a dateframe that displays the sample size (the number of countries in each continent bin), and the sum, mean, and std deviation for the estimated population of each country.
```python
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
```
*This function should return a DataFrame with index named Continent `['Asia', 'Australia', 'Europe', 'North America', 'South America']` and columns `['size', 'sum', 'mean', 'std']`*
```
def answer_eleven():
import pandas as pd
import numpy as np
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
Top15 = answer_one()
Top15['PopEst'] = (Top15['Energy Supply'] / Top15['Energy Supply per Capita']).astype(float)
Top15 = Top15.reset_index()
# Get the top continents
Top15['Continent'] = [ContinentDict[country] for country in Top15['Country']]
# Now set Index as Continent & Group By Population Estimate and apply the aggregate funs
ans = Top15.set_index('Continent').groupby(level=0)['PopEst'].agg({'size': np.size, 'sum': np.sum, 'mean': np.mean,'std': np.std})
ans = ans[['size', 'sum', 'mean', 'std']]
return ans
answer_eleven()
```
### Question 12 (6.6%)
Cut % Renewable into 5 bins. Group Top15 by the Continent, as well as these new % Renewable bins. How many countries are in each of these groups?
*This function should return a __Series__ with a MultiIndex of `Continent`, then the bins for `% Renewable`. Do not include groups with no countries.*
```
def answer_twelve():
import pandas as pd
import numpy as np
Top15 = answer_one()
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
Top15 = Top15.reset_index()
Top15['Continent'] = [ContinentDict[country] for country in Top15['Country']]
# For bin we use pd.cut and 5 bins
Top15['bins'] = pd.cut(Top15['% Renewable'],5)
return Top15.groupby(['Continent','bins']).size()
answer_twelve()
```
### Question 13 (6.6%)
Convert the Population Estimate series to a string with thousands separator (using commas). Do not round the results.
e.g. 317615384.61538464 -> 317,615,384.61538464
*This function should return a Series `PopEst` whose index is the country name and whose values are the population estimate string.*
```
def answer_thirteen():
import pandas as pd
import numpy as np
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
Top15 = answer_one()
tmp = list()
Top15['PopEst'] = (Top15['Energy Supply'] / Top15['Energy Supply per Capita'])
tmp = Top15['PopEst'].tolist()
Top15['PopEst'] = (Top15['Energy Supply'] / Top15['Energy Supply per Capita']).apply(lambda x: "{:,}".format(x), tmp)
ans = pd.Series(Top15['PopEst'])
return ans
answer_thirteen()
```
### Optional
Use the built in function `plot_optional()` to see an example visualization.
```
def plot_optional():
import matplotlib as plt
%matplotlib inline
Top15 = answer_one()
ax = Top15.plot(x='Rank', y='% Renewable', kind='scatter',
c=['#e41a1c','#377eb8','#e41a1c','#4daf4a','#4daf4a','#377eb8','#4daf4a','#e41a1c',
'#4daf4a','#e41a1c','#4daf4a','#4daf4a','#e41a1c','#dede00','#ff7f00'],
xticks=range(1,16), s=6*Top15['2014']/10**10, alpha=.75, figsize=[16,6]);
for i, txt in enumerate(Top15.index):
ax.annotate(txt, [Top15['Rank'][i], Top15['% Renewable'][i]], ha='center')
print("This is an example of a visualization that can be created to help understand the data. \
This is a bubble chart showing % Renewable vs. Rank. The size of the bubble corresponds to the countries' \
2014 GDP, and the color corresponds to the continent.")
#plot_optional() # Be sure to comment out plot_optional() before submitting the assignment!
```
| github_jupyter |
<p align="center">
<img src="https://github.com/GeostatsGuy/GeostatsPy/blob/master/TCG_color_logo.png?raw=true" width="220" height="240" />
</p>
## Subsurface Data Analytics
## Interactive Demonstration of Machine Learning Model Tuning, Generalization & Overfit
#### Michael Pyrcz, Associate Professor, University of Texas at Austin
##### [Twitter](https://twitter.com/geostatsguy) | [GitHub](https://github.com/GeostatsGuy) | [Website](http://michaelpyrcz.com) | [GoogleScholar](https://scholar.google.com/citations?user=QVZ20eQAAAAJ&hl=en&oi=ao) | [Book](https://www.amazon.com/Geostatistical-Reservoir-Modeling-Michael-Pyrcz/dp/0199731446) | [YouTube](https://www.youtube.com/channel/UCLqEr-xV-ceHdXXXrTId5ig) | [LinkedIn](https://www.linkedin.com/in/michael-pyrcz-61a648a1) | [GeostatsPy](https://github.com/GeostatsGuy/GeostatsPy)
#### John Eric McCarthy II, Undergraduate Student, The University of Texas at Austin
##### [LinkedIn](https://www.linkedin.com/in/john-mccarthy2)
Note I built this workflow from an interactive demonstration from John Eric McCarthy II's summer undergraduate research internship (SURI) that I supervised in the summer of 2020. John's original workflow is available (here)[https://github.com/GeostatsGuy/PythonNumericalDemos/blob/master/Interactive_NeuralNetwork_SingleLayer.ipynb]. Check it out for an excellent hands-on interactive demonstration of artifical neural networks.
### PGE 383 Exercise: Interactive Predictive Model Complexity Tuning, Generalization & Overfit
Here's a simple workflow, demonstration of predictive machine learning model training and testing for overfit. We use a:
* simple polynomial model
* 1 preditor feature and 1 response feature
for an high interpretability model/ simple illustration.
#### Train / Test Split
The available data is split into training and testing subsets.
* in general 15-30% of the data is withheld from training to apply as testing data
* testing data selection should be fair, the same difficulty of predictions (offset/different from the training dat
#### Machine Learning Model Traing
The training data is applied to train the model parameters such that the model minimizes mismatch with the training data
* it is common to use **mean square error** (known as a **L2 norm**) as a loss function summarizing the model mismatch
* **miminizing the loss function** for simple models an anlytical solution may be available, but for most machine this requires an iterative optimization method to find the best model parameters
This process is repeated over a range of model complexities specified by hyperparameters.
#### Machine Learning Model Tuning
The withheld testing data is retrieved and loss function (usually the **L2 norm** again) is calculated to summarize the error over the testing data
* this is repeated over over the range of specified hypparameters
* the model complexity / hyperparameters that minimize the loss function / error summary in testing is selected
This is known are model hypparameter tuning.
#### Machine Learning Model Overfit
More model complexity/flexibility than can be justified with the available data, data accuracy, frequency and coverage
* Model explains “idiosyncrasies” of the data, capturing data noise/error in the model
* High accuracy in training, but low accuracy in testing / real-world use away from training data cases – poor ability of the model to generalize
#### Workflow Goals
Learn the basics of machine learning training, tuning for model generalization while avoiding model overfit.
This includes:
* Demonstrate model training and tuning by hand with an interactive exercies
* Demonstrate the role of data error in leading to model overfit with complicated models
#### Getting Started
You will need to copy the following data files to your working directory. They are available [here](https://github.com/GeostatsGuy/GeoDataSets):
* Tabular data - [Stochastic_1D_por_perm_demo.csv](https://github.com/GeostatsGuy/GeoDataSets/blob/master/Stochastic_1D_por_perm_demo.csv)
* Tabular data - [Random_Parabola.csv](https://github.com/GeostatsGuy/GeoDataSets/blob/master/Random_Parabola.csv)
These datasets are available in the folder: https://github.com/GeostatsGuy/GeoDataSets.
#### Import Required Packages
We will also need some standard packages. These should have been installed with Anaconda 3.
```
import geostatspy.GSLIB as GSLIB # GSLIB utilies, visualization and wrapper
import geostatspy.geostats as geostats # GSLIB methods convert to Python
```
We will also need some standard packages. These should have been installed with Anaconda 3.
```
%matplotlib inline
import os # to set current working directory
import sys # supress output to screen for interactive variogram modeling
import io
import numpy as np # arrays and matrix math
import pandas as pd # DataFrames
import matplotlib.pyplot as plt # plotting
from sklearn.model_selection import train_test_split # train and test split
from sklearn.metrics import mean_squared_error # model error calculation
import scipy # kernel density estimator for PDF plot
from matplotlib.pyplot import cm # color maps
from ipywidgets import interactive # widgets and interactivity
from ipywidgets import widgets
from ipywidgets import Layout
from ipywidgets import Label
from ipywidgets import VBox, HBox
```
If you get a package import error, you may have to first install some of these packages. This can usually be accomplished by opening up a command window on Windows and then typing 'python -m pip install [package-name]'. More assistance is available with the respective package docs.
#### Build the Interactive Dashboard
The following code:
* makes a random dataset, change the random number seed and number of data for a different dataset
* loops over polygonal fits of 1st-12th order, loops over mulitple realizations and calculates the average MSE and P10 and P90 vs. order
* calculates a specific model example
* plots the example model with training and testing data, the error distributions and the MSE envelopes vs. complexity
```
l = widgets.Text(value=' Machine Learning Overfit/Generalization Demo, Prof. Michael Pyrcz and John Eric McCarthy II, The University of Texas at Austin',
layout=Layout(width='950px', height='30px'))
n = widgets.IntSlider(min=15, max = 80, value=30, step = 1, description = 'n',orientation='horizontal', style = {'description_width': 'initial'}, continuous_update=False)
split = widgets.FloatSlider(min=0.05, max = .95, value=0.20, step = 0.05, description = 'Test %',orientation='horizontal',style = {'description_width': 'initial'}, continuous_update=False)
std = widgets.FloatSlider(min=0, max = 50, value=0, step = 1.0, description = 'Noise StDev',orientation='horizontal',style = {'description_width': 'initial'}, continuous_update=False)
degree = widgets.IntSlider(min=1, max = 12, value=1, step = 1, description = 'Model Order',orientation='horizontal', style = {'description_width': 'initial'}, continuous_update=False)
ui = widgets.HBox([n,split,std,degree],)
ui2 = widgets.VBox([l,ui],)
def run_plot(n,split,std,degree):
seed = 13014; nreal = 20
np.random.seed(seed) # seed the random number generator
# make the datastet
X_seq = np.linspace(0,20,100)
X = np.random.rand(n)*20
y = X*X + 50.0 # fit a parabola
y = y + np.random.normal(loc = 0.0,scale=std,size=n) # add noise
# calculate the MSE train and test over a range of complexity over multiple realizations of test/train split
cdegrees = np.arange(1,13)
cmse_train = np.zeros([len(cdegrees),nreal]); cmse_test = np.zeros([len(cdegrees),nreal])
for j in range(0,nreal):
for i, cdegree in enumerate(cdegrees):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=split, random_state=seed+j)
ccoefs = np.polyfit(X_train,y_train,cdegree)
y_pred_train = np.polyval(ccoefs, X_train)
y_pred_test = np.polyval(ccoefs, X_test)
cmse_train[i,j] = mean_squared_error(y_train, y_pred_train)
cmse_test[i,j] = mean_squared_error(y_test, y_pred_test)
# summarize over the realizations
cmse_train_avg = cmse_train.mean(axis=1)
cmse_test_avg = cmse_test.mean(axis=1)
cmse_train_high = np.percentile(cmse_train,q=90,axis=1)
cmse_train_low = np.percentile(cmse_train,q=10,axis=1)
cmse_test_high = np.percentile(cmse_test,q=90,axis=1)
cmse_test_low = np.percentile(cmse_test,q=10,axis=1)
# cmse_train_high = np.amax(cmse_train,axis=1)
# cmse_train_low = np.amin(cmse_train,axis=1)
# cmse_test_high = np.amax(cmse_test,axis=1)
# cmse_test_low = np.amin(cmse_test,axis=1)
# build the one model example to show
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=split, random_state=seed)
coefs = np.polyfit(X_train,y_train,degree)
# calculate error
error_seq = np.linspace(-100.0,100.0,100)
error_train = np.polyval(coefs, X_train) - y_train
#print(np.polyval(coefs, X_train))
#print('truth')
#print(X_train)
error_test = np.polyval(coefs, X_test) - y_test
mse_train = mean_squared_error(y_train, np.polyval(coefs, X_train))
mse_test = mean_squared_error(y_test, np.polyval(coefs, X_test))
error_train_std = np.std(error_train)
error_test_std = np.std(error_test)
kde_error_train = scipy.stats.gaussian_kde(error_train)
kde_error_test = scipy.stats.gaussian_kde(error_test)
plt.subplot(131)
plt.plot(X_seq, np.polyval(coefs, X_seq), color="black")
plt.title("Polynomial Model of Degree = "+str(degree))
plt.scatter(X_train,y_train,c ="red",alpha=0.2,edgecolors="black")
plt.scatter(X_test,y_test,c ="blue",alpha=0.2,edgecolors="black")
plt.ylim([0,500]); plt.xlim([0,20]); plt.grid()
plt.xlabel('Porosity (%)'); plt.ylabel('Permeability (mD)')
plt.subplot(132)
plt.hist(error_train, facecolor='red',bins=np.linspace(-50.0,50.0,10),alpha=0.2,density=True,edgecolor='black',label='Train')
plt.hist(error_test, facecolor='blue',bins=np.linspace(-50.0,50.0,10),alpha=0.2,density=True,edgecolor='black',label='Test')
#plt.plot(error_seq,kde_error_train(error_seq),lw=2,label='Train',c='red')
#plt.plot(error_seq,kde_error_test(error_seq),lw=2,label='Test',c='blue')
plt.xlim([-55.0,55.0]); plt.ylim([0,0.1])
plt.xlabel('Model Error'); plt.ylabel('Frequency'); plt.title('Training and Testing Error, Model of Degree = '+str((degree)))
plt.legend(loc='upper left')
plt.grid(True)
plt.subplot(133); ax = plt.gca()
plt.plot(cdegrees,cmse_train_avg,lw=2,label='Train',c='red')
ax.fill_between(cdegrees,cmse_train_high,cmse_train_low,facecolor='red',alpha=0.05)
plt.plot(cdegrees,cmse_test_avg,lw=2,label='Test',c='blue')
ax.fill_between(cdegrees,cmse_test_high,cmse_test_low,facecolor='blue',alpha=0.05)
plt.xlim([1,12]); plt.yscale('log'); plt.ylim([10,10000])
plt.xlabel('Complexity - Polynomial Order'); plt.ylabel('Mean Square Error'); plt.title('Training and Testing Error vs. Model Complexity')
plt.legend(loc='upper left')
plt.grid(True)
plt.plot([degree,degree],[.01,100000],c = 'black',linewidth=3,alpha = 0.8)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.6, wspace=0.2, hspace=0.3)
plt.show()
# connect the function to make the samples and plot to the widgets
interactive_plot = widgets.interactive_output(run_plot, {'n':n,'split':split,'std':std,'degree':degree})
interactive_plot.clear_output(wait = True) # reduce flickering by delaying plot updating
```
### InteractiveMachine Learning Overfitting Interactive Demonstation
#### Michael Pyrcz, Associate Professo and John Eric McCarthy II, University of Texas at Austin
Change the number of sample data, train/test split and the data noise and observe overfit! Change the model order to observe a specific model example.
### The Inputs
* **n** - number of data
* **Test %** - percentage of sample data withheld as testing data
* **Noise StDev** - standard deviation of random Gaussian error added to the data
* **Model Order** - the order of the
```
display(ui2, interactive_plot) # display the interactive plot
```
#### Comments
This was a basic demonstration of machine learning model training and tuning, model generalization and complexity. I have many other demonstrations and even basics of working with DataFrames, ndarrays, univariate statistics, plotting data, declustering, data transformations and many other workflows available at https://github.com/GeostatsGuy/PythonNumericalDemos and https://github.com/GeostatsGuy/GeostatsPy.
#### The Author:
### Michael Pyrcz, Associate Professor, University of Texas at Austin
*Novel Data Analytics, Geostatistics and Machine Learning Subsurface Solutions*
With over 17 years of experience in subsurface consulting, research and development, Michael has returned to academia driven by his passion for teaching and enthusiasm for enhancing engineers' and geoscientists' impact in subsurface resource development.
For more about Michael check out these links:
#### [Twitter](https://twitter.com/geostatsguy) | [GitHub](https://github.com/GeostatsGuy) | [Website](http://michaelpyrcz.com) | [GoogleScholar](https://scholar.google.com/citations?user=QVZ20eQAAAAJ&hl=en&oi=ao) | [Book](https://www.amazon.com/Geostatistical-Reservoir-Modeling-Michael-Pyrcz/dp/0199731446) | [YouTube](https://www.youtube.com/channel/UCLqEr-xV-ceHdXXXrTId5ig) | [LinkedIn](https://www.linkedin.com/in/michael-pyrcz-61a648a1)
#### Want to Work Together?
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
* Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I'd be happy to drop by and work with you!
* Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PIs including Profs. Foster, Torres-Verdin and van Oort)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
* I can be reached at mpyrcz@austin.utexas.edu.
I'm always happy to discuss,
*Michael*
Michael Pyrcz, Ph.D., P.Eng. Associate Professor The Hildebrand Department of Petroleum and Geosystems Engineering, Bureau of Economic Geology, The Jackson School of Geosciences, The University of Texas at Austin
#### More Resources Available at: [Twitter](https://twitter.com/geostatsguy) | [GitHub](https://github.com/GeostatsGuy) | [Website](http://michaelpyrcz.com) | [GoogleScholar](https://scholar.google.com/citations?user=QVZ20eQAAAAJ&hl=en&oi=ao) | [Book](https://www.amazon.com/Geostatistical-Reservoir-Modeling-Michael-Pyrcz/dp/0199731446) | [YouTube](https://www.youtube.com/channel/UCLqEr-xV-ceHdXXXrTId5ig) | [LinkedIn](https://www.linkedin.com/in/michael-pyrcz-61a648a1)
| github_jupyter |
```
# ignore this
%load_ext music21.ipython21
```
# User's Guide, Chapter 20: Examples 2
Since the last set of example usages of `music21` in :ref:`Chapter 10 <usersGuide_10_examples1>`, we have covered the deeper features of the :class:`~music21.base.Music21Object`, looked at :class:`~music21.key.KeySignature` (and :class:`~music21.key.Key`) and :class:`~music21.meter.TimeSignature` objects, and understood how :class:`~music21.interval.Interval` objects are modeled. This chapter gives us a chance to put some of our knowledge together by analyzing pieces and repertories of music using this information.
## Picardy-less Bach endings
J.S. Bach usually ends pieces in minor with a major chord, generally called a "Picardy third," but does he ever end pieces in minor? Let's look through the chorales to find out. We'll start by using the `corpus.search` method to get all the pieces by Bach:
```
from music21 import *
corpus.search('bach')
```
Hmmm... that's too many pieces -- there are actually several examples in the corpus that are reductions of Bach pieces. So, since I happen to know that all the Bach pieces are `.xml` or compressed `.xml (.mxl)` files, we can limit just to those:
```
corpus.search('bach', fileExtensions='xml')
```
That's closer to the exact number of Bach chorales, so we'll work with it. In a few chapters, we'll show some neat ways to work with the chorales as a repository, but for now, we'll go with that.
But before we work on a whole repertory, let's work with a single piece, the first one from the search, which should be the Chorale for Cantata 1:
```
chorales = corpus.search('bach', fileExtensions='xml')
chorales[0]
```
To review, the `.parse()` method converts a MetadataEntry to an actual `Score` object:
```
bwv1 = chorales[0].parse()
bwv1.measures(0, 3).show()
```
Hmmm... that looks like it's going to be in major...let's check to be reasonably sure:
```
bwv1.analyze('key')
```
Okay, so this won't be relevant to us. Let's parse a few pieces and find one in minor:
```
for i, chorale in enumerate(chorales[:20]):
cScore = chorale.parse()
if cScore.analyze('key').mode == 'minor':
print(i, chorale)
```
Ah, good ol' Bach has quite a bit in minor. And now we know how to filter for the types of pieces we'll be interested in. Let's grab BWV 10:
```
bwv10 = corpus.parse('bwv10')
bwv10.measures(0, 5).show()
```
Looks like it's in G minor with a first cadence on B-flat. Perfect. Let's look at the end also:
```
soprano = bwv10.parts[0]
len(soprano.getElementsByClass('Measure'))
```
Okay, there are 22 measures, so let's grab just measures 21 and 22:
```
bwv10.measures(21, 22).show()
```
Looks like a nice Picardy third here. Jean-Luc would be proud! But let's see if `music21` can figure out that it's a major chord. We could `chordify` the last measure, but let's instead get the last pitch from each part:
```
lastPitches = []
for part in bwv10.parts:
lastPitch = part.pitches[-1]
lastPitches.append(lastPitch)
lastPitches
```
This only works because Bach doesn't tend to end parts early and have rests at the end, but it wouldn't be too hard to compensate for something like that -- see the docs for :meth:`~music21.stream.Score.measure` method on `Score` objects.
Okay, so let's make a chord out of those pitches, and lets make it a whole note
```
c = chord.Chord(lastPitches)
c.duration.type = 'whole'
c.show()
```
This could get ugly fast if the bass were any lower and the soprano were any higher, so let's put it in closed position:
```
cClosed = c.closedPosition()
cClosed.show()
```
Well, that looks like a G-major chord to me. But can music21 tell what it is?
```
cClosed.isMajorTriad()
cClosed.root()
```
Let's say that we're only interested in chords that end on the same root pitched as the analyzed key, so we can test for that too:
```
bwv10.analyze('key').tonic.name
cClosed.root().name
```
So we've figured out that BWV 10's chorale does what we generally expect Bach to do. But where are the exceptions? Let's look through the whole repertory and look for them.
Let's take some of the things that we've already done and make them into little functions. First the function to get the last chord from a score:
```
def getLastChord(score):
lastPitches = []
for part in score.parts:
lastPitch = part.pitches[-1]
lastPitches.append(lastPitch)
c = chord.Chord(lastPitches)
c.duration.type = 'whole'
cClosed = c.closedPosition()
return cClosed
```
Let's check that we've coded that properly, by trying it on BWV 10:
```
getLastChord(bwv10)
```
Okay, now let's write a routine that takes in a score and sees if it is relevant. It needs to be:
1. in minor
2. have a major last chord
3. have the root of the last chord be the same as the tonic of the analyzed key.
Let's try that, and return False if the piece is not relevant, but return the last chord if it is.
```
def isRelevant(score):
analyzedKey = score.analyze('key')
if analyzedKey.mode != 'minor':
return False
lastChord = getLastChord(score)
if lastChord.isMinorTriad() is False:
return False
if lastChord.root().name != analyzedKey.tonic.name:
return False
else:
return lastChord
```
Note that I've stored the result of the key analysis as a variable so that I don't need to run the same analysis twice. Little things like this can speed up working with `music21` substantially.
Now let's look through some pieces and see which are relevant. We'll store each chord in a Stream to show later, and we will add a lyric to the chord with the name of the piece:
```
relevantStream = stream.Stream()
relevantStream.append(meter.TimeSignature('4/4'))
for chorale in chorales:
score = chorale.parse()
falseOrChord = isRelevant(score)
if falseOrChord is not False:
theChord = falseOrChord # rename for clarity
theChord.lyric = score.metadata.title
relevantStream.append(theChord)
relevantStream.show()
```
This is fun information to know about, but it's only here that the real research begins. What about these pieces makes them special? Well, BWV 111 was a cantata that was missing its chorale, so this has been traditionally added, but it's not definitively by Bach (the same chorale melody in the St. Matthew Passion has a Picardy third). In fact, when we show the Chorale iterator later, it is a piece automatically skipped for that reason. BWV 248 is the Christmas oratorio (in the `music21` corpus twice, with and without continuo). It definitely is a minor triad in the original manuscript, possibly because it does not end a section and instead goes back to the chorus da capo.
But what about the remaining seven examples? They all have BWV numbers above 250, so they are part of the settings of chorales that were not connected to cantatas, sometimes called "orphan chorales." Their possible use (as composition exercises? as studies for a proposed second Schemelli chorale aria collection?) and even their authenticity has been called into question before. But the data from the `music21` collection argues against one hypothesis, that they were parts of otherwise lost cantatas that would have been similar to the existing ones. No surviving cantata ends like these chorales do, so the evidence points to the idea that the orphan chorales were different in some other way than just being orphans, either as evidence that Bach's style had changed by the time he wrote them, or that they are not by Bach.
## Gap-Fill analysis
In a remarkable set of articles and other works from 1998-2000, Paul von Hippel explored the concept of "Gap-Fill," or the supposed idea that after a large leap in the melody, the listener expects that the following motion will be in the opposite direction, thereby filling the gap that was just created. Hippel's work compared melodic motion to the average note height in a melody. When the melody leaps up it is often above the mean so there are more pitches available below the current note than above. Similarly, when it leaps down, it is often below the mean, so there are more pitches above the current note than below. Hippel's work showed that much or all of what we perceive to be gap-fill can be explained by "regression to the mean." (The work is summarized beautifully in chapters 5 & 6 of David Huron's book _Sweet Anticipation_). But there are many repertories that have not yet been explored. Let us see if there is a real Gap Fill or just regression to the mean in one piece of early fifteenth century music, using `Interval` objects as a guide.
First let's parse a piece that has been unedited except in the music21 corpus, a Gloria in the manuscript Bologna Q15
[(image available on f.45v)](https://www.diamm.ac.uk/sources/117/#/) by a composer named "D. Luca".
```
from music21 import *
luca = corpus.parse('luca/gloria')
luca.measures(1, 7).show()
```
For now, let's look at the top part alone:
```
cantus = luca.parts['Cantus']
cantus.measures(1, 20).show()
```
Let us figure out the average pitch height in the excerpt by recursing through all the `Note` objects and finding getting the average of the `.ps` value, where Middle C = 60. (Similar to the `.midi` value)
```
totalNotes = 0
totalHeight = 0
for n in cantus.recurse().getElementsByClass('Note'):
totalNotes += 1
totalHeight += n.pitch.ps
averageHeight = totalHeight/totalNotes
averageHeight
```
We can figure out approximately what note that is by creating a new `Note` object:
```
averageNote = note.Note()
averageNote.pitch.ps = round(averageHeight)
averageNote.show()
```
(It's possible to get a more exact average pitch, if we care about such things, when we get to microtones later...)
```
exactAveragePitch = pitch.Pitch(ps=averageHeight)
exactAveragePitch.step
exactAveragePitch.accidental
exactAveragePitch.microtone
```
Python has some even easier ways to get the average pitch, using the mean or the median:
```
import statistics
statistics.mean([p.ps for p in cantus.pitches])
statistics.median([p.ps for p in cantus.pitches])
```
Medians are usually more useful than means in doing statistical analysis, so we'll use medians for our remaining analyses:
```
medianHeight = statistics.median([p.ps for p in cantus.pitches])
```
Okay, now let us get all the intervals in a piece. We'll do this in an inefficient but easy to follow manner first and then later we can talk about adding efficiencies. We'll recurse through the `Part` object and get the `.next()` :class:`~music21.note.Note` object each time and create an interval for it.
```
allIntervals = []
for n in cantus.recurse().getElementsByClass('Note'):
nextNote = n.next('Note')
if nextNote is None: # last note of the piece
continue
thisInterval = interval.Interval(n, nextNote)
allIntervals.append(thisInterval)
```
Let's look at some of the intervals and also make sure that the length of our list makes sense:
```
allIntervals[0:5]
len(allIntervals)
len(cantus.recurse().getElementsByClass('Note'))
```
Yes, it makes sense that if there are 309 notes there would be 308 intervals. So we're on the right track.
Let's look at that first Interval object in a bit more detail to see some of the things that might be useful:
```
firstInterval = allIntervals[0]
firstInterval.noteStart
firstInterval.noteEnd
firstInterval.direction
```
We are only going to be interested in intervals of a third or larger, so let's review how to find generic interval size:
```
firstInterval.generic
firstInterval.generic.directed
secondInterval = allIntervals[1]
secondInterval.generic.directed
secondInterval.generic.undirected
```
In order to see whether gap-fill or regression to the mean is happening at any given moment, we need to only look at leaps up that after the leap are still below the mean or leaps down that finish above the mean. For instance, if a line leaps up and is above the mean then both the gap-fill and the regression to the mean hypothesis would predict a downward motion for the next interval, so no knowledge would be gained. But if the line leaps up and is below the mean then the gap-fill hypothesis would predict downward motion, but the regression to the mean hypothesis would predict upward motion for the next interval. So motion like this is what we want to see.
Let's define a function called `relevant()` that takes in an interval and says whether it is big enough to matter and whether the gap-fill and regression hypotheses predict different motions:
```
def relevant(thisInterval):
if thisInterval.generic.undirected < 3:
return False
noteEndPs = thisInterval.noteEnd.pitch.ps
if thisInterval.direction == interval.Direction.ASCENDING and noteEndPs < medianHeight:
return True
elif thisInterval.direction == interval.Direction.DESCENDING and noteEndPs > medianHeight:
return True
else:
return False
```
There won't be too many relevant intervals in the piece:
```
[relevant(i) for i in allIntervals].count(True)
[relevant(i) for i in allIntervals[0:10]]
```
The third interval is relevant. Let's review what that interval is. It's the C5 descending to A4, still above the average note G4. Gap-fill predicts that the next note should be higher, regression predicts that it should be lower.
```
cantus.measures(1, 3).show()
```
In this case, the regression to the mean hypothesis is correct and the gap-fill hypothesis is wrong. But that's just one case, and these sorts of tests need to take in many data points. So let us write a function that takes in a relevant interval and the following interval and says whether gap-fill or regression is correct. We will return 1 if gap-fill is correct, 2 if regression is correct, or 0 if the next interval is the same as the current.
```
def whichHypothesis(firstInterval, secondInterval):
if secondInterval.direction == interval.Direction.OBLIQUE:
return 0
elif secondInterval.direction != firstInterval.direction:
return 1
else:
return 2
whichHypothesis(allIntervals[2], allIntervals[3])
```
We can run this analysis on the small dataset of 32 relevant intervals in the cantus part. We will store our results in a three-element list containing the number of oblique intervals, the number that fit the gap-fill hypothesis, and the number which fit the regression hypothesis:
```
obliqueGapRegression = [0, 0, 0]
for i in range(len(allIntervals) - 1):
thisInterval = allIntervals[i]
nextInterval = allIntervals[i + 1]
if not relevant(thisInterval):
continue
hypothesis = whichHypothesis(thisInterval, nextInterval)
obliqueGapRegression[hypothesis] += 1
obliqueGapRegression, obliqueGapRegression[1] - obliqueGapRegression[2]
```
So for this small set of data, gap-fill is more predictive than regression. Let's run it on the whole piece. First we will need to redefine `relevant` to take the average pitch height as a parameter.
```
def relevant2(thisInterval, medianHeight):
if thisInterval.generic.undirected < 3:
return False
noteEndPs = thisInterval.noteEnd.pitch.ps
if thisInterval.direction == interval.Direction.ASCENDING and noteEndPs < medianHeight:
return True
elif thisInterval.direction == interval.Direction.DESCENDING and noteEndPs > medianHeight:
return True
else:
return False
```
And let's define a function that computes hypothesisTotal for a single part.
```
def onePartHypothesis(part):
obliqueGapRegression = [0, 0, 0]
medianHeight = statistics.median([p.ps for p in part.pitches])
allIntervals = []
for n in part.recurse().getElementsByClass('Note'):
nextNote = n.next('Note')
if nextNote is None: # last note of the piece
continue
thisInterval = interval.Interval(n, nextNote)
allIntervals.append(thisInterval)
for i in range(len(allIntervals) - 1):
thisInterval = allIntervals[i]
nextInterval = allIntervals[i + 1]
if not relevant2(thisInterval, medianHeight):
continue
hypothesis = whichHypothesis(thisInterval, nextInterval)
obliqueGapRegression[hypothesis] += 1
return obliqueGapRegression
```
When I refactor, I always make sure that everything is still working as before:
```
onePartHypothesis(cantus)
```
Looks good! Now we're ready to go:
```
obliqueGapRegression = [0, 0, 0]
for p in luca.parts:
onePartTotals = onePartHypothesis(p)
obliqueGapRegression[0] += onePartTotals[0]
obliqueGapRegression[1] += onePartTotals[1]
obliqueGapRegression[2] += onePartTotals[2]
obliqueGapRegression, obliqueGapRegression[1] - obliqueGapRegression[2]
```
The lower two parts overwhelm the first part and it is looking like regression to the mean is ahead. But it's only one piece! Let's see if there are other similar pieces in the corpus. There's a collection of works from the 14th century, mostly Italian works:
```
corpus.search('trecento')
```
Let's run 20 of them through this search and see how they work!
```
obliqueGapRegression = [0, 0, 0]
for trecentoPieceEntry in corpus.search('trecento')[:20]:
parsedPiece = trecentoPieceEntry.parse()
for p in parsedPiece.parts:
onePartTotals = onePartHypothesis(p)
obliqueGapRegression[0] += onePartTotals[0]
obliqueGapRegression[1] += onePartTotals[1]
obliqueGapRegression[2] += onePartTotals[2]
obliqueGapRegression, obliqueGapRegression[1] - obliqueGapRegression[2]
```
So it looks like neither the gap-fill hypothesis or the regression to the mean hypothesis are sufficient in themselves to explain melodic motion in this repertory. In fact, a study of the complete encoded works of Palestrina (replace 'trecento' with 'palestrina' in the search and remove the limitation of only looking at the first 20, and wait half an hour) showed that there were 19,012 relevant instances, with 3817 followed by a unison, but 7751 exhibiting gap-fill behavior and only 7444 following regression to the mean, with a difference of 2.1%. This shows that regression to the mean cannot explain all of the reversion after a leap behavior that is going on in this repertory. I'm disappointed because I loved this article, but it'll come as a relief to most teachers of modal counterpoint.
Whew! There's a lot here in these two examples, and I hope that they point to the power of corpus analysis with `music21`, but we still have quite a lot to sort through, so we might as well continue by understanding how `music21` sorts objects in :ref:`Chapter 21: : Ordering and Sorting of Stream Elements <usersGuide_21_sorting>`.
| github_jupyter |
# [Module 4.1] 세이지 메이커 배포 및 인퍼런스
본 워크샵의 모든 노트북은 `conda_python3` 추가 패키지를 설치하고 모두 이 커널 에서 작업 합니다.
- 1. 배포 준비
- 2. 로컬 앤드포인트 생성
- 3. 로컬 추론
## 참고:
- 세이지 메이커의 모델 배포 및 추론 Python SDK 가이드.
- [Deploying directly from model artifacts](https://sagemaker.readthedocs.io/en/stable/frameworks/tensorflow/deploying_tensorflow_serving.html#deploying-directly-from-model-artifacts)
---
# 1. 배포 준비
이전 노트북에서 인퍼런스 테스트를 완료한 티펙트를 가져옵니다.
```
%store
%store -r tf2_horovod_artifact_path
%store -r keras_script_artifact_path
```
## 모델 아티펙트 지정
- 앞에서 실행하여 생성된 모델 아티펙트의 경로를 지정 함.
- 주석을 제거하시고 사용하시면 됨.
```
# artifact_path = tf2_horovod_artifact_path
artifact_path = keras_script_artifact_path
print("artifact_path: ", artifact_path)
import sagemaker
import os
import time
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket()
prefix = "sagemaker/DEMO-pytorch-cnn-cifar10"
role = sagemaker.get_execution_role()
```
# 2. 모델 배포 준비
- 앞에 노트북에서 도커 이미지를 다운로드하여서 용량이 부족할 수 있기에, 용량 부족시 실행함.
## 시스템의 이전 도커 컨테이너 삭제
- 아래와 같은 명령어를 사용하여 저장 공간을 확보 합니다.
```
! df -h
! docker container prune -f
! rm -rf /tmp/tmp*
! df -h
! df -h
! docker image prune -f --all
! df -h
```
# 3. 세이지 메이커 로컬 엔드포인트 생성
- 이 과정은 세이지 메이커 엔드포인트를 생성합니다.
```
from sagemaker.tensorflow import TensorFlowModel
sm_tf_model = TensorFlowModel(
model_data= artifact_path,
framework_version='2.4.1',
#py_version='py37',
role=role,
)
instance_type = 'local_gpu'
endpoint_name = "sm-endpoint-cifar10-tf2-{}".format(int(time.time()))
sm_tf_predictor = sm_tf_model.deploy(
instance_type= instance_type,
initial_instance_count=1,
endpoint_name=endpoint_name,
wait=True,
)
```
# 4. 로컬 추론: 샘플로 9개 만 추론
- 준비된 입력 데이터로 로컬 엔드포인트에서 추론
## 데이터 읽기 단계
- `data/cifar10/eval/eval-tfrecords` 일고 9 batch_size 로 할당하여, TF dataset를 생성 합니다.
- 1 개의 배치 (9개의 이미지, 레이블 포함) 를 읽음
- 1 개의 배치 추론
```
import matplotlib.pyplot as plt
import numpy as np
from src.utils import _input, classes
batch_size = 9
sample_dir = 'data/cifar10/eval'
sample_dataset = _input(1, batch_size, sample_dir, 'eval')
```
## 추론 함수 정의
```
def predict(predictor, data):
predictions = predictor.predict(data)['predictions']
return predictions
```
## 9개의 이미지의 실제 값과 추론 값 보여주기
```
import time
# 1개의 배치만을 가져옴
images, labels = iter(sample_dataset).next()
print("images shape: ", images.numpy().shape)
# 텐서를 numpy array 로 변경
images = images.numpy()
labels = labels.numpy()
# 이미지 한장 씩 보여주기, 레이블은 가장 값이 높은 인덱스를 구하기
ground_truth_labels = []
for i in range(batch_size):
# define subplot
plt.subplot(330 + 1 + i)
# plot raw pixel data
plt.imshow(images[i])
ground_truth_labels.append(np.argmax(labels[i]))
plt.show()
# 추론 하여 예측값 구하기
predictions = predict(sm_tf_predictor, images)
# 추론 값의 가장 값이 높은 인덱스 구하기
prediction_labels = []
for i, prediction in enumerate(predictions):
prediction_labels.append(np.argmax(prediction))
time.sleep(1)
print("\nGround Truth:\n", " ".join("%4s" % classes[ground_truth_labels[j]] for j in range(batch_size)))
print("Predicted Labels:\n", " ".join("%4s" % classes[prediction_labels[j]] for j in range(batch_size)))
```
# 5. 로컬 추론: 전체 테스트 세트 10,000 개 추론
```
batch_size = 1000
eval_dir = 'data/cifar10/eval'
eval_dataset = _input(1, batch_size, eval_dir, 'eval')
def inference_batch(predictor, eval_dataset):
'''
제공된 데이터 세트의 실제 레이블, 추론 레이블의 값을 제공
'''
ground_truth_labels = []
prediction_labels = []
for batch_id, (images, labels) in enumerate(eval_dataset):
print(f"batch_id: {batch_id} - images shape: {images.numpy().shape}")
# 텐서를 numpy array 로 변경
images = images.numpy()
labels = labels.numpy()
# 이미지 한장 씩 보여주기, 레이블은 가장 값이 높은 인덱스를 구하기
for i in range(batch_size):
ground_truth_labels.append(np.argmax(labels[i]))
# 추론 하여 예측값 구하기
predictions = predict(predictor, images)
# 추론 값의 가장 값이 높은 인덱스 구하기
for i, prediction in enumerate(predictions):
prediction_labels.append(np.argmax(prediction))
time.sleep(1)
print("ground_truth_labels: ", np.array(ground_truth_labels).shape)
print("prediction_labels: ", np.array(prediction_labels).shape)
return ground_truth_labels, prediction_labels
ground_truth_labels, prediction_labels = inference_batch(sm_tf_predictor, eval_dataset)
```
## 전체 정확도 구하기
```
from sklearn.metrics import accuracy_score, confusion_matrix
def compute_accuracy(prediction_labels, ground_truth_labels):
accuracy = accuracy_score(y_pred=prediction_labels,y_true=ground_truth_labels)
display('Average accuracy: {}%'.format(round(accuracy*100,2)))
compute_accuracy(prediction_labels, ground_truth_labels)
```
## 전체 혼돈 매트릭스 구하기
```
%matplotlib inline
import seaborn as sn
import pandas as pd
import matplotlib.pyplot as plt
def show_cm_matrix(prediction_labels, ground_truth_labels):
cm = confusion_matrix(y_pred=prediction_labels,y_true=ground_truth_labels)
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
sn.set(rc={'figure.figsize': (11.7,8.27)})
sn.set(font_scale=1.4) #for label size
sn.heatmap(cm, annot=True, annot_kws={"size": 10})# font size
show_cm_matrix(prediction_labels, ground_truth_labels)
```
## Clean-up
위의 엔드포인트를 삭제 합니다.
```
sm_tf_predictor.delete_endpoint()
```
# 6. 세이지 메이커 호스트 추론
- 아래는 약 10분 정도 소요 됩니다.
```
%%time
from sagemaker.tensorflow import TensorFlowModel
sm_tf_model = TensorFlowModel(
model_data= artifact_path,
framework_version='2.4.1',
role=role,
)
instance_type = 'ml.p2.xlarge'
endpoint_name = "sm-host-endpoint-cifar10-tf2-{}".format(int(time.time()))
sm_host_tf_predictor = sm_tf_model.deploy(
instance_type= instance_type,
initial_instance_count=1,
endpoint_name=endpoint_name,
wait=True,
)
%%time
ground_truth_labels, prediction_labels = inference_batch(sm_host_tf_predictor, eval_dataset)
compute_accuracy(prediction_labels, ground_truth_labels)
show_cm_matrix(prediction_labels, ground_truth_labels)
```
# 7. 리소스 정리
```
sm_host_tf_predictor.delete_endpoint()
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
from IPython.display import display
sns.set_theme()
plt.rcParams.update({'figure.facecolor':'white'})
```
# Load data and do basic formatting
```
df = pd.read_csv("../data/processed_sensor_dwd_train.csv", index_col=0)
# convert timestamp to datetime
df['timestamp'] = pd.to_datetime(df['timestamp'])
# convert pressure to hPa
df['pressure_sensors'] = df['pressure_sensors'] / 100
df['pressure_std'] = df['pressure_std'] / 100
# add sensor IDs
df_location = df.groupby(['lat', 'lon']).count().reset_index()[['lat', 'lon']]
df_location['location_id'] = df_location.index+1
df = df.merge(df_location, on=['lat', 'lon'], how='left')
# define lists with columns
no_data_cols = ['location_id', 'timestamp', 'city', 'lat', 'lon']
sc_cols = sorted(['PM10', 'PM2p5', 'PM10_std', 'PM2p5_std', 'pressure_sensors', 'temperature_sensors', 'humidity_sensors', 'pressure_std', 'temperature_std', 'humidity_std'])
sc_cols_wo_std = [col for col in sc_cols if 'std' not in col]
dwd_cols = sorted([col for col in df.columns if (col not in no_data_cols and col not in sc_cols)])
std_cols = [col for col in sc_cols if 'std' in col]
data_cols_wo_std = sc_cols_wo_std + dwd_cols
data_cols = sc_cols + dwd_cols
# reorganize columns: first non-data columns, then sorted data columns
df = df.reindex(columns=no_data_cols + sc_cols + dwd_cols)
df
# save assignment of sensor_id to coordinates
location_id_assignment = pd.DataFrame(
data={
'location_id': df['location_id'].unique()
}
)
for l in ['lat', 'lon']:
location_id_assignment[l] = location_id_assignment.apply(lambda x: df.loc[df['location_id']==x['location_id'], l].iloc[0], axis=1)
df.info()
```
# Investigation of missing values, zeros and outliers
```
# Basic statistics of the whole sc dataset
df[sc_cols_wo_std].describe().T.round(1)
# Basic statistics of the sc dataset for Frankfurt
df[df['city']=='Frankfurt'][sc_cols_wo_std].describe().T.round(1)
# Basic statistics of the sc dataset for Bremen
df[df['city']=='Bremen'][sc_cols_wo_std].describe().T.round(1)
```
PM10: Mean is almost double of the 75th percentile -> Outliers raise the mean extremely </br>
PM2.5: similar to PM10, but less extreme </br>
humidity: al values (mean, 25th, 50th and 75th percentile) seem to be very large, the max value is above 100, what doesn't make any sense </br>
pressure: assuming the units are Pa (1 bar = 100.000 Pa): min value is below 100 -> unrealistic, max value is also unrealistic (more than 60 bar) </br>
temperature: std seems very high (54 °C), min and max value are unrealistic </br>
</br>
Bremen vs. Frankfurt </br>
PM10 and PM2.5: std for Bremen is double of std for Frankfurt </br>
humidity: 50th percentile of Bremen is already 99.9 % what seems quite high
pressure and temperature: no obvious unrealistic observations besides the min and max values
```
print("missing values in each column")
for col in df.columns:
print(f"{col}: {df[col].isna().sum()} ({round(df[col].isna().sum() / df.shape[0] * 100, 1)} %)")
print("value '0' in each column")
for col in df.columns:
print(f"{col}: {df[df[col]==0][col].count()} ({round(df[df[col]==0][col].count() / df.shape[0] * 100, 1)} %)")
def count_nan_and_0s(df: pd.DataFrame, cols: list = None) -> pd.DataFrame:
"""Counts zeros and nans per column.
Args:
df (pd.DataFrame): Dataframe to search for zeros and nans.
cols (list, optional): List of columns, if no columns are specified all will be used. Defaults to None.
thresholds (dict, optional): Thresholds for further . Defaults to None.
Returns:
pd.DataFrame: Dataframe containing counts of zeros and nans.
"""
# use all columns af none were defined
if cols == None:
cols=df.columns
# make a new dataframe and put the defined column names in the first column
df_nan_0 = pd.DataFrame()
df_nan_0['data'] = cols
# calculate missing values and zeros as absolute value and share
df_nan_0['missing_values'] = [df[col].isna().sum() for col in cols]
df_nan_0['missing_values_share'] = [df[col].isna().sum() / df.shape[0] * 100 for col in cols]
df_nan_0['0_values'] = [df[df[col]==0][col].count() for col in cols]
df_nan_0['0_values_share'] = [df[df[col]==0][col].count() / df.shape[0] * 100 for col in cols]
# transpose the dataframe and use the original column names as column names
df_nan_0 = df_nan_0.set_index('data').T.reset_index()
df_nan_0.columns = [name if i>0 else 'metric' for i, name in enumerate(df_nan_0.columns)]
return df_nan_0
# find missing values and zeros in the sc dataset
df_data_analysis = count_nan_and_0s(df, data_cols)
df_data_analysis.round(1)
# define metrics and columns to plot
metrics = ["missing_values_share", "0_values_share"]
ys = list(df_data_analysis.columns)
ys.remove('metric')
# define size of subplot
columns = 4
rows = int(np.ceil((len(df_data_analysis.columns) - 1) / columns))
# plot
fig, ax = plt.subplots(rows, columns, figsize=(20,20)) # create subplots
plt.suptitle("Data analysis of missing values and zeros", fontsize=20) # title of plot
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
plt.subplots_adjust(hspace = .5, wspace = .2, top = .93) # adjusts the space between the single subplots
for row in range(rows):
for col in range(columns):
if col + row * columns < len(ys):
# create a bar for each metric defined above for a column of ys list
sns.barplot(data=df_data_analysis[df_data_analysis['metric'].isin(metrics)], x='metric', y=ys[col + row * columns], ax=ax[row][col])
# set ylim to [0, 100] as we are plotting percentages
ax[row][col].set_ylim([0, 100])
# put the percentage above each plotted bar
ax[row][col].bar_label(ax[row][col].containers[0], fmt='%.1f')
# set the x, y and x-tick labels
ax[row][col].set_xlabel("")
ax[row][col].set_ylabel("Share of values in %")
ax[row][col].set_xticklabels(labels=["Missing values", "Zeros"])
# use the column name with slight changes as subplot name
title = f"{ys[col + row * columns]}".replace('_', ' ').replace('std', 'std. dev.').replace('2p5', '2.5').capitalize()
ax[row][col].set_title(title, fontsize = 15);
else:
# delete not needed subplots
fig.delaxes(ax[row][col])
# columns to plot
ys = data_cols_wo_std
# define size of subplot
columns = 3
rows = int(np.ceil((len(ys)) / columns))
# plot
fig, ax = plt.subplots(rows, columns, figsize=(20,20)) # create subplots
plt.suptitle("Outlier analysis", fontsize=20) # title of plot
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
plt.subplots_adjust(hspace = .7, wspace = .2, top = .93) # adjusts the space between the single subplots
for row in range(rows):
for col in range(columns):
if col + row * columns < len(ys):
# create a bar for each metric defined above for a column of ys list
sns.scatterplot(data=df, x='timestamp', y=ys[col + row * columns], ax=ax[row][col], alpha=.3)
# set the x, y and x-tick labels
ax[row][col].set_xlabel(ax[row][col].get_xlabel().capitalize())
ax[row][col].set_ylabel(ax[row][col].get_ylabel().capitalize())
# use the column name with slight changes as subplot name
title = f"{ys[col + row * columns]}".replace('_', ' ').replace('std', 'std. dev.').replace('2p5', '2.5').capitalize()
ax[row][col].set_title(title, fontsize = 15)
ax[row][col].tick_params(labelrotation=90)
else:
# delete not needed subplots
fig.delaxes(ax[row][col])
```
There are few outliers in humidity, pressure and temperature which can be dropped by setting thresholds. </br>
For PM10 and PM2.5 it is less obvious as the data is scattered all over the possible range.
# Delete unrealistic values and outliers for environmental variables
## hard thresholds based on physical estimations
We can first have a look at the extreme values measured by Deutscher Wetterdienst to get an impression what range of values is realistic.
```
print(df['humidity_dwd'].max())
print(df.query("city == 'Frankfurt'")['humidity_dwd'].min())
print(df.query("city == 'Bremen'")['humidity_dwd'].min())
print(df['pressure_dwd'].max())
print(df.query("city == 'Frankfurt'")['pressure_dwd'].min())
print(df.query("city == 'Bremen'")['pressure_dwd'].min())
print(df['temperature_dwd'].max())
print(df.query("city == 'Frankfurt'")['temperature_dwd'].min())
print(df.query("city == 'Bremen'")['temperature_dwd'].min())
# set lower and upper threshold
thresholds_env = {
'humidity_sensors': (15, 100),
'pressure_sensors': (960, 1050),
'temperature_sensors': (-20, 60),
}
def del_hard_thresholds_env(df, thresholds_env=thresholds_env):
# delete values below lower and above upper threshold
for col, thresh in thresholds_env.items():
nan_before = df[col].isna().sum()
df.iloc[df[col] <= thresh[0], list(df.columns).index(col)] = np.nan
df.iloc[df[col] >= thresh[1], list(df.columns).index(col)] = np.nan
print(f"added {df[col].isna().sum() - nan_before} nans in {col}")
print(df['temperature_sensors'].isna().sum())
del_hard_thresholds_env(df)
print(df['temperature_sensors'].isna().sum())
```
## values with std. dev. 'nan' or zero
If the standard deviation is 'nan', there was no or only one observation. If the standard deviation is zero, there was no fluctuation in the measured value, what can be assumed to be a measurement error.
```
# delete values for the defined columns if the standard deviation is zero or 'nan'
cols_env = [
'temperature_sensors',
'humidity_sensors',
'pressure_sensors',
]
def del_std_nan_env(df, cols=cols_env):
for col in cols:
nan_before = df[col].isna().sum()
df.loc[df[col.split('_')[0]+'_std']==0, col] = np.nan
df.loc[df[col.split('_')[0]+'_std']==np.nan, col] = np.nan
print(f"added {df[col].isna().sum() - nan_before} nans in {col}")
print(df['temperature_sensors'].isna().sum())
del_std_nan_env(df)
print(df['temperature_sensors'].isna().sum())
```
## dynamic thresholds based on quantiles
```
# define quantiles as threshold
thresh = {
'temperature': (.01, .85),
'humidity': (.05, .95),
'pressure': (.05, .95),
}
def del_dynamic_threshold_env(df, thresh=thresh):
# make a dataframe containing median, upper and lower threshold defined by the quantiles above
df_thresholds = df.groupby(['city', 'timestamp']).agg(
temp_median = pd.NamedAgg(column='temperature_sensors', aggfunc='median'),
temp_lower = pd.NamedAgg(column='temperature_sensors', aggfunc=lambda x: x.quantile(q=thresh['temperature'][0])),
temp_upper = pd.NamedAgg(column='temperature_sensors', aggfunc=lambda x: x.quantile(q=thresh['temperature'][1])),
hum_median = pd.NamedAgg(column='humidity_sensors', aggfunc='median'),
hum_lower = pd.NamedAgg(column='humidity_sensors', aggfunc=lambda x: x.quantile(q=thresh['humidity'][0])),
hum_upper = pd.NamedAgg(column='humidity_sensors', aggfunc=lambda x: x.quantile(q=thresh['humidity'][1])),
pres_median = pd.NamedAgg(column='pressure_sensors', aggfunc='median'),
pres_lower = pd.NamedAgg(column='pressure_sensors', aggfunc=lambda x: x.quantile(q=thresh['pressure'][0])),
pres_upper = pd.NamedAgg(column='pressure_sensors', aggfunc=lambda x: x.quantile(q=thresh['pressure'][1])),
).reset_index()
# merge the thresholds with the sc dataframe
df = df.merge(df_thresholds, how='left', on=['city', 'timestamp'])
# replace values below lower threshold and above upper threshold with 'nan'
for col, thresholds in {
'temperature_sensors': ['temp_lower', 'temp_upper'],
'humidity_sensors': ['hum_lower', 'hum_upper'],
'pressure_sensors': ['pres_lower','pres_upper'],
}.items():
nan_before = df[col].isna().sum()
df.loc[(df[col] < df[thresholds[0]]) | (df[col] > df[thresholds[1]]), col] = np.nan
print(f"{df[col].isna().sum() - nan_before} nans added in {col}")
# drop columns used for dynamic thresholding
df.drop([col for col in df_thresholds.columns if not col in no_data_cols], axis=1, inplace=True)
print(df['temperature_sensors'].isna().sum())
del_dynamic_threshold_env(df)
print(df['temperature_sensors'].isna().sum())
# df_thresholds.columns
# # replace values below lower threshold and above upper threshold with 'nan'
# for col, thresholds in {
# 'temperature_sensors': ['temp_lower', 'temp_upper'],
# 'humidity_sensors': ['hum_lower', 'hum_upper'],
# 'pressure_sensors': ['pres_lower','pres_upper'],
# }.items():
# nan_before = df[col].isna().sum()
# df.loc[(df[col] < df[thresholds[0]]) | (df[col] > df[thresholds[1]]), col] = np.nan
# print(f"{df[col].isna().sum() - nan_before} nans added in {col}")
# # drop columns used for dynamic thresholding
# df.drop([col for col in df_thresholds.columns if not col in no_data_cols], axis=1, inplace=True)
```
# Visualization of cleaned data and comparison with dwd data
```
def plot_sc_vs_dwd(city, columns=1, reduction=1):
# Plot dwd and sc data
# define size of subplot
rows = int(np.ceil(3 / columns))
fig, ax = plt.subplots(rows, columns, figsize=(20,20)) # create subplots
plt.suptitle(f"Comparison sensor data vs. dwd in {city}", fontsize=20) # title of plot
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
plt.subplots_adjust(hspace = .2, wspace = .2, top = .95) # adjusts the space between the single subplots
# Plot humidity from both datasets vs time
sns.scatterplot(data=df[(df['humidity_sensors'].notna()) & (df['city'] == city)][::reduction], x='timestamp', y='humidity_sensors', ax=ax[0], label='Sensor Community')
sns.lineplot(data=df[(df['humidity_dwd'].notna()) & (df['city']== city)], x='timestamp', y='humidity_dwd', color='red', alpha=.5, ax=ax[0], label='Deutscher Wetterdienst')
ax[0].set_ylabel('Relative Humidity in %')
# Plot pressure from both datasets vs time
sns.scatterplot(data=df[(df['pressure_sensors'].notna()) & (df['city'] == city)][::reduction], x='timestamp', y='pressure_sensors', ax=ax[1], label='Sensor Community')
sns.lineplot(data=df[(df['pressure_dwd'].notna()) & (df['city']== city)], x='timestamp', y='pressure_dwd', color='red', alpha=.5, ax=ax[1], label='Deutscher Wetterdienst')
ax[1].set_ylabel('Pressure in hPa')
# Plot temperature from both datasets vs time
sns.scatterplot(data=df[(df['temperature_sensors'].notna()) & (df['city'] == city)][::reduction], x='timestamp', y='temperature_sensors', ax=ax[2], label='Sensor Community')
sns.lineplot(data=df[(df['temperature_dwd'].notna()) & (df['city']== city)], x='timestamp', y='temperature_dwd', color='red', alpha=.5, ax=ax[2], label='Deutscher Wetterdienst')
ax[2].set_ylabel('Temperature in °C')
xlim_left = df['timestamp'].min()
xlim_right = df['timestamp'].max()
# capitalize axis titles and add legend
for i in range(3):
ax[i].legend(loc='lower right')
ax[i].set_xlabel(ax[i].get_xlabel().capitalize())
ax[i].set_xlim(xlim_left, xlim_right)
# # Plot comparison of data from both sources for Frankfurt
# plot_sc_vs_dwd('Frankfurt')
# plt.savefig("../figures/EDA_sc_vs_dwd_Frankfurt.png", bbox_inches='tight')
# plt.close()
# ;
```

```
# # Plot comparison of data from both sources for Bremen
# plot_sc_vs_dwd('Bremen')
# plt.savefig("../figures/EDA_sc_vs_dwd_Bremen.png", bbox_inches='tight')
# plt.close()
# ;
```

```
# Example of the distribution of measured temperatures in one day
sns.histplot(data=df[(df['timestamp'] > '2020-07-01') & (df['timestamp'] < '2020-07-15')], x='temperature_sensors', bins=20);
```
# Investigation of single locations
```
# group by location_id and calculate the total number of hours with measurements, date of the first and of the last measurement
location_grouped = df[(df['PM10'].notna()) & (df['PM2p5'].notna())][['location_id', 'timestamp']].\
groupby(['location_id']).\
agg(
hours = pd.NamedAgg(column='timestamp', aggfunc='count'),
date_min = pd.NamedAgg(column='timestamp', aggfunc='min'),
date_max = pd.NamedAgg(column='timestamp', aggfunc='max')
).\
reset_index().\
sort_values('hours', ascending=False)
location_grouped['date_min'] = pd.to_datetime(location_grouped['date_min'])
location_grouped['date_max'] = pd.to_datetime(location_grouped['date_max'])
location_grouped['period_length'] = location_grouped['date_max'] - location_grouped['date_min'] + pd.Timedelta(days=1)
location_grouped['hours_per_day'] = location_grouped['hours'] / location_grouped['period_length'].dt.days
location_grouped.head(5)
# plot the number of hours that were measured at each location
plt.figure(figsize=(25, 10))
g = sns.barplot(data=location_grouped, x='location_id', y='hours', order=location_grouped.sort_values('hours', ascending=False)['location_id'])
g.set_xlabel(g.get_xlabel().capitalize().replace('_', ' '))
g.set_ylabel(g.get_ylabel().capitalize())
plt.xticks(rotation=90);
# plot the number of hours per day measured per location
plt.figure(figsize=(25, 10))
g = sns.barplot(data=location_grouped.sort_values('hours_per_day', ascending=False), x='location_id', y='hours_per_day', order=location_grouped.sort_values('hours_per_day', ascending=False)['location_id'])
g.set_xlabel(g.get_xlabel().capitalize().replace('_', ' '))
g.set_ylabel(g.get_ylabel().capitalize().replace('_', ' '))
plt.xticks(rotation=90);
print(f"Total number of locations: {location_grouped.shape[0]}")
print('Locations with the least hours of measurement:')
location_grouped.tail(20)
location_grouped[['hours', 'hours_per_day']].describe().T.round(1)
```
There are some sensor locations which delivered data only for few hours
```
def plot_all_PM(df):
fig, (ax1, ax2, ax3, ax4) = plt.subplots(4, 1, figsize=(20, 20))
plt.suptitle("Sensors per City", fontsize=20) # title of plot
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
plt.subplots_adjust(hspace = .5, wspace = .2, top = .9) # adjusts the space between the single subplots
# get ids match them with the cities
labels_frankfurt = set(df.query("city=='Frankfurt'")['location_id'])
labels_bremen = set(df.query("city=='Bremen'")['location_id'])
# plot PM10 data of Frankfurt
sns.lineplot(data=df[df['city']=='Frankfurt'][::10], x='timestamp', y='PM10', hue='location_id', ax=ax1, legend=False)
ax1.legend(labels=labels_frankfurt) # assign a unique color to every id
ax1.set_title('Frankfurt - PM10', fontsize = 15) # set title and font size
ax1.legend([], [], frameon=False) # hide legend
# plot PM2.5 data for Frankfurt
sns.lineplot(data=df[df['city']=='Frankfurt'][::10], x='timestamp', y='PM2p5', hue='location_id', ax=ax2, legend=False)
ax2.legend(labels=labels_frankfurt)
ax2.set_title('Frankfurt - PM2.5', fontsize = 15)
ax2.legend([], [], frameon=False)
# plot PM10 data for Bremen
sns.lineplot(data=df[df['city']=='Bremen'][::10], x='timestamp', y='PM10', hue='location_id', ax=ax3, legend=False)
ax3.legend(labels=labels_bremen)
ax3.set_title('Bremen - PM10', fontsize = 15)
ax3.legend([], [], frameon=False)
# plot PM2.5 data for Bremen
sns.lineplot(data=df[df['city']=='Bremen'][::10], x='timestamp', y='PM2p5', hue='location_id', ax=ax4, legend=False)
ax4.legend(labels=labels_bremen)
ax4.set_title('Bremen - PM2.5', fontsize = 15)
ax4.legend([], [], frameon=False)
plot_all_PM(df)
```
# Example location (location_id=2)
```
# get location_id's occuring in Frankfurt
ids_frankfurt = df.query("city=='Frankfurt'")['location_id'].unique()
# plot PM10, PM2.5 and humidity of one location
plt.figure(figsize=(15, 8))
ax = sns.lineplot(data=df[df['location_id']==ids_frankfurt[0]], x='timestamp', y='PM10', color='b', alpha=.5)
sns.lineplot(data=df[df['location_id']==ids_frankfurt[0]], x='timestamp', y='PM2p5', color="r", alpha=.5, ax=ax)
ax2 = ax.twinx() # add second y-axis
sns.lineplot(data=df[df['location_id']==ids_frankfurt[0]], x='timestamp', y='humidity_sensors', color="g", alpha=.5, ax=ax2)
# Plot correlation heatmap for one single location
sns.heatmap(df[df['location_id']==ids_frankfurt[0]][sc_cols_wo_std].corr(), annot=True)
# make a dataframe containing timestamps of one year with resolution of one hour
one_year_full = pd.DataFrame()
one_year_full['timestamp'] = pd.date_range("2021-03-01", "2022-02-28 23:00:00", freq="H")
# add observations of one location to that dataframe
one_year_full_2 = pd.merge(one_year_full, df[df['location_id']==ids_frankfurt[0]], how='left', on='timestamp')
print(f"{one_year_full_2['PM10'].isna().sum()} missing values in PM10")
print(f"{one_year_full_2['PM2p5'].isna().sum()} missing values in PM2.5")
# get indices of observations where PM10 value is 'NaN'
missing_index = one_year_full_2.index[one_year_full_2['PM10'].isna()].tolist()
missing_periods = [] # list for periods of missing values
i = 0 # index for loop
start = None # start of a period
previous = None # index of the previous loop
while i < len(missing_index):
# if start is None, it is the first loop
if start == None:
start = previous = missing_index[i]
i += 1
continue
# if the current index is the previous index + 1, we are still moving within a closed period
if missing_index[i] == previous+1:
previous = missing_index[i]
i += 1
continue
# else one period is over and another one is starting
else:
# add the closed period to the list of missing periods
missing_periods.append(
(one_year_full_2['timestamp'][start],
one_year_full_2['timestamp'][previous],
one_year_full_2['timestamp'][previous] - one_year_full_2['timestamp'][start] + pd.Timedelta(1, 'hour'))
)
start = previous = missing_index[i]
i += 1
# add the last period to the list
missing_periods.append(
(one_year_full_2['timestamp'][start],
one_year_full_2['timestamp'][previous],
one_year_full_2['timestamp'][previous] - one_year_full_2['timestamp'][start] + pd.Timedelta(1, 'hour'))
)
# print the periods of missing PM10 values and their duration
p = 0
for start, end, duration in missing_periods:
p += 1
print(f"Period of missing values #{p}:\n\tstart: {start}\n\tend: {end}\n\tduration: {duration}\n")
```
## Set dynamic thresholds for PM data
GOAL: Calculate a dynamic median per hour for all sensors in a city. If a value is for example three times the median it is estimated to be an error.
