
code stringlengths 38 801k | repo_path stringlengths 6 263 |
|---|---|
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: env37
# language: python
# name: env37
# ---
# # 5. Live coding
# This notebook will show you how we analyse a text in real life. To do so, we will examine two judge responses to asylum's claims in the UK.
#
#
#
#
#
#
# Legend of symbols:
#
# - 🤓: Tips
#
# - 🤖📝: Your turn
#
# - ❓: Question
#
# - 💫: Extra exercise
# ## 5.1. Read text
# As we have learned in this course, the first step is to import the text into this notebook.
#
# Two approaches:
#
# - 1) Copy and paste content in a **<tt>.txt<tt>** file.
# - 2) Install **<tt>pdftotext<tt>**: https://github.com/jalan/pdftotext.
# 1)
# Read the raw file from txt
f = open('../data/asylum_claims.txt','r')
text = f.read()
f.close()
text
# Let's substitute \n by spaces
import re
text = re.sub('\n', ' ', text)
print(text)
# +
# !pip install pdfplumber
import pdfplumber
with pdfplumber.open("../data/PA059452018.pdf") as pdf:
first_page = pdf.pages[0]
pdf_11 = first_page.extract_text()
second_page = pdf.pages[1]
pdf_12 = second_page.extract_text()
third_page = pdf.pages[2]
pdf_13 = third_page.extract_text()
fourth_page = pdf.pages[3]
pdf_14 = first_page.extract_text()
fifth_page = pdf.pages[4]
pdf_15 = fifth_page.extract_text()
pdf_1 = pdf_11 + "\n" + pdf_12 + "\n" + pdf_13 + "\n" + pdf_14 + "\n" + pdf_15
# -
pdf_1
# +
with pdfplumber.open("../data/PA002402019.pdf") as pdf:
first_page = pdf.pages[0]
pdf_21 = first_page.extract_text()
second_page = pdf.pages[1]
pdf_22 = second_page.extract_text()
third_page = pdf.pages[2]
pdf_23 = third_page.extract_text()
fourth_page = pdf.pages[3]
pdf_24 = first_page.extract_text()
fifth_page = pdf.pages[4]
pdf_25 = fifth_page.extract_text()
pdf_2 = pdf_21 + "\n" + pdf_22 + "\n" + pdf_23 + "\n" + pdf_24 + "\n" + pdf_25
pdf = pdf_1 + "\n" + pdf_2
print(pdf)
# -
pdf
# ## 5.2. Basic statistics
# 🤓 It is important when analysing text to know the basic figures:
# - How many words do we have?
# - How many sentences?
# - What are the most common words?
#
#
# ❓ More questions?
# ### 5.2.1. How many words do we have?
# How many words do we have?
words_txt = text.split()
len(words_txt)
words_txt
words_pdf = pdf.split()
len(words_pdf)
words_pdf
# Word that are not common between the two lists.
set(words_pdf) ^ set(words_txt)
# ### 5.2.2. How many sentences do we have?
# How many sentences do we have?
sent_txt = text.split('.')
len(sent_txt)
# How many sentences do we have?
sent_pdf = pdf.split('.')
len(sent_pdf)
# +
# How many sentences do we have?
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
sent_txt_nltk = sent_tokenize(text)
print(len(sent_txt_nltk))
# -
# How many sentences do we have?
sent_pdf_nltk = sent_tokenize(pdf)
print(len(sent_pdf_nltk))
# ### 5.2.3. What are the most common words?
# +
# What are the most common words?
wordfreq_txt = []
# count words in text
for w in words_txt:
wordfreq_txt.append(words_txt.count(w))
# create a list with words and its frequency
word_list = list(set(zip(words_txt, wordfreq_txt)))
print("Pairs\n" + str(word_list))
# +
# What are the most common words?
wordfreq_pdf = []
# count words in text
for w in words_pdf:
wordfreq_pdf.append(words_pdf.count(w))
# create a list with words and its frequency
word_list = list(set(zip(words_pdf, wordfreq_pdf)))
# function to sort the list by second item of tuple
def sort_pairs(tup):
# reverse = None (Sorts in Ascending order)
# key is set to sort using second element of
# sublist lambda has been used
return(sorted(tup, key = lambda x: x[1], reverse = True))
word_list_sort = sort_pairs(word_list)
print("Pairs\n" + str(word_list_sort))
# +
import pandas as pd
df = pd.DataFrame(word_list_sort)
df.columns = ['words', 'counts']
# -
df.head()
# +
# !pip install matplotlib
# !pip install plotly
# !pip install kaleido
import matplotlib.pyplot as plt
import plotly.express as px
fig = px.bar(df.loc[0:10,:], x='counts', y='words', orientation='h', text = 'words',
labels={
"counts": "Frequency",
"words": "Words"
},)
fig.layout.yaxis.type = 'category'
fig.update_layout(yaxis_categoryorder = 'total ascending')
fig.update_layout(yaxis=dict(showticklabels=False))
fig.update_traces(texttemplate='%{text}', textposition='auto', marker_color='green')
fig.update_layout(uniformtext_minsize=8, uniformtext_mode='hide', title={
'text': "Words Frequency in Tribunal Appeals",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.update_layout(
autosize=False,
width=1050,
height=500)
fig.show()
# -
# ❓ Does that give information of the content?
# ## 5.3. Clean text
# We now clean the text with some techniques we have learned.
# ### 5.3.1. Lowercase
# Remove capital letters
text_clean = ' '.join(w.lower() for w in text.split())
text_clean
# ### 5.3.2. Stop words
# Remove stopwords
from nltk.corpus import stopwords
nltk.download('stopwords')
stopwords = stopwords.words('english')
text_clean = ' '.join(w for w in text_clean.split() if w not in stopwords)
text_clean
# ### 5.3.3. Lemmatization
# +
# Remove puncutaction symbols
import spacy
nlp = spacy.load('en_core_web_sm')
text_clean = [[token.lemma_ for token in sentence] for sentence in nlp(text_clean).sents]
# -
text_clean_flat = [word for sent in text_clean for word in sent]
text_clean_flat
# ### 5.3.4. Count words
# +
from collections import Counter
text_clean_counter = dict(Counter(text_clean_flat))
# -
text_clean_counter
df_clean = pd.DataFrame.from_dict(text_clean_counter, orient='index')
df_clean.head()
df_clean.loc['upper',:]
df_clean.reset_index(level=0, inplace=True)
df_clean.columns = ['words', 'counts']
df_clean
fig = px.bar(df_clean.loc[0:10,:], x='counts', y='words', orientation='h', text = 'words',
labels={
"counts": "Frequency",
"words": "Words"
},)
fig.layout.yaxis.type = 'category'
fig.update_layout(yaxis_categoryorder = 'total ascending')
fig.update_layout(yaxis=dict(showticklabels=False))
fig.update_traces(texttemplate='%{text}', textposition='auto', marker_color='purple')
fig.update_layout(uniformtext_minsize=8, uniformtext_mode='hide', title={
'text': "Words Frequency in Tribunal Appeals",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.update_layout(
autosize=False,
width=1050,
height=500)
fig.show()
# ## 5.4. Word cloud
# Now, let's show the word cloud of this text:
# +
import matplotlib.pyplot as plt
from wordcloud import WordCloud
word_cloud = WordCloud(background_color="white", repeat=True)
word_cloud.generate(text)
plt.axis("off")
plt.imshow(word_cloud, interpolation="bilinear")
plt.show()
# -
# ## 5.5. What we have learned?
# ### 🤖📝 Now it's your turn:
# 🤖📝 Find the word 'EURODAC' using the function **<tt>search<tt>** from the **<tt>re<tt>** package.
re.search('EURODAC', text)
df_clean.loc[df_clean['words'] == "eurodac"]
# 🤖📝 Create a word cloud with different colour pattern using the text from the PDF.
# +
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import numpy as np
word_cloud = WordCloud(background_color="white", repeat=True, max_words=50, colormap="plasma")
word_cloud.generate(pdf)
plt.axis("off")
plt.imshow(word_cloud, interpolation="bilinear")
plt.show()
# 'viridis', 'plasma', 'inferno', 'magma', 'cividis'
# -
# 🤖📝 Remove symbols from **<tt>df_clean<tt>** and plot again the frequency of words.
df_clean_2 = df_clean.loc[df_clean['words'] != '(']
df_clean_2 = df_clean_2.loc[df_clean_2['words'] != ')']
df_clean_2 = df_clean_2.loc[df_clean_2['words'] != ':']
df_clean_2 = df_clean_2.loc[df_clean_2['words'] != '&']
df_clean_2.head(20)
fig = px.bar(df_clean_2.loc[0:10,:], x='counts', y='words', orientation='h', text = 'words',
labels={
"counts": "Frequency",
"words": "Words"
},)
fig.layout.yaxis.type = 'category'
fig.update_layout(yaxis_categoryorder = 'total ascending')
fig.update_layout(yaxis=dict(showticklabels=False))
fig.update_traces(texttemplate='%{text}', textposition='auto', marker_color='purple')
fig.update_layout(uniformtext_minsize=8, uniformtext_mode='hide', title={
'text': "Words Frequency in Tribunal Appeals",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.update_layout(
autosize=False,
width=1050,
height=500)
fig.show()
text = re.sub('\(', ' ', text)
text = re.sub('\)', ' ', text)
text
| notebooks/05_live-coding_solutions.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Getting started with Spark: Spark SQL in Python
# This tutorial is based on [Spark SQL Guide - Getting started](https://spark.apache.org/docs/latest/sql-getting-started.html).
#
# For this demo we used the city of Vienna trees dataset ("Baumkataster") made available by [Open Data Österreich](https://www.data.gv.at) and downloadable from [here](https://www.data.gv.at/katalog/dataset/c91a4635-8b7d-43fe-9b27-d95dec8392a7) .
#
# # Table of contents
# 1. [Spark session](#sparkSession)
# 2. [Spark configuration](#sparkConfiguration)
# ## Spark session <a name="sparkSession"></a>
#
# We're going to start by creating a Spark _session_. Our Spark job will be named "Python Spark SQL basic example". `spark` is the variable holding our Spark session.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.getOrCreate()
# Read the file into a Spark [_dataframe_](https://spark.apache.org/docs/latest/sql-programming-guide.html#datasets-and-dataframes).
df = spark.read \
.load("FME_BaumdatenBearbeitet_OGD_20190205.csv",
format="csv", sep=";", header="true", encoding="iso-8859-1")
# **Note:** we assume that the file `FME_BaumdatenBearbeitet_OGD_20190205.csv` is in your local directory. If at this point you get an error message that looks like `AnalysisException: 'Path does not exist` then check your [Spark configuration](#sparkConfig) for how to define the correct file path.
# Show first three lines of Spark dataframe
df.show(3)
# For pretty-printing you can use `toPandas()`
df.toPandas().head(3)
# Show number of different trees (count German names in `df` and sort by count)
df.groupBy("NameDeutsch").count().orderBy('count', ascending=False).show()
# An example of SQL query (see [Running SQL Queries Programmatically](https://spark.apache.org/docs/latest/sql-getting-started.html#running-sql-queries-programmatically)): let's sort trees by height ("Hoehe").
df.createOrReplaceTempView("baeume")
spark.sql("SELECT BaumNr, NameDeutsch, Hoehe, lat, lon FROM baeume order by Hoehe desc").show()
# The height data doesn't seem to be up-to-date.
# ## Spark configuration <a name="sparkConfiguration"></a>
#
# Spark properties control most application settings and are configured separately for each application. These properties can be set directly on a `SparkConf` passed to your `SparkContext` (from [Apache Spark documentation](https://spark.apache.org/docs/latest/configuration.html#spark-properties)).
#
# We've already seen how to modify the `SparkConf` when we created our Spark application session with the command:
# <pre>
# spark = SparkSession \
# .builder \
# .appName("Python Spark SQL basic example") \
# .getOrCreate()
# </pre>
#
# Let us look at the rest of the Spark configuration.
from pyspark.conf import SparkConf
spark.sparkContext._conf.getAll()
# The property `spark.app.name` is the name of our app that we just defined.
#
# Another important property is `spark.master`. This defines the _master URL_ for the Spark application. A list of all admissible values for `spark.master` is given here: [master-urls](https://spark.apache.org/docs/latest/submitting-applications.html#master-urls).
#
# In this example the Spark master URL is `local[*]`, this means that our Spark application will run locally with as many worker threads as logical cores on our local machine.
#
# If you have a Hadoop cluster available you can deploy your Spark application on Yarn by setting the option `spark.master = yarn`. Let's do that and then check the Spark configuration once again.
# +
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.master('yarn') \
.getOrCreate()
spark.sparkContext._conf.getAll()
# -
# With this configuration our Spark application will run on the Hadoop cluster and its resources will be managed by Yarn.
#
# **Note:** If the Hadoop cluster is configured with HDFS as its default filesystem, then you need to upload your CSV file to Hadoop in order to be able to read it:
# <code>
# hdfs dfs -put FME_BaumdatenBearbeitet_OGD_20190205.csv FME_BaumdatenBearbeitet_OGD_20190205.csv
# </code>
# and then you can just use `.load( ...) ` again.
# + language="bash"
# hdfs dfs -put FME_BaumdatenBearbeitet_OGD_20190205.csv
# hdfs dfs -ls FME_BaumdatenBearbeitet_OGD_20190205.csv
# -
df = spark.read \
.load("FME_BaumdatenBearbeitet_OGD_20190205.csv",
format="csv", sep=";", header="true", encoding="iso-8859-1")
# Let's now re-run the previous commands. This time the application is going to be deployed on the cluster.
df.createOrReplaceTempView("baeume")
spark.sql("SELECT BaumNr, NameDeutsch, Hoehe, lat, lon FROM baeume order by Hoehe desc").show()
# **Note:** After you're done, it's important to close the Spark session in order to release cluster resources.
spark.stop()
| demoSparkSQLPython.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/starceees/Unsupervised-Learning/blob/main/Time_series_data_.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="AHOPTcB1R5P0"
# # Time series forecasting for Water quality data of River Ganga
# - The Uttarkhand Pollution board has collected water quality data of river ganga at various places(**Lakshmanjhula Rishikesh** is our area of interest) *comprising* of **Temperature** , **PH**, **Disolved Oxygen(DO)** level, **Biological Oxygen Level Demand(BOD)** level, Total Coliform level and many others important for analysing the water quailty.<br>
# - We intend to use **Time series Forecasting** methods Comprising of **Deep Learning Methods** to predict the water quality factors for the future and analyse the degradation of water in river ganga over the years.
# + [markdown] id="AxVGavKhVA9h"
# ## Data Ingesion and visualization
# The data was organized to a sigle .csv file comprizing of 120 rows with 7 columns .
# + colab={"base_uri": "https://localhost:8080/"} id="M3IH_6yrgeRH" outputId="a20a42b6-e3f3-4801-ca2e-2e65a699ba95"
from google.colab import drive
drive.mount('/content/drive')
# + id="KkDaQPLUVY5h"
import numpy as np
import math
import pandas as pd
import matplotlib.pyplot as plt
# + colab={"base_uri": "https://localhost:8080/"} id="ocQwOYl9V7yz" outputId="75a342aa-6cb8-4387-f80b-5ff3b415d72b"
url = '/content/drive/MyDrive/Projects/river_data.csv'
data = pd.read_csv(url)
print(data)
# + colab={"base_uri": "https://localhost:8080/", "height": 265} id="JPIaqGAcWIZC" outputId="aa19626a-2fac-48ae-c96f-462cebf1fd9a"
data.plot()
plt.show()
# + colab={"base_uri": "https://localhost:8080/", "height": 279} id="N8bIfyn1XWiq" outputId="fa1e25e1-5d28-431f-ec79-1c7d4ca1c302"
data.plot(x = "Month")
plt.show()
# + id="NcTdxJVGlp-M"
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
# + id="qPpEhF73GD-g"
#random seed for reproducibility
np.random.seed(7)
# + colab={"base_uri": "https://localhost:8080/"} id="l9VmOztIGTv2" outputId="e4675871-f2a3-4ab9-de56-fb9c998f5f51"
data["temp"]
# + colab={"base_uri": "https://localhost:8080/", "height": 279} id="ndkYpWT0IatV" outputId="1b4575ee-6494-4d69-86f8-fc4e81f23315"
data.plot(x= "Month",y= ["temp"])
dataset_temp = data[['temp']].dropna()
# + colab={"base_uri": "https://localhost:8080/", "height": 282} id="y1ETAbrJsK33" outputId="0f172df9-6114-4705-e13d-dd976128780e"
dataset_temp.plot()
# + colab={"base_uri": "https://localhost:8080/", "height": 417} id="Idld5T83Ine7" outputId="895b68a7-b41a-4ff5-a5ce-2d99a916cabb"
dataset_temp.values
dataset_temp.astype('float32')
# + id="EYSFwfrJXFRu"
#normalising and scaling the dataset
scaling = MinMaxScaler(feature_range=(0,1))
dataset = scaling.fit_transform(dataset_temp)
# + colab={"base_uri": "https://localhost:8080/"} id="2vq2mWOtXghu" outputId="17f4f9b4-dc30-4702-ea43-98461d777176"
dataset
# + colab={"base_uri": "https://localhost:8080/"} id="b5_hxkHIQqPe" outputId="fa42934f-6262-4952-ea8c-2e48f55d3b22"
#splitting dataset into training and testing
train_size = int(len(dataset)*0.90)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
print(len(train), len(test))
# + id="Tx7Vy9dKRn-s"
# convert an array of values into a dataset matrix
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return np.array(dataX), np.array(dataY)
# + id="2i-p_qqBeAsq"
# reshape into X=t and Y=t+1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# + id="xAAg3OgyeZB0"
# reshape input to be [samples, time steps, features]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
# + colab={"base_uri": "https://localhost:8080/"} id="wiFiTZrre04z" outputId="62ff724c-eafb-4a22-95c5-968082f30f8a"
np.shape(trainX)
# + colab={"base_uri": "https://localhost:8080/"} id="OWxweDEDe8AB" outputId="7a9b1e76-c698-4c21-c537-4e1de2e4cf99"
np.shape(trainY)
# + colab={"base_uri": "https://localhost:8080/", "height": 387} id="F6fGmZcRe-o5" outputId="f09f2907-228a-41d1-c875-5892b4a16eb5"
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# + id="IVpFVmWgYgud"
# make predictions
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# + id="8vEkcqWNZp-b" colab={"base_uri": "https://localhost:8080/", "height": 387} outputId="d99af0fb-d718-4a14-ddd0-f277d574ce94"
# invert predictions
trainPredict = scaling.inverse_transform(trainPredict)
trainY = scaling.inverse_transform([trainY])
testPredict = scaling.inverse_transform(testPredict)
testY = scaling.inverse_transform([testY])
# + colab={"base_uri": "https://localhost:8080/"} id="_v30kDGFZt9F" outputId="96226eae-3ecc-4a50-b272-175418a47f6f"
# calculate root mean squared error
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# + id="wfNCRlkWZ2Kx"
# shift train predictions for plotting
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# + id="SiOe6b3Bf7V2"
# shift test predictions for plotting
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# + colab={"base_uri": "https://localhost:8080/", "height": 265} id="sgNErC_nf74G" outputId="0e1e2306-620c-44ad-d783-d9913ab90b4c"
# plot baseline and predictions
plt.plot(scaling.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
# + id="GghOlfPZgvqb"
| Time_series_data_.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %matplotlib inline
#
# # Decision Tree Regression
#
#
# A 1D regression with decision tree.
#
# The `decision trees <tree>` is
# used to fit a sine curve with addition noisy observation. As a result, it
# learns local linear regressions approximating the sine curve.
#
# We can see that if the maximum depth of the tree (controlled by the
# `max_depth` parameter) is set too high, the decision trees learn too fine
# details of the training data and learn from the noise, i.e. they overfit.
#
# +
print(__doc__)
# Import the necessary modules and libraries
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
# Create a random dataset
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
# Fit regression model
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)
# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
# Plot the results
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black",
c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",
label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
# -
| Section 2: Elementary machine learning algorithms/decision_tree/plot_tree_regression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/M4RKM4RK/LateNightDurritos/blob/main/Copy_of_VQGAN%2BCLIP.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="CppIQlPhhwhs" endofcell="--"
# # How to Generate MIND-BLOWING A.I. Art in 5 Minutes!!
#
# **5 minute Tutorial: https://www.youtube.com/watch?v=2hgfbf5OOoI**
#
# Original Notebook made by <NAME> (https://github.com/crowsonkb, https://twitter.com/RiversHaveWings)
#
#
# -
#
# ###❗❗ **EASY TO USE - 2 CLICK VQGAN+CLIP NOTEBOOK** ❗❗
#
#
#
#
# https://colab.research.google.com/drive/1Tz8Kh19r-GreZnuGrzz6Il4Nxn5DeSxE#scrollTo=CppIQlPhhwhs
#
# -
# --
# + id="TkUfzT60ZZ9q"
# !nvidia-smi
# + id="wSfISAhyPmyp" cellView="form"
#@title 1) Download Required Python Packages
print("Download CLIP...")
# !git clone https://github.com/openai/CLIP &> /dev/null
print("Installing VQGAN...")
# !git clone https://github.com/CompVis/taming-transformers &> /dev/null
# !pip install ftfy regex tqdm omegaconf pytorch-lightning &> /dev/null
# !pip install kornia &> /dev/null
# !pip install einops &> /dev/null
# !pip install wget &> /dev/null
print("Installing Extra Libraries...")
# !pip install stegano &> /dev/null
# !apt install exempi &> /dev/null
# !pip install python-xmp-toolkit &> /dev/null
# !pip install imgtag &> /dev/null
# !pip install pillow==7.1.2 &> /dev/null
# !pip install imageio-ffmpeg &> /dev/null
# !mkdir steps
print("Installing Finished!!")
# + id="FhhdWrSxQhwg" cellView="form"
#@title 2) Choose Model to Download
#@markdown Imagenet 16384 is probably the best but try all of them! they all produce cool results
imagenet_1024 = False #@param {type:"boolean"}
imagenet_16384 = True #@param {type:"boolean"}
gumbel_8192 = False #@param {type:"boolean"}
coco = False #@param {type:"boolean"}
wikiart_1024 = False #@param {type:"boolean"}
wikiart_16384 = False #@param {type:"boolean"}
sflckr = False #@param {type:"boolean"}
ade20k = False #@param {type:"boolean"}
ffhq = False #@param {type:"boolean"}
celebahq = False #@param {type:"boolean"}
faceshq = False
if imagenet_1024:
# !curl -L -o vqgan_imagenet_f16_1024.yaml -C - 'https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1' #ImageNet 1024
# !curl -L -o vqgan_imagenet_f16_1024.ckpt -C - 'https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fckpts%2Flast.ckpt&dl=1' #ImageNet 1024
if imagenet_16384:
# !curl -L -o vqgan_imagenet_f16_16384.yaml -C - 'https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1' #ImageNet 16384
# !curl -L -o vqgan_imagenet_f16_16384.ckpt -C - 'https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fckpts%2Flast.ckpt&dl=1' #ImageNet 16384
if gumbel_8192:
# !curl -L -o gumbel_8192.yaml -C - 'https://heibox.uni-heidelberg.de/d/2e5662443a6b4307b470/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1' #Gumbel 8192
# !curl -L -o gumbel_8192.ckpt -C - 'https://heibox.uni-heidelberg.de/d/2e5662443a6b4307b470/files/?p=%2Fckpts%2Flast.ckpt&dl=1' #Gumbel 8192
if coco:
# !curl -L -o coco.yaml -C - 'https://dl.nmkd.de/ai/clip/coco/coco.yaml' #COCO
# !curl -L -o coco.ckpt -C - 'https://dl.nmkd.de/ai/clip/coco/coco.ckpt' #COCO
if faceshq:
# !curl -L -o faceshq.yaml -C - 'https://drive.google.com/uc?export=download&id=1fHwGx_hnBtC8nsq7hesJvs-Klv-P0gzT' #FacesHQ
# !curl -L -o faceshq.ckpt -C - 'https://app.koofr.net/content/links/a04deec9-0c59-4673-8b37-3d696fe63a5d/files/get/last.ckpt?path=%2F2020-11-13T21-41-45_faceshq_transformer%2Fcheckpoints%2Flast.ckpt' #FacesHQ
if wikiart_1024:
# !curl -L -o wikiart_1024.yaml -C - 'http://mirror.io.community/blob/vqgan/wikiart.yaml' #WikiArt 1024
# !curl -L -o wikiart_1024.ckpt -C - 'http://mirror.io.community/blob/vqgan/wikiart.ckpt' #WikiArt 1024
if wikiart_16384:
# !curl -L -o wikiart_16384.yaml -C - 'http://eaidata.bmk.sh/data/Wikiart_16384/wikiart_f16_16384_8145600.yaml' #WikiArt 16384
# !curl -L -o wikiart_16384.ckpt -C - 'http://eaidata.bmk.sh/data/Wikiart_16384/wikiart_f16_16384_8145600.ckpt' #WikiArt 16384
if sflckr:
# !curl -L -o sflckr.yaml -C - 'https://heibox.uni-heidelberg.de/d/73487ab6e5314cb5adba/files/?p=%2Fconfigs%2F2020-11-09T13-31-51-project.yaml&dl=1' #S-FLCKR
# !curl -L -o sflckr.ckpt -C - 'https://heibox.uni-heidelberg.de/d/73487ab6e5314cb5adba/files/?p=%2Fcheckpoints%2Flast.ckpt&dl=1' #S-FLCKR
if ade20k:
# !curl -L -o ade20k.yaml -C - 'https://static.miraheze.org/intercriaturaswiki/b/bf/Ade20k.txt' #ADE20K
# !curl -L -o ade20k.ckpt -C - 'https://app.koofr.net/content/links/0f65c2cd-7102-4550-a2bd-07fd383aac9e/files/get/last.ckpt?path=%2F2020-11-20T21-45-44_ade20k_transformer%2Fcheckpoints%2Flast.ckpt' #ADE20K
if ffhq:
# !curl -L -o ffhq.yaml -C - 'https://app.koofr.net/content/links/0fc005bf-3dca-4079-9d40-cdf38d42cd7a/files/get/2021-04-23T18-19-01-project.yaml?path=%2F2021-04-23T18-19-01_ffhq_transformer%2Fconfigs%2F2021-04-23T18-19-01-project.yaml&force' #FFHQ
# !curl -L -o ffhq.ckpt -C - 'https://app.koofr.net/content/links/0fc005bf-3dca-4079-9d40-cdf38d42cd7a/files/get/last.ckpt?path=%2F2021-04-23T18-19-01_ffhq_transformer%2Fcheckpoints%2Flast.ckpt&force' #FFHQ
if celebahq:
# !curl -L -o celebahq.yaml -C - 'https://app.koofr.net/content/links/6dddf083-40c8-470a-9360-a9dab2a94e96/files/get/2021-04-23T18-11-19-project.yaml?path=%2F2021-04-23T18-11-19_celebahq_transformer%2Fconfigs%2F2021-04-23T18-11-19-project.yaml&force' #CelebA-HQ
# !curl -L -o celebahq.ckpt -C - 'https://app.koofr.net/content/links/6dddf083-40c8-470a-9360-a9dab2a94e96/files/get/last.ckpt?path=%2F2021-04-23T18-11-19_celebahq_transformer%2Fcheckpoints%2Flast.ckpt&force' #CelebA-HQ
# + id="EXMSuW2EQWsd"
# @title 3) Download Libraries for Neural Network
import argparse
import math
from pathlib import Path
import sys
sys.path.append('./taming-transformers')
from IPython import display
from base64 import b64encode
from omegaconf import OmegaConf
from PIL import Image
from taming.models import cond_transformer, vqgan
import torch
from torch import nn, optim
from torch.nn import functional as F
from torchvision import transforms
from torchvision.transforms import functional as TF
from tqdm.notebook import tqdm
from CLIP import clip
import kornia.augmentation as K
import numpy as np
import imageio
from PIL import ImageFile, Image
from imgtag import ImgTag # metadatos
from libxmp import * # metadatos
import libxmp # metadatos
from stegano import lsb
import json
ImageFile.LOAD_TRUNCATED_IMAGES = True
def sinc(x):
return torch.where(x != 0, torch.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
def lanczos(x, a):
cond = torch.logical_and(-a < x, x < a)
out = torch.where(cond, sinc(x) * sinc(x/a), x.new_zeros([]))
return out / out.sum()
def ramp(ratio, width):
n = math.ceil(width / ratio + 1)
out = torch.empty([n])
cur = 0
for i in range(out.shape[0]):
out[i] = cur
cur += ratio
return torch.cat([-out[1:].flip([0]), out])[1:-1]
def resample(input, size, align_corners=True):
n, c, h, w = input.shape
dh, dw = size
input = input.view([n * c, 1, h, w])
if dh < h:
kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
pad_h = (kernel_h.shape[0] - 1) // 2
input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
input = F.conv2d(input, kernel_h[None, None, :, None])
if dw < w:
kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
pad_w = (kernel_w.shape[0] - 1) // 2
input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
input = F.conv2d(input, kernel_w[None, None, None, :])
input = input.view([n, c, h, w])
return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
class ReplaceGrad(torch.autograd.Function):
@staticmethod
def forward(ctx, x_forward, x_backward):
ctx.shape = x_backward.shape
return x_forward
@staticmethod
def backward(ctx, grad_in):
return None, grad_in.sum_to_size(ctx.shape)
replace_grad = ReplaceGrad.apply
class ClampWithGrad(torch.autograd.Function):
@staticmethod
def forward(ctx, input, min, max):
ctx.min = min
ctx.max = max
ctx.save_for_backward(input)
return input.clamp(min, max)
@staticmethod
def backward(ctx, grad_in):
input, = ctx.saved_tensors
return grad_in * (grad_in * (input - input.clamp(ctx.min, ctx.max)) >= 0), None, None
clamp_with_grad = ClampWithGrad.apply
def vector_quantize(x, codebook):
d = x.pow(2).sum(dim=-1, keepdim=True) + codebook.pow(2).sum(dim=1) - 2 * x @ codebook.T
indices = d.argmin(-1)
x_q = F.one_hot(indices, codebook.shape[0]).to(d.dtype) @ codebook
return replace_grad(x_q, x)
class Prompt(nn.Module):
def __init__(self, embed, weight=1., stop=float('-inf')):
super().__init__()
self.register_buffer('embed', embed)
self.register_buffer('weight', torch.as_tensor(weight))
self.register_buffer('stop', torch.as_tensor(stop))
def forward(self, input):
input_normed = F.normalize(input.unsqueeze(1), dim=2)
embed_normed = F.normalize(self.embed.unsqueeze(0), dim=2)
dists = input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2)
dists = dists * self.weight.sign()
return self.weight.abs() * replace_grad(dists, torch.maximum(dists, self.stop)).mean()
def parse_prompt(prompt):
vals = prompt.rsplit(':', 2)
vals = vals + ['', '1', '-inf'][len(vals):]
return vals[0], float(vals[1]), float(vals[2])
class MakeCutouts(nn.Module):
def __init__(self, cut_size, cutn, cut_pow=1.):
super().__init__()
self.cut_size = cut_size
self.cutn = cutn
self.cut_pow = cut_pow
self.augs = nn.Sequential(
K.RandomHorizontalFlip(p=0.5),
# K.RandomSolarize(0.01, 0.01, p=0.7),
K.RandomSharpness(0.3,p=0.4),
K.RandomAffine(degrees=30, translate=0.1, p=0.8, padding_mode='border'),
K.RandomPerspective(0.2,p=0.4),
K.ColorJitter(hue=0.01, saturation=0.01, p=0.7))
self.noise_fac = 0.1
def forward(self, input):
sideY, sideX = input.shape[2:4]
max_size = min(sideX, sideY)
min_size = min(sideX, sideY, self.cut_size)
cutouts = []
for _ in range(self.cutn):
size = int(torch.rand([])**self.cut_pow * (max_size - min_size) + min_size)
offsetx = torch.randint(0, sideX - size + 1, ())
offsety = torch.randint(0, sideY - size + 1, ())
cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))
batch = self.augs(torch.cat(cutouts, dim=0))
if self.noise_fac:
facs = batch.new_empty([self.cutn, 1, 1, 1]).uniform_(0, self.noise_fac)
batch = batch + facs * torch.randn_like(batch)
return batch
def load_vqgan_model(config_path, checkpoint_path):
config = OmegaConf.load(config_path)
if config.model.target == 'taming.models.vqgan.VQModel':
model = vqgan.VQModel(**config.model.params)
model.eval().requires_grad_(False)
model.init_from_ckpt(checkpoint_path)
elif config.model.target == 'taming.models.cond_transformer.Net2NetTransformer':
parent_model = cond_transformer.Net2NetTransformer(**config.model.params)
parent_model.eval().requires_grad_(False)
parent_model.init_from_ckpt(checkpoint_path)
model = parent_model.first_stage_model
elif config.model.target == 'taming.models.vqgan.GumbelVQ':
model = vqgan.GumbelVQ(**config.model.params)
print(config.model.params)
model.eval().requires_grad_(False)
model.init_from_ckpt(checkpoint_path)
else:
raise ValueError(f'unknown model type: {config.model.target}')
del model.loss
return model
def resize_image(image, out_size):
ratio = image.size[0] / image.size[1]
area = min(image.size[0] * image.size[1], out_size[0] * out_size[1])
size = round((area * ratio)**0.5), round((area / ratio)**0.5)
return image.resize(size, Image.LANCZOS)
def download_img(img_url):
try:
return wget.download(img_url,out="input.jpg")
except:
return
# + [markdown] id="1tthw0YaispD"
# ## Settings for this run:
# Mainly what you will have to modify will be `texts:`, there you can place the text or texts you want to generate (separated with `|`). It is a list because you can put more than one text, and so the AI tries to 'mix' the images, giving the same priority to both texts.
#
# To use an initial image to the model, you just have to upload a file to the Colab environment (in the section on the left), and then modify `init_image:` putting the exact name of the file. Example: `sample.png`
#
# You can also modify the model by changing the lines that say `model:`. Currently ImageNet 1024, ImageNet 16384, WikiArt 1024, WikiArt 16384, S-FLCKR, COCO-Stuff and Open Images are available. To activate them you have to have downloaded them first, and then you can simply select it.
#
# You can also use `target_images`, which is basically putting one or more images on it that the AI will take as a "target", fulfilling the same function as putting text on it. To put more than one you have to use `|` as a separator.
#
# **MAX height and width is 500, you can use ESRGAN to super-enhance it to 1760x1760.**
# + id="ZdlpRFL8UAlW"
#@title 4) Art Generator Parameters
text = "the multiverse of dreams by <NAME>" #@param {type:"string"}
textos = text
height = 675#@param {type:"number"}
width = 675#@param {type:"number"}
ancho=width
alto=height
model = "vqgan_imagenet_f16_16384" #@param ["vqgan_imagenet_f16_16384", "vqgan_imagenet_f16_1024", "wikiart_1024", "wikiart_16384", "coco", "faceshq", "sflckr", "ade20k", "ffhq", "celebahq", "gumbel_8192"]
modelo=model
interval_image = 50#@param {type:"number"}
intervalo_imagenes = interval_image
initial_image = ""#@param {type:"string"}
imagen_inicial= initial_image
objective_image = ""#@param {type:"string"}
imagenes_objetivo = objective_image
seed = -1#@param {type:"number"}
max_iterations = -1#@param {type:"number"}
max_iteraciones = max_iterations
input_images = ""
nombres_modelos={"vqgan_imagenet_f16_16384": 'ImageNet 16384',"vqgan_imagenet_f16_1024":"ImageNet 1024",
"wikiart_1024":"WikiArt 1024", "wikiart_16384":"WikiArt 16384", "coco":"COCO-Stuff", "faceshq":"FacesHQ", "sflckr":"S-FLCKR", "ade20k":"ADE20K", "ffhq":"FFHQ", "celebahq":"CelebA-HQ", "gumbel_8192": "Gumbel 8192"}
nombre_modelo = nombres_modelos[modelo]
if modelo == "gumbel_8192":
is_gumbel = True
else:
is_gumbel = False
if seed == -1:
seed = None
if imagen_inicial == "None":
imagen_inicial = None
elif imagen_inicial and imagen_inicial.lower().startswith("http"):
imagen_inicial = download_img(imagen_inicial)
if imagenes_objetivo == "None" or not imagenes_objetivo:
imagenes_objetivo = []
else:
imagenes_objetivo = imagenes_objetivo.split("|")
imagenes_objetivo = [image.strip() for image in imagenes_objetivo]
if imagen_inicial or imagenes_objetivo != []:
input_images = True
textos = [frase.strip() for frase in textos.split("|")]
if textos == ['']:
textos = []
args = argparse.Namespace(
prompts=textos,
image_prompts=imagenes_objetivo,
noise_prompt_seeds=[],
noise_prompt_weights=[],
size=[ancho, alto],
init_image=imagen_inicial,
init_weight=0.,
clip_model='ViT-B/32',
vqgan_config=f'{modelo}.yaml',
vqgan_checkpoint=f'{modelo}.ckpt',
step_size=0.1,
cutn=64,
cut_pow=1.,
display_freq=intervalo_imagenes,
seed=seed,
)
# + id="g7EDme5RYCrt"
#@title 5) Run the Art Generator :)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
if textos:
print('Using texts:', textos)
if imagenes_objetivo:
print('Using image prompts:', imagenes_objetivo)
if args.seed is None:
seed = torch.seed()
else:
seed = args.seed
torch.manual_seed(seed)
print('Using seed:', seed)
model = load_vqgan_model(args.vqgan_config, args.vqgan_checkpoint).to(device)
perceptor = clip.load(args.clip_model, jit=False)[0].eval().requires_grad_(False).to(device)
cut_size = perceptor.visual.input_resolution
if is_gumbel:
e_dim = model.quantize.embedding_dim
else:
e_dim = model.quantize.e_dim
f = 2**(model.decoder.num_resolutions - 1)
make_cutouts = MakeCutouts(cut_size, args.cutn, cut_pow=args.cut_pow)
if is_gumbel:
n_toks = model.quantize.n_embed
else:
n_toks = model.quantize.n_e
toksX, toksY = args.size[0] // f, args.size[1] // f
sideX, sideY = toksX * f, toksY * f
if is_gumbel:
z_min = model.quantize.embed.weight.min(dim=0).values[None, :, None, None]
z_max = model.quantize.embed.weight.max(dim=0).values[None, :, None, None]
else:
z_min = model.quantize.embedding.weight.min(dim=0).values[None, :, None, None]
z_max = model.quantize.embedding.weight.max(dim=0).values[None, :, None, None]
if args.init_image:
pil_image = Image.open(args.init_image).convert('RGB')
pil_image = pil_image.resize((sideX, sideY), Image.LANCZOS)
z, *_ = model.encode(TF.to_tensor(pil_image).to(device).unsqueeze(0) * 2 - 1)
else:
one_hot = F.one_hot(torch.randint(n_toks, [toksY * toksX], device=device), n_toks).float()
if is_gumbel:
z = one_hot @ model.quantize.embed.weight
else:
z = one_hot @ model.quantize.embedding.weight
z = z.view([-1, toksY, toksX, e_dim]).permute(0, 3, 1, 2)
z_orig = z.clone()
z.requires_grad_(True)
opt = optim.Adam([z], lr=args.step_size)
normalize = transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
pMs = []
for prompt in args.prompts:
txt, weight, stop = parse_prompt(prompt)
embed = perceptor.encode_text(clip.tokenize(txt).to(device)).float()
pMs.append(Prompt(embed, weight, stop).to(device))
for prompt in args.image_prompts:
path, weight, stop = parse_prompt(prompt)
img = resize_image(Image.open(path).convert('RGB'), (sideX, sideY))
batch = make_cutouts(TF.to_tensor(img).unsqueeze(0).to(device))
embed = perceptor.encode_image(normalize(batch)).float()
pMs.append(Prompt(embed, weight, stop).to(device))
for seed, weight in zip(args.noise_prompt_seeds, args.noise_prompt_weights):
gen = torch.Generator().manual_seed(seed)
embed = torch.empty([1, perceptor.visual.output_dim]).normal_(generator=gen)
pMs.append(Prompt(embed, weight).to(device))
def synth(z):
if is_gumbel:
z_q = vector_quantize(z.movedim(1, 3), model.quantize.embed.weight).movedim(3, 1)
else:
z_q = vector_quantize(z.movedim(1, 3), model.quantize.embedding.weight).movedim(3, 1)
return clamp_with_grad(model.decode(z_q).add(1).div(2), 0, 1)
def add_xmp_data(nombrefichero):
imagen = ImgTag(filename=nombrefichero)
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'creator', 'VQGAN+CLIP', {"prop_array_is_ordered":True, "prop_value_is_array":True})
if args.prompts:
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'title', " | ".join(args.prompts), {"prop_array_is_ordered":True, "prop_value_is_array":True})
else:
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'title', 'None', {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'i', str(i), {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'model', nombre_modelo, {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'seed',str(seed) , {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'input_images',str(input_images) , {"prop_array_is_ordered":True, "prop_value_is_array":True})
#for frases in args.prompts:
# imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'Prompt' ,frases, {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.close()
def add_stegano_data(filename):
data = {
"title": " | ".join(args.prompts) if args.prompts else None,
"notebook": "VQGAN+CLIP",
"i": i,
"model": nombre_modelo,
"seed": str(seed),
"input_images": input_images
}
lsb.hide(filename, json.dumps(data)).save(filename)
@torch.no_grad()
def checkin(i, losses):
losses_str = ', '.join(f'{loss.item():g}' for loss in losses)
tqdm.write(f'i: {i}, loss: {sum(losses).item():g}, losses: {losses_str}')
out = synth(z)
TF.to_pil_image(out[0].cpu()).save('progress.png')
add_stegano_data('progress.png')
add_xmp_data('progress.png')
display.display(display.Image('progress.png'))
def ascend_txt():
global i
out = synth(z)
iii = perceptor.encode_image(normalize(make_cutouts(out))).float()
result = []
if args.init_weight:
result.append(F.mse_loss(z, z_orig) * args.init_weight / 2)
for prompt in pMs:
result.append(prompt(iii))
img = np.array(out.mul(255).clamp(0, 255)[0].cpu().detach().numpy().astype(np.uint8))[:,:,:]
img = np.transpose(img, (1, 2, 0))
filename = f"steps/{i:04}.png"
imageio.imwrite(filename, np.array(img))
add_stegano_data(filename)
add_xmp_data(filename)
return result
def train(i):
opt.zero_grad()
lossAll = ascend_txt()
if i % args.display_freq == 0:
checkin(i, lossAll)
loss = sum(lossAll)
loss.backward()
opt.step()
with torch.no_grad():
z.copy_(z.maximum(z_min).minimum(z_max))
i = 0
try:
with tqdm() as pbar:
while True:
train(i)
if i == max_iteraciones:
break
i += 1
pbar.update()
except KeyboardInterrupt:
pass
# + id="mFo5vz0UYBrF" cellView="form"
#@markdown #**Optional Step --- Generate a video from generated frames**
init_frame = 1 #Este es el frame donde el vídeo empezará
last_frame = i #Puedes cambiar i a el número del último frame que quieres generar. It will raise an error if that number of frames does not exist.
min_fps = 10
max_fps = 30
total_frames = last_frame-init_frame
length = 15 #Tiempo deseado del vídeo en segundos
frames = []
tqdm.write('Generando video...')
for i in range(init_frame,last_frame): #
filename = f"steps/{i:04}.png"
frames.append(Image.open(filename))
#fps = last_frame/10
fps = np.clip(total_frames/length,min_fps,max_fps)
from subprocess import Popen, PIPE
p = Popen(['ffmpeg', '-y', '-f', 'image2pipe', '-vcodec', 'png', '-r', str(fps), '-i', '-', '-vcodec', 'libx264', '-r', str(fps), '-pix_fmt', 'yuv420p', '-crf', '17', '-preset', 'veryslow', 'video.mp4'], stdin=PIPE)
for im in tqdm(frames):
im.save(p.stdin, 'PNG')
p.stdin.close()
print("El vídeo está siendo ahora comprimido, espera...")
p.wait()
print("El vídeo está listo")
# + id="E8lvN6b0mb-b" cellView="form"
# @markdown #Show Video in Colab
mp4 = open('video.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
display.HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
# + id="Y0e8pHyJmi7s" cellView="form"
# @markdown # Download Video
from google.colab import files
files.download("video.mp4")
# + [markdown] id="4tuy4T9oWgHj" endofcell="--"
# -
# #**Want to Super-Enhance the Generated Image with another advanced A.I.? Enhances a 500x500 image to 1760x1760 with no quality loss!!!**:
#
# -
#
# https://colab.research.google.com/drive/1O8kr-iyRll5eQsaOH-vQIc3ImEKWsvF-?usp=sharing
# --
# + [markdown] id="GDoRyK2h053J" endofcell="--"
# -
# #**Want to share your art, but dont want anyone to steal it? Watermark it using this colab here**:
#
# -
#
# https://colab.research.google.com/drive/1OjKvOEYUOA8d1sMPL3hBVeCryGxZW-e2?usp=sharing
# --
| Copy_of_VQGAN+CLIP.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: pvnet
# language: python
# name: pvnet
# ---
# ## Point Cloud Processing
#
# __Point Clouds__ are basicially a set of points in a 3D space. Recall for our camera model `points` are prepresneted as `(x, y, z)` and as we will see we can also represent RGB colors in the point cloud as well. To create a point cloud, we ill need a special camera or sensor that is able to measure _depth_. The importance of being able to capture the RGB-D `Depth` channel is to be able to measure the distance between the points and the camera coordinate system.
#
# Typically you will find point cloud files as `.ply` and `.obj`. Below is a great visual of the end-to-end usage of how point clouds are utilize.
#
#
# 
#
#
#
# +
# %load_ext autoreload
# %autoreload 2
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from notebook_tools import *
# -
#mesh_path = "/mnt/daredevildiag/6PACK/z3d/ds1/o3d_iter0_pcd.ply"
#mesh_path = "/home/redne/pvnet/file-converter-.obj-to-.ply/coffeeCup.ply"
mesh_path = "/mnt/daredevildiag/z3d/AR_team/coffeeCup_model/coffeeCup.ply"
mesh_files = load_mesh_files(mesh_path)
mesh_files[:20]
# + active=""
# #mesh_path = "/mnt/daredevildiag/6PACK/z3d/ds1/o3d_iter0_pcd.ply"
# mesh_path = "/mnt/bopdatasets/ShellGaugeTop01/OMR-ShellGaugeTop01-bd0f2b6d-c17d-4128-8097-a138fa785b0f/ran-small/db/models/obj_000001.ply"
# mesh_files = load_mesh_files(mesh_path)
# mesh_files[:20]
# + active=""
# #mesh_path = "/mnt/daredevildiag/6PACK/z3d/ds1/o3d_iter0_pcd.ply"
# #mesh_path = "/home/redne/pvnet/file-converter-.obj-to-.ply/coffeeCup.ply"
# mesh_path = "../01_Camera_Calibration/demo/obj_01.ply"
# mesh_files = load_mesh_files(mesh_path)
# mesh_files[:20]
# -
# The information from the `.ply` point cloud data are broken down into 9 specific indexes for each row, read as
#
# - Col: 0-2 are `vertices`
# - Col: 3-5 are `normals`
# - Col: 6-8 are `colors`
pts = np.array(mesh_files[mesh_files.index("end_header") + 1:])
# ### Get 3D Corners of Verticies
# +
x = []
y = []
z = []
np_points = np.array(pts)
for i in range(0, len(pts)):
pts_groups = pts[i].split(' ')
x.append(pts_groups[0])
y.append(pts_groups[1])
z.append(pts_groups[2])
pts_coord = [x, y, z]
np_points = np.array(pts_coord).astype(float)
corners = get_3D_corners(np_points)
corners
# -
# Here we are able to plot the point cloud
fig = plt.figure()
ax = plt.subplot(111, projection='3d')
for item in corners:
# info_groups = item.split(' ')
ax.scatter(float(item[0]), float(item[1]), float(item[2]), c='r')
ax.set_zlabel('Z')
ax.set_ylabel('Y')
ax.set_xlabel('X')
plt.show()
# +
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import datetime
from sklearn.decomposition import PCA, RandomizedPCA
from mpl_toolkits.mplot3d import Axes3D
from plyfile import PlyData, PlyElement
# -
# !pip
from sklearn.p import p
| 03_3DModeling/00_notebooks/04_PointCloudProcessing_custom_z3d.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/jlmbaka/kda-deep-learning-workshop-2020/blob/main/V3_fastai_02_download_KDA_workshop.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="VGHnJuVeY52R" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="849caa58-129b-488d-b241-5b56f9c950b7"
from google.colab import drive
drive.mount('/content/gdrive', force_remount=True)
# + [markdown] id="rYQ4qsTGEQSF"
# # Démystification
# Selon, vous avons-vous besoin des éléments ci-dessous pour le deep learning ?
# 1. Beaucoup de maths V / F
# 2. Beaucoup de données V / F
# 3. Beaucoup d'ordinateurs coûteux V / F
# 4. Un doctorat en intelligence artificielle V / F
# + [markdown] id="B2Q2G4oHFhbf"
# ## Réalité
# + [markdown] id="MATZ6_8hGPtv"
# 1. Les mathématiques apprises à l'école secondaire suffisent
# 2. Des résultats records ont été obtenus parfois avec moins de 50 éléments de données
# 3. Vous pouvez obtenir gratuitement ce dont vous avez besoin pour faire la majorité de vos travaux en deep learning
# 4. Plus besoin d'avoir un doctorat grace aux différents packages mis à disposition différentes compagnies
# + [markdown] id="gTIxIktHGt03"
# ## Deep Learning
# - Le deep learning est une technique informatique permettant d'extraire et de transformer des données - avec des cas d'utilisation allant de la reconnaissance vocale humaine à la classification de l'imagerie animale - en utilisant plusieurs couches de réseaux neuronaux.
# - Chacune de ces couches prend ses entrées des couches précédentes et les affine progressivement.
# - Les couches sont entraînées par des algorithmes qui minimisent leurs erreurs et améliorent leur précision. De cette manière, le réseau apprend à exécuter une tâche spécifiée.
# + [markdown] id="fXtlhj4SHhZd"
# ## Les logiciels: PyTorch, fastai, and Jupyter
# - PyTorch: Librairie low-level publiée par Facebook
# - Fastai: Librairie high-level construite au dessus de PyTorch
# - Jupyter: Environnement intéractif qui nous permet d'écrire du code en Python et d'expérimenter
#
# + id="ALUnC3E0c9vt" colab={"base_uri": "https://localhost:8080/", "height": 1000} outputId="73b9164a-9df0-44d8-c7b6-ccf0a8d66781"
# !pip install fastai==1.0.42
# + id="LfyqF1494vXu" colab={"base_uri": "https://localhost:8080/", "height": 1000} outputId="6696672f-b0dd-4eb2-d0f7-13f0ee04b6ed"
pip freeze
# + [markdown] id="ibwny6Q7IgoF"
# ## Votre premier model
# + id="8szy4uEnIkUH"
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
# + id="BRvcFrVgIny0"
img = PILImage.create(image_cat())
img.to_thumb(192)
# + id="WrtKI6niJDFq"
uploader = widgets.FileUpload()
uploader
# + id="uzrkA26ZJE3t"
img = PILImage.create(uploader.data[0])
is_cat,_,probs = learn.predict(img)
print(f"Est-ce un chat ?: {is_cat}.")
print(f"La probablité que c'est un chat: {probs[1].item():.6f}")
# + [markdown] hide_input=false id="vMi-TAoDWhia"
# # Creating your own dataset from Google Images
#
# *by: <NAME> and <NAME>. Inspired by [<NAME>ck](https://www.pyimagesearch.com/2017/12/04/how-to-create-a-deep-learning-dataset-using-google-images/)*
# + [markdown] hide_input=true id="S9aOVdW-Whic"
# In this tutorial we will see how to easily create an image dataset through Google Images. **Note**: You will have to repeat these steps for any new category you want to Google (e.g once for dogs and once for cats).
# + hide_input=false id="66PvcZ1kWhid"
from fastai.vision import *
# + [markdown] id="jwJ3kzNeWhik"
# ## Get a list of URLs
# + [markdown] id="hSU9wqkhWhil"
# ### Search and scroll
# + [markdown] id="jpDkXjN4Whim"
# 1. Go to [Google Images](http://images.google.com) and search for the images you are interested in. The more specific you are in your Google Search, the better the results and the less manual pruning you will have to do.
#
# 2. Scroll down until you've seen all the images you want to download, or until you see a button that says 'Show more results'. All the images you scrolled past are now available to download. To get more, click on the button, and continue scrolling. The maximum number of images Google Images shows is 700.
#
# 3. It is a good idea to put things you want to exclude into the search query, for instance if you are searching for the Eurasian wolf, "canis lupus lupus", it might be a good idea to exclude other variants:
#
# "canis lupus lupus" -dog -arctos -familiaris -baileyi -occidentalis
#
# 4. You can also limit your results to show only photos by clicking on Tools and selecting Photos from the Type dropdown.
# + [markdown] id="kaYewzMfWhin"
# ### Download into file
# + [markdown] id="lygrbQ72Whio"
# 0. Now you must run some Javascript code in your browser which will save the URLs of all the images you want for you dataset.
#
# 1. In Google Chrome press <kbd>Ctrl</kbd><kbd>Shift</kbd><kbd>j</kbd> on Windows/Linux and <kbd>Cmd</kbd><kbd>Opt</kbd><kbd>j</kbd> on macOS, and a small window the javascript 'Console' will appear. In Firefox press <kbd>Ctrl</kbd><kbd>Shift</kbd><kbd>k</kbd> on Windows/Linux or <kbd>Cmd</kbd><kbd>Opt</kbd><kbd>k</kbd> on macOS. That is where you will paste the JavaScript commands.
#
# 2. You will need to get the urls of each of the images. Before running the following commands, you may want to disable ad blocking extensions (uBlock, AdBlockPlus etc.) in Chrome. Otherwise the window.open() command doesn't work. Then you can run the following commands:
#
# ```javascript
# urls=Array.from(document.querySelectorAll('.rg_i')).map(el=> el.hasAttribute('data-src')?el.getAttribute('data-src'):el.getAttribute('data-iurl'));
# window.open('data:text/csv;charset=utf-8,' + escape(urls.join('\n')));
# ```
# + [markdown] id="_qcqS2vOWhip"
# ### Create directory and upload urls file into your server
#
# + [markdown] id="458_L_3zWhir"
# Choose an appropriate name for your labeled images. You can run these steps multiple times to create different labels.
# + id="eobHe_lsW8pt"
src_list =[
('football', 'urls_football.csv'),
('basketball', 'urls_basketball.csv'),
('judo', 'urls_judo.csv'),
]
# + [markdown] id="h-QUqOCYWhi7"
# Loop through each category:
# - create the destination directory
# - upload csv files containing URLs
# + id="5bn9_hwwWhi8"
path = Path('data/sports')
for folder, _ in src_list:
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
# + id="MdeT1yzFmNXv"
# !ls data/sports/
# + id="3d7g0-3pduot" colab={"resources": {"http://localhost:8080/nbextensions/google.colab/files.js": {"data": "Ly8gQ29weXJpZ2h0IDIwMTcgR29vZ2xlIExMQwovLwovLyBMaWNlbnNlZCB1bmRlciB0aGUgQXBhY2hlIExpY2Vuc2UsIFZlcnNpb24gMi4wICh0aGUgIkxpY2Vuc2UiKTsKLy8geW91IG1heSBub3QgdXNlIHRoaXMgZmlsZSBleGNlcHQgaW4gY29tcGxpYW5jZSB3aXRoIHRoZSBMaWNlbnNlLgovLyBZb3UgbWF5IG9idGFpbiBhIGNvcHkgb2YgdGhlIExpY2Vuc2UgYXQKLy8KLy8gICAgICBodHRwOi8vd3d3LmFwYWNoZS5vcmcvbGljZW5zZXMvTElDRU5TRS0yLjAKLy8KLy8gVW5sZXNzIHJlcXVpcmVkIGJ5IGFwcGxpY2FibGUgbGF3IG9yIGFncmVlZCB0byBpbiB3cml0aW5nLCBzb2Z0d2FyZQovLyBkaXN0cmlidXRlZCB1bmRlciB0aGUgTGljZW5zZSBpcyBkaXN0cmlidXRlZCBvbiBhbiAiQVMgSVMiIEJBU0lTLAovLyBXSVRIT1VUIFdBUlJBTlRJRVMgT1IgQ09ORElUSU9OUyBPRiBBTlkgS0lORCwgZWl0aGVyIGV4cHJlc3Mgb3IgaW1wbGllZC4KLy8gU2VlIHRoZSBMaWNlbnNlIGZvciB0aGUgc3BlY2lmaWMgbGFuZ3VhZ2UgZ292ZXJuaW5nIHBlcm1pc3Npb25zIGFuZAovLyBsaW1pdGF0aW9ucyB1bmRlciB0aGUgTGljZW5zZS4KCi8qKgogKiBAZmlsZW92ZXJ2aWV3IEhlbHBlcnMgZm9yIGdvb2dsZS5jb2xhYiBQeXRob24gbW9kdWxlLgogKi8KKGZ1bmN0aW9uKHNjb3BlKSB7CmZ1bmN0aW9uIHNwYW4odGV4dCwgc3R5bGVBdHRyaWJ1dGVzID0ge30pIHsKICBjb25zdCBlbGVtZW50ID0gZG9jdW1lbnQuY3JlYXRlRWxlbWVudCgnc3BhbicpOwogIGVsZW1lbnQudGV4dENvbnRlbnQgPSB0ZXh0OwogIGZvciAoY29uc3Qga2V5IG9mIE9iamVjdC5rZXlzKHN0eWxlQXR0cmlidXRlcykpIHsKICAgIGVsZW1lbnQuc3R5bGVba2V5XSA9IHN0eWxlQXR0cmlidXRlc1trZXldOwogIH0KICByZXR1cm4gZWxlbWVudDsKfQoKLy8gTWF4IG51bWJlciBvZiBieXRlcyB3aGljaCB3aWxsIGJlIHVwbG9hZGVkIGF0IGEgdGltZS4KY29uc3QgTUFYX1BBWUxPQURfU0laRSA9IDEwMCAqIDEwMjQ7CgpmdW5jdGlvbiBfdXBsb2FkRmlsZXMoaW5wdXRJZCwgb3V0cHV0SWQpIHsKICBjb25zdCBzdGVwcyA9IHVwbG9hZEZpbGVzU3RlcChpbnB1dElkLCBvdXRwdXRJZCk7CiAgY29uc3Qgb3V0cHV0RWxlbWVudCA9IGRvY3VtZW50LmdldEVsZW1lbnRCeUlkKG91dHB1dElkKTsKICAvLyBDYWNoZSBzdGVwcyBvbiB0aGUgb3V0cHV0RWxlbWVudCB0byBtYWtlIGl0IGF2YWlsYWJsZSBmb3IgdGhlIG5leHQgY2FsbAogIC8vIHRvIHVwbG9hZEZpbGVzQ29udGludWUgZnJvbSBQeXRob24uCiAgb3V0cHV0RWxlbWVudC5zdGVwcyA9IHN0ZXBzOwoKICByZXR1cm4gX3VwbG9hZEZpbGVzQ29udGludWUob3V0cHV0SWQpOwp9CgovLyBUaGlzIGlzIHJvdWdobHkgYW4gYXN5bmMgZ2VuZXJhdG9yIChub3Qgc3VwcG9ydGVkIGluIHRoZSBicm93c2VyIHlldCksCi8vIHdoZXJlIHRoZXJlIGFyZSBtdWx0aXBsZSBhc3luY2hyb25vdXMgc3RlcHMgYW5kIHRoZSBQeXRob24gc2lkZSBpcyBnb2luZwovLyB0byBwb2xsIGZvciBjb21wbGV0aW9uIG9mIGVhY2ggc3RlcC4KLy8gVGhpcyB1c2VzIGEgUHJvbWlzZSB0byBibG9jayB0aGUgcHl0aG9uIHNpZGUgb24gY29tcGxldGlvbiBvZiBlYWNoIHN0ZXAsCi8vIHRoZW4gcGFzc2VzIHRoZSByZXN1bHQgb2YgdGhlIHByZXZpb3VzIHN0ZXAgYXMgdGhlIGlucHV0IHRvIHRoZSBuZXh0IHN0ZXAuCmZ1bmN0aW9uIF91cGxvYWRGaWxlc0NvbnRpbnVlKG91dHB1dElkKSB7CiAgY29uc3Qgb3V0cHV0RWxlbWVudCA9IGRvY3VtZW50LmdldEVsZW1lbnRCeUlkKG91dHB1dElkKTsKICBjb25zdCBzdGVwcyA9IG91dHB1dEVsZW1lbnQuc3RlcHM7CgogIGNvbnN0IG5leHQgPSBzdGVwcy5uZXh0KG91dHB1dEVsZW1lbnQubGFzdFByb21pc2VWYWx1ZSk7CiAgcmV0dXJuIFByb21pc2UucmVzb2x2ZShuZXh0LnZhbHVlLnByb21pc2UpLnRoZW4oKHZhbHVlKSA9PiB7CiAgICAvLyBDYWNoZSB0aGUgbGFzdCBwcm9taXNlIHZhbHVlIHRvIG1ha2UgaXQgYXZhaWxhYmxlIHRvIHRoZSBuZXh0CiAgICAvLyBzdGVwIG9mIHRoZSBnZW5lcmF0b3IuCiAgICBvdXRwdXRFbGVtZW50Lmxhc3RQcm9taXNlVmFsdWUgPSB2YWx1ZTsKICAgIHJldHVybiBuZXh0LnZhbHVlLnJlc3BvbnNlOwogIH0pOwp9CgovKioKICogR2VuZXJhdG9yIGZ1bmN0aW9uIHdoaWNoIGlzIGNhbGxlZCBiZXR3ZWVuIGVhY2ggYXN5bmMgc3RlcCBvZiB0aGUgdXBsb2FkCiAqIHByb2Nlc3MuCiAqIEBwYXJhbSB7c3RyaW5nfSBpbnB1dElkIEVsZW1lbnQgSUQgb2YgdGhlIGlucHV0IGZpbGUgcGlja2VyIGVsZW1lbnQuCiAqIEBwYXJhbSB7c3RyaW5nfSBvdXRwdXRJZCBFbGVtZW50IElEIG9mIHRoZSBvdXRwdXQgZGlzcGxheS4KICogQHJldHVybiB7IUl0ZXJhYmxlPCFPYmplY3Q+fSBJdGVyYWJsZSBvZiBuZXh0IHN0ZXBzLgogKi8KZnVuY3Rpb24qIHVwbG9hZEZpbGVzU3RlcChpbnB1dElkLCBvdXRwdXRJZCkgewogIGNvbnN0IGlucHV0RWxlbWVudCA9IGRvY3VtZW50LmdldEVsZW1lbnRCeUlkKGlucHV0SWQpOwogIGlucHV0RWxlbWVudC5kaXNhYmxlZCA9IGZhbHNlOwoKICBjb25zdCBvdXRwdXRFbGVtZW50ID0gZG9jdW1lbnQuZ2V0RWxlbWVudEJ5SWQob3V0cHV0SWQpOwogIG91dHB1dEVsZW1lbnQuaW5uZXJIVE1MID0gJyc7CgogIGNvbnN0IHBpY2tlZFByb21pc2UgPSBuZXcgUHJvbWlzZSgocmVzb2x2ZSkgPT4gewogICAgaW5wdXRFbGVtZW50LmFkZEV2ZW50TGlzdGVuZXIoJ2NoYW5nZScsIChlKSA9PiB7CiAgICAgIHJlc29sdmUoZS50YXJnZXQuZmlsZXMpOwogICAgfSk7CiAgfSk7CgogIGNvbnN0IGNhbmNlbCA9IGRvY3VtZW50LmNyZWF0ZUVsZW1lbnQoJ2J1dHRvbicpOwogIGlucHV0RWxlbWVudC5wYXJlbnRFbGVtZW50LmFwcGVuZENoaWxkKGNhbmNlbCk7CiAgY2FuY2VsLnRleHRDb250ZW50ID0gJ0NhbmNlbCB1cGxvYWQnOwogIGNvbnN0IGNhbmNlbFByb21pc2UgPSBuZXcgUHJvbWlzZSgocmVzb2x2ZSkgPT4gewogICAgY2FuY2VsLm9uY2xpY2sgPSAoKSA9PiB7CiAgICAgIHJlc29sdmUobnVsbCk7CiAgICB9OwogIH0pOwoKICAvLyBXYWl0IGZvciB0aGUgdXNlciB0byBwaWNrIHRoZSBmaWxlcy4KICBjb25zdCBmaWxlcyA9IHlpZWxkIHsKICAgIHByb21pc2U6IFByb21pc2UucmFjZShbcGlja2VkUHJvbWlzZSwgY2FuY2VsUHJvbWlzZV0pLAogICAgcmVzcG9uc2U6IHsKICAgICAgYWN0aW9uOiAnc3RhcnRpbmcnLAogICAgfQogIH07CgogIGNhbmNlbC5yZW1vdmUoKTsKCiAgLy8gRGlzYWJsZSB0aGUgaW5wdXQgZWxlbWVudCBzaW5jZSBmdXJ0aGVyIHBpY2tzIGFyZSBub3QgYWxsb3dlZC4KICBpbnB1dEVsZW1lbnQuZGlzYWJsZWQgPSB0cnVlOwoKICBpZiAoIWZpbGVzKSB7CiAgICByZXR1cm4gewogICAgICByZXNwb25zZTogewogICAgICAgIGFjdGlvbjogJ2NvbXBsZXRlJywKICAgICAgfQogICAgfTsKICB9CgogIGZvciAoY29uc3QgZmlsZSBvZiBmaWxlcykgewogICAgY29uc3QgbGkgPSBkb2N1bWVudC5jcmVhdGVFbGVtZW50KCdsaScpOwogICAgbGkuYXBwZW5kKHNwYW4oZmlsZS5uYW1lLCB7Zm9udFdlaWdodDogJ2JvbGQnfSkpOwogICAgbGkuYXBwZW5kKHNwYW4oCiAgICAgICAgYCgke2ZpbGUudHlwZSB8fCAnbi9hJ30pIC0gJHtmaWxlLnNpemV9IGJ5dGVzLCBgICsKICAgICAgICBgbGFzdCBtb2RpZmllZDogJHsKICAgICAgICAgICAgZmlsZS5sYXN0TW9kaWZpZWREYXRlID8gZmlsZS5sYXN0TW9kaWZpZWREYXRlLnRvTG9jYWxlRGF0ZVN0cmluZygpIDoKICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgJ24vYSd9IC0gYCkpOwogICAgY29uc3QgcGVyY2VudCA9IHNwYW4oJzAlIGRvbmUnKTsKICAgIGxpLmFwcGVuZENoaWxkKHBlcmNlbnQpOwoKICAgIG91dHB1dEVsZW1lbnQuYXBwZW5kQ2hpbGQobGkpOwoKICAgIGNvbnN0IGZpbGVEYXRhUHJvbWlzZSA9IG5ldyBQcm9taXNlKChyZXNvbHZlKSA9PiB7CiAgICAgIGNvbnN0IHJlYWRlciA9IG5ldyBGaWxlUmVhZGVyKCk7CiAgICAgIHJlYWRlci5vbmxvYWQgPSAoZSkgPT4gewogICAgICAgIHJlc29sdmUoZS50YXJnZXQucmVzdWx0KTsKICAgICAgfTsKICAgICAgcmVhZGVyLnJlYWRBc0FycmF5QnVmZmVyKGZpbGUpOwogICAgfSk7CiAgICAvLyBXYWl0IGZvciB0aGUgZGF0YSB0byBiZSByZWFkeS4KICAgIGxldCBmaWxlRGF0YSA9IHlpZWxkIHsKICAgICAgcHJvbWlzZTogZmlsZURhdGFQcm9taXNlLAogICAgICByZXNwb25zZTogewogICAgICAgIGFjdGlvbjogJ2NvbnRpbnVlJywKICAgICAgfQogICAgfTsKCiAgICAvLyBVc2UgYSBjaHVua2VkIHNlbmRpbmcgdG8gYXZvaWQgbWVzc2FnZSBzaXplIGxpbWl0cy4gU2VlIGIvNjIxMTU2NjAuCiAgICBsZXQgcG9zaXRpb24gPSAwOwogICAgd2hpbGUgKHBvc2l0aW9uIDwgZmlsZURhdGEuYnl0ZUxlbmd0aCkgewogICAgICBjb25zdCBsZW5ndGggPSBNYXRoLm1pbihmaWxlRGF0YS5ieXRlTGVuZ3RoIC0gcG9zaXRpb24sIE1BWF9QQVlMT0FEX1NJWkUpOwogICAgICBjb25zdCBjaHVuayA9IG5ldyBVaW50OEFycmF5KGZpbGVEYXRhLCBwb3NpdGlvbiwgbGVuZ3RoKTsKICAgICAgcG9zaXRpb24gKz0gbGVuZ3RoOwoKICAgICAgY29uc3QgYmFzZTY0ID0gYnRvYShTdHJpbmcuZnJvbUNoYXJDb2RlLmFwcGx5KG51bGwsIGNodW5rKSk7CiAgICAgIHlpZWxkIHsKICAgICAgICByZXNwb25zZTogewogICAgICAgICAgYWN0aW9uOiAnYXBwZW5kJywKICAgICAgICAgIGZpbGU6IGZpbGUubmFtZSwKICAgICAgICAgIGRhdGE6IGJhc2U2NCwKICAgICAgICB9LAogICAgICB9OwogICAgICBwZXJjZW50LnRleHRDb250ZW50ID0KICAgICAgICAgIGAke01hdGgucm91bmQoKHBvc2l0aW9uIC8gZmlsZURhdGEuYnl0ZUxlbmd0aCkgKiAxMDApfSUgZG9uZWA7CiAgICB9CiAgfQoKICAvLyBBbGwgZG9uZS4KICB5aWVsZCB7CiAgICByZXNwb25zZTogewogICAgICBhY3Rpb246ICdjb21wbGV0ZScsCiAgICB9CiAgfTsKfQoKc2NvcGUuZ29vZ2xlID0gc2NvcGUuZ29vZ2xlIHx8IHt9OwpzY29wZS5nb29nbGUuY29sYWIgPSBzY29wZS5nb29nbGUuY29sYWIgfHwge307CnNjb3BlLmdvb2dsZS5jb2xhYi5fZmlsZXMgPSB7CiAgX3VwbG9hZEZpbGVzLAogIF91cGxvYWRGaWxlc0NvbnRpbnVlLAp9Owp9KShzZWxmKTsK", "ok": true, "headers": [["content-type", "application/javascript"]], "status": 200, "status_text": ""}}, "base_uri": "https://localhost:8080/", "height": 192} outputId="87b2c28c-f5da-403b-dbfd-1de878355c7b"
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
# + id="OGqodC46mp-Z" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="584edd3f-581f-4285-d78e-014742f01c35"
# !ls
# + id="vv-vIGtGlq7b"
# !mv *.csv data/sports
# + id="JTVeS_7MfFDV" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="9a9ab343-1ee0-4af6-ca5a-4184fd873b4f"
# !ls data/sports/
# + id="j_IU4fYWkqk4"
# !rm -r data/sports/basketball
# + [markdown] id="GpQ5sKncWhjM"
# ## Download images
# + [markdown] id="FceEJCb3WhjN"
# Now you will need to download your images from their respective urls.
#
# fast.ai has a function that allows you to do just that. You just have to specify the urls filename as well as the destination folder and this function will download and save all images that can be opened. If they have some problem in being opened, they will not be saved.
#
# Let's download our images! Notice you can choose a maximum number of images to be downloaded. In this case we will not download all the urls.
#
# You will need to run this line once for every category.
# + id="AlN5YZzoWhjT"
for folder, file in src_list:
dest = path/folder
download_images(path/file, dest, max_pics=200)
# + id="h-AraptiWhjY" outputId="e88f0daf-1b6f-45b9-f7dc-897f1a23b891"
# If you have problems download, try with `max_workers=0` to see exceptions:
for _, file in src_list:
download_images(path/file, dest, max_pics=20, max_workers=0)
# + id="I4ZXGorXiKZv" colab={"base_uri": "https://localhost:8080/", "height": 583} outputId="4b8ce46a-1bcd-4328-fa99-b86d3dedf735"
# !ls data/sports/basketball
# + [markdown] id="K29mILCKWhje"
# Then we can remove any images that can't be opened:
# + id="FAqLIo1dWhjg" colab={"base_uri": "https://localhost:8080/", "height": 146} outputId="d41ec049-d592-493a-c747-d8f4f81c0f37"
classes = [class_name for class_name, folder in src_list]
for c in classes:
print(c)
verify_images(path/c, delete=True, max_size=500)
# + [markdown] id="ZfNMInAEWhjl"
# ## View data
# + id="Kt-sv1ZDWhjm" colab={"base_uri": "https://localhost:8080/", "height": 157} outputId="1245c685-f49c-42d9-8403-0d39a1850867"
np.random.seed(42)
data = ImageDataBunch.from_folder(
path,
train=".",
valid_pct=0.2,
ds_tfms=get_transforms(),
size=224,
num_workers=4).normalize(imagenet_stats)
# + id="-RUQgc_9Whjr"
# If you already cleaned your data, run this cell instead of the one before
# np.random.seed(42)
# data = ImageDataBunch.from_csv(path, folder=".", valid_pct=0.2, csv_labels='cleaned.csv',
# ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
# + [markdown] id="RgTbv50PWhjw"
# Good! Let's take a look at some of our pictures then.
# + id="9oLfw414Whjx" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="1558ab5d-106e-424e-b780-ecd6737e5047"
data.classes
# + id="N96UWCLzWhj2" colab={"base_uri": "https://localhost:8080/", "height": 1000} outputId="28966a07-8d1e-4e28-8487-9bd0178dc061"
data.show_batch(rows=3, figsize=(7,8))
# + id="xvBVk6XuWhj6" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="47fca2ed-54f5-4b7f-9c0b-54523016673e"
data.classes, data.c, len(data.train_ds), len(data.valid_ds)
# + [markdown] id="Dza7pmooWhkB"
# ## Train model
# + id="w0GisujjWhkC" colab={"base_uri": "https://localhost:8080/", "height": 103, "referenced_widgets": ["b1c539bf3f154195beff9eadf55504a3", "6be87d633bac4ac39f4810680ed3668a", "9b1f124318ac431ea95fb6edae1cc255", "bf0925e7315544a6b11ce04ae20a3d58", "c5ccadb37f864ef699b4ab293570b026", "2e9f4e7f152c4b53b9d6023f6e6cabbb", "89115e6c4e2f412ebcdab6d661cd0799", "af7c1fce0561482da7eee5f2be8bda6f"]} outputId="0b13db21-647b-45de-c00d-48d2a4b4250e"
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
# + id="ti-d4fvsWhkG" colab={"base_uri": "https://localhost:8080/", "height": 172} outputId="78179d5a-dabb-4829-c7b9-9f6387d55107"
learn.fit_one_cycle(4)
# + id="m7oBZslEWhkK"
learn.save('stage-1')
# + id="h9jvAVh-WhkN"
learn.unfreeze()
# + id="f4QXiutfWhkR" colab={"base_uri": "https://localhost:8080/", "height": 357} outputId="c0326d3f-a41e-48cc-85bb-019de2837603"
learn.lr_find()
# + id="prktYoyAWhkV" colab={"base_uri": "https://localhost:8080/", "height": 279} outputId="366a27d0-d6b5-4e4a-9ae9-faa3be0e2d02"
# If the plot is not showing try to give a start and end learning rate
# learn.lr_find(start_lr=1e-5, end_lr=1e-1)
learn.recorder.plot()
# + id="NkZhjKVCWhkZ" colab={"base_uri": "https://localhost:8080/", "height": 110} outputId="1edf50c8-3ca7-4119-a550-ec5080200007"
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-5))
# + id="7xTuaChvWhkf"
learn.save('stage-2')
# + [markdown] id="hVvFvmocWhkk"
# ## Interpretation
# + id="k4pmnXMHWhkl"
learn.load('stage-1');
# + id="E0N58Z_mWhkp" colab={"base_uri": "https://localhost:8080/", "height": 17} outputId="27d1fa0c-ea02-4cfb-a838-d17bccf2a31b"
interp = ClassificationInterpretation.from_learner(learn)
# + id="3Xh5PmZqWhks" colab={"base_uri": "https://localhost:8080/", "height": 311} outputId="4788bc97-7ba1-42e8-95e8-7f620530623f"
interp.plot_confusion_matrix()
# + [markdown] id="J-G1irJmWhkw"
# ## Cleaning Up
#
# Some of our top losses aren't due to bad performance by our model. There are images in our data set that shouldn't be.
#
# Using the `ImageCleaner` widget from `fastai.widgets` we can prune our top losses, removing photos that don't belong.
# + id="2f_0c4uXWhkx"
from fastai.widgets import *
# + [markdown] id="yyF4BUolWhk2"
# First we need to get the file paths from our top_losses. We can do this with `.from_toplosses`. We then feed the top losses indexes and corresponding dataset to `ImageCleaner`.
#
# Notice that the widget will not delete images directly from disk but it will create a new csv file `cleaned.csv` from where you can create a new ImageDataBunch with the corrected labels to continue training your model.
# + [markdown] id="q3qNGGOtWhk3"
# In order to clean the entire set of images, we need to create a new dataset without the split. The video lecture demostrated the use of the `ds_type` param which no longer has any effect. See [the thread](https://forums.fast.ai/t/duplicate-widget/30975/10) for more details.
# + id="LyE0ihV2Whk4"
db = (ImageList.from_folder(path)
.split_none()
.label_from_folder()
.transform(get_transforms(), size=224)
.databunch()
)
# + id="sQwSinS2Whk7"
# If you already cleaned your data using indexes from `from_toplosses`,
# run this cell instead of the one before to proceed with removing duplicates.
# Otherwise all the results of the previous step would be overwritten by
# the new run of `ImageCleaner`.
# db = (ImageList.from_csv(path, 'cleaned.csv', folder='.')
# .split_none()
# .label_from_df()
# .transform(get_transforms(), size=224)
# .databunch()
# )
# + [markdown] id="C1POS7lkWhk_"
# Then we create a new learner to use our new databunch with all the images.
# + id="fDhSHnq_WhlA"
learn_cln = cnn_learner(db, models.resnet34, metrics=error_rate)
learn_cln.load('stage-1');
# + id="txd5NJJtWhlE" colab={"base_uri": "https://localhost:8080/", "height": 17} outputId="3893bc8d-f174-4d6e-824f-81f497a4f080"
ds, idxs = DatasetFormatter().from_toplosses(learn_cln)
# + [markdown] id="jWvQop3mWhlH"
# Make sure you're running this notebook in Jupyter Notebook, not Jupyter Lab. That is accessible via [/tree](/tree), not [/lab](/lab). Running the `ImageCleaner` widget in Jupyter Lab is [not currently supported](https://github.com/fastai/fastai/issues/1539).
# + id="Vv62VRBEWhlI" colab={"base_uri": "https://localhost:8080/", "height": 349, "referenced_widgets": ["96df7b556368495db9fe0bf70890db2b", "0e1ae2b358a7461faed72005b1f88a33", "<KEY>", "1f9229087b8242e9beda114dbb75f9dc", "<KEY>", "<KEY>", "<KEY>", "<KEY>", "b0261e89b99b40d7954f6ace26656678", "ca3b858e64754fdfb8791d846d560191", "9d3d6372e5c3443390aef238f7847c74", "f102ffd8526348d797776fd62beaeebc", "e3cab15e9fbe4569a127168516001c71", "de450457335549d29b22d68a71903c19", "90b6aca2d5574ad3a2d82dbbc8c63361", "75663716e87a4d478812173bd5761389", "d1d261b61e5f4883b3f0433b4240e1c0", "<KEY>", "2f8e20d2b3ad49c5a90cf3933bc5cec1", "3c15a3e5712d4090b87b39abda418813", "<KEY>", "<KEY>", "95dbee83dcfb4142987217b3b7a974ec", "<KEY>", "5baae9ada82f4d72869ea8902298fffd", "<KEY>", "<KEY>", "96ba921ca62b4af4aa79ad3491221a65", "1a9dda0876734b9a957c60ee7056f277", "12138ceb60e744e381ec88f223260738", "144e685764c14629ae22e7f50c433959", "5925d52e55964e84bca4bee03a44de09", "<KEY>", "498b5e190d444cadb3299e93211e53ba", "<KEY>", "<KEY>", "<KEY>", "<KEY>", "65ffa0fe443f496c8c0960cabfc778a8", "<KEY>", "<KEY>", "09d258e3d37f424e8b30997e288e6331", "9672f3463f0048ffaffa1bb48cf7f76a", "2c7f0fd487a442ec8600de12ffec9498", "480cd38f7f5e4beface6169380937d62", "<KEY>", "<KEY>", "<KEY>", "<KEY>", "eed3636cebf84b0c97c5f279eded6f74", "<KEY>", "21eb7c60e76d47fa8ba13f67df9416bd", "98d58548cbed45ad9a3208f4dddffcf4", "c67eed14bd30436c9d1381fbc797323e", "<KEY>", "<KEY>", "69a362e09ed846b89441e1f978a3f700", "5668ecea21dc41c592c9cd51128564fc", "84224e6c556749848488efcaf8d025b2", "2c2c01755afb48afadc9f7942f5f930a", "<KEY>", "5976f0925eaa452795d5d57a3310c224", "<KEY>", "f20c662433ee4ff798456faf8de4e987", "38ee3c467eb9451eb53e4c1161df8c42", "<KEY>", "ade0a91ab42044dabe1802f6bde971e0", "e76f00f2a9974c34b2957873ba84071b", "e51aedbb7c054dec99abaeeda038bf74", "<KEY>", "<KEY>", "d4de0f9ce77c4130823c9e62d080dab2", "f38e32916d2d4690aac122fe009a3621", "25c8f1ed07144f028b3a7dfd296461d9", "fd5dc4ca9d4b4ca983590cda4fe7bc15", "<KEY>", "8cfaf4641f044970a7c7e5f347ec012f", "50059ac3354c4f569e3e99480556a635", "<KEY>", "8294000d60e24d318bffe21541e41118", "334a18ae33b242ef92ea682a52fa8209", "e88f32ef545247c1b1be9ff9c2ebeceb", "154b7a78ec6a433bbd0783a575fdafe4", "<KEY>", "23e1024c063e4c39829307876be52f1f", "ff331c2cc82f4b208fd28906285a6eae", "41d21687c43842c8bf204af6e35fc5f5", "33d174330e42418b803e300ff4ba1d1a", "<KEY>", "<KEY>", "<KEY>", "54ddad7b06eb4d40b9cde4b9d88f6357", "15eea4d613dd4e039be758b9f3eb3ddc", "<KEY>", "df09ac668add4c19943ca223bc263293", "6548974c83eb498a94f31e44afe266bd", "<KEY>", "<KEY>", "91196eab8993414a80a5c081e0173257", "<KEY>", "<KEY>", "<KEY>", "23e429067f8e41ff899bef364dda6695", "0926bdbf4e1c456b909be52d8eae7d4b"]} outputId="c1c40b6f-716d-4de7-8741-3804db7bbc36"
# Don't run this in google colab or any other instances running jupyter lab.
# If you do run this on Jupyter Lab, you need to restart your runtime and
# runtime state including all local variables will be lost.
ImageCleaner(ds, idxs, path)
# + [markdown] id="B5R-4ksYWhlM"
#
# If the code above does not show any GUI(contains images and buttons) rendered by widgets but only text output, that may caused by the configuration problem of ipywidgets. Try the solution in this [link](https://github.com/fastai/fastai/issues/1539#issuecomment-505999861) to solve it.
#
# + [markdown] id="gUiZdUbOWhlN"
# Flag photos for deletion by clicking 'Delete'. Then click 'Next Batch' to delete flagged photos and keep the rest in that row. `ImageCleaner` will show you a new row of images until there are no more to show. In this case, the widget will show you images until there are none left from `top_losses.ImageCleaner(ds, idxs)`
# + [markdown] id="s8oSgA8UWhlN"
# You can also find duplicates in your dataset and delete them! To do this, you need to run `.from_similars` to get the potential duplicates' ids and then run `ImageCleaner` with `duplicates=True`. The API works in a similar way as with misclassified images: just choose the ones you want to delete and click 'Next Batch' until there are no more images left.
# + [markdown] id="uYhjY_O1WhlO"
# Make sure to recreate the databunch and `learn_cln` from the `cleaned.csv` file. Otherwise the file would be overwritten from scratch, losing all the results from cleaning the data from toplosses.
# + id="-z3lTx-BWhlP" outputId="2027d310-0c5e-442b-87cf-51186eb66526"
ds, idxs = DatasetFormatter().from_similars(learn_cln)
# + id="7VlTlRUvWhlT" outputId="c62f905f-6fe6-4755-9869-9151d1dc44f0"
ImageCleaner(ds, idxs, path, duplicates=True)
# + [markdown] id="6xSlvCe8WhlW"
# Remember to recreate your ImageDataBunch from your `cleaned.csv` to include the changes you made in your data!
# + [markdown] id="mAodsx24WhlX"
# ## Putting your model in production
# + [markdown] id="gr_y0-z0WhlY"
# First thing first, let's export the content of our `Learner` object for production:
# + id="DO0q8L2IWhlY"
learn.export()
# + id="MFzR3stXq1wz" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="97f25127-1aa7-4514-cc77-ddded2211137"
# !ls data/sports
# + id="eND4YIuXuIe3"
# !mv data/sports/export.pkl gdrive/My\ Drive/kda_fastai
# + id="WwXQYOfouhU-"
# !ls gdrive/My\ Drive/kda_fastai
# + [markdown] id="9z5YWUOeWhld"
# This will create a file named 'export.pkl' in the directory where we were working that contains everything we need to deploy our model (the model, the weights but also some metadata like the classes or the transforms/normalization used).
# + [markdown] id="1J4erP8pWhle"
# You probably want to use CPU for inference, except at massive scale (and you almost certainly don't need to train in real-time). If you don't have a GPU that happens automatically. You can test your model on CPU like so:
# + id="AxxaRFwzWhlf"
defaults.device = torch.device('cpu')
# + id="YPyr1y3qWhll" colab={"base_uri": "https://localhost:8080/", "height": 211} outputId="ede97bbd-e265-4968-a63d-aed6486e5c05"
img = open_image(path/'basketball'/'00000021.jpg')
img
# + [markdown] id="AryqcNS7Whlr"
# We create our `Learner` in production enviromnent like this, just make sure that `path` contains the file 'export.pkl' from before.
# + id="v1ZKADReWhls"
learn = load_learner(path)
# + id="35YeOrFCWhly" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="93b35e22-aeaf-4775-dedc-f1b63e4173c4"
pred_class,pred_idx,outputs = learn.predict(img)
pred_class.obj
# + id="6a941Z3CrYKO" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="895b01b1-9e31-40d9-e597-eec6c09e7858"
pred_class
# + [markdown] id="IHZZq6RpWhl5"
# So you might create a route something like this ([thanks](https://github.com/simonw/cougar-or-not) to <NAME> for the structure of this code):
#
# ```python
# @app.route("/classify-url", methods=["GET"])
# async def classify_url(request):
# bytes = await get_bytes(request.query_params["url"])
# img = open_image(BytesIO(bytes))
# _,_,losses = learner.predict(img)
# return JSONResponse({
# "predictions": sorted(
# zip(cat_learner.data.classes, map(float, losses)),
# key=lambda p: p[1],
# reverse=True
# )
# })
# ```
#
# (This example is for the [Starlette](https://www.starlette.io/) web app toolkit.)
# + [markdown] id="gz26rLuu_mLJ"
# Deployez votre model dans une web app avec Render
#
# 1. Exporter le model que nous avons entrainé précédement
# 2. Upload le model sur une plareform cloud et noter l'URL
# - Google Drive: Use this [link generator](https://www.wonderplugin.com/online-tools/google-drive-direct-link-generator/)
# - Dropbox: Use this [link generator](https://syncwithtech.blogspot.com/p/direct-download-link-generator.html)
# 3. Forker et cloner ce [template](https://github.com/render-examples/fastai-v3)
# 4. Modifier le template:
# - Modifiez le fichier `server.py` dans le répertoire` app` et mettez à jour la variable `model_file_url` avec l'URL copiée ci-dessus.
# - Dans le même fichier, mettez à jour la ligne `classes = ['black', 'grizzly', 'teddys']` avec les classes que vous attendez de votre modèle.
