
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
# Example Model Explanations with Seldon
Seldon core supports various out-of-the-box explainers that leverage the [Alibi ML Expalinability](https://github.com/SeldonIO/alibi) open source library.
In this notebook we show how you can use the pre-packaged explainer functionality that simplifies the creation of advanced AI model explainers.
Seldon provides the following out-of-the-box pre-packaged explainers:
* Anchor Tabular Explainer
* AI Explainer that uses the [anchor technique](https://docs.seldon.io/projects/alibi/en/latest/methods/Anchors.html) for tabular data
* It basically answers the question of what are the most "powerul" or "important" features in a tabular prediction
* Anchor Image Explainer
* AI Explainer that uses the [anchor technique](https://docs.seldon.io/projects/alibi/en/latest/methods/Anchors.html) for image data
* It basically answers the question of what are the most "powerul" or "important" pixels in an image prediction
* Anchor Text Explainer
* AI Explainer that uses the [anchor technique](https://docs.seldon.io/projects/alibi/en/latest/methods/Anchors.html) for text data
* It basically answers the question of what are the most "powerul" or "important" tokens in a text prediction
* Counterfactual Explainer
* AI Explainer that uses the [counterfactual technique](https://docs.seldon.io/projects/alibi/en/latest/methods/CF.html) for any type of data
* It basically provides insight of what are the minimum changes you can do to an input to change the prediction to a different class
* Contrastive Explainer
* AI explainer that uses the [Contrastive Explanations](https://docs.seldon.io/projects/alibi/en/latest/methods/CEM.html) technique for any type of data
* It basically provides insights of what are the minimum changes you can do to an input to change the prediction to change the prediction or the minimum components of the input to make it the same prediction
## Running this notebook
For the [ImageNet Model](#Imagenet-Model) you will need:
- [alibi package](https://pypi.org/project/alibi/) (```pip install alibi```)
This should install the required package dependencies, if not please also install:
- [Pillow package](https://pypi.org/project/Pillow/) (```pip install Pillow```)
- [matplotlib package](https://pypi.org/project/matplotlib/) (```pip install matplotlib```)
- [tensorflow package](https://pypi.org/project/tensorflow/) (```pip install tensorflow```)
You will also need to start Jupyter with settings to allow for large payloads, for example:
```
jupyter notebook --NotebookApp.iopub_data_rate_limit=1000000000
```
## Setup Seldon Core
Follow the instructions to [Setup Cluster](seldon_core_setup.ipynb#Setup-Cluster) with [Ambassador Ingress](seldon_core_setup.ipynb#Ambassador) and [Install Seldon Core](seldon_core_setup.ipynb#Install-Seldon-Core).
Then port-forward to that ingress on localhost:8003 in a separate terminal either with:
* Ambassador: `kubectl port-forward $(kubectl get pods -n seldon -l app.kubernetes.io/name=ambassador -o jsonpath='{.items[0].metadata.name}') -n seldon 8003:8080`
* Istio: `kubectl port-forward $(kubectl get pods -l istio=ingressgateway -n istio-system -o jsonpath='{.items[0].metadata.name}') -n istio-system 8003:80`
### Create Namespace for experimentation
We will first set up the namespace of Seldon where we will be deploying all our models
```
!kubectl create namespace seldon
```
And then we will set the current workspace to use the seldon namespace so all our commands are run there by default (instead of running everything in the default namespace.)
```
!kubectl config set-context $(kubectl config current-context) --namespace=seldon
```
## Income Prediction Model
```
%%writefile resources/income_explainer.yaml
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: income
spec:
name: income
annotations:
seldon.io/rest-timeout: "100000"
predictors:
- graph:
children: []
implementation: SKLEARN_SERVER
modelUri: gs://seldon-models/sklearn/income/model
name: classifier
explainer:
type: AnchorTabular
modelUri: gs://seldon-models/sklearn/income/explainer
name: default
replicas: 1
!kubectl apply -f resources/income_explainer.yaml
!kubectl rollout status deploy/$(kubectl get deploy -l seldon-deployment-id=income -o jsonpath='{.items[0].metadata.name}')
!kubectl rollout status deploy/income-default-explainer
from seldon_core.seldon_client import SeldonClient
import numpy as np
sc = SeldonClient(deployment_name="income",namespace="seldon", gateway="ambassador", gateway_endpoint="localhost:8003")
```
Use python client library to get a prediction.
```
data = np.array([[39, 7, 1, 1, 1, 1, 4, 1, 2174, 0, 40, 9]])
r = sc.predict(data=data)
print(r.response)
```
Use curl to get a prediction.
```
!curl -d '{"data": {"ndarray":[[39, 7, 1, 1, 1, 1, 4, 1, 2174, 0, 40, 9]]}}' \
-X POST http://localhost:8003/seldon/seldon/income/api/v1.0/predictions \
-H "Content-Type: application/json"
```
Use python client library to get an explanation.
```
data = np.array([[39, 7, 1, 1, 1, 1, 4, 1, 2174, 0, 40, 9]])
explanation = sc.explain(deployment_name="income", predictor="default", data=data)
print(explanation.response["names"])
```
Using curl to get an explanation.
```
!curl -X POST -H 'Content-Type: application/json' \
-d '{"data": {"names": ["text"], "ndarray": [[52, 4, 0, 2, 8, 4, 2, 0, 0, 0, 60, 9]]}}' \
http://localhost:8003/seldon/seldon/income-explainer/default/api/v1.0/explain | jq ".names"
!kubectl delete -f resources/income_explainer.yaml
```
## Movie Sentiment Model
```
%%writefile resources/moviesentiment_explainer.yaml
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: movie
spec:
name: movie
annotations:
seldon.io/rest-timeout: "100000"
predictors:
- graph:
children: []
implementation: SKLEARN_SERVER
modelUri: gs://seldon-models/sklearn/moviesentiment
name: classifier
explainer:
type: AnchorText
name: default
replicas: 1
!kubectl apply -f resources/moviesentiment_explainer.yaml
!kubectl rollout status deploy/$(kubectl get deploy -l seldon-deployment-id=movie -o jsonpath='{.items[0].metadata.name}')
!kubectl rollout status deploy/movie-default-explainer
from seldon_core.seldon_client import SeldonClient
import numpy as np
sc = SeldonClient(deployment_name="movie", namespace="seldon", gateway_endpoint="localhost:8003", payload_type='ndarray')
!curl -d '{"data": {"ndarray":["This film has great actors"]}}' \
-X POST http://localhost:8003/seldon/seldon/movie/api/v1.0/predictions \
-H "Content-Type: application/json"
data = np.array(['this film has great actors'])
r = sc.predict(data=data)
print(r)
assert(r.success==True)
!curl -s -d '{"data": {"ndarray":["This movie has great actors"]}}' \
-X POST http://localhost:8003/seldon/seldon/movie-explainer/default/api/v1.0/explain \
-H "Content-Type: application/json" | jq ".names"
data = np.array(['this film has great actors'])
explanation = sc.explain(predictor="default", data=data)
print(explanation.response["names"])
!kubectl delete -f resources/moviesentiment_explainer.yaml
```
## Imagenet Model
```
%%writefile resources/imagenet_explainer_grpc.yaml
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: image
spec:
annotations:
seldon.io/rest-timeout: "10000000"
seldon.io/grpc-timeout: "10000000"
seldon.io/grpc-max-message-size: "1000000000"
name: image
predictors:
- componentSpecs:
- spec:
containers:
- image: docker.io/seldonio/imagenet-transformer:0.1
name: transformer
graph:
name: transformer
type: TRANSFORMER
endpoint:
type: GRPC
children:
- implementation: TENSORFLOW_SERVER
modelUri: gs://seldon-models/tfserving/imagenet/model
name: classifier
endpoint:
type: GRPC
parameters:
- name: model_name
type: STRING
value: classifier
- name: model_input
type: STRING
value: input_image
- name: model_output
type: STRING
value: predictions/Softmax:0
svcOrchSpec:
resources:
requests:
memory: 10Gi
limits:
memory: 10Gi
env:
- name: SELDON_LOG_LEVEL
value: DEBUG
explainer:
type: AnchorImages
modelUri: gs://seldon-models/tfserving/imagenet/explainer
config:
batch_size: "100"
endpoint:
type: GRPC
name: default
replicas: 1
!kubectl apply -f resources/imagenet_explainer_grpc.yaml
!kubectl rollout status deploy/$(kubectl get deploy -l seldon-deployment-id=image -o jsonpath='{.items[0].metadata.name}')
!kubectl rollout status deploy/image-default-explainer
from PIL import Image
import matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
from tensorflow.keras.applications.inception_v3 import InceptionV3, decode_predictions
import alibi
from alibi.datasets import fetch_imagenet
import numpy as np
def get_image_data():
data = []
image_shape = (299, 299, 3)
target_size = image_shape[:2]
image = Image.open("cat-raw.jpg").convert('RGB')
image = np.expand_dims(image.resize(target_size), axis=0)
data.append(image)
data = np.concatenate(data, axis=0)
return data
data = get_image_data()
from seldon_core.seldon_client import SeldonClient
import numpy as np
sc = SeldonClient(
deployment_name="image",
namespace="seldon",
grpc_max_send_message_length= 27 * 1024 * 1024,
grpc_max_receive_message_length= 27 * 1024 * 1024,
gateway="ambassador",
transport="grpc",
gateway_endpoint="localhost:8003",
client_return_type='proto')
import tensorflow as tf
data = get_image_data()
req = data[0:1]
r = sc.predict(data=req, payload_type='tftensor')
preds = tf.make_ndarray(r.response.data.tftensor)
label = decode_predictions(preds, top=1)
plt.title(label[0])
plt.imshow(data[0])
req = np.expand_dims(data[0], axis=0)
r = sc.explain(data=req, predictor="default", transport="rest", payload_type='ndarray', client_return_type="dict")
exp_arr = np.array(r.response['anchor'])
f, axarr = plt.subplots(1, 2)
axarr[0].imshow(data[0])
axarr[1].imshow(r.response['anchor'])
plt.show()
!kubectl delete -f resources/imagenet_explainer_grpc.yaml
```
| github_jupyter |
# Constructing linear model for OER adsorption energies
---
### Import Modules
```
import os
print(os.getcwd())
import sys
import time; ti = time.time()
import copy
import numpy as np
import pandas as pd
pd.set_option("display.max_columns", None)
# pd.set_option('display.max_rows', None)
# pd.options.display.max_colwidth = 100
import plotly.graph_objs as go
from IPython.display import display
# #########################################################
from proj_data import (
scatter_marker_props,
layout_shared,
layout_shared,
stoich_color_dict,
font_axis_title_size__pub,
font_tick_labels_size__pub,
scatter_shared_props,
)
# #########################################################
from methods import (
get_df_features_targets,
get_df_slab,
get_df_features_targets_seoin,
)
# #########################################################
from methods_models import run_gp_workflow
sys.path.insert(0,
os.path.join(
os.environ["PROJ_irox_oer"],
"workflow/model_building"))
from methods_model_building import (
simplify_df_features_targets,
run_kfold_cv_wf,
process_feature_targets_df,
process_pca_analysis,
pca_analysis,
run_regression_wf,
)
from methods import isnotebook
isnotebook_i = isnotebook()
if isnotebook_i:
from tqdm.notebook import tqdm
verbose = True
show_plot = True
else:
from tqdm import tqdm
verbose = False
show_plot = False
root_dir = os.path.join(
os.environ["PROJ_irox_oer"],
"workflow/model_building/gaussian_process")
```
### Script Inputs
```
# target_ads_i = "o"
target_ads_i = "oh"
feature_ads_i = "o"
# feature_ads_i = "oh"
use_seoin_data = False
if use_seoin_data:
feature_ads_i = "o"
```
### Read Data
```
df_features_targets = get_df_features_targets()
df_i = df_features_targets
# #########################################################
df_slab = get_df_slab()
# Getting phase > 1 slab ids
df_slab_i = df_slab[df_slab.phase > 1]
phase_2_slab_ids = df_slab_i.slab_id.tolist()
# #########################################################
df_seoin = get_df_features_targets_seoin()
indices_str = []
for index_i in df_i.index.tolist():
index_str_i = "__".join([str(i) for i in index_i])
indices_str.append(index_str_i)
df_i["index_str"] = indices_str
indices_str = []
for index_i in df_seoin.index.tolist():
index_str_i = "__".join([str(i) for i in index_i])
indices_str.append(index_str_i)
df_seoin["index_str"] = indices_str
```
### Combining My data with Seoin's
```
df_i = df_i.reset_index()
df_seoin.index = pd.RangeIndex(
start=df_i.index.max() + 1,
stop=df_i.index.max() + df_seoin.shape[0] + 1,
)
df_i["source"] = "mine"
df_seoin["source"] = "seoin"
if use_seoin_data:
df_comb = pd.concat([
# df_i,
df_seoin,
], axis=0)
else:
df_comb = pd.concat([
df_i,
# df_seoin,
], axis=0)
df_comb = df_comb[[
("index_str", "", ""),
("data", "stoich", ""),
# ("compenv", "", ""),
# ("slab_id", "", ""),
# ("active_site", "", ""),
("targets", "g_o", ""),
("targets", "g_oh", ""),
# ("targets", "e_o", ""),
# ("targets", "e_oh", ""),
# ("targets", "g_o_m_oh", ""),
# ("targets", "e_o_m_oh", ""),
# ("features", "oh", "O_magmom"),
# ("features", "oh", "Ir_magmom"),
# ("features", "oh", "active_o_metal_dist"),
# ("features", "oh", "angle_O_Ir_surf_norm"),
# ("features", "oh", "ir_o_mean"),
# ("features", "oh", "ir_o_std"),
# ("features", "oh", "octa_vol"),
("features", "o", "O_magmom"),
("features", "o", "Ir_magmom"),
("features", "o", "Ir_bader"),
("features", "o", "O_bader"),
("features", "o", "active_o_metal_dist"),
("features", "o", "angle_O_Ir_surf_norm"),
("features", "o", "ir_o_mean"),
("features", "o", "ir_o_std"),
("features", "o", "octa_vol"),
("features", "o", "p_band_center"),
("features", "dH_bulk", ""),
("features", "volume_pa", ""),
("features", "bulk_oxid_state", ""),
("features", "effective_ox_state", ""),
# ("features_pre_dft", "active_o_metal_dist__pre", ""),
# ("features_pre_dft", "ir_o_mean__pre", ""),
# ("features_pre_dft", "ir_o_std__pre", ""),
# ("features_pre_dft", "octa_vol__pre", ""),
# ("source", "", ""),
]]
df_comb
df_j = simplify_df_features_targets(
df_comb,
target_ads=target_ads_i,
feature_ads=feature_ads_i,
)
df_format = df_features_targets[("format", "color", "stoich", )]
```
### Single feature models
```
gp_settings = {
"noise": 0.02542,
# "noise": 0.12542,
}
# Length scale parameter
# sigma_l_default = 0.8 # Original
sigma_l_default = 1.8 # Length scale parameter
sigma_f_default = 0.2337970892240513 # Scaling parameter.
kdict = [
# Guassian Kernel (RBF)
{
'type': 'gaussian',
'dimension': 'single',
'width': sigma_l_default,
'scaling': sigma_f_default,
'scaling_bounds': ((0.0001, 10.),),
},
]
df_j = df_j.set_index("index_str")
cols_to_use = df_j["features"].columns.tolist()
if True:
data_dict = dict()
# for num_pca_i in range(1, len(cols_to_use) + 1, 1):
for num_pca_i in range(3, len(cols_to_use) + 1, 2):
if verbose:
print("")
print(40 * "*")
print(num_pca_i)
# #####################################################
out_dict = run_kfold_cv_wf(
df_features_targets=df_j,
cols_to_use=cols_to_use,
run_pca=True,
num_pca_comp=num_pca_i,
# k_fold_partition_size=30,
k_fold_partition_size=10,
model_workflow=run_gp_workflow,
model_settings=dict(
gp_settings=gp_settings,
kdict=kdict,
),
)
# #####################################################
df_target_pred = out_dict["df_target_pred"]
MAE = out_dict["MAE"]
R2 = out_dict["R2"]
PCA = out_dict["pca"]
regression_model_list = out_dict["regression_model_list"]
df_target_pred_on_train = out_dict["df_target_pred_on_train"]
MAE_pred_on_train = out_dict["MAE_pred_on_train"]
RM_2 = out_dict["RM_2"]
# #####################################################
if verbose:
print(
"MAE: ",
np.round(MAE, 5),
" eV",
sep="")
print(
"R2: ",
np.round(R2, 5),
sep="")
print(
"MAE (predicting on train set): ",
np.round(MAE_pred_on_train, 5),
sep="")
# #####################################################
data_dict_i = dict()
# #####################################################
data_dict_i["df_target_pred"] = df_target_pred
data_dict_i["MAE"] = MAE
data_dict_i["R2"] = R2
data_dict_i["PCA"] = PCA
# #####################################################
data_dict[num_pca_i] = data_dict_i
# #####################################################
data_dict[7].keys()
df_target_pred_i = data_dict[7]["df_target_pred"]
# df_target_pred_i["diff_abs"]
df_target_pred_i.sort_values("diff_abs")
df_target_pred_i.diff_abs.mean()
df_target_pred_i
df_target_pred_i.sort_values("diff_abs", ascending=False).iloc[10:].diff_abs.mean()
df_target_pred_i.sort_values("diff_abs", ascending=False).iloc[0:20]
0.18735 - 0.15694500865106495
# ('sherlock', 'kobehubu_94', 52.0)
# ('sherlock', 'kobehubu_94', 60.0)
# ('sherlock', 'vipikema_98', 47.0)
# ('sherlock', 'vipikema_98', 53.0)
# ('sherlock', 'vipikema_98', 60.0)
# ('slac', 'dotivela_46', 26.0)
# ('slac', 'dotivela_46', 32.0)
# ('slac', 'ladarane_77', 15.0)
df_target_pred_i.loc[[
"sherlock__kobehubu_94__52.0",
"sherlock__kobehubu_94__60.0",
"sherlock__vipikema_98__47.0",
"sherlock__vipikema_98__53.0",
"sherlock__vipikema_98__60.0",
"slac__dotivela_46__26.0",
"slac__dotivela_46__32.0",
"slac__ladarane_77__15.0",
]]
# df_target_pred_i
df_target_pred_i.sort_values("diff_abs", ascending=False).iloc[0:20]
df_target_pred_i.loc[[
"slac__tonipibo_76__23.0",
"slac__votafefa_68__35.0",
"slac__foligage_07__32.0",
"slac__votafefa_68__38.0",
"sherlock__wafitemi_24__33.0",
"sherlock__novoloko_50__20.0",
"sherlock__kamevuse_75__49.0",
"sherlock__novoloko_50__21.0",
"sherlock__mibumime_94__60.0",
"sherlock__kobehubu_94__60.0",
]]
import plotly.graph_objs as go
data = []
trace = go.Scatter(
mode="markers",
y=np.abs(df_target_pred_i["diff"]),
x=np.abs(df_target_pred_i["err_pred"]),
)
data.append(trace)
trace = go.Scatter(
# mode="markers",
y=np.arange(0, 2, 0.1),
x=np.arange(0, 2, 0.1),
)
data.append(trace)
# data = [trace]
fig = go.Figure(data=data)
fig.show()
import plotly.graph_objs as go
trace = go.Scatter(
y=df_target_pred_i.sort_values("diff_abs", ascending=False).diff_abs,
)
data = [trace]
fig = go.Figure(data=data)
fig.show()
assert False
# regression_model_list[3].gp_model
```
### Plotting in-fold predictions
```
# data_dict_i = data_dict[
# num_pca_best
# ]
# df_target_pred = data_dict_i["df_target_pred"]
df_target_pred = df_target_pred_on_train
# data_dict_i["df_target_pred"]
max_val = df_target_pred[["y", "y_pred"]].max().max()
min_val = df_target_pred[["y", "y_pred"]].min().min()
# #########################################################
color_list = []
# #########################################################
for ind_i, row_i in df_target_pred.iterrows():
# #####################################################
row_data_i = df_comb.loc[ind_i]
# #####################################################
stoich_i = row_data_i[("data", "stoich", "", )]
# #####################################################
color_i = stoich_color_dict.get(stoich_i, "red")
color_list.append(color_i)
# #########################################################
df_target_pred["color"] = color_list
# #########################################################
dd = 0.1
trace_parity = go.Scatter(
y=[min_val - 2 * dd, max_val + 2 * dd],
x=[min_val - 2 * dd, max_val + 2 * dd],
mode="lines",
name="Parity line",
line_color="black",
)
trace_i = go.Scatter(
y=df_target_pred["y"],
x=df_target_pred["y_pred"],
mode="markers",
name="CV Regression",
# opacity=0.8,
opacity=1.,
marker=dict(
color=df_target_pred["color"],
**scatter_marker_props.to_plotly_json(),
),
)
max_val = df_target_pred[["y", "y_pred"]].max().max()
min_val = df_target_pred[["y", "y_pred"]].min().min()
dd = 0.1
layout_mine = go.Layout(
showlegend=True,
yaxis=go.layout.YAxis(
range=[min_val - dd, max_val + dd],
title=dict(
text="Simulated ΔG<sub>*{}</sub>".format(feature_ads_i.upper()),
),
),
xaxis=go.layout.XAxis(
range=[min_val - dd, max_val + dd],
title=dict(
text="Predicted ΔG<sub>*{}</sub>".format(feature_ads_i.upper()),
),
),
)
# #########################################################
layout_shared_i = copy.deepcopy(layout_shared)
layout_shared_i = layout_shared_i.update(layout_mine)
# data = [trace_parity, trace_i, trace_j]
data = [trace_parity, trace_i, ]
fig = go.Figure(data=data, layout=layout_shared_i)
if show_plot:
fig.show()
```
## Breaking down PCA stats
```
# PCA = data_dict[len(cols_to_use)]["PCA"]
PCA = data_dict[3]["PCA"]
if verbose:
print("Explained variance percentage")
print(40 * "-")
tmp = [print(100 * i) for i in PCA.explained_variance_ratio_]
print("")
df_pca_comp = pd.DataFrame(
abs(PCA.components_),
# columns=list(df_j["features"].columns),
columns=cols_to_use,
)
if verbose:
display(df_pca_comp)
if verbose:
for i in range(df_pca_comp.shape[0]):
print(40 * "-")
print(i)
print(40 * "-")
df_pca_comp_i = df_pca_comp.loc[i].sort_values(ascending=False)
print(df_pca_comp_i.iloc[0:4].to_string())
print("")
data_dict_list = []
for num_pca_i, dict_i in data_dict.items():
MAE_i = dict_i["MAE"]
R2_i = dict_i["R2"]
# #####################################################
data_dict_i = dict()
# #####################################################
data_dict_i["num_pca"] = num_pca_i
data_dict_i["MAE"] = MAE_i
data_dict_i["R2"] = R2_i
# #####################################################
data_dict_list.append(data_dict_i)
# #####################################################
# #########################################################
df = pd.DataFrame(data_dict_list)
df = df.set_index("num_pca")
# #########################################################
layout_mine = go.Layout(
showlegend=False,
yaxis=go.layout.YAxis(
title=dict(
text="K-Fold Cross Validated MAE",
),
),
xaxis=go.layout.XAxis(
title=dict(
text="Num PCA Components",
),
),
)
# #########################################################
layout_shared_i = layout_shared.update(layout_mine)
trace_i = go.Scatter(
x=df.index,
y=df.MAE,
mode="markers",
marker=dict(
**scatter_marker_props.to_plotly_json(),
),
)
data = [trace_i, ]
fig = go.Figure(
data=data,
layout=layout_shared_i,
)
if show_plot:
fig.show()
from plotting.my_plotly import my_plotly_plot
my_plotly_plot(
figure=fig,
plot_name="MAE_vs_PCA_comp",
save_dir=root_dir,
write_html=True,
write_pdf=True,
try_orca_write=True,
)
```
## Plotting the best model (optimal num PCA components)
```
num_pca_best = 3
# num_pca_best = 1
# num_pca_best = 11
data_dict_i = data_dict[
num_pca_best
]
df_target_pred = data_dict_i["df_target_pred"]
max_val = df_target_pred[["y", "y_pred"]].max().max()
min_val = df_target_pred[["y", "y_pred"]].min().min()
color_list = []
for ind_i, row_i in df_target_pred.iterrows():
row_data_i = df_comb.loc[ind_i]
stoich_i = row_data_i[("data", "stoich", "", )]
color_i = stoich_color_dict.get(stoich_i, "red")
color_list.append(color_i)
df_target_pred["color"] = color_list
dd = 0.1
trace_parity = go.Scatter(
y=[min_val - 2 * dd, max_val + 2 * dd],
x=[min_val - 2 * dd, max_val + 2 * dd],
mode="lines",
name="Parity line",
line_color="black",
)
trace_i = go.Scatter(
y=df_target_pred["y"],
x=df_target_pred["y_pred"],
mode="markers",
name="CV Regression",
# opacity=0.8,
opacity=1.,
marker=dict(
color=df_target_pred["color"],
# color="grey",
**scatter_marker_props.to_plotly_json(),
),
)
```
# In-fold model (trained on all data, no test/train split)
```
# df_j = df_j.dropna()
out_dict = run_regression_wf(
df_features_targets=df_j,
cols_to_use=cols_to_use,
df_format=df_format,
run_pca=True,
num_pca_comp=num_pca_best,
model_workflow=run_gp_workflow,
# model_settings=None,
model_settings=dict(
gp_settings=gp_settings,
kdict=kdict,
),
)
df_target_pred = out_dict["df_target_pred"]
MAE = out_dict["MAE"]
R2 = out_dict["R2"]
if verbose:
print("MAE:", MAE)
print("R2:", R2)
max_val = df_target_pred[["y", "y_pred"]].max().max()
min_val = df_target_pred[["y", "y_pred"]].min().min()
dd = 0.1
layout_mine = go.Layout(
showlegend=True,
yaxis=go.layout.YAxis(
range=[min_val - dd, max_val + dd],
title=dict(
text="Simulated ΔG<sub>*{}</sub>".format(target_ads_i.upper()),
),
),
xaxis=go.layout.XAxis(
range=[min_val - dd, max_val + dd],
title=dict(
text="Predicted ΔG<sub>*{}</sub>".format(target_ads_i.upper()),
),
),
)
# #########################################################
layout_shared = layout_shared.update(layout_mine)
color_list = []
for ind_i, row_i in df_target_pred.iterrows():
row_data_i = df_comb.loc[ind_i]
stoich_i = row_data_i[("data", "stoich", "", )]
color_i = stoich_color_dict.get(stoich_i, "red")
color_list.append(color_i)
df_target_pred["color"] = color_list
trace_j = go.Scatter(
y=df_target_pred["y"],
x=df_target_pred["y_pred"],
mode="markers",
opacity=0.8,
name="In-fold Regression",
marker=dict(
color=df_target_pred["color"],
**scatter_marker_props.to_plotly_json(),
),
)
data = [trace_parity, trace_i, trace_j]
fig = go.Figure(data=data, layout=layout_shared)
if show_plot:
fig.show()
tmp = fig.layout.update(
go.Layout(
showlegend=False,
width=12 * 37.795275591,
height=12 / 1.61803398875 * 37.795275591,
margin=go.layout.Margin(
b=10, l=10,
r=10, t=10,
),
xaxis=go.layout.XAxis(
tickfont=go.layout.xaxis.Tickfont(
size=font_tick_labels_size__pub,
),
title=dict(
# text="Ir Effective Oxidation State",
font=dict(
size=font_axis_title_size__pub,
),
)
),
yaxis=go.layout.YAxis(
tickfont=go.layout.yaxis.Tickfont(
size=font_tick_labels_size__pub,
),
title=dict(
# text="ΔG<sub>OH</sub> (eV)",
font=dict(
size=font_axis_title_size__pub,
),
)
),
)
)
fig_cpy = copy.deepcopy(fig)
data = [trace_parity, trace_i, ]
fig_2 = go.Figure(data=data, layout=fig.layout)
# fig_2
scatter_shared_props_cpy = copy.deepcopy(scatter_shared_props)
tmp = scatter_shared_props_cpy.update(
marker=dict(
size=8,
)
)
tmp = fig_2.update_traces(patch=dict(
scatter_shared_props_cpy.to_plotly_json()
))
fig_2
from plotting.my_plotly import my_plotly_plot
my_plotly_plot(
figure=fig_2,
plot_name="GP_model",
save_dir=root_dir,
write_html=True,
write_pdf=True,
try_orca_write=True,
)
# #########################################################
print(20 * "# # ")
print("All done!")
print("Run time:", np.round((time.time() - ti) / 60, 3), "min")
print("gaussian_proc.ipynb")
print(20 * "# # ")
# #########################################################
```
```
# # TEMP
# print(222 * "TEMP | ")
# df_comb = pd.concat([
# # df_i,
# df_seoin,
# ], axis=0)
# feature_ads_i = "o"
# data_dict_list = []
# for col_i in df_comb.columns:
# num_nan_i = sum(
# df_comb[col_i].isna())
# ads_i = None
# if col_i[1] in ["o", "oh", "ooh", ]:
# tmp = 42
# ads_i = col_i[1]
# data_dict_i = dict()
# data_dict_i["col"] = col_i
# data_dict_i["num_nan"] = num_nan_i
# data_dict_i["col_type"] = col_i[0]
# data_dict_i["ads"] = ads_i
# data_dict_list.append(data_dict_i)
# df_nan = pd.DataFrame(data_dict_list)
# df_nan = df_nan[df_nan.col_type == "features"]
# df_nan = df_nan[df_nan.ads == "o"]
# df_nan.sort_values("num_nan", ascending=False)
# df_comb = df_comb.drop(columns=[
# # ('features', 'o', 'Ir_bader'),
# # ('features', 'o', 'O_bader'),
# # ('features', 'o', 'p_band_center'),
# ('features', 'o', 'Ir*O_bader/ir_o_mean'),
# ('features', 'o', 'Ir*O_bader'),
# # ('features', 'o', 'Ir_magmom'),
# # ('features', 'o', 'O_magmom'),
# # ('features', 'o', 'ir_o_std'),
# # ('features', 'o', 'octa_vol'),
# # ('features', 'o', 'ir_o_mean'),
# # ('features', 'o', 'active_o_metal_dist'),
# # ('features', 'o', 'angle_O_Ir_surf_norm'),
# # ('dH_bulk', ''),
# # ('volume_pa', ''),
# # ('bulk_oxid_state', ''),
# # ('effective_ox_state', ''),
# ],
# errors='ignore',
# )
# df_comb["features"].columns.tolist()
# df_comb.columns.tolist()
# assert False
```
| github_jupyter |
```
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
#for dirname, _, filenames in os.walk('/kaggle/input'):
#for filename in filenames:
#print(os.path.join(dirname, filename))
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import keras
from keras.preprocessing import image
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten,Dense,Dropout,BatchNormalization
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import cv2
from tensorflow.keras.applications import VGG16, InceptionResNetV2
from keras import regularizers
from tensorflow.keras.optimizers import Adam,RMSprop,SGD,Adamax
train_dir = "../input/emotion-detection-fer/train" #passing the path with training images
test_dir = "../input/emotion-detection-fer/test" #passing the path with testing images
img_size = 48 #original size of the image
"""
Data Augmentation
--------------------------
rotation_range = rotates the image with the amount of degrees we provide
width_shift_range = shifts the image randomly to the right or left along the width of the image
height_shift range = shifts image randomly to up or below along the height of the image
horizontal_flip = flips the image horizontally
rescale = to scale down the pizel values in our image between 0 and 1
zoom_range = applies random zoom to our object
validation_split = reserves some images to be used for validation purpose
"""
train_datagen = ImageDataGenerator(#rotation_range = 180,
width_shift_range = 0.1,
height_shift_range = 0.1,
horizontal_flip = True,
rescale = 1./255,
#zoom_range = 0.2,
validation_split = 0.2
)
validation_datagen = ImageDataGenerator(rescale = 1./255,
validation_split = 0.2)
"""
Applying data augmentation to the images as we read
them from their respectivve directories
"""
train_generator = train_datagen.flow_from_directory(directory = train_dir,
target_size = (img_size,img_size),
batch_size = 64,
color_mode = "grayscale",
class_mode = "categorical",
subset = "training"
)
validation_generator = validation_datagen.flow_from_directory( directory = test_dir,
target_size = (img_size,img_size),
batch_size = 64,
color_mode = "grayscale",
class_mode = "categorical",
subset = "validation"
)
"""
Modeling
model = Sequential()
model.add(Conv2D(filters = 64,kernel_size = (3,3),padding = 'same',activation = 'relu',input_shape=(img_size,img_size,1)))
model.add(MaxPool2D(pool_size = 2,strides = 2))
model.add(BatchNormalization())
model.add(Conv2D(filters = 128,kernel_size = (3,3),padding = 'same',activation = 'relu'))
model.add(MaxPool2D(pool_size = 2,strides = 2))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Conv2D(filters = 128,kernel_size = (3,3),padding = 'same',activation = 'relu'))
model.add(MaxPool2D(pool_size = 2,strides = 2))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Conv2D(filters = 256,kernel_size = (3,3),padding = 'same',activation = 'relu'))
model.add(MaxPool2D(pool_size = 2,strides = 2))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(units = 128,activation = 'relu',kernel_initializer='he_normal'))
model.add(Dropout(0.25))
model.add(Dense(units = 64,activation = 'relu',kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(units = 32,activation = 'relu',kernel_initializer='he_normal'))
model.add(Dense(7,activation = 'softmax'))
"""
model= tf.keras.models.Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(48, 48,1)))
model.add(Conv2D(64,(3,3), padding='same', activation='relu' ))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128,(5,5), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(512,(3,3), padding='same', activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(512,(3,3), padding='same', activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256,activation = 'relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(512,activation = 'relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(7, activation='softmax'))
model.compile(
optimizer = Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy']
)
epochs = 60
batch_size = 64
model.summary()
history = model.fit(x = train_generator,epochs = epochs,validation_data = validation_generator)
fig , ax = plt.subplots(1,2)
train_acc = history.history['accuracy']
train_loss = history.history['loss']
fig.set_size_inches(12,4)
ax[0].plot(history.history['accuracy'])
ax[0].plot(history.history['val_accuracy'])
ax[0].set_title('Training Accuracy vs Validation Accuracy')
ax[0].set_ylabel('Accuracy')
ax[0].set_xlabel('Epoch')
ax[0].legend(['Train', 'Validation'], loc='upper left')
ax[1].plot(history.history['loss'])
ax[1].plot(history.history['val_loss'])
ax[1].set_title('Training Loss vs Validation Loss')
ax[1].set_ylabel('Loss')
ax[1].set_xlabel('Epoch')
ax[1].legend(['Train', 'Validation'], loc='upper left')
plt.show()
model.save('model_optimal.h5')
img = image.load_img("../input/emotion-detection-fer/test/happy/im1021.png",target_size = (48,48),color_mode = "grayscale")
img = np.array(img)
plt.imshow(img)
print(img.shape) #prints (48,48) that is the shape of our image
label_dict = {0:'Angry',1:'Disgust',2:'Fear',3:'Happy',4:'Neutral',5:'Sad',6:'Surprise'}
img = np.expand_dims(img,axis = 0) #makes image shape (1,48,48)
img = img.reshape(1,48,48,1)
result = model.predict(img)
result = list(result[0])
print(result)
img_index = result.index(max(result))
print(label_dict[img_index])
plt.show()
train_loss, train_acc = model.evaluate(train_generator)
test_loss, test_acc = model.evaluate(validation_generator)
print("final train accuracy = {:.2f} , validation accuracy = {:.2f}".format(train_acc*100, test_acc*100))
```
| github_jupyter |
```
from google.colab import drive
drive.mount('/content/drive')
```
# Part 0
## Import modules and utilities
```
import json
import pandas as pd
import pprint
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import numpy as np
# !pip install -Iv seaborn==0.11.0
import seaborn as sns
print(sns.__version__)
sns.set_style()
# from scipy.stats import pearsonr
# from scipy.stats import iqr
%cd '/content/drive/My Drive/Colab Notebooks/media-agenda'
%pwd
import util
from util import DocType, Source, OptimalKClustersConfig
import senti_util
from termcolor import colored, cprint
%cd '/content/drive/My Drive/Colab Notebooks/media-agenda/plot'
%pwd
```
## Load dataframe for analysis
```
start_year = 2009
end_year = 2017
start_datetime, end_datetime, start_datetime_str, end_datetime_str = util.get_start_end_datetime(start_year, end_year)
# df = senti_util.get_sentence_cluster_sentiment_df(start_year = start_year, end_year = end_year,
# path = '/content/drive/My Drive/Colab Notebooks/media-agenda/data/sentence_cluster_sentiment_dict.json', verbose = True)
# load the dataframe
df = pd.read_csv('/content/drive/My Drive/Colab Notebooks/media-agenda/data/df_2009_to_2017_with_time_interval_indexing.csv')
# add 'bin_of_every_1_day' column
date_list = senti_util.get_date_list(start_datetime, end_datetime, freq = '1D')
date_df = pd.DataFrame({'bin_of_every_1_day': range(len(date_list)),
'date': date_list})
date_df['date'] = date_df['date'].dt.strftime('%Y-%m-%d')
df = df.merge(date_df, how = 'left', on = 'date')
df.head()
```
# Part 1
## plot distribution of sentiment in different time windows
```
def plot(source = Source, is_textblob = False, bin = 'bin_of_every_14_days', by = 'mean'):
if source == Source.SPIEGEL:
senti_choice = 'Textblob-de' if is_textblob else 'SentiWS'
else:
senti_choice = 'Textblob' if is_textblob else 'SentiWordNet'
article_df = df[(df.source == source) & (df.is_comment == False)]
comment_df = df[(df.source == source) & (df.is_comment == True)]
article_stat_df = senti_util.get_sentiment_stat(article_df, is_textblob, bin)
comment_stat_df = senti_util.get_sentiment_stat(comment_df, is_textblob, bin)
plt.figure(figsize = (24, 8))
plt.style.use('seaborn-whitegrid')
plt.rcParams.update({'font.size': 14})
if by == 'hotness':
g = sns.lineplot(data = article_stat_df, x = bin, y = 'hotness', label = 'Article Hotness')
sns.lineplot(data = comment_stat_df, x = bin, y = 'hotness', label = 'Comment Hotness')
elif by == 'mean':
g = sns.lineplot(data = article_stat_df, x = bin, y = 'mean', label = 'Article Mean')
sns.lineplot(data = comment_stat_df, x = bin, y = 'mean', label = 'Comment Mean')
elif by == 'median':
g = sns.lineplot(data = article_stat_df, x = bin, y = 'median', label = 'Article Median')
sns.lineplot(data = comment_stat_df, x = bin, y = 'median', label = 'Comment Median')
elif by == 'groupby_count':
g = sns.lineplot(data = article_stat_df, x = bin, y = 'groupby_count', label = 'Article Count')
sns.lineplot(data = comment_stat_df, x = bin, y = 'groupby_count', label = 'Comment Count')
elif by == 'dominance':
g = sns.lineplot(data = article_stat_df, x = bin, y = 'dominance', label = 'Article Dominance')
sns.lineplot(data = comment_stat_df, x = bin, y = 'dominance', label = 'Comment Dominance')
if by == 'hotness':
g.set(xlabel = bin, ylabel = 'Hotness (IQR * Dominance)')
g.set_title('{} Hotness Distribution ({} - {} with {})'.format(str.upper(source), start_year, end_year, senti_choice))
plt.ylim(0, 3)
elif by == 'groupby_count':
g.set(xlabel = bin, ylabel = 'Count')
g.set_title('{} Sentiment Distribution ({} - {} with {})'.format(str.upper(source), start_year, end_year, senti_choice))
elif by == 'dominance':
g.set(xlabel = bin, ylabel = 'Dominance (%)')
g.set_title('{} Dominance Distribution ({} - {} with {})'.format(str.upper(source), start_year, end_year, senti_choice))
else:
g.fill_between(x = article_stat_df[bin], y1 = article_stat_df.third_quantile, y2 = article_stat_df.first_quantile, alpha = 0.2, label = 'Article IQR')
g.fill_between(x = comment_stat_df[bin], y1 = comment_stat_df.third_quantile, y2 = comment_stat_df.first_quantile, alpha = 0.2, label = 'Comment IQR')
g.set(xlabel = bin, ylabel = 'Sentiment')
g.set_title('{} Sentiment Distribution ({} - {} with {})'.format(str.upper(source), start_year, end_year, senti_choice))
plt.ylim(-0.5, 0.5)
plt.legend()
plt.show()
bin = 'bin_of_every_1_day'
# bin = 'bin_of_every_3_days'
# bin = 'bin_of_every_4_days'
# bin = 'bin_of_every_7_days'
# bin = 'bin_of_every_14_days'
# bin = 'bin_of_every_28_days'
# bin = 'bin_of_every_56_days'
plot(source = Source.NYTIMES, is_textblob = False, bin = bin, by = 'mean')
plot(source = Source.NYTIMES, is_textblob = False, bin = bin, by = 'median')
plot(source = Source.NYTIMES, is_textblob = False, bin = bin, by = 'hotness')
plot(source = Source.NYTIMES, is_textblob = False, bin = bin, by = 'dominance')
plot(source = Source.NYTIMES, is_textblob = False, bin = bin, by = 'groupby_count')
# plot(source = Source.NYTIMES, is_textblob = True, bin = bin, by = 'mean')
# plot(source = Source.NYTIMES, is_textblob = True, bin = bin, by = 'median')
# plot(source = Source.NYTIMES, is_textblob = True, bin = bin, by = 'hotness')
# plot(source = Source.NYTIMES, is_textblob = True, bin = bin, by = 'dominance')
# plot(source = Source.NYTIMES, is_textblob = True, bin = bin, by = 'groupby_count')
```
| github_jupyter |
<a href="https://colab.research.google.com/github/shangeth/Google-ML-Academy/blob/master/2-Deep-Neural-Networks2_8_ANN_Computer_Vision.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
<hr>
<h1 align="center"><a href='https://shangeth.com/courses/'>Deep Learning - Beginners Track</a></h1>
<h3 align="center">Instructor: <a href='https://shangeth.com/'>Shangeth Rajaa</a></h3>
<hr>
We will use ANNs for a basic computer vision application of image classification on CIFAR10 Dataset
# Dataset
## CIFAR-10
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.

## Download the Dataset
Tensorflow has inbuilt dataset which makes it easy to get training and testing data.
```
from tensorflow.keras.datasets import cifar10
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
class_name = {
0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck',
}
```
## Visualize the Dataset
```
import matplotlib.pyplot as plt
num_imgs = 10
plt.figure(figsize=(num_imgs*2,3))
for i in range(1,num_imgs):
plt.subplot(1,num_imgs,i).set_title('{}'.format(class_name[y_train[i][0]]))
plt.imshow(x_train[i])
plt.axis('off')
plt.show()
```
## Scaling Features
```
import numpy as np
np.max(x_train), np.min(x_train)
```
The range of values in the data is 0-255,
- we can to scale it to [0,1], dividing it by 255 will do.
- or we can standardize it by subtracting mean and dividing std.
```
mean = np.mean(x_train)
std = np.std(x_train)
x_train = (x_train-mean)/std
x_test = (x_test-mean)/std
np.max(x_train), np.min(x_train), np.max(x_test), np.min(x_test)
```
## Labels to One-Hot
```
print(y_train[:5])
num_classes = 10
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
print(y_train[:5])
```
# Colour Channels
Lets check the shape of the arrays
```
x_train.shape, y_train.shape, x_test.shape, y_test.shape
```
The shape of each image is (32 x 32 x 3), previously we saw MNIST dataset had a shape of (28 x 28), why is it so?
MNIST is a gray-scale image, it has a single channel of gray scale. But CIFAR-10 is a colour image, every colour pixel has 3 channels RGB, all these 3 channels contribute to what colour you see.
Any colour image is made of 3 channels RGB.

## Visualize colour channels
```
import matplotlib.pyplot as plt
plt.figure(figsize=(9,3))
plt.subplot(1,3,1)
plt.imshow(x_train[1][:,:,0], cmap='Reds')
plt.subplot(1,3,2)
plt.imshow(x_train[1][:,:,1], cmap='Greens')
plt.subplot(1,3,3)
plt.imshow(x_train[1][:,:,2], cmap='Blues')
plt.show()
```
So when we flatten the CIFAR-10 image, it will give 32x32x3 = 3072.
# Model
```
import tensorflow as tf
from tensorflow import keras
tf.keras.backend.clear_session()
input_shape = (32,32,3) # 3072
nclasses = 10
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=input_shape),
tf.keras.layers.Dense(units=1024),
tf.keras.layers.Activation('tanh'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=512),
tf.keras.layers.Activation('tanh'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=nclasses),
tf.keras.layers.Activation('softmax')
])
model.summary()
```
## Training
```
optimizer = tf.keras.optimizers.Adam(lr=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
tf_history_dp = model.fit(x_train, y_train, batch_size=500, epochs=100, verbose=True, validation_data=(x_test, y_test))
import matplotlib.pyplot as plt
plt.figure(figsize=(20,7))
plt.subplot(1,2,1)
plt.plot(tf_history_dp.history['loss'], label='Training Loss')
plt.plot(tf_history_dp.history['val_loss'], label='Validation Loss')
plt.legend()
plt.subplot(1,2,2)
plt.plot(tf_history_dp.history['acc'], label='Training Accuracy')
plt.plot(tf_history_dp.history['val_acc'], label='Validation Accuracy')
plt.legend()
plt.show()
```
Model is clearly overfitting.
# Image Augmentation
We have discussed that, more images/data improves the model performance and avoid overfitting. But its not always possible to get new data, so we can augment the old data to create new data.
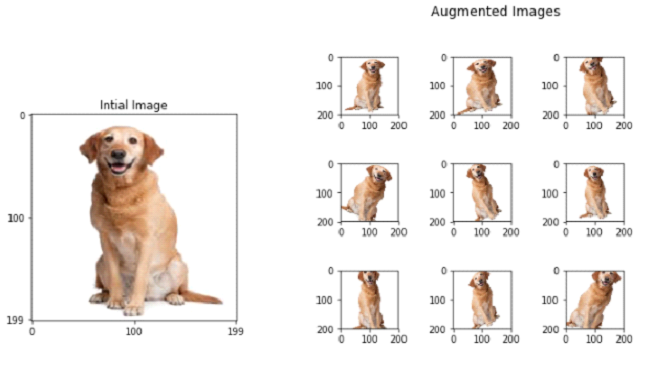
Augmentation can be:
- random crop
- rotation
- horizontal and vertical flips
- x-y shift
- colour jitter
- etc.
## Image Augmentation in Tensorflow
```
from tensorflow.keras.datasets import cifar10
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = (x_train-mean)/std
x_test = (x_test-mean)/std
num_classes = 10
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
import tensorflow as tf
from tensorflow import keras
tf.keras.backend.clear_session()
input_shape = (32,32,3) # 3072
nclasses = 10
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=input_shape),
tf.keras.layers.Dense(units=1024),
tf.keras.layers.Activation('tanh'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(units=512),
tf.keras.layers.Activation('tanh'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(units=nclasses),
tf.keras.layers.Activation('softmax')
])
model.summary()
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rotation_range=20)
test_datagen = ImageDataGenerator()
train_generator = train_datagen.flow(
x_train, y_train,
batch_size=200)
validation_generator = test_datagen.flow(
x_test, y_test,
batch_size=200)
import matplotlib.pyplot as plt
i = 1
plt.figure(figsize=(20,2))
for x_batch, y_batch in train_datagen.flow(x_train, y_train, batch_size=1):
plt.subplot(1,10,i)
plt.imshow(x_batch[0])
i += 1
if i>10:break
```
You can see the some of the images are zoomed, some are rotated...etc. SO these images are now different that the original image and for the model these are new images.
```
optimizer = tf.keras.optimizers.SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=200,
validation_data=validation_generator)
import matplotlib.pyplot as plt
tf_history_aug = model.history
plt.figure(figsize=(20,7))
plt.subplot(1,2,1)
plt.plot(tf_history_aug.history['loss'], label='Training Loss')
plt.plot(tf_history_aug.history['val_loss'], label='Validation Loss')
plt.legend()
plt.subplot(1,2,2)
plt.plot(tf_history_aug.history['acc'], label='Training Accuracy')
plt.plot(tf_history_aug.history['val_acc'], label='Validation Accuracy')
plt.legend()
plt.show()
```
The model is not overfitting and the performance is still increasing, so training for more epoch can give a good performance, but it will take more time, so we will stop here. Try to improve the model.
- Train the model longer.
- Use different architecture with aug
- use different activation
- different optimizer
There are other model architectures which work good for images, we will discuss that in the intermediate track.
# Saving a Trained Model
Saving a trained model is very important, hours of training should not be wasted and we need the trained model to be deployed in some other device. Its very simple in tf.keras
```
model_path = 'cifar10_trained_model.h5'
model.save(model_path)
!ls
```
# Loading a saved model
```
from tensorflow.keras.models import load_model
model = load_model(model_path)
model.summary()
```
| github_jupyter |
# Welter issue #9
## Generate synthetic, noised-up two-temperature model spectra, then naively fit a single temperature model to it.
### Part 2- Prepare.
Michael Gully-Santiago
Friday, January 8, 2015
See the previous notebook for the theory and background.
Steps:
1. Modify all the config and phi files to have the values from the MCMC run.
```
import warnings
warnings.filterwarnings("ignore")
import numpy as np
from astropy.io import fits
import matplotlib.pyplot as plt
% matplotlib inline
% config InlineBackend.figure_format = 'retina'
import seaborn as sns
sns.set_context('paper', font_scale=1.4)
sns.set_style('ticks')
import os
import json
import pandas as pd
import yaml
import h5py
sf_dat = pd.read_csv('../data/analysis/IGRINS_ESPaDOnS_run01_last10kMCMC.csv')
sf_dat.rename(columns={"m_val_x":"m_val"}, inplace=True)
del sf_dat['m_val_y']
```
## Set the value of the config files to all the same values.
```
ms = sf_dat.m_val
for m in ms:
index = sf_dat.index[sf_dat.m_val == m]
mdir = 'eo{:03d}'.format(m)
sf_out = '../sf/eo{:03d}/config.yaml'.format(m)
f2 = open(sf_out)
config = yaml.load(f2)
f2.close()
ii = index.values[0]
config['Theta']['grid'] = [4100.0, 3.5, 0.0]
config['Theta']['vsini'] = float(28.5)
config['Theta']['vz'] = float(15.6)
config['Theta']['vz'] = float(15.6)
config['Theta']['logOmega'] = float(-0.07)
if (sf_dat.logO_50p[ii] == sf_dat.logO_50p[ii]):
config['Theta']['logOmega'] = float(sf_dat.logO_50p[ii])
with open(sf_out, mode='w') as outfile:
outfile.write(yaml.dump(config))
for m in ms:
index = sf_dat.index[sf_dat.m_val == m]
mdir = 'eo{:03d}'.format(m)
phi_out = '../sf/eo{:03d}/s0_o0phi.json'.format(m)
jf = open(phi_out)
phi = json.load(jf)
jf.close()
ii = index.values[0]
c1, c2, c3 = sf_dat.c1_50p[ii], sf_dat.c2_50p[ii], sf_dat.c3_50p[ii]
if c1 != c1:
print("default: {}".format(m))
phi['cheb'] = [0.0,0,0]
phi['logAmp']= -1.6
phi['sigAmp']= 1.0
phi['l']= 30.0
if c1 == c1:
print("actual: {}".format(m))
phi['cheb'] = [c1, c2, c3]
if sf_dat.LA_50p[ii] > -1.4:
phi['logAmp']= -1.4
else:
phi['logAmp']= sf_dat.LA_50p[ii]
phi['sigAmp']= sf_dat.SA_50p[ii]
phi['l']= sf_dat.ll_50p[ii]
phi['fix_c0'] = True
with open(phi_out, mode='w') as outfile:
json.dump(phi, outfile, indent=2)
```
The end.
| github_jupyter |
##### Copyright 2018 Google LLC.
Licensed under the Apache License, Version 2.0 (the "License");
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
# Training a Simple Neural Network, with tensorflow/datasets Data Loading
_Forked from_ `neural_network_and_data_loading.ipynb`
_Dougal Maclaurin, Peter Hawkins, Matthew Johnson, Roy Frostig, Alex Wiltschko, Chris Leary_

Let's combine everything we showed in the [quickstart notebook](https://colab.research.google.com/github/google/jax/blob/master/notebooks/quickstart.ipynb) to train a simple neural network. We will first specify and train a simple MLP on MNIST using JAX for the computation. We will use `tensorflow/datasets` data loading API to load images and labels (because it's pretty great, and the world doesn't need yet another data loading library :P).
Of course, you can use JAX with any API that is compatible with NumPy to make specifying the model a bit more plug-and-play. Here, just for explanatory purposes, we won't use any neural network libraries or special APIs for builidng our model.
```
!pip install --upgrade -q https://storage.googleapis.com/jax-releases/cuda$(echo $CUDA_VERSION | sed -e 's/\.//' -e 's/\..*//')/jaxlib-0.1.23-cp36-none-linux_x86_64.whl
!pip install --upgrade -q jax
from __future__ import print_function, division, absolute_import
import jax.numpy as np
from jax import grad, jit, vmap
from jax import random
```
### Hyperparameters
Let's get a few bookkeeping items out of the way.
```
# A helper function to randomly initialize weights and biases
# for a dense neural network layer
def random_layer_params(m, n, key, scale=1e-2):
w_key, b_key = random.split(key)
return scale * random.normal(w_key, (n, m)), scale * random.normal(b_key, (n,))
# Initialize all layers for a fully-connected neural network with sizes "sizes"
def init_network_params(sizes, key):
keys = random.split(key, len(sizes))
return [random_layer_params(m, n, k) for m, n, k in zip(sizes[:-1], sizes[1:], keys)]
layer_sizes = [784, 512, 512, 10]
param_scale = 0.1
step_size = 0.0001
num_epochs = 10
batch_size = 128
n_targets = 10
params = init_network_params(layer_sizes, random.PRNGKey(0))
```
### Auto-batching predictions
Let us first define our prediction function. Note that we're defining this for a _single_ image example. We're going to use JAX's `vmap` function to automatically handle mini-batches, with no performance penalty.
```
from jax.scipy.special import logsumexp
def relu(x):
return np.maximum(0, x)
def predict(params, image):
# per-example predictions
activations = image
for w, b in params[:-1]:
outputs = np.dot(w, activations) + b
activations = relu(outputs)
final_w, final_b = params[-1]
logits = np.dot(final_w, activations) + final_b
return logits - logsumexp(logits)
```
Let's check that our prediction function only works on single images.
```
# This works on single examples
random_flattened_image = random.normal(random.PRNGKey(1), (28 * 28,))
preds = predict(params, random_flattened_image)
print(preds.shape)
# Doesn't work with a batch
random_flattened_images = random.normal(random.PRNGKey(1), (10, 28 * 28))
try:
preds = predict(params, random_flattened_images)
except TypeError:
print('Invalid shapes!')
# Let's upgrade it to handle batches using `vmap`
# Make a batched version of the `predict` function
batched_predict = vmap(predict, in_axes=(None, 0))
# `batched_predict` has the same call signature as `predict`
batched_preds = batched_predict(params, random_flattened_images)
print(batched_preds.shape)
```
At this point, we have all the ingredients we need to define our neural network and train it. We've built an auto-batched version of `predict`, which we should be able to use in a loss function. We should be able to use `grad` to take the derivative of the loss with respect to the neural network parameters. Last, we should be able to use `jit` to speed up everything.
### Utility and loss functions
```
def one_hot(x, k, dtype=np.float32):
"""Create a one-hot encoding of x of size k."""
return np.array(x[:, None] == np.arange(k), dtype)
def accuracy(params, images, targets):
target_class = np.argmax(targets, axis=1)
predicted_class = np.argmax(batched_predict(params, images), axis=1)
return np.mean(predicted_class == target_class)
def loss(params, images, targets):
preds = batched_predict(params, images)
return -np.sum(preds * targets)
@jit
def update(params, x, y):
grads = grad(loss)(params, x, y)
return [(w - step_size * dw, b - step_size * db)
for (w, b), (dw, db) in zip(params, grads)]
```
### Data Loading with `tensorflow/datasets`
JAX is laser-focused on program transformations and accelerator-backed NumPy, so we don't include data loading or munging in the JAX library. There are already a lot of great data loaders out there, so let's just use them instead of reinventing anything. We'll use the `tensorflow/datasets` data loader.
```
# Install tensorflow-datasets
# TODO(rsepassi): Switch to stable version on release
!pip install -q --upgrade tfds-nightly tf-nightly
import tensorflow_datasets as tfds
data_dir = '/tmp/tfds'
# Fetch full datasets for evaluation
# tfds.load returns tf.Tensors (or tf.data.Datasets if batch_size != -1)
# You can convert them to NumPy arrays (or iterables of NumPy arrays) with tfds.dataset_as_numpy
mnist_data, info = tfds.load(name="mnist", batch_size=-1, data_dir=data_dir, with_info=True)
mnist_data = tfds.as_numpy(mnist_data)
train_data, test_data = mnist_data['train'], mnist_data['test']
num_labels = info.features['label'].num_classes
h, w, c = info.features['image'].shape
num_pixels = h * w * c
# Full train set
train_images, train_labels = train_data['image'], train_data['label']
train_images = np.reshape(train_images, (len(train_images), num_pixels))
train_labels = one_hot(train_labels, num_labels)
# Full test set
test_images, test_labels = test_data['image'], test_data['label']
test_images = np.reshape(test_images, (len(test_images), num_pixels))
test_labels = one_hot(test_labels, num_labels)
print('Train:', train_images.shape, train_labels.shape)
print('Test:', test_images.shape, test_labels.shape)
```
### Training Loop
```
import time
def get_train_batches():
# as_supervised=True gives us the (image, label) as a tuple instead of a dict
ds = tfds.load(name='mnist', split='train', as_supervised=True, data_dir=data_dir)
# You can build up an arbitrary tf.data input pipeline
ds = ds.batch(128).prefetch(1)
# tfds.dataset_as_numpy converts the tf.data.Dataset into an iterable of NumPy arrays
return tfds.as_numpy(ds)
for epoch in range(num_epochs):
start_time = time.time()
for x, y in get_train_batches():
x = np.reshape(x, (len(x), num_pixels))
y = one_hot(y, num_labels)
params = update(params, x, y)
epoch_time = time.time() - start_time
train_acc = accuracy(params, train_images, train_labels)
test_acc = accuracy(params, test_images, test_labels)
print("Epoch {} in {:0.2f} sec".format(epoch, epoch_time))
print("Training set accuracy {}".format(train_acc))
print("Test set accuracy {}".format(test_acc))
```
We've now used the whole of the JAX API: `grad` for derivatives, `jit` for speedups and `vmap` for auto-vectorization.
We used NumPy to specify all of our computation, and borrowed the great data loaders from `tensorflow/datasets`, and ran the whole thing on the GPU.
| github_jupyter |
# IMPORTS
## Libraries
```
import math
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.core.display import HTML
```
## Helper Functions
```
def jupyter_settings():
%matplotlib inline
%pylab inline
plt.style.use( 'bmh' )
plt.rcParams['figure.figsize'] = [25, 12]
plt.rcParams['font.size'] = 24
display( HTML( '<style>.container { width:100% !important; }</style>') )
pd.options.display.max_columns = None
pd.options.display.max_rows = None
pd.set_option( 'display.expand_frame_repr', False )
sns.set()
jupyter_settings()
```
## Loading Data
```
salesRaw = pd.read_csv('../../01-Data/train.csv', low_memory=False)
storeRaw = pd.read_csv('../../01-Data/store.csv', low_memory=False)
```
### Merge Datasets
```
dfRaw = salesRaw.merge(storeRaw, how='left', on='Store')
```
# DESCRIPTION OF THE DATA
## Columns
```
dfRaw1 = dfRaw.copy()
dfRaw1.columns
```
## Data Dimensions
```
print(f'Number of Rows: {dfRaw1.shape[0]}')
print(f'Number of Columns: {dfRaw1.shape[1]}')
```
## Data Types
```
dfRaw1.dtypes
dfRaw1['Date'] = pd.to_datetime(dfRaw1['Date'])
```
## Not a Number
### Sum
```
dfRaw1.isnull().sum()
```
### Mean
```
dfRaw1.isnull().mean()
```
## Fillout NA
```
maxValueCompetitionDistance = dfRaw1['CompetitionDistance'].max()
dfRaw1.sample(5)
# CompetitionDistance
#distance in meters to the nearest competitor store
#maxValueCompetitionDistance = dfRaw1['CompetitionDistance'].max()
dfRaw1['CompetitionDistance'] = dfRaw1['CompetitionDistance'].apply(lambda row: 200000.0 if math.isnan(row) else row)
# CompetitionOpenSinceMonth
#gives the approximate month of the time the nearest competitor was opened
dfRaw1['CompetitionOpenSinceMonth'] = dfRaw1.apply(lambda row: row['Date'].month if math.isnan(row['CompetitionOpenSinceMonth']) else row['CompetitionOpenSinceMonth'], axis=1)
# CompetitionOpenSinceYear
# gives the approximate year of the time the nearest competitor was opened
dfRaw1['CompetitionOpenSinceYear'] = dfRaw1.apply(lambda row: row['Date'].year if math.isnan(row['CompetitionOpenSinceYear']) else row['CompetitionOpenSinceYear'], axis=1)
# Promo2SinceWeek
#describes the calendar week when the store started participating in Promo2
dfRaw1['Promo2SinceWeek'] = dfRaw1.apply(lambda row: row['Date'].week if math.isnan(row['Promo2SinceWeek']) else row['Promo2SinceWeek'], axis=1)
# Promo2SinceYear
#describes the year when the store started participating in Promo2
dfRaw1['Promo2SinceYear'] = dfRaw1.apply(lambda row: row['Date'].year if math.isnan(row['Promo2SinceYear']) else row['Promo2SinceYear'], axis=1)
# PromoInterval
#describes the consecutive intervals Promo2 is started, naming the months the promotion is started anew.\
#E.g. "Feb,May,Aug,Nov" means each round starts in February, May, August, November of any given year for that store
monthMap = {
1: 'Jan', 2: 'Feb', 3: 'Mar', 4: 'Apr', 5: 'May', 6: 'Jun', 7: 'Jul', 8: 'Aug', 9: 'Sep', 10: 'Oct', 11: 'Nov', 12: 'Dec'
}
dfRaw1['PromoInterval'].fillna(0, inplace=True)
dfRaw1['MonthMap'] = dfRaw1['Date'].dt.month.map(monthMap)
dfRaw1['IsPromo'] = dfRaw1[['PromoInterval', 'MonthMap']].apply(lambda row: 0 if row['PromoInterval'] == 0 else 1 if row['MonthMap'] in row['PromoInterval'].split(',') else 0, axis=1)
dfRaw1.isnull().sum()
```
## Change Types
```
dfRaw1.dtypes
# competiton
dfRaw1['CompetitionOpenSinceMonth'] = dfRaw1['CompetitionOpenSinceMonth'].astype(int)
dfRaw1['CompetitionOpenSinceYear'] = dfRaw1['CompetitionOpenSinceYear'].astype(int)
# promo2
dfRaw1['Promo2SinceWeek'] = dfRaw1['Promo2SinceWeek'].astype(int)
dfRaw1['Promo2SinceYear'] = dfRaw1['Promo2SinceYear'].astype(int)
```
## Descriptive Statistical
```
numAttributes = dfRaw1.select_dtypes(include=['int64', 'float64'])
catAttributes = dfRaw1.select_dtypes(exclude=['int64', 'float64', 'datetime64[ns]'])
```
### Numerical Attributes
```
### Central Tendency -> Mean, Median
ct1 = pd.DataFrame(numAttributes.apply(np.mean)).T
ct2 = pd.DataFrame(numAttributes.apply(np.median)).T
### Dispersion -> std, min, max, range, skew, kurtosis
d1 = pd.DataFrame(numAttributes.apply(np.std)).T
d2 = pd.DataFrame(numAttributes.apply(min)).T
d3 = pd.DataFrame(numAttributes.apply(max)).T
d4 = pd.DataFrame(numAttributes.apply(lambda x: x.max() - x.min())).T
d5 = pd.DataFrame(numAttributes.apply(lambda x: x.skew())).T
d6 = pd.DataFrame(numAttributes.apply(lambda x: x.kurtosis())).T
# Concatenate
m = pd.concat([d2, d3, d4, ct1, ct2, d1, d5, d6]).T.reset_index()
m.columns = ['Attributes', 'Min', 'Max', 'Range', 'Mean', 'Median', 'Std', 'Skew', 'Kurtosis']
m
sns.displot(dfRaw1['CompetitionDistance'], kde=False, height=12, aspect=2)
```
### Categorical Atributes
```
catAttributes.apply(lambda x: x.unique().shape[0])
aux = dfRaw1[(dfRaw1['StateHoliday'] != '0') & (dfRaw1['Sales'] > 0)]
plt.subplot( 1, 3, 1 )
sns.boxplot( x='StateHoliday', y='Sales', data=aux )
plt.subplot( 1, 3, 2 )
sns.boxplot( x='StoreType', y='Sales', data=aux )
plt.subplot( 1, 3, 3 )
sns.boxplot( x='Assortment', y='Sales', data=aux )
```
## Convert DataFrame to .csv
```
dfRaw1.to_csv('../../01-Data/Results/01-FirstRoundCRISP/dfDescriptionData.csv', index=False)
```
| github_jupyter |
# Working with R
* **Difficulty level**: easy
* **Time need to lean**: 15 minutes or less
* **Key points**:
* There are intuitive corresponding data types between most Python (SoS) and R datatypes
## Installation
There are several options to install `R` and its jupyter kernel [irjernel](https://github.com/IRkernel/IRkernel), the easiest of which might be using `conda` but it could be tricky to install third-party libraries of R to conda, and mixing R packages from the `base` and `r` channels can lead to devastating results.
Anyway, after you have a working R installation with `irkernel` installed, you will need to install
* The `sos-r` language module,
* The `arrow` library of R, and
* The `feather-format` module of Python
The feature modules are needed to exchange dataframe between Python and R
## Overview
SoS transfers Python variables in the following types to R as follows:
| Python | condition | R |
| --- | --- |---|
| `None` | | `NULL` |
| `integer` | | `integer` |
| `integer` | `large` | `numeric` |
| `float` | | `numeric` |
| `boolean` | | `logical` |
| `complex` | | `complex` |
| `str` | | `character` |
| Sequence (`list`, `tuple`, ...) | homogenous type | `c()` |
| Sequence (`list`, `tuple`, ...) | multiple types | `list` |
| `set` | | `list` |
| `dict` | | `list` with names |
| `numpy.ndarray` | | array |
| `numpy.matrix` | | `matrix` |
| `pandas.DataFrame` | | R `data.frame` |
SoS gets variables in the following types to SoS as follows (`n` in `condition` column is the length of R datatype):
| R | condition | Python |
| --- | --- |---|
| `NULL` | | `None` |
| `logical` | `n == 1` | `boolean` |
| `integer` | `n == 1` | `integer` |
| `numeric` | `n == 1` | `double` |
| `character` | `n == 1` | `string` |
| `complex` | `n == 1` | `complex` |
| `logical` | `n > 1` | `list` |
| `integer` | `n > 1` | `list` |
| `complex` | `n > 1` | `list` |
| `numeric` | `n > 1` | `list` |
| `character` | `n > 1` | `list` |
| `list` without names | | `list` |
| `list` with names | | `dict` (with ordered keys)|
| `matrix` | | `numpy.array` |
| `data.frame` | | `DataFrame` |
| `array` | | `numpy.array` |
One of the key problems in mapping R datatypes to Python is that R does not have scalar types and all scalar variables are actually array of size 1. That is to say, in theory, variable `a=1` should be represented in Python as `a=[1]`. However, because Python does differentiate scalar and array values, we chose to represent R arraies of size 1 as scalar types in Python.
```
%put a b
a = c(1)
b = c(1, 2)
print(f'a={a} with type {type(a)}')
print(f'b={b} with type {type(b)}')
```
## Simple data types
Most simple Python data types can be converted to R types easily,
```
null_var = None
int_var = 123
float_var = 3.1415925
logic_var = True
char_var = '1"23'
comp_var = 1+2j
%get null_var int_var float_var logic_var char_var comp_var
%preview -n null_var int_var float_var logic_var char_var comp_var
```
The variables can be sent back to SoS without losing information
```
%get null_var int_var float_var logic_var char_var comp_var --from R
%preview -n null_var int_var float_var logic_var char_var comp_var
```
However, because Python allows integers of arbitrary precision which is not supported by R, large integers would be presented in R as float point numbers, which might not be able to keep the precision of the original number.
For example, if we put a large integer with 18 significant digits to R
```
%put large_int --to R
large_int = 123456789123456789
```
The last digit would be different because of floating point presentation
```
%put large_int
large_int
```
This is not a problem with SoS because you would get the same result if you enter this number in R
```
123456789123456789
```
Consequently, if you send `large_int` back to `SoS`, the number would be different
```
%get large_int --from R
large_int
```
## Array, matrix, and dataframe
The one-dimension (vector) data is converted from SoS to R as follows:
```
import numpy
import pandas
char_arr_var = ['1', '2', '3']
list_var = [1, 2, '3']
dict_var = dict(a=1, b=2, c='3')
set_var = {1, 2, '3'}
recursive_var = {'a': {'b': 123}, 'c': True}
logic_arr_var = [True, False, True]
seri_var = pandas.Series([1,2,3,3,3,3])
%get char_arr_var list_var dict_var set_var recursive_var logic_arr_var seri_var
%preview -n char_arr_var list_var dict_var set_var recursive_var logic_arr_var seri_var
```
The multi-dimension data is converted from SoS to R as follows:
```
num_arr_var = numpy.array([1, 2, 3, 4]).reshape(2,2)
mat_var = numpy.matrix([[1,2],[3,4]])
%get num_arr_var mat_var
%preview -n num_arr_var mat_var
```
The scalar data is converted from R to SoS as follows:
```
null_var = NULL
num_var = 123
logic_var = TRUE
char_var = '1\"23'
comp_var = 1+2i
%get null_var num_var logic_var char_var comp_var --from R
%preview -n null_var num_var logic_var char_var comp_var
```
The one-dimension (vector) data is converted from R to SoS as follows:
```
num_vector_var = c(1, 2, 3)
logic_vector_var = c(TRUE, FALSE, TRUE)
char_vector_var = c(1, 2, '3')
list_var = list(1, 2, '3')
named_list_var = list(a=1, b=2, c='3')
recursive_var = list(a=1, b=list(c=3, d='whatever'))
seri_var = setNames(c(1,2,3,3,3,3),c(0:5))
%get num_vector_var logic_vector_var char_vector_var list_var named_list_var recursive_var seri_var --from R
%preview -n num_vector_var logic_vector_var char_vector_var list_var named_list_var recursive_var seri_var
```
The multi-dimension data is converted from R to SoS as follows:
```
mat_var = matrix(c(1,2,3,4), nrow=2)
arr_var = array(c(1:16),dim=c(2,2,2,2))
%get mat_var arr_var --from R
%preview -n mat_var arr_var
```
It is worth noting that R's named `list` is transferred to Python as dictionaries but SoS preserves the order of the keys so that you can recover the order of the list. For example,
```
Rlist = list(A=1, C='C', B=3, D=c(2, 3))
```
Although the dictionary might appear to have different order
```
%get Rlist --from R
Rlist
```
The order of the keys and values are actually preserved
```
Rlist.keys()
Rlist.values()
```
so it is safe to enumerate the R list in Python as
```
for idx, (key, val) in enumerate(Rlist.items()):
print(f"{idx+1} item of Rlist has key {key} and value {val}")
```
| github_jupyter |
<img src="./pictures/DroneApp_logo.png" style="float:right; max-width: 180px; display: inline" alt="INSA" /></a>
<img src="./pictures/logo_sizinglab.png" style="float:right; max-width: 100px; display: inline" alt="INSA" /></a>
## Validation of mini drone MK4
_Written by Marc Budinger, Aitor Ochotorena (INSA Toulouse) and Scott Delbecq (ISAE Supaero)_

```
import scipy
import scipy.optimize
from math import pi
from math import sqrt
import math
import timeit
import time
import numpy as np
import ipywidgets as widgets
from ipywidgets import interactive
from IPython.display import display
import pandas as pd
```
#### 2.- Problem Definition
```
# Specifications
# Load
M_load=1 # [kg] load mass
# Autonomy
t_h=15 # [min] time of hover fligth
k_maxthrust=2.5 #[-] ratio max thrust
# Architecture of the multi-rotor drone (4,6, 8 arms, ...)
Narm=4 # [-] number of arm
Np_arm=1 # [-] number of propeller per arm (1 or 2)
Npro=Np_arm*Narm # [-] Propellers number
# Motor Architecture
Mod=0 # Chose between 0 for 'Direct Drive' or 1 for Gear Drive
#Maximum climb speed
V_cl=10 # [m/s] max climb speed
CD= 1.3 #[] drag coef
A_top=0.09/2 #[m^2] top surface. For a quadcopter: Atop=1/2*Lb^2+3*pi*Dpro^2/4
# Propeller characteristics
NDmax= 105000/60*.0254# [Hz.m] max speed limit (N.D max)
# Air properties
rho_air=1.18 # [kg/m^3] air density
# MTOW
MTOW = 2. # [kg] maximal mass
# Objectif
MaxTime=False # Objective
```
#### 3.- Sizing Code
```
# -----------------------
# sizing code
# -----------------------
# inputs:
# - param: optimisation variables vector (reduction ratio, oversizing coefficient)
# - arg: selection of output
# output:
# - objective if arg='Obj', problem characteristics if arg='Prt', constraints other else
def SizingCode(param, arg):
# Design variables
# ---
k_M=param[0] # over sizing coefficient on the load mass
k_mot=param[1] # over sizing coefficient on the motor torque
k_speed_mot=param[2] # over sizing coefficient on the motor speed
k_vb=param[3] # over sizing coefficient for the battery voltage
k_ND=param[4] # slow down propeller coef : ND = kNDmax / k_ND
D_ratio=param[5] # aspect ratio e/c (thickness/side) for the beam of the frame
k_Mb=param[6] # over sizing coefficient on the battery load mass
beta=param[7] # pitch/diameter ratio of the propeller
J=param[8] # advance ratio
k_ESC=param[9] # over sizing coefficient on the ESC power
if Mod==1:
Nred=param[10] # Reduction Ratio [-]
# Hover, Climbing & Take-Off thrust
# ---
Mtotal=k_M*M_load # [kg] Estimation of the total mass (or equivalent weight of dynamic scenario)
F_pro_hov=Mtotal*(9.81)/Npro # [N] Thrust per propeller for hover
F_pro_to=F_pro_hov*k_maxthrust # [N] Max Thrust per propeller
F_pro_cl=(Mtotal*9.81+0.5*rho_air*CD*A_top*V_cl**2)/Npro # [N] Thrust per propeller for climbing
# Propeller characteristicss
# Ref : APC static
C_t_sta=4.27e-02 + 1.44e-01 * beta # Thrust coef with T=C_T.rho.n^2.D^4
C_p_sta=-1.48e-03 + 9.72e-02 * beta # Power coef with P=C_p.rho.n^3.D^5
Dpro_ref=11*.0254 # [m] diameter
Mpro_ref=0.53*0.0283 # [kg] mass
# Ref: APC dynamics
C_t_dyn=0.02791-0.06543*J+0.11867*beta+0.27334*beta**2-0.28852*beta**3+0.02104*J**3-0.23504*J**2+0.18677*beta*J**2 # thrust coef for APC props in dynamics
C_p_dyn=0.01813-0.06218*beta+0.00343*J+0.35712*beta**2-0.23774*beta**3+0.07549*beta*J-0.1235*J**2 # power coef for APC props in dynamics
#Choice of diameter and rotational speed from a maximum thrust
Dpro=(F_pro_to/(C_t_sta*rho_air*(NDmax*k_ND)**2))**0.5 # [m] Propeller diameter
n_pro_to=NDmax*k_ND/Dpro # [Hz] Propeller speed
n_pro_cl=sqrt(F_pro_cl/(C_t_dyn*rho_air*Dpro**4)) # [Hz] climbing speed
# Propeller selection with take-off scenario
Wpro_to=n_pro_to*2*3.14 # [rad/s] Propeller speed
Mpro=Mpro_ref*(Dpro/Dpro_ref)**3 # [kg] Propeller mass
Ppro_to=C_p_sta*rho_air*n_pro_to**3*Dpro**5# [W] Power per propeller
Qpro_to=Ppro_to/Wpro_to # [N.m] Propeller torque
# Propeller torque& speed for hover
n_pro_hover=sqrt(F_pro_hov/(C_t_sta*rho_air*Dpro**4)) # [Hz] hover speed
Wpro_hover=n_pro_hover*2*3.14 # [rad/s] Propeller speed
Ppro_hover=C_p_sta*rho_air*n_pro_hover**3*Dpro**5# [W] Power per propeller
Qpro_hover=Ppro_hover/Wpro_hover # [N.m] Propeller torque
V_bat_est=k_vb*1.84*(Ppro_to)**(0.36) # [V] battery voltage estimation
#Propeller torque &speed for climbing
Wpro_cl=n_pro_cl*2*3.14 # [rad/s] Propeller speed for climbing
Ppro_cl=C_p_dyn*rho_air*n_pro_cl**3*Dpro**5# [W] Power per propeller for climbing
Qpro_cl=Ppro_cl/Wpro_cl # [N.m] Propeller torque for climbing
# Motor selection & scaling laws
# ---
# Motor reference sized from max thrust
# Ref : AXI 5325/16 GOLD LINE
Tmot_ref=2.32 # [N.m] rated torque
Tmot_max_ref=85/70*Tmot_ref # [N.m] max torque
Rmot_ref=0.03 # [Ohm] resistance
Mmot_ref=0.575 # [kg] mass
Ktmot_ref=0.03 # [N.m/A] torque coefficient
Tfmot_ref=0.03 # [N.m] friction torque (zero load, nominal speed)
#Motor speeds:
if Mod==1:
W_hover_motor=Wpro_hover*Nred # [rad/s] Nominal motor speed with reduction
W_cl_motor=Wpro_cl*Nred # [rad/s] Motor Climb speed with reduction
W_to_motor=Wpro_to*Nred # [rad/s] Motor take-off speed with reduction
else:
W_hover_motor=Wpro_hover # [rad/s] Nominal motor speed
W_cl_motor=Wpro_cl # [rad/s] Motor Climb speed
W_to_motor=Wpro_to # [rad/s] Motor take-off speed
#Motor torque:
if Mod==1:
Tmot_hover=Qpro_hover/Nred # [N.m] motor nominal torque with reduction
Tmot_to=Qpro_to/Nred # [N.m] motor take-off torque with reduction
Tmot_cl=Qpro_cl/Nred # [N.m] motor climbing torque with reduction
else:
Tmot_hover=Qpro_hover# [N.m] motor take-off torque
Tmot_to=Qpro_to # [N.m] motor take-off torque
Tmot_cl=Qpro_cl # [N.m] motor climbing torque
Tmot=k_mot*Tmot_hover# [N.m] required motor nominal torque for reductor
Tmot_max=Tmot_max_ref*(Tmot/Tmot_ref)**(1) # [N.m] max torque
Mmot=Mmot_ref*(Tmot/Tmot_ref)**(3/3.5) # [kg] Motor mass
# Selection with take-off speed
Ktmot=V_bat_est/(k_speed_mot*W_to_motor) # [N.m/A] or [V/(rad/s)] Kt motor (RI term is missing)
Rmot=Rmot_ref*(Tmot/Tmot_ref)**(-5/3.5)*(Ktmot/Ktmot_ref)**(2) # [Ohm] motor resistance
Tfmot=Tfmot_ref*(Tmot/Tmot_ref)**(3/3.5) # [N.m] Friction torque
# Hover current and voltage
Imot_hover = (Tmot_hover+Tfmot)/Ktmot # [I] Current of the motor per propeller
Umot_hover = Rmot*Imot_hover + W_hover_motor*Ktmot # [V] Voltage of the motor per propeller
P_el_hover = Umot_hover*Imot_hover # [W] Hover : output electrical power
# Take-Off current and voltage
Imot_to = (Tmot_to+Tfmot)/Ktmot # [I] Current of the motor per propeller
Umot_to = Rmot*Imot_to + W_to_motor*Ktmot # [V] Voltage of the motor per propeller
P_el_to = Umot_to*Imot_to # [W] Takeoff : output electrical power
# Climbing current and voltage
Imot_cl = (Tmot_cl+Tfmot)/Ktmot # [I] Current of the motor per propeller for climbing
Umot_cl = Rmot*Imot_cl + W_cl_motor*Ktmot # [V] Voltage of the motor per propeller for climbing
P_el_cl = Umot_cl*Imot_cl # [W] Power : output electrical power for climbing
#Gear box model
if Mod==1:
mg1=0.0309*Nred**2+0.1944*Nred+0.6389 # Ratio input pinion to mating gear
WF=1+1/mg1+mg1+mg1**2+Nred**2/mg1+Nred**2 # Weight Factor (ƩFd2/C) [-]
k_sd=1000 # Surface durability factor [lb/in]
C=2*8.85*Tmot_hover/k_sd # Coefficient (C=2T/K) [in3]
Fd2=WF*C # Solid rotor volume [in3]
Mgear=Fd2*0.3*0.4535 # Mass reducer [kg] (0.3 is a coefficient evaluated for aircraft application and 0.4535 to pass from lb to kg)
Fdp2=C*(Nred+1)/Nred # Solid rotor pinion volume [in3]
dp=(Fdp2/0.7)**(1/3)*0.0254 # Pinion diameter [m] (0.0254 to pass from in to m)
dg=Nred*dp # Gear diameter [m]
di=mg1*dp # Inler diameter [m]
# Battery selection & scaling laws sized from hover
# ---
# Battery
# Ref : Prolitex TP3400-4SPX25
Mbat_ref=.329 # [kg] mass
#Ebat_ref=4*3.7*3.3*3600 # [J] energy
#Ebat_ref=220*3600*.329 # [J]
Cbat_ref= 3.400*3600#[A.s]
Vbat_ref=4*3.7#[V]
Imax_ref=170#[A]
Ncel=V_bat_est/3.7# [-] Cell number, round (up value)
V_bat=3.7*Ncel # [V] Battery voltage
Mbat=k_Mb*M_load # Battery mass
# Hover --> autonomy
C_bat = Mbat/Mbat_ref*Cbat_ref/V_bat*Vbat_ref # [A.s] Capacity of the battery
I_bat = (P_el_hover*Npro)/.95/V_bat # [I] Current of the battery
t_hf = .8*C_bat/I_bat/60 # [min] Hover time
Imax=Imax_ref*C_bat/Cbat_ref # [A] max current battery
# ESC sized from max speed
# Ref : Turnigy K_Force 70HV
Pesc_ref=3108 # [W] Power
Vesc_ref=44.4 #[V]Voltage
Mesc_ref=.115 # [kg] Mass
P_esc=k_ESC*(P_el_to*V_bat/Umot_to) # [W] power electronic power max thrust
P_esc_cl=P_el_cl*V_bat/Umot_cl # [W] power electronic power max climb
Mesc = Mesc_ref*(P_esc/Pesc_ref) # [kg] Mass ESC
Vesc = Vesc_ref*(P_esc/Pesc_ref)**(1/3)# [V] ESC voltage
# Frame sized from max thrust
# ---
Mfra_ref=.347 #[kg] MK7 frame
Marm_ref=0.14#[kg] Mass of all arms
# Length calculation
# sep= 2*pi/Narm #[rad] interior angle separation between propellers
Lbra=Dpro/2/(math.sin(pi/Narm)) #[m] length of the arm
# Static stress
# Sigma_max=200e6/4 # [Pa] Alu max stress (2 reduction for dynamic, 2 reduction for stress concentration)
Sigma_max=280e6/4 # [Pa] Composite max stress (2 reduction for dynamic, 2 reduction for stress concentration)
# Tube diameter & thickness
Dout=(F_pro_to*Lbra*32/(pi*Sigma_max*(1-D_ratio**4)))**(1/3) # [m] outer diameter of the beam
D_ratio # [m] inner diameter of the beam
# Mass
Marm=pi/4*(Dout**2-(D_ratio*Dout)**2)*Lbra*1700*Narm # [kg] mass of the arms
Mfra=Mfra_ref*(Marm/Marm_ref)# [kg] mass of the frame
# Thrust Bearing reference
# Ref : SKF 31309/DF
Life=5000 # Life time [h]
k_bear=1
Cd_bear_ref=2700 # Dynamic reference Load [N]
C0_bear_ref=1500 # Static reference load[N]
Db_ref=0.032 # Exterior reference diameter [m]
Lb_ref=0.007 # Reference lenght [m]
db_ref=0.020 # Interior reference diametere [m]
Mbear_ref=0.018 # Reference mass [kg]
# Thrust bearing model"""
L10=(60*(Wpro_hover*60/2/3.14)*(Life/10**6)) # Nominal endurance [Hours of working]
Cd_ap=(2*F_pro_hov*L10**(1/3))/2 # Applied load on bearing [N]
Fmax=2*4*F_pro_to/2
C0_bear=k_bear*Fmax # Static load [N]
Cd_bear=Cd_bear_ref/C0_bear_ref**(1.85/2)*C0_bear**(1.85/2) # Dynamic Load [N]
Db=Db_ref/C0_bear_ref**0.5*C0_bear**0.5 # Bearing exterior Diameter [m]
db=db_ref/C0_bear_ref**0.5*C0_bear**0.5 # Bearing interior Diameter [m]
Lb=Lb_ref/C0_bear_ref**0.5*C0_bear**0.5 # Bearing lenght [m]
Mbear=Mbear_ref/C0_bear_ref**1.5*C0_bear**1.5 # Bearing mass [kg]
# Objective and Constraints sum up
# ---
if Mod==0:
Mtotal_final = (Mesc+Mpro+Mmot+Mbear)*Npro+M_load+Mbat+Mfra+Marm #total mass without reducer
else:
Mtotal_final = (Mesc+Mpro+Mmot+Mgear+Mbear)*Npro+M_load+Mbat+Mfra+Marm #total mass with reducer
if MaxTime==True:
constraints = [(Mtotal-Mtotal_final)/Mtotal_final,
(NDmax-n_pro_cl*Dpro)/NDmax,
(Tmot_max-Tmot_to)/Tmot_max,
(Tmot_max-Tmot_cl)/Tmot_max,
(-J*n_pro_cl*Dpro+V_cl),
0.01+(J*n_pro_cl*Dpro-V_cl),
(V_bat-Umot_to)/V_bat,
(V_bat-Umot_cl)/V_bat,
(V_bat-Vesc)/V_bat,
(V_bat*Imax-Umot_to*Imot_to*Npro/0.95)/(V_bat*Imax),
(V_bat*Imax-Umot_cl*Imot_cl*Npro/0.95)/(V_bat*Imax),
(P_esc-P_esc_cl)/P_esc,
(MTOW-Mtotal_final)/Mtotal_final
]
else:
constraints = [(Mtotal-Mtotal_final)/Mtotal_final,
(NDmax-n_pro_cl*Dpro)/NDmax,
(Tmot_max-Tmot_to)/Tmot_max,
(Tmot_max-Tmot_cl)/Tmot_max,
(-J*n_pro_cl*Dpro+V_cl),
0.01+(J*n_pro_cl*Dpro-V_cl),
(V_bat-Umot_to)/V_bat,
(V_bat-Umot_cl)/V_bat,
(V_bat-Vesc)/V_bat,
(V_bat*Imax-Umot_to*Imot_to*Npro/0.95)/(V_bat*Imax),
(V_bat*Imax-Umot_cl*Imot_cl*Npro/0.95)/(V_bat*Imax),
(P_esc-P_esc_cl)/P_esc,
(t_hf-t_h)/t_hf,
]
# Objective and contraints
if arg=='Obj':
P=0 # Penalisation nulle
if MaxTime==False:
for C in constraints:
if (C<0.):
P=P-1e9*C
return Mtotal_final+P # for mass optimisation
else:
for C in constraints:
if (C<0.):
P=P-1e9*C
return 1/t_hf+P # for time optimisation
elif arg=='Prt':
col_names_opt = ['Type', 'Name', 'Min', 'Value', 'Max', 'Unit', 'Comment']
df_opt = pd.DataFrame()
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'k_M', 'Min': bounds[0][0], 'Value': k_M, 'Max': bounds[0][1], 'Unit': '[-]', 'Comment': 'over sizing coefficient on the load mass '}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'k_mot', 'Min': bounds[1][0], 'Value': k_mot, 'Max': bounds[1][1], 'Unit': '[-]', 'Comment': 'over sizing coefficient on the motor torque '}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'k_speed_mot', 'Min': bounds[2][0], 'Value': k_speed_mot, 'Max': bounds[2][1], 'Unit': '[-]', 'Comment': 'over sizing coefficient on the motor speed'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'k_vb', 'Min': bounds[3][0], 'Value': k_vb, 'Max': bounds[3][1], 'Unit': '[-]', 'Comment': 'over sizing coefficient for the battery voltage'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'k_ND', 'Min': bounds[4][0], 'Value': k_ND, 'Max': bounds[4][1], 'Unit': '[-]', 'Comment': 'Ratio ND/NDmax'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'D_ratio', 'Min': bounds[5][0], 'Value': D_ratio, 'Max': bounds[5][1], 'Unit': '[-]', 'Comment': 'aspect ratio e/c (thickness/side) for the beam of the frame'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'k_Mb', 'Min': bounds[6][0], 'Value': k_Mb, 'Max': bounds[6][1], 'Unit': '[-]', 'Comment': 'over sizing coefficient on the battery load mass '}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'beta_pro', 'Min': bounds[7][0], 'Value': beta, 'Max': bounds[7][1], 'Unit': '[-]', 'Comment': 'pitch/diameter ratio of the propeller'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'J', 'Min': bounds[8][0], 'Value': J, 'Max': bounds[8][1], 'Unit': '[-]', 'Comment': 'Advance ratio'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'k_ESC', 'Min': bounds[9][0], 'Value': k_ESC, 'Max': bounds[9][1], 'Unit': '[-]', 'Comment': 'over sizing coefficient on the ESC power'}])[col_names_opt]
if Mod==1:
df_opt = df_opt.append([{'Type': 'Optimization', 'Name': 'N_red', 'Min': bounds[10][0], 'Value': N_red, 'Max': bounds[10][1], 'Unit': '[-]', 'Comment': 'Reduction ratio'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 0', 'Min': 0, 'Value': constraints[0], 'Max': '-', 'Unit': '[-]', 'Comment': '(Mtotal-Mtotal_final)'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 1', 'Min': 0, 'Value': constraints[1], 'Max': '-', 'Unit': '[-]', 'Comment': '(NDmax-n_pro_cl*Dpro)/NDmax'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 2', 'Min': 0, 'Value': constraints[2], 'Max': '-', 'Unit': '[-]', 'Comment': '(Tmot_max-Tmot_to)/Tmot_max'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 3', 'Min': 0, 'Value': constraints[3], 'Max': '-', 'Unit': '[-]', 'Comment': '(Tmot_max-Tmot_cl)/Tmot_max'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 4', 'Min': 0, 'Value': constraints[4], 'Max': '-', 'Unit': '[-]', 'Comment': '(-J*n_pro_cl*Dpro+V_cl)'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 5', 'Min': 0, 'Value': constraints[5], 'Max': '-', 'Unit': '[-]', 'Comment': '0.01+(+J*n_pro_cl*Dpro-V_cl)'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 6', 'Min': 0, 'Value': constraints[6], 'Max': '-', 'Unit': '[-]', 'Comment': '(V_bat-Umot_to)/V_bat'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 7', 'Min': 0, 'Value': constraints[7], 'Max': '-', 'Unit': '[-]', 'Comment': '(V_bat-Umot_cl)/V_bat'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 8', 'Min': 0, 'Value': constraints[8], 'Max': '-', 'Unit': '[-]', 'Comment': '(V_bat-Vesc)/V_bat'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 9', 'Min': 0, 'Value': constraints[9], 'Max': '-', 'Unit': '[-]', 'Comment': '(V_bat*Imax-Umot_to*Imot_to*Npro/0.95)/(V_bat*Imax)'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 10', 'Min': 0, 'Value': constraints[10], 'Max': '-', 'Unit': '[-]', 'Comment': '(V_bat*Imax-Umot_cl*Imot_cl*Npro/0.95)/(V_bat*Imax)'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 11', 'Min': 0, 'Value': constraints[11], 'Max': '-', 'Unit': '[-]', 'Comment': '(P_esc-P_esc_cl)/P_esc'}])[col_names_opt]
if MaxTime==False:
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 12', 'Min': 0, 'Value': constraints[12], 'Max': '-', 'Unit': '[-]', 'Comment': '(t_hf-t_h)/t_hf'}])[col_names_opt]
else:
df_opt = df_opt.append([{'Type': 'Constraints', 'Name': 'Const 12', 'Min': 0, 'Value': constraints[12], 'Max': '-', 'Unit': '[-]', 'Comment': '(MTOW-Mtotal_final)/Mtotal_final'}])[col_names_opt]
df_opt = df_opt.append([{'Type': 'Objective', 'Name': 'Objective', 'Min': 0, 'Value': Mtotal_final, 'Max': '-', 'Unit': '[kg]', 'Comment': 'Total mass'}])[col_names_opt]
col_names = ['Type', 'Name', 'Value', 'Unit', 'Comment']
df = pd.DataFrame()
df = df.append([{'Type': 'Propeller', 'Name': 'F_pro_to', 'Value': F_pro_to, 'Unit': '[N]', 'Comment': 'Thrust for 1 propeller during Take Off'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'F_pro_cl', 'Value': F_pro_cl, 'Unit': '[N]', 'Comment': 'Thrust for 1 propeller during Take Off'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'F_pro_hov', 'Value': F_pro_hov, 'Unit': '[N]', 'Comment': 'Thrust for 1 propeller during Hover'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'rho_air', 'Value': rho_air, 'Unit': '[kg/m^3]', 'Comment': 'Air density'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'ND_max', 'Value': NDmax, 'Unit': '[Hz.m]', 'Comment': 'Max speed limit (N.D max)'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'Dpro_ref', 'Value': Dpro_ref, 'Unit': '[m]', 'Comment': 'Reference propeller diameter'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'M_pro_ref', 'Value': Mpro_ref, 'Unit': '[kg]', 'Comment': 'Reference propeller mass'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'C_t_sta', 'Value': C_t_sta, 'Unit': '[-]', 'Comment': 'Static thrust coefficient of the propeller'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'C_t_dyn', 'Value': C_t_dyn, 'Unit': '[-]', 'Comment': 'Dynamic thrust coefficient of the propeller'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'C_p_sta', 'Value': C_p_sta, 'Unit': '[-]', 'Comment': 'Static power coefficient of the propeller'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'C_p_dyn', 'Value': C_p_dyn, 'Unit': '[-]', 'Comment': 'Dynamic power coefficient of the propeller'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'D_pro', 'Value': Dpro, 'Unit': '[m]', 'Comment': 'Diameter of the propeller'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'n_pro_cl', 'Value': n_pro_cl, 'Unit': '[Hz]', 'Comment': 'Rev speed of the propeller during climbing'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'n_pro_to', 'Value': n_pro_to, 'Unit': '[Hz]', 'Comment': 'Rev speed of the propeller during takeoff'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'n_pro_hov', 'Value': n_pro_hover, 'Unit': '[Hz]', 'Comment': 'Rev speed of the propeller during hover'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'P_pro_cl', 'Value': Ppro_cl, 'Unit': '[W]', 'Comment': 'Power on the mechanical shaft of the propeller during climbing'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'P_pro_to', 'Value': Ppro_to, 'Unit': '[W]', 'Comment': 'Power on the mechanical shaft of the propeller during takeoff'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'P_pro_hov', 'Value': Ppro_hover, 'Unit': '[W]', 'Comment': 'Power on the mechanical shaft of the propeller during hover'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'M_pro', 'Value': Mpro, 'Unit': '[kg]', 'Comment': 'Mass of the propeller'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'Omega_pro_cl', 'Value': Wpro_cl, 'Unit': '[rad/s]', 'Comment': 'Rev speed of the propeller during climbing'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'Omega_pro_to', 'Value': Wpro_to, 'Unit': '[rad/s]', 'Comment': 'Rev speed of the propeller during takeoff'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'Omega_pro_hov', 'Value': Wpro_hover, 'Unit': '[rad/s]', 'Comment': 'Rev speed of the propeller during hover'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'T_pro_hov', 'Value': Qpro_hover, 'Unit': '[N.m]', 'Comment': 'Torque on the mechanical shaft of the propeller during hover'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'T_pro_to', 'Value': Qpro_to, 'Unit': '[N.m]', 'Comment': 'Torque on the mechanical shaft of the propeller during takeoff'}])[col_names]
df = df.append([{'Type': 'Propeller', 'Name': 'T_pro_cl', 'Value': Qpro_cl, 'Unit': '[N.m]', 'Comment': 'Torque on the mechanical shaft of the propeller during climbing'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'T_max_mot_ref', 'Value': Tmot_max_ref, 'Unit': '[N.m]', 'Comment': 'Max torque'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'R_mot_ref', 'Value': Rmot_ref, 'Unit': '[Ohm]', 'Comment': 'Resistance'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'M_mot_ref', 'Value': Mmot_ref, 'Unit': '[kg]', 'Comment': 'Reference motor mass'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'K_mot_ref', 'Value': Ktmot_ref, 'Unit': '[N.m/A]', 'Comment': 'Torque coefficient'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'T_mot_fr_ref', 'Value': Tfmot_ref, 'Unit': '[N.m]', 'Comment': 'Friction torque (zero load, nominal speed)'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'T_nom_mot', 'Value': Tmot_hover, 'Unit': '[N.m]', 'Comment': 'Continuous of the selected motor torque'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'T_mot_to', 'Value': Tmot_to, 'Unit': '[N.m]', 'Comment': 'Transient torque possible for takeoff'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'T_max_mot', 'Value': Tmot_max, 'Unit': '[N.m]', 'Comment': 'Transient torque possible for climbing'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'R_mot', 'Value': Rmot, 'Unit': '[Ohm]', 'Comment': 'Resistance'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'M_mot', 'Value': Mmot, 'Unit': '[kg]', 'Comment': 'Motor mass'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'K_mot', 'Value': Ktmot, 'Unit': '[rad/s]', 'Comment': 'Torque constant of the selected motor'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'T_mot_fr', 'Value': Tfmot, 'Unit': '[N.m]', 'Comment': 'Friction torque of the selected motor'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'I_mot_hov', 'Value': Imot_hover, 'Unit': '[A]', 'Comment': 'Motor current for hover'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'I_mot_to', 'Value': Imot_to, 'Unit': '[A]', 'Comment': 'Motor current for takeoff'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'I_mot_cl', 'Value': Imot_cl, 'Unit': '[A]', 'Comment': 'Motor current for climbing'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'U_mot_cl', 'Value': Umot_hover, 'Unit': '[V]', 'Comment': 'Motor voltage for climbing'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'U_mot_to', 'Value': Umot_to, 'Unit': '[V]', 'Comment': 'Motor voltage for takeoff'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'U_mot', 'Value': Umot_hover, 'Unit': '[V]', 'Comment': 'Nominal voltage '}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'P_el_mot_cl', 'Value': P_el_cl, 'Unit': '[W]', 'Comment': 'Motor electrical power for climbing'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'P_el_mot_to', 'Value': P_el_to, 'Unit': '[W]', 'Comment': 'Motor electrical power for takeoff'}])[col_names]
df = df.append([{'Type': 'Motor', 'Name': 'P_el_mot_hov', 'Value': P_el_hover, 'Unit': '[W]', 'Comment': 'Motor electrical power for hover'}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'M_bat_ref', 'Value': Mbat_ref, 'Unit': '[kg]', 'Comment': 'Mass of the reference battery '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'M_esc_ref', 'Value': Mesc_ref, 'Unit': '[kg]', 'Comment': 'Reference ESC mass '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'P_esc_ref', 'Value': Pesc_ref, 'Unit': '[W]', 'Comment': 'Reference ESC power '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'N_s_bat', 'Value': np.ceil(Ncel), 'Unit': '[-]', 'Comment': 'Number of battery cells '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'U_bat', 'Value': V_bat, 'Unit': '[V]', 'Comment': 'Battery voltage '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'M_bat', 'Value': Mbat, 'Unit': '[kg]', 'Comment': 'Battery mass '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'C_bat', 'Value': C_bat, 'Unit': '[A.s]', 'Comment': 'Battery capacity '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'I_bat', 'Value': I_bat, 'Unit': '[A]', 'Comment': 'Battery current '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 't_hf', 'Value': t_hf, 'Unit': '[min]', 'Comment': 'Hovering time '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'P_esc', 'Value': P_esc, 'Unit': '[W]', 'Comment': 'Power electronic power (corner power or apparent power) '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'M_esc', 'Value': Mesc, 'Unit': '[kg]', 'Comment': 'ESC mass '}])[col_names]
df = df.append([{'Type': 'Battery & ESC', 'Name': 'V_esc', 'Value': Vesc, 'Unit': '[V]', 'Comment': 'ESC voltage '}])[col_names]
df = df.append([{'Type': 'Frame', 'Name': 'N_arm', 'Value': Narm, 'Unit': '[-]', 'Comment': 'Number of arms '}])[col_names]
df = df.append([{'Type': 'Frame', 'Name': 'N_pro_arm', 'Value': Np_arm, 'Unit': '[-]', 'Comment': 'Number of propellers per arm '}])[col_names]
df = df.append([{'Type': 'Frame', 'Name': 'sigma_max', 'Value': Sigma_max, 'Unit': '[Pa]', 'Comment': 'Max admisible stress'}])[col_names]
df = df.append([{'Type': 'Frame', 'Name': 'L_arm', 'Value': Lbra, 'Unit': '[m]', 'Comment': 'Length of the arm'}])[col_names]
df = df.append([{'Type': 'Frame', 'Name': 'D_out', 'Value': Dout, 'Unit': '[m]', 'Comment': 'Outer diameter of the arm (tube)'}])[col_names]
df = df.append([{'Type': 'Frame', 'Name': 'Marm', 'Value': Marm, 'Unit': '[kg]', 'Comment': '1 Arm mass'}])[col_names]
df = df.append([{'Type': 'Frame', 'Name': 'M_frame', 'Value': Mfra, 'Unit': '[kg]', 'Comment': 'Frame mass'}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'M_load', 'Value': M_load, 'Unit': '[kg]', 'Comment': 'Payload mass'}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 't_hf', 'Value': t_h, 'Unit': '[min]', 'Comment': 'Hovering time '}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'k_maxthrust', 'Value': k_maxthrust, 'Unit': '[-]', 'Comment': 'Ratio max thrust'}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'N_arm', 'Value': Narm, 'Unit': '[-]', 'Comment': 'Number of arms '}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'N_pro_arm', 'Value': Np_arm, 'Unit': '[-]', 'Comment': 'Number of propellers per arm '}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'V_cl', 'Value': V_cl, 'Unit': '[m/s]', 'Comment': 'Climb speed'}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'CD', 'Value': CD, 'Unit': '[-]', 'Comment': 'Drag coefficient'}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'A_top', 'Value': A_top, 'Unit': '[m^2]', 'Comment': 'Top surface'}])[col_names]
df = df.append([{'Type': 'Specifications', 'Name': 'MTOW', 'Value': MTOW, 'Unit': '[kg]', 'Comment': 'Max takeoff Weight'}])[col_names]
items = sorted(df['Type'].unique().tolist())+['Optimization']
return df, df_opt
else:
return constraints
```
### 4.-Optimization variables
```
#bounds design variables
bounds= [(1,400),#k_M
(1,20),#k_mot
(1,10),#k_speed_mot
(1,5),#k_vb
(0.01,1),#k_ND
(0.05,.99),#D_ratio
(.01,60),#k_Mb
(0.3,0.6),#beta
(0.01,0.5),#J
(1,15),#k_ESC
(1,20),#Nred
]
```
### 5.-Result
```
# optimization with SLSQP algorithm
contrainte=lambda x: SizingCode(x, 'Const')
objectif=lambda x: SizingCode(x, 'Obj')
# Differential evolution omptimisation
start = time.time()
result = scipy.optimize.differential_evolution(func=objectif,
bounds=[(1,400),#k_M
(1,20),#k_mot
(1,10),#k_speed_mot
(1,5),#k_vb
(0.01,1),#k_ND
(0.05,.99),#D_ratio
(.01,60),#k_Mb
(0.3,0.6),#beta
(0.01,0.5),#J
(1,15),#k_ESC
(1,20),#Nred
],maxiter=1000,
tol=1e-12)
# Final characteristics after optimization
end = time.time()
print("Operation time: %.5f s" %(end - start))
print("-----------------------------------------------")
print("Final characteristics after optimization :")
data=SizingCode(result.x, 'Prt')[0]
data_opt=SizingCode(result.x, 'Prt')[1]
pd.options.display.float_format = '{:,.3f}'.format
def view(x=''):
#if x=='All': return display(df)
if x=='Optimization' : return display(data_opt)
return display(data[data['Type']==x])
items = sorted(data['Type'].unique().tolist())+['Optimization']
w = widgets.Select(options=items)
interactive(view, x=w)
```
**RESULTS**
|Specs.MK4|Value|
|--|--|
|Payload:| 1.0 kg|
|k_{max,thrust}| 2.5|
|Number of arms: | 4 |
|Number of propeller per arm | 1|
|Climb speed:| 10 $m/s$ |
|Drag coefficient:| 1.3 |
|Autonomy:| 15 $min$ |
|Top surface:| 0.045 $m^2$ |\\
|Specs.MK4|Reference|Algorithm|
|--|--|--|
|Total mass (g)| 1642|1613|
|Battery Mass (g) | {353} | 387 |
|Motor Mass (g) | {47} | 37 |
|Diameter Prop (m) | {0.25} | 0.22 |
|Energy (W.h) | {53.95} | 48.84 |
|Max Power (W) | {172.99} | 141 |
| github_jupyter |
# 3 - Logistic Regression from Scratch
In this tutorial we are doing logistic regression, more specifically binary logistic regression. Logistic regression involves classifying each example in a set of examples into one of $N$ classes. Binary logistic regression is a special case of logistic regression in which we only have two classes.
We are going to create logistic regression model that can correctly classify if a point belongs to class 0 or class 1 from its x, y co-ordinates. Classes are also referred to as labels, i.e. if an example belongs to class 0, we can say it has a label of 0.
Our model will use 3 parameters to predict the class. These predictions will be in the form of a real number between 0 and 1. The initial parameters will give poor predictions, but we update them using *gradient descent* in order to improve our performance.
## Generating the Data
First, we'll import our libraries, `matplotlib` for plotting and `numpy` for its functionality.
```
import matplotlib.pyplot as plt
import numpy as np
```
We'll set `numpy`'s random seed to ensure the notebook is deterministic.
```
np.random.seed(1)
```
Now we'll generate the points that make up our dataset.
In this toy example we are going to create examples that are points in 2-dimensional space. Examples from class 0 will have their x and y co-ordinates both be drawn from a Gaussian distribution with a mean of 3 and class 1 will have their examples drawn examples from a Gaussian with a mean of 6.
This basically means all examples in class 0 are centered around the point $(3,3)$ and all examples in class 1 are centered around $(6, 6)$.
We'll generate 1000 examples of each class.
```
x0s = np.random.normal(loc=3, size=(1000, 2)) # examples for class 0
y0s = np.zeros(1000) # labels for class 0
x1s = np.random.normal(loc=6, size=(1000, 2)) # examples for class 1
y1s = np.ones(1000) # labels for class 1
```
We concatenate the examples from each class together into a single `numpy` array.
```
xs = np.concatenate((x0s, x1s)) #all examples
ys = np.concatenate((y0s, y1s)) #all labels
```
Thus, our data, `xs`, is represented by a $(2000,2)$ matrix, where each row is an example, the first column, `xs[:,0]`, holds the x co-ordinates of the examples, while the second column, `xs[:,1]`, holds the y co-ordinates of the examples.
Our labels, `y`, are a $2000$-dimensional vector, with each element being either 0 or 1, to denote which class the corresponding `xs` example belongs to, i.e. the label for `xs[0]` is `y[0]`.
Next, we'll plot the data to see what it looks like, with examples from class 0 in purple and examples from class 1 in yellow.
```
plt.scatter(xs[:,0], xs[:,1], c=ys, alpha=0.25)
plt.show()
```
## Defining the Error/Loss
Next, we define our error function (also called a loss function). This is a function that calculates how "good" our predictions are, or "far away" our predictions are from the correct class. This is known as the *error* or *loss*. This will be used to tell us how much we need to update our parameters during gradient descent. If our error is small, we only change the parameters a small amount, whereas if the error is large, they need to be changed by a larger amount.
Unlike linear regression where we used mean squared error (MSE), here we'll use cross-entropy loss.
The equation for cross-entropy loss of example $n$ is given by:
$$e_n = - y_n \log(\hat{y_n}) - (1 - y_n) \log(1 - \hat{y_n})$$
$y_n$ denotes the label for example $n$, $\hat{y_n}$ (pronounced "y hat") denotes the model's prediction for example $n$ and $\log$ denotes the natural logarithm.
Looking at the case when the label ($y_n$) is 0, the loss equation simplifies to:
$$e_0 = - \log(1 - \hat{y_n})$$
When we are correct, ($\hat{y_n} = 0$), then we will have:
$$e_0 = - \log(1) = 0$$
Zero error when we are perfectly correct! However, if we are incorrect ($\hat{y_n} \ne 0$), then $e_0$ gets larger the further away $\hat{y_n}$ is from $y$.
Looking at the case when the label is 1, the loss equation becomes:
$$e_1 = - \log(\hat{y_n})$$
When we are correct, ($\hat{y_n} = 1$), then we have:
$$e_1 = - \log(1) = 0$$
Again, a zero error. Like before, the further away $\hat{y_n}$ is from 1, the larger the error.
```
def calc_error(y_hat, y, eps=1e-10):
"""
Cross-entropy loss between labels, y, and predictions, y_hat
"""
error = - y * np.log(y_hat + eps) - (1 - y) * np.log(1 - y_hat + eps)
return error
```
In the equations above, when $y = 0$ then we could ignore the whole $-y\log(\hat{y})$ term, however Python will try to calculate each term in the loss equation without simplifying. In the case where $\hat{y}=0$, this will cause Python to try and calculate $\log(0)$, which is $\infty$, and causes some warnings/errors.
To avoid this, we use a small epsilon term $\epsilon$, `eps`. This very small number is used to ensure that we never try and calculate $\log(0)$.
To check that it works, let's try check when $\hat{y} = y$. From above, we're expecting a small number, however because of the `eps` term, we will never actually get value of 0.
```
print(calc_error(0, 0))
print(calc_error(1, 1))
```
That's definitely a small number! It never becomes exactly zero because of the $\epsilon$ terms. This doesn't really matter though as our goal is to *minimize* the loss function, so the more negative we can get it, the better!
We'll define another function that averages the loss across all examples.
```
def calc_errors(y_hats, ys):
"""
Calculates the average error between a list of predictions, y_hats
and a list of labels, ys.
"""
error = np.mean([calc_error(y_hat, y) for y_hat, y in zip(y_hats, ys)])
return error
```
Unlike linear regression where the output is an unbounded real number, in binary regression the output is a real number bound between $[0,1]$. This is because you are trying to predict if an example belongs to class 0 or 1.
You can think of the real number output by the model as an indication of how strongly it believes this example should belong to a certain class, i.e. if the regressor outputs 0.1 it's pretty certain this example belongs to class 0 and if it outputs 0.6 it's not really sure, but leaning towards class 1.
How do we bound the output between $[0,1]$? We use a *sigmoid* function, which looks like this:

The sigmoid function "squashes" values between 0 and 1, i.e. large positive and negative values cause it to output approx. 1 and 0, respectively.
The equation for the sigmoid function is given by:
$$\sigma(x) = \frac{1}{1 + e^{-x}}$$
We can easily implement this in Python:
```
def sigmoid(x):
return 1 / (1 + np.e ** -x)
```
And to verify we have implemented it correctly:
```
print(f'sigmoid(large positive) = {sigmoid( 100)}')
print(f'sigmoid(large negative) = {sigmoid(-100)}')
```
## Making Predictions
Next, we'll define the variables of our model. Our model has two inputs, the x co-ordinate and the y co-ordinate, which we denote $x_0$ and $x_1$. We'll use one parameter for each, $w_0$ and $w_1$, along with a bias term, $b$. The output of our regressor is a weighted sum of the inputs and parameters, plus a bias term, and fed through the sigmoid function to give us an output $[0,1]$.
$$\hat{y} = \sigma ( w_0 x_0 + w_1 x_1 + b)$$
Commonly you will see the weighted sum terms denoted by $z$:
$$z = w_0 x_0 + w_1 x_1 + b$$
Therefore, we can also write:
$$\hat{y} = \sigma(z)$$
Let's define our initial values for $w_0, w_1, b$ which we'll initialize randomly.
```
pred_w0 = np.random.normal()
pred_w1 = np.random.normal()
pred_b = np.random.normal()
```
Next, we'll write a function that takes in an example and uses the current $w_0, w_1, b$ values to make a prediction.
As well as measuring the loss of the model, we also want to see how accurate it is. To do this we must categorize each of the real value predictions between 0 and 1 into a class.
The simplest way to do this is to say any values $\ge 0.5$ belong to class 1, and any $\lt 0.5$ belong to class 0.
Our `predict` function calculates and returns both the real value as well as the predicted class.
```
def predict(pred_w0, pred_w1, pred_b, x):
pred_val = sigmoid(pred_w0 * x[0] + pred_w1 * x[1] + pred_b)
pred_class = 1 if pred_val >= 0.5 else 0
return pred_val, pred_class
```
We'll also define a `predicts` function that returns predictions for all examples.
The `map(np.array, zip(*...` here is looks a bit complicated, but breaking it down:
- the list comprehension returns a list of two element tuples (`pred_val`, `pred_class`)
- the `zip(*...` converts the list of tuples into two tuples, one with all the `pred_val` and one with all the `pred_class`
- the `map(np.array, ...` converts the two `pred_val` and `pred_class` tuples into `numpy` arrays
We want them as `numpy` arrays so we can do certain operations on them.
```
def predicts(pred_w0, pred_w1, pred_b, xs):
pred_vals, pred_classes = map(np.array, zip(*[predict(pred_w0, pred_w1, pred_b, x) for x in xs]))
return pred_vals, pred_classes
```
Let's use our initial $w_0, w_1, b$ values to make some predictions.
We'll denote the predicted class as $\hat{c}$.
```
y_hats, c_hats = predicts(pred_w0, pred_w1, pred_b, xs)
```
We can find out how many of our predicted classes were correct out of the 2000 in our dataset.
We do this by summing the number of times $\hat{c} = y$
```
n_correct = (c_hats == ys).sum()
print(n_correct)
```
We can also convert this into an accuracy
```
accuracy = n_correct / len(c_hats)
print(accuracy)
```
50.6% is pretty bad, and is not really any better than random guessing without even looking at the values.
However, our next function will implement gradient descent, which we'll use to update our parameters and get a much better accuracy.
## Implementing Gradient Descent
Let's remind ourself of some equations:
\begin{align*}
z &= w_0 x_0 + w_1 x_1 + b\\
\hat{y} &= \sigma (z)\\
e &= - y \log(\hat{y}) - (1 - y) \log(1 - \hat{y})
\end{align*}
Looking at a single parameter in our regressor, $w_0$, we can see how changing $w_0$ will change the value of $z$, which changes $\hat{y}$, which changes $e$.
We want to find how much to change $w_0$ to reduce $e$, as our main goal is minimizing the error. We can imagine the relationship between $w_0$ and $e$ as something like:

That is, there is some optimal value of $w_0$ which gives us the minimum $e$ we can achieve.
In reality, the values of $w_1$ and $b$ interact with $w_0$ to find the minimum $e$, however for the purpose of this explanation we'll assume that $w_1$ and $b$ are fixed and $w_0$ is the only parameter we can change.
