
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
_by Max Schröder$^{1,2}$ and Frank Krüger$^1$_
$^1$ Institute of Communications Engineering, University of Rostock, Rostock <br>
$^2$ University Library, University of Rostock, Rostock
**Abstract**:
This Jupyter notebook aims at providing a very simple data analysis example by employing the IMU data inside the `_data` folder. The data in this directory has been converted from the ARFF files of the following publication of IMU data:
Frank Krüger, Albert Hein, Kristina Yordanova and Thomas Kirste<br>
Recognising user actions during cooking task (Cooking task dataset) – IMU Data<br>
Rostock : Universität Rostock , 2017<br>
https://doi.org/10.18453/rosdok_id00000154
## Python Dependencies
First of all, we will import several useful libraries:
```
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
```
While it is very good programming style to re-use existing software libraries instead of programming them by yourself, it is crucial for the portability and reproducibility of your source code that the detailed version of the library is documented and used in order to (re-)run your code.
Otherwise, the result might be different due to e.g. changes to the interface or the implementation of a specific method.
These software libraries are also called requirements.
In Python-programming, two popular systems are used for managing the computing environment, i.e. the installation and maintenance of third party software libraries:
1. pip and
2. (Ana)conda
In this workshop we will consider the pip environment.
In order to easily install software requirement using pip, one has to provide a `requirements.txt` file containing both the name and the version.
As discussed earlier the version is crucial for the reproducibility of the code.
A sample file looks like follows:
**Task 1:** Create a `requirements.txt` file that containes all imported libraries and their corresponding version.
The previous output is already formatted with respect to `requirements.txt` files and, thus, can easily be copied.
Additionally to the `requirements.txt`, this kind of information / code cell can be keept inside the notebook too.
This is for the convenience of other researchers that are able to easily check their installed versions.
## Reading Data
**Task 2:** Write a function `read_data` that takes a file name of a CSV file and reads the corresponding file from a folder called `_data` in order to return a Pandas dataframe.
Lets's actually try our function, by reading the file `_data/raw_1.csv`:
```
raw1 = read_data('raw_1.csv')
```
In order to check the result, we want to display the content of the variable `raw1`:
```
raw1
```
## Plotting Data
During research, we often want to plot several measurements in order to integrate it into an article.
Next, we will make a very basic plot of the Acceleration Sensor of the x-axis:
```
plt.plot(raw1['Sensor_T8_Acceleration_X'])
```
**Task 3:** Write a plot that displays: X-, Y-, and Z-axis in the same plot and make it a little more useful such as adding a title as well as axis-labels.
| github_jupyter |
```
%load_ext autoreload
%autoreload 2
import os
import sys
sys.path.append("../src/")
import matplotsoccer as mps
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt
data = "../data/spadl-v2.hdf"
games = pd.read_hdf(data,key="games")
epl16 = games[(games.competition_id == 8) & (games.season_id == 2016)]
epl16[:5]
def get_actions(games, hdf_url):
actions = []
for game in tqdm(list(games.itertuples())):
a = pd.read_hdf(hdf_url, key="actions/" + str(game.id))
a["left_to_right"] = a["team_id"] == game.home_team_id
actions.append(a)
actions = pd.concat(actions)
#actions = always_ltr(actions)
return actions
def always_ltr(actions):
away_idx = ~actions.left_to_right
actions.loc[away_idx, "start_x"] = 105 - actions[away_idx].start_x.values
actions.loc[away_idx, "start_y"] = 68 - actions[away_idx].start_y.values
actions.loc[away_idx, "end_x"] = 105 - actions[away_idx].end_x.values
actions.loc[away_idx, "end_y"] = 68 - actions[away_idx].end_y.values
return actions
actions = get_actions(epl16,data)
actiontypes = pd.read_hdf(data, key="actiontypes")
actiontypes.columns = ["type_id","type_name"]
actions = actions.merge(actiontypes, on="type_id")
players = pd.read_hdf(data,key="players")
actions = actions.merge(players,left_on="player_id",right_on="id")
teams = pd.read_hdf(data,key="teams")
actions = actions.merge(teams,left_on="team_id",right_on="id")
actions = actions.sort_values(["game_id","period_id","time_seconds","timestamp"])
actions.columns
player_actions = actions[actions.last_name.str.contains("Kompany")].copy()
set(player_actions.soccer_name)
player_actions = always_ltr(player_actions)
x,y = player_actions.start_x, player_actions.start_y
```
# Field
```
f = mps.field()
f = mps.field(color="green",figsize=8)
```
# Heatmap
```
ax = mps.field(show=False)
ax.scatter(x,y,s=2); plt.show()
matrix = mps.count(x,y,n=20,m=20)
hm = mps.heatmap(matrix)
```
# Actions
```
start = 29411
delta = 19
for i in range(1):
phase = actions[start+i*delta:start+delta+i*delta].copy()
phase["team"] = phase.full_name
phase["player"] = phase.soccer_name
phase = phase[["team","player","time_seconds","type_name","result","start_x","start_y","end_x","end_y"]]
# Full field
mps.actions(phase,figsize = 8)
## Zoomed in
mps.actions(phase,color="green",zoom=True,figsize=8)
shot_chart(x,y,kind="kde")
import numpy as np
from scipy.stats import binned_statistic_2d
import matplotlib.pyplot as plt
from matplotlib.patches import Circle, Rectangle, Arc
import seaborn as sns
# from bokeh.plotting import figure, ColumnDataSource
# from bokeh.models import HoverTool
from math import pi
sns.set_style('white')
sns.set_color_codes()
# In meters
PITCH_WIDTH = 68.0
PITCH_LENGTH = 105.0
def draw_pitch(ax=None, color='gray', lw=1, despine=False):
"""Returns an axes with a basketball court drawn onto to it.
This function draws a court based on the x and y-axis values that the NBA
stats API provides for the shot chart data. For example the center of the
hoop is located at the (0,0) coordinate. Twenty-two feet from the left of
the center of the hoop in is represented by the (-220,0) coordinates.
So one foot equals ±10 units on the x and y-axis.
Parameters
----------
ax : Axes, optional
The Axes object to plot the court onto.
color : matplotlib color, optional
The color of the court lines.
lw : float, optional
The linewidth the of the court lines.
Returns
-------
ax : Axes
The Axes object with the court on it.
"""
#Create figure
if ax is None:
ax = plt.gca()
ax.tick_params(labelbottom=False, labelleft=False)
ax.set_xlim(-5, PITCH_LENGTH + 5)
ax.set_ylim(-5, PITCH_WIDTH + 5)
# Create an empty array of strings with the same shape as the meshgrid, and
# populate it with two colors in a checkerboard pattern.
# ylen = int(PITCH_LENGTH/10)
# xlen = int(PITCH_WIDTH/10)
# colortuple = ((86,176,0, 100), (99,201,0, 100))
# colors = np.empty((xlen,ylen,4), dtype=int)
# for y in range(ylen):
# for x in range(xlen):
# colors[x, y] = colortuple[(x + y) % len(colortuple)]
# x0, x1 = ax.get_xlim()
# y0, y1 = ax.get_ylim()
# ax.imshow(colors, extent=[x0, x1, y0, y1], aspect='auto')
# size of the pitch is 120, 80
#Pitch Outline & Centre Line
outerLinesLeftHalf = Rectangle((0, 0), PITCH_LENGTH/2, PITCH_WIDTH, linewidth=lw, color=color, fill=False)
ax.add_patch(outerLinesLeftHalf)
outerLinesRightHalf = Rectangle((PITCH_LENGTH/2, 0), PITCH_LENGTH/2, PITCH_WIDTH, linewidth=lw, color=color, fill=False)
ax.add_patch(outerLinesRightHalf)
#Left Penalty Area
leftPenaltyArea = Rectangle((0, PITCH_WIDTH/2 - 20.16), 16.5, 40.32, linewidth=lw, color=color, fill=False)
ax.add_patch(leftPenaltyArea)
#Right Penalty Area
rightPenaltyArea = Rectangle((PITCH_LENGTH-16.5, PITCH_WIDTH/2 - 20.16), 16.5, 40.32, linewidth=lw, color=color, fill=False)
ax.add_patch(rightPenaltyArea)
#Left 6-yard Box
leftSixYardBox = Rectangle((0, PITCH_WIDTH/2 - 9.16), 5.5, 18.32, linewidth=lw, color=color, fill=False)
ax.add_patch(leftSixYardBox)
#Right 6-yard Box
rightSixYardBox = Rectangle((PITCH_LENGTH-5.5, PITCH_WIDTH/2 - 9.16), 5.5, 18.32, linewidth=lw, color=color, fill=False)
ax.add_patch(rightSixYardBox)
#Left goal
leftGoal = Rectangle((-1, PITCH_WIDTH/2 - 3.66), 2, 7.32, linewidth=lw, color=color, fill=True)
ax.add_patch(leftGoal)
#Right goal
rightGoal = Rectangle((PITCH_LENGTH-1, PITCH_WIDTH/2 - 3.66), 2, 7.32, linewidth=lw, color=color, fill=True)
ax.add_patch(rightGoal)
#Prepare Circles
centreCircle = Circle((PITCH_LENGTH/2, PITCH_WIDTH/2), 8.1, color=color, fill=False)
ax.add_patch(centreCircle)
centreSpot = Circle((PITCH_LENGTH/2, PITCH_WIDTH/2), 0.3, color=color)
ax.add_patch(centreSpot)
leftPenSpot = Circle((11, PITCH_WIDTH/2), 0.1, color=color)
ax.add_patch(leftPenSpot)
rightPenSpot = Circle((PITCH_LENGTH-11, PITCH_WIDTH/2), 0.1, color=color)
ax.add_patch(rightPenSpot)
#Prepare Arcs
# arguments for arc
# x, y coordinate of centerpoint of arc
# width, height as arc might not be circle, but oval
# angle: degree of rotation of the shape, anti-clockwise
# theta1, theta2, start and end location of arc in degree
leftArc = Arc((11,PITCH_WIDTH/2), height=18.3, width=18.3, angle=0, theta1=310, theta2=50, color=color)
ax.add_patch(leftArc)
rightArc = Arc((PITCH_LENGTH-11, PITCH_WIDTH/2), height=18.3, width=18.3, angle=0, theta1=130, theta2=230, color=color)
ax.add_patch(rightArc)
# Set the spines to match the rest of court lines, makes outer_lines
# somewhate unnecessary
for spine in ax.spines:
ax.spines[spine].set_lw(lw)
ax.spines[spine].set_color(color)
if despine:
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["left"].set_visible(False)
return ax
def shot_chart(x, y, kind="scatter", title="", color="b", cmap=None,
xlim=(0,120), ylim=(0,80),
court_color="gray", court_lw=1, outer_lines=False,
flip_court=False, kde_shade=True, gridsize=None, ax=None,
despine=False, **kwargs):
"""
Returns an Axes object with player shots plotted.
Parameters
----------
x, y : strings or vector
The x and y coordinates of the shots taken. They can be passed in as
vectors (such as a pandas Series) or as columns from the pandas
DataFrame passed into ``data``.
data : DataFrame, optional
DataFrame containing shots where ``x`` and ``y`` represent the
shot location coordinates.
kind : { "scatter", "kde", "hex" }, optional
The kind of shot chart to create.
title : str, optional
The title for the plot.
color : matplotlib color, optional
Color used to plot the shots
cmap : matplotlib Colormap object or name, optional
Colormap for the range of data values. If one isn't provided, the
colormap is derived from the valuue passed to ``color``. Used for KDE
and Hexbin plots.
{x, y}lim : two-tuples, optional
The axis limits of the plot.
court_color : matplotlib color, optional
The color of the court lines.
court_lw : float, optional
The linewidth the of the court lines.
outer_lines : boolean, optional
If ``True`` the out of bound lines are drawn in as a matplotlib
Rectangle.
flip_court : boolean, optional
If ``True`` orients the hoop towards the bottom of the plot. Default
is ``False``, which orients the court where the hoop is towards the top
of the plot.
kde_shade : boolean, optional
Default is ``True``, which shades in the KDE contours.
gridsize : int, optional
Number of hexagons in the x-direction. The default is calculated using
the Freedman-Diaconis method.
ax : Axes, optional
The Axes object to plot the court onto.
despine : boolean, optional
If ``True``, removes the spines.
kwargs : key, value pairs
Keyword arguments for matplotlib Collection properties or seaborn plots.
Returns
-------
ax : Axes
The Axes object with the shot chart plotted on it.
"""
if ax is None:
ax = plt.gca()
if cmap is None:
cmap = sns.light_palette(color, as_cmap=True)
if not flip_court:
ax.set_xlim(xlim)
ax.set_ylim(ylim)
else:
ax.set_xlim(xlim[::-1])
ax.set_ylim(ylim[::-1])
ax.tick_params(labelbottom=False, labelleft=False)
ax.set_title(title, fontsize=18)
draw_pitch(ax, color=court_color, lw=court_lw)
if kind == "scatter":
ax.scatter(x, y, c=color, **kwargs)
elif kind == "kde":
sns.kdeplot(x, y, shade=kde_shade, cmap=cmap, ax=ax, **kwargs)
ax.set_xlabel('')
ax.set_ylabel('')
elif kind == "hex":
if gridsize is None:
# Get the number of bins for hexbin using Freedman-Diaconis rule
# This is idea was taken from seaborn, which got the calculation
# from http://stats.stackexchange.com/questions/798/
from seaborn.distributions import _freedman_diaconis_bins
x_bin = _freedman_diaconis_bins(x)
y_bin = _freedman_diaconis_bins(y)
gridsize = int(np.mean([x_bin, y_bin]))
ax.hexbin(x, y, gridsize=gridsize, cmap=cmap, **kwargs)
else:
raise ValueError("kind must be 'scatter', 'kde', or 'hex'.")
# Set the spines to match the rest of court lines, makes outer_lines
# somewhate unnecessary
for spine in ax.spines:
ax.spines[spine].set_lw(court_lw)
ax.spines[spine].set_color(court_color)
if despine:
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["left"].set_visible(False)
return ax
def pass_chart(x, y, kind="scatter", title="", color="b", cmap=None,
xlim=(0,120), ylim=(0,80),
court_color="gray", court_lw=1, outer_lines=False,
flip_court=False, kde_shade=True, gridsize=None, ax=None,
despine=False, **kwargs):
"""
Returns an Axes object with player shots plotted.
Parameters
----------
x, y : strings or vector
The x and y coordinates of the shots taken. They can be passed in as
vectors (such as a pandas Series) or as columns from the pandas
DataFrame passed into ``data``.
data : DataFrame, optional
DataFrame containing shots where ``x`` and ``y`` represent the
shot location coordinates.
kind : { "scatter", "kde", "hex" }, optional
The kind of shot chart to create.
title : str, optional
The title for the plot.
color : matplotlib color, optional
Color used to plot the shots
cmap : matplotlib Colormap object or name, optional
Colormap for the range of data values. If one isn't provided, the
colormap is derived from the valuue passed to ``color``. Used for KDE
and Hexbin plots.
{x, y}lim : two-tuples, optional
The axis limits of the plot.
court_color : matplotlib color, optional
The color of the court lines.
court_lw : float, optional
The linewidth the of the court lines.
outer_lines : boolean, optional
If ``True`` the out of bound lines are drawn in as a matplotlib
Rectangle.
flip_court : boolean, optional
If ``True`` orients the hoop towards the bottom of the plot. Default
is ``False``, which orients the court where the hoop is towards the top
of the plot.
kde_shade : boolean, optional
Default is ``True``, which shades in the KDE contours.
gridsize : int, optional
Number of hexagons in the x-direction. The default is calculated using
the Freedman-Diaconis method.
ax : Axes, optional
The Axes object to plot the court onto.
despine : boolean, optional
If ``True``, removes the spines.
kwargs : key, value pairs
Keyword arguments for matplotlib Collection properties or seaborn plots.
Returns
-------
ax : Axes
The Axes object with the shot chart plotted on it.
"""
if ax is None:
ax = plt.gca()
if cmap is None:
cmap = sns.light_palette(color, as_cmap=True)
if not flip_court:
ax.set_xlim(xlim)
ax.set_ylim(ylim)
else:
ax.set_xlim(xlim[::-1])
ax.set_ylim(ylim[::-1])
ax.tick_params(labelbottom=False, labelleft=False)
ax.set_title(title, fontsize=18)
draw_pitch(ax, color=court_color, lw=court_lw)
if kind == "scatter":
for i in range(len(x)):
ax.plot((x.values[i,0],y.values[i,0]), (x.values[i,1],y.values[i,1]), c=color, **kwargs)
ax.plot(x.values[i, 0], x.values[i, 1],"o", color=color)
elif kind == "kde":
sns.kdeplot(x, y, shade=kde_shade, cmap=cmap, ax=ax, **kwargs)
ax.set_xlabel('')
ax.set_ylabel('')
elif kind == "hex":
if gridsize is None:
# Get the number of bins for hexbin using Freedman-Diaconis rule
# This is idea was taken from seaborn, which got the calculation
# from http://stats.stackexchange.com/questions/798/
from seaborn.distributions import _freedman_diaconis_bins
x_bin = _freedman_diaconis_bins(x)
y_bin = _freedman_diaconis_bins(y)
gridsize = int(np.mean([x_bin, y_bin]))
ax.hexbin(x, y, gridsize=gridsize, cmap=cmap, **kwargs)
else:
raise ValueError("kind must be 'scatter', 'kde', or 'hex'.")
# Set the spines to match the rest of court lines, makes outer_lines
# somewhate unnecessary
for spine in ax.spines:
ax.spines[spine].set_lw(court_lw)
ax.spines[spine].set_color(court_color)
if despine:
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["left"].set_visible(False)
return ax
```
| github_jupyter |
# Exploring Ensemble Methods
In this assignment, we will explore the use of boosting. We will use the pre-implemented gradient boosted trees in GraphLab Create. You will:
* Use SFrames to do some feature engineering.
* Train a boosted ensemble of decision-trees (gradient boosted trees) on the LendingClub dataset.
* Predict whether a loan will default along with prediction probabilities (on a validation set).
* Evaluate the trained model and compare it with a baseline.
* Find the most positive and negative loans using the learned model.
* Explore how the number of trees influences classification performance.
Let's get started!
## Fire up Graphlab Create
```
import graphlab
```
# Load LendingClub dataset
We will be using the [LendingClub](https://www.lendingclub.com/) data. As discussed earlier, the [LendingClub](https://www.lendingclub.com/) is a peer-to-peer leading company that directly connects borrowers and potential lenders/investors.
Just like we did in previous assignments, we will build a classification model to predict whether or not a loan provided by lending club is likely to default.
Let us start by loading the data.
```
loans = graphlab.SFrame('lending-club-data.gl/')
```
Let's quickly explore what the dataset looks like. First, let's print out the column names to see what features we have in this dataset. We have done this in previous assignments, so we won't belabor this here.
```
loans.column_names()
```
## Modifying the target column
The target column (label column) of the dataset that we are interested in is called `bad_loans`. In this column **1** means a risky (bad) loan **0** means a safe loan.
As in past assignments, in order to make this more intuitive and consistent with the lectures, we reassign the target to be:
* **+1** as a safe loan,
* **-1** as a risky (bad) loan.
We put this in a new column called `safe_loans`.
```
loans['safe_loans'] = loans['bad_loans'].apply(lambda x : +1 if x==0 else -1)
loans = loans.remove_column('bad_loans')
```
## Selecting features
In this assignment, we will be using a subset of features (categorical and numeric). The features we will be using are **described in the code comments** below. If you are a finance geek, the [LendingClub](https://www.lendingclub.com/) website has a lot more details about these features.
The features we will be using are described in the code comments below:
```
target = 'safe_loans'
features = ['grade', # grade of the loan (categorical)
'sub_grade_num', # sub-grade of the loan as a number from 0 to 1
'short_emp', # one year or less of employment
'emp_length_num', # number of years of employment
'home_ownership', # home_ownership status: own, mortgage or rent
'dti', # debt to income ratio
'purpose', # the purpose of the loan
'payment_inc_ratio', # ratio of the monthly payment to income
'delinq_2yrs', # number of delinquincies
'delinq_2yrs_zero', # no delinquincies in last 2 years
'inq_last_6mths', # number of creditor inquiries in last 6 months
'last_delinq_none', # has borrower had a delinquincy
'last_major_derog_none', # has borrower had 90 day or worse rating
'open_acc', # number of open credit accounts
'pub_rec', # number of derogatory public records
'pub_rec_zero', # no derogatory public records
'revol_util', # percent of available credit being used
'total_rec_late_fee', # total late fees received to day
'int_rate', # interest rate of the loan
'total_rec_int', # interest received to date
'annual_inc', # annual income of borrower
'funded_amnt', # amount committed to the loan
'funded_amnt_inv', # amount committed by investors for the loan
'installment', # monthly payment owed by the borrower
]
```
## Skipping observations with missing values
Recall from the lectures that one common approach to coping with missing values is to **skip** observations that contain missing values.
We run the following code to do so:
```
loans, loans_with_na = loans[[target] + features].dropna_split()
# Count the number of rows with missing data
num_rows_with_na = loans_with_na.num_rows()
num_rows = loans.num_rows()
print 'Dropping %s observations; keeping %s ' % (num_rows_with_na, num_rows)
```
Fortunately, there are not too many missing values. We are retaining most of the data.
## Make sure the classes are balanced
We saw in an earlier assignment that this dataset is also imbalanced. We will undersample the larger class (safe loans) in order to balance out our dataset. We used `seed=1` to make sure everyone gets the same results.
```
safe_loans_raw = loans[loans[target] == 1]
risky_loans_raw = loans[loans[target] == -1]
# Undersample the safe loans.
percentage = len(risky_loans_raw)/float(len(safe_loans_raw))
safe_loans = safe_loans_raw.sample(percentage, seed = 1)
risky_loans = risky_loans_raw
loans_data = risky_loans.append(safe_loans)
print "Percentage of safe loans :", len(safe_loans) / float(len(loans_data))
print "Percentage of risky loans :", len(risky_loans) / float(len(loans_data))
print "Total number of loans in our new dataset :", len(loans_data)
```
**Checkpoint:** You should now see that the dataset is balanced (approximately 50-50 safe vs risky loans).
**Note:** There are many approaches for dealing with imbalanced data, including some where we modify the learning algorithm. These approaches are beyond the scope of this course, but some of them are reviewed in this [paper](http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=5128907&url=http%3A%2F%2Fieeexplore.ieee.org%2Fiel5%2F69%2F5173046%2F05128907.pdf%3Farnumber%3D5128907 ). For this assignment, we use the simplest possible approach, where we subsample the overly represented class to get a more balanced dataset. In general, and especially when the data is highly imbalanced, we recommend using more advanced methods.
## Split data into training and validation sets
We split the data into training data and validation data. We used `seed=1` to make sure everyone gets the same results. We will use the validation data to help us select model parameters.
```
train_data, validation_data = loans_data.random_split(.8, seed=1)
```
# Gradient boosted tree classifier
Gradient boosted trees are a powerful variant of boosting methods; they have been used to win many [Kaggle](https://www.kaggle.com/) competitions, and have been widely used in industry. We will explore the predictive power of multiple decision trees as opposed to a single decision tree.
**Additional reading:** If you are interested in gradient boosted trees, here is some additional reading material:
* [GraphLab Create user guide](https://dato.com/learn/userguide/supervised-learning/boosted_trees_classifier.html)
* [Advanced material on boosted trees](http://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf)
We will now train models to predict `safe_loans` using the features above. In this section, we will experiment with training an ensemble of 5 trees. To cap the ensemble classifier at 5 trees, we call the function with **max_iterations=5** (recall that each iterations corresponds to adding a tree). We set `validation_set=None` to make sure everyone gets the same results.
```
model_5 = graphlab.boosted_trees_classifier.create(train_data, validation_set=None,
target = target, features = features, max_iterations = 5)
```
# Making predictions
Just like we did in previous sections, let us consider a few positive and negative examples **from the validation set**. We will do the following:
* Predict whether or not a loan is likely to default.
* Predict the probability with which the loan is likely to default.
```
# Select all positive and negative examples.
validation_safe_loans = validation_data[validation_data[target] == 1]
validation_risky_loans = validation_data[validation_data[target] == -1]
# Select 2 examples from the validation set for positive & negative loans
sample_validation_data_risky = validation_risky_loans[0:2]
sample_validation_data_safe = validation_safe_loans[0:2]
# Append the 4 examples into a single dataset
sample_validation_data = sample_validation_data_safe.append(sample_validation_data_risky)
sample_validation_data
```
### Predicting on sample validation data
For each row in the **sample_validation_data**, write code to make **model_5** predict whether or not the loan is classified as a **safe loan**.
**Hint:** Use the `predict` method in `model_5` for this.
```
predictions = model_5.predict(sample_validation_data)
#len(sample_validation_data[sample_validation_data["safe_loans"] != predictions])
count = 0
for i in xrange(len(sample_validation_data)):
if sample_validation_data["safe_loans"][i] != predictions[i]:
count = count + 1
print 1 - (count/float(len(predictions)))
```
**Quiz question:** What percentage of the predictions on `sample_validation_data` did `model_5` get correct?
### Prediction probabilities
For each row in the **sample_validation_data**, what is the probability (according **model_5**) of a loan being classified as **safe**?
**Hint:** Set `output_type='probability'` to make **probability** predictions using `model_5` on `sample_validation_data`:
```
model_5.predict(sample_validation_data, output_type='probability')
```
**Quiz Question:** According to **model_5**, which loan is the least likely to be a safe loan?
**Checkpoint:** Can you verify that for all the predictions with `probability >= 0.5`, the model predicted the label **+1**?
## Evaluating the model on the validation data
Recall that the accuracy is defined as follows:
$$
\mbox{accuracy} = \frac{\mbox{# correctly classified examples}}{\mbox{# total examples}}
$$
Evaluate the accuracy of the **model_5** on the **validation_data**.
**Hint**: Use the `.evaluate()` method in the model.
```
model_5.evaluate(validation_data)
```
Calculate the number of **false positives** made by the model.
```
predictions = model_5.predict(validation_data)
fp = 0
for i in xrange(len(validation_data)):
if validation_data["safe_loans"][i] != predictions[i]:
if predictions[i] == 1 and validation_data["safe_loans"][i] == -1:
fp = fp + 1
print fp
```
**Quiz question**: What is the number of **false positives** on the **validation_data**?
Calculate the number of **false negatives** made by the model.
```
fn = 0
for i in xrange(len(validation_data)):
if validation_data["safe_loans"][i] != predictions[i]:
if predictions[i] == -1 and validation_data["safe_loans"][i] == 1:
fn = fn + 1
print fn
```
## Comparison with decision trees
In the earlier assignment, we saw that the prediction accuracy of the decision trees was around **0.64** (rounded). In this assignment, we saw that **model_5** has an accuracy of **0.67** (rounded).
Here, we quantify the benefit of the extra 3% increase in accuracy of **model_5** in comparison with a single decision tree from the original decision tree assignment.
As we explored in the earlier assignment, we calculated the cost of the mistakes made by the model. We again consider the same costs as follows:
* **False negatives**: Assume a cost of \$10,000 per false negative.
* **False positives**: Assume a cost of \$20,000 per false positive.
Assume that the number of false positives and false negatives for the learned decision tree was
* **False negatives**: 1936
* **False positives**: 1503
Using the costs defined above and the number of false positives and false negatives for the decision tree, we can calculate the total cost of the mistakes made by the decision tree model as follows:
```
cost = $10,000 * 1936 + $20,000 * 1503 = $49,420,000
```
The total cost of the mistakes of the model is $49.42M. That is a **lot of money**!.
**Quiz Question**: Using the same costs of the false positives and false negatives, what is the cost of the mistakes made by the boosted tree model (**model_5**) as evaluated on the **validation_set**?
```
1618 * 20000 + 1463 * 10000
```
**Reminder**: Compare the cost of the mistakes made by the boosted trees model with the decision tree model. The extra 3% improvement in prediction accuracy can translate to several million dollars! And, it was so easy to get by simply boosting our decision trees.
## Most positive & negative loans.
In this section, we will find the loans that are most likely to be predicted **safe**. We can do this in a few steps:
* **Step 1**: Use the **model_5** (the model with 5 trees) and make **probability predictions** for all the loans in the **validation_data**.
* **Step 2**: Similar to what we did in the very first assignment, add the probability predictions as a column called **predictions** into the validation_data.
* **Step 3**: Sort the data (in descreasing order) by the probability predictions.
Start here with **Step 1** & **Step 2**. Make predictions using **model_5** for examples in the **validation_data**. Use `output_type = probability`.
```
probs = model_5.predict(validation_data, output_type='probability')
validation_data["predictions"] = probs
```
**Checkpoint:** For each row, the probabilities should be a number in the range **[0, 1]**. We have provided a simple check here to make sure your answers are correct.
```
print "Your loans : %s\n" % validation_data['predictions'].head(4)
print "Expected answer : %s" % [0.4492515948736132, 0.6119100103640573,
0.3835981314851436, 0.3693306705994325]
```
Now, we are ready to go to **Step 3**. You can now use the `prediction` column to sort the loans in **validation_data** (in descending order) by prediction probability. Find the top 5 loans with the highest probability of being predicted as a **safe loan**.
```
validation_data.sort("predictions", ascending=False).head(5)
```
** Quiz question**: What grades are the top 5 loans?
Let us repeat this excercise to find the top 5 loans (in the **validation_data**) with the **lowest probability** of being predicted as a **safe loan**:
```
validation_data.sort("predictions", ascending=True).head(5)
```
**Checkpoint:** You should expect to see 5 loans with the grade ['**D**', '**C**', '**C**', '**C**', '**B**'].
## Effect of adding more trees
In this assignment, we will train 5 different ensemble classifiers in the form of gradient boosted trees. We will train models with 10, 50, 100, 200, and 500 trees. We use the **max_iterations** parameter in the boosted tree module.
Let's get sarted with a model with **max_iterations = 10**:
```
model_10 = graphlab.boosted_trees_classifier.create(train_data, validation_set=None,
target = target, features = features, max_iterations = 10, verbose=False)
```
Now, train 4 models with **max_iterations** to be:
* `max_iterations = 50`,
* `max_iterations = 100`
* `max_iterations = 200`
* `max_iterations = 500`.
Let us call these models **model_50**, **model_100**, **model_200**, and **model_500**. You can pass in `verbose=False` in order to suppress the printed output.
**Warning:** This could take a couple of minutes to run.
```
model_50 = graphlab.boosted_trees_classifier.create(train_data, validation_set=None,
target = target, features = features, max_iterations = 50, verbose=False)
model_100 = graphlab.boosted_trees_classifier.create(train_data, validation_set=None,
target = target, features = features, max_iterations = 100, verbose=False)
model_200 = graphlab.boosted_trees_classifier.create(train_data, validation_set=None,
target = target, features = features, max_iterations = 200, verbose=False)
model_500 = graphlab.boosted_trees_classifier.create(train_data, validation_set=None,
target = target, features = features, max_iterations = 500, verbose=False)
```
## Compare accuracy on entire validation set
Now we will compare the predicitve accuracy of our models on the validation set. Evaluate the **accuracy** of the 10, 50, 100, 200, and 500 tree models on the **validation_data**. Use the `.evaluate` method.
```
print model_10.evaluate(validation_data)['accuracy']
print model_50.evaluate(validation_data)['accuracy']
print model_100.evaluate(validation_data)['accuracy']
print model_200.evaluate(validation_data)['accuracy']
print model_500.evaluate(validation_data)['accuracy']
```
**Quiz Question:** Which model has the **best** accuracy on the **validation_data**?
**Quiz Question:** Is it always true that the model with the most trees will perform best on test data?
## Plot the training and validation error vs. number of trees
Recall from the lecture that the classification error is defined as
$$
\mbox{classification error} = 1 - \mbox{accuracy}
$$
In this section, we will plot the **training and validation errors versus the number of trees** to get a sense of how these models are performing. We will compare the 10, 50, 100, 200, and 500 tree models. You will need [matplotlib](http://matplotlib.org/downloads.html) in order to visualize the plots.
First, make sure this block of code runs on your computer.
```
import matplotlib.pyplot as plt
%matplotlib inline
def make_figure(dim, title, xlabel, ylabel, legend):
plt.rcParams['figure.figsize'] = dim
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
if legend is not None:
plt.legend(loc=legend, prop={'size':15})
plt.rcParams.update({'font.size': 16})
plt.tight_layout()
```
In order to plot the classification errors (on the **train_data** and **validation_data**) versus the number of trees, we will need lists of these accuracies, which we get by applying the method `.evaluate`.
**Steps to follow:**
* **Step 1:** Calculate the classification error for model on the training data (**train_data**).
* **Step 2:** Store the training errors into a list (called `training_errors`) that looks like this:
```
[train_err_10, train_err_50, ..., train_err_500]
```
* **Step 3:** Calculate the classification error of each model on the validation data (**validation_data**).
* **Step 4:** Store the validation classification error into a list (called `validation_errors`) that looks like this:
```
[validation_err_10, validation_err_50, ..., validation_err_500]
```
Once that has been completed, the rest of the code should be able to evaluate correctly and generate the plot.
Let us start with **Step 1**. Write code to compute the classification error on the **train_data** for models **model_10**, **model_50**, **model_100**, **model_200**, and **model_500**.
```
train_err_10 = 1 - model_10.evaluate(train_data)['accuracy']
train_err_50 = 1 - model_50.evaluate(train_data)['accuracy']
train_err_100 = 1 - model_100.evaluate(train_data)['accuracy']
train_err_200 = 1 - model_200.evaluate(train_data)['accuracy']
train_err_500 = 1 - model_500.evaluate(train_data)['accuracy']
```
Now, let us run **Step 2**. Save the training errors into a list called **training_errors**
```
training_errors = [train_err_10, train_err_50, train_err_100,
train_err_200, train_err_500]
```
Now, onto **Step 3**. Write code to compute the classification error on the **validation_data** for models **model_10**, **model_50**, **model_100**, **model_200**, and **model_500**.
```
validation_err_10 = 1 - model_10.evaluate(validation_data)['accuracy']
validation_err_50 = 1 - model_50.evaluate(validation_data)['accuracy']
validation_err_100 = 1 - model_100.evaluate(validation_data)['accuracy']
validation_err_200 = 1 - model_200.evaluate(validation_data)['accuracy']
validation_err_500 = 1 - model_500.evaluate(validation_data)['accuracy']
```
Now, let us run **Step 4**. Save the training errors into a list called **validation_errors**
```
validation_errors = [validation_err_10, validation_err_50, validation_err_100,
validation_err_200, validation_err_500]
```
Now, we will plot the **training_errors** and **validation_errors** versus the number of trees. We will compare the 10, 50, 100, 200, and 500 tree models. We provide some plotting code to visualize the plots within this notebook.
Run the following code to visualize the plots.
```
plt.plot([10, 50, 100, 200, 500], training_errors, linewidth=4.0, label='Training error')
plt.plot([10, 50, 100, 200, 500], validation_errors, linewidth=4.0, label='Validation error')
make_figure(dim=(10,5), title='Error vs number of trees',
xlabel='Number of trees',
ylabel='Classification error',
legend='best')
```
**Quiz question**: Does the training error reduce as the number of trees increases?
**Quiz question**: Is it always true that the validation error will reduce as the number of trees increases?
| github_jupyter |
# Power electricity power consumption prediction model
Let's first start by importing the needed libraries
```
from pyspark.sql import SparkSession
```
And create a local parallel spark session
```
spark = SparkSession.builder \
.master("local[*]") \
.appName("Power electricity prediction") \
.getOrCreate()
```
The we read the dataframe we need to apply the prediction on
```
train = spark.read.csv('../data/engineered/powerelectricity_train.csv', header=True, inferSchema=True)
test = spark.read.csv('../data/engineered/powerelectricity_test.csv', header=True, inferSchema=True)
```
Now we will test some regression models and evaluate them using rmse
```
from pyspark.ml import Pipeline
from pyspark.ml.regression import RandomForestRegressor, GBTRegressor, LinearRegression
from pyspark.ml.feature import VectorIndexer
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.feature import VectorAssembler
train_ep = train.drop('rms_current')
train_ep = train_ep.drop('electric_power')
train_ep = train_ep.drop('srtDate')
test_ep = test.drop('rms_current')
test_ep = test_ep.drop('electric_power')
test_ep = test_ep.drop('srtDate')
features_ep = train_ep.columns.copy()
features_ep.remove('delta_y')
assembler_pe_train = VectorAssembler(inputCols=features_ep,outputCol="features")
train_ep = assembler_pe_train.transform(train_ep)
assembler_pe_test = VectorAssembler(inputCols=features_ep,outputCol="features")
test_ep = assembler_pe_test.transform(test_ep)
```
Let's start by predicting electric_power
```
rf_pe = GBTRegressor(featuresCol="features",labelCol='delta_y',maxIter=50,seed=12345)
%%time
model_pe = rf_pe.fit(train_ep)
predictions = model_pe.transform(train_ep)
print('################################ TRAIN ################################')
evaluator_rmse = RegressionEvaluator(
labelCol="delta_y", predictionCol="prediction", metricName="rmse")
rmse = evaluator_rmse.evaluate(predictions)
print("Root Mean Squared Error (RMSE) on train data = %g" % rmse)
evaluator_r2 = RegressionEvaluator(
labelCol="delta_y", predictionCol="prediction", metricName="r2")
r2 = evaluator_r2.evaluate(predictions)
print("R squared (r2) on train data = %g" % r2)
evaluator_mae = RegressionEvaluator(
labelCol="delta_y", predictionCol="prediction", metricName="mae")
mae = evaluator_mae.evaluate(predictions)
print("Mean Average Error (RMSE) on train data = %g" % mae)
predictions = model_pe.transform(test_ep)
print('################################ TEST ################################')
evaluator_rmse = RegressionEvaluator(
labelCol="delta_y", predictionCol="prediction", metricName="rmse")
rmse = evaluator_rmse.evaluate(predictions)
print("Root Mean Squared Error (RMSE) on test data = %g" % rmse)
evaluator_r2 = RegressionEvaluator(
labelCol="delta_y", predictionCol="prediction", metricName="r2")
r2 = evaluator_r2.evaluate(predictions)
print("R squared (r2) on test data = %g" % r2)
evaluator_mae = RegressionEvaluator(
labelCol="delta_y", predictionCol="prediction", metricName="mae")
mae = evaluator_mae.evaluate(predictions)
print("Mean Average Error (RMSE) on test data = %g" % mae)
```
And finally save to a file the predictions
```
import os
try:
os.mkdir('../predictions/')
except:
pass
preds = predictions.select(["prediction"])
preds.toPandas().to_csv('../predictions/preds.csv')
```
Let's take a look at the result by converting back the values to electric power
```
from sklearn.metrics import r2_score, explained_variance_score, mean_squared_error
import pandas as pd
import numpy as np
test_data = pd.read_csv('../data/engineered/powerelectricity_test.csv')
preds = pd.read_csv('../predictions/preds.csv')
test_data['pred_y'] = preds['prediction']
test_data['pred_y'] = test_data['pred_y'] + test_data['electric_power_t-X']
test_data['electric_power'] = np.exp(test_data['electric_power'])
test_data['pred_y'] = np.exp(test_data['pred_y'])
r2 = r2_score(test_data['electric_power'], test_data['pred_y'])
rmse = np.sqrt(mean_squared_error(test_data['electric_power'], test_data['pred_y']))
evs = explained_variance_score(test_data['electric_power'], test_data['pred_y'])
print(f'############## SCALED BACK #############\nr2:\t {r2}\nrmse:\t {rmse}\nevs:\t {evs}')
```
Let's save the result for visualization
```
test_data[['srtDate', 'electric_power', 'pred_y']].to_csv('../predictions/pred_reverted.csv', index=False)
```
| github_jupyter |
# Time series forecasting with ARIMA
In this notebook, we demonstrate how to:
- prepare time series data for training an ARIMA times series forecasting model
- implement a simple ARIMA model to forecast the next HORIZON steps ahead (time *t+1* through *t+HORIZON*) in the time series
- evaluate the model
The data in this example is taken from the GEFCom2014 forecasting competition<sup>1</sup>. It consists of 3 years of hourly electricity load and temperature values between 2012 and 2014. The task is to forecast future values of electricity load. In this example, we show how to forecast one time step ahead, using historical load data only.
<sup>1</sup>Tao Hong, Pierre Pinson, Shu Fan, Hamidreza Zareipour, Alberto Troccoli and Rob J. Hyndman, "Probabilistic energy forecasting: Global Energy Forecasting Competition 2014 and beyond", International Journal of Forecasting, vol.32, no.3, pp 896-913, July-September, 2016.
```
import os
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import datetime as dt
import math
from pandas.tools.plotting import autocorrelation_plot
# from pyramid.arima import auto_arima
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.preprocessing import MinMaxScaler
from common.utils import load_data, mape
from IPython.display import Image
%matplotlib inline
pd.options.display.float_format = '{:,.2f}'.format
np.set_printoptions(precision=2)
warnings.filterwarnings("ignore") # specify to ignore warning messages
```
Load the data from csv into a Pandas dataframe
```
energy = load_data('./data')[['load']]
energy.head(10)
```
Plot all available load data (January 2012 to Dec 2014)
```
energy.plot(y='load', subplots=True, figsize=(15, 8), fontsize=12)
plt.xlabel('timestamp', fontsize=12)
plt.ylabel('load', fontsize=12)
plt.show()
```
## Create training and testing data sets
We separate our dataset into train and test sets. We train the model on the train set. After the model has finished training, we evaluate the model on the test set. We must ensure that the test set cover a later period in time from the training set, to ensure that the model does not gain from information from future time periods.
We will allocate the period 1st September 2014 to 31st October to training set (2 months) and the period 1st November 2014 to 31st December 2014 to the test set (2 months). Since this is daily consumption of energy, there is a strong seasonal pattern, but the consumption is most similar to the consumption in the recent days. Therefore, using a relatively small window of time for training the data should be sufficient.
> NOTE: Since function we use to fit ARIMA model uses in-sample validation during feeting, we will omit the validation data from this notebook.
```
train_start_dt = '2014-11-01 00:00:00'
test_start_dt = '2014-12-30 00:00:00'
energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)][['load']].rename(columns={'load':'train'}) \
.join(energy[test_start_dt:][['load']].rename(columns={'load':'test'}), how='outer') \
.plot(y=['train', 'test'], figsize=(15, 8), fontsize=12)
plt.xlabel('timestamp', fontsize=12)
plt.ylabel('load', fontsize=12)
plt.show()
```
## Data preparation
Our data preparation for the training set will involve the following steps:
1. Filter the original dataset to include only that time period reserved for the training set
2. Scale the time series such that the values fall within the interval (0, 1)
Create training set containing only the model features
```
train = energy.copy()[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']]
test = energy.copy()[energy.index >= test_start_dt][['load']]
print('Training data shape: ', train.shape)
print('Test data shape: ', test.shape)
```
Scale data to be in range (0, 1). This transformation should be calibrated on the training set only. This is to prevent information from the validation or test sets leaking into the training data.
```
scaler = MinMaxScaler()
train['load'] = scaler.fit_transform(train)
train.head(10)
```
Original vs scaled data:
```
energy[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']].rename(columns={'load':'original load'}).plot.hist(bins=100, fontsize=12)
train.rename(columns={'load':'scaled load'}).plot.hist(bins=100, fontsize=12)
plt.show()
```
Let's also scale the test data
```
test['load'] = scaler.transform(test)
test.head()
```
## Implement ARIMA method
An ARIMA, which stands for **A**uto**R**egressive **I**ntegrated **M**oving **A**verage, model can be created using the statsmodels library. In the next section, we perform the following steps:
1. Define the model by calling SARIMAX() and passing in the model parameters: p, d, and q parameters, and P, D, and Q parameters.
2. The model is prepared on the training data by calling the fit() function.
3. Predictions can be made by calling the forecast() function and specifying the number of steps (horizon) which to forecast
In an ARIMA model there are 3 parameters that are used to help model the major aspects of a times series: seasonality, trend, and noise. These parameters are:
- **p** is the parameter associated with the auto-regressive aspect of the model, which incorporates past values.
- **d** is the parameter associated with the integrated part of the model, which effects the amount of differencing to apply to a time series.
- **q** is the parameter associated with the moving average part of the model.
If our model has a seasonal component, we use a seasonal ARIMA model (SARIMA). In that case we have another set of parameters: P, D, and Q which describe the same associations as p,d, and q, but correspond with the seasonal components of the model.
```
# Specify the number of steps to forecast ahead
HORIZON = 3
print('Forecasting horizon:', HORIZON, 'hours')
```
Selecting the best parameters for an Arima model can be challenging - somewhat subjective and time intesive, so we'll leave it as an exercise to the user. We used an **auto_arima()** function and some additional manual selection to find a decent model.
>NOTE: For more info on selecting an Arima model, please refer to the an arima notebook in /ReferenceNotebook directory.
```
order = (4, 1, 0)
seasonal_order = (1, 1, 0, 24)
model = SARIMAX(endog=train, order=order, seasonal_order=seasonal_order)
results = model.fit()
print(results.summary())
```
Next we display the distribution of residuals. A zero mean in the residuals may indicate that there is no bias in the prediction.
## Evaluate the model
We will perform the so-called **walk forward validation**. In practice, time series models are re-trained each time a new data becomes available. This allows the model to make the best forecast at each time step.
Starting at the beginning of the time series, we train the model on the train data set. Then we make a prediction on the next time step. The prediction is then evaluated against the known value. The training set is then expanded to include the known value and the process is repeated. (Note that we keep the training set window fixed, for more efficient training, so every time we add a new observation to the training set, we remove the observation from the beginning of the set.)
This process provides a more robust estimation of how the model will perform in practice. However, it comes at the computation cost of creating so many models. This is acceptable if the data is small or if the model is simple, but could be an issue at scale.
Walk-forward validation is the gold standard of time series model evaluation and is recommended for your own projects.
```
Image('./images/ts_cross_validation.png')
```
Create a test data point for each HORIZON step.
```
test_shifted = test.copy()
for t in range(1, HORIZON):
test_shifted['load+'+str(t)] = test_shifted['load'].shift(-t, freq='H')
test_shifted = test_shifted.dropna(how='any')
test_shifted.head(5)
```
Make predictions on the test data
```
%%time
training_window = 720 # dedicate 30 days (720 hours) for training
train_ts = train['load']
test_ts = test_shifted
history = [x for x in train_ts]
history = history[(-training_window):]
predictions = list()
# let's user simpler model for demonstration
order = (2, 1, 0)
seasonal_order = (1, 1, 0, 24)
for t in range(test_ts.shape[0]):
model = SARIMAX(endog=history, order=order, seasonal_order=seasonal_order)
model_fit = model.fit()
yhat = model_fit.forecast(steps = HORIZON)
predictions.append(yhat)
obs = list(test_ts.iloc[t])
# move the training window
history.append(obs[0])
history.pop(0)
print(test_ts.index[t])
print(t+1, ': predicted =', yhat, 'expected =', obs)
```
Compare predictions to actual load
```
eval_df = pd.DataFrame(predictions, columns=['t+'+str(t) for t in range(1, HORIZON+1)])
eval_df['timestamp'] = test.index[0:len(test.index)-HORIZON+1]
eval_df = pd.melt(eval_df, id_vars='timestamp', value_name='prediction', var_name='h')
eval_df['actual'] = np.array(np.transpose(test_ts)).ravel()
eval_df[['prediction', 'actual']] = scaler.inverse_transform(eval_df[['prediction', 'actual']])
eval_df.head()
```
Compute the **mean absolute percentage error (MAPE)** over all predictions
$$MAPE = \frac{1}{n} \sum_{t=1}^{n}|\frac{actual_t - predicted_t}{actual_t}|$$
```
if(HORIZON > 1):
eval_df['APE'] = (eval_df['prediction'] - eval_df['actual']).abs() / eval_df['actual']
print(eval_df.groupby('h')['APE'].mean())
print('One step forecast MAPE: ', (mape(eval_df[eval_df['h'] == 't+1']['prediction'], eval_df[eval_df['h'] == 't+1']['actual']))*100, '%')
print('Multi-step forecast MAPE: ', mape(eval_df['prediction'], eval_df['actual'])*100, '%')
```
Plot the predictions vs the actuals for the first week of the test set
```
if(HORIZON == 1):
## Plotting single step forecast
eval_df.plot(x='timestamp', y=['actual', 'prediction'], style=['r', 'b'], figsize=(15, 8))
else:
## Plotting multi step forecast
plot_df = eval_df[(eval_df.h=='t+1')][['timestamp', 'actual']]
for t in range(1, HORIZON+1):
plot_df['t+'+str(t)] = eval_df[(eval_df.h=='t+'+str(t))]['prediction'].values
fig = plt.figure(figsize=(15, 8))
ax = plt.plot(plot_df['timestamp'], plot_df['actual'], color='red', linewidth=4.0)
ax = fig.add_subplot(111)
for t in range(1, HORIZON+1):
x = plot_df['timestamp'][(t-1):]
y = plot_df['t+'+str(t)][0:len(x)]
ax.plot(x, y, color='blue', linewidth=4*math.pow(.9,t), alpha=math.pow(0.8,t))
ax.legend(loc='best')
plt.xlabel('timestamp', fontsize=12)
plt.ylabel('load', fontsize=12)
plt.show()
```
| github_jupyter |
# CS229: Problem Set 2
## Problem 1: Logistic Regression - Training Stability
**C. Combier**
This iPython Notebook provides solutions to Stanford's CS229 (Machine Learning, Fall 2017) graduate course problem set 2, taught by Andrew Ng.
The problem set can be found here: [./ps2.pdf](ps2.pdf)
I chose to write the solutions to the coding questions in Python, whereas the Stanford class is taught with Matlab/Octave.
## Notation
- $x^i$ is the $i^{th}$ feature vector
- $y^i$ is the expected outcome for the $i^{th}$ training example
- $m$ is the number of training examples
- $n$ is the number of features
Let's load the libraries:
```
%matplotlib inline
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set_context('notebook')
plt.rcParams['figure.figsize']=(20,20)
```
I've imported the functions from `lr_debug.py` directly into the notebook:
```
try:
xrange
except NameError:
xrange = range
def add_intercept(X_):
m, n = X_.shape
X = np.zeros((m, n + 1))
X[:, 0] = 1
X[:, 1:] = X_
return X
def load_data(filename):
D = np.loadtxt(filename)
Y = D[:, 0]
X = D[:, 1:]
return add_intercept(X), Y
def calc_grad(X, Y, theta):
m, n = X.shape
grad = np.zeros(theta.shape)
margins = Y * X.dot(theta)
probs = 1. / (1 + np.exp(margins))
grad = -(1./m) * (X.T.dot(probs * Y))
return grad
def logistic_regression(X, Y):
m, n = X.shape
theta = np.zeros(n)
learning_rate = 10
i = 0
while True:
i += 1
prev_theta = theta
grad = calc_grad(X, Y, theta)
theta = theta - learning_rate * (grad)
if i % 10000 == 0:
print('Finished %d iterations' % i)
print("DeltaT = {0}".format(prev_theta - theta))
if np.linalg.norm(prev_theta - theta) < 1e-15:
print('Converged in %d iterations' % i)
break
return
def main():
print('==== Training model on data set A ====')
Xa, Ya = load_data('./data/data_a.txt')
logistic_regression(Xa, Ya)
print('\n==== Training model on data set B ====')
Xb, Yb = load_data('./data/data_b.txt')
logistic_regression(Xb, Yb)
return
```
### Question 1.a)
Now we can run the `main()` function from `lr_debug.py`:
```
main()
```
Here's the trace of this execution:
```
==== Training model on data set A ====
Finished 10000 iterations
DeltaT = [ 4.15154545e-07 -4.27822247e-07 -4.08456454e-07]
Finished 20000 iterations
DeltaT = [ 3.06350501e-11 -3.15729665e-11 -3.01447756e-11]
Finished 30000 iterations
DeltaT = [ 3.55271368e-15 -3.55271368e-15 -3.55271368e-15]
Converged in 30372 iterations
==== Training model on data set B ====
Finished 10000 iterations
DeltaT = [ 0.00193989 -0.00193552 -0.00194607]
Finished 20000 iterations
DeltaT = [ 0.00125412 -0.00125294 -0.00125704]
Finished 30000 iterations
DeltaT = [ 0.00096045 -0.00096055 -0.00096198]
Finished 40000 iterations
DeltaT = [ 0.00079065 -0.00079152 -0.00079144]
Finished 50000 iterations
DeltaT = [ 0.00067833 -0.0006797 -0.00067868]
Finished 60000 iterations
DeltaT = [ 0.00059791 -0.00059962 -0.00059798]
Finished 70000 iterations
DeltaT = [ 0.00053719 -0.00053915 -0.00053709]
Finished 80000 iterations
DeltaT = [ 0.00048957 -0.00049171 -0.00048935]
Finished 90000 iterations
DeltaT = [ 0.00045112 -0.00045338 -0.00045082]
Finished 100000 iterations
DeltaT = [ 0.00041935 -0.0004217 -0.00041899]
...
```
- When training on dataset A, gradient descent converges in 30372 iterations
- When training on dataset B, gradient descent fails to converge
Let's take a look at the data:
```
columns = ['y','x1','x2']
dfA = pd.read_csv('./data/data_a.txt', sep="\s+", header=None)
dfA.columns = columns
dfA.y.astype('category')
dfA.head()
dfB = pd.read_csv('./data/data_b.txt', sep="\s+", header=None)
dfB.columns = columns
dfB.y.astype('category')
dfB.head()
dfA.describe()
dfB.describe()
sns.lmplot(x="x1", y="x2", hue="y", data=dfA, fit_reg=False);
sns.pairplot(dfA,vars=["x1", "x2"], hue="y", size=4, aspect=1.5, diag_kind="kde");
sns.lmplot(x="x1", y="x2", hue="y", data=dfB, fit_reg=False);
sns.pairplot(dfB,vars=["x1", "x2"], hue="y", size=4, aspect=1.5, diag_kind="kde");
```
### Question 1.b)
Let's rotate the datapoints by 45° and show a scatterplot, so we can see the boundaries more clearly:
```
dfC = dfB.copy()
dfC['x12'] = dfC['x1']+dfC['x2']
dfC['x21'] = -dfC['x1']+dfC['x2']
sns.lmplot(x="x21", y="x12", hue="y", data=dfC, fit_reg=False);
```
It seems that the data is perfectly linearly separable in the case of dataset B, however this is not the case for dataset A.
Logistic regression attempts to maximize the log-likelihood:
$$
\ell (\theta) = \sum_{i=1}^m y^i h_{\theta}(x^i)+(1-y^i) (1-h_{\theta}(x^i))
$$
Where $h_{\theta}(x) = \frac{1}{1+\exp(-\theta^T x)}$ is the sigmoid function.
The problem is a scaling issue: Since the data is linearly separable, $||\theta||$ can be made arbitrarily large and this will increase the log-likelihood indefinitely, as $\forall i, h_{\theta} (x^i) \to 1 $ when $||\theta|| \to \infty$. This happens so long as $\theta$ describes a hyperplane that separates the data perfectly.
Another way of saying this is that $\nabla_{\theta} = X^T (Y-h_{\theta} (X))$ can be made arbitrarily close to $0$ by increasing $\theta$, so long as $\theta$ describes a hyperplane that separates the data perfectly.
This does not happen when the data is not linearly separable: in this case, the log-likelihood would start decreasing due to the misclassified data points, i.e. $\exists! \theta$ such that $X^T (Y-h_{\theta} (X)) = 0$
### Question 1.c)
- **Using a different constant learning rate**
This is a scaling issue, changing the learning rate would not solve the problem
- **Decreasing the learning rate over time**
Same as above: This is a scaling issue, changing the learning rate would not solve the problem
- **Adding a regularization term $||\theta||^2$ to the loss function**
This would solve the problem, as we would be actively penalizing large values of $\theta$ by including a term proportional to $||\theta||^2$ in the objective function.
- **Linear scaling of the input features**
This would not solve the problem, as any linear transformation would still keep the data linearly separable
- **Adding zero-mean Gaussian noise to the training data or labels**
This could work, as the data could be made to be linearly inseparable with the addition of noise. However, this is not a very robust solution as convergence of the algorithm depends on the set of noise samples: there is no guarantee the algorithm would converge *in general* for all possible sets of noise samples.
### Question 1.d)
Support Vector Machines maximize the geometric margin. In the case of a linearly separable dataset, an SVM would maximize the distance between the separator and the closest data point, such that all data points are correctly classified. An SVM would therefore be immune to datasets such as B, as geometric margin is independant of $||\theta||$.
| github_jupyter |
This notebook is an optional tutorial (contains no graded exercises) with a short guide on the text-based interface to the computer known as the "command line" which many programmers use almost exclusively when coding.
## Using Data Science JupyterHub
The default environment for the course will be a web-based environment (Jupyter) hosted by the Data Science Initiative (datahub.berkeley.edu). Log in with your @berkeley credentials, or contact the instructors to create an account.
## The Terminal / Command Line / Shell
You will find it useful to know some basics about the command line (aka terminal or shell) on your computer. The command line lets you navigate around your computer and perform tasks without any graphical user interface---just text. You don't need a mouse to use the command line, just your keyboard. With experience, some people find it faster to use command line tools than graphical tools to do certain things on their computer.
So let's dive in! If you're on a Mac or Linux, find and open the Terminal. If you're on Windows, go to your start menu and type "cmd" (no quotes), then run it.
You'll be faced with a prompt where you can type things in. Press `Enter` to execute whatever you've typed. Try typing these commands (in this order if you'd like!) to get a feel for your terminal. Type `ls` or `dir` occasionally as you change things to see how the contents of your folder have changed.
See where you are
- On Mac/Linux: pwd
- On Windows: cd
See what's in the current directory
- On Mac/Linux: ls
- On Windows: dir
Change directories (into the `Documents` directory, for instance)
- On Mac/Linux: cd Documents
- On Windows: cd Documents
Go back to the "parent directory"
- On Mac/Linux: cd ..
- On Windows: cd ..
Make a directory (the directory `fooDirectory`, for instance)
- On Mac/Linux: mkdir fooDirectory
- On Windows: mkdir fooDirectory
Make another directory!
- mkdir barDirectory
Move something (move `barDirectory` into `fooDirectory` directory, for instance)
- On Mac/Linux: mv barDirectory fooDirectory
- On Windows: move barDirectory fooDirectory
Check the contents of a different directory
- On Mac/Linux: ls fooDirectory
- On Windows: dir fooDirectory
Change through multiple directories at once
- On Mac/Linux: cd fooDirectory/barDirectory
- On Windows: cd fooDirectory\barDirectory
(notice different slash directions!)
Go back to your "home" directory
- On Mac/Linux: cd
or: cd ~
- On Windows: cd %userprofile%
Rename something (rename `fooDirectory` into `RenamedDir`, for instance)
- On Mac/Linux: mv fooDirectory RenamedDir
- On Windows: move fooDirectory RenamedDir
Remove an empty directory (the directory `myDirectory`, for instance)
- On Mac/Linux: rmdir fooDirectory/barDirectory
- On Windows: rmdir fooDirectory\barDirectory
Learn more about a command (the `cd` command, for instance)
- On Mac/Linux: man cd
- On Windows: cd /?
Print the contents of a file to the terminal (`file.txt`, for instance)
- On Mac/Linux: cat file.txt
- On Windows: type file.txt
| github_jupyter |
```
# !pip install funcy
# %env OPTIMUS_CHECKPOINT_DIR=../pretrained_models/optimus_snli10/checkpoint-31250/
"""
Import our dependencies
"""
import pandas as pd
import numpy as np
import buckets as b
plurals_filename = b.get_file("s3://scored/plurals_data_scored.csv")
opposites_filename = b.get_file("s3://scored/opposite_data_scored.csv")
comparatives_filename = b.get_file("s3://scored/comparative_data_scored.csv")
plurals = pd.read_csv(plurals_filename)
opposites = pd.read_csv(opposites_filename)
comparatives = pd.read_csv(comparatives_filename)
```
## Plurals
```
print("Counts of each type of value within the plurals dataset")
plural_type_counts = plurals.subcategory.value_counts()
plural_type_counts
print("Percentage of each type which were found to be exact matches")
(plurals.groupby(by="subcategory")['score_0_exact'].agg("sum") / plural_type_counts) * 100
print("Evaluating means of bleu scores")
plurals.groupby(by="subcategory")['score_0_bleu'].agg("mean").round(4)
print("Median bleu score of each subcategory")
plurals.groupby(by="subcategory")['score_0_bleu'].agg("median").round(6)
print("Percent of exact values from entire plural set")
(plurals['score_0_exact'].agg("sum") / len(plurals.index)) * 100
print("Average bleu score for plurals")
plurals['score_0_bleu'].agg("mean").round(4)
print("Median bleu score for plurals")
plurals['score_0_bleu'].agg("median").round(6)
print("Percent of exact values from plurals where subcategory is not to-single")
(plurals[plurals['subcategory'] != 'plural|from-single']['score_0_exact'].agg("sum") / len(plurals[plurals['subcategory'] != 'plural|from-single'].index)) * 100
print("Average bleu score for plurals where subcategory is not single")
plurals[plurals['subcategory'] != 'plural|from-single']['score_0_bleu'].agg("mean").round(4)
print("Median bleu score for plurals where subcategory is not single")
plurals[plurals['subcategory'] != 'plural|from-single']['score_0_bleu'].agg("median").round(6)
print("Examples of exact matches where not \"to-single\"")
plurals.query('score_0_exact == 1 & subcategory != \'plural|from-single\'').sample(n=20)
print("Examples of exact matches where is \"to-single\"")
plurals.query('score_0_exact == 1 & subcategory == \'plural|from-single\'').sample(n=20)
print("Examples from top 10% matches where not \"to-single\"")
plurals.query('score_0_exact == 0 & subcategory != \'plural|from-single\'').sort_values(by="score_0_bleu", ascending=False).head(int(len(plurals)*0.10)).sample(n=20)
print("Examples from top 10% matches where is \"to-single\"")
plurals.query('score_0_exact == 0 & subcategory == \'plural|from-single\'').sort_values(by="score_0_bleu", ascending=False).head(int(len(plurals)*0.10)).sample(n=20)
print("Examples from bottom 25% matches where not \"to-single\"")
plurals.query('score_0_exact == 0 & subcategory != \'plural|from-single\'').sort_values(by="score_0_bleu", ascending=False).tail(int(len(plurals)*0.10)).sample(n=20)
print("Examples from bottom 25% matches where is \"to-single\"")
plurals.query('score_0_exact == 0 & subcategory == \'plural|from-single\'').sort_values(by="score_0_bleu", ascending=False).tail(int(len(plurals)*0.25)).sample(n=20)
```
## Opposites
```
opposite_type_counts = opposites.subcategory.value_counts()
opposite_type_counts
(opposites.groupby(by="subcategory")['score_0_exact'].agg("sum") / opposite_type_counts) * 100
opposites.groupby(by="subcategory")['score_0_bleu'].agg("mean").round(4)
opposites.groupby(by="subcategory")['score_0_bleu'].agg("median").round(4)
print("Percent of exact values from entire opposite set")
(opposites['score_0_exact'].agg("sum") / len(opposites.index)) * 100
print("Average bleu score for opposites")
opposites['score_0_bleu'].agg("mean").round(4)
print("Median bleu score for opposites")
opposites['score_0_bleu'].agg("median").round(6)
print("Examples of exact matches")
opposites[opposites['score_0_exact'] == 1]
print("Top 25% of bleu scores in opposites")
opposites[opposites['score_0_exact'] == 0].sort_values(by="score_0_bleu", ascending=False).head(int(len(plurals)*0.10)).sample(n=20)
print("Top 25% of bleu scores in opposites where OPTIMUS didn't generate the value in c")
opposites.query("score_0_exact == 0 & pred_0 != c.str.lower()").sort_values(by="score_0_bleu", ascending=False).head(int(len(plurals)*0.10)).sample(n=20)
print("Bottom 25% of bleu scores in opposites")
opposites[opposites['score_0_exact'] == 0].sort_values(by="score_0_bleu", ascending=False).tail(int(len(plurals)*0.25)).sample(n=20)
```
## Comparatives
```
comparative_type_counts = comparatives.subcategory.value_counts()
comparative_type_counts
(comparatives.groupby(by="subcategory")['score_0_exact'].agg("sum") / comparative_type_counts) * 100
comparatives.groupby(by="subcategory")['score_0_bleu'].agg("mean").round(4)
comparatives.groupby(by="subcategory")['score_0_bleu'].agg("median").round(4)
print("Examples of exact matches")
comparatives[comparatives['score_0_exact'] == 1].sample(n=20)
print("Top 25% of bleu scores in comparative")
comparatives[comparatives['score_0_exact'] == 0].sort_values(by="score_0_bleu", ascending=False).head(int(len(plurals)*0.10)).sample(n=20)
print("Bottom 25% of bleu scores in opposites")
comparatives[comparatives['score_0_exact'] == 0].sort_values(by="score_0_bleu", ascending=False).tail(int(len(plurals)*0.25)).sample(n=20)
```
| github_jupyter |
```
import requests
s = requests.Session()
s.
s.headers
s.headers = {
'User-Agent': 'okhttp/3.14.2',
'Accept-Encoding': 'gzip',
'Accept': '*/*',
'Connection': 'keep-alive',
}
r = s.get("https://static.meijer.com/mobileassets/info/mma_config.json")
r.json()
import os
with open(os.path.expanduser("~/.ssh/meijer5"), "r") as fid:
meijer_email, meijer_pass, = [n.strip() for n in fid.readlines()[0:2]]
s = requests.Session()
s.headers = {
'gent': 'okhttp/3.14.2',
'User-Agent': 'okhttp/3.14.2',
'Accept-Encoding': 'gzip',
'Accept': '*/*',
'Connection': 'keep-alive',
}
s
login_url = "https://login.meijer.com/as/token.oauth2"
account_services_client_id = "mma"
account_services_secret = "drAqas76Re7RekeBanaMaNEMah7paDE5"
auth_string_decoded = f"{account_services_client_id}:{account_services_secret}".encode("UTF-8")
auth_string_decoded
basic_authorization = base64.encodebytes(auth_string_decoded).decode("UTF-8").strip()
f"Basic {basic_authorization}"
request=dict()
request["url"] = "https://login.meijer.com/as/token.oauth2"
request["headers"] = {
'Authorization': f"Basic {basic_authorization}",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/x-www-form-urlencoded',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
request["params"] = {
'grant_type': 'password',
'scope': 'openid',
"username": meijer_email,
"password": meijer_pass,
}
r = s.post(**request)
assert r.status_code==200
r
auth = r.json()
access_token = auth["access_token"].strip()
base64.decodebytes(b"eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0=")
access_token.split(".")
for field in access_token.split("."):
print(base64.decodebytes(f"{field}=".encode()))
access_token = auth["access_token"].strip()
alg64, meijer_info64, token64 = access_token.split(".")
base64.decodebytes(f"{meijer_info64}=".encode()).decode()
json.loads(base64.decodebytes(f"{meijer_info64}=".encode()).decode())
meijer_info = json.loads(base64.decodebytes(f"{meijer_info64}=".encode()))
meijer_info["digital_id"]
request=dict()
request["url"] = "https://mservices.meijer.com/dgtlmma/accounts/getAccount?id="+meijer_info["digital_id"]
request["headers"] = {
'Accept': ':application/vnd.meijer.account.account-v1.0+json',
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
s = requests.Session()
r = s.get(**request)
assert r.status_code==200
r.text
request=dict()
request["url"] = "https://mservices.meijer.com/dgtlmma/accounts/getAccount?id="+meijer_info["digital_id"]
request["headers"] = {
'Accept': 'application/vnd.meijer.account.account-v1.0+json',
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
s = requests.Session()
r = s.get(**request)
assert r.status_code==200
r.text
request=dict()
request["url"] = "https://mservices.meijer.com/dgtlmma/accounts/getAccount?id="+meijer_info["digital_id"]
request["headers"] = {
'Accept': ':application/vnd.meijer.account.account-v1.0+json',
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
s = requests.Session()
r = s.get(**request)
assert r.status_code==200
r.text
# Coupons
request=dict()
request["url"] = "https://mperksservices.meijer.com/dgtlmPerksMMA/api/cms/coupon/ads"
request["headers"] = {
'Accept': "application/vnd.meijer.digitalmperks.couponads-v1.0+json",
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
s = requests.Session()
r = s.get(**request)
assert r.status_code==200
ads = r.json()
ads
# Coupons
request=dict()
request["url"] = "https://mperksservices.meijer.com/dgtlmPerksMMA/api/offers"
request["headers"] = {
'Accept': "application/vnd.meijer.digitalmperks.offers-v1.0+json",
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/vnd.meijer.digitalmperks.offers-v1.0+json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
request["data"] = '{"categoryId":"","ceilingCount":0,"ceilingDuration":0,"currentPage":1,"displayReasonFilters":[],"getOfferCountPerDepartment":true,"offerClass":1,"offerIds":[],"pageSize":9999,"rewardCouponId":0,"searchCriteria":"","showClippedCoupons":false,"showOnlySpecialOffers":false,"showRedeemedOffers":false,"sortType":"BySuggested","storeId":52,"tagId":"","upcList":[],"zip":""}'
s = requests.Session()
r = s.post(**request)
assert r.status_code == 200
coupons = r.json()
# Coupons
request=dict()
request["url"] = "https://mperksservices.meijer.com/dgtlmPerksMMA/api/offers/Clip"
request["headers"] = {
'Accept': "application/vnd.meijer.digitalmperks.clip-v1.0+json",
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/vnd.meijer.digitalmperks.clip-v1.0+json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
request["data"] = '{"meijerOfferId":33006202}'
s = requests.Session()
r = s.post(**request)
r.url
r.
for coupon in coupons["listOfCoupons"]:
break
not coupon['isClipped']
coupon# Coupons
request=dict()
request["url"] = "https://mperksservices.meijer.com/dgtlmPerksMMA/api/offers/Clip"
request["headers"] = {
'Accept': "application/vnd.meijer.digitalmperks.clip-v1.0+json",
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/vnd.meijer.digitalmperks.clip-v1.0+json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
request["json"] = {
"meijerOfferId": "33006202",
}
s = requests.Session()
r = s.post(**request)
r
r.request.method
r.request.url
# Coupons
request=dict()
request["url"] = "https://mperksservices.meijer.com/dgtlmPerksMMA/api/offers"
request["headers"] = {
'Accept': "application/vnd.meijer.digitalmperks.offers-v1.0+json",
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/vnd.meijer.digitalmperks.offers-v1.0+json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
request["json"] = json.loads('{"categoryId":"","ceilingCount":0,"ceilingDuration":0,"currentPage":1,"displayReasonFilters":[],"getOfferCountPerDepartment":true,"offerClass":1,"offerIds":[],"pageSize":9999,"rewardCouponId":0,"searchCriteria":"","showClippedCoupons":false,"showOnlySpecialOffers":false,"showRedeemedOffers":false,"sortType":"BySuggested","storeId":52,"tagId":"","upcList":[],"zip":""}')
s = requests.Session()
r = s.post(**request)
assert r.status_code == 200
coupons = r.json()['listOfCoupons']
for coupon in coupons:
break
coupon
coupon["meijerOfferId"]
coupon# Coupons
request=dict()
request["url"] = "https://mperksservices.meijer.com/dgtlmPerksMMA/api/offers/Clip"
request["headers"] = {
'Accept': "application/vnd.meijer.digitalmperks.clip-v1.0+json",
'Authorization': "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6ImtleTAxIn0.eyJzY29wZSI6WyJvcGVuaWQiXSwiY2xpZW50X2lkIjoibW1hIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5tZWlqZXIuY29tLyIsInN1YiI6IjE5MDYzNzQ0IiwiZWd1ZXN0X2lkIjoiMTA0MzMwNTYiLCJoYXNfZGlnaXRhbCI6IjEiLCJkaWdpdGFsX2lkIjoiMTkwNjM3NDQiLCJoYXNfbXBlcmtzIjoiMSIsIm1wZXJrc19zaG9wcGVyX2lkIjoiNDY4MDgxODgzMjEiLCJtcGVya3NfZXh0X3Nob3BwZXJfaWQiOiI2RjAwRjgxQi1GQTI0LTRBNEEtOEEyMy1EMjM1QjMwNDU5MzQiLCJleHAiOjE1NzI0MTEwNTR9.BzPx-yKEK_pdHzLNf5qZLyV2WCY3fVOX9Zg-GO2zOP8zjKo3wxHSk6KV31og0o_Y7oD5I4m5xSpXouj8T614kUenID0AF0QiZIjTX6vbnV7SmyLdCam46cVN72YMhCbZAOinsBTqWT2HppKfBSiUg3w5hLkFuEp5jxy1r-SdYBiznQD6l8JFEZOtnQuyNGmdI3t-jJ4ysryH-MyE8uoOt859fGEKKEhflP-rkN-CAPMTusCWHDAtI84XhiCfVXnAgomkCW-soDLyjOgN1YmzCenz7vcYdxsQ7RJ5a8aO8RA7YtzfExi1432J2SW8fmOuaMZOPJqd37VrhHH1cF7T9w",
'Platform': 'Android',
'Version': '5.20.1',
'Build': '52001000',
'Content-Type': 'application/vnd.meijer.digitalmperks.clip-v1.0+json',
'Connection': "Keep-Alive",
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0'
}
for coupon in coupons:
request["json"] = {
"meijerOfferId": coupon["meijerOfferId"],
}
s = requests.Session()
r = s.post(**request)
assert r.status_code == 200
request["json"] = {
"meijerOfferId": coupon["meijerOfferId"],
}
s = requests.Session()
r = s.post(**request)
r
```
| github_jupyter |
# Simple road segment
```
%matplotlib inline
import cvxpy as cvx
import dccp
import numpy as np
from numpy import linalg as LA
import matplotlib.pyplot as plt
```
## Defining the scene
```
a, b, c, d, e, f = np.array([0.5, 0.]), np.array([1., 0.5]), np.array([1., 1.5]), np.array([0., 1.5]), np.array([-0.5, 1.]), np.array([-0.5, 0.])
p1, p2, p3, p4, p5, p6 = np.array([1., 0.]), np.array([1., 1.]), _, np.array([0., 1.]), _, np.array([0., 0.])
obstacles = []
r1, r2 = 0.6, 0.4
dx = 0.05
n1, n2, n3, n4, n5, n6 = 50, 80, 50, 50, 50, 80
r_center = (r1 + r2) / 2
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_center_x, road_center_y = 1 + r_center * np.cos(theta1), r_center * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
plt.plot(road_top_x, road_top_y, "r", linewidth=2);
plt.plot(road_bottom_x, road_bottom_y, "r", linewidth=2);
for o, r in obstacles:
circle = plt.Circle(o, r, color='orange')
plt.gca().add_artist(circle)
plt.axis('equal');
plt.grid(True)
plt.title("Road");
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.axis('scaled');
r_center = (r1 + r2) / 2
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_center_x, road_center_y = 1 + r_center * np.cos(theta1), r_center * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
plt.plot(road_center_x, road_center_y, "grey", linewidth=60);
plt.plot(road_center_x, road_center_y, "w--", linewidth=3, dashes=(3.5, 3.5));
plt.plot(road_top_x, road_top_y, "r", linewidth=7);
plt.plot(road_top_x, road_top_y, "w--", linewidth=7, dashes=(1.5, 1.5));
plt.plot(road_bottom_x, road_bottom_y, "r", linewidth=7);
plt.plot(road_bottom_x, road_bottom_y, "w--", linewidth=7, dashes=(1.5, 1.5));
for o, r in obstacles:
circle = plt.Circle(o, r, color='orange')
plt.gca().add_artist(circle)
plt.axis('equal');
plt.grid(True)
plt.title("Road");
plt.gca().set_facecolor((0.43, 0.98, 0.4))
plt.grid(True, color=(0.42, 0.87, 0.39), linewidth=20)
plt.axis('scaled');
```
## Solver
```
a, b = np.array([0.5, 0.]), np.array([1., 0.5])
p1 = np.array([1., 0.])
obstacles = []
r1, r2 = 0.6, 0.4
dx = 0.05
n1 = 50
eps = 0.005
x1 = cvx.Variable((n1+1, 2))
constr = [x1[0] == a, x1[n1] == b]
v1 = x1[1:] - x1[:-1]
for i in range(1, n1+1):
constr.append(cvx.norm(v1[i-1]) <= dx)
constr.append(cvx.norm(x1[i] - p1) <= r1)
constr.append(cvx.norm(x1[i] - p1) >= r2 + eps)
total_v = cvx.norm(v1, "fro")
prob = cvx.Problem(cvx.Minimize(total_v), constr)
prob.is_dcp()
prob.solve(method="dccp");
traj = np.r_[x1.value]
traj
r_center = (r1 + r2) / 2
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_center_x, road_center_y = 1 + r_center * np.cos(theta1), r_center * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
plt.plot(road_top_x, road_top_y, "r", linewidth=2);
plt.plot(road_bottom_x, road_bottom_y, "r", linewidth=2);
for o, r in obstacles:
circle = plt.Circle(o, r, color='orange')
plt.gca().add_artist(circle)
plt.axis('equal');
plt.grid(True)
plt.title("Road");
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.scatter(traj[:, 0], traj[:, 1], s=2, color="blue")
plt.axis('scaled');
```
## Repeat the experiment with different road widths
```
a, b = np.array([0.5, 0.]), np.array([1., 0.5])
p1 = np.array([1., 0.])
obstacles = []
r1, r2 = 0.54, 0.46
dx = 0.05
n1 = 50
eps = 0.005
x1 = cvx.Variable((n1+1, 2))
constr = [x1[0] == a, x1[n1] == b]
v1 = x1[1:] - x1[:-1]
for i in range(1, n1+1):
constr.append(cvx.norm(v1[i-1]) <= dx)
constr.append(cvx.norm(x1[i] - p1) <= r1)
constr.append(cvx.norm(x1[i] - p1) >= r2 + eps)
total_v = cvx.norm(v1, "fro")
prob = cvx.Problem(cvx.Minimize(total_v), constr)
prob.solve(method="dccp");
traj = np.r_[x1.value]
r_center = (r1 + r2) / 2
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_center_x, road_center_y = 1 + r_center * np.cos(theta1), r_center * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
plt.plot(road_top_x, road_top_y, "r", linewidth=2);
plt.plot(road_bottom_x, road_bottom_y, "r", linewidth=2);
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.scatter(traj[:, 0], traj[:, 1], s=2, color="blue", zorder=10)
plt.grid(True)
plt.axis('scaled');
a, b = np.array([0.5, 0.]), np.array([1., 0.5])
p1 = np.array([1., 0.])
obstacles = []
r1, r2 = 0.7, 0.3
dx = 0.05
n1 = 30
eps = 0.005
x1 = cvx.Variable((n1+1, 2))
constr = [x1[0] == a, x1[n1] == b]
v1 = x1[1:] - x1[:-1]
for i in range(1, n1+1):
constr.append(cvx.norm(v1[i-1]) <= dx)
constr.append(cvx.norm(x1[i] - p1) <= r1)
constr.append(cvx.norm(x1[i] - p1) >= r2 + eps)
total_v = cvx.norm(v1, "fro")
prob = cvx.Problem(cvx.Minimize(total_v), constr)
prob.solve(method="dccp");
traj = np.r_[x1.value]
r_center = (r1 + r2) / 2
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_center_x, road_center_y = 1 + r_center * np.cos(theta1), r_center * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
plt.plot(road_top_x, road_top_y, "r", linewidth=2);
plt.plot(road_bottom_x, road_bottom_y, "r", linewidth=2);
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.scatter(traj[:, 0], traj[:, 1], s=2, color="blue", zorder=10)
plt.grid(True)
plt.axis('scaled');
a, b = np.array([0.5, 0.]), np.array([1., 0.5])
p1 = np.array([1., 0.])
obstacles = []
r1, r2 = 0.6, 0.4
dx = 0.05
n1 = 50
eps = 0.005
x1 = cvx.Variable((n1+1, 2))
constr = [x1[0] == a, x1[n1] == b]
v1 = x1[1:] - x1[:-1]
for i in range(1, n1+1):
constr.append(cvx.norm(v1[i-1]) <= dx)
constr.append(cvx.norm(x1[i] - p1) <= r1)
constr.append(cvx.norm(x1[i] - p1) >= r2 + eps)
total_v = cvx.norm(v1, "fro")
prob = cvx.Problem(cvx.Minimize(total_v), constr)
prob.solve(method="dccp");
traj = np.r_[x1.value]
r_center = (r1 + r2) / 2
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_center_x, road_center_y = 1 + r_center * np.cos(theta1), r_center * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
plt.plot(road_top_x, road_top_y, "r", linewidth=2);
plt.plot(road_bottom_x, road_bottom_y, "r", linewidth=2);
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.scatter(traj[:, 0], traj[:, 1], s=2, color="blue", zorder=10)
plt.grid(True)
plt.axis('scaled');
```
## Drawing the convex hull of the road segment
```
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
road_bottom_x_cvx = np.linspace(0.5, 1.1, 100)
road_bottom_y_cvx = -0.6 + road_bottom_x_cvx
closed_coords = np.linspace(0.4, 0.6, 100)
plt.plot(road_top_x, road_top_y, "r", linewidth=2);
plt.plot(road_bottom_x, road_bottom_y, "r--", linewidth=2);
plt.plot(road_bottom_x_cvx, road_bottom_y_cvx, "r", linewidth=2);
plt.plot([1]*100, closed_coords, "r", linewidth=2);
plt.plot(closed_coords, [0]*100, "r", linewidth=2);
plt.axis('equal');
plt.grid(True)
plt.title("Road");
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.scatter(0.8, 0.2, s=40, color="blue", marker="x")
plt.text(0.82, 0.17, "$x_0$", fontsize=14)
plt.annotate("", xy=(0.6, 0.4), xytext=(0.8, 0.2), arrowprops=dict(arrowstyle="->", color="blue"))
plt.axis('scaled');
a, b = np.array([0.5, 0.]), np.array([1., 0.5])
p1, x0 = np.array([1., 0.]), np.array([0.8, 0.2])
r1, r2 = 0.6, 0.4
dx = 0.05
n1 = 50
x1 = cvx.Variable((n1+1, 2))
constr = [x1[0] == a, x1[n1] == b]
v1 = x1[1:] - x1[:-1]
for i in range(1, n1+1):
constr.append(cvx.norm(v1[i-1]) <= dx)
constr.append(cvx.norm(x1[i] - p1) <= r1)
constr.append(cvx.norm(x1[i] - x0) >= 0)
total_v = cvx.norm(v1, "fro")
prob = cvx.Problem(cvx.Minimize(total_v), constr)
prob.solve(method="dccp");
traj = np.r_[x1.value]
theta1 = np.linspace(np.pi/2, np.pi, 500)
road_top_x, road_top_y = 1 + r1 * np.cos(theta1), r1 * np.sin(theta1)
road_bottom_x, road_bottom_y = 1 + r2 * np.cos(theta1), r2 * np.sin(theta1)
road_bottom_x_cvx = np.linspace(0.6, 1.0, 100)
road_bottom_y_cvx = -0.6 + road_bottom_x_cvx
closed_coords = np.linspace(0.4, 0.6, 100)
plt.plot(road_top_x, road_top_y, "r", linewidth=2);
plt.plot(road_bottom_x_cvx, road_bottom_y_cvx, "r", linewidth=2);
plt.plot([1]*100, closed_coords, "r", linewidth=2);
plt.plot(closed_coords, [0]*100, "r", linewidth=2);
plt.axis('equal');
plt.grid(True)
plt.title("Road");
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.scatter(0.5, 0., s=40, color="blue", marker="x")
plt.text(0.47, 0.03, "A", fontsize=14)
plt.scatter(1., 0.5, s=40, color="blue", marker="x")
plt.text(0.97, 0.53, "B", fontsize=14)
plt.scatter(1., 0., s=40, color="blue")
plt.text(0.97, 0.03, "P", fontsize=14)
plt.scatter(traj[:, 0], traj[:, 1], s=2, color="blue", zorder=10)
plt.axis('scaled');
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from bumps.names import *
from bumps.fitters import fit
import sasmodels
import bumps
from sasmodels.core import load_model
from sasmodels.bumps_model import Model, Experiment
from sasmodels.data import load_data, plot_data, empty_data1D
from sasmodels.direct_model import DirectModel
import sas
# sample meta-data
sample_info = pd.read_csv('../../data/sans/Sample_Info.csv')
# helpful meta-data dictionaries
names = dict(zip(sample_info['Sample'], sample_info['Name']))
cps = dict(zip(sample_info['Sample'], sample_info['Conjugated Polymer']))
matrix = dict(zip(sample_info['Sample'], sample_info['Commodity Polymer']))
solvent_names = dict(zip(sample_info['Sample'], sample_info['Solvent']))
# target weight percents of conjugated polymer
target = dict(zip(sample_info['Sample'], sample_info['Target Fraction']*100))
# fixing 401/402 and 403/404 sample pair target values for plotting colors only
target[401] = 0.5
target[402] = 0.1
target[403] = 5
target[404] = 1
# actual weight percentages
data = np.loadtxt('../../data/uv_vis/Corrected_wtPercents.csv', delimiter=',', skiprows=1)
actual = {}
actual_stdev = {}
actual_vol = {}
actual_stdev_vol = {}
for key, tar, act, stdev, act_vol, stdev_vol in data:
actual[key] = act
actual_stdev[key] = stdev
actual_vol[key] = act_vol
actual_stdev_vol[key] = stdev_vol
slds = {'RRe-P3HT':0.676,
'RRa-P3HT':0.676,
'P3DDT':0.316,
'PQT-12':0.676,
'Polystyrene-D8':6.464, # density 1.13
'Polystyrene-H8':1.426}
data_dir = '../../data/sans/Smeared_Data_20200629/'
files = os.listdir(data_dir)
sans_data = {}
usans_data = {}
for file in files:
if 'USANS' in file:
key = int(file.split('_')[0][3:])
usans_data[key] = load_data(data_dir + file)
elif 'SANS' in file:
key = int(file.split('_')[0][3:])
sans_data[key] = load_data(data_dir + file)
```
Loading polystyrene fit information.
```
background_files = [file for file in os.listdir('../../data/sans/PS_Fitting/ps_fit_results/power_law_background') if 'json' in file]
backgrounds = {} # key is sample key, value is ('best', '95% confidence interval')
for file in background_files:
data_read = pd.read_json('../../data/sans/PS_Fitting/ps_fit_results/power_law_background/' + file)
key = int(file.split('_')[0][3:])
p95 = data_read.loc['p95',str(key) + ' background']
backgrounds[key] = (data_read.loc['best',str(key) + ' background'], p95)
power_law_fit_info = pd.read_json('../../data/sans/PS_Fitting/ps_fit_results/power_law_porod_exp_scale/PS_porod_exp_scale-err.json')
ps_scales = {}
for key, value in power_law_fit_info.items():
if 'porod_exp' in key:
ps_porod_exp = value['best']
ps_porod_exp_95 = value['p95']
else:
key = int(key.split()[0])
ps_scales[key] = (value['best'], value['p95'])
guinier_porod_fit = pd.read_json('../../data/sans/PS_Fitting/ps_fit_results/guinier_porod_s_scale/PS_s_scale-err.json')
rgs = {}
adjusted_scales = {}
for key, value in guinier_porod_fit.items():
if key == 'ps s':
ps_s = value['best']
ps_s_95 = value['p95']
elif 'rg' in key:
key = int(key.split()[0])
rgs[key] = (value['best'], value['p95'])
elif 'scale' in key:
key = int(key.split()[0])
ps_scales[key] = (value['best'], value['p95'])
for key in rgs.keys():
q1 = (1/rgs[key][0]) * np.sqrt((ps_porod_exp - ps_s)*(3-ps_s)/2)
new_scale = ps_scales[key][0] * np.exp(-1*q1**2*rgs[key][0]**2/(3-ps_s)) * q1**(ps_porod_exp - ps_s)
new_95p = np.array(ps_scales[key][1]) * np.exp(-1*q1**2*rgs[key][0]**2/(3-ps_s)) * q1**(ps_porod_exp - ps_s)
adjusted_scales[key] = (new_scale, list(new_95p))
avg_rg = np.average([x[0] for x in rgs.values()])
max_rg = np.max([x[1][1] for x in rgs.values()])
min_rg = np.min([x[1][0] for x in rgs.values()])
avg_scale = np.average([x[0] for y, x in ps_scales.items() if y in rgs.keys()])
max_scale = np.average([x[1][1] for y, x in ps_scales.items() if y in rgs.keys()])
min_scale = np.average([x[1][0] for y, x in ps_scales.items() if y in rgs.keys()])
```
Loading the Porod analysis results, we will only utilize the previously determined background values to minimize the fitting here.
```
porod_files = [file for file in os.listdir('../../data/sans/Porod_analysis/porod_results') if 'json' in file]
for file in porod_files:
data_read = pd.read_json('../../data/sans/Porod_analysis/porod_results/' + file)
key = int(file.split('_')[0][3:])
for column, value in data_read.items():
if 'background' in column:
backgrounds[key] = (value['best'], value['p95'])
```
Loading fit parameters from the results directory.
```
results_direct = '../../data/sans/Sample_Fitting/fitting_results/ps_sphere_cylinder_lm/'
fit_keys = []
fit_sphere_radius = {}
fit_cylinder_radius = {}
fit_scale_ratio = {}
fit_cp_scale = {}
fit_cylinder_length = {}
for file in [file for file in os.listdir(results_direct) if '.csv' in file]:
data_read = np.loadtxt(results_direct+file, delimiter=',', dtype='str')
key = int(file.split('_')[0][3:])
fit_keys.append(key)
for label, x, dx in data_read:
x = float(x)
dx = float(dx)
if 'radius' in label:
if 'sphere' in label:
fit_sphere_radius[key] = (x,dx)
elif 'cylinder' in label:
fit_cylinder_radius[key] = (x,dx)
elif 'cp scale' in label:
fit_cp_scale[key] = (x,dx)
elif 'scale ratio' in label:
fit_scale_ratio[key] = (x,dx)
elif 'length' in label:
fit_cylinder_length[key] = (x,dx)
```
Convenient dictionaries for plotting.
```
# useful dictionaries with labels and colors for the plots and their legends
wt_names = {}
full_names = {}
wt_colors = {}
solvent_colors = {}
cp_colors = {}
rep_colors = {}
rep_names = {}
temp_wt_colors = {
0.1: 'firebrick',
0.5: 'darkorange',
1.0: 'darkcyan',
5.0: 'mediumblue',
10.0: 'deeppink',
25.0: 'darkorchid',
50.0: 'forestgreen',
0.0: 'black'
}
temp_solvent_colors = {
'Chloroform': 'firebrick',
'Bromobenzene': 'darkorange',
'Toluene': 'darkcyan',
'Slow Dry Chloroform': 'forestgreen'
}
temp_cp_colors = {
'RRe-P3HT': 'firebrick',
'RRa-P3HT': 'darkorange',
'P3DDT': 'forestgreen',
'PQT-12': 'darkcyan',
'None': 'black'
}
for key in names.keys():
if key in actual.keys():
frac = actual[key]
else:
frac = target[key]
frac = np.round(frac,2)
if cps[key] == 'None':
wt_names[key] = matrix[key] + ' Control'
full_names[key] = matrix[key] + ' Control'
else:
wt_names[key] = str(frac) + ' wt% ' + cps[key]
full_names[key] = str(frac) + ' wt% ' + cps[key] + ' in ' + matrix[key] + '\nfrom ' + solvent_names[key]
for key in cps.keys():
wt_colors[key] = temp_wt_colors[target[key]]
solvent_colors[key] = temp_solvent_colors[solvent_names[key]]
cp_colors[key] = temp_cp_colors[cps[key]]
os.makedirs('../../data/sans/Sample_Fitting/fitting_figures/ps_sphere_cylinder_lm', exist_ok=True)
for key in fit_keys:
#for key in [29,30]:
plt.figure(figsize=(6,6))
kernel = load_model('guinier_porod+sphere+cylinder')
vol = actual_vol[key]/100 # cp volume fraction from uv-vis
vol_stdev = actual_stdev_vol[key]/100
# model parameters
scale = Parameter(1, name=str(key) + 'scale')
background = Parameter(backgrounds[key][0], name=str(key) + 'background')
A_scale = Parameter(avg_scale*(1-vol), name=str(key) + ' PS scale')
A_rg = Parameter(avg_rg, name=str(key) + ' PS rg')
A_s = Parameter(ps_s, name=str(key) + ' PS s')
A_porod_exp = Parameter(ps_porod_exp, name=str(key) + ' PS porod_exp')
scale_ratio = Parameter(fit_scale_ratio[key][0], name=str(key) + ' B scale ratio').range(0,1)
scale_normal = bumps.bounds.Normal(mean=vol, std=vol_stdev)
cp_scale = Parameter(fit_cp_scale[key][0], name=str(key) + ' cp scale', bounds=scale_normal)
B_scale = scale_ratio * cp_scale
B_sld = Parameter(slds[cps[key]], name=str(key) + ' PS sld')
B_sld_solvent = Parameter(slds[matrix[key]], name=str(key) + ' PS solvent')
B_radius = Parameter(fit_sphere_radius[key][0], limits=[0,inf], name=str(key) + ' sphere radius').range(100,200000)
B_radius_pd = Parameter(0.5, name = str(key) + ' sphere radius pd')
B_radius_pd_n = Parameter(200, name = str(key) + ' sphere radius pd n')
B_radius_pd_nsigma = Parameter(8, name = str(key) + ' sphere radius pd nsigma')
C_scale = (1-scale_ratio) * cp_scale
C_sld = Parameter(slds[cps[key]], name=str(key) + ' PS sld')
C_sld_solvent = Parameter(slds[matrix[key]], name=str(key) + ' PS solvent')
C_radius = Parameter(fit_cylinder_radius[key][0], limits=[0,inf], name = str(key) + ' cylinder radius').range(10,1000)
C_radius_pd = Parameter(0.2, name = str(key) + ' cylinder radius pd')
C_radius_pd_n = Parameter(200, name = str(key) + ' cylinder radius pd n')
C_radius_pd_nsigma = Parameter(8, name = str(key) + ' cylinder radius pd nsigma')
C_length = Parameter(fit_cylinder_length[key][0], limits=[0,inf], name = str(key) + ' length').range(10000,300000)
C_length_pd = Parameter(0, name = str(key) + ' length pd')
C_length_pd_n = Parameter(200, name = str(key) + ' length pd n')
C_length_pd_nsigma = Parameter(8, name = str(key) + ' length pd nsigma')
# setting up the combined model for fitting
sans_model = Model(
model=kernel,
scale=scale,
background=background,
A_scale=A_scale,
A_rg=A_rg,
A_s=A_s,
A_porod_exp=A_porod_exp,
B_scale=B_scale,
B_sld=B_sld,
B_sld_solvent=B_sld_solvent,
B_radius=B_radius,
B_radius_pd_type='lognormal',
B_radius_pd=B_radius_pd,
B_radius_pd_n=B_radius_pd_n,
B_radius_pd_nsigma=B_radius_pd_nsigma,
C_scale = C_scale,
C_sld = C_sld,
C_sld_solvent = C_sld_solvent,
C_radius = C_radius,
C_radius_pd_type='lognormal',
C_radius_pd = C_radius_pd,
C_radius_pd_n = C_radius_pd_n,
C_radius_pd_nsigma = C_radius_pd_nsigma,
C_length = C_length,
C_length_pd_type='lognormal',
C_length_pd = C_length_pd,
C_length_pd_n = C_length_pd_n,
C_length_pd_nsigma = C_length_pd_nsigma,
)
sans = sans_data[key]
sans.dx = sans.dx - sans.dx
plt.errorbar(sans.x, sans.y, yerr=sans.dy, fmt='o', c='black', zorder=1, ms=4, mfc='white', mec='black')
usans = usans_data[key]
plt.errorbar(usans.x, usans.y, yerr=usans.dy, fmt='o', c='black', zorder=1, ms=4, mfc='white', mec='black')
sans_experiment=Experiment(data=sans, model=sans_model)
usans_experiment=Experiment(data=usans, model=sans_model)
usans_smearing = sasmodels.resolution.Slit1D(usans.x, 0.117)
usans_experiment.resolution = usans_smearing
sans_problem=FitProblem(sans_experiment)
usans_problem=FitProblem(usans_experiment)
plt.plot(sans.x, sans_problem.fitness.theory(), c='firebrick', linewidth=3, zorder=10)
plt.plot(usans.x, usans_problem.fitness.theory(), c='firebrick', linewidth=3, zorder=10)
plt.xscale('log')
plt.yscale('log')
plt.xlabel(r'Q ($\AA^{-1}$)', fontsize=16)
plt.ylabel(r'I(Q) (cm$^{-1}$)', fontsize=16)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.ylim(1e-03, 1e11)
plt.xlim(0.00002, 0.3)
plt.title(full_names[key] + ' (Sample ' + str(key) + ')', fontsize=16)
#plt.show()
plt.tight_layout()
plt.savefig('../../data/sans/Sample_Fitting/fitting_figures/ps_sphere_cylinder_lm/CMW' + str(key) + '_PS_Sphere_Cylinder_LMFit.png', dpi=400)
plt.close()
```
| github_jupyter |
# 2016 US Bike Share Activity Snapshot
## Table of Contents
- [Introduction](#intro)
- [Posing Questions](#pose_questions)
- [Data Collection and Wrangling](#wrangling)
- [Condensing the Trip Data](#condensing)
- [Exploratory Data Analysis](#eda)
- [Statistics](#statistics)
- [Visualizations](#visualizations)
- [Performing Your Own Analysis](#eda_continued)
- [Conclusions](#conclusions)
<a id='intro'></a>
## Introduction
> **Tip**: Quoted sections like this will provide helpful instructions on how to navigate and use a Jupyter notebook.
Over the past decade, bicycle-sharing systems have been growing in number and popularity in cities across the world. Bicycle-sharing systems allow users to rent bicycles for short trips, typically 30 minutes or less. Thanks to the rise in information technologies, it is easy for a user of the system to access a dock within the system to unlock or return bicycles. These technologies also provide a wealth of data that can be used to explore how these bike-sharing systems are used.
In this project, you will perform an exploratory analysis on data provided by [Motivate](https://www.motivateco.com/), a bike-share system provider for many major cities in the United States. You will compare the system usage between three large cities: New York City, Chicago, and Washington, DC. You will also see if there are any differences within each system for those users that are registered, regular users and those users that are short-term, casual users.
## Posing Questions
Before looking at the bike sharing data, you should start by asking questions you might want to understand about the bike share data. Consider, for example, if you were working for Motivate. What kinds of information would you want to know about in order to make smarter business decisions? If you were a user of the bike-share service, what factors might influence how you would want to use the service?
**Question 1**: Write at least two questions related to bike sharing that you think could be answered by data.
**Answer**: Q1: Select the birth year the most popular people for bikes with gendar identification in the Chicago city?
Q2: What is the number of bike trips pe month in Washington?
```
# Importing packages and functions
import csv # reading and writing to CSV files
import datetime # operations to parse dates
from pprint import pprint # use to print data structures like dictionaries in
# a nicer way than the base print function.
import pandas as pd # converts CSV files into dataframes which are more
# practical to use than plain text
import numpy as np # performs calculations
import matplotlib as mpl
def print_first_point(filename):
"""
This function prints and returns the first data point (second row) from
a csv file that includes a header row.
"""
# print city name for reference
city = filename.split('-')[0].split('/')[-1]
print('\nCity: {}'.format(city))
# Read the first from from the dataf file and store it in a variable
with open(filename, 'r') as f_in:
# Use the csv library to set up a DictReader object.
trip_reader = csv.DictReader(f_in)
# Use a function on the DictReader object to read the
# first trip from the data file and store it in a variable.
first_trip = next(trip_reader)
# Use the pprint library to print the first trip.
pprint(first_trip)
# output city name and first trip for later testing
return (city, first_trip)
# list of files for each city
data_files = ['NYC-CitiBike-2016.csv',
'Chicago-Divvy-2016.csv',
'Washington-CapitalBikeshare-2016.csv']
# print the first trip from each file, store in dictionary to check the code works
example_trips = {}
for data_file in data_files:
city, first_trip = print_first_point(data_file)
example_trips[city] = first_trip
```
### Condensing the Trip Data
It should also be observable from the above printout that each city provides different information. Even where the information is the same, the column names and formats are sometimes different. To make things as simple as possible when we get to the actual exploration, we should trim and clean the data. Cleaning the data makes sure that the data formats across the cities are consistent, while trimming focuses only on the parts of the data we are most interested in to make the exploration easier to work with.
You will generate new data files with five values of interest for each trip: trip duration, starting month, starting hour, day of the week, and user type. Each of these may require additional wrangling depending on the city:
- **Duration**: This has been given to us in seconds (New York, Chicago) or milliseconds (Washington). A more natural unit of analysis will be if all the trip durations are given in terms of minutes.
- **Month**, **Hour**, **Day of Week**: Ridership volume is likely to change based on the season, time of day, and whether it is a weekday or weekend. Use the start time of the trip to obtain these values. The New York City data includes the seconds in their timestamps, while Washington and Chicago do not. The [`datetime`](https://docs.python.org/3/library/datetime.html) package will be very useful here to make the needed conversions.
- **User Type**: It is possible that users who are subscribed to a bike-share system will have different patterns of use compared to users who only have temporary passes. Washington divides its users into two types: 'Registered' for users with annual, monthly, and other longer-term subscriptions, and 'Casual', for users with 24-hour, 3-day, and other short-term passes. The New York and Chicago data uses 'Subscriber' and 'Customer' for these groups, respectively. For consistency, you will convert the Washington labels to match the other two.
**Question 3a**: Complete the helper functions in the code cells below to address each of the cleaning tasks described above.
```
def duration_in_mins(datum, city):
"""
Takes as input a dictionary containing info about a single trip (datum) and
its origin city (city) and returns the trip duration in units of minutes.
"""
# Look up trip duration
if city == 'NYC':
duration = int(datum['tripduration'])
elif city == 'Chicago':
duration = int(datum['tripduration'])
else:
duration = int(datum['Duration (ms)'])/1000
return duration/60
def date_string_to_weekday(date):
"""
Takes date as a string in the form 'mm/dd/yyyy' and converts it
to a week day
"""
#dictionary to convert weekday number to day of week
weekday_dictionary = {0: "Monday",
1: "Tuesday",
2: "Wednesday",
3: "Thursday",
4: "Friday",
5: "Saturday",
6: "Sunday"}
#find weekday number
month, day, year = date.split('/')
week_day = datetime.datetime.weekday(datetime.date(int(year),
int(month),
int(day)))
return weekday_dictionary[week_day]
def time_of_trip(datum, city):
"""
Takes as input a dictionary containing info about a single trip (datum) and
its origin city (city) and returns the month, hour, and day of the week in
which the trip was made.
"""
if city == 'NYC':
# extract month
month = datum['starttime'].split('/')[0]
# extract hour
hour = datum['starttime'].split()[1].split(':')[0]
# get day of week
day_of_week = date_string_to_weekday(datum['starttime'].split()[0])
elif city == 'Chicago':
# extract month
month = datum['starttime'].split('/')[0]
# extract hour
hour = datum['starttime'].split()[1].split(':')[0]
# get day of week
day_of_week = date_string_to_weekday(datum['starttime'].split()[0])
else:
# extract month
month = datum['Start date'].split('/')[0]
# extract hour
hour = datum['Start date'].split()[1].split(':')[0]
# get day of week
day_of_week = date_string_to_weekday(datum['Start date'].split()[0])
return (int(month), int(hour), day_of_week)
def correct_member_type(user_type):
"""
Converts the user type for the Washington dataset so that it fits the other
datasets.
"""
# Dictionary for the conversion
user_type_dictionary = {"Registered":"Subscriber",
"Casual":"Customer"}
# Converting member type
new_user_type = user_type_dictionary[user_type]
return new_user_type
def type_of_user(datum, city):
"""
Takes as input a dictionary containing info about a single trip (datum) and
its origin city (city) and returns the type of system user that made the
trip.
"""
if city == 'NYC': user_type = datum['usertype']
elif city == 'Chicago': user_type = datum['usertype']
else: user_type = correct_member_type(datum['Member Type'])
return user_type
```
**Question 3b**: Now, use the helper functions you wrote above to create a condensed data file for each city consisting only of the data fields indicated above. In the `/examples/` folder, you will see an example datafile from the [Bay Area Bike Share](http://www.bayareabikeshare.com/open-data) before and after conversion. Make sure that your output is formatted to be consistent with the example file.
```
def condense_data(in_file, out_file, city):
"""
This function takes full data from the specified input file
and writes the condensed data to a specified output file. The city
argument determines how the input file will be parsed.
HINT: See the cell below to see how the arguments are structured!
"""
with open(out_file, 'w') as f_out, open(in_file, 'r') as f_in:
# Set up csv DictWriter object - writer requires column names for the
# First row as the "fieldnames" argument
out_colnames = ['duration', 'month', 'hour', 'day_of_week', 'user_type']
trip_writer = csv.DictWriter(f_out, fieldnames = out_colnames)
trip_writer.writeheader()
trip_reader = csv.DictReader(f_in)
# Use a function on the DictReader object to read the
# first trip from the data file and store it in a variable.
first_trip = next(trip_reader)
"""
Variables I am working with because this function is a mess:
out_colnames
"""
# Collect data from and process each row
for row in trip_reader:
# Set up a dictionary to hold the values for the cleaned and trimmed
# data points
new_point = {}
month, hour, day_of_week = time_of_trip(row, city)
new_point[out_colnames[0]] = duration_in_mins(row, city)
new_point[out_colnames[1]] = month
new_point[out_colnames[2]] = hour
new_point[out_colnames[3]] = day_of_week
new_point[out_colnames[4]] = type_of_user(row, city)
# Write row to new csv file
trip_writer.writerow(new_point)
# Run this cell to check your work# Run t
city_info = {'Washington': {'in_file': 'Washington-CapitalBikeshare-2016.csv',
'out_file': 'Washington-2016-Summary.csv'},
'Chicago': {'in_file': 'Chicago-Divvy-2016.csv',
'out_file': 'Chicago-2016-Summary.csv'},
'NYC': {'in_file': 'NYC-CitiBike-2016.csv',
'out_file': 'NYC-2016-Summary.csv'}}
for city, filenames in city_info.items():
condense_data(filenames['in_file'], filenames['out_file'], city)
print_first_point(filenames['out_file'])
```
> **Tip**: If you save a jupyter Notebook, the output from running code blocks will also be saved. However, the state of your workspace will be reset once a new session is started. Make sure that you run all of the necessary code blocks from your previous session to reestablish variables and functions before picking up where you last left off.
<a id='eda'></a>
## Exploratory Data Analysis
Now that you have the data collected and wrangled, you're ready to start exploring the data. In this section you will write some code to compute descriptive statistics from the data. You will also be introduced to the `matplotlib` library to create some basic histograms of the data.
<a id='statistics'></a>
### Statistics
First, let's compute some basic counts. The first cell below contains a function that uses the csv module to iterate through a provided data file, returning the number of trips made by subscribers and customers. The second cell runs this function on the example Bay Area data in the `/examples/` folder. Modify the cells to answer the question below.
**Question 4a**: Which city has the highest number of trips? Which city has the highest proportion of trips made by subscribers? Which city has the highest proportion of trips made by short-term customers?
**Answer**: Following are the Answers: 1.)NYC has the hihgest no.of trips. 2.)NYC has the highest proportion of trips made by subscribers. 3.)Chicago has the highest proportion of trips made by short-term customers.
```
def number_of_trips(filename):
"""
This function reads in a file with trip data and reports the number of
trips made by subscribers, customers, and total overall.
"""
# Create dataframe
df = pd.read_csv(filename)
# initialize count variables
n_subscribers = len(df[df['user_type']=='Subscriber'])
n_customers = len(df[df['user_type']=='Customer'])
# compute total number of rides
n_total = n_subscribers + n_customers
# return tallies as a tuple
return(n_subscribers, n_customers, n_total)
## Modify this and the previous cell to answer Question 4a. Remember to run
## the function on the cleaned data files you created from Question 3.
data_file = 'BayArea-Y3-Summary.csv'
print(number_of_trips(data_file))
data_file_NYC = 'NYC-2016-Summary.csv'
data_file_Washington = 'Washington-2016-Summary.csv'
data_file_Chicago = 'Chicago-2016-Summary.csv'
temp = proportion_users(data_file_NYC)
print("NYC: {}".format(number_of_trips(data_file_NYC)))
print("Proportion of Subscribers in NYC: {}% Proportion of Customers in NYC: {}%\n".format(temp[0], temp[1]))
temp = proportion_users(data_file_Washington)
print("Washington: {}".format(number_of_trips(data_file_Washington)))
print("Proportion of Subscribers in Washington: {}% Proportion of Customers in Washington: {}%\n".format(temp[0], temp[1]))
temp = proportion_users(data_file_Chicago)
print("Chicago: {}".format(number_of_trips(data_file_Chicago)))
print("Proportion of Subscribers in Chicago: {}% Proportion of Customers in Chicago: {}%\n".format(temp[0], temp[1]))
```
> **Tip**: In order to add additional cells to a notebook, you can use the "Insert Cell Above" and "Insert Cell Below" options from the menu bar above. There is also an icon in the toolbar for adding new cells, with additional icons for moving the cells up and down the document. By default, new cells are of the code type; you can also specify the cell type (e.g. Code or Markdown) of selected cells from the Cell menu or the dropdown in the toolbar.
Now, you will write your own code to continue investigating properties of the data.
**Question 4b**: Bike-share systems are designed for riders to take short trips. Most of the time, users are allowed to take trips of 30 minutes or less with no additional charges, with overage charges made for trips of longer than that duration. What is the average trip length for each city? What proportion of rides made in each city are longer than 30 minutes?
**Answer**: NYC: average travel time (min): 15.812599606691304, proportion over 30 mins: 0.07302463538260892
Chicago: average travel time (min): 16.563645039049867, proportion over 30 mins: 0.08332178011922917
Washington: average travel time (min): 18.93305161804247, proportion over 30 mins: 0.10839050131926121
```
def travel_time_stats(filename):
"""
This function calculates the average travel time of the CSV summaries.
Input is the file path and the returned value is a float.
"""
# Create dataframe
df = pd.read_csv(filename)
# Calculate average
average = np.average(df['duration'])
# Calculate proportion of rides above 30 mins
proportion = len(df[df['duration']>30])/len(df)
return average, proportion
```
**Question 4c**: Dig deeper into the question of trip duration based on ridership. Choose one city. Within that city, which type of user takes longer rides on average: Subscribers or Customers?
**Answer**: NYC, Subscriber
```
## Modify this and the previous cell to answer Question 4b. ##
filepaths = ['NYC-2016-Summary.csv',
'Chicago-2016-Summary.csv',
'Washington-2016-Summary.csv']
# Display the data created by population_overtime function
for path in filepaths:
average_travel, proportion_overtime = travel_time_stats(path)
print(path,": \n")
print("average travel time (min): ", average_travel)
print("proportion over 30 mins: ", proportion_overtime)
print("\n")
```
<a id='visualizations'></a>
### Visualizations
The last set of values that you computed should have pulled up an interesting result. While the mean trip time for Subscribers is well under 30 minutes, the mean trip time for Customers is actually _above_ 30 minutes! It will be interesting for us to look at how the trip times are distributed. In order to do this, a new library will be introduced here, `matplotlib`. Run the cell below to load the library and to generate an example plot.
```
# load library
import matplotlib.pyplot as plt
%matplotlib inline
# example histogram, data taken from bay area sample
data = [ 7.65, 8.92, 7.42, 5.50, 16.17, 4.20, 8.98, 9.62, 11.48, 14.33,
19.02, 21.53, 3.90, 7.97, 2.62, 2.67, 3.08, 14.40, 12.90, 7.83,
25.12, 8.30, 4.93, 12.43, 10.60, 6.17, 10.88, 4.78, 15.15, 3.53,
9.43, 13.32, 11.72, 9.85, 5.22, 15.10, 3.95, 3.17, 8.78, 1.88,
4.55, 12.68, 12.38, 9.78, 7.63, 6.45, 17.38, 11.90, 11.52, 8.63,]
plt.hist(data)
plt.title('Distribution of Trip Durations')
plt.xlabel('Duration (m)')
plt.show()
```
In the above cell, we collected fifty trip times in a list, and passed this list as the first argument to the `.hist()` function. This function performs the computations and creates plotting objects for generating a histogram, but the plot is actually not rendered until the `.show()` function is executed. The `.title()` and `.xlabel()` functions provide some labeling for plot context.
You will now use these functions to create a histogram of the trip times for the city you selected in question 4c. Don't separate the Subscribers and Customers for now: just collect all of the trip times and plot them.
```
# load library
import matplotlib.pyplot as plt
import pandas as pd
# Read data from CSV file of NYC-Summary-2016
df = pd.read_csv('NYC-2016-Summary.csv',delimiter=',')
duration = df['duration'].head()
plt.hist(duration)
plt.title('Distribution of Trip Duration')
plt.xlabel('duration')
plt.show()
```
If you followed the use of the .hist() and .show() functions exactly like in the example, you're probably looking at a plot that's completely unexpected. The plot consists of one extremely tall bar on the left, maybe a very short second bar, and a whole lot of empty space in the center and right. Take a look at the duration values on the x-axis. This suggests that there are some highly infrequent outliers in the data. Instead of reprocessing the data, you will use additional parameters with the .hist() function to limit the range of data that is plotted. Documentation for the function can be found [here].
Question 5: Use the parameters of the .hist() function to plot the distribution of trip times for the Subscribers in your selected city. Do the same thing for only the Customers. Add limits to the plots so that only trips of duration less than 75 minutes are plotted. As a bonus, set the plots up so that bars are in five-minute wide intervals. For each group, where is the peak of each distribution? How would you describe the shape of each distribution?
**Answer**: For NYC Subscriber Trip Durations, the peak is in 5-10 min bin, skewed to the Right.
For NYC Customer Trip Durations, the peak is in 20-25 min bin, skewed to the Right.
```
## Use this and additional cells to answer Question 5. ##
substriber_data=[]
customer_data=[]
def list_trips(filename):
with open(filename, 'r') as f_in:
# set up csv reader object
reader = csv.DictReader(f_in)
# tally up ride types
for row in reader:
if row['user_type'] == 'Subscriber':
substriber_data.append(float(row['duration']))
else:
customer_data.append(float(row['duration']))
return (substriber_data,customer_data)
data_file = 'NYC-2016-Summary.csv'
bins =[0,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75]
plt.hist(list_trips(data_file)[0],bins,histtype='bar',rwidth=0.8)
plt.title('Distribution of NYC Subscriber Trip Durations')
plt.xlabel('Duration')
plt.show()
plt.hist(list_trips(data_file)[1],bins,histtype='bar',rwidth=0.8)
plt.title('Distribution of NYC Customer Trip Durations')
plt.xlabel('Duration')
plt.show()
```
### Performing Your Own Analysis
So far, you've performed an initial exploration into the data available. You have compared the relative volume of trips made between three U.S. cities and the ratio of trips made by Subscribers and Customers. For one of these cities, you have investigated differences between Subscribers and Customers in terms of how long a typical trip lasts. Now it is your turn to continue the exploration in a direction that you choose. Here are a few suggestions for questions to explore:
How does ridership differ by month or season?
Which month / season has the highest ridership? Does the ratio of Subscriber trips to Customer trips change depending on the month or season?
Is the pattern of ridership different on the weekends versus weekdays? On what days are Subscribers most likely to use the system? What about Customers? Does the average duration of rides change depending on the day of the week?
During what time of day is the system used the most? Is there a difference in usage patterns for Subscribers and Customers?
If any of the questions you posed in your answer to question 1 align with the bullet points above, this is a good opportunity to investigate one of them. As part of your investigation, you will need to create a visualization. If you want to create something other than a histogram, then you might want to consult the Pyplot documentation. In particular, if you are plotting values across a categorical variable (e.g. city, user type), a bar chart will be useful. The documentation page for .bar() includes links at the bottom of the page with examples for you to build off of for your own use.
Question 6: Continue the investigation by exploring another question that could be answered by the data available. Document the question you want to explore below. Your investigation should involve at least two variables and should compare at least two groups. You should also use at least one visualization as part of your explorations.
Answer: Washington: Summer has the highest ridership, which is 21859, and Summer has the highest subscriber ridership, which is 16160
NYC: Fall has the highest ridership, which is 88366, and Fall has the highest subscriber ridership, which is 78554
Chicago: Summer has the highest ridership, which is 29890, and Summer has the highest subscriber ridership, which is 21198
```
def month_of_trips(filename):
with open(filename, 'r') as f_in:
# set up csv reader object
reader = csv.DictReader(f_in)
# Define the variable for each days
winter =[12,1,2]
spring =[3,4,5]
summer =[6,7,8]
fall = [9,10,11]
n_winter_sub = 0
n_spring_sub = 0
n_summer_sub = 0
n_fall_sub = 0
n_winter_cus = 0
n_spring_cus = 0
n_summer_cus = 0
n_fall_cus = 0
# convert the data
for row in reader:
if row['user_type'] == 'Subscriber':
if int(row['month']) in winter:
n_winter_sub += 1
elif int(row['month']) in spring:
n_spring_sub += 1
elif int(row['month']) in summer:
n_summer_sub += 1
else:
n_fall_sub += 1
else:
if int(row['month']) in winter:
n_winter_cus += 1
elif int(row['month']) in spring:
n_spring_cus += 1
elif int(row['month']) in summer:
n_summer_cus += 1
else:
n_fall_cus += 1
ratio_winter = n_winter_sub/n_winter_cus
ratio_spring = n_spring_sub/n_spring_cus
ratio_summer = n_summer_sub/n_summer_cus
ratio_fall = n_fall_sub/n_fall_cus
n_winter = n_winter_sub+n_winter_cus
n_spring = n_spring_sub+n_spring_cus
n_summer = n_summer_sub+n_summer_cus
n_fall = n_fall_sub+ n_fall_cus
subscriber_season ={"Winter": n_winter_sub,"Spring": n_spring_sub,"Summer": n_summer_sub, "Fall":n_fall_sub}
customer_season = {"Winter": n_winter_cus,"Spring": n_spring_cus,'Summer': n_summer_cus,'Fall': n_fall_cus}
ratio = {"Winter":ratio_winter,"Spring":ratio_spring,'Summer': ratio_summer,'Fall':ratio_fall}
n = {"Winter":n_winter,"Spring":n_spring,'Summer': n_summer,'Fall':n_fall}
# return 4 dictionary
return subscriber_season,customer_season, ratio, n
data_file1 = 'Washington-2016-Summary.csv'
data_file2 = 'NYC-2016-Summary.csv'
data_file3 = 'Chicago-2016-Summary.csv'
subscriber_season1, customer_season1, ratio1,n1 = month_of_trips(data_file1) # Get Washington's season data
max1 =max(n1, key=n1.get)
maximum1 = max(subscriber_season1, key=subscriber_season1.get)
print("Washington: {} has the highest ridership, which is {}, and {} has the highest subscriber ridership, which is {}"
.format(max1, n1[max1],maximum1, subscriber_season1[maximum1]))
subscriber_season2, customer_season2, ratio2,n2 = month_of_trips(data_file2) # Get NYC's season data
max2 =max(n2, key=n2.get)
maximum2 = max(subscriber_season2, key=subscriber_season2.get)
print("NYC: {} has the highest ridership, which is {}, and {} has the highest subscriber ridership, which is {}".
format(max2, n2[max2],maximum2, subscriber_season2[maximum2]))
subscriber_season3, customer_season3, ratio3,n3= month_of_trips(data_file3) # Get Chicago's season data
max3 =max(n3, key=n3.get)
maximum3 = max(subscriber_season3, key=subscriber_season3.get)
print("Chicago: {} has the highest ridership, which is {}, and {} has the highest subscriber ridership, which is {}".
format(max3, n3[max3],maximum3, subscriber_season3[maximum3]))
# Create Bar chart for Subscriber & Customer Rideship
x = [ k for k in subscriber_season1 ]
y = [v for v in subscriber_season1.values()]
x_pos =np.arange(len(x))
x2 = [ k for k in customer_season1]
y2 = [v for v in customer_season1.values()]
x2_pos =np.arange(len(x2))
plt.bar(x,y, alpha=0.5, label ='Subscriber', color = 'r')
plt.bar(x2,y2, alpha=0.5, label ='Customer', color ='c')
plt.title('Washington Subscriber & Customer Rideship Bar Charts')
plt.xlabel('Seasons')
plt.ylabel('Number of Trips')
plt.show()
x3 = [ k for k in ratio1]
y3 = [v for v in ratio1.values()]
plt.bar(x3,y3, alpha=0.5, label ='Ratio')
plt.title('Ratio of Subscriber trips to Customer trips')
plt.show()
```
<a id='conclusions'></a>
## Conclusions
Congratulations on completing the project! This is only a sampling of the data analysis process: from generating questions, wrangling the data, and to exploring the data. Normally, at this point in the data analysis process, you might want to draw conclusions about the data by performing a statistical test or fitting the data to a model for making predictions. There are also a lot of potential analyses that could be performed on the data which are not possible with only the data provided. For example, detailed location data has not been investigated. Where are the most commonly used docks? What are the most common routes? As another example, weather has potential to have a large impact on daily ridership. How much is ridership impacted when there is rain or snow? Are subscribers or customers affected more by changes in weather?
**Question 7**: Putting the bike share data aside, think of a topic or field of interest where you would like to be able to apply the techniques of data science. What would you like to be able to learn from your chosen subject?
**Answer**: Sales & Marketing.
Data analysis helps to reshape relationships and interact with customers, and to market products more effectively, resulting in sales activation and increase.
There are four ways in which data analysis can help to stimulate sales:
1. Market fragmentation:
Data analysis allows customer segmentation by age, location, shopping habits, product usage, and aggregation of similar data.
This allows the creation of customized and effective messages with each category of customers, whether they include people living in the same area or who are interested in the same habit or activity.
Retail segmentation also helps to identify the most profitable groups of the company.
This enables the company to focus on these categories and avoid wasting time and money on marketing for segments that are not interested in the product and are not likely to become potential customers.
2. Promote product development:
In order to maintain market competitiveness that is fully based on customers, it is necessary to develop products according to customers' opinions and observations.
Data analysis helps identify successful and unsuccessful products and services, thus improving the quality of the product or service offered and distinguishing from competitors based on information and statistics.
3. Flexibility:
Because the world is developing very rapidly, companies have to be more flexible in dealing with the needs of customers that are constantly changing.
Data analysis helps to understand customer behavior and predict how this behavior will change in the future, helping to identify the causes of customer loss, and develop products and services to keep them.
4. Innovation and change of industries:
This is largely the case for startups that have been able to make major changes in industries by relying primarily on data such as Ober and Karim.
An example of this is self-driving vehicles, which are expected to become the most transformative technologies for the future transport industry.
These cars rely on a huge amount of data, and generate billions of new data every time you use them.
For example, Google's Waimo Autonomous Vehicle generates gigabytes of data every second to see where and how to drive safely.
```
from subprocess import call
call(['python', '-m', 'nbconvert', 'Bike_Share_Analysis.ipynb'])
```
| github_jupyter |
### Import packages
```
#Importing packages
import time
import datetime
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import Model, layers, Input
```
### Define the Hyperparameter & Data info
```
#Learning Rate, Iterations, Batch Size Hyperparameters
learning_rate = 0.001
iterations = 40000
batch_size = 256
#dropout = 0.5
#epochs = 10
```
### Load CIFAR-10 Data
```
#CIFAR-10 Dataset has 60000 images of common objects, 6k images per class and 10 classes in total
(X_train, Y_train), (X_test, Y_test) = cifar10.load_data()
```
### Data Preparation
```
#Convert to float type
X_train, X_test = np.array(X_train, np.float32), np.array(X_test, np.float32)
#Flatten images to 1-D vector of 3072 features (32*32*3)
X_train, X_test = X_train.reshape([-1, 3072]), X_test.reshape([-1, 3072])
#One hot encoding of labels
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
#Normalization of images
X_train = X_train / 255.
X_test = X_test / 255.
#Use Tensorflow data for shuffling and fetching it batchwise
train_data = tf.data.Dataset.from_tensor_slices((X_train, Y_train))
train_data = train_data.repeat().shuffle(5000).batch(batch_size).prefetch(1)
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
print(Y_test.shape)
```
## Define the model, Adding BatchNorm layer after each Layer
### We will see the graphs later to understand the difference of adding BatchNormalization
```
model = tf.keras.models.Sequential()
model.add(layers.Dense(1024, input_dim = 3072 , activation = 'relu'))
model.add(layers.BatchNormalization())
model.add(layers.Dense(512, activation = 'relu'))
model.add(layers.BatchNormalization())
model.add(layers.Dense(256, activation = 'relu'))
model.add(layers.BatchNormalization())
model.add(layers.Dense(128, activation = 'relu'))
model.add(layers.BatchNormalization())
model.add(layers.Dense(10, activation = 'softmax'))
```
### Compile the model with optimizer
```
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir = log_dir, histogram_freq = 1)
model.compile(optimizer= tf.keras.optimizers.Adam(), loss = 'categorical_crossentropy', metrics = ['accuracy'])
```
### Train the model
```
history = model.fit(x = X_train, y = Y_train, validation_data = (X_test, Y_test),
epochs = 25, callbacks = [tensorboard_callback], batch_size = batch_size)
```
### Plotting Accuracy and Loss graphs
```
#Accuracy Graph
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
#Loss Graph
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
```
## Model without BatchNorm layer
```
model1 = tf.keras.models.Sequential()
model1.add(layers.Dense(1024, input_dim = 3072 , activation = 'relu'))
model1.add(layers.Dense(512, activation = 'relu'))
model1.add(layers.Dense(256, activation = 'relu'))
model1.add(layers.Dense(128, activation = 'relu'))
model1.add(layers.Dense(10, activation = 'softmax'))
```
### Compile the model with optimizer
```
log_dir_latest = "logs/fit_latest/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback_latest = tf.keras.callbacks.TensorBoard(log_dir = log_dir_latest, histogram_freq = 1)
model1.compile(optimizer= tf.keras.optimizers.Adam(), loss = 'categorical_crossentropy', metrics = ['accuracy'])
```
### Train the model
```
history1 = model1.fit(x = X_train, y = Y_train, validation_data = (X_test, Y_test),
epochs = 25, callbacks = [tensorboard_callback_latest], batch_size = batch_size)
```
### Plotting Accuracy and Loss Graphs
```
#Accuracy Graph
plt.plot(history1.history['accuracy'])
plt.plot(history1.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
#Loss Graph
plt.plot(history1.history['loss'])
plt.plot(history1.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
```
## As we compare the stats of loss going down between the two models, we clearly see that BatchNorm model reached a final loss of 0.30 at the end of 25 epochs whereas the Non-BatchNorm model reached a final loss of just 0.93
## The BatchNorm model reached the loss of 0.93 at around 11th epoch only, which brings us to a conclusion that Model with BatchNorm trains faster.
## Note: Here we demonstrate only the affect of BatchNorm, and not focusing on improving the overall test_accuracy which can be done by adding proper Regularization and Augmentation in a CNN approach network
| github_jupyter |
# Support Vector Machines
```
%load_ext autoreload
%autoreload 2
import numpy as np
from numpy import linalg as nplin
from sklearn.svm import SVC as csvm
from cs771 import genSyntheticData as gsd
from cs771 import plotData as pd
from cs771 import decisionTree as dt
import time as t
import warnings
```
**Generating Toy Data**: let us generate a similar dataset on which we found that LwP struggled and required a carefully chosen metric to perform well. However, since the LwP algorithm, with two prototypes (one for each class in a binary classification setting) learns a linear classifier even if using a Mahalanobis metric, we will see that CSVM would be able to learn a good classifier directly. Note however, that CSVM can only learn a linear classifier, i.e. it would not be able to do well on non-linearly separable problems e.g. the checkerboard data.
```
d = 2
n = 50
muPos = np.array( [-3,0] )
muNeg = np.array( [3,3] )
cov = np.array( [[16, -14] , [-14, 16]] )
XPos = gsd.genEllipticalData( d, n, muPos, cov )
XNeg = gsd.genEllipticalData( d, n, muNeg, cov )
yPos = np.ones( (n,) )
yNeg = -np.ones( (n,) )
X = np.vstack( (XPos, XNeg) )
y = np.concatenate( (yPos, yNeg) )
fig = pd.getFigure()
pd.plot2D( XPos, fig, color = 'r', marker = '+' )
pd.plot2D( XNeg, fig, color = 'g', marker = 'o' )
```
**Invoking the CSVM Classifier**: the sklearn library makes it very convenient to use the CSVM classifier. Note that the invocation requires us to specify something called a _kernel_. We will study kernels in detail later. For now, we will simply use the "linear" kernel which allows us to learn linear classifiers. Note that we get perfect classification with a healthy geometric margin without having to perform metric learning which, although useful for improving the performance of LwP and NN algorithms, can be expensive too.
```
# clf is a popular abbreviation of the word "classifier"
clf = csvm( kernel = "linear", C = 1 )
clf.fit( X, y )
w = clf.coef_[0]
b = clf.intercept_[0]
def CSVM( X ):
return X.dot(w) + b
fig2 = pd.getFigure( 7, 7 )
pd.shade2D( CSVM, fig2, mode = "batch", xlim = 10, ylim = 10 )
pd.plot2D( XPos, fig2, color = 'g', marker = '+' )
pd.plot2D( XNeg, fig2, color = 'r', marker = 'o' )
```
**Hyperparameters in CSVM**: the C hyperparameter in the CSVM formulation dictates how worried C-SVM gets about ensuring a large margin vs misclassifying points:
1. A very small value of C tells C-SVM that it is okay to misclassify a few points if that means that the margin will be very good on the rest of the points
1. A moderate or large value of C will politely request C-SVM to try its level best to not misclassify any point as far as possible even if it means sacrificing margin
If you have lots of data, it should not hurt to keep a moderate or large value of C. If you have less training data, it is better to keep a small value of C. In general, C is a hyperparameter that is tuned using validation
Try setting C = 0.001, 0.01, 0.1, 1, 10 and see what happens. As C increases, CSVM will get more and more worried about misclassifying the outlier red points and will sacrifice margin in an effort to perfectly classify every data point
```
muPos1 = np.array( [-5,5] )
muPos2 = np.array( [1,-5] )
muNeg = np.array( [-5,-5] )
r = 3
tmp1 = gsd.genSphericalData( d, n, muPos1, r)
tmp2 = gsd.genSphericalData( d, n//30, muPos2, r//2 )
XPos = np.vstack( (tmp1, tmp2) )
XNeg = gsd.genSphericalData( d, n, muNeg, r )
yPos = np.ones( (n + n//30,) )
yNeg = -np.ones( (n,) )
X = np.vstack( (XPos, XNeg) )
y = np.concatenate( (yPos, yNeg) )
clf = csvm( kernel = 'linear', C = 0.01 )
clf.fit( X, y )
w = clf.coef_[0]
b = clf.intercept_[0]
fig3 = pd.getFigure( 7, 7 )
pd.shade2D( CSVM, fig3, mode = 'batch', xlim = 10, ylim = 10 )
pd.plot2D( XPos, fig3, color = 'g', marker = '+' )
pd.plot2D( XNeg, fig3, color = 'r', marker = 'o' )
```
**Building non-Linear Classifiers using CSVM**: we have only seen the use of the CSVM algorithm to learn linear classifiers. The algorithm can be used to learn non-linear classifiers as well. The most popular way of doing so is by using non-linear _kernels_ which we shall study later. However, for now let us try to do something far simpler -- use CSVM as the stump generator while learning DTs.