# - Faire un commit des changements effectués
# 5. Créer un compte sur [Render](render.com)
# 6. Deployer l'application sur Render
# - Créez un nouveau **Web Service** sur Render et utilisez le dépôt que vous avez créé ci-dessus. Vous devrez accorder l'autorisation Render pour accéder à votre dépôt à cette étape.
#
# - Sur l'écran de déploiement, choisissez un nom pour votre service et utilisez `Docker` pour l'environnement.
#
# - Cliquez sur **Save Web Service***. C'est tout! Votre service commencera à se développer et devrait être opérationnel dans quelques minutes à l'URL affichée dans votre tableau de bord Render. Vous pouvez suivre sa progression dans les journaux de déploiement.
#
# + [markdown] id="PdRGMwtYWhl6"
# ## Things that can go wrong
# + [markdown] id="tvsMrCXDWhl6"
# - Most of the time things will train fine with the defaults
# - There's not much you really need to tune (despite what you've heard!)
# - Most likely are
# - Learning rate
# - Number of epochs
# + [markdown] id="ytMS0L6DWhl7"
# ### Learning rate (LR) too high
# + id="pSZtLaiiWhl_"
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
# + id="JYmspmfCWhmF" outputId="52a5a87c-05c5-4318-e3c3-c75d04d4a9cb"
learn.fit_one_cycle(1, max_lr=0.5)
# + [markdown] id="iH00YETLWhmM"
# ### Learning rate (LR) too low
# + id="sdKWuuu4WhmN"
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
# + [markdown] id="ufdJbLe-WhmU"
# Previously we had this result:
#
# ```
# Total time: 00:57
# epoch train_loss valid_loss error_rate
# 1 1.030236 0.179226 0.028369 (00:14)
# 2 0.561508 0.055464 0.014184 (00:13)
# 3 0.396103 0.053801 0.014184 (00:13)
# 4 0.316883 0.050197 0.021277 (00:15)
# ```
# + id="dJhzC6vaWhmV" outputId="bd2d2c49-2c68-486c-f016-83f5e9a6f243"
learn.fit_one_cycle(5, max_lr=1e-5)
# + id="sKhVGoEPWhmb" outputId="48d9be59-e9cf-4131-b251-603a99ed441d"
learn.recorder.plot_losses()
# + [markdown] id="EH0X7nmXWhme"
# As well as taking a really long time, it's getting too many looks at each image, so may overfit.
# + [markdown] id="BV5qZ3PGWhmf"
# ### Too few epochs
# + id="xCN7-AgcWhmf"
learn = cnn_learner(data, models.resnet34, metrics=error_rate, pretrained=False)
# + id="p9dHCK90Whml" outputId="49243595-32a4-4a68-92a5-d71e968ba8d7"
learn.fit_one_cycle(1)
# + [markdown] id="d2SLh0qtWhmv"
# ### Too many epochs
# + id="42mhQhjcWhmw"
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.9, bs=32,
ds_tfms=get_transforms(do_flip=False, max_rotate=0, max_zoom=1, max_lighting=0, max_warp=0
),size=224, num_workers=4).normalize(imagenet_stats)
# + id="SNjB1-GdWhm1"
learn = cnn_learner(data, models.resnet50, metrics=error_rate, ps=0, wd=0)
learn.unfreeze()
# + id="-e0za_yIWhm4" outputId="50412c64-3e52-4c0b-b394-8bd93340fb07"
learn.fit_one_cycle(40, slice(1e-6,1e-4))
| V3_fastai_02_download_KDA_workshop.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import warnings
from tqdm import tqdm
import json
from EduNLP.utils import dict2str4sif
def load_items():
with open("../../../data/OpenLUNA.json", encoding="utf-8") as f:
for line in f:
yield json.loads(line)
from EduNLP.Pretrain import GensimSegTokenizer
tokenizer = GensimSegTokenizer(depth=None)
sif_items = []
for item in tqdm(load_items(), "sifing"):
keys = ["stem"]
item["options"] = eval(item["options"])
if item["options"]:
keys.append("options")
try:
item_str = dict2str4sif(
item,
key_as_tag=True,
add_list_no_tag=False,
keys=keys,
tag_mode="head"
)
except TypeError:
continue
sif_item = tokenizer(
item_str
)
if sif_item:
sif_items.append(sif_item)
# + pycharm={"name": "#%%\n"}
sif_items[0]
# + pycharm={"name": "#%%\n"}
len(sif_items)
# + pycharm={"name": "#%%\n"}
from EduNLP.Pretrain import train_vector
from gensim.models.doc2vec import TaggedDocument
train_vector(
sif_items,
"../../../data/w2v/gensim_luna_stem_tf_",
10
)
| examples/pretrain/seg_token/d2v.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import pandas as pd ###variationalinference1init
import math, random
all_data = pd.read_csv("sensor_data_600.txt", delimiter=" ", header=None, names = ("date","time","ir","z"))#lidarのセンサ値は「z」に
data = all_data.sample(1000).sort_values(by="z").reset_index() #1000個だけサンプリングしてインデックスを振り直す
data = pd.DataFrame(data["z"])
display(data[0:3], data[-4:-1]) #とりあえず最初と最後のデータを表示
# +
##負担率の初期化## ###variationalinference1rate
K = 2 #クラスタ数
n = int(math.ceil(len(data)/K)) #クラスタあたりのセンサ値の数
for k in range(K):
data[k] = [1.0 if k == int(i/n) else 0.0 for i,d in data.iterrows()] #データをK個に分けて、一つのr_{i,k}を1に。他を0に。
display(data[0:3], data[-4:-1]) #下の出力の「0」、「1」が負担率の列
# -
def update_parameters(ds, k, mu_avg=600, zeta=1, alpha=1, beta=1, tau=1): ###variationalinference1params
R = sum([d[k] for _, d in ds.iterrows()])
S = sum([d[k]*d["z"] for _, d in ds.iterrows()])
T = sum([d[k]*(d["z"]**2) for _, d in ds.iterrows()])
hat = {}
hat["tau"] = R + tau
hat["zeta"] = R + zeta
hat["mu_avg"] = (S + zeta*mu_avg)/hat["zeta"]
hat["alpha"] = R/2 + alpha
hat["beta"] = (T + zeta*(mu_avg**2) - hat["zeta"]*(hat["mu_avg"]**2))/2 + beta
hat["z_std"] = math.sqrt(hat["beta"]/hat["alpha"])
return pd.DataFrame(hat, index=[k])
params = pd.concat([update_parameters(data, k) for k in range(K)]) ###variationalinference1paramsolve
params
# +
from scipy.stats import norm, dirichlet ###variationalinference1draw
import matplotlib.pyplot as plt
import numpy as np
def draw(ps):
pi = dirichlet([ps["tau"][k] for k in range(K)]).rvs()[0]
pdfs = [ norm(loc=ps["mu_avg"][k], scale=ps["z_std"][k]) for k in range(K) ]
xs = np.arange(600,650,0.5)
##p(z)の描画##
ys = [ sum([pdfs[k].pdf(x)*pi[k] for k in range(K)])*len(data) for x in xs] #pdfを足してデータ数をかける
plt.plot(xs, ys, color="red")
##各ガウス分布の描画##
for k in range(K):
ys = [pdfs[k].pdf(x)*pi[k]*len(data) for x in xs]
plt.plot(xs, ys, color="blue")
##元のデータのヒストグラムの描画##
data["z"].hist(bins = max(data["z"]) - min(data["z"]), align='left', alpha=0.4, color="gray")
plt.show()
# -
draw(params) ###variationalinference1graph
# +
from scipy.special import digamma ###variationalinference1responsibility
def responsibility(z, K, ps):
tau_sum = sum([ps["tau"][k] for k in range(K)])
r = {}
for k in range(K):
log_rho = (digamma(ps["alpha"][k]) - math.log(ps["beta"][k]))/2 \
- (1/ps["zeta"][k] + ((ps["mu_avg"][k] - z)**2)*ps["alpha"][k]/ps["beta"][k])/2 \
+ digamma(ps["tau"][k]) - digamma(tau_sum)
r[k] = math.exp(log_rho)
w = sum([ r[k] for k in range(K) ]) #正規化
for k in range(K): r[k] /= w
return r
# +
rs = [responsibility(d["z"], K, params) for _, d in data.iterrows() ] ###variationalinference1calcr
for k in range(K):
data[k] = [rs[i][k] for i,_ in data.iterrows()]
display(data[0:3], data[len(data)//2:len(data)//2+3], data[-4:-1]) #データの先頭、中盤、後ろを表示
| section_inference/variational_inference1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + active=""
# ### Objective :
# - understand the data about survival of patients who had undergone surgery for breast cancer
# -
# basic imports
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# columns are age, operation_year, num_nodes,
# , survival_status
# Note : survival status - 1:patient survived >=5 years
# 2: patient died within 5 years
# create a dataframe from haberman.csv, we will add header for convenience
df = pd.read_csv("haberman.csv", names=['age','operation_year','num_nodes','survival_status'])
# +
# stats about the data
# 1. shape
print("shape: ",df.shape)
# segregating data based on survival status
df_survived = df.loc[df["survival_status"]==1]
df_died = df.loc[df["survival_status"]==2]
print("--------------------------------------------")
# stats about survived and died
print("number of people survived: ",df_survived.info())
print("--------------------------------------------")
print("number of people died: ",df_died.info())
# +
# 2. columns
print(df.columns)
print("---------------------------------------------")
# 3. describe the whole dataset ie. Summary Statistics
print(df.describe())
print("---------------------------------------------")
# 4. info about the dataset
print(df.info())
# -
# Observations:
# 1. 4 columns are there ( headers we have given while importing data)
# - age
# - operation_year
# - num_nodes
# - survival_status
# 2. number of rows / datapoints / observations = 306
# 3. For all columns 306 points are there, ie. no missing or null values. So no imputation
# 4. 2 output classes ( 1 and 2) : we will convert it to 0 and 1 for binary classification
# - 1 is survived : 225 people survived
# - 2 is died : 81 people died
#
# looking at few datapoints
df.head(10)
# ** Univariate analysis to understand survival rate due a particular independent variable **
# +
# we will try out distribution plots for all
# using seaborns distplot
# AGE
sns.FacetGrid(df, hue="survival_status",size=5) \
.map(sns.distplot, 'age') \
.add_legend();
plt.show()
# -
# ** **
# AGE
sns.FacetGrid(df, hue="survival_status",size=5) \
.map(sns.distplot, 'operation_year') \
.add_legend();
plt.show()
# AGE
sns.FacetGrid(df, hue="survival_status",size=5) \
.map(sns.distplot, 'num_nodes') \
.add_legend();
plt.show()
# Observations:
# - Survival status is highly dependent on all the three independent variables
# - Still we will try to analyze the dist of data using
# - pdf
# - cdf
# - box plot
# - violin plot
# ** PDF and CDF for Age column in survived and died sub-dataset**
#
# +
# age
counts, bin_edges = np.histogram(df_survived['age'],bins=10,density=True)
pdf = counts/sum(counts)
plt.plot(bin_edges[1:],pdf)
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],cdf)
# operation_year
counts, bin_edges = np.histogram(df_died['age'],bins=20,density=True)
pdf = counts/sum(counts)
plt.plot(bin_edges[1:],pdf)
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],cdf)
plt.show()
# -
# ** PDF and CDF for obvervation_year column in survived and died sub-dataset**
# +
# operation_year
counts, bin_edges = np.histogram(df_survived['operation_year'],bins=10,density=True)
pdf = counts/sum(counts)
plt.plot(bin_edges[1:],pdf)
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],cdf)
counts, bin_edges = np.histogram(df_died['operation_year'],bins=20,density=True)
pdf = counts/sum(counts)
plt.plot(bin_edges[1:],pdf)
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],cdf)
plt.show()
# -
# ** PDF and CDF for num_nodes column in survived and died sub-dataset**
# +
# num_nodes
counts, bin_edges = np.histogram(df_survived['num_nodes'],bins=10,density=True)
pdf = counts/sum(counts)
plt.plot(bin_edges[1:],pdf)
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],cdf)
counts, bin_edges = np.histogram(df_died['num_nodes'],bins=20,density=True)
pdf = counts/sum(counts)
plt.plot(bin_edges[1:],pdf)
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],cdf)
plt.show()
# -
# - for both operation_year, num_nodes, pdf is abnormal
# - lets look at the histogram
# +
plt.figure(1)
plt.subplot(211)
plt.hist(df.operation_year,bins=10)
plt.xlabel("operation years")
plt.ylabel("frequency")
plt.subplot(212)
plt.hist(df.num_nodes,bins=10)
plt.xlabel("number of nodes")
plt.ylabel("frequency")
plt.show()
# -
# Observations
# 1. From distplot we dont get any clue about seperating the data based on 1 particular column
# 2. Looking at histograms tells that
# - number of nodes is positively skewed
# - operation years is of uniform distribution
#
# Still we will look at boxplot and violin plot to complete the univatiate analysis
# ** box plot **
# for age
sns.boxplot(x='survival_status', y ='age', data=df)
plt.show()
# for operation_year
sns.boxplot(x='survival_status', y ='operation_year', data=df)
plt.show()
# for num_nodes
sns.boxplot(x='survival_status', y ='num_nodes', data=df)
plt.show()
# Observations:
# 1. for age :
# - distribution is proper, is not skewed
# 2. for operation_year:
# - data is skewed for status=2
# 3. for num_nodes :
# - data is skewed for both status=1 and 2
# - huge numbers of outliers are present for status =1
# that will give us wrong info in our classification
#
# ** violin plot**
# - we will see the combined behaviour of pdf and boxplot
sns.violinplot(x='survival_status',y ='age', data=df,size=8)
plt.show()
sns.violinplot(x='survival_status',y ='num_nodes', data=df,size=8)
plt.show()
sns.violinplot(x='survival_status',y ='operation_year', data=df,size=8)
plt.show()
# Observations
# - Similar observations like boxplot
# - show the skewed distribution for num_nodes case
#
# ## Bivariate analysis
# #### Pair plot
#
# +
# we are getting 'survived_status' column and row as data is integer
# so we will make 1 as Positive and 2 as Negative
if '2' in df['survival_status']:
df['survival_status'] = df['survival_status'].apply(lambda x: 'Positive' if x==1 else 'Negative')
# so that running this block twice wont affect the values
plt.close()
sns.set_style("whitegrid")
sns.pairplot(df,hue='survival_status', size =3)
plt.show()
# thus we get 3c2 = 3 pair of plots
# -
# Observation
# 1. Using Pairplot/scatter plot, we are unable to find some possible seperation in data.
# ** Results **
# 1. Using bivariate we were not able to find any independent variable on which we could classify the data
# 2. same for 2-d pair plots, we were not able to find any seperability condition on all the possible pairs
# of independent variables
# 3. Maybe in higher dimensions it could be linearly seperable.
| notebooks/Haberman's Survival DataSet Analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: ML
# language: python
# name: ml
# ---
# # Training With MLM and NSP
#
# BERT was originally trained using both MLM *and* NSP. So far, we've dived into how we can use each of those individually - but not together. In this notebook, we'll explore how.
#
# First, we'll start by initializing everything we need. This time, rather than using a `BertForMaskedLM` or `BertForNextSentencePrediction` class, we use the `BertForPreTraining` class - which includes both a MLM head, and an NSP head.
# +
from transformers import BertTokenizer, BertForPreTraining
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForPreTraining.from_pretrained("bert-base-uncased")
text = (
"After <NAME> won the November 1860 presidential [MASK] on an "
"anti-slavery platform, an initial seven slave states declared their "
"secession from the country to form the Confederacy."
)
text2 = (
"War broke out in April 1861 when secessionist forces [MASK] Fort "
"Sumter in South Carolina, just over a month after Lincoln's "
"inauguration."
)
# -
# We tokenize just as before.
inputs = tokenizer(text, text2, return_tensors="pt")
inputs
# And process those `inputs` as we did before too.
outputs = model(**inputs)
outputs.keys()
# We will find that we now return two output tensors:
#
# * *prediction_logits* for our predicted output tokens - which we will use for calculating MLM loss.
#
# * *seq_relationship_logits* for our predicted `IsNextSentence` or `NotNextSentence` classifications, which we can use for calculating NSP loss.
outputs.prediction_logits
outputs.seq_relationship_logits
# But how to we return the *loss* tensor? We need to add labels, both for the MLM head, and the NSP head.
#
# We have two additional input labels for our model:
#
# * *labels* for our MLM.
# * *next_sentence_label* for NSP.
#
# All we need to do is fill both of these. First let's fill in the *\[MASK\]* tokens.
text = (
"After <NAME> won the November 1860 presidential election on an "
"anti-slavery platform, an initial seven slave states declared their "
"secession from the country to form the Confederacy."
)
text2 = (
"War broke out in April 1861 when secessionist forces attacked Fort "
"Sumter in South Carolina, just over a month after Lincoln's "
"inauguration."
)
# And tokenize our text again.
inputs = tokenizer(text, text2, return_tensors="pt")
# This time, we must `clone` our *input_ids* tensor to create a new *labels* tensor.
inputs["labels"] = inputs.input_ids.detach().clone()
# Now we can go ahead and mask *'election'* and *'attacked'* in the *input_ids* tensor.
inputs.input_ids
inputs.input_ids[0, [9, 44]] = 103
inputs.input_ids
# And now we just need to add our *next_sentence_label* tensor, which is a simple single value `LongTensor` like in the previous NSP sections.
inputs["next_sentence_label"] = torch.LongTensor([0])
# Now our `inputs` are ready for processing.
inputs
outputs = model(**inputs)
outputs.keys()
# And now we can see that we've returned another tensor, our *loss*!
outputs.loss
# We can then go ahead and use this loss when fine-tuning our models using both MLM and NSP.
| course/training/07_mlm_and_nsp_logic.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# ---
# # LAD geocoding
#
# Here we geocode GtR organisations at the LAD level
# ## 0. Preamble
# %run notebook_preamble.ipy
def flatten_list(a_list):
return([x for el in a_list for x in el])
# ### Imports
# +
#For geocoding into lads
import geopandas as gp
from shapely.geometry import Point
# -
# ### Lad shapefile
lad_shape = gp.read_file(
'../data/external/Local_Authority_Districts_December_2017_Full_Clipped_Boundaries_in_Great_Britain.shp')
# ### Change the projection
lad_shape.to_crs(epsg=4326,inplace=True)
# ### Lookups
scottish_lads = {'Aberdeen City',
'Aberdeenshire',
'Angus',
'Argyll and Bute',
'Clackmannanshire',
'Dumfries and Galloway',
'Dundee City',
'East Ayrshire',
'East Dunbartonshire',
'East Lothian',
'East Renfrewshire',
'Edinburgh, City of',
'Eilean Siar',
'Falkirk',
'Fife',
'Glasgow City',
'Highland',
'Inverclyde',
'Midlothian',
'Moray',
'North Ayrshire',
'North Lanarkshire',
'Orkney Islands',
'Perth and Kinross',
'Renfrewshire',
'Scottish Borders',
'Shetland Islands',
'South Ayrshire',
'South Lanarkshire',
'Stirling',
'West Dunbartonshire',
'West Lothian'}
# ### Some renaming
rename_lads = {'E07000146': 'King`s Lynn and West Norfolk',
'E07000112': 'Shepway',
'W06000001': 'Anglesey',
'W06000014': 'The Vale of Glamorgan',
'W06000016': 'Rhondda, <NAME>',
'S12000036': 'Edinburgh, City of',
'S12000013': '<NAME>',
'95AA': 'Antrim',
'95BB': 'Ards',
'95CC': 'Armagh',
'95DD': 'Ballymena',
'95EE': 'Ballymoney',
'95FF': 'Banbridge',
'95GG': 'Belfast',
'95HH': 'Carrickfergus',
'95II': 'Castlereagh',
'95JJ': 'Coleraine',
'95KK': 'Cookstown',
'95LL': 'Craigavon',
'95MM': 'Derry',
'95NN': 'Down',
'95OO': 'Dungannon',
'95PP': 'Fermanagh',
'95QQ': 'Larne',
'95RR': 'Limavady',
'95SS': 'Lisburn',
'95TT': 'Magherafelt',
'95UU': 'Moyle',
'95VV': 'Newry and Mourne',
'95WW': 'Newtownabbey',
'95XX': 'North Down',
'95YY': 'Omagh',
'95ZZ': 'Strabane'}
lad_shape['lad_name'] = [rename_lads[x] if x in rename_lads.keys() else name for x,name in
zip(lad_shape['lad17cd'],lad_shape['lad17nm'])]
# ## 1. Load files and spatial join
# +
gtr_dir = '../data/raw/gtr/2019-05-02/'
orgs, orgs_locs = [pd.read_csv(gtr_dir+name) for name in ['/gtr_organisations.csv','/gtr_organisations_locations.csv']]
# -
orgs_locs['coordinates'] = orgs_locs[['longitude','latitude']].apply(Point,axis=1)
org_locs = gp.GeoDataFrame(orgs_locs,geometry='coordinates')
# Spatial join (point in polygon)
lad_gtr = gp.sjoin(org_locs,lad_shape,op='within')
lad_gtr.lad_name.value_counts().head()
len(lad_gtr)
len(org_locs)
# +
matched_ids = set(lad_gtr['id'])
orgs_locs.loc[[x not in matched_ids for x in org_locs['id']]]['country_name'].value_counts().head()
# -
# Most of the unmatched orgs have missing geographical information
#Create an org id - lad lookup
org_lad_lookup = {x['id']:[x['lad17cd'],x['lad_name']] for n,x in lad_gtr.iterrows()}
# ## Create dfs for matching
#
# I want a df where every row is a project. The columns represent:
#
# * The LAD of the lead organisation
# * The LADs of the participant organisations
# * Flags for whether the lead and participating organisations are Scottish or not
link = pd.read_csv('../data/raw/gtr/2019-06-13/gtr_link_table.csv')
org_link = link.loc[['_ORG' in x for x in link['rel']]].reset_index(drop=False)
org_link.columns
org_link_grouped = org_link.groupby(['project_id','rel'])['id'].apply(lambda x: list(set(x))).reset_index(drop=False)
org_link_grouped_wide = pd.pivot_table(org_link_grouped,index='project_id',columns='rel',values='id',aggfunc=lambda x: list(x)[0])
# #### Run the lookup - we need some nested loops to deal with missing values and missing orgs
# +
def lad_allocator(var_name,df):
'''
Looks up the lad code and name of organisations participating in a project
'''
df[f'{var_name.lower()}_lad_code'],df[f'{var_name.lower()}_lad_name'] = [
[[] if type(x)==float else [org_lad_lookup[el][n] for el in x if el in org_lad_lookup.keys()] for x in df[f'{var_name}_ORG']] for
n in [0,1]]
return(df)
# -
# Each of these returns a geolabelled dataset
org_geo = lad_allocator('LEAD',org_link_grouped_wide)
org_geo = lad_allocator('PARTICIPANT',org_link_grouped_wide)
org_geo = lad_allocator('PP',org_link_grouped_wide)
org_geo = lad_allocator('COLLAB',org_link_grouped_wide)
org_geo = lad_allocator('FELLOW',org_link_grouped_wide)
# We group all the organisation geo data, and all the involved (all except the lead) in two lists
# +
org_geo['all_lad_code'],org_geo['all_lad_name'] = [[flatten_list([row[name+f'_lad_{var}'] for name in ['lead','participant','pp','collab','fellow']]) for
n, row in org_geo.iterrows()] for var in ['code','name']]
org_geo['involved_lad_code'],org_geo['involved_lad_name'] = [[flatten_list([row[name+f'_lad_{var}'] for name in ['participant','pp','collab','fellow']]) for
n, row in org_geo.iterrows()] for var in ['code','name']]
# -
org_geo.to_csv(f'../data/temp_scotland/{today_str}_gtr_org_lad_labelled.csv',compression='zip')
# ## Merge with the combined df
df = pd.read_csv('../data/processed/14_6_2019_combined_gtr_projects.csv',compression='zip')
df = df[[x for x in df.columns if 'Unnamed' not in x]]
df_w_geo = pd.merge(df,org_geo,left_on='project_id',right_on='project_id')
len(df)-len(df_w_geo)
# +
matched_ids = set(df_w_geo.project_id)
unmatched = df.loc[[x not in matched_ids for x in df['project_id']]]
# -
unmatched_ids = set(unmatched['project_id'])
link.loc[[x in unmatched_ids for x in link['project_id']]]['rel'].value_counts()
# No organisation data for the unmatched ones!
#
# **Todo** check with Joel and Russ about this
# +
#df_w_geo_w_lead = df_w_geo.dropna(axis=0,subset=['lead_lad_name'])
# -
df_w_geo['lead_scot'],df_w_geo['inv_scot'] = [[any(el in scottish_lads for el in x) for x in df_w_geo[var]] for var in ['lead_lad_name','involved_lad_name']]
df_w_geo['inv_scot_n'] = [np.sum([el in scottish_lads for el in x]) for x in df_w_geo['all_lad_name']]
df_w_geo.to_csv(f'../data/temp_scotland/{today_str}_gtr_projects_geo_labelled.csv',compression='zip')
pd.Series(flatten_list(df_w_geo['lead_lad_name'])).value_counts()
# ## Organisation to project lookup
# +
#Org focused has two columns, one with lists of projects an organisation has participated in and another with the list of roles
#org_focused = pd.concat([org_link.groupby('id')[var].apply(lambda x: list(x)) for var in ['project_id','rel']],axis=1)
org_focused = org_link.set_index('id').iloc[:,2:] #The positional indexing is to remove some unnecessary variables
# -
#Org name lookup
org_name_lookup,org_lad_lookup = [df.set_index('id').to_dict(orient='index') for df in [orgs,lad_gtr]]
# +
#Label the org_focused dataframe with names and places
org_focused['name'],org_focused['lad'] = [[df[org_id][var] if org_id in df.keys() else np.nan for org_id in org_focused.index] for df,var in zip(
[org_name_lookup,org_lad_lookup],['name','lad_name'])]
org_focused.reset_index(drop=False,inplace=True)
# -
# ### Load the enriched project dataset
from ast import literal_eval
proj_meta = pd.read_csv('../data/temp_scotland/21_5_2019_gtr_projects_geo_labelled.csv',compression='zip')
org_proj = pd.merge(org_focused,proj_meta,left_on='project_id',right_on='project_id')
# +
#We want to parse the lists in the data
list_var = [x for x in org_proj.columns if '_lad_' in x]
#If the column is in the list above, then parse it
for c in org_proj.columns:
if c in list_var:
org_proj[c] = [literal_eval(x) for x in org_proj[c]]
# -
org_proj.head()
# +
#Create a couple of variables that will help with the analysis later
#This is capturing if an organisation is in a local collaboration
org_proj['local_collab'] = [x['all_lad_name'].count(x['lad'])>1 if pd.isnull(x['lad'])==False else np.nan for pid,x in org_proj.iterrows()]
#It will easy to turn this into a measure of Scottish local collaborations (they are local collaborations for organisations in Scotland)
# -
#And we create another about Scottish collaborations
org_proj['scot_collab'] = [(x['lad'] in scottish_lads) & (len(scottish_lads & set(x['all_lad_name']))>1) for pid, x in org_proj.iterrows()]
# Now we want to tidy up this df
#
# What variables do we want to create?
#
# * Total number of projects
# * Total number of projects led
# * Total level of funding
# * Total level of funding in projects led
# * Discipline distribution (projects led)
# * Funder distribution
# * Output distribution (projects involving)
# * Local collaborations
# * Scottish local collaborations
# * Scottish local collaborations
# * Top Scottish collaborator (?)
# +
def calculate_org_stats(df):
'''
Calculates key statistics for organisations in the GTR including:
Total number of projects
Total number of projects led
Total level of funding
Total level of funding in projects led
Discipline distribution
Funder distribution
Output distribution (projects involving organisation)
How many collaborations locally
Scottish local collaborations
Scottish local collaborations
Top Scottish collaborator (?)
'''
#Storage for results we will concatenate at the end
grouped_results = []
#Created a grouped df
df_by_org = df.groupby('id')
#Get the list of projects and collaborations
proj_rel_lists = pd.concat([df_by_org[var].apply(lambda x: list(x)) for var in ['project_id','rel']],axis=1)
#Number of projects
proj_rel_lists['project_n'] = [len(x) for x in proj_rel_lists['project_id']]
#Number of led projects
proj_rel_lists['lead_project_n'] = [np.sum([x=='LEAD_ORG' for x in statuses]) for statuses in proj_rel_lists['rel']]
#Append to the store
grouped_results.append(proj_rel_lists)
#Amount of funding
funding_total = df_by_org['amount'].sum()
#Amount of funding in led projects
#We subset the org links to only focus on funded projects
funding_led = df.loc[df['rel']=='LEAD_ORG'].groupby('id')['amount'].sum()
#All funding
all_funding = pd.concat([funding_total,funding_led],axis=1)
all_funding.columns = ['all_funding','led_funding']
grouped_results.append(all_funding)
#Various distributions of categorical variables
disc_mix,fund_mix,grant_mix = [df_by_org[var].value_counts().rename(columns={var:'n'} #This is to avoid the conflict when resetting the index
).reset_index(drop=False).pivot(
index='id',columns=var,values=0).fillna(0) for var in ['disc_top','funder','grant_category']]
#Clean column names for grant types and funders (this could be a list comprehension)
grant_mix.columns = ['grantcat_'+re.sub(' ','_',x.lower()) for x in grant_mix.columns]
fund_mix.columns = ['funder_'+re.sub(' ','_',x.lower()) for x in fund_mix.columns]
grouped_results.append(pd.concat([disc_mix,fund_mix,grant_mix],axis=1))
#Outputs
#Get the variables
output_vars = [x for x in df.columns if 'out_' in x]
#Calculate sum of outputs over all papers
output_mix = df_by_org[output_vars].sum()
grouped_results.append(output_mix)
#Local collaborators:
#Create a local analysis df
collabs = pd.concat([df_by_org[var].sum() for var in ['local_collab','scot_collab']],axis=1)
#Cast as int
collabs['local_collab'],collabs['scot_collab']= [collabs[v].astype(int) for v in ['local_collab','scot_collab']]
#print(collabs['local_collab'].head())
grouped_results.append(collabs)
#return(grouped_results)
return(pd.concat(grouped_results,axis=1))
# -
org_df = calculate_org_stats(org_proj)
# +
#And now we need to add names and LADs
org_df['name'],org_df['lad'] = [[df[org_id][var] if org_id in df.keys() else np.nan for org_id in org_df.index] for df,var in zip(
[org_name_lookup,org_lad_lookup],['name','lad_name'])]
# -
org_df.to_csv(f'../data/processed/{today_str}_organisation_activities.csv',compression='zip')
| notebooks/sc_06_lad_label.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Useful codes from notes
# ## OLS – your own code (with numpy pseudoinverse)
# matrix inversion to find beta
beta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(Energies)
# and then make the prediction
ytilde = X @ beta
# +
def beta_OLS(X,y):
return np.linalg.pinv(X.T @ X) @ X.T @ y #!!!
###################################################
beta = beta_OLS(X_train, y_train)
print("Beta opt: ", beta)
# and then make the prediction
ytilde = X_train @ beta
print("Training R2: ", round(R2(y_train,ytilde),3))
print("Training MSE: ", round(MSE(y_train,ytilde),3))
ypredict = X_test @ beta
print("Test R2: ", round(R2(y_test,ypredict),3))
print("Test MSE: ", round(MSE(y_test,ypredict),3))
# -
# ## OLS – numpy
fit = np.linalg.lstsq(X, y, rcond =None)[0]
ytildenp = np.dot(fit,X.T)
# ## OLS & error analysis – sk
from sklearn.linear_model import LinearRegression
lin_model = LinearRegression()
lin_model.fit(X_train, Y_train)
y_train_predict = lin_model.predict(X_train)
# +
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
lin_model = LinearRegression()
lin_model.fit(X_train, Y_train)
# model evaluation for training set
y_train_predict = lin_model.predict(X_train)
rmse = (np.sqrt(mean_squared_error(Y_train, y_train_predict)))
r2 = r2_score(Y_train, y_train_predict)
print("The model performance for training set")
print("--------------------------------------")
print('RMSE is {}'.format(rmse))
print('R2 score is {}'.format(r2))
print("\n")
# model evaluation for testing set
y_test_predict = lin_model.predict(X_test)
# root mean square error of the model
rmse = (np.sqrt(mean_squared_error(Y_test, y_test_predict)))
# r-squared score of the model
r2 = r2_score(Y_test, y_test_predict)
print("The model performance for testing set")
print("--------------------------------------")
print('RMSE is {}'.format(rmse))
print('R2 score is {}'.format(r2))
# -
# But if you need a polynomial fit:
#
# See the examples at the
# - [https://scikit-learn.org/stable/auto_examples/linear_model/plot_polynomial_interpolation.html#sphx-glr-auto-examples-linear-model-plot-polynomial-interpolation-py]
# - [https://scikit-learn.org/stable/auto_examples/linear_model/plot_robust_fit.html#sphx-glr-auto-examples-linear-model-plot-robust-fit-py] .
#
#
# And underfitting VS overfitting:
# - [https://scikit-learn.org/stable/auto_examples/linear_model/plot_robust_fit.html#sphx-glr-auto-examples-linear-model-plot-robust-fit-py]
model = make_pipeline(PolynomialFeatures(3), LineareRegression())
model.fit(this_X, this_y)
y_plot = model.predict(x_plot[:, np.newaxis])
# ## Error analysis – your own code
# +
def R2(y_data, y_model):
return 1 - np.sum((y_data - y_model) ** 2) / np.sum((y_data - np.mean(y_data)) ** 2)
def MSE(y_data,y_model):
n = np.size(y_model)
return np.sum((y_data-y_model)**2)/n
def RelativeError(y_data,y_model):
return abs((y_data-y_model)/y_data)
# -
# ## Test and train – sk
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# +
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
def R2(y_data, y_model):
return 1 - np.sum((y_data - y_model) ** 2) / np.sum((y_data - np.mean(y_data)) ** 2)
def MSE(y_data,y_model):
n = np.size(y_model)
return np.sum((y_data-y_model)**2)/n
x = np.random.rand(100)
y = 2.0+5*x*x+0.1*np.random.randn(100)
# The design matrix now as function of a given polynomial
X = np.zeros((len(x),3))
X[:,0] = 1.0
X[:,1] = x
X[:,2] = x**2
# We split the data in test and training data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# matrix inversion to find beta
beta = np.linalg.inv(X_train.T @ X_train) @ X_train.T @ y_train
print(beta)
# and then make the prediction
ytilde = X_train @ beta
print("Training R2")
print(R2(y_train,ytilde))
print("Training MSE")
print(MSE(y_train,ytilde))
ypredict = X_test @ beta
print("Test R2")
print(R2(y_test,ypredict))
print("Test MSE")
print(MSE(y_test,ypredict))
# -
# ## Test and train – numpy
# ## Scaling
# +
from sklearn.preprocessing import MinMaxScaler, StandardScaler, Normalizer
import numpy as np
np.random.seed(100)
# setting up a 10 x 5 matrix
rows = 10
cols = 5
X = np.random.randn(rows,cols)
###############################################################
# This option does not include the standard deviation
scaler = StandardScaler(with_std=False)
scaler.fit(X)
Xscaled = scaler.transform(X)
######################################################
# -
# ## MSE VS Complexity
# +
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
np.random.seed(2018)
n = 50
maxdegree = 5
# Make data set.
x = np.linspace(-3, 3, n).reshape(-1, 1)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.normal(0, 0.1, x.shape)
TestError = np.zeros(maxdegree)
TrainError = np.zeros(maxdegree)
polydegree = np.zeros(maxdegree)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_test_scaled = scaler.transform(x_test)
for degree in range(maxdegree):
model = make_pipeline(PolynomialFeatures(degree=degree), LinearRegression(fit_intercept=False))
clf = model.fit(x_train_scaled,y_train)
y_fit = clf.predict(x_train_scaled)
y_pred = clf.predict(x_test_scaled)
polydegree[degree] = degree
TestError[degree] = np.mean( np.mean((y_test - y_pred)**2) )
TrainError[degree] = np.mean( np.mean((y_train - y_fit)**2) )
plt.plot(polydegree, TestError, label='Test Error')
plt.plot(polydegree, TrainError, label='Train Error')
plt.legend()
plt.show()
# -
# ## FrankeFunction
def FrankeFunction(x,y):
term1 = 0.75*np.exp(-(0.25*(9*x-2)**2) - 0.25*((9*y-2)**2))
term2 = 0.75*np.exp(-((9*x+1)**2)/49.0 - 0.1*(9*y+1))
term3 = 0.5*np.exp(-(9*x-7)**2/4.0 - 0.25*((9*y-3)**2))
term4 = -0.2*np.exp(-(9*x-4)**2 - (9*y-7)**2)
return term1 + term2 + term3 + term4
# ## Create X
def create_X(x, y, n ):
if len(x.shape) > 1:
x = np.ravel(x)
y = np.ravel(y)
N = len(x)
l = int((n+1)*(n+2)/2) # Number of elements in beta
X = np.ones((N,l))
for i in range(1,n+1):
q = int((i)*(i+1)/2)
for k in range(i+1):
X[:,q+k] = (x**(i-k))*(y**k)
return X
# ## <font color=grey>SVD - basics (not so useful)</font>
#
# Returns U,S,VT.
#
# **NB:** S is a vector of the singular values.
#
# As you can see from the code, the $S$ vector must be converted into a
# diagonal matrix. This may cause a problem as the size of the matrices
# do not fit the rules of matrix multiplication, where the number of
# columns in a matrix must match the number of rows in the subsequent
# matrix.
#
# If you wish to include the zero singular values, you will need to
# resize the matrices and set up a diagonal matrix as done in the above
# example
# +
import numpy as np
# SVD inversion
def SVD(A):
''' Takes as input a numpy matrix A and returns A (!!!) based on singular value decomposition (SVD).
SVD is numerically more stable than the inversion algorithms provided by
numpy and scipy.linalg at the cost of being slower.
'''
U, S, VT = np.linalg.svd(A,full_matrices=True)
"""print('test U')
print( (np.transpose(U) @ U - U @ np.transpose(U)))
print('test VT')
print( (np.transpose(VT) @ VT - VT @ np.transpose(VT)))
print(U)
print(S)
print(VT)"""
D = np.zeros((len(U),len(VT)))
for i in range(0,len(VT)):
D[i,i]=S[i]
return U @ D @ VT #X
X = np.array([ [1.0,-1.0], [1.0,-1.0]])
#X = np.array([[1, 2], [3, 4], [5, 6]])
#print(X)
C = SVD(X)
# Print the difference between the original matrix and the SVD one
print(np.round_(C-X,3))
print("If all 0, then SVD works well!")
# -
# ## <font color=grey>Inverse with SVD (simple matrix)</font>
# Let us first look at a matrix which does not causes problems and write our own function where we just use the SVD.
# +
import numpy as np
# SVD inversion
def SVDinv(A):
''' Takes as input a numpy matrix A and returns inv(A) based on singular value decomposition (SVD).
SVD is numerically more stable than the inversion algorithms provided by
numpy and scipy.linalg at the cost of being slower.
'''
U, s, VT = np.linalg.svd(A)
"""print('test U')
print( (np.transpose(U) @ U - U @np.transpose(U)))
print('test VT')
print( (np.transpose(VT) @ VT - VT @np.transpose(VT)))"""
D = np.zeros((len(U),len(VT)))
D = np.diag(s)
UT = np.transpose(U); V = np.transpose(VT); invD = np.linalg.inv(D)
return np.matmul(V,np.matmul(invD,UT))
#X = np.array([ [1.0, -1.0, 2.0], [1.0, 0.0, 1.0], [1.0, 2.0, -1.0], [1.0, 1.0, 0.0] ])
# Non-singular square matrix
X = np.array( [ [1,2,3],[2,4,5],[3,5,6]])
#print(X)
A = np.transpose(X) @ X
# Brute force inversion
B = np.linalg.inv(A) # here we could use np.linalg.pinv(A)
C = SVDinv(A)
print(np.round_(np.abs(B-C)))
# -
# ## Inverse with SVD (singular matrix) $\leftarrow$ !!!
# +
import numpy as np
# SVD inversion
def SVDinv(A):
U, s, VT = np.linalg.svd(A)
# reciprocals of singular values of s
d = 1.0 / s
# create m x n D matrix
D = np.zeros(A.shape)
# populate D with n x n diagonal matrix
D[:A.shape[1], :A.shape[1]] = np.diag(d)
UT = np.transpose(U)
V = np.transpose(VT)
return np.matmul(V,np.matmul(D.T,UT))
#Non-singular:
#X = np.array( [ [1,2,3],[2,4,5],[3,5,6]])
#A = np.transpose(X) @ X
#Singular:
A = np.array([ [0.3, 0.4], [0.5, 0.6], [0.7, 0.8],[0.9, 1.0]])
print("A\n", A)
# Brute force inversion of super-collinear matrix
B = np.linalg.pinv(A)
print("invA_np:\n", B)
# Compare our own algorithm with pinv
C = SVDinv(A)
print("invA_svd:\n",C)
print("diff:",np.round_(np.abs(C-B),3))
# -
# ## All correlation and covariance stuff [...]
# $$
# \tilde{\boldsymbol{y}}_{\mathrm{OLS}}=\boldsymbol{X}\boldsymbol{\beta} =\boldsymbol{U}\boldsymbol{U}^T\boldsymbol{y}=\sum_{j=0}^{p-1}\boldsymbol{u}_j\boldsymbol{u}_j^T\boldsymbol{y}.
# $$
# $$
# \tilde{\boldsymbol{y}}_{\mathrm{Ridge}}=\boldsymbol{X}\boldsymbol{\beta}_{\mathrm{Ridge}} = \boldsymbol{U\Sigma V^T}\left(\boldsymbol{V}\boldsymbol{\Sigma}^2\boldsymbol{V}^T+\lambda\boldsymbol{I} \right)^{-1}(\boldsymbol{U\Sigma V^T})^T\boldsymbol{y}=\sum_{j=0}^{p-1}\boldsymbol{u}_j\boldsymbol{u}_j^T\frac{\sigma_j^2}{\sigma_j^2+\lambda}\boldsymbol{y},
# $$
# $$
# \boldsymbol{\beta}^{\mathrm{Ridge}} = \left(\boldsymbol{I}+\lambda\boldsymbol{I}\right)^{-1}\boldsymbol{X}^T\boldsymbol{y}=\left(1+\lambda\right)^{-1}\boldsymbol{\beta}^{\mathrm{OLS}},
# $$
# ## Ridge - your own code
Ridgebeta = np.linalg.inv(X.T @ X+lmb*I) @ X.T @ y #why not pinv?
# ## Ridge & Lasso - MSE VS lambda – your own code
# +
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import linear_model
def R2(y_data, y_model):
return 1 - np.sum((y_data - y_model) ** 2) / np.sum((y_data - np.mean(y_data)) ** 2)
def MSE(y_data,y_model):
n = np.size(y_model)
return np.sum((y_data-y_model)**2)/n
# A seed just to ensure that the random numbers are the same for every run.
# Useful for eventual debugging.
np.random.seed(3155)
x = np.random.rand(100)
y = 2.0+5*x*x+0.1*np.random.randn(100)
# number of features p (here degree of polynomial
p = 3
# The design matrix now as function of a given polynomial
X = np.zeros((len(x),p))
X[:,0] = 1.0
X[:,1] = x
X[:,2] = x*x
# We split the data in test and training data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# matrix inversion to find beta
OLSbeta = np.linalg.inv(X_train.T @ X_train) @ X_train.T @ y_train
print(OLSbeta)
# and then make the prediction
ytildeOLS = X_train @ OLSbeta
print("Training MSE for OLS")
print(MSE(y_train,ytildeOLS))
ypredictOLS = X_test @ OLSbeta
print("Test MSE OLS")
print(MSE(y_test,ypredictOLS))
# Repeat now for Lasso and Ridge regression and various values of the regularization parameter
I = np.eye(p,p)
# Decide which values of lambda to use
nlambdas = 100
MSEPredict = np.zeros(nlambdas)
MSETrain = np.zeros(nlambdas)
MSELassoPredict = np.zeros(nlambdas)
MSELassoTrain = np.zeros(nlambdas)
lambdas = np.logspace(-4, 4, nlambdas)
for i in range(nlambdas):
lmb = lambdas[i]
Ridgebeta = np.linalg.inv(X_train.T @ X_train+lmb*I) @ X_train.T @ y_train
# include lasso using Scikit-Learn
RegLasso = linear_model.Lasso(lmb)
RegLasso.fit(X_train,y_train)
# and then make the prediction
ytildeRidge = X_train @ Ridgebeta
ypredictRidge = X_test @ Ridgebeta
ytildeLasso = RegLasso.predict(X_train)
ypredictLasso = RegLasso.predict(X_test)
MSEPredict[i] = MSE(y_test,ypredictRidge)
MSETrain[i] = MSE(y_train,ytildeRidge)
MSELassoPredict[i] = MSE(y_test,ypredictLasso)
MSELassoTrain[i] = MSE(y_train,ytildeLasso)
# Now plot the results
plt.figure()
plt.plot(np.log10(lambdas), MSETrain, label = 'MSE Ridge train')
plt.plot(np.log10(lambdas), MSEPredict, 'r--', label = 'MSE Ridge Test')
plt.plot(np.log10(lambdas), MSELassoTrain, label = 'MSE Lasso train')
plt.plot(np.log10(lambdas), MSELassoPredict, 'r--', label = 'MSE Lasso Test')
plt.xlabel('log10(lambda)')
plt.ylabel('MSE')
plt.legend()
plt.show()
# -
#
# *Comments:*
#
# We see here that we reach a plateau. What is actually happening?
#
# *Because $\beta$-values stabilize at 0 and the difference in between model and real values go constant.*
#
# *If $\lambda \rightarrow 0$ gets closer and closer to best result (OLS's).*
#
# *Comments:*
# - Lasso is much lower (first plateau)
# - Lasso drags the beta-values to 0
#
# *$\rightarrow$ typical behaviour of Lasso Regression.*
#
# **Much better result for our model!!**
#
# *Comments:*
# - Again OLS gives the best result, but Lasso do a good job up to when $\lambda$ doesnt hit a certain value.
# ## Ridge & Lasso - MSE VS lambda - SK
# +
# %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import linear_model
def R2(y_data, y_model):
return 1 - np.sum((y_data - y_model) ** 2) / np.sum((y_data - np.mean(y_data)) ** 2)
def MSE(y_data,y_model):
n = np.size(y_model)
return np.sum((y_data-y_model)**2)/n
# Make data set.
n = 10000
x = np.random.rand(n)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.randn(n)
Maxpolydegree = 5
X = np.zeros((len(x),Maxpolydegree))
X[:,0] = 1.0
for polydegree in range(1, Maxpolydegree):
for degree in range(polydegree):
X[:,degree] = x**(degree)
# We split the data in test and training data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# matrix inversion to find beta
OLSbeta = np.linalg.pinv(X_train.T @ X_train) @ X_train.T @ y_train
print(OLSbeta)
ypredictOLS = X_test @ OLSbeta
print("Test MSE OLS")
print(MSE(y_test,ypredictOLS))
# Repeat now for Lasso and Ridge regression and various values of the regularization parameter using Scikit-Learn
# Decide which values of lambda to use
nlambdas = 4
MSERidgePredict = np.zeros(nlambdas)
MSELassoPredict = np.zeros(nlambdas)
lambdas = np.logspace(-3, 1, nlambdas)
for i in range(nlambdas):
lmb = lambdas[i]
# Make the fit using Ridge and Lasso
RegRidge = linear_model.Ridge(lmb,fit_intercept=False)
RegRidge.fit(X_train,y_train)
RegLasso = linear_model.Lasso(lmb,fit_intercept=False)
RegLasso.fit(X_train,y_train)
# and then make the prediction
ypredictRidge = RegRidge.predict(X_test)
ypredictLasso = RegLasso.predict(X_test)
# Compute the MSE and print it
MSERidgePredict[i] = MSE(y_test,ypredictRidge)
MSELassoPredict[i] = MSE(y_test,ypredictLasso)
print(lmb,RegRidge.coef_)
print(lmb,RegLasso.coef_)
# Now plot the results
plt.figure()
plt.plot(np.log10(lambdas), MSERidgePredict, 'b', label = 'MSE Ridge Test')
plt.plot(np.log10(lambdas), MSELassoPredict, 'r', label = 'MSE Lasso Test')
plt.xlabel('log10(lambda)')
plt.ylabel('MSE')
plt.legend()
plt.show()
# -
# ## Resampling algorithms:
#
# ### Jackknife
# +
from numpy import *
from numpy.random import randint, randn
from time import time
def jackknife(data, stat):
n = len(data);t = zeros(n); inds = arange(n); t0 = time()
## 'jackknifing' by leaving out an observation for each i
for i in range(n):
t[i] = stat(delete(data,i) )
# analysis
print("Runtime: %g sec" % (time()-t0)); print("Jackknife Statistics :")
print("original bias std. error")
print("%8g %14g %15g" % (stat(data),(n-1)*mean(t)/n, (n*var(t))**.5))
return t
# Returns mean of data samples
def stat(data):
return mean(data)
mu, sigma = 100, 15
datapoints = 10000
x = mu + sigma*random.randn(datapoints)
# jackknife returns the data sample
t = jackknife(x, stat)
# -
# ### Bootstrap
# ### Cross-validation
# ## Useful examples
# +
# Common imports
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.linear_model as skl
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler, Normalizer
# Where to save the figures and data files
PROJECT_ROOT_DIR = "Results"
FIGURE_ID = "Results/FigureFiles"
DATA_ID = "DataFiles/"
if not os.path.exists(PROJECT_ROOT_DIR):
os.mkdir(PROJECT_ROOT_DIR)
if not os.path.exists(FIGURE_ID):
os.makedirs(FIGURE_ID)
if not os.path.exists(DATA_ID):
os.makedirs(DATA_ID)
def image_path(fig_id):
return os.path.join(FIGURE_ID, fig_id)
def data_path(dat_id):
return os.path.join(DATA_ID, dat_id)
def save_fig(fig_id):
plt.savefig(image_path(fig_id) + ".png", format='png')
def FrankeFunction(x,y):
term1 = 0.75*np.exp(-(0.25*(9*x-2)**2) - 0.25*((9*y-2)**2))
term2 = 0.75*np.exp(-((9*x+1)**2)/49.0 - 0.1*(9*y+1))
term3 = 0.5*np.exp(-(9*x-7)**2/4.0 - 0.25*((9*y-3)**2))
term4 = -0.2*np.exp(-(9*x-4)**2 - (9*y-7)**2)
return term1 + term2 + term3 + term4
def create_X(x, y, n ):
if len(x.shape) > 1:
x = np.ravel(x)
y = np.ravel(y)
N = len(x)
l = int((n+1)*(n+2)/2) # Number of elements in beta
X = np.ones((N,l))
for i in range(1,n+1):
q = int((i)*(i+1)/2)
for k in range(i+1):
X[:,q+k] = (x**(i-k))*(y**k)
return X
# Making meshgrid of datapoints and compute Franke's function
n = 5
N = 1000
x = np.sort(np.random.uniform(0, 1, N))
y = np.sort(np.random.uniform(0, 1, N))
z = FrankeFunction(x, y)
X = create_X(x, y, n=n)
# split in training and test data
X_train, X_test, y_train, y_test = train_test_split(X,z,test_size=0.2)
clf = skl.LinearRegression().fit(X_train, y_train)
# The mean squared error and R2 score
print("MSE before scaling: {:.2f}".format(mean_squared_error(clf.predict(X_test), y_test)))
print("R2 score before scaling {:.2f}".format(clf.score(X_test,y_test)))
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("Feature min values before scaling:\n {}".format(X_train.min(axis=0)))
print("Feature max values before scaling:\n {}".format(X_train.max(axis=0)))
print("Feature min values after scaling:\n {}".format(X_train_scaled.min(axis=0)))
print("Feature max values after scaling:\n {}".format(X_train_scaled.max(axis=0)))
clf = skl.LinearRegression().fit(X_train_scaled, y_train)
print("MSE after scaling: {:.2f}".format(mean_squared_error(clf.predict(X_test_scaled), y_test)))
print("R2 score for scaled data: {:.2f}".format(clf.score(X_test_scaled,y_test)))
# -
# ### Introducing pandas
#
# <font color=red>*Reminder:*
# - organize in panads
# - an idea is to show $\beta$ as a function of the order of the polinomial $\rightarrow$ table with order-of-ply on the horizontal VS $\beta$-values on the vertical.</font>
# +
import numpy as np
import pandas as pd
from IPython.display import display
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import linear_model
# Make data set.
n = 1000
x = np.random.rand(n)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.randn(n)
Maxpolydegree = 5
X = np.zeros((len(x),Maxpolydegree))
X[:,0] = 1.0
for polydegree in range(1, Maxpolydegree):
for degree in range(polydegree):
X[:,degree] = x**(degree)
# We split the data in test and training data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Decide which values of lambda to use
nlambdas = 5
lambdas = np.logspace(-3, 2, nlambdas)
for i in range(nlambdas):
lmb = lambdas[i]
# Make the fit using Ridge only
RegRidge = linear_model.Ridge(lmb,fit_intercept=False)
RegRidge.fit(X_train,y_train)
# and then make the prediction
ypredictRidge = RegRidge.predict(X_test)
Coeffs = np.array(RegRidge.coef_)
BetaValues = pd.DataFrame(Coeffs)
BetaValues.columns = ['beta']
print("Lmb:",lmb)
display(BetaValues)
# -
# ## Exercise 2: making your own data and exploring scikit-learn
#
# We generate a dataset for a function $y(x)$ where $x \in [0,1]$ and defined by random numbers computed with the uniform distribution (with 100 data points). The function $y$ is a quadratic polynomial in $x$ with added stochastic noise according to the normal distribution $\cal {N}(0,1)$:
#
# $$
# y(x)=2+5x^2+0.1 \cal {N}(0,1)
# $$
#
# ### Task
#
# 1. Write your own code for computing the parametrization of the data set fitting a second-order polynomial.
#
# - *Insert here your notes Adele*
#
# $$ n=100, p=3 $$
# $$ \tilde{y}(x_{i})=\beta_{0}+\beta_{1}x_{i}+\beta_{2}x_{i}^2 \\ \forall i=0...99$$
#
# $$
# \chi=\begin{bmatrix}
# 1& x_{0} & x_{0}^2 \\
# 1& x_{1} & x_{1}^2 \\
# \dots \\
# 1& x_{99} & x_{99}^2
# \end{bmatrix} \rightarrow \text{FEATURE MATRIX (KNOWN)}
# $$
#
# What we need to know is **PARAMETERS VECTOR**:
# $$\beta=\begin{bmatrix}
# \beta_{0}\\
# \beta_{1}\\
# \beta_{2}
# \end{bmatrix}=?
# $$
#
# How? **MINIMIZING THE MSE (cost function)**
# $$
# MSE(\boldsymbol{y},\boldsymbol{\tilde{y}}) = \frac{1}{n}
# \sum_{i=0}^{n-1}(y_i-\tilde{y}_i)^2,
# $$
#
# through the **Linear Regressione Equation**:
#
# $$ \hat{\beta}=(\chi^{T}\chi)^{-1}\chi^{T} y $$
#
# 2. Use thereafter **scikit-learn** (see again the examples in the regression slides) and compare with your own code.
#
# 3. Using scikit-learn, compute also the mean square error, a risk metric corresponding to the expected value of the squared (quadratic) error defined as
# +
# %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
# +
# Point 1
def f(x):
return 2.0+5*x**2
def poly_X(x,p): # p=degree+1
X = np.zeros((len(x),p))
for i in range(0,p):
X[:,i] = x**i
return X
def beta_OLS(X,y):
XT=X.transpose()
return np.dot(np.dot(np.linalg.inv(np.dot(XT, X)),XT),y)
# 0. Generating Data
n=100
p=3 #second-order polynomial
x_data = np.sort(np.random.rand(n))
y_data = f(x_data)+0.1*np.random.randn(n) #(return a vector with 100 rows from gaussian distribution N(0,1))
#1. Build feature matrix:
X = poly_X(x_data,p)
#2. Linear Regression Equation:
beta = beta_OLS(X,y_data)
print("Beta", beta)
#3. Prediction
ytilde= X @ beta #print(ytilde)
#plt.plot(x_data, f(x_data), color='cornflowerblue', linewidth=2,label="ground truth")
plt.scatter(x_data, y_data, color='navy', marker='o', label="Training points")
plt.plot(x_data, ytilde, color='gold', linewidth=2,label="Second-order polynomyal fit")
plt.legend()
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.title(r'Linear Regression Method')
plt.grid(True)
plt.show()
# +
#Point 2
import pandas as pd
from sklearn.model_selection import train_test_split
def save_fig(fig_id):
plt.savefig(image_path(fig_id) + ".png", format='png')
def R2(y_data, y_model):
return 1 - np.sum((y_data - y_model) ** 2) / np.sum((y_data - np.mean(y_data)) ** 2)
def MSE(y_data,y_model):
n = np.size(y_model)
return np.sum((y_data-y_model)**2)/n
x=x_data
y=y_data
# The design matrix now as function of a given polynomial
X = np.zeros((len(x),3))
X[:,0] = 1.0
X[:,1] = x
X[:,2] = x**2
# We split the data in test and training data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# matrix inversion to find beta
beta = np.linalg.inv(X_train.T @ X_train) @ X_train.T @ y_train
print("Beta opt: ", beta)
# and then make the prediction
ytilde = X_train @ beta
print("Training R2: ", round(R2(y_train,ytilde),3))
print("Training MSE: ", round(MSE(y_train,ytilde),3))
ypredict = X_test @ beta
print("Test R2: ", round(R2(y_test,ypredict),3))
print("Test MSE: ", round(MSE(y_test,ypredict),3))
plt.scatter(X_train[:,1], y_train, color='navy', marker='o', linewidth=0.1,label="Training points")
plt.scatter(X_test[:,1], y_test, color='gold', marker='o', linewidth=0.1,label="Testing points")
plt.plot(np.sort(X_train[:,1]), np.sort(ytilde), color='navy', linewidth=2,label="Second-order polynomyal training fit")
plt.plot(np.sort(X_test[:,1]), np.sort(ypredict), color='gold', linewidth=2,label="Second-order polynomyal testing fit")
plt.legend()
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.title(r'Linear Regression Method')
plt.grid(True)
plt.show()
# -
# Comments:
# - Since the noise is very little compared to the data, we get a really good fit with beta-values very close to the real ones. We can indeed see that both training and testing MSE are very close to 0, while the R2s are very close to 1.
# - If instead we try to increase the noise the MSE and R2 gets worse, because the points are more spread in space and it's harder to find a regression in between the points.
# ## Exercise 3: Normalizing our data
# +
# %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
#import pandas as pd
import sklearn.linear_model as skl
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler, Normalizer
# create X of a polynomial of degree...
# NB: accept just feauture vector (of dim = 1)
def poly_X(x,p): # p=degree+1
X = np.zeros((len(x),p))
for i in range(0,p):
X[:,i] = x.T**i
return X
# compute beta OLS
def beta_OLS(X,y):
return np.linalg.inv(X.T @ X) @ X.T @ y
# errors calculation
def R2(y_data, y_model):
return 1 - np.sum((y_data - y_model) ** 2) / np.sum((y_data - np.mean(y_data)) ** 2)
def MSE(y_data,y_model):
n = np.size(y_model)
return np.sum((y_data-y_model)**2)/n
#######################################################################
# data
np.random.seed()
n = 100
maxdegree = 5
x = np.linspace(-3, 3, n).reshape(-1, 1)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.normal(0, 0.1, x.shape)
# create matrix X
X=poly_X(x, maxdegree+1)
##### for debugging:
#print(X)
import seaborn as sns
sns.set(rc={'figure.figsize':(10,20)})
sns.heatmap(data=(X_train_scaled), annot=True)
######## --> singular matrix
# train and test your data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# rescale data
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
beta_scaled = beta_OLS(X_train_scaled, y_train)
beta = beta_OLS(X_train, y_train)
print("Beta opt: ", beta)
# and then make the prediction
ytilde_scaled = X_train @ beta_scaled
ytilde = X_train @ beta
print("Training R2 (not scaled data): ", round(R2(y_train,ytilde),3))
print("Training R2 (scaled data): ", round(R2(y_train_scaled,ytilde_scaled),3))
print("Training MSE: ", round(MSE(y_train,ytilde),3))
ypredict = X_test @ beta
print("Test R2: ", round(R2(y_test,ypredict),3))
print("Test MSE: ", round(MSE(y_test,ypredict),3))
plt.scatter(X_train[:,1], y_train, color='navy', marker='o', linewidth=0.1,label="Training points")
plt.scatter(X_test[:,1], y_test, color='gold', marker='o', linewidth=0.1,label="Testing points")
plt.plot(np.sort(X_train[:,1]), np.sort(ytilde), color='navy', linewidth=2,label="Second-order polynomyal training fit")
plt.plot(np.sort(X_test[:,1]), np.sort(ypredict), color='gold', linewidth=2,label="Second-order polynomyal testing fit")
plt.legend()
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.title(r'Linear Regression Method')
plt.grid(True)
plt.show()
# -
# **E' singular!!!**
#
# Proviamo con Sklearn:
np.random.seed(2018)
# +
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
n = 50
maxdegree = 15
# Make data set.
x = np.linspace(-3, 3, n).reshape(-1, 1)
y = np.exp(-x**2) + 1.5 * np.exp(-(x-2)**2)+ np.random.normal(0, 0.1, x.shape)
TestError = np.zeros(maxdegree)
TrainError = np.zeros(maxdegree)
polydegree = np.zeros(maxdegree)
# let's make a mean of this stocastic results:
for time in range(100):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_test_scaled = scaler.transform(x_test)
for degree in range(maxdegree):
model = make_pipeline(PolynomialFeatures(degree=degree), LinearRegression(fit_intercept=False))
clf = model.fit(x_train_scaled,y_train)
y_fit = clf.predict(x_train_scaled)
y_pred = clf.predict(x_test_scaled)
polydegree[degree] = degree
TestError[degree] = (TestError[degree]*time + np.mean( np.mean((y_test - y_pred)**2) ))/(time+1)
TrainError[degree] = (TestError[degree]*time + np.mean( np.mean((y_train - y_fit)**2) ))/(time+1)
for degree in range(maxdegree-1):
grad=TestError[degree+1]-TestError[degree]
print(grad)
if grad>np.0.1:
break
print("Suggestion of max optimized complexity, degree =", degree)
plt.figure(figsize=(12,10))
plt.plot(polydegree, TestError, label='Test Error')
plt.plot(polydegree, TrainError, label='Train Error')
plt.legend()
plt.show()
# -
# ## **––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––**
# From week 34:
#
# ### Organizing our data
#
# Let us start with reading and organizing our data.
# We start with the compilation of masses and binding energies from 2016.
# After having downloaded this file to our own computer, we are now ready to read the file and start structuring our data.
#
#
# We start with preparing folders for storing our calculations and the data file over masses and binding energies. We import also various modules that we will find useful in order to present various Machine Learning methods. Here we focus mainly on the functionality of **scikit-learn**.
# +
# Common imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.linear_model as skl
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import os
# Where to save the figures and data files
PROJECT_ROOT_DIR = "Results"
FIGURE_ID = "Results/FigureFiles"
DATA_ID = "DataFiles/"
if not os.path.exists(PROJECT_ROOT_DIR):
os.mkdir(PROJECT_ROOT_DIR)
if not os.path.exists(FIGURE_ID):
os.makedirs(FIGURE_ID)
if not os.path.exists(DATA_ID):
os.makedirs(DATA_ID)
def image_path(fig_id):
return os.path.join(FIGURE_ID, fig_id)
def data_path(dat_id):
return os.path.join(DATA_ID, dat_id)
def save_fig(fig_id):
plt.savefig(image_path(fig_id) + ".png", format='png')
infile = open(data_path("MassEval2016.dat"),'r')
# -
# Before we proceed, we define also a function for making our plots. You can obviously avoid this and simply set up various **matplotlib** commands every time you need them. You may however find it convenient to collect all such commands in one function and simply call this function.
# +
from pylab import plt, mpl
plt.style.use('seaborn')
mpl.rcParams['font.family'] = 'serif'
def MakePlot(x,y, styles, labels, axlabels):
plt.figure(figsize=(10,6))
for i in range(len(x)):
plt.plot(x[i], y[i], styles[i], label = labels[i])
plt.xlabel(axlabels[0])
plt.ylabel(axlabels[1])
plt.legend(loc=0)
# -
# Code for SVD:
# +
import numpy as np
# SVD inversion
def SVD(A):
''' Takes as input a numpy matrix A and returns inv(A) based on singular value decomposition (SVD).
SVD is numerically more stable than the inversion algorithms provided by
numpy and scipy.linalg at the cost of being slower.
'''
U, S, VT = np.linalg.svd(A,full_matrices=True)
print('test U')
print( (np.transpose(U) @ U - U @np.transpose(U)))
print('test VT')
print( (np.transpose(VT) @ VT - VT @np.transpose(VT)))
print(U)
print(S)
print(VT)
D = np.zeros((len(U),len(VT)))
for i in range(0,len(VT)):
D[i,i]=S[i]
return U @ D @ VT
X = np.array([ [1.0,-1.0], [1.0,-1.0]])
#X = np.array([[1, 2], [3, 4], [5, 6]])
print(X)
C = SVD(X)
# Print the difference between the original matrix and the SVD one
print(C-X)
# +
import numpy as np
# SVD inversion
def SVDinv(A):
''' Takes as input a numpy matrix A and returns inv(A) based on singular value decomposition (SVD).
SVD is numerically more stable than the inversion algorithms provided by
numpy and scipy.linalg at the cost of being slower.
'''
U, s, VT = np.linalg.svd(A)
print('test U')
print( (np.transpose(U) @ U - U @np.transpose(U)))
print('test VT')
print( (np.transpose(VT) @ VT - VT @np.transpose(VT)))
D = np.zeros((len(U),len(VT)))
D = np.diag(s)
UT = np.transpose(U); V = np.transpose(VT); invD = np.linalg.inv(D)
return np.matmul(V,np.matmul(invD,UT))
#X = np.array([ [1.0, -1.0, 2.0], [1.0, 0.0, 1.0], [1.0, 2.0, -1.0], [1.0, 1.0, 0.0] ])
# Non-singular square matrix
X = np.array( [ [1,2,3],[2,4,5],[3,5,6]])
print(X)
A = np.transpose(X) @ X
# Brute force inversion
B = np.linalg.inv(A) # here we could use np.linalg.pinv(A)
C = SVDinv(A)
print(np.abs(B-C))
# +
import numpy as np
# SVD inversion
def SVDinv(A):
U, s, VT = np.linalg.svd(A)
# reciprocals of singular values of s
d = 1.0 / s
# create m x n D matrix
D = np.zeros(A.shape)
# populate D with n x n diagonal matrix
D[:A.shape[1], :A.shape[1]] = np.diag(d)
UT = np.transpose(U)
V = np.transpose(VT)
return np.matmul(V,np.matmul(D.T,UT))
A = np.array([ [0.3, 0.4], [0.5, 0.6], [0.7, 0.8],[0.9, 1.0]])
print(A)
# Brute force inversion of super-collinear matrix
B = np.linalg.pinv(A)
print(B)
# Compare our own algorithm with pinv
C = SVDinv(A)
print(np.abs(C-B))
# -
# Ridge and Lasso Regression:
# +
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import linear_model
def R2(y_data, y_model):
return 1 - np.sum((y_data - y_model) ** 2) / np.sum((y_data - np.mean(y_data)) ** 2)
def MSE(y_data,y_model):
n = np.size(y_model)
return np.sum((y_data-y_model)**2)/n
# A seed just to ensure that the random numbers are the same for every run.
# Useful for eventual debugging.
X = np.array( [ [ 2, 0], [0, 1], [0,0]])
y = np.array( [4, 2, 3])
# matrix inversion to find beta
OLSbeta = np.linalg.inv(X.T @ X) @ X.T @ y
print(OLSbeta)
# and then make the prediction
ytildeOLS = X @ OLSbeta
print("Training MSE for OLS")
print(MSE(y,ytildeOLS))
ypredictOLS = X @ OLSbeta
# Repeat now for Ridge regression and various values of the regularization parameter
I = np.eye(2,2)
# Decide which values of lambda to use
nlambdas = 100
MSERidgePredict = np.zeros(nlambdas)
MSELassoPredict = np.zeros(nlambdas)
lambdas = np.logspace(-4, 4, nlambdas)
for i in range(nlambdas):
lmb = lambdas[i]
Ridgebeta = np.linalg.inv(X.T @ X+lmb*I) @ X.T @ y
#print(Ridgebeta)
# and then make the prediction
ypredictRidge = X @ Ridgebeta
MSERidgePredict[i] = MSE(y,ypredictRidge)
RegLasso = linear_model.Lasso(lmb)
RegLasso.fit(X,y)
ypredictLasso = RegLasso.predict(X)
#print(RegLasso.coef_)
MSELassoPredict[i] = MSE(y,ypredictLasso)
# Now plot the results
plt.figure()
plt.plot(np.log10(lambdas), MSERidgePredict, 'r--', label = 'MSE Ridge Train')
plt.plot(np.log10(lambdas), MSELassoPredict, 'b--', label = 'MSE Lasso Train')
plt.xlabel('log10(lambda)')
plt.ylabel('MSE')
plt.legend()
plt.show()
| useful_code/Useful_code_project1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] papermill={"duration": 0.028648, "end_time": "2022-04-09T01:19:26.580312", "exception": false, "start_time": "2022-04-09T01:19:26.551664", "status": "completed"} tags=[]
# **This notebook is an exercise in the [Time Series](https://www.kaggle.com/learn/time-series) course. You can reference the tutorial at [this link](https://www.kaggle.com/ryanholbrook/time-series-as-features).**
#
# ---
#
# + [markdown] papermill={"duration": 0.022559, "end_time": "2022-04-09T01:19:26.627617", "exception": false, "start_time": "2022-04-09T01:19:26.605058", "status": "completed"} tags=[]
# # Introduction #
#
# Run this cell to set everything up!
# + papermill={"duration": 16.790172, "end_time": "2022-04-09T01:19:43.440684", "exception": false, "start_time": "2022-04-09T01:19:26.650512", "status": "completed"} tags=[]
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.time_series.ex4 import *
# Setup notebook
from pathlib import Path
from learntools.time_series.style import * # plot style settings
from learntools.time_series.utils import plot_lags, make_lags, make_leads
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_log_error
from statsmodels.graphics.tsaplots import plot_pacf
from statsmodels.tsa.deterministic import CalendarFourier, DeterministicProcess
comp_dir = Path('../input/store-sales-time-series-forecasting')
store_sales = pd.read_csv(
comp_dir / 'train.csv',
usecols=['store_nbr', 'family', 'date', 'sales', 'onpromotion'],
dtype={
'store_nbr': 'category',
'family': 'category',
'sales': 'float32',
'onpromotion': 'uint32',
},
parse_dates=['date'],
infer_datetime_format=True,
)
store_sales['date'] = store_sales.date.dt.to_period('D')
store_sales = store_sales.set_index(['store_nbr', 'family', 'date']).sort_index()
family_sales = (
store_sales
.groupby(['family', 'date'])
.mean()
.unstack('family')
.loc['2017', ['sales', 'onpromotion']]
)
# + [markdown] papermill={"duration": 0.022952, "end_time": "2022-04-09T01:19:43.486655", "exception": false, "start_time": "2022-04-09T01:19:43.463703", "status": "completed"} tags=[]
# ----------------------------------------------------------------------------
#
# Not every product family has sales showing cyclic behavior, and neither does the series of average sales. Sales of school and office supplies, however, show patterns of growth and decay not well characterized by trend or seasons. In this question and the next, you'll model cycles in sales of school and office supplies using lag features.
#
# Trend and seasonality will both create serial dependence that shows up in correlograms and lag plots. To isolate any purely *cyclic* behavior, we'll start by deseasonalizing the series. Use the code in the next cell to deseasonalize *Supply Sales*. We'll store the result in a variable `y_deseason`.
# + papermill={"duration": 0.517067, "end_time": "2022-04-09T01:19:44.027606", "exception": false, "start_time": "2022-04-09T01:19:43.510539", "status": "completed"} tags=[]
supply_sales = family_sales.loc(axis=1)[:, 'SCHOOL AND OFFICE SUPPLIES']
y = supply_sales.loc[:, 'sales'].squeeze()
fourier = CalendarFourier(freq='M', order=4)
dp = DeterministicProcess(
constant=True,
index=y.index,
order=1,
seasonal=True,
drop=True,
additional_terms=[fourier],
)
X_time = dp.in_sample()
X_time['NewYearsDay'] = (X_time.index.dayofyear == 1)
model = LinearRegression(fit_intercept=False)
model.fit(X_time, y)
y_deseason = y - model.predict(X_time)
y_deseason.name = 'sales_deseasoned'
ax = y_deseason.plot()
ax.set_title("Sales of School and Office Supplies (deseasonalized)");
# + [markdown] papermill={"duration": 0.029035, "end_time": "2022-04-09T01:19:44.082190", "exception": false, "start_time": "2022-04-09T01:19:44.053155", "status": "completed"} tags=[]
# Does this deseasonalized series show cyclic patterns? To confirm our intuition, we can try to isolate cyclic behavior using a moving-average plot just like we did with trend. The idea is to choose a window long enough to smooth over short-term seasonality, but short enough to still preserve the cycles.
#
# # 1) Plotting cycles
#
# Create a seven-day moving average from `y`, the series of supply sales. Use a centered window, but don't set the `min_periods` argument.
# + papermill={"duration": 0.450546, "end_time": "2022-04-09T01:19:44.557881", "exception": false, "start_time": "2022-04-09T01:19:44.107335", "status": "completed"} tags=[]
# YOUR CODE HERE
y_ma = y.rolling(7, center=True).mean()
# Plot
ax = y_ma.plot()
ax.set_title("Seven-Day Moving Average");
# Check your answer
q_1.check()
# + papermill={"duration": 0.033886, "end_time": "2022-04-09T01:19:44.618868", "exception": false, "start_time": "2022-04-09T01:19:44.584982", "status": "completed"} tags=[]
# Lines below will give you a hint or solution code
#q_1.hint()
#q_1.solution()
# + [markdown] papermill={"duration": 0.028154, "end_time": "2022-04-09T01:19:44.674018", "exception": false, "start_time": "2022-04-09T01:19:44.645864", "status": "completed"} tags=[]
# Do you see how the moving average plot resembles the plot of the deseasonalized series? In both, we can see cyclic behavior indicated.
#
# -------------------------------------------------------------------------------
#
# Let's examine our deseasonalized series for serial dependence. Take a look at the partial autocorrelation correlogram and lag plot.
# + papermill={"duration": 1.989978, "end_time": "2022-04-09T01:19:46.690948", "exception": false, "start_time": "2022-04-09T01:19:44.700970", "status": "completed"} tags=[]
plot_pacf(y_deseason, lags=8);
plot_lags(y_deseason, lags=8, nrows=2);
# + [markdown] papermill={"duration": 0.030164, "end_time": "2022-04-09T01:19:46.751282", "exception": false, "start_time": "2022-04-09T01:19:46.721118", "status": "completed"} tags=[]
# # 2) Examine serial dependence in *Store Sales*
#
# Are any of the lags significant according to the correlogram? Does the lag plot suggest any relationships that weren't apparent from the correlogram?
#
# After you've thought about your answer, run the next cell.
# + papermill={"duration": 0.04088, "end_time": "2022-04-09T01:19:46.823263", "exception": false, "start_time": "2022-04-09T01:19:46.782383", "status": "completed"} tags=[]
# View the solution (Run this cell to receive credit!)
q_2.check()
# + [markdown] papermill={"duration": 0.030847, "end_time": "2022-04-09T01:19:46.885378", "exception": false, "start_time": "2022-04-09T01:19:46.854531", "status": "completed"} tags=[]
# -------------------------------------------------------------------------------
#
# Recall from the tutorial that a *leading indicator* is a series whose values at one time can be used to predict the target at a future time -- a leading indicator provides "advance notice" of changes in the target.
#
# The competition dataset includes a time series that could potentially be useful as a leading indicator -- the `onpromotion` series, which contains the number of items on a special promotion that day. Since the company itself decides when to do a promotion, there's no worry about "lookahead leakage"; we could use Tuesday's `onpromotion` value to forecast sales on Monday, for instance.
#
# Use the next cell to examine leading and lagging values for `onpromotion` plotted against sales of school and office supplies.
# + papermill={"duration": 1.23167, "end_time": "2022-04-09T01:19:48.147996", "exception": false, "start_time": "2022-04-09T01:19:46.916326", "status": "completed"} tags=[]
onpromotion = supply_sales.loc[:, 'onpromotion'].squeeze().rename('onpromotion')
# Drop days without promotions
plot_lags(x=onpromotion.loc[onpromotion > 1], y=y_deseason.loc[onpromotion > 1], lags=3, leads=3, nrows=1);
# + [markdown] papermill={"duration": 0.034205, "end_time": "2022-04-09T01:19:48.222811", "exception": false, "start_time": "2022-04-09T01:19:48.188606", "status": "completed"} tags=[]
# # 3) Examine time series features
#
# Does it appear that either leading or lagging values of `onpromotion` could be useful as a feature?
# + papermill={"duration": 0.043303, "end_time": "2022-04-09T01:19:48.302409", "exception": false, "start_time": "2022-04-09T01:19:48.259106", "status": "completed"} tags=[]
q_3.check()
# + [markdown] papermill={"duration": 0.03411, "end_time": "2022-04-09T01:19:48.370555", "exception": false, "start_time": "2022-04-09T01:19:48.336445", "status": "completed"} tags=[]
# -------------------------------------------------------------------------------
#
# # 4) Create time series features
#
# Create the features indicated in the solution to Question 3. If no features from that series would be useful, use an empty dataframe `pd.DataFrame()` as your answer.
# + papermill={"duration": 0.055621, "end_time": "2022-04-09T01:19:48.461236", "exception": false, "start_time": "2022-04-09T01:19:48.405615", "status": "completed"} tags=[]
# YOUR CODE HERE: Make features from `y_deseason`
X_lags = make_lags(y_deseason, lags=1)
# YOUR CODE HERE: Make features from `onpromotion`
# You may want to use `pd.concat`
X_promo = pd.concat([make_lags(onpromotion, lags=1),
onpromotion,
make_leads(onpromotion, leads=1),
], axis=1)
X = pd.concat([X_lags, X_promo], axis=1).dropna()
y, X = y.align(X, join='inner')
# Check your answer
q_4.check()
# + papermill={"duration": 0.044326, "end_time": "2022-04-09T01:19:48.540600", "exception": false, "start_time": "2022-04-09T01:19:48.496274", "status": "completed"} tags=[]
# Lines below will give you a hint or solution code
#q_4.hint()
#q_4.solution()
# + [markdown] papermill={"duration": 0.034821, "end_time": "2022-04-09T01:19:48.610589", "exception": false, "start_time": "2022-04-09T01:19:48.575768", "status": "completed"} tags=[]
# Use the code in the next cell if you'd like to see predictions from the resulting model.
# + papermill={"duration": 0.532139, "end_time": "2022-04-09T01:19:49.178059", "exception": false, "start_time": "2022-04-09T01:19:48.645920", "status": "completed"} tags=[]
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=30, shuffle=False)
model = LinearRegression(fit_intercept=False).fit(X_train, y_train)
y_fit = pd.Series(model.predict(X_train), index=X_train.index).clip(0.0)
y_pred = pd.Series(model.predict(X_valid), index=X_valid.index).clip(0.0)
rmsle_train = mean_squared_log_error(y_train, y_fit) ** 0.5
rmsle_valid = mean_squared_log_error(y_valid, y_pred) ** 0.5
print(f'Training RMSLE: {rmsle_train:.5f}')
print(f'Validation RMSLE: {rmsle_valid:.5f}')
ax = y.plot(**plot_params, alpha=0.5, title="Average Sales", ylabel="items sold")
ax = y_fit.plot(ax=ax, label="Fitted", color='C0')
ax = y_pred.plot(ax=ax, label="Forecast", color='C3')
ax.legend();
# + [markdown] papermill={"duration": 0.037575, "end_time": "2022-04-09T01:19:49.254461", "exception": false, "start_time": "2022-04-09T01:19:49.216886", "status": "completed"} tags=[]
# -------------------------------------------------------------------------------
#
# Winners of Kaggle forecasting competitions have often included moving averages and other rolling statistics in their feature sets. Such features seem to be especially useful when used with GBDT algorithms like XGBoost.
#
# In Lesson 2 you learned how to compute moving averages to estimate trends. Computing rolling statistics to be used as features is similar except we need to take care to avoid lookahead leakage. First, the result should be set at the right end of the window instead of the center -- that is, we should use `center=False` (the default) in the `rolling` method. Second, the target should be lagged a step.
# + [markdown] papermill={"duration": 0.037106, "end_time": "2022-04-09T01:19:49.330254", "exception": false, "start_time": "2022-04-09T01:19:49.293148", "status": "completed"} tags=[]
# # 5) Create statistical features
#
# Edit the code in the next cell to create the following features:
# - 14-day rolling median (`median`) of lagged target
# - 7-day rolling standard deviation (`std`) of lagged target
# - 7-day sum (`sum`) of items "on promotion", with centered window
# + papermill={"duration": 0.061355, "end_time": "2022-04-09T01:19:49.428781", "exception": false, "start_time": "2022-04-09T01:19:49.367426", "status": "completed"} tags=[]
y_lag = supply_sales.loc[:, 'sales'].shift(1)
onpromo = supply_sales.loc[:, 'onpromotion']
# 28-day mean of lagged target
mean_7 = y_lag.rolling(7).mean()
# YOUR CODE HERE: 14-day median of lagged target
median_14 = y_lag.rolling(14).median()
# YOUR CODE HERE: 7-day rolling standard deviation of lagged target
std_7 = y_lag.rolling(7).std()
# YOUR CODE HERE: 7-day sum of promotions with centered window
promo_7 = onpromo.rolling(7, center=True).sum()
# Check your answer
q_5.check()
# + papermill={"duration": 0.045849, "end_time": "2022-04-09T01:19:49.513402", "exception": false, "start_time": "2022-04-09T01:19:49.467553", "status": "completed"} tags=[]
# Lines below will give you a hint or solution code
#q_5.hint()
#q_5.solution()
# + [markdown] papermill={"duration": 0.038119, "end_time": "2022-04-09T01:19:49.590387", "exception": false, "start_time": "2022-04-09T01:19:49.552268", "status": "completed"} tags=[]
# Check out the Pandas [`Window` documentation](https://pandas.pydata.org/pandas-docs/stable/reference/window.html) for more statistics you can compute. Also try "exponential weighted" windows by using `ewm` in place of `rolling`; exponential decay is often a more realistic representation of how effects propagate over time.
# + [markdown] papermill={"duration": 0.038312, "end_time": "2022-04-09T01:19:49.667497", "exception": false, "start_time": "2022-04-09T01:19:49.629185", "status": "completed"} tags=[]
# # Keep Going #
#
# [**Create hybrid forecasters**](https://www.kaggle.com/ryanholbrook/hybrid-models) and combine the strengths of two machine learning algorithms.
# + [markdown] papermill={"duration": 0.038999, "end_time": "2022-04-09T01:19:49.745040", "exception": false, "start_time": "2022-04-09T01:19:49.706041", "status": "completed"} tags=[]
# ---
#
#
#
#
# *Have questions or comments? Visit the [course discussion forum](https://www.kaggle.com/learn/time-series/discussion) to chat with other learners.*
| time_series/04-time-series-as-features.ipynb |
# ---
# jupyter:
# jupytext:
# formats: ipynb,Rmd,R
# text_representation:
# extension: .r
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: R
# language: R
# name: ir
# ---
# R regression modeling exercises
# ============
#
# Exercise 0: least squares regression
# ------------------------------------
#
# Use the *states.rds* data set. Fit a model predicting energy consumed per capita (energy) from the percentage of residents living in metropolitan areas (metro). Be sure to
#
# 1. Examine/plot the data before fitting the model
# 2. Print and interpret the model `summary`
# 3. `plot` the model to look for deviations from modeling assumptions
#
# Select one or more additional predictors to add to your model and repeat steps 1-3. Is this model significantly better than the model with *metro* as the only predictor?
# Exercise 1: interactions and factors
# ------------------------------------
#
# Use the states data set.
#
# 1. Add on to the regression equation that you created in exercise 1 by generating an interaction term and testing the interaction.
#
# 2. Try adding region to the model. Are there significant differences across the four regions?
# Exercise 2: logistic regression
# -------------------------------
#
# Use the NH11 data set that we loaded earlier.
#
# 1. Use glm to conduct a logistic regression to predict ever worked (everwrk) using age (age<sub>p</sub>) and marital status (r<sub>maritl</sub>).
# 2. Predict the probability of working for each level of marital status.
#
# Note that the data is not perfectly clean and ready to be modeled. You will need to clean up at least some of the variables before fitting the model.
# Exercise 3: multilevel modeling
# -------------------------------
#
# Use the dataset, bh1996: src<sub>R</sub>\[\]{data(bh1996, package="multilevel")}
#
# From the data documentation:
#
# > Variables are Cohesion (COHES), Leadership Climate (LEAD), Well-Being (WBEING) and Work Hours (HRS). Each of these variables has two variants - a group mean version that replicates each group mean for every individual, and a within-group version where the group mean is subtracted from each individual response. The group mean version is designated with a G. (e.g., G.HRS), and the within-group version is designated with a W. (e.g., W.HRS).
#
# 1. Create a null model predicting wellbeing ("WBEING")
# 2. Calculate the ICC for your null model
# 3. Run a second multi-level model that adds two individual-level predictors, average number of hours worked ("HRS") and leadership skills ("LEAD") to the model and interpret your output.
# 4. Now, add a random effect of average number of hours worked ("HRS") to the model and interpret your output. Test the significance of this random term.
#
| R/Rstatistics/Exercises.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Convert TensorFlow Object Detection API Models
# [Documentation](https://software.intel.com/en-us/articles/OpenVINO-Using-TensorFlow#inpage-nav-6)
# ### Custom configs and meta data
# +
######FCN
# Path to the frozen TensorFlow object detection model.
"""pb_file = "./models/rfcn_resnet101_custom_trained/frozen_inference_graph.pb"
# OpenVINO subgraph replacement configuration file that describes rules to convert specific TensorFlow topologies.
# Read more in Model optimization section.
configuration_file = 'deployment_tools/model_optimizer/extensions/front/tf/rfcn_support.json'
# The modified pipline config file used for training.
pipeline = './models/rfcn_resnet101_custom_trained/rfcn_resnet101_pets.config' """
######
######SSD
# Path to the frozen TensorFlow object detection model.
pb_file = "./models/frozen_inference_graph.pb"
# OpenVINO subgraph replacement configuration file that describes rules to convert specific TensorFlow topologies.
# Read more in Model optimization section.
configuration_file = 'deployment_tools/model_optimizer/extensions/front/tf/ssd_v2_support.json'
# The modified pipline config file used for training.
pipeline = './models/ssd_mobilenet_v2_custom_trained/ssd_mobilenet_v2_coco.config'
######
# Devices: GPU (intel), CPU or MYRIAD
#plugin_device = 'GPU'
# Specify a data type for the given device or set to `None` to let the code decide.
# Data type 'FP16' or 'FP32' depends on what device to run the converted model.
# FP16: GPU and MYRIAD
# FP32 CPU and GPU
data_type = None
# Converted model take fixed size image as input,
# we simply use same size for image width and height.
img_height = 300
# Path to a sample image to inference.
fname = '../test/IMG_20190312_131424132125.jpg'
# Model Optimizer can create an event file that can be then fed to the TensorBoard tool.(Optional)
tensorboard_logdir = None # './models/ssd_mobilenet_v2_coco_2018_03_29/mo_tensorboard'
# +
import os
model_dir = os.path.dirname(os.path.realpath(pb_file))
DATA_TYPE_MAP = {
'GPU': 'FP16',
'CPU': 'FP32',
'MYRIAD': 'FP16'
}
assert plugin_device in DATA_TYPE_MAP, 'Unsupported device: `{}`, not found in `{}`'.format(
plugin_device, list(DATA_TYPE_MAP.keys()))
if data_type is None:
data_type = DATA_TYPE_MAP.get(plugin_device)
# Directory to save the converted model xml and bin files.
output_dir = os.path.join(
model_dir, data_type)
# -
# ## Model optimization
# `--tensorflow_use_custom_operations_config <path_to_subgraph_replacement_configuration_file.json>`
#
# - A subgraph replacement configuration file that describes rules to convert specific TensorFlow* topologies. For the models downloaded from the TensorFlow* Object Detection API zoo, you can find the configuration files in the `<INSTALL_DIR>/deployment_tools/model_optimizer/extensions/front/tf`
#
# Use:
# - `ssd_v2_support.json` - for frozen SSD topologies from the models zoo.
# - `faster_rcnn_support.json` - for frozen Faster R-CNN topologies from the models zoo.
# - `faster_rcnn_support_api_v1.7.json` - for Faster R-CNN topologies trained manually using the TensorFlow* Object Detection API version 1.7.0 or higher.