```
def clean_pm(df: pd.DataFrame, cols: list=['PM10', 'PM2p5'], factor: int = 3) -> pd.DataFrame:
"""deletes outliers for the given columns and considerung their timestamps and cities which are larger than factor times the median
Args:
df (pd.DataFrame): input dataframe
cols (list): columns to clean
factor (int, optional): factor that is used to calculate the threshold for keeping or deleting data. Defaults to 3.
Returns:
pd.DataFrame: cleaned dataframe
"""
for col in df.columns:
if 'threshold' in col:
df.drop(col, axis=1, inplace=True)
# define a list for saving the thresholds
thresholds = []
# for each city in the dataframe make a dataframe with timestamps
for city in df['city'].unique():
df_cur = df[df['city'] == city]
df_threshold = pd.DataFrame(
data={
'timestamp': df_cur['timestamp'].unique(),
'city': city
}
)
# for each timestamp calculate the median and threshold (factor * median)
for col in cols:
df_threshold[col+'_median'] = df_threshold.apply(lambda x: df_cur[(df_cur['timestamp'] == x['timestamp'])][col].median(), axis=1)
df_threshold[col+'_threshold'] = factor * df_threshold[col+'_median']
thresholds.append(df_threshold)
# concatenate all thresholds
df_thresholds = pd.DataFrame()
for df_threshold in thresholds:
df_thresholds = pd.concat([df_thresholds, df_threshold])
# merge thresholds with original dataframe on timestamp and city
df = df.merge(df_thresholds, how='left', on=['timestamp', 'city'])
# delete values if they are above the threshold and print number of deleted values
for col in cols:
nan_before = df[col].isna().sum()
df[col] = df.apply(lambda x: x[col] if x[col] <= x[col+'_threshold'] else np.nan, axis=1)
print(f"{df[col].isna().sum() - nan_before} NaNs added in {col}")
# for col in cols:
# df.drop([col+'_threshold'], axis=1, inplace=True)
return df
df = clean_pm(df)
plot_all_PM(df)
def get_PM_data_per_location(df: pd.DataFrame) -> tuple:
"""
Args:
df (pd.Dataframe): Dataframe containing data of PM sensors
Returns:
tuple: Tuple containing one dataframe per city and PM sensor
"""
# make dataframe containing the timestamps
df_missing_values_bremen_pm10 = pd.DataFrame(
data={
'timestamp': df['timestamp'].unique(),
}
)
# copy that dataframe for every combination of PM sensor and city
df_missing_values_bremen_pm2p5 = df_missing_values_bremen_pm10.copy()
df_missing_values_frankfurt_pm10 = df_missing_values_bremen_pm10.copy()
df_missing_values_frankfurt_pm2p5 = df_missing_values_bremen_pm10.copy()
# add sensor data for every location in Bremen
for location in df.loc[df['city'] == 'Bremen', 'location_id'].unique():
df_missing_values_bremen_pm10 = pd.merge(df_missing_values_bremen_pm10, df.loc[df['location_id']==location, ['timestamp','PM10']], on='timestamp')
df_missing_values_bremen_pm10.rename(columns={'PM10': location}, inplace=True) # rename the new column using the location_id
df_missing_values_bremen_pm10.set_index('timestamp', inplace=True) # use timestamps as index
df_missing_values_bremen_pm2p5 = pd.merge(df_missing_values_bremen_pm2p5, df.loc[df['location_id']==location, ['timestamp','PM2p5']], on='timestamp')
df_missing_values_bremen_pm2p5.rename(columns={'PM2p5': location}, inplace=True)
df_missing_values_bremen_pm2p5.set_index('timestamp', inplace=True)
# do the same for Frankfurt
for location in df.loc[df['city'] == 'Frankfurt', 'location_id'].unique():
df_missing_values_frankfurt_pm10 = pd.merge(df_missing_values_frankfurt_pm10, df.loc[df['location_id']==location, ['timestamp','PM10']], on='timestamp')
df_missing_values_frankfurt_pm10.rename(columns={'PM10': location}, inplace=True)
df_missing_values_frankfurt_pm10.set_index('timestamp', inplace=True)
df_missing_values_frankfurt_pm2p5 = pd.merge(df_missing_values_frankfurt_pm2p5, df.loc[df['location_id']==location, ['timestamp','PM2p5']], on='timestamp')
df_missing_values_frankfurt_pm2p5.rename(columns={'PM2p5': location}, inplace=True)
df_missing_values_frankfurt_pm2p5.set_index('timestamp', inplace=True)
return df_missing_values_bremen_pm10, df_missing_values_bremen_pm2p5, df_missing_values_frankfurt_pm10, df_missing_values_frankfurt_pm2p5
df_missing_values_bremen_pm10, df_missing_values_bremen_pm2p5, df_missing_values_frankfurt_pm10, df_missing_values_frankfurt_pm2p5 = get_PM_data_per_location(df)
# plot missing values per id for PM10 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm10.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Bremen', fontsize=20);
# plot missing values per id for PM2.5 in Bremen
plt.figure(figsize=(30, 15))
g = sns.heatmap(df_missing_values_bremen_pm2p5.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Bremen', fontsize=20);
# plot missing values per id for PM2.5 in Frankfurt
plt.figure(figsize=(30, 15))
g = sns.heatmap(df_missing_values_frankfurt_pm2p5.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Frankfurt', fontsize=20);
# plot missing values per id for PM10 in Frankfurt
plt.figure(figsize=(30, 15))
g = sns.heatmap(df_missing_values_frankfurt_pm10.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Frankfurt', fontsize=20);
```
# Drop sensors with only few data in the past year
```
# df.to_csv("../data/df_backup.csv")
# import numpy as np
# import pandas as pd
# import matplotlib.pyplot as plt
# import seaborn as sns
# import warnings
# warnings.filterwarnings("ignore")
# sns.set_theme()
# plt.rcParams.update({'figure.facecolor':'white'})
# df = pd.read_csv("../data/df_backup.csv", index_col=0)
# df['timestamp'] = pd.to_datetime(df['timestamp'])
def get_share_of_missing_values(df: pd.DataFrame, start_time: str):
# Get the total number of observations possible in the past year
observations_of_interest = df[(df['location_id'] == df['location_id'].unique()[0]) & (df['timestamp'] >= pd.to_datetime(start_time))].shape[0]
# make a dataframe to store missing values per location
missing_values = pd.DataFrame(columns=['location_id', 'city', 'PM10_missing', 'PM2p5_missing'])
# get missing values for every location
for location in df['location_id'].unique():
# filter for location
df_cur = df[(df['location_id'] == location) & (df['timestamp'] >= pd.to_datetime('2021-01-01'))][['city', 'PM10', 'PM2p5']]
# create a new entry in the dataframe containing location_id, city and share of missing values
new_entry = {
'location_id': int(location),
'city': df_cur['city'].iloc[0],
'PM10_missing': df_cur['PM10'].isna().sum() / observations_of_interest,
'PM2p5_missing': df_cur['PM2p5'].isna().sum() / observations_of_interest,
}
missing_values = missing_values.append(new_entry, ignore_index=True)
# cast location_id to int
missing_values['location_id'] = missing_values['location_id'].astype(int)
return missing_values
missing_values = get_share_of_missing_values(df, '2021-01-01')
missing_values
fig, ax = plt.subplots(4,1,figsize=(20,15))
plt.suptitle("Missing values per city and sensor", fontsize=20) # title of plot
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
plt.subplots_adjust(hspace = .4, wspace = .2, top = .93) # adjusts the space between the single subplots
i=0
# plot share of missing values for every city and PM sensor
for city in missing_values['city'].unique():
for col in ['PM10_missing', 'PM2p5_missing']:
sns.barplot(
data=missing_values[missing_values['city']==city],
x='location_id',
y=col,
order=missing_values[missing_values['city']==city].sort_values(col, ascending=False)['location_id'], # sort by missing values
ax=ax[i]
)
ax[i].tick_params(labelrotation=90) # rotate x tick labels
ax[i].set_title(city + ' - ' + col.split('_')[0].replace('p', '.')) # set a title (City - Sensor)
i += 1
# get the IDs of good sensors having less than 25 % missing values in PM2.5
good_sensors = missing_values.query("PM2p5_missing < 0.25")['location_id']
good_sensors
# get the data of those good sensors
def use_good_sensors_only(df, good_sensors=good_sensors):
df_good_sensors = df[df['location_id'].\
isin(good_sensors)].\
drop([col for col in df.columns if ('median' in col or 'threshold' in col)], axis=1)
return df_good_sensors
df_good_sensors = use_good_sensors_only(df)
print(df.shape)
print(df_good_sensors.shape)
```
# Clean test data
```
# import test data
df_test = pd.read_csv("../data/processed_sensor_dwd_test.csv", index_col=0)
# assign location IDs according to coordinates
df_test['location_id'] = df_test.apply(
lambda x: location_id_assignment.\
loc[(location_id_assignment['lat'] == x['lat']) & (location_id_assignment['lon'] == x['lon']), 'location_id'].\
iloc[0],
axis=1
)
df_test['location_id'].isna().sum()
# convert timestamp to datetime
df_test['timestamp'] = pd.to_datetime(df_test['timestamp'])
# sort columns
df_test = df_test.reindex(columns=no_data_cols + sc_cols + dwd_cols)
df_test.head()
# remove outliers of environmental parameters by different mechanisms
print("hard thresholds")
del_hard_thresholds_env(df_test)
print("constant values")
del_std_nan_env(df_test)
print("dnyamic thersholds")
del_dynamic_threshold_env(df_test)
# plot all PM data
plot_all_PM(df_test)
# get missing values of PM data per sensor
df_missing_values_bremen_pm10_test, \
df_missing_values_bremen_pm2p5_test, \
df_missing_values_frankfurt_pm10_test, \
df_missing_values_frankfurt_pm2p5_test = get_PM_data_per_location(df_test)
# plot missing values per id for PM10 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm10_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Bremen', fontsize=20);
# plot missing values per id for PM2.5 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm2p5_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Bremen', fontsize=20);
# plot missing values per id for PM10 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm10_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Frankfurt', fontsize=20);
# plot missing values per id for PM2.5 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm2p5_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Frankfurt', fontsize=20);
# clean PM data
df_test = clean_pm(df_test)
# get data of sensors marked as good
df_good_sensors_test = use_good_sensors_only(df_test)
print(df_test.shape)
print(df_good_sensors_test.shape)
```
## Test data after cleaning
```
# number of 'good sensors' should be identical to locations in test dataframe
print(len(good_sensors))
df_good_sensors_test['location_id'].nunique()
# plot all PM data per location
plot_all_PM(df_good_sensors_test)
# get missing values per sensor
df_missing_values_bremen_pm10_test, \
df_missing_values_bremen_pm2p5_test, \
df_missing_values_frankfurt_pm10_test, \
df_missing_values_frankfurt_pm2p5_test = get_PM_data_per_location(df_good_sensors_test)
# plot missing values per id for PM10 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm10_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Bremen', fontsize=20);
# plot missing values per id for PM2.5 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm2p5_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Bremen', fontsize=20);
# plot missing values per id for PM10 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm10_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Frankfurt', fontsize=20);
# plot missing values per id for PM2.5 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm2p5_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Frankfurt', fontsize=20);
# get share of missing values in the cleaned test dataframe
missing_values_test = get_share_of_missing_values(df_good_sensors_test, "2021-01-01")
# make a series of good sensors in test data (less than 75 % missing in PM2.5)
good_sensors_test = missing_values_test.query("PM2p5_missing < 0.25")['location_id']
# get bad sensors in test dataframe (more than 75 % of PM2.5 data missing)
bad_sensors = []
for location in list(good_sensors):
if location not in list(good_sensors_test):
bad_sensors.append(location)
print(len(bad_sensors))
bad_sensors
```
# Update dataframes using only 'good sensors' and save cleaned train and test dataframe
```
# update train dataframe according to good sensors in test data
df_good_sensors = use_good_sensors_only(df, good_sensors_test)
# save train data for good sensors
df_good_sensors.to_csv("../data/cleaned_sensors_dwd_train.csv")
# make test dataframe containing only good sensors
df_good_sensors_test = use_good_sensors_only(df_test, good_sensors_test)
# save test data
df_good_sensors_test.to_csv("../data/cleaned_sensors_dwd_test.csv")
```
# Last check of missing data in the final dataframes
```
df_missing_values_bremen_pm10_test, \
df_missing_values_bremen_pm2p5_test, \
df_missing_values_frankfurt_pm10_test, \
df_missing_values_frankfurt_pm2p5_test = get_PM_data_per_location(df_good_sensors_test)
# plot missing values per id for PM10 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm10_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Bremen - Cleaned Test Data', fontsize=20);
# plot missing values per id for PM2.5 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm2p5_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Bremen - Cleaned Test Data', fontsize=20);
# plot missing values per id for PM10 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm10_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Frankfurt - Cleaned Test Data', fontsize=20);
# plot missing values per id for PM2.5 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm2p5_test.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Frankfurt - Cleaned Test Data', fontsize=20);
df_missing_values_bremen_pm10, \
df_missing_values_bremen_pm2p5, \
df_missing_values_frankfurt_pm10, \
df_missing_values_frankfurt_pm2p5 = get_PM_data_per_location(df_good_sensors)
# plot missing values per id for PM10 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm10.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Bremen - Cleaned Train Data', fontsize=20);
# plot missing values per id for PM2.5 in Bremen
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_bremen_pm2p5.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Bremen - Cleaned Train Data', fontsize=20);
# plot missing values per id for PM10 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm10.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM10 - Frankfurt - Cleaned Train Data', fontsize=20);
# plot missing values per id for PM2.5 in Frankfurt
plt.figure(figsize=(30, 10))
g = sns.heatmap(df_missing_values_frankfurt_pm2p5.isna().T.sort_index(), cbar_kws={'label': 'Missing Data'})
g.set_title('PM2.5 - Frankfurt - Cleaned Train Data', fontsize=20);
```
# Plotting
```
df_good_sensors['location_id'].nunique()
```
## Plot PM2.5 concentration of the train time frame and add Corona lockdowns
```
# https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland#Reaktionen_und_Maßnahmen_der_Politik
# corona lockdowns (start date, end date, 'strength' (used for transparency))
corona_lockdowns = [
("2020-03-22", "2020-05-06", 3),
("2020-11-02", "2020-12-16", 1.5), # 2020-11-02: lockdown light, 2020-12-16:lockdown
("2020-12-16", "2021-03-03", 3), # 2020-11-02: lockdown light, 2020-12-16:lockdown
("2021-04-23", "2021-06-03", 3), # Bundesnotbremse
]
# # locations to save the image
# save_locations = [
# 125,
# 12,
# 11,
# 159,
# 84,
# 111,
# ]
# set the upper limits of the y axis for every location
y_limits = {
125: 105,
12: 80,
11: 70,
159: 75,
84: 75,
111: 80,
}
# set seaborn theme and set context to talk to increase the size of labels
sns.set_theme()
sns.set_context("talk")
with sns.axes_style("darkgrid"):
for location, y_limit in y_limits.items(): # for location in save_locations: # list(df_good_sensors['location_id'].unique())[:]: #
plt.figure(figsize=(25,5))
g = sns.lineplot(data=df_good_sensors[df_good_sensors['location_id']==location], x='timestamp', y='PM2p5', label='PM2.5 conc.')
# g.set_title(str(df_good_sensors.loc[df_good_sensors['location_id']==location, 'city'].iloc[0]) + ' (ID: ' + str(location) + ')')
ax = g.axes # get axes of g
g.set(
xlabel='',
ylabel=g.get_ylabel().replace('p', '.') + ' in µg/m$^3$',
facecolor='#EEEEEE',
xlim=(pd.to_datetime('2020-01-01') - pd.Timedelta(10, 'D'), pd.to_datetime('2021-12-31') + pd.Timedelta(10, 'D')),
# ylim=(-5, 105),
ylim=(-5, y_limit) # set y_lim according to the values specified above
)
# add corona lockdowns as red boxes
for lockdown in corona_lockdowns:
g.axvspan(pd.to_datetime(lockdown[0]), pd.to_datetime(lockdown[1]), alpha=lockdown[2]/10, color='red', label='Corona Lockdown')
# add a legend and show the first two entries (PM and lockdown)
handles, labels = g.get_legend_handles_labels()
g.legend(handles=handles[:2], labels=labels[:2], frameon=False)
# save figure
# if location in save_locations:
plt.savefig('../figures/EDA_PM2p5_lockdowns_' + str(location) + '.png', transparent=True, bbox_inches='tight')
# plt.savefig('../figures/EDA_PM2p5_lockdowns_' + str(location) + '.png', facecolor=g.get_facecolor(), bbox_inches='tight')
# https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland#Reaktionen_und_Maßnahmen_der_Politik
corona_lockdowns = [
("2020-03-22", "2020-05-06", 3),
("2020-11-02", "2020-12-16", 1.5), # 2020-11-02: lockdown light, 2020-12-16:lockdown
("2020-12-16", "2021-03-03", 3), # 2020-11-02: lockdown light, 2020-12-16:lockdown
("2021-04-23", "2021-06-03", 3), # Bundesnotbremse
]
# define the weeks to plot
weeks = pd.date_range(pd.to_datetime('2021-01-01'), pd.to_datetime('2021-12-31'), freq='W')
# location to plot
location=125 # good: 80
sns.set_theme()
sns.set_context("talk")
with sns.axes_style("darkgrid"):
for i, week in enumerate(weeks[:-1]):
plt.figure(figsize=(25,5))
# plot PM2.5 values for each week
g = sns.lineplot(data=df_good_sensors[df_good_sensors['location_id']==location], x='timestamp', y='PM2p5', label='PM2.5 conc.', legend=False)
# use city and location_id as title
g.set_title(str(df_good_sensors.loc[df_good_sensors['location_id']==location, 'city'].iloc[0]) + ' (ID: ' + str(location) + ')')
g.set(
xlabel='',
ylabel=g.get_ylabel().replace('p', '.') + ' in µg/m$^3$',
# facecolor='#EEEEEE',
xlim=(weeks[i], weeks[i+1]), # set x_lim to show only one week
ylim=(-5, 100),
)
# make a dataframe grouped by time and id and calculate mean for that time frame
df_good_sensors['weekday'] = df_good_sensors['timestamp'].dt.weekday
df_good_sensors['day_name'] = df_good_sensors['timestamp'].dt.day_name()
df_good_sensors['week'] = df_good_sensors['timestamp'].dt.week
df_good_sensors['hour'] = df_good_sensors['timestamp'].dt.hour
df_good_sensors_weekdays = df_good_sensors.groupby(['location_id', 'city', 'week', 'weekday', 'day_name', 'hour']).mean()[['PM10', 'PM2p5']].reset_index()
# change list in the first code line to define which locations to show
for location in [125]: # list(df_good_sensors_weekdays['location_id'].unique())[:5]: #
fig, ax = plt.subplots(1, 7, figsize=(30,10))
fig.suptitle('ID: ' + str(location)) # add ID as super title
# Plot PM2.5 per weekday and ID
for day in list(df_good_sensors_weekdays['weekday'].unique())[:]:
data = df_good_sensors_weekdays[(df_good_sensors_weekdays['weekday']==day) & (df_good_sensors_weekdays['location_id']==location)]
g=sns.lineplot(data=data, x='hour', y='PM2p5', ax=ax[day])
g.set_ylim(0, 26)
g.set_title(data['day_name'].iloc[0])
# Use the y label only for the first subplot
ax[0].set_ylabel(g.get_ylabel().replace('p', '.') + ' in µg/m$^3$',)
for a in ax[1:]:
a.set_ylabel('')
plt.show()
fig, ax = plt.subplots(1, 7, figsize=(30,10))
fig.suptitle('Average over all locations and all weeks') # add ID as super title
# Plot PM2.5 per weekday and ID
for day in list(df_good_sensors_weekdays['weekday'].unique())[:]:
data = df_good_sensors_weekdays[(df_good_sensors_weekdays['weekday']==day)]
g=sns.lineplot(data=data, x='hour', y='PM2p5', ax=ax[day])
g.set_ylim(0, 10)
g.set_xlim(0, 23)
g.set_title(data['day_name'].iloc[0])
# Use the y label only for the first subplot
ax[0].set_ylabel(g.get_ylabel().replace('p', '.') + ' in µg/m$^3$',)
for a in ax[1:]:
a.set_ylabel('')
plt.show()
location = 125
# Plot average PM2.5 for one week
plt.figure(figsize=(20,8))
g=sns.lineplot(data=df_good_sensors_weekdays[df_good_sensors_weekdays['location_id']==location], x='weekday', y='PM2p5')
g.set_ylim(0,g.get_ylim()[1]);
```
## Correlation of PM2p5 with features (regressors for Prophet) for final train data
### First look at one location
```
# load data if notebook not run so far
df_good_sensors = pd.read_csv("../data/cleaned_sensors_dwd_train.csv")
# convert timestamp to datetime
df_good_sensors['timestamp'] = pd.to_datetime(df_good_sensors['timestamp'])
df_good_sensors
# looking for most complete location
df_good_sensors.groupby(['location_id'], dropna=False).PM2p5.count().sort_values()
location = 98
# show correlation map for one location
columns_plot = ['PM10', 'PM2p5', 'humidity_dwd', 'precip', 'pressure_dwd', 'pressure_sealevel', 'temperature_dwd', 'wind_direction', 'wind_speed']
corr_mtrx = df_good_sensors.query(f'location_id == {location}')[columns_plot].corr()
plt.subplots(figsize=(10, 8))
mask = np.triu(np.ones_like(corr_mtrx, dtype=bool))
sns.heatmap(corr_mtrx, annot=True, cmap="YlGnBu_r", mask=mask, vmax=1, vmin=-1,fmt='.2f')
```
> PM2p5 correlates for this location most with humidity, temperature and wind speed.
### Second look at all locations
```
# columns to be considered for correlation
columns_corr = ['PM10', 'PM2p5', 'humidity_dwd', 'pressure_dwd', 'precip', 'wind_direction', 'wind_speed', 'temperature_dwd']
# created sorted list of location_ids
location_list = np.sort(df_good_sensors.location_id.unique())
# create DataFrame for correlations of PM2p5 with given features = prophet regressors
corr_mtrx = df_good_sensors.query(f'location_id == {location_list[0]}')[columns_corr].corr(method='pearson')
df_PM2p5_correlations = pd.DataFrame(corr_mtrx.iloc[1,2:]) # correlation of PM2p5: iloc[1,2:], PM10: iloc[0,2:]
# fill DataFrame
for i in location_list:
corr_mtrx = df_good_sensors.query(f'location_id == {i}')[columns_corr].corr(method='pearson')
df_PM2p5_correlations[i] = corr_mtrx.iloc[1,2:]
# drop double column and transpose
df_PM2p5_correlations = df_PM2p5_correlations.drop('PM2p5', axis=1).T
display(df_PM2p5_correlations)
# plot
df_PM2p5_correlations.plot(figsize=(20,12))
plt.title(' Frankfurt Bremen', fontsize=20)
plt.xlabel('location_id', fontsize=20)
plt.ylabel('correlation with PM2p5', fontsize=20)
plt.legend(fontsize=20)
plt.ylim(-0.5,0.5)
plt.xlim(0)
plt.plot([124.5, 124.5], [-0.5, 0.5], linewidth=5, color='black')
#plt.plot([0, 50], [0, 1], linewidth=2)
```
Correlations with PM2p5
> * Humidity, temperature and wind speed are the most important features for most locations.
> * For Bremen temperature and wind speed seem a little less important.
> * For Frankfurt pressure seems to play a roll in contrast to Bremen.
> * Precipitation shows unexpectedly no correlation with PM2p5. This is maybe due to a time shift: When it's raining now the PM values will increase within some hours...
> * Some locations show no correlation at all.
Let's have a deeper look at those correlations.
```
# prepare dataframe with rounded values for histplot
df_round = df_good_sensors.round(0)
# plot
plt.figure(figsize=(20,20))
plt.suptitle('25-75 % of feature values vs. PM2.5 for all locations')
plt.subplot(4,1,1)
sns.boxplot(data=df_round, y='humidity_dwd', x='PM2p5', hue='city', showfliers=False, whis=0)
plt.xlim(0,30)
plt.subplot(4,1,2)
sns.boxplot(data=df_round, y='pressure_dwd', x='PM2p5', hue='city', showfliers=False, whis=0)
plt.xlim(0,30)
plt.subplot(4,1,3)
sns.boxplot(data=df_round, y='wind_speed', x='PM2p5', hue='city', showfliers=False, whis=0)
plt.xlim(0,30)
plt.subplot(4,1,4)
sns.boxplot(data=df_round, y='temperature_dwd', x='PM2p5', hue='city', showfliers=False, whis=0)
plt.xlim(0,30);
```
> same findings like above for looking at all locations at once
```
# calc means per city
df_mean_per_city = df_good_sensors.groupby(['city'])['PM10', 'PM2p5', 'humidity_dwd', 'precip', 'pressure_dwd', 'temperature_dwd', 'wind_direction', 'wind_speed'].mean().reset_index()
df_mean_per_city
```
### Figure out which locations show hardly a correlation between PM2p5 and features
```
# create column for location_id
df_PM2p5_correlations['location_id'] = df_PM2p5_correlations.index
# add city column
df_PM2p5_correlations['city'] = df_PM2p5_correlations['location_id'].apply(lambda x: "Frankfurt" if x < 125 else 'Bremen')
df_PM2p5_correlations
# calculate sum of correlation absolutes
df_PM2p5_correlations['corr_sum_abs'] = df_PM2p5_correlations['humidity_dwd'].abs() + df_PM2p5_correlations['precip'].abs() + df_PM2p5_correlations['pressure_dwd'].abs() + df_PM2p5_correlations['temperature_dwd'].abs() + df_PM2p5_correlations['wind_direction'].abs() + df_PM2p5_correlations['wind_speed'].abs()
display(df_PM2p5_correlations)
# plot
plt.figure(figsize=(20,8))
sns.barplot(data=df_PM2p5_correlations.sort_values('corr_sum_abs'), x='location_id', y='corr_sum_abs', hue='city', order=df_PM2p5_correlations.sort_values('corr_sum_abs')['location_id'])
plt.xticks(rotation=90);
```
> * corr_sum_abs could be a measure for the quality of our PM prediction. If corr_sum_abs is small, there are few correlations with regressors and no good prediction can be expected?
> * Why are the PM values in Bremen less correlated to weather data? Is it a question of mean PM concentration?
```
# add averages of PM2p5 for comparison
df_PM2p5_correlations['PM2p5_mean'] = df_good_sensors.groupby(['location_id']).mean()['PM2p5']
df_PM2p5_correlations['PM2p5_median'] = df_good_sensors.groupby(['location_id']).median()['PM2p5']
df_PM2p5_correlations['PM2p5_quantile_99'] = df_good_sensors.groupby(['location_id']).quantile(0.99)['PM2p5']
df_PM2p5_correlations['PM2p5_max'] = df_good_sensors.groupby(['location_id']).max()['PM2p5']
df_PM2p5_correlations
# plot
plt.figure(figsize=(30,8))
plt.subplot(1,3,1)
sns.scatterplot(data=df_PM2p5_correlations, x='PM2p5_median', y='corr_sum_abs', style='city', s=200)
plt.xlim(0)
plt.ylim(0)
plt.subplot(1,3,2)
sns.scatterplot(data=df_PM2p5_correlations, x='PM2p5_quantile_99', y='corr_sum_abs', style='city', s=200)
#plt.legend(['mean Frankfurt', 'mean Bremen', 'median Frankfurt', 'median Bremen'])
plt.xlim(0)
plt.ylim(0)
plt.subplot(1,3,3)
sns.scatterplot(data=df_PM2p5_correlations, x='PM2p5_max', y='corr_sum_abs', style='city', s=200)
#plt.legend(['mean Frankfurt', 'mean Bremen', 'median Frankfurt', 'median Bremen'])
plt.xlim(0)
plt.ylim(0);
```
> * Median (left): Locations with generally small PM2p5 values show few correlation with weather data. This is reasonable as wind or humidity will not reduce PM if it's not there.
> * Overall there there is a stronger correlation for Frankfurt on weather data than for Bremen. Even though both cities cover a comparable wide range of PM values. This is mostly due to the missing correlation with air pressure.
### Have a deeper look at precipitation
Is there really no correlation with PM?
```
# plot PM as a function of precipitation without and with time shift of - 1 hour
plt.figure(figsize=(20,15))
plt.subplot(2,1,1)
sns.lineplot(x=df_good_sensors.query(f'precip > 0')['precip'], y=df_good_sensors.query('precip > 0')['PM10'].shift(-1))
sns.lineplot(x=df_good_sensors.query(f'precip > 0')['precip'], y=df_good_sensors.query('precip > 0')['PM10'])
plt.legend(['with shift -1', '', 'without shift', '', 'with shift +1'])
plt.xlim(0)
plt.ylim(0)
plt.subplot(2,1,2)
sns.lineplot(x=df_good_sensors.query(f'precip > 0')['precip'], y=df_good_sensors.query('precip > 0')['PM2p5'].shift(-1))
sns.lineplot(x=df_good_sensors.query(f'precip > 0')['precip'], y=df_good_sensors.query('precip > 0')['PM2p5'])
plt.legend(['with shift -1', '', 'without shift', '', 'with shift +1'])
plt.xlim(0)
plt.ylim(0);
```
> There is actually no correlation between PM values and amount of precipitation.
```
# add column with 1 for rain and 0 for no rain
df_good_sensors['precip_bool'] = df_good_sensors['precip'].apply(lambda x: 1 if x > 0 else 0)
# caculate statstics for PM values depending on rain (0 = no precipitation, 1 = precipitation)
df_good_sensors.groupby('precip_bool').describe()[['PM2p5', 'PM10']].T
```
> When it's raining the maximum PM values are clearly smaller than without rain. For all other statistic values there values there is no clear dependency. As a consequence precipitation seems to have no real impact on PM values in Bremen hand Frankfurt.
This observation can be explained with the comparable small PM concentration in the given cities. For Beijing it was shown that "the washing process of rainfall strongly affects PM2.5, which decreased to 10–30 μg/m3 with 5 mm of rainfall."
```
# calculate
df_delta_pm = pd.DataFrame()
for location in df_good_sensors['location_id'].unique():
df_temp = df_good_sensors[df_good_sensors['location_id']==location][['location_id', 'timestamp', 'city', 'PM10', 'PM2p5', 'precip']]
df_temp['PM2p5_shifted_1'] = df_temp['PM2p5'].shift(periods=1)
df_temp['PM2p5_shifted_2'] = df_temp['PM2p5'].shift(periods=2)
df_temp['PM2p5_shifted_3'] = df_temp['PM2p5'].shift(periods=3)
df_temp['PM2p5_delta'] = df_temp['PM2p5'].shift(periods=1) - df_temp['PM2p5']
df_temp['PM2p5_delta_percent'] = (df_temp['PM2p5'].shift(periods=1) - df_temp['PM2p5']) / df_temp['PM2p5'] * 100
df_temp['PM2p5_delta_2'] = df_temp['PM2p5'].shift(periods=2) - df_temp['PM2p5']
df_temp['PM2p5_delta_2_percent'] = (df_temp['PM2p5'].shift(periods=2) - df_temp['PM2p5']) / df_temp['PM2p5'] * 100
df_temp['PM10_delta'] = df_temp['PM10'].shift(periods=1) - df_temp['PM10']
df_temp['PM10_delta_percent'] = (df_temp['PM10'].shift(periods=1) - df_temp['PM10']) / df_temp['PM10'] * 100
df_temp['PM2p5_rolling'] = df_temp['PM2p5'].rolling(window=5).mean()
df_delta_pm = pd.concat([df_delta_pm, df_temp])
df_delta_pm
# group precipitation by city and count occurences of precipitation intensity
df_precip = df_delta_pm[['precip', 'city', 'location_id']].groupby(['city', 'precip']).count().reset_index().rename(columns={'location_id': 'count'})
# calculate the observations per city
sum_bremen = df_precip[df_precip['city']=='Bremen']['count'].sum()
sum_frankfurt = df_precip[df_precip['city']=='Frankfurt']['count'].sum()
# calculate the percentage of the count per precipitation intensity
df_precip['percent'] = np.nan
df_precip.loc[df_precip['city']=='Bremen', 'percent'] = df_precip.loc[df_precip['city']=='Bremen', 'count'] / sum_bremen * 100
df_precip.loc[df_precip['city']=='Frankfurt', 'percent'] = df_precip.loc[df_precip['city']=='Frankfurt', 'count'] / sum_frankfurt * 100
# plot precipitation
plt.figure(figsize=(25, 10))
g = sns.barplot(data=df_precip, x='precip', y='percent', hue='city')
g.axes.tick_params(labelrotation=90)
g.set_ylim(0, 3);
```
In roughly 90 % of all hours in this data no rain occured.
```
plt.figure(figsize=(20, 10))
g = sns.scatterplot(data=df_delta_pm, x='precip', y='PM2p5_delta', hue='city')
g.set_ylim(-50, 50)
plt.figure(figsize=(20, 10))
g = sns.scatterplot(data=df_delta_pm, x='precip', y='PM2p5_delta_percent', hue='city')
g.set_ylim(-200, 200)
plt.figure(figsize=(15, 10))
mask = np.triu(np.ones_like(df_delta_pm.corr(), dtype=bool))
sns.heatmap(df_delta_pm.corr(), annot=True, cmap="YlGnBu_r", mask=mask, vmax=1, vmin=-1,fmt='.2f')
```
Precipitation doesn't show correlation with any of the investigated parameters. PM2.5 concentration seem not to decrease after raining, regardless the amount of rain.
### Relationship between PM2.5 and PM10 and autocorrelation
```
# calculate
df_pm = pd.DataFrame()
for location in df_good_sensors['location_id'].unique():
df_temp = df_good_sensors[df_good_sensors['location_id']==location][['location_id', 'timestamp', 'city', 'PM10', 'PM2p5']]
for i in range(24):
df_temp[f'PM2p5_shifted_{i+1}'] = df_temp['PM2p5'].shift(periods=i+1)
df_temp['PM2p5_PM10'] = df_temp['PM2p5'] / df_temp['PM10']
df_temp['PM2p5_PM10_rolling'] = df_temp['PM2p5_PM10'].rolling(5).mean()
df_pm = pd.concat([df_pm, df_temp])
plt.figure(figsize=(30, 30))
mask = np.triu(np.ones_like(df_pm.drop(['location_id', 'PM10', 'PM2p5_PM10'], axis=1).corr(), dtype=bool))
sns.heatmap(df_pm.drop(['location_id', 'PM10', 'PM2p5_PM10'], axis=1).corr(), annot=True, cmap="YlGnBu_r", mask=mask, vmax=1, vmin=0,fmt='.2f')
```
As expected, the correlation decreases over time. In other words, PM2.5 concentrations that are closer together in a temporal manner are mor correlated.
```
sns.histplot(data=df_pm, x='PM2p5_PM10')
df_pm[df_pm['PM2p5_PM10']==0][['PM2p5_PM10', 'PM2p5', 'PM10']].describe().T
df_pm[df_pm['PM2p5_PM10']>=1][['PM2p5_PM10', 'PM2p5', 'PM10']].describe().T
locations = df_pm['location_id'].unique()[:10]
columns = 5
rows = int(np.ceil((len(locations) - 1) / columns))
fig, ax = plt.subplots(rows, columns, figsize=(25, 80 / 13 * (len(locations)//5)))
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
plt.subplots_adjust(hspace = .25, wspace = .15, top = .93) # adjusts the space between the single subplots
for row in range(rows):
for col in range(columns):
if col + row * columns < len(locations):
g=sns.histplot(
data=df_pm[df_pm['location_id']==locations[row * columns + col]],
x='PM2p5_PM10',
ax=ax[row][col],
)
ax[row][col].set_xlim(-.05, 1.05)
ax[row][col].set_title(locations[row * columns + col], fontsize = 20)
ax[row][col].tick_params(labelrotation=90)
```
In [this publication](https://www.frontiersin.org/articles/10.3389/fenvs.2021.692440/full) the authors characterized those PM2.5/PM10 histograms with a mode over 0.6 as anthropogenic. Using this classifications, in both cities are several locations that can be classified as anthropogenic.
```
type(df_pm.loc[0,'timestamp'])
df_pm['month'] = df_pm['timestamp'].dt.month
df_pm['year'] = df_pm['timestamp'].dt.year
df_pm_grouped_2021 = df_pm[['location_id', 'city', 'PM10', 'PM2p5', 'month', 'year']].groupby(['location_id', 'month', 'year', 'city']).mean().reset_index().query("year==2021")
fig, ax = plt.subplots(1, 2, figsize=(25, 10))
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
fig.subplots_adjust(hspace = .25, wspace = .15, top = .9) # adjusts the space between the single subplots
fig.suptitle("Mean PM2.5 concentration per month", fontsize=30)
i = 0
for city in df_pm_grouped_2021['city'].unique():
g=sns.barplot(
data=df_pm_grouped_2021[df_pm_grouped_2021['city']==city],
x='month',
y='PM2p5',
ax=ax[i],
color='b',
)
ax[i].set_title(city, fontsize = 20)
ax[i].set_ylim(0, 17)
ax[i].set_ylabel("PM2.5 in µg/m$^3$")
ax[i].set_xlabel("Month")
i+=1
```
The mean PM2.5 concentration per city shows a clear seasonality. The concentrations are rather high in winter and low in summer, which could be due to the increased energy need caused by heating in cold months.
```
locations = df_pm['location_id'].unique()[:10]
columns = 1
rows = int(np.ceil((len(locations) - 1) / columns))
fig, ax = plt.subplots(rows, columns, figsize=(30, (150/65)*len(locations)))
fig.tight_layout() # tight_layout automatically adjusts subplot params so that the subplot(s) fits in to the figure area
fig.subplots_adjust(hspace = .35, wspace = .15, top = .97) # adjusts the space between the single subplots
fig.suptitle("PM2.5 / PM10 ratio over time (rolling average)", fontsize=30)
for row in range(rows):
for col in range(columns):
if col + row * columns < len(locations):
g=sns.scatterplot(
data=df_pm[df_pm['location_id']==locations[row * columns + col]],
x='timestamp',
y='PM2p5_PM10_rolling',
ax=ax[row]#[col],
)
g.set_xlim(pd.to_datetime('2020-01-01'), pd.to_datetime('2021-12-31'))
g.set_ylim(-.1,1.1)
if row < rows-1:
g.set_xticklabels([])
g.set_xlabel('')
ax[row].set_title(f"ID: {locations[row * columns + col]}", fontsize = 20)
ax[row].set_ylabel("PM2.5 / PM10", fontsize = 20)
# ax[row].tick_params(labelrotation=90)
```
### Hyperparameter tuning
As we want to find general hyperparameters for both locations, we calculate the prior_scales for the use of weather data as regressors for both cities at once:
```
def calc_corr_mean (feature, df):
"""calculates mean for a features given in df
"""
return df[feature].mean()
features = ['humidity_dwd', 'pressure_dwd', 'precip', 'wind_direction', 'wind_speed', 'temperature_dwd']
# prepare DataFrame for results
df_mean_features = pd.DataFrame(['mean', 'prior_scale'])
# calc mean and add to DataFrame
for i in features:
df_mean_features[i] = round(calc_corr_mean(i, df_PM2p5_correlations), 2)
# calculate prior_scale and add to DataFrame
sum_ = df_mean_features.iloc[0:1, 1:].abs().sum(axis=1)[0]
for i in features:
df_mean_features.loc[1, i] = round(np.abs(df_mean_features.loc[0, i] / sum_), 2)
df_mean_features.T
# check if sum is 1
#df_mean_features.iloc[1:2, 1:].abs().sum(axis=1)
# plot correlations with mean values for whole data set
df_PM2p5_correlations[['humidity_dwd', 'pressure_dwd', 'precip', 'wind_direction', 'wind_speed', 'temperature_dwd']].plot(figsize=(15,8))
plt.title(' Frankfurt Bremen', fontsize=20)
plt.xlabel('location_id', fontsize=20)
plt.ylabel('correlation with PM2p5', fontsize=20)
plt.legend(fontsize=20)
plt.ylim(-0.5,0.5)
plt.xlim(0)
plt.plot([124.5, 124.5], [-0.5, 0.5], linewidth=5, color='black')
for i in features:
plt.plot([0, 182], [df_mean_features.loc[0, i], df_mean_features.loc[0, i]], linewidth=2)
```
## How severe is PM pollution in Frankfurt and Bremen?
```
# European Air Quality Index https://www.eea.europa.eu/themes/air/air-quality-index (source: Wikipedia)
def pm2p5_bins(pm):
bins = {
'1-good': [0,10], # good
'2-fair': [10,20], # fair
'3-moderate': [20,25], # moderate
'4-poor': [25,50], # poor
'5-very poor': [50,75], # very poor
'6-extremely poor': [75,800], # extremely poor
'7-undefined': [800,2000] # undefined
}
for k,v in bins.items():
if v[0] <= pm < v[1]:
return k
def pm10_bins(pm):
bins = {
'1-good': [0,20], # good
'2-fair': [20,40], # fair
'3-moderate': [40,50], # moderate
'4-poor': [50,100], # poor
'5-very poor': [100,150], # very poor
'6-extremely poor': [150,1200], # extremely poor
'7-undefined': [1200,2000] # undefined
}
for k,v in bins.items():
if v[0] <= pm < v[1]:
return k
# add air quality to DataFrame
df_good_sensors["PM2p5_quality"] = df_good_sensors["PM2p5"].apply(pm2p5_bins)
df_good_sensors["PM10_quality"] = df_good_sensors["PM10"].apply(pm10_bins)
# count number of PM measurements depending on air quality per city
# PM2p5
pm2p5_quality_count = pd.DataFrame(df_good_sensors.query("city=='Bremen'")['PM2p5_quality'].value_counts())
pm2p5_quality_count['Frankfurt'] = pd.DataFrame(df_good_sensors.query("city=='Frankfurt'")['PM2p5_quality'].value_counts())
pm2p5_quality_count.reset_index(inplace=True)
pm2p5_quality_count.columns = ['quality', 'PM2p5_Bremen', 'PM2p5_Frankfurt']
pm2p5_quality_count['PM2p5_sum'] = pm2p5_quality_count['PM2p5_Bremen'] + pm2p5_quality_count['PM2p5_Frankfurt']
#display(pm2p5_quality_count)
# PM10
pm10_quality_count = pd.DataFrame(df_good_sensors.query("city=='Bremen'")['PM10_quality'].value_counts())
pm10_quality_count['Frankfurt'] = pd.DataFrame(df_good_sensors.query("city=='Frankfurt'")['PM10_quality'].value_counts())
pm10_quality_count.reset_index(inplace=True)
pm10_quality_count.columns = ['quality', 'PM10_Bremen', 'PM10_Frankfurt']
pm10_quality_count['PM10_sum'] = pm10_quality_count['PM10_Bremen'] + pm10_quality_count['PM10_Frankfurt']
#display(pm10_quality_count)
# merge PM2p5 and PM10
quality_absolute = pm2p5_quality_count.merge(pm10_quality_count, on='quality').sort_values('quality')
display(quality_absolute)
# calculate percentages of PM measurements depending on air quality per city
# PM2p5
percentage_PM2p5 = pd.DataFrame((pd.crosstab(index=[0], columns=df_good_sensors.query("city=='Bremen'")['PM2p5_quality'], normalize="index") * 100).round(2).iloc[0,:])
percentage_PM2p5['Frankfurt'] = (pd.crosstab(index=[0], columns=df_good_sensors.query("city=='Frankfurt'")['PM2p5_quality'], normalize="index") * 100).round(2).iloc[0,:]
percentage_PM2p5['sum'] = (pd.crosstab(index=[0], columns=df_good_sensors['PM2p5_quality'], normalize="index") * 100).round(2).iloc[0,:]
percentage_PM2p5.reset_index(inplace=True)
percentage_PM2p5.columns = ['quality', 'PM2p5_Bremen', 'PM2p5_Frankfurt', 'PM2p5_sum']
#display(percentage_PM2p5)
# PM10
percentage_PM10 = pd.DataFrame((pd.crosstab(index=[0], columns=df_good_sensors.query("city=='Bremen'")['PM10_quality'], normalize="index") * 100).round(2).iloc[0,:])
percentage_PM10['Frankfurt'] = (pd.crosstab(index=[0], columns=df_good_sensors.query("city=='Frankfurt'")['PM10_quality'], normalize="index") * 100).round(2).iloc[0,:]
percentage_PM10['sum'] = (pd.crosstab(index=[0], columns=df_good_sensors['PM10_quality'], normalize="index") * 100).round(2).iloc[0,:]
percentage_PM10.reset_index(inplace=True)
percentage_PM10.columns = ['quality', 'PM10_Bremen', 'PM10_Frankfurt', 'PM10_sum']
#display(percentage_PM10)
quality_percentage = percentage_PM2p5.merge(percentage_PM10, on='quality')
quality_percentage
# plot percentages
quality_percentage[['quality', 'PM2p5_Bremen', 'PM2p5_Frankfurt', 'PM2p5_sum']].plot(kind='bar',
x='quality',
stacked=False,
colormap='tab10', # 'tab10' 'Set1' 'Dark2'
figsize=(15, 6))
plt.title('PM2.5')
plt.ylim(0,100)
plt.legend(['Bremen', 'Frankfurt', 'sum'])
plt.ylabel('measurements (%)', fontsize=15)
plt.xlabel('air quality', fontsize=15)
quality_percentage[['quality', 'PM10_Bremen', 'PM10_Frankfurt', 'PM10_sum']].plot(kind='bar',
x='quality',
stacked=False,
colormap='tab10', # 'tab10' 'Set1' 'Dark2'
figsize=(15, 6))
plt.title('PM10')
plt.ylim(0,100)
plt.legend(['Bremen', 'Frankfurt', 'sum'])
plt.ylabel('measurements (%)', fontsize=15)
plt.xlabel('air quality', fontsize=15);
```
## Comparison of DWD weather data and PM2.5 values for Frankfurt and Bremen
```
# plot histogram of dwd weather data in comparison for Frankfurt and Bremen
cmap = ['#4c72b0', '#dd8552'] # blue and orange
sns.set_theme()
sns.set_context("talk")
plt.rcParams.update({'font.size': 40})
with sns.axes_style("darkgrid"):
plt.figure(figsize=(25,16))
plt.subplot(2,3,1)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='humidity_dwd', alpha=0.5, bins=40, hue='city', palette=cmap)
plt.xlim(0,100)
plt.legend().remove() # no legend shown
plt.xlabel('relative humidity (%)')
plt.ylabel('count')
plt.subplot(2,3,4)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='temperature_dwd', alpha=0.5, bins=60, hue='city', palette=cmap)
plt.legend().remove() # no legend shown
plt.xlim(-20, 40)
plt.xlabel('temperature (°C)')
plt.ylabel('count')
plt.subplot(2,3,3)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='wind_speed', alpha=0.5, bins=60, hue='city', palette=cmap)
plt.legend().remove() # no legend shown
plt.xlim(0,15)
plt.xlabel('wind speed (m/s)')
plt.ylabel('count')
plt.subplot(2,3,2)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='pressure_dwd', alpha=0.5, bins=60, hue='city', palette=cmap)
plt.legend().remove() # no legend shown
plt.xlim(970 , 1050)
plt.xlabel('air pressure (mbar)')
plt.ylabel('count')
plt.subplot(2,3,5)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='wind_direction', alpha=0.5, bins=30, hue='city', palette=cmap)
plt.legend().remove() # no legend shown
plt.xlim(0, 360)
plt.xlabel('wind direction (°)')
plt.ylabel('count')
plt.subplot(2,3,6)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='precip', alpha=0.5, bins=40, hue='city', palette=cmap)
plt.legend().remove() # no legend shown
plt.ylim(0,500)
plt.xlim(0, 10)
plt.xlabel('precipitation (?)')
plt.ylabel('count')
# plot histogram of dwd weather data in comparison for Frankfurt and Bremen (for presentation)
cmap = ['#4c72b0', '#dd8552'] # blue and orange
sns.set_theme()
sns.set_context("talk")
with sns.axes_style("darkgrid"):
plt.figure(figsize=(16,6))
plt.subplot(1,2,1)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='humidity_dwd', alpha=0.5, bins=40, hue='city', palette=cmap)
plt.xlim(0,100)
plt.legend().remove() # no legend shown
plt.xlabel('relative humidity in %')
plt.ylabel('counts')
plt.subplot(1,2,2)
sns.histplot(data=df_good_sensors.query("location_id == 2 or location_id == 182"), x='pressure_dwd', alpha=0.5, bins=60, hue='city', palette=cmap)
plt.legend().remove() # no legend shown
plt.xlim(970 , 1050)
plt.xlabel('air pressure in mbar')
plt.ylabel('counts')
plt.tight_layout()
plt.savefig('../figures/histplot_dwd_data_per_city.png', transparent=True, bbox_inches='tight')
df_good_sensors.query("location_id > 125").shape
df_good_sensors.query("location_id < 55").shape
cmap = ['#4c72b0', '#dd8552'] # blue and orange for Frankfurt and Bremen
sns.set_theme()
sns.set_context("talk")
with sns.axes_style("darkgrid"):
plt.figure(figsize=(14,6))
sns.histplot(data=df_good_sensors.query("location_id > 125 or location_id < 55"), x='PM2p5', alpha=0.5, bins=1000, hue='city', palette=cmap)
plt.legend().remove() # no legend shown
plt.xlabel('PM$_{2.5}$ in µg/m$^3$')
plt.ylabel('count')
plt.xlim(0,50);
plt.savefig('../figures/PM2p5_hist.png', transparent=True, bbox_inches='tight')
df_good_sensors['month'] = df_good_sensors['timestamp'].dt.month
df_good_sensors.columns
# prepare data
df_dwd_grouped = df_good_sensors[['location_id', 'city', 'PM10', 'PM2p5', 'month', 'humidity_dwd', 'precip', 'pressure_dwd', 'temperature_dwd', 'wind_direction', 'wind_speed']].groupby(['location_id', 'month', 'city']).median().reset_index()
df_dwd_grouped
plt.figure(figsize=(20,16))
plt.subplot(3,2,1)
sns.barplot(data=df_dwd_grouped, x='month', y='pressure_dwd', hue='city')
plt.ylabel('mean pressure (mbar)')
plt.ylim(990, 1030)
plt.subplot(3,2,2)
sns.barplot(data=df_dwd_grouped, x='month', y='temperature_dwd', hue='city')
plt.ylabel('mean temperature ()')
#plt.ylim(990, 1020)
plt.subplot(3,2,3)
sns.barplot(data=df_dwd_grouped, x='month', y='wind_speed', hue='city')
plt.ylabel('mean wind speed ()')
#plt.ylim(990, 1020)
plt.subplot(3,2,4)
sns.barplot(data=df_dwd_grouped, x='month', y='humidity_dwd', hue='city')
plt.ylabel('mean humidity ()')
#plt.ylim(990, 1020)
plt.subplot(3,2,5)
sns.barplot(data=df_dwd_grouped, x='month', y='wind_direction', hue='city')
plt.ylabel('mean wind direction ()')
#plt.ylim(990, 1020)
plt.subplot(3,2,6)
sns.barplot(data=df_dwd_grouped, x='month', y='PM2p5', hue='city')
plt.ylabel('mean PM2.5 ()')
#plt.ylim(990, 1020)
plt.figure(figsize=(10,8))
df_pm_grouped = df_pm[['location_id', 'city', 'PM10', 'PM2p5', 'month', 'year']].groupby(['location_id', 'month', 'year', 'city']).mean().reset_index()
sns.barplot(data=df_pm_grouped, x='month', y='PM2p5', hue='city')
plt.ylabel('mean PM2.5')
```
| github_jupyter |
(DPOCFC)=
# 3.1 Definición de problemas de optimización, conjuntos y funciones convexas
```{admonition} Notas para contenedor de docker:
Comando de docker para ejecución de la nota de forma local:
nota: cambiar `<ruta a mi directorio>` por la ruta de directorio que se desea mapear a `/datos` dentro del contenedor de docker y `<versión imagen de docker>` por la versión más actualizada que se presenta en la documentación.
`docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion -p 8888:8888 -d palmoreck/jupyterlab_optimizacion:<versión imagen de docker>`
password para jupyterlab: `qwerty`
Detener el contenedor de docker:
`docker stop jupyterlab_optimizacion`
Documentación de la imagen de docker `palmoreck/jupyterlab_optimizacion:<versión imagen de docker>` en [liga](https://github.com/palmoreck/dockerfiles/tree/master/jupyterlab/optimizacion).
```
---
Nota generada a partir de [liga1](https://www.dropbox.com/s/qb3swgkpaps7yba/4.1.Introduccion_optimizacion_convexa.pdf?dl=0), [liga2](https://www.dropbox.com/s/6isby5h1e5f2yzs/4.2.Problemas_de_optimizacion_convexa.pdf?dl=0), [liga3](https://www.dropbox.com/s/ko86cce1olbtsbk/4.3.1.Teoria_de_convexidad_Conjuntos_convexos.pdf?dl=0), [liga4](https://www.dropbox.com/s/mmd1uzvwhdwsyiu/4.3.2.Teoria_de_convexidad_Funciones_convexas.pdf?dl=0), [liga5](https://drive.google.com/file/d/1xtkxPCx05Xg4Dj7JZoQ-LusBDrtYUqOF/view), [liga6](https://drive.google.com/file/d/16-_PvWNaO0Zc9x04-SRsxCRdn5fxebf2/view).
```{admonition} Al final de esta nota el y la lectora:
:class: tip
* Conocerá la definición de un problema de optimización, algunos ejemplos, definiciones y resultados que serán utilizados en los métodos para resolver problemas de optimización con énfasis en funciones convexas.
* Tendrá una lista ejemplo de funciones convexas utilizadas en aplicaciones.
```
## ¿Problemas de optimización numérica?
Una gran cantidad de aplicaciones plantean problemas de optimización. Tenemos problemas básicos que se presentan en cursos iniciales de cálculo:
*Una caja con base y tapa cuadradas debe tener un volumen de $100 cm^3$. Encuentre las dimensiones de la caja que minimicen la cantidad de material.*
Y tenemos más especializados que encontramos en áreas como Estadística, Ingeniería, Finanzas o Aprendizaje de Máquina, *Machine Learning*:
* Ajustar un modelo de regresión lineal a un conjunto de datos.
* Buscar la mejor forma de invertir un capital en un conjunto de activos.
* Elección del ancho y largo de un dispositivo en un circuito electrónico.
* Ajustar un modelo que clasifique un conjunto de datos.
En general un problema de optimización matemática o numérica tiene la forma:
$$\displaystyle \min f_o(x)$$
$$\text{sujeto a:} f_i(x) \leq b_i, i=1,\dots, m$$
donde: $x=(x_1,x_2,\dots, x_n)^T$ es la **variable de optimización del problema**, la función $f_o: \mathbb{R}^{n} \rightarrow \mathbb{R}$ es la **función objetivo**, las funciones $f_i: \mathbb{R}^n \rightarrow \mathbb{R}, i=1,\dots,m$ son las **funciones de restricción** (aquí se colocan únicamente desigualdades pero pueden ser sólo igualdades o bien una combinación de ellas) y las constantes $b_1,b_2,\dots, b_m$ son los **límites o cotas de las restricciones**.
Un vector $x^* \in \mathbb{R}^n$ es nombrado **óptimo** o solución del problema anterior si tiene el valor más pequeño de entre todos los vectores $x \in \mathbb{R}^n$ que satisfacen las restricciones. Por ejemplo, si $z \in \mathbb{R}^n$ satisface $f_1(z) \leq b_1, f_2(z) \leq b_2, \dots, f_m(z) \leq b_m$ y $x^*$ es óptimo entonces $f_o(z) \geq f_o(x^*)$.
```{margin}
A grandes rasgos dos problemas de optimización son equivalentes si con la solución de uno de ellos se obtiene la solución del otro y viceversa.
```
```{admonition} Comentarios
* Se consideran funciones objetivo $f_o: \mathbb{R}^n \rightarrow \mathbb{R}$, sin embargo, hay formulaciones que utilizan $f_o: \mathbb{R}^n \rightarrow \mathbb{R}^q$. Tales formulaciones pueden hallarlas en la optimización multicriterio, multiobjetivo, vectorial o también nombrada Pareto, ver [Multi objective optimization](https://en.wikipedia.org/wiki/Multi-objective_optimization).
* El problema de optimización definido utiliza una forma de minimización y no de maximización. Típicamente en la literatura por convención se consideran problemas de este tipo. Además minimizar $f_o$ y maximizar $-f_o$ son **problemas de optimización equivalentes**.
```
### Ejemplo
$$\displaystyle \min_{x \in \mathbb{R}^n} ||x||_2$$
$$\text{sujeto a:} Ax \leq b$$
con $A \in \mathbb{R}^{m \times n}, b \in \mathbb{R}^m$. En este problema buscamos el vector $x$ que es solución del problema $Ax \leq b$ con **mínima norma Euclidiana**. La función objetivo es $f_o(x)=||x||_2$, las funciones de restricción son las desigualdades lineales $f_i(x) = a_i^Tx \leq b_i$ con $a_i$ $i$-ésimo renglón de $A$ y $b_i$ $i$-ésima componente de $b$, $\forall i=1,\dots,m$.
```{admonition} Comentario
Un problema similar (sólo modificando desigualdad por igualdad) lo encontramos al resolver un sistema de ecuaciones lineales $Ax=b$ *underdetermined* en el que $m < n$ y se busca el vector $x$ con mínima norma Euclidiana que satisfaga tal sistema. Este sistema puede tener infinitas soluciones o ninguna solución.
```
### Ejemplo
Encuentra el punto en la gráfica de $y=x^2$ que es más cercano al punto $P=(1,0)$ bajo la norma Euclidiana.
Deseamos minimizar la cantidad $||(1,0)-(x,y)||_2$. Además $y = y(x)$ por lo que definiendo la función objetivo $f_o(x) = ||(1,0)-(x,x^2)||_2=||(1-x,-x^2)||_2=\sqrt{(1-x)^2+x^4}$, el problema de optimización (sin restricciones) es:
$$\displaystyle \min_{x \in \text{dom}f_o}\sqrt{(1-x)^2+x^4}$$
## Optimización numérica en ciencia de datos
La ciencia de datos apunta al desarrollo de técnicas y se apoya de aplicaciones de *machine learning* para la extracción de conocimiento útil tomando como fuente de información las grandes cantidades de datos. Algunas de las aplicaciones son:
* Clasificación de documentos o textos: detección de *spam*.
* [Procesamiento de lenguaje natural](https://en.wikipedia.org/wiki/Natural_language_processing): [named-entity recognition](https://en.wikipedia.org/wiki/Named-entity_recognition).
* [Reconocimiento de voz](https://en.wikipedia.org/wiki/Speech_recognition).
* [Visión por computadora](https://en.wikipedia.org/wiki/Computer_vision): reconocimiento de rostros o imágenes.
* Detección de fraude.
* [Reconocimiento de patrones](https://en.wikipedia.org/wiki/Pattern_recognition).
* Diagnóstico médico.
* [Sistemas de recomendación](https://en.wikipedia.org/wiki/Recommender_system).
Las aplicaciones anteriores involucran problemas como son:
* Clasificación.
* Regresión.
* *Ranking*.
* *Clustering*.
* Reducción de la dimensionalidad.
### Optimización numérica y *machine learning*
En cada una de las aplicaciones o problemas anteriores se utilizan **funciones de pérdida** que guían el proceso de aprendizaje. Tal proceso involucra **optimización parámetros** de la función de pérdida. Por ejemplo, si la función de pérdida en un problema de regresión es una pérdida cuadrática $\mathcal{L}(y,\hat{y}) = (\hat{y}-y)^2$ con $\hat{y} = \hat{\beta}_0 + \hat{\beta_1}x$, entonces el vector de parámetros a optimizar (aprender) es $\beta= \left[ \begin{array}{c} \beta_0\\ \beta_1 \end{array} \right]$.
```{sidebar} Un poco de historia...
La IA o Inteligencia Artificial es una rama de la Ciencia de la Computación que atrajo un gran interés en 1950.
Colloquially, the term artificial intelligence is often used to describe machines (or computers) that mimic “cognitive” functions that humans associate with the human mind, such as learning and problem solving ([S. J. Russel, P. Norvig, 1995](https://en.wikipedia.org/wiki/Artificial_Intelligence:_A_Modern_Approach))
```
*Machine learning* no sólo se apoya de la optimización pues es un área de Inteligencia Artificial que utiliza técnicas estadísticas para el diseño de sistemas capaces de aplicaciones como las escritas anteriormente, de modo que hoy en día tenemos *statistical machine learning*. No obstante, uno de los **pilares** de *machine learning* o *statistical machine learning* es la optimización.
*Machine learning* o *statistical machine learning* se apoya de las formulaciones y algoritmos en optimización. Sin embargo, también ha contribuido a ésta área desarrollando nuevos enfoques en los métodos o algoritmos para el tratamiento de grandes cantidades de datos o *big data* y estableciendo retos significativos no presentes en problemas clásicos de optimización. De hecho, al revisar literatura que intersecta estas dos disciplinas encontramos comunidades científicas que desarrollan o utilizan métodos o algoritmos exactos (ver [Exact algorithm](https://en.wikipedia.org/wiki/Exact_algorithm)) y otras que utilizan métodos de optimización estocástica (ver [Stochastic optimization](https://en.wikipedia.org/wiki/Stochastic_optimization) y [Stochastic approximation](https://en.wikipedia.org/wiki/Stochastic_approximation)) basados en métodos o algoritmos aproximados (ver [Approximation algorithm](https://en.wikipedia.org/wiki/Approximation_algorithm)). Hoy en día es común encontrar estudios que hacen referencia a **modelos o métodos de aprendizaje**.
```{admonition} Observación
:class: tip
Como ejemplo de lo anterior considérese la técnica de [**regularización**](https://en.wikipedia.org/wiki/Regularization_(mathematics)) que en *machine learning* se utiliza para encontrar soluciones que generalicen y provean una explicación no compleja del fenómeno en estudio.
La regularización sigue el principio de la navaja de Occam, ver [Occam's razor](https://en.wikipedia.org/wiki/Occam%27s_razor): para cualquier conjunto de observaciones en general se prefieren explicaciones simples a explicaciones más complicadas. Aunque la técnica de regularización es conocida en optimización, han sido varias las aplicaciones de *machine learning* las que la han posicionado como clave.