When we randomly initialize $w_0$, it starts at some point on this graph. We show this in red below:

We want to end up at the lowest point in the graph, called the global minimum, as this gives us the lowest error. We do this by taking small steps and *descending* the graph, following the *gradient* (the slope of the graph), i.e. gradient descent! We can also think of the gradient/slope as the rate of change between the two values, i.e. when the graph is steep the rate of change between them is high as $w_0$ changes only a little, whilst $e$ changes a lot more.
Thus, we want to calculate the gradient of $e$ with respect to $w_0$ to give us something like the graph above. Once we have this, we can calculate the gradient of our current $w_0$ value, which gives us both the steepness of the slope $w_0$ is currently on, and also tells us if the slope is going up or down.
The steepness of the slope (the magnitude of the gradient) is used to tell us how big of a step we take. If we are on a very steep slope then we can take a large step as we can assume we are not near the minimum. As the slope gets flatter we assume we are closer to the minimum and thus take smaller steps to avoid stepping over the minimum.
The direction of the slope (the sign of the gradient) tells us which direction to walk in. If the gradient is negative, i.e. pointing "downwards" like the left hand side of the figures above, then we increase $w_0$. If the gradient is positive, i.e. pointing "upwards" like the right hand side of the figures above, then we need to decrease $w_0$.
After we have calculated the gradient of our current $w_0$, we take a single step towards the minimum, recalculate the gradient, and then take another step. We repeatedly take steps until we have reached the minimum point of the graph.

How do we actually calculate gradients? We calculate the gradient of $e$ with respect to $w_0$ by taking the *derivative* of $e$ with respect to $w_0$ (you can also say *differentiate* $e$ with respect to $w_0$) and it is denoted by:
$$\frac{\partial e}{\partial w_0}$$
We're going to go deep into exactly how to differentiate functions, so if you don't know how to calculate them I'd suggesting doing the [Khan Academy track](https://www.khanacademy.org/math/calculus-home/taking-derivatives-calc). If you don't know how they work, all you need to know is that the derivative of a function with respect to a variable is the gradient/slope of the function with respect to that variable.
Finding $\frac{\partial e}{\partial w_0}$ isn't as straightforward as you might think. As already stated, changing $w_0$ also changes $z$, which changes $\hat{y}$, which changes $e$. Thus, to calculate the gradient between $e$ and $w_0$ we need to calculate the gradients between: $z$ and $w_0$, $\hat{y}$ and $z$, $e$ and $z$. These gradients are also calculated by taking their derivatives. We can re-write $\frac{\partial e}{\partial w_0}$ in terms of the products of each of the derivatives:
$$\frac{\partial e}{\partial w_0} = \frac{\partial e}{\partial \hat{y}} * \frac{\partial \hat{y}}{\partial z} * \frac{\partial z}{\partial w_0} $$
If we can calculate the three terms on the right, we'll have found the gradient of $e$ with respect to $w_0$ and can then use this gradient to update our $w_0$.
First, $\frac{\partial e}{\partial \hat{y}}$. This is how much the cross-entropy loss changes with respect to the prediction, we calculate this by taking the derivative of $e$ with respect to $\hat{y}$.
\begin{align*}
\frac{\partial e}{\partial \hat{y}} &= \frac{\partial}{\partial \hat{y}} - y \log(\hat{y}) - (1 - y) \log(1 - \hat{y})\\[0.5ex]
&= - (\frac{\partial}{\partial \hat{y}}y \log(\hat{y}) + (1 - y) \log(1 - \hat{y}))\\[0.5ex]
&= - (\frac{\partial}{\partial \hat{y}} y \log(\hat{y}) + \frac{\partial}{\partial \hat{y}}(1 - y) \log(1 - \hat{y}))\\[0.5ex]
&= -(\frac{y}{\hat{y}} - \frac{1-y}{1-\hat{y}})\\[0.5ex]
&= -\frac{y}{\hat{y}} + \frac{1-y}{1-\hat{y}}\\[0.5ex]
&= -\frac{y(1-\hat{y})}{\hat{y}(1-\hat{y})} + \frac{\hat{y}(1-y)}{\hat{y}(1-\hat{y})}\\[0.5ex]
&= \frac{-y(1-\hat{y})+(1-y)\hat{y}}{\hat{y}(1-\hat{y})}\\[0.5ex]
&= \frac{-y + y\hat{y} + \hat{y} - y\hat{y}}{\hat{y}(1-\hat{y})}\\[0.5ex]
&= \frac{\hat{y}-y}{\hat{y}(1-\hat{y})}
\end{align*}
Second, $\frac{\partial \hat{y}}{\partial z}$ is the rate of change between the output of the sigmoid function with respect to its input. This is done by taking the derivative of the sigmoid function:
\begin{align*}
\frac{\partial \hat{y}}{\partial z} &= \frac{\partial }{\partial z} \sigma (z) \\[0.5ex]
&= \frac{\partial }{\partial z} \frac{1}{1+e^{-z}} \\[0.5ex]
&= \frac{e^{-z}}{(1+e^{-z})^2}\\[0.5ex]
&= \frac{1+e^{-z}-1}{(1+e^{-z})^2}\\[0.5ex]
&= \frac{1+e^{-z}}{(1+e^{-z})^2} - (\frac{1}{1+e^{-z}})^2\\[0.5ex]
&= \frac{1}{(1+e^{-z})} - (\frac{1}{1+e^{-z}})^2\\[0.5ex]
&= \sigma (z) - \sigma (z)^2\\[0.5ex]
&= \sigma (z) (1 - \sigma (z))\\[0.5ex]
&= \hat{y} (1 - \hat{y})
\end{align*}
Finally, $\frac{\partial z}{\partial w_0}$ is the derivative of the weighted sum with respect to $w_0$.
\begin{align*}
\frac{\partial z}{\partial w_0} &= \frac{\partial }{\partial w_0} w_0 x_0 + w_1 x_1 + b \\[0.5ex]
&= x_0 \\
\end{align*}
Thus, the gradient of $e$ with respect to $w_0$ is:
\begin{align*}
\frac{\partial e}{\partial w_0} &= \frac{\partial e}{\partial \hat{y}} * \frac{\partial \hat{y}}{\partial z} * \frac{\partial z}{\partial w_0} \\[0.5ex]
&= \frac{\hat{y}-y}{\hat{y}(1-\hat{y})} * \hat{y} (1 - \hat{y}) * x_0 \\[0.5ex]
&= (\hat{y}-y) * x_0
\end{align*}
We calculate average gradient value over all of our $N$ examples and use it to update $w_0$. We update $w_0$ as:
$$w_0 = w_0 - (\eta * \frac{\partial e}{\partial w_0})$$
$\eta$ is called the *learning rate*, it is used to control the how much we update $w_0$. If your $\eta$ value is too small, your parameter updates will be tiny and your loss will take forever to minimize. If the value of $\eta$ is too big then the parameter updates will be huge and you may step over the minimum. The value of $\eta$ depends on the task but is usually around $10^{-1}$ and $10^{-4}$.
We are subtracting the $\eta * \frac{\partial e}{\partial w_0}$ term from $w_0$ as we are *descending* the gradient. Remember, if the gradient is positive it is pointing upwards, but we want to go downwards towards the minimum.
To find out how much we need to change $w_1$, we take the derivative of $e$ with respect to $w_1$. Similar to before, we calculate this as:
$$\frac{\partial e}{\partial w_1} = \frac{\partial e}{\partial \hat{y}} * \frac{\partial \hat{y}}{\partial z} * \frac{\partial z}{\partial w_1}$$
Both $\frac{\partial e}{\partial \hat{y}}$ and $\frac{\partial \hat{y}}{\partial z}$ are the exact same as before. We only need to calculate $\frac{\partial z}{\partial w_1}$:
\begin{align*}
\frac{\partial z}{\partial w_1} &= \frac{\partial }{\partial w_1} w_0 x_0 + w_1 x_1 + b \\[0.5ex]
&= x_1 \\
\end{align*}
Therefore, the gradient for $w_1$ is:
\begin{align*}
\frac{\partial e}{\partial w_1} &= \frac{\partial e}{\partial \hat{y}} * \frac{\partial \hat{y}}{\partial z} * \frac{\partial z}{\partial w_1} \\[0.5ex]
&= \frac{\hat{y}-y}{\hat{y}(1-\hat{y})} * \hat{y} (1 - \hat{y}) * x_1 \\[0.5ex]
&= (\hat{y}-y) * x_1
\end{align*}
For updating $b$, again $\frac{\partial e}{\partial \hat{y}}$ and $\frac{\partial \hat{y}}{\partial z}$ are the same. The only difference is $\frac{\partial z}{\partial b}$:
\begin{align*}
\frac{\partial z}{\partial b} &= \frac{\partial }{\partial b} w_0 x_0 + w_1 x_1 + b \\[0.5ex]
&= 1 \\
\end{align*}
Thus, the gradient for $b$ is:
\begin{align*}
\frac{\partial e}{\partial b} &= \frac{\partial e}{\partial \hat{y}} * \frac{\partial \hat{y}}{\partial z} * \frac{\partial z}{\partial b} \\[0.5ex]
&= \frac{\hat{y}-y}{\hat{y}(1-\hat{y})} * \hat{y} (1 - \hat{y}) * 1 \\[0.5ex]
&= (\hat{y}-y) * 1\\[0.5ex]
&= (\hat{y}-y)
\end{align*}
$w_1$ and $b$ are updated as:
\begin{align*}
w_1 &= w_1 - (\eta * \frac{\partial e}{\partial w_1})\\[0.5ex]
b &= b - (\eta * \frac{\partial e}{\partial b})
\end{align*}
And that's it! We've got our three equations for calculating the gradients for each parameter with respect to the loss and our three equations for updating our parameters using their gradients!
We implement this in code below. `gradient_step` calculates the gradients for every example, averaging them across all examples, and then performs a parameter update. As $\frac{\partial e}{\partial \hat{y}}$ and $\frac{\partial \hat{y}}{\partial z}$ can be simplified together they are combined into a single `dedz` variable.
```
def gradient_step(pred_w0, pred_w1, pred_b, xs, ys, eta=0.1):
"""
Performs one gradient descent step using all of the data points
pred_w0 (float): predicted w0 value
pred_w1 (float): predicted w1 value
pred_b (float): predicted b value
xs (ndarray[float,float]): x values for data points
ys (ndarray[float]): y values for data points
eta (float): learning rate
"""
N = len(xs) #number of examples, used to average gradients
grad_w0 = 0
grad_w1 = 0
grad_b = 0
for x, y in zip(xs, ys):
y_hat, _ = predict(pred_w0, pred_w1, pred_b, x) #get prediction
#de = (y_hat - y) / (y_hat * (1 - y_hat)) #derivative of error w.r.t. prediction
#dz = y_hat * (1 - y_hat) #derivative of sigmoid
dedz = y_hat - y #simplified equation for the two derivatives above
dw0 = x[0] #derivative of sigmoid w.r.t w0
dw1 = x[1] #derivative of sigmoid w.r.t w1
grad_w0 += (1/N) * dedz * dw0 #summing averaged gradients for w0
grad_w1 += (1/N) * dedz * dw1 #summing averaged gradients for w1
grad_b += (1/N) * dedz #summing averaged gradients for b
new_w0 = pred_w0 - (eta * grad_w0) #parameter update for w0
new_w1 = pred_w1 - (eta * grad_w1) #parameter update for w1
new_b = pred_b - (eta * grad_b) #parameter update for b
return new_w0, new_w1, new_b
```
We'll take 500 gradient steps, whilst calculating both the error and the accuracy after each step.
```
errors = []
accs = []
for _ in range(500):
pred_w0, pred_w1, pred_b = gradient_step(pred_w0, pred_w1, pred_b, xs, ys)
y_hats, c_hats = predicts(pred_w0, pred_w1, pred_b, xs)
error = calc_errors(y_hats, ys)
acc = np.equal(c_hats, ys).sum()/len(c_hats)
errors.append(error)
accs.append(acc)
```
Next, we'll plot the error and the accuracy of each step.
```
plt.plot(errors)
plt.ylabel('Cross-Entropy Loss')
plt.xlabel('Gradient Step')
plt.show()
plt.plot(accs)
plt.ylabel('Accuracy')
plt.xlabel('Gradient Step')
plt.show()
```
Now, with our updated parameters, let's check our accuracy.
```
y_hats, c_hats = predicts(pred_w0, pred_w1, pred_b, xs)
n_correct = (c_hats == ys).sum()
print(n_correct)
accuracy = n_correct / len(c_hats)
print(accuracy)
```
97.45% is a lot better than our 50.6% we started with!
We can also see which examples our regressor got wrong by checking where $\hat{c} \neq y$
```
incorrect_examples = np.where(np.equal(c_hats, ys) == False)
```
We then get the $x,y$ co-ordinates of these points.
```
incorrect_points = xs[incorrect_examples]
```
And we can plot our original data, overlaying a red cross over each example our regressor got wrong.
```
plt.scatter(xs[:,0], xs[:,1], c=ys, alpha=0.25)
plt.scatter(incorrect_points[:,0], incorrect_points[:,1], c='r', marker='x', alpha=0.75, s=20)
plt.show()
```
If we look at the ones we got wrong, we can actually see they're pretty sensible!
It seems all the errors were either at the point where the two classes overlap, or where examples from class 0 have overlapped into class 1's territory!
| github_jupyter |
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d
%%bash
# remove previous blockMeshDict that may exist
rm extMesh/system/blockMeshDict
```
# 0. Input values
## 0.0 Case parameters
```
target_yplus = 10 # target of y_plus value
U = 10 # freestream velocity in m/s
mu = 0.00001789 # viscosity in Pa*s
rho = 1.225 # density in kg/m^3
```
## 0.1 Basic parameters
```
chord = 1 # chord of the airfoil
percChord = 0.25 # percentage of the chord in which the block cut is made
Vspace = 3*chord # vertical space above and below the airfoil
wake = 7*chord # horizontal space after the trailing edge
minZ = 0.0 # minimum z-coordinate value
maxZ = 0.1 # maximum z-coordinate value
```
## 0.2 Profile configuration
```
NACAtype = '2410' # NACA 4 digit airfoil
```
## 0.3 Grid configuration
```
inflowXcells = 60 # number of cells ahead the airfoil
middleXcells = 50 # number of cells over the airfoil
outflowXcells = 350 # number of cells downstream the airfoil
yCells = 40 # number of cells above and below the airfoil
zCells = 1 # number of cells in the z-direction
```
## 0.4 Airfoil chord configuration
```
noPoints = inflowXcells + middleXcells # number of points of the airfoil (and therefore upstream and over the airfoil)
percentage = np.array([0.1, 0.15, 0.375, 0.375]) # percentage distribution of points in the chord the first two must add to percChord
divisions = np.array([0.18, 0.12, 0.4, 0.3]) # location of the noPoints divisions over the chord
expansionR = np.array([3, 1.5, 1.8, 0.8]) # expansion ratio of each one of the divisions
```
## 0.5 Grading of Y direction
```
expansionRatioYdir = 1.321 # expansion ratio of the y direction (BL)
NoLayers = 15 # number of layers of the boundary layer
yGradingOutflow = 30 # grading on the outflow direction (after BL)
```
## 0.6 Grading of outflow X direction
```
xGradingOutflow = 2 # grading on the outflow direction
```
# 1. Function declaration
```
def NACA4(s,c):
# Definition of the NACA profile as a string 'XXXX'
NACA = s
# fixed chord line
c = c
# NACA 4 digits are defined as XXXX = m p (pt)
# maximum camber
m = int(int(NACA)/1e3)/1e2
# location of maximum camber
p = int((int(NACA)-m*1e5)/1e2)/1e1
# percentage of thickness with respect to the chord
pt = int((int(NACA)-m*1e5-p*1e3))
# figure declaration
fig = plt.gcf()
fig.set_size_inches(20,12)
ax1 = plt.subplot(1,2,1)
ax2 = plt.subplot(1,2,2)
# mean camber line definition
# non-symmetrical airfoil
if p != 0:
# coordinates of the X axis
x = np.append(np.linspace(0,p/100*c,200)[:-1],np.linspace(p/100*c,c,200))
# masked array to create the piece-wise function
x_pc = x<(p*c)
# upper and lower surfaces
yc1 = ((c*m)/(p**2))*(2*p*(x/c)-(x/c)**2)
yc2 = ((c*m)/((1-p)**2))*((1-2*p)+2*p*(x/c)-(x/c)**2)
# matrix for the whole airfoil surface
yc = np.zeros(np.shape(x))
# store the surfaces as corresponds
for i in range(np.shape(x)[0]):
if x_pc[i] == True:
yc[i] = yc1[i]
else:
yc[i] = yc2[i]
# compute the mean camber line derivative for each surface
dyc1dx = (2*m)/(p**2)*(p-(x/c))
dyc2dx = (2*m)/((1-p)**2)*(p-(x/c))
# matrix for the whole airfoil mean camber line derivative
dycdx = np.zeros(np.shape(x))
# store the mean camber line derivative as corresponds
for i in range(np.shape(x)[0]):
if x_pc[i] == True:
dycdx[i] = dyc1dx[i]
else:
dycdx[i] = dyc2dx[i]
# compute the angle of the derivative
theta = np.arctan(dycdx)
# plot the mean camber line
ax1.plot(x,yc1,'--k',label='yc1')
ax1.plot(x,yc2,'-.k',label='yc2')
ax1.plot(x,0.02*x_pc,':',color='grey', label='Masked matrix')
ax1.plot(x,yc,'b-',label='Mean camber Line')
ax1.legend()
# symmetric airfoil
else:
# coordinates of the X axis
x = np.linspace(0,c,400)
# matrix for the whole airfoil surface
yc = np.zeros(np.shape(x))
# plot the mean camber line
ax1.plot(x,yc,'b-',label='Mean camber Line')
ax1.legend()
# compute the thicknes
# non-symmetrical airfoil
if p != 0:
# compute the thickness
yt = 5*pt/100*(0.2969*np.sqrt(x/c)-0.1260*(x/c)-0.3516*(x/c)**2+0.2843*(x/c)**3-0.1036*(x/c)**4)
# correct the coordinates of the mean camber line
xu = x - yt*np.sin(theta)
xl = x + yt*np.sin(theta)
yu = yc + yt*np.cos(theta)
yl = yc - yt*np.cos(theta)
# plot the airfoil
ax2.set_xlim(-c*0.1,1.1*c)
ax2.axis('equal')
ax2.axis('off')
ax2.plot(xu,yu,'b')
ax2.plot(xl,yl,'b')
ax2.fill_between(x, yu, yl,facecolor='blue',alpha=0.1)
ax2.plot(x,yc,'r',linewidth=0.7)
ax2.plot([0,c],[0,0],'g',linewidth=0.6)
return xu, xl, yu, yl
# symmetric airfoil
else:
# compute the thickness
yt = 5*pt/100*(0.2969*np.sqrt(x/c)-0.1260*(x/c)-0.3516*(x/c)**2+0.2843*(x/c)**3-0.1036*(x/c)**4)
# plot the airfoil
ax2.set_xlim(-c*0.1,1.1*c)
ax2.axis('equal')
ax2.axis('off')
ax2.plot(x,yt,'b')
ax2.plot(x,-yt,'b')
ax2.fill_between(x, -yt, yt,facecolor='blue',alpha=0.1)
ax2.plot(x,yc,'r',linewidth=0.7)
ax2.plot([0,c],[0,0],'g',linewidth=0.6)
return x, x, yt, -yt
def simple_grading(N, expRatio, L):
# size of each cell array
delta = np.zeros(N)
# position of the nodes
nodes = np.zeros(N+1)
# value of k for all the line
kVal = expRatio**((1)/(N-1))
# increment of k for each cell
k = np.zeros(N)
# compute that incremental k
for i in range(N):
k[i] = kVal**(i)
# first cell size
deltaS = L/np.sum(k)
# size of each cell
delta = deltaS*k
# compute the location of the nodes
for i in range(N):
nodes[i+1] = nodes[i] + delta[i]
return nodes
def multi_grading(perc, cells, eps, N, L):
# some initial shape and value comprobations
if np.sum(perc) != 1:
raise ValueError('Bad percentage array input')
return
if np.sum(cells) != 1:
raise ValueError('Bad cell array input')
return
if np.shape(perc)[0] != np.shape(cells)[0] or np.shape(perc)[0] != np.shape(eps)[0] or np.shape(cells)[0] != np.shape(eps)[0]:
raise ValueError('Non equal vector definition')
return
# cells per segment
segmentN = (N*cells)
# in case there are decimal values
restCells = np.modf(segmentN)[0]
# integer value of the cells
segmentN = np.trunc(segmentN)
# distribution of the 'decimal' parts of the cells
i = np.sum(restCells)
# compute the correct subdivisions of the cells
while i > 0:
segmentN[np.argmax(restCells)] = segmentN[np.argmax(restCells)] + int(i)
restCells[np.argmax(restCells)] = 0
i -= 1
# length per segment
segmentL = (L*perc)
# number of nodes
nodes = np.zeros(N+1)
# compute the location of each node in the line
for i in range(np.shape(perc)[0]):
nodesTemp = simple_grading(int(segmentN[i]), eps[i], segmentL[i])
for j in range(np.shape(nodesTemp)[0]):
if i == 0:
nodes[j] = nodesTemp[j]
else:
nodes[int(np.cumsum(segmentN)[i-1]) + j] = nodesTemp[j] + nodes[int(np.cumsum(segmentN)[i-1])]
return nodes
def grading_plot(x): #nodes is the input from simple_grading
# get a y-coordinate vector for the x-shape
y = 0.5*np.ones(np.shape(x)[0])
# create the figure
fig, ax = plt.subplots(figsize=(20, 1), dpi=100)
# plot the line and the nodes
ax.set_xlim(-x[1]*0.5,1.1*x[-1])
ax.set_ylim(0,1)
ax.axis('off')
ax.plot([x[0],x[-1]],[y[0],y[-1]],'k')
ax.scatter(x,y,c='k')
def airfoilTrueX(newX, xu, yu, xl, yl):
# get the interpolation functions for both surfaces
yuF = interp1d(xu, yu, kind='cubic')
ylF = interp1d(xl, yl, kind='cubic')
# evaluate the function in the new x-axis coordinates
yuAxis = yuF(newX)
ylAxis = ylF(newX)
# return the new y-axis coordinates referred to newX
return yuAxis, ylAxis
def BLcalculator(target_yplus, U, L, mu, rho, flow, expansionRatio, NoLayers, length, totalCells, grid_dir, outerYgrad):
# calculator of the boundary layer parameters from the different values
# computation of the Reynolds number
Re = (rho*U*L)/(mu)
# external flow friction coefficient
if flow == 'e':
cf = 0.058*Re**(-0.2)
# internal flow friction coefficient
else:
cf = 0.079*Re**(-0.25)
# height of the first cell
dy1 = target_yplus*mu/(rho*np.sqrt(0.5*cf*U**2))
# preallocation of space for the location of each layer
layerSize = dy1*np.ones(NoLayers)
# computation of the height of each layer
for i in range (1, NoLayers):
layerSize[i] = layerSize[i-1]*expansionRatio
# cumulative sum of the size of the layers, giving the total y coordinate
yCoord = np.cumsum(layerSize)
# length of the boundary layer
BL_length = yCoord[-1]
# expansion ration of the boundary layer for blockMesh
bm_expRatio = expansionRatio**(NoLayers-1)
# if the grid is oriented towards the surface
if grid_dir == 't':
# percentage of the length is divided as
perc = np.array([BL_length/length, 1-BL_length/length])
# number of cells is divided as
cells = np.array([NoLayers/totalCells, (totalCells-NoLayers)/totalCells])
# expansion ratio
exp = np.array([bm_expRatio, outerYgrad])
# if it is oriented away from it
else:
# percentage of the length is divided as
perc = np.array([1-BL_length/length, BL_length/length])
# number of cells is divided as
cells = np.array([(totalCells-NoLayers)/totalCells, NoLayers/totalCells])
# expansion ratio
exp = np.array([outerYgrad, bm_expRatio])
return perc, cells, exp
```
# 2. Point calculations
### 2.1. Spline points
```
# compute a finer axis for the profile spline than for the mesh
xAxis = multi_grading(percentage, divisions, expansionR, 10*noPoints, chord)
# compute the points of the NACA profile
xu, xl, yu, yl = NACA4(NACAtype, chord)
# compute the NACA4 airfoil in the xAXis where it will intersect the mesh
yuAxis, ylAxis = airfoilTrueX(xAxis, xu, yu, xl, yl)
# some comprobations of the percentage array
if any(np.isin(np.cumsum(percentage), percChord*np.ones(len(percentage)))) == False:
raise ValueError('Bad percentage array declaration')
if percentage[0]+percentage[1] != percChord:
raise ValueError('Bad percentage array declaration')
# plot the grading of the x-axis
grading_plot(xAxis)
```
### 2.2. Vertice points
```
# compute the twelve points of the mesh for the initial block configuration
zero = np.array([-Vspace, 0.0])
one = np.array([1-chord, 0.0])
two = np.array([1-chord+xAxis[(np.abs(xAxis-percChord*chord)).argmin()], yuAxis[(np.abs(xAxis-percChord*chord)).argmin()]])
three = np.array([1-chord+xAxis[(np.abs(xAxis-percChord*chord)).argmin()], Vspace])
four = np.array([1.0, Vspace])
five = np.array([1.0, 0.0])
six = np.array([wake, Vspace])
seven = np.array([wake, 0.0])
eight = np.array([wake, -Vspace])
nine = np.array([1.0, -Vspace])
ten = np.array([1-chord+xAxis[(np.abs(xAxis-percChord*chord)).argmin()], -Vspace])
eleven = np.array([1-chord+xAxis[(np.abs(xAxis-percChord*chord)).argmin()], ylAxis[(np.abs(xAxis-percChord*chord)).argmin()]])
```
### 2.3. Expansion ratios
```
# compute the percentage of length, cells and expansion ratios of the boundary layer
percYdir, cellsYdir, expYdir = BLcalculator(target_yplus, U, chord, mu, rho, 'e', expansionRatioYdir, NoLayers, Vspace, yCells, 't', yGradingOutflow)
```
### 2.4. Blocks definition
```
# class to order a little the code
class blocksClass:
def __init__(self, nodes, cellNo, grading):
self.nodes = nodes
self.cells = cellNo
self.grading = grading
# definition of the nodes of the 6 blocks
nodes = np.array([[1,2,3,0,13,14,15,12], # block0
[2,5,4,3,14,17,16,15], # block1
[5,7,6,4,17,19,18,16], # block2
[13,23,22,12,1,11,10,0], # block3
[23,17,21,22,11,5,9,10], # block4
[17,19,20,21,5,7,8,9]]) # block5
# number of cells for each block
cellsNo = np.array([[inflowXcells, yCells, zCells], # block0
[middleXcells, yCells, zCells], # block1
[outflowXcells, yCells, zCells], # block2
[inflowXcells, yCells, zCells], # block3
[middleXcells, yCells, zCells], # block4
[outflowXcells, yCells, zCells]]) # block5
# grading of each block
grading = np.array([[[[percentage[0], divisions[0], expansionR[0]],[percentage[1], divisions[1], expansionR[1]]], [[percYdir[0], cellsYdir[0], expYdir[0]],[percYdir[1], cellsYdir[1], expYdir[1]]], 1], # block0
[[[percentage[2], divisions[2], expansionR[2]],[percentage[3], divisions[3], expansionR[3]]], [[percYdir[0], cellsYdir[0], expYdir[0]],[percYdir[1], cellsYdir[1], expYdir[1]]], 1], # block1
[xGradingOutflow, [[percYdir[0], cellsYdir[0], expYdir[0]],[percYdir[1], cellsYdir[1], expYdir[1]]], 1], # block2
[[[percentage[0], divisions[0], expansionR[0]],[percentage[1], divisions[1], expansionR[1]]], [[percYdir[0], cellsYdir[0], expYdir[0]],[percYdir[1], cellsYdir[1], expYdir[1]]], 1], # block3
[[[percentage[2], divisions[2], expansionR[2]],[percentage[3], divisions[3], expansionR[3]]], [[percYdir[0], cellsYdir[0], expYdir[0]],[percYdir[1], cellsYdir[1], expYdir[1]]], 1], # block4
[xGradingOutflow, [[percYdir[0], cellsYdir[0], expYdir[0]],[percYdir[1], cellsYdir[1], expYdir[1]]], 1]]) # block5
# object creation
blocks = blocksClass(nodes, cellsNo, grading)
```
### 2.5. Arc edge
```
# definition of the outer arc to go from a linear shape to a circular type inlet patch
arc = np.array([Vspace*np.cos(np.deg2rad(45)), Vspace*np.sin(np.deg2rad(45))])
```
### 2.6. Boundaries
```
# creation of a class for the boundaries included in the blockMesh
class boundaryClass:
def __init__(self, name, Btype, faceNo, faces):
self.name = name
self.type = Btype
self.faceNo = faceNo
self.faces = faces
# name of the boundary
boundName = np.array(['inlet', 'outlet', 'airfoil', 'frontAndBack'])
# type of boundary
boundType = np.array(['patch', 'patch', 'patch', 'empty'])
# number of faces
boundFaceNo = np.array([4, 4, 4, 12])
# points that make up every face
boundFaces = np.array([[[3, 15, 12, 0], [0, 12, 22, 10], [10, 22, 21, 9], [9, 21, 20, 8]],
[[15, 3, 4, 16], [16, 4, 6, 18], [18, 6, 7, 19], [19, 7, 8, 20]],
[[2, 14, 17, 5], [5, 17, 23, 11], [13, 1, 11, 23], [14, 2, 1, 13]],
[[15, 14, 13, 12], [15, 16, 17, 14], [16, 18, 19, 17], [17, 19, 20, 21], [23, 17, 21, 22], [12, 13, 23, 22],
[2, 3, 0, 1], [4, 3, 2, 5], [6, 4, 7, 5], [1, 0, 10, 11], [11, 10, 9, 5], [5, 9, 8, 7]]])
# object creation
boundary = boundaryClass(boundName, boundType, boundFaceNo, boundFaces)
```
# 3. Header
```
with open('./extMesh/system/blockMeshDict', 'a') as bMD:
bMD.write('/*--------------------------------*- C++ -*----------------------------------*\ \n')
bMD.write('| ========= | | \n')
bMD.write('| \\ / F ield | OpenFOAM: The Open Source CFD Toolbox | \n')
bMD.write('| \\ / O peration | Version: 5 | \n')
bMD.write('| \\ / A nd | Web: www.OpenFOAM.org | \n')
bMD.write('| \\/ M anipulation | | \n')
bMD.write('\*---------------------------------------------------------------------------*/ \n')
bMD.write('\n')
bMD.write('FoamFile \n')
bMD.write('{ \n')
bMD.write(' version 2.0; \n')
bMD.write(' format ascii; \n')
bMD.write(' class dictionary; \n')
bMD.write(' object blockMeshDict;; \n')
bMD.write('} \n')
bMD.write('// * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * // \n')
bMD.write('\n')
bMD.write('convertToMeters 1; \n')
bMD.write('\n')
```
# 4. Vertices
```
with open('./extMesh/system/blockMeshDict', "a") as bMD:
bMD.write('vertices \n')
bMD.write('( \n')
bMD.write(' (%.8f %.8f %.8f) \n' %(zero[0], zero[1], minZ)) #0
bMD.write(' (%.8f %.8f %.8f) \n' %(one[0], one[1], minZ)) #1
bMD.write(' (%.8f %.8f %.8f) \n' %(two[0], two[1], minZ)) #2
bMD.write(' (%.8f %.8f %.8f) \n' %(three[0], three[1], minZ)) #3
bMD.write(' (%.8f %.8f %.8f) \n' %(four[0], four[1], minZ)) #4
bMD.write(' (%.8f %.8f %.8f) \n' %(five[0], five[1], minZ)) #5
bMD.write(' (%.8f %.8f %.8f) \n' %(six[0], six[1], minZ)) #6
bMD.write(' (%.8f %.8f %.8f) \n' %(seven[0], seven[1], minZ)) #7
bMD.write(' (%.8f %.8f %.8f) \n' %(eight[0], eight[1], minZ)) #8
bMD.write(' (%.8f %.8f %.8f) \n' %(nine[0], nine[1], minZ)) #9
bMD.write(' (%.8f %.8f %.8f) \n' %(ten[0], ten[1], minZ)) #10
bMD.write(' (%.8f %.8f %.8f) \n' %(eleven[0], eleven[1], minZ)) #11
bMD.write(' (%.8f %.8f %.8f) \n' %(zero[0], zero[1], maxZ)) #12
bMD.write(' (%.8f %.8f %.8f) \n' %(one[0], one[1], maxZ)) #13
bMD.write(' (%.8f %.8f %.8f) \n' %(two[0], two[1], maxZ)) #14
bMD.write(' (%.8f %.8f %.8f) \n' %(three[0], three[1], maxZ)) #15
bMD.write(' (%.8f %.8f %.8f) \n' %(four[0], four[1], maxZ)) #16
bMD.write(' (%.8f %.8f %.8f) \n' %(five[0], five[1], maxZ)) #17
bMD.write(' (%.8f %.8f %.8f) \n' %(six[0], six[1], maxZ)) #18
bMD.write(' (%.8f %.8f %.8f) \n' %(seven[0], seven[1], maxZ)) #19
bMD.write(' (%.8f %.8f %.8f) \n' %(eight[0], eight[1], maxZ)) #20
bMD.write(' (%.8f %.8f %.8f) \n' %(nine[0], nine[1], maxZ)) #21
bMD.write(' (%.8f %.8f %.8f) \n' %(ten[0], ten[1], maxZ)) #22
bMD.write(' (%.8f %.8f %.8f) \n' %(eleven[0], eleven[1], maxZ)) #23
bMD.write('); \n')
bMD.write('\n')
```
# 5. Blocks
```
with open('./extMesh/system/blockMeshDict', "a") as bMD:
bMD.write('blocks \n')
bMD.write('( \n')
for i in range(len(blocks.nodes)):
bMD.write(' hex (%i %i %i %i %i %i %i %i) (%i %i %i) simpleGrading\n' %(blocks.nodes[i][0], blocks.nodes[i][1],
blocks.nodes[i][2], blocks.nodes[i][3],
blocks.nodes[i][4], blocks.nodes[i][5],
blocks.nodes[i][6], blocks.nodes[i][7],
blocks.cells[i][0], blocks.cells[i][1],
blocks.cells[i][2]))
bMD.write(' ( \n')
for j in range(len(blocks.grading[i])):
if isinstance(blocks.grading[i][j], int) == False:
bMD.write(' ( \n')
for k in range(len(blocks.grading[i][j])):
bMD.write(' (%.3f %.3f %.3f) \n' %(blocks.grading[i][j][k][0], blocks.grading[i][j][k][1], blocks.grading[i][j][k][2]))
bMD.write(' ) \n')
else:
bMD.write(' %.3f \n' %(blocks.grading[i][j]))
bMD.write(' ) \n')
bMD.write('); \n')
bMD.write('\n')
```
# 6. Edges
```
with open('./extMesh/system/blockMeshDict', "a") as bMD:
bMD.write('edges \n')
bMD.write('( \n')
bMD.write(' arc 0 3 (%.8f %.8f %.8f) \n' %(-arc[0], arc[1], minZ))
bMD.write(' arc 12 15 (%.8f %.8f %.8f) \n' %(-arc[0], arc[1], maxZ))
bMD.write(' arc 0 10 (%.8f %.8f %.8f) \n' %(-arc[0], -arc[1], minZ))
bMD.write(' arc 12 22 (%.8f %.8f %.8f) \n' %(-arc[0], -arc[1], maxZ))
bMD.write(' spline 1 11 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin()):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], ylAxis[i], minZ))
bMD.write(' ) \n')
bMD.write(' spline 1 2 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin()):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], yuAxis[i], minZ))
bMD.write(' ) \n')
bMD.write(' spline 11 5 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin(), len(xAxis)):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], ylAxis[i], minZ))
bMD.write(' ) \n')
bMD.write(' spline 2 5 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin(), len(xAxis)):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], yuAxis[i], minZ))
bMD.write(' ) \n')
bMD.write(' spline 13 23 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin()):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], ylAxis[i], maxZ))
bMD.write(' ) \n')
bMD.write(' spline 13 14 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin()):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], yuAxis[i], maxZ))
bMD.write(' ) \n')
bMD.write(' spline 23 17 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin(), len(xAxis)):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], ylAxis[i], maxZ))
bMD.write(' ) \n')
bMD.write(' spline 14 17 ( \n')
for i in range((np.abs(xAxis-percChord*chord)).argmin(), len(xAxis)):
bMD.write(' (%.8f %.8f %.8f) \n' %(xAxis[i], yuAxis[i], maxZ))
bMD.write(' ) \n')
bMD.write('); \n')
bMD.write('\n')
fig, ax1 = plt.subplots(1, figsize = ((20,3)))
# figure with the points that will be represented
ax1.plot(xAxis, ylAxis, '.r')
ax1.plot(xAxis, yuAxis, '.b')
ax1.axis('off');
```
# 7. Boundary
```
with open('./extMesh/system/blockMeshDict', "a") as bMD:
bMD.write('boundary \n')
bMD.write('( \n')
for i in range(len(boundary.name)):
bMD.write(' %s \n' %boundary.name[i])
bMD.write(' { \n')
bMD.write(' type %s; \n' %boundary.type[i])
bMD.write(' faces \n')
bMD.write(' ( \n')
for j in range(boundary.faceNo[i]):
bMD.write(' (%i %i %i %i) \n' %(boundary.faces[i][j][0], boundary.faces[i][j][1], boundary.faces[i][j][2], boundary.faces[i][j][3]))
bMD.write(' ); \n')
bMD.write(' } \n')
bMD.write('); \n')
```
# 8. blockMesh and paraFoam
```
%%bash
cd extMesh/
blockMesh
checkMesh
nohup paraFoam
```
| github_jupyter |
<table class="ee-notebook-buttons" align="left">
<td><a target="_parent" href="https://github.com/giswqs/geemap/tree/master/tutorials/Image/09_edge_detection.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" /> View source on GitHub</a></td>
<td><a target="_parent" href="https://nbviewer.jupyter.org/github/giswqs/geemap/blob/master/tutorials/Image/09_edge_detection.ipynb"><img width=26px src="https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png" />Notebook Viewer</a></td>
<td><a target="_parent" href="https://colab.research.google.com/github/giswqs/geemap/blob/master/tutorials/Image/09_edge_detection.ipynb"><img width=26px src="https://www.tensorflow.org/images/colab_logo_32px.png" /> Run in Google Colab</a></td>
</table>
# Edge detection
[Edge detection](http://en.wikipedia.org/wiki/Edge_detection) is applicable to a wide range of image processing tasks. In addition to the edge detection kernels described in the [convolutions section](https://developers.google.com/earth-engine/image_convolutions.html), there are several specialized edge detection algorithms in Earth Engine. The Canny edge detection algorithm ([Canny 1986](http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4767851)) uses four separate filters to identify the diagonal, vertical, and horizontal edges. The calculation extracts the first derivative value for the horizontal and vertical directions and computes the gradient magnitude. Gradients of smaller magnitude are suppressed. To eliminate high-frequency noise, optionally pre-filter the image with a Gaussian kernel. For example:
## Install Earth Engine API and geemap
Install the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geemap](https://github.com/giswqs/geemap). The **geemap** Python package is built upon the [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet) and [folium](https://github.com/python-visualization/folium) packages and implements several methods for interacting with Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, and `Map.centerObject()`.
The following script checks if the geemap package has been installed. If not, it will install geemap, which automatically installs its [dependencies](https://github.com/giswqs/geemap#dependencies), including earthengine-api, folium, and ipyleaflet.
**Important note**: A key difference between folium and ipyleaflet is that ipyleaflet is built upon ipywidgets and allows bidirectional communication between the front-end and the backend enabling the use of the map to capture user input, while folium is meant for displaying static data only ([source](https://blog.jupyter.org/interactive-gis-in-jupyter-with-ipyleaflet-52f9657fa7a)). Note that [Google Colab](https://colab.research.google.com/) currently does not support ipyleaflet ([source](https://github.com/googlecolab/colabtools/issues/60#issuecomment-596225619)). Therefore, if you are using geemap with Google Colab, you should use [`import geemap.eefolium`](https://github.com/giswqs/geemap/blob/master/geemap/eefolium.py). If you are using geemap with [binder](https://mybinder.org/) or a local Jupyter notebook server, you can use [`import geemap`](https://github.com/giswqs/geemap/blob/master/geemap/geemap.py), which provides more functionalities for capturing user input (e.g., mouse-clicking and moving).
```
# Installs geemap package
import subprocess
try:
import geemap
except ImportError:
print('geemap package not installed. Installing ...')
subprocess.check_call(["python", '-m', 'pip', 'install', 'geemap'])
# Checks whether this notebook is running on Google Colab
try:
import google.colab
import geemap.eefolium as emap
except:
import geemap as emap
# Authenticates and initializes Earth Engine
import ee
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()
```
## Create an interactive map
The default basemap is `Google Satellite`. [Additional basemaps](https://github.com/giswqs/geemap/blob/master/geemap/geemap.py#L13) can be added using the `Map.add_basemap()` function.
```
Map = emap.Map(center=[40,-100], zoom=4)
Map.add_basemap('ROADMAP') # Add Google Map
Map
```
## Add Earth Engine Python script
```
# Load a Landsat 8 image, select the panchromatic band.
image = ee.Image('LANDSAT/LC08/C01/T1/LC08_044034_20140318').select('B8')
# Perform Canny edge detection and display the result.
canny = ee.Algorithms.CannyEdgeDetector(**{
'image': image, 'threshold': 10, 'sigma': 1
})
Map.setCenter(-122.054, 37.7295, 10)
Map.addLayer(canny, {}, 'canny')
```
Note that the `threshold` parameter determines the minimum gradient magnitude and the `sigma` parameter is the standard deviation (SD) of a Gaussian pre-filter to remove high-frequency noise. For line extraction from an edge detector, Earth Engine implements the Hough transform ([Duda and Hart 1972](http://dl.acm.org/citation.cfm?id=361242)). Continuing the previous example, extract lines from the Canny detector with:
```
# Perform Hough transform of the Canny result and display.
hough = ee.Algorithms.HoughTransform(canny, 256, 600, 100)
Map.addLayer(hough, {}, 'hough')
```
Another specialized algorithm in Earth Engine is `zeroCrossing()`. A zero-crossing is defined as any pixel where the right, bottom, or diagonal bottom-right pixel has the opposite sign. If any of these pixels is of opposite sign, the current pixel is set to 1 (zero-crossing); otherwise it's set to zero. To detect edges, the zero-crossings algorithm can be applied to an estimate of the image second derivative. The following demonstrates using `zeroCrossing()` for edge detection:
```
# Load a Landsat 8 image, select the panchromatic band.
image = ee.Image('LANDSAT/LC08/C01/T1/LC08_044034_20140318').select('B8')
Map.addLayer(image, {'max': 12000})
# Define a "fat" Gaussian kernel.
fat = ee.Kernel.gaussian(**{
'radius': 3,
'sigma': 3,
'units': 'pixels',
'normalize': True,
'magnitude': -1
})
# Define a "skinny" Gaussian kernel.
skinny = ee.Kernel.gaussian(**{
'radius': 3,
'sigma': 1,
'units': 'pixels',
'normalize': True,
})
# Compute a difference-of-Gaussians (DOG) kernel.
dog = fat.add(skinny)
# Compute the zero crossings of the second derivative, display.
zeroXings = image.convolve(dog).zeroCrossing()
Map.setCenter(-122.054, 37.7295, 10)
Map.addLayer(zeroXings.updateMask(zeroXings), {'palette': 'FF0000'}, 'zero crossings')
Map.addLayerControl()
Map
```
The zero-crossings output for an area near the San Francisco, CA airport should look something like Figure 1.
| github_jupyter |
# Pong with Dueling Dqn
## Step 1: Import the libraries
```
import time
import gym
import random
import torch
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
from IPython.display import clear_output
import math
%matplotlib inline
import sys
sys.path.append('../../')
from algos.agents import DDQNAgent
from algos.models import DDQNCnn
from algos.preprocessing.stack_frame import preprocess_frame, stack_frame
```
## Step 2: Create our environment
Initialize the environment in the code cell below.
```
env = gym.make('Pong-v0')
env.seed(0)
# if gpu is to be used
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Device: ", device)
```
## Step 3: Viewing our Enviroment
```
print("The size of frame is: ", env.observation_space.shape)
print("No. of Actions: ", env.action_space.n)
env.reset()
plt.figure()
plt.imshow(env.reset())
plt.title('Original Frame')
plt.show()
```
### Execute the code cell below to play Pong with a random policy.
```
def random_play():
score = 0
env.reset()
while True:
env.render()
action = env.action_space.sample()
state, reward, done, _ = env.step(action)
score += reward
if done:
env.close()
print("Your Score at end of game is: ", score)
break
random_play()
```
## Step 4:Preprocessing Frame
```
env.reset()
plt.figure()
plt.imshow(preprocess_frame(env.reset(), (30, -4, -12, 4), 84), cmap="gray")
plt.title('Pre Processed image')
plt.show()
```
## Step 5: Stacking Frame
```
def stack_frames(frames, state, is_new=False):
frame = preprocess_frame(state, (30, -4, -12, 4), 84)
frames = stack_frame(frames, frame, is_new)
return frames
```
## Step 6: Creating our Agent
```
INPUT_SHAPE = (4, 84, 84)
ACTION_SIZE = env.action_space.n
SEED = 0
GAMMA = 0.99 # discount factor
BUFFER_SIZE = 100000 # replay buffer size
BATCH_SIZE = 1024 # Update batch size
LR = 0.002 # learning rate
TAU = .1 # for soft update of target parameters
UPDATE_EVERY = 100 # how often to update the network
UPDATE_TARGET = 10000 # After which thershold replay to be started
EPS_START = 0.99 # starting value of epsilon
EPS_END = 0.01 # Ending value of epsilon
EPS_DECAY = 100 # Rate by which epsilon to be decayed
agent = DDQNAgent(INPUT_SHAPE, ACTION_SIZE, SEED, device, BUFFER_SIZE, BATCH_SIZE, GAMMA, LR, TAU, UPDATE_EVERY, UPDATE_TARGET, DDQNCnn)
```
## Step 7: Watching untrained agent play
```
# watch an untrained agent
state = stack_frames(None, env.reset(), True)
for j in range(200):
env.render()
action = agent.act(state, .9)
next_state, reward, done, _ = env.step(action)
state = stack_frames(state, next_state, False)
if done:
break
env.close()
```
## Step 8: Loading Agent
Uncomment line to load a pretrained agent
```
start_epoch = 0
scores = []
scores_window = deque(maxlen=20)
```
## Step 9: Train the Agent with DQN
```
epsilon_by_epsiode = lambda frame_idx: EPS_END + (EPS_START - EPS_END) * math.exp(-1. * frame_idx /EPS_DECAY)
plt.plot([epsilon_by_epsiode(i) for i in range(1000)])
def train(n_episodes=1000):
"""
Params
======
n_episodes (int): maximum number of training episodes
"""
for i_episode in range(start_epoch + 1, n_episodes+1):
state = stack_frames(None, env.reset(), True)
score = 0
eps = epsilon_by_epsiode(i_episode)
while True:
action = agent.act(state, eps)
next_state, reward, done, info = env.step(action)
score += reward
next_state = stack_frames(state, next_state, False)
agent.step(state, action, reward, next_state, done)
state = next_state
if done:
break
scores_window.append(score) # save most recent score
scores.append(score) # save most recent score
clear_output(True)
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
print('\rEpisode {}\tAverage Score: {:.2f}\tEpsilon: {:.2f}'.format(i_episode, np.mean(scores_window), eps), end="")
return scores
scores = train(1000)
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
```
## Step 10: Watch a Smart Agent!
```
score = 0
state = stack_frames(None, env.reset(), True)
while True:
env.render()
action = agent.act(state, .01)
next_state, reward, done, _ = env.step(action)
score += reward
state = stack_frames(state, next_state, False)
if done:
print("You Final score is:", score)
break
env.close()
```
| github_jupyter |
# Batch GP Regression
## Introduction
In this notebook, we demonstrate how to train Gaussian processes in the batch setting -- that is, given `b` training sets and `b` separate test sets, GPyTorch is capable of training independent GPs on each training set and then testing each GP separately on each test set in parallel. This can be extremely useful if, for example, you would like to do k-fold cross validation.
**Note:** When operating in batch mode, we do **NOT** account for any correlations between the different functions being modeled. If you wish to do this, see the multitask examples instead.
```
import math
import torch
import gpytorch
from matplotlib import pyplot as plt
%matplotlib inline
```
## Set up training data
In the next cell, we set up the training data for this example. For the x values, we'll be using 100 regularly spaced points on [0,1] which we evaluate the function on and add Gaussian noise to get the training labels. For the training labels, we'll be modeling four functions independently in batch mode: two sine functions with different periods and two cosine functions with different periods.
In total, `train_x` will be `4 x 100 x 1` (`b x n x 1`) and `train_y` will be `4 x 100` (`b x n`)
```
# Training data is 100 points in [0,1] inclusive regularly spaced
train_x = torch.linspace(0, 1, 100).view(1, -1, 1).repeat(4, 1, 1)
# True functions are sin(2pi x), cos(2pi x), sin(pi x), cos(pi x)
sin_y = torch.sin(train_x[0] * (2 * math.pi)) + 0.5 * torch.rand(1, 100, 1)
sin_y_short = torch.sin(train_x[0] * (math.pi)) + 0.5 * torch.rand(1, 100, 1)
cos_y = torch.cos(train_x[0] * (2 * math.pi)) + 0.5 * torch.rand(1, 100, 1)
cos_y_short = torch.cos(train_x[0] * (math.pi)) + 0.5 * torch.rand(1, 100, 1)
train_y = torch.cat((sin_y, sin_y_short, cos_y, cos_y_short)).squeeze(-1)
```
## Setting up the model
The next cell adapts the model from the Simple GP regression tutorial to the batch setting. Not much changes: the only modification is that we add a `batch_shape` to the mean and covariance modules. What this does internally is replicates the mean constant and lengthscales `b` times so that we learn a different value for each function in the batch.
```
# We will use the simplest form of GP model, exact inference
class ExactGPModel(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood):
super(ExactGPModel, self).__init__(train_x, train_y, likelihood)
self.mean_module = gpytorch.means.ConstantMean(batch_shape=torch.Size([4]))
self.covar_module = gpytorch.kernels.ScaleKernel(
gpytorch.kernels.MaternKernel(batch_shape=torch.Size([4])),
batch_shape=torch.Size([4])
)
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
# initialize likelihood and model
likelihood = gpytorch.likelihoods.GaussianLikelihood(batch_shape=torch.Size([4]))
model = ExactGPModel(train_x, train_y, likelihood)
```
## Training the model
In the next cell, we handle using Type-II MLE to train the hyperparameters of the Gaussian process. This loop is nearly identical to the simple GP regression setting with one key difference. Now, the call through the mariginal log likelihood returns `b` losses, one for each GP. Since we have different parameters for each GP, we can simply sum these losses before calling `backward`.
```
# this is for running the notebook in our testing framework
import os
smoke_test = ('CI' in os.environ)
training_iter = 2 if smoke_test else 50
# Find optimal model hyperparameters
model.train()
likelihood.train()
# Use the adam optimizer
optimizer = torch.optim.Adam([
{'params': model.parameters()}, # Includes GaussianLikelihood parameters
], lr=0.1)
# "Loss" for GPs - the marginal log likelihood
mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)
for i in range(training_iter):
# Zero gradients from previous iteration
optimizer.zero_grad()
# Output from model
output = model(train_x)
# Calc loss and backprop gradients
loss = -mll(output, train_y).sum()
loss.backward()
print('Iter %d/%d - Loss: %.3f' % (i + 1, training_iter, loss.item()))
optimizer.step()
```
## Make predictions with the model
Making predictions with batched GPs is straight forward: we simply call the model (and optionally the likelihood) on batch `b x t x 1` test data. The resulting `MultivariateNormal` will have a `b x n` mean and a `b x n x n` covariance matrix. Standard calls like `preds.confidence_region()` still function -- for example `preds.var()` returns a `b x n` set of predictive variances.
In the cell below, we make predictions in batch mode for the four functions and plot the GP fit for each one.
```
# Set into eval mode
model.eval()
likelihood.eval()
# Initialize plots
f, ((y1_ax, y2_ax), (y3_ax, y4_ax)) = plt.subplots(2, 2, figsize=(8, 8))
# Test points every 0.02 in [0,1]
# Make predictions
with torch.no_grad():
test_x = torch.linspace(0, 1, 51).view(1, -1, 1).repeat(4, 1, 1)
observed_pred = likelihood(model(test_x))
# Get mean
mean = observed_pred.mean
# Get lower and upper confidence bounds
lower, upper = observed_pred.confidence_region()
# Plot training data as black stars
y1_ax.plot(train_x[0].detach().numpy(), train_y[0].detach().numpy(), 'k*')
# Predictive mean as blue line
y1_ax.plot(test_x[0].squeeze().numpy(), mean[0, :].numpy(), 'b')
# Shade in confidence
y1_ax.fill_between(test_x[0].squeeze().numpy(), lower[0, :].numpy(), upper[0, :].numpy(), alpha=0.5)
y1_ax.set_ylim([-3, 3])
y1_ax.legend(['Observed Data', 'Mean', 'Confidence'])
y1_ax.set_title('Observed Values (Likelihood)')
y2_ax.plot(train_x[1].detach().numpy(), train_y[1].detach().numpy(), 'k*')
y2_ax.plot(test_x[1].squeeze().numpy(), mean[1, :].numpy(), 'b')
y2_ax.fill_between(test_x[1].squeeze().numpy(), lower[1, :].numpy(), upper[1, :].numpy(), alpha=0.5)
y2_ax.set_ylim([-3, 3])
y2_ax.legend(['Observed Data', 'Mean', 'Confidence'])
y2_ax.set_title('Observed Values (Likelihood)')
y3_ax.plot(train_x[2].detach().numpy(), train_y[2].detach().numpy(), 'k*')
y3_ax.plot(test_x[2].squeeze().numpy(), mean[2, :].numpy(), 'b')
y3_ax.fill_between(test_x[2].squeeze().numpy(), lower[2, :].numpy(), upper[2, :].numpy(), alpha=0.5)
y3_ax.set_ylim([-3, 3])
y3_ax.legend(['Observed Data', 'Mean', 'Confidence'])
y3_ax.set_title('Observed Values (Likelihood)')
y4_ax.plot(train_x[3].detach().numpy(), train_y[3].detach().numpy(), 'k*')
y4_ax.plot(test_x[3].squeeze().numpy(), mean[3, :].numpy(), 'b')
y4_ax.fill_between(test_x[3].squeeze().numpy(), lower[3, :].numpy(), upper[3, :].numpy(), alpha=0.5)
y4_ax.set_ylim([-3, 3])
y4_ax.legend(['Observed Data', 'Mean', 'Confidence'])
y4_ax.set_title('Observed Values (Likelihood)')
None
```
| github_jupyter |
```
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
def generate_simple_data(n_samples):
epsilon = np.random.normal(size=(n_samples)) # smaple noise from Gaussin dist with mean 0, std = 1.0
x = np.random.uniform(-10.5, 10.5, n_samples)
y = 7 * np.sin(0.75 * x) + 0.5 * x + epsilon
return x, y
#generate sample data
x, y = generate_simple_data(1000)
fig, ax = plt.subplots(1,1, figsize=(8,5))
ax.scatter(x,y, alpha=0.2, label='random sampled data')
plt.legend()
plt.show()
```
## Simple Gaussian Network
```
from src.nn.MLP import MLP
class GaussianLayer(nn.Module):
def __init__(self, input_dim, n_gaussian):
super(GaussianLayer, self).__init__()
self.n_gaussian = n_gaussian
self.z_mu = torch.nn.Linear(input_dim, n_gaussian)
self.z_sigma = torch.nn.Linear(input_dim, n_gaussian)
def forward(self, x):
mu = self.z_mu(x)
std = self.z_sigma(x)
std = torch.exp(std)
return mu, std
class GaussianNetwork(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(GaussianNetwork, self).__init__()
self.mlp = MLP(input_dim, hidden_dim)
self.gaussian_layer = GaussianLayer(hidden_dim, 1)
def forward(self, x):
x = self.mlp(x)
mu, std = self.gaussian_layer.forward(x)
return mu, std
gaussianNet = GaussianNetwork(1, 100, 1)
opt = torch.optim.Adam(gaussianNet.parameters())
x_tensor = torch.tensor(x).reshape(-1, 1).float()
y_tensor = torch.tensor(y).reshape(-1, 1).float()
```
## Visualizing the NOT trained model
```
_x_tensor = torch.linspace(-10, 10, 100).reshape(-1,1)
mu, std = gaussianNet(_x_tensor)
N_STD = 2
x_axis = np.squeeze(_x_tensor.detach().numpy())
upper = mu + N_STD *std
upper_np = np.squeeze(upper.detach().numpy())
lower = mu - N_STD * std
lower_np = np.squeeze(lower.detach().numpy())
fig, ax = plt.subplots(1,1, figsize=(8,5))
ax.scatter(x, y, alpha=0.2, label='Sampled')
ax.plot(x_axis, mu.detach().numpy(), color='orange', label='prediction')
ax.fill_between(x_axis, upper_np, lower_np, alpha=0.5, label='=+/- {} std'.format(N_STD))
plt.legend()
plt.show()
def gaussianLL(mu, std, y):
log_exp_terms = torch.pow(y-mu, 2) / (2*torch.pow(std, 2))
log_scaler_terms = -0.5 * (torch.log(torch.tensor(2.0)) + torch.log(torch.tensor(np.pi)) + 2*torch.log(std))
LL = log_scaler_terms - log_exp_terms
return LL
for i in range(1500):
mu, std = gaussianNet(x_tensor)
loss = gaussianLL(mu, std, y_tensor)
loss = -loss.mean()
opt.zero_grad()
loss.backward()
opt.step()
```
## Visualizing the trained model
```
x_tensor = torch.linspace(-10, 10, 100).reshape(-1,1)
mu, std = gaussianNet(x_tensor)
N_STD = 2
x_axis = np.squeeze(x_tensor.detach().numpy())
upper = mu + N_STD *std
upper_np = np.squeeze(upper.detach().numpy())
lower = mu - N_STD * std
lower_np = np.squeeze(lower.detach().numpy())
fig, ax = plt.subplots(1,1, figsize=(8,5))
ax.scatter(x, y, alpha=0.2, label='Sampled')
ax.plot(x_axis, mu.detach().numpy(), color='orange', label='prediction')
ax.fill_between(x_axis, upper_np, lower_np, alpha=0.5, label='=+/- {} std'.format(N_STD))
plt.legend()
plt.show()
```
| github_jupyter |
# Welcome to the Tutorial!
First I'll introduce the theory behind neural nets. then we will implement one from scratch in numpy, (which is installed on the uni computers) - just type this code into your text editor of choice. I'll also show you how to define a neural net in googles DL library Tensorflow(which is not installed on the uni computers) and train it to clasify handwritten digits.
You will understand things better if you're familiar with calculus and linear algebra, but the only thing you really need to know is basic programming. Don't worry if you don't understand the equations.
## Numpy/linear algebra crash course
(You should be able to run this all in python 2.7.8 on the uni computers.)
Vectors and matrices are the language of neural networks. For our purposes, a vector is a list of numbers and a matrix is a 2d grid of numbers. Both can be defined as instances of numpy's ndarray class:
```
import numpy as np
my_vector = np.asarray([1,2,3])
my_matrix = np.asarray([[1,2,3],[10,10,10]])
print(my_matrix*my_vector)
```
Putting an ndarray through a function will apply it elementwise:
```
print((my_matrix**2))
print((my_matrix))
```
## What is a neural network?
For our data-sciencey purposes, it's best to think of a neural network as a *function approximator* or a *statistical model*. Surprisingly enough they are made up of a network of neurons. What is a neuron?
_WARNING: huge oversimplification that will make neuroscientists cringe._

This is what a neuron in your brain looks like. On the right are the *axons*, on the left are the *dendrites*, which recieve signals from the axons of other neurons. The dendrites are connected to the axons with *synapses*. If the neuron has enough voltage across, it will "spike" and send a signal through its axon to neighbouring neurons. Some synapses are *excitory* in that if a signal goes through them it will increase the voltage across the next neuron, making it more likely to spike. Others are *inhibitory*
and do the opposite. We learn by changing the strengths of synapses(well, kinda), and that is also usually how artificial neural networks learn.

This is what a the simplest possible artificial neuron looks like. This neuron is connected to two other input neurons named \\(x_1 \\) and \\( x_2\\) with "synapses" \\(w_1\\) and \\(w_2\\). All of these symbols are just numbers(real/float).
To get the neurons output signal \\(h\\), just sum the input neurons up, weighted by their "synapses" then put them through a nonlinear function \\( f\\):
$$ h = f(x_1 w_1 + x_2 w_2)$$
\\(f\\) can be anything that maps a real number to a real number, but for ML you want something nonlinear and smooth. For this neuron, \\(f\\) is the *sigmoid function*:
$$\sigma(x) = \frac{1}{1+e^{-x}} $$
Sigmoid squashes its output into [0,1], so it's closer to "fully firing" the more positive it's input, and closer to "not firing" the more negative it's input.

If you like to think in terms of graph theory, neurons are nodes and
If you have a stats background you might have noticed that this looks similar a logistic regression on two variables. That's because it is!
As you can see, these artificial neurons are only loosely inspired by biological neurons. That's ok, our goal is to have a good model, not simulate a brain.
There are many exciting ways to arange these neurons into a network, but we will focus on one of the easier, more useful topologies called a "two layer perceptron", which looks like this:

Neurons are arranged in layers, with the first hidden layer of neurons connected to a vector(think list of numbers) of input data, \\(x\\), sometimes referred to as an "input layer". Every neuron in a given layer is connected to every neuron in the previous layer.
$$net = \sum_{i=0}^{N}x_i w_i = \vec{x} \cdot \vec{w}$$
Where \\(\vec{x}\\) is a vector of previous layer's neuron activations and \\(\vec{w} \\) is a vector of the weights(synapses) for every \\(x \in \vec{x} \\).
Look back at the diagram again. Each of these 4 hidden units will have a vector of 3 weights for each of the inputs. We can arrange them as a 3x4 *matrix* of row vectors, which we call \\(W_1\\). Then we can multiply this matrix with \\(\vec{x}\\) and apply our nonlinearity \\(f\\) to get a vector of neuron activations:
$$\vec{h} = f( \vec{x} \cdot W_1 )$$
..actually, in practice we add a unique learnable "bias" \\(b\\) to every neurons weighted sum, which has the effect of shifting the nonlinearity left or right:
$$\vec{h} = f( \vec{x} \cdot W_1 + \vec{b}_1 )$$
We pretty much do the same thing to get the output for the second hidden layer, but with a different weight matrix \\(W_2\\):
$$\vec{h_2} = f( \vec{h_1} \cdot W_2 + \vec{b}_2 )$$
So if we want to get an output for a given data vector x, we can just plug it into these equations. Here it is in numpy:
```
def sigmoid(x):
return 1.0/(1.0+np.exp(-x))
hidden_1 = sigmoid(x.dot(W1) + b_1)
output = hidden1.dot(W2) + b_2
```
## Learning
Well that's all very nice, but we need it to be able to learn
```
N,D = 300,2 # number of examples, dimension of examples
X = np.random.uniform(size=(N,D),low=0,high=20)
y = [X[i,0] * X[i,1] for i in range(N)]
class TwoLayerPerceptron:
"""Simple implementation of the most basic neural net"""
def __init__(self,X,H,Y):
N,D = X.shape
N,O = y.shape
# initialize the weights, or "connections between neurons" to random values.
self.W1 = np.random.normal(size=(D,H))
self.b1 = np.zeros(size=(H,))
self.W2 = np.random.normal(size=(H,O))
self.b2 = np.random.normal(size=(O,))
def forward_pass(X):
"""Get the outputs for batch X, and a cache of hidden states for backprop"""
hidden_inputs = X.dot(W1) + b #matrix multiply
hidden_activations = relu(hidden_inputs)
output = hidden_activations.dot(W2) + b
cache = [X, hidden_inputs, ]
return cache
def backwards_pass(self,cache):
""" """
[X,hidden_inputs, hidden_activations, output] = cache
#//TODO: backwards pass
return d_W1, d_W2, d_b1, d_b2
def subtract_gradients(self,gradients,lr=0.001):
[d_W1, d_W2, d_b1, d_b2] = gradients
self.W1 -= lr * d_W1
self.W2 -= lr * d_W2
self.b1 -= lr * d_b1
self.b2 -= lr * d_b2
hidden_activations = relu(np.dot(X,W1) + b1)
output = np.dot(hidden_activations,W2)+b2
errors = 0.5 * (output - y)**2
d_h1 = np.dot((output - y),W2.T)
d_b1 = np.sum(d_h1,axis=1)
d_a1 = sigmoid()
d_W2 = np.dot(hidden_Activations, errors)
d_W1 = np.dot(d_h1, W1.T)
W_2 += d_W2
b1 += db1
W_1 += d_W1
display(Math(r'h_1 = \sigma(X \cdot W_1 + b)'))
```
| github_jupyter |
##### Copyright © 2020 Google Inc.
<font size=-1>Licensed under the Apache License, Version 2.0 (the \"License\");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at [https://www.apache.org/licenses/LICENSE-2.0](https://www.apache.org/licenses/LICENSE-2.0)
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.</font>
<hr/>
# Orchestrating BQML training and deployment with Managed Pipelines
This notebook demonstrates how to use custom Python function-based components together with TFX standard components. In the notebook, you will orchestrate training and deployment of a BQML logistic regression model.
1. BigQuery is used to prepare training data by executing an arbitrary SQL query and writing the results to a BigQuery table
2. The table with training data is used to train a BQML logistic regression model
3. The model is deployed to AI Platform Prediction for online serving
## Setup
### Upgrade BigQuery client
```
%pip install --upgrade --user google-cloud-core==1.3.0 google-cloud-bigquery==1.26.1
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
```
### Import the requiried libraries and verify a version of TFX SDK
```
import sys
import tensorflow as tf
import tensorflow_data_validation as tfdv
import tensorflow_model_analysis as tfma
import tfx
import logging
import google.cloud
from typing import Optional, Text, List, Dict, Any
from ml_metadata.proto import metadata_store_pb2
from tfx.components.base import executor_spec
from tfx.components import Pusher
from tfx.extensions.google_cloud_ai_platform.pusher import executor as ai_platform_pusher_executor
print("Tensorflow Version:", tf.__version__)
print("TFX Version:", tfx.__version__)
print("TFDV Version:", tfdv.__version__)
print("TFMA Version:", tfma.VERSION_STRING)
print("BigQuery client:", google.cloud.bigquery.__version__)
%load_ext autoreload
%autoreload 2
```
### Update `PATH` with the location of TFX SDK
```
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
```
### Configure GCP environment settings
Modify the below constants to reflect your environment
```
PROJECT_ID = 'mlops-dev-env'
REGION = 'us-central1'
BUCKET_NAME = 'mlops-dev-workspace' # Change this to your GCS bucket name. Do not include the `gs://`.
API_KEY = '' # Change this to the API key that you created during initial setup
BASE_IMAGE = 'gcr.io/caip-pipelines-assets/tfx:latest'
```
### Create an example BigQuery dataset
```
DATASET_LOCATION = 'US'
DATASET_ID = 'covertype_dataset'
TABLE_ID =' covertype'
DATA_SOURCE = 'gs://workshop-datasets/covertype/small/dataset.csv'
SCHEMA = 'Elevation:INTEGER,\
Aspect:INTEGER,\
Slope:INTEGER,\
Horizontal_Distance_To_Hydrology:INTEGER,\
Vertical_Distance_To_Hydrology:INTEGER,\
Horizontal_Distance_To_Roadways:INTEGER,\
Hillshade_9am:INTEGER,\
Hillshade_Noon:INTEGER,\
Hillshade_3pm:INTEGER,\
Horizontal_Distance_To_Fire_Points:INTEGER,\
Wilderness_Area:STRING,\
Soil_Type:STRING,\
Cover_Type:INTEGER'
!bq --location=$DATASET_LOCATION --project_id=$PROJECT_ID mk --dataset $DATASET_ID
!bq --project_id=$PROJECT_ID --dataset_id=$DATASET_ID load \
--source_format=CSV \
--skip_leading_rows=1 \
--replace \
$TABLE_ID \
$DATA_SOURCE \
$SCHEMA
```
## Create custom components
In this section, we will create a set of custom omponents that encapsulate calls to BigQuery and BigQuery ML.
### Create a data preprocessing component
```
%%writefile preprocess_data.py
import os
import logging
import uuid
from google.cloud import bigquery
from tfx.types.experimental.simple_artifacts import Dataset
from tfx.dsl.component.experimental.decorators import component
from tfx.dsl.component.experimental.annotations import OutputArtifact, Parameter
@component
def preprocess_data(
project_id: Parameter[str],
query: Parameter[str],
transformed_data: OutputArtifact[Dataset]):
client = bigquery.Client(project=project_id)
dataset_name = f'{project_id}.bqml_demo_{uuid.uuid4().hex}'
table_name = f'{dataset_name}.{uuid.uuid4().hex}'
dataset = bigquery.Dataset(dataset_name)
client.create_dataset(dataset)
job_config = bigquery.QueryJobConfig()
job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED
job_config.write_disposition = bigquery.job.WriteDisposition.WRITE_TRUNCATE
job_config.destination = table_name
logging.info(f'Starting data preprocessing')
query_job = client.query(query, job_config)
query_job.result() # Wait for the job to complete
logging.info(f'Completed data preprocessing. Output in {table_name}')
# Write the location of the output table to metadata.
transformed_data.set_string_custom_property('output_dataset', dataset_name)
transformed_data.set_string_custom_property('output_table', table_name)
```
### Create a BQML training component
```
%%writefile create_lr_model.py
import os
import logging
from google.cloud import bigquery
from tfx.types.experimental.simple_artifacts import Dataset
from tfx.types.experimental.simple_artifacts import Model as BQModel
from tfx.dsl.component.experimental.decorators import component
from tfx.dsl.component.experimental.annotations import InputArtifact, OutputArtifact, Parameter
@component
def create_lr_model(
project_id: Parameter[str],
model_name: Parameter[str],
label_column: Parameter[str],
transformed_data: InputArtifact[Dataset],
model: OutputArtifact[BQModel]):
dataset_name = transformed_data.get_string_custom_property('output_dataset')
table_name = transformed_data.get_string_custom_property('output_table')
model_name = f'{dataset_name}.{model_name}'
query = f"""
CREATE OR REPLACE MODEL
`{model_name}`
OPTIONS
( model_type='LOGISTIC_REG',
auto_class_weights=TRUE,
input_label_cols=['{label_column}']
) AS
SELECT
*
FROM
`{table_name}`
"""
client = bigquery.Client(project=project_id)
logging.info(f'Starting training of the model: {model_name}')
query_job = client.query(query)
query_job.result()
logging.info(f'Completed training of the model: {model_name}')
# Write the location of the output table to metadata.
model.set_string_custom_property('bq_model_name', model_name)
```
### Create a BQML model export component
```
%%writefile export_model.py
import os
import logging
import subprocess
from google.cloud import bigquery
from tfx.types.experimental.simple_artifacts import Dataset
from tfx.types.experimental.simple_artifacts import Model as BQModel
from tfx.types.standard_artifacts import Model
from tfx.dsl.component.experimental.decorators import component
from tfx.dsl.component.experimental.annotations import InputArtifact, OutputArtifact, Parameter
@component
def export_model(
bq_model: InputArtifact[BQModel],
model: OutputArtifact[Model]):
bq_model_name = bq_model.get_string_custom_property('bq_model_name')
gcs_path = '{}/serving_model_dir'.format(model.uri.rstrip('/'))
client = bigquery.Client()
bqml_model = bigquery.model.Model(bq_model_name)
logging.info(f'Starting model extraction')
extract_job = client.extract_table(bqml_model, gcs_path)
extract_job.result() # Wait for results
logging.info(f'Model extraction completed')
```
### Create an AI Platform Prediction deploy component
This is an alternative to using the TFX Pusher component
```
%%writefile deploy_model.py
import os
import logging
import uuid
import googleapiclient.discovery
from tfx.types.standard_artifacts import Model
from tfx.dsl.component.experimental.decorators import component
from tfx.dsl.component.experimental.annotations import InputArtifact, OutputArtifact, Parameter
@component
def deploy_model(
project_id: Parameter[str],
model_name: Parameter[str],
runtime_version: Parameter[str],
python_version: Parameter[str],
framework: Parameter[str],
model: InputArtifact[Model]):
service = googleapiclient.discovery.build('ml', 'v1')
version_name = f'v{uuid.uuid4().hex}'
saved_model_path = '{}/serving_model_dir'.format(model.uri.rstrip('/'))
project_path = f'projects/{project_id}'
model_path = f'{project_path}/models/{model_name}'
response = service.projects().models().list(parent=project_path).execute()
if 'error' in response:
raise RuntimeError(response['error'])
if not response or not [model['name'] for model in response['models'] if model['name'] == model_path]:
request_body={'name': model_name}
response = service.projects().models().create(parent=project_path, body=request_body).execute()
if 'error' in response:
raise RuntimeError(response['error'])
request_body = {
"name": version_name,
"deployment_uri": saved_model_path,
"machine_type": "n1-standard-8",
"runtime_version": runtime_version,
"python_version": python_version,
"framework": framework
}
logging.info(f'Starting model deployment')
response = service.projects().models().versions().create(parent=model_path, body=request_body).execute()
if 'error' in response:
raise RuntimeError(response['error'])
logging.info(f'Model deployed: {response}')
```
## Define the pipeline
```
import os
# Only required for local run.
from tfx.orchestration.metadata import sqlite_metadata_connection_config
from tfx.orchestration.pipeline import Pipeline
from tfx.orchestration.ai_platform_pipelines import ai_platform_pipelines_dag_runner
from preprocess_data import preprocess_data
from create_lr_model import create_lr_model
from export_model import export_model
from deploy_model import deploy_model
def bqml_pipeline(
pipeline_name: Text,
pipeline_root: Text,
query: Text,
project_id: Text,
model_name: Text,
label_column: Text,
metadata_connection_config: Optional[
metadata_store_pb2.ConnectionConfig] = None,
ai_platform_serving_args: Optional[Dict[Text, Any]] = None):
components = []
preprocess = preprocess_data(
query=query,
project_id=project_id)
components.append(preprocess)
train = create_lr_model(
transformed_data=preprocess.outputs['transformed_data'],
project_id=project_id,
model_name=model_name,
label_column=label_column)
components.append(train)
export = export_model(
bq_model=train.outputs['model']
)
components.append(export)
if ai_platform_serving_args:
deploy = Pusher(
custom_executor_spec=executor_spec.ExecutorClassSpec(
ai_platform_pusher_executor.Executor),
model=export.outputs['model'],
custom_config={'ai_platform_serving_args': ai_platform_serving_args})
components.append(deploy)
# The alternative using a custom deploy_model component
# if ai_platform_serving_args:
# deploy = deploy_model(
# project_id=project_id,
# runtime_version=ai_platform_serving_args['runtimeVersion'],
# python_version=ai_platform_serving_args['pythonVersion'],
# framework=ai_platform_serving_args['framework'],
# model_name=ai_platform_serving_args['model_name'],
# model=export.outputs['model']
# )
#components.append(deploy)
return Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=metadata_connection_config,
components=components
)
```
## Run the pipeline locally
```
from tfx.orchestration.beam.beam_dag_runner import BeamDagRunner
query = 'SELECT * FROM `mlops-dev-env.covertype_dataset.covertype` LIMIT 1000'
label_column = 'Cover_Type'
model_name = 'covertype_classifier'
pipeline_root = 'gs://{}/pipeline_root/{}'.format(BUCKET_NAME, 'bqml-test2')
pipeline_name = 'bqml-pipeline'
metadata_connection_config=sqlite_metadata_connection_config('metadata.sqlite')
ai_platform_serving_args = {
'project_id': PROJECT_ID,
'model_name': 'CovertypeBQMLLocal',
'runtimeVersion': '1.15',
'pythonVersion': '3.7',
'framework': 'TENSORFLOW'}
logging.getLogger().setLevel(logging.INFO)
BeamDagRunner().run(bqml_pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
query=query,
project_id=PROJECT_ID,
model_name=model_name,
label_column=label_column,
metadata_connection_config=metadata_connection_config,
ai_platform_serving_args=ai_platform_serving_args))
```
### Check that the metadata was produced locally
```
from ml_metadata import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = 'metadata.sqlite'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
store.get_artifacts()
```
## Run the pipeline in Managed Pipelines
### Package the components into a custom docker image
Next, let's package the above into a container.
In future, it will be possible to do this via the TFX CLI. For now, we'll do this using a Dockerfile and Skaffold.
> Note: If you're running this notebook on AI Platform Notebooks, Docker will be installed. If you're running the notebook in a local development environment, you'll need to have Docker installed there. Confirm that you have [installed Skaffold](https://skaffold.dev/docs/install/) locally as well.
First, we'll define a `skaffold.yaml` file. We'll first define a string to use in creating the file.
```
tag = 'demo'
SK_TEMPLATE = "{{{{.IMAGE_NAME}}}}:{}".format(tag)
print(SK_TEMPLATE)
```
Now we'll write out the Skaffold yaml file.
```
image_name = f'gcr.io/{PROJECT_ID}/caip-tfx-bqml'
skaffold_template = f"""
apiVersion: skaffold/v2beta3
kind: Config
metadata:
name: my-pipeline
build:
artifacts:
- image: '{image_name}'
context: .
docker:
dockerfile: Dockerfile
tagPolicy:
envTemplate:
template: "{{SK_TEMPLATE}}"
"""
with open('skaffold.yaml', 'w') as f:
f.write(skaffold_template.format(**globals()))
```
Next, we'll define the `Dockerfile`.
```
%%writefile Dockerfile
FROM gcr.io/caip-pipelines-assets/tfx:latest
RUN pip install --upgrade google-cloud-core==1.3.0 google-cloud-bigquery==1.26.1
WORKDIR /pipeline
COPY *.py ./
ENV PYTHONPATH="/pipeline:${PYTHONPATH}"
!skaffold build
```
### Submit a run
```
query = 'SELECT * FROM `mlops-dev-env.covertype_dataset.covertype` LIMIT 1000'
label_column = 'Cover_Type'
model_name = 'covertype_classifier'
pipeline_name = 'bqml-pipeline-tests'
pipeline_root = 'gs://{}/pipeline_root/{}'.format(BUCKET_NAME, pipeline_name)
ai_platform_serving_args = {
'project_id': PROJECT_ID,
'model_name': 'CovertypeBQMLtest',
'runtimeVersion': '1.15',
'pythonVersion': '3.7',
'framework': 'TENSORFLOW'}
pipeline = bqml_pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
query=query,
project_id=PROJECT_ID,
model_name=model_name,
label_column=label_column,
ai_platform_serving_args=ai_platform_serving_args)
config = ai_platform_pipelines_dag_runner.AIPlatformPipelinesDagRunnerConfig(
project_id=PROJECT_ID,
display_name=pipeline_name,
default_image=f'{image_name}:{tag}')
runner = ai_platform_pipelines_dag_runner.AIPlatformPipelinesDagRunner(config=config)
runner.run(pipeline, api_key=API_KEY)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_12_01_ai_gym.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# T81-558: Applications of Deep Neural Networks
**Module 12: Reinforcement Learning**
* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)
* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).
# Module 12 Video Material
* **Part 12.1: Introduction to the OpenAI Gym** [[Video]](https://www.youtube.com/watch?v=_KbUxgyisjM&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_12_01_ai_gym.ipynb)
* Part 12.2: Introduction to Q-Learning [[Video]](https://www.youtube.com/watch?v=A3sYFcJY3lA&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_12_02_qlearningreinforcement.ipynb)
* Part 12.3: Keras Q-Learning in the OpenAI Gym [[Video]](https://www.youtube.com/watch?v=qy1SJmsRhvM&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_12_03_keras_reinforce.ipynb)
* Part 12.4: Atari Games with Keras Neural Networks [[Video]](https://www.youtube.com/watch?v=co0SwPWoZh0&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_12_04_atari.ipynb)
* Part 12.5: Application of Reinforcement Learning [[Video]](https://www.youtube.com/watch?v=1jQPP3RfwMI&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_12_05_apply_rl.ipynb)
# Part 12.1: Introduction to the OpenAI Gym
[OpenAI Gym](https://gym.openai.com/) aims to provide an easy-to-setup general-intelligence benchmark with a wide variety of different environments. The goal is to standardize how environments are defined in AI research publications so that published research becomes more easily reproducible. The project claims to provide the user with a simple interface. As of June 2017, developers can only use Gym with Python.
OpenAI gym is pip-installed onto your local machine. There are a few significant limitations to be aware of:
* OpenAI Gym Atari only **directly** supports Linux and Macintosh
* OpenAI Gym Atari can be used with Windows; however, it requires a particular [installation procedure](https://towardsdatascience.com/how-to-install-openai-gym-in-a-windows-environment-338969e24d30)
* OpenAI Gym can not directly render animated games in Google CoLab.
Because OpenAI Gym requires a graphics display, the only way to display Gym in Google CoLab is an embedded video. The presentation of OpenAI Gym game animations in Google CoLab is discussed later in this module.
### OpenAI Gym Leaderboard
The OpenAI Gym does have a leaderboard, similar to Kaggle; however, the OpenAI Gym's leaderboard is much more informal compared to Kaggle. The user's local machine performs all scoring. As a result, the OpenAI gym's leaderboard is strictly an "honor's system." The leaderboard is maintained the following GitHub repository:
* [OpenAI Gym Leaderboard](https://github.com/openai/gym/wiki/Leaderboard)
If you submit a score, you are required to provide a writeup with sufficient instructions to reproduce your result. A video of your results is suggested, but not required.
### Looking at Gym Environments
The centerpiece of Gym is the environment, which defines the "game" in which your reinforcement algorithm will compete. An environment does not need to be a game; however, it describes the following game-like features:
* **action space**: What actions can we take on the environment, at each step/episode, to alter the environment.
* **observation space**: What is the current state of the portion of the environment that we can observe. Usually, we can see the entire environment.
Before we begin to look at Gym, it is essential to understand some of the terminology used by this library.
* **Agent** - The machine learning program or model that controls the actions.
Step - One round of issuing actions that affect the observation space.
* **Episode** - A collection of steps that terminates when the agent fails to meet the environment's objective, or the episode reaches the maximum number of allowed steps.
* **Render** - Gym can render one frame for display after each episode.
* **Reward** - A positive reinforcement that can occur at the end of each episode, after the agent acts.
* **Nondeterministic** - For some environments, randomness is a factor in deciding what effects actions have on reward and changes to the observation space.
It is important to note that many of the gym environments specify that they are not nondeterministic even though they make use of random numbers to process actions. It is generally agreed upon (based on the gym GitHub issue tracker) that nondeterministic property means that a deterministic environment will still behave randomly even when given consistent seed value. The seed method of an environment can be used by the program to seed the random number generator for the environment.
The Gym library allows us to query some of these attributes from environments. I created the following function to query gym environments.
```
import gym
def query_environment(name):
env = gym.make(name)
spec = gym.spec(name)
print(f"Action Space: {env.action_space}")
print(f"Observation Space: {env.observation_space}")
print(f"Max Episode Steps: {spec.max_episode_steps}")
print(f"Nondeterministic: {spec.nondeterministic}")
print(f"Reward Range: {env.reward_range}")
print(f"Reward Threshold: {spec.reward_threshold}")
```
We will begin by looking at the MountainCar-v0 environment, which challenges an underpowered car to escape the valley between two mountains. The following code describes the Mountian Car environment.
```
query_environment("MountainCar-v0")
```
There are three distinct actions that can be taken: accelrate forward, decelerate, or accelerate backwards. The observation space contains two continuous (floating point) values, as evident by the box object. The observation space is simply the position and velocity of the car. The car has 200 steps to escape for each epasode. You would have to look at the code to know, but the mountian car recieves no incramental reward. The only reward for the car is given when it escapes the valley.
```
query_environment("CartPole-v1")
```
The CartPole-v1 environment challenges the agent to move a cart while keeping a pole balanced. The environment has an observation space of 4 continuous numbers:
* Cart Position
* Cart Velocity
* Pole Angle
* Pole Velocity At Tip
To achieve this goal, the agent can take the following actions:
* Push cart to the left
* Push cart to the right
There is also a continuous variant of the mountain car. This version does not simply have the motor on or off. For the continuous car the action space is a single floating point number that specifies how much forward or backward force is being applied.
```
query_environment("MountainCarContinuous-v0")
```
Note: ignore the warning above, it is a relativly inconsequential bug in OpenAI Gym.
Atari games, like breakout can use an observation space that is either equal to the size of the Atari screen (210x160) or even use the RAM memory of the Atari (128 bytes) to determine the state of the game. Yes thats bytes, not kilobytes!
```
query_environment("Breakout-v0")
query_environment("Breakout-ram-v0")
```
### Render OpenAI Gym Environments from CoLab
It is possible to visualize the game your agent is playing, even on CoLab. This section provides information on how to generate a video in CoLab that shows you an episode of the game your agent is playing. This video process is based on suggestions found [here](https://colab.research.google.com/drive/1flu31ulJlgiRL1dnN2ir8wGh9p7Zij2t).
Begin by installing **pyvirtualdisplay** and **python-opengl**.
```
!pip install gym pyvirtualdisplay > /dev/null 2>&1
!apt-get install -y xvfb python-opengl ffmpeg > /dev/null 2>&1
```
Next, we install needed requirements to display an Atari game.
```
!apt-get update > /dev/null 2>&1
!apt-get install cmake > /dev/null 2>&1
!pip install --upgrade setuptools 2>&1
!pip install ez_setup > /dev/null 2>&1
!pip install gym[atari] > /dev/null 2>&1
```
Next we define functions used to show the video by adding it to the CoLab notebook.
```
import gym
from gym.wrappers import Monitor
import glob
import io
import base64
from IPython.display import HTML
from pyvirtualdisplay import Display
from IPython import display as ipythondisplay
display = Display(visible=0, size=(1400, 900))
display.start()
"""
Utility functions to enable video recording of gym environment
and displaying it.
To enable video, just do "env = wrap_env(env)""
"""
def show_video():
mp4list = glob.glob('video/*.mp4')
if len(mp4list) > 0:
mp4 = mp4list[0]
video = io.open(mp4, 'r+b').read()
encoded = base64.b64encode(video)
ipythondisplay.display(HTML(data='''<video alt="test" autoplay
loop controls style="height: 400px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded.decode('ascii'))))
else:
print("Could not find video")
def wrap_env(env):
env = Monitor(env, './video', force=True)
return env
```
Now we are ready to play the game. We use a simple random agent.
```
#env = wrap_env(gym.make("MountainCar-v0"))
env = wrap_env(gym.make("Atlantis-v0"))
observation = env.reset()
while True:
env.render()
#your agent goes here
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
break;
env.close()
show_video()
```
| github_jupyter |
## Comparison between Lambert Beers Law and Transfer Matrix absorption and their effects in a two temperature model
In this file the absorption calculated with an exponential decay, according to Lambert Beers law and the local absorption evaluated, using the Transfer Matrix Method are being compared within the framework of a two temperature model calculation originally proposed by Anisimov et al. but more recently used by J. Hohlfeld et al. and D. Schick et al. among others.
The sample case under consideration is :
| Layer | length | refractive index |
|-------------------|-------------- |---------------------- |
| Platinum | 3nm layer | n = 1.0433 + i3.0855 |
| Cobalt | 15nm layer | n = 1.0454 + i3.2169 |
| Chromium | 5nm layer | n = 2.0150 + i2.8488 |
| Magnesium Oxide | inf- layer | n = 1.7660 |
The procedure of this session is to:
* Run a local absorption computation to obtain the local absorption profile of the layer (This is just done for reference, in fact the local absorption module is also implemented in the NTMpy package.)
* Run different simulations with the NTMpy, changing the input source from a Lambert Beer description to a Transfer Matrix description of the absorption.
```
import sys
sys.path.append("C:/Users/lUKAS/Documents/UDCM/Objects")
import TMM_abs as atmm #Import absorption file (The algorithm here is implemented in the NTMpy package)
from NTMpy import NTMpy as ntm
from matplotlib import pyplot as plt
import numpy as np
import numericalunits as u #Numerical units to show physcal dimensions. (In principle not required)
u.reset_units('SI')
#Define the complex refractive index for every layer and the length of every layer
#layers: Air Pt Co Cr MgO
n_list = [1, 1.0433+3.0855j,1.0454+3.2169j,2.0150+2.8488j,1.766]
n_Pt = n_list[1]; n_Co = n_list[2]; n_Cr = n_list[3]
d_list = [np.inf,3,15,5 ,np.inf] #in nm
th0 = np.pi/4 #in rad. (0 is perpendicular to the surface)
lam0 = 400 # wavelength in vacuum
pol = 'p' #polarization
```
Based on the suggestions made by [Steven J. Byrnes](https://arxiv.org/abs/1603.02720) the total absorption, reflection and transmission $A$, $R$, $T$ are calculated based on the idea of transfer matrices, where the refractive index, the incident angle and the length of every layer are taken into consideration. The parameters $A,R,T$ are normalized with respect to the incident power.
The results obtained have been compared with [Steven J. Byrnes- Sample 4](https://github.com/sbyrnes321/tmm/blob/master/examples.ipynb) and to results obtained by calculations, executed via COMSOL Multiphysics, where we find that the simulation done in 1D here matches almost exactly with a 2D simulation done with COMSOL Multiphysics where each layer attributes were extended homogeneously on to one more degree of freedom. Hence our 1D model is a good approximation even to a higher dimensional case.
```
plotpoints = 500
[M,M_n,t,r,T,R,A,theta] = atmm.TM(th0,lam0,n_list,d_list,pol)
[absorp,grid] = atmm.absorption(th0,lam0,n_list,d_list,pol,plotpoints)
print(f"Total transmission at the end {T:.2}\n"\
f"Total reflectance at the first layer {R:.2}\n"\
f"Total Absortpin at the entire material {A:.2}")
#--> Result obtained by calling the function absorption()
plt.figure()
plt.suptitle('Local absorbtion profile of multi layer thin film', fontsize=12)
plt.title(r"$\lambda=400$nm, $\theta_0=45^°$, polarization =$p$, total Absorbtion = {:.0f} %"\
.format(np.round(A,2)*100),fontsize=10)
plt.xlabel("Distance from surface (nm)");
plt.ylabel(r"Absorbtion per unit incident power $\left(\frac{1}{nm}\right)$")
plt.plot(grid,absorp)
plt.show()
```
Now we are considering the two-temperature model, where the equation is given below, i.e. two coupled differential equations. Note that the source term $S(x,t)$ is the part which we are going to consider with the two different approaches. Since the deposited energy and therefor also the heating depends mostly on where and how much energy is deposited.
In addition, one has to mention that we are considering zero flux boundary condition on both sides and an initial temperature of 300K along the entire material.
That is
\begin{align}
\begin{cases}
\partial_x(\varphi(0,t))= \partial_x(\varphi(L,t)) &= 0 &\text{ Neumann boundary condition}\\
\varphi(x,0) &= 300 K &\text{ initial condition}
\end{cases}
\end{align}
However, before starting the simulation the variables, given in the coupled heat diffusion equation below have to be expressed.
\begin{align}
\begin{cases}
C_i^E(\varphi^E(x,t))\cdot\rho_i\cdot\partial_t\varphi^E(x,t) &= \partial_x\left(k^E_i(\varphi^E_i(x,t))\cdot \partial_x\varphi^E_i(x,t)\right) + G_i\cdot(\varphi^L_i(x,t)-\varphi^E_i(x,t)) + S(x,t) \\
C_i^L(\varphi^L(x,t))\cdot\rho_i\cdot\partial_t\varphi^L(x,t) &= \partial_x\left(k^L_i(\varphi^L_i(x,t))\cdot \partial_x\varphi^L_i(x,t)\right) + G_i\cdot(\varphi^E_i(x,t)-\varphi^L_i(x,t))
\end{cases}
\end{align}
Where $S(x,t)$ is the source applied on the material, $C_i^{E,L}$ and $k_i^{E,L}$ are heat capacity and conductivity for every $i$´th layer with respect to the electron/lattice system, as a generic function of the temperature $\varphi^{E,L}(x,t)$ of the system. The constants $\rho_i$ and $G_i$ describe the density and the electron-lattice coupling for every layer.
```
#Platinum
length_Pt = 3*u.nm #Length of the Material
k_el_Pt = 73*u.W/(u.m*u.K);#Heat conductivity
rho_Pt = 1e3*21*u.kg/(u.m**3)#Density
C_el_Pt = lambda Te: (740*u.J/(u.m**3*u.K**2))/(1e3*21*u.kg/(u.m**3)) *Te #Electron heat capacity
C_lat_Pt = 2.8e6*u.J/(u.m**3*u.K**2)/rho_Pt#Lattice heat capacity
G_Pt = 1e16*25*u.W/(u.m**3*u.K) #Lattice electron coupling constant
#Cobalt
length_Co = 15*u.nm;
k_el_Co = 100*u.W/(u.m*u.K);
rho_Co = 1e3*8.86*u.kg/(u.m**3)
C_el_Co = lambda Te: (704*u.J/(u.m**3*u.K**2))/(1e3*8.86*u.kg/(u.m**3)) *Te
C_lat_Co = 4e6*u.J/(u.m**3*u.K**2)/rho_Co
G_Co = 1e16*93*u.W/(u.m**3*u.K)
#Chromium
length_Cr = 5*u.nm;
k_el_Cr = 95*u.W/(u.m*u.K);
rho_Cr = 1e3*7.15*u.kg/(u.m**3)
C_el_Cr = lambda Te: (194*u.J/(u.m**3*u.K**2))/(1e3*7.15*u.kg/(u.m**3)) *Te
C_lat_Cr = 3.3e6*u.J/(u.m**3*u.K**2)/rho_Cr
G_Cr = 1e16*42*u.W/(u.m**3*u.K)
# Source
s = ntm.source()
s.spaceprofile = "LB"# We are going to consider the Lambert Beer case first
s.timeprofile = "Gaussian"
s.FWHM = 0.1*u.ps
s.fluence = 1*u.mJ/u.cm**2
s.t0 = 0.5*u.ps #Peake of Gaussian
s.lambda_vac = 400 #in nm
```
Note that the Lambert Beer "law" is a heuristic one, which can be ralated to the refractive index,by
\begin{align}
\alpha &= \frac{4\pi}{\lambda_0}\cdot \operatorname{Im}(n) \\ \nonumber
I(z) &= I_0e^{-\alpha z}
\end{align}
Where the optical penetration depth $\delta_p$ = $\frac{1}{\alpha}$, $\lambda_0$ is the wavelength in vacuum and as indicated $n$ is the refractive index.
```
#Two temperatures are considered, electron and lattice
sim = ntm.simulation(2,s)
#add parameters for all layers and both systems
#lengt,refractive_index, conductivity [electron, lattice], heatCapacity [electron, lattice], density, linear Coupling
sim.addLayer(length_Pt,n_Pt,[k_el_Pt,k_el_Pt],[C_el_Pt,C_lat_Pt],rho_Pt,G_Pt) #Platinum
sim.addLayer(length_Co,n_Co,[k_el_Co,k_el_Co],[C_el_Co,C_lat_Co],rho_Co,G_Co) #Cobalt
sim.addLayer(length_Cr,n_Cr,[k_el_Cr,k_el_Cr],[C_el_Cr,C_lat_Cr],rho_Cr,G_Cr) #Chromium
sim.final_time = 5*u.ps
v = ntm.visual(sim)
#output of v.source is the full matrix of the source(x,t)
so = v.source()
[tt,avTemp] = v.average()#Averaged in space
print(avTemp.shape)
```
In the first picture we can see a surface and in the second a contour plot of the source that has been applied to the system. We see that the optical penetration depth of Platinum is very similar to the one of Cobalt and Chromium, that is their imaginary part of the refractive index is very much alike, which is why the transition appears between the different layers appears almost to be smooth.
What we can do now, in order to make our calculation of the deposited energy in the system more accurate, is to multiply the amplitude of the source times $A$, that is the amount of energy absorbed. Now we are considering some results obtained by the transfer matrix formalism, but not the entire local absorption profile.
Changing the parameters and recalculation leads to:
```
oldfluence = s.fluence
#Here the coefficient of the absorbed amount has been added
s.fluence = oldfluence*A
#Pass on the source with the modified incident fluence and simulate again
sim = ntm.simulation(2,s)
sim.addLayer(length_Pt,n_Pt,[k_el_Pt,k_el_Pt],[C_el_Pt,C_lat_Pt],rho_Pt,G_Pt) #Platinum
sim.addLayer(length_Co,n_Co,[k_el_Co,k_el_Co],[C_el_Co,C_lat_Co],rho_Co,G_Co) #Cobalt
sim.addLayer(length_Cr,n_Cr,[k_el_Cr,k_el_Cr],[C_el_Cr,C_lat_Cr],rho_Cr,G_Cr) #Chromium
sim.final_time = 5*u.ps
#Visualize result
v = ntm.visual(sim)
so = v.source()
[tt,avT] = v.average()
```
Comparing this output now to what we we were seeing before, we can clearly see that the temperature is way lower than before. This is since we are considering that not all the incident power is deposited in the material but some of it is back reflected.
Note however, that the shape of the pulse heating the material is the same!
Let us look at the full heat map via a contour plot to also see which areas in space get heated up.
```
#Input is a string corresponding to the system under consideration
v.contour('1') #Electron system
v.contour('2') #Lattice system
```
Now we will switch from the Lambert Beer law, which takes the optical penetration depth of every material into consideration to the Transfer matrix method to calculate the local absorption at every grid point, as shown above.
The only thing that has to be changed in the code is the spaceprofile type (from `"LB"` to `"TMM"`).
Some additional input parameters also have to be given, i.e. `polarization = "s"` or `"p"`.
And the incident angle `s.theta_in = number` a float number.
```
#Transfer matrix method is now considered
s = ntm.source()
s.spaceprofile = "TMM" #Change to Transfer Matrix Method
s.FWHM = 0.1*u.ps
s.fluence = 1*u.mJ/u.cm**2
s.t0 = 0.5*u.ps
s.lambda_vac = lam0
#provide additional input for the TM method, as indicated above
s.theta_in = th0
s.polarization = pol
sim = ntm.simulation(2,s)
sim.addLayer(length_Pt,n_Pt,[k_el_Pt,k_el_Pt],[C_el_Pt,C_lat_Pt],rho_Pt,G_Pt) #Platinum
sim.addLayer(length_Co,n_Co,[k_el_Co,k_el_Co],[C_el_Co,C_lat_Co],rho_Co,G_Co) #Cobalt
sim.addLayer(length_Cr,n_Cr,[k_el_Cr,k_el_Cr],[C_el_Cr,C_lat_Cr],rho_Cr,G_Cr) #Chromium
sim.final_time = 5*u.ps
v = ntm.visual(sim)
so = v.source()
[tt,avTemp] = v.average()
```
Since now we also take reflections within the material into consideration, the average temperature is higher. Most of all we see that the shape of the source is different.
We can see lots of absorption on and close to the surface of the material. On the other hand, we can also see an absorption peak at the very end. This can be explained through the appearing reflections within the layer, that occure on the Chromium- MgO- edge (recall our stack structure from the table above).
The dynamics can also be depicted in a not averaged form, that is by showing the contour plots of time and space dynamics for each system, lattice and electrons, separately.
Comparing the contour plots with respect to Lambert Beer and TMM heating, one could not only see a difference in the average temperature but also which points in space have been over/ underestimated.
```
#Input is a string corresponding to the system under consideration
v.contour('1') #Electron system
v.contour('2') #lattice system
#Same plot as in the beginning of the session just integrated as a method in the visual class
[T,R,A,absorption,xflat,grid] = v.localAbsorption()
```
Summarizing we find the TMM matrix the best method and recommend it to the user if they are interested in finding a precise description of local absorption of energy, which is in the zero-flux boundary case the most important factor of heating a material. Also, different incident angles and polarization can be considered, which makes this representation a more realistic approach to physical experiments.
However, in order to get quick results and for pedagogical reasons/ consistency checks on can also use the Lambert Beer spacial profile. Keep in mind though that one most likely overshoots the energy deposit.
Since for some configuration the time step for integrating the coupled differential equation must be chosen very small, the amount of produced data can be huge. Therefore we integrated an algorithm, that uses _block averaging_, i.e. statistics in order to compress the obtained data. We can, in this case, lower the amount of data obtained from almost 2 million-time-steps (in the case above) to only a few hundred data points, still giving us a reliable result.
```
blocks = 120 #number of points in the time grid
#Apply the blocking method to both, electron and lattice system
[blockvecE,blocktt, errorE , sigmaE] = v.blocking(avTemp[0],tt,blocks)
[blockvecL,blocktt, errorL , sigmaL] = v.blocking(avTemp[1],tt,blocks)
#Depict the data
plt.figure()
plt.suptitle(f"Average temperature blocked in time with {blocks} blocks",fontsize = 12)
plt.title(r"$err(T) = \frac{1}{\sqrt{n_b}}\sum_{i=1}^{n_b}\frac{(<T>_t-\bar{T}_i)^2}{n_b-1}$",fontsize = 9)
plt.xlabel("Time in ps"); plt.ylabel("Temperature in K")
plt.grid()
plt.errorbar(blocktt,blockvecE,yerr=errorE,ms = 3,fmt='r-o',linewidth=2,label = "Electron")
plt.errorbar(blocktt,blockvecL,yerr=errorL,ms = 3,fmt='k-o',linewidth=2,label = "Lattice")
plt.legend()
plt.show()
```
| github_jupyter |
```
# 使下面的代码支持python2和python3
from __future__ import division, print_function, unicode_literals
# 查看python的版本是否为3.5及以上
import sys
assert sys.version_info >= (3, 5)
# 查看sklearn的版本是否为0.20及以上
import sklearn
assert sklearn.__version__ >= "0.20"
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import os
# 在每一次的运行后获得的结果与这个notebook的结果相同
np.random.seed(42)
# 让matplotlib的图效果更好
%matplotlib inline
import matplotlib as mpl
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 设置保存图片的途径
PROJECT_ROOT_DIR = "."