The following table gives a broad comparison of the trade-off offered by these two types of stumps. $d$ stands for the dimensionality of the feature vectors in the following table ($d = 2$ in our toy datasets). We note that CSVM-based stumps are more expensive than those we previously studied that considered only one feature while splitting a node. However, CSVM stumps offer much more powerful splits than single-feature stumps. Indeed some of the state-of-the-art decision trees that are used in commercial recommendation systems, do indeed use CSVM-based decision stumps to split internal nodes in the tree.
| | CSVM Stump | Single-feature Stump |
|--------- |:-------------: |:--------------------: |
| Train | Costlier | Cheaper |
| Test | ${\cal O}(d)$ | ${\cal O}(1)$ |
| Storage | ${\cal O}(d)$ | ${\cal O}(1)$ |
| Power | More powerful | Less powerful |
**Generating Toy Data**: first let us regenerate the checkerboard pattern on which we were testing our DT algorithms
```
d = 2
n = 60
r = 2
tmp1 = gsd.genSphericalData( d, n, [-5, -7], r )
tmp2 = gsd.genSphericalData( d, n, [5, 0], r )
tmp3 = gsd.genSphericalData( d, n, [-5, 7], r )
XPos = np.vstack( (tmp1, tmp2, tmp3) )
yPos = np.ones( (3*n,) )
tmp1 = gsd.genSphericalData( d, n, [5, -7], r )
tmp2 = gsd.genSphericalData( d, n, [-5, 0], r )
tmp3 = gsd.genSphericalData( d, n, [5, 7], r )
XNeg = np.vstack( (tmp1, tmp2, tmp3) )
yNeg = -np.ones( (3*n,) )
X = np.vstack( (XPos, XNeg) )
y = np.concatenate( (yPos, yNeg) )
fig4 = pd.getFigure(6,8)
pd.plot2D( XPos, fig4, color = 'r', marker = '+' )
pd.plot2D( XNeg, fig4, color = 'g', marker = 'x' )
```
**Building a CSVM Stump**: there may be several ways in which one can incorporate CSVMs in building decision stumps. We take a simple approach here:
1. Train a CSVM to classify the data present at a node. Since the CSVM itself tries to classify data points correctly, this automatically promotes purity of the two children nodes.
1. Once the CSVM has been trained, we should be able to use this linear classifier as a stump directly unless the CSVM has failed to learn a good classifier
There are several ways to check if CSVM has failed to split the data at a node well.
1. Check the hinge loss or the misclassification rate that CSVM is offering on the train data at this node. If these are high then CSVM has not been successful in properly sending data to the left and left and right children.
1. A cheaper way is to check the norm of the $\mathbf w$ vector returned by CSVM. If this vector is very small (say in terms of Euclidean norm), then this means that $\mathbf w^\top \mathbf x + b \approx b$ i.e. the CSVM classifier is offering a constant prediction i.e. it will recommend that almost all data be sent to one of the nodes which will give us a horrible balance factor.
If CSVM has indeed failed then we propose to (and there may be other/better ways to handle this) choose the widest dimension and split it along the median so as to promote balance (there is no point promoting purity as this node is a lost case anyway)
**Advantages of CSVM-based stumps**: note that the boundaries of the leaf cells produced by the CSVM DT are very pleasing in that they maintain as much distance from the training points as possible and the overall decision boundary mimics that of kNN almost exactly. This is because CSVM makes a serious effort to maximize the geometric margin of the classifier it learns. This is beneficial in producing good decision boundaries for the the overal DT classifier that allow it to make confident predictions.
**Potential Limitations**: although the CSVM produces very nice decision boundaries and is in general, a powerful algorithm, it is not that simple to ensure balance with the CSVM stump. This is because the CSVM algorithm makes no attempt to balance the number of data points on each side of the hyperplane. Incorporating balance is in general a difficult thing to do.
```
def getCSVMStump( X, y, ancestorSplitFeats ):
n = y.size
bestObjective = float('inf')
clf = csvm( kernel = 'linear', C = 1.0 )
clf.fit( X, y )
w = clf.coef_[0]
b = clf.intercept_[0]
if nplin.norm( w, 2 ) < 1e-3:
warnings.warn( "\nWarning: norm(w) = %0.5f -- reverting to feature stump instead" % nplin.norm( w, 2 ), UserWarning )
# Choose the dimension along which the data is spread out the most
bestFeat = np.argmax( np.max( X, axis = 0 ) - np.min( X, axis = 0 ) )
temp = np.sort( X[:, bestFeat] )
# Split at the median along that dimension to promote balance
bestThresh = (temp[n//2 - 1] + temp[n//2 + 1])/2
w = np.zeros_like( w )
w[bestFeat] = 1
b = -bestThresh
return lambda data: data.dot(w) + b
maxLeafSize = 5
maxDepth = 3
dtSVM = dt.Tree( maxLeafSize, maxDepth )
tic = t.process_time()
dtSVM.train( X, y, getCSVMStump )
toc = t.process_time()
print( "It took %1.5f seconds to complete training the CSVM-based DT" % (toc - tic) )
fig5 = pd.getFigure()
tic = t.process_time()
pd.shade2D( dtSVM.predict, fig5, mode = 'point', xlim = 10, ylim = 10, nBins = 500 )
toc = t.process_time()
print( "It took " + str(toc - tic) + " seconds to complete testing with a CSVM-based DT")
pd.plot2D( XNeg, fig5, color = 'r', marker = '+' )
pd.plot2D( XPos, fig5, color = 'g', marker = 'x' )
```
| github_jupyter |
# Imports
```
# Import dependencies
from __future__ import absolute_import, division, print_function
import codecs # word encoding
import glob # regex
import multiprocessing
import os
import pprint
import re
import nltk
import gensim.models.word2vec as w2v
import sklearn.manifold
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
nltk.download('punkt')
nltk.download('stopwords')
```
# Prepare corpus
```
book_filenames = sorted(glob.glob("data/*.txt"))
print(book_filenames)
corpus_raw = u""
for book_filename in book_filenames:
print("Reading '{0}'...".format(book_filename))
with codecs.open(book_filename, 'r', 'utf-8') as book_file:
corpus_raw += book_file.read()
print('Corpus is now {0} characters long'.format(len(corpus_raw)))
print()
tokenizer = nltk.data.load('/home/aman/nltk_data/tokenizers/punkt/english.pickle')
raw_sentences = tokenizer.tokenize(corpus_raw)
def sentence_to_wordlist(raw):
clean = re.sub('[^a-zA-Z]', " ", raw)
words = clean.split()
return words
sentences = []
for raw_sentence in raw_sentences:
if len(raw_sentence) > 0:
sentences.append(sentence_to_wordlist(raw_sentence))
token_count = sum([len(sentence) for sentence in sentences])
print(token_count)
```
# Train word2vec
```
num_features = 300
min_word_count = 3
num_workers = multiprocessing.cpu_count()
context_size = 7
downsampling = 1e-3 # for frequent words
seed = 1
thrones2vec = w2v.Word2Vec(sg=1,seed=seed,
workers=num_workers,
size=num_features,
min_count=min_word_count,
window=context_size,
sample=downsampling)
thrones2vec.build_vocab(sentences)
thrones2vec.corpus_count
thrones2vec.train(sentences,total_examples=thrones2vec.corpus_count)
if not os.path.exists('trained'):
os.makedirs('trained')
thrones2vec.save(os.path.join('trained', 'thrones2vec.w2v'))
```
# Explore trained model
```
thrones2vec = w2v.Word2Vec.load(os.path.join("trained", "thrones2vec.w2v"))
tsne = sklearn.manifold.TSNE(n_components=2, random_state=0)
all_word_vectors_matrix = thrones2vec.syn0
# reduced due to smaller computing power
# comment this line for better results
all_word_vectors_matrix = all_word_vectors_matrix[:5000]
all_word_vectors_matrix_2d = tsne.fit_transform(all_word_vectors_matrix)
points = pd.DataFrame(
[(word, coords[0], coords[1])
for word, coords in [
(word, all_word_vectors_matrix_2d[thrones2vec.vocab[word].index])
for word in thrones2vec.vocab if thrones2vec.vocab[word].index < 5000
]
], columns=['word', 'x', 'y']
)
points.head(10)
sns.set_context('poster')
points.plot.scatter('x','y', s=10, figsize=(20,12))
plt.show()
```
## Zoom in to interesting places
```
def plot_region(x_bounds, y_bounds):
slice = points[
(x_bounds[0] <= points.x) &
(points.x <= x_bounds[1]) &
(y_bounds[0] <= points.y) &
(points.y <= y_bounds[1])
]
ax = slice.plot.scatter('x', 'y', s=35, figsize=(10,8))
for i, point in slice.iterrows():
ax.text(point.x + 0.005, point.y + 0.005, point.word, fontsize=11)
plt.show()
plot_region(x_bounds=(4.0, 7.0), y_bounds=(-1.0, 1.0))
thrones2vec.most_similar("direwolf")
def nearest_similarity_cosmul(start1, end1, end2):
similarities = thrones2vec.most_similar_cosmul(positive=[end2, start1], negative=[end1])
start2 = similarities[0][0]
print("{start1} is related to {end1}, as {start2} is related to {end2}".format(**locals()))
return start2
nearest_similarity_cosmul("Stark", "Winterfell", "Riverrun")
```
| github_jupyter |
```
from datetime import datetime
import numpy as np
import matplotlib.pyplot as plt
import incense
from incense import ExperimentLoader
import pandas as pd
import sys
sys.path.append('/Users/____/Documents/repos/multitask-learning/multitask-learning')
from mnisttask import mnist_model
import sacred_creds
import torch
import torchvision
from torchvision import transforms
loader = ExperimentLoader(
mongo_uri=sacred_creds.url,
db_name=sacred_creds.database_name
)
def build_name(exp):
if not 'enabled_tasks' in exp.config:
exp.config['enabled_tasks'] = (exp.config['enable1'], exp.config['enable2'])
return f'{exp.config["loss_type"]}: {exp.config["enabled_tasks"]}'
def last(x):
return x.iloc[79]
mnist_ids = [502,503,504,505]
fashion_mnist_ids = [506,507,508,509]
number_mnist_auto = [556, 557, 558, 559]
fashion_mnist_auto = [560, 564, 565, 566]
number_mnist_auto_smaller = [577, 578, 579, 580]
fashion_mnist_auto_smaller = [581, 582, 583, 584]
number_mnist_auto_smaller_decay = [585, 586, 587, 588]
mnist_numbers_smaller = [606,607,608,609] # Three task network, auto disabled.
fashion_mnist_numbers_smaller = [610,611,612,613] # Three task network, auto disabled.
fashion_mnist_model_2 = [621, 622, 623, 624]
fashion_mnist_auto_model_3 = [625, 626, 629, 634]
fashion_mnist_auto_model_4 = [635, 636, 637, 638]
fashion_mnist_auto_model_6 = [644, 645, 646, 647]
mnist_numbers_model_3 = [672, 673, 675, 677]
exps = loader.find_by_ids([688, 692, 693, 689])
exps.project(on=['config.loss_type', 'config.enabled_tasks',
{'metrics.val_acc1':last}, {'metrics.val_acc2':last}, {'metrics.val_acc3':last}])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 10))
for exp in exps:
exp.metrics['val_acc1'].plot(ax=axes[0][0], label=build_name(exp))
exp.metrics['val_acc2'].plot(ax=axes[0][1], label=build_name(exp))
if 'val_acc3' in exp.metrics:
exp.metrics['val_acc3'].plot(ax=axes[1][0], label=build_name(exp))
if exp.config['loss_type'] == 'learned':
exp.metrics['weight1'].plot()
exp.metrics['weight2'].plot()
if 'weight3' in exp.metrics:
exp.metrics['weight3'].plot()
axes[0][0].legend()
axes[0][1].legend()
axes[1][0].legend()
axes[1][1].legend()
axes[0][0].set_title('accuracy 1')
axes[0][1].set_title('accuracy 2')
axes[1][0].set_title('accuracy 3')
axes[1][1].set_title('weights')
```
# Visualize reconstruction
```
# transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# dataset = torchvision.datasets.MNIST('~/.torch/models/mnist', train=False, download=True, transform=transform)
transform = transforms.Compose([transforms.ToTensor()])
dataset = torchvision.datasets.FashionMNIST('~/.torch/models/fashion_mnist', train=False, download=True, transform=transform)
i = 634
exp = loader.find_by_id(i)
exp.artifacts['model_end'].save()
state = torch.load(f'{i}_model_end.None', map_location='cpu')
model = mnist_model.MultitaskMnistModel([1.0, 1.0, 1.0], exp.config['model_version'])
model.load_state_dict(state['model_state_dict'])
image, lab = dataset[12]
o1, o2, o3 = model(image.unsqueeze(0))
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(image.numpy().squeeze())
axes[1].imshow(o3.detach().numpy().squeeze())
print(o2.argmax(1))
```
| github_jupyter |
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import global_params as G
plt.rcParams['figure.figsize'] = G.SMALL_FIG
import numpy as np
from scipy import linalg
from scipy import signal
np.set_printoptions(precision=4, suppress=True)
from utilities import db
from receiver import quantalph
from equalization import *
```
## Least Squares
```
m = 1000 # Num symbols
noise_std = 0. # Std deviation for AWGN
alphabet = np.array([-1, 1])
channel = np.array([0.5, 1, -0.6])
symbols = np.random.choice(alphabet, m)
noise = noise_std*np.random.randn(m)
received = signal.lfilter(channel, 1, symbols) + noise
n = 3 # num taps = 1 + n
delay = 2
p = len(received) - delay # tx symbols to consider
R = linalg.toeplitz(received[np.arange(n, p)], received[np.arange(n, -1, -1)])
S = symbols[n-delay:p-delay] # Since this is a training sequence, it is known at receiver
f = linalg.inv(R.T@R)@R.T@S
Jmin = S.T@S - S.T@R@linalg.inv(R.T@R)@R.T@S
y = signal.lfilter(f, 1, received)
decisions = quantalph(y, alphabet)
err = 0.5*np.sum(np.abs(decisions[delay:] - symbols[:m-delay]))
print(f'Delay = {delay}, Jmin = {Jmin:.1f}, errors = {err}, equalizer = {f}')
w, h_channel = signal.freqz(channel)
w, h_eq = signal.freqz(f)
w, h_combined = signal.freqz(np.convolve(channel, f))
plt.plot(w/np.pi, db(h_channel), 'r');
plt.plot(w/np.pi, db(h_eq), 'b');
plt.plot(w/np.pi, db(h_combined), 'k');
```
## LMS
```
n = 4 # num taps
mu = .01
delta = 2
f = np.zeros(n, float)
for i in range(n, len(received)):
window = received[i:i-n:-1]
predicted = np.dot(f, window)
err = symbols[i-delta] - predicted
f = f + mu*err*window
lms_eq = f
print(f'Final filter coeffs: {lms_eq}')
# Implemented as a function
print(f'Filter coeffs from function: {lms_equalizer(received, symbols)}')
errors_vs_delay = evaluate_equalizer(channel, lms_eq, alphabet)
errors_vs_delay
```
## Decision directed Equalization
```
n = 4 # num taps
mu = .1
f = np.zeros(n, float)
f[len(f)//2] = 1 # Center-spike initialization
for i in range(n, len(received)):
window = received[i:i-n:-1]
predicted = np.dot(f, window)
decision = quantalph(np.array(predicted), alphabet)
err = decision[0] - predicted
f = f + mu*err*window
dd_eq = f
print(f'Final filter coeffs: {dd_eq}')
# Implemented as a function
print(f'Filter coeffs from function: {dd_equalizer(received, alphabet)}')
errors_vs_delay = evaluate_equalizer(channel, dd_eq, alphabet)
errors_vs_delay
```
| github_jupyter |
# Sigma_density: M Dwarfs with Spectroscopic Constraints
Calculating density constraints for M Dwarf KOIs with spectroscopic constraints on properties.
1. From spectroscopy, we know Temperature, Mass, and Radius.
2. Which isochrones (stellar models, with Temperature, Mass, and Radius as parameters) fit above star?
3. Now take into account GAIA distance for the star. From this, we know the Luminosity.
4. Look back at stellar models - which isochrone fits the Temperature, Mass Radius, and Luminority (from GAIA)?
```
import numpy as np
import matplotlib.pyplot as plt
from astropy.io import fits
from pprint import pprint
import pandas as pd
from tqdm import tqdm
from astropy.table import Table
plt.rcParams['figure.figsize'] = [10, 5]
pd.set_option("display.max_rows", None, "display.max_columns", None)
headers = ['KOI', 'KIC', 'Teff', 'ETeff', 'eTeff', 'Fe/H', 'e_Fe/H', 'M/H', 'e_M/H', 'SpType', 'Mstar', 'e_Mstar', 'Rstar', 'e_Rstar', 'Dis', 'Fe/H-T', 'e_Fe/H-T', 'Fe/H-M', 'e_Fe/H-M', 'M/H-M', 'e_M/H-M']
```
For now, removed any rows with missing data and saved them into "muirhead_data_no_missing_data.txt".
```
muirhead_data = pd.read_csv("/Users/sheilasagear/Dropbox (UFL)/Research/MetallicityProject/Data/Muirhead2013_isochrones/muirhead_data_no_missing_data.txt", sep=" ")
isochrones = pd.read_csv('/Users/sheilasagear/Dropbox (UFL)/Research/MetallicityProject/Data/Muirhead2013_isochrones/isochrones_sdss_spitzer_lowmass.dat', sep='\s\s+', engine='python')
```
#### First, let's work with muirhead_data[0]: KIC 5868793.
1. Take Teff, Mass, and Radius.
2. Which isochrones fit these Teff, Mass, and Radius?
#### Reading Gaia-Kepler data (luminosities)
```
dat = Table.read('/Users/sheilasagear/Dropbox (UFL)/Research/MetallicityProject/Data/Kepler-Gaia/kepler_dr2_4arcsec.fits', format='fits')
df = dat.to_pandas()
muirhead_gaia = df[df['kepid'].isin(list(muirhead_data.KIC))]
muirhead_gaia = muirhead_gaia.reset_index()
muirhead_gaia.rename(columns={"index": "KIC"})
#muirhead_comb: planet hosts with spectroscopic data + Gaia/Kepler data in one table
muirhead_comb = pd.concat([muirhead_data, muirhead_gaia], axis=1)
muirhead_comb_lums = muirhead_comb[muirhead_comb.lum_val.notnull()]
muirhead_comb_lums
test_planet = muirhead_comb.loc[muirhead_comb['KIC'] == 11187837.0]
test_planet.lum_val
#muirhead_comb["KIC"]
#muirhead_comb["lum_val"]
#pd.options.display.max_colwidth = 100
#test_planet['datalink_url']
def fit_isochrone(data, isochrones):
"""
Inputs:
data: pd.DataFrame. Spectroscopic data + Kepler/Gaia data for n stars in one table. (muirhead_comb)
isochrones: pd.DataFrame. Isochrones table. (isochrones)
Returns: list of pd.DataFrames. Each element of list is a pd.DataFrame of the isochrones that fit this star (index) BASED ONLY ON SPECTROSCOPY.
"""
iso_fits_final = list()
#test each star in spectroscopy sample:
#for i in tqdm(range(len(muirhead_comb))):
for i in tqdm(range(1)):
iso_fits = pd.DataFrame()
Teff_range = [data.Teff[i]-data.eTeff[i], data.Teff[i]+data.ETeff[i]]
Mstar_range = [data.Mstar[i]-data.e_Mstar[i], data.Mstar[i]+data.e_Mstar[i]]
Rstar_range = [data.Rstar[i]-data.e_Rstar[i], data.Rstar[i]+data.e_Rstar[i]]
#test each stellar model to see if it falls within error bars:
for j in range(len(isochrones)):
if Teff_range[0] < 10**isochrones.logt[j] < Teff_range[1] and Mstar_range[0] < isochrones.mstar[j] < Mstar_range[1] and Rstar_range[0] < isochrones.radius[j] < Rstar_range[1]:
iso_fits = iso_fits.append(isochrones.loc[[j]])
iso_fits['KIC'] = muirhead_comb['KIC'][i]
iso_fits['KOI'] = muirhead_comb['KOI'][i]
iso_fits_final.append(iso_fits)
return iso_fits_final
#isos = fit_isochrone(muirhead_comb, isochrones)
#isochrones['logg']
#for i in range(len(isos)):
# isos[i].to_csv("isochrone_fits/spectroscopy/iso_fits_" + str([i]) + ".csv")
#for i in range(12, len(isos)):
# isos[i].to_csv("isochrone_fits/spectroscopy/iso_fits_" + str(isos[i]['KIC'].iloc[0]) + ".csv")
def fit_isochrone_lum(data, isochrones, gaia_lum=True):
"""
Inputs:
data: pd.DataFrame. Spectroscopic data + Kepler/Gaia for n stars in one table. (muirhead_comb)
isochrones: pd.DataFrame. Isochrones table. (isochrones)
Returns: list of pd.DataFrames. Each element of list is a pd.DataFrame of the isochrones that fit this star (index) BASED ON SPECTROSCOPY AND GAIA LUMINOSITY.
"""
iso_fits_final = list()
#for i in tqdm(range(len(muirhead_comb))):
for i in range(1):
iso_fits = pd.DataFrame()
# Teff_range = [data.Teff[i]-data.eTeff[i], data.Teff[i]+data.ETeff[i]]
# Mstar_range = [data.Mstar[i]-data.e_Mstar[i], data.Mstar[i]+data.e_Mstar[i]]
# Rstar_range = [data.Rstar[i]-data.e_Rstar[i], data.Rstar[i]+data.e_Rstar[i]]
# lum_range = [data.lum_val[i]-data.lum_percentile_lower[i], data.lum_val[i]+data.lum_percentile_lower[i]]
Teff_range = [float(data.Teff)-float(data.eTeff), float(data.Teff)+float(data.ETeff)]
Mstar_range = [float(data.Mstar)-float(data.e_Mstar), float(data.Mstar)+float(data.e_Mstar)]
Rstar_range = [float(data.Rstar)-float(data.e_Rstar), float(data.Rstar)+float(data.e_Rstar)]
lum_range = [float(data.lum_val)-float(data.lum_percentile_lower), float(data.lum_val)+float(data.lum_percentile_lower)]
print(Teff_range)
print(Mstar_range)
print(Rstar_range)
print(lum_range)
for j in tqdm(range(len(isochrones))):
if gaia_lum==True:
if Teff_range[0] < 10**isochrones.logt[j] < Teff_range[1] and Mstar_range[0] < isochrones.mstar[j] < Mstar_range[1] and Rstar_range[0] < isochrones.radius[j] < Rstar_range[1] and lum_range[0] < 10**isochrones.logl_ls[j] < lum_range[1]:
iso_fits = iso_fits.append(isochrones.loc[[j]])
if gaia_lum==False:
if Teff_range[0] < 10**isochrones.logt[j] < Teff_range[1] and Mstar_range[0] < isochrones.mstar[j] < Mstar_range[1] and Rstar_range[0] < isochrones.radius[j] < Rstar_range[1]:
iso_fits = iso_fits.append(isochrones.loc[[j]])
iso_fits['KIC'] = muirhead_comb['KIC'][i]
iso_fits['KOI'] = muirhead_comb['KOI'][i]
iso_fits_final.append(iso_fits)
return iso_fits_final
iso_lums = fit_isochrone_lum(test_planet, isochrones, gaia_lum=False)
for i in range(len(iso_lums)):
try:
iso_lums[i].to_csv("jan29_21_iso_lums_" + '8733898' + ".csv")
except IndexError:
pass
isodf = pd.read_csv(r'/Users/sheilasagear/Dropbox (UFL)/Research/MetallicityProject/photoeccentric/notebooks/jan29_21_iso_lums_8733898.csv')
mstar = isodf["mstar"].mean()
mstar_err = isodf["mstar"].std()
rstar = isodf["radius"].mean()
rstar_err = isodf["radius"].std()
```
### Calculate rho
```
#Let's just do 1 star for now
ntargs = 1
# def find_density_dist_symmetric(ntargs, masses, masserr, radii, raderr):
# """Gets symmetric stellar density distribution for stars.
# Symmetric stellar density distribution = Gaussian with same sigma on each end.
# Parameters
# ----------
# ntargs: int
# Number of stars to get distribution for
# masses: np.ndarray
# Array of stellar masses (solar mass)
# masserr: np.ndarray
# Array of sigma_mass (solar mass)
# radii: np.ndarray
# Array of stellar radii (solar radii)
# raderr: np.ndarray
# Array of sigma_radius (solar radii)
# Returns
# -------
# rho_dist: np.ndarray
# Array of density distributions for each star in kg/m^3
# Each element length 1000
# mass_dist: np.ndarray
# Array of symmetric Gaussian mass distributions for each star in kg
# Each element length 1000
# rad_dist: np.ndarray
# Array of symmetric Gaussian radius distributions for each star in m
# Each element length 1000
# """
# smass_kg = 1.9885e30 # Solar mass (kg)
# srad_m = 696.34e6 # Solar radius (m)
# rho_dist = np.zeros((ntargs, 1000))
# mass_dist = np.zeros((ntargs, 1000))
# rad_dist = np.zeros((ntargs, 1000))
# for star in tqdm(range(ntargs)):
# rho_temp = np.zeros(1000)
# mass_temp = np.zeros(1000)
# rad_temp = np.zeros(1000)
# mass_temp = np.random.normal(masses[star]*smass_kg, masserr[star]*smass_kg, 1000)
# rad_temp = np.random.normal(radii[star]*srad_m, raderr[star]*srad_m, 1000)
# #Add each density point to rho_temp (for each star)
# for point in range(len(mass_temp)):
# rho_temp[point] = density(mass_temp[point], rad_temp[point])
# rho_dist[star] = rho_temp
# mass_dist[star] = mass_temp
# rad_dist[star] = rad_temp
# return rho_dist, mass_dist, rad_dist
# def density(mass, radius):
# """Get density of sphere given mass and radius.
# Parameters
# ----------
# mass: float
# Mass of sphere (kg)
# radius: float
# Radius of sphere (m)
# Returns
# rho: float
# Density of sphere (kg*m^-3)
# """
# rho = mass/((4.0/3.0)*np.pi*radius**3)
# return rho
import photoeccentric as ph
rho, mass, radius = ph.find_density_dist_symmetric(ntargs, [mstar], [mstar_err], [rstar], [rstar_err])
np.mean(rho)
np.mean(mass)
np.mean(radius)
np.savetxt("jan29_21_rhos_" + '8733898' + ".csv", rho, delimiter=',')
#masspd.to_csv("jan29_21_rhos_" + str(iso_lums[i]['KIC'].iloc[0]) + ".csv")
#radiuspd.to_csv("jan29_21_rhos_" + str(iso_lums[i]['KIC'].iloc[0]) + ".csv")
print(mstar)
print(mstar_err)
print(rstar)
print(rstar_err)
```
| github_jupyter |
## Accessing ICESat-2 Data
### Data Query and Basic Download Example Notebook
This notebook illustrates the use of icepyx for ICESat-2 data access and download from the NASA NSIDC DAAC (NASA National Snow and Ice Data Center Distributed Active Archive Center).
A complimentary notebook demonstrates in greater detail the subsetting options available when ordering data.
#### Credits
* notebook by: Jessica Scheick
* source material: [NSIDC Data Access Notebook](https://github.com/ICESAT-2HackWeek/ICESat2_hackweek_tutorials/tree/master/03_NSIDCDataAccess_Steiker) by Amy Steiker and Bruce Wallin
### Import packages, including icepyx
```
import icepyx as ipx
import os
import shutil
%matplotlib inline
```
### Quick-Start
The entire process of getting ICESat-2 data (from query to download) can ultimately be accomplished in three minimal lines of code:
`region_a = ipx.Query(short_name, spatial_extent, date_range)`
`region_a.earthdata_login(earthdata_uid, email)`
`region_a.download_granules(path)`
where the function inputs are described in more detail below.
**The rest of this notebook explains the required inputs used above, optional inputs not available in the minimal example, and the other data search and visualization tools built in to icepyx that make it easier for the user to find, explore, and download ICESat-2 data programmatically from NSIDC.** The detailed steps outlined and the methods showcased below are meant to give the user more control over the data they find and download (including options to order/download only the relevant portions of a data granule), some of which are called using default values behind the scenes if the user simply skips to the `download_granules` step.
### Create an ICESat-2 data object with the desired search parameters
There are three required inputs:
- `short_name` = the dataset of interest, known as its "short name".
See https://nsidc.org/data/icesat-2/data-sets for a list of the available datasets.
- `spatial extent` = a region of interest to search within. This can be entered as a bounding box, polygon vertex coordinate pairs, or a polygon geospatial file (currently shp, kml, and gpkg are supported).
- bounding box: Given in decimal degrees for the lower left longitude, lower left latitude, upper right longitude, and upper right latitude
- polygon vertices: Given as longitude, latitude coordinate pairs of decimal degrees with the last entry a repeat of the first.
- polygon file: A string containing the full file path and name.
- `date_range` = the date range for which you would like to search for results. Must be formatted as a set of 'YYYY-MM-DD' strings.
Below are examples of each type of spatial extent input. Please choose and run only one of the next three cells.
```
#bounding box
short_name = 'ATL06'
spatial_extent = [-55, 68, -48, 71]
date_range = ['2019-02-20','2019-02-28']
#polygon vertices (here equivalent to the bounding box, above)
short_name = 'ATL06'
spatial_extent = [(-55, 68), (-55, 71), (-48, 71), (-48, 68), (-55, 68)]
date_range = ['2019-02-20','2019-02-28']
#polygon geospatial file (metadata match but no subset match)
# short_name = 'ATL06'
# spatial_extent = './supporting_files/data-access_PineIsland/glims_polygons.kml'
# date_range = ['2019-02-22','2019-02-28']
#polygon geospatial file (subset and metadata match)
short_name = 'ATL06'
spatial_extent = './supporting_files/data-access_PineIsland/glims_polygons.shp'
date_range = ['2019-10-01','2019-10-05']
```
Create the data object using our inputs
```
region_a = ipx.Query(short_name, spatial_extent, date_range)
```
Formatted parameters and function calls allow us to see the the properties of the data object we have created.
```
print(region_a.dataset)
print(region_a.dates)
print(region_a.start_time)
print(region_a.end_time)
print(region_a.dataset_version)
print(region_a.cycles)
print(region_a.tracks)
# print(region_a.spatial_extent)
region_a.visualize_spatial_extent()
```
There are also several optional inputs to allow the user finer control over their search.
- `start_time` = start time to search for data on the start date. If no input is given, this defaults to 00:00:00.
- `end_time` = end time for the end date of the temporal search parameter. If no input is given, this defaults to 23:59:59. Times must be input as 'HH:mm:ss' strings.
- `version` = What version of the dataset to use, input as a numerical string. If no input is given, this value defaults to the most recent version of the dataset specified in `short_name`.
*NOTE* Version 001 is used as an example in the below cell. However, using it will cause 'no results' errors in granule ordering for some search parameters. These issues have been resolved in later versions of the datasets, so it is best to use the most recent version where possible. Thus, you will need to change the version associated with `region_a` and rerun the next cell for the rest of this notebook to run.
```
region_a = ipx.Query(short_name, spatial_extent, date_range, \
start_time='03:30:00', end_time='21:30:00', version='002')
print(region_a.dataset)
print(region_a.dates)
print(region_a.start_time)
print(region_a.end_time)
print(region_a.dataset_version)
print(region_a.cycles)
print(region_a.tracks)
# print(region_a.spatial_extent)
```
Finally, there are also two optional inputs to allow the user to search based on orbital parameters. Note that your search will return a no-data error if your cycles or tracks are not withint your spatial extent.
- `cycles` = Which orbital cycle of the dataset to use, input as a numerical string or a list of strings. If no input is given, this value defaults to all available cycles within the search parameters. An orbital cycle refers to the 91-day repeat period of the ICESat-2 orbit.
- `tracks` = Which [Reference Ground Track (RGT)](https://icesat-2.gsfc.nasa.gov/science/specs) of the dataset to use, input as a numerical string or a list of strings. If no input is given, this value defaults to all available RGTs within the spatial and temporal search parameters.
```
region_a = ipx.Query(short_name, spatial_extent, date_range, \
cycles='02', tracks=['0849','0902'])
print(region_a.dataset)
print(region_a.dates)
print(region_a.start_time)
print(region_a.end_time)
print(region_a.dataset_version)
print(region_a.cycles)
print(region_a.tracks)
print(region_a.orbit_number)
# print(region_a.spatial_extent)
```
Alternatively, you can also just create the data object without creating named variables first:
```
# region_a = ipx.Query('ATL06',[-55, 68, -48, 71],['2019-02-01','2019-02-28'],
# start_time='00:00:00', end_time='23:59:59', version='002')
```
### Built in methods allow us to get more information about our dataset
In addition to viewing the stored object information shown above (e.g. dataset, start and end date and time, version, etc.), we can also request summary information about the dataset itself or confirm that we have manually specified the latest version.
```
region_a.dataset_summary_info()
print(region_a.latest_version())
```
If the summary does not provide all of the information you are looking for, or you would like to see information for previous versions of the dataset, all available metadata for the collection dataset is available in a readable format.
```
region_a.dataset_all_info()
```
### Querying a dataset
In order to search the dataset collection for available data granules, we need to build our search parameters. This is done automatically behind the scenes when you run `region_a.avail_granules()`, but you can also build and view them by calling `region_a.CMRparams`. These are formatted as a dictionary of key:value pairs according to the CMR documentation.
```
#build and view the parameters that will be submitted in our query
region_a.CMRparams
```
Now that our parameter dictionary is constructed, we can search the CMR database for the available granules. Granules returned by the CMR metadata search are automatically stored within the data object. The search completed at this level relies completely on the granules' metadata. As a result, some (and in rare cases all) of the granules returned may not actually contain data in your specified region, particularly if the region is small or located near the boundaries of a given granule. If this is the case, the subsetter will not return any data when you actually place the order.
```
#search for available granules and provide basic summary info about them
region_a.avail_granules()
#get a list of granule IDs for the available granules
region_a.avail_granules(ids=True)
#print detailed information about the returned search results
region_a.granules.avail
```
### Downloading the found granules
In order to download any data from NSIDC, we must first authenticate ourselves using a valid Earthdata login. This will create a valid token to interface with the DAAC as well as start an active logged-in session to enable data download. Once you have successfully logged in for a given query instance, the token and session will be passed behind the scenes as needed for you to order and download data. Passwords are entered but not shown or stored in plain text by the system.
```
earthdata_uid = 'icepyx_devteam'
email = 'icepyx.dev@gmail.com'
region_a.earthdata_login(earthdata_uid, email)
```
Once we have generated our session, we must build the required configuration parameters needed to actually download data. These will tell the system how we want to download the data. As with the CMR search parameters, these will be built automatically when you run `region_a.order_granules()`, but you can also create and view them with `region_a.reqparams`. The default parameters, given below, should work for most users.
- `page_size` = 10. This is the number of granules we will request per order.
- `page_num` = 1. Determine the number of pages based on page size and the number of granules available. If no page_num is specified, this calculation is done automatically to set page_num, which then provides the number of individual orders we will request given the number of granules.
- `request_mode` = 'async'
- `agent` = 'NO'
- `include_meta` = 'Y'
#### More details about the configuration parameters
`request_mode` is "synchronous" by default, meaning that the request relies on a direct, continous connection between you and the API endpoint. Outputs are directly downloaded, or "streamed", to your working directory. For this tutorial, we will set the request mode to asynchronous, which will allow concurrent requests to be queued and processed without the need for a continuous connection.
**Use the streaming `request_mode` with caution: While it can be beneficial to stream outputs directly to your local directory, note that timeout errors can result depending on the size of the request, and your request will not be queued in the system if NSIDC is experiencing high request volume. For best performance, NSIDC recommends setting `page_size=1` to download individual outputs, which will eliminate extra time needed to zip outputs and will ensure faster processing times per request.**
Recall that we queried the total number and volume of granules prior to applying customization services. `page_size` and `page_num` can be used to adjust the number of granules per request up to a limit of 2000 granules for asynchronous, and 100 granules for synchronous (streaming). For now, let's select 9 granules to be processed in each zipped request. For ATL06, the granule size can exceed 100 MB so we want to choose a granule count that provides us with a reasonable zipped download size.
```
print(region_a.reqparams)
# region_a.reqparams['page_size'] = 9
# print(region_a.reqparams)
```
#### Additional Parameters: Subsetting
In addition to the required parameters (CMRparams and reqparams) that are submitted with our order, for ICESat-2 datasets we can also submit subsetting parameters to NSIDC. This utilizes the NSIDC's built in subsetter to extract only the data you are interested (spatially, temporally, variables of interest, etc.). The advantages of using the NSIDC's subsetter include:
* easily reproducible downloads, particularly when coupled with and icepyx data object
* smaller file size, meaning faster downloads, less storage required, and no need to subset the data on your own
* still easy to go back and order more data/variables with the same or similar search parameters
* no extraneous data means you can move directly to analysis and easily navigate your dataset
Certain subset parameters are specified by default unless `subset=False` is included as an input to `order_granules()`. A separate, companion notebook tutorial covers subsetting in more detail, including how to get a list of subsetting options, how to build your list of subsetting parameters, and how to generate a list of desired variables (most datasets have more than 200 variable fields!), including using pre-built default lists (these lists are still in progress and we welcome contributions!).
As for the CMR and required parameters, default subset parameters can be built and viewed using `subsetparams`. Where an input spatial file is used, rather than a bounding box or manually entered polygon, the spatial file will be used for subsetting (unless subset is set to False) but not show up in the `subsetparams` dictionary.
```
region_a.subsetparams()
region_a._geom_filepath
```
#### Place the order
Then, we can send the order to NSIDC using the order_granules function. Information about the granules ordered and their status will be printed automatically as well as emailed to the address provided. Additional information on the order, including request URLs, can be viewed by setting the optional keyword input 'verbose' to True.
```
region_a.order_granules()
# region_a.order_granules(verbose=True)
#view a short list of order IDs
region_a.granules.orderIDs
```
#### Download the order
Finally, we can download our order to a specified directory (which needs to have a full path but doesn't have to point to an existing directory) and the download status will be printed as the program runs. Additional information is again available by using the optional boolean keyword `verbose`.
```
path = './download'
region_a.download_granules(path)
```
| github_jupyter |
# Exercise 7.03
```
# Import the Libraries
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPool2D
from keras.layers import Flatten
from keras.layers import Dense
import numpy as np
from tensorflow import random
```
Set the seed and initialize the CNN model
```
seed = 42
np.random.seed(seed)
random.set_seed(seed)
# Initialising the CNN
classifier = Sequential()
```
Add the convolutional layers to the model
```
# Convolution
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
# Pooling
classifier.add(MaxPool2D(pool_size = (2, 2)))
# Add an additional convolutional layer and pooling
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPool2D(pool_size = (2, 2)))
# Flattening
classifier.add(Flatten())
```
Add the dense layers to the model
```
# Full ANN connection
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
# Compiling the CNN
classifier.compile(optimizer = 'SGD', loss = 'binary_crossentropy', metrics = ['accuracy'])
```
Create training and test dataset generators
```
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
```
Create training and test datasets
```
training_set = train_datagen.flow_from_directory('../dataset/training_set',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('../dataset/test_set',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
```
Fit the model to the training data
```
classifier.fit_generator(training_set,
steps_per_epoch = 10000,
epochs = 2,
validation_data = test_set,
validation_steps = 2500,
shuffle=False)
```
| github_jupyter |
# Natasha
Natasha solves basic NLP tasks for Russian language: tokenization, sentence segmentatoin, word embedding, morphology tagging, lemmatization, phrase normalization, syntax parsing, NER tagging, fact extraction.
Library is just a wrapper for lower level tools from <a href="https://github.com/natasha">Natasha project</a>:
* <a href="https://github.com/natasha/razdel">Razdel</a> — token, sentence segmentation for Russian
* <a href="https://github.com/natasha/navec">Navec</a> — compact Russian embeddings
* <a href="https://github.com/natasha/slovnet">Slovnet</a> — modern deep-learning techniques for Russian NLP, compact models for Russian morphology, syntax, NER.
* <a href="https://github.com/natasha/yargy">Yargy</a> — rule-based fact extraction similar to Tomita parser.
* <a href="https://github.com/natasha/ipymarkup">Ipymarkup</a> — NLP visualizations for NER and syntax markups.
Consider using these lower level tools for realword tasks. Natasha models are optimized for news articles, on other domains quality may be worse.
```
from natasha import (
Segmenter,
MorphVocab,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
NewsNERTagger,
PER,
NamesExtractor,
DatesExtractor,
MoneyExtractor,
AddrExtractor,
Doc
)
segmenter = Segmenter()
morph_vocab = MorphVocab()
emb = NewsEmbedding()
morph_tagger = NewsMorphTagger(emb)
syntax_parser = NewsSyntaxParser(emb)
ner_tagger = NewsNERTagger(emb)
names_extractor = NamesExtractor(morph_vocab)
dates_extractor = DatesExtractor(morph_vocab)
money_extractor = MoneyExtractor(morph_vocab)
addr_extractor = AddrExtractor(morph_vocab)
```
# Getting started
## Doc
`Doc` aggregates annotators, initially it has just `text` field defined:
```
text = 'Посол Израиля на Украине Йоэль Лион признался, что пришел в шок, узнав о решении властей Львовской области объявить 2019 год годом лидера запрещенной в России Организации украинских националистов (ОУН) Степана Бандеры. Свое заявление он разместил в Twitter. «Я не могу понять, как прославление тех, кто непосредственно принимал участие в ужасных антисемитских преступлениях, помогает бороться с антисемитизмом и ксенофобией. Украина не должна забывать о преступлениях, совершенных против украинских евреев, и никоим образом не отмечать их через почитание их исполнителей», — написал дипломат. 11 декабря Львовский областной совет принял решение провозгласить 2019 год в регионе годом Степана Бандеры в связи с празднованием 110-летия со дня рождения лидера ОУН (Бандера родился 1 января 1909 года). В июле аналогичное решение принял Житомирский областной совет. В начале месяца с предложением к президенту страны Петру Порошенко вернуть Бандере звание Героя Украины обратились депутаты Верховной Рады. Парламентарии уверены, что признание Бандеры национальным героем поможет в борьбе с подрывной деятельностью против Украины в информационном поле, а также остановит «распространение мифов, созданных российской пропагандой». Степан Бандера (1909-1959) был одним из лидеров Организации украинских националистов, выступающей за создание независимого государства на территориях с украиноязычным населением. В 2010 году в период президентства Виктора Ющенко Бандера был посмертно признан Героем Украины, однако впоследствии это решение было отменено судом. '
doc = Doc(text)
doc
```
After applying `segmenter` two new fields appear `sents` and `tokens`:
```
doc.segment(segmenter)
display(doc)
display(doc.sents[:2])
display(doc.tokens[:5])
```
After applying `morph_tagger` and `syntax_parser`, tokens get 5 new fields `id`, `pos`, `feats`, `head_id`, `rel` — annotation in <a href="https://universaldependencies.org/">Universal Dependencies format</a>:
```
doc.tag_morph(morph_tagger)
doc.parse_syntax(syntax_parser)
display(doc.tokens[:5])
```
After applying `ner_tagger` doc gets `spans` field with PER, LOC, ORG annotation:
```
doc.tag_ner(ner_tagger)
display(doc.spans[:5])
```
## Visualizations
Natasha wraps <a href="https://github.com/natasha/ipymarkup">Ipymarkup</a> to provide ASCII visualizations for morphology, syntax and NER annotations. `doc` and `sents` have 3 methods: `morph.print()`, `syntax.print()` and `ner.print()`:
```
doc.ner.print()
sent = doc.sents[0]
sent.morph.print()
sent.syntax.print()
```
## Lemmatization
Tokens have `lemmatize` method, it uses `pos` and `feats` assigned by `morph_tagger` to get word normal form. `morph_vocab` is just a wrapper for <a href="https://pymorphy2.readthedocs.io/en/latest/">Pymorphy2</a>:
```
for token in doc.tokens:
token.lemmatize(morph_vocab)
{_.text: _.lemma for _ in doc.tokens[:10]}
```
## Phrase normalization
Consider phrase "Организации украинских националистов", one can not just inflect every word independently to get normal form: "Организация украинский националист". Spans have method `normalize` that uses syntax annotation by `syntax_parser` to inflect phrases:
```
for span in doc.spans:
span.normalize(morph_vocab)
{_.text: _.normal for _ in doc.spans}
```
## Fact extraction
To split names like "Виктор Ющенко", "Бандера" and "Йоэль Лион" into parts use `names_extractor` and spans method `extract_fact`:
```
for span in doc.spans:
if span.type == PER:
span.extract_fact(names_extractor)
{_.normal: _.fact.as_dict for _ in doc.spans if _.fact}
```
# Reference
One may use Natasha components independently. It is not mandatory to construct `Doc` object.
## `Segmenter`
`Segmenter` is just a wrapper for <a href="https://github.com/natasha/razdel">Razdel</a>, it has two methods `tokenize` and `sentenize`:
```
tokens = list(segmenter.tokenize('Кружка-термос на 0.5л (50/64 см³, 516;...)'))
for token in tokens[:5]:
print(token)
text = '''
- "Так в чем же дело?" - "Не ра-ду-ют".
И т. д. и т. п. В общем, вся газета
'''
sents = list(segmenter.sentenize(text))
for sent in sents:
print(sent)
```
## `MorphVocab`
`MorphVocab` is a wrapper for <a href="pymorphy2.readthedocs.io/en/latest/">Pymorphy2</a>. `MorphVocab` adds cache and adapts grammems to Universal Dependencies format:
```
forms = morph_vocab('стали')
forms
morph_vocab.__call__.cache_info()
```
Also `MorphVocab` adds method `lemmatize`. Given `pos` and `feats` it selects the most suitable morph form and returns its `normal` field:
```
morph_vocab.lemmatize('стали', 'VERB', {})
morph_vocab.lemmatize('стали', 'X', {'Case': 'Gen'})
```
## `Embedding`
`Embedding` is a wrapper for <a href="https://github.com/natasha/navec/">Navec</a> — compact pretrained word embeddings for Russian language:
```
print('Words in vocab + 2 for pad and unk: %d' % len(emb.vocab.words) )
emb['навек'][:10]
```
## `MorphTagger`
`MorphTagger` wraps <a href="https://github.com/natasha/slovnet">Slovnet morphology tagger</a>. Tagger has list of words as input and returns markup object. Markup has `print` method that outputs morph tags ASCII visualization:
```
words = ['Европейский', 'союз', 'добавил', 'в', 'санкционный', 'список', 'девять', 'политических', 'деятелей']
markup = morph_tagger(words)
markup.print()
```
## `SyntaxParser`
`SyntaxParser` wraps <a href="https://github.com/natasha/slovnet">Slovnet syntax parser</a>. Interface is similar to `MorphTagger`:
```
words = ['Европейский', 'союз', 'добавил', 'в', 'санкционный', 'список', 'девять', 'политических', 'деятелей']
markup = syntax_parser(words)
markup.print()
```
## `NERTagger`
`NERTagger` wraps <a href="https://github.com/natasha/slovnet">Slovnet NER tagger</a>. Interface is similar to `MorphTagger` but has untokenized text as input:
```
text = 'Посол Израиля на Украине Йоэль Лион признался, что пришел в шок, узнав о решении властей Львовской области объявить 2019 год годом лидера запрещенной в России Организации украинских националистов (ОУН) Степана Бандеры. Свое заявление он разместил в Twitter. 11 декабря Львовский областной совет принял решение провозгласить 2019 год в регионе годом Степана Бандеры в связи с празднованием 110-летия со дня рождения лидера ОУН (Бандера родился 1 января 1909 года).'
markup = ner_tagger(text)
markup.print()
```
## `Extractor`
In addition to `names_extractor` Natasha bundles several other extractors: `dates_extractor`, `money_extractor` and `addr_extractor`. All extractors are based on <a href="https://github.com/natasha/yargy">Yargy-parser</a>, meaning that they work correctly only on small predefined set of texts. For realword tasks consider writing your own grammar, see <a href="https://github.com/natasha/yargy#documentation">Yargy docs</a> for more.
### `DatesExtractor`
```
text = '24.01.2017, 2015 год, 2014 г, 1 апреля, май 2017 г., 9 мая 2017 года'
list(dates_extractor(text))
```
### `MoneyExtractor`
```
text = '1 599 059, 38 Евро, 420 долларов, 20 млн руб, 20 т. р., 881 913 (Восемьсот восемьдесят одна тысяча девятьсот тринадцать) руб. 98 коп.'
list(money_extractor(text))
```
### `NamesExtractor`
`names_extractor` should be applied only to spans of text. To extract single fact use method `find`:
```
lines = [
'Мустафа Джемилев',
'О. Дерипаска',
'Фёдор Иванович Шаляпин',
'Янукович'
]
for line in lines:
display(names_extractor.find(line))
```
### `AddrExtractor`
```
lines = [
'Россия, Вологодская обл. г. Череповец, пр.Победы 93 б',
'692909, РФ, Приморский край, г. Находка, ул. Добролюбова, 18',
'ул. Народного Ополчения д. 9к.3'
]
for line in lines:
display(addr_extractor.find(line))
```
| github_jupyter |
### ESMA 3016
### Edgar Acuna
### Lab26: Medidas de Asociacion y Prueba de Bondad de Ajuste
```
import numpy as np
from math import sqrt
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
%matplotlib inline
```
### Ejemplo 1. Relacion entre asistir a la iglesia y faltar a clase
```
df=pd.read_table("http://academic.uprm.edu/eacuna/eje84.txt",delim_whitespace=True)
print(df)
df.info()
tabla=pd.pivot_table(df,values='Cantidad',index='Va.a.iglesia',columns='Falta.a.clase',aggfunc=np.sum)
print(tabla)
```
## Prueba de Independencia
### Ho: No hay relacion entre asistir a la iglesia y faltar a clases
### Ha: Si hay Relacion entre las variables
## Prueba de Homogeneidad
### Ho: La proporcion de estudiantes que van frecuentemente a misa y van a clase de vez en cuando=
### La proporcion de estudiantes que van frecuentemente a misa y van a clase frecuentemente=
### La proporcion de estudiantes que van frecuentemente a misa y nunca van a clase
### Ha: Las proporciones no son iguales
```
chi2, p, dof, ex=stats.chi2_contingency(tabla,correction=False)
print("El valor de la prueba Chi2 es:", chi2)
print( "El p-value de la prueba es:", p)
print( "Los grados de libertad de la prueba son:", dof)
```
### WARNING: el usar margen le confunde al programa piensa que la tabla es 4x4 en lugar de 3x3 eso hace los grados de libertad y el p-value de la Chi-square no sean correctos
### Calculando el coeficiente de contigencia
$$Coef_cont=\sqrt{\frac{\chi^2}{\chi^2+n}}$$
```
coef_cont=sqrt(chi2/(chi2+1124))
print("El coeficiente de Contigencia es:", coef_cont)
```
### Conclusion: Como el coeficiente de contigencia es menor que .30, no existe una buena asociación entre asistir a la iglesia y faltar a clases
## Ejemplo 2. Relacion entre tener pet y sobrevivir ataque cardiaco
```
# Ejemplo 2
df=pd.read_table("http://academic.uprm.edu/eacuna/eje85.txt",delim_whitespace=True)
print(df)
tabla=pd.pivot_table(df,values='conteo',index='status',columns='pet?',aggfunc=np.sum)
print(tabla)
```
## Prueba de Independencia
### Ho: No hay relacion entre entre tener pet y sobrevivir al ataque cardiaco
### Ha: Si hay Relacion entre las variables
## Prueba de Homogeneidad
### Ho: La proporcion de pacientes que tiene pet y viven= proporcion de pacientes que no tienen pet y mueren
### Ha: Las proporciones no son iguales
```
chi2, p, dof1, ex=stats.chi2_contingency(tabla,correction=False)
print( "La prueba de Chi-Square es:", chi2)
print("El p-value de la prueba es:", p)
print("Los grados de libertad:", dof1)
```
### Conclusion: Como el p-value es menor que .05 se rechaza la hipotesis nula y se concluye que si hay relacion entre tener pet y sobrevivir al ataque cardiaco.
```
tabla1=pd.pivot_table(df,values='conteo',index='status',columns='pet?',aggfunc=np.sum,margins=True)
print(tabla1)
```
## Calculando el Coediciente de Cramer para medir el grado de asociacion
$$V=\sqrt{\frac{\chi^2}{nt}}$$,
donde $t=min(r-1,c-1)$
```
#Calculando el coeficiente de Cramer
Cramer=sqrt(chi2/92)
print("El coeficiente de Cramer es:" , Cramer)
```
### Hay buena asociacion entre las variables: tener pet y sobrevir un ataque cardiaco
### Ejemplo de Bondad de ajuste (Goodness of fit) usando la Chi-Square
```
#Ejemplo de Bondad de Ajuste
#Los datos son los nacimientos por mes en Puerto Rico
#se desea probar si hay igual numero de nacimientos por mes
df=pd.read_table("http://academic.uprm.edu/eacuna/nacimientosPR.txt",delim_whitespace=True)
df
observed=df['Nacidos']
observed
```
### Ho: Hay igual probabilidad de nacer en cualquier mes del año ( p1 = p2 = … = p12 = 1/12 = .083).
### Ha: En algunos meses hay mas probabilidad de nacer que en otros..
```
a=observed.sum()/float(12)
### Calculando las frecuencias esperadas
expected=[a]*12
expected
stats.chisquare(observed, f_exp=expected)
```
### Conclusion: Como el P-value es practicamente CERO se rechaza la hipotesis Nula y se concluye que no hay igual numero de nacimientos en cada mes.
| github_jupyter |
## Notebook for Animated Data and Video Generation
#### Author: Kuan-Lin Chen, PhD Student of Schulman Lab
##### Last Updated: 2021.08.29
- Today, we're gonna demonstrate how to generate literature-quality videos and show animated data via ```matplotlib.animation```.
- We will also demonstrate the usage of **interactive notbook**, to tune the hyper-parameters of animations prior to video exportation.
```
import numpy as np
import matplotlib.pyplot as plt
```
#### Starting with an unanimated simple plot
```
fig, ax = plt.subplots(figsize=(4, 3), dpi = 100)
# set data
x = np.linspace(0, 2 * np.pi, 50)
y = np.sin(x)
ax.plot(x, y, "bo")
# set xy lim
ax.set_xlim(0, 2 * np.pi)
ax.set_ylim(-1.1, 1.1)
plt.show()
```
### Method 1 - Animate data sampling by using the ```FuncAnimation``` package
- defining the ```animate``` function
```
from matplotlib.animation import FuncAnimation
# Enable interactive plot
%matplotlib notebook
fig, ax = plt.subplots(figsize=(4, 3), dpi = 100)
line, = ax.plot([], "bo") # A tuple unpacking to unpack the only plot
ax.set_xlim(0, 2*np.pi)
ax.set_ylim(-1.1, 1.1)
# set data
x = np.linspace(0, 2 * np.pi, 50)
y = np.sin(x)
def animate(frame_num):
line.set_data((x[:frame_num], y[:frame_num]))
return line
# interval (unit: ms)
anim = FuncAnimation(fig, animate, frames = 100, interval = 20, repeat = False)
plt.show()
```
### Can save via ```anim.save(filename)```
```
# anim.save("test.mp4")
```
Ref: https://towardsdatascience.com/matplotlib-animations-in-jupyter-notebook-4422e4f0e389
### Method 2 - Animation with expeirment images
```
folder = "/Users/kuanlin/OneDrive - Johns Hopkins University/DATA/20200807_BilayerSwell/video_imgs_g2/"
fig = plt.figure(figsize = (7, 4))
plt.tight_layout()
for i in range(28):
plt.subplot(4, 7, i+1)
plt.imshow(plt.imread(folder + "vimg{}.jpeg".format(i+1)))
plt.axis(False)
plt.show()
# set plt font
plt.rc('font', family = 'serif', size = 13, weight = "bold")
from matplotlib.animation import ArtistAnimation
```
```ArtistAnimation``` allows finer control on the video, allowing text annotation with higher flexibility than previous package.
To use it we, define:
1. ```in``` as our image object for iteration
2. ```t``` as the annotation text object during iteration
Then, we send them to a list ```ims``` where we iterate via ```ArtistAnimation``` on the ```fig``` figure, with defined interval (unit: ms)
The following blocks shows clear example, can be easily edited for multiple purposes
```
timestamp = np.arange(28) * 0.25
txts = ["Actuator A (Red Swelling)"] * 13 + ["Actuator B (Yellow Swelling)"] * 15
fig = plt.figure(figsize = (6, 6))
ax = fig.add_subplot(1, 1, 1); ims = []
for i in range(28):
im = ax.imshow(plt.imread(folder + "/vimg{}.jpeg".format(i + 1)),\
animated = True, aspect = 'auto')
plt.axis("off")
plt.tight_layout()
if i in (0, 1, 2, 3, 4, 5, 13, 14, 15, 16, 17):
t = ax.annotate("t = {} hr\n{}".format(timestamp[i], txts[i]) ,(50, 80) , fontsize = 20, color = "white")
else:
t = ax.annotate("t = {} hr".format(timestamp[i]) ,(50, 50) , fontsize = 20, color = "white")
ims.append([im, t])
# interval = time between each frame (ms)
ani = ArtistAnimation(fig, ims, interval = 300, blit = True)
ani.save('sample_video.mp4')
```
| github_jupyter |
# EXPLORATORY DATA ANALYSIS (EDA)
```
# import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
sns.set_theme()
# import dataset
data = pd.read_csv('cleaned_car_data.csv')
data.head()
```
## Data Analysis
```
#the most expensive cars in the collection
data.nlargest(5, 'price')
#cars with the most miles in the collection
data.nlargest(5, 'mileage')
#oldest cars in the collection
data.nlargest(5, 'age')
data.head()
corr = data.corr()
corr
# heat map
sns.heatmap(corr,
xticklabels=corr.columns,
yticklabels=corr.columns, annot=True);
# count of cars by car make
fig = plt.figure(figsize=(20, 10))
sns.countplot(data.manufacturer);
plt.title("Distribution of car manufacturers")
plt.xticks(rotation=90)
plt.savefig('distribution-of-car-manufacturers.png')
# numbers of cars under the various car manufacturers
data.manufacturer.value_counts()
#count of cars by year
fig = plt.figure(figsize=(20,10))
sns.countplot(data.year)
plt.title("Distribution of cars by year")
plt.xticks(rotation=90);
plt.savefig('distribution-of-car-by-year.png')
# distribution of the year column
fig = plt.figure(figsize=(20,10))
sns.histplot(data = data, x = 'year', kde = True)
plt.title("Distribution of `the years")
# numbers of cars produced in each year
data.year.value_counts()
#count of cars by engine
fig = plt.figure(figsize=(8, 5))
sns.countplot(data.engine);
plt.title("Distribution of car engine type")
plt.xticks(rotation=90);
plt.savefig('distribution-of-car-engine-type.png')
# numbers of cars with the different engine types
data.engine.value_counts()
#count of cars by transmission
fig = plt.figure(figsize=(8, 5))
sns.countplot(data.transmission);
plt.title("Distribution of car transmissions")
plt.xticks(rotation=90);
plt.savefig('distribution-of-car-transmission.png')
# number of cars with the various car transmissions
data.transmission.value_counts()
# create a pivot table to find the average price per car manufacturer
pivot_table = data.pivot_table(values='price', index='manufacturer', aggfunc='mean')
result = pivot_table.sort_values('price', ascending = False)
result
sns.scatterplot(x='age', y='price', data=data)
```
There is negative correlation between the age and prices of cars. As the age increases, the price reduces
```
sns.scatterplot(x='mileage', y='price', data=data)
```
There is negative correlation between the mileage and prices of the cars. As the number of miles travelled increases, the price reduces
```
sns.scatterplot(x='mileage', y='price', data=data, hue = 'engine')
sns.scatterplot(x='age', y='mileage', data=data)
```
There is a positive correlation between the mileage and age of the cars. the number of miles travelled increases with age.
```
sns.scatterplot(x='age', y='mileage', data=data, hue = 'engine')
sns.boxplot(x='age', data = data)
plt.title("Box Plot of Age")
```
There are still outliers in the data but it's fine.
```
sns.boxplot(x="transmission", y="price", data=data)
plt.title("Box Plot of Transmission vs Price")
sns.boxplot(x="engine", y="price", data=data)
plt.title("Box Plot of Engine vs Price")
from wordcloud import WordCloud, STOPWORDS
plt.subplots(figsize=(8,4))
wordcloud = WordCloud(background_color='White',width=1920,height=1080).generate(" ".join(data['manufacturer']))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig('cast.png')
plt.show()
```
| github_jupyter |
TSG030 - SQL Server errorlog files
==================================
Steps
-----
### Parameters
```
import re
tail_lines = 500
pod = None # All
container = "mssql-server"
log_files = [ "/var/opt/mssql/log/errorlog" ]
expressions_to_analyze = [
re.compile(".{35}Error:"),
re.compile(".{35}Login failed for user '##"),
re.compile(".{35}SqlDumpExceptionHandler")
]
```
### Instantiate Kubernetes client
```
# Instantiate the Python Kubernetes client into 'api' variable
import os
from IPython.display import Markdown
try:
from kubernetes import client, config
from kubernetes.stream import stream
if "KUBERNETES_SERVICE_PORT" in os.environ and "KUBERNETES_SERVICE_HOST" in os.environ:
config.load_incluster_config()
else:
try:
config.load_kube_config()
except:
display(Markdown(f'HINT: Use [TSG118 - Configure Kubernetes config](../repair/tsg118-configure-kube-config.ipynb) to resolve this issue.'))
raise
api = client.CoreV1Api()
print('Kubernetes client instantiated')
except ImportError:
display(Markdown(f'HINT: Use [SOP059 - Install Kubernetes Python module](../install/sop059-install-kubernetes-module.ipynb) to resolve this issue.'))
raise
```
### Get the namespace for the big data cluster
Get the namespace of the Big Data Cluster from the Kuberenetes API.
**NOTE:**
If there is more than one Big Data Cluster in the target Kubernetes
cluster, then either:
- set \[0\] to the correct value for the big data cluster.
- set the environment variable AZDATA\_NAMESPACE, before starting
Azure Data Studio.
```
# Place Kubernetes namespace name for BDC into 'namespace' variable
if "AZDATA_NAMESPACE" in os.environ:
namespace = os.environ["AZDATA_NAMESPACE"]
else:
try:
namespace = api.list_namespace(label_selector='MSSQL_CLUSTER').items[0].metadata.name
except IndexError:
from IPython.display import Markdown
display(Markdown(f'HINT: Use [TSG081 - Get namespaces (Kubernetes)](../monitor-k8s/tsg081-get-kubernetes-namespaces.ipynb) to resolve this issue.'))
display(Markdown(f'HINT: Use [TSG010 - Get configuration contexts](../monitor-k8s/tsg010-get-kubernetes-contexts.ipynb) to resolve this issue.'))
display(Markdown(f'HINT: Use [SOP011 - Set kubernetes configuration context](../common/sop011-set-kubernetes-context.ipynb) to resolve this issue.'))
raise
print('The kubernetes namespace for your big data cluster is: ' + namespace)
```
### Get tail for log
```
# Display the last 'tail_lines' of files in 'log_files' list
pods = api.list_namespaced_pod(namespace)
entries_for_analysis = []
for p in pods.items:
if pod is None or p.metadata.name == pod:
for c in p.spec.containers:
if container is None or c.name == container:
for log_file in log_files:
print (f"- LOGS: '{log_file}' for CONTAINER: '{c.name}' in POD: '{p.metadata.name}'")
try:
output = stream(api.connect_get_namespaced_pod_exec, p.metadata.name, namespace, command=['/bin/sh', '-c', f'tail -n {tail_lines} {log_file}'], container=c.name, stderr=True, stdout=True)
except Exception:
print (f"FAILED to get LOGS for CONTAINER: {c.name} in POD: {p.metadata.name}")
else:
for line in output.split('\n'):
for expression in expressions_to_analyze:
if expression.match(line):
entries_for_analysis.append(line)
print(line)
print("")
print(f"{len(entries_for_analysis)} log entries found for further analysis.")
```
### Analyze log entries and suggest relevant Troubleshooting Guides
```
# Analyze log entries and suggest further relevant troubleshooting guides
from IPython.display import Markdown
import os
import json
import requests
import ipykernel
import datetime
from urllib.parse import urljoin
from notebook import notebookapp
def get_notebook_name():
"""Return the full path of the jupyter notebook. Some runtimes (e.g. ADS)
have the kernel_id in the filename of the connection file. If so, the
notebook name at runtime can be determined using `list_running_servers`.
Other runtimes (e.g. azdata) do not have the kernel_id in the filename of
the connection file, therefore we are unable to establish the filename
"""
connection_file = os.path.basename(ipykernel.get_connection_file())
# If the runtime has the kernel_id in the connection filename, use it to
# get the real notebook name at runtime, otherwise, use the notebook
# filename from build time.
try:
kernel_id = connection_file.split('-', 1)[1].split('.')[0]
except:
pass
else:
for servers in list(notebookapp.list_running_servers()):
try:
response = requests.get(urljoin(servers['url'], 'api/sessions'), params={'token': servers.get('token', '')}, timeout=.01)
except:
pass
else:
for nn in json.loads(response.text):
if nn['kernel']['id'] == kernel_id:
return nn['path']
def load_json(filename):
with open(filename, encoding="utf8") as json_file:
return json.load(json_file)
def get_notebook_rules():
"""Load the notebook rules from the metadata of this notebook (in the .ipynb file)"""
file_name = get_notebook_name()
if file_name == None:
return None
else:
j = load_json(file_name)
if "azdata" not in j["metadata"] or \
"expert" not in j["metadata"]["azdata"] or \
"log_analyzer_rules" not in j["metadata"]["azdata"]["expert"]:
return []
else:
return j["metadata"]["azdata"]["expert"]["log_analyzer_rules"]
rules = get_notebook_rules()
if rules == None:
print("")
print(f"Log Analysis only available when run in Azure Data Studio. Not available when run in azdata.")
else:
print(f"Applying the following {len(rules)} rules to {len(entries_for_analysis)} log entries for analysis, looking for HINTs to further troubleshooting.")
print(rules)
hints = 0
if len(rules) > 0:
for entry in entries_for_analysis:
for rule in rules:
if entry.find(rule[0]) != -1:
print (entry)
display(Markdown(f'HINT: Use [{rule[2]}]({rule[3]}) to resolve this issue.'))
hints = hints + 1
print("")
print(f"{len(entries_for_analysis)} log entries analyzed (using {len(rules)} rules). {hints} further troubleshooting hints made inline.")
print('Notebook execution complete.')
```
| github_jupyter |
```
import re
import networkx as nx
from IPython.display import Image, display
from collections import defaultdict, Counter
from textblob import TextBlob
from itertools import combinations
from tqdm import tqdm
from litecoder.db import City
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
mpl.style.use('seaborn-muted')
def tokenize(text):
return [str(t) for t in TextBlob(text).tokens]
def keyify(text):
text = text.lower()
text = re.sub('[^a-z0-9]', '', text)
return text
class Token:
def __init__(self, token, ignore_case=True, scrub_re='\.'):
self.ignore_case = ignore_case
self.scrub_re = scrub_re
self.token = token
self.token_clean = self._clean(token)
def _clean(self, token):
if self.ignore_case:
token = token.lower()
if self.scrub_re:
token = re.sub(self.scrub_re, '', token)
return token
def __call__(self, input_token):
return self._clean(input_token) == self.token_clean
def __repr__(self):
return '%s<%s>' % (self.__class__.__name__, self.token_clean)
def __hash__(self):
# TODO: Class identifier?
return hash((self.token_clean, self.ignore_case, self.scrub_re))
def __eq__(self, other):
return hash(self) == hash(other)
def label(self):
return '<%s>' % self.token_clean
def key(self):
return keyify(self.token)
class GeoFSA(nx.MultiDiGraph):
def __init__(self):
super().__init__()
self._next_id = 0
def add_node(self, node, **kwargs):
defaults = dict(final=set())
super().add_node(node, **{**defaults, **kwargs})
def add_edge(self, u, v, entity=None, **kwargs):
"""Ensure edges have non-empty entity sets.
"""
defaults = dict(accept_fn=None, entities=set([entity]), label=None)
kwargs = {**defaults, **kwargs}
if not len(kwargs['entities']) > 0:
raise RuntimeError('All edges must have a non-empty entity set.')
super().add_edge(u, v, **{**defaults, **kwargs})
def next_node(self):
"""Get next integer node id, counting up.
"""
node = self._next_id
self.add_node(node)
self._next_id += 1
return node
def add_token(self, accept_fn, entity, parent=None, optional=False):
"""Register a token transition.
"""
s1 = parent if parent else self.next_node()
s2 = self.next_node()
self.add_edge(
s1, s2, entity,
accept_fn=accept_fn,
label=accept_fn.label(),
)
last_node = s2
# Add skip links if optional.
if optional:
s3 = self.next_node()
self.add_edge(s2, s3, entity, label='ε')
self.add_edge(s1, s3, entity, label='ε')
last_node = s3
return last_node
def set_final(self, state, entity):
self.node[state]['final'].add(entity)
def start_nodes(self):
return [n for n in self.nodes() if self.in_degree(n) == 0]
def inner_nodes(self):
return [n for n in self.nodes() if self.out_degree(n) > 0]
def end_nodes(self):
return [n for n in self.nodes() if self.out_degree(n) == 0]
def _merge_nodes(self, u, v):
"""Merge two leaf nodes.
"""
# Add v finals -> u finals.
self.node[u]['final'].update(g.node[v]['final'])
# Redirect in edges.
for s, _, data in g.in_edges(v, data=True):
g.add_edge(s, u, **data)
# Redirect out edges.
for _, t, data in g.out_edges(v, data=True):
g.add_edge(u, t, **data)
self.remove_node(v)
def _merge_edges(self, u, v, k1, k2):
"""Merge two edges between a pair of nodes.
"""
# Add k2 entities -> k1 entities.
self[u][v][k1]['entities'].update(self[u][v][k2]['entities'])
self.remove_edge(u, v, k2)
def _end_node_merge_key(self, node):
"""Build merge key for end node.
"""
return frozenset([
data.get('accept_fn')
for _, _, data in self.in_edges(node, data=True)
])
def _inner_node_merge_key(self, node):
"""Build merge key for inner node.
"""
out_edges = frozenset([
data.get('accept_fn')
for _, _, data in self.out_edges(node, data=True)
])
descendants = frozenset(nx.descendants(self, node))
return (out_edges, descendants)
def reduce_end_nodes(self):
"""Reduce all redundant end nodes.
"""
seen = {}
for v in self.end_nodes():
key = self._end_node_merge_key(v)
u = seen.get(key)
if u:
self._merge_nodes(u, v)
else:
seen[key] = v
def _reduce_inner_nodes_iter(self):
"""Perform one iteration of inner node reduction.
"""
seen = {}
for v in self.inner_nodes():
key = self._inner_node_merge_key(v)
u = seen.get(key)
if u:
self._merge_nodes(u, v)
else:
seen[key] = v
def reduce_inner_nodes(self):
"""Reduce inner nodes until no more merges are possible.
"""
while True:
nc1 = len(self.nodes)
self._reduce_inner_nodes_iter()
nc2 = len(self.nodes)
if nc2 == nc1:
break
def _reduce_node_out_edges(self, node):
"""Reduce out edges from node.
"""
out_edges = list(self.out_edges(node, data=True, keys=True))
seen = {}
for s, t, k2, data in out_edges:
key = (t, data['accept_fn'])
k1 = seen.get(key)
if k1 is not None:
self._merge_edges(s, t, k1, k2)
else:
seen[key] = k2
def reduce_out_edges(self):
"""Reduce all out edges.
"""
for node in self.nodes():
self._reduce_node_out_edges(node)
def start_index_kv_iter(self):
"""Generate key -> start node pairs.
"""
for node in self.start_nodes():
for _, _, data in self.out_edges(node, data=True):
if data['accept_fn']:
yield data['accept_fn'].key(), node
def start_index(self):
"""Map key -> start nodes.
"""
idx = defaultdict(list)
for k, n in self.start_index_kv_iter():
idx[k].append(n)
return idx
def plot(g):
dot = nx.drawing.nx_pydot.to_pydot(g)
dot.set_rankdir('LR')
display(Image(dot.create_png()))
g = GeoFSA()
for city in tqdm(City.query.filter(City.country_iso=='US').limit(20000)):
entity = (City.__tablename__, city.wof_id)
name_tokens = tokenize(city.name)
state_tokens = tokenize(city.name_a1)
# City name
parent = None
for token in name_tokens:
parent = g.add_token(Token(token), entity, parent)
# Optional comma
comma = g.add_token(Token(','), entity, parent, optional=True)
# State name
parent = comma
for token in state_tokens:
parent = g.add_token(Token(token), entity, parent)
g.set_final(parent, entity)
# Or, state abbr
leaf = g.add_token(Token(city.us_state_abbr), entity, comma)
g.set_final(leaf, entity)
g.reduce_end_nodes()
g.reduce_inner_nodes()
g.reduce_out_edges()
class Matcher:
def __init__(self, fsa):
self.fsa = fsa
self._start_index = fsa.start_index()
self._states = set()
def _get_next_states(self, start_state, token, visited=None):
if not visited:
visited = set()
visited.add(start_state)
next_states = set()
for _, state, data in self.fsa.out_edges(start_state, data=True):
accept_fn = data['accept_fn']
# If non-empty transition, evaluate input.
if accept_fn:
if accept_fn(token):
next_states.add(state)
# Recurisvely resolve epsilons.
elif state not in visited:
next_states.update(self._get_next_states(state, token, visited))
return next_states
def __call__(self, token):
if not self._states:
self._states.update(self._start_index[keyify(token)])
next_states = set()
for state in self._states:
next_states.update(self._get_next_states(state, token))
self._states = next_states
print(self._states)
m = Matcher(g)
%time m('new')
m('pine')
m('RIDGE')
m(',')
m('AL')
tuple()
```
| github_jupyter |
# Writing Custom Dataset Exporters
This recipe demonstrates how to write a [custom DatasetExporter](https://voxel51.com/docs/fiftyone/user_guide/export_datasets.html#custom-formats) and use it to export a FiftyOne dataset to disk in your custom format.
## Setup
If you haven't already, install FiftyOne:
```
!pip install fiftyone
```
If you run into a `cv2` error when importing FiftyOne later on, it is an issue with OpenCV in Colab environments. [Follow these instructions to resolve it.](https://github.com/voxel51/fiftyone/issues/1494#issuecomment-1003148448)
In this recipe we'll use the [FiftyOne Dataset Zoo](https://voxel51.com/docs/fiftyone/user_guide/dataset_creation/zoo_datasets.html) to download the [CIFAR-10 dataset](https://www.cs.toronto.edu/~kriz/cifar.html) to use as sample data to feed our custom exporter.
Behind the scenes, FiftyOne either the
[TensorFlow Datasets](https://www.tensorflow.org/datasets) or
[TorchVision Datasets](https://pytorch.org/docs/stable/torchvision/datasets.html) libraries to wrangle the datasets, depending on which ML library you have installed.
You can, for example, install PyTorch as follows:
```
!pip install torch torchvision
```
## Writing a DatasetExporter
FiftyOne provides a [DatasetExporter](https://voxel51.com/docs/fiftyone/api/fiftyone.utils.data.html#fiftyone.utils.data.exporters.DatasetExporter) interface that defines how it exports datasets to disk when methods such as [Dataset.export()](https://voxel51.com/docs/fiftyone/api/fiftyone.core.html#fiftyone.core.dataset.Dataset.export) are used.
`DatasetExporter` itself is an abstract interface; the concrete interface that you should implement is determined by the type of dataset that you are exporting. See [writing a custom DatasetExporter](https://voxel51.com/docs/fiftyone/user_guide/export_datasets.html#custom-formats) for full details.
In this recipe, we'll write a custom [LabeledImageDatasetExporter](https://voxel51.com/docs/fiftyone/api/fiftyone.utils.data.html#fiftyone.utils.data.exporters.LabeledImageDatasetExporter) that can export an image classification dataset to disk in the following format:
```
<dataset_dir>/
data/
<filename1>.<ext>
<filename2>.<ext>
...
labels.csv
```
where `labels.csv` is a CSV file that contains the image metadata and associated labels in the following format:
```
filepath,size_bytes,mime_type,width,height,num_channels,label
<filepath>,<size_bytes>,<mime_type>,<width>,<height>,<num_channels>,<label>
<filepath>,<size_bytes>,<mime_type>,<width>,<height>,<num_channels>,<label>
...
```
Here's the complete definition of the `DatasetExporter`:
```
import csv
import os
import fiftyone as fo
import fiftyone.utils.data as foud
class CSVImageClassificationDatasetExporter(foud.LabeledImageDatasetExporter):
"""Exporter for image classification datasets whose labels and image
metadata are stored on disk in a CSV file.
Datasets of this type are exported in the following format:
<dataset_dir>/
data/
<filename1>.<ext>
<filename2>.<ext>
...
labels.csv
where ``labels.csv`` is a CSV file in the following format::
filepath,size_bytes,mime_type,width,height,num_channels,label
<filepath>,<size_bytes>,<mime_type>,<width>,<height>,<num_channels>,<label>
<filepath>,<size_bytes>,<mime_type>,<width>,<height>,<num_channels>,<label>
...
Args:
export_dir: the directory to write the export
"""
def __init__(self, export_dir):
super().__init__(export_dir=export_dir)
self._data_dir = None
self._labels_path = None
self._labels = None
self._image_exporter = None
@property
def requires_image_metadata(self):
"""Whether this exporter requires
:class:`fiftyone.core.metadata.ImageMetadata` instances for each sample
being exported.
"""
return True
@property
def label_cls(self):
"""The :class:`fiftyone.core.labels.Label` class(es) exported by this
exporter.
This can be any of the following:
- a :class:`fiftyone.core.labels.Label` class. In this case, the
exporter directly exports labels of this type
- a list or tuple of :class:`fiftyone.core.labels.Label` classes. In
this case, the exporter can export a single label field of any of
these types
- a dict mapping keys to :class:`fiftyone.core.labels.Label` classes.
In this case, the exporter can handle label dictionaries with
value-types specified by this dictionary. Not all keys need be
present in the exported label dicts
- ``None``. In this case, the exporter makes no guarantees about the
labels that it can export
"""
return fo.Classification
def setup(self):
"""Performs any necessary setup before exporting the first sample in
the dataset.
This method is called when the exporter's context manager interface is
entered, :func:`DatasetExporter.__enter__`.
"""
self._data_dir = os.path.join(self.export_dir, "data")
self._labels_path = os.path.join(self.export_dir, "labels.csv")
self._labels = []
# The `ImageExporter` utility class provides an `export()` method
# that exports images to an output directory with automatic handling
# of things like name conflicts
self._image_exporter = foud.ImageExporter(
True, export_path=self._data_dir, default_ext=".jpg",
)
self._image_exporter.setup()
def export_sample(self, image_or_path, label, metadata=None):
"""Exports the given sample to the dataset.
Args:
image_or_path: an image or the path to the image on disk
label: an instance of :meth:`label_cls`, or a dictionary mapping
field names to :class:`fiftyone.core.labels.Label` instances,
or ``None`` if the sample is unlabeled
metadata (None): a :class:`fiftyone.core.metadata.ImageMetadata`
instance for the sample. Only required when
:meth:`requires_image_metadata` is ``True``
"""
out_image_path, _ = self._image_exporter.export(image_or_path)
if metadata is None:
metadata = fo.ImageMetadata.build_for(image_or_path)
self._labels.append((
out_image_path,
metadata.size_bytes,
metadata.mime_type,
metadata.width,
metadata.height,
metadata.num_channels,
label.label, # here, `label` is a `Classification` instance
))
def close(self, *args):
"""Performs any necessary actions after the last sample has been
exported.
This method is called when the exporter's context manager interface is
exited, :func:`DatasetExporter.__exit__`.
Args:
*args: the arguments to :func:`DatasetExporter.__exit__`
"""
# Ensure the base output directory exists
basedir = os.path.dirname(self._labels_path)
if basedir and not os.path.isdir(basedir):
os.makedirs(basedir)
# Write the labels CSV file
with open(self._labels_path, "w") as f:
writer = csv.writer(f)
writer.writerow([
"filepath",
"size_bytes",
"mime_type",
"width",
"height",
"num_channels",
"label",
])
for row in self._labels:
writer.writerow(row)
```
## Generating a sample dataset
In order to use `CSVImageClassificationDatasetExporter`, we need some labeled image samples to work with.
Let's use some samples from the test split of CIFAR-10:
```
import fiftyone.zoo as foz
num_samples = 1000
#
# Load `num_samples` from CIFAR-10
#
# This command will download the test split of CIFAR-10 from the web the first
# time it is executed, if necessary
#
cifar10_test = foz.load_zoo_dataset("cifar10", split="test")
samples = cifar10_test.limit(num_samples)
# Print summary information about the samples
print(samples)
# Print a sample
print(samples.first())
```
## Exporting a dataset
With our samples and `DatasetExporter` in-hand, exporting the samples to disk in our custom format is as simple as follows:
```
export_dir = "/tmp/fiftyone/custom-dataset-exporter"
# Export the dataset
print("Exporting %d samples to '%s'" % (len(samples), export_dir))
exporter = CSVImageClassificationDatasetExporter(export_dir)
samples.export(dataset_exporter=exporter)
```
Let's inspect the contents of the exported dataset to verify that it was written in the correct format:
```
!ls -lah /tmp/fiftyone/custom-dataset-exporter
!ls -lah /tmp/fiftyone/custom-dataset-exporter/data | head -n 10
!head -n 10 /tmp/fiftyone/custom-dataset-exporter/labels.csv
```
## Cleanup
You can cleanup the files generated by this recipe by running:
```
!rm -rf /tmp/fiftyone
```
| github_jupyter |
# Qiskit Aer: Pulse simulation of two qubits using a Duffing oscillator model
This notebook shows how to use the Qiskit Aer pulse simulator, which simulates experiments specified as pulse `Schedule` objects at the Hamiltonian level. The simulator solves the Schrodinger equation for a specified Hamiltonian model and pulse `Schedule` in the frame of the drift Hamiltonian.
In particular, in this tutorial we will:
- Construct a model of a two qubit superconducting system.
- Calibrate $\pi$ pulses on each qubit in the simulated system.
- Observe cross-resonance oscillations when driving qubit 1 with target qubit 0.
The Introduction outlines the concepts and flow of this notebook.
## 1. Introduction <a name='introduction'></a>
The main sections proceed as follows.
### Section 3: Duffing oscillator model
To simulate a physical system, it is necessary to specify a model. In this notebook, we will model superconducting qubits as a collection of *Duffing oscillators*. The model is specified in terms of the following parameters:
- Each Duffing oscillator is specified by a frequency $\nu$, anharmonicity $\alpha$, and drive strength $r$, which result in the Hamiltonian terms:
\begin{equation}
2\pi\nu a^\dagger a + \pi \alpha a^\dagger a(a^\dagger a - 1) + 2 \pi r (a + a^\dagger) \times D(t),
\end{equation}
where $D(t)$ is the signal on the drive channel for the qubit, and $a^\dagger$ and $a$ are, respectively, the creation and annihilation operators for the qubit. Note that the drive strength $r$ sets the scaling of the control term, with $D(t)$ assumed to be a complex and unitless number satisfying $|D(t)| \leq 1$.
- A coupling between a pair of oscillators $(l,k)$ is specified by the coupling strength $J$, resulting in an exchange coupling term:
\begin{equation}
2 \pi J (a_l a_k^\dagger + a_l^\dagger a_k),
\end{equation}
where the subscript denotes which qubit the operators act on.
- Additionally, for numerical simulation, it is necessary to specify a cutoff dimension; the Duffing oscillator model is *infinite dimensional*, and computer simulation requires restriction of the operators to a finite dimensional subspace.
**In the code:** We will define a model of the above form for two coupled qubits using the helper function `duffing_system_model`.
### Section 4: $\pi$-pulse calibration using Ignis
Once the model is defined, we will calibrate $\pi$-pulses on each qubit. A $\pi$-pulse is defined as a pulse on the drive channel of a qubit that "flips" the qubit; i.e. that takes the ground state to the first excited state, and the first excited state to the ground state.
We will experimentally find a $\pi$-pulse for each qubit using the following procedure:
- A fixed pulse shape is set - in this case it will be a Gaussian pulse.
- A sequence of experiments is run, each consisting of a Gaussian pulse on the qubit, followed by a measurement, with each experiment in the sequence having a subsequently larger amplitude for the Gaussian pulse.
- The measurement data is fit, and the pulse amplitude that completely flips the qubit is found (i.e. the $\pi$-pulse amplitude).
**In the code:** Using Ignis we will construct `Schedule` objects for the above experiments, then fit the data to find the $\pi$-pulse amplitudes.
### Section 5: Cross-resonance oscillations
Once the $\pi$-pulses are calibrated, we will simulate the effects of cross-resonance driving on qubit $1$ with target qubit $0$. This means that we will drive qubit $1$ at the frequency of qubit $0$, with the goal of observing that the trajectory and oscillations of qubit $0$ *depends* on the state of qubit $1$. This phenomenon provides a basis for creating two-qubit *controlled* gates. Note: This section requires the calibration of the $\pi$-pulse in Section 4.
To observe cross-resonance driving, we will use experiments very similar to the $\pi$-pulse calibration case:
- Initially, qubit $1$ is either left in the ground state, or is driven to its first excited state using the $\pi$-pulse found in Section 4.
- A sequence of experiments is run, each consisting of a Gaussian pulse on qubit $1$ driven at the frequency of qubit $0$, followed by a measurement of both qubits, with each experiment of the sequence having a subsequently larger amplitude for the Gaussian pulse.
**In the code:** Functions for defining the experiments and visualizing the data are constructed, including a visualization of the trajectory of the target qubit on the Bloch sphere.
## 2. Imports <a name='imports'></a>
This notebook makes use of the following imports.
```
import numpy as np
from scipy.optimize import curve_fit, root
# visualization tools
import matplotlib.pyplot as plt
from qiskit.visualization.bloch import Bloch
```
Import qiskit libraries for working with `pulse` and calibration:
```
import qiskit.pulse as pulse
from qiskit.pulse.pulse_lib import Gaussian, GaussianSquare
from qiskit.compiler import assemble
from qiskit.ignis.characterization.calibrations import rabi_schedules, RabiFitter
```
Imports for qiskit pulse simulator:
```
# The pulse simulator
from qiskit.providers.aer import PulseSimulator
# function for constructing duffing models
from qiskit.providers.aer.pulse import duffing_system_model
```
## 3. Duffing oscillator system model <a name='duffing'></a>
An object representing a model for a collection of Duffing oscillators can be constructed using the `duffing_system_model` function. Here we construct a $2$ Duffing oscillator model with cutoff dimension $3$.
```
# cutoff dimension
dim_oscillators = 3
# frequencies for transmon drift terms, harmonic term and anharmonic term
# Number of oscillators in the model is determined from len(oscillator_freqs)
oscillator_freqs = [5.0e9, 5.2e9]
anharm_freqs = [-0.33e9, -0.33e9]
# drive strengths
drive_strengths = [0.02e9, 0.02e9]
# specify coupling as a dictionary (qubits 0 and 1 are coupled with a coefficient 0.002e9)
coupling_dict = {(0,1): 0.002e9}
# sample duration for pulse instructions
dt = 1e-9
# create the model
two_qubit_model = duffing_system_model(dim_oscillators=dim_oscillators,
oscillator_freqs=oscillator_freqs,
anharm_freqs=anharm_freqs,
drive_strengths=drive_strengths,
coupling_dict=coupling_dict,
dt=dt)
```
The function `duffing_system_model` returns a `PulseSystemModel` object, which is a general object for storing model information required for simulation with the `PulseSimulator`.
## 4 Calibrating $\pi$ pulses on each qubit using Ignis <a name='rabi'></a>
As described in the introduction, we now calibrate $\pi$ pulses on each qubit in `two_qubit_model`. The experiments in this calibration procedure are known as *Rabi experiments*, and the data we will observe are known as *Rabi oscillations*.
### 4.1 Constructing the schedules
We construct the schedules using the `rabi_schedules` function in Ignis. To do this, we need to supply an `InstructionScheduleMap` containing a measurement schedule.
```
# list of qubits to be used throughout the notebook
qubits = [0, 1]
# Construct a measurement schedule and add it to an InstructionScheduleMap
meas_amp = 0.025
meas_samples = 1200
meas_sigma = 4
meas_width = 1150
meas_pulse = GaussianSquare(duration=meas_samples, amp=meas_amp,
sigma=meas_sigma, width=meas_width)
acq_sched = pulse.Acquire(meas_samples, pulse.AcquireChannel(0), pulse.MemorySlot(0))
acq_sched += pulse.Acquire(meas_samples, pulse.AcquireChannel(1), pulse.MemorySlot(1))
measure_sched = pulse.Play(meas_pulse, pulse.MeasureChannel(0)) | pulse.Play(meas_pulse, pulse.MeasureChannel(1)) | acq_sched
inst_map = pulse.InstructionScheduleMap()
inst_map.add('measure', qubits, measure_sched)
```
Next, construct the Rabi schedules.
```
# construct Rabi experiments
drive_amps = np.linspace(0, 0.9, 48)
drive_sigma = 16
drive_duration = 128
drive_channels = [pulse.DriveChannel(0), pulse.DriveChannel(1)]
rabi_experiments, rabi_amps = rabi_schedules(amp_list=drive_amps,
qubits=qubits,
pulse_width=drive_duration,
pulse_sigma=drive_sigma,
drives=drive_channels,
inst_map=inst_map,
meas_map=[[0, 1]])
```
The `Schedule`s in `rabi_schedules` correspond to experiments to generate Rabi oscillations on both qubits in parallel. Each experiment consists of a Gaussian pulse on the qubits of a given magnitude, followed by measurement.
For example:
```
rabi_experiments[10].draw()
```
### 4.2 Simulate the Rabi experiments
To simulate the Rabi experiments, assemble the `Schedule` list into a qobj. When assembling, pass the `PulseSimulator` as the backend.
Here, we want to use local oscillators with frequencies automatically computed from Duffing model Hamiltonian.
```
# instantiate the pulse simulator
backend_sim = PulseSimulator()
# compute frequencies from the Hamiltonian
qubit_lo_freq = two_qubit_model.hamiltonian.get_qubit_lo_from_drift()
rabi_qobj = assemble(rabi_experiments,
backend=backend_sim,
qubit_lo_freq=qubit_lo_freq,
meas_level=1,
meas_return='avg',
shots=512)
```
Run the simulation using the simulator backend.
```
# run the simulation
rabi_result = backend_sim.run(rabi_qobj, two_qubit_model).result()
```
### 4.3 Fit and plot the data
Next, we use `RabiFitter` in Ignis to fit the data, extract the $\pi$-pulse amplitude, and then plot the data.
```
rabifit = RabiFitter(rabi_result, rabi_amps, qubits, fit_p0 = [0.5,0.5,0.6,1.5])
plt.figure(figsize=(15, 10))
q_offset = 0
for qubit in qubits:
ax = plt.subplot(2, 2, qubit + 1)
rabifit.plot(qubit, ax=ax)
print('Pi Amp: %f'%rabifit.pi_amplitude(qubit))
plt.show()
```
Plotted is the averaged IQ data for observing each qubit. Observe that here, each qubit oscillates between the 0 and 1 state. The amplitude at which a given qubit reaches the peak of the oscillation is the desired $\pi$-pulse amplitude.
## 5. Oscillations from cross-resonance drive <a name='cr'></a>
Next, we simulate the effects of a cross-resonance drive on qubit $1$ with target qubit $0$, observing that the trajectory and oscillations of qubit $0$ *depends* on the state of qubit $1$.
**Note:** This section depends on the $\pi$-pulse calibrations of Section 2.
### 5.1 Cross-resonance `ControlChannel` indices
Driving qubit $1$ at the frequency of qubit $0$ requires use of a pulse `ControlChannel`. The model generating function `duffing_system_model`, automatically sets up `ControlChannels` for performing cross-resonance drives between pairs of coupled qubits. The index of the `ControlChannel` for performing a particular cross-resonance drive is retrievable using the class method `control_channel_index` on the returned `PulseSystemModel`. For example, to get the `ControlChannel` index corresponding to a CR drive on qubit 1 with target 0, call the function `control_channel_index` with the tuple `(1,0)`:
```
two_qubit_model.control_channel_index((1,0))
```
Hence, to perform a cross-resonance drive on qubit $1$ with target qubit $0$, use `ControlChannel(1)`. This will be made use of when constructing `Schedule` objects in this section.
### 5.2 Functions to generate the experiment list, and analyze the output
First, we define a function `cr_drive_experiments`, which, given the drive and target indices, and the option to either start with the drive qubit in the ground or excited state, returns a list of experiments for observing the oscillations.
```
# store the pi amplitudes from Section 2 in a list
pi_amps = [rabifit.pi_amplitude(0), rabifit.pi_amplitude(1)]
def cr_drive_experiments(drive_idx,
target_idx,
flip_drive_qubit = False,
cr_drive_amps=np.linspace(0, 0.9, 16),
cr_drive_samples=800,
cr_drive_sigma=4,
pi_drive_samples=128,
pi_drive_sigma=16):
"""Generate schedules corresponding to CR drive experiments.
Args:
drive_idx (int): label of driven qubit
target_idx (int): label of target qubit
flip_drive_qubit (bool): whether or not to start the driven qubit in the ground or excited state
cr_drive_amps (array): list of drive amplitudes to use
cr_drive_samples (int): number samples for each CR drive signal
cr_drive_sigma (float): standard deviation of CR Gaussian pulse
pi_drive_samples (int): number samples for pi pulse on drive
pi_drive_sigma (float): standard deviation of Gaussian pi pulse on drive
Returns:
list[Schedule]: A list of Schedule objects for each experiment
"""
# Construct measurement commands to be used for all schedules
meas_amp = 0.025
meas_samples = 1200
meas_sigma = 4
meas_width = 1150
meas_pulse = GaussianSquare(duration=meas_samples, amp=meas_amp,
sigma=meas_sigma, width=meas_width)
acq_sched = pulse.Acquire(meas_samples, pulse.AcquireChannel(0), pulse.MemorySlot(0))
acq_sched += pulse.Acquire(meas_samples, pulse.AcquireChannel(1), pulse.MemorySlot(1))
# create measurement schedule
measure_sched = (pulse.Play(meas_pulse, pulse.MeasureChannel(0)) |
pulse.Play(meas_pulse, pulse.MeasureChannel(1))|
acq_sched)
# Create schedule
schedules = []
for ii, cr_drive_amp in enumerate(cr_drive_amps):
# pulse for flipping drive qubit if desired
pi_pulse = Gaussian(duration=pi_drive_samples, amp=pi_amps[drive_idx], sigma=pi_drive_sigma)
# cr drive pulse
cr_width = cr_drive_samples - 2*cr_drive_sigma*4
cr_rabi_pulse = GaussianSquare(duration=cr_drive_samples,
amp=cr_drive_amp,
sigma=cr_drive_sigma,
width=cr_width)
# add commands to schedule
schedule = pulse.Schedule(name='cr_rabi_exp_amp_%s' % cr_drive_amp)
# flip drive qubit if desired
if flip_drive_qubit:
schedule += pulse.Play(pi_pulse, pulse.DriveChannel(drive_idx))
# do cr drive
# First, get the ControlChannel index for CR drive from drive to target
cr_idx = two_qubit_model.control_channel_index((drive_idx, target_idx))
schedule += pulse.Play(cr_rabi_pulse, pulse.ControlChannel(cr_idx)) << schedule.duration
schedule += measure_sched << schedule.duration
schedules.append(schedule)
return schedules
```
Next we create two functions for observing the data:
- `plot_cr_pop_data` - for plotting the oscillations between the ground state and the first excited state
- `plot_bloch_sphere` - for viewing the trajectory of the target qubit on the bloch sphere
```
def plot_cr_pop_data(drive_idx,
target_idx,
sim_result,
cr_drive_amps=np.linspace(0, 0.9, 16)):
"""Plot the population of each qubit.
Args:
drive_idx (int): label of driven qubit
target_idx (int): label of target qubit
sim_result (Result): results of simulation
cr_drive_amps (array): list of drive amplitudes to use for axis labels
"""
amp_data_Q0 = []
amp_data_Q1 = []
for exp_idx in range(len(cr_drive_amps)):
exp_mem = sim_result.get_memory(exp_idx)
amp_data_Q0.append(np.abs(exp_mem[0]))
amp_data_Q1.append(np.abs(exp_mem[1]))
plt.plot(cr_drive_amps, amp_data_Q0, label='Q0')
plt.plot(cr_drive_amps, amp_data_Q1, label='Q1')
plt.legend()
plt.xlabel('Pulse amplitude, a.u.', fontsize=20)
plt.ylabel('Signal, a.u.', fontsize=20)
plt.title('CR (Target Q{0}, driving on Q{1})'.format(target_idx, drive_idx), fontsize=20)
plt.grid(True)
def bloch_vectors(drive_idx, drive_energy_level, sim_result):
"""Plot the population of each qubit.
Args:
drive_idx (int): label of driven qubit
drive_energy_level (int): energy level of drive qubit at start of CR drive
sim_result (Result): results of simulation
Returns:
list: list of Bloch vectors corresponding to the final state of the target qubit
for each experiment
"""
# get the dimension used for simulation
dim = int(np.sqrt(len(sim_result.get_statevector(0))))
# get the relevant dressed state indices
idx0 = 0
idx1 = 0
if drive_idx == 0:
if drive_energy_level == 0:
idx0, idx1 = 0, dim
elif drive_energy_level == 1:
idx0, idx1 = 1, dim + 1
if drive_idx == 1:
if drive_energy_level == 0:
idx0, idx1 = 0, 1
elif drive_energy_level == 1:
idx0, idx1 = dim, dim + 1
# construct Pauli operators for correct dressed manifold
state0 = np.array([two_qubit_model.hamiltonian._estates[idx0]])
state1 = np.array([two_qubit_model.hamiltonian._estates[idx1]])
outer01 = np.transpose(state0)@state1
outer10 = np.transpose(state1)@state0
outer00 = np.transpose(state0)@state0
outer11 = np.transpose(state1)@state1
X = outer01 + outer10
Y = -1j*outer01 + 1j*outer10
Z = outer00 - outer11
# function for computing a single bloch vector
bloch_vec = lambda vec: np.real(np.array([np.conj(vec)@X@vec, np.conj(vec)@Y@vec, np.conj(vec)@Z@vec]))
return [bloch_vec(sim_result.get_statevector(idx)) for idx in range(len(sim_result.results))]
def plot_bloch_sphere(bloch_vectors):
"""Given a list of Bloch vectors, plot them on the Bloch sphere
Args:
bloch_vectors (list): list of bloch vectors
"""
sphere = Bloch()
sphere.add_points(np.transpose(bloch_vectors))
sphere.show()
```
### 5.3 Drive qubit 1 to observe CR oscillations on qubit 0
#### Qubit 1 in the ground state
First, we drive with both qubit 0 and qubit 1 in the ground state.
```
# construct experiments
drive_idx = 1
target_idx = 0
flip_drive = False
experiments = cr_drive_experiments(drive_idx, target_idx, flip_drive)
# compute frequencies from the Hamiltonian
qubit_lo_freq = two_qubit_model.hamiltonian.get_qubit_lo_from_drift()
# assemble the qobj
cr_rabi_qobj = assemble(experiments,
backend=backend_sim,
qubit_lo_freq=qubit_lo_freq,
meas_level=1,
meas_return='avg',
shots=512)
```
Run the simulation:
```
sim_result = backend_sim.run(cr_rabi_qobj, two_qubit_model).result()
plot_cr_pop_data(drive_idx, target_idx, sim_result)
```
Observe that qubit 1 remains in the ground state, while excitations are driven in qubit 0.
We may also observe the trajectory of qubit 0 on the Bloch sphere:
```
bloch_vecs = bloch_vectors(drive_idx, int(flip_drive), sim_result)
plot_bloch_sphere(bloch_vecs)
```
#### Qubit 1 in the first excited state
Next, we again perform a CR drive qubit 1 with qubit 0 as the target, but now we start each experiment by flipping qubit 1 into the first excited state.
```
# construct experiments, now with flip_drive == True
drive_idx = 1
target_idx = 0
flip_drive = True
experiments = cr_drive_experiments(drive_idx, target_idx, flip_drive)
# compute frequencies from the Hamiltonian
qubit_lo_freq = two_qubit_model.hamiltonian.get_qubit_lo_from_drift()
# assemble the qobj
cr_rabi_qobj = assemble(experiments,
backend=backend_sim,
qubit_lo_freq=qubit_lo_freq,
meas_level=1,
meas_return='avg',
shots=512)
sim_result = backend_sim.run(cr_rabi_qobj, two_qubit_model).result()
plot_cr_pop_data(drive_idx, target_idx, sim_result)
```
Observe that now qubit 1 is in the excited state, while oscillations are again being driven on qubit 0, now at a different rate as before.
Again, observe the trajectory of qubit 0 on the Bloch sphere:
```
bloch_vecs = bloch_vectors(drive_idx, int(flip_drive), sim_result)
plot_bloch_sphere(bloch_vecs)
```
Here we see that qubit 0 takes a *different* trajectory on the Bloch sphere when qubit 1 is in the excited state. This is what enables controlled operations between two qubits.
```
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
| github_jupyter |
```
import json
import overpy
import pandas as pd
import geopandas as gpd
import numpy as np
from shapely.geometry import Point, GeometryCollection, shape, MultiPoint
from shapely.affinity import affine_transform
from scipy.ndimage import distance_transform_bf, distance_transform_edt
from matplotlib import pyplot as plt
from matplotlib import colors, patches
from mpl_toolkits.axes_grid1 import make_axes_locatable
from matplotlib_scalebar.scalebar import ScaleBar
from PIL import Image, ImageDraw
# (53.344249, -6.268799, 53.346190, -6.261815)
# area[alt_name="Dublin City"] -> .a;
overpass = overpy.Overpass()
result = overpass.query("""
area[name="County Dublin"] -> .a;
(
node(area.a)["amenity"="pub"];
way(area.a)["amenity"="pub"];
);
out meta center;
""")
# 53.346190, -6.268799
# 53.344249, -6.261815
pubs_from_nodes = [[n.id, n.tags.get('name', None), Point(n.lon, n.lat)]
for n in result.nodes]
pubs_from_ways = [[w.id, w.tags.get('name', None), Point(w.center_lon, w.center_lat)]
for w in result.ways
if w.center_lon and w.center_lat]
pubs = pd.DataFrame(pubs_from_nodes + pubs_from_ways, columns=['id', 'name', 'coord'])
pubs.set_index('id')
pubs = gpd.GeoDataFrame(pubs, geometry='coord')
pubs.crs = {'init': 'epsg:4326'}
pubs = pubs.to_crs(epsg=29902)
print(f"Plotting {len(pubs)} pubs")
pubs.plot(marker='.');
settlements = gpd.read_file("/Users/fester/Downloads/Census2011_Settlements/Census2011_Settlements.shp")
region = settlements[settlements.SETTL_NAME.str.contains("Dublin")]
region = region.to_crs(epsg=29902)
pubs = pubs[pubs.intersects(region.unary_union)]
base = region.plot(figsize=(30, 30), color='white', edgecolor='green')
pubs.plot(ax=base, marker='.', color='orange');
def poly_to_stencil(polygon, shape, fill=1):
vertices = list(zip(*polygon.exterior.coords.xy))
h, w = shape
raster = Image.new('1', (w, h), 0)
draw = ImageDraw.Draw(raster)
draw.polygon(vertices, fill)
return np.asarray(raster)
def scale_to_pixel_space(meters_per_pixel, min_x, min_y, max_x, max_y):
dx = max_x - min_x
dy = max_y - min_y
aspect_ratio = dx/dy
image_buffer_width = int(dx/meters_per_pixel)
image_buffer_height = int(image_buffer_width/aspect_ratio)
transformation_matrix = [image_buffer_width/dx, 0, 0, image_buffer_height/dy,
-image_buffer_width*min_x/dx, -image_buffer_height*min_y/dy]
canvas = np.ones((image_buffer_height, image_buffer_width), dtype=np.float)
def tr(sh):
return affine_transform(shape(sh), transformation_matrix)
return {'affine_transform': tr,
'canvas': canvas}
meters_per_pixel = 10
pixel_space = scale_to_pixel_space(meters_per_pixel, *region.total_bounds)
a_shape = shape(region.unary_union)
at = pixel_space['affine_transform']
canvas = pixel_space['canvas']
scaled_shape = at(a_shape)
scaled_points = pubs.coord.map(at)
canvas[np.round(scaled_points.y).astype(np.int), np.round(scaled_points.x).astype(np.int)] = 0
area_stencil = poly_to_stencil(scaled_shape, canvas.shape)
distance_map = distance_transform_edt(canvas)*meters_per_pixel
distance_map[area_stencil==False] = 0
fig, ax1 = plt.subplots(figsize=(8.27, 11.69))
ax1.axis('off')
ax1.set_title("Dublin, Ireland")
plot = ax1.imshow(distance_map, cmap='Greens', norm=colors.LogNorm(), origin='lower')
ax1.scatter(np.trunc(scaled_points.x), np.trunc(scaled_points.y), marker='o', s=0.25, c='#db1818')
patch = patches.Polygon(list(zip(*scaled_shape.exterior.coords.xy)),
fill=False, color='#ffb03b', linewidth=1.5)
ax1.add_patch(patch)
plot.set_clip_path(patch)
scale_bar = ScaleBar(meters_per_pixel, units='m', label_formatter=lambda v, u: f'{v*1000}m')
ax1.add_artist(scale_bar)
divider = make_axes_locatable(ax1)
cax = divider.new_vertical(size="3%", pad=0.2, pack_start=True)
cax.set_title('Distance scale')
fig.add_axes(cax)
fig.colorbar(plot, cax=cax, orientation="horizontal", format='%5.fm')
ax1.text(10, 13, "Author: Tymofii Baga (http://github.com/fester)\nData: OpenStreetMap, Central Statistics Office of Ireland",
fontsize='small')
fig.savefig("distmap.ps", format='ps', orientation='landscape', bbox_inches='tight', dpi=300)
```
| github_jupyter |
## Collection of snippets for Pandas
```
import pandas as pd
```
### Any `pd.Series` can also be a `pd.DataFrame`
```
my_list = [1, 2, 3]
index = ["This", "That", "What!"]
pd.DataFrame(my_list, index=index)
pd.DataFrame(my_list, columns=['a_number'], index=index)
```
### Creating dataframes using dictionaries
```
pd.Series({'name': 'Prathamesh', 'age': 28})
name = ['Jeremy', 'Sebastian', 'Rachel']
age = [45, 29, 40]
pd.DataFrame({'first_name': ['Prathamesh', 'This', 'Vinit'],
'surname': ["Sarang", "", "Sarang"],
'age': [28, "", 26]})
#surname
pd.DataFrame([['Prathamesh', 'Vinit'],
[28, 26], ['Sarang', 'Sarang']]).T
pd.DataFrame([['Prathamesh', 28, 'Sarang'],
['Vinit', 26, 'Sarang']],
columns=['name', 'age', 'surname'])
```
### We know that each column is a `pd.Series`
```
pd.DataFrame([pd.Series(['Prathamesh', 'Vinit']),
pd.Series([28, 29]),
pd.Series(['Sarang', 'Sarang'])]).T
```
### We know that each column is a `pd.Series`
```
pd.Series(my_dict)
pd.DataFrame(pd.Series(my_dict))
```
## Q: What would be the output of this?
```
pd.DataFrame([{'a': 1, 'b': 2}, {'b': 3, 'c': 4}])
```
## Before moving on, I also want to talk about numpy vectorization again!
```
np.array([1, 3, 4, 5, 5])
my_arr = np.array([1, 3, 4, 5, 5])
my_arr == 5
```
## Want to get the slice using filter
```
my_arr[my_arr == 5]
```
## You can do it similarly using pandas!
```
weather_df.head()
```
### Q: You need to return rows that has 'Weather == Kya Chal raha hai'
### Create a subset where Wind Speed is > 4
```
weather_df.columns
weather_df[weather_df['Wind Spd (km/h)'] == 4]
```
### Find all instances when wind speed was above 24 and visibility was 25
```
df = weather_df2[(weather_df2['Wind Spd (km/h)'] > 24) & (weather_df2['Visibility (km)']== 25)]
df.head()
```
## `df.query`
>DataFrame.query: Query the columns of a frame with a boolean expression.
```
# Using loc or iloc
# NOTE: slice is `:5:2`, not 6 !
# df.loc[row number/slice, 'Column name/s']
## iloc == numpy slicing! Damn!
## df.iloc[row number/slice, column number/slice]
```
## You can do a lot of things with the indices as well: `df.sort_index`
```
weather_df2.sort_index(ascending=False).head()
```
## If you have sort values by index, then shouldn't there be sort_by_value?
```
weather_df2.sort_values(by=['Temp (C)', 'Dew Point Temp (C)'], ascending=False)
```
## `.dt.` or `DateTime` Operator
### What if I don't want datetime values as indices, but I want to get the datetime values as datetime?
```
weather_df['datetime'] = pd.to_datetime(weather_df['datetime'])
weather_df['month'] = weather_df['datetime'].dt.month
weather_df['day'] = weather_df['datetime'].dt.day
weather_df['quarter'] = weather_df['datetime'].dt.quarter
weather_df['quarter'].value_counts()
weather_df[weather_df['quarter'] == 2].shape[0]
```
## `.join()` and `merge()` operations
### The Data
```
name = ['Magneto', 'Storm', 'Mystique',
'Batman', 'Joker', 'Catwoman', 'Hellboy']
alignment = ['bad', 'good', 'bad', 'good',
'bad', 'bad', 'good']
gender = ['male', 'female', 'female',
'male', 'male', 'female', 'male']
publisher = ['Marvel', 'Marvel', 'Marvel',
'DC', 'DC', 'DC', 'Dark Horse Comics']
superheroes1 = pd.DataFrame({'name': name,
'alignment': alignment,
'gender': gender,
'publisher': publisher})
publisher_unique = ['Marvel', 'DC', 'Image']
year_founded = ['1934', '1939', '1992']
publishers = pd.DataFrame({'publisher': publisher_unique,
'year_founded': year_founded})
superheroes2 = pd.DataFrame({'name': ['Black Widow', 'Superman'], 'alignment': ['good', 'good'],
'gender': ['female', 'male'], 'publisher': ['Marvel', 'DC']})
superheroes1
superheroes2
publishers
```
## Concat
Many a time, we are required to combine different arrays. So, instead of typing each of their elements manually, you can use array concatenation to handle such tasks easily.
```
pd.concat([superheroes1, superheroes2]).reset_index(drop=True)
superheroes = pd.concat([superheroes1, superheroes2], ignore_index=True)
```

```
superheroes
publishers
```
## Merge
Many a times you will be working with multiple dataframes all at once.
The merge function allows them to be combined into a single data frame
```
pd.merge(superheroes,
publishers,
on='publisher',
how='left')
pd.merge(superheroes,
publishers,
on='publisher',
how='inner')
pd.merge(superheroes,
publishers,
on='publisher',
how='right')
pd.merge(superheroes1,
publishers,
on='publisher',
how='outer')
```
## Join
***
Simply join two DFs having potentially different row indices
You can do both inner as well as outer joins using the join function in pandas
- Parameters {‘inner’, ‘outer’}, default ‘outer’. Outer for union and inner for intersection.
### `left` join
```
superheroes1.info()
publishers.info()
publishers
superheroes1.set_index('publisher')
superheroes1.set_index('publisher').join(publishers.set_index('publisher'), how='left', rsuffix='_publisher')
superheroes1.set_index('publisher').join(publishers.set_index('publisher'), how='left', rsuffix='_publisher').reset_index()
```
### `outer` join
### `inner` join
### `right` join
## Add a few rows as lists
```
date_time = ['2012-13-01', '2013-01-01', '2013-01-02', '2012-01-02']
```
## Letting few of them to be NaNs
```
temp = [np.nan, np.nan, 30, 12]
dew_pt_temp = [-2, np.nan, np.nan, -1]
relative_humidity = [np.nan, np.nan, np.nan, np.nan]
wind_speed = [np.nan, np.nan, np.nan, 50]
visibility = [np.nan, 10.0, np.nan, 12.1]
stn_pressure = [104.1, np.nan, 101.2, 101.24]
weather = ['Snow', None, None, 'Fog']
```
## Create a new dataframe
```
pd.DataFrame([date_time, temp, dew_pt_temp, relative_humidity, wind_speed, visibility, stn_pressure, weather])
weather_df3 = pd.DataFrame([date_time, temp, dew_pt_temp, relative_humidity, wind_speed, visibility, stn_pressure, weather]).T
weather_df3.columns.tolist()
weather_df3.columns = ['Date/Time', 'Temp (C)', 'Dew Point Temp (C)', 'Rel Hum (%)', 'Wind Spd (km/h)', 'Visibility (km)', 'Stn Press (kPa)', 'Weather']
weather_df3.columns.tolist()
```
### Display the dataframe
```
weather_df3.head()
```
### Append the `weather_df2` and `weather_df3` by rows
```
weather_df_appended_1 = weather_df.append(weather_df3)
weather_df_appended_1.reset_index(drop=True, inplace=True)
weather_df_appended_1.tail(10)
weather_df_appended2 = weather_df.append(weather_df3, ignore_index=True)
```
## Dealing with missing values
```
weather_df.tail()
```
## How do you filter out the NaNs
* Check the NaNs: `df.isna()`
* Check the Null values: `df.isnull()`
## How do you treat those nulls or NaNs:
* Drop the rows entirely!: `df.dropna()`
* Fill the values with something: `df.fillna()`
## We want count of the values: `.sum()`
```
weather_df_appended2.isnull().sum()
```
## What if we just want to check if there's null data or not?: `.any()`
```
weather_df_appended2.isnull().any()
```
### Finding the count of nan and empty strings (yes, empty string "" or " " is not handled separately, occurs mostly in character and categorical variable list)
## Remember the numpy aggregate operations?
## using df.mean to do fill operations
```
weather_df_appended2['Temp (C)'].mean()
weather_df_appended2['Temp (C)'].fillna(value=weather_df_appended2['Temp (C)'].mean()).tail()
```
## Working with string, more examples!
```
monte = pd.Series(['Graham Chapman', 'John Cleese', 'Terry Gilliam',
'Eric Idle', 'Terry Jones', 'Michael Palin'])
```
### There are generic methods: `.str.`
### But there's one essential thing: using regexes
```bash
Method Description
match() Call re.match() on each element, returning a boolean.
extract() Call re.match() on each element, returning matched groups as strings.
findall() Call re.findall() on each element
replace() Replace occurrences of pattern with some other string
contains() Call re.search() on each element, returning a boolean
count() Count occurrences of pattern
split() Equivalent to str.split(), but accepts regexps
rsplit() Equivalent to str.rsplit(), but accepts regexps
```
## Using DateTime
```
from datetime import datetime
datetime.now()
```
### `strftime` formatting in python
### [One stop source](http://strftime.org/)
```
from dateutil import parser
date = parser.parse("4th of July, 2015")
date
date.strftime("%d")
dates = pd.to_datetime([datetime(2015, 7, 3), '4th of July, 2015',
'2015-Jul-6', '07-07-2015', '20150708', '2010/11/12', '2010.11.12'])
dates
```
## Formatting is baked in `pd.to_datetime`
```
pd.to_datetime('2010/11/12', format='%Y/%m/%d')
```
## We talking about this yesterday!
```
pd.date_range(start, periods=1000, freq='M')
```
## Requested snippet:
### What if there's a date: '13-13-2018'
```
dates = pd.to_datetime([datetime(2015, 7, 3), '4th of July, 2015',
'2015-Jul-6', '07-07-2015', '20150708'])
dates
```
## Working with Categorical Variables
```
weather_df_appended2['Weather'].head()
#pd.get_dummies(weather_df, columns=['Weather'])
```
## Few other tricks:
### * Reading directly from a simple html webpage
```
tables = pd.read_html("http://www.basketball-reference.com/leagues/NBA_2016_games.html")
```
| github_jupyter |
# Overwriting feature layers
As content publishers, you may be required to keep certain web layers up to date. As new data arrives, you may have to append new features, update existing features etc. There are a couple of different options to accomplish this:
- Method 1: editing individual features as updated datasets are available
- Method 2: overwriting feature layers altogether with updated datasets
Depending on the number of features that are updated, your workflow requirements, you may adopt either or both kinds of update mechanisms.
In the sample [Updating features in a feature layer](python/sample-notebooks/updating-features-in-a-feature-layer/) we explore method 1. In this sample, we explore method 2.
**Method 2**
- [Introduction](#Introduction)
- [Publish the cities feature layer using the initial dataset](Publish-the-cities-feature-layer-using-the-initial-dataset)
- [Merge updates from spreadsheets 1 and 2](#Merge-updates-from-spreadsheets-1-and-2)
- [Write the updates to disk](#Write-the-updates-to-disk)
- [Overwrite the feature layer](#Overwrite-the-feature-layer)
- [Access the overwritten feature layer](#Access-the-overwritten-feature-layer)
- [Conclusion](#Conclusion)
```
# Import libraries
from arcgis.gis import GIS
from arcgis import features
import pandas as pd
# Connect to the GIS
gis = GIS(profile="your_enterprise_profile")
```
## Introduction
Let us consider a scenario where we need to update a feature layer containing the capital cities of the US. We have 2 csv datasets simulating an update workflow as described below:
1. capitals_1.csv -- contains the initial, incomplete dataset which is published as a feature layer
2. capitals_2.csv -- contains additional points and updates to existing points, building on top of usa_capitals_1.csv
Our goal is to update the features in the feature layer with the latest information contained in both the spreadsheets. We will accomplish this through the following steps
1. Add `capitals_1.csv` as an item.
2. Publish the csv as a feature layer. This simulates a typical scenario where a feature layer is published with initial set of data that is available.
3. After updated information is available in `capitals_2.csv`, we will merge both spread sheets.
4. Overwrite the feature layer using the new spread sheet file.
When you overwrite a feature layer, only the features get updated. All other information such as the feature layer's item id, comments, summary, description etc. remain the same. This way, any web maps or scenes that have this layer remains valid. Overwriting a feature layer also updates the related data item from which it was published. In this case, it will also update the csv data item with the updated spreadsheet file.
**Note**: Overwrite capability was introduced in ArcGIS Enterprise 10.5 and in ArcGIS Online. This capability is currently only available for feature layers. Further, ArcGIS sets some limits when overwriting feature layers:
1. The name of the file that used to update in step 4 above should match the original file name of the item.
2. The schema -- number of layers (applicable when your original file is a file geodatabase / shape file / service definition), and the name and number of attribute columns should remain the same as before.
The **method 2** explained in this sample is much simpler compared to **method 1** explained in [Updating features in a feature layer](https://developers.arcgis.com/python/sample-notebooks/updating-features-in-a-feature-layer/). However, we cannot make use of the third spreadsheet which has the additional columns for our capitals. To do that, we would first update the features through overwriting, then edit the definition of the feature layer to add new columns and then edit each feature and add the appropriate column values, similar to that explained in method 1.
## Publish the cities feature layer using the initial dataset
```
# import libraries so you use unique file names for creating items
# and services to this geosaurus.maps.arcgis.com organization
# if you've download the samples or are working with your own organization
# or Enterprise, this may not be necessary and you could just read the
# csv data directly instead of copyting the file:
#
# my_csv = os.path.join(data_path, csv_file)
import datetime as dt
import os
import shutil
# assign path variables for data
data_path = os.path.join('data', 'updating_gis_content')
csv_file = 'capitals_1.csv'
# assign variable to current timestamp to make unique file to add to portal
now = int(dt.datetime.now().timestamp())
# copy original file for adding to portal
my_csv = shutil.copy2(os.path.join(data_path, csv_file),
os.path.join(data_path, csv_file.split('.')[0] + '_' + str(now) + '.csv'))
# read the initial csv
cities_df_1 = pd.read_csv(my_csv)
cities_df_1.head()
# print the number of records in this csv
cities_df_1.shape
# add the csv as an item
item_prop = {'title':'USA Capitals spreadsheet_' + str(now)}
csv_item = gis.content.add(item_properties=item_prop, data=my_csv)
csv_item
# publish the csv item into a feature layer
cities_item = csv_item.publish()
cities_item
# update the item metadata
item_prop = {'title':'USA Capitals 2'}
cities_item.update(item_properties = item_prop,
thumbnail=os.path.join('data','updating_gis_content','capital_cities.png'))
cities_item
map1 = gis.map('USA')
map1
map1.zoom = 3
map1.center = [39, -98]
map1.add_layer(cities_item)
cities_item.url
```
## Merge updates from spreadsheet 2 with 1
The next set of updates have arrived and are stored in `capitals_2.csv`. We are told it contains corrections for the original set of features and also has new features.
Instead of applying the updates one at a time, we will merge both the spreadsheets into a new one.
```
# read the second csv set
csv2 = os.path.join('data', 'updating_gis_content', 'capitals_2.csv')
cities_df_2 = pd.read_csv(csv2)
cities_df_2.head(5)
# get the dimensions of this csv
cities_df_2.shape
```
Let us `append` the spreadsheets 1 and 2 and store it in a DataFrame called `updated_df`. Note, this step introduces duplicate rows that were updated in spreadsheet 2.
```
updated_df = cities_df_1.append(cities_df_2)
updated_df.shape
```
Next, we must drop the duplicate rows. Note, in this sample, the `city_id` column has unique values and is present in all spreadsheets. Thus, we are able to determine duplicate rows using this column and drop them.
```
updated_df.drop_duplicates(subset='city_id', keep='last', inplace=True)
# we specify argument keep = 'last' to retain edits from second spreadsheet
updated_df.shape
```
Thus we have dropped 4 rows from spreadsheet 1 and retained the same 4 rows with updated values from spreadsheet 2. Let us see how the DataFrame looks so far:
```
updated_df.head(5)
```
### Write the updates to disk
Let us create a new folder called `updated_capitals_csv` and write the updated features to a csv with the same name as our first csv file.
```
import os
if not os.path.exists(os.path.join('data', 'updating_gis_content','updated_capitals_csv')):
os.mkdir(os.path.join('data', 'updating_gis_content','updated_capitals_csv'))
updated_df.to_csv(os.path.join('data', 'updating_gis_content',
'updated_capitals_csv', 'capitals_1.csv'))
```
## Overwrite the feature layer
Let us overwrite the feature layer using the new csv file we just created. To overwrite, we will use the `overwrite()` method.
```
from arcgis.features import FeatureLayerCollection
cities_flayer_collection = FeatureLayerCollection.fromitem(cities_item)
#call the overwrite() method which can be accessed using the manager property
cities_flayer_collection.manager.overwrite(os.path.join('data', 'updating_gis_content',
'updated_capitals_csv', 'capitals_1.csv'))
```
### Access the overwritten feature layer
Let us query the feature layer and verify the number of features has increased to `51`.
```
cities_flayer = cities_item.layers[0] #there is only 1 layer
cities_flayer.query(return_count_only=True) #get the total number of features
```
Let us draw this new layer in map
```
map2 = gis.map("USA")
map2
map2.zoom = 3
map2.center = [39, -98]
map2.add_layer(cities_item)
```
As seen from the map, the number of features has increased while the symbology while the attribute columns remain the same as original.
## Conclusion
Thus, in this sample, we observed how update a feature layer by overwriting it with new content. This method is a lot simpler than method 1 explained in [Updating features in a feature layer](https://developers.arcgis.com/python/sample-notebooks/updating-features-in-a-feature-layer/) sample. However, with this simplicity, we compromise on our ability to add new columns or change the schema of the feature layer during the update. Further, if your feature layer was updated after it was published, then those updates get overwritten when you perform the overwrite operation. To retain those edits, [extract the data](https://developers.arcgis.com/python/guide/checking-out-data-from-feature-layers-using-replicas/#Verify-Extract-capability) from the feature layer, merge your updates with this extract, then overwrite the feature layer.
| github_jupyter |
# Vessels API Example
## Setup
Install the Signal Ocean SDK:
```
pip install signal-ocean
```
And put your API key in a `SIGNAL_OCEAN_API_KEY` environment variable.
```
pip install signal-ocean
signal_ocean_api_key = '' #replace with your subscription key
from signal_ocean.vessels import VesselsAPI
import pandas as pd
import seaborn as sns
from datetime import datetime
from signal_ocean import Connection
connection = Connection(signal_ocean_api_key)
```
## Call the vessels API
The Vessels API retrieves vessel information.
```
api = VesselsAPI(connection)
```
#### Get vessel classes
```
vessel_classes = api.get_vessel_classes()
aframax_vesel_class = next(vc for vc in vessel_classes if vc.name=='Aframax')
aframax_vesel_class
pd.DataFrame([vc.__dict__ for vc in vessel_classes]).tail(5)
```
#### Get vessel types
```
vessel_types = api.get_vessel_types()
tanker_vessel_type = next(vt for vt in vessel_types if vt.name=='Dry')
tanker_vessel_type
pd.DataFrame([vc.__dict__ for vc in vessel_types]).tail(3)
```
#### Get details for a specific vessel
```
imo = 9436006
v = api.get_vessel(imo)
print(f'{v.imo}: {v.vessel_name} ({v.vessel_class} / {v.commercial_operator})')
```
#### Get details for all vessels
```
vessels = api.get_vessels()
len(vessels)
df = pd.DataFrame([x.__dict__ for x in vessels])
df.columns
df[['imo', 'vessel_name', 'vessel_class']].sample(10)
```
#### Find fleet size per vessel class
```
df[pd.isnull(df['scrapped_date'])]['vessel_class'].value_counts().to_frame('vessel_count').head(10)
```
#### Find the commercial operators that currently operate the largest Aframax fleets
```
data = df[(df['vessel_class']=='Aframax')&(pd.isnull(df['scrapped_date']))]
data['commercial_operator'].value_counts().head(10)
```
#### Visualize fleet age by vessel class for VLCC, Suezmax and Aframax Tankers
```
df['vessel_age'] = df.apply(lambda r: datetime.now().year - r['year_built'], axis=1)
data = df[(pd.isnull(df['scrapped_date']))&(df['vessel_class'].isin(['VLCC', 'Suezmax', 'Aframax']))]
sns.kdeplot(data=data, x='vessel_age', hue='vessel_class', multiple="stack");
```
#### Visualize pairwise relationships for deadweight, length_overall and breadth_extreme for VLCC, Suezmax and Aframax Tankers
```
data = df[(pd.isnull(df['scrapped_date']))&(df['vessel_class'].isin(['VLCC', 'Suezmax', 'Aframax']))]
sns.pairplot(data, kind='kde', hue='vessel_class', vars=['deadweight', 'length_overall', 'breadth_extreme']);
```
#### Get all vessels the name of which contains the term signal
```
vessels = api.get_vessels('signal')
len(vessels)
df = pd.DataFrame([x.__dict__ for x in vessels])
df.head(3)
```
| github_jupyter |
# Regression Models and Simulation for Problem 3
```
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import linalg
from scipy import stats
computer_data = pd.read_csv('./computer-data-hw1.csv')
fig = plt.figure(figsize=(6, 3.75))
ax = fig.gca()
ax.grid(True)
for i, subject in enumerate(computer_data['subj'].unique()):
sub_data = computer_data[computer_data['subj'] == subject]
ax.plot(sub_data['total.age'], sub_data['literacy'].values, '-k')
for i, follow_per in enumerate(computer_data['follow.per'].unique()):
sub_data = computer_data[computer_data['follow.per'] == follow_per]
ax.plot(sub_data['total.age'], sub_data['literacy'],
'o', color=plt.cm.Set1(i), label='{}'.format(follow_per))
ax.set_xlabel('Age')
ax.set_ylabel('Literacy')
ax.set_title('Longitudal Subject Literacy Scores')
ax.legend(title='Follow Period')
fig.tight_layout()
fig.savefig('p3_data.pdf', bbox_inches='tight')
computer_data.head(n=10)
computer_data[computer_data['follow.per'] == 1].describe()
def fit_ols(X, y):
gram_matrix = X.T.dot(X)
gram_matrix_inv = linalg.cho_solve(linalg.cho_factor(gram_matrix), np.eye(len(gram_matrix)))
beta_hat = gram_matrix_inv.dot(X.T).dot(y)
sigma_2_hat = np.sum(np.square(y - X.dot(beta_hat)))/(len(y) - len(beta_hat))
return beta_hat, gram_matrix_inv*sigma_2_hat, sigma_2_hat
def fit_original(data):
X = np.column_stack((np.ones(len(data)), data[['base.age', 'delta.age']].values))
y = data['literacy'].values
return fit_ols(X, y)
fit_original(computer_data)
def fit_alternative(data):
sub_data = data[data['follow.per'] == 0][['subj', 'literacy']]
sub_data = pd.merge(data, sub_data.rename(columns={'literacy': 'base.literacy'}))
sub_data = sub_data[sub_data['follow.per'] != 0]
X = sub_data[['delta.age']].values
y = sub_data['literacy'].values - sub_data['base.literacy'].values
return fit_ols(X, y)
fit_alternative(computer_data)
```
## Simulations
```
def make_covariates(n):
X = []
for i in range(n):
base_age = stats.uniform.rvs(0, 15)
X.append([i, base_age, 0, 0])
for j in range(2):
delta_age = stats.norm.rvs(3 + j*3, scale=0.5)
X.append([i, base_age, delta_age, j + 1])
return pd.DataFrame(X, columns=['subj', 'base.age', 'delta.age', 'follow.per'])
def make_independent_covariates(n):
subj = {}
X = []
for i in range(n):
base_age = stats.uniform.rvs(0, 15)
X.append([i, base_age, 0, 0])
subj[i] = {'follow_per': 0, 'base_age': base_age}
for j in range(n*2):
i = stats.randint.rvs(low=0, high=n)
subj[i]['follow_per'] += 1
X.append([i, subj[i]['base_age'], stats.uniform.rvs(0, 10), subj[i]['follow_per']])
return pd.DataFrame(X, columns=['subj', 'base.age', 'delta.age', 'follow.per'])
def make_response(data, f):
data = data.copy()
data['literacy'] = stats.norm.rvs(f(data['base.age']) + 2*data['delta.age'], scale=1)
return data
np.random.seed(2020)
simulated_data = make_covariates(64)
```
### Both Assumptions Violated
```
beta_hat_original_estimates = []
beta_hat_alternative_estimates = []
for i in range(100):
response_data = make_response(simulated_data, lambda x: 200*np.exp(-x))
beta_hat, beta_hat_variance, sigma_2_hat = fit_original(response_data)
beta_hat_original_estimates.append(beta_hat)
beta_hat, beta_hat_variance, sigma_2_hat = fit_alternative(response_data)
beta_hat_alternative_estimates.append(beta_hat)
np.mean(beta_hat_original_estimates, 0), np.mean(beta_hat_alternative_estimates, 0)
```
### Linear $f$ but Dependent Covariates
Only the Part (b) condition is now violated.
```
beta_hat_original_estimates = []
beta_hat_alternative_estimates = []
for i in range(100):
response_data = make_response(simulated_data, lambda x: 200 - 12*x)
beta_hat, beta_hat_variance, sigma_2_hat = fit_original(response_data)
beta_hat_original_estimates.append(beta_hat)
beta_hat, beta_hat_variance, sigma_2_hat = fit_alternative(response_data)
beta_hat_alternative_estimates.append(beta_hat)
np.mean(beta_hat_original_estimates, 0), np.mean(beta_hat_alternative_estimates, 0)
```
### Non-linear $f$ but Independent Covariates
Only the Part (a) condition is violated now.