```
### Del *small scale* al *large scale machine learning*
```{sidebar} Un poco de historia...
Un ejemplo de esto se observa en métodos de optimización desarrollados en la década de los $50$'s. Mientras que métodos tradicionales en optimización basados en el cálculo del gradiente y la Hessiana de una función son efectivos para problemas de aprendizaje *small-scale* (en los que utilizamos un enfoque en ***batch*** o por lote), en el contexto del aprendizaje *large-scale*, el **método de gradiente estocástico** se posicionó en el centro de discusiones a inicios del siglo XXI.
El método de gradiente estocástico fue propuesto por Robbins y Monro en 1951, es un **algoritmo estocástico**. Ver [Stochastic gradient descent](https://en.wikipedia.org/wiki/Stochastic_gradient_descent).
```
El inicio del siglo XXI estuvo marcado, entre otros temas, por un incremento significativo en la generación de información. Esto puede contrastarse con el desarrollo de los procesadores de las máquinas, el cual tuvo un menor avance en el incremento del *performance* al del siglo XX. Asimismo, las mejoras en dispositivos de almacenamiento o *storage* abarató costos de almacenamiento y mejoras en sistemas de *networking* permitieron la transmisión de la información más eficiente. En este contexto, los modelos y métodos de *statistical machine learning* se vieron limitados por el tiempo de cómputo y no por el tamaño de muestra. La conclusión de esto fue una inclinación en la comunidad científica por el diseño o uso de métodos o modelos para procesar grandes cantidades de datos usando recursos computacionales comparativamente menores.
## ¿Optimización numérica convexa?
Aplicaciones de *machine learning* conducen al planteamiento de problemas de optimización convexa y no convexa. Por ejemplo en la aplicación de clasificación de textos, en donde se desea asignar un texto a clases definidas de acuerdo a su contenido (determinar si un documento de texto es sobre un tema), puede formularse un problema convexo a partir de una **función de pérdida convexa**.
```{sidebar} Un poco de historia...
Los tipos de redes neuronales profundas, *deep neural networks*, que han sido mayormente usadas a inicios del siglo XXI son las mismas que las que eran populares en los años $90$'s. El éxito de éstos tipos y su uso primordialmente se debe a la disponibilidad de *larger datasets* y mayores recursos computacionales.
```
Como ejemplos de aplicaciones en la **optimización no convexa** están el reconocimiento de voz y reconocimiento de imágenes. El uso de [redes neuronales](https://en.wikipedia.org/wiki/Artificial_neural_network) [profundas](https://en.wikipedia.org/wiki/Deep_learning) ha tenido muy buen desempeño en tales aplicaciones haciendo uso de cómputo en la GPU, ver [ImageNet Classification with Deep Convolutional Neural Networks](https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf), [2012: A Breakthrough Year for Deep Learning](https://medium.com/limitlessai/2012-a-breakthrough-year-for-deep-learning-2a31a6796e73). En este caso se utilizan **funciones objetivo no lineales y no convexas**.
```{admonition} Comentarios
* Desde los $40$'s se han desarrollado algoritmos para resolver problemas de optimización, se han analizado sus propiedades y se han desarrollado buenas implementaciones de software. Sin embargo, una clase de problemas de optimización en los que encontramos métodos **efectivos** son los convexos.
* Métodos para optimización no convexa utilizan parte de la teoría de convexidad desarrollada en optimización convexa. Además, un buen número de problemas de aprendizaje utilizan funciones de pérdida convexas.
```
(PESTOPT)=
## Problema estándar de optimización
En lo que continúa se considera $f_0 = f_o$ (el subíndice "0" y el subíndice "o" son iguales)
```{admonition} Definición
Un problema estándar de optimización es:
$$\displaystyle \min f_o(x)$$
$$\text{sujeto a:}$$
$$f_i(x) \leq 0, \quad \forall i=1,\dots,m$$
$$h_i(x) = 0, \quad \forall i=1,\dots,p$$
con $x=(x_1,x_2,\dots, x_n)^T$ es la **variable de optimización del problema**, $f_o: \mathbb{R}^n \rightarrow \mathbb{R}$ es la **función objetivo**, $f_i: \mathbb{R}^n \rightarrow \mathbb{R}$ $\forall i=1,\dots,m$ son las **restricciones de desigualdad**, $h_i: \mathbb{R}^n \rightarrow \mathbb{R}$, $\forall i=1,\dots,p$ son las **restricciones de igualdad**.
```
## Dominio del problema de optimización y puntos factibles
```{admonition} Definiciones
* El conjunto de puntos para los que la función objetivo y las funciones de restricción $f_i, h_i$ están definidas se nombra **dominio del problema de optimización**, esto es:
$$\mathcal{D} = \bigcap_{i=0}^m\text{dom}f_i \cap \bigcap_{i=1}^p\text{dom}h_i.$$
* Un punto $x \in \mathcal{D}$ se nombra **factible** si satisface las restricciones de igualdad y desigualdad. El conjunto de puntos factibles se nombra **conjunto de factibilidad**.
* El {ref}`problema estándar de optimización <PESTOPT>` se nombra **problema de optimización factible** si existe **al menos un punto factible**, si no entonces es infactible.
```
## Valor óptimo del problema de optimización
```{margin}
Se asumen todos los puntos en el dominio del problema de optimización $\mathcal{D}$.
```
```{admonition} Definición
El valor óptimo del problema se denota como $p^*$. En notación matemática es:
$$p^* = \inf\{f_o(x) | f_i(x) \leq 0, \forall i=1,\dots,m, h_i(x) = 0 \forall i=1,\dots,p\}$$
```
```{admonition} Comentarios
* Si el problema es **infactible** entonces $p^* = \infty$.
* Si $\exists x_k$ factible tal que $f_o(x_k) \rightarrow -\infty$ para $k \rightarrow \infty$ entonces $p^*=-\infty$ y se nombra **problema de optimización no acotado por debajo**.
```
(POPTPROBOPT)=
## Punto óptimo del problema de optimización
```{margin}
Se asumen todos los puntos en el dominio del problema de optimización $\mathcal{D}$.
```
```{admonition} Definición
$x^*$ es **punto óptimo** si es factible y $f_o(x^*) = p^*$.
El conjunto de óptimos se nombra **conjunto óptimo** y se denota:
$$X_{\text{opt}} = \{x | f_i(x) \leq 0 \forall i=1,\dots,m, h_i(x) =0 \forall i=1,\dots,p, f_o(x) = p^*\}$$
```
```{admonition} Comentarios
* La propiedad de un punto óptimo $x^*$ es que si $z$ satisface las restricciones $f_i(z) \leq 0$ $\forall i=1,...,m$, $h_i(z)=0$ $\forall i=1,..,p$ se tiene: $f_o(x^*) \leq f_o(z)$. Es **óptimo estricto** si $z$ satisface las restricciones y $f_o(x^*) < f_o(z)$.
* Si existe un punto óptimo se dice que el **valor óptimo se alcanza** y por tanto el problema de optimización tiene solución, es **soluble o *solvable***.
* Si $X_{\text{opt}} = \emptyset$ se dice que el valor óptimo no se alcanza. Obsérvese que para problemas no acotados nunca se alcanza el valor óptimo.
* Si $x$ es factible y $f_o(x) \leq p^* + \epsilon$ con $\epsilon >0$, $x$ se nombra **$\epsilon$-subóptimo** y el conjunto de puntos $\epsilon$-subóptimos se nombra **conjunto $\epsilon$-subóptimo**.
```
## Óptimo local
```{margin}
Se asumen todos los puntos en el dominio del problema de optimización $\mathcal{D}$.
```
```{admonition} Definición
Un punto factible $x$ se nombra **óptimo local** si $\exists R > 0$ tal que:
$$f_o(x) = \inf \{f_o(z) | f_i(z) \leq 0 \forall i=1,\dots,m, h_i(z) = 0 \forall i=1,\dots, p, ||z-x||_2 \leq R\}.$$
Así, $x$ resuelve:
$$\displaystyle \min f_o(z)$$
$$\text{sujeto a:}$$
$$f_i(z) \leq 0, \forall i =1,\dots,m$$
$$h_i(z) =0, \forall i=1,\dots,p$$
$$||z-x||_2 \leq R$$
```
```{admonition} Observación
:class: tip
La palabra **óptimo** se utiliza para **óptimo global**, esto es, no consideramos la última restricción $||z-x||_2 \leq R$ en el problema de optimización y exploramos en todo el $\text{dom}f$.
```
<img src="https://dl.dropboxusercontent.com/s/xyprhh7erbb6icb/min-max-points-example.png?dl=0" heigth="700" width="700">
```{admonition} Observación
:class: tip
Es común referirse al conjunto de mínimos y máximos como puntos extremos de una función.
```
## Restricciones activas, no activas y redundantes
```{margin}
Se asumen todos los puntos en el dominio del problema de optimización $\mathcal{D}$.
```
```{admonition} Definición
Si $x$ es factible y $f_i(x)=0$ entonces la restricción de desigualdad $f_i(x) \leq 0$ se nombra **restricción activa en $x$**. Se nombra **inactiva en $x$** si $f_i(x) <0$ para alguna $i=1,\dots ,m$.
```
```{admonition} Comentarios
* Las restricciones de igualdad, $h_i(x)$, siempre son activas en el conjunto factible con $i=1,\dots ,p$.
* Una restricción se nombra **restricción redundante** si al quitarla el conjunto factible no se modifica.
(PROBOPTCONVEST)=
## Problemas de optimización convexa en su forma estándar o canónica
```{margin}
Se asumen todos los puntos en el dominio del problema de optimización $\mathcal{D}$.
```
```{margin}
Recuerda que una función afín es de la forma $h(x) = Ax+b$ con $A \in \mathbb{R}^{p \times n}$ y $b \in \mathbb{R}^p$. En la definición $h_i(x) = a_i^Tx-b_i$ con $a_i \in \mathbb{R}^n$, $b_i \in \mathbb{R}$ $\forall i=1,\dots,p$ y geométricamente $h_i(x)$ es un **hiperplano** en $\mathbb{R}^n$.
```
```{admonition} Definición
Se define un problema de optimización convexa en su forma estándar o canónica como:
$$\displaystyle \min f_o(x)$$
$$\text{sujeto a:}$$
$$f_i(x) \leq 0 , i=1,\dots,m$$
$$h_i(x)=0, i=1,\dots,p$$
donde: $f_i$ son **convexas** $\forall i=0,1,\dots,m$ y $h_i$ **es afín** $\forall i =1,\dots,p$.
```
```{margin}
Un conjunto $\alpha$-subnivel es de la forma $\{x \in \text{dom}f | f(x) \leq \alpha\}$. Un conjunto subnivel contiene las curvas de nivel de $f$, ver [Level set](https://en.wikipedia.org/wiki/Level_set):
<img src="https://dl.dropboxusercontent.com/s/0woqoj8foo5eco9/level_set_of_func.png?dl=0" heigth="300" width="300">
```
```{admonition} Comentarios
* El conjunto de factibilidad de un problema de optimización convexa es un conjunto convexo. Esto se sigue pues es una intersección finita de conjuntos convexos: intersección entre las $x$'s que satisfacen $f_i(x) \leq 0$, $i=1,\dots ,m$, que se nombra **conjunto subnivel**, y las $x$'s que están en un hiperplano, esto es, que satisfacen $h_i(x) = 0$, $i=1,\dots ,p$.
* Si en el problema anterior se tiene que **maximizar** una $f_o$ función objetivo **cóncava** y se tienen misma forma estándar: $f_i$ convexa, $h_i$ afín entonces también se nombra al problema como **problema de optimización convexa**. Todos los resultados, conclusiones y algoritmos desarrollados para los problemas de minimización son aplicables para maximización. En este caso se puede resolver un problema de maximización al minimizar la función objetivo $-f_o$ que es convexa.
```
## Función convexa
```{admonition} Definición
Sea $f:\mathbb{R}^n \rightarrow \mathbb{R}$ una función con el conjunto $\text{dom}f$ convexo. $f$ se nombra convexa (en su $\text{dom}f$) si $\forall x,y \in \text{dom}f$ y $\theta \in [0,1]$ se cumple:
$$f(\theta x + (1-\theta) y) \leq \theta f(x) + (1-\theta)f(y).$$
Si la desigualdad se cumple de forma estricta $\forall x \neq y$ $f$ se nombra **estrictamente convexa**.
```
```{admonition} Observaciones
:class: tip
* La convexidad de $f$ se define para $\text{dom}f$ aunque para casos en particular se detalla el conjunto en el que $f$ es convexa.
* La desigualdad que define a funciones convexas se nombra [**desigualdad de Jensen**](https://en.wikipedia.org/wiki/Jensen%27s_inequality).
```
### Propiedades
Entre las propiedades que tiene una función convexa se encuentran las siguientes:
* Si $f$ es convexa el conjunto subnivel es un conjunto convexo.
* $\text{dom}f$ es convexo $\therefore$ $\theta x + (1-\theta)y \in \text{dom}f$
* $f$ es **cóncava** si $-f$ es convexa y **estrictamente cóncava** si $-f$ es estrictamente convexa. Otra forma de definir concavidad es con una desigualdad del tipo:
$$f(\theta x + (1-\theta) y) \geq \theta f(x) + (1-\theta)f(y).$$
y mismas definiciones para $x,y, \theta$ que en la definición de convexidad.
* Si $f$ es convexa, geométricamente el segmento de línea que se forma con los puntos $(x,f(x)), (y,f(y))$ está por encima o es igual a $f(\theta x + (1-\theta)y) \forall \theta \in [0,1]$ y $\forall x,y \in \text{dom}f$:
<img src="https://dl.dropboxusercontent.com/s/fdcx1k150nfwykv/draw_convexity_for_functions.png?dl=0" heigth="300" width="300">
## Conjuntos convexos
### Línea y segmentos de línea
```{admonition} Definición
Sean $x_1, x_2 \in \mathbb{R}^n$ con $x_1 \neq x_2$. Entonces el punto:
$$y = \theta x_1 + (1-\theta)x_2$$
con $\theta \in \mathbb{R}$ se encuentra en la línea que pasa por $x_1$ y $x_2$. $\theta$ se le nombra parámetro y si $\theta \in [0,1]$ tenemos un segmento de línea:
<img src="https://dl.dropboxusercontent.com/s/dldljf5igy8xt9d/segmento_linea.png?dl=0" heigth="200" width="200">
```
```{admonition} Comentarios
* $y = \theta x_1 + (1-\theta)x_2 = x_2 + \theta(x_1 -x_2)$ y esta última igualdad se interpreta como "$y$ es la suma del punto base $x_2$ y la dirección $x_1-x_2$ escalada por $\theta$".
* Si $\theta=0$ entonces $y=x_2$. Si $\theta \in [0,1]$ entonces $y$ se "mueve" en la dirección $x_1-x_2$ hacia $x_1$ y si $\theta>1$ entonces $y$ se encuentra en la línea "más allá" de $x_1$:
<img src="https://dl.dropboxusercontent.com/s/nbahrio7p1mj4hs/segmento_linea_2.png?dl=0" heigth="350" width="350">
El punto entre $x_1$ y $x_2$ tiene $\theta=\frac{1}{2}$.
```
### Conjunto convexo
```{admonition} Definición
Un conjunto $\mathcal{C}$ es convexo si el segmento de línea entre cualquier par de puntos de $\mathcal{C}$ está completamente contenida en $\mathcal{C}$. Esto se escribe matemáticamente como:
$$\theta x_1 + (1-\theta) x_2 \in \mathcal{C} \quad \forall \theta \in [0,1], \forall x_1, x_2 \in \mathcal{C}.$$
```
Ejemplos gráficos de conjuntos convexos:
<img src="https://dl.dropboxusercontent.com/s/gj54ism1lqojot6/ej_conj_convexos.png?dl=0" heigth="400" width="400">
Ejemplos gráficos de conjuntos no convexos:
<img src="https://dl.dropboxusercontent.com/s/k37zh5v3iq3kx04/ej_conj_no_convexos.png?dl=0" heigth="350" width="350">
```{admonition} Comentarios
* El punto $\displaystyle \sum_{i=1}^k \theta_i x_i$ con $\displaystyle \sum_{i=1}^k \theta_i=1$, $\theta_i \geq 0 \forall i=1,\dots,k$ se nombra **combinación convexa** de los puntos $x_1, x_2, \dots, x_k$. Una combinación convexa de los puntos $x_1, \dots, x_k$ puede pensarse como una mezcla o promedio ponderado de los puntos, con $\theta_i$ la fracción $\theta_i$ de $x_i$ en la mezcla.
* Un conjunto es convexo si y sólo si contiene cualquier combinación convexa de sus puntos.
* El conjunto óptimo y los conjuntos $\epsilon$-subóptimos son convexos. Ver definiciones de conjunto óptimo y $\epsilon$-subóptimos en {ref}`punto óptimo del problema de optimización<POPTPROBOPT>`.
```
## Ejemplos de funciones convexas y cóncavas
* Una función afín es convexa y cóncava en todo su dominio: $f(x) = Ax+b$ con $A \in \mathbb{R}^{m \times n}, b \in \mathbb{R}^m$, $\text{dom}f = \mathbb{R}^n$.
```{admonition} Observación
:class: tip
Por tanto las funciones lineales también son convexas y cóncavas.
```
```{margin}
Recuérdese que los conjuntos de matrices que se utilizan para definir a matrices simétricas semidefinidas positivas y simétricas definidas positivas son $\mathbb{S}_{+}^n$ y $\mathbb{S}_{++}^n$ respectivamente ($\mathbb{S}$ es el conjunto de matrices simétricas).
```
* Funciones cuadráticas: $f: \mathbb{R}^n \rightarrow \mathbb{R}$, $f(x) = \frac{1}{2} x^TPx + q^Tx + r$ son convexas en su dominio $\mathbb{R}^n$ si $P \in \mathbb{S}_+^n, q \in \mathbb{R}^n, r \in \mathbb{R}$ con $\mathbb{S}_+^n$ conjunto de **matrices simétricas positivas semidefinidas**.
```{admonition} Observación
:class: tip
Observa que por este punto la norma $2$ o Euclidiana es una función convexa en $\mathbb{R}^n$.
```
```{margin}
Recuérdese que el producto $x^T Ax$ con $A$ simétrica se le nombra forma cuadrática y es un número en $\mathbb{R}$.
```
```{admonition} Definición
$x^TPx$ con $P \in \mathbb{S}^{n}_+$ se nombra forma cuadrática semidefinida positiva.
```
```{admonition} Comentario
La función $f(x) = \frac{1}{2} x^TPx + q^Tx + r$ es estrictamente convexa si y sólo si $P \in \mathbb{S}_{++}^n$. $f$ es cóncava si y sólo si $P \in -\mathbb{S}_+^n$.
```
* Exponenciales: $f: \mathbb{R} \rightarrow \mathbb{R}$, $f(x) = e^{ax}$ para cualquier $a \in \mathbb{R}$ es convexa en su dominio $\mathbb{R}$.
* Potencias: $f: \mathbb{R} \rightarrow \mathbb{R}$, $f(x)=x^a$:
* Si $a \geq 1$ o $a \leq 0$ entonces $f$ es convexa en $\mathbb{R}_{++}$ (números reales positivos).
* Si $0 \leq a \leq 1$ entonces $f$ es cóncava en $\mathbb{R}_{++}$.
* Potencias del valor absoluto: $f: \mathbb{R} \rightarrow \mathbb{R}$, $f(x)=|x|^p$ con $p \geq 1$ es convexa en $\mathbb{R}$.
* Logaritmo: $f: \mathbb{R} \rightarrow \mathbb{R}$, $f(x) = \log(x)$ es cóncava en su dominio: $\mathbb{R}_{++}$.
* Entropía negativa: $f(x) = \begin{cases}
x\log(x) &\text{ si } x > 0 ,\\
0 &\text{ si } x = 0
\end{cases}$ es estrictamente convexa en su dominio $\mathbb{R}_+$.
* Normas: cualquier norma es convexa en su dominio.
* Función máximo: $f: \mathbb{R}^{n} \rightarrow \mathbb{R}$, $f(x) = \max\{x_1,\dots,x_n\}$ es convexa.
* Función log-sum-exp: $f: \mathbb{R}^{n} \rightarrow \mathbb{R}$, $f(x)=\log\left(\displaystyle \sum_{i=1}^ne^{x_i}\right)$ es convexa en su dominio $\mathbb{R}^n$.
* La media geométrica: $f: \mathbb{R}^{n} \rightarrow \mathbb{R}$, $f(x) = \left(\displaystyle \prod_{i=1}^n x_i \right)^\frac{1}{n}$ es cóncava en su dominio $\mathbb{R}_{++}^n$.
* Función log-determinante: $f: \mathbb{S}^{n} \rightarrow \mathbb{R}^n$, $f(x) = \log(\det(X))$ es cóncava en su dominio $\mathbb{S}_{++}^n$.
(RESUT)=
## Resultados útiles
```{margin}
Se sugiere revisar {ref}`definición de función, continuidad y derivada <FCD>` y {ref}`condición de un problema y estabilidad de un algoritmo <CPEA>` como recordatorio de definiciones. En particular las **definiciones de primera y segunda derivada, gradiente y Hessiana** para la primer nota y la **definición de número de condición de una matriz** para la segunda.
```
### Sobre funciones convexas/cóncavas
* Sea $f: \mathbb{R}^n \rightarrow \mathbb{R}$ diferenciable entonces $f$ es convexa si y sólo si $\text{dom}f$ es un conjunto convexo y se cumple:
$$f(y) \geq f(x) + \nabla f(x)^T(y-x) \forall x,y \in \text{dom}f.$$
Si se cumple de forma estricta la desigualdad $f$ se nombra estrictamente convexa. También si su $\text{dom}f$ es convexo y se tiene la desigualdad en la otra dirección "$\leq$" entonces $f$ es cóncava.
Geométricamente este resultado se ve como sigue para $\nabla f(x) \neq 0$:
<img src="https://dl.dropboxusercontent.com/s/e581e22xeejdwu0/convexidad_con_hiperplano_de_soporte.png?dl=0" heigth="350" width="350">
y el hiperplano $f(x) + \nabla f(x)^T(y-x)$ se nombra **hiperplano de soporte para la función $f$ en el punto $(x,f(x))$**. Obsérvese que si $\nabla f(x)=0$ se tiene $f(y) \geq f(x) \forall y \in \text{dom}f$ y por lo tanto $x$ es un mínimo global de $f$.
* Una función es convexa si y sólo si es convexa al restringirla a cualquier línea que intersecte su dominio, esto es, si $g(t) = f(x + tv)$ es convexa $\forall x,v \in \mathbb{R}^n$, $\forall t \in \mathbb{R}$ talque $x + tv \in \text{dom}f$
* Sea $f: \mathbb{R}^n \rightarrow \mathbb{R}$ tal que $f \in \mathcal{C}^2(\text{dom}f)$. Entonces $f$ es convexa en $\text{dom}f$ si y sólo si $\text{dom}f$ es convexo y $\nabla^2f(x) \in \mathbb{S}^n_+$ en $\text{dom}f$. Si $\nabla^2f(x) \in \mathbb{S}^n_{++}$ en $\text{dom}f$ y $\text{dom}f$ es convexo entonces $f$ es estrictamente convexa en $\text{dom}f$.
```{admonition} Comentario
Para una función: $f: \mathbb{R} \rightarrow \mathbb{R}$, la hipótesis del enunciado anterior ($\nabla^2 f(x) \in \mathbb{S}^n_{++}$ en $\text{dom}f$) es que la segunda derivada sea positiva. El recíproco no es verdadero, para ver esto considérese $f(x)=x^4$ la cual es estrictamente convexa en $\text{dom}f$ pero su segunda derivada en $0$ no es positiva.
```
(SPOPT)=
### Sobre problemas de optimización
Para **problemas de optimización sin restricciones**:
* **Condición necesaria de primer orden:** si $f_o$ es diferenciable y $x^*$ es óptimo entonces $\nabla f_o(x^*) = 0$.
* **Condición necesaria de segundo orden:** si $f_o \in \mathcal{C}^2(\text{domf})$ y $x^*$ es mínimo local entonces $\nabla^2 f_o(x^*) \in \mathbb{S}^n_{+}$
* **Condición suficiente de segundo orden:** si $f_o \in \mathcal{C}^2(\text{domf})$, $\nabla f_o(x)=0$ y $\nabla^2f_o(x) \in \mathbb{S}^n_{++}$ entonces $x$ es mínimo local estricto.
```{admonition} Comentario
Las condiciones anteriores se les conoce con el nombre de **condiciones de optimalidad** para problemas de optimización sin restricciones.
```
### Sobre problemas de optimización convexa
* Una propiedad fundamental de un óptimo local en un problema de optimización convexa es que también es un óptimo global. Si la función es estrictamente convexa entonces el conjunto óptimo contiene a lo más un punto.
* Si $f_o$ es diferenciable y $X$ es el conjunto de factibilidad entonces $x$ es óptimo si y sólo si $x \in X$ y $\nabla f_o(x)^T(y-x) \geq 0$ $\forall y \in X$. Si se considera como conjunto de factibilidad $X = \text{dom}f_o$ (que es un problema sin restricciones) la propiedad se reduce a la **condición necesaria y suficiente de primer orden**: $x$ es óptimo si y sólo si $\nabla f_o(x) = 0$.
Geométricamente el resultado anterior se visualiza para $\nabla f_o(x) \neq 0$ y $-\nabla f_o(x)$ apuntando hacia la dirección dibujada:
<img src="https://dl.dropboxusercontent.com/s/0tmpivvo5ob4oox/optimo_convexidad_con_hiperplano_de_soporte.png?dl=0" heigth="550" width="550">
```{admonition} Comentario
Por los resultados anteriores los métodos de optimización buscan resolver la **ecuación no lineal** $\nabla f_o(x)=0$ para aproximar en general mínimos locales. Dependiendo del número de soluciones de la ecuación $\nabla f_o(x)=0$ se tienen situaciones distintas. Por ejemplo, si no tiene solución entonces el/los óptimos no se alcanza(n) pues el problema puede no ser acotado por debajo o si existe el óptimo éste puede no alcanzarse. Por otro lado, si la ecuación tiene múltiples soluciones entonces cada solución es un mínimo de $f_o$.
```
(SPCRITICOS)=
### Sobre puntos críticos
```{admonition} Definición
Puntos $x \in \text{intdom}f$ en los que $\nabla f(x) = 0$ o en los que $\nabla f$ no existe, se les nombra **puntos críticos o estacionarios** de $f$.
```
* No todo punto crítico es un extremo de $f$.
* La Hessiana de $f$ nos ayuda a caracterizar los puntos críticos en mínimos o máximos locales. Si $x \in \mathbb{R}^n$ es punto crítico:
* Y además $\nabla^2f(x) \in \mathbb{S}_{++}$ entonces $x$ es mínimo local.
* Y además $\nabla^2f(x) \in -\mathbb{S}_{++}$ entonces $x$ es máximo local.
* Y además $\nabla^2f(x)$ es indefinida entonces $x$ se nombra punto silla o [*saddle point*](https://en.wikipedia.org/wiki/Saddle_point).
* Si $x \in \mathbb{R}^n$ es punto crítico y $\nabla^2f(x) \in \mathbb{S}_{+}$ no podemos concluir si es máximo o mínimo local (análogo si $\nabla^2f(x) \in -\mathbb{S}_{+}$).
```{admonition} Definición
Una matriz es indefinida si tiene eigenvalores positivos, negativos y cero.
```
## Función fuertemente convexa
```{admonition} Definición
Una función $f:\mathbb{R}^n \rightarrow \mathbb{R}$ tal que $f \in \mathcal{C}^2(\text{dom}f)$ se nombra **fuertemente convexa** en el conjunto convexo $\mathcal{S} \neq \emptyset$ si existe $m>0$ tal que $\nabla^2 f(x) - mI$ es simétrica semidefinida positiva $\forall x \in \mathcal{S}$.
```
```{admonition} Comentario
Es equivalente escribir que una función $f$ es fuertemente convexa en un conjunto $\mathcal{S}$ que escribir $\nabla^2 f(x)$ es definida positiva para toda $x \in \mathcal{S}$.
```
(RESFFUERTCON)=
### Algunos resultados que son posibles probar para funciones fuertemente convexas
Si una función es fuertemente convexa se puede probar que:
* El conjunto óptimo contiene a lo más un punto.
* $f(y) \geq f(x) + \nabla f(x)^T(y-x) + \frac{m}{2}||y-x||_2^2 \forall x,y \in \mathcal{S}$, $m > 0$. Por esto si $f$ es fuertemente convexa en $\mathcal{S}$ entonces es estrictamente convexa en $\mathcal{S}$. También esta desigualdad indica que la diferencia entre la función de $y$, $f(y)$, y la función lineal en $y$ $f(x) + \nabla f(x)^T(y-x)$ (Taylor a primer orden) está acotada por debajo por una cantidad cuadrática.
* Existe una cota superior para el **número de condición** bajo la norma 2 de la Hessiana de $f$, esto es: $\text{cond}(\nabla ^2 f(x))= \frac{\lambda_\text{max}(\nabla^2 f(x))}{\lambda_\text{min}(\nabla^2 f(x))} \leq K$ con $K>0$, $\forall x \in \mathcal{S}$.
* La propiedad que una función sea fuertemente convexa garantiza que el número de condición de la Hessiana de $f$ es una buena medida del desempeño de los algoritmos de optimización convexa sin restricciones (se revisará más adelante).
```{admonition} Observación
:class: tip
Si $f$ es fuertemente convexa en $\mathcal{S}$ entonces es estrictamente convexa en $\mathcal{S}$ pero no viceversa, considérese por ejemplo $f(x)=x^4$ la cual es estrictamente convexa en todo su dominio pero no es fuertemente convexa en todo su dominio pues su segunda derivada se anula en $x=0$.
```
**Preguntas de comprehensión.**
0)Revisar el siguiente video: [Ali Rahimi's talk at NIPS](https://www.youtube.com/watch?v=Qi1Yry33TQE) de la plática de [Ali Rahimi](https://twitter.com/alirahimi0) y la respuesta de [Yann LeCun](https://twitter.com/ylecun): [My take on Ali Rahimi's "Test of Time" award talk at NIPS](https://www2.isye.gatech.edu/~tzhao80/Yann_Response.pdf).
1)Detalla qué es un problema de optimización matemática y describe sus elementos.
2)¿Qué forma tiene un problema estándar de optimización?
3)¿Por qué se consideran problemas de minimización en la forma estándar y no los de maximización?
4)¿Qué propiedad cumple un punto que es óptimo para un problema de minimización?
5)¿Qué propiedad debe satisfacer una función para que se le llame convexa?
6)¿Qué forma tiene un problema convexo estándar con igualdades y desigualdades?
7)¿Qué es un conjunto convexo?
8)Da ejemplos de conjuntos convexos.
9)¿Qué es una combinación convexa?
10)Escribe equivalencias para definir funciones convexas.
11)¿Qué es una función cóncava?
12)Escribe ejemplos de funciones convexas.
13)¿Qué es una función estrictamente convexa?
14)Escribe resultados útiles respecto a problemas de optimización, optimización convexos y puntos críticos.
15)¿Qué es una función fuertemente convexa?
**Referencias:**
1. S. P. Boyd, L. Vandenberghe, Convex Optimization, Cambridge University Press, 2009.
| github_jupyter |
```
# connect to google colab
from google.colab import drive
drive.mount("/content/drive")
# download ktrain to use the bert model in colab
!pip install ktrain
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
import sqlite3
import pandas as pd
import numpy as np
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
#from nltk.stem.porter import PorterStemmer
import string
import matplotlib.pyplot as plt
import seaborn as sns
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import TfidfTransformer,TfidfVectorizer,CountVectorizer
from sklearn.metrics import auc, roc_curve, classification_report
from sklearn import metrics
from sklearn.model_selection import train_test_split
import ktrain
import re
from tqdm import tqdm
from gensim.models import Word2Vec, KeyedVectors
import pickle
import os
#Importing keras
import tensorflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding, Dropout, Bidirectional
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.callbacks import ModelCheckpoint
np.random.seed(7)
nltk.download('wordnet')
nltk.stem.WordNetLemmatizer().lemmatize('word')
# COLAB CONFIG
# change colab flag to false if train using jupyter notebook
COLAB_FLAG = True
COLAB_FILEPATH = './drive/My Drive/4034-amazon-review-classification/' if COLAB_FLAG == True else './'
pd.options.mode.chained_assignment = None # default='warn'
%matplotlib inline
```
# Pre-processing of data for training the model (Amazon dataset)
### Import training data
```
# using SQLite Table to read data.
con = sqlite3.connect(COLAB_FILEPATH + 'data/database.sqlite')
data_train_raw_ = pd.read_sql_query(""" SELECT * FROM Reviews """, con)
print(data_train_raw_.shape)
data_train_raw_.head(3)
```
# Filtering of train data
### Remove duplicate entries
```
# check duplication of an entry
display= pd.read_sql_query("""
SELECT *
FROM Reviews
WHERE UserId="AR5J8UI46CURR"
ORDER BY ProductID
""", con)
display.head()
#Sorting data according to ProductId in ascending order
data_train_raw=data_train_raw_.sort_values('ProductId',
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last')
# remove duplication of entries
data_train_raw=data_train_raw.drop_duplicates(subset={"UserId","ProfileName","Time","Text"},
keep='first', inplace=False)
print(f'Shape: {data_train_raw.shape}')
# Checking to see how much % of data still remains
print(f"percentage of data remains: {(data_train_raw['Id'].size*1.0)/(data_train_raw_['Id'].size*1.0)*100}")
#data_train_raw.head(3)
# sample query
display= pd.read_sql_query("""
SELECT *
FROM Reviews
WHERE Id=44737 OR Id=64422
ORDER BY ProductID
""", con)
display.head()
# choose data that the helpfulness numerator is higher than the denominator
data_train_raw=data_train_raw[data_train_raw.HelpfulnessNumerator<=data_train_raw.HelpfulnessDenominator]
#Before starting the next phase of preprocessing lets see the number of entries left
print(data_train_raw.shape)
# distribution of the score of the train data
data_train_raw['Score'].value_counts()
```
### Create a training dataframe with only the comments and the ratings
```
# create an empty dataframe
data_train = pd.DataFrame()
# to store only the required columns into the new dataframe
data_train['comments'] = data_train_raw['Text']
data_train['ratings'] = data_train_raw['Score']
data_train['type'] = "train"
print(data_train.shape)
print(data_train.dtypes)
data_train.head()
```
There are 393931 data that we will use to train and validate our model, now we will move on to pre-process our test data, which was scraped from tripadvisor
# Pre-processing the test set (scraped data from tripadvisor)
The goal is to clean the data of the test set so that the both datasets have the same columns
### Import test data
```
# read the test data
data_test_raw_ = pd.read_csv(COLAB_FILEPATH+'data/trip-advisor-comments.csv')
print(f'Shape of the dataset:{data_test_raw_.shape}')
#data_test_raw_.head()
```
### Filtering of the test data
```
# remove duplication of entries
data_test_raw=data_test_raw_.drop_duplicates(subset={"Reviewer\'s Name","Comment"},
keep='first', inplace=False)
print(f'Shape of the dataset after removing duplicates:{data_test_raw.shape}')
#data_test_raw.head()
# total number of words
no_words = 0
k = list(data_test_raw['Comment'].str.count(' ') + 1)
for i in k:
no_words += i
print(f'Number of words: {no_words}')
# total number of unique words
uniqueWords = list(set(" ".join(data_test_raw['Comment'].values).split(" ")))
count = len(uniqueWords)
print(f'Number of unique words: {count}')
data_test_raw.head(3)
#Checking to see how much % of data still remains after removing duplications
(data_test_raw['Reviewer\'s Name'].size*1.0)/(data_test_raw_['Reviewer\'s Name'].size*1.0)*100
#Before starting the next phase of preprocessing lets see the number of entries left
print(data_test_raw.shape)
# distribution of the score of the test data
data_test_raw['Rating'].value_counts()
# export the filtered test data for SOLR
data_test_raw.to_csv(COLAB_FILEPATH + 'data/trip-advisor-comments-filtered.csv', index=False)
data_test_raw = pd.read_csv(COLAB_FILEPATH + 'data/trip-advisor-comments-filtered.csv')
# create an empty dataframe
data_test = pd.DataFrame()
# to store only the required columns into the new dataframe
data_test['Restaurant Name'] = data_test_raw['Restaurant Name']
data_test['Restaurant Type'] = data_test_raw['Restaurant Type']
data_test['Reviewer\'s Name'] = data_test_raw['Reviewer\'s Name']
data_test['comments'] = data_test_raw['Comment']
data_test['ratings'] = data_test_raw['Rating']
data_test['type'] = "test"
print(data_test.shape)
print(data_test.dtypes)
data_test.head()
```
# Partition the ratings to 3 classes only
-1 (negative) <- 1,2
0 (neutral) <- 3
1 (positive) <- 4,5
```
def partition(x):
if x < 3:
return -1
elif x == 3:
return 0
else:
return 1
# append partitioned data to the train set
actualScore = data_train['ratings']
class_ = actualScore.map(partition)
data_train['ratings_class'] = class_
print("Number of data points in train data", data_train.shape)
data_train.head(3)
# append partitioned data to the test set
actualScore = data_test['ratings']
class_ = actualScore.map(partition)
data_test['ratings_class'] = class_
print("Number of data points in test data", data_test.shape)
data_test.head(3)
# check the number of data in each ratings_class
data_train['ratings_class'].value_counts()
```
Got data imbalance, need to do downsampling AFTER separating neutral data from opinionated ones
### Separate neutral data from opinionated ones
Look at the ratings_class column:
1, -1 -> opinionated
0 -> neutral
```
# neutral train data
data_neutral_train = data_train[data_train['ratings_class'] == 0]
print(data_neutral_train.shape)
#data_neutral_train.head(3)
# neutral test data
data_neutral_test = data_test[data_test['ratings_class'] == 0]
print(data_neutral_test.shape)
#data_neutral_test.head(3)
# take a look at the neutral data (train)
print(data_neutral_train['comments'].iloc[1])
print(data_neutral_train['comments'].iloc[3])
print(data_neutral_train['comments'].iloc[50])
# take a look at the neutral data (test)
print(data_neutral_test['comments'].iloc[1])
print(data_neutral_test['comments'].iloc[3])
print(data_neutral_test['comments'].iloc[50])
# got data imbalance, need to downsample
# check the number of data in each ratings_class
data_train['ratings_class'].value_counts()
```
### Downsample the positive class in the training set (ONLY the training set!) to balance out with the negative class in terms of document count
```
# data with class -1
data_negative_train = data_train[data_train['ratings_class'] == -1]
print(data_negative_train.shape)
data_negative_train.head(3)
# data with class 1, sample with the total number of entries in the negative class (downsampling)
data_positive_train = data_train[data_train['ratings_class'] == 1].sample(len(data_negative_train), replace=False)
print(data_positive_train.shape)
data_positive_train.head(3)
# concatenate the positive and negative data into a new dataframe
# this dataframe will be the training set (amazon dataset) for our test set (crawled corpus)
data_train_undersampled_ = pd.concat([data_negative_train, data_positive_train])
# randomise the order of the sampled dataframe
data_train_undersampled = data_train_undersampled_.sample(frac=1)
print(data_train_undersampled.shape)
data_train_undersampled.head()
# check the distribution of the class again
data_train_undersampled['ratings_class'].value_counts()
# get the length of train data for later use
train_data_length = len(data_train_undersampled)
train_data_length
```
### Preprocess the test dataset to separate the neutral data from the opinionated ones
So that we can fit the test set into the binary classifier model trained
```
data_opinionated_test = data_test[data_test['ratings_class'] != 0]
print(data_opinionated_test.shape)
print(data_opinionated_test['ratings_class'].value_counts())
```
**Summary of dataframes formed**
- data_neutral_train
- data_neutral_test
- data_train_undersampled (positive + negative)
- data_opinionated_test (positive + negative)
- data_test_ordered (positive + negative + neutral at the back) for SOLR
```
frames = [data_opinionated_test, data_neutral_test]
data_test_ordered = pd.concat(frames)
# check the dimension of the merged dataframe
print(data_test_ordered.shape)
#data_test_ordered.head(3)
data_test_ordered['ratings_class'].value_counts()
```
There are 8837 comments that are neutral at the back of the dataframe
```
# combine the test set for later use in SOLR
data_test_ordered.to_csv(COLAB_FILEPATH + 'data/trip-advisor-comments-filtered-ordered.csv', index=False)
# drop the unwanted columns so that it can be merged with the train set
data_opinionated_test = data_opinionated_test.drop(['Restaurant Name','Restaurant Type', 'Reviewer\'s Name'], axis=1)
data_opinionated_test.head(3)
```
# Merge 2 dataframes together
Take note of the last entry of the train set and the first entry of the test set so that we can split the dataset to train-val and test set after tokenization
```
# shape of train set
print(f'Train set dimension: {data_train_undersampled.shape}')
# shape of test set
print(f'Test set dimension: {data_opinionated_test.shape}')
```
### Perform data cleaning and Lemmatization
```
# merge the 2 dataframes together to perform tokenization
frames = [data_train_undersampled,data_opinionated_test]
data_overall = pd.concat(frames)
# check the dimension of the merged dataframe
print(data_overall.shape)
data_overall.head(3)
# check the range where the data changes from train set to test set
# debug
#data_overall.iloc[:,:]
# finding the split
data_overall.iloc[train_data_length-2:train_data_length+2,:]
# last entry of the train set
data_overall.iloc[[train_data_length-1]]
data_overall.head()
```
# Perform data cleaning and Lemmatization
```
# remove contractions
def contraction_removal(phrase):
phrase = re.sub(r"won't", "will not", phrase)
phrase = re.sub(r"can\'t", "can not", phrase)
# general
phrase = re.sub(r"n\'t", "not", phrase)
phrase = re.sub(r"\'re", "are", phrase)
phrase = re.sub(r"\'s", "is", phrase)
phrase = re.sub(r"\'d", "would", phrase)
phrase = re.sub(r"\'ll", "will", phrase)
phrase = re.sub(r"\'t", "not", phrase)
phrase = re.sub(r"\'ve", "have", phrase)
phrase = re.sub(r"\'m", "am", phrase)
return phrase
# https://gist.github.com/sebleier/554280
# we are removing the words from the stop words list: 'no', 'nor', 'not'
# <br /><br /> ==> after the above steps, we are getting "br br"
# we are including them into stop words list
# instead of <br /> if we have <br/> these tags would have revmoved in the 1st step
stopwords= set(['br', 'the', 'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've",\
"you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', \
'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their',\
'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', \
'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', \
'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', \
'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after',\
'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further',\
'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more',\
'most', 'other', 'some', 'such', 'only', 'own', 'same', 'so', 'than', 'too', 'very', \
's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', \
've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn',\
"hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn',\
"mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", \
'won', "won't", 'wouldn', "wouldn't", "\n"])
# to do data cleaning here
preprocessed_reviews = []
# tqdm is for printing the status bar
for sentence in tqdm(data_overall['comments'].values):
sentence = re.sub(r"http\S+", "", sentence)
sentence = BeautifulSoup(sentence, 'lxml').get_text()
sentence = contraction_removal(sentence)
sentence = re.sub("\S*\d\S*", "", sentence).strip()
sentence = re.sub('[^A-Za-z]+', ' ', sentence)
# https://gist.github.com/sebleier/554280
sentence = ' '.join(e.lower() for e in sentence.split() if e.lower() not in stopwords)
preprocessed_reviews.append(sentence.strip())
# perform lemmatization here
w_tokenizer = nltk.tokenize.WhitespaceTokenizer()
lemmatizer = nltk.stem.WordNetLemmatizer()
def lemmatize_text(text):
return [lemmatizer.lemmatize(w) for w in w_tokenizer.tokenize(text)]
df = pd.DataFrame(preprocessed_reviews, columns=['text'])
df['text_lemmatized'] = df.text.apply(lemmatize_text)
df.head()
text_lemmatized_list = []
# merge the elements in the list into a string
for i in df['text_lemmatized']:
listToStr = ' '.join([str(elem) for elem in i])
text_lemmatized_list.append(listToStr)
# append the lemmatized list to the main dataframe
data_overall['comments_cleaned'] = text_lemmatized_list
print(data_overall.shape)
data_overall.head()
```
### Export cleaned corpus to csv
To save the progress of the data cleaning at this point of time
```
data_overall.to_csv(COLAB_FILEPATH + 'data/data_train_test_combined.csv',
index=False)
```
### Import the cleaned corpus
```
data_overall_ = pd.read_csv(COLAB_FILEPATH + 'data/data_train_test_combined.csv')
data_overall_.head()
print(data_overall_.dtypes)
print(data_overall_.count())
# replace na with - for the row where the comments cleaned are empty
data_overall_['comments_cleaned'] = data_overall_['comments_cleaned'].fillna('-')
data_overall_.count()
# remove not useful columns
data_overall = data_overall_.drop(labels='comments', axis=1)
data_overall = data_overall.drop(labels='ratings', axis=1)
data_overall.head(10)
# check the range where the data changes from train set to test set
# count number of dataset that belongs to train
train_count = data_overall['type'].value_counts()['train']
train_count
# finding the split
data_overall.iloc[train_count-2:train_count+2,:]
print(data_overall.iloc[train_count-1,2])
print(len(data_overall[data_overall['type']=='test']))
```
# Label and define the predictor and the response
```
X = data_overall['comments_cleaned'].values
y = data_overall['ratings_class']
# one hot the classifier
y_oh = pd.get_dummies(y)
# check the one-hot classifier
y_oh[:3]
X
X_df = pd.DataFrame(X)
X_df.columns = ["cleaned_comments"]
X_df.head()
# Count the Vocabulary
count_vect = CountVectorizer()
count_vect.fit(X)
vocabulary = count_vect.get_feature_names()
print('Words in the Vocabulary : ',len(vocabulary))
```
# Pre-processing of text by doing tokenization of data
```
#Creating dictionary
corpus = dict()
ind = 0
for sent in X:
for word in sent.split():
corpus.setdefault(word,[])
corpus[word].append(ind)
ind += 1
#Frequency for each word of vocabulary
freq = []
for w in vocabulary:
#print(w, end=' ')
freq.append(len(corpus[w]))
#Frequencies in decreasing order
inc_index =np.argsort(np.array(freq))[::-1]
#Allocating ranks
word_rank = dict()
rank = 1
for i in inc_index:
word_rank[vocabulary[i]] = rank
rank +=1
data = []
for sent in X:
row = []
for word in sent.split():
if(len(word)>1):
row.append(word_rank[word])
data.append(row)
# check the tokenized representation
print(data[train_count-1], end= ' ')
# splitting of data
X_train, X_test = data[:train_count], data[train_count:]
Y_train, Y_test = y[:train_count], y[train_count:]
Y_train_oh , Y_test_oh = y_oh[:train_count], y_oh[train_count:]
```
# Deep Learning Portion
```
# padding input sequences
max_review_length = 100
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
print(X_train.shape)
print(X_train[2000])
# plot function for the accuracy and loss curve
import matplotlib.pyplot as plt
import numpy as np
import time
# https://gist.github.com/greydanus/f6eee59eaf1d90fcb3b534a25362cea4
# https://stackoverflow.com/a/14434334
# this function is used to update the plots for each epoch and error
def plt_dynamic(x, vy, ty, ax, colors=['b']):
ax.plot(x, vy, 'b', label="Validation Loss")
ax.plot(x, ty, 'r', label="Train Loss")
plt.legend()
plt.grid(True)
fig.canvas.draw()
```
### LSTM One Layer
```
vocab_size = len(vocabulary)
embedding_vector_length = 32
EPOCHS = 5
model = Sequential()
model.add(Embedding(vocab_size+1, embedding_vector_length, input_length=max_review_length))
model.add(Dropout(0.2))
model.add(LSTM(128))
model.add(Dropout(0.2))
model.add(Dense(2, activation='softmax'))
print(model.summary())
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
callbacks_list=[ModelCheckpoint(filepath=COLAB_FILEPATH+'model/LSTM-1layer-2-class-downsampled.h5',save_best_only=True,verbose=1,)]
#Fitting the data to the model
history = model.fit(X_train,
Y_train_oh,
epochs=EPOCHS,
batch_size=512,
verbose=1,
#validation_data=(X_test, Y_test),
validation_split=0.2,
callbacks=callbacks_list)
fig,ax = plt.subplots(1,1)
ax.set_xlabel('epoch') ; ax.set_ylabel('categorical_crossentropy')
# list of epoch numbers
x = list(range(1,EPOCHS+1))
vy = history.history['val_loss']
ty = history.history['loss']
plt_dynamic(x, vy, ty, ax)
import time
start = time.perf_counter()
# evaluate model with test set (crawled data)
model_lstm_1layer = tensorflow.keras.models.load_model(COLAB_FILEPATH+'model/LSTM-1layer-2-class-downsampled.h5')
time_taken = time.perf_counter()-start
time_taken
# accuracy on test data
start = time.perf_counter()
score_1layer = model_lstm_1layer.evaluate(X_test,Y_test_oh, verbose=0)
time_taken = time.perf_counter()-start
print('Test loss:', score_1layer[0])
print('Test accuracy:', score_1layer[1])
print(time_taken/len(X_test))
print(len(X_test)/time_taken)
# predict rating for the test data
Y_pred_dist_test = model_lstm_1layer.predict(X_test)
Y_pred_test = Y_pred_dist_test.argmax(axis=1)+1
print('Y_pred_test.shape:',Y_pred_test.shape)
# see the unique classes in the ground truth
print('Unqiue classes in the ground truth:',np.unique(Y_test))
print('GROUND TRUTH')
print(np.count_nonzero(Y_test == -1))
print(np.count_nonzero(Y_test == 1))
# see the unique classes in the prediction
print('Unqiue classes in the prediction:',np.unique(Y_pred_test))
print('PREDICTION')
print(np.count_nonzero(Y_pred_test == 1))
print(np.count_nonzero(Y_pred_test == 2))
#check if length the same for ground truth and prediction
print(len(Y_test) == len(Y_pred_test))
# map the prediction class from 1,2 to -1 and 1
Y_pred_test = np.where(Y_pred_test == 1, -1, Y_pred_test)
Y_pred_test = np.where(Y_pred_test == 2, 1, Y_pred_test)
print('Unqiue classes in the prediction after mapping:',np.unique(Y_pred_test))
# F1-score for binary classifier
target_names = ['-1', '1']
print(classification_report(Y_test.tolist(), Y_pred_test, target_names=target_names))
# confusion matrix
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm_arr = confusion_matrix(Y_test, Y_pred_test)
cm_arr
cm_sns = pd.crosstab(Y_test, Y_pred_test, rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(cm_sns, annot=True, fmt="d")
plt.show()
# ROC-AUC - 1 layer lstm
# Area under curve (AUC)
fpr_keras_1lstm, tpr_keras_1lstm, thresholds_keras_1lstm = roc_curve(Y_pred_test, Y_test)
auc_keras_1lstm = auc(fpr_keras_1lstm, tpr_keras_1lstm)
auc_keras_1lstm
```
# --- This section is for SOLR indexing system ---
```
Y_pred_test[:20]
len(Y_pred_test)
Y_test.to_numpy()[:20]
# load the test data file
df_solr_ = pd.read_csv(COLAB_FILEPATH + 'data/trip-advisor-comments-filtered-ordered.csv')
df_solr_.head(2)
# rename header
df_solr = df_solr_.rename(columns = {'ratings_class': 'true_label'}, inplace = False)
df_solr.head(2)
df_solr['true_label'].value_counts()
# check the difference in length
diff_len = len(df_solr['true_label'])-len(Y_pred_test)
diff_len == len(data_neutral_test)
# save the prediction into the dataframe
test_data['pred_label'] = np.append(Y_pred_test,[0]*diff_len)
test_data.head(5)
# shuffle the indexes in the dataframe
test_data_shuffled = test_data.sample(frac=1).reset_index(drop=True)
test_data_shuffled.head()
# export final data with the prediction into the csv
test_data_shuffled.to_csv(COLAB_FILEPATH + 'data/data_for_solr_updated.csv', index=False)
```
# --- Code for SOLR ends ---
### Bi-directional LSTM
```
vocab_size = len(vocabulary)
embedding_vector_length = 32
EPOCHS = 5
model = Sequential()
model.add(Embedding(vocab_size+1, embedding_vector_length, input_length=max_review_length))
model.add(Dropout(0.2))
model.add(Bidirectional(LSTM(128)))
model.add(Dropout(0.2))
model.add(Dense(2, activation='softmax'))
print(model.summary())
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
callbacks_list=[ModelCheckpoint(filepath=COLAB_FILEPATH+'model/BiLSTM-1layer-2-class-downsampled.h5',save_best_only=True,verbose=1,)]
#Fitting the data to the model
history = model.fit(X_train,
Y_train_oh,
epochs=EPOCHS,
batch_size=512,
verbose=1,
#validation_data=(X_test, Y_test),
validation_split=0.2,
callbacks=callbacks_list)
fig,ax = plt.subplots(1,1)
ax.set_xlabel('epoch') ; ax.set_ylabel('categorical_crossentropy')
# list of epoch numbers
x = list(range(1,EPOCHS+1))
vy = history.history['val_loss']
ty = history.history['loss']
plt_dynamic(x, vy, ty, ax)
# evaluate model with test set
start = time.perf_counter()
model_bilstm_1layer = tensorflow.keras.models.load_model(COLAB_FILEPATH+'model/BiLSTM-1layer-2-class-downsampled.h5')
time_taken = time.perf_counter()-start
time_taken
start = time.perf_counter()
# accuracy on test data
score_bi1layer = model_bilstm_1layer.evaluate(X_test,Y_test_oh, verbose=0)
time_taken = time.perf_counter()-start
print('Test loss:', score_bi1layer[0])
print('Test accuracy:', score_bi1layer[1])
print(time_taken/len(X_test))
print(len(X_test)/time_taken)
# predict rating for the test data
Y_pred_dist_test = model_bilstm_1layer.predict(X_test)
Y_pred_test = Y_pred_dist_test.argmax(axis=1)+1
print('Y_pred_test.shape:',Y_pred_test.shape)
# see the unique classes in the ground truth
print('Unqiue classes in the ground truth:',np.unique(Y_test))
print('GROUND TRUTH')
print(np.count_nonzero(Y_test == -1))
print(np.count_nonzero(Y_test == 1))
# see the unique classes in the prediction
print('Unqiue classes in the prediction:',np.unique(Y_pred_test))
print('PREDICTION')
print(np.count_nonzero(Y_pred_test == 1))
print(np.count_nonzero(Y_pred_test == 2))
#check if length the same for ground truth and prediction
print(len(Y_test) == len(Y_pred_test))
# map the prediction class from 1,2 to -1 and 1
Y_pred_test = np.where(Y_pred_test == 1, -1, Y_pred_test)
Y_pred_test = np.where(Y_pred_test == 2, 1, Y_pred_test)
print('Unqiue classes in the prediction after mapping:',np.unique(Y_pred_test))
# F1-score for binary classifier
target_names = ['-1', '1']
print(classification_report(Y_test.tolist(), Y_pred_test, target_names=target_names))
# confusion matrix
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm_arr = confusion_matrix(Y_test, Y_pred_test)
cm_arr
cm_sns = pd.crosstab(Y_test, Y_pred_test, rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(cm_sns, annot=True, fmt="d")
plt.show()
# ROC-AUC - bilstm
# Area under curve (AUC)
fpr_keras_bilstm, tpr_keras_bilstm, thresholds_keras_bilstm = roc_curve(Y_pred_test, Y_test)
auc_keras_bilstm = auc(fpr_keras_bilstm, tpr_keras_bilstm)
auc_keras_bilstm
```
# Preprocess data for BERT
```
# get the X_train unsplit (training + validation data)
data_train_unsplit_ = data_overall[data_overall['type']=='train']
#X_train_bert_unsplit = X_train_bert_unsplit_['comments_cleaned'].values
data_train_unsplit_.head()
# get the X_test
data_test_bert_ = data_overall[data_overall['type']=='test']
#X_test_bert = X_test_bert_['comments_cleaned'].values
data_test_bert_.head()
# do train-test-split now to divide train and validation set
# perform train-test-split to split the train and validation data
X_train_bert_, X_val_bert_, y_train_bert_, y_val_bert_ = train_test_split(data_train_unsplit_['comments_cleaned'],
data_train_unsplit_['ratings_class'],
train_size=0.80,
random_state=42)
type(X_train_bert_)
# merge into dataframe for train and val set
data_train = pd.DataFrame({'comments_cleaned': X_train_bert_,
'ratings': y_train_bert_.astype('string')})
data_train.head()
data_train['ratings'].value_counts()
data_val = pd.DataFrame({'comments_cleaned': X_val_bert_,
'ratings': y_val_bert_.astype('string')})
data_val.head()
data_val['ratings'].value_counts()
import ktrain
from ktrain import text
(X_train, y_train), (X_val, y_val), preprocess = text.texts_from_df(train_df = data_train,
text_column = 'comments_cleaned',
#label_columns = 'ratings',
label_columns = 'ratings',
val_df = data_val,
maxlen=100,
preprocess_mode='bert')
print(X_train[0].shape)
print(X_val[0].shape)
print(y_train.shape)
print(y_val.shape)
# build the model
model = text.text_classifier(name='bert',
train_data = (X_train, y_train),
preproc = preprocess)
```
# Training using BERT
```
# get learner (compiling the model)
learner = ktrain.get_learner(model=model,
train_data=(X_train,y_train),
val_data=(X_val,y_val),
batch_size=6)
# optimal learning rate (generally) to save time
OPTIMAL_LR = 2e-5
# train the BERT model
learner.fit_onecycle(lr=OPTIMAL_LR,epochs=1)
```
### Initialize the predictor
```
# initialize predictor
predictor = ktrain.get_predictor(learner.model, preprocess)
# check the classes available as a predictor value
predictor.get_classes()
# save the model
predictor.save(COLAB_FILEPATH+'model/bert-lr_2e-5_2-class-downsampled')
```
### Make prediction on the test set (to get a f1-score)
```
# load back the saved model
start = time.perf_counter()
predictor = ktrain.load_predictor(COLAB_FILEPATH+'model/bert-lr_2e-5_2-class-downsampled')
time_taken = time.perf_counter()-start
time_taken
predictor
# insert test data in a list
test_data_bert = list(data_test_bert_['comments_cleaned'])
test_data_bert[:3]
# predict the test data
start = time.perf_counter()
prediction_test = predictor.predict(test_data_bert)
time_taken = time.perf_counter()-start
print(time_taken/len(X_test))
print(len(X_test)/time_taken)
# create new dataframe for the test set and the true and predicted label
prediction = pd.DataFrame()
prediction['comments'] = data_test_bert_['comments_cleaned']
prediction['true_label'] = data_test_bert_['ratings_class']
prediction['pred_label'] = prediction_test
prediction.head()
prediction.to_csv(COLAB_FILEPATH + 'data/data_with_actual_and_pred.csv', index=False)
# import the pred and ground truth csv
prediction = pd.read_csv(COLAB_FILEPATH + 'data/data_with_actual_and_pred.csv')
prediction.head()
prediction['pred_label'].value_counts()
prediction['true_label'].value_counts()
len(prediction)
# get the prediction accuracy based on the ground truth of the test set (tripadvisor data)
count = 0
true_label_list = list(prediction['true_label'])
pred_label_list = list(prediction['pred_label'])
for i in range(len(prediction)):
if true_label_list[i] == pred_label_list[i]:
count += 1
accuracy = count/len(true_label_list)
print(f'Prediction accuracy of the tripadvisor data: {accuracy}')
# F1-score for binary classifier
target_names = ['-1', '1']
print(classification_report(true_label_list, pred_label_list, target_names=target_names))
# confusion matrix
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm_arr = confusion_matrix(true_label_list, pred_label_list)
cm_arr
len(true_label_list) == len(pred_label_list)
#cm_sns = pd.crosstab(true_label_list, pred_label_list, rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(cm_arr, annot=True, fmt="d", xticklabels=['-1','1'], yticklabels=['-1','1'])
plt.show()
# ROC-AUC - bert
# Area under curve (AUC)
fpr_keras_bert, tpr_keras_bert, thresholds_keras_bert = roc_curve(pred_label_list, true_label_list)
auc_keras_bert = auc(fpr_keras_bert, tpr_keras_bert)
auc_keras_bert
```
# Get the ROC curve
```
# get the ROC curve
plt.figure(1)
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr_keras_1lstm, tpr_keras_1lstm, label='1-layer LSTM (area = {:.5f})'.format(auc_keras_1lstm))
plt.plot(fpr_keras_bilstm, tpr_keras_bilstm, label='1-layer BiLSTM (area = {:.5f})'.format(auc_keras_bilstm))
plt.plot(fpr_keras_bert, tpr_keras_bert, label='1-layer BERT (area = {:.5f})'.format(auc_keras_bert))
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend(loc='best')
plt.show()
```
| github_jupyter |
```
import pandas
import seaborn as sns
import scipy.stats
import numpy
df = pandas.read_csv('WellsForGraphing.csv')
x = 'Plate40111_WellB02_FeatureSelected'
y = 'Plate40111_WellC02_FeatureSelected'
g = sns.jointplot(data = df, x=x,y=y,kind='reg')
g.ax_joint.annotate("Pearson = %3f "%scipy.stats.pearsonr(df[x].dropna(),df[y].dropna())[0], xy=(-3, 5))
x = 'Plate40111_WellB02_FeatureSelected'
y = 'Plate40115_WellB02_FeatureSelected'
g = sns.jointplot(data = df, x=x,y=y,kind='reg')
g.ax_joint.annotate("Pearson = %3f "%scipy.stats.pearsonr(df[x].dropna(),df[y].dropna())[0], xy=(3, 1.5))
x = 'Plate40111_WellB02_Normalized'
y = 'Plate40111_WellC02_Normalized'
g = sns.jointplot(data = df, x=x,y=y,kind='reg')
g.ax_joint.annotate("Pearson = %3f "%scipy.stats.pearsonr(df[x].dropna(),df[y].dropna())[0], xy=(-3, 5))
x = 'Plate40111_WellB02_Normalized'
y = 'Plate40115_WellB02_Normalized'
g = sns.jointplot(data = df, x=x,y=y,kind='reg')
g.ax_joint.annotate("Pearson = %3f "%scipy.stats.pearsonr(df[x].dropna(),df[y].dropna())[0], xy=(3, 1.5))
sns.jointplot(data = df, x='Plate40111_WellB02_Normalized',y='Plate40115_WellB02_Normalized',kind='resid')
sns.jointplot(data = df, x='Plate40111_WellB02_Normalized',y='Plate40111_WellC02_Normalized',kind='resid')
x = 'Plate40111_WellB02_Raw'
y = 'Plate40115_WellB02_Raw'
ax = sns.regplot(data = df, x=x,y=y)
ax.annotate("Pearson = %3f "%scipy.stats.pearsonr(df[x].dropna(),df[y].dropna())[0], xy=(0, 4000))
x = 'Plate40111_WellB02_Raw'
y = 'Plate40111_WellC02_Raw'
ax = sns.regplot(data = df, x=x,y=y)
ax.annotate("Pearson = %3f "%scipy.stats.pearsonr(df[x].dropna(),df[y].dropna())[0], xy=(0, 2500))
ax= sns.residplot(data = df, x='Plate40111_WellB02_Raw',y='Plate40111_WellC02_Raw')
ax.set_ylim([-250,1250])
ax=sns.residplot(data = df, x='Plate40111_WellB02_Raw',y='Plate40115_WellB02_Raw')
ax.set_ylim([-250,1250])
#area features are positively correlated
area_features_well_1 = numpy.array([1,1.25,1.5])
area_features_well_2 = numpy.array([1,1.25,1.5])
#intensity features are negatively correlated
intensity_features_well_1 = numpy.array([2,3,4])
intensity_features_well_2 = numpy.array([-2,-3,-4])
#texture features are positively correlated, and there are 100 of them
texture_features_well_1 = numpy.random.normal(loc=3,scale=0.2,size=100)
texture_features_well_2 = texture_features_well_1 * 1.3
well_1_without_texture = numpy.concatenate([area_features_well_1,intensity_features_well_1],axis=0)
well_2_without_texture = numpy.concatenate([area_features_well_2,intensity_features_well_2],axis=0)
well_1_with_texture = numpy.concatenate([area_features_well_1,intensity_features_well_1,texture_features_well_1],axis=0)
well_2_with_texture = numpy.concatenate([area_features_well_2,intensity_features_well_2,texture_features_well_2],axis=0)
ax = sns.regplot(x=well_1_without_texture,y=well_2_without_texture)
ax.annotate("Pearson = %3f "%scipy.stats.pearsonr(well_1_without_texture,well_2_without_texture)[0], xy=(1, -8))
ax = sns.regplot(x=well_1_with_texture,y=well_2_with_texture)
ax.annotate("Pearson = %3f "%scipy.stats.pearsonr(well_1_with_texture,well_2_with_texture)[0], xy=(1, 5))
```
| github_jupyter |
# Practicing Classes
## Exercise 1 (shopping cart)
Let's write a simple shopping cart class -- this will hold items that you intend to purchase as well as the amount, etc. And allow you to add / remove items, get a subtotal, etc.