IMAGE_PATH = os.path.join(PROJECT_ROOT_DIR, "images")
os.makedirs(IMAGE_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True):
'''
只需在clustering_test_202007121.ipynb文件所在目录处,建立一个images的文件夹,运行即可保存自动图片
:param fig_id: 图片名称
'''
path = os.path.join(PROJECT_ROOT_DIR, "images", fig_id + ".png")
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format='png', dpi=300)
# 忽略掉没用的警告 (Scipy issue #5998)
import warnings
warnings.filterwarnings(action="ignore", category=FutureWarning, module='sklearn', lineno=196)
# 读取数据集
df = pd.read_excel('Test_2.xlsx')
df
# 查看数据集是否有空值,看需不需要插值
df.info()
'''
# 插值
df.fillna(0, inplace=True)
# 或者是参考之前在多项式回归里的插值方式
'''
# 将真实的分类标签与特征分开
data = df.drop('TRUE VALUE', axis=1)
labels = df['TRUE VALUE'].copy()
np.unique(labels)
labels
# 获取数据的数量和特征的数量
n_samples, n_features = data.shape
# 获取分类标签的数量
n_labels = len(np.unique(labels))
np.unique(labels)
labels.value_counts()
```
# KMeans算法聚类
```
from sklearn import metrics
def get_marks(estimator, data, name=None, kmeans=None, af=None):
"""获取评分,有五种需要知道数据集的实际分类信息,有三种不需要,参考readme.txt
:param estimator: 模型
:param name: 初始方法
:param data: 特征数据集
"""
estimator.fit(data)
print(20 * '*', name, 20 * '*')
if kmeans:
print("Mean Inertia Score: ", estimator.inertia_)
elif af:
cluster_centers_indices = estimator.cluster_centers_indices_
print("The estimated number of clusters: ", len(cluster_centers_indices))
print("Homogeneity Score: ", metrics.homogeneity_score(labels, estimator.labels_))
print("Completeness Score: ", metrics.completeness_score(labels, estimator.labels_))
print("V Measure Score: ", metrics.v_measure_score(labels, estimator.labels_))
print("Adjusted Rand Score: ", metrics.adjusted_rand_score(labels, estimator.labels_))
print("Adjusted Mutual Info Score: ", metrics.adjusted_mutual_info_score(labels, estimator.labels_))
print("Calinski Harabasz Score: ", metrics.calinski_harabasz_score(data, estimator.labels_))
print("Silhouette Score: ", metrics.silhouette_score(data, estimator.labels_))
from sklearn.cluster import KMeans
# 使用k-means进行聚类,设置簇=2,设置不同的初始化方式('k-means++'和'random')
km1 = KMeans(init='k-means++', n_clusters=n_labels-1, n_init=10, random_state=42)
km2 = KMeans(init='random', n_clusters=n_labels-1, n_init=10, random_state=42)
print("n_labels: %d \t n_samples: %d \t n_features: %d" % (n_labels, n_samples, n_features))
get_marks(km1, data, name="k-means++", kmeans=True)
get_marks(km2, data, name="random", kmeans=True)
# 聚类后每个数据的类别
km1.labels_
# 类别的类型
np.unique(km1.labels_)
# 将聚类的结果写入原始表格中
df['km_clustering_label'] = km1.labels_
# 以csv形式导出原始表格
#df.to_csv('result.csv')
# 区别与data,df是原始数据集
df
from sklearn.model_selection import GridSearchCV
# 使用GridSearchCV自动寻找最优参数
params = {'init':('k-means++', 'random'), 'n_clusters':[2, 3, 4, 5, 6], 'n_init':[5, 10, 15]}
cluster = KMeans(random_state=42)
# 使用调整的兰德系数(adjusted_rand_score)作为评分,具体可参考readme.txt
km_best_model = GridSearchCV(cluster, params, cv=3, scoring='adjusted_rand_score',
verbose=1, n_jobs=-1)
# 由于选用的是外部评价指标,因此得有原数据集的真实分类信息
km_best_model.fit(data, labels)
# 最优模型的参数
km_best_model.best_params_
# 最优模型的评分
km_best_model.best_score_
# 获得的最优模型
km3 = km_best_model.best_estimator_
km3
# 获取最优模型的8种评分,具体含义参考readme.txt
get_marks(km3, data, name="k-means++", kmeans=True)
from sklearn.metrics import silhouette_score
from sklearn.metrics import calinski_harabasz_score
from matplotlib import pyplot as plt
def plot_scores(init, max_k, data, labels):
'''画出kmeans不同初始化方法的三种评分图
:param init: 初始化方法,有'k-means++'和'random'两种
:param max_k: 最大的簇中心数目
:param data: 特征的数据集
:param labels: 真实标签的数据集
'''
i = []
inertia_scores = []
y_silhouette_scores = []
y_calinski_harabaz_scores = []
for k in range(2, max_k):
kmeans_model = KMeans(n_clusters=k, random_state=1, init=init, n_init=10)
pred = kmeans_model.fit_predict(data)
i.append(k)
inertia_scores.append(kmeans_model.inertia_)
y_silhouette_scores.append(silhouette_score(data, pred))
y_calinski_harabaz_scores.append(calinski_harabasz_score(data, pred))
new = [inertia_scores, y_silhouette_scores, y_calinski_harabaz_scores]
for j in range(len(new)):
plt.figure(j+1)
plt.plot(i, new[j], 'bo-')
plt.xlabel('n_clusters')
if j == 0:
name = 'inertia'
elif j == 1:
name = 'silhouette'
else:
name = 'calinski_harabasz'
plt.ylabel('{}_scores'.format(name))
plt.title('{}_scores with {} init'.format(name, init))
save_fig('{} with {}'.format(name, init))
plot_scores('k-means++', 18, data, labels)
plot_scores('random', 10, data, labels)
from sklearn.metrics import silhouette_samples, silhouette_score
from matplotlib.ticker import FixedLocator, FixedFormatter
def plot_silhouette_diagram(clusterer, X, show_xlabels=True,
show_ylabels=True, show_title=True):
"""
画轮廓图表
:param clusterer: 训练好的聚类模型(这里是能提前设置簇数量的,可以稍微修改代码换成不能提前设置的)
:param X: 只含特征的数据集
:param show_xlabels: 为真,添加横坐标信息
:param show_ylabels: 为真,添加纵坐标信息
:param show_title: 为真,添加图表名
"""
y_pred = clusterer.labels_
silhouette_coefficients = silhouette_samples(X, y_pred)
silhouette_average = silhouette_score(X, y_pred)
padding = len(X) // 30
pos = padding
ticks = []
for i in range(clusterer.n_clusters):
coeffs = silhouette_coefficients[y_pred == i]
coeffs.sort()
color = mpl.cm.Spectral(i / clusterer.n_clusters)
plt.fill_betweenx(np.arange(pos, pos + len(coeffs)), 0, coeffs,
facecolor=color, edgecolor=color, alpha=0.7)
ticks.append(pos + len(coeffs) // 2)
pos += len(coeffs) + padding
plt.axvline(x=silhouette_average, color="red", linestyle="--")
plt.gca().yaxis.set_major_locator(FixedLocator(ticks))
plt.gca().yaxis.set_major_formatter(FixedFormatter(range(clusterer.n_clusters)))
if show_xlabels:
plt.gca().set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
plt.xlabel("Silhouette Coefficient")
else:
plt.tick_params(labelbottom=False)
if show_ylabels:
plt.ylabel("Cluster")
if show_title:
plt.title("init:{} n_cluster:{}".format(clusterer.init, clusterer.n_clusters))
plt.figure(figsize=(15, 4))
plt.subplot(121)
plot_silhouette_diagram(km1, data)
plt.subplot(122)
plot_silhouette_diagram(km3, data, show_ylabels=False)
save_fig("silhouette_diagram")
```
# MiniBatch KMeans
```
from sklearn.cluster import MiniBatchKMeans
# 测试KMeans算法运行速度
%timeit KMeans(n_clusters=3).fit(data)
# 测试MiniBatchKMeans算法运行速度
%timeit MiniBatchKMeans(n_clusters=5).fit(data)
from timeit import timeit
times = np.empty((100, 2))
inertias = np.empty((100, 2))
for k in range(1, 101):
kmeans = KMeans(n_clusters=k, random_state=42)
minibatch_kmeans = MiniBatchKMeans(n_clusters=k, random_state=42)
print("\r Training: {}/{}".format(k, 100), end="")
times[k-1, 0] = timeit("kmeans.fit(data)", number=10, globals=globals())
times[k-1, 1] = timeit("minibatch_kmeans.fit(data)", number=10, globals=globals())
inertias[k-1, 0] = kmeans.inertia_
inertias[k-1, 1] = minibatch_kmeans.inertia_
plt.figure(figsize=(10, 4))
plt.subplot(121)
plt.plot(range(1, 101), inertias[:, 0], "r--", label="K-Means")
plt.plot(range(1, 101), inertias[:, 1], "b.-", label="Mini-batch K-Means")
plt.xlabel("$k$", fontsize=16)
plt.ylabel("Inertia", fontsize=14)
plt.legend(fontsize=14)
plt.subplot(122)
plt.plot(range(1, 101), times[:, 0], "r--", label="K-Means")
plt.plot(range(1, 101), times[:, 1], "b.-", label="Mini-batch K-Means")
plt.xlabel("$k$", fontsize=16)
plt.ylabel("Training time (seconds)", fontsize=14)
plt.axis([1, 100, 0, 6])
plt.legend(fontsize=14)
save_fig("minibatch_kmeans_vs_kmeans")
plt.show()
```
# 降维后聚类
```
from sklearn.decomposition import PCA
# 使用普通PCA进行降维,将特征从11维降至3维
pca1 = PCA(n_components=n_labels)
pca1.fit(data)
km4 = KMeans(init=pca1.components_, n_clusters=n_labels, n_init=10)
get_marks(km4, data, name="PCA-based KMeans", kmeans=True)
# 查看训练集的维度,已降至3个维度
len(pca1.components_)
# 使用普通PCA降维,将特征降至2维,作二维平面可视化
pca2 = PCA(n_components=2)
reduced_data = pca2.fit_transform(data)
# 使用k-means进行聚类,设置簇=3,初始化方法为'k-means++'
kmeans1 = KMeans(init="k-means++", n_clusters=3, n_init=3)
kmeans2 = KMeans(init="random", n_clusters=3, n_init=3)
kmeans1.fit(reduced_data)
kmeans2.fit(reduced_data)
# 训练集的特征维度降至2维
len(pca2.components_)
# 2维的特征值(降维后)
reduced_data
# 3个簇中心的坐标
kmeans1.cluster_centers_
from matplotlib.colors import ListedColormap
def plot_data(X, real_tag=None):
"""
画散点图
:param X: 只含特征值的数据集
:param real_tag: 有值,则给含有不同分类的散点上色
"""
try:
if not real_tag:
plt.plot(X[:, 0], X[:, 1], 'k.', markersize=2)
except ValueError:
types = list(np.unique(real_tag))
for i in range(len(types)):
plt.plot(X[:, 0][real_tag==types[i]], X[:, 1][real_tag==types[i]],
'.', label="{}".format(types[i]), markersize=3)
plt.legend()
def plot_centroids(centroids, circle_color='w', cross_color='k'):
"""
画出簇中心
:param centroids: 簇中心坐标
:param circle_color: 圆圈的颜色
:param cross_color: 叉的颜色
"""
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='o', s=30, zorder=10, linewidths=8,
color=circle_color, alpha=0.9)
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='x', s=50, zorder=11, linewidths=50,
color=cross_color, alpha=1)
def plot_centroids_labels(clusterer):
labels = np.unique(clusterer.labels_)
centroids = clusterer.cluster_centers_
for i in range(centroids.shape[0]):
t = str(labels[i])
plt.text(centroids[i, 0]-1, centroids[i, 1]-1, t, fontsize=25,
zorder=10, bbox=dict(boxstyle='round', fc='yellow', alpha=0.5))
def plot_decision_boundaried(clusterer, X, tag=None, resolution=1000,
show_centroids=True, show_xlabels=True,
show_ylabels=True, show_title=True,
show_centroids_labels=False):
"""
画出决策边界,并填色
:param clusterer: 训练好的聚类模型(能提前设置簇中心数量或不能提前设置都可以)
:param X: 只含特征值的数据集
:param tag: 只含真实分类信息的数据集,有值,则给散点上色
:param resolution: 类似图片分辨率,给最小的单位上色
:param show_centroids: 为真,画出簇中心
:param show_centroids_labels: 为真,标注出该簇中心的标签
"""
mins = X.min(axis=0) - 0.1
maxs = X.max(axis=0) + 0.1
xx, yy = np.meshgrid(np.linspace(mins[0], maxs[0], resolution),
np.linspace(mins[1], maxs[1], resolution))
Z = clusterer.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 可用color code或者color自定义填充颜色
# custom_cmap = ListedColormap(["#fafab0", "#9898ff", "#a0faa0"])
plt.contourf(xx, yy, Z, extent=(mins[0], maxs[0], mins[1], maxs[1]),
cmap="Pastel2")
plt.contour(xx, yy, Z, extent=(mins[0], maxs[0], mins[1], maxs[1]),
colors='k')
try:
if not tag:
plot_data(X)
except ValueError:
plot_data(X, real_tag=tag)
if show_centroids:
plot_centroids(clusterer.cluster_centers_)
if show_centroids_labels:
plot_centroids_labels(clusterer)
if show_xlabels:
plt.xlabel(r"$x_1$", fontsize=14)
else:
plt.tick_params(labelbottom=False)
if show_ylabels:
plt.ylabel(r"$x_2$", fontsize=14, rotation=0)
else:
plt.tick_params(labelleft=False)
if show_title:
plt.title("init:{} n_cluster:{}".format(clusterer.init, clusterer.n_clusters))
plt.figure(figsize=(15, 4))
plt.subplot(121)
plot_decision_boundaried(kmeans1, reduced_data, tag=labels)
plt.subplot(122)
plot_decision_boundaried(kmeans2, reduced_data, show_centroids_labels=True)
save_fig("real_tag_vs_non")
plt.show()
kmeans3 = KMeans(init="k-means++", n_clusters=3, n_init=3)
kmeans4 = KMeans(init="k-means++", n_clusters=4, n_init=3)
kmeans5 = KMeans(init="k-means++", n_clusters=5, n_init=3)
kmeans6 = KMeans(init="k-means++", n_clusters=6, n_init=3)
kmeans3.fit(reduced_data)
kmeans4.fit(reduced_data)
kmeans5.fit(reduced_data)
kmeans6.fit(reduced_data)
plt.figure(figsize=(15, 8))
plt.subplot(221)
plot_decision_boundaried(kmeans3, reduced_data, show_xlabels=False, show_centroids_labels=True)
plt.subplot(222)
plot_decision_boundaried(kmeans4, reduced_data, show_ylabels=False, show_xlabels=False)
plt.subplot(223)
plot_decision_boundaried(kmeans5, reduced_data, show_centroids_labels=True)
plt.subplot(224)
plot_decision_boundaried(kmeans6, reduced_data, show_ylabels=False)
save_fig("reduced_and_cluster")
plt.show()
```
# AP算法聚类
```
from sklearn.cluster import AffinityPropagation
# 使用AP聚类算法
af = AffinityPropagation(preference=-500, damping=0.8)
af.fit(data)
# 获取簇的坐标
cluster_centers_indices = af.cluster_centers_indices_
cluster_centers_indices
# 获取分类的类别数量
af_labels = af.labels_
np.unique(af_labels)
get_marks(af, data=data, af=True)
# 将AP聚类聚类的结果写入原始表格中
df['ap_clustering_label'] = af.labels_
# 以csv形式导出原始表格
df.to_csv('test2_result.csv')
# 最后两列为两种聚类算法的分类信息
df
from sklearn.model_selection import GridSearchCV
# from sklearn.model_selection import RamdomizedSearchCV
# 使用GridSearchCV自动寻找最优参数,如果时间太久(约4.7min),可以使用随机搜索
params = {'preference':[-50, -100, -150, -200], 'damping':[0.5, 0.6, 0.7, 0.8, 0.9]}
cluster = AffinityPropagation()
af_best_model = GridSearchCV(cluster, params, cv=5, scoring='adjusted_rand_score', verbose=1, n_jobs=-1)
af_best_model.fit(data, labels)
# 最优模型的参数设置
af_best_model.best_params_
# 最优模型的评分,使用调整的兰德系数(adjusted_rand_score)作为评分
af_best_model.best_score_
# 获取最优模型
af1 = af_best_model.best_estimator_
af1
# 最优模型的评分
get_marks(af1, data=data, af=True)
from sklearn.externals import joblib
# 保存以pkl格式最优模型
joblib.dump(af1, "af1.pkl")
# 从pkl格式中导出最优模型
my_model_loaded = joblib.load("af1.pkl")
my_model_loaded
from sklearn.decomposition import PCA
# 使用普通PCA进行降维,将特征从11维降至3维
pca3 = PCA(n_components=n_labels)
reduced_data = pca3.fit_transform(data)
af2 = AffinityPropagation(preference=-200, damping=0.8)
get_marks(af2, reduced_data, name="PCA-based AF", af=True)
```
# 基于聚类结果的分层抽样
```
# data2是去掉真实分类信息的数据集(含有聚类后的结果)
data2 = df.drop("TRUE VALUE", axis=1)
data2
# 查看使用kmeans聚类后的分类标签值,两类
data2['km_clustering_label'].hist()
from sklearn.model_selection import StratifiedShuffleSplit
# 基于kmeans聚类结果的分层抽样
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(data2, data2["km_clustering_label"]):
strat_train_set = data2.loc[train_index]
strat_test_set = data2.loc[test_index]
def clustering_result_propotions(data):
"""
分层抽样后,训练集或测试集里不同分类标签的数量比
:param data: 训练集或测试集,纯随机取样或分层取样
"""
return data["km_clustering_label"].value_counts() / len(data)
# 经过分层抽样的测试集中,不同分类标签的数量比
clustering_result_propotions(strat_test_set)
# 经过分层抽样的训练集中,不同分类标签的数量比
clustering_result_propotions(strat_train_set)
# 完整的数据集中,不同分类标签的数量比
clustering_result_propotions(data2)
from sklearn.model_selection import train_test_split
# 纯随机取样
random_train_set, random_test_set = train_test_split(data2, test_size=0.2, random_state=42)
# 完整的数据集、分层抽样后的测试集、纯随机抽样后的测试集中,不同分类标签的数量比
compare_props = pd.DataFrame({
"Overall": clustering_result_propotions(data2),
"Stratified": clustering_result_propotions(strat_test_set),
"Random": clustering_result_propotions(random_test_set),
}).sort_index()
# 计算分层抽样和纯随机抽样后的测试集中不同分类标签的数量比,和完整的数据集中不同分类标签的数量比的误差
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Start. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
compare_props
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score
def get_classification_marks(model, data, labels, train_index, test_index):
"""
获取分类模型(二元或多元分类器)的评分:F1值
:param data: 只含有特征值的数据集
:param labels: 只含有标签值的数据集
:param train_index: 分层抽样获取的训练集中数据的索引
:param test_index: 分层抽样获取的测试集中数据的索引
:return: F1评分值
"""
m = model(random_state=42)
m.fit(data.loc[train_index], labels.loc[train_index])
test_labels_predict = m.predict(data.loc[test_index])
score = f1_score(labels.loc[test_index], test_labels_predict, average="weighted")
return score
# 用分层抽样后的训练集训练分类模型后的评分值
start_marks = get_classification_marks(LogisticRegression, data, labels, strat_train_set.index, strat_test_set.index)
start_marks
# 用纯随机抽样后的训练集训练分类模型后的评分值
random_marks = get_classification_marks(LogisticRegression, data, labels, random_train_set.index, random_test_set.index)
random_marks
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import f1_score
from sklearn.base import clone
# 分类模型
sgd_clf = SGDClassifier(max_iter=5, tol=-np.infty, random_state=42)
# 基于分层抽样的k折交叉验证
skfolds = StratifiedKFold(n_splits=5, random_state=42)
# 储存每折测试集的模型评分
score_list = []
for train_index, test_index in skfolds.split(data2, data2["km_clustering_label"]):
clone_clf = clone(sgd_clf)
strat_X_train_folds = data.loc[train_index]
strat_y_train_folds = labels.loc[train_index]
strat_X_test_fold = data.loc[test_index]
strat_y_test_fold = labels.loc[test_index]
clone_clf.fit(strat_X_train_folds, strat_y_train_folds)
test_labels_pred = clone_clf.predict(strat_X_test_fold)
score = f1_score(labels.loc[test_index], test_labels_pred, average="weighted")
score_list.append(score)
# 每折测试集的模型评分
score_list
np.array(score_list).mean()
np.array(score_list).std()
import numpy as np
from sklearn.metrics import f1_score
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone, BaseEstimator, TransformerMixin
class stratified_cross_val_score(BaseEstimator):
"""实现基于分层抽样的k折交叉验证"""
def __init__(self, model, data, labels, random_state=0, cv=5):
"""
:model: 训练的模型(回归或分类)
:data: 只含特征值的完整数据集
:labels: 只含标签值的完整数据集
:random_state: 模型的随机种子值
:cv: 交叉验证的次数
"""
self.model = model
self.data = data
self.labels = labels
self.random_state = random_state
self.cv = cv
self.score = [] # 储存每折测试集的模型评分
self.i = 0
def fit(self, X, y):
"""
:param X: 含有特征值和聚类结果的完整数据集
:param y: 含有聚类结果的完整数据集
:return: 每一折交叉验证的评分
"""
skfolds = StratifiedKFold(n_splits=self.cv, random_state=self.random_state)
for train_index, test_index in skfolds.split(X, y):
# 复制要训练的模型(分类或回归)
clone_model = clone(self.model)
strat_X_train_folds = self.data.loc[train_index]
strat_y_train_folds = self.labels.loc[train_index]
strat_X_test_fold = self.data.loc[test_index]
strat_y_test_fold = self.labels.loc[test_index]
# 训练模型
clone_model.fit(strat_X_train_folds, strat_y_train_folds)
# 预测值(这里是分类模型的分类结果)
test_labels_pred = clone_model.predict(strat_X_test_fold)
# 这里使用的是分类模型用的F1值,如果是回归模型可以换成相应的模型
score_fold = f1_score(labels.loc[test_index], test_labels_pred, average="weighted")
# 避免重复向列表里重复添加值
if self.i < self.cv:
self.score.append(score_fold)
else:
None
self.i += 1
return self.score
def transform(self, X, y=None):
return self
def mean(self):
"""返回交叉验证评分的平均值"""
return np.array(self.score).mean()
def std(self):
"""返回交叉验证评分的标准差"""
return np.array(self.score).std()
from sklearn.linear_model import SGDClassifier
# 分类模型
clf_model = SGDClassifier(max_iter=5, tol=-np.infty, random_state=42)
# 基于分层抽样的交叉验证,data是只含特征值的完整数据集,labels是只含标签值的完整数据集
clf_cross_val = stratified_cross_val_score(test_model, data, labels, cv=5, random_state=42)
# data2是含有特征值和聚类结果的完整数据集
clf_cross_val_score = clf_cross_val.fit(data2, data2["km_clustering_label"])
# 每折交叉验证的评分
clf_cross_val.score
# 交叉验证评分的平均值
clf_cross_val.mean()
# 交叉验证评分的标准差
clf_cross_val.std()
```
| github_jupyter |
# Building your first Artificial Neural Network with AWS
#### Predicting fashion type using Zalando's Fasion-MNIST dataset (https://github.com/zalandoresearch/fashion-mnist)
***
Copyright [2017]-[2017] Amazon.com, Inc. or its affiliates. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance with the License. A copy of the License is located at
http://aws.amazon.com/apache2.0/
or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
***
### Load dependencies
```
import mxnet as mx
import mxnet.notebook.callback
import numpy as np
import os
import urllib
import gzip
import struct
import math
import cv2
import scipy.misc
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
```
### Prepare training and test datasets
```
def download_data(url, force_download=True):
fname = url.split("/")[-1]
if force_download or not os.path.exists(fname):
urllib.urlretrieve(url, fname)
return fname
def to4d(img):
return img.reshape(img.shape[0], 1, 28, 28).astype(np.float32)/255
def read_data(label, image):
base_url = 'https://github.com/zalandoresearch/fashion-mnist/raw/master/data/fashion/'
with gzip.open(download_data(base_url+label, os.path.join('data',label))) as flbl:
magic, num = struct.unpack(">II", flbl.read(8))
label = np.fromstring(flbl.read(), dtype=np.int8)
with gzip.open(download_data(base_url+image, os.path.join('data',image)), 'rb') as fimg:
magic, num, rows, cols = struct.unpack(">IIII", fimg.read(16))
image = np.fromstring(fimg.read(), dtype=np.uint8).reshape(len(label), rows, cols)
return (label, image)
batch_size = 100
(train_lbl, train_img) = read_data('train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz')
(val_lbl, val_img) = read_data('t10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz')
train_data_iter = mx.io.NDArrayIter(data={'fashion_data': to4d(train_img)}, label= {'fashion_item_label': train_lbl}, batch_size=100, shuffle=True)
test_data_iter = mx.io.NDArrayIter(data={'fashion_data': to4d(val_img)}, label= {'fashion_item_label': val_lbl}, batch_size=100)
```
### Display example training data
```
for i in range(10):
plt.subplot(1,10,i+1)
dsp_img= cv2.bitwise_not(train_img[i])
plt.imshow(dsp_img, cmap='Greys_r')
plt.axis('off')
plt.show()
print('label: %s' % (train_lbl[0:10],))
# Zalando fashion labels https://github.com/zalandoresearch/fashion-mnist
fashion_labels=['T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot']
```
### Build MXNet model
```
fashion_item_label = mx.symbol.Variable('fashion_item_label')
# input
data = mx.symbol.Variable('fashion_data')
# Flatten the data from 4-D shape into 2-D (batch_size, num_channel*width*height)
data = mx.sym.flatten(data=data, name='flatten')
# 1st fully-connected layer + activation function
fc1 = mx.sym.FullyConnected(data=data, num_hidden=128)
act1 = mx.sym.Activation(data=fc1, act_type="relu")
# 2nd fully-connected layer + activation function
fc2 = mx.sym.FullyConnected(data=act1, num_hidden = 64)
act2 = mx.sym.Activation(data=fc2, act_type="relu")
# 3rd fully connected layer (MNIST uses 10 classes)
fc3 = mx.sym.FullyConnected(data=act2, num_hidden=10)
# softmax with cross entropy loss
mlp = mx.sym.SoftmaxOutput(data = fc3, label = fashion_item_label, name='softmax')
mx.viz.plot_network(mlp)
```
### Train the model and commit checkpoints
```
import logging
logging.basicConfig(level=logging.INFO)
logging.getLogger().setLevel(logging.INFO)
ctx = mx.gpu()
mod = mx.mod.Module(symbol=mlp, data_names=['fashion_data'], label_names=['fashion_item_label'], context=ctx, logger=logging)
mod.bind(data_shapes=train_data_iter.provide_data, label_shapes=train_data_iter.provide_label)
mod.init_params(initializer=mx.init.Xavier(magnitude=2.))
mod.fit(train_data_iter, # train data
eval_data=test_data_iter, # validation data
optimizer='sgd', # use SGD to train
optimizer_params={'learning_rate' : 0.1}, # use fixed learning rate
eval_metric=mx.metric.Accuracy(), # report accuracy during training
num_epoch=10, # train for at most 10 dataset passes
epoch_end_callback = mx.callback.do_checkpoint('fashion_mnist'))
```
### Run predictions for 10 example elements
```
pred_data_iter = mx.io.NDArrayIter(data={'fashion_data': to4d(val_img)[0:100]}, batch_size=100)
pred_digits = mod.predict(eval_data=pred_data_iter).asnumpy()
%matplotlib inline
import matplotlib.pyplot as plt
for i in range(10):
plt.subplot(1,10,i+1)
plt.imshow(val_img[i + 10], cmap='Greys')
plt.axis('off')
plt.show()
for x in range(10, 20):
print("Predicted fashion label for image %s is %s " % (x, np.where(pred_digits[x,0:10] == pred_digits[x,0:10].max())[0]))
```
### Downloading images for prediction from amazon.com
```
!wget -O predict1.jpg https://images-na.ssl-images-amazon.com/images/I/81OaXwn1x4L._UX679_.jpg
!wget -O predict2.jpg https://images-eu.ssl-images-amazon.com/images/I/31TcgNHsbIL._AC_UL260_SR200,260_.jpg
!wget -O predict3.jpg https://images-eu.ssl-images-amazon.com/images/I/41hWhZBIc3L._AC_UL260_SR200,260_.jpg
```
### Load model from checkpoint for prediction
```
prediction_model_check_point = 10
prediction_model_prefix = 'fashion_mnist'
prediction_sym, arg_params, aux_params = mx.model.load_checkpoint(prediction_model_prefix, prediction_model_check_point)
prediction_model = mx.mod.Module(symbol=prediction_sym, data_names=['fashion_data'], label_names=['fashion_item_label'])
prediction_model.bind(for_training=False, data_shapes=[('fashion_data', (1,1,28,28))])
prediction_model.set_params(arg_params=arg_params, aux_params=aux_params, allow_missing=True)
# define prediction function
def predict_fashion(img):
# format data to run prediction
array = np.full((1, 28, 28), img, dtype=np.float32)
array.shape
pred_data_iter = mx.io.NDArrayIter(data={'fashion_data': to4d(array)}, batch_size=1)
pred_digits = prediction_model.predict(eval_data=pred_data_iter).asnumpy()
label = (np.where(pred_digits[0] == pred_digits[0].max())[0])
print("Predicted fashion label for image is %s (%s) " % (label,fashion_labels[label[0]]))
```
### Predict labels for downloaded images
```
for i in xrange(3):
img = mpimg.imread('predict'+str(i+1)+'.jpg')
plt.imshow(img)
plt.axis('off')
plt.show()
# get colours in line with train data
img = cv2.bitwise_not(img)
img= np.array (np.mean(img, -1))
# resize image
img = scipy.misc.imresize(img, (28, 28))
predict_fashion(img)
```
| github_jupyter |
## Data Engineering Platform For Analytics
### Data Cleaning
**Importing necessary libraries**
```
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import mysql.connector as mysql
import warnings
import pymysql
from pandas.io import sql
warnings.filterwarnings("ignore")
```
#### Name Basics
```
name_basics_0 = pd.read_csv('/Users/ali/Documents/University of Chicago/Data Engineering Platform for Analytics/Project/Datasets/name.basics.tsv', sep='\t',
low_memory = False, skipinitialspace = True)
name_basics_0.head()
name_basics_0.shape
```
*The number of rows exceed the capacity of excel. Therefore we would be unable to export to excel and process through mySQL*
```
name_clean = name_basics_0
```
**Using str.split() operations to split strings into all of its components. This will allows us to examine each value for our required joins**
```
name_clean[['Profession_1', 'Profession_2', 'Profession_3']] = name_clean['primaryProfession'].str.split(',', expand=True)
name_clean[['Title_1', 'Title_2', 'Title_3', 'Title_4', 'Title_5', 'Title_6']] = name_clean['knownForTitles'].str.split(',', expand=True)
name_clean[['Profession_1', 'Profession_2', 'Profession_3', 'Title_1', 'Title_2', 'Title_3', 'Title_4', 'Title_5', 'Title_6']].head(10)
```
**Examining null values in the dataframe columns**
```
plt.figure(figsize=(14,6))
sns.heatmap(name_clean.isnull())
plt.show()
```
*As anticipated, there are no null values in Title_1 but they progressively increase for each new column containing title*
```
name_clean = name_clean.drop(columns=['primaryProfession', 'knownForTitles'])
name_basics = name_clean
name_basics.head()
```
#### Title Ratings
```
title_ratings = pd.read_csv('/Users/ali/Documents/University of Chicago/Data Engineering Platform for Analytics/Project/Datasets/title.ratings.tsv', sep='\t',
low_memory = False, skipinitialspace = True)
title_ratings.head()
```
**Looking at the length of values in the column tconst**
```
title_ratings.tconst.str.len().value_counts()
```
**Looking at total number of distinct values**
```
li = list(title_ratings.tconst.value_counts())
print(len(li))
```
*The column tconst acts as a primary key for title_ratings and we do not need to split it further*
#### Title Basics
```
title_basics_0 = pd.read_csv('/Users/ali/Documents/University of Chicago/Data Engineering Platform for Analytics/Project/Datasets/title.basics.tsv', sep='\t',
low_memory = False, skipinitialspace = True)
title_basics_0.head()
title_basics_0.shape
title_basics = title_basics_0
plt.figure(figsize=(14,6))
sns.heatmap(title_basics.isnull())
plt.show()
```
#### Title Principals
| github_jupyter |
```
import pandas as pd
from datetime import datetime, date
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
```
# Load all data at once
```
conditions = pd.read_csv("../data/csv/conditions.csv")
patients = pd.read_csv("../data/csv/patients.csv")
observations = pd.read_csv("../data/csv/observations.csv")
#care_plans = pd.read_csv("../data/csv/careplans.csv")
encounters = pd.read_csv("../data/csv/encounters.csv")
devices = pd.read_csv("../data/csv/devices.csv")
#supplies = pd.read_csv('../data/csv/supplies.csv')
procedures = pd.read_csv("../data/csv/procedures.csv")
medications = pd.read_csv("../data/csv/medications.csv")
# set your condition, this will be our prediction "target"
condition = 'Chronic congestive heart failure (disorder)'
```
# Preprocessing
```
# perform any processing that is needed for your features
patients = patients.rename(columns={'Id': 'PATIENT'})
# convert birthdate to datetime
patients['BIRTHDATE'] = pd.to_datetime(patients['BIRTHDATE'])
# calculate age
patients['AGE'] = patients['BIRTHDATE'].apply(lambda x : (datetime.now().year - x.year))
```
# Set your features
### Two possible formats: (table name, column name) OR (table name, filter column, filter value, column name)
```
features = [('patients','AGE'), ('patients','GENDER'),
('observations', 'DESCRIPTION', 'Body Mass Index', 'VALUE'),
('observations', 'DESCRIPTION', 'Left ventricular Ejection fraction', 'VALUE'),
('observations', 'DESCRIPTION', 'Systolic Blood Pressure', 'VALUE'),
('observations', 'DESCRIPTION', 'Heart rate', 'VALUE')]
```
# Build your dataset based on your feature list
```
X = patients[['PATIENT']]
for feature in features:
merge_col = 'PATIENT'
print(feature)
if len(feature) == 2:
X = X.merge(locals()[feature[0]][[merge_col, feature[1]]], on=merge_col)
elif len(feature) == 4:
table = locals()[feature[0]]
tmp = table.loc[table[feature[1]]==feature[2]].copy()
tmp[feature[3]] = pd.to_numeric(tmp[feature[3]])
tmp = tmp.groupby('PATIENT')[feature[3]].mean().reset_index()
tmp = tmp.rename(columns={feature[3]:feature[2]})
print(tmp[feature[2]].median())
X = X.merge(tmp, on='PATIENT', how='left')
X[feature[2]] = X[feature[2]].fillna(X[feature[2]].median())
X
# add your label
X = X.merge(conditions.loc[conditions['DESCRIPTION']==condition][['PATIENT','START']], on='PATIENT', how='left')
X = X.rename(columns={'START': 'label'})
X['label'] = X['label'].notnull()
X
```
# Save your preprocessed data to a CSV file
```
X.to_csv('../data/model_input.csv', index=False)
```
| github_jupyter |
```
import numpy as np
import pandas as pd
from sklearn import preprocessing
def normalizeD(data):
df = preprocessing.scale(data)
return df
def dataScaler():
data = np.loadtxt("training_ccpp_x_y_train.csv",delimiter=',')
xno = len(data[0])-1
x = data[:,0:xno]
dataTest = np.genfromtxt("test_ccpp_x_test.csv",delimiter=',')
o = np.concatenate((x, dataTest), axis=0)
data_scaled = normalizeD(o)
z = np.ones((len(data_scaled),1))
data_scaled = np.hstack((data_scaled,z))
data_test = data_scaled[7176:,:]
data_train = data_scaled[0:7176,:]
return data_train,data_test
def cost(points,m):
costt = 0
M =len(points)
for i in range(M):
y = points[i,(len(points[0])-1)]
x_total=0
for j in range((len(points[0])-1)):
x_total += m[j]*points[i,j]
costt += (1/M)*((y-x_total)**2)
return costt
def addFeatures(X):
cols = len(data[0])-1
for x in range(0,cols):
z = X[0:,x]**2
X = np.insert(X,cols,values=z,axis=1)
return X
```
# Generic Gradient Descent Code Start
```
#iterate through all the data points and find the slope
#for generic gradient descent you have only one array of m and the last c have a coeff of 1
def step_grad(points,learning_rate,m):
m_slope =np.zeros(len(points[0]))
M = len(points)
for i in range(M):
# x = points[i,0] this will not work we have to cal x_total (m1x1+m2x2+......)
x_total =0
for j in range((len(points[0])-1)):
x_total += m[j]*points[i,j]
y = points[i,(len(points[0])-1)]
l=0
for k in range((len(points[0])-1)):
m_slope[l] += (-2/M)*(y-x_total)*points[i,k]
l=l+1
#c_slope += (-2/M)*(y-m*x-c)
new_m=list([0 for j in range(len(points[0])-1)])
a=0
for i in range((len(points[0])-1)):
new_m[i]=m[i]-learning_rate*m_slope[i]
#new_m = m - learning_rate * m_slope
# new_c = c - learning_rate * c_slope
return new_m
#as said in gd defnition we have to start m&c with any random value
#substract the slope from the m or c till num_iter
def gd(points,learning_rate,num_iter):
m=np.zeros(points.shape[1])
#c=0
for i in range(num_iter):
m = step_grad(points,learning_rate,m)
#use cost function not for calculating gd but for getting yourself idea of which way code is going!
#print(i,"cost:")
print(i,"cost:",cost(points,m))
return m
#we have to load data and send it to gd function to figure out m & c
#gd requiires learning rate & number of iter
#generic data requires addition of 1 as the coeff of c to each row
#training_ccpp_x_y_train.csv
def run():
data = np.loadtxt("training_ccpp_x_y_train.csv",delimiter=',')
M = len(data[0])
y = data[:,M-1:]
dataN,dataTest = dataScaler()
new_d = np.hstack((dataN,y))
print(dataN.shape)
print(dataTest.shape)
learning_rate = 0.1
num_iter =310
print(new_d.shape)
m = gd(new_d,learning_rate,num_iter)
#print(m)
return m
#no we need a predict fuction which pedicts the data by reading the values from test set
def predict(points,m):
# z = np.ones((len(points),1))
#new_d = np.hstack((points,z))
y_pred = np.zeros(len(points))
for i in range(len(points)):
#y_pred[i]
for j in range(len(points[0])):
y_pred[i] += m[j]*points[i,j]
return y_pred
#test_ccpp_x_test.csv
m = run()
print(m)
y_pred = predict(dataTest,m)
print(y_pred.shape)
np.savetxt("comcycle.csv",y_pred,fmt="%.5f")
```
| github_jupyter |
가장 먼저 텐서플로우 패키지를 임포트해야 합니다. 보통 임포트하고 나서 이름을 축약해서 사용하려고 as 키워드를 사용합니다.
`import tensorflow as tf`
텐서플로우는 계산 그래프를 만들고 실행하는 두가지를 구분하고 있습니다. 두개의 상수를 더하는 그래프를 만들고 실행시켜 보겠습니다.
텐서플로우에서 상수를 만드는 함수는 tf.constant() 입니다. 텐서플로우에서는 이런 함수들을 API라고 부릅니다. 여기서는 편의상 함수라고 부르겠습니다. 이 함수를 사용해서 두개의 상수를 만들어 보세요.
`a = tf.constant(2)`
위에서 구한 두개의 상수를 덧셈하겠습니다. 텐서플로우의 덧셈 함수는 tf.add() 입니다.
`c = tf.add(a, b)`
지금까지 우리는 그래프를 만들었습니다. 이 그래프는 실제로 실행되지 않았고 그래프의 구조만 정의한 것입니다. 그래프를 실행하려면 tf.Session() 객체를 만들어 계산하려는 그래프를 전달하면 됩니다.
`sess = tf.Session()
sess.run(c)`
계산 그래프의 다른 부분을 넣으면 그 노드에서 필요한 하위 노드를 계산하여 결과를 돌려 줍니다. 위에서 만든 상수와 덧셈 노드를 모두 run() 함수로 실행해 보세요.
텐서플로우에서는 텐서(Tensor)라 부르는 다차원 배열을 데이터의 기본 구조로 사용합니다. 기술적으로 말하면 계산 그래프의 노드 사이를 이동하는 데이터가 텐서입니다.
텐서의 크기는 `shape` 속성을 참조해서 확인할 수 있습니다. 위에서 만든 상수 텐서와 결과의 크기를 확인해 보세요.
`a.shape`
배열이 아닌 값 하나로 이루어진 것을 스칼라(scalar)라고 부릅니다. 따러서 스칼라 텐서의 크기는 없습니다.
이번에는 파이썬의 리스트를 이용하여 텐서를 만들어 보겠습니다. 임의의 정수 리스트를 tf.constant()에 입력하고 크기를 확인해 보세요.
`c = tf.constant([1, 1])
c.shape`
텐서플로우에서는 텐서의 크기를 차원(dimension)이라고 부릅니다. 리스트의 리스트를 만들면 차원이 두개인 텐서를 만들 수 있습니다.
`d = tf.constant([[0, 1, 2], [3, 4, 5]])`
이런 텐서는 이차원 구조의 텐서가 됩니다. 이차원 텐서를 만들고 텐서의 크기와 값을 출력해 보세요. sess.run() 명령을 사용해야 값을 확인할 수 있습니다.
자주 사용되는 텐서를 편리하게 만들 수 있는 함수들이 있습니다.
tf.zeros()는 지정된 크기의 텐서를 만든 후 모두 0으로 채워서 리턴합니다. tf.ones()는 지정된 크기의 텐서를 만든 후 모두 1로 채워서 리턴합니다.
tf.zeros()와 tf.ones()로 임의의 크기의 텐서를 만든 후 값을 출력해 보세요.
정규분포 또는 가우시안 분포는 종 모양의 확률 분포를 말합니다. 랜덤한 난수를 발생시킬 때 정규 분포를 따르는 난수가 필요한 경우가 많습니다. 이 때 사용하는 함수는 tf.random_normal() 입니다. 이 함수의 기본값은 평균은 0, 표준편차는 1인 정규분포의 난수를 발생시킵니다.
tf.random_normal()로 임의의 크기의 텐서를 만든 후 값을 출력해 보세요.
파이썬의 대표적인 그래프 라이브러리는 matplotlib 입니다. 주피터 노트북에서는 매직 커맨드라고 부르는 % 기호로 시작하는 명령들이 있습니다. 아래 명령은 matplotlib 패키지를 임포트하고 matplotlib 으로 그린 그래프를 주피터 노트북에 함께 포함되도록 해줍니다.
아래 셀은 그냥 실행하세요.
```
import matplotlib.pyplot as plt
%matplotlib inline
```
위에서 사용한 tf.random_normal() 함수를 사용해 100개의 난수를 만들어 보세요.
`rnd = tf.random_normal([100])
data = sess.run(rnd)`
plt 약자를 이용해서 matplotlib의 그래프 함수를 호출할 수 있습니다. plt.hist() 함수를 사용하면 히스토그램을 그릴 수 있습니다. 위에서 만든 100개의 난수 데이터 data 의 히스토그램을 그려 보세요. 정규 분포를 따르고 있나요?
tf.truncated_normal() 함수는 정규분포의 난수를 발생시키지만 표준편차 2범위 안의 값만을 구합니다. 이는 너무 큰 값의 난수를 생성하지 않게 하려고 함입니다.
tf.truncated_normal()로 위와 같이 100개의 텐서를 만든 후 히스토그램을 그려 보세요.
tf.random_uniform() 함수는 균등분포의 난수를 발생시킵니다. 위에서와 같이 100개의 텐서를 만든 후 히스토그램을 그려 보세요.
텐서의 계산은 차원을 고려하여 수행됩니다. 두개의 원소를 갖는 텐서 두개를 만들어 덧셈을 해 보세요. 결과는 sess.run() 함수를 사용해야 구할 수 있습니다. 텐서의 원소별로 덧셈이 이루어졌나요?
`a = tf.constant([10, 20])`
이번에는 2차원 텐서 두개를 만들어 뺄셈을 해 보겠습니다. 뺄셈을 하는 명령은 tf.subtract() 입니다.
`a = tf.constant([[10, 20], [30, 40]])
b = tf.constant([[10, 20], [30, 40]])
c = tf.subtract(a, b)`
텐서의 사칙연산은 tf.add(), tf.subtract() 대신에 +, - 연산자를 사용할 수 있습니다. 하지만 +, - 연산자를 사용하더라도 실제 계산이 되는 것이 아니고 그래프를 만드는 과정입니다. 실제 계산은 run() 명령을 실행해야 합니다.
위에서 계산한 덧셈, 뺄셈을 +, - 연산자를 사용해 계산해 보세요.
텐서의 곱셈, 나눗셈 연산 함수는 tf.multiply(), tf.divide() 입니다. 함수 대신에 *, / 연산자를 사용하여 위에서 만든 두 텐서를 곱하고 나누어 보세요.
상수는 그래프의 일부분으로 수정될 수 없는 값입니다. 머신 러닝에서 알고리즘이 데이터로부터 학습한 결과를 저장할 도구가 필요합니다. 이럴 때 사용하는 것이 변수, tf.Variable() 입니다.
tf.Variable()로 변수를 만들 때에 초깃값이 주어져야 합니다. 상수 텐서를 이용하여 변수를 만들어 보세요.
`a = tf.Variable(...)`
변수를 계산 그래프에 추가하기 위해서는 초기화 과정을 하나더 거쳐야 합니다. tf.global_variables_initializer() 는 필요한 모든 변수를 그래프에 추가하여 계산 과정에 참여할 수 있도록 합니다.
`init = tf.global_variables_initializer()
sess.run(init)`
변수를 초기화한 후에 위에서 만든 변수값을 run() 명령을 사용해 출력해 보세요.
변수의 용도를 알기 위해 변수의 값을 바꾸는 계산 그래프를 만들어 보겠습니다.
`a = tf.Variable(tf.constant(2))
upd = a.assign_add(tf.constant(3))
init = tf.global_variables_initializer()
sess.run(init)
sess.run(upd)`
`sess.run(upd)` 명령을 여러번 실행해 보세요 값이 어떻게 바뀌나요?
변수를 초기화할 때 수동으로 값을 지정하지 않고 난수를 발생시켜 채우는 경우가 많습니다. tf.random.normal() 함수를 사용하여 임의의 크기의 변수를 만들고, 변수를 초기화한 다음에, run() 명령으로 값을 출력해 보세요.
2차원 텐서의 경우 원소를 참조하려면 인덱스를 두개 사용합니다.
`a[1][2]`
첫번째 인덱스는 행을 나타내고 두번째 인덱스는 열을 지칭합니다.
`a = tf.Variable([[1, -2, 2], [3, -1, 1]])
sess.run(tf.global_variables_initializer())
sess.run(a[1][2])`
2x3 크기의 텐서를 만들고 행, 열을 지정하여 값을 출력해 보세요.
tf.reduce_sum()은 행, 열 방향으로 또는 전체의 합을 계산합니다.
`tf.reduce_sum(a, 0)`
첫번째 매개변수는 대상 텐서를 지정하고 두번째 매개변수는 행(0) 또는 열(1) 방향을 지정합니다. 두번째 매개변수에 아무런 값도 지정하지 않으면 행렬 전체에 대한 합을 계산합니다.
위에서 만든 텐서의 행, 열 방향 합을 구해 보세요. 그리고 행렬의 전체 합도 계산해 보세요.
tf.reduce_mean()은 tf.reduce_sum()과 아주 비슷하게 동작합니다. 다른 점은 합을 계산하는 것이 아니라 평균을 계산합니다.
위에서 만든 텐서의 행, 열 방향 평균을 구해 보세요. 그리고 행렬의 전체 평균도 계산해 보세요.
뉴럴 네트워크 알고리즘은 행렬 계산으로 이루어져 있다고 해도 과언이 아닙니다. 그 중에서도 행렬의 내적이 많이 사용됩니다. 내적은 두 행렬을 곱할 때 첫번째 행렬의 행과 두번째 행렬의 열을 곱하여 결과를 만듭니다.
따라서 내적을 하려면 첫번째 행렬의 행과 두번째 행렬의 열의 차원이 같아야 합니다. 예제를 위해 tf.Variable() 함수를 사용하여 2x3 크기의 변수와 3x2 크기의 변수를 만들어 보세요.
내적을 하는 명령은 tf.matmul() 입니다. 위에서 만든 두개의 텐서를 matmul() 함수를 이용해 곱해 보세요. 곱한 결과를 보려면 변수를 초기화하고 run() 명령을 사용해야 합니다.
`dot = tf.matmul(a, b)`
앞에서 언급한 대로 변수는 알고리즘이 데이터로부터 학습한 것을 저장하는 용도로 사용됩니다. 알고리즘에 데이터를 전달하기 위해 상수를 사용하려면 매번 그래프를 새로 만들어 주어야 합니다. 뉴럴 네트워크 알고리즘은 반복이 많이 필요로 하기 때문에 매번 그래프를 만들어 주면 저장한 변수 값을 잃게 됩니다.
엔지니어가 학습 데이터를 반복 과정 중간에 주입할 도구가 필요한데 이를 플레이스홀더(placeholder)라고 합니다.
위에서 만든 3x2 크기의 변수를 대신하는 동일 크기의 플레이스홀더를 만들겠습니다. 플레이스홀더는 tf.placeholder() 함수로 만듭니다. 플레이스 홀더를 만들 때 입력할 데이터 타입을 지정해 주어야 합니다. tf.int32, tf.float32 등이 있습니다.
`b = tf.placeholder(tf.int32, [3, 2])`
이 플레이스홀더는 값이 없는 채로 계산 그래프에 추가됩니다.
tf.matmul() 함수를 사용하여 2x3 크기의 변수와 3x2 크기의 플레이스홀더를 내적합니다. 그런다음 변수를 초기화를 위한 global_variables_initializer() 함수를 호출합니다.
`dot = tf.matmul(a, b)
init = tf.global_variables_initializer()
sess.run(init)`
마지막으로 sess.run(dot, ...) 함수를 호출할 때 두번째 인자 feed_dict 로 플레이스홀더 b 에 3x2 크기의 배열을 전달합니다.
`sess.run(dot, feed_dict={b: [...]})`
feed_dict 매개변수의 값은 딕셔너리이며 키는 플레이스홀더이고 값은 플레이스홀더에 지정한 크기와 같아야 합니다. 보통 이렇게 feed_dict 에 값을 전달하는 과정을 데이터를 주입한다라고 종종 표현합니다.
동일한 b 플레이스홀더에 위와 다른 값을 주입해 계산해 보세요. 계산 그래프를 다시 만들지 않아도 b 값에 따라서 결과가 변경됩니다.
수고하셨습니다! ^^
| github_jupyter |
```
%matplotlib inline
# Importing standard Qiskit libraries
from qiskit import QuantumCircuit, execute, Aer, IBMQ
from qiskit.compiler import transpile, assemble
from qiskit.visualization import plot_bloch_multivector, plot_histogram
from qiskit.visualization import *
from math import sqrt, pi
# Loading your IBM Q account(s)
provider = IBMQ.load_account()
```
## Quick Exercises 1
### 1. Write down the tensor product of the qubits:
a. |0⟩|1⟩
$$ \begin{bmatrix} 0 \\ 1 \\ 0 \\ 0 \end{bmatrix} $$
b. |0⟩|+⟩
$$ \frac{1}{\sqrt{2}} \begin{bmatrix} 1 \\ 1 \\ 0 \\ 0 \end{bmatrix} $$
c. |+⟩|1⟩
$$ \frac{1}{\sqrt{2}} \begin{bmatrix} 0 \\ 1 \\ 0 \\ 1 \end{bmatrix} $$
d. |−⟩|+⟩
$$ \frac{1}{2} \begin{bmatrix} 1 \\ 1 \\ -1 \\ -1 \end{bmatrix} $$
### 2. Write the state: $$ |\psi⟩= \frac{1}{\sqrt{2}} |00⟩+ \frac{i}{\sqrt{2}} |01⟩ $$ as two separate qubits
This is simply a matter of expanding the tensor product. The answer is apparent when completed
$$ |\psi⟩= \frac{1}{\sqrt{2}} |00⟩+ \frac{i}{\sqrt{2}} |01⟩ = \frac{1}{\sqrt{2}} \begin{bmatrix} 1 \\ i \\ 0 \\ 0 \end{bmatrix} = |0⟩|\circlearrowright⟩ $$
## Quick Exercises 2
### 1. Calculate the single qubit unitary (U) created by the sequence of gates: U=XZH. Use Qiskit's unitary simulator to check your results.
$$ \displaystyle U = XZH = \frac{1}{\sqrt{2}} \begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix} \begin{bmatrix} 1 & 0 \\ 0 & -1 \end{bmatrix} \begin{bmatrix} 1 & 1 \\ 1 & -1 \end{bmatrix} = \frac{1}{\sqrt{2}} \begin{bmatrix} -1 & 1 \\ 1 & 1 \end{bmatrix}$$
```
circuit21 = QuantumCircuit(1, 1)
circuit21.h(0)
circuit21.z(0)
circuit21.x(0)
circuit21.draw('mpl')
from qiskit_textbook.tools import array_to_latex
unitarySim = Aer.get_backend('unitary_simulator')
matrixcircuit21 = execute(circuit21, backend = unitarySim).result().get_unitary()
array_to_latex(matrixcircuit21, pretext="\\text{circuit21 = } ")
```
### 2. Try changing the gates in the circuit above. Calculate their tensor product, and then check your answer using the unitary simulator.
```
circuit22 = QuantumCircuit(3, 3)
circuit22.h(0)
circuit22.z(1)
circuit22.x(2)
circuit22.draw('mpl')
matrixcircuit22 = execute(circuit22, backend = unitarySim).result().get_unitary()
array_to_latex(matrixcircuit22, pretext="\\text{Circuit = } ")
```
## Quick Exercises 3
### 1. Create a quantum circuit that produces the Bell state: $ \frac{1}{\sqrt{2}}(|01⟩+|10⟩)$. Use the statevector simulator to verify your result.
```
circuit31 = QuantumCircuit(2, 2)
circuit31.x(1)
circuit31.h(0)
circuit31.cx(0, 1)
circuit31.draw('mpl')
svsim = Aer.get_backend('statevector_simulator')
finalSV = execute(circuit31, backend = svsim).result().get_statevector()
array_to_latex(finalSV, pretext="\\text{Statevector = }")
```
### 2. The circuit you created in question 1 transforms the state |00⟩ to $ \frac{1}{\sqrt{2}} (|01⟩+|10⟩)$, calculate the unitary of this circuit using Qiskit's simulator. Verify this unitary does in fact perform the correct transformation.
```
matrixcircuit31 = execute(circuit31, backend = unitarySim).result().get_unitary()
array_to_latex(matrixcircuit31, pretext="U_{31} = ")
```
Now that we have the circuit's unitary matrix, we only need to multiply by the initial state vector. Define the map $ T : \mathbf{C}^4 \to \mathbf{C}^4 $ as
$$ T(x) = U_{31} \cdot x = \begin{bmatrix}
0 & 0 & \tfrac{1}{\sqrt{2}} & \tfrac{1}{\sqrt{2}} \\
\tfrac{1}{\sqrt{2}} & -\tfrac{1}{\sqrt{2}} & 0 & 0 \\
\tfrac{1}{\sqrt{2}} & \tfrac{1}{\sqrt{2}} & 0 & 0 \\
0 & 0 & \tfrac{1}{\sqrt{2}} & -\tfrac{1}{\sqrt{2}} \\
\end{bmatrix} \cdot \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \end{bmatrix} $$
The input state vector will be |00⟩. We feed this into T
$$ T(|00⟩ ) = \begin{bmatrix}
0 & 0 & \tfrac{1}{\sqrt{2}} & \tfrac{1}{\sqrt{2}} \\
\tfrac{1}{\sqrt{2}} & -\tfrac{1}{\sqrt{2}} & 0 & 0 \\
\tfrac{1}{\sqrt{2}} & \tfrac{1}{\sqrt{2}} & 0 & 0 \\
0 & 0 & \tfrac{1}{\sqrt{2}} & -\tfrac{1}{\sqrt{2}} \\
\end{bmatrix} \cdot \begin{bmatrix} 1 \\ 0 \\ 0 \\ 0\end{bmatrix} = \frac{1}{\sqrt{2}} \begin{bmatrix} 0 \\ 1 \\ 1 \\ 0\end{bmatrix} $$
### 3. Think about other ways you could represent a statevector visually. Can you design an interesting visualization from which you can read the magnitude and phase of each amplitude?
```
from qiskit.visualization import plot_state_qsphere
plot_state_qsphere(finalSV)
circuit31.measure([0, 1], [0, 1])
qasmSim = Aer.get_backend('qasm_simulator')
counts = execute(circuit31, backend = qasmSim, shots = 1024).result().get_counts()
plot_histogram(counts)
```
| github_jupyter |
```
import zipfile
%matplotlib inline
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import pandas as pd
import torch
import torchvision
import torchvision.transforms as transforms
from operator import is_not
from functools import partial
from math import isclose
import time
```
### load the data from files
```
df_events = pd.read_csv("events.csv")
df_game_info = pd.read_csv("ginf.csv")
```
### Creat training and testing labels number of goals in home and away match
```
df_game_info_select=df_game_info[['fthg','ftag']].fillna(-1)
l1=np.array(df_game_info_select.values, dtype=int)
l1=l1
l1.shape
```
### one-hot encoding from labels
```
coded_l1=np.empty((l1.shape[0],2))
for j in range (l1.shape[0]):
coded_l1[j,0]=int(np.binary_repr(l1[j,0]))
coded_l1[j,1]=int(np.binary_repr(l1[j,1]))
coded_l1.shape
```
### select features from events
```
df_events_select=df_events[['event_type','event_type2','shot_place','shot_outcome','location','side']]
#put NAn = -1
df_events_select=df_events_select.fillna(-1)
colums=['id_odsp','event_type','event_type2','shot_place','shot_outcome','location','side',]
```
### convert from pandas to numpy arry
```
event_np=df_events_select.values
event_np=np.array(event_np,dtype=int)
event_np.shape
```
### pne-hot encoding events
```
coded_events=np.ones((event_np.shape[0],6))
for i in range (event_np.shape[0]):
for j in range (event_np.shape[1]):
coded_events[i,j]=int(np.binary_repr(event_np[i,j]))
coded_events.shape
```
### create event id to connect event-data with info-data
```
c1=df_events['id_odsp']
c1=(c1.values).reshape(-1,1)
c1.shape
full=np.concatenate((c1,event_np),axis=1)
full.shape
coded_full=np.concatenate((c1,coded_events),axis=1)
coded_full
```
### divide events to home and away numpy arrries
```
full_home=[]
full_away=[]
for i in range (full.shape[0]):
if full[i,6]==1:
full_home.append(full[i])
if full[i,6]==2:
full_away.append(full[i])
full_home=np.array(full_home)[:,:6]
full_away=np.array(full_away)[:,:6]
print('full_home.shape',full_home.shape)
print('full_away.shape',full_away.shape)
```
### divide codedevents to home and away numpy arrries
```
coded_full_home=[]
coded_full_away=[]
for i in range (coded_full.shape[0]):
if coded_full[i,6]==1:
coded_full_home.append(coded_full[i])
if coded_full[i,6]==10:
coded_full_away.append(coded_full[i])
coded_full_home=np.array(coded_full_home)[:,:6]
coded_full_away=np.array(coded_full_away)[:,:6]
print('coded_full_home.shape',coded_full_home.shape)
print('coded_full_away.shape',coded_full_away.shape)
```
## create 3-d numpy array (match,events,events values)
### create 3-d numpy array to home matches events
```
a3=-1*np.ones((9074,180,5),dtype=int) #180 maxumim number of events per match
j=0
c=0
for i in range (full_home.shape[0]-1):
if full_home[i,0]==full_home[i+1,0]:
a3[c,j]=full_home[i,1:]
j+=1
else:
j=0
c+=1
print('c',c)
full1=a3
full1.shape
```
### create 3-d numpy array to away matches events
```
a3=-1*np.ones((9074,180,5),dtype=int) #180 maxumim number of events per match
j=0
c1=0
for i in range (full_away.shape[0]-1):
if full_away[i,0]==full_away[i+1,0]:
a3[c1,j]=full_away[i,1:]
j+=1
else:
j=0
c1+=1
print('c1',c1)
full2=a3
full2.shape
```
### create 3-d numpy array to coded home matches events
```
a3=-1*np.ones((9074,180,5),dtype=int) #180 maxumim number of events per match
j=0
c=0
for i in range (coded_full_home.shape[0]-1):
if coded_full_home[i,0]==coded_full_home[i+1,0]:
a3[c,j]=coded_full_home[i,1:]
j+=1
else:
j=0
c+=1
print('c',c)
full3=a3
full3.shape
```
### create 3-d numpy array to coded away matches events
```
a3=-1*np.ones((9074,180,5),dtype=int) #180 maxumim number of events per match
j=0
c=0
for i in range (coded_full_away.shape[0]-1):
if coded_full_away[i,0]==coded_full_away[i+1,0]:
a3[c,j]=coded_full_away[i,1:]
j+=1
else:
j=0
c+=1
print('c',c)
full4=a3
full4.shape
```
### vectorize data from (180*5) to (1,900)
```
training_data1=np.empty((9074,900))
for i in range (full1.shape[0]):
training_data1[i]=full1[i].reshape(-1)
training_data1.shape
training_data2=np.empty((9074,900))
for i in range (full2.shape[0]):
training_data2[i]=full2[i].reshape(-1)
training_data2.shape
training_data3=np.empty((9074,900))
for i in range (full3.shape[0]):
training_data3[i]=full3[i].reshape(-1)
training_data3.shape
training_data4=np.empty((9074,900))
for i in range (full4.shape[0]):
training_data4[i]=full4[i].reshape(-1)
training_data4.shape
```
# Part 2
# Training function using RNN
```
import torch
import torch.nn as nn
# Set the random seed for reproducible results.
torch.manual_seed(1)
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
# This just calls the base class constructor.
super().__init__()
# Neural network layers assigned as attributes of a Module subclass
# have their parameters registered for training automatically.
self.rnn = torch.nn.RNN(input_size, hidden_size, nonlinearity='relu', batch_first=True)
self.linear = torch.nn.Linear(hidden_size, output_size)
def forward(self, x):
# The RNN also returns its hidden state but we don't use it.
# While the RNN can also take a hidden state as input, the RNN
# gets passed a hidden state initialized with zeros by default.
x, _ = self.rnn(x)
x = self.linear(x)
return x
class SimpleLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.lstm = torch.nn.LSTM(input_size, hidden_size, batch_first=True)
self.linear = torch.nn.Linear(hidden_size, output_size)
def forward(self, x):
x, _ = self.lstm(x)
x = self.linear(x)
return x
def train(model, train_data_gen,labels, criterion, optimizer):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Set the model to training mode. This will turn on layers that would
# otherwise behave differently during evaluation, such as dropout.
model.train()
# Store the number of sequences that were classified correctly.
num_correct = 0
# Iterate over every batch of sequences. Note that the length of a data generator
# is defined as the number of batches required to produce a total of roughly 1000
# sequences given a batch size.
for batch_idx in range(len(train_data_gen)):
# For each new batch, clear the gradient buffers of the optimized parameters.
# Otherwise, gradients from the previous batch would be accumulated.
optimizer.zero_grad()
# Request a batch of sequences and class labels, convert them into tensors
# of the correct type, and then send them to the appropriate device.
data, target = train_data_gen[batch_idx],labels[batch_idx]
data=data.view(1,1,900)
target=target.view(1,1,1)
# print('data.shape',data.shape)
# print('target.shape',target.shape)
data, target = data.float().to(device), target.long().to(device)
# Perform the forward pass of the model.
output = model(data)
loss = criterion(output.float(), target.float())
# print(loss)
loss.backward()
optimizer.step()
y_pred = output
if abs(y_pred - target.float()) <= 0.5:
num_correct+=1
# num_correct += (y_pred == target.float()).int().sum().item()
return num_correct, loss.item()
def test(model, test_data_gen,labels_test, criterion):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Set the model to evaluation mode. This will turn off layers that would
# otherwise behave differently during training, such as dropout.
model.eval()
# Store the number of sequences that were classified correctly.
num_correct = 0
# A context manager is used to disable gradient calculations during inference
# to reduce memory usage, as we typically don't need the gradients at this point.
with torch.no_grad():
for batch_idx in range(len(test_data_gen)):
data, target = test_data_gen[batch_idx],labels_test[batch_idx]
# print('test taget',target)
data=data.view(1,1,900)
target=target.view(1,1,1)
data, target = (data).float().to(device), (target).long().to(device)
output = model(data)
loss = criterion(output.float(), target.float())
y_pred = output
if abs(y_pred - target.float()) <= 0.5:
num_correct+=1
return num_correct, loss.item()
def train_and_test(model, train_data_gen,labels, test_data_gen,labels_test, criterion, optimizer, max_epochs, verbose=True):
# Automatically determine the device that PyTorch should use for computation.
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
text_file_loss = open("loss_away_one_hot.txt", "w")
text_file_acc = open("acc_away_one_hot.txt", "w")
# Track the value of the loss function and model accuracy across epochs.
history_train = {'loss': [], 'acc': []}
history_test = {'loss': [], 'acc': []}
for epoch in range(max_epochs):
num_correct, loss = train(model, train_data_gen,labels, criterion, optimizer)
# accuracy = float(num_correct) / (len(train_data_gen) * train_data_gen.batch_size) * 100
accuracy = float(num_correct) / (train_data_gen.shape[0]) * 100
history_train['loss'].append(loss)
history_train['acc'].append(accuracy)
# Do the same for the testing loop.
num_correct, loss = test(model, test_data_gen,labels_test, criterion)
accuracy = float(num_correct) / (len(test_data_gen) * test_data_gen) * 100
# accuracy = float(num_correct) / (len(test_data_gen) * test_data_gen.numpy().batch_size) * 100
history_test['loss'].append(loss)
history_test['acc'].append(accuracy)
if verbose or epoch + 1 == max_epochs:
text_file_loss.write('{} , '.format(history_train['loss'][-1]))
text_file_acc.write('{} , '.format(history_train['acc'][-1]))
print('[Epoch {} / {}] loss: {}, acc {}%'.format(epoch + 1,max_epochs,history_train['loss'][-1],history_train['acc'][-1]))
return model
```
## Train one-hot encoding data
### home without one-hot encoding
```
train_d=training_data1[0:2000]
# train_d=np,atrain_d,
train_d=torch.from_numpy(train_d)
print('train_d.shape',train_d.shape)
train_label=l1[0:2000,0].reshape(-1,1)
# np.concatenate((),axis=1)
train_label=torch.from_numpy(train_label)
print('train_label.shape',train_label.shape)
test_d=training_data1[2000:2100]
test_d=torch.from_numpy(test_d)
print('test_d.shape',test_d.shape)
test_label=l1[2000:2100,0]
test_label=torch.from_numpy(test_label)
print('test_label.shape',test_label.shape)
# Setup the training and test data generators.
batch_size = 100
train_data_gen = train_d
test_data_gen = test_d
labels = train_label
labels_test=test_label
# print('train_data_gen.shape',train_data_gen.shape)
# print('labels.shape',labels.shape)
# Setup the RNN and training settings.
input_size = 900
hidden_size = 500
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size)
criterion = torch.nn.MSELoss()
# optimizer = torch.optim.RMSprop(model.parameters(), lr=0.001)
optimizer =torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-3)
max_epochs = 100
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Train the model.
start=time.perf_counter()
model = train_and_test(model, train_data_gen,labels, test_data_gen,labels_test, criterion, optimizer, max_epochs)
# model=train(model, train_data_gen,labels, criterion, optimizer)
print(model)
print('Total time is {} Second'.format(time.perf_counter()-start))
#torch.save(model,'without_one_hot_encoding_last')
```
### away without one-hot encoding
```
train_d=training_data2[0:2000]
# train_d=np,atrain_d,
train_d=torch.from_numpy(train_d)
print('train_d.shape',train_d.shape)
train_label=l1[0:2000,1].reshape(-1,1)
# np.concatenate((),axis=1)
train_label=torch.from_numpy(train_label)
print('train_label.shape',train_label.shape)
test_d=training_data2[2000:2100]
test_d=torch.from_numpy(test_d)
print('test_d.shape',test_d.shape)
test_label=l1[2000:2100,1]
test_label=torch.from_numpy(test_label)
print('test_label.shape',test_label.shape)
# Setup the training and test data generators.
batch_size = 100
train_data_gen = train_d
test_data_gen = test_d
labels = train_label
labels_test=test_label
# print('train_data_gen.shape',train_data_gen.shape)
# print('labels.shape',labels.shape)
# Setup the RNN and training settings.
input_size = 900
hidden_size = 500
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size)
criterion = torch.nn.MSELoss()
# optimizer = torch.optim.RMSprop(model.parameters(), lr=0.001)
optimizer =torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-3)
max_epochs = 100
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Train the model.
start=time.perf_counter()
model = train_and_test(model, train_data_gen,labels, test_data_gen,labels_test, criterion, optimizer, max_epochs)
# model=train(model, train_data_gen,labels, criterion, optimizer)
print(model)
print('Total time is {} Second'.format(time.perf_counter()-start))
#torch.save(model,'without_one_hot_encoding_last')
```
### home one-hot encoding
```
train_d=training_data3[0:2000]
# train_d=np,atrain_d,
train_d=torch.from_numpy(train_d)
print('train_d.shape',train_d.shape)
train_label=coded_l1[0:2000,0].reshape(-1,1)
# np.concatenate((),axis=1)
train_label=torch.from_numpy(train_label)
print('train_label.shape',train_label.shape)
test_d=training_data3[2000:2100]
test_d=torch.from_numpy(test_d)
print('test_d.shape',test_d.shape)
test_label=coded_l1[2000:2100,0]
test_label=torch.from_numpy(test_label)
print('test_label.shape',test_label.shape)
# Setup the training and test data generators.
batch_size = 100
train_data_gen = train_d
test_data_gen = test_d
labels = train_label
labels_test=test_label
# print('train_data_gen.shape',train_data_gen.shape)
# print('labels.shape',labels.shape)
# Setup the RNN and training settings.
input_size = 900
hidden_size = 500
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size)
criterion = torch.nn.MSELoss()
# optimizer = torch.optim.RMSprop(model.parameters(), lr=0.001)
optimizer =torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-3)
max_epochs = 100
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Train the model.
start=time.perf_counter()
model = train_and_test(model, train_data_gen,labels, test_data_gen,labels_test, criterion, optimizer, max_epochs)
# model=train(model, train_data_gen,labels, criterion, optimizer)
print(model)
print('Total time is {} Second'.format(time.perf_counter()-start))
#torch.save(model,'without_one_hot_encoding_last')
```
### Away one-hot encoding
```
train_d=training_data4[0:2000]
# train_d=np,atrain_d,
train_d=torch.from_numpy(train_d)
print('train_d.shape',train_d.shape)
train_label=coded_l1[0:2000,1].reshape(-1,1)
# np.concatenate((),axis=1)
train_label=torch.from_numpy(train_label)
print('train_label.shape',train_label.shape)
test_d=training_data4[2000:2100]
test_d=torch.from_numpy(test_d)
print('test_d.shape',test_d.shape)
test_label=coded_l1[2000:2100,1]
test_label=torch.from_numpy(test_label)
print('test_label.shape',test_label.shape)
# Setup the training and test data generators.
batch_size = 100
train_data_gen = train_d
test_data_gen = test_d
labels = train_label
labels_test=test_label
# print('train_data_gen.shape',train_data_gen.shape)
# print('labels.shape',labels.shape)
# Setup the RNN and training settings.
input_size = 900
hidden_size = 500
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size)
criterion = torch.nn.MSELoss()
# optimizer = torch.optim.RMSprop(model.parameters(), lr=0.001)
optimizer =torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-3)
max_epochs = 100
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Train the model.
start=time.perf_counter()
model = train_and_test(model, train_data_gen,labels, test_data_gen,labels_test, criterion, optimizer, max_epochs)
# model=train(model, train_data_gen,labels, criterion, optimizer)
print(model)
print('Total time is {} Second'.format(time.perf_counter()-start))
#torch.save(model,'without_one_hot_encoding_last')
```
| github_jupyter |
## One Hot Encoding of Frequent Categories
We learned in Section 3 that high cardinality and rare labels may result in certain categories appearing only in the train set, therefore causing over-fitting, or only in the test set, and then our models wouldn't know how to score those observations.
We also learned in the previous lecture on one hot encoding, that if categorical variables contain multiple labels, then by re-encoding them with dummy variables we will expand the feature space dramatically.
**In order to avoid these complications, we can create dummy variables only for the most frequent categories**
This procedure is also called one hot encoding of top categories.
In fact, in the winning solution of the KDD 2009 cup: ["Winning the KDD Cup Orange Challenge with Ensemble Selection"](http://www.mtome.com/Publications/CiML/CiML-v3-book.pdf), the authors limit one hot encoding to the 10 most frequent labels of the variable. This means that they would make one binary variable for each of the 10 most frequent labels only.
OHE of frequent or top categories is equivalent to grouping all the remaining categories under a new category. We will have a better look at grouping rare values into a new category in a later notebook in this section.
### Advantages of OHE of top categories
- Straightforward to implement
- Does not require hrs of variable exploration
- Does not expand massively the feature space
- Suitable for linear models
### Limitations
- Does not add any information that may make the variable more predictive
- Does not keep the information of the ignored labels
Often, categorical variables show a few dominating categories while the remaining labels add little information. Therefore, OHE of top categories is a simple and useful technique.
### Note
The number of top variables is set arbitrarily. In the KDD competition the authors selected 10, but it could have been 15 or 5 as well. This number can be chosen arbitrarily or derived from data exploration.
## In this demo:
We will see how to perform one hot encoding with:
- pandas and NumPy
- Feature-Engine
And the advantages and limitations of these implementations using the House Prices dataset.
```
import numpy as np
import pandas as pd
# to split the datasets
from sklearn.model_selection import train_test_split
# for one hot encoding with feature-engine
from feature_engine.encoding import OneHotEncoder
# load dataset
data = pd.read_csv(
'../houseprice.csv',
usecols=['Neighborhood', 'Exterior1st', 'Exterior2nd', 'SalePrice'])
data.head()
# let's have a look at how many labels each variable has
for col in data.columns:
print(col, ': ', len(data[col].unique()), ' labels')
# let's explore the unique categories
data['Neighborhood'].unique()
data['Exterior1st'].unique()
data['Exterior2nd'].unique()
```
### Encoding important
It is important to select the top or most frequent categories based of the train data. Then, we will use those top categories to encode the variables in the test data as well
```
# let's separate into training and testing set
X_train, X_test, y_train, y_test = train_test_split(
data[['Neighborhood', 'Exterior1st', 'Exterior2nd']], # predictors
data['SalePrice'], # target
test_size=0.3, # percentage of obs in test set
random_state=0) # seed to ensure reproducibility
X_train.shape, X_test.shape
# let's first examine how OHE expands the feature space
pd.get_dummies(X_train, drop_first=True).shape
```
From the initial 3 categorical variables, we end up with 53 variables.
These numbers are still not huge, and in practice we could work with them relatively easily. However, in real-life datasets, categorical variables can be highly cardinal, and with OHE we can end up with datasets with thousands of columns.
## OHE with pandas and NumPy
### Advantages
- quick
- returns pandas dataframe
- returns feature names for the dummy variables
### Limitations:
- it does not preserve information from train data to propagate to test data
```
# let's find the top 10 most frequent categories for the variable 'Neighborhood'
X_train['Neighborhood'].value_counts().sort_values(ascending=False).head(10)
# let's make a list with the most frequent categories of the variable
top_10 = [
x for x in X_train['Neighborhood'].value_counts().sort_values(
ascending=False).head(10).index
]
top_10
# and now we make the 10 binary variables
for label in top_10:
X_train['Neighborhood' + '_' + label] = np.where(
X_train['Neighborhood'] == label, 1, 0)
X_test['Neighborhood' + '_' + label] = np.where(
X_test['Neighborhood'] == label, 1, 0)
# let's visualise the result
X_train[['Neighborhood'] + ['Neighborhood'+'_'+c for c in top_10]].head(10)
# we can turn the previous commands into 2 functions
def calculate_top_categories(df, variable, how_many=10):
return [
x for x in df[variable].value_counts().sort_values(
ascending=False).head(how_many).index
]
def one_hot_encode(train, test, variable, top_x_labels):
for label in top_x_labels:
train[variable + '_' + label] = np.where(
train[variable] == label, 1, 0)
test[variable + '_' + label] = np.where(
test[variable] == label,1, 0)
# and now we run a loop over the remaining categorical variables
for variable in ['Exterior1st', 'Exterior2nd']:
top_categories = calculate_top_categories(X_train, variable, how_many=10)
one_hot_encode(X_train, X_test, variable, top_categories)
# let's see the result
X_train.head()
```
Note how we now have 30 additional dummy variables instead of the 53 that we would have had if we had created dummies for all categories.
## One hot encoding of top categories with Feature-Engine
### Advantages
- quick
- creates the same number of features in train and test set
### Limitations
- None to my knowledge
```
# let's separate into training and testing set
X_train, X_test, y_train, y_test = train_test_split(
data[['Neighborhood', 'Exterior1st', 'Exterior2nd']], # predictors
data['SalePrice'], # target
test_size=0.3, # percentage of obs in test set
random_state=0) # seed to ensure reproducibility
X_train.shape, X_test.shape
ohe_enc = OneHotEncoder(
top_categories=10, # you can change this value to select more or less variables
# we can select which variables to encode
variables=['Neighborhood', 'Exterior1st', 'Exterior2nd'],
drop_last=False)
ohe_enc.fit(X_train)
# in the encoder dict we can observe each of the top categories
# selected for each of the variables
ohe_enc.encoder_dict_
# this is the list of variables that the encoder will transform
ohe_enc.variables_
X_train = ohe_enc.transform(X_train)
X_test = ohe_enc.transform(X_test)
# let's explore the result
X_train.head()
```
**Note**
If the argument variables is left to None, then the encoder will automatically identify **all categorical variables**. Is that not sweet?
The encoder will not encode numerical variables. So if some of your numerical variables are in fact categories, you will need to re-cast them as object before using the encoder.
| github_jupyter |
# Qiskit Algorithms Migration Guide
**Restructuring the applications**
The Qiskit 0.25.0 release includes a restructuring of the applications and algorithms. What previously has been referred to as Qiskit Aqua, the single applications and algorithms module of Qiskit, is now split into dedicated application modules for Optimization, Finance, Machine Learning and Nature (including Physics & Chemistry). The core algorithms and opflow operator functionality are moved to Qiskit Terra.
**Algorithm interfaces**
Additionally to the restructuring, all algorithms follow a new unified paradigm: algorithms are classified according to the problems they solve, and within one application class algorithms can be used interchangeably to solve the same problem. This means that, unlike before, algorithm instances are decoupled from the problem they solve. We can summarize this in a flowchart:
<img src="algorithmflow.png" alt="Drawing" style="width: 1000px;"/>
For example, the variational quantum eigensolver, `VQE` is a `MinimumEigensolver` as it computes the minimum eigenvalue of an operator. The problem here is specified with the operator, whose eigenvalue we seek, while properties such as the variational ansatz circuit and classical optimizer are properties of the algorithm. That means the `VQE` has the following structure
```python
vqe = VQE(ansatz, optimizer)
result = vqe.compute_minimum_eigenvalue(operator)
```
We can exchange the `VQE` with any other algorithm that implements the `MinimumEigensolver` interface to compute the eigenvalues of your operator, e.g.
```
numpy_based = NumPyMinimumEigensolver()
classical_reference = numpy_based.compute_minimum_eigenvalue(operator)
```
This allows you to easily switch between different algorithms, check against classical references, and provide your own implementation $-$ you just have to implement the existing interface.
This notebook serves as migration guide to facilitate changing your current code using Qiskit Aqua to the new structure.
We're disabling deprecation warning for this notebook so you won't see any when we instantiate an object from `qiskit.aqua`. Note though, that the entire package is deprecated and will emit a warning like the following:
```
from qiskit.aqua.components.optimizers import COBYLA
optimizer = COBYLA()
import warnings
warnings.simplefilter('ignore', DeprecationWarning)
```
# QuantumInstance
The `QuantumInstance` moved the import location from
```
qiskit.aqua.QuantumInstance
```
to
```
qiskit.utils.QuantumInstance
```
**Previously:**
```
from qiskit import Aer
from qiskit.aqua import QuantumInstance as AquaQuantumInstance
backend = Aer.get_backend('statevector_simulator')
aqua_qinstance = AquaQuantumInstance(backend, seed_simulator=2, seed_transpiler=2)
```
**New:**
```
from qiskit import Aer
from qiskit.utils import QuantumInstance
backend = Aer.get_backend('statevector_simulator')
qinstance = QuantumInstance(backend, seed_simulator=2, seed_transpiler=2)
```
# Operators
The Opflow operators moved from
```
qiskit.aqua.operators
```
to
```
qiskit.opflow
```
**Previously:**
```
from qiskit.aqua.operators import X, I, Y
op = (X ^ I) + (Y ^ 2)
```
**New:**
```
from qiskit.opflow import X, I, Y
op = (X ^ I) + (Y ^ 2)
```
**Additional features:**
With `qiskit.opflow` we introduce a new, more efficient representation of sums of Pauli strings, which can significantly speed up computations on very large sums of Paulis. This efficient representation is automatically used if Pauli strings are summed:
```
op = (X ^ X ^ Y ^ Y) + (X ^ 4) + (Y ^ 4) + (I ^ X ^ I ^ I)
type(op)
```
# Optimizers
The classical optimization routines changed locations from
```
qiskit.aqua.components.optimizers
```
to
```
qiskit.algorithms.optimizers
```
**Previously:**
```
from qiskit.aqua.components.optimizers import SPSA
spsa = SPSA(maxiter=10)
```
**New:**
```
from qiskit.algorithms.optimizers import SPSA
spsa = SPSA(maxiter=10)
```
# Grover
## Summary
The previous structure
```python
grover = Grover(oracle_settings, algorithm_settings)
result = grover.run()
```
is changed to split problem/oracle settings and algorithm settings, to
```python
grover = Grover(algorithm_settings)
problem = AmplificationProblem(oracle_settings)
result = grover.amplify(problem)
```
<!-- See the documentation of the [deprecated Grover](https://qiskit.org/documentation/stubs/qiskit.aqua.algorithms.Grover.html#qiskit.aqua.algorithms.Grover) and [new Grover](#). -->
## Migration guide
For oracles provided as circuits and a `is_good_state` function to determine good states
```
from qiskit.circuit import QuantumCircuit
oracle = QuantumCircuit(2)
oracle.cz(0, 1)
def is_good_state(bitstr):
return sum(map(int, bitstr)) == 2
```
**Previously:**
```
from qiskit.aqua.algorithms import Grover
grover = Grover(oracle, is_good_state, quantum_instance=aqua_qinstance)
result = grover.run()
print('Top measurement:', result.top_measurement)
```
**New:**
```
from qiskit.algorithms import Grover, AmplificationProblem
problem = AmplificationProblem(oracle=oracle, is_good_state=is_good_state)
grover = Grover(quantum_instance=qinstance)
result = grover.amplify(problem)
print('Top measurement:', result.top_measurement)
```
Since we are streamlining all algorithms to use the `QuantumCircuit` class as base primitive, defining oracles using the `qiskit.aqua.compontents.Oracle` class is deprecated. Instead of using e.g. the `LogicalExpressionOracle` you can now use the `PhaseOracle` circuit from the circuit library.
**Previously:**
```
from qiskit.aqua.components.oracles import LogicalExpressionOracle
from qiskit.aqua.algorithms import Grover
oracle = LogicalExpressionOracle('x & ~y')
grover = Grover(oracle, quantum_instance=aqua_qinstance)
result = grover.run()
print('Top measurement:', result.top_measurement)
```
**New:**
```
from qiskit.circuit.library import PhaseOracle
from qiskit.algorithms import Grover, AmplificationProblem
oracle = PhaseOracle('x & ~y')
problem = AmplificationProblem(oracle=oracle, is_good_state=oracle.evaluate_bitstring)
grover = Grover(quantum_instance=qinstance)
result = grover.amplify(problem)
print('Top measurement:', result.top_measurement)
```
The `qiskit.aqua.components.oracles.TruthTableOracle` is not yet ported, but the behaviour can easily be achieved with the `qiskit.circuit.classicalfunction` module, see the tutorials on Grover's algorithm.
## More examples
To construct the circuit we can call `construct_circuit` and pass the problem instance we are interested in:
```
power = 2
grover.construct_circuit(problem, power).draw('mpl', style='iqx')
```
# Amplitude estimation
## Summary
For all amplitude estimation algorithms
* `AmplitudeEstimation`
* `IterativeAmplitudeEstimation`
* `MaximumLikelihoodAmplitudeEstimation`, and
* `FasterAmplitudeEstimation`
the interface changed from
```python
qae = AmplitudeEstimation(algorithm_settings, estimation_settings)
result = qae.run()
```
to split problem/oracle settings and algorithm settings
```python
qae = AmplitudeEstimation(algorithm_settings)
problem = EstimationProblem(oracle_settings)
result = qae.amplify(problem)
```
<!-- See the documentation of the [deprecated amplitude estimation algorithms](https://qiskit.org/documentation/apidoc/qiskit.aqua.algorithms.html#amplitude-estimators) and [new ones](#). -->
## Migration guide
Here, we'd like to estimate the probability of measuring a $|1\rangle$ in our single qubit. If the state preparation is provided as circuit
```
import numpy as np
probability = 0.25
rotation_angle = 2 * np.arcsin(np.sqrt(probability))
state_preparation = QuantumCircuit(1)
state_preparation.ry(rotation_angle, 0)
objective_qubits = [0] # the good states are identified by qubit 0 being in state |1>
print('Target probability:', probability)
state_preparation.draw(output='mpl', style='iqx')
```
**Previously:**
```
from qiskit.aqua.algorithms import AmplitudeEstimation
# instantiate the algorithm and passing the problem instance
ae = AmplitudeEstimation(3, state_preparation, quantum_instance=aqua_qinstance)
# run the algorithm
result = ae.run()
# print the results
print('Grid-based estimate:', result.estimation)
print('Improved continuous estimate:', result.mle)
```
**Now:**
```
from qiskit.algorithms import AmplitudeEstimation, EstimationProblem
problem = EstimationProblem(state_preparation=state_preparation, objective_qubits=objective_qubits)
ae = AmplitudeEstimation(num_eval_qubits=3, quantum_instance=qinstance)
result = ae.estimate(problem)
print('Grid-based estimate:', result.estimation)
print('Improved continuous estimate:', result.mle)
```
Note that the old class used the last qubit in the `state_preparation` as objective qubit as default, if no other indices were specified. This default does not exist anymore to improve transparency and remove implicit assumptions.
## More examples
To construct the circuit for amplitude estimation, we can do
```
ae.construct_circuit(estimation_problem=problem).draw('mpl', style='iqx')
```
Now that the problem is separated from the algorithm we can exchange `AmplitudeEstimation` with any other algorithm that implements the `AmplitudeEstimator` interface.
```
from qiskit.algorithms import IterativeAmplitudeEstimation
iae = IterativeAmplitudeEstimation(epsilon_target=0.01, alpha=0.05, quantum_instance=qinstance)
result = iae.estimate(problem)
print('Estimate:', result.estimation)
from qiskit.algorithms import MaximumLikelihoodAmplitudeEstimation
mlae = MaximumLikelihoodAmplitudeEstimation(evaluation_schedule=[0, 2, 4], quantum_instance=qinstance)
result = mlae.estimate(problem)
print('Estimate:', result.estimation)
```
# Minimum eigenvalues
## Summary
* The interface remained mostly the same, but where previously it was possible to pass the operator in the initializer .
* The operators must now be constructed with operators from `qiskit.opflow` instead of `qiskit.aqua.operators`.
* The `VQE` argument `var_form` has been renamend to `ansatz`.
## Migration guide
Assume we want to find the minimum eigenvalue of
$$
H = Z \otimes I.
$$
### NumPy-based eigensolver
**Previously:**
Previously we imported the operators from `qiskit.aqua.operators`:
```
from qiskit.aqua.operators import Z, I
observable = Z ^ I
```
and then solved for the minimum eigenvalue using
```
from qiskit.aqua.algorithms import NumPyMinimumEigensolver
mes = NumPyMinimumEigensolver()
result = mes.compute_minimum_eigenvalue(observable)
print(result.eigenvalue)
```
It used to be possible to pass the observable in the initializer, which is now not allowed anymore due to the problem-algorithm separation.
```
mes = NumPyMinimumEigensolver(observable)
result = mes.compute_minimum_eigenvalue()
print(result.eigenvalue)
```
**Now:**
Now we need to import from `qiskit.opflow` but the other syntax remains exactly the same:
```
from qiskit.opflow import Z, I
observable = Z ^ I
from qiskit.algorithms import NumPyMinimumEigensolver
mes = NumPyMinimumEigensolver()
result = mes.compute_minimum_eigenvalue(observable)
print(result.eigenvalue)
```
### VQE
The same changes hold for VQE. Let's use the `RealAmplitudes` circuit as ansatz:
```
from qiskit.circuit.library import RealAmplitudes
ansatz = RealAmplitudes(2, reps=1)
ansatz.draw(output='mpl', style='iqx')
```
**Previously:**
Previously, we had to import both the optimizer and operators from Qiskit Aqua:
```
from qiskit.aqua.algorithms import VQE
from qiskit.aqua.components.optimizers import COBYLA
from qiskit.aqua.operators import Z, I
observable = Z ^ I
vqe = VQE(var_form=ansatz, optimizer=COBYLA(), quantum_instance=aqua_qinstance)
result = vqe.compute_minimum_eigenvalue(observable)
print(result.eigenvalue)
```
**Now:**
Now we import optimizers from `qiskit.algorithms.optimizers` and operators from `qiskit.opflow`.
```
from qiskit.algorithms import VQE
from qiskit.algorithms.optimizers import COBYLA
from qiskit.opflow import Z, I
observable = Z ^ I
vqe = VQE(ansatz=ansatz, optimizer=COBYLA(), quantum_instance=qinstance)
result = vqe.compute_minimum_eigenvalue(observable)
print(result.eigenvalue)
```
Note that the `qiskit.aqua.components.variational_forms` are completely deprecated in favor of circuit objects. Most variational forms have already been ported to circuit library in previous releases and now also `UCCSD` is part of the Qiskit Nature's circuit library:
**Previously:**
```
from qiskit.circuit import ParameterVector
from qiskit.chemistry.components.variational_forms import UCCSD
varform = UCCSD(4, (1, 1), qubit_mapping='jordan_wigner', two_qubit_reduction=False)
parameters = ParameterVector('x', varform.num_parameters)
circuit = varform.construct_circuit(parameters)
circuit.draw('mpl', style='iqx')
```
**New:**
```
from qiskit_nature.mappers.second_quantization import JordanWignerMapper
from qiskit_nature.operators.second_quantization.qubit_converter import QubitConverter
from qiskit_nature.circuit.library import UCCSD
qubit_converter = QubitConverter(JordanWignerMapper())
circuit = UCCSD(qubit_converter, (1, 1), 4)
circuit.draw('mpl', style='iqx')
```
### QAOA
For Hamiltonians from combinatorial optimization (like ours: $Z \otimes I$) we can use the QAOA algorithm.
**Previously:**
```
from qiskit.aqua.algorithms import QAOA
from qiskit.aqua.components.optimizers import COBYLA
from qiskit.aqua.operators import Z, I
observable = Z ^ I
qaoa = QAOA(optimizer=COBYLA(), quantum_instance=aqua_qinstance)
result = qaoa.compute_minimum_eigenvalue(observable)
print(result.eigenvalue)
```
**Now:**
```
from qiskit.algorithms import QAOA
from qiskit.algorithms.optimizers import COBYLA
from qiskit.opflow import Z, I
observable = Z ^ I
qaoa = QAOA(optimizer=COBYLA(), quantum_instance=qinstance)
result = qaoa.compute_minimum_eigenvalue(observable)
print(result.eigenvalue)
```
**More examples:**
```
qaoa.construct_circuit([1, 2], observable)[0].draw(output='mpl', style='iqx')
```
### Classical CPLEX
The `ClassicalCPLEX` algorithm is now available via the `CplexOptimizer` interface in the machine learning module.
**Previously:**
```
from qiskit.aqua.algorithms import ClassicalCPLEX
from qiskit.aqua.operators import WeightedPauliOperator
from qiskit.quantum_info import Pauli
op = WeightedPauliOperator([
[1, Pauli('ZZIII')],
[1, Pauli('ZIIIZ')],
[1, Pauli('IZZII')]
])
cplex = ClassicalCPLEX(op, display=0)
result = cplex.run()
print('Energy:', result['energy'])
```
**New:**
```
from qiskit_optimization import QuadraticProgram
from qiskit_optimization.algorithms import CplexOptimizer
from qiskit.opflow import I, Z
op = (Z ^ Z ^ I ^ I ^ I) + (Z ^ I ^ I ^ I ^ Z) + (I ^ Z ^ Z ^ I ^ I)
qp = QuadraticProgram()
qp.from_ising(op)
cplex = CplexOptimizer()
result = cplex.solve(qp)
print('Energy:', result.fval)
```
# (General) Eigenvalues
## Summary
As for the `MinimumEigenSolver`, the only change for the `EigenSolver` is the type for the observable and the import path.
## Migration guide
**Previously:**
```
from qiskit.aqua.algorithms import NumPyEigensolver
from qiskit.aqua.operators import I, Z
observable = Z ^ I
es = NumPyEigensolver(k=3) # get the lowest 3 eigenvalues
result = es.compute_eigenvalues(observable)
print(result.eigenvalues)
```
**Now:**
```
from qiskit.algorithms import NumPyEigensolver
from qiskit.aqua.operators import I, Z
observable = Z ^ I
es = NumPyEigensolver(k=3) # get the lowest 3 eigenvalues
result = es.compute_eigenvalues(observable)
print(result.eigenvalues)
```
# Shor's algorithm
## Summary
The arguments `N` and `a` moved from the initializer to the `Shor.factor` method.
## Migration guide
We'll be using a shot-based readout for speed here.
```
aqua_qasm_qinstance = AquaQuantumInstance(Aer.get_backend('qasm_simulator'))
qasm_qinstance = QuantumInstance(Aer.get_backend('qasm_simulator'))
```
**Previously:**
```
from qiskit.aqua.algorithms import Shor
shor = Shor(N=9, a=2, quantum_instance=aqua_qinstance)
result = shor.run()
print('Factors:', result['factors'])
```
**New:**
```
from qiskit.algorithms import Shor
shor = Shor(quantum_instance=qinstance)
result = shor.factor(N=9, a=2)
print('Factors:', result.factors)
```
# HHL
## Summary
HHL has been completely refactored to allow an intuitive interface and return an efficient, circuit-based representation of the result.
## Migration guide
Assume we want to solve the following linear system
$$
\begin{pmatrix}
1 & -1/3 \\
-1/3 & 1 \\
\end{pmatrix}
\vec x
=
\begin{pmatrix}
1 \\ 0
\end{pmatrix}
$$
```
import numpy as np
matrix = np.array([[1, -1/3], [-1/3, 1]])
vector = np.array([1, 0])
```
**Previously:**
```
from qiskit.circuit.library import QFT
from qiskit.aqua.algorithms import HHL
from qiskit.aqua.components.eigs import EigsQPE
from qiskit.aqua.components.reciprocals import LookupRotation
from qiskit.aqua.components.initial_states import Custom
from qiskit.aqua.operators import MatrixOperator
def create_eigs(matrix, num_auxiliary, num_time_slices, negative_evals):
ne_qfts = [None, None]
if negative_evals:
num_auxiliary += 1
ne_qfts = [QFT(num_auxiliary - 1), QFT(num_auxiliary - 1).inverse()]
return EigsQPE(MatrixOperator(matrix=matrix),
QFT(num_auxiliary).inverse(),
num_time_slices=num_time_slices,
num_ancillae=num_auxiliary,
expansion_mode='suzuki',
expansion_order=2,
evo_time=None,
negative_evals=negative_evals,
ne_qfts=ne_qfts)
orig_size = len(vector)
matrix, vector, truncate_powerdim, truncate_hermitian = HHL.matrix_resize(matrix, vector)
# Initialize eigenvalue finding module
eigs = create_eigs(matrix, 3, 50, False)
num_q, num_a = eigs.get_register_sizes()
# Initialize initial state module
init_state = Custom(num_q, state_vector=vector)
# Initialize reciprocal rotation module
reci = LookupRotation(negative_evals=eigs._negative_evals, evo_time=eigs._evo_time)
algo = HHL(matrix, vector, truncate_powerdim, truncate_hermitian, eigs,
init_state, reci, num_q, num_a, orig_size)
result = algo.run(aqua_qinstance)
print(result.solution)
```
**Now:**
```
from qiskit.algorithms.linear_solvers import HHL
hhl = HHL()
result = hhl.solve(matrix, vector)
result.state.draw('mpl', style='iqx')
```
Note that the solution vector is not returned, since that would require an exponentially expensive simulation of the solution circuit. Instead, the circuit can be used to evaluate observables on the solution. For details, see the documentation and docstrings of HHL.
### NumPy-based linear solver
**Previously:**
```
from qiskit.aqua.algorithms import NumPyLSsolver
ls = NumPyLSsolver(matrix, vector)
result = ls.run()
print(result.solution)
```
**Now:**
```
from qiskit.algorithms import NumPyLinearSolver
ls = NumPyLinearSolver()
result = ls.solve(matrix, vector)
print(result.state)
```
# Phase estimation
## Summary
Phase estimation has been completely refactored and instead of just one `qiskit.aqua.algorithms.QPE` class that was used to compute the eigenvalue of a Hamiltonian, we now have two separate implementations: the `HamiltonianPhaseEstimation` taking the role of the old `QPE` and a new `PhaseEstimation` algorithm for textbook phase estimation.
The iterative phase estimation, `qiskit.aqua.algorithms.IQPE` is not yet replaced but will follow soon.
## Migration guide
Let's consider the problem of finding the eigenvalue of
$$
H = 0.5 X + Y + Z
$$
with the input state $|0\rangle$.
```
state_in = np.array([1, 0])
```
**Previously:**
```
from qiskit.circuit.library import QFT
from qiskit.aqua.algorithms import QPE
from qiskit.aqua.components.initial_states import Custom
from qiskit.aqua.operators import I, X, Y, Z
n_ancillae = 5
num_time_slices = 1
op = 0.5 * X + Y + Z
state_preparation = Custom(op.num_qubits, state_vector=state_in)
iqft = QFT(n_ancillae, do_swaps=False).inverse().reverse_bits()
qpe = QPE(op, state_preparation, iqft, num_time_slices, n_ancillae,
expansion_mode='trotter',
shallow_circuit_concat=True)
result = qpe.run(aqua_qinstance)
print(result.eigenvalue)
```
**New:**
```
from qiskit import BasicAer
from qiskit.algorithms import HamiltonianPhaseEstimation
from qiskit.opflow import I, X, Y, Z, StateFn, PauliTrotterEvolution, Suzuki
n_ancillae = 5
num_time_slices = 1
op = 0.5 * X + Y + Z
state_preparation = StateFn(state_in)
evolution = PauliTrotterEvolution('trotter', reps=num_time_slices)
qpe = HamiltonianPhaseEstimation(n_ancillae, quantum_instance=qinstance)
result = qpe.estimate(op, state_preparation, evolution=evolution)
print(result.most_likely_eigenvalue)
```
## More examples
Now we can also do standard phase estimation to solve
$$
U|\psi\rangle = e^{2\pi i\phi}|\psi\rangle.
$$
```
from qiskit.circuit import QuantumCircuit
from qiskit.algorithms import PhaseEstimation
unitary = QuantumCircuit(1)
unitary.z(0)
state_in = QuantumCircuit(1)
state_in.x(0) # eigenstate |1> with eigenvalue -1, hence a phase of phi = 0.5
pe = PhaseEstimation(num_evaluation_qubits=3, quantum_instance=qinstance)
result = pe.estimate(unitary, state_in)
print(result.most_likely_phase)
```
# VQC
## Summary
`VQC` changed the location to `qiskit_machine_learning.algorithms.VQC` and is now implemented as `NeuralNetworkClassification` object instead of a generic variational algorithm. The interface has been updated accordingly, see the tutorials below.
## Migration guide
Since the examples are rather lengthy, we refer to a comparison of the previous and new tutorials.
**Previously:**
https://github.com/Qiskit/qiskit-tutorials/blob/master/tutorials/machine_learning/03_vqc.ipynb
**New:**
https://github.com/Qiskit/qiskit-machine-learning/blob/main/docs/tutorials/02_neural_network_classifier_and_regressor.ipynb
# QSVM
## Summary
The `QSVM` workflow has been replaced by a more generic `QuantumKernel` routine to better highlight the possibly advantage of quantum computers in computing kernels.
## Migration guide
**Previously:**
https://github.com/Qiskit/qiskit-tutorials/blob/master/tutorials/machine_learning/01_qsvm_classification.ipynb
**New:**
https://github.com/Qiskit/qiskit-machine-learning/blob/main/docs/tutorials/03_quantum_kernel.ipynb
# QGAN
## Summary
The interface and methods remained the same, only the import location of the algorithm and it's components changed from `qiskit.aqua` to `qiskit_machine_learning`.
## Migration guide
**Previously:**
https://github.com/Qiskit/qiskit-tutorials/blob/master/tutorials/machine_learning/04_qgans_for_loading_random_distributions.ipynb
**New:**
https://github.com/Qiskit/qiskit-machine-learning/blob/main/docs/tutorials/04_qgans_for_loading_random_distributions.ipynb
# Educational algorithms
All educational algorithms have been deprecated and most are now available in the textbook.
## Deutsch-Josza
Moved to the textbook: https://qiskit.org/textbook/ch-algorithms/deutsch-jozsa.html.
## Bernstein-Vazirani
Moved to the textbook: https://qiskit.org/textbook/ch-algorithms/bernstein-vazirani.html.
## Simon
Moved to the textbook: https://qiskit.org/textbook/ch-algorithms/simon.html.
## EOH
The Evolution of Hamiltonian algorithm is can now be implemented with basic tools from `qiskit.opflow`.
**Previously:**
```
from qiskit.aqua.algorithms import EOH
from qiskit.aqua.operators import WeightedPauliOperator
from qiskit.aqua.components.initial_states import Custom
from qiskit.quantum_info import Pauli
hamiltonian = WeightedPauliOperator([[1, Pauli('XX')], [1, Pauli('ZZ')], [1j, Pauli('YY')]])
observable = WeightedPauliOperator([[1, Pauli('XI')]])
initial_state = Custom(2, 'uniform')
evo_time = 2
num_time_slices = 10
eoh = EOH(observable, initial_state, hamiltonian, evo_time=evo_time, num_time_slices=num_time_slices)
result = eoh.run(aqua_qinstance)
result['avg']
```
**New:**
```
import numpy as np
from qiskit.opflow import I, X, Y, Z, PauliTrotterEvolution, StateFn
hamiltonian = (X ^ X) + (Z ^ Z) + 1j * (Y ^ Y)
observable = X ^ I
initial_state = StateFn(np.ones(4) / 2)
evo_time = 2
num_time_slices = 10
# get the evolution operator
evolved_hamiltonian = (evo_time * hamiltonian).exp_i()
evo = PauliTrotterEvolution(reps=num_time_slices)
evo.convert(evolved_hamiltonian)
# get the evolved state
evolved_state = evolved_hamiltonian @ initial_state
# evaluate the target observable at the evolved state
print((~StateFn(observable) @ evolved_state).eval())
```
| github_jupyter |
## Подготовка
1. Клонировать репозиторий
2. Скачать и сохранить ключ доступа к Google service account (json) в папку проекта. [Authenticating as a service account | Authentication | Google Cloud](https://cloud.google.com/docs/authentication/production)
3. В файле `.env` заполнить поля:
* **GOOGLE_APPLICATION_CREDENTIALS** — путь к Google service account , сохраненному на **шаге 3**. К примеру, `./prod_credentials.json`
* **GOOGLE_BIGQUERY_PROJECT_ID** — название проекта в BigQuery _(где находятся сгенерированные таблицы с помощью ETL)_. К примеру, `ml-development-294708`
* **GOOGLE_BIGQUERY_DEBUG_DATASET_ID** — название датасета _(где находятся сгенерированные таблицы с помощью ETL)_. К примеру, `WW_WIRE_PARDOT`
* **GPU2** — доступна ли видеокарта для обучения
4. Установить необходимые для работы программы модули командой в терминале:
`pip3 install numpy pandas-gbq envparse gdelt`
```
import pandas as pd
from pathlib import Path
from envparse import env
env.read_envfile()
issues = {"taxes" : ["ECON_TAXATION",],
"unemployment" : [ "UNEMPLOYMENT", ],
"domesticeconomy" : ["ECON_BANKRUPTCY", "ECON_BOYCOTT", "ECON_COST_OF_LIVING", "ECON_CUTOUTLOOK", "ECON_DEREGULATION", "ECON_EARNINGSREPORT", "ECON_ENTREPRENEURSHIP", "ECON_HOUSING_PRICES", "ECON_INFORMAL_ECONOMY", "ECON_IPO", "ECON_INTEREST_RATE", "ECON_MONOPOLY", "ECON_MOU", "ECON_NATIONALIZE", "ECON_PRICECONTROL", "ECON_REMITTANCE", "ECON_STOCKMARKET", "ECON_SUBSIDIES", "ECON_UNIONS", "SLFID_ECONOMIC_DEVELOPMENT", "SLFID_ECONOMIC_POWER", "SOC_ECONCOOP"],
"trade" : ["ECON_TRADE_DISPUTE", "ECON_FOREIGNINVEST", "ECON_FREETRADE", "ECON_CURRENCY_EXCHANGE_RATE", "ECON_CURRENCY_RESERVES", "ECON_DEBT"],
"terrorism" : ["TAX_TERROR_GROUP", "SUICIDE_ATTACK", "EXTREMISM", "JIHAD", "TERROR", "WMD"],
"military" : ["ACT_FORCEPOSTURE", "ARMEDCONFLICT", "BLOCKADE", "CEASEFIRE", "MILITARY", "MILITARY_COOPERATION", "PEACEKEEPING", "RELEASE_HOSTAGE", "SEIGE", "SLFID_MILITARY_BUILDUP", "SLFID_MILITARY_READINESS", "SLFID_MILITARY_SPENDING", "SLFID_PEACE_BUILDING", "TAX_MILITARY_TITLE"],
"internationalrelations" : ["GOV_INTERGOVERNMENTAL", "SOC_DIPLOMCOOP", "RELATIONS"],
"immigration/refugees" : ["BORDER", "CHECKPOINT", "DISPLACED", "EXILE", "IMMIGRATION", "REFUGEES", "SOC_FORCEDRELOCATION", "SOC_MASSMIGRATION", "UNREST_CHECKPOINT", "UNREST_CLOSINGBORDER"],
"healthcare" : ["GENERAL_HEALTH", "HEALTH_SEXTRANSDISEASE", "HEALTH_VACCINATION", "MEDICAL", "MEDICAL_SECURITY"],
"guncontrol" : ["FIREARM_OWNERSHIP", "MIL_SELF_IDENTIFIED_ARMS_DEAL", "MIL_WEAPONS_PROLIFERATION"],
"drug" : ["CRIME_ILLEGAL_DRUGS", "DRUG_TRADE", "TAX_CARTELS", "CRIME_CARTELS"],
"policesystem" : ["UNREST_POLICEBRUTALITY", "SECURITY_SERVICES"],
"racism" : ["DISCRIMINATION", "HATE_SPEECH"],
"civilliberties" : ["GENDER_VIOLENCE", "LGBT", "MOVEMENT_SOCIAL", "MOVEMENT_WOMENS", "SLFID_CIVIL_LIBERTIES"],
"environment" : ["ENV_BIOFUEL", "ENV_CARBONCAPTURE", "ENV_CLIMATECHANGE", "ENV_COAL", "ENV_DEFORESTATION", "ENV_FISHERY", "ENV_FORESTRY", "ENV_GEOTHERMAL", "ENV_GREEN", "ENV_HYDRO", "ENV_METALS", "ENV_MINING", "ENV_NATURALGAS", "ENV_NUCLEARPOWER", "ENV_OIL", "ENV_OVERFISH", "ENV_POACHING", "ENV_WATERWAYS ", "ENV_SOLAR", "ENV_SPECIESENDANGERED", "ENV_SPECIESEXTINCT", "ENV_WINDPOWER", "FUELPRICES", "MOVEMENT_ENVIRONMENTAL", "SELF_IDENTIFIED_ENVIRON_DISASTER", "SLFID_MINERAL_RESOURCES", "SLFID_NATURAL_RESOURCES", "WATER_SECURITY"],
"partypolitics" : ["TAX_POLITICAL_PARTY"],
"electionfraud" : ["ELECTION_FRAUD"],
"education" : ["EDUCATION"],
"media/internet" : ["CYBER_ATTACK", "INTERNET_BLACKOUT", "INTERNET_CENSORSHIP", "MEDIA_CENSORSHIP", "MEDIA_MSM", "MEDIA_SOCIAL", "SURVEILLANCE", "FREESPEECH"],
}
', '.join(issues['internationalrelations'])
q = f"""
SELECT SourceCommonName, theme, count from (
SELECT SourceCommonName, theme, COUNT(*) as count
FROM (
SELECT
SourceCommonName,
SPLIT(V2Themes, ';') theme
FROM `gdelt-bq.gdeltv2.gkg`
WHERE
DATE >= 20150200000000 AND
DATE < 20151099999999
)
CROSS JOIN UNNEST(theme) AS theme
GROUP BY SourceCommonName, theme
) WHERE count > 100
ORDER BY count DESC
"""
gbq_df = pd.read_gbq(
q, # запрос к GDELT
project_id=env('GOOGLE_BIGQUERY_PROJECT_ID'), # Указыываем свой ProjectID
reauth=True
)
gbq_df.head(10)
import gdelt
# Version 2 queries
gd2 = gdelt.gdelt(version=2)
# Single 15 minute interval pull, output to json format with mentions table
results = gd2.Search('2016 Nov 1', table='mentions',output='json')
print(len(results))
# Full day pull, output to pandas dataframe, events table
results = gd2.Search(['2016 11 01'],table='events',coverage=True)
print(len(results))
results
from gydelt.gydelt import GetData, ProcessData
GD = GetData()
# data = GD.read_from_file(path='sample data/fromGKG.txt', parse_dates=['Date'])
data = GD.fire_query(
project_id=env('GOOGLE_BIGQUERY_PROJECT_ID'),
search_dict={
'Locations': 'China;;',
'Persons': 'Donald Trump;;'
}, auth_file='./service_account.json',
limit=1000
)
# This would mean that the 'Locations' should have BOTH 'United States' and 'China' and 'Persons' should NOT have 'Donald Trump'
data.head(5)
PD = ProcessData(data_frame=data)
# Calling the wrapper function to pre-process the whole data
processed_data_1 = PD.pre_process()
processed_data_1.head(5)
```
| github_jupyter |
still being tweaked!
to try: add lambdas between modalities, annealing betas
### Extensions to a multimodal VAE
Another way this model can be extended is to fully let the latent $z$ "cause" both the emotion ratings and the facial expression. This is an example of a Multimodal VAE (Wu & Goodman, 2018).
There is a nice theoretical motivation for this model too. Throughout the past few examples, we've assumed that the space of emotions is exactly what we measured (e.g., some value of happiness, some value of sadness), but maybe the latent space is more structured, but not along these discrete emotion categories -- perhaps along dimensions like "good" vs "bad", or . In emotion theory, this undifferentiated space is called affect, and often, this is a low-dimensional space (2 to 3 dimensions capture most of the variance in empirical data).
We could thus posit a latent *affect* that generates the emotion ratings. That is, the emotion ratings is some projection of the latent affect space onto these emotion concepts that are given meaning by the language and culture that one resides in.
But in fact, we would still want a latent $z$ that captures non-emotional aspects of the face. For simplicity, for this example, we assume that this latent $z$ will capture some aspects of affect as well as the face. Learning to disentangle latent variables (e.g. the latent variables that are important for emotions and the latent variables that are not) is also an active area of research (Narayanaswamy et al, 2017).
And finally, we can add the "outcome to appraisal to affect" part back into this multimodal model.
<div style="width: 300px; margin: auto; ">
</div>
```
#from __future__ import division, print_function, absolute_import
from __future__ import print_function
%matplotlib inline
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torch.nn import functional as F
from torch.utils.data import Dataset, DataLoader
import pyro
import pyro.distributions as dist
from pyro.distributions import Normal
from pyro.infer import SVI, Trace_ELBO
from pyro.optim import Adam
from torchvision import transforms, utils, datasets
from torchvision.transforms import ToPILImage
from skimage import io, transform
from scipy.special import expit
from PIL import Image
from matplotlib.pyplot import imshow
from pyro.contrib.examples.util import print_and_log, set_seed
import pyro.poutine as poutine
# custom helperCode for this tutorial, in helperCode.py
import helperCode
from utils.custom_mlp import MLP, Exp
from visdom import Visdom
#from utils.vae_plots import plot_llk, plot_vae_samples
from utils.mnist_cached import mkdir_p, setup_data_loaders
from utils.vae_plots import plot_conditional_samples_ssvae, plot_vae_samples
#IMG_WIDTH = 100
#IMG_SIZE = IMG_WIDTH*IMG_WIDTH*3
# Note that we downsample to 64 x 64 here, because we wanted a nice power of 2
#(and DCGAN architecture assumes input image of 64x64)
IMG_WIDTH = 64
IMG_SIZE = IMG_WIDTH*IMG_WIDTH*3
BATCH_SIZE = 32
DEFAULT_HIDDEN_DIMS = [500, 500]#[200,200] #[500, 500]
DEFAULT_Z_DIM = 50#10#50#2
# FACE_VAR_NAMES = ['facePath']
OUTCOME_VAR_NAMES = ['payoff1', 'payoff2', 'payoff3',
'prob1', 'prob2', 'prob3',
'win', 'winProb', 'angleProp']
EMOTION_VAR_NAMES = ['happy', 'sad', 'anger', 'surprise',
'disgust', 'fear', 'content', 'disapp']
OUTCOME_VAR_DIM = len(OUTCOME_VAR_NAMES)
EMOTION_VAR_DIM = len(EMOTION_VAR_NAMES)
class Swish(nn.Module):
"""https://arxiv.org/abs/1710.05941"""
def forward(self, x):
return x * F.sigmoid(x)
def swish(x):
return x * F.sigmoid(x)
```
#### Dataset
(This part is the same as the SSVAE Tutorial)
We will be using the same dataset as the previous examples. We will consider the trials in which participants only saw a facial expression, and rated how they thought the character feels, or what we call the "facial expression only" trials.
Here is a preview of the 18 faces (which are in ../CognitionData/faces/).
```
faces_path = os.path.join(os.path.abspath('..'), "CognitionData", "faces")
# initializing two temp arrays
faceArray1 = np.zeros(shape=(100,1,3), dtype='uint8')
faceArray2 = np.zeros(shape=(100,1,3), dtype='uint8')
count = 0
for thisFace in helperCode.FACE_FILENAMES:
newFaceArray = np.array(Image.open(os.path.join(faces_path, thisFace + ".png")))
if count < 6 or count > 14:
faceArray1 = np.concatenate((faceArray1, newFaceArray), axis=1)
else:
faceArray2 = np.concatenate((faceArray2, newFaceArray), axis=1)
count += 1
# concatenating the arrays and removing the first temp column
faceArray = np.concatenate((faceArray1, faceArray2), axis=0)
faceArray = faceArray[:,1:,:]
Image.fromarray(faceArray)
```
This next chunk defines a function to read in the data, and stores the data in `face_outcome_emotion_dataset`. There are N=1,587 observations, and each observation consists of:
- an accompanying face image
- a 9-dimension outcome vector that parameterizes the gamble that agents played, and
- an 8-dimensional emotion rating vector
```
# data location
dataset_path = os.path.join(os.path.abspath('..'), "CognitionData", "data_faceWheel.csv")
class FaceOutcomeEmotionDataset(Dataset):
"""Face Outcome Emotion dataset."""
def __init__(self, csv_file, img_dir, transform=None):
"""
Args:
csv_file (string): Path to the experiment csv file
img_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.expdata = pd.read_csv(csv_file)
self.img_dir = img_dir
self.transform = transform
## Normalizing the data:
####
## payoff1, payoff2, payoff3 and win are between 0 and 100
## need to normalize to [0,1] to match the rest of the variables,
## by dividing payoff1, payoff2, payoff3 and win by 100
####
self.expdata.loc[:,"payoff1"] = self.expdata.loc[:,"payoff1"]/100
self.expdata.loc[:,"payoff2"] = self.expdata.loc[:,"payoff2"]/100
self.expdata.loc[:,"payoff3"] = self.expdata.loc[:,"payoff3"]/100
self.expdata.loc[:,"win"] = self.expdata.loc[:,"win"]/100
# Emotions were rated on a 1-9 Likert scale.
# use emo <- (emo-1)/8 to transform to within [0,1]
self.expdata.loc[:,"happy":"disapp"] = (self.expdata.loc[:,"happy":"disapp"]-1)/8
def __len__(self):
return len(self.expdata)
def __getitem__(self, idx):
ratings = np.array(self.expdata.iloc[idx]["happy":"disapp"], np.float32)
outcomes = np.array(self.expdata.iloc[idx]["payoff1":"angleProp"], np.float32)
#outcomes = np.array(self.expdata.iloc[idx]["payoff1":"winProb"], np.float32)
img_name = os.path.join(self.img_dir, self.expdata.iloc[idx]["facePath"] + ".png")
try:
image = Image.open(img_name).convert('RGB')
#image = np.array(image).astype(np.float32)
if self.transform:
image = self.transform(image)
except:
print(img_name)
raise
return image, ratings, outcomes
data_transform = transforms.Compose([
# Note that we downsample to 64 x 64 here, because we wanted a nice power of 2
#(and DCGAN architecture assumes input image of 64x64)
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor()
])
# reads in datafile.
print("Reading in dataset...")
face_outcome_emotion_dataset = FaceOutcomeEmotionDataset(csv_file=dataset_path,
img_dir=faces_path,
transform=data_transform)
face_outcome_emotion_loader = torch.utils.data.DataLoader(face_outcome_emotion_dataset,
batch_size=BATCH_SIZE, shuffle=True,
num_workers=4)
N_samples = len(face_outcome_emotion_dataset)
print("Number of observations:", N_samples)
# taking a sample observation
img1, emo1, out1 = face_outcome_emotion_dataset[5]
print("Sample Observation: ")
print(helperCode.EMOTION_VAR_NAMES)
print(emo1)
print(helperCode.OUTCOME_VAR_NAMES)
print(out1)
Image.fromarray(helperCode.TensorToPILImage(img1*255.))
```
https://arxiv.org/abs/1802.05335
```
class ProductOfExperts(nn.Module):
"""
Return parameters for product of independent experts.
See https://arxiv.org/pdf/1410.7827.pdf for equations.
@param loc: M x D for M experts
@param scale: M x D for M experts
"""
def forward(self, loc, scale, eps=1e-8):
scale = scale + eps # numerical constant for stability
# precision of i-th Gaussian expert (T = 1/sigma^2)
T = 1. / scale
product_loc = torch.sum(loc * T, dim=0) / torch.sum(T, dim=0)
product_scale = 1. / torch.sum(T, dim=0)
return product_loc, product_scale
class ImageEncoder(nn.Module):
"""
define the PyTorch module that parametrizes q(z|image).
This goes from images to the latent z
This is the standard DCGAN architecture.
@param z_dim: integer
size of the tensor representing the latent random variable z
"""
def __init__(self, z_dim):
super(ImageEncoder, self).__init__()
#torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1,
# padding=0, dilation=1, groups=1, bias=True)
# H_out = floor( (H_in + 2*padding - dilation(kernel_size-1) -1) / stride +1)
self.features = nn.Sequential(
nn.Conv2d(3, 32, 4, 2, 1, bias=False),
Swish(),
nn.Conv2d(32, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
Swish(),
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
Swish(),
nn.Conv2d(128, 256, 4, 1, 0, bias=False),
nn.BatchNorm2d(256),
Swish())
# Here, we define two layers, one to give z_loc and one to give z_scale
self.z_loc_layer = nn.Sequential(
nn.Linear(256 * 5 * 5, 512), # it's 256 * 5 * 5 if input is 64x64.
#nn.Linear(256 * 9 * 9, 512), # it's 256 * 9 * 9 if input is 100x100.
Swish(),
nn.Dropout(p=0.1),
nn.Linear(512, z_dim))
self.z_scale_layer = nn.Sequential(
nn.Linear(256 * 5 * 5, 512), # it's 256 * 5 * 5 if input is 64x64.
#nn.Linear(256 * 9 * 9, 512), # it's 256 * 9 * 9 if input is 100x100.
Swish(),
nn.Dropout(p=0.1),
nn.Linear(512, z_dim))
self.z_dim = z_dim
def forward(self, image):
hidden = self.features(image)
hidden = hidden.view(-1, 256 * 5 * 5) # it's 256 * 5 * 5 if input is 64x64.
#image = image.view(-1, 256 * 9 * 9) # it's 256 * 9 * 9 if input is 100x100.
z_loc = self.z_loc_layer(hidden)
z_scale = torch.exp(self.z_scale_layer(hidden)) #add exp so it's always positive
return z_loc, z_scale
class ImageDecoder(nn.Module):
"""
define the PyTorch module that parametrizes p(image|z).
This goes from the latent z to the images
This is the standard DCGAN architecture.
@param z_dim: integer
size of the tensor representing the latent random variable z
"""
def __init__(self, z_dim):
super(ImageDecoder, self).__init__()
self.upsample = nn.Sequential(
nn.Linear(z_dim, 256 * 5 * 5), # it's 256 * 5 * 5 if input is 64x64.
#nn.Linear(z_dim, 256 * 9 * 9), # it's 256 * 9 * 9 if input is 100x100.
Swish())
self.hallucinate = nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 1, 0, bias=False),
nn.BatchNorm2d(128),
Swish(),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
Swish(),
nn.ConvTranspose2d(64, 32, 4, 2, 1, bias=False),
nn.BatchNorm2d(32),
Swish(),
nn.ConvTranspose2d(32, 3, 4, 2, 1, bias=False))
def forward(self, z):
# the input will be a vector of size |z_dim|
z = self.upsample(z)
z = z.view(-1, 256, 5, 5) # it's 256 * 5 * 5 if input is 64x64.
#z = z.view(-1, 256, 9, 9) # it's 256 * 9 * 9 if input is 100x100.
# but if 100x100, the output image size is 96x96
image = self.hallucinate(z) # this is the image
return image # NOTE: no sigmoid here. See train.py
class RatingEncoder(nn.Module):
"""
define the PyTorch module that parametrizes q(z|rating).
This goes from ratings to the latent z
@param z_dim: integer
size of the tensor representing the latent random variable z
"""
def __init__(self, z_dim):
super(RatingEncoder, self).__init__()
self.net = nn.Linear(helperCode.EMOTION_VAR_DIM, 512)
self.z_loc_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, z_dim))
self.z_scale_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, z_dim))
self.z_dim = z_dim
def forward(self, rating):
hidden = self.net(rating)
z_loc = self.z_loc_layer(hidden)
z_scale = torch.exp(self.z_scale_layer(hidden))
return z_loc, z_scale
class RatingDecoder(nn.Module):
"""
define the PyTorch module that parametrizes p(rating|z).
This goes from the latent z to the ratings
@param z_dim: integer
size of the tensor representing the latent random variable z
"""
def __init__(self, z_dim):
super(RatingDecoder, self).__init__()
self.net = nn.Sequential(
nn.Linear(z_dim, 512),
Swish())
self.rating_loc_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, helperCode.EMOTION_VAR_DIM))
self.rating_scale_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, helperCode.EMOTION_VAR_DIM))
def forward(self, z):
#batch_size = z.size(0)
hidden = self.net(z)
rating_loc = self.rating_loc_layer(hidden)
rating_scale = torch.exp(self.rating_scale_layer(hidden))
# rating is going to be a |emotions| * 9 levels
#rating = h.view(batch_size, EMOTION_VAR_DIM, 9)
return rating_loc, rating_scale # NOTE: no softmax here. See train.py
class OutcomeEncoder(nn.Module):
"""
define the PyTorch module that parametrizes q(z|outcome).
This goes from outcomes to the latent z
@param z_dim: integer
size of the tensor representing the latent random variable z
"""
def __init__(self, z_dim):
super(OutcomeEncoder, self).__init__()
self.net = nn.Linear(helperCode.OUTCOME_VAR_DIM, 512)
self.z_loc_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, z_dim))
self.z_scale_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, z_dim))
self.z_dim = z_dim
def forward(self, outcomes):
hidden = self.net(outcomes)
z_loc = self.z_loc_layer(hidden)
z_scale = torch.exp(self.z_scale_layer(hidden))
return z_loc, z_scale
class OutcomeDecoder(nn.Module):
"""
define the PyTorch module that parametrizes p(outcomes|z).
This goes from the latent z to the outcomes
@param z_dim: integer
size of the tensor representing the latent random variable z
"""
def __init__(self, z_dim):
super(OutcomeDecoder, self).__init__()
self.net = nn.Sequential(
nn.Linear(z_dim, 512),
Swish())
self.outcome_loc_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, helperCode.OUTCOME_VAR_DIM))
self.outcome_scale_layer = nn.Sequential(
nn.Linear(512, 512),
Swish(),
nn.Linear(512, helperCode.OUTCOME_VAR_DIM))
def forward(self, z):
hidden = self.net(z)
outcome_loc = self.outcome_loc_layer(hidden)
outcome_scale = torch.exp(self.outcome_scale_layer(hidden))
return outcome_loc, outcome_scale # no nonlinearity here | will be added later
class MVAE(nn.Module):
"""
This class encapsulates the parameters (neural networks), models & guides needed to train a
multimodal variational auto-encoder.
Modified from https://github.com/mhw32/multimodal-vae-public
Multimodal Variational Autoencoder.