```
beta_hat_original_estimates = []
beta_hat_alternative_estimates = []
np.random.seed(2019)
for i in range(1024):
simulated_data = make_independent_covariates(64)
response_data = make_response(simulated_data, lambda x: 200*np.exp(-x))
beta_hat, beta_hat_variance, sigma_2_hat = fit_original(response_data)
beta_hat_original_estimates.append(beta_hat)
beta_hat, beta_hat_variance, sigma_2_hat = fit_alternative(response_data)
beta_hat_alternative_estimates.append(beta_hat)
np.mean(beta_hat_original_estimates, 0), np.mean(beta_hat_alternative_estimates, 0)
```
### Standard Error Simulations
```
beta_hat_estimates = []
beta_hat_l_variances = []
is_covered = []
is_covered_sandwich = []
np.random.seed(2019)
for i in range(2048):
simulated_data = make_independent_covariates(64)
response_data = make_response(simulated_data, lambda x: 200*np.exp(-x))
beta_hat, beta_hat_variance, sigma_2_hat = fit_original(response_data)
X = np.column_stack((np.ones(len(response_data)), response_data[['base.age', 'delta.age']].values))
y = response_data['literacy']
gram_inverse = beta_hat_variance/sigma_2_hat
sandwich_variance = X.T.dot(np.diag(np.square(y - X.dot(beta_hat)))).dot(X)
sandwich_variance = gram_inverse.dot(sandwich_variance).dot(gram_inverse)
beta_hat_estimates.append(beta_hat)
beta_hat_l_variances.append(beta_hat_variance[2,2])
is_covered.append(np.abs(beta_hat[2] - 2) <= stats.norm.ppf(0.975)*np.sqrt(beta_hat_variance[2,2]))
is_covered_sandwich.append(np.abs(beta_hat[2] - 2) <= stats.norm.ppf(0.975)*np.sqrt(sandwich_variance[2,2]))
np.sum(is_covered)/len(is_covered), np.sum(is_covered_sandwich)/len(is_covered_sandwich)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/NeuromatchAcademy/course-content-dl/blob/main/tutorials/W3D3_ReinforcementLearningForGames/W3D3_Tutorial1.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a> <a href="https://kaggle.com/kernels/welcome?src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content-dl/main/tutorials/W3D3_ReinforcementLearningForGames/W3D3_Tutorial1.ipynb" target="_parent"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open in Kaggle"/></a>
# Tutorial 1: Learn to play games with RL
**Week 3, Day 3: Reinforcement Learning for Games**
**By Neuromatch Academy**
__Content creators:__ Mandana Samiei, Raymond Chua, Tim Lilicrap, Blake Richards
__Content reviewers:__ Arush Tagade, Lily Cheng, Melvin Selim Atay, Kelson Shilling-Scrivo
__Content editors:__ Melvin Selim Atay, Spiros Chavlis
__Production editors:__ Namrata Bafna, Spiros Chavlis
**Our 2021 Sponsors, including Presenting Sponsor Facebook Reality Labs**
<p align='center'><img src='https://github.com/NeuromatchAcademy/widgets/blob/master/sponsors.png?raw=True'/></p>
---
# Tutorial Objectives
In this tutotial, you will learn how to implement a game loop and improve the performance of a random player.
The specific objectives for this tutorial:
* Understand the format of two-players games
* Learn about value network and policy network
In the Bonus sections you will learn about Monte Carlo Tree Search (MCTS) and compare its performance to policy-based and value-based players.
```
# @title Tutorial slides
# @markdown These are the slides for the videos in the tutorial
# @markdown If you want to locally download the slides, click [here](https://osf.io/3zn9w/download)
from IPython.display import IFrame
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/3zn9w/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)
```
---
# Setup
```
# @title Install dependencies
!pip install coloredlogs --quiet
!pip install git+https://github.com/NeuromatchAcademy/evaltools --quiet
from evaltools.airtable import AirtableForm
# generate airtable form
atform = AirtableForm('appn7VdPRseSoMXEG','W3D3_T1','https://portal.neuromatchacademy.org/api/redirect/to/2baacd95-3fb5-4399-bf95-bbe5de255d2b')
# Imports
import os
import math
import time
import torch
import random
import logging
import coloredlogs
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from tqdm.notebook import tqdm
from pickle import Unpickler
log = logging.getLogger(__name__)
coloredlogs.install(level='INFO') # Change this to DEBUG to see more info.
# @title Set random seed
# @markdown Executing `set_seed(seed=seed)` you are setting the seed
# for DL its critical to set the random seed so that students can have a
# baseline to compare their results to expected results.
# Read more here: https://pytorch.org/docs/stable/notes/randomness.html
# Call `set_seed` function in the exercises to ensure reproducibility.
import random
import torch
def set_seed(seed=None, seed_torch=True):
if seed is None:
seed = np.random.choice(2 ** 32)
random.seed(seed)
np.random.seed(seed)
if seed_torch:
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
print(f'Random seed {seed} has been set.')
# In case that `DataLoader` is used
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
np.random.seed(worker_seed)
random.seed(worker_seed)
# @title Set device (GPU or CPU). Execute `set_device()`
# especially if torch modules used.
# inform the user if the notebook uses GPU or CPU.
def set_device():
device = "cuda" if torch.cuda.is_available() else "cpu"
if device != "cuda":
print("WARNING: For this notebook to perform best, "
"if possible, in the menu under `Runtime` -> "
"`Change runtime type.` select `GPU` ")
else:
print("GPU is enabled in this notebook.")
return device
SEED = 2021
set_seed(seed=SEED)
DEVICE = set_device()
# @title Download the modules
# @markdown Run this cell!
# @markdown Download from OSF. Original repo: https://github.com/raymondchua/nma_rl_games.git
import os, io, sys, shutil, zipfile
from urllib.request import urlopen
# download from github repo directly
#!git clone git://github.com/raymondchua/nma_rl_games.git --quiet
REPO_PATH = 'nma_rl_games'
if os.path.exists(REPO_PATH):
download_string = "Redownloading"
shutil.rmtree(REPO_PATH)
else:
download_string = "Downloading"
zipurl = 'https://osf.io/kf4p9/download'
print(f"{download_string} and unzipping the file... Please wait.")
with urlopen(zipurl) as zipresp:
with zipfile.ZipFile(io.BytesIO(zipresp.read())) as zfile:
zfile.extractall()
print("Download completed.")
print(f"Add the {REPO_PATH} in the path and import the modules.")
# add the repo in the path
sys.path.append('nma_rl_games/alpha-zero')
# @markdown Import modules designed for use in this notebook
import Arena
from utils import *
from Game import Game
from MCTS import MCTS
from NeuralNet import NeuralNet
from othello.OthelloPlayers import *
from othello.OthelloLogic import Board
from othello.OthelloGame import OthelloGame
from othello.pytorch.NNet import NNetWrapper as NNet
```
The hyperparameters used throughout the notebook.
```
args = dotdict({
'numIters': 1, # in training setting this was 1000 and num of episodes=100
'numEps': 1, # Number of complete self-play games to simulate during a new iteration.
'tempThreshold': 15, # To control exploration and exploitation
'updateThreshold': 0.6, # During arena playoff, new neural net will be accepted if threshold or more of games are won.
'maxlenOfQueue': 200, # Number of game examples to train the neural networks.
'numMCTSSims': 15, # Number of games moves for MCTS to simulate.
'arenaCompare': 10, # Number of games to play during arena play to determine if new net will be accepted.
'cpuct': 1,
'maxDepth':5, # Maximum number of rollouts
'numMCsims': 5, # Number of monte carlo simulations
'mc_topk': 3, # top k actions for monte carlo rollout
'checkpoint': './temp/',
'load_model': False,
'load_folder_file': ('/dev/models/8x100x50','best.pth.tar'),
'numItersForTrainExamplesHistory': 20,
# define neural network arguments
'lr': 0.001, # lr: learning rate
'dropout': 0.3,
'epochs': 10,
'batch_size': 64,
'device': DEVICE,
'num_channels': 512,
})
```
---
# Section 0: Introduction
```
# @title Video 0: Introduction
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1Yh411B7EP", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"5kQ-xGbjlJo", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 0: Introduction')
display(out)
```
---
# Section 1: Create a game/agent loop for RL
*Time estimate: ~15mins*
```
# @title Video 1: A game loop for RL
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1Wy4y1V7bt", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"aH2Hs8f6KrQ", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 1: A game loop for RL')
display(out)
```
***Goal***: How to setup a game environment with multiple players for reinforcement learning experiments.
***Exercise***:
* Build an agent that plays random moves
* Connect with connect 4 game
* Generate games including wins and losses
```
class OthelloGame(Game):
square_content = {
-1: "X",
+0: "-",
+1: "O"
}
@staticmethod
def getSquarePiece(piece):
return OthelloGame.square_content[piece]
def __init__(self, n):
self.n = n
def getInitBoard(self):
# return initial board (numpy board)
b = Board(self.n)
return np.array(b.pieces)
def getBoardSize(self):
# (a,b) tuple
return (self.n, self.n)
def getActionSize(self):
# return number of actions, n is the board size and +1 is for no-op action
return self.n*self.n + 1
def getNextState(self, board, player, action):
# if player takes action on board, return next (board,player)
# action must be a valid move
if action == self.n*self.n:
return (board, -player)
b = Board(self.n)
b.pieces = np.copy(board)
move = (int(action/self.n), action%self.n)
b.execute_move(move, player)
return (b.pieces, -player)
def getValidMoves(self, board, player):
# return a fixed size binary vector
valids = [0]*self.getActionSize()
b = Board(self.n)
b.pieces = np.copy(board)
legalMoves = b.get_legal_moves(player)
if len(legalMoves)==0:
valids[-1]=1
return np.array(valids)
for x, y in legalMoves:
valids[self.n*x+y]=1
return np.array(valids)
def getGameEnded(self, board, player):
# return 0 if not ended, 1 if player 1 won, -1 if player 1 lost
# player = 1
b = Board(self.n)
b.pieces = np.copy(board)
if b.has_legal_moves(player):
return 0
if b.has_legal_moves(-player):
return 0
if b.countDiff(player) > 0:
return 1
return -1
def getCanonicalForm(self, board, player):
# return state if player==1, else return -state if player==-1
return player*board
def getSymmetries(self, board, pi):
# mirror, rotational
assert(len(pi) == self.n**2+1) # 1 for pass
pi_board = np.reshape(pi[:-1], (self.n, self.n))
l = []
for i in range(1, 5):
for j in [True, False]:
newB = np.rot90(board, i)
newPi = np.rot90(pi_board, i)
if j:
newB = np.fliplr(newB)
newPi = np.fliplr(newPi)
l += [(newB, list(newPi.ravel()) + [pi[-1]])]
return l
def stringRepresentation(self, board):
return board.tobytes()
def stringRepresentationReadable(self, board):
board_s = "".join(self.square_content[square] for row in board for square in row)
return board_s
def getScore(self, board, player):
b = Board(self.n)
b.pieces = np.copy(board)
return b.countDiff(player)
@staticmethod
def display(board):
n = board.shape[0]
print(" ", end="")
for y in range(n):
print(y, end=" ")
print("")
print("-----------------------")
for y in range(n):
print(y, "|", end="") # print the row #
for x in range(n):
piece = board[y][x] # get the piece to print
print(OthelloGame.square_content[piece], end=" ")
print("|")
print("-----------------------")
```
## Section 1.1: Create a random player
### Coding Exercise 1.1: Implement a random player
```
class RandomPlayer():
def __init__(self, game):
self.game = game
def play(self, board):
#################################################
## TODO for students: ##
## 1. Please compute the valid moves using getValidMoves(). ##
## 2. Compute the probability over actions.##
## 3. Pick a random action based on the probability computed above.##
# Fill out function and remove ##
raise NotImplementedError("Implement the random player")
#################################################
valids = ...
prob = ...
a = ...
return a
# add event to airtable
atform.add_event('Coding Exercise 1.1: Implement a random player')
# to_remove solution
class RandomPlayer():
def __init__(self, game):
self.game = game
def play(self, board):
valids = self.game.getValidMoves(board, 1)
prob = valids/valids.sum()
a = np.random.choice(self.game.getActionSize(), p=prob)
return a
# add event to airtable
atform.add_event('Coding Exercise 1.1: Implement a random player')
```
## Section 1.2. Initiate the game board
```
# Display the board
set_seed(seed=SEED)
game = OthelloGame(6)
board = game.getInitBoard()
game.display(board)
# observe the game board size
print(f'Board size = {game.getBoardSize()}')
# observe the action size
print(f'Action size = {game.getActionSize()}')
```
## Section 1.3. Create two random agents to play against each other
```
# define the random player
player1 = RandomPlayer(game).play # player 1 is a random player
player2 = RandomPlayer(game).play # player 2 is a random player
# define number of games
num_games = 20
# start the competition
set_seed(seed=SEED)
arena = Arena.Arena(player1, player2 , game, display=None) # to see the steps of the competition set "display=OthelloGame.display"
result = arena.playGames(num_games, verbose=False) # return ( number of games won by player1, num of games won by player2, num of games won by nobody)
print(f"\n\n{result}")
```
```
(11, 9, 0)
```
## Section 1.4. Compute win rate for the random player (player 1)
```
print(f"Number of games won by player1 = {result[0]}, "
f"Number of games won by player2 = {result[1]} out of {num_games} games")
win_rate_player1 = result[0]/num_games
print(f"\nWin rate for player1 over 20 games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 11, Number of games won by player2 = 9 out of 20 games
Win rate for player1 over 20 games: 55.0%
```
---
# Section 2: Train a value function from expert game data
*Time estimate: ~25mins*
**Goal:** Learn how to train a value function from a dataset of games played by an expert.
**Exercise:**
* Load a dataset of expert generated games.
* Train a network to minimize MSE for win/loss predictions given board states sampled throughout the game. This will be done on a very small number of games. We will provide a network trained on a larger dataset.
```
# @title Video 2: Train a value function
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1pg411j7f7", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"f9lZq0WQJFg", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 2: Train a value function')
display(out)
```
## Section 2.1. Load expert data
```
def loadTrainExamples(folder, filename):
trainExamplesHistory = []
modelFile = os.path.join(folder, filename)
examplesFile = modelFile + ".examples"
if not os.path.isfile(examplesFile):
print(f'File "{examplesFile}" with trainExamples not found!')
r = input("Continue? [y|n]")
if r != "y":
sys.exit()
else:
print("File with train examples found. Loading it...")
with open(examplesFile, "rb") as f:
trainExamplesHistory = Unpickler(f).load()
print('Loading done!')
# examples based on the model were already collected (loaded)
return trainExamplesHistory
path = "nma_rl_games/alpha-zero/pretrained_models/data/"
loaded_games = loadTrainExamples(folder=path, filename='checkpoint_1.pth.tar')
```
## Section 2.2. Define the Neural Network Architecture for Othello
### Coding Exercise 2.2: Implement the NN `OthelloNNet` for Othello
```
class OthelloNNet(nn.Module):
def __init__(self, game, args):
# game params
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.args = args
super(OthelloNNet, self).__init__()
self.conv1 = nn.Conv2d(1, args.num_channels, 3, stride=1, padding=1)
self.conv2 = nn.Conv2d(args.num_channels, args.num_channels, 3, stride=1,
padding=1)
self.conv3 = nn.Conv2d(args.num_channels, args.num_channels, 3, stride=1)
self.conv4 = nn.Conv2d(args.num_channels, args.num_channels, 3, stride=1)
self.bn1 = nn.BatchNorm2d(args.num_channels)
self.bn2 = nn.BatchNorm2d(args.num_channels)
self.bn3 = nn.BatchNorm2d(args.num_channels)
self.bn4 = nn.BatchNorm2d(args.num_channels)
self.fc1 = nn.Linear(args.num_channels * (self.board_x - 4) * (self.board_y - 4), 1024)
self.fc_bn1 = nn.BatchNorm1d(1024)
self.fc2 = nn.Linear(1024, 512)
self.fc_bn2 = nn.BatchNorm1d(512)
self.fc3 = nn.Linear(512, self.action_size)
self.fc4 = nn.Linear(512, 1)
def forward(self, s):
# s: batch_size x board_x x board_y
s = s.view(-1, 1, self.board_x, self.board_y) # batch_size x 1 x board_x x board_y
s = F.relu(self.bn1(self.conv1(s))) # batch_size x num_channels x board_x x board_y
s = F.relu(self.bn2(self.conv2(s))) # batch_size x num_channels x board_x x board_y
s = F.relu(self.bn3(self.conv3(s))) # batch_size x num_channels x (board_x-2) x (board_y-2)
s = F.relu(self.bn4(self.conv4(s))) # batch_size x num_channels x (board_x-4) x (board_y-4)
s = s.view(-1, self.args.num_channels * (self.board_x - 4) * (self.board_y - 4))
s = F.dropout(F.relu(self.fc_bn1(self.fc1(s))), p=self.args.dropout, training=self.training) # batch_size x 1024
s = F.dropout(F.relu(self.fc_bn2(self.fc2(s))), p=self.args.dropout, training=self.training) # batch_size x 512
pi = self.fc3(s) # batch_size x action_size
v = self.fc4(s) # batch_size x 1
#################################################
## TODO for students: Please compute a probability distribution over 'pi' using log softmax (for numerical stability)
# Fill out function and remove
raise NotImplementedError("Calculate the probability distribution and the value")
#################################################
# return a probability distribution over actions at the current state and the value of the current state.
return ..., ...
# add event to airtable
atform.add_event('Coding Exercise 2.2: Implement the NN OthelloNNet for Othello')
# to_remove solution
class OthelloNNet(nn.Module):
def __init__(self, game, args):
# game params
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.args = args
super(OthelloNNet, self).__init__()
self.conv1 = nn.Conv2d(1, args.num_channels, 3, stride=1, padding=1)
self.conv2 = nn.Conv2d(args.num_channels, args.num_channels, 3, stride=1,
padding=1)
self.conv3 = nn.Conv2d(args.num_channels, args.num_channels, 3, stride=1)
self.conv4 = nn.Conv2d(args.num_channels, args.num_channels, 3, stride=1)
self.bn1 = nn.BatchNorm2d(args.num_channels)
self.bn2 = nn.BatchNorm2d(args.num_channels)
self.bn3 = nn.BatchNorm2d(args.num_channels)
self.bn4 = nn.BatchNorm2d(args.num_channels)
self.fc1 = nn.Linear(args.num_channels * (self.board_x - 4) * (self.board_y - 4), 1024)
self.fc_bn1 = nn.BatchNorm1d(1024)
self.fc2 = nn.Linear(1024, 512)
self.fc_bn2 = nn.BatchNorm1d(512)
self.fc3 = nn.Linear(512, self.action_size)
self.fc4 = nn.Linear(512, 1)
def forward(self, s):
# s: batch_size x board_x x board_y
s = s.view(-1, 1, self.board_x, self.board_y) # batch_size x 1 x board_x x board_y
s = F.relu(self.bn1(self.conv1(s))) # batch_size x num_channels x board_x x board_y
s = F.relu(self.bn2(self.conv2(s))) # batch_size x num_channels x board_x x board_y
s = F.relu(self.bn3(self.conv3(s))) # batch_size x num_channels x (board_x-2) x (board_y-2)
s = F.relu(self.bn4(self.conv4(s))) # batch_size x num_channels x (board_x-4) x (board_y-4)
s = s.view(-1, self.args.num_channels * (self.board_x - 4) * (self.board_y - 4))
s = F.dropout(F.relu(self.fc_bn1(self.fc1(s))), p=self.args.dropout, training=self.training) # batch_size x 1024
s = F.dropout(F.relu(self.fc_bn2(self.fc2(s))), p=self.args.dropout, training=self.training) # batch_size x 512
pi = self.fc3(s) # batch_size x action_size
v = self.fc4(s) # batch_size x 1
# return a probability distribution over actions at the current state and the value of the current state.
return F.log_softmax(pi, dim=1), torch.tanh(v)
# add event to airtable
atform.add_event('Coding Exercise 2.2: Implement the NN OthelloNNet for Othello')
```
## Section 2.3. Define the Value network
During the training the ground truth will be uploaded from the **MCTS simulations** available at 'checkpoint_x.path.tar.examples'.
### Coding Exercise 2.3: Implement the `ValueNetwork`
```
class ValueNetwork(NeuralNet):
def __init__(self, game):
self.nnet = OthelloNNet(game, args)
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.nnet.to(args.device)
def train(self, games):
"""
examples: list of examples, each example is of form (board, pi, v)
"""
optimizer = optim.Adam(self.nnet.parameters())
for examples in games:
for epoch in range(args.epochs):
print('EPOCH ::: ' + str(epoch + 1))
self.nnet.train()
v_losses = [] # to store the losses per epoch
batch_count = int(len(examples) / args.batch_size) # len(examples)=200, batch-size=64, batch_count=3
t = tqdm(range(batch_count), desc='Training Value Network')
for _ in t:
sample_ids = np.random.randint(len(examples), size=args.batch_size) # read the ground truth information from MCTS simulation using the loaded examples
boards, pis, vs = list(zip(*[examples[i] for i in sample_ids])) # length of boards, pis, vis = 64
boards = torch.FloatTensor(np.array(boards).astype(np.float64))
target_vs = torch.FloatTensor(np.array(vs).astype(np.float64))
# predict
boards, target_vs = boards.contiguous().to(args.device), target_vs.contiguous().to(args.device)
#################################################
## TODO for students:
## 1. Compute the value predicted by OthelloNNet() ##
## 2. First implement the loss_v() function below and then use it to update the value loss. ##
# Fill out function and remove
raise NotImplementedError("Compute the output")
#################################################
# compute output
_, out_v = ...
l_v = ... # total loss
# record loss
v_losses.append(l_v.item())
t.set_postfix(Loss_v=l_v.item())
# compute gradient and do SGD step
optimizer.zero_grad()
l_v.backward()
optimizer.step()
def predict(self, board):
"""
board: np array with board
"""
# timing
start = time.time()
# preparing input
board = torch.FloatTensor(board.astype(np.float64))
board = board.contiguous().to(args.device)
board = board.view(1, self.board_x, self.board_y)
self.nnet.eval()
with torch.no_grad():
_, v = self.nnet(board)
return v.data.cpu().numpy()[0]
def loss_v(self, targets, outputs):
#################################################
## TODO for students: Please compute Mean squared error and return as output. ##
# Fill out function and remove
raise NotImplementedError("Calculate the loss")
#################################################
# Mean squared error (MSE)
return ...
def save_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
filepath = os.path.join(folder, filename)
if not os.path.exists(folder):
print("Checkpoint Directory does not exist! Making directory {}".format(folder))
os.mkdir(folder)
else:
print("Checkpoint Directory exists! ")
torch.save({'state_dict': self.nnet.state_dict(),}, filepath)
print("Model saved! ")
def load_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
# https://github.com/pytorch/examples/blob/master/imagenet/main.py#L98
filepath = os.path.join(folder, filename)
if not os.path.exists(filepath):
raise ("No model in path {}".format(filepath))
checkpoint = torch.load(filepath, map_location=args.device)
self.nnet.load_state_dict(checkpoint['state_dict'])
# add event to airtable
atform.add_event('Coding Exercise 2.3: Implement the ValueNetwork')
# to_remove solution
class ValueNetwork(NeuralNet):
def __init__(self, game):
self.nnet = OthelloNNet(game, args)
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.nnet.to(args.device)
def train(self, games):
"""
examples: list of examples, each example is of form (board, pi, v)
"""
optimizer = optim.Adam(self.nnet.parameters())
for examples in games:
for epoch in range(args.epochs):
print('EPOCH ::: ' + str(epoch + 1))
self.nnet.train()
v_losses = [] # to store the losses per epoch
batch_count = int(len(examples) / args.batch_size) # len(examples)=200, batch-size=64, batch_count=3
t = tqdm(range(batch_count), desc='Training Value Network')
for _ in t:
sample_ids = np.random.randint(len(examples), size=args.batch_size) # read the ground truth information from MCTS simulation using the loaded examples
boards, pis, vs = list(zip(*[examples[i] for i in sample_ids])) # length of boards, pis, vis = 64
boards = torch.FloatTensor(np.array(boards).astype(np.float64))
target_vs = torch.FloatTensor(np.array(vs).astype(np.float64))
# predict
# to run on GPU if available
boards, target_vs = boards.contiguous().to(args.device), target_vs.contiguous().to(args.device)
# compute output
_, out_v = self.nnet(boards)
l_v = self.loss_v(target_vs, out_v) # total loss
# record loss
v_losses.append(l_v.item())
t.set_postfix(Loss_v=l_v.item())
# compute gradient and do SGD step
optimizer.zero_grad()
l_v.backward()
optimizer.step()
def predict(self, board):
"""# Mean squared error (MSE)
board: np array with board
"""
# timing
start = time.time()
# preparing input
board = torch.FloatTensor(board.astype(np.float64))
board = board.contiguous().to(args.device)
board = board.view(1, self.board_x, self.board_y)
self.nnet.eval()
with torch.no_grad():
_, v = self.nnet(board)
return v.data.cpu().numpy()[0]
def loss_v(self, targets, outputs):
# Mean squared error (MSE)
return torch.sum((targets - outputs.view(-1)) ** 2) / targets.size()[0]
def save_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
filepath = os.path.join(folder, filename)
if not os.path.exists(folder):
print("Checkpoint Directory does not exist! Making directory {}".format(folder))
os.mkdir(folder)
else:
print("Checkpoint Directory exists! ")
torch.save({'state_dict': self.nnet.state_dict(),}, filepath)
print("Model saved! ")
def load_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
# https://github.com/pytorch/examples/blob/master/imagenet/main.py#L98
filepath = os.path.join(folder, filename)
if not os.path.exists(filepath):
raise ("No model in path {}".format(filepath))
checkpoint = torch.load(filepath, map_location=args.device)
self.nnet.load_state_dict(checkpoint['state_dict'])
# add event to airtable
atform.add_event('Coding Exercise 2.3: Implement the ValueNetwork')
```
## Section 2.4. Train the value network and observe the MSE loss progress
**Important:** Only run this cell if you do not have access to the pretrained models in the `rl_for_games` repository.
```
if not os.listdir('nma_rl_games/alpha-zero/pretrained_models/models/'):
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.train(loaded_games)
```
---
# Section 3: Use a trained value network to play games
*Time estimate: ~25mins*
**Goal**: Learn how to use a value function in order to make a player that works better than a random player.
**Exercise:**
* Sample random valid moves and use the value function to rank them
* Choose the best move as the action and play it
Show that doing so beats the random player
**Hint:** You might need to change the sign of the value based on the player
```
# @title Video 3: Play games using a value function
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1Ug411j7ig", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"tvmzVHPBKKs", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 3: Play games using a value function')
display(out)
```
## Coding Exercise 3: Value-based player
```
model_save_name = 'ValueNetwork.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.load_checkpoint(folder=path, filename=model_save_name)
class ValueBasedPlayer():
def __init__(self, game, vnet):
self.game = game
self.vnet = vnet
def play(self, board):
valids = self.game.getValidMoves(board, 1)
candidates = []
max_num_actions = 4
va = np.where(valids)[0]
va_list = va.tolist()
random.shuffle(va_list)
#################################################
## TODO for students: In the first part, please return the next board state using getNextState(), then predict
## the value of next state using value network, and finally add the value and action as a tuple to the candidate list.
## Note that you need to reverse the sign of the value. In zero-sum games the players flip every turn. In detail, we train
## a value function to think about the game from one player's (either black or white) perspective. In order to use the same
## value function to estimate how good the position is for the other player, we need to take the negative of the output of
## the function. E.g., if the value function is trained for white's perspective and says that white is likely to win the game
## from the current state with an output of 0.75, this similarly means that it would suggest that black is very unlikely (-0.75)
## to win the game from the current state.##
# Fill out function and remove
raise NotImplementedError("Implement the value-based player")
#################################################
for a in va_list:
nextBoard, _ = ...
value = ...
candidates += ...
if len(candidates) == max_num_actions:
break
candidates.sort()
return candidates[0][1]
# add event to airtable
atform.add_event('Coding Exercise 3: Value-based player')
# playing games between a value-based player and a random player
set_seed(seed=SEED)
num_games = 20
player1 = ValueBasedPlayer(game, vnet).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
## Uncomment the code below to check your code!
# result = arena.playGames(num_games, verbose=False)
# print(f"\n\n{result}")
# to_remove solution
class ValueBasedPlayer():
def __init__(self, game, vnet):
self.game = game
self.vnet = vnet
def play(self, board):
valids = self.game.getValidMoves(board, 1)
candidates = []
max_num_actions = 4
va = np.where(valids)[0]
va_list = va.tolist()
random.shuffle(va_list)
for a in va_list:
# return next board state using getNextState() function
nextBoard, _ = self.game.getNextState(board, 1, a)
# predict the value of next state using value network
value = self.vnet.predict(nextBoard)
# add the value and the action as a tuple to the candidate lists, note that you might need to change the sign of the value based on the player
candidates += [(-value, a)]
if len(candidates) == max_num_actions:
break
candidates.sort()
return candidates[0][1]
# add event to airtable
atform.add_event('Coding Exercise 3: Value-based player')
# playing games between a value-based player and a random player
set_seed(seed=SEED)
num_games = 20
player1 = ValueBasedPlayer(game, vnet).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
## Uncomment the code below to check your code!
result = arena.playGames(num_games, verbose=False)
print(f"\n\n{result}")
```
```
(14, 6, 0)
```
**Result of pitting a value-based player against a random player**
```
print(f"Number of games won by player1 = {result[0]}, "
f"Number of games won by player2 = {result[1]}, out of {num_games} games")
win_rate_player1 = result[0]/num_games # result[0] is the number of times that player 1 wins
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 14, Number of games won by player2 = 6, out of 20 games
Win rate for player1 over 20 games: 70.0%
```
---
# Section 4: Train a policy network from expert game data
*Time estimate: ~20mins*
**Goal**: How to train a policy network via supervised learning / behavioural cloning.
**Exercise**:
* Train a network to predict the next move in an expert dataset by maximizing the log likelihood of the next action.
```
# @title Video 4: Train a policy network
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1hQ4y127GJ", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"vj9gKNJ19D8", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 4: Train a policy network')
display(out)
```
## Coding Exercise 4: Implement `PolicyNetwork`
```
class PolicyNetwork(NeuralNet):
def __init__(self, game):
self.nnet = OthelloNNet(game, args)
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.nnet.to(args.device)
def train(self, games):
"""
examples: list of examples, each example is of form (board, pi, v)
"""
optimizer = optim.Adam(self.nnet.parameters())
for examples in games:
for epoch in range(args.epochs):
print('EPOCH ::: ' + str(epoch + 1))
self.nnet.train()
pi_losses = []
batch_count = int(len(examples) / args.batch_size)
t = tqdm(range(batch_count), desc='Training Policy Network')
for _ in t:
sample_ids = np.random.randint(len(examples), size=args.batch_size)
boards, pis, _ = list(zip(*[examples[i] for i in sample_ids]))
boards = torch.FloatTensor(np.array(boards).astype(np.float64))
target_pis = torch.FloatTensor(np.array(pis))
# predict
boards, target_pis = boards.contiguous().to(args.device), target_pis.contiguous().to(args.device)
#################################################
## TODO for students: ##
## 1. Compute the policy (pi) predicted by OthelloNNet() ##
## 2. Implement the loss_pi() function below and then use it to update the policy loss. ##
# Fill out function and remove
raise NotImplementedError("Compute the output")
#################################################
# compute output
out_pi, _ = ...
l_pi = ...
# record loss
pi_losses.append(l_pi.item())
t.set_postfix(Loss_pi=l_pi.item())
# compute gradient and do SGD step
optimizer.zero_grad()
l_pi.backward()
optimizer.step()
def predict(self, board):
"""
board: np array with board
"""
# timing
start = time.time()
# preparing input
board = torch.FloatTensor(board.astype(np.float64))
board = board.contiguous().to(args.device)
board = board.view(1, self.board_x, self.board_y)
self.nnet.eval()
with torch.no_grad():
pi,_ = self.nnet(board)
return torch.exp(pi).data.cpu().numpy()[0]
def loss_pi(self, targets, outputs):
#################################################
## TODO for students: To implement the loss function, please compute and return the negative log likelihood of targets.
## For more information, here is a reference that connects the expression to the neg-log-prob: https://gombru.github.io/2018/05/23/cross_entropy_loss/
# Fill out function and remove
raise NotImplementedError("Compute the loss")
#################################################
return ...
def save_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
filepath = os.path.join(folder, filename)
if not os.path.exists(folder):
print("Checkpoint Directory does not exist! Making directory {}".format(folder))
os.mkdir(folder)
else:
print("Checkpoint Directory exists! ")
torch.save({'state_dict': self.nnet.state_dict(),}, filepath)
print("Model saved! ")
def load_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
# https://github.com/pytorch/examples/blob/master/imagenet/main.py#L98
filepath = os.path.join(folder, filename)
if not os.path.exists(filepath):
raise ("No model in path {}".format(filepath))
checkpoint = torch.load(filepath, map_location=args.device)
self.nnet.load_state_dict(checkpoint['state_dict'])
# add event to airtable
atform.add_event('Coding Exercise 4: Implement PolicyNetwork')
# to_remove solution
class PolicyNetwork(NeuralNet):
def __init__(self, game):
self.nnet = OthelloNNet(game, args)
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.nnet.to(args.device)
def train(self, games):
"""
examples: list of examples, each example is of form (board, pi, v)
"""
optimizer = optim.Adam(self.nnet.parameters())
for examples in games:
for epoch in range(args.epochs):
print('EPOCH ::: ' + str(epoch + 1))
self.nnet.train()
pi_losses = []
batch_count = int(len(examples) / args.batch_size)
t = tqdm(range(batch_count), desc='Training Policy Network')
for _ in t:
sample_ids = np.random.randint(len(examples), size=args.batch_size)
boards, pis, _ = list(zip(*[examples[i] for i in sample_ids]))
boards = torch.FloatTensor(np.array(boards).astype(np.float64))
target_pis = torch.FloatTensor(np.array(pis))
# predict
boards, target_pis = boards.contiguous().to(args.device), target_pis.contiguous().to(args.device)
# compute output
out_pi, _ = self.nnet(boards)
l_pi = self.loss_pi(target_pis, out_pi)
# record loss
pi_losses.append(l_pi.item())
t.set_postfix(Loss_pi=l_pi.item())
# compute gradient and do SGD step
optimizer.zero_grad()
l_pi.backward()
optimizer.step()
def predict(self, board):
"""
board: np array with board
"""
# timing
start = time.time()
# preparing input
board = torch.FloatTensor(board.astype(np.float64))
board = board.contiguous().to(args.device)
board = board.view(1, self.board_x, self.board_y)
self.nnet.eval()
with torch.no_grad():
pi,_ = self.nnet(board)
return torch.exp(pi).data.cpu().numpy()[0]
def loss_pi(self, targets, outputs):
## To implement the loss function, please compute and return the negative log likelihood of targets.
## For more information, here is a reference that connects the expression to the neg-log-prob: https://gombru.github.io/2018/05/23/cross_entropy_loss/
return -torch.sum(targets * outputs) / targets.size()[0]
def save_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
filepath = os.path.join(folder, filename)
if not os.path.exists(folder):
print("Checkpoint Directory does not exist! Making directory {}".format(folder))
os.mkdir(folder)
else:
print("Checkpoint Directory exists! ")
torch.save({'state_dict': self.nnet.state_dict(),}, filepath)
print("Model saved! ")
def load_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
# https://github.com/pytorch/examples/blob/master/imagenet/main.py#L98
filepath = os.path.join(folder, filename)
if not os.path.exists(filepath):
raise ("No model in path {}".format(filepath))
checkpoint = torch.load(filepath, map_location=args.device)
self.nnet.load_state_dict(checkpoint['state_dict'])
# add event to airtable
atform.add_event('Coding Exercise 4: Implement PolicyNetwork')
```
### Train the policy network
**Important:** Only run this cell if you do not have access to the pretrained models in the `rl_for_games` repository.
```
if not os.listdir('nma_rl_games/alpha-zero/pretrained_models/models/'):
set_seed(seed=SEED)
game = OthelloGame(6)
pnet = PolicyNetwork(game)
pnet.train(loaded_games)
```
---
# Section 5: Use a trained policy network to play games
Time estimate: ~20mins
**Goal**: How to use a policy network to play games.
**Exercise:**
* Use the policy network to give probabilities for the next move.
* Build a player that takes the move given the maximum probability by the network.
* Compare this to another player that samples moves according to the probability distribution output by the network.
```
# @title Video 5: Play games using a policy network
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1aq4y1S7o4", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"yHtVqT2Nstk", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 5: Play games using a policy network')
display(out)
```
## Coding Exercise 5: Implement the `PolicyBasedPlayer`
```
model_save_name = 'PolicyNetwork.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
set_seed(seed=SEED)
game = OthelloGame(6)
pnet = PolicyNetwork(game)
pnet.load_checkpoint(folder=path, filename=model_save_name)
class PolicyBasedPlayer():
def __init__(self, game, pnet, greedy=True):
self.game = game
self.pnet = pnet
self.greedy = greedy
def play(self, board):
valids = self.game.getValidMoves(board, 1)
#################################################
## TODO for students: ##
## 1. Compute the action probabilities using policy network pnet()
## 2. Mask invalid moves using valids variable and the action probabilites computed above.
## 3. Compute the sum over valid actions and store them in sum_vap.
# Fill out function and remove
raise NotImplementedError("Define the play")
#################################################
action_probs = ...
vap = ... # masking invalid moves
sum_vap = ...
if sum_vap > 0:
vap /= sum_vap # renormalize
else:
# if all valid moves were masked we make all valid moves equally probable
print("All valid moves were masked, doing a workaround.")
vap = vap + valids
vap /= np.sum(vap)
if self.greedy:
# greedy policy player
a = np.where(vap == np.max(vap))[0][0]
else:
# sample-based policy player
a = np.random.choice(self.game.getActionSize(), p=vap)
return a
# add event to airtable
atform.add_event('Coding Exercise 5: Implement the PolicyBasedPlayer')
# playing games
set_seed(seed=SEED)
num_games = 20
player1 = PolicyBasedPlayer(game, pnet, greedy=True).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
## Uncomment below to test!
# result = arena.playGames(num_games, verbose=False)
# print(f"\n\n{result}")
# win_rate_player1 = result[0] / num_games
# print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
# to_remove solution
class PolicyBasedPlayer():
def __init__(self, game, pnet, greedy=True):
self.game = game
self.pnet = pnet
self.greedy = greedy
def play(self, board):
valids = self.game.getValidMoves(board, 1)
action_probs = self.pnet.predict(board)
vap = action_probs*valids # masking invalid moves
sum_vap = np.sum(vap)
if sum_vap > 0:
vap /= sum_vap # renormalize
else:
# if all valid moves were masked we make all valid moves equally probable
print("All valid moves were masked, doing a workaround.")
vap = vap + valids
vap /= np.sum(vap)
if self.greedy:
# greedy policy player
a = np.where(vap == np.max(vap))[0][0]
else:
# sample-based policy player
a = np.random.choice(self.game.getActionSize(), p=vap)
return a
# add event to airtable
atform.add_event('Coding Exercise 5: Implement the PolicyBasedPlayer')
# playing games
set_seed(seed=SEED)
num_games = 20
player1 = PolicyBasedPlayer(game, pnet, greedy=True).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
## Uncomment below to test!
result = arena.playGames(num_games, verbose=False)
print(f"\n\n{result}")
win_rate_player1 = result[0] / num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Win rate for player1 over 20 games: 80.0%
```
### Comparing a policy based player versus a random player
There's often randomness in the results as we are running the players for a low number of games (only 20 games due compute + time costs). So, when students are running the cells they might not get the expected result. To better measure the strength of players you can run more games!
```
set_seed(seed=SEED)
num_games = 20
game = OthelloGame(6)
player1 = PolicyBasedPlayer(game, pnet, greedy=False).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
result = arena.playGames(num_games, verbose=False)
print(f"\n\n{result}")
win_rate_player1 = result[0]/num_games
print(f"Win rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Win rate for player1 over 20 games: 95.0%
```
### Compare greedy policy based player versus value based player
```
set_seed(seed=SEED)
num_games = 20
game = OthelloGame(6)
player1 = PolicyBasedPlayer(game, pnet).play
player2 = ValueBasedPlayer(game, vnet).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
result = arena.playGames(num_games, verbose=False)
print(f"\n\n{result}")
win_rate_player1 = result[0]/num_games
print(f"Win rate for player 1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Win rate for player 1 over 20 games: 55.0%
```
### Compare greedy policy based player versus sample-based policy player
```
set_seed(seed=SEED)
num_games = 20
game = OthelloGame(6)
player1 = PolicyBasedPlayer(game, pnet).play # greedy player
player2 = PolicyBasedPlayer(game, pnet, greedy=False).play # sample-based player
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
result = arena.playGames(num_games, verbose=False)
print(f"\n\n{result}")
win_rate_player1 = result[0]/num_games
print(f"Win rate for player 1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Win rate for player 1 over 20 games: 50.0%
```
---
# Section 6: Plan using Monte Carlo rollouts
*Time estimate: ~15mins*
**Goal**: Teach the students the core idea behind using simulated rollouts to understand the future and value actions.
**Exercise**:
* Build a loop to run Monte Carlo simulations using the policy network.
* Use this to obtain better estimates of the value of moves.
```
# @title Video 6: Play using Monte-Carlo rollouts
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1Rb4y1U7BW", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"DtCWDIlSo18", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 6: Play using Monte-Carlo rollouts')
display(out)
```
## Coding Exercise 6: `MonteCarlo`
```
class MonteCarlo():
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.Ps = {} # stores initial policy (returned by neural net)
self.Es = {} # stores game.getGameEnded ended for board s
# call this rollout
def simulate(self, canonicalBoard):
"""
This function performs one monte carlo rollout
"""
s = self.game.stringRepresentation(canonicalBoard)
init_start_state = s
temp_v = 0
isfirstAction = None
for i in range(self.args.maxDepth): # maxDepth
if s not in self.Es:
self.Es[s] = self.game.getGameEnded(canonicalBoard, 1)
if self.Es[s] != 0:
# terminal state
temp_v= -self.Es[s]
break
self.Ps[s], v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
self.Ps[s] = self.Ps[s] * valids # masking invalid moves
sum_Ps_s = np.sum(self.Ps[s])
if sum_Ps_s > 0:
self.Ps[s] /= sum_Ps_s # renormalize
else:
# if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log.error("All valid moves were masked, doing a workaround.")
self.Ps[s] = self.Ps[s] + valids
self.Ps[s] /= np.sum(self.Ps[s])
#################################################
## TODO for students: Take a random action.
## 1. Take the random action.
## 2. Find the next state and the next player from the environment.
## 3. Get the canonical form of the next state.
# Fill out function and remove
raise NotImplementedError("Take the action, find the next state")
#################################################
a = ...
next_s, next_player = self.game.getNextState(..., ..., ...)
next_s = self.game.getCanonicalForm(..., ...)
s = self.game.stringRepresentation(next_s)
temp_v = v
return temp_v
# add event to airtable
atform.add_event('Coding Exercise 6: MonteCarlo')
# to_remove solution
class MonteCarlo():
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.Ps = {} # stores initial policy (returned by neural net)
self.Es = {} # stores game.getGameEnded ended for board s
# call this rollout
def simulate(self, canonicalBoard):
"""
This function performs one monte carlo rollout
"""
s = self.game.stringRepresentation(canonicalBoard)
init_start_state = s
temp_v = 0
isfirstAction = None
for i in range(self.args.maxDepth): # maxDepth
if s not in self.Es:
self.Es[s] = self.game.getGameEnded(canonicalBoard, 1)
if self.Es[s] != 0:
# terminal state
temp_v= -self.Es[s]
break
self.Ps[s], v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
self.Ps[s] = self.Ps[s] * valids # masking invalid moves
sum_Ps_s = np.sum(self.Ps[s])
if sum_Ps_s > 0:
self.Ps[s] /= sum_Ps_s # renormalize
else:
# if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log.error("All valid moves were masked, doing a workaround.")
self.Ps[s] = self.Ps[s] + valids
self.Ps[s] /= np.sum(self.Ps[s])
# Take a random action
a = np.random.choice(self.game.getActionSize(), p=self.Ps[s])
# Find the next state and the next player
next_s, next_player = self.game.getNextState(canonicalBoard, 1, a)
next_s = self.game.getCanonicalForm(next_s, next_player)
s = self.game.stringRepresentation(next_s)
temp_v = v
return temp_v
# add event to airtable
atform.add_event('Coding Exercise 6: MonteCarlo')
```
---
# Section 7: Use Monte Carlo simulations to play games
*Time estimate: ~20mins*
**Goal:** Teach students how to use simple Monte Carlo planning to play games.
```
# @title Video 7: Play with planning
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1bh411B7S4", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"plmFzAy3H5s", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 7: Play with planning')
display(out)
```
## Coding Exercise 7: Monte-Carlo simulations
* Incorporate Monte Carlo simulations into an agent.
* Run the resulting player versus the random, value-based, and policy-based players.
```
# Load MC model from the repository
mc_model_save_name = 'MC.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
class MonteCarloBasedPlayer():
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
#################################################
## TODO for students: Instantiate the Monte Carlo class.
# Fill out function and remove
raise NotImplementedError("Use Monte Carlo!")
#################################################
self.mc = ...
self.K = self.args.mc_topk
def play(self, canonicalBoard):
self.qsa = []
s = self.game.stringRepresentation(canonicalBoard)
Ps, v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
Ps = Ps * valids # masking invalid moves
sum_Ps_s = np.sum(Ps)
if sum_Ps_s > 0:
Ps /= sum_Ps_s # renormalize
else:
# if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log = logging.getLogger(__name__)
log.error("All valid moves were masked, doing a workaround.")
Ps = Ps + valids
Ps /= np.sum(Ps)
num_valid_actions = np.shape(np.nonzero(Ps))[1]
if num_valid_actions < self.K:
top_k_actions = np.argpartition(Ps,-num_valid_actions)[-num_valid_actions:]
else:
top_k_actions = np.argpartition(Ps,-self.K)[-self.K:] # to get actions that belongs to top k prob
#################################################
## TODO for students:
## 1. For each action in the top-k actions
## 2. Get the next state using getNextState() function. You can find the implementation of this function in Section 1 in OthelloGame() class.
## 3. Get the canonical form of the getNextState().
# Fill out function and remove
raise NotImplementedError("Loop for the top actions")
#################################################
for action in ...:
next_s, next_player = self.game.getNextState(..., ..., ...)
next_s = self.game.getCanonicalForm(..., ...)
values = []
# do some rollouts
for rollout in range(self.args.numMCsims):
value = self.mc.simulate(canonicalBoard)
values.append(value)
# average out values
avg_value = np.mean(values)
self.qsa.append((avg_value, action))
self.qsa.sort(key=lambda a: a[0])
self.qsa.reverse()
best_action = self.qsa[0][1]
return best_action
def getActionProb(self, canonicalBoard, temp=1):
if self.game.getGameEnded(canonicalBoard, 1) != 0:
return np.zeros((self.game.getActionSize()))
else:
action_probs = np.zeros((self.game.getActionSize()))
best_action = self.play(canonicalBoard)
action_probs[best_action] = 1
return action_probs
# add event to airtable
atform.add_event('Coding Exercise 7: MonteCarlo siumulations')
set_seed(seed=SEED)
game = OthelloGame(6)
# Run the resulting player versus the random player
rp = RandomPlayer(game).play
num_games = 20 # Feel free to change this number
n1 = NNet(game) # nNet players
n1.load_checkpoint(folder=path, filename=mc_model_save_name)
args1 = dotdict({'numMCsims': 10, 'maxRollouts':5, 'maxDepth':5, 'mc_topk': 3})
## Uncomment below to check Monte Carlo agent!
# print('\n******MC player versus random player******')
# mc1 = MonteCarloBasedPlayer(game, n1, args1)
# n1p = lambda x: np.argmax(mc1.getActionProb(x))
# arena = Arena.Arena(n1p, rp, game, display=OthelloGame.display)
# MC_result = arena.playGames(num_games, verbose=False)
# print(f"\n\n{MC_result}")
# print(f"\nNumber of games won by player1 = {MC_result[0]}, "
# f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
# win_rate_player1 = MC_result[0]/num_games
# print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
# to_remove solution
class MonteCarloBasedPlayer():
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.mc = MonteCarlo(game, nnet, args)
self.K = self.args.mc_topk
def play(self, canonicalBoard):
self.qsa = []
s = self.game.stringRepresentation(canonicalBoard)
Ps, v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
Ps = Ps * valids # masking invalid moves
sum_Ps_s = np.sum(Ps)
if sum_Ps_s > 0:
Ps /= sum_Ps_s # renormalize
else:
# if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log = logging.getLogger(__name__)
log.error("All valid moves were masked, doing a workaround.")
Ps = Ps + valids
Ps /= np.sum(Ps)
num_valid_actions = np.shape(np.nonzero(Ps))[1]
if num_valid_actions < self.K:
top_k_actions = np.argpartition(Ps,-num_valid_actions)[-num_valid_actions:]
else:
top_k_actions = np.argpartition(Ps,-self.K)[-self.K:] # to get actions that belongs to top k prob
for action in top_k_actions:
next_s, next_player = self.game.getNextState(canonicalBoard, 1, action)
next_s = self.game.getCanonicalForm(next_s, next_player)
values = []
# do some rollouts
for rollout in range(self.args.numMCsims):
value = self.mc.simulate(canonicalBoard)
values.append(value)
# average out values
avg_value = np.mean(values)
self.qsa.append((avg_value, action))
self.qsa.sort(key=lambda a: a[0])
self.qsa.reverse()
best_action = self.qsa[0][1]
return best_action
def getActionProb(self, canonicalBoard, temp=1):
if self.game.getGameEnded(canonicalBoard, 1) != 0:
return np.zeros((self.game.getActionSize()))
else:
action_probs = np.zeros((self.game.getActionSize()))
best_action = self.play(canonicalBoard)
action_probs[best_action] = 1
return action_probs
# add event to airtable
atform.add_event('Coding Exercise 7: MonteCarlo siumulations')
set_seed(seed=SEED)
game = OthelloGame(6)
# Run the resulting player versus the random player
rp = RandomPlayer(game).play
num_games = 20 # Feel free to change this number
n1 = NNet(game) # nNet players
n1.load_checkpoint(folder=path, filename=mc_model_save_name)
args1 = dotdict({'numMCsims': 10, 'maxRollouts':5, 'maxDepth':5, 'mc_topk': 3})
## Uncomment below to check Monte Carlo agent!
print('\n******MC player versus random player******')
mc1 = MonteCarloBasedPlayer(game, n1, args1)
n1p = lambda x: np.argmax(mc1.getActionProb(x))
arena = Arena.Arena(n1p, rp, game, display=OthelloGame.display)
MC_result = arena.playGames(num_games, verbose=False)
print(f"\n\n{MC_result}")
print(f"\nNumber of games won by player1 = {MC_result[0]}, "
f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
win_rate_player1 = MC_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 11, number of games won by player2 = 9, out of 20 games
Win rate for player1 over 20 games: 55.0%
```
### Monte-Carlo player against Value-based player
```
print('\n******MC player versus value-based player******')
set_seed(seed=SEED)
vp = ValueBasedPlayer(game, vnet).play # value-based player
arena = Arena.Arena(n1p, vp, game, display=OthelloGame.display)
MC_result = arena.playGames(num_games, verbose=False)
print(f"\n\n{MC_result}")
print(f"\nNumber of games won by player1 = {MC_result[0]}, "
f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
win_rate_player1 = MC_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 10, number of games won by player2 = 10, out of 20 games
Win rate for player1 over 20 games: 50.0%
```
### Monte-Carlo player against Policy-based player
```
print('\n******MC player versus policy-based player******')
set_seed(seed=SEED)
pp = PolicyBasedPlayer(game, pnet).play # policy player
arena = Arena.Arena(n1p, pp, game, display=OthelloGame.display)
MC_result = arena.playGames(num_games, verbose=False)
print(f"\n\n{MC_result}")
print(f"\nNumber of games won by player1 = {MC_result[0]}, "
f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
win_rate_player1 = MC_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 10, number of games won by player2 = 10, out of 20 games
Win rate for player1 over 20 games: 50.0%
```
---
# Section 8: Ethical aspects
*Time estimate: ~5mins*
```
# @title Video 8: Unstoppable opponents
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1WA411w7mw", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"q7181lvoNpM", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 8: Unstoppable opponents')
display(out)
```
---
# Summary
In this tutotial, you have learned how to implement a game loop and improve the performance of a random player. More specifically, you are now able to understand the format of two-players games. We learned about value-based and policy-based players, and we compare them with the MCTS method.
```
# @title Video 9: Outro
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1a64y1s7Sh", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"uQ26iIUzmtw", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 9: Outro')
display(out)
# @title Airtable Submission Link
from IPython import display as IPydisplay
IPydisplay.HTML(
f"""
<div>
<a href= "{atform.url()}" target="_blank">
<img src="https://github.com/NeuromatchAcademy/course-content-dl/blob/main/tutorials/static/SurveyButton.png?raw=1"
alt="button link end of day Survey" style="width:410px"></a>
</div>""" )
```
---
# Bonus 1: Plan using Monte Carlo Tree Search (MCTS)
*Time estimate: ~30mins
**Goal:** Teach students to understand the core ideas behind Monte Carlo Tree Search (MCTS).
```
# @title Video 10: Plan with MCTS
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV1yQ4y127Sr", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"Hhw6Ed0Zmco", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 10: Plan with MCTS')
display(out)
```
## Bonus Coding Exercise 1: MCTS planner
* Plug together pre-built Selection, Expansion & Backpropagation code to complete an MCTS planner.
* Deploy the MCTS planner to understand an interesting position, producing value estimates and action counts.
```
class MCTS():
"""
This class handles the MCTS tree.
"""
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.Qsa = {} # stores Q values for s,a (as defined in the paper)
self.Nsa = {} # stores #times edge s,a was visited
self.Ns = {} # stores #times board s was visited
self.Ps = {} # stores initial policy (returned by neural net)
self.Es = {} # stores game.getGameEnded ended for board s
self.Vs = {} # stores game.getValidMoves for board s
def search(self, canonicalBoard):
"""
This function performs one iteration of MCTS. It is recursively called
till a leaf node is found. The action chosen at each node is one that
has the maximum upper confidence bound as in the paper.
Once a leaf node is found, the neural network is called to return an
initial policy P and a value v for the state. This value is propagated
up the search path. In case the leaf node is a terminal state, the
outcome is propagated up the search path. The values of Ns, Nsa, Qsa are
updated.
NOTE: the return values are the negative of the value of the current
state. This is done since v is in [-1,1] and if v is the value of a
state for the current player, then its value is -v for the other player.
Returns:
v: the negative of the value of the current canonicalBoard
"""
s = self.game.stringRepresentation(canonicalBoard)
if s not in self.Es:
self.Es[s] = self.game.getGameEnded(canonicalBoard, 1)
if self.Es[s] != 0:
# terminal node
return -self.Es[s]
if s not in self.Ps:
# leaf node
self.Ps[s], v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
self.Ps[s] = self.Ps[s] * valids # masking invalid moves
sum_Ps_s = np.sum(self.Ps[s])
if sum_Ps_s > 0:
self.Ps[s] /= sum_Ps_s # renormalize
else:
# if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log = logging.getLogger(__name__)
log.error("All valid moves were masked, doing a workaround.")
self.Ps[s] = self.Ps[s] + valids
self.Ps[s] /= np.sum(self.Ps[s])
self.Vs[s] = valids
self.Ns[s] = 0
return -v
valids = self.Vs[s]
cur_best = -float('inf')
best_act = -1
#################################################
## TODO for students:
## Implement the highest upper confidence bound depending whether we observed the state-action pair which is stored in self.Qsa[(s, a)]. You can find the formula in the slide 52 in video 8 above.
# Fill out function and remove
raise NotImplementedError("Complete the for loop")
#################################################
# pick the action with the highest upper confidence bound
for a in range(self.game.getActionSize()):
if valids[a]:
if (s, a) in self.Qsa:
u = ... + ... * ... * math.sqrt(...) / (1 + ...)
else:
u = ... * ... * math.sqrt(... + 1e-8)
if u > cur_best:
cur_best = u
best_act = a
a = best_act
next_s, next_player = self.game.getNextState(canonicalBoard, 1, a)
next_s = self.game.getCanonicalForm(next_s, next_player)
v = self.search(next_s)
if (s, a) in self.Qsa:
self.Qsa[(s, a)] = (self.Nsa[(s, a)] * self.Qsa[(s, a)] + v) / (self.Nsa[(s, a)] + 1)
self.Nsa[(s, a)] += 1
else:
self.Qsa[(s, a)] = v
self.Nsa[(s, a)] = 1
self.Ns[s] += 1
return -v
def getNsa(self):
return self.Nsa
# to_remove solution
class MCTS():
"""
This class handles the MCTS tree.
"""
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.Qsa = {} # stores Q values for s,a (as defined in the paper)
self.Nsa = {} # stores #times edge s,a was visited
self.Ns = {} # stores #times board s was visited
self.Ps = {} # stores initial policy (returned by neural net)
self.Es = {} # stores game.getGameEnded ended for board s
self.Vs = {} # stores game.getValidMoves for board s
def search(self, canonicalBoard):
"""
This function performs one iteration of MCTS. It is recursively called
till a leaf node is found. The action chosen at each node is one that
has the maximum upper confidence bound as in the paper.
Once a leaf node is found, the neural network is called to return an
initial policy P and a value v for the state. This value is propagated
up the search path. In case the leaf node is a terminal state, the
outcome is propagated up the search path. The values of Ns, Nsa, Qsa are
updated.
NOTE: the return values are the negative of the value of the current
state. This is done since v is in [-1,1] and if v is the value of a
state for the current player, then its value is -v for the other player.
Returns:
v: the negative of the value of the current canonicalBoard
"""
s = self.game.stringRepresentation(canonicalBoard)
if s not in self.Es:
self.Es[s] = self.game.getGameEnded(canonicalBoard, 1)
if self.Es[s] != 0:
# terminal node
return -self.Es[s]
if s not in self.Ps:
# leaf node
self.Ps[s], v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
self.Ps[s] = self.Ps[s] * valids # masking invalid moves
sum_Ps_s = np.sum(self.Ps[s])
if sum_Ps_s > 0:
self.Ps[s] /= sum_Ps_s # renormalize
else:
# if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log = logging.getLogger(__name__)
log.error("All valid moves were masked, doing a workaround.")
self.Ps[s] = self.Ps[s] + valids
self.Ps[s] /= np.sum(self.Ps[s])
self.Vs[s] = valids
self.Ns[s] = 0
return -v
valids = self.Vs[s]
cur_best = -float('inf')
best_act = -1
# pick the action with the highest upper confidence bound
for a in range(self.game.getActionSize()):
if valids[a]:
if (s, a) in self.Qsa:
u = self.Qsa[(s, a)] + self.args.cpuct * self.Ps[s][a] * math.sqrt(self.Ns[s]) / (1 + self.Nsa[(s, a)])
else:
u = self.args.cpuct * self.Ps[s][a] * math.sqrt(self.Ns[s] + 1e-8)
if u > cur_best:
cur_best = u
best_act = a
a = best_act
next_s, next_player = self.game.getNextState(canonicalBoard, 1, a)
next_s = self.game.getCanonicalForm(next_s, next_player)
v = self.search(next_s)
if (s, a) in self.Qsa:
self.Qsa[(s, a)] = (self.Nsa[(s, a)] * self.Qsa[(s, a)] + v) / (self.Nsa[(s, a)] + 1)
self.Nsa[(s, a)] += 1
else:
self.Qsa[(s, a)] = v
self.Nsa[(s, a)] = 1
self.Ns[s] += 1
return -v
def getNsa(self):
return self.Nsa
```
---
# Bonus 2: Use MCTS to play games
*Time estimate: ~10mins*
**Goal:** Teach the students how to use the results of an MCTS to play games.
**Exercise:**
* Plug the MCTS planner into an agent.
* Play games against other agents.
* Explore the contributions of prior network, value function, number of simulations / time to play, and explore/exploit parameters.
```
# @title Video 11: Play with MCTS
from ipywidgets import widgets
out2 = widgets.Output()
with out2:
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id=f"BV13q4y1H7H6", width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
display(video)
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"1BRXb-igKAU", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
out = widgets.Tab([out1, out2])
out.set_title(0, 'Youtube')
out.set_title(1, 'Bilibili')
# add event to airtable
atform.add_event('Video 11: Play with MCTS')
display(out)
```
## Bonus Coding Exercise 2: Agent that uses an MCTS planner
* Plug the MCTS planner into an agent.
* Play games against other agents.
* Explore the contributions of prior network, value function, number of simulations / time to play, and explore/exploit parameters.
```
# Load MCTS model from the repository
mcts_model_save_name = 'MCTS.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
class MonteCarloTreeSearchBasedPlayer():
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.mcts = MCTS(game, nnet, args)
def play(self, canonicalBoard, temp=1):
for i in range(self.args.numMCTSSims):
#################################################
## TODO for students:
# Run MCTS search function.
# Fill out function and remove
raise NotImplementedError("Plug the planner")
#################################################
...
s = self.game.stringRepresentation(canonicalBoard)
#################################################
## TODO for students:
# Call the Nsa function from MCTS class and store it in the self.Nsa
# Fill out function and remove
raise NotImplementedError("Compute Nsa (number of times edge s,a was visited)")
#################################################
self.Nsa = ...
self.counts = [self.Nsa[(s, a)] if (s, a) in self.Nsa else 0 for a in range(self.game.getActionSize())]
if temp == 0:
bestAs = np.array(np.argwhere(self.counts == np.max(self.counts))).flatten()
bestA = np.random.choice(bestAs)
probs = [0] * len(self.counts)
probs[bestA] = 1
return probs
self.counts = [x ** (1. / temp) for x in self.counts]
self.counts_sum = float(sum(self.counts))
probs = [x / self.counts_sum for x in self.counts]
return np.argmax(probs)
def getActionProb(self, canonicalBoard, temp=1):
action_probs = np.zeros((self.game.getActionSize()))
best_action = self.play(canonicalBoard)
action_probs[best_action] = 1
return action_probs
set_seed(seed=SEED)
game = OthelloGame(6)
rp = RandomPlayer(game).play # all players
num_games = 20 # games
n1 = NNet(game) # nnet players
n1.load_checkpoint(folder=path, filename=mcts_model_save_name)
args1 = dotdict({'numMCTSSims': 50, 'cpuct':1.0})
## Uncomment below to check your agent!
# print('\n******MCTS player versus random player******')
# mcts1 = MonteCarloTreeSearchBasedPlayer(game, n1, args1)
# n1p = lambda x: np.argmax(mcts1.getActionProb(x, temp=0))
# arena = Arena.Arena(n1p, rp, game, display=OthelloGame.display)
# MCTS_result = arena.playGames(num_games, verbose=False)
# print(f"\n\n{MCTS_result}")
# print(f"\nNumber of games won by player1 = {MCTS_result[0]}, "
# f"number of games won by player2 = {MCTS_result[1]}, out of {num_games} games")
# win_rate_player1 = MCTS_result[0]/num_games
# print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
# to_remove solution
class MonteCarloTreeSearchBasedPlayer():
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.mcts = MCTS(game, nnet, args)
def play(self, canonicalBoard, temp=1):
for i in range(self.args.numMCTSSims):
self.mcts.search(canonicalBoard)
s = self.game.stringRepresentation(canonicalBoard)
self.Nsa = self.mcts.getNsa()
self.counts = [self.Nsa[(s, a)] if (s, a) in self.Nsa else 0 for a in range(self.game.getActionSize())]
if temp == 0:
bestAs = np.array(np.argwhere(self.counts == np.max(self.counts))).flatten()
bestA = np.random.choice(bestAs)
probs = [0] * len(self.counts)
probs[bestA] = 1
return probs
self.counts = [x ** (1. / temp) for x in self.counts]
self.counts_sum = float(sum(self.counts))
probs = [x / self.counts_sum for x in self.counts]
return np.argmax(probs)
def getActionProb(self, canonicalBoard, temp=1):
action_probs = np.zeros((self.game.getActionSize()))
best_action = self.play(canonicalBoard)
action_probs[best_action] = 1
return action_probs
set_seed(seed=SEED)
game = OthelloGame(6)
rp = RandomPlayer(game).play # all players
num_games = 20 # games
n1 = NNet(game) # nnet players
n1.load_checkpoint(folder=path, filename=mcts_model_save_name)
args1 = dotdict({'numMCTSSims': 50, 'cpuct':1.0})
## Uncomment below to check your agent!
print('\n******MCTS player versus random player******')
mcts1 = MonteCarloTreeSearchBasedPlayer(game, n1, args1)
n1p = lambda x: np.argmax(mcts1.getActionProb(x, temp=0))
arena = Arena.Arena(n1p, rp, game, display=OthelloGame.display)
MCTS_result = arena.playGames(num_games, verbose=False)
print(f"\n\n{MCTS_result}")
print(f"\nNumber of games won by player1 = {MCTS_result[0]}, "
f"number of games won by player2 = {MCTS_result[1]}, out of {num_games} games")
win_rate_player1 = MCTS_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 19, num of games won by player2 = 1, out of 20 games
Win rate for player1 over 20 games: 95.0%
```
### MCTS player against Value-based player
```
print('\n******MCTS player versus value-based player******')
set_seed(seed=SEED)
vp = ValueBasedPlayer(game, vnet).play # value-based player
arena = Arena.Arena(n1p, vp, game, display=OthelloGame.display)
MC_result = arena.playGames(num_games, verbose=False)
print(f"\n\n{MC_result}")
print(f"\nNumber of games won by player1 = {MC_result[0]}, "
f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
win_rate_player1 = MC_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 14, number of games won by player2 = 6, out of 20 games
Win rate for player1 over 20 games: 70.0%
```
### MCTS player against Policy-based player
```
print('\n******MCTS player versus policy-based player******')
set_seed(seed=SEED)
pp = PolicyBasedPlayer(game, pnet).play # policy-based player
arena = Arena.Arena(n1p, pp, game, display=OthelloGame.display)
MC_result = arena.playGames(num_games, verbose=False)
print(f"\n\n{MC_result}")
print(f"\nNumber of games won by player1 = {MC_result[0]}, "
f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
win_rate_player1 = MC_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")
```
```
Number of games won by player1 = 20, number of games won by player2 = 0, out of 20 games
Win rate for player1 over 20 games: 100.0%
```
| github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Setup" data-toc-modified-id="Setup-1"><span class="toc-item-num">1 </span>Setup</a></span></li><li><span><a href="#Cobb-Dogulas" data-toc-modified-id="Cobb-Dogulas-2"><span class="toc-item-num">2 </span>Cobb-Dogulas</a></span></li><li><span><a href="#Constant-Elasticity-of-Substitution-(CES)" data-toc-modified-id="Constant-Elasticity-of-Substitution-(CES)-3"><span class="toc-item-num">3 </span>Constant Elasticity of Substitution (CES)</a></span></li><li><span><a href="#Perfect-substitutes" data-toc-modified-id="Perfect-substitutes-4"><span class="toc-item-num">4 </span>Perfect substitutes</a></span></li><li><span><a href="#Perfect-complements" data-toc-modified-id="Perfect-complements-5"><span class="toc-item-num">5 </span>Perfect complements</a></span></li><li><span><a href="#Quasi-linear-(log)" data-toc-modified-id="Quasi-linear-(log)-6"><span class="toc-item-num">6 </span>Quasi-linear (log)</a></span></li><li><span><a href="#Quasi-linear-(sqrt)" data-toc-modified-id="Quasi-linear-(sqrt)-7"><span class="toc-item-num">7 </span>Quasi-linear (sqrt)</a></span></li><li><span><a href="#Concave" data-toc-modified-id="Concave-8"><span class="toc-item-num">8 </span>Concave</a></span></li><li><span><a href="#Quasi-quasi-linear" data-toc-modified-id="Quasi-quasi-linear-9"><span class="toc-item-num">9 </span>Quasi-quasi-linear</a></span></li><li><span><a href="#Saturated-(non-montone)" data-toc-modified-id="Saturated-(non-montone)-10"><span class="toc-item-num">10 </span>Saturated (non-montone)</a></span></li><li><span><a href="#Arbitrary-function" data-toc-modified-id="Arbitrary-function-11"><span class="toc-item-num">11 </span>Arbitrary function</a></span><ul class="toc-item"><li><span><a href="#Cobb-Douglas-once-again" data-toc-modified-id="Cobb-Douglas-once-again-11.1"><span class="toc-item-num">11.1 </span>Cobb-Douglas once again</a></span></li></ul></li></ul></div>
**Description:** This is a Jupyter Notebook with Python code. You do not need any knowledge or either Jupyter or Python to run it.
**To run all:** Kernel $\rightarrow$ Restart & Run All
**To run each cell press:**
1. <kbd>Ctrl</kbd>+<kbd>Enter</kbd> to just run the cell
2. <kbd>Ctrl</kbd>+<kbd>Shift</kbd>+<kbd>Enter</kbd> to the run the cell and proceed to the next
# Setup
```
# imports and settings
%matplotlib inline
%load_ext autoreload
%autoreload 1
import context
import numecon.course_micro1.utility as utility
%aimport numecon.course_micro1.utility
%%html
<style>
.output_wrapper, .output {
height:auto !important;
max-height:5000px; /* your desired max-height here */
}
.output_scroll {
box-shadow:none !important;
webkit-box-shadow:none !important;
}
</style>
```
# Cobb-Dogulas
$$u(x_1,x_2) = x_1^{\alpha}x_2^{\beta}$$
```
utility.cobb_douglas()
```
# Constant Elasticity of Substitution (CES)
$$u(x_1,x_2) = (\alpha x_1^{-\beta}+(1-\alpha)x_2^{-\beta})^{-1/\beta}$$
```
utility.ces()
```
# Perfect substitutes
$$u(x_1,x_2) = \alpha x_1 + \beta x_2$$
```
utility.perfect_substitutes()
```
# Perfect complements
$$u(x_1,x_2) = \min{\{\alpha x_1 + \beta x_2}\}$$
```
utility.perfect_complements()
```
# Quasi-linear (log)
$$u(x_1,x_2) = \alpha\log(x_1) + \beta x_2$$
```
utility.quasi_linear_log()
```
# Quasi-linear (sqrt)
$$u(x_1,x_2) = \alpha\sqrt{x_1} + \beta x_2$$
```
utility.quasi_linear_sqrt()
```
# Concave
$$ u(x_1,x_2) = \alpha x_1^2 + \beta x_2^2 $$
```
utility.concave()
```
# Quasi-quasi-linear
$$ u(x_1,x_2) = x_1^{\alpha} (x_2 + \beta) $$
```
utility.quasi_quasi_linear()
```
# Saturated (non-montone)
$$ u(x_1,x_2) = -(x_1-\alpha)^2 - (x_2-\beta)^2 $$
```
utility.saturated()
```
# Arbitrary function
$$ u(x_1,x_2,) = f(x_1,x_2,\alpha,\beta)$$
## Cobb-Douglas once again
```
def my_utility_func(x1,x2,alpha,beta):
return x1**alpha*x2**beta
alpha = 0.50
beta = 0.50
alpha_bounds = [0.05,0.99]
beta_bounds = [0.05,0.99]
utility.arbitrary(my_utility_func,alpha,beta,alpha_bounds,beta_bounds,plot_type='line')
```
| github_jupyter |
(Underfitting_and_Overfitting_2)=
# Chapter 12 -- Early-stopping, Dropout & Mini-batch
## Early-stopping
<img src="images/earlyStopping.PNG" width="700">
Figure 12.1: Should early stop at epoch = 20 because the error in the testing set begins torise after that.
One of the main reason for overfitting is that the student studies too hard (too much epoch/iteration). So we need to let the program know that it needs to stop when it is about to overfit. If everything goes well, then the cost should be decreasing with more epoch/iterations. However, after certain epoch, the accuracy begins to drop, then we should stop at this iteration as more iterations would result in overfitting. This is known as the Early Stopping. A simple method to evaluate the underfitting and overfitting is shown below:
```
def evaluate(self, test_data):
"""Return the number of test inputs for which the neural
network outputs the correct result. Note that the neural
network's output is assumed to be the index of whichever
neuron in the final layer has the highest activation."""
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
```
## Dropout
In the neural net, we have lots of neurons. If those neurons keep working without taking a rest, then it is highly likely to make the model overfit. Thus, we choose to drop out some neurons and let it rest, while keeping the others working, and do it over and over again over iterations with different sets of neurons.
<img src="images/dropout.PNG" width="600">
Figure 12.2
There are different ways of understanding how this approach helps to resolve the problem of overfitting. In philosophy, the drop out increases the diversity of the net. With the `new blood' from the other neurons, each set of weights are different and are therefore more likely to perform better. The other explanation is that each neuron learns certain features in the data set, if lots of neurons learn a particular feature at the same time, then it would not be performing better than single individual neuron who is in charge of its own feature and then many of those neurons combined.
A related heuristic explanation for dropout is given in one of the earliest papers to use the technique: "This technique reduces complex co-adaptations of neurons, since a neuron cannot rely on the presence of particular other neurons. It is, therefore, forced to learn more robust features that are useful in conjunction with many different random subsets of the other neurons." In other words, if we think of our network as a model which is making predictions, then we can think of dropout as a way of making sure that the model is robust to the loss of any individual piece of evidence. In this, it's somewhat similar to L1 and L2 regularization, which tend to reduce weights, and thus make the network more robust to losing any individual connection in the network.
## Mini-batch
There are a number of challenges in applying the gradient descent rule. To understand what the problem is, let's look back at the cost equation {eq}`eq6_11` in chapter Gradient Descent 2. Notice that this cost function has the form of summation, that is, it's an average over costs or individual training examples (e.g. the average of all four students). In practice, to compute the gradient $\nabla C$ we need to compute the gradients of $\nabla C_x$ separately for each training input, $x$, and then average them. Unfortunately, when the number of training inputs is very large this can take a long time, and learning thus occurs slowly.
An idea called stochastic gradient descent can be used to speed up learning. The idea is to estimate the gradient $\nabla C$ by computing $\nabla C_x$ for a small sample of randomly chosen training inputs. By averaging over this small sample it turns out that we can quickly get a good estimate of the true gradient $\nabla C$, and this helps speed up gradient descent, and thus learning.
To make these ideas more precise, stochastic gradient descent works by randomly picking out a small number $m$ of randomly chosen training inputs. We'll label those random training inputs $X_1$,$X_2$,...,$X_m$, and refer to them as a mini-batch. Provided the sample size $m$ is large enough we expect that the average value of the $\nabla C_{X_j}$ will be roughly equal to the average over all $\nabla C_x$, that is
$$
\frac{\sum^m_{j=1\nabla C_{X_j}}}{m} \approx \frac{\sum_x \nabla C_x}{n} = \nabla C
$$ (eq12_1)
where the second sum is over the entire set of training data.
Swapping sides we get
$$
\nabla C \approx \frac{\sum^m_{j=1\nabla C_{X_j}}}{m}
$$ (eq12_2)
confirming that we can estimate the overall gradient by computing gradients just for the randomly chosen mini-batch.
To connect this explicitly to learning in neural networks, suppose $w_k$ and $b_l$ denote the weights and biases in our neural network. Then stochastic gradient descent works by picking out a randomly chosen mini-batch of training inputs, and training with those,
$$
w_i^{'} = w_i - \eta \nabla C = w_i - \eta \frac{1}{m} \sum_{i=1}^{m_{j}} \frac{\delta C_{X_j}}{\delta w_k}
$$ (eq12_3)
where the sums are over all the training examples $X_j$ in the current mini-batch. Then we pick out another randomly chosen mini-batch and train with those. And so on, until we've exhausted the training inputs, which is said to complete an epoch of training. At that point we start over with a new training epoch.
We can think of stochastic gradient descent as being like political polling: it's much easier to sample a small mini-batch than it is to apply gradient descent to the full batch, just as carrying out a poll is easier than running a full election. For example, if we have a training set of size $n=60,000$, as in MNIST, and choose a mini-batch size of (say) $m=10$, this means we'll get a factor of $6,000$ speedup in estimating the gradient!
Another example would be instead of calculating the average cost gradient for all four students, calculate three students and pray that those randomly chosen three students can represent the four students on average. Of course, the estimate won't be perfect - there will be statistical fluctuations - but it doesn't need to be perfect: all we really care about is moving in a general direction that will help decrease $C$, and that means we don't need an exact computation of the gradient. In practice, stochastic gradient descent is a commonly used and powerful technique for learning in neural networks, and it's the basis for most of the learning techniques we'll develop in this book.
Recall from the chapter backpropagation that the code of backprop method was contained in the update_mini_batch of the Network class. In particular, the update_mini_batch method updates the Network's weights and biases by computing the gradient for the current mini_batch of training examples:
```
class Network(object):
...
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The "mini_batch" is a list of tuples "(x, y)", and "eta"
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
```
| github_jupyter |
<img src="https://github.com/OpenMined/design-assets/raw/master/logos/OM/horizontal-primary-light.png" alt="he-black-box" width="600"/>
# Secure Multi Party Computation: Data Scientist
## Private Inference Image Evaluation
Welcome!
This tutorial will show you how to evaluate Encrypted images using Duet and SyMPC. This notebook illustrates the Data Owner 1 view on the operations.
## 0 - Libraries
Let's import the main libraries
```
import torch # tensor computation
import syft as sy # core library for remote execution
sy.load("sympc")
```
## 1 - Launch a Duet Server
```
# Start Duet local instance
duet = sy.launch_duet(loopback=True)
```
## Automate request response
Now the data owner instead of handling the requests manually, he will accept the request of type `reconstruct` automatically.
```
duet.requests.add_handler(action="accept")
```
###### Congratulations!!! - Time to Join the Community!
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the movement toward privacy preserving, decentralized ownership of AI and the AI supply chain (data), you can do so in the following ways!
### Star PySyft and SyMPC on GitHub
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we're building.
* [Star PySyft](https://github.com/OpenMined/PySyft)
* [Star SyMPC](https://github.com/OpenMined/SyMPC/)
### Join our Slack!
The best way to keep up to date on the latest advancements is to join our community! You can do so by filling out the form at http://slack.openmined.org
### Join a Code Project!
The best way to contribute to our community is to become a code contributor! At any time you can go to PySyft GitHub Issues page and filter for "Projects". This will show you all the top level Tickets giving an overview of what projects you can join! If you don't want to join a project, but you would like to do a bit of coding, you can also look for more "one off" mini-projects by searching for GitHub issues marked "good first issue".
* [PySyft Good First Issue Tickets](https://github.com/OpenMined/PySyft/labels/Good%20first%20issue%20%3Amortar_board%3A)
* [SyMPC Good First Issue Tickets](https://github.com/OpenMined/SyMPC/labels/good%20first%20issue)
### Donate
If you don't have time to contribute to our codebase, but would still like to lend support, you can also become a Backer on our Open Collective. All donations go toward our web hosting and other community expenses such as hackathons and meetups!
* [OpenMined's Open Collective Page](https://opencollective.com/openmined)
| github_jupyter |
```
%matplotlib inline
import scipy.io as sio
import numpy as np
import matplotlib.pyplot as plt
from proteus.visu import matrix as visu
from proteus.matrix import tseries as ts
import nibabel as nib
from nibabel.affines import apply_affine
import pandas as pd
from sklearn.cross_validation import KFold
from sklearn.linear_model import LinearRegression
from nilearn.masking import compute_epi_mask
from proteus.matrix import registration
reload(registration)
```
# Load data low motion
we load the data depending on the source HC0040123, SZ0040142 and SZ0040084
```
subj_id='HC0040123'
# original subject from pierre exp
covar = pd.read_csv('/home/cdansereau/data/deepmotion/cobre/xp_2016_07_27_final/fmri_'+subj_id+'_session1_run1_n_confounds.tsv.gz',sep='\t')
covar.columns
vol_nii = nib.load('/home/cdansereau/data/deepmotion/cobre/xp_2016_07_27_final/rest_'+subj_id+'.nii.gz')
```
We extract the functional volume and relevant covariates (slow time drift and motion params)
```
vol = vol_nii.get_data()
Xmotion = covar.iloc[:,0:6].values
Xdrift = covar.iloc[:,8:14].values
fd = covar['FD'].values
```
# Extract mask
```
# compute the functional mask for the subject
mask_b = compute_epi_mask(vol_nii).get_data().astype(bool)
mask = vol[...,0]>-10000
# show functional
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.imshow(vol.mean(3)[:,:,20])
plt.colorbar()
plt.subplot(1,2,2)
plt.imshow(mask_b[:,:,20],clim=(0.0, 1.))
plt.colorbar()
```
Create some functional to help with the visualization
```
# R2 score
def getR2(y,ypred,mask=[]):
if mask==[]:
R2 = 1. - np.sum((y-ypred)**2,0)/np.sum(y**2,0)
else:
R2 = 1. - np.sum((y[:,mask]-ypred[:,mask])**2,0)/np.sum(y[:,mask]**2,0)
return R2
def getMap(val,mask):
if len(val.shape)==2:
new_map = np.zeros((mask.shape[0],mask.shape[1],mask.shape[2],val.shape[1])).astype(float)
else:
new_map = np.zeros_like(mask).astype(float)
new_map[mask] = val
return new_map
def getspec(vol):
nx,ny,nz = vol.shape
nrows = int(np.ceil(np.sqrt(nz)))
ncolumns = int(np.ceil(nz/(1.*nrows)))
return nrows,ncolumns,nx,ny,nz
def montage(vol1):
vol = np.swapaxes(vol1,0,1)
nrows,ncolumns,nx,ny,nz = getspec(vol)
mozaic = np.zeros((nrows*nx,ncolumns*ny))
indx,indy = np.where(np.ones((nrows,ncolumns)))
for ii in np.arange(vol.shape[2]):
# we need to flip the image in the x axis
mozaic[(indx[ii]*nx):((indx[ii]+1)*nx),(indy[ii]*ny):((indy[ii]+1)*ny)] = vol[::-1,:,ii]
return mozaic
cut_idx = 20
def show_diff(ref_vals,pred_vals,mask,frame=10,cut=cut_idx):
plt.figure(figsize=(15,5))
ref_vol = getMap(ref_vals[frame,:],mask)
lim_val = [ref_vol[:,:,cut].min(),ref_vol[:,:,cut].max()]
plt.subplot(1,3,1)
visu.mat(getMap(ref_vals[frame,:],mask)[:,:,cut],lim=lim_val)
plt.subplot(1,3,2)
visu.mat(getMap(pred_vals[frame,:],mask)[:,:,cut],lim=lim_val)
plt.subplot(1,3,3)
visu.mat(getMap((ref_vals-pred_vals)[frame,:],mask)[:,:,cut],lim=lim_val)
def show_report(ref_vals,pred_vals,mask,frames,mask_b=[],cut=cut_idx):
n_frames = len(frames)
# R2
if mask_b ==[]:
R2 = getR2(ref_vals,pred_vals)
fig=plt.figure(figsize=(15,5+5*len(frames)))
ax = plt.subplot(n_frames+1,2,1)
plt.title('R2 Mean:'+str(round(R2.mean(),3))+' Min:'+str(round(R2.min(),3))+' Max:'+str(round(R2.max(),3)))
visu.mat(getMap(R2,mask)[:,:,cut],lim=[-1,1])
plt.subplot(n_frames+1,2,2)
plt.title('R2 distribution')
plt.hist(R2,100)
else:
R2 = getR2(ref_vals[:,mask_b[mask]],pred_vals[:,mask_b[mask]])
fig=plt.figure(figsize=(15,5+5*len(frames)))
ax = plt.subplot(n_frames+1,2,1)
plt.title('R2 Mean:'+str(round(R2.mean(),3))+' Min:'+str(round(R2.min(),3))+' Max:'+str(round(R2.max(),3)))
visu.mat(getMap(R2,mask_b)[:,:,cut],lim=[-1,1])
plt.subplot(n_frames+1,2,2)
plt.title('R2 distribution')
plt.hist(R2,100)
# frames
for ii in range(n_frames):
ref_vol = getMap(ref_vals[frames[ii],:],mask)
lim_val = [ref_vol[:,:,cut].min(),ref_vol[:,:,cut].max()]
plt.subplot(n_frames+1,3,3+3*ii+1)
visu.mat(getMap(ref_vals[frames[ii],:],mask)[:,:,cut],lim=lim_val)
if ii == 0: plt.title('Reference')
plt.ylabel('Frame '+str(frames[ii]))
plt.subplot(n_frames+1,3,3+3*ii+2)
visu.mat(getMap(pred_vals[frames[ii],:],mask)[:,:,cut],lim=lim_val)
if ii == 0: plt.title('Prediction')
plt.subplot(n_frames+1,3,3+3*ii+3)
visu.mat(getMap((ref_vals-pred_vals)[frames[ii],:],mask)[:,:,cut],lim=lim_val)
if ii == 0: plt.title('Difference')
def show_report_od(ref_vals,pred_vals,mask,frames,cut=cut_idx):
n_frames = len(frames)
fig=plt.figure(figsize=(15,5*len(frames)))
# frames
for ii in range(n_frames):
ref_vol = getMap(ref_vals[frames[ii],:],mask)
lim_val = [ref_vol[:,:,cut].min(),ref_vol[:,:,cut].max()]
plt.subplot(n_frames+1,3,3+3*ii+1)
visu.mat(getMap(ref_vals[frames[ii],:],mask)[:,:,cut],lim=lim_val)
if ii == 0: plt.title('Reference')
plt.ylabel('Frame '+str(frames[ii]))
plt.subplot(n_frames+1,3,3+3*ii+2)
visu.mat(getMap(pred_vals[frames[ii],:],mask)[:,:,cut],lim=lim_val)
if ii == 0: plt.title('Prediction')
plt.subplot(n_frames+1,3,3+3*ii+3)
visu.mat(getMap((ref_vals-pred_vals)[frames[ii],:],mask)[:,:,cut],lim=lim_val)
if ii == 0: plt.title('Difference')
def vol2vec(vol):
mask = vol<inf
return vol[mask],mask
def vec2vol(vec,mask):
new_vol = np.zeros_like(mask)
new_vol[mask] = vec
return new_vol
```
# Convolutional model
## mask outside the brain to be at zeros
## normalization of the input image
###in a range 0 to 1
### center the robust median to zero (see old work on deppmotion)
```
import theano
import theano.tensor as T
def mean_squared_error_masked(y_true, y_pred):
return T.mean(T.mean(T.mean(T.square(y_pred - y_true), axis=-1), axis=-1), axis=-1)
from keras.utils import np_utils, generic_utils
from keras.optimizers import SGD, RMSprop
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers.normalization import BatchNormalization
from keras.layers.core import Dropout
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from keras.layers.convolutional import Convolution3D
from keras.layers.convolutional import UpSampling3D
from keras.engine.topology import Merge
from keras.layers.core import RepeatVector,Reshape
from keras.regularizers import l2, activity_l2
#from keras.layers.core import SpatialDropout3D
def build_model(output_size,kdim=[3,3,3],motion_out_size=32):
# motion branch
model_motion = Sequential()
model_motion.add(Dense(32,input_dim=6,init='uniform',W_regularizer=None))
model_motion.add(Activation('tanh'))
model_motion.add(Dropout(0.5))
#model_motion.add(Dense(32,init='uniform',W_regularizer=None))
#model_motion.add(Activation('tanh'))
#model_motion.add(Dropout(0.5))
model_motion.add(Dense(motion_out_size,init='uniform',W_regularizer=None))
model_motion.add(Activation('tanh'))
#model_motion.add(Dropout(0.5))
model_motion.add(RepeatVector(output_size[0]*output_size[1]*output_size[2]))
print model_motion.output_shape
# convolution branch
model_conv = Sequential()
#model.add(UpSampling3D(size=(2, 2, 2), dim_ordering='default',input_shape=(1, output_size[0], output_size[1], output_size[2])))
model_conv.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2], input_shape=(1, output_size[0], output_size[1], output_size[2]),border_mode='same',W_regularizer=None,init='uniform'))
model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
#model_conv.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',W_regularizer=None,init='uniform'))
#model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
#model_conv.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',init='uniform'))
#model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
model_conv.add(Convolution3D(motion_out_size,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',W_regularizer=None,init='uniform'))
model_conv.add(Activation('tanh'))
print model_conv.output_shape
model_conv.add(Reshape((output_size[0]*output_size[1]*output_size[2],motion_out_size)))
print model_conv.output_shape
merged_model = Sequential()
merged_model.add(Merge([model_motion, model_conv], mode='mul'))
merged_model.add(Reshape((motion_out_size,output_size[0],output_size[1],output_size[2])))
merged_model.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',W_regularizer=None,init='uniform'))
merged_model.add(Activation('tanh'))
merged_model.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',W_regularizer=None,init='uniform'))
merged_model.add(Activation('tanh'))
merged_model.add(Convolution3D(1,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',init='uniform'))
merged_model.add(Activation('linear'))
print merged_model.output_shape
#addavg_model = Sequential()
#addavg_model.add(Merge([merged_model, model_conv.layers[0]], mode='sum'))
sgd = SGD(lr=.1, decay=1e-5, momentum=0.5, nesterov=False)
merged_model.compile(loss='mean_squared_error', optimizer=sgd)
#merged_model.compile(loss=mean_squared_error_masked, optimizer=sgd) #compute the loss inside the brain only
return merged_model
nb_epoch = 1
validation_split = 0.2
# put the outside of the brain to zero
vol[~mask_b]=0
ts = vol[mask].T
kf = KFold(n=ts.shape[0], n_folds=10, shuffle=False,random_state=None)
pred_vals = []
ref_vals = []
k=1
for train, test in kf:
ssx = MinMaxScaler(feature_range=(-1,1))
ssy = MinMaxScaler(feature_range=(-1,1))
ssvol = MinMaxScaler(feature_range=(0,1))
#print train
print ('-'*20)+'kfold '+ str(k)+('-'*20)
k+=1
# Train
lreg_d = LinearRegression(fit_intercept=True,normalize=False)
lreg_d.fit(Xdrift[train,:],ts[train,:])
new_ts = ts-lreg_d.predict(Xdrift)
lreg_md = LinearRegression(fit_intercept=True,normalize=False)
lreg_md.fit(Xdrift[train,:],Xmotion[train,:])
new_Xmotion = Xmotion - lreg_md.predict(Xdrift)
mean_volume = ssvol.fit_transform(lreg_d.intercept_.reshape(-1, 1))
mean_volume = mean_volume.reshape((vol[...,0].shape))[np.newaxis,np.newaxis,...]
y_ = ssy.fit_transform(new_ts[train,:]).reshape((len(train),vol.shape[0],vol.shape[1],vol.shape[2]))[:,np.newaxis,...]
# Learn the regression parameters to predict time series
model = build_model(vol.shape[:3])
#model.lr=10
#model.momentum=0.5
x_augm,y_augm = [ssx.fit_transform(new_Xmotion[train,:]),np.concatenate((mean_volume,)* len(train), axis=0)],y_
#x_augm,y_augm = data_augm(ssx.fit_transform(new_Xmotion[train,:]),np.concatenate((mean_volume,)* len(train), axis=0),y_)
hist = model.fit(x_augm, y_augm,verbose=1, nb_epoch=nb_epoch, batch_size=1,validation_split=validation_split)
plt.figure()
if validation_split == 0.:
plt.plot(range(nb_epoch),hist.history['loss'])
else:
plt.plot(range(nb_epoch),hist.history['loss'],range(nb_epoch),hist.history['val_loss'])
plt.legend(['loss','val_loss'],bbox_to_anchor=(0., 1.02, 1., .102), loc=3,
ncol=2, mode="expand", borderaxespad=0.)
## Test on independent data
X_test = ssx.transform(new_Xmotion[test,:])
mean_volumes_ = np.concatenate((mean_volume,)* len(test), axis=0)
test_data = model.predict([X_test,mean_volumes_],batch_size=1)
test_denorm = ssy.inverse_transform(test_data.reshape((len(test),vol.shape[0]*vol.shape[1]*vol.shape[2])))
pred_vals.append(test_denorm)
#.reshape((vol[...,test].shape))
ref_vals.append(new_ts[test,:])
break
print 'Average R2: ',getR2(np.vstack(ref_vals),np.vstack(pred_vals),mask=mask_b[mask]).mean()
from keras.utils import np_utils, generic_utils
from keras.optimizers import SGD, RMSprop
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers.normalization import BatchNormalization
from keras.layers.core import Dropout
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from keras.layers.convolutional import Convolution3D
from keras.layers.convolutional import UpSampling3D
from keras.engine.topology import Merge
from keras.layers.core import RepeatVector,Reshape
from keras.regularizers import l2, activity_l2
#from keras.layers.core import SpatialDropout3D
def build_model(output_size,kdim=[3,3,3],motion_out_size=32):
# convolution branch
model_conv = Sequential()
#model.add(UpSampling3D(size=(2, 2, 2), dim_ordering='default',input_shape=(1, output_size[0], output_size[1], output_size[2])))
model_conv.add(Convolution3D(80,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2], input_shape=(6, output_size[0], output_size[1], output_size[2]),border_mode='same',W_regularizer=None,init='uniform'))
model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
#model_conv.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',W_regularizer=None,init='uniform'))
#model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
#model_conv.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',init='uniform'))
#model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
model_conv.add(Convolution3D(1,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',init='uniform'))
#model_conv.add(Activation('linear'))
print model_conv.output_shape
sgd = SGD(lr=1e-2, decay=1e-6, momentum=0.9, nesterov=False)
model_conv.compile(loss='mean_squared_error', optimizer=sgd)
#model_conv.compile(loss=mean_squared_error_masked, optimizer=sgd) #compute the loss inside the brain only
return model_conv
nb_epoch = 50
validation_split = 0.2
# put the outside of the brain to zero
vol[~mask_b]=0
ts = vol[mask].T
kf = KFold(n=ts.shape[0], n_folds=10, shuffle=False,random_state=None)
pred_vals = []
ref_vals = []
k=1
for train, test in kf:
ssx = MinMaxScaler(feature_range=(-1,1))
ssy = MinMaxScaler(feature_range=(-1,1))
ssvol = MinMaxScaler(feature_range=(0,1))
#print train
print ('-'*20)+'kfold '+ str(k)+('-'*20)
k+=1
# Train
lreg_d = LinearRegression(fit_intercept=True,normalize=False)
lreg_d.fit(Xdrift[train,:],ts[train,:])
new_ts = ts-lreg_d.predict(Xdrift)
lreg_md = LinearRegression(fit_intercept=True,normalize=False)
lreg_md.fit(Xdrift[train,:],Xmotion[train,:])
new_Xmotion = Xmotion - lreg_md.predict(Xdrift)
mean_volume = ssvol.fit_transform(lreg_d.intercept_.reshape(-1, 1))
mean_volume = mean_volume.reshape((vol[...,0].shape))[np.newaxis,np.newaxis,...]
y_ = ssy.fit_transform(new_ts[train,:]).reshape((len(train),vol.shape[0],vol.shape[1],vol.shape[2]))[:,np.newaxis,...]
# Learn the regression parameters to predict time series
model = build_model(vol.shape[:3])
#model.lr=10
#model.momentum=0.5
x_augm,y_augm = np.concatenate((mean_volume,)* len(train), axis=0)*ssx.fit_transform(new_Xmotion[train,:])[:,:,np.newaxis,np.newaxis,np.newaxis],y_
#x_augm,y_augm = data_augm(ssx.fit_transform(new_Xmotion[train,:]),np.concatenate((mean_volume,)* len(train), axis=0),y_)
hist = model.fit(x_augm, y_augm,verbose=1, nb_epoch=nb_epoch, batch_size=1,validation_split=validation_split)
plt.figure()
if validation_split == 0.:
plt.plot(range(nb_epoch),hist.history['loss'])
else:
plt.plot(range(nb_epoch),hist.history['loss'],range(nb_epoch),hist.history['val_loss'])
plt.legend(['loss','val_loss'],bbox_to_anchor=(0., 1.02, 1., .102), loc=3,
ncol=2, mode="expand", borderaxespad=0.)
## Test on independent data
#X_test = ssx.transform(new_Xmotion[test,:])
#mean_volumes_ = np.concatenate((mean_volume,)* len(test), axis=0)
x_augm = np.concatenate((mean_volume,)* len(test), axis=0)*ssx.transform(new_Xmotion[test,:])[:,:,np.newaxis,np.newaxis,np.newaxis]
test_data = model.predict(x_augm,batch_size=1)
test_denorm = ssy.inverse_transform(test_data.reshape((len(test),vol.shape[0]*vol.shape[1]*vol.shape[2])))
pred_vals.append(test_denorm)
#.reshape((vol[...,test].shape))
ref_vals.append(new_ts[test,:])
break
print 'Average R2: ',getR2(np.vstack(ref_vals),np.vstack(pred_vals),mask=mask_b[mask]).mean()
[ssx.fit_transform(new_Xmotion[train,:]).shape,np.concatenate((mean_volume,)* len(train), axis=0).shape]
(np.concatenate((mean_volume,)* len(train), axis=0)*ssx.fit_transform(new_Xmotion[train,:])[:,:,np.newaxis,np.newaxis,np.newaxis]).shape
def flip_data(data,motion,y,flip_x,flip_y,flip_z):
#mat_motion = np.reshape(motion,(motion.shape[0],motion.shape[1]/3,3))
if flip_x:
new_data = data[...,::-1,:,:]
new_y = y[...,::-1,:,:]
new_motion = motion*np.array([-1,1,1,1,1,1])
else:
new_data = data.copy()
new_y = y.copy()
new_motion = motion.copy()
if flip_y:
new_data = new_data[...,:,::-1,:]
new_y = y[...,:,::-1,:]
new_motion = new_motion*np.array([1,-1,1,1,1,1])
if flip_z:
new_data = new_data[...,:,:,::-1]
new_y = y[...,:,:,::-1]
new_motion = new_motion*np.array([1,1,-1,1,1,1])
return new_data, new_motion, new_y
def data_augm(motion,data,y):
sequence = np.array([[0,0,0],
[0,0,1],
[0,1,0],
[0,1,1],
[1,0,0],
[1,0,1],
[1,1,0],
[1,1,1]])
new_data = []
new_motion = []
new_y = []
#print sequence.shape
for i in range(sequence.shape[0]):
augm,augm_motion,augm_y = flip_data(data,motion,y,sequence[i,0],sequence[i,1],sequence[i,2])
if i==0:
new_data = augm
new_motion = augm_motion
new_y = augm_y
else:
new_data = np.vstack((new_data,augm))
new_motion = np.vstack((new_motion,augm_motion))
new_y = np.vstack((new_y,augm_y))
#print new_data.shape,new_motion.shape
return [new_data,new_motion],new_y
a1,a2 = data_augm(ssx.fit_transform(new_Xmotion[train,:]),np.concatenate((mean_volume,)* len(train), axis=0),y_)
a1[1].shape
(ssx.fit_transform(new_Xmotion[train,:])*np.array([1,1,-1,1,1,1]))
visu.mat(mean_volume[0,0,:,:,17])
model.get_weights()[-2]
show_report(np.vstack(ref_vals),np.vstack(pred_vals),mask,frames=np.arange(0,10),mask_b=mask_b)
print fd[0:10]
from keras.utils import np_utils, generic_utils
from keras.optimizers import SGD, RMSprop
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers.normalization import BatchNormalization
from keras.layers.core import Dropout
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from keras.layers.convolutional import Convolution3D
from keras.layers.convolutional import UpSampling3D
from keras.engine.topology import Merge
from keras.layers.core import RepeatVector,Reshape
from keras.regularizers import l2, activity_l2
#from keras.layers.core import SpatialDropout3D
def build_model(output_size,kdim=[3,3,3],motion_out_size=32):
# convolution branch
model_conv = Sequential()
#model.add(UpSampling3D(size=(2, 2, 2), dim_ordering='default',input_shape=(1, output_size[0], output_size[1], output_size[2])))
model_conv.add(Convolution3D(5,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2], input_shape=(6, output_size[0], output_size[1], output_size[2]),border_mode='same',W_regularizer=None,init='uniform'))
model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
#model_conv.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',W_regularizer=None,init='uniform'))
#model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
#model_conv.add(Convolution3D(32,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',init='uniform'))
#model_conv.add(Activation('tanh'))
#model_conv.add(SpatialDropout3D(0.5))
model_conv.add(Convolution3D(1,kernel_dim1=kdim[0],kernel_dim2=kdim[1],kernel_dim3=kdim[2],border_mode='same',init='uniform'))
#model_conv.add(Activation('linear'))
print model_conv.output_shape
sgd = SGD(lr=1e-2, decay=1e-6, momentum=0.9, nesterov=False)
model_conv.compile(loss='mean_squared_error', optimizer=sgd)
#model_conv.compile(loss=mean_squared_error_masked, optimizer=sgd) #compute the loss inside the brain only
return model_conv
nb_epoch = 3
validation_split = 0.2
# put the outside of the brain to zero
vol[~mask_b]=0
ts = vol[mask].T
kf = KFold(n=ts.shape[0], n_folds=10, shuffle=False,random_state=None)
pred_vals = []
ref_vals = []
k=1
for train, test in kf:
ssx = MinMaxScaler(feature_range=(-1,1))
ssy = MinMaxScaler(feature_range=(-1,1))
ssvol = MinMaxScaler(feature_range=(0,1))
#print train
print ('-'*20)+'kfold '+ str(k)+('-'*20)
k+=1
# Train
lreg_d = LinearRegression(fit_intercept=True,normalize=False)
lreg_d.fit(Xdrift[train,:],ts[train,:])
new_ts = ts-lreg_d.predict(Xdrift)
lreg_md = LinearRegression(fit_intercept=True,normalize=False)
lreg_md.fit(Xdrift[train,:],Xmotion[train,:])
new_Xmotion = Xmotion - lreg_md.predict(Xdrift)
mean_volume = ssvol.fit_transform(lreg_d.intercept_.reshape(-1, 1))
mean_volume = mean_volume.reshape((vol[...,0].shape))[np.newaxis,np.newaxis,...]
y_ = ssy.fit_transform(new_ts[train,:]).reshape((len(train),vol.shape[0],vol.shape[1],vol.shape[2]))[:,np.newaxis,...]
# Learn the regression parameters to predict time series
model = build_model(vol.shape[:3])
#model.lr=10
#model.momentum=0.5
x_augm,y_augm = np.concatenate((mean_volume,)* len(train), axis=0)*ssx.fit_transform(new_Xmotion[train,:])[:,:,np.newaxis,np.newaxis,np.newaxis],y_.copy()
#x_augm,y_augm = data_augm(ssx.fit_transform(new_Xmotion[train,:]),np.concatenate((mean_volume,)* len(train), axis=0),y_)
hist = model.fit(x_augm, y_augm,verbose=1, nb_epoch=nb_epoch, batch_size=1,validation_split=validation_split)
plt.figure()
if validation_split == 0.:
plt.plot(range(nb_epoch),hist.history['loss'])
else:
plt.plot(range(nb_epoch),hist.history['loss'],range(nb_epoch),hist.history['val_loss'])
plt.legend(['loss','val_loss'],bbox_to_anchor=(0., 1.02, 1., .102), loc=3,
ncol=2, mode="expand", borderaxespad=0.)
## Test on independent data
#X_test = ssx.transform(new_Xmotion[test,:])
#mean_volumes_ = np.concatenate((mean_volume,)* len(test), axis=0)
x_augm = np.concatenate((mean_volume,)* len(test), axis=0)*ssx.transform(new_Xmotion[test,:])[:,:,np.newaxis,np.newaxis,np.newaxis]
test_data = model.predict(x_augm,batch_size=1)
test_denorm = ssy.inverse_transform(test_data.reshape((len(test),vol.shape[0]*vol.shape[1]*vol.shape[2])))
pred_vals.append(test_denorm)
#.reshape((vol[...,test].shape))
ref_vals.append(new_ts[test,:])
break
print 'Average R2: ',getR2(np.vstack(ref_vals),np.vstack(pred_vals),mask=mask_b[mask]).mean()
```
| github_jupyter |
```
from gensim.models.doc2vec import Doc2Vec
from gensim.models import doc2vec
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from scipy.spatial.distance import cosine, jaccard, hamming, correlation
from collections import Counter
import nltk
from nltk import word_tokenize
from nltk.corpus import stopwords
import re
from sklearn.model_selection import train_test_split
import math
import gensim
import json
import sys
import pandas as pd
import numpy as np
import gc
import multiprocessing
import functools
from tqdm import tqdm
def cosine(v1, v2):
v1 = np.array(v1)
v2 = np.array(v2)
return np.dot(v1, v2) / (np.sqrt(np.sum(v1**2)) * np.sqrt(np.sum(v2**2)))
def concatenate(data):
X_set1 = data['question1']
X_set2 = data['question2']
X = X_set1.append(X_set2, ignore_index=True)
return X
class LabeledLineSentence(object):
def __init__(self, doc_list, labels_list):
self.labels_list = labels_list
self.doc_list = doc_list
def __iter__(self):
for idx, doc in enumerate(self.doc_list):
yield doc2vec.TaggedDocument(words=word_tokenize(doc),
tags=[self.labels_list[idx]])
def get_data(src_train, src_test):
df_train = pd.read_csv(src_train)
df_test = pd.read_csv(src_test)
df_train = df_train.loc[:, ['question1', 'question2']]
df_test = df_test.loc[:, ['question1', 'question2']]
df_train.fillna('NULL', inplace = True)
df_test.fillna('NULL', inplace = True)
data = pd.concat((df_train, df_test))
del df_train, df_test
gc.collect()
return data
def get_dists_doc2vec(data):
docvec1s = np.zeros((data.shape[0], 300), dtype = 'float32')
docvec2s = np.zeros((data.shape[0], 300), dtype = 'float32')
for i in tqdm(range(data.shape[0])):
doc1 = word_tokenize(data.iloc[i, -2])
doc2 = word_tokenize(data.iloc[i, -1])
docvec1 = model1.infer_vector(doc1, alpha=start_alpha, steps=infer_epoch)
docvec2 = model1.infer_vector(doc2, alpha=start_alpha, steps=infer_epoch)
docvec1s[i, :] = docvec1
docvec2s[i, :] = docvec2
return docvec1s, docvec2s
src = '/media/w/1c392724-ecf3-4615-8f3c-79368ec36380/DS Projects/Kaggle/Quora/data/embeddings/doc2vec/enwiki_dbow/'
model_path = src + 'doc2vec.bin'
eng_stopwords = set(stopwords.words('english'))
src_train = 'df_train_spacylemmat_fullclean.csv'
src_test = 'df_test_spacylemmat_fullclean.csv'
model1 = Doc2Vec.load(model_path)
data = get_data(src_train, src_test)
start_alpha = 0.01
infer_epoch = 10
results = get_dists_doc2vec(data)
df_train = pd.read_csv(src_train)
docvec1s, docvec2s = results[0], results[1]
docvec1s = np.array(docvec1s)
docvec1s_tr = docvec1s[:df_train.shape[0]]
docvec1s_te = docvec1s[df_train.shape[0]:]
docvec2s = np.array(docvec2s)
docvec2s_tr = docvec2s[:df_train.shape[0]]
docvec2s_te = docvec2s[df_train.shape[0]:]
np.save('train_q1_doc2vec_vectors_pretrained_fullcleanDF', docvec1s_tr)
np.save('test_q1_doc2vec_vectors_pretrained_fullcleanDF', docvec1s_te)
np.save('train_q2_doc2vec_vectors_pretrained_fullcleanDF', docvec2s_tr)
np.save('test_q2_doc2vec_vectors_pretrained_fullcleanDF', docvec2s_te)
```
| github_jupyter |
# Bernstein-Vazirani Algorithm
In this section, we first introduce the Bernstein-Vazirani problem, and classical and quantum algorithms to solve it. We then implement the quantum algorithm using Qiskit, and run on a simulator and device.
## Contents
1. [Introduction](#introduction)
1.1 [Bernstein-Vazirani Problem](#bvproblem)
1.2 [Bernstein-Vazirani Algorithm](#bvalgorithm)
2. [Example](#example)
3. [Qiskit Implementation](#implementation)
3.1 [Simulation](#simulation)
3.2 [Device](#device)
4. [Problems](#problems)
5. [References](#references)
## 1. Introduction <a id='introduction'></a>
The Bernstein-Vazirani algorithm, first introduced in Reference [1], can be seen as an extension of the Deutsch-Josza algorithm covered in the last section. It showed that there can be advantages in using a quantum computer as a computational tool for more complex problems compared to the Deutsch-Josza problem.
### 1a. Bernstein-Vazirani Problem <a id='bvproblem'> </a>
We are again given a hidden function Boolean $f$, which takes as as input a string of bits, and returns either $0$ or $1$, that is:
<center>$f(\{x_0,x_1,x_2,...\}) \rightarrow 0 \textrm{ or } 1 \textrm{ where } x_n \textrm{ is }0 \textrm{ or } 1 $.
Instead of the function being balanced or constant as in the Deutsch-Josza problem, now the function is guaranteed to return the bitwise product of the input with some string, $s$. In other words, given an input $x$, $f(x) = s \cdot x \, \text{(mod 2)}$. We are expected to find $s$.
### 1b. Bernstein-Vazirani Algorithm <a id='bvalgorithm'> </a>
#### Classical Solution
Classically, the oracle returns $f_s(x) = s \cdot x \mod 2$ given an input $x$. Thus, the hidden bit string $s$ can be revealed by querying the oracle with $x = 1, 2, \ldots, 2^i, \ldots, 2^{n-1}$, where each query reveals the $i$-th bit of $s$ (or, $s_i$). For example, with $x=1$ one can obtain the least significant bit of $s$, and so on. This means we would need to call the function $f_s(x)$ $n$ times.
#### Quantum Solution
Using a quantum computer, we can solve this problem with 100% confidence after only one call to the function $f(x)$. The quantum Bernstein-Vazirani algorithm to find the hidden integer is very simple: (1) start from a $|0\rangle^{\otimes n}$ state, (2) apply Hadamard gates, (3) query the oracle, (4) apply Hadamard gates, and (5) measure, generically illustrated below:

The correctness of the algorithm is best explained by looking at the transformation of a quantum register $|a \rangle$ by $n$ Hadamard gates, each applied to the qubit of the register. It can be shown that:
$$
|a\rangle \xrightarrow{H^{\otimes n}} \frac{1}{\sqrt{2^n}} \sum_{x\in \{0,1\}^n} (-1)^{a\cdot x}|x\rangle.
$$
In particular, when we start with a quantum register $|0\rangle$ and apply $n$ Hadamard gates to it, we have the familiar quantum superposition:
$$
|0\rangle \xrightarrow{H^{\otimes n}} \frac{1}{\sqrt{2^n}} \sum_{x\in \{0,1\}^n} |x\rangle,
$$
which is slightly different from the Hadamard transform of the reqister $|a \rangle$ by the phase $(-1)^{a\cdot x}$.
Now, the quantum oracle $f_a$ returns $1$ on input $x$ such that $a \cdot x \equiv 1 \mod 2$, and returns $0$ otherwise. This means we have the following transformation:
$$
|x \rangle \xrightarrow{f_a} | x \rangle = (-1)^{a\cdot x} |x \rangle.
$$
The algorithm to reveal the hidden integer follows naturally by querying the quantum oracle $f_a$ with the quantum superposition obtained from the Hadamard transformation of $|0\rangle$. Namely,
$$
|0\rangle \xrightarrow{H^{\otimes n}} \frac{1}{\sqrt{2^n}} \sum_{x\in \{0,1\}^n} |x\rangle \xrightarrow{f_a} \frac{1}{\sqrt{2^n}} \sum_{x\in \{0,1\}^n} (-1)^{a\cdot x}|x\rangle.
$$
Because the inverse of the $n$ Hadamard gates is again the $n$ Hadamard gates, we can obtain $a$ by
$$
\frac{1}{\sqrt{2^n}} \sum_{x\in \{0,1\}^n} (-1)^{a\cdot x}|x\rangle \xrightarrow{H^{\otimes n}} |a\rangle.
$$
## 2. Example <a id='example'></a>
Let's go through a specific example for $n=2$ qubits and a secret string $s=11$. Note that we are following the formulation in Reference [2] that generates a circuit for the Bernstein-Vazirani quantum oracle using only one register.
<ol>
<li> The register of two qubits is initialized to zero:
$$\lvert \psi_0 \rangle = \lvert 0 0 \rangle$$
</li>
<li> Apply a Hadamard gate to both qubits:
$$\lvert \psi_1 \rangle = \frac{1}{2} \left( \lvert 0 0 \rangle + \lvert 0 1 \rangle + \lvert 1 0 \rangle + \lvert 1 1 \rangle \right) $$
</li>
<li> For the string $s=11$, the quantum oracle can be implemented as $\text{Q}_f = Z_{1}Z_{2}$:
$$\lvert \psi_2 \rangle = \frac{1}{2} \left( \lvert 0 0 \rangle - \lvert 0 1 \rangle - \lvert 1 0 \rangle + \lvert 1 1 \rangle \right)$$
</li>
<li> Apply a Hadamard gate to both qubits:
$$\lvert \psi_3 \rangle = \lvert 1 1 \rangle$$
</li>
<li> Measure to find the secret string $s=11$
</li>
</ol>
## 3. Qiskit Implementation <a id='implementation'></a>
We now implement the Bernstein-Vazirani algorithm with Qiskit for a two bit function with $s=11$.
```
# initialization
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'svg' # Makes the images look nice
import numpy as np
# importing Qiskit
from qiskit import IBMQ, BasicAer
from qiskit.providers.ibmq import least_busy
from qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister, execute
# import basic plot tools
from qiskit.visualization import plot_histogram
```
We first set the number of qubits used in the experiment, and the hidden integer $s$ to be found by the algorithm. The hidden integer $s$ determines the circuit for the quantum oracle.
```
nQubits = 2 # number of physical qubits used to represent s
s = 3 # the hidden integer
# make sure that a can be represented with nqubits
s = s % 2**(nQubits)
```
We then use Qiskit to program the Bernstein-Vazirani algorithm.
```
# Creating registers
# qubits for querying the oracle and finding the hidden integer
qr = QuantumRegister(nQubits)
# bits for recording the measurement on qr
cr = ClassicalRegister(nQubits)
bvCircuit = QuantumCircuit(qr, cr)
barriers = True
# Apply Hadamard gates before querying the oracle
for i in range(nQubits):
bvCircuit.h(qr[i])
# Apply barrier
if barriers:
bvCircuit.barrier()
# Apply the inner-product oracle
for i in range(nQubits):
if (s & (1 << i)):
bvCircuit.z(qr[i])
else:
bvCircuit.iden(qr[i])
# Apply barrier
if barriers:
bvCircuit.barrier()
#Apply Hadamard gates after querying the oracle
for i in range(nQubits):
bvCircuit.h(qr[i])
# Apply barrier
if barriers:
bvCircuit.barrier()
# Measurement
bvCircuit.measure(qr, cr)
bvCircuit.draw(output='mpl')
```
### 3a. Experiment with Simulators <a id='simulation'></a>
We can run the above circuit on the simulator.
```
# use local simulator
backend = BasicAer.get_backend('qasm_simulator')
shots = 1024
results = execute(bvCircuit, backend=backend, shots=shots).result()
answer = results.get_counts()
plot_histogram(answer)
```
We can see that the result of the measurement is the binary representation of the hidden integer $3$ $(11)$.
### 3b. Experiment with Real Devices <a id='device'></a>
We can run the circuit on the real device as below.
```
# Load our saved IBMQ accounts and get the least busy backend device with less than or equal to 5 qubits
IBMQ.load_account()
provider = IBMQ.get_provider(hub='ibm-q')
provider.backends()
backend = least_busy(provider.backends(filters=lambda x: x.configuration().n_qubits <= 5 and
x.configuration().n_qubits >= 2 and
not x.configuration().simulator and x.status().operational==True))
print("least busy backend: ", backend)
# Run our circuit on the least busy backend. Monitor the execution of the job in the queue
from qiskit.tools.monitor import job_monitor
shots = 1024
job = execute(bvCircuit, backend=backend, shots=shots)
job_monitor(job, interval = 2)
# Get the results from the computation
results = job.result()
answer = results.get_counts()
plot_histogram(answer)
```
As we can see, most of the results are $11$. The other results are due to errors in the quantum computation.
## 4. Problems <a id='problems'></a>
1. The above [implementation](#implementation) of Bernstein-Vazirani is for a secret bit string of $s = 11$. Modify the implementation for a secret string os $s = 1011$. Are the results what you expect? Explain.
2. The above [implementation](#implementation) of Bernstein-Vazirani is for a secret bit string of $s = 11$. Modify the implementation for a secret string os $s = 1110110101$. Are the results what you expect? Explain.
## 5. References <a id='references'></a>
1. Ethan Bernstein and Umesh Vazirani (1997) "Quantum Complexity Theory" SIAM Journal on Computing, Vol. 26, No. 5: 1411-1473, [doi:10.1137/S0097539796300921](https://doi.org/10.1137/S0097539796300921).
2. Jiangfeng Du, Mingjun Shi, Jihui Wu, Xianyi Zhou, Yangmei Fan, BangJiao Ye, Rongdian Han (2001) "Implementation of a quantum algorithm to solve the Bernstein-Vazirani parity problem without entanglement on an ensemble quantum computer", Phys. Rev. A 64, 042306, [10.1103/PhysRevA.64.042306](https://doi.org/10.1103/PhysRevA.64.042306), [arXiv:quant-ph/0012114](https://arxiv.org/abs/quant-ph/0012114).
```
import qiskit
qiskit.__qiskit_version__
```
| github_jupyter |
# Regression Discontinuity Design
In this notebook, we explore how one might perform an experiment and analyze the data collected using regression discontinuity design (RDD). Typically an RDD is applied when the assignment of treatment $T$ is determined by whether an observed covariate $X$ lies on one side of a fixed threshold value $c$. Under the assumption that the outcome variable $Y$ varies continuously with $X$ for treated (or untreated) individuals, one can estimate the treatment effect $\mathbb{E}[Y \mid do(T=1)] - \mathbb{E}[Y \mid do(T=0)]$ by performing regressions on both sides of the threshold.
```
%load_ext autoreload
%autoreload 2
!pip install rdd
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from rdd import rdd
import statsmodels.formula.api as smf
import whynot as wn
from whynot import DynamicsExperiment, parameter
from whynot.simulators import world2
```
## Simulator: [World2](https://whynot-docs.readthedocs-hosted.com/en/latest/simulators.html#world2-simulator)
We use the World2 simulator. In this experiment, we set up the following: $X$ is the initial population level (Year 1900), $Y$ is the population at the end of the simulation (Year 2000), and the treatment is lowering the pollution factor from 1 to 0.75 in Year 1901. The threshold for assigning treatment is $c = 2e8$. In other words, the pollution factor is lowered $(T=1)$ if and only if the initial pollution level is higher than $c$.
Running the following commands shows us the default values of the simulator parameters.
```
wn.world2.State()
wn.world2.Config()
```
## Constructing a regression discontinuity experiment
We construct a causal experiment by specifying the **initial state distribution**, the **treatment rule** (in this case a threshold), the **observed covariates**, and **the outcome** to measure.
```
def sample_initial_states(rng):
"""Sample an initial world2 state by randomly perturbing the default initial state."""
state = world2.State()
state.population *= rng.uniform(0.75, 2)
state.natural_resources *= rng.uniform(0.25, 10.)
state.capital_investment *= rng.uniform(0.5, 2.0)
state.pollution *= rng.uniform(0.2, 2.)
state.capital_investment_in_agriculture *= rng.uniform(0.5, 1.5)
return state
@parameter(name="treatment_threshold", default=2e8,
description="Threshold for treatment")
def threshold_treatment_propensity(untreated_run, treatment_threshold):
"""Assign treatment with probability 1 if initial pollution is above threshold, and 0 otherwise."""
if untreated_run.initial_state.pollution >= treatment_threshold:
return 1.0
return 0.
# Construct the experiment object
ThresholdTreatment = DynamicsExperiment(
name="world2_threshold_treatment",
description="Experiment with threshold treatment on World 2.",
simulator=world2,
simulator_config=world2.Config(end_time=2000),
intervention=world2.Intervention(time=1901, pollution=0.75),
state_sampler=sample_initial_states,
propensity_scorer=threshold_treatment_propensity,
outcome_extractor=lambda run: run[2000].population,
covariate_builder=lambda run: run.initial_state.pollution)
```
## Generating data
We instantiate the experiment and collect 1000 independent samples.
```
dataset = ThresholdTreatment.run(num_samples=1000, seed=1234)
(X, W, Y) = dataset.covariates, dataset.treatments, dataset.outcomes
```
For convenience we scale down the values for population and pollution.
```
data = pd.DataFrame({'y':Y / 1e8, 'x': X.flatten() / 1e8})
threshold = 2.0
```
## Visualizing the data
Let's take a look at the data. Visually, the population numbers are higher to the left of the threshold $c$.
```
plt.figure(figsize=(10, 6))
plt.scatter(data.x, data.y, color="blue")
plt.xlabel(f"Initial Pollution ({scaling:.1e})", fontsize="18")
plt.ylabel(f"Final Population ({scaling:.1e})", fontsize="18")
plt.axvline(x=threshold, color="black", linestyle="--")
plt.show()
plt.close()
```
## Running the regression discontinuity analysis
Now, we perform the regression discontinuity analysis. First, we set up the dataframe by creating two new columns: one for the treatment variable $T$ and one for the centered covariate $X$.
```
data['treat'] = data['x'].map(lambda x: x >= threshold)
data['x_centered'] = data['x'].map(lambda x: x - threshold)
```
The bandwidth of the RDD is a window around the threshold $c$. We use only the data points inside the window and ignore data points beyond it. We can pick the optimal bandwidth, in this case, using the Imbens-Kalyanamaran optimal bandwidth calculation.
```
bandwidth_opt = rdd.optimal_bandwidth(data['y'], data['x'], cut=threshold)
print("Optimal bandwidth:", bandwidth_opt)
```
We regress $Y$ on $X$ and $T$ by ordinary least squares. We can make two observations: $T$ has a statistically significant effect on $Y$ (there is a positive jump discontinuity at the threshold), and $Y$ decreases with $X$. Both observations corroborate with our intuition about how the World2 model should behave. Lowering the pollution factor increases the future pollution, and higher initial pollution levels decreases the futture pollution.
```
data_cut = data[(data['x_centered'] >= -bandwidth_opt) & (data['x_centered'] <= bandwidth_opt)]
result = smf.ols(formula = "y ~ x_centered + treat", data = data_cut).fit()
print(result.summary())
```
## Plot the RDD analysis results
```
%matplotlib inline
plt.figure(num=None, figsize=(10, 6), dpi=80, facecolor='w', edgecolor='k')
plt.scatter(data_cut.x_centered, data_cut.y, color="blue")
plt.plot(data_cut.x_centered[data_cut.x_centered < 0],
result.predict()[data_cut.x_centered < 0], '-', color="r")
plt.plot(data_cut.x_centered[data_cut.x_centered >= 0],
result.predict()[data_cut.x_centered >= 0], '-', color="r")
plt.axvline(x=0,color="black", linestyle="--")
plt.xlabel(f"Initial Pollution Centered at Threshold ({scaling:.1e})", fontsize="20")
plt.ylabel(f"Final Population {scaling:.1e}", fontsize="20");
```
| github_jupyter |
# Exploring n-gram LM
This Jupyter Notebook lets you explore some n-gram LM.
```
import kenlm
import random
import langdetect
from random import shuffle
from util.lm_corpus_util import process_sentence
from util.lm_util import load_lm, load_vocab
def create_test_pair(sentence):
words = sentence.lower().split()
sentence_original = ' '.join(words)
sentence_shuffled = sentence_original
while sentence_shuffled == sentence_original:
shuffle(words)
sentence_shuffled = ' '.join(words)
return sentence_original, sentence_shuffled
def score_sentence(model, sentence):
score = model.score(sentence)
print(f'score for \'{sentence}\': ', score)
for prob, ngram_length, oov in model.full_scores(sentence):
print({'probability': prob, "n-gram length": ngram_length, "oov?": oov})
print("perplexity:", model.perplexity(sentence))
print()
return score
def check_lm(model, sentences, language=None):
ok = True
for sentence in sentences:
language = language if language else {'en': 'english', 'de': 'german'}[langdetect.detect(sentence)]
print(f'original sentence ({language}):', sentence)
sentence = process_sentence(sentence, language=language)
print('normalized sentence:', sentence)
original, shuffled = create_test_pair(sentence)
print()
print('scoring original sentence: ')
score_original = score_sentence(model, original)
print('scoring shuffled sentence: ')
score_shuffled = score_sentence(model, shuffled)
if score_original < score_shuffled:
ok = False
if ok:
print('model seems to be OK')
english_sentences = [
'Language modeling is fun', # normal sentence
'New York', # only one shuffled variant (York New), which should have a lower probabilty
'adasfasf askjh aksf' # some OOV words
]
german_sentences = [
'Seine Pressebeauftragte ist ratlos.',
'Fünf Minuten später steht er im Eingang des Kulturcafés an der Zürcher Europaallee.',
'Den Leuten wird bewusst, dass das System des Neoliberalismus nicht länger tragfähig ist.',
'Doch daneben gibt es die beeindruckende Zahl von 30\'000 Bienenarten, die man unter dem Begriff «Wildbienen» zusammenfasst.',
'Bereits 1964 plante die US-Airline Pan American touristische Weltraumflüge für das Jahr 2000.',
]
german_sayings = [
'Ich bin ein Berliner',
'Man soll den Tag nicht vor dem Abend loben',
'Was ich nicht weiss macht mich nicht heiss',
'Ein Unglück kommt selten allein',
'New York'
]
```
## English models
### DeepSpeech (5-gram, 250k words)
The following model was trained for the Mozilla implementation of DeepSpeech and is included in [download of the pre-trained model](https://github.com/mozilla/DeepSpeech#getting-the-pre-trained-model). The model's vocabulary is contained in the file (). The file `vocab.txt` contatins the vocabulary of the model (one word per line), which comprises also very exotic words and probably spelling errors and is therefore very big (973.673 words). To train the \ac{LM}, $n$-grams of order 4 and 5 were pruned with a threshold value of 1, meaning only 4- and 5-grams with a minimum count of 2 and higher are estimated ([see the details about how Mozilla trained the LM](https://github.com/mozilla/DeepSpeech/tree/master/data/lm)). Because spelling errors are probably unique within the training corpus, 4- or 5-grams containing a misspelled word are unique too and are therefore pruned.
Such a large vocabulary is counter-productive to use in a spell checker because it raises the probability that minor misspellings are "corrected" to the wrong word or that a very rare or misspelled word is used. Unfortunately,`vocab.txt` does not contain any information about how often it appears in the corpus. Therefore, a vocabulary of the 250.000 most frequent word in standard format (one line, words separated by single space) is created using the following commands:
```bash
n=250000 # use 250k most frequent words
# download file
wget http://www.openslr.org/resources/11/librispeech-lm-norm.txt.gz
# decompress file
gunzip librispeech-lm-norm.txt.gz
# count word occurrences and keep n most frequent words
cat librispeech-lm-norm.txt |
pv -s $(stat --printf="%s" librispeech-lm-norm.txt) | # show a progress bar
tr '[:upper:]' '[:lower:]' | # lowercase everything
tr -s '[:space:]' '\n' | # replace spaces with one newline
sort | # sort alphabetically
uniq -c | # count occurrences
sort -bnr | # numeric sort
tr -d '[:digit:] ' | # remove counts from lines
head -${n} | # keep n most frequent words words
tr '\n' ' ' > lm.vocab # replace line breaks with spaces and write to lm.vocab
```
```
model = load_lm('/media/daniel/IP9/lm/ds_en/lm.binary')
check_lm(model, english_sentences, 'english')
```
### Custom model (4-gram, details unknown)
The following model was trained on the TIMIT corpus and downloaded from https://www.dropbox.com/s/2n897gu5p3o2391/libri-timit-lm.klm. Details as the vocabulary or the data structure are not known.
```
model = load_lm('/media/daniel/IP9/lm/timit_en/libri-timit-lm.klm')
check_lm(model, english_sentences, 'english')
```
### LibriSpeech (4-gram)
The following model has been trained on the LibriSpeech corpus. The ARPA file was downloaded from http://www.openslr.org/11. The ARPA model has been lowercased for the sake of consistence. Apart from that, no other preprocessing was done. The model was trained using a vocabulary of 200k words.
A KenLM binary model was trained on the lowercased ARPA model using the _Trie_ data structure. This data structure is also what was used to train the German model (see below).
```
model = load_lm('/media/daniel/IP9/lm/libri_en/librispeech-4-gram.klm')
check_lm(model, english_sentences, 'english')
```
## German models
### SRI model (3-Gram, CMUSphinx)
The following is a 3-gram LM that has been trained with CMUSphinx. The ARPA file was downloaded from https://cmusphinx.github.io/wiki/download/ and converted to a binary KenLM model.
```
model = load_lm('/media/daniel/IP9/lm/srilm_de/srilm-voxforge-de-r20171217.klm')
check_lm(model, german_sentences, 'german')
```
### Custom KenLM (2-gram, probing, all words)
The following 2-gram model was trained on sentences from articles and pages in a Wikipedia dump. The dump was downloaded on 2018-09-21 and contains the state from 2018-09-01. The current dump of the German Wikipedia can be downloaded at http://download.wikimedia.org/dewiki/latest/dewiki-latest-pages-articles.xml.bz2.
The model was not pruned. Probing was used as data structure. The following command was used to create the model:
```bash
lmplz -o 2 -T /home/daniel/tmp -S 40% <wiki_de.txt.bz2 | build_binary /dev/stdin wiki_de_2_gram.klm
```
```
model = load_lm('/media/daniel/IP9/lm/wiki_de/wiki_de_2_gram.klm')
check_lm(model, german_sentences, 'german')
```
### Custom KenLM (4-gram, trie, 500k words)
The following 4-gram model was trained on the same dump like the 2-gram model above, but with a limited vocabulary of the first 500k most frequent words in the corpus. Additionally, a _Trie_ was used as data structure instead of the hash table in _Probing_. The model was built with the following program
```bash
lmplz --order 4 \
--temp_prefix /tmp/ \
--memory 40% \
--limit_vocab_file wiki_de_500k.vocab \
--text wiki_de.txt.bz2 \
--arpa wiki_de_trie_4_gram_500k.arpa
build_binary trie wiki_de_trie_4_gram_500k.arpa wiki_de_trie_4_gram_500k.klm
```
Where `wiki_de.txt.bz2` is the training corpus and `wiki_de_500k.vocab` is a text file containing the 500k most frequent words from the training corpus.
```
model = load_lm('/media/daniel/IP9/lm/wiki_de/wiki_de_4_gram_500k_trie.klm')
check_lm(model, german_sentences, 'german')
```
### Custom KenLM (5-gram, trie, pruned)
The following model was trined like the 4-gram model above, but with a higher order (5-gram instead of 4-gram). Additionally, the vocabulary was not pruned. The model was quantized with 8 bits and pointers were compressed to save memory.
```bash
lmplz --order 5 \
--temp_prefix /tmp/ \
--memory 40% \
--text wiki_de.txt.bz2 \
--arpa wiki_de_5_gram_pruned.arpa
build_binary -a 255 \
-q 8 \
trie wiki_de_5_gram_pruned.arpa \
wiki_de_5_gram_pruned.klm
```
The file `wiki_de_5_gram_pruned.klm` is the binary KenLM model that was used to implement a simple spell checker in this project. The spell checker uses a truncated vocabulary of the 250k most frequent words and the model is then used to calculate the likelihood (score) for each sentence. Note that although the spell checker uses a truncated vocabulary, the model was trained on the full text corpus without limiting the vocabulary.
```
model = load_lm('/media/daniel/IP9/lm/wiki_de/wiki_de_5_gram_pruned.klm')
check_lm(model, german_sentences, 'german')
```
# A simple word predictor
The trained model can be used together with its vocabulary to create a simple word predictor that lets you start a sentence and will propose possible continuations:
```
from tabulate import tabulate
def predict_next_word(model, vocab, language):
inp = input('Your turn now! Enter a word or the beginning of a sentence and the LM will predict a continuation. Enter nothing to quit.\n')
sentence = process_sentence(inp, language)
while (inp):
score = model.score(sentence, bos=False, eos=False)
print(f'score for \'{sentence}\': {score}')
top_5 = sorted(((word, model.score(sentence.lower() + ' ' + word)) for word in vocab), key=lambda t: t[1], reverse=True)[:5]
print(f'top 5 words:')
print(tabulate(top_5, headers=['word', 'log10-probability']))
inp = input('Enter continuation:\n')
sentence += ' ' + process_sentence(inp, language)
print('Done!')
```
## English
```
from util.lm_util import load_lm, load_vocab
from util.lm_corpus_util import process_sentence
model = load_lm('/media/daniel/IP9/lm/ds_en/lm.binary')
vocab = load_vocab('/media/daniel/IP9/lm/ds_en/lm_80k.vocab')
predict_next_word(model, vocab, 'german')
```
## German
```
from util.lm_util import load_lm, load_vocab
from util.lm_corpus_util import process_sentence
model = load_lm('/media/daniel/IP9/lm/wiki_de/wiki_de_5_gram.klm')
vocab = load_vocab('/media/daniel/IP9/lm/wiki_de/wiki_de_80k.vocab')
predict_next_word(model, vocab, 'german')
```
# A simple spell checker
The trained model together with its vocabulary can be used to implement a simple spell checker. For each word of a sentence, the spell checker checks if it appears in the vocabulary. If it does, it is not changed. If it does not, all words in the vocabulary with edit distance 1 are searched. If there are none, all words in the vocabulary with edit distance 2 are searched. If there are none, the original word is kept. This is done for each word in the sentence. The spell checker then calculates the probabilities for all combinations of words using beam search with a beam width of 1024. The most probable combination is used as corrected sentence. The following sections illustrate examples for English and German.