We'll use two classes: `Item` will be a single item and `ShoppingCart` will be the collection of items you wish to purchase.
First, our store needs an inventory -- here's what we have for sale:
```
INVENTORY_TEXT = """
apple, 0.60
banana, 0.20
grapefruit, 0.75
grapes, 1.99
kiwi, 0.50
lemon, 0.20
lime, 0.25
mango, 1.50
papaya, 2.95
pineapple, 3.50
blueberries, 1.99
blackberries, 2.50
peach, 0.50
plum, 0.33
clementine, 0.25
cantaloupe, 3.25
pear, 1.25
quince, 0.45
orange, 0.60
"""
# this will be a global -- convention is all caps
INVENTORY = {}
for line in INVENTORY_TEXT.splitlines():
if line.strip() == "":
continue
item, price = line.split(",")
INVENTORY[item] = float(price)
INVENTORY
```
### `Item`
Here's the start of an item class -- we want it to hold the name and quantity.
You should have the following features:
* the name should be something in our inventory
* Our shopping cart will include a list of all the items we want to buy, so we want to be able to check for duplicates. Implement the equal test, `==`, using `__eq__`
* we'll want to consolidate dupes, so implement the `+` operator, using `__add__` so we can add items together in our shopping cart. Note, add should raise a ValueError if you try to add two `Items` that don't have the same name.
Here's a start:
```
class Item(object):
""" an item to buy """
def __init__(self, name, quantity=1):
if name not in INVENTORY:
raise ValueError
self.name = name
self.quantity = quantity
def __repr__(self):
pass
def __eq__(self, other):
pass
def __add__(self, other):
pass
```
Here are some tests your code should pass:
```
a = Item("apple", 10)
b = Item("banana", 20)
c = Item("apple", 20)
# won't work
a + b
# will work
a += c
a
a == b
a == c
```
How do they behave in a list?
```
items = []
items.append(a)
items.append(b)
items
c in items
```
### `ShoppingCart`
Now we want to create a shopping cart. The main thing it will do is hold a list of items.
```
class ShoppingCart(object):
def __init__(self):
self.items = []
def subtotal(self):
""" return a subtotal of our items """
pass
def add(self, name, quantity):
""" add an item to our cart """
pass
def remove(self, name):
""" remove all of item name from the cart """
pass
def report(self):
""" print a summary of the cart """
pass
```
Here are some tests
```
sc = ShoppingCart()
sc.add("orange", 19)
sc.add("apple", 2)
sc.report()
sc.add("apple", 9)
sc.report()
sc.subtotal()
sc.remove("apple")
sc.report()
```
## Exercise 2: Poker Odds
Use the deck of cards class from the notebook we worked through outside of class to write a _Monte Carlo_ code that plays a lot of hands of straight poker (like 100,000). Count how many of these hands has a particular poker hand (like 3-of-a-kind). The ratio of # of hands with 3-of-a-kind to total hands is an approximation to the odds of getting a 3-of-a-kind in poker.
You'll want to copy-paste those classes into a `.py` file to allow you to import and reuse them here
## Exercise 3: Tic-Tac-Toe
Revisit the tic-tac-toe game you developed in the functions exercises but now write it as a class with methods to do each of the main steps.
| github_jupyter |
```
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql.functions import *
spark = SparkSession \
.builder \
.appName("Session5") \
.getOrCreate()
df= spark.read.option("multiline","true").json("./data/train_schedules.json")
#Json records- list of dictionaries with keys as columns, json objects-
df.show(4)
df = spark.read.text("./data/train_schedules.json")#Not the right way to read json
df.show(4)
df.select("train_number", "station_code", "departure",).show(4)
df.select(df.train_number, df.station_code, df.departure).show(4)
df.head(4)
df.count()
df.select(col("train_number"), col("station_code"), col("departure")) \
.show(4)
# Execute the same query using SQL
df.createOrReplaceTempView("schedules")
query= """
SELECT train_number, station_code, departure
FROM schedules
LIMIT 4
"""
spark.sql(query).show()
df.printSchema()
df.columns
df.groupBy("station_name").count().orderBy("station_name").show(6)
query= """
SELECT station_name, count(1) as count
FROM schedules
group by station_name
LIMIT 6
"""
spark.sql(query).show()
df.dtypes
df= df.withColumn("departure",to_timestamp("departure"))
df= df.withColumn("arrival",to_timestamp("arrival"))
# Create temporary table called schedules
df.createOrReplaceTempView("schedules")
spark.sql("DESCRIBE schedules").show()
# Adding row numbers
# Upcoming arrival time
query= """
SELECT train_number, station_code , station_name, departure, ROW_NUMBER() OVER (ORDER BY train_number) AS row_number,
LEAD(departure, 1) OVER (ORDER BY train_number) AS upcoming_arrival
FROM schedules
WHERE train_number= 12301
"""
spark.sql(query).show(20)
# Adding row numbers
# Upcoming arrival time
query= """
SELECT train_number, station_code , (UNIX_TIMESTAMP(departure, 'Yyyy-mm-dd')),
LEAD(departure, 1) OVER (ORDER BY train_number) AS upcoming_arrival
FROM schedules
WHERE train_number= 12301
"""
spark.sql(query).show(4)
```
### Window Function
```
# OVER Clause: Adding row numbers
df.createOrReplaceTempView("schedules")
query= """
SELECT train_number, station_code , departure, ROW_NUMBER() OVER (ORDER BY train_number) AS row_number
FROM schedules
WHERE train_number= 12301
"""
spark.sql(query).show(5)
# LEAD Clause: Upcoming arrival time
query= """
SELECT train_number, station_code , departure, ROW_NUMBER() OVER (ORDER BY train_number) AS row_number,
LEAD(departure, 1) OVER (ORDER BY train_number) AS upcoming_arrival
FROM schedules
WHERE train_number= 12301
"""
spark.sql(query).show(5)
```
## Doing Basic Statistics
```
from pyspark.ml.stat import *
from pyspark.ml.linalg import Vectors
from pyspark.sql import Row
credit= spark.read.csv('./data/german_credit.csv', sep= ',', header= True)
# Summary statistics
num_cols = ['Account Balance','No of dependents']
credit.select(num_cols).describe().show()
from pyspark.sql.functions import col, skewness, kurtosis
credit.select(skewness("Age (years)"),kurtosis("Age (years)")).show()
# Correlation
from pyspark.ml.linalg import Vectors
from pyspark.ml.stat import Correlation
data = [(Vectors.sparse(4, [(0, 1.0), (3, -2.0)]),),
(Vectors.dense([4.0, 5.0, 0.0, 3.0]),),
(Vectors.dense([6.0, 7.0, 0.0, 8.0]),),
(Vectors.sparse(4, [(0, 9.0), (3, 1.0)]),)]
df = spark.createDataFrame(data, ["features"])
r1 = Correlation.corr(df, "features").head()
print("Pearson correlation matrix:\n" + str(r1[0]))
r2 = Correlation.corr(df, "features", "spearman").head()
print("Spearman correlation matrix:\n" + str(r2[0]))
df.show()
import numpy as np
print(data[1])
n1 = np.array(data[0])
n2 = np.array(data[1])
n3 = np.array(data[2])
n4 = np.array(data[3])
print(n1)
print(n2)
print(n3)
print(n4)
# Chi-Square Test
from pyspark.ml.linalg import Vectors
from pyspark.ml.stat import Correlation
data = [(Vectors.sparse(4, [(0, 1.0), (3, -2.0)]),),
(Vectors.dense([4.0, 5.0, 0.0, 3.0]),),
(Vectors.dense([6.0, 7.0, 0.0, 8.0]),),
(Vectors.sparse(4, [(0, 9.0), (3, 1.0)]),)]
df = spark.createDataFrame(data, ["features"])
r1 = Correlation.corr(df, "features").head()
print("Pearson correlation matrix:\n" + str(r1[0]))
r2 = Correlation.corr(df, "features", "spearman").head()
print("Spearman correlation matrix:\n" + str(r2[0]))
# Chi-square test
# Kolmogrov Smirnov Test
# Correlation
# Multivariate Gaussian
```
| github_jupyter |
```
# -*- coding: utf-8 -*-
import numpy as np
from dewloosh.core.tools import issequence
class CoordinateArrayBase(np.ndarray):
def __new__(subtype, shape=None, dtype=float, buffer=None,
offset=0, strides=None, order=None, frame=None):
# Create the ndarray instance of our type, given the usual
# ndarray input arguments. This will call the standard
# ndarray constructor, but return an object of our type.
# It also triggers a call to InfoArray.__array_finalize__
obj = super().__new__(subtype, shape, dtype,
buffer, offset, strides, order)
# set the new 'info' attribute to the value passed
obj.frame = frame
obj.inds = None
obj._indsbuf = None
# Finally, we must return the newly created object:
return obj
def __array_finalize__(self, obj):
# ``self`` is a new object resulting from
# ndarray.__new__(InfoArray, ...), therefore it only has
# attributes that the ndarray.__new__ constructor gave it -
# i.e. those of a standard ndarray.
#
# We could have got to the ndarray.__new__ call in 3 ways:
# From an explicit constructor - e.g. InfoArray():
# obj is None
# (we're in the middle of the InfoArray.__new__
# constructor, and self.info will be set when we return to
# InfoArray.__new__)
if obj is None: return
# From view casting - e.g arr.view(InfoArray):
# obj is arr
# (type(obj) can be InfoArray)
# From new-from-template - e.g infoarr[:3]
# type(obj) is InfoArray
#
# Note that it is here, rather than in the __new__ method,
# that we set the default value for 'info', because this
# method sees all creation of default objects - with the
# InfoArray.__new__ constructor, but also with
# arr.view(InfoArray).
#
# Store indices if obj is a result of a slicing operation
# and clean up the reference
self.frame = getattr(obj, 'frame', None)
if isinstance(obj, CoordinateArrayBase):
self.inds = obj._indsbuf
obj._indsbuf = None
# We do not need to return anything
def __getitem__(self, key):
key = (key,) if not isinstance(key, tuple) else key
if isinstance(key[0], slice):
slc = key[0]
start, stop, step = slc.start, slc.stop, slc.step
start = 0 if start == None else start
step = 1 if step == None else step
stop = len(self) if stop == None else stop
self._indsbuf = list(range(start, stop, step))
elif issequence(key[0]):
self._indsbuf = key[0]
elif isinstance(key[0], int):
self._indsbuf = [key[0]]
return super().__getitem__(key)
@property
def x(self):
return self[:, 0] if len(self.shape) > 1 else self[0]
@property
def y(self):
return self[:, 1] if len(self.shape) > 1 else self[1]
@property
def z(self):
return self[:, 2] if len(self.shape) > 1 else self[2]
c = np.array([[0, 0, 0], [0, 0, 1.]])
coords = c.view(CoordinateArrayBase)
coords
coords.base is c
coords[0,:].base.frame
coords[1, :].z
coords[0, 0];
coords[:, 0];
coords[0, :];
coords[:, :];
coords[[0, 1], :2];
coords[:2, :].inds
from numpy.lib.mixins import NDArrayOperatorsMixin
class CoordinateArray(NDArrayOperatorsMixin):
def __init__(self, *args, frame=None, **kwargs):
buf = np.array(*args, **kwargs)
self._array = CoordinateArrayBase(shape=buf.shape, buffer=buf,
dtype=buf.dtype, frame=frame)
def __repr__(self):
return f"{self.__class__.__name__}({self._array}, frame={self._array.frame})"
def __array__(self, dtype=None):
return self._array
def __getitem__(self, key):
return self._array.__getitem__(key)
@property
def x(self):
return self._array.x
@property
def y(self):
return self._array.y
@property
def z(self):
return self._array.z
COORD = CoordinateArray([[0, 0, 0], [0, 0, 1.]])
COORD[:,:].inds
```
| github_jupyter |
```
from __future__ import print_function
from bqplot import *
import numpy as np
import pandas as pd
from ipywidgets import Layout
```
## Scatter Chart
#### Scatter Chart Selections
Click a point on the `Scatter` plot to select it. Now, run the cell below to check the selection. After you've done this, try holding the `ctrl` (or `command` key on Mac) and clicking another point. Clicking the background will reset the selection.
```
x_sc = LinearScale()
y_sc = LinearScale()
x_data = np.arange(20)
y_data = np.random.randn(20)
scatter_chart = Scatter(x=x_data, y=y_data, scales= {'x': x_sc, 'y': y_sc}, colors=['dodgerblue'],
interactions={'click': 'select'},
selected_style={'opacity': 1.0, 'fill': 'DarkOrange', 'stroke': 'Red'},
unselected_style={'opacity': 0.5})
ax_x = Axis(scale=x_sc)
ax_y = Axis(scale=y_sc, orientation='vertical', tick_format='0.2f')
Figure(marks=[scatter_chart], axes=[ax_x, ax_y])
scatter_chart.selected
```
Alternately, the `selected` attribute can be directly set on the Python side (try running the cell below):
```
scatter_chart.selected = [1, 2, 3]
```
#### Scatter Chart Interactions and Tooltips
```
from ipywidgets import *
x_sc = LinearScale()
y_sc = LinearScale()
x_data = np.arange(20)
y_data = np.random.randn(20)
dd = Dropdown(options=['First', 'Second', 'Third', 'Fourth'])
scatter_chart = Scatter(x=x_data, y=y_data, scales= {'x': x_sc, 'y': y_sc}, colors=['dodgerblue'],
names=np.arange(100, 200), names_unique=False, display_names=False, display_legend=True,
labels=['Blue'])
ins = Button(icon='fa-legal')
scatter_chart.tooltip = ins
scatter_chart2 = Scatter(x=x_data, y=np.random.randn(20),
scales= {'x': x_sc, 'y': y_sc}, colors=['orangered'],
tooltip=dd, names=np.arange(100, 200), names_unique=False, display_names=False,
display_legend=True, labels=['Red'])
ax_x = Axis(scale=x_sc)
ax_y = Axis(scale=y_sc, orientation='vertical', tick_format='0.2f')
Figure(marks=[scatter_chart, scatter_chart2], axes=[ax_x, ax_y])
def print_event(self, target):
print(target)
# Adding call back to scatter events
# print custom mssg on hover and background click of Blue Scatter
scatter_chart.on_hover(print_event)
scatter_chart.on_background_click(print_event)
# print custom mssg on click of an element or legend of Red Scatter
scatter_chart2.on_element_click(print_event)
scatter_chart2.on_legend_click(print_event)
# Adding figure as tooltip
x_sc = LinearScale()
y_sc = LinearScale()
x_data = np.arange(10)
y_data = np.random.randn(10)
lc = Lines(x=x_data, y=y_data, scales={'x': x_sc, 'y':y_sc})
ax_x = Axis(scale=x_sc)
ax_y = Axis(scale=y_sc, orientation='vertical', tick_format='0.2f')
tooltip_fig = Figure(marks=[lc], axes=[ax_x, ax_y], layout=Layout(min_width='600px'))
scatter_chart.tooltip = tooltip_fig
# Changing interaction from hover to click for tooltip
scatter_chart.interactions = {'click': 'tooltip'}
```
## Line Chart
```
# Adding default tooltip to Line Chart
x_sc = LinearScale()
y_sc = LinearScale()
x_data = np.arange(100)
y_data = np.random.randn(3, 100)
def_tt = Tooltip(fields=['name', 'index'], formats=['', '.2f'], labels=['id', 'line_num'])
line_chart = Lines(x=x_data, y=y_data, scales= {'x': x_sc, 'y': y_sc},
tooltip=def_tt, display_legend=True, labels=["line 1", "line 2", "line 3"] )
ax_x = Axis(scale=x_sc)
ax_y = Axis(scale=y_sc, orientation='vertical', tick_format='0.2f')
Figure(marks=[line_chart], axes=[ax_x, ax_y])
# Adding call back to print event when legend or the line is clicked
line_chart.on_legend_click(print_event)
line_chart.on_element_click(print_event)
```
## Bar Chart
```
# Adding interaction to select bar on click for Bar Chart
x_sc = OrdinalScale()
y_sc = LinearScale()
x_data = np.arange(10)
y_data = np.random.randn(2, 10)
bar_chart = Bars(x=x_data, y=[y_data[0, :].tolist(), y_data[1, :].tolist()], scales= {'x': x_sc, 'y': y_sc},
interactions={'click': 'select'},
selected_style={'stroke': 'orange', 'fill': 'red'},
labels=['Level 1', 'Level 2'],
display_legend=True)
ax_x = Axis(scale=x_sc)
ax_y = Axis(scale=y_sc, orientation='vertical', tick_format='0.2f')
Figure(marks=[bar_chart], axes=[ax_x, ax_y])
# Adding a tooltip on hover in addition to select on click
def_tt = Tooltip(fields=['x', 'y'], formats=['', '.2f'])
bar_chart.tooltip=def_tt
bar_chart.interactions = {
'legend_hover': 'highlight_axes',
'hover': 'tooltip',
'click': 'select',
}
# Changing tooltip to be on click
bar_chart.interactions = {'click': 'tooltip'}
# Call back on legend being clicked
bar_chart.type='grouped'
bar_chart.on_legend_click(print_event)
```
## Histogram
```
# Adding tooltip for Histogram
x_sc = LinearScale()
y_sc = LinearScale()
sample_data = np.random.randn(100)
def_tt = Tooltip(formats=['', '.2f'], fields=['count', 'midpoint'])
hist = Hist(sample=sample_data, scales= {'sample': x_sc, 'count': y_sc},
tooltip=def_tt, display_legend=True, labels=['Test Hist'], select_bars=True)
ax_x = Axis(scale=x_sc, tick_format='0.2f')
ax_y = Axis(scale=y_sc, orientation='vertical', tick_format='0.2f')
Figure(marks=[hist], axes=[ax_x, ax_y])
# Changing tooltip to be displayed on click
hist.interactions = {'click': 'tooltip'}
# Changing tooltip to be on click of legend
hist.interactions = {'legend_click': 'tooltip'}
```
## Pie Chart
```
pie_data = np.abs(np.random.randn(10))
sc = ColorScale(scheme='Reds')
tooltip_widget = Tooltip(fields=['size', 'index', 'color'], formats=['0.2f', '', '0.2f'])
pie = Pie(sizes=pie_data, scales={'color': sc}, color=np.random.randn(10),
tooltip=tooltip_widget, interactions = {'click': 'tooltip'}, selected_style={'fill': 'red'})
pie.selected_style = {"opacity": "1", "stroke": "white", "stroke-width": "2"}
pie.unselected_style = {"opacity": "0.2"}
Figure(marks=[pie])
# Changing interaction to select on click and tooltip on hover
pie.interactions = {'click': 'select', 'hover': 'tooltip'}
```
| github_jupyter |
```
import torch
import torch.nn as nn
import math
from matplotlib import pyplot
from sklearn.preprocessing import MinMaxScaler
torch.manual_seed(0)
np.random.seed(0)
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
continue
import joblib
import numpy as np
from smartapi import SmartConnect
from rich import print
from smartapi import SmartWebSocket
import ipywidgets as widgets
import json
import pandas as pd
pd.set_option('plotting.backend', 'pandas_bokeh')
import pandas_bokeh
pandas_bokeh.output_notebook()
import datetime
import threading
import ast
import http.client
import mimetypes
conn = http.client.HTTPSConnection("apiconnect.angelbroking.com")
import time
from dateutil import parser, tz
from tqdm import tqdm
import nsepython
obj=SmartConnect(api_key="ANGEL_HISTORICAL_DATA_API_KEY",
#access_token = "your access token",
#refresh_token = "your refresh_token"
)
data = obj.generateSession("ANGEL_CLIENT_ID","ANGEL_PASSWORD")
refreshToken= data['data']['refreshToken']
feedToken=obj.getfeedToken()
userProfile= obj.getProfile(refreshToken)
headers = {
'Authorization': f'Bearer {obj.access_token}',
'Content-Type': 'application/json',
'Accept': 'application/json',
'X-UserType': 'USER',
'X-SourceID': 'WEB',
'X-ClientLocalIP': obj.clientLocalIP,
'X-ClientPublicIP': obj.clientPublicIP,
'X-MACAddress': obj.clientMacAddress,
'X-PrivateKey': obj.api_key
}
print (f"LOGIN : {userProfile['data']['name']}")
calculate_loss_over_all_values = False
input_window = 300
output_window = 5
batch_size = 10 # batch size
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
class TransAm(nn.Module):
def __init__(self,feature_size=30,num_layers=2,dropout=0.2):
super(TransAm, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(feature_size)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=feature_size, nhead=10, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(feature_size,1)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self,src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.pos_encoder(src)
output = self.transformer_encoder(src,self.src_mask)#, self.src_mask)
output = self.decoder(output)
return output
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = np.append(input_data[i:i+tw][:-output_window] , output_window * [0])
train_label = input_data[i:i+tw]
#train_label = input_data[i+output_window:i+tw+output_window]
inout_seq.append((train_seq ,train_label))
return torch.FloatTensor(inout_seq)
def get_data2(inst):
global scaler
old_lst=[]
interval='5minute'
todaydt=datetime.date.today()
hud_ago=todaydt-datetime.timedelta(days=50) #59
to_date=datetime.date.isoformat(todaydt)
from_date=datetime.date.isoformat(hud_ago)
for i2 in range(1):
new_lst = module.kite.historical_data(inst, from_date, to_date, interval,continuous=False)
old_lst = new_lst + old_lst
todaydt=todaydt-datetime.timedelta(days=51) #60
hud_ago=hud_ago-datetime.timedelta(days=51) #60
to_date=datetime.date.isoformat(todaydt)
from_date=datetime.date.isoformat(hud_ago)
df=pd.DataFrame(old_lst)
df_nifty = df
this_inst_df = df_nifty
amplitude = this_inst_df['close'].to_numpy()[-905:]
amplitude = amplitude.reshape(-1)
scaler = MinMaxScaler(feature_range=(-15, 15))
amplitude = scaler.fit_transform(amplitude.reshape(-1, 1)).reshape(-1)
sampels = int(amplitude.shape[0]*0)
train_data = amplitude[:sampels]
test_data = amplitude
train_sequence = create_inout_sequences(train_data,input_window)
train_sequence = train_sequence[:-output_window]
test_data = create_inout_sequences(test_data,input_window)
test_data = test_data[:-output_window]
return train_sequence.to(device),test_data.to(device)
def get_batch(source, i,batch_size):
seq_len = min(batch_size, len(source) - 1 - i)
data = source[i:i+seq_len]
input = torch.stack(torch.stack([item[0] for item in data]).chunk(input_window,1)) # 1 is feature size
target = torch.stack(torch.stack([item[1] for item in data]).chunk(input_window,1))
return input, target
def evaluate(eval_model, data_source):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
eval_batch_size = 1000
with torch.no_grad():
for i in range(0, len(data_source) - 1, eval_batch_size):
data, targets = get_batch(data_source, i,eval_batch_size)
output = eval_model(data)
if calculate_loss_over_all_values:
total_loss += len(data[0])* criterion(output, targets).to(device).item()
else:
total_loss += len(data[0])* criterion(output[-output_window:], targets[-output_window:]).to(device).item()
return total_loss / len(data_source)
plot_counter = 0
def plot_and_loss(eval_model, data_source,epoch,tknip):
global plot_counter
eval_model.eval()
total_loss = 0.
test_result = torch.Tensor(0)
truth = torch.Tensor(0)
with torch.no_grad():
for i in range(0, len(data_source) - 1):
data, target = get_batch(data_source, i,1)
# look like the model returns static values for the output window
output = eval_model(data)
if calculate_loss_over_all_values:
total_loss += criterion(output, target).item()
else:
total_loss += criterion(output[-output_window:], target[-output_window:]).item()
test_result = torch.cat((test_result.to(device), output[-1].view(-1).to(device)), 0) #todo: check this. -> looks good to me
truth = torch.cat((truth.to(device), target[-1].view(-1).to(device)), 0)
test_result = test_result.cpu().numpy()
truth = truth.cpu().numpy()
len(test_result)
return total_loss / i
def predict_future_open(eval_model, data_source,steps,tkn):
eval_model.eval()
total_loss = 0.
test_result = torch.Tensor(0)
truth = torch.Tensor(0)
_ , data = get_batch(data_source, 0,1)
with torch.no_grad():
for i in range(0, steps,1):
input = torch.clone(data[-input_window:])
input[-output_window:] = 0
output = eval_model(data[-input_window:])
data = torch.cat((data, output[-1:]))
data = data.cpu().view(-1)
pyplot.plot(data,color="red")
pyplot.plot(data[:input_window],color="blue")
pyplot.grid(True, which='both')
pyplot.axhline(y=0, color='k')
return data
def predict_future(eval_model, data_source,steps,tkn):
eval_model.eval()
total_loss = 0.
test_result = torch.Tensor(0)
truth = torch.Tensor(0)
_ , data = get_batch(data_source, 0,1)
with torch.no_grad():
for i in range(0, steps,1):
input = torch.clone(data[-input_window:])
input[-output_window:] = 0
output = eval_model(data[-input_window:])
data = torch.cat((data, output[-1:]))
data = data.cpu().view(-1)
pyplot.plot(data,color="red")
pyplot.plot(data[:input_window],color="blue")
pyplot.grid(True, which='both')
pyplot.axhline(y=0, color='k')
pyplot.savefig(f'./nmnm/transformer-future_{plot_counter}_{steps}_{tkn}.png')
pyplot.close()
model= torch.load('./best_model_multi8.pt',map_location=torch.device('cpu'))
# train_data, val_data = get_data2(2029825)
# predict_future(model,val_data,2000,2029825)
# look_up = 1001
# inst_check_list = [1793,5633,6401,3861249,2995969,25601,325121,6483969,40193,41729,54273,
# 60417,5436929,70401,1510401,4267265,4268801]
# for one in tqdm(inst_check_list):
# train_data, val_data = get_data2(one)
# col_list = []
# orig_data = np.array([])
# orig_data
# for one_part_point in range(15): # total_parts
# # print(val_data[-(300*(one_part_point+1))::].shape)
# dpp = predict_future_open(model, val_data[-(300*(one_part_point+1))::],2000,123123)
# col_list.append(np.append(orig_data,dpp))
# orig_data = np.append(orig_data,dpp[:input_window])
# # col_list.append(dpp)
# col_list.append(orig_data)
# pyplot.savefig(f'./nmnm/test_plot.png')
# pyplot.close()
# plot_df = pd.DataFrame(col_list)
# trps = plot_df.transpose()
# trps.plot()
# pd.DataFrame(orig_data).plot()
# # predict_future(model,val_data,look_up,one)
col_list = []
orig_data = np.array([])
test_len = 15
for one_part_point in tqdm(range(test_len)): # total_parts
dpp = predict_future_open(model, val_data[input_window*(one_part_point):input_window*(one_part_point+1)],1000,123123)
col_list.append(np.append(orig_data,dpp))
orig_data = np.append(orig_data,dpp[:input_window])
col_list.append(orig_data)
pyplot.savefig(f'./nmnm/test_plot.png')
pyplot.close()
plot_df = pd.DataFrame(col_list)
trps = plot_df.transpose()
trps.plot()
# for jj in range(8):
# print(jj+1)
# model= torch.load(f'./best_model_multi{jj+1}.pt',map_location=torch.device('cpu'))
# col_list = []
# orig_data = np.array([])
# test_len = 8
# for one_part_point in tqdm(range(test_len)): # total_parts
# dpp = predict_future_open(model, val_data[input_window*(one_part_point):input_window*(one_part_point+1)],100,123123)
# col_list.append(np.append(orig_data,dpp))
# orig_data = np.append(orig_data,dpp[:input_window])
# col_list.append(orig_data)
# pyplot.savefig(f'./nmnm/test_plot.png')
# pyplot.close()
# plot_df = pd.DataFrame(col_list)
# trps = plot_df.transpose()
# trps.plot()
# print('*'*60)
train_data, val_data = get_data2(3356417)
val_data[-1][0]
train_data, val_data = get_data2(3529217)
col_list = []
orig_data = np.array([])
test_len = 2
model= torch.load(f'./best_model_multi18.pt',map_location=torch.device('cpu'))
for one_part_point in tqdm(range(test_len)): # total_parts
dpp = predict_future_open(model, val_data[input_window*(one_part_point):input_window*(one_part_point+1)],
1000,123123)
mod = dpp[0].numpy()
if (orig_data.size != 0): #check not empty
org = orig_data[-1]
diff = org-mod
dpp = dpp + diff
col_list.append(np.append(orig_data,dpp))
orig_data = np.append(orig_data,dpp[:input_window])
pyplot.savefig(f'./nmnm/test_plot.png')
pyplot.close()
plot_df = pd.DataFrame(col_list)
trps = plot_df.transpose()
trps.plot()
train_data, val_data = get_data2(3356417) #3529217
col_list = []
orig_data = np.array([])
test_len = 2
model= torch.load(f'./best_model_multi18.pt',map_location=torch.device('cpu'))
for one_part_point in tqdm(range(test_len)): # total_parts
dpp = predict_future_open(model, val_data[input_window*(one_part_point):input_window*(one_part_point+1)],
1000,123123)
if (orig_data.size != 0): #check not empty
diff = orig_data[-1] - dpp[301].numpy()
dpp = dpp - diff
col_list.append(np.append(orig_data,dpp))
orig_data = np.append(orig_data,dpp[:input_window])
pyplot.savefig(f'./nmnm/test_plot.png')
pyplot.close()
plot_df = pd.DataFrame(col_list)
trps = plot_df.transpose()
trps.plot()
for i in range(14,19):
for jj in [1459457,70401,261889,]:
# for jj in [3861249,6401,3677697,3669505]:
print('*'*50)
print(i)
print(jj)
train_data, val_data = get_data2(jj)
col_list = []
orig_data = np.array([])
test_len = 6
model= torch.load(f'./best_model_multi{i}.pt',map_location=torch.device('cpu'))
for one_part_point in tqdm(range(test_len)): # total_parts
dpp = predict_future_open(model, val_data[input_window*(one_part_point):input_window*(one_part_point+1)],
300,123123)
mod = dpp[0].numpy()
if (orig_data.size != 0): #check not empty
org = orig_data[-1]
diff = org-mod
dpp = dpp + diff
col_list.append(np.append(orig_data,dpp))
orig_data = np.append(orig_data,dpp[:input_window])
pyplot.savefig(f'./nmnm/test_plot.png')
pyplot.close()
plot_df = pd.DataFrame(col_list)
trps = plot_df.transpose()
trps.plot()
loss_df = pd.read_excel('../valid_loss_map_df_5x (17).xlsx')
loss_df['name'] =''
type(loss_df['inst'][0])
all_inst = pd.read_excel('./all_inst.xlsx')
df3 = pd.merge(loss_df,all_inst,left_on=['inst'], right_on = ['instrument_token'], how = 'left')
df3['ltp']=0.0
df3 = df3[0:143]
inedx_counter = 0
for one_symbol in tqdm(df3.tradingsymbol):
ltp = module.kite.quote([f'NSE:{one_symbol}'])[f'NSE:{one_symbol}']['last_price']
df3.at[inedx_counter, 'ltp'] = ltp
# print(one_symbol)
# print(ltp)
inedx_counter += 1
model_loss_list =[]
criterion = nn.MSELoss()
for i in tqdm(range(18)):
this_model = f'./best_model_multi{i+1}.pt'
this_total_loss = 0.0
model = torch.load(this_model, map_location=torch.device('cpu'))
inedx_counter = 0
df3['loss'] = 0.0
for one_inst in tqdm(df3.inst.astype(dtype='int32')):
_, val_data_ip = get_data2(one_inst)
this_loss = plot_and_loss(model, val_data_ip, 1, one_inst)
this_total_loss+=this_loss
df3.at[inedx_counter, 'loss'] = this_loss
inedx_counter+=1
print(this_model)
print(this_total_loss)
model_loss_list.append({'model':this_model,'this_total_loss':this_total_loss})
model_loss_list_edf = pd.DataFrame(model_loss_list)
model_loss_list_edf
this_model = f'./best_model_multi7.pt'
this_total_loss = 0.0
model = torch.load(this_model, map_location=torch.device('cpu'))
inedx_counter = 0
df3['loss'] = 0.0
for one_inst in tqdm(df3.inst.astype(dtype='int32')):
_, val_data_ip = get_data2(one_inst)
this_loss = plot_and_loss(model, val_data_ip, 1, one_inst)
df3.at[inedx_counter, 'loss'] = this_loss
inedx_counter+=1
print(this_model)
print(this_total_loss)
import matplotlib.pyplot as plt
plt.matshow(df3.corr())
plt.show()
df3['ltp_by_loss'] = df3['ltp']/df3['loss']
# df3[['ltp_by_loss']]
df3['ltp_by_lossx10'] = df3['ltp_by_loss']*20
df3['lossx10'] = df3['loss']*20
df3[['ltp','lossx10','ltp_by_lossx10']].plot()
ax = df3[['ltp','lossx10','ltp_by_lossx10']].plot.hist(bins=100, alpha=0.3)
df3[df3.ltp_by_loss > 180]
this_model = f'./best_model_multi3.pt'
this_total_loss = 0.0
model = torch.load(this_model, map_location=torch.device('cpu'))
inedx_counter = 0
df3['loss'] = 0.0
for one_inst in tqdm(df3.inst.astype(dtype='int32')):
_, val_data_ip = get_data2(one_inst)
this_loss = plot_and_loss(model, val_data_ip, 1, one_inst)
df3.at[inedx_counter, 'loss'] = this_loss
inedx_counter+=1
print(this_model)
print(this_total_loss)
import matplotlib.pyplot as plt
plt.matshow(df3.corr())
plt.show()
df3['ltp_by_loss'] = df3['ltp']/df3['loss']
# df3[['ltp_by_loss']]
df3['ltp_by_lossx10'] = df3['ltp_by_loss']*20
df3['lossx10'] = df3['loss']*20
df3[['ltp','lossx10','ltp_by_lossx10']].plot()
ax = df3[['ltp','lossx10','ltp_by_lossx10']].plot.hist(bins=100, alpha=0.3)
df3[df3.ltp_by_loss > 180]
df3.to_excel('./df3.xlsx',index=False)
import QuantConnect_Reserved
```
| github_jupyter |
<h1>MANDATORY PACKAGES</h1>
```
import os
import datetime
import numpy as np
from collections import namedtuple
import pandas as pd
import ftputil #pip install ftputil
from shapely.geometry import box #conda install Shapely
import folium # conda install -c conda-forge folium
from folium import plugins
```
<ul><b>Warning!</b>: Some of the packages will need a prior installation. A clear indication of this will be the see a <i style="color:red">ModuleNotFoundError: No module named '{module name}}'</i> when running the next cell.<br>
For each package throwing this error, please open first the Anaconda Powershell Prompt and run the installing command specified after the '#' next to the package.</ul>
<h1>AUXILIARY FUNCTIONS</h1>
```
def cmems_hosts():
#dictionary of available FTP servers hosting CMEMS data
return {'NRT': 'nrt.cmems-du.eu', 'REP': 'my.cmems-du.eu'}
def bbox_check(netCDF, search_area):
#filter-out netCDFs whose bounding-box is not within the aimed area (search_area)
#please use shapely documentation (https://shapely.readthedocs.io/en/stable/manual.html) to play with different relationships between geometric objects – contains, intersects, overlaps, touches, etc
geospatial_lat_min = float(netCDF['geospatial_lat_min'])
geospatial_lat_max = float(netCDF['geospatial_lat_max'])
geospatial_lon_min = float(netCDF['geospatial_lon_min'])
geospatial_lon_max = float(netCDF['geospatial_lon_max'])
targeted_bounding_box = box(search_area[0], search_area[1], search_area[2], search_area[3])
bounding_box = box(geospatial_lon_min, geospatial_lat_min, geospatial_lon_max, geospatial_lat_max)
if targeted_bounding_box.contains(bounding_box):
return True
else:
return False
def timerange_check(netCDF, search_timerange):
#filter-out netCDFs whose timerange does not overlap with the aimed times (search_timerange)
date_format = "%Y-%m-%dT%H:%M:%SZ"
targeted_ini = datetime.datetime.strptime(search_timerange[0], date_format)
targeted_end = datetime.datetime.strptime(search_timerange[1], date_format)
time_start = datetime.datetime.strptime(netCDF['time_coverage_start'].decode('utf-8'), date_format)
time_end = datetime.datetime.strptime(netCDF['time_coverage_end'].decode('utf-8'), date_format)
Range = namedtuple('Range', ['start', 'end'])
r1 = Range(start=targeted_ini, end=targeted_end)
r2 = Range(start=time_start, end=time_end)
latest_start = max(r1.start, r2.start)
earliest_end = min(r1.end, r2.end)
delta = (earliest_end - latest_start).days + 1
overlap = max(0, delta)
if overlap != 0:
return True
else:
return False
def parameters_check(netCDF, search_parameters):
#filter-out those netCDFs not containing any of the aimed parameters (search_parameters)
#see more at: https://archimer.ifremer.fr/doc/00422/53381/
params = netCDF['parameters'].decode('utf-8').split(' ')
result = False
for param in params:
if param in search_parameters:
result = True
return result
def sources_check(netCDF, search_sources):
#filter-out those netCDFs not coming from the aimed data sources (search_sources)
#see more at http://resources.marine.copernicus.eu/documents/PUM/CMEMS-INS-PUM-013-048.pdf
ftplink = netCDF['file_name'].decode('utf-8')
result = False
for source in search_sources:
if source == 'TS':
source = 'TS_TS'
if '_'+source+'_' in ftplink:
result = True
return result
#dictionary of checkers
checkers = {
'bbox': bbox_check,
'timerange': timerange_check,
'parameters': parameters_check,
'sources': sources_check
}
def search(configuration, treshold=None, output=None, output_dir=None):
#access the FTPserver, product and archive to search for netCDFs matching the conditions set in the configuration
#if output is set to None (default behaviour) it returns the lis of matching files per archive.
#if output is set to 'files' it download the matching files.
#if output is set to 'map' it returns a map with the matching files's bbox-centrois.
matches = {}
host = [cmems_hosts()[key] for key in cmems_hosts().keys() if key in configuration['product']][0]
map = folium.Map(zoom_start=5)
with ftputil.FTPHost(host, configuration['user'], configuration['password']) as ftp_host:
archives = configuration['archives']
for item in archives:
marker_cluster = plugins.MarkerCluster(name=item,overlay=True,control=True)
counter, matches[item], index_file = 0, [],'index_'+item+'.txt'
columns = ['catalog_id', 'file_name','geospatial_lat_min', 'geospatial_lat_max', 'geospatial_lon_min','geospatial_lon_max','time_coverage_start', 'time_coverage_end', 'provider', 'date_update', 'data_mode', 'parameters']
#open the index file to read
with ftp_host.open("Core"+'/'+configuration['product']+'/'+index_file, "r") as indexfile:
#read the index file as a comma-separate-value file
index = np.genfromtxt(indexfile, skip_header=6, unpack=False, delimiter=',', dtype=None, names=columns)
dataframe = pd.DataFrame(index)
#loop over the lines/netCDFs and download the most suitable ones for you
if treshold != None and counter > treshold:
continue
for netCDF in index:
values = [checkers[key](netCDF,val) for key,val in configuration['searching_criteria'].items() if val != None]
if False not in values: #save netCDF if meeting all selection criteria
counter = counter + 1
decoded_metadata = [metadata.decode('utf-8') if isinstance(metadata, bytes) else metadata for metadata in list(netCDF)]
matches[item].append({key: val for key,val in zip(columns,decoded_metadata)})
#getting ftplink, filepath and filename
ftplink = netCDF['file_name'].decode('utf-8')
filepath = '/'.join(ftplink.split('/')[3:len(ftplink.split('/'))])
ncdf_file_name = ftplink[ftplink.rfind('/')+1:]
if output=='map':
lat_min = netCDF['geospatial_lat_min']
lat_max = netCDF['geospatial_lat_max']
lon_min = netCDF['geospatial_lon_min']
lon_max = netCDF['geospatial_lon_max']
try:
bounding_box = box(lon_min, lat_min, lon_max, lat_max)
except Exception as e:
bounding_box = box(float(lon_min), float(lat_min), float(lon_max), float(lat_max))
x,y = bounding_box.centroid.x, bounding_box.centroid.y
marker = folium.Marker([y,x])
popup_content = '<br>'.join('<b>'+key+'</b> : '+str(val) for key,val in zip(columns,decoded_metadata))
folium.Popup(popup_content).add_to(marker)
marker_cluster.add_child(marker)
if output=='files':
directory = output_dir if output_dir != None else os.getcwd()
os.chdir(directory)
print('...Downloading from '+item+' : '+ncdf_file_name)
ftp_host.download(filepath, ncdf_file_name) #download netCDF
ftp_host.close()
marker_cluster.add_to(map)
folium.LayerControl().add_to(map)
if output == None:
[print('Found '+str(len(matches[item]))+' macthes in '+item) for item in archives]
print('Search completed!')
return matches
if output == 'map':
[print('Found '+str(len(matches[item]))+' macthes in '+item) for item in archives]
print('....Displaying files boundingBox centroids:')
print('warning!: open the notebook with chrome if map does not display')
return map
if output == 'files':
print('Download completed!')
return
```
<h1>SETTINGS</h1>
```
configuration = {
'user': 'protllan', #type CMEMS user name <= Don't you have one? ask here: http://marine.copernicus.eu/services-portfolio/register-now/
'password': 'PazCMEMS2016', #type CMEMS password <= Don't you have one? ask here: http://marine.copernicus.eu/services-portfolio/register-now/
'product': 'INSITU_IBI_NRT_OBSERVATIONS_013_033', #options: INSITU_IBI_TS_REP_OBSERVATIONS_013_040 or INSITU_IBI_NRT_OBSERVATIONS_013_033
'archives': ['history'], #options: history (NRT & REP), monthly (NRT), latest (NRT)
'searching_criteria':{
'bbox': [-8.6, 36.78, -12.6, 41.9], #Define here the area you want to check for data (expected order: south-east longitude, south-east latitude, north-west longitude, north-west latitude)
'timerange': ['2019-04-01T00:00:00Z', '2019-05-30T23:59:59Z'],#Define here the time-range you want to check for data (expected format: "YYYY-mm-ddTHH:MM:SSZ")
'parameters': ['TEMP', 'PSAL'], #Define here the parameters you are interested in (see more at: https://archimer.ifremer.fr/doc/00422/53381/
'sources': ['MO']#Define here the sources you are interested in (see more at: http://resources.marine.copernicus.eu/documents/PUM/CMEMS-INS-PUM-013-048.pdf),
}
}
```
If you do not want to apply any of the above searching_criteria provide an None value instead.
Achives refers to the collection of netCDFs to explore:
<ul>
<li><b>Latest</b>: to access last 30 days of data => one file/platform/day</li>
<li><b>Monthy</b>: to access last 5 years of data => one file/platform/month</li>
<li><b>History</b>: to access all available data => one file/platform</li>
</ul>
<H1>MATCHING FILES</H1>
Search files matching the above configuration:
```
search_result = search(configuration)
```
Get a quick view of the files:
```
pd.DataFrame(search_result['history'])
```
Locate on a map matching files bounding-box centroids:
```
search(configuration, output='map')
```
Download the files matching the configuration:
```
search(configuration, output='files')
```
| github_jupyter |
```
# import any necessary packages
import os
import pandas as pd
import numpy as np
# need to import the sktime utils
from sktime.forecasting.all import *
from sktime.forecasting.ets import AutoETS
%matplotlib inline
# check current working directory
print(os.getcwd())
df = pd.read_csv(os.getcwd() + "/../default/user_history.csv")
df
# remove sleep notes, heart rate and activity, and for now, Wake up emoji
list(df)
# need to drop extraneous columns (not needed anymore)
# df = df.drop('Heart rate', 1)
# df = df.drop('Activity (steps)', 1)
# df = df.drop('Sleep Notes', 1)
# df = df.drop('Wake up', 1)
# df = df.drop('End', 1)
df
```
# chop sleep quality percentages to range between 0 and 10
This is no longer needed.
```python
def truncate_percentage_to_range(x):
x = x.strip('%')
x = int(x) / 10.0
return x
def time_to_minutes(x):
s = x.split(":")
s = int(s[0]) * 60 + int(s[1])
return s
def extract_date(x):
s = x.split(" ")
return s[0]
df['Sleep quality'] = df['Sleep quality'].apply(truncate_percentage_to_range)
df['Time in bed'] = df['Time in bed'].apply(time_to_minutes)
df['Start'] = df['Start'].apply(extract_date)
df = df.rename(columns={'Start':'Date'})
```
```
df
# Plot the data over the dates
# At first glance, we have 887 rows starting in 2014. 887 / 365 is approx 2.4 years,
# but technically this data set spans from the beginning of 2015 to the beginning of 2018,
# a time of over 3 years. There's definetly some gaps.
df.plot(x="Date", y = "Sleep quality")
user_df = pd.read_csv(os.getcwd() + "/../test/test_inputs/sample_7_days.csv")
user_df["Time in bed"] = 60 * user_df["Time in bed"]
user_df
# frames = [df, user_df]
# result = pd.concat(frames, ignore_index=True)
result = df.append(user_df)
result
list(result)
y = load_airline() # numpy array
y_train, y_test = temporal_train_test_split(y, test_size=36)
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = ThetaForecaster(sp=12) # monthly seasonal periodicity
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
smape_loss(y_test, y_pred)
plot_series(y_train, y_test, labels=["y_train", "y_test"])
print(y_train.shape[0], y_test.shape[0])
print("y:", y)
print("\ny_train:", y_train)
print("\ny_test:", y_test)
# relative forecasting horizon
rfh = np.arange(len(y_test)) + 1
# absolute forecasting horizon
afh = ForecastingHorizon(y_test.index, is_relative=False)
print("rfh", rfh)
print("afh", afh)
# actual forecasting pipeline:
# we first need to specify or build a model, then fit it to the training data,
# and finally call predict to generate the forecasts for the given forecasting horizon
## Predicting using the last value
# specify the model
forecast_naive = NaiveForecaster(strategy="last")
forecast_naive_seasonal = NaiveForecaster(strategy="last", sp=12)
forecast_exponential_smoothing = ExponentialSmoothing(trend="add", seasonal="multiplicative", sp=12)
forecast_auto_ets = AutoETS(auto=True, sp=12, n_jobs=-1)
forecast_arima = AutoARIMA(sp=12, suppress_warnings=True)
# fit it to the training data
forecast_naive.fit(y_train)
forecast_naive_seasonal.fit(y_train)
forecast_exponential_smoothing.fit(y_train)
forecast_auto_ets.fit(y_train)
forecast_arima.fit(y_train)
# generate a prediction
y_pred_naive = forecast_naive.predict(afh)
y_pred_naive_szn = forecast_naive_seasonal.predict(afh)
y_pred_exp_smooth = forecast_exponential_smoothing.predict(afh)
y_pred_ets = forecast_auto_ets.predict(afh)
y_pred_arima = forecast_arima.predict(afh)
# generate plots
plot_series(y_train, y_test, y_pred_naive, labels=["y_train", "y_test", "y_pred_naive"])
plot_series(y_train, y_test, y_pred_naive_szn, labels=["y_train", "y_test", "y_pred_naive_szn"])
plot_series(y_train, y_test, y_pred_exp_smooth, labels=["y_train", "y_test", "y_pred_exp_smooth"])
plot_series(y_train, y_test, y_pred_ets, labels=["y_train", "y_test", "y_pred_ets"])
plot_series(y_train, y_test, y_pred_arima, labels=["y_train", "y_test", "y_pred_arima"])
# return the error (lower smape_loss, the higher the accuracy)
print("naive: ", smape_loss(y_pred_naive, y_test))
print("naive seasonal: ", smape_loss(y_pred_naive_szn, y_test))
print("exponential smoothing, seasonal: ", smape_loss(y_pred_exp_smooth, y_test))
print("auto ets: ", smape_loss(y_pred_exp_smooth, y_pred_ets))
print("arima: ", smape_loss(y_pred_exp_smooth, y_pred_arima))
```
# Coverage of forecasting from the sktime tuts:
Reduction to regression works as follows: We first need to transform the data into the required tabular format. We can do this by cutting the training series into windows of a fixed length and stacking them on top of each other. Our target variable consists of the subsequent observation for each window.
```
feature_window[:5, :]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
[ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
[ 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[ 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]])
target_window[:5]:
array([10, 11, 12, 13, 14])
```
So this seems to be that the order is recursive. And, we are predicting only one value.
# Ensemble
https://tostr.pl/blog/ensemble-learning-stacking-models-with-scikit-learn/
```
forecast_ensemble = EnsembleForecaster(
[
("ses", ExponentialSmoothing(seasonal="multiplicative", sp=12)),
(
"holt",
ExponentialSmoothing(
trend="add", damped_trend=False, seasonal="multiplicative", sp=12
),
),
(
"damped",
ExponentialSmoothing(
trend="add", damped_trend=True, seasonal="multiplicative", sp=12
),
),
]
)
forecast_ensemble.fit(y_train)
y_pred_ensemble = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred_ensemble, labels=["y_train", "y_test", "y_pred_ensemble"])
smape_loss(y_test, y_pred_ensemble)
# Online forecasting imports
from sklearn.metrics import mean_squared_error
from sktime.forecasting.online_learning import (
NormalHedgeEnsemble,
OnlineEnsembleForecaster,
)
# First we need to initialize a PredictionWeightedEnsembler that will keep track of the loss accumulated by each forecaster and define which loss function we would like to use.
hedge_expert = NormalHedgeEnsemble(n_estimators=3, loss_func=mean_squared_error)
online_forecast = OnlineEnsembleForecaster(
[
("ses", ExponentialSmoothing(seasonal="multiplicative", sp=12)),
(
"holt",
ExponentialSmoothing(
trend="add", damped_trend=False, seasonal="multiplicative", sp=12
),
),
(
"damped",
ExponentialSmoothing(
trend="add", damped_trend=True, seasonal="multiplicative", sp=12
),
),
],
ensemble_algorithm=hedge_expert,
)
online_forecast.fit(y_train)
y_pred_online = online_forecast.update_predict(y_test)
plot_series(y_train, y_test, y_pred_online, labels=["y_train", "y_test", "y_pred_online"])
smape_loss(y_test[1:], y_pred_online)
df
df.iloc[:, 0:2]
df.iloc[:, 0:3:2]
# attempt with our sleep data
## Predicting using the last value
# split the data into date, sleep quality and date, sleep time
df_quality = df.iloc[:,0:2]
df_quality.set_index('Date', inplace=True)
print(df_quality)
# clean up strictly non-positive values (lowest bound is 0.0, exclusive)
def raise_minimum(x):
if x <= 0.0:
return 0.1
return x
df_quality['Sleep quality'] = df_quality['Sleep quality'].apply(raise_minimum)
# transform data to a compatible data type
print(type(y_train),type(df_quality),'\n')
df_quality.dropna(inplace=True)
s_quality = df_quality.squeeze()
s_quality.name = "Sleep quality from 0 to 10"
s_quality.index = pd.PeriodIndex(s_quality.index, freq="D", name="Period")
print('sleep quality\n',s_quality)
print(y_train)
print("minimum: ",df_quality.min())
```
# Test without appending user data to the provided data
```
# generate a forecasting horizon
r_sleep_fh = np.arange(len(user_df)) + 1
# specify the model
forecast = ExponentialSmoothing(trend="add", seasonal="multiplicative", sp=7)
# # fit it to the training data
forecast.fit(s_quality)
# # generate a prediction
prediction = forecast.predict(r_sleep_fh)
# # generate plots
# todo - format s_user_quality
plot_series(s_quality[-7:], prediction, labels=["train", "prediction"])
# # return the error (lower smape_loss, the higher the accuracy)
# print("naive: ", smape_loss(y_pred_naive, y_test))
```
# Test with user data having been appended
```
# generate a forecasting horizon
r_sleep_fh = np.arange(len(user_df)) + 1
# specify the model
forecast = ExponentialSmoothing(trend="add", seasonal="multiplicative", sp=7)
# the trick - append user_df to s_quality
user_df_quality = user_df.iloc[:,0:2]
user_df_quality.set_index('Date', inplace=True)
user_s = user_df_quality.squeeze()
user_s.name = "Sleep quality from 0 to 10"
user_s.index = pd.PeriodIndex(user_s.index, freq="D", name="Period")
user_s = user_s + 0.1
# # fit it to the training data
forecast.fit(s_quality.append(user_s, ignore_index=True))
# # generate a prediction
prediction = forecast.predict(r_sleep_fh)
print(type(user_s.index))
print(type(s_quality.index))
print(user_s)
print(s_quality)
prediction
# plot_series(s_quality[-7:], prediction, labels=["train", "prediction"])
# # return the error (lower smape_loss, the higher the accuracy)
# print("naive: ", smape_loss(y_pred_naive, y_test))
# convert prediction series to data frame
sleep_prediction_df = prediction.to_frame()
sleep_prediction_df = sleep_prediction_df.rename(columns={0:"Sleep Quality"})
print(list(sleep_prediction_df))
sleep_prediction_df
sleep_prediction_df.to_csv("file1.csv")
```
| github_jupyter |
# Clustering
In contrast to *supervised* machine learning, *unsupervised* learning is used when there is no "ground truth" from which to train and validate label predictions. The most common form of unsupervised learning is *clustering*, which is simllar conceptually to *classification*, except that the the training data does not include known values for the class label to be predicted. Clustering works by separating the training cases based on similarities that can be determined from their feature values. Think of it this way; the numeric features of a given entity can be though of as vector coordinates that define the entity's position in n-dimensional space. What a clustering model seeks to do is to identify groups, or *clusters*, of entities that are close to one another while being separated from other clusters.
For example, let's take a look at the Palmer Islands penguin dataset, which contains measurements of penguins.
Let's start by examining a dataset that contains observations of multiple classes. We'll use a dataset that contains observations of three different species of penguin.
> **Citation**: The penguins dataset used in the this exercise is a subset of data collected and made available by [Dr. Kristen
Gorman](https://www.uaf.edu/cfos/people/faculty/detail/kristen-gorman.php)
and the [Palmer Station, Antarctica LTER](https://pal.lternet.edu/), a
member of the [Long Term Ecological Research
Network](https://lternet.edu/).
```
import pandas as pd
# load the training dataset (dropping rows with nulls)
penguins = pd.read_csv('data/penguins.csv').dropna()
# Display a random sample of 10 observations (just the features)
penguin_features = penguins[penguins.columns[0:4]]
penguin_features.sample(10)
```
As you can see, the dataset contains four data points (or *features*) for each instance (*observation*) of an penguin. So you could interpret these as coordinates that describe each instance's location in four-dimensional space.
Now, of course four dimensional space is difficult to visualise in a three-dimensional world, or on a two-dimensional plot; so we'll take advantage of a mathematical technique called *Principal Component Analysis* (PCA) to analyze the relationships between the features and summarize each observation as coordinates for two principal components - in other words, we'll translate the four dimensional feature values into two-dimensional coordinates.
```
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA
# Normalize the numeric features so they're on the same scale
penguin_features[penguins.columns[0:4]] = MinMaxScaler().fit_transform(penguin_features[penguins.columns[0:4]])
# Get two principal components
pca = PCA(n_components=2).fit(penguin_features.values)
penguins_2d = pca.transform(penguin_features.values)
penguins_2d[0:10]
```
Now that we have the data points translated to two dimensions, we can visualize them in a plot:
```
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(penguins_2d[:,0],penguins_2d[:,1])
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Penguin Data')
plt.show()
```
Hopefully you can see at least two, arguably three, reasonably distinct groups of data points; but here lies one of the fundamental problems with clustering - without known class labels, how do you know how many clusters to separate your data into?
One way we can try to find out is to use a data sample to create a series of clustering models with an incrementing number of clusters, and measure how tightly the data points are grouped within each cluster. A metric often used to measure this tightness is the *within cluster sum of squares* (WCSS), with lower values meaning that the data points are closer. You can then plot the WCSS for each model.
```
#importing the libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
%matplotlib inline
# Create 10 models with 1 to 10 clusters
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i)
# Fit the Iris data points
kmeans.fit(penguin_features.values)
# Get the WCSS (inertia) value
wcss.append(kmeans.inertia_)
#Plot the WCSS values onto a line graph
plt.plot(range(1, 11), wcss)
plt.title('WCSS by Clusters')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
```
The plot shows a large reduction in WCSS (so greater *tightness*) as the number of clusters increases from one to two, and a further noticable reduction from two to three clusters. After that, the reduction is less pronounced, resulting in an "elbow" in the chart at around three clusters. This is a good indication that there are two to three reasonably well separated clusters of data points.
## K-Means Clustering
The algorithm we used to create our test clusters is *K-Means*. This is a commonly used clustering algorithm that separates a dataset into *K* clusters of equal variance. The number of clusters, *K*, is user defined. The basic algorithm has the following steps:
1. A set of K centroids are randomly chosen.
2. Clusters are formed by assigning the data points to their closest centroid.
3. The means of each cluster is computed and the centroid is moved to the mean.
4. Steps 2 and 3 are repeated until a stopping criteria is met. Typically, the algorithm terminates when each new iteration results in negligable movement of centroids and the clusters become static.
5. When the clusters stop changing, the algorithm has *converged*, defining the locations of the clusters - note that the random starting point for the centroids means that re-running the algorithm could result in slightly different clusters, so training usually involves multiple iterations, reinitializing the centroids each time, and the model with the best WCSS is selected.
Let's try using K-Means on our penguin data with a K value of 3.
```
from sklearn.cluster import KMeans
# Create a model based on 3 centroids
model = KMeans(n_clusters=3, init='k-means++', n_init=20, max_iter=200)
# Fit to the iris data and predict the cluster assignments for each data point
km_clusters = model.fit_predict(penguin_features.values)
# View the cluster assignments
km_clusters
```
Let's see those cluster assignments with the two-dimensional data points.
```
def plot_clusters(samples, clusters):
col_dic = {0:'blue',1:'green',2:'orange'}
mrk_dic = {0:'*',1:'x',2:'+'}
colors = [col_dic[x] for x in clusters]
markers = [mrk_dic[x] for x in clusters]
for sample in range(len(clusters)):
plt.scatter(samples[sample][0], samples[sample][1], color = colors[sample], marker=markers[sample], s=100)
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Assignments')
plt.show()
plot_clusters(penguins_2d, km_clusters)
```
The clusters look reasonably well separated.
So what's the practical use of clustering? In some cases, you may have data that you need to group into distict clusters without knowing how many clusters there are or what they indicate. For example a marketing organization might want to separate customers into distinct segments, and then investigate how those segments exhibit different purchasing behaviors.
Sometimes, clustering is used as an initial step towards creating a classification model. You start by identifying distinct groups of data points, and then assign class labels to those clusters. You can then use this labelled data to train a classification model.
In the case of the penguin data, the different species of penguin are already known, so we can use the class labels identifying the species to plot the class assignments and compare them to the clusters identified by our unsupervised algorithm
```
penguin_species = penguins[penguins.columns[4]]
plot_clusters(penguins_2d, penguin_species.values)
```
There may be some differences in the cluster assignments and class labels, but the K-Means model should have done a reasonable job of clustering the penguin observations so that birds of the same species are generally in the same cluster.
## Hierarchical Clustering
Hierarchical clustering methods make fewer distributional assumptions when compared to K-means methods. However, K-means methods are generally more scalable, sometimes very much so.
Hierarchical clustering creates clusters by either a *divisive* method or *agglomerative* method. The divisive method is a "top down" approach starting with the entire dataset and then finding partitions in a stepwise manner. Agglomerative clustering is a "bottom up** approach. In this lab you will work with agglomerative clustering which roughly works as follows:
1. The linkage distances between each of the data points is computed.
2. Points are clustered pairwise with their nearest neighbor.
3. Linkage distances between the clusters are computed.
4. Clusters are combined pairwise into larger clusters.
5. Steps 3 and 4 are repeated until all data points are in a single cluster.
The linkage function can be computed in a number of ways:
- Ward linkage measures the increase in variance for the clusters being linked,
- Average linkage uses the mean pairwise distance between the members of the two clusters,
- Complete or Maximal linkage uses the maximum distance between the members of the two clusters.
Several different distance metrics are used to compute linkage functions:
- Euclidian or l2 distance is the most widely used. This metric is only choice for the Ward linkage method.
- Manhattan or l1 distance is robust to outliers and has other interesting properties.
- Cosine similarity, is the dot product between the location vectors divided by the magnitudes of the vectors. Notice that this metric is a measure of similarity, whereas the other two metrics are measures of difference. Similarity can be quite useful when working with data such as images or text documents.
### Agglomerative Clustering
Let's see an example of clustering the penguin data using an agglomerative clustering algorithm.
```
from sklearn.cluster import AgglomerativeClustering
agg_model = AgglomerativeClustering(n_clusters=3)
agg_clusters = agg_model.fit_predict(penguin_features.values)
agg_clusters
```
So what do the agglomerative cluster assignments look like?
```
import matplotlib.pyplot as plt
%matplotlib inline
def plot_clusters(samples, clusters):
col_dic = {0:'blue',1:'green',2:'orange'}
mrk_dic = {0:'*',1:'x',2:'+'}
colors = [col_dic[x] for x in clusters]
markers = [mrk_dic[x] for x in clusters]
for sample in range(len(clusters)):
plt.scatter(samples[sample][0], samples[sample][1], color = colors[sample], marker=markers[sample], s=100)
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Assignments')
plt.show()
plot_clusters(penguins_2d, agg_clusters)
```
In this notebook, you've explored clustering; an unsupervised form of machine learning.
To learn more about clustering with scikit-learn, see the [scikit-learn documentation](https://scikit-learn.org/stable/modules/clustering.html).
| github_jupyter |
# Ensembles and Random Forests
This notebook covers what bagging and random forests are and how to apply them using scikit-learn
*Adapted from Chapter 8 of [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/)* among many others.
### What is Ensembling
**Ensemble learning (or "ensembling")** is the process of combining several predictive models in order to produce a combined model that is more accurate than any individual model.
- **Regression:** Take the average of the predictions.
- **Classification:** Take a vote and use the most common prediction.
For ensembling to work well, the models must be:
- **Accurate:** They outperform the null model.