@param z_dim: integer
size of the tensor representing the latent random variable z
Currently all the neural network dimensions are hard-coded;
in a future version will make them be inputs into the constructor
"""
def __init__(self, z_dim, use_cuda=False):
super(MVAE, self).__init__()
self.z_dim = z_dim
self.image_encoder = ImageEncoder(z_dim)
self.image_decoder = ImageDecoder(z_dim)
self.rating_encoder = RatingEncoder(z_dim)
self.rating_decoder = RatingDecoder(z_dim)
self.outcome_encoder = OutcomeEncoder(z_dim)
self.outcome_decoder = OutcomeDecoder(z_dim)
self.experts = ProductOfExperts()
self.use_cuda = use_cuda
# relative weights of losses in the different modalities
self.LAMBDA_IMAGES = 1.0
self.LAMBDA_RATINGS = 50.0
self.LAMBDA_OUTCOMES = 100.0
# using GPUs for faster training of the networks
if self.use_cuda:
self.cuda()
def model(self, images=None, ratings=None, outcomes=None, annealing_beta=1.0):
# register this pytorch module and all of its sub-modules with pyro
pyro.module("mvae", self)
batch_size = 0
if images is not None:
batch_size = images.size(0)
elif ratings is not None:
batch_size = ratings.size(0)
elif outcomes is not None:
batch_size = outcomes.size(0)
with pyro.iarange("data", batch_size):
# if outcomes is not None:
# # sample from outcome prior, compute p(z|outcome)
# outcome_prior_loc = torch.zeros(torch.Size((batch_size, helperCode.OUTCOME_VAR_DIM)))
# outcome_prior_scale = torch.ones(torch.Size((batch_size, helperCode.OUTCOME_VAR_DIM)))
# with poutine.scale(scale=self.LAMBDA_OUTCOMES):
# pyro.sample("obs_outcome", dist.Normal(outcome_prior_loc, outcome_prior_scale).independent(1),
# obs=outcomes.reshape(-1, helperCode.OUTCOME_VAR_DIM))
# z_loc, z_scale = self.outcome_encoder.forward(outcomes)
# else:
# # setup hyperparameters for prior p(z)
# z_loc = torch.zeros(torch.Size((batch_size, self.z_dim)))
# z_scale = torch.ones(torch.Size((batch_size, self.z_dim)))
# sample from outcome prior N(0.5,0.1), compute p(z|outcome)
outcome_prior_loc = torch.zeros(torch.Size((batch_size, helperCode.OUTCOME_VAR_DIM))) + 0.5
outcome_prior_scale = torch.ones(torch.Size((batch_size, helperCode.OUTCOME_VAR_DIM))) * 0.1
if outcomes is not None:
# if outcome is provided as an observed input, score against it
with poutine.scale(scale=self.LAMBDA_OUTCOMES):
pyro.sample("obs_outcome", dist.Normal(outcome_prior_loc, outcome_prior_scale).independent(1),
obs=outcomes.reshape(-1, helperCode.OUTCOME_VAR_DIM))
else:
# else if outcome is not provided, just sample from priors
with poutine.scale(scale=self.LAMBDA_OUTCOMES):
outcomes = pyro.sample("obs_outcome", dist.Normal(outcome_prior_loc, outcome_prior_scale).independent(1))
z_loc, z_scale = self.outcome_encoder.forward(outcomes)
# sample from prior (value will be sampled by guide when computing the ELBO)
with poutine.scale(scale=annealing_beta):
z = pyro.sample("latent", dist.Normal(z_loc, z_scale).independent(1))
# decode the latent code z
img_loc = self.image_decoder.forward(z)
# score against actual images
if images is not None:
with poutine.scale(scale=self.LAMBDA_IMAGES):
pyro.sample("obs_img", dist.Bernoulli(img_loc).independent(1),
obs=images.reshape(-1, 3,IMG_WIDTH,IMG_WIDTH))
rating_loc, rating_scale = self.rating_decoder.forward(z)
if ratings is not None:
with poutine.scale(scale=self.LAMBDA_RATINGS):
pyro.sample("obs_rating", dist.Normal(rating_loc, rating_scale).independent(1),
obs=ratings.reshape(-1, helperCode.EMOTION_VAR_DIM))
# return the loc so we can visualize it later
return img_loc, rating_loc
def guide(self, images=None, ratings=None, outcomes=None, annealing_beta=1.0):
# register this pytorch module and all of its sub-modules with pyro
pyro.module("mvae", self)
batch_size = 0
if images is not None:
batch_size = images.size(0)
elif ratings is not None:
batch_size = ratings.size(0)
elif outcomes is not None:
batch_size = outcomes.size(0)
with pyro.iarange("data", batch_size):
# use the encoder to get the parameters used to define q(z|x)
# initialize the prior expert.
# we initalize an additional dimension, along which we concatenate all the
# different experts.
# self.experts() then combines the information from these different modalities
# by multiplying the gaussians together
z_loc = torch.zeros(torch.Size((1, batch_size, self.z_dim))) + 0.5
z_scale = torch.ones(torch.Size((1, batch_size, self.z_dim))) * 0.1
if self.use_cuda:
z_loc, z_scale = z_loc.cuda(), z_scale.cuda()
if outcomes is not None:
outcome_z_loc, outcome_z_scale = self.outcome_encoder.forward(outcomes)
z_loc = torch.cat((z_loc, outcome_z_loc.unsqueeze(0)), dim=0)
z_scale = torch.cat((z_scale, outcome_z_scale.unsqueeze(0)), dim=0)
if images is not None:
image_z_loc, image_z_scale = self.image_encoder.forward(images)
z_loc = torch.cat((z_loc, image_z_loc.unsqueeze(0)), dim=0)
z_scale = torch.cat((z_scale, image_z_scale.unsqueeze(0)), dim=0)
if ratings is not None:
rating_z_loc, rating_z_scale = self.rating_encoder.forward(ratings)
z_loc = torch.cat((z_loc, rating_z_loc.unsqueeze(0)), dim=0)
z_scale = torch.cat((z_scale, rating_z_scale.unsqueeze(0)), dim=0)
z_loc, z_scale = self.experts(z_loc, z_scale)
# sample the latent z
with poutine.scale(scale=annealing_beta):
pyro.sample("latent", dist.Normal(z_loc, z_scale).independent(1))
def forward(self, image=None, rating=None, outcome=None):
z_loc, z_scale = self.infer(image, rating, outcome)
z = pyro.sample("latent", dist.Normal(z_loc, z_scale).independent(1))
# reconstruct inputs based on that gaussian
image_recon = self.image_decoder(z)
rating_recon = self.rating_decoder(z)
outcome_recon = self.outcome_decoder(z)
return image_recon, rating_recon, outcome_recon, z_loc, z_scale
def infer(self, images=None, ratings=None, outcomes=None):
batch_size = 0
if images is not None:
batch_size = images.size(0)
elif ratings is not None:
batch_size = ratings.size(0)
elif outcomes is not None:
batch_size = outcomes.size(0)
# initialize the prior expert
# we initalize an additional dimension, along which we concatenate all the
# different experts.
# self.experts() then combines the information from these different modalities
# by multiplying the gaussians together
z_loc = torch.zeros(torch.Size((1, batch_size, self.z_dim))) + 0.5
z_scale = torch.ones(torch.Size((1, batch_size, self.z_dim))) * 0.1
if self.use_cuda:
z_loc, z_scale = z_loc.cuda(), z_scale.cuda()
if outcomes is not None:
outcome_z_loc, outcome_z_scale = self.outcome_encoder.forward(outcomes)
z_loc = torch.cat((z_loc, outcome_z_loc.unsqueeze(0)), dim=0)
z_scale = torch.cat((z_scale, outcome_z_scale.unsqueeze(0)), dim=0)
if images is not None:
image_z_loc, image_z_scale = self.image_encoder.forward(images)
z_loc = torch.cat((z_loc, image_z_loc.unsqueeze(0)), dim=0)
z_scale = torch.cat((z_scale, image_z_scale.unsqueeze(0)), dim=0)
if ratings is not None:
rating_z_loc, rating_z_scale = self.rating_encoder.forward(ratings)
z_loc = torch.cat((z_loc, rating_z_loc.unsqueeze(0)), dim=0)
z_scale = torch.cat((z_scale, rating_z_scale.unsqueeze(0)), dim=0)
z_loc, z_scale = self.experts(z_loc, z_scale)
return z_loc, z_scale
# define a helper function for reconstructing images
def reconstruct_img(self, images):
# encode image x
z_loc, z_scale = self.image_encoder(images)
# sample in latent space
z = dist.Normal(z_loc, z_scale).sample()
# decode the image (note we don't sample in image space)
img_loc = self.image_decoder.forward(z)
return img_loc
pyro.clear_param_store()
class Args:
learning_rate = 5e-4 #5e-5
num_epochs = 5 #2 #1000
hidden_layers = DEFAULT_HIDDEN_DIMS
z_dim = DEFAULT_Z_DIM
seed = 10
cuda = False
visdom_flag = False
#visualize = True
#logfile = "./tmp.log"
args = Args()
# setup the VAE
mvae = MVAE(z_dim=args.z_dim, use_cuda=args.cuda)
# setup the optimizer
adam_args = {"lr": args.learning_rate}
optimizer = Adam(adam_args)
# setup the inference algorithm
svi = SVI(mvae.model, mvae.guide, optimizer, loss=Trace_ELBO())
train_elbo = []
# training loop
for epoch in range(args.num_epochs):
# initialize loss accumulator
epoch_loss = 0.
# do a training epoch over each mini-batch returned
# by the data loader
for batch_num, (faces, ratings, outcomes) in enumerate(face_outcome_emotion_loader):
# if on GPU put mini-batch into CUDA memory
if args.cuda:
faces, ratings, outcomes = faces.cuda(), ratings.cuda(), outcomes.cuda()
# do ELBO gradient and accumulate loss
#print("Batch: ", batch_num, "out of", len(train_loader))
epoch_loss += svi.step(images=faces, ratings=ratings, outcomes=outcomes)
epoch_loss += svi.step(images=faces, ratings=ratings, outcomes=None)
epoch_loss += svi.step(images=faces, ratings=None, outcomes=outcomes)
epoch_loss += svi.step(images=None, ratings=ratings, outcomes=outcomes)
epoch_loss += svi.step(images=faces, ratings=None, outcomes=None)
epoch_loss += svi.step(images=None, ratings=ratings, outcomes=None)
epoch_loss += svi.step(images=None, ratings=None, outcomes=outcomes)
#images=None, ratings=None, outcomes=None
# report training diagnostics
normalizer_train = len(face_outcome_emotion_loader.dataset)
total_epoch_loss_train = epoch_loss / normalizer_train
train_elbo.append(total_epoch_loss_train)
print("[epoch %03d] average training loss: %.4f" % (epoch, total_epoch_loss_train))
# save model
savemodel = False
if savemodel:
pyro.get_param_store().save('trained_models/mvae_pretrained.save')
loadmodel = False
if loadmodel:
pyro.get_param_store().load('trained_models/mvae_pretrained.save')
pyro.module("mvae", mvae, update_module_params=True)
NUM_SAMPLES = 10
input_array = np.zeros(shape=(IMG_WIDTH, 1, 3), dtype="uint8")
reconstructed_array = np.zeros(shape=(IMG_WIDTH, 1, 3), dtype="uint8")
for batch_num, (faces, ratings, outcomes) in enumerate(face_outcome_emotion_loader):
# pick NUM_SAMPLES random test images from the first mini-batch and
# visualize how well we're reconstructing them
if batch_num == 0:
reco_indices = np.random.randint(0, faces.size(0), NUM_SAMPLES)
for index in reco_indices:
input_img = faces[index, :]
# storing the input image
input_img_display = np.array(input_img*255., dtype='uint8')
input_img_display = input_img_display.transpose((1, 2, 0))
input_array = np.concatenate((input_array, input_img_display), axis=1)
# generating the reconstructed image and adding to array
input_img = input_img.view(1, 3, IMG_WIDTH, IMG_WIDTH)
reconstructed_img = mvae.reconstruct_img(input_img)
reconstructed_img = reconstructed_img.view(3, IMG_WIDTH, IMG_WIDTH).detach().numpy()
reconstructed_img = np.array(reconstructed_img*255., dtype='uint8')
reconstructed_img = reconstructed_img.transpose((1, 2, 0))
reconstructed_array = np.concatenate((reconstructed_array, reconstructed_img), axis=1)
# remove first, blank column, and concatenate
input_array = input_array[:,1:,:]
reconstructed_array = reconstructed_array[:,1:,:]
display_array = np.concatenate((input_array, reconstructed_array), axis=0)
Image.fromarray(display_array)
# taking a sample observation
img1, emo1, out1 = face_outcome_emotion_dataset[5]
print("Sample Observation: ")
print(helperCode.EMOTION_VAR_NAMES)
print(emo1)
print(helperCode.OUTCOME_VAR_NAMES)
print(out1)
Image.fromarray(helperCode.TensorToPILImage(img1))
class testModule(nn.Module):
"""
define the PyTorch module that parametrizes q(z|image).
This goes from images to the latent z
This is the standard DCGAN architecture.
"""
def __init__(self, z_dim):
super(testModule, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=4, stride=2, padding=1, bias=False),
Swish(),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
Swish(),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
Swish(),
nn.Conv2d(128, 256, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
Swish())
self.classifier = nn.Sequential(
#nn.Linear(256 * 5 * 5, 512), # it's 256 * 5 * 5 if input is 64x64.
nn.Linear(256 * 9 * 9, 512), # it's 256 * 9 * 9 if input is 100x100.
Swish(),
nn.Dropout(p=0.1),
nn.Linear(512, z_dim * 2))
self.z_dim = z_dim
def forward(self, image):
image = self.features(image)
# image = image.view(-1, 256 * 5 * 5) # it's 256 * 5 * 5 if input is 64x64.
image = image.view(-1, 256 * 9 * 9) # it's 256 * 9 * 9 if input is 100x100.
image = self.classifier(image)
return image[:, :self.z_dim], image[:, self.z_dim:]
class testModuleDecoder(nn.Module):
"""
define the PyTorch module that parametrizes p(image|z).
This goes from the latent z to the images
This is the standard DCGAN architecture.
@param z_dim: integer
size of the tensor representing the latent random variable z
"""
def __init__(self, z_dim):
super(testModuleDecoder, self).__init__()
self.upsample = nn.Sequential(
nn.Linear(z_dim, 256 * 9 * 9),
Swish())
self.hallucinate = nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 1, 0, bias=False),
nn.BatchNorm2d(128),
Swish(),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
Swish(),
nn.ConvTranspose2d(64, 32, 4, 2, 1, bias=False),
nn.BatchNorm2d(32),
Swish(),
nn.ConvTranspose2d(32, 3, 4, 2, 1, bias=False))
def forward(self, z):
# the input will be a vector of size |z_dim|
z = self.upsample(z)
z = z.view(-1, 256, 9, 9)
image = self.hallucinate(z) # this is the image
return image # NOTE: no sigmoid here. See train.py
#torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1,
# padding=0, dilation=1, groups=1, bias=True)
# self.classifier = nn.Sequential(
# nn.Linear(256 * 5 * 5, 512),
# Swish(),
# nn.Dropout(p=0.1),
# nn.Linear(512, z_dim * 2))
# self.z_dim = z_dim
testN = testModule(100)
testN2 = testModuleDecoder(100)
#testN.net
imgBatch = torch.unsqueeze(img1, 0)
print(imgBatch.shape)
testN.forward(imgBatch)
testN2.forward(imgBatch).shape
#mvae.image_encoder(imgBatch)
# def forward(self, image):
# image = image.view(-1, 256 * 5 * 5)
# image = self.classifier(image)
# return image[:, :self.z_dim], image[:, self.z_dim:]
mvae.image_encoder
```
-----
Written by: Desmond Ong (desmond.c.ong@gmail.com), Harold Soh (hsoh@comp.nus.edu.sg), Mike Wu (wumike@stanford.edu)
References:
Pyro [VAE tutorial](http://pyro.ai/examples/vae.html)
Wu, M., & Goodman, N. D. (2018). Multimodal Generative Models for Scalable Weakly-Supervised Learning. To appear, NIPS 2018, https://arxiv.org/abs/1802.05335
Repo here: https://github.com/mhw32/multimodal-vae-public
DCGAN https://arxiv.org/pdf/1511.06434.pdf
Hoffman, M. D., Blei, D. M., Wang, C., & Paisley, J. (2013). Stochastic variational inference. *The Journal of Machine Learning Research*, 14(1), 1303-1347.
Kingma, D. P., Mohamed, S., Rezende, D. J., & Welling, M. (2014). Semi-supervised learning with deep generative models. In *Advances in Neural Information Processing Systems*, pp. 3581-3589. https://arxiv.org/abs/1406.5298
Kingma, D. P., & Welling, M. (2014). Auto-encoding variational bayes. Auto-Encoding Variational Bayes. In *The International Conference on Learning Representations*. https://arxiv.org/abs/1312.6114
Narayanaswamy, S., Paige, T. B., van de Meent, J. W., Desmaison, A., Goodman, N. D., Kohli, P., Wood, F. & Torr, P. (2017). Learning Disentangled Representations with Semi-Supervised Deep Generative Models. In *Advances in Neural Information Processing Systems*, pp. 5927-5937. https://arxiv.org/abs/1706.00400
Data from https://github.com/desmond-ong/affCog, from the following paper:
Ong, D. C., Zaki, J., & Goodman, N. D. (2015). Affective Cognition: Exploring lay theories of emotion. *Cognition*, 143, 141-162.
| github_jupyter |
## Dependencies
```
from tweet_utility_scripts import *
from transformers import TFDistilBertModel, DistilBertConfig
from tokenizers import BertWordPieceTokenizer
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input, Dropout, GlobalAveragePooling1D, GlobalMaxPooling1D, Concatenate
```
# Load data
```
test = pd.read_csv('/kaggle/input/tweet-sentiment-extraction/test.csv')
print('Test samples: %s' % len(test))
display(test.head())
```
# Model parameters
```
MAX_LEN = 128
question_size = 3
base_path = '/kaggle/input/qa-transformers/distilbert/'
base_model_path = base_path + 'distilbert-base-uncased-distilled-squad-tf_model.h5'
config_path = base_path + 'distilbert-base-uncased-distilled-squad-config.json'
tokenizer_path = base_path + 'bert-large-uncased-vocab.txt'
input_base_path = '/kaggle/input/22-tweet-train-distilbert-base-sparsecat-logit/'
model_path_list = glob.glob(input_base_path + '*.h5')
model_path_list.sort()
print('Models to predict:')
print(*model_path_list, sep = "\n")
```
# Tokenizer
```
tokenizer = BertWordPieceTokenizer(tokenizer_path , lowercase=True)
```
# Pre process
```
test['text'].fillna('', inplace=True)
test["text"] = test["text"].apply(lambda x: x.lower())
x_test = get_data_test(test, tokenizer, MAX_LEN)
```
# Model
```
module_config = DistilBertConfig.from_pretrained(config_path, output_hidden_states=False)
def model_fn():
input_ids = Input(shape=(MAX_LEN,), dtype=tf.int32, name='input_ids')
attention_mask = Input(shape=(MAX_LEN,), dtype=tf.int32, name='attention_mask')
token_type_ids = Input(shape=(MAX_LEN,), dtype=tf.int32, name='token_type_ids')
base_model = TFDistilBertModel.from_pretrained(base_model_path, config=module_config, name="base_model")
sequence_output = base_model({'input_ids': input_ids, 'attention_mask': attention_mask, 'token_type_ids': token_type_ids})
last_state = sequence_output[0]
x = GlobalAveragePooling1D()(last_state)
y_start = Dense(MAX_LEN, name='y_start')(x)
y_end = Dense(MAX_LEN, name='y_end')(x)
model = Model(inputs=[input_ids, attention_mask, token_type_ids], outputs=[y_start, y_end])
return model
```
# Make predictions
```
NUM_TEST_IMAGES = len(test)
test_start_preds = np.zeros((NUM_TEST_IMAGES, MAX_LEN))
test_end_preds = np.zeros((NUM_TEST_IMAGES, MAX_LEN))
for model_path in model_path_list:
print(model_path)
model = model_fn()
model.load_weights(model_path)
test_preds = model.predict(x_test)
test_start_preds += test_preds[0] / len(model_path_list)
test_end_preds += test_preds[1] / len(model_path_list)
```
# Post process
```
test['start'] = test_start_preds.argmax(axis=-1)
test['end'] = test_end_preds.argmax(axis=-1)
test['text_len'] = test['text'].apply(lambda x : len(x))
test["end"].clip(0, test["text_len"], inplace=True)
test["start"].clip(0, test["end"], inplace=True)
test['selected_text'] = test.apply(lambda x: decode(x['start'], x['end'], x['text'], question_size, tokenizer), axis=1)
test["selected_text"].fillna('', inplace=True)
```
# Visualize predictions
```
display(test.head(10))
```
# Test set predictions
```
submission = pd.read_csv('/kaggle/input/tweet-sentiment-extraction/sample_submission.csv')
submission['selected_text'] = test["selected_text"]
submission.to_csv('submission.csv', index=False)
submission.head(10)
```
| github_jupyter |
## Imports
```
import sys
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torchvision
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data.sampler import SubsetRandomSampler
sys.path.insert(0, '../../../Utils/')
import models
from train import *
from metrics import *
print("Python: %s" % sys.version)
print("Pytorch: %s" % torch.__version__)
# determine device to run network on (runs on gpu if available)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
```
## Hyperparameters
```
n_epochs = 100
batch_size = 128
lr = 0.01
k = 3
target_net_type = models.mlleaks_cnn
shadow_net_type = models.mlleaks_cnn
```
## Load CIFAR10
```
# define series of transforms to pre process images
train_transform = torchvision.transforms.Compose([
#torchvision.transforms.Pad(2),
#torchvision.transforms.RandomRotation(10),
#torchvision.transforms.RandomHorizontalFlip(),
#torchvision.transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1),
torchvision.transforms.ToTensor(),
#torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = torchvision.transforms.Compose([
#torchvision.transforms.Pad(2),
torchvision.transforms.ToTensor(),
#torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
classes = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
# load training set
cifar10_trainset = torchvision.datasets.CIFAR10('../../../Datasets/', train=True, transform=train_transform, download=True)
cifar10_trainloader = torch.utils.data.DataLoader(cifar10_trainset, batch_size=batch_size, shuffle=True, num_workers=2)
# load test set
cifar10_testset = torchvision.datasets.CIFAR10('../../../Datasets/', train=False, transform=test_transform, download=True)
cifar10_testloader = torch.utils.data.DataLoader(cifar10_testset, batch_size=32, shuffle=False, num_workers=2)
# helper function to unnormalize and plot image
def imshow(img):
img = np.array(img)
img = img / 2 + 0.5
img = np.moveaxis(img, 0, -1)
plt.imshow(img)
# display sample from dataset
imgs,labels = iter(cifar10_trainloader).next()
imshow(torchvision.utils.make_grid(imgs))
total_size = len(cifar10_trainset)
split1 = total_size // 4
split2 = split1*2
split3 = split1*3
indices = list(range(total_size))
shadow_train_idx = indices[:split1]
shadow_out_idx = indices[split1:split2]
target_train_idx = indices[split2:split3]
target_out_idx = indices[split3:]
shadow_train_sampler = SubsetRandomSampler(shadow_train_idx)
shadow_out_sampler = SubsetRandomSampler(shadow_out_idx)
target_train_sampler = SubsetRandomSampler(target_train_idx)
target_out_sampler = SubsetRandomSampler(target_out_idx)
shadow_train_loader = torch.utils.data.DataLoader(cifar10_trainset, batch_size=batch_size, sampler=shadow_train_sampler, num_workers=1)
shadow_out_loader = torch.utils.data.DataLoader(cifar10_trainset, batch_size=batch_size, sampler=shadow_out_sampler, num_workers=1)
#attack_train_loader = torch.utils.data.DataLoader(cifar10_trainset, batch_size=32, sampler=shadow_train_sampler, num_workers=1)
#attack_out_loader = torch.utils.data.DataLoader(cifar10_trainset, batch_size=32, sampler=shadow_out_sampler, num_workers=1)
target_train_loader = torch.utils.data.DataLoader(cifar10_trainset, batch_size=batch_size, sampler=target_train_sampler, num_workers=1)
target_out_loader = torch.utils.data.DataLoader(cifar10_trainset, batch_size=batch_size, sampler=target_out_sampler, num_workers=1)
# the model being attacked (architecture can be different than shadow)
target_net = target_net_type().to(device)
target_net.apply(models.weights_init)
target_loss = nn.CrossEntropyLoss()
target_optim = optim.Adam(target_net.parameters(), lr=lr)
# shadow net mimics the target network (architecture can be different than target)
shadow_net = shadow_net_type().to(device)
shadow_net.apply(models.weights_init)
shadow_loss = nn.CrossEntropyLoss()
shadow_optim = optim.Adam(shadow_net.parameters(), lr=lr)
# attack net is a binary classifier to determine membership
attack_net = models.mlleaks_mlp(n_in=k).to(device)
attack_net.apply(models.weights_init)
#attack_loss = nn.BCEWithLogitsLoss()
attack_loss = nn.BCELoss()
attack_optim = optim.Adam(attack_net.parameters(), lr=lr)
train(shadow_net, shadow_train_loader, cifar10_testloader, shadow_optim, shadow_loss, n_epochs, classes=classes)
train_attacker(attack_net, shadow_net, shadow_train_loader, shadow_out_loader, attack_optim, attack_loss, n_epochs=50, k=k)
train(target_net, target_train_loader, cifar10_testloader, target_optim, target_loss, n_epochs, classes=classes)
eval_attack_net(attack_net, target_net, target_train_loader, target_out_loader, k)
print("\nPerformance on training set: ")
train_accuracy = eval_target_net(target_net, target_train_loader, classes=None)
print("\nPerformance on test set: ")
test_accuracy = eval_target_net(target_net, cifar10_testloader, classes=None)
```
## Results
Attack performance: accuracy = 60.13, precision = 0.56, recall = 0.92
Performance on training set:
Accuracy = 96.11 %
Performance on test set:
Accuracy = 56.44 %
| github_jupyter |
# Showing Live Power with Plotly
This notebook shows how PYNQ and Plotly can be used to create a live updating plot of the power used by the board. This notebook should be run in JupyterLab with the Plotly JupyterLab extensions installed.
Please refer to the official Plotly [installation instructions](https://github.com/plotly/plotly.py#installation) and the [JupyterLab support](https://github.com/plotly/plotly.py#jupyterlab-support-python-35) section for more info on how to install everything you need.
Notice that power monitoring functionalities *will not work* on Amazon AWS F1.
## Reading and recording power data
The first step is to read the power data from the board and get into a suitable format for passing to Plotly for display. Reading the data is accomplished through the `sensors` attribute of an Alveo `Device`. The `active_device` property will return the first device in the system which is what we will use for the rest of this notebook.
```
from pynq import Device
sensors = Device.active_device.sensors
sensors
```
For measuring the power there are 3 rails of interest - the `12v_aux` and `12v_pex` rails which together account for the vast majority of power consumed by the board and the `vccint` rail which is the main FPGA power supply.
To record the power data PYNQ has a `DataRecorder` class inside the `pmbus` module which will record data from the sensors directly into a Pandas dataframe that we can use with Plotly. The constructor takes the sensors we want to record.
```
from pynq.pmbus import DataRecorder
recorder = DataRecorder(sensors["12v_aux"].power,
sensors["12v_pex"].power,
sensors["vccint"].power)
```
We can now get the dataframe
```
import pandas as pd
f = recorder.frame
```
To start recording the sensor data call `DataRecorder.record` with the sampling rate in seconds - 10 times per second in this case
```
recorder.record(0.1)
```
We can use Pandas to inspect the data we are recording
```
f.head()
```
## Plotting the Dataframe
First we need to create a blank graph we can populate with data. Plotly does this by having a layout dictionary in which we specify the axes and labels
```
import plotly.graph_objs as go
layout = {
'xaxis': {
'title': 'Time (s)'
},
'yaxis': {
'title': 'Power (W)',
'rangemode': 'tozero',
'autorange': True
}
}
plot = go.FigureWidget(layout=layout)
plot
```
Next we need a function to actually plot the data. While we could the the dataframe directly from the DataRecorder we can format it to be more immediately informative as well as only display the most recently recorded samples. Here we make use of a number of plotly functions to limit and average the data so that we get both instantaneous and moving average power over a specified period of time.
```
def update_data(frame, start, end, plot):
ranged = frame[start:end]
average_ranged = frame[start-pd.tseries.offsets.Second(5):end]
rolling = (average_ranged['12v_aux_power'] + average_ranged['12v_pex_power']).rolling(
pd.tseries.offsets.Second(5)
).mean()[ranged.index]
powers = pd.DataFrame(index=ranged.index)
powers['board_power'] = ranged['12v_aux_power'] + ranged['12v_pex_power']
powers['rolling'] = rolling
data = [
go.Scatter(x=powers.index, y=powers['board_power'], name="Board Power"),
go.Scatter(x=powers.index, y=powers['rolling'], name="5 Second Avg")
]
plot.update(data=data)
```
To actually update the graph in a live fashion we need to create a new thread that will update our graph periodically
```
import threading
import time
do_update = True
def thread_func():
while do_update:
now = pd.Timestamp.fromtimestamp(time.time())
past = now - pd.tseries.offsets.Second(60)
update_data(recorder.frame, past, now, plot)
time.sleep(0.5)
from threading import Thread
t = Thread(target=thread_func)
t.start()
```
Now the graph is updating try running other notebooks to see how power consumption changes based on load.
## Cleaning Up
To clean up we need to stop both the update thread we created and the DataRecorder
```
do_update = False
t.join()
recorder.stop()
```
Copyright (C) 2020 Xilinx, Inc
| github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import random
def seed_everything(seed=2020):
random.seed(seed)
np.random.seed(seed)
seed_everything(42)
warnings.filterwarnings("ignore")
%matplotlib inline
```
# Pulsar star
```
data = pd.read_csv("../../data/pulsar_stars.csv")
data.head()
data.shape
data.columns = data.columns.str.strip()
data.columns = ['IP Mean', 'IP Sd', 'IP Kurtosis', 'IP Skewness',
'DM-SNR Mean', 'DM-SNR Sd', 'DM-SNR Kurtosis', 'DM-SNR Skewness', 'target_class']
# data['target_class'].value_counts()
# view the percentage distribution of target_class column
data['target_class'].value_counts()/np.float(len(data))
df_ab = data[data['target_class']==1]
df_nnorm = data[data['target_class']!=1]
df_ab.head()
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df_values = df_ab.copy()
column_list = list(df_values.columns)
df_values = df_values.drop(['target_class'], axis=1)
df_norm = scaler.fit_transform(df_values)
# X = df_norm.drop(['target_class'],axis=1)
# y= df_norm['target_class']
column_list
df_norm.shape[1]
```
# Autoencoder
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.preprocessing import StandardScaler
from keras.models import Sequential, Model
from keras.layers import Dense, BatchNormalization, Dropout, Flatten, Input
from keras import backend as K
import keras
from matplotlib.colors import LogNorm
n_features = df_norm.shape[1]
dim = 15
def build_model(dropout_rate=0.15, activation='tanh'):
main_input = Input(shape=(n_features, ), name='main_input')
x = Dense(dim*2, activation=activation)(main_input)
x = BatchNormalization()(x)
x = Dropout(dropout_rate)(x)
x = Dense(dim*2, activation=activation)(x)
x = BatchNormalization()(x)
x = Dropout(dropout_rate/2)(x)
x = Dense(dim, activation=activation)(x)
x = Dropout(dropout_rate/4)(x)
encoded = Dense(n_features, activation='tanh')(x)
input_encoded = Input(shape=(n_features, ))
x = Dense(dim, activation=activation)(input_encoded)
x = Dense(dim, activation=activation)(x)
x = Dense(dim*2, activation=activation)(x)
decoded = x = Dense(n_features, activation='linear')(x)
encoder = Model(main_input, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(main_input, decoder(encoder(main_input)), name="autoencoder")
return encoder, decoder, autoencoder
K.clear_session()
c_encoder, c_decoder, c_autoencoder = build_model()
c_autoencoder.compile(optimizer='nadam', loss='mse')
c_autoencoder.summary()
%%time
epochs = 50
batch_size = 9548
history = c_autoencoder.fit(df_norm, df_norm,
epochs=epochs,
batch_size=batch_size,
shuffle=True,
verbose=1)
loss_history = history.history['loss']
plt.figure(figsize=(10, 5))
plt.plot(loss_history);
ae = c_encoder.predict(df_norm)
ae.shape
ae
df_ae = pd.DataFrame(ae)
df_ae['target_class'] = 1
df_ae.columns = column_list
df_ae.head(10)
df_nvalues = df_nnorm.drop(['target_class'], axis=1)
scaled_nnorm = scaler.fit_transform(df_nvalues)
df_scaler_nnorm = pd.DataFrame(scaled_nnorm, index=df_nvalues.index, columns=df_nvalues.columns)
df_scaler_nnorm['target_class'] = data.target_class
df_scaler_nnorm.head()
df_train = pd.concat([df_ae, df_scaler_nnorm], ignore_index=True)
df_train.shape
X = df_train.drop(['target_class'], axis=1)
y = df_train['target_class']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
# Model
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score,roc_curve,auc
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import matthews_corrcoef, confusion_matrix,precision_recall_curve,auc,f1_score,roc_auc_score,roc_curve,recall_score,classification_report
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
def model(algorithm,dtrain_x,dtrain_y,dtest_x,dtest_y):
print ("MODEL - OUTPUT")
print ("*****************************************************************************************")
algorithm.fit(dtrain_x,dtrain_y)
predictions = algorithm.predict(dtest_x)
print (algorithm)
print ("\naccuracy_score :",accuracy_score(dtest_y,predictions))
print ("\nrecall score:\n",(recall_score(dtest_y,predictions)))
print ("\nf1 score:\n",(f1_score(dtest_y,predictions)))
# print ("\nclassification report :\n",(classification_report(dtest_y,predictions)))
print ("\nmatthews_corrcoef:\n", (matthews_corrcoef(dtest_y, predictions)))
#cross validation
# Graph
plt.figure(figsize=(13,10))
plt.subplot(221)
sns.heatmap(confusion_matrix(dtest_y,predictions),annot=True,fmt = "d",linecolor="k",linewidths=3)
plt.title("CONFUSION MATRIX",fontsize=20)
predicting_probabilites = algorithm.predict_proba(dtest_x)[:,1]
fpr,tpr,thresholds = roc_curve(dtest_y,predicting_probabilites)
plt.subplot(222)
plt.plot(fpr,tpr,label = ("Area_under the curve :",auc(fpr,tpr)),color = "r")
plt.plot([1,0],[1,0],linestyle = "dashed",color ="k")
plt.legend(loc = "best")
plt.title("ROC - CURVE & AREA UNDER CURVE",fontsize=20)
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
model(clf ,X_train,y_train,X_test,y_test)
clf = DecisionTreeClassifier()
model(clf ,X_train,y_train,X_test,y_test)
svc=SVC(probability=True)
model(svc ,X_train,y_train,X_test,y_test)
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
model(clf ,X_train,y_train,X_test,y_test)
```
| github_jupyter |
```
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (20, 6)
import numpy as np
from mimikit.utils import audio, show
from mimikit.extract.segment import from_recurrence_matrix
from mimikit.data import FileType, make_root_db
from librosa.util import sync
from sklearn.neighbors import NearestNeighbors
from sklearn.metrics import pairwise_distances as pwd
import sklearn.cluster as C
# where you have audio files
my_music_folder = "not a folder"
# the file with your data :
my_db = "not a db.h5"
if not os.path.exists(my_db):
make_root_db(my_db, my_music_folder)
db = FileType(my_db)
piece = db.metadata.iloc[[0]]
X = db.fft.get(piece).T
X.shape
```
## Segment X
```
segments = from_recurrence_matrix(X.T,
L=6,
k=None,
sym=True,
bandwidth=1.,
thresh=0.2,
min_dur=4)
# aggregate each segment
Sx = sync(X, segments.stop.values, aggregate=np.median, axis=0)
Sx.shape, segments.describe()
```
## Clustering Methods
```
def distance_matrices(X, metric="euclidean", n_neighbors=1, radius=1e-3):
Dx = pwd(X, X, metric=metric, n_jobs=-1)
NN = NearestNeighbors(n_neighbors=n_neighbors, radius=radius, metric="precomputed", n_jobs=-1)
NN.fit(Dx)
Kx = NN.kneighbors_graph(n_neighbors=n_neighbors, mode='connectivity')
Rx = NN.radius_neighbors_graph(radius=radius, mode='connectivity')
return Dx, Kx, Rx
class ArgMax(object):
def __init__(self):
self.labels_ = None
def fit(self, X):
maxes = np.argmax(X, axis=1)
uniques, self.labels_ = np.unique(maxes, return_inverse=True)
return self
def cluster(X, Dx=None, n_clusters=128, metric="euclidean", estimator="argmax"):
estimators = {
"argmax": ArgMax(),
"kmeans": C.KMeans(n_clusters=n_clusters,
n_init=4,
max_iter=200,
n_jobs=-1),
"spectral": C.SpectralClustering(n_clusters=n_clusters,
affinity="nearest_neighbors",
n_neighbors=32,
assign_labels="discretize",
n_jobs=-1),
"agglo_ward": C.AgglomerativeClustering(
n_clusters=n_clusters,
affinity="euclidean",
compute_full_tree='auto',
linkage='ward',
distance_threshold=None,),
"agglo_single": C.AgglomerativeClustering(
n_clusters=n_clusters,
affinity="precomputed",
compute_full_tree='auto',
linkage='single',
distance_threshold=None,),
"agglo_complete": C.AgglomerativeClustering(
n_clusters=n_clusters,
affinity="precomputed",
compute_full_tree='auto',
linkage='complete',
distance_threshold=None,)
}
needs_distances = estimator in {"agglo_single", "agglo_complete"}
if needs_distances:
if Dx is None:
Dx, _, _ = distance_matrices(X, metric=metric)
X_ = Dx
else:
X_ = X
cls = estimators[estimator]
cls.fit(X_)
return cls.labels_
```
### Ordering functions
```
def label_order(labels):
"""return a dictionary where each labels_index (key) is paired
with its sorted appearance indices (values)"""
l_set, indices = np.unique(labels, return_inverse=True)
rg = np.arange(labels.size)
return {label: rg[indices == label] for label in l_set}
def replace_by_neighbor(Kx):
"""replace each time_index by one of its neighbor (at random)"""
order = []
for i in range(Kx.shape[0]):
order += [np.random.choice(Kx[i].A.nonzero()[1], 1)[0]]
return np.r_[order]
def replace_by_label(labels):
"""replace each time_index by an other index having the same label (at random)"""
l_order = label_order(labels)
order = []
for i in range(labels.size):
candidates = l_order[labels[i]]
order += [np.random.choice(candidates, 1)[0]]
return np.r_[order]
def segment_shuffle(segments, sampling_rate=1.):
"""shuffle each segment internally while preserving length and relative order.
The parameter `sampling_rate` controls how much of each segment is sampled"""
N = len(segments)
order = []
for i in range(N):
s_i = np.arange(segments.iloc[i, 0].item(), segments.iloc[i, 1].item())
np.random.shuffle(s_i)
order += [np.random.choice(s_i, int(len(s_i) * sampling_rate), replace=sampling_rate > 1.)]
return np.concatenate(order)
```
## Compute Distances, Neighbors and Clusters
```
Dx, Kx, Rx = distance_matrices(X, metric="euclidean", n_neighbors=8, radius=2.)
labels = cluster(X, Dx=Dx, n_clusters=64, estimator="spectral")
# show the distribution of distances
plt.hist(Dx.flat[:], bins=X.shape[0]//4, density=True, alpha=.65)
plt.title("Distances Densities")
plt.figure()
plt.hist(labels, bins=len(set(labels)), color="green", alpha=.65)
plt.title("Cluster's Densities")
None
```
## Re-Order X by Labels/Neighbors/etc...
```
label_o = label_order(labels)
by_neighb = replace_by_neighbor(Kx)
by_label = replace_by_label(labels)
seg_shuff = segment_shuffle(segments)
for k in label_o.keys():
if len(label_o[k]) <= 1: # this throws error in griffinlim...
continue
if len(label_o[k]) > 100: # discard small neighborhoods
print("label", k)
audio(X[label_o[k]].T)
print("by_neighb")
audio(X[by_neighb].T)
print("by_label")
audio(X[by_label].T)
print("segment_shuffle")
audio(X[seg_shuff].T)
```
| github_jupyter |
# Nice Markdown
### `>` for quotes
Quotes are easy, just prefix them with \>
> A capacity, and taste, for reading gives access to whatever has already been discovered by others.
—Abraham Lincoln
### `***` to make a horizontal divider
To insert a horizontal divider, also known as a horizontal rule, just put `***`, `~~~` or `---` on a new line.
***
Note: `---`, on a line directly below text, will cause that text to be rendered as a header, make sure the `---` is in it's own paragraph
### `|` to create tables
To create a table using markdown, I recommend you save yourself the trouble and use a [Good Markdown Table Generator](https://www.tablesgenerator.com/markdown_tables) instead of creating them manually using `|`. That being said, it's good to understand how tables work in Markdown so that you can quickly adjust them if needed, without having to completely remake them from scratch.
#### Building tables the hard way
The first row is just the names of your headers, separated by `|`
| Header 1 | Header 2 | Header 3 |
***
Then below that, we divide our headers from our data with `-` separated by `|`.
| ----- | ----- | ----- |
Combine them and we get something that's starting to look like a table
| Header 1 | Header 2 | Header 3 |
| ----- | ----- | ----- |
***
Next we can add data, you guessed it, separated by `|`.
| bananas | 9 | \$90.00 |
Combine everything we've done so far and we have:
| Header 1 | Header 2 | Header 3 |
| ----- | ----- | ----- |
| bananas | 9 | \$90.00 |
***
#### A basic completed table
| Header 1 | Header 2 | Header 3 |
| ----- | ----- | ----- |
| bananas | 9 | \$90.00 |
| apples | 6 | \$3.25 |
| oranges | 17 | \$4.50 |
Note that we needed to escape the \$ because that's the symbol Markdown uses for displaying inline equations using MathJax, something we'll see later in this chapter
#### Customizing Tables
What you need to know:
- Tables will stretch/shrink to fit the data, number of hyphens doesn't matter
- For separating headers and data, you need at least 3 hyphens
- You can use `:` in the row with hyphens to align each column
- `|:----|` for left-align
- `|----:|` for center-align
- `|----:|` for right-align (unnecessary because it's the default alignment)
- You can use inline markdown inside your tables
#### A customized table
I've taken some data from a piece I wrote about [The Most Common Python Functions](https://medium.com/@robertbracco1/most-common-python-functions-aafdc01b71ef) and inserted it into a table with some special alignments, as well as inline markdown (1st column is displayed as code).
| Command | Projects Using | Total Uses |
| :----- | :-----: | -----: |
| `len` | 69.02% | 222626 |
| `print` | 50.10% | 170384 |
| `format` | 45.59% | 124423 |
| `isinstance` | 45.69% | 104212 |
| `str` | 54.91% | 98316 |
One limitation of Markdown tables is that you can only use column headers. If you want your headers to be at the start of each row, you'll need to use HTML.
### MathJax for creating pretty equations
MathJax is a subset of the typesetting language LaTeX and is meant to display beautifully formatted equaltions, inside of media like Jupyter Notebooks and academic papers. Equations start and end with \\$ for inline equations, and \$\$ for block display.
I personally don't know MathJax, but here are links in case you do
- [StackExchange MathJax basic tutorial and quick reference wiki](https://math.meta.stackexchange.com/questions/5020/mathjax-basic-tutorial-and-quick-reference)
- [Interactive LaTeX Editor](https://www.codecogs.com/latex/eqneditor.php)
- [MathJax Homepage](https://www.mathjax.org/)
And two simple examples from the StackExchange Basic tutorial to get you started
- inline equation $\sum_{i=0}^n i^2 = \frac{(n^2+n)(2n+1)}{6}$
- block equation $$\sum_{i=0}^n i^2 = \frac{(n^2+n)(2n+1)}{6}$$
### `[description](#title-of-section)` for internal links
<div class="alert alert-block alert-warning"><strong>Note: </strong>There is a better way to navigate between headers, using the "Table of Contents" extension, something we cover in section 2.1 Essential Extensions</div>
If you hover over any header, you will notice a blue link icon appear to the right. This is because all headers are in fact links, and you can link to them from inside the same notebook.
The url is # and then header title separated by hyphens. For instance, the next section is called "Use HTML inside cells", so we link to the url "#Use-HTML-inside-cells", using the syntax for normal links we learned in the Essential Markdown section
Let's [see if it works](#Use-HTML-inside-cells)
### Use HTML inside cells
In general, markdown does a pretty good job, and I'd recommend sticking to it wherever possible. Sometimes, however the flexibility of Markdown isn't enough and we want to do things like
<span style='color:red'>print in other colors</span> or <span style='font-size:24px'>change the font size without a header</span>.
You may have also noticed the colored blocks I used for displaying
<div class="alert alert-block alert-info">Special info</div>
<div class="alert alert-block alert-warning">Alerts</div>
and
<div class="alert alert-block alert-success">Helpful tips</div>
All of this is acheived using HTML. Just type valid html in a markdown cell and it will automatically be rendered when you run the cell. HTML in general is outside the scope of this book, so if you don't know HTML and would like to use it to sty
HTML is outside the scope of this book, but there are plenty of excellent resources out there in case you want to learn more.
**You absolutely do not require any knowledge of HTML to use Jupyter, or to complete this book, so feel free to skip this section and move on**
#### HTML Tables
HTML Tables are outside the scope of this book, but I've included an example with both Column Headers and Row Headers (something that can't be acheived in Markdown.
If you need more as well as a link to [this GeeksForGeeks article](https://www.geeksforgeeks.org/html-tables/) that is full of code examples for the use cases you may need. Note that if you want to use the examples from the article that use CSS, inside of Jupyter, you'll need to use inline CSS in your table, which can be a huge pain. I currently don't know of a better way, as Jupyter is careful not to evaluate certain CSS due to possible security vulnerabilities
<table>
<tr>
<th>Command</th>
<th>Projects Using</th>
<th>Total Uses</th>
</tr>
<tr>
<td><code>len</code></td>
<td>69.02%</td>
<td>222626</td>
</tr>
<tr>
<td><code>print</code></td>
<td>50.10%</td>
<td>170384</td>
</tr>
<tr>
<td><code>format</code></td>
<td>45.59%</td>
<td>124423</td>
</tr>
<tr>
<td><code>isinstance</code></td>
<td>45.69%</td>
<td>104212</td>
</tr>
<tr>
<td><code>str</code></td>
<td>54.91%</td>
<td>98316</td>
</tr>
</table>
<table>
<tr>
<th>Command</th>
<td><code>len</code></td>
<td><code>print</code></td>
<td><code>format</code></td>
<td><code>isinstance</code></td>
<td><code>str</code></td>
</tr>
<tr>
<th>Projects Using</th>
<td>69.02%</td>
<td>50.10%</td>
<td>45.59%</td>
<td>45.69%</td>
<td>54.91%</td>
</tr>
<tr>
<th>Total Uses</th>
<td>222626</td>
<td>170384</td>
<td>124423</td>
<td>104212</td>
<td>98316</td>
</tr>
</table>
#### HTML Entity Embeddings for Symbols
Entities are special items in HTML that start with `&` and end with `;` and are used to display icons. For instance say we needed the © symbol, we can create it in HTML by writing "&copy;", or by using it's entity number "&#169";
If you want more, check out this [complete list of HTML entities](https://dev.w3.org/html5/html-author/charref)
### `Ipython.display` for including videos
Credit to [Christopher Lovell](https://github.com/christopherlovell) for [figuring this out](https://gist.github.com/christopherlovell/e3e70880c0b0ad666e7b5fe311320a62)
```
from IPython.display import HTML
HTML('<iframe width="560" height="315" src="https://player.vimeo.com/video/26763844?title=0&byline=0&portrait=0" frameborder="0" allowfullscreen></iframe>')
```
And if you have a youtube video, there's a special function for embedding it.
Credit to [Stack Overflow user Bakkal](https://stackoverflow.com/users/238639/bakkal) for [figuring this out](https://stackoverflow.com/questions/27315161/displaying-a-youtube-clip-in-python)
```
from IPython.display import YouTubeVideo
# a talk about IPython at Sage Days at U. Washington, Seattle.
# Video credit: William Stein.
YouTubeVideo('XfoYk_Z5AkI')
```
| github_jupyter |
```
# Deep Learning with Python Ch8: VAE
##############################
# variational autoencoders #
##############################
# VAE encoder network
import numpy as np
import keras
from keras import layers
from keras import backend as K
from keras.models import Model
img_shape = (28, 28, 1) # gray scale image
latent_dim = 2 # dimension of the latent space: 2D here
batch_size = 16
input_img = keras.Input(shape=img_shape)
x = layers.Conv2D(32, 3, padding='same', activation='relu')(input_img)
x = layers.Conv2D(64, 3, padding='same', activation='relu', strides=(2,2))(x)
x = layers.Conv2D(64, 3, padding='same', activation='relu')(x)
x = layers.Conv2D(64, 3, padding='same', activation='relu')(x)
shape_before_flattening = K.int_shape(x)
x = layers.Flatten()(x)
x = layers.Dense(32, activation='relu')(x)
# input image is encoded into these 2 parameters
z_mean = layers.Dense(latent_dim)(x)
z_log_var = layers.Dense(latent_dim)(x)
# latent space sampling fn
# sample point z from the latent space (or a distribution) defined by z_mean and z_log_var
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim), mean=0, stddev=1)
return z_mean + K.exp(z_log_var) * epsilon
# in keras, everything must be a built-in layer
# otherwise, it should be wrapped in a Lambda (aka custom layer)
z = layers.Lambda(sampling)([z_mean, z_log_var])
# VAE decoder network
# input where you feed z
decoder_input = layers.Input(K.int_shape(z)[1:])
# upsample the input
x = layers.Dense(np.prod(shape_before_flattening[1:]), activation='relu')(decoder_input)
# reshape z into a feature map of the same shape as the feature map
# just before the last Flatten layer in the encoder network
x = layers.Reshape(shape_before_flattening[1:])(x)
# decode z into a feature map of the same size as the original image input
x = layers.Conv2DTranspose(32, 3, padding='same', activation='relu', strides=(2,2))(x)
x = layers.Conv2D(1, 3, padding='same', activation='sigmoid')(x)
# initiate decoder model that turns decoder_input into the decoded image
decoder = Model(decoder_input, x)
# apply the decoder model to z to recover decoded z:
# map point z sampled from the latent space to image
z_decoded = decoder(z)
# set up a custom layer that uses built-in add_loss layer to compute VAE loss
class CustomVariationLayer(keras.layers.Layer):
def vae_loss(self, x, z_decoded):
x = K.flatten(x)
z_decoded = K.flatten(z_decoded)
# reconstruction loss: match decoded sample to initial input
xent_loss = keras.metrics.binary_crossentropy(x, z_decoded)
# regularization loss: learn well-formed latent space and reduce overfitting
kl_loss = -5e-4 * K.mean(1+z_log_var-K.square(z_mean)-K.exp(z_log_var), axis=-1)
return K.mean(xent_loss + kl_loss)
# implement custom layers by writing a call method
def call(self, inputs):
x = inputs[0]
z_decoded = inputs[1]
loss = self.vae_loss(x, z_decoded)
self.add_loss(loss, inputs=inputs)
return x # you don't use this output, but layer must return sth
y = CustomVariationLayer()([input_img, z_decoded])
# train VAE
from keras.datasets import mnist
# turn input_img and y into a model
vae = Model(input_img, y)
vae.summary()
# loss is taken care of in the custom layer,
# so no need to specify an external loss at compiling
vae.compile(optimizer='rmsprop', loss=None)
# load data
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32')/255
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.astype('float32')/255
x_test = x_test.reshape(x_test.shape + (1,))
# train model
# loss it already taken care of, so no need to pass target data
vae.fit(x=x_train, y=None, shuffle=True, epochs=10, batch_size=batch_size,
validation_data=(x_test, None), verbose=0)
# sample a grid of points from the latent space and decode them into images
%matplotlib inline
import matplotlib.pyplot as plt
from scipy.stats import norm
n = 15 # display a 15 x 15 grid
digit_size = 28
figure = np.zeros((digit_size*n, digit_size*n))
# transform linearly spaced coordinate to produce values of the latent variable z
# as the prior of the latent space is Gaussian
gridx = norm.ppf(np.linspace(0.05, 0.95, n))
gridy = norm.ppf(np.linspace(0.05, 0.95, n))
for i, xi in enumerate(gridx):
for j, yi in enumerate(gridy):
z_sample = np.array([[xi, yi]])
# repeat z multiple times to form a complete batch
z_sample = np.tile(z_sample, batch_size).reshape(batch_size, 2)
# decode the batch into digit images
x_decoded = decoder.predict(z_sample, batch_size=batch_size)
# reshape 1st digit in the batch from 28x28x1 to 28x28
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[i*digit_size:(i+1)*digit_size, j*digit_size:(j+1)*digit_size] = digit
plt.imshow(figure, cmap='Greys_r')
plt.show()
```
| github_jupyter |
# Rate of Returns Over Multiple Periods
## Numpy.cumsum and Numpy.cumprod
You've just leared about active returns and passive returns. Another important concept related to returns is "Cumulative returns" which is defined as the returns over a time period. You can read more about rate of returns [here](https://en.wikipedia.org/wiki/Rate_of_return)!
There are two ways to calcualte cumulative returns, depends on how the returns are calculated. Let's take a look at an example.
```
import numpy as np
import pandas as pd
from datetime import datetime
dates = pd.date_range(datetime.strptime('1/1/2016', '%m/%d/%Y'), periods=12, freq='M')
start_price, stop_price = 0.24, 0.3
abc_close_prices = np.arange(start_price, stop_price, (stop_price - start_price)/len(dates))
abc_close = pd.Series(abc_close_prices, dates)
abc_close
```
Here, we have the historical prices for stock ABC for 2016. We would like to know the yearly cumulative returns for stock ABC in 2016 using time-weighted method, assuming returns are reinvested. How do we do it? Here is the formula:
Assume the returns over n successive periods are:
$ r_1, r_2, r_3, r_4, r_5, ..., r_n $
The cumulative return of stock ABC over period n is the compounded return over period n:
$ (1 + r_1)(1 + r_2)(1 + r_3)(1 + r_4)(1 + r_5)...(1 + r_n) - 1 $
First, let's calculate the returns of stock ABC.
```
len(abc_close)
returns = abc_close / abc_close.shift(1) - 1
returns
len(returns)
```
The cumulative return equals to the product of the daily returns for the n periods.
That's a very long formula. Is there a better way to calculate this.
The answer is yes, we can use numpy.cumprod().
For example, if we have the following time series: 1, 5, 7, 10 and we want the product of the four numbers. How do we do it? Let's take a look!
```
lst = [1,5,7,10]
np.cumprod(lst)
```
The last element in the list is 350, which is the product of 1, 5, 7, and 10.
OK, let's use numpy.cumprod() to get the cumulative returns for stock ABC
```
(returns + 1).cumprod()[len(returns)-1] - 1
```
The cumulative return for stock ABC in 2016 is 22.91%.
The other way to calculate returns is to use log returns.
The formula of log return is the following:
$ LogReturn = ln(\frac{P_t}{P_t - 1}) $
The cumulative return of stock ABC over period n is the compounded return over period n:
$ \sum_{i=1}^{n} r_i = r_1 + r_2 + r_3 + r_4 + ... + r_n $
Let's see how we can calculate the cumulative return of stock ABC using log returns.
First, let's calculate log returns.
```
log_returns = (np.log(abc_close).shift(-1) - np.log(abc_close)).dropna()
log_returns.head()
```
The cumulative sum equals to the sum of the daily returns for the n periods which is a very long formula.
To calculate cumulative sum, we can simply use numpy.cumsum().
Let's take a look at our simple example of time series 1, 5, 7, 10.
```
lst = [1,5,7,10]
np.cumsum(lst)
```
The last element is 23 which equals to the sum of 1, 5, 7, 10
OK, let's use numpy.cumsum() to get the cumulative returns for stock ABC
```
cum_log_return = log_returns.cumsum()[len(log_returns)-1]
np.exp(cum_log_return) - 1
```
The cumulative return for stock ABC in 2016 is 22.91% using log returns.
## Quiz: Arithmetic Rate of Return
Now, let's use cumprod() and cumsum() to calculate average rate of return.
For consistency, let's assume the rate of return is calculated as $ \frac{P_t}{P_t - 1} - 1 $
### Arithmetic Rate of Return:
$ \frac{1}{n} \sum_{i=1}^{n} r_i = \frac{1}{n}(r_1 + r_2 + r_3 + r_4 + ... + r_n) $
```
import quiz_tests
def calculate_arithmetic_rate_of_return(close):
"""
Compute returns for each ticker and date in close.
Parameters
----------
close : DataFrame
Close prices for each ticker and date
Returns
-------
arithmnetic_returns : Series
arithmnetic_returns at the end of the period for each ticker
"""
# TODO: Implement Function
returns = close / close.shift(1) - 1
arithmetic_returns = returns.cumsum(axis =0).iloc[returns.shape[0]-1]/returns.shape[0]
return arithmetic_returns
quiz_tests.test_calculate_arithmetic_rate_of_return(calculate_arithmetic_rate_of_return)
```
## Quiz Solution
If you're having trouble, you can check out the quiz solution [here](cumsum_and_cumprod_solution.ipynb).
| github_jupyter |
```
# Copyright 2021 Google LLC
# Use of this source code is governed by an MIT-style
# license that can be found in the LICENSE file or at
# https://opensource.org/licenses/MIT.
# Notebook authors: Kevin P. Murphy (murphyk@gmail.com)
# and Mahmoud Soliman (mjs@aucegypt.edu)
# This notebook reproduces figures for chapter 16 from the book
# "Probabilistic Machine Learning: An Introduction"
# by Kevin Murphy (MIT Press, 2021).
# Book pdf is available from http://probml.ai
```
<a href="https://opensource.org/licenses/MIT" target="_parent"><img src="https://img.shields.io/github/license/probml/pyprobml"/></a>
<a href="https://colab.research.google.com/github/probml/pyprobml/blob/master/book1/figures/chapter16_exemplar-based_methods_figures.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Figure 16.1:<a name='16.1'></a> <a name='knn'></a>
(a) Illustration of a $K$-nearest neighbors classifier in 2d for $K=5$. The nearest neighbors of test point $\mathbf x $ have labels $\ 1, 1, 1, 0, 0\ $, so we predict $p(y=1|\mathbf x , \mathcal D ) = 3/5$. (b) Illustration of the Voronoi tesselation induced by 1-NN. Adapted from Figure 4.13 of <a href='#Duda01'>[DHS01]</a> .
Figure(s) generated by [knn_voronoi_plot.py](https://github.com/probml/pyprobml/blob/master/scripts/knn_voronoi_plot.py)
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
google.colab.files.view("./knn_voronoi_plot.py")
%run knn_voronoi_plot.py
```
## Figure 16.2:<a name='16.2'></a> <a name='knnThreeClass'></a>
Decision boundaries induced by a KNN classifier. (a) $K=1$. (b) $K=2$. (c) $K=5$. (d) Train and test error vs $K$.
Figure(s) generated by [knn_classify_demo.py](https://github.com/probml/pyprobml/blob/master/scripts/knn_classify_demo.py)
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
google.colab.files.view("./knn_classify_demo.py")
%run knn_classify_demo.py
```
## Figure 16.3:<a name='16.3'></a> <a name='curse'></a>
Illustration of the curse of dimensionality. (a) We embed a small cube of side $s$ inside a larger unit cube. (b) We plot the edge length of a cube needed to cover a given volume of the unit cube as a function of the number of dimensions. Adapted from Figure 2.6 from <a href='#HastieBook'>[HTF09]</a> .
Figure(s) generated by [curse_dimensionality.py](https://github.com/probml/pyprobml/blob/master/scripts/curse_dimensionality.py)
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
google.colab.files.view("./curse_dimensionality.py")
%run curse_dimensionality.py
```
## Figure 16.4:<a name='16.4'></a> <a name='LCA'></a>
Illustration of latent coincidence analysis (LCA) as a directed graphical model. The inputs $\mathbf x , \mathbf x ' \in \mathbb R ^D$ are mapped into Gaussian latent variables $\mathbf z , \mathbf z ' \in \mathbb R ^L$ via a linear mapping $\mathbf W $. If the two latent points coincide (within length scale $\kappa $) then we set the similarity label to $y=1$, otherwise we set it to $y=0$. From Figure 1 of <a href='#Der2012'>[ML12]</a> . Used with kind permission of Lawrence Saul.
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
show_image("/pyprobml/book1/figures/images/Figure_16.4.png")
```
## Figure 16.5:<a name='16.5'></a> <a name='tripletNet'></a>
Networks for deep metric learning. (a) Siamese network. (b) Triplet network. Adapted from Figure 5 of <a href='#Kaya2019'>[MH19]</a> .
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
show_image("/pyprobml/book1/figures/images/Figure_16.5_A.png")
show_image("/pyprobml/book1/figures/images/Figure_16.5_B.png")
```
## Figure 16.6:<a name='16.6'></a> <a name='tripletBound'></a>
Speeding up triplet loss minimization. (a) Illustration of hard vs easy negatives. Here $a$ is the anchor point, $p$ is a positive point, and $n_i$ are negative points. Adapted from Figure 4 of <a href='#Kaya2019'>[MH19]</a> . (b) Standard triplet loss would take $8 \times 3 \times 4 = 96$ calculations, whereas using a proxy loss (with one proxy per class) takes $8 \times 2 = 16$ calculations. From Figure 1 of <a href='#Do2019cvpr'>[Tha+19]</a> . Used with kind permission of Gustavo Cerneiro.
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
show_image("/pyprobml/book1/figures/images/Figure_16.6_A.png")
show_image("/pyprobml/book1/figures/images/Figure_16.6_B.png")
```
## Figure 16.7:<a name='16.7'></a> <a name='SEC'></a>
Adding spherical embedding constraint to a deep metric learning method. Used with kind permission of Dingyi Zhang.
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
show_image("/pyprobml/book1/figures/images/Figure_16.7.png")
```
## Figure 16.8:<a name='16.8'></a> <a name='smoothingKernels'></a>
A comparison of some popular normalized kernels.
Figure(s) generated by [smoothingKernelPlot.py](https://github.com/probml/pyprobml/blob/master/scripts/smoothingKernelPlot.py)
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
google.colab.files.view("./smoothingKernelPlot.py")
%run smoothingKernelPlot.py
```
## Figure 16.9:<a name='16.9'></a> <a name='parzen'></a>
A nonparametric (Parzen) density estimator in 1d estimated from 6 data points, denoted by x. Top row: uniform kernel. Bottom row: Gaussian kernel. Left column: bandwidth parameter $h=1$. Right column: bandwidth parameter $h=2$. Adapted from http://en.wikipedia.org/wiki/Kernel_density_estimation .
Figure(s) generated by [Kernel_density_estimation](http://en.wikipedia.org/wiki/Kernel_density_estimation) [parzen_window_demo2.py](https://github.com/probml/pyprobml/blob/master/scripts/parzen_window_demo2.py)
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
google.colab.files.view("./parzen_window_demo2.py")
%run parzen_window_demo2.py
```
## Figure 16.10:<a name='16.10'></a> <a name='kernelRegression'></a>
An example of kernel regression in 1d using a Gaussian kernel.
Figure(s) generated by [kernelRegressionDemo.py](https://github.com/probml/pyprobml/blob/master/scripts/kernelRegressionDemo.py)
```
#@title Click me to run setup { display-mode: "form" }
try:
if PYPROBML_SETUP_ALREADY_RUN:
print('skipping setup')
except:
PYPROBML_SETUP_ALREADY_RUN = True
print('running setup...')
!git clone https://github.com/probml/pyprobml /pyprobml &> /dev/null
%cd -q /pyprobml/scripts
import pyprobml_utils as pml
import colab_utils
import os
os.environ["PYPROBML"] = ".." # one above current scripts directory
import google.colab
from google.colab.patches import cv2_imshow
%reload_ext autoreload
%autoreload 2
def show_image(img_path,size=None,ratio=None):
img = colab_utils.image_resize(img_path, size)
cv2_imshow(img)
print('finished!')
google.colab.files.view("./kernelRegressionDemo.py")
%run kernelRegressionDemo.py
```
## References:
<a name='Duda01'>[DHS01]</a> R. O. Duda, P. E. Hart and D. G. Stork. "Pattern Classification". (2001).
<a name='HastieBook'>[HTF09]</a> T. Hastie, R. Tibshirani and J. Friedman. "The Elements of Statistical Learning". (2009).
<a name='Kaya2019'>[MH19]</a> K. Mahmut and B. HasanSakir. "Deep Metric Learning: A Survey". In: Symmetry (2019).
<a name='Der2012'>[ML12]</a> D. Matthew and S. LawrenceK. "Latent Coincidence Analysis: A Hidden Variable Model forDistance Metric Learning". (2012).
<a name='Do2019cvpr'>[Tha+19]</a> D. Thanh-Toan, T. Toan, R. Ian, K. Vijay, H. Tuan and C. Gustavo. "A Theoretically Sound Upper Bound on the Triplet Loss forImproving the Efficiency of Deep Distance Metric Learning". (2019).
| github_jupyter |
# MNIST Classification
In this lesson we discuss in how to create a simple IPython Notebook to solve
an image classification problem. MNIST contains a set of pictures
## Import Libraries
Note: https://python-future.org/quickstart.html
```
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
from keras.utils import to_categorical, plot_model
from keras.datasets import mnist
```
## Warm Up Exercise
## Pre-process data
### Load data
First we load the data from the inbuilt mnist dataset from Keras
Here we have to split the data set into training and testing data.
The training data or testing data has two components.
Training features and training labels.
For instance every sample in the dataset has a corresponding label.
In Mnist the training sample contains image data represented in terms of
an array. The training labels are from 0-9.
Here we say x_train for training data features and y_train as the training labels. Same goes for testing data.
```
(x_train, y_train), (x_test, y_test) = mnist.load_data()
```
### Identify Number of Classes
As this is a number classification problem. We need to know how many classes are there.
So we'll count the number of unique labels.
```
num_labels = len(np.unique(y_train))
num_labels
```
### Convert Labels To One-Hot Vector
Read more on one-hot vector.
```
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
```
## Image Reshaping
The training model is designed by considering the data as a vector.
This is a model dependent modification. Here we assume the image is
a squared shape image.
```
image_size = x_train.shape[1]
input_size = image_size * image_size
```
## Resize and Normalize
The next step is to continue the reshaping to a fit into a vector
and normalize the data. Image values are from 0 - 255, so an
easy way to normalize is to divide by the maximum value.
```
x_train = np.reshape(x_train, [-1, input_size])
x_train = x_train.astype('float32') / 255
x_test = np.reshape(x_test, [-1, input_size])
x_test = x_test.astype('float32') / 255
```
## Create a Keras Model
Keras is a neural network library. The summary function provides tabular summary on the model you created. And the plot_model function provides a grpah on the network you created.
```
# Create Model
# network parameters
batch_size = 4
hidden_units = 64
model = Sequential()
model.add(Dense(hidden_units, input_dim=input_size))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.summary()
plot_model(model, to_file='mlp-mnist.png', show_shapes=True)
```
## Compile and Train
A keras model need to be compiled before it can be used to train
the model. In the compile function, you can provide the optimization
that you want to add, metrics you expect and the type of loss function
you need to use.
Here we use adam optimizer, a famous optimizer used in neural networks.
The loss funtion we have used is the categorical_crossentropy.
Once the model is compiled, then the fit function is called upon passing the number of epochs, traing data and batch size.
The batch size determines the number of elements used per minibatch in optimizing the function.
**Note: Change the number of epochs, batch size and see what happens.**
```
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=3, batch_size=batch_size)
```
## Testing
Now we can test the trained model. Use the evaluate function by passing
test data and batch size and the accuracy and the loss value can be retrieved.
**MNIST_V1.0|Exercise: Try to observe the network behavior by changing the number of epochs, batch size and record the best accuracy that you can gain. Here you can record what happens when you change these values. Describe your observations in 50-100 words.**
```
loss, acc = model.evaluate(x_test, y_test, batch_size=batch_size)
print("\nTest accuracy: %.1f%%" % (100.0 * acc))
```
## Final Note
This programme can be defined as a hello world programme in deep
learning. Objective of this exercise is not to teach you the depths of
deep learning. But to teach you basic concepts that may need to design a
simple network to solve a problem. Before running the whole code, read
all the instructions before a code section.
## Homework
**Solve Exercise MNIST_V1.0.**
### Reference:
[Orignal Source to Source Code](https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Keras)
| github_jupyter |
<a id="introduction"></a>
## Introduction to RAPIDS
#### By Paul Hendricks
-------
While the world’s data doubles each year, CPU computing has hit a brick wall with the end of Moore’s law. For the same reasons, scientific computing and deep learning has turned to NVIDIA GPU acceleration, data analytics and machine learning where GPU acceleration is ideal.
NVIDIA created RAPIDS – an open-source data analytics and machine learning acceleration platform that leverages GPUs to accelerate computations. RAPIDS is based on Python, has Pandas-like and Scikit-Learn-like interfaces, is built on Apache Arrow in-memory data format, and can scale from 1 to multi-GPU to multi-nodes. RAPIDS integrates easily into the world’s most popular data science Python-based workflows. RAPIDS accelerates data science end-to-end – from data prep, to machine learning, to deep learning. And through Arrow, Spark users can easily move data into the RAPIDS platform for acceleration.
In this notebook, we will discuss and show at a high level what each of the packages in the RAPIDS are as well as what they do. Subsequent notebooks will dive deeper into the various areas of data science and machine learning and show how you can use RAPIDS to accelerate your workflow in each of these areas.
**Table of Contents**
* [Introduction to RAPIDS](#introduction)
* [Setup](#setup)
* [Pandas](#pandas)
* [cuDF](#cudf)
* [Scikit-Learn](#scikitlearn)
* [cuML](#cuml)
* [Dask](#dask)
* [Dask cuDF](#daskcudf)
* [Conclusion](#conclusion)
Before going any further, let's make sure we have access to `matplotlib`, a popular Python library for visualizing data. The Conda install of RAPIDS no longer includes it by default, but the Docker install does.
```
import os
try:
import matplotlib
except ModuleNotFoundError:
os.system('conda install -y -c conda-forge matplotlib')
import matplotlib
```
<a id="setup"></a>
## Setup
This notebook was tested using the `rapidsai/rapidsai-core-dev-nightly:22.04-cuda11.5-devel-ubuntu20.04-py3.9` container from [DockerHub](https://hub.docker.com/r/rapidsai/rapidsai-core-dev-nightly) and run on the NVIDIA GV100 GPU. Please be aware that your system may be different and you may need to modify the code or install packages to run the below examples.
If you think you have found a bug or an error, please file an issue here: https://github.com/rapidsai-community/notebooks-contrib/issues
Before we begin, let's check out our hardware setup by running the `nvidia-smi` command.
```
!nvidia-smi
```
Next, let's see what CUDA version we have. If it's not found, that's okay, you may not have nvcc or be in a Docker container.
```
!nvcc --version
```
Next, let's load some helper functions from `matplotlib` and configure the Jupyter Notebook for visualization.
```
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
%matplotlib inline
```
Let's see how much GPU memory is available. Since this is a tutorial, we want to keep that data as big as possible without you running out of memory (OOM).
```
import pynvml
pynvml.nvmlInit()
gpu_mem = round(pynvml.nvmlDeviceGetMemoryInfo(pynvml.nvmlDeviceGetHandleByIndex(0)).total/1024**3)
print("your GPU has", gpu_mem, "GB")
```
<a id="pandas"></a>
## Pandas
Data scientists typically work with two types of data: unstructured and structured. Unstructured data often comes in the form of text, images, or videos. Structured data - as the name suggests - comes in a structured form, often represented by a table or CSV. We'll focus the majority of these tutorials on working with these types of data.
There exist many tools in the Python ecosystem for working with structured, tabular data but few are as widely used as Pandas. Pandas represents data in a table and allows a data scientist to manipulate the data to perform a number of useful operations such as filtering, transforming, aggregating, merging, visualizing and many more.
For more information on Pandas, check out the excellent documentation: http://pandas.pydata.org/pandas-docs/stable/
Below we show how to create a Pandas DataFrame, an internal object for representing tabular data.
```
import pandas as pd; print('Pandas Version:', pd.__version__)
# here we create a Pandas DataFrame with
# two columns named "key" and "value"
df = pd.DataFrame()
df['key'] = [0, 0, 2, 2, 3]
df['value'] = [float(i + 10) for i in range(5)]
print(df)
```
We can perform many operations on this data. For example, let's say we wanted to sum all values in the in the `value` column. We could accomplish this using the following syntax:
```
aggregation = df['value'].sum()
print(aggregation)
```
<a id="cudf"></a>
## cuDF
Pandas is fantastic for working with small datasets that fit into your system's memory. However, datasets are growing larger and data scientists are working with increasingly complex workloads - the need for accelerated compute arises.
cuDF is a package within the RAPIDS ecosystem that allows data scientists to easily migrate their existing Pandas workflows from CPU to GPU, where computations can leverage the immense parallelization that GPUs provide.
Below, we show how to create a cuDF DataFrame.
```
import cudf; print('cuDF Version:', cudf.__version__)
# here we create a cuDF DataFrame with
# two columns named "key" and "value"
df = cudf.DataFrame()
df['key'] = [0, 0, 2, 2, 3]
df['value'] = [float(i + 10) for i in range(5)]
print(df)
```
As before, we can take this cuDF DataFrame and perform a `sum` operation over the `value` column. The key difference is that any operations we perform using cuDF use the GPU instead of the CPU.
```
aggregation = df['value'].sum()
print(aggregation)
```
Note how the syntax for both creating and manipulating a cuDF DataFrame is identical to the syntax necessary to create and manipulate Pandas DataFrames; the cuDF API is based on the Pandas API. This design choice minimizes the cognitive burden of switching from a CPU based workflow to a GPU based workflow and allows data scientists to focus on solving problems while benefitting from the speed of a GPU!
<a id="scikitlearn"></a>
## Scikit-Learn
After our data has been preprocessed, we often want to build a model so as to understand the relationships between different variables in our data. Scikit-Learn is an incredibly powerful toolkit that allows data scientists to quickly build models from their data. Below we show a simple example of how to create a Linear Regression model.
```
import numpy as np; print('NumPy Version:', np.__version__)
# create the relationship: y = 2.0 * x + 1.0
if(gpu_mem <= 16):
n_rows = 35000 # let's use 35 thousand data points. Very small GPU memory sizes will require you to reduce this number further
elif(gpu_mem > 17):
n_rows = 100000 # let's use 100 thousand data points
w = 2.0
x = np.random.normal(loc=0, scale=1, size=(n_rows,))
b = 1.0
y = w * x + b
# add a bit of noise
noise = np.random.normal(loc=0, scale=2, size=(n_rows,))
y_noisy = y + noise
```
We can now visualize our data using the `matplotlib` library.
```
plt.scatter(x, y_noisy, label='empirical data points')
plt.plot(x, y, color='black', label='true relationship')
plt.legend()
```
We'll use the `LinearRegression` class from Scikit-Learn to instantiate a model and fit it to our data.
```
import sklearn; print('Scikit-Learn Version:', sklearn.__version__)
from sklearn.linear_model import LinearRegression
# instantiate and fit model
linear_regression = LinearRegression()
%%time
linear_regression.fit(np.expand_dims(x, 1), y)
# create new data and perform inference
inputs = np.linspace(start=-5, stop=5, num=1000)
outputs = linear_regression.predict(np.expand_dims(inputs, 1))
```
Let's now visualize our empirical data points, the true relationship of the data, and the relationship estimated by the model. Looks pretty close!
```
plt.scatter(x, y_noisy, label='empirical data points')
plt.plot(x, y, color='black', label='true relationship')
plt.plot(inputs, outputs, color='red', label='predicted relationship (cpu)')
plt.legend()
```
<a id="cuml"></a>
## cuML
The mathematical operations underlying many machine learning algorithms are often matrix multiplications. These types of operations are highly parallelizable and can be greatly accelerated using a GPU. cuML makes it easy to build machine learning models in an accelerated fashion while still using an interface nearly identical to Scikit-Learn. The below shows how to accomplish the same Linear Regression model but on a GPU.
First, let's convert our data from a NumPy representation to a cuDF representation.
```
# create a cuDF DataFrame
df = cudf.DataFrame({'x': x, 'y': y_noisy})
print(df.head())
```
Next, we'll load the GPU accelerated `LinearRegression` class from cuML, instantiate it, and fit it to our data.
```
import cuml; print('cuML Version:', cuml.__version__)
from cuml.linear_model import LinearRegression as LinearRegression_GPU
# instantiate and fit model
linear_regression_gpu = LinearRegression_GPU()
%%time
linear_regression_gpu.fit(df[['x']], df['y'])
```
We can use this model to predict values for new data points, a step often called "inference" or "scoring". All model fitting and predicting steps are GPU accelerated.
```
# create new data and perform inference
new_data_df = cudf.DataFrame({'inputs': inputs})
outputs_gpu = linear_regression_gpu.predict(new_data_df[['inputs']])
```
Lastly, we can overlay our predicted relationship using our GPU accelerated Linear Regression model (green line) over our empirical data points (light blue circles), the true relationship (blue line), and the predicted relationship from a model built on the CPU (red line). We see that our GPU accelerated model's estimate of the true relationship (green line) is identical to the CPU based model's estimate of the true relationship (red line)!
```
plt.scatter(x, y_noisy, label='empirical data points')
plt.plot(x, y, color='black', label='true relationship')
plt.plot(inputs, outputs, color='red', label='predicted relationship (cpu)')
plt.plot(inputs, outputs_gpu.to_numpy(), color='green', label='predicted relationship (gpu)')
plt.legend()
```
<a id="dask"></a>
## Dask
Dask is a library the allows facillitates distributed computing. Written in Python, it allows one to compose complex workflows using basic Python primitives like integers or strings as well as large data structures like those found in NumPy, Pandas, and cuDF. In the following examples and notebooks, we'll show how to use Dask with cuDF to accelerate common ETL tasks and train machine learning models like Linear Regression and XGBoost.
To learn more about Dask, check out the documentation here: http://docs.dask.org/en/latest/
#### Client/Workers
Dask operates by creating a cluster composed of a "client" and multiple "workers". The client is responsible for scheduling work; the workers are responsible for actually executing that work.
Typically, we set the number of workers to be equal to the number of computing resources we have available to us. For CPU based workflows, this might be the number of cores or threads on that particlular machine. For example, we might set `n_workers = 8` if we have 8 CPU cores or threads on our machine that can each operate in parallel. This allows us to take advantage of all of our computing resources and enjoy the most benefits from parallelization.
To get started, we'll create a local cluster of workers and client to interact with that cluster.
```
import dask; print('Dask Version:', dask.__version__)
from dask.distributed import Client, LocalCluster
# create a local cluster with 4 workers
n_workers = 4
cluster = LocalCluster(n_workers=n_workers)
client = Client(cluster)
```
Let's inspect the `client` object to view our current Dask status. We should see the IP Address for our Scheduler as well as the the number of workers in our Cluster.
```
# show current Dask status
client
```
You can also see the status and more information at the Dashboard, found at `http://<ip_address>/status`. You can ignore this for now, we'll dive into this in subsequent tutorials.
With our client and cluster of workers setup, it's time to execute our first distributed program. We'll define a function called `sleep_1` that sleeps for 1 second and returns the string "Success!". Executed in serial four times, this function should take around 4 seconds to execute.
```
import time
def sleep_1():
time.sleep(1)
return 'Success!'
%%time
for _ in range(n_workers):
sleep_1()
```
As expected, our workflow takes about 4 seconds to run. Now let's execute this same workflow in distributed fashion using Dask.
```
from dask.delayed import delayed
%%time
# define delayed execution graph
sleep_operations = [delayed(sleep_1)() for _ in range(n_workers)]
# use client to perform computations using execution graph
sleep_futures = client.compute(sleep_operations, optimize_graph=False, fifo_timeout="0ms")
# collect and print results
sleep_results = client.gather(sleep_futures)
print(sleep_results)
```
Using Dask, we see that this whole workflow takes a little over a second - each worker is truly executing in parallel!
<a id="daskcudf"></a>
## Dask cuDF
In the previous example, we saw how we can use Dask with very basic objects to compose a graph that can be executed in a distributed fashion. However, we aren't limited to basic data types though.
We can use Dask with objects such as Pandas DataFrames, NumPy arrays, and cuDF DataFrames to compose more complex workflows. With larger amounts of data and embarrasingly parallel algorithms, Dask allows us to scale ETL and Machine Learning workflows to Gigabytes or Terabytes of data. In the below example, we show how we can process 100 million rows by combining cuDF with Dask.
Before we start working with cuDF DataFrames with Dask, we need to setup a Local CUDA Cluster and Client to work with our GPUs. This is very similar to how we setup a Local Cluster and Client in vanilla Dask.
```
import dask; print('Dask Version:', dask.__version__)
from dask.distributed import Client
# import dask_cuda; print('Dask CUDA Version:', dask_cuda.__version__)
from dask_cuda import LocalCUDACluster
# create a local CUDA cluster
cluster = LocalCUDACluster()
client = Client(cluster)
```
Let's inspect our `client` object:
```
client
```
As before, you can also see the status of the Client along with information on the Scheduler and Dashboard.
With our client and workers setup, let's create our first distributed cuDF DataFrame using Dask. We'll instantiate our cuDF DataFrame in the same manner as the previous sections but instead we'll use significantly more data. Lastly, we'll pass the cuDF DataFrame to `dask_cudf.from_cudf` and create an object of type `dask_cudf.core.DataFrame`.
```
import dask_cudf; print('Dask cuDF Version:', dask_cudf.__version__)
# identify number of workers
workers = client.has_what().keys()
n_workers = len(workers)
# create a cuDF DataFrame with two columns named "key" and "value"
df = cudf.DataFrame()
n_rows = 100000000 # let's process 100 million rows in a distributed parallel fashion
df['key'] = np.random.binomial(1, 0.2, size=(n_rows))
df['value'] = np.random.normal(size=(n_rows))
# create a distributed cuDF DataFrame using Dask
distributed_df = dask_cudf.from_cudf(df, npartitions=n_workers)
# inspect our distributed cuDF DataFrame using Dask
print('-' * 15)
print('Type of our Dask cuDF DataFrame:', type(distributed_df))
print('-' * 15)
print(distributed_df.head())
```
The above output shows the first several rows of our distributed cuDF DataFrame.
With our Dask cuDF DataFrame defined, we can now perform the same `sum` operation as we did with our cuDF DataFrame. The key difference is that this operation is now distributed - meaning we can perform this operation using multiple GPUs or even multiple nodes, each of which may have multiple GPUs. This allows us to scale to larger and larger amounts of data!
```
aggregation = distributed_df['value'].sum()
print(aggregation.compute())
```
<a id="conclusion"></a>
## Conclusion
In this notebook, we showed at a high level what each of the packages in the RAPIDS are as well as what they do.
To learn more about RAPIDS, be sure to check out:
* [Open Source Website](http://rapids.ai)
* [GitHub](https://github.com/rapidsai/)
* [Press Release](https://nvidianews.nvidia.com/news/nvidia-introduces-rapids-open-source-gpu-acceleration-platform-for-large-scale-data-analytics-and-machine-learning)
* [NVIDIA Blog](https://blogs.nvidia.com/blog/2018/10/10/rapids-data-science-open-source-community/)
* [Developer Blog](https://devblogs.nvidia.com/gpu-accelerated-analytics-rapids/)
* [NVIDIA Data Science Webpage](https://www.nvidia.com/en-us/deep-learning-ai/solutions/data-science/)
| github_jupyter |
[Multiply Strings](https://leetcode.com/problems/multiply-strings/)。给两个合法字符串表示的整数,对它们做乘法。
思路:大数相乘,只能由低往高逐位相乘然后错位相加。$m$位的数字与$n$位的数字相乘的结果是$m+n$位,设立一个$m+n$位的res数组,对应位的初始值为$0$,由低往高遍历两个数字的位数,相乘的结果加到res数组的对应位上去,超过$9$时需要进位。
```
def multiply(num1: str, num2: str) -> str:
# 为了便于由低往高位计算,先反转
num1 = num1[::-1]
num2 = num2[::-1]
m, n = len(num1), len(num2)
res = [0 for _ in range(m+n)]
for idx1 in range(m):
for idx2 in range(n):
cur_idx = idx1+idx2
# ord('0')=48. 该位值加上两位相乘的结果
res[cur_idx] += (ord(num1[idx1])-48)*(ord(num2[idx2])-48)
# 大于9才需要进位
if res[cur_idx] > 9:
res[cur_idx+1] += res[cur_idx]//10
res[cur_idx] = res[cur_idx] % 10
res = res[::-1]
# 去除首位的0
while res[0] == 0 and len(res) > 1:
del res[0]
return ''.join(map(str, res))
```
[Plus One](https://leetcode.com/problems/plus-one/)。给定一个正整数数组,每个元素的范围为$[0,9]$,表示一个正整数,在其表示的正整数上加$1$,同样返回一个数组。
思路:首先在最低位$+1$,然后由低往高循环判断是否需要进位。如果在最高位产生进位的话,还需要增长数组的长度。
```
def plusOne(digits):
n = len(digits)
digits[-1] += 1 # +1
# 开始进位
i = n-1
while i >= 0:
if digits[i] < 10:
return digits
else:
if i == 0: # 如果在最高位产生了进位,说明数组需要变长
digits.insert(0, 0)
i += 1
digits[i-1] += digits[i]//10
digits[i] = digits[i] % 10
i -= 1
return digits
```
[Length of Last Word](https://leetcode.com/problems/length-of-last-word/)。给定一个只包含空格与字母的字符串,求最后一个单词的长度。
思路:首要任务是找到最后一个单词的位置,可以由后往前遍历,遇到第一个非空格字符就记录下位置,
```
def lengthOfLastWord(s: str) -> int:
word_start = None
for idx, ch in enumerate(s[::-1]):
if word_start is None and ch != ' ': # 这里不能用not wordstart来判断,因为wordstart可能是0
word_start = idx
elif word_start is not None and ch == ' ':
return idx-word_start
# 如果扫描完还没返回,只有两种情况,一是全空格,二是只有一个单词
return idx-word_start+1 if word_start is not None else 0
```
[Simplify Path](https://leetcode.com/problems/simplify-path/)。给定一个系统路径,将其简化。
思路:使用一个栈。把原字串按'/'分割,提取出所有的位置。如果位置是'.',表示当前目录,忽略即可;如果是'..',说明返回上级目录,那么需要弹栈;其他情况是进入下级目录,压入栈即可。
```
def simplifyPath(path: str) -> str:
res = '/'
if not path:
return res
s = list()
for loc in path.split('/'):
if loc == '': # str.split()方法会产生空字符
continue
if loc == '..':
if s:
s.pop()
elif loc == '.':
continue
else:
s.append(loc)
return res+'/'.join(s) if s else res
```
[Compare Version Numbers](https://leetcode.com/problems/compare-version-numbers/)。给定一个版本号字符串,比较两版本号的大小。
思路:把版本字串按'.'分割,对每一字段做整形转换。由高位往低位逐位比较,当其中一个版本号字段较少时,默认设为$0$。
```
def compareVersion(version1: str, version2: str) -> int:
v1 = list(map(int, version1.split('.')))
v2 = list(map(int, version2.split('.')))
v1 += [0 for _ in range(len(v2)-len(v1))]
v2 += [0 for _ in range(len(v1)-len(v2))]
for i in range(len(v1)):
if v1[i] > v2[i]:
return 1
elif v1[i] < v2[i]:
return -1
else:
continue
return 0
```
[Reverse Vowels of a String](https://leetcode.com/problems/reverse-vowels-of-a-string/)。给一个字串,对其中的元音字母做翻转。
思路:双指针,从前往后找一个元音字母,由后往前找一个元音字母,交换。
```
def reverseVowels(s: str) -> str:
s = list(s)
vows = ('a', 'e', 'i', 'o', 'u', 'A', 'E', 'I', 'O', 'U')
start, end = 0, len(s)-1
while start < end:
while start < end and s[start] not in vows:
start += 1
while start < end and s[end] not in vows:
end -= 1
s[start], s[end] = s[end], s[start]
start += 1
end -= 1
return ''.join(s)
```
[Mini Parser](https://leetcode.com/problems/mini-parser/)。给定一个嵌套整形列表的字串,如'[123,[456,[789]]]',将其解析成整形列表。
思路:递归。使用一个变量记录层级,在同一层级遇到嵌套列表时,使用递归。类似于在句子中找单词一样,需要设立一个变量记录元素的起始位置,当遇到','或扫描到末尾时,说明找到一个同级元素。而层级关系可以通过'['和']'来记录。
```
def deserialize(s: str):
if s[0] != '[': # 如果不是列表,则一定是单个整数
return NestedInteger(int(s))
if len(s) < 3: # 如果长度小于等于2,一定是空列表
return NestedInteger()
res = NestedInteger()
item_start = 1 # 同一级别元素的起始位置
level = 0 # 级别,0表示同级
for i in range(1, len(s)): # 从第二个字符开始遍历,找同级元素
if level == 0 and (s[i] == ',' or i == len(s)-1): # 同一层级的元素
res.add(deserialize(s[item_start:i]))
item_start = i+1 # 更新起始位置
elif s[i] == '[': # 遇到左括号层级+1
level += 1
elif s[i] == ']': # 右括号层级-1
level -= 1
return res
```
[Repeated Substring Pattern](https://leetcode.com/problems/repeated-substring-pattern/)。判断一个字串是否可由一个模式重复多次来生成。
思路:若一个字串包含某种模式pattern,那该pattern至少重复两次。原字串的首字符为pattern的首字符,原字串的尾字符为pattern的尾字符。将原字串加倍,设为$2s$,如果其包含pattern的话,其至少可以写成$4p$,去掉首尾字符,可以写成$2p$,然后在该字串中寻找原字串。
```
def repeatedSubstringPattern(s: str) -> bool:
return s in (s+s)[1:-1]
```
[Validate IP Address](https://leetcode.com/problems/validate-ip-address/)。判断IP地址的有效性。
思路:纯逻辑实现题,需要考虑各种不规范输入。
```
def validIPAddress(IP: str) -> str:
def isIPv4(s):
s = s.split('.')
if not all(map(lambda x: x.isdigit(), IP.split('.'))) or len(s) != 4:
return False
nums = list(map(int, s))
for i in range(4):
if str(nums[i]) != s[i] or nums[i] > 255:
return False
return True
def isIPv6(s):
s = s.split(':')
if len(s) != 8:
return False
for i in range(8):
if len(s[i]) > 4 or len(s[i]) < 1:
return False
else:
for ch in s[i]:
# ord('0')=48, ord('9')=57, ord('A')=65, ord('F')=70,ord('a')=97, ord('f')=102
if ord(ch) < 48 or 57 < ord(ch) < 65 or 70 < ord(ch) < 97 or ord(ch) > 102:
return False
return True
if '.' in IP:
res = "IPv4" if isIPv4(IP) else "Neither"
else:
res = 'IPv6' if isIPv6(IP) else "Neither"
return res
```
[Detect Capital](https://leetcode.com/problems/detect-capital/)。判别一个单词是否正确使用了大写规则,合法的大写规则有三种:只有首字母大写,全部字母大写和全部字母小写。
思路:当首字母与第二字母均大写时,后面字母必须全部大写;当首字母与第二字母均小写时,后面字母必须全部小写;当首字母大写第二字母小写时,后面字母必须全部小写。
```
# ord('A')=65, ord('Z')=90, ord('a')=97, ord('z')=122
def detectCapitalUse(word: str) -> bool:
if len(word) < 2:
return True
def isUpper(ch):
return 65 <= ord(ch) <= 90
def isLower(ch):
return 97 <= ord(ch) <= 122
if isUpper(word[0]):
if isUpper(word[1]):
return all(map(isUpper, word[2:]))
else:
return all(map(isLower, word[2:]))
else:
return all(map(isLower, word[1:]))
```
[Longest Uncommon Subsequence I](https://leetcode.com/problems/longest-uncommon-subsequence-i/)。最长非公共子序列。
思路:注意,是求非公共子序列。若两字串不相等,那么较长的那一个字串即是最长非公共子序列;若两字串相等,则不存在非公共子序列,即$-1$。
```
def findLUSlength(a: str, b: str) -> int:
return max(len(a),len(b)) if a!=b else -1
```
[Longest Uncommon Subsequence II](https://leetcode.com/problems/longest-uncommon-subsequence-ii/)。给若干个字串,找出它们的最长非公共子序列。
思路:由上题应该就知道,字串们的最长非公共子序列要么不存在,要么一定是字串中的某一个。在对字串做两两比较时,长的字串是LUS,但是短的不是。将字串数组中所有字串都轮流取出来与其他所有字串比较,只要其不是某个长字串的子序列,就可以成为候选LUS,记录最大长度即可。所以关键在于判断子序列。
```
def findLUSlength(strs) -> int:
strs.sort(key=len, reverse=True)
res = -1
def isSub(s1, s2):
'''
判断s1是不是s2的一个子序列,len(s1)<=len(s2)
'''
i = 0
for ch in s2:
if ch == s1[i]:
i += 1
if i == len(s1):
return True
return False
for i in range(len(strs)): # 选出的字串
for j in range(len(strs)): # 比较的字串
if i != j and isSub(strs[i], strs[j]):
break
if j == len(strs)-1:
res = max(res, len(strs[i]))
return res
```
[Complex Number Multiplication](https://leetcode.com/problems/complex-number-multiplication/)。虚数乘法,给两个字符串形式的虚数,返回相乘结果。
思路:$(a+bi)\times{c+di}=ac-bd+(ad+bc)i$
```
def complexNumberMultiply(num1: str, num2: str) -> str:
a, b = num1.split('+')
a, b = int(a), int(b[:-1])
c, d = num2.split('+')
c, d = int(c), int(d[:-1])
real = a*c-b*d
img = a*d+b*c
return str(real)+'+'+str(img)+'i'
```
[Minimum Time Difference](https://leetcode.com/problems/minimum-time-difference/)。给定一系列时钟值,求这一系列时间值之间的最小时差,以分钟为单位。
思路:首先将字串转成整形格式,排序后逐个相减,首位相减时要注意隔天。
```
def findMinDifference(timePoints) -> int:
mpd = 24*60 # min_per_day
def str2min(s):
h, m = s.split(':')
return int(h)*60+int(m)
mins = sorted(list(map(str2min, timePoints)))
res = mpd
for i in range(len(mins)-1):
res = min(res, abs(mins[i+1]-mins[i]))
res = min(res, abs(mins[0]+mpd-mins[-1]))
return res
```
[Reverse String II](https://leetcode.com/problems/reverse-string-ii/)。给一字符串与一整数$k$,以$k$为周期做如下操作:翻转,不翻转,翻转,……。
思路:设立一个周期指针$p$,指针移动的步长为$k$。在设立一个翻转标志位,$p$每移动一次就翻转标志位。
```
def reverseStr(s: str, k: int) -> str:
flag = 1 # 翻转flag
p = 0
s = list(s) # 转成列表便于翻转
def reverse(l):
return l[::-1]
while p*k < len(s):
if flag:
s[p*k:(p+1)*k] = s[p*k:(p+1)*k][::-1]
p += 1
flag ^= 1 # 转置flag
return ''.join(s)
```
[Valid Parenthesis String](https://leetcode.com/problems/valid-parenthesis-string/)。一字串只有三种模式:'('、')'和'\*'。其中'\*'号可以替换成任意字符甚至空字符,判断该字串是否合法。
思路:因为'\*'号可以替换任意字符,所以在遇到')'时,优先使用'('去做抵消,不存在'('才使用'\*'去抵消。这样一轮扫描后,若还剩下')'则直接返回false,否则只会剩下'('和'\*'。然后'('和'\*'的抵消规则如下,只有位于'('后面的'\*'才能抵消一个'('。所以维护两个数组```left_brackets```和```starts```,其分别记录字串中'('和'\*'的位置。
```
def checkValidString(s: str) -> bool:
left_brackets, starts = list(), list()
# 消灭右括号
for idx, ch in enumerate(s):
if ch == '(':
left_brackets.append(idx)
elif ch == '*':
starts.append(idx)
else:
if left_brackets:
left_brackets.pop()
elif starts:
starts.pop()
else:
return False
# 消灭左括号
while left_brackets:
if not starts or starts[-1] < left_brackets[-1]:
return False
else:
starts.pop()
left_brackets.pop()
return True
```
[Count Binary Substrings](https://leetcode.com/problems/count-binary-substrings/)。给一串'01'字串求出其中有多少个'0'的数量等于'1'的数量、且'0'挨在一起并且'1'也挨在一起的子串。
思路:该题跟找回文串的思路很类似,都是从中心往外扩展的思路。由题意合法的子串长度肯定是偶数,那么先找到一个最小的核心'01'或'10',然后往左右扩展。
```
def countBinarySubstrings(s: str) -> int:
n = len(s)
res = 0
if n < 2:
return res
def expand(left, right):
nonlocal res
while left >= 0 and right < n and s[left] == s[left+1] and s[right] == s[right-1]:
res += 1
left -= 1
right += 1
for i in range(n-1):
if s[i] != s[i+1]:
res += 1
expand(i-1, i+2)
return res
```
[Ambiguous Coordinates](https://leetcode.com/problems/ambiguous-coordinates/)。给一带括号的字符串,给其加上逗号与小数点构成坐标形式,求所有可能的合法坐标。如'0.0'、'00'、'1.0'或'01'这种数字都是不合法的。
思路:要构成坐标,至少得两个数字,且答案中有且只能有一个逗号,能否加小数点需要看横纵坐标数字的位数,该题难点就在这里。编写一个函数,专门用于将字串转换成合法的(带小数点的)数字即可。主要需要考虑各种非法情况:
- 单字符直接返回;
- 首尾都是0,返回空;
- 首字符是0,小数点只能加在首位后面;
- 尾字符是0,不能加小数点
```
def ambiguousCoordinates(S: str):
S = S[1:-1]
res = list()
if len(S) < 2:
return res
def func(string):
if len(string) == 1: # 单字符无法加小数点
return [string]
elif string[0] == '0' and string[-1] == '0': # 首尾都是0,非法
return list()
elif string[0] == '0': # 首是0,小数点只能加在最前面
return ['0.{}'.format(string[1:])]
elif string[-1] == '0': # 尾是0,无法加小数点
return [string]
else:
res = [string] # 自身肯定是合法的数
for i in range(1, len(string)):
res.append('{}.{}'.format(string[:i], string[i:]))
return res
n = len(S)
res = list()
for comma_idx in range(1, n):
xs, ys = func(S[:comma_idx]), func(S[comma_idx:])
for x in xs:
for y in ys:
res.append('({}, {})'.format(x, y))
return res
```
| github_jupyter |
```
import torch
import torch.utils.data
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import numpy as np
import h5py
from data_utils import get_data
import matplotlib.pyplot as plt
from solver_pytorch import Solver
# Load data from all .mat files, combine them, eliminate EOG signals, shuffle and
# seperate training data, validation data and testing data.
# Also do mean subtraction on x.
data = get_data('../project_datasets',num_validation=100, num_test=100)
for k in data.keys():
print('{}: {} '.format(k, data[k].shape))
# class flatten to connect to FC layer
class Flatten(nn.Module):
def forward(self, x):
N, C, H = x.size() # read in N, C, H
return x.view(N, -1)
# turn x and y into torch type tensor
dtype = torch.FloatTensor
X_train = Variable(torch.Tensor(data.get('X_train'))).type(dtype)
y_train = Variable(torch.Tensor(data.get('y_train'))).type(torch.IntTensor)
X_val = Variable(torch.Tensor(data.get('X_val'))).type(dtype)
y_val = Variable(torch.Tensor(data.get('y_val'))).type(torch.IntTensor)
X_test = Variable(torch.Tensor(data.get('X_test'))).type(dtype)
y_test = Variable(torch.Tensor(data.get('y_test'))).type(torch.IntTensor)
# train a 1D convolutional neural network
# optimize hyper parameters
best_model = None
parameters =[] # a list of dictionaries
parameter = {} # a dictionary
best_params = {} # a dictionary
best_val_acc = 0.0
# hyper parameters in model
filter_nums = [30]
filter_sizes = [4]
pool_sizes = [4]
# hyper parameters in solver
batch_sizes = [100]
lrs = [5e-4]
for filter_num in filter_nums:
for filter_size in filter_sizes:
for pool_size in pool_sizes:
linear_size = int((X_test.shape[2]-filter_size)/4)+1
linear_size = int((linear_size-pool_size)/pool_size)+1
linear_size *= filter_num
for batch_size in batch_sizes:
for lr in lrs:
model = nn.Sequential(
nn.Conv1d(22, filter_num, kernel_size=filter_size, stride=4),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.BatchNorm1d(num_features=filter_num),
nn.MaxPool1d(kernel_size=pool_size, stride=pool_size),
Flatten(),
nn.Linear(linear_size, 20),
nn.ReLU(inplace=True),
nn.Linear(20, 4)
)
model.type(dtype)
solver = Solver(model, data,
lr = lr, batch_size=batch_size,
verbose=True, print_every=50)
solver.train()
# save training results and parameters of neural networks
parameter['filter_num'] = filter_num
parameter['filter_size'] = filter_size
parameter['pool_size'] = pool_size
parameter['batch_size'] = batch_size
parameter['lr'] = lr
parameters.append(parameter)
print('Accuracy on the validation set: ', solver.best_val_acc)
print('parameters of the best model:')
print(parameter)
if solver.best_val_acc > best_val_acc:
best_val_acc = solver.best_val_acc
best_model = model
best_solver = solver
best_params = parameter
# Plot the loss function and train / validation accuracies of the best model
plt.subplot(2,1,1)
plt.plot(best_solver.loss_history)
plt.title('Training loss history')
plt.xlabel('Iteration')
plt.ylabel('Training loss')
plt.subplot(2,1,2)
plt.plot(best_solver.train_acc_history, '-o', label='train accuracy')
plt.plot(best_solver.val_acc_history, '-o', label='validation accuracy')
plt.xlabel('Iteration')
plt.ylabel('Accuracies')
plt.legend(loc='upper center', ncol=4)
plt.gcf().set_size_inches(10, 10)
plt.show()
print('Accuracy on the validation set: ', best_val_acc)
print('parameters of the best model:')
print(best_params)
# test set
y_test_pred = model(X_test)
_, y_pred = torch.max(y_test_pred,1)
test_accu = np.mean(y_pred.data.numpy() == y_test.data.numpy())
print('Test accuracy', test_accu, '\n')
```
| github_jupyter |
# Deep Recurrent Q-Network
This notebook provides an example implementation of a Deep Recurrent Q-Network which can solve Partially Observable Markov Decision Processes. To learn more about DRQNs, see my blog post on them here: https://medium.com/p/68463e9aeefc .
For more reinforcment learning tutorials, as well as the additional required `gridworld.py` and `helper.py` see:
https://github.com/awjuliani/DeepRL-Agents
```
import numpy as np
import random
import tensorflow as tf
import matplotlib.pyplot as plt
import scipy.misc
import os
import csv
import itertools
import tensorflow.contrib.slim as slim
%matplotlib inline
from helper import *
```
### Load the game environment
```
from gridworld import gameEnv
```
Feel free to adjust the size of the gridworld. Making it smaller (adjusting `size`) provides an easier task for our DRQN agent, while making the world larger increases the challenge.
Initializing the Gridworld with `True` limits the field of view, resulting in a partially observable MDP. Initializing it with `False` provides the agent with the entire environment, resulting in a fully MDP.
```
env = gameEnv(partial=False,size=9)
env = gameEnv(partial=True,size=9)
```
Above are examples of a starting environment in our simple game. The agent controls the blue square, and can move up, down, left, or right. The goal is to move to the green squares (for +1 reward) and avoid the red squares (for -1 reward). When the agent moves through a green or red square, it is randomly moved to a new place in the environment.
### Implementing the network itself
```
class Qnetwork():
def __init__(self,h_size,rnn_cell,myScope):
#The network recieves a frame from the game, flattened into an array.
#It then resizes it and processes it through four convolutional layers.
self.scalarInput = tf.placeholder(shape=[None,21168],dtype=tf.float32)
self.imageIn = tf.reshape(self.scalarInput,shape=[-1,84,84,3])
self.conv1 = slim.convolution2d( \
inputs=self.imageIn,num_outputs=32,\
kernel_size=[8,8],stride=[4,4],padding='VALID', \
biases_initializer=None,scope=myScope+'_conv1')
self.conv2 = slim.convolution2d( \
inputs=self.conv1,num_outputs=64,\
kernel_size=[4,4],stride=[2,2],padding='VALID', \
biases_initializer=None,scope=myScope+'_conv2')
self.conv3 = slim.convolution2d( \
inputs=self.conv2,num_outputs=64,\
kernel_size=[3,3],stride=[1,1],padding='VALID', \
biases_initializer=None,scope=myScope+'_conv3')
self.conv4 = slim.convolution2d( \
inputs=self.conv3,num_outputs=h_size,\
kernel_size=[7,7],stride=[1,1],padding='VALID', \
biases_initializer=None,scope=myScope+'_conv4')
self.trainLength = tf.placeholder(dtype=tf.int32)
#We take the output from the final convolutional layer and send it to a recurrent layer.
#The input must be reshaped into [batch x trace x units] for rnn processing,
#and then returned to [batch x units] when sent through the upper levles.
self.batch_size = tf.placeholder(dtype=tf.int32,shape=[])
self.convFlat = tf.reshape(slim.flatten(self.conv4),[self.batch_size,self.trainLength,h_size])
self.state_in = rnn_cell.zero_state(self.batch_size, tf.float32)
self.rnn,self.rnn_state = tf.nn.dynamic_rnn(\
inputs=self.convFlat,cell=rnn_cell,dtype=tf.float32,initial_state=self.state_in,scope=myScope+'_rnn')
self.rnn = tf.reshape(self.rnn,shape=[-1,h_size])
#The output from the recurrent player is then split into separate Value and Advantage streams
self.streamA,self.streamV = tf.split(self.rnn,2,1)
self.AW = tf.Variable(tf.random_normal([h_size//2,4]))
self.VW = tf.Variable(tf.random_normal([h_size//2,1]))
self.Advantage = tf.matmul(self.streamA,self.AW)
self.Value = tf.matmul(self.streamV,self.VW)
self.salience = tf.gradients(self.Advantage,self.imageIn)
#Then combine them together to get our final Q-values.
self.Qout = self.Value + tf.subtract(self.Advantage,tf.reduce_mean(self.Advantage,axis=1,keep_dims=True))
self.predict = tf.argmax(self.Qout,1)
#Below we obtain the loss by taking the sum of squares difference between the target and prediction Q values.
self.targetQ = tf.placeholder(shape=[None],dtype=tf.float32)
self.actions = tf.placeholder(shape=[None],dtype=tf.int32)
self.actions_onehot = tf.one_hot(self.actions,4,dtype=tf.float32)
self.Q = tf.reduce_sum(tf.multiply(self.Qout, self.actions_onehot), axis=1)
self.td_error = tf.square(self.targetQ - self.Q)
#In order to only propogate accurate gradients through the network, we will mask the first
#half of the losses for each trace as per Lample & Chatlot 2016
self.maskA = tf.zeros([self.batch_size,self.trainLength//2])
self.maskB = tf.ones([self.batch_size,self.trainLength//2])
self.mask = tf.concat([self.maskA,self.maskB],1)
self.mask = tf.reshape(self.mask,[-1])
self.loss = tf.reduce_mean(self.td_error * self.mask)
self.trainer = tf.train.AdamOptimizer(learning_rate=0.0001)
self.updateModel = self.trainer.minimize(self.loss)
```
### Experience Replay
These classes allow us to store experies and sample then randomly to train the network.
Episode buffer stores experiences for each individal episode.
Experience buffer stores entire episodes of experience, and sample() allows us to get training batches needed from the network.
```
class experience_buffer():
def __init__(self, buffer_size = 1000):
self.buffer = []
self.buffer_size = buffer_size
def add(self,experience):
if len(self.buffer) + 1 >= self.buffer_size:
self.buffer[0:(1+len(self.buffer))-self.buffer_size] = []
self.buffer.append(experience)
def sample(self,batch_size,trace_length):
sampled_episodes = random.sample(self.buffer,batch_size)
sampledTraces = []
for episode in sampled_episodes:
point = np.random.randint(0,len(episode)+1-trace_length)
sampledTraces.append(episode[point:point+trace_length])
sampledTraces = np.array(sampledTraces)
return np.reshape(sampledTraces,[batch_size*trace_length,5])
```
### Training the network
```
#Setting the training parameters
batch_size = 4 #How many experience traces to use for each training step.
trace_length = 8 #How long each experience trace will be when training
update_freq = 5 #How often to perform a training step.
y = .99 #Discount factor on the target Q-values
startE = 1 #Starting chance of random action
endE = 0.1 #Final chance of random action
anneling_steps = 10000 #How many steps of training to reduce startE to endE.
num_episodes = 10000 #How many episodes of game environment to train network with.
pre_train_steps = 10000 #How many steps of random actions before training begins.
load_model = False #Whether to load a saved model.
path = "./drqn" #The path to save our model to.
h_size = 512 #The size of the final convolutional layer before splitting it into Advantage and Value streams.
max_epLength = 50 #The max allowed length of our episode.
time_per_step = 1 #Length of each step used in gif creation
summaryLength = 100 #Number of epidoes to periodically save for analysis
tau = 0.001
tf.reset_default_graph()
#We define the cells for the primary and target q-networks
cell = tf.contrib.rnn.BasicLSTMCell(num_units=h_size,state_is_tuple=True)
cellT = tf.contrib.rnn.BasicLSTMCell(num_units=h_size,state_is_tuple=True)
mainQN = Qnetwork(h_size,cell,'main')
targetQN = Qnetwork(h_size,cellT,'target')
init = tf.global_variables_initializer()
saver = tf.train.Saver(max_to_keep=5)
trainables = tf.trainable_variables()
targetOps = updateTargetGraph(trainables,tau)
myBuffer = experience_buffer()
#Set the rate of random action decrease.
e = startE
stepDrop = (startE - endE)/anneling_steps
#create lists to contain total rewards and steps per episode
jList = []
rList = []
total_steps = 0
#Make a path for our model to be saved in.
if not os.path.exists(path):
os.makedirs(path)
##Write the first line of the master log-file for the Control Center
with open('./Center/log.csv', 'w') as myfile:
wr = csv.writer(myfile, quoting=csv.QUOTE_ALL)
wr.writerow(['Episode','Length','Reward','IMG','LOG','SAL'])
with tf.Session() as sess:
if load_model == True:
print ('Loading Model...')
ckpt = tf.train.get_checkpoint_state(path)
saver.restore(sess,ckpt.model_checkpoint_path)
sess.run(init)
updateTarget(targetOps,sess) #Set the target network to be equal to the primary network.
for i in range(num_episodes):
episodeBuffer = []
#Reset environment and get first new observation
sP = env.reset()
s = processState(sP)
d = False
rAll = 0
j = 0
state = (np.zeros([1,h_size]),np.zeros([1,h_size])) #Reset the recurrent layer's hidden state
#The Q-Network
while j < max_epLength:
j+=1
#Choose an action by greedily (with e chance of random action) from the Q-network
if np.random.rand(1) < e or total_steps < pre_train_steps:
state1 = sess.run(mainQN.rnn_state,\
feed_dict={mainQN.scalarInput:[s/255.0],mainQN.trainLength:1,mainQN.state_in:state,mainQN.batch_size:1})
a = np.random.randint(0,4)
else:
a, state1 = sess.run([mainQN.predict,mainQN.rnn_state],\
feed_dict={mainQN.scalarInput:[s/255.0],mainQN.trainLength:1,mainQN.state_in:state,mainQN.batch_size:1})
a = a[0]
s1P,r,d = env.step(a)
s1 = processState(s1P)
total_steps += 1
episodeBuffer.append(np.reshape(np.array([s,a,r,s1,d]),[1,5]))
if total_steps > pre_train_steps:
if e > endE:
e -= stepDrop
if total_steps % (update_freq) == 0:
updateTarget(targetOps,sess)
#Reset the recurrent layer's hidden state
state_train = (np.zeros([batch_size,h_size]),np.zeros([batch_size,h_size]))
trainBatch = myBuffer.sample(batch_size,trace_length) #Get a random batch of experiences.
#Below we perform the Double-DQN update to the target Q-values
Q1 = sess.run(mainQN.predict,feed_dict={\
mainQN.scalarInput:np.vstack(trainBatch[:,3]/255.0),\
mainQN.trainLength:trace_length,mainQN.state_in:state_train,mainQN.batch_size:batch_size})
Q2 = sess.run(targetQN.Qout,feed_dict={\
targetQN.scalarInput:np.vstack(trainBatch[:,3]/255.0),\
targetQN.trainLength:trace_length,targetQN.state_in:state_train,targetQN.batch_size:batch_size})
end_multiplier = -(trainBatch[:,4] - 1)
doubleQ = Q2[range(batch_size*trace_length),Q1]
targetQ = trainBatch[:,2] + (y*doubleQ * end_multiplier)
#Update the network with our target values.
sess.run(mainQN.updateModel, \
feed_dict={mainQN.scalarInput:np.vstack(trainBatch[:,0]/255.0),mainQN.targetQ:targetQ,\
mainQN.actions:trainBatch[:,1],mainQN.trainLength:trace_length,\
mainQN.state_in:state_train,mainQN.batch_size:batch_size})
rAll += r
s = s1
sP = s1P
state = state1
if d == True:
break
#Add the episode to the experience buffer
bufferArray = np.array(episodeBuffer)
episodeBuffer = list(zip(bufferArray))
myBuffer.add(episodeBuffer)
jList.append(j)
rList.append(rAll)
#Periodically save the model.
if i % 1000 == 0 and i != 0:
saver.save(sess,path+'/model-'+str(i)+'.cptk')
print ("Saved Model")
if len(rList) % summaryLength == 0 and len(rList) != 0:
print (total_steps,np.mean(rList[-summaryLength:]), e)
saveToCenter(i,rList,jList,np.reshape(np.array(episodeBuffer),[len(episodeBuffer),5]),\
summaryLength,h_size,sess,mainQN,time_per_step)
saver.save(sess,path+'/model-'+str(i)+'.cptk')
```
### Testing the network
```
e = 0.01 #The chance of chosing a random action
num_episodes = 10000 #How many episodes of game environment to train network with.
load_model = True #Whether to load a saved model.
path = "./drqn" #The path to save/load our model to/from.
h_size = 512 #The size of the final convolutional layer before splitting it into Advantage and Value streams.
h_size = 512 #The size of the final convolutional layer before splitting it into Advantage and Value streams.
max_epLength = 50 #The max allowed length of our episode.
time_per_step = 1 #Length of each step used in gif creation
summaryLength = 100 #Number of epidoes to periodically save for analysis
tf.reset_default_graph()
cell = tf.contrib.rnn.BasicLSTMCell(num_units=h_size,state_is_tuple=True)
cellT = tf.contrib.rnn.BasicLSTMCell(num_units=h_size,state_is_tuple=True)
mainQN = Qnetwork(h_size,cell,'main')
targetQN = Qnetwork(h_size,cellT,'target')
init = tf.global_variables_initializer()
saver = tf.train.Saver(max_to_keep=2)
#create lists to contain total rewards and steps per episode
jList = []
rList = []
total_steps = 0
#Make a path for our model to be saved in.
if not os.path.exists(path):
os.makedirs(path)
##Write the first line of the master log-file for the Control Center
with open('./Center/log.csv', 'w') as myfile:
wr = csv.writer(myfile, quoting=csv.QUOTE_ALL)
wr.writerow(['Episode','Length','Reward','IMG','LOG','SAL'])
#wr = csv.writer(open('./Center/log.csv', 'a'), quoting=csv.QUOTE_ALL)
with tf.Session() as sess:
if load_model == True:
print ('Loading Model...')
ckpt = tf.train.get_checkpoint_state(path)
saver.restore(sess,ckpt.model_checkpoint_path)
else:
sess.run(init)
for i in range(num_episodes):
episodeBuffer = []
#Reset environment and get first new observation
sP = env.reset()
s = processState(sP)
d = False
rAll = 0
j = 0
state = (np.zeros([1,h_size]),np.zeros([1,h_size]))
#The Q-Network
while j < max_epLength: #If the agent takes longer than 200 moves to reach either of the blocks, end the trial.
j+=1
#Choose an action by greedily (with e chance of random action) from the Q-network
if np.random.rand(1) < e:
state1 = sess.run(mainQN.rnn_state,\
feed_dict={mainQN.scalarInput:[s/255.0],mainQN.trainLength:1,mainQN.state_in:state,mainQN.batch_size:1})
a = np.random.randint(0,4)
else:
a, state1 = sess.run([mainQN.predict,mainQN.rnn_state],\
feed_dict={mainQN.scalarInput:[s/255.0],mainQN.trainLength:1,\
mainQN.state_in:state,mainQN.batch_size:1})
a = a[0]
s1P,r,d = env.step(a)
s1 = processState(s1P)
total_steps += 1
episodeBuffer.append(np.reshape(np.array([s,a,r,s1,d]),[1,5])) #Save the experience to our episode buffer.
rAll += r
s = s1
sP = s1P
state = state1
if d == True:
break
bufferArray = np.array(episodeBuffer)
jList.append(j)
rList.append(rAll)
#Periodically save the model.
if len(rList) % summaryLength == 0 and len(rList) != 0:
print (total_steps,np.mean(rList[-summaryLength:]), e)
saveToCenter(i,rList,jList,np.reshape(np.array(episodeBuffer),[len(episodeBuffer),5]),\
summaryLength,h_size,sess,mainQN,time_per_step)
print ("Percent of succesful episodes: " + str(sum(rList)/num_episodes) + "%")
```
| github_jupyter |
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.

# Automated Machine Learning
**BikeShare Demand Forecasting**
## Contents
1. [Introduction](#Introduction)
1. [Setup](#Setup)
1. [Compute](#Compute)
1. [Data](#Data)
1. [Train](#Train)
1. [Featurization](#Featurization)
1. [Evaluate](#Evaluate)
## Introduction
This notebook demonstrates demand forecasting for a bike-sharing service using AutoML.
AutoML highlights here include built-in holiday featurization, accessing engineered feature names, and working with the `forecast` function. Please also look at the additional forecasting notebooks, which document lagging, rolling windows, forecast quantiles, other ways to use the forecast function, and forecaster deployment.
Make sure you have executed the [configuration notebook](../../../configuration.ipynb) before running this notebook.
Notebook synopsis:
1. Creating an Experiment in an existing Workspace
2. Configuration and local run of AutoML for a time-series model with lag and holiday features
3. Viewing the engineered names for featurized data and featurization summary for all raw features
4. Evaluating the fitted model using a rolling test
## Setup
```
import azureml.core
import pandas as pd
import numpy as np
import logging
from azureml.core import Workspace, Experiment, Dataset
from azureml.train.automl import AutoMLConfig
from datetime import datetime
```
This sample notebook may use features that are not available in previous versions of the Azure ML SDK.