## English
```
from util.lm_util import load_lm, load_vocab, correction
model = load_lm('/media/daniel/IP9/lm/ds_en/lm.binary')
vocab = load_vocab('/media/daniel/IP9/lm/ds_en/lm_80k.vocab')
sentence = 'i seee i sey saind the blnd manp to his deaf dauhgter'
sentence_corr = correction(sentence, language='en', lm=model, lm_vocab=vocab)
print(f'original sentence: {sentence}')
print(f'corrected sentence: {sentence_corr}')
```
## German
```
from util.lm_util import load_lm, load_vocab, correction
model = load_lm('/media/daniel/IP9/lm/wiki_de/wiki_de_5_gram.klm')
vocab = load_vocab('/media/daniel/IP9/lm/wiki_de/wiki_de_80k.vocab')
print('superheld' in vocab)
sentence = 'man isd nur dannn ein supeerheld wenn man sihc selbsd fur supehr häält'
sentence_corr = correction(sentence, language='de', lm=model, lm_vocab=vocab)
print(f'original sentence: {sentence}')
print(f'corrected sentence: {sentence_corr}')
```
| github_jupyter |
# Geospatial Data in Python
## Vector Data
We are going to use [geopandas](https://geopandas.org/) to work with some vector data layers. Geopandas is built on top of pandas, the main addition is its ability to handle **Geometries**. For this, it relies on another package called [shapely](https://shapely.readthedocs.io/en/stable/manual.html)
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import geopandas as gpd
%matplotlib inline
Y = np.array([2,12,18,12,2])
X = np.array([12,12,15,18,18])
fig,ax=plt.subplots()
ax.scatter(X,Y)
ax.grid()
ax.set_title('Verticies')
```
## Shapely Objects
### Point(s)
```
from shapely.geometry import Point
point = Point([X[0],Y[0]])
point
from shapely.geometry import MultiPoint
mulit_point = MultiPoint([x for x in zip(X, Y)])
mulit_point
```
### Polygon(s)
```
from shapely.geometry import Polygon
poly = Polygon([coord for coord in zip(X, Y)])
poly
from shapely.geometry import MultiPolygon
Mpol = []
for i in range(0,61,20):
Mpol.append(Polygon([coord for coord in zip(X+i, Y+i)]))
print(Mpol)
Mpoly = MultiPolygon(Mpol)
Mpoly
```
### Line(s)
```
from shapely.geometry import LineString
line = LineString([x for x in zip(X, Y)])
line
from shapely.geometry import MultiLineString
Mlin = []
for i in range(0,61,20):
Mlin.append(LineString([coord for coord in zip(X+i, Y+i)]))
print(Mlin)
Mline = MultiLineString(Mlin)
Mline
```
## Unzip Data
- Below is a .zip file of census sub-divisions from Simply Analytics.
- We need to unzip it and inspect the metadata
```
import zipfile
Shape_file='SimplyAnalytics_Shapefiles_2021-11-18_04_29_59_93f600838bff00a6da2283b90dbf31c8'
with zipfile.ZipFile('data/'+Shape_file+'.zip', 'r') as zip_ref:
zip_ref.extractall('data/Census/')
```
## Reading the shapefile
We can rely on [geopandas](https://geopandas.org/en/stable/), a spatial extension for pandas. We can use Geopandas to read, manipulate, and write geospatial data.
* We can open .txt files with pandas to view the metadata
```
import geopandas as gpd
# the .read_file() function reads shapefiles
BC_FSA = gpd.read_file('data/Census/'+Shape_file+'.shp')
meta_data = pd.read_csv('data/Census/variable_names.txt',header=None,sep='#')
print('Vrriable Names: \n',meta_data.values)
BC_FSA
```
## Editing Data
```
## Note - This is the terminology used by the census
## It can be found in the variable_name file that comes with the download
BC_FSA = BC_FSA.rename(columns={
'VALUE0': 'Population',
})
BC_FSA.head()
```
## Plotting the Data
- Display the data and inspect the projection
```
fig,ax=plt.subplots(figsize=(8,8))
BC_FSA.plot(ax=ax)
ax.legend()
BC_FSA.crs
```
## Re-project the Data
```
BC_FSA_Albers = BC_FSA.to_crs('EPSG:3005')
fig,ax=plt.subplots(figsize=(8,8))
BC_FSA_Albers.plot(ax=ax)
ax.legend()
BC_FSA_Albers.crs
```
## Inspect the Geometry
```
BC_FSA_Albers.area
```
## Map by a Column
```
fig,ax=plt.subplots(figsize=(8,8))
BC_FSA_Albers.plot(column='Population',ax=ax,legend=True,scheme="quantiles",edgecolor='k')
```
## Spatial Overlay
```
BC_Boundary = gpd.read_file('data/Census/BC_Boudary_File.shp')
fig,ax = plt.subplots(1,2,figsize=(8,5))
BC_FSA_Albers.plot(edgecolor='k',ax=ax[0])
BC_Boundary.plot(edgecolor='k',ax=ax[1])
ax[0].set_title('Input Layer')
ax[1].set_title('Clip Layer')
```
## Clip
This will take a little while to process
```
BC_FSA_Clip = gpd.clip(BC_FSA_Albers,BC_Boundary)
fig,ax = plt.subplots(figsize=(5,7))
BC_FSA_Clip.plot(edgecolor='k',ax=ax)
ax.set_title('Final Result')
```
## Calculate Population Density
```
BC_FSA_Clip['Pop_Density'] = BC_FSA_Clip['Population']/BC_FSA_Clip.area*1e6
BC_FSA_Clip['Pop_Density']=BC_FSA_Clip['Pop_Density'].fillna(0)
fig,ax=plt.subplots(figsize=(10,10))
BC_FSA_Clip.plot(column='Pop_Density',ax=ax,legend=True,scheme="User_Defined",
classification_kwds=dict(bins=[
BC_FSA_Clip['Pop_Density'].quantile(.25),
BC_FSA_Clip['Pop_Density'].quantile(.5),
BC_FSA_Clip['Pop_Density'].quantile(.75),
BC_FSA_Clip['Pop_Density'].max()]),
edgecolor='black',linewidth=.25)
ax.grid()
# ## Set Zoom & Turn Grid off
x = 1.225e6
y = 0.45e6
v = 8.5e4
h = 8.5e4
ax.set_xlim(x-h,x+h)
ax.set_ylim(y-h,y+h)
ax.grid()
# BC_FSA_Clip.to_file('data//BC_FSAisions.shp')
```
## Data Classification
```
BC_FSA_Clip.loc[((BC_FSA_Clip['Pop_Density']<=400)|(BC_FSA_Clip['Population']<=1000)),
'Community_Type']='Rural'
BC_FSA_Clip.loc[(BC_FSA_Clip['Community_Type']!='Rural'),
'Community_Type']='Urban'
print('Community Type Summary BC')
print(BC_FSA_Clip.groupby('Community_Type').count()['name'].sort_values())
fig,ax=plt.subplots(figsize=(8,8))
BC_FSA_Clip.plot(column='Community_Type',ax=ax,legend=True,cmap='Pastel2',edgecolor='k',linewidth=.25)
ax.set_xlim(x-h,x+h)
ax.set_ylim(y-h,y+h)
# ax.grid()
ax.set_title('Community Type SW BC')
```
# Saving Data
## Shapefiles
We can save new layer as a shapefile. [Shapefiles](https://en.wikipedia.org/wiki/Shapefile) are only one type of vector file. They have certain restrictions to minimize storage space (eg. limiting column names), they aren't human readable, are restricted to one geometry type (Polygon, line, or point), and they split the data into multiple files.
Note the **"UserWarnings"**
* The first one isn't too serious, but it explains why the data came with a generic column header
*
```
print(BC_FSA_Clip.groupby(BC_FSA_Clip['geometry'].type).count()['Population'])
BC_FSA_Clip.loc[BC_FSA_Clip['geometry'].type !='GeometryCollection'].to_file('data/Outputs/BC_FSA.shp')
```
## Geojson
We can save the new layer as a [geojson](https://en.wikipedia.org/wiki/GeoJSON) file to get around the issue.
* This is a simple file type often used in web-centered applications that stores data as a **human readable** dictionary.
* The file takes up more space, but is also a bit more accessible/flexible.
```
print(BC_FSA_Clip.groupby(BC_FSA_Clip['geometry'].type).count()['Population'])
BC_FSA_Clip.to_file("data/Outputs/BC_FSA.json", driver = "GeoJSON")
```
| github_jupyter |
```
import sys, os
if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/spring20/setup_colab.sh -O- | bash
!pip install --upgrade https://github.com/Theano/Theano/archive/master.zip
!pip install --upgrade https://github.com/Lasagne/Lasagne/archive/master.zip
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/spring20/week05_explore/bayes.py
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/spring20/week05_explore/action_rewards.npy
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/spring20/week05_explore/all_states.npy
!touch .setup_complete
# This code creates a virtual display to draw game images on.
# It will have no effect if your machine has a monitor.
if type(os.environ.get("DISPLAY")) is not str or len(os.environ.get("DISPLAY")) == 0:
!bash ../xvfb start
os.environ['DISPLAY'] = ':1'
from abc import ABCMeta, abstractmethod, abstractproperty
import enum
import numpy as np
np.set_printoptions(precision=3)
np.set_printoptions(suppress=True)
import pandas
import matplotlib.pyplot as plt
%matplotlib inline
```
## Contents
* [1. Bernoulli Bandit](#Part-1.-Bernoulli-Bandit)
* [Bonus 1.1. Gittins index (5 points)](#Bonus-1.1.-Gittins-index-%285-points%29.)
* [HW 1.1. Nonstationary Bernoulli bandit](#HW-1.1.-Nonstationary-Bernoulli-bandit)
* [2. Contextual bandit](#Part-2.-Contextual-bandit)
* [2.1 Bulding a BNN agent](#2.1-Bulding-a-BNN-agent)
* [2.2 Training the agent](#2.2-Training-the-agent)
* [HW 2.1 Better exploration](#HW-2.1-Better-exploration)
* [3. Exploration in MDP](#Part-3.-Exploration-in-MDP)
* [Bonus 3.1 Posterior sampling RL (3 points)](#Bonus-3.1-Posterior-sampling-RL-%283-points%29)
* [Bonus 3.2 Bootstrapped DQN (10 points)](#Bonus-3.2-Bootstrapped-DQN-%2810-points%29)
```
```
## Part 1. Bernoulli Bandit
We are going to implement several exploration strategies for simplest problem - bernoulli bandit.
The bandit has $K$ actions. Action produce 1.0 reward $r$ with probability $0 \le \theta_k \le 1$ which is unknown to agent, but fixed over time. Agent's objective is to minimize regret over fixed number $T$ of action selections:
$$\rho = T\theta^* - \sum_{t=1}^T r_t$$
Where $\theta^* = \max_k\{\theta_k\}$
**Real-world analogy:**
Clinical trials - we have $K$ pills and $T$ ill patient. After taking pill, patient is cured with probability $\theta_k$. Task is to find most efficient pill.
A research on clinical trials - https://arxiv.org/pdf/1507.08025.pdf
```
class BernoulliBandit:
def __init__(self, n_actions=5):
self._probs = np.random.random(n_actions)
@property
def action_count(self):
return len(self._probs)
def pull(self, action):
if np.any(np.random.random() > self._probs[action]):
return 0.0
return 1.0
def optimal_reward(self):
""" Used for regret calculation
"""
return np.max(self._probs)
def step(self):
""" Used in nonstationary version
"""
pass
def reset(self):
""" Used in nonstationary version
"""
class AbstractAgent(metaclass=ABCMeta):
def init_actions(self, n_actions):
self._successes = np.zeros(n_actions)
self._failures = np.zeros(n_actions)
self._total_pulls = 0
@abstractmethod
def get_action(self):
"""
Get current best action
:rtype: int
"""
pass
def update(self, action, reward):
"""
Observe reward from action and update agent's internal parameters
:type action: int
:type reward: int
"""
self._total_pulls += 1
if reward == 1:
self._successes[action] += 1
else:
self._failures[action] += 1
@property
def name(self):
return self.__class__.__name__
class RandomAgent(AbstractAgent):
def get_action(self):
return np.random.randint(0, len(self._successes))
```
### Epsilon-greedy agent
**for** $t = 1,2,...$ **do**
**for** $k = 1,...,K$ **do**
$\hat\theta_k \leftarrow \alpha_k / (\alpha_k + \beta_k)$
**end for**
$x_t \leftarrow \arg\max_{k}\hat\theta$ with probability $1 - \epsilon$ or random action with probability $\epsilon$
Apply $x_t$ and observe $r_t$
$(\alpha_{x_t}, \beta_{x_t}) \leftarrow (\alpha_{x_t}, \beta_{x_t}) + (r_t, 1-r_t)$
**end for**
\emph{Notation}: $\alpha$ is successes and $\beta$ is failures!
Implement the algorithm above in the cell below:
```
class EpsilonGreedyAgent(AbstractAgent):
def __init__(self, epsilon=0.01):
self._epsilon = epsilon
def get_action(self):
r_eps = np.random.random()
prob = self._successes / ( self._successes + self._failures )
res = np.argmax(prob) if r_eps > self._epsilon else np.random.choice(len(self._successes))
return res
@property
def name(self):
return self.__class__.__name__ + "(epsilon={})".format(self._epsilon)
```
### UCB Agent
Epsilon-greedy strategy heve no preference for actions. It would be better to select among actions that are uncertain or have potential to be optimal. One can come up with idea of index for each action that represents otimality and uncertainty at the same time. One efficient way to do it is to use UCB1 algorithm:
**for** $t = 1,2,...$ **do**
**for** $k = 1,...,K$ **do**
$w_k \leftarrow \alpha_k / (\alpha_k + \beta_k) + \sqrt{2log\ t \ / \ (\alpha_k + \beta_k)}$
**end for**
**end for**
$x_t \leftarrow \arg\max_{k} w_{k}$
Apply $x_t$ and observe $r_t$
$(\alpha_{x_t}, \beta_{x_t}) \leftarrow (\alpha_{x_t}, \beta_{x_t}) + (r_t, 1-r_t)$
**end for**
__Note:__ in practice, one can multiply $\sqrt{2log\ t \ / \ (\alpha_k + \beta_k)}$ by some tunable parameter to regulate agent's optimism and wilingness to abandon non-promising actions.
More versions and optimality analysis - https://homes.di.unimi.it/~cesabian/Pubblicazioni/ml-02.pdf
```
class UCBAgent(AbstractAgent):
def get_action(self):
sum_s_f = self._successes + self._failures
prob = self._successes / sum_s_f
ucb = np.sqrt( 2 * np.log2(self._total_pulls) / sum_s_f )
w = prob + ucb
return np.argmax(w)
```
### Thompson sampling
UCB1 algorithm does not take into account actual distribution of rewards. If we know the distribution - we can do much better by using Thompson sampling:
**for** $t = 1,2,...$ **do**
**for** $k = 1,...,K$ **do**
Sample $\hat\theta_k \sim Beta(\alpha_k, \beta_k)$
**end for**
$x_t \leftarrow \arg\max_{k}\hat\theta$
Apply $x_t$ and observe $r_t$
$(\alpha_{x_t}, \beta_{x_t}) \leftarrow (\alpha_{x_t}, \beta_{x_t}) + (r_t, 1-r_t)$
**end for**
More on Thompson Sampling:
https://web.stanford.edu/~bvr/pubs/TS_Tutorial.pdf
```
class ThompsonSamplingAgent(AbstractAgent):
def get_action(self):
eps = 1e-12
sample = np.random.beta(self._successes + eps, self._failures + eps)
return np.argmax(sample)
print(np.random.beta([1,2,3],[3,2,1]))
from collections import OrderedDict
def get_regret(env, agents, n_steps=5000, n_trials=50):
scores = OrderedDict({
agent.name: [0.0 for step in range(n_steps)] for agent in agents
})
for trial in range(n_trials):
env.reset()
for a in agents:
a.init_actions(env.action_count)
for i in range(n_steps):
optimal_reward = env.optimal_reward()
for agent in agents:
action = agent.get_action()
reward = env.pull(action)
agent.update(action, reward)
scores[agent.name][i] += optimal_reward - reward
env.step() # change bandit's state if it is unstationary
for agent in agents:
scores[agent.name] = np.cumsum(scores[agent.name]) / n_trials
return scores
def plot_regret(agents, scores):
for agent in agents:
plt.plot(scores[agent.name])
plt.legend([agent.name for agent in agents])
plt.ylabel("regret")
plt.xlabel("steps")
plt.show()
# Uncomment agents
agents = [
EpsilonGreedyAgent(),
UCBAgent(),
ThompsonSamplingAgent()
]
regret = get_regret(BernoulliBandit(), agents, n_steps=10000, n_trials=10)
plot_regret(agents, regret)
```
# Bonus 1.1. Gittins index (5 points).
Bernoulli bandit problem has an optimal solution - Gittins index algorithm. Implement finite horizon version of the algorithm and demonstrate it's performance with experiments. some articles:
- Wikipedia article - https://en.wikipedia.org/wiki/Gittins_index
- Different algorithms for index computation - http://www.ece.mcgill.ca/~amahaj1/projects/bandits/book/2013-bandit-computations.pdf (see "Bernoulli" section)
# HW 1.1. Nonstationary Bernoulli bandit
What if success probabilities change over time? Here is an example of such bandit:
```
class DriftingBandit(BernoulliBandit):
def __init__(self, n_actions=5, gamma=0.01):
"""
Idea from https://github.com/iosband/ts_tutorial
"""
super().__init__(n_actions)
self._gamma = gamma
self._successes = None
self._failures = None
self._steps = 0
self.reset()
def reset(self):
self._successes = np.zeros(self.action_count) + 1.0
self._failures = np.zeros(self.action_count) + 1.0
self._steps = 0
def step(self):
action = np.random.randint(self.action_count)
reward = self.pull(action)
self._step(action, reward)
def _step(self, action, reward):
self._successes = self._successes * (1 - self._gamma) + self._gamma
self._failures = self._failures * (1 - self._gamma) + self._gamma
self._steps += 1
self._successes[action] += reward
self._failures[action] += 1.0 - reward
self._probs = np.random.beta(self._successes, self._failures)
```
And a picture how it's reward probabilities change over time
```
drifting_env = DriftingBandit(n_actions=5)
drifting_probs = []
for i in range(20000):
drifting_env.step()
drifting_probs.append(drifting_env._probs)
plt.figure(figsize=(17, 8))
plt.plot(pandas.DataFrame(drifting_probs).rolling(window=20).mean())
plt.xlabel("steps")
plt.ylabel("Success probability")
plt.title("Reward probabilities over time")
plt.legend(["Action {}".format(i) for i in range(drifting_env.action_count)])
plt.show()
```
Your task is to invent an agent that will have better regret than stationary agents from above.
```
# YOUR AGENT HERE SECTION
class myAgent(AbstractAgent):
def get_action(self):
eps = 1e-12
sample = np.random.beta(self._successes + eps, self._failures + eps)
return np.argmax(sample)
def update(self, action, reward):
self._total_pulls += 1
if reward == 1:
self._successes[action] += 1
else:
self._failures[action] += 1
g = 0.01
self._successes = self._successes * (1 - g) + g
self._failures = self._failures * (1 - g) + g
drifting_agents = [
ThompsonSamplingAgent(),
EpsilonGreedyAgent(),
UCBAgent(),
myAgent()
]
regret = get_regret(DriftingBandit(), drifting_agents, n_steps=10000, n_trials=10)
plot_regret(drifting_agents, regret)
```
## Part 2. Contextual bandit
Now we will solve much more complex problem - reward will depend on bandit's state.
**Real-word analogy:**
> Contextual advertising. We have a lot of banners and a lot of different users. Users can have different features: age, gender, search requests. We want to show banner with highest click probability.
If we want use strategies from above, we need some how store reward distributions conditioned both on actions and bandit's state.
One way to do this - use bayesian neural networks. Instead of giving pointwise estimates of target, they maintain probability distributions
<img src="https://github.com/yandexdataschool/Practical_RL/blob/spring20/week05_explore/bnn.png?raw=1">
Picture from https://arxiv.org/pdf/1505.05424.pdf
More material:
* A post on the matter - [url](http://twiecki.github.io/blog/2016/07/05/bayesian-deep-learning/)
* Theano+PyMC3 for more serious stuff - [url](http://pymc-devs.github.io/pymc3/notebooks/bayesian_neural_network_advi.html)
* Same stuff in tensorflow - [url](http://edwardlib.org/tutorials/bayesian-neural-network)
Let's load our dataset:
```
all_states = np.load("all_states.npy")
action_rewards = np.load("action_rewards.npy")
state_size = all_states.shape[1]
n_actions = action_rewards.shape[1]
print("State size: %i, actions: %i" % (state_size, n_actions))
for s in all_states[:1]:
print(s)
print(s.shape)
print()
for ar in action_rewards[:3]:
print(ar)
print(ar.shape)
print()
print(np.max(action_rewards))
import theano
import theano.tensor as T
import lasagne
from lasagne import init
from lasagne.layers import *
import bayes
as_bayesian = bayes.bbpwrap(bayes.NormalApproximation(std=0.1))
BayesDenseLayer = as_bayesian(DenseLayer)
```
## 2.1 Bulding a BNN agent
Let's implement epsilon-greedy BNN agent
```
class BNNAgent:
"""a bandit with bayesian neural net"""
def __init__(self, state_size, n_actions):
input_states = T.matrix("states")
target_actions = T.ivector("actions taken")
target_rewards = T.vector("rewards")
self.total_samples_seen = theano.shared(
np.int32(0), "number of training samples seen so far")
batch_size = target_actions.shape[0] # por que?
# Network
inp = InputLayer((None, state_size), name='input')
# YOUR NETWORK HERE
hl_1 = BayesDenseLayer(inp, num_units=32,
nonlinearity=lasagne.nonlinearities.rectify)
out = BayesDenseLayer(hl_1, num_units=n_actions,
nonlinearity=lasagne.nonlinearities.softmax)
# Prediction
# lasagne.layers.get_output
prediction_all_actions = get_output(out, inputs=input_states)
self.predict_sample_rewards = theano.function(
[input_states], prediction_all_actions)
# Training
# select prediction for target action
prediction_target_actions = prediction_all_actions[T.arange(
batch_size), target_actions]
# loss = negative log-likelihood (mse) + KL
negative_llh = T.sum((prediction_target_actions - target_rewards)**2)
kl = bayes.get_var_cost(out) / (self.total_samples_seen + batch_size)
loss = (negative_llh + kl)/batch_size
self.weights = get_all_params(out, trainable=True)
self.out = out
# gradient descent
updates = lasagne.updates.adam(loss, self.weights)
# update counts
updates[self.total_samples_seen] = self.total_samples_seen + \
batch_size.astype('int32')
self.train_step = theano.function([input_states, target_actions, target_rewards],
[negative_llh, kl],
updates=updates,
allow_input_downcast=True)
def sample_prediction(self, states, n_samples=1):
"""Samples n_samples predictions for rewards,
:returns: tensor [n_samples, state_i, action_i]
"""
assert states.ndim == 2, "states must be 2-dimensional"
return np.stack([self.predict_sample_rewards(states) for _ in range(n_samples)])
def get_action(self, states):
"""
Picks action by
- with p=1-epsilon, taking argmax of average rewards
- with p=epsilon, taking random action
This is exactly e-greedy policy.
"""
epsilon = 0.25
batch_size = states.shape[0]
reward_samples = self.sample_prediction(states, n_samples=100)
# ^-- samples for rewards, shape = [n_samples,n_states,n_actions]
best_actions = reward_samples.mean(axis=0).argmax(axis=-1)
# ^-- we take mean over samples to compute expectation, then pick best action with argmax
random_actions = np.random.choice(n_actions, size=batch_size)
should_explore = np.random.choice([0, 1], batch_size, p=[1-epsilon, epsilon])
chosen_actions = np.where(should_explore, random_actions, best_actions)
return chosen_actions
def train(self, states, actions, rewards, n_iters=10):
"""
trains to predict rewards for chosen actions in given states
"""
loss_sum = kl_sum = 0
for _ in range(n_iters):
loss, kl = self.train_step(states, actions, rewards)
loss_sum += loss
kl_sum += kl
return loss_sum / n_iters, kl_sum / n_iters
@property
def name(self):
return self.__class__.__name__
```
## 2.2 Training the agent
```
N_ITERS = 100
def get_new_samples(states, action_rewards, batch_size=10):
"""samples random minibatch, emulating new users"""
batch_ix = np.random.randint(0, len(states), batch_size)
return states[batch_ix], action_rewards[batch_ix]
from IPython.display import clear_output
from pandas import DataFrame
moving_average = lambda x, **kw: DataFrame(
{'x': np.asarray(x)}).x.ewm(**kw).mean().values
def train_contextual_agent(agent, batch_size=10, n_iters=100):
rewards_history = []
for i in range(n_iters):
b_states, b_action_rewards = get_new_samples(
all_states, action_rewards, batch_size)
b_actions = agent.get_action(b_states)
b_rewards = b_action_rewards[
np.arange(batch_size), b_actions
]
mse, kl = agent.train(b_states, b_actions, b_rewards, n_iters=100)
rewards_history.append(b_rewards.mean())
if i % 10 == 0:
clear_output(True)
print("iteration #%i\tmean reward=%.3f\tmse=%.3f\tkl=%.3f" %
(i, np.mean(rewards_history[-10:]), mse, kl))
plt.plot(rewards_history)
plt.plot(moving_average(np.array(rewards_history), alpha=0.1))
plt.title("Reward per epesode")
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.show()
samples = agent.sample_prediction(
b_states[:1], n_samples=100).T[:, 0, :]
for i in range(len(samples)):
plt.hist(samples[i], alpha=0.25, label=str(i))
plt.legend(loc='best')
print('Q(s,a) std:', ';'.join(
list(map('{:.3f}'.format, np.std(samples, axis=1)))))
print('correct', b_action_rewards[0].argmax())
plt.title("p(Q(s, a))")
plt.show()
return moving_average(np.array(rewards_history), alpha=0.1)
bnn_agent = BNNAgent(state_size=state_size, n_actions=n_actions)
greedy_agent_rewards = train_contextual_agent(
bnn_agent, batch_size=10, n_iters=N_ITERS)
```
## HW 2.1 Better exploration
Use strategies from first part to gain more reward in contextual setting
```
class ThompsonBNNAgent(BNNAgent):
def get_action(self, states):
"""
picks action based by taking _one_ sample from BNN and taking action with highest sampled reward (yes, that simple)
This is exactly thompson sampling.
"""
reward_samples = self.sample_prediction(states, n_samples=1)
# ^-- samples for rewards, shape = [n_samples,n_states,n_actions]
best_actions = reward_samples[0].argmax(axis=-1)
return best_actions
t_agent = ThompsonBNNAgent(state_size=state_size, n_actions=n_actions)
thompson_agent_rewards = train_contextual_agent(t_agent, batch_size=10, n_iters=N_ITERS)
class BayesUCBBNNAgent(BNNAgent):
def __init__(self, state_size, n_actions, n_iters):
super().__init__(state_size, n_actions)
self.n_iters = n_iters
self.c_iter = 1
def get_action(self, states):
"""
Compute q-th percentile of rewards P(r|s,a) for all actions
Take actions that have highest percentiles.
This implements bayesian UCB strategy
"""
reward_samples = self.sample_prediction(states, n_samples=100)
# ^-- samples for rewards, shape = [n_samples,n_states,n_actions]
q = 1 - 1/(self.c_iter * np.sqrt(np.log2(self.n_iters)))
reward_quantiles = np.quantile(reward_samples, q=q, axis=0)
best_actions = reward_quantiles.argmax(axis=-1)
self.c_iter += self.c_iter
return best_actions
b_ucb_agent = BayesUCBBNNAgent(state_size=state_size, n_actions=n_actions, n_iters=N_ITERS)
ucb_agent_rewards = train_contextual_agent(b_ucb_agent, batch_size=10, n_iters=N_ITERS)
plt.figure(figsize=(17, 8))
plt.plot(greedy_agent_rewards)
plt.plot(thompson_agent_rewards)
plt.plot(ucb_agent_rewards)
plt.legend([
"Greedy BNN",
"Thompson sampling BNN",
"UCB BNN"
])
plt.show()
```
## Part 3. Exploration in MDP
The following problem, called "river swim", illustrates importance of exploration in context of mdp's.
<img src="https://github.com/yandexdataschool/Practical_RL/blob/spring20/week05_explore/river_swim.png?raw=1">
Picture from https://arxiv.org/abs/1306.0940
Rewards and transition probabilities are unknown to an agent. Optimal policy is to swim against current, while easiest way to gain reward is to go left.
```
class RiverSwimEnv:
LEFT_REWARD = 5.0 / 1000
RIGHT_REWARD = 1.0
def __init__(self, intermediate_states_count=4, max_steps=16):
self._max_steps = max_steps
self._current_state = None
self._steps = None
self._interm_states = intermediate_states_count
self.reset()
def reset(self):
self._steps = 0
self._current_state = 1
return self._current_state, 0.0, False
@property
def n_actions(self):
return 2
@property
def n_states(self):
return 2 + self._interm_states
def _get_transition_probs(self, action):
if action == 0:
if self._current_state == 0:
return [0, 1.0, 0]
else:
return [1.0, 0, 0]
elif action == 1:
if self._current_state == 0:
return [0, .4, .6]
if self._current_state == self.n_states - 1:
return [.4, .6, 0]
else:
return [.05, .6, .35]
else:
raise RuntumeError(
"Unknown action {}. Max action is {}".format(action, self.n_actions))
def step(self, action):
"""
:param action:
:type action: int
:return: observation, reward, is_done
:rtype: (int, float, bool)
"""
reward = 0.0
if self._steps >= self._max_steps:
return self._current_state, reward, True
transition = np.random.choice(
range(3), p=self._get_transition_probs(action))
if transition == 0:
self._current_state -= 1
elif transition == 1:
pass
else:
self._current_state += 1
if self._current_state == 0:
reward = self.LEFT_REWARD
elif self._current_state == self.n_states - 1:
reward = self.RIGHT_REWARD
self._steps += 1
return self._current_state, reward, False
```
Let's implement q-learning agent with epsilon-greedy exploration strategy and see how it performs.
```
class QLearningAgent:
def __init__(self, n_states, n_actions, lr=0.2, gamma=0.95, epsilon=0.1):
self._gamma = gamma
self._epsilon = epsilon
self._q_matrix = np.zeros((n_states, n_actions))
self._lr = lr
def get_action(self, state):
if np.random.random() < self._epsilon:
return np.random.randint(0, self._q_matrix.shape[1])
else:
return np.argmax(self._q_matrix[state])
def get_q_matrix(self):
""" Used for policy visualization
"""
return self._q_matrix
def start_episode(self):
""" Used in PSRL agent
"""
pass
def update(self, state, action, reward, next_state):
# Finish implementation of q-learnig agent
"""
You should do your Q-Value update here:
Q(s,a) := (1 - alpha) * Q(s,a) + alpha * (r + gamma * V(s'))
"""
# agent parameters
g = self._gamma
lr = self._lr
Q_mtx = self._q_matrix
Q_sa = (1 - lr) * Q_mtx[state][action] \
+ lr * ( reward + g * np.max(Q_mtx[next_state]) )
self._q_matrix[state][action]= Q_sa
def train_mdp_agent(agent, env, n_episodes):
episode_rewards = []
for ep in range(n_episodes):
state, ep_reward, is_done = env.reset()
agent.start_episode()
while not is_done:
action = agent.get_action(state)
next_state, reward, is_done = env.step(action)
agent.update(state, action, reward, next_state)
state = next_state
ep_reward += reward
episode_rewards.append(ep_reward)
return episode_rewards
env = RiverSwimEnv()
agent = QLearningAgent(env.n_states, env.n_actions)
rews = train_mdp_agent(agent, env, 1000)
plt.figure(figsize=(15, 8))
plt.plot(moving_average(np.array(rews), alpha=.1))
plt.xlabel("Episode count")
plt.ylabel("Reward")
plt.show()
```
Let's visualize our policy:
```
def plot_policy(agent):
fig = plt.figure(figsize=(15, 8))
ax = fig.add_subplot(111)
ax.matshow(agent.get_q_matrix().T)
ax.set_yticklabels(['', 'left', 'right'])
plt.xlabel("State")
plt.ylabel("Action")
plt.title("Values of state-action pairs")
plt.show()
plot_policy(agent)
```
As your see, agent uses suboptimal policy of going left and does not explore the right state.
## Bonus 3.1 Posterior sampling RL (3 points)
Now we will implement Thompson Sampling for MDP!
General algorithm:
>**for** episode $k = 1,2,...$ **do**
>> sample $M_k \sim f(\bullet\ |\ H_k)$
>> compute policy $\mu_k$ for $M_k$
>> **for** time $t = 1, 2,...$ **do**
>>> take action $a_t$ from $\mu_k$
>>> observe $r_t$ and $s_{t+1}$
>>> update $H_k$
>> **end for**
>**end for**
In our case we will model $M_k$ with two matricies: transition and reward. Transition matrix is sampled from dirichlet distribution. Reward matrix is sampled from normal-gamma distribution.
Distributions are updated with bayes rule - see continious distribution section at https://en.wikipedia.org/wiki/Conjugate_prior
Article on PSRL - https://arxiv.org/abs/1306.0940
### Value Iteration
Now let's build something to solve this MDP. The simplest algorithm so far is __V__alue __I__teration
Here's the pseudo-code for VI:
---
`1.` Initialize $V^{(0)}(s)=0$, for all $s$
`2.` For $i=0, 1, 2, \dots$
`3.` $ \quad V_{(i+1)}(s) = \max_a \sum_{s'} P(s' | s,a) \cdot [ r(s,a,s') + \gamma V_{i}(s')]$, for all $s$
---
```
def sample_normal_gamma(mu, lmbd, alpha, beta):
""" https://en.wikipedia.org/wiki/Normal-gamma_distribution
"""
tau = np.random.gamma(alpha, beta)
mu = np.random.normal(mu, 1.0 / np.sqrt(lmbd * tau))
return mu, tau
class PsrlAgent:
def __init__(self, n_states, n_actions, horizon=10):
self._n_states = n_states
self._n_actions = n_actions
self._horizon = horizon
# params for transition sampling - Dirichlet distribution
self._transition_counts = np.zeros(
(n_states, n_states, n_actions)) + 1.0
# params for reward sampling - Normal-gamma distribution
self._mu_matrix = np.zeros((n_states, n_actions)) + 1.0
self._state_action_counts = np.zeros(
(n_states, n_actions)) + 1.0 # lambda
self._alpha_matrix = np.zeros((n_states, n_actions)) + 1.0
self._beta_matrix = np.zeros((n_states, n_actions)) + 1.0
# mean reward from observations
self._reward_mean_obs = np.zeros((n_states, n_actions)) + 1.0
self._reward_var_obs = np.zeros((n_states, n_actions)) + 1.0
self._lambda_0 = np.zeros((n_states, n_actions)) + 1.0
def _value_iteration(self, transitions, rewards):
# YOU CODE HERE
# parameters
g = 0.9 # discount for MDP
num_iter = 10**4 # maximum iterations, excluding initialization
min_diff = 0.001 # stop VI if new values are this close to old values (or closer)
# initialize V(s)
all_states = list(range(self._n_states))
V = np.zeros((self._n_states,1)) #state_values
for i in range(num_iter):
V_next = np.zeros((self._n_states,1))
for s in all_states:
pos_actions = [0,1]
l_Qsa = []
for a in pos_actions:
Q_sa = rewards[s,a] + g * np.dot(transitions[s,:,a], V)
l_Qsa.append(Q_sa)
V_next[s] = np.max(l_Qsa)
# Compute difference
diff = np.max( np.abs(V_next - V) )
V = V_next
if diff < min_diff:
break
return V
def start_episode(self):
# (n_states, n_actions)
mu_0 = self._mu_matrix
lmbd_0 = self._lambda_0
alpha_0 = self._alpha_matrix
beta_0 = self._beta_matrix
sa_counts = self._state_action_counts
mean_r = self._reward_mean_obs
var_r = self._reward_var_obs
# WIKI - Conjugate_prior
# https://en.wikipedia.org/wiki/Conjugate_prior
# mu = (v * mu_0 + n * hx ) / (v + n)
# lamb = v + n
# alpha = alpha + n/2
# beta = beta + 0.5 * sum_{i=1}^{n}(x_i - hx)^2 + 0.5 * (hx - mu_0)^2 (n * v) / (v + n)
mu_p = (lmbd_0 * mu_0 + sa_counts * mean_r ) / (lmbd_0 + sa_counts)
lmbd_p = lmbd_0 + sa_counts
alpha_p = alpha_0 + sa_counts / 2
beta_p = beta_0 + 0.5 * sa_counts * var_r + 0.5 * np.square(mean_r - mu_0) * (sa_counts * lmbd_0) / (lmbd_0 + sa_counts)
# (n_states, n_actions)
self._alpha_matrix
self._beta_matrix
# sample new mdp (update the transition matrix)
self._sampled_transitions = np.apply_along_axis(
np.random.dirichlet, 1, self._transition_counts)
sampled_reward_mus, sampled_reward_stds = sample_normal_gamma(
mu_p, #self._mu_matrix,
lmbd_p, #self._state_action_counts,
alpha_p, #self._alpha_matrix,
beta_p, #self._beta_matrix
)
self._sampled_rewards = sampled_reward_mus
self._current_value_function = self._value_iteration(
self._sampled_transitions,
self._sampled_rewards)
# Our Policy
def get_action(self, state):
return np.argmax(self._sampled_rewards[state] +
np.dot(np.transpose(self._current_value_function), self._sampled_transitions[state]))
def update(self, state, action, reward, next_state):
#<YOUR CODE>
# update rules - https://en.wikipedia.org/wiki/Conjugate_prior
# (n_states, n_states, n_actions)
self._transition_counts[state, next_state, action] += 1
# (n_states, n_actions)
self._state_action_counts[state, action] += 1
n_obs_sa = self._state_action_counts[state, action]
prev_mean_reward = self._reward_mean_obs[state, action]
prev_var_reward = self._reward_var_obs[state, action]
self._reward_mean_obs[state, action] = ((n_obs_sa - 1) * prev_mean_reward + reward ) / n_obs_sa
self._reward_var_obs[state, action] = ((n_obs_sa - 1) * prev_var_reward + np.square(reward - prev_mean_reward)) / n_obs_sa
def get_q_matrix(self):
return self._sampled_rewards + np.dot(self._sampled_transitions, self._current_value_function)
from pandas import DataFrame
moving_average = lambda x, **kw: DataFrame(
{'x': np.asarray(x)}).x.ewm(**kw).mean().values
n_episodes = 1000
horizon = 20
#debug
#n_episodes = 1
#horizon = 1
env = RiverSwimEnv(max_steps=horizon)
agent = PsrlAgent(env.n_states, env.n_actions, horizon=horizon)
rews = train_mdp_agent(agent, env, n_episodes)
plt.figure(figsize=(15, 8))
plt.plot(moving_average(np.array(rews), alpha=0.1))
plt.xlabel("Episode count")
plt.ylabel("Reward")
plt.show()
plot_policy(agent)
```
## Bonus 3.2 Bootstrapped DQN (10 points)
Implement Bootstrapped DQN algorithm and compare it's performance with ordinary DQN on BeamRider Atari game. Links:
- https://arxiv.org/abs/1602.04621
| github_jupyter |
This notebook contains the scripts used in the AEI working paper [_A Budget-Neutral Universal Basic Income_](https://www.aei.org/wp-content/uploads/2017/05/UBI-working-paper.pdf).
```
from taxcalc import *
from functions2 import *
import copy
import pandas as pd
import numpy as np
# Total benefits from cps
cps = pd.read_csv('cps_benefit.csv')
cps['tot_benefits'] = cps['MedicareX'] + cps['MEDICAID'] + cps['SS'] + cps['SSI'] + cps['SNAP'] + cps['VB']
cps_rev = (cps['tot_benefits'] * cps['s006']).sum()
# Total benefits from other programs
other_programs = pd.read_csv('benefitprograms.csv')
other_programs['Cost'] *= 1000000
other_rev = other_programs['Cost'].sum()
# Allocate benefits from other programs to individual
cps['dist_ben'] = cps['MEDICAID'] + cps['SSI'] + cps['SNAP'] + cps['VB']
cps['ratio'] = cps.dist_ben * cps.s006 / (cps.dist_ben * cps.s006).sum()
cps['other'] = cps.ratio * other_programs['Cost'].sum() / cps.s006
# Base calculator
recs = Records('puf_benefits.csv', weights='puf_weights_new.csv', adjust_ratios='puf_ratios copy.csv')
calc = Calculator(records=recs, policy=Policy(), verbose=False)
calc.advance_to_year(2014)
calc.calc_all()
# Calculator to measure lost revenue from SS repeal
r_ss = Records('puf_benefits.csv', weights='puf_weights_new.csv', adjust_ratios='puf_ratios copy.csv')
c_ss = Calculator(records=r_ss, policy=Policy(), verbose=False)
c_ss.records.e02400 = np.zeros(len(c_ss.records.e02400))
c_ss.advance_to_year(2014)
c_ss.calc_all()
# Lost Revenue
ss_lostrev = ((c_ss.records.combined - calc.records.combined) * c_ss.records.s006).sum()
cps_storage = copy.deepcopy(cps)
```
# UBI with original Tax Reform
```
# Calculator with original tax refrom
recs_reform = Records('puf_benefits.csv', weights='puf_weights_new.csv', adjust_ratios='puf_ratios copy.csv')
pol_reform = Policy()
tax_reform = {
2014: {
'_ALD_StudentLoan_hc': [1.0],
'_ALD_SelfEmploymentTax_hc': [1.0],
'_ALD_SelfEmp_HealthIns_hc': [1.0],
'_ALD_KEOGH_SEP_hc': [1.0],
'_ALD_EarlyWithdraw_hc': [1.0],
'_ALD_Alimony_hc': [1.0],
'_ALD_Dependents_hc': [1.0],
'_ALD_EducatorExpenses_hc': [1.0],
'_ALD_HSADeduction_hc': [1.0],
'_ALD_IRAContributions_hc': [1.0],
'_ALD_DomesticProduction_hc': [1.0],
'_ALD_Tuition_hc': [1.0],
'_CR_RetirementSavings_hc': [1.0],
'_CR_ForeignTax_hc': [1.0],
'_CR_ResidentialEnergy_hc': [1.0],
'_CR_GeneralBusiness_hc': [1.0],
'_CR_MinimumTax_hc': [1.0],
'_CR_AmOppRefundable_hc': [1.0],
'_CR_AmOppNonRefundable_hc': [1.0],
'_CR_SchR_hc': [1.0],
'_CR_OtherCredits_hc': [1.0],
'_CR_Education_hc': [1.0],
'_II_em': [0.0],
'_STD': [[0.0, 0.0, 0.0, 0.0, 0.0]],
'_STD_Aged': [[0.0, 0.0, 0.0, 0.0, 0.0]],
'_ID_Medical_hc': [1.0],
'_ID_StateLocalTax_hc': [1.0],
'_ID_RealEstate_hc': [1.0],
'_ID_InterestPaid_hc': [1.0],
'_ID_Casualty_hc': [1.0],
'_ID_Miscellaneous_hc': [1.0],
'_CDCC_c': [0.0],
'_CTC_c': [0.0],
'_EITC_c': [[0.0, 0.0, 0.0, 0.0]],
'_LLC_Expense_c': [0.0],
'_ETC_pe_Single': [0.0],
'_ETC_pe_Married': [0.0]
}
}
pol_reform.implement_reform(tax_reform)
calc_reform = Calculator(records=recs_reform, policy=pol_reform, verbose=False)
calc_reform.records.e02400 = np.zeros(len(calc_reform.records.e02400))
calc_reform.advance_to_year(2014)
calc_reform.calc_all()
# Revenue from tax reform
tax_rev = ((calc_reform.records.combined - calc.records.combined) * calc_reform.records.s006).sum()
# Total UBI Revenue
revenue = cps_rev + other_rev + ss_lostrev + tax_rev
revenue
# Number above and below 18
u18 = (calc_reform.records.nu18 * calc_reform.records.s006).sum()
abv18 = ((calc_reform.records.n1821 + calc_reform.records.n21) * calc_reform.records.s006).sum()
# Find original UBI amounts
ubi18, ubiu18 = ubi_amt(revenue, u18, abv18)
ubi18, ubiu18
# Find UBI after accounting for UBI tax revenue
diff = 9e99
ubi_tax_rev = 0
prev_ubi_tax_rev = 0
while abs(diff) >= 100:
ubi18, ubiu18 = ubi_amt(revenue + ubi_tax_rev, u18, abv18)
diff, ubi_tax_rev = ubi_finder(ubi18, ubiu18,
tax_reform=tax_reform, revenue=revenue,
calc_reform=calc_reform)
if diff > 0:
ubi_tax_rev = prev_ubi_tax_rev * 0.5
prev_ubi_tax_rev = ubi_tax_rev
ubi18, ubiu18
# Calculator with UBI and tax reform
recs_ubi1 = Records('puf_benefits.csv', weights='puf_weights_new.csv', adjust_ratios='puf_ratios copy.csv')
pol_ubi1 = Policy()
pol_ubi1.implement_reform(tax_reform)
ubi_ref = {
2014: {
'_UBI1': [ubiu18],
'_UBI2': [ubi18],
'_UBI3': [ubi18]
}
}
pol_ubi1.implement_reform(ubi_ref)
calc_ubi1 = Calculator(records=recs_ubi1, policy=pol_ubi1, verbose=False)
calc_ubi1.records.e02400 = np.zeros(len(calc_ubi1.records.e02400))
calc_ubi1.advance_to_year(2014)
calc_ubi1.calc_all()
# Get MTR's
mtrs = calc_ubi1.mtr()
pd.options.display.float_format = '{:,.2f}'.format
```
## For all Tax Units
```
table_data1 = prep_table_data(calc=calc_ubi1, calc_base=calc, mtrs=mtrs, bins='income')
avg_ben, avg_ben_mult = cps_avg_ben(cps_storage, other_programs, group='all', bins='income')
table(table_data1, avg_ben, avg_ben_mult)
```
## Tax Units w/ Someone above 65
```
table_data2 = prep_table_data(calc=calc_ubi1, calc_base=calc, mtrs=mtrs, group='65 or over', bins='income')
#somehow s006 has to be the first variable in table? why?!!
avg_ben, avg_ben_mult = cps_avg_ben(cps_storage, other_programs, group='65 or over', bins='income')
table(table_data2, avg_ben, avg_ben_mult)
```
## Tax Units w/out Someone Over 65
```
table_data3 = prep_table_data(calc=calc_ubi1, calc_base=calc, mtrs=mtrs, group='under 65', bins='income')
avg_ben, avg_ben_mult = cps_avg_ben(cps_storage, other_programs, group='under 65', bins='income')
table(table_data3, avg_ben, avg_ben_mult)
```
# UBI + Original Tax Reform + New Provisions
New Provisions: No AMT, personal income and pass through rates: <$50K (single) / <$100K (joint) - 10%, >$50K (single) / >$100K (joint) - 50%
```
# Calculator with second reform policy
recs_reform2 = Records('puf_benefits.csv', weights='puf_weights_new.csv', adjust_ratios='puf_ratios copy.csv')
pol_reform2 = Policy()
pol_reform2.implement_reform(tax_reform)
tax_reform2 = {
2014: {
'_ALD_StudentLoan_hc': [1.0],
'_ALD_SelfEmploymentTax_hc': [1.0],
'_ALD_SelfEmp_HealthIns_hc': [1.0],
'_ALD_KEOGH_SEP_hc': [1.0],
'_ALD_EarlyWithdraw_hc': [1.0],
'_ALD_Alimony_hc': [1.0],
'_ALD_Dependents_hc': [1.0],
'_ALD_EducatorExpenses_hc': [1.0],
'_ALD_HSADeduction_hc': [1.0],
'_ALD_IRAContributions_hc': [1.0],
'_ALD_DomesticProduction_hc': [1.0],
'_ALD_Tuition_hc': [1.0],
'_CR_RetirementSavings_hc': [1.0],
'_CR_ForeignTax_hc': [1.0],
'_CR_ResidentialEnergy_hc': [1.0],
'_CR_GeneralBusiness_hc': [1.0],
'_CR_MinimumTax_hc': [1.0],
'_CR_AmOppRefundable_hc': [1.0],
'_CR_AmOppNonRefundable_hc': [1.0],
'_CR_SchR_hc': [1.0],
'_CR_OtherCredits_hc': [1.0],
'_CR_Education_hc': [1.0],
'_II_em': [0.0],
'_STD': [[0.0, 0.0, 0.0, 0.0, 0.0]],
'_STD_Aged': [[0.0, 0.0, 0.0, 0.0, 0.0]],
'_ID_Medical_hc': [1.0],
'_ID_StateLocalTax_hc': [1.0],
'_ID_RealEstate_hc': [1.0],
'_ID_InterestPaid_hc': [1.0],
'_ID_Casualty_hc': [1.0],
'_ID_Miscellaneous_hc': [1.0],
'_CDCC_c': [0.0],
'_CTC_c': [0.0],
'_EITC_c': [[0.0, 0.0, 0.0, 0.0]],
'_LLC_Expense_c': [0.0],
'_ETC_pe_Single': [0.0],
'_ETC_pe_Married': [0.0],
'_II_rt2': [.10],
'_II_rt3': [.10],
'_II_rt4': [.10],
'_II_rt5': [.10],
'_II_rt6': [.10],
'_II_rt7': [.50],
'_II_brk1': [[50000, 100000, 50000, 50000, 100000]],
'_II_brk2': [[50000, 100000, 50000, 50000, 100000]],
'_II_brk3': [[50000, 100000, 50000, 50000, 100000]],
'_II_brk4': [[50000, 100000, 50000, 50000, 100000]],
'_II_brk5': [[50000, 100000, 50000, 50000, 100000]],
'_II_brk6': [[50000, 100000, 50000, 50000, 100000]],
'_PT_rt2': [.10],
'_PT_rt3': [.10],
'_PT_rt4': [.10],
'_PT_rt5': [.10],
'_PT_rt6': [.10],
'_PT_rt7': [.50],
'_PT_brk1': [[50000, 100000, 50000, 50000, 100000]],
'_PT_brk2': [[50000, 100000, 50000, 50000, 100000]],
'_PT_brk3': [[50000, 100000, 50000, 50000, 100000]],
'_PT_brk4': [[50000, 100000, 50000, 50000, 100000]],
'_PT_brk5': [[50000, 100000, 50000, 50000, 100000]],
'_PT_brk6': [[50000, 100000, 50000, 50000, 100000]],
'_AMT_rt1': [0.0],
'_AMT_rt2': [0.0]
}
}
pol_reform2.implement_reform(tax_reform2)
calc_reform2 = Calculator(records=recs_reform2, policy=pol_reform2, verbose=False)
calc_reform2.records.e02400 = np.zeros(len(calc_reform2.records.e02400))
calc_reform2.advance_to_year(2014)
calc_reform2.calc_all()
# Revenue from tax reform
tax_rev2 = ((calc_reform2.records.combined - calc.records.combined) * calc_reform2.records.s006).sum()
revenue2 = cps_rev + other_rev + ss_lostrev + tax_rev2
revenue2
# Find original UBI amounts
ubi18, ubiu18 = ubi_amt(revenue2, u18, abv18)
ubi18, ubiu18
# Find UBI after accounting for UBI tax revenue
diff = 9e99
ubi_tax_rev = 0
prev_ubi_tax_rev = 0
while abs(diff) >= 300:
ubi18, ubiu18 = ubi_amt(revenue2 + ubi_tax_rev, u18, abv18)
diff, ubi_tax_rev = ubi_finder(ubi18, ubiu18,
tax_reform=tax_reform2, revenue=revenue2,
calc_reform=calc_reform2)
if diff > 0:
ubi_tax_rev = prev_ubi_tax_rev * 0.5
prev_ubi_tax_rev = ubi_tax_rev
print diff
ubi18, ubiu18
# Calculator with UBI and tax reform
recs_ubi2 = Records('puf_benefits.csv', weights='puf_weights_new.csv', adjust_ratios='puf_ratios copy.csv')
pol_ubi2 = Policy()
pol_ubi2.implement_reform(tax_reform)
ubi_ref2 = {
2014: {
'_UBI1': [ubiu18],
'_UBI2': [ubi18],
'_UBI3': [ubi18]
}
}
pol_ubi2.implement_reform(ubi_ref2)
calc_ubi2 = Calculator(records=recs_ubi2, policy=pol_ubi2, verbose=False)
calc_ubi2.records.e02400 = np.zeros(len(calc_ubi2.records.e02400))
calc_ubi2.advance_to_year(2014)
calc_ubi2.calc_all()
# Get MTR's
# try using baseline MTR
mtrs2 = calc.mtr()
```
## For all Tax Units
```
table_data4 = prep_table_data(calc=calc_ubi2, calc_base=calc, mtrs=mtrs2, bins='income')
avg_ben, avg_ben_mult = cps_avg_ben(cps_storage, other_programs, group='all', bins='income')
table(table_data4, avg_ben, avg_ben_mult)
```
## Tax Units with Someone Over 65
```
table_data5 = prep_table_data(calc=calc_ubi2, calc_base=calc, mtrs=mtrs2, group='65 or over', bins='income')
avg_ben, avg_ben_mult = cps_avg_ben(cps_storage, other_programs, group='65 or over', bins='income')
table(table_data5, avg_ben, avg_ben_mult)
```
## Tax Units w/out Someone Over 65
```
table_data6 = prep_table_data(calc=calc_ubi2, calc_base=calc, mtrs=mtrs2, group='under 65', bins='income')
avg_ben, avg_ben_mult = cps_avg_ben(cps_storage, other_programs, group='under 65', bins='income')
table(table_data6, avg_ben, avg_ben_mult)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/MIT-LCP/hack-aotearoa/blob/master/01_explore_patients.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# eICU Collaborative Research Database
# Notebook 1: Exploring the patient table
The aim of this notebook is to get set up with access to a demo version of the [eICU Collaborative Research Database](http://eicu-crd.mit.edu/). The demo is a subset of the full database, limited to ~1000 patients.
We begin by exploring the `patient` table, which contains patient demographics and admission and discharge details for hospital and ICU stays. For more detail, see: http://eicu-crd.mit.edu/eicutables/patient/
## Prerequisites
- If you do not have a Gmail account, please create one at http://www.gmail.com.
- If you have not yet signed the data use agreement (DUA) sent by the organizers, please do so now to get access to the dataset.
## Load libraries and connect to the data
Run the following cells to import some libraries and then connect to the database.
```
# Import libraries
import numpy as np
import os
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib.path as path
# Make pandas dataframes prettier
from IPython.display import display, HTML
# Access data using Google BigQuery.
from google.colab import auth
from google.cloud import bigquery
```
Before running any queries, you need to first authenticate yourself by running the following cell. If you are running it for the first time, it will ask you to follow a link to log in using your Gmail account, and accept the data access requests to your profile. Once this is done, it will generate a string of verification code, which you should paste back to the cell below and press enter.
```
auth.authenticate_user()
```
We'll also set the project details.
```
project_id='hack-aotearoa'
os.environ["GOOGLE_CLOUD_PROJECT"]=project_id
```
# "Querying" our database with SQL
Now we can start exploring the data. We'll begin by running a simple query to load all columns of the `patient` table to a Pandas DataFrame. The query is written in SQL, a common language for extracting data from databases. The structure of an SQL query is:
```sql
SELECT <columns>
FROM <table>
WHERE <criteria, optional>
```
`*` is a wildcard that indicates all columns
# BigQuery
Our dataset is stored on BigQuery, Google's database engine. We can run our query on the database using some special ("magic") [BigQuery syntax](https://googleapis.dev/python/bigquery/latest/magics.html).
```
%%bigquery patient
SELECT *
FROM `physionet-data.eicu_crd_demo.patient`
```
We have now assigned the output to our query to a variable called `patient`. Let's use the `head` method to view the first few rows of our data.
```
# view the top few rows of the patient data
patient.head()
```
## Questions
- What does `patientunitstayid` represent? (hint, see: http://eicu-crd.mit.edu/eicutables/patient/)
- What does `patienthealthsystemstayid` represent?
- What does `uniquepid` represent?
```
# select a limited number of columns to view
columns = ['uniquepid', 'patientunitstayid','gender','age','unitdischargestatus']
patient[columns].head()
```
- Try running the following query, which lists unique values in the age column. What do you notice?
```
# what are the unique values for age?
age_col = 'age'
patient[age_col].sort_values().unique()
```
- Try plotting a histogram of ages using the command in the cell below. What happens? Why?
```
# try plotting a histogram of ages
patient[age_col].plot(kind='hist', bins=15)
```
Let's create a new column named `age_num`, then try again.
```
# create a column containing numerical ages
# If ‘coerce’, then invalid parsing will be set as NaN
agenum_col = 'age_num'
patient[agenum_col] = pd.to_numeric(patient[age_col], errors='coerce')
patient[agenum_col].sort_values().unique()
patient[agenum_col].plot(kind='hist', bins=15)
```
## Questions
- Use the `mean()` method to find the average age. Why do we expect this to be lower than the true mean?
- In the same way that you use `mean()`, you can use `describe()`, `max()`, and `min()`. Look at the admission heights (`admissionheight`) of patients in cm. What issue do you see? How can you deal with this issue?
```
adheight_col = 'admissionheight'
patient[adheight_col].describe()
# set threshold
adheight_col = 'admissionheight'
patient[patient[adheight_col] < 10] = None
```
| github_jupyter |
```
import pandas as pd
from numpy import array
import numpy as np
import math
from xgboost import XGBRegressor
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
train = pd.read_csv('Train.csv')
print(train)
pressure_list = train['Pressure (KPa)'].tolist()
temp_list = train['Air temperature (C)'].tolist()
pressure_list_without_nan = []
for i in range(len(pressure_list)):
if (np.isnan(pressure_list[i])):
pressure_list_without_nan.append(pressure_list_without_nan[i - 24*12])
else:
pressure_list_without_nan.append(pressure_list[i])
temp_list_without_nan = []
for i in range(len(temp_list)):
if (np.isnan(temp_list[i])):
temp_list_without_nan.append(temp_list_without_nan[i - 24*12])
else:
temp_list_without_nan.append(temp_list[i])
def firstNanIndex(listfloats, k):
for i, item in enumerate(listfloats):
if i > k and math.isnan(item) == True:
return i
def firstNonNan(listfloats, j):
bol = False
for i, item in enumerate(listfloats[j:]):
if math.isnan(item) == False:
bol = True
return i+j, item
if (bol == False):
return len(listfloats) -1 , listfloats[len(listfloats)-1]
def cleanSerie(columnName):
field = train[columnName].tolist()
cleanedList = [x for x in field if (math.isnan(x) == False)]
return cleanedList
field1_without_Nan = cleanSerie('Soil humidity 1')
field1_without_Nan = field1_without_Nan[:-3]
field1 = train['Soil humidity 1'].tolist()
index1 = firstNanIndex(field1, 0)
field1 = field1[:index1+ 1153]
field2_without_Nan = cleanSerie('Soil humidity 2')
field2_without_Nan = field2_without_Nan[:-3]
field2 = train['Soil humidity 2'].tolist()
index2 = firstNanIndex(field2, 0)
field2 = field2[:index2+ 1747]
field3_without_Nan = cleanSerie('Soil humidity 3')
field3_without_Nan = field3_without_Nan[:-3]
field3 = train['Soil humidity 3'].tolist()
index3 = firstNanIndex(field3, 0)
field3 = field3[:index3+ 1153]
field4_without_Nan = cleanSerie('Soil humidity 4')
field4_without_Nan = field4_without_Nan[:-5]
field4 = train['Soil humidity 4'].tolist()
index4 = firstNanIndex(field4, 0)
field4 = field4[:index4+ 1729]
def prepare_data(train,field_number, field_without_Nan, preds_horizon):
target = train[['Pressure (KPa)','Air temperature (C)', 'Soil humidity ' + str(field_number),'Irrigation field ' +str(field_number)]][:len(field_without_Nan)]
target['last'] = target[['Soil humidity ' + str(field_number)]].shift(1)
target['diff'] = target['Soil humidity ' + str(field_number)] - target['last']
target['pressure'] = target['Pressure (KPa)']
target['pressure_last'] = target[['pressure']].shift(1)
target['diff_pressure'] = target['pressure'] - target['pressure_last']
target['temperature'] = target['Air temperature (C)']
target['temperature_last'] = target[['temperature']].shift(1)
target['diff_temperature'] = target['temperature'] - target['temperature_last']
del target['Air temperature (C)']
del target['temperature_last']
del target['pressure_last']
del target['temperature']
del target['pressure']
del target['Pressure (KPa)']
target['irrigation_now'] = train['Irrigation field ' +str(field_number)][:len(field_without_Nan)]
X = target.dropna()
del X['Soil humidity ' + str(field_number)]
del X['last']
Y = X['diff']
del X['Irrigation field ' +str(field_number)]
del X['diff']
return X, Y
def train_xgboost(data_X, data_Y, random_state=0):
my_imputer = SimpleImputer()
final_train = my_imputer.fit_transform(data_X)
train_X, test_X, train_y, test_y = train_test_split(final_train, data_Y, test_size=0.1, random_state=random_state)
my_model = XGBRegressor(n_estimators=1500, learning_rate=0.1, random_state=random_state)
my_model.fit(train_X, train_y, early_stopping_rounds=5,eval_metric=["rmse"], eval_set=[(test_X, test_y)], verbose=False)
return my_model
def findStep(last_prediction, moisture_list, index):
j = index
while(np.isnan(moisture_list[j])):
j =j+1
step = (moisture_list[j] - last_prediction ) /(j-index)
return step
def get_Predictions(model, field_number, field_without_Nan, field, train_last_index, preds_horizon):
moisture = field[len(field_without_Nan)-1:]
irrigationFrame = train[['Irrigation field ' +str(field_number)]][len(field_without_Nan)-1:len(field_without_Nan)+preds_horizon]
preds = []
k=0
index=-1
bol = False
for i in range(preds_horizon):
index= index + 1
temperature = temp_list_without_nan[train_last_index + index]
temperature_last = temp_list_without_nan[train_last_index + index - 1]
temperature_diff = temperature - temperature_last
pressure = pressure_list_without_nan[train_last_index + index]
pressure_last = pressure_list_without_nan[train_last_index + index - 1]
pressure_diff = pressure - pressure_last
irrigation = irrigationFrame.iloc[i+1]['Irrigation field ' + str(field_number)]
if(np.isnan(irrigation)):
irrigation =0
if(irrigation == 0):
bol = False
x= np.array([pressure_diff, temperature_diff, irrigation])
x = x[np.newaxis,...]
prediction = model.predict(x)
if(irrigation == 1 and index ==0):
x= np.array([pressure_diff, temperature_diff, irrigation])
x = x[np.newaxis,...]
prediction = model.predict(x)
if(irrigation == 1 and index > 0):
if(bol == False):
step =findStep(preds[-1], moisture, index)
prediction = [step]
bol = True
else:
prediction = [step]
if np.isnan(moisture[i]):
preds.append(prediction[0]+ preds[-1])
k=k+1
else:
preds.append(prediction[0]+ moisture[i])
k=0
k=k+1
return preds
seed = 90973
data_X, data_Y = prepare_data(train,1, field1_without_Nan, 1153)
print(data_X)
model1 = train_xgboost(data_X, data_Y, seed)
preds1 = get_Predictions(model1,1, field1_without_Nan,field1, 8914, 1153)
print(preds1)
data_X, data_Y = prepare_data(train,2, field2_without_Nan, 1747)
model2 = train_xgboost(data_X, data_Y, seed)
preds2 = get_Predictions(model2,2, field2_without_Nan,field2, 26301, 1747)
data_X, data_Y = prepare_data(train,3, field3_without_Nan, 1153)
model3 = train_xgboost(data_X, data_Y, seed)
preds3 = get_Predictions(model3,3, field3_without_Nan,field3, 16083, 1153)
data_X, data_Y = prepare_data(train,4, field4_without_Nan, 1729)
model4 = train_xgboost(data_X, data_Y, seed)
preds4 = get_Predictions(model4,4, field4_without_Nan,field4, 26301, 1729)
total =[]
total.extend(preds1)
total.extend(preds2)
total.extend(preds3)
total.extend(preds4)
submission =pd.read_csv('SampleSubmission.csv')
submission['Values']= total
submission.to_csv('submission.csv', index=False)
```
| github_jupyter |
# Comparing methods of hurricane forecast uncertainty
[](https://github.com/eabarnes1010/course_ml_ats/tree/main/code)
[](https://colab.research.google.com/github/eabarnes1010/course_ml_ats/blob/main/code/ann_uq_hurricanes.ipynb)
_Ongoing research by Elizabeth A. Barnes, Randal J. Barnes and Mark DeMaria_
We will be forecasting the error of the Consensus forecast (mean across multiple hurricane models) of hurricane intensity 72 hours in advance for hurricanes over the Eastern Pacific / Central Pacific. That is, our network will be used as a post-processing technique. Our input features (predictors) are composed of 11 variables that include information we think might be helpful, e.g. the models that went into the Consensus forecast, the environment (e.g. sea-surface temperature, shear), and the current latitude of the storm.
We will be predicting parameters of the conditional SHASH distribution for each prediction and then plotting these distributions.
## Initial import and module statements
```
try:
import google.colab
IN_COLAB = True
except:
IN_COLAB = False
print('IN_COLAB = ' + str(IN_COLAB))
import datetime
import os
import pickle
import pprint
import time
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import regularizers
from sklearn import preprocessing
import tensorflow_probability as tfp
from tensorflow.keras import optimizers
from IPython.display import clear_output
from tqdm import tqdm
from numpy.random import default_rng
mpl.rcParams["figure.facecolor"] = "white"
mpl.rcParams["figure.dpi"] = 150
np.warnings.filterwarnings("ignore", category=np.VisibleDeprecationWarning)
import sys
print(f"python version = {sys.version}")
print(f"numpy version = {np.__version__}")
print(f"tensorflow version = {tf.__version__}")
```
## Lots of predefined functions
### Plotting functions
```
def plot_history(history, model_name):
"""Plot the model.fit training history and save the resulting figure.
Creates a 2-by-2 block of subplots. The four plots are:
1 -- training and validations loss history.
2 -- training and validations customMAE history.
3 -- training and validations InterquartileCapture history.
4 -- training and validations SignTest history.
Arguments
---------
history : tf.keras.callbacks.History
The history must have at least the following eight items
in the history.history.keys()
"loss",
"val_loss",
"custom_mae",
"val_custom_mae",
"interquartile_capture",
"val_interquartile_capture",
"sign_test",
"val_sign_test"
model_name : str
The resulting figure is saved to:
"figures/model_diagnostics/" + model_name + ".png"
Returns
-------
None
"""
TRAIN_COLOR = "#7570b3"
VALID_COLOR = "#e7298a"
FIGSIZE = (14, 10)
FONTSIZE = 12
DPIFIG = 300.0
best_epoch = np.argmin(history.history["val_loss"])
plt.figure(figsize=FIGSIZE)
# Plot the training and validations loss history.
plt.subplot(2, 2, 1)
plt.plot(
history.history["loss"],
"o",
color=TRAIN_COLOR,
markersize=3,
label="train",
)
plt.plot(
history.history["val_loss"],
"o",
color=VALID_COLOR,
markersize=3,
label="valid",
)
plt.axvline(x=best_epoch, linestyle="--", color="tab:gray")
plt.title("Log-likelihood Loss Function")
plt.ylabel("Loss")
plt.xlabel("Epoch")
plt.grid(True)
plt.legend(frameon=True, fontsize=FONTSIZE)
# Plot the training and validations customMAE history.
try:
plt.subplot(2, 2, 2)
plt.plot(
history.history["custom_mae"],
"o",
color=TRAIN_COLOR,
markersize=3,
label="train",
)
plt.plot(
history.history["val_custom_mae"],
"o",
color=VALID_COLOR,
markersize=3,
label="valid",
)
plt.axvline(x=best_epoch, linestyle="--", color="tab:gray")
plt.title("Mean |true - median|")
plt.xlabel("Epoch")
plt.grid(True)
plt.legend(frameon=True, fontsize=FONTSIZE)
except:
print('no mae metric, skipping plot')
# Plot the training and validations InterquartileCapture history.
try:
plt.subplot(2, 2, 3)
plt.plot(
history.history["interquartile_capture"],
"o",
color=TRAIN_COLOR,
markersize=3,
label="train",
)
plt.plot(
history.history["val_interquartile_capture"],
"o",
color=VALID_COLOR,
markersize=3,
label="valid",
)
plt.axvline(x=best_epoch, linestyle="--", color="tab:gray")
plt.title("Fraction Between 25 and 75 Percentile")
plt.xlabel("Epoch")
plt.grid(True)
plt.legend(frameon=True, fontsize=FONTSIZE)
except:
print('no interquartile_capture, skipping plot')
# Plot the training and validations SignTest history.
try:
plt.subplot(2, 2, 4)
plt.plot(
history.history["sign_test"],
"o",
color=TRAIN_COLOR,
markersize=3,
label="train",
)
plt.plot(
history.history["val_sign_test"],
"o",
color=VALID_COLOR,
markersize=3,
label="valid",
)
plt.axvline(x=best_epoch, linestyle="--", color="tab:gray")
plt.title("Fraction Above the Median")
plt.xlabel("Epoch")
plt.grid(True)
plt.legend(frameon=True, fontsize=FONTSIZE)
except:
print('no sign-test, skipping plot')
# Draw and save the plot.
plt.tight_layout()
# plt.savefig("figures/model_diagnostics/" + model_name + ".png", dpi=DPIFIG)
plt.show()
class TrainingInstrumentation(tf.keras.callbacks.Callback):
"""Plot real-time training instrumentation panel.
If x_data and onehot_data are not given, the instrumentation panel
includes only the real-time plot of the training and validation loss.
If the x_data and onehot_data are given, the instrumentation panel also
includes the PIT histogram plot, and histogram plots for each of the
local conditional distribution parameters, updated in real time.
Parameters
----------
x_data : tensor, default=None
The x_train (or x_valid) tensor. If either x_data or onehot_data
is specifed, then both must be specified and they must have the
same number of rows.
onehot_data : tensor, default=None
The onehot_train (or onehot_valid) tensor. If either x_data or
onehot_data is specifed, then both must be specified and they must
have the same number of rows.
figsize: (float, float), default=(13, 7)
Size of the instrumentation panel.
interval: int, default=1
Number of epochs (steps) between refreshing the instruments. By
default, interval=1, and the intruments are updated ever epoch.
Usage
-----
* Include TrainingInstrumentation() as a callback in model.fit; e.g.
training_callback = TrainingInstrumentation(
x_train_std, onehot_train, interval=10
)
...
history = model.fit(
...
callbacks=[training_callback],
)
Notes
-----
* This Class is explcitly designed for the SHASH distribution, with
parameter names 'mu', 'sigma', 'gamma', and 'tau'.
"""
def __init__(
self,
x_data=None,
onehot_data=None,
figsize=(13, 7),
interval=1,
):
super().__init__()
self.x_data = x_data
self.onehot_data = onehot_data
self.figsize = figsize
self.interval = interval
def on_train_begin(self, logs={}):
self.loss = []
self.val_loss = []
def on_epoch_end(self, epoch, logs={}):
self.loss.append(logs.get("loss"))
self.val_loss.append(logs.get("val_loss"))
if epoch % self.interval == 0:
clear_output(wait=True)
plt.figure(figsize=self.figsize)
best_epoch = np.argmin(self.val_loss)
plt.subplot(3, 2, 1)
plt.plot(self.loss, "o", color="#7570b3", label="train", markersize=2)
plt.plot(self.val_loss, "o", color="#e7298a", label="valid", markersize=2)
plt.axvline(x=best_epoch, linestyle="--", color="gray")
plt.title(f"Loss After {epoch} Epochs")
plt.grid(True)
plt.legend(
[
f"train = {logs.get('loss'):.3f}",
f"valid = {logs.get('val_loss'):.3f}",
]
)
if (self.x_data is not None) and (self.onehot_data is not None):
preds = self.model.predict(self.x_data)
if preds.shape[1] >= 1:
mu = preds[:, 0]
plt.subplot(3, 2, 3)
plt.hist(mu, bins=30, color="#7fc97f", edgecolor="k")
plt.legend(["mu"])
if preds.shape[1] >= 2:
# sigma = tf.math.exp(preds[:, 1])
sigma = preds[:, 1]
plt.subplot(3, 2, 4)
plt.hist(sigma, bins=30, color="#beaed4", edgecolor="k")
plt.legend(["sigma"])
else:
sigma = tf.zeros_like(mu)
if preds.shape[1] >= 3:
gamma = preds[:, 2]
plt.subplot(3, 2, 5)
plt.hist(gamma, bins=30, color="#fdc086", edgecolor="k")
plt.legend(["gamma"])
else:
gamma = tf.zeros_like(mu)
if preds.shape[1] >= 4:
# tau = tf.math.exp(preds[:, 3])
tau = preds[:, 3]
plt.subplot(3, 2, 6)
plt.hist(tau, bins=30, color="#ffff99", edgecolor="k")
plt.legend(["tau"])
else:
tau = tf.ones_like(mu)
F = shash_cdf(self.onehot_data[:, 0], mu, sigma, gamma, tau)
plt.subplot(3, 2, 2)
plt.hist(
F.numpy(),
bins=np.linspace(0, 1, 21),
color="#386cb0",
edgecolor="k",
)
plt.legend(["PIT"])
plt.axhline(y=F.shape[0] / 20, color="b", linestyle="--")
plt.show()
def params(x_inputs, model):
"""Function to make shash parameter predictions for shash2, shash3, shash4
Arguments
---------
x_inputs : floats
matrix of inputs to the network
model : tensorflow model
neural network for predictions
Returns
-------
vector of predicted parameters
"""
y_pred = model.predict(x_inputs)
mu_pred = y_pred[:, 0]
sigma_pred = y_pred[:, 1]
gamma_pred = np.zeros(np.shape(y_pred[:, 0]),dtype='float32')
if np.shape(y_pred)[1] >= 3:
gamma_pred = y_pred[:, 2]
tau_pred = np.ones(np.shape(y_pred[:, 0]),dtype='float32')
if np.shape(y_pred)[1] >=4 :
tau_pred = y_pred[:, 3]
return mu_pred, sigma_pred, gamma_pred, tau_pred
def percentile_value(mu_pred, sigma_pred, gamma_pred, tau_pred, percentile_frac=0.5):
"""Function to obtain percentile value of the shash distribution."""
return shash_quantile(
pr=percentile_frac, mu=mu_pred, sigma=sigma_pred, gamma=gamma_pred, tau=tau_pred
).numpy()
```
### Metrics and loss functions / scalings
```
class Exponentiate(keras.layers.Layer):
"""Custom layer to exp the sigma and tau estimates inline."""
def __init__(self, **kwargs):
super(Exponentiate, self).__init__(**kwargs)
def call(self, inputs):
return tf.math.exp(inputs)
class InterquartileCapture(tf.keras.metrics.Metric):
"""Compute the fraction of true values between the 25 and 75 percentiles.
"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.count = self.add_weight("count", initializer="zeros")
self.total = self.add_weight("total", initializer="zeros")
def update_state(self, y_true, pred, sample_weight=None):
mu = pred[:, 0]
sigma = pred[:, 1]
if pred.shape[1] >= 3:
gamma = pred[:, 2]
else:
gamma = tf.zeros_like(mu)
if pred.shape[1] >= 4:
tau = pred[:, 3]
else:
tau = tf.ones_like(mu)
lower = shash_quantile(0.25, mu, sigma, gamma, tau)
upper = shash_quantile(0.75, mu, sigma, gamma, tau)
batch_count = tf.reduce_sum(
tf.cast(
tf.math.logical_and(
tf.math.greater(y_true[:, 0], lower),
tf.math.less(y_true[:, 0], upper)
),
tf.float32
)
)
batch_total = len(y_true[:, 0])
self.count.assign_add(tf.cast(batch_count, tf.float32))
self.total.assign_add(tf.cast(batch_total, tf.float32))
def result(self):
return self.count / self.total
def get_config(self):
base_config = super().get_config()
return {**base_config}
class SignTest(tf.keras.metrics.Metric):
"""Compute the fraction of true values above the median.
"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.count = self.add_weight("count", initializer="zeros")
self.total = self.add_weight("total", initializer="zeros")
def update_state(self, y_true, pred, sample_weight=None):
mu = pred[:, 0]
sigma = pred[:, 1]
if pred.shape[1] >= 3:
gamma = pred[:, 2]
else:
gamma = tf.zeros_like(mu)
if pred.shape[1] >= 4:
tau = pred[:, 3]
else:
tau = tf.ones_like(mu)
median = shash_median(mu, sigma, gamma, tau)
batch_count = tf.reduce_sum(
tf.cast(tf.math.greater(y_true[:, 0], median), tf.float32)
)
batch_total = len(y_true[:, 0])
self.count.assign_add(tf.cast(batch_count, tf.float32))
self.total.assign_add(tf.cast(batch_total, tf.float32))
def result(self):
return self.count / self.total
def get_config(self):
base_config = super().get_config()
return {**base_config}
class CustomMAE(tf.keras.metrics.Metric):
"""Compute the prediction mean absolute error.
The "predicted value" is the median of the conditional distribution.
Notes
-----
* The computation is done by maintaining running sums of total predictions
and correct predictions made across all batches in an epoch. The
running sums are reset at the end of each epoch.
"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.error = self.add_weight("error", initializer="zeros")
self.total = self.add_weight("total", initializer="zeros")
def update_state(self, y_true, pred, sample_weight=None):
mu = pred[:, 0]
sigma = pred[:, 1]
if pred.shape[1] >= 3:
gamma = pred[:, 2]
else:
gamma = tf.zeros_like(mu)
if pred.shape[1] >= 4:
tau = pred[:, 3]
else:
tau = tf.ones_like(mu)
predictions = shash_median(mu, sigma, gamma, tau)
error = tf.math.abs(y_true[:, 0] - predictions)
batch_error = tf.reduce_sum(error)
batch_total = tf.math.count_nonzero(error)
self.error.assign_add(tf.cast(batch_error, tf.float32))
self.total.assign_add(tf.cast(batch_total, tf.float32))
def result(self):
return self.error / self.total
def get_config(self):
base_config = super().get_config()
return {**base_config}
def compute_NLL(y, distr):
return -distr.log_prob(y)
def compute_shash_NLL(y_true, pred):
"""Negative log-likelihood loss using the sinh-arcsinh normal distribution.
Arguments
---------
y_true : tensor
The ground truth values.
shape = [batch_size, n_parameter]
pred :
The predicted local conditionsal distribution parameter values.
shape = [batch_size, n_parameters]
Returns
-------
loss : tensor, shape = [1, 1]
The average negative log-likelihood of the batch using the predicted
conditional distribution parameters.
Notes
-----
* The value of n_parameters depends on the chosen form of the conditional
sinh-arcsinh normal distribution.
shash2 -> n_parameter = 2, i.e. mu, sigma
shash3 -> n_parameter = 3, i.e. mu, sigma, gamma
shash4 -> n_parameter = 4, i.e. mu, sigma, gamma, tau
* Since sigma and tau must be strictly positive, the network learns the
log of these two parameters.
* If gamma is not learned (i.e. shash2), they are set to 0.
* If tau is not learned (i.e. shash2 or shash3), they are set to 1.
"""
mu = pred[:, 0]
sigma = pred[:, 1]
if pred.shape[1] >= 3:
gamma = pred[:, 2]
else:
gamma = tf.zeros_like(mu)
if pred.shape[1] >= 4:
tau = pred[:, 3]
else:
tau = tf.ones_like(mu)
loss = -shash_log_prob(y_true[:, 0], mu, sigma, gamma, tau)
return tf.reduce_mean(loss, axis=-1)
```
### Define and compute the SHASH distribution
```
"""sinh-arcsinh normal distribution w/o using tensorflow_probability.
Functions
---------
cdf(x, mu, sigma, gamma, tau=None)
cumulative distribution function (cdf).
log_prob(x, mu, sigma, gamma, tau=None)
log of the probability density function.
mean(mu, sigma, gamma, tau=None)
distribution mean.
median(mu, sigma, gamma, tau=None)
distribution median.
prob(x, mu, sigma, gamma, tau=None)
probability density function (pdf).
quantile(pr, mu, sigma, gamma, tau=None)
inverse cumulative distribution function.
rvs(mu, sigma, gamma, tau=None, size=1)
generate random variates.
stddev(mu, sigma, gamma, tau=None)
distribution standard deviation.
variance(mu, sigma, gamma, tau=None)
distribution variance.
Notes
-----
* This module uses only tensorflow. This module does not use the
tensorflow_probability library.
* The sinh-arcsinh normal distribution was defined in [1]. A more accessible
presentation is given in [2].
* The notation and formulation used in this code was taken from [3], page 143.
In the gamlss.dist/CRAN package the distribution is called SHASHo.
* There is a typographical error in the presentation of the probability
density function on page 143 of [3]. There is an extra "2" in the denomenator
preceeding the "sqrt{1 + z^2}" term.
References
----------
[1] Jones, M. C. & Pewsey, A., Sinh-arcsinh distributions,
Biometrika, Oxford University Press, 2009, 96, 761-780.
DOI: 10.1093/biomet/asp053.
[2] Jones, C. & Pewsey, A., The sinh-arcsinh normal distribution,
Significance, Wiley, 2019, 16, 6-7.
DOI: 10.1111/j.1740-9713.2019.01245.x.
https://rss.onlinelibrary.wiley.com/doi/10.1111/j.1740-9713.2019.01245.x
[3] Stasinopoulos, Mikis, et al. (2021), Distributions for Generalized
Additive Models for Location Scale and Shape, CRAN Package.
https://cran.r-project.org/web/packages/gamlss.dist/gamlss.dist.pdf
"""
import numpy as np
import scipy
import scipy.stats
import tensorflow as tf
__author__ = "Randal J. Barnes and Elizabeth A. Barnes"
__date__ = "14 January 2022"
SQRT_TWO = 1.4142135623730950488016887
ONE_OVER_SQRT_TWO = 0.7071067811865475244008444
TWO_PI = 6.2831853071795864769252868
SQRT_TWO_PI = 2.5066282746310005024157653
ONE_OVER_SQRT_TWO_PI = 0.3989422804014326779399461
def _jones_pewsey_P(q):
"""P_q function from page 764 of [1].
Arguments
---------
q : float, array like
Returns
-------
P_q : array like of same shape as q.
Notes
-----
* The formal equation is
jp = 0.25612601391340369863537463 * (
scipy.special.kv((q + 1) / 2, 0.25) +
scipy.special.kv((q - 1) / 2, 0.25)
)
The strange constant 0.25612... is "sqrt( sqrt(e) / (8*pi) )" computed
with a high-precision calculator. The special function
scipy.special.kv
is the Modified Bessel function of the second kind: K(nu, x).
* But, we cannot use the scipy.special.kv function during tensorflow
training. This code uses a 6th order polynomial approximation in
place of the formal function.
* This approximation is well behaved for 0 <= q <= 10. Since q = 1/tau
or q = 2/tau in our applications, the approximation is well behaved
for 1/10 <= tau < infty.
"""
# A 6th order polynomial approximation of log(_jones_pewsey_P) for the
# range 0 <= q <= 10. Over this range, the max |error|/true < 0.0025.
# These coefficients were computed by minimizing the maximum relative
# error, and not by a simple least squares regression.
coeffs = [
9.37541380598926e-06,
-0.000377732651131894,
0.00642826706073389,
-0.061281078712518,
0.390956214318641,
-0.0337884356755193,
0.00248824801827172
]
return tf.math.exp(tf.math.polyval(coeffs, q))
def shash_cdf(x, mu, sigma, gamma, tau=None):
"""Cumulative distribution function (cdf).
Parameters
----------
x : float (batch size x 1) Tensor
The values at which to compute the probability density function.
mu : float (batch size x 1) Tensor
The location parameter. Must be the same shape as x.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as x.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as x.
tau : float (batch size x 1) Tensor or None
The tail-weight parameter. Must be strictly positive. Must be the same
shape as x. If tau is None then the default value of tau=1 is used.
Returns
-------
F : float (batch size x 1) Tensor.
The computed cumulative probability distribution function (cdf)
evaluated at the values of x. F has the same shape as x.
Notes
-----
* This function uses the tensorflow.math.erf function rather than the
tensorflow_probability normal distribution functions.
"""
y = (x - mu) / sigma
if tau is None:
z = tf.math.sinh(tf.math.asinh(y) - gamma)
else:
z = tf.math.sinh(tau * tf.math.asinh(y) - gamma)
return 0.5 * (1.0 + tf.math.erf(ONE_OVER_SQRT_TWO * z))
def shash_log_prob(x, mu, sigma, gamma, tau=None):
"""Log-probability density function.
Parameters
----------
x : float (batch size x 1) Tensor
The values at which to compute the probability density function.
mu : float (batch size x 1) Tensor
The location parameter. Must be the same shape as x.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as x.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as x.
tau : float (batch size x 1) Tensor
The tail-weight parameter. Must be strictly positive. Must be the same
shape as x. If tau is None then the default value of tau=1 is used.
Returns
-------
f : float (batch size x 1) Tensor.
The natural logarithm of the computed probability density function
evaluated at the values of x. f has the same shape as x.
Notes
-----
* This function is included merely to emulate the tensorflow_probability
distributions.
"""
return tf.math.log(shash_prob(x, mu, sigma, gamma, tau))
def shash_mean(mu, sigma, gamma, tau=None):
"""The distribution mean.
Arguments
---------
mu : float (batch size x 1) Tensor
The location parameter.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as mu.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as mu.
tau : float (batch size x 1) Tensor
The tail-weight parameter. Must be strictly positive. Must be the same
shape as mu. If tau is None then the default value of tau=1 is used.
Returns
-------
x : float (batch size x 1) Tensor.
The computed distribution mean values.
Notes
-----
* This equation for evX can be found on page 764 of [1].
"""
if tau is None:
evX = tf.math.sinh(gamma) * 1.35453080648132
else:
evX = tf.math.sinh(gamma / tau) * _jones_pewsey_P(1.0 / tau)
return mu + sigma * evX
def shash_median(mu, sigma, gamma, tau=None):
"""The distribution median.
Arguments
---------
mu : float (batch size x 1) Tensor
The location parameter.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as mu.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as mu.
tau : float (batch size x 1) Tensor
The tail-weight parameter. Must be strictly positive. Must be the same
shape as mu. If tau is None then the default value of tau=1 is used.
Returns
-------
x : float (batch size x 1) Tensor.
The computed distribution mean values.
Notes
-----
* This code uses the basic formula:
E(a*X + b) = a*E(X) + b
* The E(X) is computed using the moment equation given on page 764 of [1].
"""
if tau is None:
return mu + sigma * tf.math.sinh(gamma)
else:
return mu + sigma * tf.math.sinh(gamma / tau)
def shash_prob(x, mu, sigma, gamma, tau=None):
"""Probability density function (pdf).
Parameters
----------
x : float (batch size x 1) Tensor
The values at which to compute the probability density function.
mu : float (batch size x 1) Tensor
The location parameter. Must be the same shape as x.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as x.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as x.
tau : float (batch size x 1) Tensor
The tail-weight parameter. Must be strictly positive. Must be the same
shape as x. If tau is None then the default value of tau=1 is used.
Returns
-------
f : float (batch size x 1) Tensor.
The computed probability density function evaluated at the values of x.
f has the same shape as x.
Notes
-----
* This code uses the equations on page 143 of [3], and the associated
notation.
"""
y = (x - mu) / sigma
if tau is None:
rsqr = tf.math.square(tf.math.sinh(tf.math.asinh(y) - gamma))
return (
ONE_OVER_SQRT_TWO_PI
/ sigma
* tf.math.sqrt((1 + rsqr) / (1 + tf.math.square(y)))
* tf.math.exp(-rsqr / 2)
)
else:
rsqr = tf.math.square(tf.math.sinh(tau * tf.math.asinh(y) - gamma))
return (
ONE_OVER_SQRT_TWO_PI
* (tau / sigma)
* tf.math.sqrt((1 + rsqr) / (1 + tf.math.square(y)))
* tf.math.exp(-rsqr / 2)
)
def shash_quantile(pr, mu, sigma, gamma, tau=None):
"""Inverse cumulative distribution function.
Arguments
---------
pr : float (batch size x 1) Tensor.
The probabilities at which to compute the values.
mu : float (batch size x 1) Tensor
The location parameter. Must be the same shape as pr.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as pr.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as pr.
tau : float (batch size x 1) Tensor
The tail-weight parameter. Must be strictly positive. Must be the same
shape as pr. If tau is None then the default value of tau=1 is used.
Returns
-------
x : float (batch size x 1) Tensor.
The computed values at the specified probabilities. f has the same
shape as pr.
"""
z = tf.math.ndtri(pr)
if tau is None:
return mu + sigma * tf.math.sinh(tf.math.asinh(z) + gamma)
else:
return mu + sigma * tf.math.sinh((tf.math.asinh(z) + gamma) / tau)
def shash_rvs(mu, sigma, gamma, tau=None, size=1):
"""Generate an array of random variates.
Arguments
---------
mu : float or double scalar
The location parameter.
sigma : float or double scalar
The scale parameter. Must be strictly positive.
gamma : float or double scalar
The skewness parameter.
tau : float or double scalar, or None
The tail-weight parameter. Must be strictly positive.
If tau is None then the default value of tau=1 is used.
size : int or tuple of ints, default=1.
The number of random variates.
Returns
-------
x : double ndarray of size=size
The generated random variates.
"""
z = scipy.stats.norm.rvs(size=size)
if tau is None:
return mu + sigma * np.sinh(np.arcsinh(z) + gamma)
else:
return mu + sigma * np.sinh((np.arcsinh(z) + gamma) / tau)
def shash_stddev(mu, sigma, gamma, tau=None):
"""The distribution standard deviation.
Arguments
---------
mu : float (batch size x 1) Tensor
The location parameter.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as mu.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as mu.
tau : float (batch size x 1) Tensor
The tail-weight parameter. Must be strictly positive. Must be the same
shape as mu. If tau is None then the default value of tau=1 is used.
Returns
-------
x : float (batch size x 1) Tensor.
The computed distribution standard deviation values.
"""
return tf.math.sqrt(variance(mu, sigma, gamma, tau))
def shash_variance(mu, sigma, gamma, tau=None):
"""The distribution variance.
Arguments
---------
mu : float (batch size x 1) Tensor
The location parameter.
sigma : float (batch size x 1) Tensor
The scale parameter. Must be strictly positive. Must be the same
shape as mu.
gamma : float (batch size x 1) Tensor
The skewness parameter. Must be the same shape as mu.
tau : float (batch size x 1) Tensor
The tail-weight parameter. Must be strictly positive. Must be the same
shape as mu. If tau is None then the default value of tau=1 is used.
Returns
-------
x : float (batch size x 1) Tensor.
The computed distribution variance values.
Notes
-----
* This code uses two basic formulas:
var(X) = E(X^2) - (E(X))^2
var(a*X + b) = a^2 * var(X)
* The E(X) and E(X^2) are computed using the moment equations given on
page 764 of [1].
"""
if tau is None:
evX = tf.math.sinh(gamma) * 1.35453080648132
evX2 = (tf.math.cosh(2 * gamma) * 3.0 - 1.0) / 2
else:
evX = tf.math.sinh(gamma / tau) * _jones_pewsey_P(1.0 / tau)
evX2 = (tf.math.cosh(2 * gamma / tau) * _jones_pewsey_P(2.0 / tau) - 1.0) / 2
return tf.math.square(sigma) * (evX2 - tf.math.square(evX))
```
### Build the SHASH tf model
```
def make_model(settings, x_train, onehot_train, model_compile=False):
if settings["uncertainty_type"][:5] == "shash":
model = build_shash_model(
x_train,
onehot_train,
hiddens=settings["hiddens"],
output_shape=onehot_train.shape[1],
ridge_penalty=settings["ridge_param"],
act_fun=settings["act_fun"],
dropout_rate=settings["dropout_rate"],
rng_seed=settings["rng_seed"],
)
if model_compile == True:
model.compile(
optimizer=optimizers.SGD(
learning_rate=settings["learning_rate"],
momentum=settings["momentum"],
nesterov=settings["nesterov"],
),
loss=compute_shash_NLL,
metrics=[
CustomMAE(name="custom_mae"),
InterquartileCapture(name="interquartile_capture"),
SignTest(name="sign_test"),
],
)
else:
raise NotImplementedError
return model
def build_shash_model(
x_train, onehot_train, hiddens, output_shape, ridge_penalty=[0.0,], act_fun="relu", rng_seed=999, dropout_rate=[0.0,],
):
"""Build the fully-connected shash network architecture with
internal scaling.
Arguments
---------
x_train : numpy.ndarray
The training split of the x data.
shape = [n_train, n_features].
onehot_train : numpy.ndarray
The training split of the scaled y data is in the first column.
The remaining columns are filled with zeros. The number of columns
equal the number of distribution parameters.
shape = [n_train, n_parameters].
hiddens : list (integers)
Numeric list containing the number of neurons for each layer.
output_shape : integer {2, 3, 4}
The number of distribution output parameters to be learned.
ridge_penalty : float, default=0.0
The L2 regularization penalty for the first layer.
act_fun : function, default="relu"
The activation function to use on the deep hidden layers.
Returns
-------
model : tensorflow.keras.models.Model
Notes
-----
* The number of output units is determined by the output_shape argument.
If output_shape is:
2 -> output_layer = [mu_unit, sigma_unit]
3 -> output_layer = [mu_unit, sigma_unit, gamma_unit]
4 -> output_layer = [mu_unit, sigma_unit, gamma_unit, tau_unit]
* Unlike most of EAB's models, the features are normalized within the
network. That is, the x_train, y_train, ... y_test should not be
externally normalized or scaled.
* In essence, the network is learning the shash parameters for the
normalized y values. Say mu_z and sigma_z where
z = (y - y_avg)/y_std
The mu_unit and sigma_unit layers rescale the learned mu_z
and sigma_z parameters back to the dimensions of the y values.
Specifically,
mu_y = y_std * mu_z + y_avg
sigma_y = y_std * sigma_z
However, since the model works with log(sigma) we must use
log(sigma_y) = log(y_std * sigma_z) = log(y_std) + log(sigma_z)
* Note the gamma and tau parameters of the shash distribution are
dimensionless by definition. So we do not need to rescale gamma
and tau.
"""
# set inputs
if len(hiddens) != len(ridge_penalty):
ridge_penalty = np.ones(np.shape(hiddens))*ridge_penalty
if len(hiddens) != len(dropout_rate):
dropout_rate = np.ones((len(hiddens)+1,))*dropout_rate
# The avg and std for feature normalization are computed from x_train.
# Using the .adapt method, these are set once and do not change, but
# the constants travel with the model.
inputs = tf.keras.Input(shape=x_train.shape[1:])
normalizer = tf.keras.layers.Normalization()
normalizer.adapt(x_train)
x = normalizer(inputs)
x = tf.keras.layers.Dropout(
rate=dropout_rate[0],
seed=rng_seed,
)(x)
# linear network only
if hiddens[0] == 0:
x = tf.keras.layers.Dense(
units=1,
activation="linear",
use_bias=True,
kernel_regularizer=regularizers.l1_l2(l1=0.00, l2=ridge_penalty[0]),
bias_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+0),
kernel_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+0),
)(x)
else:
# Initialize the first hidden layer.
x = tf.keras.layers.Dense(
units=hiddens[0],
activation=act_fun,
use_bias=True,
kernel_regularizer=regularizers.l1_l2(l1=0.00, l2=ridge_penalty[0]),
bias_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+0),
kernel_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+0),
)(x)
# Initialize the subsequent hidden layers.
for ilayer, layer_size in enumerate(hiddens[1:]):
x = tf.keras.layers.Dropout(
rate=dropout_rate[ilayer+1],
seed=rng_seed,
)(x)
x = tf.keras.layers.Dense(
units=layer_size,
activation=act_fun,
use_bias=True,
kernel_regularizer=regularizers.l1_l2(l1=0.00, l2=ridge_penalty[ilayer+1]),
bias_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+ilayer+1),
kernel_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+ilayer+1),
)(x)
# final dropout prior to output layer
x = tf.keras.layers.Dropout(
rate=dropout_rate[-1],
seed=rng_seed,
)(x)
# Compute the mean and standard deviation of the y_train data to rescale
# the mu and sigma parameters.
y_avg = np.mean(onehot_train[:, 0])
y_std = np.std(onehot_train[:, 0])
# mu_unit. The network predicts the scaled mu_z, then the resclaing
# layer scales it up to mu_y.
mu_z_unit = tf.keras.layers.Dense(
units=1,
activation="linear",
use_bias=True,
bias_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+100),
kernel_initializer=tf.keras.initializers.RandomNormal(seed=rng_seed+100),
name="mu_z_unit",
)(x)
mu_unit = tf.keras.layers.Rescaling(
scale=y_std,
offset=y_avg,
name="mu_unit",
)(mu_z_unit)
# sigma_unit. The network predicts the log of the scaled sigma_z, then
# the resclaing layer scales it up to log of sigma y, and the custom
# Exponentiate layer converts it to sigma_y.
log_sigma_z_unit = tf.keras.layers.Dense(
units=1,
activation="linear",
use_bias=True,
bias_initializer=tf.keras.initializers.Zeros(),
kernel_initializer=tf.keras.initializers.Zeros(),
name="log_sigma_z_unit",
)(x)
log_sigma_unit = tf.keras.layers.Rescaling(
scale=1.0,
offset=np.log(y_std),
name="log_sigma_unit",
)(log_sigma_z_unit)
sigma_unit = Exponentiate(
name="sigma_unit",
)(log_sigma_unit)
# Add gamma and tau units if requested.
if output_shape == 2:
output_layer = tf.keras.layers.concatenate([mu_unit, sigma_unit], axis=1)
else:
# gamma_unit. The network predicts the gamma directly.
gamma_unit = tf.keras.layers.Dense(
units=1,
activation="linear",
use_bias=True,
bias_initializer=tf.keras.initializers.Zeros(),
kernel_initializer=tf.keras.initializers.Zeros(),
name="gamma_unit",
)(x)
if output_shape == 3:
output_layer = tf.keras.layers.concatenate(
[mu_unit, sigma_unit, gamma_unit], axis=1
)
else:
# tau_unit. The network predicts the log of the tau, then
# the custom Exponentiate layer converts it to tau.
log_tau_unit = tf.keras.layers.Dense(
units=1,
activation="linear",
use_bias=True,
bias_initializer=tf.keras.initializers.Zeros(),
kernel_initializer=tf.keras.initializers.Zeros(),
name="log_tau_unit",
)(x)
tau_unit = Exponentiate(
name="tau_unit",
)(log_tau_unit)
if output_shape == 4:
output_layer = tf.keras.layers.concatenate(
[mu_unit, sigma_unit, gamma_unit, tau_unit], axis=1
)
else:
raise NotImplementedError
model = tf.keras.models.Model(inputs=inputs, outputs=output_layer)
return model
```
## Train the network
### Set parameters
```
# ------------ MODIFY ------------
# many of the parameters below are things that you can easily modify
settings = {
"filename": "nnfit_vlist_intensity_and_track_extended.dat",
"uncertainty_type": 'shash4', # OPTIONS: "shash2", "shash3", "shash4"
"leadtime": 72,
"basin": "EP|CP",
"target": "intensity",
"undersample": False,
"hiddens": [15, 10],
"dropout_rate": [0.,0.,0.],
"ridge_param": [0.0,0.0],
"learning_rate": 0.0001,
"momentum": 0.9,
"nesterov": True,
"batch_size": 64,
"rng_seed": 888,
"act_fun": "relu",
"n_epochs": 25_000,
"patience": 100,
"test_condition": (2018,),
"val_condition": "random",
"n_val": 256,
"n_train": "max",
}
```
### Get the data
```
import pickle
if IN_COLAB:
!pip install wget
import wget
filename = wget.download("https://raw.githubusercontent.com/eabarnes1010/course_ml_ats/main/data/EPCP72_data.pickle")
else:
filename = '../data/EPCP72_data.pickle'
with open(filename,'rb') as f:
data = pickle.load(f)
( data_summary,
x_train,
onehot_train,
x_val,
onehot_val,
x_test,
onehot_test,
df_train,
df_val,
df_test,
) = data
print('data is loaded')
if settings["uncertainty_type"]=="shash2":
onehot_train = onehot_train[:,0:2]
onehot_val = onehot_val[:,0:2]
onehot_test = onehot_test[:,0:2]
elif settings["uncertainty_type"]=="shash3":
print("SHASH3 is how the data was loaded. Changing nothing.")
elif settings["uncertainty_type"]=="shash4":
onehot_train = np.append(onehot_train,onehot_train[:,1:2],axis=1)
onehot_val = np.append(onehot_val,onehot_val[:,1:2],axis=1)
onehot_test = np.append(onehot_test,onehot_test[:,1:2],axis=1)
else:
raise NotImplementedError("No such uncertainty_type implemented here.")
print("onehot_train.shape = " + str(onehot_train.shape))
print("onehot_val.shape = " + str(onehot_val.shape))
print("onehot_test.shape = " + str(onehot_test.shape))
```
### Train
```
# define the callbacks
earlystoping_callback = tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
mode="min",
patience=settings["patience"],
restore_best_weights=True,
verbose=1,
)
training_callback = TrainingInstrumentation(
x_train,
onehot_train,
interval=50,
)
callbacks = [earlystoping_callback,
# training_callback, # uncomment if you want to see the training stats updated
]
# set network seed and train the model
NETWORK_SEED_LIST = [settings["rng_seed"]]
for network_seed in NETWORK_SEED_LIST:
tf.random.set_seed(network_seed) # This sets the global random seed.
# Make, compile, and train the model
tf.keras.backend.clear_session()
model = make_model(
settings,
x_train,
onehot_train,
model_compile=True,
)
model.summary()
# train the network
start_time = time.time()
history = model.fit(
x_train,
onehot_train,
validation_data=(x_val, onehot_val),
batch_size=settings["batch_size"],
epochs=settings["n_epochs"],
shuffle=True,
verbose=0,
callbacks=callbacks,
)
stop_time = time.time()
# Display the results, and save the model rum.
best_epoch = np.argmin(history.history["val_loss"])
fit_summary = {
"network_seed": network_seed,
"elapsed_time": stop_time - start_time,
"best_epoch": best_epoch,
"loss_train": history.history["loss"][best_epoch],
"loss_valid": history.history["val_loss"][best_epoch],
}
pprint.pprint(fit_summary, width=80)
plot_history(history, 'class example')
```
## Plot the predicted distributions
### Plotting functions
```
clr_shash = 'teal'
clr_bnn = 'orange'
clr_truth = 'dimgray'
### for white background...
plt.rc('text',usetex=False)
plt.rc('font',**{'family':'sans-serif','sans-serif':['Avant Garde']})
plt.rc('savefig',facecolor='white')
plt.rc('axes',facecolor='white')
plt.rc('axes',labelcolor='dimgrey')
plt.rc('axes',labelcolor='dimgrey')
plt.rc('xtick',color='dimgrey')
plt.rc('ytick',color='dimgrey')
def adjust_spines(ax, spines):
for loc, spine in ax.spines.items():
if loc in spines:
spine.set_position(('outward', 5))
else:
spine.set_color('none')
if 'left' in spines:
ax.yaxis.set_ticks_position('left')
else:
ax.yaxis.set_ticks([])
if 'bottom' in spines:
ax.xaxis.set_ticks_position('bottom')
else:
ax.xaxis.set_ticks([])
def plot_sample(ax, onehot_val, shash_incs, shash_cpd, sample=130):
plt.sca(ax)
if(shash_cpd.shape[0]<sample):
sample = shash_cpd.shape[0]-1
bins = np.arange(np.min(shash_incs),np.max(shash_incs)+2,2)
# results for SHASH
plt.plot(shash_incs,
shash_cpd[sample,:],
color=clr_shash,
linewidth=4,
label='SHASH',
)
# truth
plt.axvline(x=onehot_val[sample,0],color=clr_truth,linestyle='--', label='Actual / Label')
plt.legend()
ax = plt.gca()
xticks = ax.get_xticks()
yticks = np.around(ax.get_yticks(),3)
plt.xticks(xticks.astype(int),xticks.astype(int))
plt.yticks(yticks,yticks)
plt.title('Sample ' + str(sample),fontsize=16)
plt.xlabel('predicted deviation from consensus (knots)')
plt.ylabel('probability density function')
```
### Compute the predicted distributions
First we need to evaluate and create the PDFs for the predicted parameters - otherwise, we would just be plotting the predicted parameters of the SHASH.
```
x_eval = x_test
onehot_eval = onehot_test
shash_incs = np.arange(-160,161,1)
shash_cpd = np.zeros((np.shape(x_eval)[0],len(shash_incs)))
shash_med = np.zeros((np.shape(x_eval)[0],))
# loop through samples for shash calculation and get PDF for each sample
for j in tqdm(range(0,np.shape(shash_cpd)[0])):
mu_pred, sigma_pred, gamma_pred, tau_pred = params( x_eval[np.newaxis,j], model )
shash_cpd[j,:] = shash_prob(shash_incs, mu_pred, sigma_pred, gamma_pred, tau_pred)
shash_med[j] = shash_median(mu_pred,sigma_pred,gamma_pred,tau_pred)
```
### Make plots of multiple samples
```
rng = np.random.default_rng(999)
f, axs = plt.subplots(5, 3, figsize=(15*.85,20*.85))
axs = axs.flatten()
random_samples = rng.choice(np.arange(0,onehot_eval.shape[0]),len(axs),replace=False)
for isample, sample in enumerate(random_samples):
ax = axs[isample]
plot_sample(ax, onehot_eval, shash_incs, shash_cpd, sample=sample)
ax.set_xticks(ticks=np.arange(-200,200,20),minor=False)
ax.set_xticklabels(np.arange(-200,200,20))
ax.set_xlim(-75,75)
ax.legend(fontsize=8)
ax.set_ylim(-0.0005,None)
plt.tight_layout()
plt.show()
```
| github_jupyter |
##### Copyright 2020 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Pandas DataFrame to Fairness Indicators Case Study
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/responsible_ai/fairness_indicators/tutorials/Fairness_Indicators_Pandas_Case_Study"><img src="https://www.tensorflow.org/images/tf_logo_32px.png" />View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/fairness-indicators/blob/master/g3doc/tutorials/Fairness_Indicators_Pandas_Case_Study.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/fairness-indicators/tree/master/g3doc/tutorials/Fairness_Indicators_Pandas_Case_Study.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/fairness-indicators/g3doc/tutorials/Fairness_Indicators_Pandas_Case_Study.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Download notebook</a>
</td>
</table>
## Case Study Overview
In this case study we will apply [TensorFlow Model Analysis](https://www.tensorflow.org/tfx/model_analysis/get_started) and [Fairness Indicators](https://www.tensorflow.org/tfx/guide/fairness_indicators) to evaluate data stored as a Pandas DataFrame, where each row contains ground truth labels, various features, and a model prediction. We will show how this workflow can be used to spot potential fairness concerns, independent of the framework one used to construct and train the model. As in this case study, we can analyze the results from any machine learning framework (e.g. TensorFlow, JAX, etc) once they are converted to a Pandas DataFrame.
For this exercise, we will leverage the Deep Neural Network (DNN) model that was developed in the [Shape Constraints for Ethics with Tensorflow Lattice](https://colab.research.google.com/github/tensorflow/lattice/blob/master/docs/tutorials/shape_constraints_for_ethics.ipynb#scrollTo=uc0VwsT5nvQi) case study using the Law School Admissions dataset from the Law School Admissions Council (LSAC). This classifier attempts to predict whether or not a student will pass the bar, based on their Law School Admission Test (LSAT) score and undergraduate GPA. This classifier attempts to predict whether or not a student will pass the bar, based on their LSAT score and undergraduate GPA.
## LSAC Dataset
The dataset used within this case study was originally collected for a study called '[LSAC National Longitudinal Bar Passage Study. LSAC Research Report Series](https://eric.ed.gov/?id=ED469370)' by Linda Wightman in 1998. The dataset is currently hosted [here](http://www.seaphe.org/databases.php).
* **dnn_bar_pass_prediction**: The LSAT prediction from the DNN model.
* **gender**: Gender of the student.
* **lsat**: LSAT score received by the student.
* **pass_bar**: Ground truth label indicating whether or not the student eventually passed the bar.
* **race**: Race of the student.
* **ugpa**: A student's undergraduate GPA.
```
!pip install -q -U pip==20.2
!pip install -q -U \
tensorflow-model-analysis==0.29.0 \
tensorflow-data-validation==0.29.0 \
tfx-bsl==0.29.0
```
## Importing required packages:
```
import os
import tempfile
import pandas as pd
import six.moves.urllib as urllib
import pprint
import tensorflow_model_analysis as tfma
from google.protobuf import text_format
import tensorflow as tf
tf.compat.v1.enable_v2_behavior()
```
## Download the data and explore the initial dataset.
```
# Download the LSAT dataset and setup the required filepaths.
_DATA_ROOT = tempfile.mkdtemp(prefix='lsat-data')
_DATA_PATH = 'https://storage.googleapis.com/lawschool_dataset/bar_pass_prediction.csv'
_DATA_FILEPATH = os.path.join(_DATA_ROOT, 'bar_pass_prediction.csv')
data = urllib.request.urlopen(_DATA_PATH)
_LSAT_DF = pd.read_csv(data)
# To simpliy the case study, we will only use the columns that will be used for
# our model.
_COLUMN_NAMES = [
'dnn_bar_pass_prediction',
'gender',
'lsat',
'pass_bar',
'race1',
'ugpa',
]
_LSAT_DF.dropna()
_LSAT_DF['gender'] = _LSAT_DF['gender'].astype(str)
_LSAT_DF['race1'] = _LSAT_DF['race1'].astype(str)
_LSAT_DF = _LSAT_DF[_COLUMN_NAMES]
_LSAT_DF.head()
```
## Configure Fairness Indicators.
There are several parameters that you’ll need to take into account when using Fairness Indicators with a DataFrame
* Your input DataFrame must contain a prediction column and label column from your model. By default Fairness Indicators will look for a prediction column called `prediction` and a label column called `label` within your DataFrame.
* If either of these values are not found a KeyError will be raised.
* In addition to a DataFrame, you’ll also need to include an `eval_config` that should include the metrics to compute, slices to compute the metrics on, and the column names for example labels and predictions.
* `metrics_specs` will set the metrics to compute. The `FairnessIndicators` metric will be required to render the fairness metrics and you can see a list of additional optional metrics [here](https://www.tensorflow.org/tfx/model_analysis/metrics).
* `slicing_specs` is an optional slicing parameter to specify what feature you’re interested in investigating. Within this case study race1 is used, however you can also set this value to another feature (for example gender in the context of this DataFrame). If `slicing_specs` is not provided all features will be included.
* If your DataFrame includes a label or prediction column that is different from the default `prediction` or `label`, you can configure the `label_key` and `prediction_key` to a new value.
* If `output_path` is not specified a temporary directory will be created.
```
# Specify Fairness Indicators in eval_config.
eval_config = text_format.Parse("""
model_specs {
prediction_key: 'dnn_bar_pass_prediction',
label_key: 'pass_bar'
}
metrics_specs {
metrics {class_name: "AUC"}
metrics {
class_name: "FairnessIndicators"
config: '{"thresholds": [0.50, 0.90]}'
}
}
slicing_specs {
feature_keys: 'race1'
}
slicing_specs {}
""", tfma.EvalConfig())
# Run TensorFlow Model Analysis.
eval_result = tfma.analyze_raw_data(
data=_LSAT_DF,
eval_config=eval_config,
output_path=_DATA_ROOT)
```
## Explore model performance with Fairness Indicators.
After running Fairness Indicators, we can visualize different metrics that we selected to analyze our models performance. Within this case study we’ve included Fairness Indicators and arbitrarily picked AUC.
When we first look at the overall AUC for each race slice we can see a slight discrepancy in model performance, but nothing that is arguably alarming.
* **Asian**: 0.58
* **Black**: 0.58
* **Hispanic**: 0.58
* **Other**: 0.64
* **White**: 0.6
However, when we look at the false negative rates split by race, our model again incorrectly predicts the likelihood of a user passing the bar at different rates and, this time, does so by a lot.
* **Asian**: 0.01
* **Black**: 0.05
* **Hispanic**: 0.02
* **Other**: 0.01
* **White**: 0.01
Most notably the difference between Black and White students is about 380%, meaning that our model is nearly 4x more likely to incorrectly predict that a black student will not pass the bar, than a whilte student. If we were to continue with this effort, a practitioner could use these results as a signal that they should spend more time ensuring that their model works well for people from all backgrounds.
```
# Render Fairness Indicators.
tfma.addons.fairness.view.widget_view.render_fairness_indicator(eval_result)
```
# tfma.EvalResult
The [`eval_result`](https://www.tensorflow.org/tfx/model_analysis/api_docs/python/tfma/EvalResult) object, rendered above in `render_fairness_indicator()`, has its own API that can be used to read TFMA results into your programs.
## [`get_slice_names()`](https://www.tensorflow.org/tfx/model_analysis/api_docs/python/tfma/EvalResult#get_slice_names) and [`get_metric_names()`](https://www.tensorflow.org/tfx/model_analysis/api_docs/python/tfma/EvalResult#get_metric_names)
To get the evaluated slices and metrics, you can use the respective functions.
```
pp = pprint.PrettyPrinter()
print("Slices:")
pp.pprint(eval_result.get_slice_names())
print("\nMetrics:")
pp.pprint(eval_result.get_metric_names())
```
## [`get_metrics_for_slice()`](https://www.tensorflow.org/tfx/model_analysis/api_docs/python/tfma/EvalResult#get_metrics_for_slice) and [`get_metrics_for_all_slices()`](https://www.tensorflow.org/tfx/model_analysis/api_docs/python/tfma/EvalResult#get_metrics_for_all_slices)
If you want to get the metrics for a particular slice, you can use `get_metrics_for_slice()`. It returns a dictionary mapping metric names to [metric values](https://github.com/tensorflow/model-analysis/blob/cdb6790dcd7a37c82afb493859b3ef4898963fee/tensorflow_model_analysis/proto/metrics_for_slice.proto#L194).
```
baseline_slice = ()
black_slice = (('race1', 'black'),)
print("Baseline metric values:")
pp.pprint(eval_result.get_metrics_for_slice(baseline_slice))
print("Black metric values:")
pp.pprint(eval_result.get_metrics_for_slice(black_slice))
```
If you want to get the metrics for all slices, `get_metrics_for_all_slices()` returns a dictionary mapping each slice to the corresponding `get_metrics_for_slices(slice)`.
```
pp.pprint(eval_result.get_metrics_for_all_slices())
```
## Conclusion
Within this case study we imported a dataset into a Pandas DataFrame that we then analyzed with Fairness Indicators. Understanding the results of your model and underlying data is an important step in ensuring your model doesn't reflect harmful bias. In the context of this case study we examined the the LSAC dataset and how predictions from this data could be impacted by a students race. The concept of “what is unfair and what is fair have been introduced in multiple disciplines for well over 50 years, including in education, hiring, and machine learning.”<sup>1</sup> Fairness Indicator is a tool to help mitigate fairness concerns in your machine learning model.
For more information on using Fairness Indicators and resources to learn more about fairness concerns see [here](https://www.tensorflow.org/responsible_ai/fairness_indicators/guide).
---
1. Hutchinson, B., Mitchell, M. (2018). 50 Years of Test (Un)fairness: Lessons for Machine Learning. https://arxiv.org/abs/1811.10104
## Appendix
Below are a few functions to help convert ML models to Pandas DataFrame.
```
# TensorFlow Estimator to Pandas DataFrame:
# _X_VALUE = # X value of binary estimator.
# _Y_VALUE = # Y value of binary estimator.
# _GROUND_TRUTH_LABEL = # Ground truth value of binary estimator.
def _get_predicted_probabilities(estimator, input_df, get_input_fn):
predictions = estimator.predict(
input_fn=get_input_fn(input_df=input_df, num_epochs=1))
return [prediction['probabilities'][1] for prediction in predictions]
def _get_input_fn_law(input_df, num_epochs, batch_size=None):
return tf.compat.v1.estimator.inputs.pandas_input_fn(
x=input_df[[_X_VALUE, _Y_VALUE]],
y=input_df[_GROUND_TRUTH_LABEL],
num_epochs=num_epochs,
batch_size=batch_size or len(input_df),
shuffle=False)
def estimator_to_dataframe(estimator, input_df, num_keypoints=20):
x = np.linspace(min(input_df[_X_VALUE]), max(input_df[_X_VALUE]), num_keypoints)
y = np.linspace(min(input_df[_Y_VALUE]), max(input_df[_Y_VALUE]), num_keypoints)
x_grid, y_grid = np.meshgrid(x, y)
positions = np.vstack([x_grid.ravel(), y_grid.ravel()])
plot_df = pd.DataFrame(positions.T, columns=[_X_VALUE, _Y_VALUE])
plot_df[_GROUND_TRUTH_LABEL] = np.ones(len(plot_df))
predictions = _get_predicted_probabilities(
estimator=estimator, input_df=plot_df, get_input_fn=_get_input_fn_law)
return pd.DataFrame(
data=np.array(np.reshape(predictions, x_grid.shape)).flatten())
```
| github_jupyter |
# Lab: TfTransform #
**Learning Objectives**
1. Preprocess data and engineer new features using TfTransform
1. Create and deploy Apache Beam pipeline
1. Use processed data to train taxifare model locally then serve a prediction
## Introduction
While Pandas is fine for experimenting, for operationalization of your workflow it is better to do preprocessing in Apache Beam. This will also help if you need to preprocess data in flight, since Apache Beam allows for streaming. In this lab we will pull data from BigQuery then use Apache Beam TfTransform to process the data.
Only specific combinations of TensorFlow/Beam are supported by tf.transform so make sure to get a combo that works. In this lab we will be using:
* TFT 0.24.0
* TF 2.3.0
* Apache Beam [GCP] 2.24.0
Each learning objective will correspond to a __#TODO__ in the notebook where you will complete the notebook cell's code before running. Refer to the [solution notebook](https://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/courses/machine_learning/deepdive2/feature_engineering/solutions/5_tftransform_taxifare.ipynb) for reference.
```
!sudo chown -R jupyter:jupyter /home/jupyter/training-data-analyst
!pip install tensorflow==2.3.0 tensorflow-transform==0.24.0 apache-beam[gcp]==2.24.0
```
**NOTE**: You may ignore specific incompatibility errors and warnings. These components and issues do not impact your ability to complete the lab.
Download .whl file for tensorflow-transform. We will pass this file to Beam Pipeline Options so it is installed on the DataFlow workers
```
!pip install --user google-cloud-bigquery==1.25.0
!pip download tensorflow-transform==0.24.0 --no-deps
```
<b>Restart the kernel</b> (click on the reload button above).
```
%%bash
pip freeze | grep -e 'flow\|beam'
import tensorflow as tf
import tensorflow_transform as tft
import shutil
print(tf.__version__)
# change these to try this notebook out
BUCKET = 'bucket-name'
PROJECT = 'project-id'
REGION = 'us-central1'
import os
os.environ['BUCKET'] = BUCKET
os.environ['PROJECT'] = PROJECT
os.environ['REGION'] = REGION
%%bash
gcloud config set project $PROJECT
gcloud config set compute/region $REGION
%%bash
if ! gsutil ls | grep -q gs://${BUCKET}/; then
gsutil mb -l ${REGION} gs://${BUCKET}
fi
```
## Input source: BigQuery
Get data from BigQuery but defer the majority of filtering etc. to Beam.
Note that the dayofweek column is now strings.
```
from google.cloud import bigquery
def create_query(phase, EVERY_N):
"""Creates a query with the proper splits.
Args:
phase: int, 1=train, 2=valid.
EVERY_N: int, take an example EVERY_N rows.
Returns:
Query string with the proper splits.
"""
base_query = """
WITH daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek)
SELECT
(tolls_amount + fare_amount) AS fare_amount,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers,
'notneeded' AS key
FROM
`nyc-tlc.yellow.trips`, daynames
WHERE
trip_distance > 0 AND fare_amount > 0
"""
if EVERY_N is None:
if phase < 2:
# training
query = """{0} AND ABS(MOD(FARM_FINGERPRINT(CAST
(pickup_datetime AS STRING), 4)) < 2""".format(base_query)
else:
query = """{0} AND ABS(MOD(FARM_FINGERPRINT(CAST(
pickup_datetime AS STRING), 4)) = {1}""".format(base_query, phase)
else:
query = """{0} AND ABS(MOD(FARM_FINGERPRINT(CAST(
pickup_datetime AS STRING)), {1})) = {2}""".format(
base_query, EVERY_N, phase)
return query
query = create_query(2, 100000)
df_valid = bigquery.Client().query(query).to_dataframe()
display(df_valid.head())
df_valid.describe()
```
## Create ML dataset using tf.transform and Dataflow
Let's use Cloud Dataflow to read in the BigQuery data and write it out as TFRecord files. Along the way, let's use tf.transform to do scaling and transforming. Using tf.transform allows us to save the metadata to ensure that the appropriate transformations get carried out during prediction as well.
`transformed_data` is type `pcollection`.
5 __TODO's__ in the following cell block
1. Convert day of week from string->int with `tft.string_to_int`
1. Scale `pickuplat`, `pickuplon`, `dropofflat`, `dropofflon` between 0 and 1 with `tft.scale_to_0_1`
1. Scale our engineered features `latdiff` and `londiff` between 0 and 1
1. Analyze and transform our training data using `beam_impl.AnalyzeAndTransformDataset()`
1. Read eval data from BigQuery using `beam.io.BigQuerySource` and filter rows using our `is_valid` function
```
import datetime
import tensorflow as tf
import apache_beam as beam
import tensorflow_transform as tft
import tensorflow_metadata as tfmd
from tensorflow_transform.beam import impl as beam_impl
def is_valid(inputs):
"""Check to make sure the inputs are valid.
Args:
inputs: dict, dictionary of TableRow data from BigQuery.
Returns:
True if the inputs are valid and False if they are not.
"""
try:
pickup_longitude = inputs['pickuplon']
dropoff_longitude = inputs['dropofflon']
pickup_latitude = inputs['pickuplat']
dropoff_latitude = inputs['dropofflat']
hourofday = inputs['hourofday']
dayofweek = inputs['dayofweek']
passenger_count = inputs['passengers']
fare_amount = inputs['fare_amount']
return fare_amount >= 2.5 and pickup_longitude > -78 \
and pickup_longitude < -70 and dropoff_longitude > -78 \
and dropoff_longitude < -70 and pickup_latitude > 37 \
and pickup_latitude < 45 and dropoff_latitude > 37 \
and dropoff_latitude < 45 and passenger_count > 0
except:
return False
def preprocess_tft(inputs):
"""Preprocess the features and add engineered features with tf transform.
Args:
dict, dictionary of TableRow data from BigQuery.
Returns:
Dictionary of preprocessed data after scaling and feature engineering.
"""
import datetime
print(inputs)
result = {}
result['fare_amount'] = tf.identity(inputs['fare_amount'])
# Build a vocabulary
# TODO 1: convert day of week from string->int with tft.string_to_int
result['hourofday'] = tf.identity(inputs['hourofday']) # pass through
# TODO 2: scale pickup/dropoff lat/lon between 0 and 1 with tft.scale_to_0_1
result['passengers'] = tf.cast(inputs['passengers'], tf.float32) # a cast
# Arbitrary TF func
result['key'] = tf.as_string(tf.ones_like(inputs['passengers']))
# Engineered features
latdiff = inputs['pickuplat'] - inputs['dropofflat']
londiff = inputs['pickuplon'] - inputs['dropofflon']
# TODO 3: Scale our engineered features latdiff and londiff between 0 and 1
dist = tf.sqrt(latdiff * latdiff + londiff * londiff)
result['euclidean'] = tft.scale_to_0_1(dist)
return result
def preprocess(in_test_mode):
"""Sets up preprocess pipeline.
Args:
in_test_mode: bool, False to launch DataFlow job, True to run locally.
"""
import os
import os.path
import tempfile
from apache_beam.io import tfrecordio
from tensorflow_transform.coders import example_proto_coder
from tensorflow_transform.tf_metadata import dataset_metadata
from tensorflow_transform.tf_metadata import dataset_schema
from tensorflow_transform.beam import tft_beam_io
from tensorflow_transform.beam.tft_beam_io import transform_fn_io
job_name = 'preprocess-taxi-features' + '-'
job_name += datetime.datetime.now().strftime('%y%m%d-%H%M%S')
if in_test_mode:
import shutil
print('Launching local job ... hang on')
OUTPUT_DIR = './preproc_tft'
shutil.rmtree(OUTPUT_DIR, ignore_errors=True)
EVERY_N = 100000
else:
print('Launching Dataflow job {} ... hang on'.format(job_name))
OUTPUT_DIR = 'gs://{0}/taxifare/preproc_tft/'.format(BUCKET)
import subprocess
subprocess.call('gsutil rm -r {}'.format(OUTPUT_DIR).split())
EVERY_N = 10000
options = {
'staging_location': os.path.join(OUTPUT_DIR, 'tmp', 'staging'),
'temp_location': os.path.join(OUTPUT_DIR, 'tmp'),
'job_name': job_name,
'project': PROJECT,
'num_workers': 1,
'max_num_workers': 1,
'teardown_policy': 'TEARDOWN_ALWAYS',
'no_save_main_session': True,
'direct_num_workers': 1,
'extra_packages': ['tensorflow_transform-0.24.0-py3-none-any.whl']
}
opts = beam.pipeline.PipelineOptions(flags=[], **options)
if in_test_mode:
RUNNER = 'DirectRunner'
else:
RUNNER = 'DataflowRunner'
# Set up raw data metadata
raw_data_schema = {
colname: dataset_schema.ColumnSchema(
tf.string, [], dataset_schema.FixedColumnRepresentation())
for colname in 'dayofweek,key'.split(',')
}
raw_data_schema.update({
colname: dataset_schema.ColumnSchema(
tf.float32, [], dataset_schema.FixedColumnRepresentation())
for colname in
'fare_amount,pickuplon,pickuplat,dropofflon,dropofflat'.split(',')
})
raw_data_schema.update({
colname: dataset_schema.ColumnSchema(
tf.int64, [], dataset_schema.FixedColumnRepresentation())
for colname in 'hourofday,passengers'.split(',')
})
raw_data_metadata = dataset_metadata.DatasetMetadata(
dataset_schema.Schema(raw_data_schema))
# Run Beam
with beam.Pipeline(RUNNER, options=opts) as p:
with beam_impl.Context(temp_dir=os.path.join(OUTPUT_DIR, 'tmp')):
# Save the raw data metadata
(raw_data_metadata |
'WriteInputMetadata' >> tft_beam_io.WriteMetadata(
os.path.join(
OUTPUT_DIR, 'metadata/rawdata_metadata'), pipeline=p))
# TODO 4: Analyze and transform our training data
# using beam_impl.AnalyzeAndTransformDataset()
raw_dataset = (raw_data, raw_data_metadata)
# Analyze and transform training data
transformed_dataset, transform_fn = (
raw_dataset | beam_impl.AnalyzeAndTransformDataset(
preprocess_tft))
transformed_data, transformed_metadata = transformed_dataset
# Save transformed train data to disk in efficient tfrecord format
transformed_data | 'WriteTrainData' >> tfrecordio.WriteToTFRecord(
os.path.join(OUTPUT_DIR, 'train'), file_name_suffix='.gz',
coder=example_proto_coder.ExampleProtoCoder(
transformed_metadata.schema))
# TODO 5: Read eval data from BigQuery using beam.io.BigQuerySource
# and filter rows using our is_valid function
raw_test_dataset = (raw_test_data, raw_data_metadata)
# Transform eval data
transformed_test_dataset = (
(raw_test_dataset, transform_fn) | beam_impl.TransformDataset()
)
transformed_test_data, _ = transformed_test_dataset
# Save transformed train data to disk in efficient tfrecord format
(transformed_test_data |
'WriteTestData' >> tfrecordio.WriteToTFRecord(
os.path.join(OUTPUT_DIR, 'eval'), file_name_suffix='.gz',
coder=example_proto_coder.ExampleProtoCoder(
transformed_metadata.schema)))
# Save transformation function to disk for use at serving time
(transform_fn |
'WriteTransformFn' >> transform_fn_io.WriteTransformFn(
os.path.join(OUTPUT_DIR, 'metadata')))
# Change to True to run locally
preprocess(in_test_mode=False)
```
This will take __10-15 minutes__. You cannot go on in this lab until your DataFlow job has successfully completed.
**Note**: The above command may fail with an error **`Workflow failed. Causes: There was a problem refreshing your credentials`**. In that case, `re-run` the command again.
Let's check to make sure that there is data where we expect it to be now.
```
%%bash
# ls preproc_tft
gsutil ls gs://${BUCKET}/taxifare/preproc_tft/
```
## Train off preprocessed data ##
Now that we have our data ready and verified it is in the correct location we can train our taxifare model locally.
```
%%bash
rm -r ./taxi_trained
export PYTHONPATH=${PYTHONPATH}:$PWD
python3 -m tft_trainer.task \
--train_data_path="gs://${BUCKET}/taxifare/preproc_tft/train*" \
--eval_data_path="gs://${BUCKET}/taxifare/preproc_tft/eval*" \
--output_dir=./taxi_trained \
!ls $PWD/taxi_trained/export/exporter
```
Now let's create fake data in JSON format and use it to serve a prediction with gcloud ai-platform local predict
```
%%writefile /tmp/test.json
{"dayofweek":0, "hourofday":17, "pickuplon": -73.885262, "pickuplat": 40.773008, "dropofflon": -73.987232, "dropofflat": 40.732403, "passengers": 2.0}
%%bash
sudo find "/usr/lib/google-cloud-sdk/lib/googlecloudsdk/command_lib/ml_engine" -name '*.pyc' -delete
%%bash
model_dir=$(ls $PWD/taxi_trained/export/exporter/)
gcloud ai-platform local predict \
--model-dir=./taxi_trained/export/exporter/${model_dir} \
--json-instances=/tmp/test.json
```
Copyright 2021 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
| github_jupyter |
# <img style="float: left; padding-right: 10px; width: 45px" src="https://raw.githubusercontent.com/Harvard-IACS/2018-CS109A/master/content/styles/iacs.png"> CS109A Introduction to Data Science
## Lecture 1: Example part 2
**Harvard University**<br/>
**Fall 2020**<br/>
**Instructors**: Pavlos Protopapas, Kevin Rader, and Chris Tanner
```
import sys
import datetime
import numpy as np
import scipy as sp
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from math import radians, cos, sin, asin, sqrt
from sklearn.linear_model import LinearRegression
sns.set(style="ticks")
%matplotlib inline
import os
DATA_HOME = os.getcwd()
if 'ED_USER_NAME' in os.environ:
DATA_HOME = '/course/data'
HUBWAY_STATIONS_FILE = os.path.join(DATA_HOME, 'hubway_stations.csv')
HUBWAY_TRIPS_FILE = os.path.join(DATA_HOME, 'hubway_trips_sample.csv')
hubway_data = pd.read_csv(HUBWAY_TRIPS_FILE, index_col=0, low_memory=False)
hubway_data.head()
```
# Who? Who's using the bikes?
Refine into specific hypotheses:
- More men or more women?
- Older or younger people?
- Subscribers or one time users?