# - ...
#
#
# If the `--input_shape` command line parameter is not specified, the Model Optimizer generates an input layer with the height and width as defined in the `pipeline.config`.
#
# If the --input_shape `[1, H, W, 3]` command line parameter is specified, the Model Optimizer sets the input layer height to H and width to W and convert the model.
#
#
# NOTE: If you convert a TensorFlow* Object Detection API model to use with the Inference Engine sample applications, you must specify the `--reverse_input_channels` parameter also. The samples load images in `BGR` channels order, while TensorFlow* models were trained with images in `RGB` order. When the `--reverse_input_channels` command line parameter is specified, the Model Optimizer performs first convolution or other channel dependent operation weights modification so the output will be like the image is passed with `RGB` channels order.
# +
import os
if tensorboard_logdir:
tensorboard_logdir_arg = '--tensorboard_logdir {}'.format(
tensorboard_logdir)
os.makedirs(tensorboard_logdir, exist_ok=True)
print(tensorboard_logdir_arg)
else:
tensorboard_logdir_arg = ''
# Absolute path to `configuration_file`
configuration_file = os.path.join(
os.environ["INTEL_CVSDK_DIR"], configuration_file)
# Prepare command line argument string.
input_shape = [1, img_height, img_height, 3]
input_shape_str = str(input_shape).replace(' ', '')
input_shape_str
# -
# Locate the path to `mo_tf.py` script.
# +
import platform
is_win = 'windows' in platform.platform().lower()
"""
# OpenVINO 2018
if is_win:
mo_tf_path = 'C:/Intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py'
else:
# mo_tf.py path in Linux
mo_tf_path = '~/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py'
"""
# OpenVINO 2019
if is_win:
mo_tf_path = '"C:\Program Files (x86)\IntelSWTools\openvino_2019.1.133\deployment_tools\model_optimizer\mo_tf.py"'
else:
# mo_tf.py path in Linux
mo_tf_path = '/opt/intel/openvino_2019.1.133/deployment_tools/model_optimizer/mo_tf.py'
# -
# Start the model optimization script.
# !python {mo_tf_path} \
# --input_model {pb_file} \
# --output_dir {output_dir} \
# --tensorflow_use_custom_operations_config {configuration_file} \
# --tensorflow_object_detection_api_pipeline_config {pipeline} \
# --input_shape {input_shape_str} \
# --data_type {data_type} \
# {tensorboard_logdir_arg}
# ## Inference test with OpenVINO Inference Engine(IE)
#
# Check path like `C:\Intel\computer_vision_sdk\python\python3.5` or `~/intel/computer_vision_sdk/python/python3.5` exists in `PYTHONPATH`.
# +
import os
output_dir = os.path.join(model_dir, data_type)
assert os.path.isdir(output_dir), '`{}` does not exist'.format(output_dir)
# +
import platform
is_win = 'windows' in platform.platform().lower()
"""
# OpenVINO 2018.
if is_win:
message = "Please run `C:\\Intel\\computer_vision_sdk\\bin\\setupvars.bat` before running this."
else:
message = "Add the following line to ~/.bashrc and re-run.\nsource ~/intel/computer_vision_sdk/bin/setupvars.sh"
"""
# OpenVINO 2019.
if is_win:
message = 'Please run "C:\Program Files (x86)\IntelSWTools\openvino_2019.1.133\bin\setupvars.bat" before running this.'
else:
message = "Add the following line to ~/.bashrc and re-run.\nsource /opt/intel/openvino/bin/setupvars.sh"
import os
assert 'computer_vision_sdk' in os.environ['PYTHONPATH'], message
# -
from PIL import Image
import numpy as np
try:
from openvino import inference_engine as ie
from openvino.inference_engine import IENetwork, IEPlugin
except Exception as e:
exception_type = type(e).__name__
print("The following error happened while importing Python API module:\n[ {} ] {}".format(
exception_type, e))
sys.exit(1)
# +
import glob
import os
# Plugin initialization for specified device and load extensions library if specified.
plugin_dir = None
model_xml = glob.glob(os.path.join(output_dir, '*.xml'))[-1]
model_bin = glob.glob(os.path.join(output_dir, '*.bin'))[-1]
# Devices: GPU (intel), CPU, MYRIAD
plugin = IEPlugin(plugin_device, plugin_dirs=plugin_dir)
# Read IR
net = IENetwork(model=model_xml, weights=model_bin)
assert len(net.inputs.keys()) == 1
assert len(net.outputs) == 1
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
# Load network to the plugin
exec_net = plugin.load(network=net)
del net
# -
def pre_process_image(imagePath, img_shape):
"""pre process an image from image path.
Arguments:
imagePath {str} -- input image file path.
img_shape {tuple} -- Target height and width as a tuple.
Returns:
np.array -- Preprocessed image.
"""
# Model input format
assert isinstance(img_shape, tuple) and len(img_shape) == 2
n, c, h, w = [1, 3, img_shape[0], img_shape[1]]
image = Image.open(imagePath)
processed_img = image.resize((h, w), resample=Image.BILINEAR)
processed_img = np.array(processed_img).astype(np.uint8)
# Change data layout from HWC to CHW
processed_img = processed_img.transpose((2, 0, 1))
processed_img = processed_img.reshape((n, c, h, w))
return processed_img, np.array(image)
# Run inference
img_shape = (img_height, img_height)
processed_img, image = pre_process_image(fname, img_shape)
res = exec_net.infer(inputs={input_blob: processed_img})
print(res['DetectionOutput'].shape)
# The Inference Engine DetectionOutput layer implementation produces one tensor with seven numbers for each actual detection:
#
# - 0: batch index
# - 1: class label
# - 2: class probability
# - 3: x_1 box coordinate (0~1 as a fraction of the image width reference to the upper left corner)
# - 4: y_1 box coordinate (0~1 as a fraction of the image height reference to the upper left corner)
# - 5: x_2 box coordinate (0~1 as a fraction of the image width reference to the upper left corner)
# - 6: y_2 box coordinate (0~1 as a fraction of the image height reference to the upper left corner)
# Filter the results with a prediction probability threshold.
# +
probability_threshold = 0.5
preds = [pred for pred in res['DetectionOutput'][0][0] if pred[2] > probability_threshold]
# -
preds
# ## Visualize the detection results
# +
# %matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.patches as patches
ax = plt.subplot(1, 1, 1)
plt.imshow(image) # slice by z axis of the box - box[0].
for pred in preds:
class_label = pred[1]
probability = pred[2]
print('Predict class label:{:.0f}, with probability: {:.2f}'.format(
class_label, probability))
box = pred[3:]
box = (box * np.array(image.shape[:2][::-1] * 2)).astype(int)
x_1, y_1, x_2, y_2 = box
rect = patches.Rectangle((x_1, y_1), x_2-x_1, y_2 -
y_1, linewidth=2, edgecolor='red', facecolor='none')
ax.add_patch(rect)
ax.text(x_1, y_1, '{:.0f} - {:.2f}'.format(class_label,
probability), fontsize=12, color='yellow')
# -
# ### Benchmark the inference speed
import time
times = []
for i in range(20):
start_time = time.time()
res = exec_net.infer(inputs={input_blob: processed_img})
delta = (time.time() - start_time)
times.append(delta)
mean_delta = np.array(times).mean()
fps = 1/mean_delta
print('average(sec):{:.3f},fps:{:.2f}'.format(mean_delta,fps))
# ## Visualize frozen `.pb` file (optional)
# ### Option 1: Visualize the frozen `.pb` file with TensorBoard
# +
import os
log_dir = "./tensorboard"
pb_file = os.path.abspath(pb_file).replace('\\', '/')
log_dir = os.path.abspath(log_dir).replace('\\', '/')
os.makedirs(log_dir, exist_ok=True)
assert os.path.isfile(pb_file)
print('--model_dir {}'.format(pb_file))
print('--log_dir {}'.format(log_dir))
# -
from tensorflow.python.tools import import_pb_to_tensorboard
# File path to `import_pb_to_tensorboard.py`
import_pb_to_tensorboard_py = import_pb_to_tensorboard.__file__
import_pb_to_tensorboard_py = import_pb_to_tensorboard_py.replace('\\', '/')
import_pb_to_tensorboard_py
# #### Create TensorBoard event file.
get_ipython().system_raw(
'python {} --model_dir {} --log_dir {} &'
.format(import_pb_to_tensorboard_py, pb_file, log_dir)
)
# !ls {log_dir}
# #### Run TensorBoard
get_ipython().system_raw(
'tensorboard --logdir {} &'
.format(log_dir)
)
# ### Option 2: Visualize with OpenVINO `summarize_graph.py` utility.
# If you just want to know the input(s) and output(s) of the model.
# +
import platform
is_win = 'windows' in platform.platform().lower()
if is_win:
summarize_graph_path = 'C:/Intel/computer_vision_sdk/deployment_tools/model_optimizer/mo/utils/summarize_graph.py'
else:
# summarize_graph.py path in Linux
summarize_graph_path = '~/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo/utils/summarize_graph.py'
# -
# !python {summarize_graph_path} --input_model {pb_file}
| deploy/openvino_convert_tf_object_detection-Copy1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # extra class( 16/7/19)
# # Day 21
import pandas as pd
import numpy as np
outside = ['G1','G1','G1','G2','G2','G2']
inside = [1,2,3,1,2,3]
higher_index = list(zip(outside,inside))
print(higher_index)
higher_index = pd.MultiIndex.from_tuples(higher_index)
higher_index
type(higher_index)
from numpy.random import randn as rn
df = pd.DataFrame(data = np.round(rn(6,3),2), index = higher_index, columns = ['A','B','C'])
df
df.loc['G1'].loc[[1,3],['A','C']]
df.index.names = ["outer","inner"]
df
df.loc['G1']
# # Cross -Section to get the data (for outer indices):
# ## .xs('Name')
# ## To extract the data of G1 only:
df.xs('G1')
# # Cross - Section to get the data for inner indices:
# ## To extract the data of inner index 2 for both the outer indices:
df.xs(2,level = "inner")
# # To tackle the case of NaN (missing data) from the dataset:
# ## We should either drop or fill that place of missing data:
# # drop.na for [drop]:
# ### Here we passed a dictionary to a dataframe having some null values by using np.nan :
df1 = pd.DataFrame({'A':[1,2,np.nan],'B':[5,np.nan,np.nan],'C':[1,2,3]})
df1
df1["States"] = "CA NV AZ".split()
df1
df1.set_index("States",inplace = True)
df1
# ### Drop null values index wise (row wise): [AXIS = 0]
df1.dropna(axis = 0) #axis = 0 stands for row wise
# ### Drop null values col wise: [AXIS = 1]
df1.dropna(axis = 1) #axis = 1 stands for col wise
df1
# ## Setting threshold for the null values in the dataset so that some NaN can be retained even after dropping:
# ### thresh works in D.O way, notice the codes below:
# ### [AXIS = 0]
df1.dropna(axis = 0, thresh = 0)
df1.dropna(axis = 0,thresh = 1)
df1.dropna(axis = 0,thresh = 2)
df1.dropna(axis = 0,thresh = 3)
df1.dropna(axis = 0, thresh = 4)
df1.dropna(axis = 0,thresh = 5)
# ### [AXIS = 1]
df1.dropna(axis = 1, thresh = 0)
df1.dropna(axis = 1,thresh = 1)
df1.dropna(axis = 1,thresh = 2)
df1.dropna(axis = 1,thresh = 3)
df1.dropna(axis = 1, thresh = 4)
df1.dropna(axis = 1,thresh = 5)
# ## Example 2 for thresh:
df1 = pd.DataFrame({'A':[1,2,np.nan,np.nan],'B':[5,np.nan,np.nan,np.nan],'C':[1,2,3,np.nan]})
df1
df1.dropna(axis = 0, thresh = 0)
df1.dropna(axis = 0,thresh = 1)
df1.dropna(axis = 0,thresh = 2)
df1.dropna(axis = 0,thresh = 3)
df1.dropna(axis = 0, thresh = 4)
df1.dropna(axis = 0,thresh = 5)
# ## Example 3 for thresh:
df1 = pd.DataFrame({'A':[1,2,np.nan,3],'B':[5,np.nan,np.nan,np.nan],'C':[1,2,3,np.nan]})
df1
df1.dropna(axis = 0, thresh = 0)
df1.dropna(axis = 0,thresh = 1)
df1.dropna(axis = 0,thresh = 2)
df1.dropna(axis = 0,thresh = 3)
df1.dropna(axis = 0, thresh = 4)
df1.dropna(axis = 0,thresh = 5)
# # .fillna [fill]:
df1 = pd.DataFrame({'A':[1,2,np.nan,3],'B':[5,np.nan,np.nan,np.nan],'C':[1,2,3,np.nan]})
df1
df1.fillna(value = "Yosh")
type(df1)
df1.fillna(value = 1)
type(df1)
df1 = pd.DataFrame({'A':[1,2,np.nan,3],'B':[5,np.nan,np.nan,np.nan],'C':[1,2,3,np.nan]})
df1["States"] = "CA NV AZ NY".split()
df1
df1.set_index("States",inplace = True)
df1
type(df1.loc[['CA'],['A']])
df1.loc['NV'].loc['B'].fillna(value = 0.0)
df1['B'].mean()
df1.fillna(value = df1['B'].mean())
df1.loc[['NV'],['C']]
# # Using method = "ffill"
new_df = df1.fillna(method = "ffill")
df1
new_df
# # Using method = "bfill"
new_df = df1.fillna(method = "bfill")
df1
new_df
# # Examples for ffill and bfill:
# ## Example 1:
df = pd.DataFrame({'temperature':[32,np.nan,28,np.nan,32,np.nan,"sunny",np.nan,34,40]})
df
df.fillna(method = "ffill")
df.fillna(method = "bfill")
# ## Example 2:
df = pd.DataFrame({'temperature':[32,np.nan,np.nan,np.nan,32,np.nan,"sunny",np.nan,34,40]})
df
df.fillna(method = "ffill")
df.fillna(method = "bfill")
# # Setting limits to the ffill/bfill to multiple NaN's:
df
df.fillna(method = "ffill",limit=1)
df.fillna(method = "bfill",limit=1)
# # Interpolate function:
df
# ## Doesn't work for different data type[ use preferrable interger/float]:
new_df = df.interpolate()
df = pd.DataFrame({'temperature':[32,np.nan,np.nan,np.nan,32,np.nan,np.nan,np.nan,34,40]})
df
new_df = df.interpolate()
new_df
df = pd.DataFrame({'temperature':[1,np.nan,np.nan,np.nan,2,np.nan,np.nan,np.nan,3,4,np.nan,np.nan,np.nan,4,np.nan,5,np.nan]})
df
new_df = df.interpolate()
new_df
# So the index 0 has 1.0, index 4 has 2.0 : index 1,2,3 = NaN
# interpolate() considers : 2-1/4 = 0.25 increment( since there are 4 index diff between the non null values), consider this logic with diff dataset as shown above
# # Day 22:
# # Pandas Time-Series:
import pandas as pd
import numpy as np
dir(pd)
df = pd.read_csv("C:\\Users\\MAHE\\Desktop\\Data Science\\DataSets\\dataset1\\stock.csv",sep = "\t")
df
# # parse_dates:
df
df = pd.read_csv("C:\\Users\\MAHE\\Desktop\\Data Science\\DataSets\\dataset1\\stock.csv",sep = "\t",parse_dates = ["Date"],index_col = "Date")
df
# Result is in yyyy-mm-dd format, and it is in descending order
# # Indexing and slicing:
df.index
# ## 1.For a particular date:
df['2017-06-21']
# ## 2. For the data in a particular period of time:
df['2017-06']
df['2017-06-09':'2017-06-01'] #Give the slicing indices as per the dataset, here it is in D.O. hence 09 comes before 01
# # Q. Avg price of closing price of a particular month:
# +
#Close is the column here
# -
df['2017-06'].Close.mean()
# # Q. Find the average closing price of a sample of every month:
# ## .resample("x") x = Y(year)/M(month)
df['Close'].resample("M")
df["Close"].resample("M").mean()
df["Close"].resample("Y").mean()
# # Plotting the dataset in a graph:
# # [Matplotlib]
import matplotlib.pyplot as plt
# +
# The line below is important and is specific only to Jupyter nb
# -
# %matplotlib inline
df["Close"].plot(kind = "line")
df["Close"].plot(kind = "bar")
df["Close"].resample("M").mean().plot(kind = "bar")
# # (...cotd of numpy)
import numpy as np
dir(np)
a = np.array([1,2,3,4])
a
b = np.array([[1,2,3],[4,5,6],[7,8,9]])
b
# # Difference in the indexing and slicing:
b[:,1] #Returns in the vector form -> Indexing
b[:,1:2] #Returns in a matrix form ->Slicing
# Though the answer is the same numerically, the format differs for the indexing and slicing methods
# ## Print the elements row-wise:
for i in b:
print(i)
# # Built-in-func:
dir(b)
# # .flat() method: [prints the elements cell by cell in a flattened format]
for cell in b.flat:
print(cell)
# # .reshape(num_rows , num_cols):
#
#
# # [num_rows * num_cols = num_elem_of_original_mat]
b
d = b.reshape(9,1)
d
l = np.arange(6)
print(l)
e = np.arange(9,15).reshape(3,2) # (15-1)-9 = 6 = 3*2
e
d = np.arange(6).reshape(3,2) # (6-1)-0 = 3*2
d
a = np.array([[[1,2,3],[4,5,6],[7,8,9]],[[11,12,13],[14,15,16],[17,18,19]],[[21,22,23],[24,25,26],[27,28,29]]])
b = a.reshape(9,3,1)
b
# # Stacking:
#
# # [all the input array dimensions except for the concatenation axis must match exactly]
d
e
# # Vertical stacking:
np.vstack((d,e))
# # Horizontal stacking:
np.hstack((d,e))
# # np.hsplit() , np.vsplit()
f = np.arange(30).reshape(2,15)
print(f)
np.hsplit(f,3)
np.hsplit(f,5)
g = np.hsplit(f,3)
g[2]
np.vsplit(f,2)
h = np.vsplit(f,2)
h[1]
n = 2000
if n%4==0:
if n%100==0:
print(0)
else:
print("Leap year")
else:
print("Not a leap year")
# # Day 23 18-06-2019
# # Pandas Time series and Time complexity:
import pandas as pd
# # Yearly basis:
y = pd.Period("2016")
y
y.start_time
y.end_time
# ## To find out whether its a leap year or not?
y.is_leap_year
# # Monthly Period
m = pd.Period("2017-12") #Only december month is considered
m.start_time
m.end_time
n = m+1
n #Becomes next month
# # Daily Basis:
a = pd.Period("2016-02-28",freq = 'D')
a
a.start_time
a.end_time
a+1
a+2
# # Hourly period:
h = pd.Period("2017-08-15 23:00:00", freq = "H")
h
h.start_time
h.end_time
h+pd.offsets.Hour(1)
h+1
# # Quaterly period:
q1 = pd.Period("2017Q1",freq = "Q-JAN")
q1
q1.start_time
q1.end_time
# # Use asfreq to convert period to a different frequency:
#q1 is quarterly here, from the previous result
q1.asfreq("M", how = "start")
q1.asfreq("M", how = "end")
# # Weekly period:
w = pd.Period("2017-07-05", freq = "W")
w # Period("start date / end date", "W-SUN[check]"
w-1
w = pd.Period("2019-06-18", freq = "W")
w
w-1
w1 = pd.Period("2019-06-17", freq = "W")
w1
w1-1
w2 = pd.Period("2019-04-29", freq = "W")
w2
w2-1
w2-w1
w3 = pd.Period("2019-07-17 23:00:00", freq = "H")
w4 = pd.Period("2018-04-23 12:23:00", freq = "H")
w4-w3
# # PeriodIndex and period_range
r = pd.period_range("2011","2019",freq = "q")
r
len(r)
r[0].start_time
r[0].end_time
r[3].start_time
# ## [check fiscal year ]
r = pd.period_range("2011","2019")
r
r = pd.period_range("2011","2019", freq = "q-jan")
r
r[0].start_time
r[0].end_time
r = pd.PeriodIndex(start = "2019-01", freq = "3M", periods = 10)
r
import numpy as np
import pandas as pd
ps = pd.Series(np.random.randn(len(r)),r)
ps
ps["2019"]
ps["2019":"2020"]
pst = ps.to_timestamp()
pst #Starting date of every quarter is added here
pst.index
import os
os.getcwd()
os.chdir("C:\\Users\\MAHE\\Desktop")
os.getcwd()
df = pd.read_csv("apple.csv")
df
df.set_index("Line Item",inplace = True)
df
# # Rows-> col , col- > Rows:
# ## [ .T]
df = df.T
df
df.index = pd.PeriodIndex(df.index, freq = "Q-JAN")
df
df.index
df.index[0]
df.index[0].start_time
df.index[0].end_time
# Filing income tax: When we file for 2019: 2018 April to March 2019 31st
#
# filing for 2017 q1: 2016 q1 to q4
df.index[4].start_time
df["Start Date"] = df.index.map(lambda x: x.start_time)
df["Start Date"]
df
# Difference between financial year and fiscal year?
#
#
# Financial year: 1st April [curr_year] - March 31st[next_yr]
#
# Fiscal year: Present year ( For some companies, financial yr differs from the rest, their calculations changes because of this)
#
# UK: April 6th [curr_yr] - April 5th [next_yr]
df["End Date"] = df.index.map(lambda x: x.end_time)
df["End Date"]
df
# # Day 24:
# # Time-Zone:
import pandas as pd
import numpy as np
import os
os.getcwd()
os.chdir("C:\\Users\\MAHE\\Desktop\\Data Science\\DataSets\\dataset1")
os.getcwd()
df2 = pd.read_csv("data2.csv")
df2
df = pd.read_csv("data2.csv",index_col = "DateTime", parse_dates = True)
df.index
df.tz_localize(tz = "US/Eastern")
df.index = df.index.tz_localize(tz = "US/Eastern")
df
df = df.tz_convert("Europe/Western")
df
df = df.tz_convert("Europe/Berlin")
df
from pytz import all_timezones
print(all_timezones)
df.index = df.index.tz_convert("Asia/Calcutta")
df
| Data-Science-HYD-2k19/Day-based/Cumulative/Day 21 - 30 (classwork).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.6.13 64-bit (''attendance'': conda)'
# language: python
# name: python3
# ---
# +
# pip install opencv-python
# pip install face_recognition
# -
import cv2
import face_recognition
img_folder = 'images/'
img = cv2.imread(img_folder + 'louisrossi.png')
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # it's bgr default
img_encoding = face_recognition.face_encodings(rgb_img)[0]
cv2.imshow('img', img)
cv2.waitKey(0)
| Attendance/facerecognition/facerecognitiontest.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="UcXKLK68ZbAp" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 314} outputId="2535475f-79e8-41cc-f6ce-f2a41742a89f" executionInfo={"status": "ok", "timestamp": 1582920315603, "user_tz": -60, "elapsed": 6076, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
# !pip install eli5
# + id="RYj6-V2fZxb_" colab_type="code" colab={}
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import cross_val_score
import eli5
from eli5.sklearn import PermutationImportance
from ast import literal_eval
from tqdm import tqdm_notebook
# + id="fORWJrDnaIGi" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="e059ac04-d77d-4ebb-cca8-d8aa90cf923a" executionInfo={"status": "ok", "timestamp": 1582920444179, "user_tz": -60, "elapsed": 973, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
# cd "/content/drive/My Drive/Colab Notebooks/DW_matrix"
# + id="ehiAAZGwaSS5" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="fbfb189f-1741-4da5-c4d1-e2249621cd78" executionInfo={"status": "ok", "timestamp": 1582920518215, "user_tz": -60, "elapsed": 3723, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07435370255154987946"}}
# ls data
# + id="KfnmdHBzahxM" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="fcf09316-c462-4dcc-d336-d264530031f0" executionInfo={"status": "ok", "timestamp": 1582921317857, "user_tz": -60, "elapsed": 1248, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07435370255154987946"}}
df = pd.read_csv('data/shoes_prices.csv', low_memory=False)
df = df[df.prices_currency == "USD"].copy()
df["prices_amountmin"] = df.prices_amountmin.astype(np.float)
filter_max = np.percentile(df["prices_amountmin"], 99)
df = df[df["prices_amountmin"] < filter_max]
df.shape
# + id="r13WrWkpbCo2" colab_type="code" colab={}
def run_model(feats, model = DecisionTreeRegressor(max_depth=5)):
X = df[feats].values
y = df['prices_amountmin'].values
scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error')
return np.mean(scores), np.std(scores)
# + id="L_nQ3kpUbgUz" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="2dd857a5-adc4-4b41-bfde-f59d9475acf2" executionInfo={"status": "ok", "timestamp": 1582921444530, "user_tz": -60, "elapsed": 881, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
df['brand_cat'] = df['brand'].map(lambda x: str(x).lower()).factorize()[0]
run_model(['brand_cat'])
# + id="CGqSdUy3bruS" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="0d359549-4cce-465e-e4c9-8b8784bb3b4d" executionInfo={"status": "ok", "timestamp": 1582921464013, "user_tz": -60, "elapsed": 4318, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
model = RandomForestRegressor(max_depth=5, n_estimators=100, random_state=0)
run_model(['brand_cat'], model)
# + id="o_dbNAircdWR" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 148} outputId="8f7d6bb0-6c91-42e0-88ac-a16d726236cc" executionInfo={"status": "ok", "timestamp": 1582921551052, "user_tz": -60, "elapsed": 859, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
df.features.head().values
# + id="giYDfd-ndzXp" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 522} outputId="496c3410-69bd-4e81-be82-be51456b1eba" executionInfo={"status": "ok", "timestamp": 1582921988504, "user_tz": -60, "elapsed": 862, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
df.head()
# + id="HmJy20sOft_O" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="81773145-5463-4e92-a54f-b41911c85b87" executionInfo={"status": "ok", "timestamp": 1582921962456, "user_tz": -60, "elapsed": 1173, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
str_dict = '[{"key":"Gender","value":["Men"]},{"key":"Shoe Size","value":["M"]},{"key":"Shoe Category","value":["Men\'s Shoes"]},{"key":"Color","value":["Multicolor"]},{"key":"Manufacturer Part Number","value":["8190-W-NAVY-7.5"]},{"key":"Brand","value":["Josmo"]}]'
literal_eval(str_dict)[0]['value']
# + id="ND97VG2cgAY_" colab_type="code" colab={}
def parse_features(x):
output_dict = {}
if str(x) == 'nan': return output_dict
features = literal_eval(x.replace('\\"', '"'))
for item in features:
key = item['key'].lower().strip()
value = item['value'][0].lower().strip()
output_dict[key] = value
return output_dict
df['features_parsed'] = df['features'].map(parse_features)
# + id="T-9oqWtBgj1W" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="ae6cf26a-aa71-45e5-f6cc-7d65d7fff585" executionInfo={"status": "ok", "timestamp": 1582922524514, "user_tz": -60, "elapsed": 829, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
keys = set()
df['features_parsed'].map(lambda x: keys.update(x.keys() ))
len(keys)
# + id="IQPct1Wng44F" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 67, "referenced_widgets": ["2a2887811d144d2d9888d165f95fa536", "<KEY>", "9db21c06cd6945be89912e944ce2e5d6", "b27e53f037b049a39506614cad9be7a5", "4c423053e13940cb968f4e82a51d870b", "c3ae646a91564cd4b5087a580f28f82e", "6540b5324d194a4d816211f4a7bdc4c4", "178845a254704355ab6e4ba7167c78ba"]} outputId="516eb74a-2d8b-4edc-fe8a-d90880311d29" executionInfo={"status": "ok", "timestamp": 1582922833042, "user_tz": -60, "elapsed": 5082, "user": {"displayName": "<NAME>0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
def get_name_feat(key):
return 'feat_' + key
for key in tqdm_notebook(keys):
df[get_name_feat(key)] = df.features_parsed.map(lambda feats: feats[key] if key in feats else np.nan)
# + id="9H7BhZI3i0m7" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 165} outputId="d005ee0d-3447-4c8f-b506-170f0c6f77c9" executionInfo={"status": "ok", "timestamp": 1582922868403, "user_tz": -60, "elapsed": 862, "user": {"displayName": "<NAME>0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
df.columns
# + id="Zi5mucFkjhwg" colab_type="code" colab={}
keys_stat = {}
for key in keys:
keys_stat[key] = df[False == df[get_name_feat(key)].isnull() ].shape[0] /df.shape[0] *100
# + id="BBvZ0ZwwkIzC" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 109} outputId="4d866d4d-569b-41f2-f9da-003ecc8d2c19" executionInfo={"status": "ok", "timestamp": 1582923133514, "user_tz": -60, "elapsed": 837, "user": {"displayName": "<NAME>0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
{k:v for k,v in keys_stat.items() if v > 30}
# + id="gVy1De8AkLTf" colab_type="code" colab={}
df['feat_brand_cat'] = df['feat_brand'].factorize()[0]
df['feat_color_cat'] = df['feat_color'].factorize()[0]
df['feat_gender_cat'] = df['feat_gender'].factorize()[0]
df['feat_manufacturer part number_cat'] = df['feat_manufacturer part number'].factorize()[0]
df['feat_material_cat'] = df['feat_material'].factorize()[0]
df['feat_sport_cat'] = df['feat_sport'].factorize()[0]
df['feat_style_cat'] = df['feat_style'].factorize()[0]
for key in keys:
df[get_name_feat(key) + '_cat'] = df[get_name_feat(key)].factorize()[0]
# + id="oLDsgcURqZv9" colab_type="code" colab={}
df['brand'] = df['brand'].map(lambda x: str(x).lower())
# + id="_WBP8Jk6rOEe" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="126f3989-6339-4d53-c0d6-de54d6f2dc31" executionInfo={"status": "ok", "timestamp": 1582924957756, "user_tz": -60, "elapsed": 4204, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
model = RandomForestRegressor(max_depth= 5, n_estimators=100)
run_model(['brand_cat'], model)
# + id="uDfX0TaYredb" colab_type="code" colab={}
model = RandomForestRegressor(max_depth= 5, n_estimators=100)
feats= ['brand_cat', 'feat_brand_cat','feat_sport_cat', 'feat_style_cat', 'feat_gender_cat','feat_material_cat' ]
result = run_model(feats, model)
# + id="mqGQp77zrwdG" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 157} outputId="c63cb3e2-325d-4116-b29a-bec0065d26a5" executionInfo={"status": "ok", "timestamp": 1582926094280, "user_tz": -60, "elapsed": 4031, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07435370255154987946"}}
X = df[feats].values
y = df['prices_amountmin'].values
m = RandomForestRegressor(max_depth=5, n_estimators=100, random_state=0)
m.fit(X, y)
print(result)
perm = PermutationImportance(m, random_state=1).fit(X,y);
eli5.show_weights(perm, feature_names=feats)
# + id="a16gO86NsOO7" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 129} outputId="5d9669b7-d3a1-4754-b4cd-4eb158f1b4cb" executionInfo={"status": "ok", "timestamp": 1582925502424, "user_tz": -60, "elapsed": 788, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07435370255154987946"}}
df[df['brand'] == 'nike'].features_parsed.sample(5).values
# + id="L4mZPLIQsvV2" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="3a9b0938-6107-4ba7-8167-ca14ee96c4e5" executionInfo={"status": "ok", "timestamp": 1582926132192, "user_tz": -60, "elapsed": 824, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
pwd
# + id="WDINa18qv-_8" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="d3402523-bc4a-46a1-c9c2-9ec5c50922ba" executionInfo={"status": "ok", "timestamp": 1582926153518, "user_tz": -60, "elapsed": 3867, "user": {"displayName": "<NAME>\u0144ski", "photoUrl": "", "userId": "07435370255154987946"}}
# ls matrix_one/
# + id="6Z-VE0mowAB4" colab_type="code" colab={}
# !git add matrix_one
| matrix_one/Day5.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="-5zceVtRCaiv" colab_type="text"
# # Assignment 1: Exploring and Visualizing Data
# <NAME>
# ## Background Data
# The MSPA Software Survey was collected in December 2016. Data from the survey were used to inform data science curriculum planning. These data are provided in the comma-delimited text file <mspa-survey-data.csv>.
# ## Management Questions
# Imagine that you are an academic administrator responsible for defining the future direction of the graduate program. The MSPA Survey has been designed with these objectives in mind:
#
# 1. Learn about current student software preferences.
# 2. Learn about student interest in potential new courses.
# 3. Guide software and systems planning for current and future courses.
# 4. Guide data science curriculum planning.
# + [markdown] id="nYEMbhy2CzhL" colab_type="text"
# # Setup & Data Ingest
# Load necessary libraries and read in data.
# + [markdown] id="0qZWiksSE96h" colab_type="text"
# ### Colab Setup
# + id="WVgHjB-8wMZT" colab_type="code" colab={}
# Mount google drive for easier file load
from google.colab import drive
drive.mount('/content/gdrive')
# + [markdown] id="kGc5tYFCFJ_W" colab_type="text"
# ### Initial Imports
# + id="ePXywTrhwMY0" colab_type="code" colab={}
# Import necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# + [markdown] id="BWtxf9-nFyzK" colab_type="text"
# ### Initial Dataframe(s) Creation
# + id="nENa0SBjwUO1" colab_type="code" colab={}
# Read in the survey data
valid_survey_input = pd.read_csv('/content/gdrive/My Drive/northwestern/422-msds/422-colab/data-files/mspa-survey-data.csv')
# + [markdown] id="VQrdb1UJGaan" colab_type="text"
# # Exploratory Data Analysis (EDA)
# Data Cleaning
# Compute Summary Statistics
# Exploratory Visualizations
# + [markdown] id="ks9OAB1ZHV2x" colab_type="text"
# ### Data Cleaning
# + id="svM252TmHZrl" colab_type="code" colab={}
# Reset index as column 'RespondentID'
valid_survey_input.set_index('RespondentID', drop = True, inplace = True)
# + id="iaC7IgSUG2Sv" colab_type="code" outputId="eba74bd0-a963-4c46-8cf9-e3da61aa5de2" executionInfo={"status": "ok", "timestamp": 1554684109658, "user_tz": 420, "elapsed": 362, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 335}
# View first 5 rows of data
valid_survey_input.head()
# + id="-pkAMML7H1WZ" colab_type="code" outputId="68bd8a11-930e-44bf-99a4-d8eb82d700fb" executionInfo={"status": "ok", "timestamp": 1554684112967, "user_tz": 420, "elapsed": 438, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 255}
# View columns names
valid_survey_input.columns
# + id="vgCH5X1zIQ_q" colab_type="code" colab={}
# Shorten the variable/column names for software preference variables
survey_df = valid_survey_input.rename(index=str, columns={
'Personal_JavaScalaSpark': 'My_Java',
'Personal_JavaScriptHTMLCSS': 'My_JS',
'Personal_Python': 'My_Python',
'Personal_R': 'My_R',
'Personal_SAS': 'My_SAS',
'Professional_JavaScalaSpark': 'Prof_Java',
'Professional_JavaScriptHTMLCSS': 'Prof_JS',
'Professional_Python': 'Prof_Python',
'Professional_R': 'Prof_R',
'Professional_SAS': 'Prof_SAS',
'Industry_JavaScalaSpark': 'Ind_Java',
'Industry_JavaScriptHTMLCSS': 'Ind_JS',
'Industry_Python': 'Ind_Python',
'Industry_R': 'Ind_R',
'Industry_SAS': 'Ind_SAS'})
# + id="LgpGwa_ELVV-" colab_type="code" colab={}
# Define subset DataFrame for analysis of software preferences
software_df = survey_df.loc[:, 'My_Java':'Ind_SAS']
# + [markdown] id="16y21LacMWrO" colab_type="text"
# ### Summary Statistics
# + id="8pKfURxpLl5L" colab_type="code" outputId="de37b698-72e1-41d8-9878-1ff62b1e8441" executionInfo={"status": "ok", "timestamp": 1554685544787, "user_tz": 420, "elapsed": 437, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 34}
# Identify the shape of the dataframe
df_shape = software_df.shape
print('The dataframe has {0} rows and {1} columns'.format(df_shape[0], df_shape[1]))
# + id="moQslPwWMrTv" colab_type="code" outputId="de946912-5b9e-4d87-eba6-57d30dfd6dac" executionInfo={"status": "ok", "timestamp": 1554684126026, "user_tz": 420, "elapsed": 394, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 317}
# Summary stats for consolidated df
software_df.describe()
# + [markdown] id="jtthegLWMgxB" colab_type="text"
# ### Exploratory Visualizations
# + [markdown] id="yXBkegeHe4C5" colab_type="text"
# #### Correlation Heatmap
# + id="8LwCsjg-NxqI" colab_type="code" colab={}
# Correlation heat map setup for seaborn
def corr_chart(df_corr):
corr=df_corr.corr()
#screen top half to get a triangle
top = np.zeros_like(corr, dtype=np.bool)
top[np.triu_indices_from(top)] = True
fig=plt.figure()
fig, ax = plt.subplots(figsize=(12,12))
sns.heatmap(corr, mask=top, cmap='coolwarm',
center = 0, square=True,
linewidths=.5, cbar_kws={'shrink':.5},
annot = True, annot_kws={'size': 9}, fmt = '.3f')
plt.xticks(rotation=45) # rotate variable labels on columns (x axis)
plt.yticks(rotation=0) # use horizontal variable labels on rows (y axis)
plt.title('Correlation Heat Map')
plt.savefig('plot-corr-map.pdf',
bbox_inches = 'tight', dpi=None, facecolor='w', edgecolor='b',
orientation='portrait', papertype=None, format=None,
transparent=True, pad_inches=0.25, frameon=None)
np.set_printoptions(precision=3)
# + id="5F9fwgG-N0vF" colab_type="code" outputId="01a33b1e-f70a-4284-ccc3-0a06cf225031" executionInfo={"status": "ok", "timestamp": 1554684157141, "user_tz": 420, "elapsed": 2616, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 652}
# Product Correlation heat map
corr_chart(df_corr = software_df)
# + [markdown] id="f1V-6e_be80o" colab_type="text"
# #### R vs Python Scatterplot
# + id="MQ4-IouGOGrI" colab_type="code" outputId="27fb28eb-bf5b-4fc8-ee9b-d6d5720cd7ea" executionInfo={"status": "ok", "timestamp": 1554684162100, "user_tz": 420, "elapsed": 818, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 376}
# Single scatter plot example
fig, axis = plt.subplots()
axis.set_xlabel('Personal Preference for R')
axis.set_ylabel('Personal Preference for Python')
plt.title('R and Python Perferences')
scatter_plot = axis.scatter(survey_df['My_R'],
survey_df['My_Python'],
facecolors = 'none',
edgecolors = 'blue')
# + [markdown] id="r_0eg0UMfE_a" colab_type="text"
# #### Histograms of All Preference Fields
# + id="oFfVwE0FbABh" colab_type="code" outputId="3bd9262d-fc26-4462-ced2-2e0de32b4680" executionInfo={"status": "ok", "timestamp": 1554684393361, "user_tz": 420, "elapsed": 3679, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 1439}
# Histograms of all fields
software_df.hist(bins=20, figsize=(20,20))
# + [markdown] id="kiJo2MZffL68" colab_type="text"
# #### Python Course Interest
# + id="FJzJGdz9ahcV" colab_type="code" outputId="56019af3-a95c-458a-ba70-527c4f5c70dd" executionInfo={"status": "ok", "timestamp": 1554689068489, "user_tz": 420, "elapsed": 389, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 421}
# Create pivot table to display average interest in
# python course based on classes completed
py_int = pd.pivot_table(survey_df, values='Python_Course_Interest',
index='Courses_Completed', aggfunc=np.mean)
py_int.reset_index(inplace=True)
py_int
# + id="WLTCCYlVr9xc" colab_type="code" outputId="6e924f69-9798-4d10-899f-09ed2c5837c2" executionInfo={"status": "ok", "timestamp": 1554689252983, "user_tz": 420, "elapsed": 783, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 393}
# Bar chart for interest by course complete count
plt.bar(py_int.iloc[:, 0], py_int.iloc[:, 1])
plt.title('Python Average Interest by Course Complete Count')
plt.xlabel('Courses Completed')
plt.ylabel('Average Interest (100 point scale)')
# + [markdown] id="jpYP_9aGs4IB" colab_type="text"
# *Students who are 1/3 and 2/3 of the way through the program show the strongest interest in python*
# + [markdown] id="7Gx8GQXkfccM" colab_type="text"
# #### Summary Stats for All Course Interest
# + id="sGgg9uoVdWw7" colab_type="code" outputId="5965a253-2037-423b-88f9-433ecbea5fbf" executionInfo={"status": "ok", "timestamp": 1554685404555, "user_tz": 420, "elapsed": 429, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 297}
survey_df.iloc[:, 15:19].describe()
# + [markdown] id="I9Gt6ZkBfgpJ" colab_type="text"
# *We can see that the python course has the highest average interest of the 4 courses*
# + [markdown] id="Wnmu8dIQfuij" colab_type="text"
# # Model Prep
# + [markdown] id="85W0OrKHkXnF" colab_type="text"
# ### Import Scaling Functionality
# + id="DE6aaI6YgqH8" colab_type="code" colab={}
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelBinarizer
# + [markdown] id="7h4gzsgBkSOK" colab_type="text"
# ### Example of One Hot Encoding a Categorical Variable
# + id="8Ptfhk3Ygsj-" colab_type="code" outputId="9b4d3ded-16cd-46f4-acfb-274ca8abefd3" executionInfo={"status": "ok", "timestamp": 1554686298187, "user_tz": 420, "elapsed": 473, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 136}
encoder = LabelBinarizer()
grad_dt = survey_df['Graduate_Date'].dropna()
grad_dt_one_hot = encoder.fit_transform(grad_dt)
grad_dt_one_hot
# + [markdown] id="c7n3dtYKmRSJ" colab_type="text"
# ### Scaling Courses Completed
# + id="O_jW7LvLk0Vn" colab_type="code" colab={}
# Select Courses completed to transform
X = survey_df['Courses_Completed'].dropna()
# + id="ZV_0jfH0k9QC" colab_type="code" outputId="5190b64f-24cb-4748-ce2e-ea685bc69682" executionInfo={"status": "ok", "timestamp": 1554687316175, "user_tz": 420, "elapsed": 732, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 444}
# Unscaled
unscaled_fig, ax = plt.subplots()
sns.distplot(X).set_title('Unscaled')
# + id="sgXEitD3ler5" colab_type="code" outputId="47afc229-735d-42c1-827a-df4002cc7d49" executionInfo={"status": "ok", "timestamp": 1554687418485, "user_tz": 420, "elapsed": 609, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 430}
# Standard Scaler
standard_fig, ax = plt.subplots()
sns.distplot(StandardScaler().fit_transform(
X.values.reshape(-1,1))).set_title('StandardScaler')
# + id="a8sTTiU7mEO0" colab_type="code" outputId="0a499ff1-6318-44e6-9535-cf21d522279c" executionInfo={"status": "ok", "timestamp": 1554687495180, "user_tz": 420, "elapsed": 716, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 430}
# MinMaxScaler
minmax_fig, ax = plt.subplots()
sns.distplot(MinMaxScaler().fit_transform(
X.values.reshape(-1,1))).set_title('MinMaxScaler')
# + id="QZfG-gIcmLEw" colab_type="code" outputId="b5548dde-eb78-4a4f-ce68-208d15c0bf80" executionInfo={"status": "ok", "timestamp": 1554687514075, "user_tz": 420, "elapsed": 666, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 444}
# Log Scale
log_fig, ax = plt.subplots()
sns.distplot(np.log(X)).set_title('NaturalLog')
# + [markdown] id="rro60naomfPK" colab_type="text"
# ### Scaling Python Course Interest
# + id="s_l2kBCKmkny" colab_type="code" colab={}
# Python Course Interest Variable
pci = survey_df['Python_Course_Interest'].dropna()
# + id="Uoq1AeqpnjY8" colab_type="code" colab={}
# Perform transformations for easier plotting
pci_standard_scaled = StandardScaler().fit_transform(pci.values.reshape(-1,1))
pci_min_max_scaled = MinMaxScaler().fit_transform(pci.values.reshape(-1,1))
# + id="09LUCeSmpk4x" colab_type="code" outputId="ea9c324e-bb59-4496-b335-008a279f7ba3" executionInfo={"status": "ok", "timestamp": 1554688420264, "user_tz": 420, "elapsed": 730, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 444}
# Unscaled
fig, ax = plt.subplots()
sns.distplot(pci).set_title('Unscaled')
# + id="JgBHIvAKo4C0" colab_type="code" outputId="a334880f-9b15-4583-c152-40fdc5f067f0" executionInfo={"status": "ok", "timestamp": 1554688373913, "user_tz": 420, "elapsed": 614, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 430}
# MinMax Scaled
fig, ax = plt.subplots()
sns.distplot(pci_min_max_scaled).set_title('MinMaxScaler')
# + id="2piHetyJoj5_" colab_type="code" outputId="bf809acb-a32e-4d0c-9ff7-b7e1189c9dc1" executionInfo={"status": "ok", "timestamp": 1554688361518, "user_tz": 420, "elapsed": 634, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07072554209136753857"}} colab={"base_uri": "https://localhost:8080/", "height": 430}
# Standard Scaler
fig, ax = plt.subplots()
sns.distplot(pci_standard_scaled).set_title('StandardScaler')
# + [markdown] id="MBsLuZhnqPgq" colab_type="text"
# # Recommendations
#
#
# * Administration should strongly consider implementing a python course based on survey results
# * Provide students with the option of R or Python for various courses. It appears that students prefer one or the other
# * Based on historgrams of software preferences, Python and R have higher value to students as opposed to languages like Java and JS
#
#
| homework_assignment_01.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
#export
from data_lab.imports import *
import getpass
# +
#default_exp develop.treatments
# -
# # Develop Treatments
#
# ...
# +
# export
store = utils.store
start = utils.start
revise = utils.revise
# +
assert isinstance(store(name='foo'), dict)
assert not store() # Not valid, no name
version = start(name='foo', version='0.1.0')['version']
assert utils.string_version(version) == '0.1.0'
previous = datetime.utcnow() - dt.timedelta(days=1)
now = datetime.utcnow()
existing = start(name='foo', contributors='someone_else', now=previous)
assert utils.string_version(existing['version']) == '0.0.1'
revised = revise(name='foo', item=existing, now=now)
assert revised['state'] == 'revised'
assert revised['updated_at'] == now
assert 'someone_else' in revised['contributors']
assert getpass.getuser() in revised['contributors']
assert utils.string_version(revised['version']) == '0.0.2'
# -
# This only uses the existing utilities, I'll extend/specialize these tools here.
| nbs/02.01.develop.treatments.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # 간단한 통계 기능 소개<br>Simple introduction to statistics features
#
#
# ## `pandas`
#
#
# `pandas`의 통계 기능에 대해 알아보자.<br>Let's check the statistics features of the `pandas`
#
#
# +
# NumPy & matplotlib
import pylab as py
# Data table
import pandas as pd
# -
# 데이터 배열 생성<br>Creating data arrays
#
#
# +
t_deg = py.linspace(-360, 360, 24+1)
t_rad = py.deg2rad(t_deg)
sin_t = py.sin(t_rad)
cos_t = py.cos(t_rad)
# -
# 데이터 표 생성<br>Creating data table
#
#
# +
df = pd.DataFrame(
{
't_rad': t_rad,
'sin': sin_t,
'cos': cos_t,
},
index=t_deg,
columns=['t_rad', 'sin', 'cos']
)
# -
# 데이터 표 내용<br>Content of the data table
#
#
# +
# https://www.shanelynn.ie/using-pandas-dataframe-creating-editing-viewing-data-in-python/
# set maximum number of rows to display
pd.options.display.max_rows = 10
df
# -
# 데이터 표 정보<br>Data table info
#
#
# +
print(f'df.shape = {df.shape}')
print(f'df.columns = {df.columns}')
# -
# 이름으로 열 선택<br>Selecting a column by its name
#
#
# +
print(f'df["sin"] = \n{df["sin"]}')
# -
# 논리식으로 행 선택<br>Choosing rows by a boolean logic
#
#
# +
print(f"df[abs(df.sin)<1e-3] = \n{df[abs(df.sin)<1e-3]}")
# -
# 다양한 통계<br>Various statistics
#
#
# +
df.describe()
# -
# 산포도 행렬<br>Scatter matrix
#
#
# +
import pandas.plotting as plotting
plotting.scatter_matrix(df[['t_rad', 'cos','sin']])
# -
# ## 회귀 분석<br>Regression Analysis
#
#
# 회귀분석이란 예를 들어 $x$ 와 $y$ 두 변수 사이의 관계를 통계적인 방법으로 탐색하는 것이다.<br>
# Regression analysis is to search for a relationship statistically, for example, between $x$ and $y$. [[wikipedia](https://en.wikipedia.org/wiki/Regression_analysis)]
#
#
# [](https://youtu.be/yMgFHbjbAW8)
#
#
# ### 데이터 준비<br>Prepare data
#
#
# 참값이 아래에서 구한 값과 같았다고 가정하자.<br>
# Let's assume that following cell generates the true value.
#
#
# +
import pylab as py
a = 0.5
b = 2.0
x_array = py.linspace(0, 5, 20 + 1)
y_true = a * x_array + b
# -
# 방금 구한 참값을 그림으로 표시해 보자.<br>
# Let's plot the true values that we just generated.
#
#
# +
py.plot(x_array, y_true, '.-', label='true')
py.grid(True)
py.ylim(ymin=0)
py.legend(loc=0)
py.xlabel('x')
py.ylabel('y');
# -
# 잡음이 섞인 측정값도 준비해 보자.<br>
# Lets' prepare for the measurements contaminated by some noise.
#
#
# +
import numpy.random as nr
nr.seed()
w_array = nr.normal(0, 0.25, size=x_array.shape)
y_measurement = y_true + w_array
# -
# 이것도 그려 보자.<br>
# Let's plot this too.
#
#
# +
py.plot(x_array, y_true, label='true')
py.plot(x_array, y_measurement, '.', label='measurements')
py.grid(True)
py.ylim(ymin=0)
py.legend(loc=0)
py.xlabel('x')
py.ylabel('y');
# -
# ### 선형회귀와 추정<br>Linear Regression and Estimation
#
#
# $x$와 $y$사이의 관계가 다음과 같았다고 가정해 보자.<br>
# Let's assume that $x$ and $y$ have following relationship.
#
#
# $$
# y = ax + b
# $$
#
#
# $a$와 $b$가 어떤 값을 가지면 위에서 구한 데이터와 비교해 볼 때 가장 적합하겠는가?<br>How can we find $a$ and $b$ fitting the curve the best against the data above?
#
#
# 이러한 탐색 과정을 *선형회귀*라고 부를 수 있을 것이다.<br>We may call this search process as *Linear Regression*.
#
#
# 선형 회귀 결과는 다음과 같다<br>The results from the linear regression is as follows.<br>
# ref : The SciPy community, "scipy.stats.linregress", SciPy documentation, May 05, 2018 [Online] Available : https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.linregress.html.
#
#
# +
import scipy.stats as ss
slope, intercept, r_value, p_value, std_err = ss.linregress(x_array, y_measurement)
print(f'slope = {slope}')
print(f'intercept = {intercept}')
print(f'correlation coefficient = {r_value}')
# -
# 이 결과를 이용하여 $y$값을 추정해 보자.<br>
# Let's estimate $y$ using this result.
#
#
# $$
# y_{estim} = slope \cdot x_{array} + intercept
# $$
#
#
# +
def linear_model(a, b, x_i):
return a * x_i + b
y_lin_reg = linear_model(slope, intercept, x_array)
# -
# 이 결과를 그려보자.<br>
# Let's plot this result.
#
#
# +
py.plot(x_array, y_true, label='true', alpha=0.3)
py.plot(x_array, y_measurement, 'o', label='measurements')
py.plot(x_array, y_lin_reg, '.-', label='lin reg')
py.grid(True)
py.ylim(ymin=0)
py.legend(loc=0)
py.xlabel('x')
py.ylabel('y');
# -
# ### 다항식 회귀 사례<br>Polynomial Regression Example
#
#
# 이번에는 $x$와 $y$사이의 관계가 다음과 같았은 다항식의 형태를 가진다고 가정해 보자.<br>
# This time, let's assume that $x$ and $y$ are related in the following polynomial form.
#
#
# $$
# y = ax^2 + bx + c
# $$
#
#
# 데이터를 위한 최적의 곡선을 찾기 위해 $b$와 $c$에 더하여 $a$도 바꾸어 볼 수 있다.<br>
# Now we can tweak $a$ in addition to $b$ and $c$ to fit the curve to the data.
#
#
# references :
#
# * <NAME>, "Introduction to Linear Regression and Polynomial Regression", Towards Data Science, Medium, Jan 13, 2019, [Online](https://towardsdatascience.com/introduction-to-linear-regression-and-polynomial-regression-f8adc96f31cb).
# * <NAME>, "Robust nonlinear regressio in scipy", Scipy Cookbook, Aug 17, 2018, [Online](https://scipy-cookbook.readthedocs.io/items/robust_regression.html).
#
#
# `scipy.optimize` 의 `leastsq()`를 사용할 것이므로 해당 모듈을 읽어들인다.<br>
# We are going to use `leastsq()` of `scipy.optimize`.
#
#
# +
import scipy.optimize as so
# -
# `scipy.optmize.leastsq()` 에 대해서는 아래 셀에서 `#`를 지우고 <kbd>Shift</kbd>+<kbd>Enter</kbd>를 눌러 본다.<br>
# Regarding `scipy.optmize.leastsq()`, delete `#` in the following cell and press <kbd>Shift</kbd>+<kbd>Enter</kbd>.
#
#
# +
# help(so.leastsq)
# -
# 계수를 매개변수로 받아들이는 2차 다항식 모델을 함수로 구현한다.<br>
# Accepting coefficients from parameters, let's implement a function of a second order polynomial.
#
#
# +
def polynomial_model_2(param, x_i):
a, b, c = param
return a * x_i ** 2 + b * x_i + c
# -
# 각 점에서 측정값과 추정값 사이의 오차를 계산하는 함수를 구현한다.<br>
# Implement another function calculating the error between estimation and measurement at each data point.
#
#
# +
def polynomial_error(param, x_i, y_i, model=polynomial_model_2):
y_i_estimation = model(param, x_i)
error_array = y_i_estimation - y_i
return error_array
# -
# 다항식의 계수를 회귀로 추정한 결과는 다음과 같다.<br>
# The following cell estimates the coefficients of the polynomial using the regression.
#
#
# +
any_initial_guess = (1, 1, 1)
polynomial_regression_param = so.leastsq(
polynomial_error,
any_initial_guess,
args=(x_array, y_measurement)
)
polynomial_regression_param
# -
# 해당 계수는 예를 들어 다음과 같이 사용할 수 있을 것이다.<br>
# We could use the coefficients as follows.
#
#
# +
a_reg, b_reg, c_reg = polynomial_regression_param[0]
y_poly_reg = a_reg * x_array ** 2 + b_reg * x_array + c_reg
# -
# 이 결과를 그려보자.<br>
# Let's plot this result.
#
#
# +
py.plot(x_array, y_true, label='true', alpha=0.3)
py.plot(x_array, y_measurement, 'o', label='measurements')
py.plot(x_array, y_lin_reg, '.-', label='lin reg')
py.plot(x_array, y_poly_reg, '.', label='poly reg 2')
py.grid(True)
py.ylim(ymin=0)
py.legend(loc=0)
py.xlabel('x')
py.ylabel('y');
# -
# ### 과적합<br>Overfitting
#
#
# 이제 좀 더 일반적인 경우를 생각해 보자.<br>Let's think about a more general case.
#
#
# 다항식의 최고 차수가 2차 대신 $n$차인 경우를 생각해 보자.<br>What if the highest order of the polynomial is $n$ instead of two?
#
#
# +
def polynomial_model_n(param, x_i):
return py.polyval(param, x_i)
# +
n_reg = 10
any_initial_guess = py.ones((n_reg,))
polynomial_regression_param_n = so.leastsq(
polynomial_error,
any_initial_guess,
args=(x_array, y_measurement, polynomial_model_n)
)
polynomial_regression_param_n
# +
y_poly_reg_n = polynomial_model_n(polynomial_regression_param_n[0], x_array)
# -
# 이 결과를 그려보자.<br>
# Let's plot this result.
#
#
# +
py.plot(x_array, y_true, label='true', alpha=0.3)
py.plot(x_array, y_measurement, 'o', label='measurements')
py.plot(x_array, y_lin_reg, '.', label='lin reg')
py.plot(x_array, y_poly_reg, '.', label='poly reg 2')
py.plot(x_array, y_poly_reg_n, '.', label='poly reg n')
py.grid(True)
py.ylim(ymin=0)
py.legend(loc=0)
py.xlabel('x')
py.ylabel('y');
# -
# 측정값 사이는 어떨까?<br>
# What about between the measurements?
#
#
# +
py.plot(x_array, y_true, label='true', alpha=0.3)
py.plot(x_array, y_measurement, 'o', label='measurements')
x_detailed = py.linspace(x_array.min(), x_array.max(), len(x_array) * 10)
py.plot(x_detailed, linear_model(slope, intercept, x_detailed), '-', label='lin reg')
py.plot(x_detailed, polynomial_model_2(polynomial_regression_param[0], x_detailed), '-', label='poly reg 2')
py.plot(x_detailed, polynomial_model_n(polynomial_regression_param_n[0], x_detailed), '-', label='poly reg n')
py.grid(True)
py.ylim(ymin=0)
py.legend(loc=0)
py.xlabel('x')
py.ylabel('y');
# -
# ## 연습 문제<br>Exercises
#
#
# 도전 과제 1: 위 선형 회귀에 사용되었던 자료를 판다스 데이터프레임으로 저장하고 다양한 통계값을 계산해 보시오.<br>Try this 1: Store the data for linear regression in a `pandas.DataFrame` and calculate various statistics.
#
#
# 도전 과제 2: 공신력 있는 기관에서 공개한 변수가 2개 이상인 자료를 찾아 도전 과제 1을 반복하시오.<br>Try this 2: Find data having more than two variables from a credible organization and repeat Try this 1 above.
#
#
# 도전 과제 3: 도전 과제 2의 자료에 대해 선형회귀를 적용해 보시오.<br>Try this 3: Apply linear regerssion to data of Try this 2.
#
#
# 도전 과제 4: 선형회귀의 수학적 원리를 설명해 보시오.<br>Try this 4: Describe mathematic of the linear regression
#
#
# 도전 과제 5: 도전과제 4 를 구현하여 위 사이파이 선형회귀 결과와 비교해 보시오.<br>Try this 5: Implement Try this 4 and compare with the linear regression result using SciPy.
#
#
# ## `alpha`
#
#
# `alpha`로 그래프의 투명도를 선택할 수 있다.<br>With `alpha`, we can control the plots' transparency.
#
#
# +
import pylab as py
x = py.linspace(0, 1)
for alpha_value in py.arange(1, 0-0.01, -0.1):
y = alpha_value * x
py.plot(x, y, alpha=alpha_value, label=f"$\\alpha$={alpha_value:3.1f}")
py.legend(loc=0);
# -
# ## 소프트웨어 시험 함수<br>Software Test Functions
#
#
# 아래는 위 함수가 맞게 작성되었는지 확인한다.<br>Followings test functions above.
#
#
# +
def test_polynomial_model_2():
param = (1, -3, 2)
x_test = py.array([0, 1, 2])
y_result = polynomial_model_2(param, x_test)
y_expected = py.polyval(param, x_test)
assert y_result.shape == y_expected.shape, f"\ny_result = {y_result}\n!= y_expected = {y_expected}"
# +
test_polynomial_model_2()
# +
def test_square_error_sum_true():
param = (1, -3, 2)
x_test = py.array([0, 1, 2])
y_test_true = py.array([2, 0, 0])
y_result = polynomial_error(param, x_test, y_test_true)
y_expected = py.polyval(param, x_test) - y_test_true
assert y_result.tolist() == y_expected.tolist(), f"\ny_result = {y_result}\n!= y_expected = {y_expected}"
# +
test_square_error_sum_true()
# +
def test_square_error_sum_not_true():
param = (1, -3, 2)
x_test = py.array([0, 1, 2])
y_test_not_true = py.array([1, 1, 1])
y_result = polynomial_error(param, x_test, y_test_not_true)
y_expected = py.polyval(param, x_test) - y_test_not_true
assert y_result.tolist() == y_expected.tolist(), f"\ny_result = {y_result}\n!= y_expected = {y_expected}"
# +
test_square_error_sum_not_true()
# -
# ## 참고문헌<br>References
#
#
# * <NAME>, <NAME>, 파이썬 라이브러리를 활용한 데이터 분석, 2판, 한빛미디어, 2019, ISBN 979-11-6224-190-5 ([코드와 데이터](https://github.com/wesm/pydata-book/)) <br><NAME>, Python for Data Analysis, 2nd Ed., O'Reilly, 2017. ([Code and data](https://github.com/wesm/pydata-book/))
# * Varoquaux, Statistics in Python, Scipy lecture notes, 2018 Sept 01, [Online] Available: http://www.scipy-lectures.org/packages/statistics/index.html.
#
#
# ## Final Bell<br>마지막 종
#
#
# +
# stackoverfow.com/a/24634221
import os
os.system("printf '\a'");
# -
| 20_interpolation/20_statistics.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="V1WhCjLli0ve" colab_type="code" colab={}
import numpy as np
import matplotlib.pyplot as plt
# + id="nbiEbGuUi8i6" colab_type="code" colab={}
x_data = np.array([0.27, 0.35, 0.44, 0.58, 0.66, 0.77, 0.4, 0.32, 0.20, 0.15, 0.08])
# + id="I7EHHs2nkleI" colab_type="code" colab={}
def AF(x): #Activation Function
if x < 0:
return 0
elif x >= 2:
return 2
else:
return x
# + id="pIdF2-XgpQ6d" colab_type="code" outputId="64a5f9e3-1fd1-430f-e28b-354f129f83ec" executionInfo={"status": "ok", "timestamp": 1592249461308, "user_tz": -270, "elapsed": 1644, "user": {"displayName": "Micro Artificial Intelligence", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gjd4jgZ1lHNuBBnQK5f7tGnhbrjuQkXvspvHTDj=s64", "userId": "15902609544232068748"}} colab={"base_uri": "https://localhost:8080/", "height": 1000}
np.set_printoptions(formatter={'float': '{: 0.3f}'.format})
def find_place(itr, R1, R2, length):
k1_1 = itr - R1
k1_2 = itr + R1
k2_1 = itr - R2
k2_2 = itr + R2
if k1_1 < 0:
k1_1 = 0
if k2_1 < 0:
k2_1 = 0
if k1_2 >= length:
k1_2 = length - 1
if k2_2 >= length:
k2_2 = length - 1
return k1_1, k1_2, k2_1, k2_2
def MexicianHat(data=x_data, C1=0.6, C2=-0.4, R1=2, R2=4, t_max=5):
f, ax = plt.subplots(1, 1, figsize=(12, 12))
print("HyperParameters :=> R1: ",R1, ", R2: ", R2, ", T_Max : ", t_max)
print("################################################")
x = data.copy()
x_old = x.copy()
t = 1
x_length = len(data)
while t < t_max:
for i in range(0, x_length):
k1_1, k1_2, k2_1, k2_2 = find_place(itr=i, R1=R1, R2=R2, length=x_length)
sum1 = 0
for j in range(k1_1, k1_2+1):
sum1 += x_old[j]
sum2 = 0
for j in range(k2_1, k1_1):
sum2 += x_old[j]
sum3 = 0
for j in range(k1_2+1, k2_2+1):
sum3 += x_old[j]
x[i] = AF((C1 * sum1) + (C2 * sum2) + (C2 * sum3))
x_old = x.copy()
t+=1
print("Epoch {0} ===> {1}".format(t+1, x))
print("******************************")
b = x.ravel()
plt.plot(b, label="Epoch {0}".format(t), marker="X", drawstyle='default', linestyle='--', markersize=9)
plt.legend()
plt.title("Mexican Hat - t_max=10", fontsize=17)
plt.show()
MexicianHat(data=x_data, C1=0.6, C2=-0.5, R1=1, R2=3, t_max=10)
# + id="_nowdTm4oBbi" colab_type="code" colab={}
| MexicanHat_Part2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python (pygta5)
# language: python
# name: pygta5
# ---
import numpy as np
import pandas as pd
from grabscreen import grab_screen
import cv2
import time
from directkeys import PressKey,ReleaseKey, W, A, S, D
from models import inception_v3 as googlenet
from getkeys import key_check
from collections import deque, Counter
import random
from statistics import mode,mean
import numpy as np
#from motion import motion_detection
GAME_WIDTH = 1920
GAME_HEIGHT = 1080
how_far_remove = 800
rs = (20,15)
log_len = 25
motion_req = 800
motion_log = deque(maxlen=log_len)
WIDTH = 480
HEIGHT = 270
LR = 1e-3
EPOCHS = 1
choices = deque([], maxlen=5)
hl_hist = 250
choice_hist = deque([], maxlen=hl_hist)
w = [1,0,0,0,0,0,0,0,0]
s = [0,1,0,0,0,0,0,0,0]
a = [0,0,1,0,0,0,0,0,0]
d = [0,0,0,1,0,0,0,0,0]
wa = [0,0,0,0,1,0,0,0,0]
wd = [0,0,0,0,0,1,0,0,0]
sa = [0,0,0,0,0,0,1,0,0]
sd = [0,0,0,0,0,0,0,1,0]
nk = [0,0,0,0,0,0,0,0,1]
#Importing Gamepad library
from vjoy2 import *
# +
#Definitions of the keyboard
# +
t_time = 0.25
def straight():
PressKey(W)
ReleaseKey(A)
ReleaseKey(D)
ReleaseKey(S)
def left():
if random.randrange(0,3) == 1:
PressKey(W)
else:
ReleaseKey(W)
PressKey(A)
ReleaseKey(S)
ReleaseKey(D)
#ReleaseKey(S)
def right():
if random.randrange(0,3) == 1:
PressKey(W)
else:
ReleaseKey(W)
PressKey(D)
ReleaseKey(A)
ReleaseKey(S)
def reverse():
PressKey(S)
ReleaseKey(A)
ReleaseKey(W)
ReleaseKey(D)
def forward_left():
PressKey(W)
PressKey(A)
ReleaseKey(D)
ReleaseKey(S)
def forward_right():
PressKey(W)
PressKey(D)
ReleaseKey(A)
ReleaseKey(S)
def reverse_left():
PressKey(S)
PressKey(A)
ReleaseKey(W)
ReleaseKey(D)
def reverse_right():
PressKey(S)
PressKey(D)
ReleaseKey(W)
ReleaseKey(A)
def no_keys():
if random.randrange(0,3) == 1:
PressKey(W)
else:
ReleaseKey(W)
ReleaseKey(A)
ReleaseKey(S)
ReleaseKey(D)
# -
model = googlenet(WIDTH, HEIGHT, 3, LR, output=29)
MODEL_NAME = 'model/test'
model.load(MODEL_NAME)
print('We have loaded a previous model!!!!')
# # Analysis of the prediction
import io
import cv2
import numpy as np
from IPython.display import clear_output, Image, display
import PIL.Image
from matplotlib import pyplot as plt
from numpy import load
def showarray(a, fmt='jpeg'):
a_n = np.uint8(np.clip(a, 0, 255))
try :
f = io.BytesIO()
PIL.Image.fromarray(a_n).save(f, fmt)
display(Image(data=f.getvalue()))
except:
#a = a[:, :, ::-1] # convert image from RGB (skimage) to BGR (opencv)
# display image
plt.imshow(a)
plt.show()
# +
last_time = time.time()
for i in list(range(4))[::-1]:
print(i+1)
time.sleep(1)
paused = False
mode_choice = 0
#screen = grab_screen(region=(0,40,GAME_WIDTH,GAME_HEIGHT+40))
# load array
screen = cv2.imread('test.png',1)
screen = cv2.cvtColor(screen, cv2.COLOR_BGR2RGB)
prev = cv2.resize(screen, (WIDTH,HEIGHT))
t_minus = prev
t_now = prev
t_plus = prev
# -
# The capture of the screen should be something like this
showarray(screen)
last_time = time.time()
screen = cv2.resize(screen, (WIDTH,HEIGHT))
# It is resized the screen
showarray(screen)
# +
#The capture of the screen should be something like this
# +
import cv2
def delta_images(t0, t1, t2):
d1 = cv2.absdiff(t2, t0)
return d1
def motion_detection(t_minus, t_now, t_plus):
delta_view = delta_images(t_minus, t_now, t_plus)
retval, delta_view = cv2.threshold(delta_view, 16, 255, 3)
cv2.normalize(delta_view, delta_view, 0, 255, cv2.NORM_MINMAX)
img_count_view = cv2.cvtColor(delta_view, cv2.COLOR_RGB2GRAY)
delta_count = cv2.countNonZero(img_count_view)
dst = cv2.addWeighted(screen,1.0, delta_view,0.6,0)
delta_count_last = delta_count
return delta_count
# -
print(len(t_minus), len(t_now), len(t_plus))
delta_count_last = motion_detection(t_minus, t_now, t_plus)
t_minus = t_now
t_now = t_plus
t_plus = screen
t_plus = cv2.blur(t_plus,(4,4))
showarray(t_plus)
prediction = model.predict([screen.reshape(WIDTH,HEIGHT,3)])[0]
prediction=prediction.round(decimals=2, out=None)
prediction
columns=['W', 'S', 'A', 'D', 'WA', 'WD', 'SA', 'SD',' NOKEY','LT', 'RT', 'Lx', 'Ly', 'Rx', 'Ry', 'UP', 'DOWN', 'LEFT', 'RIGHT',
'START', 'SELECT', 'L3', 'R3', 'LB', 'RB', 'A', 'B', 'X', 'Y']
len(columns)
# +
dato=np.array([[0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.52, 0. , 0. ,
0. , 0.48, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. ]])
columna=['W', 'S', 'A', 'D', 'WA', 'WD', 'SA', 'SD',' NOKEY','LT', 'RT', 'Lx', 'Ly', 'Rx', 'Ry', 'UP', 'DOWN', 'LEFT', 'RIGHT',
'START', 'SELECT', 'L3', 'R3', 'LB', 'RB', 'A', 'B', 'X', 'Y']
df_pred = pd.DataFrame(dato,
columns=columna)
df_pred_transposed = df_pred.T
# -
dato.shape
df_pred_transposed
# In the previous code we have seen the prediction of our neural network, it is a numpy.ndarray with 29 elements of the input
len([4.5, 0.1, 0.1, 0.1, 1.8, 1.8, 0.5, 0.5, 0.2,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1])
prediction = np.array(prediction) * np.array([4.5, 0.1, 0.1, 0.1, 1.8, 1.8, 0.5, 0.5, 0.2,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1])
dato=np.array([prediction])
columna=['W', 'S', 'A', 'D', 'WA', 'WD', 'SA', 'SD',' NOKEY','LT', 'RT', 'Lx', 'Ly', 'Rx', 'Ry', 'UP', 'DOWN', 'LEFT', 'RIGHT',
'START', 'SELECT', 'L3', 'R3', 'LB', 'RB', 'A', 'B', 'X', 'Y']
df_pred = pd.DataFrame(dato,
columns=columna)
df_pred_transposed = df_pred.T
df_pred_transposed
prediction_list=list(prediction)
#python convert list to absolute value
result = [abs(element) for element in prediction_list]
# numpy.argmax(a, axis=None, out=None, *, keepdims=<no value>)[source]
#
# Returns the indices of the maximum values along an axis.
#
# Returns index_arrayndarray of ints
#
mode_choice=np.argmax(result)
val_prediction=prediction_list[mode_choice]
# This is the value of the prediction
val_prediction
mode_choice
# That means that according to the image taken the model predict press the index 12 which means press Lx.
# The next step is call the gampad to execute this action.
def action(mode_choice):
#mode_choise : Input number from 0 to 28
#KEYBOARD INPUT
if mode_choice == 0:
straight()
choice_picked = 'straight'
elif mode_choice == 1:
reverse()
choice_picked = 'reverse'
elif mode_choice == 2:
left()
choice_picked = 'left'
elif mode_choice == 3:
right()
choice_picked = 'right'
elif mode_choice == 4:
forward_left()
choice_picked = 'forward+left'
elif mode_choice == 5:
forward_right()
choice_picked = 'forward+right'
elif mode_choice == 6:
reverse_left()
choice_picked = 'reverse+left'
elif mode_choice == 7:
reverse_right()
choice_picked = 'reverse+right'
elif mode_choice == 8:
no_keys()
choice_picked = 'nokeys'
#GAMEPAD INPUT
elif mode_choice == 9:
gamepad_lt()
choice_picked ='LT'
elif mode_choice == 10:
gamepad_rt()
choice_picked ='RT'
elif mode_choice == 11:
if val_prediction < 0:
game_lx_left()
choice_picked ='Lx'
else:
game_lx_right()
choice_picked ='Lx'
elif mode_choice == 12:
if val_prediction < 0:
game_ly_down()
choice_picked ='Ly'
else:
game_ly_up()
choice_picked ='Ly'
elif mode_choice == 13:
if val_prediction < 0:
look_rx_left()
choice_picked ='Rx'
else:
look_rx_right()
choice_picked ='Rx'
elif mode_choice == 14:
if val_prediction < 0:
look_ry_down()
choice_picked ='Ry'
else:
look_ry_up()
choice_picked ='Ry'
elif mode_choice == 15:
#To be defined
choice_picked ='UP'
elif mode_choice == 16:
#To be defined
choice_picked ='DOWN'
elif mode_choice == 17:
#To be defined
choice_picked ='LEFT'
elif mode_choice == 18:
#To be defined
choice_picked ='RIGHT'
elif mode_choice == 19:
#To be defined
choice_picked ='START'
elif mode_choice == 20:
#To be defined
choice_picked ='SELECT'
elif mode_choice == 21:
#To be defined
choice_picked ='L3'
elif mode_choice == 22:
#To be defined
choice_picked ='R3'
elif mode_choice == 23:
#To be defined
choice_picked ='LB'
elif mode_choice == 24:
#To be defined
choice_picked ='RB'
elif mode_choice == 25:
button_A()
choice_picked ='A'
elif mode_choice == 26:
button_B()
choice_picked ='B'
elif mode_choice == 27:
button_X()
choice_picked ='X'
elif mode_choice == 28:
button_Y()
choice_picked ='Y'
#print(choice_picked)
action(mode_choice)
time.sleep(1)
ultimate_release()
ultimate_release()
# +
import IPython
IPython.Application.instance().kernel.do_shutdown(True) #automatically restarts kernel
# -
# # Full code
# +
import numpy as np
import pandas as pd
from grabscreen import grab_screen
import cv2
import time
from directkeys import PressKey,ReleaseKey, W, A, S, D
from models import inception_v3 as googlenet
from getkeys import key_check
from collections import deque, Counter
import random
from statistics import mode,mean
import numpy as np
from motion import motion_detection
#Importing Gamepad library
from vjoy2 import *
#Importing escape library
import msvcrt
GAME_WIDTH = 1920
GAME_HEIGHT = 1080
how_far_remove = 800
rs = (20,15)
log_len = 25
motion_req = 800
motion_log = deque(maxlen=log_len)
WIDTH = 480
HEIGHT = 270
LR = 1e-3
EPOCHS = 1
choices = deque([], maxlen=5)
hl_hist = 250
choice_hist = deque([], maxlen=hl_hist)
w = [1,0,0,0,0,0,0,0,0]
s = [0,1,0,0,0,0,0,0,0]
a = [0,0,1,0,0,0,0,0,0]
d = [0,0,0,1,0,0,0,0,0]
wa = [0,0,0,0,1,0,0,0,0]
wd = [0,0,0,0,0,1,0,0,0]
sa = [0,0,0,0,0,0,1,0,0]
sd = [0,0,0,0,0,0,0,1,0]
nk = [0,0,0,0,0,0,0,0,1]
t_time = 0.25
def straight():
PressKey(W)
ReleaseKey(A)
ReleaseKey(D)
ReleaseKey(S)
def left():
if random.randrange(0,3) == 1:
PressKey(W)
else:
ReleaseKey(W)
PressKey(A)
ReleaseKey(S)
ReleaseKey(D)
#ReleaseKey(S)
def right():
if random.randrange(0,3) == 1:
PressKey(W)
else:
ReleaseKey(W)
PressKey(D)
ReleaseKey(A)
ReleaseKey(S)
def reverse():
PressKey(S)
ReleaseKey(A)
ReleaseKey(W)
ReleaseKey(D)
def forward_left():
PressKey(W)
PressKey(A)
ReleaseKey(D)
ReleaseKey(S)
def forward_right():
PressKey(W)
PressKey(D)
ReleaseKey(A)
ReleaseKey(S)
def reverse_left():
PressKey(S)
PressKey(A)
ReleaseKey(W)
ReleaseKey(D)
def reverse_right():
PressKey(S)
PressKey(D)
ReleaseKey(W)
ReleaseKey(A)
def no_keys():
if random.randrange(0,3) == 1:
PressKey(W)
else:
ReleaseKey(W)
ReleaseKey(A)
ReleaseKey(S)
ReleaseKey(D)
model = googlenet(WIDTH, HEIGHT, 3, LR, output=29)
MODEL_NAME = 'model/test'
model.load(MODEL_NAME)
print('We have loaded a previous model!!!!')
# +
def main():
aborted = False
last_time = time.time()
for i in list(range(4))[::-1]:
print(i+1)
time.sleep(1)
paused = False
mode_choice = 0
screen = grab_screen(region=(0,40,GAME_WIDTH,GAME_HEIGHT+40))
screen = cv2.cvtColor(screen, cv2.COLOR_BGR2RGB)
prev = cv2.resize(screen, (WIDTH,HEIGHT))
t_minus = prev
t_now = prev
t_plus = prev
while(True):
if not paused:
screen = grab_screen(region=(0,40,GAME_WIDTH,GAME_HEIGHT+40))
screen = cv2.cvtColor(screen, cv2.COLOR_BGR2RGB)
last_time = time.time()
screen = cv2.resize(screen, (WIDTH,HEIGHT))
#print(len(t_minus), len(t_now), len(t_plus))
delta_count_last = motion_detection(t_minus, t_now, t_plus,screen)
delta_count=delta_count_last
t_minus = t_now
t_now = t_plus
t_plus = screen
t_plus = cv2.blur(t_plus,(4,4))
prediction = model.predict([screen.reshape(WIDTH,HEIGHT,3)])[0]
prediction=prediction.round(decimals=2, out=None)
prediction = np.array(prediction) * np.array([4.5, 0.1, 0.1, 0.1, 1.8, 1.8, 0.5, 0.5, 0.2,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1])
prediction_list=list(prediction)
#python convert list to absolute value
result = [abs(element) for element in prediction_list]
mode_choice=np.argmax(result)
val_prediction=prediction_list[mode_choice]
#KEYBOARD INPUT
if mode_choice == 0:
straight()
choice_picked = 'straight'
elif mode_choice == 1:
reverse()
choice_picked = 'reverse'
elif mode_choice == 2:
left()
choice_picked = 'left'
elif mode_choice == 3:
right()
choice_picked = 'right'
elif mode_choice == 4:
forward_left()
choice_picked = 'forward+left'
elif mode_choice == 5:
forward_right()
choice_picked = 'forward+right'
elif mode_choice == 6:
reverse_left()
choice_picked = 'reverse+left'
elif mode_choice == 7:
reverse_right()
choice_picked = 'reverse+right'
elif mode_choice == 8:
no_keys()
choice_picked = 'nokeys'
#GAMEPAD INPUT
elif mode_choice == 9:
gamepad_lt()
choice_picked ='LT'
elif mode_choice == 10:
gamepad_rt()
choice_picked ='RT'
elif mode_choice == 11:
if val_prediction < 0:
game_lx_left()
choice_picked ='Lx'
else:
game_lx_right()
choice_picked ='Lx'
elif mode_choice == 12:
if val_prediction < 0:
game_ly_down()
choice_picked ='Ly'
else:
game_ly_up()
choice_picked ='Ly'
elif mode_choice == 13:
if val_prediction < 0:
look_rx_left()
choice_picked ='Rx'
else:
look_rx_right()
choice_picked ='Rx'
elif mode_choice == 14:
if val_prediction < 0:
look_ry_down()
choice_picked ='Ry'
else:
look_ry_up()
choice_picked ='Ry'
elif mode_choice == 15:
#To be defined
choice_picked ='UP'
elif mode_choice == 16:
#To be defined
choice_picked ='DOWN'
elif mode_choice == 17:
#To be defined
choice_picked ='LEFT'
elif mode_choice == 18:
#To be defined
choice_picked ='RIGHT'
elif mode_choice == 19:
#To be defined
choice_picked ='START'
elif mode_choice == 20:
#To be defined
choice_picked ='SELECT'
elif mode_choice == 21:
#To be defined
choice_picked ='L3'
elif mode_choice == 22:
#To be defined
choice_picked ='R3'
elif mode_choice == 23:
#To be defined
choice_picked ='LB'
elif mode_choice == 24:
#To be defined
choice_picked ='RB'
elif mode_choice == 25:
button_A()
choice_picked ='A'
elif mode_choice == 26:
button_B()
choice_picked ='B'
elif mode_choice == 27:
button_X()
choice_picked ='X'
elif mode_choice == 28:
button_Y()
choice_picked ='Y'
motion_log.append(delta_count)
motion_avg = round(mean(motion_log),3)
print('loop took {} seconds. Motion: {}. Choice: {}'.format( round(time.time()-last_time, 3) , motion_avg, choice_picked))
if motion_avg < motion_req and len(motion_log) >= log_len:
print('WERE PROBABLY STUCK FFS, initiating some evasive maneuvers.')
# 0 = reverse straight, turn left out
# 1 = reverse straight, turn right out
# 2 = reverse left, turn right out
# 3 = reverse right, turn left out
quick_choice = random.randrange(0,4)
if quick_choice == 0:
reverse()
time.sleep(random.uniform(1,2))
forward_left()
time.sleep(random.uniform(1,2))
elif quick_choice == 1:
reverse()
time.sleep(random.uniform(1,2))
forward_right()
time.sleep(random.uniform(1,2))
elif quick_choice == 2:
reverse_left()
time.sleep(random.uniform(1,2))
forward_right()
time.sleep(random.uniform(1,2))
elif quick_choice == 3:
reverse_right()
time.sleep(random.uniform(1,2))
forward_left()
time.sleep(random.uniform(1,2))
for i in range(log_len-2):
del motion_log[0]
keys = key_check()
# First of all, check if ESCape was pressed
if msvcrt.kbhit() and ord(msvcrt.getch()) == 27:
aborted = True
break
# p pauses game and can get annoying.
if 'T' in keys:
if paused:
paused = False
time.sleep(1)
else:
paused = True
ReleaseKey(A)
ReleaseKey(W)
ReleaseKey(D)
time.sleep(1)
if aborted:
ultimate_release()
print("Program was aborted")
# -
# To abort the code, go to your command prompt terminal where your notebook where opened, and there you can press "ESC" to abort the program or "T" pause the AI program.
# Things to do before run the main()
# 1. **Open your Genshin Impact Game**
# 2. **Go to the bridge of Mondstat**
# 
# 3. **Change the time to 12:00**
# 
# 4. **Verify that you are using your controller.**
# 
# 5. **Run the main()**
# 6. **Return to the windows of your game**
# <center>
# <video width="620" height="440" src="img/video.mp4" type="video/mp4" controls>
# </video>
# </center>
import os
# Path
path = os.getcwd()
# Join various path components
app=os.path.join(path, "vjoy-gamepad", "JoystickTest.exe")
#print(app)
import os
#os.startfile("C:\BOT-MMORPG-WITH-AI\versions\0.01\vjoy-gamepad\JoystickTest.exe")
os.startfile(app)
# 
# To run just run the main cell below:
main()
| versions/0.01/3-test_model.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import os
import sys
import skimage.data as imd
def load_ml_data(data_directory):
dirs = [d for d in os.listdir(data_directory)
if os.path.isdir(os.path.join(data_directory,d))]
labels = []
images = []
for d in dirs:
label_dir = os.path.join(data_directory, d)
file_names = [os.path.join(label_dir, f)
for f in os.listdir(label_dir) if f.endswith(".ppm")]
for f in file_names:
images.append(imd.imread(f))
labels.append(int(d))
return images, labels
# -
main_dir = "../datasets/belgian/"
train_data_dir = os.path.join(main_dir, "Training")
test_data_dir = os.path.join(main_dir, "Testing")
images, labels = load_ml_data(train_data_dir)
labels
import numpy as np
images = np.array(images)
labels = np.array(labels)
type(images)
from skimage import transform
w, h = 9999, 9999
for image in images:
if image.shape[0] < h:
h = image.shape[0]
elif image.shape[1] < w:
w = image.shape[1]
print("Tamaño minimo: {0}x{1}".format(h,w))
images[0]
images30 = [transform.resize(image, (30, 30)) for image in images]
import matplotlib.pyplot as plt
import random
rand_signs = random.sample(range(0, len(labels)), 6)
for i in range(len(rand_signs)):
temp_im = images30[rand_signs[i]]
plt.subplot(1, 6, i+1)
plt.axis("off")
plt.imshow(temp_im)
plt.show()
print(" Forma: {}, min: {}, max: {}".format(temp_im.shape, temp_im.min(), temp_im.max()))
from skimage.color import rgb2gray
images30 = np.array(images30)
images30 = rgb2gray(images30)
rand_signs = random.sample(range(0, len(labels)), 6)
for i in range(len(rand_signs)):
temp_im = images30[rand_signs[i]]
plt.subplot(1, 6, i+1)
plt.axis("off")
plt.imshow(temp_im, cmap="gray")
plt.show()
print(" Forma: {}, min: {}, max: {}".format(temp_im.shape, temp_im.min(), temp_im.max()))
import tensorflow as tf
images.shape
# +
x = tf.placeholder(dtype = tf.float32, shape = [None, 30,30])
y = tf.placeholder(dtype = tf.int32, shape = [None])
images_flat = tf.contrib.layers.flatten(x)
logits = tf.contrib.layers.fully_connected(images_flat, 62, tf.nn.relu)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y, logits=logits))
"""
Classification function using logistical regresion and cross entropy
"""
train_opt = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
final_pred = tf.argmax(logits, 1)
accuracy = tf.reduce_mean(tf.cast(final_pred, tf.float32))
# +
tf.set_random_seed(666)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(601):
_, accuracy_val = sess.run([train_opt, accuracy],
feed_dict= {
x: images30,
y: list(labels)
})
if i % 50 == 0:
print("EPOCH", i)
print("Eficacia: ", accuracy_val)
# -
sample_idx = random.sample(range(len(images30)), 40)
sample_images = [images30[i] for i in sample_idx]
sample_labels = [labels[i] for i in sample_idx]
prediction = sess.run([final_pred], feed_dict={x:sample_images})[0] # We only need labels
prediction
plt.figure(figsize=(16,20))
for i in range(len(sample_images)):
truth = sample_labels[i]
predi = prediction[i]
plt.subplot(10,4,i+1)
plt.axis("off")
color = "green" if truth==predi else "red"
plt.text(32,15, "Real: {0}\nPrediccion:{1}".format(truth, predi),
fontsize = 14, color = color)
plt.imshow(sample_images[i], cmap="gray")
plt.show()
test_images, test_labels = load_ml_data(test_data_dir)
test_images30 = [transform.resize(im,(30,30)) for im in test_images]
test_images30 = rgb2gray(np.array(test_images30))
prediction = sess.run([final_pred], feed_dict={x:test_images30})[0]
match_count = sum([int(l0 == lp) for l0, lp in zip(test_labels, prediction)])
acc = match_count/len(test_labels)*100
print("Eficacia de la red neuronal: {:.2f}".format(acc))
| src/Traffic Sign recognition.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Атрибуты класса и экземпляра
#
# При объявлении класса создается новое пространство имен и используется как локальная область видимости (по аналогии с функциями), внутри которой могут объявляться переменные (атрибуты) и функции, которые называются методами и имеют немного отличный от обычных функций вид объявления. Таким образом все атрибуты можно разделить на несколько видов:
# - атрибуты данных:
# - атрибуты класса;
# - атрибуты экземпляры.
# - методы (о методах речь пойдет в следующем разделе).
#
# Содержание области видимости класса можно посмотреть с помощью функции ```dir```.
#
# Доступ к любым атрибутам осуществляется с помощью точечной нотации, синтаксис которой является стандартным для многих языков программирования.