```
print("This notebook was created using version 1.19.0 of the Azure ML SDK")
print("You are currently using version", azureml.core.VERSION, "of the Azure ML SDK")
```
As part of the setup you have already created a <b>Workspace</b>. To run AutoML, you also need to create an <b>Experiment</b>. An Experiment corresponds to a prediction problem you are trying to solve, while a Run corresponds to a specific approach to the problem.
```
ws = Workspace.from_config()
# choose a name for the run history container in the workspace
experiment_name = 'automl-bikeshareforecasting'
experiment = Experiment(ws, experiment_name)
output = {}
output['Subscription ID'] = ws.subscription_id
output['Workspace'] = ws.name
output['SKU'] = ws.sku
output['Resource Group'] = ws.resource_group
output['Location'] = ws.location
output['Run History Name'] = experiment_name
pd.set_option('display.max_colwidth', -1)
outputDf = pd.DataFrame(data = output, index = [''])
outputDf.T
```
## Compute
You will need to create a [compute target](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-set-up-training-targets#amlcompute) for your AutoML run. In this tutorial, you create AmlCompute as your training compute resource.
#### Creation of AmlCompute takes approximately 5 minutes.
If the AmlCompute with that name is already in your workspace this code will skip the creation process.
As with other Azure services, there are limits on certain resources (e.g. AmlCompute) associated with the Azure Machine Learning service. Please read this article on the default limits and how to request more quota.
```
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your cluster.
amlcompute_cluster_name = "bike-cluster"
# Verify that cluster does not exist already
try:
compute_target = ComputeTarget(workspace=ws, name=amlcompute_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2',
max_nodes=4)
compute_target = ComputeTarget.create(ws, amlcompute_cluster_name, compute_config)
compute_target.wait_for_completion(show_output=True)
```
## Data
The [Machine Learning service workspace](https://docs.microsoft.com/en-us/azure/machine-learning/service/concept-workspace) is paired with the storage account, which contains the default data store. We will use it to upload the bike share data and create [tabular dataset](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.data.tabulardataset?view=azure-ml-py) for training. A tabular dataset defines a series of lazily-evaluated, immutable operations to load data from the data source into tabular representation.
```
datastore = ws.get_default_datastore()
datastore.upload_files(files = ['./bike-no.csv'], target_path = 'dataset/', overwrite = True,show_progress = True)
```
Let's set up what we know about the dataset.
**Target column** is what we want to forecast.
**Time column** is the time axis along which to predict.
```
target_column_name = 'cnt'
time_column_name = 'date'
dataset = Dataset.Tabular.from_delimited_files(path = [(datastore, 'dataset/bike-no.csv')]).with_timestamp_columns(fine_grain_timestamp=time_column_name)
dataset.take(5).to_pandas_dataframe().reset_index(drop=True)
```
### Split the data
The first split we make is into train and test sets. Note we are splitting on time. Data before 9/1 will be used for training, and data after and including 9/1 will be used for testing.
```
# select data that occurs before a specified date
train = dataset.time_before(datetime(2012, 8, 31), include_boundary=True)
train.to_pandas_dataframe().tail(5).reset_index(drop=True)
test = dataset.time_after(datetime(2012, 9, 1), include_boundary=True)
test.to_pandas_dataframe().head(5).reset_index(drop=True)
```
## Forecasting Parameters
To define forecasting parameters for your experiment training, you can leverage the ForecastingParameters class. The table below details the forecasting parameter we will be passing into our experiment.
|Property|Description|
|-|-|
|**time_column_name**|The name of your time column.|
|**forecast_horizon**|The forecast horizon is how many periods forward you would like to forecast. This integer horizon is in units of the timeseries frequency (e.g. daily, weekly).|
|**country_or_region_for_holidays**|The country/region used to generate holiday features. These should be ISO 3166 two-letter country/region codes (i.e. 'US', 'GB').|
|**target_lags**|The target_lags specifies how far back we will construct the lags of the target variable.|
|**drop_column_names**|Name(s) of columns to drop prior to modeling|
## Train
Instantiate a AutoMLConfig object. This defines the settings and data used to run the experiment.
|Property|Description|
|-|-|
|**task**|forecasting|
|**primary_metric**|This is the metric that you want to optimize.<br> Forecasting supports the following primary metrics <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i>
|**blocked_models**|Models in blocked_models won't be used by AutoML. All supported models can be found at [here](https://docs.microsoft.com/en-us/python/api/azureml-train-automl-client/azureml.train.automl.constants.supportedmodels.forecasting?view=azure-ml-py).|
|**experiment_timeout_hours**|Experimentation timeout in hours.|
|**training_data**|Input dataset, containing both features and label column.|
|**label_column_name**|The name of the label column.|
|**compute_target**|The remote compute for training.|
|**n_cross_validations**|Number of cross validation splits.|
|**enable_early_stopping**|If early stopping is on, training will stop when the primary metric is no longer improving.|
|**forecasting_parameters**|A class that holds all the forecasting related parameters.|
This notebook uses the blocked_models parameter to exclude some models that take a longer time to train on this dataset. You can choose to remove models from the blocked_models list but you may need to increase the experiment_timeout_hours parameter value to get results.
### Setting forecaster maximum horizon
The forecast horizon is the number of periods into the future that the model should predict. Here, we set the horizon to 14 periods (i.e. 14 days). Notice that this is much shorter than the number of days in the test set; we will need to use a rolling test to evaluate the performance on the whole test set. For more discussion of forecast horizons and guiding principles for setting them, please see the [energy demand notebook](https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/automated-machine-learning/forecasting-energy-demand).
```
forecast_horizon = 14
```
### Config AutoML
```
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(
time_column_name=time_column_name,
forecast_horizon=forecast_horizon,
country_or_region_for_holidays='US', # set country_or_region will trigger holiday featurizer
target_lags='auto', # use heuristic based lag setting
drop_column_names=['casual', 'registered'] # these columns are a breakdown of the total and therefore a leak
)
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
blocked_models = ['ExtremeRandomTrees'],
experiment_timeout_hours=0.3,
training_data=train,
label_column_name=target_column_name,
compute_target=compute_target,
enable_early_stopping=True,
n_cross_validations=3,
max_concurrent_iterations=4,
max_cores_per_iteration=-1,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
```
We will now run the experiment, you can go to Azure ML portal to view the run details.
```
remote_run = experiment.submit(automl_config, show_output=False)
remote_run
remote_run.wait_for_completion()
```
### Retrieve the Best Model
Below we select the best model from all the training iterations using get_output method.
```
best_run, fitted_model = remote_run.get_output()
fitted_model.steps
```
## Featurization
You can access the engineered feature names generated in time-series featurization. Note that a number of named holiday periods are represented. We recommend that you have at least one year of data when using this feature to ensure that all yearly holidays are captured in the training featurization.
```
fitted_model.named_steps['timeseriestransformer'].get_engineered_feature_names()
```
### View the featurization summary
You can also see what featurization steps were performed on different raw features in the user data. For each raw feature in the user data, the following information is displayed:
- Raw feature name
- Number of engineered features formed out of this raw feature
- Type detected
- If feature was dropped
- List of feature transformations for the raw feature
```
# Get the featurization summary as a list of JSON
featurization_summary = fitted_model.named_steps['timeseriestransformer'].get_featurization_summary()
# View the featurization summary as a pandas dataframe
pd.DataFrame.from_records(featurization_summary)
```
## Evaluate
We now use the best fitted model from the AutoML Run to make forecasts for the test set. We will do batch scoring on the test dataset which should have the same schema as training dataset.
The scoring will run on a remote compute. In this example, it will reuse the training compute.
```
test_experiment = Experiment(ws, experiment_name + "_test")
```
### Retrieving forecasts from the model
To run the forecast on the remote compute we will use a helper script: forecasting_script. This script contains the utility methods which will be used by the remote estimator. We copy the script to the project folder to upload it to remote compute.
```
import os
import shutil
script_folder = os.path.join(os.getcwd(), 'forecast')
os.makedirs(script_folder, exist_ok=True)
shutil.copy('forecasting_script.py', script_folder)
```
For brevity, we have created a function called run_forecast that submits the test data to the best model determined during the training run and retrieves forecasts. The test set is longer than the forecast horizon specified at train time, so the forecasting script uses a so-called rolling evaluation to generate predictions over the whole test set. A rolling evaluation iterates the forecaster over the test set, using the actuals in the test set to make lag features as needed.
```
from run_forecast import run_rolling_forecast
remote_run = run_rolling_forecast(test_experiment, compute_target, best_run, test, target_column_name)
remote_run
remote_run.wait_for_completion(show_output=False)
```
### Download the prediction result for metrics calcuation
The test data with predictions are saved in artifact outputs/predictions.csv. You can download it and calculation some error metrics for the forecasts and vizualize the predictions vs. the actuals.
```
remote_run.download_file('outputs/predictions.csv', 'predictions.csv')
df_all = pd.read_csv('predictions.csv')
from azureml.automl.core.shared import constants
from azureml.automl.runtime.shared.score import scoring
from sklearn.metrics import mean_absolute_error, mean_squared_error
from matplotlib import pyplot as plt
# use automl metrics module
scores = scoring.score_regression(
y_test=df_all[target_column_name],
y_pred=df_all['predicted'],
metrics=list(constants.Metric.SCALAR_REGRESSION_SET))
print("[Test data scores]\n")
for key, value in scores.items():
print('{}: {:.3f}'.format(key, value))
# Plot outputs
%matplotlib inline
test_pred = plt.scatter(df_all[target_column_name], df_all['predicted'], color='b')
test_test = plt.scatter(df_all[target_column_name], df_all[target_column_name], color='g')
plt.legend((test_pred, test_test), ('prediction', 'truth'), loc='upper left', fontsize=8)
plt.show()
```
Since we did a rolling evaluation on the test set, we can analyze the predictions by their forecast horizon relative to the rolling origin. The model was initially trained at a forecast horizon of 14, so each prediction from the model is associated with a horizon value from 1 to 14. The horizon values are in a column named, "horizon_origin," in the prediction set. For example, we can calculate some of the error metrics grouped by the horizon:
```
from metrics_helper import MAPE, APE
df_all.groupby('horizon_origin').apply(
lambda df: pd.Series({'MAPE': MAPE(df[target_column_name], df['predicted']),
'RMSE': np.sqrt(mean_squared_error(df[target_column_name], df['predicted'])),
'MAE': mean_absolute_error(df[target_column_name], df['predicted'])}))
```
To drill down more, we can look at the distributions of APE (absolute percentage error) by horizon. From the chart, it is clear that the overall MAPE is being skewed by one particular point where the actual value is of small absolute value.
```
df_all_APE = df_all.assign(APE=APE(df_all[target_column_name], df_all['predicted']))
APEs = [df_all_APE[df_all['horizon_origin'] == h].APE.values for h in range(1, forecast_horizon + 1)]
%matplotlib inline
plt.boxplot(APEs)
plt.yscale('log')
plt.xlabel('horizon')
plt.ylabel('APE (%)')
plt.title('Absolute Percentage Errors by Forecast Horizon')
plt.show()
```
| github_jupyter |
# Example: CanvasXpress tree Chart No. 1
This example page demonstrates how to, using the Python package, create a chart that matches the CanvasXpress online example located at:
https://www.canvasxpress.org/examples/tree-1.html
This example is generated using the reproducible JSON obtained from the above page and the `canvasxpress.util.generator.generate_canvasxpress_code_from_json_file()` function.
Everything required for the chart to render is included in the code below. Simply run the code block.
```
from canvasxpress.canvas import CanvasXpress
from canvasxpress.js.collection import CXEvents
from canvasxpress.render.jupyter import CXNoteBook
cx = CanvasXpress(
render_to="tree1",
data={
"y": {
"vars": [
"Order"
],
"smps": [
"A",
"B",
"C",
"D",
"E",
"F",
"G",
"H",
"I",
"J",
"K",
"L",
"M",
"N",
"O",
"P"
],
"data": [
[
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16
]
]
},
"x": {
"Level1": [
"L1.1",
"L1.1",
"L1.1",
"L1.1",
"L1.2",
"L1.2",
"L1.2",
"L1.2",
"L1.3",
"L1.3",
"L1.3",
"L1.3",
"L1.4",
"L1.4",
"L1.4",
"L1.4"
],
"Level2": [
"L2.1",
"L2.1",
"L2.2",
"L2.2",
"L2.1",
"L2.1",
"L2.2",
"L2.2",
"L2.1",
"L2.1",
"L2.2",
"L2.2",
"L2.1",
"L2.1",
"L2.2",
"L2.2"
],
"Level3": [
"L3.1",
"L3.2",
"L3.1",
"L3.2",
"L3.1",
"L3.2",
"L3.1",
"L3.2",
"L3.1",
"L3.2",
"L3.1",
"L3.2",
"L3.1",
"L3.2",
"L3.1",
"L3.2"
],
"Annot1": [
"A",
"B",
"C",
"A",
"B",
"C",
"A",
"B",
"C",
"A",
"B",
"C",
"A",
"B",
"C",
"A"
],
"Annot2": [
5,
10,
15,
20,
25,
30,
35,
40,
40,
35,
30,
25,
20,
15,
10,
5
]
}
},
config={
"graphType": "Tree",
"hierarchy": [
"Level1",
"Level2",
"Level3"
],
"showTransition": True,
"title": "Collapsible Tree"
},
width=613,
height=613,
events=CXEvents(),
after_render=[],
other_init_params={
"version": 35,
"events": False,
"info": False,
"afterRenderInit": False,
"noValidate": True
}
)
display = CXNoteBook(cx)
display.render(output_file="tree_1.html")
```
| github_jupyter |
# Text to Propositions
```
import spacy
import textacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("So I have had a good day today. I found out we got the other half of our funding for my travel grant, which paid for my friend to come with me. So that’s good, she and I will both get some money back. I took my dogs to the pet store so my girl dog could get a new collar, but she wanted to beat everyone up. This is an ongoing issue with her. She’s so little and cute too but damn she acts like she’s gonna go for the jugular with everyone she doesn’t know! She did end up with a cute new collar tho, it has pineapples on it. I went to the dentist and she’s happy with my Invisalign progress. We have three more trays and then she does an impression to make sure my teeth are where they need to be before they get the rest of the trays. YAY! And I don’t have to make another payment until closer to the end of my treatment. I had some work emails with the festival, and Jessie was bringing up some important points, and one of our potential artists was too expensive to work with, so Mutual Friend was asking for names for some other people we could work with. So I suggested like, three artists, and Jessie actually liked the idea of one of them doing it. Which is nice. I notice she is very encouraging at whatever I contribute to our collective. It’s sweet. I kind of know this is like, the only link we have with each other right now besides social media, so it seems like she’s trying to make sure I know she still wants me to be involved and doesn’t have bad feelings for me. And there was a short period when I was seriously thinking of leaving the collective and not working with this festival anymore. I was so sad, and felt so upset, and didn’t know what to do about Jessie. It felt really close to me throwing in the towel. But I hung on through the festival and it doesn’t seem so bad from this viewpoint now with more time that has passed. And we have been gentle, if reserved, with each other. I mean her last personal email to me however many weeks ago wasn’t very nice. But it seems like we’ve been able to put it aside for work reasons. I dunno. I still feel like if anything was gonna get mended between us, she would need to make the first moves on that. I really don’t want to try reaching out and get rejected even as a friend again. I miss her though. And sometimes I think she misses me. But I don’t want to approach her assuming we both miss each other and have her turn it on me again and make out like all these things are all in my head. I don’t know about that butch I went on a date with last night. I feel more of a friend vibe from her, than a romantic one. I can’t help it, I am just not attracted to butches. And I don’t know how to flirt with them. And I don’t think of them in a sexy way. But I WOULD like another butch buddy. I mean yeah maybe Femmes do play games, or maybe I just chased all the wrong Femmes. Maybe I’ll just leave this and not think about it much until I get back to town in January.")
```
## Extract Subject Verb Object Triples
```
svo_triples = textacy.extract.subject_verb_object_triples(doc)
for triple in svo_triples:
print(triple)
```
## Extract Named Entities
```
for ent in doc.ents:
print(ent.text, ent.label_)
# returns (entity, cue, fragment)
statements = textacy.extract.semistructured_statements(doc, 'I', cue='feel')
for entity, cue, fragment in statements:
print(entity, cue, '-->', fragment)
# get cues
all_statements = []
for sent in doc.sents:
verbs = textacy.spacier.utils.get_main_verbs_of_sent(sent)
print('sent:', sent, '\nverbs:', verbs)
for verb in verbs:
objects = textacy.spacier.utils.get_objects_of_verb(verb)
subjects = textacy.spacier.utils.get_subjects_of_verb(verb)
for subject in subjects:
statements = textacy.extract.semistructured_statements(doc, subject.text, verb.lemma_)
for statement in statements:
print(subject, verb, statement)
all_statements += [statement]
print('\n')
for statement in set(all_statements):
print(statement)
from allennlp.predictors import Predictor
predictor = Predictor.from_path("https://s3-us-west-2.amazonaws.com/allennlp/models/decomposable-attention-elmo-2018.02.19.tar.gz")
prediction = predictor.predict(
hypothesis="Two women are sitting on a blanket near some rocks talking about politics.",
premise="Two women are wandering along the shore drinking iced tea."
)
prediction
type(prediction['premise_tokens'][0])
import pandas as pd
doc = nlp("I guess I am feeling kinda tired. I feel overwhelmed, a bit, maybe hungry. I dunno. I find myself wanting something, but I'm not sure what it is. I feel stressed certainly, too much to do maybe? But I'm not totally sure what I should be doing? Now it's a lot later and it's really time for me to get to bed...but a part of me wants to stay up, nonetheless")
results = pd.DataFrame([], columns=['premise', 'hypothesis', 'entailment', 'contradiction', 'neutral', 'e+c'])
i = 0
for premise in doc.sents:
# entailment, contradiction, neutral = None
for hypothesis in doc.sents:
if (premise != hypothesis):
prediction = predictor.predict(hypothesis=hypothesis.text, premise=premise.text)
entailment, contradiction, neutral = prediction['label_probs']
results.loc[i] = [premise.text, hypothesis.text, entailment, contradiction, neutral, (entailment + (1 - contradiction)) / 2]
i += 1
results.sort_values(by='e+c', ascending=False).loc[results['neutral'] < .5]
hypothesis = 'I feel stressed'
results = pd.DataFrame([], columns=['premise', 'hypothesis', 'entailment', 'contradiction', 'neutral'])
i = 0
for premise in doc.sents:
prediction = predictor.predict(hypothesis=hypothesis, premise=premise.text)
entailment, contradiction, neutral = prediction['label_probs']
results.loc[i] = [premise.text, hypothesis, entailment, contradiction, neutral]
i += 1
results.sort_values(by='entailment', ascending=False)
def demo(shape):
nlp = spacy.load('en_vectors_web_lg')
nlp.add_pipe(KerasSimilarityShim.load(nlp.path / 'similarity', nlp, shape[0]))
doc1 = nlp(u'The king of France is bald.')
doc2 = nlp(u'France has no king.')
print("Sentence 1:", doc1)
print("Sentence 2:", doc2)
entailment_type, confidence = doc1.similarity(doc2)
print("Entailment type:", entailment_type, "(Confidence:", confidence, ")")
from textacy.vsm import Vectorizer
vectorizer = Vectorizer(
tf_type='linear', apply_idf=True, idf_type='smooth', norm='l2',
min_df=3, max_df=0.95, max_n_terms=100000
)
model = textacy.tm.TopicModel('nmf', n_topics=20)
model.fit
import textacy.keyterms
terms = textacy.keyterms.key_terms_from_semantic_network(doc)
terms
terms = textacy.keyterms.sgrank(doc)
terms
doc.text
import textacy.lexicon_methods
textacy.lexicon_methods.download_depechemood(data_dir='data')
textacy.lexicon_methods.emotional_valence(words=[word for word in doc], dm_data_dir='data/DepecheMood_V1.0')
from event2mind_hack import load_event2mind_archive
from allennlp.predictors.predictor import Predictor
archive = load_event2mind_archive('data/event2mind.tar.gz')
predictor = Predictor.from_archive(archive)
predictor.predict(
source="PersonX drops a hint"
)
import math
math.exp(-1)
import pandas as pd
import math
xintent = pd.DataFrame({
'tokens': prediction['xintent_top_k_predicted_tokens'],
'p_log': prediction['xintent_top_k_log_probabilities']
})
xintent['p'] = xintent['p_log'].apply(math.exp)
xintent.sort_values(by='p', ascending=False)
xreact = pd.DataFrame({
'tokens': prediction['xreact_top_k_predicted_tokens'],
'p_log': prediction['xreact_top_k_log_probabilities']
})
xreact['p'] = xreact['p_log'].apply(math.exp)
xreact.sort_values(by='p', ascending=False)
oreact = pd.DataFrame({
'tokens': prediction['oreact_top_k_predicted_tokens'],
'p_log': prediction['oreact_top_k_log_probabilities']
})
oreact['p'] = oreact['p_log'].apply(math.exp)
oreact.sort_values(by='p', ascending=False)
```
| github_jupyter |
# Homework 3
**Due: 02/18/2020**
## References
+ Lectures 9-10 (inclusive).
## Instructions
## Instructions
+ Type your name and email in the "Student details" section below.
+ Develop the code and generate the figures you need to solve the problems using this notebook.
+ For the answers that require a mathematical proof or derivation you can either:
- Type the answer using the built-in latex capabilities. In this case, simply export the notebook as a pdf and upload it on gradescope; or
- You can print the notebook (after you are done with all the code), write your answers by hand, scan, turn your response to a single pdf, and upload on gradescope.
+ The total homework points are 100. Please note that the problems are not weighed equally.
## Student details
+ **First Name:**
+ **Last Name:**
+ **Email:**
## Readings
Before attempting the homework, it is probably a good idea to:
+ Read chapter 3 of Bishop (Pattern recognition and machine learning);
+ Review the slides of lectures 7, 8, & 9; and
+ Review the corresponding lecture handouts.
```
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import seaborn as sns
sns.set_context('paper')
sns.set_style('white')
sns.set()
import scipy.stats as st
from sklearn.datasets import make_spd_matrix
```
# Problem 1
Suppose you conduct some experiments and collect a dataset of $N$ pairs of input and target variables, $\mathcal{D} = (x_{1:N}, y_{1:N})$, where $x_i \in \mathbb{R}$ and $y_i \in \mathbb{R}$, $\forall i$.
Assume a Gaussian likelihood with the mean being a generalized linear model with weights $\mathbf{w}\in\mathbb{R}^m$ and basis functions $\boldsymbol{\phi}(x)\in\mathbb{R}^M$, and the noise variance being a constant $\sigma^2$.
On the weights, use an isotropic Gaussian prior, with precision parameter, $\alpha$.
1. Derive expressions for $\mathbf{m}_{N}$ and $\mathbf{S}_{N}$, the posterior mean and covariance of the model parameters respectively. Ask the question: What do I know about the weights given all the data I have seen? You will need Bayes rule for updating the weights and little bit of algebra. In particular, you will need a trick called "completing the square."
2. Use the results from part 1 to derive the posterior predictive distribution at an arbitrary test input $x^{*}$. Ask the question: What do I know about the $y^*$ at $x^*$ given all the data I have seen? You will need the sum rule of probability theory to connect this question to the likehood and the posterior you obtained in step 1.
3. Suppose now you perform an additional experiment and receive a data-point, $\mathcal{D}_{N+1}=(x_{N+1}, y_{N+1})$. Using the current posterior distribution over the parameters as the new prior, show that updating the model with the $(N+1)^{th}$ data-point results in the same posterior distribution shown above, with $N$ replaced by $N+1$.
The required expressions for all of the above cases are well-known in closed form. It is, however, useful to work through the algebra atleast once. Feel free to consult Bishop's book, but in the end present your own derivation from scratch.
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
# Problem 2
[Conjugate priors](https://en.wikipedia.org/wiki/Conjugate_prior) are an extremely useful tool in Bayesian inference.
If the posterior distribution over the unknown parameters, $\boldsymbol{\theta}$, of a statistical model is in the same family of distributions as the prior, the prior is said to be conjugate to the chosen likelihood. We saw one such example in class where a Gaussian prior over the unknown weights of the linear regression model lead to a Gaussian posterior under the Gaussian likelihood model. We used a fixed value of $\sigma^2$ in our analysis of the linear regression model in class.
As before, consider a Gaussian likelihood with the mean being a generalized linear model with weights $\mathbf{w}\in\mathbb{R}^m$ and basis functions $\boldsymbol{\phi}(x)\in\mathbb{R}^M$, and the noise variance being a constant $\sigma^2$
Let's treat the noise parameter also as an unknown. Let $\beta$ be the inverse noise variance, i.e., $\beta = \frac{1}{\sigma^2}$ $^{(1)}$.
Show that the following prior over $w$ and $\beta$:
$$
p(\mathbf{w}, \beta) = \mathcal{N}(\mathbf{w}|0, \alpha^{-1}\mathbf{I}) \mathrm{Gamma}(\beta| a_0, b_0),
$$
is conjugate.
That is, show that the posterior over $\mathbf{w}$ and $\beta$ has the same form as the prior:
$$p(\mathbf{w}, \beta|\mathcal{D}_N, \alpha) = \mathcal{N}(w|\mathbf{m}_N, \mathbf{S}_N) \mathrm{Gamma}(\beta| a_N, b_N).$$
In doing so, recover the expressions for $\mathbf{m}_N$, $\mathbf{S}_N$, $a_N$ and $b_N$. Discuss any interesting observation you make about the form of the posterior distribution parameters.
The [Gamma distribution](https://en.wikipedia.org/wiki/Gamma_distribution) has probability density:
$$
\mathrm{Gamma}(\beta|a_0, b_0) = \frac{b_0^{a_0}}{\Gamma(a)}\beta^{a_0-1}e^{-b_0\beta}
$$
(1) - _You will frequently encounter in literature the use of the precision rather than the variance when using the normal distribution. Doing so often simplifies computation_.
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
# Problem 3 - Some exercises on the multivariate normal
The Bayesian linear regression model discussed in class makes extensive usage of the multivariate Gaussian distribution. ```numpy``` and ```scipy``` offer nice implementations of the multivariate normal distribution for computing densities and generating samples. However, it is useful to go through the process of developing your method for doing these things atleast once.
Consider the random variable $\mathbf{X} \sim \mathcal{N}(\mathbf{X}|\mu, \Sigma)$, where, $\mathbf{X} \in \mathbb{R}^d$ and $\mu$ and $\Sigma$ are its mean vector and covariance matrix respectively.
## Density of a multivariate Gaussian
The expression for the density of the multivariate Gaussian distribution can be found [here](https://en.wikipedia.org/wiki/Multivariate_normal_distribution).
Note that evaluating the density function of MVN (multivariate normal) requires evaluating the inverse of the covariance matrix, $\Sigma$. Inverting a matrix is inefficient and numerically unstable and should be avoided as much as possible.
Instead you can compute the density of the random variable $\mathbf{X}$ at an arbitrary point $\mathbf{x}$ as follows:
1. Use [```scipy.linalg.cho_factor```](https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.linalg.cho_factor.html#scipy.linalg.cho_factor) to perform the Cholesky decomposition of $\Sigma$ i.e. find $\mathbf{L}$ such that $\Sigma = \mathbf{L} \mathbf{L}^T$.
2. Solve, for $\mathbf{z}$, the system of linear equations $\mathbf{L} \mathbf{L}^T \mathbf{z} = \mathbf{x} -\mu$. You can use [```scipy.linalg.cho_solve```](https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.linalg.cho_solve.html).
3. Put everything together to compute $p(\mathbf{x}) = \frac{1}{\sqrt{(2\pi)^d | \Sigma|}}\exp\Big[ -\frac{1}{2}(\mathbf{x}-\mu)^T \mathbf{z} \Big]$.
Here is an example with an arbitrary mean and covariance in 2 dimensions:
```
from scipy.linalg import cho_factor, cho_solve
d =2
mean = np.array([1, 2])[:, None]
cov = np.array([[2, 1], [1, 4]])
L = cho_factor(cov, lower=True)
diagL = np.diag(L[0])
detcov = np.prod(diagL) ** 2 #Sigma = LL^T ; Determinant of prod = prod. of determinant.
Z = 1./np.sqrt(((2*np.pi)**2)*detcov) #normalizing constant
#define a grid over x
x1 = np.linspace(-5, 10, 50)
X1, X2 = np.meshgrid(x1, x1)
Xgrid = np.hstack([X1.flatten()[:, None], X2.flatten()[:, None]])[:, :, None]
Pdfs = np.array([Z*np.exp(-0.5*np.dot((xp-mean).T, cho_solve(L, xp-mean))) for xp in Xgrid]) ## See note below
## For those new to Python, the above line uses the concept of list comprehensions in Python.
## See here: http://www.secnetix.de/olli/Python/list_comprehensions.hawk
## This is extremely useful for looping over simple expressions.
## See also the map function: http://book.pythontips.com/en/latest/map_filter.html
#visualize the density
plt.contourf(X1, X2, Pdfs.reshape((50, 50)), 100, cmap = 'magma')
plt.colorbar()
```
Define a function ```mvnpdf``` which accepts an input $\mathbf{x}$ of any arbitrary dimension, $d$, and also accepts a mean vector and covariance matrix and returns the density of the normal distribution with given mean and covariance at point $\mathbf{x}$. Feel free to re-use any/all code from the example given above.
```
## write code here.
```
**Note: You can assume that the density is non-degenerate, i.e., the covariance matrix is positive definite.**
Let's test your implementation. Use ```numpy.random.randn``` and ```sklearn.datasets.make_spd_matrix``` to generate random mean vector and covariance matrix, $\mu$ and $\Sigma$ for a random variable in $2$ dimensions. Visualize the contours of the density function. Use ```scipy.stats.multivariate_normal``` to verify that you get the correct result.
```
# write code here.
```
### Sampling from a multivariate Gaussian
Recall that a univariate random variable, $\mathbf{q} \sim \mathcal{N}({\mathbf{q}|\mu, \sigma^2})$, can be expressed as $\mathbf{q} = \mu + \sigma \mathbf{z}$, where, $\mathbf{z} \sim \mathcal{N}({\mathbf{z}|0, 1})$ is a standard normal random variable. This suggests an easy approach for sampling from a univariate distribution with arbitrary mean and variance - Sample from the standard normal distribution $\mathcal{N}(0, 1)$, scale the result by standard deviation $\sigma$ and then translate by $\mu$.
The approach to sampling from a multivariate Gaussian is analogous to the univariate case. Here are the steps:
1. Compute the Cholesky decomposition of the covariance matrix $\Sigma$ i.e. find $\mathbf{L}$ such that $\Sigma = \mathbf{L} \mathbf{L}^T$.
2. Sample a vector $\mathbf{z}$ from the multivariate standard normal in the given dimensions, i.e., $\mathcal{N}(\mathbf{0}_{d}, ,\mathbf{I}_{d\times d})$.
3. Scale and shift: $\mathbf{x} = \mu + \mathbf{L}\mathbf{z}$.
The code below samples from the MVN defined in the previous section of this question.
```
nsamples = 1000
samples = np.array([mean+np.dot(np.tril(L[0]), np.random.randn(2, 1)) for i in xrange(nsamples)])[:, :, 0]
x1 = samples[:,0]
x2 = samples[:,1]
#plot samples and compare to the pdf
plt.contourf(X1, X2, Pdfs.reshape((50, 50)), 100, cmap = 'magma')
plt.colorbar()
plt.scatter(x1, x2, marker='x')
```
Note that the generated samples look like they have been drawn from the MVN defined earlier.
Define a function ```mvnsamples``` which accepts as input the mean vector and covariance matrix of a multivariate distribution of any arbitrary dimension, $d$, and returns $n$ samples from the distribution. $n$ is also to be passed as a parameter to the function.
```
# type code here.
```
Let's test your implementation. For the same mean and covariance generated earlier, draw $n$ samples and visualize it with a scatter plot. Make sure to compare the scatter plot with the density contours to verify your sampler is implemented correctly.
```
# type code here.
```
# Problem 4 - Linear regression on noisy dataset
Consider the following dataset:
```
data = np.loadtxt('hw3_data1.txt')
X = data[0, :]
Y = data[1, :]
plt.figure(figsize=(12, 8))
plt.plot(X, Y, 'ro', label = 'Data')
plt.xlabel('$x$', fontsize=14)
plt.ylabel('$y$', fontsize=14)
plt.legend(loc='best', fontsize = 14)
```
We will try to fit the following linear regression model for this dataset:
$$
f(x;\mathbf{w}) = w_0 + w_1 x,
$$
where, $w_0$ and $w_1$ are model parameters.
## Part A
### Bayesian linear regression (Part 1)
Consider the additive noise model:
$$
y = f(x;\mathbf{w}) + \epsilon = w_0 + w_1 x + \epsilon,
$$
where, $\epsilon \sim \mathcal{N}(\epsilon|0, \sigma^2)$.
Consider the following isotropic prior on the weights:
$$
p(\mathbf{w}) = \mathcal{N}(\mathbf{w}|0, \alpha^{-1}\mathbf{I}).
$$
The density function of multivariate Gaussians can be found [here](https://en.wikipedia.org/wiki/Multivariate_normal_distribution). We will take a look at how to efficiently compute the density of multivariate Gaussians later in the course but for the time being let's use [scipy's implementation](https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.stats.multivariate_normal.html) of the same to visualize the prior.
Generate a grid of $w_0$ and $w_1$ values and use scipy's ```multivariate_normal.pdf``` method to compute the prior probability density at each location of the grid. Note that the prior mean and covariance are shown in the expression above. Show the contour plot of the prior pdf. If you aren't already familiar, check out [this tutorial](https://jakevdp.github.io/PythonDataScienceHandbook/04.04-density-and-contour-plots.html) on matplotlib contour plots.
```
# write your code here
```
Generate some samples of $\mathbf{w}$ from the prior and visualize the corresponding. You can use ```numpy.multivariate_normal```. An example using arbitrary mean and covariance is shown below:
```
mean = np.array([1, 2])
cov = np.array([[2, 0], [0, 2]])
w_sample = np.random.multivariate_normal(mean = mean, cov = cov, size = 1)
w_0 = w_sample[0, 0]
w_1 = w_sample[0, 1]
x = np.linspace(-2, 2, 100)
plt.plot(x, w_0 + w_1*x, label='$f(\mathbf{x};\mathbf{w}) = w_0 + w_1 x$')
plt.xlabel('$x$')
plt.ylabel('$f(x;\mathbf{w})$')
plt.legend(loc='best', fontsize=14)
plt.tight_layout()
```
**Note**: Please make sure all samples of $f$ are shown in the same plot.
```
# nsamples = 5 (whatever number you want)
#
# Sample and visualize
#
```
Define a function that accepts the prior precision $\alpha$ and the noise variance $\sigma^2$ and returns the posterior mean and covariance of $w$.
```
def postmeanvar(a, sigma2):
"""
write code here to return posterior mean and covariance of w.
"""
return
```
Visualize the posterior distribution over $w$ using scipy's ```multivariate_normal.pdf``` function.
```
#
# Visualize the posterior
#
```
**How is the posterior different from the prior?**
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
Plot some samples from the posterior distribution:
```
#
# Code to plot some samples from posterior
#
```
Visualize the mean and variance of the posterior predictive distribution. Make sure to distinguish between
measurement noise and epistemic uncertainty.
```
#
# Visualize posterior predictive distribution.
#
```
It is a good idea to set aside a part of your dataset for the purpose of testing the accuracy of your trained model.
Consider the following test dataset:
```
testdata = np.loadtxt('hw3_data1_test.txt')
Xtest = testdata[0, :]
Ytest = testdata[1, :]
```
Make predictions on the test inputs, ```Xtest```, using the posterior predictive distribution under the Bayesian model. Compare it to the least squares predictions. Recall that the least squares estimate of $\mathbf{w}$ is given by:
$$
\mathbf{w}_{\mathrm{LS}} = (\mathbf{\Phi}^T \mathbf{\Phi})^{-1} \mathbf{\Phi}^T y_{1:N}.
$$
Use ```numpy.lstsq``` to obtain $\mathbf{w}_{\mathrm{LS}}$. The prediction at a new test location $x^*$ is given by $y^* = \mathbf{w}_{\mathrm{LS}, 0} + \mathbf{w}_{\mathrm{LS}, 1}x^*$.
```
#
# Ypred_ls = #least squares prediction.
# Ypred_bayes = #bayesian model prediction.
```
**Which model (Bayesian or least squares) offers better predictions? Why do you think that is?**
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
**In what situations (if any) would you expect simple least squares regression to perform better than the Bayesian regression?**
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
## Part C
### Evidence approximation
Picking the hyperparameters $\alpha$ and $\sigma^2$ is tricky. In theory, the fully approach to modeling the uncertainty in the hyperparameters is simple - put priors on them and make predictions on test data by marginalizing wrt to the hyperparameters and model weights. In practice, the resulting integrals are intractable. A popular and easy to implement approach to hyperparameter selection is [cross validation](https://en.wikipedia.org/wiki/Cross-validation_(statistics)). The idea is to choose a set of hyperparameter values, train the model at each value in the set and test it predictive accuracy. Finally, you select the values of the hyperparameters that offer the best predictive capacity.
A more systematic approach is to maximize the model evidence. The evidence is the marginal likelihood of the data conditional on the hyperparameters, i.e., $p(y|x, \alpha, \sigma^2)$.
Under the Gaussian likelihood and isotropic Gaussian prior model, the log evidence is given by:
$$
log p(y|x, \alpha, \beta) = \frac{M}{2} \log \alpha + \frac{N}{2} \log \beta - E(\mathbf{m}) -\frac{1}{2} \log \mathrm{det}(A) - \frac{N}{2} \log 2\pi,
$$
where,
$\beta$ is the inverse noise variance (or precision),
$$A = \alpha \mathbf{I} + \beta \Phi^T \Phi,$$ $$\mathbf{m} = \beta A^{-1} \Phi^T y_{1:N},$$
and $M$ is the number of model parameters, which in this case is 2.
The term $E(\mathbf{m})$ is a regularized misfit term given by:
$$
E(\mathbf{m}) = \frac{\beta}{2} \| y_{1:N} - \Phi \mathbf{m} \|_{2}^{2} + \frac{\alpha}{2} \| \mathbf{m} \|_{2}^{2}.
$$
Set up a function ```evidence``` that accepts the prior precision, $\alpha$ and the inverse noise variance, $\beta$, and returns the value of the evidence function. Feel free to parameterize your implementation of the ```evidence``` in whatever way you see fit.
```
def evidence():
"""
Set this up.
"""
return
```
Use a suitable second order unconstrained optimization routine from ```scipy.optimize``` to minimize the **negative log evidence**. A popular method is the [BFGS algorithm.](https://docs.scipy.org/doc/scipy/reference/optimize.minimize-bfgs.html). Be sure to read the documentation carefully.
```
#
# Set up the optimization routine and minimize the negative log evidence.
#
```
Use the estimates of the hyperparameters obtained by maximizing the evidence to recompute the posterior mean and variance of the model parameters under the constant prior precision and likelihood variance model.
```
#
# compute posterior mean and variance.
#
```
**Does this differ from your earlier estimate of the posterior mean and variance?**
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
**Visualize the following:**
1. The posterior density of $\mathbf{w}$.
2. A few models sampled from the posterior.
3. The posterior predictive distribution with noise variance and epistemic uncertainty.
```
#
# Visualizations.
#
```
Finally, use the model you just trained to make predictions on the test data:
```
#
# Ypred_ev =
#
```
**How do the predictions compare to the previous versions?**
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
# Problem 5
### Bayesian linear regression (Part 2)
We will now look at a somewhat more complicated example. The following dataset was generated using a molecular dynamics simulation of a plastic material (thanks to [Professor Alejandro Strachan](https://engineering.purdue.edu/MSE/people/ptProfile?id=33239) for sharing the data!).
In particular, we took a rectangular chunk of the material and we started applying tensile forces along one dimension.
What you see in the data set below is the instantaneous measurements of *strain* (percent enlogation of the material in the pulling direction) vs the normal *stress* (force per square area in MPa = $10^6 \text{N}/m^2$).
This [video](https://youtu.be/K6vOkQ5F9r0) will help you understand how the dataset was generated.
```
data = np.loadtxt('stress_strain.txt')
epsilon = data[:, 0]
sigma = data[:, 1]
fig, ax = plt.subplots(figsize = (10, 6))
ax.plot(epsilon, sigma, '.')
ax.set_xlabel('Strain $\epsilon$', fontsize = 14)
ax.set_ylabel('Stress $\sigma$', fontsize = 14)
```
This is a noisy dataset.
We would like to process it in order to extract what is known as the [stress-strain curve](https://en.wikipedia.org/wiki/Stress–strain_curve) of the material.
The stress-strain curve characterizes the type of the material (the chemical bonds, the crystaline structure, any defects, etc.).
It is a required input to the equations of [elasticity](https://en.wikipedia.org/wiki/Elasticity_(physics)) otherwise known as a *constitutive relation*.
### Part A
The very first part of the stress-strain curve is very close to being linear.
It is called the *elastic regime*.
In that region, say $\epsilon < \epsilon_l=0.04$, the relationship between stress and strain is:
$$
\sigma(\epsilon) = E\epsilon.
$$
The constant $E$ is known as the *Young modulus* of the material.
Use a generalized linear model and Bayesian linear regression to:
+ Compute the posterior of $E$ given the data;
+ Visualize your epistemic and aleatory uncertainty about the stress-strain curve in the elastic regime;
+ Take five plaussible samples of the linear stress-strain curve and visualize them.
In your answer, you should first clearly describe your model in text using the notation of the lectures and then code the solution.
```
# enter code here.
```
### Part B
Now, come up with a generalized linear model that can capture the non-linear part of the stress-strain relation.
Remember, you can use any model you want as soon as:
+ it is linear in the parameters to be estimated,
+ it clearly has a well-defined elastic regime (see Part A).
Use your model to:
+ Derive, compute, and visualize a probabilistic estimate of the peak of the stress-strain curve (the so-called *yield stress*). This is not necessarily going to be Gaussian or even analytically available;
+ Visualize your epistemic and aleatory uncertainty about the stress-strain curve.
+ Take five plaussible samples of the linear stress-strain curve and visualize them.
In your answer, you should first clearly describe your model in text using the notation of the lectures and then code the solution.
*Hint: You can use the Heavide step function to turn on or off models for various ranges of $\epsilon$. The idea is quite simple. Here is a model that has the right form in the elastic regime and an arbitrary form in the non-linear regime:*
$$
f(\epsilon) = E\epsilon \left[(1 - H(\epsilon - \epsilon_l)\right] + g(\epsilon;\mathbf{w}_g)H(\epsilon - \epsilon_l),
$$
where
$$
H(x) = \begin{cases}
0,\;\text{if}\;x < 0\\
1,\;\text{otherwise}.
\end{cases}
$$
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
### Part C
The model you constructed in part B may have a disctontinuity at $\epsilon=\epsilon_l$.
How can you enforce continuity of $\sigma(\epsilon)$ and its first derivative at that point?
Can you reparameterize the model of part B, so that this condition is automatically satisfied?
If yes, then repeat the analysis of part B.
*Enter your model description/solution here. Delete that ``<br>`` line (it just makes some white space).*
<br><br><br><br><br><br><br><br><br><br>
```
# Enter your code here
```
-End-
| github_jupyter |
# Module 3. Deployment on MMS(Multi Model Server)
---
본 모듈에서는 모델의 배포(deployment)를 수행합니다. 노트북 실행에는 약 15분 가량 소요되며, 핸즈온 실습 시에는 25분을 권장드립니다.
<br>
## 1. Inference script
---
아래 코드 셀은 `src` 디렉토리에 SageMaker 추론 스크립트인 `inference.py`를 저장합니다.<br>
이 스크립트는 SageMaker 상에서 MMS(Multi Model Server)를 쉽고 편하게 배포할 수 이는 high-level 툴킷인 SageMaker inference toolkit의 인터페이스를
사용하고 있으며, 여러분께서는 인터페이스에 정의된 핸들러(handler) 함수들만 구현하시면 됩니다.
#### MMS(Multi Model Server)란?
- [https://github.com/awslabs/multi-model-server](https://github.com/awslabs/multi-model-server) (2017년 12월 초 MXNet 1.0 릴리스 시 최초 공개, MXNet용 모델 서버로 시작)
- Prerequisites: Java 8, MXNet (단, MXNet 사용 시에만)
- MMS는 프레임워크에 구애받지 않도록 설계되었기 때문에, 모든 프레임워크의 백엔드 엔진 역할을 할 수 있는 충분한 유연성을 제공합니다.
- SageMaker MXNet 추론 컨테이너와 PyTorch 추론 컨테이너는 SageMaker inference toolkit으로 MMS를 래핑하여 사용합니다.
- 2020년 4월 말 PyTorch용 배포 웹 서비스인 torchserve가 출시되면서, 향후 PyTorch 추론 컨테이너는 MMS 기반에서 torchserve 기반으로 마이그레이션될 예정입니다.
```
%%writefile ./src/inference.py
import os
import pandas as pd
import gluonts
import numpy as np
import argparse
import json
import pathlib
from mxnet import gpu, cpu
from mxnet.context import num_gpus
import matplotlib.pyplot as plt
from gluonts.dataset.util import to_pandas
from gluonts.mx.distribution import DistributionOutput, StudentTOutput, NegativeBinomialOutput, GaussianOutput
from gluonts.model.deepar import DeepAREstimator
from gluonts.mx.trainer import Trainer
from gluonts.evaluation import Evaluator
from gluonts.evaluation.backtest import make_evaluation_predictions, backtest_metrics
from gluonts.model.predictor import Predictor
from gluonts.dataset.field_names import FieldName
from gluonts.dataset.common import ListDataset
def model_fn(model_dir):
path = pathlib.Path(model_dir)
predictor = Predictor.deserialize(path)
print("model was loaded successfully")
return predictor
def transform_fn(model, request_body, content_type='application/json', accept_type='application/json'):
related_cols = ['Temperature', 'Fuel_Price', 'CPI', 'Unemployment']
item_cols = ['Type', 'Size']
FREQ = 'W'
pred_length = 12
data = json.loads(request_body)
target_test_df = pd.DataFrame(data['target_values'], index=data['timestamp'])
related_test_df = pd.DataFrame(data['related_values'], index=data['timestamp'])
item_df = pd.DataFrame(data['item'], index=data['store_id'])
item_df.columns = item_cols
target = target_test_df.values
num_steps, num_series = target_test_df.shape
start_dt = target_test_df.index[0]
num_related_cols = len(related_cols)
num_features_per_feature = int(related_test_df.shape[1] / num_related_cols)
related_list = []
for feature_idx in range(0, num_related_cols):
start_idx = feature_idx * num_features_per_feature
end_idx = start_idx + num_features_per_feature
related_list.append(related_test_df.iloc[:, start_idx:end_idx].values)
test_lst = []
for i in range(0, num_series):
target_vec = target[:-pred_length, i]
related_vecs = [related[:, i] for related in related_list]
item = item_df.loc[i+1]
dic = {FieldName.TARGET: target_vec,
FieldName.START: start_dt,
FieldName.FEAT_DYNAMIC_REAL: related_vecs,
FieldName.FEAT_STATIC_CAT: [item[0]],
FieldName.FEAT_STATIC_REAL: [item[1]]
}
test_lst.append(dic)
test_ds = ListDataset(test_lst, freq=FREQ)
response_body = {}
forecast_it = model.predict(test_ds)
for idx, f in enumerate(forecast_it):
response_body[f'store_{idx}'] = f.samples.mean(axis=0).tolist()
return json.dumps(response_body)
```
<br>
## 2. Test Inference code
---
엔드포인트 배포 전, 추론 스크립트를 검증합니다.
```
%store -r
from src.inference import model_fn, transform_fn
import json
import numpy as np
import pandas as pd
# Prepare test data
target_test_df = pd.read_csv("data/target_train.csv", index_col=0, header=[0,1])
related_test_df = pd.read_csv("data/related_train.csv", index_col=0, header=[0,1])
item_df = pd.read_csv("data/item.csv", index_col=0)
input_data = {'target_values': target_test_df.values.tolist(),
'related_values': related_test_df.values.tolist(),
'item': item_df.values.tolist(),
'timestamp': related_test_df.index.tolist(),
'store_id': item_df.index.tolist()
}
request_body = json.dumps(input_data)
# Test inference script
model = model_fn('./model')
response = transform_fn(model, request_body)
outputs = json.loads(response)
print(outputs['store_0'])
```
<br>
## 3. Local Endpoint Inference
---
충분한 검증 및 테스트 없이 훈련된 모델을 곧바로 실제 운영 환경에 배포하기에는 많은 위험 요소들이 있습니다. 따라서, 로컬 모드를 사용하여 실제 운영 환경에 배포하기 위한 추론 인스턴스를 시작하기 전에 노트북 인스턴스의 로컬 환경에서 모델을 배포하는 것을 권장합니다. 이를 로컬 모드 엔드포인트(Local Mode Endpoint)라고 합니다.
```
import os
import time
import sagemaker
from sagemaker.mxnet import MXNetModel
role = sagemaker.get_execution_role()
local_model_path = f'file://{os.getcwd()}/model/model.tar.gz'
endpoint_name = "local-endpoint-walmart-sale-forecast-{}".format(int(time.time()))
```
아래 코드 셀을 실행 후, 로그를 확인해 보세요. MMS에 대한 세팅값들을 확인하실 수 있습니다.
```bash
algo-1-u3xwd_1 | MMS Home: /usr/local/lib/python3.6/site-packages
algo-1-u3xwd_1 | Current directory: /
algo-1-u3xwd_1 | Temp directory: /home/model-server/tmp
algo-1-u3xwd_1 | Number of GPUs: 0
algo-1-u3xwd_1 | Number of CPUs: 2
algo-1-u3xwd_1 | Max heap size: 878 M
algo-1-u3xwd_1 | Python executable: /usr/local/bin/python3.6
algo-1-u3xwd_1 | Config file: /etc/sagemaker-mms.properties
algo-1-u3xwd_1 | Inference address: http://0.0.0.0:8080
algo-1-u3xwd_1 | Management address: http://0.0.0.0:8080
algo-1-u3xwd_1 | Model Store: /.sagemaker/mms/models
...
```
```
local_model = MXNetModel(model_data=local_model_path,
role=role,
source_dir='src',
entry_point='inference.py',
framework_version='1.8.0',
py_version='py37')
predictor = local_model.deploy(instance_type='local',
initial_instance_count=1,
endpoint_name=endpoint_name,
wait=True)
```
로컬에서 컨테이너를 배포했기 때문에 컨테이너가 현재 실행 중임을 확인할 수 있습니다.
```
!docker ps
```
### Inference using SageMaker SDK
SageMaker SDK의 `predict()` 메서드로 쉽게 추론을 수행할 수 있습니다.
```
outputs = predictor.predict(input_data)
print(outputs['store_0'], outputs['store_20'])
```
### Inference using Boto3 SDK
SageMaker SDK의 `predict()` 메서드로 추론을 수행할 수도 있지만, 이번에는 boto3의 `invoke_endpoint()` 메서드로 추론을 수행해 보겠습니다.<br>
Boto3는 서비스 레벨의 low-level SDK로, ML 실험에 초점을 맞춰 일부 기능들이 추상화된 high-level SDK인 SageMaker SDK와 달리
SageMaker API를 완벽하게 제어할 수 있습으며, 프로덕션 및 자동화 작업에 적합합니다.
참고로 `invoke_endpoint()` 호출을 위한 런타임 클라이언트 인스턴스 생성 시, 로컬 배포 모드에서는 `sagemaker.local.LocalSagemakerRuntimeClient()`를 호출해야 합니다.
```
client = sagemaker.local.LocalSagemakerClient()
runtime_client = sagemaker.local.LocalSagemakerRuntimeClient()
endpoint_name = local_model.endpoint_name
response = runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='application/json',
Accept='application/json',
Body=json.dumps(input_data)
)
outputs = json.loads(response['Body'].read().decode())
print(outputs['store_0'], outputs['store_20'])
```
### Local Mode Endpoint Clean-up
엔드포인트를 계속 사용하지 않는다면, 엔드포인트를 삭제해야 합니다.
SageMaker SDK에서는 `delete_endpoint()` 메소드로 간단히 삭제할 수 있습니다.
```
def delete_endpoint(client, endpoint_name):
response = client.describe_endpoint_config(EndpointConfigName=endpoint_name)
model_name = response['ProductionVariants'][0]['ModelName']
client.delete_model(ModelName=model_name)
client.delete_endpoint(EndpointName=endpoint_name)
client.delete_endpoint_config(EndpointConfigName=endpoint_name)
print(f'--- Deleted model: {model_name}')
print(f'--- Deleted endpoint: {endpoint_name}')
print(f'--- Deleted endpoint_config: {endpoint_name}')
delete_endpoint(client, endpoint_name)
```
<br>
## 4. SageMaker Hosted Endpoint Inference
---
이제 실제 운영 환경에 엔드포인트 배포를 수행해 보겠습니다. 로컬 모드 엔드포인트와 대부분의 코드가 동일하며, 모델 아티팩트 경로(`model_data`)와 인스턴스 유형(`instance_type`)만 변경해 주시면 됩니다. SageMaker가 관리하는 배포 클러스터를 프로비저닝하는 시간이 소요되기 때문에 추론 서비스를 시작하는 데에는 약 5~10분 정도 소요됩니다.
```
import os
import boto3
import sagemaker
from sagemaker.mxnet import MXNet
boto_session = boto3.Session()
sagemaker_session = sagemaker.Session(boto_session=boto_session)
role = sagemaker.get_execution_role()
bucket = sagemaker.Session().default_bucket()
model_path = os.path.join(s3_model_dir, "model.tar.gz")
endpoint_name = "endpoint-walmart-sale-forecast-{}".format(int(time.time()))
model = MXNetModel(model_data=model_path,
role=role,
source_dir='src',
entry_point='inference.py',
framework_version='1.8.0',
py_version='py37')
predictor = model.deploy(instance_type="ml.c5.large",
initial_instance_count=1,
endpoint_name=endpoint_name,
wait=True)
```
추론을 수행합니다. 로컬 모드의 코드와 동일합니다.
```
import boto3
client = boto3.client('sagemaker')
runtime_client = boto3.client('sagemaker-runtime')
endpoint_name = model.endpoint_name
response = runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='application/json',
Accept='application/json',
Body=json.dumps(input_data)
)
outputs = json.loads(response['Body'].read().decode())
print(outputs['store_0'], outputs['store_20'])
```
### SageMaker Hosted Endpoint Clean-up
엔드포인트를 계속 사용하지 않는다면, 불필요한 과금을 피하기 위해 엔드포인트를 삭제해야 합니다.
SageMaker SDK에서는 `delete_endpoint()` 메소드로 간단히 삭제할 수 있으며, UI에서도 쉽게 삭제할 수 있습니다.
```
delete_endpoint(client, endpoint_name)
```
| github_jupyter |
```
import numpy as np
import pandas as pd
from numpy.random import randn
np.random.seed(61)
df = pd.DataFrame(randn(5,4), index=["A","B","C","D","E"], columns=["Z","X","W","Y"])
df
df["Z"]
df.X
#columns
df[["X","W"]]
df["T"] = df["X"] + df["W"]
df
#default axis=0
df.drop("T",axis=1, inplace=True)
df
df.drop("E")
df.shape
#rows
df.loc["A":"C"]
df.loc["A"]["W"]
df.iloc[0]["W"]
df.iloc[0,2]
df.loc["A","W"]
df < 0
df[df<0]
df2=df[df<0]
df[df["W"]>0.2]
df[df["W"]>0.2]["Z"]
df[df["W"]>0.2]["X"]
df[(df["W"]>0.2) | (df["Y"] < 0)]
df[(df["W"]>0.2) | (df["Y"] < 0)].loc["E"]
df.reset_index()
new_idx = "AA BB CC DD EE".split()
new_idx
df["idx"] = new_idx
df.set_index("idx")
df
#multiIndex
outside = ['G1','G1','G1','G2','G2','G2']
inside = [1,2,3,1,2,3]
hier_index = list(zip(outside,inside))
hier_index = pd.MultiIndex.from_tuples(hier_index)
df = pd.DataFrame(np.random.randn(6,2),index=hier_index,columns=['A','B'])
df
df.loc["G1"].loc[1]
df.index.names
df.index.names = ["X","Y"]
df
df.loc["G1"].loc[1]["B"]
df.xs("G1")
df.xs(1,level="Y")
df2["Y"].loc["B"]=np.nan
df2
df2.dropna()
df2.dropna(thresh=2)
df2.dropna(how="all", axis=1)
df2.fillna(333)
data = {'Company':['GOOG','GOOG','MSFT','MSFT','FB','FB'],
'Person':['Sam','Charlie','Amy','Vanessa','Carl','Sarah'],
'Sales':[200,120,340,124,243,350]}
df = pd.DataFrame(data)
df
byc=df.groupby("Company")
byc.mean()
byc.sum()
df.groupby("Company").sum().iloc[1]
df.groupby("Company").count()
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
pd.concat([df1,df2,df3])
pd.concat([df1,df2,df3], axis=1)
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
left
right
pd.merge(left,right,how='inner',on='key')
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
left.join(right)
left.join(right, how='outer')
df = pd.DataFrame({'col1':[1,2,3,4],'col2':[444,555,666,444],'col3':['abc','def','ghi','xyz']})
df.head()
df["col2"].unique()
df["col2"].nunique()
df["col2"].value_counts()
df["col1"].apply(lambda x: x**2)
df.columns
df.index
df
df.sort_values(by="col2")
df.isna()
data = {'A':['foo','foo','foo','bar','bar','bar'],
'B':['one','one','two','two','one','one'],
'C':['x','y','x','y','x','y'],
'D':[1,3,2,5,4,1]}
df = pd.DataFrame(data)
df
df.pivot_table(values='D',index=['A', 'B'],columns=['C'])
#pd.read_excel('Excel_Sample.xlsx',sheetname='Sheet1')
# Pandas read_html function will read tables off of a webpage and return a list of DataFrame objects
#You may need to install htmllib5,lxml, and BeautifulSoup4. In your terminal/command prompt run:
#conda install lxml
#conda install html5lib
#conda install BeautifulSoup4
#df = pd.read_html('http://www.fdic.gov/bank/individual/failed/banklist.html')
#sqlite
#from sqlalchemy import create_engine
#engine = create_engine('sqlite:///:memory:')
#df.to_sql('data', engine)
#sql_df = pd.read_sql('data',con=engine)
```
| github_jupyter |
# Graph matching
Some of this lesson is taken directly from the [`graspologic` tutorials on graph matching](https://microsoft.github.io/graspologic/latest/tutorials/index.html#matching), mostly written by Ali Saad-Eldin with help from myself.
## Why match graphs?
Graph matching comes up in a ton of different contexts!
- Computer vision: comparing objects
- Communication networks:
- Finding noisy subgraphs
- Matching different social networks
- Neuroscience: finding the same nodes on different sides of a brain
```{figure} ./images/graph-match-cv.jpeg
Application of graph matching in computer vision. Figure from [here](https://cv.snu.ac.kr/research/~ProgGM/).
```
```{figure} ./images/the-wire.png
Potential application of graph matching in a communication subnetwork. Figure from *The Wire*, Season 3, Episode 7.
```
```{figure} ./images/match-neuron-morphology.png
Application of graph matching to predict homologous neurons in a brain connectome.
```
## Permutations
To start to understand graph matching, we first need to understand permutations and
permutation matrices.
A [**permutation**](https://en.wikipedia.org/wiki/Permutation) can be thought of as a
specific ordering or arrangement of some number of objects.
```{admonition} Question
:class: tip
How many permutations are there of $n$ objects?
```
Permutations, for us, will be represented by [**permutation matrices**](https://en.wikipedia.org/wiki/Permutation_matrix).
A permutation matrix is $n \times n$, with all zeros except for $n$ 1s. Let's look at
what a permutation matrix times a vector looks like.
```{figure} ./images/perm-matrix.png
:width: 200px
A permutation matrix multiplied by a vector. The red elements of the matrix indicate the
1s. Image from [Wikipedia](https://en.wikipedia.org/wiki/Permutation_matrix).
```
So, we see that if we look at the permutation matrix, the *row index* represents the
index of the original position of object $i$. The *column index* represents the new
position of an object. So, if we have a 1 at position $(1, 4)$, that means the first
object in the original arrangement moves to be the fourth object.
Note that this also works for matrices: each column of a matrix $A$ would be permuted
the same way as the vector in the example above. So, we can think of
$$PA$$
as permuting the *rows* of the matrix $A$.
Note that post-multiplication by the matrix $P$ works the opposite way (try it out
yourself if you don't see this, or refer to the Wikipedia article). For this reason, if
we wanted to permute the columns of $A$ in the same way, we'd have to do
$$AP^T$$
```{admonition} Question
:class: tip
How can we permute the rows *and* columns of the matrix $A$ in the same way? Why do
we care about this for networks?
```
## Graph matching problem
Why do we care about permutations for the problem of [**graph matching**](https://en.wikipedia.org/wiki/Graph_matching)?
Graph matching refers to the problem of finding a mapping between the nodes of one graph ($A$)
and the nodes of some other graph, $B$. For now, consider the case where the two networks
have exactly the same number of nodes. Then, this problem amounts to finding a *permutation*
of the nodes of one network with regard to the nodes of the other. Mathematically, we
can think of this as comparing $A$ vs. $P B P^T$.
```{note}
You can think of graph matching as a more general case of the [**graph isomorphism problem**](https://en.wikipedia.org/wiki/Graph_isomorphism_problem).
In the case of graph matching, we don't assume that the graphs must be exactly the same
when matched, while for the graph isomorphism problem, we do.
```
How can we measure the quality of this alignment between two networks, given what
we've talked about so far? Like when we talked about approximating matrices in the [embeddings](embeddings.ipynb)
section, one natural way to do this is via the Frobenius norm of the difference.
$$e(P) = \|A - PBP^T\|_F$$
```{admonition} Question
:class: tip
In words, what is this quantity $e(P)$ measuring with respect to the edges of two
unweighted networks?
```
We can use this same definition above for any type of network: unweighted or weighted,
directed or undirected, with or without self-loops.
```{figure} ./images/network-matching-explanation.png
Diagram explaining graph matching.
```
## Solving the graph matching problem
Many solutions for the problem above have been proposed - note that all of these are
approximate solutions, and they tend to scale fairly poorly (in the number of nodes)
compared to some of the other algorithms we have discussed so far. Nevertheless, a lot
of progress has been made. I'm just going to focus on one family of algorithms based
on the work of {cite:t}`vogelstein2015fast`.
As we discussed when looking at the spectral method for maximizing modularity, we have a
discrete problem, but we'd like to use continuous optimization tools where we can take
gradients. To make this possible, the Fast Approximate Quadradic (FAQ) method first
relaxes the constraint that $P$ be a permutation matrix. Via the Birkhoff-von Neumann theorem, it can be shown that the [convex hull](https://en.wikipedia.org/wiki/Convex_hull)
of the permutation matrices is the set of [**doubly stochastic matrices**](https://en.wikipedia.org/wiki/Doubly_stochastic_matrix). A doubly stochastic matrix just has row
and columns sums equal to 1, but does not necessarily have to have all nonzero elements
equal to 1. This theorem is just saying that if I take a weighted average of any two
permutation matrices, the row and columns sums of the result must be 1.
It can be shown that minimizing our $e(P)$ above is equivalent to
$$\min_P -\text{trace}(APB^T P^T)$$
```{note}
The [**quadratic assignment problem**](https://en.wikipedia.org/wiki/Quadratic_assignment_problem) can be written as $\min_P \text{trace}(APB^T P^T)$ - since these are just a sign flip away, any algorithm which solves one can be
easily used to solve the other.
```
Calling our doubly stochastic matrices $D$, we now have
$$\min_D -\text{trace}(ADB^T D^T)$$
Given this relaxation, we can now begin to take gradients in our space of matrices. I won't go into every detail, but the algorithm we end up using is
something like:
1. Start with some initial position - note that this position is a doubly stochastic matrix.
2. Compute the gradient of the expression above with respect to $D$. This gives us our "step direction."
3. Compute a step size (how far to go in that direction in the space of matrices) by searching over the line between our current position and the one computed in 2.
4. Update our position based on 3.
5. Repeat 2.-4. until some convergence criterion is reached.
6. Project back to the set of permutation matrices.
## Graph matching with `graspologic`
### Basic graph matching
Thankfully, all of this is implemented in `graspologic`. Let's start by generating a random network (ER). We'll then make a permuted copy of itself.
```
import numpy as np
from graspologic.match import GraphMatch
from graspologic.simulations import er_np
n = 50
p = 0.3
np.random.seed(1)
G1 = er_np(n=n, p=p)
node_shuffle_input = np.random.permutation(n)
G2 = G1[np.ix_(node_shuffle_input, node_shuffle_input)]
print("Number of edge disagreements: ", np.sum(abs(G1-G2)))
import matplotlib.pyplot as plt
from graspologic.plot import heatmap
fig, axs = plt.subplots(1,2,figsize=(10, 5))
heatmap(G1, cbar=False, title = 'G1 [ER-NP(50, 0.3) Simulation]', ax=axs[0])
_ = heatmap(G2, cbar=False, title = 'G2 [G1 Randomly Shuffled]', ax=axs[1])
```
Now, let's solve the graph matching problem.
```
gmp = GraphMatch()
gmp = gmp.fit(G1,G2)
G2 = G2[np.ix_(gmp.perm_inds_, gmp.perm_inds_)]
print("Number of edge disagreements: ", np.sum(abs(G1-G2)))
```
So, we've exactly recovered the correct permutation - note that this won't always be true.
### Adding seed nodes
Next, we explore the use of "seed" nodes. Imagine you have two networks that you want to match, but you already know that a handful of these nodes are correctly paired. These nodes are called seeds, which you can incorporate into
the optimization in `graspologic` via techniques described in {cite:t}`fishkind2019seeded`.
For this example, we use a slightly different network model - we create two stochastic block models, but the edges are *correlated* so that the two networks are similar but not exactly the same.
```
import seaborn as sns
from graspologic.simulations import sbm_corr
sns.set_context('talk')
np.random.seed(8888)
directed = False
loops = False
n_per_block = 75
n_blocks = 3
block_members = np.array(n_blocks * [n_per_block])
n_verts = block_members.sum()
rho = .9
block_probs = np.array([[0.7, 0.3, 0.4], [0.3, 0.7, 0.3], [0.4, 0.3, 0.7]])
fig, ax = plt.subplots(1, 1, figsize=(4, 4))
sns.heatmap(block_probs, cbar=False, annot=True, square=True, cmap="Reds", ax=ax)
ax.set_title("SBM block probabilities")
A1, A2 = sbm_corr(block_members, block_probs, rho, directed=directed, loops=loops)
fig, axs = plt.subplots(1, 3, figsize=(10, 5))
heatmap(A1, ax=axs[0], cbar=False, title="Graph 1")
heatmap(A2, ax=axs[1], cbar=False, title="Graph 2")
_ = heatmap(A1 - A2, ax=axs[2], cbar=False, title="Diff (G1 - G2)")
```
Here we see that after shuffling the second graph, there are many more edge disagreements, as expected.
```
node_shuffle_input = np.random.permutation(n_verts)
A2_shuffle = A2[np.ix_(node_shuffle_input, node_shuffle_input)]
node_unshuffle_input = np.array(range(n_verts))
node_unshuffle_input[node_shuffle_input] = np.array(range(n_verts))
fig, axs = plt.subplots(1, 3, figsize=(10, 5))
heatmap(A1, ax=axs[0], cbar=False, title="Graph 1")
heatmap(A2_shuffle, ax=axs[1], cbar=False, title="Graph 2 shuffled")
_ = heatmap(A1 - A2_shuffle, ax=axs[2], cbar=False, title="Diff (G1 - G2 shuffled)")
```
First, we will run graph matching on graph 1 and the shuffled graph 2 with no seeds, and return the match ratio, that is the fraction of vertices that have been correctly matched.
```
sgm = GraphMatch()
sgm = sgm.fit(A1,A2_shuffle)
A2_unshuffle = A2_shuffle[np.ix_(sgm.perm_inds_, sgm.perm_inds_)]
fig, axs = plt.subplots(1, 3, figsize=(10, 5))
heatmap(A1, ax=axs[0], cbar=False, title="Graph 1")
heatmap(A2_unshuffle, ax=axs[1], cbar=False, title="Graph 2 unshuffled")
heatmap(A1 - A2_unshuffle, ax=axs[2], cbar=False, title="Diff (G1 - G2 unshuffled)")
match_ratio = 1-(np.count_nonzero(abs(sgm.perm_inds_-node_unshuffle_input))/n_verts)
print("Match Ratio with no seeds: ", match_ratio)
```
While the predicted permutation for graph 2 did recover the basic structure of the stochastic block model (i.e. graph 1 and graph 2 look qualitatively similar), we see that the number of edge disagreements between them is still quite high, and the match ratio quite low.
Next, we will run SGM with 10 randomly selected seeds. Although 10 seeds is only about 4% of the 300 node graph, we will observe below how much more accurate the matching will be compared to having no seeds.
```
import random
W1 = np.sort(random.sample(list(range(n_verts)),10))
W1 = W1.astype(int)
W2 = np.array(node_unshuffle_input[W1])
sgm = GraphMatch()
sgm = sgm.fit(A1,A2_shuffle,W1,W2)
A2_unshuffle = A2_shuffle[np.ix_(sgm.perm_inds_, sgm.perm_inds_)]
fig, axs = plt.subplots(1, 3, figsize=(10, 5))
heatmap(A1, ax=axs[0], cbar=False, title="Graph 1")
heatmap(A2_unshuffle, ax=axs[1], cbar=False, title="Graph 2 unshuffled")
heatmap(A1 - A2_unshuffle, ax=axs[2], cbar=False, title="Diff (G1 - G2 unshuffled)")
match_ratio = 1-(np.count_nonzero(abs(sgm.perm_inds_-node_unshuffle_input))/n_verts)
print("Match Ratio with 10 seeds: ", match_ratio)
```
### Graphs with different numbers of nodes
I won't go into all of the details, but it is also possible to match networks
with different numbers of nodes.
Here, we just create two correlated SBMs, and then remove some nodes from each block in one of the networks.
```
# simulating G1', G2, deleting 25 vertices
np.random.seed(1)
directed = False
loops = False
block_probs = [[0.9,0.4,0.3,0.2],
[0.4,0.9,0.4,0.3],
[0.3,0.4,0.9,0.4],
[0.2,0.3,0.4,0.7]]
n =100
n_blocks = 4
rho = 0.5
block_members = np.array(n_blocks * [n])
n_verts = block_members.sum()
G1p, G2 = sbm_corr(block_members,block_probs, rho, directed, loops)
G1 = np.zeros((300,300))
c = np.copy(G1p)
step1 = np.arange(4) * 100 + 75
step2 = np.arange(5) * 75
step3 = np.arange(4) * 100
for i in range(len(step1)):
block1 = np.arange(step1[i], step1[i]+25)
c[block1,:] = -1
c[:, block1] = -1
for j in range(len(step3)):
G1[step2[i]:step2[i+1], step2[j]:step2[j+1]] = G1p[step3[i]: step1[i], step3[j]:step1[j]]
topleft_G1 = np.zeros((400,400))
topleft_G1[:300,:300] = G1
fig, axs = plt.subplots(1, 4, figsize=(20, 10))
heatmap(G1p, ax=axs[0], cbar=False, title="G1'")
heatmap(G2, ax=axs[1], cbar=False, title="G2")
heatmap(c, ax=axs[2], cbar=False, title="G1")
_ = heatmap(topleft_G1, ax=axs[3], cbar=False, title="G1 (to top left corner)")
```
Now, we have two networks which have two different sizes, and only some of the nodes in the smaller network are well represented in the other. We can still use graph matching here in `graspologic` - this code compares two different methods of doing so using techniques dubbed "padding" in {cite:t}`fishkind2019seeded`.
```
np.random.seed(1)
gmp_naive = GraphMatch(padding='naive')
seed1 = np.random.choice(np.arange(300),8)
seed2 = [int(x/75)*25 + x for x in seed1]
gmp_naive = gmp_naive.fit(G2, G1, seed2, seed1)
G1_naive = topleft_G1[gmp_naive.perm_inds_][:, gmp_naive.perm_inds_]
gmp_adopted = GraphMatch(padding='adopted')
gmp_adopted = gmp_adopted.fit(G2, G1, seed2, seed1)
G1_adopted = topleft_G1[gmp_adopted.perm_inds_][:, gmp_adopted.perm_inds_]
fig, axs = plt.subplots(1, 2, figsize=(14, 7))
heatmap(G1_naive, ax=axs[0], cbar=False, title="Naive Padding")
heatmap(G1_adopted, ax=axs[1], cbar=False, title="Adopted Padding")
naive_matching = np.concatenate([gmp_naive.perm_inds_[x * 100 : (x * 100) + 75] for x in range(n_blocks)])
adopted_matching = np.concatenate([gmp_adopted.perm_inds_[x * 100 : (x * 100) + 75] for x in range(n_blocks)])
print(f'Match ratio of nodes remaining in G1, with naive padding: {sum(naive_matching == np.arange(300))/300}')
print(f'Match ratio of nodes remaining in G1, with adopted padding: {sum(adopted_matching == np.arange(300))/300}')
```
### Practical considerations
- While the number of edges in the two networks matters, the most important scaling factor is the number of nodes. Solving the graph matching problem using our code may take a while when you have more than a few thousand nodes.
- The current implementation only works for dense arrays. There is no reason we couldn't make it work for sparse (and we plan to) but because the most important factor in the scaling is the number of nodes, this wouldn't make a drastic difference.
- As with many algorithms we've talked about in this course, the results will likely be different with different runs of the algorithm. This is primarily because of the initialization. The `n_init` parameter to `GraphMatch` allows you to do multiple initializations and take the best.
- You can play with the `max_iter` and `eps` parameters to control how hard the algorithm will try to keep improving its results. Scaling these can give you better performance (but will possibly take longer) or quicker results (but the accuracy may suffer).
- I recommend always leaving the `shuffle_input` parameter set to `True` - for reasons I won't go into, the input order of the two networks will matter otherwise, and this can give inflated or misleading performance if you aren't careful.
## Application
In a recent paper, we applied these same tools for matching the nodes in the left and right *Drosophila* larva mushroom body connectome datasets, the same
ones you get from `graspologic.datasets.load_drosophila_left()` etc.
```{figure} ./images/gm-stat-conn.png
Figure from {cite:t}`chung2021statistical`.
```
## References
```{bibliography}
:filter: docname in docnames
:style: unsrt
```
| github_jupyter |
```
from jkg_evaluators import dragonfind_10_to_500
cow_alive_list_test_1 = [False, False, True, True, True]
def my_solution2(cow_alive_list):
fat_alive_cow_index = 0
thin_alive_cow_index = len(cow_alive_list) - 1
while (fat_alive_cow_index +1) < thin_alive_cow_index:
middle_cow = int((fat_alive_cow_index +
thin_alive_cow_index) / 2)
if cow_alive_list[middle_cow]:
thin_alive_cow_index = middle_cow
else:
fat_alive_cow_index = middle_cow
print("l: ",fat_alive_cow_index, " u: ", thin_alive_cow_index)
return middle_cow + 1
def my_solution3(is_dead,number_of_cows):
fat_alive_cow_index = 0
thin_alive_cow_index = number_of_cows - 1
while (fat_alive_cow_index +1) < thin_alive_cow_index:
i= int((fat_alive_cow_index +
thin_alive_cow_index) / 2)
if is_dead(i):
fat_alive_cow_index=i
else:
thin_alive_cow_index=i
return i + 2
dragonfind_10_to_500.evaluate(my_solution3)
my_solution2(cow_alive_list_test_1)
```
<a style='text-decoration:none;line-height:16px;display:flex;color:#5B5B62;padding:10px;justify-content:end;' href='https://deepnote.com?utm_source=created-in-deepnote-cell&projectId=978e47b7-a961-4dca-a945-499e8b781a34' target="_blank">
<img alt='Created in deepnote.com' style='display:inline;max-height:16px;margin:0px;margin-right:7.5px;' src='data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iVVRGLTgiPz4KPHN2ZyB3aWR0aD0iODBweCIgaGVpZ2h0PSI4MHB4IiB2aWV3Qm94PSIwIDAgODAgODAiIHZlcnNpb249IjEuMSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIiB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayI+CiAgICA8IS0tIEdlbmVyYXRvcjogU2tldGNoIDU0LjEgKDc2NDkwKSAtIGh0dHBzOi8vc2tldGNoYXBwLmNvbSAtLT4KICAgIDx0aXRsZT5Hcm91cCAzPC90aXRsZT4KICAgIDxkZXNjPkNyZWF0ZWQgd2l0aCBTa2V0Y2guPC9kZXNjPgogICAgPGcgaWQ9IkxhbmRpbmciIHN0cm9rZT0ibm9uZSIgc3Ryb2tlLXdpZHRoPSIxIiBmaWxsPSJub25lIiBmaWxsLXJ1bGU9ImV2ZW5vZGQiPgogICAgICAgIDxnIGlkPSJBcnRib2FyZCIgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoLTEyMzUuMDAwMDAwLCAtNzkuMDAwMDAwKSI+CiAgICAgICAgICAgIDxnIGlkPSJHcm91cC0zIiB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjM1LjAwMDAwMCwgNzkuMDAwMDAwKSI+CiAgICAgICAgICAgICAgICA8cG9seWdvbiBpZD0iUGF0aC0yMCIgZmlsbD0iIzAyNjVCNCIgcG9pbnRzPSIyLjM3NjIzNzYyIDgwIDM4LjA0NzY2NjcgODAgNTcuODIxNzgyMiA3My44MDU3NTkyIDU3LjgyMTc4MjIgMzIuNzU5MjczOSAzOS4xNDAyMjc4IDMxLjY4MzE2ODMiPjwvcG9seWdvbj4KICAgICAgICAgICAgICAgIDxwYXRoIGQ9Ik0zNS4wMDc3MTgsODAgQzQyLjkwNjIwMDcsNzYuNDU0OTM1OCA0Ny41NjQ5MTY3LDcxLjU0MjI2NzEgNDguOTgzODY2LDY1LjI2MTk5MzkgQzUxLjExMjI4OTksNTUuODQxNTg0MiA0MS42NzcxNzk1LDQ5LjIxMjIyODQgMjUuNjIzOTg0Niw0OS4yMTIyMjg0IEMyNS40ODQ5Mjg5LDQ5LjEyNjg0NDggMjkuODI2MTI5Niw0My4yODM4MjQ4IDM4LjY0NzU4NjksMzEuNjgzMTY4MyBMNzIuODcxMjg3MSwzMi41NTQ0MjUgTDY1LjI4MDk3Myw2Ny42NzYzNDIxIEw1MS4xMTIyODk5LDc3LjM3NjE0NCBMMzUuMDA3NzE4LDgwIFoiIGlkPSJQYXRoLTIyIiBmaWxsPSIjMDAyODY4Ij48L3BhdGg+CiAgICAgICAgICAgICAgICA8cGF0aCBkPSJNMCwzNy43MzA0NDA1IEwyNy4xMTQ1MzcsMC4yNTcxMTE0MzYgQzYyLjM3MTUxMjMsLTEuOTkwNzE3MDEgODAsMTAuNTAwMzkyNyA4MCwzNy43MzA0NDA1IEM4MCw2NC45NjA0ODgyIDY0Ljc3NjUwMzgsNzkuMDUwMzQxNCAzNC4zMjk1MTEzLDgwIEM0Ny4wNTUzNDg5LDc3LjU2NzA4MDggNTMuNDE4MjY3Nyw3MC4zMTM2MTAzIDUzLjQxODI2NzcsNTguMjM5NTg4NSBDNTMuNDE4MjY3Nyw0MC4xMjg1NTU3IDM2LjMwMzk1NDQsMzcuNzMwNDQwNSAyNS4yMjc0MTcsMzcuNzMwNDQwNSBDMTcuODQzMDU4NiwzNy43MzA0NDA1IDkuNDMzOTE5NjYsMzcuNzMwNDQwNSAwLDM3LjczMDQ0MDUgWiIgaWQ9IlBhdGgtMTkiIGZpbGw9IiMzNzkzRUYiPjwvcGF0aD4KICAgICAgICAgICAgPC9nPgogICAgICAgIDwvZz4KICAgIDwvZz4KPC9zdmc+' > </img>
Created in <span style='font-weight:600;margin-left:4px;'>Deepnote</span></a>
| github_jupyter |
To try this example, Go to Cell -> Run all
Report problems with this example on [GitHub Issues](https://github.com/jina-ai/jina/issues/new/choose)
Make sure to run this command to install Jina 2.0 for this notebook
```
!pip install jina
```
## Minimum Working Example for Jina 2.0
This notebook explains code adapted from the [38-Line Get Started](https://github.com/jina-ai/jina#get-started).
The demo indices every line of its *own source code*, then searches for the most similar line to `"request(on=something)"`. No other library required, no external dataset required. The dataset is the codebase.
### Import
For this demo, we only need to import `numpy` and `jina`:
```
import numpy as np
from jina import Document, DocumentArray, Executor, Flow, requests
```
### Character embedding
For embedding every line of the code, we want to represent it into a vector using simple character embedding and mean-pooling.
The character embedding is a simple identity matrix.
To do that we need to write a new `Executor`:
```
class CharEmbed(Executor): # a simple character embedding with mean-pooling
offset = 32 # letter `a`
dim = 127 - offset + 1 # last pos reserved for `UNK`
char_embd = np.eye(dim) * 1 # one-hot embedding for all chars
@requests
def foo(self, docs: DocumentArray, **kwargs):
for d in docs:
r_emb = [ord(c) - self.offset if self.offset <= ord(c) <= 127 else (self.dim - 1) for c in d.text]
d.embedding = self.char_embd[r_emb, :].mean(axis=0) # mean-pooling
```
### Indexing
To store & retrieve encoded results, we need an indexer. At index time, it stores `DocumentArray` into memory. At query time, it computes the Euclidean distance between the embeddings of query Documents and all embeddings of the stored Documents.
The indexing and searching are represented by `@request('/index')` and `@request('/search')`, respectively.
```
class Indexer(Executor):
_docs = DocumentArray() # for storing all document in memory
@requests(on='/index')
def foo(self, docs: DocumentArray, **kwargs):
self._docs.extend(docs) # extend stored `docs`
@requests(on='/search')
def bar(self, docs: DocumentArray, **kwargs):
q = np.stack(docs.get_attributes('embedding')) # get all embedding from query docs
d = np.stack(self._docs.get_attributes('embedding')) # get all embedding from stored docs
euclidean_dist = np.linalg.norm(q[:, None, :] - d[None, :, :], axis=-1) # pairwise euclidean distance
for dist, query in zip(euclidean_dist, docs): # add & sort match
query.matches = [Document(self._docs[int(idx)], copy=True, scores={'euclid': d}) for idx, d in enumerate(dist)]
query.matches.sort(key=lambda m: m.scores['euclid'].value) # sort matches by its value
```
### Callback function
Callback function is invoked when the search is done.
```
def print_matches(req): # the callback function invoked when task is done
for idx, d in enumerate(req.docs[0].matches[:3]): # print top-3 matches
print(f'[{idx}]{d.scores["euclid"].value:2f}: "{d.text}"')
```
### Flow
```
f = Flow(port_expose=12345).add(uses=CharEmbed, parallel=2).add(uses=Indexer) # build a Flow, with 2 parallel CharEmbed, tho unnecessary
source_code = """
import numpy as np
from jina import Document, DocumentArray, Executor, Flow, requests
class CharEmbed(Executor): # a simple character embedding with mean-pooling
offset = 32 # letter `a`
dim = 127 - offset + 1 # last pos reserved for `UNK`
char_embd = np.eye(dim) * 1 # one-hot embedding for all chars
@requests
def foo(self, docs: DocumentArray, **kwargs):
for d in docs:
r_emb = [ord(c) - self.offset if self.offset <= ord(c) <= 127 else (self.dim - 1) for c in d.text]
d.embedding = self.char_embd[r_emb, :].mean(axis=0) # average pooling
class Indexer(Executor):
_docs = DocumentArray() # for storing all documents in memory
@requests(on='/index')
def foo(self, docs: DocumentArray, **kwargs):
self._docs.extend(docs) # extend stored `docs`
@requests(on='/search')
def bar(self, docs: DocumentArray, **kwargs):
q = np.stack(docs.get_attributes('embedding')) # get all embeddings from query docs
d = np.stack(self._docs.get_attributes('embedding')) # get all embeddings from stored docs
euclidean_dist = np.linalg.norm(q[:, None, :] - d[None, :, :], axis=-1) # pairwise euclidean distance
for dist, query in zip(euclidean_dist, docs): # add & sort match
query.matches = [Document(self._docs[int(idx)], copy=True, scores={'euclid': d}) for idx, d in enumerate(dist)]
query.matches.sort(key=lambda m: m.scores['euclid'].value) # sort matches by their values
f = Flow(port_expose=12345, protocol='http', cors=True).add(uses=CharEmbed, parallel=2).add(uses=Indexer) # build a Flow, with 2 parallel CharEmbed, tho unnecessary
with f:
f.post('/index', DocumentArray([Document(text=t.strip()) for t in source_code.split('\n') if t.strip() ])) # index all lines of this notebook's source code
f.post('/search', Document(text='@request(on=something)'), on_done=print_matches)
"""
with f:
f.post('/index', DocumentArray([Document(text=t.strip()) for t in source_code.split('\n') if t.strip() ])) # index all lines of this notebook's source code
f.post('/search', Document(text='@request(on=something)'), on_done=print_matches)
```
It finds the lines most similar to "request(on=something)" from the server code snippet and prints the following:
[0]0.123462: "f.post('/search', Document(text='@request(on=something)'), on_done=print_matches)"
[1]0.157459: "@requests(on='/index')"
[2]0.171835: "@requests(on='/search')"
Need help in understanding Jina? Ask a question to friendly Jina community on [Slack](https://slack.jina.ai/) (usual response time: 1hr)
| github_jupyter |
################################################################################
**Author**: _Pradip Kumar Das_
**License:** https://github.com/PradipKumarDas/Competitions/blob/main/LICENSE
**Profile & Contact:** [LinkedIn](https://www.linkedin.com/in/daspradipkumar/) | [GitHub](https://github.com/PradipKumarDas) | [Kaggle](https://www.kaggle.com/pradipkumardas) | pradipkumardas@hotmail.com (Email)
################################################################################
# IPL 2021 Match Score Prediction Contest Organized by IIT Madras Online B.Sc. Programme Team
## Few Shallow Machine Learning Based Regression Models
```
# Imports required packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
import pickle
# Sets Pandas option to show all columns
pd.set_option('display.max_columns', None)
# Downloads the dataset from cricsheet.org/downloads (overwrites the file if exists)
!wget https://cricsheet.org/downloads/ipl_csv2.zip -O Data/ipl_csv2.zip
# Unzips the data (overwrites existing files having same name)
!unzip -o -d Data Data/ipl_csv2.zip all_matches.csv README.txt
# Load data for all matches
data = pd.read_csv("Data/all_matches.csv")
# Checks top few rows of the data
data.head()
# Checks bottom rows of the data
data.tail()
# Checks for missing values
data.isna().sum()
# Inserts a new calculated column called "score_off_ball" which is a sum of values in
# columns "runs_off_bat" and "extras" just after column "extras" to indicate contributing score off the ball
# to make calculating total score at the end of the match easy
data.insert(loc=13, column="score_off_ball", value=data.runs_off_bat + data.extras)
```
#### Checks for venues for duplicates with slightly different names, if any, and updates the rows with the same venue names accordingly
```
data.venue.value_counts().sort_index()
# Updates these venues that are mentioned in different names with same name
data.venue[data.venue.str.contains("Brabourne",
case=False)] = "Brabourne Stadium"
data.venue[data.venue.str.contains("Chinnaswamy",
case=False)] = "M. Chinnaswamy Stadium"
data.venue[data.venue.str.contains("Chidambaram",
case=False)] = "M. A. Chidambaram Stadium"
data.venue[data.venue.str.contains(r'Punjab Cricket|IS Bindra|Inderjit Singh Bindra',
case=False)] = "IS Bindra Stadium"
data.venue[data.venue.str.contains("Rajiv Gandhi",
case=False)] = "Rajiv Gandhi International Cricket Stadium"
data.venue[data.venue.str.contains("Wankhede",
case=False)] = "Wankhede Stadium"
```
#### Checks for teams for duplicates with slightly different names, if any, and updates the rows with the same team names accordingly
```
data.batting_team.append(data.bowling_team).value_counts().sort_index()
# Updates team name from "Delhi Daredevils" with the new name "Delhi Capitals"
data.batting_team[data.batting_team.str.contains("Delhi Daredevils", case=False)] = "Delhi Capitals"
data.bowling_team[data.bowling_team.str.contains("Delhi Daredevils", case=False)] = "Delhi Capitals"
# Updates team name from "Kings XI Punjab" with the new name "Punjab Kings"
data.batting_team[data.batting_team.str.contains("Kings XI Punjab", case=False)] = "Punjab Kings"
data.bowling_team[data.bowling_team.str.contains("Kings XI Punjab", case=False)] = "Punjab Kings"
# Updates appropriate team name for "Rising Pune Supergiant"
data.batting_team[data.batting_team.str.contains("Rising Pune Supergiants", case=False)] = "Rising Pune Supergiant"
data.bowling_team[data.bowling_team.str.contains("Rising Pune Supergiants", case=False)] = "Rising Pune Supergiant"
```
## Let's first build a simple linear regression machine learning model as baselined machine learning model as we did for common sense based non-machine learning model.
```
# First, lets have small dataset for that
data_simple = data[data.ball <= 6.0][["match_id",
"venue",
"innings",
"batting_team",
"bowling_team",
"score_off_ball"]]
# Checks shape of the filtered data
data_simple.shape
# Resets its index
data_simple.reset_index(drop = True, inplace = True)
# Calculates the match wise total score after end of 6 overs
data_simple = data_simple.groupby(
["match_id", "venue", "innings", "batting_team", "bowling_team"]).score_off_ball.sum()
# Checks how the scores look
data_simple
# Resets the multi-indexes of the series to get tabular data
data_simple = data_simple.reset_index()
# Checks once again how to data looks
data_simple
# Renames column "score_off_ball" to "score_6_overs"
data_simple.rename(columns={"score_off_ball": "score_6_overs"}, inplace = True)
data_simple
# Encodes venues with one-hot encoding technique
venue_count = len(data_simple.venue.unique())
venue_encoder = OneHotEncoder(handle_unknown='ignore')
venue_encoded = pd.DataFrame(venue_encoder.fit_transform(data_simple[["venue"]]).toarray(),
columns=[("venue_" + str(i)) for i in range(venue_count)])
# Saves the encoder into persistent store for later use
with open("Models/Venue_Encoder.pickle", "wb") as f:
pickle.dump(venue_encoder, f, pickle.HIGHEST_PROTOCOL)
# Joins the encoded venue columns with the dataset
data_simple = data_simple.join(venue_encoded).drop(["venue"], axis = 1)
# Encodes innings with one-hot encoding technique
innings_count = len(data_simple.innings.unique())
innings_encoder = OneHotEncoder(handle_unknown='ignore')
innings_encoded = pd.DataFrame(innings_encoder.fit_transform(data_simple[["innings"]]).toarray(),
columns=[("innings_" + str(i)) for i in range(innings_count)])
# Saves the encoder into persistent store for later use
with open("Models/Innings_Encoder.pickle", "wb") as f:
pickle.dump(innings_encoder, f, pickle.HIGHEST_PROTOCOL)
# Joins the encoded innings columns with the dataset
data_simple = data_simple.join(innings_encoded).drop(["innings"], axis = 1)
# Now, encodes teams with one-hot encoding technique
team_count = len(data_simple.batting_team.append(data_simple.bowling_team).unique())
team_encoder = OneHotEncoder(handle_unknown='ignore')
team_encoder.fit(pd.DataFrame(data_simple.batting_team.append(data_simple.bowling_team)))
batting_team_encoded = pd.DataFrame(team_encoder.transform(data_simple[["batting_team"]]).toarray(),
columns=[("batting_team_" + str(i)) for i in range(team_count)])
bowling_team_encoded = pd.DataFrame(team_encoder.transform(data_simple[["bowling_team"]]).toarray(),
columns=[("bowling_team_" + str(i)) for i in range(team_count)])
# Saves the encoder into persistent store for later use
with open("Models/Team_Encoder.pickle", "wb") as f:
pickle.dump(team_encoder, f, pickle.HIGHEST_PROTOCOL)
# Joins the encoded team columns with the dataset
data_simple = data_simple.join(batting_team_encoded).drop(["batting_team"], axis = 1)
data_simple = data_simple.join(bowling_team_encoded).drop(["bowling_team"], axis = 1)
```
### Now, build a simple linear regression based machine learning model.
```
# Removes the column "match_id" as it is not required for machine learning model
data_simple.drop(["match_id"], axis=1, inplace=True)
# Checks how the dataset looks before converting into array to feed into machine learning model
data_simple
# Converts DataFrame into 2D tensor
data_simple_array = data_simple.to_numpy()
# Seperates training labels
X_train, y_train = data_simple_array[:,1:], data_simple_array[:,0]
# Splits the available data into train and test data sets
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size = 0.2, shuffle = True)
# Create linear regressor
linear_regressor = LinearRegression(fit_intercept=True, normalize=False)
# Fits the model with training data
linear_regressor.fit(X_train, y_train)
# Performs predictions on the test data
predictions_linear_regressor = linear_regressor.predict(X_test)
# Calculates mean absolute error for all predictions
mean_absolute_error(y_test, predictions_linear_regressor)
# Saves the model into persistent store for later use
with open("Models/Linear_Regressor.pickle", "wb") as f:
pickle.dump(linear_regressor, f, pickle.HIGHEST_PROTOCOL)
# Code for reading from persistent model
# with open("Models/Linear_Regressor.pickle", "rb") as f:
# linear_regressor = pickle.load(f)
```
## With simple Linear Regression approach Mean Absolute Error (MAE) is around 9 which is better than that of what was achieved i.e. 10.7 using by Common Sense based model and hence it justified the effort and time to build machine learning models. This better performance will be treated as machine learning based baselined performance.
## Now, let's experiment with Decision Tree model to check if these can beat this machine learning based baselined performance.
```
# Creates decision tree regressor
decisionTree_regressor = DecisionTreeRegressor()
# Fits the model with training data
decisionTree_regressor.fit(X_train, y_train)
# Performs predictions on the test data
predictions_decisionTree_regressor = decisionTree_regressor.predict(X_test)
# Calculates mean absolute error for all predictions
mean_absolute_error(y_test, predictions_decisionTree_regressor)
# Saves the model into persistent store for later use
with open("Models/Decisition_Tree_Regressor.pickle", "wb") as f:
pickle.dump(decisionTree_regressor, f, pickle.HIGHEST_PROTOCOL)
```
## Decision tree based model scored around 11 as Mean Absolute Error (MAE) on test data. This is to note that this MAE is higher from both Common Sense based model and Linear Regressor model.
## Let's now try Random Forrest model.
```
# Creates Random Forest regressor
randomForest_regressor = RandomForestRegressor()
# Fits the model with training data
randomForest_regressor.fit(X_train, y_train)
# Performs predictions on the test data
predictions_randomForest_regressor = randomForest_regressor.predict(X_test)
# Calculates mean absolute error for all predictions
mean_absolute_error(y_test, predictions_randomForest_regressor)
# Saves the model into persistent store for later use
with open("Models/Random_Forest_Regressor.pickle", "wb") as f:
pickle.dump(randomForest_regressor, f, pickle.HIGHEST_PROTOCOL)
```
## The MAE of the Random Forest model is slightly higher than that of Linear Regression model, but less than that of both Common Sense and Decision Tree model.
## Let's now try Gradient Boosted Regressor with XGBoost
```
# Creates XGBoost regressor
xgboost_regressor = XGBRegressor()
# Fits the model with training data
xgboost_regressor.fit(X_train, y_train)
# Performs predictions on the test data
predictions_xgboost_regressor = xgboost_regressor.predict(X_test)
# Calculates mean absolute error for all predictions
mean_absolute_error(y_test, predictions_xgboost_regressor)
# Saves the model into persistent store for later use
with open("Models/Gradient_Boosted_Regressor.pickle", "wb") as f:
pickle.dump(xgboost_regressor, f, pickle.HIGHEST_PROTOCOL)
```
## Above output shows the Mean Absolute Error (MAE) is 8.95 and this performance on the test data is better than the performances of all the models e.g. Common Sense, Decision Tree and Random Forest that we have used so far.
## Hence, 8.95 is now being considered as new machine learning baselined performance.
## Next, refer the next notebook where we shall try out Deep Learning techniques to find if it can overperform present baselined performance.
| github_jupyter |
# Mark and Recapture
Think Bayes, Second Edition
Copyright 2020 Allen B. Downey
License: [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)
```
# If we're running on Colab, install empiricaldist
# https://pypi.org/project/empiricaldist/
import sys
IN_COLAB = 'google.colab' in sys.modules
if IN_COLAB:
!pip install empiricaldist
# Get utils.py
import os
if not os.path.exists('utils.py'):
!wget https://github.com/AllenDowney/ThinkBayes2/raw/master/soln/utils.py
from utils import set_pyplot_params
set_pyplot_params()
```
This chapter introduces "mark and recapture" experiments, in which we sample individuals from a population, mark them somehow, and then take a second sample from the same population. Seeing how many individuals in the second sample are marked, we can estimate the size of the population.
Experiments like this were originally used in ecology, but turn out to be useful in many other fields. Examples in this chapter include software engineering and epidemiology.
Also, in this chapter we'll work with models that have three parameters, so we'll extend the joint distributions we've been using to three dimensions.
But first, grizzly bears.
## The Grizzly Bear Problem
In 1996 and 1997 researchers deployed bear traps in locations in British Columbia and Alberta, Canada, in an effort to estimate the population of grizzly bears. They describe the experiment in "[Estimating Population Size of Grizzly Bears Using Hair Capture, DNA Profiling, and Mark-Recapture Analysis](https://www.researchgate.net/publication/229195465_Estimating_Population_Size_of_Grizzly_Bears_Using_Hair_Capture_DNA_Profiling_and_Mark-Recapture_Analysis)".
The "trap" consists of a lure and several strands of barbed wire intended to capture samples of hair from bears that visit the lure. Using the hair samples, the researchers use DNA analysis to identify individual bears.
During the first session, the researchers deployed traps at 76 sites. Returning 10 days later, they obtained 1043 hair samples and identified 23 different bears. During a second 10-day session they obtained 1191 samples from 19 different bears, where 4 of the 19 were from bears they had identified in the first batch.
To estimate the population of bears from this data, we need a model for the probability that each bear will be observed during each session. As a starting place, we'll make the simplest assumption, that every bear in the population has the same (unknown) probability of being sampled during each session.
With these assumptions we can compute the probability of the data for a range of possible populations.
As an example, let's suppose that the actual population of bears is 100.
After the first session, 23 of the 100 bears have been identified.
During the second session, if we choose 19 bears at random, what is the probability that 4 of them were previously identified?
I'll define
* $N$: actual population size, 100.
* $K$: number of bears identified in the first session, 23.
* $n$: number of bears observed in the second session, 19 in the example.
* $k$: the number of bears in the second session that had previously been identified, 4.
For given values of $N$, $K$, and $n$, the probability of finding $k$ previously-identified bears is given by the [hypergeometric distribution](https://en.wikipedia.org/wiki/Hypergeometric_distribution):
$${K \choose k}{N-K \choose n-k}/{N \choose n}$$
where the [binomial coefficient](https://en.wikipedia.org/wiki/Binomial_coefficient), ${K \choose k}$, is the number of subsets of size $k$ we can choose from a population of size $K$.
To understand why, consider:
* The denominator, ${ N \choose n}$, is the number of subsets of $n$ we could choose from a population of $N$ bears.
* The numerator is the number of subsets that contain $k$ bears from the previously identified $K$ and $n-k$ from the previously unseen $N-K$.
SciPy provides `hypergeom`, which we can use to compute this probability for a range of values of $k$.
```
import numpy as np
from scipy.stats import hypergeom
N = 100
K = 23
n = 19
ks = np.arange(12)
ps = hypergeom(N, K, n).pmf(ks)
```
The result is the distribution of $k$ with given parameters $N$, $K$, and $n$.
Here's what it looks like.
```
import matplotlib.pyplot as plt
from utils import decorate
plt.bar(ks, ps)
decorate(xlabel='Number of bears observed twice',
ylabel='PMF',
title='Hypergeometric distribution of k (known population 100)')
```
The most likely value of $k$ is 4, which is the value actually observed in the experiment.
That suggests that $N=100$ is a reasonable estimate of the population, given this data.
We've computed the distribution of $k$ given $N$, $K$, and $n$.
Now let's go the other way: given $K$, $n$, and $k$, how can we estimate the total population, $N$?
## The Update
As a starting place, let's suppose that, prior to this study, an expert estimates that the local bear population is between 50 and 500, and equally likely to be any value in that range.
I'll use `make_uniform` to make a uniform distribution of integers in this range.
```
import numpy as np
from utils import make_uniform
qs = np.arange(50, 501)
prior_N = make_uniform(qs, name='N')
prior_N.shape
```
So that's our prior.
To compute the likelihood of the data, we can use `hypergeom` with constants `K` and `n`, and a range of values of `N`.
```
Ns = prior_N.qs
K = 23
n = 19
k = 4
likelihood = hypergeom(Ns, K, n).pmf(k)
```
We can compute the posterior in the usual way.
```
posterior_N = prior_N * likelihood
posterior_N.normalize()
```
And here's what it looks like.
```
posterior_N.plot(color='C4', label='_nolegend')
decorate(xlabel='Population of bears (N)',
ylabel='PDF',
title='Posterior distribution of N')
```
The most likely value is 109.
```
posterior_N.max_prob()
```
But the distribution is skewed to the right, so the posterior mean is substantially higher.
```
posterior_N.mean()
```
And the credible interval is quite wide.
```
posterior_N.credible_interval(0.9)
```
This solution is relatively simple, but it turns out we can do a little better if we model the unknown probability of observing a bear explicitly.
## Two Parameter Model
Next we'll try a model with two parameters: the number of bears, `N`, and the probability of observing a bear, `p`.
We'll assume that the probability is the same in both rounds, which is probably reasonable in this case because it is the same kind of trap in the same place.
We'll also assume that the probabilities are independent; that is, the probability a bear is observed in the second round does not depend on whether it was observed in the first round. This assumption might be less reasonable, but for now it is a necessary simplification.
Here are the counts again:
```
K = 23
n = 19
k = 4
```
For this model, I'll express the data in different notation:
* `k10` is the number of bears observed in the first round but not the second,
* `k01` is the number of bears observed in the second round but not the first, and
* `k11` is the number of bears observed in both rounds.
Here are their values.
```
k10 = 23 - 4
k01 = 19 - 4
k11 = 4
```
Suppose we know the actual values of `N` and `p`. We can use them to compute the likelihood of this data.
For example, suppose we know that `N=100` and `p=0.2`.
We can use `N` to compute `k00`, which is the number of unobserved bears.
```
N = 100
observed = k01 + k10 + k11
k00 = N - observed
k00
```
For the update, it will be convenient to store the data as a list that represents the number of bears in each category.
```
x = [k00, k01, k10, k11]
x
```
Now, if we know `p=0.2`, we can compute the probability a bear falls in each category. For example, the probability of being observed in both rounds is `p*p`, and the probability of being unobserved in both rounds is `q*q` (where `q=1-p`).
```
p = 0.2
q = 1-p
y = [q*q, q*p, p*q, p*p]
y
```
Now the probability of the data is given by the [multinomial distribution](https://en.wikipedia.org/wiki/Multinomial_distribution):
$$\frac{N!}{\prod x_i!} \prod y_i^{x_i}$$
where $N$ is actual population, $x$ is a sequence with the counts in each category, and $y$ is a sequence of probabilities for each category.
SciPy provides `multinomial`, which provides `pmf`, which computes this probability.
Here is the probability of the data for these values of `N` and `p`.
```
from scipy.stats import multinomial
likelihood = multinomial.pmf(x, N, y)
likelihood
```
That's the likelihood if we know `N` and `p`, but of course we don't. So we'll choose prior distributions for `N` and `p`, and use the likelihoods to update it.
## The Prior
We'll use `prior_N` again for the prior distribution of `N`, and a uniform prior for the probability of observing a bear, `p`:
```
qs = np.linspace(0, 0.99, num=100)
prior_p = make_uniform(qs, name='p')
```
We can make a joint distribution in the usual way.
```
from utils import make_joint
joint_prior = make_joint(prior_p, prior_N)
joint_prior.shape
```
The result is a Pandas `DataFrame` with values of `N` down the rows and values of `p` across the columns.
However, for this problem it will be convenient to represent the prior distribution as a 1-D `Series` rather than a 2-D `DataFrame`.
We can convert from one format to the other using `stack`.
```
from empiricaldist import Pmf
joint_pmf = Pmf(joint_prior.stack())
joint_pmf.head(3)
type(joint_pmf)
type(joint_pmf.index)
joint_pmf.shape
```
The result is a `Pmf` whose index is a `MultiIndex`.
A `MultiIndex` can have more than one column; in this example, the first column contains values of `N` and the second column contains values of `p`.
The `Pmf` has one row (and one prior probability) for each possible pair of parameters `N` and `p`.
So the total number of rows is the product of the lengths of `prior_N` and `prior_p`.
Now we have to compute the likelihood of the data for each pair of parameters.
## The Update
To allocate space for the likelihoods, it is convenient to make a copy of `joint_pmf`:
```
likelihood = joint_pmf.copy()
```
As we loop through the pairs of parameters, we compute the likelihood of the data as in the previous section, and then store the result as an element of `likelihood`.
```
observed = k01 + k10 + k11
for N, p in joint_pmf.index:
k00 = N - observed
x = [k00, k01, k10, k11]
q = 1-p
y = [q*q, q*p, p*q, p*p]
likelihood[N, p] = multinomial.pmf(x, N, y)
```
Now we can compute the posterior in the usual way.
```
posterior_pmf = joint_pmf * likelihood
posterior_pmf.normalize()
```
We'll use `plot_contour` again to visualize the joint posterior distribution.
But remember that the posterior distribution we just computed is represented as a `Pmf`, which is a `Series`, and `plot_contour` expects a `DataFrame`.
Since we used `stack` to convert from a `DataFrame` to a `Series`, we can use `unstack` to go the other way.
```
joint_posterior = posterior_pmf.unstack()
```
And here's what the result looks like.
```
from utils import plot_contour
plot_contour(joint_posterior)
decorate(title='Joint posterior distribution of N and p')
```
The most likely values of `N` are near 100, as in the previous model. The most likely values of `p` are near 0.2.
The shape of this contour indicates that these parameters are correlated. If `p` is near the low end of the range, the most likely values of `N` are higher; if `p` is near the high end of the range, `N` is lower.
Now that we have a posterior `DataFrame`, we can extract the marginal distributions in the usual way.
```
from utils import marginal
posterior2_p = marginal(joint_posterior, 0)
posterior2_N = marginal(joint_posterior, 1)
```
Here's the posterior distribution for `p`:
```
posterior2_p.plot(color='C1')
decorate(xlabel='Probability of observing a bear',
ylabel='PDF',
title='Posterior marginal distribution of p')
```
The most likely values are near 0.2.
Here's the posterior distribution for `N` based on the two-parameter model, along with the posterior we got using the one-parameter (hypergeometric) model.
```
posterior_N.plot(label='one-parameter model', color='C4')
posterior2_N.plot(label='two-parameter model', color='C1')
decorate(xlabel='Population of bears (N)',
ylabel='PDF',
title='Posterior marginal distribution of N')
```
The mean is a little lower and the 90% credible interval is a little narrower.
```
print(posterior_N.mean(),
posterior_N.credible_interval(0.9))
print(posterior2_N.mean(),
posterior2_N.credible_interval(0.9))
```
The two-parameter model yields a narrower posterior distribution for `N`, compared to the one-parameter model, because it takes advantage of an additional source of information: the consistency of the two observations.
To see how this helps, consider a scenario where `N` is relatively low, like 138 (the posterior mean of the two-parameter model).
```
N1 = 138
```
Given that we saw 23 bears during the first trial and 19 during the second, we can estimate the corresponding value of `p`.
```
mean = (23 + 19) / 2
p = mean/N1
p
```
With these parameters, how much variability do you expect in the number of bears from one trial to the next? We can quantify that by computing the standard deviation of the binomial distribution with these parameters.
```
from scipy.stats import binom
binom(N1, p).std()
```
Now let's consider a second scenario where `N` is 173, the posterior mean of the one-parameter model. The corresponding value of `p` is lower.
```
N2 = 173
p = mean/N2
p
```
In this scenario, the variation we expect to see from one trial to the next is higher.
```
binom(N2, p).std()
```
So if the number of bears we observe is the same in both trials, that would be evidence for lower values of `N`, where we expect more consistency.
If the number of bears is substantially different between the two trials, that would be evidence for higher values of `N`.
In the actual data, the difference between the two trials is low, which is why the posterior mean of the two-parameter model is lower.
The two-parameter model takes advantage of additional information, which is why the credible interval is narrower.
## Joint and marginal distributions
Marginal distributions are called "marginal" because in a common visualization they appear in the margins of the plot.
Seaborn provides a class called `JointGrid` that creates this visualization.
The following function uses it to show the joint and marginal distributions in a single plot.
```
import pandas as pd
from seaborn import JointGrid
def joint_plot(joint, **options):
"""Show joint and marginal distributions.
joint: DataFrame that represents a joint distribution
options: passed to JointGrid
"""
# get the names of the parameters
x = joint.columns.name
x = 'x' if x is None else x
y = joint.index.name
y = 'y' if y is None else y
# make a JointGrid with minimal data
data = pd.DataFrame({x:[0], y:[0]})
g = JointGrid(x=x, y=y, data=data, **options)
# replace the contour plot
g.ax_joint.contour(joint.columns,
joint.index,
joint,
cmap='viridis')
# replace the marginals
marginal_x = marginal(joint, 0)
g.ax_marg_x.plot(marginal_x.qs, marginal_x.ps)
marginal_y = marginal(joint, 1)
g.ax_marg_y.plot(marginal_y.ps, marginal_y.qs)
joint_plot(joint_posterior)
```
A `JointGrid` is a concise way to represent the joint and marginal distributions visually.
## The Lincoln index problem
In [an excellent blog post](http://www.johndcook.com/blog/2010/07/13/lincoln-index/), John D. Cook wrote about the Lincoln index, which is a way to estimate the
number of errors in a document (or program) by comparing results from
two independent testers.
Here's his presentation of the problem:
>"Suppose you have a tester who finds 20 bugs in your program. You
want to estimate how many bugs are really in the program. You know
there are at least 20 bugs, and if you have supreme confidence in your
tester, you may suppose there are around 20 bugs. But maybe your
tester isn't very good. Maybe there are hundreds of bugs. How can you
have any idea how many bugs there are? There's no way to know with one
tester. But if you have two testers, you can get a good idea, even if
you don't know how skilled the testers are."
Suppose the first tester finds 20 bugs, the second finds 15, and they
find 3 in common; how can we estimate the number of bugs?
This problem is similar to the Grizzly Bear problem, so I'll represent the data in the same way.
```
k10 = 20 - 3
k01 = 15 - 3
k11 = 3
```
But in this case it is probably not reasonable to assume that the testers have the same probability of finding a bug.
So I'll define two parameters, `p0` for the probability that the first tester finds a bug, and `p1` for the probability that the second tester finds a bug.
I will continue to assume that the probabilities are independent, which is like assuming that all bugs are equally easy to find. That might not be a good assumption, but let's stick with it for now.
As an example, suppose we know that the probabilities are 0.2 and 0.15.
```
p0, p1 = 0.2, 0.15
```
We can compute the array of probabilities, `y`, like this:
```
def compute_probs(p0, p1):
"""Computes the probability for each of 4 categories."""
q0 = 1-p0
q1 = 1-p1
return [q0*q1, q0*p1, p0*q1, p0*p1]
y = compute_probs(p0, p1)
y
```
With these probabilities, there is a
68% chance that neither tester finds the bug and a
3% chance that both do.
Pretending that these probabilities are known, we can compute the posterior distribution for `N`.
Here's a prior distribution that's uniform from 32 to 350 bugs.
```
qs = np.arange(32, 350, step=5)
prior_N = make_uniform(qs, name='N')
prior_N.head(3)
```
I'll put the data in an array, with 0 as a place-keeper for the unknown value `k00`.
```
data = np.array([0, k01, k10, k11])
```
And here are the likelihoods for each value of `N`, with `ps` as a constant.
```
likelihood = prior_N.copy()
observed = data.sum()
x = data.copy()
for N in prior_N.qs:
x[0] = N - observed
likelihood[N] = multinomial.pmf(x, N, y)
```
We can compute the posterior in the usual way.
```
posterior_N = prior_N * likelihood
posterior_N.normalize()
```
And here's what it looks like.
```
posterior_N.plot(color='C4')
decorate(xlabel='Number of bugs (N)',
ylabel='PMF',
title='Posterior marginal distribution of n with known p1, p2')
print(posterior_N.mean(),
posterior_N.credible_interval(0.9))
```
With the assumption that `p0` and `p1` are known to be `0.2` and `0.15`, the posterior mean is 102 with 90% credible interval (77, 127).
But this result is based on the assumption that we know the probabilities, and we don't.
## Three-parameter model
What we need is a model with three parameters: `N`, `p0`, and `p1`.
We'll use `prior_N` again for the prior distribution of `N`, and here are the priors for `p0` and `p1`:
```
qs = np.linspace(0, 1, num=51)
prior_p0 = make_uniform(qs, name='p0')
prior_p1 = make_uniform(qs, name='p1')
```
Now we have to assemble them into a joint prior with three dimensions.
I'll start by putting the first two into a `DataFrame`.
```
joint2 = make_joint(prior_p0, prior_N)
joint2.shape
```
Now I'll stack them, as in the previous example, and put the result in a `Pmf`.
```
joint2_pmf = Pmf(joint2.stack())
joint2_pmf.head(3)
```
We can use `make_joint` again to add in the third parameter.
```
joint3 = make_joint(prior_p1, joint2_pmf)
joint3.shape
```
The result is a `DataFrame` with values of `N` and `p0` in a `MultiIndex` that goes down the rows and values of `p1` in an index that goes across the columns.
```
joint3.head(3)
```
Now I'll apply `stack` again:
```
joint3_pmf = Pmf(joint3.stack())
joint3_pmf.head(3)
```
The result is a `Pmf` with a three-column `MultiIndex` containing all possible triplets of parameters.
The number of rows is the product of the number of values in all three priors, which is almost 170,000.
```
joint3_pmf.shape
```
That's still small enough to be practical, but it will take longer to compute the likelihoods than in the previous examples.
Here's the loop that computes the likelihoods; it's similar to the one in the previous section:
```
likelihood = joint3_pmf.copy()
observed = data.sum()
x = data.copy()
for N, p0, p1 in joint3_pmf.index:
x[0] = N - observed
y = compute_probs(p0, p1)
likelihood[N, p0, p1] = multinomial.pmf(x, N, y)
```
We can compute the posterior in the usual way.
```
posterior_pmf = joint3_pmf * likelihood
posterior_pmf.normalize()
```
Now, to extract the marginal distributions, we could unstack the joint posterior as we did in the previous section.
But `Pmf` provides a version of `marginal` that works with a `Pmf` rather than a `DataFrame`.
Here's how we use it to get the posterior distribution for `N`.
```
posterior_N = posterior_pmf.marginal(0)
```
And here's what it looks look.
```
posterior_N.plot(color='C4')
decorate(xlabel='Number of bugs (N)',
ylabel='PDF',
title='Posterior marginal distributions of N')
posterior_N.mean()
```
The posterior mean is 105 bugs, which suggests that there are still many bugs the testers have not found.