- **Independent:** Their predictions are generated using different processes.
**The big idea:** If you have a collection of individually imperfect (and independent) models, the "one-off" mistakes made by each model are probably not going to be made by the rest of the models, and thus the mistakes will be discarded when you average the models.
There are two basic **methods for ensembling:**
- Manually ensembling your individual models.
- Using a model that ensembles for you.
```
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplotlib
# Visualize decision tree using matplotlib wrapper
from sklearn import tree
# Model imports
from sklearn.tree import DecisionTreeRegressor
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
# Set a threshold for which features to include.
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import train_test_split
# Metrics imports
from sklearn import metrics
from subprocess import call
```
### Bagging
A weakness of **decision trees** is that they don't tend to have the best predictive accuracy. This is partially because of **high variance**, meaning that different splits in the training data can lead to very different trees.
**Bagging** is a general-purpose procedure for reducing the variance of a machine learning method but is particularly useful for decision trees. Bagging is short for **bootstrap aggregation**, meaning the aggregation of bootstrap samples.
A **bootstrap sample** is a random sample with replacement. So, it has the same size as the original sample but might duplicate some of the original observations. A sample in the case of bagged trees is a row of data.

```
# Set a seed for reproducibility.
np.random.seed(1)
# Create an array of 1 through 20.
nums = np.arange(1, 21)
print(nums)
# Sample that array 20 times with replacement.
print(np.random.choice(a=nums, size=20, replace=True))
```
**How does bagging work (for decision trees)?**
1. Grow N trees using N bootstrap samples from the training data. To reiterate, we randomly select samples from the original dataset. We can pick the same sample more than once.
2. Train each tree on its bootstrap sample and make predictions.
3. Combine the predictions:
* Average the predictions for **regression trees**.
* Take a vote for **classification trees**.
Notes:
* **Each bootstrap sample** should be the same size as the original training set. (It may contain repeated rows.)
* **N** should be a large enough value that the error seems to have "stabilized".
* The trees are **grown deep** so that they have low bias/high variance.
Bagging increases predictive accuracy by **reducing the variance**, similar to how cross-validation reduces the variance associated with train/test split (for estimating out-of-sample error) by splitting many times an averaging the results.
### Load Data
The data we will use is the Breast Cancer Wisconsin (Diagnostic) Data Set: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic) which I converted to a csv for convenience. The goal of this prediction is successfully classifying cancer as malignant (1) or benign (0).
```
df = pd.read_csv('data/wisconsinBreastCancer.csv')
df.head()
```
### Arrange Data into Features Matrix and Target Vector
```
X = df.loc[:, df.columns != 'diagnosis']
X.shape
y = df.loc[:, 'diagnosis'].values
y.shape
```
### Show Bootstrapping
```
# Set a seed for reproducibility.
np.random.seed(123)
# Create ten bootstrap samples (which will be used to select rows from the DataFrame).
samples = [np.random.choice(a=14, size=14, replace=True) for _ in range(1, 6)]
samples
# Show the rows for a bootstrapped sample
X.iloc[samples[0], :]
```
### Split the data into training and testing sets
```
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
random_state = 0,
test_size = .2)
```
### Bagged Decision Trees in `scikit-learn` (with N = 100)
<b>Step 1:</b> Import the model you want to use
In sklearn, all machine learning models are implemented as Python classes
```
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
```
<b>Step 2:</b> Make an instance of the Model
```
# Instruct BaggingClassifier to use DecisionTreeClassifier as the "base estimator"
# We are making 100 trees, bootstrapping our sample, and more
bagclf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=100,
bootstrap=True,
oob_score=True,
random_state=1)
```
<b>Step 3:</b> Training the model on the data, storing the information learned from the data. Model is learning the relationship between features and labels
```
bagclf.fit(X_train, y_train)
```
<b>Step 4:</b> Predict the labels of new data
Uses the information the model learned during the model training process
```
# class predictions (not predicted probabilities)
predictions = bagclf.predict(X_test)
predictions
# calculate classification accuracy
score = bagclf.score(X_test, y_test)
score
```
### Compare your testing accuracy to the null accuracy
Null accuracy is usually considered the accuracy obtained by always predicting the most frequent class.
When interpreting the predictive power of a model, it's best to compare it to a baseline using a dummy model, sometimes called a baseline model. A dummy model is simply using the mean, median, or most common value as the prediction. This forms a benchmark to compare your model against and becomes especially important in classification where your null accuracy might be 95 percent.
For example, suppose your dataset is **imbalanced** -- it contains 99% one class and 1% the other class. Then, your baseline accuracy (always guessing the first class) would be 99%. So, if your model is less than 99% accurate, you know it is worse than the baseline. Imbalanced datasets generally must be trained differently (with less of a focus on accuracy) because of this.
```
pd.DataFrame(y_test)[0].value_counts(dropna = False)
67 / (67 + 47)
```
Since this particular model has an accuracy of roughly x%. By comparison, the null accuracy was 58.77% for the split when this notebook was run. The model provides some value.
### Visualizing your Estimators
You can select and visualization individual trees from a Bagged Tree (and Random Forests which we will learn about).
```
bagclf.estimators_
# We have 100 estimators
print(len(bagclf.estimators_))
bagclf.estimators_[0]
# This may not the best way to view each estimator as it is small
plt.figure(figsize=(10,2))
for index in range(0, 5):
plt.subplot(1, 5, 1 + index )
tree.plot_tree(bagclf.estimators_[index],
feature_names = X_train.columns,
class_names=['benign', 'malignant'],
filled = True);
plt.tight_layout()
# Ignore this cell. It is how to generate multiple images and combine
# Beyond the scope of this course
# https://stackoverflow.com/questions/30227466/combine-several-images-horizontally-with-python
"""
def concat_images(imga, imgb):
"""
#Combines two color image ndarrays side-by-side.
"""
ha,wa = imga.shape[:2]
hb,wb = imgb.shape[:2]
max_height = np.max([ha, hb])
total_width = wa+wb
new_img = np.zeros(shape=(max_height, total_width, 3))
new_img[:ha,:wa]=imga
new_img[:hb,wa:wa+wb]=imgb
return new_img
def concat_n_images(image_path_list):
"""
#Combines N color images from a list of image paths.
"""
output = None
for i, img_path in enumerate(image_path_list):
img = plt.imread(img_path)[:,:,:3]
if i==0:
output = img
else:
output = concat_images(output, img)
return output
image_list = []
for index in range(0, 5):
filename = "images/estimator" +str(index).zfill(3)
tree.export_graphviz(bagclf.estimators_[index],
out_file=filename + ".dot",
feature_names = X_train.columns,
class_names=['benign', 'malignant'],
filled = True)
call(['dot', '-Tpng', filename + ".dot", '-o', filename + ".png", '-Gdpi=1000'])
image_list.append(filename + '.png')
"""
#combinedImages = concat_n_images(image_list)
#matplotlib.image.imsave('images/5estimators.png', combinedImages)
```
### Estimating out-of-sample error
For bagged models, out-of-sample error can be estimated without using **train/test split** or **cross-validation**!
On average, each bagged tree uses about **two-thirds** of the observations. For each tree, the **remaining observations** are called "out-of-bag" observations.
```
# show the first bootstrap sample
samples[0]
```
The code below utilizes python sets since a property of sets is that they cannot have multiple occurrences of the same element. You can read more about them here: https://towardsdatascience.com/python-sets-and-set-theory-2ace093d1607
```
# show the "in-bag" observations for each sample
for sample in samples:
print(set(sample))
# show the "out-of-bag" observations for each sample
for sample in samples:
print(sorted(set(range(14)).difference(set(sample))))
```
If you don't know/forgot what a set difference is, the set returned from the difference can be visualized as the red part of the Venn diagram below.

How to calculate **"out-of-bag error":**
1. For every observation in the training data, predict its response value using **only** the trees in which that observation was out-of-bag. Average those predictions (for regression) or take a vote (for classification).
2. Compare all predictions to the actual response values in order to compute the out-of-bag error.
When N is sufficiently large, the **out-of-bag error** is an accurate estimate of **out-of-sample error**.
```
bagclf.oob_score_
```
<b>Advantages of bagged trees</b>
Typically better performance than decision trees
Can be used for classification or regression
Don't require feature scaling
They allow you to estimate out-of-sample error without using train/test split or cross-validation.
<b>Disadvantages of bagged trees</b>
They are less interpretable than decision trees
They are slower to train
They are slower to predict (not much of a problem)
Individual models can be correlated with each other.
### Random Forests
Random Forests offer a variation on bagged trees with potentially better performance. Bagging tends to reduce the variance and random forests try to further reduce the variance. Suppose there is **one very strong feature** in the data set. When using bagged trees, most of the trees could use that feature as the top split, resulting in an ensemble of similar trees that are **highly correlated**. Averaging highly correlated quantities does might not significantly reduce variance (which is the entire goal of bagging). By randomly leaving out candidate features from each split, **Random Forests "decorrelates" the trees**, such that the averaging process can reduce the variance of the resulting model.

**How do random forests work?**
1. Grow N trees using N bootstrap samples from the training data. However, when building each tree, each time a split is considered, a **random sample of m features** is chosen as split candidates from the **full set of p features**. The split is only allowed to use **one of those m features**. A new random sample of features is chosen for **every single tree at every single split**.
2. Train each tree on its bootstrap sample and make predictions.
3. Combine the predictions:
* Average the predictions for **regression trees**.
* Take a vote for **classification trees**.
Notes:
* **Each bootstrap sample** should be the same size as the original training set. (It may contain repeated rows.)
* **N** should be a large enough value that the error seems to have "stabilized".
* The trees are **grown deep** so that they have low bias/high variance.
<b>Advantages of random forests</b>
Typically better performance than decision trees
Can be used for classification or regression
Don't require feature scaling
They allow you to estimate out-of-sample error without using train/test split or cross-validation.
<b>Disadvantages of random forests</b>
They are less interpretable than decision trees
They are slower to train
They are slower to predict
### Random Forests in `scikit-learn` (with N = 100)
<b>Step 1:</b> Import the model you want to use
In sklearn, all machine learning models are implemented as Python classes
```
from sklearn.ensemble import RandomForestClassifier
```
<b>Step 2:</b> Make an instance of the Model
```
clf = RandomForestClassifier(n_estimators=100,
bootstrap=True,
oob_score=True,
random_state=1)
```
<b>Step 3:</b> Training the model on the data, storing the information learned from the data. Model is learning the relationship between features and labels
```
clf.fit(X_train, y_train)
```
<b>Step 4:</b> Predict the labels of new data
Uses the information the model learned during the model training process
```
# class predictions (not predicted probabilities)
predictions = clf.predict(X_test)
predictions
# calculate classification accuracy
score = clf.score(X_test, y_test)
score
```
While the score here is similar to what we had before for bagged trees, keep in mind that this is a small dataset (relatively speaking) and we haven't hyperparameter tuned our dataset.
### Tuning n_estimators
A tuning parameter is **n_estimators**, which represents the number of trees that should be grown.
```
help(RandomForestClassifier)
#[1] + list(range(10, 310, 10))
# List of values to try for n_estimators:
estimator_range = [1] + list(range(10, 310, 10))
# List to store the average RMSE for each value of n_estimators:
scores = []
# Use five-fold cross-validation with each value of n_estimators (Warning: Slow!).
for estimator in estimator_range:
clf = RandomForestClassifier(n_estimators=estimator, random_state=1)
clf.fit(X_train, y_train)
scores.append(clf.score(X_test, y_test))
plt.figure(figsize = (5,5))
plt.plot(estimator_range, scores);
plt.xlabel('n_estimators', fontsize =20);
plt.ylabel('Accuracy', fontsize = 20);
plt.grid()
```
At some point there looks to be diminishing returns for accuracy.
**Which model is best?** The best classifier for a particular task is task-dependent. In many business cases, interpretability is more important than accuracy. So, decision trees may be preferred. In other cases, accuracy on unseen data might be paramount, in which case random forests would likely be better (since they typically overfit less).
| github_jupyter |
This notebook contains the code for the meta-analysis of healthy lung data for ACE2, TMPRSS2, and CTSL. It contains the pseudo-bulk analysis for the complex model with interaction terms that was run on the patient-level data.
```
import scanpy as sc
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pandas as pd
from matplotlib import rcParams
from matplotlib import colors
from matplotlib import patches
import seaborn as sns
import batchglm
import diffxpy.api as de
import patsy as pat
from statsmodels.stats.multitest import multipletests
import logging, warnings
import statsmodels.api as sm
plt.rcParams['figure.figsize']=(8,8) #rescale figures
sc.settings.verbosity = 3
#sc.set_figure_params(dpi=200, dpi_save=300)
sc.logging.print_versions()
de.__version__
logging.getLogger("tensorflow").setLevel(logging.ERROR)
logging.getLogger("batchglm").setLevel(logging.INFO)
logging.getLogger("diffxpy").setLevel(logging.INFO)
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 35)
warnings.filterwarnings("ignore", category=DeprecationWarning, module="tensorflow")
#User inputs
folder = '/storage/groups/ml01/workspace/malte.luecken/2020_cov19_study'
adata_diffxpy = '/storage/groups/ml01/workspace/malte.luecken/2020_cov19_study/COVID19_lung_atlas_revision_v3.h5ad'
output_folder = 'diffxpy_out/'
de_output_base = 'COVID19_lung_atlas_revision_v3_lung_cov19_poissonglm_smoking_pseudo_nUMIoffset_testInts'
```
# Read the data
```
adata = sc.read(adata_diffxpy)
adata
adata.obs.age = adata.obs.age.astype(float)
adata.obs.dtypes
adata.obs['dataset'] = adata.obs['last_author/PI']
adata.obs.dataset.value_counts()
```
# Filter the data
Keep only datsets with:
- more than 1 donor
- non-fetal
- lung
```
# Remove fetal datasets
dats_to_remove = set(['Rawlins', 'Spence', 'Linnarsson'])
dat = adata.obs.groupby(['donor']).agg({'sex':'first', 'age':'first', 'dataset':'first'})
# Single donor filter
don_tab = dat['dataset'].value_counts()
dats_to_remove.update(set(don_tab.index[don_tab == 1]))
dats_to_remove = list(dats_to_remove)
dats_to_remove
adata = adata[~adata.obs.dataset.isin(dats_to_remove)].copy()
adata.obs.lung_vs_nasal.value_counts()
# Filter for only lung data
adata = adata[adata.obs.lung_vs_nasal.isin(['lung']),].copy()
adata
adata.obs['sample'].nunique()
adata.obs['donor'].nunique()
adata.obs['dataset'].nunique()
```
# Binarize smoking status
```
adata.obs.smoking.value_counts()
adata.obs['smoking_status'] = adata.obs.smoked_boolean
#adata.obs['smoking_status'] = [True if stat in ['current', 'smoked', 'active', 'former', 'heavy', 'light'] else False if stat in ['never', 'nonsmoker'] else "nan" for stat in adata.obs.smoking]
adata.obs.smoking_status.value_counts()
```
## Filter out data w/o smoking status
```
pd.crosstab(adata.obs.dataset, adata.obs.smoking)
adata = adata[~adata.obs.smoking_status.isin(['nan']),].copy()
adata
adata.obs.dataset.value_counts()
adata.obs['sample'].nunique()
adata.obs['donor'].nunique()
```
# Check the data
```
np.mean(adata.X.astype(int) != adata.X)
for dat in adata.obs.dataset.unique():
val = np.mean(adata[adata.obs.dataset.isin([dat]),:].X.astype(int) != adata[adata.obs.dataset.isin([dat]),:].X)
if val != 0:
print(f'dataset= {dat}; value= {val}')
adata[adata.obs.dataset.isin([dat]),:].X[:20,:20].A
```
All counts are (or nearly are) integers
```
adata.obs.age.value_counts()
adata.obs.sex.value_counts()
```
# Fit models and perform DE
```
cluster_key = 'ann_level_2'
clust_tbl = adata.obs[cluster_key].value_counts()
clusters = clust_tbl.index[clust_tbl > 1000]
ct_to_rm = clusters[[ct.startswith('1') for ct in clusters]]
clusters = clusters.drop(ct_to_rm.tolist()).tolist()
clusters
```
Calculate DE genes per cluster.
```
adata
```
# Generate pseudobulks
```
for gene in adata.var_names:
adata.obs[gene] = adata[:,gene].X.A
dat_pseudo = adata.obs.groupby(['donor', 'ann_level_2']).agg({'ACE2':'mean', 'TMPRSS2':'mean', 'CTSL':'mean', 'total_counts':'mean', 'age':'first', 'smoking_status':'first', 'sex':'first', 'dataset':'first'}).dropna().reset_index(level=[0,1])
adata_pseudo = sc.AnnData(dat_pseudo[['ACE2', 'TMPRSS2', 'CTSL']], obs=dat_pseudo.drop(columns=['ACE2', 'TMPRSS2', 'CTSL']))
adata_pseudo.obs.head()
adata_pseudo.obs['total_counts_scaled'] = adata_pseudo.obs['total_counts']/adata_pseudo.obs['total_counts'].mean()
# Get interquartile range for ages to test
adata_pseudo.obs.groupby(['donor']).agg({'age':'first'}).age.quantile([0.25,0.5,0.75])
formula = "1 + sex + age + sex:age + smoking_status + sex:smoking_status + age:smoking_status + dataset"
tested_coef = ["sex[T.male]", "age", "smoking_status[T.True]"]
dmat = de.utils.design_matrix(
data=adata,
formula="~" + formula,
as_numeric=["age"],
return_type="patsy"
)
to_test = dict()
to_test['age'] = [31,62]
to_test['sex[T.male]'] = [0,1]
to_test['smoking_status[T.True]'] = [0,1]
dmat[1]
```
### Function definition to test effect sizes at particular covariate values
```
def calc_effects(dmat, cov_mat, params, effect, coefs):
from patsy.design_info import DesignMatrix
from diffxpy.api.stats import wald_test_chisq
dmat_cond = isinstance(dmat, tuple) and isinstance(dmat[0], DesignMatrix)
if not dmat_cond:
raise ValueError("`dmat` should be a patsy output Design Matrix.")
effect_list = ['sex[T.male]', 'age', 'smoking_status[T.True]']
if not effect in effect_list:
raise ValueError(f'{effect} is not one of: '
f'{effect_list}')
if not isinstance(coefs, dict):
raise TypeError('`coefs` should contain a dictionary of coefficients '
'where the effects should be evaluated.')
## Note: this is only correct when 3 covariates are tested in combinations
#if np.sum([coef in coefs for coef in effect_list]) < 2:
# raise ValueError('The `coefs` dict must contain values for the two '
# 'coefficient not tested in:'
# f'{effect_list}')
if 'smoking_status[T.True]' in coefs and coefs['smoking_status[T.True]'] not in [0,1]:
raise ValueError('Smoking status should be encoded as 0 or 1.')
if 'sex[T.male]' in coefs and coefs['sex[T.male]'] not in [0,1]:
raise ValueError('Sex should be encoded as 0 or 1.')
if 'age' in coefs and not (isinstance(coefs['age'], float) or isinstance(coefs['age'], int)):
raise ValueError('Age should be a numerical value.')
coef_list = []
for term in dmat[1]:
if effect not in term:
coef_list.append(0)
elif term == effect:
coef_list.append(1)
else:
t_list = term.split(':')
t_list.remove(effect)
coef_list.append(coefs[t_list[0]])
C = np.array(coef_list)
val = np.matmul(C,np.array(params))
stderr = np.sqrt(np.matmul(np.matmul(C.T,cov_mat),C))
pval = wald_test_chisq(np.array([val]).reshape(1,1), np.array([stderr**2]).reshape(1,1,1))[0]
return (val, stderr, pval)
```
## Poisson GLM
```
# Poisson GLM loop
de_results_lvl2_glm = dict()
# Test over clusters
for clust in clusters:
adata_pseudo_tmp = adata_pseudo[adata_pseudo.obs[cluster_key] == clust,:].copy()
print(f'In cluster {clust}:')
print(adata_pseudo_tmp.obs['smoking_status'].value_counts())
print(adata_pseudo_tmp.obs['sex'].value_counts())
# Filter out genes to reduce multiple testing burden
sc.pp.filter_genes(adata_pseudo_tmp, min_cells=4)
if adata_pseudo_tmp.n_vars == 0:
print('No genes expressed in more than 10 cells!')
continue
if len(adata_pseudo_tmp.obs.smoking_status.value_counts())==1:
print(f'{clust} only has 1 type of smoker/nonsmoker sample.')
continue
print(f'Testing {adata_pseudo_tmp.n_vars} genes...')
print(f'Testing in {adata_pseudo_tmp.n_obs} donors...')
print("")
# List to store results
de_results_list = []
# Set up design matrix
dmat = de.utils.design_matrix(
data=adata_pseudo_tmp, #[idx_train],
formula="~" + formula,
as_numeric=["age"],
return_type="patsy"
)
# Test if model is full rank
if np.linalg.matrix_rank(np.asarray(dmat[0])) < np.min(dmat[0].shape):
print(f'Cannot test {clust} as design matrix is not full rank.')
continue
for i, gene in enumerate(adata_pseudo_tmp.var_names):
# Specify model
pois_model = sm.GLM(
endog=adata_pseudo_tmp.X[:, i], #[idx_train, :],
exog=dmat[0],
offset=np.log(adata_pseudo_tmp.obs['total_counts_scaled'].values),
family=sm.families.Poisson()
)
# Fit the model
pois_results = pois_model.fit()
# Get the covariance matrix
cov_mat = pois_results.cov_params()
# Test over coefs
for coef in tested_coef:
iter_coefs = tested_coef.copy()
iter_coefs.remove(coef)
for c1 in to_test[iter_coefs[0]]:
for c2 in to_test[iter_coefs[1]]:
coef_vals = {iter_coefs[0]:c1, iter_coefs[1]:c2}
val, stderr, pval = calc_effects(
dmat = dmat,
cov_mat = cov_mat,
params = pois_results.params,
effect = coef,
coefs = coef_vals)
case = '_'.join([iter_coefs[0]+':'+str(c1), iter_coefs[1]+':'+str(c2)])
case = case.replace('smoking_status[T.True]:0','NS').replace('smoking_status[T.True]:1','S')
case = case.replace('sex[T.male]:0','F').replace('sex[T.male]:1','M')
case = case.replace('age:31','31yr').replace('age:62','62yr')
case = case.replace('_',' ')
# Output the results nicely
de_results_temp = pd.DataFrame({
"gene": gene,
"cell_identity": clust,
"covariate": coef,
"eval_at": case,
"coef": val,
"coef_sd": stderr,
"pval": pval
}, index= [clust+"_"+gene+"_"+coef])
de_results_list.append(de_results_temp)
de_results = pd.concat(de_results_list)
de_results['adj_pvals'] = multipletests(de_results['pval'].tolist(), method='fdr_bh')[1]
# Store the results
de_results_lvl2_glm[clust] = de_results
# Join the dataframes:
full_res_lvl2_glm = pd.concat([de_results_lvl2_glm[i] for i in de_results_lvl2_glm.keys()], ignore_index=True)
```
## Inspect some results
```
de_results_lvl2_glm.keys()
full_res_lvl2_glm
full_res_lvl2_glm.loc[full_res_lvl2_glm['gene'] == 'ACE2',]
full_res_lvl2_glm.loc[full_res_lvl2_glm['gene'] == 'TMPRSS2',]
```
# Level 3 annotation
```
cluster_key = 'ann_level_3'
clust_tbl = adata.obs[cluster_key].value_counts()
clusters = clust_tbl.index[clust_tbl > 1000]
ct_to_rm = clusters[[ct.startswith('1') or ct.startswith('2') for ct in clusters]]
clusters = clusters.drop(ct_to_rm.tolist()).tolist()
clusters
adata_sub = adata[adata.obs.ann_level_3.isin(clusters),:]
adata_sub
adata_sub.obs.donor.nunique()
adata_sub.obs['sample'].nunique()
```
## Generate pseudobulk
```
for gene in adata_sub.var_names:
adata_sub.obs[gene] = adata_sub[:,gene].X.A
dat_pseudo_sub = adata_sub.obs.groupby(['donor', 'ann_level_3']).agg({'ACE2':'mean', 'TMPRSS2':'mean', 'CTSL':'mean', 'total_counts':'mean', 'age':'first', 'smoking_status':'first', 'sex':'first', 'dataset':'first'}).dropna().reset_index(level=[0,1])
adata_pseudo_sub = sc.AnnData(dat_pseudo_sub[['ACE2', 'TMPRSS2', 'CTSL']], obs=dat_pseudo_sub.drop(columns=['ACE2', 'TMPRSS2', 'CTSL']))
adata_pseudo_sub.obs.head()
adata_pseudo_sub.obs['total_counts_scaled'] = adata_pseudo_sub.obs['total_counts']/adata_pseudo_sub.obs['total_counts'].mean()
```
## Poisson GLM
First check if there are any datasets with only 1 sex or 1 smoking status, which would make the model overparameterized (not full rank).
```
np.any(adata_pseudo_tmp.obs.smoking_status.value_counts() == 1)
np.any(pd.crosstab(adata_pseudo_tmp.obs.smoking_status, adata_pseudo_tmp.obs.sex) == 1)
clusters
# Poisson GLM loop
de_results_lvl3_glm = dict()
# Test over clusters
for clust in clusters:
adata_pseudo_tmp = adata_pseudo_sub[adata_pseudo_sub.obs[cluster_key] == clust,:].copy()
print(f'In cluster {clust}:')
print(adata_pseudo_tmp.obs['smoking_status'].value_counts())
print(adata_pseudo_tmp.obs['sex'].value_counts())
# Filter out genes to reduce multiple testing burden
sc.pp.filter_genes(adata_pseudo_tmp, min_cells=4)
if adata_pseudo_tmp.n_vars == 0:
print('No genes expressed in more than 10 cells!')
continue
if len(adata_pseudo_tmp.obs.smoking_status.value_counts())==1:
print(f'{clust} only has 1 type of smoker/nonsmoker sample.')
continue
if np.any(adata_pseudo_tmp.obs.smoking_status.value_counts()==1):
print(f'{clust} only has 1 smoker or 1 nonsmoker sample.')
continue
if np.any(adata_pseudo_tmp.obs.sex.value_counts()==1):
print(f'{clust} only has 1 male or 1 female sample.')
continue
if np.any(pd.crosstab(adata_pseudo_tmp.obs.smoking_status, adata_pseudo_tmp.obs.sex) == 1):
print('Want at least 2 in each smoking/sex category.')
continue
print(f'Testing {adata_pseudo_tmp.n_vars} genes...')
print(f'Testing in {adata_pseudo_tmp.n_obs} donors...')
print("")
# List to store results
de_results_list = []
# Set up design matrix
dmat = de.utils.design_matrix(
data=adata_pseudo_tmp,
formula="~" + formula,
as_numeric=["age"],
return_type="patsy"
)
# Test if model is full rank
if np.linalg.matrix_rank(np.asarray(dmat[0])) < np.min(dmat[0].shape):
print(f'Cannot test {clust} as design matrix is not full rank.')
continue
for i, gene in enumerate(adata_pseudo_tmp.var_names):
# Specify model
pois_model = sm.GLM(
endog=adata_pseudo_tmp.X[:, i],
exog=dmat[0],
offset=np.log(adata_pseudo_tmp.obs['total_counts_scaled'].values),
family=sm.families.Poisson()
)
# Fit the model
pois_results = pois_model.fit()
# Get the covariance matrix
cov_mat = pois_results.cov_params()
# Test over coefs
for coef in tested_coef:
iter_coefs = tested_coef.copy()
iter_coefs.remove(coef)
for c1 in to_test[iter_coefs[0]]:
for c2 in to_test[iter_coefs[1]]:
coef_vals = {iter_coefs[0]:c1, iter_coefs[1]:c2}
val, stderr, pval = calc_effects(
dmat = dmat,
cov_mat = cov_mat,
params = pois_results.params,
effect = coef,
coefs = coef_vals)
case = '_'.join([iter_coefs[0]+':'+str(c1), iter_coefs[1]+':'+str(c2)])
case = case.replace('smoking_status[T.True]:0','NS').replace('smoking_status[T.True]:1','S')
case = case.replace('sex[T.male]:0','F').replace('sex[T.male]:1','M')
case = case.replace('age:31','31yr').replace('age:62','62yr')
case = case.replace('_',' ')
# Output the results nicely
de_results_temp = pd.DataFrame({
"gene": gene,
"cell_identity": clust,
"covariate": coef,
"eval_at": case,
"coef": val,
"coef_sd": stderr,
"pval": pval
}, index= [clust+"_"+gene+"_"+coef])
de_results_list.append(de_results_temp)
de_results = pd.concat(de_results_list)
de_results['adj_pvals'] = multipletests(de_results['pval'].tolist(), method='fdr_bh')[1]
# Store the results
de_results_lvl3_glm[clust] = de_results
# Join the dataframes:
full_res_lvl3_glm = pd.concat([de_results_lvl3_glm[i] for i in de_results_lvl3_glm.keys()], ignore_index=True)
```
## Inspect some results
```
de_results_lvl3_glm.keys()
full_res_lvl3_glm
full_res_lvl3_glm.loc[full_res_lvl3_glm['gene'] == 'ACE2',]
full_res_lvl3_glm.loc[full_res_lvl3_glm['gene'] == 'TMPRSS2',]
```
# Store results
```
#res_summary_lvl2.to_csv(folder+'/'+output_folder+de_output_base+'_lvl2_summary.csv')
full_res_lvl2_glm.to_csv(folder+'/'+output_folder+de_output_base+'_lvl2_full.csv')
#res_summary_lvl3.to_csv(folder+'/'+output_folder+de_output_base+'_lvl3_summary.csv')
full_res_lvl3_glm.to_csv(folder+'/'+output_folder+de_output_base+'_lvl3_full.csv')
```
| github_jupyter |
# Reader and Writer Packages
## OpenPyXL
### Reading with OpenPyXL
```
import pandas as pd
import openpyxl
import excel
import datetime as dt
# Open the workbook to read cell values.
# The file is automatically closed again after loading the data.
book = openpyxl.load_workbook("xl/stores.xlsx", data_only=True)
# Get a worksheet object by name or index (0-based)
sheet = book["2019"]
sheet = book.worksheets[0]
# Get a list with all sheet names
book.sheetnames
# Loop through the sheet objects.
# Instead of "name", openpyxl uses "title".
for i in book.worksheets:
print(i.title)
# Getting the dimensions,
# i.e. the used range of the sheet
sheet.max_row, sheet.max_column
# Read the value of a single cell
# using "A1" notation and using cell indices (1-based)
sheet["B6"].value
sheet.cell(row=6, column=2).value
# Read in a range of cell values by using our excel module
data = excel.read(book["2019"], (2, 2), (8, 6))
data[:2] # Print the first two rows
```
### Writing with OpenPyXL
```
import openpyxl
from openpyxl.drawing.image import Image
from openpyxl.chart import BarChart, Reference
from openpyxl.styles import Font, colors
from openpyxl.styles.borders import Border, Side
from openpyxl.styles.alignment import Alignment
from openpyxl.styles.fills import PatternFill
import excel
# Instantiate a workbook
book = openpyxl.Workbook()
# Get the first sheet and give it a name
sheet = book.active
sheet.title = "Sheet1"
# Writing individual cells using A1 notation
# and cell indices (1-based)
sheet["A1"].value = "Hello 1"
sheet.cell(row=2, column=1, value="Hello 2")
# Formatting: fill color, alignment, border and font
font_format = Font(color="FF0000", bold=True)
thin = Side(border_style="thin", color="FF0000")
sheet["A3"].value = "Hello 3"
sheet["A3"].font = font_format
sheet["A3"].border = Border(top=thin, left=thin,
right=thin, bottom=thin)
sheet["A3"].alignment = Alignment(horizontal="center")
sheet["A3"].fill = PatternFill(fgColor="FFFF00", fill_type="solid")
# Number formatting (using Excel's formatting strings)
sheet["A4"].value = 3.3333
sheet["A4"].number_format = "0.00"
# Date formatting (using Excel's formatting strings)
sheet["A5"].value = dt.date(2016, 10, 13)
sheet["A5"].number_format = "mm/dd/yy"
# Formula: you must use the English name of the formula
# with commas as delimiters
sheet["A6"].value = "=SUM(A4, 2)"
# Image
sheet.add_image(Image("images/python.png"), "C1")
# Two-dimensional list (we're using our excel module)
data = [[None, "North", "South"],
["Last Year", 2, 5],
["This Year", 3, 6]]
excel.write(sheet, data, "A10")
# Chart
chart = BarChart()
chart.type = "col"
chart.title = "Sales Per Region"
chart.x_axis.title = "Regions"
chart.y_axis.title = "Sales"
chart_data = Reference(sheet, min_row=11, min_col=1,
max_row=12, max_col=3)
chart_categories = Reference(sheet, min_row=10, min_col=2,
max_row=10, max_col=3)
# from_rows interprets the data in the same way
# as if you would add a chart manually in Excel
chart.add_data(chart_data, titles_from_data=True, from_rows=True)
chart.set_categories(chart_categories)
sheet.add_chart(chart, "A15")
# Saving the workbook creates the file on disk
book.save("openpyxl.xlsx")
book = openpyxl.Workbook()
sheet = book.active
sheet["A1"].value = "This is a template"
book.template = True
book.save("template.xltx")
```
### Editing with OpenPyXL
```
# Read the stores.xlsx file, change a cell
# and store it under a new location/name.
book = openpyxl.load_workbook("xl/stores.xlsx")
book["2019"]["A1"].value = "modified"
book.save("stores_edited.xlsx")
book = openpyxl.load_workbook("xl/macro.xlsm", keep_vba=True)
book["Sheet1"]["A1"].value = "Click the button!"
book.save("macro_openpyxl.xlsm")
```
## XlsxWriter
```
import datetime as dt
import xlsxwriter
import excel
# Instantiate a workbook
book = xlsxwriter.Workbook("xlxswriter.xlsx")
# Add a sheet and give it a name
sheet = book.add_worksheet("Sheet1")
# Writing individual cells using A1 notation
# and cell indices (0-based)
sheet.write("A1", "Hello 1")
sheet.write(1, 0, "Hello 2")
# Formatting: fill color, alignment, border and font
formatting = book.add_format({"font_color": "#FF0000",
"bg_color": "#FFFF00",
"bold": True, "align": "center",
"border": 1, "border_color": "#FF0000"})
sheet.write("A3", "Hello 3", formatting)
# Number formatting (using Excel's formatting strings)
number_format = book.add_format({"num_format": "0.00"})
sheet.write("A4", 3.3333, number_format)
# Date formatting (using Excel's formatting strings)
date_format = book.add_format({"num_format": "mm/dd/yy"})
sheet.write("A5", dt.date(2016, 10, 13), date_format)
# Formula: you must use the English name of the formula
# with commas as delimiters
sheet.write("A6", "=SUM(A4, 2)")
# Image
sheet.insert_image(0, 2, "images/python.png")
# Two-dimensional list (we're using our excel module)
data = [[None, "North", "South"],
["Last Year", 2, 5],
["This Year", 3, 6]]
excel.write(sheet, data, "A10")
# Chart: see the file "sales_report_xlsxwriter.py" in the
# companion repo to see how you can work with indices
# instead of cell addresses
chart = book.add_chart({"type": "column"})
chart.set_title({"name": "Sales per Region"})
chart.add_series({"name": "=Sheet1!A11",
"categories": "=Sheet1!B10:C10",
"values": "=Sheet1!B11:C11"})
chart.add_series({"name": "=Sheet1!A12",
"categories": "=Sheet1!B10:C10",
"values": "=Sheet1!B12:C12"})
chart.set_x_axis({"name": "Regions"})
chart.set_y_axis({"name": "Sales"})
sheet.insert_chart("A15", chart)
# Closing the workbook creates the file on disk
book.close()
book = xlsxwriter.Workbook("macro_xlxswriter.xlsm")
sheet = book.add_worksheet("Sheet1")
sheet.write("A1", "Click the button!")
book.add_vba_project("xl/vbaProject.bin")
sheet.insert_button("A3", {"macro": "Hello", "caption": "Button 1",
"width": 130, "height": 35})
book.close()
```
## pyxlsb
```
import pyxlsb
import excel
# Loop through sheets. With pyxlsb, the workbook
# and sheet objects can be used as context managers.
# book.sheets returns a list of sheet names, not objects!
# To get a sheet object, use get_sheet() instead.
with pyxlsb.open_workbook("xl/stores.xlsb") as book:
for sheet_name in book.sheets:
with book.get_sheet(sheet_name) as sheet:
dim = sheet.dimension
print(f"Sheet '{sheet_name}' has "
f"{dim.h} rows and {dim.w} cols")
# Read in the values of a range of cells by using our excel module.
# Instead of "2019", you could also use its index (1-based).
with pyxlsb.open_workbook("xl/stores.xlsb") as book:
with book.get_sheet("2019") as sheet:
data = excel.read(sheet, "B2")
data[:2] # Print the first two rows
from pyxlsb import convert_date
convert_date(data[1][3])
df = pd.read_excel("xl/stores.xlsb", engine="pyxlsb")
```
## xlrd, xlwt and xlutils
### Reading with xlrd
```
import xlrd
import xlwt
from xlwt.Utils import cell_to_rowcol2
import xlutils
import excel
# Open the workbook to read cell values. The file is
# automatically closed again after loading the data.
book = xlrd.open_workbook("xl/stores.xls")
# Get a list with all sheet names
book.sheet_names()
# Loop through the sheet objects
for sheet in book.sheets():
print(sheet.name)
# Get a sheet object by name or index (0-based)
sheet = book.sheet_by_index(0)
sheet = book.sheet_by_name("2019")
# Dimensions
sheet.nrows, sheet.ncols
# Read the value of a single cell
# using "A1" notation and using cell indices (0-based).
# The "*" unpacks the tuple that cell_to_rowcol2 returns
# into individual arguments.
sheet.cell(*cell_to_rowcol2("B3")).value
sheet.cell(2, 1).value
# Read in a range of cell values by using our excel module
data = excel.read(sheet, "B2")
data[:2] # Print the first two rows
```
### Writing with xlwt
```
import xlwt
from xlwt.Utils import cell_to_rowcol2
import datetime as dt
import excel
# Instantiate a workbook
book = xlwt.Workbook()
# Add a sheet and give it a name
sheet = book.add_sheet("Sheet1")
# Writing individual cells using A1 notation
# and cell indices (0-based)
sheet.write(*cell_to_rowcol2("A1"), "Hello 1")
sheet.write(r=1, c=0, label="Hello 2")
# Formatting: fill color, alignment, border and font
formatting = xlwt.easyxf("font: bold on, color red;"
"align: horiz center;"
"borders: top_color red, bottom_color red,"
"right_color red, left_color red,"
"left thin, right thin,"
"top thin, bottom thin;"
"pattern: pattern solid, fore_color yellow;")
sheet.write(r=2, c=0, label="Hello 3", style=formatting)
# Number formatting (using Excel's formatting strings)
number_format = xlwt.easyxf(num_format_str="0.00")
sheet.write(3, 0, 3.3333, number_format)
# Date formatting (using Excel's formatting strings)
date_format = xlwt.easyxf(num_format_str="mm/dd/yyyy")
sheet.write(4, 0, dt.datetime(2012, 2, 3), date_format)
# Formula: you must use the English name of the formula
# with commas as delimiters
sheet.write(5, 0, xlwt.Formula("SUM(A4, 2)"))
# Two-dimensional list (we're using our excel module)
data = [[None, "North", "South"],
["Last Year", 2, 5],
["This Year", 3, 6]]
excel.write(sheet, data, "A10")
# Picture (only allows to add bmp format)
sheet.insert_bitmap("images/python.bmp", 0, 2)
# This writes the file to disk
book.save("xlwt.xls")
```
### Editing with xlutils
```
import xlutils.copy
book = xlrd.open_workbook("xl/stores.xls", formatting_info=True)
book = xlutils.copy.copy(book)
book.get_sheet(0).write(0, 0, "changed!")
book.save("stores_edited.xls")
```
# Advanced Topics
## Working with Big Files
### Writing with OpenPyXL
```
book = openpyxl.Workbook(write_only=True)
# With write_only=True, book.active doesn't work
sheet = book.create_sheet()
# This will produce a sheet with 1000 x 200 cells
for row in range(1000):
sheet.append(list(range(200)))
book.save("openpyxl_optimized.xlsx")
```
### Writing with XlsxWriter
```
book = xlsxwriter.Workbook("xlsxwriter_optimized.xlsx",
options={"constant_memory": True})
sheet = book.add_worksheet()
# This will produce a sheet with 1000 x 200 cells
for row in range(1000):
sheet.write_row(row , 0, list(range(200)))
book.close()
```
### Reading with xlrd
```
with xlrd.open_workbook("xl/stores.xls", on_demand=True) as book:
sheet = book.sheet_by_index(0) # Only loads the first sheet
with xlrd.open_workbook("xl/stores.xls", on_demand=True) as book:
with pd.ExcelFile(book, engine="xlrd") as f:
df = pd.read_excel(f, sheet_name=0)
```
### Reading with OpenPyXL
```
book = openpyxl.load_workbook("xl/big.xlsx",
data_only=True, read_only=True,
keep_links=False)
# Perform the desired read operations here
book.close() # Required with read_only=True
```
### Reading in Parallel
```
%%time
data = pd.read_excel("xl/big.xlsx",
sheet_name=None, engine="openpyxl")
%%time
import parallel_pandas
data = parallel_pandas.read_excel("xl/big.xlsx", sheet_name=None)
```
## Formatting DataFrames in Excel
```
with pd.ExcelFile("xl/stores.xlsx", engine="openpyxl") as xlfile:
# Read a DataFrame
df = pd.read_excel(xlfile, sheet_name="2020")
# Get the OpenPyXL workbook object
book = xlfile.book
# From here on, it's OpenPyXL code
sheet = book["2019"]
value = sheet["B3"].value # Read a single value
with pd.ExcelWriter("pandas_and_openpyxl.xlsx",
engine="openpyxl") as writer:
df = pd.DataFrame({"col1": [1, 2, 3, 4], "col2": [5, 6, 7, 8]})
# Write a DataFrame
df.to_excel(writer, "Sheet1", startrow=4, startcol=2)
# Get the OpenPyXL workbook and sheet objects
book = writer.book
sheet = writer.sheets["Sheet1"]
# From here on, it's OpenPyXL code
sheet["A1"].value = "This is a Title" # Write a single cell value
df = pd.DataFrame({"col1": [1, -2], "col2": [-3, 4]},
index=["row1", "row2"])
df.index.name = "ix"
df
from openpyxl.styles import PatternFill
with pd.ExcelWriter("formatting_openpyxl.xlsx",
engine="openpyxl") as writer:
# Write out the df with the default formatting to A1
df.to_excel(writer, startrow=0, startcol=0)
# Write out the df with custom index/header formatting to A6
startrow, startcol = 0, 5
# 1. Write out the data part of the DataFrame
df.to_excel(writer, header=False, index=False,
startrow=startrow + 1, startcol=startcol + 1)
# Get the sheet object and create a style object
sheet = writer.sheets["Sheet1"]
style = PatternFill(fgColor="D9D9D9", fill_type="solid")
# 2. Write out the styled column headers
for i, col in enumerate(df.columns):
sheet.cell(row=startrow + 1, column=i + startcol + 2,
value=col).fill = style
# 3. Write out the styled index
index = [df.index.name if df.index.name else None] + list(df.index)
for i, row in enumerate(index):
sheet.cell(row=i + startrow + 1, column=startcol + 1,
value=row).fill = style
# Formatting index/headers with XlsxWriter
with pd.ExcelWriter("formatting_xlsxwriter.xlsx",
engine="xlsxwriter") as writer:
# Write out the df with the default formatting to A1
df.to_excel(writer, startrow=0, startcol=0)
# Write out the df with custom index/header formatting to A6
startrow, startcol = 0, 5
# 1. Write out the data part of the DataFrame
df.to_excel(writer, header=False, index=False,
startrow=startrow + 1, startcol=startcol + 1)
# Get the book and sheet object and create a style object
book = writer.book
sheet = writer.sheets["Sheet1"]
style = book.add_format({"bg_color": "#D9D9D9"})
# 2. Write out the styled column headers
for i, col in enumerate(df.columns):
sheet.write(startrow, startcol + i + 1, col, style)
# 3. Write out the styled index
index = [df.index.name if df.index.name else None] + list(df.index)
for i, row in enumerate(index):
sheet.write(startrow + i, startcol, row, style)
from openpyxl.styles import Alignment
with pd.ExcelWriter("data_format_openpyxl.xlsx",
engine="openpyxl") as writer:
# Write out the DataFrame
df.to_excel(writer)
# Get the book and sheet objects
book = writer.book
sheet = writer.sheets["Sheet1"]
# Formatting individual cells
nrows, ncols = df.shape
for row in range(nrows):
for col in range(ncols):
# +1 to account for the header/index
# +1 since OpenPyXL is 1-based
cell = sheet.cell(row=row + 2,
column=col + 2)
cell.number_format = "0.000"
cell.alignment = Alignment(horizontal="center")
with pd.ExcelWriter("data_format_xlsxwriter.xlsx",
engine="xlsxwriter") as writer:
# Write out the DataFrame
df.to_excel(writer)
# Get the book and sheet objects
book = writer.book
sheet = writer.sheets["Sheet1"]
# Formatting the columns (individual cells can't be formatted)
number_format = book.add_format({"num_format": "0.000",
"align": "center"})
sheet.set_column(first_col=1, last_col=2,
cell_format=number_format)
df.style.applymap(lambda x: "number-format: 0.000;"
"text-align: center")\
.to_excel("styled.xlsx")
df = pd.DataFrame({"Date": [dt.date(2020, 1, 1)],
"Datetime": [dt.datetime(2020, 1, 1, 10)]})
with pd.ExcelWriter("date.xlsx",
date_format="yyyy-mm-dd",
datetime_format="yyyy-mm-dd hh:mm:ss") as writer:
df.to_excel(writer)
```
| github_jupyter |
Features
---
MLlib Main Guide: https://spark.apache.org/docs/2.4.3/ml-features.html
This module contains algorithms for working with features, roughly divided into these groups:
- Extraction: Extracting features from “raw” data
- Transformation: Scaling, converting, or modifying features
- Selection: Selecting a subset from a larger set of features
- Locality Sensitive Hashing (LSH): This class of algorithms combines aspects of feature transformation with other algorithms.
## pyspark.ml.feature
Class structure: https://spark.apache.org/docs/2.4.3/api/python/pyspark.ml.html#module-pyspark.ml.feature
GitHub: https://github.com/apache/spark/blob/v2.4.3/python/pyspark/ml/feature.py
### [Feature Extractors](https://spark.apache.org/docs/2.4.3/ml-features.html#feature-extractors)
- [HashingTF](https://spark.apache.org/docs/2.4.3/ml-features.html#tf-idf)
- [IDF & IDFModel](https://spark.apache.org/docs/2.4.3/ml-features.html#tf-idf)
- [Word2Vec & Word2VecModel](https://spark.apache.org/docs/2.4.3/ml-features.html#word2vec)
- [CountVectorizer & CountVectorizerModel](https://spark.apache.org/docs/2.4.3/ml-features.html#countvectorizer)
- [FeatureHasher](https://spark.apache.org/docs/2.4.3/ml-features.html#featurehasher)
### [Feature Transformers](https://spark.apache.org/docs/2.4.3/ml-features.html#feature-transformers)
- [Tokenizer](https://spark.apache.org/docs/2.4.3/ml-features.html#tokenizer)
- [RegexTokenizer](https://spark.apache.org/docs/2.4.3/ml-features.html#tokenizer)
- [StopWordsRemover](https://spark.apache.org/docs/2.4.3/ml-features.html#stopwordsremover)
- [NGram](https://spark.apache.org/docs/2.4.3/ml-features.html#n-gram)
- [Binarizer](https://spark.apache.org/docs/2.4.3/ml-features.html#binarizer)
- [PCA](https://spark.apache.org/docs/2.4.3/ml-features.html#pca)
- [PCAModel](https://spark.apache.org/docs/2.4.3/ml-features.html#pca)
- [PolynomialExpansion](https://spark.apache.org/docs/2.4.3/ml-features.html#polynomialexpansion)
- [DCT](https://spark.apache.org/docs/2.4.3/ml-features.html#discrete-cosine-transform-dct)
- [StringIndexer & StringIndexerModel](https://spark.apache.org/docs/2.4.3/ml-features.html#stringindexer)
- [IndexToString](https://spark.apache.org/docs/2.4.3/ml-features.html#indextostring)
- [OneHotEncoder & OneHotEncoderModel](https://spark.apache.org/docs/2.4.3/ml-features.html#onehotencoder-deprecated-since-230)
- [OneHotEncoderEstimator](https://spark.apache.org/docs/2.4.3/ml-features.html#onehotencoderestimator)
- [VectorIndexer](https://spark.apache.org/docs/2.4.3/ml-features.html#vectorindexer)
- [VectorIndexerModel](https://spark.apache.org/docs/2.4.3/ml-features.html#vectorindexer)
- [Normalizer](https://spark.apache.org/docs/2.4.3/ml-features.html#normalizer)
- [StandardScaler & StandardScalerModel](https://spark.apache.org/docs/2.4.3/ml-features.html#standardscaler)
- [MinMaxScaler & MinMaxScalerModel](https://spark.apache.org/docs/2.4.3/ml-features.html#minmaxscaler)
- [MaxAbsScaler & MaxAbsScalerModel](https://spark.apache.org/docs/2.4.3/ml-features.html#maxabsscaler)
- [Bucketizer](https://spark.apache.org/docs/2.4.3/ml-features.html#bucketizer)
- [ElementwiseProduct](https://spark.apache.org/docs/2.4.3/ml-features.html#elementwiseproduct)
- [SQLTransformer](https://spark.apache.org/docs/2.4.3/ml-features.html#sqltransformer)
- [VectorAssembler](https://spark.apache.org/docs/2.4.3/ml-features.html#vectorassembler)
- [VectorSizeHint](https://spark.apache.org/docs/2.4.3/ml-features.html#vectorsizehint)
- [QuantileDiscretizer](https://spark.apache.org/docs/2.4.3/ml-features.html#quantilediscretizer)
- [Imputer & ImputerModel](https://spark.apache.org/docs/2.4.3/ml-features.html#imputer)
Not available in Python:
- [Interaction](https://spark.apache.org/docs/2.4.3/ml-features.html#interaction)
## [Feature Selectors](https://spark.apache.org/docs/2.4.3/ml-features.html#feature-selectors)
- [VectorSlicer](https://spark.apache.org/docs/2.4.3/ml-features.html#vectorslicer)
- [RFormula & RFormulaModel](https://spark.apache.org/docs/2.4.3/ml-features.html#rformula)
- [ChiSqSelector & ChiSqSelectorModel](https://spark.apache.org/docs/2.4.3/ml-features.html#chisqselector)
## [Locality Sensitive Hashing (LSH)](https://spark.apache.org/docs/2.4.3/ml-features.html#locality-sensitive-hashing)
- [BucketedRandomProjectionLSH & BucketedRandomProjectionLSHModel](https://spark.apache.org/docs/2.4.3/ml-features.html#bucketed-random-projection-for-euclidean-distance)
- [MinHashLSH & MinHashLSHModel](https://spark.apache.org/docs/2.4.3/ml-features.html#minhash-for-jaccard-distance)
```
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
from pyspark.ml.feature import QuantileDiscretizer
data = [(0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2)]
df = spark.createDataFrame(data, ["id", "hour"])
discretizer = QuantileDiscretizer(numBuckets=3, inputCol="hour", outputCol="result")
result = discretizer.fit(df).transform(df)
result.show()
from pyspark.ml.feature import Word2Vec
# Input data: Each row is a bag of words from a sentence or document.
documentDF = spark.createDataFrame(
[
("Hi I heard about Spark".split(" "),),
("I wish Java could use case classes".split(" "),),
("Logistic regression models are neat".split(" "),),
],
["text"],
)
# Learn a mapping from words to Vectors.
word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="text", outputCol="result")
model = word2Vec.fit(documentDF)
result = model.transform(documentDF)
for row in result.collect():
text, vector = row
print(f"Text: {text} => \nVector: {vector}\n")
from pyspark.ml.feature import FeatureHasher
dataset = spark.createDataFrame(
[
(2.2, True, "1", "foo"),
(3.3, False, "2", "bar"),
(4.4, False, "3", "baz"),
(5.5, False, "4", "foo"),
],
["real", "bool", "stringNum", "string"],
)
hasher = FeatureHasher(
inputCols=["real", "bool", "stringNum", "string"], outputCol="features"
)
featurized = hasher.transform(dataset)
featurized.show(truncate=False)
from pyspark.ml.feature import StringIndexer
df = spark.createDataFrame(
[
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c"),
(6, "d"),
(7, "a"),
(8, "d"),
],
["id", "category"],
)
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")
indexed = indexer.fit(df).transform(df)
indexed.show()
from pyspark.ml.feature import VectorIndexer
data = spark.read.format("libsvm").load(
"/usr/local/spark-2.4.3-bin-hadoop2.7/data/mllib/sample_libsvm_data.txt"
)
indexer = VectorIndexer(inputCol="features", outputCol="indexed", maxCategories=10)
indexerModel = indexer.fit(data)
categoricalFeatures = indexerModel.categoryMaps
print(
f"Chose {len(categoricalFeatures)} categorical "
f"features: {[str(k) for k in categoricalFeatures.keys()]}"
)
# Create new column "indexed" with categorical values transformed to indices
indexedData = indexerModel.transform(data)
indexedData.show()
from pyspark.ml.feature import Bucketizer
splits = [-float("inf"), -0.5, 0.0, 0.5, float("inf")]
data = [
(-999.9,),
(-0.5,),
(-0.3,),
(-0.4,),
(-0.2,),
(0.0,),
(0.1,),
(0.2,),
(0.3,),
(999.9,),
]
dataFrame = spark.createDataFrame(data, ["features"])
bucketizer = Bucketizer(
splits=splits, inputCol="features", outputCol="bucketedFeatures"
)
# Transform original data into its bucket index.
bucketedData = bucketizer.transform(dataFrame)
print(f"Bucketizer output with {len(bucketizer.getSplits())-1} buckets")
bucketedData.show()
```
| github_jupyter |
# Computing the optimal statistic with enterprise
In this notebook you will learn how to compute the optimal statistic. The optimal statistic is a frequentist detection statistic for the stochastic background. It assesses the significance of the cross-correlations, and compares them to the Hellings-Downs curve.
For more information, see Anholm et al. 2009, Demorest et al. 2013, Chamberlin et al. 2015, Vigeland et al. 2018.
This notebook shows you how to compute the optimal statistic for the 12.5yr data set. You can download a pickle of the pulsars and the noisefiles here: https://paper.dropbox.com/doc/NG-12.5yr_v3-GWB-Analysis--A2vs2wHh5gR4VTgm2DeODR2zAg-DICJei6NxsPjxnO90mGMo. You will need the following files:
* Channelized Pickled Pulsars (DE438) - Made in Py3
* Noisefiles (make sure you get the one that says it contains all the pulsar parameters)
```
from __future__ import (absolute_import, division,
print_function, unicode_literals)
import numpy as np
import pickle
import json
import matplotlib.pyplot as plt
%matplotlib inline
from enterprise.signals import signal_base
from enterprise.signals import gp_signals
from enterprise_extensions import model_utils, blocks
from enterprise_extensions.frequentist import optimal_statistic as opt_stat
# Load up the pulsars from the pickle file
# Change the picklefile to point to where you have saved the pickle of the pulsars that you downloaded
picklefile = '/Users/vigeland/Documents/Research/NANOGrav/nanograv_data/12p5yr/channelized_v3_DE438_45psrs.pkl'
with open(picklefile, 'rb') as f:
psrs = pickle.load(f)
len(psrs)
# Load up the noise dictionary to get values for the white noise parameters
# Change the noisefile to point to where you have saved the noisefile
noisefile = '/Users/vigeland/Documents/Research/NANOGrav/nanograv_data/12p5yr/channelized_12p5yr_v3_full_noisedict.json'
with open(noisefile, 'r') as f:
noisedict = json.load(f)
# Initialize the optimal statistic object
# You can give it a list of pulsars and the noise dictionary, and it will create the pta object for you
# Alternatively, you can make the pta object yourself and give it to the OptimalStatistic object as an argument
# find the maximum time span to set GW frequency sampling
Tspan = model_utils.get_tspan(psrs)
# Here we build the signal model
# First we add the timing model
s = gp_signals.TimingModel()
# Then we add the white noise
# There are three types of white noise: EFAC, EQUAD, and ECORR
# We use different white noise parameters for every backend/receiver combination
# The white noise parameters are held constant
s += blocks.white_noise_block(vary=False, inc_ecorr=True, select='backend')
# Next comes the individual pulsar red noise
# We model the red noise as a Fourier series with 30 frequency components,
# with a power-law PSD
s += blocks.red_noise_block(prior='log-uniform', Tspan=Tspan, components=30)
# Finally, we add the common red noise, which is modeled as a Fourier series with 5 frequency components
# The common red noise has a power-law PSD with spectral index of 4.33
s += blocks.common_red_noise_block(psd='powerlaw', prior='log-uniform', Tspan=Tspan,
components=5, gamma_val=4.33, name='gw')
# We set up the PTA object using the signal we defined above and the pulsars
pta = signal_base.PTA([s(p) for p in psrs])
# We need to set the white noise parameters to the values in the noise dictionary
pta.set_default_params(noisedict)
os = opt_stat.OptimalStatistic(psrs, pta=pta)
# Load up the maximum-likelihood values for the pulsars' red noise parameters and the common red process
# These values come from the results of a Bayesian search (model 2A)
# Once you have done your own Bayesian search,
# you can make your own parameter dictionary of maximum-likelihood values
with open('data/12p5yr_maxlike.json', 'r') as f:
ml_params = json.load(f)
# Compute the optimal statistic
# The optimal statistic returns five quantities:
# - xi: an array of the angular separations between the pulsar pairs (in radians)
# - rho: an array of the cross-correlations between the pulsar pairs
# - sig: an array of the uncertainty in the cross-correlations
# - OS: the value of the optimal statistic
# - OS_sig: the uncertainty in the optimal statistic
xi, rho, sig, OS, OS_sig = os.compute_os(params=ml_params)
print(OS, OS_sig, OS/OS_sig)
# Plot the cross-correlations and compare to the Hellings-Downs curve
# Before plotting, we need to bin the cross-correlations
def weightedavg(rho, sig):
weights, avg = 0., 0.
for r,s in zip(rho,sig):
weights += 1./(s*s)
avg += r/(s*s)
return avg/weights, np.sqrt(1./weights)
def bin_crosscorr(zeta, xi, rho, sig):
rho_avg, sig_avg = np.zeros(len(zeta)), np.zeros(len(zeta))
for i,z in enumerate(zeta[:-1]):
myrhos, mysigs = [], []
for x,r,s in zip(xi,rho,sig):
if x >= z and x < (z+10.):
myrhos.append(r)
mysigs.append(s)
rho_avg[i], sig_avg[i] = weightedavg(myrhos, mysigs)
return rho_avg, sig_avg
# sort the cross-correlations by xi
idx = np.argsort(xi)
xi_sorted = xi[idx]
rho_sorted = rho[idx]
sig_sorted = sig[idx]
# bin the cross-correlations so that there are the same number of pairs per bin
npairs = 66
xi_mean = []
xi_err = []
rho_avg = []
sig_avg = []
i = 0
while i < len(xi_sorted):
xi_mean.append(np.mean(xi_sorted[i:npairs+i]))
xi_err.append(np.std(xi_sorted[i:npairs+i]))
r, s = weightedavg(rho_sorted[i:npairs+i], sig_sorted[i:npairs+i])
rho_avg.append(r)
sig_avg.append(s)
i += npairs
xi_mean = np.array(xi_mean)
xi_err = np.array(xi_err)
def get_HD_curve(zeta):
coszeta = np.cos(zeta*np.pi/180.)
xip = (1.-coszeta) / 2.
HD = 3.*( 1./3. + xip * ( np.log(xip) -1./6.) )
return HD/2
# now make the plot
(_, caps, _) = plt.errorbar(xi_mean*180/np.pi, rho_avg, xerr=xi_err*180/np.pi, yerr=sig_avg, marker='o', ls='',
color='0.1', fmt='o', capsize=4, elinewidth=1.2)
zeta = np.linspace(0.01,180,100)
HD = get_HD_curve(zeta+1)
plt.plot(zeta, OS*HD, ls='--', label='Hellings-Downs', color='C0', lw=1.5)
plt.xlim(0, 180);
#plt.ylim(-4e-30, 5e-30);
plt.ylabel(r'$\hat{A}^2 \Gamma_{ab}(\zeta)$')
plt.xlabel(r'$\zeta$ (deg)');
plt.legend(loc=4);
plt.tight_layout();
plt.show();
```
To compute the noise-marginalized optimal statistic (Vigeland et al. 2018), you will need the chain from a Bayesian search for a common red process without spatial correlations (model 2A).
```
# Change chaindir to point to where you have the chain from your Bayesian search
chaindir = 'chains/model_2a/'
params = list(np.loadtxt(chaindir + '/params.txt', dtype='str'))
chain = np.loadtxt(chaindir + '/chain_1.txt')
N = 1000 # number of times to compute the optimal statistic
burn = int(0.25*chain.shape[0]) # estimate of when the chain has burned in
noisemarg_OS, noisemarg_OS_err = np.zeros(N), np.zeros(N)
for i in range(N):
# choose a set of noise values from the chain
# make sure that you pull values from after the chain has burned in
idx = np.random.randint(burn, chain.shape[0])
# construct a dictionary with these parameter values
param_dict = {}
for p in params:
param_dict.update({p: chain[idx, params.index(p)]})
# compute the optimal statistic at this set of noise values and save in an array
_, _, _, noisemarg_OS[i], noisemarg_OS_err[i] = os.compute_os(params=param_dict)
plt.hist(noisemarg_OS)
plt.figure();
plt.hist(noisemarg_OS/noisemarg_OS_err)
```
| github_jupyter |
# 4. Training a classifier
## What about data?
보통 이미지나 텍스트, 오디오, 그리고 비디오 데이터를 처리하기 위해서는 일단 표준 파이썬 패키지를 이용해서 numpy array 형식으로 이들을 불러와서 Tensor로 변환하는 방법을 사용한다.
`torchvision` 패키지에서는 CIFAR10, MNIST와 이미지 데이터를 변환하는 함수들을 가지고 있다. 즉 `torchvision.datasets` 패키지와 `torchvision.transforms` 패키지, 그리고 `torch.utils.data.DataLoader` 패키지를 사용한다.
이 튜토리얼에서는 CIFAR10 데이터셋을 사용하게 될 것이다. 사진 10당 label하나로 이루어진 이미지 데이터셋이다.
## Training an image classifier
아래의 절차를 순서대로 따르며 문제를 해결해보자.
1. `torchvision` 패키지를 이용해 CIFAR10 데이터셋을 불러오고 normalizing을 한다.
2. CNN을 만든다.
3. loss function을 만든다.
4. 만든 모델을 훈련시킨다.
5. 테스트
### 1. Loading and normalizing CIFAR10
`torchvision` 패키지를 이용해서 CIFAR10 데이터셋을 불러오자.
```
import torch
import torchvision
import torchvision.transforms as transforms
```
torchvision 패키지로 불러온 데이터셋은 [0, 1]의 범위를 갖는 이미지인데, Tensor로 바꾸고, [-1, 1]까지의 범위로 normalize를 시킬 것이다.