#
# ```python
# obj.attribute
# ```
#
# Атрибутами выступают все имена, определенные в пространстве имен класса. Рассмотрим пример простейшего класса ```A```.
#
# ## Атрибуты класса
#
# Атрибуты класса объявляются непосредственно внутри пространства имен класса, по аналогии с локальными переменными. В примере ниже класс ```A``` содержит один атрибут класса ```foo```.
#
# Все атрибуты являются ссылками на другие объекты. Здесь атрибут ```foo``` класса ```A``` ссылается на объект целого числа ```6174```.
# +
class A:
foo = 6174
print(f'{A = }')
print(f'До изменения: {A.foo = }')
A.foo = 0
print(f'После изменения: {A.foo = }')
# -
# Классы позволяют по-настоящему оценить динамическую природу Python. Он позволяет динамически, т.е. в процессе выполнения, создавать **любые** атрибуты.
# +
def get_attrs(obj):
"""Получение все атрибутов кроме 'магических'."""
return [attr for attr in dir(obj) if not (attr.startswith("__") and attr.endswith("__"))]
print(f'Состав исходной области видимости: {get_attrs(A)}')
# динамически добавляем новый атрибут
A.bar = 42
print(f'Область видимости после добавления атрибута: {get_attrs(A)}')
# -
# Экземпляр класса создается с использованием круглых скобок («вызов» класса). Подробнее механизм создания экземпляра класса будет рассмотрен в разделе о "магических" методах.
#
# Создаваемый экземпляр сразу связывается с именем, стоящим слева от знака равенства.
#
# Экземпляры класса имеют доступ к атрибутам класса. Для этого достаточно использовать точечную нотацию. Изменение таких атрибутов у класса ведет к их изменению в экземплярах, но **обратное не верно**. Далее мы поймем почему.
# +
a = A()
b = A()
print(f'(1) До изменения: {a.foo = }')
print(f'(2) До изменения: {b.foo = }')
A.foo = 6174
print(f'(1) После изменения: {a.foo = }')
print(f'(2) После изменения: {b.foo = }')
# -
# Чтобы убедиться в доступности атрибутом можно воспользоваться функцией ```get_attrs```, реализованной выше.
# +
print(f'Атрибуты класса {A.__name__}: {get_attrs(A)}')
print(f'Атрибуты экземпляра a: {get_attrs(a)}')
print(f'Атрибуты экземпляра b: {get_attrs(b)}')
# -
# На самом деле здесь происходит небольшая магия. Непосредственно экземпляры класса не имеют атрибутов класса, т.е. экземпляры ```a``` и ```b``` не имеют атрибутов ```foo``` и ```bar```. Дело в том, что здесь работает механизм поиска атрибутов, о котором мы подробнее поговорим далее. Когда мы запрашиваем атрибут класса у экземпляра, т.е. пишем ```a.foo```, он ищет этот атрибут сначала в экземпляре, не найдя его, он перейдет на уровень выше - на уровень класса и будет искать его там.
#
# Для того, чтобы убедиться в этом проверим на что ссылаются эти атрибуты с помощью оператора ```is```.
# все атрибуты ссылаются на один объект в памяти
print(f'{A.foo is a.foo is b.foo = }')
# С тем, что атрибутов класса на самом деле нет в экземпляре, связана одна интересная особенность, о которой обязательно нужно помнить. Она может привести к различного рода ошибкам и некорректному поведения программы особенно у новичков. Дело в том, что при создании атрибутов экземпляра с таким же именем как у атрибута класса, первый "загораживает" второй. Это поведение аналогично поведения переменных в областях видимости разного уровня.
#
# В качестве примера попытаемся изменить значение атрибута класса ```foo``` через экземпляр ```b```. Для частоты эксперимента заменим значение атрибута ```b.foo``` на тоже самое значение, которое было ранее у всех остальных атрибутов, а именно ```6174```. Первое, что подумает новичок - ничего не произойдет. Однако, это не так. Подробно разберем происходящее здесь.
#
# Изначально класс ```A``` содержал атрибут класса ```foo```. У экземпляров этого атрибута не было. Они получали его значение через свой класс.
#
# <img src="image/attr_cls.png">
#
# В ходе выполнения строки ```b.foo = 6174``` интерпретатор сначала выполнил поиск атрибута ```foo``` в экземпляре. Не найдя его, он создал этот атрибут внутри экземпляра со значением ```6174```. Обратите внимание, что при создании атрибута его поиск происходит только **в текущем** объекте. После выполнения этой строки будет существовать два **разных** атрибута ```foo```. Один в экземпляре ```b```, он будет атрибутом экземпляра, а другой в классе ```A```, он является атрибутом класса. Эти два атрибута ссылаются на *разные* объекты, поэтому оператор ```is``` возвращает ```False```.
#
# Особенности на этом не заканчиваются. Теперь при обращении ```b.foo``` будет возвращаться объект, связанный с этим атрибутом, а не с атрибутом ```A.foo```, т.е. атрибут экземпляра "загородил" собой атрибут класса. Это поведение полностью аналогично обычным переменным из разных областей видимости, например, локальные переменные с тем же именем, что и у глобальной переменной, "загородят" последнюю. Стоит отметить, что теперь атрибут ```b.foo``` никак не будет влиять на ```A.foo```, это **разные** объекты.
# +
print('Атрибуты до изменения:')
print(f'{A.foo = }, {a.foo = }, {b.foo = }')
print('-' * 25)
# Заменяем на такое же значение, по ощущениям ничего не должно измениться.
b.foo = 6174
# Что-то пошло не так. Атрибут b.foo отличается от остальных
print(f'{A.foo is a.foo is b.foo = }')
print(f'{A.foo is b.foo = }')
print(f'{a.foo is b.foo = }')
# +
A.foo = 42
print(f'{A.foo = }')
print(f'{a.foo = }')
print(f'{b.foo = }') # Magic!!!
# -
# До "загороженного" атрибута класса ```foo``` можно добраться из экземпляра. Для этого используется обходной путь. У экземпляра есть "магический" атрибут ```__class__```. Он хранить класс.
#
# <img src="image/attr_self.png">
print(f'{b.__class__.foo = }')
print(f'{b.__class__.foo is b.foo = }')
# +
print(f'{a.__class__.foo = }')
print(f'{a.__class__.foo is a.foo = }')
a.foo = 0
print(f'{a.foo = }')
print(f'{a.__class__.foo = }')
print(f'{a.__class__.foo is a.foo = }')
# -
# ## Атрибуты экземпляра
#
# Экземпляр класса тоже может содержать атрибуты. Они называются атрибутами экземпляра. Эти атрибуты создаются и инициализируются в специальном методе ```__init__```. Этот метод всегда принимает в качестве первого аргумента ```self```. В качестве этого аргумента передается сам экземпляр. Более подробно работа методов будет рассмотрена в следующем разделе.
#
# Метод ```__init__``` только инициализирует экземпляр, т.е. создает атрибуты и заполняет их определенными значениями. Обратите внимание на то, что метод ```__init__``` не должен ничего возвращать, т.е. в нем нельзя размещать инструкцию ```return```.
class A:
# метод инициализации экземпляра
def __init__(self, x, y):
"""
:param self: экземпляр текущего класса, обязательный аргумент
:type self: A
:param x: дополнительное значение для атрибута self.x
:param y: дополнительное значение для атрибута self.y
"""
self.x = x
self.y = y
# К атрибутам экземпляра класс не имеет доступа. В этом можно убедиться с помощью функции ```get_attrs```. Область видимости класса ```A``` не содержит этих атрибутов.
print(f'{get_attrs(A)}')
# Когда мы объявили метод инициализации экземпляра, его создание несколько измениться. Теперь при вызове класса необходимо передавать дополнительные аргументы ```x``` и ```y```. Обратите внимание, что аргумент ```self``` мы не передаем. Он передается автоматически.
#
# После создания и инициализации экземпляра атрибуты ```x``` и ```y``` появятся в его области видимости. При это они будут различны для разных экземпляров.
# +
a = A(1, 2)
b = A(4, 5)
print(f'{get_attrs(a)}')
print(f'{get_attrs(b)}')
# +
print(f'{a.x = }, {a.y = }')
print(f'{b.x = }, {b.y = }')
print(f'{a.x is b.x = }, {a.y is b.y = }')
# -
# Изменение атрибута у одного из экземпляров никак не отражается на другом.
a.x = 10
print(f'{a.x = }, {a.y = }')
print(f'{b.x = }, {b.y = }')
# # Полезные ссылки
| python_pd/06_classes/02_attr.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
os.environ["TF_FORCE_GPU_ALLOW_GROWTH"]="true"
import tensorflow.compat.v1 as tf
from tensorflow import keras
from tensorflow.keras import backend as K
model_1 = keras.models.Sequential([
keras.layers.Conv2D(filters=2, kernel_size=1, input_shape=(1,1,4)),
keras.layers.Conv2D(filters=4, kernel_size=1)
])
model_1.inputs
model_1.outputs
model_2 = keras.models.Sequential([
keras.layers.Conv2D(filters=3, kernel_size=1, input_shape=(1,1,6)),
keras.layers.Conv2D(filters=6, kernel_size=1)
])
model_2.inputs
model_2.outputs
model_1_input_0 = model_1.inputs[0]
model_1_output_0 = model_1.outputs[0]
model_2_input_0 = model_2.inputs[0]
model_2_output_0 = model_2.outputs[0]
# # concat output, not rmse loss
concat_rms = keras.layers.concatenate([model_1_output_0, model_2_output_0], axis=-1)
output_model = keras.models.Sequential([
keras.layers.Conv2D(filters=5, kernel_size=1),
keras.layers.Conv2D(filters=10, kernel_size=1)
])
output_model_ouput = output_model(concat_rms)
output_model_ouput
total_model = keras.Model([model_1_input_0, model_2_input_0], output_model_ouput)
total_model.save("total_modif.h5", save_format='h5')
total_model.outputs
# +
tf_session = keras.backend.get_session()
# write out tensorflow checkpoint & meta graph
saver = tf.train.Saver()
save_path = saver.save(tf_session,"total_modif/total_modif.ckpt")
# -
# !CUDA_VISIBLE_DEVICES=-1 python freeze_graph.py \
# --input_meta_graph total_modif/total_modif.ckpt.meta \
# --input_checkpoint total_modif/total_modif.ckpt \
# --output_graph total_modif/total_modif.pb \
# --output_node_names=sequential_2/conv2d_5/BiasAdd \
# --input_binary=true
| experiments/anomaly_detector_modified.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import pandas as pd
# Paths
PROJECT_DIR = "/data/notebooks/uves_jprieto"
# Data dir
DATA_DIR = os.path.join(PROJECT_DIR, "data")
# Model checkpoints
CHECKPOINT_DIR = os.path.join(PROJECT_DIR, "data/descriptors")
# +
uves_flag_file=os.path.join(DATA_DIR, 'UVES_hidden_flag_results.txt')
uves_flag_df=pd.read_csv(uves_flag_file, comment='#', sep=';')
uves_flag_df['filename'] = uves_flag_df['filename']+'.fits'
uves_flag_df.head()
# -
corrupted_df = uves_flag_df[(uves_flag_df['image_type'] == 'bias_blue') & (uves_flag_df['flag'] == 'CORRUPTED')]
corrupted_df.head()
list(corrupted_df['filename'])
| notebooks/06_Analyze_ESO_flags.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:deepl35]
# language: python
# name: conda-env-deepl35-py
# ---
# +
# Build from the previous network.
# Add a dropout layer after the pooling layer. Set the dropout rate to 50%. (Using Keras v1.2.1 from the starter kit? See this archived documentation about dropout.)
# Load pickled data
import pickle
import numpy as np
import tensorflow as tf
# tf.python.control_flow_ops = tf
with open('small_train_traffic.p', mode='rb') as f:
data = pickle.load(f)
X_train, y_train = data['features'], data['labels']
# Initial Setup for Keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten, Dropout
from keras.layers.convolutional import Convolution2D
from keras.layers.pooling import MaxPooling2D
# TODO: Build Convolutional Pooling Neural Network with Dropout in Keras Here
model = Sequential()
model.add(Convolution2D(32, kernel_size=(3, 3), input_shape=(32, 32, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.5))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(5))
model.add(Activation('softmax'))
# preprocess data
X_normalized = np.array(X_train / 255.0 - 0.5 )
from sklearn.preprocessing import LabelBinarizer
label_binarizer = LabelBinarizer()
y_one_hot = label_binarizer.fit_transform(y_train)
model.compile('adam', 'categorical_crossentropy', ['accuracy'])
history = model.fit(X_normalized, y_one_hot, nb_epoch=3, validation_split=0.2)
# -
| 1_12_Keras/Quiz_8_Keras_Dropout.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import stat
from itertools import filterfalse
import hashlib
def hash_value_for_file(f, hash_function, block_size=2**20):
while True:
# we use the read passing the size of the block to avoid
# heavy ram usage
data = f.read(block_size)
if not data:
# if we don't have any more data to read, stop.
break
# we partially calculate the hash
hash_function.update(data)
return hash_function.digest()
# +
_cache = {}
BUFSIZE = 8*1024
def cmp(local_file, remote_file, shallow=True):
"""Compare two files.
Arguments:
local_file -- First file name
remote_file -- Second file name
sftp_client -- The Paramiko Object of the SFTP Connection to the Server
shallow -- Just check stat signature (do not read the files).
defaults to True.
Return value:
True if the files are the same, False otherwise.
This function uses a cache for past comparisons and the results,
with cache entries invalidated if their stat information
changes. The cache may be cleared by calling clear_cache().
"""
s1 = _sig(os.stat(local_file))
s2 = _sig(os.stat(remote_file))
if s1[0] != stat.S_IFREG or s2[0] != stat.S_IFREG:
return False
if shallow and s1 == s2:
return True
if s1[1] != s2[1]:
return False
outcome = _cache.get((local_file, remote_file, s1, s2))
if outcome is None:
outcome = _do_cmp(local_file, remote_file)
if len(_cache) > 100: # limit the maximum size of the cache
clear_cache()
_cache[local_file, remote_file, s1, s2] = outcome
return outcome
def _sig(st):
return (stat.S_IFMT(st.st_mode),
st.st_size,
st.st_mtime)
def _do_cmp(f1, f2):
bufsize = BUFSIZE
with open(f1, 'rb') as fp1, open(f2, 'rb') as fp2:
while True:
b1 = fp1.read(bufsize)
b2 = fp2.read(bufsize)
if b1 != b2:
return False
if not b1:
return True
def clear_cache():
"""Clear the filecmp cache."""
_cache.clear()
# -
def benchMD5():
with open('SSH_Connection.ipynb', 'rb') as input_file:
md5 = hashlib.md5()
hashA = hash_value_for_file(input_file, md5)
with open('SSH_Connection.ipynb', 'rb') as input_file:
md5 = hashlib.md5()
hashB = hash_value_for_file(input_file, md5)
def benchSHA1():
with open('SSH_Connection.ipynb', 'rb') as input_file:
sha1 = hashlib.sha1()
hashA = hash_value_for_file(input_file, sha1)
with open('SSH_Connection.ipynb', 'rb') as input_file:
sha1 = hashlib.sha1()
hashB = hash_value_for_file(input_file, sha1)
# %timeit -n 100000 benchMD5()
# %timeit -n 100000 benchSHA1()
# %timeit -n 100000 cmp('SSH_Connection.ipynb', 'SSH_Connection.ipynb'); clear_cache()
# %timeit -n 100000 cmp('SSH_Connection.ipynb', 'SSH_Connection.ipynb', shallow=False); clear_cache()
| notebooks/rfilecmp_experimental_benchmarking.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from nltk.translate.bleu_score import sentence_bleu
refs = [
'назовите меня каким угодно инструментом вы хоть и можете меня терзать но играть на мне не можете',
'объявите меня каким угодно инструментом вы можете расстроить меня но играть на мне нельзя'
]
refs = [ref.split() for ref in refs]
sents = [
'назовите мне какой инструмент вы хотите хотя можете меня беспокоить но вы не можете играть на меня',
'назовите меня какой инструмент вы будете хотя вы можете раздражать меня все же вы не можете играть на меня',
'позвони мне какой инструмент ты будешь хотя ты можешь меня волновать но ты не можешь играть на меня',
'назови меня каким угодно инструментом ты можешь меня расстроить но не играть на мне',
'позвони мне на каком инструменте вы будете хотя вы можете беспокоиться меня но вы не можете играть на мне',
'считай меня чем тебе угодно ты можешь мучить меня но не играть мною'
]
sents = [sent.split() for sent in sents]
scores = [(sentence_bleu(refs, sent, weights=(0.5, 0.5)), ' '.join(sent))
for i, sent in enumerate(sents)]
scores.sort(reverse=True)
scores
| blue_calc.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
x=(5+2)*(12/4)
print(x)
print(11/3)
print(11//3)
print(2**5)
bin(12)
bin(4)
12|4
bin(12|4)
a=2
a+=2
print(a)
b=5
a*=b
print(a)
c=10
c**=b
print(c)
print(c^b)
13%2==1
72%2==1
255%2==1
a=63
50<a<100
x=6
x>1 and x<7
x>1 or 5
not x<1
a=[4,5,6]
b=[4,5,6]
a==b
a is b
a is not b
b=a
a is b
4 in a
5 not in a
x=1
type(x)
x=1.5
type(x)
type(7/3)
type(7//3)
a=0.000007
b=7e-6
a==b
float(25)
c=complex(4,5)
print(c)
c.real
c.imag
c.conjugate()
abs(c)
| Module 02 Exercise.ipynb |
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: SageMath 9.0
# language: sage
# name: sagemath
# ---
# %display typeset
# <p>O modelo de <NAME> é um elegante modelo de um sistema excitável. Históricamente foi desenvolvido de um esforço por simplificar o modelo original de Hodgkin-Huxley mantendo suas propriedades dinâmicas intactas. Mas este modelo é um ponto de partida para o estudo do fenômeno da excitabilidade que, sendo bastante comum em biologia, não se restringe à eletrofisiologia dos neurônios.</p>
# <p><img src="http://www.scholarpedia.org/w/images/e/e4/Richard_FitzHugh_analog_computer.jpg" alt="Computador analógico usado por <NAME>." width="571" height="706" /></p>
# <p><NAME> com o computador analógico usado para calcular o modelo.</p>
# <h4>O que é excitabilidade? </h4>
# <p>Um sistema excitável pode ser descrito como um sistema dinâmico que possui um estado de repouso para o qual sempre retorna após sofrer pequenas pertubações. Entretanto se a perturbação ou estímulo ultrapassar seu limiar de excitabilidade, o sistma fará uma excursão mais longa pelo espaço de estados antes de retornar ao seu estado de repouso. Durante esta escursão será refratário a novos estímulos, ou seja, novos estímulos não afetarão sua trajetória. Mas após retornar ao repouso, estará sujeito a uma nova excitação.</p>
# <p>O modelo de Fitzhugh-Nagumo consiste em duas equações apenas. A primeira busca representar a excitação do sistema:</p>
# <p>$$\frac{dx}{dt} = c \left(x-\frac{1}{3}x^3 \right)$$</p>
# <p>Esta equação admite 3 equilíbrios:</p>
var('c')
solve(c*(x-x^3/3),x)
p=plot(1*(x-x^3/3),(-2,2))
po = point([(-sqrt(3),0),(0,0),(sqrt(3),0)],color='red',pointsize=40)
show(p+po)
# <p>Pelo gráfico, podemos ver que temos dois equilíbrios estáveis ($x=\pm \sqrt{3}$) e um instável ($x=0$). Mas esta equação sozinha, nos dá uma sistema bistável, e não um excitável. Para isso temos que acrescentar uma variável, $y$, de "recuperação", que neutralize a excitação e leve o sistema de volta para o equilíbrio de "repouso".</p>
# <p>$$\frac{dx}{dt} = c \left(x-\frac{1}{3}x^3 -y + j \right)$$</p>
# <p>$$\frac{dy}{dt}=\frac{1}{c}(x+a-by)$$</p>
# <p>o parâmetro j representa o estímulo externo, no caso do neurônio a correte de despolarização injetada na célula. Os parâmetros $a$ e $b$ são positivos e tomam valores preferencialmente nas seguintes faixas: $1-\frac{2b}{3} \lt a \lt 1$ e $0 \lt b \lt 1$. A forma como $c$ aparece em ambas as equações serve para ajustarmos a intensidade da excitabilidade em relação à recuperação. Aumentando $c$, aumentamos a excitabilidade e diminuimos a recuperação.</p>
# <h2>Análise no Plano de Fase</h2>
# <p>Para nos ajudar nesta análise, vamos definir as nuliclinas de ambas as variáveis:</p>
# <p>$$\frac{dy}{dt}=0 \Rightarrow y = \frac{1}{b}x + \frac{a}{b}$$</p>
# <p>$$\frac{dx}{dt}=0 \Rightarrow y= x- \frac{1}{3}x^3 +j$$</p>
# <p> </p>
# <p>Note que o parâmetro $c$ não afeta nenhuma das nuliclinas.</p>
var('x y a b c j')
dxdt = c*((x-(x**3)/3)-y+j)
solve(dxdt,y)
dydt = (x+a-b*y)/c
solve(dydt,y)
var('y')
c=10
j=0.3
a=.7
b=.8
vf = plot_vector_field([c*((x-(x**3)/3)-y+j),(x+a-b*y)/c],(x,-2,2),(y,-1.5,1.5),axes_labels=[r'$x$',r'$y$'])
xnull = plot(x-x^3/3+j,(-2,2),color='blue',ymin=-1.5,ymax=1.5, legend_label="Nuliclina de $x$")
ynull = plot((a+x)/b,(-2,2),color='green',ymin=-1.5,ymax=1.5, legend_label="Nuliclina de $y$")
show(vf+xnull+ynull)
# A interseção entre as nuliclinas é um equilíbrio do systema. Podemos calcular o seu valor.
sols=solve([dxdt,dydt],[x,y])
for sol in sols:
show(sol)
pe = point((sol[0].rhs(),sol[1].rhs()), color='red',pointsize=50)
show(vf+xnull+ynull+pe)
# Vamos calcular a Jacobiana do sistema:
Jac = jacobian([dxdt,dydt], [x,y])
Jac
Jac.eigenvalues()
def fun(t,Y, params):
x, y = Y
c,j,a,b=params
#j=0.9*(heaviside(t-20)-heaviside(t-50))
return[
c*(x-x**3/3-y+j),
(x+a-b*y)/c
]
jfun = lambda t,st,p: jacobian([c*((x-(x**3)/3)-y+j),(x+a-b*y)/c], [x,y]).subs(x=st[0], c=p[0],j=p[1],a=p[2],b=p[3])
jfun (0,[sol[0].rhs(),sol[1].rhs()],[c,j,a,b])
T = ode_solver()
T.algorithm='rk8pd'
T.function= fun
T.jacobian = jfun
t_range = [0,80]
y0 = [-1.19940806511,-0.624260036595]#[.5,.5]
T.ode_solve(t_range,y0,params=[3,0.6,.7,.8],num_points=500)
#fun(0,[1.49900000000000,0.0833333333333333],[0.08,0,.7,.8])
px = list_plot([(p[0],p[1][0]) for p in T.solution], plotjoined=True, legend_label="x");
py = list_plot([(p[0],p[1][1]) for p in T.solution], color='green', legend_label="y");
px.legend()
show(px+py);
#print T.solution
@interact
def traj_plot(x0=slider(-2,2,.1, -1.19940806511),y0=slider(-1.5,1.5,.1,-0.624260036595)):
inits = [x0,y0]#[.5,.5]
T.ode_solve(t_range,inits,params=[c,j,a,b],num_points=500)
traj = list_plot([(p[1][0],p[1][1]) for p in T.solution],color="orange", plotjoined=True);
pi = point([inits[0],inits[1]],color='green', pointsize=50)
show(vf+xnull+ynull+pe+traj+pi)
T = ode_solver()
T.algorithm='rk8pd'
#cfun = nagumo_C(0.4)
T.function= fun
t_range = [0,200]
y0 = [-1.19940806511,-0.624260036595]
T.ode_solve(t_range,y0,params=[3,1.35,.7,.8],num_points=500)
px = list_plot([(p[0],p[1][0]) for p in T.solution], plotjoined=True, legend_label="x");
py = list_plot([(p[0],p[1][1]) for p in T.solution], color='green', legend_label="y");
show(px+py);
import numpy as np
@interact
def bifurcation(j_min=slider(0,1,0.01,0),j_max=slider(0,2,0.01,1.4)):
T = ode_solver()
T.algorithm='rk8pd'
pts = []
for j in np.linspace(j_min,j_max,200):
#cfun = nagumo_C(j)
T.function= fun
t_range = [0,50]
y0 = [-1.19940806511,-0.624260036595]
T.ode_solve(t_range,y0,params=[3,j,.7,.8], num_points=500)
sol = T.solution
pts += [(j,p[1][0]) for n,p in enumerate(sol[0:]) if abs(p[1][1]-0.5) < 0.01]
show(points(pts,pointsize=2), gridlines=True)
| Planilhas Sage/MM4 - Aula 5 - O Modelo de Fitzhugh-Nagumo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
from gaussians import PokeDescribeNAME
from models import df, COLORS_by_TYPE
from time import sleep
from typing import List
import matplotlib.pyplot as plt
PokeNames = df[~df.name.isna()].name.values
stats = ['hp', 'attack', 'defense', 'sp_attack', 'sp_defense', 'speed']
def SHOW(n: str, sts: List[str] = stats):
assert n in PokeNames
raichu = PokeDescribeNAME(df, n)
c = COLORS_by_TYPE[raichu.typ]
import matplotlib.pyplot as plt
fig = plt.figure(1)
## yes, this should be a for-loop,
## with `int(f"61{i+1}")` as the arg to sublplot.
## I was so pissed after wasting hours attempting the `fig (ax1, ..., axn) = ` destructuring angle
## that i wanted to do teh worst code possible, out of spite.
plt.subplot(611)
plt.plot(raichu.bells.x, raichu.bells.hp, color=c)
plt.axvline(raichu.means[sts[0]], color=c)
plt.axis('off')
plt.grid(False)
plt.subplot(612)
plt.plot(raichu.bells.x, raichu.bells.attack, color=c)
plt.axvline(raichu.means[sts[1]], color=c)
plt.axis('off')
plt.grid(False)
plt.subplot(613)
plt.plot(raichu.bells.x, raichu.bells.defense, color=c)
plt.axvline(raichu.means[sts[2]], color=c)
plt.axis('off')
plt.grid(False)
plt.subplot(614)
plt.plot(raichu.bells.x, raichu.bells.sp_attack, color=c)
plt.axvline(raichu.means[sts[3]], color=c)
plt.axis('off')
plt.grid(False)
plt.subplot(615)
plt.plot(raichu.bells.x, raichu.bells.sp_defense, color=c)
plt.axvline(raichu.means[sts[4]], color=c)
plt.axis('off')
plt.grid(False)
plt.subplot(616)
plt.plot(raichu.bells.x, raichu.bells.speed, color=c)
plt.axvline(raichu.means[sts[5]], color=c)
plt.axis('off')
plt.grid(False)
plt.savefig(f"bellcurve_pngs/{n}_gaussian2.png", transparent=True)
plt.clf();
#print(f"{n} is done! ")
pass
# +
for na in PokeNames:
SHOW(na)
# -
| plt_jpgs.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import tensorflow as tf
import numpy as np
import mnist_data
import os
import vae
import plot_utils
import glob
import sys
import time
import scipy
from sklearn.decomposition import PCA
from skimage.feature import hog
""" parameters """
# source activate tensorflow_p36 && pip install pillow && pip install scikit-image && pip install scikit-learn
# source activate tensorflow_p36 && python run_main.py --dim_z 10 --num_epochs 300
# source activate tensorflow_p36 && python mc_attack_cvae.py 299 5 && python mc_attack_cvae.py 299 5 && sudo shutdown -P now
# combined:
# source activate tensorflow_p36 && pip install pillow && pip install scikit-image && pip install scikit-learn && python run_main.py --dim_z 10 --num_epochs 300 && python mc_attack_cvae.py 299 5 && python mc_attack_cvae.py 299 5 && sudo shutdown -P now
# source activate tensorflow_p36 && python mc_attack_cvae.py 299 5 && python mc_attack_cvae.py 299 5 && sudo shutdown -P now
# source activate tensorflow_p36 && python mc_attack_cvae.py 299 5 && python mc_attack_cvae.py 299 5 && python mc_attack_cvae.py 299 5 && sudo shutdown -P now
model_no = '299' # which model to attack
exp_nos = 1 # how many different experiments ofr specific indexes
instance_no = np.random.randint(10000)
experiment = 'MC_ATTACK_CVAE' + str(instance_no)
percentage = np.loadtxt('percentage.csv')
dt = np.dtype([('instance_no', int),
('exp_no', int),
('method', int), # 1 = white box, 2 = euclidean_PCA, 3 = hog, 4 = euclidean_PCA category, 5 = hog category, 6 = ais
('pca_n', int),
('percentage_of_data', float),
('percentile', float),
('mc_euclidean_no_batches', int), # stuff
('mc_hog_no_batches', int), # stuff
('sigma_ais', float),
('11_perc_mc_attack_log', float),
('11_perc_mc_attack_eps', float),
('11_perc_mc_attack_frac', float),
('50_perc_mc_attack_log', float),
('50_perc_mc_attack_eps', float),
('50_perc_mc_attack_frac', float),
('50_perc_white_box', float),
('11_perc_white_box', float),
('50_perc_ais', float),
('50_perc_ais_acc_rate', float),
])
experiment_results = []
IMAGE_SIZE_MNIST = 28
n_hidden = 500
dim_img = IMAGE_SIZE_MNIST**2 # number of pixels for a MNIST image
dim_z = 10
""" prepare MNIST data """
train_total_data, train_size, valid_total_data, validation_size, test_total_data, test_size, _, _ = mnist_data.prepare_MNIST_data(reuse=True)
# compatibility with old attack
vaY = np.where(valid_total_data[:,784:795] == 1)[1]
trY = np.where(train_total_data[:,784:795] == 1)[1]
teY = np.where(test_total_data[:,784:795] == 1)[1]
vaX = valid_total_data[:,0:784]
trX = train_total_data[:,0:784]
teX = test_total_data[:,0:784]
n_samples = train_size
""" build graph """
# input placeholders
# In denoising-autoencoder, x_hat == x + noise, otherwise x_hat == x
x_hat = tf.placeholder(tf.float32, shape=[None, dim_img], name='input_img')
x = tf.placeholder(tf.float32, shape=[None, dim_img], name='target_img')
y = tf.placeholder(tf.float32, shape=[None, mnist_data.NUM_LABELS], name='target_labels')
# dropout
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
# input for PMLR
z_in = tf.placeholder(tf.float32, shape=[None, dim_z], name='latent_variable')
fack_id_in = tf.placeholder(tf.float32, shape=[None, mnist_data.NUM_LABELS], name='latent_variable')
# network architecture
x_, z, loss, neg_marginal_likelihood, KL_divergence = vae.autoencoder(x_hat, x, y, dim_img, dim_z, n_hidden, keep_prob)
decoded = vae.decoder(z_in, fack_id_in, dim_img, n_hidden)
sess = tf.InteractiveSession()
saver = tf.train.Saver()
saver = tf.train.import_meta_graph('models/mnist_gan.ckpt-'+model_no+'.meta')
saver.restore(sess, './models/mnist_gan.ckpt-'+model_no)
# +
def OneHot(X, n=10, negative_class=0.):
X = np.asarray(X).flatten()
if n is None:
n = np.max(X) + 1
Xoh = np.ones((len(X), n)) * negative_class
Xoh[np.arange(len(X)), X] = 1.
return Xoh
# indexes 1,11,21,31,... are ones, 2,12,22 are twos etc.
def generate_samples_for_digits(sample_size=100):
Z_np_sample_buffer = np.random.randn(sample_size, dim_z)
digits = np.zeros((sample_size,)).astype(int)
for i in range(len(digits)):
digits[i] = i%10
Y_np_sample = OneHot( digits)
generated_samples = sess.run(decoded, feed_dict={z_in: Z_np_sample_buffer, fack_id_in: Y_np_sample, keep_prob : 1})
if (np.any(np.isnan(generated_samples))) or (not np.all(np.isfinite(generated_samples))):
print('Problem')
print(generated_samples[0])
print(generated_samples[1])
generated_samples = generate_samples_for_digits(sample_size)
return generated_samples
def print_elapsed_time():
end_time = int(time.time())
d = divmod(end_time-start_time,86400) # days
h = divmod(d[1],3600) # hours
m = divmod(h[1],60) # minutes
s = m[1] # seconds
print('Elapsed Time: %d days, %d hours, %d minutes, %d seconds' % (d[0],h[0],m[0],s))
def calculate_results_matrices(distances_real_vs_sample,distances_real_vs_train, d_min=0.1):
results_sample = np.zeros((len(distances_real_vs_sample),4))
for i in range(len(results_sample)):
# indicate that dataset is a sample
results_sample[i][0] = 0
integral_approx = 0
integral_approx_log = 0
integral_approx_eps = 0
for eps in distances_real_vs_sample[i]:
if eps < d_min:
integral_approx = integral_approx + d_min/eps
integral_approx_log = integral_approx_log + (-np.log(eps/d_min))
integral_approx_eps = integral_approx_eps + 1
integral_approx = integral_approx/len(distances_real_vs_sample[0])
integral_approx_log = integral_approx_log/len(distances_real_vs_sample[0])
integral_approx_eps = integral_approx_eps/len(distances_real_vs_sample[0])
results_sample[i][1] = integral_approx_log
results_sample[i][2] = integral_approx_eps
results_sample[i][3] = integral_approx
results_train = np.zeros((len(distances_real_vs_train),4))
for i in range(len(results_train)):
# indicate that dataset is a training data set
results_train[i][0] = 1
integral_approx = 0
integral_approx_log = 0
integral_approx_eps = 0
for eps in distances_real_vs_train[i]:
if eps < d_min:
integral_approx = integral_approx + d_min/eps
integral_approx_log = integral_approx_log + (-np.log(eps/d_min))
integral_approx_eps = integral_approx_eps + 1
integral_approx = integral_approx/len(distances_real_vs_train[0])
integral_approx_log = integral_approx_log/len(distances_real_vs_train[0])
integral_approx_eps = integral_approx_eps/len(distances_real_vs_train[0])
results_train[i][1] = integral_approx_log
results_train[i][2] = integral_approx_eps
results_train[i][3] = integral_approx
return results_sample,results_train
def mc_attack_sample(results_sample, results_train):
results = np.concatenate((results_sample, results_train))
np.random.shuffle(results)
mc_attack_log = results[results[:,1].argsort()][:,0][-len(results_train):].mean()
np.random.shuffle(results)
mc_attack_eps = results[results[:,2].argsort()][:,0][-len(results_train):].mean()
np.random.shuffle(results)
mc_attack_frac = results[results[:,3].argsort()][:,0][-len(results_train):].mean()
successfull_set_attack_1 = results_train[:,1].sum() > results_sample[:,1].sum()
successfull_set_attack_2 = results_train[:,2].sum() > results_sample[:,2].sum()
successfull_set_attack_3 = results_train[:,3].sum() > results_sample[:,3].sum()
return mc_attack_log, mc_attack_eps, mc_attack_frac, successfull_set_attack_1, successfull_set_attack_2, successfull_set_attack_3
def mc_attack(results_sample, results_train):
mc_attack_log, mc_attack_eps, mc_attack_frac, successfull_set_attack_1, successfull_set_attack_2, successfull_set_attack_3 = mc_attack_sample(results_sample, results_train)
print('50_perc_mc_attack_log: %.3f'%(mc_attack_log))
print('50_perc_mc_attack_eps: %.3f'%(mc_attack_eps))
print('50_perc_mc_attack_frac: %.3f'%(mc_attack_frac))
print('successfull_set_attack_1: %.3f'%(successfull_set_attack_1))
print('successfull_set_attack_2: %.3f'%(successfull_set_attack_2))
print('successfull_set_attack_3: %.3f'%(successfull_set_attack_3))
iterations = 1000
results_attacks = np.zeros((iterations, 3))
for i in range(len(results_attacks)):
np.random.shuffle(results_train)
res = mc_attack_sample(results_sample, results_train[0:10])
results_attacks[i][0] = res[0]
results_attacks[i][1] = res[1]
results_attacks[i][2] = res[2]
print('11_perc_mc_attack_log: %.3f'%(results_attacks[:,0].mean()))
print('11_perc_mc_attack_eps: %.3f'%(results_attacks[:,1].mean()))
print('11_perc_mc_attack_frac: %.3f'%(results_attacks[:,2].mean()))
return mc_attack_log, mc_attack_eps, mc_attack_frac, results_attacks[:,0].mean(), results_attacks[:,1].mean(), results_attacks[:,2].mean(), successfull_set_attack_1, successfull_set_attack_2, successfull_set_attack_3
def euclidean_PCA_mc_attack_category(n_components_pca, trX_inds, vaX_inds, exp_no, mc_euclidean_no_batches, mc_sample_size, percentiles):
pca = PCA(n_components=n_components_pca)
pca.fit_transform(teX.reshape((len(teX),784)))
euclidean_trX = np.reshape(trX, (len(trX),784,))
euclidean_trX = euclidean_trX[trX_inds]
euclidean_trX = pca.transform(euclidean_trX)
euclidean_vaX = np.reshape(vaX, (len(vaX),784,))
euclidean_vaX = euclidean_vaX[vaX_inds]
euclidean_vaX = pca.transform(euclidean_vaX)
distances_trX = np.zeros((len(euclidean_trX), mc_euclidean_no_batches*mc_sample_size // 10))
distances_vaX = np.zeros((len(euclidean_vaX), mc_euclidean_no_batches*mc_sample_size // 10))
for i in range(mc_euclidean_no_batches):
print('Working on %d/%d'%(i, mc_euclidean_no_batches))
euclidean_generated_samples = generate_samples_for_digits(mc_sample_size)
euclidean_generated_samples = np.reshape(euclidean_generated_samples, (len(euclidean_generated_samples),784,))
euclidean_generated_samples = pca.transform(euclidean_generated_samples)
for digit in range(10):
# indexes of 1's, 2's, 3's etc.
digit_indexes_train = np.where(trY[trX_inds] == digit)
digit_indexes_sample = [digit+10*i for i in range(mc_sample_size//10)]
# only compare to current digit
distances_trX[digit_indexes_train,i*mc_sample_size//10:(i+1)*mc_sample_size//10] = scipy.spatial.distance.cdist(euclidean_trX[digit_indexes_train], euclidean_generated_samples[digit_indexes_sample], 'euclidean')
for digit in range(10):
# indexes of 1's, 2's, 3's etc.
digit_indexes_va = np.where(vaY[vaX_inds] == digit)
digit_indexes_sample = [digit+10*i for i in range(mc_sample_size//10)]
# only compare to current digit
distances_vaX[digit_indexes_va,i*mc_sample_size//10:(i+1)*mc_sample_size//10] = scipy.spatial.distance.cdist(euclidean_vaX[digit_indexes_va], euclidean_generated_samples[digit_indexes_sample], 'euclidean')
print_elapsed_time()
for percentile in percentiles:
print_elapsed_time()
print('Calculating Results Matrices for '+str(percentile)+' Percentile...')
d_min = np.percentile(np.concatenate((distances_trX,distances_vaX)),percentile)
results_sample,results_train = calculate_results_matrices(distances_vaX, distances_trX,d_min)
# save data
new_row = np.zeros(1, dtype = dt)[0]
new_row['instance_no'] = instance_no
new_row['exp_no'] = exp_no
new_row['method'] = 4 # euclidean PCA cat
new_row['pca_n'] = n_components_pca
new_row['percentage_of_data'] = percentage
new_row['percentile'] = percentile
new_row['mc_euclidean_no_batches'] = mc_euclidean_no_batches
mc_attack_results = mc_attack(results_sample, results_train)
new_row['50_perc_mc_attack_log'] = mc_attack_results[0]
new_row['50_perc_mc_attack_eps'] = mc_attack_results[1]
new_row['50_perc_mc_attack_frac'] = mc_attack_results[2]
new_row['11_perc_mc_attack_log'] = mc_attack_results[3]
new_row['11_perc_mc_attack_eps'] = mc_attack_results[4]
new_row['11_perc_mc_attack_frac'] = mc_attack_results[5]
experiment_results.append(new_row)
np.savetxt(experiment+'.csv', np.array(experiment_results, dtype = dt))
print('Calculating Results Matrices for flexible d_min...')
distances = np.concatenate((distances_trX,distances_vaX))
d_min = np.percentile([distances[i].min() for i in range(len(distances))], 50)
results_sample,results_train = calculate_results_matrices(distances_vaX, distances_trX,d_min)
# save data
new_row = np.zeros(1, dtype = dt)[0]
new_row['instance_no'] = instance_no
new_row['exp_no'] = exp_no
new_row['method'] = 4 # euclidean PCA cat
new_row['pca_n'] = n_components_pca
new_row['percentage_of_data'] = percentage
new_row['percentile'] = -1 # dynamic
new_row['mc_euclidean_no_batches'] = mc_euclidean_no_batches
mc_attack_results = mc_attack(results_sample, results_train)
new_row['50_perc_mc_attack_log'] = mc_attack_results[0]
new_row['50_perc_mc_attack_eps'] = mc_attack_results[1]
new_row['50_perc_mc_attack_frac'] = mc_attack_results[2]
new_row['11_perc_mc_attack_log'] = mc_attack_results[3]
new_row['11_perc_mc_attack_eps'] = mc_attack_results[4]
new_row['11_perc_mc_attack_frac'] = mc_attack_results[5]
experiment_results.append(new_row)
np.savetxt(experiment+'.csv', np.array(experiment_results, dtype = dt))
print('Calculating Results Matrices for flexible d_min...')
distances = np.concatenate((distances_trX,distances_vaX))
d_min = np.percentile([distances[i].min() for i in range(len(distances))], 10)
results_sample,results_train = calculate_results_matrices(distances_vaX, distances_trX,d_min)
# save data
new_row = np.zeros(1, dtype = dt)[0]
new_row['instance_no'] = instance_no
new_row['exp_no'] = exp_no
new_row['method'] = 4 # euclidean PCA cat
new_row['pca_n'] = n_components_pca
new_row['percentage_of_data'] = percentage
new_row['percentile'] = -1 # dynamic
new_row['mc_euclidean_no_batches'] = mc_euclidean_no_batches
mc_attack_results = mc_attack(results_sample, results_train)
new_row['50_perc_mc_attack_log'] = mc_attack_results[0]
new_row['50_perc_mc_attack_eps'] = mc_attack_results[1]
new_row['50_perc_mc_attack_frac'] = mc_attack_results[2]
new_row['11_perc_mc_attack_log'] = mc_attack_results[3]
new_row['11_perc_mc_attack_eps'] = mc_attack_results[4]
new_row['11_perc_mc_attack_frac'] = mc_attack_results[5]
experiment_results.append(new_row)
np.savetxt(experiment+'.csv', np.array(experiment_results, dtype = dt))
return results_sample,results_train
def generate_batch_hog_features(samples):
features_matrix = np.zeros((len(samples),81))
for i in range(len(samples)):
features_matrix[i] = hog(samples[i].reshape((28, 28)), orientations=9, pixels_per_cell=(9, 9), visualise=False) #, transform_sqrt=True, block_norm='L2-Hys')
return features_matrix
def hog_mc_attack_category(trX_inds, vaX_inds, exp_no, mc_hog_no_batches, mc_sample_size, percentiles):
feature_matrix_vaX = generate_batch_hog_features(vaX[vaX_inds])
feature_matrix_trX = generate_batch_hog_features(trX[trX_inds])
distances_trX = np.zeros((len(feature_matrix_trX), mc_hog_no_batches*mc_sample_size // 10))
distances_vaX = np.zeros((len(feature_matrix_vaX), mc_hog_no_batches*mc_sample_size // 10))
for i in range(mc_hog_no_batches):
print('Working on %d/%d'%(i, mc_hog_no_batches))
generated_samples = generate_samples_for_digits(mc_sample_size)
generated_samples = generated_samples - generated_samples.min()
generated_samples = generated_samples*255/generated_samples.max()
feature_matrix_generated = generate_batch_hog_features(generated_samples)
for digit in range(10):
# indexes of 1's, 2's, 3's etc.
digit_indexes_train = np.where(trY[trX_inds] == digit)
digit_indexes_sample = [digit+10*i for i in range(mc_sample_size//10)]
# only compare to current digit
distances_trX[digit_indexes_train,i*mc_sample_size//10:(i+1)*mc_sample_size//10] = scipy.spatial.distance.cdist(feature_matrix_trX[digit_indexes_train], feature_matrix_generated[digit_indexes_sample], 'euclidean')
for digit in range(10):
# indexes of 1's, 2's, 3's etc.
digit_indexes_va = np.where(vaY[vaX_inds] == digit)
digit_indexes_sample = [digit+10*i for i in range(mc_sample_size//10)]
# only compare to current digit
distances_vaX[digit_indexes_va,i*mc_sample_size//10:(i+1)*mc_sample_size//10] = scipy.spatial.distance.cdist(feature_matrix_vaX[digit_indexes_va], feature_matrix_generated[digit_indexes_sample], 'euclidean')
print_elapsed_time()
for percentile in percentiles:
print_elapsed_time()
print('Calculating Results Matrices for '+str(percentile)+' Percentile...')
d_min = np.percentile(np.concatenate((distances_trX,distances_vaX)),percentile)
results_sample,results_train = calculate_results_matrices(distances_vaX, distances_trX,d_min)
# save data
new_row = np.zeros(1, dtype = dt)[0]
new_row['instance_no'] = instance_no
new_row['exp_no'] = exp_no
new_row['method'] = 5 # hog cat
new_row['percentage_of_data'] = percentage
new_row['percentile'] = percentile
new_row['mc_hog_no_batches'] = mc_hog_no_batches
mc_attack_results = mc_attack(results_sample, results_train)
new_row['50_perc_mc_attack_log'] = mc_attack_results[0]
new_row['50_perc_mc_attack_eps'] = mc_attack_results[1]
new_row['50_perc_mc_attack_frac'] = mc_attack_results[2]
new_row['11_perc_mc_attack_log'] = mc_attack_results[3]
new_row['11_perc_mc_attack_eps'] = mc_attack_results[4]
new_row['11_perc_mc_attack_frac'] = mc_attack_results[5]
experiment_results.append(new_row)
np.savetxt(experiment+'.csv', np.array(experiment_results, dtype = dt))
print('Calculating Results Matrices for flexible d_min...')
distances = np.concatenate((distances_trX,distances_vaX))
d_min = np.median([distances[i].min() for i in range(len(distances))])
results_sample,results_train = calculate_results_matrices(distances_vaX, distances_trX,d_min)
# save data
new_row = np.zeros(1, dtype = dt)[0]
new_row['instance_no'] = instance_no
new_row['exp_no'] = exp_no
new_row['method'] = 5 # hog cat
new_row['percentage_of_data'] = percentage
new_row['percentile'] = -1
new_row['mc_hog_no_batches'] = mc_hog_no_batches
mc_attack_results = mc_attack(results_sample, results_train)
new_row['50_perc_mc_attack_log'] = mc_attack_results[0]
new_row['50_perc_mc_attack_eps'] = mc_attack_results[1]
new_row['50_perc_mc_attack_frac'] = mc_attack_results[2]
new_row['11_perc_mc_attack_log'] = mc_attack_results[3]
new_row['11_perc_mc_attack_eps'] = mc_attack_results[4]
new_row['11_perc_mc_attack_frac'] = mc_attack_results[5]
experiment_results.append(new_row)
np.savetxt(experiment+'.csv', np.array(experiment_results, dtype = dt))
return results_sample,results_train
# +
start_time = int(time.time())
for exp_no in range(exp_nos):
trX_inds = np.arange(len(trX))
np.random.shuffle(trX_inds)
trX_inds = trX_inds[0:100]
vaX_inds = np.arange(len(trX))
np.random.shuffle(vaX_inds)
vaX_inds = vaX_inds[0:100]
# white box attack
#wb_attack(trX_inds, vaX_inds, exp_no)
#print(experiment+': Finished White Box in experiment %d of %d'%(exp_no+1, exp_nos))
## hog mc attack
## 100 iterations each having 10000 instances for monte carlo simulation
## higher amount of instances exceeds memory
# 100
#hog_mc_attack(trX_inds, vaX_inds, exp_no, 100, 10000, [1,0.1,0.01, 0.001, 0.001])
#print(experiment+': Finished HOG (Default) Monte Carlo in experiment %d of %d'%(exp_no+1, exp_nos))
## euclidean pca mc attack
## 3 mins
# 200
#euclidean_PCA_mc_attack(40, trX_inds, vaX_inds, exp_no, 200, 10000, [1,0.1,0.01,0.001])
#print(experiment+': Finished PCA Monte Carlo in experiment %d of %d'%(exp_no+1, exp_nos))
## pca category
# 8:00 mins 500
# 500
## 300 iterations each having 30000 instances for monte carlo simulation (1h together with below)
results_sample_pca,results_train_pca = euclidean_PCA_mc_attack_category(40, trX_inds, vaX_inds, exp_no, 10, 30000, [1,0.1, 0.01, 0.001])
print(experiment+': Finished CATEGORY PCA Monte Carlo in experiment %d of %d'%(exp_no+1, exp_nos))
# hog category (6s per Iteration, )
# 300
#results_sample_hog,results_train_hog = hog_mc_attack_category(trX_inds, vaX_inds, exp_no, 10, 30000, [1,0.1,0.01, 0.001])
#print(experiment+': Finished CATEGORY HOG (Default) Monte Carlo in experiment %d of %d'%(exp_no+1, exp_nos))
#results_train_combined = results_train_pca + results_train_hog
#results_train_combined[:,0] = 1
#results_train_combined
#mc_attack(results_sample_pca + results_sample_hog, results_train_combined)
#print(experiment+': Finished Bagging Monte Carlo in experiment %d of %d'%(exp_no+1, exp_nos))
print_elapsed_time()
# -
| Monte-Carlo-Attacks/Monte-Carlo-Fashion_MNIST_CVAE/Untitled.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
os.chdir(r'C:\Users\Roli\Downloads')
import pandas as pd
import numpy as np
# !pip install mlxtend
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
df = pd.read_excel('Online_Retail.xlsx')
df['Description'] = df['Description'].str.strip()
df.dropna(axis=0, subset=['InvoiceNo'], inplace=True)
df['InvoiceNo'] = df['InvoiceNo'].astype('str')
df = df[~df['InvoiceNo'].str.contains('C')]
df
basket = (df[df['Country']=='France'].groupby(['InvoiceNo','Description'])['Quantity'].sum().unstack().reset_index().fillna(0).set_index('InvoiceNo'))
basket.to_csv('output1.csv')
def encode_units(x):
if x<=0:
return 0
if x>=1:
return 1
basket_sets = basket.applymap(encode_units)
basket_sets.to_csv('output2.csv')
basket_sets.drop('POSTAGE', inplace=True, axis=1)
frequent_itemsets = apriori(basket_sets, min_support=0.07, use_colnames=True)
rules = association_rules(frequent_itemsets, metric='lift', min_threshold=1)
len(rules)
rules
# +
#Grid Search
# -
os.chdir(r'F:\D\Edureka\Edureka - 24 June - Python\Class 17')
dataset = pd.read_csv('Social_Network_Ads.csv')
dataset
x = dataset.iloc[:, [2,3]].values
x
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x = sc.fit_transform(x)
x
y = dataset.iloc[:,4].values
y
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.3)
from sklearn.svm import SVC
classifier = SVC(kernel='sigmoid')
classifier.fit(x_train, y_train)
from sklearn.neighbors import KNeighborsClassifier
classifier_knn = KNeighborsClassifier()
classifier_knn.fit(x_train, y_train)
y_pred_svm = classifier.predict(x_test)
y_pred_knn = classifier_knn.predict(x_test)
y_pred_svm
y_pred_knn
from sklearn.metrics import confusion_matrix, accuracy_score
confusion_matrix(y_test, y_pred_svm)
accuracy_score(y_test, y_pred_svm)
from sklearn.metrics import confusion_matrix, accuracy_score
confusion_matrix(y_test, y_pred_knn)
accuracy_score(y_test, y_pred_knn)
from sklearn.model_selection import GridSearchCV
parameters = [{'C':[1,2,3,4], 'kernel':['sigmoid','rbf','linear']}]
grid_search = GridSearchCV(estimator=classifier,
param_grid=parameters,
scoring='accuracy',
n_jobs=-1)
grid_search = grid_search.fit(x_train, y_train)
best_accuracy = grid_search.best_score_
best_parameters = grid_search.best_params_
best_accuracy
best_parameters
n_neigh=list(range(1,21))
from sklearn.model_selection import GridSearchCV
parameters = [{'n_neighbors':[8,21,23]}]
grid_search = GridSearchCV(estimator=classifier_knn,
param_grid=parameters,
scoring='accuracy',
n_jobs=-1)
grid_search = grid_search.fit(x_train, y_train)
best_accuracy = grid_search.best_score_
best_parameters = grid_search.best_params_
best_accuracy
best_parameters
grid_search.best_estimator_
| Basics/OnlineLearning/Python_Basics/10_Python_Basics.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### import everything
# +
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.datasets import make_moons
# %matplotlib inline
matplotlib.rcParams['figure.figsize'] = (10.0, 8.0)
# -
# ### 製作2維資料
# +
data, label = make_moons(n_samples=500, noise=0.2, random_state=0)
label = label.reshape(500, 1)
plt.scatter(data[:,0], data[:,1], s=40, c=label, cmap=plt.cm.Accent)
# -
# ### Multilayer neural network
model = Sequential()
model.add(Dense(50, input_shape=(2,), activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='sgd', loss='binary_crossentropy')
model.summary()
# ### 更新權重1000次
# %%time
model.fit(data, label, epochs=1000, verbose=0)
# ### Accuary
result = model.predict(data)
result[result >= 0.5] = 1
result[result < 0.5] = 0
print('Accuary:', float(sum(label == result)[0]) / label.shape[0])
# ### 畫出結果
def plot_decision_boundary(X, y, model):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
pred_every_point = np.c_[xx.ravel(), yy.ravel()]
Z = model.predict(pred_every_point)
Z[Z>=0.5] = 1
Z[Z<0.5] = 0
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], s=40, c=y, cmap=plt.cm.BuGn)
plot_decision_boundary(data, label, model)
# # Your turn!
#
# * 隱藏層的層數是否影響收斂步數?
# * 隱藏層的層數是否影響訓練時間?
# * 隱藏層的神經元數量是否影響收斂步數?
# * 隱藏層的神經元數量是否影響訓練時間?
# * 過多的層數或過度的訓練是否會造成overfitting?
# +
model = Sequential()
#####################
# Hidden layer隨你加 #
#####################
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='sgd', loss='binary_crossentropy')
model.summary()
# +
# %%time
epochs = # 給定訓練步數,看是否影響準確度
model.fit(data, label, epochs=epochs, verbose=0)
# +
# 觀看你的神經網路的準確度
result = model.predict(data)
result[result >= 0.5] = 1
result[result < 0.5] = 0
print('Accuary:', float(sum(label == result)[0]) / label.shape[0])
| example/pycon-2017-tutorial-rl-master/MLP_Keras.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] colab_type="text" id="_zZCXltaL-2y"
# # Fitting a Model the Bayesian Way with Emcee
# + [markdown] colab_type="text" id="CdhUAs_6L-2z"
# This notebook is a continuation from the [previous one](NNLS.ipynb) (Introduction to fitting). The first part is identical: make some fake data (emission line) and fit it with a non-linear model (Gaussian + background). But this time, we place priors on the parameters and use Markov Chain Monte Carlo to solve the problem. [Another notebook](Pystan.ipynb) will do the same, but using a different MCMC sampler (``pystan``).
#
# This notebook requires the ``emcee`` and ``corner`` packages. You can install them by running:
#
# pip install emcee
# pip install corner
# + [markdown] colab_type="text" id="u0PyWC4yL-20"
# ## 1 Making a Fake Emission Line
# + [markdown] colab_type="text" id="HFOE2q0wL-21"
# The "true" data is some background flux of photons (a continuum from the source or background) plus a Gaussian line with some amplitude, width and center. I set these up as variables so it's easy to play around with them and see how things change.
# + colab={} colab_type="code" id="LtRKq3siL-22"
from numpy import * # mmmmmm crunchy
# Start by defining some parameters. Change these if you like!
cont_zp = 500.0
cont_slope = 5.0
amplitude = 150.0
width = 0.5
center = 5.0
# Next, a grid of wavelenght channels (assumed to have no uncertainty)
wave = linspace(0,10,100)
# The 'true' observations
flux = amplitude*exp(-0.5*power(wave-center,2)/width**2)+ \
cont_zp + cont_slope*wave
# The actual observations = true observations + Poisson noise
obs_flux = random.poisson(flux)
# + [markdown] colab_type="text" id="XPgxDszPL-26"
# So we have the wavelength on the x-axis, which is assumed to have no uncertainty. The measured flux is different from the "true" flux due to Poisson noise. Let's plot the true flux and observed flux to see how things look.
# + colab={"base_uri": "https://localhost:8080/", "height": 279} colab_type="code" id="Qkwg2fcNL-26" outputId="2a0b6e27-7640-4a7f-c5e4-f8e04fc0d065"
# %matplotlib inline
from matplotlib.pyplot import plot,step,xlabel,ylabel,show,subplots
plot(wave, flux, 'r-')
step(wave, obs_flux, color='k')
xlabel('Wavelength (Angstroms)')
ylabel('Counts')
show()
# + [markdown] colab_type="text" id="USGlG7hML-2_"
# ## 2 Bayes' Theorem
# + [markdown] colab_type="text" id="6zMz_scXL-2_"
# Bayesian statistics is based on Bayes' theorem (for an excellent intro, see [3blue1brown's video](https://www.youtube.com/watch?v=HZGCoVF3YvM)). It's actually a very simple idea and an equally simple equation. It's *dealing* with the equation that gets complicated. Let's say we have some data $\vec{D}$. In the case of our emission line, the data is the number of counts in each wavelength bin. We have a model with some number of parameters $\vec{\theta}$. Bayes' theorem simply states:
# $$P\left(\vec{\theta}\left|\vec{D}\right.\right) = \frac{P\left(\vec{D}\left|\vec{\theta}\right.\right)P\left(\vec{\theta}\right)}{P\left(\vec{D}\right)}$$
# What this says is that the probability that we get a particular set of parameters given a fixed set of data (which is what we want) is proportional to the probability that we get the data given a fixed set of parameters (which we can calculate) times the probability of the parameters (the priors). The denominator is the probability that we got the data we did, which requires integrating over all possible parameters:
# $$P\left(\vec{D}\right) = \int P\left(\vec{D}\left|\vec{\theta}\right.\right)P\left(\vec{\theta}\right)\ d\vec{\theta}$$
# and really just ensures that the probability is normalized to 1.
#
# You might wonder what the difference between the priors $P\left(\vec{\theta}\right)$ and $P\left(\vec{\theta}\left|\vec{D}\right.\right)$ (called the likelihood) is. The likelihood is what your data tells you about the parameters. The priors are constraints that are external to the data. It could be a previous experiment's result that you are incorporating into your own. It could be a purely logical constraint (e.g., the age of the universe must be greater than 0), it could even be a *gut feeling*.
#
# Working with the above equation isn't too bad if the number of parameters is small and the priors and likelihoods are all simple. In fact, if you use uniform priors and normally-distributed errors, you get the good-old least-squares formalism. But pretty quickly you can get in a situation where the equation (and integrals of the equation) are not possible to evaluate analytically. This is where Markov Chain Monte Carlo (MCMC) is useful.
# + [markdown] colab_type="text" id="mZx-GhD2L-3A"
# ### 3 The Priors
# + [markdown] colab_type="text" id="BIrZwJbWL-3B"
# Our five parameters are <tt>cont_zp</tt>, ``cont_slope``, <tt>amp</tt>, <tt>center</tt>, and <tt>width</tt>. As in the previous tutorial, the order of these parameters will be fixed. The MCMC module we will be using is called [<tt>emcee</tt>](https://emcee.readthedocs.io/en/stable/). Let's first define the model: a function that, given the parameters, predicts the observations.
# + colab={} colab_type="code" id="REc1exY0L-3C"
def model(x, cont, slope, amp, center, width):
model = amp*exp(-0.5*power(x-center,2)/width**2) + cont + \
slope*x
return model
# + [markdown] colab_type="text" id="skrISiLlL-3F"
# Now we write some python functions that give us the ingredients of Bayes' formula. First up are the priors. We make a function that takes the parameters as a list (keeping the order we've established). Let's say we insist the width of the line must be positive (what does a negative width even mean?) and we know it's an *emission* line, so ``amp`` should be positive. If we don't specify anything, parameters are assumed to have a uniform (equal) probability. Emcee also wants the natural logarithm of the probability, so we call it `lnprior()`.
# + colab={} colab_type="code" id="EUSkkswEL-3F"
def lnprior(p):
cont,slope,amp,center,width = p
if width <= 0 or slope < 0:
# ln(0)
return -inf
return 0
# + [markdown] colab_type="text" id="_gMgcl_1L-3J"
# Next, we need the likelihood $P(\vec{D}|\vec{\theta})$. Given the parameters $\vec{\theta}$, the model $M(x,\vec{\theta})$ is given by the function ``model()``. Under our assumpsions, this model will differ from the observed data because of Poisson errors. For large counts, the Poisson distribution is well-approximated by a normal distribution with variance ($\sigma^2$) equal to the counts. So, given a set of parameters $\vec{\theta}$, the probability we measure the flux in channel $i$ to be $f_i$ given by:
# $$P\left(f_i\left|\vec{\theta}\right.\right) = N\left(M(\vec{\theta}), \sqrt{f_i}\right)$$,
# where $N$ is the normal distribution. For the entire data-set, we have to multiply the probabilities of all the individual channels. Or, since we need the log of the probability:
# $$P\left(\vec{D}\left|\vec{\theta}\right.\right) = \Pi_i P\left(f_i\left|\vec{\theta}\right.\right)$$
# We'll use scipy's stats module, which has the normal distribution (and its logarithm) built in. Just like the priors, emcee wants the natural logarithm of the probability, so instead of multiplying all the probabilities, we sum all the logarithms of the probabilities.
# + colab={} colab_type="code" id="oVies-IdL-3K"
from scipy.stats import norm
def lnlike(p, wave, flux):
cont,slope,amp,center,width = p
m = model(wave, *p)
return sum(norm.logpdf(flux, loc=m, scale=sqrt(flux)))
# + [markdown] colab_type="text" id="oWVb0LcsL-3N"
# Lastly, we construct the numerator of Bayes' formula. We won't compute the denominator, since it is a constant and we are only interested in the shape of $P\left(\vec{\theta}\left|\vec{D}\right.\right)$, since we are only interested in parameter inference. In other words, we only care about the relative probability of different values of the parameters. If we were comparing two models and wanted to know which was more likely the correct one, then we'd need the compute the denominator as well to get a full probability.
# + colab={} colab_type="code" id="x8m5y_dAL-3N"
def lnprob(p, wave, flux):
# priors
lp = lnprior(p)
if not isfinite(lp): return -inf
return lp + lnlike(p, wave, flux)
# + [markdown] colab_type="text" id="PtEeAxkrL-3S"
# Now that we have the probability all figured out, we could in principle figure out where it is maximal and compute the 1-2-3-sigma intervals. This may or may not be possible in "closed form". The more parameters, priors and complicated the model gets, the less likely you'll be able to compute the derivatives (for optimization) and integrals (for expectation values and confidence intervals). But we can always compute these numerically and that's what MCMC is all about. With the ``emcee`` module, we do this by creating a bunch of "walkers" that wander around parameter space, always seeking higher probability regions, but also randomly sampling the space. After a certain amount of time, they wander around randomly enough that they lose track of where they started. When this happens, the steps the walkers take is a reflection of $P\left(\vec{\theta}\left|\vec{D}\right.\right)$. So inferences about the moments of $P\left(\vec{\theta}\left|\vec{D}\right.\right)$ can be determined by doing statistics on the walkers' steps. For example, the expectation (mean value) of the amplitude is:
# $$\left<A\right> \equiv \int P\left(\vec{\theta}\left|\vec{D}\right.\right)A d\vec{\theta} \simeq mean(A_i)$$
# where A_i are the values of ``amp`` at each step $i$. The more steps you take, the more accurate the estimate.
#
# So now we create a number of walkers and start them off in random locations around parameter space. In this example, we know the true values so we just perturb around that. When you don't know the true values, you could start in completely random locations or use other tools (like ``curve_fit``) to find an initial starting point.
# + colab={} colab_type="code" id="4MOlTa1pL-3S"
Nwalker,Ndim = 50,5
ptrue = array([500.,5.0,150.,5.0, 0.5])
# add a random vector 0.1 times the true vector to the true vector
p0 = [ptrue + 0.1*random.randn(Ndim)*ptrue for i in range(Nwalker)]
# + [markdown] colab_type="text" id="VG6_0fAkL-3W"
# So we now have ``Nwalker`` initial points. We can run the emcee sampler, givin it the ``lnprob`` function and any extra arguments it needs. The ``run_mcmc`` function takes the initial starting points and how many steps you want each to take. It returns the last position, probability, and state of each walker.
# + colab={} colab_type="code" id="NENX5CyLL-3W"
import emcee
sampler = emcee.EnsembleSampler(Nwalker, Ndim, lnprob, args=(wave, obs_flux))
pos,prob,state = sampler.run_mcmc(p0, 500)
# + [markdown] colab_type="text" id="GuLd418CUPF7"
# So let's see what each walker did. We'll graph the value of each parameter as a function of step number. Each walker will have its own line.
# + colab={"base_uri": "https://localhost:8080/", "height": 265} colab_type="code" id="d5Gw2vqHMz3B" outputId="a5db600a-9d79-4773-c33b-c8181524469e"
fig,ax = subplots(4,1)
res = [ax[i].plot(sampler.chain[:,:,i].T, '-', color='k', alpha=0.3) for i in range(4)]
res = [ax[i].axhline(ptrue[i]) for i in range(4)]
# + [markdown] colab_type="text" id="UWX1SJ8PUt_-"
# As you can see, the walkers can start out rather far from the true value (blue horizontal lines), but after some time, they all converge to a value close to the true value (though not equal, thanks to the noise we added). It's at this point that we say the MCMC chain has converged. Since we're sure this is the case (make sure), we can reset the chains and run for a longer time to get good statistics.
# + colab={} colab_type="code" id="DKbSXYwbPLZT"
sampler.reset()
pos,prob,state = sampler.run_mcmc(pos, 1000)
# + [markdown] colab_type="text" id="Kin2Msu8VXqM"
# Once the sampler is done, we can do statisics on the "chains". The ``sampler`` object has an attribute ``flatchain``, where all the walkers are combined. This gives us Nwalkers*Nsteps samples from the posterior. We could get the best-fit values and errors by doing statistics on the chains:
# + colab={"base_uri": "https://localhost:8080/", "height": 136} colab_type="code" id="6NdCu_eSVqQj" outputId="cab7b81d-0092-44ca-f273-6b09b3f17d18"
print(mean(sampler.flatchain, axis=0)) # best-fit, well really expectation value
print(std(sampler.flatchain, axis=0)) # errors
# deviation from true parameters in units of standard error
print((mean(sampler.flatchain, axis=0)-ptrue)/std(sampler.flatchain, axis=0))
print(cov(sampler.flatchain.T)) # covariance matrix
# + [markdown] colab_type="text" id="522yGJcrV6QG"
# Lastly, we can visualize the *posterior* probabilities of the parameters as well as the covariances between them by plotting a ``corner`` plot.
# + colab={"base_uri": "https://localhost:8080/", "height": 682} colab_type="code" id="m1F8Ms01Oeaa" outputId="50eb4bb3-1fcd-47eb-9447-6c9c601aa14d"
import corner
rmp = corner.corner(sampler.flatchain, labels=['cont_zp','cont_slope','amp','cent','width'],
truths=[cont_zp,cont_slope,amplitude,center,width])
# -
# These corner plots show the covariance between parameters and the histograms show the posterior probability distribution for each parameter. In this case they are all pretty Guassian, so the mean of the distribution is very close to the maximum likelihood (mode) and the standard deviation is a good estimate of the uncertainy. As before, we see that the continuum zero-point and slope are highly covariant, as is the amplitude and width.
| MoreNotebooks/ModelFitting/Emcee.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/manuelP88/text_classification/blob/main/gossip_vs_propaganda_text_classification.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + colab={"base_uri": "https://localhost:8080/"} id="Tya5dmHkxn0c" outputId="24646c8c-3f29-43aa-c9e7-7eb217a3d658"
# !pip install datasets
# !pip install transformers
# !pip install torch
# + id="ot359abHysPy"
import warnings
from datasets import load_dataset, DatasetDict
import pandas as pd
import torch
import torch.utils.data as torch_data
from transformers import DistilBertModel, DistilBertTokenizer, AdamW, DistilBertForSequenceClassification
from datasets import load_metric
import transformers.modeling_outputs
from transformers import get_scheduler
from torch import cuda
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
import types
# + id="BGWYW-cj0HGG"
def require_not_None(obj, message="Require not None") -> object:
if obj is None:
raise Exception(message)
return obj
def load_dataset_from_csv_enc_labels(csv_path=None) -> pd.DataFrame:
require_not_None(csv_path)
# Import the csv into pandas dataframe and add the headers
df = pd.read_csv(
csv_path,
sep='§',
#names=['url', 'domain', 'label', 'title', 'text'],
engine='python'
)
df = df[['domain', 'text', 'label']]
encode_dict = {}
def encode_cat(x):
if x not in encode_dict.keys():
encode_dict[x] = len(encode_dict)
return encode_dict[x]
df['enc_label'] = df['label'].apply(lambda x: encode_cat(x))
if len(encode_dict.keys()) != 2: raise Exception("error! More tan 2 categories are detected!")
return df
# + id="CpDE8j_V0UtM"
def train_test_split(train:pd.DataFrame, frac: float = 0.8, random_state:int=200):
require_not_None(train)
require_not_None(frac)
train_dataset = train.sample(frac=frac, random_state=random_state)
test_dataset = train.drop(train_dataset.index).reset_index(drop=True)
train_dataset = train_dataset.reset_index(drop=True)
return train_dataset, test_dataset
# + id="o6IRHSzF-0Lg"
batch_size = 16
LEARNING_RATE = 1e-05
num_epochs = 20
# + id="JbwZ7DXa0ZU6" colab={"base_uri": "https://localhost:8080/"} outputId="8c332aaa-2ee3-444a-86b3-736b657dc8ef"
from google.colab import drive
drive.mount('/drive')
ds2 = '/drive/My Drive/Colab Notebooks/datasets/gossip_vs_propaganda.csv'
model_out = '/drive/My Drive/Colab Notebooks/models/gossip_vs_propaganda_model'
df = load_dataset_from_csv_enc_labels( ds2 )
# + colab={"base_uri": "https://localhost:8080/"} id="cCMA8PSspwB3" outputId="9646dc7e-03d3-4f98-893b-00d81e71ae0c"
df.label.value_counts()
# + id="XVvsWG4_rLXv"
def downsample(df:pd.DataFrame, label_col_name:str, random_state:int=200) -> pd.DataFrame:
# find the number of observations in the smallest group
nmin = df[label_col_name].value_counts().min()
return (df
# split the dataframe per group
.groupby(label_col_name)
# sample nmin observations from each group
.apply(lambda x: x.sample(nmin, random_state=random_state))
# recombine the dataframes
.reset_index(drop=True)
)
# + colab={"base_uri": "https://localhost:8080/"} id="sIYxPWxarOwo" outputId="f831f9a9-6f88-4994-be2e-847c8629f3f9"
df = downsample(df, "label")
df.label.value_counts()
# + colab={"base_uri": "https://localhost:8080/"} id="ukt7sIgarpo0" outputId="db69ea65-11c2-4cf6-d49f-40f5397f696b"
train_dataset, test_dataset = train_test_split(df, frac=0.2)#0,8
train_dataset, val_dataset = train_test_split(train_dataset, frac=0.8)
warnings.warn("What are the right dimensions of train-validation-test sets?")
print("FULL Dataset: {}".format(df.shape))
print("TRAIN Dataset: {}".format(train_dataset.shape))
print("TEST Dataset: {}".format(test_dataset.shape))
print("VALID Dataset: {}".format(val_dataset.shape))
# + colab={"base_uri": "https://localhost:8080/", "height": 346} id="epdPSEdIlD2M" outputId="a7c26c42-2de7-4c85-f441-2a3e780e407f"
df.groupby("label")["label"].count().plot(kind='bar')
# + id="S2rXrQUeqK0c" colab={"base_uri": "https://localhost:8080/", "height": 346} outputId="37431576-c29f-4bf2-a1f8-4e851f304633"
train_dataset.groupby("label")["label"].count().plot(kind='bar')
# + colab={"base_uri": "https://localhost:8080/", "height": 346} id="R8eUfLKmqC6b" outputId="3128f11e-b360-4731-eb57-bdab28117b63"
test_dataset.groupby("label")["label"].count().plot(kind='bar')
# + colab={"base_uri": "https://localhost:8080/", "height": 346} id="NyXzdCNHqF_b" outputId="5971a9a1-ba53-486b-e292-ecc225de39f5"
val_dataset.groupby("label")["label"].count().plot(kind='bar')
# + id="HSR_hPIj11G2"
class GossipScience(torch_data.Dataset):
def __init__(self, dataframe, tokenizer, max_len=512):
self.len = len(dataframe)
self.data = dataframe
self.tokenizer = tokenizer
self.max_len = max_len
def _get_value(self, index):
text = str(self.data.text[index])
text = " ".join(text.split())
return text
def __getitem__(self, index):
value = self._get_value(index)
inputs = self.tokenizer.encode_plus(
value, add_special_tokens=True,
max_length=self.max_len, truncation=True,
padding="max_length"
)
return {
'input_ids': torch.tensor(inputs['input_ids'], dtype=torch.long),
'attention_mask': torch.tensor(inputs['attention_mask'], dtype=torch.long),
'labels': torch.tensor(self.data.enc_label[index], dtype=torch.long)
}
def get_my_item(self, index):
return self.__getitem__(index)
def __len__(self):
return self.len
# + id="HLODtXtA3TJp"
# + id="Jal5sPrE2AB3" colab={"base_uri": "https://localhost:8080/"} outputId="9d0bbdb3-e3bb-4913-c496-9dc9da23b015"
checkpoint = 'distilbert-base-cased'
tokenizer = DistilBertTokenizer.from_pretrained( checkpoint )
training_set = GossipScience(train_dataset, tokenizer)
testing_set = GossipScience(test_dataset, tokenizer)
validation_set = GossipScience(val_dataset, tokenizer)
train_params = {'batch_size': batch_size, 'shuffle': True}
test_params = {'batch_size': batch_size, 'shuffle': True}
validation_params = {'batch_size': batch_size, 'shuffle': True}
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
training_loader:torch_data.DataLoader = torch_data.DataLoader(training_set, **train_params)
test_loader:torch_data.DataLoader = torch_data.DataLoader(testing_set, **test_params)
validation_loader:torch_data.DataLoader = torch_data.DataLoader(validation_set, **validation_params)
model = DistilBertForSequenceClassification.from_pretrained( checkpoint )
warnings.warn("You have to train a more complex model!")
# + id="zs_LTmxiBQMe" colab={"base_uri": "https://localhost:8080/"} outputId="df566d5e-b74e-4e9b-9750-5c3633178372"
import torch
torch.cuda.is_available()
# + colab={"base_uri": "https://localhost:8080/"} id="8lJkKDDZ7HMS" outputId="7f31432c-a394-4865-c9e0-3627dfe856e2"
training_loader
# + id="VNJS9ax5e1AH" colab={"base_uri": "https://localhost:8080/", "height": 404, "referenced_widgets": ["d332742e78e0458d9285374e91a08d13", "19b6996719a746fd98ab07dea8d57d78", "0bd3c5a3edef493d99121f56707b32ee", "c870dea98a1e4866867b258eb33a8bac", "<KEY>", "db45ee8a22844c11938d7f75d30c40b3", "214339fd9ded4e3b9a2468f2ac94f338", "<KEY>", "5c7337eb47a549a386aaca3958aebe20", "e5eef51fdc704a47883c2c0cebb67c18", "c0b6d49771aa4d5f964ebc1d27bb38f8"]} outputId="9b9b7eef-ec7a-450a-e86b-cc2a680cd3eb"
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)
num_training_steps = num_epochs * len(training_loader)
progress_bar = tqdm(range(num_training_steps))
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
loss_fct = torch.nn.CrossEntropyLoss()
model.to(device)
accuracies:dict = {}
avg_training_loss: dict = {}
avg_validation_loss: dict = {}
validation_accuracy: dict = {}
for epoch in range(num_epochs):
accuracies[epoch] = []
training_loss = 0.0
valid_loss = 0.0
tr_accuracy = load_metric("accuracy")
model.train()
count=0
for batch in training_loader:
optimizer.zero_grad()
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = loss_fct(outputs.get('logits'), batch.get("labels"))
predictions = torch.argmax(outputs.get('logits'), dim=-1)
tr_accuracy.add_batch(predictions=predictions, references=batch["labels"])
accuracies[epoch].append( tr_accuracy.compute()['accuracy'] )
loss.backward()
optimizer.step()
training_loss+=loss.data.item()
lr_scheduler.step()
progress_bar.update(1)
count=count+1
training_loss/=len(training_loader)
avg_training_loss[epoch] = training_loss
accuracy = load_metric("accuracy")
model.eval()
for batch in validation_loader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = loss_fct(outputs.get('logits'), batch.get("labels"))
valid_loss+=loss.data.item()
predictions = torch.argmax(outputs.get('logits'), dim=-1)
accuracy.add_batch(predictions=predictions, references=batch["labels"])
valid_loss/=len(validation_loader)
avg_validation_loss[epoch] = valid_loss
validation_accuracy[epoch] = accuracy.compute()['accuracy']
print("Epoch: "+str(epoch)+", Training Loss: "+str(avg_training_loss[epoch])+", Validation Loss: "+str(avg_validation_loss[epoch])+", accuracy = "+str(validation_accuracy[epoch]))
# + id="5H65DtkXEB83"
def plot_multiple_line(points:list=None, xlabel:str=None, ylabel:str=None, title:str=None):
plt.figure()
x_axis:int = range(0, max( [len(i) for i in points] ))
for i in range(len(points)):
plt.plot(x_axis, [x for x in points[i]])
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.title(title)
# + id="9-PPZsQEHbzG"
def plot_dict(d:dict=None, xlabel:str=None, ylabel:str=None, title:str=None):
lists = sorted(d.items()) # sorted by key, return a list of tuples
x, y = zip(*lists) # unpack a list of pairs into two tuples
plt.plot(x, y)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.title(title)
# + id="YKqm7R-J5BHt" colab={"base_uri": "https://localhost:8080/", "height": 294} outputId="337b1c7a-dd61-4256-8555-941ae4303490"
plot_multiple_line(list(accuracies.values()), 'batch', 'accuracy', 'Training Accuracy vs. Batches in same epoch')
# + id="aGZMi8v59ymm" colab={"base_uri": "https://localhost:8080/", "height": 294} outputId="b738b840-3206-405f-8b2c-2982e8218d83"
plot_dict(avg_training_loss, 'epoch', 'loss', 'Training Loss vs. No. of epochs')
# + id="_2hATy45JcA5" colab={"base_uri": "https://localhost:8080/", "height": 294} outputId="4ea66ab0-f6b6-4074-852d-abc97a148f8b"
plot_dict(avg_validation_loss, 'epoch', 'loss', 'Validation Loss vs. No. of epochs')
# + id="g67OosbdJuYj" colab={"base_uri": "https://localhost:8080/", "height": 294} outputId="4a127539-4e6c-42b0-dc87-5a11ade58d27"
plot_dict(validation_accuracy, 'epoch', 'accuracy', 'Validation Accuracy vs. No. of epochs')
# + colab={"base_uri": "https://localhost:8080/"} id="kL-h0c7HSr9_" outputId="63e1296a-7034-4e5a-f934-b104e212f136"
test_accuracy = load_metric("accuracy")
avg_test_loss = 0
model.eval()
for batch in test_loader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = loss_fct(outputs.get('logits'), batch.get("labels"))
avg_test_loss+=loss.data.item()
predictions = torch.argmax(outputs.get('logits'), dim=-1)
test_accuracy.add_batch(predictions=predictions, references=batch["labels"])
avg_test_loss/=len(test_loader)
print("Test Loss: "+str(avg_test_loss)+", accuracy = "+str(test_accuracy.compute()['accuracy']))
# + id="<KEY>"
torch.save(model, model_out)
| gossip_vs_propaganda_text_classification.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import ee
import geemap
import pandas as pd
Map = geemap.Map()
def registros(cod, m2, ha):
diccionario = {}
diccionario["COMUNA"] = cod
diccionario[year + str("_m2")] = m2
diccionario[year + str("_ha")] = ha
return diccionario
df = pd.read_excel("SUBC.xlsx")
comunas = df["COD_SUBC"].unique().tolist()
startDate = ['2001-01-01', '2002-01-01', '2003-01-01', '2004-01-01', '2005-01-01', '2006-01-01', '2007-01-01', '2008-01-01', '2009-01-01', '2010-01-01', '2011-01-01', '2012-01-01', '2013-01-01', '2014-01-01', '2015-01-01', '2016-01-01', '2017-01-01', '2018-01-01', '2019-01-01', '2020-01-01']
endDate = ['2002-01-01', '2003-01-01', '2004-01-01', '2005-01-01', '2006-01-01', '2007-01-01', '2008-01-01', '2009-01-01', '2010-01-01', '2011-01-01', '2012-01-01', '2013-01-01', '2014-01-01', '2015-01-01', '2016-01-01', '2017-01-01', '2018-01-01', '2019-01-01', '2020-01-01', '2021-01-01']
for j in zip(startDate,endDate):
Fecha_inicial = str(j[0])
Fecha_final = str(j[1])
year = Fecha_inicial[:4]
# year_text_m2 = year
# year_text_ha = year
print(year)
puntos = []
for i in comunas:
studyArea = ee.FeatureCollection("users/testHector/Subsubcuencas_v2")
studyArea = studyArea.filterMetadata("COD_SUBC","equals", str(i).zfill(4))
dataset = ee.ImageCollection('MODIS/006/MCD64A1').filter(ee.Filter.date(Fecha_inicial, Fecha_final))
image = dataset.sum()
mask = image.select(0).mask().rename('mask')
area = ee.Image.pixelArea().multiply(mask).rename('area')
#sumDictionarypolygon1 = mask.addBands(area).reduceRegion({
sumDictionarypolygon1 = area.reduceRegion(
reducer = ee.Reducer.sum(),
geometry = studyArea.geometry(),
scale = 500,
maxPixels = 1e9
)
# print('sum for pol 1 mask, scale=500', sumDictionarypolygon1.values(obj))
area_m2 = sumDictionarypolygon1.getInfo()
aQuemada_m2 = float(area_m2['area'])
aQuemada_ha = float(area_m2['area']) / 10000
# print(aQuemada_m2)
# print(aQuemada_ha)
diccionario = registros(i, aQuemada_m2, aQuemada_ha)
puntos.append(diccionario.copy())
data = pd.DataFrame(puntos)
data.to_excel("subc_ha_quemada_anual/" + str(year) + ".xlsx", index=False)
| algoritmos/puntos_calor/descarga_conteoP_subc_anual.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="jVkAVV4pixpb" executionInfo={"status": "ok", "timestamp": 1629179463408, "user_tz": -330, "elapsed": 1138, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
import os
project_name = "reco-tut-mal"; branch = "main"; account = "sparsh-ai"
project_path = os.path.join('/content', project_name)
# + colab={"base_uri": "https://localhost:8080/"} id="RDSfrKdHi4C8" executionInfo={"status": "ok", "timestamp": 1629179466786, "user_tz": -330, "elapsed": 2791, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="43522c86-71f9-4f9d-990c-efa4f6169878"
if not os.path.exists(project_path):
# !cp /content/drive/MyDrive/mykeys.py /content
import mykeys
# !rm /content/mykeys.py
path = "/content/" + project_name;
# !mkdir "{path}"
# %cd "{path}"
import sys; sys.path.append(path)
# !git config --global user.email "<EMAIL>"
# !git config --global user.name "reco-tut"
# !git init
# !git remote add origin https://"{mykeys.git_token}":x-oauth-basic@github.com/"{account}"/"{project_name}".git
# !git pull origin "{branch}"
# !git checkout main
else:
# %cd "{project_path}"
# + id="22P-ZOjbi4C_" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1629180306723, "user_tz": -330, "elapsed": 12, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="df49eaa1-b340-4777-c6c5-399b29a61edb"
# !git status
# + id="9LDKaBYRi4DA" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1629180317294, "user_tz": -330, "elapsed": 838, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="5f3e68f9-79a5-49a7-89f5-9505a2d8447b"
# !git add . && git commit -m 'commit' && git push origin "{branch}"
# + [markdown] id="0cMqCJXmltX9"
# ---
# + id="5iqk_gJnmDZp" executionInfo={"status": "ok", "timestamp": 1629179379601, "user_tz": -330, "elapsed": 4, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
from bs4 import BeautifulSoup as bs
import requests
from IPython.display import clear_output
import pandas as pd
import numpy as np
import csv
# + [markdown] id="uikBmz8JpCTA"
# ## Scraping the List
# + [markdown] id="Kytxt5b0mDZt"
# ### Preparing the recipe
# + id="9fem73Z9mDZv" executionInfo={"status": "ok", "timestamp": 1629178468704, "user_tz": -330, "elapsed": 1309, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
#Loading the webpage with anime list using 'request' library
r = requests.get("https://myanimelist.net/topanime.php")
#reading the content with bautiful soup library
soup = bs(r.content)
contents = soup.prettify()
#find the table with anime titles in html sript and narrowing down elements to scrape
table = soup.find(class_="top-ranking-table")
title_rows = table.find_all("h3")
# + id="sBcs1jEZmDZ0" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1629178507299, "user_tz": -330, "elapsed": 493, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="16fdaead-eb68-44e3-f57d-85235b32a120"
print(title_rows[0].prettify())
print(title_rows[1].prettify())
# + id="EHjNb3DTmDZ1" executionInfo={"status": "ok", "timestamp": 1629178623071, "user_tz": -330, "elapsed": 521, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
#storing all titles and the web page links for the titles of first page
anime_list=[]
for row in title_rows:
anime_link=[]
anime_link.append(row.find("a").get_text())
anime_link.append(row.a['href'])
anime_list.append(anime_link)
# + colab={"base_uri": "https://localhost:8080/"} id="mTi4HbyrnPk-" executionInfo={"status": "ok", "timestamp": 1629178630464, "user_tz": -330, "elapsed": 467, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="9b7d5f28-ea9f-4773-abbb-a81186f813ab"
anime_list[0]
# + [markdown] id="G9WmkwoFpIKa"
# ### Full scraping
# + id="37-cnaY2mDZ9" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1629179344279, "user_tz": -330, "elapsed": 553808, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="dc8304e3-6492-4c77-e11c-01453dc9ccb2"
anime_list1=[]
#each webpage has 50 titles and total 18349 titles were present running the loop to scrape info of all anime titles
for i in range(0,18301,50):
r1=requests.get("https://myanimelist.net/topanime.php?limit="+str(i))
table1=(bs(r1.content)).find_all("h3")
clear_output(wait=True)
print("current progress:",i)
for row in table1:
anime_link=[]
anime_link.append(row.find("a").get_text())
anime_link.append(row.a['href'])
anime_list1.append(anime_link)
# + id="Qcayg_WZmDaC" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1629179354274, "user_tz": -330, "elapsed": 459, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="4445584f-38ac-4c35-e973-15e909814b98"
len(anime_list1)
# + id="ZJDzSfd_mDaJ" colab={"base_uri": "https://localhost:8080/", "height": 204} executionInfo={"status": "ok", "timestamp": 1629179384052, "user_tz": -330, "elapsed": 15, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="d7bdf643-cc73-4c25-d06e-ba0e29d6c6e6"
df = pd.DataFrame(anime_list1)
df.head()
# + id="reBdrELLmDaM" colab={"base_uri": "https://localhost:8080/", "height": 204} executionInfo={"status": "ok", "timestamp": 1629179440493, "user_tz": -330, "elapsed": 599, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="cc7b50c7-0b22-4cbf-874e-eafef795561a"
index_names = df[df[0]=="More"].index
df.drop(index_names,inplace=True)
df.reset_index(drop=True, inplace=True)
df.head()
# + id="z-Lt3aS9mDaO" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1629179447416, "user_tz": -330, "elapsed": 447, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="aeb3e262-7402-4f0d-d67c-a951e040cea9"
df.info()
# + id="yt41j-sXmDaN" executionInfo={"status": "ok", "timestamp": 1629179953988, "user_tz": -330, "elapsed": 456, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
df.to_csv('./data/bronze/anime_list.csv', index=None, header=False)
# + [markdown] id="joFHsQHFpLfv"
# ## Scraping the Info
# + [markdown] id="zr5m6Cg3pVtw"
# ### Preparing the recipe
# + id="P1gbsjrZpMpZ" executionInfo={"status": "ok", "timestamp": 1629179717487, "user_tz": -330, "elapsed": 1486, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
#loading the web page with request library
r = requests.get("https://myanimelist.net/anime/5114/Fullmetal_Alchemist__Brotherhood")
soup = bs(r.content)
#all the information required was there in class=borderClass (found with inspect element in web page)
AnimeDetails = soup.find(class_="borderClass")
# + id="8o5d_uP0pvgs" executionInfo={"status": "ok", "timestamp": 1629179722944, "user_tz": -330, "elapsed": 487, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
#all required informaiton was under different 'div' elements
AnimeInfo=[]
for index,i in enumerate(AnimeDetails.findAll('div')):
if index>=6:
content_value=i.get_text()
AnimeInfo.append(content_value)
#cleaning the data and removing unwanted formats and elements
details=[]
for i in range(0 , len(AnimeInfo)):
AnimeInfo[i]= AnimeInfo[i].replace('\n','')
details.append(AnimeInfo[i].split(':',1))
details.append(['Title','Fullmetal Alchemist: Brotherhood'])
# + id="PNbWFCegpxdJ" executionInfo={"status": "ok", "timestamp": 1629179959180, "user_tz": -330, "elapsed": 706, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}}
#getting the info of all the titles and web page links that were scrapped in last file
with open('./data/bronze/anime_list.csv', newline='', encoding="utf8") as f:
reader = csv.reader(f)
data = list(reader)
# + [markdown] id="NB6XYChdrqnt"
# ### Full scraping
# + colab={"base_uri": "https://localhost:8080/"} id="H8poD9y7sIBz" executionInfo={"status": "ok", "timestamp": 1629179964425, "user_tz": -330, "elapsed": 535, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="40127336-1698-4433-a81c-cfc8a0308125"
data[0]
# + colab={"base_uri": "https://localhost:8080/"} id="NBLwpTDar0f5" executionInfo={"status": "ok", "timestamp": 1629180208476, "user_tz": -330, "elapsed": 28905, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="0b67e193-fbaa-4bca-fb49-36ec13612fe2"
#total 18,349 titles were present in the website
anime = pd.DataFrame()
for j in range(0,18349):
df1=pd.DataFrame()
url=data[j][1]
r=requests.get(url)
soup=bs(r.content)
AnimeDetails=soup.find(class_="borderClass")
AnimeInfo=[]
if j%10==0:
clear_output(wait=True)
print("current progress:",j)
for index,i in enumerate(AnimeDetails.findAll('div')):
if index>=6:
content_value=i.get_text()
AnimeInfo.append(content_value)
details=[]
for k in range(0 , len(AnimeInfo)):
AnimeInfo[k]= AnimeInfo[k].replace('\n','')
details.append(AnimeInfo[k].split(':',1))
title=[]
title.append("Title")
title.append(data[j][0])
details.append(title)
df1=pd.DataFrame(details)
df1=df1.set_index(0)
df1=df1.transpose()
df1.dropna(axis=1,inplace=True)
frames=[anime,df1]
anime=pd.concat(frames)
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} id="D2K49AUftQKj" executionInfo={"status": "ok", "timestamp": 1629180728465, "user_tz": -330, "elapsed": 828, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13037694610922482904"}} outputId="bc58ab0f-1287-444f-9714-05db9688abe7"
anime.head(10)
# + id="xpwQu1eJsCp7"
# Saving the data as csv file
anime.to_csv('./data/bronze/anime_data.csv', compression='gzip')
| _docs/nbs/reco-tut-mal-t1-01-data-extraction.ipynb |
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Q#
# language: qsharp
# name: iqsharp
# ---
# # Superposition Kata Workbook
#
# **What is this workbook?**
# A workbook is a collection of problems, accompanied by solutions to them.
# The explanations focus on the logical steps required to solve a problem; they illustrate the concepts that need to be applied to come up with a solution to the problem, explaining the mathematical steps required.