Here are the posteriors for `p0` and `p1`.
```
posterior_p1 = posterior_pmf.marginal(1)
posterior_p2 = posterior_pmf.marginal(2)
posterior_p1.plot(label='p1')
posterior_p2.plot(label='p2')
decorate(xlabel='Probability of finding a bug',
ylabel='PDF',
title='Posterior marginal distributions of p1 and p2')
posterior_p1.mean(), posterior_p1.credible_interval(0.9)
posterior_p2.mean(), posterior_p2.credible_interval(0.9)
```
Comparing the posterior distributions, the tester who found more bugs probably has a higher probability of finding bugs. The posterior means are about 23% and 18%. But the distributions overlap, so we should not be too sure.
This is the first example we've seen with three parameters.
As the number of parameters increases, the number of combinations increases quickly.
The method we've been using so far, enumerating all possible combinations, becomes impractical if the number of parameters is more than 3 or 4.
However there are other methods that can handle models with many more parameters, as we'll see in Chapter xxx.
## Summary
The problems in this chapter are examples of "[mark and recapture](https://en.wikipedia.org/wiki/Mark_and_recapture)" experiments, which are used in ecology to estimate animal populations. They also have applications in engineering, as in the Lincoln index problem. And in the exercises you'll see that they are used in epidemiology, too.
This chapter introduces two new probability distributions:
* The hypergeometric distribution is a variation of the binomial distribution in which samples are drawn from the population without replacement.
* The multinomial distribution is a generalization of the binomial distribution where there are more than two possible outcomes.
Also in this chapter, we saw the first example of a model with three parameters. We'll see more in subsequent chapters.
## Exercises
**Exercise:** [In an excellent paper](http://chao.stat.nthu.edu.tw/wordpress/paper/110.pdf), Anne Chao explains how mark and recapture experiments are used in epidemiology to estimate the prevalence of a disease in a human population based on multiple incomplete lists of cases.
One of the examples in that paper is a study "to estimate the number of people who were infected by hepatitis in an outbreak that occurred in and around a college in northern Taiwan from April to July 1995."
Three lists of cases were available:
1. 135 cases identified using a serum test.
2. 122 cases reported by local hospitals.
3. 126 cases reported on questionnaires collected by epidemiologists.
In this exercise, we'll use only the first two lists; in the next exercise we'll bring in the third list.
Make a joint prior and update it using this data, then compute the posterior mean of `N` and a 90% credible interval.
The following array contains 0 as a place-holder for the unknown value of `k00`, followed by known values of `k01`, `k10`, and `k11`.
```
data2 = np.array([0, 73, 86, 49])
```
These data indicate that there are 73 cases on the second list that are not on the first, 86 cases on the first list that are not on the second, and 49 cases on both lists.
To keep things simple, we'll assume that each case has the same probability of appearing on each list. So we'll use a two-parameter model where `N` is the total number of cases and `p` is the probability that any case appears on any list.
Here are priors you can start with (but feel free to modify them).
```
qs = np.arange(200, 500, step=5)
prior_N = make_uniform(qs, name='N')
prior_N.head(3)
qs = np.linspace(0, 0.98, num=50)
prior_p = make_uniform(qs, name='p')
prior_p.head(3)
# Solution
joint_prior = make_joint(prior_p, prior_N)
joint_prior.head(3)
# Solution
prior_pmf = Pmf(joint_prior.stack())
prior_pmf.head(3)
# Solution
observed = data2.sum()
x = data2.copy()
likelihood = prior_pmf.copy()
for N, p in prior_pmf.index:
x[0] = N - observed
q = 1-p
y = [q*q, q*p, p*q, p*p]
likelihood.loc[N, p] = multinomial.pmf(x, N, y)
# Solution
posterior_pmf = prior_pmf * likelihood
posterior_pmf.normalize()
# Solution
joint_posterior = posterior_pmf.unstack()
# Solution
plot_contour(joint_posterior)
decorate(title='Joint posterior distribution of N and p')
# Solution
marginal_N = marginal(joint_posterior, 1)
marginal_N.plot(color='C4')
decorate(xlabel='Number of cases (N)',
ylabel='PDF',
title='Posterior marginal distribution of N')
# Solution
marginal_N.mean(), marginal_N.credible_interval(0.9)
```
**Exercise:** Now let's do the version of the problem with all three lists. Here's the data from Chou's paper:
```
Hepatitis A virus list
P Q E Data
1 1 1 k111 =28
1 1 0 k110 =21
1 0 1 k101 =17
1 0 0 k100 =69
0 1 1 k011 =18
0 1 0 k010 =55
0 0 1 k001 =63
0 0 0 k000 =??
```
Write a loop that computes the likelihood of the data for each pair of parameters, then update the prior and compute the posterior mean of `N`. How does it compare to the results using only the first two lists?
Here's the data in a NumPy array (in reverse order).
```
data3 = np.array([0, 63, 55, 18, 69, 17, 21, 28])
```
Again, the first value is a place-keeper for the unknown `k000`. The second value is `k001`, which means there are 63 cases that appear on the third list but not the first two. And the last value is `k111`, which means there are 28 cases that appear on all three lists.
In the two-list version of the problem we computed `ps` by enumerating the combinations of `p` and `q`.
```
q = 1-p
ps = [q*q, q*p, p*q, p*p]
```
We could do the same thing for the three-list version, computing the probability for each of the eight categories. But we can generalize it by recognizing that we are computing the cartesian product of `p` and `q`, repeated once for each list.
And we can use the following function (based on [this StackOverflow answer](https://stackoverflow.com/questions/58242078/cartesian-product-of-arbitrary-lists-in-pandas/58242079#58242079)) to compute Cartesian products:
```
def cartesian_product(*args, **options):
"""Cartesian product of sequences.
args: any number of sequences
options: passes to `MultiIndex.from_product`
returns: DataFrame with one column per sequence
"""
index = pd.MultiIndex.from_product(args, **options)
return pd.DataFrame(index=index).reset_index()
```
Here's an example with `p=0.2`:
```
p = 0.2
t = (1-p, p)
df = cartesian_product(t, t, t)
df
```
To compute the probability for each category, we take the product across the columns:
```
y = df.prod(axis=1)
y
```
Now you finish it off from there.
```
# Solution
observed = data3.sum()
x = data3.copy()
likelihood = prior_pmf.copy()
for N, p in prior_pmf.index:
x[0] = N - observed
t = (1-p, p)
df = cartesian_product(t, t, t)
y = df.prod(axis=1)
likelihood.loc[N, p] = multinomial.pmf(x, N, y)
# Solution
posterior_pmf = prior_pmf * likelihood
posterior_pmf.normalize()
# Solution
joint_posterior = posterior_pmf.unstack()
# Solution
plot_contour(joint_posterior)
decorate(title='Joint posterior distribution of N and p')
# Solution
marginal3_N = marginal(joint_posterior, 1)
# Solution
marginal_N.plot(label='After two lists', color='C4')
marginal3_N.plot(label='After three lists', color='C1')
decorate(xlabel='Number of cases (N)',
ylabel='PDF',
title='Posterior marginal distribution of N')
# Solution
marginal_N.mean(), marginal_N.credible_interval(0.9)
# Solution
marginal3_N.mean(), marginal3_N.credible_interval(0.9)
```
| github_jupyter |
```
# connect to google colab
from google.colab import drive
drive.mount("/content/drive")
# base path
DATA_PATH = './drive/MyDrive/fyp-code/codes/data/ecpe/'
MODEL_PATH = './drive/MyDrive/fyp-code/codes/model/ecpe/EC/long_summarized/'
############################################ IMPORT ##########################################################
import sys, os
import numpy as np
import torch
from torch import nn
from torch import optim
from torch.nn import functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
# call the zip folder with all the self defined modules
base_folder = '/content/drive/MyDrive/fyp-code/codes'
training_path = os.path.join(base_folder, "utils_ecpe.zip")
!unzip $training_path
from funcs import *
from prepare_data import *
############################################ FLAGS ############################################################
# file names of the data files
LOOKUP = 'ecpe_long_summarized_max_5_clauses_annotated.csv'
DATA = 'long_summarized'
TRAIN_DATA = 'ecpe_long_summarized_max_5_clauses_annotated_train'
VAL_DATA = 'ecpe_long_summarized_max_5_clauses_annotated_val'
# fixed parameters
train_file_path = DATA_PATH + LOOKUP # clause keyword file
w2v_file = DATA_PATH+'w2v_200.txt' # embedding file
embedding_dim = 200 # dimension of word embedding
embedding_dim_pos = 30 # dimension of position embedding
max_sen_len = 30 # max number of tokens per sentence
max_doc_len = 41 # max number of tokens per document
n_class = 2 # number of distinct class
training_epochs = 20 # number of train epochs
keep_prob1 = 0.8 # word embedding training dropout keep prob
keep_prob2 = 1.0 # softmax layer dropout keep prob
keep_prob3 = 1.0 # softmax layer dropout keep prob
l2_reg = 0.00010 # l2 regularization
cause = 1.0 # lambda1
pos = 1.0 # lambda2
pair = 2.5 # lambda3
# hyperparameters considered for tuning (will be tuned later when the class is called)
n_hidden = None # number of hidden unit
batch_size = None # number of example per batch
learning_rate = None # learning rate
diminish_factor = None # give less weight to -ve examples
############################################ MODEL ############################################################
class E2E_PextE(nn.Module):
def __init__(self, embedding_dim, embedding_dim_pos, sen_len, doc_len, keep_prob1, keep_prob2, \
keep_prob3, n_hidden, n_class):
super(E2E_PextE, self).__init__()
self.embedding_dim = embedding_dim; self.embedding_dim_pos = embedding_dim_pos
self.sen_len = sen_len; self.doc_len = doc_len
self.keep_prob1 = keep_prob1; self.keep_prob2 = keep_prob2
self.n_hidden = n_hidden; self.n_class = n_class
self.dropout1 = nn.Dropout(p = 1 - keep_prob1)
self.dropout2 = nn.Dropout(p = 1 - keep_prob2)
self.dropout3 = nn.Dropout(p = 1 - keep_prob3)
self.relu = nn.ReLU()
self.pos_linear = nn.Linear(2*n_hidden, n_class)
self.cause_linear = nn.Linear(2*n_hidden, n_class)
self.pair_linear1 = nn.Linear(4*n_hidden + embedding_dim_pos, n_hidden//2)
self.pair_linear2 = nn.Linear(n_hidden//2, n_class)
self.word_bilstm = nn.LSTM(embedding_dim, n_hidden, batch_first = True, bidirectional = True)
self.cause_bilstm = nn.LSTM(2*n_hidden + n_class, n_hidden, batch_first = True, bidirectional = True)
self.pos_bilstm = nn.LSTM(2*n_hidden, n_hidden, batch_first = True, bidirectional = True)
self.attention = Attention(n_hidden, sen_len)
def get_clause_embedding(self, x):
'''
input shape: [batch_size, doc_len, sen_len, embedding_dim]
output shape: [batch_size, doc_len, 2 * n_hidden]
'''
x = x.reshape(-1, self.sen_len, self.embedding_dim)
x = self.dropout1(x)
# x is of shape (batch_size * max_doc_len, max_sen_len, embedding_dim)
x, hidden_states = self.word_bilstm(x.float())
# x is of shape (batch_size * max_doc_len, max_sen_len, 2 * n_hidden)
s = self.attention(x).reshape(-1, self.doc_len, 2 * self.n_hidden)
# s is of shape (batch_size, max_doc_len, 2 * n_hidden)
return s
def get_emotion_prediction(self, x):
'''
input shape: [batch_size, doc_len, 2 * n_hidden]
output(s) shape: [batch_size, doc_len, 2 * n_hidden], [batch_size, doc_len, n_class]
'''
x_context, hidden_states = self.pos_bilstm(x.float())
# x_context is of shape (batch_size, max_doc_len, 2 * n_hidden)
x = x_context.reshape(-1, 2 * self.n_hidden)
x = self.dropout2(x)
# x is of shape (batch_size * max_doc_len, 2 * n_hidden)
pred_pos = F.softmax(self.pos_linear(x), dim = -1)
# pred_pos is of shape (batch_size * max_doc_len, n_class)
pred_pos = pred_pos.reshape(-1, self.doc_len, self.n_class)
# pred_pos is of shape (batch_size * max_doc_len, n_class)
return x_context, pred_pos
def get_cause_prediction(self, x):
'''
input shape: [batch_size, doc_len, 2 * n_hidden + n_class]
output(s) shape: [batch_size, doc_len, 2 * n_hidden], [batch_size, doc_len, n_class]
'''
x_context, hidden_states = self.cause_bilstm(x.float())
# x_context is of shape (batch_size, max_doc_len, 2 * n_hidden)
x = x_context.reshape(-1, 2 * self.n_hidden)
x = self.dropout2(x)
# x is of shape (batch_size * max_doc_len, 2 * n_hidden)
pred_cause = F.softmax(self.cause_linear(x), dim = -1)
# pred_pos is of shape (batch_size * max_doc_len, n_class)
pred_cause = pred_cause.reshape(-1, self.doc_len, self.n_class)
# pred_pos is of shape (batch_size * max_doc_len, n_class)
return x_context, pred_cause
def get_pair_prediction(self, x1, x2, distance):
'''
input(s) shape: [batch_size * doc_len, 2 * n_hidden], [batch_size * doc_len, 2 * n_hidden],
[batch_size, doc_len * doc_len, embedding_dim_pos]
output shape: [batch_size, doc_len * doc_len, n_class]
'''
x = create_pairs(x1, x2)
# x is of shape (batch_size, max_doc_len * max_doc_len, 4 * n_hidden)
x_distance = torch.cat([x, distance.float()], -1)
# x_distance is of shape (batch_size, max_doc_len * max_doc_len, 4 * n_hidden + embedding_dim_pos)
x_distance = x_distance.reshape(-1, 4 * self.n_hidden + self.embedding_dim_pos)
x_distance = self.dropout3(x_distance)
# x is of shape (batch_size * max_doc_len * max_doc_len, 4 * n_hidden + embedding_dim_pos)
pred_pair = F.softmax(self.pair_linear2(self.relu(self.pair_linear1(x_distance))), dim = -1)
# pred_pair is of shape (batch_size * max_doc_len * max_doc_len, n_class)
pred_pair = pred_pair.reshape(-1, self.doc_len * self.doc_len, self.n_class)
# pred_pair is of shape (batch_size, max_doc_len * max_doc_len, n_class)
return pred_pair
def forward(self, x, distance):
'''
input(s) shape: [batch_size, doc_len, sen_len, embedding_dim],
[batch_size, doc_len * doc_len, embedding_dim_pos]
output(s) shape: [batch_size, doc_len, n_class], [batch_size, doc_len, n_class],
[batch_size, doc_len * doc_len, n_class]
'''
s = self.get_clause_embedding(x)
x_pos, pred_pos = self.get_emotion_prediction(s)
s_pred_pos = torch.cat([s, pred_pos], 2)
x_cause, pred_cause = self.get_cause_prediction(s_pred_pos)
pred_pair = self.get_pair_prediction(x_pos, x_cause, distance)
return pred_pos, pred_cause, pred_pair
def load_data_pair(input_file, word_idx, max_doc_len = 75, max_sen_len = 45):
print('load data_file: {}'.format(input_file))
pair_id_all, y_position, y_cause, y_pair, x, sen_len, doc_len, distance = [], [], [], [], [], [], [], []
n_cut = 0
inputFile = open(input_file, 'r')
while True:
line = inputFile.readline()
if line == '': break
line = line.strip().split()
doc_id = int(line[0])
d_len = int(line[1])
######################################## doc_len_condition ########################################
if d_len >= max_doc_len :
for i in range(d_len+1) :
line = inputFile.readline().strip().split(',')
continue
######################################## doc_len_condition ########################################
pairs = eval('[' + inputFile.readline().strip() + ']')
pos_list, cause_list = zip(*pairs)
pairs = [[pos_list[i], cause_list[i]] for i in range(len(pos_list))]
pair_id_all.extend([doc_id*10000+p[0]*100+p[1] for p in pairs])
y_position_tmp, y_cause_tmp, y_pair_tmp, sen_len_tmp, x_tmp, distance_tmp = \
np.zeros((max_doc_len, 2)), np.zeros((max_doc_len, 2)), np.zeros((max_doc_len * max_doc_len, 2)), \
np.zeros((max_doc_len, )), np.zeros((max_doc_len, max_sen_len)), np.zeros((max_doc_len * max_doc_len, ))
for i in range(d_len):
line = inputFile.readline().strip().split(',')
words = line[-1]
sen_len_tmp[i] = min(len(words.split()), max_sen_len)
for j, word in enumerate(words.split()):
word = word.lower()
if j >= max_sen_len:
n_cut += 1
break
elif word not in word_idx : x_tmp[i][j] = 24166
else : x_tmp[i][j] = int(word_idx[word])
for i in range(d_len):
for j in range(d_len):
# Check whether i is an emotion clause
if i+1 in pos_list :
y_position_tmp[i][0] = 0; y_position_tmp[i][1] = 1
else :
y_position_tmp[i][0] = 1; y_position_tmp[i][1] = 0
# Check whether j is a cause clause
if j+1 in cause_list :
y_cause_tmp[j][0] = 0; y_cause_tmp[j][1] = 1
else :
y_cause_tmp[j][0] = 1; y_cause_tmp[j][1] = 0
# Check whether i, j clauses are emotion cause pairs
pair_id_curr = doc_id*10000+(i+1)*100+(j+1)
if pair_id_curr in pair_id_all :
y_pair_tmp[i*max_doc_len+j][0] = 0; y_pair_tmp[i*max_doc_len+j][1] = 1
else :
y_pair_tmp[i*max_doc_len+j][0] = 1; y_pair_tmp[i*max_doc_len+j][1] = 0
# Find the distance between the clauses, and use the same embedding beyond 10 clauses
distance_tmp[i*max_doc_len+j] = min(max(j-i+100, 90), 110)
y_position.append(y_position_tmp)
y_cause.append(y_cause_tmp)
y_pair.append(y_pair_tmp)
x.append(x_tmp)
sen_len.append(sen_len_tmp)
doc_len.append(d_len)
distance.append(distance_tmp)
y_position, y_cause, y_pair, x, sen_len, doc_len, distance = map(torch.tensor, \
[y_position, y_cause, y_pair, x, sen_len, doc_len, distance])
for var in ['y_position', 'y_cause', 'y_pair', 'x', 'sen_len', 'doc_len', 'distance']:
print('{}.shape {}'.format( var, eval(var).shape ))
print('n_cut {}'.format(n_cut))
print('load data done!\n')
return y_position, y_cause, y_pair, x, sen_len, doc_len, distance
############################################ TRAIN #####################################################
def train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, n_hidden, batch_size, learning_rate, diminish_factor):
word_idx_rev, word_id_mapping, word_embedding, pos_embedding = load_w2v(
embedding_dim, embedding_dim_pos, train_file_path, w2v_file)
word_embedding = torch.from_numpy(word_embedding)
# Train distance embeddings
pos_embedding = torch.autograd.Variable(torch.from_numpy(pos_embedding))
pos_embedding.requires_grad_(True)
#torch.save(word_embedding, MODEL_PATH+DATA+'_'+'word_embedding'+'.pth')
torch.save(word_embedding, f'{MODEL_PATH}{DATA}_word_embedding_nhid-{n_hidden}_bs-{batch_size}_lr-{learning_rate}_dimf-{diminish_factor}.pth')
#torch.save(word_id_mapping, MODEL_PATH+DATA+'_'+'word_id_mapping'+'.pth')
torch.save(word_id_mapping, f'{MODEL_PATH}{DATA}_word_id_mapping_nhid-{n_hidden}_bs-{batch_size}_lr-{learning_rate}_dimf-{diminish_factor}.pth')
acc_cause_list, p_cause_list, r_cause_list, f1_cause_list = [], [], [], []
acc_pos_list, p_pos_list, r_pos_list, f1_pos_list = [], [], [], []
acc_pair_list, p_pair_list, r_pair_list, f1_pair_list = [], [], [], []
#################################### LOOP OVER FOLDS ####################################
# do 5 fold cross validation
for fold in range(1, 2):
print('############# fold {} begin ###############'.format(fold))
############################# RE-INITIALIZE MODEL PARAMETERS #############################
for layer in Model.parameters():
nn.init.uniform_(layer.data, -0.10, 0.10)
#################################### TRAIN/TEST DATA ####################################
train_file_name = '{}_{}.txt'.format(TRAIN_DATA,fold)
val_file_name = '{}_{}.txt'.format(VAL_DATA,fold)
tr_y_position, tr_y_cause, tr_y_pair, tr_x, tr_sen_len, tr_doc_len, tr_distance = load_data_pair(
DATA_PATH+train_file_name, word_id_mapping, max_doc_len, max_sen_len)
val_y_position, val_y_cause, val_y_pair, val_x, val_sen_len, val_doc_len, val_distance = \
load_data_pair(DATA_PATH+val_file_name, word_id_mapping, max_doc_len, max_sen_len)
max_f1_cause, max_f1_pos, max_f1_pair, max_f1_avg = [-1.] * 4
#################################### LOOP OVER EPOCHS ####################################
for epoch in range(1, training_epochs + 1):
step = 1
#################################### GET BATCH DATA ####################################
for train, _ in get_batch_data_pair(
tr_x, tr_sen_len, tr_doc_len, tr_y_position, tr_y_cause, tr_y_pair, tr_distance, batch_size):
tr_x_batch, tr_sen_len_batch, tr_doc_len_batch, tr_true_y_pos, tr_true_y_cause, \
tr_true_y_pair, tr_distance_batch = train
Model.train()
tr_pred_y_pos, tr_pred_y_cause, tr_pred_y_pair = Model(embedding_lookup(word_embedding, \
tr_x_batch), embedding_lookup(pos_embedding, tr_distance_batch))
############################## LOSS FUNCTION AND OPTIMIZATION ##############################
loss = pos_cause_criterion(tr_true_y_pos, tr_pred_y_pos, tr_doc_len_batch)*pos + \
pos_cause_criterion(tr_true_y_cause, tr_pred_y_cause, tr_doc_len_batch)*cause + \
pair_criterion(tr_true_y_pair, tr_pred_y_pair, tr_doc_len_batch)*pair
optimizer.zero_grad()
loss.backward()
optimizer.step()
#################################### PRINT AFTER EPOCHS ####################################
if step % 25 == 0:
# print(Model.pair_linear.weight.shape); print(Model.pair_linear.weight.grad)
print('Fold {}, Epoch {}, step {}: train loss {:.4f} '.format(fold, epoch, step, loss))
acc, p, r, f1 = acc_prf_aux(tr_pred_y_pos, tr_true_y_pos, tr_doc_len_batch)
print('emotion_predict: train acc {:.4f} p {:.4f} r {:.4f} f1 score {:.4f}'.format(
acc, p, r, f1))
acc, p, r, f1 = acc_prf_aux(tr_pred_y_cause, tr_true_y_cause, tr_doc_len_batch)
print('cause_predict: train acc {:.4f} p {:.4f} r {:.4f} f1 score {:.4f}'.format(
acc, p, r, f1))
acc, p, r, f1 = acc_prf_pair(tr_pred_y_pair, tr_true_y_pair, tr_doc_len_batch)
print('pair_predict: train acc {:.4f} p {:.4f} r {:.4f} f1 score {:.4f}'.format(
acc, p, r, f1))
step += 1
#################################### TEST ON 1 FOLD ####################################
with torch.no_grad():
Model.eval()
val_pred_y_pos, val_pred_y_cause, val_pred_y_pair = Model(embedding_lookup(word_embedding, \
val_x), embedding_lookup(pos_embedding, val_distance))
loss = pos_cause_criterion(val_y_position, val_pred_y_pos, val_doc_len)*pos + \
pos_cause_criterion(val_y_cause, val_pred_y_cause, val_doc_len)*cause + \
pair_criterion(val_y_pair, val_pred_y_pair, val_doc_len)*pair
print('Fold {} Epoch {} val loss {:.4f}'.format(fold, epoch, loss))
acc, p, r, f1 = acc_prf_aux(val_pred_y_pos, val_y_position, val_doc_len)
result_avg_pos = [acc, p, r, f1]
if f1 > max_f1_pos:
max_acc_pos, max_p_pos, max_r_pos, max_f1_pos = acc, p, r, f1
print('emotion_predict: val acc {:.4f} p {:.4f} r {:.4f} f1 {:.4f}'.format(acc, p, r, f1))
print('max_acc {:.4f} max_p {:.4f} max_r {:.4f} max_f1 {:.4f}\n'.format(
max_acc_pos, max_p_pos, max_r_pos, max_f1_pos))
acc, p, r, f1 = acc_prf_aux(val_pred_y_cause, val_y_cause, val_doc_len)
result_avg_cause = [acc, p, r, f1]
if f1 > max_f1_cause:
max_acc_cause, max_p_cause, max_r_cause, max_f1_cause = acc, p, r, f1
print('cause_predict: val acc {:.4f} p {:.4f} r {:.4f} f1 {:.4f}'.format(acc, p, r, f1))
print('max_acc {:.4f} max_p {:.4f} max_r {:.4f} max_f1 {:.4f}\n'.format(
max_acc_cause, max_p_cause, max_r_cause, max_f1_cause))
acc, p, r, f1 = acc_prf_pair(val_pred_y_pair, val_y_pair, val_doc_len)
result_avg_pair = [acc, p, r, f1]
if f1 > max_f1_pair:
max_acc_pair, max_p_pair, max_r_pair, max_f1_pair = acc, p, r, f1
print('pair_predict: val acc {:.4f} p {:.4f} r {:.4f} f1 {:.4f}'.format(acc, p, r, f1))
print('max_acc {:.4f} max_p {:.4f} max_r {:.4f} max_f1 {:.4f}\n'.format(
max_acc_pair, max_p_pair, max_r_pair, max_f1_pair))
#################################### STORE BETTER PAIR F1 ####################################
if result_avg_pair[-1] > max_f1_avg:
#torch.save(pos_embedding, MODEL_PATH+DATA+"_"+"pos_embedding_fold_{}.pth".format(fold))
torch.save(pos_embedding, f'{MODEL_PATH}{DATA}_pos_embedding_fold-{fold}_nhid-{n_hidden}_bs-{batch_size}_lr-{learning_rate}_dimf-{diminish_factor}.pth')
#torch.save(Model.state_dict(), MODEL_PATH+DATA+"_"+"E2E-EC_fold_{}.pth".format(fold))
torch.save(Model.state_dict(), f'{MODEL_PATH}{DATA}_E2E-EC_fold-{fold}_nhid-{n_hidden}_bs-{batch_size}_lr-{learning_rate}_dimf-{diminish_factor}.pth')
max_f1_avg = result_avg_pair[-1]
result_avg_cause_max = result_avg_cause
result_avg_pos_max = result_avg_pos
result_avg_pair_max = result_avg_pair
print('avg max cause: max_acc {:.4f} max_p {:.4f} max_r {:.4f} max_f1 {:.4f}'.format(
result_avg_cause_max[0], result_avg_cause_max[1], result_avg_cause_max[2], result_avg_cause_max[3]))
print('avg max pos: max_acc {:.4f} max_p {:.4f} max_r {:.4f} max_f1 {:.4f}'.format(
result_avg_pos_max[0], result_avg_pos_max[1], result_avg_pos_max[2], result_avg_pos_max[3]))
print('avg max pair: max_acc {:.4f} max_p {:.4f} max_r {:.4f} max_f1 {:.4f}\n'.format(
result_avg_pair_max[0], result_avg_pair_max[1], result_avg_pair_max[2], result_avg_pair_max[3]))
print('############# fold {} end ###############'.format(fold))
acc_cause_list.append(result_avg_cause_max[0])
p_cause_list.append(result_avg_cause_max[1])
r_cause_list.append(result_avg_cause_max[2])
f1_cause_list.append(result_avg_cause_max[3])
acc_pos_list.append(result_avg_pos_max[0])
p_pos_list.append(result_avg_pos_max[1])
r_pos_list.append(result_avg_pos_max[2])
f1_pos_list.append(result_avg_pos_max[3])
acc_pair_list.append(result_avg_pair_max[0])
p_pair_list.append(result_avg_pair_max[1])
r_pair_list.append(result_avg_pair_max[2])
f1_pair_list.append(result_avg_pair_max[3])
#################################### FINAL TEST RESULTS ON 10 FOLDS ####################################
all_results = [acc_cause_list, p_cause_list, r_cause_list, f1_cause_list, \
acc_pos_list, p_pos_list, r_pos_list, f1_pos_list, acc_pair_list, p_pair_list, r_pair_list, f1_pair_list,]
acc_cause, p_cause, r_cause, f1_cause, acc_pos, p_pos, r_pos, f1_pos, acc_pair, p_pair, r_pair, f1_pair = \
map(lambda x: np.array(x).mean(), all_results)
print('\ncause_predict: val f1 in 1 fold: {}'.format(np.array(f1_cause_list).reshape(-1,1)))
print('average : acc {:.4f} p {:.4f} r {:.4f} f1 {:.4f}\n'.format(acc_cause, p_cause, r_cause, f1_cause))
print('emotion_predict: val f1 in 1 fold: {}'.format(np.array(f1_pos_list).reshape(-1,1)))
print('average : acc {:.4f} p {:.4f} r {:.4f} f1 {:.4f}\n'.format(acc_pos, p_pos, r_pos, f1_pos))
print('pair_predict: val f1 in 1 fold: {}'.format(np.array(f1_pair_list).reshape(-1,1)))
print('average : acc {:.4f} p {:.4f} r {:.4f} f1 {:.4f}\n'.format(acc_pair, p_pair, r_pair, f1_pair))
```
## Calling the class for the varying hyperparamters
```
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 64
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 64
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 64
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 64
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 128
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 128
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 128
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 128
BATCH_SIZE = 128
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 64
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 64
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 64
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 64
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 128
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 128
LEARNING_RATE = 0.005
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 128
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.400
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
# HYPERPARAMETERS TO BE TUNED
N_HIDDEN = 256
BATCH_SIZE = 128
LEARNING_RATE = 0.001
DIMINISH_FACTOR = 0.200
# MAIN MODEL
Model = E2E_PextE(embedding_dim, embedding_dim_pos, max_sen_len, max_doc_len, \
keep_prob1, keep_prob2, keep_prob3, N_HIDDEN, n_class)
Model.to(device)
print(Model)
x = torch.rand([BATCH_SIZE, max_doc_len, max_sen_len, embedding_dim]).to(device)
distance = torch.rand([BATCH_SIZE, max_doc_len * max_doc_len, embedding_dim_pos]).to(device)
pred_pos, pred_cause, pred_pair = Model(x, distance)
print("Random i/o shapes x: {}, distance: {}, y_pos: {}, y_cause: {}, y_pair: {}".format(
x.shape, distance.shape, pred_pos.shape, pred_cause.shape, pred_pair.shape))
pos_cause_criterion = ce_loss_aux(); pair_criterion = ce_loss_pair(DIMINISH_FACTOR)
optimizer = optim.Adam(Model.parameters(), lr=LEARNING_RATE, weight_decay=l2_reg)
train_and_eval(Model, pos_cause_criterion, pair_criterion, optimizer, N_HIDDEN, BATCH_SIZE, LEARNING_RATE, DIMINISH_FACTOR)
```
| github_jupyter |
<img src="ku_logo_uk_v.png" alt="drawing" width="130" style="float:right"/>
# <span style="color:#2c061f"> Exercise 2 </span>
<br>
## <span style="color:#374045"> Introduction to Programming and Numerical Analysis </span>
#### <span style="color:#d89216"> <br> Sebastian Honoré </span>
## Plan for today
<br>
1. Welcome
2. Github
3. Overview of Jupyter lab/notebook
4. Datacamp
## Important information
The deadline for finishing the 4 courses on datacamp has been postponed to March 7th!
## Padlet
Want me to go through something during classes? or find something hard to understand? Suggestions for exercise classes? Write it on: https://ucph.padlet.org/sebastianhonore/mqeo0l6lezrfrola. You can also upvote comments to signify their importance.
<center>
<img src="giphy.gif" width="500" align="center">
<center/>
## Github
As you may already know Git is a version control system that enables programmers to coordinate their work across computers. This is a really cool system, but hard to wrap your head around.
In this course we use Git to retrieve lecture notebooks and problemsets. Later on you will also have to upload your assignments on Github.
I will from now on uploade exercise slides in the repo: https://github.com/s-honore/NumEcon.git
## Github in VS Code
Note: We only use VS Code in this course to connect with Github
1. Pres »Ctrl+Shift+P«.
2. Write: »git: clone«
3. Write »https://github.com/NumEconCopenhagen/lectures-2021« Or: »https://github.com/NumEconCopenhagen/exercises-2021« ⇒ the repo will be downloaded to your computer
4. Update to the newest version of the code with »git: sync«
5. Create a copy of the cloned folder, where you work with the code (otherwise: merge conflicts!) - Really important
## Alternative to VS Code
**Github Desktop**
- Download: https://desktop.github.com
- Clone in Github Desktop:
- "Add" -> "Clone Repository" -> paste URL -> Select local path -> Clone
- Syncronize in Github Desktop:
- Select repository on left hand side -> "Fetch Origin"
## Overview of Jupyter Lab/Notebook
By now you most of you have likely only worked within the Datacamp programming environment. In practice you will work within Jupyter Lab or Jupyter Notebook. What is the difference between the two?
- Jupyter Lab is a next-generation user interface.
- Better structured
- possible to have multiple notebooks open simultaneously.
- Use whatever feels right for you. I personally use Jupyter Lab when programming, but Jupyter Notebook for tasks like making slides etc.
## Things to know
Creating a new file:
- Navigate to desired local path and press "new" in upper right corner -> select "Python 3"
Jupyter consist of cells:
- Cells can be in different modes: »Edit« or »Command«
- »Edit« allows you to type into the cell
- look for green border around the cell
- »Command« allows you to alter the notebook, but you can't type into the cell
- look for blue border
- To enter »Command«-mode press <kbd>ESC</kbd>
- Add cell above press <kbd>A</kbd>
- Add cell below press <kbd>B</kbd>
- Delete a cell press <kbd>D</kbd>+<kbd>D</kbd>
- Switch from typing code to markdown press <kbd>M</kbd>
- Run a cell press <kbd>Shift</kbd>+<kbd>Enter</kbd>
- Indent <kbd>Tab</kbd>
## Jupyter Kernel
In order to run a notebook Jupyter relies on a kernel. Essentially, this is just a Python Interpreter.
It is adviseable to restart this kernel once in a while to clear memory. Why?
```
#define a global variable
X=10
# Define simple function
def f(X):
Y=X*2
return Y
print(f(X))
```
## kernel continued
You may have written a never-ending while-loop. In this case you need to interrupt the kernel. Unfortunately, no shortcut exists. Therefore, navigate to "Kernel" and either interrupt or restart.
## Datacamp
Time to work on your courses in Datacamp. Please go to your dedicated Teams channel.
Need help? Write in general channel and i will assist you.
| github_jupyter |
<a href="https://colab.research.google.com/github/YeonKang/Tensorflow-with-Colab/blob/master/Lab11_4_mnist_CNN_ensemble_keras.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
```
**Importing Libraries**
```
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import os
print(tf.__version__)
print(keras.__version__)
```
**Hyper Parameters**
```
learning_rate = 0.001
training_epochs = 15
batch_size = 100
tf.random.set_seed(777)
```
**Creating Checkpoint Directory**
```
cur_dir = os.getcwd()
ckpt_dir_name = 'checkpoints'
model_dir_name = 'minst_cnn_emsemble'
checkpoint_dir = os.path.join(cur_dir, ckpt_dir_name, model_dir_name)
os.makedirs(checkpoint_dir, exist_ok=True)
checkpoint_prefix = os.path.join(checkpoint_dir, model_dir_name)
```
**MNIST/Fashion MNIST Data**
```
## MNIST Dataset #########################################################
mnist = keras.datasets.mnist
class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
##########################################################################
## Fashion MNIST Dataset #################################################
#mnist = keras.datasets.fashion_mnist
#class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
##########################################################################
```
**Datasets**
```
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.astype(np.float32) / 255.
test_images = test_images.astype(np.float32) / 255.
train_images = np.expand_dims(train_images, axis=-1)
test_images = np.expand_dims(test_images, axis=-1)
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(
buffer_size=100000).batch(batch_size)
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(batch_size)
```
**Model Class**
```
class MNISTModel(tf.keras.Model):
def __init__(self):
super(MNISTModel, self).__init__()
self.conv1 = keras.layers.Conv2D(filters=32, kernel_size=[3, 3], padding='SAME', activation=tf.nn.relu)
self.pool1 = keras.layers.MaxPool2D(padding='SAME')
self.conv2 = keras.layers.Conv2D(filters=64, kernel_size=[3, 3], padding='SAME', activation=tf.nn.relu)
self.pool2 = keras.layers.MaxPool2D(padding='SAME')
self.conv3 = keras.layers.Conv2D(filters=128, kernel_size=[3, 3], padding='SAME', activation=tf.nn.relu)
self.pool3 = keras.layers.MaxPool2D(padding='SAME')
self.pool3_flat = keras.layers.Flatten()
self.dense4 = keras.layers.Dense(units=256, activation=tf.nn.relu)
self.drop4 = keras.layers.Dropout(rate=0.4)
self.dense5 = keras.layers.Dense(units=10)
def call(self, inputs, training=False):
net = self.conv1(inputs)
net = self.pool1(net)
net = self.conv2(net)
net = self.pool2(net)
net = self.conv3(net)
net = self.pool3(net)
net = self.pool3_flat(net)
net = self.dense4(net)
net = self.drop4(net)
net = self.dense5(net)
return net
models = []
num_models = 3
for m in range(num_models):
models.append(MNISTModel())
```
**Loss Function**
```
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(
y_pred=logits, y_true=labels, from_logits=True))
return loss
```
**Calculating Gradient**
```
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
```
**Caculating Model's Accuracy**
```
def evaluate(models, images, labels):
predictions = np.zeros_like(labels)
for model in models:
logits = model(images, training=False)
predictions += logits
correct_prediction = tf.equal(tf.argmax(predictions, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
```
**Optimizer**
```
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
```
**Creating Checkpoints**
```
checkpoints = []
for m in range(num_models):
checkpoints.append(tf.train.Checkpoint(cnn=models[m]))
```
**Training**
```
print('Learning started. It takes sometime.')
for epoch in range(training_epochs):
avg_loss = 0.
avg_train_acc = 0.
avg_test_acc = 0.
train_step = 0
test_step = 0
for images, labels in train_dataset:
for model in models:
#train(model, images, labels)
grads = grad(model, images, labels)
optimizer.apply_gradients(zip(grads, model.variables))
loss = loss_fn(model, images, labels)
avg_loss += loss / num_models
acc = evaluate(models, images, labels)
avg_train_acc += acc
train_step += 1
avg_loss = avg_loss / train_step
avg_train_acc = avg_train_acc / train_step
for images, labels in test_dataset:
acc = evaluate(models, images, labels)
avg_test_acc += acc
test_step += 1
avg_test_acc = avg_test_acc / test_step
print('Epoch:', '{}'.format(epoch + 1), 'loss =', '{:.8f}'.format(avg_loss),
'train accuracy = ', '{:.4f}'.format(avg_train_acc),
'test accuracy = ', '{:.4f}'.format(avg_test_acc))
for idx, checkpoint in enumerate(checkpoints):
checkpoint.save(file_prefix=checkpoint_prefix+'-{}'.format(idx))
print('Learning Finished!')
```
| github_jupyter |
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
pd.set_option('display.float_format', lambda x: '%.3f' % x)
%matplotlib inline
```
## Allstate Claims Severity
[Kaggle](https://www.kaggle.com/c/allstate-claims-severity)
When you’ve been devastated by a serious car accident, your focus is on the things that matter the most: family, friends, and other loved ones. Pushing paper with your insurance agent is the last place you want your time or mental energy spent. This is why Allstate, a personal insurer in the United States, is continually seeking fresh ideas to improve their claims service for the over 16 million households they protect. Allstate is currently developing automated methods of predicting the cost, and hence severity, of claims.
```
data = pd.read_csv('train.csv')
data.info()
data.head()
```
You must predict the value for the `loss` column. Variables prefaced with `cat` are categorical, while those prefaced with `cont` are continuous.
Let's check is there a missing data?
```
data.isnull().any().any()
```
## Analyze target variable
```
data['loss'].describe()
```
- There're 188 318 rows (objects).
- Minumum is 0.67 and maxiumum 121 012.25.
- The avarage (mean) is 3037.338
- There's a big difference between 75th and 100th(max), should be long tail by right side.
```
data['loss'].hist(bins=100)
```
As usually, for those tasks, distrubution is right skewed (long tail by right side) and there're some outliers.
There're few approaches how to manage outliers:
1. remove 1 or 2 % the biggest values (usually this is outliers)
2. transform data by function which is work fine with outliers (e.g. log transformation)
```
data[ data.loss < np.percentile(data.loss, 99) ]['loss'].hist(bins=100)
data['log_loss'] = np.log( data['loss'] + 1 )
data['log_loss'].hist(bins=100)
```
## Categorical variables
Has prefix `cat` in the name
```
cat_feats = [feat for feat in data.columns if 'cat' in feat]
print(len(cat_feats), cat_feats)
```
There're 116 categorical variables.
Let's check cardinality (how many unique values each category has)
```
unq_values = [data[cat].nunique() for cat in cat_feats]
id_cat_feats = range(len(cat_feats))
plt.figure(figsize=(30, 10))
plt.plot(id_cat_feats, unq_values)
plt.xticks(id_cat_feats, cat_feats, rotation='vertical')
plt.show()
```
Let's remove last 20 elements, to verify how looks like smaller data.
```
cut_last_elems = 20
plt.figure(figsize=(30, 10))
plt.plot(id_cat_feats[:-cut_last_elems], unq_values[:-cut_last_elems])
plt.xticks(id_cat_feats[:-cut_last_elems], cat_feats[:-cut_last_elems], rotation='vertical')
plt.show()
```
#### Questions
1. Are there hight cardinality (let say more than 50 unique values)?
2. How many unique values have average categorical variables?
3. How this information could help you?
## Continuous variables
Has prefix `cont` in the name
```
cont_feats = [feat for feat in data.columns if 'cont' in feat]
print(len(cont_feats), cont_feats)
_ = data[ cont_feats ].hist(bins=30, figsize=(20, 20))
```
What you can say about:
- distributions
- range (min and max)
- outliers
## Evaluation
### [Mean absolute error](https://en.wikipedia.org/wiki/Mean_absolute_error)
In practise the means, that you will calculate difference between your prediction and actual value for each points.
Letter sum up all of them and devide by count of points.
What the problem do you know about mae?
## Base Line
Let's build the simplest model
```
from sklearn.dummy import DummyRegressor
from sklearn.metrics import mean_absolute_error
def base_line_model(data, target_variable='loss', strategy='mean'):
X = data[cont_feats].values
y = data[target_variable].values
model = DummyRegressor(strategy=strategy)
model.fit(X, y)
y_pred = model.predict(X)
if target_variable == 'log_loss':
y = np.exp(y) - 1
y_pred = np.exp(y_pred) - 1
y_pred[ y_pred < 0 ] = 0
score = mean_absolute_error(y, y_pred)
return score
for strategy in ['mean', 'median']:
for target_variable in ['loss', 'log_loss']:
score = base_line_model(data, target_variable=target_variable, strategy=strategy)
print(strategy, target_variable, score)
```
## Evaluation
To avoid overfitting is need more advaned way to validate result (e.g. cross validation)
### Task implement cross-validation
you can use DummyRegressor like a model
Tips
```
from sklearn.cross_validation import KFold
nfolds = 3
folds = KFold(data.shape[0], n_folds=nfolds, shuffle = True, random_state = 2017)
for num_iter, (train_index, test_index) in enumerate(folds):
pass
#X_train, y_train = X[train_index], y[train_index]
#X_test, y_test = X[test_index], y[test_index]
```
| github_jupyter |
# Metrics Heatmap
<a href="https://colab.research.google.com/github/netdata/netdata-community/blob/main/netdata-agent-api/netdata-pandas/metrics_heatmap.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
In this notebook we will use the [netdata-pandas](https://github.com/netdata/netdata-pandas) Python package to pull some data from some demo Netdata servers and make some pretty looking heatmaps, because we all love a good heatmap don't we.
**Note**: you can click the "Open in Colab" button above to open this notebook in [Google Colab](https://colab.research.google.com/notebooks/intro.ipynb#recent=true) where you can just get going with it without having to set up python enviornments or any messy stuff like that.
```
# if you need to, uncomment below to install netdata-pandas and seaborn packages
#!pip install plotly==4.14.1 netdata-pandas==0.0.33 scikit-learn==0.23.2
import numpy as np
import pandas as pd
from netdata_pandas.data import get_data
import plotly.express as px
from sklearn.cluster import KMeans, AgglomerativeClustering
```
Lets pull some data for the last 30 minutes.
```
# inputs
hosts = ['london.my-netdata.io']
charts_regex = 'system.*'
before = 0
after = -60*30
resample_freq = '30s'
# get the data
df_raw = get_data(hosts=hosts, charts_regex=charts_regex, after=after, before=before, index_as_datetime=True)
print(df_raw.shape)
df_raw.head()
```
## Heatmaps!
```
# lets resample to 10 sec frequency
df = df_raw.resample(resample_freq).mean()
# lets min-max normalize our data so metrics can be compared on a heatmap
df=(df-df.min())/(df.max()-df.min())
# drop na cols
df = df.dropna(how='all', axis=1)
# lets sort cols by their std to try make heatmap prettier
df = df[df.std().sort_values(ascending=False).index]
print(df.shape)
df.head(10)
# lets cluster the columns to show similar metrics next to each other on the heatmap
#clustering = KMeans(n_clusters=int(round(len(df.columns)*0.2,0))).fit(df.fillna(0).transpose().values)
clustering = AgglomerativeClustering(n_clusters=int(round(len(df.columns)*0.2,0))).fit(df.fillna(0).transpose().values)
# get order of cols from the cluster labels
cols_sorted = pd.DataFrame(
zip(df.columns, clustering.labels_),
columns=['metric', 'cluster']
).sort_values('cluster')['metric'].values.tolist()
# re-order cols
df = df[cols_sorted]
# now plot our heatmap
fig = px.imshow(df.transpose(), color_continuous_scale='Greens')
fig.update_layout(
autosize=False,
width=1000,
height=1200)
# fig.show() # for interactive
fig.show("svg") # static svg so can be displayed on github, best use above line
```
| github_jupyter |
**Import necessary libraries**
```
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import math
```
**Load the Seismic Data**
```
GroundAccel = pd.read_csv("El-Centro-2.txt", delimiter='\s+') # time [t] vs. g
GroundAccel["ug_ddot"] *= 9.81 # [m/s2]
GroundAccel.head(3) # Display first 3 rows to check the data
```
**Plot the ground acceleration data**
```
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
ax.plot(GroundAccel["t"], GroundAccel["ug_ddot"])
ax.set_xlabel("time [s]")
ax.set_ylabel("$\ddot{u_g}$ [m/s2]")
plt.show()
```
**A function to obtain recurrence coeff. (Aydınoğlu, 2003)**
```
def recurr_coeff(beta_ej, ksi, omega, deltat):
if (abs(beta_ej)<1e-10):
if (abs(ksi)<1e-10):
A11 = 1
A12 = deltat
A21 = 0
A22 = 1
B11 = -(1./2.)*deltat**2
B12 = -(1./6.)*deltat**2
B21 = -A12
B22 = B11/delta
return [A11, A12, A21, A22, B11, B12, B21, B22]
else:
eta = 2*ksi*omega
G = math.exp(-eta*deltat)
A11 = 1
A12 = (1-G)/eta
A21 = 0
A22 = G
B11 = (A12-deltat)/eta
B12 = -(B11/deltat+0.5*deltat)/eta
B21 = -A12
B22 = B11/deltat
return [A11, A12, A21, A22, B11, B12, B21, B22]
else:
if (abs(beta_ej-ksi**2)<1e-10):
A11 = (1+ksi*omega*deltat)*math.exp(-ksi*omega*deltat)
A12 = deltat*math.exp(-ksi*omega*deltat)
A21 = -beta_ej*(omega**2)*A12
A22 = (1-ksi*omega*deltat)*math.exp(-ksi*omega*deltat)
else:
if (beta_ej>ksi**2):
omegaD = omega*(beta_ej-ksi**2)**0.5
E = math.cos(omegaD*deltat)*math.exp(-ksi*omega*deltat)
F = math.sin(omegaD*deltat)*math.exp(-ksi*omega*deltat)
else:
omegaD = omega*(-beta_ej+ksi**2)**0.5
E = math.cosh(omegaD*deltat)*math.exp(-ksi*omega*deltat)
F = math.sinh(omegaD*deltat)*math.exp(-ksi*omega*deltat)
A11 = E+(ksi*omega/omegaD)*F
A12 = F/omegaD
A21 = -beta_ej*(omega**2)*A12
A22 = E-(ksi*omega/omegaD)*F
B11 = (A11-1)/(beta_ej*omega**2)
B12 = (A12-2*ksi*omega*B11-deltat)/(beta_ej*(omega**2)*deltat)
B21 = -A12
B22 = B11/deltat
return [A11, A12, A21, A22, B11, B12, B21, B22]
```
**Define the function which performs time stepping**
```
def hysteresis_bilinear(T, ksi, alpha, theta, fy_over_m, deltat, tend):
""""
Inputs:
T : initial period [s]
ksi : linear damping coeff.
alpha : post-yield stiffness ratio
theta : stability coeff.
fy_over_m : yield pseudo-acc. [m/s2]
deltat : time step [s]
tend : end time of simulation [s]
Outputs:
u_arr : displacements [m]
u_dot_arr : velocities [m/s]
u_ddot_arr : accelerations [m/s2]
fs_over_m_arr : pseudo-acc. [m/s2]
t_arr : corresponding times [s]
EI_over_m_arr : input energy per unit mass due to ground acc. [m2/s2]
Ek_over_m_arr : kinetic energy per unit mass [m2/s2]
Ed_over_m_arr : damping energy per unit mass [m2/s2]
Ees_over_m_arr : elastic energy per unit mass [m2/s2]
Eps_over_m_arr : plastic energy per unit mass [m2/s2]
"""
omega = 2*math.pi/T # Initial natural freq.
beta_ej_elastic = 1-theta # Effective stiffness ratio for elastic segments
beta_ej_yielding = alpha-theta # Effective stiffness ratio for yielding segments
t = 0 # Initial time
u = 0 # Initial displacement
u_dot = 0 # Initial velocity
fs_over_m = 0 # Initial pseudo-acc.
mode = "elastic" # Starting mode - elastic or yielding
beta_ej = beta_ej_elastic # Initial effective stiffness ratio
ug_ddot = np.interp(t, GroundAccel["t"], GroundAccel["ug_ddot"]) # Ground accel at t=0
uG_ddot = ug_ddot+fs_over_m-beta_ej*(omega**2)*u # Effective pseudo ground accel at t=0
u_ddot = ug_ddot
# Initiate arrays to store data for post-processing
u_arr = [u]
u_dot_arr = [u_dot]
u_ddot_arr = [-uG_ddot]
fs_over_m_arr = [fs_over_m]
t_arr = [t]
deltat_ref = deltat # Input time step to be used as reference.
# At the intersection points of linear segments,
# a smaller time step may be required.
Ek_over_m_arr = [0]
Ed_over_m_arr = [0]
EI_over_m_arr = [0]
Ees_over_m_arr = [0]
Eps_over_m_arr = [0]
while (t<tend):
t += deltat
# Save old solutions
ug_ddot_old = ug_ddot
u_old = u
u_dot_old = u_dot
u_ddot_old = u_ddot
fs_over_m_old = fs_over_m
# Calculate ground acceleration increment
ug_ddot = np.interp(t, GroundAccel["t"], GroundAccel["ug_ddot"])
delta_ug_ddot = ug_ddot-ug_ddot_old
# Update u, u_dot and fs_over_m for elastic mode
if (mode == "elastic"):
AB = recurr_coeff(beta_ej, ksi, omega, deltat)
u = AB[0]*u_old+AB[1]*u_dot_old+AB[4]*uG_ddot+AB[5]*delta_ug_ddot
u_dot = AB[2]*u_old+AB[3]*u_dot_old+AB[6]*uG_ddot+AB[7]*delta_ug_ddot
u_ddot = -2*ksi*omega*u_dot-beta_ej*(omega**2)*u-uG_ddot-delta_ug_ddot
fs_over_m += beta_ej*(omega**2)*(u-u_old)
# Energy calculations
Ek_over_m = 0.5*(u_ddot_old*u_dot_old+u_ddot*u_dot)*deltat
Ed_over_m = 2*ksi*omega*0.5*(u_dot_old**2+u_dot**2)*deltat
EI_over_m = -0.5*(ug_ddot_old*u_dot_old+ug_ddot*u_dot)*deltat
Ees_over_m = 0.5*(fs_over_m_old*u_dot_old+fs_over_m*u_dot)*deltat
Eps_over_m = 0
# Check for plastic transition
fy_over_m_TOP = beta_ej_yielding*(omega**2)*u+(1-alpha)*fy_over_m
fy_over_m_BOTTOM = beta_ej_yielding*(omega**2)*u-(1-alpha)*fy_over_m
if (fs_over_m>fy_over_m_TOP or fs_over_m<fy_over_m_BOTTOM):
if (abs(fs_over_m-fy_over_m_TOP)<1e-10 or abs(fs_over_m-fy_over_m_BOTTOM)<1e-10):
mode = "yielding"
beta_ej = beta_ej_yielding
deltat = deltat_ref
else:
ug_ddot = ug_ddot_old
u = u_old
u_dot = u_dot_old
fs_over_m = fs_over_m_old
t -= deltat
deltat *= 0.5
continue
# Update u, u_dot and fs_over_m for plastic mode
elif (mode == "yielding"):
AB = recurr_coeff(beta_ej, ksi, omega, deltat)
u = AB[0]*u_old+AB[1]*u_dot_old+AB[4]*uG_ddot+AB[5]*delta_ug_ddot
u_dot = AB[2]*u_old+AB[3]*u_dot_old+AB[6]*uG_ddot+AB[7]*delta_ug_ddot
u_ddot = -2*ksi*omega*u_dot-beta_ej*(omega**2)*u-uG_ddot-delta_ug_ddot
fs_over_m += beta_ej*(omega**2)*(u-u_old)
# Energy calculations
Ek_over_m = 0.5*(u_ddot_old*u_dot_old+u_ddot*u_dot)*deltat
Ed_over_m = 2*ksi*omega*0.5*(u_dot_old**2+u_dot**2)*deltat
EI_over_m = -0.5*(ug_ddot_old*u_dot_old+ug_ddot*u_dot)*deltat
Ees_over_m = 0
Eps_over_m = 0.5*(fs_over_m_old*u_dot_old+fs_over_m*u_dot)*deltat
# Check for elastic transition
if ((u_dot>0 and u_dot_old<0) or (u_dot<0 and u_dot_old>0)):
if abs(u_dot)<1e-10:
mode = "elastic"
beta_ej = beta_ej_elastic
deltat = deltat_ref
else:
ug_ddot = ug_ddot_old
u = u_old
u_dot = u_dot_old
fs_over_m = fs_over_m_old
t -= deltat
deltat *= 0.5
continue
uG_ddot = ug_ddot+fs_over_m-beta_ej*(omega**2)*u # Calculate effective pseudo-acc.
# Fill the arrays for post-processing
u_arr.append(u)
u_dot_arr.append(u_dot)
u_ddot_arr.append(u_ddot+ug_ddot)
fs_over_m_arr.append(fs_over_m)
t_arr.append(t)
Ek_over_m_arr.append(Ek_over_m_arr[-1]+Ek_over_m)
Ed_over_m_arr.append(Ed_over_m_arr[-1]+Ed_over_m)
EI_over_m_arr.append(EI_over_m_arr[-1]+EI_over_m)
Ees_over_m_arr.append(Ees_over_m_arr[-1]+Ees_over_m)
Eps_over_m_arr.append(Eps_over_m_arr[-1]+Eps_over_m)
return u_arr, u_dot_arr, u_ddot_arr, fs_over_m_arr, t_arr, EI_over_m_arr, \
Ek_over_m_arr, Ed_over_m_arr, Ees_over_m_arr, Eps_over_m_arr
```
**Inputs**
```
ksi = 0.003
alpha = 0.0
theta = 0.0
fy_over_m = 9.955
T = 0.527
deltat = T/1000
tend = 9.02
```
**Plot time vs energy**
```
u_arr, u_dot_arr, u_ddot_arr, fs_over_m_arr, t_arr, \
EI_over_m_arr, Ek_over_m_arr, Ed_over_m_arr, Ees_over_m_arr, Eps_over_m_arr = \
hysteresis_bilinear(T, ksi, alpha, theta, fy_over_m, deltat, tend)
Test = pd.read_csv("test_energy.txt", delimiter='\s+')
Test["EI"] *= 9.81
Test["Ek"] *= 9.81
Test["Ed"] *= 9.81
Test["Ep"] *= 9.81
Test["Es"] *= 9.81
print(-EI_over_m_arr[-1]+Ek_over_m_arr[-1]+Ed_over_m_arr[-1]+Ees_over_m_arr[-1]+Eps_over_m_arr[-1])
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
ax.plot(t_arr, EI_over_m_arr, label="computed")
ax.plot(Test["t"], Test["EI"], label="test")
ax.set_xlabel("t [s]")
ax.set_ylabel("EI_over_m")
ax.legend()
plt.show()
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
ax.plot(t_arr, Ees_over_m_arr, label="computed")
ax.plot(Test["t"], Test["Es"], label="test")
ax.set_xlabel("t [s]")
ax.set_ylabel("Ees_over_m")
ax.legend()
plt.show()
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
ax.plot(t_arr, Eps_over_m_arr, label="computed")
ax.plot(Test["t"], Test["Ep"], label="test")
ax.set_xlabel("t [s]")
ax.set_ylabel("Eps_over_m")
ax.legend()
plt.show()
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
ax.plot(t_arr, Ek_over_m_arr, label="computed")
ax.plot(Test["t"], Test["Ek"], label="test")
ax.set_xlabel("t [s]")
ax.set_ylabel("Ek_over_m")
ax.legend()
plt.show()
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
ax.plot(t_arr, Ed_over_m_arr, label="computed")
ax.plot(Test["t"], Test["Ed"], label="test")
ax.set_xlabel("t [s]")
ax.set_ylabel("Ed_over_m")
ax.legend()
plt.show()
```
**Inputs other than initial period**
```
ksi = 0.003
alpha = 0.0
theta = 0.0
fy_over_m = 1e100
tend = 9.02
```
**Plot energy spectrums**
```
T = 1e-3
deltaT = 0.02
Tend = 4
EI_over_m_max_arr = []
T_arr = []
while(T<Tend):
deltat = T/100 if T/100<0.005 else 0.005
u_arr, u_dot_arr, u_ddot_arr, fs_over_m_arr, t_arr, \
EI_over_m_arr, Ek_over_m_arr, Ed_over_m_arr, Ees_over_m_arr, Eps_over_m_arr = \
hysteresis_bilinear(T, ksi, alpha, theta, fy_over_m, deltat, tend)
EI_over_m_max_arr.append(max(abs(i) for i in EI_over_m_arr))
T_arr.append(T)
T += deltaT
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
ax.plot(T_arr, EI_over_m_max_arr, label="computed")
ax.set_xlabel("T [s]")
ax.set_ylabel("EI_over_m")
ax.legend()
plt.show()
```
| github_jupyter |
# Use the Shirt Class
You've seen what a class looks like and how to instantiate an object. Now it's your turn to write code that insantiates a shirt object.
# Explanation of the Code
This exercise using Jupyter notebook includes three files:
- shirt_exercise.ipynb, which is the file you are currently looking at
- answer.py containing answers to the exercise
- tests.py, tests for checking your code - you can run these tests using the last code cell at the bottom of this notebook
# Your Task
The shirt_exercise.ipynb file, which you are currently looking at if you are reading this, has an exercise to help guide you through coding with an object in Python.
Fill out the TODOs in each section of the Jupyter notebook. You can find a solution in the answer.py file.
First, run this code cell below to load the Shirt class.
```
class Shirt:
def __init__(self, shirt_color, shirt_size, shirt_style, shirt_price):
self.color = shirt_color
self.size = shirt_size
self.style = shirt_style
self.price = shirt_price
def change_price(self, new_price):
self.price = new_price
def discount(self, discount):
return self.price * (1 - discount)
### TODO:
# - insantiate a shirt object with the following characteristics:
# - color red, size S, style long-sleeve, and price 25
# - store the object in a variable called shirt_one
#
#
###
shirt_one = Shirt('red', 'S', 'long sleeve', 25)
### TODO:
# - print the price of the shirt using the price attribute
# - use the change_price method to change the price of the shirt to 10
# - print the price of the shirt using the price attribute
# - use the discount method to print the price of the shirt with a 12% discount
#
###
print(shirt_one.price)
shirt_one.change_price(32)
print(shirt_one.price)
shirt_one.discount(10)
print(shirt_one.price)
### TODO:
#
# - instantiate another object with the following characteristics:
# . - color orange, size L, style short-sleeve, and price 10
# - store the object in a variable called shirt_two
#
###
### TODO:
#
# - calculate the total cost of shirt_one and shirt_two
# - store the results in a variable called total
#
###
### TODO:
#
# - use the shirt discount method to calculate the total cost if
# shirt_one has a discount of 14% and shirt_two has a discount
# of 6%
# - store the results in a variable called total_discount
###
```
# Test your Code
The following code cell tests your code.
There is a file called tests.py containing a function called run_tests(). The run_tests() function executes a handful of assert statements to check your work. You can see this file if you go to the Jupyter Notebook menu and click on "File->Open" and then open the tests.py file.
Execute the next code cell. The code will produce an error if your answers in this exercise are not what was expected. Keep working on your code until all tests are passing.
If you run the code cell and there is no output, then you passed all the tests!
As mentioned previously, there's also a file with a solution. To find the solution, click on the Jupyter logo at the top of the workspace, and then enter the folder titled 1.OOP_syntax_shirt_practice
```
# Unit tests to check your solution
from tests import run_tests
run_tests(shirt_one, shirt_two, total, total_discount)
```
| github_jupyter |
```
import pandas as pd
import numpy as np
import math
import chart_studio.plotly as py
import plotly.tools as tls
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score, accuracy_score, log_loss, mean_squared_error, f1_score, matthews_corrcoef, classification_report, roc_curve, auc
# Load model from file
#xnn_dir = '/home/kimm/article-information-2019/data/xnn_output/simulation_results/'
#xnn_dir = '/Users/kmontgomery/Documents/git/article-information-2019/data/xnn_output/simulation_results/'
xnn_dir = '/Users/phall/workspace/article-information-2019/data/xnn_output/simulation_results/'
label = "sim_final"
filename = 'main_20000_' + label + '.csv'
TEST = pd.read_csv(xnn_dir + filename)
Feature_names = ['binary1', 'binary2', 'cat1_0', 'cat1_1', 'cat1_2', 'cat1_3', 'cat1_4',
'fried1_std', 'fried2_std', 'fried3_std', 'fried4_std', 'fried5_std']
TEST.columns
def get_prauc(frame, y, yhat, pos=1, neg=0, res=0.01):
""" Calculates precision, recall, and f1 for a pandas dataframe of y
and yhat values.
Args:
frame: Pandas dataframe of actual (y) and predicted (yhat) values.
y: Name of actual value column.
yhat: Name of predicted value column.
pos: Primary target value, default 1.
neg: Secondary target value, default 0.
res: Resolution by which to loop through cutoffs, default 0.01.
Returns:
Pandas dataframe of precision, recall, and f1 values.
"""
frame_ = frame.copy(deep=True) # don't destroy original data
dname = 'd_' + str(y) # column for predicted decisions
eps = 1e-20 # for safe numerical operations
# init p-r roc frame
prroc_frame = pd.DataFrame(columns=['cutoff', 'recall', 'precision', 'f1'])
# loop through cutoffs to create p-r roc frame
for cutoff in np.arange(0, 1 + res, res):
# binarize decision to create confusion matrix values
frame_[dname] = np.where(frame_[yhat] > cutoff , 1, 0)
# calculate confusion matrix values
tp = frame_[(frame_[dname] == pos) & (frame_[y] == pos)].shape[0]
fp = frame_[(frame_[dname] == pos) & (frame_[y] == neg)].shape[0]
tn = frame_[(frame_[dname] == neg) & (frame_[y] == neg)].shape[0]
fn = frame_[(frame_[dname] == neg) & (frame_[y] == pos)].shape[0]
# calculate precision, recall, and f1
recall = (tp + eps)/((tp + fn) + eps)
precision = (tp + eps)/((tp + fp) + eps)
f1 = 2/((1/(recall + eps)) + (1/(precision + eps)))
# add new values to frame
prroc_frame = prroc_frame.append({'cutoff': cutoff,
'recall': recall,
'precision': precision,
'f1': f1},
ignore_index=True)
# housekeeping
del frame_
return prroc_frame
# calculate and display recall and precision
#prauc_frame = get_prauc(test_yhat, y, yhat)
prauc_frame = get_prauc(TEST, 'outcome', '0')
prauc_frame.style.set_caption('Recall and Precision')
# Calculate the best F1 threshold
xnn_cut = prauc_frame.loc[prauc_frame['f1'].idxmax(), 'cutoff'] # value associated w/ index of max. F1
print('Best F1 threshold: %.2f' % xnn_cut)
# Calculate test statistics
Prediction = list(TEST['0'])
Classification = list(TEST['0'].apply(lambda x: int(x >= 0.38)))
Actual = list(TEST['outcome'].apply(int))
test_statistics = {}
#classification_rep = classification_report(Actual, Classification, output_dict=True)
classification_rep = classification_report(Actual, Classification, digits=3)
test_statistics['AUC'] = roc_auc_score(Actual, Prediction)
test_statistics['accuracy_score'] = accuracy_score(Actual, Classification)
test_statistics['log_loss'] = log_loss(Actual, Prediction)
test_statistics['rmse'] = math.sqrt(mean_squared_error(Actual, Prediction))
test_statistics['mcc'] = matthews_corrcoef(Actual, Classification)
#test_statistics['precision'] = classification_rep[1]['precision']
#test_statistics['sensitivity'] = classification_rep[1]['recall']
test_statistics['F1'] = f1_score(Actual, Classification)
print(test_statistics)
# recall of the positive class is also known as “sensitivity”
# recall of the negative class is “specificity”
print(classification_rep)
fpr, tpr, threshold = roc_curve(Actual, Prediction)
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
# Shapley and prediction matrix
SHAPLEY = TEST[[str(col) for col in range(0, 14)]].copy()
# Take the absolute value of the Shapley values
for col in range(1, 14):
SHAPLEY[str(col)] = SHAPLEY[str(col)].apply(abs)
Global_Shapley_Feature_Importance = SHAPLEY[[str(col) for col in range(1, 14)]].mean()
Global_Shapley_Feature_Importance.index = Feature_names + ['Intercept']
## Global_Shapley_Feature_Importance = Global_Shapley_Feature_Importance.sort_values(ascending=False)
print("Global Shapley Feature Importance")
Global_Shapley_Feature_Importance
Feature_importance = pd.DataFrame(Global_Shapley_Feature_Importance)
SHAPLEY.iloc[0:4,]
# Find the average shapley value for each quintile
SHAPLEY = SHAPLEY.sort_values('0')
len_Quintile=int(len(SHAPLEY)/5)
quintile_dict = {}
for quintile in range(1, 6):
if quintile == 5:
QUINTILE = SHAPLEY.iloc[(len_Quintile * (quintile - 1)):, 1:14].copy()
else:
QUINTILE = SHAPLEY.iloc[(len_Quintile * (quintile - 1)):(len_Quintile*quintile), 1:14].copy()
QUINTILE = QUINTILE.mean()
QUINTILE.index = Feature_names + ['Intercept']
# QUINTILE = QUINTILE.sort_values(ascending=False)
quintile_dict[quintile] = QUINTILE
Feature_importance['Quintile '+str(quintile)] = QUINTILE
print(quintile_dict[quintile])
Feature_importance = Feature_importance.rename(columns={"0": "Global Feature_Importance"})
Feature_importance.to_csv(xnn_dir + "Results_simulation_Feature_Importance.csv")
Feature_importance
# Plot the ridge functions
Ridge_x = pd.read_csv(xnn_dir + "ridge_x_" + label + ".csv")
Ridge_y = pd.read_csv(xnn_dir + "ridge_y_" + label + ".csv")
Ridge_y = Ridge_y.applymap(lambda x: eval(x)[0])
Ridge_x.to_csv(xnn_dir + 'Results_simulation_Ridge_x_values.csv', index=False)
Ridge_y.to_csv(xnn_dir + 'Results_simulation_Ridge_y_values.csv', index=False)
for row_num in range(Ridge_y.shape[0]):
plt.plot(Ridge_x.iloc[row_num,:], Ridge_y.iloc[row_num,:], 'o')
plt.xlabel("x")
plt.ylabel("Subnetwork " + str(row_num))
plt.show()
# Plot the projection layers
WP = pd.read_csv(xnn_dir + "wp_" + label + ".csv")
x = list(map(lambda x: 'x' + str(x+1), range(len(WP))))
WP.to_csv(xnn_dir + "Results_simulation_projection_layer.csv", index=False)
titles = ["Projection Layer " + str(ii) for ii in range(len(WP))]
for ind in range(len(WP)):
plt.bar(x, WP.iloc[ind,:], 1, color="blue")
plt.xlabel(titles[ind])
plt.ylabel("")
plt.show()
# Plot the deep lift score from the ridge function
Scores = pd.read_csv(xnn_dir + "scores_" + label + ".csv")
# Print the scores
x = list(map(lambda x: 'x' + str(x+1), range(Scores.shape[1])))
titles = ["layerwise average input", "layerwise average ridge",
"layerwise average input 2", "layerwise average ridge 2",
"shap input", "deep lift input", "deep lift ridge"]
ind = 6
Scores.iloc[ind,:].to_csv(xnn_dir + "Results_deep_lift_ridge_function_scores.csv")
plt.bar(x, Scores.iloc[ind,:], 1, color="blue")
plt.xlabel(titles[ind])
plt.ylabel("")
plt.show()
Scores
TEST.columns
# Rename the test prediction and shapley columns
TEST.iloc[0:4,]
TEST = TEST.rename(columns={"0": "probability",
"1": Feature_names[0]+"_Shapley_score",
"2": Feature_names[1]+"_Shapley_score",
"3": Feature_names[2]+"_Shapley_score",
"4": Feature_names[3]+"_Shapley_score",
"5": Feature_names[4]+"_Shapley_score",
"6": Feature_names[5]+"_Shapley_score",
"7": Feature_names[6]+"_Shapley_score",
"8": Feature_names[7]+"_Shapley_score",
"9": Feature_names[8]+"_Shapley_score",
"10": Feature_names[9]+"_Shapley_score",
"11": Feature_names[10]+"_Shapley_score",
"12": Feature_names[11]+"_Shapley_score",
"13": "Intercept_Shapley_score"})
#Feature_names
# Save the results
TEST.columns
TEST.to_csv(xnn_dir + "Results_simulation_test_set.csv", index=False)
```
| github_jupyter |
```
import numpy as np
import pickle as pk
import pandas as pd
import timeit as tm
import csv
import sys
# Open training data to pandas
train_dat_pandas = pd.read_csv('../data/clean_data/sum/train_vectors.csv', index_col=0, encoding='utf-8')
# Open training labels to pandas
train_lbl_pandas = pd.read_csv('../data/clean_data/sum/train_labels.csv', index_col=0, encoding='utf-8')
# Save headers
headers = [list(train_dat_pandas)]
# Convert pandas to numpy matrix
train_dat = train_dat_pandas.as_matrix()
print 'training data dimensions:', train_dat.shape
# Convert pandas to numpy matrix
train_lbl = train_lbl_pandas.as_matrix()
print 'training label dimensions:', train_lbl.shape
# Open test data
test_dat_pandas = pd.read_csv('../data/clean_data/sum/test_vectors.csv', index_col=0, encoding='utf-8')
# Open test labels
test_lbl_pandas = pd.read_csv('../data/clean_data/sum/test_labels.csv', index_col=0, encoding='utf-8')
# Convert pandas to numpy matrix
test_dat = test_dat_pandas.as_matrix()
print 'testing data dimensions:', test_dat.shape
# Convert pandas to numpy matrix
test_lbl = test_lbl_pandas.as_matrix()
print 'testing label dimensions:', test_lbl.shape
full_dat_pandas = pd.concat([train_dat_pandas, test_dat_pandas])
full_dat = full_dat_pandas.as_matrix()
full_lbl_pandas = pd.concat([train_lbl_pandas, test_lbl_pandas])
full_lbl = full_lbl_pandas.as_matrix()
# Feature vector scalling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(train_dat)
train_dat = scaler.transform(train_dat)
print train_dat.shape
test_dat = scaler.transform(test_dat)
print test_dat.shape
scaler.fit_transform(full_dat)
from sklearn.linear_model import LinearRegression
# Fit Linear Regression
lin_reg = LinearRegression(n_jobs=-1, normalize=True)
lin_reg.fit(train_dat, train_lbl)
# Generate predictions
predictions = lin_reg.predict(test_dat)
print predictions.shape
# Compute RMSE
import math
errors = []
# compute squared errors
for i in xrange(predictions.shape[0]):
p = predictions[i]
t = test_lbl[i]
# compute distance
squared_distance = 0.0
for j in xrange(predictions.shape[1]):
squared_distance += (p[j] - t[j])**2
errors.append(squared_distance)
rmse = math.sqrt(sum(errors)/len(errors))
print 'Root mean squared error:', rmse
print lin_reg.score(test_dat, test_lbl)
from sklearn.ensemble import RandomForestRegressor
reg = RandomForestRegressor(n_jobs=-1, n_estimators=10, verbose=2)
reg.fit(train_dat, train_lbl)
print reg.score(test_dat, test_lbl)
from sklearn.grid_search import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
parameters = {'max_depth':[None, 2, 4, 8, 16, 32, 64], 'max_features':['sqrt', 'log2', None]}
reg_internal = RandomForestRegressor()
reg = GridSearchCV(reg_internal, parameters, n_jobs=-1, cv=5, pre_dispatch='n_jobs', refit=True, verbose=1)
reg.fit(train_dat, train_lbl)
print 'Score on test data:', reg.score(test_dat, test_lbl)
print 'best params:', reg.best_params_
predictions = reg.predict(test_dat)
print predictions
from sklearn.ensemble import RandomForestRegressor
champion = RandomForestRegressor(n_jobs=-1,
max_depth=reg.best_params_['max_depth'],
max_features=reg.best_params_['max_features'])
champion.fit(full_dat, full_lbl)
# Save model
from sklearn.externals import joblib
joblib.dump(champion, '../models/RandomForestRegressor.p')
```
| github_jupyter |
```
from google.colab import drive
drive.mount('/content/drive/')
```
**Please note that you may have to change the path below based on the location of the folder**
```
%cd '/content/drive/My Drive/fnc-main'
#import libraries
from __future__ import print_function
import os
import sys
import numpy as np
import json
import pandas as pd
import time
from xgboost import XGBClassifier
from sklearn.ensemble import GradientBoostingClassifier
from feature_engineering import refuting_features, polarity_features, hand_features, gen_or_load_feats
from feature_engineering import word_overlap_features, NMF_cos_50, LDA_cos_25
from utils.dataset import DataSet
from utils.generate_test_splits import kfold_split, get_stances_for_folds
from utils.score import report_score, LABELS, score_submission
from utils.system import parse_params, check_version
#Model 2 dependencies
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten,BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import ModelCheckpoint
from sklearn.metrics import accuracy_score,confusion_matrix,f1_score
import matplotlib.pyplot as plt
import random
from random import choice
#setting seed to replicate results
seed=786
np.random.seed(seed)
from tensorflow import set_random_seed
set_random_seed(seed)
#save features in dataframe
train_feature_data = pd.DataFrame(columns=['headline','body_id','stance'])
comp_feature_data = pd.DataFrame(columns=['headline','body_id','stance'])
root_path="./hierarchicalModel-data/"
#genereate features to train
def generate_features(stances,dataset,name):
h, b, y = [],[],[]
rows = []
for stance in stances:
row = []
y.append(LABELS.index(stance['Stance']))
h.append(stance['Headline'])
b.append(dataset.articles[stance['Body ID']])
row.append(stance['Headline'])
row.append(dataset.articles[stance['Body ID']])
row.append(LABELS.index(stance['Stance']))
rows.append(row)
X_overlap = gen_or_load_feats(word_overlap_features, h, b, "features/overlap."+name+".npy")
X_refuting = gen_or_load_feats(refuting_features, h, b, "features/refuting."+name+".npy")
X_polarity = gen_or_load_feats(polarity_features, h, b, "features/polarity."+name+".npy")
X_hand = gen_or_load_feats(hand_features, h, b, "features/hand."+name+".npy")
######Topic Modelling - New Features Added######
X_NMF = gen_or_load_feats(NMF_cos_50, h, b, "features/nmf."+name+".npy")
X_LDA = gen_or_load_feats(LDA_cos_25, h, b, "features/lda-25."+name+".npy")
X = np.c_[X_hand, X_polarity, X_refuting, X_overlap, X_NMF, X_LDA]
if(name == "competition"):
if not (os.path.isfile(root_path+'comp_feature_data.csv')):
comp_feature_data['stance'] = y
comp_feature_data['headline'] = h
comp_feature_data['body_id'] = b
for i in range(0,X.shape[1]):
comp_feature_data[i] = X[:,i]
if(name == "full"):
if not (os.path.isfile(root_path+'train_feature_data.csv')):
train_feature_data['stance'] = y
train_feature_data['headline'] = h
train_feature_data['body_id'] = b
for i in range(0,X.shape[1]):
train_feature_data[i] = X[:,i]
return X,y
#Load the training dataset and generate folds
d = DataSet()
X_full,y_full = generate_features(d.stances,d,"full")
#for binary classification - related and unrelated
y_full = [x if x==3 else 2 for x in y_full]
#removing folds return train and holdout split - check if distribution same - does it matter
folds,hold_out = kfold_split(d,n_folds=10)
fold_stances, hold_out_stances = get_stances_for_folds(d,folds,hold_out)
X_holdout,y_holdout = generate_features(hold_out_stances,d,"holdout")
y_holdout = [x if x==3 else 2 for x in y_holdout]
#load training data
X_train, y_train = generate_features(fold_stances, d, "train_n")
y_train = [x if x==3 else 2 for x in y_train]
# Load the competition dataset
competition_dataset = DataSet("competition_test")
X_competition, y_competition = generate_features(competition_dataset.stances, competition_dataset, "competition")
y_competition = [x if x==3 else 2 for x in y_competition]
```
Classifier 1 training (XGBoost) starts here :
```
#Train classifier on 2 classes
param = {'eta':1, 'objectve' : "binary:logistic" , 'n_estimators':150, 'seed':10}
clf = XGBClassifier(**param)
start = int(round(time.time()*1000))
end = int(round(time.time()*1000))
train_time = end - start
clf.fit(X_train, y_train, eval_set=[(X_train, y_train), (X_holdout, y_holdout)], verbose=True)
#predict on train and holdout
y_pred_train = clf.predict(X_train)
y_pred = clf.predict(X_holdout)
y_pred_onfull = clf.predict(X_full)
#save features for training data
if not (os.path.isfile(root_path+'train_feature_data.csv')):
train_feature_data['predicted_stance'] = y_pred_onfull
train_feature_data.to_csv(root_path+'train_feature_data.csv', index = False)
#check file
feature_df = pd.read_csv(root_path+'train_feature_data.csv')
print("train data file size : ", feature_df.shape)
print("train data file: ", feature_df.head())
#get scores for binary classification: all Related mapped to 'discuss' class
predicted = [LABELS[int(a)] for a in y_pred_train]
actual = [LABELS[int(a)] for a in y_train]
print("Scores on the train set")
report_score(actual,predicted)
print("")
print("")
predicted = [LABELS[int(a)] for a in y_pred]
actual = [LABELS[int(a)] for a in y_holdout]
print("Scores on the dev set")
report_score(actual,predicted)
print("")
print("")
test_pred = clf.predict(X_competition)
predicted = [LABELS[int(a)] for a in test_pred]
actual = [LABELS[int(a)] for a in y_competition]
print("Scores on the test set")
report_score(actual,predicted)
#save features of competition dataset
if not (os.path.isfile(root_path+'comp_feature_data.csv')):
comp_feature_data['predicted_stance'] = test_pred
comp_feature_data.to_csv(root_path+'comp_feature_data.csv', index = False)
#check file
feature_df = pd.read_csv(root_path+'comp_feature_data.csv')
print("comp data file size : ", feature_df.shape)
print("comp data file: ", feature_df.head())
print("train time: ",train_time)
```
Hierarchical Architecture along with code forClassifier 2 (BERT + DNN ) starts here :
```
# Getting BERT Embeddings for Train and Test Data
df_train=pd.read_csv(root_path+"Train_BERT.csv")
df_test=pd.read_csv(root_path+"Test_BERT.csv")
df_train=df_train.drop(["Unnamed: 0"],axis=1)
df_test=df_test.drop(["Unnamed: 0"],axis=1)
# Filtering BERT Embeddings only for Training Data for 3 Classes i.e. Dropping Rows for related class because they are not used to train DNN model.
df_related=df_train[df_train["Stance"]!=4]
df_train=df_related
# Separating Stance from Embeddings for Training Data.
X=df_train.drop(["Stance"],axis=1)
y=df_train["Stance"]
# Separating Stance from Embeddings for Testing Data.
X_comp=df_test.drop(["Stance"],axis=1)
y_comp=df_test["Stance"]
# Training and Validation Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=seed)
y_gold=y_comp
## Data Cleaning because of label offset in input files
y_train=np.where(y_train==1, 0, y_train)
y_train=np.where(y_train==2, 1, y_train)
y_train=np.where(y_train==3, 2, y_train)
y_test=np.where(y_test==1, 0, y_test)
y_test=np.where(y_test==2, 1, y_test)
y_test=np.where(y_test==3, 2, y_test)
y_t=y_train
y_val=y_test
## Encdoding label for multiclass classification with DNN in Keras
y_train = keras.utils.to_categorical(y_train, 3)
y_test = keras.utils.to_categorical(y_test, 3)
# Training XG Boost Classifier on BERT Embeddings for 3 class classification
model_xg = XGBClassifier()
model_xg.fit(X_train, y_t)
# Prediction of Training and Validation Results
y_pred_xg_train = model_xg.predict(X_train)
y_pred_xg_val = model_xg.predict(X_test)
print("Training Confusion Matrix for 3 Class prediction by XGBoost+BERT \n",confusion_matrix(y_t,y_pred_xg_train),"\nF1 Score Train ",f1_score(y_t,y_pred_xg_train,average='macro'))
print("Validation Confusion Matrix for 3 Class prediction by XGBoost+BERT\n",confusion_matrix(y_val,y_pred_xg_val),"\nF1 Score Train ",f1_score(y_val,y_pred_xg_val,average='macro'))
y_comp_xg = model_xg.predict(X_comp)
# Model 1 for BERT + DNN
model = Sequential()
model.add(Dense(768))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(300))
model.add(BatchNormalization())
model.add(Activation('relu'))
# model.add(Dropout(0.5))
# model.add(Dense(200))
# model.add(BatchNormalization())
# model.add(Activation('relu'))
model.add(Dense(3))
model.add(Activation('softmax'))
# Model2 BERT+DNN with different class weights
model2 = Sequential()
model2.add(Dense(768))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dropout(0.5))
model2.add(Dense(500))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dropout(0.5))
model2.add(Dense(500))
model2.add(Activation('relu'))
model2.add(Dropout(0.5))
model2.add(Dense(500))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dense(3))
model2.add(Activation('softmax'))
# Initiate adam optimizer and compile both models
opt = keras.optimizers.adam(lr=0.01)
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
model2.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
#Defining Class weights for model2
class_weight = {0: 1.,
1: 2.,
2: 1.}
# Code to train model 1 and save best check point
filepath=root_path+"weights.best.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
history=model.fit(X_train.values, y_train,
batch_size=32,
callbacks=callbacks_list,
epochs=20,
validation_data=(X_test.values, y_test),
shuffle=True)
#Training for Model2 and Saving best weights
filepath=root_path+"weights2.best.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
history2=model2.fit(X_train.values, y_train,
batch_size=32,
callbacks=callbacks_list,
epochs=20,
validation_data=(X_test.values, y_test),
shuffle=True,class_weight=class_weight)
# Loading Best weights into the mode
model.load_weights(root_path+"weights.best.hdf5")
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
model2.load_weights(root_path+"weights2.best.hdf5")
model2.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
#Predictions for Train, Validation and Test data for both models
p_model1=model.predict_classes(X_comp.values)
p_model2=model2.predict_classes(X_comp.values)
p_model1_train=model.predict_classes(X_train.values)
p_model1_val=model.predict_classes(X_test.values)
p_model2_train=model2.predict_classes(X_train.values)
p_model2_val=model2.predict_classes(X_test.values)
# Printing Confusion matrix and F1 Score for all the models
print("Training Confusion Matrix for 3 Class prediction by BERT+DNN Model1 \n",confusion_matrix(y_t,p_model1_train),"\nF1 Score Train ",f1_score(y_t,p_model1_train,average='macro'))
print("Validation Confusion Matrix for 3 Class prediction by BERT+DNN Model1\n",confusion_matrix(y_val,p_model1_val),"\nF1 Score Train ",f1_score(y_val,p_model1_val,average='macro'))
print("Training Confusion Matrix for 3 Class prediction by BERT+DNN Model2\n",confusion_matrix(y_t,p_model2_train),"\nF1 Score Train ",f1_score(y_t,p_model2_train,average='macro'))
print("Validation Confusion Matrix for 3 Class prediction by BERT+DNN Model2\n",confusion_matrix(y_val,p_model2_val),"\nF1 Score Train ",f1_score(y_val,p_model2_val,average='macro'))
print("Training Confusion Matrix for 3 Class prediction by BERT+XGboost Model1 \n",confusion_matrix(y_t,y_pred_xg_train),"\nF1 Score Train ",f1_score(y_t,y_pred_xg_train,average='macro'))
print("Validation Confusion Matrix for 3 Class prediction by BERT+XGBoost Model1\n",confusion_matrix(y_val,y_pred_xg_val),"\nF1 Score Train ",f1_score(y_val,y_pred_xg_val,average='macro'))
# Predictions from Classifier 1 or Stage 1 or Relatedness layer
df_classifier1=pd.read_csv(root_path+"comp_feature_data.csv")
p_classifier1=df_classifier1["predicted_stance"].values
y_gold=df_classifier1["stance"].values
```
**Models Tested Individually and with Ensembles**
```
### Classfier1 + Classifier2(BERT+DNN Model1)
final_label=[]
for i,item in enumerate(p_classifier1):
if item==3:
final_label.append(item)
else:
final_label.append(p_model1[i])
final_label=np.array(final_label)
report_score([LABELS[e] for e in y_gold],[LABELS[e] for e in final_label])
### Classfier1 + Classifier2(BERT+DNN Model 2)
final_label2=[]
for i,item in enumerate(p_classifier1):
if item==3:
final_label2.append(item)
else:
final_label2.append(p_model2[i])
final_label2=np.array(final_label2)
report_score([LABELS[e] for e in y_gold],[LABELS[e] for e in final_label2])
### Classfier1 + Classifier2(BERT+XGBoost)
final_label3=[]
for i,item in enumerate(p_classifier1):
if item==3:
final_label3.append(item)
else:
final_label3.append(y_comp_xg[i])
final_label3=np.array(final_label3)
report_score([LABELS[e] for e in y_gold],[LABELS[e] for e in final_label3])
```
**BEST PERFORMING ENSEMBLE in terms of F1 Score performance. Codalab results reflects this**
```
### Ensemble1
final_label4=[]
for i,item in enumerate(p_classifier1):
if item==3:
final_label4.append(item)
else:
if final_label[i]==1 or final_label[i]==1 :
final_label4.append(1)
else:
final_label4.append(final_label3[i])
final_label4=np.array(final_label4)
report_score([LABELS[e] for e in y_gold],[LABELS[e] for e in final_label4])
### Ensemble2
final_label5=[]
for i,item in enumerate(p_classifier1):
if item==3:
final_label5.append(item)
else:
if final_label[i]==1 or final_label2[i]==1 :
final_label5.append(choice([final_label[i],final_label2[i]]))
else:
final_label5.append(choice([final_label[i],final_label2[i],final_label2[i]]))
final_label5=np.array(final_label5)
report_score([LABELS[e] for e in y_gold],[LABELS[e] for e in final_label5])
```
| github_jupyter |
```
import os
import random
import numpy as np
from collections import namedtuple
from sklearn.preprocessing import LabelEncoder
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
```
# Stanford Sentiment Treebank - movie reviews with fine-grained labels
```
# Stanford Sentiment Treebank - movie reviews with fine-grained labels
# https://nlp.stanford.edu/sentiment/
ST_sentence = namedtuple("Stanford_Sentiment", "id sentence")
ST_score = namedtuple("Stanford_Sentiment", "id score")
sentences = dict()
scores = dict()
train = []
dev = []
test = []
for filename in ['datasetSentences.txt','datasetSplit.txt', 'sentiment_labels.txt']:
with open("ST/"+filename,'r') as f_input:
for line in f_input:
# skip headers
if line.startswith("sentence_index") or line.startswith('phrase id'):
continue
# load sentences
if filename=='datasetSentences.txt':
sent_id, sentence = line.split('\t', 1)
sentences[sent_id] = sentence.strip()
# load splits
if filename=='datasetSplit.txt':
sent_id, split = line.split(',', 1)
split = int(split.strip())
if split == 1:
train.append(sent_id)
if split == 2:
test.append(sent_id)
if split == 3:
dev.append(sent_id)
# sentences_id
if filename=='sentiment_labels.txt':
sent_id, sent_score = line.split('|', 1)
#sent_score = float(sent_score.strip())
sample = ST_score(sent_id, float(sent_score.strip()))
scores[sent_id] = sent_score.strip()
```
# Samples and Classes/Labels
```
print("Total Nr. Samples: {}".format(len(sentences)))
print("Total Nr. Scores : {}".format(len(scores)))
print()
print("Train : {}".format(len(train)))
print("Dev : {}".format(len(dev)))
print("Test : {}".format(len(test)))
# built two lists with sentences and labels
x_train_data = [sentences[x] for x in train]
y_train_data = [scores[x] for x in train]
x_dev_data = [sentences[x] for x in dev]
y_dev_data = [scores[x] for x in dev]
x_test_data = [sentences[x] for x in test]
y_test_data = [scores[x] for x in test]
# convert list of tokens/words to indexes
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x_train_data)
sequences_train = tokenizer.texts_to_sequences(x_train_data)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
# get the max sentence lenght, needed for padding
max_input_lenght = max([len(x) for x in sequences_train])
max_input_lenght
# pad all the sequences of indexes to the 'max_input_lenght'
x_train_data_padded = pad_sequences(sequences_train, maxlen=max_input_lenght, padding='post', truncating='post')
x_dev_data_padded = pad_sequences(tokenizer.texts_to_sequences(x_dev_data), maxlen=max_input_lenght, padding='post', truncating='post')
x_test_data_padded = pad_sequences(tokenizer.texts_to_sequences(x_test_data), maxlen=max_input_lenght, padding='post', truncating='post')
```
## Transform scores to classes as re-labeled by Socher et al. (2013)
- 0 - 2.0 : very negative
- 2.0 - 4.0 : negative
- 4.0 - 6.0 : neutral
- 6.0 - 8.0 : negative
- 8.0 - 10.0 : very positive
```
def convert_to_categories(y_data):
y_categories = []
for score in y_data:
if 0.0<=float(score)<0.2:
y_categories.append('very_negative')
elif 0.2<=float(score)<0.4:
y_categories.append('negative')
elif 0.4<=float(score)<0.6:
y_categories.append('neutral')
elif 0.6<=float(score)<0.8:
y_categories.append('positive')
elif 0.8<=float(score)<=1.0:
y_categories.append('very positive')
return y_categories
# Convert from scores to categories
y_train_data_categ = convert_to_categories(y_train_data)
y_dev_data_categ = convert_to_categories(y_dev_data)
y_test_data_categ = convert_to_categories(y_test_data)
# Encode the labels, each must be a vector with dim = num. of possible labels
le = LabelEncoder()
le.fit(y_train_data_categ)
labels_encoded_train = le.transform(y_train_data_categ)
labels_encoded_dev = le.transform(y_dev_data_categ)
labels_encoded_test = le.transform(y_test_data_categ)
categorical_labels_train = to_categorical(labels_encoded_train, num_classes=None)
categorical_labels_dev = to_categorical(labels_encoded_dev, num_classes=None)
categorical_labels_test = to_categorical(labels_encoded_test, num_classes=None)
print(x_train_data_padded.shape)
print(categorical_labels_train.shape)
print(x_dev_data_padded.shape)
print(labels_encoded_dev.shape)
print(x_test_data_padded.shape)
print(categorical_labels_test.shape)
from convnets_utils import *
```
# CNN with random word embeddings
```
model_1 = get_cnn_rand(200, len(word_index)+1, max_input_lenght, 5)
history = model_1.fit(x=x_train_data_padded, y=categorical_labels_train, batch_size=50, epochs=15)
loss, accuracy = model_1.evaluate(x_test_data_padded, categorical_labels_test, verbose=0)
accuracy
raw_predictions = model_1.predict(x_test_data_padded)
class_predictions = [np.argmax(x) for x in raw_predictions]
print(classification_report(y_test_data_categ, le.inverse_transform(class_predictions)))
```
# CNN with pre-trained static word embeddings
```
embeddings_index = load_fasttext_embeddings()
embeddings_matrix = create_embeddings_matrix(embeddings_index, word_index, 100)
embedding_layer_static = get_embeddings_layer(embeddings_matrix, 'embedding_layer_static', max_input_lenght, trainable=False)
model_2 = get_cnn_pre_trained_embeddings(embedding_layer_static, max_input_lenght, 5)
history = model_2.fit(x=x_train_data_padded, y=categorical_labels_train, batch_size=50, epochs=15)
loss, accuracy = model_2.evaluate(x_test_data_padded, categorical_labels_test, verbose=0)
accuracy
raw_predictions = model_2.predict(x_test_data_padded)
class_predictions = [np.argmax(x) for x in raw_predictions]
print(classification_report(y_test_data_categ, le.inverse_transform(class_predictions)))
```
# CNN with pre-trained dynamic word embeddings
```
embedding_layer_dynamic = get_embeddings_layer(embeddings_matrix, 'embedding_layer_dynamic',
max_input_lenght, trainable=True)
model_3 = get_cnn_pre_trained_embeddings(embedding_layer_dynamic, max_input_lenght, 5)
history = model_3.fit(x=x_train_data_padded, y=categorical_labels_train,
batch_size=50,
epochs=5)
loss, accuracy = model_3.evaluate(x_test_data_padded, categorical_labels_test, verbose=0)
accuracy
raw_predictions = model_3.predict(x_test_data_padded)
class_predictions = [np.argmax(x) for x in raw_predictions]
print(classification_report(y_test_data_categ, le.inverse_transform(class_predictions)))
```
# CNN multichanell with pre-trained dynamic and static word embeddings
```
model_4 = get_cnn_multichannel(embedding_layer_static, embedding_layer_dynamic, max_input_lenght, 5)
history = model_4.fit(x=[x_train_data_padded,x_train_data_padded], y=categorical_labels_train,
batch_size=50,
epochs=5,
validation_split=0.33)
loss, accuracy = model_4.evaluate(x=[x_test_data_padded,x_test_data_padded], y=categorical_labels_test, verbose=0)
accuracy
raw_predictions = model_4.predict(x=[x_test_data_padded,x_test_data_padded])
class_predictions = [np.argmax(x) for x in raw_predictions]
print(classification_report(y_test_data_categ, le.inverse_transform(class_predictions)))
```
| github_jupyter |
# 主数据获取器
# 参考资料
* [1] [知乎 - 抓取数据的代码](https://zhuanlan.zhihu.com/p/34956727)
* [2] [CSDN - macOS下使用Automator转换CSV编码格式](https://blog.csdn.net/wqdwin/article/details/76058154)
* [3] [CSDN - 带有搜索框的爬取](https://blog.csdn.net/hguo11/article/details/69813583)
* [4] [CSDN - PhantomJS, Selenium, Python3配置](https://blog.csdn.net/zxy987872674/article/details/53082896)
* [5] [CSDN - Beauttifulsoup爬取网站table](https://blog.csdn.net/belldeep/article/details/78887318)
* [6] [CSDN - Python爬取类似股票表格](https://blog.csdn.net/mini_mooned/article/details/53575289)
* [7] [CSDN - 使用Python+selenium+BeautifulSoup抓取动态网页的关键信息](https://blog.csdn.net/vincentluo91/article/details/52947214)
* [8] [CSDN - 使用Decimal进行精确计算](https://blog.csdn.net/weixin_37989267/article/details/79473706)
* [9] [CNBLOGS - Python异常处理](https://www.cnblogs.com/cui0x01/p/6196378.html)
# 数据分析方向
### 目标 (Main Goal):
* 主要行业:电子信息,新能源,新材料,新技术 (OK)
* 金叉(MACD上穿)
* 成交量环比增幅30%以上(OK)
* 换手率大于5%(OK)
* 营业收入增加30%以上(同年)
* 净利润增加30%以上(同年)
### 各列中英文对应表
* code = 代码,name = 名称,close = 最新价
* percent_chg = 涨跌幅,change = 涨跌额
* volume = 成交量,turn_volume = 成交额,amplitude = 振幅
* high = 最高,low = 最低
* now_open = 今开,previous_close = 昨收
* volume_rate = 量比,turnover_rate = 换手率,pr_ratio = 市盈率(实时变化 暂不采用)
### SFrame命名中英文对应表
* info = 电子信息
* energy = 新能源
* material = 新材料
* tech = 全息技术
# 为每个子分区建立不同的list
```
# Import Statement
from selenium import webdriver
from bs4 import BeautifulSoup
from decimal import Decimal
from selenium.common.exceptions import ElementNotVisibleException
import time
from time import sleep
import urllib
import re
import requests
import csv
import pymysql
import os
import os,sys
import turicreate as tc
import pandas as pd
# 定义要搜索的URL信息
search_area = {'电子信息' : 'http://quote.eastmoney.com/center/boardlist.html#boards-BK04471',
'新能源' : 'http://quote.eastmoney.com/center/boardlist.html#boards-BK04931',
'新材料':'http://quote.eastmoney.com/center/boardlist.html#boards-BK05231',
'全息技术':'http://quote.eastmoney.com/center/boardlist.html#boards-BK06991'}
```
# 解析表格
```
# 一个从页面获取页数的函数
def getPageNumber(bs):
all_buttons = bs.findAll(class_ = "paginate_button")
if len(all_buttons) == 2:
return 1 # 处理只有一页的情况
else:
return len(all_buttons) - 2 # 下一页和Go按钮
# 一个自动判断量词的函数
def smartMultiply(string):
if(string[len(string)-1:len(string)] == '万'):
string = Decimal(string[0:len(string)-1])
string = float(string) * 10000
elif(string[len(string)-1:len(string)] == '亿'):
string = Decimal(string[0:len(string)-1])
string = float(string) * 100000000
elif(string[len(string)-1:len(string)] == '%'):
string = Decimal(string[0:len(string)-1])
string = float(string) * 0.01
else:
string = float(string)
return string
# 从一个静态BeautifulSoup页面解析表格并存储进SFrame
def grabData(bs, SFrame):
# 解出表格
table = bs.findAll(role = 'row')
table = table[7: len(table)-1]
# 分析每个表格
counter = 0
while counter < len(table):
row_sframe = tc.SFrame({'code':[str(table[counter].find(class_ = ' listview-col-Code').string)],
'name':[str(table[counter].find(class_ = ' listview-col-Name').string)],
'close':[smartMultiply(table[counter].find(class_ = ' listview-col-Close').string)],
'percent_chg':[smartMultiply(table[counter].find(class_ = 'listview-col-ChangePercent sorting_1').string)],
'change':[smartMultiply(table[counter].find(class_ = ' listview-col-Change').string)],
'volume':[smartMultiply(table[counter].find(class_ = ' listview-col-Volume').string)],
'turn_volume':[smartMultiply(table[counter].find(class_ = ' listview-col-Amount').string)],
'amplitude':[smartMultiply(table[counter].find(class_ = ' listview-col-Amplitude').string)],
'high':[smartMultiply(table[counter].find(class_ = ' listview-col-High').string)],
'low':[smartMultiply(table[counter].find(class_ = ' listview-col-Low').string)],
'now_open':[smartMultiply(table[counter].find(class_ = ' listview-col-Open').string)],
'previous_close':[smartMultiply(table[counter].find(class_ = ' listview-col-PreviousClose').string)],
'volume_rate':[smartMultiply(table[counter].find(class_ = ' listview-col-VolumeRate').string)],
'turnover_rate':[smartMultiply(table[counter].find(class_ = ' listview-col-TurnoverRate').string)],
'report_url':['http://emweb.securities.eastmoney.com/f10_v2/FinanceAnalysis.aspx?type=web&code=sz' + table[counter].find(class_ = ' listview-col-Code').string + '#lrb-0'],
})
counter += 1
# print(row_sframe)
SFrame = SFrame.append(row_sframe)
return SFrame
# 自动处理数据的主程序
def makeData(topic, SFrame):
browser = webdriver.Chrome() # Get local session of chrome
url = search_area[topic] # Example: '电子信息'
browser.get(url) #Load page
browser.implicitly_wait(2) #智能等待2秒
# 第一次访问时判定菜单数量来决定浏览多少次表格
bs = BeautifulSoup(browser.page_source, "lxml")
page_number = getPageNumber(bs)
# 循环浏览页面直到搜集完毕所有table
counter = 0
while counter < page_number:
SFrame = grabData(bs, SFrame)
try:
browser.find_element_by_id('main-table_next').click()
except ElementNotVisibleException:
print('Warning: Some data are out of reach.')
bs = BeautifulSoup(browser.page_source, "lxml")
counter += 1
SFrame = SFrame[1:len(SFrame)] # 删掉占位符
SFrame = SFrame.unique()
return SFrame
# 创建占位符的函数, 因为SFrame不允许创建空行,于是预先准备占位符用于定义各列数据类型。
def initSFrame():
sframe = tc.SFrame({'code':['000000'],'name':['哔哩哔哩'],
'close':[0.0],'percent_chg':[0.0],
'change':[0.0],'volume':[0.0],'turn_volume':[0.0], 'amplitude':[0.0],
'high':[0.0], 'low':[0.0],
'now_open':[0.0], 'previous_close':[0.0], 'volume_rate':[0.0],
'turnover_rate':[0.0], 'report_url':['http://www.bilibili.com']})
return sframe
# 创建四个空SFrame,以占位行开头
info = initSFrame()
energy = initSFrame()
material = initSFrame()
tech = initSFrame()
# 获取信息
info = makeData('电子信息', info)
energy = makeData('新能源', energy)
material = makeData('新材料', material)
tech = makeData('全息技术', tech)
```
# 初步数据分析
```
# 初步筛选分析程序
def analyze_stock(SFrame):
SFrame = analysis_turnover_rate(SFrame)
SFrame = analysis_volume_rate(SFrame)
return SFrame
# 返回所有换手率大于5%的行
def analysis_turnover_rate(SFrame):
return SFrame[SFrame['turnover_rate'] > 0.05]
# 返回所有量比大于30%的行
def analysis_volume_rate(SFrame):
return SFrame[ SFrame['volume_rate'] > 0.3]
analyze_info = analyze_stock(info)
analyze_energy = analyze_stock(energy)
analyze_material = analyze_stock(material)
analyze_tech = analyze_stock(tech)
# analyze_tech.show() # Debug
```
# 深度分析报表
```
def getReport(url, income_limit, profit_limit):
browser = webdriver.Chrome() # Get local session of chrome
browser.get(url) #Load page
soup = BeautifulSoup(browser.page_source, "lxml")
browser.close()
ulist = []
trs = soup.find_all('tr')
for tr in trs:
ui = []
for td in tr:
ui.append(td.string)
ulist.append(ui)
income_increase = 0
profit_increase = 0
for element in ulist:
if ('营业总收入' in element):
income_data_list = element
now_data = smartMultiply(income_data_list[3])
past_data = smartMultiply(income_data_list[11])
income_increase = (now_data - past_data) / past_data
# print('现营业总收入', now_data)
# print('一年前营业总收入', past_data)
# print('营业总收入增长', income_increase)
elif('净利润' in element):
profit_data_list = element
now_data = smartMultiply(profit_data_list[3])
past_data = smartMultiply(profit_data_list[11])
profit_increase = (now_data - past_data) / past_data
# print('现净利润', now_data)
# print('一年前净利润', past_data)
# print('净利润增长', income_increase)
# increase_list = [income_increase, profit_increase] # [营业总收入增长, 净利润增长]
if(income_increase > income_limit and profit_increase > profit_limit):
print('营业总收入增长', income_increase)
print('净利润增长', profit_increase)
return income_increase > income_limit and profit_increase > profit_limit
# 跑一下
# url = 'http://emweb.securities.eastmoney.com/f10_v2/FinanceAnalysis.aspx?type=web&code=sz002195#lrb-0'
# getReport(url)
```
# 推荐股票
```
def recommendStock(SFrame):
income_limit = 0.25
profit_limit = 0.25
counter = 0
while counter < len(SFrame):
if getReport(SFrame[counter]['report_url'], income_limit, profit_limit):
print(SFrame[counter]['name'], SFrame[counter]['code'])
counter += 1
recommendStock(analyze_info)
recommendStock(analyze_energy)
recommendStock(analyze_material)
recommendStock(analyze_tech)
```
# ============================================================
# ----------------------------------------TRASH----------------------------------------
# ============================================================
```
analyze_info['increase'] = analyze_info['report_url'].apply(getReport)
url = 'http://emweb.securities.eastmoney.com/f10_v2/FinanceAnalysis.aspx?type=web&code=sz002195#lrb-0'
browser = webdriver.Chrome() # Get local session of chrome
browser.get(url) #Load page
soup = BeautifulSoup(browser.page_source, "lxml")
browser.close()
ulist = []
trs = soup.find_all('tr')
for tr in trs:
ui = []
for td in tr:
ui.append(td.string)
ulist.append(ui)
income_increase = 0
profit_increase = 0
for element in ulist:
if ('营业总收入' in element):
income_data_list = element
now_data = smartMultiply(income_data_list[3])
past_data = smartMultiply(income_data_list[11])
income_increase = (now_data - past_data) / past_data
print('现营业总收入', now_data)
print('一年前营业总收入', past_data)
print('营业总收入增长', income_increase)
elif('净利润' in element):
profit_data_list = element
now_data = smartMultiply(profit_data_list[3])
past_data = smartMultiply(profit_data_list[11])
profit_increase = (now_data - past_data) / past_data
print('现净利润', now_data)
print('一年前净利润', past_data)
print('净利润增长', income_increase)
# 参考了[7], 利用selenium解析出来的page source抓取表格
# 居然有urllib解析不出的表格!!我去买彩票算了!!
browser = webdriver.Chrome() # Get local session of chrome
url = search_area['电子信息']
browser.get(url) #Load page
browser.implicitly_wait(2) #智能等待xx秒
time.sleep(5) #加载时间较长,等待加载完毕
# 把selenium的webdriver调用page_source函数在传入BeautifulSoup中,就可以用BeautifulSoup解析网页了
bs = BeautifulSoup(browser.page_source, "lxml")
code = table[0].find(class_ = ' listview-col-Code').string # code
print('代码', code)
name = table[0].find(class_ = ' listview-col-Name').string # name
print('名称', name)
close = smartMultiply(table[0].find(class_ = ' listview-col-Close').string)
print('最新价', close)
percent_chg = smartMultiply(table[0].find(class_ = 'listview-col-ChangePercent sorting_1').string)
print('涨跌幅', percent_chg)
change = smartMultiply(table[0].find(class_ = ' listview-col-Change').string)
print('涨跌额', change)
volume = smartMultiply(table[0].find(class_ = ' listview-col-Volume').string)
print('成交量', volume)
turn_volume = smartMultiply(table[0].find(class_ = ' listview-col-Amount').string)
print('成交额', turn_volume)
amplitude = smartMultiply(table[0].find(class_ = ' listview-col-Amplitude').string)
print('振幅', amplitude)
high = smartMultiply(table[0].find(class_ = ' listview-col-High').string)
print('最高', high)
low = smartMultiply(table[0].find(class_ = ' listview-col-Low').string)
print('最低', low)
now_open = smartMultiply(table[0].find(class_ = ' listview-col-Open').string)
print('今开', now_open)
previous_close = smartMultiply(table[0].find(class_ = ' listview-col-PreviousClose').string)
print('昨收', previous_close)
volume_rate = smartMultiply(table[0].find(class_ = ' listview-col-VolumeRate').string)
print('量比', volume_rate)
turnover_rate = smartMultiply(table[0].find(class_ = ' listview-col-TurnoverRate').string)
print('换手率', turnover_rate)
pr_rate = smartMultiply(table[0].find(class_ = ' listview-col-PERation').string)
print('市盈率', pr_rate)
def get_allele_feq(browser, snp):
browser.get(
'https://www.ncbi.nlm.nih.gov/variation/tools/1000genomes/?q=%s' %snp) #Load page
# browser.implicitly_wait(60) #智能等待xx秒
time.sleep(30) #加载时间较长,等待加载完毕
# browser.find_element_by_css_selector("div[title=\"Han Chinese in Bejing, China\"]") #use selenium function to find elements
# 把selenium的webdriver调用page_source函数在传入BeautifulSoup中,就可以用BeautifulSoup解析网页了
bs = BeautifulSoup(browser.page_source, "lxml")
# bs.find_all("div", title="Han Chinese in Bejing, China")
try:
race = bs.find(string="CHB")
race_data = race.find_parent("div").find_parent(
"div").find_next_sibling("div")
# print race_data
race_feq = race_data.find("span", class_="gt-selected").find_all("li") # class_ 防止Python中类关键字重复,产生语法错误
base1_feq = race_feq[0].text #获取标签的内容
base2_feq = race_feq[1].text
return snp, base1_feq, base2_feq # T=0.1408 C=0.8592
except NoSuchElementException:
return "%s:can't find element" %snp
browser = webdriver.Chrome() # Get local session of chrome
fh = open("./4diseases_snps_1kCHB_allele_feq.list2", 'w')
snps = open("./4diseases_snps.list.uniq2",'r')
for line in snps:
snp = line.strip()
response = get_allele_feq(browser, snp)
time.sleep(1)
fh.write("\t".join(response)) #unicode 编码的对象写到文件中后相当于print效果
fh.write("\n")
print "\t".join(response)
time.sleep(1) # sleep a few seconds
fh.close()
browser.quit() # 退出并关闭窗口的每一个相关的驱动程序
#coding:utf-8
# 用搜索框获取URL模块[3](暂时不用)
#这里设置用哪个,关于具体的使用可以百度,建议用phantomjs.exe读者可以做对比
driver = webdriver.Chrome('/usr/local/bin/chromedriver')
driver.get('http://www.eastmoney.com')
# 找到输入框,并输入文字
driver.find_element_by_id('code_suggest').send_keys('新能源')
sleep(2)
# 点击搜索按钮
driver.find_element_by_id('search_view_btn3').click()
#获取当前的URL的地址
print(driver.current_url)
#关闭浏览器
driver.close()
# 导入需要使用到的模块
# 爬虫抓取网页函数
def getHtml(url):
html = urllib.request.urlopen(url).read()
html = html.decode('gbk')
return html
# 抓取网页股票代码函数
def getStackCode(html):
s = r'<li><a target="_blank" href="http://quote.eastmoney.com/\S\S(.*?).html">'
pat = re.compile(s)
code = pat.findall(html)
return code
Url = 'http://quote.eastmoney.com/stocklist.html' # 东方财富网股票数据连接地址
filepath = '../Datasets/Eastmoney/Stock_History/' # 定义数据文件保存路径
# 实施抓取
code = getStackCode(getHtml(Url))
# 获取所有股票代码(以6开头的,应该是沪市数据)集合
CodeList = []
for item in code:
if item[0] == '6':
CodeList.append(item)
# 抓取数据并保存到本地csv文件
for code in CodeList:
print('正在获取股票%s数据'%code)
url = 'http://quotes.money.163.com/service/chddata.html?code=0'+code+\
'&end=20161231&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
urllib.request.urlretrieve(url, filepath+code+'.csv')
news_data = tc.SFrame('../Datasets/Eastmoney/Stock_History/600000.csv', decode='utf-8')
```
| github_jupyter |
## Dependencies
```
import json
from tweet_utility_scripts import *
from transformers import TFDistilBertModel, DistilBertConfig
from tokenizers import BertWordPieceTokenizer
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input, Dropout, GlobalAveragePooling1D, GlobalMaxPooling1D, Concatenate
```
# Load data
```
test = pd.read_csv('/kaggle/input/tweet-sentiment-extraction/test.csv')
print('Test samples: %s' % len(test))
display(test.head())
```
# Model parameters
```
input_base_path = '/kaggle/input/32-tweet-train-distilbert-base-poisson-smooth/'
with open(input_base_path + 'config.json') as json_file:
config = json.load(json_file)
config
base_path = '/kaggle/input/qa-transformers/distilbert/'
tokenizer_path = input_base_path + 'vocab.txt'
model_path_list = glob.glob(input_base_path + '*.h5')
model_path_list.sort()
print('Models to predict:')
print(*model_path_list, sep = "\n")
```
# Tokenizer
```
tokenizer = BertWordPieceTokenizer(tokenizer_path , lowercase=True)
```
# Pre process
```
test['text'].fillna('', inplace=True)
test["text"] = test["text"].apply(lambda x: x.lower())
x_test = get_data_test(test, tokenizer, config['MAX_LEN'])
```
# Model
```
module_config = DistilBertConfig.from_pretrained(config['config_path'], output_hidden_states=False)
def model_fn(MAX_LEN):
input_ids = Input(shape=(MAX_LEN,), dtype=tf.int32, name='input_ids')
attention_mask = Input(shape=(MAX_LEN,), dtype=tf.int32, name='attention_mask')
token_type_ids = Input(shape=(MAX_LEN,), dtype=tf.int32, name='token_type_ids')
base_model = TFDistilBertModel.from_pretrained(config['base_model_path'], config=module_config, name="base_model")
sequence_output = base_model({'input_ids': input_ids, 'attention_mask': attention_mask, 'token_type_ids': token_type_ids})
last_state = sequence_output[0]
x = GlobalAveragePooling1D()(last_state)
y_start = Dense(MAX_LEN, activation='sigmoid', name='y_start')(x)
y_end = Dense(MAX_LEN, activation='sigmoid', name='y_end')(x)
model = Model(inputs=[input_ids, attention_mask, token_type_ids], outputs=[y_start, y_end])
return model
```
# Make predictions
```
NUM_TEST_IMAGES = len(test)
test_start_preds = np.zeros((NUM_TEST_IMAGES, config['MAX_LEN']))
test_end_preds = np.zeros((NUM_TEST_IMAGES, config['MAX_LEN']))
for model_path in model_path_list:
print(model_path)
model = model_fn(config['MAX_LEN'])
model.load_weights(model_path)
test_preds = model.predict(x_test)
test_start_preds += test_preds[0] / len(model_path_list)
test_end_preds += test_preds[1] / len(model_path_list)
```
# Post process
```
test['start'] = test_start_preds.argmax(axis=-1)
test['end'] = test_end_preds.argmax(axis=-1)
test['text_len'] = test['text'].apply(lambda x : len(x))
test["end"].clip(0, test["text_len"], inplace=True)
test["start"].clip(0, test["end"], inplace=True)
test['selected_text'] = test.apply(lambda x: decode(x['start'], x['end'], x['text'], config['question_size'], tokenizer), axis=1)
test["selected_text"].fillna('', inplace=True)
```
# Visualize predictions
```
display(test.head(10))
```
# Test set predictions
```
submission = pd.read_csv('/kaggle/input/tweet-sentiment-extraction/sample_submission.csv')
submission['selected_text'] = test["selected_text"]
submission.to_csv('submission.csv', index=False)
submission.head(10)
```
| github_jupyter |
# Seq2Seq time series outlier detection on ECG data
## Method
The [Sequence-to-Sequence](https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf) (Seq2Seq) outlier detector consists of 2 main building blocks: an encoder and a decoder. The encoder consists of a [Bidirectional](https://en.wikipedia.org/wiki/Bidirectional_recurrent_neural_networks) [LSTM](https://colah.github.io/posts/2015-08-Understanding-LSTMs/) which processes the input sequence and initializes the decoder. The LSTM decoder then makes sequential predictions for the output sequence. In our case, the decoder aims to reconstruct the input sequence. If the input data cannot be reconstructed well, the reconstruction error is high and the data can be flagged as an outlier. The reconstruction error is measured as the mean squared error (MSE) between the input and the reconstructed instance.