```
# Let's do some cleaning first by removing empty cells or replacing them with NaN.
# Pandas can do this.
# we will learn a lot about pandas
hubway_data['gender'] = hubway_data['gender'].replace(np.nan, 'NaN', regex=True).values
# we drop
hubway_data['birth_date'].dropna()
age_col = 2020.0 - hubway_data['birth_date'].values
# matplotlib can create a plot with two sub-plots.
# we will learn a lot about matplotlib
fig, ax = plt.subplots(1, 2, figsize=(15, 6))
# find all the unique value of the column gender
# numpy can do this
# we will learn a lot about numpy
gender_counts = np.unique(hubway_data['gender'].values, return_counts=True)
ax[0].bar(range(3), gender_counts[1], align='center', color=['black', 'green', 'teal'], alpha=0.5)
ax[0].set_xticks([0, 1, 2])
ax[0].set_xticklabels(['none', 'male', 'female'])
ax[0].set_title('Users by Gender')
age_col = 2020.0 - hubway_data['birth_date'].dropna().values
age_counts = np.unique(age_col, return_counts=True)
ax[1].bar(age_counts[0], age_counts[1], align='center', width=0.4, alpha=0.6)
ax[1].axvline(x=np.mean(age_col), color='red', label='average age')
ax[1].axvline(x=np.percentile(age_col, 25), color='red', linestyle='--', label='lower quartile')
ax[1].axvline(x=np.percentile(age_col, 75), color='red', linestyle='--', label='upper quartile')
ax[1].set_xlim([1, 90])
ax[1].set_xlabel('Age')
ax[1].set_ylabel('Number of Checkouts')
ax[1].legend()
ax[1].set_title('Users by Age')
plt.tight_layout()
plt.savefig('who.png', dpi=300)
```
### Challenge
There is actually a mistake in the code above. Can you find it?
Soon you will be skillful enough to answers many "who" questions
# Where? Where are bikes being checked out?
Refine into specific hypotheses:
1. More in Boston than Cambridge?
2. More in commercial or residential?
3. More around tourist attractions?
```
# using pandas again to read the station locations
station_data = pd.read_csv(HUBWAY_STATIONS_FILE, low_memory=False)[['id', 'lat', 'lng']]
station_data.head()
# Sometimes the data is given to you in pieces and must be merged!
# we want to combine the trips data with the station locations. pandas to the rescue...
hubway_data_with_gps = hubway_data.join(station_data.set_index('id'), on='strt_statn')
hubway_data_with_gps.head()
```
# <img style="width: 100%" alt="Heatmap" src="https://static.us.edusercontent.com/files/mRGDd7ddzN03xvXp4FZyKEc2">
OK - we cheated above and we skip some of the code which generated this plot.
# When? When are the bikes being checked out?
Refine into specific hypotheses:
1. More during the weekend than on the weekdays?
2. More during rush hour?
3. More during the summer than the fall?
```
# Sometimes the feature you want to explore doesn’t exist in the data, and must be engineered!
# to find the time of the day we will use the start_date column and extrat the hours.
# we use list comprehension
# we will be doing a lot of those
check_out_hours = hubway_data['start_date'].apply(lambda s: int(s[-8:-6]))
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
check_out_counts = np.unique(check_out_hours, return_counts=True)
ax.bar(check_out_counts[0], check_out_counts[1], align='center', width=0.4, alpha=0.6)
ax.set_xlim([-1, 24])
ax.set_xticks(range(24))
ax.set_xlabel('Hour of Day')
ax.set_ylabel('Number of Checkouts')
ax.set_title('Time of Day vs Checkouts')
plt.show()
```
# Why? For what reasons/activities are people checking out bikes?
Refine into specific hypotheses:
1. More bikes are used for recreation than commute?
2. More bikes are used for touristic purposes?
3. Bikes are use to bypass traffic?
Do we have the data to answer these questions with reasonable certainty?
What data do we need to collect in order to answer these questions?
# How? Questions that combine variables.
1. How does user demographics impact the duration the bikes are being used? Or where they are being checked out?
2. How does weather or traffic conditions impact bike usage?
3. How do the characteristics of the station location affect the number of bikes being checked out?
How questions are about modeling relationships between different variables.
```
# Here we define the distance from a point as a python function.
# We set Boston city center long and lat to be the default value.
# you will become experts in building functions and using functions just like this
def haversine(pt, lat2=42.355589, lon2=-71.060175):
"""
Calculate the great circle distance between two points
on the earth (specified in decimal degrees)
"""
lon1 = pt[0]
lat1 = pt[1]
# convert decimal degrees to radians
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
# haversine formula
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat/2)**2 + cos(lat1) * cos(lat2) * sin(dlon/2)**2
c = 2 * asin(sqrt(a))
r = 3956 # Radius of earth in miles
return c * r
# use only the checkouts that we have gps location
station_counts = np.unique(hubway_data_with_gps['strt_statn'].dropna(), return_counts=True)
counts_df = pd.DataFrame({'id':station_counts[0], 'checkouts':station_counts[1]})
counts_df = counts_df.join(station_data.set_index('id'), on='id')
counts_df.head()
# add to the pandas dataframe the distance using the function we defined above and using map
counts_df.loc[:, 'dist_to_center'] = list(map(haversine, counts_df[['lng', 'lat']].values))
counts_df.head()
# we will use sklearn to fit a linear regression model
# we will learn a lot about modeling and using sklearn
reg_line = LinearRegression()
reg_line.fit(counts_df['dist_to_center'].values.reshape((len(counts_df['dist_to_center']), 1)), counts_df['checkouts'].values)
# use the fitted model to predict
distances = np.linspace(counts_df['dist_to_center'].min(), counts_df['dist_to_center'].max(), 50)
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
ax.scatter(counts_df['dist_to_center'].values, counts_df['checkouts'].values, label='data')
ax.plot(distances, reg_line.predict(distances.reshape((len(distances), 1))), color='red', label='Regression Line')
ax.set_xlabel('Distance to City Center (Miles)')
ax.set_ylabel('Number of Checkouts')
ax.set_title('Distance to City Center vs Checkouts')
ax.legend()
```
# <font color='blue'> Notice all axis are labeled, we used legends and titles when necessary. Also notice we commented our code. </font>
```
```
| github_jupyter |
# Report for choldgraf
```
import seaborn as sns
import pandas as pd
import numpy as np
import altair as alt
from markdown import markdown
from IPython.display import Markdown
from ipywidgets.widgets import HTML, Tab
from ipywidgets import widgets
from datetime import timedelta
from matplotlib import pyplot as plt
import os.path as op
from mycode import alt_theme
from warnings import simplefilter
simplefilter('ignore')
def author_url(author):
return f"https://github.com/{author}"
# Parameters
fmt_date = "{:%Y-%m-%d}"
n_days = 30 * 2
start_date = fmt_date.format(pd.datetime.today() - timedelta(days=n_days))
end_date = fmt_date.format(pd.datetime.today())
renderer = "html"
person = "jasongrout"
# Parameters
person = "choldgraf"
n_days = 90
alt.renderers.enable(renderer);
alt.themes.register('my_theme', alt_theme)
alt.themes.enable("my_theme")
```
## Load data
```
from pathlib import Path
path_data = Path("./")
comments = pd.read_csv(path_data.joinpath('../data/comments.csv'), index_col=0)
issues = pd.read_csv(path_data.joinpath('../data/issues.csv'), index_col=0)
prs = pd.read_csv(path_data.joinpath('../data/prs.csv'), index_col=0)
comments = comments.query('author == @person').drop_duplicates()
issues = issues.query('author == @person').drop_duplicates()
closed_by = prs.query('mergedBy == @person')
prs = prs.query('author == @person').drop_duplicates()
# Time columns
# Also drop dates outside of our range
time_columns = ['updatedAt', 'createdAt', 'closedAt']
for col in time_columns:
for item in [comments, issues, prs, closed_by]:
if col not in item.columns:
continue
dt = pd.to_datetime(item[col]).dt.tz_localize(None)
item[col] = dt
item.query("updatedAt < @end_date and updatedAt > @start_date", inplace=True)
```
## Repository summaries
```
summaries = []
for idata, name in [(issues, 'issues'), (prs, 'prs'), (comments, 'comments')]:
idata = idata.groupby(["repo", "org"]).agg({'id': "count"}).reset_index().rename(columns={'id': 'count'})
idata["kind"] = name
summaries.append(idata)
summaries = pd.concat(summaries)
repo_summaries = summaries.groupby(["repo", "kind"]).agg({"count": "sum"}).reset_index()
org_summaries = summaries.groupby(["org", "kind"]).agg({"count": "sum"}).reset_index()
repo_summaries['logcount'] = np.log(repo_summaries["count"])
ch1 = alt.Chart(repo_summaries, width=600, title="Activity per repository").mark_bar().encode(
x='repo',
y='count',
color='kind',
tooltip="kind"
)
ch2 = alt.Chart(repo_summaries, width=600, title="Log activity per repository").mark_bar().encode(
x='repo',
y='logcount',
color='kind',
tooltip="kind"
)
ch1 | ch2
alt.Chart(org_summaries, width=600).mark_bar().encode(
x='org',
y='count',
color='kind',
tooltip="org"
)
```
## By repository over time
### Comments
```
comments_time = comments.groupby('repo').resample('W', on='createdAt').count()['author'].reset_index()
comments_time = comments_time.rename(columns={'author': 'count'})
comments_time_total = comments_time.groupby('createdAt').agg({"count": "sum"}).reset_index()
ch1 = alt.Chart(comments_time, width=600).mark_line().encode(
x='createdAt',
y='count',
color='repo',
tooltip="repo"
)
ch2 = alt.Chart(comments_time_total, width=600).mark_line(color="black").encode(
x='createdAt',
y='count',
)
ch1 + ch2
```
### PRs
```
prs_time = prs.groupby('repo').resample('W', on='createdAt').count()['author'].reset_index()
prs_time = prs_time.rename(columns={'author': 'count'})
prs_time_total = prs_time.groupby('createdAt').agg({"count": "sum"}).reset_index()
ch1 = alt.Chart(prs_time, width=600).mark_line().encode(
x='createdAt',
y='count',
color='repo',
tooltip="repo"
)
ch2 = alt.Chart(prs_time_total, width=600).mark_line(color="black").encode(
x='createdAt',
y='count',
)
ch1 + ch2
closed_by_time = closed_by.groupby('repo').resample('W', on='closedAt').count()['author'].reset_index()
closed_by_time = closed_by_time.rename(columns={'author': 'count'})
alt.Chart(closed_by_time, width=600).mark_line().encode(
x='closedAt',
y='count',
color='repo',
tooltip="repo"
)
```
## By type over time
```
prs_time = prs[['author', 'createdAt']].resample('W', on='createdAt').count()['author'].reset_index()
prs_time = prs_time.rename(columns={'author': 'prs'})
comments_time = comments[['author', 'createdAt']].resample('W', on='createdAt').count()['author'].reset_index()
comments_time = comments_time.rename(columns={'author': 'comments'})
total_time = pd.merge(prs_time, comments_time, on='createdAt', how='outer')
total_time = total_time.melt(id_vars='createdAt', var_name="kind", value_name="count")
alt.Chart(total_time, width=600).mark_line().encode(
x='createdAt',
y='count',
color='kind'
)
```
| github_jupyter |
# Chapter 14
*Modeling and Simulation in Python*
Copyright 2021 Allen Downey
License: [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International](https://creativecommons.org/licenses/by-nc-sa/4.0/)
```
# download modsim.py if necessary
from os.path import basename, exists
def download(url):
filename = basename(url)
if not exists(filename):
from urllib.request import urlretrieve
local, _ = urlretrieve(url, filename)
print('Downloaded ' + local)
download('https://raw.githubusercontent.com/AllenDowney/' +
'ModSimPy/master/modsim.py')
# import functions from modsim
from modsim import *
```
[Click here to run this chapter on Colab](https://colab.research.google.com/github/AllenDowney/ModSimPy/blob/master//chapters/chap14.ipynb)
```
download('https://github.com/AllenDowney/ModSimPy/raw/master/' +
'chap11.py')
download('https://github.com/AllenDowney/ModSimPy/raw/master/' +
'chap12.py')
download('https://github.com/AllenDowney/ModSimPy/raw/master/' +
'chap13.py')
# import code from previous notebooks
from chap11 import make_system
from chap11 import update_func
from chap11 import run_simulation
from chap11 import plot_results
from chap12 import calc_total_infected
from chap13 import sweep_beta
from chap13 import sweep_parameters
```
In the previous chapter we swept the parameters of the SIR model: the contact rate, `beta`, and the recovery rate, `gamma`.
For each pair of parameters, we ran a simulation and computed the total fraction of the population infected.
In this chapter we investigate the relationship between the parameters and this metric, using both simulation and analysis.
## Nondimensionalization
The figures in the previous chapter suggest that there is a relationship between the parameters of the SIR model, `beta` and `gamma`, and the fraction of the population that is infected. Let's think what that relationship might be.
- When `beta` exceeds `gamma`, there are more contacts
than recoveries during each day. The difference between `beta` and `gamma` might be called the "excess contact rate", in units of contacts per day.
- As an alternative, we might consider the ratio `beta/gamma`, which
is the number of contacts per recovery. Because the numerator and
denominator are in the same units, this ratio is **dimensionless**, which means it has no units.
Describing physical systems using dimensionless parameters is often a
useful move in the modeling and simulation game. In fact, it is so useful that it has a name: **nondimensionalization** (see
<http://modsimpy.com/nondim>).
So we'll try the second option first.
## Exploring the results
In the previous chapter, we wrote a function, `sweep_parameters`,
that takes an array of values for `beta` and an array of values for `gamma`.
It runs a simulation for each pair of parameters and returns a `SweepFrame` with the results.
I'll run it again with the following arrays of parameters.
```
beta_array = [0.1, 0.2, 0.3, 0.4, 0.5,
0.6, 0.7, 0.8, 0.9, 1.0 , 1.1]
gamma_array = [0.2, 0.4, 0.6, 0.8]
frame = sweep_parameters(beta_array, gamma_array)
```
Here's what the first few rows look like:
```
frame.head()
```
The `SweepFrame` has one row for each value of `beta` and one column for each value of `gamma`.
We can print the values in the `SweepFrame` like this:
```
for gamma in frame.columns:
column = frame[gamma]
for beta in column.index:
metric = column[beta]
print(beta, gamma, metric)
```
This is the first example we've seen with one `for` loop inside another:
- Each time the outer loop runs, it selects a value of `gamma` from
the columns of the `SweepFrame` and extracts the corresponding
column.
- Each time the inner loop runs, it selects a value of `beta` from the index of the column and selects the corresponding element, which is the fraction of the population that got infected.
Since there are 11 rows and 4 columns, the total number of lines in the output is 44.
The following function uses the same loop to enumerate the elements of the `SweepFrame`, but instead of printing a line for each element, it plots a point.
```
from matplotlib.pyplot import plot
def plot_sweep_frame(frame):
for gamma in frame.columns:
column = frame[gamma]
for beta in column.index:
metric = column[beta]
plot(beta/gamma, metric, '.', color='C1')
```
On the $x$-axis, it plots the ratio `beta/gamma`.
On the $y$-axis, it plots the fraction of the population that's infected.
Here's what it looks like:
```
plot_sweep_frame(frame)
decorate(xlabel='Contact number (beta/gamma)',
ylabel='Fraction infected')
```
The results fall on a single curve, at least approximately. That means that we can predict the fraction of the population that will be infected based on a single parameter, the ratio `beta/gamma`. We don't need to know the values of `beta` and `gamma` separately.
## Contact number
From Section xxx, recall that the number of new infections in a
given day is $\beta s i N$, and the number of recoveries is
$\gamma i N$. If we divide these quantities, the result is
$\beta s / \gamma$, which is the number of new infections per recovery
(as a fraction of the population).
When a new disease is introduced to a susceptible population, $s$ is
approximately 1, so the number of people infected by each sick person is $\beta / \gamma$. This ratio is called the "contact number\" or "basic reproduction number\" (see <http://modsimpy.com/contact>). By convention it is usually denoted $R_0$, but in the context of an SIR model, that notation is confusing, so we'll use $c$ instead.
The results in the previous section suggest that there is a relationship between $c$ and the total number of infections. We can derive this relationship by analyzing the differential equations from
Section xxx:
$$\begin{aligned}
\frac{ds}{dt} &= -\beta s i \\
\frac{di}{dt} &= \beta s i - \gamma i\\
\frac{dr}{dt} &= \gamma i\end{aligned}$$
In the same way we divided the
contact rate by the infection rate to get the dimensionless quantity
$c$, now we'll divide $di/dt$ by $ds/dt$ to get a ratio of rates:
$$\frac{di}{ds} = \frac{\beta s i - \gamma i}{-\beta s i}$$
Which we can simplify as
$$\frac{di}{ds} = -1 + \frac{\gamma}{\beta s}$$
Replacing $\beta/\gamma$ with $c$, we can write
$$\frac{di}{ds} = -1 + \frac{1}{c s}$$
Dividing one differential equation by another is not an obvious move, but in this case it is useful because it gives us a relationship between $i$, $s$ and $c$ that does not depend on time. From that relationship, we can derive an equation that relates $c$ to the final value of $s$. In theory, this equation makes it possible to infer $c$ by observing the course of an epidemic.
Here's how the derivation goes. We multiply both sides of the previous
equation by $ds$:
$$di = \left( -1 + \frac{1}{cs} \right) ds$$
And then integrate both sides:
$$i = -s + \frac{1}{c} \log s + q$$
where $q$ is a constant of integration. Rearranging terms yields:
$$q = i + s - \frac{1}{c} \log s$$
Now let's see if we can figure out what $q$ is. At the beginning of an epidemic, if the fraction infected is small and nearly everyone is susceptible, we can use the approximations $i(0) = 0$ and $s(0) = 1$ to compute $q$:
$$q = 0 + 1 + \frac{1}{c} \log 1$$
Since $\log 1 = 0$, we get $q = 1$.
Now, at the end of the epidemic, let's assume that $i(\infty) = 0$, and $s(\infty)$ is an unknown quantity, $s_{\infty}$. Now we have:
$$q = 1 = 0 + s_{\infty}- \frac{1}{c} \log s_{\infty}$$
Solving for $c$, we get $$c = \frac{\log s_{\infty}}{s_{\infty}- 1}$$ By relating $c$ and $s_{\infty}$, this equation makes it possible to estimate $c$ based on data, and possibly predict the behavior of future epidemics.
## Analysis and simulation
Let's compare this analytic result to the results from simulation. I'll create an array of values for $s_{\infty}$.
```
s_inf_array = linspace(0.003, 0.99, 50)
```
And compute the corresponding values of $c$:
```
from numpy import log
c_array = log(s_inf_array) / (s_inf_array - 1)
```
To get the total infected, we compute the difference between $s(0)$ and
$s(\infty)$, then store the results in a `Series`:
```
frac_infected = 1 - s_inf_array
```
The ModSim library provides a function called `make_series` we can use to put `c_array` and `frac_infected` in a Pandas `Series`.
```
frac_infected_series = make_series(c_array, frac_infected)
```
Now we can plot the results:
```
plot_sweep_frame(frame)
frac_infected_series.plot(label='analysis')
decorate(xlabel='Contact number (c)',
ylabel='Fraction infected')
```
When the contact number exceeds 1, analysis and simulation agree. When
the contact number is less than 1, they do not: analysis indicates there should be no infections; in the simulations there are a small number of infections.
The reason for the discrepancy is that the simulation divides time into a discrete series of days, whereas the analysis treats time as a
continuous quantity.
When the contact number is large, these two models agree; when it is small, they diverge.
## Estimating contact number
The previous figure shows that if we know the contact number, we can estimate the fraction of the population that will be infected with just a few arithmetic operations.
We don't have to run a simulation.
Also, we can read the figure the other way; if we know what fraction of the population was affected by a past outbreak, we can estimate the contact number.
Then, if we know one of the parameters, like `gamma`, we can use the contact number to estimate the other parameter, like `beta`.
At least in theory, we can.
In practice, it might not work very well, because of the shape of the curve.
* When the contact number is low, the curve is quite steep, which means that small changes in $c$ yield big changes in the number of infections. If we observe that the total fraction infected is anywhere from 20% to 80%, we would conclude that $c$ is near 2.
* And when the contact number is high, the curve is nearly flat, which means that it's hard to see the difference between values of $c$ between 3 and 6.
So it might not be practical to use this curve to estimate $c$.
## Summary
In this chapter we used simulations to explore the relationship between `beta`, `gamma`, and the fraction infected.
Then we used analysis to explain that relationship.
With that, we are done with the SIR model.
In the next chapter we move on to thermal systems and the notorious coffee cooling problem.
## Exercises
**Exercise:** At the beginning of this chapter, I suggested two ways to relate `beta` and `gamma`: we could compute their difference or their ratio.
Because the ratio is dimensionless, I suggested we explore it first, and that led us to discover the contact number, which is `beta/gamma`.
When we plotted the fraction infected as a function of the contact number, we found that this metric falls on a single curve, at least approximately.
That indicates that the ratio is enough to predict the results; we don't have to know `beta` and `gamma` individually.
But that leaves a question open: what happens if we do the same thing using the difference instead of the ratio?
Write a version of `plot_sweep_frame`, called `plot_sweep_frame_difference`, that plots the fraction infected versus the difference `beta-gamma`.
What do the results look like, and what does that imply?
```
# Solution goes here
# Solution goes here
# Solution goes here
```
**Exercise:** Suppose you run a survey at the end of the semester and find that 26% of students had the Freshman Plague at some point.
What is your best estimate of `c`?
Hint: if you display `frac_infected_series`, you can read off the answer.
```
# Solution goes here
# Solution goes here
```
**Exercise**: So far the only metric we have considered is the total fraction of the population that gets infected over the course of an epidemic. That is an important metric, but it is not the only one we care about.
For example, if we have limited resources to deal with infected people, we might also be concerned about the number of people who are sick at the peak of the epidemic, which is the maximum of `I`.
Write a version of `sweep_beta` that computes this metric, and use it to compute a `SweepFrame` for a range of values of `beta` and `gamma`.
Make a contour plot that shows the value of this metric as a function of `beta` and `gamma`.
Then use `plot_sweep_frame` to plot the maximum of `I` as a function of the contact number, `beta/gamma`.
Do the results fall on a single curve?
```
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
```
## Under the hood
ModSim provides `make_series` to make it easier to create a Pandas Series. In this chapter, we used it like this:
```
frac_infected_series = make_series(c_array, frac_infected)
```
If you import `Series` from Pandas, you can make a `Series` yourself, like this:
```
from pandas import Series
frac_infected_series = Series(frac_infected, c_array)
```
The difference is that the arguments are in reverse order: the first argument is stored as the values in the `Series`; the second argument is stored as the `index`.
I find that order counterintuitive, which is why I use `make_series`.
`make_series` takes the same optional keyword arguments as `Series`, which you can read about at <https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html>.
| github_jupyter |
```
import requests
from lxml import html
import redis
from random import randint
import time
from ipywidgets import Image
import plotly.graph_objs as go
from mlrepricer import helper, redisdb, helper
from mlrepricer.oldsql import schemas
from mlrepricer.oldsql.database import SQLite
import pandas as pd
import numpy as np
```
How you get started with redis.
```
redisdb.server_start()
r = redis.StrictRedis(**helper.rediscred, decode_responses=True)
type(r)
```
Iterate over pictures:
```
pictures = dict()
for asin in r.scan_iter():
if asin.startswith('pic'):
pictures.update({asin: list(r.smembers(asin))[0]})
t = schemas.pricemonitor(SQLite)() # tableobject
df = pd.read_sql_query(f'SELECT * FROM {t.table}', t.conn, parse_dates=[t.eventdate], index_col='ID')
filter1 = helper.cleanup(df)
norm = helper.normalize(filter1)
norm.head()
fig = go.FigureWidget(
data=[
dict(
x=norm['time_changed'],
y=norm['price'],
)
],
)
scatter = fig.data[0]
scatter.text = norm['sellerid']
scatter.hoverinfo = 'text'
from ipywidgets import HTML
details = HTML()
def hover_fn(trace, points, state):
ind = points.point_inds[0]
details.value = norm.iloc[ind].to_frame().to_html()
scatter.on_hover(hover_fn)
from ipywidgets import Image, Layout
image_widget = Image(
value=pictures['pic_B075NJNLJT'],
layout=Layout(height='400px', width='400px')
)
image_widget
def hover_fn(trace, points, state):
ind = points.point_inds[0]
# Update details HTML widget
details.value = norm.iloc[ind].to_frame().to_html()
# Update image widget
model_year = 'pic_' + norm['asin'][ind]
image_widget.value = m[model_year]
scatter.on_hover(hover_fn)
from ipywidgets import HBox, VBox
VBox([fig,
HBox([image_widget, details])])
# that would be one picture
pic = list(r.smembers('pic_B01F2RLCJ8'))[0]
#r.delete('pic_B01J670I36')
# lets use the list of pictures, you can change the index to play around
Image(value=m[49])
def download_image(asin):
country = 'de'
site = requests.get(f'https://amazon.{country}/dp/{asin}')
parser = html.fromstring(site.text)
IMG = "//img[@id='landingImage']"
image_link = parser.xpath(IMG)[0].get('src')
image = requests.get(image_link).content
assert isinstance(image, bytes)
return image
def dump_into_redis(image):
r.sadd(f'pic_{asin}', image)
for asin in r.scan_iter():
if asin != 'updated_asins' and not asin.startswith('pic'):
if not r.exists('pic_'+asin):
print(asin)
time.sleep(randint(2,4))
try:
dump_into_redis(download_image(asin))
except:
time.sleep(randint(5, 6))
```
| github_jupyter |
# News API Quickstart
The News API's main functions are `fetch_urls()` and `fetch_urls_to_file()`. The latter outputs the retrieved content to a .jsonl file.
Both functions require these two arguments:
- `urls`: a dictionary or a list of dictionaries. Each dictionary should have a `url` key and a URL string as its value.
- To pass along extra info to the output, you can add (JSON serializable) key-value pairs to the input dictionary.
- `fetch_function`:
- `request_active_url()`: request the URL directly (the URL is actively served by the URL domain).
- `request_archived_url()`: request the oldest archived version of the URL from the Internet Archive's Wayback Machine.
- `fetch_url()`: call `request_active_url()`. If it fails, call `request_archived_url()` as a fallback option.
`fetch_urls_to_file()` also requires `path` and `filename` arguments.
Every `fetch_function` returns a stringified JSON object with the following keys. If additional key-value pairs are included in the input dictionary, they are added to the output as well.
- `article_maintext` (str): main text of the article extracted by [news-please](https://github.com/fhamborg/news-please)
- `original_url` (str): the input URL
- `resolved_url` (str): `response_url` processed for errors
- `http://example.com/__CLIENT_ERROR__`
- `http://example.com/__CONNECTIONPOOL_ERROR__`
- `resolved_domain` (str): domain of `resolved_url`
- `resolved_netloc` (str): network location of `resolved_url`
- `standardized_url` (str): netloc + path + query of `resolved_url`
- Common analytics-related prefixes and query parameters are removed. The URL is also lower-cased.
- `is_generic_url` (bool): indicates if the standardized URL is likely a generic URL which doesn't refer to a specific article's webpage. If `True`, `article_maintext` and `resolved_text` should probably be excluded as noisy data.
- `response_code` (int): response status code
- `response_reason` (str): response status code reason
- `fetch_error` (bool): indicates success or failure of the HTTP request
- `resolved_text` (str): the HTML returned by the server. This is useful if news-please's article extractor didn't succeed (`article_maintext`) and custom extraction logic is needed.
- `FETCH_FUNCTION` (str): "request_active_url" or "request_archived_url"
- `FETCH_AT` (str): "2021-11-05T23:25:15.611729+00:00" (timezone-aware UTC)
```
import json
import os
import urlexpander
dir_out = os.path.join('..', 'examples', 'output')
def filter_keys(fetched, exclude_keys=['resolved_text', 'article_maintext']):
"""remove keys which show actual HTML/article text
Args:
fetched (dict)
excluded_keys (list)
Returns:
fetched (dict) - filtered
"""
return {k: fetched[k] for k in fetched.keys() if k not in exclude_keys}
```
## Example URLs
The first example with Breitbart's URL includes the minimum required information. \
The second example with One America News' URL adds an extra key-value pair, which will be passed along to the output.
```
examples = [
{"url": "http://feedproxy.google.com/~r/breitbart/~3/bh9JQvQPihk/"},
{
"url": "http://www.oann.com/pm-abe-to-send-message-japan-wont-repeat-war-atrocities-2/",
"outlet": "One America News",
},
]
```
## Fetch URLs (generator)
When `fetch_function=urlexpander.fetch_url`, we first try to retrieve the article with a direct server request. If it fails, we try to fetch an archived version.
```
# generator
g_ftc = urlexpander.fetch_urls(urls=examples, fetch_function=urlexpander.fetch_url)
# fetch
r_ftc = [json.loads(r) for r in g_ftc]
# filter out keys with actual text
r_ftc = [filter_keys(r) for r in r_ftc]
print(f"Fetched {len(r_ftc)} URLs.")
```
In the Breitbart example, the direct request to the server succeeds. Since `fetch_error` is `False`, it doesn't trigger the fallback function to the archive.
```
# returns from the first attempt
r_ftc[0]
```
In the One America News example, the retrieved content comes from the fallback request to the Internet Archive's Wayback Machine (`FETCH_FUNCTION: 'request_archived_url'`). This means that the first attempt with the direct server response failed.
```
# The HTML is stored in `resolved_text` and the extracted article is stored in `article_maintext`.
# Due to copyright, these two keys are filtered out before displaying the output.
r_ftc[1]
```
To illustrate the two steps more clearly, we can retrieve the second example with `fetch_function=urlexpander.request_active_url` and `fetch_function=urlexpander.request_archived_url` separately.
```
# generators
g_exp = urlexpander.fetch_urls(urls=examples[1], fetch_function=urlexpander.request_active_url)
g_wbm = urlexpander.fetch_urls(urls=examples[1], fetch_function=urlexpander.request_archived_url)
# fetch
r_exp = [json.loads(r) for r in g_exp][0]
r_wbm = [json.loads(r) for r in g_wbm][0]
# filter out keys with actual text
r_exp = filter_keys(r_exp)
r_wbm = filter_keys(r_wbm)
```
The first attempt with `request_active_url` returns an error which triggers the fallback attempt to the archive.
```
r_exp
```
The `response_code` and `response_reason` indicate that the Wayback Machine has an archived version available. This is the same output we got when `fetch_function=urlexpander.fetch_url`.
```
r_wbm
```
## Fetch URLs and store the fetched content in a .jsonl file
```
# set filenames
fn_ftc = f"news_api_examples.jsonl"
# write to file
urlexpander.fetch_urls_to_file(
urls=examples,
fetch_function=urlexpander.fetch_url,
path=dir_out,
filename=fn_ftc,
write_mode="a",
)
# read from file
g_ftc_file = urlexpander.load_fetched_from_file(path=dir_out, filename=fn_ftc)
# fetch
r_ftc_file = [json.loads(r) for r in g_ftc_file]
# filter out keys with actual text
r_ftc_file = [filter_keys(r) for r in r_ftc_file]
print(f"Loaded fetched content for {len(r_ftc_file)} URLs from {fn_ftc}.")
r_ftc_file[0]
r_ftc_file[1]
```
| github_jupyter |
```
fc1_outputs = [64,128,256,512]
for fc1_output in fc1_outputs:
wandb.init(project=PROJECT_NAME,name=f'fc1_output-{fc1_output}')
model = Test_Model(conv1_output=32,conv2_output=8,conv3_output=64,fc1_output=fc1_output).to(device)
optimizer = optim.SGD(model.parameters(),lr=0.1)
criterion = nn.CrossEntropyLoss()
for _ in tqdm(range(EPOCHS)):
for i in range(0,len(X_train),BATCH_SIZE):
X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)
y_batch = y_train[i:i+BATCH_SIZE].to(device)
model.to(device)
preds = model(X_batch.float())
preds.to(device)
loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))
optimizer.zero_grad()
loss.backward()
optimizer.step()
wandb.log({'loss':get_loss(criterion,y_train,model,X_train),'accuracy':test(model,X_train,y_train),'val_accuracy':test(model,X_test,y_test),'val_loss':get_loss(criterion,y_test,model,X_test)})
for index in range(10):
print(torch.argmax(preds[index]))
print(y_batch[index])
print('\n')
wandb.finish()
test_index = 0
from load_data import *
# load_data()
from load_data import *
X_train,X_test,y_train,y_test = load_data()
len(X_train),len(y_train)
len(X_test),len(y_test)
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class Test_Model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.c1 = nn.Conv2d(1,64,5)
self.c2 = nn.Conv2d(64,128,5)
self.c3 = nn.Conv2d(128,256,5)
self.fc4 = nn.Linear(256*10*10,256)
self.fc6 = nn.Linear(256,128)
self.fc5 = nn.Linear(128,4)
def forward(self,X):
preds = F.max_pool2d(F.relu(self.c1(X)),(2,2))
preds = F.max_pool2d(F.relu(self.c2(preds)),(2,2))
preds = F.max_pool2d(F.relu(self.c3(preds)),(2,2))
# print(preds.shape)
preds = preds.view(-1,256*10*10)
preds = F.relu(self.fc4(preds))
preds = F.relu(self.fc6(preds))
preds = self.fc5(preds)
return preds
device = torch.device('cuda')
BATCH_SIZE = 32
IMG_SIZE = 112
model = Test_Model().to(device)
optimizer = optim.SGD(model.parameters(),lr=0.1)
criterion = nn.CrossEntropyLoss()
EPOCHS = 125
from tqdm import tqdm
PROJECT_NAME = 'Weather-Clf'
import wandb
# test_index += 1
# wandb.init(project=PROJECT_NAME,name=f'test')
# for _ in tqdm(range(EPOCHS)):
# for i in range(0,len(X_train),BATCH_SIZE):
# X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)
# y_batch = y_train[i:i+BATCH_SIZE].to(device)
# model.to(device)
# preds = model(X_batch.float())
# preds.to(device)
# loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
# wandb.log({'loss':loss.item()})
# wandb.finish()
# for index in range(10):
# print(torch.argmax(preds[index]))
# print(y_batch[index])
# print('\n')
class Test_Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1,16,5)
self.conv2 = nn.Conv2d(16,32,5)
self.conv3 = nn.Conv2d(32,64,5)
self.fc1 = nn.Linear(64*10*10,16)
self.fc2 = nn.Linear(16,32)
self.fc3 = nn.Linear(32,64)
self.fc4 = nn.Linear(64,32)
self.fc5 = nn.Linear(32,6)
def forward(self,X):
preds = F.max_pool2d(F.relu(self.conv1(X)),(2,2))
preds = F.max_pool2d(F.relu(self.conv2(preds)),(2,2))
preds = F.max_pool2d(F.relu(self.conv3(preds)),(2,2))
# print(preds.shape)
preds = preds.view(-1,64*10*10)
preds = F.relu(self.fc1(preds))
preds = F.relu(self.fc2(preds))
preds = F.relu(self.fc3(preds))
preds = F.relu(self.fc4(preds))
preds = F.relu(self.fc5(preds))
return preds
model = Test_Model().to(device)
optimizer = optim.SGD(model.parameters(),lr=0.1)
criterion = nn.CrossEntropyLoss()
# test_index += 1
# wandb.init(project=PROJECT_NAME,name=f'test-{test_index}')
# for _ in tqdm(range(EPOCHS)):
# for i in range(0,len(X_train),BATCH_SIZE):
# X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)
# y_batch = y_train[i:i+BATCH_SIZE].to(device)
# model.to(device)
# preds = model(X_batch.float())
# preds.to(device)
# loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
# wandb.log({'loss':loss.item()})
# wandb.finish()
class Test_Model(nn.Module):
def __init__(self,conv1_output=16,conv2_output=32,conv3_output=64,fc1_output=16,fc2_output=32,fc3_output=64,activation=F.relu):
super().__init__()
self.conv3_output = conv3_output
self.conv1 = nn.Conv2d(1,conv1_output,5)
self.conv2 = nn.Conv2d(conv1_output,conv2_output,5)
self.conv3 = nn.Conv2d(conv2_output,conv3_output,5)
self.fc1 = nn.Linear(conv3_output*10*10,fc1_output)
self.fc2 = nn.Linear(fc1_output,fc2_output)
self.fc3 = nn.Linear(fc2_output,fc3_output)
self.fc4 = nn.Linear(fc3_output,fc2_output)
self.fc5 = nn.Linear(fc2_output,6)
self.activation = activation
def forward(self,X):
preds = F.max_pool2d(self.activation(self.conv1(X)),(2,2))
preds = F.max_pool2d(self.activation(self.conv2(preds)),(2,2))
preds = F.max_pool2d(self.activation(self.conv3(preds)),(2,2))
# print(preds.shape)
preds = preds.view(-1,self.conv3_output*10*10)
preds = self.activation(self.fc1(preds))
preds = self.activation(self.fc2(preds))
preds = self.activation(self.fc3(preds))
preds = self.activation(self.fc4(preds))
preds = self.activation(self.fc5(preds))
return preds
# conv1_output = 32
# conv2_output = 8
# conv3_output = 64
# fc1_output =
# fc2_output
# fc3_output
# activation
# optimizer
# loss
# lr
# num of epochs
def get_loss(criterion,y,model,X):
model.to('cpu')
preds = model(X.view(-1,1,112,112).to('cpu').float())
preds.to('cpu')
loss = criterion(preds,torch.tensor(y,dtype=torch.long).to('cpu'))
loss.backward()
return loss.item()
def test(net,X,y):
device = 'cpu'
net.to(device)
correct = 0
total = 0
net.eval()
with torch.no_grad():
for i in range(len(X)):
real_class = torch.argmax(y[i]).to(device)
net_out = net(X[i].view(-1,1,112,112).to(device).float())
net_out = net_out[0]
predictied_class = torch.argmax(net_out)
if predictied_class == real_class:
correct += 1
total += 1
net.train()
net.to('cuda')
return round(correct/total,3)
EPOCHS = 3
fc1_outputs = [64,128,256,512]
for fc1_output in fc1_outputs:
wandb.init(project=PROJECT_NAME,name=f'fc1_output-{fc1_output}')
model = Test_Model(conv1_output=32,conv2_output=8,conv3_output=64,fc1_output=fc1_output).to(device)
optimizer = optim.SGD(model.parameters(),lr=0.1)
criterion = nn.CrossEntropyLoss()
for _ in tqdm(range(EPOCHS)):
for i in range(0,len(X_train),BATCH_SIZE):
X_batch = X_train[i:i+BATCH_SIZE].view(-1,1,112,112).to(device)
y_batch = y_train[i:i+BATCH_SIZE].to(device)
model.to(device)
preds = model(X_batch.float())
preds.to(device)
loss = criterion(preds,torch.tensor(y_batch,dtype=torch.long))
optimizer.zero_grad()
loss.backward()
optimizer.step()
wandb.log({'loss':get_loss(criterion,y_train,model,X_train),'accuracy':test(model,X_train,y_train),'val_accuracy':test(model,X_test,y_test),'val_loss':get_loss(criterion,y_test,model,X_test)})
for index in range(10):
print(torch.argmax(preds[index]))
print(y_batch[index])
print('\n')
wandb.finish()
```
| github_jupyter |
[](https://pythonista.io)
# Persistencia de objetos.
Cuando un programa termina su ejecución, el estado de los objetos que contenía es eliminado.
Sin embargo, existen varias formas de permitir que el estado de un objeto "persista".
## El módulo ```pickle```.
### Serialización mediante la función ```dump()```.
La serialización es una técnica que permite conservar el estado de un objeto almacenando los valores/objetos ligados a los atributos del objeto de origen.
Python cuenta con el módulo ```pickle```, el cual es capaz de serializar un objeto.
La función```dump()``` del módulo ```pickle```, permite guardar un objeto en un archivo.
Sintaxis:
```
pickle.dump( <objeto>, <archivo>)
```
### La función ```load()```.
La función _load_() del módulo _pickle_, permite cargar un objeto desde un archivo y regresarlo.
```
pickle.load( <archivo>)
```
**Ejemplo:**
```
import pickle
help(pickle)
lista = [[1, 2, 3], [4, 5, 6]]
with open("salmuera.bin", "wb") as archivo:
pickle.dump(lista, archivo)
%cat salmuera.bin
!type salmuera.bin
with open("salmuera.bin", "br") as archivo:
otra_lista = pickle.load(archivo)
otra_lista
id(lista)
id(otra_lista)
lista == otra_lista
lista is otra_lista
```
## La función _dumps()_.
La función _dumps()_ del módulo _pickle_, permite convertir el estado de un objeto en un objeto de tipo _bytes_.
Sintaxis:
```
pickle.dumps( <objeto>)
```
## La función _loads()_.
La función loads() del módulo pickle, regresa un objeto con el estado almacenado en un objeto de tipo _bytes_.
Sintaxis:
```
pickle.loads( <objeto tipo str>)
```
**Ejemplo:**
```
class Persona:
def __init__(self):
from time import time
self.__clave = str(int(time() / 0.017))[1:]
@property
def clave(self):
return self.__clave
@property
def nombre(self):
return " ".join(self.lista_nombre)
@nombre.setter
def nombre(self, nombre):
if len(nombre) < 2 or len(nombre) > 3 or type(nombre) not in (list, tuple):
raise ValueError("Formato incorrecto.")
else:
self.lista_nombre = nombre
individuo = Persona()
individuo.nombre = ['Juan', 'Pérez', 'Sánchez']
salmuera = pickle.dumps(individuo)
salmuera
otro_individuo = pickle.loads(salmuera)
otro_individuo.nombre
otro_individuo.clave
individuo.clave
individuo == otro_individuo
id(individuo)
id(otro_individuo)
```
## Restricciones.
Las funciones del módulo _pickle_ sólo guardan el estado de un objeto, por lo que es necesario que el intérprete tenga acceso a la clase a partir de la cual fueron instanciados los objetos, así como los otros objetos que pudieran habérsele agregado al objeto en cuestión.
**Ejemplo:**
```
class Persona:
def __init__(self):
from time import time
self.__clave = str(int(time() / 0.017))[1:]
@property
def clave(self):
return self.__clave
@property
def nombre(self):
return " ".join(self.lista_nombre)
@nombre.setter
def nombre(self, nombre):
if len(nombre) < 2 or len(nombre) > 3 or type(nombre) not in (list, tuple):
raise ValueError("Formato incorrecto.")
else:
self.lista_nombre = nombre
def saluda():
print('Hola')
fulanito = Persona()
perenganito = Persona()
fulanito.saluda = saluda
fulanito.saluda()
conserva = pickle.dumps(fulanito)
conserva
menganito = pickle.loads(conserva)
menganito.saluda()
del saluda
perenganito = pickle.loads(conserva)
fulanito.saluda()
```
## Precauciones con respecto a la serialización de objetos.
* La serialización no es de ningún modo una técnica de cifrado, por lo que no se debe de utilizar de tal forma.
* La serialización puede representar un riesgo de seguridad si las clases originales son sustituidas por otras clases con las mismas interfaces y estructura pero con implementaciones distintas. Por lo tanto, se recomienda que la serialización se utilice exclusivamente para garantizar la persistencia de los objetos, pero no como un formato de transmisión de datos.
<p style="text-align: center"><a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Licencia Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/80x15.png" /></a><br />Esta obra está bajo una <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Licencia Creative Commons Atribución 4.0 Internacional</a>.</p>
<p style="text-align: center">© José Luis Chiquete Valdivieso. 2019.</p>
| github_jupyter |
# Generate initial min-snap trajectory
```
#!/usr/bin/env python
# coding: utf-8
%matplotlib inline
%reload_ext autoreload
%autoreload 2
import os, sys, time, copy, argparse
import numpy as np
import matplotlib.pyplot as plt
sys.path.insert(0, '../')
from pyTrajectoryUtils.pyTrajectoryUtils.utils import *
from mfboTrajectory.utils import *
from mfboTrajectory.minSnapTrajectoryWaypoints import MinSnapTrajectoryWaypoints
traj_tool = TrajectoryTools(MAX_POLY_DEG = 9, MAX_SYS_DEG = 4, N_POINTS = 20)
min_snap = MinSnapTrajectoryWaypoints(MAX_POLY_DEG = 9, MAX_SYS_DEG = 4, N_POINTS = 20)
# Choose waypoints (check waypoints folder)
points, t_set = get_waypoints('../constraints_data/waypoints_constraints.yaml', 'traj_1', flag_t_set=True)
########################################################
# Min snap trajectory
# Input
# alpha_scale - scale overall time with alpha_scale value
# yaw_mode - 0: set all yaw to 0, 1: set trajectory yaw forward, 2: set trajectory yaw as the reference yaw (points[:,3])
# flag_loop - whether the trajectory has same initial and final position and attitude
# deg_init_min, deg_init_max - the initial state is set to 0 from deg_init_min - th derivative to deg_init_max - th derivative
# (e.g. deg_init_min=0, deg_init_max=2: initial position is set to points[0,:] and initial velocity, acceleration is set to zero)
# deg_end_min, deg_end_max - the final state is set to 0 from deg_end_min - th derivative to deg_end_max - th derivative
# ded_init_yaw_min=0, deg_init_yaw_max - set the initial yaw value and it's derivative to zero
# ded_end_yaw_min=0, deg_end_yaw_max - set the fianl yaw value and it's derivative to zero
# flag_rand_init - whether to use random initialization on optimization process.
# (randomly generate set of time allocation and select the on minimze the overall snap)
# flag_numpy_opt - whether to use numpy-based gradient descent to find initial value (often improve the final result).
# Output
# t_set - time allocation between waypoints
# d_ordered - position and derivatives on each waypoint
# d_ordered_yaw - yaw value and angular speed, acceleration on each waypoint
t_set, d_ordered, d_ordered_yaw = min_snap.get_min_snap_traj(
points, alpha_scale=1.0, flag_loop=False, yaw_mode=2, \
deg_init_min=0, deg_init_max=4, \
deg_end_min=0, deg_end_max=2, \
deg_init_yaw_min=0, deg_init_yaw_max=2, \
deg_end_yaw_min=0, deg_end_yaw_max=2, \
flag_rand_init=False, flag_numpy_opt=False)
print("t_set = np.array([{}])".format(','.join([str(x) for x in t_set])))
print("########################################################")
########################################################
# Change trajectory speed
# multiply alpha_set with t_set and generate new d_orderd (derivates on each waypoints) and d_ordered_yaw
# Check pyTrajectoryUtils/MinSnapTrajectoryUtils class for the details
# Set yaw_mode - 0: set all yaw to 0, 1: set trajectory yaw forward, 2: set trajectory yaw as the reference yaw (points[:,3])
t_set_new, d_ordered, d_ordered_yaw = min_snap.update_traj(
points=points, \
t_set=t_set, \
alpha_set=2.0*np.ones_like(t_set), \
yaw_mode=2, \
flag_run_sim=False)
print("t_set_new = np.array([{}])".format(','.join([str(x) for x in t_set_new])))
print("########################################################")
########################################################
# Add rampIn trajectory
# t_set_new, d_ordered, d_ordered_yaw = min_snap.append_rampin(t_set_new, d_ordered, d_ordered_yaw)
########################################################
# Run simulation with indi controller
debug_array = min_snap.sim.run_simulation_from_der( \
t_set=t_set_new, d_ordered=d_ordered, d_ordered_yaw=d_ordered_yaw, \
max_pos_err=0.2, min_pos_err=0.1, max_yaw_err=90., min_yaw_err=60.0, freq_ctrl=200)
min_snap.sim.plot_result( \
debug_array[0], flag_save=False, \
save_dir="../trajectory/result", save_idx="0", \
t_set=t_set_new, d_ordered=d_ordered)
print("########################################################")
########################################################
# Check whether the reference motor speed exceed the maximum motor speed
print("Sanity check (ref. motor speed) result : {}". \
format(min_snap.sanity_check(t_set_new, d_ordered, d_ordered_yaw, flag_parallel=True)))
print("########################################################")
########################################################
# Trajectory tools - plot and save trajectory
traj_tool.plot_trajectory(t_set_new, d_ordered, d_ordered_yaw,
flag_save=False, save_dir='', save_idx='test')
# Save trajectory in yaml format (save time allocation and the coefficients of piece-wise polynomial trajectory)
traj_tool.save_trajectory_yaml(t_set, d_ordered, d_ordered_yaw, \
traj_dir="../trajectory/", \
traj_name="test")
# Save trajectory in csv format (save time allocation and the coefficients of piece-wise polynomial trajectory)
traj_tool.save_trajectory_csv(t_set, d_ordered, d_ordered_yaw, \
traj_dir="../trajectory/", \
traj_name="test", \
freq=200)
# Plot 2D projection of trajectory
fig, axs = plt.subplots(1,1)
fig.set_size_inches((6,5))
traj_tool.plot_trajectory_2D_single(axs, t_set_new, d_ordered, d_ordered_yaw)
plt.show()
# Get the maximum speed of reference trajectory
traj_tool.get_max_speed(t_set_new, d_ordered, flag_print=True)
# Plot trajectory 3D-animation
traj_tool.plot_trajectory_animation( \
t_set_new, d_ordered, d_ordered_yaw, \
flag_save=False, save_dir='../trajectory', save_file='test')
print("########################################################")
########################################################
# Low fidelity check
alpha_sta = 1.00
t_set_sta, d_ordered, d_ordered_yaw = min_snap.update_traj_(points, t_set, alpha_sta*np.ones_like(t_set))
print("low fidelity evaluation: {}".\
format(min_snap.sanity_check(t_set_sta, d_ordered, d_ordered_yaw, flag_parallel=True)))
t_set_debug = t_set_sta
########################################################
# High fidelity check
alpha_sim = 2.0
t_set_sim, d_ordered, d_ordered_yaw = min_snap.update_traj_(points, t_set, alpha_sim*np.ones_like(t_set))
print("high fidelity evaluation: {}".\
format(min_snap.run_sim_loop(t_set_sim, d_ordered, d_ordered_yaw, flag_debug=True)))
t_set_debug = t_set_sim
print("########################################################")
########################################################
# Debug tools
traj_tool.plot_trajectory(t_set_debug, d_ordered, d_ordered_yaw, flag_save=False)
fig, axs = plt.subplots(1,1)
fig.set_size_inches((12,5))
traj_tool.plot_trajectory_2D_single(axs, t_set_debug, d_ordered, d_ordered_yaw)
plt.show()
traj_tool.get_max_speed(t_set_debug, d_ordered, flag_print=True)
```
# Plot optimization result
```
#!/usr/bin/env python
# coding: utf-8
%matplotlib inline
%reload_ext autoreload
%autoreload 2
import os, sys, time, copy, argparse
import numpy as np
import matplotlib.pyplot as plt
sys.path.insert(0, '../')
from pyTrajectoryUtils.pyTrajectoryUtils.utils import *
from mfboTrajectory.utils import *
from mfboTrajectory.multiFidelityModelWaypoints import check_dataset_init
from mfboTrajectory.minSnapTrajectoryWaypoints import MinSnapTrajectoryWaypoints
traj_tool = TrajectoryTools(MAX_POLY_DEG = 9, MAX_SYS_DEG = 4, N_POINTS = 20)
min_snap = MinSnapTrajectoryWaypoints(MAX_POLY_DEG = 9, MAX_SYS_DEG = 4, N_POINTS = 20)
def get_min_time_array(filedir, filename, MAX_ITER=50):
yamlFile = os.path.join(filedir, filename)
min_time_array = []
num_failure = 0
with open(yamlFile, "r") as input_stream:
yaml_in = yaml.load(input_stream)
for i in range(MAX_ITER+1):
if 'iter{}'.format(i) in yaml_in:
min_time_array.append(np.float(yaml_in['iter{}'.format(i)]['min_time']))
if 'exp_result' in yaml_in['iter{}'.format(i)]:
num_failure += 1-np.float(yaml_in['iter{}'.format(i)]['exp_result'])
return min_time_array, num_failure
def get_snap_array(filedir, filename, points, t_set_sim, MAX_ITER=50):
yamlFile = os.path.join(filedir, filename)
min_time_array = []
snap_array = []
snap_min = 1.0
num_failure = 0
with open(yamlFile, "r") as input_stream:
yaml_in = yaml.load(input_stream)
for i in range(MAX_ITER+1):
if 'iter{}'.format(i) in yaml_in:
min_time_array.append(np.float(yaml_in['iter{}'.format(i)]['min_time']))
if len(min_time_array) == 1 or min_time_array[-2] > min_time_array[-1]:
alpha_set = np.array(yaml_in['iter{}'.format(i)]['alpha_cand'])
print(t_set_sim)
_, _, _, snap = min_snap.update_traj(points, t_set_sim, alpha_set, \
yaw_mode=2, \
flag_run_sim=False, flag_return_snap=True)
snap_min = snap
snap_array.append(snap_min)
if 'exp_result' in yaml_in['iter{}'.format(i)]:
num_failure += 1-np.float(yaml_in['iter{}'.format(i)]['exp_result'])
return min_time_array, num_failure, snap_array
sample_name = ['traj_1']
rand_seed = [123]
model_name = ['test_waypoints']
lb = 0.1
ub = 1.9
MAX_ITER = 5
fig = plt.figure(figsize=(10,8))
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212)
for sample_name_ in sample_name[:]:
points, t_set_sta = get_waypoints('../constraints_data/waypoints_constraints.yaml', 'traj_1', flag_t_set=True)
t_dim = t_set_sta.shape[0]
res_init, data_init = check_dataset_init(sample_name_, t_dim, N_L=1000, N_H=20, \
lb=lb, ub=ub, sampling_mode=2, dataset_dir="../mfbo_data")
if res_init:
alpha_sim, X_L, Y_L, X_H, Y_H = data_init
t_set_sim = t_set_sta*alpha_sim
else:
continue
for model_idx_, model_name_ in enumerate(model_name[:]):
test_data = np.empty((0,MAX_ITER+1))
test_data_snap = np.empty((0,MAX_ITER+1))
mean_failure = 0
for rand_seed_ in rand_seed[:]:
data, num_failure, data_snap = get_snap_array('../mfbo_data/{}'.format(sample_name_), \
'result_{}_{}.yaml'.format(model_name_, rand_seed_), \
points, t_set_sim)
mean_failure += num_failure
if len(data) is not MAX_ITER+1:
print("Incomplete result: {}_{}_{}".format(sample_name_,model_name_,rand_seed_))
test_data = np.append(test_data, np.expand_dims(data,0), axis=0)
test_data_snap = np.append(test_data_snap, np.expand_dims(data_snap,0), axis=0)
test_data_mean = test_data.mean(axis=0)
test_data_std = test_data.std(axis=0)
test_data_snap_mean = test_data_snap.mean(axis=0)
test_data_snap_std = test_data_snap.std(axis=0)
mean_failure /= (1.0*len(rand_seed))
print(mean_failure)
ax1.plot(range(test_data_mean.shape[0]), test_data_mean, '-', label='{}'.format(sample_name_))
ax1.fill_between(range(test_data_mean.shape[0]), \
test_data_mean-test_data_std, test_data_mean+test_data_std, \
alpha=0.2)
ax2.plot(range(test_data_snap_mean.shape[0]), test_data_snap_mean, '-', label='{}'.format(sample_name_))
ax2.fill_between(range(test_data_snap_mean.shape[0]), \
test_data_snap_mean-test_data_snap_std, test_data_snap_mean+test_data_snap_std, \
alpha=0.2)
ax1.set_title("Simulation result of waypoints trajectory", {'fontsize':20}, y=1.02)
ax1.set_ylabel("Relative flight time", {'fontsize':16})
ax1.set_xlabel("Iterations", {'fontsize':16})
ax1.tick_params(axis='both', which='major', labelsize=14)
ax2.set_ylabel("Relative smoothness", {'fontsize':16})
ax2.set_xlabel("Iterations", {'fontsize':16})
ax2.tick_params(axis='both', which='major', labelsize=14)
ax1.grid()
ax2.grid()
plt.tight_layout()
plt.show()
plt.pause(1e-6)
```
| github_jupyter |
```
import json
import pickle
import os
import pandas as pd
import requests
import numpy as np
import config
data_path = os.path.join("headHunter_data")
text_processing_url = config.text_processing_url
pd.options.display.max_rows = 10
pd.set_option('display.max_columns', None)
with open(os.path.join(data_path, "hh_ids.dat"), 'rb') as inf:
ids = pickle.load(inf)
with open(os.path.join(data_path, "hh_vacancies.dat"), 'rb') as inf:
vacancies = pickle.load(inf)
with open(os.path.join(data_path, "hh_vacancies_ext.dat"), 'rb') as inf:
vacancies_ext = pickle.load(inf)
print(len(vacancies_ext))
print(len(ids))
vac_rows = []
for vac in vacancies:
try:
row = {"id": vac["id"], "title": vac["name"],
"title_normalized": "",
"title_lemmas": "",
"title_lemmas_tags": "",
"title_tokens": "",
"lang_title": "",
"requirement_norm": "",
"requirement_lemmas": "",
"requirement_lemmas_tags": "",
"requirement_tokens": "",
"responsibility_norm": "",
"responsibility_lemmas": "",
"responsibility_lemmas_tags": "",
"responsibility_tokens": "",
"requirement": vac["snippet"]["requirement"],
"responsibility": vac["snippet"]["responsibility"],
"url": vac["url"]}
vac_rows.append(row)
except KeyError:
print(row)
None
vac_df = pd.DataFrame(vac_rows)
print()
vac_rows = []
for i, vac in enumerate(vacancies_ext):
try:
row = {"id": vac["id"], "text": vac["description"],
"text_normalized": "",
"text_lemmas": "",
"text_lemmas_tags": "",
"text_tokens": "",
"lang_text": "",
"specializations": [i["name"] for i in vac["specializations"]],
"profarea_names": [i["profarea_name"] for i in vac["specializations"]]}
vac_rows.append(row)
except KeyError:
print("Key error, index =", i, "Item =", vacancies_ext[i])
None
vac_df_ext = pd.DataFrame(vac_rows)
vac_df.drop_duplicates(["id"], inplace=True)
vac_df_ext.drop_duplicates(["id"], inplace=True)
full_df = vac_df_ext.merge(vac_df, left_on='id', right_on='id', how='outer')
print(len(full_df))
#delete unuseful variables
del vac_rows
del vac_df_ext
del vac_df
del vacancies
del vacancies_ext
del ids
```
### Drop already preprocessed rows
```
exist_df = pd.read_csv(os.path.join(data_path, "hh_dataset.csv"), sep='\t')
exist_df = exist_df.loc[np.logical_or(exist_df["lang_text"]=="russian",
exist_df["lang_text"]=="english")]
exist_df.reset_index(drop=True, inplace=True)
print(exist_df.info())
exist_ids = [str(i) for i in exist_df["id"].values]
new_ids = [str(i) for i in full_df["id"].values]
print(len(exist_ids))
print(len(new_ids))
to_drop_ids = list(set(new_ids).intersection(set(exist_ids)))
print(len(to_drop_ids))
to_proc_ids = list(set(new_ids).difference(set(exist_ids)))
print(len(to_proc_ids))
%%time
for i in to_drop_ids:
full_df = full_df.loc[full_df["id"] != i]
#full_df.drop(full_df["id"] == i], inplace=True)
full_df.reset_index(drop=True, inplace=True)
print(len(full_df))
print(full_df.info())
```
### Normalize text and title using text_preprocessing service
```
%%time
for index, row in full_df.iterrows():
requirement = row["requirement"]
responsibility = row["responsibility"]
fields = ["title", "text"]
for field in fields:
text = row[field]
r = requests.post(text_processing_url + config.STEM_TEXT_PATH,
json=text)
full_df.loc[index, field + "_normalized"] = r.text
r = requests.post(text_processing_url + config.LEMM_TEXT_PATH,
json=text)
full_df.loc[index, field + "_lemmas"] = r.text
r = requests.post(text_processing_url + config.TAG_TEXT_PATH,
json=text)
full_df.loc[index, field + "_lemmas_tags"] = r.text
r = requests.post(text_processing_url + config.TOKEN_TEXT_PATH,
json=text)
full_df.loc[index, field + "_tokens"] = r.text
r = requests.post(text_processing_url + config.DETECT_LANG_PATH ,
json=text)
full_df.loc[index, "lang_" + field] = r.text
fields = ["requirement", "responsibility"]
for field in fields:
text = row[field]
r = requests.post(text_processing_url + config.STEM_TEXT_PATH,
json=text)
full_df.loc[index, field + "_norm"] = r.text
r = requests.post(text_processing_url + config.LEMM_TEXT_PATH,
json=text)
full_df.loc[index, field + "_lemmas"] = r.text
r = requests.post(text_processing_url + config.TAG_TEXT_PATH,
json=text)
full_df.loc[index, field + "_lemmas_tags"] = r.text
r = requests.post(text_processing_url + config.TOKEN_TEXT_PATH,
json=text)
full_df.loc[index, field + "_tokens"] = r.text
if index % 500 == 0:
print(index)
print(len(full_df))
full_df.tail()
print(full_df.loc[4, "requirement_lemmas"])
print()
print(full_df.loc[4, "responsibility_lemmas"])
print()
print(full_df.loc[4, "text_tokens"])
print(len(exist_df))
exist_df.head()
full_df = full_df.append(exist_df, ignore_index=True, sort=True)
print("Final size of dataset =", len(full_df))
full_df.drop_duplicates(["id"], inplace=True)
print("Final size of dataset =", len(full_df))
full_df.info()
full_df.tail()
full_df.to_csv(os.path.join("hh_dataset.csv"),
sep='\t', header=True, index=None)
vacancies[0]
vacancies_ext[0]
```
| github_jupyter |
\*Contents in this Jupyter Notebook are from and can be found in [DATAI's kaggle kernel](https://www.kaggle.com/kanncaa1). The order of the content were changed for this workshop session.
Data scientist need to have these skills:
1. Basic Tools: Like python, R or SQL. You do not need to know everything. What you only need is to learn how to use **python**
1. Basic Statistics: Like mean, median or standart deviation. If you know basic statistics, you can use **python** easily.
1. Data Munging: Working with messy and difficult data. Like a inconsistent date and string formatting. As you guess, **python** helps us.
1. Data Visualization: Title is actually explanatory. We will visualize the data with **python** like matplot and seaborn libraries.
1. Machine Learning: You do not need to understand math behind the machine learning technique. You only need is understanding basics of machine learning and learning how to implement it while using **python**.
**Content:**
1. Introduction to Python:
1. Matplotlib
1. Dictionaries
1. Pandas
1. Logic, control flow and filtering
1. Loop data structures
1. Python Data Science Toolbox:
1. User defined function
1. Scope
1. Nested function
1. Default and flexible arguments
1. Lambda function
1. Anonymous function
1. Iterators
1. List comprehension
1. Cleaning Data
1. Diagnose data for cleaning
1. Explotary data analysis
1. Visual exploratory data analysis
1. Tidy data
1. Pivoting data
1. Concatenating data
1. Data types
1. Missing data and testing with assert
1. Pandas Foundation
1. Review of pandas
1. Building data frames from scratch
1. Visual exploratory data analysis
1. Statistical explatory data analysis
1. Indexing pandas time series
1. Resampling pandas time series
1. Manipulating Data Frames with Pandas
1. Indexing data frames
1. Slicing data frames
1. Filtering data frames
1. Transforming data frames
1. Index objects and labeled data
1. Hierarchical indexing
1. Pivoting data frames
1. Stacking and unstacking data frames
1. Melting data frames
1. Categoricals and groupby
1. Data Visualization
1. Seaborn: https://www.kaggle.com/kanncaa1/seaborn-for-beginners
1. Bokeh: https://www.kaggle.com/kanncaa1/interactive-bokeh-tutorial-part-1
1. Bokeh: https://www.kaggle.com/kanncaa1/interactive-bokeh-tutorial-part-2
1. Statistical Thinking
1. https://www.kaggle.com/kanncaa1/basic-statistic-tutorial-for-beginners
1. [Machine Learning](#1)
1. [Supervised Learning](#2)
1. [EDA(Exploratory Data Analysis)](#3)
1. [K-Nearest Neighbors (KNN)](#4)
1. [Regression](#5)
1. [Cross Validation (CV)](#6)
1. [ROC Curve](#7)
1. [Hyperparameter Tuning](#8)
1. [Pre-procesing Data](#9)
1. [Unsupervised Learning](#10)
1. [Kmeans Clustering](#11)
1. [Evaluation of Clustering](#12)
1. [Standardization](#13)
1. [Hierachy](#14)
1. [T - Distributed Stochastic Neighbor Embedding (T - SNE)](#15)
1. [Principle Component Analysis (PCA)](#16)
1. Deep Learning
1. https://www.kaggle.com/kanncaa1/deep-learning-tutorial-for-beginners
1. Time Series Prediction
1. https://www.kaggle.com/kanncaa1/time-series-prediction-tutorial-with-eda
1. Deep Learning with Pytorch
1. Artificial Neural Network: https://www.kaggle.com/kanncaa1/pytorch-tutorial-for-deep-learning-lovers
1. Convolutional Neural Network: https://www.kaggle.com/kanncaa1/pytorch-tutorial-for-deep-learning-lovers
1. Recurrent Neural Network: https://www.kaggle.com/kanncaa1/recurrent-neural-network-with-pytorch
```
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
# import warnings
import warnings
# ignore warnings
warnings.filterwarnings("ignore")
from subprocess import check_output
print(check_output(["ls", "../input"]).decode("utf8"))
# Any results you write to the current directory are saved as output.
# read csv (comma separated value) into data
data = pd.read_csv('../input/column_2C_weka.csv')
print(plt.style.available) # look at available plot styles
plt.style.use('ggplot')
```
<a id="1"></a> <br>
# 8. MACHINE LEARNING (ML)
In python there are some ML libraries like sklearn, keras or tensorflow. We will use sklearn.
<a id="2"></a> <br>
## A. SUPERVISED LEARNING
* Supervised learning: It uses data that has labels. Example, there are orthopedic patients data that have labels *normal* and *abnormal*.
* There are features(predictor variable) and target variable. Features are like *pelvic radius* or *sacral slope*(If you have no idea what these are like me, you can look images in google like what I did :) )Target variables are labels *normal* and *abnormal*
* Aim is that as given features(input) predict whether target variable(output) is *normal* or *abnormal*
* Classification: target variable consists of categories like normal or abnormal
* Regression: target variable is continious like stock market
* If these explanations are not enough for you, just google them. However, be careful about terminology: features = predictor variable = independent variable = columns = inputs. target variable = responce variable = class = dependent variable = output = result
<a id="3"></a> <br>
### EXPLORATORY DATA ANALYSIS (EDA)
* In order to make something in data, as you know you need to explore data. Detailed exploratory data analysis is in my Data Science Tutorial for Beginners
* I always start with *head()* to see features that are *pelvic_incidence, pelvic_tilt numeric, lumbar_lordosis_angle, sacral_slope, pelvic_radius* and *degree_spondylolisthesis* and target variable that is *class*
* head(): default value of it shows first 5 rows(samples). If you want to see for example 100 rows just write head(100)
```
# to see features and target variable
data.head()
# Well know question is is there any NaN value and length of this data so lets look at info
data.info()
```
As you can see:
* length: 310 (range index)
* Features are float
* Target variables are object that is like string
* Okey we have some ideas about data but lets look go inside data deeper
* describe(): I explain it in previous tutorial so there is a Quiz :)
* Why we need to see statistics like mean, std, max or min? I hate from quizzes :) so answer: In order to visualize data, values should be closer each other. As you can see values looks like closer. At least there is no incompatible values like mean of one feature is 0.1 and other is 1000. Also there are another reasons that I will mention next parts.
```
data.describe()
```
pd.plotting.scatter_matrix:
* green: *normal* and red: *abnormal*
* c: color
* figsize: figure size
* diagonal: histohram of each features
* alpha: opacity
* s: size of marker
* marker: marker type
```
color_list = ['red' if i=='Abnormal' else 'green' for i in data.loc[:,'class']]
pd.plotting.scatter_matrix(data.loc[:, data.columns != 'class'],
c=color_list,
figsize= [15,15],
diagonal='hist',
alpha=0.5,
s = 200,
marker = '*',
edgecolor= "black")
plt.show()
```
Okay, as you understand in scatter matrix there are relations between each feature but how many *normal(green)* and *abnormal(red)* classes are there.
* Searborn library has *countplot()* that counts number of classes
* Also you can print it with *value_counts()* method
<br> This data looks like balanced. Actually there is no definiton or numeric value of balanced data but this data is balanced enough for us.
<br> Now lets learn first classification method KNN
```
sns.countplot(x="class", data=data)
data.loc[:,'class'].value_counts()
```
<a id="4"></a> <br>
### K-NEAREST NEIGHBORS (KNN)
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
* KNN: Look at the K closest labeled data points
* Classification method.
* First we need to train our data. Train = fit
* fit(): fits the data, train the data.
* predict(): predicts the data
<br> If you do not understand what is KNN, look at youtube there are videos like 4-5 minutes. You can understand better with it.
<br> Lets learn how to implement it with sklearn
* x: features
* y: target variables(normal, abnormal)
* n_neighbors: K. In this example it is 3. it means that Look at the 3 closest labeled data points
```
# KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 3)
x,y = data.loc[:,data.columns != 'class'], data.loc[:,'class']
knn.fit(x,y)
prediction = knn.predict(x)
print('Prediction: {}'.format(prediction))
```
We have fit the data and predict it with KNN.
But there's a BIG problem in this process - the model is trained with `x` and again predict with `x`.
<br>We need to split our data train and test sets.
* train: use train set by fitting
* test: make prediction on test set.
* With train and test sets, fitted data and tested data are completely different
* train_test_split(x,y,test_size = 0.3,random_state = 1)
* x: features
* y: target variables (normal,abnormal)
* test_size: percentage of test size. Example test_size = 0.3, test size = 30% and train size = 70%
* random_state: sets a seed. If this seed is same number, train_test_split() produce exact same split at each time
* fit(x_train,y_train): fit on train sets
* score(x_test,y_test)): predict and give accuracy on test sets
```
# train test split
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3,random_state = 1)
knn = KNeighborsClassifier(n_neighbors = 3)
x,y = data.loc[:,data.columns != 'class'], data.loc[:,'class']
knn.fit(x_train,y_train)
prediction = knn.predict(x_test)
#print('Prediction: {}'.format(prediction))
print('With KNN (K=3) accuracy is: ',knn.score(x_test,y_test)) # accuracy
```
Accuracy is 86% so is it good ? I do not know actually, we will see at the end of tutorial.
<br> Now the question is why we choose K = 3 or what value we need to choose K. The answer is in model complexity
<br> Model complexity:
* K has general name. It is called a hyperparameter. For now just know K is hyperparameter and we need to choose it that gives best performace.
* Literature says if k is small, model is complex model can lead to overfit. It means that model memorizes the train sets and cannot predict test set with good accuracy.
* If k is big, model that is less complex model can lead to underfit.
* At below, I range K value from 1 to 25(exclude) and find accuracy for each K value. As you can see in plot, when K is 1 it memozize train sets and cannot give good accuracy on test set (overfit). Also if K is 18, model is lead to underfit. Again accuracy is not enough. However look at when K is 18(best performance), accuracy has highest value almost 88%.
```
# Model complexity
neig = np.arange(1, 25)
train_accuracy = []
test_accuracy = []
# Loop over different values of k
for i, k in enumerate(neig):
# k from 1 to 25(exclude)
knn = KNeighborsClassifier(n_neighbors=k)
# Fit with knn
knn.fit(x_train,y_train)
#train accuracy
train_accuracy.append(knn.score(x_train, y_train))
# test accuracy
test_accuracy.append(knn.score(x_test, y_test))
# Plot
plt.figure(figsize=[13,8])
plt.plot(neig, test_accuracy, label = 'Testing Accuracy')
plt.plot(neig, train_accuracy, label = 'Training Accuracy')
plt.legend()
plt.title('K-value VS Accuracy')
plt.xlabel('Number of Neighbors')
plt.ylabel('Accuracy')
plt.xticks(neig)
plt.savefig('graph.png')
plt.show()
print("Best accuracy is {} with K = {}".format(np.max(test_accuracy),1+test_accuracy.index(np.max(test_accuracy))))
```
### Up to this point what you learn:
* Supervised learning
* Exploratory data analysis
* KNN
* How to split data
* How to fit, predict data
* How to measure medel performance (accuracy)
* How to choose hyperparameter (K)
**<br> What happens if I chance the title KNN and make it some other classification technique like Random Forest?**
* The answer is **nothing**. What you need to is just watch a video about what is random forest in youtube and implement what you learn in KNN. Because the idea and even most of the codes (only KNeighborsClassifier need to be RandomForestClassifier ) are same. You need to split, fit, predict your data and measue performance and choose hyperparameter of random forest(like max_depth).
<a id="5"></a> <br>
### REGRESSION
* Supervised learning
* We will learn linear and logistic regressions
* This orthopedic patients data is not proper for regression so I only use two features that are *sacral_slope* and *pelvic_incidence* of abnormal
* I consider feature is pelvic_incidence and target is sacral_slope
* Lets look at scatter plot so as to understand it better
* reshape(-1,1): If you do not use it shape of x or y becaomes (210,) and we cannot use it in sklearn, so we use shape(-1,1) and shape of x or y be (210, 1).
```
# create data1 that includes pelvic_incidence that is feature and sacral_slope that is target variable
data1 = data[data['class'] =='Abnormal']
x = np.array(data1.loc[:,'pelvic_incidence']).reshape(-1,1)
y = np.array(data1.loc[:,'sacral_slope']).reshape(-1,1)
# Scatter
plt.figure(figsize=[10,10])
plt.scatter(x=x,y=y)
plt.xlabel('pelvic_incidence')
plt.ylabel('sacral_slope')
plt.show()
```
Now we have our data to make regression. In regression problems target value is continuously varying variable such as price of house or sacral_slope. Lets fit line into this points.
<br> Linear regression
* y = ax + b where y = target, x = feature and a = parameter of model
* We choose parameter of model(a) according to minimum error function that is lost function
* In linear regression we use Ordinary Least Square (OLS) as lost function.
* OLS: sum all residuals but some positive and negative residuals can cancel each other so we sum of square of residuals. It is called OLS
* Score: Score uses R^2 method that is ((y_pred - y_mean)^2 )/(y_actual - y_mean)^2
```
# LinearRegression
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
# Predict space
predict_space = np.linspace(min(x), max(x)).reshape(-1,1)
# Fit
reg.fit(x,y)
# Predict
predicted = reg.predict(predict_space)
# R^2
print('R^2 score: ',reg.score(x, y))
# Plot regression line and scatter
plt.plot(predict_space, predicted, color='black', linewidth=3)
plt.scatter(x=x,y=y)
plt.xlabel('pelvic_incidence')
plt.ylabel('sacral_slope')
plt.show()
```
<a id="6"></a> <br>
### CROSS VALIDATION
\*[Why Train Validation Test Data](https://medium.com/datadriveninvestor/data-science-essentials-why-train-validation-test-data-b7f7d472dc1f)
> The primary objective of test data is to give an unbiased estimate of model accuracy. It should be used at the very end and only for a couple of times. If you tune your model after looking at the test accuracies, you are technically leaking information and hence cheating.
<br> Cross Validation (CV)
* K folds = K fold CV.
* Look at this image it defines better than me :)
* When K is increase, computationally cost is increase
* cross_val_score(reg,x,y,cv=5): use reg(linear regression) with x and y that we define at above and K is 5. It means 5 times(split, train,predict)

```
# CV
from sklearn.model_selection import cross_val_score
reg = LinearRegression()
k = 5
cv_result = cross_val_score(reg,x,y,cv=k) # uses R^2 as score
print('CV Scores: ',cv_result)
print('CV scores average: ',np.sum(cv_result)/k)
```
### Regularized Regression
[Regularization](https://en.wikipedia.org/wiki/Regularization_(mathematics)) is a technique used in machine learning to mitigate the problem of [overfitting](https://en.wikipedia.org/wiki/Overfitting).
Overfitting vs. Underfitting
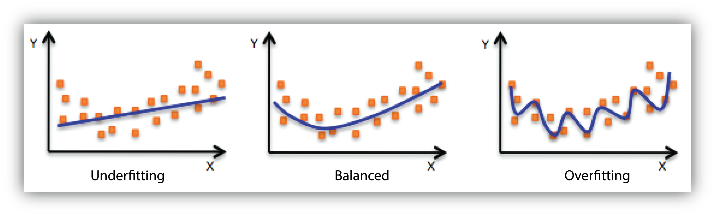
As we learn linear regression choose parameters (coefficients) while minimizing lost function. If linear regression thinks that one of the feature is important, it gives high coefficient to this feature. However, this can cause overfitting that is like memorizing in KNN. In order to avoid overfitting, we use regularization that penalize large coefficients.
* Ridge regression: First regularization technique. Also it is called L2 regularization.
* Ridge regression lost fuction = OLS + alpha * sum(parameter^2)
* alpha is parameter we need to choose to fit and predict. Picking alpha is similar to picking K in KNN. As you understand alpha is hyperparameter that we need to choose for best accuracy and model complexity. This process is called hyperparameter tuning.
* What if alpha is zero? lost function = OLS so that is linear rigression :)
* If alpha is small that can cause overfitting
* If alpha is big that can cause underfitting. But do not ask what is small and big. These can be change from problem to problem.
* Lasso regression: Second regularization technique. Also it is called L1 regularization.
* Lasso regression lost fuction = OLS + alpha * sum(absolute_value(parameter))
* It can be used to select important features od the data. Because features whose values are not shrinked to zero, is chosen by lasso regression
* In order to choose feature, I add new features in our regression data
<br> Linear vs Ridge vs Lasso
First impression: Linear
Feature Selection: 1.Lasso 2.Ridge
Regression model: 1.Ridge 2.Lasso 3.Linear
```
# Ridge
from sklearn.linear_model import Ridge
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state = 2, test_size = 0.3)
ridge = Ridge(alpha = 0.1, normalize = True)
ridge.fit(x_train,y_train)
ridge_predict = ridge.predict(x_test)
print('Ridge score: ',ridge.score(x_test,y_test))
# Lasso
from sklearn.linear_model import Lasso
x = np.array(data1.loc[:,['pelvic_incidence','pelvic_tilt numeric','lumbar_lordosis_angle','pelvic_radius']])
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state = 3, test_size = 0.3)
lasso = Lasso(alpha = 0.1, normalize = True)
lasso.fit(x_train,y_train)
ridge_predict = lasso.predict(x_test)
print('Lasso score: ',lasso.score(x_test,y_test))
print('Lasso coefficients: ',lasso.coef_)
```
As you can see *pelvic_incidence* and *pelvic_tilt numeric* are important features but others are not important
<br> Now lets discuss accuracy. Is it enough for measurement of model selection. For example, there is a data that includes 95% normal and 5% abnormal samples and our model uses accuracy for measurement metric. Then our model predict 100% normal for all samples and accuracy is 95% but it classify all abnormal samples wrong. Therefore we use [confusion matrix](https://en.wikipedia.org/wiki/Confusion_matrix) as a model performance measurement.
<br> While using confusion matrix lets use Random forest classifier to diversify classification methods.
* tp = true positive(20), fp = false positive(7), fn = false negative(8), tn = true negative(58)
* tp = Prediction is positive(normal) and actual is positive(normal).
* fp = Prediction is positive(normal) and actual is negative(abnormal).
* fn = Prediction is negative(abnormal) and actual is positive(normal).
* tn = Prediction is negative(abnormal) and actual is negative(abnormal)
* precision = tp / (tp+fp)
* recall = tp / (tp+fn)
* f1 = 2 * precision * recall / ( precision + recall)
Confusion matrix example on phishing email prediction:
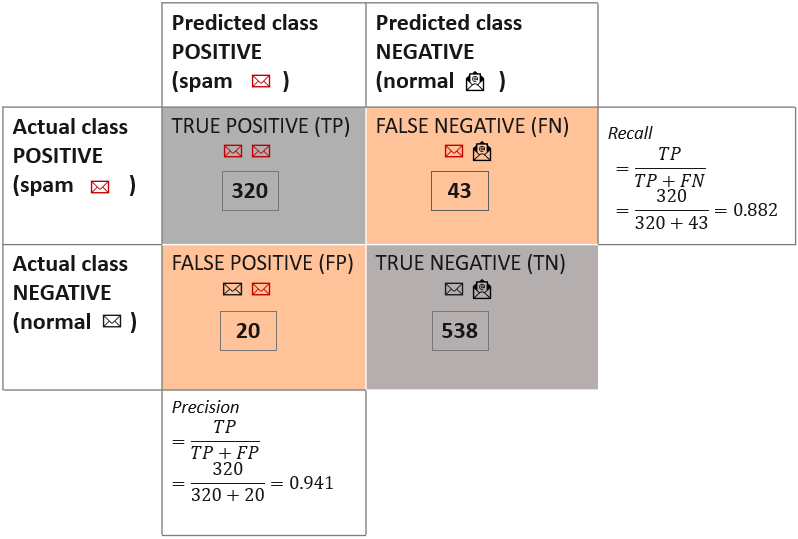
```
# Confusion matrix with random forest
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.ensemble import RandomForestClassifier
x,y = data.loc[:,data.columns != 'class'], data.loc[:,'class']
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3,random_state = 1)
rf = RandomForestClassifier(random_state = 4)
rf.fit(x_train,y_train)
y_pred = rf.predict(x_test)
cm = confusion_matrix(y_test,y_pred)
print('Confusion matrix: \n',cm)
print('Classification report: \n',classification_report(y_test,y_pred))
# visualize with seaborn library
sns.heatmap(cm,annot=True,fmt="d")
plt.show()
```
<a id="7"></a> <br>
### ROC Curve with Logistic Regression

* [Receiver operating characteristic curve](https://en.wikipedia.org/wiki/Receiver_operating_characteristic) - plotting the recall or true positive rate (TPR, TP / (TP+FN)) against the fall-out or false positive rate (FPR, FP / (FP + TN)) at various threshold settings.
* logistic regression output is probabilities
* If probability is higher than 0.5 data is labeled 1(abnormal) else 0(normal)
* By default logistic regression threshold is 0.5
* ROC is receiver operationg characteristic. In this curve x axis is false positive rate and y axis is true positive rate
* If the curve in plot is closer to left-top corner, test is more accurate.
* ROC curve score is area under curve (AUC) that is computation area under the curve from prediction scores
* We want auc to closer 1
* fpr = False Positive Rate
* tpr = True Positive Rate
* If you want, I made ROC, Random forest and K fold CV in this tutorial. https://www.kaggle.com/kanncaa1/roc-curve-with-k-fold-cv/
```
# ROC Curve with logistic regression
from sklearn.metrics import roc_curve
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
# abnormal = 1 and normal = 0
data['class_binary'] = [1 if i == 'Abnormal' else 0 for i in data.loc[:,'class']]
x,y = data.loc[:,(data.columns != 'class') & (data.columns != 'class_binary')], data.loc[:,'class_binary']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state=42)
logreg = LogisticRegression()
logreg.fit(x_train,y_train)
y_pred_prob = logreg.predict_proba(x_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
# Plot ROC curve
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr, tpr)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC')
plt.show()
```
<a id="8"></a> <br>
### HYPERPARAMETER TUNING
For machine learning models, there are hyperparameters that are need to be tuned
* For example:
* k at KNN
* alpha at Ridge and Lasso
* Random forest parameters like max_depth
* linear regression parameters(coefficients)
* Hyperparameter tuning:
* try all of combinations of different parameters
* fit all of them
* measure prediction performance
* see how well each performs
* finally choose best hyperparameters
* This process is most difficult part of this tutorial. Because we will write a lot of for loops to iterate all combinations. Just I am kidding sorry for this :) (We actually did it at KNN part)
* We only need is one line code that is GridSearchCV
* grid: K is from 1 to 50(exclude)
* GridSearchCV takes knn and grid and makes grid search. It means combination of all hyperparameters. Here it is k.
```
# grid search cross validation with 1 hyperparameter
from sklearn.model_selection import GridSearchCV
grid = {'n_neighbors': np.arange(1,50)}
knn = KNeighborsClassifier()
knn_cv = GridSearchCV(knn, grid, cv=3) # GridSearchCV
knn_cv.fit(x,y)# Fit
# Print hyperparameter
print("Tuned hyperparameter k: {}".format(knn_cv.best_params_))
print("Best score: {}".format(knn_cv.best_score_))
```
Other grid search example with 2 hyperparameter
* First hyperparameter is C:logistic regression regularization parameter
* If C is high: overfit
* If C is low: underfit
* Second hyperparameter is penalty(lost function): l1 (Lasso) or l2(Ridge) as we learnt at linear regression part.
```
np.logspace(-3, 3, 7)
# grid search cross validation with 2 hyperparameter
# 1. hyperparameter is C:logistic regression regularization parameter
# 2. penalty l1 or l2
# Hyperparameter grid
param_grid = {'C': np.logspace(-3, 3, 7), 'penalty': ['l1', 'l2']}
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size = 0.3,random_state = 12)
logreg = LogisticRegression()
logreg_cv = GridSearchCV(logreg,param_grid,cv=3)
logreg_cv.fit(x_train,y_train)
# Print the optimal parameters and best score
print("Tuned hyperparameters : {}".format(logreg_cv.best_params_))
print("Best Accuracy: {}".format(logreg_cv.best_score_))
```
<a id="9"></a> <br>
### PRE-PROCESSING DATA
* In real life data can include objects or categorical data in order to use them in sklearn we need to encode them into numerical data
* In previous dataset, class is *abnormal* and *normal*. Lets convert them into numeric value.
* 2 different feature is created with the name *class_Abnormal* and *class_Normal*
* However, we will drop one of the column because this is a binary class and we should only need one column.
```
# Load data
data = pd.read_csv('../input/column_2C_weka.csv')
# get_dummies
df = pd.get_dummies(data)
df.head(10)
# drop one of the feature
df.drop("class_Normal",axis = 1, inplace = True)
df.head(10)
# instead of two steps we can make it with one step pd.get_dummies(data,drop_first = True)
```
Other preprocessing step is centering, scaling or normalizing
* Some algorithms, such as KNN uses form of distance, which means they're sensitive to the value of the features. For example, when your dataset has a column `age` with values like 31, 23, 46, and etc., and another column `salary` with values like 55000, 70000, 100000, and etc. without normalize or scale the data, distance-based algorithms will be biased because the distances between `salary` is always larger than `age`.
* standardization: ( x - x.mean) / x.variance or x - x.min / x.range
* [pipeline](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html): The purpose of the pipeline is to assemble several steps like svm(classifier) and standardization(pre-processing)
* How we create parameters name: for example SVM_ _C : stepName__parameterName
* Then grid search to find best parameters
```
# SVM, pre-process and pipeline
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
steps = [('scalar', StandardScaler()),
('SVM', SVC())]
pipeline = Pipeline(steps)
parameters = {'SVM__C':[1, 10, 100],
'SVM__gamma':[0.1, 0.01]}
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state = 1)
cv = GridSearchCV(pipeline,param_grid=parameters,cv=3)
cv.fit(x_train,y_train)
y_pred = cv.predict(x_test)
print("Accuracy: {}".format(cv.score(x_test, y_test)))
print("Tuned Model Parameters: {}".format(cv.best_params_))
```
<a id="10"></a> <br>
## UNSUPERVISED LEARNING
* Unsupervised learning: It uses data that has unlabeled and uncover hidden patterns from unlabeled data. Example, there are orthopedic patients data that do not have labels. You do not know which orthopedic patient is normal or abnormal.
* As you know orthopedic patients data is labeled (supervised) data. It has target variables. In order to work on unsupervised learning, lets drop target variables and to visualize just consider *pelvic_radius* and *degree_spondylolisthesis*
<a id="11"></a> <br>
### KMEANS
[kmeans clustering](https://en.wikipedia.org/wiki/K-means_clustering)
* Lets try our first unsupervised method that is KMeans Cluster
* KMeans Cluster: The algorithm works iteratively to assign each data point to one of K groups based on the features that are provided. Data points are clustered based on feature similarity
* KMeans(n_clusters = 2): n_clusters = 2 means that create 2 cluster
```
# As you can see there is no labels in data
data = pd.read_csv('../input/column_2C_weka.csv')
plt.scatter(data['pelvic_radius'],data['degree_spondylolisthesis'])
plt.xlabel('pelvic_radius')
plt.ylabel('degree_spondylolisthesis')
plt.show()
# KMeans Clustering
data2 = data.loc[:,['degree_spondylolisthesis','pelvic_radius']]
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 2)
kmeans.fit(data2)
labels = kmeans.predict(data2)
plt.scatter(data['pelvic_radius'],data['degree_spondylolisthesis'],c = labels)
plt.xlabel('pelvic_radius')
plt.xlabel('degree_spondylolisthesis')
plt.show()
```
<a id="12"></a> <br>
### EVALUATING OF CLUSTERING
We cluster data in two groups. Okey well is that correct clustering? In order to evaluate clustering we will use cross tabulation table.
* There are two clusters that are *0* and *1*
* First class *0* includes 138 abnormal and 100 normal patients
* Second class *1* includes 72 abnormal and 0 normal patiens
*The majority of two clusters are abnormal patients.
```
# cross tabulation table
df = pd.DataFrame({'labels':labels,"class":data['class']})
ct = pd.crosstab(df['labels'],df['class'])
print(ct)
```
The new question is that we know how many class data includes, but what if number of class is unknow in data. This is kind of like hyperparameter in KNN or regressions.
* inertia: how spread out the clusters are distance from each sample
* lower inertia means more clusters
* What is the best number of clusters ?
*There are low inertia and not too many cluster trade off so we can choose elbow
```
# inertia
inertia_list = np.empty(8)
for i in range(1,8):
kmeans = KMeans(n_clusters=i)
kmeans.fit(data2)
inertia_list[i] = kmeans.inertia_
plt.plot(range(0,8),inertia_list,'-o')
plt.xlabel('Number of cluster')
plt.ylabel('Inertia')
plt.show()
```
<a id="13"></a> <br>
### STANDARDIZATION
* Standardizaton is important for both supervised and unsupervised learning
* Do not forget standardization as pre-processing
* As we already have visualized data so you got the idea. Now we can use all features for clustering.
* We can use pipeline like supervised learning.
```
data = pd.read_csv('../input/column_2C_weka.csv')
data3 = data.drop('class',axis = 1)
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
scalar = StandardScaler()
kmeans = KMeans(n_clusters = 2)
pipe = make_pipeline(scalar,kmeans)
pipe.fit(data3)
labels = pipe.predict(data3)
df = pd.DataFrame({'labels':labels,"class":data['class']})
ct = pd.crosstab(df['labels'],df['class'])
print(ct)
```
<a id="14"></a> <br>
### HIERARCHY
* vertical lines are clusters
* height on dendogram: distance between merging cluster
* method= 'single' : closest points of clusters
```
from scipy.cluster.hierarchy import linkage,dendrogram
merg = linkage(data3.iloc[200:220,:],method = 'single')
dendrogram(merg, leaf_rotation = 90, leaf_font_size = 6)
plt.show()
```
<a id="15"></a> <br>
### T - Distributed Stochastic Neighbor Embedding (T - SNE)
* learning rate: 50-200 in normal
* fit_transform: it is both fit and transform. t-sne has only have fit_transform
* Varieties have same position relative to one another
```
from sklearn.manifold import TSNE
model = TSNE(learning_rate=100)
transformed = model.fit_transform(data2)
x = transformed[:,0]
y = transformed[:,1]
plt.scatter(x,y,c = color_list )
plt.xlabel('pelvic_radius')
plt.xlabel('degree_spondylolisthesis')
plt.show()
```
<a id="16"></a> <br>
### PRINCIPLE COMPONENT ANALYSIS (PCA)
* Fundemental dimension reduction technique
* first step is decorrelation:
* rotates data samples to be aligned with axes
* shifts data asmples so they have mean zero
* no information lost
* fit() : learn how to shift samples
* transform(): apply the learned transformation. It can also be applies test data
* Resulting PCA features are not linearly correlated
* Principle components: directions of variance
```
# PCA
from sklearn.decomposition import PCA
model = PCA()
model.fit(data3)
transformed = model.transform(data3)
print('Principle components: ',model.components_)
# PCA variance
scaler = StandardScaler()
pca = PCA()
pipeline = make_pipeline(scaler,pca)
pipeline.fit(data3)
plt.bar(range(pca.n_components_), pca.explained_variance_)
plt.xlabel('PCA feature')
plt.ylabel('variance')
plt.show()
```
* Second step: intrinsic dimension: number of feature needed to approximate the data essential idea behind dimension reduction
* PCA identifies intrinsic dimension when samples have any number of features
* intrinsic dimension = number of PCA feature with significant variance
* In order to choose intrinsic dimension try all of them and find best accuracy
* Also check intuitive way of PCA with this example: https://www.kaggle.com/kanncaa1/tutorial-pca-intuition-and-image-completion
```
# apply PCA
pca = PCA(n_components = 2)
pca.fit(data3)
transformed = pca.transform(data3)
x = transformed[:,0]
y = transformed[:,1]
plt.scatter(x,y,c = color_list)
plt.show()
```
# CONCLUSION
This is the end of DATA SCIENCE tutorial. The first part is here:
<br> https://www.kaggle.com/kanncaa1/data-sciencetutorial-for-beginners/
<br>**If you have any question or suggest, I will be happy to hear it.**
| github_jupyter |
# Sample supervised segmentation on Gray images
Image segmentation is widely used as an initial phase of many image processing tasks in computer vision and image analysis. Many recent segmentation methods use superpixels, because they reduce the size of the segmentation problem by an order of magnitude. In addition, features on superpixels are much more robust than features on pixels only. We use spatial regularization on superpixels to make segmented regions more compact. The segmentation pipeline comprises: (i) computation of superpixels; (ii) extraction of descriptors such as color and texture; (iii) soft classification, using a standard classifier for supervised learning; (iv) final segmentation using Graph Cut. We use this segmentation pipeline on four real-world applications in medical imaging. We also show that unsupervised segmentation is sufficient for some situations, and provides similar results to those obtained using trained segmentation.
Borovec, J., Svihlik, J., Kybic, J., & Habart, D. (2017). **Supervised and unsupervised segmentation using superpixels, model estimation, and Graph Cut.** Journal of Electronic Imaging.
```
%matplotlib inline
import os, sys, glob, time
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from skimage.segmentation import mark_boundaries
sys.path += [os.path.abspath('.'), os.path.abspath('..')] # Add path to root
import imsegm.utilities.data_io as tl_data
import imsegm.pipelines as segm_pipe
```
## Load image
```
path_dir = os.path.join(tl_data.update_path('data-images'), 'drosophila_ovary_slice')
path_images = os.path.join(path_dir, 'image')
print ([os.path.basename(p) for p in glob.glob(os.path.join(path_images, '*.jpg'))])
# loading images
path_img = os.path.join(path_images, 'insitu7545.jpg')
img = np.array(Image.open(path_img))[:, :, 0]
path_img = os.path.join(path_images, 'insitu4174.jpg')
img2 = np.array(Image.open(path_img))[:, :, 0]
# loading annotations
path_annots = os.path.join(path_dir, 'annot_struct')
path_annot = os.path.join(path_annots, 'insitu7545.png')
annot = np.array(Image.open(path_annot))
```
Show that training example with annotation and testing image
```
FIG_SIZE = (8. * np.array(img.shape[:2]) / np.max(img.shape))[::-1]
fig = plt.figure(figsize=FIG_SIZE * 3)
_= plt.subplot(1,3,1), plt.imshow(img, cmap=plt.cm.Greys_r), plt.contour(annot, colors='y')
_= plt.subplot(1,3,2), plt.imshow(annot, cmap=plt.cm.jet)
_= plt.subplot(1,3,3), plt.imshow(img2, cmap=plt.cm.Greys_r)
```
## Segment Image
Set segmentation parameters:
```
sp_size = 25
sp_regul = 0.2
dict_features = {'color': ['mean', 'std', 'median'], 'tLM': ['mean']}
```
Train the classifier
```
classif, list_slic, list_features, list_labels = segm_pipe.train_classif_color2d_slic_features([img], [annot],
sp_size=sp_size, sp_regul=sp_regul, dict_features=dict_features, pca_coef=None)
```
Perform the segmentation with trained classifier
```
dict_debug = {}
seg, _ = segm_pipe.segment_color2d_slic_features_model_graphcut(img2, classif, sp_size=sp_size, sp_regul=sp_regul,
gc_regul=1., dict_features=dict_features, gc_edge_type='model', debug_visual=dict_debug)
fig = plt.figure(figsize=FIG_SIZE)
plt.imshow(img2, cmap=plt.cm.Greys_r)
plt.imshow(seg, alpha=0.6, cmap=plt.cm.jet)
_= plt.contour(seg, levels=np.unique(seg), colors='w')
```
## Visualise intermediate steps
```
print ('debug fields: %s' % repr(dict_debug.keys()))
plt.figure(), plt.imshow(mark_boundaries(img2, dict_debug['slic'])), plt.title('SLIC')
plt.figure(), plt.imshow(dict_debug['slic_mean']), plt.title('SLIC mean')
plt.figure(), plt.imshow(dict_debug['img_graph_edges']), plt.title('graph edges')
for i, im_u in enumerate(dict_debug['imgs_unary_cost']):
plt.figure(), plt.title('unary cost: %i' % i), plt.imshow(im_u)
# plt.figure(), plt.imshow(dict_debug['img_graph_segm'])
```
| github_jupyter |
# Code slide Part -1
```
import numpy as np
```
NumPy
=====
Provides
1. An array object of arbitrary homogeneous items
2. Fast mathematical operations over arrays
3. Linear Algebra, Fourier Transforms, Random Number Generation
For more information about introduction to NumPy. Read this [Doc](https://docs.scipy.org/doc/numpy-1.13.0/user/whatisnumpy.html)
```
numpy_array = np.array([1, 2, 3.0])
```
ndarray = block of memory + indexing scheme + data type descriptor
raw data
how to locate an element
how to interpret an element
Ref: [Link](http://scipy-lectures.org/advanced/advanced_numpy/#id4)
```
numpy_array #Typecasted to float to maintain homogenity
numpy_array.dtype
```
[List of Supported Data Types](https://docs.scipy.org/doc/numpy/user/basics.types.html)
```
type(numpy_array)
type(numpy_array[0])
numpy_array.append(9.0) # Should throw error
```
### NOTE
Numpy arrays are fixed size arrays unlike Python List/Dict ojects which are dynamic in nature.
Any insertion/deletion/concatination when/if performed creates a new copy of the array.
How this strict rule of homogenity and size helps Numpy?
We will witness shortly.
# Code Slide Part-2
```
a = np.array([[1,2,3],[4,5,6]])
a
a.shape
a.strides
```
The strides of an array tell us how many bytes we have to skip in memory to move to the next position along a certain axis.
This StackOveflow Q/A explains it quite well. [Link](https://stackoverflow.com/questions/53097952/how-to-understand-numpy-strides-for-layman)
```
b = a.T # Transpose of a
b
b.shape
b.strides
c = a.reshape((6)) # Convert in 1-D array
c
c.shape
c.strides
a.__array_interface__['data'][0] # kinda databuff mem position
b.__array_interface__['data'][0] # kinda databuff mem position
c.__array_interface__['data'][0] # kinda databuff mem position
databuff_mem_loc_a = a.__array_interface__['data'][0]
databuff_mem_loc_b = b.__array_interface__['data'][0]
databuff_mem_loc_c = c.__array_interface__['data'][0]
assert(databuff_mem_loc_a == databuff_mem_loc_b == databuff_mem_loc_c)
```
# Code Slide Part-3
## (A): Glimpse of Universal functions
```
a = np.array([1, 2, 3])
b = np.array([2, 3, -1])
a * b # Common Mathematical operations are overridden for arrays
# Element wise multiplication. Use np.dot for matrix multiplication
np.greater(a,b) # Comparision function
np.logical_and(a>0, b>0)
np.sum(a) # Univariate functions, takes in single argument
np.min(b)
```
Thus, a ufunc is a “vectorized” wrapper for a function that takes a fixed number of specific inputs,
and produces a fixed number of specific outputs.
-Numpy Docs.
Complete list of uFuncs: [Link](https://docs.scipy.org/doc/numpy/reference/ufuncs.html#available-ufuncs)
## (B): Execution Time Comparision for * operation
```
import pandas as pd
import matplotlib.pyplot as plt
from time import time
%matplotlib inline
def return_time_taken(object_size):
python_list = list(range(object_size))
start_ = time()
_ = [element * element for element in python_list]
end_ = time()
del(python_list)
del(_)
time_taken_lists = end_ - start_
numpy_array = np.arange(object_size)
start_ = time()
numpy_array*numpy_array
end_ = time()
del(numpy_array)
time_taken_np = end_ - start_
return (time_taken_lists, time_taken_np)
df = pd.DataFrame(columns=["C", "tL", "tN"])
object_size = 1
while object_size !=100000000:
results = return_time_taken(object_size)
df = df.append({"C": object_size, "tL": results[0], "tN": results[1]},ignore_index=True) #Optimise this
object_size *= 10
df
df.plot(x="C",y=["tL","tN"], figsize=(10,5), grid=True)
plt.xlabel("Size of Object")
plt.ylabel("Time in(sec)")
plt.legend(["List looping", "Numpy Vectorization"])
plt.title("Input Object Size vs. Execution Time for *")
plt.show()
```
| github_jupyter |
```
# default_exp vision.models.xresnet
#export
from fastai.torch_basics import *
from torchvision.models.utils import load_state_dict_from_url
#hide
from nbdev.showdoc import *
```
# XResnet
> Resnet from bags of tricks paper
```
#export
def init_cnn(m):
if getattr(m, 'bias', None) is not None: nn.init.constant_(m.bias, 0)
if isinstance(m, (nn.Conv1d,nn.Conv2d,nn.Conv3d,nn.Linear)): nn.init.kaiming_normal_(m.weight)
for l in m.children(): init_cnn(l)
#export
class XResNet(nn.Sequential):
@delegates(ResBlock)
def __init__(self, block, expansion, layers, p=0.0, c_in=3, n_out=1000, stem_szs=(32,32,64),
widen=1.0, sa=False, act_cls=defaults.activation, ndim=2, ks=3, stride=2, **kwargs):
store_attr('block,expansion,act_cls,ndim,ks')
if ks % 2 == 0: raise Exception('kernel size has to be odd!')
stem_szs = [c_in, *stem_szs]
stem = [ConvLayer(stem_szs[i], stem_szs[i+1], ks=ks, stride=stride if i==0 else 1,
act_cls=act_cls, ndim=ndim)
for i in range(3)]
block_szs = [int(o*widen) for o in [64,128,256,512] +[256]*(len(layers)-4)]
block_szs = [64//expansion] + block_szs
blocks = self._make_blocks(layers, block_szs, sa, stride, **kwargs)
super().__init__(
*stem, MaxPool(ks=ks, stride=stride, padding=ks//2, ndim=ndim),
*blocks,
AdaptiveAvgPool(sz=1, ndim=ndim), Flatten(), nn.Dropout(p),
nn.Linear(block_szs[-1]*expansion, n_out),
)
init_cnn(self)
def _make_blocks(self, layers, block_szs, sa, stride, **kwargs):
return [self._make_layer(ni=block_szs[i], nf=block_szs[i+1], blocks=l,
stride=1 if i==0 else stride, sa=sa and i==len(layers)-4, **kwargs)
for i,l in enumerate(layers)]
def _make_layer(self, ni, nf, blocks, stride, sa, **kwargs):
return nn.Sequential(
*[self.block(self.expansion, ni if i==0 else nf, nf, stride=stride if i==0 else 1,
sa=sa and i==(blocks-1), act_cls=self.act_cls, ndim=self.ndim, ks=self.ks, **kwargs)
for i in range(blocks)])
#export
def _xresnet(pretrained, expansion, layers, **kwargs):
# TODO pretrain all sizes. Currently will fail with non-xrn50
url = 'https://s3.amazonaws.com/fast-ai-modelzoo/xrn50_940.pth'
res = XResNet(ResBlock, expansion, layers, **kwargs)
if pretrained: res.load_state_dict(load_state_dict_from_url(url, map_location='cpu')['model'], strict=False)
return res
def xresnet18 (pretrained=False, **kwargs): return _xresnet(pretrained, 1, [2, 2, 2, 2], **kwargs)
def xresnet34 (pretrained=False, **kwargs): return _xresnet(pretrained, 1, [3, 4, 6, 3], **kwargs)
def xresnet50 (pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3, 4, 6, 3], **kwargs)
def xresnet101(pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3, 4, 23, 3], **kwargs)
def xresnet152(pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3, 8, 36, 3], **kwargs)
def xresnet18_deep (pretrained=False, **kwargs): return _xresnet(pretrained, 1, [2,2,2,2,1,1], **kwargs)
def xresnet34_deep (pretrained=False, **kwargs): return _xresnet(pretrained, 1, [3,4,6,3,1,1], **kwargs)
def xresnet50_deep (pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3,4,6,3,1,1], **kwargs)
def xresnet18_deeper(pretrained=False, **kwargs): return _xresnet(pretrained, 1, [2,2,1,1,1,1,1,1], **kwargs)
def xresnet34_deeper(pretrained=False, **kwargs): return _xresnet(pretrained, 1, [3,4,6,3,1,1,1,1], **kwargs)
def xresnet50_deeper(pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3,4,6,3,1,1,1,1], **kwargs)
#export
se_kwargs1 = dict(groups=1 , reduction=16)
se_kwargs2 = dict(groups=32, reduction=16)
se_kwargs3 = dict(groups=32, reduction=0)
g0 = [2,2,2,2]
g1 = [3,4,6,3]
g2 = [3,4,23,3]
g3 = [3,8,36,3]
#export
def xse_resnet18(n_out=1000, pretrained=False, **kwargs): return XResNet(SEBlock, 1, g0, n_out=n_out, **se_kwargs1, **kwargs)
def xse_resnext18(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, g0, n_out=n_out, **se_kwargs2, **kwargs)
def xresnext18(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, g0, n_out=n_out, **se_kwargs3, **kwargs)
def xse_resnet34(n_out=1000, pretrained=False, **kwargs): return XResNet(SEBlock, 1, g1, n_out=n_out, **se_kwargs1, **kwargs)
def xse_resnext34(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, g1, n_out=n_out, **se_kwargs2, **kwargs)
def xresnext34(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, g1, n_out=n_out, **se_kwargs3, **kwargs)
def xse_resnet50(n_out=1000, pretrained=False, **kwargs): return XResNet(SEBlock, 4, g1, n_out=n_out, **se_kwargs1, **kwargs)
def xse_resnext50(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 4, g1, n_out=n_out, **se_kwargs2, **kwargs)
def xresnext50(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 4, g1, n_out=n_out, **se_kwargs3, **kwargs)
def xse_resnet101(n_out=1000, pretrained=False, **kwargs): return XResNet(SEBlock, 4, g2, n_out=n_out, **se_kwargs1, **kwargs)
def xse_resnext101(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 4, g2, n_out=n_out, **se_kwargs2, **kwargs)
def xresnext101(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 4, g2, n_out=n_out, **se_kwargs3, **kwargs)
def xse_resnet152(n_out=1000, pretrained=False, **kwargs): return XResNet(SEBlock, 4, g3, n_out=n_out, **se_kwargs1, **kwargs)
def xsenet154(n_out=1000, pretrained=False, **kwargs):
return XResNet(SEBlock, g3, groups=64, reduction=16, p=0.2, n_out=n_out)
def xse_resnext18_deep (n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, g0+[1,1], n_out=n_out, **se_kwargs2, **kwargs)
def xse_resnext34_deep (n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, g1+[1,1], n_out=n_out, **se_kwargs2, **kwargs)
def xse_resnext50_deep (n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 4, g1+[1,1], n_out=n_out, **se_kwargs2, **kwargs)
def xse_resnext18_deeper(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, [2,2,1,1,1,1,1,1], n_out=n_out, **se_kwargs2, **kwargs)
def xse_resnext34_deeper(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 1, [3,4,4,2,2,1,1,1], n_out=n_out, **se_kwargs2, **kwargs)
def xse_resnext50_deeper(n_out=1000, pretrained=False, **kwargs): return XResNet(SEResNeXtBlock, 4, [3,4,4,2,2,1,1,1], n_out=n_out, **se_kwargs2, **kwargs)
tst = xse_resnext18()
x = torch.randn(64, 3, 128, 128)
y = tst(x)
tst = xresnext18()
x = torch.randn(64, 3, 128, 128)
y = tst(x)
tst = xse_resnet50()
x = torch.randn(8, 3, 64, 64)
y = tst(x)
tst = xresnet18(ndim=1, c_in=1, ks=15)
x = torch.randn(64, 1, 128)
y = tst(x)
tst = xresnext50(ndim=1, c_in=2, ks=31, stride=4)
x = torch.randn(8, 2, 128)
y = tst(x)
tst = xresnet18(ndim=3, c_in=3, ks=3)
x = torch.randn(8, 3, 32, 32, 32)
y = tst(x)
```
## Export -
```
#hide
from nbdev.export import *
notebook2script()
```
| github_jupyter |
<a href="https://colab.research.google.com/github/arjunparmar/VIRTUON/blob/main/Image_seg%20unet.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
from google.colab import drive
drive.mount('/content/drive')
import tensorflow as tf
import os as os
import random
import numpy as np
import json
from tqdm import tqdm
import pandas as pd
import matplotlib.pyplot as plt
from skimage.io import imread, imshow
from skimage.transform import resize
from tensorflow import keras
from keras.preprocessing.image import load_img,img_to_array
from tensorflow.keras import Sequential, Model
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Input, Conv2DTranspose,MaxPool2D
from tensorflow.keras.layers import concatenate, Activation, MaxPooling2D, Dropout, BatchNormalization
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from keras.optimizers import Adam
from keras.losses import binary_crossentropy
from tensorflow.keras.utils import Sequence,to_categorical
from keras.metrics import MeanIoU
import tensorflow.keras.backend as K
np.random.seed(42)
BASE_DIR = '/content/drive/Shareddrives/Virtuon/Clothing Co-Parsing Dataset'
IMG_WIDTH = 256
IMG_HEIGHT = 256
IMG_CHANNELS = 3
metadata_df = pd.read_csv(os.path.join(BASE_DIR,'metadata.csv'))
metadata_df = metadata_df[['image_path','label_type','label_path']]
metadata_df['image_path'] = metadata_df['image_path'].apply(lambda im_path: os.path.join(BASE_DIR,im_path))
metadata_df['label_path'] = metadata_df['label_path'].apply(lambda l_path: os.path.join(BASE_DIR,'labels',l_path))
#Selecting pixel level annoted dataset only
metadata_df = metadata_df[metadata_df['label_type'] == 'pixel-level']
#shuffle dataframe
metadata_df = metadata_df.sample(frac=1).reset_index(drop=True)
#train / val split 0.05
valid_df = metadata_df.sample(frac=.1,random_state=42)
train_df = metadata_df.drop(valid_df.index)
print("No. of test images " , len(valid_df),"\nNo. of train images " ,len(train_df))
class_dict = pd.read_csv(os.path.join(BASE_DIR,'class_dict.csv')).drop(index=[1,2,3,9,15,29,34,33,56,57])
classes_name = class_dict['class_name'].tolist() #series
classes_name[0] = 'none'
classes_rgb = class_dict[['r','g','b']].values.tolist() #values will be tensors
print("#classes = ",len(class_dict))
print("classes and their rgb values are " , classes_name)
print(classes_rgb)
cloth = ['shirt','sweater','sweatshirt','t-shirt','tie','top','vest','blazer', 'blouse', 'bra', 'cardigan', 'coat', 'hoodie', 'jacket',
'jumper', 'romper','suit','swimwear','bodysuit', 'cape', 'dress', 'intimate','pumps','sandals','shoes','sneakers','socks',
'wedges','clogs', 'flats', 'heels', 'loafers', 'boots','skirt','stockings','tights', 'jeans', 'leggings', 'panties',
'pants','shorts']
hair = ['hair', 'hat']
skin = ['skin','scarf','sunglasses', 'glasses', 'gloves']
bg = ['none']
print(len(cloth) + len(hair) + len(skin) + len(bg) )
def one_hot_mask_creator_tf(image,classes_names=classes_name,classes_rgb=classes_rgb,im_shape = (IMG_HEIGHT,IMG_WIDTH),n_classes=8):
'''
creates 3D tensor of one-hot-encoded mask of shape im_shape and n_classes channels
'''
height,width = im_shape
t_image = [tf.zeros([height,width], dtype = tf.float32) for i in range(n_classes)]
temp_image_1 = tf.zeros([height,width], dtype = tf.float32)
for cls_name , rgb in zip(classes_name,classes_rgb):
if cloth.count(cls_name) == 1:
value = 0
if hair.count(cls_name) == 1:
value = 1
if skin.count(cls_name) == 1:
value = 2
if bg.count(cls_name) == 1:
value = 3
temp = tf.math.equal(image,rgb)
temp = tf.reduce_all(temp,axis=-1)
temp = tf.cast(temp, tf.float32)
temp_image_1 = tf.math.add(temp_image_1, temp)
t_image[value] = tf.math.add(t_image[value], temp)
temp_image_1 = tf.cast(tf.math.less_equal(temp_image_1, 0), dtype = tf.float32)
t_image[3] = tf.math.add(t_image[3], temp_image_1)
for i in range(8):
t_image[i] = tf.cast(tf.math.greater_equal(t_image[i], 1), dtype = tf.float32)
mask = tf.stack(t_image, axis = -1)
return mask
index = 6
img_path = train_df['label_path'][index]
x = train_df['image_path'][index]
mask = one_hot_mask_creator_tf(img_to_array(load_img(img_path,target_size=(256,256),color_mode="rgb",interpolation='bilinear')))
plt.imshow(img_to_array(load_img(x,target_size=(256,256),color_mode="rgb",interpolation='bilinear')) / 255.0)
plt.imshow(mask[:,:,3])
plt.imshow(mask[:,:,0],alpha = 0.5)
def one_hot_mask_decoder(masks,classes_rgb=classes_rgb,im_shape=(IMG_HEIGHT,IMG_WIDTH)):
# mask size = (im_h,im_w,n_classes)
# classes_rgb = np.array(classes_rgb)
high_indexes = np.argmax(masks,axis=-1)
color_codes = np.array(classes_rgb)
label = color_codes[high_indexes]
return label
def parse_function(filename, label):
image_string = tf.io.read_file(filename)
#Don't use tf.image.decode_image, or the output shape will be undefined
image = tf.io.decode_png(image_string, channels=3)
#This will convert to float values in [0, 1]
image = tf.image.convert_image_dtype(image, tf.float32)
resized_image = tf.image.resize(image, [256, 256])
image_string = tf.io.read_file(label)
#Don't use tf.image.decode_image, or the output shape will be undefined
label = tf.io.decode_png(image_string, channels=3)
#This will convert to float values in [0, 1]
# image = tf.image.convert_image_dtype(image, tf.float32)
label = tf.image.resize(label, [256, 256])
label = one_hot_mask_creator_tf(label)
print(label.shape)
print(resized_image)
return resized_image, label
filenames = train_df['image_path'].values
labels = train_df['label_path'].values
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
dataset = dataset.shuffle(len(filenames))
dataset = dataset.map(parse_function, num_parallel_calls=tf.data.experimental.AUTOTUNE)
# dataset = dataset.map(train_preprocess, num_parallel_calls=4)
dataset = dataset.batch(8).repeat()
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
#Build the model
inputs = tf.keras.layers.Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
s = tf.keras.layers.Lambda(lambda x: x / 255)(inputs)
#Contraction path
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(s)
c1 = tf.keras.layers.Dropout(0.1)(c1)
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)
p1 = tf.keras.layers.MaxPooling2D((2, 2))(c1)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)
c2 = tf.keras.layers.Dropout(0.1)(c2)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)
p2 = tf.keras.layers.MaxPooling2D((2, 2))(c2)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)
c3 = tf.keras.layers.Dropout(0.2)(c3)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)
p3 = tf.keras.layers.MaxPooling2D((2, 2))(c3)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p3)
c4 = tf.keras.layers.Dropout(0.2)(c4)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)
p4 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(c4)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p4)
c5 = tf.keras.layers.Dropout(0.3)(c5)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)
#Expansive path
u6 = tf.keras.layers.Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(c5)
u6 = tf.keras.layers.concatenate([u6, c4])
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
c6 = tf.keras.layers.Dropout(0.2)(c6)
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c6)
u7 = tf.keras.layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(c6)
u7 = tf.keras.layers.concatenate([u7, c3])
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
c7 = tf.keras.layers.Dropout(0.2)(c7)
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c7)
u8 = tf.keras.layers.Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(c7)
u8 = tf.keras.layers.concatenate([u8, c2])
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
c8 = tf.keras.layers.Dropout(0.1)(c8)
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c8)
u9 = tf.keras.layers.Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(c8)
u9 = tf.keras.layers.concatenate([u9, c1], axis=3)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
c9 = tf.keras.layers.Dropout(0.1)(c9)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c9)
outputs = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid')(c9)
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
import tensorflow.keras.backend as K
def DiceBCELoss(targets, inputs, smooth=1e-6):
#flatten label and prediction tensors
inputs = K.flatten(inputs)
targets = K.flatten(targets)
inputs = K.expand_dims(inputs,0)
targets = K.expand_dims(targets,0)
BCE = binary_crossentropy(targets, inputs)
intersection = K.sum(K.dot(targets, K.transpose(inputs)))
dice_loss = 1 - (2*intersection + smooth) / (K.sum(targets) + K.sum(inputs) + smooth)
# Dice_BCE = BCE + dice_loss
return 1 - dice_loss
def IoULoss(targets, inputs, smooth=1e-6):
#flatten label and prediction tensors
inputs = K.flatten(inputs)
targets = K.flatten(targets)
inputs = K.expand_dims(inputs,0)
targets = K.expand_dims(targets,0)
intersection = K.sum(K.dot(targets, K.transpose(inputs)))
total = K.sum(targets) + K.sum(inputs)
union = total - intersection
IoU = (intersection + smooth) / (union + smooth)
return 1 - IoU
ALPHA = 0.5
BETA = 0.5
def TverskyLoss(targets, inputs, alpha=ALPHA, beta=BETA, smooth=1e-6):
#flatten label and prediction tensors
inputs = K.flatten(inputs)
targets = K.flatten(targets)
#True Positives, False Positives & False Negatives
TP = K.sum((inputs * targets))
FP = K.sum(((1-targets) * inputs))
FN = K.sum((targets * (1-inputs)))
Tversky = (TP + smooth) / (TP + alpha*FP + beta*FN + smooth)
return 1 - Tversky
optimizer = Adam(learning_rate=1e-4)
loss = TverskyLoss
metrics = [MeanIoU(8)]
# Compile our model
input = Input(shape=(IMG_HEIGHT,IMG_HEIGHT,3),name='img')
model = get_u_net(input,n_filters=64,batchnorm=True,)
model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
callback = [
EarlyStopping(patience=10, verbose=1),
ReduceLROnPlateau(factor=0.1, patience=5, min_lr=1e-5, verbose=1),
tf.keras.callbacks.TensorBoard(log_dir= os.path.join(BASE_DIR,'taksh/logs')),
tf.keras.callbacks.ModelCheckpoint(os.path.join(BASE_DIR,'taksh')
,verbose=1
,save_weights_only=True
,save_best_only=True,
monitor='val_mean_io_u',
mode='max'
)
]
params = {
'batch_size' : 8,
'n_channels' : 3,
'n_classes' : 8,
'im_shape' : (IMG_HEIGHT,IMG_WIDTH),
'shuffle' : True,
}
filenames_test = valid_df['image_path'].values
labels_test = valid_df['label_path'].values
valid_dataset = tf.data.Dataset.from_tensor_slices((filenames_test, labels_test))
valid_dataset = valid_dataset.shuffle(len(filenames_test))
valid_dataset = valid_dataset.map(parse_function, num_parallel_calls=tf.data.experimental.AUTOTUNE)
valid_dataset = valid_dataset.batch(8)
valid_dataset = valid_dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
results = model.fit(x=dataset,
epochs=50,
verbose=1,
callbacks=callback,
validation_data = valid_dataset,
use_multiprocessing=True,
workers=6, steps_per_epoch = 113)
%time
x = train_df['image_path'][6]
y_true = train_df['label_path'][6]
x = img_to_array(load_img(x,target_size=(256,256),color_mode="rgb",interpolation='bilinear'))
y_true = img_to_array(load_img(y_true,target_size=(256,256),color_mode="rgb",interpolation='bilinear'))
mask = model.predict(x.reshape(1,256,256,3))
plt.imshow(x/255.0)
decoded_mask = one_hot_mask_decoder(masks=mask.squeeze(),classes_rgb=[(128,128,128),(192,192,192),(255,0,255), (0,255,255),(255,255,0),(0,0,255), (0,255,0),(255,0,0)])
plt.imshow(decoded_mask)
plt.imshow(one_hot_mask_creator_tf(y_true)[:,:,3])
```
| github_jupyter |
This notebook is meant to be viewed as a [RISE](https://github.com/damianavila/RISE) slideshow. When run, a custom stylesheet will be applied:
* *italic* text will be shown in *blue*,
* **bold** text will be showin in **red**, and
* ~~strikethrough~~ text will be shown in ~~green~~.
The code below is meant to be run before the presentation to ensure that Sage and its dependencies are properly initialized, so no waiting is required during the presentation.
```
import drg
p = [[[1, 0, 0, 0], [0, 6, 0, 0], [0, 0, 3, 0], [0, 0, 0, 6]],
[[0, 1, 0, 0], [1, 2, 1, 2], [0, 1, 0, 2], [0, 2, 2, 2]],
[[0, 0, 1, 0], [0, 2, 0, 4], [1, 0, 2, 0], [0, 4, 0, 2]],
[[0, 0, 0, 1], [0, 2, 2, 2], [0, 2, 0, 1], [1, 2, 1, 2]]]
scheme = drg.ASParameters(p)
scheme.kreinParameters()
```
# Computing distance-regular graph and association scheme parameters in SageMath with [`sage-drg`](https://github.com/jaanos/sage-drg)
### Janoš Vidali
#### University of Ljubljana
Based on joint work with <b>Alexander Gavrilyuk</b>, <b>Aleksandar Jurišić</b>, <b>Sho Suda</b> and <b>Jason Williford</b>
[Live slides](https://mybinder.org/v2/gh/jaanos/sage-drg/master?filepath=jupyter/2021-06-22-8ecm/8ECM-sage-drg.ipynb) on [Binder](https://mybinder.org)
https://github.com/jaanos/sage-drg
## Association schemes
* **Association schemes** were defined by *Bose* and *Shimamoto* in *1952* as a theory underlying **experimental design**.
* They provide a ~~unified approach~~ to many topics, such as
- *combinatorial designs*,
- *coding theory*,
- generalizing *groups*, and
- *strongly regular* and *distance-regular graphs*.
## Examples
* *Hamming schemes*: **$X = \mathbb{Z}_n^d$**, **$x \ R_i \ y \Leftrightarrow \operatorname{weight}(x-y) = i$**
* *Johnson schemes*: **$X = \{S \subseteq \mathbb{Z}_n \mid |S| = d\}$** ($2d \le n$), **$x \ R_i \ y \Leftrightarrow |x \cap y| = d-i$**
<center><img src="as.png" /></center>
## Definition
* Let **$X$** be a set of *vertices* and **$\mathcal{R} = \{R_0 = \operatorname{id}_X, R_1, \dots, R_D\}$** a set of *symmetric relations* partitioning *$X^2$*.
* **$(X, \mathcal{R})$** is said to be a **$D$-class association scheme** if there exist numbers **$p^h_{ij}$** ($0 \le h, i, j \le D$) such that, for any *$x, y \in X$*,
**$$
x \ R_h \ y \Rightarrow |\{z \in X \mid x \ R_i \ z \ R_j \ y\}| = p^h_{ij}
$$**
* We call the numbers **$p^h_{ij}$** ($0 \le h, i, j \le D$) **intersection numbers**.
## Main problem
* Does an association scheme with given parameters ~~exist~~?
- If so, is it ~~unique~~?
- Can we determine ~~all~~ such schemes?
* ~~Lists~~ of feasible parameter sets have been compiled for [**strongly regular**](https://www.win.tue.nl/~aeb/graphs/srg/srgtab.html) and [**distance-regular graphs**](https://www.win.tue.nl/~aeb/drg/drgtables.html).
* Recently, lists have also been compiled for some [**$Q$-polynomial association schemes**](http://www.uwyo.edu/jwilliford/).
* Computer software allows us to *efficiently* compute parameters and check for *existence conditions*, and also to obtain new information which would be helpful in the ~~construction~~ of new examples.
## Bose-Mesner algebra
* Let **$A_i$** be the *binary matrix* corresponding to the relation *$R_i$* ($0 \le i \le D$).
* The vector space **$\mathcal{M}$** over *$\mathbb{R}$* spanned by *$A_i$* ($0 \le i \le D$) is called the **Bose-Mesner algebra**.
* *$\mathcal{M}$* has a second basis ~~$\{E_0, E_1, \dots, E_D\}$~~ consisting of *projectors* to the *common eigenspaces* of *$A_i$* ($0 \le i \le D$).
* There exist the **eigenmatrix** ~~$P$~~ and the **dual eigenmatrix** ~~$Q$~~ such that
*$$
A_j = \sum_{i=0}^D P_{ij} E_i, \qquad E_j = {1 \over |X|} \sum_{i=0}^D Q_{ij} A_i.
$$*
* There are ~~nonnegative~~ constants **$q^h_{ij}$**, called **Krein parameters**, such that
**$$
E_i \circ E_j = {1 \over |X|} \sum_{h=0}^D q^h_{ij} E_h ,
$$**
where **$\circ$** is the *entrywise matrix product*.
## Parameter computation: general association schemes
```
%display latex
import drg
p = [[[1, 0, 0, 0], [0, 6, 0, 0], [0, 0, 3, 0], [0, 0, 0, 6]],
[[0, 1, 0, 0], [1, 2, 1, 2], [0, 1, 0, 2], [0, 2, 2, 2]],
[[0, 0, 1, 0], [0, 2, 0, 4], [1, 0, 2, 0], [0, 4, 0, 2]],
[[0, 0, 0, 1], [0, 2, 2, 2], [0, 2, 0, 1], [1, 2, 1, 2]]]
scheme = drg.ASParameters(p)
scheme.kreinParameters()
```
## Metric and cometric schemes
* If **$p^h_{ij} \ne 0$** (resp. **$q^h_{ij} \ne 0$**) implies **$|i-j| \le h \le i+j$**, then the association scheme is said to be **metric** (resp. **cometric**).
* The *parameters* of a *metric* (or **$P$-polynomial**) association scheme can be ~~determined~~ from the **intersection array**
*$$
\{b_0, b_1, \dots, b_{D-1}; c_1, c_2, \dots, c_D\}
\quad (b_i = p^i_{1,i+1}, c_i = p^i_{1,i-1}).
$$*
* The *parameters* of a *cometric* (or **$Q$-polynomial**) association scheme can be ~~determined~~ from the **Krein array**
*$$
\{b^*_0, b^*_1, \dots, b^*_{D-1}; c^*_1, c^*_2, \dots, c^*_D\}
\quad (b^*_i = q^i_{1,i+1}, c^*_i = q^i_{1,i-1}).
$$*
* *Metric* association schemes correspond to *distance-regular graphs*.
## Parameter computation: metric and cometric schemes
```
from drg import DRGParameters
syl = DRGParameters([5, 4, 2], [1, 1, 4])
syl
syl.order()
from drg import QPolyParameters
q225 = QPolyParameters([24, 20, 36/11], [1, 30/11, 24])
q225
q225.order()
syl.pTable()
syl.kreinParameters()
syl.distancePartition()
syl.distancePartition(3)
```
## Parameter computation: parameters with variables
Let us define a *one-parametric family* of *intersection arrays*.
```
r = var("r")
f = DRGParameters([2*r^2*(2*r+1), (2*r-1)*(2*r^2+r+1), 2*r^2], [1, 2*r^2, r*(4*r^2-1)])
f.order(factor=True)
f1 = f.subs(r == 1)
f1
```
The parameters of `f1` are known to ~~uniquely determine~~ the *Hamming scheme $H(3, 3)$*.
```
f2 = f.subs(r == 2)
f2
```
## Feasibility checking
A parameter set is called **feasible** if it passes all known *existence conditions*.
Let us verify that *$H(3, 3)$* is feasible.
```
f1.check_feasible()
```
No error has occured, since all existence conditions are met.
Let us now check whether the second member of the family is feasible.
```
f2.check_feasible()
```
In this case, ~~nonexistence~~ has been shown by *matching* the parameters against a list of **nonexistent families**.
## Triple intersection numbers
* In some cases, **triple intersection numbers** can be computed.
**$$
[h \ i \ j] = \begin{bmatrix} x & y & z \\ h & i & j \end{bmatrix} = |\{w \in X \mid w \ R_i \ x \land w \ R_j \ y \land w \ R_h \ z\}|
$$**
* If **$x \ R_W \ y$**, **$x \ R_V \ z$** and **$y \ R_U \ z$**, then we have
*$$
\sum_{\ell=1}^D [\ell\ j\ h] = p^U_{jh} - [0\ j\ h], \qquad
\sum_{\ell=1}^D [i\ \ell\ h] = p^V_{ih} - [i\ 0\ h], \qquad
\sum_{\ell=1}^D [i\ j\ \ell] = p^W_{ij} - [i\ j\ 0],
$$*
where
*$$
[0\ j\ h] = \delta_{jW} \delta_{hV}, \qquad
[i\ 0\ h] = \delta_{iW} \delta_{hU}, \qquad
[i\ j\ 0] = \delta_{iV} \delta_{jU}.
$$*
* Additionally, **$q^h_{ij} = 0$** ~~if and only if~~
~~$$
\sum_{r,s,t=0}^D Q_{ri}Q_{sj}Q_{th} \begin{bmatrix} x & y & z \\ r & s & t \end{bmatrix} = 0
$$~~
for ~~all $x, y, z \in X$~~.
## Example: parameters for a bipartite DRG of diameter $5$
We will show that a distance-regular graph with intersection array **$\{55, 54, 50, 35, 10; 1, 5, 20, 45, 55\}$** ~~does not exist~~. The existence of such a graph would give a *counterexample* to a conjecture by MacLean and Terwilliger, see [Bipartite distance-regular graphs: The $Q$-polynomial property and pseudo primitive idempotents](http://dx.doi.org/10.1016/j.disc.2014.04.025) by M. Lang.
```
p = drg.DRGParameters([55, 54, 50, 35, 10], [1, 5, 20, 45, 55])
p.check_feasible(skip=["sporadic"])
p.order()
p.kreinParameters()
```
We now compute the triple intersection numbers with respect to three vertices **$x, y, z$ at mutual distances $2$**. Note that we have ~~$p^2_{22} = 243$~~, so such triples must exist. The parameter **$\alpha$** will denote the number of vertices adjacent to all of *$x, y, z$*.
```
p.distancePartition(2)
S222 = p.tripleEquations(2, 2, 2, params={"alpha": (1, 1, 1)})
show(S222[1, 1, 1])
show(S222[5, 5, 5])
```
Let us consider the set **$A$** of **common neighbours of $x$ and $y$**, and the set **$B$** of vertices at **distance $2$ from both $x$ and $y$**. By the above, each vertex in *$B$* has ~~at most one neighbour~~ in *$A$*, so there are ~~at most $243$~~ edges between *$A$* and *$B$*. However, each vertex in *$A$* is adjacent to both *$x$* and *$y$*, and the other ~~$53$~~ neighbours are in *$B$*, amounting to a total of ~~$5 \cdot 53 = 265$~~ edges. We have arrived to a ~~contradiction~~, and we must conclude that a graph with intersection array *$\{55, 54, 50, 35, 10; 1, 5, 20, 45, 55\}$* ~~does not exist~~.
## Double counting
* Let **$x, y \in X$** with **$x \ R_r \ y$**.