```
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog',
'frog', 'horse', 'ship', 'truck')
```
`matplotlib` 패키지를 이용해서 이미지를 확인해보자.
```
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5 # normalize를 다시 해제한다.
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
```
### 2. Define a Convolution Neural Network
```
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
```
### 3. Define a Loss function and optimizer
```
import torch.optim as optim
cost_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
```
### 4. Train the network
```
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = net(inputs)
cost = cost_func(outputs, labels)
cost.backward()
optimizer.step()
running_loss += cost.data[0]
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f'
% (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
```
### 5. Test the network on the test data
```
dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruch:', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
```
훈련된 모델이 어떤 결론을 내리는지 확인해보자.
```
outputs = net(Variable(images))
```
모델이 추측한 내용을 알기 위해서는 각 class에 대해 추측한 수치 중에서 가장 높은 수치를 찾아야 한다.
```
_, predicted = torch.max(outputs.data, 1)
print('Predicted:', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
```
얼마나 잘 맞추는지 정확도를 구해보자
```
correct = 0
total = 0
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
```
## Training on GPU
neural net을 GPU상에서 돌리기 위해서는
를 하면 된다. 이렇게 하면 net안에 존재하는 모든 parameter들과 buffer들을 CUDA Tensor로 바꾸게 된다.
모델을 GPU상에 돌리면 이 모델에 대한 입력 또한 마찬가지로 GPU상에서 돌려야 한다. 근데 사실 네트워크의 크기가 작다면 속도 상승을 체감하지 못할 것이다.
이제 Tensor에 대한 라이브러리와 neural network에 대해서 더 공부해보자.
| github_jupyter |
<h1>Demand forecasting with BigQuery and TensorFlow</h1>
In this notebook, we will develop a machine learning model to predict the demand for taxi cabs in New York.
To develop the model, we will need to get historical data of taxicab usage. This data exists in BigQuery. Let's start by looking at the schema.
```
import google.datalab.bigquery as bq
import pandas as pd
import numpy as np
import shutil
%bigquery schema --table "nyc-tlc:green.trips_2015"
```
<h2> Analyzing taxicab demand </h2>
Let's pull the number of trips for each day in the 2015 dataset using Standard SQL.
```
%bq query
SELECT EXTRACT (DAYOFYEAR from pickup_datetime) AS daynumber FROM `nyc-tlc.green.trips_2015` LIMIT 10
```
<h3> Modular queries and Pandas dataframe </h3>
Let's use the total number of trips as our proxy for taxicab demand (other reasonable alternatives are total trip_distance or total fare_amount). It is possible to predict multiple variables using Tensorflow, but for simplicity, we will stick to just predicting the number of trips.
We will give our query a name 'taxiquery' and have it use an input variable '$YEAR'. We can then invoke the 'taxiquery' by giving it a YEAR. The to_dataframe() converts the BigQuery result into a <a href='http://pandas.pydata.org/'>Pandas</a> dataframe.
```
%bq query -n taxiquery
WITH trips AS (
SELECT EXTRACT (DAYOFYEAR from pickup_datetime) AS daynumber FROM `nyc-tlc.green.trips_*`
where _TABLE_SUFFIX = @YEAR
)
SELECT daynumber, COUNT(1) AS numtrips FROM trips
GROUP BY daynumber ORDER BY daynumber
query_parameters = [
{
'name': 'YEAR',
'parameterType': {'type': 'STRING'},
'parameterValue': {'value': 2015}
}
]
trips = taxiquery.execute(query_params=query_parameters).result().to_dataframe()
trips[:5]
```
<h3> Benchmark </h3>
Often, a reasonable estimate of something is its historical average. We can therefore benchmark our machine learning model against the historical average.
```
avg = np.mean(trips['numtrips'])
print 'Just using average={0} has RMSE of {1}'.format(avg, np.sqrt(np.mean((trips['numtrips'] - avg)**2)))
```
The mean here is about 55,000 and the root-mean-square-error (RMSE) in this case is about 10,000. In other words, if we were to estimate that there are 55,000 taxi trips on any given day, that estimate is will be off on average by about 10,000 in either direction.
Let's see if we can do better than this -- our goal is to make predictions of taxicab demand whose RMSE is lower than 10,000.
What kinds of things affect people's use of taxicabs?
<h2> Weather data </h2>
We suspect that weather influences how often people use a taxi. Perhaps someone who'd normally walk to work would take a taxi if it is very cold or rainy.
Googler <a href="https://twitter.com/felipehoffa">Felipe Hoffa</a> has made weather observations from the US National Oceanic and Atmospheric Administration <a href-="http://stackoverflow.com/questions/34804654/how-to-get-the-historical-weather-for-any-city-with-bigquery/34804655">publicly</a> available in BigQuery. Let's use that dataset and find the station number corresponding to New York's La Guardia airport.
```
%bq query
SELECT * FROM `fh-bigquery.weather_gsod.stations`
WHERE state = 'NY' AND wban != '99999' AND name LIKE '%LA GUARDIA%'
```
<h3> Variables </h3>
Let's pull out the minimum and maximum daily temperature (in Fahrenheit) as well as the amount of rain (in inches) for La Guardia airport.
```
%bq query -n wxquery
SELECT EXTRACT (DAYOFYEAR FROM CAST(CONCAT(@YEAR,'-',mo,'-',da) AS TIMESTAMP)) AS daynumber,
MIN(EXTRACT (DAYOFWEEK FROM CAST(CONCAT(@YEAR,'-',mo,'-',da) AS TIMESTAMP))) dayofweek,
MIN(min) mintemp, MAX(max) maxtemp, MAX(IF(prcp=99.99,0,prcp)) rain
FROM `fh-bigquery.weather_gsod.gsod*`
WHERE stn='725030' AND _TABLE_SUFFIX = @YEAR
GROUP BY 1 ORDER BY daynumber DESC
query_parameters = [
{
'name': 'YEAR',
'parameterType': {'type': 'STRING'},
'parameterValue': {'value': 2015}
}
]
weather = wxquery.execute(query_params=query_parameters).result().to_dataframe()
weather[:5]
```
<h3> Merge datasets </h3>
Let's use Pandas to merge (combine) the taxi cab and weather datasets day-by-day.
```
data = pd.merge(weather, trips, on='daynumber')
data[:5]
```
<h3> Exploratory analysis </h3>
Is there a relationship between maximum temperature and the number of trips?
```
j = data.plot(kind='scatter', x='maxtemp', y='numtrips')
```
The scatterplot above doesn't look very promising.
Is there a relationship between the day of the week and the number of trips?
```
j = data.plot(kind='scatter', x='dayofweek', y='numtrips')
```
Hurrah, we seem to have found a predictor. It appears that people use taxis more later in the week. Perhaps New Yorkers make weekly resolutions to walk more and then lose their determination later in the week, or maybe it reflects tourism dynamics in New York City.
Perhaps if we took out the <em>confounding</em> effect of the day of the week, maximum temperature will start to have an effect. Let's see if that's the case:
```
j = data[data['dayofweek'] == 7].plot(kind='scatter', x='maxtemp', y='numtrips')
```
Removing the confounding factor does seem to reflect an underlying trend around temperature. But ... the data are a little sparse, don't you think? This is something that you have to keep in mind -- the more predictors you start to consider (here we are using two: day of week and maximum temperature), the more rows you will need so as to avoid <em> overfitting </em> the model.
<h3> Adding 2014 data </h3>
Let's add in 2014 data to the Pandas dataframe. Note how useful it was for us to modularize our queries around the YEAR.
```
query_parameters = [
{
'name': 'YEAR',
'parameterType': {'type': 'STRING'},
'parameterValue': {'value': 2014}
}
]
weather = wxquery.execute(query_params=query_parameters).result().to_dataframe()
trips = taxiquery.execute(query_params=query_parameters).result().to_dataframe()
data2014 = pd.merge(weather, trips, on='daynumber')
data2014[:5]
data2 = pd.concat([data, data2014])
data2.describe()
j = data2[data2['dayofweek'] == 7].plot(kind='scatter', x='maxtemp', y='numtrips')
```
The data do seem a bit more robust. If we had more data, it would be better of course. But in this case, we only have 2014 and 2015 data, so that's what we will go with.
<h2> Machine Learning with Tensorflow </h2>
We'll use 80% of our dataset for training and 20% of the data for testing the model we have trained. Let's shuffle the rows of the Pandas dataframe so that this division is random. The predictor (or input) columns will be every column in the database other than the number-of-trips (which is our target, or what we want to predict).
The machine learning models that we will use -- linear regression and neural networks -- both require that the input variables are numeric in nature.
The day of the week, however, is a categorical variable (i.e. Tuesday is not really greater than Monday). So, we should create separate columns for whether it is a Monday (with values 0 or 1), Tuesday, etc.
Against that, we do have limited data (remember: the more columns you use as input features, the more rows you need to have in your training dataset), and it appears that there is a clear linear trend by day of the week. So, we will opt for simplicity here and use the data as-is. Try uncommenting the code that creates separate columns for the days of the week and re-run the notebook if you are curious about the impact of this simplification.
```
import tensorflow as tf
shuffled = data2.sample(frac=1)
# It would be a good idea, if we had more data, to treat the days as categorical variables
# with the small amount of data, we have though, the model tends to overfit
#predictors = shuffled.iloc[:,2:5]
#for day in xrange(1,8):
# matching = shuffled['dayofweek'] == day
# key = 'day_' + str(day)
# predictors[key] = pd.Series(matching, index=predictors.index, dtype=float)
predictors = shuffled.iloc[:,1:5]
predictors[:5]
shuffled[:5]
targets = shuffled.iloc[:,5]
targets[:5]
```
Let's update our benchmark based on the 80-20 split and the larger dataset.
```
trainsize = int(len(shuffled['numtrips']) * 0.8)
avg = np.mean(shuffled['numtrips'][:trainsize])
rmse = np.sqrt(np.mean((targets[trainsize:] - avg)**2))
print 'Just using average={0} has RMSE of {1}'.format(avg, rmse)
```
<h2> Linear regression with tf.contrib.learn </h2>
We scale the number of taxicab rides by 100,000 so that the model can keep its predicted values in the [0-1] range. The optimization goes a lot faster when the weights are small numbers. We save the weights into ./trained_model_linear and display the root mean square error on the test dataset.
```
SCALE_NUM_TRIPS = 100000.0
trainsize = int(len(shuffled['numtrips']) * 0.8)
testsize = len(shuffled['numtrips']) - trainsize
npredictors = len(predictors.columns)
noutputs = 1
tf.logging.set_verbosity(tf.logging.WARN) # change to INFO to get output every 100 steps ...
shutil.rmtree('./trained_model_linear', ignore_errors=True) # so that we don't load weights from previous runs
estimator = tf.contrib.learn.LinearRegressor(model_dir='./trained_model_linear',
optimizer=tf.train.AdamOptimizer(learning_rate=0.1),
enable_centered_bias=False,
feature_columns=tf.contrib.learn.infer_real_valued_columns_from_input(predictors.values))
print "starting to train ... this will take a while ... use verbosity=INFO to get more verbose output"
def input_fn(features, targets):
return tf.constant(features.values), tf.constant(targets.values.reshape(len(targets), noutputs)/SCALE_NUM_TRIPS)
estimator.fit(input_fn=lambda: input_fn(predictors[:trainsize], targets[:trainsize]), steps=10000)
pred = np.multiply(list(estimator.predict(predictors[trainsize:].values)), SCALE_NUM_TRIPS )
rmse = np.sqrt(np.mean(np.power((targets[trainsize:].values - pred), 2)))
print 'LinearRegression has RMSE of {0}'.format(rmse)
```
The test error of about 7000 indicates that we are doing better with the machine learning model than we would be if we were to just use the historical average (our benchmark).
<h2> Neural network with tf.contrib.learn </h2>
Let's make a more complex model with a few hidden nodes.
```
SCALE_NUM_TRIPS = 100000.0
trainsize = int(len(shuffled['numtrips']) * 0.8)
testsize = len(shuffled['numtrips']) - trainsize
npredictors = len(predictors.columns)
noutputs = 1
tf.logging.set_verbosity(tf.logging.WARN) # change to INFO to get output every 100 steps ...
shutil.rmtree('./trained_model', ignore_errors=True) # so that we don't load weights from previous runs
estimator = tf.contrib.learn.DNNRegressor(model_dir='./trained_model',
hidden_units=[5, 2],
optimizer=tf.train.AdamOptimizer(learning_rate=0.01),
enable_centered_bias=False,
feature_columns=tf.contrib.learn.infer_real_valued_columns_from_input(predictors.values))
print "starting to train ... this will take a while ... use verbosity=INFO to get more verbose output"
def input_fn(features, targets):
return tf.constant(features.values), tf.constant(targets.values.reshape(len(targets), noutputs)/SCALE_NUM_TRIPS)
estimator.fit(input_fn=lambda: input_fn(predictors[:trainsize], targets[:trainsize]), steps=10000)
pred = np.multiply(list(estimator.predict(predictors[trainsize:].values)), SCALE_NUM_TRIPS )
rmse = np.sqrt(np.mean((targets[trainsize:].values - pred)**2))
print 'Neural Network Regression has RMSE of {0}'.format(rmse)
```
Using a neural network results in poorer performance than the linear model when I ran it -- it might be because convergence is harder.
<h2> Running a trained model </h2>
So, we have trained a model, and saved it to a file. Let's use this model to predict taxicab demand given the expected weather for three days.
Here we make a Dataframe out of those inputs, load up the saved model (note that we have to know the model equation -- it's not saved in the model file) and use it to predict the taxicab demand.
```
input = pd.DataFrame.from_dict(data =
{'dayofweek' : [4, 5, 6],
'mintemp' : [30, 60, 50],
'maxtemp' : [40, 70, 60],
'rain' : [0, 0.8, 0]})
# read trained model from ./trained_model
estimator = tf.contrib.learn.LinearRegressor(model_dir='./trained_model_linear',
enable_centered_bias=False,
feature_columns=tf.contrib.learn.infer_real_valued_columns_from_input(input.values))
pred = np.multiply(list(estimator.predict(input.values)), SCALE_NUM_TRIPS )
print pred
```
Looks like we should tell some of our taxi drivers to take the day off on Wednesday (day=4) and be there in full strength on Thursday (day=5). No wonder -- the forecast calls for extreme weather fluctuations on Thursday.
Note that Thursdays are usually "slow" days (taxi demand peaks on the weekends), but the machine learning model tells us to expect heavy demand this particular Thursday because of the weather.
| github_jupyter |
<b>This notebook divide a single mailing list corpus into threads.</b>
What it does:
-identifies the more participated threads
-identifies the long lasting threads
-export each thread's emails into seperate .csv files, setting thresholds of participation and duration
Parameters to set options:
-set a single URL related to a mailing list, setting the 'url' variable
-it exports files in the file path specified in the variable ‘path’
-you can set a threshold of participation and of duration for the threads to export, by setting 'min_participation' and 'min_duration' variables
```
%matplotlib inline
from bigbang.archive import Archive
from bigbang.archive import load as load_archive
from bigbang.thread import Thread
from bigbang.thread import Node
from bigbang.utils import remove_quoted
import matplotlib.pyplot as plt
import datetime
import pandas as pd
import csv
from collections import defaultdict
import os
```
First, collect data from a public email archive.
```
#Insert a list of archive names
archives_names = ["ietf"]
cwd = os.getcwd()
archives_paths = list()
for archive_name in archives_names:
archives_paths.append('../../archives/'+archive_name+'.csv')
archives_list = [load_archive(archive_path).data for archive_path in archives_paths]
archives = Archive(pd.concat(archives_list))
archives_data = archives.data
```
Let's check the number of threads in this mailing list corpus
```
print(len(archives.get_threads()))
```
We can plot the number of people participating in each thread.
```
n_people = [t.get_num_people() for t in archives.get_threads()]
plt.hist(n_people, bins = 20)
plt.xlabel('number of email-address in a thread')
plt.show()
```
The *duration* of a thread is the amount of elapsed time between its first and last message.
Let's plot the number of threads per each number of days of duration
```
duration = [t.get_duration().days for t in archives.get_threads()]
plt.hist(duration, bins = (10))
plt.xlabel('duration of a thread(days)')
plt.show()
```
Let's take a look at the largest threads!
```
#set how many threads subjects you want to display
n_top = 5
threads_emailcount = defaultdict(int)
for thread in archives.get_threads():
threads_emailcount[thread] = thread.get_num_messages()
for thread, count in sorted(iter(threads_emailcount.items()), reverse = True, key = lambda k_v:(k_v[1],k_v[0]))[:n_top]:
try:print(thread.get_root().data['Subject'] +' ('+str(count)+' emails)')
except: pass
```
Export the content of each thread into a .csv file (named: thread_1.csv, thread2.csv, ...).
You can set a minimum level of participation and duration, based on the previous analyses
```
#Insert the participation threshold (number of people)
#(for no threeshold: 'min_participation = 0')
min_participation = 0
#Insert the duration threshold (number of days)
#(for no threeshold: 'min_duration = 0')
min_duration = 0
i = 0
for thread in arx.get_threads():
if thread.get_num_people() >= min_participation and thread.get_duration().days >= min_duration:
i += 1
f = open(cwd+'/thread_'+str(i)+'.csv', "wb")
f_w = csv.writer(f)
f_w.writerow(thread.get_content())
f.close()
```
| github_jupyter |
<a href="https://colab.research.google.com/github/vukhanhlinh/atom-assignments/blob/main/python-for-data/Ex01%20-%20Syntax%2C%20Variables%20and%20Numbers.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Exercise 01 - Syntax, Variables and Numbers
Welcome to your first set of Python coding problems!
**Notebooks** are composed of blocks (called "cells") of text and code. Each of these is editable, though you'll mainly be editing the code cells to answer some questions.
To get started, try running the code cell below (by pressing the `►| Run` button, or clicking on the cell and pressing `ctrl+Enter`/`shift+Enter` on your keyboard).
```
print("You've successfully run some Python code")
print("Congratulations!")
```
Try adding another line of code in the cell above and re-running it.
Now let's get a little fancier: Add a new code cell by clicking on an existing code cell, hitting the `escape` key *(turn to command mode)*, and then hitting the `a` or `b` key.
- The `a` key will add a cell above the current cell.
- The `b` adds a cell below.
Great! Now you know how to use Notebooks.
## 0. Creating a Variable
**What is your favorite color? **
To complete this question, create a variable called `color` in the cell below with an appropriate `string` value.
```
color = 'white'
print(color)
```
<hr/>
## 1. Simple Arithmetic Operation
Complete the code below. In case it's helpful, here is the table of available arithmatic operations:
| Operator | Name | Description |
|--------------|----------------|--------------------------------------------------------|
| ``a + b`` | Addition | Sum of ``a`` and ``b`` |
| ``a - b`` | Subtraction | Difference of ``a`` and ``b`` |
| ``a * b`` | Multiplication | Product of ``a`` and ``b`` |
| ``a / b`` | True division | Quotient of ``a`` and ``b`` |
| ``a // b`` | Floor division | Quotient of ``a`` and ``b``, removing fractional parts |
| ``a % b`` | Modulus | Integer remainder after division of ``a`` by ``b`` |
| ``a ** b`` | Exponentiation | ``a`` raised to the power of ``b`` |
| ``-a`` | Negation | The negative of ``a`` |
<span style="display:none"></span>
```
pi = 3.14159 # approximate
diameter = 3
radius = diameter / 2 # Create a variable called 'radius' equal to half the diameter
print('diameter:' + str(diameter))
area = pi * radius ** 2 # Create a variable called 'area', using the formula for the area of a circle: pi times the radius squared
print('area: ' + str(area))
```
**Results**:
- Area = 7.0685775
## 2. Variable Reassignment
Add code to the following cell to swap variables `a` and `b` (so that `a` refers to the object previously referred to by `b` and vice versa).
```
# If you're curious, these are examples of lists. We'll talk about
# them in depth a few lessons from now. For now, just know that they're
# yet another type of Python object, like int or float.
a = [1, 2, 3]
b = [3, 2, 1]
######################################################################
# Your code goes here. Swap the values to which a and b refer.
# Hint: Try using a third variable
c = b
b = a
a = c
print(a)
print(b)
```
## 3. Order of Operations
a) Add parentheses to the following expression so that it evaluates to 1.
*Hint*: Following its default "**PEMDAS**"-like rules for order of operations, Python will first divide 3 by 2, then subtract the result from 5. You need to add parentheses to force it to perform the subtraction first.
```
x = (5 - 3 )// 2
x
```
<small>Questions, like this one, marked a spicy pepper are a bit harder. Don't feel bad if you can't get these.</small>
b) <span title="A bit spicy" style="color: darkgreen ">🌶️</span> Add parentheses to the following expression so that it evaluates to **0**.
```
y= 8 -(3 * 2) - (1 + 1)
y
```
## 4. Your Turn
Alice, Bob and Carol have agreed to pool their Halloween candies and split it evenly among themselves.
For the sake of their friendship, any candies left over will be smashed. For example, if they collectively
bring home 91 candies, they'll take 30 each and smash 1.
Write an arithmetic expression below to calculate how many candies they must smash for a given haul.
> *Hint*: You'll probably want to use the modulo operator, `%`, to obtain the remainder of division.
```
# Variables representing the number of candies collected by Alice, Bob, and Carol
alice_candies = 121
bob_candies = 77
carol_candies = 109
# Your code goes here! Replace the right-hand side of this assignment with an expression
total = (alice_candies + bob_candies + carol_candies )
to_take = total // 3
to_smash = total % 3
print('total: ' + str(total))
print('to take: ' + str(to_take))
print('to smash: ' + str(to_smash))
```
# Keep Going 💪
| github_jupyter |
```
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
import pandas as pd
import numpy as np
import altair as alt
import altair_saver
import glob
import os
import copy
alt.data_transformers.disable_max_rows()
def personal():
return {
'config': {
'view': {
'height': 300,
'width': 400,
},
'range': {
'category': {'scheme': 'set2'},
'ordinal': {'scheme': 'set2'},
},
'legend': {
'labelLimit': 0,
},
'background': 'white',
'mark': {
'clip': True,
},
'line': {
'size': 3,
# 'opacity': 0.4
},
}
}
def publication():
colorscheme = 'set2'
stroke_color = '333'
title_size = 24
label_size = 20
line_width = 5
return {
'config': {
'view': {
'height': 500,
'width': 600,
'strokeWidth': 0,
'background': 'white',
},
'title': {
'fontSize': title_size,
},
'range': {
'category': {'scheme': colorscheme},
'ordinal': {'scheme': colorscheme},
},
'axis': {
'titleFontSize': title_size,
'labelFontSize': label_size,
'grid': False,
'domainWidth': 5,
'domainColor': stroke_color,
'tickWidth': 3,
'tickSize': 9,
'tickCount': 4,
'tickColor': stroke_color,
'tickOffset': 0,
},
'legend': {
'titleFontSize': title_size,
'labelFontSize': label_size,
'labelLimit': 0,
'titleLimit': 0,
'orient': 'top-left',
# 'padding': 10,
'titlePadding': 10,
# 'rowPadding': 5,
'fillColor': '#ffffff88',
# 'strokeColor': 'black',
'cornerRadius': 0,
},
'rule': {
'size': 3,
'color': '999',
# 'strokeDash': [4, 4],
},
'line': {
'size': line_width,
# 'opacity': 0.4
},
}
}
alt.themes.register('personal', personal)
alt.themes.register('publication', publication)
alt.themes.enable('personal')
def load_jobs(pattern, subdir='exploration'):
jobs = glob.glob(f'results/{subdir}/{pattern}')
results = []
for job in jobs:
name = os.path.basename(os.path.normpath(job))
train_data = pd.read_csv(job + '/train.csv')
train_data['test'] = False
test_data = pd.read_csv(job + '/test.csv')
test_data['test'] = True
data = pd.concat([train_data, test_data], sort=False)
data['name'] = name
results.append(data)
df = pd.concat(results, sort=False)
return df.reset_index(drop=True)
def plot_with_bars(base_chart, y_col, test, extent='ci'):
dummy_chart = base_chart.mark_circle(size=0, opacity=1).encode(
y=f'mean({y_col}):Q',
).transform_filter(alt.datum.test == test)
mean_chart = base_chart.encode(
y=f'mean({y_col}):Q'
).transform_filter(alt.datum.test == test)
err_chart = base_chart.encode(
y=f'{y_col}:Q'
).transform_filter(alt.datum.test == test).mark_errorband(extent=extent)
return dummy_chart + err_chart + mean_chart
def make_base_chart(data, title, color):
chart = alt.Chart(data, title=title).mark_line().encode(
x=alt.X('episode', title='Episode'),
color=color,
tooltip=['Algorithm', 'episode']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-10, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}]
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-10, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
return chart
alt.themes.enable('publication')
jobs = [
load_jobs('arxiv2_grid40_intrinsic_seed*', subdir='intrinsic'),
load_jobs('arxiv2_grid40_slow_seed*', subdir='slow'),
load_jobs('arxiv2_grid40_seed*', subdir='exploration'),
load_jobs('arxiv2_grid40_noopt_seed*', subdir='exploration'),
load_jobs('arxiv2_grid40_noexplore_seed*', subdir='exploration'),
]
data = pd.concat(jobs, sort=False)
data['Algorithm'] = 'Ours: IR + FP + FA + Optimism'
data.loc[data['name'].str.contains('noopt'), 'Algorithm'] = 'IR + FP + Fast adaptation'
data.loc[data['name'].str.contains('slow'), 'Algorithm'] = 'IR + Factored policies'
data.loc[data['name'].str.contains('intrinsic'), 'Algorithm'] = 'Intrinsic reward'
data.loc[data['name'].str.contains('noexplore'), 'Algorithm'] = 'No exploration'
algorithms = [
'No exploration',
'Intrinsic reward',
'IR + Factored policies',
'IR + FP + Fast adaptation',
'Ours: IR + FP + FA + Optimism'
]
subset = data
subset = subset[(subset['episode'] <= 1000)]
chart = make_base_chart(
subset,
title="Gridworld 40x40 with reward",
color=alt.Color('Algorithm', scale=alt.Scale(domain=algorithms)))
chart = plot_with_bars(chart, 'rolling_mean_score', test=True)
chart.layer[0].encoding.y['scale'] = alt.Scale(domain=[-0.5, 25], nice=False)
chart.layer[0].encoding.color['legend'] = alt.Legend(orient='bottom', legendX=300, legendY=100)
# altair_saver.save(chart, 'pv100_reward.pdf', method='node')
chart
alt.themes.enable('publication')
jobs = [
load_jobs('arxiv2_pv100_intrinsic_seed*', subdir='intrinsic'),
load_jobs('arxiv2_pv100_slow_seed*', subdir='slow'),
load_jobs('arxiv2_pv100_seed*', subdir='exploration'),
load_jobs('arxiv2_pv100_noopt_seed*', subdir='exploration'),
load_jobs('arxiv2_pv100_noexplore_seed*', subdir='exploration'),
]
data = pd.concat(jobs, sort=False)
data['Algorithm'] = 'Ours: IR + FP + FA + Optimism'
data.loc[data['name'].str.contains('noopt'), 'Algorithm'] = 'IR + FP + Fast adaptation'
data.loc[data['name'].str.contains('slow'), 'Algorithm'] = 'IR + Factored policies'
data.loc[data['name'].str.contains('intrinsic'), 'Algorithm'] = 'Intrinsic reward'
data.loc[data['name'].str.contains('noexplore'), 'Algorithm'] = 'No exploration'
algorithms = [
'No exploration',
'Intrinsic reward',
'IR + Factored policies',
'IR + FP + Fast adaptation',
'Ours: IR + FP + FA + Optimism'
]
subset = data
subset = subset[(subset['episode'] <= 1000)]
chart = make_base_chart(
subset,
title="Point Velocity with reward",
color=alt.Color('Algorithm', scale=alt.Scale(domain=algorithms)))
chart = plot_with_bars(chart, 'rolling_mean_score', test=True)
chart.layer[0].encoding.y['scale'] = alt.Scale(domain=[-1, 70], nice=False)
chart
alt.themes.enable('publication')
jobs = [
load_jobs('arxiv2_grid40_intrinsic_seed*', subdir='intrinsic'),
load_jobs('arxiv2_grid40_slow_seed*', subdir='slow'),
load_jobs('arxiv2_grid40_seed*', subdir='exploration'),
load_jobs('arxiv2_grid40_noopt_seed*', subdir='exploration'),
load_jobs('arxiv2_grid40_noexplore_seed*', subdir='exploration'),
]
data = pd.concat(jobs, sort=False)
data['Algorithm'] = 'Ours: UFO'
data.loc[data['name'].str.contains('noopt'), 'Algorithm'] = 'UF only'
data.loc[data['name'].str.contains('slow'), 'Algorithm'] = 'U only'
data.loc[data['name'].str.contains('intrinsic'), 'Algorithm'] = 'BBE'
data.loc[data['name'].str.contains('noexplore'), 'Algorithm'] = 'Undirected exploration'
algorithms = [
'Undirected exploration',
'BBE',
'U only',
'UF only',
'Ours: UFO'
]
subset = data
subset = subset[(subset['episode'] <= 1000)]
chart = make_base_chart(
subset,
title="",
color=alt.Color('Algorithm', scale=alt.Scale(domain=algorithms)))
chart = plot_with_bars(chart, 'rolling_mean_score', test=True)
chart.layer[0].encoding.y['scale'] = alt.Scale(domain=[-0.5, 25], nice=False)
for layer in chart.layer:
layer.encoding.y['title'] = 'Reward'
chart.layer[0].encoding.color['legend'] = alt.Legend(orient='bottom', legendX=300, legendY=100)
# altair_saver.save(chart, 'pv100_reward.pdf', method='node')
chart_gridworld = chart
jobs = [
load_jobs('arxiv2_pv100_intrinsic_seed*', subdir='intrinsic'),
load_jobs('arxiv2_pv100_slow_seed*', subdir='slow'),
load_jobs('arxiv2_pv100_seed*', subdir='exploration'),
load_jobs('arxiv2_pv100_noopt_seed*', subdir='exploration'),
load_jobs('arxiv2_pv100_noexplore_seed*', subdir='exploration'),
]
data = pd.concat(jobs, sort=False)
data['Algorithm'] = 'Ours: UFO'
data.loc[data['name'].str.contains('noopt'), 'Algorithm'] = 'UF only'
data.loc[data['name'].str.contains('slow'), 'Algorithm'] = 'U only'
data.loc[data['name'].str.contains('intrinsic'), 'Algorithm'] = 'BBE'
data.loc[data['name'].str.contains('noexplore'), 'Algorithm'] = 'Undirected exploration'
algorithms = [
'Undirected exploration',
'BBE',
'U only',
'UF only',
'Ours: UFO'
]
subset = data
subset = subset[(subset['episode'] <= 1000)]
chart = make_base_chart(
subset,
title="",
color=alt.Color('Algorithm', scale=alt.Scale(domain=algorithms)))
chart = plot_with_bars(chart, 'rolling_mean_score', test=True)
chart.layer[0].encoding.y['scale'] = alt.Scale(domain=[-1, 70], nice=False)
for layer in chart.layer:
layer.encoding.y['title'] = 'Reward'
chart_pv = chart
chart = alt.concat(chart_gridworld, chart_pv, spacing=50)
# chart = chart.configure(spacing=20)
# altair_saver.save(chart, 'grid40_pv100_reward_ufo.pdf', method='node')
chart
alt.themes.enable('personal')
jobs = [
load_jobs('arxiv_grid20*', subdir='intrinsic'),
load_jobs('arxiv_grid20*', subdir='slow'),
load_jobs('arxiv_grid20*', subdir='exploration'),
]
data = pd.concat(jobs, sort=False)
subset = data
# subset['replay1M'] = subset['name'].str.contains('replay1M')
# subset = subset[subset['eval'] == False]
subset = subset[(subset['episode'] <= 300)]
chart = alt.Chart(subset, title="Gridworld 20x20", width=400, height=300).mark_line(size=3).encode(
x='episode',
color='name',
# opacity='test',
tooltip=['name', 'episode', 'score', 'novelty_score', 'count_score:Q']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
(
chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == True)
) & (
chart.encode(y='sum_novelty:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='count_score:Q').transform_filter(alt.datum.test == False)
)
jobs = [
load_jobs('grid20*', subdir='intrinsic'),
load_jobs('grid20_slow_real_noflip', subdir='slow'),
load_jobs('grid_optcheck', subdir='exploration'),
]
data = pd.concat(jobs, sort=False)
subset = data
# subset['replay1M'] = subset['name'].str.contains('replay1M')
# subset = subset[subset['eval'] == False]
subset = subset[(subset['episode'] > 2) & (subset['episode'] <= 300)]
chart = alt.Chart(subset, title="Gridworld 20x20", width=400, height=300).mark_line(size=3).encode(
x='episode',
color='name',
opacity='test',
tooltip=['name', 'episode', 'score', 'novelty_score', 'count_score:Q']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
(
chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == True)
) & (
chart.encode(y='sum_novelty:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='count_score:Q').transform_filter(alt.datum.test == False)
)
jobs = [
'grid40*',
]
data = pd.concat([load_jobs(j) for j in jobs], sort=False)
subset = data
# subset['replay1M'] = subset['name'].str.contains('replay1M')
# subset = subset[subset['eval'] == False]
subset = subset[(subset['episode'] > 2) & (subset['episode'] <= 1000)]
chart = alt.Chart(subset, title="Gridworld 40x40", width=400, height=300).mark_line(size=3).encode(
x='episode',
color='name',
detail='name',
tooltip=['name', 'episode', 'score', 'novelty_score', 'count_score:Q']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
(chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == True) | \
chart.encode(y='count_score:Q').transform_filter(alt.datum.test == False)) & \
(chart.encode(y='sum_novelty:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='policy_entropy:Q').transform_filter(alt.datum.test == True)) & \
chart.encode(y='explore_entropy:Q').transform_filter(alt.datum.test == False)
jobs = [
# 'pv100_noexplore',
# 'pv100_sigmoidstretch_clipvalue',
# 'pv100_clipvalue',
# 'pv100_sigmoidstretch_clipvalue_tupdate10',
# 'pv100_clipvalue_tupdate10',
# 'pv100_clipvalue_tupdate1',
# 'pv100_clipvalue_tupdate10_temp0.1',
# 'pv100_testtemp0.3*',
# 'pv100replay1M*',
'pv100entropy*',
]
data = pd.concat([load_jobs(j) for j in jobs], sort=False)
subset = data
# subset['replay1M'] = subset['name'].str.contains('replay1M')
# subset = subset[subset['eval'] == False]
subset = subset[(subset['episode'] > 2) & (subset['episode'] <= 1000)]
chart = alt.Chart(subset, title="Point Velocity", width=400, height=300).mark_line(size=3).encode(
x='episode',
color='name',
detail='name',
tooltip=['name', 'episode', 'score', 'novelty_score', 'count_score:Q']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
(chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == True) | \
chart.encode(y='count_score:Q').transform_filter(alt.datum.test == False)) & \
(chart.encode(y='sum_novelty:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='policy_entropy:Q').transform_filter(alt.datum.test == True)) & \
chart.encode(y='explore_entropy:Q').transform_filter(alt.datum.test == False)
jobs = [
'pm_temp0.1*',
'pm_noexplore*',
]
data = pd.concat([load_jobs(j) for j in jobs], sort=False)
subset = data
# subset['replay1M'] = subset['name'].str.contains('replay1M')
# subset = subset[subset['eval'] == False]
subset = subset[(subset['episode'] > 2) & (subset['episode'] <= 300)]
chart = alt.Chart(subset, title="Point Mass", width=400, height=300).mark_line(size=3).encode(
x='episode',
color='name',
detail='name',
tooltip=['name', 'episode', 'score', 'novelty_score', 'count_score:Q']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
(chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == True) | \
chart.encode(y='count_score:Q').transform_filter(alt.datum.test == False)) & \
(chart.encode(y='sum_novelty:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='policy_entropy:Q').transform_filter(alt.datum.test == False))
jobs = [
# 'pm_temp0.1*',
'swingup_noexplore_ptemp0.1-0.03',
# 'swingup_temp0.1_ptemp0.1-0.03',
# 'swingup_temp0.1_ptemp0.1-0.03_pddqn',
'swingup_divergence*',
# 'swingup_divergence_pddqn_plr1e-3*',
# 'swingup_divergence_plr1e-3*',
]
data = pd.concat([load_jobs(j) for j in jobs], sort=False)
subset = data
# subset['replay1M'] = subset['name'].str.contains('replay1M')
# subset = subset[subset['eval'] == False]
subset = subset[(subset['episode'] > 2) & (subset['episode'] <= 10000)]
chart = alt.Chart(subset, title="Swingup Sparse", width=400, height=300).mark_line(size=3).encode(
x='episode',
color='name',
detail='name',
tooltip=['name', 'episode', 'score', 'novelty_score', 'count_score:Q']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-10, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-10, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
(chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == True) | \
chart.encode(y='count_score:Q').transform_filter(alt.datum.test == False)) & \
(chart.encode(y='sum_novelty:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='policy_entropy:Q').transform_filter(alt.datum.test == False))
jobs = [
'pv100entropy_temp0.1_ptemp0.1-0.03',
'pv100_novtemp*',
# 'pv100_derp',
'pv100_rootcount',
]
data = pd.concat([load_jobs(j) for j in jobs], sort=False)
subset = data
# subset['replay1M'] = subset['name'].str.contains('replay1M')
# subset = subset[subset['eval'] == False]
subset = subset[(subset['episode'] > 2) & (subset['episode'] <= 1000)]
chart = alt.Chart(subset, title="Does a harder Qex update improve exploration on PV?", width=400, height=300).mark_line(size=3).encode(
x='episode',
color='name',
detail='name',
tooltip=['name', 'episode', 'score', 'novelty_score', 'count_score:Q']
).transform_calculate(
has_score=(alt.datum.score > 0.1),
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
sum_score='sum(score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
count_score='sum(has_score)',
frame=[None, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name', 'test'],
sort=[{'field': 'episode', 'order': 'ascending'}],
)
(chart.encode(y='rolling_mean_score:Q').transform_filter(alt.datum.test == True) | \
chart.encode(y='count_score:Q').transform_filter(alt.datum.test == False)) & \
(chart.encode(y='sum_novelty:Q').transform_filter(alt.datum.test == False) | \
chart.encode(y='policy_entropy:Q').transform_filter(alt.datum.test == True)) & \
chart.encode(y='explore_entropy:Q').transform_filter(alt.datum.test == False)
data = pd.concat([
load_jobs('point-mass_noexplore*'),
# load_jobs('point-mass_clipvalue'),
load_jobs('point-mass_clipvalue_exptemp1'),
load_jobs('point-mass_clipvalue_exptemp5'),
# load_jobs('point-mass_sigmoidstretch_clipvalue_exptemp1'),
], sort=False)
subset = data
subset = subset[subset['test'] == False]
subset = subset[subset['episode'] <= 1000]
chart = alt.Chart(subset, title="Can we learn policies faster than baseline?").mark_line().encode(
x='episode',
y='rolling_mean_score:Q',
color='name',
detail='eval',
tooltip=['episode', 'score', 'novelty_score']
).transform_window(
rolling_mean_score='mean(score)',
frame=[-20, 20]
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-20, 20]
)
chart + chart.mark_circle().encode().interactive()
data = pd.concat([
load_jobs('point-mass_clipvalue_exptemp1'),
load_jobs('point-mass_sigmoidmargin_clipvalue_exptemp1'),
load_jobs('point-mass_sigmoidstretch_clipvalue_exptemp1'),
], sort=False)
subset = data
subset = subset[subset['test'] == False]
subset = subset[subset['episode'] <= 1000]
chart = alt.Chart(subset, title="Does restricting Q range help?").mark_line().encode(
x='episode',
y='rolling_mean_novelty:Q',
color='name',
detail='eval',
tooltip=['episode', 'score', 'novelty_score']
).transform_window(
rolling_mean_score='mean(score)',
frame=[-40, 0]
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-40, 0]
)
chart + chart.mark_circle().encode().interactive()
data = pd.concat([
load_jobs('swingupsparse*'),
], sort=False)
subset = data
subset = subset[subset['test'] == False]
subset = subset[subset['episode'] <= 1000]
chart = alt.Chart(subset, title="Cartpole Swingup").mark_line().encode(
x='episode',
y='rolling_mean_score:Q',
color='name',
detail='eval',
tooltip=['episode', 'score', 'novelty_score']
).transform_window(
rolling_mean_score='mean(score)',
frame=[-40, 0]
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-40, 0]
)
chart + chart.mark_circle().encode().interactive()
jobs = [
'pv100_clipvalue',
'pv100_clipvalue_tupdate10',
'pv100_clipvalue_tupdate1',
]
data = pd.concat([load_jobs(j) for j in jobs], sort=False)
subset = data
subset = subset[subset['test'] == False]
subset = subset[subset['episode'] <= 1000]
chart = alt.Chart(subset, title="Do faster target updates help exploration? Not really.").mark_line().encode(
x='episode',
y='sum_novelty:Q',
color='name',
detail='eval',
tooltip=['episode', 'score', 'novelty_score']
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name']
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name']
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name']
)
chart + chart.mark_circle().encode().interactive()
jobs = [
'pv100_sigmoidstretch_clipvalue',
'pv100_clipvalue',
'pv100_sigmoidstretch_clipvalue_tupdate10',
'pv100_clipvalue_tupdate10',
]
data = pd.concat([load_jobs(j) for j in jobs], sort=False)
subset = data
subset = subset[subset['test'] == False]
subset = subset[subset['episode'] <= 1000]
chart = alt.Chart(subset, title="Are sigmoid networks better? Not really, for PV.").mark_line().encode(
x='episode',
y='sum_novelty:Q',
color='name',
detail='eval',
tooltip=['episode', 'score', 'novelty_score']
).transform_window(
sum_novelty='sum(novelty_score)',
frame=[None, 0],
groupby=['name']
).transform_window(
rolling_mean_score='mean(score)',
frame=[-5, 0],
groupby=['name']
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-5, 0],
groupby=['name']
)
chart + chart.mark_circle().encode().interactive()
data = pd.concat([
load_jobs('pv100_sigmoidstretch_clipvalue'),
load_jobs('pv100_clipvalue'),
load_jobs('pv100_sigmoidstretch_clipvalue_tupdate10'),
load_jobs('pv100_noexplore'),
], sort=False)
subset = data
subset = subset[subset['test'] == False]
subset = subset[subset['episode'] <= 1000]
chart = alt.Chart(subset, title="Point Velocity").mark_line().encode(
x='episode',
y='score:Q',
color='name',
detail='eval',
tooltip=['episode', 'score', 'novelty_score']
).transform_window(
rolling_mean_score='mean(score)',
frame=[-40, 0],
groupby=['name']
).transform_window(
rolling_mean_novelty='mean(novelty_score)',
frame=[-40, 0],
groupby=['name']
)
chart + chart.mark_circle().encode().interactive()
```
| github_jupyter |
# Generate example models for modeling class
Here just a couple of functions (and simple data conversions from gempy models) to create some models:
```
import numpy as np
from scipy.interpolate import Rbf
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import cm
from numpy.linalg import lstsq
```
## Layer stack
The first model we will consider is a simple layer stack of (completely) parallel layers, e.g. something we would expect to observe in a sedimentary system:
```
l1 = lambda x : 0.25*x + 10
l2 = lambda x : 0.25*x + 20
l3 = lambda x : 0.25*x + 30
```
### Randomly sample points
We now randomly extract a set of interface points from these lines:
```
n_pts = 4 # Points per layer
# set seed for reproducibility
np.random.seed(123)
l1_pts_x = np.random.uniform(0,100,n_pts)
l1_pts_y = l1(l1_pts_x)
l2_pts_x = np.random.uniform(0,100,n_pts)
l2_pts_y = l2(l2_pts_x)
l3_pts_x = np.random.uniform(0,100,n_pts)
l3_pts_y = l3(l3_pts_x)
# plt.plot(xvals, l1(xvals))
# plt.plot(xvals, l2(xvals))
# plt.plot(xvals, l3(xvals))
plt.plot(l1_pts_x, l1_pts_y, 'o')
plt.plot(l2_pts_x, l2_pts_y, 'o')
plt.plot(l3_pts_x, l3_pts_y, 'o')
plt.axis('equal');
# combine data in arrays
x = np.hstack([l1_pts_x, l2_pts_x, l3_pts_x])
y = np.hstack([l1_pts_y, l2_pts_y, l3_pts_y])
# give points values
z = np.hstack([np.ones(n_pts)*10, np.ones(n_pts)*20, np.ones(n_pts)*30])
```
### Save points for further use
```
np.save("pts_line_model_x", x)
np.save("pts_line_model_y", y)
np.save("pts_line_model_z", z)
```
## Simple fold model
```
l1 = lambda x : 10*np.sin(0.1*x) + 10
l2 = lambda x : 10*np.sin(0.1*x) + 20
l3 = lambda x : 10*np.sin(0.1*x) + 30
n_pts = 10 # Points per layer
l1_pts_x = np.random.uniform(0,100,n_pts)
l1_pts_y = l1(l1_pts_x)
l2_pts_x = np.random.uniform(0,100,n_pts)
l2_pts_y = l2(l2_pts_x)
l3_pts_x = np.random.uniform(0,100,n_pts)
l3_pts_y = l3(l3_pts_x)
xvals = np.linspace(0,100,1000)
plt.plot(xvals, l1(xvals))
plt.plot(xvals, l2(xvals))
plt.plot(xvals, l3(xvals))
plt.plot(l1_pts_x, l1_pts_y, 'o')
plt.plot(l2_pts_x, l2_pts_y, 'o')
plt.plot(l3_pts_x, l3_pts_y, 'o')
plt.axis('equal')
# combine data in arrays
x = np.hstack([l1_pts_x, l2_pts_x, l3_pts_x])
y = np.hstack([l1_pts_y, l2_pts_y, l3_pts_y])
# give points values
z = np.hstack([np.ones(n_pts)*10, np.ones(n_pts)*20, np.ones(n_pts)*30])
np.save("pts_fold_model_x", x)
np.save("pts_fold_model_y", y)
np.save("pts_fold_model_z", z)
```
## Recumbend fold
aka "Jan's model" - for more examples see:
https://github.com/cgre-aachen/gempy/tree/master/notebooks/examples
Note: we don't generate this model from scratch, but load the csv files and extract the relevant information
```
rock1 = np.loadtxt('jan_model3_rock1.csv', delimiter=',', skiprows=1, usecols=[0,1,2])
rock2 = np.loadtxt('jan_model3_rock2.csv', delimiter=',', skiprows=0, usecols=[0,1,2])
# select only points for y = 500
rock1 = rock1[np.where(rock1[:,1]==500)]
rock2 = rock2[np.where(rock2[:,1]==500)]
plt.plot(rock1[:,0], rock1[:,2], 'o')
plt.plot(rock2[:,0], rock2[:,2], 'o')
# combine data:
x = np.hstack([rock1[:,0], rock2[:,0]])
y = np.hstack([rock1[:,2], rock2[:,2]])
z = np.hstack([np.ones_like(rock1[:,0])*10, np.ones_like(rock2[:,0])*20])
np.save("pts_jans_fold_model_x", x)
np.save("pts_jans_fold_model_y", y)
np.save("pts_jans_fold_model_z", z)
```
## Fault model
Here also an example of a fault model, e.g. to be used to show the influence of multiple interacting scalar fields:
```
n_pts = 10 # Points per layer
# Linear functions for line data
l1 = lambda x : 0.25*x + 30
l2 = lambda x : 0.25*x + 40
l3 = lambda x : 0.25*x + 50
# set seed for reproducibility
np.random.seed(123)
# sampling points
l1_pts_x = np.random.uniform(0,90,n_pts)
l1_pts_y = l1(l1_pts_x)
l2_pts_x = np.random.uniform(0,90,n_pts)
l2_pts_y = l2(l2_pts_x)
l3_pts_x = np.random.uniform(0,90,n_pts)
l3_pts_y = l3(l3_pts_x)
# define fault
fault_point_1 = (40,60)
fault_point_2 = (60,20)
# interpolate fault - to obtain offset for data set:
x_coords, y_coords = [40,60], [60,20] # zip(*points)
A = np.vstack([x_coords, np.ones(len(x_coords))]).T
m, c = lstsq(A, y_coords, rcond=None)[0]
offset = 10 # offset of block on right side of fault
f = lambda x : m*x + c
# Create filters to determine points on each side of fault
filter_l1 = f(l1_pts_x) < l1_pts_y
filter_l2 = f(l2_pts_x) < l2_pts_y
filter_l3 = f(l3_pts_x) < l3_pts_y
# create copies of arrays to avoid confusion...
l1_pts_x_fault = l1_pts_x.copy()
l1_pts_y_fault = l1_pts_y.copy()
l2_pts_x_fault = l2_pts_x.copy()
l2_pts_y_fault = l2_pts_y.copy()
l3_pts_x_fault = l3_pts_x.copy()
l3_pts_y_fault = l3_pts_y.copy()
# Adjust y-values
l1_pts_y_fault[filter_l1] -= offset
l2_pts_y_fault[filter_l2] -= offset
l3_pts_y_fault[filter_l3] -= offset
# Adjust x-values
l1_pts_x_fault[filter_l1] -= 1/m*offset
l2_pts_x_fault[filter_l2] -= 1/m*offset
l3_pts_x_fault[filter_l3] -= 1/m*offset
```
## Adding noise
Of course, all of the previous examples are just too perfect to be realistic geological observations - let's add some noise to test the sensitivity of the algorithms:
*Note: we only add noise to the y-component*
```
y = np.load("pts_line_model_y.npy")
y += np.random.normal(0, 2, len(y))
np.save("pts_line_model_y_noise", y)
```
| github_jupyter |
# Sup01-Quickly Visualize DEM Attributes with Datashader
[Datashader](https://datashader.org/index.html) is a general-purpose tool for rasterizing (and re-rasterizing) data of many different types that certainly include DEM data. Moreover, Datashader provides a few geospatial-specific utilities (***datashader.geo***) that could be easily applied to calculate DEM Attributes such as:
* [Slope](#Slope)
* [Aspect](#Aspect).
Datashader provides a good [user guide](https://datashader.org/user_guide/index.html) to explain key concepts of Datashader in detail. This notebook will follow the guide and apply the functions of datashader.geo to quickly calculate and visualize the DEM Attributes. To increase visuilzatioin effects, we will overlap ***Slope*** and ***Aspect*** onto DEM and its [Hillshade](#Hillshade).
It should be mentioned that Datashader is extremely powerful for creating meaningful representations of large datasets quickly and flexibly. In addition, it supports xarray.DataArray internally without having to convert data into numpy.array after reading DEM data.
```
import numpy as np
import xarray as xr
from xarray import DataArray
import datashader as ds
import datashader.geo as dsgeo
from datashader.transfer_functions import shade, stack
from datashader.colors import Elevation
import warnings
warnings.filterwarnings("ignore")
```
## Open up the DEM
Set all terrain values < 0 to nan.
```
infile = "data/es_dem/pre_DTM.tif"
da_dem = xr.open_rasterio(infile).drop('band')[0]
# Have to check the res property.
# No support for res in both directioins of (x, y) or (lat, lon).
da_dem.attrs['res'] = da_dem.attrs['res'][0]
nodata = da_dem.nodatavals[0]
da_dem = da_dem.where(da_dem>nodata, np.nan)
shade(da_dem, cmap=['black', 'white'], how='linear')
```
The grayscale value above shows the elevation linearly in intensity (with the large black areas indicating low elevation), but it will look more like a landscape if we map the lowest values to colors representing water, and the highest to colors representing mountaintops:
```
shade(da_dem, cmap=Elevation, how='linear')
```
## Hillshade
[Hillshade](https://en.wikipedia.org/wiki/Terrain_cartography) is a technique used to visualize terrain as shaded relief, illuminating it with a hypothetical light source. The illumination value for each cell is determined by its orientation to the light source, which is based on slope and aspect.
```
illuminated = dsgeo.hillshade(da_dem)
shade(illuminated, cmap=['gray', 'white'], alpha=255, how='linear')
```
You can combine hillshading with elevation colormapping to convey differences in terrain with elevation:
```
stack(shade(illuminated, cmap=['gray', 'white'], alpha=255, how='linear'),
shade(da_dem , cmap=Elevation, alpha=128, how='linear'))
```
## Slope
[Slope](https://en.wikipedia.org/wiki/Slope) is the inclination of a surface. In geography, *slope* is amount of change in elevation of a terrain regarding its surroundings. Horn (1981) calculates the slope of a focal cell by using a central difference estimation of a surface fitted to the focal cell and its neighbours. The slope chosen is the maximum of this surface and can be returned in several formats.
Datashader's slope function returns slope in degrees. Below we highlight areas at risk for avalanche by looking at [slopes around 38 degrees](http://wenatcheeoutdoors.org/2016/04/07/avalanche-abcs-for-snowshoers/).
```
risky = dsgeo.slope(da_dem)
risky.data = np.where(np.logical_and(risky.data > 25, risky.data < 50), 1, np.nan)
stack(shade(da_dem, cmap=['black', 'white'], how='linear'),
shade(illuminated, cmap=['black', 'white'], how='linear', alpha=128),
shade(risky, cmap='red', how='linear', alpha=200))
```
## Aspect
Horn (1981) calculates aspect as the direction of the maximum slope of the focal cell. The value returned is in Degrees. [Aspect](https://en.wikipedia.org/wiki/Aspect_(geography)) is the orientation of slope, measured clockwise in degrees from 0 to 360, where 0 is north-facing, 90 is east-facing, 180 is south-facing, and 270 is west-facing.
Below, we look to find slopes that face close to North.
```
north_faces = dsgeo.aspect(da_dem)
north_faces.data = np.where(np.logical_or(north_faces.data > 350 ,
north_faces.data < 10), 1, np.nan)
stack(shade(da_dem, cmap=['black', 'white'], how='linear'),
shade(illuminated, cmap=['black', 'white'], how='linear', alpha=128),
shade(north_faces, cmap=['aqua'], how='linear', alpha=100))
```
## References
https://datashader.org/
https://datashader.org/user_guide/index.html
https://desktop.arcgis.com/en/arcmap/10.3/tools/spatial-analyst-toolbox/how-slope-works.htm
Horn, B.K.P., 1981. Hill shading and the reflectance map. Proceedings of the IEEE 69, 14–47. doi:10.1109/PROC.1981.11918
Travis E, Oliphant. A guide to NumPy, USA: Trelgol Publishing, (2006).
Stéfan van der Walt, S. Chris Colbert and Gaël Varoquaux. The NumPy Array: A Structure for Efficient Numerical Computation, Computing in Science & Engineering, 13, 22-30 (2011), DOI:10.1109/MCSE.2011.37
Fernando Pérez and Brian E. Granger. IPython: A System for Interactive Scientific Computing, Computing in Science & Engineering, 9, 21-29 (2007), DOI:10.1109/MCSE.2007.53
John D. Hunter. Matplotlib: A 2D Graphics Environment, Computing in Science & Engineering, 9, 90-95 (2007), DOI:10.1109/MCSE.2007.55
| github_jupyter |
```
# default_exp seoml
# Above comment sets package name nbdev will export when running nbdev_build_lib
# hide
# Used in nbdev auto-documentation.
from nbdev.showdoc import *
# Activates the uncompromising PEP8 code formatter https://pypi.org/project/nb-black/
%load_ext lab_black
%reload_ext lab_black
```
# Welcome to the seoml template.
> Example Template to pull, store, visualize and transform data into various deliverables.
<img src="./gfx/intro.png"/>
This Notebook contains common SEO jobs such as pulling all your data from Google Search Console [GSC](https://search.google.com/search-console/about) and tracking search engine result pages (SERPs). SQLite is used to store the data locally. Learn from and customize it for your needs. It is an example of using Jupyter Notebook as an exploratory environment and "extracting" finished jobs into fully automatable packages. Learn more about [seoml](https://github.com/miklevin/seoml/blob/main/README.md).
## Instructions
1. If running from Jupyter for the 1st time, change ***site*** below to one of your sites.
1. Run the code-blocks in this template from the top-down.
1. Customize to your own needs.
# NEXT STEP:
## The following code-block does these things:
1. Imports all the "global" packages.
1. Sets a default argument values (if run for the first time from Jupyter).
1. Sets up logging to send output both here and to rotating giles in ./logs folder.
1. Creates tiny global helper functions using lambda one-liners.
1. Detects the context from which script is run: Jupyter vs. Command-line vs. import.
1. Parses input when run from the command-line, or uses default or previously-used arguments.
1. Tests that args have been acquired.
## Run next step.
```
# export
# Import all globals
import pickle
import argparse
from pathlib import Path
from pprint import pprint
from datetime import date
from pyfiglet import Figlet
import logging, logging.handlers
site = "mikelev.in" # Set a default argument values (if run for the first time from Jupyter).
# Set up logging to send output both here and to rotating giles in ./logs folder.
ldr = Path("./logs")
if not ldr.exists():
Path.mkdir(ldr)
dft = "%Y-%m-%dT%H:%M:%S"
fmt = "%(asctime)s %(levelname)s %(name)s.%(funcName)s:%(lineno)d %(message)s"
rfh = logging.handlers.RotatingFileHandler
hlr = [rfh(ldr / "log.txt", maxBytes=100000, backupCount=10), logging.StreamHandler()]
logging.basicConfig(level=logging.INFO, handlers=hlr, format=fmt, datefmt=dft)
logger = logging.getLogger(__name__)
# Create tiny global helper functions using lambda one-liners.
fig = lambda x: print(Figlet(font="standard", width=200).renderText(x).rstrip())
log = lambda x: logger.info(x)
pkl = lambda x: pickle.dumps(x)
unpkl = lambda x: pickle.loads(x)
# Detect the context from which script is run: Jupyter vs. Command-line vs. import.
if hasattr(__builtins__, "__IPYTHON__"):
# If run from Jupyter, use default or previously-used arguments.
from IPython.display import display, Markdown
mkd = lambda x: display(Markdown(x))
try:
with open("./seoml/args.pkl", "rb") as handle:
args = pickle.load(handle)
log(f"Run from Jupyter, args from Pickle: {args}")
except:
args = argparse.Namespace()
args.site = site
log(f"Run from Jupyter, args from Global: {args}")
elif __name__ == "__main__":
# If run from Command-Line, parse input.
parser = argparse.ArgumentParser()
add_arg = parser.add_argument
mkd = lambda x: print(x)
add_arg("-n", "--site", required=True)
args = parser.parse_args()
with open("args.pkl", "wb") as handle:
pickle.dump(args, handle)
log(f"Run from Terminal, args from Command-Line: {args}")
else:
# If imported as a module, use default or previously-used arguments.
mkd = lambda x: print(x)
try:
with open("./args.pkl", "rb") as handle:
args = pickle.load(handle)
log(f"Run from Import, args from Pickle: {args}")
except:
args = argparse.Namespace()
args.site = site
log(f"Run from Import, args from Global: {args}")
assert type(args) == argparse.Namespace # Test that args have been acquired.
# Create h1 - h6 beautification functions
[exec(z, globals()) for z in [f"h{x} = lambda y: mkd('{'#'*x} %s' % y)" for x in range(1, 7)]]
h1("Create globals & helper functions, parse args.")
fig("Setup Complete!")
h3(f"site={site}")
print("(Change it to one of yours.)") if site == "mikelev.in" else print("Good job!")
h2("Done!")
```
---
# NEXT STEP: Create Data-Collection Keys.
We are about to make requests of some system (GSC) using some arguments (dates, dimensions). So long as these arguments can be expressed as strings, they can also be used as the keys in a key/value database to retreive the data again locally. With this technique, we can retreive all the data we need and store it fast without worrying about the rows and columns of tabular data (like Excel or SQL).
Python's namedtuples are perfect here because they are hashable and immutable (what keys need to be). So we can use the same arguments we used to origianlly fetch the data to again retreive it locally. It's no mistake if this sounds like a cache to you. The technique's called memoization, and is found everywhere. The closer your custom datatype is to your actual API-call, the easier it will be.
## The following code-block does these things:
1. Imports the namedtuple factory function from collections.
1. Creates a subclass (Gurls) from the namedtuple factory function.
1. Creates an instance of the subclass (gurls) by providing arguments.
## Run next step.
```
h1("Create Data-Collection Keys using nametuples.")
from collections import namedtuple
print("https://docs.python.org/3/library/collections.html#collections.namedtuple")
Gurls = namedtuple("Gurls", "startDate, endDate, dimensions, rowLimit, startRow") # Create subclass
gurls = Gurls("2020-01-01", "2020-01-01", ["page"], 5000, 0) # Create instance
print(f"gurls = {gurls}")
print(f"Gurls is {type(Gurls)} while gurls is {type(gurls)}.")
h2("Done!")
```
---
# NEXT STEP: Setup Persistent Dictionary.
Key/value pairs is a very tranditional way to do simple databases (that don't have rows & columns like SQL or Excel). Python's built-in dict datatype is actually a tiny non-persistent database. So all we need to do is make it persistent, meaning that the data is still there the next time we run the script. This gives us a place to rapidly "dump" raw data as we collect it. Client/server databases like Redis or memcached are used for this "at scale". But for our use, serverless Sqlite is sufficient.
This first delete_me.db database is just to show you how to use the standard Python dict API as a persistent dictionary. The dict becomes persistent through the use of the "with sqldict() as dictname" context manager API pattern. In other words, "dictname" is created after the "as" of "with open" and can only be used within that with's indent. An extra dictname.commit() is also required to write the data to disk (making it persistent).
Reads a row of data back out of database.
## The following code-block does these things:
1. Imports the sqlitedict 3rd-party package (you must install sqlitedict).
1. Creates its own subfolder (using site name) in which to store the data.
1. Creates an example database.
1. Writes a row of data into the database.
1. Reads a row of data back out of database.
## Run next step.
```
h1("Setup Persistent Dictionary using SqliteDict.")
from sqlitedict import SqliteDict as sqldict
db_name = "delete_me.db"
# Pick either the single cache or the daily cache for the cache that's used.
single_cache = Path(f"./cache/{site}")
daily_cache = Path(f"./cache/{site}-{date.today()}")
cache_used = single_cache # Pick one.
if not cache_used.exists():
Path.mkdir(cache_used, parents=True) # Create subfolder
h3(f"File Location: {cache_used}")
sample_data = f"When key is {gurls}, value is this message. I could be a big blob."
h3("Data goes in:")
with sqldict(Path(cache_used / db_name)) as db: # Create example database
# This looks like a good place for a loop.
key = pkl(gurls)
db[key] = sample_data # Write a row of data into the database
db.commit()
print(f"{db[key]}")
h3("Data comes out:")
with sqldict(Path(cache_used / db_name)) as db:
for i, key in enumerate(db):
print(f"{i + 1} of {len(db)}: {db[key]}") # Read a row of data back out of database.
break
assert len(db) > 0
h2("Done!")
```
---
# NEXT STEP: Build a list of API-calls.
The above step of creating a custom namedtuple gave us the building-block we need to create a list of every call we need to make to the Google Search Console API. Conceptually, we are treating the list of Gurls that will eventually pull the data as being just as important as the data that gets pulled. These "arguments" to the API are actually as important as the data itself, as they will work as the "keys" to later pull the data and a means of ensuring there is no missing gaps in the data. It is closely related to the database concept of Primary Keys.
To accomplish this, we create nested loops. One outer loop spins through each day of the last 16 months, while the inner loop spins through 10 "steps" that must be taken through each day to ensure that the maximum number of pages come back for the site for each day in GSC.