Since even for normal data the reconstruction error can be state-dependent, we add an outlier threshold estimator network to the Seq2Seq model. This network takes in the hidden state of the decoder at each timestep and predicts the estimated reconstruction error for normal data. As a result, the outlier threshold is not static and becomes a function of the model state. This is similar to [Park et al. (2017)](https://arxiv.org/pdf/1711.00614.pdf), but while they train the threshold estimator separately from the Seq2Seq model with a Support-Vector Regressor, we train a neural net regression network end-to-end with the Seq2Seq model.
The detector is first trained on a batch of unlabeled, but normal (*inlier*) data. Unsupervised training is desireable since labeled data is often scarce. The Seq2Seq outlier detector is suitable for both **univariate and multivariate time series**.
## Dataset
The outlier detector needs to spot anomalies in electrocardiograms (ECG's). The dataset contains 5000 ECG's, originally obtained from [Physionet](https://archive.physionet.org/cgi-bin/atm/ATM) under the name *BIDMC Congestive Heart Failure Database(chfdb)*, record *chf07*. The data has been pre-processed in 2 steps: first each heartbeat is extracted, and then each beat is made equal length via interpolation. The data is labeled and contains 5 classes. The first class which contains almost 60% of the observations is seen as *normal* while the others are outliers. The detector is trained on heartbeats from the first class and needs to flag the other classes as anomalies.
This notebook requires the `seaborn` package for visualization which can be installed via `pip`:
```
!pip install seaborn
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import os
import pandas as pd
import seaborn as sns
from sklearn.metrics import accuracy_score, confusion_matrix, f1_score, precision_score, recall_score
from alibi_detect.od import OutlierSeq2Seq
from alibi_detect.utils.fetching import fetch_detector
from alibi_detect.utils.saving import save_detector, load_detector
from alibi_detect.datasets import fetch_ecg
from alibi_detect.utils.visualize import plot_roc
```
## Load dataset
Flip train and test data because there are only 500 ECG's in the original training set and 4500 in the test set:
```
(X_test, y_test), (X_train, y_train) = fetch_ecg(return_X_y=True)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
```
Since we treat the first class as the normal, *inlier* data and the rest of *X_train* as outliers, we need to adjust the training (inlier) data and the labels of the test set.
```
inlier_idx = np.where(y_train == 1)[0]
X_inlier, y_inlier = X_train[inlier_idx], np.zeros_like(y_train[inlier_idx])
outlier_idx = np.where(y_train != 1)[0]
X_outlier, y_outlier = X_train[outlier_idx], y_train[outlier_idx]
y_test[y_test == 1] = 0 # class 1 represent the inliers
y_test[y_test != 0] = 1
print(X_inlier.shape, X_outlier.shape)
```
Some of the outliers in *X_train* are used in combination with some of the inlier instances to infer the threshold level:
```
n_threshold = 1000
perc_inlier = 60
n_inlier = int(perc_inlier * .01 * n_threshold)
n_outlier = int((100 - perc_inlier) * .01 * n_threshold)
idx_thr_in = np.random.choice(X_inlier.shape[0], n_inlier, replace=False)
idx_thr_out = np.random.choice(X_outlier.shape[0], n_outlier, replace=False)
X_threshold = np.concatenate([X_inlier[idx_thr_in], X_outlier[idx_thr_out]], axis=0)
y_threshold = np.zeros(n_threshold).astype(int)
y_threshold[-n_outlier:] = 1
print(X_threshold.shape, y_threshold.shape)
```
Apply min-max scaling between 0 and 1 to the observations using the inlier data:
```
xmin, xmax = X_inlier.min(), X_inlier.max()
rng = (0, 1)
X_inlier = ((X_inlier - xmin) / (xmax - xmin)) * (rng[1] - rng[0]) + rng[0]
X_threshold = ((X_threshold - xmin) / (xmax - xmin)) * (rng[1] - rng[0]) + rng[0]
X_test = ((X_test - xmin) / (xmax - xmin)) * (rng[1] - rng[0]) + rng[0]
X_outlier = ((X_outlier - xmin) / (xmax - xmin)) * (rng[1] - rng[0]) + rng[0]
print('Inlier: min {:.2f} --- max {:.2f}'.format(X_inlier.min(), X_inlier.max()))
print('Threshold: min {:.2f} --- max {:.2f}'.format(X_threshold.min(), X_threshold.max()))
print('Test: min {:.2f} --- max {:.2f}'.format(X_test.min(), X_test.max()))
```
Reshape the observations to *(batch size, sequence length, features)* for the detector:
```
shape = (-1, X_inlier.shape[1], 1)
X_inlier = X_inlier.reshape(shape)
X_threshold = X_threshold.reshape(shape)
X_test = X_test.reshape(shape)
X_outlier = X_outlier.reshape(shape)
print(X_inlier.shape, X_threshold.shape, X_test.shape)
```
We can now visualize scaled instances from each class:
```
idx_plt = [np.where(y_outlier == i)[0][0] for i in list(np.unique(y_outlier))]
X_plt = np.concatenate([X_inlier[0:1], X_outlier[idx_plt]], axis=0)
for i in range(X_plt.shape[0]):
plt.plot(X_plt[i], label='Class ' + str(i+1))
plt.title('ECGs of Different Classes')
plt.xlabel('Time step')
plt.legend()
plt.show()
```
## Load or define Seq2Seq outlier detector
The pretrained outlier and adversarial detectors used in the example notebooks can be found [here](https://console.cloud.google.com/storage/browser/seldon-models/alibi-detect). You can use the built-in ```fetch_detector``` function which saves the pre-trained models in a local directory ```filepath``` and loads the detector. Alternatively, you can train a detector from scratch:
```
load_outlier_detector = True
filepath = 'my_path' # change to (absolute) directory where model is downloaded
detector_type = 'outlier'
dataset = 'ecg'
detector_name = 'OutlierSeq2Seq'
filepath = os.path.join(filepath, detector_name)
if load_outlier_detector: # load pretrained outlier detector
od = fetch_detector(filepath, detector_type, dataset, detector_name)
else: # define model, initialize, train and save outlier detector
# initialize outlier detector
od = OutlierSeq2Seq(1,
X_inlier.shape[1], # sequence length
threshold=None,
latent_dim=40)
# train
od.fit(X_inlier,
epochs=100,
verbose=False)
# save the trained outlier detector
save_detector(od, filepath)
```
Let's inspect how well the sequence-to-sequence model can predict the ECG's of the inlier and outlier classes. The predictions in the charts below are made on ECG's from the test set:
```
ecg_pred = od.seq2seq.decode_seq(X_test)[0]
i_normal = np.where(y_test == 0)[0][0]
plt.plot(ecg_pred[i_normal], label='Prediction')
plt.plot(X_test[i_normal], label='Original')
plt.title('Predicted vs. Original ECG of Inlier Class 1')
plt.legend()
plt.show()
i_outlier = np.where(y_test == 1)[0][0]
plt.plot(ecg_pred[i_outlier], label='Prediction')
plt.plot(X_test[i_outlier], label='Original')
plt.title('Predicted vs. Original ECG of Outlier')
plt.legend()
plt.show()
```
It is clear that the model can reconstruct the inlier class but struggles with the outliers.
If we trained a model from scratch, the warning thrown when we initialized the model tells us that we need to set the outlier threshold. This can be done with the `infer_threshold` method. We need to pass a time series of instances and specify what percentage of those we consider to be normal via `threshold_perc`, equal to the percentage of *Class 1* in *X_threshold*. The `outlier_perc` parameter defines the percentage of features used to define the outlier threshold. In this example, the number of features considered per instance equals 140 (1 for each timestep). We set the ```outlier_perc``` at 95, which means that we will use the 95% features with highest reconstruction error, adjusted for by the threshold estimate.
```
od.infer_threshold(X_threshold, outlier_perc=95, threshold_perc=perc_inlier)
print('New threshold: {}'.format(od.threshold))
```
Let's save the outlier detector with the updated threshold:
```
save_detector(od, filepath)
```
We can load the same detector via `load_detector`:
```
od = load_detector(filepath)
```
## Detect outliers
```
od_preds = od.predict(X_test,
outlier_type='instance', # use 'feature' or 'instance' level
return_feature_score=True, # scores used to determine outliers
return_instance_score=True)
```
## Display results
F1 score, accuracy, recall and confusion matrix:
```
y_pred = od_preds['data']['is_outlier']
labels = ['normal', 'outlier']
f1 = f1_score(y_test, y_pred)
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
rec = recall_score(y_test, y_pred)
print('F1 score: {:.3f} -- Accuracy: {:.3f} -- Precision: {:.3f} -- Recall: {:.3f}'.format(f1, acc, prec, rec))
cm = confusion_matrix(y_test, y_pred)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sns.heatmap(df_cm, annot=True, cbar=True, linewidths=.5)
plt.show()
```
We can also plot the ROC curve based on the instance level outlier scores:
```
roc_data = {'S2S': {'scores': od_preds['data']['instance_score'], 'labels': y_test}}
plot_roc(roc_data)
```
| github_jupyter |
# Compare original and Compiled models
## First start by downloading them ...
```
%store -r model_optimized
%store -r model_original
!aws s3 cp {model_optimized} ./
!aws s3 cp {model_original} ./
!mkdir original & tar -xzvf model.tar.gz -C original
!mkdir compiled & tar -xzvf model-ml_m4.tar.gz -C compiled
```
## Local inference - original model
We will upgrade to TF 2.0 to demonstrate how you can use saved_models from older (in this case, 1.18.0) versions/
```
!pip install --upgrade pip
!conda uninstall wrapt -y
!pip install tensorflow==2.0.0
!pip install opencv-python
import tensorflow as tf
import cv2
print(tf.__version__)
tf.get_logger().setLevel('ERROR')
tf.executing_eagerly()
```
### Load model and serving signature
```
path = !find ./original/ -type f -name "*.pb"
path = path[0][:-14]
print(path)
loaded = tf.saved_model.load(path)
!saved_model_cli show --dir {path} --tag_set serve --signature_def serving_default
print(list(loaded.signatures.keys()))
infer = loaded.signatures["serving_default"]
```
Load example image ...
```
image = cv2.imread("data/cat.png", 1)
print(image.shape)
# resize, as our model is expecting images in 32x32.
image = cv2.resize(image, (32, 32))
i = tf.image.convert_image_dtype(image.reshape(-1,32,32,3),tf.float32)
```
Check single inference ...
```
%%time
infer(i)['probabilities']
```
Get mean value
```
time_original = %timeit -n25 -r25 -o infer(i)['probabilities']
```
## Local inference - compiled model
DLR or Deep Learning Runtime is a part of Neo (https://github.com/neo-ai/neo-ai-dlr) is a compact, common runtime for deep learning models and decision tree models compiled by AWS SageMaker Neo, TVM, or Treelite. DLR uses the TVM runtime, Treelite runtime, NVIDIA TensorRT™, and can include other hardware-specific runtimes. DLR provides unified Python/C++ APIs for loading and running compiled models on various devices. DLR currently supports platforms from Intel, NVIDIA, and ARM, with support for Xilinx, Cadence, and Qualcomm coming soon.
```
!pip install dlr
from dlr import DLRModel
import numpy
input_shape = {'data': [1, 3, 224, 224]} # A single RGB 224x224 image
output_shape = [1, 1000] # The probability for each one of the 1,000 classes
device = 'cpu' # Go, Raspberry Pi, go!
model = DLRModel(model_path='compiled')
image = cv2.imread("data/cat.png", 1)
print(image.shape)
# resize, as our model is expecting images in 32x32.
image = cv2.resize(image, (32, 32))
input_data = {'Placeholder': numpy.asarray(image).astype(float).tolist()}
```
Check single inference ...
```
%%time
model.run(input_data)
```
Get mean value ...
```
time_compiled = %timeit -n25 -r25 -o model.run(input_data)
o1 = float(str(time_compiled)[:4])
o2 = float(str(time_original)[:4])
'{} vs {}ms ... {}x speedup!'.format(o2,o1,o2/o1)
```
# Thank you!
| github_jupyter |
# 2016-12-02: Dimensionality reduction
## Breast vs ovary cancer data
For this lab, we will work with gene expression data measured on breast and ovary tumors. The data originally comes from http://gemler.fzv.uni-mb.si/index.php but has been downsized so that it is easier to work with in our labs.
The data is similar to the Endometrium vs. Uterus cancer we have been working with for several weeks.
The data we will work with contains the expression of 3,000 genes, measured for 344 breast tumors and 198 ovary tumors.
### Imports
```
import numpy as np # numeric python
# scikit-learn (machine learning)
from sklearn import preprocessing
from sklearn import decomposition
# Graphics
%pylab inline
```
### Loading the data
It is stored in a CSV file, `small_Breast_Ovary.csv`. It has the same format as the `small_Endometrium_Uterus.csv` file. Load the data, creating a 2-dimensional numpy array X containing the gene expression data, and an 1-dimensional numpy array y containing the labels.
**Question** What are the dimensions of X? How many samples come from ovary tumors? How many come from breast tumors?
## Principal Component Analysis
PCA documentation: http://scikit-learn.org/0.17/modules/decomposition.html#pca and
http://scikit-learn.org/0.17/modules/generated/sklearn.decomposition.PCA.html#sklearn.decomposition.PCA
### Data normalization
Remember that PCA works on normalized data (mean 0, standard deviation 1). Normalize the data.
### 30 first principal components
```
pca = decomposition.PCA(n_components=30)
pca.fit(X_norm)
```
**Question:** Plot the fraction of variance explained by each component. Use `pca.explained_variance_ratio_`
```
# TODO
plt.xlim([0, 29])
plt.xlabel("Number of PCs", fontsize=16)
plt.ylabel("Fraction of variance explained", fontsize=16)
```
**Question:** Use `pca.transform` to project the data onto its principal components. How is `pca.explained_variance_ratio_` computed? Check this is the case by computing it yourself.
**Question:** Plot the data in the space of the two first components; color breast samples in blue and ovary samples in orange. What do you observe? Can you separate the two classes visually?
```
for color_name, tissue, tissue_name in zip(['blue', 'orange'], [-1, 1], ['breast', 'ovary']):
plt.scatter(#TODO,
c=color_name, label=tissue_name)
plt.legend(loc=(1.1, 0), fontsize=14)
plt.xlabel("PC 1", fontsize=16)
plt.ylabel("PC 2", fontsize=16)
```
**Bonus question:** Rather than visually, actually try to separate the two classes by a logistic regression line (using only the two first PCs). Plot the decision boundary. You can draw inspiration from http://scikit-learn.org/stable/auto_examples/linear_model/plot_iris_logistic.html#sphx-glr-auto-examples-linear-model-plot-iris-logistic-py for the plot.
### Outliers
**Question:** How many outliers do you observe in your data? Identify which entries of the X matrix they correspond to, and remove them from your data.
**Question:** Repeat the PCA procedure on the data without outliers. Can you now visually separate the two tissues?
### Classifying dimensionality-reduced data
**Question:** How many PCs do you think are sufficient to represent your data? What do you expect will happen if you use the projection of the gene expressions on these PCs and run a cross-validation of a classification algorithm? Try it out. Is there a risk of overfitting when you do this?
**Question:** Working on the original features, how do you expect your decision boundary (and AUC) to change, for different algorithms, depending on whether or not the outliers are included in the data? Try it out.
| github_jupyter |
# Risk Adjustment and Machine Learning
### Loading health data
```
# Import pandas and assign to it the pd alias
import pandas as pd
# Load csv to pd.dataframe using pd.read_csv
df_salud = pd.read_csv('../suficiencia.csv')
# Index is not appropiately set
print(df_salud.head())
# pd.read_csv inferred unconvenient data types for some columns
for columna in df_salud.columns:
print(columna,df_salud[columna].dtype)
# TO DO: declare a dict named dtype with column names as keys and data types as values
# We need MUNI_2010, MUNI_2011, DPTO_2010 and DPTO_2011 as data type 'category'. We need SEXO_M and SEXO_F as bool as well.
dtype = {}
# TO DO: declare a integer variable with the column number to be taken as index
index_col =
# We reload csv file using index_col and dtype parameters
df_salud = pd.read_csv('../suficiencia.csv',index_col= index_col,dtype=dtype)
# Index is appropriately set
print(df_salud.head())
# TO DO: check pd.read_csv has convenient data types
# Check last code cell for help.
# TO DO: print mean value for expenditure in 2010 and 2011
# Expenditure is given by variables 'VALOR_TOT_2010' and 'VALOR_TOT_2011'
```
### Exploring health data
We are interested in exploring risk profiles of individuals. Lets estimate expenditure and enrollee density distribution for different expenditure intervals. We will consider intervals of \$10,000 COP between \$0 and \$3,000,000 COP.
```
# We will be using plotly to graph the distributions.
import plotly
import plotly.graph_objs as go
plotly.offline.init_notebook_mode(connected=True)
# Set interval and step size
tamanho = 10**6*3
step_size = 10**4
# Enrollee distribution is straightforward using plotly.
trace2010 = go.Histogram(
x=df_salud['VALOR_TOT_2010'],
name='2010',
histnorm='probability',
xbins=dict(start=0.0,end=tamanho,size=step_size),
legendgroup='2010'
)
# TO DO: declare a second trace for the 2011 enrollee distribution
trace2011 = go.Histogram(
)
layout = go.Layout(
legend=dict(
xanchor='center',
yanchor='top',
orientation='h',
y=-0.25,
x=0.5,
),
yaxis=dict(
title='Density',
rangemode='tozero'
),
xaxis=dict(
title='Expenditure'
),
title='Enrolle density'
)
# TO DO Add both traces to a list and pass it to go.Figure data parameter
fig = go.Figure(data=, layout=layout)
plotly.offline.iplot(fig)
```
Expenditure distribution needs extra work since we are accumulating expenditure and not enrollees. For this purpose we first sort enrollees, then we calculate accumulated expenditure up to each interval and normalize it by total expenditure and finally we differentiate the series.
```
# TO DO: import numpy with alias np
# TO DO: write function to calculate expenditure cumulative density for a given year
def calculate_expenditure_cumulative_density(year):
return cumulative_density
density_2010 = np.diff(calculate_expenditure_cumulative_density('2010'))
density_2011 = np.diff(calculate_expenditure_cumulative_density('2011'))
# TO DO: declare a trace for 2010 expenditure distribution. Use color '#1f77b4' for markers.
trace_2010 = go.Scatter(
)
trace_2011 = go.Scatter(
x=list(range(0,tamanho,step_size)),
y=density_2011,
legendgroup='2011',
name='2011',
marker=dict(color='#ff7f0e'),
type='bar'
)
layout = go.Layout(
legend=dict(
xanchor='center',
yanchor='top',
orientation='h',
y=-0.25,
x=0.5,
),
yaxis=dict(
title='Density',
rangemode='tozero'
),
xaxis=dict(
title='Expenditure'
),
title='Expenditure density'
)
# Add both traces to a list and pass it to go.Figure data parameter. Add the layout parameter as well.
fig = go.Figure(data=,layout=)
plotly.offline.iplot(fig)
```
How about cumulative density for enrollees and expenditure? Enrollee cumulative density needs some extra work since we did not explicitly calculate enrollee density before.
```
# We will be using scipy
from scipy import stats
# TO DO: scipy.stats.percentileofscore(series,score) returns percentile value of score in series
def calculate_enrollee_cumulative_density(year):
return cumulative_density
enrollee_cumulative_density_2010 = calculate_enrollee_cumulative_density('2010')
enrollee_cumulative_density_2011 = calculate_enrollee_cumulative_density('2011')
expenditure_cumulative_density_2010 = calculate_expenditure_cumulative_density('2010')
expenditure_cumulative_density_2011 = calculate_expenditure_cumulative_density('2011')
# TO DO: Create cumulative expenditure and enrollees traces and plot them. Use previous color conventions.
trace_enrollee_2010 = go.Scatter(
)
trace_enrollee_2011 = go.Scatter(
)
trace_expenditure_2010 = go.Scatter(
)
trace_expenditure_2011 = go.Scatter(
)
layout = go.Layout(
legend=dict(
xanchor='center',
yanchor='top',
orientation='h',
y=-0.25,
x=0.5,
),
yaxis=dict(
title='Cumulative density (%)',
rangemode='tozero'
),
xaxis=dict(
title='Expenditure'
),
title='Cumulative density of enrollees and expenditure'
)
```
### Benchmarking the problem
Before fitting any models it is convenient to have a benchmark from a model as simple as possible. We estimate the mean absolute error (MAE) of the simple model
$$ y_{it}^{pred} = \frac{1}{N}\sum_{N}{y_{it}} $$
```
ymean = df_salud['VALOR_TOT_2011'].mean()
# TO DO : write a function that calculates beanchmark MAE
def calculate_benchmark_mae(row):
return mae
print('BENCHMARK MAE',df_salud.apply(calculate_mae,axis=1).mean())
```
### MSPS risk adjustment
Colombian Ministry of Health and Social Protection currently employs a linear regression of annual health expenditure on sociodemographic risk factors that include gender, age groups and location as the risk-adjustment mechanism.
<br/>
$$
y_{it} = \beta_{0} + \sum_{K}{\beta_{j}D_{jit}} + \epsilon_{i}
$$
<br/>
We will start by calculating age groups from variable 'EDAD_2011'.
```
# Creating a grouping variable is straightforward with pd.cut
bins = [0,1,4,18,44,49,54,59,64,69,74,150]
labels = ['0_1','2_4','5_18','19_44','45_49','50_54','55_59','60_64','65_69','70_74','74_']
df_salud['AGE_GROUP'] = pd.cut(df_salud['EDAD_2011'],bins,labels=labels,include_lowest=True)
print(df_salud[['EDAD_2011','AGE_GROUP']])
# We also need to create dummy variables using pd.get_dummies
age_group_dummies = pd.get_dummies(df_salud['AGE_GROUP'],prefix='AGE_GROUP')
df_salud = pd.concat([df_salud,age_group_dummies],axis=1)
for column in df_salud.columns:
print(column)
```
We also need to group location codes into government defined categories. This requires some extra work. Make sure you have divipola.csv file in your home.
```
# Download divipola.csv from your email and mo
divipola = pd.read_csv('../divipola.csv',index_col=0)
def give_location_group(row,divipola=divipola):
codigo_dpto = str(row['DPTO_2011']).rjust(2,'0')
codigo_muni = str(row['MUNI_2011']).rjust(3,'0')
codigo = codigo_dpto + codigo_muni
try:
grupo = divipola.loc[int(codigo)]['zona']
# Exception management for a single observation where last digit of municipality code is not valid
except KeyError:
return 'C'
return grupo
location_group_dummies = pd.get_dummies(df_salud.apply(give_location_group,axis=1),prefix='LOCATION_GROUP')
df_salud = pd.concat([df_salud,location_group_dummies],axis=1)
for column in df_salud.columns:
print(column)
```
Now we are ready to fit MSPS linear model.
```
# We will be using sklearn
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
# Feature space
# One reference category is excluded for each dummy group
features = ['SEXO_M',
'AGE_GROUP_2_4',
'AGE_GROUP_5_18',
'AGE_GROUP_19_44',
'AGE_GROUP_45_49',
'AGE_GROUP_50_54',
'AGE_GROUP_55_59',
'AGE_GROUP_60_64',
'AGE_GROUP_65_69',
'AGE_GROUP_70_74',
'AGE_GROUP_74_',
'LOCATION_GROUP_N',
'LOCATION_GROUP_Z',]
# Target space
target = ['VALOR_TOT_2011']
# TO DO: calculate 10 cv mae for linear regression model using sklearn.model_selection.cross_val_score. Take a look at the needed parameters.
reg = linear_model.LinearRegression()
neg_mae = cross_val_score(estimator=,X=,y=,cv=,scoring=)
print('REGRESSION MAE',-1*neg_mae.mean())
reg = reg.fit(df_salud[features].values,df_salud[target].values)
# TO DO: predict over enrollees with enrollees with 2011 expenditure above $3,000,000
upper =
y_pred_upper = [y[0] for y in reg.predict(upper[features])]
print('REGRESSION MAE UPPER',(y_pred_upper-upper['VALOR_TOT_2011']).mean())
# TO DO: predict over enrollees with enrollees with 2011 expenditure below or equal to $3,000,000
lower =
y_pred_lower = [y[0] for y in reg.predict(lower[features])]
print('REGRESSION MAE LOWER',(y_pred_lower-lower['VALOR_TOT_2011']).mean())
```
### Risk adjustment using machine learning
How about a regression tree?
```
# We will be using sklearn
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import cross_val_score
# Feature space
# One reference category is excluded for each dummy group
features = ['SEXO_M',
'AGE_GROUP_2_4',
'AGE_GROUP_5_18',
'AGE_GROUP_19_44',
'AGE_GROUP_45_49',
'AGE_GROUP_50_54',
'AGE_GROUP_55_59',
'AGE_GROUP_60_64',
'AGE_GROUP_65_69',
'AGE_GROUP_70_74',
'AGE_GROUP_74_',
'LOCATION_GROUP_N',
'LOCATION_GROUP_Z',]
# Target space
target = ['VALOR_TOT_2011']
reg_tree = DecisionTreeRegressor(min_samples_leaf=1000)
neg_mae = cross_val_score(estimator=,X=,y=,cv=,scoring=)
print('TREE REGRESSION MAE',-1*neg_mae.mean())
```
What does a tree look like?
```
# We will use modules from sklearn, ipython and pydotplus to visualize trees
from sklearn.externals.six import StringIO
from IPython.display import Image, display
from sklearn.tree import export_graphviz
import pydotplus
def plot_tree(tree):
dot_data = StringIO()
export_graphviz(
tree,
out_file=dot_data,
filled=True,
special_characters=True,
precision=0,
feature_names=features
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
display(Image(graph.create_png()))
reg_tree = DecisionTreeRegressor(min_samples_leaf=1000)
reg_tree = reg_tree.fit(df_salud[features].values,df_salud[target].values)
plot_tree(reg_tree)
upper = df_salud[df_salud['VALOR_TOT_2011'] > (3*10**6)]
y_pred_upper = reg_tree.predict(upper[features])
print('TREE REGRESSION MAE UPPER',(y_pred_upper-upper['VALOR_TOT_2011']).mean())
lower = df_salud[df_salud['VALOR_TOT_2011'] <= (3*10**6)]
y_pred_lower = reg_tree.predict(lower[features])
print('TREE REGRESSION MAE LOWER',(y_pred_lower-lower['VALOR_TOT_2011']).mean())
# Feature space
# One reference category is excluded for each dummy group
features = ['SEXO_M',
'AGE_GROUP_2_4',
'AGE_GROUP_5_18',
'AGE_GROUP_19_44',
'AGE_GROUP_45_49',
'AGE_GROUP_50_54',
'AGE_GROUP_55_59',
'AGE_GROUP_60_64',
'AGE_GROUP_65_69',
'AGE_GROUP_70_74',
'AGE_GROUP_74_',
'LOCATION_GROUP_N',
'LOCATION_GROUP_Z',
'DIAG_1_C_2010',
'DIAG_1_P_2010',
'DIAG_1_D_2010',]
# Target space
target = ['VALOR_TOT_2011']
reg_tree = DecisionTreeRegressor(min_samples_leaf=100)
neg_mae = cross_val_score(estimator=reg_tree,X=df_salud[features],y=df_salud[target],cv=10,scoring='neg_mean_absolute_error')
print('TREE REGRESSION MAE',-1*neg_mae.mean())
reg_tree = DecisionTreeRegressor(min_samples_leaf=100)
reg_tree = reg_tree.fit(df_salud[features].values,df_salud[target].values)
plot_tree(reg_tree)
upper = df_salud[df_salud['VALOR_TOT_2011'] > (3*10**6)]
y_pred_upper = reg_tree.predict(upper[features])
print('TREE REGRESSION MAE UPPER',(y_pred_upper-upper['VALOR_TOT_2011']).mean())
lower = df_salud[df_salud['VALOR_TOT_2011'] <= (3*10**6)]
y_pred_lower = reg_tree.predict(lower[features])
print('TREE REGRESSION MAE LOWER',(y_pred_lower-lower['VALOR_TOT_2011']).mean())
```
| github_jupyter |
## Model Comparison - Full Feature Set
Author: Daniel Hui
License: MIT
This notebook exaluates a few different modelling options for the data, for comparison
```
import pandas as pd
import numpy as np
# visualization imports
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
pd.set_option('display.max_columns', 500)
pd.set_option('display.float_format', lambda x: '%.4f' % x)
```
### Load Dataset
```
checkout_target_df = pd.read_csv('01_Data/"Checkout_Features_Target.csv',index_col=0)
checkout_target_df.head(3)
checkout_target_df.describe()
checkout_target_df.info()
len(checkout_target_df)
```
### Train / Test / Split
```
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn import metrics
y = checkout_target_df["Checkout"]
X = checkout_target_df.drop(["Checkout","BibNum"],axis=1)
#hold out portion of the data for final testing
X, X_test, y, y_test = train_test_split(X, y, test_size=.2, random_state=20) #keep at 20 to be consistent
#hold out 20% for validation
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=.25, random_state=50)
print(len(X_train),len(X_val),len(X_test))
```
### KNN Classifier
This first part will grid search for the best Neighbor value
```
for i in range(5,31,5):
adjacents = i
knn = KNeighborsClassifier(n_neighbors=adjacents)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_val)
print(adjacents, " neighbors. Accuracy: ", metrics.accuracy_score(y_val, y_pred))
print(adjacents, " neighbors. Precision: ", metrics.precision_score(y_val, y_pred))
print(adjacents, " neighbors. Recall: ", metrics.recall_score(y_val, y_pred))
print(adjacents, " neighbors. f1: ", metrics.f1_score(y_val, y_pred))
print("----------")
# Let's go with N=15
knn = KNeighborsClassifier(n_neighbors=15)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_val)
print("Accuracy: ",metrics.accuracy_score(y_val, y_pred))
print("Precision: ",metrics.precision_score(y_val, y_pred))
print("Recall: ",metrics.recall_score(y_val, y_pred))
print("F1: ",metrics.f1_score(y_val, y_pred))
confusion_matrix(y_val, y_pred)
```
### Logistic Regression
```
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
std_scale = StandardScaler()
X_train_scaled = std_scale.fit_transform(X_train)
lr_model = LogisticRegression(C=10000)
lr_model.fit(X_train_scaled,y_train)
y_train_pred = lr_model.predict(X_train_scaled)
print("Accuracy: ",metrics.accuracy_score(y_train, y_train_pred))
print("Precision: ",metrics.precision_score(y_train, y_train_pred))
print("Recall: ",metrics.recall_score(y_train, y_train_pred))
print("F1: ",metrics.f1_score(y_train, y_train_pred))
X_val_scaled = std_scale.transform(X_val)
y_val_pred = lr_model.predict(X_val_scaled)
print("Accuracy: ",metrics.accuracy_score(y_val, y_val_pred))
print("Precision: ",metrics.precision_score(y_val, y_val_pred))
print("Recall: ",metrics.recall_score(y_val, y_val_pred))
print("F1: ",metrics.f1_score(y_val, y_val_pred))
confusion_matrix(y_val, y_val_pred)
coefficients = lr_model.coef_[0] * -1
features = np.array(X_train.columns)
lr_model_dict = list(zip(features,coefficients))
plt.bar(features,coefficients)
pd.DataFrame(lr_model_dict).sort_values(by=1,ascending=False).head(20)
X_val_scaled = std_scale.transform(X_val)
thresh_ps = np.linspace(.50,.85,1000)
model_val_probs = lr_model.predict_proba(X_val_scaled)[:,1] # first column is the probability for 0 condition
# second column is the probability for the 1 condition
precision_scores = []
for p in thresh_ps:
model_val_labels = model_val_probs >= p
precision_scores.append(precision_score(y_val,model_val_labels))
plt.plot(thresh_ps, precision_scores)
plt.title('Precision Score vs. Positive Class Decision Probability Threshold')
plt.xlabel('P threshold')
plt.ylabel('Precision')
best_precision_score = np.max(precision_scores)
best_thresh_p = thresh_ps[np.argmax(precision_scores)]
print('Logistic Regression Model best F1 score %.3f at prob decision threshold >= %.3f'
% (best_precision_score, best_thresh_p))
```
### Naive Bayes
```
from sklearn import naive_bayes
from sklearn.metrics import accuracy_score, classification_report
model = naive_bayes.GaussianNB()
model.fit(X_train,y_train)
y_train_predict = model.predict(X_train)
print("Accuracy: ", accuracy_score(y_train, y_train_predict ))
print("Recall: ",recall_score(y_train,y_train_predict)) # Recall
print("Precision: ",precision_score(y_train,y_train_predict)) # Precision
print("f1: ",f1_score(y_train,y_train_predict))
y_val_predict = model.predict(X_val)
print("Accuracy: ", accuracy_score(y_val, y_val_predict ))
print("Recall: ",recall_score(y_val,y_val_predict)) # Recall
print("Precision: ",precision_score(y_val,y_val_predict)) # Precision
print("f1: ",f1_score(y_val,y_val_predict))
confusion_matrix(y_train, model.predict(X_train) )
```
### Random Forest
```
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
# Try with different max features
rfmodel = RandomForestClassifier(n_estimators = 1000, max_features = 7,
min_samples_leaf = 4, n_jobs=4, max_depth=6)
rfmodel.fit(X_train,y_train)
y_train_predict = rfmodel.predict(X_train)
print("Train Accuracy: ", accuracy_score(y_train, y_train_predict ))
print("Train Recall: ",recall_score(y_train, y_train_predict)) # Recall
print("Train Precision: ",precision_score(y_train, y_train_predict)) # Precision
print("Train f1: ",f1_score(y_train, y_train_predict))
y_val_predict = rfmodel.predict(X_val)
print("Validation Accuracy: ", accuracy_score(y_val, y_val_predict ))
print("Validation Recall: ",recall_score(y_val, y_val_predict)) # Recall
print("Validation Precision: ",precision_score(y_val, y_val_predict)) # Precision
print("Validation f1: ",f1_score(y_val, y_val_predict))
confusion_matrix(y_val, y_val_predict)
```
### GradientBoostingClassifier
```
# Try with different max features
gbmodel = GradientBoostingClassifier(n_estimators = 1000, max_features = 3,
min_samples_leaf = 10,learning_rate=0.005)
gbmodel.fit(X_train,y_train)
y_train_predict = gbmodel.predict(X_train)
print("Train Accuracy: ", accuracy_score(y_train, y_train_predict ))
print("Train Recall: ",recall_score(y_train, y_train_predict)) # Recall
print("Train Precision: ",precision_score(y_train, y_train_predict)) # Precision
print("Train f1: ",f1_score(y_train, y_train_predict))
y_val_predict = gbmodel.predict(X_val)
print("Validation Accuracy: ", accuracy_score(y_val, y_val_predict ))
print("Validation Recall: ",recall_score(y_val, y_val_predict)) # Recall
print("Validation Precision: ",precision_score(y_val, y_val_predict)) # Precision
print("Validation f1: ",f1_score(y_val, y_val_predict))
confusion_matrix(y_val, y_val_predict)
```
### XGBoost Classifier
```
import xgboost as xgb
gbm = xgb.XGBClassifier(
n_estimators=40000,
max_depth=4,
objective='binary:logistic', #new objective
learning_rate=.15,
subsample=.8,
min_child_weight=3,
colsample_bytree=.8
)
eval_set=[(X_train,y_train),(X_val,y_val)]
fit_model = gbm.fit(
X_train, y_train,
eval_set=eval_set,
eval_metric='error', #new evaluation metric: classification error (could also use AUC, e.g.)
early_stopping_rounds=50,
verbose=False
)
# accuracy_score(y_test, gbm.predict(X_test, ntree_limit=gbm.best_ntree_limit))
y_train_predict = fit_model.predict(X_train)
print("Train Accuracy: ", accuracy_score(y_train, y_train_predict ))
print("Train Recall: ",recall_score(y_train, y_train_predict)) # Recall
print("Train Precision: ",precision_score(y_train, y_train_predict)) # Precision
print("Train f1: ",f1_score(y_train, y_train_predict))
y_val_predict = fit_model.predict(X_val)
print("Validation Accuracy: ", accuracy_score(y_val, y_val_predict ))
print("Validation Recall: ",recall_score(y_val, y_val_predict)) # Recall
print("Validation Precision: ",precision_score(y_val, y_val_predict)) # Precision
print("Validation f1: ",f1_score(y_val, y_val_predict))
confusion_matrix(y_val, y_val_predict)
xgb.plot_importance(gbm, importance_type='gain')
```
### Neural Network
```
from keras.models import Model, Sequential
from keras.layers import Dense, Activation, Dropout
'''
In this network structure, note that we follow a very common heuristic of "funneling"
to lower dimensional representations over time with multiple layers. Tuning the exact
choice of number of nodes and layers is quite challenging and there aren't generically
correct choices, but this heuristic often works pretty well.
'''
NN = Sequential()
NN.add(Dense(64, input_dim = 64)) # need feature input dim (30 features) for first hidden layer
NN.add(Activation('sigmoid'))
NN.add(Dense(124))
NN.add(Activation('sigmoid'))
#NN.add(Dropout(0.01))
NN.add(Dense(248))
NN.add(Activation('sigmoid'))
#NN.add(Dropout(0.01))
NN.add(Dense(124))
NN.add(Activation('sigmoid'))
NN.add(Dense(62))
NN.add(Activation('sigmoid'))
#NN.add(Dropout(0.01))
NN.add(Dense(32))
NN.add(Activation('sigmoid'))
NN.add(Dense(16))
NN.add(Activation('sigmoid'))
NN.add(Dense(1))
NN.add(Activation('sigmoid'))
NN.compile(loss='binary_crossentropy', optimizer='adam', metrics=["accuracy"]) #adam #RMSProp
NN.fit(X_train, y_train, epochs=100, batch_size=500, verbose=1) # track progress as we fit
from sklearn.metrics import accuracy_score
y_train_pred = NN.predict_classes(X_train)
print("Train Accuracy: ", accuracy_score(y_train, y_train_pred))
print("Train F1: ", f1_score(y_train, y_train_pred))
print("-------------")
y_val_pred = NN.predict_classes(X_val)
print("Validation Accuracy: ", accuracy_score(y_val, y_val_pred))
print("Validation F1: ", f1_score(y_val, y_val_pred))
```
| github_jupyter |
```
import ray
import random, logging
import xml.etree.ElementTree as etree
def parse_post(xml):
return etree.fromstring(xml)
posts = [
'<row Id="1" Title="Eliciting priors from experts" />',
'<row Id="2" Title="What is normality?" />',
'<row Id="3" Title="What are some valuable Statistical Analysis open source projects?" />',
'<row Id="4" Title="Assessing the significance of differences in distributions" />',
'<row Id="5" Title="The Two Cultures: statistics vs. machine learning?" />',
'<row Id="6" Title="Locating freely available data samples" />',
'<row Id="7" Title="Forecasting demographic census" />',
'<row Id="8" Title="Multivariate Interpolation Approaches" />',
'<row Id="9" Title="How can I adapt ANOVA for binary data?" />'
]
[ parse_post(xml) for xml in posts ]
def parse_post(xml):
post = etree.fromstring(xml)
print(post.get('Id'))
return post
[ parse_post(xml) for xml in posts ]
# Start Ray. If you're connecting to an existing cluster, you would use
# ray.init(address=<cluster-address>) instead.
ray.init(logging_level=logging.ERROR)
@ray.remote
def parse_post(xml):
post = etree.fromstring(xml)
print(post.get('Id'))
return post
future = parse_post.remote(posts[0])
ray.get(future)
futures = [parse_post.remote(xml) for xml in posts ]
futures
ray.get(futures)
[ el.get('Id') for el in ray.get(futures) ]
# similar to rdd.cache()
ref = ray.put("Jonathan")
ray.get(ref)
ref
```
## Actors
Scheme made them [concrete](https://dspace.mit.edu/handle/1721.1/5794). Erlang made them [useful](https://erlang.org/doc/getting_started/conc_prog.html). Akka made them [cool](https://akka.io/). And now Ray makes them [easy](https://docs.ray.io/en/latest/ray-overview/index.html)!
```
!pip install faker
@ray.remote
class Child(object):
def __init__(self):
from faker import Faker
self.name = Faker().name()
self.age = 1
def grow(self):
self.age += 1
return self.age
def greet(self):
return (
f'My name is {self.name} '
f'and I am {self.age} years old'
)
children = [Child.remote() for i in range(10)]
children
futures = [ c.greet.remote() for c in children ]
futures
for future in ray.get(futures):
print(future)
for c in children:
for _ in range(random.randint(1,10)):
c.grow.remote()
for future in ray.get([ c.greet.remote() for c in children ]):
print(future)
c = children[0]
ray.get([c.grow.remote() for _ in range(5)])
# actors stay around as long as they are in scope
# since nothing really goes out of scope in a notebook
# we have to manually terminate them
[ ray.kill(person) for person in children ]
ray.shutdown()
```
## Simulating a pandemic
> note this is a toy model simulation, results should not be used to inform health decisions or personal behavior
### The SIR epidemic model:
$S(t)$: susceptible individuals who have not yet been infected at time $t$
$I(t)$: number of infectious individuals at time $t$
$R(t)$: number of individuals who have recovered (and are immune) at time $t$
#### Parameters
$\beta$: probablity of transmitted the disease from an infected to a susceptible individual
$\gamma$: recovery rate ~ $\frac{1}{\text{duration of disease}}$
We will follow the [EMOD compartamental model](https://idmod.org/docs/emod/malaria/model-compartments.html) to simulate the SIR model as a series of discrete timesteps. For something like reinforcement learning, instead of disease dynamics you simulate actions in an environment/game.
```
ray.init(logging_level=logging.ERROR)
# parameters
b = 0.5
b_0 = 0.2
g = 0.2
dim = 5
@ray.remote
class Person(object):
def __init__(self, i):
self.index = i
self.state = 'i' if random.random() < b_0 else 's'
self.x = random.randint(0, dim)
self.y = random.randint(0, dim)
def location(self):
return (self.x, self.y)
def health(self):
return self.state
def index(self):
return self.index
def status(self):
return f"Individual {self.index} at {self.location()} is currently {self.state}"
def walk(self):
if self.state == 'i':
if random.random() < g:
print(f"{self.index} has recovered ⚕️")
self.state = 'r'
self.x += random.randint(-1, 1)
self.y += random.randint(-1, 1)
self.x = max(min(self.x, dim), 0)
self.y = max(min(self.y, dim), 0)
def contract(self):
print(f"{self.index} has become sick 🤮")
self.state = 'i'
def interact(self, stranger):
x, y = ray.get(stranger.location.remote())
state = ray.get(stranger.health.remote())
# is the stranger close to me
if (abs(x - self.x) <= 1) and (abs(y - self.y) <= 1):
# is either of us infected?
if self.state == 'i' or state == 'i':
# can either of us _get_ infected?
if self.state == 's' or state == 's':
# which one of us can get the disease
contract = self.contract if self.state == 's' else stranger.contract.remote
# roll the dice babeeeeee
if random.random() < b:
contract()
people = [Person.remote(i) for i in range(15)]
people
ray.get([p.location.remote() for p in people])
ray.get([p.health.remote() for p in people])
from itertools import combinations
for i in range(20):
print(f'\nIteration {i}\n\n')
for person in people:
person.walk.remote()
pairs = list(combinations(people, 2))
for p1, p2 in pairs:
p1.interact.remote(p2)
for person in people:
print(ray.get(person.status.remote()))
```
| github_jupyter |
## Managing Geometry Properties of Imported Networks
The ``Imported`` geometry class is used to store the geometrical properties of imported networks. When importing an extracted network into OpenPNM using any of the ``io`` classes, all the geometrical and topological properties are lumped together on the *network* object. OpenPNM is generally designed such that geometrical properties are stored on a *geometry* object, so this class address this issue. The main function of the ``Imported`` class is to automatically strip the geometrical properties off of the network and transfer them onto itself.
> **What problem does the Imported class solve?** Although OpenPNM can function with the geometrical properties on the network, a problem arises if the user wishes to add *more* pores to the network, such as boundary pores. In this case, they will probably wish to add pore-scale models to calculate size information, say 'pore.volume'. If they add this to the network, this model will overwrite the pre-existing 'pore.volume' values. The solution to this problem is an intrinsic part of OpenPNM: create a separate geometry object to manage it's own 'pore.volume' model and values. However, this **won't work**! OpenPNM will not allow an array called 'pore.volume' to exist on the network *and* a geometry object. The reason is that networks store values for *every* pore, so when adding new pores the network the 'pore.volume' array will increase to accommodate them. If you attempt to put 'pore.volume' values on the geometry object, you're are essentially putting *two* values in those locations. Therefore, the ``Imported`` class solves this problem by first transferring the 'pore.volume' array (and all other geometrical properties) from the network to itself.
```
import numpy as np
import openpnm as op
import matplotlib.pyplot as plt
ws = op.Workspace()
ws.settings['loglevel'] = 50 # Supress warnings, but see error messages
```
Let's start by generating a random network using the Delaunay class. This will repreent an imported network:
```
np.random.seed(0)
pn = op.network.Delaunay(shape=[1, 1, 0], points=100)
```
This network generator adds nicely defined boundary pores around the edges/faces of the network. Let's remove these for the sake of this example:
```
op.topotools.trim(network=pn, pores=pn.pores('boundary'))
fig, ax = plt.subplots(1, 1, figsize=[5, 5])
op.topotools.plot_coordinates(network=pn, c='r', ax=ax)
op.topotools.plot_connections(network=pn, ax=ax)
```
This network does not have any geometrical properties on it when generated. To mimic the situation of an imported network, let's manually enter some values for ``'pore.diameter'``. We'll just assign random numbers to illustrate the point:
```
pn['pore.diameter'] = np.random.rand(pn.Np)
```
Now when we ``print`` the network we'll see all the topological data ('pore.coords' and 'throat.conns'), all the labels that were added by the generator (e.g. 'pore.left'), as well as the new geometry info we just added ('pore.diameter'):
```
print(pn)
```
OpenPNM was designed to work by assigning geomtrical information to **Geometry** objects. The presence of 'pore.diameter' on the network can be a problem in some cases. For instance, let's add some boundary pores to the left edge:
```
Ps = pn['pore.surface']*(pn['pore.coords'][:, 0] < 0.1)
Ps = pn.toindices(Ps)
op.topotools.add_boundary_pores(network=pn, pores=Ps,
move_to=[0, None, None],
apply_label='left')
```
Visualizing this networks shows the newl added pores where we intended:
```
fig, ax = plt.subplots(figsize=[7, 7])
ax = op.topotools.plot_coordinates(network=pn, pores=pn.pores('left', mode='not'), c='r', ax=ax)
ax = op.topotools.plot_coordinates(network=pn, pores=pn.pores('left'), c='g', ax=ax)
ax = op.topotools.plot_connections(network=pn, ax=ax)
```
Now we have internal pores (red) and boundary pores (green). We would like to assign geometrical information to the boundary pores that we just created. This is typically done by creating a **Geometry** object, then either assigning numerical values or attaching a pore-scale model that calculates the values. The problem is that OpenPNM prevents you from having 'pore.diameter' on the network AND a geometry object at the same time.
```
Ps = pn.pores('left')
Ts = pn.find_neighbor_throats(pores=Ps)
geo_bndry = op.geometry.GenericGeometry(network=pn, pores=Ps, throats=Ts)
```
Now we we try to assign ``'pore.diameter'``, we'll get the following exception (The "try-except" structure is used for the purpose of this notebook example, but is not needed in an actual script):
```
try:
geo_bndry['pore.diameter'] = 0
except Exception as e:
print(e)
```
The solution is to remove the geometrical information from the network *before* adding the boundary pores, and place them on their own geometry. In this example it is easy to transfer the ``'pore.diameter'`` array, but in the case of a real extracted network there could be quite a few arrays to move. OpenPNM has a facility for doing this: the ``Imported`` geometry class.
## Using the Imported Geometry Class
Let's create a network and add a geometric properties again, this time *before* adding boundary pores.
```
pn = op.network.Delaunay(shape=[1, 1, 0], points=100)
pn['pore.diameter'] = np.random.rand(pn.Np)
```
Here we pass the network to the ``Imported`` geometry class. This class literally removes all numerical data from the network to itself. Everything is moved except topological info ('pore.coords' and 'throat.conns') and labels ('pore.left').
```
geo = op.geometry.Imported(network=pn)
```
Printing ``geo`` reveals that the 'pore.diameter' array has been transferred from the network automatically:
```
print(geo)
```
Now that the geometrical information is properly assigned to a geometry object, we can now use OpenPNM as intended. Let's extend this network by adding a single new pore.
```
op.topotools.extend(network=pn, pore_coords = [[1.2, 1.2, 0]], labels='new')
```
The new pore can clearly be seen outside the top-right corner of the domain.
```
fig, ax = plt.subplots(figsize=[7, 7])
fig = op.topotools.plot_coordinates(network=pn, pores=pn.pores('left', mode='not'), c='r', ax=ax)
fig = op.topotools.plot_coordinates(network=pn, pores=pn.pores('left'), c='g', ax=ax)
fig = op.topotools.plot_connections(network=pn, ax=ax)
```
We can now create a geometry just for this single pore and we will be free to add any properties we wish:
```
geo2 = op.geometry.GenericGeometry(network=pn, pores=pn.pores('new'))
geo2['pore.diameter'] = 2.0
print(geo2)
```
Note that the network has the ability to fetch the 'pore.diameter' array from the geometry sub-domain object and create a single full array containing the values from all the locations. In the printout below we can see the value of 2.0 in the very last element, which is where new pores are added to the list.
```
print(pn['pore.diameter'])
```
| github_jupyter |
##### Copyright 2020 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Playing CartPole with the Actor-Critic Method
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/tutorials/reinforcement_learning/actor_critic">
<img src="https://www.tensorflow.org/images/tf_logo_32px.png" />
View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/reinforcement_learning/actor_critic.ipynb">
<img src="https://www.tensorflow.org/images/colab_logo_32px.png" />
Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/docs/blob/master/site/en/tutorials/reinforcement_learning/actor_critic.ipynb">
<img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />
View source on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/reinforcement_learning/actor_critic.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Download notebook</a>
</td>
</table>
This tutorial demonstrates how to implement the [Actor-Critic](https://papers.nips.cc/paper/1786-actor-critic-algorithms.pdf) method using TensorFlow to train an agent on the [Open AI Gym](https://gym.openai.com/) CartPole-V0 environment.
The reader is assumed to have some familiarity with [policy gradient methods](https://papers.nips.cc/paper/1713-policy-gradient-methods-for-reinforcement-learning-with-function-approximation.pdf) of reinforcement learning.
**Actor-Critic methods**
Actor-Critic methods are [temporal difference (TD) learning](https://en.wikipedia.org/wiki/Temporal_difference_learning) methods that represent the policy function independent of the value function.
A policy function (or policy) returns a probability distribution over actions that the agent can take based on the given state.
A value function determines the expected return for an agent starting at a given state and acting according to a particular policy forever after.
In the Actor-Critic method, the policy is referred to as the *actor* that proposes a set of possible actions given a state, and the estimated value function is referred to as the *critic*, which evaluates actions taken by the *actor* based on the given policy.
In this tutorial, both the *Actor* and *Critic* will be represented using one neural network with two outputs.
**CartPole-v0**
In the [CartPole-v0 environment](https://gym.openai.com/envs/CartPole-v0), a pole is attached to a cart moving along a frictionless track.
The pole starts upright and the goal of the agent is to prevent it from falling over by applying a force of -1 or +1 to the cart.
A reward of +1 is given for every time step the pole remains upright.
An episode ends when (1) the pole is more than 15 degrees from vertical or (2) the cart moves more than 2.4 units from the center.
<center>
<figure>
<image src="images/cartpole-v0.gif">
<figcaption>
Trained actor-critic model in Cartpole-v0 environment
</figcaption>
</figure>
</center>
The problem is considered "solved" when the average total reward for the episode reaches 195 over 100 consecutive trials.
## Setup
Import necessary packages and configure global settings.
```
!pip install gym
!pip install pyglet
%%bash
# Install additional packages for visualization
sudo apt-get install -y xvfb python-opengl > /dev/null 2>&1
pip install pyvirtualdisplay > /dev/null 2>&1
pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
```
## Model
The *Actor* and *Critic* will be modeled using one neural network that generates the action probabilities and critic value respectively. This tutorial uses model subclassing to define the model.
During the forward pass, the model will take in the state as the input and will output both action probabilities and critic value $V$, which models the state-dependent [value function](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#value-functions). The goal is to train a model that chooses actions based on a policy $\pi$ that maximizes expected [return](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#reward-and-return).
For Cartpole-v0, there are four values representing the state: cart position, cart-velocity, pole angle and pole velocity respectively. The agent can take two actions to push the cart left (0) and right (1) respectively.
Refer to [OpenAI Gym's CartPole-v0 wiki page](http://www.derongliu.org/adp/adp-cdrom/Barto1983.pdf) for more information.
```
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
```
## Training
To train the agent, you will follow these steps:
1. Run the agent on the environment to collect training data per episode.
2. Compute expected return at each time step.
3. Compute the loss for the combined actor-critic model.
4. Compute gradients and update network parameters.
5. Repeat 1-4 until either success criterion or max episodes has been reached.
### 1. Collecting training data
As in supervised learning, in order to train the actor-critic model, you need
to have training data. However, in order to collect such data, the model would
need to be "run" in the environment.
Training data is collected for each episode. Then at each time step, the model's forward pass will be run on the environment's state in order to generate action probabilities and the critic value based on the current policy parameterized by the model's weights.
The next action will be sampled from the action probabilities generated by the model, which would then be applied to the environment, causing the next state and reward to be generated.
This process is implemented in the `run_episode` function, which uses TensorFlow operations so that it can later be compiled into a TensorFlow graph for faster training. Note that `tf.TensorArray`s were used to support Tensor iteration on variable length arrays.
```
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
```
### 2. Computing expected returns
The sequence of rewards for each timestep $t$, $\{r_{t}\}^{T}_{t=1}$ collected during one episode is converted into a sequence of expected returns $\{G_{t}\}^{T}_{t=1}$ in which the sum of rewards is taken from the current timestep $t$ to $T$ and each reward is multiplied with an exponentially decaying discount factor $\gamma$:
$$G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}$$
Since $\gamma\in(0,1)$, rewards further out from the current timestep are given less weight.
Intuitively, expected return simply implies that rewards now are better than rewards later. In a mathematical sense, it is to ensure that the sum of the rewards converges.
To stabilize training, the resulting sequence of returns is also standardized (i.e. to have zero mean and unit standard deviation).
```
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
```
### 3. The actor-critic loss
Since a hybrid actor-critic model is used, the chosen loss function is a combination of actor and critic losses for training, as shown below:
$$L = L_{actor} + L_{critic}$$
#### Actor loss
The actor loss is based on [policy gradients with the critic as a state dependent baseline](https://www.youtube.com/watch?v=EKqxumCuAAY&t=62m23s) and computed with single-sample (per-episode) estimates.
$$L_{actor} = -\sum^{T}_{t=1} log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]$$
where:
- $T$: the number of timesteps per episode, which can vary per episode
- $s_{t}$: the state at timestep $t$
- $a_{t}$: chosen action at timestep $t$ given state $s$
- $\pi_{\theta}$: is the policy (actor) parameterized by $\theta$
- $V^{\pi}_{\theta}$: is the value function (critic) also parameterized by $\theta$
- $G = G_{t}$: the expected return for a given state, action pair at timestep $t$
A negative term is added to the sum since the idea is to maximize the probabilities of actions yielding higher rewards by minimizing the combined loss.
<br>
##### Advantage
The $G - V$ term in our $L_{actor}$ formulation is called the [advantage](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#advantage-functions), which indicates how much better an action is given a particular state over a random action selected according to the policy $\pi$ for that state.
While it's possible to exclude a baseline, this may result in high variance during training. And the nice thing about choosing the critic $V$ as a baseline is that it trained to be as close as possible to $G$, leading to a lower variance.
In addition, without the critic, the algorithm would try to increase probabilities for actions taken on a particular state based on expected return, which may not make much of a difference if the relative probabilities between actions remain the same.
For instance, suppose that two actions for a given state would yield the same expected return. Without the critic, the algorithm would try to raise the probability of these actions based on the objective $J$. With the critic, it may turn out that there's no advantage ($G - V = 0$) and thus no benefit gained in increasing the actions' probabilities and the algorithm would set the gradients to zero.
<br>
#### Critic loss
Training $V$ to be as close possible to $G$ can be set up as a regression problem with the following loss function:
$$L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})$$
where $L_{\delta}$ is the [Huber loss](https://en.wikipedia.org/wiki/Huber_loss), which is less sensitive to outliers in data than squared-error loss.
```
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
```
### 4. Defining the training step to update parameters
All of the steps above are combined into a training step that is run every episode. All steps leading up to the loss function are executed with the `tf.GradientTape` context to enable automatic differentiation.
This tutorial uses the Adam optimizer to apply the gradients to the model parameters.
The sum of the undiscounted rewards, `episode_reward`, is also computed in this step. This value will be used later on to evaluate if the success criterion is met.
The `tf.function` context is applied to the `train_step` function so that it can be compiled into a callable TensorFlow graph, which can lead to 10x speedup in training.
```
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
```
### 5. Run the training loop
Training is executed by running the training step until either the success criterion or maximum number of episodes is reached.
A running record of episode rewards is kept in a queue. Once 100 trials are reached, the oldest reward is removed at the left (tail) end of the queue and the newest one is added at the head (right). A running sum of the rewards is also maintained for computational efficiency.
Depending on your runtime, training can finish in less than a minute.
```
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
```
## Visualization
After training, it would be good to visualize how the model performs in the environment. You can run the cells below to generate a GIF animation of one episode run of the model. Note that additional packages need to be installed for OpenAI Gym to render the environment's images correctly in Colab.
```
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
```
## Next steps
This tutorial demonstrated how to implement the actor-critic method using Tensorflow.
As a next step, you could try training a model on a different environment in OpenAI Gym.
For additional information regarding actor-critic methods and the Cartpole-v0 problem, you may refer to the following resources:
- [Actor Critic Method](https://hal.inria.fr/hal-00840470/document)
- [Actor Critic Lecture (CAL)](https://www.youtube.com/watch?v=EKqxumCuAAY&list=PLkFD6_40KJIwhWJpGazJ9VSj9CFMkb79A&index=7&t=0s)
- [Cartpole learning control problem \[Barto, et al. 1983\]](http://www.derongliu.org/adp/adp-cdrom/Barto1983.pdf)
For more reinforcement learning examples in TensorFlow, you can check the following resources:
- [Reinforcement learning code examples (keras.io)](https://keras.io/examples/rl/)
- [TF-Agents reinforcement learning library](https://www.tensorflow.org/agents)
| github_jupyter |
# 1. Notebook Setup
Once you have downloaded all the data onto your local machine, you can continue with this notebook
## Imports
In the first step, we only important some Python packages and create a Spark session.
```
import os.path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels as sm
```
## Directories
Here we setup the directories which point to the source data and to intermediate directories. Note that we also set a `spark_tempdir` directory where Spark can spill data to. That directory should have at least 150GB of free space.
```
# Source directory where all downloaded data is stored in
weather_basedir = "file:///dimajix/data/weather-noaa"
# Output directory for intermediate results and aggregations
structured_basedir = "file:///srv/ssd/dimajix/weather-dwh"
# Temporary directory for Spark
spark_tempdir = "/srv/ssd/tmp/jupyter-spark"
```
The intermediate directories are located below the `structured_basedir` path and will contain derived data. Since our data set is rather large, persisting intermediate transformations and preaggregates will speed up our work significantly.
```
hourly_weather_location = os.path.join(structured_basedir, "weather-measurements")
stations_location = os.path.join(structured_basedir, "weather-stations")
daily_weather_location = os.path.join(structured_basedir, "daily-weather-measurements")
daily_country_weather_location = os.path.join(structured_basedir, "daily-country-weather-measurements")
```
## Spark Session
Finally a Spark session is created. You might want to adjust the settings, I used Spark local mode with 48GB RAM.
```
from pyspark.sql import SparkSession
import pyspark.sql.functions as f
if not 'spark' in locals():
spark = SparkSession.builder \
.master("local[*]") \
.config("spark.driver.memory","48G") \
.config("spark.local.dir", spark_tempdir) \
.getOrCreate()
spark
```
# 2. Load Data
```
country = "GM"
# Read in data again and filter for selected country
daily_country_weather = spark.read.parquet(daily_country_weather_location).filter(f.col("CTRY") == country)
daily_country_weather.printSchema()
```
# 3. Yearly Average Temperature
Now we can calculate the average temperature per year of the selected country.
```
yearly_weather = daily_country_weather \
.withColumn("year", f.year(f.col("date"))) \
.groupBy("year").agg(
f.avg(f.col("avg_temperature")).alias("avg_temperature"),
f.avg(f.col("avg_wind_speed")).alias("avg_wind_speed"),
f.avg(f.col("max_wind_speed")).alias("max_wind_speed")
)\
.orderBy(f.col("year")).toPandas()
yearly_weather.set_index("year", drop=True, inplace=True)
```
## 3.1 Plot
```
plt.figure(figsize=(24,6))
sns.regplot(x=yearly_weather.index, y=yearly_weather["avg_temperature"], color="r")
```
## 3.2 Identifying new Records
```
running_max = yearly_weather["avg_temperature"].expanding().max()
running_min = yearly_weather["avg_temperature"][::-1].expanding().min()[::-1]
plt.figure(figsize=(24,6))
sns.relplot(x=yearly_weather.index, y=yearly_weather["avg_temperature"], color="r", aspect=4)
plt.plot(running_max)
plt.plot(running_min)
```
## 3.3 Number of Records
```
def count_max_records(series):
running_max = series.expanding().max()
records = running_max > running_max.shift(1)
return records.sum() + 1
def count_min_records(series):
running_min = series.expanding().min()
records = running_min < running_min.shift(1)
return records.sum() + 1
len(yearly_weather.index)
count_max_records(yearly_weather["avg_temperature"])
count_min_records(yearly_weather["avg_temperature"][::-1])
```
### Expected Number of Mimima / Maxima
```
def harmonic_sum(n):
i = 1
s = 0.0
for i in range(1, n+1):
s = s + 1/i;
return s;
harmonic_sum(len(yearly_weather.index))
```
### Distribution of Number of Minima using Monte Carlo
```
num_samples = 10000
permutation_size = len(yearly_weather.index)
samples = np.zeros(num_samples, dtype=int)
for i in range(0,num_samples):
p = np.random.permutation(permutation_size)
num_maximums = count_max_records(pd.Series(p))
samples[i] = num_maximums
sns.histplot(data=samples)
from statsmodels.distributions.empirical_distribution import ECDF
ecdf = ECDF(samples)
```
### Probability of having 12 or more Maximums/Minimums
```
1 - ecdf(11)
ecdf.mean()
```
| github_jupyter |
# CrossColumnMultiplyTransformer
This notebook shows the functionality in the CrossColumnMultiplyTransformer class. This transformer changes the values of one column via a multiplicative adjustment, based on the values in other columns. <br>
```
import pandas as pd
import numpy as np
import tubular
from tubular.mapping import CrossColumnMultiplyTransformer
tubular.__version__
```
## Create dummy dataset
```
df = pd.DataFrame(
{
"factor1": [np.nan, "1.0", "2.0", "1.0", "3.0", "3.0", "2.0", "2.0", "1.0", "3.0"],
"factor2": ["z", "z", "x", "y", "x", "x", "z", "y", "x", "y"],
"target": [18.5, 21.2, 33.2, 53.3, 24.7, 19.2, 31.7, 42.0, 25.7, 33.9],
"target_int": [2, 1, 3, 4, 5, 6, 5, 8, 9, 8],
}
)
df.head()
df.dtypes
```
## Simple usage
### Initialising CrossColumnMultiplyTransformer
The user must pass in a dict of mappings, each item within must be a dict of mappings for a specific column. <br>
The column to be adjusted is also specified by the user. <br>
As shown below, if not all values of a column are required to define mappings, then these can be excluded from the dictionary. <br>
All multiplicative adjustments defined must be numeric (int or float)
```
mappings = {
'factor1': {
'1.0': 1.1,
'2.0': 0.5,
'3.0': 4,
}
}
adjust_column = "target"
map_1 = CrossColumnMultiplyTransformer(adjust_column = adjust_column, mappings = mappings, copy = True, verbose = True)
```
### CrossColumnMultiplyTransformer fit
There is not fit method for the CrossColumnMultiplyTransformer as the user sets the mappings dictionary when initialising the object.
### CrossColumnMultiplyTransformer transform
Only one column mappings was specified when creating map_1 so only this column will be all be used to adjust the value of the adjust_column when the transform method is run.
```
df[['factor1','target']].head(10)
df[df['factor1'].isin(['1.0', '2.0','3.0'])]['target'].groupby(df['factor1']).mean()
df_2 = map_1.transform(df)
df_2[['factor1','target']].head(10)
df_2[df_2['factor1'].isin(['1.0', '2.0','3.0'])]['target'].groupby(df_2['factor1']).mean()
```
## Column dtype conversion
If all the column to be multiplied has dtype int, but the multipliers specified are non-integer, then the column will be converted to a float dtype.
```
mappings_2 = {
'factor1': {
'1.0': 1.1,
'2.0': 0.5,
'3.0': 4,
}
}
adjust_column_2 = "target_int"
map_2 = CrossColumnMultiplyTransformer(adjust_column = adjust_column_2, mappings=mappings_2, copy = True, verbose = True)
df['target_int'].dtype
df['target_int'].value_counts(dropna = False)
df_3 = map_2.transform(df)
df_3['target'].dtype
df_3['target'].value_counts(dropna = False)
```
# Specifying multiple columns
If more than one column is used to define the mappings, then as multiplication is a commutative operation it does not matter which order the multipliers are applied in.
```
mappings_4 = {
'factor1': {
'1.0': 1.1,
'2.0': 0.5,
'3.0': 4,
},
'factor2': {
'x': 6,
}
}
adjust_column_4 = "target"
map_4 = CrossColumnMultiplyTransformer(adjust_column = adjust_column_4, mappings = mappings_4, copy = True, verbose = True)
df[['factor1','factor2','target']].head()
```
In the above example, the target would only be adjusted for row 1 by a factor of 1.1 (as factor1 = '1.0'), whereas row 2 would be adjusted by a factor of 3 (factor1 = '2.0' means a multiplier of 0.5 and factor2 = 'x' giving a multiplier of 6, 0.5 x 6 = 3)
```
df_5 = map_4.transform(df)
df_5[['factor1','factor2','target']].head()
```
| github_jupyter |
Before you begin, execute this cell to import numpy and packages from the D-Wave Ocean suite, and all necessary functions the gate-model framework you are going to use, whether that is the Forest SDK or Qiskit. In the case of Forest SDK, it also starts the qvm and quilc servers.
```
%run -i "assignment_helper.py"
```
# The Ising model
**Exercise 1** (1 point). The Ising model is a basic model of statistical mechanics that explains a lot about how quantum optimizers work. Its energy is described by its Hamiltonian:
$$ H=-\sum_{<i,j>} J_{ij} \sigma_i \sigma_{j} - \sum_i h_i \sigma_i$$.
Write a function that calculates this energy amount for a linear chain of spins. The function takes three arguments: `J`, `h`, and `σ`, corresponding to the coupling strengths, the onsite field at each site, and the specific spin configuration
```
def calculate_energy(J, h, σ):
#
# YOUR CODE HERE
E_int = -sum(J_ij*σ[i]*σ[i+1] for i, J_ij in enumerate(J))
E_ext_mag = -sum(h_i*σ[i] for i, h_i in enumerate(h))
return E_int + E_ext_mag
J = [1.0, -1.0]
σ = [+1, -1, +1]
h = [0.5, 0.5, 0.4]
assert abs(calculate_energy(J, h, σ)+0.4) < 0.01
J = [-1.0, 0.5, 0.9]
σ = [+1, -1, -1, -1]
h = [4, 0.2, 0.4, 0.7]
assert abs(calculate_energy(J, h, σ)+5.1) < 0.01
```
**Exercise 2** (2 points). The sign of the coupling defines the nature of the interaction, ferromagnetic or antiferromagnetic, corresponding to positive and negative $J$ values, respectively. Setting the couplings to zero, we have a non-interacting model. Create an arbitrary antiferromagnetic model on three sites with no external field. Define the model through variables `J` and `h`. Iterate over all solutions and write the optimal one in a variable called `σ`. If the optimum is degenerate, that is, you have more than one optimal configuration, keep one.
```
import itertools
#
# YOUR CODE HERE
J = [-1.0, -1.0]
h = [0.0, 0.0, 0.0]
E_dict = {}
σ = None
for s in itertools.product(*[{+1,-1} for _ in range(3)]):
e = calculate_energy(J, h, s)
E_dict[e] = s
#print(E_dict)
emin = min(E_dict.keys())
# update σ
σ = E_dict[emin]
#print(σ)
assert all([J_i < 0 for J_i in J])
assert all([h_i == 0 for h_i in h])
assert len(J) == 2
assert len(h) == 3
assert all([σ[i]*σ[i+1] == -1 for i, _ in enumerate(J)]), "The configuration is not the optimum of an antiferromagnetic system"
```
**Exercise 3** (1 point). Iterating over all solutions is clearly not efficient, since there are exponentially many configurations in the number of sites. From the perspective of computer science, this is a combinatorial optimization problem, and it is a known NP-hard problem. Many heuristic methods have been invented to tackle the problem. One of them is simulated annealing. It is implemented in dimod. Create the same antiferromagnetic model in dimod as above. Keep in mind that dimod uses a plus and not a minus sign in the Hamiltonian, so the sign of your couplings should be reversed. Store the model in an object called `model`, which should be a `BinaryQuadraticModel`.
```
#
# YOUR CODE HERE
import dimod
J = {(0, 1): 1.0, (1, 2): 1.0}
h = {0:0, 1:0, 2:0}
model = dimod.BinaryQuadraticModel(h, J, 0.0, dimod.SPIN)
```
The simulated annealing solver requires us to define the couplings as a dictionary between spins, and we must also pass the external field values as a dictionary. The latter is all zeros for us.
```
assert isinstance(model, dimod.binary_quadratic_model.BinaryQuadraticModel), "Wrong model type"
assert model.vartype == dimod.SPIN, "Wrong variables: binary model instead of spin system"
assert all([J_i > 0 for J_i in J.values()]), "The model is not antiferromagnetic"
```
**Exercise 4** (1 point). Sample the solution space a hundred times and write the response in an object called `response`.
```
#
# YOUR CODE HERE
sampler = dimod.SimulatedAnnealingSampler()
response = sampler.sample(model, num_reads=100)
assert len(response) == 100, "Not the correct number of samples"
sample = response.first.sample
assert all([sample[i]*sample[i+1] == -1 for i, _ in enumerate(J.values())]), "The optimal configuration is not antiferromagnetic"
```
# The transverse-field Ising model
**Exercise 5** (1 point). Adiabatic quantum computation and quantum annealing rely on quantum variants of the classical Ising model, and so do some variational algorithms like the quantum approximate optimization algorithm. To understand the logic behind these simple quantum-many body systems, first let us take another look at the classical Ising model, but write the Hamiltonian of the system in the quantum mechanical formalism, that is, with operators:
$$ H=-\sum_{<i,j>} J_{ij} \sigma^Z_i \sigma^Z_{j} - \sum_i h_i \sigma^Z_i$$.
Assume that you only have two sites. Create the Hamiltonian $H=-\sigma^Z_1\sigma^Z_2$ as a $4\times 4$ numpy array called `H`. Recall that on a single site, $\sigma^Z$ is the Pauli-Z matrix $\begin{bmatrix}1 & 0\\ 0& -1\end{bmatrix}$.
```
#
# YOUR CODE HERE
PauliZ = np.array([[1, 0], [0, -1]])
ZZ = np.kron(PauliZ, PauliZ)
H = -ZZ
H
#
# AUTOGRADER TEST - DO NOT REMOVE
#
```
Now take a look at the eigenvector corresponding to the two smallest eigenvalues (both are -1):
```
_, eigenvectors = np.linalg.eigh(H)
print(eigenvectors[:, 0:1])
print(eigenvectors[:, 1:2])
```
This is just the $|00\rangle$ and $|11\rangle$ states, confirming our classical intuition that in this ferromagnetic case (J=1), the two spins should be aligned to get the minimum energy, the ground state energy.
We copy the function that calculates the energy expectation value $<H>$ of a Hamiltonian $H$ and check the expectation value in the $|00\rangle$ state:
```
def calculate_energy_expectation(state, hamiltonian):
return float(np.dot(state.T.conj(), np.dot(hamiltonian, state)).real)
ψ = np.kron([[1], [0]], [[1], [0]])
calculate_energy_expectation(ψ, H)
```
It comes to -1.
**Exercise 6** (1 point). If we add a term that does not commute with the Pauli-Z operator, the Hamiltonian will display non-classical effects. Add a Pauli-X term to both sites, so your total Hamiltonian will be $H=-\sigma^Z_1\sigma^Z_2-\sigma^Z_1-\sigma^X_2$, in the object `H`.
```
#
# YOUR CODE HERE
PauliX = np.array([[0, 1],
[1, 0]])
IX = np.kron(np.eye(2), PauliX)
ZI = np.kron(PauliZ, np.eye(2))
H = -ZZ - ZI - IX
#
# AUTOGRADER TEST - DO NOT REMOVE
#
```
If you take a look at the matrix of the Hamiltonian, it has off-diagonal terms:
```
H
```
The energy expectation value in the $|00\rangle$ will be lower:
```
ψ = np.kron([[1], [0]], [[1], [0]])
calculate_energy_expectation(ψ, H)
```
**Exercise 7** (1 point). Is this the ground state energy? Use the eigenvector corresponding to the smallest eigenvalue and calculate the expectation value of it. Store the value in a variable called `energy_expectation_value`.
```
#
# YOUR CODE HERE
eigenvalues, eigenvectors = np.linalg.eigh(H)
evec1 = eigenvectors[:, 0:1]
evec2 = eigenvectors[:, 1:2]
energy_expectation_value = calculate_energy_expectation(evec1, H)
energy_expectation_value
#
# AUTOGRADER TEST - DO NOT REMOVE
#
```
Naturally, this value also corresponds to the lowest eigenvalue and indeed, this is the ground state energy. So by calculating the eigendecomposition of the typically non-diagonal Hamiltonian, we can extract both the ground state and its energy. The difficulty comes from the exponential scaling of the matrix representing the Hamiltinonian as a function of the number of sites. This is the original reason going back to the early 1980s to build a quantum computer: this device would implement (or simulate) the Hamiltonian in hardware. Say, a couple of hundred spins would be beyond the computational capacity of supercomputers, but having the physical spins and being able to set a specific Hamiltonian, we can extract quantities of interest, such the ground state.
| github_jupyter |
## Import the necessary libraries
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import norm, skew
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
```
## Read the train set and test set
```
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.head()
test.head()
print('Size of the sets')
train.shape, test.shape
train.SalePrice.describe()
```
### Removing outliers
```
plt.scatter(train.GrLivArea, train.SalePrice, c = 'blue')
plt.xlabel("GrLivArea")
plt.ylabel("SalePrice")
plt.show()
train[(train.GrLivArea > 4000) & (train.SalePrice < 300000)]
#Deleting outliers
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<300000)].index)
plt.scatter(train.GrLivArea, train.SalePrice, c = "blue")
plt.xlabel("GrLivArea")
plt.ylabel("SalePrice")
plt.show()
#Save the 'Id' column
train_ID = train['Id']
test_ID = test['Id']
#Now drop the 'Id' colum since it's unnecessary for the prediction process.
train.drop("Id", axis = 1, inplace = True)
test.drop("Id", axis = 1, inplace = True)
```
Plot the distribution of sale prices
```
sns.set(rc={'figure.figsize':(9,7)})
sns.distplot(train.SalePrice)
print("Skewness: %f" % train['SalePrice'].skew())
print("Kurtosis: %f" % train['SalePrice'].kurt())
```
As we can see, the data of Sale Price is right-skewed. So we take the log variable to see
```
#We use the numpy fuction log1p which applies log(1+x) to all elements of the column
train["SalePrice"] = np.log1p(train["SalePrice"])
sns.distplot(train["SalePrice"] , fit=norm)
fig = plt.figure()
res = stats.probplot(train["SalePrice"], plot=plt)
```
## Data Cleaning and Preprocessing
```
# Metadata of the dataset
object_col_names = train.select_dtypes(include=[np.object]).columns.tolist()
int_col_names = train.select_dtypes(include=[np.int64]).columns.tolist()
float_col_names = train.select_dtypes(include=[np.float64]).columns.tolist()
target_var = 'SalesPrice'
num_col_names = int_col_names + float_col_names
total_col_names = object_col_names + int_col_names + float_col_names
if len(total_col_names) == train.shape[1]:
print('Number of Features count matching. Train Dataset Features: ', train.shape[1], ' Features Count: ', len(total_col_names))
else:
print('Number of Features count not matching. Train Dataset Features: ', train.shape[1], ' Features Count: ', len(total_col_names))
print('\nTotal number of object features: ', len(object_col_names))
print(object_col_names)
print('\nTotal number of integer features: ', len(int_col_names))
print(int_col_names)
print('\nTotal number of float features: ', len(float_col_names))
print(float_col_names)
# most correlated features with SalePrice
plt.figure(figsize=(10,10))
corrmat = train.corr()
top_corr_features = corrmat.index[abs(corrmat["SalePrice"])>0.5]
sns.heatmap(train[top_corr_features].corr(),annot=True,cmap="RdYlGn")
```
### Concatenate the train set and the test set
```
y_train = train.SalePrice.values
mydata = pd.concat((train, test)).reset_index(drop=True)
mydata.drop(['SalePrice'], axis=1, inplace=True)
print("mydata size is : {}".format(mydata.shape))
```
### Missing data
```
mydata_na = mydata.isnull().sum()
mydata_na = mydata_na.drop(mydata_na[mydata_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Value' :mydata_na})
missing_data.head()
missing_data.index.tolist()
```
### Filling the NA values
We can observe that some houses have BsmtCond but not BsmtQual, so I fill the NAs of those houses with the TA which means typical values
```
set1 = set(mydata.index[mydata['BsmtCond'].isnull()].tolist())
set2 = set(mydata.index[mydata['BsmtQual'].isnull()].tolist())
idx = set1.symmetric_difference(set2)
for i in idx:
x = mydata.iloc[i]
print(x['BsmtCond'])
print(x['BsmtQual'])
for i in idx:
if type(mydata.iloc[i]['BsmtCond']) == type(np.nan):
mydata['BsmtCond'][i] = 'TA' # typical value
if type(mydata.iloc[i]['BsmtQual']) == type(np.nan):
mydata['BsmtQual'][i] = 'TA' # typical value
```
Fill none columns
```
none_col = ['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'MasVnrType',
'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'KitchenQual',
'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2']
for col in none_col:
mydata[none_col] = mydata[none_col].fillna('None')
```
Fill 0-columns
```
zero_col = ['GarageArea', 'GarageCars', 'MasVnrArea', 'BsmtFullBath', 'BsmtHalfBath',
'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF','GarageYrBlt']
for col in zero_col:
mydata[col] = mydata[col].fillna(0)
```
Fill mode columns
```
mode_col = ['MSZoning', 'Exterior1st', 'Exterior2nd']
for col in mode_col:
mydata[col] = mydata[col].fillna(mydata[col].mode()[0])
```
Fill LotFrontage with median of the neighborhood
```
mydata["LotFrontage"] = mydata.groupby("Neighborhood")["LotFrontage"].transform(lambda x: x.fillna(x.median()))
```
Fill the rest with the mode
```
mydata['Functional'] = mydata['Functional'].fillna('Typ')
mydata['Utilities'] = mydata['Utilities'].fillna('AllPub')
mydata['Electrical'] = mydata['Electrical'].fillna('SBrkr')
mydata['SaleType'] = mydata['SaleType'].fillna('Oth')
```
Check if there is any missing value left
```
mydata_na = mydata.isnull().sum()
mydata_na = mydata_na.drop(mydata_na[mydata_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Value' :mydata_na})
missing_data.head()
```
Utilities : Since this is a categorical data and most of the data are of same category, Its not gonna effect on model. So we choose to drop it.
```
mydata = mydata.drop(['Utilities'], axis=1)
print('Size of dataset after removing Utilities feature: {} rows, {} columns'.format(mydata.shape[0], mydata.shape[1]))
```
### Convert some of the numerical values to categorical in order for them to not affect the rating
```
#MSSubClass
mydata['MSSubClass'] = mydata['MSSubClass'].apply(str)
#Year and month sold are transformed into categorical features too.
mydata['YrSold'] = mydata['YrSold'].astype(str)
mydata['MoSold'] = mydata['MoSold'].astype(str)
#Changing OverallCond into a categorical variable
mydata['OverallCond'] = mydata['OverallCond'].astype(str)
```
## Label encoding
By now, we can’t have text in our data if we’re going to run any kind of model on it. So before we can run a model, we need to make this data ready for the models.
And to convert this kind of categorical text data into model-understandable numerical data, we use the Label Encoder.
Suppose, we have a feature State which has 3 category i.e India , France, China . So, Label Encoder will categorize them as 0, 1, 2.
```
from sklearn.preprocessing import LabelEncoder
cols = ['FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond', 'YrSold', 'MoSold',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond']
# process columns, apply LabelEncoder to categorical features
for c in cols:
label_enc = LabelEncoder()
label_enc.fit(list(mydata[c].values))
mydata[c] = label_enc.transform(list(mydata[c].values))
# Adding total area feature
mydata['TotalSF'] = mydata['TotalBsmtSF'] + mydata['1stFlrSF'] + mydata['2ndFlrSF'] #+ mydata["GarageArea"]
numeric_feats = mydata.dtypes[mydata.dtypes != "object"].index
# Check the skew of all numerical features
skewed_feats = mydata[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
print("\nSkew in numerical features: \n")
skewness = pd.DataFrame({'Skew' :skewed_feats})
skewness.head(10)
skewness = skewness[abs(skewness) > 0.75]
print("There are {} skewed numerical features to Box Cox transform".format(skewness.shape[0]))
from scipy.special import boxcox1p
skewed_features = skewness.index
lam = 0.15
for feat in skewed_features:
#mydata[feat] += 1
mydata[feat] = boxcox1p(mydata[feat], lam)
mydata = pd.get_dummies(mydata)
print(mydata.shape)
train = mydata[:train.shape[0]]
test = mydata[train.shape[0]:]
```
## Applying the models
```
# import all the necessary libraries
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LinearRegression, Ridge, SGDRegressor, HuberRegressor
from sklearn.svm import SVR, LinearSVR
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, ExtraTreesRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
import lightgbm as lgb
#Validation function
n_folds = 5
def kfold_cv_rmsle(model, X, y):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(X.values)
rmsle = np.sqrt(-cross_val_score(model, X.values, y, scoring="neg_mean_squared_error", cv = kf))
return(rmsle)
def kfold_cv_pred(model, X, y):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(X.values)
y_pred = cross_val_predict(model, X.values, y, cv=kf)
return(y_pred)
```
Here we test a number of models to see which models to be chosen in my case
```
models = [Ridge(),make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1)),
RandomForestRegressor(),GradientBoostingRegressor(),SVR(),LinearSVR(),
make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=1)),
make_pipeline(RobustScaler(), BayesianRidge()),KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5),
ExtraTreesRegressor(),HuberRegressor(),xgb.XGBRegressor(),lgb.LGBMRegressor()]
names = ["Ridge", "Lasso", "RF", "GBR", "SVR", "LinSVR", "ENet","Bay","Ker","Extra","Huber","Xgb","LBG"]
for name, model in zip(names, models):
score = kfold_cv_rmsle(model, train, y_train)
print("{}: {:.6f}, {:.6f}".format(name,score.mean(),score.std()))
```
As such I decide to include those models that have scores lower than 0.13. However in the code below I will not use all declared models since some are actually making it worse
```
Rid = Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True,
max_iter=None, tol=0.001, solver='auto', random_state=None)
Hub = HuberRegressor(epsilon=1.35, max_iter=100, alpha=0.0001, warm_start=False, fit_intercept=True, tol=1e-05)
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))
Bay = BayesianRidge()
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)
```
Testing with some of the models
```
HubMd = Hub.fit(train.values, y_train)
RidMd = Rid.fit(train.values, y_train)
BayMd = Bay.fit(train.values, y_train)
LassoMd = lasso.fit(train.values,y_train)
ENetMd = ENet.fit(train.values,y_train)
KRRMd = KRR.fit(train.values,y_train)
GBoostMd = GBoost.fit(train.values,y_train)
from sklearn.metrics import mean_squared_error
Hub_train_pred = HubMd.predict(train.values)
Rid_train_pred = RidMd.predict(train.values)
Bay_train_pred = BayMd.predict(train.values)
lasso_train_pred = LassoMd.predict(train.values)
ENet_train_pred = ENetMd.predict(train.values)
KRR_train_pred = KRRMd.predict(train.values)
GBoost_train_pred = GBoostMd.predict(train.values)
# checking the error on the train data
avg_train_pred = (Rid_train_pred+Bay_train_pred+ENet_train_pred+KRR_train_pred+GBoost_train_pred)/5
avg_rmsle = np.sqrt(mean_squared_error(y_train, avg_train_pred))
print("Average Model RMSLE score: {:.4f}".format(avg_rmsle))
avg_train_pred = np.expm1(avg_train_pred)
avg_train_pred
```
Checking the result with the average of the above models
```
Hub_test_pred = np.expm1(HubMd.predict(test.values))
Rid_test_pred = np.expm1(RidMd.predict(test.values))
Bay_test_pred = np.expm1(BayMd.predict(test.values))
lasso_test_pred = np.expm1(LassoMd.predict(test.values))
ENet_test_pred = np.expm1(ENetMd.predict(test.values))
KRR_test_pred = np.expm1(KRRMd.predict(test.values))
GBoost_test_pred = np.expm1(GBoostMd.predict(test.values))
myMd = (Rid_test_pred+Bay_test_pred+ENet_test_pred+KRR_test_pred+GBoost_test_pred)/5
myMd[:20]
```
However this result doesn't give good score when I try, so we come up with new method
### Out-of-fold prediction
```
nfolds = 7 # set folds for out-of-fold prediction
def get_oof(model, x_train, y_train, x_test):
oof_train = np.zeros((train.shape[0],))
oof_test = np.zeros((test.shape[0],))
oof_test_skf = np.empty((nfolds, test.shape[0]))
kf = KFold(nfolds, shuffle=False, random_state=42).split(train.values)
for i, (train_index, test_index) in enumerate(kf):
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_te = x_train[test_index]
model.fit(x_tr, y_tr)
oof_train[test_index] = model.predict(x_te)
oof_test_skf[i, :] = model.predict(x_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
```
#### Create our OOF train and test predictions. These base results will be used as new features
```
Hub_oof_train, Hub_oof_test = get_oof(Hub, train.values, y_train, test.values)
Rid_oof_train, Rid_oof_test = get_oof(Rid, train.values, y_train, test.values)
Bay_oof_train, Bay_oof_test = get_oof(Bay, train.values, y_train, test.values)
ENet_oof_train, ENet_oof_test = get_oof(ENet, train.values, y_train, test.values)
KRR_oof_train, KRR_oof_test = get_oof(KRR, train.values, y_train, test.values)
GB_oof_train, GB_oof_test = get_oof(GBoost, train.values, y_train, test.values)
XGB_oof_train, XGB_oof_test = get_oof(model_xgb, train.values, y_train, test.values)
lasso_oof_train, lasso_oof_test = get_oof(lasso, train.values, y_train, test.values)
base_predictions_train = pd.DataFrame( {'Kernel Ridge': KRR_oof_train.ravel(),
'Bayesian Ridge': Bay_oof_train.ravel(),
'Lasso': lasso_oof_train.ravel(),
'Elastic Net': ENet_oof_train.ravel(),
'XGBoost': XGB_oof_train.ravel(),
'GBoost': GB_oof_train.ravel(),
'Ridge': Rid_oof_train.ravel(),
'Hub': Hub_oof_train.ravel(),
} )
base_predictions_train.head()
x_train = np.concatenate((lasso_oof_train, Rid_oof_train, Bay_oof_train, KRR_oof_train, ENet_oof_train,
GB_oof_train, XGB_oof_train), axis=1)
x_test = np.concatenate((lasso_oof_test, Rid_oof_test, Bay_oof_test, KRR_oof_test, ENet_oof_test,
GB_oof_test, XGB_oof_test), axis=1)
```
Stacking the models with Kernel Ridge as the base
```
Stacked_Model = KRR.fit(x_train, y_train)
rmsle_score = np.sqrt(-cross_val_score(Stacked_Model, x_train, y_train, scoring="neg_mean_squared_error", cv = kf))
print("Stacked Lasso Model score: {:.4f} ({:.4f})\n".format(rmsle_score.mean(), rmsle_score.std()))
finalMd = Stacked_Model.predict(x_test)
finalMd = np.expm1(finalMd)
finalMd[:20]
```
However the result above alone is not good either. So I use the method as referenced here: https://www.kaggle.com/serigne/stacked-regressions-top-4-on-leaderboard but by library's function not by our own function
```
from mlxtend.regressor import StackingRegressor
stregr = StackingRegressor(regressors=[KRR, GBoost, lasso, Hub, Bay, Rid],
meta_regressor= KRR)
stregr.fit(train.values, y_train)
stregr_train_pred = stregr.predict(train.values)
stregr_rmsle = np.sqrt(mean_squared_error(y_train, stregr_train_pred))
print("Stacking Regressor Model RMSLE score: {:.4f}".format(avg_rmsle))
stregr_train_pred = np.expm1(stregr_train_pred)
stregr_train_pred
stregr_test_pred = stregr.predict(test.values)
finalMd1 = np.expm1(stregr_test_pred)
finalMd1[:20]
```
Test for the error to determine the weight
```
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))
# stacked regressor
stregr.fit(train.values, y_train)
stacked_train_pred = stregr.predict(train.values)
stacked_pred = np.expm1(stregr.predict(test.values))
print(rmsle(y_train, stacked_train_pred))
# a trial with extreme gradient boost
model_xgb.fit(train, y_train)
xgb_train_pred = model_xgb.predict(train)
xgb_pred = np.expm1(model_xgb.predict(test))
print(rmsle(y_train, xgb_train_pred))
# light gradient boost trial
model_lgb.fit(train, y_train)
lgb_train_pred = model_lgb.predict(train)
lgb_pred = np.expm1(model_lgb.predict(test.values))
print(rmsle(y_train, lgb_train_pred))
```
However due to trial and error, I decided not to use those advanced models thus set their weights to 0
```
ensemble = stacked_pred*1 + xgb_pred*0.0 + lgb_pred*0.0
ensemble[:20]
```
Read our svm method which is implemented in R
reference is from here: https://www.kaggle.com/agehsbarg/top-10-0-10943-stacking-mice-and-brutal-force
```
data = pd.read_csv('svm_solution_32.csv')
data = np.array(data['SalePrice'])
```
I notice that the final score is more correct if we round up the prices at higher quantile by a factor of 1.09, and those prices at lower quantile by a factor of 0.9. <br/>
Final score: <br/>
```
Id = test_ID
fin_score = pd.DataFrame({'SalePrice': (finalMd*0.6 + ensemble*0.2 + data*0.2)}) # adding the final weight due to score
fin_data = pd.concat([Id,fin_score],axis=1)
q1 = fin_data['SalePrice'].quantile(0.01)
q2 = fin_data['SalePrice'].quantile(0.99)
fin_data['SalePrice'] = fin_data['SalePrice'].apply(lambda x: x if x > q1 else x*0.9)
fin_data['SalePrice'] = fin_data['SalePrice'].apply(lambda x: x if x < q2 else x*1.09)
fin_data.to_csv('kaggle_submission_fin.csv',index=False) # to submission
fin_data.head(20)
```
| github_jupyter |
# Laboratorio 2: Armado de un esquema de aprendizaje automático
En el laboratorio final se espera que puedan poner en práctica los conocimientos adquiridos en el curso, trabajando con un conjunto de datos de clasificación.
El objetivo es que se introduzcan en el desarrollo de un esquema para hacer tareas de aprendizaje automático: selección de un modelo, ajuste de hiperparámetros y evaluación.
El conjunto de datos a utilizar está en `./data/loan_data.csv`. Si abren el archivo verán que al principio (las líneas que empiezan con `#`) describen el conjunto de datos y sus atributos (incluyendo el atributo de etiqueta o clase).
Se espera que hagan uso de las herramientas vistas en el curso. Se espera que hagan uso especialmente de las herramientas brindadas por `scikit-learn`.
```
import numpy as np
import pandas as pd
# TODO: Agregar las librerías que hagan falta
np.random.seed(0) # Para mayor determinismo
```
## Carga de datos
La celda siguiente se encarga de la carga de datos (haciendo uso de pandas). Estos serán los que se trabajarán en el resto del laboratorio.
```
dataset = pd.read_csv("./data/loan_data.csv", comment="#")
display(dataset.head())
# División entre instancias y etiquetas
X, y = dataset.iloc[:, 1:], dataset.TARGET
```
## Ejercicio 1: División de datos en conjuntos de entrenamiento y evaluación
La primer tarea consiste en dividir el conjunto de datos cargados en el apartado anterior en conjuntos de entrenamiento (o *training*) y evaluación (o *test*).
El primero será utilizado para la creación/selección del modelo de clasificación. El segundo se utilizará sólo al final (una vez elegidos los mejores hiperparámetros) para ver cuál es el resultado final del modelo sobre un conjunto de datos independiente.
```
# TODO: Dividir en datos de entrenamiento y evaluación
```
## Ejercicio 2: Elección de un modelo
Basándose en lo visto en el teórico escojan y justifiquen un modelo de aprendizaje automático. Recuerden que los pasos para elegir un modelo son:
### Selección de hipótesis
*TODO*
### Selección de regularizador
*TODO*
### Selección de función de coste
*TODO*
### Justificación de las selecciones
*TODO*
## Ejercicio 3: Selección de hiperparámetros
Utilizando búsqueda exhaustiva (*grid search*) con *5-fold cross-validation* y utilizando como métrica el área bajo la curva de ROC (o *ROC-AUC*), hagan una selección de los mejores hiperparámetros para su conjunto de datos y el modelo que hayan elegido en el apartado anterior.
```
# TODO: Selección de hiperparámetros
```
## Ejercicio 4: Métricas sobre el conjunto de evaluación
Una vez encontrados los mejores hiperparámetros para el modelo seleccionado en los apartados anteriores se evalúa el modelo final entrenado sobre el conjunto de datos de evaluación seleccionado en el ejercicio 1. Pueden utilizar las métricas que crean convenientes. Es mejor utilizar más de una métrica. Particularmente el *reporte de clasificación* y la *matriz de confusión* son buenos ejemplos de métricas.
```
# TODO: Evaluación del modelo
```
## Ejercicio 5 (opcional): Curvas de ROC
Como ejercicio adicional (opcional), pueden redefinir el umbral de decisión óptimo del problema a partir de los resultados que muestren curvas de ROC como justificación.
Pueden ver esto mediante la [graficación de las curvas de ROC](http://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html). En el link que se les brinda se muestra como hacer para graficar curvas de ROC para problemas multiclase. Sin embargo se puede adaptar fácilmente a un problema binario obviando la parte donde se calcula la curva clase por clase.
```
# TODO: Redefinir umbral de clasificación a través de los resultados vistos por graficar curvas de ROC
```
| github_jupyter |
# Getting started with Captum - Titanic Data Analysis
In this notebook, we will demonstrate the basic features of the Captum interpretability library through an example model trained on the Titanic survival data. We will first train a deep neural network on the data using PyTorch and use Captum to understand which of the features were most important and how the network reached its prediction.
**Note:** Before running this tutorial, please install the scipy, pandas, and matplotlib packages.
```
# Initial imports
import numpy as np
import torch
from captum.attr import IntegratedGradients
from captum.attr import LayerConductance
from captum.attr import NeuronConductance
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
from scipy import stats
import pandas as pd
```
We will begin by importing and cleaning the dataset. Download the dataset from https://biostat.app.vumc.org/wiki/pub/Main/DataSets/titanic3.csv and update the cell below with the path to the dataset csv.
```
# Download dataset from: https://biostat.app.vumc.org/wiki/pub/Main/DataSets/titanic3.csv
# Update path to dataset here.
dataset_path = "titanic3.csv"
# Read dataset from csv file.
titanic_data = pd.read_csv(dataset_path)
```
With the data loaded, we now preprocess the data by converting some categorical features such as gender, location of embarcation, and passenger class into one-hot encodings (separate feature columns for each class with 0 / 1). We also remove some features that are more difficult to analyze, such as name, and fill missing values in age and fare with the average values.
```
titanic_data = pd.concat([titanic_data,
pd.get_dummies(titanic_data['sex']),
pd.get_dummies(titanic_data['embarked'],prefix="embark"),
pd.get_dummies(titanic_data['pclass'],prefix="class")], axis=1)
titanic_data["age"] = titanic_data["age"].fillna(titanic_data["age"].mean())
titanic_data["fare"] = titanic_data["fare"].fillna(titanic_data["fare"].mean())
titanic_data = titanic_data.drop(['name','ticket','cabin','boat','body','home.dest','sex','embarked','pclass'], axis=1)
```
After processing, the features we have are:
* Age - Passenger Age
* Sibsp - Number of Siblings / Spouses Aboard
* Parch - Number of Parents / Children Aboard
* Fare - Fare Amount Paid in British Pounds
* Female - Binary variable indicating whether passenger is female
* Male - Binary variable indicating whether passenger is male
* EmbarkC - Binary variable indicating whether passenger embarked at Cherbourg
* EmbarkQ - Binary variable indicating whether passenger embarked at Queenstown
* EmbarkS - Binary variable indicating whether passenger embarked at Southampton
* Class1 - Binary variable indicating whether passenger was in first class
* Class2 - Binary variable indicating whether passenger was in second class
* Class3 - Binary variable indicating whether passenger was in third class
(Reference: http://campus.lakeforest.edu/frank/FILES/MLFfiles/Bio150/Titanic/TitanicMETA.pdf)
We now convert the data to numpy arrays and separate the training and test sets.
```
# Set random seed for reproducibility.
np.random.seed(131254)
# Convert features and labels to numpy arrays.
labels = titanic_data["survived"].to_numpy()
titanic_data = titanic_data.drop(['survived'], axis=1)
feature_names = list(titanic_data.columns)
data = titanic_data.to_numpy()
# Separate training and test sets using
train_indices = np.random.choice(len(labels), int(0.7*len(labels)), replace=False)
test_indices = list(set(range(len(labels))) - set(train_indices))
train_features = data[train_indices]
train_labels = labels[train_indices]
test_features = data[test_indices]
test_labels = labels[test_indices]
```
We are now ready to define the neural network architecture we will use for the task. We have defined a simple architecture using 2 hidden layers, the first with 12 hidden units and the second with 8 hidden units, each with Sigmoid non-linearity. The final layer performs a softmax operation and has 2 units, corresponding to the outputs of either survived (1) or not survived (0).
```
import torch
import torch.nn as nn
torch.manual_seed(1) # Set seed for reproducibility.
class TitanicSimpleNNModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(12, 12)
self.sigmoid1 = nn.Sigmoid()
self.linear2 = nn.Linear(12, 8)
self.sigmoid2 = nn.Sigmoid()
self.linear3 = nn.Linear(8, 2)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
lin1_out = self.linear1(x)
sigmoid_out1 = self.sigmoid1(lin1_out)
sigmoid_out2 = self.sigmoid2(self.linear2(sigmoid_out1))
return self.softmax(self.linear3(sigmoid_out2))
```
We can either use a pretrained model or train the network using the training data for 200 epochs. Note that the results of later steps may not match if retraining. The pretrained model can be downloaded here: https://github.com/pytorch/captum/blob/master/tutorials/models/titanic_model.pt
```
net = TitanicSimpleNNModel()
USE_PRETRAINED_MODEL = True
if USE_PRETRAINED_MODEL:
net.load_state_dict(torch.load('models/titanic_model.pt'))
print("Model Loaded!")
else:
criterion = nn.CrossEntropyLoss()
num_epochs = 200
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
input_tensor = torch.from_numpy(train_features).type(torch.FloatTensor)
label_tensor = torch.from_numpy(train_labels)
for epoch in range(num_epochs):
output = net(input_tensor)
loss = criterion(output, label_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print ('Epoch {}/{} => Loss: {:.2f}'.format(epoch+1, num_epochs, loss.item()))
torch.save(net.state_dict(), 'models/titanic_model.pt')
```
We can now evaluate the training and test accuracies of our model.
```
out_probs = net(input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Train Accuracy:", sum(out_classes == train_labels) / len(train_labels))
test_input_tensor = torch.from_numpy(test_features).type(torch.FloatTensor)
out_probs = net(test_input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Test Accuracy:", sum(out_classes == test_labels) / len(test_labels))
```
Beyond just considering the accuracy of the classifier, there are many important questions to understand how the model is working and it's decision, which is the purpose of Captum, to help make neural networks in PyTorch more interpretable.
The first question we can ask is which of the features were actually important to the model to reach this decision? This is the first main component of Captum, the ability to obtain **Feature Attributions**. For this example, we will apply Integrated Gradients, which is one of the Feature Attribution methods included in Captum. More information regarding Integrated Gradients can be found in the original paper here: https://arxiv.org/pdf/1703.01365.pdf
To apply integrated gradients, we first create an IntegratedGradients object, providing the model object.
```
ig = IntegratedGradients(net)
```
To compute the integrated gradients, we use the attribute method of the IntegratedGradients object. The method takes tensor(s) of input examples (matching the forward function of the model), and returns the input attributions for the given examples. For a network with multiple outputs, a target index must also be provided, defining the index of the output for which gradients are computed. For this example, we provide target = 1, corresponding to survival.
The input tensor provided should require grad, so we call requires\_grad\_ on the tensor. The attribute method also takes a baseline, which is the starting point from which gradients are integrated. The default value is just the 0 tensor, which is a reasonable baseline / default for this task.
The returned values of the attribute method are the attributions, which match the size of the given inputs, and delta, which approximates the error between the approximated integral and true integral.
```
test_input_tensor.requires_grad_()
attr, delta = ig.attribute(test_input_tensor,target=1, return_convergence_delta=True)
attr = attr.detach().numpy()
```
To understand these attributions, we can first average them across all the inputs and print / visualize the average attribution for each feature.
```
# Helper method to print importances and visualize distribution
def visualize_importances(feature_names, importances, title="Average Feature Importances", plot=True, axis_title="Features"):
print(title)
for i in range(len(feature_names)):
print(feature_names[i], ": ", '%.3f'%(importances[i]))
x_pos = (np.arange(len(feature_names)))
if plot:
plt.figure(figsize=(12,6))
plt.bar(x_pos, importances, align='center')
plt.xticks(x_pos, feature_names, wrap=True)
plt.xlabel(axis_title)
plt.title(title)
visualize_importances(feature_names, np.mean(attr, axis=0))
```
From the feature attribution information, we obtain some interesting insights regarding the importance of various features. We see that the strongest features appear to be age and being male, which are negatively correlated with survival. Embarking at Queenstown and the number of parents / children appear to be less important features generally.
An important thing to note is that the average attributions over the test set don't necessarilly capture all the information regarding feature importances. We should also look at the distribution of attributions for each feature. It is possible that features have very different attributions for different examples in the dataset.
For instance, we can visualize the distribution of attributions for sibsp, the number of siblings / spouses.
```
plt.hist(attr[:,1], 100);
plt.title("Distribution of Sibsp Attribution Values");
```
We note that a vast majority of the examples have an attribution value of 0 for sibsp, which likely corresponds to having a value of 0 for the feature (IntegratedGradients would provide an attribution of 0 when the feature value matches the baseline of 0). More significantly, we see that although the average seems smaller in magnitude in the plot above, there are a small number of examples with extremely negative attributions for this feature.
To better understand this, we can bucket the examples by the value of the sibsp feature and plot the average attribution for the feature. In the plot below, the size of the dot is proportional to the number of examples with that value.
```
bin_means, bin_edges, _ = stats.binned_statistic(test_features[:,1], attr[:,1], statistic='mean', bins=6)
bin_count, _, _ = stats.binned_statistic(test_features[:,1], attr[:,1], statistic='count', bins=6)
bin_width = (bin_edges[1] - bin_edges[0])
bin_centers = bin_edges[1:] - bin_width/2
plt.scatter(bin_centers, bin_means, s=bin_count)
plt.xlabel("Average Sibsp Feature Value");
plt.ylabel("Average Attribution");
```
We see that the larger magnitude attributions correspond to the examples with larger Sibsp feature values, suggesting that the feature has a larger impact on prediction for these examples. Since there are substantially fewer of these examples (compared to those with a feature value of 0), the average attribution does not completely capture this effect.
Now that we have a better understanding of the importance of different input features, the next question we can ask regarding the function of the neural network is how the different neurons in each layer work together to reach the prediction. For instance, in our first hidden layer output containing 12 units, are all the units used for prediction? Do some units learn features positively correlated with survival while others learn features negatively correlated with survival?
This leads us to the second type of attributions available in Captum, **Layer Attributions**. Layer attributions allow us to understand the importance of all the neurons in the output of a particular layer. For this example, we will be using Layer Conductance, one of the Layer Attribution methods in Captum, which is an extension of Integrated Gradients applied to hidden neurons. More information regarding conductance can be found in the original paper here: https://arxiv.org/abs/1805.12233.
To use Layer Conductance, we create a LayerConductance object passing in the model as well as the module (layer) whose output we would like to understand. In this case, we choose net.sigmoid1, the output of the first hidden layer.
```
cond = LayerConductance(net, net.sigmoid1)
```
We can now obtain the conductance values for all the test examples by calling attribute on the LayerConductance object. LayerConductance also requires a target index for networks with mutliple outputs, defining the index of the output for which gradients are computed. Similar to feature attributions, we provide target = 1, corresponding to survival. LayerConductance also utilizes a baseline, but we simply use the default zero baseline as in integrated gradients.
```
cond_vals = cond.attribute(test_input_tensor,target=1)
cond_vals = cond_vals.detach().numpy()
```
We can begin by visualizing the average conductance for each neuron.
```
visualize_importances(range(12),np.mean(cond_vals, axis=0),title="Average Neuron Importances", axis_title="Neurons")
```
We can also look at the distribution of each neuron's attributions. Below we look at the distributions for neurons 7 and 9, and we can confirm that their attribution distributions are very close to 0, suggesting they are not learning substantial features.
```
plt.hist(cond_vals[:,9], 100);
plt.title("Neuron 9 Distribution")
plt.figure()
plt.hist(cond_vals[:,7], 100);
plt.title("Neuron 7 Distribution");
```
Now, we can look at the distributions of neurons 0 and 10, which appear to be learning strong features negatively correlated with survival.
```
plt.hist(cond_vals[:,0], 100);
plt.title("Neuron 0 Distribution")
plt.figure()
plt.hist(cond_vals[:,10], 100);
plt.title("Neuron 10 Distribution");
```
We have identified that some of the neurons are not learning important features, while others are. Can we now understand what each of these important neurons are looking at in the input? For instance, are they identifying different features in the input or similar ones?
To answer these questions, we can apply the third type of attributions available in Captum, **Neuron Attributions**. This allows us to understand what parts of the input contribute to activating a particular input neuron. For this example, we will apply Neuron Conductance, which divides the neuron's total conductance value into the contribution from each individual input feature.
To use Neuron Conductance, we create a NeuronConductance object, analogously to Conductance, passing in the model as well as the module (layer) whose output we would like to understand, in this case, net.sigmoid1, as before.
```
neuron_cond = NeuronConductance(net, net.sigmoid1)
```
We can now obtain the neuron conductance values for all the test examples by calling attribute on the NeuronConductance object. Neuron Conductance requires the neuron index in the target layer for which attributions are requested as well as the target index for networks with mutliple outputs, similar to layer conductance. As before, we provide target = 1, corresponding to survival, and compute neuron conductance for neurons 0 and 10, the significant neurons identified above. The neuron index can be provided either as a tuple or as just an integer if the layer output is 1-dimensional.
```
neuron_cond_vals_10 = neuron_cond.attribute(test_input_tensor, neuron_selector=10, target=1)
neuron_cond_vals_0 = neuron_cond.attribute(test_input_tensor, neuron_selector=0, target=1)
visualize_importances(feature_names, neuron_cond_vals_0.mean(dim=0).detach().numpy(), title="Average Feature Importances for Neuron 0")
```
From the data above, it appears that the primary input feature used by neuron 0 is age, with limited importance for all other features.
```
visualize_importances(feature_names, neuron_cond_vals_10.mean(dim=0).detach().numpy(), title="Average Feature Importances for Neuron 10")
```
From the visualization above, it is evident that neuron 10 primarily relies on the gender and class features, substantially different from the focus of neuron 0.
## Summary
In this demo, we have applied different attribution techniques in Captum including Integrated Gradients for feature attribution and Conductance for layer and neuron attribution in order to better understand the neural network predicting survival. Although larger networks are more difficult to analyze than this simple network, these basic building blocks for attribution can be utilized to improve model interpretability, breaking the traditional "black-box" characterization of neural networks and delving deeper into understanding how and why they make their decisions.
| github_jupyter |
### Connect To Database Server
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456"
)
if db.is_connected():
print("Database Connected")
```
### Create Database
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456"
)
cursor = db.cursor()
cursor.execute("CREATE DATABASE employee_data")
print("Database Created Successful !!!")
```
### Create Table
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
cursor = db.cursor()
sql = """CREATE TABLE customers (
customer_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
address Varchar(255)
)
"""
cursor.execute(sql)
print("Table Created Successful !!!")
```
### Insert One Data
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
cursor = db.cursor()
sql = "INSERT INTO customers (name, address) VALUES (%s, %s)"
val = ("Mr Taif", "Dhaka")
cursor.execute(sql, val)
db.commit()
print("{} data added".format(cursor.rowcount))
```
### Insert Many Data
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
cursor = db.cursor()
sql = "INSERT INTO customers (name, address) VALUES (%s, %s)"
values = [
("Shakib", "Magura"),
("Tamin", "Ctg"),
("Taskin", "Dhaka"),
("Mushfiq", "Rajshahi")
]
for val in values:
cursor.execute(sql, val)
db.commit()
print("{} data added".format(cursor.rowcount))
```
### Select
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
cursor = db.cursor()
sql = "SELECT * FROM customers"
cursor.execute(sql)
result = cursor.fetchone()
print(result)
```
### Fetch All Data
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
cursor = db.cursor()
sql = "SELECT * FROM customers"
cursor.execute(sql)
results = cursor.fetchall()
for data in results:
print(data)
```
### Delete Data
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
cursor = db.cursor()
sql = "DELETE FROM customers WHERE customer_id=%s"
val = (4, )
cursor.execute(sql, val)
db.commit()
print("{} data deleted".format(cursor.rowcount))
```
### Update Data
```
import mysql.connector
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
cursor = db.cursor()
sql = "UPDATE customers SET name=%s, address=%s WHERE customer_id=%s"
val = ("ShakibAL", "Dhaka", 2)
cursor.execute(sql, val)
db.commit()
print("{} data changed".format(cursor.rowcount))
```
### curds_app
```
import mysql.connector
import os
db = mysql.connector.connect(
host="127.0.0.1",
user="root",
password="123456",
database="employee_data",
)
def insert_data(db):
name = input("Enter Name: ")
address = input("Enter Address: ")
val = (name, address)
cursor = db.cursor()
sql = "INSERT INTO customers (name, address) VALUES (%s, %s)"
cursor.execute(sql, val)
db.commit()
print("{} data Inserted".format(cursor.rowcount))
def show_data(db):
cursor = db.cursor()
sql = "SELECT * FROM customers"
cursor.execute(sql)
results = cursor.fetchall()
if cursor.rowcount < 0:
print("There is not any data")
else:
for data in results:
print(data)
def update_data(db):
cursor = db.cursor()
show_data(db)
customer_id = input("Choose id customer> ")
name = input("New Name: ")
address = input("New Address: ")
sql = "UPDATE customers SET name=%s, address=%s WHERE customer_id=%s"
val = (name, address, customer_id)
cursor.execute(sql, val)
db.commit()
print("{} data successfully changed".format(cursor.rowcount))
def delete_data(db):
cursor = db.cursor()
show_data(db)
customer_id = input("Choose id customer> ")
sql = "DELETE FROM customers WHERE customer_id=%s"
val = (customer_id,)
cursor.execute(sql, val)
db.commit()
print("{} data successfully deleted".format(cursor.rowcount))
def search_data(db):
cursor = db.cursor()
keyword = input("Keyword: ")
sql = "SELECT * FROM customers WHERE name LIKE %s OR address LIKE %s"
val = ("%{}%".format(keyword), "%{}%".format(keyword))
cursor.execute(sql, val)
results = cursor.fetchall()
if cursor.rowcount < 0:
print("There is not any data")
else:
for data in results:
print(data)
def show_menu(db):
print("=== APPLICATION DATABASE PYTHON ===")
print("1. Insert Data")
print("2. Show Data")
print("3. Update Data")
print("4. Delete Data")
print("5. Search Data")
print("0. GO Out")
print("------------------")
menu = input("Choose menu> ")
#clear screen
os.system("clear")
if menu == "1":
insert_data(db)
elif menu == "2":
show_data(db)
elif menu == "3":
update_data(db)
elif menu == "4":
delete_data(db)
elif menu == "5":
search_data(db)
elif menu == "0":
exit()
else:
print("Menu WRONG!")
if __name__ == "__main__":
while(True):
show_menu(db)
```
| github_jupyter |
# Transfer Learning
Most of the time you won't want to train a whole convolutional network yourself. Modern ConvNets training on huge datasets like ImageNet take weeks on multiple GPUs. Instead, most people use a pretrained network either as a fixed feature extractor, or as an initial network to fine tune. In this notebook, you'll be using [VGGNet](https://arxiv.org/pdf/1409.1556.pdf) trained on the [ImageNet dataset](http://www.image-net.org/) as a feature extractor. Below is a diagram of the VGGNet architecture.
<img src="assets/cnnarchitecture.jpg" width=700px>
VGGNet is great because it's simple and has great performance, coming in second in the ImageNet competition. The idea here is that we keep all the convolutional layers, but replace the final fully connected layers with our own classifier. This way we can use VGGNet as a feature extractor for our images then easily train a simple classifier on top of that. What we'll do is take the first fully connected layer with 4096 units, including thresholding with ReLUs. We can use those values as a code for each image, then build a classifier on top of those codes.
You can read more about transfer learning from [the CS231n course notes](http://cs231n.github.io/transfer-learning/#tf).
## Pretrained VGGNet
We'll be using a pretrained network from https://github.com/machrisaa/tensorflow-vgg.
This is a really nice implementation of VGGNet, quite easy to work with. The network has already been trained and the parameters are available from this link.