#
# Note that a workbook should not be the primary source of knowledge on the subject matter; it assumes that you've already read a tutorial or a textbook and that you are now seeking to improve your problem-solving skills. You should attempt solving the tasks of the respective kata first, and turn to the workbook only if stuck. While a textbook emphasizes knowledge acquisition, a workbook emphasizes skill acquisition.
#
# This workbook describes the solutions to the problems offered in the [Superposition kata](./Superposition.ipynb).
# Since the tasks are offered as programming problems, the explanations also cover some elements of Q# that might be non-obvious for a first-time user.
#
# **What you should know for this workbook**
#
# You should be familiar with the following concepts before tackling the Superposition kata (and this workbook):
# 1. Basic linear algebra
# 2. The concept of qubit and multi-qubit systems
# 3. Single-qubit and multi-qubit quantum gates
# To begin, first prepare this notebook for execution (if you skip this step, you'll get "Syntax does not match any known patterns" error when you try to execute Q# code in the next cells):
%package Microsoft.Quantum.Katas::0.12.20070124
# > The package versions in the output of the cell above should always match. If you are running the Notebooks locally and the versions do not match, please install the IQ# version that matches the version of the `Microsoft.Quantum.Katas` package.
# > <details>
# > <summary><u>How to install the right IQ# version</u></summary>
# > For example, if the version of `Microsoft.Quantum.Katas` package above is 0.1.2.3, the installation steps are as follows:
# >
# > 1. Stop the kernel.
# > 2. Uninstall the existing version of IQ#:
# > dotnet tool uninstall microsoft.quantum.iqsharp -g
# > 3. Install the matching version:
# > dotnet tool install microsoft.quantum.iqsharp -g --version 0.1.2.3
# > 4. Reinstall the kernel:
# > dotnet iqsharp install
# > 5. Restart the Notebook.
# > </details>
#
# ## <a name="plus-state"></a> Task 1.1. Plus state.
#
# **Input:** A qubit in the $|0\rangle$ state.
#
# **Goal:** Change the state of the qubit to $|+\rangle = \frac{1}{\sqrt{2}} \big(|0\rangle + |1\rangle\big)$.
# ### Solution
#
# Look up any list of quantum gates, for example, [Quantum logic gate @ Wikipedia](https://en.wikipedia.org/wiki/Quantum_gate). Typically one of the first gates described will be the [Hadamard gate](https://en.wikipedia.org/wiki/Quantum_logic_gate#Hadamard_(H)_gate):
#
# $$H = \frac{1}{\sqrt2} \begin{bmatrix} 1 & 1 \\ 1 & -1 \end{bmatrix}$$
#
# This gate converts $|0\rangle$ into $|+\rangle = \frac{1}{\sqrt{2}} \big(|0\rangle + |1\rangle\big)$ and $|1\rangle$ into $|−\rangle = \frac{1}{\sqrt{2}} \big(|0\rangle - |1\rangle\big)$. The first of these transformations is exactly the one we're looking for!
#
# To implement this operation in Q#, look at the list of [intrinsic gates](https://docs.microsoft.com/qsharp/api/qsharp/microsoft.quantum.intrinsic) available in Q#.
# [Hadamard gate](https://docs.microsoft.com/en-us/qsharp/api/qsharp/microsoft.quantum.intrinsic.h) is one of them.
# `Microsoft.Quantum.Intrinsic` namespace is open in Notebooks by default, so you can use the gates in the code right away.
# +
%kata T101_PlusState_Test
operation PlusState (q : Qubit) : Unit {
H(q);
}
# -
# [Return to task 1.1 of the Superposition kata.](./Superposition.ipynb#plus-state)
# ## <a name="minus-state"></a> Task 1.2. Minus State.
#
# **Input:** A qubit in the $|0\rangle$ state.
#
# **Goal:** Change the state of the qubit to $|-\rangle = \frac{1}{\sqrt{2}} \big(|0\rangle - |1\rangle\big)$.
# ### Solution
#
# As we've seen in the previous task, the Hadamard gate maps the basis state $|0\rangle$ to $\frac{1}{\sqrt2}\big(|0\rangle + |1\rangle\big)$ and $|1\rangle$ to $\frac{1}{\sqrt2}\big(|0\rangle - |1\rangle\big)$.
# If our qubit was already in the $|1\rangle$ state, we would simply apply the Hadamard gate to prepare the required $|-\rangle$ state.
# However, there is another operation we can use to change the state $|0\rangle$ to $|1\rangle$, namely the [X gate](https://en.wikipedia.org/wiki/Quantum_logic_gate#Pauli-X_gate):
#
# $$X = \begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix}$$
#
# This gate transforms $|0\rangle \longmapsto |1\rangle$ and $|1\rangle \longmapsto |0\rangle$.
#
# Here is the sequence of the steps to arrive to the solution:
#
# <table style="background-color: white; border:1px solid; tr { background-color:transparent; }">
# <col width=400>
# <col width=300>
# <col width=300>
# <tr>
# <th style="text-align:center; border:1px solid">Description of operation</th>
# <th style="text-align:center; border:1px solid">Notation</th>
# <th style="text-align:center; border:1px solid">Circuit</th>
# </tr>
# <tr>
# <td style="text-align:left; border:1px solid">Apply the X gate to $|0\rangle$ to get $|1\rangle$</td>
# <td style="text-align:center; border:1px solid">$X|0\rangle = |1\rangle$</td>
# <td style="text-align:center; border:1px solid"><img src="./img/testcircuit.png"/></td>
# </tr>
# <tr>
# <td style="text-align:left; border:1px solid">Apply the Hadamard gate to $|1\rangle$ to get $\frac{1}{\sqrt2}\big(|0\rangle - |1\rangle\big)$</td>
# <td style="text-align:center; border:1px solid">$H|1\rangle = \frac{1}{\sqrt2}\big(|0\rangle - |1\rangle\big)$</td>
# <td style="text-align:center; border:1px solid"><img src="./img/singlehadamard.png"/></td>
# </tr>
# </table>
#
# In Q#, each gate is applied to the qubit sequentially, transforming its internal state. [X gate](https://docs.microsoft.com/en-us/qsharp/api/qsharp/microsoft.quantum.intrinsic.x) is another gate in the `Microsoft.Quantum.Intrinsic` namespace.
# +
%kata T102_MinusState_Test
operation MinusState (q : Qubit) : Unit {
X(q);
H(q);
}
# -
# [Return to task 1.2 of the Superposition kata.](./Superposition.ipynb#minus-state)
# ## <a name="superposition-of-all-basis-vectors-on-two-qubits"></a>Task 1.3. Superposition of all basis vectors on two qubits.
#
# **Input:** Two qubits in the $|00\rangle$ state (stored in an array of length 2).
#
# **Goal:** Change the state of the qubits to $|+\rangle \otimes |+\rangle = \frac{1}{2} \big(|00\rangle + |01\rangle + |10\rangle + |11\rangle\big)$.
# ### Solution
#
# We know that the Hadamard gate maps the basis state $|0\rangle$ to $\frac{1}{\sqrt2}(|0\rangle + |1\rangle)$, so it is a logical starting point for solving this problem.
#
# Next, we see that the final state has a $\frac{1}{2}$ term hinting that we might be applying two operations involving a $\frac{1}{\sqrt{2}}$ term.
#
# Now, how do we get the $|00\rangle + |01\rangle + |10\rangle + |11\rangle$ expression? Let's see what does multiplying the expression $|0\rangle + |1\rangle$ by itself look like:
#
# $$\big(|0\rangle + |1\rangle\big) \otimes \big(|0\rangle + |1\rangle\big) = |0\rangle|0\rangle + |0\rangle|1\rangle + |1\rangle|0\rangle + |1\rangle|1\rangle = \\
# = |00\rangle + |01\rangle + |10\rangle + |11\rangle$$
#
# Thus, applying the Hadamard gate to each qubit in isolation will deliver the desired final result:
#
# $$H|0\rangle \otimes H|0\rangle = \frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big) \otimes \frac{1}{\sqrt2}\big(|0\rangle + |1\rangle\big) = \\
# = \frac{1}{2} (|00\rangle + |01\rangle + |10\rangle + |11\rangle)$$
#
# Q# arrays are similar to arrays in other languages: you can access the $i$-th element of the array `qs` as `qs[i]` (indices are 0-based).
# +
%kata T103_AllBasisVectors_TwoQubits_Test
operation AllBasisVectors_TwoQubits (qs : Qubit[]) : Unit {
H(qs[0]);
H(qs[1]);
}
# -
# [Return to task 1.3 of the Superposition kata.](./Superposition.ipynb#superposition-of-all-basis-vectors-on-two-qubits)
# ### <a name="superposition-of-basis-vectors-with-phase-flip"></a>Task 1.4. Superposition of basis vectors with phase flip.
#
# **Input:** Two qubits in the $|00\rangle$ sate (stored in an array of length 2).
#
# **Goal:** Change the state of the qubits to $\frac{1}{2}\big(|00\rangle+|01\rangle+|10\rangle-|11\rangle \big)$.
# ### Solution
#
# Here we start with the end state of the previous task $\frac{1}{2} \big(|00\rangle + |01\rangle + |10\rangle + |11\rangle\big)$. Looking at the desired state, the phase of the $|11\rangle$ state is flipped ($+$ changed to a $-$).
#
# A regular phase flip on one qubit can be done using a [Z gate](../tutorials/SingleQubitGates/SingleQubitGates.ipynb#Pauli-Gates):
# $$\begin{bmatrix} 1 & 0 \\ 0 & -1 \end{bmatrix}$$
# This gate will perform a phase flip only on the $|1\rangle$ state:
#
# $$Z(\alpha|0\rangle + \beta|1\rangle) = \alpha|0\rangle - \beta|1\rangle$$
#
# In our case we only want to flip the phase of the $|11\rangle$ state and not the $|01\rangle$ state. To accomplish this, we can use a controlled Z gate; this will make sure that the $Z$ gate is only applied if the control bit is in the $|1\rangle$ state, and the $|01\rangle$ state will not change.
#
# > In Q# we can apply a controlled gate by using the `Controlled` keyword before the gate. The controlled gate will take two parameters; the first parameter is an array of control qubits (you can have multiple qubits used as a control), and the second parameter is a tuple of parameters passed to the original gate (in this case it's just the qubit to which you want to apply the gate if the control bit is $|1\rangle$).
# +
%kata T104_AllBasisVectorWithPhaseFlip_TwoQubits_Test
operation AllBasisVectorWithPhaseFlip_TwoQubits (qs : Qubit[]) : Unit {
AllBasisVectors_TwoQubits(qs);
Controlled Z ([qs[0]], qs[1]);
}
# -
# [Return to task 4 of the Superposition kata.](./Superposition.ipynb#superposition-of-basis-vectors-with-phase-flip)
# ## <a name="superposition-of-basis-vectors-with-phases"></a>Task 1.5. Superposition of basis vectors with phases.
#
# **Input:** Two qubits in the $|00\rangle$ state (stored in an array of length 2).
#
# **Goal:** Change the state of the qubits to $\frac{1}{2} \big(|00\rangle + i|01\rangle - |10\rangle - i|11\rangle\big)$.
# ### Solution
#
# We will start approaching the problem from the desired end result. Let’s see if we can factor any expressions out of $\big(|00\rangle + i|01\rangle - |10\rangle - i|11\rangle\big)$:
#
# \begin{equation}
# |00\rangle + i|01\rangle - |10\rangle - i|11\rangle
# = |00\rangle + \big(|0\rangle - |1\rangle\big) i|1\rangle - |10\rangle = \\
# = \big(|0\rangle - |1\rangle\big) |0\rangle + \big(|0\rangle - |1\rangle\big) i|1\rangle
# = \big(|0\rangle - |1\rangle\big) \otimes \big(|0\rangle + i|1\rangle\big)
# \label{5.1} \tag{5.1}
# \end{equation}
#
# The fact that we were able to factor out the state into a tensor product of two terms means the state is separable.
#
# This is looking promising. Now let’s try to approach the problem from the other end, i.e. from the starting state of $|00\rangle$.
# As we've seen in the previous task, applying a Hadamard operation to each $|0\rangle$ gets us closer to the factored-out expression:
#
# \begin{equation}
# H|0\rangle \otimes H|0\rangle = \frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big) \otimes \frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big)
# =\frac{1}{2} \big(|0\rangle + |1\rangle\big) \otimes \big(|0\rangle + |1\rangle\big)
# \label{5.2} \tag{5.2}
# \end{equation}
#
# If we compare equations 5.1 and 5.2 (while ignoring the $\frac{1}{2}$ term in equation 5.2), we end up with the following transformations that we need to perform on the individual qubits:
#
# \begin{equation}
# |0\rangle + |1\rangle \overset{???}\rightarrow |0\rangle - |1\rangle
# \label{5.3} \tag{5.3}
# \end{equation}
#
# \begin{equation}
# |0\rangle + |1\rangle \overset{???}\rightarrow |0\rangle + i|1\rangle
# \label{5.4} \tag{5.4}
# \end{equation}
#
#
# Next lets take a look at our basic gates, in particular the <a href="https://en.wikipedia.org/wiki/Quantum_logic_gate#Pauli-Z_(%7F'%22%60UNIQ--postMath-00000021-QINU%60%22'%7F)_gate">Pauli Z gate</a>:
#
# $$Z = \begin{bmatrix} 1 & 0 \\ 0 & -1 \end{bmatrix}$$
#
# If it is applied to the state $\frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big)$, it will leave the basis state $|0\rangle$ unchanged and will map $|1\rangle$ to $-|1\rangle$. Thus,
#
# $$Z\frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big) = \frac{1}{\sqrt2} \big(|0\rangle - |1\rangle\big)$$
#
# So the Z gate is the answers to the question of how to do the conversion 5.3.
#
# Looking for another gate to address the conversion 5.4, we find the <a href="https://docs.microsoft.com/en-us/qsharp/api/qsharp/microsoft.quantum.intrinsic.s">S gate</a>:
#
# $$S = \begin{bmatrix} 1 & 0 \\ 0 & i \end{bmatrix}$$
#
# If it is applied to the state $\frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big)$, it will leave the basis state $|0\rangle$ unchanged and will map $|1\rangle$ to $i|1\rangle$. Thus,
#
# $$S\frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big) = \frac{1}{\sqrt2} \big(|0\rangle + i|1\rangle\big)$$
#
# So the S gate now answers the question of how to do the conversion 5.4.
#
# To summarize, the state we need to prepare can be represented as follows:
# $$ZH|0\rangle \otimes SH|0\rangle$$
#
# Remember that in Q# the gates have to be applied in reverse order compared to the mathematical notation - the gate closest to the ket symbol is applied first.
# +
%kata T105_AllBasisVectorsWithPhases_TwoQubits_Test
operation AllBasisVectorsWithPhases_TwoQubits (qs : Qubit[]) : Unit {
H(qs[0]);
Z(qs[0]);
H(qs[1]);
S(qs[1]);
}
# -
# [Return to task 1.5 of the Superposition kata.](./Superposition.ipynb#superposition-of-basis-vectors-with-phases)
# ## <a name="bell-state"></a> Task 1.6. Bell state $|\Phi^{+}\rangle$.
#
# **Input:** Two qubits in the $|00\rangle$ state (stored in an array of length 2).
#
# **Goal:** Change the state of the qubits to $|\Phi^{+}\rangle = \frac{1}{\sqrt{2}} \big (|00\rangle + |11\rangle\big)$.
# ### Solution
#
# The first thing we notice is that, unlike in the previous task, we cannot represent this state as a tensor product of two individual qubit states - this goal state is NOT separable.
#
# > How can we see this? Let's assume that this state can be represented as a tensor product of two qubit states:
# >
# > $$|\psi_1\rangle \otimes |\psi_2\rangle = (\alpha_1|0\rangle + \beta_1|1\rangle) \otimes (\alpha_2|0\rangle + \beta_2|1\rangle) = \alpha_1\alpha_2|00\rangle + \alpha_1\beta_2|01\rangle + \beta_1\alpha_2|10\rangle + \beta_1\beta_2|11\rangle$$
# >
# >In order for this state to be equal to $\frac{1}{\sqrt2}\big(|00\rangle + |11\rangle\big)$, we need to have $\alpha_1\alpha_2 = \beta_1\beta_2 = \frac{1}{\sqrt2}$ and at the same time $\alpha_1\beta_2 = \beta_1\alpha_2 = 0$, which is impossible.
# >
# >This is the first time we encounter the phenomena called **entanglement**, in which the states of the qubits are linked together and can not be considered individually.
#
# Let's see what steps we can take to prepare this state without factoring it into states of individual qubits.
#
# ---
#
# First, we notice that we should end with a superposition of two of the four computational basis for two qubits: $|00\rangle, |01\rangle, |10\rangle, |11\rangle$.
#
# This gives us a hint that we should start by preparing a superposition on at least one of the qubits. Let’s try creating a superposition on the first qubit with a Hadamard gate:
#
# $$H|0\rangle \otimes |0\rangle = \frac{1}{\sqrt2} (|0\rangle + |1\rangle) \otimes |0\rangle = \frac{1}{\sqrt2} (|00\rangle + |10\rangle)$$
#
# Well, we got pretty close, except we need to transform the $|10\rangle$ state to $|11\rangle$.
# How can we do this?
#
# We can take advantage of controlled gates, specifically the [controlled NOT gate](https://en.wikipedia.org/wiki/Controlled_NOT_gate), also referred to as CNOT. This gate acts on two qubits, hence it is represented as a $4 \times 4$ unitary matrix. The CNOT gate changes the target qubit from state $|0\rangle$ to $|1\rangle$ and vice versa when the control qubit is $|1\rangle$ and does nothing to the target qubit when the control qubit is $|0\rangle$. The control qubit always remains unchanged.
# <table style="background-color: white; border:1px solid; tr { background-color:transparent; }">
# <col width=300>
# <col width=300>
# <tr>
# <th style="text-align:center; border:1px solid">Matrix</th>
# <th style="text-align:center; border:1px solid">Circuit</th>
# </tr>
# <tr>
# <td style="text-align:center; border:1px solid">$\text{CNOT} = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{bmatrix}$</td>
# <td style="text-align:center; border:1px solid"><img src="./img/CNOTGateCircuit.png"/></td>
# </tr>
# </table> <br>
# <center>The matrix and circuit representation of CNOT</center><br>
#
# If we apply the CNOT gate to the state $\frac{1}{\sqrt2} (|00\rangle + |10\rangle)$, taking the first qubit as the control and the second one as target, we'll get exactly the desired goal state.
# <img src="./img/Task6OutputHadamardasControl.png" width="200"/>
#
# <table style="background-color: white; border:1px solid; tr { background-color:transparent; }">
# <col width=500>
# <col width=300>
# <col width=300>
# <tr>
# <th style="text-align:center; border:1px solid">Steps required to reach goal state</th>
# <th style="text-align:center; border:1px solid">Notation</th>
# <th style="text-align:center; border:1px solid">Circuit</th>
# </tr>
# <tr>
# <td style="text-align:left; border:1px solid">1. Apply a Hadamard gate to the first qubit. <br/> 2. Applying a CNOT with first qubit as control and second qubit as target.</td>
# <td style="text-align:center; border:1px solid; font-bold; font-size: 16px; ">$\frac{1}{\sqrt2} (|00\rangle + |11\rangle)$</td>
# <td style="text-align:center; border:1px solid"><img src="./img/Task6HadamardCNOTCircuit.png"/></td>
# </tr>
# </table>
#
# In matrix representation we can represent this operation as a product of two $4 \times 4$ matrices, with the matrix corresponding to the first step being the tensor product of a Hadamard gate on the first qubit and identity gate on the second qubit.
#
# $$H \otimes I = \frac{1}{\sqrt2} \begin{bmatrix} 1 & 1 \\ 1 & -1 \end{bmatrix} \otimes \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} =
# \frac{1}{\sqrt2}\begin{bmatrix} 1 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 \\ 1 & 0 & -1 & 0 \\ 0 & 1 & 0 & -1 \end{bmatrix}$$
#
# $$\underset{\text{CNOT}}{\underbrace{\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{bmatrix}}}
# \cdot
# \underset{H \otimes I}{\underbrace{\frac{1}{\sqrt2} \begin{bmatrix} 1 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 \\ 1 & 0 & -1 & 0 \\ 0 & 1 & 0 & -1 \end{bmatrix}}}
# \cdot
# \underset{|0\rangle}{\underbrace{ \begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \end{bmatrix}}}
# = \frac{1}{\sqrt2} \begin{bmatrix} 1 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 \\ 0 & 1 & 0 & -1 \\ 1 & 0 & -1 & 0 \end{bmatrix}
# \cdot
# \begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \end{bmatrix}
# = \underset{goal}{\underbrace{ \frac{1}{\sqrt2} \begin{bmatrix} 1 \\ 0 \\ 0 \\ 1 \end{bmatrix}}}
# \label{6.1} \tag{6.1}
# $$
#
# Note that in the matrix representation and in Dirac notation the gates are applied from right to left (the rightmost operation happens firts), while in circuit notation the operations are applied from left to right (the leftmost operation happens first).
# +
%kata T106_BellState_Test
operation BellState (qs : Qubit[]) : Unit {
H(qs[0]);
CNOT(qs[0], qs[1]);
}
# -
# [Return to task 1.6 of the Superposition kata.](./Superposition.ipynb#bell-state)
# ## <a name="all-bell-states"></a> Task 1.7. All Bell states.
#
# **Inputs:**
#
# 1. Two qubits in the $|00\rangle$ state (stored in an array of length 2).
# 2. An integer `index`.
#
# **Goal:** Change the state of the qubits to one of the Bell states, based on the value of index:
#
# <table>
# <col width="50"/>
# <col width="200"/>
# <tr>
# <th style="text-align:center">Index</th>
# <th style="text-align:center">State</th>
# </tr>
# <tr>
# <td style="text-align:center">0</td>
# <td style="text-align:center">$|\Phi^{+}\rangle = \frac{1}{\sqrt{2}} \big (|00\rangle + |11\rangle\big)$</td>
# </tr>
# <tr>
# <td style="text-align:center">1</td>
# <td style="text-align:center">$|\Phi^{-}\rangle = \frac{1}{\sqrt{2}} \big (|00\rangle - |11\rangle\big)$</td>
# </tr>
# <tr>
# <td style="text-align:center">2</td>
# <td style="text-align:center">$|\Psi^{+}\rangle = \frac{1}{\sqrt{2}} \big (|01\rangle + |10\rangle\big)$</td>
# </tr>
# <tr>
# <td style="text-align:center">3</td>
# <td style="text-align:center">$|\Psi^{-}\rangle = \frac{1}{\sqrt{2}} \big (|01\rangle - |10\rangle\big)$</td>
# </tr>
# </table>
# ### Solutions
#
# > The [Bell states](https://en.wikipedia.org/wiki/Bell_state) form an orthonormal basis in the 4-dimensional space that describes the states of a 2-qubit system.
# You can check that the norm of each of these states is 1, and their inner product of each pair of states is 0.
#
# The goal is to transform the $|00\rangle$ basis state into one of the Bell basis states, depending on the value of `index` given as an input.
#
# We will describe two solutions, one of which will be based on the previous task, and the second one will help us understand the unitary transformation that converts the computational basis into the Bell basis.
#
# #### Solution 1
#
# Let's use the first Bell state we prepared in the previous task and transform it according to the value of `index`.
#
# <table>
# <col width=300>
# <col width=50>
# <col width=300>
# <tr bgcolor="white">
# <td bgcolor="white" style="text-align:center"><img src="./img/Task6HadamardCNOTCircuit.png"/></td>
# <td bgcolor="white" style="text-align:center;font-size: 30px">$\Longrightarrow$</td>
# <td bgcolor="white" style="text-align:center;font-size: 20px">$\frac{1}{\sqrt2} \big(|00\rangle + |11\rangle\big)$</td>
# </tr>
# </table>
#
# What transformation do we need to apply to get to the final state?
#
# * If `index = 0`, we do nothing - the prepared state is already $|\Phi^{+}\rangle$.
#
# * If `index = 1`, we need to add a relative phase of $-1$ to the $|11\rangle$ term. Remember that Z gate does exactly that with a qubit:
#
# $$Z(H|0\rangle) \otimes |0\rangle = \frac{1}{\sqrt2} \big(|0\rangle - |1\rangle\big) \otimes |0\rangle = \frac{1}{\sqrt2} \big(|00\rangle - |10\rangle\big)$$
#
# If we now apply the CNOT as before, we will have:
#
# $$\frac{1}{\sqrt2} \big(|00\rangle - |\overset{\curvearrowright}{10}\rangle\big) \underset{\text{CNOT}}{\Longrightarrow} \frac{1}{\sqrt2} \big(|00\rangle - |11\rangle\big) = |\Phi^{-}\rangle$$
#
# * If `index = 2`, we need to change the second qubit in both $|00\rangle$ and $|11\rangle$ terms, which can be done applying an X gate:
#
# $$H|0\rangle \otimes X|0\rangle = H|0\rangle \otimes |1\rangle = \frac{1}{\sqrt2} \big(|0\rangle + |1\rangle\big) \otimes |1\rangle = \frac{1}{\sqrt2} \big(|01\rangle + |11\rangle\big)$$
#
# If we now apply the CNOT as before, we will have:
#
# $$\frac{1}{\sqrt2} \big(|01\rangle + |\overset{\curvearrowright}{11}\rangle\big) \underset{\text{CNOT}}{\Longrightarrow} \frac{1}{\sqrt2} \big(|01\rangle + |10\rangle\big) = |\Psi^{+}\rangle$$
#
# * If `index = 3`, we use the same logic to realize that we need to apply both the Z and X corrections to get $|\Psi^{-}\rangle$ state.
#
# The final sequence of steps is as follows:
# 1. Apply the H gate to the first qubit.
# 2. Apply the Z gate to the first qubit if `index = 1` or `index == 3`.
# 3. Apply the X gate to the second qubit if `index = 2` or `index == 3`.
# 4. Apply the CNOT gate with the first qubit as control and the second qubit as target.
#
# <table style="background-color: white; border:1px solid; tr { background-color:transparent; }">
# <col width=200>
# <col width=200>
# <tr>
# <th style="text-align:center; border:1px solid">Index 0</th>
# <th style="text-align:center; border:1px solid">Index 1</th>
# </tr>
# <tr>
# <td style="text-align:center; border:1px solid"><img src="./img/Task7.Index0.png"/></td>
# <td style="text-align:center; border:1px solid"><img src="./img/Task7.Index1.png"/></td>
# </tr>
# <tr>
# <th style="text-align:center; border:1px solid">Index 2</th>
# <th style="text-align:center; border:1px solid">Index 3</th>
# </tr>
# <tr>
# <td style="text-align:center; border:1px solid"><img src="./img/Task7.Index2.png"/></td>
# <td style="text-align:center; border:1px solid"><img src="./img/Task7.Index3.png"/></td>
# </tr>
# </table>
# <center>Circuits to be applied to prepare the four Bell States</center>
# +
%kata T107_AllBellStates_Test
operation AllBellStates (qs : Qubit[], index : Int) : Unit {
H(qs[0]);
if (index == 1) {
Z(qs[0]);
}
if (index == 2) {
X(qs[1]);
}
if (index == 3) {
Z(qs[0]);
X(qs[1]);
}
CNOT(qs[0], qs[1]);
}
# -
# #### Solution 2
#
# Let's take a closer look at the unitary transformation $\text{CNOT}\cdot(H \otimes I)$ discussed in task 6 (see equation 6.1).
#
# <table>
# <col width=300>
# <col width=50>
# <col width=300>
# <tr bgcolor="white">
# <td bgcolor="#FFFFFF" style="text-align:center"><img src="./img/Task6HadamardCNOTCircuit.PNG"/></td>
# <td bgcolor="#FFFFFF" style="text-align:center;font-size: 30px">$\Leftrightarrow$</td>
# <td bgcolor="#FFFFFF" style="text-align:center;font-size: 20px">$\frac{1}{\sqrt2} \begin{bmatrix} 1 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 \\ 0 & 1 & 0 & -1 \\ \underset{|\Phi^{+}\rangle}{\underbrace{1}} & \underset{|\Psi^{+}\rangle}{\underbrace{0}} & \underset{|\Phi^{-}\rangle}{\underbrace{-1}} & \underset{|\Psi^{-}\rangle}{\underbrace{0}} \end{bmatrix}$</td>
# </tr>
# </table>
#
# Notice that each of the columns in the unitary matrix corresponds to one of the Bell States.
# This unitary transformation transforms the computational basis into the Bell basis, which is exactly what the task asks us to do.
#
# We see that this transformation converts $|00\rangle$ into the first Bell state, $|01\rangle$ into the second Bell state, etc.
# We just need to make sure we set the qubits to the correct state before applying this transformation, using X gates to change the initial $|0\rangle$ states to $|1\rangle$ if needed.
#
# In Q#, we can use the <a href="https://docs.microsoft.com/en-us/qsharp/api/qsharp/microsoft.quantum.convert.intasboolarray">IntAsBoolArray</a> function to convert the input `index` to the right bit pattern.
# +
%kata T107_AllBellStates_Test
open Microsoft.Quantum.Convert;
operation AllBellStates (qs : Qubit[], index : Int) : Unit {
let bitmask = IntAsBoolArray(index, 2);
if (bitmask[0]) {
X(qs[0]);
}
if (bitmask[1]) {
X(qs[1]);
}
H(qs[0]);
CNOT(qs[0], qs[1]);
}
# -
# [Return to task 1.7 of the Superposition kata.](./Superposition.ipynb#all-bell-states)
# The solutions to the rest of the tasks are included in the [Superposition Kata Workbook, Part 2](./Workbook_Superposition_Part2.ipynb).
| Superposition/Workbook_Superposition.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.8 64-bit (''base'': conda)'
# name: python3
# ---
# # <font color='blue'>Data Science Academy - Python Fundamentos - Capítulo 2</font>
#
# ## Download: http://github.com/dsacademybr
# Versão da Linguagem Python
from platform import python_version
print('Versão da Linguagem Python Usada Neste Jupyter Notebook:', python_version())
# ## Exercícios Cap02
# Exercício 1 - Imprima na tela os números de 1 a 10. Use uma lista para armazenar os números.
list1 = list(range(1, 11))
# print(list1)
# Exercício 2 - Crie uma lista de 5 objetos e imprima na tela
list2 = ["Um", "Dois", "Três", "Quatro", "Cinco"]
print(list2)
# Exercício 3 - Crie duas strings e concatene as duas em uma terceira string
string1 = 'Um'
string2 = 'Dois'
string3 = string1 + ', ' + string2
print(string3)
# Exercício 4 - Crie uma tupla com os seguintes elementos: 1, 2, 2, 3, 4, 4, 4, 5 e depois utilize a função count do
# objeto tupla para verificar quantas vezes o número 4 aparece na tupla
tuple1 = (1, 2, 2, 3, 4, 4, 4, 5)
print(tuple1)
print(tuple1.count(4))
# Exercício 5 - Crie um dicionário vazio e imprima na tela
dict1 = dict()
dict2 = {}
print(dict1)
print(dict2)
# +
# Exercício 6 - Crie um dicionário com 3 chaves e 3 valores e imprima na tela
dict1 = {
'Um': 1,
'Dois': 2,
'Três': 3,
}
print(dict1)
# -
# Exercício 7 - Adicione mais um elemento ao dicionário criado no exercício anterior e imprima na tela
dict1['Quatro'] = 4
print(dict1)
# Exercício 8 - Crie um dicionário com 3 chaves e 3 valores. Um dos valores deve ser uma lista de 2 elementos numéricos.
# Imprima o dicionário na tela.
dict2 = {
'1': 'Um',
'2': 'Dois',
'3': ['três e meio', 'três quartos']
}
print(dict2)
# +
# Exercício 9 - Crie uma lista de 4 elementos. O primeiro elemento deve ser uma string,
# o segundo uma tupla de 2 elementos, o terceiro um dcionário com 2 chaves e 2 valores e
# o quarto elemento um valor do tipo float.
# Imprima a lista na tela.
list3 = [
'Primeiro elemento',
('Um', 'Dois'),
{
'dict1': 1,
'dict2': 2
},
5.9
]
print(list3)
# +
# Exercício 10 - Considere a string abaixo. Imprima na tela apenas os caracteres da posição 1 a 18.
frase = 'Cientista de Dados é o profissional mais sexy do século XXI'
print(frase[1:18])
# -
# # Fim
# ### Obrigado
#
# ### Visite o Blog da Data Science Academy - <a href="http://blog.dsacademy.com.br">Blog DSA</a>
# Parabéns se você chegou até aqui. Use o voucher PYTHONDSA9642 para comprar qualquer curso ou Formação da DSA com 5% de desconto.
| python-fundamentals-data-analysis-3.0/PythonFundamentos/Cap02/Notebooks/DSA-Python-Cap02-Exercicios.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Most examples work across multiple plotting backends, this example is also available for:
#
# * [Matplotlib - autompg_violins](../matplotlib/autompg_violins.ipynb)
# +
import numpy as np
import holoviews as hv
from bokeh.sampledata.autompg import autompg
hv.extension('bokeh')
# -
# ## Declaring data
violin = hv.Violin(autompg, ('yr', 'Year'), ('mpg', 'Miles per Gallon')).redim.range(mpg=(8, 45))
# ## Plot
# %%opts Violin [height=500 width=900] (violin_line_color='black' violin_fill_color=hv.Cycle('Category20'))
violin
| examples/gallery/demos/bokeh/autompg_violins.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# for numbers
import xarray as xr
import numpy as np
import pandas as pd
# for figures
import matplotlib as mpl
import matplotlib.pyplot as plt
import cartopy
import cartopy.crs as ccrs
# -
# # Description of this code
#
# We define a function called `quick_map` that is a convenience function. It needs the longitude and latitude meshes and the array of data to map. The key word argument `title` can be supplied to put a title on the map. The `**kwargs` is a dictionary of optional key word arguments that get passed into `pcolormesh`. The map defaults to the Robinson projection; we can change this if there is a projection that we like better. The colormap is not specified, so it will default, if you want to specify one, just include `cmap` in the `kwargs` dict.
#
# The code then loads the event statistics for observations and models (2 separate files), and gets the event ID numbers (lat, lon, event).
#
# The first figures then just make the maps of total number of events.
#
# Then we start to explore ways to divide the events by time (e.g., by month.) I'm still working on this part.
def quick_map(lons, lats, data, title=None, **kwargs):
f, a = plt.subplots(subplot_kw={"projection":ccrs.Robinson()})
# pass in norm as kwarg if needed
# norm = mpl.colors.Normalize(vmin=1979, vmax=2019)
img = a.pcolormesh(lons, lats, data, transform=ccrs.PlateCarree(), **kwargs)
a.set_title(title)
f.colorbar(img, shrink=0.4)
return f, a
# # Quick events stats
# In the `event_attributes_compressed` files, we have `Event_ID`, `initial_index`, and `duration`. These are useful for doing basic statistics of the events (defined with the 90th percentile TMAX).
#
# Next, we load these files, and map the total number of events.
stem = "/project/amp/brianpm/TemperatureExtremes/Derived/"
obsfil = "CPC_tmax_90pct_event_attributes_compressed.nc"
mdlfil = "f.e13.FAMIPC5CN.ne30_ne30.beta17.TREFMXAV.90pct_event_attributes_compressed.nc"
obs_ds = xr.open_dataset(stem+obsfil)
mdl_ds = xr.open_dataset(stem+mdlfil)
obs_ids = obs_ds['Event_ID'] # each point has a series of events that are labeled as increasing integers
mdl_ids = mdl_ds['Event_ID']
# number of events:
obs_nevents = obs_ids.max(dim='events')
mdl_nevents = mdl_ids.max(dim='events')
lons, lats = np.meshgrid(mdl_ds['lon'], mdl_ds['lat'])
# plot of number of events
norm = mpl.colors.Normalize(vmin=0, vmax=1000.)
res = {'norm':norm}
fig1, ax1 = quick_map(lons, lats, obs_nevents, title="OBSERVATIONS: Total Events", **res)
ax1.add_feature(cartopy.feature.OCEAN, zorder=100)
ax1.set_extent([-180, 180,-60, 60])
fig2, ax2 = quick_map(lons, lats, mdl_nevents, title="CESM1: Total Events", **res)
ax2.add_feature(cartopy.feature.OCEAN, zorder=100)
ax2.set_extent([-180, 180,-60, 60])
# # Events divided by month
#
# We have the index of each event, but not the actual time. Here we show how to retrieve the actual dates of events.
#
# original data:
obs_data = xr.open_mfdataset("/project/amp/jcaron/CPC_Tminmax/tmax.*.nc", combine='by_coords')
# %%time
time = obs_data['time'].compute()
def get_event_dates(time_coord, init, dur):
start_date = time_coord[init]
finish_date = time_coord[init+dur]
return start_date, finish_date
# + jupyter={"outputs_hidden": true}
s = obs_ids[:, 100, 100]
x = obs_ds['initial_index'][:,100,100]
d = obs_ds['duration'][:,100,100]
for i, event in enumerate(s):
# print(i)
if event == 0:
continue
else:
initial = x[i].astype(int)
duration = d[i].astype(int)
st, fn = get_event_dates(time, initial, duration)
print(f"start: {st.values}, end: {fn.values}")
# -
# Now the issue is that we'd like to do this for every event.
#
# Since we already have duration, we really just need the starting time for each event at each location. We should write this when we first calculate the attributes.
# stack spatial points so only 1-d
obs_stack = obs_ds.stack(z=("lat","lon"))
obs_stack
# %%time
stdata = np.zeros(obs_stack['Event_ID'].shape, dtype='datetime64[s]')
print(stdata.shape)
for j in range(len(obs_stack.events)):
print(f"Working on event {j}")
for i in range(len(obs_stack.z)):
if obs_stack["Event_ID"][j, i].max() <= 0:
stdata[j, i] = '0000-01-01' # missing
else:
ndx = obs_stack['initial_index'][j, i].astype(int).item()
stdata[j, i] = time[ndx].values
start_time = xr.DataArray(stdata, coords=obs_stack.coords, dims=obs_stack.dims)
time[9].values
# + active=""
# obs_event_fil = xr.open_dataset(stem+"CPC_tmax_90pct_event_detection.nc")
# mdl_event_fil = xr.open_dataset(stem+"f.e13.FAMIPC5CN.ne30_ne30.beta17.TREFMXAV.90pct_event_detection.nc")
# -
print(obs_event_fil['time'].min())
print(obs_event_fil['time'].max())
print(mdl_event_fil['time'].min())
print(mdl_event_fil['time'].max())
tt = np.array([time[1000].values])
| notebooks/ams_maps.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] slideshow={"slide_type": "slide"}
# # MAT281
#
# ## Aplicaciones de la Matemática en la Ingeniería
# + [markdown] slideshow={"slide_type": "slide"}
# ## ¿Qué contenido aprenderemos?
# * Manipulación de datos con ```pandas```.
# - Crear objetos (Series, DataFrames, Index).
# - Análisis exploratorio.
# - Realizar operaciones y filtros.
# - Aplicar funciones y métodos.
# + [markdown] slideshow={"slide_type": "slide"}
# ## Motivación
# -
# En los últimos años, el interés por los datos ha crecido sostenidamente, algunos términos de moda tales como *data science*, *machine learning*, *big data*, *artifial intelligence*, *deep learning*, etc. son prueba fehaciente de ello. Por dar un ejemplo, las búsquedas la siguiente imagen muestra el interés de búsqueda en Google por *__Data Science__* en los últimos cinco años.
#
# [Fuente](https://trends.google.com/trends/explore?date=today%205-y&q=data%20science)
# 
#
# Muchos se ha dicho respecto a esto, declaraciones tales como:
#
# * _"The world’s most valuable resource is no longer oil, but data."_
# * _"AI is the new electricity."_
# * _"Data Scientist: The Sexiest Job of the 21st Century."_
# <script type="text/javascript" src="https://ssl.gstatic.com/trends_nrtr/1544_RC05/embed_loader.js"></script> <script type="text/javascript"> trends.embed.renderExploreWidget("TIMESERIES", {"comparisonItem":[{"keyword":"data science","geo":"","time":"today 5-y"}],"category":0,"property":""}, {"exploreQuery":"date=today%205-y&q=data%20science","guestPath":"https://trends.google.com:443/trends/embed/"}); </script>
# Los datos por si solos no son útiles, su verdadero valor está en el análisis y en todo lo que esto conlleva, por ejemplo:
#
# * Predicciones
# * Clasificaciones
# * Optimización
# * Visualización
# * Aprendizaje
# Por esto es importante recordar al tío Ben: _"Un gran poder conlleva una gran responsabilidad"_.
# + [markdown] slideshow={"slide_type": "slide"}
# ## Numpy
#
# Desde la propia página web:
#
# NumPy is the fundamental package for scientific computing with Python. It contains among other things:
#
# * a powerful N-dimensional array object
# * sophisticated (broadcasting) functions
# * tools for integrating C/C++ and Fortran code
# * useful linear algebra, Fourier transform, and random number capabilities
#
# Besides its obvious scientific uses, NumPy can also be used as an efficient multi-dimensional container of generic data. Arbitrary data-types can be defined. This allows NumPy to seamlessly and speedily integrate with a wide variety of databases.
#
# -
# **Idea**: Realizar cálculos numéricos eficientemente.
# + [markdown] slideshow={"slide_type": "slide"}
# ## Pandas
#
# -
# Desde el repositorio de GitHub:
#
# pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with "relational" or "labeled" data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
# Actualmente cuenta con más de 1200 contribuidores y casi 18000 commits!
import pandas as pd
pd.__version__
# ## Series
# Arreglos unidimensionales con etiquetas. Se puede pensar como una generalización de los diccionarios de Python.
# +
# pd.Series?
# -
# Para crear una instancia de una serie existen muchas opciones, las más comunes son:
#
# * A partir de una lista.
# * A partir de un _numpy.array_.
# * A partir de un diccionario.
# * A partir de un archivo (por ejemplo un csv).
my_serie = pd.Series(range(3, 33, 3))
my_serie
type(my_serie)
# +
# Presiona TAB y sorpréndete con la cantidad de métodos!
# my_serie.
# -
# Las series son arreglos unidemensionales que constan de _data_ e _index_.
my_serie.values
type(my_serie.values)
my_serie.index
type(my_serie.index)
# A diferencia de numpy, pandas ofrece más flexibilidad para los valores e índices.
my_serie_2 = pd.Series(range(3, 33, 3), index=list('abcdefghij'))
my_serie_2
# Acceder a los valores de una serie es muy fácil!
my_serie_2['b']
my_serie_2.loc['b']
my_serie_2.iloc[1]
# ```loc```?? ```iloc```??
# +
# # pd.Series.loc?
# -
# A modo de resumen:
#
# * ```loc``` es un método que hace referencia a las etiquetas (*labels*) del objeto .
# * ```iloc``` es un método que hace referencia posicional del objeto.
# **Consejo**: Si quieres editar valores siempre utiliza ```loc``` y/o ```iloc```.
my_serie_2.loc['d'] = 1000
my_serie_2
# ### Trabajar con fechas
# Pandas incluso permite que los index sean fechas! Por ejemplo, a continuación se crea una serie con las tendencia de búsqueda de *data science* en Google.
import os
ds_trend = pd.read_csv(os.path.join('data', 'dataScienceTrend.csv'), index_col=0, squeeze=True)
ds_trend.head(10)
ds_trend.tail(10)
ds_trend.dtype
ds_trend.index
# **OJO!** Los valores del Index son _strings_ (_object_ es una generalización).
# **Solución:** _Parsear_ a elementos de fecha con la función ```pd.to_datetime()```.
# +
# # pd.to_datetime?
# -
ds_trend.index = pd.to_datetime(ds_trend.index, format='%Y-%m-%d')
ds_trend.index
# Para otros tipos de _parse_ puedes visitar la documentación [aquí](https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior).
#
# La idea de los elementos de fecha es poder realizar operaciones que resulten naturales para el ser humano. Por ejemplo:
ds_trend.index.min()
ds_trend.index.max()
ds_trend.index.max() - ds_trend.index.min()
# Volviendo a la Serie, podemos trabajar con todos sus elementos, por ejemplo, determinar rápidamente la máxima tendencia.
max_trend = ds_trend.max()
max_trend
# Para determinar el _index_ correspondiente al valor máximo usualmente se utilizan dos formas:
#
# * Utilizar una máscara (*mask*)
# * Utilizar métodos ya implementados
# Mask
ds_trend[ds_trend == max_trend]
# Built-in method
ds_trend.idxmax()
# ## Dataframes
# Arreglo bidimensional y extensión natural de una serie. Podemos pensarlo como la generalización de un numpy.array.
# Utilizando el dataset de los jugadores de la NBA la flexibilidad de pandas se hace mucho más visible. No es necesario que todos los elementos sean del mismo tipo!
import os
player_data = pd.read_csv(os.path.join('data', 'player_data.csv'), index_col='name')
player_data.head()
player_data.info(memory_usage=True)
type(player_data)
player_data.dtypes
# Puedes pensar que un dataframe es una colección de series
player_data['birth_date'].head()
type(player_data['birth_date'])
# ### Exploración
player_data.describe()
player_data.describe(include='all')
player_data.max()
# Para extraer elementos lo más recomendable es el método loc.
player_data.loc['<NAME>', 'college']
# Evita acceder con doble corchete
player_data['college']['<NAME>-Aziz']
# Aunque en ocasiones funcione, no se asegura que sea siempre así. [Más info aquí.](https://pandas.pydata.org/pandas-docs/stable/indexing.html#why-does-assignment-fail-when-using-chained-indexing)
# ### Valores perdidos/nulos
# Pandas ofrece herramientas para trabajar con valors nulos, pero es necesario conocerlas y saber aplicarlas. Por ejemplo, el método ```isnull()``` entrega un booleano si algún valor es nulo.
# Por ejemplo: ¿Qué jugadores no tienen registrado su fecha de nacimiento?
player_data.index.shape
player_data[player_data['birth_date'].isnull()]
# Si deseamos encontrar todas las filas que contengan por lo menos un valor nulo.
player_data.isnull()
# +
# # pd.DataFrame.any?
# -
rows_null_mask = player_data.isnull().any(axis=1) # axis=1 hace referencia a las filas.
rows_null_mask.head()
player_data[rows_null_mask].head()
player_data[rows_null_mask].shape
# Para determinar aquellos que no tienen valors nulos el prodecimiento es similar.
player_data[player_data.notnull().all(axis=1)].head()
# ¿Te fijaste que para usar estas máscaras es necesario escribir por lo menos dos veces el nombre del objeto? Una buena práctica para generalizar las máscaras consiste en utilizar las funciones ``lambda``
player_data[lambda df: df.notnull().all(axis=1)].head()
# Una función lambda es una función pequeña y anónima. Pueden tomar cualquer número de argumentos pero solo tienen una expresión.
# Pandas incluso ofrece opciones para eliminar elementos nulos!
# +
# pd.DataFrame.dropna?
# -
# Cualquier registro con null
print(player_data.dropna().shape)
# Filas con elementos nulos
print(player_data.dropna(axis=0).shape)
# Columnas con elementos nulos
print(player_data.dropna(axis=1).shape)
# ## Ejemplo práctico
#
# ¿Para cada posición, cuál es la máxima cantidad de tiempo que ha estado un jugador?
#
# Un _approach_ para resolver la pregunta anterior tiene los siguientes pasos:
#
# 1. Determinar el tiempo de cada jugador en su posición.
# 2. Determinar todas las posiciones.
# 3. Iterar sobre cada posición y encontrar el mayor valor.
# 1. Determinar el tiempo de cada jugador en su posición.
player_data['duration'] = player_data['year_end'] - player_data['year_start']
player_data.head()
# 2. Determinar todas las posiciones.
positions = player_data['position'].unique()
positions
# 3. Iterar sobre cada posición y encontrar el mayor valor.
nba_position_duration = pd.Series()
for position in positions:
df_aux = player_data.loc[lambda x: x['position'] == position]
max_duration = df_aux['duration'].max()
nba_position_duration.loc[position] = max_duration
nba_position_duration
# + [markdown] slideshow={"slide_type": "slide"}
# ## Resumen
# * Pandas posee una infinidad de herramientas para trabajar con datos, incluyendo la carga, manipulación, operaciones y filtrado de datos.
# * La documentación oficial (y StackOverflow) son tus mejores amigos.
# * La importancia está en darle sentido a los datos, no solo a coleccionarlos.
# -
# # Evaluación Laboratorio
# * Nombre:
# * Rol:
# #### Instruciones
#
# 1. Pon tu nombre y rol en la celda superior.
# 2. Debes enviar este **.ipynb** con el siguiente formato de nombre: **```04_data_manipulation_NOMBRE_APELLIDO.ipynb```** con tus respuestas a <EMAIL> y <EMAIL> .
# 3. Se evaluara tanto el código como la respuesta en una escala de 0 a 4 con valores enteros.
# 4. La entrega es al final de esta clase.
# ## Dataset jugadores NBA (2pts)
#
# 1. ¿Cuál o cuáles son los jugadores más altos de la NBA?
# 2. Crear un DataFrame llamado ```nba_stats``` donde los índices sean las distintas posiciones y que posea las siguientes columns:
# - nm_players: Cantidad de jugadores distintos que utilizan esa posición.
# - mean_duration: Duración de años promedio.
# - tallest: Mayor altura en cm.
# - young_birth: Fecha de nacimiento del jugador/es más joven.
tallest_player = # FIX ME
nba_stats = #FIX ME
# ## Dataset del Gasto Neto Mensualizado por año de las Instituciones Públicas (2pts)
#
# Este dataset incluye las cifras (actualizadas a la moneda del año 2017), el gasto ejecutado
# por las distintas instituciones en los variados programas del Presupuesto, y desglosado
# hasta el máximo nivel del clasificador presupuestario. Los montos contemplan el Gasto
# Neto, es decir, integran los gastos que afectan el patrimonio público, excluyendo aquéllos
# que sólo se traducen en movimientos de activos y pasivos financieros que sirven de
# fuente de financiamiento de los primeros
#
#
# 1. Cargar el dataset ```gasto_fiscal.csv``` que se encuentra en la carpeta ```data``` en un DataFrame llamado **```gasto_fiscal```**. ¿Cuánta MB de memoria está utilizando? ¿Cuáles son las columnas que consumen más y menos memoria? ¿Cuál crees que es la razón?
# 2. Crear un DataFrame llamado ```gasto_fiscal_stats```, donde los _index_ sean cada Partida y las columnas correspondan a:
# - A la suma total de los montos desde el año 2011 al 2014.
# - Cantidad de registros con monto igual a cero.
# - Mes con mayor gasto
# - Porcentaje del mes con mayor gasto respecto al gasto total.
gasto_fiscal = # FIX ME
# gasto_fiscal_mb = # FIX ME
# more_memory_columns = []
# less_memory_columns = []
# reason = ''
gasto_fiscal_stats = # FIX ME
#
| m01_introduccion/04_data_manipulation/04_data_manipulation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Test Dataset Preparation
# +
import pickle
import pandas as pd
import requests
import scrapy
from scrapy import Selector
from scrapy.crawler import CrawlerProcess
# -
with open('date_dict.pickle', 'rb') as handle:
date_dict = pickle.load(handle)
with open('place_dict.pickle', 'rb') as handle:
place_dict = pickle.load(handle)
with open('url_dict.pickle', 'rb') as handle:
url_dict = pickle.load(handle)
with open('text_dict.pickle', 'rb') as handle:
text_dict = pickle.load(handle)
source_url = 'https://archivepmo.nic.in/drmanmohansingh/all-speeches.php'
html = requests.get(source_url).content
sel = Selector( text = html )
# +
# Collecting urls which couldn't be scraped
url_prefix = 'https://archivepmo.nic.in/drmanmohansingh/'
url_suffixes = sel.xpath('//div[@class = "speechPan"]/ul//li').xpath('./a/@href').extract()
urls = [url_prefix +url_suffix for url_suffix in url_suffixes]
missed_urls = list(set(urls) - set(url_dict.values()))
len(missed_urls),missed_urls[:5]
# -
# Checking if speeches can be scraped, and if scraped are they of sufficent length. if not urls dropped
for url_speech in missed_urls:
html_speech = requests.get( url_speech ).content
sel = Selector(text = html_speech)
try:
((sel.xpath('//*[@class = "innerHead"]/text()')).extract_first())
((sel.xpath('//div[@class = "contentInner"]//h2[@class = "date"]/text()'))[0].extract())
((sel.xpath('//div[@class = "contentInner"]//h2[@class = "date"]/text()'))[1].extract())
text = "".join((sel.css('div.contentInner div.rt')).css('p::text').extract())
if len(text)<500:
missed_urls.remove(url_speech)
print("Something went wrong. Removing the url")
except:
print("Something went wrong. Removing the url")
missed_urls.remove(url_speech)
len(missed_urls)
#Creating another spider to collect the missed speeches so that they can be made into a test set
class MMS_Missed_Speech_Spider( scrapy.Spider ):
name = 'mms_missed_speeches_spider'
def start_requests( self ):
for url in missed_urls:
yield scrapy.Request( url = url, callback = self.parse )
def parse( self, response ):
#Extracting url
speech_url = response.url
#Extracting title of speech
title = (response.xpath('//*[@class = "innerHead"]/text()')).extract_first()
#Extracting date of speech
date = (response.xpath('//div[@class = "contentInner"]//h2[@class = "date"]/text()'))[0].extract()
#Extracting place of speech
place = (response.xpath('//div[@class = "contentInner"]//h2[@class = "date"]/text()'))[1].extract()
#Extracting speech text
text = "".join((response.css('div.contentInner div.rt')).css('p::text').extract())
#Storing in respective dict_testionaries
place_dict_test[title] = place
date_dict_test[title] = date
url_dict_test[title] = speech_url
text_dict_test[title] = text
date_dict_test = {}
place_dict_test = {}
text_dict_test = {}
url_dict_test = {}
process = CrawlerProcess()
process.crawl(MMS_Missed_Speech_Spider)
process.start()
len(date_dict_test),len(place_dict_test),len(text_dict_test),len(url_dict_test)
# +
#Creating test dataset
date_df = pd.DataFrame.from_dict(date_dict_test, orient='index',columns= ['date'])
place_df = pd.DataFrame.from_dict(place_dict_test, orient='index', columns= ['place'])
text_df = pd.DataFrame.from_dict(text_dict_test, orient='index', columns= ['text'])
url_df = pd.DataFrame.from_dict(url_dict_test, orient='index', columns= ['url'])
df_combined_test = pd.concat([date_df, place_df,url_df,text_df], axis=1, sort=False, join = 'inner')
df_combined_test.index.rename('title',inplace=True)
df_combined_test.reset_index(drop = False,inplace= True)
df_combined_test.head()
# -
#Storing test dataset into a file
df_combined_test.to_excel('PM_MMS_Speech_test.xlsx',index=False)
| Test Dataset Preparation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + id="2n7Wa6k7-TFN"
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# + id="hsZRFZoxAhUg"
dataset = pd.read_csv('/content/Salary_Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
# + colab={"base_uri": "https://localhost:8080/"} id="PL8YxGzxAlKo" outputId="5f872beb-bfef-4d7f-9a3e-c506a4236656"
print(X)
# + colab={"base_uri": "https://localhost:8080/"} id="mrHk9BmNAoag" outputId="4e423476-a1b7-4971-fa05-1038d9d9afa1"
print(y)
# + id="5-dnQvbVAtQy"
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# + colab={"base_uri": "https://localhost:8080/"} id="MIKIA3wNAzUd" outputId="230c598b-b4a7-4734-e87d-fe4a5baf8705"
print(X_train)
# + colab={"base_uri": "https://localhost:8080/"} id="3FYJkC8-A1ZS" outputId="e771a311-8ea3-40cb-93ff-e1c0c92fb985"
print(y_train)
# + colab={"base_uri": "https://localhost:8080/"} id="dGKD7T10A4iR" outputId="7220b861-003e-4335-94b1-f0f8fb799391"
print(X_test)
# + colab={"base_uri": "https://localhost:8080/"} id="N2I5KPv2A6Zw" outputId="a572aeac-35b8-4eff-b4c4-26de422db120"
print(y_test)
# + colab={"base_uri": "https://localhost:8080/"} id="5x1QTf2TA8vC" outputId="50fbdeeb-6982-4885-91e6-737237f1e74a"
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train,y_train)
# + id="hqYwvlFBBROT"
y_pred = regressor.predict(X_test)
# + colab={"base_uri": "https://localhost:8080/", "height": 295} id="TrDJR_qtBez6" outputId="26f16165-9db7-4578-ec2f-b0aa1ad97a03"
plt.scatter(X_train, y_train, color = 'green')
plt.plot(X_train, regressor.predict(X_train), color = 'purple')
plt.title('Salary vs Experience (Training Dataset)')
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()
# + colab={"base_uri": "https://localhost:8080/", "height": 295} id="M4EO3wXACAKf" outputId="1a0ced75-3708-473d-e69b-88239bc3c829"
plt.scatter(X_test, y_test, color = 'green')
plt.plot(X_train, regressor.predict(X_train), color = 'purple')
plt.title('Salary vs Experience (Test Dataset)')
plt.xlabel('Years of Experience')
plt.ylabel('Salary')
plt.show()
| P1-Simple Linear Regression/simple.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### ResNet for model prediction
# !wget https://vignette.wikia.nocookie.net/liberapedia/images/b/bc/Elephant.jpg/revision/latest?cb=20130413020301
# !mv latest?cb=20130413020301 elephant.jpg
# +
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from tensorflow.keras.preprocessing import image
import numpy as np
model = ResNet50(weights='imagenet')
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x.shape
# -
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
x.shape
preds = model.predict(x)
print(preds.shape)
preds
# decode the results into a list of tuples (class, description, probability)
# (one such list for each sample in the batch)
print('Predicted:', decode_predictions(preds, top=3)[0])
| 03_Applied_AI_DeepLearning/notebooks/week_3_4_resnet_imagenet.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 0.5.2
# language: julia
# name: julia-0.5
# ---
# # Lecture 10 - Asymptotics
#
# February 12, 2019
#
# ## Math 502 - University of Calgary
# ## Mathematical Modeling for Industry
# ## Winter 2019
#
#
# ## The example of octave stretch in a piano
# This example is based on the fact that a piano wire is not a perfectly elastic spring, but has characteristics like a metal beam. There is a small parameter $\epsilon$ in the problem, that measures the departure from perfect elasticity. This change actually affects the tuning of a real piano.
#
#
# Music notes are typically generated by vibrations in some object (the strings of a violin, the wires in a piano, the metal bars in a xylophone, even vibrations of an air column in a clarinet, flute, saxophone, etc.) The pitch of a note is characterized by a frequency of vibration -- for instance, concert "A" is set at 440 Hertz (cycles per second). Pairs of notes sound nice together if their frequencies are in the ratio of a small integer fraction. For instance, A is 440 Hz, and E is 660Hz, which is 3/2 the frequency of A. (This interval, from A to E, is called a perfect fifth. It is the first tone step you hear in the song "Twinkle twinkle little star", or in French "Ah! vous dirai-je, maman.") A leap by an octave is a doubling of frequency, such as 440Hz to 880 Hz (this the leap you hear in the tune "SomeWhere over the rainbow" from the Wizard of Oz.)
#
# A simple string vibrates with a fundamental frequency, as well with harmonics that are frequencies at integer multiples of the fundamental By tuning to the harmonics, it is possible to tune a piano by ear -- adjusting the tension on a string until the frequencies line up. However, a real piano has more complicated harmonics, so simple tuning gives a slight error in the alignment of the notes. Indeed, over the 8 octaves of a piano, the errors accumulate into something that is clearly noticable by ear.
#
# We will show here the PDE describing the vibrations of a simple string, and then consider the case of a real piano wire that has more complex vibrations.
#
# ### Wave equation for a simple string
# The PDE governing the vibrations of a simple is derived from Newton's law (mass times acceleration equals force), giving
# $$\rho A \frac{\partial^2 y}{\partial t^2} = T \frac{\partial^2 y}{\partial x^2}, \mbox{ for $0<x<L$},$$
# where $y=y(x,t)$ is the (vertical) displacement of a string from rest, $\rho$ is the density of the string, $A$ is the cross-sectional area of the string, and $T$ is the tension on the string (so the term $T \frac{\partial^2 y}{\partial x^2}$ represents the force on the string due to the curvature of the vibrating string). It is pretty standard to rewrite the PDE as
# $$ \frac{\partial^2 y}{\partial t^2} - c^2 \frac{\partial^2 y}{\partial x^2}=0, \mbox{ for $0<x<L$},$$ where
# $c^2 = T/\rho A$ is the speed of propagation (squared) for vibrations in the string.
#
#
# We include the boundary conditions
# $$y(0) = 0, \qquad y(L) = 0,$$
# where $L$ is the length of the string.
#
# By separating variables, we find the normal modes of vibration as
# $$y_n = e^{i\omega_n t} \sin\frac{n\pi }{L}x, \mbox{ with } \omega_n = \frac{n\pi }{L}c.$$
# So we see here the temporal frequencies $\omega_n$ are simple integer multiples of the fundamental frequency $\omega_1$.
#
# To get a non-dimensional version, we scale $x$ with $L$, $t$ with $L/c$, and dropping primes to get
# $$ \frac{\partial^2 y}{\partial t^2} - \frac{\partial^2 y}{\partial x^2}=0, \mbox{ for $0<x<1$, with $y(0)=y(1)=0$}.$$
# Now the normal modes are
# $$y_n = e^{i\Omega_n t} \sin n\pi x, \mbox{ with } \Omega_n = n\pi.$$
#
# ### Wave equation for a real piano wire
# A real piano wire is a bit more like a flexible beam, so there is a bending stiffness. From engineering beam models, we expect a PDE of the form
# $$ \rho A \frac{\partial^2 y}{\partial t^2} - T \frac{\partial^2 y}{\partial x^2}
# + E A k^2 \frac{\partial^4 y}{\partial x^4} = 0,$$
# where $E$ is Young's modulus for the wire, and $k$ is the radius of gyration.
#
# We note that for a circular wire of radius $a$, that the radius of gyration is given by $k^2 = \frac{1}{2}a^2.$
#
# Scaling $x,t$ as before, we obtain the equation
# $$ \frac{\partial^2 y}{\partial t^2} - \frac{\partial^2 y}{\partial x^2}
# + \epsilon \frac{\partial^4 y}{\partial x^4} = 0,$$
# where the dimensionless parameter $\epsilon$ is given by
# $$\epsilon - \frac{Ek^2}{\rho L^2 c^2} = \frac{EAk^2}{TL^2}.$$
#
# Note that area $A$ is proportional to radius squared ($a^2$) as is $k^2$, so the parameter $\epsilon$ depends on the fourth order of the radius of the wire. (i.e. skinny wires are closer to the simple string example above.)
#
# For a typical piano wire, we might have a radius of $a=1mm$, so $k^2 = \frac{1}{2}\times 10^{-6} m^2$, $L=1m$, $T=1000N$ (Newtons), and for steel we have a density $\rho = 7800 kg/m^3$ and modulus $E = 2\times 10^{11}$ in SI units. This gives
# $$\epsilon \approx 3.1\times 10^{-4},$$
# so indeed it is a small parameter.
#
# The corresponding fundamental frequency, in the simple string, would be
# $$\omega_1 = \frac{\pi c}{L} \approx 280Hz,$$
# which is about middle C on the piano.
# To solve a 4th order PDE, we need two more boundary conditions. It is reasonable to include the conditions
# $$\frac{\partial^2y}{\partial x^2} = 0, \mbox{ at } x=0, x=1,$$
# which represents a "straight wire" condition at the ends of the vibrating string. (Basically, the string oscillates about the bridge support, without curving.)
#
# Or, to be honest, maybe this is just some hack to ensure we still can use the sine function in the separation of variables. Think about this.
#
# Anyhow, we now try a solution using separation of variables, taking this function
# $$y_n = e^{i\Omega_n t}\sin n\pi x$$
# and plugging into our fourth order PDE, to obtain the fourth order algebraic equation
# $$-\Omega_n^2 + n^2\pi^2 + \epsilon n^4 \pi^4 = 0.$$
# Thus the normal mode frequencies are given as
# $$\Omega_n = n\pi(1+ \epsilon n^2 \pi^2)^{1/2} \approx n\pi(1 + \frac{1}{2}\epsilon n^2 \pi^2 + o(\epsilon)),$$
# where we have used a first order approximation to the square root function. This is our first asymptotic expansion, where here we show how the harmonics depend on the small parameter $\epsilon$. The harmonic frequencies do grow with $n$, but not quite linearly as there is an order epsilon correction.
#
# So already, we see the normal mode frequencies are not simple integer multiples of some basic frequency.
#
# To investigate further, we observe the fundamental frequency is
# $$\Omega_1 \approx \pi(1 + \frac{1}{2}\epsilon \pi^2), $$
# and the n-th harmonic has frequency
# $$\Omega_n \approx n\Omega_1 \frac{1+\frac{1}{2}\epsilon n^2\pi^2}{1+\frac{1}{2}\epsilon \pi^2}
# \approx n\Omega_1 \left(1 + \frac{1}{2}\epsilon \pi^2 (n^2-1) \right).$$
# This is a second asymptotics expansion. (Maybe you should work out the details yourself for this expansion. Where is the $n^2 - 1$ come from?)
#
# So again, we see the frequencies are approximately an integer multiple $n\Omega_1$ of the fundamental frequency $\Omega_1$, but there is a small correction.
#
# ### Octave stretch
# So, in tuning a piano, we often tune by octaves, so the second harmonic $\Omega_2$ is important. In our example, with $\epsilon = 3.1\times 10^{-4}$, we find the ratio $\Omega_2/\Omega_1$ is
# $$ 2(1 + \frac{3}{2}\epsilon \pi^2) = 2\cdot (1.00458).$$
# Such a small discrepency is not really noticable, but over 7 octaves we have
# $$ (1 + \frac{3}{2}\epsilon \pi^2)^7 \approx 1 + \frac{21}{3}\epsilon\pi^2 \approx 1.033,$$
# which is more than half a semitone discrepancy. Which is easily noticable by ear.
#
#
# +
## Of course we can use some math to compute exactly.
eps = .00031
ratio = 2*(1 + 1.5*eps*pi^2)
ratio^7
[eps,ratio/2,ratio^7/2^7]
# -
## Notice our first order approximations were quite accurate!
| Lecture10_Feb12_PianoAsymptotics.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python3.8 (geekbrains)
# language: python
# name: geekbrains
# ---
# +
from keras.models import Sequential
from keras.layers import Input, Dense, Flatten, Convolution2D, MaxPooling2D, Dropout
from keras.utils import to_categorical
from keras.datasets import mnist
from keras.utils import plot_model
from keras.regularizers import l1, l2
from keras.layers.normalization import BatchNormalization
from keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
import pydotplus
from keras.utils import plot_model
from keras.utils import vis_utils
vis_utils.pydot = pydotplus
# -
(X_train, y_train), (X_test, y_test) = mnist.load_data()
plt.imshow(X_train[0], cmap='gray');
num_epochs = 50
batch_size=32
result = {}
# # Simple Model
model_name = 'Simple Model'
def simple_nn(X_train, y_train):
X_train = (X_train / 255) - 0.5
X_train = X_train.reshape((-1, 784))
model = Sequential([
Dense(64, activation='relu', input_shape=(784,)),
Dense(64, activation='relu'),
Dense(10, activation='softmax'),
])
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'],
)
history = model.fit(
X_train,
to_categorical(y_train),
epochs=num_epochs,
batch_size=batch_size,
validation_split=0.25,
verbose=0
)
print(f'Best validation accuracy: {max(history.history["val_accuracy"])}')
print(f'Best validation loss: {min(history.history["val_loss"])}')
return (model, history.history)
model, result[model_name] = simple_nn(X_train, y_train)
plot_model(model, show_shapes=True)
# # Drop out
model_name = 'Drop out'
drop_prob_1 = 0.25
drop_prob_2 = 0.5
def drop_out_model(X_train, y_train):
X_train = (X_train / 255) - 0.5
X_train = X_train.reshape((-1, 784))
model = Sequential([
Dense(64, activation='relu', input_shape=(784,)),
Dropout(drop_prob_1),
Dense(64, activation='relu'),
Dropout(drop_prob_1),
Dense(10, activation='softmax'),
])
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'],
)
history = model.fit(
X_train,
to_categorical(y_train),
epochs=num_epochs,
batch_size=batch_size,
validation_split=0.25,
verbose=0
)
print(f'Best validation accuracy: {max(history.history["val_accuracy"])}')
print(f'Best validation loss: {min(history.history["val_loss"])}')
return (model, history.history)
model, result[model_name] = drop_out_model(X_train, y_train)
plot_model(model, show_shapes=True)
# # L2-regularisation
model_name = 'L2-regularisation'
l2_lambda = 0.0001
def l2_model(X_train, y_train):
X_train = (X_train / 255) - 0.5
X_train = X_train.reshape((-1, 784))
model = Sequential([
Dense(64, activation='relu', input_shape=(784,), kernel_regularizer=l2(l2_lambda)),
Dense(64, activation='relu', kernel_regularizer=l2(l2_lambda)),
Dense(10, activation='softmax'),
])
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'],
)
history = model.fit(
X_train,
to_categorical(y_train),
epochs=num_epochs,
batch_size=batch_size,
validation_split=0.25,
verbose=0
)
print(f'Best validation accuracy: {max(history.history["val_accuracy"])}')
print(f'Best validation loss: {min(history.history["val_loss"])}')
return (model, history.history)
model, result[model_name] = l2_model(X_train, y_train)
plot_model(model, show_shapes=True)
# # Batch normalization
model_name = 'Batch normalization'
drop_prob_1 = 0.25
drop_prob_2 = 0.5
def batch_model(X_train, y_train):
X_train = (X_train / 255) - 0.5
X_train = X_train.reshape((-1, 784))
model = Sequential([
Dense(64, activation='relu', input_shape=(784,)),
BatchNormalization(axis=1),
Dense(64, activation='relu'),
BatchNormalization(axis=1),
Dense(10, activation='softmax'),
])
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'],
)
history = model.fit(
X_train,
to_categorical(y_train),
epochs=num_epochs,
batch_size=batch_size,
validation_split=0.25,
verbose=0
)
print(f'Best validation accuracy: {max(history.history["val_accuracy"])}')
print(f'Best validation loss: {min(history.history["val_loss"])}')
return (model, history.history)
model, result[model_name] = batch_model(X_train, y_train)
plot_model(model, show_shapes=True)
# # Early stopping
model_name = 'Early stopping'
drop_prob_1 = 0.25
drop_prob_2 = 0.5
def stopping_model(X_train, y_train):
X_train = X_train.reshape((-1, 784))
model = Sequential([
Dense(64, activation='relu', input_shape=(784,)),
BatchNormalization(axis=1),
Dense(64, activation='relu'),
BatchNormalization(axis=1),
Dense(10, activation='softmax'),
])
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'],
)
history = model.fit(
X_train,
to_categorical(y_train),
epochs=num_epochs,
batch_size=batch_size,
validation_split=0.25,
verbose=0,
callbacks=[EarlyStopping(monitor='val_loss', patience=5)]
)
print(f'Best validation accuracy: {max(history.history["val_accuracy"])}')
print(f'Best validation loss: {min(history.history["val_loss"])}')
return (model, history.history)
model, result[model_name] = stopping_model(X_train, y_train)
plot_model(model, show_shapes=True)
# # Result
# +
fig, (ax1, ax2) = plt.subplots(2, 1)
fig.set_figheight(30)
fig.set_figwidth(20)
ax1.set_title('Model accuracy')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Accuracy')
ax2.set_title('Model loss')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Loss')
for name, history in result.items():
ax1.plot(history['accuracy'], label=f'{name} Train')
ax1.plot(history['val_accuracy'], label=f'{name} Test')
ax2.plot(history['loss'], label=f'{name} Train')
ax2.plot(history['val_loss'], label=f'{name} Test')
ax1.legend(loc='lower right')
ax2.legend(loc='upper right')
fig.tight_layout()
| lesson_02.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %matplotlib inline
#
# Training GNN with Neighbor Sampling for Node Classification
# ===========================================================
#
# This tutorial shows how to train a multi-layer GraphSAGE for node
# classification on ``ogbn-arxiv`` provided by [Open Graph
# Benchmark (OGB)](https://ogb.stanford.edu/). The dataset contains around
# 170 thousand nodes and 1 million edges.
#
# By the end of this tutorial, you will be able to
#
# - Train a GNN model for node classification on a single GPU with DGL's
# neighbor sampling components.
#
# This tutorial assumes that you have read the [Introduction of Neighbor
# Sampling for GNN Training](L0_neighbor_sampling_overview.ipynb).
#
# Loading Dataset
# ---------------
#
# OGB already prepared the data as DGL graph.
#
#
#
# +
import dgl
import torch
import numpy as np
from ogb.nodeproppred import DglNodePropPredDataset
dataset = DglNodePropPredDataset('ogbn-arxiv')
device = 'cpu' # change to 'cuda' for GPU
# -
# OGB dataset is a collection of graphs and their labels. ``ogbn-arxiv``
# dataset only contains a single graph. So you can
# simply get the graph and its node labels like this:
#
#
#
# +
graph, node_labels = dataset[0]
# Add reverse edges since ogbn-arxiv is unidirectional.
graph = dgl.add_reverse_edges(graph)
graph.ndata['label'] = node_labels[:, 0]
print(graph)
print(node_labels)
node_features = graph.ndata['feat']
num_features = node_features.shape[1]
num_classes = (node_labels.max() + 1).item()
print('Number of classes:', num_classes)
# -
# You can get the training-validation-test split of the nodes with
# ``get_split_idx`` method.
#
#
#
idx_split = dataset.get_idx_split()
train_nids = idx_split['train']
valid_nids = idx_split['valid']
test_nids = idx_split['test']
# How DGL Handles Computation Dependency
# --------------------------------------
#
# In the [previous tutorial](L0_neighbor_sampling_overview.ipynb), you
# have seen that the computation dependency for message passing of a
# single node can be described as a series of *message flow graphs* (MFG).
#
# 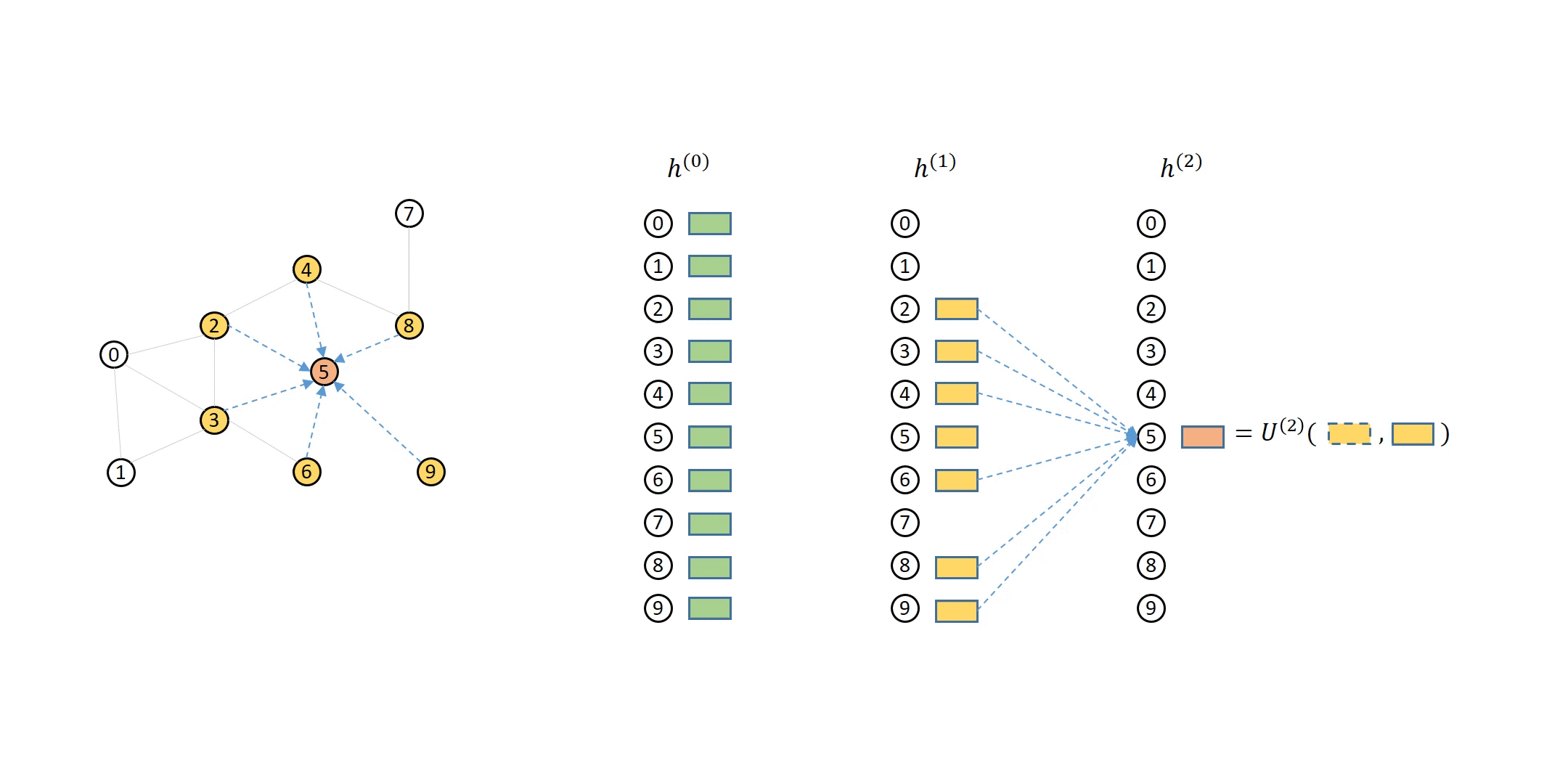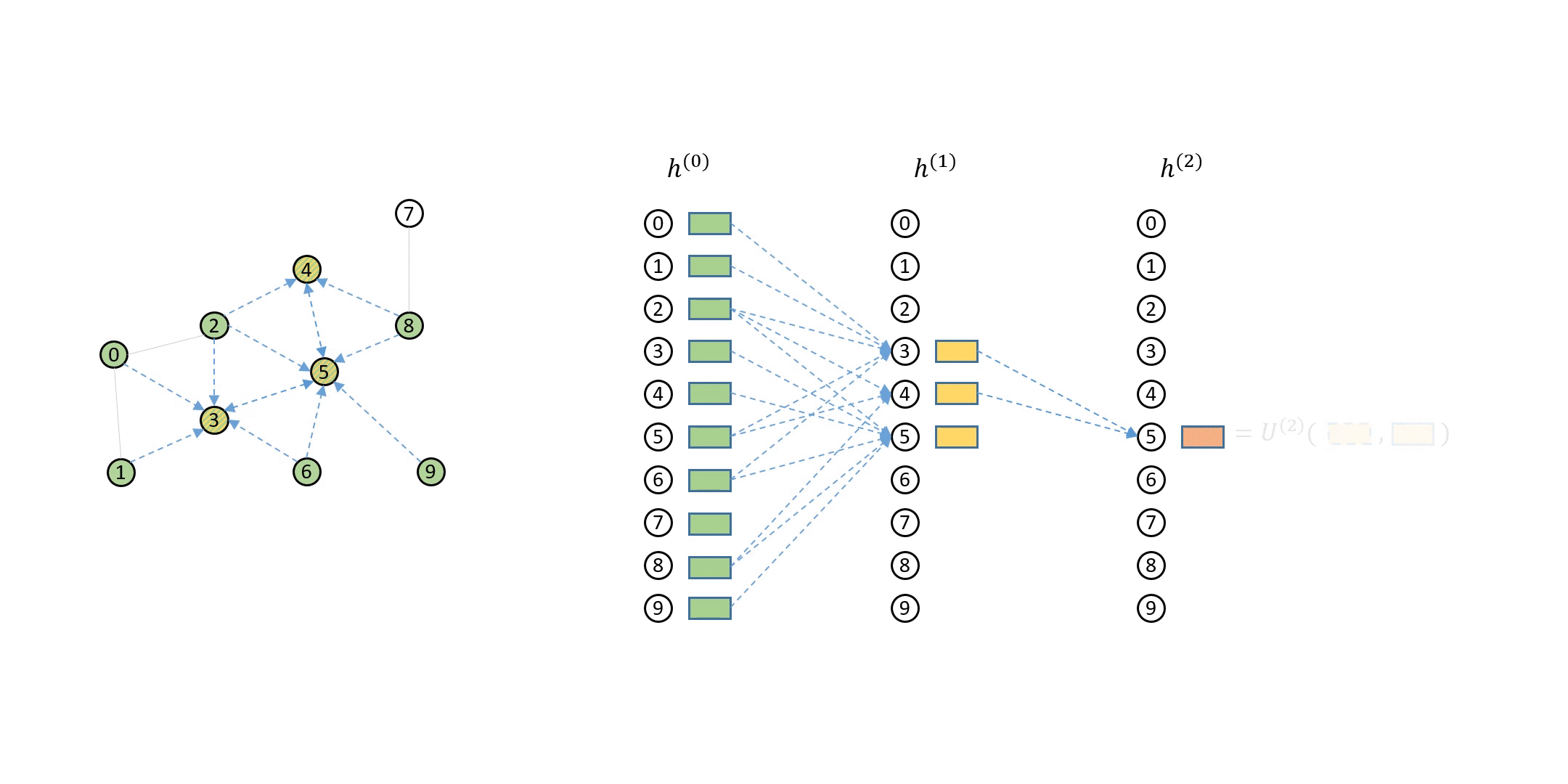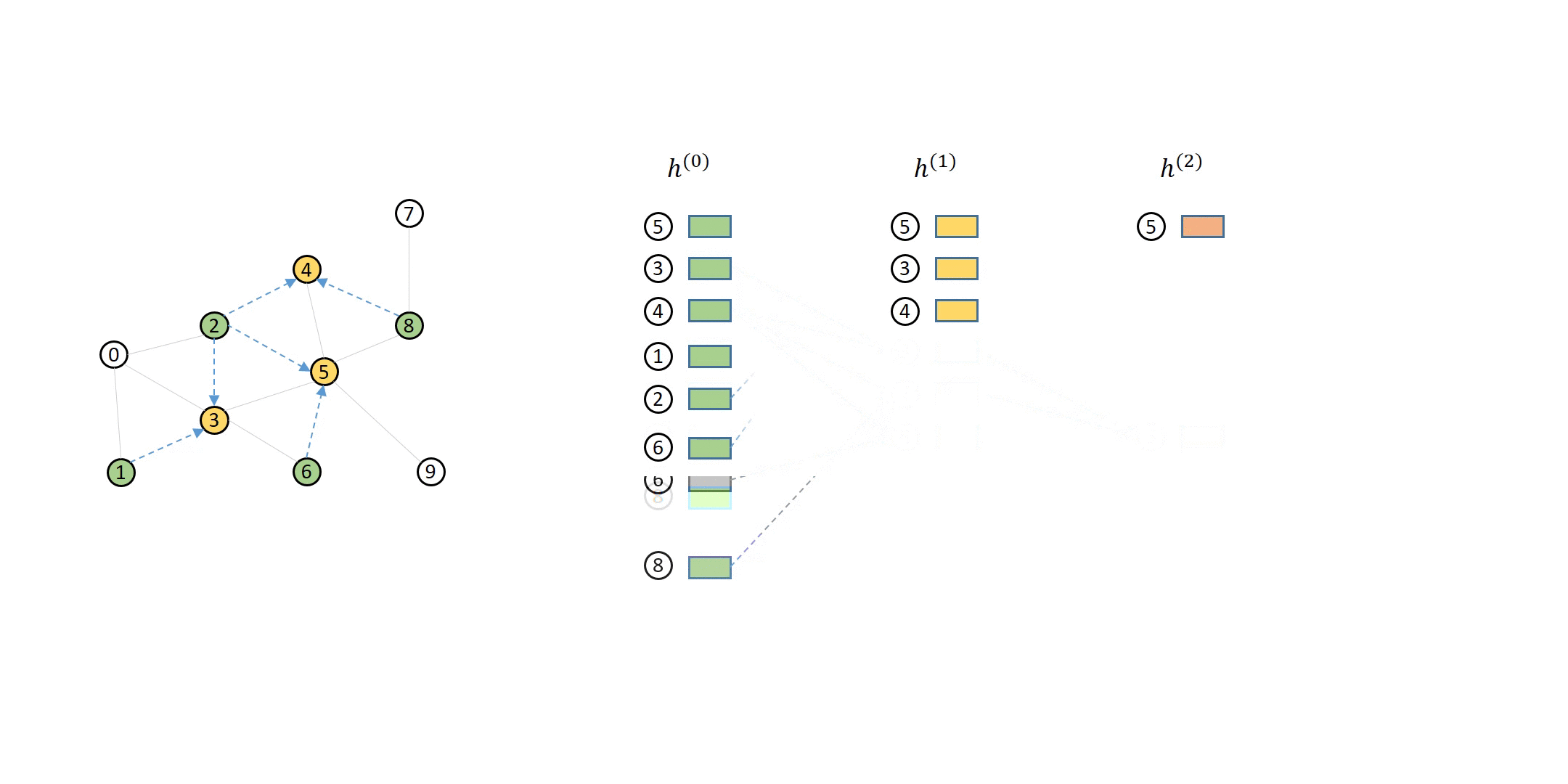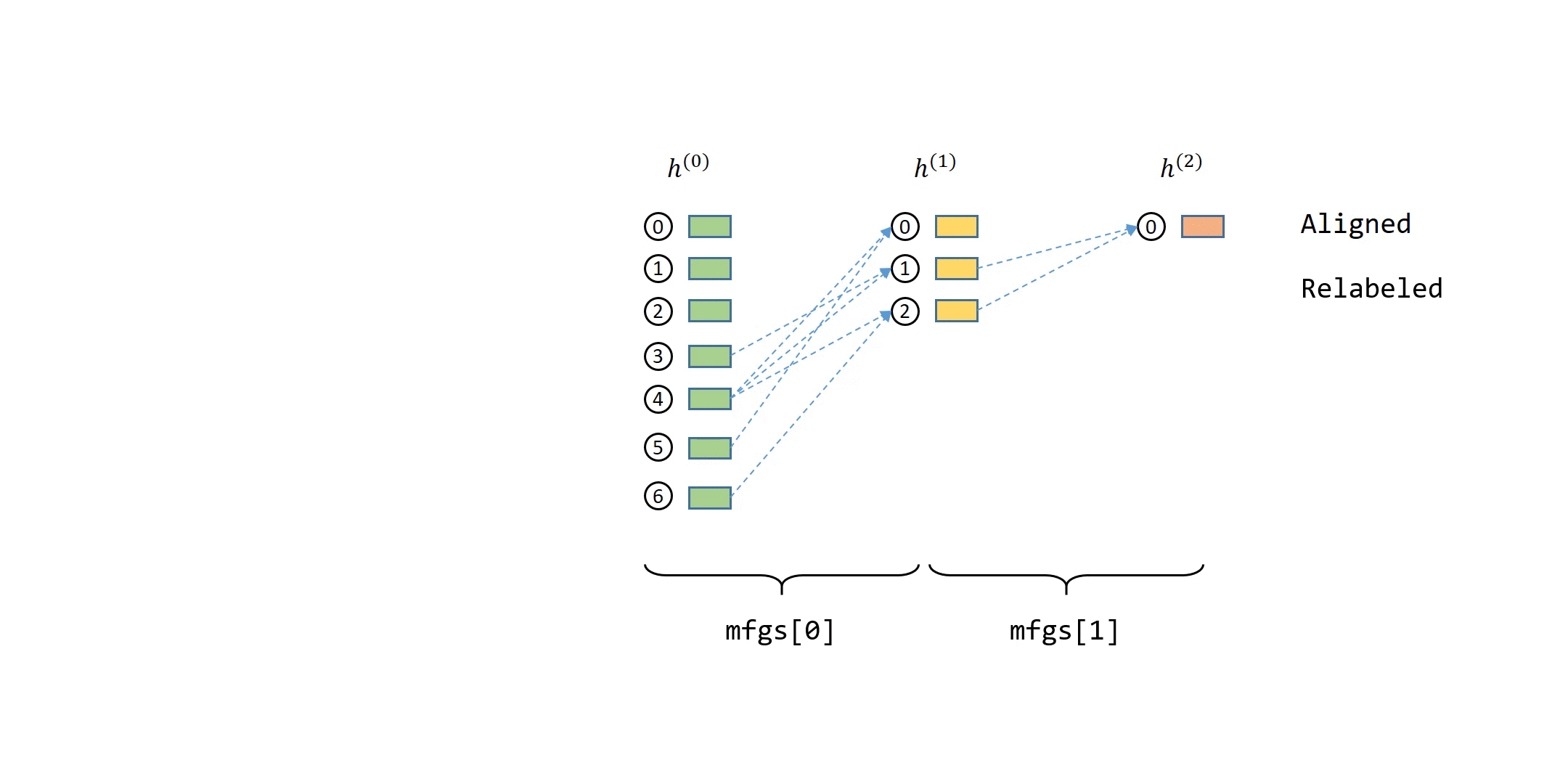
# Defining Neighbor Sampler and Data Loader in DGL
# ------------------------------------------------
#
# DGL provides tools to iterate over the dataset in minibatches
# while generating the computation dependencies to compute their outputs
# with the MFGs above. For node classification, you can use
# ``dgl.dataloading.NodeDataLoader`` for iterating over the dataset.
# It accepts a sampler object to control how to generate the computation
# dependencies in the form of MFGs. DGL provides
# implementations of common sampling algorithms such as
# ``dgl.dataloading.MultiLayerNeighborSampler`` which randomly picks
# a fixed number of neighbors for each node.
#
# <div class="alert alert-info">
#
# **Note**: To write your own neighbor sampler, please refer to [this user guide section](https://docs.dgl.ai/guide/minibatch-custom-sampler.html).