## The following code-block does these things:
1. Imports the date-datatype and date-adding functions.
1. Creates list of api-friendly string dates.
1. Creates step-by intervals needed for each day.
1. Create a list of gurls object by comining each day with step.
1. Shows the first 30 items in the list.
## Run next step.
```
h1("Build a list of all the API data-calls to be made (and used as keys).")
from datetime import date, timedelta as td
from dateutil.relativedelta import relativedelta as rd
months = 16 # GSC data typically available
# Create list of api-friendly string dates.
today = date.today()
date_diff = today - (today - rd(months=months))
dates = [f"{today - td(days=x + 1)}" for x in range(0, date_diff.days)] # Create a list of dates
h3(f"Here's first and last 4 days of last {months} months ({len(dates)} days total):")
print(f"Recent: {dates[0:4]}...")
print(f"Oldest: {dates[-4:]}")
# Create step-by intervals needed for each day.
step_by = 5000
total_steps = 10
start_rows = [x for x in range(0, step_by * 10, step_by)]
h3(f'Next we need {total_steps} "start rows" for paging through "chunked" data:')
print(f"{start_rows}")
# Create a list of gurls object by comining each day with step.
h3("Finally we populate a list with Gurls to be our DB-keys and API-calls (showing first 30).")
lot_gurls = []
for i, _date in enumerate(dates):
for _start in start_rows:
gurls = Gurls(_date, _date, ["page"], step_by, _start + 1)
lot_gurls.append(gurls)
pprint(lot_gurls[0:30])
h2("Done!")
```
---
# NEXT STEP: Rearrange the list for breaking out of days.
This step is a list comprehension to turn flat-list structure into nesteed-list structure. Each sub-list will represent a single day with each of its steps. The reason for this transformation is so that once we encounter a step within the day that doesn't return any data, we can break out of that day and immdiately move onto the next knowing that we have already retreived the maximum number of URLs for that day. Attempts to break without this nested list structure would simply go to the next item in the list and likely belong to the same day.
## The following code-block does these things:
1. Group the days into sub-lists, each containing 1 day with all its steps.
1. Shows the first 3 days as an example.
## Run next step.
```
h1("Group the days into sub-lists, each containing 1 day with all its steps.")
lot_days = [lot_gurls[x : x + 10] for x in range(0, len(lot_gurls), 10)]
lot_days.reverse()
h3("Showing first 3 day-groups.")
pprint(lot_days[:3])
h2("Done!")
```
---
# NEXT STEP: Get Google OAuth2 login credentials for Google services.
This is often the biggest barrier to noobs, so I wrote the ohawf package to handle it for you. If you haven't already, **pip instal ohawf**. When this is run for the first time it will begin the Google OAuth2 prompt processs. You click on or copy/paste the long URL into a browser. Choose which account you want to connect as. This will control what Google Search Console sites you can access. Refer to https://pypi.org/project/ohawf/ for more details.
## The following code-block does these things:
1. Imports packages to allow Google login and connecting to google services.
1. Logs you in or refreshes authentication token.
1. Connects to Google Search Console to list owned sites
## Run next step.
```
h1("Get Google OAuth2 login credentials for Google services.")
import ohawf
from apiclient.discovery import build
credentials = ohawf.Credentials().get() # Log you in or refreshes authentication token.
log(credentials)
h3("Connecting to Google Search Console to list owned sites:")
gsc_service = build("webmasters", "v3", credentials=credentials, cache_discovery=False)
gsc_sites = gsc_service.sites().list().execute()
[print(x["siteUrl"]) for x in gsc_sites["siteEntry"]]
h2("Done!")
```
---
# NEXT STEP: Get all URLs from site.
This step loops through all the API request objects
## The following code-block does these things:
1. Creates get_urls() helper-function to execute queries against GSC.
1. Defines what an "empty" API-response looks like (contains no rows).
1. Creates a database to store responses to API-calls.
1. Steps through each day, skipping ones that already have data.
1. Fetches data for each day, step by step. Breaks to next day on empty response.
## Run next step.
```
h1("Get all URLs from site.")
get_urls = lambda s, r: gsc_service.searchanalytics().query(siteUrl=s, body=r).execute()
empty_response = {"responseAggregationType": "byPage"} # An api-response with no rows.
db_name = "gurls.db"
with sqldict(Path(cache_used / db_name)) as db: # Creates database
h3("Dots (.) represent cached-data and exclamation (!) represents api-hits.")
print("Day:", end="")
for i, day in enumerate(lot_days):
print(f" {len(lot_days) - i}", end="")
for step, gurls in enumerate(day):
key = pkl(gurls)
if key in db: # Skips if data already collected
print(f".", end="")
break
else:
response = get_urls(site, lot_days[i][step]._asdict()) # Fetch data
if response == empty_response:
break
else:
print("!", end="")
db[key] = response
db.commit()
print("Done!")
```
---
# NEXT STEP: Get all URLs from site.
## The following code-block does these things:
1.
## Run next step.
```
h3("Data comes out:")
with sqldict(Path(cache_used / db_name)) as db:
for i, key in enumerate(db):
# print(f"{i + 1} of {len(db)}: {db[key]}")
print(f"{i + 1} of {len(db)} size: {len(db[key])}")
last = db[key]
break
```
---
# NEXT STEP: Get all URLs from site.
## The following code-block does these things:
1.
## Run next step.
```
all_urls = set()
with sqldict(Path(cache_used / db_name)) as db:
for key in db:
rec = db[key]
if "rows" in rec:
all_urls.update({x["keys"][0] for x in rec["rows"]})
print(".", end="")
import sqlite3
sql = """CREATE TABLE IF NOT EXISTS url (
url TEXT NOT NULL PRIMARY KEY
) WITHOUT ROWID;"""
connection = sqlite3.connect(Path(cache_used / "urls.db"))
cursor = connection.cursor()
cursor.execute(sql)
connection.commit()
for url in all_urls:
try:
cursor.execute(f'INSERT INTO url (url) VALUES ("{url}");')
except:
pass
connection.commit()
cursor.close()
connection.close()
connection = sqlite3.connect(Path(cache_used / "urls.db"))
cursor = connection.cursor()
records = cursor.execute("SELECT url FROM url LIMIT 1000;")
for i, record in enumerate(records):
print(i + 1, record[0])
cursor.close()
connection.close()
import sqlite3
sql = """CREATE TABLE IF NOT EXISTS url_history (
date TEXT,
url TEXT,
clicks INTEGER,
ctr FLOAT,
impressions FLOAT,
position FLOAT,
PRIMARY KEY (date, url)
) WITHOUT ROWID;"""
connection = sqlite3.connect(Path(cache_used / "url_history.db"))
cursor = connection.cursor()
cursor.execute(sql)
connection.commit()
with sqldict(Path(cache_used / db_name)) as db:
for key in db:
rec = db[key]
if "rows" in rec:
rows = rec["rows"]
for row in rows:
vals = [row[x] if i else f"'{row[x][0]}'" for i, x in enumerate(row)]
vals = [f"'{unpkl(key).startDate}'"] + vals
vals = ", ".join([f"{x}" for x in vals])
stmt = f"INSERT INTO url_history VALUES ({vals});"
try:
cursor.execute(stmt)
except:
continue
connection.commit()
print(".", end="")
cursor.close()
connection.close()
import pandas as pd
connection = sqlite3.connect(Path(cache_used / "url_history.db"))
df = pd.read_sql_query("SELECT * FROM url_history", connection)
connection.close()
df
pip install pycausalimpact
```
| github_jupyter |
```
from IPython.core.display import HTML
with open('style.css', 'r') as file:
css = file.read()
HTML(css)
```
# The $3 \times 3$ Sliding Puzzle
<img src="8-puzzle.png">
The picture above shows an instance of the $3 \times 3$
<a href="https://en.wikipedia.org/wiki/Sliding_puzzle">sliding puzzle</a>:
There is a board of size $3 \times 3$ with 8 tiles on it. These tiles are numbered with digits from the set $\{1,\cdots, 8\}$. As the the $3 \times 3$ board has an area of $9$ but there are only $8$ tiles, there is an empty square on the board. Tiles adjacent to the empty square can be moved into the square, thereby emptying the space that was previously occupied by theses tiles. The goal of the $3 \times 3$ puzzle is to transform the state shown on the left of the picture above into the state shown on the right.
In order to get an idea of the sliding puzzle, you can play it online at <a href="http://mypuzzle.org/sliding">http://mypuzzle.org/sliding</a>.
## Utilities to Display the Solution
We use a different color for each tile.
```
Colors = ['white', 'lightblue', 'pink', 'magenta',
'orange', 'red', 'yellow', 'lightgreen', 'salmon'
]
def get_style(n):
return 'background-color: ' + Colors[n] + ';">'
CSS_Table = { 'border' : '2px solid darkblue',
'border-style': 'double',
'border-width': '4px'
}
CSS_TD = { 'border' : '2px solid black',
'border-style': 'groove',
'border-width': '8px',
'padding' : '15px',
'font-size' : '150%',
}
def css_style(Dictionary):
result = ''
for k, v in Dictionary.items():
result += k + ':' + v + ';'
return result
```
The function `state_to_html` displays a given state as an `Html` tabel.
```
def state_to_html(State):
result = '<table style="' + css_style(CSS_Table) + '">\n'
for row in State:
result += '<tr>'
for number in row:
result += '<td style="' + css_style(CSS_TD)
if number > 0:
result += get_style(number) + str(number)
else:
result += get_style(number)
result += '</td>'
result += '</tr>\n'
result += '</table>'
return result
```
Given a non-empty set `S`, the function `arb` returns an arbitrary element of `S`.
The set `S` is left unchanged.
```
def arb(S):
for x in S:
return x
%run Breadth-First-Fast.ipynb
```
## Problem Specific Code
We will represent states as tuples of tuples. For example, the start state that is shown in the picture at the beginnning of this notebook is represented as follows:
```
start = ((8, 0, 6),
(5, 4, 7),
(2, 3, 1)
)
test = ((1, 2, 3),
(4, 0, 5),
(6, 7, 8)
)
```
Note that the empty tile is represented by the digit $0$.
**Exercise 1**: Define the goal state below.
```
goal = ((0, 1, 2),
(3, 4, 5),
(6, 7, 8)
)
```
**Exercise 2:**
The function $\texttt{findZero}(S)$ takes a state $S$ and returns a pair $(r, c)$ that specifies the row and the column of the blank in the state $S$. For example, we should have:
$$ \texttt{findZero}(\texttt{start}) = (0, 1) \quad\mbox{and}\quad
\texttt{findZero}(\texttt{goal}) = (0, 0)
$$
```
def findZero(State):
findZero(start)
findZero(goal)
```
We have to represent states as tuples of tuples in order to be able to insert them into sets. However, as tuples are immutable, we need to be able to convert them to lists in order to change them. The function $\texttt{listOfLists}(S)$ takes a state $S$ and transforms it into a list of lists.
```
def listOfLists(S):
'Transform a tuple of tuples into a list of lists.'
return [ [x for x in row] for row in S ]
listOfLists(start)
```
As lists can not be inserted into sets, we also need a function that takes a list of list and transforms it back into a tuple of tuple.
```
def tupleOfTuples(S):
'Transform a list of lists into a tuple of tuples.'
return tuple(tuple(x for x in row) for row in S)
tupleOfTuples([[8, 0, 6], [5, 4, 7], [2, 3, 1]])
```
**Exercise 3**: Implement a function $\texttt{moveUp}(S, r, c)$ that computes the state that results from moving the tile below the blank space **up** in state $S$. The variables $r$ and $c$ specify the location of the *row* and *column* of the blank tile. Therefore we have $S[r][c] = 0$.
In your implementation you may assume that there is indeed a tile below the blank space, i.e. we have $r < 2$.
```
listOfLists(start)
def moveUp(S, r, c):
newS=listOfLists(S)
moving= newS[r+1][c]
newS[r][c]=moving
newS[r+1][c]=0
return tupleOfTuples(newS)
HTML(state_to_html(test))
```
**Exercise 4**: Implement a function $\texttt{moveDown}(S, r, c)$ that computes the state that results from moving the tile below the blank space **down** in state $S$. The variables $r$ and $c$ specify the location of the *row* and *column* of the blank tile. Therefore we have $S[r][c] = 0$.
In your implementation you may assume that there is indeed a tile above the blank space, i.e. we have $r > 0$.
```
def moveDown(S, r, c):
'Move the tile above the blank down.'
"your code here"
newS=listOfLists(S)
moving= newS[r-1][c]
newS[r][c]=moving
newS[r-1][c]=0
return tupleOfTuples(newS)
```
**Exercise 5:**
Similarly to the previous exercise, implement functions $\texttt{moveRight}(S, r, c)$ and $\texttt{moveLeft}(S, r, c)$.
```
def moveRight(S, r, c):
'Move the tile left of the blank to the right.'
"your code here"
newS=listOfLists(S)
moving= newS[r][c-1]
newS[r][c]=moving
newS[r][c-1]=0
return tupleOfTuples(newS)
def moveLeft(S, r, c):
newS=listOfLists(S)
moving= newS[r][c+1]
newS[r][c]=moving
newS[r][c+1]=0
return tupleOfTuples(newS)
```
**Exercise 6:**. Implement a function $\texttt{nextStates}(S)$ that takes a state $S$ representet as a tuple of tuple and that computes the set of states that are reachable from $S$ in one step. Remember to use the previously defined functions `findZero`, `moveUp`, $\cdots$, `moveLeft`. However, when you do use the function `moveUp`, then you should also check that it is possible to move a tile up.
```
print(start)
up=moveUp(start,0,1)
stat=set()
stat | {up}
def nextStates(State):
next_states = set()
reihe , spalte = findZero(State)
#moveup
if reihe<2:
next_states = next_states | {moveUp(State,reihe,spalte)}
#movedown
if reihe>0:
next_states = next_states | {moveDown(State,reihe,spalte)}
#moveright
if spalte>0:
next_states = next_states | {moveRight(State,reihe,spalte)}
#moveleft
if spalte<2:
next_states = next_states | {moveLeft(State,reihe,spalte)}
return next_states
nextStates(test)
```
The computation of the relation `R` might take about 10 seconds. The reason is that `R` contains $967,680$ different pairs.
The following computation takes about 3 seconds on my desktop computer, which has an 3,4 GHz Quad-Core Intel Core i5 (7500) Prozessor.
```
%%time
Path = search(nextStates, start, goal)
```
The tuple Path that is a solution to the sliding problem has a length of **32**. If your path is shorter, then you have to inspect it carefully to identify the problem. In order to do this, use the function <tt>printPath</tt> that is implemented at the bottom of this notebook.
```
len(Path)
```
Print the solution via `HTML` tables.
```
for State in Path:
display(HTML(state_to_html(State)))
```
| github_jupyter |
# Several models training #
In this notebook we are going to show how to use Azure Machine Learning service in order to automate Form Recognizer service training. You will be able to see how to setup AML workspace, create a compute, execute a basic python script as a pipeline step, and store all metadata from Form Recognizer in AML model store.
```
from azureml.core import Workspace
from azureml.core.datastore import Datastore
from azureml.core.compute import AmlCompute
from azureml.core.compute import ComputeTarget
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import PipelineData
from azureml.pipeline.core import Pipeline
from azureml.core import Experiment
from msrest.exceptions import HttpOperationError
from azureml.data.data_reference import DataReference
```
In order to execute this notebook, you need to provide some parameters. There are several formal categories to provide.
### Azure Machine Learning Workspace parameters ###
- subscription_id: subscription id where you host or going to create Azure Machine LEarning Workspace
- wrksp_name: a name of the Azure Machine Learning Workspace
- resource_group: a resource group name where you are going to have your AML workspace;
### Form Recognizer Parameters ###
- fr_endpoint: Form Recognizer endpoint
- fr_key: Form Recognizer key to invoke REST API
### Input data parameters ###
- sas_uri: You need to create a container where you need to place all your data in separate folders. Each folder is a data source for a model in Form Recognizer. This parameter is a Shared Access Signature for the **container** that you can generate in Storage Explorer or from command line
- storage_name: a storage name that contains input data
- storage_key: a storage key to get access to the storage with input data
- container_name: the name of the container that contains folder with input data
You can leave all other parameters as is or modify some of them.
```
subscription_id = "<provide here>"
wrksp_name = "<provide here>"
resource_group = "<provide here>"
region = "westus2"
compute_name = "mycluster"
min_nodes = 0
max_nodes = 4
vm_priority = "lowpriority"
vm_size = "Standard_F2s_v2"
project_folder = "multifolder_training_steps"
fr_endpoint = "<provide here>"
fr_key = "<provide here>"
sas_uri = "<provide here>"
storage_name = "<provide here>"
storage_key = "<provide here>"
container_name = "<provide here>"
datastore_name = "training_ds"
```
In the beginning we need to get a reference to Azure Machine Learning workspace. We will use this reference to create all needed entities. If the workspace doesn't exist we will create a new workspace based on provided parameters.
```
try:
aml_workspace = Workspace.get(
name=wrksp_name,
subscription_id=subscription_id,
resource_group=resource_group)
print("Found the existing Workspace")
except Exception as e:
print(f"Creating AML Workspace: {wrksp_name}")
aml_workspace = Workspace.create(
name=wrksp_name,
subscription_id=subscription_id,
resource_group=resource_group,
create_resource_group=True,
location=region)
```
We will have several steps in our machine learning pipeline. All temporary data we will store in the default blob storage that is associated woth AML workspace. In the cell below we are getting a reference to the blob.
```
blob_datastore = aml_workspace.get_default_datastore()
```
In the next cell we need to create a compute that we are going to use to run pipeline. The compute is auto-scalable and it uses min_nodes as minimum number of nodes. If this value is 0, it means that compute will deploy a node (or several) just when it needs to run a step. In our case we are not going to use more than one node at the time, because we have two steps only and both of them are just basic Python scripts.
```
if compute_name in aml_workspace.compute_targets:
compute_target = aml_workspace.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print(f"Found existing compute target {compute_name} so using it")
else:
compute_config = AmlCompute.provisioning_configuration(
vm_size=vm_size,
vm_priority=vm_priority,
min_nodes=min_nodes,
max_nodes=max_nodes,
)
compute_target = ComputeTarget.create(aml_workspace, compute_name,
compute_config)
compute_target.wait_for_completion(show_output=True)
```
This part is different compare to our basic pipeline. Because we have several folders in the container, we will need to list all of them. It means that we need to mount our input storage container to the compute cluster. In order to do that we need to register the blob container as a data store in Azure ML, and we can create a data reference to a specific folder after that
```
try:
training_datastore = Datastore.get(aml_workspace, datastore_name)
print("Found Blob Datastore with name: %s" % datastore_name)
except HttpOperationError:
training_datastore = Datastore.register_azure_blob_container(
workspace=aml_workspace,
datastore_name=datastore_name,
account_name=storage_name,
container_name=container_name,
account_key=storage_key)
print("Registered blob datastore with name: %s" % datastore_name)
training_src = DataReference(
datastore=training_datastore,
data_reference_name="training_src",
path_on_datastore="/")
```
Now, we have our workspace and compute there. It's time to start creating a pipeline. It will be two steps in our pipeline: train a form recognizer model and preserve metadata information about the model in AML model store to make it available to scoring pipeline.
Because we have two steps, we will need an entity to pass data from one step to another. We will use pipeline data. Every time when we run the pipeline, it will create an unique folder in our default blob and store our pipeline data there.
```
training_output = PipelineData(
"training_output",
datastore=blob_datastore)
```
Our first step is to execute training process that we implemented in train.py script. This script has several parameters like sas and form recognizer details, and it will save output inside out pipeline data folder.
You can see that our data reference is an input parameter now. AML will mount it to the training cluster automatically, and we will be able to get access to data using just a local folder notation.
```
training_step = PythonScriptStep(
name = "training",
script_name="train.py",
inputs=[training_src],
outputs=[training_output],
arguments=[
"--sas_uri", sas_uri,
"--output", training_output,
"--fr_endpoint", fr_endpoint,
"--fr_key", fr_key,
"--training_folder", training_src],
compute_target=compute_target,
source_directory=project_folder
)
```
The second step is taking output from the training step and register it in AML store. In fact, we could implement these two steps as a single step, but we wanted to show some aspects of AML (passing data between steps and multistep pipeline)
```
register_step = PythonScriptStep(
name = "registering",
script_name="register.py",
inputs=[training_output],
outputs=[],
arguments=["--input", training_output],
compute_target=compute_target,
source_directory=project_folder
)
```
Finally, we can create a pipeline based on our two steps above. We just need to combine all the steps in an array and create Pipeline object using it.
```
steps = [training_step, register_step]
pipeline = Pipeline(workspace=aml_workspace, steps=steps)
```
It's time to execute our pipeline. We use Experiment class to create a real execution and passing our pipeline as a parameter
```
pipeline_run = Experiment(aml_workspace, 'train_multifolder_exp').submit(pipeline)
pipeline_run.wait_for_completion()
```
In the case of success, we would like to preserve pipeline to execute it later using the Azure portal, Python SDK or Rest API
```
pipeline.publish(
name="multifolder_training",
description="Training form recognizer based on several data folders")
```
| github_jupyter |
# Matrix walking
```
def walk(A):
arow = A[0]
n = len(arow)
for i in range(n):
for j in range(n):
# process A[i][j] such as:
print(f" {A[i][j]}", end='')
print()
matrix =\
[[1, 1, 1, 0, 0],
[0, 0, 1, 1, 1],
[0, 1, 1, 1, 0],
[1, 1, 0, 0, 1],
[0, 1, 1, 1, 1]]
walk(matrix)
```
# Tree walking
First, let's construct some trees
## Constructing binary tree
```
class TreeNode:
def __init__(self, value, left=None, right=None):
self.value = value
self.left = left
self.right = right
def __repr__(self):
return self.value.__repr__()
from lolviz import *
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
treeviz(root)
root.left.left = TreeNode(4)
root.left.right = TreeNode(5)
treeviz(root)
```
## Walking binary tree
```
def walk_tree(p:TreeNode) -> None:
if p is None: return
print(p.value) # "visit" node in preorder traversal position
walk_tree(p.left)
walk_tree(p.right)
walk_tree(root)
```
## Search binary tree
```
def search_tree(p:TreeNode, x:object) -> TreeNode:
if p is None: return None
if x==p.value: return p
q = search_tree(p.left, x)
if q is not None: return q
return search_tree(p.right, x)
for i in range(6):
p = search_tree(root, i)
print(p)
```
## Constructing Binary Search Tree (BST)
```
# reuse TreeNode class
def add(p:TreeNode, value) -> None:
"add nodes like a binary search tree"
if p is None:
return TreeNode(value)
if value < p.value:
p.left = add(p.left, value)
elif value > p.value:
p.right = add(p.right, value)
# do nothing if equal (already there)
return p
from lolviz import *
root = add(None, 9)
treeviz(root)
add(root, 5)
treeviz(root)
add(root, 42)
treeviz(root)
add(root, 8)
treeviz(root)
add(root, 15)
treeviz(root)
add(root, 1)
treeviz(root)
add(root, 5) # already there
treeviz(root)
```
## Walk binary search tree looking for element
```
def search(p:TreeNode, x:object) -> TreeNode:
if p is None: return None
if x<p.value: return search(p.left, x)
if x>p.value: return search(p.right, x)
return p
p = search(root,9)
p.value
for v in [9,15,5,42,8,1]:
p = search(root,v)
print(p.value)
p = search(root,999999) # test missing result
print(p)
```
# Constructing graphs
```
class Node:
def __init__(self, value):
self.value = value
self.edges = [] # outgoing edges
def add(self, target):
self.edges.append(target)
sf = Node("SF")
la = Node("LA")
sac = Node("Sacramento")
oak = Node("Oakland")
baker = Node("Bakersfield")
sj = Node("San Jose")
sf.add(sj)
sj.add(baker)
sf.add(oak)
oak.add(sac)
sac.add(baker)
baker.add(la)
objviz(sf)
```
## Walking graphs
```
def walk_graph(p:Node) -> None:
if p is None: return
print(p.value) # "visit" node in preorder traversal position
for q in p.edges:
walk_graph(q)
walk_graph(sf)
```
## Dealing with cycles
```
oak.add(sf) # add cycle
objviz(sf)
def walk_graph2(p:Node, seen:set) -> None:
if p is None: return
if p in seen: return
seen.add(p)
print(p.value) # "visit" node in preorder traversal position
for q in p.edges:
walk_graph2(q, seen)
# walk_graph(sf) # loops forever
walk_graph2(sf, set()) # pass in blank seen set
```
| github_jupyter |

## Introduction to Data-X
Mostly basics about Anaconda, Git, Python, and Jupyter Notebooks
#### Author: Alexander Fred Ojala
---
# Useful Links
1. Managing conda environments:
- https://conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html
2. Github:
- https://readwrite.com/2013/09/30/understanding-github-a-journey-for-beginners-part-1/
- https://readwrite.com/2013/10/02/github-for-beginners-part-2/
3. Learning Python (resources):
- https://www.datacamp.com/
- [Python Bootcamp](https://bids.berkeley.edu/news/python-boot-camp-fall-2016-training-videos-available-online
)
4. Datahub: http://datahub.berkeley.edu/ (to run notebooks in the cloud)
5. Google Colab: https://colab.research.google.com (also running notebooks in the cloud)
5. Data-X website resources: https://data-x.blog
6. Book: [Hands on Machine Learning with Scikit-Learn and Tensorflow](https://www.amazon.com/Hands-Machine-Learning-Scikit-Learn-TensorFlow/dp/1491962291/ref=sr_1_1?ie=UTF8&qid=1516300239&sr=8-1&keywords=hands+on+machine+learning+with+scikitlearn+and+tensorflow)
# Introduction to Jupyter Notebooks
From the [Project Jupyter Website](https://jupyter.org/):
* *__Project Jupyter__ exists to develop open-source software, open-standards, and services for interactive computing across dozens of programming languages. Collaborative, Reproducible.*
* *__The Jupyter Notebook__ is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.*
# Notebook contains 2 cell types Markdown & Code
###### Markdown cells
Where you write text.
Or, equations in Latex: $erf(x) = \frac{1}{\sqrt\pi}\int_{-x}^x e^{-t^2} dt$
Centered Latex Matrices:
$$
\begin{bmatrix}
x_{11} & x_{12} & x_{13} & \dots & x_{1n} \\
x_{21} & x_{22} & x_{23} & \dots & x_{2n} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
x_{d1} & x_{d2} & x_{d3} & \dots & x_{dn}
\end{bmatrix}
$$
<div class='alert alert-warning'>Bootstrap CSS and `HTML`</div>
Python (or any other programming language) Code
```python
# simple adder function
def adder(x,y):
return x+y
```
# Header 1
## Header 2
### Header 3...
**bold**, *italic*
Divider
_____
* Bullet
* Lists
1. Enumerated
2. Lists
Useful images:

<img src='https://image.slidesharecdn.com/juan-rodriguez-ucberkeley-120331003737-phpapp02/95/juanrodriguezuc-berkeley-3-728.jpg?cb=1333154305' width='200px'>
---
An internal (HTML) link to section in the notebook:
## <a href='#bottom'>Link: Take me to the bottom of the notebook</a>
___
## **Find a lot of useful Markdown commands here:**
### https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
___
# Code Cells
In them you can interactively run Python commands
```
print('hello world!')
print('2nd row')
# Comment in a code cells
# Lines evaluated sequentially
# A cell displays output of last line
2+2
3+3
5+5
# Stuck in an infinite loop
while True:
continue
# Cells evaluated sequentially
tmp_str = 'this is now stored in memory'
print(tmp_str)
print("Let's Start Over")
print(tmp_str)
```
## Jupyter / Ipython Magic
```
# Magic commands (only for Jupyter and IPython, won't work in script)
%ls
# Time several runs of same operation
%timeit [i for i in range(1000)];
# Time operation
%time
[x for x in range(1000)];
%ls resources/
# %load resources/print_hw3.py
def print_hw(x):
for i in range(int(x)):
print(str(i)+' hello python script!')
print_hw(3)
%matplotlib inline
%lsmagic
?%alias
?str
```
## Terminal / Command Prompt commands
```
# Shell commands
!cat resources/random.txt
!ls # in mac
!dir #in windows
# show first lines of a data file
!head -n 1 resources/sample_data.csv
# count rows of a data file
!wc resources/sample_data.csv
```
# Useful tips (Keyboard shortcuts etc):
4. Enter selection mode / Cell mode (Esc / Return)
1. Insert cells (press A or B in selection mode)
2. Delete / Cut cells (press X in selection mode)
3. Mark several cells (Shift in selection mode)
6. Merge cells (Select, then Shift+M)
# Printing to pdf
### (USEFUL FOR HOMEWORKS)
**Easiest**: File -> Print Preview.
Then save that page as a PDF (Ctrl + P, Save as PDF usually works).
**Pro:** Install a Latex compiler. Then: File -> Download As -> PDF.
# Quick Review of Python Topics
### Check what Python distribution you are running
```
!which python #works on unix system, maybe not Windows
# Check that it is Python 3
import sys # import built in package
print(sys.version)
```
## Python as a calculator
```
# Addition
2.1 + 2
# Mult
10*10.0
# Floor division
7//3
# Floating point division, note py2 difference
7/3
type(2)
type(2.0)
a = 3
b = 5
print (b**a) # ** is exponentiation
print (b%a) # modulus operator = remainder
type(5) == type(5.0)
# boolean checks
a = True
b = False
print (a and b)
# conditional programming
if 5 == 5:
print('correct!')
else:
print('what??')
print (isinstance(1,int))
```
## String slicing and indices
<img src="resources/spam.png" width="480">
```
# Strings and slicing
x = "abcdefghijklmnopqrstuvwxyz"
print(x)
print(x[1]) # zero indexed
print (type(x))
print (len(x))
print(x)
print (x[1:6:2]) # start:stop:step
print (x[::3])
print (x[::-1])
```
### Manipulating text
```
# Triple quotes are useful for multiple line strings
y = '''The quick brown
fox jumped over
the lazy dog.'''
print (y)
```
### String operators and methods
```
# tokenize by space
words = y.split(' ')
print (words)
# remove break line character
[w.replace('\n','') for w in words]
```
<div class='alert alert-success'>TAB COMPLETION TIPS</div>
```
words.append('last words')
import pandas as pd
?pd.read_excel
y.
str()
```
# Data Structures
## **Tuple:** Sequence of Python objects. Immutable.
```
t = ('a','b', 3)
print (t)
print (type (t))
t[1]
t[1] = 2 #error
```
## **List:** Sequence of Python objects. Mutable
```
y = list() # create empty list
type(y)
type([])
# Append to list
y.append('hello')
y.append('world')
print(y)
y.pop(1)
print(y)
# List addition (merge)
y + ['data-x']
# List multiplication
y*4
# list of numbers
even_nbrs = list(range(0,20,2)) # range has lazy evaluation
print (even_nbrs)
# supports objects of different data types
z = [1,4,'c',4, 2, 6]
print (z)
# list length (number of elements)
print(len(z))
# it's easy to know if an element is in a list
print ('c' in z)
print (z[2]) # print element at index 2
# traverse / loop over all elements in a list
for i in z:
print (i)
# lists can be sorted,
# but not with different data types
z.sort()
#z.sort() # doesn't work
z.pop(2)
z
z.sort() # now it works!
z
print (z.count(4)) # how many times is there a 4
# loop examples
for x in z:
print ("this item is ", x)
# print with index
for i,x in enumerate(z):
print ("item at index ", i," is ", x )
# print all even numbers up to an integer
for i in range(0,10,2):
print (i)
# list comprehesion is like f(x) for x as an element of Set X
# S = {x² : x in {0 ... 9}}
S = [x**2 for x in range(10)]
print (S)
# All even elements from S
# M = {x | x in S and x even}
M = [x for x in S if x % 2 == 0]
print (M)
# Matrix representation with Lists
print([[1,2,3],[4,5,6]]) # 2 x 3 matrix
```
# Sets (collection of unique elements)
```
# a set is not ordered
a = set([1, 2, 3, 3, 3, 4, 5,'a'])
print (a)
b = set('abaacdef')
print (b) # not ordered
print (a|b) # union of a and b
print(a&b) # intersection of a and b
a.remove(5)
print (a) # removes the '5'
```
# Dictionaries: Key Value pairs
Almost like JSON data
```
# Dictionaries, many ways to create them
# First way to create a dictionary is just to assign it
D1 = {'f1': 10, 'f2': 20, 'f3':25}
D1
D1['f2']
# 2. creating a dictionary using the dict()
D2 = dict(f1=10, f2=20, f3 = 30)
print (D2['f3'])
# 3. Another way, start with empty dictionary
D3 = {}
D3['f1'] = 10
D3['f2'] = 20
print (D3['f1'])
# Dictionaries can be more complex, ie dictionary of dictionaries or of tuples, etc.
D5 = {}
D5['a'] = D1
D5['b'] = D2
print (D5['a']['f3'])
D5
# traversing by key
# key is imutable, key can be number or string
for k in D1.keys():
print (k)
# traversing by values
for v in D1.values():
print(v)
# traverse by key and value is called item
for k, v in D1.items(): # tuples with keys and values
print (k,v)
```
# User input
```
# input
# raw_input() was renamed to input() in Python v3.x
# The old input() is gone, but you can emulate it with eval(input())
print ("Input a number:")
s = input() # returns a string
a = int(s)
print ("The number is ", a)
```
# Import packages
```
import numpy as np
np.subtract(3,1)
```
# Functions
```
def adder(x,y):
s = x+y
return(s)
adder(2,3)
```
# Classes
```
class Holiday():
def __init__(self,holiday='Holidays'):
self.base = 'Happy {}!'
self.greeting = self.base.format(holiday)
def greet(self):
print(self.greeting)
easter = Holiday('Easter')
hanukkah = Holiday('Hanukkah')
easter.greeting
hanukkah.greet()
# extend class
class Holiday_update(Holiday):
def update_greeting(self, new_holiday):
self.greeting = self.base.format(new_holiday)
hhg = Holiday_update('July 4th')
hhg.greet()
hhg.update_greeting('Labor day / End of Burning Man')
hhg.greet()
```
<div id='bottom'></div>
| github_jupyter |
# Part 4: Projects and Automated ML Pipeline
This part of the MLRun getting-started tutorial walks you through the steps for working with projects, source control (git), and automating the ML pipeline.
MLRun Project is a container for all your work on a particular activity. All the associated code, functions,
jobs/workflows and artifacts. Projects can be mapped to `git` repositories which enable versioning, collaboration, and CI/CD.
Users can create project definitions using the SDK or a yaml file and store those in MLRun DB, file, or archive.
Once the project is loaded you can run jobs/workflows which refer to any project element by name, allowing separation between configuration and code. See the [Projects, Automation & CI/CD](https://docs.mlrun.org/en/latest/projects/overview.html) section for details.
Projects contain `workflows` which execute the registered functions in a sequence/graph (DAG), can reference project parameters, secrets and artifacts by name. MLRun currently supports two workflow engines, `local` (for simple tasks) and [Kubeflow Pipelines](https://www.kubeflow.org/docs/pipelines/pipelines-quickstart/) (for more complex/advanced tasks), MLRun also supports a real-time workflow engine (see: [MLRun serving graphs](https://docs.mlrun.org/en/latest/serving/serving-graph.html)).
> **Note**: The Iguazio Data Science Platform has a default (pre-deployed) shared Kubeflow Pipelines service (`pipelines`).
An ML Engineer can gather the different functions created by the Data Engineer and Data Scientist and create this automated pipeline.
The tutorial consists of the following steps:
1. [Setting up Your Project](#gs-tutorial-4-step-setting-up-project)
2. [Updating Project and Function Definitions](#gs-tutorial-4-step-import-functions)
3. [Defining and Saving a Pipeline Workflow](#gs-tutorial-4-step-pipeline-workflow-define-n-save)
4. [Registering the Workflow](#gs-tutorial-4-step-register-workflow)
5. [Running A Pipeline](#gs-tutorial-4-step-run-pipeline)
6. [Viewing the Pipeline on the Dashboard (UI)](#gs-tutorial-4-step-ui-pipeline-view)
7. [Invoking the Model](#gs-tutorial-4-step-invoke-model)
By the end of this tutorial you'll learn how to
- Create an operational pipeline using previously defined functions.
- Run the pipeline and track the pipeline results.
<a id="gs-tutorial-4-prerequisites"></a>
## Prerequisites
The following steps are a continuation of the previous parts of this getting-started tutorial and rely on the generated outputs.
Therefore, make sure to first run parts 1—[3](03-model-serving.ipynb) of the tutorial.
<a id="gs-tutorial-4-step-setting-up-project"></a>
## Step 1: Setting Up Your Project
To run a pipeline, you first need to create a Python project object and import the required functions for its execution.
Create a project by using the `new_project` MLRun method, or use `get_or_create_project` which loads a project from MLRun DB or the archive/context if it exists or create a new project when its not.
Both methods have the following parameters:
- **`name`** (Required) — the project name.
- **`context`** — the path to a local project directory (the project's context directory).
The project directory contains a project-configuration file (default: **project.yaml**), which defines the project, and additional generated Python code.
The project file is created when you save your project (using the `save` MLRun project method or when saving your first function within the project).
- **`init_git`** — set to `True` to perform Git initialization of the project directory (`context`) in case its not initialized.
> **Note:** It's customary to store project code and definitions in a Git repository.
The following code gets or creates a user project named "getting-started-<username>".
> **Note:** Platform projects are currently shared among all users of the parent tenant, to facilitate collaboration. Therefore,
>
> - Set `user_project` to `True` if you wish to create a project unique to your user.
> You can easily change the default project name for this tutorial by changing the definition of the `project_name_base` variable in the following code.
> - Don't include in your project proprietary information that you don't want to expose to other users.
> Note that while projects are a useful tool, you can easily develop and run code in the platform without using projects.
```
import mlrun
# Set the base project name
project_name_base = 'getting-started'
# Initialize the MLRun project object
project = mlrun.get_or_create_project(project_name_base, context="./", user_project=True, init_git=True)
print(f'Project name: {project.metadata.name}')
```
<a id="gs-tutorial-4-step-import-functions"></a>
## Step 2: Updating Project and Function Definitions
We need to save the definitions for the function we use in the projects so it is possible to automatically convert code to functions or import external functions whenever we load new versions of our code or when we run automated CI/CD workflows. In addition we may want to set other project attributes such as global parameters, secrets, and data.
Our code maybe stored in Python files, notebooks, external repositories, packaged containers, etc. We use the `project.set_function()` method to register our code in the project, the definitions will be saved to the project object as well as in a YAML file in the root of our project.
Functions can also be imported from MLRun marketplace (using the `hub://` schema).
We used the following functions in this tutorial:
- `prep-data` — the first function, which ingests the Iris data set (in Notebook 01)
- `describe` — generates statistics on the data set (from the marketplace)
- `train-iris` — the model-training function (in Notebook 02)
- `test-classifier` — the model-testing function (from the marketplace)
- `mlrun-model` — the model-serving function (in Notebook 03)
> Note: `set_function` uses the `code_to_function` and `import_function` methods under the hood (used in the previous notebooks), but in addition it saves the function configurations in the project spec for use in automated workflows and CI/CD.
We add the function definitions to the project along with parameters and data artifacts and save the project.
<a id="gs-tutorial-4-view-project-functions"></a>
```
project.set_function('01-mlrun-basics.ipynb', 'prep-data', kind='job', image='mlrun/mlrun')
project.set_function('02-model-training.ipynb', 'train', kind='job', image='mlrun/mlrun', handler='train_iris')
project.set_function('hub://describe', 'describe')
project.set_function('hub://test_classifier', 'test')
project.set_function('hub://v2_model_server', 'serving')
# set project level parameters and save
project.spec.params = {'label_column': 'label'}
project.save()
```
<br>When we save the project it stores the project definitions in the `project.yaml`, this will allow us to load the project from the source control (GIT) and run it with a single command or API call.
The project YAML for this project can be printed using:
```
print(project.to_yaml())
```
### Saving and Loading Projects from GIT
After we saved our project and its elements (functions, workflows, artifacts, etc.) we can commit all our changes to a GIT repository, this can be done using standard GIT tools or using MLRun `project` methods such as `pull`, `push`, `remote` which will call the Git API for you.
Projects can then be loaded from Git using MLRun `load_project` method, example:
project = mlrun.load_project("./myproj", "git://github.com/mlrun/project-demo.git", name=project_name)
or using MLRun CLI:
mlrun project -n myproj -u "git://github.com/mlrun/project-demo.git" ./myproj
Read the [Projects, Automation & CI/CD](https://docs.mlrun.org/en/latest/projects/overview.html) section for more details
<a id="gs-tutorial-4-kubeflow-pipelines"></a>
### Using Kubeflow Pipelines
You're now ready to create a full ML pipeline.
This is done by using [Kubeflow Pipelines](https://www.kubeflow.org/docs/pipelines/overview/pipelines-overview/) —
an open-source framework for building and deploying portable, scalable machine-learning workflows based on Docker containers.
MLRun leverages this framework to take your existing code and deploy it as steps in the pipeline.
> **Note:** When using the Iguazio Data Science Platform, Kubeflow Pipelines is available as a default (pre-deployed) shared platform service.
<a id="gs-tutorial-4-step-pipeline-workflow-define-n-save"></a>
## Step 3: Defining and Saving a Pipeline Workflow
A pipeline is created by running an MLRun **"workflow"**.
The following code defines a workflow and writes it to a file in your local directory;
(the file name is **workflow.py**).
The workflow describes a directed acyclic graph (DAG) for execution using Kubeflow Pipelines, and depicts the connections between the functions and the data as part of an end-to-end pipeline.
The workflow file has two parts — initialization of the function objects, and definition of a pipeline DSL (domain-specific language) for connecting the function inputs and outputs.
Examine the code to see how functions objects are initialized and used (by name) within the workflow.
The defined pipeline includes the following steps:
- Ingest the Iris flower data set (`ingest`).
- Train and the model (`train`).
- Test the model with its test data set.
- Deploy the model as a real-time serverless function (`deploy`).
> **Note**: A pipeline can also include continuous build integration and deployment (CI/CD) steps, such as building container images and deploying models.
```
%%writefile './workflow.py'
from kfp import dsl
from mlrun import run_function, deploy_function
DATASET = 'cleaned_data'
MODEL = 'iris'
LABELS = "label"
# Create a Kubeflow Pipelines pipeline
@dsl.pipeline(
name="Getting-started-tutorial",
description="This tutorial is designed to demonstrate some of the main "
"capabilities of the Iguazio Data Science Platform.\n"
"The tutorial uses the Iris flower data set."
)
def kfpipeline(source_url):
# Ingest the data set
ingest = run_function(
'prep-data',
handler='prep_data',
inputs={'source_url': source_url},
params={'label_column': LABELS},
outputs=[DATASET])
# Train a model
train = run_function(
"train",
params={"label_column": LABELS},
inputs={"dataset": ingest.outputs[DATASET]},
outputs=['my_model', 'test_set'])
# Test and visualize the model
test = run_function(
"test",
params={"label_column": LABELS},
inputs={"models_path": train.outputs['my_model'],
"test_set": train.outputs['test_set']})
# Deploy the model as a serverless function
deploy = deploy_function("serving", models={f"{MODEL}_v1": train.outputs['my_model']})
```
<a id="gs-tutorial-4-step-register-workflow"></a>
## Step 4: Registering the Workflow
Use the `set_workflow` MLRun project method to register your workflow with MLRun.
The following code sets the `name` parameter to the selected workflow name ("main") and the `code` parameter to the name of the workflow file that is found in your project directory (**workflow.py**).
```
# Register the workflow file as "main"
project.set_workflow('main', 'workflow.py')
```
<a id="gs-tutorial-4-step-run-pipeline"></a>
## Step 5: Running A Pipeline
First run the following code to save your project:
```
project.save()
```
Use the `run` MLRun project method to execute your workflow pipeline with Kubeflow Pipelines.
The tutorial code sets the following method parameters; (for the full parameters list, see the MLRun documentation or embedded help):
- **`name`** — the workflow name (in this case, "main" — see the previous step).
- **`arguments`** — A dictionary of Kubeflow Pipelines arguments (parameters).
The tutorial code sets this parameter to an empty arguments list (`{}`), but you can edit the code to add arguments.
- **`artifact_path`** — a path or URL that identifies a location for storing the workflow artifacts.
You can use `{{workflow.uid}}` in the path to signify the ID of the current workflow run iteration.
The tutorial code sets the artifacts path to a **<worker ID>** directory (`{{workflow.uid}}`) in a **pipeline** directory under the projects container (**/v3io/projects/getting-started-tutorial-project name/pipeline/<worker ID>**).
- **`dirty`** — set to `True` to allow running the workflow also when the project's Git repository is dirty (i.e., contains uncommitted changes).
(When the notebook that contains the execution code is in the same Git directory as the executed workflow, the directory will always be dirty during the execution.)
- **`watch`** — set to `True` to wait for the pipeline to complete and output the execution graph as it updates.
The `run` method returns the ID of the executed workflow, which the code stores in a `run_id` variable.
You can use this ID to track the progress or your workflow, as demonstrated in the following sections.
> **Note**: You can also run the workflow from a command-line shell by using the `mlrun` CLI.
> The following CLI command defines a similar execution logic as that of the `run` call in the tutorial:
> ```
> mlrun project /User/getting-started-tutorial/conf -r main -p "$V3IO_HOME_URL/getting-started-tutorial/pipeline/{{workflow.uid}}/"
> ```
```
import os
from mlrun import mlconf
import mlrun
# Set the source-data URL
source_url = mlrun.get_sample_path('data/iris/iris.data.raw.csv')
pipeline_path = mlconf.artifact_path
run_id = project.run(
'main',
arguments={'source_url' : source_url},
artifact_path=os.path.join(pipeline_path, "pipeline", '{{workflow.uid}}'),
dirty=True,
watch=True)
```
<a id="gs-tutorial-4-step-ui-pipeline-view"></a>
## Step 6: Viewing the Pipeline on the Dashboard (UI)
Navigate to the **Pipelines** page on the dashboard (UI).
After the pipelines execution completes, you should be able to view the pipeline and see its functions:
- `prep-data`
- `train`
- `test`
- `deploy-serving`
<img src="./images/kubeflow-pipeline.png" alt="pipeline" width="600"/>
<a id="gs-tutorial-4-step-invoke-model"></a>
## Step 7: Invoking the Model
Now that your model is deployed using the pipeline, you can invoke it as usual:
```
serving_func = project.func('serving')
my_data = {'inputs': [[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}
serving_func.invoke('/v2/models/iris_v1/infer', my_data)
```
You can also make an HTTP call directly:
```
import requests
import json
predict_url = f'http://{serving_func.status.address}/v2/models/iris_v1/predict'
resp = requests.put(predict_url, json=json.dumps(my_data))
print(resp.json())
```
<a id="gs-tutorial-4-done"></a>
## Done!
Congratulation! You've completed the getting started tutorial.
You might also want to explore the following demos:
- For an example of distributed training of an image-classification pipeline using TensorFlow (versions 1 or 2), Keras, and Horovod, see the [**image-classification with distributed training demo**](https://github.com/mlrun/demos/tree/release/v0.6.x-latest/image-classification-with-distributed-training).
- To learn more about deploying live endpoints and concept drift, see the [**network-operations (NetOps) demo**](https://github.com/mlrun/demos/tree/release/v0.6.x-latest/network-operations).
- To learn how to deploy your model with streaming information, see the [**model-deployment pipeline demo**](https://github.com/mlrun/demos/tree/release/v0.6.x-latest/model-deployment-pipeline).
For additional information and guidelines, see the MLRun [**How-To Guides and Demos**](https://docs.mlrun.org/en/latest/howto/index.html).
| github_jupyter |
```
from tqdm import tqdm_notebook as tqdm
from presidio_evaluator.data_generator.main import generate, read_synth_dataset
import datetime
import json
```
# Generate fake PII data using Presidio's data generator
Presidio's data generator allows you to generate a synthetic dataset with two preriquisites:
1. A fake PII csv (We used https://www.fakenamegenerator.com/)
2. A text file with template sentences or paragraphs. In this file, each PII entity placeholder is written in brackets. The name of the PII entity should be one of the columns in the fake PII csv file.
The generator creates fake sentences based on the provided fake PII csv AND a list of [extension functions](../presidio_evaluator/data_generator/extensions.py) and a few additional 3rd party libraries like `Faker`, and `haikunator`.
For example:
1. **A fake PII csv**:
| FIRST_NAME | LAST_NAME | EMAIL |
|-------------|-------------|-----------|
| David | Brown | david.brown@jobhop.com |
| Mel | Brown | melb@hobjob.com |
2. **Templates**:
My name is [FIRST_NAME]
You can email me at [EMAIL]. Thanks, [FIRST_NAME]
What's your last name? It's [LAST_NAME]
Every time I see you falling I get down on my knees and pray
### Generate files
Based on these two prerequisites, a requested number of examples and an output file name:
```
EXAMPLES = 100
SPAN_TO_TAG = True #Whether to create tokens + token labels (tags)
TEMPLATES_FILE = '../../presidio_evaluator/data_generator/' \
'raw_data/templates.txt'
KEEP_ONLY_TAGGED = False
LOWER_CASE_RATIO = 0.1
IGNORE_TYPES = {"IP_ADDRESS", 'US_SSN', 'URL'}
cur_time = datetime.date.today().strftime("%B_%d_%Y")
OUTPUT = "../../data/generated_size_{}_date_{}.json".format(EXAMPLES, cur_time)
fake_pii_csv = '../../presidio_evaluator/data_generator/' \
'raw_data/FakeNameGenerator.com_3000.csv'
utterances_file = TEMPLATES_FILE
dictionary_path = None
examples = generate(fake_pii_csv=fake_pii_csv,
utterances_file=utterances_file,
dictionary_path=dictionary_path,
output_file=OUTPUT,
lower_case_ratio=LOWER_CASE_RATIO,
num_of_examples=EXAMPLES,
ignore_types=IGNORE_TYPES,
keep_only_tagged=KEEP_ONLY_TAGGED,
span_to_tag=SPAN_TO_TAG)
```
To read a dataset file into the InputSample format, use `read_synth_dataset`:
```
input_samples = read_synth_dataset(OUTPUT)
input_samples[0]
```
The full structure of each input_sample is the following. It includes different feature values per token as calculated by Spacy
```
input_samples[0].to_dict()
```
#### Verify randomness of dataset
```
from collections import Counter
count_per_template_id = Counter([sample.metadata['Template#'] for sample in input_samples])
for key in sorted(count_per_template_id):
print("{}: {}".format(key,count_per_template_id[key]))
print(sum(count_per_template_id.values()))
```
#### Transform to the CONLL structure:
```
from presidio_evaluator import InputSample
conll = InputSample.create_conll_dataset(input_samples)
conll.head(5)
```
#### Copyright notice:
Data generated for evaluation was created using Fake Name Generator.
Fake Name Generator identities by the [Fake Name Generator](https://www.fakenamegenerator.com/)
are licensed under a [Creative Commons Attribution-Share Alike 3.0 United States License](http://creativecommons.org/licenses/by-sa/3.0/us/). Fake Name Generator and the Fake Name Generator logo are trademarks of Corban Works, LLC.
| github_jupyter |
# Multiple Measurements
In this notebook, let's go over the steps a robot takes to help localize itself from an initial, uniform distribution to sensing and updating that distribution and finally normalizing that distribution.
1. The robot starts off knowing nothing; the robot is equally likely to be anywhere and so `p` is a uniform distribution.
2. Then the robot senses a grid color: red or green, and updates this distribution `p` according to the values of pHit and pMiss.
3. We normalize `p` such that its components sum to 1.
4. **We repeat steps 2 and 3 for however many measurements are taken**
<img src='images/robot_sensing.png' width=50% height=50% />
```
# importing resources
import matplotlib.pyplot as plt
import numpy as np
```
A helper function for visualizing a distribution.
```
def display_map(grid, bar_width=1):
if(len(grid) > 0):
x_labels = range(len(grid))
plt.bar(x_labels, height=grid, width=bar_width, color='b')
plt.xlabel('Grid Cell')
plt.ylabel('Probability')
plt.ylim(0, 1) # range of 0-1 for probability values
plt.title('Probability of the robot being at each cell in the grid')
plt.xticks(np.arange(min(x_labels), max(x_labels)+1, 1))
plt.show()
else:
print('Grid is empty')
```
### QUIZ: Measure Twice
Below is the normalized sense function, add code that can loop over muliple measurements, now in a *list* `measurements`. Add to this code so that it updates the probability twice and gives the posterior distribution after both measurements are incorporated.
Make sure that your code allows for any sequence of measurements whether two measurements or more have been taken.
```
# given initial variables
p=[0.2, 0.2, 0.2, 0.2, 0.2]
# the color of each grid cell in the 1D world
world=['green', 'red', 'red', 'green', 'green']
# measurements, now a *list* of sensor readings ('red' or 'green')
measurements = ['red', 'green']
pHit = 0.6
pMiss = 0.2
# sense function
def sense(p, Z):
''' Takes in a current probability distribution, p, and a sensor reading, Z.
Returns a *normalized* distribution after the sensor measurement has been made, q.
This should be accurate whether Z is 'red' or 'green'. '''
q=[]
# loop through all grid cells
for i in range(len(p)):
# check if the sensor reading is equal to the color of the grid cell
# if so, hit = 1
# if not, hit = 0
hit = (Z == world[i])
q.append(p[i] * (hit * pHit + (1-hit) * pMiss))
# sum up all the components
s = sum(q)
# divide all elements of q by the sum to normalize
for i in range(len(p)):
q[i] = q[i] / s
return q
## TODO: Add your code for accounting for 2 motion measurements, here
## Grab and print out the resulting distribution, p
for k in range(len(measurements)):
p = sense(p, measurements)
# You should *still* see a uniform distribution!
print(p)
display_map(p)
```
| github_jupyter |
This script is used to generate the frequency, total days, and intensity of the UHWs using **CMIP urban predictions**
The data sets are from:
```bash
/glade/scratch/zhonghua/CMIP5_pred_min/
```
The results are saved at:
```
/glade/scratch/zhonghua/uhws_min/UHWs_CMIP/
```
Note:
**2006**: Using 2006 itself to calculate the percentile, frequency, total days, and intensity
**2061**: Using the percentile of **2006** to calculate frequency, total days, and intensity of 2061
```
import xarray as xr
import datetime
import pandas as pd
import numpy as np
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
import time
import gc
import util
# from s3fs.core import S3FileSystem
# s3 = S3FileSystem()
save_dir = "/glade/scratch/zhonghua/uhws_min/UHWs_CMIP/"
CMIP5_ls = ["ACCESS1-0", "ACCESS1-3", "CanESM2", "CNRM-CM5", "CSIRO-Mk3-6-0",
"FGOALS-s2","GFDL-CM3", "GFDL-ESM2G", "GFDL-ESM2M", "HadGEM2-CC",
"HadGEM2-ES", "IPSL-CM5A-MR", "MIROC5", "MIROC-ESM", "MIROC-ESM-CHEM",
"MRI-CGCM3", "MRI-ESM1"]
```
## Step 1: Start the pipeline to use 98% percentile (2006) to get frequency (events/year), total days (days/year), and intensity (K) of 2006 and 2061
```
frequency_2006_ls=[]
duration_2006_ls=[]
intensity_2006_ls=[]
quantile_avail_2006_ls=[]
frequency_2061_ls=[]
duration_2061_ls=[]
intensity_2061_ls=[]
for model in CMIP5_ls:
print("start model:",model)
# start 2006
start_time_2006=time.time()
df_2006=util.load_df("/glade/scratch/zhonghua/CMIP5_pred_min/2006/"+model+".csv")
cmip_2006_hw, quantile_avail_2006=util.get_heat_waves_df(df_2006, 0.98, 2, "cmip", None)
frequency_2006_ls.append(util.get_frequency(cmip_2006_hw,model))
duration_2006_ls.append(util.get_duration(cmip_2006_hw,model))
intensity_2006_ls.append(util.get_intensity(cmip_2006_hw,model))
quantile_avail_2006_ls.append(quantile_avail_2006.copy().rename(columns={"quant": model}).set_index(["lat","lon"]))
print("It took",time.time()-start_time_2006,"to deal with",model,"for year 2006")
# start 2061
start_time_2061=time.time()
df_2061=util.load_df("/glade/scratch/zhonghua/CMIP5_pred_min/2061/"+model+".csv")
cmip_2061_hw, quantile_avail_2061=util.get_heat_waves_df(df_2061, None, 2, "cmip", quantile_avail_2006)
frequency_2061_ls.append(util.get_frequency(cmip_2061_hw,model))
duration_2061_ls.append(util.get_duration(cmip_2061_hw,model))
intensity_2061_ls.append(util.get_intensity(cmip_2061_hw,model))
print("It took",time.time()-start_time_2061,"to deal with",model,"for year 2061")
print("\n")
del df_2006, df_2061, quantile_avail_2006, quantile_avail_2061
gc.collect()
frequency_2006 = pd.concat(frequency_2006_ls, axis=1)
duration_2006 = pd.concat(duration_2006_ls, axis=1)
intensity_2006 = pd.concat(intensity_2006_ls, axis=1)
quantile_avail_2006 = pd.concat(quantile_avail_2006_ls, axis=1)
frequency_2061 = pd.concat(frequency_2061_ls, axis=1)
duration_2061 = pd.concat(duration_2061_ls, axis=1)
intensity_2061 = pd.concat(intensity_2061_ls, axis=1)
# here the quantile 2006 and quantile 2061 should be same
frequency_2006.to_csv(save_dir+"2006_frequency.csv")
duration_2006.to_csv(save_dir+"2006_totaldays.csv")
intensity_2006.to_csv(save_dir+"2006_intensity.csv")
quantile_avail_2006.to_csv(save_dir+"2006_percentile.csv")
frequency_2061.to_csv(save_dir+"2061_frequency.csv")
duration_2061.to_csv(save_dir+"2061_totaldays.csv")
intensity_2061.to_csv(save_dir+"2061_intensity.csv")
```
| github_jupyter |
# Dealing with limited data for semantic segmentation
> Strategies for efficiently collecting more data to target specific areas of underperforming models and techniques to adopt to maximize utility of the data
After we have evaluated how well a model has performed, we do one of two things:
1. decide we are happy with how the model has performed on the validation set, and report the model performance on the test set (and validation set). Hooray!
2. Diagnose issues with our model in terms of false positives or false negatives and make a plan for improving performance on classes that are underperforming.
One of the most fundamental and high impact practices to improve model performance, particularly with deep learning, is to increase the overall size of the training dataset, focusing on classes that are underperforming. However, in remote sensing it is difficult and time consuming to acquire high quality training data labels, particularly compared to other domains where computer vision and machine learning techniques are used.
Because of this unique difficulty when annotating geospatial imagery, we need to do two things:
1. closely inspect our original labeled dataset for quality issues, such as mismatch with the imagery due to date, incorrect class labels, and incorrect label boundaries
2. weigh the cost and benefits of annotating new labels or try other approaches to maximize our model's performance with the data we already have.
Part 1 of this Lesson will describe considerations for setting up an annotation campaign, keeping in mind data quality issues that have come up during the RAMI and Terrabio projects.
Part 2 will cover techniques for maximizing the performance of models trained with limited data, assuming label quality is sufficient.
## Specific concepts that will be covered
Part 1:
* How to decide on a class hierarchy prior to an annotation campaign and what inputs should be made available to an annotator
* How to efficiently annotate geospatial imagery for semantic segmentation (pixel-wise classification)
* When it makes sense to annotate for instance segmentation (predictions are vectors) instead of semantic segmentation (predictions are rasters)
* Choosing a sampling strategy that represents classes of interest
Part 2:
* Transfer Learning from pretrained models. We'll use a pretrained U-net with a Mobilenet backbone model as an example.
* Data augmentation, or multiplying your training data with image transforms
**Audience:** This post is geared towards intermediate users who are comfortable with basic machine learning concepts.
**Time Estimated**: 60-120 min
# Part 1: Setting up an Annotation Campaign
## Deciding what classes to annotate and what imagery to use as a basemap
Annotating objects of interest in remotely sensed imagery is particularly challenging. Satellite images can be difficult to interpret and may require domain knowledge/training to annotate. The imagery that is best suited for annotation may not be in RGB format. And boundaries of the object of interest may be very complex or even mixed with surrounding pixels.
:::{figure-md} Sundarbans-fig
<img src="https://miro.medium.com/max/436/1*pN8_LyZtq8-6AsY_tzSjqQ.png" width="450px">
A flooded forest in Sundarbans National Park, India [https://towardsdatascience.com/land-cover-classification-in-satellite-imagery-using-python-ae39dbf2929).
:::
The example above, a mangrove in Sundarban National Park, India, illustrates many of these difficulties. While rivers have relatively clear cut boundaries, flooded zones in the center of the image are more complex, with many dfferent land cover types mixed together in a close setting. When looking at the image on the left, some considerations for setting up an annotation would be:
* how many classes should there be?
- we should identify common classes that are well represented in our imagery and that we care about
- we can lump classes in with the background class if they are 1) rare and 2) they are not of interest. However, if we find with our models that a class of interest is confused with a rare class that we don't care about, it might be worth annotating this class in order to more holistically test our model's performance
- if we are primarily interested in mapping flooded forest, we might prioritize mapping flooded forest zones as a whole (ignoring microscale differences in cover, such as areas with slightly more canopy). It may also be a good idea to annotate rivers since this class could be easily confused with flooded areas.
* how specific should these classes be?
- there's always an ideal set of classes we wish we could map and then there is what is possible with the data available
- some classes we wish to separate may be too spectrally similar with the data available to us
- a good example of this in the image above might be two different species of mangroves. With Landsat, Sentinel-2, or Planet imagery, we would not be able to map species level differences in naturally occurring mangrove trees.
* phrased another way, is there a spectral or textural signal in the satellite imagery that annotators can see when annotating?
- if there's no signal, we either need to procure a better imagery source or refine the classes to make them more general to accomodate data limitations
- if there is a textural signal used in the modeling approach, the groundtruth data needs to be created as polygons, not points. Point-based reference data does not capture textural information and can only be used to train general-purpose machine learning algorithms like Random Forest or densely connected neural networks. CNNs require groundtruth data to be annotated as polygons.
* what is the timestamp of the image? all labels need to have the correct timestamp metadata that corresponds to the imag eused for annotation.
* this helps us consider what time periods the ML model was trained on and also when these labels are relevant. if the modeling approach needs to incorporate time series data, the labels must have timestamps to develop the model.
## Tips for efficiently annotating geospatial imagery for semantic segmentation (pixel-wise classification)
An additional consideration for an annotation campaign is, can our annotators accurately and efficiently annotate the classes we prioritize. Let's consider the following example, where want to map urban tree cover, buildings, and parking lots.
:::{figure-md} LULC Labeling
<img src="./images/lulc_labeling.gif" width="450px">
Our Data Team labeling segments in a complex scene using JOSM, the Java Open Street Map Editor.
:::
LULC classes are often directly adjacent to each other. Therefore, it can be very helpful to annotate in a platform that supports snapping edges to existing annotations and editing both in tandem, as the gif demonstrates. The background class does not need to be annotated manually.
It's also a good practice to time annotators to see how long they take to map a given area, in order to assess the cost and benefit of annotating a set of classes. This can help you decide if you need to divide an area into smaller tasks for multiple annotators to work together to finish annotating an AOI.
Annotations should be reviewed by some supervisor/expert that can assess quality, diagnose issues, and work with annotators to incorporate their feedback, possibly adjusting the task or improving instruction given to annotators ahead of the annotation task
## When it makes sense to annotate for instance segmentation (predictions are vectors) instead of semantic segmentation (predictions are rasters)
The output of U-nets and other semantic segmentation models tell you the class probability (or a set of class probabilities) at a single pixel. If you're interested in estiamting total area of parking lots, or knowing all the locations of parking lot pixels, semantic segmentation will suffice.