* Let **$\alpha_1, \alpha_2, \dots \alpha_u$** and **$\kappa_1, \kappa_2, \dots \kappa_u$** be numbers such that there are precisely *$\kappa_\ell$* vertices **$z \in X$** with **$x \ R_s \ z \ R_t \ y$** such that
**$$
\begin{bmatrix} x & y & z \\ h & i & j \end{bmatrix} = \alpha_\ell \qquad (1 \le \ell \le u).
$$**
* Let **$\beta_1, \beta_2, \dots \beta_v$** and **$\lambda_1, \lambda_2, \dots \lambda_v$** be numbers such that there are precisely *$\lambda_\ell$* vertices **$w \in X$** with **$x \ R_h \ w \ R_i \ y$** such that
**$$
\begin{bmatrix} w & x & y \\ j & s & t \end{bmatrix} = \beta_\ell \qquad (1 \le \ell \le v).
$$**
* Double-counting pairs *$(w, z)$* with **$w \ R_j \ z$** gives
~~$$
\sum_{\ell=1}^u \kappa_\ell \alpha_\ell = \sum_{\ell=1}^v \lambda_\ell \beta_\ell
$$~~
* Special case: **$u = 1, \alpha_1 = 0$** implies ~~$v = 1, \beta_1 = 0$~~.
## Example: parameters for a $3$-class $Q$-polynomial scheme
~~Nonexistence~~ of some *$Q$-polynomial* association schemes has been proven by obtaining a *contradiction* in *double counting* with triple intersection numbers.
```
q225
q225.check_quadruples()
```
*Integer linear programming* has been used to find solutions to multiple systems of *linear Diophantine equations*,
*eliminating* inconsistent solutions.
## More results
There is no *distance-regular graph* with intersection array
* ~~$\{83, 54, 21; 1, 6, 63\}$~~ (~~$1080$~~ vertices)
* ~~$\{135, 128, 16; 1, 16, 120\}$~~ (~~$1360$~~ vertices)
* ~~$\{104, 70, 25; 1, 7, 80\}$~~ (~~$1470$~~ vertices)
* ~~$\{234, 165, 12; 1, 30, 198\}$~~ (~~$1600$~~ vertices)
* ~~$\{195, 160, 28; 1, 20, 168\}$~~ (~~$2016$~~ vertices)
* ~~$\{125, 108, 24; 1, 9, 75\}$~~ (~~$2106$~~ vertices)
* ~~$\{126, 90, 10; 1, 6, 105\}$~~ (~~$2197$~~ vertices)
* ~~$\{203, 160, 34; 1, 16, 170\}$~~ (~~$2640$~~ vertices)
* ~~$\{53, 40, 28, 16; 1, 4, 10, 28\}$~~ (~~$2916$~~ vertices)
~~Nonexistence~~ of *$Q$-polynomial association schemes* [GVW21] with parameters listed as *feasible* by [Williford](http://www.uwyo.edu/jwilliford/) has been shown for
* ~~$29$~~ cases of *$3$-class primitive* $Q$-polynomial association schemes
- *double counting* has been used in ~~two~~ cases
* ~~$92$~~ cases of *$4$-class $Q$-bipartite* $Q$-polynomial association schemes
* ~~$11$~~ cases of *$5$-class $Q$-bipartite* $Q$-polynomial association schemes
## Nonexistence of infinite families
Association schemes with the following parameters do not exist.
* *distance-regular graphs* with *intersection arrays* ~~$\{(2r+1)(4r+1)(4t-1), 8r(4rt-r+2t), (r+t)(4r+1); 1, (r+t)(4r+1), 4r(2r+1)(4t-1)\}$~~ (**$r, t \ge 1$**)
* *primitive $Q$-polynomial association schemes* with *Krein arrays* ~~$\{2r^2-1, 2r^2-2, r^2+1; 1, 2, r^2-1\}$~~ (**$r \ge 3$ odd**)
* *$Q$-bipartite $Q$-polynomial association schemes* with *Krein arrays* ~~$\left\{m, m-1, {m(r^2-1) \over r^2}, m-r^2+1; 1, {m \over r^2}, r^2-1, m\right\}$~~ (**$m, r \ge 3$ odd**)
* *$Q$-bipartite $Q$-polynomial association schemes* with *Krein arrays* ~~$\left\{{r^2+1 \over 2}, {r^2-1 \over 2}, {(r^2+1)^2 \over 2r(r+1)},
{(r-1)(r^2+1) \over 4r}, {r^2+1 \over 2r};
1, {(r-1)(r^2+1) \over 2r(r+1)}, {(r+1)(r^2 + 1) \over 4r},
{(r-1)(r^2+1) \over 2r}, {r^2+1 \over 2}\right\}$~~ (**$r \ge 5$**, **$r \equiv 3 \pmod{4}$**)
* *$Q$-antipodal $Q$-polynomial association schemes* with *Krein arrays* ~~$\left\{r^2 - 4, r^2 - 9, \frac{12(s-1)}{s}, 1; 1, \frac{12}{s}, r^2 - 9, r^2 - 4\right\}$~~ (**$r \ge 5$**, **$s \ge 4$**)
- **Corollary**: a *tight $4$-design* in **$H((9a^2+1)/5,6)$** ~~does not exist~~ [GSV20].
## Using Schönberg's theorem
* **Schönberg's theorem**: A *polynomial* **$f: [-1, 1] \to \mathbb{R}$** of degree **$D$** is ~~positive definite on $S^{m-1}$~~ iff it is a ~~nonnegative linear combination~~ of *Gegenbauer polynomials* **$Q^m_{\ell}$** (**$0 \le \ell \le D$**).
* **Theorem** (*Kodalen, Martin*): If **$(X, \mathcal{R})$** is an *association scheme*, then
~~$$
Q_{\ell}^{m_i} \left({1 \over m_i} L^*_i \right) = {1 \over |X|} \sum_{j=0}^D \theta_{\ell j} L^*_j
$$~~
for some ~~nonnegative constants~~ **$\theta_{\ell j}$** (**$0 \le j \le D$**), where **$m_i = \operatorname{rank}(E_i)$** and **$L^*_i = (q^h_{ij})_{h,j=0}^D$**.
```
q594 = drg.QPolyParameters([9, 8, 81/11, 63/8], [1, 18/11, 9/8, 9])
q594.order()
q594.check_schoenberg()
```
## The Terwilliger polynomial
* *Terwilliger* has observed that for a *$Q$-polynomial distance-regular graph $\Gamma$*, there exists a ~~polynomial $T$ of degree $4$~~ whose coefficients can be expressed in terms of the *intersection numbers* of *$\Gamma$* such that ~~$T(\theta) \ge 0$~~ for each *non-principal eigenvalue* **$\theta$** of the **local graph** at a vertex of *$\Gamma$*.
* `sage-drg` can be used to *compute* this polynomial.
```
p750 = drg.DRGParameters([49, 40, 22], [1, 5, 28])
p750.order()
T750 = p750.terwilligerPolynomial()
T750
sorted(s.rhs() for s in solve(T750 == 0, x))
plot(T750, (x, -4, 5))
```
We may now use **[BCN, Thm. 4.4.4]** to further *restrict* the possible *non-principal eigenvalues* of the *local graphs*.
```
l, u = -1 - p750.b[1] / (p750.theta[1] + 1), -1 - p750.b[1] / (p750.theta[3] + 1)
l, u
plot(T750, (x, -4, 5)) + line([(l, 0), (u, 0)], color="red", thickness=3)
```
Since graph eigenvalues are *algebraic integers* and all *non-integral eigenvalues* of the *local graph* lie on a subinterval of ~~$(-4, -1)$~~, it can be shown that the only permissible *non-principal eigenvalues* are ~~$-3, -2, 3$~~.
We may now set up a *system of equations* to determine the *multiplicities*.
```
var("m1 m2 m3")
solve([1 + m1 + m2 + m3 == p750.k[1],
1 * p750.a[1] + m1 * 3 + m2 * (-2) + m3 * (-3) == 0,
1 * p750.a[1]^2 + m1 * 3^2 + m2 * (-2)^2 + m3 * (-3)^2 == p750.k[1] * p750.a[1]],
(m1, m2, m3))
```
Since all multiplicities are not *nonnegative integers*, we conclude that there is no *distance-regular graph* with intersection array
* ~~$\{49, 40, 22; 1, 5, 28\}$~~ (~~$750$~~ vertices)
* ~~$\{109, 80, 22; 1, 10, 88\}$~~ (~~$1200$~~ vertices)
* ~~$\{164, 121, 33; 1, 11, 132\}$~~ (~~$2420$~~ vertices)
## Distance-regular graphs with classical parameters
We use a similar technique to prove ~~nonexistence~~ of certain *distance-regular graphs* with *classical parameters* **$(D, b, \alpha, \beta)$**:
* ~~$(3, 2, 2, 9)$~~ (~~$430$~~ vertices)
* ~~$(3, 2, 5, 21)$~~ (~~$1100$~~ vertices)
* ~~$(6, 2, 2, 107)$~~ (~~$87\,725\,820\,468$~~ vertices)
* ~~$(b, \alpha) = (2, 1)$~~ and
- ~~$D = 4$~~, ~~$\beta \in \{8, 10, 12\}$~~
- ~~$D = 5$~~, ~~$\beta \in \{16, 17, 19, 20, 21, 28\}$~~
- ~~$D = 6$~~, ~~$\beta \in \{32, 33, 34, 35, 36, 38, 40, 46, 49, 54, 60\}$~~
- ~~$D = 7$~~, ~~$\beta \in \{64, 65, 66, 67, 69, 70, 71, 72, 73, 74, 77, 79, 81, 84, 85, 92, 99, 124\}$~~
- ~~$D = 8$~~, ~~$\beta \in \{128, 129, 130, 131, 133, 134, 135, 136, 137, 139, 140, 141, 151, 152, 155, 158, 160, 165, 168, 174, 175, 183, 184, 190, 202, 238, 252\}$~~
- ~~$D \ge 3$~~, ~~$\beta \in \{2^{D-1}, 2^D-4\}$~~
## Local graphs with at most four eigenvalues
* **Lemma** (*Van Dam*): A *connected graph* on **$n$** vertices with *spectrum*
**$$
{\theta_0}^{\ell_0} \quad
{\theta_1}^{\ell_1} \quad
{\theta_2}^{\ell_2} \quad
{\theta_3}^{\ell_3}
$$**
is ~~walk-regular~~ with precisely
~~$$
w_r = {1 \over n} \sum_{i=0}^3 \ell_i \cdot {(\theta_i)}^r
$$~~
*closed $r$-walks* (**$r \ge 3$**) through *each vertex*.
- If **$r$** is *odd*, **$w_r$** must be ~~even~~.
* A *distance-regular graph* **$\Gamma$** with *classical parameters* **$(D, 2, 1, \beta)$** has *local graphs* with
- precisely **three distinct eigenvalues** if **$\beta = 2^D - 1$**, and then *$\Gamma$* is a ~~bilinear forms graph~~ (Gavrilyuk, Koolen)
- precisely **four distinct eigenvalues** if **$(\beta+1) \mid (2^D-2)(2^D-1)$**, and then ~~$\beta = 2^D-2$~~ (or *$w_3$* is ~~nonintegral~~)
* There is no *distance-regular graph* with *classical parameters* **$(D, 2, 1, \beta)$** such that
- ~~$(D, \beta) \in \{(3, 5), (4, 9), (4, 13), (5, 29), (6, 41), (6, 61), (7, 125), (8, 169), (8, 253)\}$~~
- ~~$D \ge 3$~~ and ~~$\beta = 2^D - 3$~~
| github_jupyter |
```
import joblib
import itertools
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
import numpy as np
from sklearn.metrics import confusion_matrix
import seaborn as sns
from sklearn.multioutput import MultiOutputClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.multioutput import MultiOutputRegressor
from RF_Model_Functions import *
from IPython.display import Image
from sklearn.externals.six import StringIO
import pydotplus
from scipy.signal import savgol_filter
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LinearRegression
from sklearn.multioutput import MultiOutputRegressor
from sklearn.metrics import mean_squared_error
spectra_train = joblib.load('cache/r20200406_234541_50.0sc_50.0sp_1_CPU/spectral/y_new_train.joblib')
spectra_test = joblib.load('cache/r20200406_234541_50.0sc_50.0sp_1_CPU/spectral/y_test.joblib')
labels_train = joblib.load('cache/r20200406_234541_50.0sc_50.0sp_1_CPU/spectral/x_new_train.joblib').reset_index()
labels_test = joblib.load('cache/r20200406_234541_50.0sc_50.0sp_1_CPU/spectral/x_test.joblib').reset_index()
labels_train_smaller = joblib.load('cache/r20200406_234541_50.0sc_50.0sp_1_CPU/spectral/x_train.joblib').reset_index()
spectra_train_smaller = joblib.load('cache/r20200406_234541_50.0sc_50.0sp_1_CPU/spectral/y_train.joblib')
```
Visualize Training Set - Histograms of the size parameters
```
labels_test_A_V = labels_test.drop(columns=['index', 'ShortestDim',
'MiddleDim', 'LongDim', 'Material_SiN',
'Material_SiO2', 'Material_Au',
'Geometry_parallelepiped',
'Geometry_wire',
'Geometry_sphere', 'Geometry_TriangPrismIsosc'])
labels_test_short = labels_test.drop(columns=['index', 'log Area/Vol',
'MiddleDim', 'LongDim', 'Material_SiN',
'Material_SiO2', 'Material_Au',
'Geometry_parallelepiped',
'Geometry_wire',
'Geometry_sphere', 'Geometry_TriangPrismIsosc'])
labels_test_mid = labels_test.drop(columns=['index', 'ShortestDim',
'log Area/Vol', 'LongDim', 'Material_SiN',
'Material_SiO2', 'Material_Au',
'Geometry_parallelepiped',
'Geometry_wire',
'Geometry_sphere', 'Geometry_TriangPrismIsosc'])
labels_test_long = labels_test.drop(columns=['index', 'ShortestDim',
'MiddleDim', 'log Area/Vol', 'Material_SiN',
'Material_SiO2', 'Material_Au',
'Geometry_parallelepiped',
'Geometry_wire',
'Geometry_sphere', 'Geometry_TriangPrismIsosc'])
plt.hist(np.asarray(labels_test_A_V), 100)
plt.title("Histogram Log(Area/Volume)")
plt.show()
plt.hist(np.asarray(labels_test_short), 100)
plt.title("Histogram Shortest Dim")
plt.show()
plt.hist(np.asarray(labels_test_mid), 100)
plt.title("Histogram Middle Dim")
plt.show()
plt.hist(np.asarray(labels_test_long), 100)
plt.title("Histogram Long Dim")
plt.show()
from_one_hot_dict = {(1.,0.,0.,0.) : 0, (0.,1.,0.,0.) : 1, (0.,0.,1.,0.) : 2, (0.,0.,0.,1.) : 3}
from_one_hot_dict_materials = {(1.,0.,0.) : 0, (0.,1.,0.) : 1, (0.,0.,1.) : 2}
```
Load RF models
```
RF_Models = joblib.load("RF_Models_Shape_Classification.joblib")
rf_shape_classifier_all = RF_Models[3][1][1]
rf_shape_classifier_cm = RF_Models[3][1][2]
rf_shape_classifier_predictions = RF_Models[3][1][3]
rf_shape_classifier_test_set = RF_Models[3][1][4]
rf_binary_sphere = joblib.load("RF Binary Classification Geometry_sphere.joblib")
rf_binary_wire = joblib.load("RF Binary Classification Geometry_wire.joblib")
rf_binary_parallelepiped = joblib.load("RF Binary Classification Geometry_parallelepiped.joblib")
rf_binary_triangle = joblib.load("RF Binary Classification Geometry_TriangPrismIsosc.joblib")
rf_size_regression = joblib.load("RF Size Regression.joblib")
Size_regression_rf_area_vol = joblib.load("RF Size Regression Area over Volume.joblib")
Size_regression_rf_shortest_dim = joblib.load("RF Size Regression shortest dim.joblib")
Size_regression_rf_middle_dim = joblib.load("RF Size Regression middle dim.joblib")
Size_regression_rf_long_dim = joblib.load("RF Size Regression long dim.joblib")
accuracies_size_regression_shape = joblib.load("accuracies_size_regression_shape.joblib")
accuracies_size_regression_material = joblib.load("accuracies_size_regression_material.joblib")
accuracy_size_regression_SiO2 = accuracies_size_regression_material[0][1]
accuracy_size_regression_SiN = accuracies_size_regression_material[1][1]
accuracy_size_regression_Au = accuracies_size_regression_material[2][1]
accuracy_size_regression_Parallelepiped = accuracies_size_regression_shape[0][1]
accuracy_size_regression_Sphere = accuracies_size_regression_shape[1][1]
accuracy_size_regression_Triangle = accuracies_size_regression_shape[2][1]
accuracy_size_regression_Wire = accuracies_size_regression_shape[3][1]
```
Visualize feature importances for shape classification and size regression
```
plt.plot(rf_shape_classifier_all.feature_importances_)
plt.title("Feature Importances Multiclass Shape Prediction ")
plt.ylabel("Frequency Used")
plt.xlabel("Parameter")
plt.show()
plt.plot(Size_regression_rf_area_vol[1].feature_importances_)
#plt.scatter(293,0.48)
plt.title("Feature Importances Size Regression Area/Vol")
plt.ylabel("Frequency Used")
plt.xlabel("Parameter")
plt.show()
plt.plot(Size_regression_rf_shortest_dim[1].feature_importances_)
#plt.scatter(269,0.40)
plt.title("Feature Importances Size Regression shortest dim")
plt.ylabel("Frequency Used")
plt.xlabel("Parameter")
plt.show()
plt.plot(Size_regression_rf_middle_dim[1].feature_importances_)
plt.title("Feature Importances Size Regression middle dim")
plt.ylabel("Frequency Used")
plt.xlabel("Parameter")
plt.show()
plt.plot(Size_regression_rf_long_dim[1].feature_importances_)
plt.title("Feature Importances Size Regression long dim")
plt.ylabel("Frequency Used")
plt.xlabel("Parameter")
```
Calculate MSEs for the four size regression models
```
predictions_size_regression_A_V = Size_regression_rf_area_vol[1].predict(spectra_test)
predictions_size_regression_short = Size_regression_rf_shortest_dim[1].predict(spectra_test)
predictions_size_regression_middle = Size_regression_rf_middle_dim[1].predict(spectra_test)
predictions_size_regression_long = Size_regression_rf_long_dim[1].predict(spectra_test)
mse_A_V = mean_squared_error(np.asarray(labels_test_A_V), predictions_size_regression_A_V, multioutput = 'uniform_average')
mse_short = mean_squared_error(np.asarray(labels_test_short), predictions_size_regression_short, multioutput = 'uniform_average')
mse_middle = mean_squared_error(np.asarray(labels_test_mid), predictions_size_regression_middle, multioutput = 'uniform_average')
mse_long = mean_squared_error(np.asarray(labels_test_long), predictions_size_regression_long, multioutput = 'uniform_average')
print("Range", (np.min(np.asarray(labels_test_A_V)), np.max(np.asarray(labels_test_A_V))),
(np.min(np.asarray(labels_test_short)), np.max(np.asarray(labels_test_short))),
(np.min(np.asarray(labels_test_mid)), np.max(np.asarray(labels_test_mid))),
(np.min(np.asarray(labels_test_long)), np.max(np.asarray(labels_test_long))))
print("Averages", np.mean(np.asarray(labels_test_A_V)), np.mean(np.asarray(labels_test_short)),
np.mean(np.asarray(labels_test_mid)), np.mean(np.asarray(labels_test_long)))
print("Medians", np.median(np.asarray(labels_test_A_V)), np.median(np.asarray(labels_test_short)),
np.median(np.asarray(labels_test_mid)), np.median(np.asarray(labels_test_long)))
print("MSE", mse_A_V, mse_short, mse_middle, mse_long)
```
Calculate and plot residuals squared for size regression models
```
residuals_A_V = np.square(predictions_size_regression_A_V - np.asarray(labels_test_A_V).T[0])
residuals_short = np.square(predictions_size_regression_short - np.asarray(predictions_size_regression_short).T[0])
residuals_mid = np.square(predictions_size_regression_middle - np.asarray(predictions_size_regression_middle).T[0])
residuals_long = np.square(predictions_size_regression_long - np.asarray(predictions_size_regression_long).T[0])
np.asarray(labels_test_A_V).T[0]
plt.hist(residuals_A_V, 100)
plt.title("Residuals Squared Log(Area/Volume)")
plt.show()
plt.hist(residuals_short, 100)
plt.title("Residuals Squared Shortest Dim")
plt.show()
plt.hist(residuals_mid, 100)
plt.title("Residuals Squared Middle Dim")
plt.show()
plt.hist(residuals_long, 100)
plt.title("Residuals Squared Long Dim")
plt.show()
np.median(residuals_long)
```
Plot shape classification binary model feature importances
```
plt.plot(rf_binary_parallelepiped[1].feature_importances_)
plt.plot(rf_binary_wire[1].feature_importances_)
plt.title("Parallelepiped and Wire Feature Importances")
plt.xlabel("Wavelength Index")
plt.ylabel("Importance")
plt.legend(labels = ["Parallelepiped", "Wire"])
plt.plot(rf_binary_sphere[1].feature_importances_)
plt.title("Sphere Feature Importances")
plt.xlabel("Wavelength Index")
plt.ylabel("Importance")
# Code to label which wavelenghts are the most important. They will likely move slightly if the models are
# rebuilt, since some random changes in the random forest models will change the important features.
#plt.scatter(306,0.015)
#plt.scatter(269,0.04)
```
Barplots and confusion matricies for the accuracies of various model types
```
binary_accuracies = (rf_binary_triangle[2], rf_binary_parallelepiped[2], rf_binary_sphere[2], rf_binary_wire[2])
catagories = ["Triangle", "Parallelepiped", "Sphere", "Wire"]
sns.barplot(catagories, binary_accuracies).set(title = "Binary Classification Accuracies", ylabel = "Accuracy", ylim = [0.5, 1.05])
accuracies = [accuracy_size_regression_SiO2, accuracy_size_regression_SiN, accuracy_size_regression_Au]
categories = ["SiO2", "SiN", "Au"]
title = "Size Regression Materials"
sns.barplot(categories, accuracies).set(title = title, ylabel = "Correlation", ylim = [0.7, 1])
plt.savefig(str(title) + '.png', format='png')
cm = rf_shape_classifier_cm
cm_normalized = normalize_cm(cm, list(rf_shape_classifier_test_set), 4)
plot_confusion_matrix(np.asarray(cm_normalized), ["Triangle", "Parallelepiped", "Sphere", "Wire"])
accuracies = (0.72, 0.63, 0.99, 0.78)
catagories = ["Triangle", "Parallelepiped", "Sphere", "Wire"]
sns.barplot(catagories, accuracies).set(title = "Shape Classification Accuracies", ylabel = "Accuracy", ylim = [0.5, 1.04])
predictions = rf_size_regression[1].predict(spectra_test)
labels_test_size = labels_test.drop(columns=['index', 'Material_SiN', 'Geometry_sphere',
'Material_SiO2', 'Material_Au',
'Geometry_parallelepiped',
'Geometry_wire',
'Geometry_TriangPrismIsosc'])
mean_squared_error(np.asarray(labels_test_size), predictions, multioutput = 'uniform_average')
indicies_to_drop_test_list_Parallelepiped = drop_indicies(labels_test, 'Geometry_parallelepiped', 0, False)
indicies_to_drop_test_list_Sphere = drop_indicies(labels_test, 'Geometry_sphere', 0, False)
indicies_to_drop_test_list_Triangle = drop_indicies(labels_test, 'Geometry_TriangPrismIsosc', 0, False)
indicies_to_drop_test_list_Wire = drop_indicies(labels_test, 'Geometry_wire', 0, False)
labels_test_size_Parallelepiped = labels_test_size.drop(indicies_to_drop_test_list_Parallelepiped[1])
labels_test_size_Sphere = labels_test_size.drop(indicies_to_drop_test_list_Sphere[1])
labels_test_size_Triangle = labels_test_size.drop(indicies_to_drop_test_list_Triangle[1])
labels_test_size_Wire = labels_test_size.drop(indicies_to_drop_test_list_Wire[1])
spectra_test_Parallelepiped = spectra_test_df.drop(indicies_to_drop_test_list_Parallelepiped[1])
spectra_test_Sphere = spectra_test_df.drop(indicies_to_drop_test_list_Sphere[1])
spectra_test_Triangle = spectra_test_df.drop(indicies_to_drop_test_list_Triangle[1])
spectra_test_Wire = spectra_test_df.drop(indicies_to_drop_test_list_Wire[1])
predictions_size_regression_Parallelepiped = rf_size_regression[1].predict(spectra_test_Parallelepiped)
predictions_size_regression_Sphere = rf_size_regression[1].predict(spectra_test_Sphere)
predictions_size_regression_Triangle = rf_size_regression[1].predict(spectra_test_Triangle)
predictions_size_regression_Wire = rf_size_regression[1].predict(spectra_test_Wire)
mse_parallelepiped = mean_squared_error(np.asarray(labels_test_size_Parallelepiped), predictions_size_regression_Parallelepiped, multioutput = 'uniform_average')
mse_sphere = mean_squared_error(np.asarray(labels_test_size_Sphere), predictions_size_regression_Sphere, multioutput = 'uniform_average')
mse_triangle = mean_squared_error(np.asarray(labels_test_size_Triangle), predictions_size_regression_Triangle, multioutput = 'uniform_average')
mse_wire = mean_squared_error(np.asarray(labels_test_size_Wire), predictions_size_regression_Wire, multioutput = 'uniform_average')
print(mse_parallelepiped,mse_sphere,mse_triangle,mse_wire)
mses = [mse_triangle, mse_parallelepiped, mse_sphere, mse_wire]
catagories = ["Triangle", "Parallelepiped", "Sphere", "Wire"]
sns.barplot(catagories, mses).set(title = "Size Regression MSE", ylabel = "MSE", ylim = [0, 6.8])
accuracy_size_regression_Parallelepiped = rf_size_regression[1].score(spectra_test_Parallelepiped, labels_test_size_Parallelepiped)
accuracy_size_regression_Sphere = rf_size_regression[1].score(spectra_test_Sphere, labels_test_size_Sphere)
accuracy_size_regression_Triangle = rf_size_regression[1].score(spectra_test_Triangle, labels_test_size_Triangle)
accuracy_size_regression_Wire = rf_size_regression[1].score(spectra_test_Wire, labels_test_size_Wire)
mses = [accuracy_size_regression_Triangle, accuracy_size_regression_Parallelepiped, accuracy_size_regression_Sphere, accuracy_size_regression_Wire]
catagories = ["Triangle", "Parallelepiped", "Sphere", "Wire"]
sns.barplot(catagories, mses).set(title = "Size Regression Correlation", ylabel = "R^2", ylim = [0.5, 1.04])
mses
```
| github_jupyter |
# INFO 3350/6350
## Lecture 13: Feature standardization, normalization, and dimension reduction
## To do
* HW 6 (corpus building) due Thursday, 11:59pm
* Make sure you have the updated guidelines from CMS (updated Saturday afternoon, March 5)
* Next week (feature importance and explainability)
* Monday: Read "The importance of human-interpretable ML"
* Wednesday: Read articles by Underwood and by Yauney
* Response to Underwood or Yauney due by 4:00pm by next Tuesday, 3/15, if assigned to you by NetID.
* Friday: Section as usual
## Measuring classifier performance
In this lecture -- and for the next couple of weeks -- we'll talk about factors that affect classifier performance. But how should we *measure* performance?
In the last lecture, we scored our classifiers on **accuracy**, that is, the fraction of all predictions that are correct. This can be fine, but it's not well suited to cases in which we have different-size classes and it doesn't capture whether we do equally well on any one class.
Machine learning tends instead to measure performance using **precision**, **recall**, and $F_1$. Here's what those terms mean:
* **Precision** is the fraction of positive predictions for a given class that are correct. In other words, when we predict that an object belongs to a class, how likely are we to be right about it?
* **Recall** is the fraction of all positive instances in the data set that are predicted positive. In other words, from among all the objects we *should* have assigned to a class, what fraction of them did we catch?
You can see that precision and recall tend to involve a tradeoff in real-world settings. You can achieve high precision if you're very conservative about labeling marginal cases. You can get high recall by being much more liberal with your labels. Consider two limit cases of a simple problem:
> I ask you to bring me all the books by Toni Morrison that are held in the Cornell libraries. Favoring precision, you bring me just one book, a first-edition copy of _The Bluest Eye_ (great book, by the way) and nothing else. You're right that it's by Morrison, so your precision is perfect (1.0). But your recall is really bad. If there are 108 Morrison volumes in the library (which there are, for certain deifnitions of "by", "in", "Cornell," "libraries," and "books"), you have correctly retrieved less than 1% of them. Or maybe you favor recall, so you bring me every book in the library (about 8 million of them). Yikes. In this case, recall is perfect (you *did* bring me every book by Morrison), but your precision is terrible (of the 8 million books you labeled as "by Toni Morrison," only 20 of them were correct (about 0.00025%).
* $F_1$ is one way to assess the combination of precision and recall. It's just the *harmonic mean* of those two numbers. A harmonic mean is a conservative estimate of the average value, because it is affected more by small values than by large ones.
* You don't really need to know how to calculate $F_1$, but it's not hard. You take the reciprocal of the (familiar, plain vanilla) arithmetic mean of the reciprocals of your observations.
* In the first Morrison example (high precision, low recall), precision = 1.0 and recall = 0.01 (rounding a bit).
* The regular (non-harmonic) mean would be about 0.5 ($=(1.0 + 0.01)/2$)
* $F_1$ is:
$$F_1 = \left( \frac{1.0^{-1}+0.01^{-1}}{2} \right)^{-1} = \frac{2}{1 + 100} = 0.02$$
$F_1$ for the high-recall case would be even worse, since precision in that case is even closer to zero. Most real-world cases aren't as extreme as these, but the idea is the same. $F_1$ avoids artificially inflated estimates of classifier performance. In general, it's what you (and other machine learning researchers) want to use as your accuracy/performance metric.
## Normalization and standardization
First, note that the terms "normalization" and "standardization" are sometimes used interchangably or inconsistently. So be sure you understand what's going on in any given instance if you encounter there terms in the wild. In this class, we'll try to be consistent with the definitions below.
### Normalization (`l1`, `l2`)
* Normalization is the process by which we ensure that each vector in our feature matrix has the same length
* Normalization works *row-wise*, not *column-wise*. That is, we normalize the features attached to each *observation*.
* The details vary, depending on our distance (length) metric
* The two most commonly used normalizations are `l1` and `l2`
* `l1` normalization adjusts the features so that they sum to one in each vector.
* This means that the *Manhattan length* of each vector is one
* It also means that the normalized value of each feature represents the fraction of the total feature counts/weight accounted for by that feature in a given document
* As previously discussed, `l1` norms preserve the original ratios between the features. This is often good for accuracy on downstream tasks.
* `l2` normalization adjusts each vector so that the sum of the squared features is one
* This means that the *Euclidean length* of each vector is one
* `l2` norms decrease the effective weight of low-frequency features (hence, they increase the relative weight of high-frequency features). This can be good for interpretation, because it means that downstream tasks rely on a comparatively sparse set of important features.
### Standardization (*z*-scores)
* Even when we normalize our vectors, distances and similarities are dominated by common terms
* Common terms contribute most of the weight to the overall vector
* This might be what we want ...
* ... or it might not.
* What if we care about the comparative usage rates of each included feature (word)?
* That is, what if every word should contribute equally?
* We could scale between, say, 0 and 1
* But then we're at the mercy of high and low outliers
* Instead, we often scale to mean zero and standard deviation one.
* This is called a "standard score" or "*z*-score."
* Standardization works *column-wise*. That is, it makes every *feature*, across all observations, as important as every other feature.
Typically, you'll normalize first, then scale. But some situations call for just one or the other, or are not especially sensitive to either one. You might *not* want to normalize or scale if your feature data share a common (and meaningful) scale and are already normally distributed. Leaving your data alone in that case may not make much diffrence for your task performance and may make it easier to interpret your results.
# An example
Consider the following example of normalization and standardization:
```
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, MinMaxScaler, normalize
from sklearn.metrics.pairwise import euclidean_distances
sample = [
[10,11,11,12],
[0,0,1,1],
[0,5,7,10]
]
df = pd.DataFrame(sample).T
df.columns = ['the', 'cat', 'she']
print('raw features:')
display(df)
print("raw mean:", round(np.mean(df.to_numpy()),2))
print('raw distances:')
display(pd.DataFrame(euclidean_distances(df)).mask(lambda x: x==0,np.nan).style.background_gradient(cmap='RdYlGn', axis=None))
print('\n\nmin-max scaling:')
minmax = MinMaxScaler().fit_transform(df)
display(minmax)
print("min-max mean:", round(np.mean(minmax),3))
print('min-max distances:')
display(pd.DataFrame(euclidean_distances(minmax)).mask(lambda x: x==0,np.nan).style.background_gradient(cmap='RdYlGn', axis=None))
print('\n\nz-scores:')
zscores = StandardScaler().fit_transform(df)
display(zscores)
print('z-score mean:', round(np.mean(zscores),3))
print('z-score distances:')
display(pd.DataFrame(euclidean_distances(zscores)).mask(lambda x: x==0,np.nan).style.background_gradient(cmap='RdYlGn', axis=None))
print('\n=====\nl1 norm:')
l1 = normalize(df, norm='l1')
display(l1)
print('l1 mean:', round(np.mean(l1),3))
print('l1 distances:')
display(pd.DataFrame(euclidean_distances(l1)).mask(lambda x: x==0,np.nan).style.background_gradient(cmap='RdYlGn', axis=None))
print('\n\nl2 norm:')
l2 = normalize(df, norm='l2')
display(l2)
print('l2 mean:', round(np.mean(l2),3))
print('l2 distances:')
display(pd.DataFrame(euclidean_distances(l2)).mask(lambda x: x==0,np.nan).style.background_gradient(cmap='RdYlGn', axis=None))
print('\n=====\nz-scored l2 norm:')
zl2 = StandardScaler().fit_transform(l2)
display(zl2)
print('z-scored l2 mean:', round(np.mean(zl2),3))
print('z-scored l2 distances:')
display(pd.DataFrame(euclidean_distances(zl2)).mask(lambda x: x==0,np.nan).style.background_gradient(cmap='RdYlGn', axis=None))
# a single plot with all six feature (not distance) matrices
import matplotlib.pyplot as plt
plt.figure(figsize=(8,8))
for i, mat in enumerate([df, minmax, zscores, l1, l2, zl2]):
plt.subplot(int(f'23{i+1}'))
plt.imshow(mat)
plt.title(i)
plt.show()
```
**You almost certainly want to standardize your feature data, probably with *z*-scores, unless there's a good reason to do otherwise.**
## Dimension reduction
### The curse of dimensionality
* Low density of samples
* Hard to identify "typical" or "average" points.
* Everything is an outlier.
* All points are far apart (or have low similarity, or are uncorrelated).
* Multicolinearity
* Always true when you have more dimensions than samples.
* Many variables might be substituted for one another.
* But *which ones*?
* This is a problem if we want to *interpret* our model.
* Overfitting
* Too much "detail" in our training data.
* For example, say we care about cats in our texts.
* Do we need features `['cat', 'cats', 'kitten', 'kittens', 'kitty', 'kitties', 'Cat', 'Cats', ...]`?
* Probably not; any one of these, or their sum, would do.
The trick, then, is to figure out *which* features to keep (feature selection) and/or how collapse multiple features into one (dimension reduction).
Note that this explains why the Decision Tree classifier with a shallow tree depth performed well in the current problem set: it effectively performs dimension reduction via feature selection.
## Feature selection
We'll talk more about this later, but for now, a few key points:
* If a feature has the same value for most objects (that is, it has low variance), it is unlikely to be informative and is a good candidate for elimination.
* We're looking to hold on to as much of the underlying variance (information) in the data as possible, while eliminating as many features as possible.
* Any measure of correlation or mutual information would help us identify features that provide similar information.
* We might then drop one or more of those variables with little loss of overall information.
* We can also work empirically and *post hoc* by calculating feature importances from our classifier (where possible).
* We then retain only the *n* most important features and examine the impact on classifier performance.
## Linear and manifold methods
But we can also *transform* our features, rather than just dropping some and retaining others.
Specifically, we can look for mathematical *combinations* of features that hold on to all or most of the underlying variance.
Consider:
```
# linearly related variables
x = np.linspace(0,5)
y = x
plt.scatter(x,y)
plt.show()
```
* If we know *x*, we already know the *exact* value of *y*!
* Here, we could just drop *x* or *y*.
But what about this case?:
```
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=1000, centers=1)
transformation = [[-0.6, -0.6], [0.4, 0.8]]
X_aniso = np.dot(X, transformation)
plt.scatter(X_aniso[:,0], X_aniso[:,1], alpha=0.3);
```
### Principal component analysis (PCA)
```
from sklearn.decomposition import PCA
# A function to draw vectors
def draw_vector(v0, v1, ax=None):
ax = ax or plt.gca()
arrowprops=dict(arrowstyle='->',
linewidth=2,
shrinkA=0, shrinkB=0)
ax.annotate('', v1, v0, arrowprops=arrowprops)
# Set up and fit PCA
pca = PCA(n_components=2, whiten=True) # whiten enforces some extra regularity on output
X_pca = pca.fit_transform(X_aniso)
# Plotting
fig, ax = plt.subplots(3,1, figsize=(4.5, 12))
# Input data
ax[0].scatter(X_aniso[:, 0], X_aniso[:, 1], alpha=0.2)
for length, vector in zip(pca.explained_variance_, pca.components_):
v = vector * 3 * np.sqrt(length)
draw_vector(pca.mean_, pca.mean_ + v, ax=ax[0])
ax[0].axis('equal');
ax[0].set(xlabel='x', ylabel='y', title='Input')
# PCA 2-D
ax[1].scatter(X_pca[:, 0], X_pca[:, 1], alpha=0.2)
draw_vector([0, 0], [0, 3], ax=ax[1])
draw_vector([0, 0], [3, 0], ax=ax[1])
ax[1].axis('equal')
ax[1].set(xlabel='PC0', ylabel='PC1',
title='PCs')
# PCA 1-D
ax[2].scatter(X_pca[:,0], np.zeros(shape=len(X_aniso)), alpha=0.1)
ax[2].set(xlabel='PC0', ylabel='None', title='1-D')
plt.tight_layout()
plt.show()
print("Explained variance:", pca.explained_variance_ratio_)
```
### Truncated SVD
Singular Value Decomposition (SVD) is closely related to PCA. The only difference, from our perspective, is that, because PCA needs to standardize input data, it requires dense (rather than sparse) input. So, we use SVD (via `TrunctedSVD`) when we want to preserve input sparsity (e.g., when our dataset is very large). "Truncated" just means that we retain fewer dimensions in our output than existed in the input.
```
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=1)
X = svd.fit_transform(X_aniso)
plt.scatter(X[:,0], np.zeros(shape=len(X)), alpha=0.1)
plt.show()
print('Explained variance:', round(svd.explained_variance_ratio_[0],4))
svd.fit_transform(StandardScaler().fit_transform(X_aniso))
print('Explained variance using standardized data:', round(svd.explained_variance_ratio_[0],4))
```
Notes:
* Standardizing our input data captures about the same amount of variance as does PCA. It's slightly different because we used the `whiten` option with PCA, which assures unit variance in each each reduced output dimension at the typical cost of a small amount of lost variance.
* We've used a one-dimensional plot here *not* because SVD is doing something different from PCA, but to show what dimension *reduction* looks like. We had 2-D inputs; it doesn't really make sense to use 2-D outputs!
### *t*-SNE
*t*-distributed Stochastic Neighbor Embedding is a *manifold* method. Features are projected into a multidimensional manifold rather than onto lines.
TSNE is (or was; see below) widely used for visualization, because it's good at maintaining internal structure ("lumpiness").
```
from sklearn.manifold import TSNE
tsne = TSNE(init='random', learning_rate='auto')
X = tsne.fit_transform(X_aniso)
plt.scatter(X[:,0], X[:,1], alpha=0.3);
```
### UMAP
Uniform Manifold Approximation and Projection (UMAP) is a manifold method, like *t*-SNE. It's more computationally efficient than *t*-SNE and tends to perform a bit better, too (in the sense that it preserves more of the underlying density structure. UMAP is generally preferred to *t*-SNE for visualization these days.
```
import umap
umap_reducer = umap.UMAP()
X = umap_reducer.fit_transform(X_aniso)
plt.scatter(X[:,0], X[:,1], alpha=0.3);
```
There are a bunch of parameters that control the performance of UMAP (and of *t*-SNE, too). If you make any real use of UMAP, you should read (and understand) [the documentation](https://umap-learn.readthedocs.io/en/latest/parameters.html#).
| github_jupyter |
```
from datetime import datetime
import json
import os
import numpy as np
import tensorflow as tf
import pandas as pd
import tensorflow_hub as hub
from keras import Sequential
from keras.callbacks import ModelCheckpoint
from keras.layers import Dense, Activation, Dropout, Embedding, Conv1D, GlobalMaxPooling1D, Bidirectional, CuDNNLSTM, \
SpatialDropout1D, MaxPooling1D,Conv2D,MaxPooling2D,Flatten
import matplotlib.pyplot as plt
from utility.train_data_loader import load_train_data
epochs = 10
batch_size = 256
specialization = "fashion"
gen_test = True
categories_file = open("../data/categories.json", "r")
categories = json.load(categories_file)
all_subcategories = {k.lower(): v for k, v in categories['Mobile'].items()}
all_subcategories.update({k.lower(): v for k, v in categories['Fashion'].items()})
all_subcategories.update({k.lower(): v for k, v in categories['Beauty'].items()})
data_root = "../../"+specialization+"_image/"
datagen = tf.keras.preprocessing.image.ImageDataGenerator(rotation_range=8, width_shift_range=0.08, shear_range=0.3,
height_shift_range=0.08, zoom_range=0.08,rescale=1./255)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rotation_range=8, width_shift_range=0.08, shear_range=0.3,
height_shift_range=0.08, zoom_range=0.08,rescale=1./255)
test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rotation_range=8, width_shift_range=0.08, shear_range=0.3,
height_shift_range=0.08, zoom_range=0.08,rescale=1./255)
feature_extractor_url = "https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/2"
trainData = load_train_data()
testData = pd.read_csv("../data/test.csv")
validation_data_specialized = trainData[trainData['image_path'].str.contains(specialization)][::100]
validation_data_specialized['image_path'] = validation_data_specialized['image_path']. \
map(lambda x: x.replace(specialization + '_image/', ''))
test_data_specialized = testData[testData['image_path'].str.contains(specialization)]
test_data_specialized['image_path'] = test_data_specialized['image_path'].\
map(lambda x: x.replace(specialization+'_image/', ''))
inverted_categories_specialized = {k.lower(): v for k, v in categories[specialization.capitalize()].items()}
train_data_specialized = trainData[trainData['image_path'].str.contains(specialization)][::]
df_train = pd.DataFrame()
df_valid = pd.DataFrame()
num_train=2000
num_valid=int(0.1*num_train)
for k,v in inverted_categories_specialized.items():
rows = train_data_specialized.loc[train_data_specialized['Category'] == v]
num_images = rows.shape[0]
if(num_train+num_valid>num_images):
nt=int(0.9*num_images)
nv=int(0.1*num_images)
else:
nt=num_train
nv=num_valid
# print(nt,nv)
rows_train = rows[:nt]
df_train = df_train.append(rows_train)
rows_valid = rows[nt:(nt+num_valid)]
df_valid = df_valid.append(rows_valid)
train_data_specialized = df_train
validation_data_specialized = df_valid
train_data_specialized['image_path'] = train_data_specialized['image_path']. \
map(lambda x: x.replace(specialization + '_image/', ''))
validation_data_specialized['image_path'] = validation_data_specialized['image_path']. \
map(lambda x: x.replace(specialization + '_image/', ''))
IMAGE_SIZE = hub.get_expected_image_size(hub.Module(feature_extractor_url))
image_generator = datagen.flow_from_dataframe(train_data_specialized,
directory=os.path.join(data_root),
x_col="image_path",
y_col="item_category",
target_size=IMAGE_SIZE,
color_mode="grayscale",
class_mode="categorical",
shuffle=True,
batch_size=64,
)
label_names = sorted(image_generator.class_indices.items(), key=lambda pair:pair[1])
label_names = np.array([key.title() for key, value in label_names])
def feature_extractor(x):
feature_extractor_module = hub.Module(feature_extractor_url)
return feature_extractor_module(x)
for image_batch, label_batch in image_generator:
print("Image batch shape: ", image_batch.shape)
print("Label batch shape: ", label_batch.shape)
break
input_shape = IMAGE_SIZE+[1]
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(inverted_categories_specialized), activation='softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
valid_generator = valid_datagen.flow_from_dataframe(validation_data_specialized,
directory=os.path.join(data_root),
x_col="image_path",
y_col="item_category",
target_size=IMAGE_SIZE,
color_mode="grayscale",
class_mode="categorical",
shuffle=True,
batch_size=64,
)
test_generator = test_datagen.flow_from_dataframe(test_data_specialized,
directory=os.path.join(data_root),
x_col="image_path",
y_col=None,
target_size=IMAGE_SIZE,
color_mode="grayscale",
class_mode=None,
shuffle=False,
batch_size=64,
)
print(test_data_specialized.shape)
def gen_filename_h5():
return 'epoch_'+str(epochs) + '_' + datetime.now().strftime("%m_%d_%Y_%H_%M_%S")
def gen_filename_csv():
return 'epoch_'+str(epochs) + '_' + datetime.now().strftime("%m_%d_%Y_%H_%M_%S")
# Checkpoint auto
filepath = "../checkpoints/"+gen_filename_h5()+"v2.hdf5"
checkpointer = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
steps_per_epoch = image_generator.samples//image_generator.batch_size
valid_steps_per_epoch = valid_generator.samples // valid_generator.batch_size
test_steps_per_epoch = test_generator.samples // test_generator.batch_size
history = model.fit_generator(generator=image_generator,
steps_per_epoch=steps_per_epoch,
validation_data=valid_generator,
validation_steps=valid_steps_per_epoch,
epochs=epochs,
callbacks=[checkpointer],
)
def perform_test():
prediction_specialized = model.predict_generator(test_generator, verbose=1, steps=test_steps_per_epoch+1)
return prediction_specialized
if gen_test:
prediction_specialized = perform_test()
predicted_label_specialized = [np.argmax(prediction_specialized[i]) for i in range(len(prediction_specialized))]
print(prediction_specialized.shape)
df = pd.DataFrame({'itemid': test_data_specialized['itemid'].astype(int), 'Category': predicted_label_specialized})
df.to_csv(path_or_buf='res' + gen_filename_csv() + '.csv', index=False)
print(prediction_specialized.shape)
```
| github_jupyter |
# Data Poisoning Attack using LFM and ItemAE on Synthetic Dataset
Our goal is to promote an item of our choice. So we will poison a recommender model (victim) by feeding malicious data of fake users. So when the victim model will re-train itself on real+fake data next time, it will recommender our target time often.
This fake data is carefully crafted by adversarial training.
```
!pip install higher
import random
from functools import partial
import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
import higher
```
## Data
### Synthetic Toy Dataset
We synthesize a toy datset that is more controllable. Specifically, each data point in $X$ is generated by $x=\mu \nu^\top$, where both $\nu \in \mathcal{R}^d$ and $\mu\in \mathcal{R}^d$ are sampled from $\mathcal{N}_d(\mathbf{0}, \mathbf{I})$ with $d<<\min(|U|, |V|)$. By generating data point for $\forall x \in X$, the synthesized dataset is presumably to have low-rank, similar to other real-world recommendation datsets. Lastly, we binarize $X$ to transform it into implicit feedback data by setting a threshold $\epsilon$. By controlling the value of $(|U|,V|,d,\epsilon)$, we are able to have arbitrary-size synthetic datasets with different ranks and sparsity levels.
Define some hyperparameters for synthetic data generation
```
n_users = 1000 # number of total users (normal and fake), |U| + |V|
n_items = 300 # number of items |I|
n_fakes = 100 # number of fake user |V|
data_ranks = 20 # synthetic data rank d
binary_threshold = 5 # threshold epsilon
# Without loss of generality, let's suppose we're targeting the item `i0`.
# i.e., we want to push `i0` to true users' recommendation lists.
target_item = 0
```
Generate the synthetic data following the above procedure
```
dense_data_x = torch.mm(torch.randn(n_users, data_ranks),
torch.randn(data_ranks, n_items))
data_x = torch.zeros_like(dense_data_x)
test_items = np.empty([n_users - n_fakes], dtype=np.int64)
for i, x in enumerate(dense_data_x):
# Apply thresholding to make synthetic data for implicit feedback.
# it means the current user has interacted (views/bought/consumed etc.) with items
# whose value is 1 and vica-versa
x_binary = torch.where(x > binary_threshold,
torch.ones_like(x), torch.zeros_like(x))
# For the true users, sample 1 item per user as the test item.
nnz_inds = torch.nonzero(x_binary).view(-1)
rand_ind = np.random.randint(0, nnz_inds.shape[0])
test_item = nnz_inds[rand_ind]
# Also we have to remove it from training data.
if i < (n_users - n_fakes):
x_binary[test_item] = 0.0
test_items[i] = test_item.item()
data_x[i] = x_binary
target_x = torch.zeros_like(data_x)
target_x[:, target_item] = 1.0
print(data_x)
print("data sparsity: %.2f" % (1 - data_x.sum().item() / data_x.view(-1).shape[0]))
print(target_x)
```
## Models
We have to learn 2 functions - A fake data generator and a recommender. We will first generate fake data of dimension a x b where a are no. of fake users and b are no. of items in the catalog.
After generating the fake user's data, we will train the recommender on real+fake data and evaluate its performance. i.e. How good it is in recommending our target item to real users.
On the basis of this loss, we will update the gradients of both the functions/models (data generator and recommender).
**Solve the bi-level optimization problem to learn fake data for adversearial goal**
Given a well-trained surrogate model that is under-attack and a set of fake users $V = \{v_1, v_2,..,v_{|V|}\}$, the fake data $\widehat{X} \in \{0,1\}^{|V| \times |I|}$ will be learned to optimize an adversarial objective function ${\mathcal{L}_{\rm{adv}}}$:
$$
\min_{\widehat{X}}{\mathcal{L}_{\rm{adv}}}(R_{\theta^*}),
$$
$$
\textrm{subject to}\quad \theta^* = \text{argmin}_\theta \big ( {\mathcal{L}_{\rm{train}}}(X, R_{\theta}) + {\mathcal{L}_{\rm{train}}}(\widehat{X}, \widehat{R}_{\theta}) \big ),
$$
The inner objective shows that after fake data $\widehat{X}$ are injected, the surrogate model will first consume them (i.e., train from scratch with the poisoned dataset), we then obtain the trained model parameters $\theta^*$.
The outer objective shows that after fake data are consumed, we can achieve the malicious goal defined on normal user's predictions $R_{\theta^*}$.
### LFM
Standard Latent Factor Model
```
class LatentFactorModel(nn.Module):
def __init__(self, n_users, n_items, hidden_dim):
super(LatentFactorModel, self).__init__()
self.n_users = n_users
self.n_items = n_items
self.dim = hidden_dim
# Random-normal initialization of item embedding matrix
self.V = nn.Parameter(
torch.randn([self.n_items, self.dim]), requires_grad=True)
# Random-normal initialization of user embedding matrix
self.U = nn.Parameter(
torch.randn([self.n_users, self.dim]), requires_grad=True)
self.params = nn.ParameterList([self.V, self.U])
def forward(self, user_id=None, item_id=None):
if user_id is None and item_id is None:
return torch.mm(self.U, self.V.t())
if user_id is not None:
return torch.mm(self.U[[user_id]], self.V.t())
if item_id is not None:
return torch.mm(self.U, self.V[[item_id]].t())
```
### ItemAE
Approximate the adversarial gradient with parial derivatives.
this method uses itembased autoencoder optimized with Adam as surrogate model. The special design of ItemAE allows us to obtain non-zero partial derivatives. Thus, when accumulating adversarial gradients, we unroll either 0 steps (using only partial derivative) or 10% of total training steps.
```
class ItemAE(nn.Module):
def __init__(self, input_dim, hidden_dims):
super(ItemAE, self).__init__()
self.q_dims = [input_dim] + hidden_dims
self.p_dims = self.q_dims[::-1]
self.q_layers = nn.ModuleList([nn.Linear(d_in, d_out) for
d_in, d_out in
zip(self.q_dims[:-1],
self.q_dims[1:])])
self.p_layers = nn.ModuleList([nn.Linear(d_in, d_out) for
d_in, d_out in
zip(self.p_dims[:-1],
self.p_dims[1:])])
def encode(self, input):
h = input
for i, layer in enumerate(self.q_layers):
h = layer(h)
h = F.selu(h)
return h
def decode(self, z):
h = z
for i, layer in enumerate(self.p_layers):
h = layer(h)
if i != len(self.p_layers) - 1:
h = F.selu(h)
return h
def forward(self, data):
z = self.encode(data.t())
return self.decode(z).t()
```
### Model factory
```
def get_model(name="LFM"):
model, inner_opt = None, None
if name == "LFM":
hidden_dim = 16
model = LatentFactorModel(n_users, n_items, hidden_dim)
inner_opt = optim.Adam(model.parameters(), lr=0.5)
elif name == "ItemAE":
hidden_dims = [64, 32]
model = ItemAE(n_users, hidden_dims)
inner_opt = optim.Adam(model.parameters(), lr=1e-2)
return model, inner_opt
```
## Utils
```
def set_random_seed(seed, use_cuda):
random.seed(seed)
np.random.seed(seed)
if use_cuda:
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
else:
torch.manual_seed(seed)
def project_data(data, threshold=0.5):
result = data.clone()
return torch.where(result > threshold,
torch.ones_like(result), torch.zeros_like(result))
```
## Trainer
### Loss functions
We use the softmax loss as the adversarial objective $\mathcal{L}_{\rm{adv}}$ and the weighted MSE as the surrogate training objective $\mathcal{L}_{\rm{train}}$, one can also define & explore other objectives.
```
def softmax_cross_entropy_with_logits(logits, targets):
log_probs = F.log_softmax(logits, dim=1)
loss = -log_probs * targets
return loss.sum()
def mse_loss(logits, targets, weight=1):
weights = torch.ones_like(logits)
weights[targets > 0] = weight
loss = weights * (targets - logits)**2
return loss.sum()
```
### Evaluation function
```
def evaluate(data_x, preds, test_items, target_item=None, cutoff=10):
test_rankings = []
target_rankings = []
filtered_preds = preds.clone()
filtered_preds.require_grad = False
filtered_preds[torch.where(data_x)] = -np.inf
rankings = filtered_preds.argsort(dim=1, descending=True).tolist()
for user, test_item in enumerate(test_items):
rank = rankings[user]
test_rank = rank.index(test_item)
test_rankings.append(test_rank)
if target_item is not None:
target_rank = rank.index(target_item)
target_rankings.append(target_rank)
test_rankings = np.asarray(test_rankings)
target_rankings = np.asarray(target_rankings)
mean_hr_test = (test_rankings < cutoff).mean()
mean_rank_test = test_rankings.mean()
result = {"hr@%d_test" % cutoff: "%.4f" % mean_hr_test,
"mean_rank_test": "%.4f" % mean_rank_test}
if target_item is not None:
mean_hr_target = (target_rankings < cutoff).mean()
mean_rank_target = target_rankings.mean()
result["hr@%d_target" % cutoff] = "%.4f" % mean_hr_target
result["mean_rank_target"] = "%.4f" % mean_rank_target
return result
```
### Training Hyperparams
```
seed = 1234 # random seed
use_cuda = False # whether to use GPU
verbose = False # whether to output full log
n_inner_iter = 100 # epochs for inner optimization
n_outer_iter = 50 # epochs for outer optimization
unroll_epochs = 100 # how many epochs to unroll
# Learning rate and momentum for outer objective optimizer, make sure
# they are carefully tuned for different surrogate and unroll_epochs.
outer_lr = 1.0
outer_momentum = 0.99
surrogate = "LFM" # which surrogate model to use (LFM or ItemAE)
```
### Training
```
device = "cuda" if use_cuda else "cpu"
set_random_seed(seed, use_cuda)
inner_loss_func = partial(mse_loss, weight=20)
outer_loss_func = softmax_cross_entropy_with_logits
data_x.requires_grad_()
outer_opt = optim.SGD([data_x], lr=outer_lr, momentum=outer_momentum)
data_x = data_x.to(device)
target_x = target_x.to(device)
results = {"adv_loss": [], "hr@10_target": [], "hr@10_test": []}
for j in range(1, n_outer_iter + 1):
torch.manual_seed(seed)
model, inner_opt = get_model(surrogate)
model = model.to(device)
outer_opt.zero_grad()
### Begin: Inner-level optimization
# Train a few steps without tracking gradients.
for i in range(1, n_inner_iter - unroll_epochs + 1):
model.train()
preds = model() if surrogate == "LFM" else model(data_x)
inner_loss = inner_loss_func(preds, data_x)
inner_opt.zero_grad()
inner_loss.backward()
inner_opt.step()
# Evaluate recommendation performance along training steps.
model.eval()
result = evaluate(data_x, preds.detach(), test_items)
if verbose and i % 10 == 0:
print("inner epoch: %d, loss: %.2f, %s" % (
i, inner_loss.item(), str(result)))
# Start using tracking gradients.
with higher.innerloop_ctx(model, inner_opt) as (fmodel, diffopt):
if verbose:
print("Switching to higher mode at epoch %d" % i)
for i in range(n_inner_iter - unroll_epochs + 1, n_inner_iter + 1):
fmodel.train()
preds = fmodel() if surrogate == "LFM" else fmodel(data_x)
inner_loss = inner_loss_func(preds, data_x)
diffopt.step(inner_loss)
# Evaluate recommendation performance along training steps.
fmodel.eval()
result = evaluate(data_x, preds.detach(), test_items)
if verbose and i % 10 == 0:
print("inner epoch: %d, loss: %.2f, %s" % (
i, inner_loss.item(), str(result)))
### End: Inner-level optimization
### Start: outer-level optimization
preds = fmodel() if surrogate == "LFM" else fmodel(data_x)
outer_loss = outer_loss_func(preds[:-n_fakes, ],
target_x[:-n_fakes, ])
results["adv_loss"].append(float("%.4f" % outer_loss.item()))
grad_x = torch.autograd.grad(outer_loss, data_x)[0]
# Only change the fake data by setting normal data gradient to 0.
grad_x[:-n_fakes, :] = 0.0
if data_x.grad is None:
data_x.grad = grad_x
else:
data_x.grad.data = grad_x
outer_opt.step()
# Project fake data onto allowable area.
data_x.data = project_data(data_x.data, 0.2)
### End: outer-level optimization
# Evaluate the recommendation performance and attack performance.
fmodel.eval()
preds = fmodel() if surrogate == "LFM" else fmodel(data_x)
result = evaluate(data_x, preds.detach(), test_items, target_item)
results["hr@10_target"].append(float(result["hr@10_target"]))
results["hr@10_test"].append(float(result["hr@10_test"]))
print("outer epoch: %d, loss: %.2f, %s" % (
j, outer_loss.item(), str(result)))
print("-" * 100)
```
## Visualization
```
import matplotlib
import matplotlib.pyplot as plt
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(12,4))
ax1.plot(results['adv_loss'])
ax1.set_xlabel("iteration")
ax1.set_title("adversarial loss")
ax2.plot(results['hr@10_target'])
ax2.set_xlabel("iteration")
ax2.set_title("HR@10 for target item")
ax3.plot(results['hr@10_test'])
ax3.set_xlabel("iteration")
ax3.set_title("HR@10 for test item")
```
| github_jupyter |
```
from glypy.io import glycoct
import extract_motif
from glypy.algorithms.subtree_search import subtree_of
import hierarchical_enrichment
import customize_motif_vec
import glycan_io
import extract_motif
import motif_class
import __init__
import json_utility
import glycan_profile
from importlib import reload
import pandas as pd
import plot_glycan_utilities
import matplotlib.pyplot as plt
from glypy.io import glycoct, iupac
import numpy as np
import clustering_analysis_pip
reload(__init__)
reload(extract_motif)
reload(motif_class)
reload(glycan_profile)
reload(plot_glycan_utilities)
%matplotlib inline
```
# Table relative abd
```
# abundance_data_table = json_utility.load_json("../intermediate_file/NBT_dict_name_abundance_cross_profile.json")
# load glycoprofile Mass Spectrum m/z and glycan structure info
# load CHO paper abundance table
mz_abd_table = glycan_profile.load_cho_mz_abundance()
# load glycoprofile Mass Spectrum m/z and glycan structure info
profile_mz_to_id = glycan_profile.load_glycan_profile_dic()
# normalize CHO abundance table
norm_mz_abd_dict = glycan_profile.get_norm_mz_abd_table(mz_abd_table)
# load match_dict
match_dict = json_utility.load_json(__init__.json_address + "match_dict.json")
# digitalize the glycoprofile
glycoprofile_list = glycan_profile.get_glycoprofile_list(profile_mz_to_id, norm_mz_abd_dict, match_dict)
# generate table
table_generator = glycan_profile.MotifAbdTableGenerator(glycoprofile_list)
motif_abd_table = table_generator.table_against_wt_relative_abd()
# motif_abd_table.head()
# load motif vector and return edge_list
# motif_vector = json_utility.load_json("../intermediate_file/Unicarbkb_motif_vec_12259.json")
# motif_lib = gc_glycan_motif.GlycanMotifLib(motif_dict)
motif_lib = motif_class.MotifLabNGlycan(json_utility.load_json(__init__.merged_motif_dict_addr)) # unicarbkb_motifs_12259.json
tree_type_dp, edge_list = motif_lib.motif_dependence_tree()
dropper = motif_class.NodesDropper(motif_lib, motif_class.get_weight_dict(motif_abd_table))
# hier_enrich_glycoprofile_occurence(glycoprofile, scoredMotifs_occurence_vector, np.array(edge_list),motif_vector)
reload(__init__)
reload(extract_motif)
reload(motif_class)
reload(glycan_profile)
reload(plot_glycan_utilities)
reload(clustering_analysis_pip)
dropper = motif_class.NodesDropper(motif_lib, motif_class.get_weight_dict(motif_abd_table))
import seaborn as sns
# sns.set("RdBu_r", 7)
dropper.drop_node()
print("", len(dropper.drop_node()))
df_ncore = motif_abd_table[motif_abd_table.index.isin(dropper.nodes_kept)]
# draw plot
# motif_with_n_glycan_core_all_motif(motif_, _table, weight_dict)
""" with n_glycan_core using jaccard for binary and use braycurtis for float
"""
df_ncore.to_csv(__init__.json_address + r"abundance_matrix.txt")
name_prefix = 'dropped'
# sns.palplot(sns.color_palette("RdBu_r", 7))
g = sns.clustermap(df_ncore.T, metric="braycurtis",method='single',cmap=sns.diverging_palette(247,10,99,54,1,20),linewidths=.01,figsize=(20,20),linecolor='black')
draw_profile_cluster(g, df_ncore, profile_name, name_prefix, color_threshold=0.95)
cccluster_dict = draw_motif_cluster(g, df_ncore, name_prefix, color_threshold=0.23)
sns.choose_diverging_palette()
247,10,99,33,1,10
import numpy as np
from scipy import stats
a = np.array([1,2,3,4,5,6,7,8,9,0])
a.mean()
a.var()
tt = (1-a.mean())/np.sqrt(a.var()/8)
stats.t.sf(np.abs(tt), len(a)-1)*2
from scipy.cluster import hierarchy
ytdist = np.array([662., 877., 255., 412., 996., 295., 468., 268.,400., 754., 564., 138., 219., 869., 669.])
Z = hierarchy.linkage(ytdist, 'single')
```
# Table Existance
```
motif_exist_table = table_generator.table_existance()
# motif_lib = motif_class.MotifLabNGlycan(json_utility.load_json(__init__.merged_motif_dict_addr)) # unicarbkb_motifs_12259.json
# tree_type_dp, edge_list = motif_lib.motif_dependence_tree()
import hierarchical_enrichment
scoredMotifs_occurence_vector=[sum(i) for i in np.array(motif_exist_table)]
method='chi_squared'
relative='child'
motif_hierarchy = np.array(edge_list)
motif_vec= motif_lib.motif_vec
hierarchical_enrichment.hier_enrich_glycoprofile_occurence(glycoprofile_list, scoredMotifs_occurence_vector, np.array(edge_list), motif_vec)
motif_hierarchy
motif_exist_table
```
| github_jupyter |
# Quickstart guide
``imcascade`` is a non-parametric framework for fitting objects in astronomical images. This is accomplished by modelling the objects a series of Gaussians. For full details please read our paper here: *Put ArXiv link here*. What follows is a (very) brief introduction to the basic usage of ``imcascade``.
```
# This cell is hidden from documentation but the analytic profile and psf are calculated here using the astropy definitions
import numpy as np
import matplotlib.pyplot as plt
from astropy.modeling.functional_models import Sersic2D, Moffat2D
from astropy.convolution import convolve
grid = np.arange(0,150)
X,Y = np.meshgrid(grid,grid)
s2d = Sersic2D(r_eff = 5,n = 1.5, x_0 = 75.2, y_0 = 75.2)
im = s2d(X,Y)
im = im*100./np.sum(im)
grid2 = np.arange(0,31)
X,Y = np.meshgrid(grid2,grid2)
m2d = Moffat2D(gamma = 3,alpha = 3, x_0 = 15., y_0 = 15.)
psf = m2d(X,Y)
psf = psf/ np.sum(psf)
sci = convolve(im,psf) + np.random.normal(loc = 0, scale = 5e-2, size = im.shape)
```
In this short example we will fit an analytic, circular, Sersic profile with $n = 1.5$, $r_e = 5$ and total flux, $F = 100$, we have convolved the profile with a Moffat PSF with $\alpha = 3$ and $\gamma = 3$ and added purely Gaussian noise.
In a hidden cell I have intialized the cutout in the 2D array ``sci`` and the pixelized PSF saved in the 2D array ``psf``. Below I show to 2D images of each
```
fig,(ax1,ax2) = plt.subplots(1,2, figsize = (12,6))
ax1.imshow(sci)
ax1.set_title('Image to be fit')
ax2.imshow(psf)
ax2.set_title('PSF image')
plt.show()
```
The ``initialize_fitter`` function is designed to take a pixelized science images (as 2D arrays or fits files) and help initalize a ``Fitter`` instance which will be used below to fit galaxies. This function is designed to help users get started using our experiences to help guide some of the decisions, which may not be applicable in all situations. For more details about these choices or other options please see [the in depth example](example.ipynb) for a longer discussion about all possibilities.
```
from imcascade.fitter import initialize_fitter
fitter = initialize_fitter(sci,psf)
```
This function uses the ``psf_fitter`` module to fit the given pixelized psf with a sum of Gaussians, which is required for our method. Next it estimates the effective radius and uses nine logarithmically spaced widths for the Gaussian components ranging from the PSF HWHM to $10\times r_e$. It then derrives pixel weights and masks using [sep](https://sep.readthedocs.io/en/v1.1.x/) (or the gain,exposure time and readnoise to calculate the rms). There are also options to use pre-calculated version of these if the user has them.
Now we will run our least-squares minimization routine
```
_ = fitter.run_ls_min()
```
Now we will use our ``results`` submodule to help us analyze the results
```
from imcascade.results import ImcascadeResults
res_ls = ImcascadeResults(fitter)
res_ls.run_basic_analysis()
```
We can see our fit matches the true profile pretty well!
Next we will explore the Posterior distribution using Dynesty, and our method of pre-rendered images to help speed up the run time.
```
post = fitter.run_dynesty(method = 'express')
```
Now if we run the analysis again, we will have slightly different central values and error as the 16th-84th percentile range of the posterior.
```
res_dyn = ImcascadeResults(fitter)
res_dyn.run_basic_analysis()
```
| github_jupyter |
```
from glob import glob
import os.path as osp
import os
import pickle
import json
import numpy as np
downsample = 3
min_change_duration = 0.3
with open('../data/export/k400_mr345_val_min_change_duration'+str(min_change_duration)+'.pkl', 'rb') as f:
gt_dict = pickle.load(f)
exp_path = '../data/exp_k400/'
output_seg_dir = 'detect_seg'
OUTPUT_BDY_PATH = exp_path + output_seg_dir + '/{}.pkl'
list_rec = []
list_prec = []
list_f1 = []
for d in [0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5]: # threshold vary from percentage of video duration
tp_all = 0
num_pos_all = 0
num_det_all = 0
for vid_id in list(gt_dict.keys()):
# filter by avg_f1 score
if gt_dict[vid_id]['f1_consis_avg']<0.3:
continue
output_bdy_path = OUTPUT_BDY_PATH.format(vid_id)
if not os.path.exists(output_bdy_path):
continue
with open(output_bdy_path, 'rb') as f:
bdy_idx_save = pickle.load(f, encoding='latin1')
bdy_idx_list_smt = np.array(bdy_idx_save['bdy_idx_list_smt'])*downsample # already offset, index starts from 0
myfps = gt_dict[vid_id]['fps']
ins_start = 0
ins_end = gt_dict[vid_id]['num_frames']-1 #number of frames
# remove detected boundary outside the action instance
tmp = []
for det in bdy_idx_list_smt:
tmpdet = det + ins_start
if tmpdet >= (ins_start) and tmpdet <= (ins_end):
tmp.append(tmpdet)
bdy_idx_list_smt = tmp
if bdy_idx_list_smt == []:
num_pos_all += len(gt_dict[vid_id]['substages_myframeidx'][0])
continue
num_det = len(bdy_idx_list_smt)
num_det_all += num_det
# compare bdy_idx_list_smt vs. each rater's annotation, pick the one leading the best f1 score
bdy_idx_list_gt_allraters = gt_dict[vid_id]['substages_myframeidx']
f1_tmplist = np.zeros(len(bdy_idx_list_gt_allraters))
tp_tmplist = np.zeros(len(bdy_idx_list_gt_allraters))
num_pos_tmplist = np.zeros(len(bdy_idx_list_gt_allraters))
for ann_idx in range(len(bdy_idx_list_gt_allraters)):
bdy_idx_list_gt = bdy_idx_list_gt_allraters[ann_idx]
num_pos = len(bdy_idx_list_gt)
tp = 0
offset_arr = np.zeros((len(bdy_idx_list_gt), len(bdy_idx_list_smt)))
for ann1_idx in range(len(bdy_idx_list_gt)):
for ann2_idx in range(len(bdy_idx_list_smt)):
offset_arr[ann1_idx, ann2_idx] = abs(bdy_idx_list_gt[ann1_idx]-bdy_idx_list_smt[ann2_idx])
for ann1_idx in range(len(bdy_idx_list_gt)):
if offset_arr.shape[1] == 0:
break
min_idx = np.argmin(offset_arr[ann1_idx, :])
if offset_arr[ann1_idx, min_idx] <= d*(ins_end-ins_start+1):
tp += 1
offset_arr = np.delete(offset_arr, min_idx, 1)
num_pos_tmplist[ann_idx] = num_pos
fn = num_pos - tp
fp = num_det - tp
if num_pos == 0:
rec = 1
else:
rec = tp/(tp+fn)
if (tp+fp) == 0:
prec = 0
else:
prec = tp/(tp+fp)
if (rec+prec) == 0:
f1 = 0
else:
f1 = 2*rec*prec/(rec+prec)
tp_tmplist[ann_idx] = tp
f1_tmplist[ann_idx] = f1
ann_best = np.argmax(f1_tmplist)
tp_all += tp_tmplist[ann_best]
num_pos_all += num_pos_tmplist[ann_best]
fn_all = num_pos_all - tp_all
fp_all = num_det_all - tp_all
if num_pos_all == 0:
rec = 1
else:
rec = tp_all/(tp_all+fn_all)
if (tp_all+fp_all) == 0:
prec = 0
else:
prec = tp_all/(tp_all+fp_all)
if (rec+prec) == 0:
f1 = 0
else:
f1 = 2*rec*prec/(rec+prec)
list_rec.append(rec); list_prec.append(prec); list_f1.append(f1)
print("rec: " + str(np.mean(list_rec)))
print("prec: " + str(np.mean(list_prec)))
print("F1: " + str(np.mean(list_f1)))
print("rec: " + str(list_rec))
print("prec: " + str(list_prec))
print("F1: " + str(list_f1))
np.save(exp_path + output_seg_dir + '.eval.mindur'+str(min_change_duration)+'.npy', [list_rec, list_prec, list_f1])
```
#### previous code on evaluating PA mistakenly used `bdy_idx_list_smt = bdy_idx_save['bdy_idx_list_smt']*downsample`, where `bdy_idx_save['bdy_idx_list_smt']` is a list in python. This should be corrected to `np.array(bdy_idx_save['bdy_idx_list_smt'])*downsample`.
Previous results (note that this is wrong):
```python
rec: 0.5120347890388846
prec: 0.6296935118133276
F1: 0.5646457523112234
rec: [0.2224389645442277, 0.34249901256941057, 0.42121638808139533, 0.4786563154539659, 0.5235172882292662, 0.5611844953259, 0.5960510617990933, 0.6286171489531938, 0.6589695856397865, 0.6871976297926069]
prec: [0.26524760441811135, 0.43132177602223687, 0.542666959256821, 0.6151561699948797, 0.665174456879526, 0.7017043376490381, 0.7309048350523005, 0.7585984931607052, 0.7819618169848584, 0.8041986687147977]
F1: [0.24196443465785875, 0.38181264852334607, 0.4742902077113394, 0.5383891474555547, 0.5859051840779351, 0.6236266950970577, 0.6566255955314605, 0.6875182307549522, 0.7152166349987957, 0.7411087443039341]
```
| github_jupyter |
```
import lifelines
import pymc as pm
from pyBMA.CoxPHFitter import CoxPHFitter
import matplotlib.pyplot as plt
import numpy as np
from numpy import log
from datetime import datetime
import pandas as pd
%matplotlib inline
```
The first step in any data analysis is acquiring and munging the data
Our starting data set can be found here:
http://jakecoltman.com in the pyData post
It is designed to be roughly similar to the output from DCM's path to conversion
Download the file and transform it into something with the columns:
id,lifetime,age,male,event,search,brand
where lifetime is the total time that we observed someone not convert for and event should be 1 if we see a conversion and 0 if we don't. Note that all values should be converted into ints
It is useful to note that end_date = datetime.datetime(2016, 5, 3, 20, 36, 8, 92165)
```
running_id = 0
output = [[0]]
with open("E:/output.txt") as file_open:
for row in file_open.read().split("\n"):
cols = row.split(",")
if cols[0] == output[-1][0]:
output[-1].append(cols[1])
output[-1].append(True)
else:
output.append(cols)
output = output[1:]
for row in output:
if len(row) == 6:
row += [datetime(2016, 5, 3, 20, 36, 8, 92165), False]
output = output[1:-1]
def convert_to_days(dt):
day_diff = dt / np.timedelta64(1, 'D')
if day_diff == 0:
return 23.0
else:
return day_diff
df = pd.DataFrame(output, columns=["id", "advert_time", "male","age","search","brand","conversion_time","event"])
df["lifetime"] = pd.to_datetime(df["conversion_time"]) - pd.to_datetime(df["advert_time"])
df["lifetime"] = df["lifetime"].apply(convert_to_days)
df["male"] = df["male"].astype(int)
df["search"] = df["search"].astype(int)
df["brand"] = df["brand"].astype(int)
df["age"] = df["age"].astype(int)
df["event"] = df["event"].astype(int)
df = df.drop('advert_time', 1)
df = df.drop('conversion_time', 1)
df = df.set_index("id")
df = df.dropna(thresh=2)
df.median()
###Parametric Bayes
#Shout out to Cam Davidson-Pilon
## Example fully worked model using toy data
## Adapted from http://blog.yhat.com/posts/estimating-user-lifetimes-with-pymc.html
## Note that we've made some corrections
N = 2500
##Generate some random data
lifetime = pm.rweibull( 2, 5, size = N )
birth = pm.runiform(0, 10, N)
censor = ((birth + lifetime) >= 10)
lifetime_ = lifetime.copy()
lifetime_[censor] = 10 - birth[censor]
alpha = pm.Uniform('alpha', 0, 20)
beta = pm.Uniform('beta', 0, 20)
@pm.observed
def survival(value=lifetime_, alpha = alpha, beta = beta ):
return sum( (1-censor)*(log( alpha/beta) + (alpha-1)*log(value/beta)) - (value/beta)**(alpha))
mcmc = pm.MCMC([alpha, beta, survival ] )
mcmc.sample(50000, 30000)
pm.Matplot.plot(mcmc)
mcmc.trace("alpha")[:]
```
Problems:
1 - Try to fit your data from section 1
2 - Use the results to plot the distribution of the median
Note that the media of a Weibull distribution is:
$$β(log 2)^{1/α}$$
```
censor = np.array(df["event"].apply(lambda x: 0 if x else 1).tolist())
alpha = pm.Uniform("alpha", 0,50)
beta = pm.Uniform("beta", 0,50)
@pm.observed
def survival(value=df["lifetime"], alpha = alpha, beta = beta ):
return sum( (1-censor)*(np.log( alpha/beta) + (alpha-1)*np.log(value/beta)) - (value/beta)**(alpha))
mcmc = pm.MCMC([alpha, beta, survival ] )
mcmc.sample(10000)
def weibull_median(alpha, beta):
return beta * ((log(2)) ** ( 1 / alpha))
plt.hist([weibull_median(x[0], x[1]) for x in zip(mcmc.trace("alpha"), mcmc.trace("beta"))])
```
Problems:
4 - Try adjusting the number of samples for burning and thinnning
5 - Try adjusting the prior and see how it affects the estimate
```
censor = np.array(df["event"].apply(lambda x: 0 if x else 1).tolist())
alpha = pm.Uniform("alpha", 0,50)
beta = pm.Uniform("beta", 0,50)
@pm.observed
def survival(value=df["lifetime"], alpha = alpha, beta = beta ):
return sum( (1-censor)*(np.log( alpha/beta) + (alpha-1)*np.log(value/beta)) - (value/beta)**(alpha))
mcmc = pm.MCMC([alpha, beta, survival ] )
mcmc.sample(10000, burn = 3000, thin = 20)
pm.Matplot.plot(mcmc)
#Solution to Q5
## Adjusting the priors impacts the overall result
## If we give a looser, less informative prior then we end up with a broader, shorter distribution
## If we give much more informative priors, then we get a tighter, taller distribution
censor = np.array(df["event"].apply(lambda x: 0 if x else 1).tolist())
## Note the narrowing of the prior
alpha = pm.Normal("alpha", 1.7, 10000)
beta = pm.Normal("beta", 18.5, 10000)
####Uncomment this to see the result of looser priors
## Note this ends up pretty much the same as we're already very loose
#alpha = pm.Uniform("alpha", 0, 30)
#beta = pm.Uniform("beta", 0, 30)
@pm.observed
def survival(value=df["lifetime"], alpha = alpha, beta = beta ):
return sum( (1-censor)*(np.log( alpha/beta) + (alpha-1)*np.log(value/beta)) - (value/beta)**(alpha))
mcmc = pm.MCMC([alpha, beta, survival ] )
mcmc.sample(10000, burn = 5000, thin = 20)
pm.Matplot.plot(mcmc)
#plt.hist([weibull_median(x[0], x[1]) for x in zip(mcmc.trace("alpha"), mcmc.trace("beta"))])
```
Problems:
7 - Try testing whether the median is greater than a different values
```
medians = [weibull_median(x[0], x[1]) for x in zip(mcmc.trace("alpha"), mcmc.trace("beta"))]
testing_value = 14.9
number_of_greater_samples = sum([x >= testing_value for x in medians])
100 * (number_of_greater_samples / len(medians))
```
If we want to look at covariates, we need a new approach.
We'll use Cox proprtional hazards, a very popular regression model.
To fit in python we use the module lifelines:
http://lifelines.readthedocs.io/en/latest/
```
#Fitting solution
cf = lifelines.CoxPHFitter()
cf.fit(df, 'lifetime', event_col = 'event')
cf.summary
```
Once we've fit the data, we need to do something useful with it. Try to do the following things:
1 - Plot the baseline survival function
2 - Predict the functions for a particular set of features
3 - Plot the survival function for two different set of features
4 - For your results in part 3 caculate how much more likely a death event is for one than the other for a given period of time
```
#Solution to 1
fig, axis = plt.subplots(nrows=1, ncols=1)
cf.baseline_survival_.plot(ax = axis, title = "Baseline Survival")
regressors = np.array([[1,45,0,0]])
survival = cf.predict_survival_function(regressors)
survival.head()
#Solution to plotting multiple regressors
fig, axis = plt.subplots(nrows=1, ncols=1, sharex=True)
regressor1 = np.array([[1,45,0,1]])
regressor2 = np.array([[1,23,1,1]])
survival_1 = cf.predict_survival_function(regressor1)
survival_2 = cf.predict_survival_function(regressor2)
plt.plot(survival_1,label = "45 year old male - search")
plt.plot(survival_2,label = "45 year old male - display")
plt.legend(loc = "upper right")
odds = survival_1 / survival_2
plt.plot(odds, c = "red")
```
Model selection
Difficult to do with classic tools (here)
Problem:
1 - Calculate the BMA coefficient values
2 - Try running with different priors
```
#### BMA Coefficient values
#### Different priors
```
| github_jupyter |
# Imports
```
from itertools import combinations, groupby, product
from scipy.spatial.distance import squareform
from numpy import pi as PI
from scipy.integrate import quad
from collections import Counter
from scipy.special import iv
from functools import partial
from math import factorial
import time
import scipy
import numpy as np
import pandas as pd
import ringity as rng
import seaborn as sns
import networkx as nx
import matplotlib.pyplot as plt
sns.set()
%matplotlib inline
```
### Decorator
```
def support(f, left_limit, right_limit):
"""This function can be used as a decorater
to restrict the support of its input function."""
def f_rest(x, *args, **kwargs):
return np.where(left_limit <= x <= right_limit, f(x, *args, **kwargs), 0)
return f_rest
```
### Auxilary functions
```
def mu_eta_2_alpha_beta(mu, eta):
nu = (1-eta)/eta
alpha = mu *nu
beta = (1-mu)*nu
return alpha, beta
@partial(np.vectorize, excluded={'rho'})
@partial(support, left_limit=0, right_limit=np.inf)
def integral(mu, eta, kappa, a):
alpha, beta = mu_eta_2_alpha_beta(mu=mu, eta=eta)
return 2*PI*a*quad(lambda t: scipy.stats.beta.cdf(t, a=alpha, b=beta)*rng.f_delta(2*PI*a*(1-t), kappa=kappa),
0, 1)[0]
def get_mu(rho, eta, kappa, a):
if kappa == 0:
mu = 1-rho/(2*a)
elif eta == 0:
mu = scipy.optimize.newton(lambda mu: rng.F_delta(2*a*PI*(1-mu), kappa=kappa)-rho, 1-rho/(2*a),
fprime = lambda mu: -2*a*PI*rng.f_delta(2*a*PI*(1-mu), kappa=kappa),
maxiter=100)
else:
mu = scipy.optimize.newton(lambda mu: integral(mu, eta=eta, kappa=kappa, a=a)-rho, 1-rho/(2*a), maxiter=100)
return mu
```
### Unconditional distributions
```
def f_P(t, rho, eta, kappa, a):
if eta == 0:
return 0.
mu = get_mu(rho=rho, eta=eta, kappa=kappa, a=a)
alpha, beta = mu_eta_2_alpha_beta(mu=mu, eta=eta)
ppf = np.nan_to_num(scipy.stats.beta.ppf(t, a=alpha, b=beta))
numer = rng.f_s(ppf, kappa=kappa, a=a)
denom = scipy.stats.beta.pdf(ppf, a=alpha, b=beta)
return np.true_divide(numer, denom,
out = np.zeros_like(numer),
where = denom!=0)
def f_P_mu(t, mu, eta):
if eta == 0:
return 0.
alpha, beta = mu_eta_2_alpha_beta(mu=mu, eta=eta)
ppf = scipy.stats.beta.ppf(t, a=alpha, b=beta)
numer = rng.f_s(ppf, kappa=kappa, a=a)
denom = scipy.stats.beta.pdf(ppf, a=alpha, b=beta)
return np.true_divide(numer, denom,
out = np.zeros_like(numer),
where = denom!=0)
def F_P(t, rho, eta, kappa, a):
if eta == 0:
ppf = np.where(t < 1, 1-rho, 1.)
else:
alpha, beta = get_alpha_beta(rho=rho, eta=eta, kappa=kappa, a=a)
ppf = np.nan_to_num(scipy.stats.beta.ppf(t, a=alpha, b=beta), nan=1.)
return np.where(t<=0, 0.,
rng.F_s(ppf, kappa=kappa, a=a))
def F_P_mu(t, mu, eta):
if eta == 0:
ppf = np.where(t < 1, mu, 1.)
else:
alpha, beta = mu_eta_2_alpha_beta(mu=mu, eta=eta)
ppf = np.nan_to_num(scipy.stats.beta.ppf(t, a=alpha, b=beta), nan=1.)
return np.where(t<=0, 0.,
rng.F_s(ppf, kappa=kappa, a=a))
```
### Conditional distributions
```
@partial(np.vectorize, excluded={'theta', 'kappa'})
@partial(support, left_limit=0, right_limit=PI)
def cond_Delta(x, theta, kappa):
return (np.exp(kappa*np.cos(theta+x)) + np.exp(kappa*np.cos(theta-x)))/(2*PI*iv(0,kappa))
@partial(np.vectorize, excluded={'theta', 'kappa'})
@partial(support, left_limit=0, right_limit=PI)
def Cond_Delta(x, theta, kappa):
return scipy.integrate.quad(lambda t : np.exp(kappa*np.cos(theta-t))/(2*PI*iv(0,kappa)), -x, x)[0]
@partial(np.vectorize, excluded={'theta', 'kappa', 'a'})
@partial(support, left_limit=0, right_limit=1)
def cond_s(t, theta, kappa, a):
return 2*a*PI*cond_Delta(2*a*PI*(1-t), theta=theta, kappa=kappa)
@partial(np.vectorize, excluded={'theta', 'kappa', 'a'})
@partial(support, left_limit=0, right_limit=np.inf)
def Cond_s(t, theta, kappa, a):
return np.where(2-1/a < t, 1 - Cond_Delta(2*a*PI*(1-t), theta=theta, kappa=kappa), 0)
@partial(np.vectorize, excluded={'theta', 'kappa', 'a', 'A', 'B'})
@partial(support, left_limit=0, right_limit=1)
def cond_P(t, theta, mu, eta):
nu = (1-eta)/eta
alpha = mu *nu
beta = (1-mu)*nu
ppf = scipy.stats.beta.ppf(t, a=alpha, b=beta)
return cond_s(ppf, theta=theta, kappa=kappa, a=a)/scipy.stats.beta.pdf(ppf, a=alpha, b=beta)
@partial(np.vectorize, excluded={'theta', 'kappa', 'a', 'A', 'B'})
@partial(support, left_limit=0, right_limit=np.inf)
def Cond_P(t, theta, mu, eta):
nu = (1-eta)/eta
alpha = mu *nu
beta = (1-mu)*nu
ppf = scipy.stats.beta.ppf(t, a=alpha, b=beta)
return Cond_s(ppf, theta=theta, kappa=kappa, a=a)
def cond_Delta(x, theta, kappa):
return np.where(x<=0, 0,
np.where(x>=PI, 0,
(np.exp(kappa*np.cos(theta+x)) + np.exp(kappa*np.cos(theta-x)))/(2*PI*iv(0,kappa))))
def cond_s(t, theta, kappa, a):
return np.where(t<=0, 0,
np.where(t>=1, 0,
2*a*PI*cond_Delta(2*a*PI*(1-t), theta=theta, kappa=kappa)))
```
### Interaction probability function
```
@partial(np.vectorize, excluded={'a'})
@partial(support, left_limit=0, right_limit=np.inf)
def WS_integral(mu, a):
return rng.F_delta(2*a*PI*(1-mu), kappa=kappa)
@partial(np.vectorize, excluded={'rho'})
@partial(support, left_limit=0, right_limit=np.inf)
def WS(t, mu):
return np.where(t < mu, 0, 1)
@partial(np.vectorize, excluded={'rho'})
@partial(support, left_limit=0, right_limit=np.inf)
def ER(t, mu):
return 1-mu # INCOMPLETE !
#@partial(np.vectorize, excluded={'rho'})
#@partial(support, left_limit=0, right_limit=np.inf)
#def integral(mu, eta, kappa, a):
# if eta == 0:
# return rng.F_delta(2*a*PI*(1-mu), kappa=kappa)
# else:
# nu = (1-eta)/eta
# alpha = mu *nu
# beta = (1-mu)*nu
# return 2*PI*a*quad(lambda t: scipy.stats.beta.cdf(t, a=alpha, b=beta)*rng.f_delta(2*PI*a*(1-t), kappa=kappa), 0, 1)[0]
#
#
#def get_mu(rho, eta, kappa, a):
# if kappa == 0:
# mu = 1-rho/(2*a)
# elif eta == 0:
# mu = scipy.optimize.newton(lambda mu: integral(mu, eta=eta, kappa=kappa, a=a)-rho, 1-rho/(2*a),
# fprime = lambda mu: -2*a*PI*rng.f_delta(2*a*PI*(1-mu), kappa=kappa),
# maxiter=100)
# else:
# mu = scipy.optimize.newton(lambda mu: integral(mu, eta=eta, kappa=kappa, a=a)-rho, 1-rho/(2*a), maxiter=100)
# return mu
#
#def get_alpha_beta(rho, eta, kappa, a):
# mu = get_mu(rho=rho, eta=eta, kappa=kappa, a=a)
# nu = (1-eta)/eta
# alpha = mu *nu
# beta = (1-mu)*nu
# return alpha, beta
def get_ipf(mu, eta):
if eta == 0:
return partial(WS, mu=mu)
elif eta == 1:
return partial(ER, mu=mu)
else:
nu = (1-eta)/eta
alpha = mu *nu
beta = (1-mu)*nu
return partial(scipy.stats.beta.cdf, a=alpha, b=beta)
```
### Degree distribution
```
def rho_dot(theta, mu, eta):
alpha, beta = mu_eta_2_alpha_beta(mu=mu, eta=eta)
def integral(x):
return a/rng.bessel(kappa) * quad(lambda t : scipy.stats.beta.cdf(t, a=alpha, b=beta) *
(np.exp(kappa*np.cos(x+2*a*PI*(1-t))) +
np.exp(kappa*np.cos(x-2*a*PI*(1-t)))),
0, 1)[0]
return np.vectorize(integral)(theta)
def deg_distribution(N, kappa, mu, eta, size=2**7):
thetas = np.random.vonmises(mu=0, kappa=kappa, size=size)
p_count = rho_dot(thetas, mu=mu, eta=eta)
return {i:np.mean(scipy.stats.binom.pmf(i, n=N-1, p=p_count)) for i in range(N)}
```
### Main
```
def overlap(d, a):
x1 = np.where(2*PI*a-d > 0, 2*PI*a-d , 0)
x2 = np.where(d-2*PI*(1-a) > 0, d-2*PI*(1-a), 0)
return x1 + x2
def MY_numpy_model(
N,
rho,
eta = 0,
kappa = 0,
a = 0.5,
verbose = False):
assert 0 <= kappa
assert 0 < a <= 0.5
mu = get_mu(rho=rho, eta=eta, kappa=kappa, a=a)
ipf = get_ipf(mu=mu, eta=eta)
times = np.random.vonmises(mu=0, kappa=kappa, size=N)
abs_dist = scipy.spatial.distance.pdist(times.reshape(N,1))
sqNDM = np.where(abs_dist<PI, abs_dist, 2*PI-abs_dist)
sqNSM = overlap(sqNDM, a)/(2*PI*a)
sqNPM = ipf(sqNSM)
if verbose:
x = [np.cos(2*PI*t) for t in times]
y = [np.sin(2*PI*t) for t in times]
plt.plot(x, y, '*', markersize=1);
plt.axis('off')
return times, tuple(map(squareform, [sqNDM, sqNSM, sqNPM]))
```
# Testing
```
def test(theta, mu, eta):
nu = (1-eta)/eta
alpha = mu *nu
beta = (1-mu)*nu
def integral(x):
return a/rng.bessel(kappa) * quad(lambda t : scipy.stats.beta.cdf(t, a=alpha, b=beta) *
(np.exp(kappa*np.cos(x+2*a*PI*(1-t))) +
np.exp(kappa*np.cos(x-2*a*PI*(1-t)))),
0, 1)[0]
return np.vectorize(integral)(theta)
x = np.linspace(-PI,PI, 100)
theta = 0
kappa = 0.9
a = 0.399
eta = 0.05
mu = 0.123
rho = 0.06
rho_dot(0.123, mu, eta), test(0.123, mu, eta)
y1 = rho_dot(x, mu, eta)
y2 = test(x, mu, eta)
plt.plot(x, y1);
plt.plot(x, y2);
np.allclose(y1, y2)
%%timeit
rho_dot(x, mu, eta)
%%timeit
test(x, mu, eta)
```
# Clustering coefficient
```
sample_size = 2**2
default = 0.05
N = 2**9
rho = default
kappa = 0
etas = [0, 1/3, 2/3, 1]
a_list = np.linspace(0.01,0.5,30)
c_dict = dict()
for eta in etas:
c_dict[eta] = []
for nr,a in enumerate(a_list, 1):
print(f"{eta:.2f}", nr, end='\r')
c_tmp = []
for i in range(sample_size):
times, (NDM, NSM, NPM) = MY_numpy_model(N=N, rho=rho, eta=eta, kappa=kappa, a=a, verbose=False)
R = squareform(np.random.uniform(size=round(N*(N-1)/2)))
A = np.where(NPM>R, 1, 0)
G = nx.from_numpy_array(A)
c_tmp.append(np.mean(list(nx.clustering(G).values())))
c_dict[eta].append(np.mean(c_tmp))
print()
c_dict[1] = []
for nr,a in enumerate(a_list, 1):
print(nr, end='\r')
c_tmp = []
for i in range(sample_size):
G = nx.erdos_renyi_graph(N, rho)
c_tmp.append(np.mean(list(nx.clustering(G).values())))
c_dict[1].append(np.mean(c_tmp))
c_fig, ax = plt.subplots(figsize=(8,6))
c_fig.patch.set_alpha(0)
ax.patch.set_alpha(0)
ax.tick_params(axis='both', which='major', labelsize=24)
ax.spines['left'].set_linewidth(2.5)
ax.spines['left'].set_color('k')
ax.spines['bottom'].set_linewidth(2.5)
ax.spines['bottom'].set_color('k')
ax.set_xlabel("window size (a)", fontsize=24)
ax.set_ylabel("clustering coefficient (c)", fontsize=24)
for eta in sorted(etas):
ax.plot(a_list[1:], c_dict[eta][1:], linewidth=5, label=f'eta={eta:.2f}');
plt.legend(fontsize=16)
plt.savefig("/Users/markusyoussef/Desktop/ccoefficeint.png")
```
# Realisations
```
sample_size = 2**4
default = 0.05
N = 2**10
rho = default
eta = 0
kappa = 1.
a = 0.5 - default/2
times_list = []
NDM_list = []
NSM_list = []
NPM_list = []
deg_list = []
fullscore_list = []
thinscore_list = []
t1 = time.time()
for i in range(sample_size):
times, (NDM, NSM, NPM) = MY_numpy_model(N=N, rho=rho, eta=eta, kappa=kappa, a=a, verbose=False)
times_list.append(times)
NDM_list.append(NDM)
NSM_list.append(NSM)
NPM_list.append(NPM)
R = squareform(np.random.uniform(size=round(N*(N-1)/2)))
A = np.where(NPM>R, 1, 0)
G = nx.from_numpy_array(A)
deg_list += [deg for _,deg in G.degree]
# fullscore_list.append(rng.diagram(1-NPM).GGS)
# thinscore_list.append(rng.diagram(G, induce=True).GGS)
t2 = time.time()
print(f'time: {t2-t1}sek')
t1 = time.time()
mu = get_mu(rho=rho, eta=eta, kappa=kappa, a=a)
print(mu)
t2 = time.time()
print(f'time: {t2-t1}sek')
print(rho, nx.density(G))
pos = {node: (np.cos(times[node]), np.sin(times[node])) for node in G.nodes()}
nx_fig = plt.figure()
ax = nx_fig.gca()
rng.plot_nx(G, pos=pos, ax=ax)
```
# Degree distribution
```
sim_size = 2**12
t1 = time.time()
deg_dict = deg_distribution(N=N, kappa=kappa, mu=mu, eta=eta, size=sim_size)
t2 = time.time()
print(t2-t1)
degCount_obs = Counter(sorted(deg_list))
degs_obs, cnts_obs = zip(*degCount_obs.items())
cnts_obs = np.array(cnts_obs)/sample_size
cnts_exp = [deg_dict[deg]*N for deg in degs_obs]
width = 1
deg_fig, ax = plt.subplots(figsize=(8,6))
deg_fig.patch.set_alpha(0)
ax.bar(np.array(degs_obs), cnts_obs, width=width, color='b');
ax.plot(np.array(degs_obs), cnts_exp, '*', markersize=15, color='red');
rng.ax_setup(ax)
```
# Testing unconditional distributions
### Distribution of the distance $D$
```
bins = 51
weights = np.sort(np.concatenate([squareform(NDM) for NDM in NDM_list]))
freq, delta = np.histogram(weights, bins=bins)
delta = np.array([(a+b)/2 for a,b in zip(delta[:-1],delta[1:])])
width = delta[1]-delta[0]
freq = np.array(freq)
freq = freq/(np.sum(freq)*(width))
x = np.linspace(0, PI, 101)
delta_pdf_fig, ax = plt.subplots(figsize=(8,6))
delta_pdf_fig.patch.set_alpha(0)
ax.bar(delta, freq, width=width, color='b', log=False);
ax.plot(x, rng.f_delta(x, kappa=kappa), color='red', linewidth=7.5);
ax.set_xlabel(r'$\Delta$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated pdf of $D$', fontsize=24);
rng.ax_setup(ax)
delta_cdf_fig, ax = plt.subplots(figsize=(8,6))
delta_cdf_fig.patch.set_alpha(0)
cumfreq = (width)*np.cumsum(freq)
ax.bar(delta, cumfreq, width=width, color='b');
ax.plot(x, rng.F_delta(x,kappa), color='red', linewidth=7.5);
ax.set_xlabel(r'$\Delta$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated cdf of $D$', fontsize=24);
rng.ax_setup(ax)
```
### Distribution of the similarity $S$
```
bins = 51
weights = np.sort(np.concatenate([squareform(NSM) for NSM in NSM_list]))
freq, s = np.histogram(weights, bins=bins, range=(0,1))
s = np.array([(a+b)/2 for a,b in zip(s[:-1],s[1:])])
width = s[1]-s[0]
freq = np.array(freq)
freq = freq/(np.sum(freq)*(width))
x = np.linspace(0,1, 101)
s_pdf_fig, ax = plt.subplots(figsize=(8,6))
s_pdf_fig.patch.set_alpha(0)
ax.bar(s, freq, width=width, color='b', log=False);
ax.plot(x, rng.f_s(x, kappa=kappa, a=a), color='red', linewidth=7.5);
ax.plot(max(2-1/a,0)+width/2, freq[0], '*', color='red', markersize=15);
ax.set_xlabel(r'$s$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated pdf of $S$', fontsize=24);
rng.ax_setup(ax)
s_cdf_fig, ax = plt.subplots(figsize=(8,6))
s_cdf_fig.patch.set_alpha(0)
cumfreq = (width)*np.cumsum(freq)
ax.bar(s, cumfreq, width=width, color='b');
ax.plot(x, rng.F_s(x,kappa=kappa, a=a), color='red', linewidth=7.5);
ax.set_xlabel(r'$S$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated cdf of $s$', fontsize=24);
rng.ax_setup(ax)
```
### Distribution of the interaction probability $P$
```
bins = 51
weights = np.sort(np.concatenate([squareform(NPM) for NPM in NPM_list]))
freq, P = np.histogram(weights, bins=bins, range=(0,1))
P = np.array([(a+b)/2 for a,b in zip(P[:-1],P[1:])])
width = P[1]-P[0]
freq = np.array(freq)
freq = freq/(np.sum(freq)*(width))
x = np.linspace(0,1, 501)
P_pdf_fig, ax = plt.subplots(figsize=(8,6))
P_pdf_fig.patch.set_alpha(0)
ax.bar(P, freq, width=width, color='b', log=False);
ax.plot(x, f_P_mu(x, mu=mu, eta=eta), color='red', linewidth=7.5);
ax.plot( width/2, freq[0] , '*', color='red', markersize=15);
ax.plot(1-width/2, freq[-1], '*', color='red', markersize=15);
# ax.set_xlabel(r'$P$', fontsize=24)
# ax.set_ylabel('normalized frequency', fontsize=24)
# ax.set_title(r'Simulated and calculated pdf of $P$', fontsize=24);
rng.ax_setup(ax)
P_cdf_fig, ax = plt.subplots(figsize=(8,6))
P_cdf_fig.patch.set_alpha(0)
cumfreq = (width)*np.cumsum(freq)
ax.bar(P, cumfreq, width=width, color='b');
ax.plot(x, F_P_mu(x, mu=mu, eta=eta), color='red', linewidth=7.5);
# ax.set_xlabel(r'$P$', fontsize=24)
# ax.set_ylabel('normalized frequency', fontsize=24)
# ax.set_title(r'Simulated and calculated cdf of $P$', fontsize=24);
rng.ax_setup(ax)
```
# Testing conditional distributions
### Choosing a node
```
n = np.random.randint(N)
theta = times[n]
```
### Distribution of the conditional distance $D_{\vartheta}$
```
bins = 51
weights = np.sort(NDM[n,:])
freq, delta = np.histogram(weights, bins=bins)
delta = np.array([(a+b)/2 for a,b in zip(delta[:-1],delta[1:])])
width = delta[1]-delta[0]
freq = np.array(freq)
freq = freq/(np.sum(freq)*(width))
x = np.linspace(0, PI, 101)
pdf_fig, ax = plt.subplots(figsize=(8,6))
pdf_fig.patch.set_alpha(0)
ax.bar(delta, freq, width=width, color='b');
ax.plot(x, cond_Delta(x, theta=theta, kappa=kappa), color='red', linewidth=7.5);
ax.set_xlabel(r'$\Delta$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated pdf of $D_{\vartheta}}$', fontsize=24);
rng.ax_setup(ax)
cdf_fig, ax = plt.subplots(figsize=(8,6))
cdf_fig.patch.set_alpha(0)
cumfreq = (width)*np.cumsum(freq)
ax.bar(delta, cumfreq, width=width, color='b');
ax.plot(x, Cond_Delta(x, theta=theta, kappa=kappa), color='red', linewidth=7.5);
ax.set_xlabel(r'$\Delta$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated cdf of $D_{\vartheta}}$', fontsize=24);
rng.ax_setup(ax)
```
### Distribution of the conditional similarity $S_{\vartheta}$
```
bins = 51
weights = np.sort(NSM[n,:])
freq, s = np.histogram(weights, bins=bins)
s = np.array([(a+b)/2 for a,b in zip(s[:-1],s[1:])])
width = s[1]-s[0]
freq = np.array(freq)
freq = freq/(np.sum(freq)*(width))
x = np.linspace(0,1, 101)
pdf_fig, ax = plt.subplots(figsize=(8,6))
pdf_fig.patch.set_alpha(0)
ax.bar(s, freq, width=width, color='b', log=True);
ax.plot(x, cond_s(x, theta=theta, kappa=kappa, a=a), color='red', linewidth=7.5);
ax.plot(s[0], freq[0] , '*', color='red', markersize=15);
ax.set_xlabel(r'$s$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated pdf of $S_{\vartheta}$', fontsize=24);
rng.ax_setup(ax)
cdf_fig, ax = plt.subplots(figsize=(8,6))
cdf_fig.patch.set_alpha(0)
cumfreq = (width)*np.cumsum(freq)
ax.bar(s, cumfreq, width=width, color='b');
ax.plot(x, Cond_s(x, theta=theta, kappa=kappa, a=a), color='red', linewidth=7.5);
ax.set_xlabel(r'$s$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated cdf of $S_{\vartheta}}$', fontsize=24);
rng.ax_setup(ax)
```
### Distribution of the conditional interaction probability $P_{\vartheta}$
```
bins = 51
weights = np.sort(NPM[n,:])
freq, P = np.histogram(weights, bins=bins, range=(0,1))
P = np.array([(a+b)/2 for a,b in zip(P[:-1],P[1:])])
width = P[1]-P[0]
freq = np.array(freq)
freq = freq/(np.sum(freq)*width)
pdf_fig, ax = plt.subplots(figsize=(8,6))
pdf_fig.patch.set_alpha(0)
ax.bar(P, freq, width=width, color='b', log=True);
ax.plot(x, cond_P(x, theta=theta, mu=mu, eta=eta), color='red', linewidth=7.5);
ax.plot(P[0], freq[0] , '*', color='red', markersize=15);
ax.plot(P[-1], freq[-1] , '*', color='red', markersize=15);
ax.set_xlabel(r'$P$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated pdf of $P_{\vartheta}}$', fontsize=24);
rng.ax_setup(ax)
cdf_fig, ax = plt.subplots(figsize=(8,6))
cdf_fig.patch.set_alpha(0)
cumfreq = width*np.cumsum(freq)
ax.bar(P, cumfreq, width=width, color='b');
ax.plot(x, Cond_P(x, theta=theta, mu=mu, eta=eta), color='red', linewidth=7.5);
ax.set_xlabel(r'$P$', fontsize=24)
ax.set_ylabel('normalized frequency', fontsize=24)
ax.set_title(r'Simulated and calculated cdf of $P_{\vartheta}}$', fontsize=24);
rng.ax_setup(ax)
```
## Small world experiment
```
import os
import re
from collections import OrderedDict
```
### Producing data
```
N = 2**10
k = 18
rho = k/(N-1)
p_list = np.append(0, np.logspace(-5,0,20))
t1 = time.time()
for i in range(1):
for j,p in enumerate(p_list):
t_tmp = time.time()
print(f'{i}-{j}: {t_tmp-t1:.2f}sec', end='\r')
G = nx.watts_strogatz_graph(N,k,p)
wsL = nx.average_shortest_path_length(G)
wsC = nx.average_clustering(G)
with open(f'data/little_big_planet/ws/L{p:.6f}_WS_N{N}_k{k}.txt', 'a') as file:
file.write(str(wsL)+'\n')
with open(f'data/little_big_planet/ws/C{p:.6f}_WS_N{N}_k{k}.txt', 'a') as file:
file.write(str(wsC)+'\n')
times, (NDM, NSM, NPM) = MY_numpy_model(N=N, eta=p, rho=rho, verbose=False)
R = squareform(np.random.uniform(size=round(N*(N-1)/2)))
A = np.where(NPM>R, 1, 0)
G = nx.from_numpy_array(A)
if not nx.is_connected(G):
print('It happened!')
continue
myL = nx.average_shortest_path_length(G)
myC = nx.average_clustering(G)
with open(f'data/little_big_planet/my/L{p:.6f}_MY_N{N}_k{k}.txt', 'a') as file:
file.write(str(myL)+'\n')
with open(f'data/little_big_planet/my/C{p:.6f}_MY_N{N}_k{k}.txt', 'a') as file:
file.write(str(myC)+'\n')
t2 = time.time()
```
### Watts-Strogatz
```
WS_L_25 = {}
WS_L_mean = {}
WS_L_75 = {}
WS_C_25 = {}
WS_C_mean = {}
WS_C_75 = {}
for name in os.listdir('data/little_big_planet/ws'):
if not name.endswith('.txt'):
continue
df = pd.DataFrame(pd.Series(np.genfromtxt(f'data/little_big_planet/ws/{name}')))
prop, p = name.split('_')[0][0], float(name.split('_')[0][1:])
if prop == 'L':
WS_L_25[p] = np.array(df.describe().loc['25%'])
WS_L_mean[p] = np.array(df.describe().loc['mean'])
WS_L_75[p] = np.array(df.describe().loc['75%'])
elif prop == 'C':
WS_C_25[p] = np.array(df.describe().loc['25%'])
WS_C_mean[p] = np.array(df.describe().loc['mean'])
WS_C_75[p] = np.array(df.describe().loc['75%'])
p, ws_L_25 = map(np.array, zip(*sorted(WS_L_25.items())))
p, ws_L_mean = map(np.array, zip(*sorted(WS_L_mean.items())))
p, ws_L_75 = map(np.array, zip(*sorted(WS_L_75.items())))
p, ws_C_25 = map(np.array, zip(*sorted(WS_C_25.items())))
p, ws_C_mean = map(np.array, zip(*sorted(WS_C_mean.items())))
p, ws_C_75 = map(np.array, zip(*sorted(WS_C_75.items())))
ws_L0 = ws_L_mean[0]
ws_C0 = ws_C_mean[0]
WS_fig, ax = plt.subplots(figsize=(8,6))
WS_fig.patch.set_alpha(0)
ax.patch.set_alpha(0)
plt.semilogx(p, ws_L_mean/ws_L0, linewidth=7.5, color='b', label='L');
plt.semilogx(p, ws_C_mean/ws_C0, linewidth=7.5, color='r' , label='C');
plt.fill_between(p, ws_L_25.flatten()/ws_L0 , ws_L_75.flatten()/ws_L0 , alpha=0.25, color='b');
plt.fill_between(p, ws_C_25.flatten()/ws_C0 , ws_C_75.flatten()/ws_C0 , alpha=0.25, color='r');
ax.set_xlabel(r'$p$', fontsize=24)
ax.set_ylabel(r'$L/L_0$', fontsize=24)
ax.set_title('WS - path length vs clustering', fontsize=24);
ax.tick_params(axis='both', which='major', labelsize=24)
ax.spines['left'].set_linewidth(2.5)
ax.spines['left'].set_color('k')
ax.spines['bottom'].set_linewidth(2.5)
ax.spines['bottom'].set_color('k')
ax.legend(fontsize=28, shadow=True, facecolor=[0.95, 0.95, 0.95, 0]);
```
### New Model
```
MY_L_25 = {}
MY_L_mean = {}
MY_L_75 = {}
MY_C_25 = {}
MY_C_mean = {}
MY_C_75 = {}
for name in os.listdir('data/little_big_planet/my'):
if not name.endswith('.txt'):
continue
df = pd.DataFrame(np.genfromtxt(f'data/little_big_planet/my/{name}'))
prop, p = name.split('_')[0][0], float(name.split('_')[0][1:])
if prop == 'L':
MY_L_25[p] = np.array(df.describe().loc['25%'])
MY_L_mean[p] = np.array(df.describe().loc['mean'])
MY_L_75[p] = np.array(df.describe().loc['75%'])
elif prop == 'C':
MY_C_25[p] = np.array(df.describe().loc['25%'])
MY_C_mean[p] = np.array(df.describe().loc['mean'])
MY_C_75[p] = np.array(df.describe().loc['75%'])
p, my_L_25 = map(np.array, zip(*sorted(MY_L_25.items())))
p, my_L_mean = map(np.array, zip(*sorted(MY_L_mean.items())))
p, my_L_75 = map(np.array, zip(*sorted(MY_L_75.items())))
p, my_C_25 = map(np.array, zip(*sorted(MY_C_25.items())))
p, my_C_mean = map(np.array, zip(*sorted(MY_C_mean.items())))
p, my_C_75 = map(np.array, zip(*sorted(MY_C_75.items())))
my_L0 = my_L_mean[0]
my_C0 = my_C_mean[0]
MY_fig, ax = plt.subplots(figsize=(8,6))
MY_fig.patch.set_alpha(0)
ax.patch.set_alpha(0)
plt.semilogx(p, my_L_mean/my_L0, linewidth=7.5, color='b', label='L');
plt.semilogx(p, my_C_mean/my_C0, linewidth=7.5, color='r' , label='C');
plt.fill_between(p, my_L_25.flatten()/my_L0 , my_L_75.flatten()/my_L0 , alpha=0.25, color='b');
plt.fill_between(p, my_C_25.flatten()/my_C0 , my_C_75.flatten()/my_C0 , alpha=0.25, color='r');
ax.set_xlabel(r'$p$', fontsize=24)
ax.set_ylabel(r'$L/L_0$', fontsize=24)
ax.set_title('Ring model - path length vs clustering', fontsize=24);
ax.tick_params(axis='both', which='major', labelsize=24)
ax.spines['left'].set_linewidth(2.5)
ax.spines['left'].set_color('k')
ax.spines['bottom'].set_linewidth(2.5)
ax.spines['bottom'].set_color('k')
ax.legend(fontsize=28, shadow=True, facecolor=[0.95, 0.95, 0.95, 0],
loc='lower left');
```
## Both
```
SI_fig, axes = plt.subplots(1,2, figsize=(16,6))
SI_fig.patch.set_alpha(0)
SI_fig.suptitle('Path length vs clustering', fontsize=24)
plt.semilogx(p, ws_L_mean/ws_L0, linewidth=7.5, color='b', label='L');
plt.semilogx(p, ws_C_mean/ws_C0, linewidth=7.5, color='r' , label='C');
plt.fill_between(p, ws_L_25.flatten()/ws_L0 , ws_L_75.flatten()/ws_L0 , alpha=0.25, color='b');
plt.fill_between(p, ws_C_25.flatten()/ws_C0 , ws_C_75.flatten()/ws_C0 , alpha=0.25, color='r');
axes[1].set_xlabel(r'$p$', fontsize=20)
axes[1].set_ylabel(r'$L/L_0$ resp. $C/C_0$', fontsize=20)
axes[1].set_title('Watts-Strogatz', fontsize=20);
axes[1].tick_params(axis='both', which='major', labelsize=20)
axes[1].spines['left'].set_linewidth(2.5)
axes[1].spines['left'].set_color('k')
axes[1].spines['bottom'].set_linewidth(2.5)
axes[1].spines['bottom'].set_color('k')
axes[1].legend(fontsize=28, shadow=True, facecolor=[0.95, 0.95, 0.95, 0],
loc='lower left');
axes[0].patch.set_alpha(0)
axes[1].patch.set_alpha(0)
axes[0].semilogx(p, my_L_mean/my_L0, linewidth=7.5, color='b', label='L');
axes[0].semilogx(p, my_C_mean/my_C0, linewidth=7.5, color='r' , label='C');
axes[0].fill_between(p, my_L_25.flatten()/my_L0 , my_L_75.flatten()/my_L0 , alpha=0.25, color='b');
axes[0].fill_between(p, my_C_25.flatten()/my_C0 , my_C_75.flatten()/my_C0 , alpha=0.25, color='r');
axes[0].set_xlabel(r'$p$', fontsize=20)
axes[0].set_ylabel(r'$L/L_0$ resp. $C/C_0$', fontsize=20)
axes[0].set_title('Ring model', fontsize=20);
axes[0].tick_params(axis='both', which='major', labelsize=20)
axes[0].spines['left'].set_linewidth(2.5)
axes[0].spines['left'].set_color('k')
axes[0].spines['bottom'].set_linewidth(2.5)
axes[0].spines['bottom'].set_color('k')
axes[0].legend(fontsize=28, shadow=True, facecolor=[0.95, 0.95, 0.95, 0],
loc='lower left');
SI_fig.savefig('FigureS4.pdf')
```
| github_jupyter |
# Pandas Crash Course
<img style="float: right; border:3px solid black" src="images/10_Panda_DailyMail_7_Nov_2013.jpg" border="5" width=30%>
Pandas is a Python package that aims to make working with data as easy and intuitive as possible. It fills the role of a foundational real world data manipulation library and interfaces with many other Python packages.
By the end of this file you should have seen simple examples of:
1. Pandas Series and DataFrame objects
1. Data IO
1. Data types
1. Indexing and setting data
1. Dealing with missing data
1. Concatinating and merging data
1. Grouping Operations
1. Operations on Pandas data objects
1. Applying any function to Pandas data objects
1. Plotting
Further Reading:
http://pandas.pydata.org/pandas-docs/stable/10min.html
https://pandas.pydata.org/pandas-docs/stable/comparison_with_sql.html#compare-with-sql-join
Image Credit: David Jenkins at Bifengxia Panda Reserve in Chengdu
```
# Python imports
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
```
## Pandas Series and DataFrame objects
There are two main data structures in pandas:
- Series (1 dimensional data)
- Dataframes (2 dimensional data)
- There are other, lesser used data structures used for higher dimensional data, but are less frequently used
- Panel (3 dimensional data) - panel will be removed from future versions of Pandas and replaced with xarray
- Xarray (>2 dimensions)
Here, the 1- and 2-dimensional data sets are the focus of this lesson.
Pandas DataFrames are analogus to R's data.frame, but aim to provide additional functionality.
Both dataframes and series data structures have indicies, which are shown on the left:
```
series1 = pd.Series([1,2,3,4])
print(series1)
```
Dataframes use the IPython display method to look pretty, but will show just fine when printed also. (There's a way to make all of the dataframes print pretty via the IPython.display.display method, but this isn't necessary to view the values):
```
df1 = pd.DataFrame([[1,2,3,4],[10,20,30,40]])
print(df1)
df1
```
Indices can be named:
```
# Rename the columns
df1.columns = ['A','B','C','D']
df1.index = ['zero','one']
df1
# Create the dataframe with the columns
df1 = pd.DataFrame([[1,2,3,4],[10,20,30,40]], columns=['A','B','C',"D"], index=['zero','one'])
df1
```
## Data Input Output
```
df1 = pd.DataFrame(np.random.randn(5,4), columns = ['A','B','C','D'], index=['zero','one','two','three','four'])
print(df1)
```
### CSV Files
```
df1.to_csv('datafiles/pandas_df1.csv')
!ls datafiles
df2 = pd.read_csv('datafiles/pandas_df1.csv', index_col=0)
print(df2)
```
### hdf5 files
```
df1.to_hdf('datafiles/pandas_df1.h5', 'df')
!ls datafiles
df2 = pd.read_hdf('datafiles/pandas_df1.h5', 'df')
print(df2)
```
## Data types
Show the datatypes of each column:
```
df2.dtypes
```
We can create dataframes of multiple datatypes:
```
col1 = range(6)
col2 = np.random.rand(6)
col3 = ['zero','one','two','three','four','five']
col4 = ['blue', 'cow','blue', 'cow','blue', 'cow']
df_types = pd.DataFrame( {'integers': col1, 'floats': col2, 'words': col3, 'cow color': col4} )
print(df_types)
df_types.dtypes
```
We can also set the 'cow color' column to a category:
```
df_types['cow color'] = df_types['cow color'].astype("category")
df_types.dtypes
```
## Indexing and Setting Data
Pandas does a *lot* of different operations, here are the meat and potatoes. The following describes the indexing of data, but setting the data is as simple as a reassignment.
```
time_stamps = pd.date_range(start='2000-01-01', end='2000-01-20', freq='D') # Define index of time stamps
df1 = pd.DataFrame(np.random.randn(20,4), columns = ['A','B','C','D'], index=time_stamps)
print(df1)
```
### Head and Tail
Print the beginning and ending entries of a pandas data structure
```
df1.head(3) # Show the first n rows, default is 5
df1.tail() # Show the last n rows
```
We can also separate the metadata (labels, etc) from the data, yielding a numpy-like output.
```
df1.columns
df1.values
```
### Indexing Data
Pandas provides the means to index data via named columns, or as numpy like indices. Indexing is [row, column], just as it was in numpy.
Data is visible via column:
```
df1['A'].head() # df1.A.head() is equivalent
```
Note that tab completion is enabled for column names:
```
df1.A
```
<div>
<img style="float: left;" src="images/10-01_column-tab.png" width=30%>
</div>
We can specify row ranges:
```
df1[:2]
```
#### Label based indexing (.loc)
Slice based on the labels.
```
df1.loc[:'2000-01-5',"A"] # Note that this includes the upper index
```
#### Integer based indexing (.iloc)
Slice based on the index number.
```
df1.iloc[:3,0] # Note that this does not include the upper index like numpy
```
#### Fast single element label indexing (.at) - fast .loc
Intended for fast, single indexes.
```
index_timestamp = pd.Timestamp('2000-01-03') # Create a timestamp object to index
df1.at[index_timestamp,"A"] # Index using timestamp (vs string)
```
#### Fast single element label indexing (.iat) - fast .iloc
Intended for fast, single indexes.
```
df1.iat[3,0]
```
### Logical indexing
A condition is used to select the values within a slice or the entire Pandas object. Using a conditional statement, a true/false DataFrame is produced:
```
df1.head()>0.5
```
That matrix can then be used to index the DataFrame:
```
df1[df1>0.5].head() # Note that the values that were 'False' are 'NaN'
```
#### Logical indexing via `isin`
It's also possible to filter via the index value:
```
df_types
bool_series = df_types['cow color'].isin(['blue'])
print(bool_series) # Show the logical indexing
df_types[bool_series] # Index where the values are true
```
### Sorting by column
```
df_types.sort_values(by="floats")
```
## Dealing with Missing Data
By convention, pandas uses the `NaN` value to represent missing data. There are a few functions surrounding the handling of `NaN` values:
```
df_nan = pd.DataFrame(np.random.rand(6,2), columns = ['A','B'])
df_nan
df_nan['B'] = df_nan[df_nan['B']>0.5] # Prints NaN Where ['B'] <= 0.5
print(df_nan)
```
Print a logical DataFrame where `NaN` is located:
```
df_nan.isnull()
```
Drop all rows with `NaN`:
```
df_nan.dropna(how = 'any')
```
Replace `NaN` entries:
```
df_nan.fillna(value = -1)
```
## Concatenating and Merging Data
Bringing together DataFrames or Series objects:
#### Concatenate
```
df1 = pd.DataFrame(np.zeros([3,3], dtype=np.int))
df1
df2 = pd.concat([df1, df1], axis=0)
df2 = df2.reset_index(drop=True) # Renumber indexing
df2
```
#### Append
Adding an additional group after the first group:
```
newdf = pd.DataFrame({0: [1], 1:[1], 2:[1]})
print(newdf)
df3 = df2.append(newdf, ignore_index=True)
df3
```
### SQL-like merging
Pandas can do structured query language (SQL) like merges of data:
```
left = pd.DataFrame({'numbers': ['K0', 'K1', 'K2', 'K3'],
'English': ['one', 'two', 'three', 'four'],
'Spanish': ['uno', 'dos', 'tres', 'quatro'],
'German': ['erste', 'zweite','dritte','vierte']})
left
right = pd.DataFrame({'numbers': ['K0', 'K1', 'K2', 'K3'],
'French': ['un', 'deux', 'trois', 'quatre'],
'Afrikaans': ['een', 'twee', 'drie', 'vier']})
right
result = pd.merge(left, right, on='numbers')
result
```
## Grouping Operations
Often, there is a need to summarize the data or change the output of the data to make it easier to work with, especially for categorical data types.
```
dfg = pd.DataFrame({'A': ['clogs','sandals','jellies']*2,
'B': ['socks','footies']*3,
'C': [1,1,1,3,2,2],
'D': np.random.rand(6)})
dfg
```
#### Pivot Table
Without changing the data in any way, summarize the output in a different format. Specify the indicies, columns, and values:
```
dfg.pivot_table(index=['A','B'], columns=['C'], values='D')
```
#### Stacking
Column labels can be brought into the rows.
```
dfg.stack()
```
#### Groupby
Groupby groups values, creating a Python object to which functions can be applied:
```
dfg.groupby(['B']).count()
dfg.groupby(['A']).mean()
```
## Operations on Pandas Data Objects
Wether it's the entire data frame or a series within a single dataframe, there are a variety of methods that can be applied. Here's a list of a few helpful ones:
#### Simple statistics (mean, stdev, etc).
```
dfg['D'].mean()
```
#### Rotation
Note that the values rotated out leave `NaN` behind:
```
dfg['D']
dfg_Ds = dfg['D'].shift(2)
dfg_Ds
```
#### Add, subtract, multiply, divide:
Operations are element-wise:
```
dfg['D'].div(dfg_Ds )
```
#### Histogram
```
dfg
dfg['C'].value_counts()
```
#### Describe
Excluding NaN values, print some descriptive statistics about the collection of values.
```
df_types.describe()
```
#### Transpose
Exchange the rows and columns (flip about the diagonal):
```
df_types.T
```
## Applying Any Function to Pandas Data Objects
Pandas objects have methods that allow function to be applied with greater control, namely the `.apply` function:
```
def f(x): # Define function
return x + 1
dfg['C'].apply(f)
```
Lambda functions may also be used
```
dfg['C'].apply(lambda x: x + 1)
```
#### String functions:
Pandas has access to string methods:
```
dfg['A'].str.title() # Make the first letter uppercase
```
## Plotting
Pandas exposes the matplotlib library for use.
```
n = 100
X = np.linspace(0, 5, n)
Y1,Y2 = np.log((X)**2+2), np.sin(X)+2
dfp = pd.DataFrame({'X' : X, 'Y1': Y1, 'Y2': Y2})
dfp.head()
dfp.plot(x = 'X')
plt.show()
```
Matplotlib styles are available too:
```
style_name = 'classic'
plt.style.use(style_name)
dfp.plot(x = 'X')
plt.title('Log($x^2$) and Sine', fontsize=16)
plt.xlabel('X Label', fontsize=16)
plt.ylabel('Y Label', fontsize=16)
plt.show()
mpl.rcdefaults() # Reset matplotlib rc defaults
```
| github_jupyter |
# Consistance Tests: SED
This is going to be the figure that shows that this is self consistent with regard to the selected model having an SED that matches the data. It will be 6 sub-plots each showing the selected model's SED and the data.
```
import numpy as np
import matplotlib.pyplot as plt
import fsps
from astropy.cosmology import FlatLambdaCDM
import seaborn as sns
from matplotlib.ticker import MultipleLocator
```
set up cosmology to get age of the universe at the observed redshift to know when to stop the stellar popultion. -- define A(z) better.
Also define the FSPS object and other useful values like the x-axis for plotting.
```
cosmo = FlatLambdaCDM(H0=70, Om0=0.27)
sp = fsps.StellarPopulation(zcontinuous=2, cloudy_dust=True, add_neb_emission = True, sfh=5)
wavelengths = [3551, 4686, 6166, 7480, 8932] # for u, g, r, i, z filters
filters = ['u', 'g', 'r', 'i', 'z']
```
Define data and best fit models
```
data = {
1 : np.array([20.36, 18.76, 17.99, 17.67, 17.39]),
2 : np.array([20.31, 18.74, 17.98, 17.66, 17.39]),
3 : np.array([16.15, 15.43, 15.4, 15.19, 15.21]),
4 : np.array([17.65, 16.74, 16.49, 16.26, 16.16]),
5 : np.array([19.69, 18.29, 17.7, 17.45, 17.29]),
6 : np.array([17.66, 16.58, 16.25, 16.01, 15.86]),
7 : np.array([17.62, 16.80, 16.57, 16.34, 16.26]),
8 : np.array([19.72, 18.37, 17.88, 17.68, 17.56])
}
uncert = {
1 : np.array([0.1, 0.1, 0.1, 0.1, 0.1]),
2 : np.array([0.1, 0.1, 0.1, 0.1, 0.1]),
3 : np.array([0.1, 0.1,0.1, 0.1, 0.1]),
4 : np.array([0.1, 0.1, 0.1, 0.1, 0.1]),
5 : np.array([0.1, 0.1,0.1, 0.1, 0.1]),
6 : np.array([0.1, 0.1, 0.1, 0.1, 0.1]),
7 : np.array([0.1, 0.1, 0.1, 0.1, 0.1]),
8 : np.array([0.1, 0.1, 0.1, 0.1, 0.1])
}
# logz, t_dust, tau, t_start, t_trans, sf_slope
# from 2017-10-02 job 277287.1-6:1
# model = {
# 1 : np.array([0.46, 0.17, 5.22, 1.41, 5.27, -0.88]), # should be negative metalicity??
# 2 : np.array([-0.56, 0.18, 0.53, 2.11, 10.43, -0.44]),
# 3 : np.array([-0.67, 0.10, 7.8, 4.35, 10.93, 1.16]),
# 4 : np.array([-0.47, 0.17, 5.57, 2.4, 7.81, 0.08]),
# 5 : np.array([-1.1, 0.1, 7.71, 2.63, 8.87, -0.96]),
# 6 : np.array([-0.38, 0.43, 7.35, 6.60, 11.41, -0.03])
# }
# c = {
# 1 : -24.93,
# 2 : -24.98,
# 3 : -25.23,
# 4 : -24.98,
# 5 : -24.63,
# 6 : -25.24
# }
# logz, t_dust, tau, t_start, t_trans, phi
# from 2017-12-19 crcjob 423492
model = {
1 : np.array([-0.50, 0.18, 0.67, 2.1, 9.50, -0.65]), # very different, but much more accurat values
2 : np.array([-0.55, 0.19, 0.66, 2.0, 9.66, -0.53]), # very differnet
3 : np.array([-0.70, 0.09, 5.95, 8.80, 12.34, 0.68]),
4 : np.array([-0.48, 0.19, 5.81, 3.92, 12.17, 0.34]),
5 : np.array([-1.15, 0.12, 5.04, 3.56, 8.20, -0.83]),
6 : np.array([-0.39, 0.35, 6.90, 4.98, 12.66, -0.03]),
7 : np.array([-0.44, 0.1, 5.80, 2.29, 9.04, 0.08]),
8 : np.array([-1.44, 0.09, 4.70, 4.8, 10.24, -0.77])
}
c = {
1 : -24.97,
2 : -24.97,
3 : -25.15,
4 : -24.96,
5 : -24.65,
6 : -25.37,
7 : -24.85,
8 : -24.12
}
redshift = 0.05
```
Get the SED for the model.