```
from urllib.request import urlretrieve
from os.path import isfile, isdir
from tqdm import tqdm
vgg_dir = 'tensorflow_vgg/'
# Make sure vgg exists
if not isdir(vgg_dir):
raise Exception("VGG directory doesn't exist!")
class DLProgress(tqdm):
last_block = 0
def hook(self, block_num=1, block_size=1, total_size=None):
self.total = total_size
self.update((block_num - self.last_block) * block_size)
self.last_block = block_num
if not isfile(vgg_dir + "vgg16.npy"):
with DLProgress(unit='B', unit_scale=True, miniters=1, desc='VGG16 Parameters') as pbar:
urlretrieve(
'https://s3.amazonaws.com/content.udacity-data.com/nd101/vgg16.npy',
vgg_dir + 'vgg16.npy',
pbar.hook)
else:
print("Parameter file already exists!")
```
## Flower power
Here we'll be using VGGNet to classify images of flowers. To get the flower dataset, run the cell below. This dataset comes from the [TensorFlow inception tutorial](https://www.tensorflow.org/tutorials/image_retraining).
```
import tarfile
dataset_folder_path = 'flower_photos'
class DLProgress(tqdm):
last_block = 0
def hook(self, block_num=1, block_size=1, total_size=None):
self.total = total_size
self.update((block_num - self.last_block) * block_size)
self.last_block = block_num
if not isfile('flower_photos.tar.gz'):
with DLProgress(unit='B', unit_scale=True, miniters=1, desc='Flowers Dataset') as pbar:
urlretrieve(
'http://download.tensorflow.org/example_images/flower_photos.tgz',
'flower_photos.tar.gz',
pbar.hook)
if not isdir(dataset_folder_path):
with tarfile.open('flower_photos.tar.gz') as tar:
tar.extractall()
tar.close()
```
## ConvNet Codes
Below, we'll run through all the images in our dataset and get codes for each of them. That is, we'll run the images through the VGGNet convolutional layers and record the values of the first fully connected layer. We can then write these to a file for later when we build our own classifier.
Here we're using the `vgg16` module from `tensorflow_vgg`. The network takes images of size $244 \times 224 \times 3$ as input. Then it has 5 sets of convolutional layers. The network implemented here has this structure (copied from [the source code](https://github.com/machrisaa/tensorflow-vgg/blob/master/vgg16.py):
```
self.conv1_1 = self.conv_layer(bgr, "conv1_1")
self.conv1_2 = self.conv_layer(self.conv1_1, "conv1_2")
self.pool1 = self.max_pool(self.conv1_2, 'pool1')
self.conv2_1 = self.conv_layer(self.pool1, "conv2_1")
self.conv2_2 = self.conv_layer(self.conv2_1, "conv2_2")
self.pool2 = self.max_pool(self.conv2_2, 'pool2')
self.conv3_1 = self.conv_layer(self.pool2, "conv3_1")
self.conv3_2 = self.conv_layer(self.conv3_1, "conv3_2")
self.conv3_3 = self.conv_layer(self.conv3_2, "conv3_3")
self.pool3 = self.max_pool(self.conv3_3, 'pool3')
self.conv4_1 = self.conv_layer(self.pool3, "conv4_1")
self.conv4_2 = self.conv_layer(self.conv4_1, "conv4_2")
self.conv4_3 = self.conv_layer(self.conv4_2, "conv4_3")
self.pool4 = self.max_pool(self.conv4_3, 'pool4')
self.conv5_1 = self.conv_layer(self.pool4, "conv5_1")
self.conv5_2 = self.conv_layer(self.conv5_1, "conv5_2")
self.conv5_3 = self.conv_layer(self.conv5_2, "conv5_3")
self.pool5 = self.max_pool(self.conv5_3, 'pool5')
self.fc6 = self.fc_layer(self.pool5, "fc6")
self.relu6 = tf.nn.relu(self.fc6)
```
So what we want are the values of the first fully connected layer, after being ReLUd (`self.relu6`). To build the network, we use
```
with tf.Session() as sess:
vgg = vgg16.Vgg16()
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
with tf.name_scope("content_vgg"):
vgg.build(input_)
```
This creates the `vgg` object, then builds the graph with `vgg.build(input_)`. Then to get the values from the layer,
```
feed_dict = {input_: images}
codes = sess.run(vgg.relu6, feed_dict=feed_dict)
```
```
import os
import numpy as np
import tensorflow as tf
from tensorflow_vgg import vgg16
from tensorflow_vgg import utils
data_dir = 'flower_photos/'
contents = os.listdir(data_dir)
classes = [each for each in contents if os.path.isdir(data_dir + each)]
```
Below I'm running images through the VGG network in batches.
```
# Set the batch size higher if you can fit in in your GPU memory
batch_size = 10
codes_list = []
labels = []
batch = []
codes = None
with tf.Session() as sess:
vgg = vgg16.Vgg16()
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
with tf.name_scope("content_vgg"):
vgg.build(input_)
for each in classes:
print("Starting {} images".format(each))
class_path = data_dir + each
files = os.listdir(class_path)
for ii, file in enumerate(files, 1):
# Add images to the current batch
# utils.load_image crops the input images for us, from the center
img = utils.load_image(os.path.join(class_path, file))
batch.append(img.reshape((1, 224, 224, 3)))
labels.append(each)
# Running the batch through the network to get the codes
if ii % batch_size == 0 or ii == len(files):
images = np.concatenate(batch)
feed_dict = {input_: images}
codes_batch = sess.run(vgg.relu6, feed_dict=feed_dict)
# Here I'm building an array of the codes
if codes is None:
codes = codes_batch
else:
codes = np.concatenate((codes, codes_batch))
# Reset to start building the next batch
batch = []
print('{} images processed'.format(ii))
# write codes to file
with open('codes', 'w') as f:
codes.tofile(f)
# write labels to file
import csv
with open('labels', 'w') as f:
writer = csv.writer(f, delimiter='\n')
writer.writerow(labels)
```
## Building the Classifier
Now that we have codes for all the images, we can build a simple classifier on top of them. The codes behave just like normal input into a simple neural network. Below I'm going to have you do most of the work.
```
# read codes and labels from file
import csv
with open('labels') as f:
reader = csv.reader(f, delimiter='\n')
labels = np.array([each for each in reader if len(each) > 0]).squeeze()
with open('codes') as f:
codes = np.fromfile(f, dtype=np.float32)
codes = codes.reshape((len(labels), -1))
```
### Data prep
As usual, now we need to one-hot encode our labels and create validation/test sets. First up, creating our labels!
> **Exercise:** From scikit-learn, use [LabelBinarizer](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelBinarizer.html) to create one-hot encoded vectors from the labels.
```
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
lb.fit(labels)
labels_vecs = lb.transform(labels)
```
Now you'll want to create your training, validation, and test sets. An important thing to note here is that our labels and data aren't randomized yet. We'll want to shuffle our data so the validation and test sets contain data from all classes. Otherwise, you could end up with testing sets that are all one class. Typically, you'll also want to make sure that each smaller set has the same the distribution of classes as it is for the whole data set. The easiest way to accomplish both these goals is to use [`StratifiedShuffleSplit`](http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedShuffleSplit.html) from scikit-learn.
You can create the splitter like so:
```
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2)
```
Then split the data with
```
splitter = ss.split(x, y)
```
`ss.split` returns a generator of indices. You can pass the indices into the arrays to get the split sets. The fact that it's a generator means you either need to iterate over it, or use `next(splitter)` to get the indices. Be sure to read the [documentation](http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedShuffleSplit.html) and the [user guide](http://scikit-learn.org/stable/modules/cross_validation.html#random-permutations-cross-validation-a-k-a-shuffle-split).
> **Exercise:** Use StratifiedShuffleSplit to split the codes and labels into training, validation, and test sets.
```
from sklearn.model_selection import StratifiedShuffleSplit
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2)
train_idx, val_idx = next(ss.split(codes, labels_vecs))
half_val_len = int(len(val_idx)/2)
val_idx, test_idx = val_idx[:half_val_len], val_idx[half_val_len:]
train_x, train_y = codes[train_idx], labels_vecs[train_idx]
val_x, val_y = codes[val_idx], labels_vecs[val_idx]
test_x, test_y = codes[test_idx], labels_vecs[test_idx]
print("Train shapes (x, y):", train_x.shape, train_y.shape)
print("Validation shapes (x, y):", val_x.shape, val_y.shape)
print("Test shapes (x, y):", test_x.shape, test_y.shape)
```
If you did it right, you should see these sizes for the training sets:
```
Train shapes (x, y): (2936, 4096) (2936, 5)
Validation shapes (x, y): (367, 4096) (367, 5)
Test shapes (x, y): (367, 4096) (367, 5)
```
### Classifier layers
Once you have the convolutional codes, you just need to build a classfier from some fully connected layers. You use the codes as the inputs and the image labels as targets. Otherwise the classifier is a typical neural network.
> **Exercise:** With the codes and labels loaded, build the classifier. Consider the codes as your inputs, each of them are 4096D vectors. You'll want to use a hidden layer and an output layer as your classifier. Remember that the output layer needs to have one unit for each class and a softmax activation function. Use the cross entropy to calculate the cost.
```
inputs_ = tf.placeholder(tf.float32, shape=[None, codes.shape[1]])
labels_ = tf.placeholder(tf.int64, shape=[None, labels_vecs.shape[1]])
fc = tf.contrib.layers.fully_connected(inputs_, 256)
logits = tf.contrib.layers.fully_connected(fc, labels_vecs.shape[1], activation_fn=None)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels_, logits=logits)
cost = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer().minimize(cost)
predicted = tf.nn.softmax(logits)
correct_pred = tf.equal(tf.argmax(predicted, 1), tf.argmax(labels_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
```
### Batches!
Here is just a simple way to do batches. I've written it so that it includes all the data. Sometimes you'll throw out some data at the end to make sure you have full batches. Here I just extend the last batch to include the remaining data.
```
def get_batches(x, y, n_batches=10):
""" Return a generator that yields batches from arrays x and y. """
batch_size = len(x)//n_batches
for ii in range(0, n_batches*batch_size, batch_size):
# If we're not on the last batch, grab data with size batch_size
if ii != (n_batches-1)*batch_size:
X, Y = x[ii: ii+batch_size], y[ii: ii+batch_size]
# On the last batch, grab the rest of the data
else:
X, Y = x[ii:], y[ii:]
# I love generators
yield X, Y
```
### Training
Here, we'll train the network.
> **Exercise:** So far we've been providing the training code for you. Here, I'm going to give you a bit more of a challenge and have you write the code to train the network. Of course, you'll be able to see my solution if you need help.
```
epochs = 10
iteration = 0
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for x, y in get_batches(train_x, train_y):
feed = {inputs_: x,
labels_: y}
loss, _ = sess.run([cost, optimizer], feed_dict=feed)
print("Epoch: {}/{}".format(e+1, epochs),
"Iteration: {}".format(iteration),
"Training loss: {:.5f}".format(loss))
iteration += 1
if iteration % 5 == 0:
feed = {inputs_: val_x,
labels_: val_y}
val_acc = sess.run(accuracy, feed_dict=feed)
print("Epoch: {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Validation Acc: {:.4f}".format(val_acc))
saver.save(sess, "checkpoints/flowers.ckpt")
```
### Testing
Below you see the test accuracy. You can also see the predictions returned for images.
```
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
feed = {inputs_: test_x,
labels_: test_y}
test_acc = sess.run(accuracy, feed_dict=feed)
print("Test accuracy: {:.4f}".format(test_acc))
%matplotlib inline
import matplotlib.pyplot as plt
from scipy.ndimage import imread
```
Below, feel free to choose images and see how the trained classifier predicts the flowers in them.
```
test_img_path = 'flower_photos/roses/10894627425_ec76bbc757_n.jpg'
test_img = imread(test_img_path)
plt.imshow(test_img)
# Run this cell if you don't have a vgg graph built
with tf.Session() as sess:
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
vgg = vgg16.Vgg16()
vgg.build(input_)
with tf.Session() as sess:
img = utils.load_image(test_img_path)
img = img.reshape((1, 224, 224, 3))
feed_dict = {input_: img}
code = sess.run(vgg.relu6, feed_dict=feed_dict)
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
feed = {inputs_: code}
prediction = sess.run(predicted, feed_dict=feed).squeeze()
plt.imshow(test_img)
plt.barh(np.arange(5), prediction)
_ = plt.yticks(np.arange(5), lb.classes_)
```
| github_jupyter |
```
import pandas as pd
import numpy as np
# Azure
azure_compute_src = './data/azure.merged.compute.xz.pkl'
azure_compute_data = pd.read_pickle(azure_compute_src, compression="xz")
# AWS
aws_compute_src = './data/aws.src.compute.xz.pkl'
aws_compute_data = pd.read_pickle(aws_compute_src, compression="xz")
# GCP
gcp_compute_src = './data/gcp.compute.xz.pkl'
df_gcp = pd.read_pickle(gcp_compute_src, compression="xz")
df_gcp['provider'] = 'GCP'
```
## Inspect AWS
```
aws_compute_data.columns
aws_compute_data['price_description']
aws_compute_data_trimmed = aws_compute_data.drop(columns=['sku','offercode','processor_architecture','usagetype','operation',
'pd_key','price_description','unit','network_performance'])
aws_compute_data_trimmed.columns
# windows only
aws_compute_data_windows = aws_compute_data_trimmed[aws_compute_data_trimmed['os'] == 'Windows']
aws_compute_data_windows.head()
```
## Map Schemas
```
# Since a smaller set of data, I'm going to use AWS as the base
df_aws = aws_compute_data_windows.drop(columns=['os'])
df_aws['provider'] = 'AWS'
df_aws.columns
azure_compute_data.columns
df_azure = azure_compute_data[['location','armSkuName','Purpose','vCPU(s)','Clock',
'RAM','Temporary storage','unitPrice','Single Customer']]
df_azure = df_azure.rename(columns={'armSkuName':'instance_type',
'Purpose':'instance_family','vCPU(s)':'vcpu','Clock':'clock_speed',
'RAM':'memory','Temporary storage':'storage',
'Single Customer':'tenancy', 'unitPrice':'price'})
df_azure['provider'] = 'Azure'
df_azure
```
## Align Values
```
def compare_col_vals(df1, df2, col_name):
d1_u = df1[col_name].unique()
d2_u = df2[col_name].unique()
for item in d1_u:
if not any([x in item for x in d2_u]):
print ("{} mismatched".format(item))
```
### Instance Family
```
aws_instances = df_aws['instance_family'].unique()
aws_instances
df_aws = df_aws.dropna(subset=['instance_family'])
azure_instances = df_azure['instance_family'].unique()
azure_instances
compare_col_vals(df_aws,df_azure,'instance_family')
#df_azure[df_azure['instance_family'].isnull()] = 'General purpose' # need to reload data
df_aws.loc[df_aws['instance_family'] == 'FPGA Instances' , 'instance_family'] = 'High Performance'
df_aws.loc[df_aws['instance_family'] == 'GPU instance' , 'instance_family'] = 'GPU optimized'
df_azure.loc[df_azure['instance_family'] == 'Memory' , 'instance_family'] = 'Memory optimized'
df_azure.loc[df_azure['instance_family'] == 'GPU Optimized' , 'instance_family'] = 'GPU optimized'
df_azure.loc[df_azure['instance_family'] == 'Storage Optimized', 'instance_family'] = 'Storage optimized'
df_azure.loc[df_azure['instance_family'] == 'General' , 'instance_family'] = 'General purpose'
df_azure.loc[df_azure['instance_family'] == 'Compute' , 'instance_family'] = 'Compute optimized'
df_aws = df_aws[df_aws['instance_family'] != 'Micro instances']
compare_col_vals(df_aws,df_azure,'instance_family')
compare_col_vals(df_azure, df_aws,'instance_family')
compare_col_vals(df_gcp, df_azure,'instance_family')
compare_col_vals(df_azure, df_gcp,'instance_family')
```
### vcpu
```
#compare_col_vals(df_aws, df_azure,'vcpu')
col = 'vcpu'
aws_u = df_aws[col].unique()
aws_u
azu_u = df_azure[col].unique()
azu_u
df_gcp[col].unique()
```
### clock_speed
```
#compare_col_vals(df_aws,df_azure,'clock_speed')
col = 'clock_speed'
aws_u = df_aws[col].unique()
aws_u
azu_u = df_azure[col].unique()
azu_u
df_gcp[col].unique()
```
### memory
```
compare_col_vals(df_aws,df_azure,'memory')
col = 'memory'
aws_u = df_aws[col].unique()
aws_u
azu_u = df_azure[col].unique()
azu_u
df_gcp[col].unique()
df_gcp_str = df_gcp.copy()
df_gcp_str[col] = df_gcp[col].astype(str) + ' GiB'
df_gcp_str[col] = df_gcp_str[col].str.replace('.0', ' ')
df_gcp_str[col].unique()
```
### storage
```
col = 'storage'
aws_u = df_aws[col].unique()
aws_u
azu_u = df_azure[col].unique()
azu_u
df_gcp_storage = df_gcp_str.copy()
df_gcp_storage[col] = np.nan
df_gcp_storage[col].unique()
```
### tenancy
```
col = 'tenancy'
aws_u = df_aws[col].unique()
aws_u
azu_u = df_azure[col].unique()
azu_u
df_azure.loc[df_azure[col]==False, col] = 'Shared'
df_azure.loc[df_azure[col]==True, col] = 'Dedicated'
azu_u = df_azure[col].unique()
azu_u
df_azure[df_azure[col]=='Dedicated']
df_azure
```
### price
```
col = 'price'
aws_u = df_aws[col].unique()
aws_u
azu_u = df_azure[col].unique()
azu_u
df_gcp_price = df_gcp_storage.rename(columns={'on demand price':'price'})
df_gcp_price[col].unique()
df_gcp_price_drop = df_gcp_price.drop(columns=['local_ssd'])
# Good enough..
```
## Merge AWS and Azure dataframes
```
df_merged = df_aws.append(df_azure)
df_merged.reset_index(drop=True, inplace=True)
```
## Merge GCP
```
df_full_merge = df_merged.append(df_gcp_price_drop)
df_full_merge.reset_index(drop=True, inplace=True)
df_full_merge
df_full_merge.to_pickle('./data/all.merged.compute.xz.pkl', compression='xz')
df_full_merge.to_csv('./data/all.merged.compute.csv')
df_full_merge.sort_values(by='price',ascending=False).head(10)
df_azure.sort_values(by='price',ascending=False).head(10)
```
| github_jupyter |
# Pacemaker identification with neural networks
This is a sample notebook to go with the pacemaker dataset.
This is the dataset used by the paper ["Cardiac Rhythm Device Identification Using Neural Networks"](http://electrophysiology.onlinejacc.org/content/5/5/576).
# Load the necessary libraries
```
import time
import torch
import datetime
import torchvision
import torch.nn as nn
from collections import deque
from torchvision import models
from torchvision import transforms
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, Loss, Precision
```
# Settings
## Settings for our dataset
We use the mean and standard deviation of the ImageNet dataset so our images are of similar distribution to the pre-trained models we'll load.
```
TRAIN_DIR = "./Train"
TEST_DIR = "./Test"
IMG_SIZE = 224
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
```
## Settings for training
```
EPOCHS = 20 # Go through the entire dataset 20 times during training
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
BATCH_SIZE = 16 if torch.cuda.is_available() and torch.cuda.get_device_name() == "Quadro P1000" else 32
VERBOSE = True # Print progress of each training loop
```
# Set up our data pipeline
For training examples we'll use data augmentation to distort the images and make them look a bit different, so the neural network sees more examples, effectively.
For the testing set, we won't adulterate them (so we can judge a more 'real world' performance)
```
transforms_train = transforms.Compose([
transforms.RandomResizedCrop(IMG_SIZE, scale=(0.9, 1.0), ratio=(1.0, 1.0)),
transforms.RandomAffine(degrees=5,
translate=(0.05, 0.05),
scale=(0.95, 1.05),
shear=5),
transforms.ColorJitter(.3, .3, .3),
transforms.ToTensor(),
transforms.Normalize(mean=MEAN, std=STD),
])
transforms_test = transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.ToTensor(),
transforms.Normalize(mean=MEAN, std=STD),
])
train_data = torchvision.datasets.ImageFolder(TRAIN_DIR, transform=transforms_train)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
test_data = torchvision.datasets.ImageFolder(TEST_DIR, transform=transforms_test)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
n_classes = len(train_data.classes)
```
# Preview our data
```
plt.figure(figsize=(16,10)) # Larger plot size
img = train_data[0][0].numpy().transpose((1, 2, 0))
img = STD * img + MEAN
plt.subplot(2, 2, 1)
plt.imshow(img)
plt.axis('off')
plt.title("Training set example")
img = test_data[0][0].numpy().transpose((1, 2, 0))
img = STD * img + MEAN
plt.subplot(2, 2, 2)
plt.imshow(img)
plt.axis('off')
plt.title("Testing set example")
```
# Create our network
We'll use DenseNet121 (Xception used in the original paper isn't in the Pytorch model zoo, sadly, and DenseNet is still very nice).
Because this network will have been trained on ImageNet which has 1000 classes, and we are training on our pacemakers which have 45 classes, we need to replace the final layer of the network with a layer with 45 outputs.
```
model = models.densenet121(pretrained=True)
model.classifier = nn.Linear(model.classifier.in_features, n_classes)
model = model.to(DEVICE)
```
# Set up training scheme
Here we tell it we want it to calculate its performance using CrossEntropyLoss (because it's a categorical problem).
We're going to use the Ignite framework here just to make our training loops a little easier.
```
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam((p for p in model.parameters() if p.requires_grad))
trainer = create_supervised_trainer(model,
optimizer,
loss,
device=DEVICE)
evaluator = create_supervised_evaluator(model,
metrics={'accuracy': Accuracy(),
'loss': Loss(loss),
'precision': Precision()},
device=DEVICE)
```
# Set up some functions to print out our progress
These are called 'callbacks', or 'hooks'. Ignite will run these funcstions when certain things happen, e.g. end of an epoch (every cycle, i.e. time the network's been trained a full copy of the dataset), or every iteration (every 'batch' of pictures).
```
@trainer.on(Events.STARTED)
def initialise_custom_engine_vars(engine):
engine.iteration_timings = deque(maxlen=100)
engine.iteration_loss = deque(maxlen=100)
@trainer.on(Events.ITERATION_COMPLETED)
def log_training_loss(engine):
engine.iteration_timings.append(time.time())
engine.iteration_loss.append(engine.state.output)
seconds_per_iteration = np.mean(np.gradient(engine.iteration_timings)) if len(engine.iteration_timings) > 1 else 0
eta = seconds_per_iteration * (len(train_loader)-(engine.state.iteration % len(train_loader)))
if VERBOSE:
print(f"\rEPOCH: {engine.state.epoch:03d} | "
f"BATCH: {engine.state.iteration % len(train_loader):03d} of {len(train_loader):03d} | "
f"LOSS: {engine.state.output:.3f} ({np.mean(engine.iteration_loss):.3f}) | "
f"({seconds_per_iteration:.2f} s/it; ETA {str(datetime.timedelta(seconds=int(eta)))})", end='')
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(engine):
evaluator.run(train_loader)
metrics = evaluator.state.metrics
acc, loss, precision = metrics['accuracy'], metrics['loss'], metrics['precision'].cpu()
print(f"\nEnd of epoch {engine.state.epoch:03d}")
print(f"TRAINING Accuracy: {acc:.3f} | Loss: {loss:.3f}")
@trainer.on(Events.EPOCH_COMPLETED)
def log_validation_results(engine):
evaluator.run(test_loader)
metrics = evaluator.state.metrics
acc, loss, precision = metrics['accuracy'], metrics['loss'], metrics['precision'].cpu()
print(f"TESTING Accuracy: {acc:.3f} | Loss: {loss:.3f}\n")
```
# Now train!
```
trainer.run(train_loader, max_epochs=EPOCHS)
```
We seem to have achieved a respectable accuracy of over 90% on the testing set at some stages, which is good considering there are 45 classes.
You may well see accuracies above those reported in our paper when you train this network - one reason for this is because in our paper we did not continuously measure performance against the testing set during training (we used a proportion of the training set to do this), but only once at the end. This the 'correct' practice, because it prevents "lucky" runs being reported as the true accuracy.
# Make some predictions to test our network
Here we will take an example of each of the classes in the testing dataset and run it through the network.
```
model.eval()
plt.figure(figsize=(20,50)) # Larger plot size
for i_class in range(n_classes):
i_img = i_class * 5 # 5 examples per class
img_tensor, _ = test_data[i_img]
img_numpy = img_tensor.numpy().transpose((1, 2, 0))
img_numpy = STD * img_numpy + MEAN
with torch.no_grad():
predictions = model(torch.unsqueeze(img_tensor, 0).to(DEVICE))
predicted_class = torch.argmax(predictions).cpu().numpy()
true_class = test_data.classes[i_class][:20]
pred_class = test_data.classes[predicted_class][:20]
correct = "CORRECT" if true_class == pred_class else "INCORRECT"
plt.subplot(9, 5, i_class+1)
plt.imshow(img_numpy)
plt.axis('off')
plt.title(f"{correct}\nTrue class: {true_class}\nPredicted class: {pred_class}")
plt.subplots_adjust(wspace=0, hspace=1)
```
| github_jupyter |
```
# Copyright 2021 Google LLC
# Use of this source code is governed by an MIT-style
# license that can be found in the LICENSE file or at
# https://opensource.org/licenses/MIT.
# Author(s): Kevin P. Murphy (murphyk@gmail.com) and Mahmoud Soliman (mjs@aucegypt.edu)
```
<a href="https://opensource.org/licenses/MIT" target="_parent"><img src="https://img.shields.io/github/license/probml/pyprobml"/></a>
<a href="https://colab.research.google.com/github/probml/pyprobml/blob/master/notebooks/figures//chapter6_figures.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Cloning the pyprobml repo
```
!git clone https://github.com/probml/pyprobml
%cd pyprobml/scripts
```
# Installing required software (This may take few minutes)
```
!apt-get install octave -qq > /dev/null
!apt-get install liboctave-dev -qq > /dev/null
%%capture
%load_ext autoreload
%autoreload 2
DISCLAIMER = 'WARNING : Editing in VM - changes lost after reboot!!'
from google.colab import files
def interactive_script(script, i=True):
if i:
s = open(script).read()
if not s.split('\n', 1)[0]=="## "+DISCLAIMER:
open(script, 'w').write(
f'## {DISCLAIMER}\n' + '#' * (len(DISCLAIMER) + 3) + '\n\n' + s)
files.view(script)
%run $script
else:
%run $script
def show_image(img_path):
from google.colab.patches import cv2_imshow
import cv2
img = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
img=cv2.resize(img,(600,600))
cv2_imshow(img)
```
## Figure 6.1:<a name='6.1'></a> <a name='\pycodebernoulli\_entropy\_fig'></a>
Entropy of a Bernoulli random variable as a function of $\theta $. The maximum entropy is $\qopname o log _2 2 = 1$.
Figure(s) generated by [bernoulli_entropy_fig.py](https://github.com/probml/pyprobml/blob/master/scripts/bernoulli_entropy_fig.py)
```
interactive_script("bernoulli_entropy_fig.py")
```
## Figure 6.2:<a name='6.2'></a> <a name='seqlogo'></a>
(a) Some aligned DNA sequences. Each row is a sequence, each column is a location within the sequence. (b) The corresponding \bf position weight matrix represented as a sequence logo. Each column represents a probablity distribution over the alphabet $\ A,C,G,T\ $ for the corresponding location in the sequence. The size of the letter is proportional to the probability. The height of column $t$ is given by $2-H_t$, where $0 \leq H_t \leq 2$ is the entropy (in bits) of the distribution $\mathbf p _t$. Thus deterministic distributions (with an entropy of 0, corresponding to highly conserved locations) have height 2, and uniform distributions (with an entropy of 2) have height 0.
Figure(s) generated by [seqlogoDemo.m](https://github.com/probml/pmtk3/blob/master/demos/seqlogoDemo.m)
```
!octave -W seqlogoDemo.m >> _
```
## Figure 6.3:<a name='6.3'></a> <a name='KLreverse'></a>
Illustrating forwards vs reverse KL on a bimodal distribution. The blue curves are the contours of the true distribution $p$. The red curves are the contours of the unimodal approximation $q$. (a) Minimizing forwards KL, $\KL \left ( p \middle \delimiter "026B30D q \right )$, wrt $q$ causes $q$ to ``cover'' $p$. (b-c) Minimizing reverse KL, $\KL \left ( q \middle \delimiter "026B30D p \right )$ wrt $q$ causes $q$ to ``lock onto'' one of the two modes of $p$. Adapted from Figure 10.3 of <a href='#BishopBook'>[Bis06]</a> .
Figure(s) generated by [KLfwdReverseMixGauss.m](https://github.com/probml/pmtk3/blob/master/demos/KLfwdReverseMixGauss.m)
```
!octave -W KLfwdReverseMixGauss.m >> _
```
## Figure 6.4:<a name='6.4'></a> <a name='fig:entropy'></a>
The marginal entropy, joint entropy, conditional entropy and mutual information represented as information diagrams. Used with kind permission of Katie Everett.
```
show_image("/content/pyprobml/notebooks/figures/images/ceb4.png")
```
## Figure 6.5:<a name='6.5'></a> <a name='MIC'></a>
Left: Correlation coefficient vs maximal information criterion (MIC) for all pairwise relationships in the WHO data. Right: scatter plots of certain pairs of variables. The red lines are non-parametric smoothing regressions fit separately to each trend. From Figure 4 of <a href='#Reshef11'>[Res+11]</a> . Used with kind permission of David Reshef.
```
show_image("/content/pyprobml/notebooks/figures/images/{MICfig4}.png")
```
## References:
<a name='BishopBook'>[Bis06]</a> C. Bishop "Pattern recognition and machine learning". (2006).
<a name='Reshef11'>[Res+11]</a> D. Reshef, Y. Reshef, H. Finucane, S. Grossman, G. McVean, P. Turnbaugh, E. Lander, M. Mitzenmacher and P. Sabeti. "Detecting Novel Associations in Large Data Sets". In: Science (2011).
| github_jupyter |
# Assignment: effect of clouds on the planetary energy balance
In this exercise you are going to compute the effect of clouds on the planetary energy balance, with the help of a simple 1-column model of the atmosphere.
```
# These are the modules we need
import numpy as np
import matplotlib.pyplot as plt
```
We define some constants:
```
s_0 = 1367 # Solar constant (W m-2)
sigma = 5.670e-8 # Stefan–Boltzmann constant
t_s = 288 # Average temperature of the Earth's surface (K)
gamma = -6.5 # Lapse-rate in the atmoshpere (K km-1)
surface_albedo = 0.12 # Albedo of the surface of the Earth
```
## Effect of low clouds on the EB
To isolate the effect of clouds, we assume a very simple representation of the atmosphere as a simple column, free of other greenhouse gases and other clouds. The Temperature of the cloud would then be:
$T_{Cloud} = T_{Surface} + \gamma \, z $,
with $z$ the cloud altitude (km) and $\gamma$ the lapse-rate.
**Q: compute the temperature (K) of a cloud at z = 2km, assuming a constant lapse rate and an average surface temperature of 288K:**
```
# your answer here
```
Now assume that the cloud absorbs all the IR radiation emited by the surface (a reasonable approximation), while emmitting IR directly back to space according to its own temperature. So the total energy change of the climate system in the longwave (LW) spectrum would be:
$\Delta E_{LW} = \sigma T_{Surface}^4 - \sigma T_{Cloud}^4$
**Q: compute the effect of a low cloud on the LW energy balance of the climate system. Is the cloud a LW energy loss or an energy gain for the system?**
```
# your answer here
```
Now consider the shortwave effect of the cloud if it has an albedo of 0.5. The net difference for the climate system is simply the increased loss in solar energy because of an increased reflection:
$\Delta E_{SW} = - S_0 / 4 \cdot (\alpha _{Cloud} - \alpha _{Earth} ) $
**Q: compute the effect of a low cloud on the shortwave (SW) energy balance of the climate system. Is the cloud a SW energy loss or an energy gain for the system?**
```
# your answer here
```
Finally, the net energy difference for the climate system is:
$\Delta E_{TOT} = \Delta E_{SW} + \Delta E_{LW}$
**Q: compute the effect of a low cloud on the total (SW + LW) energy balance of the climate system. Is the low cloud a total energy loss or an energy gain for the system?**
```
# your answer here
```
## Effect of high clouds on the EB
**Q: repeat the calculations above to compute the effect of a high cloud (z = 10km, albedo unchanged) on the total energy balance of the climate system. Is the high cloud a total energy loss or an energy gain for the system?**
```
# your answer here
```
## And now automate things a little bit
**Q: repeat the calculations above for the whole range of altitudes between 2 and 10 km (see the previous lesson for how to do this). Plot the curve.**
```
# your answer here
```
**Q: repeat the calculations above, for three values of the cloud albedo: 0.3, 0.5, 0.7. Plot the three curves on the same plot and add a legend to the plots (see the [Python Primer](https://fabienmaussion.info/climate_system/primer.html) notebook for guidance).**
```
# your answer here
```
**Q: discuss the features of the plot, and the conditions necessary for a cloud to be an energy gain or an energy loss for the climate system. Now search for typical values of cloud albedos depending on their type, and come back to your plot for comparison.**
If you complicate things a bit by noticing that high clouds have a low albedo and low clouds a high albedo while thick clouds have a high albedo but also a high cloud top you can imagine that the system becomes extremely sensitive.
**The processes governing cloud albedo are complex. The uncertainty about changes in the clouds frequency, altitude, and albedo are one of the highest uncertainties in the climate models.**
More info: http://www.skepticalscience.com/clouds-negative-feedback-basic.htm (basic and intermediate)
| github_jupyter |
```
#default_exp basics.interp
```
# Showing prediction results for specific items (Beginner)
> Extending the `Interpretation` class with the `show_at` method
```
#hide
from nbdev.showdoc import *
from wwf.utils import *
#hide_input
state_versions(['fastai', 'fastcore', 'wwf'])
```
## My problem
I often want to look at the predictions of specific items in the validation set, to see if I can find patterns in the errors made by the model. This notebook extends the `Interpretation` object created on top of a learner to add a shortcut method, `show_at` that does exactly this. Let's use as example the "is a cat" classifier, as trained in the [fastbook](https://github.com/fastai/fastbook/blob/master/01_intro.ipynb)
```
# export
from fastai.basics import *
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
```
Creating a `ClassificationInterpretation` from the learner will give us shorcuts to interpret its results. By default, the Intepretation object will be created around the validation dataloader
```
interp = ClassificationInterpretation.from_learner(learn)
```
Let's say we are interested in the predictions for the first item of the validation set. Normally, what I do to visualize both the item and predictions for a single item is to first show it in the dataset and then see its prediction in `interp.preds` or `interp.decoded`
```
item_idx = 0
show_at(dls.valid.dataset, item_idx)
print(interp.decoded[item_idx])
```
It would be much easier if we could just call `show_at` as a method of the `interp` object, and plot the results in the same way that `learn.show_results` does it. Here's a piece of code by Zach Mueller, taken from the discord community, to achieve this goal.
```
#exports
@patch
@delegates(TfmdDL.show_results)
def show_at(self:Interpretation, idxs, **kwargs):
"Show predictions on the items at `idxs`"
inp, _, targ, dec, _ = self[idxs]
self.dl.show_results((inp, dec), targ, **kwargs)
```
As you can see, the code of the `show_at` method is pretty simple. It uses the fastcore's
`@patch` decorator to add the method to the class `Interpretation` (therefore the `self:Interpretation` as first argument), and the `@delegates` decorator to replace
`**kwargs` in the signature of the method with the arguments of `show_results`. All the function does is grab the inputs, targets and decoded predictions from the corresponding attributes of the Interpretation object, and call `show_results` from its dataloader. By default, when the `Interpretation` object is created using the method `from_learner`, this dataloader is the validation dataloader used in the training.
Grabbing the inputs, targets and decoded predictions is done by calling `self[idxs]`. For that to work, we need a `__getitem__` method in the class `Interpretation`. That method calls `getattr` for every indexable attribute within
Interpretation (i.e, inputs, predictions, decoded predictions, targets, and losses).
```
#exports
@patch
def __getitem__(self:Interpretation, idxs):
"Get the inputs, preds, targets, decoded outputs, and losses at `idxs`"
if not is_listy(idxs): idxs = [idxs]
attrs = 'inputs,preds,targs,decoded,losses'
res = L([getattr(self, attr)[idxs] for attr in attrs.split(',')])
return res
```
Let's see now an example of how `show_at` work for a single item, in this case, the first element of the validation dataset.
```
interp.show_at(0)
```
Here's another example to show the predictions of multiple items, namely the three
elements of the validation set with the largest loss
```
interp.show_at(interp.top_losses(3)[1])
```
Additionaly, the method `__getitem__` is also very useful when you want to know everything (data, prediction, decoded prediction, actual label) of a specific item of the dataset.
```
interp[:3]
```
| github_jupyter |
## Smith-Hutton Problem
We want to solve the following PDE:
\begin{equation}
u \frac{\partial \phi}{\partial x} + v \frac{\partial \phi}{\partial y} = 0
\end{equation}
The independen variables (i.e, $x$, $y$) are used as input values for the NN, and the solution (i.e. $\phi(x,y)$) is the output. In order to find the solution, at each step the NN outputs are derived w.r.t the inputs. Then, a loss function that matches the PDE is built and the weights are updated accordingly. If the loss function goes to zero, we can assume that our NN is indeed the solution to our PDE. We will try to find a general solution for different values of $u$, so it will be set also as an input. The geometry of the problem is as follows:

```
# autoreload nangs
%reload_ext autoreload
%autoreload 2
%matplotlib inline
#imports
import math
import numpy as np
import matplotlib.pyplot as plt
import torch
```
First we define our PDE and set the values for training.
```
from nangs.pde import PDE
from nangs.bocos import PeriodicBoco, DirichletBoco, NeumannBoco
from nangs.solutions import MLP
class MyPDE(PDE):
def __init__(self, inputs=None, outputs=None):
super().__init__(inputs, outputs)
def computePDELoss(self, grads, inputs, outputs, params):
dpdx, dpdy = grads['p']['x'], grads['p']['y']
x, y = inputs['x'], inputs['y']
u, v = 2*y*(1-x**2), -2*x*(1-y**2)
return [u*dpdx + v*dpdy]
# instanciate pde
pde = MyPDE(inputs=['x', 'y'], outputs=['p'])
# define input values
x = np.linspace(-1,1,60)
y = np.linspace(0,1,30)
pde.setValues({'x': x, 'y': y})
x_v = np.linspace(-1,1,30)
y_v = np.linspace(0,1,15)
pde.setValues({'x': x_v, 'y': y_v}, train=False)
```
Boundary conditions.
```
# left and rigth b.c
ALPHA = 10
x1, x2 = np.array([-1, 1]), np.array([1])
p = np.zeros(2*len(y))
for i in range(2*len(y)): p[i] = 1. - math.tanh(ALPHA)
boco = DirichletBoco('left_rigth', {'x': x1, 'y': y}, {'p': p})
pde.addBoco(boco)
# top b.c
y2 = np.array([1])
p = np.zeros(len(x))
for i in range(len(x)): p[i] = 1. - math.tanh(ALPHA)
boco = DirichletBoco('top', {'x': x, 'y': y2}, {'p': p})
pde.addBoco(boco)
# bottom b.c
y1 = np.array([0])
x1, x2, p1 = [], [], []
for i in range(len(x)):
if x[i] < 0:
x1.append(x[i])
p1.append(1.+math.tanh(ALPHA*(2*x[i]+1)))
else:
x2.append(x[i])
x1, x2, p1 = np.array(x1), np.array(x2), np.array(p1)
# bottom left b.c
boco = DirichletBoco('bottom_left', {'x': x1, 'y': y1}, {'p': p1})
pde.addBoco(boco)
# bottom right b.c
boco = NeumannBoco('bottom_right', {'x': x2, 'y': y1}, grads={'p': 'y'})
pde.addBoco(boco)
plt.plot(x1,p1)
plt.xlabel('x')
plt.ylabel('p ', rotation=np.pi/2)
plt.title('Solution at y=0')
plt.grid()
plt.show()
```
The objective is to reproduce the inflow ($y$=0 and $x<0$) at the outlet ($y$=0 and $x>0$).
Now we define a topology for our solution and set the training parameters. Then we can find a solution for our PDE.
```
# define solution topology
mlp = MLP(pde.n_inputs, pde.n_outputs, 5, 2048)
optimizer = torch.optim.Adam(mlp.parameters(), lr=3e-4)
pde.compile(mlp, optimizer)
# find the solution
hist = pde.solve()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15,5))
ax1.plot(hist['train_loss'], label="train_loss")
ax1.plot(hist['val_loss'], label="val_loss")
ax1.grid(True)
ax1.legend()
ax1.set_yscale("log")
for boco in pde.bocos:
ax2.plot(hist['bocos'][boco.name], label=boco.name)
ax2.legend()
ax2.grid(True)
ax2.set_yscale("log")
plt.show()
```
Finally, we can evaluate our solution.
```
# evaluate the solution
x = np.linspace(-1,1,100)
y = np.linspace(0,1,50)
pde.evaluate({'x': x, 'y': y})
p = pde.outputs['p']
plt.imshow(p.reshape((len(y),len(x))), vmin=p.min(), vmax=p.max(), origin='lower',
extent=[x.min(), x.max(), y.min(), y.max()])
plt.colorbar()
plt.show()
x = np.linspace(-1,1,200)
y = np.array([0])
pde.evaluate({'x': x, 'y': y})
p = pde.outputs['p']
plt.plot(x1,p1)
plt.plot(x1+1,np.flip(p1), label="exact")
plt.plot(x, p, '.k', label="predicted")
plt.legend()
plt.xlabel('x')
plt.ylabel('p ', rotation=np.pi/2)
plt.title('Solution at y=0')
plt.grid()
plt.show()
```
| github_jupyter |
# GPU Extreme gradient boosting trained on TF-IDF reduced 50 dimensions
1. Same emotion dataset from [NLP-dataset](https://github.com/huseinzol05/NLP-Dataset)
2. Same splitting 80% training, 20% testing, may vary depends on randomness
3. Same regex substitution '[^\"\'A-Za-z0-9 ]+'
## Example
Based on Term-frequency Inverse document frequency
After that we apply SVD to reduce the dimensions, n_components = 50
```
import xgboost as xgb
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import TruncatedSVD
import numpy as np
import re
from sklearn.cross_validation import train_test_split
import sklearn.datasets
from sklearn import pipeline
from sklearn.model_selection import StratifiedKFold
def clearstring(string):
string = re.sub('[^\"\'A-Za-z0-9 ]+', '', string)
string = string.split(' ')
string = filter(None, string)
string = [y.strip() for y in string]
string = ' '.join(string)
return string
# because of sklean.datasets read a document as a single element
# so we want to split based on new line
def separate_dataset(trainset):
datastring = []
datatarget = []
for i in range(len(trainset.data)):
data_ = trainset.data[i].split('\n')
# python3, if python2, just remove list()
data_ = list(filter(None, data_))
for n in range(len(data_)):
data_[n] = clearstring(data_[n])
datastring += data_
for n in range(len(data_)):
datatarget.append(trainset.target[i])
return datastring, datatarget
trainset_data = sklearn.datasets.load_files(container_path = 'data', encoding = 'UTF-8')
trainset_data.data, trainset_data.target = separate_dataset(trainset_data)
train_X, test_X, train_Y, test_Y = train_test_split(trainset_data.data, trainset_data.target, test_size = 0.2)
decompose = pipeline.Pipeline([('count', TfidfVectorizer()),
('svd', TruncatedSVD(n_components=50))]).fit(trainset_data.data)
params_xgd = {
'min_child_weight': 10.0,
'objective': 'multi:softprob',
'eval_metric': 'mlogloss',
'num_class': len(trainset_data.target_names),
'max_depth': 7,
'max_delta_step': 1.8,
'colsample_bytree': 0.4,
'subsample': 0.8,
'eta': 0.03,
'gamma': 0.65,
'num_boost_round' : 700,
'gpu_id': 0,
'tree_method': 'gpu_hist'
}
train_X = decompose.transform(train_X)
test_X = decompose.transform(test_X)
d_train = xgb.DMatrix(train_X, train_Y)
d_valid = xgb.DMatrix(test_X, test_Y)
watchlist = [(d_train, 'train'), (d_valid, 'valid')]
#with open('clf.p', 'rb') as fopen:
# clf = pickle.load(fopen)
clf = xgb.train(params_xgd, d_train, 100000, watchlist, early_stopping_rounds=100, maximize=False, verbose_eval=50)
np.mean(test_Y == np.argmax(clf.predict(xgb.DMatrix(test_X), ntree_limit=clf.best_ntree_limit), axis = 1))
from sklearn import metrics
print(metrics.classification_report(test_Y, np.argmax(clf.predict(xgb.DMatrix(test_X), ntree_limit=clf.best_ntree_limit), axis = 1), target_names = trainset_data.target_names))
clf.save_model('xgb-tfidf-svd50.model')
bst = xgb.Booster(params_xgd)
bst.load_model('xgb-tfidf-svd50.model')
import json
with open('xgb-tfidf-svd50-param', 'w') as fopen:
fopen.write(json.dumps(params_xgd))
np.mean(test_Y == np.argmax(bst.predict(xgb.DMatrix(test_X)), axis = 1))
```
| github_jupyter |
```
import glob
import h5py
import librosa
from librosa import cqt
from librosa.core import amplitude_to_db
from librosa.display import specshow
import matplotlib.pyplot as plt
import numpy as np
import os
import scipy
from scipy.spatial import ConvexHull
from sklearn.model_selection import ParameterGrid
from sklearn.manifold import Isomap
import time
from tqdm import tqdm
hop_size = 512
q = 24
setting = {
'Q': 24,
'k': 3,
'comp': 'log',
'instr': 'TpC', # Replace by 'Tp' for trumpet or 'Hp' for harp
}
with h5py.File("TinySOL.h5", "r") as f:
features_dict = {
key:f[key][()]
for key in f.keys()
if setting["instr"] in key
}
CQT_OCTAVES = 7
features_keys = list(features_dict.keys())
q = setting['Q']
# Batch process and store in a folder
batch_str = [setting['instr']]
batch_features = []
for feature_key in features_keys:
# Get features that match setting
if all(x in feature_key for x in batch_str):
batch_features.append(features_dict[feature_key])
batch_features = np.stack(batch_features, axis=1)
# Isomap parameters
hop_size = 512
compression = 'log'
features = amplitude_to_db(batch_features)
n_neighbors = setting['k']
n_dimensions = 3
n_octaves = 3
# Prune feature matrix
bin_low = np.where((np.std(features, axis=1) / np.std(features)) > 0.1)[0][0] + q
bin_high = bin_low + n_octaves*q
X = features[bin_low:bin_high, :]
# Z-score Standardization- improves contrast in correlation matrix
mus = np.mean(X, axis=1)
sigmas = np.std(X, axis=1)
X_std = (X - mus[:, np.newaxis]) / (1e-6 + sigmas[:, np.newaxis]) # 1e-6 to avoid runtime division by zero
# Pearson correlation matrix
rho_std = np.dot(X_std, X_std.T) / X_std.shape[1]
# Isomap embedding
isomap = Isomap(n_components= n_dimensions, n_neighbors= n_neighbors)
coords = isomap.fit_transform(rho_std)
# Convex hull
xy_coords = coords[:, :2]
hull = ConvexHull(xy_coords)
hull_vertices = xy_coords[hull.vertices, :]
# Center of gravity
hull_center = np.mean(hull_vertices, axis=0)
xy_coords.shape
n_iterations = 500
# Initialize
center = np.copy(hull_center)
centers = []
losses = []
for iteration in range(n_iterations):
# Compute gradient
# Equation 5 from Coope 1992.
# "Circle fitting by linear and nonlinear least squares".
xy_vectors = center - xy_coords
radius = np.mean(np.linalg.norm(xy_vectors, axis=1))
azimuths = xy_vectors / np.linalg.norm(xy_vectors, axis=1)[:, np.newaxis]
gradient = 2 * (np.mean(xy_vectors, axis=0) - radius * np.mean(azimuths, axis=0))
# Compute candidate directions
directions = hull_vertices - center
inner_products = np.dot(directions, gradient)
best_direction = directions[np.argmin(inner_products)]
# Gradient descent update
learning_rate = 0.01 * 2*iteration/(2+iteration)
center += learning_rate * best_direction
# Compute loss
loss = np.linalg.norm(xy_vectors)**2 - np.sum(np.linalg.norm(xy_vectors, axis=1))**2 / xy_vectors.shape[0]
losses.append(loss)
centers.append(np.copy(center))
centers = np.array(centers)
plt.plot(losses)
plt.figure(figsize=(8, 8))
plt.plot(
np.concatenate([hull_vertices[:, 0], hull_vertices[:, 0]]),
np.concatenate([hull_vertices[:, 1], hull_vertices[:, 1]]),
'-s', color='b')
plt.plot(hull_center[np.newaxis, 0], hull_center[np.newaxis, 1], 'd', color='r')
plt.plot(centers[:, 0], centers[:, 1], '-', color='g')
plt.plot(centers[-1, 0], centers[-1, 1], 's', color='g')
plt.plot(xy_coords[:, 0], xy_coords[:, 1], '.', color='k', alpha=1.0)
```
| github_jupyter |
# 机器学习纳米学位
## 监督学习
## 项目2: 为*CharityML*寻找捐献者
欢迎来到机器学习工程师纳米学位的第二个项目!在此文件中,有些示例代码已经提供给你,但你还需要实现更多的功能让项目成功运行。除非有明确要求,你无须修改任何已给出的代码。以**'练习'**开始的标题表示接下来的代码部分中有你必须要实现的功能。每一部分都会有详细的指导,需要实现的部分也会在注释中以'TODO'标出。请仔细阅读所有的提示!
除了实现代码外,你还必须回答一些与项目和你的实现有关的问题。每一个需要你回答的问题都会以**'问题 X'**为标题。请仔细阅读每个问题,并且在问题后的**'回答'**文字框中写出完整的答案。我们将根据你对问题的回答和撰写代码所实现的功能来对你提交的项目进行评分。
>**提示:**Code 和 Markdown 区域可通过**Shift + Enter**快捷键运行。此外,Markdown可以通过双击进入编辑模式。
## 开始
在这个项目中,你将使用1994年美国人口普查收集的数据,选用几个监督学习算法以准确地建模被调查者的收入。然后,你将根据初步结果从中选择出最佳的候选算法,并进一步优化该算法以最好地建模这些数据。你的目标是建立一个能够准确地预测被调查者年收入是否超过50000美元的模型。这种类型的任务会出现在那些依赖于捐款而存在的非营利性组织。了解人群的收入情况可以帮助一个非营利性的机构更好地了解他们要多大的捐赠,或是否他们应该接触这些人。虽然我们很难直接从公开的资源中推断出一个人的一般收入阶层,但是我们可以(也正是我们将要做的)从其他的一些公开的可获得的资源中获得一些特征从而推断出该值。
这个项目的数据集来自[UCI机器学习知识库](https://archive.ics.uci.edu/ml/datasets/Census+Income)。这个数据集是由Ron Kohavi和Barry Becker在发表文章_"Scaling Up the Accuracy of Naive-Bayes Classifiers: A Decision-Tree Hybrid"_之后捐赠的,你可以在Ron Kohavi提供的[在线版本](https://www.aaai.org/Papers/KDD/1996/KDD96-033.pdf)中找到这个文章。我们在这里探索的数据集相比于原有的数据集有一些小小的改变,比如说移除了特征`'fnlwgt'` 以及一些遗失的或者是格式不正确的记录。
----
## 探索数据
运行下面的代码单元以载入需要的Python库并导入人口普查数据。注意数据集的最后一列`'income'`将是我们需要预测的列(表示被调查者的年收入会大于或者是最多50,000美元),人口普查数据中的每一列都将是关于被调查者的特征。
```
# 为这个项目导入需要的库
import numpy as np
import pandas as pd
from time import time
from IPython.display import display # 允许为DataFrame使用display()
# 导入附加的可视化代码visuals.py
import visuals as vs
# 为notebook提供更加漂亮的可视化
%matplotlib inline
# 导入人口普查数据
data = pd.read_csv("census.csv")
# 成功 - 显示第一条记录
display(data.head(n=1))
```
### 练习:数据探索
首先我们对数据集进行一个粗略的探索,我们将看看每一个类别里会有多少被调查者?并且告诉我们这些里面多大比例是年收入大于50,000美元的。在下面的代码单元中,你将需要计算以下量:
- 总的记录数量,`'n_records'`
- 年收入大于50,000美元的人数,`'n_greater_50k'`.
- 年收入最多为50,000美元的人数 `'n_at_most_50k'`.
- 年收入大于50,000美元的人所占的比例, `'greater_percent'`.
**提示:** 您可能需要查看上面的生成的表,以了解`'income'`条目的格式是什么样的。
```
# TODO:总的记录数
n_records = len(data)
# TODO:被调查者的收入大于$50,000的人数
n_greater_50k = len(data.loc[data["income"]==">50K"])
# TODO:被调查者的收入最多为$50,000的人数
n_at_most_50k = len(data.loc[data["income"]=="<=50K"])
# TODO:被调查者收入大于$50,000所占的比例
greater_percent = float(n_greater_50k)/n_records
# 打印结果
print "Total number of records: {}".format(n_records)
print "Individuals making more than $50,000: {}".format(n_greater_50k)
print "Individuals making at most $50,000: {}".format(n_at_most_50k)
print "Percentage of individuals making more than $50,000: {:.2f}%".format(greater_percent*100)
```
----
## 准备数据
在数据能够被作为输入提供给机器学习算法之前,它经常需要被清洗,格式化,和重新组织 - 这通常被叫做**预处理**。幸运的是,对于这个数据集,没有我们必须处理的无效或丢失的条目,然而,由于某一些特征存在的特性我们必须进行一定的调整。这个预处理都可以极大地帮助我们提升几乎所有的学习算法的结果和预测能力。
### 转换倾斜的连续特征
一个数据集有时可能包含至少一个靠近某个数字的特征,但有时也会有一些相对来说存在极大值或者极小值的不平凡分布的的特征。算法对这种分布的数据会十分敏感,并且如果这种数据没有能够很好地规一化处理会使得算法表现不佳。在人口普查数据集的两个特征符合这个描述:'`capital-gain'`和`'capital-loss'`。
运行下面的代码单元以创建一个关于这两个特征的条形图。请注意当前的值的范围和它们是如何分布的。
```
# 将数据切分成特征和对应的标签
income_raw = data['income']
features_raw = data.drop('income', axis = 1)
# 可视化原来数据的倾斜的连续特征
vs.distribution(data)
```
对于高度倾斜分布的特征如`'capital-gain'`和`'capital-loss'`,常见的做法是对数据施加一个<a href="https://en.wikipedia.org/wiki/Data_transformation_(statistics)">对数转换</a>,将数据转换成对数,这样非常大和非常小的值不会对学习算法产生负面的影响。并且使用对数变换显著降低了由于异常值所造成的数据范围异常。但是在应用这个变换时必须小心:因为0的对数是没有定义的,所以我们必须先将数据处理成一个比0稍微大一点的数以成功完成对数转换。
运行下面的代码单元来执行数据的转换和可视化结果。再次,注意值的范围和它们是如何分布的。
```
# 对于倾斜的数据使用Log转换
skewed = ['capital-gain', 'capital-loss']
features_raw[skewed] = data[skewed].apply(lambda x: np.log(x + 1))
# 可视化经过log之后的数据分布
vs.distribution(features_raw, transformed = True)
```
### 规一化数字特征
除了对于高度倾斜的特征施加转换,对数值特征施加一些形式的缩放通常会是一个好的习惯。在数据上面施加一个缩放并不会改变数据分布的形式(比如上面说的'capital-gain' or 'capital-loss');但是,规一化保证了每一个特征在使用监督学习器的时候能够被平等的对待。注意一旦使用了缩放,观察数据的原始形式不再具有它本来的意义了,就像下面的例子展示的。
运行下面的代码单元来规一化每一个数字特征。我们将使用[`sklearn.preprocessing.MinMaxScaler`](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html)来完成这个任务。
```
# 导入sklearn.preprocessing.StandardScaler
from sklearn.preprocessing import MinMaxScaler
# 初始化一个 scaler,并将它施加到特征上
scaler = MinMaxScaler()
numerical = ['age', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week']
features_raw[numerical] = scaler.fit_transform(data[numerical])
# 显示一个经过缩放的样例记录
display(features_raw.head(n = 1))
```
### 练习:数据预处理
从上面的**数据探索**中的表中,我们可以看到有几个属性的每一条记录都是非数字的。通常情况下,学习算法期望输入是数字的,这要求非数字的特征(称为类别变量)被转换。转换类别变量的一种流行的方法是使用**独热编码**方案。独热编码为每一个非数字特征的每一个可能的类别创建一个_“虚拟”_变量。例如,假设`someFeature`有三个可能的取值`A`,`B`或者`C`,。我们将把这个特征编码成`someFeature_A`, `someFeature_B`和`someFeature_C`.
| | 一些特征 | | 特征_A | 特征_B | 特征_C |
| :-: | :-: | | :-: | :-: | :-: |
| 0 | B | | 0 | 1 | 0 |
| 1 | C | ----> 独热编码 ----> | 0 | 0 | 1 |
| 2 | A | | 1 | 0 | 0 |
此外,对于非数字的特征,我们需要将非数字的标签`'income'`转换成数值以保证学习算法能够正常工作。因为这个标签只有两种可能的类别("<=50K"和">50K"),我们不必要使用独热编码,可以直接将他们编码分别成两个类`0`和`1`,在下面的代码单元中你将实现以下功能:
- 使用[`pandas.get_dummies()`](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.get_dummies.html?highlight=get_dummies#pandas.get_dummies)对`'features_raw'`数据来施加一个独热编码。
- 将目标标签`'income_raw'`转换成数字项。
- 将"<=50K"转换成`0`;将">50K"转换成`1`。
```
# TODO:使用pandas.get_dummies()对'features_raw'数据进行独热编码
features = pd.get_dummies(features_raw)
# TODO:将'income_raw'编码成数字值
income = pd.get_dummies(income_raw)['>50K']
# 打印经过独热编码之后的特征数量
encoded = list(features.columns)
print "{} total features after one-hot encoding.".format(len(encoded))
# 移除下面一行的注释以观察编码的特征名字
print encoded
```
### 混洗和切分数据
现在所有的 _类别变量_ 已被转换成数值特征,而且所有的数值特征已被规一化。和我们一般情况下做的一样,我们现在将数据(包括特征和它们的标签)切分成训练和测试集。其中80%的数据将用于训练和20%的数据用于测试。
运行下面的代码单元来完成切分。
```
# 导入 train_test_split
from sklearn.model_selection import train_test_split
# 将'features'和'income'数据切分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, income, test_size = 0.2, random_state = 0)
# 显示切分的结果
print "Training set has {} samples.".format(X_train.shape[0])
print "Testing set has {} samples.".format(X_test.shape[0])
```
----
## 评价模型性能
在这一部分中,我们将尝试四种不同的算法,并确定哪一个能够最好地建模数据。这里面的三个将是你选择的监督学习器,而第四种算法被称为一个*朴素的预测器*。
### 评价方法和朴素的预测器
*CharityML*通过他们的研究人员知道被调查者的年收入大于\$50,000最有可能向他们捐款。因为这个原因*CharityML*对于准确预测谁能够获得\$50,000以上收入尤其有兴趣。这样看起来使用**准确率**作为评价模型的标准是合适的。另外,把*没有*收入大于\$50,000的人识别成年收入大于\$50,000对于*CharityML*来说是有害的,因为他想要找到的是有意愿捐款的用户。这样,我们期望的模型具有准确预测那些能够年收入大于\$50,000的能力比模型去**查全**这些被调查者*更重要*。我们能够使用**F-beta score**作为评价指标,这样能够同时考虑查准率和查全率:
$$ F_{\beta} = (1 + \beta^2) \cdot \frac{precision \cdot recall}{\left( \beta^2 \cdot precision \right) + recall} $$
尤其是,当$\beta = 0.5$的时候更多的强调查准率,这叫做**F$_{0.5}$ score** (或者为了简单叫做F-score)。
通过查看不同类别的数据分布(那些最多赚\$50,000和那些能够赚更多的),我们能发现:很明显的是很多的被调查者年收入没有超过\$50,000。这点会显著地影响**准确率**,因为我们可以简单地预测说*“这个人的收入没有超过\$50,000”*,这样我们甚至不用看数据就能做到我们的预测在一般情况下是正确的!做这样一个预测被称作是**朴素的**,因为我们没有任何信息去证实这种说法。通常考虑对你的数据使用一个*朴素的预测器*是十分重要的,这样能够帮助我们建立一个模型的表现是否好的基准。那有人说,使用这样一个预测是没有意义的:如果我们预测所有人的收入都低于\$50,000,那么*CharityML*就不会有人捐款了。
### 问题 1 - 朴素预测器的性能
*如果我们选择一个无论什么情况都预测被调查者年收入大于\$50,000的模型,那么这个模型在这个数据集上的准确率和F-score是多少?*
**注意:** 你必须使用下面的代码单元将你的计算结果赋值给`'accuracy'` 和 `'fscore'`,这些值会在后面被使用,请注意这里不能使用scikit-learn,你需要根据公式自己实现相关计算。
```
# TODO: 计算准确率
accuracy = (income==income.replace(0,1)).mean()
# TODO: 使用上面的公式,并设置beta=0.5计算F-score
precision=float(n_greater_50k)/n_records
recall=1
fscore = (1+0.5**2)*precision*recall/(0.5**2*precision+recall)
# 打印结果
print "Naive Predictor: [Accuracy score: {:.4f}, F-score: {:.4f}]".format(accuracy, fscore)
```
### 监督学习模型
**下面的监督学习模型是现在在** [`scikit-learn`](http://scikit-learn.org/stable/supervised_learning.html) **中你能够选择的模型**
- 高斯朴素贝叶斯 (GaussianNB)
- 决策树
- 集成方法 (Bagging, AdaBoost, Random Forest, Gradient Boosting)
- K近邻 (KNeighbors)
- 随机梯度下降分类器 (SGDC)
- 支撑向量机 (SVM)
- Logistic回归
### 问题 2 - 模型应用
列出从上面的监督学习模型中选择的三个适合我们这个问题的模型,你将在人口普查数据上测试这每个算法。对于你选择的每一个算法:
- *描述一个该模型在真实世界的一个应用场景。(你需要为此做点研究,并给出你的引用出处)*
- *这个模型的优势是什么?他什么情况下表现最好?*
- *这个模型的缺点是什么?什么条件下它表现很差?*
- *根据我们当前数据集的特点,为什么这个模型适合这个问题。*
**回答:**Gradient Boosting,Logistic回归,随机梯度下降分类器
Gradient Boosting:
- 学习排名(雅虎) 。
- 高维特征选择,预测性强,对异常值容忍度高,二分类最好。
- 每次对目标值与预测值残差进行拟合,不能并行,多分类表现不太好。
- 高维特征,分类问题。
Logistic回归:
- 冠心病危险因素(中国循证医学杂志)。
- 模型清晰,直接、快速,自变量和Logistic概率是线性关系表现最好。
- 要求严格的假设,需要处理异常值,自变量和Logistic概率不是线性关系表现最差。
- 当前数据集处理是二分类问题 。
随机梯度下降分类器:
- 图片识别(TensorFlow)。
- 高效,容易实现,进行严格特征归一化效果最好。
- 需要许多超参数,特征归一化不足则很差。
- 当前数据集样本量多,多变量,且是分类问题,随机梯度下降很适合处理这类问题。
### 练习 - 创建一个训练和预测的流水线
为了正确评估你选择的每一个模型的性能,创建一个能够帮助你快速有效地使用不同大小的训练集并在测试集上做预测的训练和测试的流水线是十分重要的。
你在这里实现的功能将会在接下来的部分中被用到。在下面的代码单元中,你将实现以下功能:
- 从[`sklearn.metrics`](http://scikit-learn.org/stable/modules/classes.html#sklearn-metrics-metrics)中导入`fbeta_score`和`accuracy_score`。
- 用样例训练集拟合学习器,并记录训练时间。
- 用学习器来对训练集进行预测并记录预测时间。
- 在最前面的300个*训练数据*上做预测。
- 计算训练数据和测试数据的准确率。
- 计算训练数据和测试数据的F-score。
```
# TODO:从sklearn中导入两个评价指标 - fbeta_score和accuracy_score
from sklearn.metrics import fbeta_score, accuracy_score
def train_predict(learner, sample_size, X_train, y_train, X_test, y_test):
'''
inputs:
- learner: the learning algorithm to be trained and predicted on
- sample_size: the size of samples (number) to be drawn from training set
- X_train: features training set
- y_train: income training set
- X_test: features testing set
- y_test: income testing set
'''
results = {}
# TODO:使用sample_size大小的训练数据来拟合学习器
# TODO: Fit the learner to the training data using slicing with 'sample_size'
start = time() # 获得程序开始时间
#print (y_train['>50K'])[0:3]
learner = learner.fit(X_train[0:sample_size],(y_train)[0:sample_size])
end = time() # 获得程序结束时间
# TODO:计算训练时间
results['train_time'] = end-start
# TODO: 得到在测试集上的预测值
# 然后得到对前300个训练数据的预测结果
start = time() # 获得程序开始时间
predictions_test = learner.predict(X_test)
predictions_train = learner.predict(X_train[0:300])
end = time() # 获得程序结束时间
# TODO:计算预测用时
results['pred_time'] = end-start
# TODO:计算在最前面的300个训练数据的准确率
results['acc_train'] = accuracy_score(y_train[0:300],predictions_train)
# TODO:计算在测试集上的准确率['>50K']
results['acc_test'] = accuracy_score(y_test, predictions_test)
# TODO:计算在最前面300个训练数据上的F-score
results['f_train'] = fbeta_score(y_train[0:300],predictions_train, beta=0.5)
# TODO:计算测试集上的F-score
results['f_test'] = fbeta_score(y_test, predictions_test, beta=0.5)
# 成功
print "{} trained on {} samples.".format(learner.__class__.__name__, sample_size)
# 返回结果
return results
```
### 练习:初始模型的评估
在下面的代码单元中,您将需要实现以下功能:
- 导入你在前面讨论的三个监督学习模型。
- 初始化三个模型并存储在`'clf_A'`,`'clf_B'`和`'clf_C'`中。
- 如果可能对每一个模型都设置一个`random_state`。
- **注意:**这里先使用每一个模型的默认参数,在接下来的部分中你将需要对某一个模型的参数进行调整。
- 计算记录的数目等于1%,10%,和100%的训练数据,并将这些值存储在`'samples'`中
**注意:**取决于你选择的算法,下面实现的代码可能需要一些时间来运行!
```
# TODO:从sklearn中导入三个监督学习模型
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import (BaggingClassifier, RandomForestClassifier,GradientBoostingClassifier,AdaBoostClassifier)
from sklearn.svm import SVC
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
# TODO:初始化三个模型
clf_A = GradientBoostingClassifier(random_state=0)
clf_B = LogisticRegression(random_state=0)
clf_C = SGDClassifier(random_state=0)
# TODO:计算1%, 10%, 100%的训练数据分别对应多少点
samples_1 = int(X_train.shape[0]*0.01)
samples_10 = int(X_train.shape[0]*0.1)
samples_100 = X_train.shape[0]
# 收集学习器的结果
results = {}
for clf in [clf_A, clf_B, clf_C]:
clf_name = clf.__class__.__name__
results[clf_name] = {}
for i, samples in enumerate([samples_1, samples_10, samples_100]):
results[clf_name][i] = \
train_predict(clf, samples, X_train, y_train, X_test, y_test)
# 对选择的三个模型得到的评价结果进行可视化
vs.evaluate(results, accuracy, fscore)
```
----
## 提高效果
在这最后一节中,您将从三个有监督的学习模型中选择*最好的*模型来使用学生数据。你将在整个训练集(`X_train`和`y_train`)上通过使用网格搜索优化至少调节一个参数以获得一个比没有调节之前更好的F-score。
### 问题 3 - 选择最佳的模型
*基于你前面做的评价,用一到两段向*CharityML*解释这三个模型中哪一个对于判断被调查者的年收入大于\$50,000是最合适的。*
**提示:**你的答案应该包括关于评价指标,预测/训练时间,以及该算法是否适合这里的数据的讨论。
**回答:**GradientBoosting,相比较而言,虽然训练时间和预测时间比其他模型长,但准确率和F-score最高的。
### 问题 4 - 用通俗的话解释模型
*用一到两段话,向*CharityML*用外行也听得懂的话来解释最终模型是如何工作的。你需要解释所选模型的主要特点。例如,这个模型是怎样被训练的,它又是如何做出预测的。避免使用高级的数学或技术术语,不要使用公式或特定的算法名词。*
**回答: **
- 在GradientBoosting中,采取分层学习的方法,通过M个步骤来得到最终模型F,在第m步学习一个较弱的$F_ {m}$模型,在m+1步不直接优化$F_ {m+1}$,而是用一个基本模型h(x)使得其学习目标值y-$F_ {m}$,这样就会使m+1步的模型预测值$F_ {m+1}$=$F_ {m}$+h(x)更接近于真实值y。
- 通过上面训练的模型F对测试集进行预测。
### 练习:模型调优
调节选择的模型的参数。使用网格搜索(GridSearchCV)来至少调整模型的重要参数(至少调整一个),这个参数至少需给出并尝试3个不同的值。你要使用整个训练集来完成这个过程。在接下来的代码单元中,你需要实现以下功能:
- 导入[`sklearn.model_selection.GridSearchCV`](http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html)和[`sklearn.metrics.make_scorer`](http://scikit-learn.org/stable/modules/generated/sklearn.metrics.make_scorer.html).
- 初始化你选择的分类器,并将其存储在`clf`中。
- 如果能够设置的话,设置`random_state`。
- 创建一个对于这个模型你希望调整参数的字典。
- 例如: parameters = {'parameter' : [list of values]}。
- **注意:** 如果你的学习器(learner)有 `max_features` 参数,请不要调节它!
- 使用`make_scorer`来创建一个`fbeta_score`评分对象(设置$\beta = 0.5$)。
- 在分类器clf上用'scorer'作为评价函数运行网格搜索,并将结果存储在grid_obj中。
- 用训练集(X_train, y_train)训练grid search object,并将结果存储在`grid_fit`中。
**注意:** 取决于你选择的参数列表,下面实现的代码可能需要花一些时间运行!
```
# TODO:导入'GridSearchCV', 'make_scorer'和其他一些需要的库
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import make_scorer
from sklearn.metrics import fbeta_score, accuracy_score
# TODO:初始化分类器
clf = GradientBoostingClassifier(random_state=0)
# TODO:创建你希望调节的参数列表
#parameters = {'max_depth':range(5,16,2)}
parameters = {'n_estimators' : range(50, 550, 50), 'learning_rate' :np.linspace(0.01, 0.2, 20) }
# TODO:创建一个fbeta_score打分对象
scorer = make_scorer(fbeta_score, beta=0.5)
# TODO:在分类器上使用网格搜索,使用'scorer'作为评价函数.
#grid_obj = GridSearchCV(clf,parameters,scorer,cv=10)
rdm_obj = RandomizedSearchCV(clf,parameters,scoring=scorer, n_iter = 6)
# TODO:用训练数据拟合网格搜索对象并找到最佳参数
#grid_fit=grid_obj.fit(X_train, y_train)
rdm_obj.fit(X_train, y_train)
# 得到estimator
#best_clf = grid_obj.best_estimator_
best_clf = rdm_obj.best_estimator_
# 使用没有调优的模型做预测
#predictions = (clf.fit(X_train, y_train)).predict(X_test)
#best_predictions = best_clf.predict(X_test)
predictions = (clf.fit(X_train, y_train)).predict(X_test)
best_predictions = best_clf.predict(X_test)
# 汇报调参前和调参后的分数
print "Unoptimized model\n------"
print "Accuracy score on testing data: {:.4f}".format(accuracy_score(y_test, predictions))
print "F-score on testing data: {:.4f}".format(fbeta_score(y_test, predictions, beta = 0.5))
print "\nOptimized Model\n------"
print "Final accuracy score on the testing data: {:.4f}".format(accuracy_score(y_test, best_predictions))
print "Final F-score on the testing data: {:.4f}".format(fbeta_score(y_test, best_predictions, beta = 0.5))
```
### 问题 5 - 最终模型评估
_你的最优模型在测试数据上的准确率和F-score是多少?这些分数比没有优化的模型好还是差?你优化的结果相比于你在**问题 1**中得到的朴素预测器怎么样?_
**注意:**请在下面的表格中填写你的结果,然后在答案框中提供讨论。
#### 结果:
| 评价指标 | 基准预测器 | 未优化的模型 | 优化的模型 |
| :------------: | :-----------------: | :---------------: | :-------------: |
| 准确率 | 0.2478 | 0.8630 | 0.8722 |
| F-score| 0.2917 | 0.7395 | 0.7557 |
**回答:**0.8722,0.7557.好,相比于在问题 1中得到的朴素预测器好很多。
----
## 特征的重要性
在数据上(比如我们这里使用的人口普查的数据)使用监督学习算法的一个重要的任务是决定哪些特征能够提供最强的预测能力。通过专注于一些少量的有效特征和标签之间的关系,我们能够更加简单地理解这些现象,这在很多情况下都是十分有用的。在这个项目的情境下这表示我们希望选择一小部分特征,这些特征能够在预测被调查者是否年收入大于\$50,000这个问题上有很强的预测能力。
选择一个有`feature_importance_`属性(这是一个根据这个选择的分类器来对特征的重要性进行排序的函数)的scikit学习分类器(例如,AdaBoost,随机森林)。在下一个Python代码单元中用这个分类器拟合训练集数据并使用这个属性来决定这个人口普查数据中最重要的5个特征。
### 问题 6 - 观察特征相关性
当**探索数据**的时候,它显示在这个人口普查数据集中每一条记录我们有十三个可用的特征。
_在这十三个记录中,你认为哪五个特征对于预测是最重要的,你会怎样对他们排序?理由是什么?_
**回答:**occupation,education_level,workclass,race,sex.从事工作不同薪水是很大区别,受教育水平限制了你从事的工作类型,工作类别也很能看出薪水区别,白种人及亚裔相对比黑人工资高,男性相对比女性高。
### 练习 - 提取特征重要性
选择一个`scikit-learn`中有`feature_importance_`属性的监督学习分类器,这个属性是一个在做预测的时候根据所选择的算法来对特征重要性进行排序的功能。
在下面的代码单元中,你将要实现以下功能:
- 如果这个模型和你前面使用的三个模型不一样的话从sklearn中导入一个监督学习模型。
- 在整个训练集上训练一个监督学习模型。
- 使用模型中的`'.feature_importances_'`提取特征的重要性。
```
# TODO:导入一个有'feature_importances_'的监督学习模型
from sklearn.ensemble import AdaBoostClassifier
# TODO:在训练集上训练一个监督学习模型
model = AdaBoostClassifier().fit(X_train, y_train)
# TODO: 提取特征重要性
importances = model.feature_importances_
# 绘图
vs.feature_plot(importances, X_train, y_train)
```
### 问题 7 - 提取特征重要性
观察上面创建的展示五个用于预测被调查者年收入是否大于\$50,000最相关的特征的可视化图像。
_这五个特征和你在**问题 6**中讨论的特征比较怎么样?如果说你的答案和这里的相近,那么这个可视化怎样佐证了你的想法?如果你的选择不相近,那么为什么你觉得这些特征更加相关?_
**回答:**不相近,从下面的图中可以看出大部分大于50K的人的education-num是比小于等于50K的人的education-num大;大部分大于50K的人的hours-per-week是比小于等于50K的人的hours-per-week要长;大于50K的人的age的中位数和下四分位是比小于等于50K的人的age的中位数和下四分位大;大于50K的人的capital-gain和小于等于50K的人的capital-gain大部分为0,而大于50K的人的capital-gain的异常值的中位数比小于等于50K的人的capital-gain异常值要大;大于50K的人的capital-loss和小于等于50K的人的capital-loss大部分为0,而大于50K的人的capital-loss的异常值的中位数比小于等于50K的人的capital-loss异常值要大。
- 收入大于50K相比收入小于等于50K,education-num更大,hours-per-week更长,capital-gain更大,age更大,capital-loss更大。
```
import seaborn as sns
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,10))
ax1 = fig.add_subplot(10,1,1)
ax2 = fig.add_subplot(10,1,3)
ax3 = fig.add_subplot(10,1,5)
ax4 = fig.add_subplot(10,1,7)
ax5 = fig.add_subplot(10,1,9)
%config InlineBackend.figure_format = 'retina'
sns.boxplot(x='education-num', y='income', data=data,ax=ax1)
sns.boxplot(x='hours-per-week', y='income', data=data,ax=ax2)
sns.boxplot(x='capital-gain', y='income', data=data,ax=ax3)
sns.boxplot(x='age', y='income', data=data,ax=ax4)
sns.boxplot(x='capital-loss', y='income', data=data,ax=ax5)
```
### 特征选择
如果我们只是用可用特征的一个子集的话模型表现会怎么样?通过使用更少的特征来训练,在评价指标的角度来看我们的期望是训练和预测的时间会更少。从上面的可视化来看,我们可以看到前五个最重要的特征贡献了数据中**所有**特征中超过一半的重要性。这提示我们可以尝试去*减小特征空间*,并简化模型需要学习的信息。下面代码单元将使用你前面发现的优化模型,并*只使用五个最重要的特征*在相同的训练集上训练模型。
```
# 导入克隆模型的功能
from sklearn.base import clone
# 减小特征空间
X_train_reduced = X_train[X_train.columns.values[(np.argsort(importances)[::-1])[:5]]]
X_test_reduced = X_test[X_test.columns.values[(np.argsort(importances)[::-1])[:5]]]
# 在前面的网格搜索的基础上训练一个“最好的”模型
clf = (clone(best_clf)).fit(X_train_reduced, y_train)
# 做一个新的预测
reduced_predictions = clf.predict(X_test_reduced)
# 对于每一个版本的数据汇报最终模型的分数
print "Final Model trained on full data\n------"
print "Accuracy on testing data: {:.4f}".format(accuracy_score(y_test, best_predictions))
print "F-score on testing data: {:.4f}".format(fbeta_score(y_test, best_predictions, beta = 0.5))
print "\nFinal Model trained on reduced data\n------"
print "Accuracy on testing data: {:.4f}".format(accuracy_score(y_test, reduced_predictions))
print "F-score on testing data: {:.4f}".format(fbeta_score(y_test, reduced_predictions, beta = 0.5))
```
### 问题 8 - 特征选择的影响
*最终模型在只是用五个特征的数据上和使用所有的特征数据上的F-score和准确率相比怎么样?*
*如果训练时间是一个要考虑的因素,你会考虑使用部分特征的数据作为你的训练集吗?*
**回答:**只用五个特征的数据的F-score和准确率比使用所有的特征数据的F-score和准确率差,不会,会用更好的模型。
> **注意:** 当你写完了所有的代码,并且回答了所有的问题。你就可以把你的 iPython Notebook 导出成 HTML 文件。你可以在菜单栏,这样导出**File -> Download as -> HTML (.html)**把这个 HTML 和这个 iPython notebook 一起做为你的作业提交。
| github_jupyter |
```
# Import relevant libraries
import numpy as np; np.random.seed(42); import tensorflow as tf; tf.set_random_seed(42);
import matplotlib.pyplot as plt; import pylab; import cv2;
import os; from os import listdir; from os.path import isfile, join
from Architecture import *
%matplotlib inline
# Image specifications
img_height = 128; img_width = 128; img_channels = 3; batch_size = 1; rel_path = '...Path to this Jupyter Notebook...';
# Define some placeholders
with tf.name_scope("Placeholders"):
lr = tf.placeholder(tf.float32, shape = [], name = "Learning_rate");
train_mode = tf.placeholder(tf.bool, shape = [], name = "BatchNorm_TrainMode")
input_A = tf.placeholder(tf.float32, [batch_size, img_height, img_width, img_channels], name = "Input_A")
input_B = tf.placeholder(tf.float32, [batch_size, img_height, img_width, img_channels], name = "Input_B")
global_step = tf.Variable(0, name = "global_step", trainable = False)
# Output of the generator which should ideally belong to target domain B in our case
with tf.variable_scope("Generator_", reuse = False):
fake_img = generator_unet_128(input_A)
# Output of the discriminator which is probability of the real image being 1
with tf.variable_scope("Discriminator_", reuse = False):
prob_real_img = discriminator_patch_gan(input_A, input_B)
# Output of the discriminator which is probability of the fake image being 1
with tf.variable_scope("Discriminator_", reuse = True):
prob_fake_img = discriminator_patch_gan(input_A, fake_img)
def LSGAN_loss():
"""
Returns:
g_loss: Generator_loss [minimizing the squared difference b/w prob_fake_img and 1]
d_loss: Discriminator_loss [minimizing the squared difference b/w prob_real_img & 1, and b/w prob_fake_img & 0]
"""
L1_weight = 200; L1_loss = tf.reduce_mean(tf.abs(input_B - fake_img))
g_loss = 0.5*tf.reduce_mean(tf.squared_difference(prob_fake_img, 1)) + L1_weight*L1_loss
d_loss = 0.5*tf.reduce_mean(tf.squared_difference(prob_real_img, 1)) + 0.5*tf.reduce_mean(tf.square(prob_fake_img))
return g_loss, d_loss
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
# Initialize an Adam optimizer with default beta2
optimizer = tf.train.AdamOptimizer(lr, beta1 = 0.5); model_vars = tf.trainable_variables()
# Seperate the variables corresponding to the discriminator and generator
d_vars = [var for var in model_vars if 'Discriminator_' in var.name]
g_vars = [var for var in model_vars if 'Generator_' in var.name]
g_loss, d_loss = LSGAN_loss();
# Define different optimizers for Discriminator and Generator
d_trainer = optimizer.minimize(d_loss, var_list = d_vars)
g_trainer = optimizer.minimize(g_loss, var_list = g_vars)
def generate_fake_validation_images(sess, epoch):
"""
loc: Path of the validation set
num_images: Number of the images in the validation set
"""
loc = '...path to Validation set...';
file_loc = [rel_path + loc + s for s in os.listdir(rel_path + loc)]
val_dataset = tf.data.Dataset.from_tensor_slices(tf.constant(file_loc))
val_dataset = val_dataset.map(lambda x: tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(tf.read_file(x)), [img_height, img_width]), 127.5), 1))
val_iterator = val_dataset.make_one_shot_iterator(); next_element = val_iterator.get_next()
if not os.path.exists("./Output/Validation/epoch_" + str(epoch) + "/"):
os.makedirs("./Output/Validation/epoch_" + str(epoch) + "/")
for i in range(0, len(file_loc)):
try:
# Get the next image
next_image = sess.run(validation_next_element)
# next_image = np.expand_dims(cv2.cvtColor(next_image, cv2.COLOR_RGBA2RGB), axis = 0)
# Generate a fake image
fake_gen_img = sess.run(fake_img, feed_dict = {input_A: next_image})
# Save the fake image at the specified location
plt.imsave("./Output/Validation/epoch_" + str(epoch) + "/img_" + str(i) + "_fake.png",((fake_gen_img[0] + 1)*127.5).astype(np.uint8))
plt.imsave("./Output/Validation/epoch_" + str(epoch) + "/img_" + str(i) + ".png",((next_image[0] + 1)*127.5).astype(np.uint8))
except tf.errors.OutOfRangeError: break
# Specific boolean to be set to True
Train = True; Test = False; Restore_and_train = False
def in_training_mode(num_epochs = 100, num_iters, log_dir = "./checkpoints/"):
"""
num_epochs: Number of epochs to train
log_dir: Path where to save checkpoints
num_iters: Number of training iterations in one epoch
"""
print("Training Started")
for epoch in range(sess.run(global_step), num_epochs):
logs_dir = log_dir; d_l = 0; g_l = 0; num_iters = num_iters;
if not os.path.exists(logs_dir): os.makedirs(logs_dir)
sess.run(train_iterator.initializer)
if epoch < 20: curr_lr = 0.0002;
elif epoch % 20 == 0: curr_lr = curr_lr/2
for ptr in range(1, num_iters):
try:
# Get the next element of the dataset
a_next_image, b_next_image = sess.run(train_next_element)
# a_next_image = np.expand_dims(cv2.cvtColor(a_next_image, cv2.COLOR_RGBA2RGB), axis = 0)
# b_next_image = np.expand_dims(cv2.cvtColor(b_next_image, cv2.COLOR_RGBA2RGB), axis = 0)
# Run the train step to update the parameters of the discriminator with 4 times the curr_lr
# NOTE: This is done to avoid running multiple iterations of discriminator step as in the case of WGAN
_, dis_loss = sess.run([d_trainer, d_loss], feed_dict = {input_A: a_next_image, input_B: b_next_image, lr: curr_lr})
# Run the train step to update the parameters of the generator with the curr_lr
_, gen_loss = sess.run([g_trainer, g_loss], feed_dict = {input_A: a_next_image, input_B: b_next_image, lr: curr_lr})
# Calculate the d_loss and g_loss
d_l += dis_loss; g_l += gen_loss
# Print some statistics
if(ptr % 10000 == 0):
print(str(epoch*num_iters + ptr) + ' iterations completed and losses are:')
print('Generator_loss_: ' + str(g_l/ptr)); print('Discriminator_loss_: ' + str(d_l/ptr))
except tf.errors.OutOfRangeError:
# Initialize the iterator again
sess.run(training_iterator.initializer); continue;
# Generate fake validation images at the end of each epoch only to check the progress of the model
generate_fake_validation_images(sess, epoch)
# Save the checkpoints
saver.save(sess, logs_dir + 'composites', global_step = global_step)
# Increment the global variable
sess.run(tf.assign(global_step, epoch + 1))
if Train:
"""
num_epochs: number of epochs to run
"""
# Sorting the filename wrt unique indices of each image
def sort_composite_filename(x): return int(x[4:-4])
# Create a datset of composites
comp_dir = '/images/Composite/';
comp_fileloc = [rel_path + comp_dir + s for s in sorted(os.listdir(rel_path + comp_dir), key = sort_composite_filename)]
comp_dataset = tf.data.Dataset.from_tensor_slices(tf.constant(comp_fileloc));
comp_dataset = comp_dataset.map(lambda x: tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(tf.read_file(x)), [img_height, img_width]), 127.5), 1))
# Sorting the filename wrt unique indices of each image
def sort_natural_filename(x): return int(x[4:-4])
# Create a datset of natural images
nat_dir = '/images/Natural/'
nat_fileloc = [rel_path + nat_dir + s for s in sorted(os.listdir(rel_path + nat_dir), key = sort_natural_filename)]
nat_dataset = tf.data.Dataset.from_tensor_slices(tf.constant(nat_fileloc));
nat_dataset = nat_dataset.map(lambda x: tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(tf.read_file(x)), [img_height, img_width]), 127.5), 1))
# Create a final dataset by zipping the above two [in order to ensure that composite and its ground truth are together]
train_dataset = tf.data.Dataset.zip((comp_dataset, nat_dataset)).shuffle(2000).repeat()
train_dataset = (train_dataset.batch(batch_size)).prefetch(10);
# Create an interator over the dataset
train_iterator = train_dataset.make_initializable_iterator(); train_next_element = train_iterator.get_next()
# Set the gpu config options
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.9)
sess = tf.Session(config = tf.ConfigProto(gpu_options = gpu_options))
# Initialize the global variables
sess.run(tf.global_variables_initializer()); saver = tf.train.Saver(max_to_keep = 10)
in_training_mode(100, len(nat_fileloc));
if Restore_and_train:
"""
num_epochs: number of epochs to run
"""
# Set the gpu config options
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.9)
sess = tf.Session(config = tf.ConfigProto(gpu_options = gpu_options))
sess.run(tf.global_variables_initializer())
# Load the model with the latest checkpoints
saver = tf.train.Saver(max_to_keep = 10)
saver.restore(sess, tf.train.latest_checkpoint('./checkpoints/ls_pix2pix/'))
print ('Loaded checkpoint! Training from last checkpoint started !!')
# Train it again for n number of epochs
in_training_mode(num_epochs)
if Test:
# Set the config options
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.9)
sess = tf.Session(config = tf.ConfigProto(gpu_options = gpu_options))
sess.run(tf.global_variables_initializer()); saver = tf.train.Saver()
# Load the model with the latest checkpoints
saver.restore(sess, tf.train.latest_checkpoint('./checkpoints/ls_pix2pix/'))
print ('Loaded checkpoint! Generating fake images corresponding to Test Composites!!')
# Evaluate it on test set
loc = '...path to Test set...';
file_loc = [rel_path + loc + s for s in os.listdir(rel_path + loc)]
test_dataset = tf.data.Dataset.from_tensor_slices(tf.constant(file_loc))
test_dataset = test_dataset.map(lambda x: tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(tf.read_file(x)), [img_height, img_width]), 127.5), 1))
# Initialize the test iterator
test_iterator = test_dataset.make_one_shot_iterator(); test_next_element = test_iterator.get_next()
# Make the directory if it doesn't exists
if not os.path.exists("./Output/Test/"): os.makedirs("./Output/Test/")
# Set the number of test images in test folder!!
num_images = 10;
for i in range(0, num_images):
try:
# Get the next element
next_image = sess.run(test_next_element)
# next_image = np.expand_dims(cv2.cvtColor(next_image, cv2.COLOR_RGBA2RGB), axis = 0)
# Generate the fake image
fake_gen_img = sess.run(fake_img, feed_dict = {input_A: next_image})
# Save the image at specified location
plt.imsave("./Output/Test/fake_img_" + str(i) + ".png",((fake_gen_img[0] + 1)*127.5).astype(np.uint8))
plt.imsave("./Output/Test/img_" + str(i) + ".png",((next_image[0] + 1)*127.5).astype(np.uint8))
except tf.errors.OutOfRangeError: break
```
| github_jupyter |
```
"""
We use following lines because we are running on Google Colab
If you are running notebook on a local computer, you don't need this cell
"""
from google.colab import drive
drive.mount('/content/gdrive')
import os
os.chdir('/content/gdrive/My Drive/finch/tensorflow1/spoken_language_understanding/atis/main')
import tensorflow as tf
import tensorflow_hub as hub
import pprint
import logging
import time
import numpy as np
from sklearn.metrics import classification_report, f1_score
from pathlib import Path
print("TensorFlow Version", tf.__version__)
print('GPU Enabled:', tf.test.is_gpu_available())
def get_vocab(vocab_path):
word2idx = {}
with open(vocab_path) as f:
for i, line in enumerate(f):
line = line.rstrip()
word2idx[line] = i
return word2idx
def data_generator(f_path, params):
print('Reading', f_path)
with open(f_path) as f:
for line in f:
line = line.rstrip()
text, slot_intent = line.split('\t')
words = text.split()[1:-1]
slot_intent = slot_intent.split()
slots, intent = slot_intent[1:-1], slot_intent[-1]
assert len(words) == len(slots)
yield (words, (intent, slots))
def dataset(is_training, params):
_shapes = ([None], ((), [None]))
_types = (tf.string, (tf.string, tf.string))
_pads = ('<pad>', ('_', 'O'))
if is_training:
ds = tf.data.Dataset.from_generator(
lambda: data_generator(params['train_path'], params),
output_shapes = _shapes,
output_types = _types,)
ds = ds.shuffle(params['num_samples'])
ds = ds.padded_batch(params['batch_size'], _shapes, _pads)
ds = ds.prefetch(tf.data.experimental.AUTOTUNE)
else:
ds = tf.data.Dataset.from_generator(
lambda: data_generator(params['test_path'], params),
output_shapes = _shapes,
output_types = _types,)
ds = ds.padded_batch(1, _shapes, _pads)
ds = ds.prefetch(tf.data.experimental.AUTOTUNE)
return ds
def model_fn(features, labels, mode, params):
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
vocab = tf.contrib.lookup.index_table_from_file(
params['word_path'], num_oov_buckets=1)
words = vocab.lookup(features)
seq_len = tf.count_nonzero(words, 1, dtype=tf.int32)
embedding = np.load(params['vocab_path'])
embedding = tf.Variable(embedding, name='embedding', dtype=tf.float32)
x = tf.nn.embedding_lookup(embedding, words)
elmo = hub.Module("https://tfhub.dev/google/elmo/2", trainable=False)
e = elmo(inputs={'tokens':features, 'sequence_len':seq_len}, signature='tokens', as_dict=True)['lstm_outputs1']
x = tf.concat((x, e), -1)
x = tf.layers.dropout(x, params['dropout_rate'], training=is_training)
x = tf.layers.dense(x, params['rnn_units'], tf.nn.elu)
x = tf.layers.dropout(x, params['dropout_rate'], training=is_training)
cell_fw = tf.nn.rnn_cell.GRUCell(params['rnn_units'])
cell_bw = tf.nn.rnn_cell.GRUCell(params['rnn_units'])
o, _ = tf.nn.bidirectional_dynamic_rnn(cell_fw, cell_bw, x, seq_len, dtype=tf.float32)
x = tf.concat(o, -1)
y_intent = tf.layers.dense(tf.reduce_max(x, 1), params['intent_size'])
y_slots = tf.layers.dense(x, params['slot_size'])
if labels is not None:
intent, slots = labels
vocab = tf.contrib.lookup.index_table_from_file(
params['intent_path'], num_oov_buckets=1)
intent = vocab.lookup(intent)
vocab = tf.contrib.lookup.index_table_from_file(
params['slot_path'], num_oov_buckets=1)
slots = vocab.lookup(slots)
loss_intent = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=intent, logits=y_intent)
loss_intent = tf.reduce_mean(loss_intent)
loss_slots = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=slots, logits=y_slots)
weights = tf.cast(tf.sign(slots), tf.float32)
padding = tf.fill(tf.shape(weights), 1e-2)
weights = tf.where(tf.equal(weights, 0.), padding, weights)
loss_slots = tf.reduce_mean(loss_slots * weights)
loss_op = loss_intent + loss_slots
if mode == tf.estimator.ModeKeys.TRAIN:
variables = tf.trainable_variables()
tf.logging.info('\n'+pprint.pformat(variables))
grads = tf.gradients(loss_op, variables)
grads, _ = tf.clip_by_global_norm(grads, params['clip_norm'])
global_step=tf.train.get_or_create_global_step()
decay_lr = tf.train.exponential_decay(
params['lr'], global_step, 1000, .9)
hook = tf.train.LoggingTensorHook({'lr': decay_lr}, every_n_iter=100)
optim = tf.train.AdamOptimizer(decay_lr)
train_op = optim.apply_gradients(
zip(grads, variables), global_step=global_step)
return tf.estimator.EstimatorSpec(mode=mode,
loss=loss_op,
train_op=train_op,
training_hooks=[hook],)
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode=mode,
loss=loss_op)
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode,
predictions={'intent': tf.argmax(y_intent, -1),
'slots': tf.argmax(y_slots, -1)})
params = {
'model_dir': '../model/elmo_bigru',
'log_path': '../log/elmo_bigru.txt',
'train_path': '../data/atis.train.w-intent.iob',
'test_path': '../data/atis.test.w-intent.iob',
'word_path': '../vocab/word.txt',
'vocab_path': '../vocab/word.npy',
'intent_path': '../vocab/intent.txt',
'slot_path': '../vocab/slot.txt',
'batch_size': 16,
'num_samples': 4978,
'rnn_units': 300,
'dropout_rate': 0.2,
'clip_norm': 5.0,
'lr': 3e-4,
'num_patience': 3,
}
params['word2idx'] = get_vocab(params['word_path'])
params['intent2idx'] = get_vocab(params['intent_path'])
params['slot2idx'] = get_vocab(params['slot_path'])
params['word_size'] = len(params['word2idx']) + 1
params['intent_size'] = len(params['intent2idx']) + 1
params['slot_size'] = len(params['slot2idx']) + 1
def is_descending(history: list):
history = history[-(params['num_patience']+1):]
for i in range(1, len(history)):
if history[i-1] <= history[i]:
return False
return True
# Create directory if not exist
Path(os.path.dirname(params['log_path'])).mkdir(exist_ok=True)
Path(params['model_dir']).mkdir(exist_ok=True, parents=True)
# Logging
logger = logging.getLogger('tensorflow')
logger.setLevel(logging.INFO)
fh = logging.FileHandler(params['log_path'])
logger.addHandler(fh)
# Create an estimator
_eval_steps = params['num_samples']//params['batch_size'] + 1
config = tf.estimator.RunConfig(
save_checkpoints_steps=_eval_steps,)
estimator = tf.estimator.Estimator(
model_fn=model_fn,
model_dir=params['model_dir'],
config=config,
params=params)
# Train on training data and Evaluate on testing data
train_spec = tf.estimator.TrainSpec(
input_fn=lambda: dataset(is_training=True, params=params),)
eval_spec = tf.estimator.EvalSpec(
input_fn=lambda: dataset(is_training=False, params=params),
steps=None,
throttle_secs=10,)
best_f1 = .0
history_f1 = []
tf.enable_eager_execution()
while True:
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
intent = []
slots = []
for w, (i, s) in dataset(is_training=False, params=params):
intent.append(i.numpy())
slots.append(s.numpy())
intent = [i for batch in intent for i in batch]
intent = [params['intent2idx'].get(str(t, 'utf-8'), len(params['intent2idx'])) for t in intent]
slots = [j for batch in slots for i in batch for j in i]
slots = [params['slot2idx'].get(str(s, 'utf-8'), len(params['slot2idx'])) for s in slots]
predicted = list(estimator.predict(input_fn=lambda: dataset(is_training=False, params=params)))
y_slots = [j for i in predicted for j in i['slots']]
y_intent = [i['intent'] for i in predicted]
logger.info('\n'+classification_report(y_true = intent,
y_pred = y_intent,
labels = list(params['intent2idx'].values()),
target_names = list(params['intent2idx'].keys()),
digits=3))
logger.info('\n'+classification_report(y_true = slots,
y_pred = y_slots,
labels = list(params['slot2idx'].values()),
target_names = list(params['slot2idx'].keys()),
sample_weight = np.sign(slots),
digits=3))
f1_slots = f1_score(y_true = slots,
y_pred = y_slots,
labels = list(params['slot2idx'].values()),
sample_weight = np.sign(slots),
average='micro',)
history_f1.append(f1_slots)
if f1_slots > best_f1:
best_f1 = f1_slots
logger.info("Best Slot F1: {:.3f}".format(best_f1))
if len(history_f1) > params['num_patience'] and is_descending(history_f1):
logger.info("Testing Slot F1 not improved over {} epochs, Early Stop".format(params['num_patience']))
break
```
| github_jupyter |
```
%matplotlib inline
%config InlineBackend.figure_format='retina'
import numpy as np
import matplotlib.pyplot as plt
import os
import sys
import tensorflow
import pandas as pd
import re
import collections
from pprint import pprint
from matplotlib import cm
from tensorboard.backend.event_processing import event_accumulator
```
## Get the folders we want to plot
```
log_dir = '../train/logs/'
folders = []
for folder in os.listdir(log_dir):
folder = os.path.join(log_dir, folder)
if not os.path.isdir(folder):
continue
folders.append(folder)
folders = list(filter(lambda _: ('REG_0.00e+00' in _), folders))
```
## Loop over these folders
```
data = dict()
for folder in sorted(folders):
# Load the log file
ea = event_accumulator.EventAccumulator(folder)
ea.Reload()
# Read out the parameters of that run from the log file name
datetime, event, dist, size, lr, thresh, reg = re.findall(r"\[(.*?)\]", folder)
# Save the relevant properties as pandas DataFrames in a dictionary
if event not in data:
data[event] = dict()
if dist not in data[event]:
data[event][dist] = dict()
data[event][dist]['loss'] = pd.DataFrame(ea.Scalars('loss'))
data[event][dist]['hamming_dist'] = pd.DataFrame(ea.Scalars('hamming_dist'))
data[event][dist]['val_loss'] = pd.DataFrame(ea.Scalars('val_loss'))
data[event][dist]['val_hamming_dist'] = pd.DataFrame(ea.Scalars('val_hamming_dist'))
colors = cm.get_cmap('tab20c')(np.linspace(0, 1, 20))
linestyles = ['-', '--', ':', '-.']
for h, metric in enumerate(['loss', 'val_loss', 'hamming_dist', 'val_hamming_dist']):
for i, event in enumerate(['GW150914', 'GW151226', 'GW170104']):
for j, dist in enumerate(['0100_0300', '0250_0500', '0400_0800', '0700_1200']):
plt.plot(data[event][dist][metric]['step']+1,
data[event][dist][metric]['value'],
color=colors[4*i+j],
linestyle=linestyles[j],
linewidth=2,
label='{}_{}'.format(event, dist))
plt.gcf().set_size_inches(12, 4, forward=True)
plt.ylim(0, [0.4, 0.4, 0.15, 0.15][h])
plt.xlim(0, 51)
plt.xlabel('Epoch')
plt.ylabel(metric)
plt.legend(loc='best')
plt.title('{}'.format(metric))
plt.grid(ls=':')
# Shrink current axis by 20%
box = plt.gca().get_position()
plt.gca().set_position([box.x0, box.y0, box.width * 0.8, box.height])
# Put a legend to the right of the current axis
plt.gca().legend(loc='center left', bbox_to_anchor=(1, 0.5), frameon=False)
plt.show()
```
| github_jupyter |
```
%matplotlib inline
```
# 592B, Class 2.2 (09/12). Fourier series, aliasing, Sampling theorem
```
import numpy as np
import matplotlib.pyplot as plt
import scipy.io.wavfile as wavfile
from ipywidgets import interactive
from IPython.display import Audio, display
```
## Sine waves and cosine waves
Let's review the relation between sine and cosine waves. Let's plot a sine wave and a cosine wave:
$$y_{sin} = A \sin(440\pi t)$$
$$y_{cos} = A \cos(440\pi t)$$
```
fs = 44100 # define the sampling rate, f_s = 144100 Hz
t_start = 0 # We start sampling at t = 0s
t_stop = 3 # We stop sampling at t = 3s
ns = (t_stop - t_start) * fs + 1
print(ns)
x = np.linspace(t_start, t_stop, ns)
print(len(x))
f = 440 # frequency of y_sin
y_sin = np.sin(2*np.pi*f*x) #do we need x1 and x2, or common x okay
y_cos = np.cos(2*np.pi*f*x)
print(x[0:10])
print(1/fs)
plt.figure("Sine vs. cosine")
plt.title("Sine vs. cosine")
plt.xlim(0,1/f) # What is 1/f?
plt.plot(x,y_sin, 'g', label='$y_{sin}$')
plt.plot(x,y_cos, 'b', label='$y_{cos}$')
plt.legend(loc="upper right")
plt.xlabel('Time (s)')
plt.ylabel('Amplitude (dB)')
```
*** In-class exercise: how could I get the blue line by modifying the parameters of $y_{sin}(t)$?***
```
y_cos_2 = np.sin(2*np.pi*f*x + np.pi/2)-1
plt.figure("Sine vs. cosine")
plt.title("Sine vs. cosine")
plt.xlim(0,1/f) # What is 1/f?
plt.plot(x,y_sin, 'g', label='$y_{sin}$')
plt.plot(x,y_cos_2, 'b', label='$y_{cos}$')
plt.legend(loc="upper right")
plt.xlabel('Time (s)')
plt.ylabel('Amplitude (dB)')
```
## Leftovers from Tuesday: converting between samples and timepoints
We read in some Hmong audio and plotted it, as in the cell below.
```
# From https://stackoverflow.com/questions/18644166/how-to-manipulate-wav-file-data-in-python
fs, hmong_data = wavfile.read('rms-sample-sounds/hmong_m6_24_c.wav')
n = 4096 # number of samples to plot
# Set up a new figure
plt.figure("hmong")
# plot the first n samples
plt.plot(hmong_data[0:n])
# label the axes
plt.ylabel("Amplitude (dB?)")
plt.xlabel("Samples [n]")
# set the title
plt.title("Hmong wave file")
print(len(hmong_data))
print(fs)
```
Then you were working on this:
***In-class exercise: Plot the first second of the Hmong audio file, with a real time axis, i.e., time should be in seconds, not in samples. Hint: knowing the sampling rate will help you do this! I put a cell below for you to get started.***
***And if you finish that, can you also write a function that will plot the audio file from some start time `t_start` to some stop time `t_stop`?***
```
# Recall that fs is 22050 Hz. So that means the first second is the first 22050 samples.
ns = fs # number of samples is 22050
# So we can use np.linspace to define a vector of sampled time points from 0 to 1 seconds.
x = np.linspace(0, 1, ns)
# Set up a new figure
plt.figure("hmong with time on x-axis")
# plot the first n samples
plt.plot(x, hmong_data[0:ns])
# label the axes
plt.ylabel("Amplitude (dB?)")
plt.xlabel("Time (s)")
# set the title
plt.title("Hmong wave file with time on x-axis")
# In general, suppose we want to plot the audio from t_start to t_stop.
# Then we could do: x = np.linspace(t_start, t_stop, ns)
# But what's ns? We did that in the Class 1.2 notebook.
# ns = (t_stop - t_start) / Ts + 1
# Or, if we are ignoring the +/- 1 sample, ns = (t_stop - t_start) * fs
# So, we can do this:
def plot_with_time_axis(t_start, t_stop, fs_data, DEBUG = True, data=hmong_data):
ns = int((t_stop - t_start) * fs_data) # number of samples from t_start to t_stop
if DEBUG: print("ns = ", ns)
n_start = int(round(t_start * fs_data)) # sample number corresponding to t_start
if DEBUG: print("n_start = ", n_start)
n_stop = int(round(t_stop * fs_data)) # sample number corresponding to t_stop
if DEBUG:
print("n_stop = ", n_stop)
print("len(data[n_start:n_stop]) = ", len(data[n_start:n_stop]))
x = np.linspace(t_start, t_stop, ns)
if DEBUG: print("len(x)= ", len(x))
plt.figure()
plt.plot(x, data[n_start:n_stop])
# label the axes
plt.ylabel("Amplitude (dB?)")
plt.xlabel("Time (s)")
plot_with_time_axis(0.5, 0.8, fs, DEBUG = False)
plot_with_time_axis(0.5, 0.55, fs, DEBUG = False) # oops, an error! Why?
# how could we make this code more robust? -> HW
```
## Adding up sine waves: towards Fourier series
Let's take the two sinusoidal signals we worked on last week and in your homework and try adding them up.
```
fs = 44100 # define the sampling rate, f_s = 44.1 kHz
t_start = 0 # We start sampling at t = 0s
t_stop = 1 # We stop sampling at t = 1s
ns = (t_stop - t_start) * fs + 1
x = np.linspace(t_start, t_stop, ns)
f1 = 440 # frequency of y_1(t)
f2 = 220 # frequency of y_2(t)
y1 = np.sin(2*np.pi*f1*x)
y2 = np.sin(2*np.pi*f2*x)
y1_plus_y2 = y1+y2
plt.figure("Adding up sines") # Create a new figure
plt.xlim(0,0.01)
plt.plot(x , y1, "-g", label="y1") # plot (x,y1) as a green line
plt.plot(x , y2, "-b", label="y2") # plot (x,y2) as a blue line
plt.plot(x , y1_plus_y2, "-r", label="y1+y2") # plot (x,y2) as a blue line
#plt.stem(x,y1, 'r', )
plt.legend(loc="upper right")
plt.xlabel('Time (s)')
plt.ylabel('Amplitude (dB)')
plt.title("Adding up sines")
```
You should play with setting other parameters! Remember, you can listen to your generated sinusoids too, using `Audio`.
Below is some code that creates an interactive "widget" for both plotting and playing two sine waves and their superposition (sum).
You need to import these libraries, as we did at the beginning of the notebook:
```python
from ipywidgets import interactive
from IPython.display import Audio, display
```
The code is inspired by this [beat frequencies demo](https://ipywidgets.readthedocs.io/en/stable/examples/Beat%20Frequencies.html).
```
def plot_play_summed_sines(f1 = 440, f2 = 880, t_start = 0, t_stop = 2, fs = 44100, xlim_max = 0.08):
x = np.linspace(t_start, t_stop, fs * (t_stop - t_start))
y1 = np.sin(2*np.pi*f1*x)
y2 = np.sin(2*np.pi*f2*x)
plt.xlim(t_start,xlim_max)
plt.plot(x , y1, "-g", label="y1")
plt.plot(x , y2, "-b", label="y2")
plt.plot(x , y1 + y2, "-r", label="y1+y2")
plt.legend(loc="upper right")
plt.xlabel('Time (s)')
plt.ylabel('Amplitude (dB)')
plt.title("Adding up sines")
display(Audio(data=y1, rate=fs))
display(Audio(data=y2, rate=fs))
display(Audio(data=y1+y2, rate=fs))
v = interactive(plot_play_summed_sines, f1=(100,900), f2=(100,900), t_start = (0,0), t_stop = (0,5))
display(v)
```
## A first look at Fourier series
Recall from last week that a standard definition of a sinusoidal signal (i.e., a sine wave) is given as function of time $t$:
$$y(t) = A \sin (\omega t + \phi) $$
where:
- $A$ is the amplitude
- $\omega$ is the angular frequency, n.b., $\omega = 2\pi f$ (where $f$ is the frequency in cycles per second (Hertz or Hz))
- $\phi$ is the phase shift
One standard definition of a Fourier series is:
\begin{equation}
f(t) = a_0 + \displaystyle\sum\limits_{n=1}^N \left(a_n\cos(2\pi nt) + b_n\sin(2\pi nt)\right)
\end{equation}
where
$n \in \mathbb{Z}$, and $a_0 \ldots a_N$ and $b_0 \ldots b_N$ are called **Fourier coefficients**. Note that these are amplitude values for each component sinusoidal function in the sum: they provide weights for the individual components in the sum. We'll see later that these determine the amplitude of peaks in a spectrum of $f(t)$.
***Discussion: Why is there no $b_0$ in the formula?***
Let's see what each of the individual $a_n\cos(2\pi nt) + b_n\sin(2\pi nt)$ terms look like, for $a_n = b_n = 1$ for all $n$, for $n <6$, otherwise 0. And let's include the $a_0$ term by starting at $N=0$.
```
# Inspired by https://matplotlib.org/examples/pylab_examples/subplots_demo.html Three subplots sharing both x/y axes
t_start = 0; t_stop = 1; fs = 1000
x = np.linspace(t_start, t_stop, fs * (t_stop - t_start))
y = [np.sin(2*np.pi*n*x) + np.cos(2*np.pi*n*x) for n in np.arange(0,6)]
f_fourier_series, (ax1, ax2, ax3, ax4, ax5, ax6) = plt.subplots(6, sharex=True, sharey=True)
ax1.plot(x , y[0], "-", label="n = 0")
ax1.set_title('Fourier series up to N = 5, a_n = b_n = 1')
ax2.plot(x , y[1], "-", label="n = 1")
ax3.plot(x , y[2], "-", label="n = 2")
ax4.plot(x , y[3], "-", label="n = 3")
ax5.plot(x , y[4], "-", label="n = 4")
ax6.plot(x , y[5], "-", label="n = 5")
plt.xlabel('Time (s)')
plt.ylabel('Amplitude (dB)')
# Fine-tune figure; make subplots close to each other and hide x ticks for
# all but bottom plot.
f_fourier_series.subplots_adjust(hspace=0)
plt.setp([a.get_xticklabels() for a in f_fourier_series.axes[:-1]], visible=False)
```
These are the first 6 terms in a **set of basis functions**, in particular, the **Fourier basis functions**. Each term, for some given $N$, is a basis function. In the limit, as $N \rightarrow \infty$ we can approximate any function with this set of basis functions. And each of the basis functions are **orthogonal** to one another. For intuition, we'll review vector spaces and orthogonal vectors.
Below, we "multiply" one basis function by another to illustrate orthogonality: the integral of the product of any two of the basis functions is 0.
```
t_start = 0; t_stop = 3; fs = 1000
x = np.linspace(t_start, t_stop, fs * (t_stop - t_start))
y = [np.sin(2*np.pi*f*x) + np.cos(2*np.pi*f*x) for f in np.arange(0,6)]
f_ortho, (ax1, ax2, ax3, ax4, ax5, ax6) = plt.subplots(6, sharex=True, sharey=True)
ax1.plot(x , y[1]*y[2], "-", label="n = 0")
ax1.plot((t_start, t_stop), (0, 0), 'r-')
ax1.set_title('Fourier series up to N = 5, a_n = b_n = 1')
ax2.plot(x , y[1]*y[3], "-", label="n = 1")
ax2.plot((t_start, t_stop), (0, 0), 'r-')
ax3.plot(x , y[2]*y[3], "-", label="n = 2")
ax3.plot((t_start, t_stop), (0, 0), 'r-')
ax4.plot(x , y[3]*y[4], "-", label="n = 3")
ax4.plot((t_start, t_stop), (0, 0), 'r-')
ax5.plot(x , y[4]*y[5], "-", label="n = 4")
ax5.plot((t_start, t_stop), (0, 0), 'r-')
ax6.plot(x , y[5]*y[1], "-", label="n = 5")
ax6.plot((t_start, t_stop), (0, 0), 'r-')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude (dB)')
# Fine-tune figure; make subplots close to each other and hide x ticks for
# all but bottom plot.
f_ortho.subplots_adjust(hspace=0)
plt.setp([a.get_xticklabels() for a in f_ortho.axes[:-1]], visible=False)
```
In your homework, you'll explore building up a complex wave as a Fourier series.
| github_jupyter |
## 練習時間
假設我們資料中類別的數量並不均衡,在評估準確率時可能會有所偏頗,試著切分出 y_test 中,0 類別與 1 類別的數量是一樣的 (亦即 y_test 的類別是均衡的)
```
import numpy as np
X = np.arange(1000).reshape(200, 5)
y = np.zeros(200)
y[:40] = 1
y
```
可以看見 y 類別中,有 160 個 類別 0,40 個 類別 1 ,請試著使用 train_test_split 函數,切分出 y_test 中能各有 10 筆類別 0 與 10 筆類別 1 。(HINT: 參考函數中的 test_size,可針對不同類別各自作切分後再合併)
```
def split_test_to_balance(X, y, test_size, random_state=123):
'''
Split data to training set and testing set. (only useful for binary classification.)
If target label is unbalance, the target label of testing set will be balance.
parameter:
test_size: int, number of samples
float, proportion of sample size
'''
np.random.seed(random_state)
unique_y, y_count = np.unique(y.astype(np.int), return_counts=True)
dat = np.hstack((X, y.reshape(-1, 1)))
if type(test_size) is float:
label_size = np.ceil(dat.shape[0] * test_size / len(unique_y)) # the lowest label size
elif type(test_size) is int:
label_size = np.ceil(test_size / len(unique_y))
else:
raise TypeError("'test_size' input type error.")
if label_size <= y_count.min():
dat_index = np.arange(dat.shape[0])
zero_count, one_count = 0, 0
total_count = zero_count + one_count
test_index = list()
while total_count < (label_size * len(unique_y)):
row_num = np.random.choice(dat_index, size=1, replace=False)
if dat[row_num[0], -1] == 0:
if zero_count < label_size:
zero_count += 1
test_index.append(row_num[0])
else:
if one_count < label_size:
one_count += 1
test_index.append(row_num[0])
row_num_ind = np.where(dat_index == row_num) # get `row_num` index number in dat_index
dat_index = np.delete(dat_index, row_num_ind)
total_count = zero_count + one_count
train_ind = np.setdiff1d(np.arange(dat.shape[0]), np.array(test_index))
X_train, X_test, y_train, y_test = X[train_ind, :], X[test_index, :], y[train_ind], y[test_index]
return X_train, X_test, y_train, y_test
else:
raise ValueError('test_size is larger than one of y label size.')
X_train, X_test, y_train, y_test = split_test_to_balance(X, y, test_size=0.3)
print('X_train shape: {}'.format(X_train.shape))
print('X_test shape: {}'.format(X_test.shape))
print('y_train shape: {}'.format(y_train.shape))
print('y_test shape: {}'.format(y_test.shape))
uni_test_y, test_y_count = np.unique(y_test, return_counts=True)
print('y label: {}, y label count: {}'.format(uni_test_y, test_y_count))
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.