#
# </div>
#
# The syntax of ``dgl.dataloading.NodeDataLoader`` is mostly similar to a
# PyTorch ``DataLoader``, with the addition that it needs a graph to
# generate computation dependency from, a set of node IDs to iterate on,
# and the neighbor sampler you defined.
#
# Let’s say that each node will gather messages from 4 neighbors on each
# layer. The code defining the data loader and neighbor sampler will look
# like the following.
#
#
#
sampler = dgl.dataloading.MultiLayerNeighborSampler([4, 4])
train_dataloader = dgl.dataloading.NodeDataLoader(
# The following arguments are specific to NodeDataLoader.
graph, # The graph
train_nids, # The node IDs to iterate over in minibatches
sampler, # The neighbor sampler
device=device, # Put the sampled MFGs on CPU or GPU
# The following arguments are inherited from PyTorch DataLoader.
batch_size=1024, # Batch size
shuffle=True, # Whether to shuffle the nodes for every epoch
drop_last=False, # Whether to drop the last incomplete batch
num_workers=0 # Number of sampler processes
)
# You can iterate over the data loader and see what it yields.
#
#
#
input_nodes, output_nodes, mfgs = example_minibatch = next(iter(train_dataloader))
print(example_minibatch)
print("To compute {} nodes' outputs, we need {} nodes' input features".format(len(output_nodes), len(input_nodes)))
# ``NodeDataLoader`` gives us three items per iteration.
#
# - An ID tensor for the input nodes, i.e., nodes whose input features
# are needed on the first GNN layer for this minibatch.
# - An ID tensor for the output nodes, i.e. nodes whose representations
# are to be computed.
# - A list of MFGs storing the computation dependencies
# for each GNN layer.
#
#
#
# You can get the source and destination node IDs of the MFGs
# and verify that the first few source nodes are always the same as the destination
# nodes. As we described in the [overview](L0_neighbor_sampling_overview.ipynb),
# destination nodes' own features from the previous layer may also be necessary in
# the computation of the new features.
#
#
#
mfg_0_src = mfgs[0].srcdata[dgl.NID]
mfg_0_dst = mfgs[0].dstdata[dgl.NID]
print(mfg_0_src)
print(mfg_0_dst)
print(torch.equal(mfg_0_src[:mfgs[0].num_dst_nodes()], mfg_0_dst))
# Defining Model
# --------------
#
# Let’s consider training a 2-layer GraphSAGE with neighbor sampling. The
# model can be written as follows:
#
#
#
# +
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import SAGEConv
class Model(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(Model, self).__init__()
self.conv1 = SAGEConv(in_feats, h_feats, aggregator_type='mean')
self.conv2 = SAGEConv(h_feats, num_classes, aggregator_type='mean')
self.h_feats = h_feats
def forward(self, mfgs, x):
# Lines that are changed are marked with an arrow: "<---"
h_dst = x[:mfgs[0].num_dst_nodes()] # <---
h = self.conv1(mfgs[0], (x, h_dst)) # <---
h = F.relu(h)
h_dst = h[:mfgs[1].num_dst_nodes()] # <---
h = self.conv2(mfgs[1], (h, h_dst)) # <---
return h
model = Model(num_features, 128, num_classes).to(device)
# -
# If you compare against the code in the
# [introduction](1_introduction.ipynb), you will notice several
# differences:
#
# - **DGL GNN layers on MFGs**. Instead of computing on the
# full graph:
#
# ```python
# h = self.conv1(g, x)
# ```
#
# you only compute on the sampled MFG:
#
# ```python
# h = self.conv1(mfgs[0], (x, h_dst))
# ```
#
# All DGL’s GNN modules support message passing on MFGs,
# where you supply a pair of features, one for source nodes and another
# for destination nodes.
#
# - **Feature slicing for self-dependency**. There are statements that
# perform slicing to obtain the previous-layer representation of the
# nodes:
#
# ```python
# h_dst = x[:mfgs[0].num_dst_nodes()]
# ```
#
# ``num_dst_nodes`` method works with MFGs, where it will
# return the number of destination nodes.
#
# Since the first few source nodes of the yielded MFG are
# always the same as the destination nodes, these statements obtain the
# representations of the destination nodes on the previous layer. They are
# then combined with neighbor aggregation in ``dgl.nn.SAGEConv`` layer.
#
# <div class="alert alert-info">
#
# **Note**: See the [custom message passing tutorial](L4_message_passing.ipynb) for more details on how to
# manipulate MFGs produced in this way, such as the usage
# of ``num_dst_nodes``.
#
#
# </div>
#
#
#
# Defining Training Loop
# ----------------------
#
# The following initializes the model and defines the optimizer.
#
#
#
opt = torch.optim.Adam(model.parameters())
# When computing the validation score for model selection, usually you can
# also do neighbor sampling. To do that, you need to define another data
# loader.
#
#
#
valid_dataloader = dgl.dataloading.NodeDataLoader(
graph, valid_nids, sampler,
batch_size=1024,
shuffle=False,
drop_last=False,
num_workers=0,
device=device
)
# The following is a training loop that performs validation every epoch.
# It also saves the model with the best validation accuracy into a file.
#
#
#
# +
import tqdm
import sklearn.metrics
best_accuracy = 0
best_model_path = 'model.pt'
for epoch in range(10):
model.train()
with tqdm.tqdm(train_dataloader) as tq:
for step, (input_nodes, output_nodes, mfgs) in enumerate(tq):
# feature copy from CPU to GPU takes place here
inputs = mfgs[0].srcdata['feat']
labels = mfgs[-1].dstdata['label']
predictions = model(mfgs, inputs)
loss = F.cross_entropy(predictions, labels)
opt.zero_grad()
loss.backward()
opt.step()
accuracy = sklearn.metrics.accuracy_score(labels.cpu().numpy(), predictions.argmax(1).detach().cpu().numpy())
tq.set_postfix({'loss': '%.03f' % loss.item(), 'acc': '%.03f' % accuracy}, refresh=False)
model.eval()
predictions = []
labels = []
with tqdm.tqdm(valid_dataloader) as tq, torch.no_grad():
for input_nodes, output_nodes, mfgs in tq:
inputs = mfgs[0].srcdata['feat']
labels.append(mfgs[-1].dstdata['label'].cpu().numpy())
predictions.append(model(mfgs, inputs).argmax(1).cpu().numpy())
predictions = np.concatenate(predictions)
labels = np.concatenate(labels)
accuracy = sklearn.metrics.accuracy_score(labels, predictions)
print('Epoch {} Validation Accuracy {}'.format(epoch, accuracy))
if best_accuracy < accuracy:
best_accuracy = accuracy
torch.save(model.state_dict(), best_model_path)
# -
# Conclusion
# ----------
#
# In this tutorial, you have learned how to train a multi-layer GraphSAGE
# with neighbor sampling.
| L1_large_node_classification.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] slideshow={"slide_type": "slide"}
# # Biological Computing in Python II
# -
# ```{epigraph}
# ...some things in life are bad. They can really make you mad. Other things just make you swear and curse. When you're chewing on life's gristle, don't grumble; give a whistle, and this'll help things turn out for the best. And... always look on the bright side of life...
#
# -- Monty Python
#
# ```
# In this chapter, we will build on the [first Python Chapter](05-Python_I.ipynb), covering some more advanced topics.
#
# ## Numerical computing in Python
#
# Python is a good choice for numerical computing (recall [this comparison](05-Python_I:Why-python)). Using the right packages, you can do some serious number crunching in Python.
#
# We will use the `numpy` and `scipy` packages. The latter offers a data structure called numpy array that is suitable for efficient computing, along with basic operations on these arrays.
#
# On the other hand, scipy is proper numerical computing package (which *uses* numpy arrays) that can do a lot of things, including:
#
# * Linear algebra (matrix and vector operations) using `scipy.linalg`
# * Dealing with sparse matrix problems using `scipy.sparse`
# * Numerical integration (including solving of Ordinary Differential Equations (ODEs)) using `scipy.integrate`
# * Random number generation and using statistical functions and transformations using `scipy.stats`
# * Optimization using `scipy.optimize`
# * Fourier transforms using `scipy.fft`
# * Signal Processing using `scipy.signal`
#
# We will learn more about scipy further below. First, let's start with `numpy`.
# ### Numpy
#
# Numpy provides the `numpy array` data structure, along with methods for for data creation, manipulations and basic numerical calculations. Numpy arrays are similar in some respects to Python lists, but are homogeneous in type (the default is float), allow efficient (fast) manipulations, and are more naturally multidimensional (e.g., you can store multiple matrices in one array).
#
# ```{note}
# numpy arrays are analogous to the [R `matrix`](R-matrices) data structure.
# ```
#
# Let's start by importing numpy:
import numpy as np
a = np.array(range(5)) # a one-dimensional array
a
print(type(a))
print(type(a[0]))
# Thus the last two outputs tell you that firstly, that numpy arrays belong to a data structure type (and a class) called `numpy.ndarray`, and secondly, that at position `0` (remember, Python indexing starts at 0) it holds an [64 bit integer](https://en.wikipedia.org/wiki/9,223,372,036,854,775,807). All elements in `a` are of type `int` because that is what `range()` returns (try `?range`).
#
# ---
#
# :::{figure-md} Python-numpy-array
#
# <img src="./graphics/numpyarray.png" alt="Python numpy array" width="700px">
#
# **A graphical depiction of numpy/numpy arrays.** These can have multiple dimensions (even greater than 3). <br>
# (Source: [http://pages.physics.cornell.edu/~myers/teaching/ComputationalMethods/python/arrays.html](http://pages.physics.cornell.edu/~myers/teaching/ComputationalMethods/python/arrays.html))
#
# :::
#
# ---
#
# You can also specify the data type of the array:
a = np.array(range(5), float)
a
a.dtype # Check type
# You can also get a 1-D arrays as follows:
x = np.arange(5)
x
x = np.arange(5.) #directly specify float using decimal
x
# As with other Python variables (e.g., created as a list or a dictionary), you can apply methods to variables created as numpy arrays. For example, type `x.` and hit TAB to see all methods you can apply to`x`. To see dimensions of `x`:
x.shape
# ```{tip}
# Remember, you can type `:?x.methodname` to get info on a particular method (command). For example, try `?x.shape`.
# ```
#
# You can also convert to and from Python lists (recall [list comprehensions](Python-Comprehensions) from the [Python I chapter](./05-Python_I.ipynb)):
b = np.array([i for i in range(10) if i % 2 == 1]) #odd numbers between 1 and 10
b
c = b.tolist() #convert back to list
c
# To make a matrix, you need a 2-D numpy array:
mat = np.array([[0, 1], [2, 3]])
mat
mat.shape
# ### Indexing and accessing arrays
#
# As with other Python data objects such as lists, numpy array elements can be accessed using square brackets (`[ ]`) with the usual `[row,column]` reference. Indexing of numpy arrays works like that for other data structures, with index values starting at 0. So, you can obtain all the elements of a particular row as:
mat[1] # accessing whole 2nd row, remember indexing starts at 0
mat[:,1] #accessing whole second column
# And accessing particular elements:
mat[0,0] # 1st row, 1st column element
mat[1,0] # 2nd row, 1st column element
# Note that (like all other programming languages) row index always comes before column index. That is, `mat[1]` is always going to mean "whole second row", and `mat[1,1]` means 1st row and 1st column element. Therefore, to access the whole second column, you need:
mat[:,0] #accessing whole first column
# Python indexing also accepts negative values for going back to the start
# from the end of an array:
mat[0,1]
mat[0,-1]
mat[-1,0]
mat[0,-2]
# Very interesting, but rather useless for this simple matrix!
# ### Manipulating arrays
#
# Manipulating numpy arrays is pretty straightforward.
#
# ```{note}
# **Why numpy arrays are computationally efficient:** The data associated with a numpy array object (its metadata – number of dimensions, shape, data type, etc – as well as the actual data) are stored in a homogeneous and contiguous block of memory (a "data buffer"), at a particular address in the system's RAM (Random Access Memory). This makes numpy arrays more efficient than a pure Python data structures like lists whose data are scattered across the system memory.
# ```
#
# #### Replacing, adding or deleting elements
#
# Let's look at how you can replace, add, or delete an array element (a single entry, or whole row(s) or whole column(s)):
mat[0,0] = -1 #replace a single element
mat
mat[:,0] = [12,12] #replace whole column
mat
np.append(mat, [[12,12]], axis = 0) #append row, note axis specification
np.append(mat, [[12],[12]], axis = 1) #append column
newRow = [[12,12]] #create new row
mat = np.append(mat, newRow, axis = 0) #append that existing row
mat
np.delete(mat, 2, 0) #Delete 3rd row
# And concatenation:
mat = np.array([[0, 1], [2, 3]])
mat0 = np.array([[0, 10], [-1, 3]])
np.concatenate((mat, mat0), axis = 0)
# #### Flattening or reshaping arrays
#
# You can also "flatten" or "melt" arrays, that is, change array dimensions (e.g., from a matrix to a vector):
mat.ravel()
mat.reshape((4,1))
# This is different from ravel: check the documentation by using `?np.reshape`.
mat.reshape((1,4))
# ```{note}
# You might have noticed that flattening and reshaping is "row-priority": elements of the vector are allocated to a matrix row-wise, and vice versa(e.g., with `ravel` unraveling also happens row by row).
# ```
mat.reshape((3, 1))
# This gives an error because total elements must remain the same!
#
# This is a bit different than how [`R` behaves](R-Recycling), where you won't get an error (R "recycles" data) (which can be dangerous!)
#
# ### Pre-allocating arrays
#
# As in other computer languages, it is usually more efficient to preallocate an array rather than append / insert / concatenate additional elements, rows, or columns. *Why*? – because you might run out of contiguous space in the specific system memory (RAM) address where the current array is stored. Preallocation allocates all the RAM memory you need in one call, while resizing the array (through `append`, `insert`, `concatenate`, `resize`, etc.) may require copying the array to a larger block of memory, slowing things down, and significantly so if the matrix/array is very large.
#
# For example, if you know the size of your matrix or array, you can initialize it with ones or zeros:
np.ones((4,2)) #(4,2) are the (row,col) array dimensions
np.zeros((4,2)) # or zeros
m = np.identity(4) #create an identity matrix
m
m.fill(16) #fill the matrix with 16
m
# ### `numpy` matrices
#
# Scipy/Numpy also has a `matrix` data structure class. Numpy matrices are strictly 2-dimensional, while numpy arrays are N-dimensional. Matrix objects are a subclass of numpy arrays, so they inherit all the attributes and methods of numpy arrays (ndarrays).
#
# The main advantage of scipy matrices is that they provide a convenient notation for matrix multiplication: for example, if `a` and `b` are matrices, then `a * b` is their matrix product.
#
# #### Matrix-vector operations
#
# Now let's perform some common matrix-vector operations on arrays (you can also try the same using matrices instead of arrays):
mm = np.arange(16)
mm = mm.reshape(4,4) #Convert to matrix
mm
mm.transpose()
mm + mm.transpose()
mm - mm.transpose()
mm * mm.transpose() # Note that this is element-wise multiplication
mm // mm.transpose()
# Note that we used integer division `//`. Note also the warning you get (because of zero division). So let's avoid the divide by zero:
mm // (mm + 1).transpose()
mm * np.pi
mm.dot(mm) # No this is matric multiplication, or the dot product
# There is also a numpy matrix class:
mm = np.matrix(mm) # convert to scipy/numpy matrix class
mm
print(type(mm))
# This data structure makes matrix multiplication syntactically easier:
mm * mm # instead of mm.dot(mm)
# ```{warning}
# However, it is not recommended that you use the numpy matrix class because it may be removed [in the future](https://numpy.org/doc/stable/reference/generated/numpy.matrix.html).
# ```
# ```{tip}
# You can do a lot more with matrices and vectors by importing the `linalg` sub-package from scipy: `scipy.linalg`.
# ```
# ### The `scipy` package
#
# Now let's move on to `scipy`.
#
# ```{note}
# **scipy vs numpy**: It's a bit confusing. Please have a look at [this](https://www.scipy.org/scipylib/faq.html#what-is-the-difference-between-numpy-and-scipy) and [this](https://docs.scipy.org/doc/scipy/reference/release.1.4.0.html#scipy-deprecations). Basically, there is some overlap between what these two packages can do, and this redundancy will eventually be phased out completely. The recommended approach is to use numpy for creating and manipulating data and scipy for more complex numerical operations.
# ```
#
# We will look at two particularly useful `scipy` sub-packages here: `scipy.stats` and `scipy.integrate`.
#
# (Python-scipy-stats)=
# #### Scipy stats
#
# Let's take a quick spin in `scipy.stats`.
#
# *Why not use `R` for stats?* — because often you might just need to calculate some summary stats of your simulation results within Python, or you simulations may require the generation of random numbers.
#
# First, import scipy:
import scipy as sc
# Or you can use `from scipy import stats`.
#
# Let's generate 10 samples from the normal distribution ($\mathcal{N}(\mu,\,\sigma^{2})$):
sc.stats.norm.rvs(size = 10)
# By default, [as in R](R-random-numbers), these are numbers from the *standard* normal distribution ($\mathcal{N}(0,\,1)$).
# ```{tip}
# **Continuing on the numpy vs scipy theme**: Both scipy and numpy can generate random numbers (e.g., `np.random.normal(size=10)` would work equally well above). In fact, scipy uses the `numpy.random` package under the hood for drawing random numbers. You may choose to use either, but for sanity, its probably a good idea to just stick with `scipy.stats` for all your stats number crunching.
# ```
#
# Also, as you learned [in R](R-random-numbers), you can "seed" random numbers to get the same sequence every time (important for reproducibility – when you need to know what specific random numbers were input into a particular program routine or algorithm).
np.random.seed(1234)
sc.stats.norm.rvs(size = 10)
# But setting a *global* random number state is not always needed or in some many cases, recommended, because using something like `np.random.seed(1234)` will set the seed for all following instances where a random number is generated. In many scenarios a more robust way is to use the `random_state` argument for each specific generation of a set of random numbers:
sc.stats.norm.rvs(size=5, random_state=1234)
# We will not move on from `scipy.stats`. Before we do so, here's an example of generating random integers between 0 and 10:
sc.stats.randint.rvs(0, 10, size = 7)
# And again with a random seed:
sc.stats.randint.rvs(0, 10, size = 7, random_state=1234)
sc.stats.randint.rvs(0, 10, size = 7, random_state=3445) # a different seed
# #### Numerical integration using `scipy`
#
# OK, on to to and `scipy.integrate`.
#
# Numerical integration is the approximate computation of an integral using numerical techniques. You need numerical integration whenever you have a complicated function that cannot be integrated analytically using anti-derivatives. For example, calculating the area under a curve is a particularly useful application. Another one is solving ordinary differential equations (ODEs), commonly used for modelling biological systems.
import scipy.integrate as integrate
# ##### Area under a curve
#
# Let's calculate the area under an arbitrary curve.
y = np.array([5, 20, 18, 19, 18, 7, 4]) # The y values; can also use a python list here
# Let's visualize the curve. We can use the `matplotlib` package for this:
import matplotlib.pylab as p
p.plot(y)
# Now compute the area using the [composite trapezoidal rule](https://en.wikipedia.org/wiki/Trapezoidal_rule):
area = integrate.trapz(y, dx = 2)
print("area =", area)
# The argument `dx` defines the spacing between points of the curve (the x-axis values). The default is 1 (don't forget to check out the documentation: `?integrate.trapz`). Changing this will change the area, of course:
area = integrate.trapz(y, dx = 1)
print("area =", area)
area = integrate.trapz(y, dx = 3)
print("area =", area)
# Now, the same, using [Simpson's rule](https://en.wikipedia.org/wiki/Simpson%27s_rule):
area = integrate.simps(y, dx = 2)
print("area =", area)
area = integrate.simps(y, dx = 1)
print("area =", area)
area = integrate.simps(y, dx = 3)
print("area =", area)
# ##### The Lotka-Volterra model
#
# Now let's try numerical integration in Python for solving a classical model in biology — the Lotka-Volterra (LV) model for a predator-prey system in two-dimensional space (e.g., on land). The LV model is:
#
# \begin{align}
# \frac{dR}{dt} &= r R - a C R \nonumber \\
# \frac{dC}{dt} &= - z C + e a C R
# \end{align}
#
# where,
#
# * $C$ and $R$ are consumer (e.g., predator) and resource (e.g., prey) population abundances (either number $\times$ area$^{-1}$ ).
# * $r$ is the intrinsic (per-capita) growth rate of the resource population (time$^{-1}$).
# * $a$ is per-capita "search rate" for the resource ($\text{area}\times \text{time}^{-1}$) multiplied by its attack success probability, which determines the encounter and consumption rate of the consumer on the resource.
# * $z$ is mortality rate ($\text{time}^{-1}$) and $e$ is the consumer's efficiency (a fraction) in converting resource to consumer biomass.
#
# We have already imported scipy above (`import scipy as sc`) so we can proceed to solve the LV model using numerical integration.
#
# First, import `scipy`'s `integrate` submodule:
# Now define a function that returns the growth rate of consumer and resource population at any given time step.
def dCR_dt(pops, t=0):
R = pops[0]
C = pops[1]
dRdt = r * R - a * R * C
dCdt = -z * C + e * a * R * C
return np.array([dRdt, dCdt])
type(dCR_dt)
# So `dCR_dt` has been stored as a function object in the current Python session, all ready to go.
#
# Now assign some parameter values:
r = 1.
a = 0.1
z = 1.5
e = 0.75
# Define the time vector; let's integrate from time point 0 to 15, using 1000 sub-divisions of time:
t = np.linspace(0, 15, 1000)
# Note that the units of time are arbitrary here.
# Set the initial conditions for the two populations (10 resources and 5 consumers per unit area), and convert the two into an array (because our `dCR_dt` function take an array as input).
R0 = 10
C0 = 5
RC0 = np.array([R0, C0])
# Now numerically integrate this system forward from those starting conditions:
pops, infodict = integrate.odeint(dCR_dt, RC0, t, full_output=True)
pops
# So `pops` contains the result (the population trajectories). Also check what's in infodict (it's a dictionary with additional information)
type(infodict)
infodict.keys()
# Check what the `infodict` output is by reading the help documentation with `?scipy.integrate.odeint`. For example, you can return a message to screen about whether the integration was successful:
infodict['message']
# So it worked, great!
#
# But we would like to visualize the results. Let's do it using the `matplotlib` package.
#
# Again, to visualize the results of your numerical simulations in Python (or for data exploration/analyses), you can use `matplotlib`, which uses Matlab like plotting syntax.
#
# First import the package:
import matplotlib.pylab as p
# Now open an empty figure object (analogous to an R graphics object).
f1 = p.figure()
p.plot(t, pops[:,0], 'g-', label='Resource density') # Plot
p.plot(t, pops[:,1] , 'b-', label='Consumer density')
p.grid()
p.legend(loc='best')
p.xlabel('Time')
p.ylabel('Population density')
p.title('Consumer-Resource population dynamics')
p.show()# To display the figure
# Finally, save the figure as a pdf:
f1.savefig('../results/LV_model.pdf') #Save figure
# ```{tip}
# You can use many other graphics output formats in matplotlib; check the documentation of `p.savefig`.
# ```
# ### Practicals
#
# 1. Create a self-standing script using the above example and save it as `LV1.py` in your code directory. In addition to generating the above figure, it should also generate the following figure:
#
# ---
# :::{figure-md} LV-phase-plot
#
#
# <img src="./graphics/LV_model_CR.png" alt="Lotka-Volterra phase plot" width="400px">
#
# **Generate this figure as part of the `LV1.py` script.**
#
# :::
#
# ---
#
# It should save both figures in pdf to the `results` directory, *without displaying them on screen*.
# ### The need for speed: profiling code
#
# Donald Knuth says: *Premature optimization is the root of all evil*.
#
# Indeed, computational speed may not be your initial concern. Also, you should focus on developing clean, reliable, reusable code rather than worrying first about how fast your code runs. However, speed will become an issue when and if your analysis or modeling becomes complex enough (e.g., food web or large network simulations). In that case, knowing which parts of your code take the most time is useful – optimizing those parts may save you lots of time.
#
# #### Profiling
#
# To find out what is slowing down your code you need to "profile" your code: locate the sections of your code where speed bottlenecks exist.
#
# Profiling is easy in `ipython` – simply use the command:
#
# ```python
# # %run -p your_function_name
# ```
#
# Let's write an illustrative program (name it `profileme.py`) and run it:
# +
def my_squares(iters):
out = []
for i in range(iters):
out.append(i ** 2)
return out
def my_join(iters, string):
out = ''
for i in range(iters):
out += string.join(", ")
return out
def run_my_funcs(x,y):
print(x,y)
my_squares(x)
my_join(x,y)
return 0
run_my_funcs(10000000,"My string")
# -
# Look carefully at what each of these functions does.
#
# Now run the script with `run -p profileme.py`, and you should see something like:
#
# ```bash
# 20000063 function calls (20000062 primitive calls) in 9.026 seconds
#
# Ordered by: internal time
#
# ncalls tottime percall cumtime percall filename:lineno(function)
# 1 3.335 3.335 3.732 3.732 profileme.py:1(my_squares)
# 1 2.698 2.698 5.200 5.200 profileme.py:7(my_join)
# 10000001 2.502 0.000 2.502 0.000 {method 'join' of 'str' objects}
# 10000008 0.397 0.000 0.397 0.000 {method 'append' of 'list' objects}
# 1 0.093 0.093 9.025 9.025 profileme.py:13(run_my_funcs)
# [more output]
# ```
# The column headings in the profiling results are:
#
# | Column name | Meaning |
# | :- | - |
# | `filename:lineno(function)` | The filename, line number, and function name|
# | `ncalls` | Number of times the function was called |
# | `tottime` | Total time spent in the function (excluding time spent in calls to sub-functions of that function)|
# | `percall` | `tottime` divided by `ncalls`|
# | `cumtime` | Cumulative time spent in the function *and* all its sub-functions|
# | `percall` | `cumtime` divided by `ncalls`|
#
# (Please also see the official Python [documentation](https://docs.python.org/3.6/library/profile.html))
#
# The difference between `tottime` and `cumtime` columns often holds the most important information about performance. For example, in the above output, `cumtime` is much higher than `tottime` for `my_join` than for `my_squares`. This is because the sub-function (method) `join` is taking an additional 2.502 seconds (due to 10000001 calls), giving a `cumtime` of 2.698 + 2.502 = 5.2 seconds. In comparison, the sub-function (method) `append` is taking an additional 0.397 seconds (due to 10000008 calls), giving a `cumtime` of 3.335 + 0.397 = 3.732 seconds. Note also that the `tottime`s for `join` and `append` include the "overhead" of running their respective loop.
#
# Thus, we can infer that the `my_join` function is hogging most of the time, followed by `my_squares`, and furthermore, that its the string method `join` that is slowing `my_join` down, and list method `append` that is slowing `my_squares` down. In other words, `.join`ing the string, and `.append`ing values to a list repeatedly are both not particularly fast, though the latter is less costly.
#
# Can we do better? *Yes!*
#
# Let's try this alternative approach to writing the program (save it as `profileme2.py`, and again, run it):
# +
def my_squares(iters):
out = [i ** 2 for i in range(iters)]
return out
def my_join(iters, string):
out = ''
for i in range(iters):
out += ", " + string
return out
def run_my_funcs(x,y):
print(x,y)
my_squares(x)
my_join(x,y)
return 0
run_my_funcs(10000000,"My string")
# -
# We did two things: converted the loop to a list comprehension, and replaced the `.join` with an explicit string concatenation.
#
# Now profile this program (`run -p profileme2.py`), and you should get something like:
#
# ```bash
# 64 function calls (63 primitive calls) in 4.585 seconds
#
# Ordered by: internal time
#
# ncalls tottime percall cumtime percall filename:lineno(function)
# 1 2.497 2.497 2.497 2.497 profileme2.py:2(<listcomp>)
# 1 1.993 1.993 1.993 1.993 profileme2.py:5(my_join)
# 1 0.094 0.094 4.584 4.584 profileme2.py:11(run_my_funcs)
# [more output]
# ```
#
# Woo hoo! So we about halved the time! Not quite enough to grab a pint, but ah well...
#
# $\star$ Another approach would be to preallocate a `numpy` array instead of using a list for `my_squares` - *Try it*
#
# You can also modify how the profiling results are displayed, and more, by using flags. For example, `-s` allows sorting the report by a particular column, `-l` limits the number of lines displayed or filters the results by function name, and `-T` saves the report in a text file.
#
# For example, try
#
# ```python
# run -p -s cumtime profileme2.py
# ```
# This will do the profiling and display the results sorted by `cumtime`.
# #### Profiling without ipython
#
# You may want to execute the code that you need to profile from outside IPython (e.g., using a bash script). In this case, we you can use the module cProfile (ipython actually uses this when you do `%run -p`).
#
# here is an example (run from bash):
#
# ```bash
# python3 -m cProfile profileme2.py
# ```
#
# Or,
#
# ```bash
# python3 -m cProfile -o profires myscript.py
# ```
# Here the results are stored in a file called `profires`, which can be read using the `pstats` module. Read the documentation of `cProfile` and `pstats` modules; there are many analyses you can perform on such exported profiling reports.
# #### Quick profiling with `timeit`
#
# Additionally, you can use the `timeit` module if you want to figure out what the best way to do something specific as part of a larger program (say a particular command or a loop) might be.
#
# Type and run the following code in a python script called `timeitme.py`:
#
# ```python
# ##############################################################################
# # loops vs. list comprehensions: which is faster?
# ##############################################################################
#
# iters = 1000000
#
# import timeit
#
# from profileme import my_squares as my_squares_loops
#
# from profileme2 import my_squares as my_squares_lc
#
# ##############################################################################
# # loops vs. the join method for strings: which is faster?
# ##############################################################################
#
# mystring = "my string"
#
# from profileme import my_join as my_join_join
#
# from profileme2 import my_join as my_join
#
# ```
# Note how we imported the functions using `from profileme import my_squares as my_squares_loops`, etc., which highlights the convenience of Python's elegant object-oriented approach.
#
# Now run the two sets of comparisons using `timeit()` in ipython and make sure every line makes sense:
#
# ```python
# # %timeit my_squares_loops(iters)
# # %timeit my_squares_lc(iters)
# # %timeit (my_join_join(iters, mystring))
# # %timeit (my_join(iters, mystring))
# ```
#
# Note that embedding the `%timeit()` commands within the script won't work calling magic commands from inside a script is not a good idea!
#
# Of course, a simple approach would have been to time the functions like this:
#
# ```python
# import time
# start = time.time()
# my_squares_loops(iters)
# print("my_squares_loops takes %f s to run." % (time.time() - start))
#
# start = time.time()
# my_squares_lc(iters)
# print("my_squares_lc takes %f s to run." % (time.time() - start))
# ```
# But you'll notice that if you run it multiple times, the time taken changes each time. So `timeit` takes a sample of runs and returns the average, which is better.
#
# *But remember, don't go crazy with profiling for the sake of shaving a couple of milliseconds, tempting as that may be!*
# ### Vectorization revisited
# We have now had fairly extensive practice in iteratively creating solutions to problems using for loops. Thus far all our problems have been mathematically quite straightforward, and not very computationally intensive. As you begin to move on from your taught modules into project work, you may find yourselves solving larger and more complex problems, at which point you will start to discover that for-loops have a fundamental weakness - speed!
#
# In a nutshell, there are two issues keeping loops slow:
#
# * Producing solutions to a large problem one loop iteration at a time means that our scripts and functions spend a lot of time doing stuff other than actually solving the problem we want them to solve - e.g. shuffling data around between variables in each loop iteration, or storing the result of the current loop's calculations in a (sometimes temporary) variable.
# * Loops (at least in Python) are not generally able to take advantage of the parallel computing capabilities of modern-day computers, and thus must literally compute a solution one loop iteration at a time. vectorized functions tend to be optimised to spread their computations over multiple processors/threads, which can be much faster!
#
# These issues become especially pronounced in the case of nested loops - which often appear in more spatially-explicit problems or time-dependent ones.
#
# The following two examples will showcase the difference in runtime between a loop method and a vectorized method using numpy. The first is a relatively simple (if artificial) problem, intended to demonstrate basically at-a-glace the difference between the two approaches. The second is taken from current research on metabolic models of bacterial communities.
#
# #### An example
#
# Let us imagine we have two simple 1D arrays $a = (a_1, a_2, ... , a_N)$ and $b = (b_1, b_2, ... ,b_N)$, each of length N, and that we want to calculate a new array $c$ in which each entry is just the product of the two corresponding entries in $a$ and $b$:
#
# $$c = (a_1 \times b_1, a_2 \times b_2, ... , a_N \times b_N)$$
#
# This operation is called the *entrywise* product of $a$ and $b$.
#
# Below are a loop-based function and a vectorized function to calculate the entrywise product of two 1D arrays of the same length. We will test them both on larger and larger 1D arrays to see how the vectorized approach is faster.
# +
def loop_product(a, b):
N = len(a)
c = np.zeros(N)
for i in range(N):
c[i] = a[i] * b[i]
return c
def vect_product(a, b):
return np.multiply(a, b)
# -
# The `multiply` function from numpy is a vectorized implementation of the elementwise product that we have explicitly written in the function `loop_product` above it. In general, numpy is an excellent choice for vectorized implementations of functions involving matrix maths (or maths using higher-dimensional analogues of matricies).
#
# Let's try comparing the runtimes of `loop_product` and `vect_product` on increasingly large randomly-generated 1D arrays:
# +
import timeit
array_lengths = [1, 100, 10000, 1000000, 10000000]
t_loop = []
t_vect = []
for N in array_lengths:
print("\nSet N=%d" %N)
#randomly generate our 1D arrays of length N
a = np.random.rand(N)
b = np.random.rand(N)
# time loop_product 3 times and save the mean execution time.
timer = timeit.repeat('loop_product(a, b)', globals=globals().copy(), number=3)
t_loop.append(1000 * np.mean(timer))
print("Loop method took %d ms on average." %t_loop[-1])
# time vect_product 3 times and save the mean execution time.
timer = timeit.repeat('vect_product(a, b)', globals=globals().copy(), number=3)
t_vect.append(1000 * np.mean(timer))
print("vectorized method took %d ms on average." %t_vect[-1])
# -
# Phew! That last one just exploded in terms of the time it took!
#
# Now let's compare the timings on a plot:
p.figure()
p.plot(array_lengths, t_loop, label="loop method")
p.plot(array_lengths, t_vect, label="vect method")
p.xlabel("Array length")
p.ylabel("Execution time (ms)")
p.legend()
p.show()
# #### When to vectorize?
#
# Thus vectorizing your code can have it running in a fraction of the time it otherwise would. Why not always vectorize then?
#
# Generally, you should follow the same principles as with any code profiling: don't spend time speeding up code that isn't slow in the first place, or code which you will probably not need to run more than a small number of times.
#
# #### "No free lunch!"
#
# There are trade-offs to vectorizing, most notably memory usage. One downside of calculating many steps simultaneously is that your computer needs to hold much more in memory in order to do it. If you try to vectorize a problem thats *too* large, you will probably run into memory errors. One easy example is to re-run the above example, but make it **even bigger**:
# ```python
# N = 1000000000
#
# a = np.random.rand(N)
# b = np.random.rand(N)
# c = vect_product(a, b)
#
# # if no error, remove a, b, c from memory.
# del a
# del b
# del c
# ```
# This will almost certainly return a memory error (i.e. your computer ran out of RAM in which to store the entirety of the very large arrays $a$, $b$ and $c$ while it was still calculating (if you didn't get an error, try again with an extra 0 in $N$).
#
# Again, this is a rather contrived example - you probably won't be taking element-wise products of arrays with a billion entries in your research - but more complex problems can easily become too big for memory while still remaining biologically reasonable!
#
# *Check out the CMEE module on High Performance Computing to learn about using Imperial College's supercomputing cluster to run extremely large problems*
#
# ```{tip}
# You can use the `multiprocessing` package for parallelizing your code on your own computer.
# ```
# ### Practicals
#
# #### Lotka-Volterra model problem
#
# Copy and modify `LV1.py` into another script called `LV2.py` that has the following features:
#
# * It takes arguments for the four LV model parameters $r$, $a$, $z$ ,$e$ from the command line:
# ```
# LV2.py arg1 arg2 ... etc
# ```
# * It runs the Lotka-Volterra model with prey density dependence $r R \left(1 - \frac{R} {K}\right)$, which changes the coupled ODEs to,
#
# \begin{align}
# \frac{dR}{dt} &= r R \left(1 - \frac{R} {K}\right) - a C R\\
# \frac{dC}{dt} &= - z C + e a C R
# \end{align}
#
# * It saves the plot as `.pdf` in an appropriate location.
# * The chosen parameter values should show in the plot (e.g., $r = 1, a = .5 $, etc) You can change time length $t$ too.
# * The parameters values should be adjusted such that both predator and prey persist with prey density dependence ( the final (non-zero) population values should be printed to screen).
#
# Also, include a script that runs both `LV1.py` and `LV2.py` with appropriate arguments. This script should also profile the two scripts and print the results to screen for each of the scripts using the `%run -p` approach. Look at and compare the speed bottlenecks in `LV1.py` and `LV2.py`. *Think about how you could further speed up the scripts.*
#
#
# #### Groupwork practical: Compare R and Python Vectorization
#
# Implement the Python versions of `Vectorize1.R`and ` Vectorize2.R` [from the R Chapter](R-Vectorization) (call them `Vectorize1.py` and `Vectorize2.py` respectively). Then write a shell script that compares the computational speed of the four scripts. the script should display meaningful summary of the results in the terminal. In particular, it should print the timings of the equivalent R and Python functions (not just the timing of the R and Python scripts as a whole).
#
# #### Groupwork practical: Discrete time LV Model
#
# *Write every subsequent extra credit script file with a new name such as `LV3.py`,`LV4.py`, etc.*
#
# * Write a discrete-time version of the LV model called `LV3.py`. The discrete-time model is:
#
# \begin{align}
# R_{t+1} &= R_t (1 + r \left(1 - \frac{R_t}{K}\right) - a C_t)\\
# C_{t+1} &= C_t (1 - z + e a R_t)
# \end{align}
#
# Include this script in `run_LV.py`, and profile it as well.
#
# #### Groupwork practical: Discrete time LV model with stochasticity
#
# * Write a version of the discrete-time model (which you implemented in `LV3.py`) simulation with a random gaussian fluctuation in resource's growth rate at each time-step:
#
# \begin{align}
# R_{t+1} &= R_t (1 + (r + \epsilon) \left(1 - \frac{R_t}{K}\right)- a C_t)\\
# C_{t+1} &= C_t (1 - z + e a R_t)
# \end{align}
#
# where $\epsilon$ is a random fluctuation drawn from a gaussian distribution (use `sc.stats` or `np.random`). Include this script in ` run_LV.py`, and profile it as well. You can also add fluctuations to both populations simultaneously this way:
#
# \begin{align}
# R_{t+1} &= R_t (1 + (r + \epsilon) \left(1 - \frac{R_t}{K}\right) - a C_t)\\
# C_{t+1} &= C_t (1 - (z + \epsilon) + e a R_t)
# \end{align}
#
# *As always, test, add, commit and push all your new code and data to your git repository.*
# (Python_II:python-regex)=
# ## Regular expressions in Python
#
# Let's shift gears now, and look at a very important tool set that you should learn, or at least be aware of — *Regular expressions*.
#
# Regular expressions (regex) are a tool to find patterns (not just a particular sequence of characters) in strings. For example, `<EMAIL>` is a specific sequence of characters, but, in fact, all email addresses have such a pattern: alphanumeric characters, a "@", alphanumeric characters, a ".", alphanumeric characters. Using regex, you can search for all email addresses in a text file by searching for this pattern.
#
# There are many uses of regex, such as:
#
# * Parsing (reading) text files and finding and replacing or deleting specific patterns
# * Finding DNA motifs in sequence data
# * Navigating through files in a directory
# * Extracting information from html and xml files
#
# Thus, if you are interested in data mining, need to clean or process data in any other way, or convert a bunch of information into usable data, knowing regex is absolutely necessary.
#
#
# ---
#
# :::{figure-md} XKCD-on-Regex
#
# <img src="./graphics/regex.png" alt="XKCD on Regex" width="400px">
#
# **Regular expressions can really improve your quality of life.**<br> (Source: [XKCD](https://www.xkcd.com/208/))
#
# :::
#
# ---
#
#
#
# Regex packages are available for most programming languages (recall [`grep` in UNIX](Using-grep); that is how regex first became popular).
#
# ### Metacharacters vs. regular characters
#
# A regex may consist of a combination of special "metacharacters" (modifiers) and "regular" or literal characters. There are 14 metacharacters:
#
# |Metacharacter|Description|
# |:-|:-|
# |`[` `]` | Used to enclose a specific character "class" — the set of characters that you wish to match. For example, `[12]` means match target to "1" and if that does not match then match target to "2"; `[0-9]` means match to any character in range "0" to "9"|
# |`\`| Inhibits the "specialness" of a (meta)character so that it can be interpreted literally. So, for example, use `\.` to match an actual period, and `\\` to match an actual back slash. |
# | `.` | Match any character except line break (newline); e.g., `he..o` will match *hello* as well as *he12o* |
# |`^` | Indicates that the string to be matched is at the start of a longer string; e.g., `^hello` will match "hello" in "hello fellow!", but not in "fellow, hello!" |
# |`$` | Match the end of a string; for example, `world$` will match "world" in "Hello world", but not in "Hello world!" |
# |`*` | Match zero or more occurrences of the character or pattern that precedes it.|
# |`+` | Match 1 or more occurrences of the character or pattern that precedes it.|
# |`?`| Match the preceding pattern element zero *or* one times|
# |`{` `}`| Match exactly the specified number of occurrences; e.g., `.{2}` finds the first two instances of any character (except newline)|
# | `|`| Match either or |
# |`(` `)`| Capture and group; examples of this appear below |
#
# Everything other than these metacharacters is interpreted literally (e.g., *a* is matched by entering `a` in the regex) – a regular character.
#
# ```{note}
# **The difference between `*`, `+`, and `?`**:
# `*` matches zero or more times, so whatever's being repeated may *not* be present at all, while `+` *requires* at least one occurrence. So, for example, `ra+t` will match "rat" (one 'a' is present) and "raaat" (three "a"s), but won't match "rt". On the other hand, `?` matches a pattern either once or zero times, so it makes the pattern matching more flexible. For example, `home-?brew` matches either "homebrew" or "home-brew".
# ```
# ### Regex special sequences
#
# Along with inhibiting the "specialness" of a metacharacter so that it can be interpreted literally (see examples in table above), the backslash (`\`) can be followed by various standard character types to denote various *special sequences*.
#
# Below is a list of *commonly encountered* special sequences in [Unicode](https://en.wikipedia.org/wiki/Unicode) string patterns. For a complete list look [here](https://docs.python.org/3/library/re.html#re-syntax).
#
# |Sequence|Description|
# |:-|:-|
# |`\d`| Matches any numeric (integer); this is equivalent to the regex class [0-9]|
# |`\D`| Matches any non-digit character not covered by ` \d` (i.e., match a non-digit); this is equivalent to the class [^0-9]|
# |`\n`| Matches a newline|
# |`\t`| Matches a tab space|
# |`\s`|Matches any whitespace character; this is equivalent to the class [ \t\n\r\f\v]|
# |`\S`| Matches any non-whitespace character; this is equivalent to the class [^ \t\n\r\f\v]|
# |`\w`| Matches any "alphanumeric" character (including underscore); this is equivalent to the class [a-zA-Z0-9_]|
# |`\W`| Matches any non-alphanumeric character not covered by `\w`, i.e., any non-alphanumeric character excluding underscore, such as `?`, `!`, `+`, `<`, etc. ; this is equivalent to the class [^a-zA-Z0-9_]|
#
# In the above table,
# * `\r` stands for a "[carriage-return](https://en.wikipedia.org/wiki/Carriage_return#Computers)", which is usually (but not always) the same as as a newline (`\n`);
# * `\f` stands fior ["form feed"](https://en.wikipedia.org/wiki/Page_break) (or a page break character)
# * `\v` stands for ["vertical whitespace"](https://en.wikipedia.org/wiki/Whitespace_character), which includes all characters treated as line breaks in the Unicode standard.
#
# These are rarely encountered, but can exist in certain text files.
#
# ```{note}
# The reason why we have specified underscore as belonging to `\w` (i.e., the regex set [A-Za-z0-9_]) is because this is the specification of this class in Python regex in particular. This class definition is shared by most, but not all regex "flavors" (i.e., regex in other languages, such as Perl or Bash (recall `grep`)). The goal is to not to worry about it, but to keep in mind that `\w` will also match any pattern that includes one or more `_`'s!
# ```
# ### Some regex examples
#
# So combining metacharacters, regular characters and special sequences allows you to find pretty much any pattern. Here are some examples:
#
# |Regex|Description|
# |:-|:-|
# |`aX9`| match the character string *aX9* exactly (case sensitively)|
# |`aX9\n`| match the character string *aX9* (case sensitively) followed by a newline|
# |`8`| match the number *8*|
# |`\d8`| match the number *8* preceded by any decimal number|
# |`[atgc]` | match any character listed: `a`, `t`, `g`, `c`|
# | `at|gc` | match `at` or `gc`|
# |`[^atgc]`| match any character not listed: any character except `a`, `t`, `g`, `c`|
# | `[^a-z]` | match everything except lower case *a* to *z* |
# | `[^Ff]`| match anything except upper or lower case *f* |
# |`\w{n}`| match the preceding pattern element (any alphanumeric character) *exactly* `n` times|
# |`\w{n,}`| match the preceding pattern element (any alphanumeric character) *at least* `n` times|
# |`\w{n,m}`| match the preceding pattern element (any alphanumeric character) at least `n` but not more than `m` times|
#
# ```{tip}
# Metacharacters are not active inside classes. For example, `[a-z$]` will match any of the characters `a` to `z`, but also `$`, because inside a character class it loses its special metacharacter status.
# ```
# ### Regex in Python
#
# Regex functions in python are in the module `re`.
#
# Let's import it:
import re
# The simplest `python` regex function is `re.search`, which searches the string for match to a given pattern — returns a *match object* if a match is found and `None` if not. Thus, the command `match = re.search(pat, str)` finds matches of the pattern `pat` in the given string `str` and stores the search result in a variable named `match`.
#
# ```{tip}
# **Always** put `r` in front of your regex — it tells python to read the regex in its "raw" (literal) form. Without raw string notation (`r"text"`), every backslash (`\`) in a regular expression would have to be prefixed with another one to escape it. Read more about this [here](https://docs.python.org/3.5/library/re.html).
# ```
#
# OK, let's try some regexes (type all that follows in `regexs.py`):
my_string = "a given string"
# Find a space in the string:
match = re.search(r'\s', my_string)
print(match)
# That's only telling you that a match was found (the object was created successfully).
#
# To see the match, use:
match.group()
# Now let's try another pattern:
match = re.search(r'\d', my_string)
print(match)
# No surprise, because there are no numeric characters in our string!
# To know whether a pattern was matched, we can use an `if`:
# +
MyStr = 'an example'
match = re.search(r'\w*\s', MyStr) # what pattern is this?
if match:
print('found a match:', match.group())
else:
print('did not find a match')
# -
# Here are some more regexes (add all that follows to `regexs.py`):
match = re.search(r'2' , "it takes 2 to tango")
match.group()
match = re.search(r'\d' , "it takes 2 to tango")
match.group()
match = re.search(r'\d.*' , "it takes 2 to tango")
match.group()
match = re.search(r'\s\w{1,3}\s', 'once upon a time')
match.group()
match = re.search(r'\s\w*$', 'once upon a time')
match.group()
# Let's switch to a more compact syntax by directly returning the matched group (by directly appending `.group()` to the result).
re.search(r'\w*\s\d.*\d', 'take 2 grams of H2O').group()
re.search(r'^\w*.*\s', 'once upon a time').group() # 'once upon a '
# Note that *, `+`, and `{ }` are all "greedy": They repeat the previous regex token as many times as possible.
#
# As a result, they may match more text than you want. To make it non-greedy and terminate at the first found instance of a pattern, use `?`:
re.search(r'^\w*.*?\s', 'once upon a time').group()
# To further illustrate greediness in regexes, let's try matching an HTML tag:
re.search(r'<.+>', 'This is a <EM>first</EM> test').group()
# But we wanted just `<EM>`!
#
# It's because `+` is greedy. Instead, we can make `+` "lazy":
re.search(r'<.+?>', 'This is a <EM>first</EM> test').group()
# OK, moving on from greed and laziness...
re.search(r'\d*\.?\d*','1432.75+60.22i').group()
# Note `\` before the `.`, to be able to find a literal `.`
#
# Otherwise, `re.search` will consider it to be a regex element (`.` means "match any character except newline").
#
# A couple more examples:
re.search(r'[AGTC]+', 'the sequence ATTCGT').group()
re.search(r'\s+[A-Z]\w+\s*\w+', "The bird-shit frog's name is Theloderma asper.").group()
# ---
#
# :::{figure-md} Theloderma-asper
#
# <img src="./graphics/thelodermaasper.JPG" alt="Bird-shit Frog" width="350px">
#
# **In case you were wondering what *Theloderma asper*, the "bird-shit frog", looks like.** Samraat snapped this one in a North-East Indian rainforest ages ago.
#
# :::
#
# ---
# How about looking for email addresses in a string? For example, let's try matching a string consisting of an academic's name, email address and research area or interest (no need to type this into any python file):
MyStr = '<NAME>, <EMAIL>, Systems biology and ecological theory'
match = re.search(r"[\w\s]+,\s[\w\.@]+,\s[\w\s]+",MyStr)
match.group()
# Note the use of `[ ]`'s: for example, `[\w\s]` ensures that any combination of word characters and spaces is found.
#
# Let's see if this regex works on a different pattern of email addresses:
MyStr = '<NAME>, <EMAIL>, Systems biology and ecological theory'
match = re.search(r"[\w\s]+,\s[\w\.@]+,\s[\w\s]+",MyStr)
match.group()
# Nope! So let's make the email address part of the regex more robust:
match = re.search(r"[\w\s]+,\s[\w\.-]+@[\w\.-]+,\s[\w\s]+",MyStr)
match.group()
# ### Practicals: Some RegExercises
#
# The following exercises are not for submission as part of your coursework, but we will discuss them in class on a subsequent day.
#
# 1. Try the regex we used above for finding names (`[\w\s]+`) for cases where the person's name has something unexpected, like a `?` or a `+`. Does it work? How can you make it more robust?
# * Translate the following regular expressions into regular English:
# * `r'^abc[ab]+\s\t\d'`
# * `r'^\d{1,2}\/\d{1,2}\/\d{4}$'`
# * `r'\s*[a-zA-Z,\s]+\s*'`
# * Write a regex to match dates in format YYYYMMDD, making sure that:
# * Only seemingly valid dates match (i.e., year greater than 1900)
# * First digit in month is either 0 or 1
# * First digit in day $\leq 3$
# ### Grouping regex patterns
#
# You can group regex patterns into meaningful blocks using parentheses. Let's look again at the example of finding email addresses.
MyStr = '<NAME>, <EMAIL>, Systems biology and ecological theory'
match = re.search(r"[\w\s]+,\s[\w\.-]+@[\w\.-]+,\s[\w\s]+",MyStr)
match.group()
# Without grouping the regex:
match.group(0)
# Now create groups using `( )`:
match = re.search(r"([\w\s]+),\s([\w\.-]+@[\w\.-]+),\s([\w\s&]+)",MyStr)
if match:
print(match.group(0))
print(match.group(1))
print(match.group(2))
print(match.group(3))
# Nice! This is very handy for extracting specific patterns from text data. Note that we excluded the `,`'s and the `\s`'s from the grouping parentheses because we don't want them to be returned in the match group list.
#
# Have a look at `re4.py` in the TheMulQuaBio's code repository for more on parsing email addresses using regexes.
# ### Useful `re` commands
#
# Here are some important functions in the `re` module:
#
# |Command|What it does|
# |:-|:-|
# | `re.search(reg, text)`| Scans the string and finds the first match of the pattern, returning a `match` object if successful and `None` otherwise.|
# | `re.match(reg, text)`| Like `re.search`, but only matches the beginning of the string.|
# | `re.compile(reg)`| Compiles (stores) a regular expression for repeated use, improving efficiency.|
# | `re.split(ref, text)`| Splits the text by the occurrence of the pattern described by the regular expression.|
# | `re.findall(ref, text)`| Like `re.search`, but returns a list of all matches. If groups are present, returns a list of groups.|
# | `re.finditer(ref, text)`| Like `re.findall`, but returns an iterator containing the match objects over which you can iterate. Useful for "crawling" efficiently through text till you find all necessary number of matches.|
# | `re.sub(ref, repl, text)`| Substitutes each non-overlapping occurrence of the match with the text in `repl`.|
# |||
#
# Many of these commands also work on whole contents of files. We will look at an example of this below. Let us try some particularly useful applications of some of these commands.
#
# ### Finding all matches
#
# Above we used re.search() to find the first match for a pattern. In many scenarios, you will need to find *all* the matches of a pattern. The function `re.findall()` does precisely this and returns all matches as a list of strings, with each string representing one match.
#
# Let's try this on an extension of the email example above for some data with multiple addresses:
MyStr = "<NAME>, <EMAIL>, Systems biology and ecological theory; Another academic, <EMAIL>, Some other stuff thats equally boring; Yet another academic, <EMAIL>, Some other stuff thats even more boring"
# Now `re.findall()` returns a list of all the emails found:
emails = re.findall(r'[\w\.-]+@[\w\.-]+', MyStr)
for email in emails:
print(email)
# Nice!
# ### Finding in files
#
# You will generally be wanting to apply regex searches to whole files. You might be tempted to write a loop to iterate over the lines of the file, calling `re.findall()` on each line. However, `re.findall()` can return a list of all the matches in a single step.
#
# Let's try finding all species names that correspond to Oaks in a data file:
# +
f = open('../data/TestOaksData.csv', 'r')
found_oaks = re.findall(r"Q[\w\s].*\s", f.read())
found_oaks
# -
# This works because recall that `f.read()` returns the whole text of a file in a single string). Also, the file is closed after reading.
# ### Groups within multiple matches
#
# Grouping pattern matches using `( )` as you learned above, can be combined with `re.findall()`. If the pattern includes *two or more* groups, then instead of returning a list of strings, `re.findall()` returns a list of tuples. Each tuple represents one match of the pattern, and inside the tuple is group(1), group(2), etc.
#
# Let's try it:
# +
MyStr = "<NAME>, <EMAIL>, Systems biology and ecological theory; Another academic, <EMAIL>, Some other stuff thats equally boring; Yet another academic, <EMAIL>, Some other stuff thats even more boring"
found_matches = re.findall(r"([\w\s]+),\s([\w\.-]+@[\w\.-]+)", MyStr)
found_matches
# -
for item in found_matches:
print(item)
# ### Extracting text from webpages
#
# OK, let's step up the ante here. How about extracting text from a web page to create your own data? Let's try extracting data from [this page](https://www.imperial.ac.uk/silwood-park/academic-staff/).
#
# You will need a new package `urllib3`. Install it, and import it (also `import re` if needed).
import urllib3
conn = urllib3.PoolManager() # open a connection
r = conn.request('GET', 'https://www.imperial.ac.uk/silwood-park/academic-staff/')
webpage_html = r.data #read in the webpage's contents
# This is returned as bytes (not strings).
type(webpage_html)
# So decode it (remember, the default decoding that this method applies is *utf-8*):
My_Data = webpage_html.decode()
#print(My_Data)
# That's a lot of potentially useful information! Let's extract all the names of academics:
pattern = r"Dr\s+\w+\s+\w+"
regex = re.compile(pattern) # example use of re.compile(); you can also ignore case with re.IGNORECASE
for match in regex.finditer(My_Data): # example use of re.finditer()
print(match.group())
# Again, nice! However, its' not perfect.
#
# You can improve this by:
# * Extracting Prof names as well
# * Eliminating the repeated matches
# * Grouping to separate title from first and second names
# * Extracting names that have unexpected characters, such as in hyphenated names (a "-" in the name)
#
# *Try making these improvements.*
#
# Of course, you can match and extract other types of patterns as well, such as urls and email addresses (though this example web page does not have email addresses).
# ### Replacing text
#
# Using the same web page data, let's try using the `re.sub` command on the same web page data (`My_Data`) to replace text:
New_Data = re.sub(r'\t'," ", My_Data) # replace all tabs with a space
# print(New_Data)
# ### Practicals
#
# #### Blackbirds problem
#
# Complete the code `blackbirds.py` that you find in the `TheMulQuaBio` (necessary data file is also there).
# ## Using Python to build workflows
#
# You can use python to build an automated data analysis or simulation workflow that involves multiple languages, especially the ones you have already learnt: R, $\LaTeX$, and UNIX bash. For example, you could, in theory, write a single Python script to generate and update your masters dissertation, tables, plots, and all. Python is ideal for building such workflows because it has packages for practically every purpose.
#
# *Thus this topic may be useful for your [Miniproject](Appendix-MiniProj.ipynb), which will involve building a reproducible computational workflow.*
#
# ### Using `subprocess`
#
# For building a workflow in Python the `subprocess` module is key. With this module you can run non-Python commands and scripts, obtain their outputs, and also crawl through and manipulate directories.
#
# First, import the module (this is part of the python standard library, so you won't need to install it):
import subprocess
# #### Running processes
#
# There are two main ways to run commands through subprocess: `run` (available in Python 3.5 onwards) for basic usage, and `Popen` (`P`rocess `open`) for more advanced usage. We will work directly with `popen` because `run()` is a wrapper around `Popen`. Using `Popen` directly gives more control over how the command is run, and how its input and output are processed.
#
# Let's try running some commands in the UNIX bash.
#
# $\star$ In a terminal, first `cd` to your `code` directory, launch `ipython3`, then and type:
p = subprocess.Popen(["echo", "I'm talkin' to you, bash!"], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# This creates an object `p`, from which you can extract the output and other information of the command you ran. Before we do anything more, let's look at our `subprocess.popen` call carefully.
#
# * The command line arguments were passed as a list of strings, which avoids the need for escaping quotes or other special characters that might be interpreted by the shell (for example, in this case, there are apostrophes in the string that is being `echo`ed in bash).
# * `stdout` is the output from the process "spawned" by your command. This is a sequence of bytes (which you will need to decode - more on this below).
# * `stderr` is the error code (from which you can capture whether the process ran successfully or not). The method PIPE creates a new "pipe" (literally, a connection) to the output of to the "child" process.
stdout, stderr = p.communicate()
stderr
# Nothing here, because the echo command does no return an any code. the `b` indicates that the output is in bits (unencoded). By default, stdout, stderr (and other outputs of `p.communicate`) are returned as binary (byte) format.
#
# Now check what's in `stdout`:
stdout
# Let's encode and print it.
print(stdout.decode())
# You can also use a `universal_newlines = True` so that these outputs are returned as encoded text (default being *utf-8* usually), with line endings converted to '\n'. For more information [see the documentation](https://docs.python.org/3.5/library/subprocess.html).
#
# Let's try something else:
p = subprocess.Popen(["ls", "-l"], stdout=subprocess.PIPE)
stdout, stderr = p.communicate()
# Now use `print(stdout.decode())` to see the output.
# Recall that the `ls -l` command lists all files in a long listing format.
#
# You can also call python itself from bash (!):
# ```python
# p = subprocess.Popen(["python3", "boilerplate.py"], stdout=subprocess.PIPE, stderr=subprocess.PIPE) # A bit silly!
# stdout, stderr = p.communicate()
#
# print(stdout.decode())
# ```
#
# This should give you the output of your `boilerplate.py` script (remember, your current path will need to be in the appropriate code directory of the relevant week's directory).
# Similarly, to compile a $\LaTeX$ document (using `pdflatex` in this case), you can do something like:
#
# ```python
# subprocess.os.system("pdflatex yourlatexdoc.tex")
# ```
# ### Handling directory and file paths
#
# You can also use `subprocess.os` to make your code OS (Linux, Windows, Mac) independent. For example to assign paths:
subprocess.os.path.join('directory', 'subdirectory', 'file')
# The result would be appropriately different on Windows (with backslashes instead of forward slashes).
#
# Note that in all cases you can "catch" the output of `subprocess` so that you can then use the output within your
# python script. A simple example, where the output is a platform-dependent directory path, is:
MyPath = subprocess.os.path.join('directory', 'subdirectory', 'file')
MyPath
# Explore what `subprocess` can do by tabbing
# `subprocess.`, and also for submodules, e.g., type
# `subprocess.os.` and then tab.
#
# ### Running `R`
#
# R is likely an important part of your project's analysis and data visualization components in particular — for example for statistical analyses and pretty plotting (`ggplot2`!).
#
# You can run `R` from Python easily. Try the following:
#
# $\star$ Create an R script file called `TestR.R` in your `code` directory with the following content:
#
# ```r
# print("Hello, this is R!")
# ```
# Now, create a script `TestR.py` with the following content :
import subprocess
subprocess.Popen("Rscript --verbose TestR.R > ../Results/TestR.Rout 2> ../Results/TestR_errFile.Rout", shell=True).wait()
#
# Now run `TestR.py` (or `%cpaste`) and check`TestR.Rout` and `TestR_errorFile.Rout`.
#
# Also check what happens if you run (type directly in `ipython` or `python` console):
subprocess.Popen("Rscript --verbose NonExistScript.R > ../Results/outputFile.Rout 2> ../Results/errorFile.Rout", shell=True).wait()
# What do you see on the screen?
#
# Now open and check `outputFile.Rout`and `errorFile.Rout.
#
# ```{tip}
# It is possible that the location of `RScript` is different in your Unix/Linux system. To locate it, try `find /usr -name 'Rscript'` in the bash terminal (not in Python!). For example, you might need to specify the path to it using `/usr/lib/R/bin/Rscript`.
# ```
# ### Practicals
#
#
# As always, test, add, commit and push all your new code and data to your git repository.
#
# #### Using `os` problem 1
#
# Open `using_os.py` and complete the tasks assigned (hint: you might want to look at `subprocess.os.walk()`)
#
# #### Using `os` problem 2
#
# Open `fmr.R` and work out what it does; check that you have `NagyEtAl1999.csv`. Now write python code called
# `run_fmr_R.py` that:
#
# Runs `fmr.R` to generate the desired result
#
# `run_fmr_R.py` should also print to the python screen whether the run was successful, and the contents of the R console output
#
# * `git add`, `commit` and `push` all your week's code by the given deadline.
# ## Networks in Python
#
# ALL biological systems have a network representation, consisting of nodes for the biological entities of interest, and edges or links for the relationships between them. Here are some examples:
# * Metabolic networks
# * Gene regulatory networks
# * Individual-Individual (e.g., social networks)
# * Who-eats-whom (Food web) networks
# * Mutualistic (e.g., plant-pollinator) networks
#
# *Can you think of a few more examples from biology?*
#
# You can easily simulate, analyze, and visualize biological networks in both `python` and `R` using some nifty packages. A full network analysis tutorial is out of the scope of our Python module's objectives, but let's try a simple visualization using the ` networkx` python package.
#
# For this you need to first install the package, for example, by using:
#
# ```bash
# sudo apt-get install python3-networkx
# ```
#
# ### Food web network example
#
# As an example, let's plot a food web network.
#
# The best way to store a food web dataset is as an "adjacency list" of who eats whom: a matrix with consumer name/id in 1st column, and resource name/id in 2nd column, and a separate matrix of species names/ids and properties such as biomass (node's abundance), or average body mass. You will see what these data structures look like below.
#
# First, import the necessary modules:
import networkx as nx
import scipy as sc
import matplotlib.pylab as p
# Let's generate a "synthetic" food web. We can do this with the following function that generates a random adjacency list of a $N$-species food web with "connectance probability" $C$: the probability of having a link between any pair of species in the food web.
def GenRdmAdjList(N = 2, C = 0.5):
"""
"""
Ids = range(N)
ALst = []
for i in Ids:
if np.random.uniform(0,1,1) < C:
Lnk = np.random.choice(Ids,2).tolist()
if Lnk[0] != Lnk[1]: #avoid self (e.g., cannibalistic) loops
ALst.append(Lnk)
return ALst
# Note that we are using a uniform random distribution between `[0,1]` to generate a connectance probability between each species pair.
# Now assign number of species (`MaxN`) and connectance (`C`):
MaxN = 30
C = 0.75
# Now generate an adjacency list representing a random food web:
AdjL = np.array(GenRdmAdjList(MaxN, C))
AdjL
# So that's what an adjacency list looks like. The two columns of numbers correspond to the consumer and resource ids, respectively.
#
# Now generate species (node) data:
Sps = np.unique(AdjL) # get species ids
# Now generate body sizes for the species. We will use a log$_{10}$ scale because species body sizes tend to be [log-normally distributed](08-Data_R.ipynb#Histograms).
SizRan = ([-10,10]) #use log10 scale
Sizs = np.random.uniform(SizRan[0],SizRan[1],MaxN)
Sizs
# Let's visualize the size distribution we have generated.
p.hist(Sizs) #log10 scale
p.hist(10 ** Sizs) #raw scale
# Now let's plot the network, with node sizes proportional to (log) body size:
p.close('all') # close all open plot objects
# Let's use a circular configuration. For this, we need to calculate the coordinates, easily done using networkx:
pos = nx.circular_layout(Sps)
# See `networkx.layout` for inbuilt functions to compute other types of node coordinates.
#
# Now generate a networkx graph object:
G = nx.Graph()
# Now add the nodes and links (edges) to it:
G.add_nodes_from(Sps)
G.add_edges_from(tuple(AdjL))
# Note that the function `add_edges_from` needs the adjacency list as a tuple.
# Now generate node sizes that are proportional to (log) body sizes:
NodSizs= 1000 * (Sizs-min(Sizs))/(max(Sizs)-min(Sizs))
# Now render (plot) the graph:
nx.draw_networkx(G, pos, node_size = NodSizs)
# You might get a warning. In that case, try upgrading the networkx package.
#
# ### Practicals
#
# #### Plot the foodweb
#
# Type the above code for plotting a food web network in a program file called `DrawFW.py`. This file should save the plotted network as a pdf.
#
# #### Groupwork: networks in R
#
# You can also do nice network visualizations in R. Here you will convert a network visualization script written in `R` using the `igraph` package to a python script that does the same thing.
#
# * First copy the script file called `Nets.R` and the data files it calls and run it. This script visualizes the [QMEE CDT collaboration network](http://www.imperial.ac.uk/qmee-cdt), coloring the the nodes by the type of node (organization type: "University","Hosting Partner", "Non-hosting Partner").
#
# * Now, convert this script to a Python script that does the same thing, including writing to a `.svg` file using the same QMEE CDT link and node data. You can use `networkx` or some other python network visualization package.
# ## Readings and Resources
#
# ### Scientific computing
#
# * In general, scores of good module/package-specific cookbooks are out there — google "cookbook" along with the name of the package you are interested in (e.g., "scipy cookbook").
#
# * For SciPy, read the [official documentation](https://docs.scipy.org/doc/); in particular, read about the scipy [modules](https://docs.scipy.org/doc/scipy/reference/) you think will be important to you.
#
# * The "ecosystem" for Scientific computing in python: <http://www.scipy-lectures.org/>
#
# * Many great examples of applications in the [scipy cookbook](https://scipy-cookbook.readthedocs.io/)
#
# * Scipy stats: https://docs.scipy.org/doc/scipy/reference/tutorial/stats.html
#
# * A Primer on Scientific Programming with Python <http://www.springer.com/us/book/9783642549595>; Multiple copies of this book are available from the central library and can be requested to Silwood from the IC library website. You can also find a pdf - seach online.
#
# ### Regular expressions
#
# * Python regex documentation: https://docs.python.org/3.6/howto/regex.html
#
# * Google's short class on regex in python: https://developers.google.com/edu/python/regular-expressions
# And this exercise: https://developers.google.com/edu/python/exercises/baby-names
#
# * Good intro to regex, tips and a great array of canned solutions: http://www.regular-expressions.info
#
# * Use and abuse of regex: <https://blog.codinghorror.com/regex-use-vs-regex-abuse/>
#
# ### Other stuff
#
# * [The matplotlib website](http://matplotlib.org)
#
# * Alternatives to matplotlib for plotting in python: https://towardsdatascience.com/matplotlib-vs-seaborn-vs-plotly-f2b79f5bddb
#
# * Some of you might find the python package `biopython` particularly useful — check out <http://biopython.org/>, and especially, the cookbook
| content/_build/html/_sources/notebooks/06-Python_II.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Component FDTD simulations
#
# ## Lumerical FDTD
#
# You can write the [Sparameters](https://en.wikipedia.org/wiki/Scattering_parameters) for all components in the UBC `ubcpdk.components` PDK using lumerical FDTD plugin in gdsfactory
# +
import ubcpdk
import gdsfactory.simulation as sim
import matplotlib.pyplot as plot
for cell in ubcpdk.cells.values():
component = cell()
print(component.name)
component.plot()
# ubcpdk.tech.write_sparameters_lumerical(component=component)
# +
# df = ubcpdk.tech.get_sparameters_data_lumerical(component=ubcpdk.components.straight())
# +
# sim.plot_sparameters(df)
# -
# ## Meep
#
# Meep in an open source FDTD library developed at MIT.
# See [docs](https://meep.readthedocs.io/en/latest/Python_Tutorials/GDSII_Import/) and [code](https://github.com/NanoComp/meep).
#
# We will use the gdsfactory meep plugin to run simulation using meep.
#
#
# Notice that most examples run with `resolution=20` so they run fast.
#
# The resolution is in pixels/um so i reccommend that you run with at least `resolution=100` for 1/100 um/pixel (10 nm/ pixel)
import ubcpdk
import ubcpdk.simulation.gmeep as gm
c = ubcpdk.components.straight(length=3)
c
df = gm.write_sparameters_meep_1x1(component=c, run=False)
df = gm.write_sparameters_meep_1x1(component=c, run=True)
gm.plot.plot_sparameters(df)
gm.plot.plot_sparameters(df, logscale=False)
c = ubcpdk.components.y_splitter()
c
df = gm.write_sparameters_meep(component=ubcpdk.components.y_splitter(), run=False) # lr stands for left-right ports
# +
import gdsfactory as gf
df = gm.write_sparameters_meep(gf.components.coupler_ring(), xmargin=3, ymargin_bot=3, run=False) # lr stands for left-right ports
# -
| docs/notebooks/11_sparameters.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.7.2 64-bit ('venv')
# language: python
# name: python37264bitvenv210d5aeff0b04aaca13bce6dee08a38b
# ---
# !cd .. & ./setup.sh
# # Finding the best set of parameters
# +
from covidsimulation.regions.br_saopaulo import params as br_saopaulo_params, score_fn as br_saopaulo_score_fn, \
sp_official_deaths
from covidsimulation.callibrate import callibrate_parameters
from covidsimulation import Parameters
from tqdm.notebook import tqdm
max_simulation_day = max(d[0] for d in sp_official_deaths) + 1
def set_d0_infections(p: Parameters, v):
p.d0_infections = v
def set_population_1_seed_infections(p: Parameters, v):
p.population_segments[1].seed_infections = v
callibrate_parameters(
[
(set_d0_infections, list(range(8000, 13000, 1000))),
(set_population_1_seed_infections, (4, 50, 12)),
],
br_saopaulo_score_fn,
br_saopaulo_params,
duration=max_simulation_day,
simulation_size=20000, # Recommended: simulation_size >= 200000
n=4, # Recommended: n > 8
# tqdm=tqdm, # uncomment to display progress
)
# -
# # Showing the simulations that best fit history
# +
from covidsimulation import run_simulations, plot
stats = run_simulations(
sim_params=br_saopaulo_params,
simulate_capacity=True,
duration=60,
number_of_simulations=40,
simulation_size=200000,
tqdm=tqdm,
)
# +
# Before filtering best simulations
fig = plot([
(stats.get_metric('deaths'), 'mortes'),
(stats.get_metric('confirmed_deaths'), 'confirmadas'),
], 'Mortes - Real x Confirmadas - Cenário atual provável', False, stop=90)
fig # Or fig.show() if just fig doesn't work
# +
# Filtering best simulations
stats.filter_best_scores(br_saopaulo_score_fn, 0.25)
fig = plot([
(stats.get_metric('deaths'), 'mortes'),
(stats.get_metric('confirmed_deaths'), 'confirmadas'),
], 'Mortes - Real x Confirmadas - Cenário atual provável', False, stop=90)
fig # Or fig.show() if just fig doesn't work
# -
| examples/Callibration.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/pacificblue/Coursera-ICL-TensorFlow-2-for-Deep-Learning-Specialization/blob/main/ICL_Customising_your_models_with_TensorFlow_2/Week%204%20Build%20Resnet.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="RTehttYqbiZO"
# # Programming Assignment
# + [markdown] id="f0d-2RopbiZQ"
# ## Residual network
# + [markdown] id="yK03DPBRbiZR"
# ### Instructions
#
# In this notebook, you will use the model subclassing API together with custom layers to create a residual network architecture. You will then train your custom model on the Fashion-MNIST dataset by using a custom training loop and implementing the automatic differentiation tools in Tensorflow to calculate the gradients for backpropagation.
#
# Some code cells are provided you in the notebook. You should avoid editing provided code, and make sure to execute the cells in order to avoid unexpected errors. Some cells begin with the line:
#
# `#### GRADED CELL ####`
#
# Don't move or edit this first line - this is what the automatic grader looks for to recognise graded cells. These cells require you to write your own code to complete them, and are automatically graded when you submit the notebook. Don't edit the function name or signature provided in these cells, otherwise the automatic grader might not function properly. Inside these graded cells, you can use any functions or classes that are imported below, but make sure you don't use any variables that are outside the scope of the function.
#
# ### How to submit
#
# Complete all the tasks you are asked for in the worksheet. When you have finished and are happy with your code, press the **Submit Assignment** button at the top of this notebook.
#
# ### Let's get started!
#
# We'll start running some imports, and loading the dataset. Do not edit the existing imports in the following cell. If you would like to make further Tensorflow imports, you should add them here.
# + id="2HDFAM9JbiZT"
#### PACKAGE IMPORTS ####
# Run this cell first to import all required packages. Do not make any imports elsewhere in the notebook
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Layer, BatchNormalization, Conv2D, Dense, Flatten, Add
import numpy as np
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
# If you would like to make further imports from tensorflow, add them here
# + [markdown] id="7LURF_ZYbiZX"
# #### The Fashion-MNIST dataset
#
# In this assignment, you will use the [Fashion-MNIST dataset](https://github.com/zalandoresearch/fashion-mnist). It consists of a training set of 60,000 images of fashion items with corresponding labels, and a test set of 10,000 images. The images have been normalised and centred. The dataset is frequently used in machine learning research, especially as a drop-in replacement for the MNIST dataset.
#
# - <NAME>, <NAME>, and <NAME>. "Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms." arXiv:1708.07747, August 2017.
#
# Your goal is to construct a ResNet model that classifies images of fashion items into one of 10 classes.
# + [markdown] id="JikW1jd8biZY"
# #### Load the dataset
# + [markdown] id="38Z9Eoq4biZZ"
# For this programming assignment, we will take a smaller sample of the dataset to reduce the training time.
# + id="ur9hxTa4biZa"
# Load and preprocess the Fashion-MNIST dataset
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_images = train_images.astype(np.float32)
test_images = test_images.astype(np.float32)
train_images = train_images[:5000] / 255.
train_labels = train_labels[:5000]
test_images = test_images / 255.
train_images = train_images[..., np.newaxis]
test_images = test_images[..., np.newaxis]
# + id="_nl7FV8GbiZe"
# Create Dataset objects for the training and test sets
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
train_dataset = train_dataset.batch(32)
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels))
test_dataset = test_dataset.batch(32)
# + id="-VsLCYrPbiZh"
# Get dataset labels
image_labels = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# + [markdown] id="3UKYy3Q1biZk"
# #### Create custom layers for the residual blocks
# + [markdown] id="kqm8M28ZbiZl"
# You should now create a first custom layer for a residual block of your network. Using layer subclassing, build your custom layer according to the following spec:
#
# * The custom layer class should have `__init__`, `build` and `call` methods. The `__init__` method has been completed for you. It calls the base `Layer` class initializer, passing on any keyword arguments
# * The `build` method should create the layers. It will take an `input_shape` argument, and should extract the number of filters from this argument. It should create:
# * A BatchNormalization layer: this will be the first layer in the block, so should use its `input shape` keyword argument
# * A Conv2D layer with the same number of filters as the layer input, a 3x3 kernel size, `'SAME'` padding, and no activation function
# * Another BatchNormalization layer
# * Another Conv2D layer, again with the same number of filters as the layer input, a 3x3 kernel size, `'SAME'` padding, and no activation function
# * The `call` method should then process the input through the layers:
# * The first BatchNormalization layer: ensure to set the `training` keyword argument
# * A `tf.nn.relu` activation function
# * The first Conv2D layer
# * The second BatchNormalization layer: ensure to set the `training` keyword argument
# * Another `tf.nn.relu` activation function
# * The second Conv2D layer
# * It should then add the layer inputs to the output of the second Conv2D layer. This is the final layer output
# + id="PWXDT-jWbiZm"
#### GRADED CELL ####
# Complete the following class.
# Make sure to not change the class or method names or arguments.
class ResidualBlock(Layer):
def __init__(self, **kwargs):
super(ResidualBlock, self).__init__(**kwargs)
def build(self, input_shape):
"""
This method should build the layers according to the above specification. Make sure
to use the input_shape argument to get the correct number of filters, and to set the
input_shape of the first layer in the block.
"""
def call(self, inputs, training=False):
"""
This method should contain the code for calling the layer according to the above
specification, using the layer objects set up in the build method.
"""
# + id="SF8Goq8LbiZo"
# Test your custom layer - the following should create a model using your layer
test_model = tf.keras.Sequential([ResidualBlock(input_shape=(28, 28, 1), name="residual_block")])
test_model.summary()
# + [markdown] id="Y2PoqmxCbiZy"
# You should now create a second custom layer for a residual block of your network. This layer will be used to change the number of filters within the block. Using layer subclassing, build your custom layer according to the following spec:
#
# * The custom layer class should have `__init__`, `build` and `call` methods
# * The class initialiser should call the base `Layer` class initializer, passing on any keyword arguments. It should also accept a `out_filters` argument, and save it as a class attribute
# * The `build` method should create the layers. It will take an `input_shape` argument, and should extract the number of input filters from this argument. It should create:
# * A BatchNormalization layer: this will be the first layer in the block, so should use its `input shape` keyword argument
# * A Conv2D layer with the same number of filters as the layer input, a 3x3 kernel size, `"SAME"` padding, and no activation function
# * Another BatchNormalization layer
# * Another Conv2D layer with `out_filters` number of filters, a 3x3 kernel size, `"SAME"` padding, and no activation function
# * A final Conv2D layer with `out_filters` number of filters, a 1x1 kernel size, and no activation function
# * The `call` method should then process the input through the layers:
# * The first BatchNormalization layer: ensure to set the `training` keyword argument
# * A `tf.nn.relu` activation function
# * The first Conv2D layer
# * The second BatchNormalization layer: ensure to set the `training` keyword argument
# * Another `tf.nn.relu` activation function
# * The second Conv2D layer
# * It should then take the layer inputs, pass it through the final 1x1 Conv2D layer, and add to the output of the second Conv2D layer. This is the final layer output
# + id="HiK_lavabiZz"
#### GRADED CELL ####
# Complete the following class.
# Make sure to not change the class or method names or arguments.
class FiltersChangeResidualBlock(Layer):
def __init__(self, out_filters, **kwargs):
"""
The class initialiser should call the base class initialiser, passing any keyword
arguments along. It should also set the number of filters as a class attribute.
"""
def build(self, input_shape):
"""
This method should build the layers according to the above specification. Make sure
to use the input_shape argument to get the correct number of filters, and to set the
input_shape of the first layer in the block.
"""
def call(self, inputs, training=False):
"""
This method should contain the code for calling the layer according to the above
specification, using the layer objects set up in the build method.
"""
# + id="LWacV9I5biZ3"
# Test your custom layer - the following should create a model using your layer
test_model = tf.keras.Sequential([FiltersChangeResidualBlock(16, input_shape=(32, 32, 3), name="fc_resnet_block")])
test_model.summary()
# + [markdown] id="TMY3Ak7YbiZ6"
# #### Create a custom model that integrates the residual blocks
#
# You are now ready to build your ResNet model. Using model subclassing, build your model according to the following spec:
#
# * The custom model class should have `__init__` and `call` methods.
# * The class initialiser should call the base `Model` class initializer, passing on any keyword arguments. It should create the model layers:
# * The first Conv2D layer, with 32 filters, a 7x7 kernel and stride of 2.
# * A `ResidualBlock` layer.
# * The second Conv2D layer, with 32 filters, a 3x3 kernel and stride of 2.
# * A `FiltersChangeResidualBlock` layer, with 64 output filters.
# * A Flatten layer
# * A final Dense layer, with a 10-way softmax output
# * The `call` method should then process the input through the layers in the order given above. Ensure to pass the `training` keyword argument to the residual blocks, to ensure the correct mode of operation for the batch norm layers.
#
# In total, your neural network should have six layers (counting each residual block as one layer).
# + id="53xs9JBKbiZ7"
#### GRADED CELL ####
# Complete the following class.
# Make sure to not change the class or method names or arguments.
class ResNetModel(Model):
def __init__(self, **kwargs):
"""
The class initialiser should call the base class initialiser, passing any keyword
arguments along. It should also create the layers of the network according to the
above specification.
"""
def call(self, inputs, training=False):
"""
This method should contain the code for calling the layer according to the above
specification, using the layer objects set up in the initialiser.