However, if you'd like to count parking lots (or agricultural fields or mines) and know the location and extent of individiual parking lots, an instance segmentation approach is required. The output of an instance segmentation approach tells you the class probabilities at each pixel as well as the object membership of a pixel.
There are many ways to get to an instance segmentation output. Some deep learning models, such as Mask R-CNN, train a model end-to-end to take raster inputs and return instance segmentation outputs (which can be thought of as vectors or polygon coordinates). Another approach is to post-process the results from a semantic segmentation model to delineate polygon boundaries from a map of class probabilities or class ids.
### Choosing a sampling strategy that represents classes of interest
Detection problems in remote sensing are unique because oftentimes we are dealing with very large, megapizxel images, but small objects of interest. Because of this, it is important to sample our annotation areas so that we capture many examples of the classes we care about detecting. A simple random sample of tiles within an AOI is most likely not the correct approach here, as it would undersample our classes of interest and lead to class imbalance.
An example of this challenge is marine debris detection with Planet Labs imagery.
:::{figure-md} Marine Debris Detection with Planet Labs
<img src="./images/marine_debris.png" width="450px">
An annotated Planet Labs image containing marine plastic pollution.
:::
In this case, Lilly's AOI was the entire ocean. a simple random sample of the whole ocean, or even all coastlines or major currents, would result in an overhelming amount of the background class. Instead annotation areas were targeted based on geolocated reports of marine debris. An approach DevSeed uses in a lot of projects is to try to develop as many represnetative sampels of the main class of interest as possible, and additionally develop representative samples of hard negatives (which look like the class of interest). We then control the amount of "easy negatives" that are introduced in the training set so that we minimize class imbalance.
## Part 2: Limited Data Techniques
We'll shift gears now to learning techniques for magnifying the impact of the data that we already have, assuming that we've considered all the questions above. To start with, we'll make sure we have our libraires installed and imported.
```
# install required libraries
!pip install -q rasterio==1.2.10
!pip install -q geopandas==0.10.2
!pip install -q git+https://github.com/tensorflow/examples.git
!pip install -q -U tfds-nightly
!pip install -q focal-loss
!pip install -q tensorflow-addons==0.8.3
#!pip install -q matplotlib==3.5 # UNCOMMENT if running on LOCAL
!pip install -q scikit-learn==1.0.1
!pip install -q scikit-image==0.18.3
!pip install -q tf-explain==0.3.1
!pip install -q segmentation_models
!pip install -q albumentations
# import required libraries
import os, glob, functools, fnmatch, io, shutil
from zipfile import ZipFile
from itertools import product
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['axes.grid'] = False
mpl.rcParams['figure.figsize'] = (12,12)
from sklearn.model_selection import train_test_split
import matplotlib.image as mpimg
import pandas as pd
from PIL import Image
import rasterio
from rasterio import features, mask
import geopandas as gpd
import pandas as pd
import tensorflow as tf
from tensorflow.python.keras import layers, losses, models
from tensorflow.python.keras import backend as K
import tensorflow_addons as tfa
from keras.utils.vis_utils import plot_model
from tensorflow_examples.models.pix2pix import pix2pix
from focal_loss import SparseCategoricalFocalLoss
from tf_explain.callbacks.activations_visualization import ActivationsVisualizationCallback
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
from IPython.display import clear_output
from time import sleep
from tqdm.notebook import tqdm
import datetime
import skimage.io as skio
import segmentation_models as sm
from segmentation_models.losses import bce_jaccard_loss
from albumentations import (
Compose, Blur, HorizontalFlip, VerticalFlip,
Rotate, ChannelShuffle
)
# set your root directory and tiled data folders
if 'google.colab' in str(get_ipython()):
# this is a google colab specific command to ensure TF version 2 is used.
# it won't work in a regular jupyter notebook, for a regular notebook make sure you install TF version 2
%tensorflow_version 2.x
# mount google drive
from google.colab import drive
drive.mount('/content/gdrive')
root_dir = '/content/gdrive/My Drive/servir-tf-devseed/'
workshop_dir = '/content/gdrive/My Drive/servir-tf-devseed-workshop'
print('Running on Colab')
else:
root_dir = os.path.abspath("./data/servir-tf-devseed")
workshop_dir = os.path.abspath('./servir-tf-devseed-workshop')
print(f'Not running on Colab, data needs to be downloaded locally at {os.path.abspath(root_dir)}')
img_dir = os.path.join(root_dir,'indices/') # or os.path.join(root_dir,'images_bright/') if using the optical tiles
label_dir = os.path.join(root_dir,'labels/')
# go to root directory
%cd $root_dir
```
### Enabling GPU
This notebook can utilize a GPU and works better if you use one. Hopefully this notebook is using a GPU, and we can check with the following code.
If it's not using a GPU you can change your session/notebook to use a GPU. See [Instructions](https://colab.research.google.com/notebooks/gpu.ipynb#scrollTo=sXnDmXR7RDr2)
```
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
```
### Check out the labels
```
# Read the classes
class_index = pd.read_csv(os.path.join(root_dir,'terrabio_classes.csv'))
class_names = class_index.class_name.unique()
print(class_index)
train_df = pd.read_csv(os.path.join(root_dir, "train_file_paths.csv"))
validate_df = pd.read_csv(os.path.join(root_dir, "validate_file_paths.csv"))
test_df = pd.read_csv(os.path.join(root_dir, "test_file_paths.csv"))
x_train_filenames = train_df["img_names"]
y_train_filenames = train_df["label_names"]
x_val_filenames = train_df["img_names"]
y_val_filenames = train_df["label_names"]
x_test_filenames = train_df["img_names"]
y_test_filenames = train_df["label_names"]
num_train_examples = len(x_train_filenames)
num_val_examples = len(x_val_filenames)
num_test_examples = len(x_test_filenames)
```
### Setting up our Augmentations
[albumentations](https://albumentations.ai/docs/examples/tensorflow-example/) is a library that contains hundreds of options for transforming images to multiply your training dataset. While each additional image may not be as additively valuable as independent samples, showing your model harder to classify copies of your existing samples can help improve your model's ability to generalize. Plus, augmentations are basically free training data!
Common augmentations include brightening images, applying blur, saturation, flipping, rotating, and randomly cropping and resizing. We'll apply a few augmentations from the `albumentations` library to highlight how to set up an augmentation pipeline. This differs from coding your own augmentations, like we did in episode 3 with our horizontal flip and veritcal flip functions, saving time and lines of code.
```
# set input image shape
img_shape = (224, 224, 3)
# set batch size for model
batch_size = 8
transforms = Compose([
Rotate(limit=40),
HorizontalFlip(),
VerticalFlip(),
Blur(blur_limit=[3,3], p=.5),
ChannelShuffle(),
])
def aug_fn(image, img_size):
data = {"image":image}
aug_data = transforms(**data)
aug_img = aug_data["image"]
aug_img = tf.cast(aug_img/255.0, tf.float32)
aug_img = tf.image.resize(aug_img, size=[img_size, img_size])
return aug_img
# Function to augment the images and labels
def _augment(img, label_img, img_size):
label_img = tf.image.resize(label_img, [224,224])
img = tf.image.resize(img, [224,224])
aug_img = tf.numpy_function(func=aug_fn, inp=[img, img_size], Tout=tf.float32)
return aug_img, label_img
```
Now we will call our augmentation pipeline whenever we load a batch in our training or validation datasets. The augmentation pipeline that we form with `Compose()` is called in `get_baseline_dataset` during the dataset creation process.
```
# load your data
# Function for reading the tiles into TensorFlow tensors
# See TensorFlow documentation for explanation of tensor: https://www.tensorflow.org/guide/tensor
def _process_pathnames(fname, label_path):
# We map this function onto each pathname pair
img_str = tf.io.read_file(fname)
img = tf.image.decode_png(img_str, channels=3)
label_img_str = tf.io.read_file(label_path)
# These are png images so they return as (num_frames, h, w, c)
label_img = tf.image.decode_png(label_img_str, channels=1)
# The label image should have any values between 0 and 8, indicating pixel wise
# foreground class or background (0). We take the first channel only.
label_img = label_img[:, :, 0]
label_img = tf.expand_dims(label_img, axis=-1)
return img, label_img
# Main function to tie all of the above four dataset processing functions together
def get_baseline_dataset(filenames,
labels,
threads=5,
batch_size=batch_size,
shuffle=True):
num_x = len(filenames)
# Create a dataset from the filenames and labels
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
dataset = dataset.map(_process_pathnames, num_parallel_calls=threads)
# Map our preprocessing function to every element in our dataset, taking
# advantage of multithreading
dataset = dataset.map(functools.partial(_augment, img_size=224), num_parallel_calls=threads).prefetch(threads)
if shuffle:
dataset = dataset.shuffle(num_x)
# It's necessary to repeat our data for all epochs
dataset = dataset.repeat().batch(batch_size)
print(dataset)
return dataset
# dataset configuration for training
train_ds = get_baseline_dataset(x_train_filenames,
y_train_filenames,
batch_size=batch_size)
val_ds = get_baseline_dataset(x_val_filenames,
y_val_filenames,
batch_size=batch_size)
```
Let's view some of our augmentations
```
def view_image(ds):
image, label = next(iter(ds)) # extract 1 batch from the dataset
image = image.numpy()
print(image.shape)
fig = plt.figure(figsize=(22, 22))
for i in range(8):
ax = fig.add_subplot(2, 4, i+1, xticks=[], yticks=[])
ax.imshow(image[i])
plt.tight_layout()
```
Boom, more training data! Channel Shuffle presents the most extreme augmentation to the human eye. Try to adjust the Blur augmentation to create a more aggressive blurring effect.
```
view_image(train_ds)
```
Now that we have a variety of augmentations that will be applied to each image in each batch, let's train a model using our augmentations and pretraining.
### Display functions for monitoring model progress and visualizing arrays
```
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.preprocessing.image.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
def show_predictions(image=None, mask=None, dataset=None, num=1):
if image is None and dataset is None:
# this is just for showing keras callback output. in practice this should be broken out into a different function
sample_image = skio.imread(f'{img_dir}/tile_terrabio_17507.png') * (1/255.)
sample_mask = skio.imread(f'{label_dir}/tile_terrabio_17507.png')
mp = create_mask(model.predict(sample_image[tf.newaxis, ...]))
mpe = tf.keras.backend.eval(mp)
display([sample_image, sample_mask[..., tf.newaxis], mpe])
elif dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
mp = create_mask(model.predict(image[tf.newaxis, ...]))
mpe = tf.keras.backend.eval(mp)
display([image, mask, mpe])
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
callbacks = [
DisplayCallback()
]
```
We'll use the `segmentation_models` implementation of a U-net, since it handles downlaoding pretrained weights from a variety of sources. To set up the U-Net in a manner that is equivalent with the U-Net we made from scratch in episode 3, we need to specify the correct activation function for multi-category pixel segmentation,`softmax`, and the correct number of classes: 9.
```
# define model
sm.set_framework('tf.keras')
sm.framework()
model = sm.Unet('mobilenetv2', activation='softmax', classes = 9, encoder_weights="imagenet", input_shape=(224,224,3))
```
We'll compile our model with the same optimizer, loss function, and accuracy metrics from Lesson 3.
```
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.00001),
loss=SparseCategoricalFocalLoss(gamma=2, from_logits=True), #tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy', sm.metrics.iou_score])
EPOCHS=4
model_history = model.fit(
train_ds,
epochs=EPOCHS,
steps_per_epoch=int(np.ceil(num_train_examples / float(batch_size))),
validation_data=val_ds,
validation_steps=int(np.ceil(num_val_examples / float(batch_size))),
callbacks=callbacks
)
```
And we can view the model's loss plot and compare to Lesson 3. Was there an improvement?
```
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
epochs = range(EPOCHS)
plt.figure()
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 2])
plt.legend()
plt.show()
```
| github_jupyter |
# Linear regression with an evolutionary algorithm
In this notebook, we will show how to use Auxein and a simple evolutionary algorithm to perfom a [simple linear regression](https://en.wikipedia.org/wiki/Simple_linear_regression).
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import os
import logging
logging.getLogger().setLevel(logging.CRITICAL)
```
As a first step, we will randomly generate $100$ data points in the form of $(x_{i},y_{i})$ representing our observations of a linear function $y = f(x)$ affected by some uniform noise.
```
size = 100
x = np.arange(size)
delta = np.random.uniform(-15,15, size=(size,))
y = .4*x + 3 + delta
```
And then we visualise our observations drawn from $(x_{i},y_{i})$:
```
plt.scatter(x, y);
```
From now on, we will only assume that we have our observations $(x_{i},y_{i})$ and that we do not know the function $y = f(x)$ that generated them.
Our goal is to find a function $\hat{f} = ax + b$ such as $\hat{f} \sim f$, which means finding $a$ and $b$ of the linear equation.
The first thing to do is to use the $(x,y)$ observations and wrap them with a [Fitness function](https://github.com/auxein/auxein/blob/master/auxein/fitness/core.py#L15) $\phi$ that Auxein can explore.
Auxein comes with some pre-defined fitness functions. In this case, for our linear regression problem, we will use the [MultipleLinearRegression](https://github.com/auxein/auxein/blob/master/auxein/fitness/observation_based.py#L39).
```
from auxein.fitness.observation_based import MultipleLinearRegression
fitness_function = MultipleLinearRegression(x.reshape(size, 1), y)
```
Then, the second step is to create an initial `population` of individuals. Each `individual` maps to candidate solution, which in this case would be a vector $(a, b)$.
Auxein provides some utility functions to create initial populations, like the `build_fixed_dimension_population` used below.
```
from auxein.population.dna_builders import UniformRandomDnaBuilder
from auxein.population import build_fixed_dimension_population
population = build_fixed_dimension_population(2, 100, fitness_function, UniformRandomDnaBuilder((-10, -5)))
```
Once we have a `fitness_function` and an initial `population`, we need to set up a [Playground](https://github.com/auxein/auxein/blob/master/auxein/playgrounds/static.py#L27).
A playground is basically the object that represents our experiment.
```
from auxein.playgrounds import Static
from auxein.mutations import SelfAdaptiveSingleStep
from auxein.recombinations import SimpleArithmetic
from auxein.parents.distributions import SigmaScaling
from auxein.parents.selections import StochasticUniversalSampling
from auxein.replacements import ReplaceWorst
```
In order to instantiate a `playground` the following must be specified:
* `mutation` strategy, which describes how `individual` dna will mutate. In this case we will use the [SelfAdaptiveSingleStep](https://github.com/auxein/auxein/blob/master/auxein/mutations/core.py#L62).
* parents `distribution`, which gives a probability distribution for parents `selection`. We here use [SigmaScaling](https://github.com/auxein/auxein/blob/master/auxein/parents/distributions/core.py#L43) for distribution and [StochasticUniversalSampling](https://github.com/auxein/auxein/blob/master/auxein/parents/selections/core.py#L27) for selection.
* `recombination` defines how fresh dna are created when `individual`s breed. Here we use the basic [SimpleArithmetic](https://github.com/auxein/auxein/blob/master/auxein/recombinations/core.py#L23).
* for `replacement` we will use the basic [ReplaceWorst](https://github.com/auxein/auxein/blob/master/auxein/replacements/core.py#L34) which basically only replaces the 2-worst performing individuals.
```
offspring_size = 2
playground = Static(
population = population,
fitness = fitness_function,
mutation = SelfAdaptiveSingleStep(0.05),
distribution = SigmaScaling(),
selection = StochasticUniversalSampling(offspring_size = offspring_size),
recombination = SimpleArithmetic(alpha = 0.5),
replacement = ReplaceWorst(offspring_size = offspring_size)
)
```
Invoking `playground.train(max_generations = 250)` will trigger the evolution process up to a maximum of $250$ generations.
```
stats = playground.train(250)
```
Once the training phase has ended, the `playground` returns a dictionary with some basic statistics on the population.
```
population.get_stats()
```
To get the most performant `individual` we can invoke `playground.get_most_performant()` and grab the dna of the individual.
```
[a, b] = playground.get_most_performant().genotype.dna
```
In our case, the dna is a vector of dimension $2$ where the first scalar is our $a$ coefficient and the second is $b$.
```
[a, b]
```
Once we have $a$ and $b$, it might be useful to plot $\hat{f} = ax + b$ against our observations $(x_{i},y_{i})$, to visually inspect the quality of our regression:
```
y_pred = a*x + b
plt.scatter(x, y);
plt.plot(x, y_pred, color='red');
```
It would be also useful to see how the mean fitness value changed over the generations. Intuitively, an increasing mean fitness might indicate that the evolution process is selecting better solutions for our problem.
```
mean_fitness_values = []
for g in stats['generations'].values():
mean_fitness_values.append(g['mean_fitness'])
plt.plot(list(stats['generations'].keys()), mean_fitness_values, color='red');
```
It's probably worth noting as after a certain number of generations, the mean fitness doesn't improve anymore, making totally pointless to keep the evolution process going on.
| github_jupyter |
# SVR with StandardScaler & Power Transformer
This Code template is for regression analysis using a Support Vector Regressor(SVR) based on the Support Vector Machine algorithm with PowerTransformer as Feature Transformation Technique and StandardScaler for Feature Scaling in a pipeline.
### Required Packages
```
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as se
from sklearn.preprocessing import PowerTransformer, StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import RandomOverSampler
from sklearn.svm import SVR
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
warnings.filterwarnings('ignore')
```
### Initialization
Filepath of CSV file
```
file_path= "/content/Folds5x2_pp.csv"
```
List of features which are required for model training .
```
features = [ "AT","V","AP","RH"]
```
Target feature for prediction.
```
target='PE'
```
### Data Fetching
Pandas is an open-source, BSD-licensed library providing high-performance, easy-to-use data manipulation and data analysis tools.
We will use panda's library to read the CSV file using its storage path.And we use the head function to display the initial row or entry.
```
df=pd.read_csv(file_path)
df.head()
```
### Feature Selections
It is the process of reducing the number of input variables when developing a predictive model. Used to reduce the number of input variables to both reduce the computational cost of modelling and, in some cases, to improve the performance of the model.
We will assign all the required input features to X and target/outcome to Y.
```
X=df[features]
Y=df[target]
```
### Data Preprocessing
Since the majority of the machine learning models in the Sklearn library doesn't handle string category data and Null value, we have to explicitly remove or replace null values. The below snippet have functions, which removes the null value if any exists. And convert the string classes data in the datasets by encoding them to integer classes.
```
def NullClearner(df):
if(isinstance(df, pd.Series) and (df.dtype in ["float64","int64"])):
df.fillna(df.mean(),inplace=True)
return df
elif(isinstance(df, pd.Series)):
df.fillna(df.mode()[0],inplace=True)
return df
else:return df
def EncodeX(df):
return pd.get_dummies(df)
```
Calling preprocessing functions on the feature and target set.
```
x=X.columns.to_list()
for i in x:
X[i]=NullClearner(X[i])
X=EncodeX(X)
Y=NullClearner(Y)
X.head()
```
#### Correlation Map
In order to check the correlation between the features, we will plot a correlation matrix. It is effective in summarizing a large amount of data where the goal is to see patterns.
```
f,ax = plt.subplots(figsize=(18, 18))
matrix = np.triu(X.corr())
se.heatmap(X.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax, mask=matrix)
plt.show()
```
### Data Splitting
The train-test split is a procedure for evaluating the performance of an algorithm. The procedure involves taking a dataset and dividing it into two subsets. The first subset is utilized to fit/train the model. The second subset is used for prediction. The main motive is to estimate the performance of the model on new data.
```
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=123)
```
### Model
Support vector machines (SVMs) are a set of supervised learning methods used for classification, regression and outliers detection.
A Support Vector Machine is a discriminative classifier formally defined by a separating hyperplane. In other terms, for a given known/labelled data points, the SVM outputs an appropriate hyperplane that classifies the inputted new cases based on the hyperplane. In 2-Dimensional space, this hyperplane is a line separating a plane into two segments where each class or group occupied on either side.
Here we will use SVR, the svr implementation is based on libsvm. The fit time scales at least quadratically with the number of samples and maybe impractical beyond tens of thousands of samples.
#### Model Tuning Parameters
1. C : float, default=1.0
> Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. The penalty is a squared l2 penalty.
2. kernel : {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, default=’rbf’
> Specifies the kernel type to be used in the algorithm. It must be one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ or a callable. If none is given, ‘rbf’ will be used. If a callable is given it is used to pre-compute the kernel matrix from data matrices; that matrix should be an array of shape (n_samples, n_samples).
3. gamma : {‘scale’, ‘auto’} or float, default=’scale’
> Gamma is a hyperparameter that we have to set before the training model. Gamma decides how much curvature we want in a decision boundary.
4. degree : int, default=3
> Degree of the polynomial kernel function (‘poly’). Ignored by all other kernels.Using degree 1 is similar to using a linear kernel. Also, increasing degree parameter leads to higher training times.
#### Feature Transformation
PowerTransformer applies a power transform featurewise to make data more Gaussian-like.
Power transforms are a family of parametric, monotonic transformations that are applied to make data more Gaussian-like. This is useful for modeling issues related to heteroscedasticity (non-constant variance), or other situations where normality is desired.
```
model=make_pipeline(StandardScaler(),PowerTransformer(),SVR())
model.fit(x_train, y_train)
```
#### Model Accuracy
We will use the trained model to make a prediction on the test set.Then use the predicted value for measuring the accuracy of our model.
> **score**: The **score** function returns the coefficient of determination <code>R<sup>2</sup></code> of the prediction.
```
print("Accuracy score {:.2f} %\n".format(model.score(x_test,y_test)*100))
```
> **r2_score**: The **r2_score** function computes the percentage variablility explained by our model, either the fraction or the count of correct predictions.
> **mae**: The **mean abosolute error** function calculates the amount of total error(absolute average distance between the real data and the predicted data) by our model.
> **mse**: The **mean squared error** function squares the error(penalizes the model for large errors) by our model.
```
y_pred=model.predict(x_test)
print("R2 Score: {:.2f} %".format(r2_score(y_test,y_pred)*100))
print("Mean Absolute Error {:.2f}".format(mean_absolute_error(y_test,y_pred)))
print("Mean Squared Error {:.2f}".format(mean_squared_error(y_test,y_pred)))
```
#### Prediction Plot
First, we make use of a plot to plot the actual observations, with x_train on the x-axis and y_train on the y-axis.
For the regression line, we will use x_train on the x-axis and then the predictions of the x_train observations on the y-axis.
```
plt.figure(figsize=(14,10))
plt.plot(range(20),y_test[0:20], color = "green")
plt.plot(range(20),model.predict(x_test[0:20]), color = "red")
plt.legend(["Actual","prediction"])
plt.title("Predicted vs True Value")
plt.xlabel("Record number")
plt.ylabel(target)
plt.show()
```
#### Creator: Ageer Harikrishna, Github: [Profile](https://github.com/ageerHarikrishna)
| github_jupyter |
# Hotspots on a network
A class of algorithms which are based on the classical (prospective / retrospective) hotspotting techniques where a grid is replaced by edges on a network/graph.
## Sources
1. Rosser et al. "Predictive Crime Mapping: Arbitrary Grids or Street Networks?" Journal of Quantitative Criminology 33 (2017) 569--594 [10.1007/s10940-016-9321-x](https://link.springer.com/article/10.1007/s10940-016-9321-x)
2. Okabe et al. "A kernel density estimation method for networks, its computational method and a GIS‐based tool" International Journal of Geographical Information Science 23 (2009) 7--32 [10.1080/13658810802475491](http://www.tandfonline.com/doi/abs/10.1080/13658810802475491)
## Algorithm
We follow (1), which itself uses (2) for the KDE method.
- We need geometry giving the street network we'll work on.
- For the moment, we use freely available data from the [OS Open Road](https://www.ordnancesurvey.co.uk/business-and-government/products/os-open-roads.html) for the UK, and [TIGER/Line](https://www.census.gov/geo/maps-data/data/tiger-line.html) for the USA.
- For us, a "network" or "graph" is a collection of vertices in the plane, with edges connecting (some of) the vertices, as straight lines. Informally, the "network" is the subset of the plane formed by the union of all the edges. Curved streets can be approximated by adding further vertices. This usage correlates with the above geometry sources.
- All events need to be assigned to the network. Following (1) we simply orthogonally project each event to the network (this is equivalent as assigning each event to the closest point on the network).
- We then "simply" change the grid-based hotspotting technique to work on the network, using (2). We give details below.
The resulting "hotspot" is actually a "risk" estimate for each point on the network, where a higher risk corresponds to the belief that future events are more likely. As usual, we generate an actual "hotspot(s)" by chosing a "coverage level", say 10%, and then selecting the 10% of the network which is most risky, where we use the natural length of edges in the network to decide what "10%" means.
We might naturally want to compare such a prediction with a grid-based prediction. To do this, (1) suggests (although they don't quite use these words) generating a network prediction from a grid prediction. We do this by giving edge network point the "risk" of the grid cell it occurs in. Once this is done, we can then compare network predictions directly. (For example, to generate 10% coverage, we work from most risky to least risky grid cell, adding all the network which intersects with that cell, until we have selected 10% of the network by length.)
## KDE on a network
We follow (2); the summary in (1) is very clear. Let $s'$ be an event on the network. We seek to derive a formula for the (space-like) kernel induced at a point $s$. As a base, we start with a one-dimensional kernel function $f:\mathbb R\rightarrow [0,\infty)$. We assume that $f$ is symmetric, $f(-t) = f(t)$, and it should be normalised, $\int_{\mathbb R} f(t) \ dt = 1$. (Source (2) gives further conditions, but these are details, and will be satisfied by our kernels.) We always suppose our kernels have a finite "support", a value $t_\max$ such that $f(t)=0$ for any $|t|>t_\max$.
We consider all paths in the network from $s'$ to $s$, ignoring any "cyclic" paths. This is not entirely specified in (1), so we use this algorithm:
- We perform a [Breadth-first search](https://en.wikipedia.org/wiki/Breadth-first_search) starting at $s'$ and considering all possible vertices adjacent to $s'$, forming a set of possible paths. For each possible path, we consider the adjacent vertices to the end vertex, forming a new set of possible paths. We continue, discarding paths where:
- We form a cycle, by visiting a vertex we have visited before. We ignore such paths.
- We get to $s$. We consider such paths.
- The length of the path is greater than the support of the base kernel $f$.
- This gives us a finite set of possible paths, $P$.
- For each path $p\in P$ we will visit vertices $v_1, \cdots, v_{m(p)}$ between $s'$ and $s$. For each $i$ let $n_i$ be the order of the vertex $v_i$, that is, the number of neighbours which $v_i$ has.
- Let $l(p)$ be the length of that path.
- Our network kernel estimate is then
$$ k_{s'}^{(p)}(s) = \sum_{P} \frac{f(l(p))}{(n_1-1)\cdots(n_{m(p)}-1)} $$
- This corresponds to "splitting" the kernel at each vertex by the number of possible paths out of that vertex. See (2) for further details.
- The final kernel estimate is obtained by summing over all events $s'$.
## Which kernels to use
(1) considers a "prospective" hotspotting technique, which takes account of time. We consider forming a prediction at time $t$. Consider events which occur at time $t_i$ for $i=1,\cdots,n$, and which occur at a place $s_i$ on the network. We combine a time and space kernel.
- The time kernel is
$$ g(t) = \frac{1}{h_T} \exp\Big( -\frac{t}{h_T} \Big). $$
That is, exponential decay, with a "bandwidth" $h_T$.
- The space kernel uses a base kernel which is linear decay:
$$ f(s) = \begin{cases} \frac{h_S - s}{h_S^2} &: 0 \leq s \leq h_S,\\ 0 &: |s| > h_S. \end{cases} $$
Here $h_S$ is the "spatial bandwidth" or "support" as above.
Thus the final network "risk" estimate is at time $t$ and network location $s$,
$$ \lambda(s,t) = \sum_{t_i<t} \frac{1}{h_T} \exp\Big( -\frac{t-t_i}{h_T} \Big)
\Big( \sum_i \sum_{p:s_i\rightarrow s, l(p) \leq h_S} \frac{h_S - l(p)}{h_S^2(n_1-1)\cdots(n_{m(p)}-1)}\Big) $$
## Efficiency
We are interested in an estimate of the risk at a fixed time $t$. Source (1) suggests sampling $\lambda(s) = \lambda(s,t)$ at various points $s$ across the network; (1) suggests every 30 metres. We make some comments on how to improve this, and towards efficient computation:
- If we are only sampling at points, then we may as well actually just deem every edge in the network to have a risk which is constant across that edge. If an edge is too long, then it can simply be split into parts by adding addition vertices.
- Thus, we will assign, say, the risk at the _centre_ of each edge to the whole edge.
- To correctly normalise, we should multiply this point risk by the length of the edge. An alternative, if the form of the spacial kernel is analytically tractable, is to integrate it over the edge.
- It is more efficient to work over each event at time $t_i<t$ in turn, performing the "walk" across the network from that point, adding to the risk of each edge as we encounter it.
To find all paths between a point in the middle of an edge between vertices $u_1, u_2$ and a point in the middle of an edge between vertices $u_3, u_4$, we can proceed as follows:
- Decide we will first move to vertex $u_1$, and will finally move to vertex $u_3$.
- Find all such paths, ignoring any path which uses the edges between $u_1, u_2$ and $u_3, u_4$, to avoid circular paths.
- Do the for paths $u_1 \rightarrow u_4$, then $u_2\rightarrow u_3$ and finally $u_2\rightarrow u_4$.
Finally, once we have summed all the "risks" for each edge, we should normalise and divide by the length of the edge.
- This assigns to each edge the average/expected risk.
- We can then e.g. take the top 10% of edges to form network "hotspots"
- (Or apply some more involved hotspot generation algorithm).
## Approximation
The above procedure is very slow if the "spatial bandwidth" of the kernel becomes large (and in practical situations, it is large). We have implemented a caching scheme which:
- Uses a lot of memory. For the South side of Chicago, we need a 12GB machine.
- Is only of benefit if the same network and events collection will be tested for multiple kernels (for example) or across multiple days.
An alternative scheme, as explored more in the `Geometry reduction` notebook, is to approximate the sum over all paths by:
- Simply compute the shortest path.
- But continue to take account of node degree.
- We can use a variation of Dijkstra's algorithm to do this.
- This seems to lead to a reasonably good approximation.
# Comparison to grid based methods
We again follow (1). Given a grid prediction, we can intersect the grid with the network, and assign the risk of each grid cell to every network part which intersects that cell.
- As (1) notes, this typically leads to a slightly artificial intersection of the grid and network
- It seems likely that the better performance of the network hotspot to the grid hotspot found in (1) is mostly due to the "over coverage" from this intersection procedure. It would be interesting to make this conjecture precise and to test it.
# Examples
For networks, it is hard(er) to produce toy examples. So instead of giving examples here, we give examples using real data from Chicago.
- See the folder "Case study Chicago"
- The notebook "Input data" describes how we produced the data we need as input
- The notebook "Hotspotting" shows how to produce a hotspot map on a network
- The notebook "Grid to network hotspotting" shows how to move from a grid prediction to a network prediction
- The notebook "Cross-Validation" shows a replication of the work of Rosser et al, but for Chicago, on choosing optimal bandwidths
- The notebook "Cross-Validation grid" does the same for gird based predictions with the Chicago data
| github_jupyter |
# Load
```
import pandas as pd
import numpy as np
prices = pd.read_csv(r"data/car_prices.csv")
display(prices.head())
```
# Clean
```
prices = prices.drop(columns=["car_ID"])
print(prices.isna().sum())
from pandas.core.common import SettingWithCopyWarning
import warnings
warnings.simplefilter(action="ignore", category=SettingWithCopyWarning)
prices["Make"] = np.nan
prices["Model"] = np.nan
for i in range(len(prices["CarName"].copy().str.split())):
curr_make = prices["CarName"].copy().str.split().loc[i][0]
prices["Make"].loc[i] = curr_make
curr_model = prices["CarName"].copy().loc[i].replace(curr_make, "")
if curr_model != "":
prices["Model"].loc[i] = curr_model
else:
prices["Model"].loc[i] = curr_make
prices = prices.drop(columns=["CarName"])
prices["symboling"] = prices["symboling"].astype("object")
for col in prices.columns:
if prices[col].dtype != "object":
prices[col] = prices[col].astype("float64")
cont_features = prices.select_dtypes(include="float64")
non_cont_features = prices.drop(columns=cont_features.columns)
print(prices.info())
prices["Make"] = prices["Make"].str.replace("porcshce", "porsche")
```
# EDA
```
from math import trunc
import seaborn as sns
import matplotlib.pyplot as plt
curr_row = 0
fig, ax = plt.subplots(7, 2, figsize=(18,34))
for col in range(len(cont_features.drop(columns="price").columns)):
curr_feature = cont_features[cont_features.drop(columns="price").columns[col]]
ax[trunc(curr_row), col%2].title.set_text(f'{cont_features.drop(columns="price").columns[col]} Histogram')
sns.histplot(curr_feature, ax=ax[trunc(curr_row), col%2], color="lightsteelblue")
curr_row+=0.5
curr_row = 0
fig, ax = plt.subplots(5, 2, figsize=(18,34))
for col in range(len(non_cont_features.drop(columns=["Model", "Make"]).columns)):
curr_feature = non_cont_features[non_cont_features.drop(columns=["Model", "Make"]).columns[col]]
ax[trunc(curr_row), col%2].title.set_text(f'{non_cont_features.drop(columns=["Model", "Make"]).columns[col]} Histogram')
sns.histplot(curr_feature, ax=ax[trunc(curr_row), col%2], color="teal")
curr_row+=0.5
plt.figure(figsize=(15,6))
plt.title("Car Price Histogram")
plt.hist(cont_features["price"], edgecolor='black', linewidth=1.2)
plt.xlabel("Price")
plt.ylabel("Count")
plt.show()
print("Price Statistics:")
print(prices["price"].describe())
plt.figure(figsize=(15,6))
plt.bar(prices.groupby("Make")["price"].mean().index, prices.groupby("Make")["price"].mean().values)
plt.xticks(rotation=45)
plt.xlabel("Make")
plt.ylabel("Avg. Price")
plt.show()
plt.figure(figsize=(15,6))
plt.bar(prices.groupby("Make")["price"].count().index, prices.groupby("Make")["price"].count().values, color="purple")
plt.xticks(rotation=45)
plt.xlabel("Make")
plt.ylabel("Count")
plt.show()
plt.figure(figsize=(15,10))
plt.title("Correlation Heatmap")
sns.heatmap(cont_features.corr(), annot = True, fmt='.2g',cmap= 'coolwarm')
plt.xticks(rotation=45)
plt.show()
curr_row = 0
fig, ax = plt.subplots(7, 2, figsize=(18,32))
for col in range(len(prices.select_dtypes(include=["int64", "float64"]).drop(columns=["price"]).columns)):
curr_feature = prices[prices.select_dtypes(include=["int64", "float64"]).drop(columns=["price"]).columns[col]]
ax[trunc(curr_row), col%2].title.set_text(f'Price be {cont_features.drop(columns="price").columns[col]}')
ax[trunc(curr_row), col%2].scatter(curr_feature, prices["price"])
ax[trunc(curr_row), col%2].set_xlabel(cont_features.drop(columns="price").columns[col])
ax[trunc(curr_row), col%2].set_ylabel("Price")
curr_row+=0.5
fig.tight_layout()
```
# Split
```
from sklearn.model_selection import train_test_split
X, y = prices.drop(columns=["price"]), prices["price"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, stratify=prices["doornumber"], random_state=26)
train_index = X_train.index
test_index = X_test.index
```
# Preprocessing
```
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
ohe = OneHotEncoder(sparse=False)
oe = OrdinalEncoder()
scaler = StandardScaler()
```
## Preprocess Categorical Features
```
ord_cols = ["aspiration", "doornumber", "cylindernumber"]
nom_cols = list(non_cont_features.drop(columns=ord_cols).columns)
cat_pipe = ColumnTransformer([
("ordinal encode", oe, ord_cols),
("nominal encode", ohe, nom_cols),
], remainder="drop")
prices_cat = pd.DataFrame(cat_pipe.fit_transform(non_cont_features))
prices_cat.columns = list(ord_cols+list(range(len(prices_cat.columns)-len(ord_cols))))
X_train_cat = pd.DataFrame(prices_cat.loc[train_index])
X_test_cat = pd.DataFrame(prices_cat.loc[test_index])
```
## Preprocess Numerical Features
```
disc_cols = ["symboling"]
cont_cols = cont_features.drop(columns="price").columns
num_pipe = ColumnTransformer(
[("scale continuous", scaler, cont_cols)
], remainder="drop")
X_train_num = pd.DataFrame(num_pipe.fit_transform(cont_features.loc[train_index]), index=train_index, columns=cont_cols)
X_test_num = pd.DataFrame(num_pipe.transform(cont_features.loc[test_index]), index=test_index, columns=cont_cols)
X_train_num = pd.DataFrame(pd.concat([X_train_num, prices[disc_cols].loc[train_index]], axis=1))
X_test_num = pd.DataFrame(pd.concat([X_test_num, prices[disc_cols].loc[test_index]], axis=1))
X_train = pd.concat([X_train_num, X_train_cat], axis=1)
X_test = pd.concat([X_test_num, X_test_cat], axis=1)
new_cols = []
for col in X_train.columns:
new_col = str(col)
new_cols.append(new_col)
X_train.columns, X_test.columns = new_cols, new_cols
```
# Model
## Select and Hypertune Model
* Possible model options - SVR or XGBoost
* We will measure the performance of each
```
from sklearn.model_selection import RandomizedSearchCV, cross_val_score
from sklearn.svm import SVR
from math import sqrt
svr_params = {
"kernel": ["linear", "poly", "rbf"],
"gamma": ["scale", "auto"],
"epsilon": [0.1, 0.001, 0.0001],
"C": [0.1, 1, 5, 10]
}
svr_search = RandomizedSearchCV(SVR(), svr_params, cv=10, random_state=26).fit(X_train, y_train)
print(svr_search.best_params_)
temp_svr = SVR(kernel="linear", gamma="auto", epsilon=0.1, C=10)
svr_scores = cross_val_score(temp_svr, X_train, y_train, cv=10, scoring='neg_median_absolute_error')
print("SVR MAE:", abs(svr_scores).mean())
import xgboost as xgb
X_train = X_train.astype("float64")
y_train = y_train.astype("float64")
xgb_params = {
"colsample_bytree": [0.2, 0.3, 0.6, 0.75, 0.9],
"learning_rate": [0.001, 0.01, 0.1],
"max_depth":[5, 10, 25, 50, 100],
"alpha":[0, 5, 10, 15],
"n_estimators": [10, 15, 25, 50],
"min_child_weight": [ 1, 3, 5, 7 ],
"gamma": [0.0, 0.1, 0.2 , 0.3, 0.4]
}
xgb_search = RandomizedSearchCV(xgb.XGBRegressor(objective='reg:squarederror', use_label_encoder=True, random_state=26),
param_distributions=xgb_params, cv=10, random_state=26)
xgb_search.fit(np.array(X_train), np.array(y_train))
print("Params:", xgb_search.best_params_)
temp_xgb = xgb.XGBRegressor(objective ='reg:squarederror', use_label_encoder=True, random_state=26, n_estimators=25,
min_child_weight=3, max_depth=25, learning_rate=0.1, gamma=0.2, colsample_bytree=0.75,
alpha=15)
xgb_scores = cross_val_score(temp_xgb, np.array(X_train), np.array(y_train), cv=10, scoring='neg_median_absolute_error',
error_score="raise")
print("XGBoost MAE:", abs(xgb_scores).mean())
```
We'll use XGBoost since it has a better MAE.
## Train Model
```
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
reg = xgb.XGBRegressor(objective ='reg:squarederror', use_label_encoder=True, random_state=26, n_estimators=25,
min_child_weight=3, max_depth=25, learning_rate=0.1, gamma=0.2, colsample_bytree=0.75,
alpha=15)
reg.fit(np.array(X_train), np.array(y_train))
```
## Test Model
```
y_pred = reg.predict(np.array(X_test))
scatter_index = sqrt(mean_squared_error(y_test, y_pred))/y_test.mean()
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("SI:", scatter_index)
print("MAE:", mae)
print("R2:", r2)
```
# Save Model
```
import pickle
pickle.dump(reg, open("reg.pkl", 'wb'))
```
| github_jupyter |
<!--BOOK_INFORMATION-->
<img align="left" style="padding-right:10px;" src="figures/PDSH-cover-small.png">
*This notebook contains an excerpt from the [Python Data Science Handbook](http://shop.oreilly.com/product/0636920034919.do) by Jake VanderPlas; the content is available [on GitHub](https://github.com/jakevdp/PythonDataScienceHandbook).*
*The text is released under the [CC-BY-NC-ND license](https://creativecommons.org/licenses/by-nc-nd/3.0/us/legalcode), and code is released under the [MIT license](https://opensource.org/licenses/MIT). If you find this content useful, please consider supporting the work by [buying the book](http://shop.oreilly.com/product/0636920034919.do)!*
<!--NAVIGATION-->
< [Data Indexing and Selection](03.02-Data-Indexing-and-Selection.ipynb) | [Contents](Index.ipynb) | [Handling Missing Data](03.04-Missing-Values.ipynb) >
<a href="https://colab.research.google.com/github/jakevdp/PythonDataScienceHandbook/blob/master/notebooks/03.03-Operations-in-Pandas.ipynb"><img align="left" src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open in Colab" title="Open and Execute in Google Colaboratory"></a>
# Operating on Data in Pandas
One of the essential pieces of NumPy is the ability to perform quick element-wise operations, both with basic arithmetic (addition, subtraction, multiplication, etc.) and with more sophisticated operations (trigonometric functions, exponential and logarithmic functions, etc.).
Pandas inherits much of this functionality from NumPy, and the ufuncs that we introduced in [Computation on NumPy Arrays: Universal Functions](02.03-Computation-on-arrays-ufuncs.ipynb) are key to this.
Pandas includes a couple useful twists, however: for unary operations like negation and trigonometric functions, these ufuncs will *preserve index and column labels* in the output, and for binary operations such as addition and multiplication, Pandas will automatically *align indices* when passing the objects to the ufunc.
This means that keeping the context of data and combining data from different sources–both potentially error-prone tasks with raw NumPy arrays–become essentially foolproof ones with Pandas.
We will additionally see that there are well-defined operations between one-dimensional ``Series`` structures and two-dimensional ``DataFrame`` structures.
## Ufuncs: Index Preservation
Because Pandas is designed to work with NumPy, any NumPy ufunc will work on Pandas ``Series`` and ``DataFrame`` objects.
Let's start by defining a simple ``Series`` and ``DataFrame`` on which to demonstrate this:
```
import pandas as pd
import numpy as np
rng = np.random.RandomState(42)
ser = pd.Series(rng.randint(0, 10, 4))
ser
df = pd.DataFrame(rng.randint(0, 10, (3, 4)),
columns=['A', 'B', 'C', 'D'])
df
```
If we apply a NumPy ufunc on either of these objects, the result will be another Pandas object *with the indices preserved:*
```
np.exp(ser)
```
Or, for a slightly more complex calculation:
```
np.sin(df * np.pi / 4)
```
Any of the ufuncs discussed in [Computation on NumPy Arrays: Universal Functions](02.03-Computation-on-arrays-ufuncs.ipynb) can be used in a similar manner.
## UFuncs: Index Alignment
For binary operations on two ``Series`` or ``DataFrame`` objects, Pandas will align indices in the process of performing the operation.
This is very convenient when working with incomplete data, as we'll see in some of the examples that follow.
### Index alignment in Series
As an example, suppose we are combining two different data sources, and find only the top three US states by *area* and the top three US states by *population*:
```
area = pd.Series({'Alaska': 1723337, 'Texas': 695662,
'California': 423967}, name='area')
population = pd.Series({'California': 38332521, 'Texas': 26448193,
'New York': 19651127}, name='population')
```
Let's see what happens when we divide these to compute the population density:
```
population / area
```
The resulting array contains the *union* of indices of the two input arrays, which could be determined using standard Python set arithmetic on these indices:
```
area.index | population.index
```
Any item for which one or the other does not have an entry is marked with ``NaN``, or "Not a Number," which is how Pandas marks missing data (see further discussion of missing data in [Handling Missing Data](03.04-Missing-Values.ipynb)).
This index matching is implemented this way for any of Python's built-in arithmetic expressions; any missing values are filled in with NaN by default:
```
A = pd.Series([2, 4, 6], index=[0, 1, 2])
B = pd.Series([1, 3, 5], index=[1, 2, 3])
A + B
```
If using NaN values is not the desired behavior, the fill value can be modified using appropriate object methods in place of the operators.
For example, calling ``A.add(B)`` is equivalent to calling ``A + B``, but allows optional explicit specification of the fill value for any elements in ``A`` or ``B`` that might be missing:
```
A.add(B, fill_value=0)
```
### Index alignment in DataFrame
A similar type of alignment takes place for *both* columns and indices when performing operations on ``DataFrame``s:
```
A = pd.DataFrame(rng.randint(0, 20, (2, 2)),
columns=list('AB'))
A
B = pd.DataFrame(rng.randint(0, 10, (3, 3)),
columns=list('BAC'))
B
A + B
```
Notice that indices are aligned correctly irrespective of their order in the two objects, and indices in the result are sorted.
As was the case with ``Series``, we can use the associated object's arithmetic method and pass any desired ``fill_value`` to be used in place of missing entries.
Here we'll fill with the mean of all values in ``A`` (computed by first stacking the rows of ``A``):
```
fill = A.stack().mean()
A.add(B, fill_value=fill)
```
The following table lists Python operators and their equivalent Pandas object methods:
| Python Operator | Pandas Method(s) |
|-----------------|---------------------------------------|
| ``+`` | ``add()`` |
| ``-`` | ``sub()``, ``subtract()`` |
| ``*`` | ``mul()``, ``multiply()`` |
| ``/`` | ``truediv()``, ``div()``, ``divide()``|
| ``//`` | ``floordiv()`` |
| ``%`` | ``mod()`` |
| ``**`` | ``pow()`` |
## Ufuncs: Operations Between DataFrame and Series
When performing operations between a ``DataFrame`` and a ``Series``, the index and column alignment is similarly maintained.
Operations between a ``DataFrame`` and a ``Series`` are similar to operations between a two-dimensional and one-dimensional NumPy array.
Consider one common operation, where we find the difference of a two-dimensional array and one of its rows:
```
A = rng.randint(10, size=(3, 4))
A
A - A[0]
```
According to NumPy's broadcasting rules (see [Computation on Arrays: Broadcasting](02.05-Computation-on-arrays-broadcasting.ipynb)), subtraction between a two-dimensional array and one of its rows is applied row-wise.
In Pandas, the convention similarly operates row-wise by default:
```
df = pd.DataFrame(A, columns=list('QRST'))
df - df.iloc[0]
```
If you would instead like to operate column-wise, you can use the object methods mentioned earlier, while specifying the ``axis`` keyword:
```
df.subtract(df['R'], axis=0)
```
Note that these ``DataFrame``/``Series`` operations, like the operations discussed above, will automatically align indices between the two elements:
```
halfrow = df.iloc[0, ::2]
halfrow
df - halfrow
```
This preservation and alignment of indices and columns means that operations on data in Pandas will always maintain the data context, which prevents the types of silly errors that might come up when working with heterogeneous and/or misaligned data in raw NumPy arrays.
<!--NAVIGATION-->
< [Data Indexing and Selection](03.02-Data-Indexing-and-Selection.ipynb) | [Contents](Index.ipynb) | [Handling Missing Data](03.04-Missing-Values.ipynb) >
<a href="https://colab.research.google.com/github/jakevdp/PythonDataScienceHandbook/blob/master/notebooks/03.03-Operations-in-Pandas.ipynb"><img align="left" src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open in Colab" title="Open and Execute in Google Colaboratory"></a>
| github_jupyter |
```
!pip install scikit-learn==1.0
!pip install xgboost==1.4.2
!pip install catboost==0.26.1
!pip install pandas==1.3.3
!pip install radiant-mlhub==0.3.0
!pip install rasterio==1.2.8
!pip install numpy==1.21.2
!pip install pathlib==1.0.1
!pip install tqdm==4.62.3
!pip install joblib==1.0.1
!pip install matplotlib==3.4.3
!pip install Pillow==8.3.2
!pip install torch==1.9.1
!pip install plotly==5.3.1
import warnings
warnings.filterwarnings('ignore')
# warnings.filterwarnings('RuntimeWarning')
from radiant_mlhub import Collection
import tarfile
import os
from pathlib import Path
import json
from tqdm import tqdm
from joblib import Parallel,delayed
import datetime
import rasterio
import numpy as np
import pandas as pd
import gc
gc.collect()
competition_train_df = pd.read_csv('test_data_sentinel2.csv')
def get_date_format(month,day):
'''
Structures the dates in a particular format
'''
if (str(month)=='nan') or (str(day)=='nan'):
return 'nan'
else:
if month>=10:
if day>=10:
return f'month_{str(int(month))}_day_{str(int(day))}'
else:
return f'month_{str(int(month))}_day_0{str(int(day))}'
else:
if day>=10:
return f'month_0{str(int(month))}_day_{str(int(day))}'
else:
return f'month_0{str(int(month))}_day_0{str(int(day))}'
competition_train_df['month'] = pd.to_datetime(competition_train_df['datetime']).dt.month.values
competition_train_df['day'] = pd.to_datetime(competition_train_df['datetime']).dt.day.values
competition_train_df['dates'] = competition_train_df.apply(lambda z: get_date_format(z['month'],z['day']),axis=1)
unique_dates = competition_train_df['dates'].unique()
unique_dates = np.array([z for z in unique_dates if 'nan' not in z])
print(f'Length of unique dates {len(unique_dates)}')
date_dict = dict(zip(competition_train_df['datetime'].dropna().unique(),unique_dates))
date_dict = dict(sorted(date_dict.items(), key=lambda item: item[1]))
date_order_to_consider = np.array(list(date_dict.values()))
tile_ids_train = competition_train_df['tile_id'].unique()
def get_bands(tile_date_times,tile_df,band,date_dict):
'''
Getting band dictionary with dates
'''
X_tile = np.zeros((256 * 256, 76))
X_tile[:] = np.nan
for date_time in tile_date_times[:1]:
source = rasterio.open(tile_df[(tile_df['datetime']==date_time) & (tile_df['asset']==band)]['file_path'].values[0])
### Flattening the file to get a vector for the image
array = np.expand_dims(source.read(1).flatten(), axis=1)
### Capturing the date at which we need to replace the vector
val = date_dict[date_time]
### index at which replacement is to be done
indices = np.where(date_order_to_consider==val)[0][0]
X_tile[:,indices] = array.ravel()
return X_tile
def get_dataframe(data_dict_band,band,y,field_ids):
X = np.array([values.tolist() for _,values in tqdm(data_dict_band.items())]).reshape(-1,76)
colnames = [band+'_'+z for z in date_order_to_consider]
data = pd.DataFrame(X,columns=colnames)
data['field_id'] = field_ids
mean_df = data.groupby('field_id').mean().reset_index()
low_df = data.groupby('field_id').quantile(0.25).reset_index()
up_df = data.groupby('field_id').quantile(0.75).reset_index()
med_df = data.groupby('field_id').median().reset_index()
return mean_df,low_df,up_df,med_df
len(tile_ids_train)
import xarray as xr
from rasterio.warp import transform
def convert_lat_lon(filename,crs):
da = xr.open_rasterio(filename)
x = da['x']
y = da['y']
ny, nx = len(da['y']), len(da['x'])
y, x = np.meshgrid(da['y'], da['x'])
lon,lat = transform(crs, {'init': 'EPSG:4326'},
x.flatten(), y.flatten())
lon = np.asarray(lon).reshape((ny, nx))
lat = np.asarray(lat).reshape((ny, nx))
return lon,lat
lb = 0
ub = 200
bands_available = ['B01']
bigdf = []
for band in bands_available:
for batch in tqdm(range(0,6)):
print(f'Performing operations for batch {batch+1}/14 for band {band}')
data_dict_band = {}
count = 1
y = np.empty((0, 1))
field_ids = np.empty((0, 1))
encode_x_val = np.empty((0, 1))
encode_y_val = np.empty((0, 1))
for tile_id in tile_ids_train[lb+(batch*200):ub+(batch*200)]:
if tile_id != '1951': # avoid using this specific tile for the Hackathon as it might have a missing file
tile_df = competition_train_df[competition_train_df['tile_id']==tile_id]
field_id_src = rasterio.open(tile_df[tile_df['asset']=='field_ids']['file_path'].values[0])
field_id_array = field_id_src.read(1)
lon,lat = convert_lat_lon(tile_df[tile_df['asset']=='field_ids']['file_path'].values[0],field_id_src.crs)
encode_x = np.zeros((256,256))
encode_y = np.zeros((256,256))
for i in range(field_id_array.shape[0]):
for j in range(field_id_array.shape[1]):
if field_id_array[i,j]>0:
encode_x[i,j] = lat[i][j]
encode_y[i,j] = lon[i][j]
tempdf = pd.DataFrame(columns = ['field_id','long','lat'])
tempdf['field_id'] = field_id_array.flatten()
tempdf['long'] = encode_y.flatten()
tempdf['lat'] = encode_x.flatten()
tempdf = tempdf[tempdf['field_id']!=0]
# print(tempdf.groupby(['field_id']).agg({'X':'median','Y':'median'}).reset_index().rename({'index':'field_id'}))
gdf = tempdf.groupby(['field_id']).agg({'long':'median','lat':'median'}).reset_index().rename({'index':'field_id'})
if len(bigdf)==0:
bigdf = gdf
else:
bigdf = bigdf.append(gdf)
print(bigdf.shape)
count = count+1
gc.collect()
# mean_df,low_df,up_df,med_df = get_dataframe(data_dict_band,band,y,field_ids)
batchid = int(batch)+1
# mean_df.to_csv(f'train_position.csv',index=False)
# del field_ids,data_dict_band,label_src,field_id_src,label_array,field_id_array,y,mean_df,med_df,up_df,low_df
# del tile_df,tile_date_times
# gc.collect()
gc.collect()
gc.collect()
test_coordinates = bigdf[bigdf['field_id']!=0]
test_coordinates.to_csv('test_coordinates_lat_lon.csv',index=False)
test_coordinates
```
| github_jupyter |
# Introdução Data Science - Ana Beatriz Macedo<img src="https://octocat-generator-assets.githubusercontent.com/my-octocat-1626096942740.png" width="324" height="324" align="right">
## Link para download: https://github.com/AnabeatrizMacedo241/DataScience-101
## Github: https://github.com/AnabeatrizMacedo241
## Linkedin: https://www.linkedin.com/in/ana-beatriz-oliveira-de-macedo-85b05b215/

### Nessa sétima parte veremos Regex(As expressões regulares)
Com essa ferramenta, será possível acessar palavras-chaves ou padrões entre caracteres de um texto. Cheque a documentação para obter mais detalhes: https://docs.python.org/3/library/re.html
```
#Importanto a biblioteca
import re
#Abaixo vão alguns métodos de uso...
```
<img src="https://denhamcoder.files.wordpress.com/2019/11/110719_1134_netregexche1.png?w=748" width="650" height="550" align="center">
```
frase = 'Usando Regex com Python em Data Science'
#Usamos re por conta de biblioteca e depois usamos o método findall() para procurar elementos
re.findall("\AUsando", frase)
re.findall("\d",frase) #Não há nenhum dígito em frase
frase2 = "Aula 7 com Regex"
re.findall("\d", frase2) #Agora retorna número
re.findall("\D", frase2) #Retorna apenas as letras e espaços da frase2
re.findall("\S", frase2) #Dessa forma, retorna sem espaços
re.findall("\s", frase2) #retorna somente os espaços
re.findall('[a-zA-Z]', frase) #Retorna todas as letras maiúsculas e minúsculas
re.findall('[aeiou]', frase) #Retornando apenas as vogais, mas veja que ele não trouxe o "U"
re.findall('[AEIOUaeiou]', frase) #Agora veio com o "U" maiúsculo
frase3 = '[0,1,2,3,4,5,6,7,8,9,11]' #Veja que os últimos números são retornados separados
re.findall('[0-9]', frase3)
re.findall('[0-9][0-9]',frase3) #Dessa forma, conseguimos apenas decimais
#O método search() é muito similar ao findall()
frase4 = 'Aprendendo a usar Regex'
procurando_Py = re.search("Python", frase4)
print(procurando_Py)
#Ele retorna None, pois não acha a palavra 'Python' na frase4
procurando_Regex = re.search('Regex', frase4)
print(procurando_Regex)
#Entre os caracteres 18-23 está a palavra 'Regex'
#re.sub() substitui um elemento da string por outro
substituir = re.sub('a usar ', '', frase4)
print(substituir)
apenas_regex = re.search(r"\bR\w+", frase4) #Procura por palavras que começam em 'R'e como 0 '\w+' retornam o resto
print(apenas_regex.group())
#Agora vamos alterar um texto
texto = '@espn: Estreias, habitualmente, são jogos complicados. A primeira partida de Russell Westbrook(@russwest44) no Los Angeles Lakers seguiu tal tradição. O armador da National Basketball Association , vindo do Washington Wizards,teve uma atuação de pouquíssimo brilho na derrota da nova equipe dele para o Golden State Warriors.Após o 121×114 no Staples Center, um relevantíssimo trio tratou de tranquilizar o atleta. LeBron James(@kingjames), das grandes estrelas do Lakers e da liga,deu uma dica para o atleta. “Eu disse a Russell Westbrook para ir para casa e assistir a uma comédia. Pedi para ele colocar um sorriso em seu rosto porque ele é muito duro consigo mesmo. Eu só disse para ele não ser duro com ele mesmo, pois isso é só um jogo. É um desafio entrar em um novo sistema e tentar se encaixar, mas também tem que trazer o que você tem de melhor para se encaixar mais fácil”, comentou .'
texto
#Pegando, apenas, os números da partida
re.findall('\d{3}', texto)
#Substituindo 'National Basketball Association' por NBA
texto2 = re.sub('National Basketball Association', 'NBA', texto)
#Eliminando as mentions do twitter
texto3 = re.sub('@[A-Za-z0-9]+', '', texto2)
texto3
#Substituindo espaços maiores que 1
texto4 = re.sub(' +', ' ', texto3)
texto4
#Eleminando os ':' do começo
texto5 = re.sub(':', '',texto4)
texto5
#Retirando os parênteses após os nomes dos jogadores
texto6 = re.sub('[()+]', '', texto5)
texto6
```
### Até a próxima aula e bons estudos!
## Ana Beatriz Macedo

| github_jupyter |
# Problem set 6¶
# P.2 Problem 2
```
library(dplyr)
df_quart = read.csv('quartet.csv')
df_quart %>% head(2)
```
## P.2.b
- PS6 corresponding problem: 2.b
```
par(mfrow=c(2,2))
#Plot 1
plot(df_quart$y1, df_quart$x1,
xlim = c(0,10),
ylim= c(0,10),
main='wt')
abline(lm(y1~x1, data= df_quart), col="red")
#Plot 2
plot(df_quart$y2, df_quart$x2,
xlim = c(0,10),
ylim= c(0,10),
main='wt')
abline(lm(y1~x1, data= df_quart), col="red")
#Plot 3
#ADD data here!
#Plot 4
#ADD data here!
```
## P.2.C
- PS6 corresponding problem: 2.c
#### Notice that the R-squared are similar. Does this make sense given what you see in the graphs in P.2.B
```
summary(lm(y1~x1, data= df_quart))$r.squared
summary(lm(y2~x2, data= df_quart))$r.squared
summary(lm(y3~x3, data= df_quart))$r.squared
summary(lm(y4~x4, data= df_quart))$r.squared
```
# P.3 Problem 3
```
df_safrica = read.csv('safrica.csv')
df_safrica %>% head(2)
```
## P.3.A
- PS6 corresponding problem: 2.a
```
reg_output_a = lm(wage~female, data=df_safrica)
reg_output_a
summary(reg_output_a)
```
## P.3.B Interpret regressions
- PS6 corresponding problem: 2.b
### Step 1: What do we want to predict?
### Left hand side (LHS) is always what we are predicting
- In our case we want to predict wage GIVEN some information (Demographics, education, etc)
### Predicting Wage: Answer to 3.a
```
reg_3a = lm(wage~female, data=df_safrica)
reg_3a
```
### Predicting female: NOT ANSWER
- This is an intersting type of regression known as [logistic regression](https://en.wikipedia.org/wiki/Logistic_regression#:~:text=Logistic%20regression%20is%20a%20statistical,a%20form%20of%20binary%20regression) which we will not cover in this course
```
lm(female~wage, data=df_safrica)
```
### Step 2: Think about what the data represents
```
df_safrica$wage[c(0:5)]
df_safrica$female[c(0:5)]
```
### Step 3: Read coefficient
$$
y = \beta_0 + \beta_1*x_1
\\
\text{Wage} = \text{Intercept}+ \text{Female}*x_1 \\
\text{Wage} = 6.85+ -.412*x_1$$
```
reg_3a
reg_3a_female = reg_3a$coeff['female'] %>% as.numeric()
reg_3a_female
reg_3a_intercept = reg_3a$coeff['(Intercept)'] %>% as.numeric()
reg_3a_intercept
```
### Step 4: Sanity check! Think of examples!
#### This is what we did in the cigs example in PS5 see 4.3 in [this](https://github.com/corybaird/PLCY_610_public/blob/master/Discussion_sections/Disc10_PS5/Dics10_PS5.ipynb) notebook
$$\text{Wage} = \text{Intercept}+ \text{Female}*x_1\\
\text{Wage} = 6.85+ -.412*x_1$$
```
women_wage = reg_3a_intercept + reg_3a_female*1
women_wage %>% round(2)
men_wage = reg_3a_intercept + reg_3a_female*0
men_wage %>% round(2)
```
## P.3.C
- PS6 corresponding problem: 2.c
```
reg_3c = lm(wage~female+educ, data=df_safrica)
reg_3c
summary(reg_3c)
```
### P.3.C.1 Interpret regressions: Sanity check! Think of examples!
$$\text{Wage} = \text{Intercept}+ \text{Female}*x_1+\text{education}*x_2\\
\text{Wage} = 2.10404 + -1.42746*x_1+ 0.80026 *x_2$$
```
reg_function = function(female_dummy, years_educ){
#Regression
reg_3c = lm(wage~female+educ, data=df_safrica)
#Coeffs
reg_3c_female = reg_3c$coeff['female'] %>% as.numeric()
reg_3a_intercept = reg_3c$coeff['(Intercept)'] %>% as.numeric()
reg_3c_educ = reg_3c$coeff['educ'] %>% as.numeric()
predict_wage = reg_3a_intercept + reg_3c_female*female_dummy + reg_3c_educ*years_educ
return (predict_wage)
}
#Try different combinations of this
reg_function(female_dummy=1, years_educ= 10)
```
### P.3.C.2 Compare r-squared
```
summary(reg_3c)$r.squared
summary(reg_3a)$r.squared
```
## P.3.D
- PS6 corresponding problem: 2.d
```
reg_3c = lm(wage~female+educ+age+union+married+urban, data=df_safrica)
reg_3c
```
## P.3.E
- PS6 corresponding problem: 2.e
#### REMEMBER WHEN YOU INTERPRET THE REGRESSION YOU HOLD ALL OTHER VARIABLES CONSTANT
```
reg_3c
```
## P3.F
```
summary(reg_3c)$fstat
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.