```
def get_sed(sp, redshift, logzsol, dust2, tau, tStart, sfTrans, phi):
"""same as `calculateAge.runFSPS()` as of 2017-10-05
"""
sdss_bands = ['sdss_u', 'sdss_g', 'sdss_r', 'sdss_i', 'sdss_z']
sp.params['logzsol'] = logzsol
dust1 = 2.0*dust2
sp.params['dust1'] = dust1
sp.params['dust2'] = dust2
sp.params['tau'] = tau
sp.params['sf_start'] = tStart
sp.params['sf_trunc'] = sfTrans
sp.params['sf_slope'] = np.tan(phi)
tage = cosmo.age(redshift).to('Gyr').value
return sp.get_mags(tage=tage, redshift=redshift, bands=sdss_bands)
model_sed = {}
for i in range(1, 9):
model_sed[i] = get_sed(sp, redshift, *model[i])
model_sed
```
Make the figure
```
plt.figure('SED Consistence Test')
sns.set(context='talk', style='ticks', font='serif', color_codes=True)
# row and column sharing
# ???sharey=True,
f, ((ax1, ax2), (ax3, ax4), (ax5, ax6), (ax7, ax8)) = plt.subplots(4, 2, sharex='col', figsize=(6, 9))
# add uncertainty
ax1.errorbar(wavelengths, data[1], yerr=uncert[1], alpha=0.65)
ax1.plot(wavelengths, model_sed[1] + c[1])
ax1.invert_yaxis()
ax1.tick_params(axis='both', which='both', top='on', right='on', direction='in')
# ax1.set_ylim(20.75, 16.25)
# ax1.set_title('1')
# ax1.text(0.5, 0.5, '1')
ax1.yaxis.set_major_locator(MultipleLocator(1))
ax1.set_ylim(20.65, 17.15)
ax2.errorbar(wavelengths, data[2], yerr=uncert[2], alpha=0.65)
ax2.plot(wavelengths, model_sed[2] + c[2])
ax2.invert_yaxis()
ax2.tick_params(axis='both', which='both', top='on', right='on', direction='in')
# ax2.set_ylim(20.6, 17.1)
ax2.yaxis.set_major_locator(MultipleLocator(1))
ax2.set_ylim(20.65, 17.15)
ax3.errorbar(wavelengths, data[3], yerr=uncert[3], alpha=0.65)
ax3.plot(wavelengths, model_sed[3] + c[3])
ax3.invert_yaxis()
ax3.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax3.yaxis.set_major_locator(MultipleLocator(1))
# ax3.set_ylim((16.5, 14.5)) # Good if we are not using a consistent 3.5 mag range
# ax3.set_ylim((17.25, 13.75)) # Tick marks are evenly spaced from top and bottom axes
ax3.set_ylim((17.25, 13.75))
ax4.errorbar(wavelengths, data[4], yerr=uncert[4], alpha=0.65)
ax4.plot(wavelengths, model_sed[4] + c[4])
ax4.invert_yaxis()
ax4.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax4.yaxis.set_major_locator(MultipleLocator(1))
# ax4.set_ylim((17.9, 15.8)) # Good if we are not using a consistent 3.5 mag range
# ax4.set_ylim((18.25, 14.75)) # Tick marks are evenly spaced from top and bottom axes
ax4.set_ylim((18.5, 15))
ax5.errorbar(wavelengths, data[5], yerr=uncert[5], alpha=0.65)
ax5.plot(wavelengths, model_sed[5] + c[5])
ax5.invert_yaxis()
ax5.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax5.set_ylim((20.25, 16.75))
ax6.errorbar(wavelengths, data[6], yerr=uncert[6], alpha=0.65)
ax6.plot(wavelengths, model_sed[6] + c[6])
ax6.invert_yaxis()
ax6.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax6.set_ylim((18.5, 15))
ax7.errorbar(wavelengths, data[7], yerr=uncert[7], alpha=0.65)
ax7.plot(wavelengths, model_sed[7] + c[7])
ax7.invert_yaxis()
ax7.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax7.yaxis.set_major_locator(MultipleLocator(1))
# ax7.set_ylim((18.2, 15.8)) #good tighter
ax7.set_ylim((18.75, 15.25))
ax8.errorbar(wavelengths, data[8], yerr=uncert[8], alpha=0.65, label='input')
ax8.plot(wavelengths, model_sed[8] + c[8], label='best fit')
ax8.invert_yaxis()
ax8.tick_params(axis='both', which='both', top='on', right='on', direction='in')
# ax8.yaxis.set_major_locator(MultipleLocator(0.5))
ax8.set_ylim((20.25, 16.75))
plt.legend()
ax7.set_xticks(wavelengths)
ax7.set_xticklabels(filters)
ax8.set_xticks(wavelengths)
ax8.set_xticklabels(filters)
# ax3.set_ylabel('Magnitude [mag]', size=14)
f.text(0.03, 0.5, 'Magnitude [mag]', ha='center', va='center', size=14, rotation=90)
# ax5.set_xlabel('SDSS Filters')
# ax6.set_xlabel('SDSS Filters')
# https://stackoverflow.com/questions/6963035/pyplot-axes-labels-for-subplots
f.text(0.5, 0.07, 'SDSS Filter', ha='center', va='center', size=14)
# lable figures
f.text(0.17, 0.86, '1', ha='center', va='center', size=10)
f.text(0.60, 0.86, '2', ha='center', va='center', size=10)
f.text(0.17, 0.664, '3', ha='center', va='center', size=10)
f.text(0.60, 0.664, '4', ha='center', va='center', size=10)
f.text(0.17, 0.468, '5', ha='center', va='center', size=10)
f.text(0.60, 0.468, '6', ha='center', va='center', size=10)
f.text(0.17, 0.268, '7', ha='center', va='center', size=10)
f.text(0.60, 0.268, '8', ha='center', va='center', size=10)
# # add ages
# f.text(0.3, 0.73, '10.7 Gyr', ha='center', va='center', size=10)
# f.text(0.72, 0.73, '1.4 Gyr', ha='center', va='center', size=10)
# f.text(0.3, 0.53, '1.8 Gyr', ha='center', va='center', size=10)
# f.text(0.72, 0.53, '4.3 Gyr', ha='center', va='center', size=10)
# f.text(0.3, 0.33, '10.7 Gyr', ha='center', va='center', size=10)
# f.text(0.72, 0.33, '1.8 Gyr', ha='center', va='center', size=10)
# f.text(0.3, 0.13, '2.4 Gyr', ha='center', va='center', size=10)
# f.text(0.72, 0.13, '0.44 Gyr', ha='center', va='center', size=10)
# ax1.set_title('Sharing x per column, y per row')
# ax2.scatter(x, y)
# ax3.scatter(x, 2 * y ** 2 - 1, color='r')
# ax4.plot(x, 2 * y ** 2 - 1, color='r')
#cutting white space does not work for these sub figures
# f.set_tight_layout({'pad': 1.5}) #cut edge whitespace
plt.savefig('consistancy_sed.pdf')
plt.show()
```
## Understaning why data does not use `get_sed()`
Why did I just use data that defined the SED's rather than recalculating them just like I did for the best fit model? Lets look at what the SED would be given our data star formation hisotry (currently table 4 in the paper).
```
# test that data is correct SED's to fit.
data_sfh = {
1 : np.array([-0.5, 0.1, 0.5, 1.5, 9.0, -0.785]),
2 : np.array([-0.5, 0.1, 0.5, 1.5, 9.0, 1.504]),
3 : np.array([-0.5, 0.1, 7.0, 3.0, 10., 1.504]),
4 : np.array([-0.5, 0.1, 7.0, 3.0, 13., 0.0]),
5 : np.array([-1.5, 0.1, 0.5, 1.5, 9.0, -0.785]),
6 : np.array([-0.5, 0.8, 7.0, 3.0, 10., 1.504]),
7 : np.array([-0.5, 0.1, 0.5, 1.5, 6.0, 1.504]),
8 : np.array([-0.5, 0.1, 0.1, 8.0, 12.0, 1.52])
}
data_sed = {}
for i in range(1, 9):
data_sed[i] = get_sed(sp, redshift, *model[i]) - 25
data_sed
plt.figure('SED Consistence Test')
sns.set(context='talk', style='ticks', font='serif', color_codes=True)
# row and column sharing
# ???sharey=True,
f, ((ax1, ax2), (ax3, ax4), (ax5, ax6), (ax7, ax8)) = plt.subplots(4, 2, sharex='col', figsize=(6, 9))
# add uncertainty
ax1.errorbar(wavelengths, data_sed[1], yerr=uncert[1], alpha=0.65)
ax1.plot(wavelengths, model_sed[1] + c[1])
ax1.invert_yaxis()
ax1.tick_params(axis='both', which='both', top='on', right='on', direction='in')
# ax1.set_title('1')
# ax1.text(0.5, 0.5, '1')
ax2.errorbar(wavelengths, data_sed[2], yerr=uncert[2], alpha=0.65)
ax2.plot(wavelengths, model_sed[2] + c[2])
ax2.invert_yaxis()
ax2.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax3.errorbar(wavelengths, data_sed[3], yerr=uncert[3], alpha=0.65)
ax3.plot(wavelengths, model_sed[3] + c[3])
ax3.invert_yaxis()
ax3.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax3.yaxis.set_major_locator(MultipleLocator(1))
ax3.set_ylim((16.5, 14.5))
# ax3.set_title('3')
ax4.errorbar(wavelengths, data_sed[4], yerr=uncert[4], alpha=0.65)
ax4.plot(wavelengths, model_sed[4] + c[4])
ax4.invert_yaxis()
ax4.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax4.yaxis.set_major_locator(MultipleLocator(1))
ax4.set_ylim((17.9, 15.8))
# ax4.set_title('4')
ax5.errorbar(wavelengths, data_sed[5], yerr=uncert[5], alpha=0.65)
ax5.plot(wavelengths, model_sed[5] + c[5])
ax5.invert_yaxis()
ax5.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax6.errorbar(wavelengths, data_sed[6], yerr=uncert[6], alpha=0.65)
ax6.plot(wavelengths, model_sed[6] + c[6])
ax6.invert_yaxis()
ax6.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax7.errorbar(wavelengths, data_sed[7], yerr=uncert[7], alpha=0.65)
ax7.plot(wavelengths, model_sed[7] + c[7])
ax7.invert_yaxis()
ax7.tick_params(axis='both', which='both', top='on', right='on', direction='in')
ax7.yaxis.set_major_locator(MultipleLocator(1))
ax7.set_ylim((18.2, 15.8))
ax8.errorbar(wavelengths, data_sed[8], yerr=uncert[8], alpha=0.65, label='input')
ax8.plot(wavelengths, model_sed[8] + c[8], label='best fit')
ax8.invert_yaxis()
ax8.tick_params(axis='both', which='both', top='on', right='on', direction='in')
# ax8.yaxis.set_major_locator(MultipleLocator(0.5))
plt.legend()
ax7.set_xticks(wavelengths)
ax7.set_xticklabels(filters)
ax8.set_xticks(wavelengths)
ax8.set_xticklabels(filters)
# ax3.set_ylabel('Magnitude [mag]', size=14)
f.text(0.03, 0.5, 'Magnitude [mag]', ha='center', va='center', size=14, rotation=90)
# ax5.set_xlabel('SDSS Filters')
# ax6.set_xlabel('SDSS Filters')
# https://stackoverflow.com/questions/6963035/pyplot-axes-labels-for-subplots
f.text(0.5, 0.07, 'SDSS Filter', ha='center', va='center', size=14)
# lable figures
f.text(0.17, 0.86, '1', ha='center', va='center', size=10)
f.text(0.60, 0.86, '2', ha='center', va='center', size=10)
f.text(0.17, 0.664, '3', ha='center', va='center', size=10)
f.text(0.60, 0.664, '4', ha='center', va='center', size=10)
f.text(0.17, 0.468, '5', ha='center', va='center', size=10)
f.text(0.60, 0.468, '6', ha='center', va='center', size=10)
f.text(0.17, 0.268, '7', ha='center', va='center', size=10)
f.text(0.60, 0.268, '8', ha='center', va='center', size=10)
plt.show()
```
Notes:
At the high slopes there to keep true fidelity, there need to be many more than 4 significant digits between $\phi$ and $m_{\text{sf}}$. But the representation above is self-consistent. The best fit SED's are being compared to the SED inputs found in `data/circlePhotometry.tsv`. The corner plots will compare the MCMC distributions with the "true" values and no graphical representation will be able to convey the 5th and 6th decimal precision needed to accurately convert between $\phi$ and $m_{\text{sf}}$. Finally, the priors are correct, because there I did write $\phi$ to 6th decimal place.
| github_jupyter |
```
# default_exp preproc_decorator
%load_ext autoreload
%autoreload 2
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
```
# Preprocessing Decorator
A decorator to simplify data preprocessing
```
# export
import logging
from types import GeneratorType
from typing import Callable
from inspect import signature
from sklearn.preprocessing import MultiLabelBinarizer
from bert_multitask_learning.read_write_tfrecord import (write_single_problem_chunk_tfrecord,
write_single_problem_gen_tfrecord)
from bert_multitask_learning.special_tokens import PREDICT
from bert_multitask_learning.utils import LabelEncoder, get_or_make_label_encoder, load_transformer_tokenizer
def preprocessing_fn(func: Callable):
"""Usually used as a decorator.
The input and output signature of decorated function should be:
func(params: bert_multitask_learning.BaseParams,
mode: str) -> Union[Generator[X, y], Tuple[List[X], List[y]]]
Where X can be:
- Dicitionary of 'a' and 'b' texts: {'a': 'a test', 'b': 'b test'}
- Text: 'a test'
- Dicitionary of modalities: {'text': 'a test', 'image': np.array([1,2,3])}
Where y can be:
- Text or scalar: 'label_a'
- List of text or scalar: ['label_a', 'label_a1'] (for seq2seq and seq_tag)
This decorator will do the following things:
- load tokenizer
- call func, save as example_list
- create label_encoder and count the number of rows of example_list
- create bert features from example_list and write tfrecord
Args:
func (Callable): preprocessing function for problem
"""
def wrapper(params, mode, get_data_num=False, write_tfrecord=True):
problem = func.__name__
tokenizer = load_transformer_tokenizer(
params.transformer_tokenizer_name, params.transformer_tokenizer_loading)
proc_fn_signature_names = list(signature(
func).parameters.keys())
# proc func can return generator or tuple of lists
# and it can have an optional get_data_num argument to
# avoid iterate through the whole dataset to create
# label encoder and get number of rows of data
if len(proc_fn_signature_names) == 2:
example_list = func(params, mode)
else:
example_list = func(params, mode, get_data_num)
if isinstance(example_list, GeneratorType):
if get_data_num:
# create label encoder and data num
cnt = 0
label_list = []
logging.info(
"Preprocessing function returns generator, might take some time to create label encoder...")
for example in example_list:
if isinstance(example[0], int):
data_num, label_encoder = example
return data_num, None
cnt += 1
try:
_, label = example
label_list.append(label)
except ValueError:
pass
# create label encoder
label_encoder = get_or_make_label_encoder(
params, problem=problem, mode=mode, label_list=label_list)
if label_encoder is None:
return cnt, 0
if isinstance(label_encoder, LabelEncoder):
return cnt, len(label_encoder.encode_dict)
if isinstance(label_encoder, MultiLabelBinarizer):
return cnt, label_encoder.classes_.shape[0]
# label_encoder is tokenizer
try:
return cnt, len(label_encoder.vocab)
except AttributeError:
# models like xlnet's vocab size can only be retrieved from config instead of tokenizer
return cnt, params.bert_decoder_config.vocab_size
else:
# create label encoder
label_encoder = get_or_make_label_encoder(
params, problem=problem, mode=mode, label_list=[])
if mode == PREDICT:
return example_list, label_encoder
if write_tfrecord:
return write_single_problem_gen_tfrecord(
func.__name__,
example_list,
label_encoder,
params,
tokenizer,
mode)
else:
return {
'problem': func.__name__,
'gen': example_list,
'label_encoder': label_encoder,
'tokenizer': tokenizer
}
else:
# if proc func returns integer as the first element,
# that means it returns (num_of_data, label_encoder)
if isinstance(example_list[0], int):
data_num, label_encoder = example_list
inputs_list, target_list = None, None
else:
try:
inputs_list, target_list = example_list
except ValueError:
inputs_list = example_list
target_list = None
label_encoder = get_or_make_label_encoder(
params, problem=problem, mode=mode, label_list=target_list)
data_num = len(inputs_list)
if get_data_num:
if label_encoder is None:
return data_num, 0
if isinstance(label_encoder, LabelEncoder):
return data_num, len(label_encoder.encode_dict)
if isinstance(label_encoder, MultiLabelBinarizer):
return data_num, label_encoder.classes_.shape[0]
if hasattr(label_encoder, 'vocab'):
# label_encoder is tokenizer
return data_num, len(label_encoder.vocab)
elif hasattr(params, 'decoder_vocab_size'):
return data_num, params.decoder_vocab_size
else:
raise ValueError('Cannot determine num of classes for problem {0}.'
'This is usually caused by {1} dose not has attribute vocab. In this case, you should manually specify vocab size to params: params.decoder_vocab_size = 32000'.format(problem, type(label_encoder).__name__))
if mode == PREDICT:
return inputs_list, target_list, label_encoder
if write_tfrecord:
return write_single_problem_chunk_tfrecord(
func.__name__,
inputs_list,
target_list,
label_encoder,
params,
tokenizer,
mode)
else:
return {
'problem': func.__name__,
'inputs_list': inputs_list,
'target_list': target_list,
'label_encoder': label_encoder,
'tokenizer': tokenizer
}
return wrapper
```
## User-Defined Preprocessing Function
The user-defined preprocessing function should return two elements: features and targets, except for `pretrain` problem type.
For features and targets, it can be one of the following format:
- tuple of list
- generator of tuple
Please note that if preprocessing function returns generator of tuple, then corresponding problem cannot be chained using `&`.
```
# hide
import bert_multitask_learning
from bert_multitask_learning.params import BaseParams
from typing import Tuple
import shutil
import tempfile
import numpy as np
import os
# setup params for testing
params = BaseParams()
params.ckpt_dir = tempfile.mkdtemp()
params.tmp_file_dir = tempfile.mkdtemp()
```
### Tuple of List
#### Single Modal
```
@preprocessing_fn
def toy_cls(params: BaseParams, mode: str) -> Tuple[list, list]:
"Simple example to demonstrate singe modal tuple of list return"
if mode == bert_multitask_learning.TRAIN:
toy_input = ['this is a toy input' for _ in range(10)]
toy_target = ['a' for _ in range(10)]
else:
toy_input = ['this is a toy input for test' for _ in range(10)]
toy_target = ['a' for _ in range(10)]
return toy_input, toy_target
# hide
def preproc_dec_test():
params.add_problem(problem_name='toy_cls', problem_type='cls', processing_fn=toy_cls)
assert (10, 1)==toy_cls(params=params, mode=bert_multitask_learning.TRAIN, get_data_num=True, write_tfrecord=False)
toy_cls(params=params, mode=bert_multitask_learning.TRAIN, get_data_num=False, write_tfrecord=True)
assert os.path.exists(os.path.join(params.tmp_file_dir, 'toy_cls', 'train_feature_desc.json'))
preproc_dec_test()
```
#### Multi-modal
```
@preprocessing_fn
def toy_cls(params: BaseParams, mode: str) -> Tuple[list, list]:
"Simple example to demonstrate multi-modal tuple of list return"
if mode == bert_multitask_learning.TRAIN:
toy_input = [{'text': 'this is a toy input', 'image': np.random.uniform(size=(16))} for _ in range(10)]
toy_target = ['a' for _ in range(10)]
else:
toy_input = [{'text': 'this is a toy input for test', 'image': np.random.uniform(size=(16))} for _ in range(10)]
toy_target = ['a' for _ in range(10)]
return toy_input, toy_target
# hide
preproc_dec_test()
```
#### A, B Token Multi-modal
TODO: Implement this. Not working yet.
```
# hide
@preprocessing_fn
def toy_cls(params: BaseParams, mode: str) -> Tuple[list, list]:
"Simple example to demonstrate A, B token multi-modal tuple of list return"
if mode == bert_multitask_learning.TRAIN:
toy_input = [
{
'a': {
'text': 'this is a toy input',
'image': np.random.uniform(size=(16))
},
'b':{
'text': 'this is a toy input',
'image': np.random.uniform(size=(16))
}
} for _ in range(10)]
toy_target = ['a' for _ in range(10)]
else:
toy_input = [
{
'a': {
'text': 'this is a toy input for test',
'image': np.random.uniform(size=(16))
},
'b':{
'text': 'this is a toy input for test',
'image': np.random.uniform(size=(16))
}
} for _ in range(10)]
toy_target = ['a' for _ in range(10)]
return toy_input, toy_target
# # hide
# params.add_problem(problem_name='toy_cls', problem_type='cls', processing_fn=toy_cls)
# assert (10, 1)==toy_cls(params=params, mode=bert_multitask_learning.TRAIN, get_data_num=True, write_tfrecord=False)
# shutil.rmtree(os.path.join(params.tmp_file_dir, 'toy_cls'))
# toy_cls(params=params, mode=bert_multitask_learning.TRAIN, get_data_num=False, write_tfrecord=True)
# assert os.path.exists(os.path.join(params.tmp_file_dir, 'toy_cls', 'train_feature_desc.json'))
```
### Generator of Tuple
#### Single Modal
```
@preprocessing_fn
def toy_cls(params: BaseParams, mode: str) -> Tuple[list, list]:
"Simple example to demonstrate singe modal tuple of list return"
if mode == bert_multitask_learning.TRAIN:
toy_input = ['this is a toy input' for _ in range(10)]
toy_target = ['a' for _ in range(10)]
else:
toy_input = ['this is a toy input for test' for _ in range(10)]
toy_target = ['a' for _ in range(10)]
for i, t in zip(toy_input, toy_target):
yield i, t
# hide
preproc_dec_test()
```
#### Multi-modal
```
@preprocessing_fn
def toy_cls(params: BaseParams, mode: str) -> Tuple[list, list]:
"Simple example to demonstrate multi-modal tuple of list return"
if mode == bert_multitask_learning.TRAIN:
toy_input = [{'text': 'this is a toy input', 'image': np.random.uniform(size=(16))} for _ in range(10)]
toy_target = ['a' for _ in range(10)]
else:
toy_input = [{'text': 'this is a toy input for test', 'image': np.random.uniform(size=(16))} for _ in range(10)]
toy_target = ['a' for _ in range(10)]
for i, t in zip(toy_input, toy_target):
yield i, t
# hide
preproc_dec_test()
```
| github_jupyter |
```
%matplotlib inline
```
Note: if plots don't show, there is a recent matplotlib issue that may be related:
https://github.com/matplotlib/matplotlib/issues/18396
# Filter Out Background Noise
Use soundpy to filter out background noise from audio signals.
To see how soundpy implements this, see `soundpy.builtin.filtersignal`.
```
# to be able to import soundpy from parent directory:
import os
package_dir = '../'
os.chdir(package_dir)
```
Let's import soundpy, assuming it is in your working directory:
```
import soundpy as sp;
import IPython.display as ipd
```
### soundpy offers an example audio file. Let's use it and add some white background noise.
Speech sample:
```
# Use function 'string2pathlib' to turn string path into pathlib object
# This allows flexibility across operating systems
speech = sp.string2pathlib('audiodata/python.wav')
```
## Hear and see the speech
```
# set feature_type for visualization: 'stft' (same as 'powspec'), 'fbank', 'mfcc'
feature_type = 'stft'
# For filtering, we will set the sample rate to be quite high:
sr = 48000
s, sr = sp.loadsound(speech, sr=sr)
ipd.Audio(s,rate=sr)
sp.plotsound(s, sr=sr, feature_type='signal', title='Speech (signal)')
sp.plotsound(s, sr=sr, feature_type=feature_type, title='Speech ({})'.format(feature_type.upper()))
```
## Add noise: 10 SNR
Go ahead and play with different SNR levels and see how the filtering handles it.
```
snr = 20
s_snr = sp.augment.add_white_noise(s, sr=sr, snr=snr)
ipd.Audio(s_snr,rate=sr)
sp.plotsound(s_snr, sr=sr, feature_type='signal', title='Noisy Speech {} SNR (signal)'.format(snr))
sp.plotsound(s_snr, sr=sr, feature_type=feature_type, title='Noisy Speech {} SNR ({})'.format(snr, feature_type.upper()))
```
## Wiener Filter
```
wf_snr, sr = sp.filtersignal(s_snr,
sr=sr,
filter_type='wiener', # default filter
filter_scale=2, # default = 1
duration_noise_ms = 120, # amount of time at beg of signal for noise reference
)
ipd.Audio(wf_snr,rate=sr)
sp.plotsound(wf_snr, sr=sr, feature_type='signal',
title='Filtered Noisy Speech {} SNR (signal) \nWiener Filter'.format(snr))
sp.plotsound(wf_snr, sr=sr, feature_type=feature_type,
title='Filtered Noisy Speech {} SNR ({}) \nWiener Filter'.format(snr, feature_type.upper()))
```
## Wiener Filter with Postfilter
In this case, **the post filter doesn't improve the signal** (rather makes it worse). But if you have a filtered signal that has a lot of 'musical noise' or artifacts resulting from filtering, this postfilter should reduce those artifacts.
```
wf_snr_pf, sr = sp.filtersignal(s_snr,
sr=sr,
filter_type='wiener',
filter_scale=2,
duration_noise_ms = 120,
apply_postfilter = True)
ipd.Audio(wf_snr_pf,rate=sr)
sp.plotsound(wf_snr_pf, sr=sr, feature_type='signal',
title='Filtered Noisy Speech {} SNR (signal) \nWiener Filter with Post Filter'.format(snr))
sp.plotsound(wf_snr_pf, sr=sr, feature_type=feature_type,
title='Filtered Noisy Speech {} SNR ({}) \nWiener Filter with Post Filter'.format(snr, feature_type.upper()))
```
| github_jupyter |
# Обзор базовых подходов к решению задачи Uplift Моделирования
<br>
<center>
<a href="https://colab.research.google.com/github/maks-sh/scikit-uplift/blob/master/notebooks/RetailHero.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg">
</a>
<br>
<b><a href="https://github.com/maks-sh/scikit-uplift/">SCIKIT-UPLIFT REPO</a> | </b>
<b><a href="https://scikit-uplift.readthedocs.io/en/latest/">SCIKIT-UPLIFT DOCS</a> | </b>
<b><a href="https://scikit-uplift.readthedocs.io/en/latest/user_guide/index.html">USER GUIDE</a></b>
<br>
<b><a href="https://nbviewer.jupyter.org/github/maks-sh/scikit-uplift/blob/master/notebooks/RetailHero_EN.ipynb">ENGLISH VERSION</a></b>
<br>
<b><a href="https://habr.com/ru/company/ru_mts/blog/485980/">СТАТЬЯ НА HABR ЧАСТЬ 1</a> | </b>
<b><a href="https://habr.com/ru/company/ru_mts/blog/485976/">СТАТЬЯ НА HABR ЧАСТЬ 2</a> | </b>
<b><a href="https://habr.com/ru/company/ru_mts/blog/538934/">СТАТЬЯ НА HABR ЧАСТЬ 3</a></b>
</center>
## Содержание
* [Введение](#Введение)
* [1. Подходы с одной моделью](#1.-Подходы-с-одной-моделью)
* [1.1 Одна модель](#1.1-Одна-модель-с-признаком-коммуникации)
* [1.2 Трансформация классов](#1.2-Трансформация-классов)
* [2. Подходы с двумя моделями](#2.-Подходы-с-двумя-моделями)
* [2.1 Две независимые модели](#2.1-Две-независимые-модели)
* [2.2 Две зависимые модели](#2.3-Две-зависимые-модели)
* [Заключение](#Заключение)
## Введение
Прежде чем переходить к обсуждению uplift моделирования, представим некоторую ситуацию.
К вам приходит заказчик с некоторой проблемой: необходимо с помощью sms рассылки прорекламировать достаточно популярный продукт.
У вас как у самого настоящего, топового дата саентиста в голове уже вырисовался план:
<p align="center">
<img src="https://raw.githubusercontent.com/maks-sh/scikit-uplift/master/docs/_static/images/memchik_RU.png" alt="Топовый дс"/>
</p>
И тут вы начинаете понимать, что продукт и без того популярный, что без коммуникации продукт достаточно часто устанавливается клиентами, что обычная бинарная классификация обнаружит много таких клиентов, а стоимость коммуникация для нас критична...
Исторически, по воздействию коммуникации маркетологи разделяют всех клиентов на 4 категории:
<p align="center">
<img src="https://habrastorage.org/webt/mb/ed/iw/mbediw3l1dh76tk6_0-zgaxz-ss.jpeg" width='40%' alt="Категории клиентов"/>
</p>
1. **`Не беспокоить`** - человек, который будет реагировать негативно, если с ним прокоммуницировать. Яркий пример: клиенты, которые забыли про платную подписку. Получив напоминание об этом, они обязательно ее отключат. Но если их не трогать, то клиенты по-прежнему будут приносить деньги. В терминах математики: $W_i = 1, Y_i = 0$ или $W_i = 0, Y_i = 1$.
2. **`Потерянный`** - человек, который не совершит целевое действие независимо от коммуникаций. Взаимодействие с такими клиентами не приносит дополнительного дохода, но создает дополнительные затраты. В терминах математики: $W_i = 1, Y_i = 0$ или $W_i = 0, Y_i = 0$.
3. **`Лояльный`** - человек, который будет реагировать положительно, несмотря ни на что - самый лояльный вид клиентов. По аналогии с предыдущим пунктом, такие клиенты также расходуют ресурсы. Однако в данном случае расходы гораздо больше, так как **лояльные** еще и пользуются маркетинговым предложением (скидками, купонами и другое). В терминах математики: $W_i = 1, Y_i = 1$ или $W_i = 0, Y_i = 1$.
4. **`Убеждаемый`** - это человек, который положительно реагирует на предложение, но при его отсутствии не выполнил бы целевого действия. Это те люди, которых мы хотели бы определить нашей моделью, чтобы с ними прокоммуницировать. В терминах математики: $W_i = 0, Y_i = 0$ или $W_i = 1, Y_i = 1$.
Стоит отметить, что в зависимости от клиентской базы и особенностей компании возможно отсутствие некоторых из этих типов клиентов.
Таким образом, в данной задаче нам хочется не просто спрогнозировать вероятность выполнения целевого действия, а сосредоточить рекламный бюджет на клиентах, которые выполнят целевое действие только при нашем взаимодействии. Иначе говоря, для каждого клиента хочется отдельно оценить две условные вероятности:
* Выполнение целевого действия при нашем воздействии на клиента.
Таких клиентов будем относить к **тестовой группе (aka treatment)**: $P^T = P(Y=1 | W = 1)$,
* Выполнение целевого действия без воздействия на клиента.
Таких клиентов будем относить к **контрольной группе (aka control)**: $P^C = P(Y=1 | W = 0)$,
где $Y$ - бинарный флаг выполнения целевого действия, $W$ - бинарный флаг наличия коммуникации (в англоязычной литературе - _treatment_)
Сам же причинно-следственный эффект **называется uplift** и оценивается как разность двух этих вероятностей:
$$ uplift = P^T - P^C = P(Y = 1 | W = 1) - P(Y = 1 | W = 0)$$
Прогнозирование uplift - это задача причинно-следственного вывода. Дело в том, что нужно оценить разницу между двумя событиями, которые являются взаимоисключающими для конкретного клиента (либо мы взаимодействуем с человеком, либо нет; нельзя одновременно совершить два этих действия). Именно поэтому для построения моделей uplift предъявляются дополнительные требования к исходным данным.
Для получения обучающей выборки для моделирования uplift необходимо провести эксперимент:
1. Случайным образом разбить репрезентативную часть клиентской базы на тестовую и контрольную группу
2. Прокоммуницировать с тестовой группой
Данные, полученные в рамках дизайна такого пилота, позволят нам в дальнейшем построить модель прогнозирования uplift. Стоит также отметить, что эксперимент должен быть максимально похож на кампнию, которая будет запущена позже в более крупном масштабе. Единственным отличием эксперимента от кампании должен быть тот факт, что во время пилота для взаимодействия мы выбираем случайных клиентов, а во время кампании - на основе спрогнозированного значения Uplift. Если кампания, которая в конечном итоге запускается, существенно отличается от эксперимента, используемого для сбора данных о выполнении целевых действий клиентами, то построенная модель может быть менее надежной и точной.
Итак, подходы к прогнозированию uplift направлены на оценку чистого эффекта от воздействия маркетинговых кампаний на клиентов.
**Подробнее про uplift можно прочитать в [цикле статьй на хабре](https://habr.com/ru/company/ru_mts/blog/485980/).**
Все классические подходы к моделированию uplift можно разделить на два класса:
1. Подходы с применением одной моделью
2. Подходы с применением двух моделей
Скачаем [данные конкурса RetailHero.ai](https://ods.ai/competitions/x5-retailhero-uplift-modeling/data):
```
import sys
# install uplift library scikit-uplift and other libraries
!{sys.executable} -m pip install scikit-uplift catboost pandas
from sklearn.model_selection import train_test_split
from sklift.datasets import fetch_x5
import pandas as pd
pd.set_option('display.max_columns', None)
%matplotlib inline
dataset = fetch_x5()
dataset.data.keys()
print(f"Dataset type: {type(dataset)}\n")
print(f"Dataset features shape: {dataset.data['clients'].shape}")
print(f"Dataset features shape: {dataset.data['train'].shape}")
print(f"Dataset target shape: {dataset.target.shape}")
print(f"Dataset treatment shape: {dataset.treatment.shape}")
```
Описание датасета вы найдёте в <a href="https://www.uplift-modeling.com/en/latest/api/datasets/fetch_x5.html">документации</a>.
Импортируем нужные библиотеки и предобработаем данные:
```
# Извлечение данных
df_clients = dataset.data['clients'].set_index("client_id")
df_train = pd.concat([dataset.data['train'], dataset.treatment , dataset.target], axis=1).set_index("client_id")
indices_test = pd.Index(set(df_clients.index) - set(df_train.index))
# Извлечение признаков
df_features = df_clients.copy()
df_features['first_issue_time'] = \
(pd.to_datetime(df_features['first_issue_date'])
- pd.Timestamp('1970-01-01')) // pd.Timedelta('1s')
df_features['first_redeem_time'] = \
(pd.to_datetime(df_features['first_redeem_date'])
- pd.Timestamp('1970-01-01')) // pd.Timedelta('1s')
df_features['issue_redeem_delay'] = df_features['first_redeem_time'] \
- df_features['first_issue_time']
df_features = df_features.drop(['first_issue_date', 'first_redeem_date'], axis=1)
indices_learn, indices_valid = train_test_split(df_train.index, test_size=0.3, random_state=123)
```
Для удобства объявим некоторые переменные:
```
X_train = df_features.loc[indices_learn, :]
y_train = df_train.loc[indices_learn, 'target']
treat_train = df_train.loc[indices_learn, 'treatment_flg']
X_val = df_features.loc[indices_valid, :]
y_val = df_train.loc[indices_valid, 'target']
treat_val = df_train.loc[indices_valid, 'treatment_flg']
X_train_full = df_features.loc[df_train.index, :]
y_train_full = df_train.loc[:, 'target']
treat_train_full = df_train.loc[:, 'treatment_flg']
X_test = df_features.loc[indices_test, :]
cat_features = ['gender']
models_results = {
'approach': [],
'uplift@30%': []
}
```
## 1. Подходы с одной моделью
### 1.1 Одна модель с признаком коммуникации
Самое простое и интуитивное решение: модель обучается одновременно на двух группах, при этом бинарный флаг коммуникации выступает в качестве дополнительного признака. Каждый объект из тестовой выборки скорим дважды: с флагом коммуникации равным 1 и равным 0. Вычитая вероятности по каждому наблюдению, получим искомы uplift.
<p align="center">
<img src="https://raw.githubusercontent.com/maks-sh/scikit-uplift/master/docs/_static/images/SoloModel_RU.png" alt="Solo model with treatment as a feature"/>
</p>
```
# Инструкция по установке пакета: https://github.com/maks-sh/scikit-uplift
# Ссылка на документацию: https://scikit-uplift.readthedocs.io/en/latest/
from sklift.metrics import uplift_at_k
from sklift.viz import plot_uplift_preds
from sklift.models import SoloModel
# sklift поддерживает любые модели,
# которые удовлетворяют соглашениями scikit-learn
# Для примера воспользуемся catboost
from catboost import CatBoostClassifier
sm = SoloModel(CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True))
sm = sm.fit(X_train, y_train, treat_train, estimator_fit_params={'cat_features': cat_features})
uplift_sm = sm.predict(X_val)
sm_score = uplift_at_k(y_true=y_val, uplift=uplift_sm, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('SoloModel')
models_results['uplift@30%'].append(sm_score)
# Получим условные вероятности выполнения целевого действия при взаимодействии для каждого объекта
sm_trmnt_preds = sm.trmnt_preds_
# И условные вероятности выполнения целевого действия без взаимодействия для каждого объекта
sm_ctrl_preds = sm.ctrl_preds_
# Отрисуем распределения вероятностей и их разность (uplift)
plot_uplift_preds(trmnt_preds=sm_trmnt_preds, ctrl_preds=sm_ctrl_preds);
# С той же легкостью можно обратиться к обученной модели.
# Например, чтобы построить важность признаков:
sm_fi = pd.DataFrame({
'feature_name': sm.estimator.feature_names_,
'feature_score': sm.estimator.feature_importances_
}).sort_values('feature_score', ascending=False).reset_index(drop=True)
sm_fi
```
### 1.2 Трансформация классов
Достаточно интересный и математически подтвержденный подход к построению модели, представленный еще в 2012 году. Метод заключается в прогнозировании немного измененного таргета:
$$
Z_i = Y_i \cdot W_i + (1 - Y_i) \cdot (1 - W_i),
$$
где
* $Z_i$ - новая целевая переменная $i$-ого клиента;
* $Y_i$ - целевая перемнная $i$-ого клиента;
* $W_i$ - флаг коммуникации $i$-ого клиента;
Другими словами, новый класс равен 1, если мы знаем, что на конкретном наблюдении, результат при взаимодействии был бы таким же хорошим, как и в контрольной группе, если бы мы могли знать результат в обеих группах:
$$
Z_i = \begin{cases}
1, & \mbox{if } W_i = 1 \mbox{ and } Y_i = 1 \\
1, & \mbox{if } W_i = 0 \mbox{ and } Y_i = 0 \\
0, & \mbox{otherwise}
\end{cases}
$$
Распишем подробнее, чему равна вероятность новой целевой переменной:
$$
P(Z=1|X = x) = \\
= P(Z=1|X = x, W = 1) \cdot P(W = 1|X = x) + \\
+ P(Z=1|X = x, W = 0) \cdot P(W = 0|X = x) = \\
= P(Y=1|X = x, W = 1) \cdot P(W = 1|X = x) + \\
+ P(Y=0|X = x, W = 0) \cdot P(W = 0|X = x).
$$
Выше мы обсуждали, что обучающая выборка для моделирования uplift собирается на основе рандомизированного разбиения части клиенской базы на тестовую и контрольную группы. Поэтому коммуникация $ W $ не может зависить от признаков клиента $ X_1, ..., X_m $. Принимая это, мы имеем: $ P(W | X_1, ..., X_m, ) = P(W) $ и
$$
P(Z=1|X = x) = \\
= P^T(Y=1|X = x) \cdot P(W = 1) + \\
+ P^C(Y=0|X = x) \cdot P(W = 0)
$$
Также допустим, что $P(W = 1) = P(W = 0) = \frac{1}{2}$, т.е. во время эксперимента контрольные и тестовые группы были разделены в равных пропорциях. Тогда получим следующее:
$$
P(Z=1|X = x) = \\
= P^T(Y=1|X = x) \cdot \frac{1}{2} + P^C(Y=0|X = x) \cdot \frac{1}{2} \Rightarrow \\
2 \cdot P(Z=1|X = x) = \\
= P^T(Y=1|X = x) + P^C(Y=0|X = x) = \\
= P^T(Y=1|X = x) + 1 - P^C(Y=1|X = x) \Rightarrow \\
\Rightarrow P^T(Y=1|X = x) - P^C(Y=1|X = x) = \\
= uplift = 2 \cdot P(Z=1|X = x) - 1
$$
Таким образом, увеличив вдвое прогноз нового таргета и вычтя из него единицу мы получим значение самого uplift'a, т.е.
$$
uplift = 2 \cdot P(Z=1) - 1
$$
Исходя из допущения описанного выше: $P(W = 1) = P(W = 0) = \frac{1}{2}$, данный подход следует использовать только в случаях, когда количество клиентов, с которыми мы прокоммуницировлаи, равно количеству клиентов, с которыми коммуникации не было.
```
from sklift.models import ClassTransformation
ct = ClassTransformation(CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True))
ct = ct.fit(X_train, y_train, treat_train, estimator_fit_params={'cat_features': cat_features})
uplift_ct = ct.predict(X_val)
ct_score = uplift_at_k(y_true=y_val, uplift=uplift_ct, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('ClassTransformation')
models_results['uplift@30%'].append(ct_score)
```
## 2. Подходы с двумя моделями
Подход с двумя моделями можно встретить почти в любой работе по uplift моделированию, он часто используется в качестве бейзлайна. Однако использование двух моделей может привести к некоторым неприятным последствиям: если для обучения будут использоваться принципиально разные модели или природа данных тестовой и контрольной групп будут сильно отличаться, то возвращаемые моделями скоры будут не сопоставимы между собой. Вследствие чего расчет uplift будет не совсем корректным. Для избежания такого эффекта необходимо калибровать модели, чтобы их скоры можно было интерпертировать как вероятности. Калибровка вероятностей модели отлично описана в [документации scikit-learn](https://scikit-learn.org/stable/modules/calibration.html).
### 2.1 Две независимые модели
Как понятно из названия, подход заключается в моделировании условных вероятностей тестовой и контрольной групп отдельно. В статьях утверждается, что такой подход достаточно слабый, так как обе модели фокусируются на прогнозировании результата отдельно и поэтому могут пропустить "более слабые" различия в выборках.
<p align= "center">
<img src="https://raw.githubusercontent.com/maks-sh/scikit-uplift/master/docs/_static/images/TwoModels_vanila_RU.png" alt="Two Models vanila"/>
</p>
```
from sklift.models import TwoModels
tm = TwoModels(
estimator_trmnt=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
estimator_ctrl=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
method='vanilla'
)
tm = tm.fit(
X_train, y_train, treat_train,
estimator_trmnt_fit_params={'cat_features': cat_features},
estimator_ctrl_fit_params={'cat_features': cat_features}
)
uplift_tm = tm.predict(X_val)
tm_score = uplift_at_k(y_true=y_val, uplift=uplift_tm, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('TwoModels')
models_results['uplift@30%'].append(tm_score)
plot_uplift_preds(trmnt_preds=tm.trmnt_preds_, ctrl_preds=tm.ctrl_preds_);
```
### 2.2 Две зависимые модели
Подход зависимого представления данных основан на методе цепочек классификаторов, первоначально разработанном для задач многоклассовой классификации. Идея состоит в том, что при наличии $L$ различных меток можно построить $L$ различных классификаторов, каждый из которых решает задачу бинарной классификации и в процессе обучения каждый следующий классификатор использует предсказания предыдущих в качестве дополнительных признаков. Авторы данного метода предложили использовать ту же идею для решения проблемы uplift моделирования в два этапа. В начале мы обучаем классификатор по контрольным данным:
$$
P^C = P(Y=1| X, W = 0),
$$
затем исполним предсказания $P_C$ в качестве нового признака для обучения второго классификатора на тестовых данных, тем самым эффективно вводя зависимость между двумя наборами данных:
$$
P^T = P(Y=1| X, P_C(X), W = 1)
$$
Чтобы получить uplift для каждого наблюдения, вычислим разницу:
$$
uplift(x_i) = P^T(x_i, P_C(x_i)) - P^C(x_i)
$$
Интуитивно второй классификатор изучает разницу между ожидаемым результатом в тесте и контроле, т.е. сам uplift.
<p align= "center">
<img src="https://raw.githubusercontent.com/maks-sh/scikit-uplift/master/docs/_static/images/TwoModels_ddr_control_RU.png" alt="Two dependent models"/>
</p>
```
tm_ctrl = TwoModels(
estimator_trmnt=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
estimator_ctrl=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
method='ddr_control'
)
tm_ctrl = tm_ctrl.fit(
X_train, y_train, treat_train,
estimator_trmnt_fit_params={'cat_features': cat_features},
estimator_ctrl_fit_params={'cat_features': cat_features}
)
uplift_tm_ctrl = tm_ctrl.predict(X_val)
tm_ctrl_score = uplift_at_k(y_true=y_val, uplift=uplift_tm_ctrl, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('TwoModels_ddr_control')
models_results['uplift@30%'].append(tm_ctrl_score)
plot_uplift_preds(trmnt_preds=tm_ctrl.trmnt_preds_, ctrl_preds=tm_ctrl.ctrl_preds_);
```
Аналогичным образом можно сначала обучить классификатор $P^T$, а затем использовать его предсказания в качестве признака для классификатора $P^C$.
```
tm_trmnt = TwoModels(
estimator_trmnt=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
estimator_ctrl=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
method='ddr_treatment'
)
tm_trmnt = tm_trmnt.fit(
X_train, y_train, treat_train,
estimator_trmnt_fit_params={'cat_features': cat_features},
estimator_ctrl_fit_params={'cat_features': cat_features}
)
uplift_tm_trmnt = tm_trmnt.predict(X_val)
tm_trmnt_score = uplift_at_k(y_true=y_val, uplift=uplift_tm_trmnt, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('TwoModels_ddr_treatment')
models_results['uplift@30%'].append(tm_trmnt_score)
plot_uplift_preds(trmnt_preds=tm_trmnt.trmnt_preds_, ctrl_preds=tm_trmnt.ctrl_preds_);
```
## Заключение
Рассмотрим, какой метод лучше всего показал себя в этой задаче, и проскорим им тестовую выборку:
```
pd.DataFrame(data=models_results).sort_values('uplift@30%', ascending=False)
```
Из таблички выше можно понять, что в текущей задаче лучше всего справился подход трансформации целевой перемнной. Обучим модель на всей выборке и предскажем на тест.
```
ct_full = ClassTransformation(CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True))
ct_full = ct_full.fit(
X_train_full,
y_train_full,
treat_train_full,
estimator_fit_params={'cat_features': cat_features}
)
X_test.loc[:, 'uplift'] = ct_full.predict(X_test.values)
sub = X_test[['uplift']].to_csv('sub1.csv')
!head -n 5 sub1.csv
ct_full_fi = pd.DataFrame({
'feature_name': ct_full.estimator.feature_names_,
'feature_score': ct_full.estimator.feature_importances_
}).sort_values('feature_score', ascending=False).reset_index(drop=True)
ct_full_fi
```
Итак, мы познакомились с uplift моделированием и рассмотрели основные классические подходы его построения. Что дальше? Дальше можно с головй окунуться в разведывательный анализ данных, генерацию новых признаков, подбор моделей и их гиперпарметров, а также изучение новых подходов и библиотек.
**Спасибо, что дочитали до конца.**
**Мне будет приятно, если вы поддержите проект звездочкой на [гитхабе](https://github.com/maks-sh/scikit-uplift/) или расскажете о нем своим друзьям.**
| github_jupyter |
<img src='https://mundiwebservices.com/build/assets/Mundi-Logo-CMYK-colors.png' align='left' width='15%' ></img>
## Copernicus Atmosphere Monitoring Service (CAMS)
### Near real time data :
The Copernicus Atmosphere Monitoring Service (CAMS) created by the European Centre for Medium-Range Weather Forecasts (ECMWF) aims to provide air quality (athmospheric gases, aerosols particles...) data all around the world based on different data source :
* Satellite observations such as Sentinel 5P satellite from ESA or ESA-AURA from NASA...
* In situ observations based on different locations such as weather station, weather ships or aircrafts...
See how it works on the diagram below:
<img src='https://atmosphere.copernicus.eu/sites/default/files/inline-images/GOS-fullsize_0.jpg' width='50%' align='left' ></img>
The idea of this notebook is to help you discover the power of CAMS by selecting air quality data you want to display on a specific geographical zone, time interval and generating a GIF file representing these data on a map. This notebook is based on the Near real time dataset which provides air quality data near time interval and hours selected without reanalysis made.
```
from camslib import configure_ecmwfapi, setup, download_images, setup_dir, get_projection_map, display_GIF_images, request_ecmwfapi, display_gif_folder
import ecmwfapi
output_dir = setup_dir()
output_filename = setup(output_dir)
```
### 1 - Configure the CAMS API :
- 1- To access CAMS data, you have first <a href="https://apps.ecmwf.int/registration/"> to create an account on ECMWF</a>, if it is not already done !
- 2- To configure your ECMWFapi, which will give you the ability to access CAMS data,
<a href="https://api.ecmwf.int/v1/key/">you have to know your ECMWF Key.</a>
- 3- To access CAMS data, please enter the email you use to log in on ECMWF and your ECMWF API Key :
```
configure_ecmwfapi()
```
### 2 - Select your CAMS parameters and submit the API request:
You have different options with CAMS to analyse air quality data. Here are the parameters we offer you to define in the ECMWF API request :
- 1- The most important is to define what kind of air quality data you want to display. We propose the 5 most important : Nitrogen dioxyde, Ozone, Sulfur dioxyde, Particulate Matter <2.5 um, Particulate Matter <10 um.
- 2- Select the time interval where you want to get air quality data.
- 3- Select the hours where you want to get air quality data on each day of the time interval. `00:00:00` hour is selected by default and you can add these : `06:00`, `12:00`, `18:00`. You can select one or more. Be careful: if you select a 30 days time interval and 4 hours, it will download 120 images.
Then, the API request is submitted, and you will get in response a output.grib file on your `work/cams_data/cams_ecmwfapi/images_data` directory gathering all data. Be careful, you cannot load many "active" or "queued" requests. Please wait until the request is done or see <a href="https://apps.ecmwf.int/webmars/joblist/">your job list</a> to have more informations on the request status.
```
request_ecmwfapi(output_filename)
```
### 3 - Display data on a map
We will ask you now for different information in order to specify where and how you want to display the data on the map. One image per selected hour and day will be downloaded on your `work/cams_data/cams_ecmwfapi/images_data` directory.
#### Note
The run time may take several minutes.
```
get_projection_map(output_dir, output_filename)
display_gif_folder()
```
| github_jupyter |
<a href="https://colab.research.google.com/github/DemonFlexCouncil/DDSP-48kHz-Stereo/blob/master/ddsp/colab/ddsp_48kHz_stereo.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
##### Copyright 2020 Google LLC.
Licensed under the Apache License, Version 2.0 (the "License");
```
# Copyright 2020 Google LLC. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
```
# Train & Timbre Transfer--DDSP Autoencoder on GPU--48kHz/Stereo
Made by [Google Magenta](https://magenta.tensorflow.org/)--altered by [Demon Flex Council](https://soundcloud.com/demonflexcouncil)
This notebook demonstrates how to install the DDSP library and train it for synthesis based on your own data using command-line scripts. If run inside of Colab, it will automatically use a free Google Cloud GPU.
**A Little Background**
A producer friend of mine turned me on to Magenta’s DDSP, and I’m glad he did. In my mind it represents the way forward for AI music. Finally we have a glimpse inside the black box, with access to musical parameters as well as neural net hyperparameters. And DDSP leverages decades of studio knowledge by utilizing traditional processors like synthesizers and effects. One can envision a time when DDSP-like elements will sit at the heart of production DAWs.
DDSP will accept most audio sample rates and formats. However, native 48kHz/stereo datasets and primers will sound best. Output files are always 48kHz/stereo. You can upload datasets and primers via the browser or use Google Drive.
The algorithm was designed to model single instruments played monophonically, but it can also produce interesting results with denser, polyphonic material and percussion.
<img src="https://storage.googleapis.com/ddsp/additive_diagram/ddsp_autoencoder.png" alt="DDSP Autoencoder figure" width="700">
**Note that we prefix bash commands with a `!` inside of Colab, but you would leave them out if running directly in a terminal.**
### Install Dependencies
First we install the required dependencies with `pip`.
```
%tensorflow_version 2.x
# !pip install -qU ddsp[data_preparation]
!pip install -qU git+https://github.com/DemonFlexCouncil/ddsp@ddsp
# Initialize global path for using google drive.
DRIVE_DIR = ''
# Helper Functions
sample_rate = 48000
n_fft = 6144
```
### Setup Google Drive (Optional, Recommeded)
This notebook requires uploading audio and saving checkpoints. While you can do this with direct uploads / downloads, it is recommended to connect to your google drive account. This will enable faster file transfer, and regular saving of checkpoints so that you do not lose your work if the colab kernel restarts (common for training more than 12 hours).
#### Login and mount your drive
This will require an authentication code. You should then be able to see your drive in the file browser on the left panel.
```
from google.colab import drive
drive.mount('/content/drive')
```
#### Set your base directory
* In drive, put all of the audio files with which you would like to train in a single folder.
* Typically works well with 10-20 minutes of audio from a single monophonic source (also, one acoustic environment).
* Use the file browser in the left panel to find a folder with your audio, right-click **"Copy Path", paste below**, and run the cell.
```
#@markdown (ex. `/content/drive/My Drive/...`) Leave blank to skip loading from Drive.
DRIVE_DIR = '' #@param {type: "string"}
import os
assert os.path.exists(DRIVE_DIR)
print('Drive Folder Exists:', DRIVE_DIR)
```
### Make directories to save model and data
```
#@markdown Check the box below if you'd like to train with latent vectors.
LATENT_VECTORS = False #@param{type:"boolean"}
!git clone https://github.com/DemonFlexCouncil/gin.git
if LATENT_VECTORS:
GIN_FILE = 'gin/solo_instrument.gin'
else:
GIN_FILE = 'gin/solo_instrument_noz.gin'
AUDIO_DIR_LEFT = 'data/audio-left'
AUDIO_DIR_RIGHT = 'data/audio-right'
MODEL_DIR_LEFT = 'data/model-left'
MODEL_DIR_RIGHT = 'data/model-right'
AUDIO_FILEPATTERN_LEFT = AUDIO_DIR_LEFT + '/*'
AUDIO_FILEPATTERN_RIGHT = AUDIO_DIR_RIGHT + '/*'
!mkdir -p $AUDIO_DIR_LEFT $AUDIO_DIR_RIGHT $MODEL_DIR_LEFT $MODEL_DIR_RIGHT
if DRIVE_DIR:
SAVE_DIR_LEFT = os.path.join(DRIVE_DIR, 'ddsp-solo-instrument-left')
SAVE_DIR_RIGHT = os.path.join(DRIVE_DIR, 'ddsp-solo-instrument-right')
INPUT_DIR = os.path.join(DRIVE_DIR, 'dataset-input')
PRIMERS_DIR = os.path.join(DRIVE_DIR, 'primers')
OUTPUT_DIR = os.path.join(DRIVE_DIR, 'resynthesis-output')
!mkdir -p "$SAVE_DIR_LEFT" "$SAVE_DIR_RIGHT" "$INPUT_DIR" "$PRIMERS_DIR" "$OUTPUT_DIR"
```
### Upload training audio
Upload training audio to the "dataset-input" folder inside the DRIVE_DIR folder if using Drive (otherwise prompts local upload.)
```
!pip install note_seq
import glob
import os
from ddsp.colab import colab_utils
from google.colab import files
import librosa
import numpy as np
from scipy.io.wavfile import write as write_audio
if DRIVE_DIR:
wav_files = glob.glob(os.path.join(INPUT_DIR, '*.wav'))
aiff_files = glob.glob(os.path.join(INPUT_DIR, '*.aiff'))
aif_files = glob.glob(os.path.join(INPUT_DIR, '*.aif'))
ogg_files = glob.glob(os.path.join(INPUT_DIR, '*.ogg'))
flac_files = glob.glob(os.path.join(INPUT_DIR, '*.flac'))
mp3_files = glob.glob(os.path.join(INPUT_DIR, '*.mp3'))
audio_files = wav_files + aiff_files + aif_files + ogg_files + flac_files + mp3_files
else:
uploaded_files = files.upload()
audio_files = list(uploaded_files.keys())
for fname in audio_files:
# Convert to 48kHz.
audio, unused_sample_rate = librosa.load(fname, sr=48000, mono=False)
if (audio.ndim == 2):
audio = np.swapaxes(audio, 0, 1)
# Mono to stereo.
if (audio.ndim == 1):
print('Converting mono to stereo.')
audio = np.stack((audio, audio), axis=-1)
target_name_left = os.path.join(AUDIO_DIR_LEFT,
os.path.basename(fname).replace(' ', '_').replace('aiff', 'wav').replace('aif', 'wav').replace('ogg', 'wav').replace('flac', 'wav').replace('mp3', 'wav'))
target_name_right = os.path.join(AUDIO_DIR_RIGHT,
os.path.basename(fname).replace(' ', '_').replace('aiff', 'wav').replace('aif', 'wav').replace('ogg', 'wav').replace('flac', 'wav').replace('mp3', 'wav'))
# Split to dual mono.
write_audio(target_name_left, sample_rate, audio[:, 0])
write_audio(target_name_right, sample_rate, audio[:, 1])
```
### Preprocess raw audio into TFRecord dataset
We need to do some preprocessing on the raw audio you uploaded to get it into the correct format for training. This involves turning the full audio into short (4-second) examples, inferring the fundamental frequency (or "pitch") with [CREPE](http://github.com/marl/crepe), and computing the loudness. These features will then be stored in a sharded [TFRecord](https://www.tensorflow.org/tutorials/load_data/tfrecord) file for easier loading. Depending on the amount of input audio, this process usually takes a few minutes.
* (Optional) Transfer dataset from drive. If you've already created a dataset, from a previous run, this cell will skip the dataset creation step and copy the dataset from `$DRIVE_DIR/data`
```
!pip install apache_beam
import glob
import os
TRAIN_TFRECORD_LEFT = 'data/train-left.tfrecord'
TRAIN_TFRECORD_RIGHT = 'data/train-right.tfrecord'
TRAIN_TFRECORD_FILEPATTERN_LEFT = TRAIN_TFRECORD_LEFT + '*'
TRAIN_TFRECORD_FILEPATTERN_RIGHT = TRAIN_TFRECORD_RIGHT + '*'
# Copy dataset from drive if dataset has already been created.
drive_data_dir = os.path.join(DRIVE_DIR, 'data')
drive_dataset_files = glob.glob(drive_data_dir + '/*')
if DRIVE_DIR and len(drive_dataset_files) > 0:
!cp "$drive_data_dir"/* data/
else:
# Make a new dataset.
if (not glob.glob(AUDIO_FILEPATTERN_LEFT)) or (not glob.glob(AUDIO_FILEPATTERN_RIGHT)):
raise ValueError('No audio files found. Please use the previous cell to '
'upload.')
!ddsp_prepare_tfrecord \
--input_audio_filepatterns=$AUDIO_FILEPATTERN_LEFT \
--output_tfrecord_path=$TRAIN_TFRECORD_LEFT \
--num_shards=10 \
--sample_rate=$sample_rate \
--alsologtostderr
!ddsp_prepare_tfrecord \
--input_audio_filepatterns=$AUDIO_FILEPATTERN_RIGHT \
--output_tfrecord_path=$TRAIN_TFRECORD_RIGHT \
--num_shards=10 \
--sample_rate=$sample_rate \
--alsologtostderr
# Copy dataset to drive for safe-keeping.
if DRIVE_DIR:
!mkdir "$drive_data_dir"/
print('Saving to {}'.format(drive_data_dir))
!cp $TRAIN_TFRECORD_FILEPATTERN_LEFT "$drive_data_dir"/
!cp $TRAIN_TFRECORD_FILEPATTERN_RIGHT "$drive_data_dir"/
```
### Save dataset statistics for timbre transfer
Quantile normalization helps match loudness of timbre transfer inputs to the loudness of the dataset, so let's calculate it here and save in a pickle file.
```
from ddsp.colab import colab_utils
import ddsp.training
data_provider_left = ddsp.training.data.TFRecordProvider(TRAIN_TFRECORD_FILEPATTERN_LEFT, sample_rate=sample_rate)
data_provider_right = ddsp.training.data.TFRecordProvider(TRAIN_TFRECORD_FILEPATTERN_RIGHT, sample_rate=sample_rate)
dataset_left = data_provider_left.get_dataset(shuffle=False)
dataset_right = data_provider_right.get_dataset(shuffle=False)
if DRIVE_DIR:
PICKLE_FILE_PATH_LEFT = os.path.join(SAVE_DIR_LEFT, 'dataset_statistics_left.pkl')
PICKLE_FILE_PATH_RIGHT = os.path.join(SAVE_DIR_RIGHT, 'dataset_statistics_right.pkl')
else:
PICKLE_FILE_PATH_LEFT = os.path.join(MODEL_DIR_LEFT, 'dataset_statistics_left.pkl')
PICKLE_FILE_PATH_RIGHT = os.path.join(MODEL_DIR_RIGHT, 'dataset_statistics_right.pkl')
colab_utils.save_dataset_statistics(data_provider_left, PICKLE_FILE_PATH_LEFT, batch_size=1)
colab_utils.save_dataset_statistics(data_provider_right, PICKLE_FILE_PATH_RIGHT, batch_size=1)
```
Let's load the dataset in the `ddsp` library and have a look at one of the examples.
```
from ddsp.colab import colab_utils
import ddsp.training
from matplotlib import pyplot as plt
import numpy as np
data_provider_left = ddsp.training.data.TFRecordProvider(TRAIN_TFRECORD_FILEPATTERN_LEFT, sample_rate=sample_rate)
dataset_left = data_provider_left.get_dataset(shuffle=False)
data_provider_right = ddsp.training.data.TFRecordProvider(TRAIN_TFRECORD_FILEPATTERN_RIGHT, sample_rate=sample_rate)
dataset_right = data_provider_right.get_dataset(shuffle=False)
try:
ex_left = next(iter(dataset_left))
except StopIteration:
raise ValueError(
'TFRecord contains no examples. Please try re-running the pipeline with '
'different audio file(s).')
try:
ex_right = next(iter(dataset_right))
except StopIteration:
raise ValueError(
'TFRecord contains no examples. Please try re-running the pipeline with '
'different audio file(s).')
print('Top: Left, Bottom: Right')
colab_utils.specplot(ex_left['audio'])
colab_utils.specplot(ex_right['audio'])
f, ax = plt.subplots(6, 1, figsize=(14, 12))
x = np.linspace(0, 4.0, 1000)
ax[0].set_ylabel('loudness_db L')
ax[0].plot(x, ex_left['loudness_db'])
ax[1].set_ylabel('loudness_db R')
ax[1].plot(x, ex_right['loudness_db'])
ax[2].set_ylabel('F0_Hz L')
ax[2].set_xlabel('seconds')
ax[2].plot(x, ex_left['f0_hz'])
ax[3].set_ylabel('F0_Hz R')
ax[3].set_xlabel('seconds')
ax[3].plot(x, ex_right['f0_hz'])
ax[4].set_ylabel('F0_confidence L')
ax[4].set_xlabel('seconds')
ax[4].plot(x, ex_left['f0_confidence'])
ax[5].set_ylabel('F0_confidence R')
ax[5].set_xlabel('seconds')
ax[5].plot(x, ex_right['f0_confidence'])
```
### Train Model
We will now train a "solo instrument" model. This means the model is conditioned only on the fundamental frequency (f0) and loudness with no instrument ID or latent timbre feature. If you uploaded audio of multiple instruemnts, the neural network you train will attempt to model all timbres, but will likely associate certain timbres with different f0 and loudness conditions.
First, let's start up a [TensorBoard](https://www.tensorflow.org/tensorboard) to monitor our loss as training proceeds.
Initially, TensorBoard will report `No dashboards are active for the current data set.`, but once training begins, the dashboards should appear.
```
%reload_ext tensorboard
import tensorboard as tb
if DRIVE_DIR:
tb.notebook.start('--logdir "{}"'.format(SAVE_DIR_LEFT))
tb.notebook.start('--logdir "{}"'.format(SAVE_DIR_RIGHT))
else:
tb.notebook.start('--logdir "{}"'.format(MODEL_DIR_LEFT))
tb.notebook.start('--logdir "{}"'.format(MODEL_DIR_RIGHT))
```
### We will now begin training.
Note that we specify [gin configuration](https://github.com/google/gin-config) files for the both the model architecture ([solo_instrument.gin](TODO)) and the dataset ([tfrecord.gin](TODO)), which are both predefined in the library. You could also create your own. We then override some of the spefic params for `batch_size` (which is defined in in the model gin file) and the tfrecord path (which is defined in the dataset file).
#### Training Notes:
* Models typically perform well when the loss drops to the range of ~5.0-7.0.
* Depending on the dataset this can take anywhere from 5k-40k training steps usually.
* On the colab GPU, this can take from around 3-24 hours.
* We **highly recommend** saving checkpoints directly to your drive account as colab will restart naturally after about 12 hours and you may lose all of your checkpoints.
* By default, checkpoints will be saved every 250 steps with a maximum of 10 checkpoints (at ~60MB/checkpoint this is ~600MB). Feel free to adjust these numbers depending on the frequency of saves you would like and space on your drive.
* If you're restarting a session and `DRIVE_DIR` points a directory that was previously used for training, training should resume at the last checkpoint.
```
#@markdown Enter number of steps to train. Restart runtime to interrupt training.
NUM_STEPS = 1000 #@param {type:"slider", min: 1000, max:40000, step:1000}
NUM_LOOPS = int(NUM_STEPS / 1000)
if DRIVE_DIR:
TRAIN_DIR_LEFT = SAVE_DIR_LEFT
TRAIN_DIR_RIGHT = SAVE_DIR_RIGHT
else:
TRAIN_DIR_LEFT = MODEL_DIR_LEFT
TRAIN_DIR_RIGHT = MODEL_DIR_RIGHT
for i in range (0, NUM_LOOPS):
!ddsp_run \
--mode=train \
--alsologtostderr \
--save_dir="$TRAIN_DIR_LEFT" \
--gin_file="$GIN_FILE" \
--gin_file=datasets/tfrecord.gin \
--gin_param="TFRecordProvider.file_pattern='$TRAIN_TFRECORD_FILEPATTERN_LEFT'" \
--gin_param="batch_size=6" \
--gin_param="train_util.train.num_steps=1000" \
--gin_param="train_util.train.steps_per_save=250" \
--gin_param="trainers.Trainer.checkpoints_to_keep=10"
!ddsp_run \
--mode=train \
--alsologtostderr \
--save_dir="$TRAIN_DIR_RIGHT" \
--gin_file="$GIN_FILE" \
--gin_file=datasets/tfrecord.gin \
--gin_param="TFRecordProvider.file_pattern='$TRAIN_TFRECORD_FILEPATTERN_RIGHT'" \
--gin_param="batch_size=6" \
--gin_param="train_util.train.num_steps=1000" \
--gin_param="train_util.train.steps_per_save=250" \
--gin_param="trainers.Trainer.checkpoints_to_keep=10"
# Remove extra gin files.
if DRIVE_DIR:
!cd "$SAVE_DIR_LEFT" && mv "operative_config-0.gin" "$DRIVE_DIR"
!cd "$SAVE_DIR_LEFT" && rm operative_config*
!cd "$DRIVE_DIR" && mv "operative_config-0.gin" "$SAVE_DIR_LEFT"
!cd "$SAVE_DIR_RIGHT" && mv "operative_config-0.gin" "$DRIVE_DIR"
!cd "$SAVE_DIR_RIGHT" && rm operative_config*
!cd "$DRIVE_DIR" && mv "operative_config-0.gin" "$SAVE_DIR_RIGHT"
else:
!cd "$MODEL_DIR_LEFT" && mv "operative_config-0.gin" "$AUDIO_DIR_LEFT"
!cd "$MODEL_DIR_LEFT" && rm operative_config*
!cd "$AUDIO_DIR_LEFT" && mv "operative_config-0.gin" "$MODEL_DIR_LEFT"
!cd "$MODEL_DIR_RIGHT" && mv "operative_config-0.gin" "$AUDIO_DIR_RIGHT"
!cd "$MODEL_DIR_RIGHT" && rm operative_config*
!cd "$AUDIO_DIR_RIGHT" && mv "operative_config-0.gin" "$MODEL_DIR_RIGHT"
```
### Resynthesis
Check how well the model reconstructs the training data
```
!pip install note_seq
from ddsp.colab.colab_utils import play, specplot, download
import ddsp.training
import gin
from matplotlib import pyplot as plt
import numpy as np
from scipy.io.wavfile import write as write_audio
data_provider_left = ddsp.training.data.TFRecordProvider(TRAIN_TFRECORD_FILEPATTERN_LEFT, sample_rate=sample_rate)
data_provider_right = ddsp.training.data.TFRecordProvider(TRAIN_TFRECORD_FILEPATTERN_RIGHT, sample_rate=sample_rate)
dataset_left = data_provider_left.get_batch(batch_size=1, shuffle=False)
dataset_right = data_provider_right.get_batch(batch_size=1, shuffle=False)
try:
batch_left = next(iter(dataset_left))
except OutOfRangeError:
raise ValueError(
'TFRecord contains no examples. Please try re-running the pipeline with '
'different audio file(s).')
try:
batch_right = next(iter(dataset_right))
except OutOfRangeError:
raise ValueError(
'TFRecord contains no examples. Please try re-running the pipeline with '
'different audio file(s).')
# Parse the gin configs.
if DRIVE_DIR:
gin_file_left = os.path.join(SAVE_DIR_LEFT, 'operative_config-0.gin')
gin_file_right = os.path.join(SAVE_DIR_RIGHT, 'operative_config-0.gin')
else:
gin_file_left = os.path.join(MODEL_DIR_LEFT, 'operative_config-0.gin')
gin_file_right = os.path.join(MODEL_DIR_RIGHT, 'operative_config-0.gin')
gin.parse_config_file(gin_file_left)
gin.parse_config_file(gin_file_right)
# Load models
model_left = ddsp.training.models.Autoencoder()
model_right = ddsp.training.models.Autoencoder()
if DRIVE_DIR:
model_left.restore(SAVE_DIR_LEFT)
model_right.restore(SAVE_DIR_RIGHT)
else:
model_left.restore(MODEL_DIR_LEFT)
model_right.restore(MODEL_DIR_RIGHT)
# Resynthesize audio.
audio_left = batch_left['audio']
audio_right = batch_right['audio']
outputs_left = model_left(batch_left, training=False)
audio_gen_left = model_left.get_audio_from_outputs(outputs_left)
outputs_right = model_right(batch_right, training=False)
audio_gen_right = model_right.get_audio_from_outputs(outputs_right)
# Merge to stereo.
audio_left_stereo = np.expand_dims(np.squeeze(audio_left.numpy()), axis=1)
audio_right_stereo = np.expand_dims(np.squeeze(audio_right.numpy()), axis=1)
audio_stereo = np.concatenate((audio_left_stereo, audio_right_stereo), axis=1)
audio_gen_left_stereo = np.expand_dims(np.squeeze(audio_gen_left.numpy()), axis=1)
audio_gen_right_stereo = np.expand_dims(np.squeeze(audio_gen_right.numpy()), axis=1)
audio_gen_stereo = np.concatenate((audio_gen_left_stereo, audio_gen_right_stereo), axis=1)
# Play.
print('Original Audio')
play(audio_stereo, sample_rate=sample_rate)
print('Resynthesis')
play(audio_gen_stereo, sample_rate=sample_rate)
# Plot.
print('Spectrograms: Top two are Original Audio L/R, bottom two are Resynthesis L/R')
specplot(audio_left)
specplot(audio_right)
specplot(audio_gen_left)
specplot(audio_gen_right)
WRITE_PATH = OUTPUT_DIR + "/resynthesis.wav"
write_audio("resynthesis.wav", sample_rate, audio_gen_stereo)
write_audio(WRITE_PATH, sample_rate, audio_gen_stereo)
!ffmpeg-normalize resynthesis.wav -o resynthesis.wav -t -15 -ar 48000 -f
download("resynthesis.wav")
```
## Timbre Transfer
### Install & Import
Install ddsp, define some helper functions, and download the model. This transfers a lot of data and should take a minute or two.
```
# Ignore a bunch of deprecation warnings
import warnings
warnings.filterwarnings("ignore")
import copy
import os
import time
import crepe
import ddsp
import ddsp.training
from ddsp.colab import colab_utils
from ddsp.colab.colab_utils import (
auto_tune, detect_notes, fit_quantile_transform,
get_tuning_factor, download, play, record,
specplot, upload, DEFAULT_SAMPLE_RATE)
import gin
from google.colab import files
import librosa
import matplotlib.pyplot as plt
import numpy as np
import pickle
import tensorflow.compat.v2 as tf
import tensorflow_datasets as tfds
# Helper Functions
sample_rate = 48000
n_fft = 2048
print('Done!')
```
### Primer Audio File
```
from google.colab import files
from ddsp.colab.colab_utils import play
import re
#@markdown * Audio should be monophonic (single instrument / voice).
#@markdown * Extracts fundmanetal frequency (f0) and loudness features.
#@markdown * Choose an audio file on Drive or upload an audio file.
#@markdown * If you are using Drive, place the audio file in the "primers" folder inside the DRIVE_DIR folder. Enter the file name below.
PRIMER_FILE = "" #@param {type:"string"}
DRIVE_OR_UPLOAD = "Drive" #@param ["Drive", "Upload (.wav)"]
# Check for .wav extension.
match = re.search(r'.wav', PRIMER_FILE)
if match:
print ('')
else:
PRIMER_FILE = PRIMER_FILE + ".wav"
if DRIVE_OR_UPLOAD == "Drive":
PRIMER_PATH = PRIMERS_DIR + "/" + PRIMER_FILE
# Convert to 48kHz.
audio, unused_sample_rate = librosa.load(PRIMER_PATH, sr=48000, mono=False)
if (audio.ndim == 2):
audio = np.swapaxes(audio, 0, 1)
else:
# Load audio sample here (.wav file)
# Just use the first file.
audio_files = files.upload()
fnames = list(audio_files.keys())
audios = []
for fname in fnames:
audio, unused_sample_rate = librosa.load(fname, sr=48000, mono=False)
if (audio.ndim == 2):
audio = np.swapaxes(audio, 0, 1)
audios.append(audio)
audio = audios[0]
# Mono to stereo.
if (audio.ndim == 1):
print('Converting mono to stereo.')
audio = np.stack((audio, audio), axis=-1)
# Setup the session.
ddsp.spectral_ops.reset_crepe()
# Compute features.
audio_left = np.squeeze(audio[:, 0]).astype(np.float32)
audio_right = np.squeeze(audio[:, 1]).astype(np.float32)
audio_left = audio_left[np.newaxis, :]
audio_right = audio_right[np.newaxis, :]
start_time = time.time()
audio_features_left = ddsp.training.metrics.compute_audio_features(audio_left, n_fft=n_fft, sample_rate=sample_rate)
audio_features_right = ddsp.training.metrics.compute_audio_features(audio_right, n_fft=n_fft, sample_rate=sample_rate)
audio_features_left['loudness_db'] = audio_features_left['loudness_db'].astype(np.float32)
audio_features_right['loudness_db'] = audio_features_right['loudness_db'].astype(np.float32)
audio_features_mod_left = None
audio_features_mod_right = None
print('Audio features took %.1f seconds' % (time.time() - start_time))
play(audio, sample_rate=sample_rate)
TRIM = -15
# Plot Features.
fig, ax = plt.subplots(nrows=6,
ncols=1,
sharex=True,
figsize=(6, 16))
ax[0].plot(audio_features_left['loudness_db'][:TRIM])
ax[0].set_ylabel('loudness_db L')
ax[1].plot(audio_features_right['loudness_db'][:TRIM])
ax[1].set_ylabel('loudness_db R')
ax[2].plot(librosa.hz_to_midi(audio_features_left['f0_hz'][:TRIM]))
ax[2].set_ylabel('f0 [midi] L')
ax[3].plot(librosa.hz_to_midi(audio_features_right['f0_hz'][:TRIM]))
ax[3].set_ylabel('f0 [midi] R')
ax[4].plot(audio_features_left['f0_confidence'][:TRIM])
ax[4].set_ylabel('f0 confidence L')
_ = ax[4].set_xlabel('Time step [frame] L')
ax[5].plot(audio_features_right['f0_confidence'][:TRIM])
ax[5].set_ylabel('f0 confidence R')
_ = ax[5].set_xlabel('Time step [frame] R')
```
## Load the Model
```
def find_model_dir(dir_name):
# Iterate through directories until model directory is found
for root, dirs, filenames in os.walk(dir_name):
for filename in filenames:
if filename.endswith(".gin") and not filename.startswith("."):
model_dir = root
break
return model_dir
if DRIVE_DIR:
model_dir_left = find_model_dir(SAVE_DIR_LEFT)
model_dir_right = find_model_dir(SAVE_DIR_RIGHT)
else:
model_dir_left = find_model_dir(MODEL_DIR_LEFT)
model_dir_right = find_model_dir(MODEL_DIR_RIGHT)
gin_file_left = os.path.join(model_dir_left, 'operative_config-0.gin')
gin_file_right = os.path.join(model_dir_right, 'operative_config-0.gin')
# Load the dataset statistics.
DATASET_STATS_LEFT = None
DATASET_STATS_RIGHT = None
dataset_stats_file_left = os.path.join(model_dir_left, 'dataset_statistics_left.pkl')
dataset_stats_file_right = os.path.join(model_dir_right, 'dataset_statistics_right.pkl')
print(f'Loading dataset statistics from {dataset_stats_file_left}')
try:
if tf.io.gfile.exists(dataset_stats_file_left):
with tf.io.gfile.GFile(dataset_stats_file_left, 'rb') as f:
DATASET_STATS_LEFT = pickle.load(f)
except Exception as err:
print('Loading dataset statistics from pickle failed: {}.'.format(err))
print(f'Loading dataset statistics from {dataset_stats_file_right}')
try:
if tf.io.gfile.exists(dataset_stats_file_right):
with tf.io.gfile.GFile(dataset_stats_file_right, 'rb') as f:
DATASET_STATS_RIGHT = pickle.load(f)
except Exception as err:
print('Loading dataset statistics from pickle failed: {}.'.format(err))
# Parse gin config,
with gin.unlock_config():
gin.parse_config_file(gin_file_left, skip_unknown=True)
# Assumes only one checkpoint in the folder, 'ckpt-[iter]`.
if DRIVE_DIR:
latest_checkpoint_fname_left = os.path.basename(tf.train.latest_checkpoint(SAVE_DIR_LEFT))
latest_checkpoint_fname_right = os.path.basename(tf.train.latest_checkpoint(SAVE_DIR_RIGHT))
else:
latest_checkpoint_fname_left = os.path.basename(tf.train.latest_checkpoint(MODEL_DIR_LEFT))
latest_checkpoint_fname_right = os.path.basename(tf.train.latest_checkpoint(MODEL_DIR_RIGHT))
ckpt_left = os.path.join(model_dir_left, latest_checkpoint_fname_left)
ckpt_right = os.path.join(model_dir_right, latest_checkpoint_fname_right)
# Ensure dimensions and sampling rates are equal
time_steps_train = gin.query_parameter('DefaultPreprocessor.time_steps')
n_samples_train = gin.query_parameter('Additive.n_samples')
hop_size = int(n_samples_train / time_steps_train)
time_steps = int(audio_left.shape[1] / hop_size)
n_samples = time_steps * hop_size
# print("===Trained model===")
# print("Time Steps", time_steps_train)
# print("Samples", n_samples_train)
# print("Hop Size", hop_size)
# print("\n===Resynthesis===")
# print("Time Steps", time_steps)
# print("Samples", n_samples)
# print('')
gin_params = [
'Additive.n_samples = {}'.format(n_samples),
'FilteredNoise.n_samples = {}'.format(n_samples),
'DefaultPreprocessor.time_steps = {}'.format(time_steps),
'oscillator_bank.use_angular_cumsum = True', # Avoids cumsum accumulation errors.
]
with gin.unlock_config():
gin.parse_config(gin_params)
# Trim all input vectors to correct lengths
for key in ['f0_hz', 'f0_confidence', 'loudness_db']:
audio_features_left[key] = audio_features_left[key][:time_steps]
audio_features_right[key] = audio_features_right[key][:time_steps]
audio_features_left['audio'] = audio_features_left['audio'][:, :n_samples]
audio_features_right['audio'] = audio_features_right['audio'][:, :n_samples]
# Set up the model just to predict audio given new conditioning
model_left = ddsp.training.models.Autoencoder()
model_right = ddsp.training.models.Autoencoder()
model_left.restore(ckpt_left)
model_right.restore(ckpt_right)
# Build model by running a batch through it.
start_time = time.time()
unused_left = model_left(audio_features_left, training=False)
unused_right = model_right(audio_features_right, training=False)
print('Restoring model took %.1f seconds' % (time.time() - start_time))
#@title Modify conditioning
#@markdown These models were not explicitly trained to perform timbre transfer, so they may sound unnatural if the incoming loudness and frequencies are very different then the training data (which will always be somewhat true).
#@markdown ## Note Detection
#@markdown You can leave this at 1.0 for most cases
threshold = 1 #@param {type:"slider", min: 0.0, max:2.0, step:0.01}
#@markdown ## Automatic
ADJUST = True #@param{type:"boolean"}
#@markdown Quiet parts without notes detected (dB)
quiet = 30 #@param {type:"slider", min: 0, max:60, step:1}
#@markdown Force pitch to nearest note (amount)
autotune = 0 #@param {type:"slider", min: 0.0, max:1.0, step:0.1}
#@markdown ## Manual
#@markdown Shift the pitch (octaves)
pitch_shift = 0 #@param {type:"slider", min:-2, max:2, step:1}
#@markdown Adjsut the overall loudness (dB)
loudness_shift = 0 #@param {type:"slider", min:-20, max:20, step:1}
audio_features_mod_left = {k: v.copy() for k, v in audio_features_left.items()}
audio_features_mod_right = {k: v.copy() for k, v in audio_features_right.items()}
## Helper functions.
def shift_ld(audio_features, ld_shift=0.0):
"""Shift loudness by a number of ocatves."""
audio_features['loudness_db'] += ld_shift
return audio_features
def shift_f0(audio_features, pitch_shift=0.0):
"""Shift f0 by a number of ocatves."""
audio_features['f0_hz'] *= 2.0 ** (pitch_shift)
audio_features['f0_hz'] = np.clip(audio_features['f0_hz'],
0.0,
librosa.midi_to_hz(110.0))
return audio_features
mask_on_left = None
mask_on_right = None
if ADJUST and DATASET_STATS_LEFT and DATASET_STATS_RIGHT is not None:
# Detect sections that are "on".
mask_on_left, note_on_value_left = detect_notes(audio_features_left['loudness_db'],
audio_features_left['f0_confidence'],
threshold)
mask_on_right, note_on_value_right = detect_notes(audio_features_right['loudness_db'],
audio_features_right['f0_confidence'],
threshold)
if np.any(mask_on_left) or np.any(mask_on_right):
# Shift the pitch register.
target_mean_pitch_left = DATASET_STATS_LEFT['mean_pitch']
target_mean_pitch_right = DATASET_STATS_RIGHT['mean_pitch']
pitch_left = ddsp.core.hz_to_midi(audio_features_left['f0_hz'])
pitch_right = ddsp.core.hz_to_midi(audio_features_right['f0_hz'])
mean_pitch_left = np.mean(pitch_left[mask_on_left])
mean_pitch_right = np.mean(pitch_right[mask_on_right])
p_diff_left = target_mean_pitch_left - mean_pitch_left
p_diff_right = target_mean_pitch_right - mean_pitch_right
p_diff_octave_left = p_diff_left / 12.0
p_diff_octave_right = p_diff_right / 12.0
round_fn_left = np.floor if p_diff_octave_left > 1.5 else np.ceil
round_fn_right = np.floor if p_diff_octave_right > 1.5 else np.ceil
p_diff_octave_left = round_fn_left(p_diff_octave_left)
p_diff_octave_right = round_fn_right(p_diff_octave_right)
audio_features_mod_left = shift_f0(audio_features_mod_left, p_diff_octave_left)
audio_features_mod_right = shift_f0(audio_features_mod_right, p_diff_octave_right)
# Quantile shift the note_on parts.
_, loudness_norm_left = colab_utils.fit_quantile_transform(
audio_features_left['loudness_db'],
mask_on_left,
inv_quantile=DATASET_STATS_LEFT['quantile_transform'])
_, loudness_norm_right = colab_utils.fit_quantile_transform(
audio_features_right['loudness_db'],
mask_on_right,
inv_quantile=DATASET_STATS_RIGHT['quantile_transform'])
# Turn down the note_off parts.
mask_off_left = np.logical_not(mask_on_left)
mask_off_right = np.logical_not(mask_on_right)
loudness_norm_left[mask_off_left] -= quiet * (1.0 - note_on_value_left[mask_off_left][:, np.newaxis])
loudness_norm_right[mask_off_right] -= quiet * (1.0 - note_on_value_right[mask_off_right][:, np.newaxis])
loudness_norm_left = np.reshape(loudness_norm_left, audio_features_left['loudness_db'].shape)
loudness_norm_right = np.reshape(loudness_norm_right, audio_features_right['loudness_db'].shape)
audio_features_mod_left['loudness_db'] = loudness_norm_left
audio_features_mod_right['loudness_db'] = loudness_norm_right
# Auto-tune.
if autotune:
f0_midi_left = np.array(ddsp.core.hz_to_midi(audio_features_mod_left['f0_hz']))
f0_midi_right = np.array(ddsp.core.hz_to_midi(audio_features_mod_right['f0_hz']))
tuning_factor_left = get_tuning_factor(f0_midi_left, audio_features_mod_left['f0_confidence'], mask_on_left)
tuning_factor_right = get_tuning_factor(f0_midi_right, audio_features_mod_right['f0_confidence'], mask_on_right)
f0_midi_at_left = auto_tune(f0_midi_left, tuning_factor_left, mask_on_left, amount=autotune)
f0_midi_at_right = auto_tune(f0_midi_right, tuning_factor_right, mask_on_right, amount=autotune)
audio_features_mod_left['f0_hz'] = ddsp.core.midi_to_hz(f0_midi_at_left)
audio_features_mod_right['f0_hz'] = ddsp.core.midi_to_hz(f0_midi_at_right)
else:
print('\nSkipping auto-adjust (no notes detected or ADJUST box empty).')
else:
print('\nSkipping auto-adujst (box not checked or no dataset statistics found).')
# Manual Shifts.
audio_features_mod_left = shift_ld(audio_features_mod_left, loudness_shift)
audio_features_mod_right = shift_ld(audio_features_mod_right, loudness_shift)
audio_features_mod_left = shift_f0(audio_features_mod_left, pitch_shift)
audio_features_mod_right = shift_f0(audio_features_mod_right, pitch_shift)
# Plot Features.
has_mask_left = int(mask_on_left is not None)
has_mask_right = int(mask_on_right is not None)
n_plots = 4 + has_mask_left + has_mask_right
fig, axes = plt.subplots(nrows=n_plots,
ncols=1,
sharex=True,
figsize=(2*n_plots, 10))
if has_mask_left:
ax = axes[0]
ax.plot(np.ones_like(mask_on_left[:TRIM]) * threshold, 'k:')
ax.plot(note_on_value_left[:TRIM])
ax.plot(mask_on_left[:TRIM])
ax.set_ylabel('Note-on Mask L')
ax.set_xlabel('Time step [frame]')
ax.legend(['Threshold', 'Likelihood','Mask'])
if has_mask_right:
ax = axes[0 + has_mask_left]
ax.plot(np.ones_like(mask_on_right[:TRIM]) * threshold, 'k:')
ax.plot(note_on_value_right[:TRIM])
ax.plot(mask_on_right[:TRIM])
ax.set_ylabel('Note-on Mask R')
ax.set_xlabel('Time step [frame]')
ax.legend(['Threshold', 'Likelihood','Mask'])
ax = axes[0 + has_mask_left + has_mask_right]
ax.plot(audio_features_left['loudness_db'][:TRIM])
ax.plot(audio_features_mod_left['loudness_db'][:TRIM])
ax.set_ylabel('loudness_db L')
ax.legend(['Original','Adjusted'])
ax = axes[1 + has_mask_left + has_mask_right]
ax.plot(audio_features_right['loudness_db'][:TRIM])
ax.plot(audio_features_mod_right['loudness_db'][:TRIM])
ax.set_ylabel('loudness_db R')
ax.legend(['Original','Adjusted'])
ax = axes[2 + has_mask_left + has_mask_right]
ax.plot(librosa.hz_to_midi(audio_features_left['f0_hz'][:TRIM]))
ax.plot(librosa.hz_to_midi(audio_features_mod_left['f0_hz'][:TRIM]))
ax.set_ylabel('f0 [midi] L')
_ = ax.legend(['Original','Adjusted'])
ax = axes[3 + has_mask_left + has_mask_right]
ax.plot(librosa.hz_to_midi(audio_features_right['f0_hz'][:TRIM]))
ax.plot(librosa.hz_to_midi(audio_features_mod_right['f0_hz'][:TRIM]))
ax.set_ylabel('f0 [midi] R')
_ = ax.legend(['Original','Adjusted'])
!pip3 install ffmpeg-normalize
from scipy.io.wavfile import write as write_audio
#@title #Resynthesize Audio
af_left = audio_features_left if audio_features_mod_left is None else audio_features_mod_left
af_right = audio_features_right if audio_features_mod_right is None else audio_features_mod_right
# Run a batch of predictions.
start_time = time.time()
outputs_left = model_left(af_left, training=False)
audio_gen_left = model_left.get_audio_from_outputs(outputs_left)
outputs_right = model_right(af_right, training=False)
audio_gen_right = model_right.get_audio_from_outputs(outputs_right)
print('Prediction took %.1f seconds' % (time.time() - start_time))
# Merge to stereo.
audio_gen_left = np.expand_dims(np.squeeze(audio_gen_left.numpy()), axis=1)
audio_gen_right = np.expand_dims(np.squeeze(audio_gen_right.numpy()), axis=1)
audio_gen_stereo = np.concatenate((audio_gen_left, audio_gen_right), axis=1)
# Play
print('Resynthesis with primer')
play(audio_gen_stereo, sample_rate=sample_rate)
WRITE_PATH = OUTPUT_DIR + "/resynthesis_primer.wav"
write_audio("resynthesis_primer.wav", sample_rate, audio_gen_stereo)
write_audio(WRITE_PATH, sample_rate, audio_gen_stereo)
!ffmpeg-normalize resynthesis_primer.wav -o resynthesis_primer.wav -t -15 -ar 48000 -f
colab_utils.download("resynthesis_primer.wav")
```
| github_jupyter |
<a href="https://colab.research.google.com/github/astrodeepnet/sbi_experiments/blob/ramp_bijector/notebooks/score_matching/NF_implicit.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Nomalizing Flow with implicit coupling layers
```
!pip install --quiet --upgrade dm-haiku optax tensorflow-probability
!pip install --quiet git+https://github.com/astrodeepnet/sbi_experiments.git@ramp_bijector
%pylab inline
%load_ext autoreload
%autoreload 2
import jax
import jax.numpy as jnp
import numpy as onp
import haiku as hk
import optax
from functools import partial
from tqdm import tqdm
from tensorflow_probability.substrates import jax as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
tfpk = tfp.math.psd_kernels
d=2
batch_size = 1024
from sbiexpt.distributions import get_two_moons
from sbiexpt.bijectors import ImplicitRampBijector
@jax.jit
def get_batch(seed):
two_moons = get_two_moons(sigma= 0.05)
batch = two_moons.sample(batch_size, seed=seed) / 5 + 0.45
return batch
batch = get_batch(jax.random.PRNGKey(0))
hist2d(batch[:,0], batch[:,1],100, range=[[0,1],[0,1]]); gca().set_aspect('equal');
class CustomCoupling(hk.Module):
"""This is the coupling layer used in the Flow."""
def __call__(self, x, output_units, **condition_kwargs):
# NN to get a b and c
net = hk.Linear(128)(x)
net = jax.nn.leaky_relu(net)
net = hk.Linear(128)(net)
net = jax.nn.leaky_relu(net)
log_a_bound=4
min_density_lower_bound=1e-4
log_a = jax.nn.tanh(hk.Linear(output_units)(net)) * log_a_bound
b = jax.nn.sigmoid(hk.Linear(output_units)(net))
c = min_density_lower_bound + jax.nn.sigmoid(hk.Linear(output_units)(net)) * (1 - min_density_lower_bound)
return ImplicitRampBijector(lambda x: x**5, jnp.exp(log_a),b,c)
class Flow(hk.Module):
"""A normalizing flow using the coupling layers defined
above."""
def __call__(self):
chain = tfb.Chain([
tfb.RealNVP(d//2, bijector_fn=CustomCoupling(name = 'b1')),
tfb.Permute([1,0]),
tfb.RealNVP(d//2, bijector_fn=CustomCoupling(name = 'b2')),
tfb.Permute([1,0]),
tfb.RealNVP(d//2, bijector_fn=CustomCoupling(name = 'b3')),
tfb.Permute([1,0]),
tfb.RealNVP(d//2, bijector_fn=CustomCoupling(name = 'b4')),
tfb.Permute([1,0]),
])
nvp = tfd.TransformedDistribution(
tfd.Independent(tfd.TruncatedNormal(0.5*jnp.ones(d),
0.3*jnp.ones(d),
0.01,0.99),
reinterpreted_batch_ndims=1),
bijector=chain)
return nvp
model_NF = hk.without_apply_rng(hk.transform(lambda x : Flow()().log_prob(x)))
model_inv = hk.without_apply_rng(hk.transform(lambda x : Flow()().bijector.inverse(x)))
model_sample = hk.without_apply_rng(hk.transform(lambda : Flow()().sample(1024, seed=next(rng_seq))))
rng_seq = hk.PRNGSequence(12)
params = model_NF.init(next(rng_seq), jnp.zeros([1,d]))
# TO DO
@jax.jit
def loss_fn(params, batch):
log_prob = model_NF.apply(params, batch)
return -jnp.mean(log_prob)
@jax.jit
def update(params, opt_state, batch):
"""Single SGD update step."""
loss, grads = jax.value_and_grad(loss_fn)(params, batch)
updates, new_opt_state = optimizer.update(grads, opt_state)
new_params = optax.apply_updates(params, updates)
return loss, new_params, new_opt_state
learning_rate=0.0002
optimizer = optax.adam(learning_rate)
opt_state = optimizer.init(params)
losses = []
master_seed = hk.PRNGSequence(0)
for step in tqdm(range(5000)):
batch = get_batch(next(master_seed))
l, params, opt_state = update(params, opt_state, batch)
losses.append(l)
plot(losses[25:])
x = jnp.stack(jnp.meshgrid(jnp.linspace(0.1,0.9,128),
jnp.linspace(0.1,0.9,128)),-1)
im = model_NF.apply(params, x.reshape(-1,2)).reshape([128,128])
contourf(x[...,0],x[...,1],jnp.exp(im),100); colorbar()
hist2d(batch[:,0], batch[:,1],100, range=[[0,1],[0,1]]);gca().set_aspect('equal');
x = model_inv.apply(params, batch)
hist2d(x[:,0], x[:,1],100, range=[[0,1],[0,1]]);gca().set_aspect('equal');
x = model_sample.apply(params)
hist2d(x[:,0], x[:,1],100, range=[[0,1],[0,1]]);gca().set_aspect('equal');
coupl = hk.without_apply_rng(hk.transform(lambda x: CustomCoupling(name = 'b2')(x,1)))
predicate = lambda module_name, name, value: 'flow/b2' in module_name
params_b1 = hk.data_structures.filter(predicate, params)
params_b1=hk.data_structures.to_mutable_dict(params_b1)
params_b1={k.split('flow/')[1]:params_b1[k] for k in params_b1.keys()}
t = jnp.linspace(0,1)
bij = coupl.apply(params_b1, t.reshape([50,1]))
plot(t,bij(t)[30])
inv = bij.inverse(1*bij(t))
plot(t,inv.T)
plot(bij.forward_log_det_jacobian(t.reshape([50,1])))
plot(bij.inverse_log_det_jacobian(t.reshape([50,1])))
```
| github_jupyter |
# PG AI - Reinforcement Learning
## **Problem Statement**
Prepare an agent by implementing Deep Q-Learning that can perform unsupervised trading in stock trade. The aim of this project is to train an agent that uses Q-learning and neural networks to predict the profit or loss by building a model and implementing it on a dataset that is available for evaluation.
The stock trading environment provides the agent with a set of actions:<br>
* Buy<br>
* Sell<br>
* Sit
This project has following sections:
* Import the libraries
* Create a DQN agent
* Preprocess the data
* Train and build the model
* Evaluate the model and agent
<br><br>
**Steps to perform**<br>
In the section **create a DQN agent**, create a class called agent where:
* Action size is defined as 3
* Experience replay memory to deque is 1000
* Empty list for stocks that has already been bought
* The agent must possess the following hyperparameters:<br>
* gamma= 0.95<br>
* epsilon = 1.0<br>
* epsilon_final = 0.01<br>
* epsilon_decay = 0.995<br>
Note: It is advised to compare the results using different values in hyperparameters.
* Neural network has 3 hidden layers
* Action and experience replay are defined
## **Solution**
### **Import the libraries**
```
##import keras
#from keras.models import Sequential
##from keras.models import load_model
#from keras.layers import Dense
#from keras.optimizers import Adam
#import numpy as np
#import random
#from collections import deque
import random
import gym
import numpy as np
from collections import deque
#from keras import backend as K
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
import tensorflow.keras
#from keras.models import Sequential
from tensorflow.keras.models import load_model
```
### **Create a DQN agent**
```
#Action space include 3 actions: Buy, Sell, and Sit
#Setting up the experience replay memory to deque with 1000 elements inside it
#Empty list with inventory is created that contains the stocks that were already bought
#Setting up gamma to 0.95, that helps to maximize the current reward over the long-term
#Epsilon parameter determines whether to use a random action or to use the model for the action.
#In the beginning random actions are encouraged, hence epsilon is set up to 1.0 when the model is not trained.
#And over time the epsilon is reduced to 0.01 in order to decrease the random actions and use the trained model
#We're then set the speed of decreasing epsililon in the epsilon_decay parameter
class Agent:
def __init__(self, state_size, is_eval=False, model_name=""):
self.state_size = state_size # normalized previous days
self.action_size = 3 # sit, buy, sell
self.memory = deque(maxlen=1000)
self.inventory = []
self.model_name = model_name
self.is_eval = is_eval
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.model = load_model("" + model_name) if is_eval else self._model()
#Defining our neural network:
#Define the neural network function called _model and it just takes the keyword self
#Define the model with Sequential()
#Define states i.e. the previous n days and stock prices of the days
#Defining 3 hidden layers in this network
#Changing the activation function to relu because mean-squared error is used for the loss
def _model(self):
model = Sequential()
model.add(Dense(units=64, input_dim=self.state_size, activation="relu"))
model.add(Dense(units=32, activation="relu"))
model.add(Dense(units=8, activation="relu"))
model.add(Dense(self.action_size, activation="linear"))
model.compile(loss="mse", optimizer=Adam(lr=0.001))
return model
def act(self, state):
if not self.is_eval and np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
options = self.model.predict(state)
return np.argmax(options[0])
def expReplay(self, batch_size):
mini_batch = []
l = len(self.memory)
for i in range(l - batch_size + 1, l):
mini_batch.append(self.memory[i])
for state, action, reward, next_state, done in mini_batch:
target = reward
if not done:
target = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
mini_batch = []
l = len(self.memory)
for i in range(l - batch_size + 1, l):
mini_batch.append(self.memory[i])
for state, action, reward, next_state, done in mini_batch:
target = reward
if not done:
target = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
```
### **Preprocess the stock market data**
```
import math
# prints formatted price
def formatPrice(n):
return ("-$" if n < 0 else "$") + "{0:.2f}".format(abs(n))
# returns the vector containing stock data from a fixed file
def getStockDataVec(key):
vec = []
lines = open("" + key + ".csv", "r").read().splitlines()
for line in lines[1:]:
vec.append(float(line.split(",")[4]))
return vec
# returns the sigmoid
def sigmoid(x):
return 1 / (1 + math.exp(-x))
# returns an an n-day state representation ending at time t
def getState(data, t, n):
d = t - n + 1
block = data[d:t + 1] if d >= 0 else -d * [data[0]] + data[0:t + 1] # pad with t0
res = []
for i in range(n - 1):
res.append(sigmoid(block[i + 1] - block[i]))
return np.array([res])
```
### **Train and build the model**
```
if len(sys.argv) != 4:
print ("Usage: python train.py [stock] [window] [episodes]")
exit()
#stock_name = input("Enter stock_name, window_size, Episode_count")
#window_size = input()
#episode_count = input()
stock_name = "GSPC_Training_Dataset"
window_size = 10
episode_count = 1
#Fill the given information when prompted:
#Enter stock_name = GSPC_Training_Dataset
#window_size = 10
#Episode_count = 100 or it can be 10 or 20 or 30 and so on.
agent = Agent(window_size)
data = getStockDataVec(stock_name)
l = len(data) - 1
batch_size = 32
for e in range(episode_count + 1):
print ("Episode " + str(e) + "/" + str(episode_count))
state = getState(data, 0, window_size + 1)
total_profit = 0
agent.inventory = []
for t in range(l):
action = agent.act(state)
# sit
next_state = getState(data, t + 1, window_size + 1)
reward = 0
if action == 1: # buy
agent.inventory.append(data[t])
print ("Buy: " + formatPrice(data[t]))
elif action == 2 and len(agent.inventory) > 0: # sell
bought_price = agent.inventory.pop(0)
reward = max(data[t] - bought_price, 0)
total_profit += data[t] - bought_price
print ("Sell: " + formatPrice(data[t]) + " | Profit: " + formatPrice(data[t] - bought_price))
done = True if t == l - 1 else False
agent.memory.append((state, action, reward, next_state, done))
state = next_state
if done:
print ("--------------------------------")
print ("Total Profit: " + formatPrice(total_profit))
if len(agent.memory) > batch_size:
agent.expReplay(batch_size)
#if e % 10 == 0:
agent.model.save("model_ep" + str(e))
```
### **Evaluate the model and agent**
```
if len(sys.argv) != 3:
print ("Usage: python evaluate.py [stock] [model]")
exit()
stock_name = "GSPC_Evaluation_Dataset"
#model_name = r"C:\Users\saaim\Jupyter\PGP-AI---RL\CEP 2-20201025T144252Z-001\CEP 2\model_ep2\saved_model.pb"
#Note:
#Fill the given information when prompted:
#Enter stock_name = GSPC_Evaluation_Dataset
#Model_name = respective model name
for i in range(episode_count):
model_name = r"model_ep" + str(i)
print ("\n--------------------------------\n" + model_name + "\n--------------------------------\n")
model = tf.keras.models.load_model(model_name)
window_size = model.layers[0].input.shape.as_list()[1]
agent = Agent(window_size, True, model_name)
data = getStockDataVec(stock_name)
l = len(data) - 1
batch_size = 32
state = getState(data, 0, window_size + 1)
total_profit = 0
agent.inventory = []
for t in range(l):
action = agent.act(state)
# sit
next_state = getState(data, t + 1, window_size + 1)
reward = 0
if action == 1: # buy
agent.inventory.append(data[t])
print ("Buy: " + formatPrice(data[t]))
elif action == 2 and len(agent.inventory) > 0: # sell
bought_price = agent.inventory.pop(0)
reward = max(data[t] - bought_price, 0)
total_profit += data[t] - bought_price
print ("Sell: " + formatPrice(data[t]) + " | Profit: " + formatPrice(data[t] - bought_price))
done = True if t == l - 1 else False
agent.memory.append((state, action, reward, next_state, done))
state = next_state
if done:
print (stock_name + " Total Profit: " + formatPrice(total_profit))
print ("--------------------------------")
```
**Note: Run the training section for considerable episodes so that while evaluating the model it can generate significant profit.
e.g. 100 episodes**
| github_jupyter |
<table class="ee-notebook-buttons" align="left">
<td><a target="_blank" href="https://github.com/giswqs/earthengine-py-notebooks/tree/master/Image/image_overview.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" /> View source on GitHub</a></td>
<td><a target="_blank" href="https://nbviewer.jupyter.org/github/giswqs/earthengine-py-notebooks/blob/master/Image/image_overview.ipynb"><img width=26px src="https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png" />Notebook Viewer</a></td>
<td><a target="_blank" href="https://colab.research.google.com/github/giswqs/earthengine-py-notebooks/blob/master/Image/image_overview.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" /> Run in Google Colab</a></td>
</table>
## Install Earth Engine API and geemap
Install the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geemap](https://github.com/giswqs/geemap). The **geemap** Python package is built upon the [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet) and [folium](https://github.com/python-visualization/folium) packages and implements several methods for interacting with Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, and `Map.centerObject()`.
The following script checks if the geemap package has been installed. If not, it will install geemap, which automatically installs its [dependencies](https://github.com/giswqs/geemap#dependencies), including earthengine-api, folium, and ipyleaflet.
**Important note**: A key difference between folium and ipyleaflet is that ipyleaflet is built upon ipywidgets and allows bidirectional communication between the front-end and the backend enabling the use of the map to capture user input, while folium is meant for displaying static data only ([source](https://blog.jupyter.org/interactive-gis-in-jupyter-with-ipyleaflet-52f9657fa7a)). Note that [Google Colab](https://colab.research.google.com/) currently does not support ipyleaflet ([source](https://github.com/googlecolab/colabtools/issues/60#issuecomment-596225619)). Therefore, if you are using geemap with Google Colab, you should use [`import geemap.eefolium`](https://github.com/giswqs/geemap/blob/master/geemap/eefolium.py). If you are using geemap with [binder](https://mybinder.org/) or a local Jupyter notebook server, you can use [`import geemap`](https://github.com/giswqs/geemap/blob/master/geemap/geemap.py), which provides more functionalities for capturing user input (e.g., mouse-clicking and moving).
```
# Installs geemap package
import subprocess
try:
import geemap
except ImportError:
print('geemap package not installed. Installing ...')
subprocess.check_call(["python", '-m', 'pip', 'install', 'geemap'])
# Checks whether this notebook is running on Google Colab
try:
import google.colab
import geemap.eefolium as geemap
except:
import geemap
# Authenticates and initializes Earth Engine
import ee
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()
```
## Create an interactive map
The default basemap is `Google Maps`. [Additional basemaps](https://github.com/giswqs/geemap/blob/master/geemap/basemaps.py) can be added using the `Map.add_basemap()` function.
```
Map = geemap.Map(center=[40,-100], zoom=4)
Map
```
## Add Earth Engine Python script
```
# Add Earth Engine dataset
```
## Display Earth Engine data layers
```
Map.addLayerControl() # This line is not needed for ipyleaflet-based Map.
Map
```
| github_jupyter |
### Youtube 댓글 크롤링 & 분석(검색어: 타다 금지법)
### Scrapy Code
#### 1. items.py
```
# 1. 프로젝트 생성
!scrapy startproject youtube
# 2. items.py 작성
!cat youtube/youtube/items.py
%%writefile youtube/youtube/items.py
import scrapy
class YoutubeItem(scrapy.Item):
title = scrapy.Field()
user_id = scrapy.Field()
comment = scrapy.Field()
like_num = scrapy.Field()
link = scrapy.Field()
# 3. spider.py 작성
%%writefile youtube/youtube/spiders/spider.py
import requests
import time
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from scrapy.http import TextResponse
from bs4 import BeautifulSoup
from youtube.items import YoutubeItem
from scrapy.spiders import Spider
class YoutubeCrawler(scrapy.Spider):
item = YoutubeItem()
name = "YoutubeCrawler"
allow_domains = ["youtube.com"]
start_urls = ['https://www.youtube.com/results?search_query=타다 금지법&sp=EgIIAw%253D%253D']
def __init__(self):
scrapy.Spider.__init__(self)
options = Options()
options.headless = True
self.driver = webdriver.Chrome('/home/ubuntu/chromedriver', options=options)
def parse(self, response):
item = YoutubeItem()
self.driver.get(response.url)
time.sleep(5)
page=self.driver.page_source
soup = BeautifulSoup(page,'lxml')
all_ = soup.find_all('a','yt-simple-endpoint style-scope ytd-video-renderer')
#이번주 업로드된 동영상 링크(sample로 2개만)
links= ["https://www.youtube.com/" + all_[n].get('href') for n in range(0,2)]
for link in links:
yield scrapy.Request(link, callback=self.get_content)
def get_content(self, response):
self.driver.get(response.url)
#모든 댓글 가져오기 위해, 페이지 스크롤 끝까지 내리기
body = self.driver.find_element_by_tag_name("body")
num_of_pagedowns = 10
while num_of_pagedowns:
body.send_keys(Keys.PAGE_DOWN)
time.sleep(2)
num_of_pagedowns -= 1
#댓글: 최근 날짜 순으로 정렬
try:
self.driver.find_element_by_xpath('//*[@id="sort-menu"]').click()
self.driver.find_element_by_xpath('//*[@id="menu"]/a[2]/paper-item/paper-item-body/div[text()="최근 날짜순"]').click()
except Exception as e:
pass
#제목
title = self.driver.find_element_by_css_selector('#container > h1 > yt-formatted-string').text
#사용자 id
user_ids = self.driver.find_elements_by_css_selector('#author-text > span')
# 댓글
comments = self.driver.find_elements_by_css_selector('#content-text')
#좋아요 수
like_nums = self.driver.find_elements_by_css_selector('#vote-count-middle')
item = YoutubeItem()
for j in range(len(comments)):
item["title"] = title
item["comment"] = comments[j].text
item["user_id"] = user_ids[j].text
item["like_num"] = like_nums[j].text
item["link"] = response.url
yield item
%%writefile run.sh
cd youtube
scrapy crawl YoutubeCrawler -o YoutubeCrawling.csv
!./run.sh
# 데이터 잘 가져왔는지 엑셀로 확인
items_df = pd.read_csv("youtube/YoutubeCrawling.csv")
items_df[["title", "user_id", "comment", "like_num", "link"]]
# 4. pipeline.py 설정(pymongo 연결)
%%writefile youtube/youtube/mongodb.py
import pymongo
client = pymongo.MongoClient('mongodb://###')
db = client.youtube
collection = db.result
!cat youtube/youtube/pipelines.py
%%writefile youtube/youtube/pipelines.py
from .mongodb import collection
class YoutubePipeline(object):
def process_item(self, item, spider):
data = {"title": item["title"],
"user_id": item["user_id"],
"comment": item["comment"],
"like_num" : item["like_num"],
"link": item["link"]}
collection.insert(data)
return item
# settings.py 파일에서 아래 주석 해제
#ITEM_PIPELINES = {
#'naver_article.pipelines.NaverArticlePipeline': 300,
#}
!./run.sh
# Robo3T 결과
from PIL import Image as pil
pil_img = pil.open("robo3t.png")
pil_img
## 댓글 분석
```
| github_jupyter |
```
import os
import caselawnet
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import json
import networkx as nx
import community
filepath = '/media/sf_VBox_Shared/CaseLaw/2018-01-29-lido/derived/'
nodes_df = pd.read_csv(os.path.join(filepath, 'article_nodes_nodup_min5.csv'), index_col='id')
edges_df = pd.read_csv(os.path.join(filepath, 'article_to_article_min5.csv'))
nodes_df.head()
graph = nx.from_pandas_edgelist(edges_df, source='source', target='target', edge_attr='weight')
attributes = ['title', 'authority', 'book', 'community']
for att in attributes:
nx.set_node_attributes(graph, nodes_df[att].to_dict(), att)
```
## Assortativity
```
for att in attributes[1:]:
ass = nx.attribute_assortativity_coefficient(graph, att)
mod = community.modularity(nodes_df[att].to_dict(), graph)
print(att, 'assortativity:', ass, 'modularity:', mod)
```
## Degree distributions
```
degree_hist = nx.degree_histogram(graph)
ax = plt.subplot(311)
ax.bar(range(len(degree_hist)), degree_hist);
ax = plt.subplot(312)
ax.bar(range(len(degree_hist)), degree_hist);
ax.set_xscale("log", nonposx='clip')
ax = plt.subplot(313)
ax.bar(range(len(degree_hist)), degree_hist);
ax.set_xscale("log")
ax.set_yscale("log")
```
## Connected components
```
import numpy as np
ccs = list(nx.connected_components(graph))
ccs_multiple = [c for c in ccs if len(c) > 1]
ccs_sizes = np.array([len(c) for c in ccs])
ccs_multiple_sizes = np.array([len(c) for c in ccs_multiple])
print("Number of connected components:", len(ccs))
print("Relative size of largest component:", np.max(ccs_sizes)/np.sum(ccs_sizes))
print("Number of non-singleton components:", len(ccs_multiple_sizes))
print("Relative size of largest component without singletons:", np.max(ccs_multiple_sizes)/np.sum(ccs_multiple_sizes))
plt.bar(range(len(ccs)), sorted(ccs_sizes, reverse=True))
plt.gca().set_xscale('log')
plt.gca().set_yscale('log')
# Save largest cc
gcc_ids = list(ccs[np.argmax(ccs_sizes)])
nodes_gcc = nodes_df.loc[gcc_ids]
edges_gcc = edges_df[edges_df['source'].isin(gcc_ids) & edges_df['target'].isin(gcc_ids)]
print(len(nodes_gcc), len(edges_gcc))
nodes_gcc.to_csv(os.path.join(filepath, 'article_nodes_nodup_min5_gcc.csv'))
edges_gcc.to_csv(os.path.join(filepath, 'article_to_article_min5_gcc.csv'), index=False)
```
## communities
```
community_sizes = nodes_df.groupby('community').size()
print("Number of communities:", len(community_sizes))
print("Average size of community", community_sizes.mean())
```
| github_jupyter |
# Spider-Man
*Modeling and Simulation in Python*
Copyright 2021 Allen Downey
License: [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International](https://creativecommons.org/licenses/by-nc-sa/4.0/)
```
# install Pint if necessary
try:
import pint
except ImportError:
!pip install pint
# download modsim.py if necessary
from os.path import exists
filename = 'modsim.py'
if not exists(filename):
from urllib.request import urlretrieve
url = 'https://raw.githubusercontent.com/AllenDowney/ModSim/main/'
local, _ = urlretrieve(url+filename, filename)
print('Downloaded ' + local)
# import functions from modsim
from modsim import *
```
In this case study we'll develop a model of Spider-Man swinging from a springy cable of webbing attached to the top of the Empire State Building. Initially, Spider-Man is at the top of a nearby building, as shown in this diagram.

The origin, `O⃗`, is at the base of the Empire State Building. The vector `H⃗` represents the position where the webbing is attached to the building, relative to `O⃗`. The vector `P⃗` is the position of Spider-Man relative to `O⃗`. And `L⃗` is the vector from the attachment point to Spider-Man.
By following the arrows from `O⃗`, along `H⃗`, and along `L⃗`, we can see that
`H⃗ + L⃗ = P⃗`
So we can compute `L⃗` like this:
`L⃗ = P⃗ - H⃗`
The goals of this case study are:
1. Implement a model of this scenario to predict Spider-Man's trajectory.
2. Choose the right time for Spider-Man to let go of the webbing in order to maximize the distance he travels before landing.
3. Choose the best angle for Spider-Man to jump off the building, and let go of the webbing, to maximize range.
I'll create a `Params` object to contain the quantities we'll need:
1. According to [the Spider-Man Wiki](http://spiderman.wikia.com/wiki/Peter_Parker_%28Earth-616%29), Spider-Man weighs 76 kg.
2. Let's assume his terminal velocity is 60 m/s.
3. The length of the web is 100 m.
4. The initial angle of the web is 45 degrees to the left of straight down.
5. The spring constant of the web is 40 N / m when the cord is stretched, and 0 when it's compressed.
Here's a `Params` object with the parameters of the system.
```
params = Params(height = 381, # m,
g = 9.8, # m/s**2,
mass = 75, # kg,
area = 1, # m**2,
rho = 1.2, # kg/m**3,
v_term = 60, # m / s,
length = 100, # m,
angle = (270 - 45), # degree,
k = 40, # N / m,
t_0 = 0, # s,
t_end = 30, # s
)
```
Compute the initial position
```
def initial_condition(params):
"""Compute the initial position and velocity.
params: Params object
"""
H⃗ = Vector(0, params.height)
theta = np.deg2rad(params.angle)
x, y = pol2cart(theta, params.length)
L⃗ = Vector(x, y)
P⃗ = H⃗ + L⃗
return State(x=P⃗.x, y=P⃗.y, vx=0, vy=0)
initial_condition(params)
```
Now here's a version of `make_system` that takes a `Params` object as a parameter.
`make_system` uses the given value of `v_term` to compute the drag coefficient `C_d`.
```
def make_system(params):
"""Makes a System object for the given conditions.
params: Params object
returns: System object
"""
init = initial_condition(params)
mass, g = params.mass, params.g
rho, area, v_term = params.rho, params.area, params.v_term
C_d = 2 * mass * g / (rho * area * v_term**2)
return System(params, init=init, C_d=C_d)
```
Let's make a `System`
```
system = make_system(params)
system.init
```
### Drag and spring forces
Here's drag force, as we saw in Chapter 22.
```
def drag_force(V⃗, system):
"""Compute drag force.
V⃗: velocity Vector
system: `System` object
returns: force Vector
"""
rho, C_d, area = system.rho, system.C_d, system.area
mag = rho * vector_mag(V⃗)**2 * C_d * area / 2
direction = -vector_hat(V⃗)
f_drag = direction * mag
return f_drag
V⃗_test = Vector(10, 10)
drag_force(V⃗_test, system)
```
And here's the 2-D version of spring force. We saw the 1-D version in Chapter 21.
```
def spring_force(L⃗, system):
"""Compute drag force.
L⃗: Vector representing the webbing
system: System object
returns: force Vector
"""
extension = vector_mag(L⃗) - system.length
if extension < 0:
mag = 0
else:
mag = system.k * extension
direction = -vector_hat(L⃗)
f_spring = direction * mag
return f_spring
L⃗_test = Vector(0, -system.length-1)
f_spring = spring_force(L⃗_test, system)
f_spring
```
Here's the slope function, including acceleration due to gravity, drag, and the spring force of the webbing.
```
def slope_func(t, state, system):
"""Computes derivatives of the state variables.
state: State (x, y, x velocity, y velocity)
t: time
system: System object with g, rho, C_d, area, mass
returns: sequence (vx, vy, ax, ay)
"""
x, y, vx, vy = state
P⃗ = Vector(x, y)
V⃗ = Vector(vx, vy)
g, mass = system.g, system.mass
H⃗ = Vector(0, system.height)
L⃗ = P⃗ - H⃗
a_grav = Vector(0, -g)
a_spring = spring_force(L⃗, system) / mass
a_drag = drag_force(V⃗, system) / mass
A⃗ = a_grav + a_drag + a_spring
return V⃗.x, V⃗.y, A⃗.x, A⃗.y
```
As always, let's test the slope function with the initial conditions.
```
slope_func(0, system.init, system)
```
And then run the simulation.
```
results, details = run_solve_ivp(system, slope_func)
details.message
```
### Visualizing the results
We can extract the x and y components as `Series` objects.
The simplest way to visualize the results is to plot x and y as functions of time.
```
def plot_position(results):
results.x.plot(label='x')
results.y.plot(label='y')
decorate(xlabel='Time (s)',
ylabel='Position (m)')
plot_position(results)
```
We can plot the velocities the same way.
```
def plot_velocity(results):
results.vx.plot(label='vx')
results.vy.plot(label='vy')
decorate(xlabel='Time (s)',
ylabel='Velocity (m/s)')
plot_velocity(results)
```
Another way to visualize the results is to plot y versus x. The result is the trajectory through the plane of motion.
```
def plot_trajectory(results, label):
x = results.x
y = results.y
make_series(x, y).plot(label=label)
decorate(xlabel='x position (m)',
ylabel='y position (m)')
plot_trajectory(results, label='trajectory')
```
## Letting go
Now let's find the optimal time for Spider-Man to let go. We have to run the simulation in two phases because the spring force changes abruptly when Spider-Man lets go, so we can't integrate through it.
Here are the parameters for Phase 1, running for 9 seconds.
```
params1 = params.set(t_end=9)
system1 = make_system(params1)
results1, details1 = run_solve_ivp(system1, slope_func)
plot_trajectory(results1, label='phase 1')
```
The final conditions from Phase 1 are the initial conditions for Phase 2.
```
t_0 = results1.index[-1]
t_0
init = results1.iloc[-1]
init
t_end = t_0 + 10
```
Here is the `System` for Phase 2. We can turn off the spring force by setting `k=0`, so we don't have to write a new slope function.
```
system2 = system1.set(init=init, t_0=t_0, t_end=t_end, k=0)
```
Here's an event function that stops the simulation when Spider-Man reaches the ground.
```
def event_func(t, state, system):
"""Stops when y=0.
state: State object
t: time
system: System object
returns: height
"""
x, y, vx, vy = state
return y
```
Run Phase 2.
```
results2, details2 = run_solve_ivp(system2, slope_func,
events=event_func)
details2.message
```
Plot the results.
```
plot_trajectory(results1, label='phase 1')
plot_trajectory(results2, label='phase 2')
```
Now we can gather all that into a function that takes `t_release` and `V_0`, runs both phases, and returns the results.
```
def run_two_phase(t_release, params):
"""Run both phases.
t_release: time when Spider-Man lets go of the webbing
"""
params1 = params.set(t_end=t_release)
system1 = make_system(params1)
results1, details1 = run_solve_ivp(system1, slope_func)
t_0 = results1.index[-1]
t_end = t_0 + 10
init = results1.iloc[-1]
system2 = system1.set(init=init, t_0=t_0, t_end=t_end, k=0)
results2, details2 = run_solve_ivp(system2, slope_func,
events=event_func)
return results1.append(results2)
```
And here's a test run.
```
t_release = 9
results = run_two_phase(t_release, params)
plot_trajectory(results, 'trajectory')
x_final = results.iloc[-1].x
x_final
```
### Animation
Here's a draw function we can use to animate the results.
```
from matplotlib.pyplot import plot
xlim = results.x.min(), results.x.max()
ylim = results.y.min(), results.y.max()
def draw_func(t, state):
plot(state.x, state.y, 'bo')
decorate(xlabel='x position (m)',
ylabel='y position (m)',
xlim=xlim,
ylim=ylim)
# animate(results, draw_func)
```
## Maximizing range
To find the best value of `t_release`, we need a function that takes possible values, runs the simulation, and returns the range.
```
def range_func(t_release, params):
"""Compute the final value of x.
t_release: time to release web
params: Params object
"""
results = run_two_phase(t_release, params)
x_final = results.iloc[-1].x
print(t_release, x_final)
return x_final
```
We can test it.
```
range_func(9, params)
```
And run it for a few values.
```
for t_release in linrange(3, 15, 3):
range_func(t_release, params)
```
Now we can use `maximize_scalar` to find the optimum.
```
bounds = [6, 12]
res = maximize_scalar(range_func, params, bounds=bounds)
```
Finally, we can run the simulation with the optimal value.
```
best_time = res.x
results = run_two_phase(best_time, params)
plot_trajectory(results, label='trajectory')
x_final = results.iloc[-1].x
x_final
```
| github_jupyter |
# Imports
```
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
```
# Terminology
matrix: A, B, C
vector: v, z, w
scalar: α, β, λ
# Vectors
## Plot 2D & 3D vector
```
v_2D = [3, -2]
plt.plot([0, v_2D[0]], [0, v_2D[1]])
plt.axis('equal')
plt.plot([-4, 4], [0, 0], 'k--')
plt.plot([0, 0], [-4, 4], 'k--')
plt.grid()
plt.axis((-4, 4, -4, 4))
plt.show()
v_3D = [4, -3, 2]
fig = plt.figure(figsize=plt.figaspect(1))
ax = fig.gca(projection='3d')
ax.plot([0, v_3D[0]], [0, v_3D[1]], [0, v_3D[2]], linewidth=3)
ax.plot([0, 0], [0, 0], [-4, 4], 'k--')
ax.plot([0, 0], [-4, 4], [0, 0], 'k--')
ax.plot([-4, 4], [0, 0], [0, 0], 'k--')
plt.show()
```
# Addition / Substraction
```
v1 = np.array([3, -1])
v2 = np.array([2, 4])
v3 = v1 + v2
plt.plot([0, v1[0]], [0, v1[1]], 'b', label='v1')
plt.plot([0, v2[0]] + v1[0], [0, v2[1]] + v1[1], 'r', label='v2')
plt.plot([0, v3[0]], [0, v3[1]], 'k', label='v1+v2')
plt.legend()
plt.axis('square')
plt.axis((-6, 6, -6, 6))
plt.grid()
plt.show()
```
# Vector-scalar multiplication
w = λv
```
v1 = np.array([3, -1])
l = 1.5 # l is lambda λ
v1m = v1 * l # m is for modulated (scalar-modulated)
axlim = 1.5 * max([
abs(max(v1)),
abs(max(v1m))
])
plt.plot([0, v1[0]], [0, v1[1]], 'b', label='v_1')
plt.plot([0, v1m[0]], [0, v1m[1]], 'r:', label='\lambda v_1')
plt.axis('square')
plt.axis((-axlim, axlim, -axlim, axlim))
plt.grid()
plt.show()
```
# Vector-vector multiplication
Also called the "scalar product"
The result of the dot product is a scalar = λ
λ = a*b = <a, b> = aTb = (n Σ i=1) * (ai * bi)
aTb means first vector transpose times the second vector
<img src="https://www.gstatic.com/education/formulas2/355397047/en/dot_product.svg" />
if the vectors are not of the same size, then the dot product is "not defined"
```
v1 = np.array([1, 2, 3, 4, 5, 6])
v2 = np.array([-1, 3, 0.5, 0, 2, -2])
dp1 = sum(np.multiply(v1, v2))
dp2 = np.dot(v1, v2)
dp3 = np.matmul(v1, v2)
dp1, dp2, dp3
```
# Dot Product properties
```
n = 10
a = np.random.randn(n)
b = np.random.randn(n)
c = np.random.randn(n)
# distributive
asso1 = np.dot(a, (b + c))
asso2 = np.dot(a, b) + np.dot(a, c)
[asso1, asso2]
```
Special cases for assiciative to work:
1. One vector is the zeros vector
2. a == b == c
3. ...
```
n = 3
a = np.random.randn(n)
b = np.random.randn(n)
c = np.random.randn(n)
# not associative
asso1 = np.dot(a, np.dot(b, c))
asso2 = np.dot(np.dot(a, b), c)
[asso1, asso2]
```
Dot products with matrix columns
```
A = np.array([[0.71233043, -2.13180073], [-1.36657859, 0.7194631]])
B = np.array([[0.47879716, 0.082513], [0.30793807, 1.1744372]])
dps = np.zeros(2)
for i in range(2):
dps[i] = np.dot(A[:, i], B[:, i])
dps, [
(A[0][0] * B[0][0]) + (A[1][0] * B[1][0]),
(A[0][1] * B[0][1]) + (A[1][1] * B[1][1])
]
```
Is dot product commutative? YES
```
a = np.random.randn(100)
b = np.random.randn(100)
dp_ab = np.dot(a, b)
dp_ba = np.dot(b, a)
dp_ab, dp_ba, dp_ab-dp_ba
a = [2, 4]
b = [3, 5]
np.dot(a, b), np.dot(b, a)
```
## Magnitude of a vector / Length of a vector
||v|| = sqr v'*v
Via Pythagoras / geometry
||v||^2 = (v1)^2 + (v2)^2
```
v = np.array([1, 2, 3, 4, 5, 6])
# regular dot product
vl_1 = np.sqrt(sum(np.multiply(v, v)))
# take the norm
vl_2 = np.linalg.norm(v)
vl_1, vl_2
```
| github_jupyter |
```
import os
import sys
def add_sys_path(p):
p = os.path.abspath(p)
if p not in sys.path:
sys.path.append(p)
add_sys_path('..')
from importlib import reload
import word_mover_grammar as wmg
import word_mover_grammar as wmg
reload(wmg)
reload(wmg.extended_grammar);
reload(wmg.earley);
flies = """
S : NP VP
NP: N | A NP
VP: V | VP NP | VP PP
PP: P NP
N: fruit | flies | bananas
A: fruit
V: like | flies
P: like
"""
productions = [
['^', ('S',)],
['S', ('NP', 'VP',)],
['NP', ('N',)],
['NP', ('A', 'NP',)],
['VP', ('V',)],
['VP', ('VP', 'NP',)],
['VP', ('VP', 'PP',)],
['PP', ('P', 'NP',)],
['N', ('fruit',)],
['N', ('flies',)],
['N', ('bananas',)],
['A', ('fruit',)],
['V', ('like',)],
['V', ('flies',)],
['P', ('like',)],
]
parser = wmg.earley.EarleyParser(productions)
symbols = wmg.extended_grammar.rules2symbols(productions)
words = 'fruit flies like bananas'.split()
result = parser.parse(words)
print(result.success)
result.final_state in result.forest
result.print()
tree = result.sample_a_tree()
wmg.earley.print_tree(tree, result.final_state)
wmg.earley.print_tree_vertically(tree, result.final_state)
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
words = 'косой косил косой косой'.split()
productions = [
['^', ('S',)],
['S', ('NP', 'VP',)],
['NP', ('N',)],
['NP', ('A', 'NP',)],
['VP', ('V',)],
['VP', ('VP', 'NP',)],
['N', ('заяц',)],
['N', ('косой',)],
['A', ('кривой',)],
['A', ('косой',)],
['V', ('косил',)],
]
parser = wmg.earley.EarleyParser(productions)
result = parser.parse(words)
print(result.success)
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
```
# Создание грамматики из текста
```
import yaml
# начнём с классического Yaml. Это почти гранет, только с дефисами.
grammar_text = """
^:
- S
S:
- NP, VP
VP:
- V
- VP NP
- VP PP
NP:
- N
- A NP
PP:
- P NP
N:
- fruit
- flies
- bananas
A:
- fruit
V:
- like
- flies
P:
- like
"""
grammar_dict = yaml.safe_load(grammar_text)
rules = []
for k, vs in grammar_dict.items():
for v in vs:
rules.append((k, tuple(v.split())))
rules
wmg.extended_grammar.rules2symbols(rules)
symbols['^'].deep_sample()
```
# w2v
```
# начнём с классического Yaml. Это почти гранет, только с дефисами.
grammar_text = """
^:
- S
S:
- TURN COLOR_OF_DEVICE COLOR
COLOR:
- синий
- зеленый
TURN:
- включи
- сделай
- поставь
COLOR_OF_DEVICE:
- COLOR_N
- COLOR_N DEVICE
COLOR_N:
- цвет
- свет
DEVICE:
- лампочки
"""
grammar_dict = yaml.safe_load(grammar_text)
rules = []
for k, vs in grammar_dict.items():
for v in vs:
rules.append((k, tuple(v.split())))
rules
grammar = wmg.extended_grammar.rules2symbols(rules, w2v=w2v)
parser = wmg.earley.EarleyParser(grammar)
result = parser.parse('сделай цвет лампочки оранжевым'.split())
print(result.success)
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
```
# Парсер гранета
```
import compress_fasttext
small_model = compress_fasttext.models.CompressedFastTextKeyedVectors.load(
'https://github.com/avidale/compress-fasttext/releases/download/v0.0.1/ft_freqprune_100K_20K_pq_100.bin'
)
small_model.init_sims()
def w2v(text):
return small_model.word_vec(text, use_norm=True)
from pymorphy2 import MorphAnalyzer
analyzer = MorphAnalyzer()
def lemmer(text):
return [p.normal_form for p in analyzer.parse(text)]
text = """
root:
включи $What $Where
$What:
%w2v
свет | кондиционер
%regex
.+[аеиюя]т[ое]р
$Where:
в $Room
на $Room
$Room:
%lemma
ванна | кухня | спальня
"""
reload(wmg)
reload(wmg.grammar);
reload(wmg.earley);
reload(wmg.text_to_grammar);
grammar = wmg.text_to_grammar.load_granet(text)
parser = wmg.earley.EarleyParser(grammar, w2v=w2v, lemmer=lemmer)
tokens = 'включи компьютер в спальне'.split()
result = parser.parse(tokens)
print(result.success)
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state, w=16)
print('=======')
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state, w=16)
print('=======')
small_model.most_similar('кондиционер')
```
### Неоднозначные фразы
```
reload(wmg)
reload(wmg.grammar);
reload(wmg.earley);
reload(wmg.text_to_grammar);
flies = """
S : NP VP
NP: N | A NP
VP: V | VP NP | VP PP
PP: P NP
N: fruit | flies | bananas
A: fruit
V -> like | flies | are
V:
%regex
.+ed
P: like
"""
g = wmg.text_to_grammar.load_granet(flies)
parser = wmg.earley.EarleyParser(g)
result = parser.parse('bananas are fruit'.split())
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
result = parser.parse('fruit flies like bananas'.split())
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
result = parser.parse('fruit jumped like bananas'.split())
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
''.split('#', 1)
'ab -> cd'.split('->')
'->' in 'abc'
print("'kek'".strip("8"))
reload(wmg)
reload(wmg.grammar);
reload(wmg.earley);
reload(wmg.text_to_grammar);
pajamas = wmg.text_to_grammar.load_granet(
"""
S -> NP VP
PP -> P NP
NP -> Det N | Det N PP | 'I'
VP -> V NP | VP PP
Det -> 'an' | 'my'
N -> 'elephant' | 'pajamas'
V -> 'shot'
P -> 'in'
"""
)
parser = wmg.earley.EarleyParser(pajamas)
result = parser.parse(['I', 'shot', 'an', 'elephant', 'in', 'my', 'pajamas'])
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
pajamas = wmg.text_to_grammar.load_granet(
"""
S -> я тебя .