"""
# + id="QZG77KapbiZ-"
# Create the model
resnet_model = ResNetModel()
# + [markdown] id="KlHXCYYLbiaB"
# #### Define the optimizer and loss function
# + [markdown] id="dxfc-oYdbiaB"
# We will use the Adam optimizer with a learning rate of 0.001, and the sparse categorical cross entropy function.
# + id="C33dTTFzbiaC"
# Create the optimizer and loss
optimizer_obj = tf.keras.optimizers.Adam(learning_rate=0.001)
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy()
# + [markdown] id="wAhzpm3TbiaG"
# #### Define the grad function
# + [markdown] id="RFL3r1zZbiaH"
# You should now create the `grad` function that will compute the forward and backward pass, and return the loss value and gradients that will be used in your custom training loop:
#
# * The `grad` function takes a model instance, inputs, targets and the loss object above as arguments
# * The function should use a `tf.GradientTape` context to compute the forward pass and calculate the loss
# * The function should compute the gradient of the loss with respect to the model's trainable variables
# * The function should return a tuple of two elements: the loss value, and a list of gradients
# + id="_6k5MsJVbiaI"
#### GRADED CELL ####
# Complete the following function.
# Make sure to not change the function name or arguments.
@tf.function
def grad(model, inputs, targets, loss):
"""
This function should compute the loss and gradients of your model, corresponding to
the inputs and targets provided. It should return the loss and gradients.
"""
# + [markdown] id="p_48RRAGbiaK"
# #### Define the custom training loop
# + [markdown] id="PDKxVoDEbiaL"
# You should now write a custom training loop. Complete the following function, according to the spec:
#
# * The function takes the following arguments:
# * `model`: an instance of your custom model
# * `num_epochs`: integer number of epochs to train the model
# * `dataset`: a `tf.data.Dataset` object for the training data
# * `optimizer`: an optimizer object, as created above
# * `loss`: a sparse categorical cross entropy object, as created above
# * `grad_fn`: your `grad` function above, that returns the loss and gradients for given model, inputs and targets
# * Your function should train the model for the given number of epochs, using the `grad_fn` to compute gradients for each training batch, and updating the model parameters using `optimizer.apply_gradients`.
# * Your function should collect the mean loss and accuracy values over the epoch, and return a tuple of two lists; the first for the list of loss values per epoch, the second for the list of accuracy values per epoch.
#
# You may also want to print out the loss and accuracy at each epoch during the training.
# + id="JOvFcrLpbiaM"
#### GRADED CELL ####
# Complete the following function.
# Make sure to not change the function name or arguments.
def train_resnet(model, num_epochs, dataset, optimizer, loss, grad_fn):
"""
This function should implement the custom training loop, as described above. It should
return a tuple of two elements: the first element is a list of loss values per epoch, the
second is a list of accuracy values per epoch
"""
# + id="yD9Pxs_PbiaO"
# Train the model for 8 epochs
train_loss_results, train_accuracy_results = train_resnet(resnet_model, 8, train_dataset, optimizer_obj,
loss_obj, grad)
# + [markdown] id="9w0AOlo2biaR"
# #### Plot the learning curves
# + id="EQxQxQxgbiaS"
fig, axes = plt.subplots(1, 2, sharex=True, figsize=(12, 5))
axes[0].set_xlabel("Epochs", fontsize=14)
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].set_title('Loss vs epochs')
axes[0].plot(train_loss_results)
axes[1].set_title('Accuracy vs epochs')
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epochs", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
# + [markdown] id="IQ_A0So1biaU"
# #### Evaluate the model performance on the test dataset
# + id="qVyiUCMjbiaV"
# Compute the test loss and accuracy
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.CategoricalAccuracy()
for x, y in test_dataset:
model_output = resnet_model(x)
epoch_loss_avg(loss_obj(y, model_output))
epoch_accuracy(to_categorical(y), model_output)
print("Test loss: {:.3f}".format(epoch_loss_avg.result().numpy()))
print("Test accuracy: {:.3%}".format(epoch_accuracy.result().numpy()))
# + [markdown] id="TTV7htZDbiaX"
# #### Model predictions
#
# Let's see some model predictions! We will randomly select four images from the test data, and display the image and label for each.
#
# For each test image, model's prediction (the label with maximum probability) is shown, together with a plot showing the model's categorical distribution.
# + id="1o1RDRWEbiaY"
# Run this cell to get model predictions on randomly selected test images
num_test_images = test_images.shape[0]
random_inx = np.random.choice(test_images.shape[0], 4)
random_test_images = test_images[random_inx, ...]
random_test_labels = test_labels[random_inx, ...]
predictions = resnet_model(random_test_images)
fig, axes = plt.subplots(4, 2, figsize=(16, 12))
fig.subplots_adjust(hspace=0.5, wspace=-0.2)
for i, (prediction, image, label) in enumerate(zip(predictions, random_test_images, random_test_labels)):
axes[i, 0].imshow(np.squeeze(image))
axes[i, 0].get_xaxis().set_visible(False)
axes[i, 0].get_yaxis().set_visible(False)
axes[i, 0].text(5., -2., f'Class {label} ({image_labels[label]})')
axes[i, 1].bar(np.arange(len(prediction)), prediction)
axes[i, 1].set_xticks(np.arange(len(prediction)))
axes[i, 1].set_xticklabels(image_labels, rotation=0)
pred_inx = np.argmax(prediction)
axes[i, 1].set_title(f"Categorical distribution. Model prediction: {image_labels[pred_inx]}")
plt.show()
# + [markdown] id="S6qxLOmbbiaa"
# Congratulations for completing this programming assignment! You're now ready to move on to the capstone project for this course.
| ICL_Customising_your_models_with_TensorFlow_2/Week 4 Build Resnet.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Regional Map Method
# 
# ### Import Functions
# + tags=["hide_input"]
import sys
# !{sys.executable} -m pip install netCDF4
# !{sys.executable} -m pip install xarray
import opedia
import math
import common as com
from opedia import plotRegional as REG
import netCDF4
import xarray as xr
import numpy as np
from datetime import datetime
from dateutil.parser import parse
from bokeh.plotting import figure, show, output_file
from bokeh.layouts import column
from bokeh.palettes import all_palettes
from bokeh.models import HoverTool, LinearColorMapper, BasicTicker, ColorBar, DatetimeTickFormatter
from bokeh.models.annotations import Title
from bokeh.embed import components
from tqdm import tqdm_notebook as tqdm
from netCDF4 import num2date, date2num
# %run -i 'externalfunctions.py'
# -
# ### Testing Space ###
# +
# NetCDF4 file(s) to read from:
xFile = xr.open_dataset('http://3.88.71.225:80/thredds/dodsC/las/id-a1d60eba44/data_usr_local_tomcat_content_cbiomes_20190510_20_darwin_v0.2_cs510_darwin_v0.2_cs510_nutrients.nc.jnl')
tables = [xFile]
variables = ['O2']
startDate = '2016-04-30'
endDate = '2017-04-30'
lat1, lat2 = -50, 90
lon1, lon2 = -100, 170
depth1, depth2 = 0, 50
fname = 'regional'
exportDataFlag = False
regionalMap(tables, variables, startDate, endDate, lat1, lat2, lon1, lon2, depth1, depth2, fname, exportDataFlag)
| content/02/regionalmap.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python (antgen)
# language: python
# name: similarity-env
# ---
# ## Noise-to-Aggregate-Ratio (NAR)
import nilmtk
print(nilmtk.__version__)
# ### NAR: What is the noise level in a dataset?
#
#
# The aggregate power signal of a real-world dataset consists not exclusively of known appliance-level signals, but also contains several unknown appliance-level signals that contribute to the error term epsilon.
#
# The Noise-to-Aggregate Ratio, NAR, is defined as:
#
# 
#
# the ratio between noise and aggregate signal over a time window T, where xi is the power consumption of appliance i, y the aggregate power signal, and T the length of the observed time frame. The noise-to-aggregate ratio (NAR) can be computed for all AC power types, as long as energy readings of aggregate and submeters are available.
# A ratio of 0.25 reports that 25\% of the total energy consumption stems from unmetered appliances and noise. Hence, the ratio indicates to what degree information on the aggregate's components is available.
#
# #### Implementation
#
# Our source code builds on functions provided by [NILMTK](https://github.com/nilmtk/nilmtk) to foster reproducibility of results.
# Our implementation of the NAR can be obtained from *NAR.py* and defines the following function:
#
# ```python
# from NAR import noise_aggregate_ratio
#
# NAR_p = noise_aggregate_ratio(elec, power_type='active')
# NAR_s = noise_aggregate_ratio(elec, power_type='apparent')
# ```
#
# with the following input parameters:
#
# * *elec_meter:* MeterGroup object of a household or a simple [MeterGroup](http://nilmtk.github.io/nilmtk/master/_modules/nilmtk/metergroup.html)
# * *power_type:* String that defines the AC power type of interest: active or apparent
# ## Usage Notes
#
# We will demonstrate the use of NAR by the help of a simple example. First, we have to load the dataset using NILMTK
# +
from nilmtk import DataSet
from NAR import noise_aggregate_ratio
d_dir = '/Users/christoph/datasets/'
dataset = ['iAWE', 1]
dset = DataSet(d_dir+'{}.h5'.format(dataset[0]))
household = dataset[1]
elec = dset.buildings[household].elec
print(elec)
# -
# Now, we can compute the NAR's for active and apprent power of iAWE:
NAR_p = 100 * noise_aggregate_ratio(elec, power_type='active')
print('{} %'.format(NAR_p))
NAR_s = 100 * noise_aggregate_ratio(elec, power_type='apparent')
print('{} %'.format(NAR_s))
# As we see, house 1 of iAWE has a NAR of 63 % for active power and a NAR of 61 % for apparent power.
# #### Why should you use NAR and not proportion-of-energy?
#
# NILMTK includes a function called [*proportion_of_energy(self, other)*](http://nilmtk.github.io/nilmtk/master/_modules/nilmtk/electric.html#Electric.proportion_of_energy) that was introduced to report the amount of energy consumed by one appliance. However, we found some fundamental problems with that function, which must not be ignored.
#
# The first problem with this function is that it mixes active and apparent power during computation, which must not be done in any situation.
#
# ```python
# elif n_shared_ac_types == 0:
# ac_type = select_best_ac_type(self_ac_types)
# other_ac_type = select_best_ac_type(other_ac_types)
# ...
# return total_energy[ac_type] / other_total_energy[other_ac_type]
#
# ```
# The second problem with this function is that it returns the average proportion of energy for several power types.
# ```python
# if n_shared_ac_types > 1:
# return (total_energy[shared_ac_types] /other_total_energy[shared_ac_types]).mean()
# ```
#
# ### NAR in common LF energy consumption data sets
#
# We derived the NAR with respect to active and apparent power for some of the most commonly-used energy consumption data sets. Please note that our focus is on their *low-frequency* version.
#
# | Data Set | House | Duration in days | Meters | NAR for P in \%| NAR for S in \%|
# |----------|-------:|------------------:|--------:|-----------:|-----------:|
# | AMPds2 | 1 | 730 | 20 | 18 | 6 |
# | COMBED | 1 | 28 | 13 | 34 | - |
# | DRED | 1 | 153 | 12 | - | 28 |
# | ECO | 1 | 245 | 7 | 68 | - |
# | ECO | 6 | 219 | 7 | 74 | - |
# | iAWE | 1 | 73 | 10 | 63 | 61 |
# | REDD | 1 | 36 | 16 | - | - |
# | REFIT | 1 | 638 | 9 | 65 | - |
# | REFIT | 8 | 555 | 9 | 78 | - |
# | REFIT | 17 | 443 | 9 | 45 | - |
# | UK-DALE | 1 | 658 | 52 | 33 | 87 |
# | UK-DALE | 2 | 176 | 18 | 41 | - |
# | UK-DALE | 5 | 137 | 24 | 31 | - |
#
| NAR.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/semishen/ML100Days/blob/master/Day_011_HW.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="b_nTVx_xaa6B" colab_type="text"
# # 處理 outliers
# * 新增欄位註記
# * outliers 或 NA 填補
# 1. 平均數 (mean)
# 2. 中位數 (median, or Q50)
# 3. 最大/最小值 (max/min, Q100, Q0)
# 4. 分位數 (quantile)
# + id="JsBJjSohajr3" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 127} outputId="714c1f0f-d1c9-4381-c3c9-41a8a05cd7e4"
from google.colab import drive
drive.mount('/content/drive')
# + [markdown] id="x4gjbwThaa6C" colab_type="text"
# # [作業目標]
# - 仿造範例的資料操作, 試著進行指定的離群值處理
# + [markdown] id="I_34LL_9aa6D" colab_type="text"
# # [作業重點]
# - 計算 AMT_ANNUITY 的分位點 (q0 - q100) (Hint : np.percentile, In[3])
# - 將 AMT_ANNUITY 的 NaN 用中位數取代 (Hint : q50, In[4])
# - 將 AMT_ANNUITY 數值轉換到 -1 ~ 1 之間 (Hint : 參考範例, In[5])
# - 將 AMT_GOOD_PRICE 的 NaN 用眾數取代 (In[6])
# + id="zgdL697Paa6D" colab_type="code" colab={}
# Import 需要的套件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# + id="XIONIywPaa6H" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 321} outputId="e582f423-2de0-4279-c00a-127d44aaa4e9"
app_train = pd.read_csv('drive/My Drive/Colab Notebooks/ML100Days/data/application_train.csv')
app_train.head()
# + id="hYUfisSQfQlO" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="618aeb55-1b43-444a-a444-c643c69b999c"
app_train.shape
# + [markdown] id="gaCZiXgIaa6K" colab_type="text"
# ## 1. 列出 AMT_ANNUITY 的 q0 - q100
# ## 2.1 將 AMT_ANNUITY 中的 NAs 暫時以中位數填補
# ## 2.2 將 AMT_ANNUITY 的數值標準化至 -1 ~ 1 間
# ## 3. 將 AMT_GOOD_PRICE 的 NAs 以眾數填補
#
# + id="aLW86XyLaa6K" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 419} outputId="65ce11ae-35df-4542-d13d-453ddf7f39f9"
df_amt_annuity = app_train['AMT_ANNUITY']
df_amt_annuity = df_amt_annuity[~df_amt_annuity.isna()] #delete na
# 1: 計算 AMT_ANNUITY 的 q0 - q100
q_all = list(np.quantile(df_amt_annuity, q=(i/101))for i in list(range(101)))
pd.DataFrame({'q': list(range(101)),
'value': q_all})
# + id="lcNShvOSn4fJ" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="3e24ce10-421d-4d5c-a31e-a8847210a855"
q_all[50]
# + id="HKC5Ax8_aa6N" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 53} outputId="71536263-753f-4010-e7c1-96ef637a3953"
# 2.1 將 NAs 以 q50 填補
print("Before replace NAs, numbers of row that AMT_ANNUITY is NAs: %i" % sum(app_train['AMT_ANNUITY'].isnull()))
q_50 = q_all[50]
app_train.loc[app_train['AMT_ANNUITY'].isnull(),'AMT_ANNUITY'] = q_50
print("After replace NAs, numbers of row that AMT_ANNUITY is NAs: %i" % sum(app_train['AMT_ANNUITY'].isnull()))
# + [markdown] id="n6_UIJEQaa6Q" colab_type="text"
# ### Hints: Normalize function (to -1 ~ 1)
# $ y = 2*(\frac{x - min(x)}{max(x) - min(x)} - 0.5) $
# + id="p8MoWQPraa6R" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 377} outputId="8f222b3b-79cb-41de-e23a-7ea89eb359cc"
# 2.2 Normalize values to -1 to 1
print("== Original data range ==")
print(app_train['AMT_ANNUITY'].describe())
def normalize_value(x):
x = 2*((x-np.min(x))/(np.max(x)-np.min(x))-0.5)
return x
app_train['AMT_ANNUITY_NORMALIZED'] = normalize_value(app_train['AMT_ANNUITY'])
print("== Normalized data range ==")
app_train['AMT_ANNUITY_NORMALIZED'].describe()
# + id="sAECfohhaa6T" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 71} outputId="d7c4158d-ea6d-4ffe-c7fd-75d0d6b1be5e"
# 3
print("Before replace NAs, numbers of row that AMT_GOODS_PRICE is NAs: %i" % sum(app_train['AMT_GOODS_PRICE'].isnull()))
droped_list = ~(app_train['AMT_GOODS_PRICE'].isnull())
droped_df = app_train[droped_list]['AMT_GOODS_PRICE']
# print(droped_df.value_counts())
# 列出重複最多的數值
value_most = droped_df.value_counts().index[0]
print(value_most)
mode_goods_price = list(app_train['AMT_GOODS_PRICE'].value_counts().index)
app_train.loc[app_train['AMT_GOODS_PRICE'].isnull(), 'AMT_GOODS_PRICE'] = mode_goods_price[0]
print("After replace NAs, numbers of row that AMT_GOODS_PRICE is NAs: %i" % sum(app_train['AMT_GOODS_PRICE'].isnull()))
| Day_011_HW.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
# %matplotlib inline
t = np.linspace(0.1, 1, 100, endpoint=True)
x_diff = t**2
# +
mpl.rcParams['font.size'] = 16
mpl.rcParams['lines.linewidth'] = 2
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=plt.figaspect(1/2.))
ax = ax1
ax.plot(t, x_diff)
ax.set_ylabel(r"$x - \hat{x}$", rotation=0)
ax.yaxis.set_label_coords(-0.15, 0.95)
ax.set_xlabel(r"$t$")
x_ticks = [0.2, 0.8]
x_labels = [r"t'", "T(t')"]
ax.xaxis.set_ticks(x_ticks)
ax.xaxis.set_major_formatter(mpl.ticker.FixedFormatter(x_labels))
y_ticks = [x_diff[np.argmin(np.abs(t - i))] for i in x_ticks]
y_labels = [0, r"$\Delta x$"]
ax.yaxis.set_ticks(y_ticks)
ax.yaxis.set_major_formatter(mpl.ticker.FixedFormatter(y_labels))
ax.plot(x_ticks, [y_ticks[0], y_ticks[0]], color="grey")
ax.plot([x_ticks[1], x_ticks[1]], y_ticks, color="grey")
ax = ax2
ax.set_ylabel(r"$T(t)$", rotation=0)
ax.set_xlabel(r"$t$")
ax.yaxis.set_label_coords(-0.15, 0.95)
y2 = 0.5/(t**2 + 0.05)
y_ticks2 = [y2[np.argmin(np.abs(t - i))] for i in x_ticks]
ax.plot(t, y2)
ax.yaxis.set_ticks([y_ticks2[0]])
ax.yaxis.set_major_formatter(mpl.ticker.FixedFormatter([r"$T(t')$"]))
ax.xaxis.set_ticks(x_ticks[:1])
ax.xaxis.set_major_formatter(mpl.ticker.FixedFormatter(x_labels))
con = mpl.patches.ConnectionPatch(xyB=[x_ticks[1], y_ticks[0]],
xyA=[x_ticks[0], y_ticks2[0]],
coordsA="data", coordsB="data",
arrowstyle="<|-", shrinkA=5, shrinkB=5,
axesA=ax2, axesB=ax1, color="orange", lw=3)
ax2.add_artist(con)
plt.tight_layout()
#plt.savefig("../figures/divergence.pdf")
| code/prediction_horizon.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="b-cx3kMxVYJF" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 139} outputId="13900d9f-b711-4e4c-8fac-69e24da64730"
from google.colab import drive
drive.mount('/content/gdrive')
import os
os.environ['KAGGLE_CONFIG_DIR'] = "/content/gdrive/My Drive/Kaggle"
# %cd /content/gdrive/My Drive/Kaggle
# + id="zmHTsz6PVzmu" colab_type="code" colab={}
import tensorflow as tf
from tensorflow import keras
enc_model = keras.models.load_model('./encoder-model.h5', compile=False)
inf_model = keras.models.load_model('./inf-model.h5', compile=False)
# + id="CXWSbNbR0wB1" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="f054af9b-ebb5-40bb-d2cc-60dec23328c3"
print(tf.__version__)
# + id="FYHqJz_-WpYC" colab_type="code" colab={}
import json
vocab_max_size = 10000
with open('word_dict.json') as f:
word_dict = json.load(f)
tokenizer = keras.preprocessing.text.Tokenizer(filters='', num_words=vocab_max_size)
tokenizer.word_index = word_dict
# + id="ZUoqRDG4XRhZ" colab_type="code" colab={}
import numpy as np
max_length_in = 21
max_length_out = 20
def tokenize_text(text):
text = '<start> ' + text.lower() + ' <end>'
text_tensor = tokenizer.texts_to_sequences([text])
text_tensor = keras.preprocessing.sequence.pad_sequences(text_tensor, maxlen=max_length_in, padding="post")
return text_tensor
# Reversed map from a tokenizer index to a word
index_to_word = dict(map(reversed, tokenizer.word_index.items()))
# Given an input string, an encoder model (infenc_model) and a decoder model (infmodel),
def decode_sequence(input_sentence):
sentence_tensor = tokenize_text(input_sentence)
# Encode the input as state vectors.
state = enc_model.predict(sentence_tensor)
target_seq = np.zeros((1, 1))
target_seq[0, 0] = tokenizer.word_index['<start>']
curr_word = "<start>"
decoded_sentence = ''
i = 0
while curr_word != "<end>" and i < (max_length_out - 1):
print(target_seq.shape)
output_tokens, h = inf_model.predict([target_seq, state])
curr_token = np.argmax(output_tokens[0, 0])
if (curr_token == 0):
break;
curr_word = index_to_word[curr_token]
decoded_sentence += ' ' + curr_word
target_seq[0, 0] = curr_token
state = h
i += 1
return decoded_sentence
# + id="L1dnYIrPZZO3" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="a7045848-dd2c-48bf-a283-78d1ebebd4f9"
print(tokenize_text('have a'))
# + id="32IeWplxfCTh" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 306} outputId="7b82f129-65b4-4000-d720-c594a83ff1ae"
enc_model.summary()
# + id="pv_nVaw0fAs9" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 374} outputId="94c4e2da-ea9c-4fcc-b673-8cb6b4e4826f"
inf_model.summary()
# + id="x8UYM9E3Xj_i" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 131} outputId="148553d4-8e6e-4ce0-ef52-bbdf62e500c9"
import pandas as pd
texts = [
'have a']
output = list(map(lambda text: (text, decode_sequence(text)), texts))
output_df = pd.DataFrame(output, columns=["input", "output"])
output_df.head(len(output))
# + id="QtCu-pGiTEHi" colab_type="code" colab={}
enc_model.save('./encoder-model-2.h5')
inf_model.save('./inf-model-2.h5')
| Load_Smart_Compose_Keras_model.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#import seaborn as sns
totDF = pd.read_csv('../data/raw/Cleaned_data_set.csv')
#totClean = totClean.drop(totClean.columns[0],axis=1)#.reset_index()
totClean['mothers_age'].value_counts()
totDF['admit_NICU'] = totDF['admit_NICU'].replace(' ', 'U')
totDF['mothers_bmi'] = pd.to_numeric(totDF['mothers_bmi'], errors = 'coerce')
totDF['mother_bmirecode'] = pd.cut(totDF['mothers_bmi'],[19.0, 25.0,30.0,35.0,40.0,90.0], right = False)
val_check(totDF,'mothers_bmi_recode')
print(totDF['mothers_bmi_recode'].value_counts())
print(totDF['mothers_bmi_recode'].count())
print(totClean['mothers_bmi_recode'].value_counts())
print(totClean['mothers_bmi_recode'].count())
print(totDF['mothers_bmi'].value_counts())
print(totDF['mothers_bmi'].count())
print(totClean['mothers_bmi'].value_counts())
print(totClean['mothers_bmi'].count())
# ### Values to do analysis on
#
# Mom age
#
# Mom’s age to first baby
#
# Multiple Births
#
# Plurality
#
# BMI / Mom’s weight / weight gain M&C
#
# previous children - if prior_living_births, prior_dead_births, prior_terminations
#
# mean of mothers age vs mean of first child birthed
# #### Only include 2014-2017
totDF['mothers_bmi_recode']
dfNo13 = totDF.loc[totDF['birth_year'] != 2013.0]
dfNo13 = dfNo13.drop(totDF.columns[0:2],axis=1)
dfNo13.drop(4933,axis=0,inplace=True)
dfNo13
def plot_gpYR(df,col,xlab,ylab,title,kind='line'):
groupDF = df.groupby('birth_year')[col].value_counts().unstack()
plt.figure(figsize=(20,20))
groupDF.plot(kind=kind,logy=True, legend=True)
plt.xlabel(xlab)
plt.ylabel(ylab)
plt.title(title)
return
def val_check(data_frame, column_name = str):
df = pd.DataFrame(data_frame)
col = column_name
print( "Value counts of %s \n" %(col), df[col].value_counts())
print("Value counts of %s by year \n" %(col), df.groupby(['birth_year'])[col].value_counts())
def clean_col (df,groups):
df = df.mask(df == ' ')
numerics = ['int16', 'int32', 'int64']
if df[groups].dtypes == numerics:
df[groups] = list(map(lambda g: df[g].astype(float),groups))
return df
totDF['mothers_age'].value_counts()
totDF.plot()
# #### Create a new feature that for mothers first child
totDF['is_first_child'] = (totDF['prior_living_births']+totDF['prior_dead_births']+totDF['prior_terminations']) <= 0
# #### Create a new feature of mothers age in a range
totDF['mothers_age_groups']= pd.cut(totDF['mothers_age'], 4, labels = ['12-19', '20-29', '30-39','40-50'])
totDF['plurality']#.value_counts()
totDF.loc[totDF['plurality'] == 5]
totDF.groupby('plurality')['birth_year'].value_counts()
# #### Bool mask
# Only include rows where it is the mother's first child
#
# %time first_child = totDF.mask(totDF['is_first_child'] == False)
# print(first_child['mothers_age_groups'].value_counts())
# print(totDF['mothers_age_groups'].value_counts())
# ### Time Series Graphs
plot_gpYR(first_child,'mothers_age_groups','Year of birth',
"Mother's Age Group",'Number of First Time Mothers, in Each Age Group ')
plt.savefig('./Saved_Visualizations/mother_1stchild_ts.pdf')
plt.savefig('./Saved_Visualizations/mother_1stchild_ts.png')
# +
plot_gpYR(totDF,'mothers_age_groups','Year of birth',
'Mothers Age Groups','Ages of Mothers Having Children')
plt.savefig('./Saved_Visualizations/mother_agegroup_ts.pdf')
plt.savefig('./Saved_Visualizations/mother_agegroup_ts.png')
# -
plot_gpYR(totDF,'plurality','Years of birth',
'Number of cases of Plurality', 'Plurality per year')
plt.savefig('./Saved_Visualizations/plurality_ts.pdf')
plt.savefig('./Saved_Visualizations/plurality_ts.png')
plot_gpYR(totDF,'plurality','Years of birth',
'Number of cases of Plurality','Plurality per year')#,kind='bar')
| notebooks/CHTimeSeries.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import json
import re
import ast
import sys
import nltk
import traceback
import astor
import token as tk
from tokenize import generate_tokens
from io import StringIO
import itertools
from gensim.models import FastText
from gensim.models import KeyedVectors
from time import time
import numpy as np
import pickle
# +
# File Path
test_path="data/conala-corpus/conala-test.json"
test_clean_output_path="data/conala-corpus/.test.seq2seq"
# most relevant document path
fasttext_path = 'test_list_most_relevant_doc_fasttext.pkl'
supervised_path = 'test_list_most_relevant_doc_super.pkl'
unsupervised_path = 'test_list_most_relevant_doc_unsuper.pkl'
# +
QUOTED_STRING_RE = re.compile(r"(?P<quote>[`'\"])(?P<string>.*?)(?P=quote)")
def canonicalize_intent(intent):
str_matches = QUOTED_STRING_RE.findall(intent)
slot_map = dict()
return intent, slot_map
def replace_strings_in_ast(py_ast, string2slot):
for node in ast.walk(py_ast):
for k, v in list(vars(node).items()):
if k in ('lineno', 'col_offset', 'ctx'):
continue
# Python 3
# if isinstance(v, str) or isinstance(v, unicode):
if isinstance(v, str):
if v in string2slot:
val = string2slot[v]
# Python 3
# if isinstance(val, unicode):
# try: val = val.encode('ascii')
# except: pass
setattr(node, k, val)
else:
# Python 3
# if isinstance(v, str):
# str_key = unicode(v)
# else:
# str_key = v.encode('utf-8')
str_key = v
if str_key in string2slot:
val = string2slot[str_key]
if isinstance(val, str):
try: val = val.encode('ascii')
except: pass
setattr(node, k, val)
def canonicalize_code(code, slot_map):
string2slot = {x[1]['value']: x[0] for x in list(slot_map.items())}
py_ast = ast.parse(code)
replace_strings_in_ast(py_ast, string2slot)
canonical_code = astor.to_source(py_ast)
return canonical_code
def decanonicalize_code(code, slot_map):
try:
slot2string = {x[0]: x[1]['value'] for x in list(slot_map.items())}
py_ast = ast.parse(code)
replace_strings_in_ast(py_ast, slot2string)
raw_code = astor.to_source(py_ast)
# for slot_name, slot_info in slot_map.items():
# raw_code = raw_code.replace(slot_name, slot_info['value'])
return raw_code.strip()
except:
return code
def detokenize_code(code_tokens):
newline_pos = [i for i, x in enumerate(code_tokens) if x == '\n']
newline_pos.append(len(code_tokens))
start = 0
lines = []
for i in newline_pos:
line = ' '.join(code_tokens[start: i])
start = i + 1
lines.append(line)
code = '\n'.join(lines).strip()
return code
def encode_tokenized_code(code_tokens):
tokens = []
for token in code_tokens:
if token == '\t':
tokens.append('_TAB_')
elif token == '\n':
tokens.append('_NEWLINE_')
def get_encoded_code_tokens(code):
code = code.strip()
#print(code)
token_stream = generate_tokens(StringIO(code).readline)
tokens = []
indent_level = 0
new_line = False
for toknum, tokval, (srow, scol), (erow, ecol), _ in token_stream:
if toknum == tk.NEWLINE:
tokens.append('#NEWLINE#')
new_line = True
elif toknum == tk.INDENT:
indent_level += 1
# new_line = False
# for i in range(indent_level):
# tokens.append('#INDENT#')
elif toknum == tk.STRING:
tokens.append(tokval.replace(' ', '#SPACE#').replace('\t', '#TAB#').replace('\r\n', '#NEWLINE#').replace('\n', '#NEWLINE#'))
elif toknum == tk.DEDENT:
indent_level -= 1
# for i in range(indent_level):
# tokens.append('#INDENT#')
# new_line = False
else:
tokval = tokval.replace('\n', '#NEWLINE#')
if new_line:
for i in range(indent_level):
tokens.append('#INDENT#')
new_line = False
tokens.append(tokval)
# remove ending None
if len(tokens[-1]) == 0:
tokens = tokens[:-1]
if '\n' in tokval:
pass
return tokens
def tokenize(code):
token_stream = generate_tokens(StringIO(code).readline)
tokens = []
for toknum, tokval, (srow, scol), (erow, ecol), _ in token_stream:
if toknum == tk.ENDMARKER:
break
tokens.append(tokval)
return tokens
def compare_ast(node1, node2):
# Python 3
# if not isinstance(node1, str) and not isinstance(node1, unicode):
if not isinstance(node1, str):
if type(node1) is not type(node2):
return False
if isinstance(node1, ast.AST):
for k, v in list(vars(node1).items()):
if k in ('lineno', 'col_offset', 'ctx'):
continue
if not compare_ast(v, getattr(node2, k)):
return False
return True
elif isinstance(node1, list):
return all(itertools.starmap(compare_ast, zip(node1, node2)))
else:
return node1 == node2
def encoded_code_tokens_to_code(encoded_tokens, indent=' '):
decoded_tokens = []
for i in range(len(encoded_tokens)):
token = encoded_tokens[i]
token = token.replace('#TAB#', '\t').replace('#SPACE#', ' ')
if token == '#INDENT#': decoded_tokens.append(indent)
elif token == '#NEWLINE#': decoded_tokens.append('\n')
else:
token = token.replace('#NEWLINE#', '\n')
decoded_tokens.append(token)
decoded_tokens.append(' ')
code = ''.join(decoded_tokens).strip()
return code
def find_sub_sequence(sequence, query_seq):
for i in range(len(sequence)):
if sequence[i: len(query_seq) + i] == query_seq:
return i, len(query_seq) + i
raise IndexError
def replace_sequence(sequence, old_seq, new_seq):
matched = False
for i in range(len(sequence)):
if sequence[i: i + len(old_seq)] == old_seq:
matched = True
sequence[i:i + len(old_seq)] = new_seq
return matched
# -
# read and clean data
def read_clean_dataset(dataset_path, output_path):
train = json.load(open(dataset_path))
for i, example in enumerate(train):
# updating `train` in place
intent = example['intent']
rewritten_intent = example['rewritten_intent']
snippet = example['snippet']
# print(i)
# code_tokens = get_encoded_code_tokens(snippet)
# print(' '.join(code_tokens))
failed = False
intent_tokens = []
if rewritten_intent:
try:
canonical_intent, slot_map = canonicalize_intent(rewritten_intent)
#print(canonical_intent, slot_map)
snippet = snippet
canonical_snippet = canonicalize_code(snippet, slot_map)
#print("canonical_snippet:", canonical_snippet, slot_map)
intent_tokens = nltk.word_tokenize(canonical_intent)
decanonical_snippet = decanonicalize_code(canonical_snippet, slot_map)
#print("decanonical_snippet: ",decanonical_snippet)
snippet_reconstr = astor.to_source(ast.parse(snippet)).strip()
#print("snippet_reconstr: ",decanonical_snippet)
decanonical_snippet_reconstr = astor.to_source(ast.parse(decanonical_snippet)).strip()
#print("decanonical_snippet_reconstr: ",decanonical_snippet_reconstr)
encoded_reconstr_code = get_encoded_code_tokens(decanonical_snippet_reconstr)
decoded_reconstr_code = encoded_code_tokens_to_code(encoded_reconstr_code)
# syntax error in snippet
if not compare_ast(ast.parse(decoded_reconstr_code), ast.parse(snippet)):
print(i)
print('Original Snippet: %s' % snippet_reconstr)
print('Tokenized Snippet: %s' % ' '.join(encoded_reconstr_code))
print('decoded_reconstr_code: %s' % decoded_reconstr_code)
except:
print('*' * 20, file=sys.stderr)
print(i, file=sys.stderr)
print(intent, file=sys.stderr)
print(snippet, file=sys.stderr)
traceback.print_exc()
failed = True
finally:
example['slot_map'] = slot_map
if rewritten_intent is None:
encoded_reconstr_code = get_encoded_code_tokens(snippet.strip())
else:
encoded_reconstr_code = get_encoded_code_tokens(canonical_snippet.strip())
if not intent_tokens:
intent_tokens = nltk.word_tokenize(intent)
example['intent_tokens'] = intent_tokens
example['snippet_tokens'] = encoded_reconstr_code
json.dump(train, open(output_path, 'w'), indent=2)
# ## Print Case
def print_result(list_most_relevant_doc, ques_list):
# save the correct idx which one of ten result match correct code snippet
index_list = []
# save the ranking position which the best answer in
ranking_list = []
for j, ques_sim_dict in enumerate(list_most_relevant_doc):
for pid, idx in enumerate(ques_sim_dict['similar']):
if ques_list[idx]['question_id'] == ques_sim_dict['question_id']:
index_list.append(j)
ranking_list.append(pid)
break
return index_list, ranking_list
# +
read_clean_dataset(test_path, test_clean_output_path)
test_clean = json.load(open(test_clean_output_path))
test_size=len(test_clean)
test_ques_list=[] # [{"question_id": int, "intent_tokens": [...]}, ...]
for idx, example in enumerate(test_clean):
test_ques_list.append({"question_id": example["question_id"], "intent_tokens": example["intent_tokens"]})
# +
with open(fasttext_path, 'rb') as f:
fasttext_doc = pickle.load(f)
with open(supervised_path, 'rb') as f:
supervised_doc = pickle.load(f)
with open(unsupervised_path, 'rb') as f:
unsupervised_doc = pickle.load(f)
# +
f_idx_list, f_ranking_list= print_result(fasttext_doc, test_ques_list)
print(len(f_idx_list))
s_idx_list, s_ranking_list= print_result(supervised_doc, test_ques_list)
print(len(s_idx_list))
u_idx_list, u_ranking_list= print_result(unsupervised_doc, test_ques_list)
print(len(u_idx_list))
# -
# save the id that only supervised learning correctly match
final_idx = []
for i, j in enumerate(s_idx_list):
if j not in f_idx_list and j not in u_idx_list:
final_idx.append((i,j))
len(final_idx)
for (pid, idx) in final_idx:
print(idx, test_clean[idx]['question_id'])
print(test_clean[idx]['intent'])
print(test_clean[idx]['snippet'])
print(s_ranking_list[pid])
print("")
print("##FastText###")
for j, z in enumerate(fasttext_doc[idx]['similar']):
print(j+1 , test_clean[z]['snippet'])
print("##SuperVised Starspace###")
for j, z in enumerate(supervised_doc[idx]['similar']):
print(j+1 , test_clean[z]['snippet'])
print("##UnsuperVised Starspace###")
for j, z in enumerate(unsupervised_doc[idx]['similar']):
print(j+1 , test_clean[z]['snippet'])
print("##Done###")
print("")
| Case_Study.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import itertools
import os
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
print("TF version:", tf.__version__)
print("Hub version:", hub.__version__)
print("GPU is", "available" if tf.test.is_gpu_available() else "NOT AVAILABLE")
# +
module_selection = ("mobilenet_v2_100_224", 224)
handle_base, pixels = module_selection
MODULE_HANDLE ="https://tfhub.dev/google/imagenet/{}/feature_vector/4".format(handle_base)
IMAGE_SIZE = (pixels, pixels)
print("Using {} with input size {}".format(MODULE_HANDLE, IMAGE_SIZE))
BATCH_SIZE = 32
# -
data_dir = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
# +
datagen_kwargs = dict(rescale=1./255, validation_split=.20)
dataflow_kwargs = dict(target_size=IMAGE_SIZE, batch_size=BATCH_SIZE,
interpolation="bilinear")
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
**datagen_kwargs)
valid_generator = valid_datagen.flow_from_directory(
data_dir, subset="validation", shuffle=False, **dataflow_kwargs)
do_data_augmentation = False
if do_data_augmentation:
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range=40,
horizontal_flip=True,
width_shift_range=0.2, height_shift_range=0.2,
shear_range=0.2, zoom_range=0.2,
**datagen_kwargs)
else:
train_datagen = valid_datagen
train_generator = train_datagen.flow_from_directory(
data_dir, subset="training", shuffle=True, **dataflow_kwargs)
# -
do_fine_tuning = False
print("Building model with", MODULE_HANDLE)
model = tf.keras.Sequential([
# Explicitly define the input shape so the model can be properly
# loaded by the TFLiteConverter
tf.keras.layers.InputLayer(input_shape=IMAGE_SIZE + (3,)),
hub.KerasLayer(MODULE_HANDLE, trainable=do_fine_tuning),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(train_generator.num_classes,
kernel_regularizer=tf.keras.regularizers.l2(0.0001))
])
model.build((None,)+IMAGE_SIZE+(3,))
model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(lr=0.005, momentum=0.9),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True, label_smoothing=0.1),
metrics=['accuracy'])
steps_per_epoch = train_generator.samples // train_generator.batch_size
validation_steps = valid_generator.samples // valid_generator.batch_size
hist = model.fit(
train_generator,
epochs=5, steps_per_epoch=steps_per_epoch,
validation_data=valid_generator,
validation_steps=validation_steps).history
# +
plt.figure()
plt.ylabel("Loss (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(hist["loss"])
plt.plot(hist["val_loss"])
plt.figure()
plt.ylabel("Accuracy (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(hist["accuracy"])
plt.plot(hist["val_accuracy"])
# +
def get_class_string_from_index(index):
for class_string, class_index in valid_generator.class_indices.items():
if class_index == index:
return class_string
x, y = next(valid_generator)
image = x[0, :, :, :]
true_index = np.argmax(y[0])
plt.imshow(image)
plt.axis('off')
plt.show()
# Expand the validation image to (1, 224, 224, 3) before predicting the label
prediction_scores = model.predict(np.expand_dims(image, axis=0))
predicted_index = np.argmax(prediction_scores)
print("True label: " + get_class_string_from_index(true_index))
print("Predicted label: " + get_class_string_from_index(predicted_index))
# -
model.save('flower.h5')
list(valid_generator.class_indices.keys())
with open('classlist.txt', 'w') as filehandle:
for listitem in list(valid_generator.class_indices.keys()):
filehandle.write('%s\n' % listitem)
| Flower_Retraining.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Production model
# [](https://github.com/ampl/amplcolab/blob/master/ampl-lecture/prod_lecture.ipynb) [](https://colab.research.google.com/github/ampl/amplcolab/blob/master/ampl-lecture/prod_lecture.ipynb) [](https://kaggle.com/kernels/welcome?src=https://github.com/ampl/amplcolab/blob/master/ampl-lecture/prod_lecture.ipynb) [](https://console.paperspace.com/github/ampl/amplcolab/blob/master/ampl-lecture/prod_lecture.ipynb) [](https://studiolab.sagemaker.aws/import/github/ampl/amplcolab/blob/master/ampl-lecture/prod_lecture.ipynb)
#
# Description: generic model for production problem
#
# Tags: ampl-only, ampl-lecture
#
# Notebook author: N/A
#
# Model author: N/A
#
# Install dependencies
# !pip install -q amplpy ampltools
# Google Colab & Kaggle interagration
MODULES=['ampl', 'coin']
from ampltools import cloud_platform_name, ampl_notebook
from amplpy import AMPL, register_magics
if cloud_platform_name() is None:
ampl = AMPL() # Use local installation of AMPL
else:
ampl = ampl_notebook(modules=MODULES) # Install AMPL and use it
register_magics(ampl_object=ampl) # Evaluate %%ampl_eval cells with ampl.eval()
# This notebook provides the implementation of the production problem described in the book *AMPL: A Modeling Language for Mathematical Programming*
# by <NAME>, <NAME>, and <NAME>.
#
# ## Example: production model
#
# It is usual to adopt mathematical notation as a general and concise way of expressing problems based on variables, constraints, and objectives. We can write a compact description of the general form of a production problem, which we call a *model*, using algebraic notation for the objective and the constraints.
#
# ### Algebraic formulation
#
# Given:
#
# * $P$, a set of products
# * $a_j$ = tons per hour of product $j$, for each $j \in P$
# * $b$ = hours available at the mill
# * $c_j$ = profit per ton of product $j$, for each $j \in P$
# * $u_j$ = maximum tons of product $j$, for each $j \in P$
#
# Define variables: $X_j$ = tons of product $j$ to be made, for each $j \in P$.
#
# Maximize:
# $$\sum \limits_{j \in P} c_j X_j$$
#
# Subject to:
# $$\sum \limits_{j \in P} \frac{1}{a_j} X_j \leq b$$
#
# $$0 \leq X_j \leq u_j, \text{ for each }j \in P$$
#
# The model describes an infinite number of related optimization problems. If we provide specific values for data, however, the model becomes a specific problem, or instance of the model, that can be solved. Each different collection of data values defines a different instance.
#
#
# ### Model implementation
#
# The general formulation above can be written with AMPL as follows:
# +
# %%writefile prod.mod
# Sets and parameters
set P;
param a {j in P};
param b;
param c {j in P};
param u {j in P};
# Variables
var X {j in P};
# Objective function
maximize Total_Profit: sum {j in P} c[j] * X[j];
# Time and Limits constraints
subject to Time: sum {j in P} (1/a[j]) * X[j] <= b;
subject to Limit {j in P}: 0 <= X[j] <= u[j];
# -
# ### Data
#
# Due to the model and data separation, the abstract formulation works for any correct data input we provide to AMPL. A possible instance of the production problem is the following:
# +
# %%writefile prod.dat
set P := bands coils;
param: a c u :=
bands 200 25 6000
coils 140 30 4000 ;
param b := 40;
# -
# ### Solve the problem
#
# We can load the generated model and data files, and solve them by using a linear solver as CBC. Finally, the solution (values for X) is displayed.
# %%ampl_eval
model prod.mod;
data prod.dat;
option solver cbc;
solve;
display X;
| ampl-lecture/prod_lecture.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.8.5 64-bit
# name: python3
# ---
# + id="dKV8MCK1Y12g"
# # !pip install datasets transformers pandasql dask -qqq
# torch.cuda.empty_cache()
# + id="-oei2ojLYoHV"
model_checkpoint = "t5-small"
model_path=f'yazdipour/sparql-qald9-t5-small-2021-10-19_00-01'
# -
from transformers import pipeline, AutoTokenizer, AutoModelForSeq2SeqLM
prefix = "translate english to sparql2: "
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(model_path).to("cuda")
translator = pipeline(
"translation_xx_to_yy",
model=model,
tokenizer=tokenizer,
device=0 #0 for cuda, -1 for cpu
)
def replace_all(text, dict):
for i, j in dict.items():
text = text.replace(i, j)
return text
def decode_props(qry):
qry = qry.replace('[','{').replace(']','}')
return qry
translate= lambda q: decode_props(translator(prefix+q, max_length=100)[0]['translation_text'])
# !pip install beautifultable -qqq
from beautifultable import BeautifulTable
def pretty_translate(t,q):
ans = translate(q)
# print('QUESTION:\n' + q + '\nTARGET:\n'+ t +'\nRESULT:\n' + ans[0]+ '\nRESULT-DECODED:\n' + ans[1])
table = BeautifulTable(maxwidth=140)
# table.column_headers = ["", "Man Utd","Man City","T Hotspur"]
table.rows.append(['QUESTION', q])
table.rows.append(['Target', t])
table.rows.append(['RESULT-Raw', ans])
print(table)
# # TESTING
prefix
translator(prefix+'Who is <NAME>?', max_length=100)
# <re.Match object; span=(52, 66), match=':marlin_manson'>
# ('select distinct ?sbj where { ?sbj wdt:instance_of wd:marlin_manson . ?sbj wdt:instance_of wd:human }',
# 'select distinct ?sbj where { ?sbj wdt:P31 wd:marlin_manson . ?sbj wdt:P31 wd:Q5 }')
translate('Who is <NAME>?')
translate('Who is <NAME>?')
translate('what is?')
pretty_translate('select distinct ?sbj where { ?sbj wdt:P35 wd:Q127998 . ?sbj wdt:P31 wd:Q6256 }','Who is the country for head of state of Mahmoud Abbas?')
pretty_translate('select distinct ?sbj where { ?sbj wdt:P35 wd:Q127998 . ?sbj wdt:P31 wd:Q6256 }',"What country is Mahmoud Abbas the head of state of?")
pretty_translate('select distinct ?sbj where { ?sbj wdt:P35 wd:Q127998 . ?sbj wdt:P31 wd:Q6256 }','Who is the country for head of state of Mahmoud Abbas?')
pretty_translate("SELECT ?answer WHERE { wd:Q16538 wdt:P725 ?answer . ?answer wdt:P106 wd:Q177220}","Which female actress is the voice over on South Park and is employed as a singer?".lower())
pretty_translate("SELECT ?answer WHERE { wd:Q16538 wdt:P725 ?answer . ?answer wdt:P106 wd:Q177220}","Which female actress on South Park is the voice over and is used as a singer?")
# <NAME> (Q173746)
pretty_translate("select distinct ?answer where { wd:Q173746 wdt:P3973 ?answer}","Which is the PIM authority ID of Paul Erd?")
pretty_translate("SELECT ?obj WHERE { wd:Q1045 p:P1082 ?s . ?s ps:P1082 ?obj . ?s pq:P585 ?x filter(contains(YEAR(?x),'2009')) }",
"What was the population of Somalia in 2009-0-0?")
translate('Humans born in New York City') #random query - answer seems correct
# From QALD
target = "ASK WHERE { <http://dbpedia.org/resource/Taiko> a <http://dbpedia.org/class/yago/WikicatJapaneseMusicalInstruments> }"
q = "Are Taiko some kind of Japanese musical instrument?"
pretty_translate(target, q)
# From QALD
target = "PREFIX dct: <http://purl.org/dc/terms/> PREFIX dbc: <http://dbpedia.org/resource/Category:> SELECT DISTINCT ?uri WHERE { ?uri dct:subject dbc:Assassins_of_Julius_Caesar }"
q = "Who killed Caesar?"
pretty_translate(target, q)
# From QALD
q = 'What is the highest mountain in Germany?'
target = "PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX onto: <http://dbpedia.org/ontology/> \nSELECT ?uri WHERE { ?uri rdf:type onto:Mountain ; onto:elevation ?elevation ; onto:locatedInArea <http://dbpedia.org/resource/Germany> } ORDER BY DESC(?elevation) LIMIT 1"
pretty_translate(target, q)
# From QALD
q = 'Which American presidents were in office during the Vietnam War?'
target = "PREFIX dbo: <http://dbpedia.org/ontology/> PREFIX res: <http://dbpedia.org/resource/> PREFIX dct: <http://purl.org/dc/terms/> PREFIX dbc: <http://dbpedia.org/resource/Category:> SELECT ?uri WHERE { ?uri dct:subject dbc:Presidents_of_the_United_States . res:Vietnam_War dbo:commander ?uri }"
pretty_translate(target, q)
# From QALD
q = 'How many gold medals did <NAME> win at the 2008 Olympics?'
target = "PREFIX dbo: <http://dbpedia.org/ontology/> PREFIX dbr: <http://dbpedia.org/resource/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT Count(?sub) as ?c WHERE { ?sub dbo:goldMedalist dbr:Michael_Phelps . filter (contains (str(?sub), \"2008\") && contains (str(?sub), \"Olympics\")) }"
pretty_translate(target, q)
# From QALD
q = 'What is the profession of <NAME>?'
target = "PREFIX dbpedia2: <http://dbpedia.org/property/> PREFIX res: <http://dbpedia.org/resource/> SELECT DISTINCT ?string WHERE { res:Frank_Herbert dbpedia2:occupation ?string }"
pretty_translate(target, q)
# From QALD
q = 'How many seats does the home stadium of FC Porto have?'
target = "PREFIX dbo: <http://dbpedia.org/ontology/> PREFIX dbp: <http://dbpedia.org/property/> PREFIX dbr: <http://dbpedia.org/resource/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX db: <http://dbpedia.org/> SELECT ?capacity WHERE { { dbr:FC_Porto dbo:ground ?ground . ?ground dbo:capacity ?capacity } UNION { dbr:FC_Porto dbo:ground ?ground . ?ground dbp:capacity ?capacity } }"
pretty_translate(target, q)
# From QALD
q = 'Which frequent flyer program has the most airlines?'
target = "SELECT ?uri WHERE { ?airline <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://dbpedia.org/ontology/Airline> . ?airline <http://dbpedia.org/property/frequentFlyer> ?uri. } GROUP BY ?uri ORDER BY DESC(COUNT(DISTINCT ?airline)) OFFSET 0 LIMIT 1"
pretty_translate(target, q)
# From QALD
q = 'Which European countries have a constitutional monarchy?'
target = "PREFIX dbo: <http://dbpedia.org/ontology/> PREFIX dct: <http://purl.org/dc/terms/> PREFIX dbc: <http://dbpedia.org/resource/Category:> PREFIX dbr: <http://dbpedia.org/resource/> SELECT ?uri WHERE { ?uri dct:subject dbc:Countries_in_Europe ; dbo:governmentType dbr:Constitutional_monarchy }"
pretty_translate(target, q)
# From QALD
q = 'Which countries have places with more than two caves?'
target = "PREFIX dbo: <http://dbpedia.org/ontology/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT DISTINCT ?uri WHERE { ?cave rdf:type dbo:Cave ; dbo:location ?uri . ?uri rdf:type dbo:Country } GROUP BY ?uri HAVING ( COUNT(?cave) > 2 )"
pretty_translate(target, q)
# From QALD
q = 'Which airports are located in California, USA?'
target = "SELECT DISTINCT ?uri WHERE { ?uri a <http://dbpedia.org/ontology/Airport> { ?uri <http://dbpedia.org/ontology/location> <http://dbpedia.org/resource/California> } UNION { ?uri <http://dbpedia.org/ontology/city> <http://dbpedia.org/resource/California> } UNION { ?uri <http://dbpedia.org/ontology/city> ?city . ?city <http://dbpedia.org/ontology/isPartOf> <http://dbpedia.org/resource/California> } UNION { ?uri <http://dbpedia.org/ontology/operator> <http://dbpedia.org/resource/California> } }"
pretty_translate(target, q)
# From QALD
q = "What are the nicknames of San Francisco?"
target = "SELECT DISTINCT ?string WHERE { res:San_Francisco foaf:nick ?string }"
pretty_translate(target, q)
# From QALD
q = "What is <NAME>’s birth name?"
target = "SELECT DISTINCT ?string WHERE { res:Angela_Merkel dbp:birthName ?string }"
pretty_translate(target, q)
# From QALD
q = "Who is the mayor of Berlin?"
target = "SELECT DISTINCT ?uri WHERE { res:Berlin dbp:leader ?uri }"
pretty_translate(target, q)
# From QALD
q = "Which software has been published by Mean Hamster Software?"
target = "SELECT DISTINCT ?uri WHERE { ?uri rdf:type onto:Software { ?uri prop:publisher \"Mean Hamster Software\"@en } UNION { ?uri onto:publisher res:Mean_Hamster_Software } }"
pretty_translate(target, q)
# From QALD
q = "Which country was Bill Gates born in?"
target = "SELECT DISTINCT ?country WHERE { { dbr:Bill_Gates dbo:birthPlace ?birthPlace . ?birthPlace dbo:country ?country } UNION { dbr:Bill_Gates dbo:birthPlace ?birthPlace . ?birthPlace dbo:isPartOf ?place . ?place dbo:country ?country } }"
pretty_translate(target, q)
# From QALD
q = "How many grand-children did <NAME> have?"
target = "SELECT COUNT(DISTINCT ?y AS ?y) WHERE { <http://dbpedia.org/resource/Jacques_Cousteau> <http://dbpedia.org/ontology/child> ?x . ?x <http://dbpedia.org/ontology/child> ?y . }"
pretty_translate(target, q)
# From QALD
q = "Give me all professional skateboarders from Sweden."
target = "SELECT DISTINCT ?uri WHERE { ?uri dbo:occupation dbr:Skateboarder { ?uri dbo:birthPlace dbr:Sweden } UNION { ?uri dbo:birthPlace ?place . ?place dbo:country dbr:Sweden } }"
pretty_translate(target, q)
# From QALD
q = "Which monarchs of the United Kingdom were married to a German?"
target = "SELECT DISTINCT ?uri WHERE { ?uri rdf:type yago:WikicatMonarchsOfTheUnitedKingdom ; dbo:spouse ?spouse . ?spouse dbo:birthPlace res:Germany }"
pretty_translate(target, q)
# From QALD
q = "Give me all Argentine films."
target = "SELECT DISTINCT ?uri WHERE { { ?uri rdf:type yago:ArgentineFilms } UNION { ?uri rdf:type dbo:Film { ?uri dbo:country res:Argentina } UNION { ?uri dbp:country \"Argentina\"@en } } }"
pretty_translate(target, q)
# From QALD
q = "How did <NAME> die?"
target = "SELECT DISTINCT ?s WHERE { <http://dbpedia.org/resource/Michael_Jackson> <http://dbpedia.org/property/deathCause> ?s }"
pretty_translate(target, q)
# From QALD
q = "Where did <NAME> died?"
target = "."
pretty_translate(target, q)
# From QALD
q = "Which classes does the Millepede belong to?"
target = "SELECT DISTINCT ?String WHERE { res:Millipede dbp:taxon ?String }"
pretty_translate(target, q)
# From QALD
q = "Which classes does the Millepede belong to?"
target = "SELECT DISTINCT ?String WHERE { res:Millipede dbp:taxon ?String }"
pretty_translate(target, q)
| main/qald/t5-2021-10-11/seq2seq_t5_use_online.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + hide_input=true init_cell=true slideshow={"slide_type": "skip"} tags=["Hide"]
# This code cell starts the necessary setup for Hour of CI lesson notebooks.
# First, it enables users to hide and unhide code by producing a 'Toggle raw code' button below.
# Second, it imports the hourofci package, which is necessary for lessons and interactive Jupyter Widgets.
# Third, it helps hide/control other aspects of Jupyter Notebooks to improve the user experience
# This is an initialization cell
# It is not displayed because the Slide Type is 'Skip'
from IPython.display import HTML, IFrame, Javascript, display
from ipywidgets import interactive
import ipywidgets as widgets
from ipywidgets import Layout
import getpass # This library allows us to get the username (User agent string)
# import package for hourofci project
import sys
sys.path.append('../../supplementary') # relative path (may change depending on the location of the lesson notebook)
import hourofci
import warnings
warnings.filterwarnings('ignore') # Hide warnings
# load javascript to initialize/hide cells, get user agent string, and hide output indicator
# hide code by introducing a toggle button "Toggle raw code"
# HTML('''
# <script type="text/javascript" src=\"../../supplementary/js/custom.js\"></script>
# <input id="toggle_code" type="button" value="Toggle raw code">
# ''')
HTML('''
<script type="text/javascript" src=\"../../supplementary/js/custom.js\"></script>
<style>
.output_prompt{opacity:0;}
</style>
<input id="toggle_code" type="button" value="Toggle raw code">
''')
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## Big Data - a Beginners' Lesson
# ### Part 1 of 2
# ### In this lesson, you will:
# * Learn about and explore big data
# * Process and visualize big data
#
# ## Lesson Outline:
# * WTH is Big Data?
# * The ‘V’s of Big Data
# * Show Me the Data!
# * Show Me the Magic! (may overflow into the intermediate lesson)
# * Show me the $$!
# * Show me the Map(sss)!
#
#
#
# + [markdown] slideshow={"slide_type": "slide"}
# ## Thank you for helping our study
#
#
# <a href="#/slide-1-0" class="navigate-right" style="background-color:blue;color:white;padding:8px;margin:2px;font-weight:bold;">Continue with the lesson</a>
#
# Throughout this lesson you will see reminders, like the one below, to ensure that all participants understand that they are in a voluntary research study.
#
# ### Reminder
#
# <font size="+1">
#
# By continuing with this lesson you are granting your permission to take part in this research study for the Hour of Cyberinfrastructure: Developing Cyber Literacy for GIScience project. In this study, you will be learning about cyberinfrastructure and related concepts using a web-based platform that will take approximately one hour per lesson. Participation in this study is voluntary.
#
# Participants in this research must be 18 years or older. If you are under the age of 18 then please exit this webpage or navigate to another website such as the Hour of Code at https://hourofcode.com, which is designed for K-12 students.
#
# If you are not interested in participating please exit the browser or navigate to this website: http://www.umn.edu. Your participation is voluntary and you are free to stop the lesson at any time.
#
# For the full description please navigate to this website: <a href="../../gateway-lesson/gateway/gateway-1.ipynb">Gateway Lesson Research Study Permission</a>.
#
# </font>
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## WTH is Big Data?
#
# This is a “heat” map of something. :)
# <table>
# <tr style="background: #fff; text-align: left; vertical-align: top;">
# <td style="width: 100%; background: #fff; text-align: left; vertical-align: top;"> <img src='supplementary/heatmap.jpg' width="700" height="900" alt='map'></td>
# </tr>
# </table>
#
# + hide_input=true slideshow={"slide_type": "-"} tags=["Hide", "Init"]
import time
from IPython.display import clear_output
widget1 = widgets.RadioButtons(
options = ['Temperature', 'Road', 'Night light', 'Social media post'],
description = '<p style="display:inline;"> Guess what does <p style="display:inline; color:#FFA500;">orange</p>/<p style="display:inline;color:#1E90FF;">blue</p>/<p style="display:inline; color:#F0FFFF; background-color:#000000;">white</p> represent?</p>', style={'description_width': 'initial'},
layout = Layout(width='100%'),
value = None
)
display(widget1)
# hourofci.SubmitBtn2(widget1)
def SubmitBtn(widget):
button = widgets.Button(
description = 'Submit',
layout=Layout(width='auto', height='auto'),
disabled = False,
button_style = '',
icon = 'check'
)
display(button)
output = widgets.Output()
display(output)
def submit(b):
clear_output()
display(widget)
display(button)
display(output)
print("Great! Move to the next slide to see the answer.")
def countdown(t):
while t:
out.update(t)
time.sleep(1)
t -= 1
out.update(countdown(int(30)))
out.update(HTML(''' <br/>
<a id='button' href="#/slide-4-0" class="navigate-right" style="background-color:Green;color:white;padding:8px;margin:2px;font-weight:bold;">Nice try! Continue to see the answer!</a>
'''))
button.on_click(submit)
SubmitBtn(widget1)
# + [markdown] hide_input=false slideshow={"slide_type": "slide"}
# ## WTH is Big Data?
#
# This is a “heat” map of geotagged social media posts.
# <table>
# <tr style="background: #fff; text-align: left; vertical-align: top;">
# <td style="width: 100%; background: #fff; text-align: left; vertical-align: top;"> <img src='supplementary/heatmap.jpg' width="700" height="900" alt='map'></td>
# </tr>
# </table>
#
# * <p style="display:inline;"> <p style="display:inline; color:#FFA500;">Orange = flickr</p>; <p style="display:inline;color:#1E90FF;">blue = tweet</p>; <p style="display:inline; color:#F0FFFF; background-color:#000000;">white = both</p>. → Do you see any spatial pattern(s)? </p>
#
#
#
#
# + hide_input=true slideshow={"slide_type": "-"} tags=["Hide", "Init"]
class Output:
def __init__(self, name='countdown'):
self.h = display(display_id=name)
self.content = ''
self.mime_type = None
self.dic_kind = {
'text': 'text/plain',
'markdown': 'text/markdown',
'html': 'text/html',
}
def display(self):
self.h.display({'text/plain': ''}, raw=True)
def _build_obj(self, content, kind, append, new_line):
self.mime_type = self.dic_kind.get(kind)
if not self.mime_type:
return content, False
if append:
sep = '\n' if new_line else ''
self.content = self.content + sep + content
else:
self.content = content
return {self.mime_type: self.content}, True
def update(self, content, kind=None, append=False, new_line=True):
obj, raw = self._build_obj(content, kind, append, new_line)
self.h.update(obj, raw=raw)
print('Think about it for 30 seconds!')
out = Output(name='countdown')
out.display()
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## WTH is Big Data?
#
# <p style="display:inline;">This “heat” map tells us a lot about <p style="display:inline; color:#ff0000;">PEOPLE</p>!! </p>
#
#
# <table>
# <tr style="background: #fff; text-align: left; vertical-align: top;">
# <td style="width: 50%; background: #fff; text-align: left; vertical-align: top;"> <img src='supplementary/heatmap.jpg' width="700" height="900" alt='map'></td>
# <td style="background: #fff; text-align: left; font-size: 16px;">What do these pattern(s) tell us?
# <br/><strong>1. Where people are</strong> <br/>
# → notice how big cities and transportation network show up
# <br/><strong>2. What people share </strong> <br/>
# → flickr vs tweets <br/>
# Social media is an example of <p style="display:inline; color:#0096FF;">BIG DATA</p>.
# </td>
# </tr>
# </tr>
# </table>
#
#
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## WTH is Big Data?
#
#
# <table><br/><br/>
# <tr style="background: #fff; text-align: left; vertical-align: top;"><p style="display:inline; color:#0096FF; font-size: 24px;">Definition:</p>
# <td style="background: #fff; text-align: left; font-size: 24px; vertical-align: top;"><i> Datasets that are often characterized as a large volume of complex data produced at an accelerating pace. </td>
# <td style="width: 50%; background: #fff; text-align: left; vertical-align: top;"> <center><p style="display:inline; color:#0096FF; font-size: 24px;">The 3Vs of Big Data</p><img src='supplementary/3v.png' width="700" height="900" alt='map'></td>
# </tr>
#
# </table>
#
#
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## The ‘V’s of Big Data
# <br/>
#
# <p style="display:inline; color:#0096FF; font-size: 20px;">Volume</p> <p style="display:inline; font-size: 20px;">- the metric to measure data volume of big data at the scale of astronomical units (e.g. petabytes, exabytes, zettabytes, yottabytes)
#
#
# <table><br/><br/>
# <tr style="background: #fff; text-align: left; vertical-align: top;"><td style="width: 50%; background: #fff; text-align: left; vertical-align: top;"> <img src='supplementary/dobrilova.png' width="700" height="900" alt='map'></td>
# <td style="background: #fff; text-align: left; font-size: 18px; ">
# <ul>
# <li>2022 Figures (Dobrilova 2022)</li>
# <ul>
# <li>FB: 4.2M likes; 211k new photos</li>
# <li>IG: 347k browsing; 44k new photos</li>
# <li>Twitter: 87.5k new tweets</li>
# <li>Tumbler: 37k new posts</li>
# <li>Youtube: 4.5M videos watched; 1000 hrs of new videos uploaded</li>
# <li>Netflix: 694k hrs of video watched</li>
# <li>Texting: ~60M texts sent</li></ul>
# <li>How many msgs/posts/videos are there every day/month/year?</li>
# </ul>
# </td>
# </tr>
# </table>
#
#
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## The ‘V’s of Big Data
# <br/>
# <p style="display:inline; color:#0096FF; font-size: 20px;">Velocity</p> <p style="display:inline; font-size: 20px;">- The rate at which big data are generated over time. Watch the following video:</p>
# + hide_input=true slideshow={"slide_type": "-"} tags=["Hide", "Init"]
from IPython.display import YouTubeVideo
# print('Watch: OpenStreetMap for Haiti 12th Jan 2010')
YouTubeVideo('e89Tqr75mMw', width=800,height=480)
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## The ‘V’s of Big Data
# <br/>
#
# <p style="display:inline; color:#0096FF; font-size: 20px;">Variety</p> <p style="display:inline; font-size: 20px;">- The degree of heterogeneity in how big data are encoded, structured, formatted and represented
#
#
# <table><br/><br/>
# <tr style="background: #fff; text-align: left; vertical-align: top;"><td style="width: 50%; background: #fff; text-align: left; vertical-align: top;"> <img src='supplementary/Variety.png' width="700" height="900" alt='map'></td>
# </tr>
# </table>
#
#
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## The [Other] ‘V’s of Big Data
# <br/>
# <p style="display:inline; font-size: 20px;">Value - The usefulness of big data in providing unique insights to problem solving and/or decision making. Watch the following video:
#
# + hide_input=true slideshow={"slide_type": "-"} tags=["Hide", "Init"]
from IPython.display import YouTubeVideo
YouTubeVideo('rwOIQzcXx7Y', width=800,height=480)
# + [markdown] slideshow={"slide_type": "-"}
# Explore the tools here: https://coronavirus.jhu.edu/covid-19-daily-video
# <ul>
# <li>Where are COVID-19 cases rising?</li>
# <li>What are the trends of COVID-19 cases and testing?</li>
# <li>Which countries have flattened the curves?</li>
# </ul>
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## The [Other] ‘V’s of Big Data
# <br/>
#
# <p style="display:inline; font-size: 20px;">Veracity - The quality of big data and its implications to subsequent application</p>
#
#
#
# <table>
# <tr style="background-color:transparent">
# <td style="width: 50%">
# <img src='supplementary/Veracity.png' width="600"/>
# </td>
# <td style="padding-right:10px; width:700px">
# <ul style="text-align: left; font-size: 18px; ">
# <strong>Examine the emojis:</strong>
# <li>Do you agree/disagree? Why? </li>
# <ul>
# <li>Grapes in TX</li>
# <li>Snowman in D.C.</li>
# </ul>
# </ul>
# <ul style="text-align: left; font-size: 18px; ">
# <strong>To understand the biases, think about the following questions:</strong>
# <li>Who produced the data?</li>
# <li>When was the survey conducted?</li>
# </ul>
# </td>
# </tr>
# </table>
#
#
# + [markdown] hide_input=true slideshow={"slide_type": "slide"}
# ## The [Other] ‘V’s of Big Data
#
#
#
# <br/>
#
# <p style="display:inline; font-size: 20px;">Veracity → We should be aware of any biases (e.g. sampling) and quality issues</p>
# <table>
# <tr style="background: #fff; text-align: left; vertical-align: top;"><td style="width: 20%; background: #fff; text-align: left; vertical-align: top;"> <img src='supplementary/Veracity.png' ></td>
# <td style="width: 20%; background: #fff; text-align: left; vertical-align: top;"> <img src='supplementary/veracity2.png' ></td>
#
# </table>
#
#
# + [markdown] slideshow={"slide_type": "slide"}
# ## The [Other] ‘V’s of Big Data
#
# <br/>
# <p style="display:inline; font-size: 20px;">Visualization - A data rendering process to highlight the spatial, temporal and/or thematic pattern of big data through charts, graphics and creative illustrations.</p>
# <br/>
# <p style="display:inline; font-size: 15px;">Explore the JHU <a href="https://coronavirus.jhu.edu/us-map">COVID-19 Dashboard</a>: (see screenshot to relate the instructions)
# <br/>
# <ul style="font-size: 15px;">
# <li>Where are the hotspots/coldspots?</li>
# <li>Using the left panel, which county has the highest confirmed cases?</li>
# <li>Click on that county (or any county) in the map</li>
# <li>In the popup window, scroll down to see the infographics</li>
# <li>Click it to open up a new tab, examine the infographics</li>
# <li>Which visualization tool(s) helps you to understand the data the best?</li>
# </ul></p>
# <center><img src='supplementary/dashboard.png' alt='dashboard' width="1000" height="800">
#
#
# + [markdown] slideshow={"slide_type": "slide"}
# ## Show Me the Data!
# <body style="display:inline; font-size: 15px;">In the JHU COVID-19 Dashboard:
# <br/>
# <ul>
# <li>Are there any missing data?</li>
# <li>Scroll down the bottom panel, click the link “Downloadable Database: Github”</li>
# <li>Examine the data sources</li>
# <li>Up at the top, click on “csse_covid_19_data” folder</li>
# <li>Click into the “csse_covid_19_daily_reports” folder</li>
# <li>Find the .csv with today’s date and click into it</li>
# <li>Examine the data</li>
# </ul></body>
# <center><img src='supplementary/gitshot.png' alt='git' width="800" height="800">
#
#
# + [markdown] slideshow={"slide_type": "slide"}
# ## Show Me the Data!
#
# <br/>
#
# In Jupyter Notebook (see this file):
# <ul>
# <li>Introduce Pandas module</li>
# <li>Introduce Pandas data structures</li>
# <ul>
# <li>Series</li>
# <li>Dictionary</li>
# <li>Dataframe</li>
# </ul>
# <li>Explore and import the JHU COVID-19 data</li>
# <li>Calculate data</li>
# </ul>
#
#
# + [markdown] slideshow={"slide_type": "slide"}
# ## Show Me the Magic!!
#
# <br/>
#
# In Jupyter Notebook:
# <ul>
# <li>Process the data (using NYTimes COVID-19 recent cases data at county level)</li>
# <ul>
# <li>Dealing with NaN</li>
# <li>Filter cases to a selected state (e.g. TX)</li>
# <li>Create a spatial snapshot on a specific date → filter TX cases to a selected date (e.g. today)</li>
# <li>Create a temporal snapshot of a specific county → filter TX cases to a specific county (e.g. Travis County)</li>
# </ul>
# </ul>
#
#
# + [markdown] slideshow={"slide_type": "slide"}
# ## Show Me the $$!!
#
# <br/>
#
# In Jupyter Notebook:
# <ul>
# <li>Analyze the data (using NYTimes COVID-19 <a href="https://github.com/nytimes/covid-19-data/blob/master/us-counties-recent.csv">recent cases</a> and <a href="https://github.com/nytimes/covid-19-data/blob/master/mask-use/mask-use-by-county.csv">mask use</a> data at county level)</li>
# <ul>
# <li>Explore the spatial pattern and distribution of TX COVID-19 data</li>
# <ul>
# <li>Cluster analysis</li>
# </ul>
# <li>Explore the temporal trend of TX COVID-19 data</li>
# <ul>
# <li>Line graph</li>
# </ul>
# <li>Examine the relationship between COVID-19 confirmed cases and mask use</li>
# <ul>
# <li>Scatter plot</li>
# <li>Correlation analysis</li>
# </ul>
# </ul>
# </ul>
#
# + [markdown] slideshow={"slide_type": "slide"}
# ## Show Me the Map(sss)!!
#
# <br/>
#
# In Jupyter Notebook:
# <ul>
# <li>Visualize the data (using NYTimes COVID-19 <a href="https://github.com/nytimes/covid-19-data/blob/master/us-counties-recent.csv">recent cases</a> and <a href="https://github.com/nytimes/covid-19-data/blob/master/mask-use/mask-use-by-county.csv">mask use</a> data at county level)</li>
# <ul>
# <li>Load spatial data (e.g. county polygons)</li>
# <li>Join COVID-19 data with spatial data</li>
# <li>Introduce basic cartographic design</li>
# <li>Create maps of different variables</li>
# <li>Explore data classification methods</li>
# </ul>
# </ul>
#
# + [markdown] hide_input=false slideshow={"slide_type": "slide"}
#
# <font size="+1"><a style="background-color:blue;color:white;padding:12px;margin:10px;font-weight:bold;" href="bigdata-3.ipynb">Click here to go to the next notebook.</a></font>
| beginner-lessons/big-data/bigdata-2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Assignment 4
# #### Student ID: *Double click here to fill the Student ID*
#
# #### Name: *Double click here to fill the name*
# 部分習題需要寫數學式。
#
# 若不想用打的,可用手寫後,進行拍照或掃描,並使用以下指令引入圖片。
#
# 請確認圖片清晰程度為可辨識。
#
# ``
# # 4
# When the number of features $p$ is large, there tends to be a deterioration
# in the performance of KNN and other local approaches that perform prediction using only observations that are near the test observation for which a prediction must be made. This phenomenon is known as the curse of dimensionality, and it ties into the fact that parametric approaches often perform poorly when $p$ is large. We will now investigate this curse.
# (a) Suppose that we have a set of observations, each with measurements on $p = 1$ feature, $X$. We assume that $X$ is uniformly (evenly) distributed on $[0, 1]$. Associated with each observation is a response value. Suppose that we wish to predict a test observation’s response using only observations that are within $10\%$ of the range of $X$ closest to that test observation. For instance, in order to predict the response for a test observation with $X = 0.6$, we will use observations in the range $[0.55, 0.65]$. On average, what fraction of the available observations will we use to make the prediction?
# > Ans: *double click here to answer the question.*
# (b) Now suppose that we have a set of observations, each with measurements on $p = 2$ features, $X_1$ and $X_2$. We assume that $(X_1,X_2)$ are uniformly distributed on $[0, 1] \times [0, 1]$. We wish to predict a test observation’s response using only observations that are within $10\%$ of the range of $X_1$ and within $10\%$ of the range of $X_2$ closest to that test observation. For instance, in order to predict the response for a test observation with $X_1 = 0.6$ and $X_2 = 0.35$, we will use observations in the range $[0.55, 0.65]$ for $X_1$ and in the range $[0.3, 0.4]$ for $X_2$. On average, what fraction of the available observations will we use to make the prediction?
# > Ans: *double click here to answer the question.*
# (c) Now suppose that we have a set of observations on $p = 100$ features.
# Again the observations are uniformly distributed on each feature, and again each feature ranges in value from 0 to 1. We wish to predict a test observation’s response using observations within the $10\%$ of each feature’s range that is closest to that test observation. What fraction of the available observations will we use to make the prediction?
# > Ans: *double click here to answer the question.*
# (d) Using your answers to parts (a)–(c), argue that a drawback of
# KNN when $p$ is large is that there are very few training observations
# "near" any given test observation.
# > Ans: *double click here to answer the question.*
# (e) Now suppose that we wish to make a prediction for a test observation
# by creating a $p$-dimensional hypercube centered around the test observation that contains, on average, $10\%$ of the training observations. For $p = 1, 2,$ and $100$, what is the length of each side of the hypercube? Comment on your answer.
#
# Note: A hypercube is a generalization of a cube to an arbitrary number of dimensions. When $p = 1$, a hypercube is simply a line segment, when $p = 2$ it is a square, and when $p = 100$ it is a $100$-dimensional cube.
# > Ans: *double click here to answer the question.*
# # 5
# We now examine the differences between LDA and QDA.
# (a) If the Bayes decision boundary is linear, do we expect LDA or
# QDA to perform better on the training set? On the test set?
# > Ans: *double click here to answer the question.*
# (b) If the Bayes decision boundary is non-linear, do we expect LDA
# or QDA to perform better on the training set? On the test set?
# > Ans: *double click here to answer the question.*
# (c) In general, as the sample size $n$ increases, do we expect the test
# prediction accuracy of QDA relative to LDA to improve, decline,
# or be unchanged? Why?
# > Ans: *double click here to answer the question.*
# (d) True or False: Even if the Bayes decision boundary for a given
# problem is linear, we will probably achieve a superior test error
# rate using QDA rather than LDA because QDA is flexible
# enough to model a linear decision boundary. Justify your answer.
# > Ans: *double click here to answer the question.*
# ## Applied
# # 14
# In this problem, you will develop a model to predict whether a given
# car gets high or low gas mileage based on the <span style='color:red'>Auto</span> data set.
# (a) Create a binary variable, <span style='color:red'>mpg01</span>, that contains a 1 if <span style='color:red'>mpg</span> contains a value above its median, and a 0 if <span style='color:red'>mpg</span> contains a value below its median. You can compute the median using the <span style='color:red'>np.median()</span> function.
# (b) Explore the data graphically in order to investigate the association
# between <span style='color:red'>mpg01</span> and the other features. Which of the other features seem most likely to be useful in predicting <span style='color:red'>mpg01</span>? Scatterplots and boxplots may be useful tools to answer this question. Describe your findings.
# (c) Split the data into a training set and a test set.
# (d) Perform LDA on the training data in order to predict <span style='color:red'>mpg01</span> using the variables that seemed most associated with <span style='color:red'>mpg01</span> in (b). What is the test error of the model obtained?
# (e) Perform QDA on the training data in order to predict <span style='color:red'>mpg01</span> using the variables that seemed most associated with <span style='color:red'>mpg01</span> in (b). What is the test error of the model obtained?
# (f) Perform logistic regression on the training data in order to predict <span style='color:red'>mpg01</span> using the variables that seemed most associated with <span style='color:red'>mpg01</span> in (b). What is the test error of the model obtained?
# (g) Perform naive Bayes on the training data in order to predict <span style='color:red'>mpg01</span> using the variables that seemed most associated with <span style='color:red'>mpg01</span> in (b). What is the test error of the model obtained?
# # 16
# Using the <span style='color:red'>Boston</span> data set, fit classification models in order to predict whether a given census tract has a crime rate above or below the median. Explore logistic regression, LDA, naive Bayes, and KNN models using various subsets of the predictors. Describe your findings.
#
# Hint: You will have to create the response variable yourself, using the variables that are contained in the <span style='color:red'>Boston</span> data set.
| static_files/assignments/Assignment4.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/EnisBerk/speech_audio_understanding/blob/master/tensorflow2pytorch_master.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="dRpHisuHplqc" colab_type="code" outputId="b3001b99-57dd-4921-8726-ab4627a7f7b7" colab={"base_uri": "https://localhost:8080/", "height": 921}
# !pip3 install https://download.pytorch.org/whl/cu100/torch-1.0.1.post2-cp36-cp36m-linux_x86_64.whl
# !pip3 install torchvision
# !pip install numpy scipy resampy six pysoundfile pydub
# !pip install -U git+https://github.com/Microsoft/MMdnn.git@master
# !pip install tensorflow six
# + id="Co0iEWLopmjm" colab_type="code" colab={}
import tensorflow as tf
import torch
import imp
import numpy as np
from google.colab import files
from pydub import AudioSegment
# + id="5N7qeYWVpn0e" colab_type="code" outputId="98b75012-eaeb-4804-a43e-7a492f6052fd" colab={"base_uri": "https://localhost:8080/", "height": 136}
# !curl -O https://storage.googleapis.com/audioset/vggish_model.ckpt
# !curl -O https://storage.googleapis.com/audioset/vggish_pca_params.npz
# !git clone https://github.com/tensorflow/models.git
# Copy the source files to the current directory.
# !cp models/research/audioset/* .
# + id="phc-bfovpqHc" colab_type="code" outputId="d591ecc7-c470-4647-b415-cc27db7901dc" colab={"base_uri": "https://localhost:8080/", "height": 156}
import vggish_slim
import vggish_params
import vggish_input
def CreateVGGishNetwork(hop_size=0.96): # Hop size is in seconds.
"""Define VGGish model, load the checkpoint, and save model.
"""
vggish_slim.define_vggish_slim()
checkpoint_path = 'vggish_model.ckpt'
vggish_params.EXAMPLE_HOP_SECONDS = hop_size
vggish_slim.load_vggish_slim_checkpoint(sess, checkpoint_path)
features_tensor = sess.graph.get_tensor_by_name(
vggish_params.INPUT_TENSOR_NAME)
embedding_tensor = sess.graph.get_tensor_by_name(
vggish_params.OUTPUT_TENSOR_NAME)
saver = tf.train.Saver()
save_path = saver.save(sess, "tf_vggish_model.ckpt")
print("INPUT_TENSOR_NAME: ",vggish_params.INPUT_TENSOR_NAME)
print("OUTPUT_TENSOR_NAME: ",vggish_params.OUTPUT_TENSOR_NAME)
layers = {'conv1': 'vggish/conv1/Relu',
'pool1': 'vggish/pool1/MaxPool',
'conv2': 'vggish/conv2/Relu',
'pool2': 'vggish/pool2/MaxPool',
'conv3': 'vggish/conv3/conv3_2/Relu',
'pool3': 'vggish/pool3/MaxPool',
'conv4': 'vggish/conv4/conv4_2/Relu',
'pool4': 'vggish/pool4/MaxPool',
'fc1': 'vggish/fc1/fc1_2/Relu',
'fc2': 'vggish/fc2/Relu',
'embedding': 'vggish/embedding',
'features': 'vggish/input_features',
}
g = tf.get_default_graph()
for k in layers:
layers[k] = g.get_tensor_by_name( layers[k] + ':0')
return {'features': features_tensor,
'embedding': embedding_tensor,
'layers': layers,
}
# + id="SDhdM0JSpqyk" colab_type="code" outputId="e405f8ae-1c34-4e0a-a69e-e3c73196e599" colab={"base_uri": "https://localhost:8080/", "height": 241}
tf.reset_default_graph()
sess = tf.Session()
vgg=CreateVGGishNetwork()
# + id="ZlNOalT2qKep" colab_type="code" outputId="80de6c2d-3c87-444d-f95c-180ba9650ec1" colab={"base_uri": "https://localhost:8080/", "height": 547}
# !mmconvert -sf tensorflow -in tf_vggish_model.ckpt.meta -iw tf_vggish_model.ckpt --dstNode vggish/embedding -df pytorch -om tf_to_pytorch_vggish_model.pth
# + id="ZvcU6ooqPgbA" colab_type="code" colab={}
# + id="7S6Y8ibcN5On" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 224} outputId="5c34eedb-68cc-4d2f-8770-f0f661a2c921"
MainModel = imp.load_source('MainModel', "tf_to_pytorch_vggish_model.py")
the_model = torch.load("tf_to_pytorch_vggish_model.pth")
the_model.eval()
# + id="agt9n0bYN6Wr" colab_type="code" colab={}
#Generate Input
num_secs = 3
freq = 1000
sr = 44100
t = np.linspace(0, num_secs, int(num_secs * sr))
x = np.sin(2 * np.pi * freq * t) # Unit amplitude input signal
# + id="aopWIP19PX8N" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 473} outputId="13f51e2a-e466-47ff-8160-8ee685cf1d14"
#THIS CELL WILL GIVE ERROR:
# line 39 at tf_to_pytorch_vggish_model.py changes input shape:
# vggish_Reshape = torch.reshape(input = x, shape = (-1,96,64,1))
# however it should be (-1,1,96,64) since pytorch uses N,C,H,W
#pre-process input
input_batch = vggish_input.waveform_to_examples(x, sr)
input_batch=torch.from_numpy(input_batch)
output=the_model(input_batch)
# + id="L9Kc29zGRCYG" colab_type="code" colab={}
# GET MODIFIED tf_to_pytorch_vggish_model.py for correct input shape
# !curl -O https://gist.githubusercontent.com/EnisBerk/321dcd19bf388eed8a0f5af5562324a3/raw/f581e7547c7eb6fa4cc46395d8370fddd1bbaa8f/tf_to_pytorch_vggish_model.py
# RELOAD It
MainModel = imp.load_source('MainModel', "tf_to_pytorch_vggish_model.py")
the_model = torch.load("tf_to_pytorch_vggish_model.pth")
the_model.eval()
# + id="Ztb6V1ooSCSY" colab_type="code" colab={}
#THIS CELL WILL GIVE ERROR:
#pytorch weights are float32 so input needs to be float32 as well
#pre-process input
input_batch = vggish_input.waveform_to_examples(x, sr)
input_batch=torch.from_numpy(input_batch)
output=the_model.forward(input_batch)
# + id="sD_NM4m3TfZ0" colab_type="code" colab={}
# Finally this works, however results are different than tensorflow
input_batch = vggish_input.waveform_to_examples(x, sr)
# make input float32
input_batch=input_batch.astype(np.float32)
input_batch=torch.from_numpy(input_batch)
output=the_model.forward(input_batch)
# + id="-ghQ4egVRze7" colab_type="code" colab={}
# INFERENCE WITH tensorflow
# Produce a batch of log mel spectrogram examples.
input_batch = vggish_input.waveform_to_examples(x, sr)
# cast to float to make sure inputs are same
input_batch=input_batch.astype(np.float32)
[embedding_batch] = sess.run([vgg['embedding']],
feed_dict={vgg['features']: input_batch})
# + id="-n9mxrfKUbL7" colab_type="code" colab={}
print("checksum(tf): ",embedding_batch.sum())
print("checksum(pytorch):",output.sum())
# + id="UddqAcoWYaNe" colab_type="code" colab={}
# + id="6i-0rdLhZ7wJ" colab_type="code" colab={}
| notebooks/deprecated/tensorflow2pytorch_master.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import copy
from torch import nn
from torch import optim
import torch.nn.functional as F
import syft as sy
import torch as th
from helpers import Model, connect_to_workers
from sklearn.metrics import confusion_matrix
from tqdm import tqdm, tqdm_notebook
# BEWARE, ignoreing warnings is not always a good idea
# I am doing it for presentation
# +
features = np.load('../data/features.npy')
labels = np.load('../data/labels_dim.npy')
data = th.tensor(features, dtype=th.float32, requires_grad=True)
target = th.tensor(labels, dtype=th.float32, requires_grad=False).reshape(-1,2)
hook = sy.TorchHook(th)
# -
class Arguments():
def __init__(self, in_size, out_size, hidden_layers,
activation=F.softmax, dim=-1):
self.batch_size = 1
self.drop_p = None
self.epochs = 1
self.lr = 0.001
self.in_size = in_size
self.out_size = out_size
self.hidden_layers = hidden_layers
self.precision_fractional=10
self.activation = activation
self.dim = dim
# +
checkpoint = th.load('base_model.pt') # use model trained earlier to save time
dataset = [(data[i], target[i]) for i in range(len(data))]
# instantiate model
in_size = checkpoint['in_size']
out_size = checkpoint['out_size']
hidden_layers = checkpoint['hidden_layers']
# for MSE loss, we want to use softmax and not log_softmax
args = Arguments(in_size, out_size, hidden_layers,
activation=F.softmax, dim=1)
# PyTorch's softmax activation only works with floats
workers, trusted_aggregator = connect_to_workers(len(dataset), hook, True)
# -
# <a id="fl_model_avg"></a>
# ### Federated Learning with Model Averaging
# We can perform federated learning in a way that trains a model on the data of each remote worker, and uses a *'trusted aggregator'* to combine the models into one. In this way, the non-trusted party, me for example, cannot tell which remote worker has updated gradients in what way. Gradient updates can be reverse engineered to understand what data has been passed through the network. This is an added layer of privacy protection in federated learning. The downside of this approach, however, is that it requires all parties to trust said aggregator.
#
# A couple of quick things to note before starting this notebook, is that based on the way model averaging is performed, we cannot use [NLLLoss](https://pytorch.org/docs/stable/nn.html#nllloss), and therefore we are using [MSELoss](https://pytorch.org/docs/stable/nn.html#mseloss). This also means that we have to get the labels in a little differently (one-hot-encoded labels versus just the label). This also has an implication in terms of the activation function (if any) that we want to use. Instead of using [LogSoftmax](https://pytorch.org/docs/stable/nn.html#logsoftmax) which returns the log of the softmax function output, we would want to use the normal [Softmax](https://pytorch.org/docs/stable/nn.html#softmax).