"""
)
parser = wmg.earley.EarleyParser(pajamas)
result = parser.parse('я тебя зарежу'.split())
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
pajamas = wmg.text_to_grammar.load_granet(
"""
S:
- привет
- пока
"""
)
parser = wmg.earley.EarleyParser(pajamas)
result = parser.parse('привет'.split())
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state)
print('=======')
pajamas
```
# Slots
```
from pymorphy2 import MorphAnalyzer
analyzer = MorphAnalyzer()
def lemmer(text):
return [p.normal_form for p in analyzer.parse(text)]
reload(wmg)
reload(wmg.grammar);
reload(wmg.earley);
reload(wmg.text_to_grammar);
text = """
root:
включи $What $Where
slots:
what:
source: $What
where:
source: $Where
$What:
свет | кондиционер
%regex
.+[аеиюя]т[ое]р
$Where:
в $Room
на $Room
$Room:
%lemma
ванна | кухня | спальня
"""
g = wmg.text_to_grammar.load_granet(text)
slotmap = {'where': '$Where', 'what': '$What'}
inverse_slotmap = {v: k for k, v in slotmap.items()}
parser = wmg.earley.EarleyParser(g, lemmer=lemmer)
tokens = 'включи компьютер в спальне'.split()
result = parser.parse(tokens)
print(result.success)
for tree in result.iter_trees():
wmg.earley.print_tree(tree, result.final_state, w=16)
print('=======')
print(result.slots)
result.slots['what'].value
type(result.final_state)
t = wmg.earley.ParseTree(head=result.final_state, children_dict=tree)
class Slot:
def __init__(self, type, value, text, tokens):
self.type = type
self.value = value
self.text = text
self.tokens = tokens
def __repr__(self):
return str(self.__dict__)
slots = {}
def fill_slots(tree, node, slots, slotmap, tokens):
lhs = node.lhs
if lhs not in slots and lhs in slotmap:
text = ' '.join(tokens[node.left: node.right])
slot = Slot(
tokens={
'start': node.left,
'end': node.right,
},
value=text,
text=text,
type='string',
)
slots[slotmap[lhs]] = slot
for child in tree.get(node, []):
fill_slots(tree, child, slots, slotmap, tokens)
fill_slots(tree, result.final_state, slots, slotmap=inverse_slotmap, tokens=tokens)
slots
import word_mover_grammar as wmg
cfg = """
root:
turn the $What $Where on
turn on the $What $Where
$What: light | conditioner
$Where: in the $Room
$Room: bathroom | kitchen | bedroom | living room
slots:
what:
source: $What
room:
source: $Room
"""
grammar = wmg.text_to_grammar.load_granet(cfg)
parser = wmg.earley.EarleyParser(grammar)
result = parser.parse('turn on the light in the living room'.split())
print(result.slots)
result.slots
```
| github_jupyter |
```
# !wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
# !unzip uncased_L-12_H-768_A-12.zip
# !wget https://raw.githubusercontent.com/huseinzol05/NLP-Models-Tensorflow/master/abstractive-summarization/dataset/ctexts.json
# !wget https://raw.githubusercontent.com/huseinzol05/NLP-Models-Tensorflow/master/abstractive-summarization/dataset/headlines.json
import bert
from bert import run_classifier
from bert import optimization
from bert import tokenization
from bert import modeling
import numpy as np
import tensorflow as tf
from tensor2tensor.utils import beam_search
import json
from unidecode import unidecode
import re
with open('ctexts.json','r') as fopen:
ctexts = json.load(fopen)
with open('headlines.json','r') as fopen:
headlines = json.load(fopen)
BERT_VOCAB = 'uncased_L-12_H-768_A-12/vocab.txt'
BERT_INIT_CHKPNT = 'uncased_L-12_H-768_A-12/bert_model.ckpt'
BERT_CONFIG = 'uncased_L-12_H-768_A-12/bert_config.json'
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
def topic_modelling(string, n = 200):
vectorizer = TfidfVectorizer()
tf = vectorizer.fit_transform([string])
tf_features = vectorizer.get_feature_names()
compose = TruncatedSVD(1).fit(tf)
return ' '.join([tf_features[i] for i in compose.components_[0].argsort()[: -n - 1 : -1]])
import warnings
warnings.simplefilter("ignore", category=PendingDeprecationWarning)
warnings.simplefilter("ignore", category=RuntimeWarning)
%%time
h, c = [], []
for i in range(len(ctexts)):
try:
c.append(topic_modelling(ctexts[i]))
h.append(headlines[i])
except:
pass
import collections
import itertools
def build_dataset(words, n_words, atleast=1):
count = [['PAD', 0], ['GO', 1], ['EOS', 2], ['UNK', 3]]
counter = collections.Counter(words).most_common(n_words)
counter = [i for i in counter if i[1] >= atleast]
count.extend(counter)
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
index = dictionary.get(word, 0)
if index == 0:
unk_count += 1
data.append(index)
count[0][1] = unk_count
reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reversed_dictionary
concat = ' '.join(h).split()
vocabulary_size = len(list(set(concat)))
data, count, dictionary, rev_dictionary = build_dataset(concat, vocabulary_size)
print('vocab from size: %d'%(vocabulary_size))
print('Most common words', count[4:10])
print('Sample data', data[:10], [rev_dictionary[i] for i in data[:10]])
print('filtered vocab size:',len(dictionary))
print("% of vocab used: {}%".format(round(len(dictionary)/vocabulary_size,4)*100))
MAX_SEQ_LENGTH = 200
tokenization.validate_case_matches_checkpoint(True,BERT_INIT_CHKPNT)
tokenizer = tokenization.FullTokenizer(
vocab_file=BERT_VOCAB, do_lower_case=True)
from tqdm import tqdm
input_ids, input_masks, segment_ids = [], [], []
for text in tqdm(c):
tokens_a = tokenizer.tokenize(text)
if len(tokens_a) > MAX_SEQ_LENGTH - 2:
tokens_a = tokens_a[:(MAX_SEQ_LENGTH - 2)]
tokens = ["[CLS]"] + tokens_a + ["[SEP]"]
segment_id = [0] * len(tokens)
input_id = tokenizer.convert_tokens_to_ids(tokens)
input_mask = [1] * len(input_id)
padding = [0] * (MAX_SEQ_LENGTH - len(input_id))
input_id += padding
input_mask += padding
segment_id += padding
input_ids.append(input_id)
input_masks.append(input_mask)
segment_ids.append(segment_id)
bert_config = modeling.BertConfig.from_json_file(BERT_CONFIG)
GO = dictionary['GO']
PAD = dictionary['PAD']
EOS = dictionary['EOS']
UNK = dictionary['UNK']
for i in range(len(h)):
h[i] = h[i] + ' EOS'
h[0]
bert_config = modeling.BertConfig.from_json_file(BERT_CONFIG)
epoch = 20
batch_size = 5
warmup_proportion = 0.1
num_train_steps = int(len(input_ids) / batch_size * epoch)
num_warmup_steps = int(num_train_steps * warmup_proportion)
def embed_seq(x, vocab_sz, embed_dim, name, zero_pad=True):
embedding = tf.get_variable(name, [vocab_sz, embed_dim])
if zero_pad:
embedding = tf.concat([tf.zeros([1, embed_dim]), embedding[1:, :]], 0)
x = tf.nn.embedding_lookup(embedding, x)
return x
def position_encoding(inputs):
T = tf.shape(inputs)[1]
repr_dim = inputs.get_shape()[-1].value
pos = tf.reshape(tf.range(0.0, tf.to_float(T), dtype=tf.float32), [-1, 1])
i = np.arange(0, repr_dim, 2, np.float32)
denom = np.reshape(np.power(10000.0, i / repr_dim), [1, -1])
enc = tf.expand_dims(tf.concat([tf.sin(pos / denom), tf.cos(pos / denom)], 1), 0)
return tf.tile(enc, [tf.shape(inputs)[0], 1, 1])
def layer_norm(inputs, epsilon=1e-8):
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)
normalized = (inputs - mean) / (tf.sqrt(variance + epsilon))
params_shape = inputs.get_shape()[-1:]
gamma = tf.get_variable('gamma', params_shape, tf.float32, tf.ones_initializer())
beta = tf.get_variable('beta', params_shape, tf.float32, tf.zeros_initializer())
return gamma * normalized + beta
def cnn_block(x, dilation_rate, pad_sz, hidden_dim, kernel_size):
x = layer_norm(x)
pad = tf.zeros([tf.shape(x)[0], pad_sz, hidden_dim])
x = tf.layers.conv1d(inputs = tf.concat([pad, x, pad], 1),
filters = hidden_dim,
kernel_size = kernel_size,
dilation_rate = dilation_rate)
x = x[:, :-pad_sz, :]
x = tf.nn.relu(x)
return x
class Translator:
def __init__(self, size_layer, num_layers, embedded_size,
to_dict_size, learning_rate, kernel_size = 2, n_attn_heads = 16):
self.X = tf.placeholder(tf.int32, [None, None])
self.Y = tf.placeholder(tf.int32, [None, None])
self.X_seq_len = tf.count_nonzero(self.X, 1, dtype=tf.int32)
self.Y_seq_len = tf.count_nonzero(self.Y, 1, dtype=tf.int32)
batch_size = tf.shape(self.X)[0]
self.batch_size = batch_size
main = tf.strided_slice(self.Y, [0, 0], [batch_size, -1], [1, 1])
decoder_input = tf.concat([tf.fill([batch_size, 1], GO), main], 1)
self.embedding = tf.Variable(tf.random_uniform([to_dict_size, embedded_size], -1, 1))
self.num_layers = num_layers
self.kernel_size = kernel_size
self.size_layer = size_layer
self.n_attn_heads = n_attn_heads
self.dict_size = to_dict_size
self.training_logits = self.forward(self.X, decoder_input)
masks = tf.sequence_mask(self.Y_seq_len, tf.reduce_max(self.Y_seq_len), dtype=tf.float32)
self.cost = tf.contrib.seq2seq.sequence_loss(logits = self.training_logits,
targets = self.Y,
weights = masks)
self.optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost)
y_t = tf.argmax(self.training_logits,axis=2)
y_t = tf.cast(y_t, tf.int32)
self.prediction = tf.boolean_mask(y_t, masks)
mask_label = tf.boolean_mask(self.Y, masks)
correct_pred = tf.equal(self.prediction, mask_label)
correct_index = tf.cast(correct_pred, tf.float32)
self.accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
def forward(self, x, y, reuse = False):
with tf.variable_scope('forward',reuse=reuse):
with tf.variable_scope('forward',reuse=reuse):
model = modeling.BertModel(
config=bert_config,
is_training=True,
input_ids=x,
use_one_hot_embeddings=False)
encoder_embedded = model.get_sequence_output()
decoder_embedded = tf.nn.embedding_lookup(self.embedding, y)
g = tf.identity(decoder_embedded)
for i in range(self.num_layers):
dilation_rate = 2 ** i
pad_sz = (self.kernel_size - 1) * dilation_rate
with tf.variable_scope('decode_%d'%i,reuse=reuse):
attn_res = h = cnn_block(decoder_embedded, dilation_rate,
pad_sz, self.size_layer, self.kernel_size)
C = []
for j in range(self.n_attn_heads):
h_ = tf.layers.dense(h, self.size_layer//self.n_attn_heads)
g_ = tf.layers.dense(g, self.size_layer//self.n_attn_heads)
zu_ = tf.layers.dense(encoder_embedded, self.size_layer//self.n_attn_heads)
ze_ = tf.layers.dense(encoder_embedded, self.size_layer//self.n_attn_heads)
d = tf.layers.dense(h_, self.size_layer//self.n_attn_heads) + g_
dz = tf.matmul(d, tf.transpose(zu_, [0, 2, 1]))
a = tf.nn.softmax(dz)
c_ = tf.matmul(a, ze_)
C.append(c_)
c = tf.concat(C, 2)
h = tf.layers.dense(attn_res + c, self.size_layer)
decoder_embedded += h
return tf.layers.dense(decoder_embedded, self.dict_size)
size_layer = 256
num_layers = 4
embedded_size = 256
learning_rate = 2e-5
def beam_search_decoding(length = 20, beam_width = 5):
initial_ids = tf.fill([model.batch_size], GO)
def symbols_to_logits(ids):
x = tf.contrib.seq2seq.tile_batch(model.X, beam_width)
logits = model.forward(x, ids, reuse = True)
return logits[:, tf.shape(ids)[1]-1, :]
final_ids, final_probs, _ = beam_search.beam_search(
symbols_to_logits,
initial_ids,
beam_width,
length,
len(dictionary),
0.0,
eos_id = EOS)
return final_ids
tf.reset_default_graph()
sess = tf.InteractiveSession()
model = Translator(size_layer, num_layers, embedded_size,
len(dictionary), learning_rate)
model.generate = beam_search_decoding()
sess.run(tf.global_variables_initializer())
def get_assignment_map_from_checkpoint(tvars, init_checkpoint):
"""Compute the union of the current variables and checkpoint variables."""
assignment_map = {}
initialized_variable_names = {}
name_to_variable = collections.OrderedDict()
for var in tvars:
name = var.name
m = re.match('^(.*):\\d+$', name)
if m is not None:
name = m.group(1)
name_to_variable[name] = var
init_vars = tf.train.list_variables(init_checkpoint)
assignment_map = collections.OrderedDict()
for x in init_vars:
(name, var) = (x[0], x[1])
if 'bert' not in name:
continue
assignment_map[name] = name_to_variable['forward/forward/'+name]
initialized_variable_names[name] = 1
initialized_variable_names[name + ':0'] = 1
return (assignment_map, initialized_variable_names)
tvars = tf.trainable_variables()
assignment_map, initialized_variable_names = get_assignment_map_from_checkpoint(tvars,
BERT_INIT_CHKPNT)
saver = tf.train.Saver(var_list = assignment_map)
saver.restore(sess, BERT_INIT_CHKPNT)
def str_idx(corpus, dic):
X = []
for i in corpus:
ints = []
for k in i.split():
ints.append(dic.get(k,UNK))
X.append(ints)
return X
Y = str_idx(h, dictionary)
from sklearn.cross_validation import train_test_split
train_X, test_X, train_Y, test_Y = train_test_split(input_ids, Y, test_size = 0.05)
def pad_sentence_batch(sentence_batch, pad_int):
padded_seqs = []
seq_lens = []
max_sentence_len = max([len(sentence) for sentence in sentence_batch])
for sentence in sentence_batch:
padded_seqs.append(sentence + [pad_int] * (max_sentence_len - len(sentence)))
seq_lens.append(len(sentence))
return padded_seqs, seq_lens
sess.run(model.generate, feed_dict = {model.X: [test_X[0]]})
import time
for EPOCH in range(10):
lasttime = time.time()
train_acc, train_loss, test_acc, test_loss = 0, 0, 0, 0
pbar = tqdm(
range(0, len(train_X), batch_size), desc = 'train minibatch loop'
)
for i in pbar:
index = min(i + batch_size, len(train_X))
batch_x = train_X[i : index]
batch_y, _ = pad_sentence_batch(train_Y[i : index], PAD)
acc, cost, _ = sess.run(
[model.accuracy, model.cost, model.optimizer],
feed_dict = {
model.Y: batch_y,
model.X: batch_x
},
)
assert not np.isnan(cost)
train_loss += cost
train_acc += acc
pbar.set_postfix(cost = cost, accuracy = acc)
pbar = tqdm(range(0, len(test_X), batch_size), desc = 'test minibatch loop')
for i in pbar:
index = min(i + batch_size, len(test_X))
batch_x = test_X[i : index]
batch_y, _ = pad_sentence_batch(test_Y[i : index], PAD)
acc, cost = sess.run(
[model.accuracy, model.cost],
feed_dict = {
model.Y: batch_y,
model.X: batch_x
},
)
test_loss += cost
test_acc += acc
pbar.set_postfix(cost = cost, accuracy = acc)
train_loss /= len(train_X) / batch_size
train_acc /= len(train_X) / batch_size
test_loss /= len(test_X) / batch_size
test_acc /= len(test_X) / batch_size
print('time taken:', time.time() - lasttime)
print(
'epoch: %d, training loss: %f, training acc: %f, valid loss: %f, valid acc: %f\n'
% (EPOCH, train_loss, train_acc, test_loss, test_acc)
)
generated = [rev_dictionary[i] for i in sess.run(model.generate, feed_dict = {model.X: [test_X[0]]})[0,0,:]]
' '.join(generated)
' '.join([rev_dictionary[i] for i in test_Y[0]])
```
| github_jupyter |
# Training and Serving CARET models using AI Platform Custom Containers and Cloud Run
## Overview
This notebook illustrates how to use [CARET](https://topepo.github.io/caret/) R package to build an ML model to estimate the baby's weight given a number of factors, using the [BigQuery natality dataset](https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=samples&t=natality&page=table&_ga=2.99329886.-1705629017.1551465326&_gac=1.109796023.1561476396.CI2rz-z4hOMCFc6RhQods4oEXA). We use [AI Platform Training](https://cloud.google.com/ml-engine/docs/tensorflow/training-overview) with **Custom Containers** to train the TensorFlow model at scale. Rhen use the [Cloud Run](https://cloud.google.com/run/docs/) to serve the trained model as a Web API for online predictions.
R is one of the most widely used programming languages for statistical modeling, which has a large and active community of data scientists and ML professional.
With over 10,000 packages in the open-source repository of CRAN, R caters to all statistical data analysis applications, ML, and visualisation.
## Dataset
The dataset used in this tutorial is natality data, which describes all United States births registered in the 50 States, the District of Columbia, and New York City from 1969 to 2008, with more than 137 million records.
The dataset is available in [BigQuery public dataset](https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=samples&t=natality&page=table&_ga=2.99329886.-1705629017.1551465326&_gac=1.109796023.1561476396.CI2rz-z4hOMCFc6RhQods4oEXA). We use the data extracted from BigQuery and stored as CSV in Cloud Storage (GCS) in the [Exploratory Data Analysis](01_EDA-with-R-and-BigQuery) notebook.
In this notebook, we focus on Exploratory Data Analysis, while the goal is to predict the baby's weight given a number of factors about the pregnancy and the baby's mother.
## Objective
The goal of this tutorial is to:
1. Create a CARET regression model
2. Train the CARET model using on AI Platform Training with custom R container
3. Implement a Web API wrapper to the trained model using Plumber R package
4. Build Docker container image for the prediction Web API
5. Deploy the prediction Web API container image model on Cloud Run
6. Invoke the deployed Web API for predictions.
7. Use the AI Platform Notebooks to drive the workflow.
## Costs
This tutorial uses billable components of Google Cloud Platform (GCP):
1. Create a TensorFlow premade Estimator trainer using R interface
2. Train and export the Estimator on AI Platform Training using the cloudml APIs
3. Deploy the exported model to AI Platform prediction using the cloudml APIs
4. Invoke the deployed model API for predictions.
5. Use the AI Platform Notebooks to drive the workflow.
Learn about GCP pricing, use the [Pricing Calculator](https://cloud.google.com/products/calculator/) to generate a cost estimate based on your projected usage.
## 0. Setup
```
version
```
Install and import the required libraries.
This may take several minutes if not installed already...
```
install.packages(c("caret"))
library(caret) # used to build a regression model
```
Set your `PROJECT_ID`, `BUCKET_NAME`, and `REGION`
```
# Set the project id
PROJECT_ID <- "r-on-gcp"
# Set yout GCS bucket
BUCKET_NAME <- "r-on-gcp"
# Set your training and model deployment region
REGION <- 'europe-west1'
```
## 1. Building a CARET Regression Model
### 1.1. Load data
If you run the [Exploratory Data Analysis](01_EDA-with-R-and-BigQuery) Notebook, you should have the **train_data.csv** and **eval_data.csv** files uploaded to GCS. You can download them to train your model locally using the following cell. However, if you have the files available locally, you can skip the following cell.
```
dir.create(file.path('data'), showWarnings = FALSE)
gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data/*_data.csv")
command <- paste("gsutil cp -r", gcs_data_dir, "data/")
print(command)
system(command, intern = TRUE)
train_file <- "data/train_data.csv"
eval_file <- "data/eval_data.csv"
header <- c(
"weight_pounds",
"is_male", "mother_age", "mother_race", "plurality", "gestation_weeks",
"mother_married", "cigarette_use", "alcohol_use",
"key")
target <- "weight_pounds"
key <- "key"
features <- setdiff(header, c(target, key))
train_data <- read.table(train_file, col.names = header, sep=",")
eval_data <- read.table(eval_file, col.names = header, sep=",")
```
### 1.2. Train the model
In this example, we will train an XGboost Tree model for regression.
```
trainControl <- trainControl(method = 'boot', number = 10)
hyper_parameters <- expand.grid(
nrounds = 100,
max_depth = 6,
eta = 0.3,
gamma = 0,
colsample_bytree = 1,
min_child_weight = 1,
subsample = 1
)
print('Training the model...')
model <- train(
y=train_data$weight_pounds,
x=train_data[, features],
preProc = c("center", "scale"),
method='xgbTree',
trControl=trainControl,
tuneGrid=hyper_parameters
)
print('Model is trained.')
```
### 1.2. Evaluate the model
```
eval(model)
```
### 1.3. Save the trained model
```
model_dir <- "models"
model_name <- "caret_babyweight_estimator"
# Saving the trained model
dir.create(model_dir, showWarnings = FALSE)
dir.create(file.path(model_dir, model_name), showWarnings = FALSE)
saveRDS(model, file.path(model_dir, model_name, "trained_model.rds"))
```
### 1.4. Implementing a model prediction function
This is an implementation of wrapper function to the model to perform prediction. The function expects a list of instances in a JSON format, and returns a list of predictions (estimated weights). This prediction function implementation will be used when serving the model as a Web API for online predictions.
```
xgbtree <- readRDS(file.path(model_dir, model_name, "trained_model.rds"))
estimate_babyweights <- function(instances_json){
library("rjson")
instances <- jsonlite::fromJSON(instances_json)
df_instances <- data.frame(instances)
# fix data types
boolean_columns <- c("is_male", "mother_married", "cigarette_use", "alcohol_use")
for(col in boolean_columns){
df_instances[[col]] <- as.logical(df_instances[[col]])
}
estimates <- predict(xgbtree, df_instances)
return(estimates)
}
instances_json <- '
[
{
"is_male": "TRUE",
"mother_age": 28,
"mother_race": 8,
"plurality": 1,
"gestation_weeks": 28,
"mother_married": "TRUE",
"cigarette_use": "FALSE",
"alcohol_use": "FALSE"
},
{
"is_male": "FALSE",
"mother_age": 38,
"mother_race": 18,
"plurality": 1,
"gestation_weeks": 28,
"mother_married": "TRUE",
"cigarette_use": "TRUE",
"alcohol_use": "TRUE"
}
]
'
estimate <- round(estimate_babyweights(instances_json), digits = 2)
print(paste("Estimated weight(s):", estimate))
```
## 3. Submit a Training Job to AI Platform with Custom Containers
In order to train your CARET model in at scale using AI Platform Training, you need to implement your training logic in an R script file, containerize it in a Docker image, and submit the Docker image to AI Platform Training.
The [src/caret/training](src/caret/training) directory includes the following code files:
1. [model_trainer.R](src/caret/training/model_trainer.R) - This is the implementation of the CARET model training logic.
1. [Dockerfile](src/caret/training/Dockerfile) - This is the definition of the Docker container image to run the **model_trainer.R** script.
To submit the training job with the custom container to AI Platform, you need to do the following steps:
1. set your PROJECT_ID and BUCKET_NAME in training/model_trainer.R, and PROJECT_ID in training/Dockerfile so that the first line reads "FROM gcr.io/[PROJECT_ID]/caret_base"
2. **Build** a Docker container image with that runs the model_trainer.R
3. **Push** the Docker container image to **Container Registry**.
4. **Submit** an **AI Platform Training** job with the **custom container**.
### 3.1. Build and Push the Docker container image.
#### A - Build base image
This can take several minutes ...
```
# Create base image
base_image_url <- paste0("gcr.io/", PROJECT_ID, "/caret_base")
print(base_image_url)
setwd("src/caret")
getwd()
print("Building the base Docker container image...")
command <- paste0("docker build -f Dockerfile --tag ", base_image_url, " ./")
print(command)
system(command, intern = TRUE)
print("Pushing the baseDocker container image...")
command <- paste0("gcloud docker -- push ", base_image_url)
print(command)
system(command, intern = TRUE)
setwd("../..")
getwd()
```
#### B - Build trainer image
```
training_image_url <- paste0("gcr.io/", PROJECT_ID, "/", model_name, "_training")
print(training_image_url)
setwd("src/caret/training")
getwd()
print("Building the Docker container image...")
command <- paste0("docker build -f Dockerfile --tag ", training_image_url, " ./")
print(command)
system(command, intern = TRUE)
print("Pushing the Docker container image...")
command <- paste0("gcloud docker -- push ", training_image_url)
print(command)
system(command, intern = TRUE)
setwd("../../..")
getwd()
```
#### C- Verifying uploaded images to Container Registry
```
command <- paste0("gcloud container images list --repository=gcr.io/", PROJECT_ID)
system(command, intern = TRUE)
```
### 3.2. Submit an AI Plaform Training job with the custom container.
```
job_name <- paste0("train_caret_contrainer_", format(Sys.time(), "%Y%m%d_%H%M%S"))
command = paste0("gcloud beta ai-platform jobs submit training ", job_name,
" --master-image-uri=", training_image_url,
" --scale-tier=BASIC",
" --region=", REGION
)
print(command)
system(command, intern = TRUE)
```
Verify the trained model in GCS after the job finishes
```
model_name <- 'caret_babyweight_estimator'
gcs_model_dir <- paste0("gs://", BUCKET_NAME, "/models/", model_name)
command <- paste0("gsutil ls ", gcs_model_dir)
system(command, intern = TRUE)
```
## 4. Deploy the trained model to Cloud Run
In order to serve the trained CARET model as a Web API, you need to wrap it with a prediction function, as serve this prediction function as a REST API. Then you containerize this Web API and deploy it in Cloud Run.
The [src/caret/serving](src/caret/serving) directory includes the following code files:
1. [model_prediction.R](src/caret/serving/model_prediction.R) - This script downloads the trained model from GCS and loads (only once). It includes **estimate** function, which accepts instances in JSON format, and return the of baby weight estimate for each instance.
2. [model_api.R](src/caret/serving/model_prediction.R) - This is a [plumber](https://www.rplumber.io/) Web API that runs **model_prediction.R**.
3. [Dockerfile](src/caret/serving/Dockerfile) - This is the definition of Docker container image that runs the **model_api.R**
To deploy the prediction Web API to Cloud Run, you need to do the following steps:
1. set your PROJECT_ID and BUCKET_NAME in serving/model_prediction.R, and PROJECT_ID in serving/Dockerfile so that the first line reads "FROM gcr.io/[PROJECT_ID]/caret_base"
2. **Build** the Docker container image for the prediction API.
3. **Push** the Docker container image to **Cloud Registry**.
4. Enable the Cloud Run API if not enabled yet, click "Enable" at https://console.developers.google.com/apis/api/run.googleapis.com/overview .
5. **Deploy** the Docker container to **Cloud Run**.
### (Optional) 4.0. Upload the trained model to GCS
If you train your model using the model_trainer.R in AI Platform, it will upload the saved model to GCS. However, if you only train your model locally and have your saved model locally, you need to upload it to GCS.
```
model_name <- 'caret_babyweight_estimator'
gcs_model_dir = paste0("gs://", BUCKET_NAME, "/models/", model_name, "/")
command <- paste0("gsutil cp -r models/", model_name ,"/* ",gcs_model_dir)
print(command)
system(command, intern = TRUE)
```
### 4.1. Build and Push prediction Docker container image
```
serving_image_url <- paste0("gcr.io/", PROJECT_ID, "/", model_name, "_serving")
print(serving_image_url)
setwd("src/caret/serving")
getwd()
print("Building the Docker container image...")
command <- paste0("docker build -f Dockerfile --tag ", serving_image_url, " ./")
print(command)
system(command, intern = TRUE)
print("Pushing the Docker container image...")
command <- paste0("gcloud docker -- push ", serving_image_url)
print(command)
system(command, intern = TRUE)
setwd("../../..")
getwd()
command <- paste0("gcloud container images list --repository=gcr.io/", PROJECT_ID)
system(command, intern = TRUE)
```
### 4.2. Deploy prediction container to Cloud Run
```
service_name <- "caret-babyweight-estimator"
command <- paste(
"gcloud beta run deploy", service_name,
"--image", serving_image_url,
"--platform managed",
"--allow-unauthenticated",
"--region", REGION
)
print(command)
system(command, intern = TRUE)
```
## 5. Invoke the Model API for Predictions
When the **caret-babyweight-estimator** service is deployed to Cloud Run:
1. Go to Cloud Run in the [Cloud Console](https://console.cloud.google.com/run/).
2. Select the **caret-babyweight-estimator** service.
3. Copy the service URL, and use it to update the **url** variable in the following cell.
```
# Update to the deployed service URL
url <- "https://caret-babyweight-estimator-lbcii4x34q-uc.a.run.app/"
endpoint <- "estimate"
instances_json <- '
[
{
"is_male": "TRUE",
"mother_age": 28,
"mother_race": 8,
"plurality": 1,
"gestation_weeks": 28,
"mother_married": "TRUE",
"cigarette_use": "FALSE",
"alcohol_use": "FALSE"
},
{
"is_male": "FALSE",
"mother_age": 38,
"mother_race": 18,
"plurality": 1,
"gestation_weeks": 28,
"mother_married": "TRUE",
"cigarette_use": "TRUE",
"alcohol_use": "TRUE"
}
]
'
library("httr")
full_url <- paste0(url, endpoint)
response <- POST(full_url, body = instances_json)
estimates <- content(response)
print(paste("Estimated weight(s):", estimate))
```
# License
Authors: Daniel Sparing & Khalid Salama
---
**Disclaimer**: This is not an official Google product. The sample code provided for an educational purpose.
---
Copyright 2019 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| github_jupyter |
# Transfer Learning with CNN - Rodrigo Puerto Pedrera
Este documento corresponde a la entrega práctica final de la asignatura de cuarto curso: Computación bioinspirada. Corresponde a la entrega de dificultad media establecida. Trata sobre la realización de una red neuronal convolucional que se ajuste al dataset *CIFAR 10* (de la web: [skymind.ai/wiki/open-datasets](https://skymind.ai/wiki/open-datasets)) para la clasificación de los datos en al menos 4 categorías. Se pide realizar la práctica mediante la técnica de transferencia de aprendizaje.
>[Transfer Learning with CNN - Rodrigo Puerto Pedrera](#scrollTo=fI_VRq2nbJBv)
>>[Planificación del proyecto](#scrollTo=7ge5_Xb5detx)
>>[Parte teórica](#scrollTo=8gtFcyoxih9m)
>>>[¿Qué es una CNN (Convolutional neural network)?](#scrollTo=S4NQhRMGjIHf)
>>>>[¿Qué es una convolución?](#scrollTo=FV3RNt8FsANg)
>>>>[¿Qué es el pooling?](#scrollTo=q8-hdh6213fe)
>>>[¿Qué es la técnica de transferencia de aprendizaje?](#scrollTo=btIngNC08om6)
>>>>[¿Cuándo y cómo afinar? ¿Cómo decidimos qué modelo utilizar?](#scrollTo=Y2TJf6d0GtBN)
>>>[Pero, ¿qué es el overfitting?](#scrollTo=kr7BM_Yf2Be8)
>>>>[¿Cuándo tenemos riesgo de overfitting?](#scrollTo=dQG8JZXY3UgX)
>>>>[¿Cómo prevenir el sobreajuste de datos?](#scrollTo=VJuPnTKt5DLn)
>>>>[¿Técnicas para solucionar el overfitting?](#scrollTo=_Mf5zjlWvy7R)
>>[Parte práctica](#scrollTo=CwYJC2SX6FVP)
>>>[¿Qué modelo se ha escogido?](#scrollTo=1DN0W2pJ6cDZ)
>>>[Análisis de tareas](#scrollTo=rNKudQoJ1V5t)
>>>>[Descarga y almacenamiento del dataset](#scrollTo=dggtw2G23GnV)
>>>>[Entrenamiento del pre-modelo.](#scrollTo=HzjC7SaPeVHi)
>>>>[Entrenamiento del modelo con los pesos pre-entrenados.](#scrollTo=ReBf5Bm9QLyo)
>>>>[Visualización de los resultados obtenidos.](#scrollTo=GBrdnCKDtWkl)
>>>>[Guardado del modelo](#scrollTo=wGTJeG7abbct)
>>[Conclusiones](#scrollTo=B3cuziDLLdxL)
## Planificación del proyecto
Puesto que este documento es el proyecto final de la asignatura y se consta de un mes para su entrega, es necesario de planificar el transcurso de desarrollo. Para ello se dividirá el documento en: parte teórica y parte práctica. La parte teórica será realizada al inicio de la elaboración y constará de:
* ¿Qué es una CNN (Convolutional neural networks)?
* ¿Qué es una convolución?
* ¿Qué es el pooling?
* ¿Qué es la técnica de transferencia de aprendizaje?
* ¿Cuándo y cómo afinar? ¿Cómo decidimos qué modelo utilizar?
* Pero, ¿qué es el overfitting?
* ¿Cuando tenemos riesgo de overfitting?
* ¿Cómo prevenir el sobreajuste de datos?
* ¿Técnicas para solucionar el overfitting?
En la parte práctica se desarrollará la red, ayudándonos de gráficas para ver el correcto funcionamiento de ella. Los puntos que se introducirán se verán más abajo.
## Parte teórica
Se necesita una guía teórica para poder entender la resolución práctica del proyecto desarrollado más adelante. Por ello, a continuación se detalla los diferentes conceptos que nos van a servir de utilidad para descifrar el código mostrado en la parte teórica.
### ¿Qué es una CNN (Convolutional neural network)?
Una red neuronal convolucional es un tipo de red neuronal artificial donde las neuronas corresponden a campos receptivos de una manera muy similar a las neuronas en la corteza visual primaria de un cerebro biológico. Este tipo de red es una variación de un perceptron multicapa, sin embargo, debido a que su aplicación es realizada en matrices bidimensionales, son muy efectivas para tareas de visión artificial, como en la clasificación y segmentación de imágenes, entre otras aplicaciones.

En la imagen anterior tenemos una representación muy básica de lo que es una CNN. Este tipo de red se compone de:
1. Una capa de entrada (imagen)
2. Varias capas alternas de convolución y reducción (pooling).
3. Una ANN clasificatoria.
Las redes neuronales convolucionales consisten en múltiples capas de filtros convolucionales de una o más dimensiones. Después de cada capa, por lo general se añade una función para realizar un mapeo causal no-lineal.
Como redes de clasificación, al principio se encuentra la fase de extracción de características, compuesta de neuronas convolucionales y de reducción de muestreo. Al final de la red se encuentran neuronas de perceptron sencillas para realizar la clasificación final sobre las características extraídas. La fase de extracción de características se asemeja al proceso estimulante en las células de la corteza visual. Esta fase se compone de capas alternas de neuronas convolucionales y neuronas de reducción de muestreo. Según progresan los datos a lo largo de esta fase, se disminuye su dimensionalidad, siendo las neuronas en capas lejanas mucho menos sensibles a perturbaciones en los datos de entrada, pero al mismo tiempo siendo estas activadas por características cada vez más complejas.
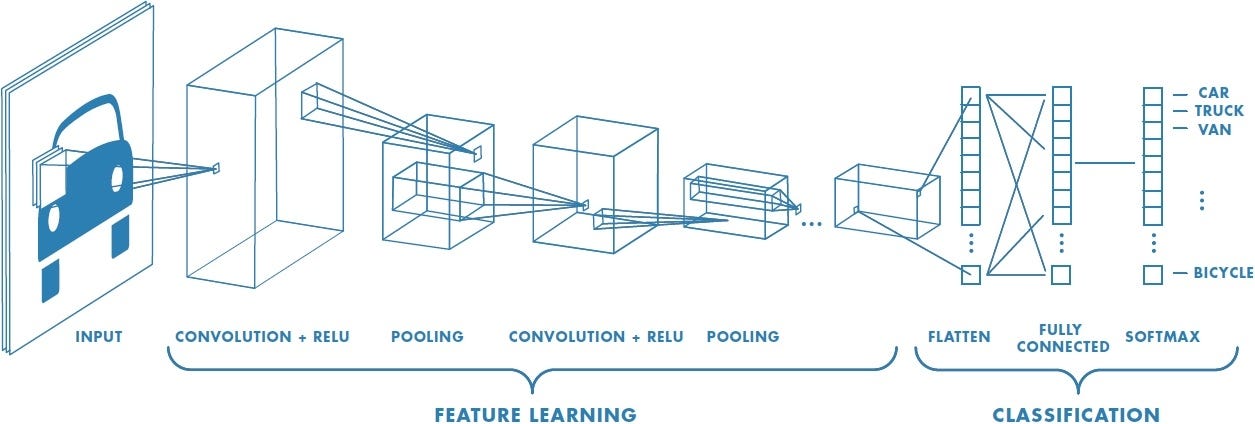
Por lo tanto, tenemos dos conceptos importantes que aprender, qué es una convolución y qué es el pooling.
#### ¿Qué es una convolución?
Una convolución es la suma ponderada de una región de entrada por una matriz de pesos. Una definición más práctica: "Es el producto matricial para cada pixel de la imagen de entrada". ¿Pero para qué nos sirve la convolución? El operador de convolución tiene el efecto de filtrar la imagen de entrada con un núcleo previamente entrenado. Esto transforma los datos de tal manera que ciertas características (determinadas por la forma del núcleo) se vuelven más dominantes en la imagen de salida al tener estas un valor numérico más alto asignados a los pixeles que las representan. Estos núcleos tienen habilidades de procesamiento de imágenes específicas, como por ejemplo la detección de bordes que se puede realizar con núcleos que resaltan la gradiente en una dirección en particular.
**En resumen, aplicamos la convolución para obtener las características más importantes (según el kernel proporcionado) de la entrada que le pasemos.**

#### ¿Qué es el pooling?
La capa de reducción o pooling se coloca generalmente después de la capa convolucional. **Su utilidad principal radica en la reducción de las dimensiones espaciales (ancho x alto) del volumen de entrada para la siguiente capa convolucional**. No afecta a la dimensión de profundidad del volumen. La operación realizada por esta capa también se llama reducción de muestreo, ya que la reducción de tamaño conduce también a la pérdida de información. Sin embargo, una pérdida de este tipo puede ser beneficioso para la red por dos razones:
* Disminución en el tamaño conduce a una menor sobrecarga de cálculo para las próximas capas de la red.
* Reducir el overfitting.
Las redes neuronales cuentan con cierta tolerancia a pequeñas perturbaciones en los datos de entrada. Por ejemplo, si dos imágenes casi idénticas (diferenciadas únicamente por un traslado de algunos pixeles lateralmente) se analizan con una red neuronal, el resultado debería de ser esencialmente el mismo. Esto se obtiene, en parte, dado a la reducción de muestreo que ocurre dentro de una red neuronal convolucional. Al reducir la resolución, las mismas características corresponderán a un mayor campo de activación en la imagen de entrada.
Originalmente, las redes neuronales convolucionales utilizaban un proceso de subsampling para llevar a cabo esta operación. Sin embargo, estudio recientes han demostrado que otras operaciones, como por ejemplo max-pooling, son mucho más eficaces en resumir características sobre una región. Además, existe evidencia que este tipo de operación es similar a como la corteza visual puede resumir información internamente.
La operación de max-pooling encuentra el valor máximo entre una ventana de muestra y pasa este valor como resumen de características sobre esa área. Como resultado, el tamaño de los datos se reduce por un factor igual al tamaño de la ventana de muestra sobre la cual se opera.
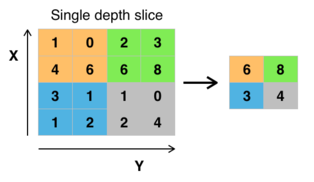
### ¿Qué es la técnica de transferencia de aprendizaje?
En la práctica es muy difícil entrenar un modelo desde cero. Esto se debe a que es difícil encontrar conjuntos de datos lo suficientemente grandes como para lograr una buena precisión en las predicciones debido al sobreajuste que sufren las redes neuronales. Aquí es cuando debemos aplicar una técnica conocida como transferencia de conocimiento: Esta se basa en el uso de modelos previamente entrenados (Oquab et al., 2014).
Las redes neuronales convolucionales requieren grandes conjuntos de datos y una gran cantidad de tiempo
para entrenar. Algunas redes pueden tomar hasta 2-3 semanas a través de múltiples GPU para entrenar.
La transferencia de aprendizaje es una técnica muy útil que trata de abordar ambos problemas.
En lugar de entrenar la red desde cero, la transferencia de aprendizaje utiliza un modelo entrenado en un
conjunto de datos diferente, y lo adapta al problema que estamos tratando de resolver.
Existen dos estrategias para ello:
* *Utilizar el modelo entrenado como un extractor de características fijas*: En esta estrategia, se elimina la
última capa full-connected del modelo entrenado, congelamos los pesos de las capas restantes, y
hacemos, a medida, un clasificador de aprendizaje automático en la salida de las capas convolucionales.
* *Afinar el modelo entrenado*: Partiendo de un modelo entrenado, lo seguimos entrenando con las
imágenes de nuestro problemas para intentar especializarlo en nuestro objetivo.
En las redes neuronales de las primeras capas obtenemos características de bajo nivel como los bordes para luego, en las capas posteriores, capturar las de alto nivel. Al utilizar modelos previamente entrenados, aprovechamos las características de bajo nivel y resolvemos el problema del sobreajuste. Además, reducimos la carga de entrenamiento que tienen un alto costo computacional para los modelos más complejos.
#### ¿Cuándo y cómo afinar? ¿Cómo decidimos qué modelo utilizar?
Esta es una función de varios factores, pero los dos más importantes son:
* El tamaño del nuevo conjunto de datos (pequeño o grande)
* Su similitud con el conjunto de datos original de la red anfitrion.
Teniendo en cuenta que los kernels de la CNN son más genéricos en las capas iniciales y más específicos (del
conjunto de datos original) en las capas finales, tenemos cuatro escenarios:
1. **El nuevo conjunto de datos es pequeño y similar al conjunto de datos original**. Debido a que los datos
son pequeños, no es una buena idea ajustar la CNN debido a problemas de overfitting. Dado que los
datos son similares a los datos originales, esperamos que los kernels de nivel superior en CNN también
sean relevantes para este conjunto de datos. Por lo tanto, la mejor idea podría ser entrenar un
clasificador lineal final adaptado para nuestro caso.
2. **El nuevo conjunto de datos es grande y similar al conjunto de datos original**. Ya que tenemos más datos,
si entrenamos la red completa es probable que no generemos overfitting.
3. **El nuevo conjunto de datos es pequeño y muy diferente del conjunto de datos original**. Como los datos
son pequeños, es probable que sea mejor entrenar solo un clasificador lineal. Como el conjunto de datos
es muy diferente, los kernels de capas superiores no van a ser relevantes por lo que vaciar los pesos de
estos kernels e intentar el entrenamiento es lo más recomendable.
4. **El nuevo conjunto de datos es grande y muy diferente del conjunto de datos original**. Dado que el
conjunto de datos es muy grande, podemos entrenar la red desde cero aunque la capas iniciales pueden
ser provechosas por lo que estos pesos nos pueden venir bien.
### Pero, ¿qué es el overfitting?
El overfitting es el efecto de sobreentrenar un algoritmo de aprendizaje con unos ciertos datos para los que se conoce el resultado deseado. El algoritmo de aprendizaje debe alcanzar un estado en el que será capaz de predecir el resultado en otros casos a partir de lo aprendido con los datos de entrenamiento, generalizando para poder resolver situaciones distintas a las acaecidas durante el entrenamiento. Sin embargo, cuando un sistema se entrena demasiado (se sobreentrena) o se entrena con datos extraños, el algoritmo de aprendizaje puede quedar ajustado a unas características muy específicas de los datos de entrenamiento que no tienen relación causal con la función objetivo. Durante la fase de sobreajuste el éxito al responder las muestras de entrenamiento sigue incrementándose mientras que su actuación con muestras nuevas va empeorando.
El error de entrenamiento se muestra en azul, mientras que el error de validación se muestra en rojo. Si el error de validación se incrementa mientras que el de entrenamiento decrece puede que se esté produciendo una situación de sobreajuste.
#### ¿Cuándo tenemos riesgo de overfitting?
La primera es que debe existir un equilibrio entre la cantidad de datos que tenemos y la complejidad del modelo. En nuestro ejemplo, cuando usamos un modelo con 10 parámetros para describir un problema para el que tenemos 10 datos, el resultado es previsible: vamos a construir un modelo a medida de los datos que tenemos, estamos resolviendo un sistema de ecuaciones con tantas incógnitas como ecuaciones. Dicho de otra manera: si este modelo con 10 parámetros lo hubiésemos ajustado con un total de 100 datos en lugar de 10, seguramente funcionaría mejor que un modelo más básico.

#### ¿Cómo prevenir el sobreajuste de datos?
Para intentar que estos problemas nos afecten lo menos posible, podemos llevar a cabo diversas acciones.
* **Cantidad mínima de muestras tanto para entrenar el modelo como para validarlo**.
* **Clases variadas y equilibradas en cantidad**: En caso de aprendizaje supervisado y suponiendo que tenemos que clasificar diversas clases o categorías, es importante que los datos de entrenamiento estén balanceados. Supongamos que tenemos que diferenciar entre manzanas, peras y bananas, debemos tener muchas fotos de las 3 frutas y en cantidades similares. Si tenemos muy pocas fotos de peras, esto afectará en el aprendizaje de nuestro algoritmo para identificar esa fruta.
* **Conjunto de validación de datos**. Siempre subdividir nuestro conjunto de datos y mantener una porción del mismo “oculto” a nuestra máquina entrenada. Esto nos permitirá obtener una valoración de aciertos/fallos real del modelo y también nos permitirá detectar fácilmente efectos del overfitting /underfitting.
* **Parameter Tunning o Ajuste de Parámetros**: deberemos experimentar sobre todo dando más/menos “tiempo/iteraciones” al entrenamiento y su aprendizaje hasta encontrar el equilibrio.
* **Cantidad excesiva de Dimensiones (features), con muchas variantes distintas, sin suficientes muestras**. A veces conviene eliminar o reducir la cantidad de características que utilizaremos para entrenar el modelo. Una herramienta útil para hacerlo es PCA.
* Podemos caer en overfitting si usamos **capas ocultas en exceso**, ya que haríamos que el modelo memorice las posibles salidas, en vez de ser flexible y adecuar las activaciones a las entradas nuevas.
#### ¿Técnicas para solucionar el overfitting?
Para conseguir un modelo que generalice bien es importante prestar atención a la arquitectura empleada.
La cantidad de capas, la elección de capas, el ajuste de los hiperparámetros y el uso de
técnicas de prevención de overfitting es esencial.
Este proceso recibe el nombre de regularización y existen múltiples técnicas para llevarlo a cabo.
Algunas de las más exitosas son:
* Data augmentation
* Regularización de pesos: L1, L2 y elastic net regularization
* Máximum norm constraints
* Dropout
* Early stopping
## Parte práctica
Una vez visto todos los conceptos necesarios para poder entender lo descrito a continuación, procedemos a explicar paso a paso el desarrollo del proyecto práctico.
### ¿Qué modelo se ha escogido?
Keras cuenta con varios modelos pre-entrenados que podemos usar en transfer
learning:
* Xception
* VGG16
* VGG19
* ResNet50
* InceptionV3
* InceptionResNetV2
* MobileNet
* DenseNet
* NASNet
Para escoger qué modelo utilizar debemos ver las características existentes en el dataset proporcionado; se ha escogido el dataset proporcionado en la página [skymind.ai/wiki/open-datasets](https://skymind.ai/wiki/open-datasets); se ha elegido el dataset *CIFAR 10*.

FInalmente, el modelo escogido será ResNet50. La explicación más sencilla posible de su elección son los buenos resultados obtenidos en las primeras pruebas. Una explicación más formada es lo definido anteriormente en la parte teórica: en nuestro caso el conjunto de datos (CIFAR 10) es grande y algo similar a los datos del pre-modelo, coincidiendo algunas clases y teniendo otras similares. Aunque no es el mejor pre-modelo que podemos escoger para este dataset, se intentarán obtener los mejores resultados posibles.
### Análisis de tareas
Para tener una mayor organización en torno a la información del proyecto, definiremos diferentes puntos para encontrar más facilmente en qué posición nos encontramos.
1. Descarga y almacenamiento del dataset.
2. Entrenamiento del pre-modelo.
3. Entrenamiento del modelo con los pesos pre-entrenados.
4. Visualización de los resultados obtenidos.
5. Guardado del modelo
#### Descarga y almacenamiento del dataset
Keras nos ofrece la posibilidad de importar el dataset CIFAR10 de una manera más sencilla. Aunque también existe la posibilidad de descargar los datos mediante la invocación *wget* a la URL de [skymind.ai/wiki/open-datasets](https://skymind.ai/wiki/open-datasets); aunque de este modo (wget) será algo más complejo.
```
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
```
Una vez importados, podemos ver el tamaño de las imágenes descargadas; con esto sabremos qué dimensión poner de entrada y si es necesario redimensionarlas.
```
import numpy as np
print("Existen {} imágenes de entrenamiento y {} imágenes de test.".format(x_train.shape[0], x_test.shape[0]))
print('Hay {} clases únicas para predecir.'.format(np.unique(y_train).shape[0]))
```
Es necesario etiquetar cada salida. Como tenemos 10 clases que clasificar, deberemos etiquetar cada salida con un array de 10 valores; los cuales pueden estar en 0 o 1, sólo puede haber una con el valor positivo (etiqueta correcta).
CIFAR 10 tiene 10 clases para poder clasificarlas, como en el proyecto se nos pide al menos 4, se ha decidido implementar las 10 clases que tenemos disponible.
```
from keras.utils import np_utils
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
```
Finalmente, podemos ver que se han descargado correctamente los datos con la función 'imshow' de la librería matplot.
```
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(10, 10))
for i in range(1, 9):
img = x_train[i-1]
fig.add_subplot(2, 4, i)
plt.imshow(img)
print("Dimensiones de las imágenes: ", x_train.shape[1:])
```
#### Entrenamiento del pre-modelo.
Una vez descargado el dataset para el proyecto, importaremos el pre-modelo que se va a utilizar.
```
from keras.applications.resnet50 import ResNet50
height = 64
width = 64
premodel = ResNet50(weights='imagenet', include_top=False, input_shape=(height, width, 3))
premodel.summary()
```
Como hemos visto en el apartado anterior, las dimensiones de la imagen eran de 32x32x3, y por lo tanto no coincide con las dimensiones de entrada que le hemos asignado al pre-modelo. **Es decir, es necesario que reescalar las dimensiones del dataset.**
Otro punto a definir es la invocación al pre-modelo con el parámetro 'include_top' igual a 'False'. *¿Por qué se hace esto?* El modelo ResNet50 está entrenado con el dataset 'imagenet', y clasifica entre imágenes que no coinciden con el dataset escogido. Por lo que, es necesario que la última capa de la red sea creada para especializarse en las clases de CIFAR10.
```
from scipy.misc import imresize
import numpy as np
def resize(images) :
X = np.zeros((images.shape[0],height,width,3))
for i in range(images.shape[0]):
X[i]= imresize(images[i], (height,width,3), interp='bilinear', mode=None)
return X
x_train_new = x_train.astype('float32')
x_test_new = x_test.astype('float32')
x_train_new = resize(x_train_new)
x_test_new = resize(x_test_new)
```
Una vez que tenemos las imágenes redimensionadas y normalizadas podremos llamar a la instrucción «predict» que nos devolverá el kernel con dimesión de {H x W x C}. Esto lo hacemos con los vectores: x_train y x_test.
```
from keras.applications.resnet50 import preprocess_input
resnet_train_input = preprocess_input(x_train_new)
train_features = premodel.predict(resnet_train_input)
```
Haremos lo mismo con el conjunto de test.
```
resnet_test_input = preprocess_input(x_test_new)
test_features = premodel.predict(resnet_test_input)
```
A partir de aquí, tenemos como resultados las imágenes predecidas por el pre-modelo. Estas imágenes en realidad se tratan de los kernels que residen en el interior de ella, puesto que no existe ninguna capa de clasificación (las hemos retirado al invocar el modelo).
#### Entrenamiento del modelo con los pesos pre-entrenados.
Una vez que el pre-modelo nos ha dado sus predicciones, crearemos el modelo expecífico para nuestro dataset. Para ello crearemos una ANN, con varias capas densas, y utilizando la técnica de Dropout (para prevenir el overfitting).
```
from keras.layers import Input, GlobalAveragePooling2D, Dense,Dropout
from keras.models import Model, Sequential
model = Sequential()
model.add(GlobalAveragePooling2D(input_shape=train_features.shape[1:]))
model.add(Dense(2048, activation='relu', name='fc1'))
model.add(Dropout(0.3))
model.add(Dense(1024, activation='relu', name='fc2'))
model.add(Dropout(0.3))
model.add(Dense(10, activation='softmax'))
model.summary()
```
Puesto que la capa «GlobalAveragePooling2D» es relativamente actual y nueva, se necesita dar una pequeña explicación sobre ella. Entonces, **¿qué hace el Global Average Pool?**
El tamaño del kernel es de dimensiones { H x W }; por lo tanto, toma la media global a través de altura y ancho, y le da un tensor con dimensiones de { 1 x C } para una entrada de { H x W x C }; en resumen, redimensiona el kernel de la última capa que nos llega del pre-modelo en un formato correcto para poder introducir una capa Dense (en nuestro caso se introduciría directamente a la «softmax»). Una vez definido el modelo, procedemos a compilarlo.
Una vez tenemos el modelo creado. Unicamente tenemos que compilarlo y empezar a entrenarlo. Como optimizador se ha escogido el «*sgd*», el cual ha sido elegido debido a su buen funcionamiento a gran escala; es decir, como tenemos aproximadamente unos 6,5 millones de parámetros a entrenar, este optimizador nos viene a la perfección debido a la gran cantidad de actualizaciones que habrá en los parámetros.
```
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
```
Y por último, terminamos entrenando el modelo y comprobamos si existe overfitting o algún tipo de problema. El tamaño del lote se ha escogido a base de prueba y error; lo mismo para el número de épocas.
```
history = model.fit(train_features, y_train, batch_size=256, epochs=7, validation_split=0.2, verbose=1, shuffle=True)
```
#### Visualización de los resultados obtenidos.
Una vez que tenemos el modelo entrenado, podemos ver las gráficas. En este caso, no se percibe la existencia de overfitting; el error de validación y de entrenamiento es muy parejo, y sólo nos haría falta ver el accuracity que puede llegar a conseguir la red.
```
ent_loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(ent_loss) + 1)
plt.plot(epochs, ent_loss, 'b', label='Training')
plt.plot(epochs, val_loss, 'r', label='Validation')
plt.title('Loss of Training and Validation')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
```
Finalmente, se puede comprobar el porcentaje de acierto que llega a obtener la red.
```
score = model.evaluate(test_features, y_test)
print('Accuracy on the Test Images: ', score[1])
```
#### Guardado del modelo
Una vez que hemos comprobado que nuestro modelo está bien implementado y operable. Podemos pasar al guardado de la topología y de sus pesos. Este guardado irá destinado al disco duro de nuestro ordenador personal, en el cual reside el programa gráfico que se ha implementado.
```
model.save('model.h5')
```
## Conclusiones
Este tipo de técnica es de las más raras que se pueden ver por papers, artículos científicos, etc., pero podemos ver que una ventaja que tiene es la rápidez con la que podemos entrenarla. Los resultados obtenidos no son muy buenos, aunque tampoco malos; el nivel de ajuste llega a ser perfecto, pero el porcentaje de acierto: 77%, es bajo con respecto a lo que puede conseguir la técnica de Transfer Learning.
Aún así, se puede llegar a estar contento con el ajuste conseguido puesto que es la primera red convolucional realizada mediante esta técnica.
| github_jupyter |
```
%matplotlib inline
import numpy, scipy, matplotlib.pyplot as plt, IPython.display as ipd
import librosa, librosa.display
plt.rcParams['figure.figsize'] = (14, 5)
plt.style.use('seaborn-muted')
plt.rcParams['figure.figsize'] = (14, 5)
plt.rcParams['axes.grid'] = True
plt.rcParams['axes.spines.left'] = False
plt.rcParams['axes.spines.right'] = False
plt.rcParams['axes.spines.bottom'] = False
plt.rcParams['axes.spines.top'] = False
plt.rcParams['axes.xmargin'] = 0
plt.rcParams['axes.ymargin'] = 0
plt.rcParams['image.cmap'] = 'gray'
plt.rcParams['image.interpolation'] = None
```
[← Back to Index](index.html)
# Energy and RMSE
The **energy** ([Wikipedia](https://en.wikipedia.org/wiki/Energy_(signal_processing%29); FMP, p. 66) of a signal corresponds to the total magntiude of the signal. For audio signals, that roughly corresponds to how loud the signal is. The energy in a signal is defined as
$$ \sum_n \left| x(n) \right|^2 $$
The **root-mean-square energy (RMSE)** in a signal is defined as
$$ \sqrt{ \frac{1}{N} \sum_n \left| x(n) \right|^2 } $$
Let's load a signal:
```
x, sr = librosa.load('audio/simple_loop.wav')
sr
x.shape
librosa.get_duration(x, sr)
```
Listen to the signal:
```
ipd.Audio(x, rate=sr)
```
Plot the signal:
```
librosa.display.waveplot(x, sr=sr)
```
Compute the short-time energy using a list comprehension:
```
hop_length = 256
frame_length = 512
energy = numpy.array([
sum(abs(x[i:i+frame_length]**2))
for i in range(0, len(x), hop_length)
])
energy.shape
```
Compute the RMSE using [`librosa.feature.rmse`](https://librosa.github.io/librosa/generated/librosa.feature.rmse.html):
```
rmse = librosa.feature.rmse(x, frame_length=frame_length, hop_length=hop_length, center=True)
rmse.shape
rmse = rmse[0]
```
Plot both the energy and RMSE along with the waveform:
```
frames = range(len(energy))
t = librosa.frames_to_time(frames, sr=sr, hop_length=hop_length)
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, energy/energy.max(), 'r--') # normalized for visualization
plt.plot(t[:len(rmse)], rmse/rmse.max(), color='g') # normalized for visualization
plt.legend(('Energy', 'RMSE'))
```
## Questions
Write a function, `strip`, that removes leading silence from a signal. Make sure it works for a variety of signals recorded in different environments and with different signal-to-noise ratios (SNR).
```
def strip(x, frame_length, hop_length):
# Compute RMSE.
rmse = librosa.feature.rmse(x, frame_length=frame_length, hop_length=hop_length, center=True)
# Identify the first frame index where RMSE exceeds a threshold.
thresh = 0.01
frame_index = 0
while rmse[0][frame_index] < thresh:
frame_index += 1
# Convert units of frames to samples.
start_sample_index = librosa.frames_to_samples(frame_index, hop_length=hop_length)
# Return the trimmed signal.
return x[start_sample_index:]
```
Let's see if it works.
```
y = strip(x, frame_length, hop_length)
ipd.Audio(y, rate=sr)
librosa.display.waveplot(y, sr=sr)
```
It worked!
[← Back to Index](index.html)
| github_jupyter |
# discrete_tf - Example2
Very simple discrete transfer function. The Python code should be platform agnostic, `ctypes` will load the appropriate shared library.
- This example validates the transfer function numerator and denominator againsnt `python-control`
- Generates a step response with the default transfen function $\frac{3}{2s+1}$
- Simulate a sine-wave input through the Simulink model & compare it to `python-control` forced response.
- Configure the model with the transfer function $\frac{1}{1s+1}$ and plot a step response. Compare the step response to the `python-control` forced-response with the same input.

- [Pythonic discrete_tf](https://nbviewer.jupyter.org/github/dapperfu/python_SimulinkDLL/blob/master/Example2/discrete_tf-python_class.ipynb) Pythonize the code below into a DiscreteTF class, uses additional Python tools like pandas
# Python Setup
```
import ctypes
import os
import platform
import matplotlib.pyplot as plt
import pandas as pd
from rtwtypes import *
```
Platform Specific Code. This is the only section of the code base that needs to be written specifically for the platform. After the
```
if platform.system() == "Linux":
dll_path = os.path.abspath("discrete_tf.so")
dll = ctypes.cdll.LoadLibrary(dll_path)
elif platform.system() == "Windows":
dll_path = os.path.abspath(f"discrete_t_win64.dll")
dll = ctypes.windll.LoadLibrary(dll_path)
```
Platform Agnostic Setup:
```
# Model entry point functions
model_initialize = dll.discrete_tf_initialize
model_step = dll.discrete_tf_step
model_terminate = dll.discrete_tf_terminate
# Input Parameters
InputSignal = real_T.in_dll(dll, "InputSignal")
num = (real_T * 2).in_dll(dll, "num")
den = (real_T * 2).in_dll(dll, "den")
# Output Signals
OutputSignal = real_T.in_dll(dll, "OutputSignal")
SimTime = real_T.in_dll(dll, "SimTime")
```
Validate that the transfer function numerator and denominator generated in Matlab match those generated with Python tools.
```
matlab tf() ->
matlab c2d() ->
Simulink Tunable Parameter ->
dll ->
Python == control.c2d(control.TransferFunction)
```
```
import control
import numpy as np
# How fast the simulink model is running.
Ts = 1e-3
# Static Gain
K = 3
# Time Constant.
tau = 2
sys = control.TransferFunction([K], [tau, 1])
sysd = control.c2d(sys, Ts)
sysd
list(num)
list(den)
np.isclose(num[1], sysd.num)
np.isclose(den[:], sysd.den)
```
# Running The Model.
Run the model and store the step, input, output and simulation time to a pandas dataframe.
```
model_initialize()
rows = list()
for step in range(1000):
model_step()
rows.append(
{
"time": float(SimTime.value),
"input": float(InputSignal.value),
"output": float(OutputSignal.value),
}
)
df = pd.DataFrame(rows)
df
```
# Step Response
Generate a step response to test the transfer function.
Unit step @ 1s.
```
model_initialize()
InputSignal.value = 0.0
data = list()
for step in range(int(15 * 1e3)):
# If Time is >=1s, Input signal = 1s.
if step >= 1 * 1e3:
InputSignal.value = 1.0
else:
InputSignal.value = 0.0
model_step()
# Log the response.
data.append(
{
"time": float(SimTime.value),
"input": float(InputSignal.value),
"output": float(OutputSignal.value),
}
)
df = pd.DataFrame(data)
df
df.plot(x="time", y=["input", "output"])
```
Plot the ```control.forced_response``` for the same given input.
```
T, yout = control.forced_response(sysd, df.time, df.input)
plt.plot(T, yout, T, df.input)
plt.legend(["Response", "Input Step"])
plt.xlabel("Time (s)")
plt.ylabel("Response")
plt.title("Step response modeled in Python");
```
Find the max error between the Simulink step transfer function step response and the `control.forced_response` for the same input signal.
```
# Max error
np.max(yout - df.output)
```
Sending the Simulink shared library has the same response to the same signal tested with the `python-control` library.
# Sinewave Input
Generate a sinewave with ``numpy``. Plot the input and output of the transfer function with ``pandas``.
```
model_initialize()
rows = list()
f = 0.5 # Hz
Ts = 1e-3
for step in range(int(10 * 1e3)):
InputSignal.value = np.sin(2 * np.pi * step * f * Ts)
row_tmp = {
"step": model_step(),
"time": float(SimTime.value),
"input": float(InputSignal.value),
"output": float(OutputSignal.value),
}
rows.append(row_tmp)
df = pd.DataFrame(rows)
df.plot(x="time", y=["input", "output"])
```
Generate a forced response with `python-control` and compare it to the Simulink model's response.
```
T, yout = control.forced_response(sysd, df.time, df.input)
plt.figure()
plt.plot(T, yout, df.time, df.output)
plt.xlabel("Time (s)")
plt.ylabel("Response")
plt.legend(["control.forced_response", "simulink shared library response"])
plt.figure()
plt.plot(T, (yout - df.output))
plt.xlabel("Time (s)")
plt.title("Response Difference");
```
# Changing the TransferFunction
Change the transfer function to have a static gain of 1 and a timeconstant of 1s.
Mark $1\tau$ and $2\tau$ on the graph.
```
# How fast the simulink model is running.
Ts = 1e-3
# Static Gain
K = 1
# Time Constant.
tau = 1
sys = control.TransferFunction([K], [tau, 1])
sysd = control.c2d(sys, Ts)
sysd
num[1] = sysd.num[0][0][0]
den[0] = sysd.den[0][0][0]
den[1] = sysd.den[0][0][1]
model_initialize()
InputSignal.value = 0.0
rows = list()
for step in range(int(15 * 1e3)):
if step >= 1 * 1e3:
InputSignal.value = 1.0
else:
InputSignal.value = 0.0
row_tmp = {
"step": model_step(),
"time": float(SimTime.value),
"input": float(InputSignal.value),
"output": float(OutputSignal.value),
}
rows.append(row_tmp)
df = pd.DataFrame(rows)
df.plot(x="time", y=["input", "output"])
plt.ylabel("Response (s)")
plt.hlines([1 - np.exp(-tau), 1 - np.exp(-2 * tau)], xmin=0, xmax=14, colors="r")
plt.vlines([2, 3], ymin=0, ymax=1, colors="g")
```
## Validate Step Response
Using the characteristics of a first order transfer function test that the transfer function matches.
Find the index of where the step occurs.
```
step_idx = np.where(df.input > 0)[0][0]
step_idx
```
Calculate where the response crosses $63.2\%$ & $86.4\%$
```
tau1_idx = np.where(df.output < (1 - np.exp(-1 * tau)))[0][-1]
tau2_idx = np.where(df.output < (1 - np.exp(-2 * tau)))[0][-1]
```
Subtract off the time of the step and compare to $\tau$ and $2\tau$
```
assert np.equal(df.time[tau1_idx] - df.time[step_idx], tau)
assert np.equal(df.time[tau2_idx] - df.time[step_idx], 2 * tau)
```
| github_jupyter |
# Image dataset
We will work on the MNIST dataset. Each image has a handwritten digit, e.g., 0,1,2,3,4,5,6,7,8,9. The task is to train a neural network model by 60,000 images (training dataset), and then predict the class label for each of the testing image, 0,1,2,3,4,5,6,7,8, or 9. There are10,000 images in the testing dataset.
```
import numpy as np
import matplotlib.pyplot as plt
# load training and testing dataset
from google.colab import drive
drive.mount('/content/gdrive')
data_path = "/content/gdrive/My Drive/Data/"
train_data = np.loadtxt(data_path + "mnist_train.csv", delimiter=",") #load file as a matrix
test_data = np.loadtxt(data_path + "mnist_test.csv", delimiter=",")
# the number of training images we have
train_data.shape
# the number of testing images we have
test_data.shape
image_size = 28 # width and length
image_pixels = image_size * image_size
# Normalize the pixels range from [0 255] to [0.01, 1].
# To avoid 0 values as inputs, each pixel is multiplied by 0.99 / 255, and then adding 0.01.
train_imgs = np.asfarray(train_data[:, 1:]) * 0.99 / 255 + 0.01 #The slicing operator [:, 1:0] Will grab all rows [1-6000] and coloumns [1-785]
test_imgs = np.asfarray(test_data[:, 1:]) * 0.99 / 255 + 0.01 #
for i in range(3):
img = train_imgs[i].reshape((image_size,image_size))
plt.imshow(img, cmap="Greys")
plt.show()
# the first column is the label
train_labels = np.asfarray(train_data[:, :1])
test_labels = np.asfarray(test_data[:, :1])
print(test_labels[1:10,:])
# You may want to make one-hot encoding for the labels
lr = np.arange(10)
for label in range(10):
one_hot = (lr==label).astype(np.int)
print("label: ", label, " in one-hot representation: ", one_hot)
#Then transform training and testing labels into one hot representation
train_labels_one_hot = (lr==train_labels).astype(np.float)
test_labels_one_hot = (lr==test_labels).astype(np.float)
print(test_labels_one_hot[1:10,:])
```
## (8 points) implement a Multi-layer Neural Network model as a classifier. It is unnecessary to write the backpropagation training process by yourself. You can use machine learning libraries for training the neural network.
### (a) (1pts) In the multi-layer neural network you designed, how many hidden layers, and how many hidden units? How many parameters to learn in your model?
The Multi-Layer Perceptron (MLP) designed below produces relatively high accurate results on both training and test data. The neural network has 784 input parameters, 1 hidden layer with 80 neurons and 10 neurons on it's output layer. Therefore, the total number of parameters are:
$Parameters = 784 \times 80 + 80 \times 10 + 90 (Bias) = 63,610$
```
from keras.models import Sequential
from keras.layers import Dense
#defining the neural network
nn = Sequential([
Dense(80, input_dim = 784, activation='relu'),
Dense(10, activation='softmax')
])
nn.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
history = nn.fit(train_imgs,train_labels_one_hot, epochs = 40 , batch_size=64)
nn.summary()
```
### (b) (1pts) Show your learning curve (the decrease of loss function over iterations), and make sure that your model is well-trained.
```
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.title('Loss Function vs. Iterations')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()
```
### (C) (1pts) what is the classification accuracy on your training data? And on the testing data? Hint: accuracy higher than 0.94 is expected.
```
from sklearn.metrics import accuracy_score, confusion_matrix
prob_matrix = nn.predict(test_imgs) #returns an array of length 10000 whose elements are 10-element arrays with probabilities
def probability_to_decision(probability_matrix):
predictions = []
for i in range(len(probability_matrix)):
predictions.append(np.argmax(probability_matrix[i])) #appends the index whose value is the maximum within a given array
return predictions
training_predictions = probability_to_decision(nn.predict(train_imgs))
test_predictions = probability_to_decision(prob_matrix)
print("Accuracy Score on Testing Data: ", accuracy_score(test_predictions, test_labels))
print("Accuracy Score on Training Data: ", accuracy_score(training_predictions, train_labels))
```
### (d) (2pts) please show the confusion matrix from your prediction results on the testing data, and discuss what you can observe from the confusion matrix (how the model made what kinds of wrong classifications).
In the confusion matrix below, the diagonal lines represent the number of accurately classified samples for each class. For example, the first diagonal tells us that 967 samples of class '0' were accurately classified as '0' by our MLP model. The off-diagonal numbers indicate the number of errors the model made. For example the value in row labeled '4' with column labeled '9' indicates that there were 11 instances where the model predicted a sample to '9' when in reality, it's true label was '4'. This number is the highest non-diagonal value in the confusion matrix, which indicates that our model has the toughest time recognizing between the number 4 and number 9, however, this number is significantly lower than the diagonal values. The other two highest rate of missclassification is when the model predicted '9' when the true value was '3' and when the model predicted '2' when the actual value was '7', each of which has a misclassification value of 10.
```
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sn
plt.figure(figsize = (16,5))
ax = plt.subplot()
conf_matrix = confusion_matrix(test_labels, test_predictions)
sn.heatmap(conf_matrix, ax = ax, annot=True, fmt='g', cmap='BuPu')
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
ax.set_xlabel('Predicted Number')
ax.set_ylabel('Actual Number');
```
### (e) (2pts) please report the precision, recall and F1-measure for each of the 10 classes, and the Marco-F1 value as an overall evaluation score.
```
from sklearn.metrics import classification_report
from sklearn.metrics import f1_score
print(classification_report(test_labels,test_predictions))
print("F1 Macro Score for MLP Model #1: ", f1_score(test_labels, test_predictions, average='macro'))
```
### (f) (1pts) Please compare the Marco-F1 score of your 3 different models (with different number of parameters), and discuss which one is better and why.
Below we build two more MLP models with different number of parameters. The three models, number of parameters and resulting macro-F1 score on testing data are summarized below
1. For Model #1, we have 1 hidden layers with 80 hidden units each with a relu activation funcntion, and an output layer with 10 units. The number of parameters in this fully connected MLP is: Parameters = (784 x 80) + (80 x 10) + 90 (Bias) = 63,610. F1 Macro Score for MLP Model #1: 0.9770709917430167
2. For Model #2, we have 2 hidden layers, each with 20 hidden units with a relu activation fcuntion, and an output layer with 10 units. The number of parameters in this fully connected MLP is: Parameters = (784 x 20) + (20 x 20) + (20 x 10) + 50 (Bias) = 16,330. F1 Macro Score for MLP Model #2: 0.9606301491190019
3. For Model #3, we have 2 hidden layers, each with 200 hidden units with a relu activation fcuntion, and an output layer with 10 units. The number of parameters in this fully connected MLP is: Parameters = (784 x 200) + (200 x 200) + (200 x 10) + 510 (Bias) = 199,210. F1 Macro Score for MLP Model #3: 0.9816683213182724
Note that the Macro-F1 Score is used to assess the quality of different models of multiclass problems where all classes are given equal contribution regarless of the number of instances. From the three models discussed above, Model #3 has the highest Macro Score and is therefore the superior model since it has higher accuracy than the remaining models. Note that this is probably due to the high number of parameters, they are possibly able to capture more significant data that improves their accuracy.
```
# MLP model #2
nn2 = Sequential([
Dense(20, input_dim = 784, activation='relu'),
Dense(20, activation = 'relu'),
Dense(10, activation = 'softmax')
])
nn2.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
history = nn2.fit(train_imgs,train_labels_one_hot, epochs = 40 , batch_size=64)
nn2.summary()
#Comparison Metrics for Model #2
prob_matrix2 = nn2.predict(test_imgs) #returns an array of length 10000 whose elements are 10-element arrays with probabilities
test_predictions_nn2 = probability_to_decision(prob_matrix2)
print(classification_report(test_labels,test_predictions_nn2))
print("F1 Macro Score for MLP Model #2: ", f1_score(test_labels, test_predictions_nn2, average='macro'))
#MLP model #3
nn3 = Sequential([
Dense(200, input_dim = 784, activation='relu'),
Dense(200, activation='relu'),
Dense(10, activation = 'softmax')
])
nn3.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
history = nn3.fit(train_imgs,train_labels_one_hot, epochs = 40 , batch_size=64)
nn3.summary()
#Comparison Metrics for Model #3
prob_matrix3 = nn3.predict(test_imgs) #returns an array of length 10000 whose elements are 10-element arrays with probabilities
test_predictions_nn3 = probability_to_decision(prob_matrix3)
print(classification_report(test_labels,test_predictions_nn3))
print("F1 Macro Score for MLP Model #3: ", f1_score(test_labels, test_predictions_nn3, average='macro'))
```
## (2) Implement the Convolutional Neural Network (CNN) model.
### (a) (1pts) In the CNN model you designed, how many convolution layers? For each convolution layer, what’s the size of filter (local receptive field), and stride step? How pooling is applied? How many parameters to learn in your model?
Here we will utilize Keras to build a CNN. We will use a stack of simple Conv2D() and MaxPooling to define our CNN.
The Conv2D() function will create feature maps by sliding a filter across the image and performing a weighted sum at each step. This funciton has the following parameters that need to be defined.
1. filters = takes an integer with the number of feature maps to construct. Recall that each feature map attempts to identify a single feature in the image.
2. kernal size = integer or tuple defining the size of the filter to be applied against each image.
3. strides = integer or tuple defining the step to move the filter in each direction (horizontally and vertically)
4. activation = activation function to be applied in each neuron
The MaxPooling2D(pool_size = pool_size ) creates a condensed version of a feature map by picking the activation with highest value in a 2D region of space defined by the pool_size parameter.
```
image_size = 28 # width and length
image_pixels = image_size * image_size
train_imgs_reshaped = np.expand_dims(train_imgs.reshape(60000,28,28), axis = 3)
test_imgs_reshaped = np.expand_dims(test_imgs.reshape(10000,28,28), axis=3)
test_imgs_reshaped.shape
```
On Model #1 of our CNN, we will apply a **single stack of a convolution layer which will apply 5 different filters of size = (4,4) by sliding across our image with stride step = (1,1)**. Since each feature map shares the same weight, the number of learnable parameters after this convolution layer will be 5 x (4 x 4 + 1) = 85 . The number of neurons after the convolution layer is (28 - 4)/1 + 1 = (25x25). Since we have 5 filter, the total number of neurons in this layer is 5 x (25 x 25). Thereafter, we will perform a **Max Pooling of size (2 x 2) with a stride of 2 in each feature map which will pick out the neuron with maximum value in a region of 2x2**. The number of neurons then reduces to (12 x 12) x 5. The condensed feature maps will be then passed onto 10 neurons in the output layer with a softmax activation function. **Thus the total number of learnable parameters for this model will be 7,295**
```
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
n_filters = 5
filter_size = 4
stride_step = (1,1)
pool_size = (2,2)
activation = None
cnn = Sequential([
Conv2D(n_filters, filter_size, strides=stride_step, activation = activation, input_shape=(28,28,1)),
MaxPooling2D(pool_size = pool_size ),
Flatten(),
Dense(10, activation='softmax')
])
cnn.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
history = cnn.fit(train_imgs_reshaped,train_labels_one_hot, epochs = 15, batch_size=64)
cnn.summary()
```
### (b) (1pts) Show your learning curve (the decrease of loss function over iterations), and make sure that your model is well-trained.
```
plt.figure()
plt.plot(history.history['loss'])
plt.title('Loss Function vs. Iterations')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()
```
### (c) (1pts) what is the classification accuracy on your training data? And on the testing data? Hint: accuracy higher than 0.94 is expected.
```
prob_arrays = cnn.predict(test_imgs_reshaped)
test_predictions_cnn1 = probability_to_decision(prob_arrays)
training_predictions_cnn1 = probability_to_decision(cnn.predict(train_imgs_reshaped))
print("Accuracy Score on Test Data: ", accuracy_score(test_labels, test_predictions_cnn1))
print("Accuracy Score on Training Data: ", accuracy_score(train_labels, training_predictions_cnn1))
```
### (d) (2pts) please show the confusion matrix from your prediction results on the testing data, and discuss what you can observe from the confusion matrix (how the model made what kinds of wrong classifications).
```
conf_matrix = confusion_matrix(test_labels, test_predictions_cnn1)
plt.figure(figsize = (16,5))
ax = plt.subplot()
sn.heatmap(conf_matrix, ax = ax, annot=True, fmt='g')
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
```
### (e) (1.5 pts) please report the precision, recall and F1-measure for each of the 10 classes, and the Macro-F1 value as an overall evaluation score.
```
print(classification_report(test_labels, test_predictions_cnn1))
print("F1 Macro Score for CNN Model #1: ", f1_score(test_labels, test_predictions_cnn1, average='macro'))
```
### (f) (1.5 pts) Please compare the Macro-F1 score of your 3 different models (with different number of parameters), and discuss which one is better and why. Please compare the performance of your best CNN model and that of your best multi-layer neural network model. Which one is better?
Summaries of the 3 models:
1. On Model #1 of our CNN, we will use single stack of a convolution layer which will apply 5 different filters of size = (4,4) with stride step = (1,1). Thereafter, we will perform a Max Pooling of size (2 x 2) with a stride of 2 in each feature map which will pick out the neuron with maximum value in a region of 2x2. Then the values are passed onto 10 neurons with a softmax activation function **Thus the total number of learnable parameters for this model will be 7,295. F1 Macro Score for CNN Model #1: 0.9708064721114766**
2. In Model #2 we will use use two layes of convolution. At the first layer, we apply a 5 filters of size (4 x 4) with stride step (1, 1). In the second convolution layer, we will apply 10 filters of size (3 x 3) with stride step (1 x 1). The output of both convolution layers are passed through a max pooling of size (2 x 2) with stride step 2. **In this model, the total number of learnable parameters are 3,055 and the total execution time equals to 4m and 22s. F1 Macro Score for CNN Model #2: 0.9838117133260837**
3. Model #3 will have two convolution layers, the first will utilize 3 filters of size (3 x 3) with stride step (1 x 1). The second will use 6 more filters of size (3 x 3) with step (1 x 1). Each convolution layers uses a 'relu' activation function on the activation which are then passed through a max pooling of size (2 x 2). The activations maps are then connected to a regular MLP with 80 hidden units in the first layer and 10 units in the output layer with a softmax activation function **The total number of learnable parameters for this model is 13,088 and the execution time is 3m and 29 seconds. F1 Macro Score for Model #3: 0.9865926401388665**
The CNN model with the highest Macro F1 score is CNN Model #3, achiecing Macro Score of 0.9865. This model outperforms the best MLP model previously discussed while having significantly less parameters to learn (13,088 compared to 199,210). It seems that performing convolution layers followed by pooling layer greatly improves the performance of the models. Even the second best CNN model outperforms our best MLP model. **The overall winner is CNN Model #3**
```
# Model #2
#Filters is the number of filters in the convolution output
activation = None
cnn2 = Sequential([
Conv2D(filters = 5, kernel_size = (4, 4), strides = (1,1), activation = activation, input_shape=(28,28,1)),
MaxPooling2D(pool_size = (2,2) ),
Conv2D(filters = 10, kernel_size = (3, 3), strides = (1,1), activation = activation),
MaxPooling2D(pool_size = (2,2) ),
Flatten(),
Dense(10, activation='softmax')
])
cnn2.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
history = cnn2.fit(train_imgs_reshaped,train_labels_one_hot, epochs = 15, batch_size=64)
cnn2.summary()
prob_arrays2 = cnn2.predict(test_imgs_reshaped)
test_predictions_cnn2 = probability_to_decision(prob_arrays2)
print(classification_report(test_labels,test_predictions_cnn2))
print("Accuracy Score on Test Data: ", accuracy_score(test_labels, test_predictions_cnn2))
print("F1 Macro Score for CNN Model #2: ", f1_score(test_labels, test_predictions_cnn2, average='macro'))
# Model 3
activation = 'relu'
cnn3 = Sequential([
Conv2D(filters = 3, kernel_size = (3, 3), strides = (1,1), activation = activation, input_shape=(28,28,1)),
MaxPooling2D(pool_size = (2,2) ),
Conv2D(filters = 6, kernel_size = (3, 3), strides = (1,1), activation = activation),
MaxPooling2D(pool_size = (2,2) ),
Flatten(),
Dense(80, activation='relu'),
Dense(10, activation='softmax')
])
cnn3.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
history = cnn3.fit(train_imgs_reshaped,train_labels_one_hot, epochs = 15, batch_size=64)
cnn3.summary()
prob_arrays3 = cnn3.predict(test_imgs_reshaped)
test_predictions_cnn3 = probability_to_decision(prob_arrays3)
print(classification_report(test_labels,test_predictions_cnn3))
print("Accuracy Score on Test Data: ", accuracy_score(test_labels, test_predictions_cnn3))
print("F1 Macro Score for CNN Model #3: ", f1_score(test_labels, test_predictions_cnn3, average='macro'))
```
| github_jupyter |
# Anomaly Detection Example
<a href="https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/"><img src="https://cdn.analyticsvidhya.com/wp-content/uploads/2019/02/Outliers.jpeg" /></a>
<blockquote>
“Outliers are not necessarily a bad thing. These are just observations that are not following the same pattern as the other ones. But it can be the case that an outlier is very interesting. For example, if in a biological experiment, a rat is not dead whereas all others are, then it would be very interesting to understand why. This could lead to new scientific discoveries. So, it is important to detect outliers.”
– Pierre Lafaye de Micheaux, Author and Statistician
</blockquote>
The following example was inspired by <a href="https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/">this example</a>.
It uses a special Python toolkit dedicated to Outliers Detection called <a href="https://pyod.readthedocs.io/en/latest/index.html">PyOD</a>, additional info are <a href="http://www.jmlr.org/papers/volume20/19-011/19-011.pdf">here</a>.
<br />
<br />
PyOD is a comprehensive and scalable Python toolkit for detecting outlying objects in multivariate data. This exciting yet challenging field is commonly referred as Outlier Detection or Anomaly Detection.
```
#install the needed toolkit
!pip install pyod
#import std packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# Import models from PyOD
from pyod.models.abod import ABOD
from pyod.models.cblof import CBLOF
from pyod.models.hbos import HBOS
from pyod.models.iforest import IForest
from pyod.models.knn import KNN
from pyod.models.lof import LOF
#Import data-generation tool from PyOD
from pyod.utils.data import generate_data, get_outliers_inliers
```
## Setup
```
random_state = np.random.RandomState(3)
outliers_fraction = 0.1
# Define six outlier detection tools to be compared
#
classifiers = {
'Angle-based Outlier Detector (ABOD)': ABOD(contamination=outliers_fraction),
'Histogram-base Outlier Detection (HBOS)': HBOS(contamination=outliers_fraction),
'Cluster-based Local Outlier Factor (CBLOF)':CBLOF(contamination=outliers_fraction,check_estimator=False, random_state=random_state),
'Isolation Forest': IForest(contamination=outliers_fraction,random_state=random_state),
'K Nearest Neighbors (KNN)': KNN(contamination=outliers_fraction),
'Average KNN': KNN(method='mean',contamination=outliers_fraction)
}
```
## Data gathering and visualization
```
#generate random data with two features
X_train, Y_train,X_test, Y_test = generate_data(n_train=500,n_test=200, n_features=2,random_state=3,contamination=outliers_fraction)
# store outliers and inliers in different numpy arrays
x_outliers, x_inliers = get_outliers_inliers(X_train,Y_train)
xt_outliers, xt_inliers = get_outliers_inliers(X_test,Y_test)
n_inliers = len(x_inliers)
n_outliers = len(x_outliers)
#separate the two features and use it to plot the data
F1 = X_train[:,[0]].reshape(-1,1)
F2 = X_train[:,[1]].reshape(-1,1)
# create a meshgrid
xx , yy = np.meshgrid(np.linspace(-10, 10, 200), np.linspace(-10, 10, 200))
# scatter plot
plt.figure(figsize=[15,9])
plt.scatter(x_outliers[:,0],x_outliers[:,1],c='black',edgecolor='k',label='Outliers')
plt.scatter(x_inliers[:,0],x_inliers[:,1],c='white',edgecolor='k',label='Inliers')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
```
## Train different models evaluate and visualize results
```
#set the figure size
plt.figure(figsize=(19, 20))
dfx = pd.DataFrame(X_train)
dfx['y'] = Y_train
for i, (clf_name,clf) in enumerate(classifiers.items()) :
# fit the dataset to the model
clf.fit(X_train)
# predict raw anomaly score
scores_pred = clf.decision_function(X_train)*-1
# prediction of a datapoint category outlier or inlier
y_pred = clf.predict(X_train)
# no of errors in prediction
n_errors = (y_pred != Y_train).sum()
dfx['outlier'] = y_pred.tolist()
# IX1 - inlier feature 1, IX2 - inlier feature 2
IX1 = np.array(dfx[0][dfx['outlier'] == 0]).reshape(-1,1)
IX2 = np.array(dfx[1][dfx['outlier'] == 0]).reshape(-1,1)
# OX1 - outlier feature 1, OX2 - outlier feature 2
OX1 = dfx[0][dfx['outlier'] == 1].values.reshape(-1,1)
OX2 = dfx[1][dfx['outlier'] == 1].values.reshape(-1,1)
# True - outlier feature 1, OX2 - outlier feature 2
TX1 = dfx[0][dfx['y'] == 1].values.reshape(-1,1)
TX2 = dfx[1][dfx['y'] == 1].values.reshape(-1,1)
text ='No of mis-detected outliers : '+clf_name+" "+str(n_errors)
if(n_errors==0):
text ="\033[1m"+"\033[91m"+'No of mis-detected outliers : '+clf_name+" "+str(n_errors)+"\033[0m"
print(text)
# rest of the code is to create the visualization
# threshold value to consider a datapoint inlier or outlier
threshold = stats.scoreatpercentile(scores_pred,100 *outliers_fraction)
# decision function calculates the raw anomaly score for every point
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) * -1
Z = Z.reshape(xx.shape)
subplot = plt.subplot(2, 3, i + 1)
# fill blue colormap from minimum anomaly score to threshold value
subplot.contourf(xx, yy, Z, levels = np.linspace(Z.min(), threshold, 10),cmap=plt.cm.Blues_r)
# draw red contour line where anomaly score is equal to threshold
a = subplot.contour(xx, yy, Z, levels=[threshold],linewidths=2, colors='red')
# fill orange contour lines where range of anomaly score is from threshold to maximum anomaly score
subplot.contourf(xx, yy, Z, levels=[threshold, Z.max()],colors='orange')
# scatter plot of inliers with white dots
b = subplot.scatter(IX1,IX2, c='white',s=100, edgecolor='k')
# scatter plot of detected outliers with black dots
c = subplot.scatter(OX1,OX2, c='black',s=100, edgecolor='k')
# scatter plot of true outliers with red dots
d = subplot.scatter(x_outliers[:,0],x_outliers[:,1], c='red',s=20,)
subplot.axis('tight')
subplot.legend(
[a.collections[0], b, c, d],
['learned decision function', 'inliers', 'detected outliers','true outliers'],
loc='lower right')
subplot.set_title(clf_name)
subplot.set_xlim((-10, 10))
subplot.set_ylim((-10, 10))
plt.show()
```
## Test Dataset
```
#set the figure size
plt.figure(figsize=(19, 20))
dfxt = pd.DataFrame(X_test)
dfxt['y'] = Y_test
for i, (clf_name,clf) in enumerate(classifiers.items()) :
# predict raw anomaly score
scores_pred = clf.decision_function(X_test)*-1
# prediction of a datapoint category outlier or inlier
y_pred = clf.predict(X_test)
# no of errors in prediction
n_errors = (y_pred != Y_test).sum()
dfxt['outlier'] = y_pred.tolist()
# IX1 - inlier feature 1, IX2 - inlier feature 2
IX1 = np.array(dfxt[0][dfx['outlier'] == 0]).reshape(-1,1)
IX2 = np.array(dfxt[1][dfx['outlier'] == 0]).reshape(-1,1)
# OX1 - outlier feature 1, OX2 - outlier feature 2
OX1 = dfxt[0][dfxt['outlier'] == 1].values.reshape(-1,1)
OX2 = dfxt[1][dfxt['outlier'] == 1].values.reshape(-1,1)
# True - outlier feature 1, OX2 - outlier feature 2
TX1 = dfxt[0][dfxt['y'] == 1].values.reshape(-1,1)
TX2 = dfxt[1][dfxt['y'] == 1].values.reshape(-1,1)
text ='No of mis-detected outliers : '+clf_name+" "+str(n_errors)
if(n_errors==0):
text ="\033[1m"+"\033[91m"+'No of mis-detected outliers : '+clf_name+" "+str(n_errors)+"\033[0m"
print(text)
# rest of the code is to create the visualization
# threshold value to consider a datapoint inlier or outlier
threshold = stats.scoreatpercentile(scores_pred,100 *outliers_fraction)
# decision function calculates the raw anomaly score for every point
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) * -1
Z = Z.reshape(xx.shape)
subplot = plt.subplot(2, 3, i + 1)
# fill blue colormap from minimum anomaly score to threshold value
subplot.contourf(xx, yy, Z, levels = np.linspace(Z.min(), threshold, 10),cmap=plt.cm.Blues_r)
# draw red contour line where anomaly score is equal to threshold
a = subplot.contour(xx, yy, Z, levels=[threshold],linewidths=2, colors='red')
# fill orange contour lines where range of anomaly score is from threshold to maximum anomaly score
subplot.contourf(xx, yy, Z, levels=[threshold, Z.max()],colors='orange')
# scatter plot of inliers with white dots
#b = subplot.scatter(X_train[:-n_outliers, 0], X_train[:-n_outliers, 1], c='white',s=100, edgecolor='k')
b = subplot.scatter(IX1,IX2, c='white',s=100, edgecolor='k')
# scatter plot of outliers with black dots
#c = subplot.scatter(X_train[-n_outliers:, 0], X_train[-n_outliers:, 1], c='black',s=100, edgecolor='k')
c = subplot.scatter(OX1,OX2, c='black',s=100, edgecolor='k')
# scatter plot of true outliers with red dots
d = subplot.scatter(xt_outliers[:,0],xt_outliers[:,1], c='red',s=20,)
subplot.axis('tight')
subplot.legend(
[a.collections[0], b, c, d],
['learned decision function', 'inliers', 'detected outliers','true outliers'],
loc='lower right')
subplot.set_title(clf_name)
subplot.set_xlim((-10, 10))
subplot.set_ylim((-10, 10))
plt.show()
```
| github_jupyter |
# Python Basics with Numpy (optional assignment)
Welcome to your first assignment. This exercise gives you a brief introduction to Python. Even if you've used Python before, this will help familiarize you with functions we'll need.
**Instructions:**
- You will be using Python 3.
- Avoid using for-loops and while-loops, unless you are explicitly told to do so.
- Do not modify the (# GRADED FUNCTION [function name]) comment in some cells. Your work would not be graded if you change this. Each cell containing that comment should only contain one function.
- After coding your function, run the cell right below it to check if your result is correct.
**After this assignment you will:**
- Be able to use iPython Notebooks
- Be able to use numpy functions and numpy matrix/vector operations
- Understand the concept of "broadcasting"
- Be able to vectorize code
Let's get started!
## About iPython Notebooks ##
iPython Notebooks are interactive coding environments embedded in a webpage. You will be using iPython notebooks in this class. You only need to write code between the ### START CODE HERE ### and ### END CODE HERE ### comments. After writing your code, you can run the cell by either pressing "SHIFT"+"ENTER" or by clicking on "Run Cell" (denoted by a play symbol) in the upper bar of the notebook.
We will often specify "(≈ X lines of code)" in the comments to tell you about how much code you need to write. It is just a rough estimate, so don't feel bad if your code is longer or shorter.
**Exercise**: Set test to `"Hello World"` in the cell below to print "Hello World" and run the two cells below.
```
### START CODE HERE ### (≈ 1 line of code)
test = "Heelo World"
### END CODE HERE ###
print ("test: " + test)
```
**Expected output**:
test: Hello World
<font color='blue'>
**What you need to remember**:
- Run your cells using SHIFT+ENTER (or "Run cell")
- Write code in the designated areas using Python 3 only
- Do not modify the code outside of the designated areas
## 1 - Building basic functions with numpy ##
Numpy is the main package for scientific computing in Python. It is maintained by a large community (www.numpy.org). In this exercise you will learn several key numpy functions such as np.exp, np.log, and np.reshape. You will need to know how to use these functions for future assignments.
### 1.1 - sigmoid function, np.exp() ###
Before using np.exp(), you will use math.exp() to implement the sigmoid function. You will then see why np.exp() is preferable to math.exp().
**Exercise**: Build a function that returns the sigmoid of a real number x. Use math.exp(x) for the exponential function.
**Reminder**:
$sigmoid(x) = \frac{1}{1+e^{-x}}$ is sometimes also known as the logistic function. It is a non-linear function used not only in Machine Learning (Logistic Regression), but also in Deep Learning.
<img src="images/Sigmoid.png" style="width:500px;height:228px;">
To refer to a function belonging to a specific package you could call it using package_name.function(). Run the code below to see an example with math.exp().
```
# GRADED FUNCTION: basic_sigmoid
import math
def basic_sigmoid(x):
"""
Compute sigmoid of x.
Arguments:
x -- A scalar
Return:
s -- sigmoid(x)
"""
### START CODE HERE ### (≈ 1 line of code)
s = 1/(1+math.exp(-x))
### END CODE HERE ###
return s
basic_sigmoid(3)
```
**Expected Output**:
<table style = "width:40%">
<tr>
<td>** basic_sigmoid(3) **</td>
<td>0.9525741268224334 </td>
</tr>
</table>
Actually, we rarely use the "math" library in deep learning because the inputs of the functions are real numbers. In deep learning we mostly use matrices and vectors. This is why numpy is more useful.
```
### One reason why we use "numpy" instead of "math" in Deep Learning ###
x = [1, 2, 3]
basic_sigmoid(x) # you will see this give an error when you run it, because x is a vector.
```
In fact, if $ x = (x_1, x_2, ..., x_n)$ is a row vector then $np.exp(x)$ will apply the exponential function to every element of x. The output will thus be: $np.exp(x) = (e^{x_1}, e^{x_2}, ..., e^{x_n})$
```
import numpy as np
# example of np.exp
x = np.array([1, 2, 3])
print(np.exp(x)) # result is (exp(1), exp(2), exp(3))
```
Furthermore, if x is a vector, then a Python operation such as $s = x + 3$ or $s = \frac{1}{x}$ will output s as a vector of the same size as x.
```
# example of vector operation
x = np.array([1, 2, 3])
print (x + 3)
```
Any time you need more info on a numpy function, we encourage you to look at [the official documentation](https://docs.scipy.org/doc/numpy-1.10.1/reference/generated/numpy.exp.html).
You can also create a new cell in the notebook and write `np.exp?` (for example) to get quick access to the documentation.
**Exercise**: Implement the sigmoid function using numpy.
**Instructions**: x could now be either a real number, a vector, or a matrix. The data structures we use in numpy to represent these shapes (vectors, matrices...) are called numpy arrays. You don't need to know more for now.
$$ \text{For } x \in \mathbb{R}^n \text{, } sigmoid(x) = sigmoid\begin{pmatrix}
x_1 \\
x_2 \\
... \\
x_n \\
\end{pmatrix} = \begin{pmatrix}
\frac{1}{1+e^{-x_1}} \\
\frac{1}{1+e^{-x_2}} \\
... \\
\frac{1}{1+e^{-x_n}} \\
\end{pmatrix}\tag{1} $$
```
# GRADED FUNCTION: sigmoid
import numpy as np # this means you can access numpy functions by writing np.function() instead of numpy.function()
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size
Return:
s -- sigmoid(x)
"""
### START CODE HERE ### (≈ 1 line of code)
s = 1/(1 + np.exp(-x))
### END CODE HERE ###
return s
x = np.array([1, 2, 3])
sigmoid(x)
```
**Expected Output**:
<table>
<tr>
<td> **sigmoid([1,2,3])**</td>
<td> array([ 0.73105858, 0.88079708, 0.95257413]) </td>
</tr>
</table>
### 1.2 - Sigmoid gradient
As you've seen in lecture, you will need to compute gradients to optimize loss functions using backpropagation. Let's code your first gradient function.
**Exercise**: Implement the function sigmoid_grad() to compute the gradient of the sigmoid function with respect to its input x. The formula is: $$sigmoid\_derivative(x) = \sigma'(x) = \sigma(x) (1 - \sigma(x))\tag{2}$$
You often code this function in two steps:
1. Set s to be the sigmoid of x. You might find your sigmoid(x) function useful.
2. Compute $\sigma'(x) = s(1-s)$
```
# GRADED FUNCTION: sigmoid_derivative
def sigmoid_derivative(x):
"""
Compute the gradient (also called the slope or derivative) of the sigmoid function with respect to its input x.
You can store the output of the sigmoid function into variables and then use it to calculate the gradient.
Arguments:
x -- A scalar or numpy array
Return:
ds -- Your computed gradient.
"""
### START CODE HERE ### (≈ 2 lines of code)
s = 1/(1+np.exp(-x))
ds = s * (1-s)
### END CODE HERE ###
return ds
x = np.array([1, 2, 3])
print ("sigmoid_derivative(x) = " + str(sigmoid_derivative(x)))
```
**Expected Output**:
<table>
<tr>
<td> **sigmoid_derivative([1,2,3])**</td>
<td> [ 0.19661193 0.10499359 0.04517666] </td>
</tr>
</table>
### 1.3 - Reshaping arrays ###
Two common numpy functions used in deep learning are [np.shape](https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.shape.html) and [np.reshape()](https://docs.scipy.org/doc/numpy/reference/generated/numpy.reshape.html).
- X.shape is used to get the shape (dimension) of a matrix/vector X.
- X.reshape(...) is used to reshape X into some other dimension.
For example, in computer science, an image is represented by a 3D array of shape $(length, height, depth = 3)$. However, when you read an image as the input of an algorithm you convert it to a vector of shape $(length*height*3, 1)$. In other words, you "unroll", or reshape, the 3D array into a 1D vector.
<img src="images/image2vector_kiank.png" style="width:500px;height:300;">
**Exercise**: Implement `image2vector()` that takes an input of shape (length, height, 3) and returns a vector of shape (length\*height\*3, 1). For example, if you would like to reshape an array v of shape (a, b, c) into a vector of shape (a*b,c) you would do:
``` python
v = v.reshape((v.shape[0]*v.shape[1], v.shape[2])) # v.shape[0] = a ; v.shape[1] = b ; v.shape[2] = c
```
- Please don't hardcode the dimensions of image as a constant. Instead look up the quantities you need with `image.shape[0]`, etc.
```
# GRADED FUNCTION: image2vector
def image2vector(image):
"""
Argument:
image -- a numpy array of shape (length, height, depth)
Returns:
v -- a vector of shape (length*height*depth, 1)
"""
### START CODE HERE ### (≈ 1 line of code)
v = image.reshape(image.shape[0] * image.shape[1] * image.shape[2])
### END CODE HERE ###
return v
# This is a 3 by 3 by 2 array, typically images will be (num_px_x, num_px_y,3) where 3 represents the RGB values
image = np.array([[[ 0.67826139, 0.29380381],
[ 0.90714982, 0.52835647],
[ 0.4215251 , 0.45017551]],
[[ 0.92814219, 0.96677647],
[ 0.85304703, 0.52351845],
[ 0.19981397, 0.27417313]],
[[ 0.60659855, 0.00533165],
[ 0.10820313, 0.49978937],
[ 0.34144279, 0.94630077]]])
print ("image2vector(image) = " + str(image2vector(image)))
```
**Expected Output**:
<table style="width:100%">
<tr>
<td> **image2vector(image)** </td>
<td> [[ 0.67826139]
[ 0.29380381]
[ 0.90714982]
[ 0.52835647]
[ 0.4215251 ]
[ 0.45017551]
[ 0.92814219]
[ 0.96677647]
[ 0.85304703]
[ 0.52351845]
[ 0.19981397]
[ 0.27417313]
[ 0.60659855]
[ 0.00533165]
[ 0.10820313]
[ 0.49978937]
[ 0.34144279]
[ 0.94630077]]</td>
</tr>
</table>
### 1.4 - Normalizing rows
Another common technique we use in Machine Learning and Deep Learning is to normalize our data. It often leads to a better performance because gradient descent converges faster after normalization. Here, by normalization we mean changing x to $ \frac{x}{\| x\|} $ (dividing each row vector of x by its norm).
For example, if $$x =
\begin{bmatrix}
0 & 3 & 4 \\
2 & 6 & 4 \\
\end{bmatrix}\tag{3}$$ then $$\| x\| = np.linalg.norm(x, axis = 1, keepdims = True) = \begin{bmatrix}
5 \\
\sqrt{56} \\
\end{bmatrix}\tag{4} $$and $$ x\_normalized = \frac{x}{\| x\|} = \begin{bmatrix}
0 & \frac{3}{5} & \frac{4}{5} \\
\frac{2}{\sqrt{56}} & \frac{6}{\sqrt{56}} & \frac{4}{\sqrt{56}} \\
\end{bmatrix}\tag{5}$$ Note that you can divide matrices of different sizes and it works fine: this is called broadcasting and you're going to learn about it in part 5.
**Exercise**: Implement normalizeRows() to normalize the rows of a matrix. After applying this function to an input matrix x, each row of x should be a vector of unit length (meaning length 1).
```
# GRADED FUNCTION: normalizeRows
def normalizeRows(x):
"""
Implement a function that normalizes each row of the matrix x (to have unit length).
Argument:
x -- A numpy matrix of shape (n, m)
Returns:
x -- The normalized (by row) numpy matrix. You are allowed to modify x.
"""
### START CODE HERE ### (≈ 2 lines of code)
# Compute x_norm as the norm 2 of x. Use np.linalg.norm(..., ord = 2, axis = ..., keepdims = True)
x_norm = np.linalg.norm(x, axis=1, keepdims=True)
# Divide x by its norm.
x = x/x_norm
### END CODE HERE ###
return x
x = np.array([
[0, 3, 4],
[1, 6, 4]])
print("normalizeRows(x) = " + str(normalizeRows(x)))
```
**Expected Output**:
<table style="width:60%">
<tr>
<td> **normalizeRows(x)** </td>
<td> [[ 0. 0.6 0.8 ]
[ 0.13736056 0.82416338 0.54944226]]</td>
</tr>
</table>
**Note**:
In normalizeRows(), you can try to print the shapes of x_norm and x, and then rerun the assessment. You'll find out that they have different shapes. This is normal given that x_norm takes the norm of each row of x. So x_norm has the same number of rows but only 1 column. So how did it work when you divided x by x_norm? This is called broadcasting and we'll talk about it now!
### 1.5 - Broadcasting and the softmax function ####
A very important concept to understand in numpy is "broadcasting". It is very useful for performing mathematical operations between arrays of different shapes. For the full details on broadcasting, you can read the official [broadcasting documentation](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html).
**Exercise**: Implement a softmax function using numpy. You can think of softmax as a normalizing function used when your algorithm needs to classify two or more classes. You will learn more about softmax in the second course of this specialization.
**Instructions**:
- $ \text{for } x \in \mathbb{R}^{1\times n} \text{, } softmax(x) = softmax(\begin{bmatrix}
x_1 &&
x_2 &&
... &&
x_n
\end{bmatrix}) = \begin{bmatrix}
\frac{e^{x_1}}{\sum_{j}e^{x_j}} &&
\frac{e^{x_2}}{\sum_{j}e^{x_j}} &&
... &&
\frac{e^{x_n}}{\sum_{j}e^{x_j}}
\end{bmatrix} $
- $\text{for a matrix } x \in \mathbb{R}^{m \times n} \text{, $x_{ij}$ maps to the element in the $i^{th}$ row and $j^{th}$ column of $x$, thus we have: }$ $$softmax(x) = softmax\begin{bmatrix}
x_{11} & x_{12} & x_{13} & \dots & x_{1n} \\
x_{21} & x_{22} & x_{23} & \dots & x_{2n} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
x_{m1} & x_{m2} & x_{m3} & \dots & x_{mn}
\end{bmatrix} = \begin{bmatrix}
\frac{e^{x_{11}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{12}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{13}}}{\sum_{j}e^{x_{1j}}} & \dots & \frac{e^{x_{1n}}}{\sum_{j}e^{x_{1j}}} \\
\frac{e^{x_{21}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{22}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{23}}}{\sum_{j}e^{x_{2j}}} & \dots & \frac{e^{x_{2n}}}{\sum_{j}e^{x_{2j}}} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
\frac{e^{x_{m1}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m2}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m3}}}{\sum_{j}e^{x_{mj}}} & \dots & \frac{e^{x_{mn}}}{\sum_{j}e^{x_{mj}}}
\end{bmatrix} = \begin{pmatrix}
softmax\text{(first row of x)} \\
softmax\text{(second row of x)} \\
... \\
softmax\text{(last row of x)} \\
\end{pmatrix} $$
```
# GRADED FUNCTION: softmax
def softmax(x):
"""Calculates the softmax for each row of the input x.
Your code should work for a row vector and also for matrices of shape (n, m).
Argument:
x -- A numpy matrix of shape (n,m)
Returns:
s -- A numpy matrix equal to the softmax of x, of shape (n,m)
"""
### START CODE HERE ### (≈ 3 lines of code)
# Apply exp() element-wise to x. Use np.exp(...).
x_exp = np.exp(x)
# Create a vector x_sum that sums each row of x_exp. Use np.sum(..., axis = 1, keepdims = True).
x_sum = np.sum(x_exp, axis=1, keepdims=True)
# Compute softmax(x) by dividing x_exp by x_sum. It should automatically use numpy broadcasting.
s = x_exp/x_sum
### END CODE HERE ###
return s
x = np.array([
[9, 2, 5, 0, 0],
[7, 5, 0, 0 ,0]])
print("softmax(x) = " + str(softmax(x)))
```
**Expected Output**:
<table style="width:60%">
<tr>
<td> **softmax(x)** </td>
<td> [[ 9.80897665e-01 8.94462891e-04 1.79657674e-02 1.21052389e-04
1.21052389e-04]
[ 8.78679856e-01 1.18916387e-01 8.01252314e-04 8.01252314e-04
8.01252314e-04]]</td>
</tr>
</table>
**Note**:
- If you print the shapes of x_exp, x_sum and s above and rerun the assessment cell, you will see that x_sum is of shape (2,1) while x_exp and s are of shape (2,5). **x_exp/x_sum** works due to python broadcasting.
Congratulations! You now have a pretty good understanding of python numpy and have implemented a few useful functions that you will be using in deep learning.
<font color='blue'>
**What you need to remember:**
- np.exp(x) works for any np.array x and applies the exponential function to every coordinate
- the sigmoid function and its gradient
- image2vector is commonly used in deep learning
- np.reshape is widely used. In the future, you'll see that keeping your matrix/vector dimensions straight will go toward eliminating a lot of bugs.
- numpy has efficient built-in functions
- broadcasting is extremely useful
## 2) Vectorization
In deep learning, you deal with very large datasets. Hence, a non-computationally-optimal function can become a huge bottleneck in your algorithm and can result in a model that takes ages to run. To make sure that your code is computationally efficient, you will use vectorization. For example, try to tell the difference between the following implementations of the dot/outer/elementwise product.
```
import time
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### CLASSIC DOT PRODUCT OF VECTORS IMPLEMENTATION ###
tic = time.process_time()
dot = 0
for i in range(len(x1)):
dot+= x1[i]*x2[i]
toc = time.process_time()
print ("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC OUTER PRODUCT IMPLEMENTATION ###
tic = time.process_time()
outer = np.zeros((len(x1),len(x2))) # we create a len(x1)*len(x2) matrix with only zeros
for i in range(len(x1)):
for j in range(len(x2)):
outer[i,j] = x1[i]*x2[j]
toc = time.process_time()
print ("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC ELEMENTWISE IMPLEMENTATION ###
tic = time.process_time()
mul = np.zeros(len(x1))
for i in range(len(x1)):
mul[i] = x1[i]*x2[i]
toc = time.process_time()
print ("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC GENERAL DOT PRODUCT IMPLEMENTATION ###
W = np.random.rand(3,len(x1)) # Random 3*len(x1) numpy array
tic = time.process_time()
gdot = np.zeros(W.shape[0])
for i in range(W.shape[0]):
for j in range(len(x1)):
gdot[i] += W[i,j]*x1[j]
toc = time.process_time()
print ("gdot = " + str(gdot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### VECTORIZED DOT PRODUCT OF VECTORS ###
tic = time.process_time()
dot = np.dot(x1,x2)
toc = time.process_time()
print ("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED OUTER PRODUCT ###
tic = time.process_time()
outer = np.outer(x1,x2)
toc = time.process_time()
print ("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED ELEMENTWISE MULTIPLICATION ###
tic = time.process_time()
mul = np.multiply(x1,x2)
toc = time.process_time()
print ("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED GENERAL DOT PRODUCT ###
tic = time.process_time()
dot = np.dot(W,x1)
toc = time.process_time()
print ("gdot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
```
As you may have noticed, the vectorized implementation is much cleaner and more efficient. For bigger vectors/matrices, the differences in running time become even bigger.
**Note** that `np.dot()` performs a matrix-matrix or matrix-vector multiplication. This is different from `np.multiply()` and the `*` operator (which is equivalent to `.*` in Matlab/Octave), which performs an element-wise multiplication.
### 2.1 Implement the L1 and L2 loss functions
**Exercise**: Implement the numpy vectorized version of the L1 loss. You may find the function abs(x) (absolute value of x) useful.
**Reminder**:
- The loss is used to evaluate the performance of your model. The bigger your loss is, the more different your predictions ($ \hat{y} $) are from the true values ($y$). In deep learning, you use optimization algorithms like Gradient Descent to train your model and to minimize the cost.
- L1 loss is defined as:
$$\begin{align*} & L_1(\hat{y}, y) = \sum_{i=0}^m|y^{(i)} - \hat{y}^{(i)}| \end{align*}\tag{6}$$
```
# GRADED FUNCTION: L1
def L1(yhat, y):
"""
Arguments:
yhat -- vector of size m (predicted labels)
y -- vector of size m (true labels)
Returns:
loss -- the value of the L1 loss function defined above
"""
### START CODE HERE ### (≈ 1 line of code)
loss = np.sum(np.abs(yhat - y))
### END CODE HERE ###
return loss
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L1 = " + str(L1(yhat,y)))
```
**Expected Output**:
<table style="width:20%">
<tr>
<td> **L1** </td>
<td> 1.1 </td>
</tr>
</table>
**Exercise**: Implement the numpy vectorized version of the L2 loss. There are several way of implementing the L2 loss but you may find the function np.dot() useful. As a reminder, if $x = [x_1, x_2, ..., x_n]$, then `np.dot(x,x)` = $\sum_{j=0}^n x_j^{2}$.
- L2 loss is defined as $$\begin{align*} & L_2(\hat{y},y) = \sum_{i=0}^m(y^{(i)} - \hat{y}^{(i)})^2 \end{align*}\tag{7}$$
```
# GRADED FUNCTION: L2
def L2(yhat, y):
"""
Arguments:
yhat -- vector of size m (predicted labels)
y -- vector of size m (true labels)
Returns:
loss -- the value of the L2 loss function defined above
"""
### START CODE HERE ### (≈ 1 line of code)
loss = np.sum((yhat - y)**2)
### END CODE HERE ###
return loss
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L2 = " + str(L2(yhat,y)))
```
**Expected Output**:
<table style="width:20%">
<tr>
<td> **L2** </td>
<td> 0.43 </td>
</tr>
</table>
Congratulations on completing this assignment. We hope that this little warm-up exercise helps you in the future assignments, which will be more exciting and interesting!
<font color='blue'>
**What to remember:**
- Vectorization is very important in deep learning. It provides computational efficiency and clarity.
- You have reviewed the L1 and L2 loss.
- You are familiar with many numpy functions such as np.sum, np.dot, np.multiply, np.maximum, etc...
| github_jupyter |
### HCR using LeNet
```
import numpy as np
import pandas as pd
from matplotlib.pyplot import imshow
import matplotlib.pyplot as plt
from PIL import Image
from random import randint
import keras
from keras.models import Model, Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense, Input
X_FNAME = "/content/alphanum-hasy-data-X.npy"
Y_FNAME = "/content/alphanum-hasy-data-y.npy"
SYMBOL_FNAME = "/content/symbols.csv"
X = np.load(X_FNAME)
y = np.load(Y_FNAME)
SYMBOLS = pd.read_csv(SYMBOL_FNAME)
SYMBOLS = SYMBOLS[["symbol_id", "latex"]]
print("X.shape", X.shape)
print("y.shape", y.shape)
print("SYMBOLS")
SYMBOLS.head(2)
```
<h1> Analysing the data
```
def symbol_id_to_symbol(symbol_id = None):
if symbol_id:
symbol_data = SYMBOLS.loc[SYMBOLS['symbol_id'] == symbol_id]
if not symbol_data.empty:
return str(symbol_data["latex"].values[0])
else:
print("This should not have happend, wrong symbol_id = ", symbol_id)
return None
else:
print("This should not have happend, no symbol id passed")
return None
# test some values
print("21 = ", symbol_id_to_symbol(21))
print("32 = ", symbol_id_to_symbol(32))
print("90 = ", symbol_id_to_symbol(90))
f, ax = plt.subplots(2, 3, figsize=(12, 10))
ax_x = 0
ax_y = 0
for i in range(6):
randKey = randint(0, X.shape[0])
ax[ax_x, ax_y].imshow(X[randKey], cmap='gray')
ax[ax_x, ax_y].title.set_text("Value : " + symbol_id_to_symbol(y[randKey]))
# for proper subplots
if ax_x == 1:
ax_x = 0
ax_y = ax_y + 1
else:
ax_x = ax_x + 1
# print labels vs frequency matrix
unique, counts = np.unique(y, return_counts=True)
y_info_dict = { "labels" : unique, "counts": counts }
y_info_frame = pd.DataFrame(y_info_dict)
y_info_frame["labels"] = y_info_frame["labels"].apply(lambda x: symbol_id_to_symbol(x))
y_info_frame.head()
y_info_frame.shape
f, ax = plt.subplots(figsize=(10, 20))
my_colors = ['r', 'g', 'b', 'k', 'y', 'm', 'c']
y_info_frame["counts"].plot(kind='barh', legend=False, color=my_colors, alpha=0.5)
wrap = ax.set_yticklabels(list(y_info_frame["labels"]))
rects = ax.patches
bar_labels_counts = list(y_info_frame["counts"])
for i in range(len(bar_labels_counts)):
label_value = str(bar_labels_counts[i])
ax.text(40, rects[i].get_y(), label_value, ha='center',
va='bottom', size='medium', color="black", fontweight="bold")
```
<h1> Pre processing data </h1>
```
X.shape ## already in 32*32 shape
cv2_imshow(X[0])
np.unique(y)
y_new = []
for val in y:
if val >=31 and val <=56:
val = val-31
y_new.append(val)
elif val >=70 and val <=79:
val = val-44
y_new.append(val)
else:
val = val-54
y_new.append(val)
y_n = np.array(y_new)
y_n.shape
from tensorflow.keras.utils import to_categorical
y_onehot = to_categorical(y_n, num_classes=62)
print("Shape of y:", y_onehot.shape)
print("One value of y:", y_onehot[0])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2)
print("Train dataset shape")
print(X_train.shape, y_train.shape)
print("Test dataset shape")
print(X_test.shape, y_test.shape)
X_train = X_train.reshape(X_train.shape[0], 32, 32, 1) #grayscale
X_test = X_test.reshape(X_test.shape[0], 32, 32, 1)
# normalize data
X_train = X_train / 255.0
X_test = X_test / 255.0
```
<h1> LeNet model </h1>
```
np.random.seed(0)
model = Sequential()
model.add(Conv2D(filters=6, kernel_size=(5, 5), activation='relu', input_shape=(32,32,1)))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
model.add(Conv2D(filters=16, kernel_size=(5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=1))
model.add(Flatten())
model.add(Dense(units=120, activation='relu'))
model.add(Dense(units=84, activation='relu'))
model.add(Dense(units=62, activation = 'softmax'))
model.summary()
model.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer="adam")
history = model.fit(x = X_train, y = y_train, batch_size = 32, epochs = 20)
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train'], loc='upper right')
plt.show()
plt.plot(history.history['accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train'], loc='upper left')
plt.show()
model.evaluate(X_test, y_test)
```
### Adding a dropout layer
```
model_dropout = Sequential()
model_dropout.add(Conv2D(filters=6, kernel_size=(5, 5), activation='relu', input_shape=(32,32,1)))
model_dropout.add(MaxPooling2D(pool_size=(2, 2), strides=2))
model_dropout.add(Conv2D(filters=16, kernel_size=(5, 5), activation='relu'))
model_dropout.add(MaxPooling2D(pool_size=(2, 2), strides=1))
model_dropout.add(Dropout(rate=0.2))
model_dropout.add(Flatten())
model_dropout.add(Dense(units=120, activation='relu'))
model_dropout.add(Dense(units=84, activation='relu'))
model_dropout.add(Dense(units=62, activation = 'softmax'))
model_dropout.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer="adam")
history = model_dropout.fit(x = X_train, y = y_train, batch_size = 32, epochs = 15)
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train'], loc='upper right')
plt.show()
plt.plot(history.history['accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train'], loc='upper left')
plt.show()
model_dropout.evaluate(X_test, y_test) ## accuracy increased
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import requests as req
import shapely as shp
from pandana.loaders import osm
from time import sleep
```
### We need to give OSM an area to consider for the query. We do this by creating a bounding box around the area we are interested in; in this case, Portland
```
# save the bounding box--PDX
bbox = {'xmax': -122.2575, 'ymax': 45.7859, 'xmin': -123.1095, 'ymin': 45.1453}
nw = shp.geometry.Point(bbox['xmin'], bbox['ymax'])
sw = shp.geometry.Point(bbox['xmin'], bbox['ymin'])
se = shp.geometry.Point(bbox['xmax'], bbox['ymin'])
ne = shp.geometry.Point(bbox['xmax'], bbox['ymax'])
pd.set_option('max_columns', None)
```
### OSM has a lot of data and we don't want to be overwhelmed. We can use the taginfo api to get useful meta data from OSM
```
# get the most frequently used amenity tag in OSM from the taginfo api
r = req.get('https://taginfo.openstreetmap.org/api/4/tags/popular?query=amenity')
r.status_code
```
#### Convert the json to a dataframe for easy use
```
tags = pd.concat(pd.DataFrame.from_dict(d, orient='index').transpose() for d in r.json()['data'])
tags.sort_values(by='count_nodes', ascending=False)
# the loader for some reason can't take a list of tags so we will have to iterate and concat
tag_pairs = tags.apply(lambda row: row['key'] + '=' + row['value'], axis=1).tolist()
tag_pairs
# we are only interested in some of these; let's filter now to spare the api
keepers = ['restaurant', 'cafe', 'pub', 'bar', 'theater', 'college', 'cinema', 'arts_centre', 'nightclub', 'university']
new_ls = []
for keeper in keepers:
new_ls.append('amenity={}'.format(keeper))
new_ls
```
### Generally, the OSM api is not meant to be used over such a large area. In thise case since we are interested in such a small subset of data it will do. Still, the sleep time (t) might need adjusting in order to get the data back. Too long and you risk timing out, too short you might get throttled
```
def pdx_amenities(pairs):
t = 4
dfs = []
for pair in pairs:
try:
df = osm.node_query(bbox['ymin'], bbox['xmin'], bbox['ymax'], bbox['xmax'], tags=pair).reset_index()
keep_cols = ['id', 'lat', 'lon']
if 'name' in df.columns.tolist():
keep_cols.append('name')
df = df[keep_cols]
df['amenity'] = pair.split('=')[1]
dfs.append(df)
except RuntimeError as e:
print(pair + ': ')
print(e)
# try to avoid auto throttle
sleep(t)
return pd.concat(dfs, ignore_index=True)
test = pdx_amenities(new_ls)
test.head(20)
test.groupby('amenity').size().sort_values(ascending=False)
test.id.size
# create some useful grouping
test['alias'] = test.apply(lambda row: 'food_drink' if row['amenity'] in ('restaurant', 'pub', 'bar') else 'entertainment' if row['amenity'] in ('cinema', 'arts_centre', 'nightclub', 'theater') else 'college' if row['amenity'] in ('college', 'university') else row['amenity'], axis=1)
test
```
### Write the data to a csv for later use
```
test.to_csv('./data/osm.csv', index=False)
```
| github_jupyter |
```
%%capture
!rm -rf shakespeare_data/plays_xml
!unzip -P rtad shakespeare_data/plays.zip -d shakespeare_data/plays_xml
%%capture
import numpy as np
import networkx as nx
from lxml import etree
import itertools
from datascience import *
import matplotlib.pyplot as plt
%matplotlib inline
```
# Social Network Analysis: NetworkX
Mark Algee-Hewitt looks at thousands of plays across centuries. But as we've learned so far, to do this we first have to figure out how to calculate the metrics we're interested in for a single text. Let's take a look at a single play. Luckily, there are databases that exists that have already annotated a lot of plays in a markup language called XML. Especially well researched corpora have extensive metadata. We'll look at the Shakespeare corpus with data obtained from https://www.playshakespeare.com/ .
We'll start by looking at *Othello*.
```
with open("shakespeare_data/plays_xml/othello_ps_v3.xml") as f:
othello_xml = etree.fromstring(f.read().encode())
```
If we're trying to build a network we need two things: 1) nodes and 2) edges. For Algee-Hewitt, and for us today, that means we need to know the characters in *Othello*, and with whom they communicate. We'd also like to know how often that specific interaction occurs.
We can get all elements of the XML tree by `iter`ating over all the nodes:
```
all_elements = list(othello_xml.iter())
all_elements
```
That's a lot of information! Let's grab out all of the speakers. All the `speaker` elements will have a `text` attribute that has their actual name, or abbreviation of their name.
```
[e.text for e in all_elements if e.tag == "speaker"]
```
To get a unique list we'll use `set`:
```
set([e.text for e in all_elements if e.tag == "speaker"])
```
Great start! In Network Analysis there are two fundamental principles. A ***node*** is an entity, it can have relationships with other entities. In literature, this is often a character, but it could be a Twitter user, organization, geographic location, or even words!
We may be interested in a node's properties. If it's a character, we may want to know how often they speak, age, etc. We can add this to the network as further layers.
The second concept is an ***edge***. An edge connects nodes. We're foremost interested in the volume of connections between nodes. For literature, this would be the number of times two characters interact.
As we learned from Moretti and our readings for today, this is a very difficult task for most texts. Where does on character's speech end and another's begin? Luckily, in plays this is slightly easier to identify (though still not perfectly clear).
For Shakespeare, we'll settle for them being present in the same *scene*. If they're in the same scene together, we'll increase our measure of their interaction.
Thus for each character we want to know how many lines the speak in the entire play, along with which scenes they appear in. We can then collate this wil the other characters.
The `get_cast_dict` function below will parse the XML data and extract this information.
```
cast_dict = {}
for c in set([e.text for e in all_elements if e.tag == "speaker"]):
cast_dict[c] = {"num_lines": 0,
"scenes": []}
cast_dict
# extract all scene elements from the xml
scenes = [e for e in all_elements if e.tag == "scene"]
scenes
elements = [e.find("acttitle").text for e in all_elements if e.tag == "act"]
def get_cast_dict(all_elements):
'''
returns a dictionary with the total number of lines and scenes a character appears in
'''
cast_dict = {}
# first get a unique set of all characters appearing in the play
for c in set([e.text for e in all_elements if e.tag == "speaker"]):
cast_dict[c] = {"num_lines": 0,
"scenes": []}
# extract all scene elements from the xml
scenes = [e for e in all_elements if e.tag == "scene"]
acts = [e for e in all_elements if e.tag == "act"]
# acts = [e.find("acttitle").text for e in all_elements if e.tag == "act"]
for a in acts:
# get title of acts
act_title = a.find("acttitle").text
# get scene elements
scenes = [e for e in a if e.tag == "scene"]
# iterate through each scene
for sc in scenes:
# grab all the speeches in the scene
speeches = [s for s in sc.getchildren() if s.tag == "speech"]
# iterate through speeches
for s in speeches:
# increment number of lines for the speaker
cast_dict[s.find("speaker").text]["num_lines"] += len(s.findall("line"))
# find all the speaker for each speech
speakers = [s.find("speaker").text for s in speeches]
# add the title of the scene for each speaker appearing in the scene
for s in set(speakers):
cast_dict[s]["scenes"].append(act_title + " " + sc.find("scenetitle").text)
# reassign scenes to only a unique set
for c in cast_dict.keys():
cast_dict[c]["scenes"] = list(set(cast_dict[c]["scenes"]))
return cast_dict
cast_dict = get_cast_dict(all_elements)
cast_dict
```
That's all we need to make a basic network and do some analysis! We have all the character names and the scenes in which they appear. We can collate some of this information to find out in which scenes certain characters appear together. This will happen in our `make_graph` function.
The `NetworkX` Python library will parse this dictionary for us to make a graph object. Let's write a function:
```
def make_graph(c_dict):
'''
This function accepts a dictionary with number of lines and scenes to create a
NetworkX graph object
'''
# setup graph object
G = nx.Graph()
# add nodes with attributes of number of lines and scenes
for c in c_dict.keys():
if c_dict[c]["num_lines"] > 0:
G.add_node(
c,
number_of_lines=c_dict[c]["num_lines"],
scenes=c_dict[c]["scenes"]
)
# make edges by iterating over all combinations of nodes
for (node1, data1), (node2, data2) in itertools.combinations(G.nodes(data=True), 2):
# count scenes together by getting union of their sets
scenes_together = len(set(data1['scenes']) & set(data2['scenes']))
if scenes_together:
# add more weight for more scenes together
G.add_edge(node1, node2, weight=scenes_together)
return G
G = make_graph(cast_dict)
```
We can graph this using `matplotlib`:
```
# nodes should be sized by number of lines
node_size = [data['number_of_lines'] for __, data in G.nodes(data=True)]
node_color = 'blue'
plt.figure(figsize=(13,8)) # make the figure size a little larger
plt.axis('off') # remove the axis, which isn't meaningful in this case
plt.title("Othello's Social Network", fontsize=20)
# The 'k' argument determines how spaced out the nodes will be from
# one another on the graph.
pos = nx.spring_layout(G, k=0.5)
nx.draw_networkx(
G,
pos=pos,
node_size=node_size,
node_color=node_color,
edge_color='gray', # change edge color
alpha=0.3, # make nodes more transparent to make labels clearer
font_size=14,
)
```
Our graph, `G`, is a powerful object. We can calculate many of the standard network analysis statistics. There are various measures of centrality, many of which were referenced in the reading.
```
network_tab = Table()
network_tab.append_column(label="Characters", values=[c for c in sorted(cast_dict.keys())])
network_tab.show()
```
Wikipedia defines "[degree centrality](https://en.wikipedia.org/wiki/Centrality#Degree_centrality)":
>Historically first and conceptually simplest is degree centrality, which is defined as the number of links incident upon a node (i.e., the number of ties that a node has).
```
dc = [x[1] for x in sorted(nx.degree_centrality(G).items(), key=lambda x: x[0])]
network_tab.append_column(label="Degree Centrality", values=dc)
network_tab.show()
```
Wikipedia defines "[betweeness centrality](https://en.wikipedia.org/wiki/Centrality#Betweenness_centrality)":
>Betweenness is a centrality measure of a vertex within a graph (there is also edge betweenness, which is not discussed here). Betweenness centrality quantifies the number of times a node acts as a bridge along the shortest path between two other nodes.
```
bc = [x[1] for x in sorted(nx.betweenness_centrality(G).items(), key=lambda x: x[0])]
network_tab.append_column(label="Betweenness Centrality", values=bc)
network_tab.show()
```
Wikipedia defines "[eigenvector centrality](https://en.wikipedia.org/wiki/Centrality#Eigenvector_centrality)":
> Eigenvector centrality (also called eigencentrality) is a measure of the influence of a node in a network. It assigns relative scores to all nodes in the network based on the concept that connections to high-scoring nodes contribute more to the score of the node in question than equal connections to low-scoring nodes.
>$x_v = \frac{1}{\lambda} \sum_{t \in M(v)}x_t = \frac{1}{\lambda} \sum_{t \in G} a_{v,t}x_t$
```
ec = [x[1] for x in sorted(nx.eigenvector_centrality(G).items(), key=lambda x: x[0])]
network_tab.append_column(label="Eigenvector Centrality", values=ec)
network_tab.show()
```
# Challenge
What is the overlap ((rank) correlation) between the three measurements presented above? What does that mean for the play?
# Bonus: Making a prettier graph
`matplotlib` isn't always the most beautiful option. A popular way of visualizing networks is by using Javascript's [D3](https://d3js.org/) library. Luckily, `networkx` allows us to export the network information to JSON:
```
from networkx.readwrite import json_graph
import json
d3_data = json_graph.node_link_data(G)
d3_data
```
We can then add this to a D3 template:
```
import re
with open('network.html', 'r') as f:
net_html = f.read()
pattern = re.compile(r'(<script type="application/json" id="net">)(\s*.*)')
net_html = net_html.replace(re.findall(pattern, net_html)[-1][-1].strip(), json.dumps(d3_data).strip())
with open('network.html', 'w') as f:
f.write(net_html)
```
We'll then `IFrame` in the HTML file
```
from IPython.display import IFrame
IFrame('network.html', width=700, height=900)
```
---
# Gini Coefficient
Algee-Hewitt was calculating the gini coefficient of the eigenvector centralities. He essentially wanted to know whether importance in a network was evenly distributed, or concentrated in the hands of a few. The lower the gini coefficient, the more equal the distribution, the closer to 1, the closer one gets to complete inequality. I've found a function online that will calculate the gini coefficient for you!
```
def gini(array):
"""Calculate the Gini coefficient of a numpy array."""
# https://github.com/oliviaguest/gini
array = np.sort(array) # values must be sorted
index = np.arange(1, array.shape[0] + 1) # index per array element
n = array.shape[0] # number of array elements
return ((np.sum((2 * index - n - 1) * array)) / (n * np.sum(array))) #Gini coefficient
```
Just to demonstrate, let's make a very unequal array:
```
np.concatenate((np.zeros(99), np.ones(1)))
```
The gini coefficient should be close to 1:
```
gini(np.concatenate((np.zeros(99), np.ones(1))))
```
What if we have half zeroes and half ones?
```
gini(np.concatenate((np.zeros(50), np.ones(50))))
```
All ones?
```
gini(np.ones(50))
```
Now we can use the `gini` function on *Othello* to see how evenly distributed centrality is:
```
import numpy as np
gini(network_tab['Eigenvector Centrality'])
```
Great, but that's not terribly interesting itself, we want to see how it relates to other plays. We'll do that for homework.
First, let's write a function to calculate Algee-Hewitt's second measure. He takes the percentage of characters in the top quartile of eigenvector centralities. You'll want to use the `np.percentile` method!
## Challenge
```
def percentage_top_quartile(character_table):
# YOUR CODE HERE
return percentage
percentage_top_quartile(network_tab['Eigenvector Centrality'])
```
# Homework
I've downloaded 40 other Shakespeare texts in the exact same XML structure.
```
!ls shakespeare_data/plays_xml/
```
Write some code to loop through at least 5 of these plays and print the most central character in each play according to eigenvector centrality:
Now use the `gini` function to calculate the gini coefficient of the eigenvector centralities for each of the 5 plays and create a bar chart. Do the same for the percentage in the top quartile. What do these results mean?
Much of this code is adapted from http://www.adampalay.com/blog/2015/04/17/shakespeare-social-networks/ .
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.