# #### Send Data to Remote Worker
# In this step we need to send a copy of the model to each remote worker, as well as a new optimizer object
# +
# Send data to remote workers
# Cast the result in BaseDatasets
remote_dataset_list = []
for i in range(len(dataset)):
d, t = data[i], target[i]
# send to worker before adding to dataset
r_d = d.reshape(1, -1).send(workers[i])
r_t = t.reshape(1, -1).send(workers[i])
dtset = sy.BaseDataset(r_d, r_t)
remote_dataset_list.append(dtset)
# Build the FederatedDataset object
n_train_items = int(len(dataset)*0.7)
n_test_items = len(dataset) - n_train_items
# split into train/test
train_remote_dataset = sy.FederatedDataset(remote_dataset_list[:n_train_items])
test_remote_dataset = sy.FederatedDataset(remote_dataset_list[n_train_items:])
print(train_remote_dataset.workers[:5])
# -
model = Model(args)
model.load_state_dict(checkpoint['model_state'])
#send copy of model to remote client worker
models = [model.copy().send(w) for w in workers]
optimizers = [optim.SGD(params=m.parameters(), lr=args.lr) for m in models]
# PARALLEL federated learning with trusted aggregator
def federated_train_trusted_agg(models, datasets, optimizers):
for e in range(1, args.epochs+1):
running_loss = 0
for i in range(n_train_items): # train each model concurrently
model = models[i] # choose remote model to use
opt = optimizers[i] #choose remote optimizer to use
# get remote dataset loc (by worker id)
_d = datasets.datasets[model.location.id]
# NB the steps below all happen remotely
opt.zero_grad()
# zero out gradients so that one forward pass
# doesnt pick up previous forward's gradients
outputs = model.forward(_d.data) # make prediction
# get shape of (1,2) as we need at least two dimension
outputs = outputs.reshape(1, -1)
# NllLoss does not work well with federation...
loss = ((outputs - _d.targets)**2).sum()
#or
#loss = F.mse_loss(outputs, _d.targets)
loss.backward()
opt.step()
# FEDERATION STEP
_loss = loss.get().data # get loss from remote worker
if th.isnan(_loss) or _loss > 10:
print(model.location.id, outputs.get(), _d.targets.get(), _loss)
continue
running_loss += _loss
print('Epoch: {} \tLoss: {:.6f}'.format(
e, running_loss/i))
# move trained models to trusted thrid party
for m in models:
m.move(trusted_aggregator)
federated_train_trusted_agg(models, train_remote_dataset, optimizers)
# Now that we have parallel training implemented, we want to add logic that averages the models of each remote worker after each iteration.
def set_model_avg(base_model, models):
'''
Average weights and biases of models on trusted aggregator
Parameters
::models - list: pointers to remote models, should be on trusted aggregator
Returns
::avg_weights
::avg_bias
'''
# average out each hidden layer individually
for i in range(len(base_model.hidden_layers)):
weights, biases = zip(*[(m.hidden_layers[i].weight.data,
m.hidden_layers[i].bias.data) for m in models])
base_model.hidden_layers[i].weight\
.set_((sum(weights)/len(models)).get())
base_model.hidden_layers[i].bias.set_((sum(biases)/len(models)).get())
# average out output layer
weights, biases = zip(*[(m.output.weight.data,
m.output.bias.data) for m in models])
base_model.output.weight.set_((sum(weights)/len(models)).get())
base_model.output.bias.set_((sum(biases)/len(models)).get())
# Average the model on trusted aggregator
with th.no_grad():
set_model_avg(model, models)
# #### Putting it Together
# Now put together the training and averaging step into one, where the overall model is averaged on a trusted aggregator after every epoch.
# +
# %%time
print((f'Federated Training \n {len(workers)} remote workers'
f'\n {len(remote_dataset)} datum'
'\n 1 Trusted Aggregator'))
model = Model(args)
model.load_state_dict(checkpoint['model_state'])
for i in range(1, args.epochs+1):
models = [model.copy().send(w) for w in workers]
optimizers = [optim.SGD(params=m.parameters(), lr=args.lr) for m in models]
federated_train_trusted_agg(models, train_remote_dataset, optimizers)
# Average the model on trusted aggregator
with th.no_grad():
set_model_avg(model, models)
# -
# We have now trained a deep learning model using federated learning with a trusted aggregator! Make sure to test the model on a hold-out dataset. For the purpose of these examples, I will exclude testing sets for the sake of time.
# Nevertheless, this **data is not yet encrypted** and we could deduce things specific to the applicant just by getting or looking at the remote data. <br>
# In comes **encrypted deep learning**! Here we want to encrypt gradients such that no trusted aggregator is needed! To check out this exciting code [click here](https://github.com/mkucz95/private_ai_finance#encrypted-deep-learning).
# ***
| notebooks/federated_dl_model_averaging.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: ds_tutorials
# language: python
# name: ds_tutorials
# ---
# %matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import statsmodels.api as sm
import numpy as np
# +
# Read the 2015-2016 wave of NHANES data
da = pd.read_csv("data/nhanes_2015_2016.csv")
# Drop unused columns, and drop rows with any missing values.
vars = ["BPXSY1", "RIDAGEYR", "RIAGENDR", "RIDRETH1", "DMDEDUC2", "BMXBMI", "SMQ020"]
da = da[vars].dropna()
# -
model = sm.OLS.from_formula('BPXSY1 ~ RIDAGEYR', data=da)
result = model.fit()
result.summary()
da.BPXSY1.std()
cc = da[["BPXSY1", "RIDAGEYR"]].corr()
print(cc.BPXSY1.RIDAGEYR**2)
cc = np.corrcoef(da.BPXSY1, result.fittedvalues)
print(cc[0, 1]**2)
# #### Thus, we see that in a linear model fit with only one covariate, the regression R-squared is equal to the squared Pearson correlation between the covariate and the outcome, and is also equal to the squared Pearson correlation between the fitted values and the outcome.
# ### Adding a second variable
# Create a labeled version of the gender variable
da["RIAGENDRx"] = da.RIAGENDR.replace({1: "Male", 2: "Female"})
model = sm.OLS.from_formula('BPXSY1 ~ RIDAGEYR + RIAGENDRx', data=da)
result = model.fit()
result.summary()
# #### The model that was fit above uses both age and gender to explain the variation in SBP. It finds that two people with the same gender whose ages differ by one year tend to have blood pressure values differing by 0.47 units, which is essentially the same age parameter that we found above in the model based on age alone. This model also shows us that comparing a man and a woman of the same age, the man will on average have 3.23 units greater SBP.
#
# #### It is very important to emphasize that the age coefficient of 0.47 is only meaningful when comparing two people of the same gender, and the gender coefficient of 3.23 is only meaningful when comparing two people of the same age. Moreover, these effects are additive, meaning that if we compare, say, a 50 year old man to a 40 year old woman, the man's blood pressure will on average be around 3.23 + 10*0.47 = 7.93 units higher, with the first term in this sum being attributable to gender, and the second term being attributable to age.
#
# #### We noted above that the regression coefficient for age did not change by much when we added gender to the model. It is important to note however that in general, the estimated coefficient of a variable in a regression model will change when other variables are added or removed. The only circumstance in which a regresion parameters is unchanged when other variables are added or removed from the model is when those variables are uncorrelated with the variables that remain in the model.
#
# #### Below we confirm that gender and age are nearly uncorrelated in this data set (the correlation of around -0.02 is negligible). Thus, it is expected that when we add gender to the model, the age coefficient is unaffected.
# We need to use the original, numerical version of the gender
# variable to calculate the correlation coefficient.
da[["RIDAGEYR", "RIAGENDR"]].corr()
# #### Observe that in the regression output shown above, an R-squared value of 0.215 is listed. Earlier we saw that for a model with only one covariate, the R-squared from the regression could be defined in two different ways, either as the squared correlation coefficient between the covariate and the outcome, or as the squared correlation coefficient between the fitted values and the outcome. When more than one covariate is in the model, only the second of these two definitions continues to hold:
cc = np.corrcoef(da.BPXSY1, result.fittedvalues)
cc[0, 1]**2
# ### Categorical variables and reference levels
#
# #### In the model fit above, gender is a categorical variable, and only a coefficient for males is included in the regression output (i.e. there is no coefficient for females in the tables above). Whenever a categorical variable is used as a covariate in a regression model, one level of the variable is omitted and is automatically given a coefficient of zero. This level is called the reference level of the covariate. Here, the female level of the gender variable is the reference level. This does not mean that being a woman has no impact on blood pressure. It simply means that we have written the model so that female blood pressure is the default, and the coefficient for males (3.23) shifts the blood pressure by that amount for males only.
#
# #### We could alternatively have set 'male' to be the reference level, in which case males would be the default, and the female coefficient would have been around -3.23 (meaning that female blood pressure is 3.23 units lower than the male blood pressure).
#
# #### When using a categorical variable as a predictor in a regression model, it is recoded into "dummy variables" (also known as "indicator variables"). A dummy variable for a single level, say a, of a variable x, is a variable that is equal to 1 when x=a and is equal to 0 when x is not equal to a. These dummy variables are all included in the regression model, to represent the variable that they are derived from.
#
# #### Statsmodels, like most software, will automatically recode a categorical variable into dummy variables, and will select a reference level (it is possible to override this choice, but we do not cover that here). When interpreting the regression output, the level that is omitted should be seen as having a coefficient of 0, with a standard error of 0. It is important to note that the selection of a reference level is arbitrary and does not imply an assumption or constraint about the model, or about the population that it is intended to capture.
# ### A model with three variables
model = sm.OLS.from_formula('BPXSY1 ~ RIDAGEYR + BMXBMI + RIAGENDRx', data=da)
result = model.fit()
result.summary()
da[["RIDAGEYR", "RIAGENDR", "BMXBMI"]].corr()
# ### Visualization of the fitted models
#
# #### In this section we demonstrate some graphing techniques that can be used to gain a better understanding of a regression model that has been fit to data.
#
# #### We start with plots that allow us to visualize the fitted regression function, that is, the mean systolic blood pressure expressed as a function of the covariates. These plots help to show the estimated role of one variable when the other variables are held fixed. We will also plot 95% simultaneous confidence bands around these fitted lines. Although the estimated mean curve is never exact based on a finite sample of data, we can be 95% confident that the true mean curve falls somewhere within the shaded regions of the plots below.
#
# #### This type of plot requires us to fix the values of all variables other than the independent variable (SBP here), and one independent variable that we call the focus variable (which is age here). Below we fix the gender as "female" and the BMI as 25. Thus, the graphs below show the relationship between expected SBP and age for women with BMI equal to 25.
# +
from statsmodels.sandbox.predict_functional import predict_functional
# Fix certain variables at reference values. Not all of these
# variables are used here, but we provide them with a value anyway
# to prevent a warning message from appearing.
values = {"RIAGENDRx": "Female", "RIAGENDR": 1, "BMXBMI": 25,
"DMDEDUC2": 1, "RIDRETH1": 1, "SMQ020": 1}
# The returned values are the predicted values (pr), the confidence bands (cb),
# and the function values (fv).
pr, cb, fv = predict_functional(result, 'RIDAGEYR',
values=values, ci_method='simultaneous')
ax = sns.lineplot(fv, pr, lw=4)
ax.fill_between(fv, cb[:, 0], cb[:, 1], color='grey', alpha=0.4)
ax.set_xlabel('Age')
_ = ax.set_ylabel('SBP')
# +
del values["BMXBMI"] # Delete this as it is now the focus variable
values["RIDAGEYR"] = 50
pr, cb, fv = predict_functional(result, "BMXBMI",
values=values, ci_method="simultaneous")
ax = sns.lineplot(fv, pr, lw=4)
ax.fill_between(fv, cb[:, 0], cb[:, 1], color='grey', alpha=0.4)
ax.set_xlabel("BMI")
_ = ax.set_ylabel("SBP")
# -
# #### The error band for BMI is notably wider than the error band for age, indicating that there is less certainty about the relationship between BMI and SBP compared to the relationship between age and SBP.
#
# #### The discussion so far has primarily focused on the mean structure of the population, that is, the model for the average SBP of a person with a given age, gender, and BMI. A regression model can also be used to assess the variance structure of the population, that is, how much and in what manner the observations deviate from their mean. We will focus on informal, graphical methods for assessing this.
#
# #### To begin with, we plot the residuals against the fitted values. Recall that the fitted values are the estimated means for each observation, and the residuals are the difference between an observation and its fitted mean. For example, the model may estimate that a 50 year old female will have on average an SBP of 125. But a specific 50 year old female may have a blood pressure of 110 or 150, for example. The fitted values for both of these women are 125, and their residuals are -15, and 25, respectively.
#
# #### The simplest variance pattern that we can see in a linear regression occurs when the points are scattered around the mean, with the same degree of scatter throughout the range of the covariates. When there are multiple covariates, it is hard to assess whether the variance is uniform throughout this range, but we can easily check for a "mean/variance relationship", in which there is a systematic relationship between the variance and the mean, i.e. the variance either increases or decreases systematically with the mean. The plot of residuals on fitted values is used to assess whether such a mean/variance relationship is present.
#
# #### Below we show the plot of residuals on fitted values for the NHANES data. It appears that we have a modestly increasing mean/variance relationship. That is, the scatter around the mean blood pressure is greater when the mean blood pressure itself is greater.
pp = sns.scatterplot(result.fittedvalues, result.resid)
pp.set_xlabel("Fitted Values")
_ = pp.set_ylabel('Residuals')
# #### A "component plus residual plot" or "partial residual plot" is intended to show how the data would look if all but one covariate could be fixed at reference values. By controlling the values of these covariates, all remaining variation is due either to the "focus variable" (the one variable that is left unfixed, and is plotted on the horizontal axis), or to sources of variation that are unexplained by any of the covariates.
#
# #### For example, the partial residual plot below shows how age (horizontal axis) and SBP (vertical axis) would be related if gender and BMI were fixed. Note that the origin of the vertical axis in these plots is not meaningful (we are not implying that anyone's blood pressure would be negative), but the differences along the vertical axis are meaningful. This plot implies that when BMI and gender are held fixed, the average blood pressures of an 80 and 18 year old differ by around 30 mm/Hg. This plot also shows, as discussed above, that the deviations from the mean are somewhat smaller at the low end of the range compared to the high end of the range. We also see that at the high end of the range, the deviations from the mean are somewhat right-skewed, with exceptionally high SBP values being more common than exceptionally low SBP values.
# +
# This is not part of the main Statsmodels API, so needs to be imported separately
from statsmodels.graphics.regressionplots import plot_ccpr
ax = plt.axes()
plot_ccpr(result, 'RIDAGEYR', ax)
ax.lines[0].set_alpha(0.2) # Reduce overplotting with transparency
_ = ax.lines[1].set_color('orange')
# -
# #### Next we have a partial residual plot that shows how BMI (horizontal axis) and SBP (vertical axis) would be related if gender and age were fixed. Compared to the plot above, we see here that age is more uniformly distributed than BMI. Also, it appears that there is more scatter in the partial residuals for BMI compared to what we saw above for age. Thus there seems to be less information about SBP in BMI, although a trend certainly exists.
ax = plt.axes()
plot_ccpr(result, 'BMXBMI', ax)
ax.lines[0].set_alpha(0.2)
ax.lines[1].set_color('orange')
# #### Another important plot used for understanding a regression model is an "added variable plot". This is a plot that may reveal nonlinearity in the relationship between one covariate and the outcome. Below, we create an added variable plot for age as a predictor of SBP. Note that the two variables being plotted (age and blood pressure) have been centered. The scale of the variables is unchanged, but the origin has been translated to zero. The red line is an estimte of the relationship between age and blood pressure. Unlike the relationship in the model, it is not forced to be linear, and there is in fact a hint that the shape is slightly flatter for the first 15 years or so of age. This would imply that blood pressure increases slightly more slowly for people in theie 20s and early 30s, then begins increasing faster after that point.
# +
# This is not part of the main Statsmodels API, so needs to be imported separately
from statsmodels.graphics.regressionplots import add_lowess
# This is an equivalent way to fit a linear regression model, it needs to be
# done this way to be able to make the added variable plot
model = sm.GLM.from_formula('BPXSY1 ~ RIDAGEYR + BMXBMI + RIAGENDRx', data=da)
result = model.fit()
result.summary()
fig = result.plot_added_variable('RIDAGEYR')
ax = fig.get_axes()[0]
ax.lines[0].set_alpha(0.2)
_ = add_lowess(ax)
# -
| nhanes_linear_model.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="sS50nXMfHDK4" executionInfo={"status": "ok", "timestamp": 1617800818207, "user_tz": -480, "elapsed": 5071, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}}
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
from tensorflow.keras import Model
from tensorflow.keras.applications.efficientnet import EfficientNetB2
from keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# + colab={"base_uri": "https://localhost:8080/"} id="4jcr2KacHKyG" executionInfo={"status": "ok", "timestamp": 1617800839583, "user_tz": -480, "elapsed": 26437, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AO<KEY>XC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="a2e0ab7a-6cf4-495b-d914-0dbecc9a7379"
from google.colab import drive
drive.mount('/content/drive')
# + id="AylBbT9nHMtQ" executionInfo={"status": "ok", "timestamp": 1617800839584, "user_tz": -480, "elapsed": 26434, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}}
IMAGE_SIZE = (260, 260)
VALIDATION_SPLIT = 0.2
BATCH_SIZE = 56
# + id="1JbQsToaHi5H" executionInfo={"status": "ok", "timestamp": 1617800839584, "user_tz": -480, "elapsed": 26431, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}}
gdrive_dir = "/content/drive/MyDrive"
working_dir = os.path.join(gdrive_dir, "CS3244 Project")
data_dir = os.path.join(working_dir, "landmarks/local")
model_root_dir = os.path.join(working_dir, "models/XiZhe")
# + colab={"base_uri": "https://localhost:8080/"} id="pXznbJxRILb-" executionInfo={"status": "ok", "timestamp": 1617800841376, "user_tz": -480, "elapsed": 28218, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="1d7c0216-b3d7-4e45-8fbd-1d610abefe83"
print("number of labels: ", len(os.listdir(data_dir)))
# + colab={"base_uri": "https://localhost:8080/"} id="AnqcL-beIicu" executionInfo={"status": "ok", "timestamp": 1617800855451, "user_tz": -480, "elapsed": 42288, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="fed925a4-eef3-46a1-bc15-e7d46d7548a3"
dataflow_kwargs = dict(target_size=IMAGE_SIZE, batch_size=BATCH_SIZE, interpolation="bilinear")
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale = 1./255,
validation_split = VALIDATION_SPLIT,
rotation_range = 30,
width_shift_range = 0.1,
height_shift_range = 0.1,
shear_range = 0.1,
zoom_range = 0.1,
brightness_range = [0.9,1.1],
fill_mode = 'nearest'
)
train_generator = train_datagen.flow_from_directory(
data_dir,
subset = "training",
shuffle = True,
target_size = IMAGE_SIZE ,
batch_size = BATCH_SIZE,
class_mode = 'categorical',
)
validation_datagen = ImageDataGenerator(
rescale=1./255,
validation_split = VALIDATION_SPLIT
)
validation_generator = validation_datagen.flow_from_directory(
data_dir,
subset = "validation",
shuffle = False,
target_size = IMAGE_SIZE,
batch_size = BATCH_SIZE,
class_mode = 'categorical'
)
# + id="4spq6-56KoK_" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1617800897321, "user_tz": -480, "elapsed": 84155, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="3781ec1c-caa3-4102-87c6-f75b6723fea3"
load_model_dir = os.path.join(model_root_dir, "efficientnet_b2_intl_classification_v2b7")
international_model = tf.keras.models.load_model(load_model_dir)
# + colab={"base_uri": "https://localhost:8080/"} id="rfJyCMLC1uvi" executionInfo={"status": "ok", "timestamp": 1617800897322, "user_tz": -480, "elapsed": 84151, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="6053f729-f8bf-4fa6-da7b-fe2b1f7df369"
international_model.summary()
# + id="MZp6Jv7u19Cr" executionInfo={"status": "ok", "timestamp": 1617800897323, "user_tz": -480, "elapsed": 84150, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}}
last_layer = international_model.get_layer("dense_1")
last_output = last_layer.output
# + id="LZCDXnQs2des" executionInfo={"status": "ok", "timestamp": 1617800980935, "user_tz": -480, "elapsed": 1241, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}}
x = layers.Dense(11, activation='softmax', name='output')(last_output)
model = Model(international_model.input, x)
# + colab={"base_uri": "https://localhost:8080/"} id="mvzZBo_0LY_S" executionInfo={"status": "ok", "timestamp": 1617800987520, "user_tz": -480, "elapsed": 1899, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="a6510574-80af-49b4-debf-a29cc24a5ecf"
model.summary()
# + colab={"base_uri": "https://localhost:8080/"} id="8yru5Hz3Lqen" executionInfo={"status": "ok", "timestamp": 1617800991148, "user_tz": -480, "elapsed": 1524, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="88275979-905c-4be0-a17d-6e61e1e09b2a"
model.compile(
loss = 'categorical_crossentropy',
optimizer = "adam",
metrics = ['accuracy']
)
steps_per_epoch = int(train_generator.samples / BATCH_SIZE)
validation_steps = int(validation_generator.samples / BATCH_SIZE)
print("Steps per epoch:", steps_per_epoch)
print("Validation steps:", validation_steps)
# + colab={"base_uri": "https://localhost:8080/", "height": 477} id="2Gbok504LuQU" executionInfo={"status": "error", "timestamp": 1617801117609, "user_tz": -480, "elapsed": 124295, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GjmgksAe7yAfXC-cWctzj8DTNi3_LjcTp_7zpPaiA=s64", "userId": "11869197586808586351"}} outputId="96c67d73-b190-4b3b-8018-b6532733ff89"
history = model.fit(
train_generator,
steps_per_epoch = steps_per_epoch,
epochs = 60,
validation_data = validation_generator,
validation_steps = validation_steps
)
# + id="N62Ya8DlP41K"
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend(loc=0)
plt.figure()
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# + id="mrrAT8AtP52E"
url = "https://www.visitsingapore.com/content/dam/desktop/global/see-do-singapore/recreation-leisure/merlionpark_carousel1_1640x640.jpeg"
try:
image_data = requests.get(url, stream=True).raw
except Exception as e:
print('Warning: Could not download image from %s' % url)
print('Error: %s' %e)
raise
try:
pil_image = Image.open(image_data)
except Exception as e:
print('Warning: Failed to parse image')
print('Error: %s' %e)
raise
try:
img = pil_image.convert('RGB').resize(IMAGE_SIZE)
except:
print('Warning: Failed to format image')
raise
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
print(pil_image.size)
classes = model.predict(x)
labels = list(train_generator.class_indices.keys())
for i in range(len(classes[0])):
print("%s: %s" % (labels[i], classes[0][i]))
| colabs/efficientnet-landmark-local.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Kaggle Contest on *Observing Dark World*
#
# A personal motivation for learning Bayesian methods was trying to piece together the winning solution to Kaggle's [*Observing Dark Worlds*](http://www.kaggle.com/c/DarkWorlds) contest. From the contest's website:
#
#
#
# >There is more to the Universe than meets the eye. Out in the cosmos exists a form of matter that outnumbers the stuff we can see by almost 7 to 1, and we don’t know what it is. What we do know is that it does not emit or absorb light, so we call it Dark Matter. Such a vast amount of aggregated matter does not go unnoticed. In fact we observe that this stuff aggregates and forms massive structures called Dark Matter Halos. Although dark, it warps and bends spacetime such that any light from a background galaxy which passes close to the Dark Matter will have its path altered and changed. This bending causes the galaxy to appear as an ellipse in the sky.
#
# <img src="http://timsalimans.com/wp-content/uploads/2012/12/dm.jpg">
#
#
# The contest required predictions about where dark matter was likely to be. The winner, [<NAME>](http://timsalimans.com/), used Bayesian inference to find the best locations for the halos (interestingly, the second-place winner also used Bayesian inference). With Tim's permission, we provided his solution [1] here:
#
# 1. Construct a prior distribution for the halo positions $p(x)$, i.e. formulate our expectations about the halo positions before looking at the data.
# 2. Construct a probabilistic model for the data (observed ellipticities of the galaxies) given the positions of the dark matter halos: $p(e | x)$.
# 3. Use Bayes’ rule to get the posterior distribution of the halo positions, i.e. use to the data to guess where the dark matter halos might be.
# 4. Minimize the expected loss with respect to the posterior distribution over the predictions for the halo positions: $\hat{x} = \arg \min_{\text{prediction} } E_{p(x|e)}[ L( \text{prediction}, x) ]$ , i.e. tune our predictions to be as good as possible for the given error metric.
# The loss function in this problem is very complicated. For the very determined, the loss function is contained in the file DarkWorldsMetric.py in the parent folder. Though I suggest not reading it all, suffice to say the loss function is about 160 lines of code — not something that can be written down in a single mathematical line. The loss function attempts to measure the accuracy of prediction, in a Euclidean distance sense, such that no shift-bias is present. More details can be found on the metric's [main page](http://www.kaggle.com/c/DarkWorlds/details/evaluation).
#
# We will attempt to implement Tim's winning solution using [Tensorflow Probability](https://medium.com/tensorflow/introducing-tensorflow-probability-dca4c304e245) (full whitepaper [here](https://arxiv.org/pdf/1711.10604.pdf)) and our knowledge of loss functions.
# %matplotlib inline
# %load_ext autoreload
# %autoreload 2
from utils import *
# +
reset_sess()
import wget
# Downloading the zip file containing the Galaxy Data
url1 = 'https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/blob/master/Chapter5_LossFunctions/data.zip?raw=true'
filename1 = wget.download(url1)
filename1
# -
# !unzip -q data.zip -d data
# We also want to import the data files and Loss functions specific to this Kaggle Competition. You can download the files directly from the [Observing Dark Worlds competition's Data page](https://www.kaggle.com/c/DarkWorlds/data) or, if you already have a Kaggle account, install the [Kaggle API](https://github.com/Kaggle/kaggle-api) and run the following terminal command:
#
# ```
# kaggle competitions download -c DarkWorlds
# ```
#
# And once the competition information is available locally, we can simply unzip the data.
# One last thing to set up is the function we use for plotting galaxies from the files, which we define here:
#
# #### Defining our galaxy-plotting function
# +
reset_sess()
def draw_sky(galaxies):
"""
From a given file of galaxy data,
plot the shapes and positions of
galaxies.
Args:
galaxies: 4-column, float32 Numpy array
containing x-coordinates, y-coordinates,
and the two axes of ellipcity.
Returns:
fig: image of galaxy plot
"""
size_multiplier = 45
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111, aspect='equal')
n = galaxies.shape[0]
for i in range(n):
g = galaxies[i, :]
x, y = g[0], g[1]
d = np.sqrt(g[2] ** 2 + g[3] **2)
a = 1.0 / (1 - d)
b = 1.0 / (1 + d)
theta = np.degrees(np.arctan2(g[3], g[2])*0.5 )
ax.add_patch(Ellipse(xy=(x, y), width=size_multiplier * a, height=size_multiplier * b,
angle=theta))
ax.autoscale_view(tight=True)
return fig
# -
# ### Examining Our Data
#
# The dataset is actually 300 separate files, each representing a sky. In each file, or sky, are between 300 and 720 galaxies. Each galaxy has an $x$ and $y$ position associated with it, ranging from 0 to 4200, and measures of ellipticity: $e_1$ and $e_2$. Information about what these measures mean can be found [here](https://www.kaggle.com/c/DarkWorlds/details/an-introduction-to-ellipticity), but for our purposes it does not matter besides for visualization purposes. Thus a typical sky might look like the following:
# +
reset_sess()
n_sky = 3
data = np.genfromtxt('data/Train_Skies/Train_Skies/Training_Sky%d.csv' % (n_sky),
dtype=np.float32,
skip_header=1,
delimiter=',',
usecols=[1, 2, 3, 4])
galaxy_positions = np.array(data[:, :2], dtype=np.float32)
gal_ellipticities = np.array(data[:, 2:], dtype=np.float32)
ellipticity_mean = np.mean(data[:, 2:], axis=0)
ellipticity_stddev = np.std(data[:, 2:], axis=0)
num_galaxies = np.array(galaxy_positions).shape[0]
print("Data on galaxies in sky %d." % n_sky)
print("position_x, position_y, e_1, e_2")
print(data[:3])
print('Number of galaxies: ', num_galaxies)
print("e_1 & e_2 mean: ", ellipticity_mean)
print("e_1 & e_2 std_dev: ", ellipticity_stddev)
# -
fig = draw_sky(data)
plt.title('Galaxy positions and ellipticities of sky %d.' % n_sky)
plt.xlabel('x-position')
plt.ylabel('y-position');
# ### Priors
# Each sky has one, two or three dark matter halos in it. Tim's solution details that his prior distribution of halo positions was uniform, i.e.
#
# $$
# \begin{aligned}
# x_i & \sim \mathrm{Uniform}(0, 4200) \\
# y_i & \sim \mathrm{Uniform}(0, 4200),\,\, i=1, 2, 3
# \end{aligned}
# $$
# Tim and other competitors noted that most skies had one large halo and other halos, if present were much smaller. Larger halos, having more mass, will influence the surrounding galaxies more. He decided that the large halos would have a mass distributed as a *log*-uniform random variable between 40 and 180, i.e.
#
# $$
# m_{\mathrm{large}} = \log \mathrm{Uniform}(40, 180)
# $$
#
# and in Tensorflow Probability,
# ```python
# # Log-Uniform distribution
# mass_large = tfd.TransformedDistribution(
# distribution=tfd.Uniform(name='exp_mass_large', low=40., high=180.),
# bijector=tfb.Exp())
# ```
# (This is what we mean when we say *log*-uniform).
# For smaller galaxies, Tim set the mass to be the logarithm of 20. Why did Tim not create a prior for the smaller mass, nor treat it as an unknown? I believe this decision was made to speed up convergence of the algorithm. This is not too restrictive, as by construction the smaller halos have less influence on the galaxies.
#
# Tim logically assumed that the ellipticity of each galaxy is dependent on the position of the halos, the distance between the galaxy and halo, and the mass of the halos. Thus the vector of ellipticity of each galaxy, $\mathbf{e}_i$, are *children* variables of the vector of halo positions $(\mathbf{x}, \mathbf{y})$, distance (which we will formalize), and halo masses.
#
# Tim conceived a relationship to connect positions and ellipticity by reading literature and forum posts. He supposed the following was a reasonable relationship:
#
# $$
# e_i|(\mathbf{x}, \mathbf{y}) \sim \mathrm{Normal}(\sum_{j=\mathrm{halo positions}}d_{i,j}m_j f(r_{i,j}), \sigma^2)
# $$
#
# where $d_{i,j}$ is the *tangential direction* (the direction in which halo $j$ bends the light of galaxy $i$), $m_j$ is the mass of halo $j$, $f(r_{i,j})$ is a *decreasing function* of the Euclidean distance between halo $j$ and galaxy $i$.
#
# The variance, or $\sigma^2$, was simply estimated to be 0.05 from eyeballing the data. This means the standard deviation (sd) of the measurements of $e_i$ for the full range of $i$ works out to be approximately 0.223607.
#
# Tim's function $f$ was defined:
#
# $$
# f(r_{i,j}) = \frac{1}{\min(r_{i,j}, 240)}
# $$
# for large halos, and for small halos
# $$
# f(r_{i,j}) = \frac{1}{\min(r_{i,j}, 70)}
# $$
# This fully bridges our observations and unknown. This model is incredibly simple, and Tim mentions this simplicity was purposefully designed: it prevents the model from overfitting.
# ### Training & Tensorflow implementation
# For each sky, we run our Bayesian model to find the posteriors for the halo positions - we ignore the (known) halo position. This is slightly different than perhaps traditional approaches to Kaggle competitions, where this model uses no data from other skies nor the known halo location. That does not mean other data are not necessary - in fact, the model was created by comparing different skies.
#
# **Constructing a prior distribution for the halo positions $p(x)$, i.e. formulate our expectations about the halo positions before looking at the data.**
#
# When constructing our prior and likelihood distributions, we are going to use these to set up a loss function that is very similar to that of a [variational autoencoder](https://github.com/tensorflow/probability/blob/master/tensorflow_probability/examples/vae.py) (though a much lower dimension one).
# +
def euclidean_distance(x, y):
"""
Calculates the euclidean distance between point x and point y.
Args:
x: a Tensorflow tensor for element-wise
calculation
y: a Tensorflow tensor for element-wise
calculation
Returns:
a Tensor containing the euclidean
distance between x and y
"""
return tf.sqrt(tf.reduce_sum(tf.squared_difference(x, y), axis=1), name='euclid_dist')
def f_distance(gxy_pos, halo_pos, c):
"""
Provides our element-wise maximum as in NumPy,
but instead for Tensorflow tensors
Args:
gxy_pos: a 2-D numpy array of observed galaxy
positions
halo_pos: a 2-D numpy array with halo positions
c: a scalar of shape order 0
Returns:
Maximum of either the euclidean distance of gxy_pos
& halo_pos, or the constant c.
"""
return tf.maximum(euclidean_distance(gxy_pos, halo_pos), c, name='f_dist')[:, None]
def tangential_distance(glxy_position, halo_position):
"""
Calculates the tangential distance between
coordinates glxy_position & halo_position.
Args:
glxy_position: a 2-d numpy array of observed galaxy
positions
halo_positions: a 2-d numpy array with halo positions
Returns:
vectors with direction of dominant halo.
"""
x_delta, y_delta = tf.unstack(
glxy_position - halo_position, num=2, axis=-1)
angle = 2. * tf.atan(y_delta / x_delta)
return tf.stack([-tf.cos(angle), -tf.sin(angle)], axis=-1, name='tan_dist')
# -
def posterior_log_prob(mass_large, halo_pos):
"""
Our posterior log probability, as a function of states
Closure over: data
Args:
mass_large: scalar of halo mass, taken from state
halo_pos: tensor of halo position(s), taken from state
Returns:
scalar sum of log probabilities
"""
rv_mass_large = tfd.Uniform(name='rv_mass_large', low=40., high=180.)
# Set the random size of the halo's mass (the big halo for now)
# We use tfd.Independent to change the batch and event shapes
rv_halo_pos = tfd.Independent(tfd.Uniform(
low=[0., 0.],
high=[4200., 4200.]),
reinterpreted_batch_ndims=1, name='rv_halo_position')
ellpty_mvn_loc = (mass_large /
f_distance(data[:, :2], halo_pos, 240.) *
tangential_distance(data[:, :2], halo_pos))
ellpty = tfd.MultivariateNormalDiag(loc=ellpty_mvn_loc,
scale_diag=[0.223607, 0.223607],
name='ellpty')
return (tf.reduce_sum(ellpty.log_prob(data[:, 2:]), axis=0) +
rv_halo_pos.log_prob(halo_pos) +
rv_mass_large.log_prob(mass_large))
# **Constructing a probabilistic model for the data (observed ellipticities of the galaxies) given the positions of the dark matter halos:** $p(e|x)$
#
# Given data, we use a Metropolis Random Walk (MRW) Markove chain Monte Carlo method to calculate the precise posterior distribution over the model's parameters. It is possible to use Hamiltonian Monte Carlo (HMC) for problems like this, but Metropolis is more appropriate for this case due to its comparative simplicity.
#
# Tim's model gives us an approximate posterior to start with. That is, we assume the posterior must be proportional to the normal distribution of distances inferred from galaxy ellipcities.
reset_sess()
# +
# Inferring the posterior distribution
number_of_steps = 5000
burnin = 4500
# Set the chain's start state.
initial_chain_state = [
tf.fill([1], 80., name='init_mass_large'),
tf.fill([1, 2], 2100., name='init_halo_pos')
]
# Since HMC operates over unconstrained space, we need to transform the
# samples to they live in real space.
unconstraining_bijectors = [
tfp.bijectors.Identity(),
tfp.bijectors.Identity()
]
# Define a closure over our joint_log_prob.
unnormalized_posterior_log_prob = lambda *args: posterior_log_prob(*args)
# Initialize the step size. (It will be automatically adapted.)
with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE):
step_size = tf.get_variable(
name='step_size',
initializer=tf.constant(0.06, dtype=tf.float32),
trainable=False,
use_resource=True
)
# Defining the HMC
hmc = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=unnormalized_posterior_log_prob,
num_leapfrog_steps=6,
step_size=step_size,
step_size_update_fn=tfp.mcmc.make_simple_step_size_update_policy(
num_adaptation_steps=int(burnin*0.8)),
state_gradients_are_stopped=True),
bijector=unconstraining_bijectors
)
# Sampling from the chain.
[
mass_large,
halo_pos
], kernel_results = tfp.mcmc.sample_chain(
num_results=number_of_steps,
num_burnin_steps=burnin,
current_state=initial_chain_state,
kernel=hmc
)
# +
# Some of the steps of the MCMC will involve just getting close to where the right answers are
# so we get the samples random walk, and cut off the trial (or `burn_in`) steps
burned_halo_position_samples = tf.stack(tf.map_fn(lambda x: x[0], halo_pos), axis=0)[burnin:]
# we'll take the mean and standard deviations of the samples to put
# together the approximate posterior distribution for the large halo
halo_mean = tf.reduce_mean(burned_halo_position_samples, axis=0)
halo_stdev = tf.sqrt(
tf.reduce_mean(tf.squared_difference(burned_halo_position_samples, halo_mean),
axis=0))
approx_posterior = tfd.MultivariateNormalDiag(loc=halo_mean, scale_diag=halo_stdev, name='approx_posterior')
approx_post_samples_num = 5000
# Getting 50,000 samples from the approximate posterior distribution
posterior_predictive_samples = approx_posterior.sample(
sample_shape=approx_post_samples_num)
# Initializing our variables
init_g = tf.global_variables_initializer()
# +
# Running the Initializer on our model
evaluate(init_g)
# performing our computations
[
posterior_predictive_samples_,
kernel_results_,
] = evaluate([
posterior_predictive_samples,
kernel_results,
])
print("acceptance rate: {}".format(
kernel_results_.inner_results.is_accepted.mean()))
print("final step size: {}".format(
kernel_results_.inner_results.extra.step_size_assign[-100:].mean()))
print("posterior_predictive_samples_ value: \n {}".format(
posterior_predictive_samples_))
# +
t = posterior_predictive_samples_.reshape(5000,2)
fig = draw_sky(data)
plt.title("Galaxy positions and ellipcities of sky %d." % n_sky)
plt.xlabel("x-position")
plt.ylabel("y-position")
plt.scatter(t[:,0], t[:,1], alpha = 0.015, c = "#F15854") # Red
plt.xlim(0, 4200)
plt.ylim(0, 4200);
# -
# Associated with eacy sky is another data point, located in `.data/Training_halos.csv` that holds the locations of up to three dark matter halos contained in the sky. For example, the night sky we trained on has halo locations:
halo_data = np.genfromtxt('data/Training_halos.csv',
delimiter=',',
usecols=[1, 2, 3, 4, 5, 6, 7, 8, 9],
skip_header=1)
print(halo_data[n_sky])
# +
fig = draw_sky(data)
plt.title('Galaxy positions and ellipticities of sky %d.' % n_sky)
plt.xlabel('x-position')
plt.ylabel('y-position')
plt.scatter(t[:,0], t[:, 1], alpha=0.015, c='#F15854')
plt.scatter(halo_data[n_sky-1][3], halo_data[n_sky-1][4],
label='True halo position',
c='k', s=70)
plt.legend(scatterpoints=1, loc='lower left')
plt.xlim(0, 4200)
plt.ylim(0, 4200);
print('True halo location:', halo_data[n_sky][3], halo_data[n_sky][4])
# -
mean_posterior = t.mean(axis=0).reshape(1, 2)
print('Mean posterior: \n {}'.format(mean_posterior[0]))
# +
reset_sess()
import wget
url = 'https://raw.githubusercontent.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/master/Chapter5_LossFunctions/DarkWorldsMetric.py'
filename = wget.download(url)
filename
# +
from DarkWorldsMetric import main_score
halo_data_sub = halo_data[n_sky-1]
nhalo_all = halo_data_sub[0].reshape(1, 1)
x_true_all = halo_data_sub[3].reshape(1, 1)
y_true_all = halo_data_sub[4].reshape(1, 1)
x_ref_all = halo_data_sub[1].reshape(1, 1)
y_ref_all = halo_data_sub[2].reshape(1, 1)
sky_prediction = mean_posterior
print('Using the mean:', sky_prediction[0])
main_score(nhalo_all, x_true_all, y_true_all, x_ref_all, y_ref_all, sky_prediction)
random_guess = tfd.Independent(tfd.Uniform(
low=[0., 0.],
high=[4200., 4200.]),
reinterpreted_batch_ndims=1,
name='rv_halo_position').sample()
random_guess_ = evaluate([random_guess])
print('\n Using a random location:', random_guess_[0])
main_score(nhalo_all, x_true_all, y_true_all, x_ref_all, y_ref_all, random_guess_)
# +
reset_sess() # Our custom function from before
n_sky = 215 #choosing a file/sky to examine.
data = np.genfromtxt("data/Train_Skies/Train_Skies/\
Training_Sky%d.csv" % (n_sky),
dtype = np.float32,
skip_header = 1,
delimiter = ",",
usecols = [1,2,3,4])
# It's handy to specify the data type beforehand
galaxy_positions = np.array(data[:, :2], dtype=np.float32)
gal_ellipticities = np.array(data[:, 2:], dtype=np.float32)
ellipticity_mean = np.mean(data[:, 2:], axis=0)
ellipticity_stddev = np.std(data[:, 2:], axis=0)
num_galaxies = np.array(galaxy_positions).shape[0]
print("Data on galaxies in sky %d."%n_sky)
print("position_x, position_y, e_1, e_2 ")
print(data[:3])
print("Number of Galaxies: ", num_galaxies)
print("e_1 & e_2 mean: ", ellipticity_mean)
print("e_1 & e_2 std_dev: ", ellipticity_stddev)
# -
| ipynb/Kaggle-Observing-Dark-World.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Solve time dependent Schroedinger equation in 1D, using FFT method
# Harmonic oscillator coherent state
import numpy as np
from scipy.fftpack import fft, ifft
from scipy.integrate import simps
import matplotlib.pyplot as plt
# %matplotlib inline
# The general solution follows the method of http://jakevdp.github.com/blog/2012/09/05/quantum-python/
#
# * Use the potential to propagate a half time step in x space
# * FFT
# * Use the kinetic energy operator to propagate one whole time step in k space
# * IFFT
# * Use the potential to propagate a half time step in x space
#
# For time varying potentials, the propagation term is exp(-i integral(V(x),dt)/hbar). The integral can be done analytically or numerically. Here, if numerical integration is used, we use one step of the trapezoidal approximation. This may not work if the time step is too large.
#
# Hard boundaries are assumed. Be sure xmin and xmax are sufficiently far from the region of interest for the initial state you choose.
#constants (change these to fit the problem)
hbar = 1.0
m = 1.0 #mass
tmin = 0.0 # initial time
tmax = 10.0 # final time
Nt = 2000 # number of time steps
xmin = -10.0 # minimum x value
xmax = 10.0 # maximum x value
Nx = 4096 # number of steps in x (and k). Must be even, power of 2 is better
#calculate lists
xlist = np.linspace(xmin,xmax,Nx)
tlist = np.linspace(tmin,tmax,Nt)
dx = xlist[1]-xlist[0] # delta x
dt = tlist[1]-tlist[0] # delta t
dk = 2 * np.pi/np.abs(xmax-xmin) # delta k (from FFT definition)
kmax = 0.5*Nx*dk # (Nyquist limit)
klist = np.roll(np.arange(-Nx//2+1,Nx//2+1),Nx//2+1)*dk #list of k values, indexed according to FFT convention, double // means integer part of quotient
# The potential below is a harmonic oscillator potential. Try using other potentials.
#define potential function (needs to be vectorizable)
def V(x,t):
# This is a harmonic oscillator. Try other potentials, such as other polynomials, or sin2(x)
return 0.5*x*x
# integral of V dt, evaluated at x
def intV(x,ti,tf):
#indef = lambda x,t: 0.5*x**2*t# indefinite integral
#out = indef(x,tf)-indef(x,ti)
out = 0.5*(V(x,ti)+V(x,tf))*(tf-ti) #trapezoidal rule (backup plan)
return out
#initial wavefunction at t=tmin (normalization optional)
def psi0(x):
a=2.0 #offset
# this should be the ground state wavefunction, but it needs a bit of a fudge factor to be stationary under the numerical approximations
return np.exp(-np.sqrt(0.505)*(x-a)**2)/np.pi**(0.25)
psilist = np.zeros([Nx,Nt],dtype=np.cfloat) # initialize array to store wavefunction
psilist[:,0]=psi0(xlist) # store initial wavefunction
#main loop
for tindex in np.arange(1,Nt):
psix = psilist[:,tindex-1]*np.exp(-1.j*intV(xlist,tlist[tindex-1],tlist[tindex]+0.5*dt)/hbar)
psix[0:3] = 0; psix[-4:-1] = 0; # enforce boundary conditions
psik = fft(psix)
psik = psik * np.exp(-0.5j*hbar*klist*klist*dt/m)
psix = ifft(psik)
psix = psix*np.exp(-1.j*intV(xlist,tlist[tindex]-0.5*dt,tlist[tindex])/hbar)
psix[0:3] = 0; psix[-4:-1] = 0; # enforce boundary conditions
psilist[:,tindex] = psix
tdraw = 250 # time index for plot (-1 is last time value)
Nf = simps(np.abs(psilist[:,tdraw])**2) # normalization of final state
Ni = simps(np.abs(psilist[:,0])**2) # normalization of initial state
fig, ax1 = plt.subplots()
ax1.plot(xlist,np.abs(psilist[:,tdraw])**2/Nf,label='t={0:.1f}'.format(tlist[tdraw]))
ax1.plot(xlist,np.abs(psilist[:,0])**2/Ni,'k',label='t={0:.1f}'.format(tmin))
ax2 = ax1.twinx()
ax2.plot(xlist,V(xlist,tmin),'r',label='V(x,tmin)')
ax1.set_ylabel('$|\psi(x)|^2$')
ax2.set_ylabel('$V(x)$')
ax1.set_xlabel('$x$')
ax1.legend()
ax1.set_title("Initial and final wavefunction")
ax2.legend()
# Calculate expectation values of x, p, x2, p2
EVxlist = np.zeros(Nt)
EVplist = np.zeros(Nt)
EVx2list = np.zeros(Nt)
EVp2list = np.zeros(Nt)
Nlistx = np.zeros(Nt)
Nlistp = np.zeros(Nt)
Elist = np.zeros(Nt)
for t in range(Nt):
Nlistx[t] = simps(np.abs(psilist[:,t])**2) # Normalization denominator
EVxlist[t] = simps(xlist*np.abs(psilist[:,t])**2)/Nlistx[t] # x
EVx2list[t] = simps(xlist**2*np.abs(psilist[:,t])**2)/Nlistx[t]-EVxlist[t]**2 # Var(x)
psik = fft(psilist[:,t])
Nlistp[t] = simps(np.abs(psik)**2) # Normalization denominator
EVplist[t] = hbar*simps(klist*np.abs(psik)**2)/Nlistp[t] # p
EVp2list[t] = (simps((hbar*klist)**2*np.abs(psik)**2)/Nlistp[t]-EVplist[t]**2) # Var(p)
Elist[t] = 0.25/m*simps((hbar*klist)**2*np.abs(psik)**2)/Nlistp[t]+simps(V(xlist,t)*np.abs(psilist[:,t]**2))/Nlistx[t] # Energy
plt.plot(tlist,EVxlist,label=r'$\langle x \rangle$')
plt.plot(tlist,np.sqrt(EVx2list),label=r'$\sqrt{\langle x^2 \rangle-\langle x \rangle ^2}$')
plt.legend()
plt.xlabel('Time')
plt.title('Center of mass and width')
plt.plot(tlist,EVplist,label=r'$\langle p \rangle$')
plt.plot(tlist,np.sqrt(EVp2list),label=r'$\sqrt{\langle p^2 \rangle-\langle p \rangle ^2}$')
plt.legend()
plt.xlabel('Time')
plt.title("Average momentum and momentum width")
plt.plot(tlist,Elist,label=r'$\langle E \rangle$')
#plt.plot(tlist,np.sqrt(EVx2list),label=r'$\sqrt{\langle x^2 \rangle-\langle x \rangle ^2}$')
plt.legend()
plt.xlabel('Time')
plt.title('Energy')
| TDSE/TDSE.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# %matplotlib inline
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
cancer.keys()
df_cancer = pd.DataFrame(cancer['data'], columns= cancer['feature_names'])
df_cancer.head()
from sklearn.model_selection import train_test_split
# +
X = df_cancer
y = cancer['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# -
from sklearn.svm import SVC
model = SVC()
model.fit(X_train,y_train)
prediction = model.predict(X_test)
from sklearn.metrics import classification_report,confusion_matrix
print(confusion_matrix(y_test,prediction))
print(classification_report(y_test,prediction))
from sklearn.model_selection import GridSearchCV
paramGrid = {'C': [0.1,1,10,1000], 'gamma' : [1,0.1,0.001,0.0001]}
grid = GridSearchCV(SVC(),paramGrid,verbose=3)
grid.fit(X_train,y_train)
grid.best_params_
grid.best_estimator_
gridPrediction = grid.predict(X_test)
print(confusion_matrix(y_test,gridPrediction))
| Codes/.ipynb_checkpoints/Sample-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Facies classification utilizing an Adaptive Boosted Random Forest
#
# [<NAME>](http://www.linkedin.com/in/ryan-thielke-b987012a)
#
#
# In the following, we provide a possible solution to the facies classification problem described in https://github.com/seg/2016-ml-contest.
#
# ## Exploring the data
# +
import warnings
warnings.filterwarnings("ignore")
# %matplotlib inline
import sys
sys.path.append("..")
#Import standard pydata libs
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# -
filename = '../facies_vectors.csv'
training_data = pd.read_csv(filename)
#training_data['Well Name'] = training_data['Well Name'].astype('category')
#training_data['Formation'] = training_data['Formation'].astype('category')
training_data['train'] = 1
training_data.describe()
validation_data = pd.read_csv("../validation_data_nofacies.csv")
#validation_data['Well Name'] = validation_data['Well Name'].astype('category')
#validation_data['Formation'] = validation_data['Formation'].astype('category')
validation_data['train'] = 0
validation_data.describe()
all_data = training_data.append(validation_data)
all_data.describe()
# +
#Visualize the distribution of facies for each well
wells = training_data['Well Name'].unique()
fig, ax = plt.subplots(5,2, figsize=(20,20))
for i, well in enumerate(wells):
row = i % ax.shape[0]
column = i // ax.shape[0]
counts = training_data[training_data['Well Name']==well].Facies.value_counts()
data_for_well = [counts[j] if j in counts.index else 0 for j in range(1,10)]
ax[row, column].bar(range(1,10), data_for_well, align='center')
ax[row, column].set_title("{well}".format(well=well))
ax[row, column].set_ylabel("Counts")
ax[row, column].set_xticks(range(1,10))
plt.show()
# -
plt.figure(figsize=(10,10))
sns.heatmap(training_data.drop(['Formation', 'Well Name'], axis=1).corr())
# # Feature Engineering
#
# Here we will do a couple things to clean the data and attempt to create new features for our model to consume.
#
# First, we will smooth the PE and GR features.
# Second, we replace missing PE values with the mean of the entire dataset (might want to investigate other methods)
# Last, we will encode the formations into integer values
avg_PE_facies = training_data[['Facies', 'PE']].groupby('Facies').mean()
avg_PE_facies = avg_PE_facies.to_dict()
all_data['PE2'] = all_data.Facies.map(avg_PE_facies['PE'])
dfs = []
for well in all_data['Well Name'].unique():
df = all_data[all_data['Well Name']==well].copy(deep=True)
df.sort_values('Depth', inplace=True)
for col in ['PE', 'GR']:
smooth_col = 'smooth_'+col
df[smooth_col] = pd.rolling_mean(df[col], window=10)
df[smooth_col].fillna(method='ffill', inplace=True)
df[smooth_col].fillna(method='bfill', inplace=True)
dfs.append(df)
all_data = pd.concat(dfs)
all_data['PE'] = all_data.PE.fillna(all_data.PE2)
all_data['smooth_PE'] = all_data.smooth_PE.fillna(all_data.PE2)
formation_encoder = dict(zip(all_data.Formation.unique(), range(len(all_data.Formation.unique()))))
all_data['enc_formation'] = all_data.Formation.map(formation_encoder)
def to_binary_vec(value, vec_length):
vec = np.zeros(vec_length)
vec[value] = 1
return vec
dfs = list()
for well in all_data['Well Name'].unique():
tmp_df = all_data[all_data['Well Name'] == well].copy(deep=True)
tmp_df.sort_values('Depth', inplace=True)
for feature in ['Depth', 'ILD_log10', 'DeltaPHI', 'PHIND', 'smooth_PE', 'smooth_GR']:
tmp_df['3prev_'+feature] = tmp_df[feature] / tmp_df[feature].shift(4)
#tmp_df['2prev_'+feature] = tmp_df[feature] / tmp_df[feature].shift(-1)
tmp_df['3prev_'+feature].fillna(method='bfill', inplace=True)
#tmp_df['2prev_'+feature].fillna(method='ffill', inplace=True)
tmp_df['3prev_'+feature].replace([np.inf, -np.inf], 0, inplace=True)
#tmp_df['2prev_'+feature].replace([np.inf, -np.inf], 0, inplace=True)
tmp_df['3prev_enc'] = tmp_df['enc_formation'].shift(3).fillna(method='bfill')
tmp_df['2prev_enc'] = tmp_df['enc_formation'].shift(2).fillna(method='bfill')
dfs.append(tmp_df)
all_data = pd.concat(dfs)
all_data.columns
#Let's build a model
from sklearn import preprocessing
from sklearn.ensemble import AdaBoostClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics, cross_validation
from classification_utilities import display_cm
# +
#We will take a look at an F1 score for each well
estimators=200
learning_rate=.01
random_state=0
facies_labels = ['SS', 'CSiS', 'FSiS', 'SiSh', 'MS',
'WS', 'D','PS', 'BS']
title_length = 20
training_data = all_data[all_data.train==1]
scores = list()
wells = training_data['Well Name'].unique()
for well in wells:
blind = training_data[training_data['Well Name']==well]
train = training_data[(training_data['Well Name']!=well)]
train_X = train.drop(['Formation', 'Well Name', 'Facies', 'Depth', 'PE2', 'train'], axis=1)
train_Y = train.Facies.values
test_X = blind.drop(['Formation', 'Well Name', 'Facies', 'Depth', 'PE2', 'train'], axis=1)
test_Y = blind.Facies.values
clf = AdaBoostClassifier(RandomForestClassifier(n_estimators=200), n_estimators=200, learning_rate=learning_rate, random_state=random_state, algorithm='SAMME.R')
clf.fit(train_X,train_Y)
print(clf.feature_importances_)
pred_Y = clf.predict(test_X)
f1 = metrics.f1_score(test_Y, pred_Y, average='micro')
scores.append(f1)
print("*"*title_length)
print("{well}={f1:.4f}".format(well=well,f1=f1))
print("*"*title_length)
print("Avg F1: {score}".format(score=sum(scores)/len(scores)))
# -
train_X, test_X, train_Y, test_Y = cross_validation.train_test_split(training_data.drop(['Formation', 'Well Name','Facies', 'Depth', 'PE2', 'train'], axis=1), training_data.Facies.values, test_size=.2)
print(train_X.shape)
print(train_Y.shape)
print(test_X.shape)
print(test_Y.shape)
clf = AdaBoostClassifier(RandomForestClassifier(n_estimators=estimators), n_estimators=estimators, random_state=0,learning_rate=learning_rate, algorithm='SAMME.R')
clf.fit(train_X, train_Y)
pred_Y = clf.predict(test_X)
cm = metrics.confusion_matrix(y_true=test_Y, y_pred=pred_Y)
display_cm(cm, facies_labels, display_metrics=True)
validation_data = all_data[all_data.train==0]
validation_data.describe()
# +
X = training_data.drop(['Formation', 'Well Name', 'Depth','Facies', 'train', 'PE2'], axis=1)
Y = training_data.Facies.values
test_X = validation_data.drop(['Formation', 'Well Name', 'Depth', 'train', 'PE2', 'Facies'], axis=1)
clf = AdaBoostClassifier(RandomForestClassifier(n_estimators=estimators), n_estimators=estimators, learning_rate=learning_rate, random_state=0)
clf.fit(X,Y)
predicted_facies = clf.predict(test_X)
validation_data['Facies'] = predicted_facies
# -
validation_data.to_csv("Kr1m_SEG_ML_Attempt2.csv", index=False)
| Kr1m/Kr1m_SEG_ML_Attempt2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # VacationPy
# ----
#
# #### Note
# * Keep an eye on your API usage. Use https://developers.google.com/maps/reporting/gmp-reporting as reference for how to monitor your usage and billing.
#
# * Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.
# +
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import gmaps
import os
from pprint import pprint
# Import API key
from api_keys import g_key
# -
# ### Store Part I results into DataFrame
# * Load the csv exported in Part I to a DataFrame
# +
# Load csv
weather_file = "../WeatherPy/WeatherPY3.csv"
# Read and display csv with Pandas
weather_df = pd.read_csv(weather_file)
weather_df.head()
# -
# ### Humidity Heatmap
# * Configure gmaps.
# * Use the Lat and Lng as locations and Humidity as the weight.
# * Add Heatmap layer to map.
# +
# Configure gmaps
gmaps.configure(api_key=g_key)
#Determine max Humidity
humidity_max=weather_df['Humidity'].max()
humidity_max
# -
# Store latitude and longitude in locations
locations = weather_df[["Lat", "Lng"]]
# locations
rating = weather_df["Humidity"].astype(float)
# +
# Plot heatmap
fig = gmaps.figure()
# Create heat layer
heat_layer = gmaps.heatmap_layer(locations, weights=rating, dissipating=False, max_intensity=100, point_radius=1)
# Add layer
fig.add_layer(heat_layer)
# Display figure
fig
# -
# ### Create new DataFrame fitting weather criteria
# * Narrow down the cities to fit weather conditions.
# * Drop any rows will null values.
# Create a dataframe narrowing down cities to fit my very broad definition of ideal weather locations for a vacation.
hotel_df= weather_df[(weather_df["Max Temp"]>60) & (weather_df["Max Temp"]<=90) & (weather_df["Humidity"]>=30) & (weather_df["Humidity"]<=60) & (weather_df["Cloudiness"]<60)]
hotel_df
# ### Hotel Map
# * Store into variable named `hotel_df`.
# * Add a "Hotel Name" column to the DataFrame.
# * Set parameters to search for hotels with 5000 meters.
# * Hit the Google Places API for each city's coordinates.
# * Store the first Hotel result into the DataFrame.
# * Plot markers on top of the heatmap.
# Add a "Hotel Name" column to dataframe
hotel_df["Hotel Name"] = ""
hotel_df.head()
# +
# Set parameters to search for a hotel
params = {
"radius": 5000,
"types": "lodging",
"key": g_key
}
# Iterate through
for index, row in hotel_df.iterrows():
# get lat, lng from df
lat = row["Lat"]
lng = row["Lng"]
params["location"] = f"{lat},{lng}"
# Use the search term: "Hotel" and our lat/lng
base_url = "https://maps.googleapis.com/maps/api/place/nearbysearch/json"
# make request and print url
name_address = requests.get(base_url, params=params)
# convert to json
name_address = name_address.json()
# Grab the first hotel from the results and store the name
try:
hotel_df.loc[index, "Hotel Name"] = name_address["results"][0]["name"]
except (KeyError, IndexError):
print("Missing field/result... skipping.")
hotel_df
# +
# NOTE: Do not change any of the code in this cell
# Using the template add the hotel marks to the heatmap
info_box_template = """
<dl>
<dt>Name</dt><dd>{Hotel Name}</dd>
<dt>City</dt><dd>{City}</dd>
<dt>Country</dt><dd>{Country}</dd>
</dl>
"""
# Store the DataFrame Row
# NOTE: be sure to update with your DataFrame name
hotel_info = [info_box_template.format(**row) for index, row in hotel_df.iterrows()]
locations = hotel_df[["Lat", "Lng"]]
# -
#Convert "Hotel Name" column from the hotel_df to a list
hotels= hotel_df["Hotel Name"].tolist()
hotels
# +
# Create a map with markers of hotel locations
hotel_layer = gmaps.marker_layer(locations)
fig = gmaps.figure()
fig.add_layer(hotel_layer)
#Display map
fig
# +
# Add marker layer ontop of heat map
fig=gmaps.figure()
fig.add_layer(heat_layer)
fig.add_layer(hotel_layer)
# Display figure
fig
# -
# +
# locations, fill_color='rgba(0, 150, 0, 0.4)',
# stroke_color='rgba(0, 0, 150, 0.4)', scale=2,
# info_box_content=[f"Hotels: {hotels}" for Name in hotel_info]
#gmaps.configure(api_key=g_key)
# for idx, each_row in hotel_df.iterrows():
# complete_url= f'{base_url}address={cities}&key=g_key'
# response=requests.get(complete_url)
# data=response.json()
# base_url= "https://maps.googleapis.com/maps/api/place/findplacefromtext/json?"
#response = requests.get(f"http://api.openweathermap.org/data/2.5/weather?q={city_name}&appid={weather_api_key}&units=Imperial").json()
# city.append(response['name'])
#for idx, each_row in hotel_df.head(5).iterrows():
# query_param= {
# 'key': g_key,
# 'location':f"{each_row['Lat'], each_row['Lng']}",
# 'radius': 5000,
# 'type': 'lodging'
# }
# response=requests.get(base_url, query_param)
#complete_url=f'{base_url}address={each_row["City"]}, {each_row["State"]}&key={g_key}'
#data=response.json(),
# query_url= (f"{base_url}, {query_param}, &key={g_key}")
# response = requests.get(f"{query_url}&key={g_key}")
#response= requests.get(base_url, query_param, g_key)
# +
# params = {
# "radius": 5000,
# "types": "lodging",
# "key": g_key
# }
# # Iterate through
# for index, row in hotel_df.iterrows():
# # get lat, lng from df
# lat = row["Lat"]
# lng = row["Lng"]
# params["location"] = f"{lat},{lng}"
# base_url= "https://maps.googleapis.com/maps/api/place/findplacefromtext/json?"
# response = requests.get(base_url, params=params)
# data=response.json()
# try:
# row.loc[index, "Hotel Name"]= data["results"][0]["name"]
# except:
# print("City not found. Skipping...")
# pass
# hotel_df.head()
# +
#for idx, each_row in weather_df.iterrows():
# params = {
# "radius": target_radius
#}
# lat= hotel_df.loc['Lat']
# lng= hotel_df.loc['Lng']
#city_name= hotel_df['City']
# +
# query_params={
# 'key': g_key,
# # 'location': city,
# 'radius': 5000,
# 'types': 'lodging'
# }
# for idx, each_row in hotel_df.iterrows():
# try:
# lat= each_row["Lat"]
# lon= each_row["Lng"]
# #city= (f"{lat},{lon}")
# query_params['location'] = f"{lat},{lng}"
# base_url= "https://maps.googleapis.com/maps/api/place/findplacefromtext/json?"
# response = requests.get(base_url, params=query_params)
# data=response.json()
# each_row.loc[index, "Hotel Name"]= data["results"][0]["name"]
# except:
# print("City not found. Skipping...")
# pass
# hotel_df.head()
# +
# # city=city_name.tolist()
# # base_url = "https://maps.googleapis.com/maps/api/place/nearbysearch/json"
# base_url= "https://maps.googleapis.com/maps/api/place/findplacefromtext/json?"
# for idx, each_row in hotel_df.iterrows():
# try:
# lat= each_row["Lat"]
# lon= each_row["Lng"]
# city= (f"{lat},{lon}")
# query_params={
# 'key': g_key,
# # 'location': city,
# 'radius': 5000,
# 'types': 'lodging'
# }
# response = requests.get(base_url, params=query_params)
# data=response.json()
# each_row.loc[index, "Hotel Name"]= data["results"][0]["name"]
# # hotel_name= each_row["Hotel Name"]
# except:
# print("City not found. Skipping...")
# pass
# # for idx, each_row in hotel_df.iterrows():
# # lat= each_row["Lat"]
# # lon= each_row["Lng"]
# # city= (f"{lat},{lon}")
# # query_params={
# # 'key': g_key,
# # 'location': city,
# # 'radius': 5000,
# # 'types': 'lodging'
# # }
# # base_url= "https://maps.googleapis.com/maps/api/place/findplacefromtext/json?"
# # response = requests.get(base_url, params=query_params)
# # data=response.json()
# # try:
# # each_row.loc[index, "Hotel Name"]= data["results"][0]["name"]
# # #hotel_name= each_row["Hotel Name"]
# # except:
# # print("City not found. Skipping...")
# # pass
# hotel_df.head()
# # hotel_name= each_row["Hotel Name"]
# #pprint(data)
# # response=requests.get(complete_url)
# #query_param
# # for idx, each_row in hotel_df(3).iterrows():
# # complete_url=f'{base_url}{query_param}'
# # for idx, each_row in hotel_df():
# # for idx, each_row in hotel_df(3).iterrows():
# # query_param={
# # 'key': g_key,
# # 'location': {each_row['City']},
# # 'radius': 5000,
# # 'type': 'lodging'
# # }
# #response=requests.get(base_url, query_param)
# # 'location': {each_row['City']},
# # pprint(response.json())
# #response=requests.get(gmaps.configure(api_key=g_key))
| Vacation Py/VacationPy.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# 
# # Qiskit Finance: Pricing Fixed-Income Assets
# ### Introduction
#
# We seek to price a fixed-income asset knowing the distributions describing the relevant interest rates. The cash flows $c_t$ of the asset and the dates at which they occur are known. The total value $V$ of the asset is thus the expectation value of:
#
# $$V = \sum_{t=1}^T \frac{c_t}{(1+r_t)^t}$$
#
# Each cash flow is treated as a zero coupon bond with a corresponding interest rate $r_t$ that depends on its maturity. The user must specify the distribution modeling the uncertainty in each $r_t$ (possibly correlated) as well as the number of qubits he wishes to use to sample each distribution. In this example we expand the value of the asset to first order in the interest rates $r_t$. This corresponds to studying the asset in terms of its duration.
# <br>
# <br>
# The approximation of the objective function follows the following paper:<br>
# <a href="https://arxiv.org/abs/1806.06893">Quantum Risk Analysis. <NAME>. 2018.</a>
import matplotlib.pyplot as plt
# %matplotlib inline
import numpy as np
from qiskit import Aer
from qiskit.aqua.algorithms.single_sample.amplitude_estimation.ae import AmplitudeEstimation
from qiskit.aqua.components.uncertainty_models import MultivariateNormalDistribution
from qiskit.aqua.components.uncertainty_problems import FixedIncomeExpectedValue
backend = Aer.get_backend('statevector_simulator')
# ### Uncertainty Model
#
# We construct a circuit factory to load a multivariate normal random distribution in $d$ dimensions into a quantum state.
# The distribution is truncated to a given box $\otimes_{i=1}^d [low_i, high_i]$ and discretized using $2^{n_i}$ grid points, where $n_i$ denotes the number of qubits used for dimension $i = 1,\ldots, d$.
# The unitary operator corresponding to the circuit factory implements the following:
# $$\big|0\rangle_{n_1}\ldots\big|0\rangle_{n_d} \mapsto \big|\psi\rangle = \sum_{i_1=0}^{2^n_-1}\ldots\sum_{i_d=0}^{2^n_-1} \sqrt{p_{i_1,...,i_d}}\big|i_1\rangle_{n_1}\ldots\big|i_d\rangle_{n_d},$$
# where $p_{i_1, ..., i_d}$ denote the probabilities corresponding to the truncated and discretized distribution and where $i_j$ is mapped to the right interval $[low_j, high_j]$ using the affine map:
# $$ \{0, \ldots, 2^{n_{j}}-1\} \ni i_j \mapsto \frac{high_j - low_j}{2^{n_j} - 1} * i_j + low_j \in [low_j, high_j].$$
#
# In addition to the uncertainty model, we can also apply an affine map, e.g. resulting from a principal component analysis. The interest rates used are then given by:
# $$ \vec{r} = A * \vec{x} + b,$$
# where $\vec{x} \in \otimes_{i=1}^d [low_i, high_i]$ follows the given random distribution.
# +
# can be used in case a principal component analysis has been done to derive the uncertainty model, ignored in this example.
A = np.eye(2)
b = np.zeros(2)
# specify the number of qubits that are used to represent the different dimenions of the uncertainty model
num_qubits = [2, 2]
# specify the lower and upper bounds for the different dimension
low = [0, 0]
high = [0.12, 0.24]
mu = [0.12, 0.24]
sigma = 0.01*np.eye(2)
# construct corresponding distribution
u = MultivariateNormalDistribution(num_qubits, low, high, mu, sigma)
# -
# plot contour of probability density function
x = np.linspace(low[0], high[0], 2**num_qubits[0])
y = np.linspace(low[1], high[1], 2**num_qubits[1])
z = u.probabilities.reshape(2**num_qubits[0], 2**num_qubits[1])
plt.contourf(x, y, z)
plt.xticks(x, size=15)
plt.yticks(y, size=15)
plt.grid()
plt.xlabel('$r_1$ (%)', size=15)
plt.ylabel('$r_2$ (%)', size=15)
plt.colorbar()
plt.show()
# ### Cash flow, payoff function, and exact expected value
#
# In the following we define the cash flow per period, the resulting payoff function and evaluate the exact expected value.
#
# For the payoff function we first use a first order approximation and then apply the same approximation technique as for the linear part of the payoff function of the [European Call Option](european_call_option_pricing.ipynb).
# +
# specify cash flow
cf = [1.0, 2.0]
periods = range(1, len(cf)+1)
# plot cash flow
plt.bar(periods, cf)
plt.xticks(periods, size=15)
plt.yticks(size=15)
plt.grid()
plt.xlabel('periods', size=15)
plt.ylabel('cashflow ($)', size=15)
plt.show()
# -
# estimate real value
cnt = 0
exact_value = 0.0
for x1 in np.linspace(low[0], high[0], pow(2, num_qubits[0])):
for x2 in np.linspace(low[1], high[1], pow(2, num_qubits[1])):
prob = u.probabilities[cnt]
for t in range(len(cf)):
# evaluate linear approximation of real value w.r.t. interest rates
exact_value += prob * (cf[t]/pow(1 + b[t], t+1) - (t+1)*cf[t]*np.dot(A[:, t], np.asarray([x1, x2]))/pow(1 + b[t], t+2))
cnt += 1
print('Exact value: \t%.4f' % exact_value)
# +
# specify approximation factor
c_approx = 0.125
# get fixed income circuit appfactory
fixed_income = FixedIncomeExpectedValue(u, A, b, cf, c_approx)
# +
# set number of evaluation qubits (samples)
m = 5
# construct amplitude estimation
ae = AmplitudeEstimation(m, fixed_income)
# -
# result = ae.run(quantum_instance=LegacySimulators.get_backend('qasm_simulator'), shots=100)
result = ae.run(quantum_instance=backend)
print('Exact value: \t%.4f' % exact_value)
print('Estimated value:\t%.4f' % result['estimation'])
print('Probability: \t%.4f' % result['max_probability'])
# +
# plot estimated values for "a" (direct result of amplitude estimation, not rescaled yet)
plt.bar(result['values'], result['probabilities'], width=0.5/len(result['probabilities']))
plt.xticks([0, 0.25, 0.5, 0.75, 1], size=15)
plt.yticks([0, 0.25, 0.5, 0.75, 1], size=15)
plt.title('"a" Value', size=15)
plt.ylabel('Probability', size=15)
plt.xlim((0,1))
plt.ylim((0,1))
plt.grid()
plt.show()
# plot estimated values for fixed-income asset (after re-scaling and reversing the c_approx-transformation)
plt.bar(result['mapped_values'], result['probabilities'], width=3/len(result['probabilities']))
plt.plot([exact_value, exact_value], [0,1], 'r--', linewidth=2)
plt.xticks(size=15)
plt.yticks([0, 0.25, 0.5, 0.75, 1], size=15)
plt.title('Estimated Option Price', size=15)
plt.ylabel('Probability', size=15)
plt.ylim((0,1))
plt.grid()
plt.show()
# -
import qiskit.tools.jupyter
# %qiskit_version_table
# %qiskit_copyright
| qiskit/advanced/aqua/finance/simulation/fixed_income_pricing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import pandas as pd
# %matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
# +
train = pd.read_csv("train_ctrUa4K.csv")
test = pd.read_csv("test_lAUu6dG.csv")
print("Train shape : {}, Test shape : {}".format(train.shape,test.shape))
train.head()
# -
## Checking null values
print("Null Values - training")
for col in train.columns:
print("{} : {}".format(col, len(train[train[col].isna()])))
print()
print("Null Values - testing")
for col in test.columns:
print("{} : {}".format(col, len(test[test[col].isna()])))
#check unique values
categorical_columns = ['Gender','Married','Dependents','Education','Self_Employed','Loan_Amount_Term','Credit_History','Property_Area']
continuous_columns = ['ApplicantIncome','CoapplicantIncome','LoanAmount']
for cat_col in categorical_columns:
print("{} : {}".format(cat_col,train[cat_col].unique()))
# ### Visualizations
fig,ax = plt.subplots(figsize=(20,10),ncols=3,nrows=2)
#sns.barplot(x="Gender",y="Loan_",hue="Marital_Status",estimator=np.mean,data=df_train,ax=ax[0])
sns.countplot(x="Gender",hue="Loan_Status",data=train,ax=ax[0][0])
sns.countplot(x="Married",hue="Loan_Status",data=train,ax=ax[0][1])
sns.countplot(x="Dependents",hue="Loan_Status",data=train,ax=ax[0][2])
sns.countplot(x="Property_Area",hue="Loan_Status",data=train,ax=ax[1][0])
sns.countplot(x="Self_Employed",hue="Loan_Status",data=train, ax=ax[1][1])
sns.countplot(x="Credit_History",hue="Loan_Status",data=train, ax=ax[1][2])
# +
#there are mostly male applicant lets replace NA with Male - (13,11)
train.Gender.fillna("Male",inplace=True);test.Gender.fillna("Male",inplace=True)
#there are moslty married applicant lets replace them with Married (3,0)
train.Married.fillna("Yes",inplace=True)
#most people dont have dependents (15,10)
train.Dependents.fillna(0,inplace=True);test.Dependents.fillna(0,inplace=True)
#property area, it has no na values
#most people are not self_employed
train.Self_Employed.fillna("No",inplace=True);test.Self_Employed.fillna("No",inplace=True)
#most people have credit history, but NA value (50,29)
train.Credit_History.fillna(-1,inplace=True);test.Credit_History.fillna(-1,inplace=True)
#most people are graduate but it has no NA values
# +
fig,ax = plt.subplots(figsize=(20,10),ncols=3,nrows=2)
sns.countplot(x="Education",hue="Loan_Status",data=train,ax=ax[0][0])
# Loan_Status vs ApplicantIncome
applicantIncome = train.ApplicantIncome[ train.ApplicantIncome < np.percentile(train.ApplicantIncome,95)]
loanStatus = train.Loan_Status[ train.ApplicantIncome < np.percentile(train.ApplicantIncome,95)]
sns.boxplot(x=loanStatus,y=applicantIncome,ax=ax[0][1])
# Loan_Status vs CoapplicantIncome
coapplicantIncome = train.CoapplicantIncome[ train.CoapplicantIncome < np.percentile(train.CoapplicantIncome,96)]
loanStatus = train.Loan_Status[ train.CoapplicantIncome < np.percentile(train.CoapplicantIncome,96)]
sns.boxplot(x=loanStatus,y=coapplicantIncome,ax=ax[0][2])
#Loan_Status vs LoanAmount
sns.boxplot(x="Loan_Status",y="LoanAmount",data=train,ax=ax[1][0])
sns.countplot(x="Loan_Amount_Term",hue="Loan_Status",data=train,ax=ax[1][1])
sns.violinplot("LoanAmount",data=train,ax=ax[1][2])
# +
#Dealing with applicant Income
# replace very high applicant income with 95th percentile
applicantIncome_th = np.percentile(train.ApplicantIncome, 95)
train.loc[ train[train.ApplicantIncome > applicantIncome_th].index, "ApplicantIncome" ] = applicantIncome_th
test.loc[ test[test.ApplicantIncome > applicantIncome_th].index, "ApplicantIncome" ] = applicantIncome_th
# +
#Dealing with co applicant Income
#replace very high co applicant income with 96 percentile
coapplicantIncome_th = np.percentile(train.CoapplicantIncome, 96)
train.loc[ train[train.CoapplicantIncome > coapplicantIncome_th].index, "CoapplicantIncome" ] = coapplicantIncome_th
test.loc[ test[test.CoapplicantIncome > coapplicantIncome_th].index, "CoapplicantIncome" ] = coapplicantIncome_th
# -
#Dealing with loan Amount
loanAmount_mean = np.mean(train.LoanAmount)
train.LoanAmount.fillna(loanAmount_mean,inplace=True)
test.LoanAmount.fillna(loanAmount_mean, inplace=True)
#Dealing with Loan Amount Term (14,6)
train.Loan_Amount_Term.fillna(36.0,inplace=True)
test.Loan_Amount_Term.fillna(36.0,inplace=True)
submission = pd.DataFrame({"Loan_ID":test.Loan_ID})
Y = train.Loan_Status
train.drop(["Loan_ID","Loan_Status"],axis=1,inplace=True)
test.drop(["Loan_ID"],axis=1,inplace=True)
# +
df = train.append(test,sort=False,ignore_index=True)
#some preprocessing
#1. Label Encoding
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df.Gender = le.fit_transform(df.Gender)
df.Married = le.fit_transform(df.Married)
df.Property_Area = le.fit_transform(df.Property_Area)
df.Self_Employed = le.fit_transform(df.Self_Employed)
df.Education = le.fit_transform(df.Education)
df.Dependents.replace('3+','3',inplace=True)
# -
#2. Scaling
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
df.ApplicantIncome = mms.fit_transform(df.ApplicantIncome.values.reshape((len(df.ApplicantIncome),1))).reshape((len(df.ApplicantIncome)))
df.CoapplicantIncome = mms.fit_transform(df.CoapplicantIncome.values.reshape((len(df.CoapplicantIncome),1))).reshape((len(df.CoapplicantIncome)))
df.LoanAmount = mms.fit_transform(df.LoanAmount.values.reshape((len(df.LoanAmount),1))).reshape((len(df.LoanAmount)))
df.Loan_Amount_Term = mms.fit_transform(df.Loan_Amount_Term.values.reshape((len(df.Loan_Amount_Term),1))).reshape((len(df.Loan_Amount_Term)))
df.dtypes
df = df.astype({ 'Dependents':int, 'Credit_History':int})
TargetEncoder = LabelEncoder()
TargetEncoder.fit(Y)
Y = TargetEncoder.transform(Y)
X = df[:614]
X_test = df[614:]
print("Train shape :{}, Test shape : {}, Train Target Length : {}".format(X.shape,X_test.shape,len(Y)))
# ### Models to try
# 1. Logistic Regression
# 2. RandomForest
# 3. Support Vector Classifier
# 4. XGBoost Classifier
from sklearn.metrics import accuracy_score, confusion_matrix
def accuracy(model,x,y):
y_ = model.predict(x)
return accuracy_score(y_,y)
from sklearn.model_selection import cross_val_score, StratifiedKFold
def score(clf):
score = cross_val_score(estimator=clf,X=X,y=Y,scoring=accuracy,n_jobs=-1,
cv=StratifiedKFold(n_splits=3,shuffle=True)).mean()
return score
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l2',C=1.0)
print("Logistic Regression Accuracy : {}".format(score(lr)))
from sklearn.svm import SVC
svc = SVC(C=1.0)
print("SVC Accuracy : {}".format(score(svc)))
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=50)
print("RFC Accuracy : {}".format(score(rfc)))
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimators=50,max_depth=6,learning_rate=0.05)
print("XGB Accuracy : {}".format(score(xgb)))
# #### Lets improve XGB Classifier since it is doing best
# +
from hyperopt import fmin, hp, tpe
def objective(params):
params = {
'n_estimators': int(params['n_estimators']),
'max_depth':int(params['max_depth']),
'learning_rate':params['learning_rate'],
'colsample_bylevel':params['colsample_bylevel'],
'colsample_bytree':params['colsample_bytree']
}
xgb = XGBClassifier(**params,n_jobs=4)
acc = score(xgb)
if acc>0.80: print("{}:{}".format(params,acc))
return -1*acc
space = {
'n_estimators':hp.quniform('n_estimators',20,160,20),
'max_depth':hp.quniform('max_depth',2,18,4),
'learning_rate':hp.uniform('learning_rate',0.05,0.2),
'colsample_bylevel': hp.choice('colsample_bylevel',[0.2,0.4,0.6,1]),
'colsample_bytree': hp.choice('colsample_bytree',[0.2,0.4,0.6,1])
}
best = fmin(fn=objective,
space=space,
algo=tpe.suggest,
max_evals=100)
# -
best
xgb = XGBClassifier( n_estimators= int(best['n_estimators']),
max_depth=int(best['max_depth']),
learning_rate=best['learning_rate'],
colsample_bylevel=1,
colsample_bytree=0.2
)
xgb.fit(X,Y)
Y_test = xgb.predict(X_test)
submission['Loan_Status'] = TargetEncoder.inverse_transform(Y_test)
submission.head()
submission.to_csv("submission1.csv",index=False)
| .ipynb_checkpoints/Solution 1-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# + [markdown] nbsphinx="hidden" slideshow={"slide_type": "skip"}
# This notebook is part of the $\omega radlib$ documentation: http://wradlib.org/wradlib-docs.
#
# Copyright (c) 2016, $\omega radlib$ developers.
# Distributed under the MIT License. See LICENSE.txt for more info.
# + [markdown] slideshow={"slide_type": "slide"}
# # A one hour tour of wradlib
#
# 
# + [markdown] slideshow={"slide_type": "fragment"}
# This notebook provides a guided tour of some $\omega radlib$ notebooks.
# + [markdown] slideshow={"slide_type": "skip"}
# *(find all wradlib notebooks in the [docs](http://wradlib.org/wradlib-docs/latest/notebooks.html).)*
# + [markdown] slideshow={"slide_type": "slide"}
# ## Some background, first
# + [markdown] slideshow={"slide_type": "fragment"}
# Development started in 2011...or more precisely:
#
# `October 26th, 2011`
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Key motivation
#
# `A community platform for collaborative development of algorithms`
# + [markdown] slideshow={"slide_type": "slide"}
# ## Development team
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Core team (in aphabetical order)
#
# - <NAME> (University of Potsdam)
# - <NAME> (University of Bonn)
# - *<NAME> (retired from radar science)*
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Contributions from
#
# - <NAME> (University of Potsdam, Germany)
# - <NAME> (RMI, Belgium)
# - <NAME> (University of Potsdam, Germany)
# - <NAME> (Argonne National Laboratory, USA)
# - <NAME> (University of Kwazulu-Natal, South Africa)
# - ...
# + [markdown] slideshow={"slide_type": "slide"}
# ## Your entry points
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Just start out from [wradlib.org](http://wradlib.org)
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Documentation
#
# Check out the [online docs](http://wradlib.org/wradlib-docs/latest/) with [tutorials and examples](http://wradlib.org/wradlib-docs/latest/notebooks.html) and a comprehensive [library reference](http://wradlib.org/wradlib-docs/latest/reference.html)
# + [markdown] slideshow={"slide_type": "fragment"}
# ### User group
#
# Get help and connect more than 120 users at the [wradlib user group](https://groups.google.com/forum/?fromgroups#!forum/wradlib-users)!
# + [markdown] slideshow={"slide_type": "fragment"}
# ### For developers
#
# Fork us from https://github.com/wradlib/wradlib or [raise an issue](https://github.com/wradlib/wradlib/issues)!
# + [markdown] slideshow={"slide_type": "slide"}
# ## Installation
# + [markdown] slideshow={"slide_type": "fragment"}
# The are many ways to install wradlib, but this is our recommendation:
# + [markdown] slideshow={"slide_type": "fragment"}
# ### 1. Install Anaconda
#
# Get it [here](https://www.continuum.io/why-anaconda/) for Windows, Linux, or Mac.
# + [markdown] slideshow={"slide_type": "fragment"}
# ### 2. Create a fresh environment and add conda-forge channel
#
# ```bash
# $ conda create --name wradlibenv python=2.7
# $ conda config --add channels conda-forge
# ```
# + [markdown] slideshow={"slide_type": "fragment"}
# ### 3. Activate environment and install wradlib
#
# ```bash
# $ activate wradlibenv
# $ (wradlibenv) conda install wradlib
# ```
# + [markdown] slideshow={"slide_type": "fragment"}
# ### 4. Make sure `GDAL_DATA` is set
#
# The environment variable `GDAL_DATA` should point to `.../anaconda/envs/wradlibenv/share/gdal`
# + [markdown] slideshow={"slide_type": "slide"}
# ## Download the sample data
# + [markdown] slideshow={"slide_type": "fragment"}
# ### 1. Download the sample data
#
# Download the data from [here](https://github.com/wradlib/wradlib-data) either as a ziip archive or by `git clone https://github.com/wradlib/wradlib-data`
# + [markdown] slideshow={"slide_type": "fragment"}
# ### 2. Set the environment variable `WRADLIB_DATA`
#
# `WRADLIB_DATA` should point to the upper level `wradlib-data` directory in which you saved the data.
# + [markdown] slideshow={"slide_type": "fragment"}
# Get more detailed instructions [here](http://wradlib.org/wradlib-docs/latest/gettingstarted.html)!
# + [markdown] slideshow={"slide_type": "slide"}
# ## Development paradigm
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Keep the magic to a minimum
# + [markdown] slideshow={"slide_type": "fragment"}
# - transparent
# - flexible
# - but also lower level
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Flat (or no) data model
# + [markdown] slideshow={"slide_type": "fragment"}
# - pass data as numpy arrays,
# - and pass metadata as dictionaries.
# + [markdown] slideshow={"slide_type": "slide"}
# ## Import wradlib
# + slideshow={"slide_type": "fragment"}
import wradlib
# + slideshow={"slide_type": "fragment"}
# check installed version
print(wradlib.__version__)
# + [markdown] slideshow={"slide_type": "fragment"}
# In the next cell, type `wradlib.` and hit `Tab`.
#
# *Inpect the available modules and functions.*
# + slideshow={"slide_type": "fragment"}
# + [markdown] slideshow={"slide_type": "slide"}
# ## Reading and viewing data
# + [markdown] nbsphinx-toctree={"maxdepth": 2} slideshow={"slide_type": "fragment"}
# ### Read and quick-view
# Let's see how we can [read and quick-view a radar scan](visualisation/wradlib_plot_ppi_example.ipynb).
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Zoo of file formats
# This notebook shows you how to [access various file formats](fileio/wradlib_radar_formats.ipynb).
# + [markdown] slideshow={"slide_type": "slide"}
# ## Addressing errors
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Attenuation
#
# In [this example](attenuation/wradlib_attenuation.ipynb), we reconstruct path-integrated attenuation from single-pol data of the German Weather Service.
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Clutter detection
#
# wradlib provides several methods for clutter detection. [Here](classify/wradlib_fuzzy_echo_classify.ipynb), we look at an example that uses dual-pol moments and a simple fuzzy classification.
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Partial beam blockage
#
# In [this example](beamblockage/wradlib_beamblock.ipynb), wradlib attempts to quantify terrain-induced beam blockage from a DEM.
# + [markdown] slideshow={"slide_type": "slide"}
# ## Integration with other geodata
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Average precipitation over your river catchment
#
# In this example, we [compute zonal statistics](zonalstats/wradlib_zonalstats_quickstart.ipynb) over polygons imported in a shapefile.
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Over and underlay of other geodata
#
# Often, you need to [present your radar data in context with other geodata](visualisation/wradlib_overlay.ipynb) (DEM, rivers, gauges, catchments, ...).
# + [markdown] slideshow={"slide_type": "slide"}
# ## Merging with other sensors
# + [markdown] slideshow={"slide_type": "fragment"}
# ### Adjusting radar-based rainfall estimates by rain gauges
#
# In [this example](multisensor/wradlib_adjust_example.ipynb), we use synthetic radar and rain gauge observations and confront them with different adjustment techniques.
| notebooks/wradlib_in_an_hour.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
# +
filepath = '/Volumes/backup_128G/z_repository/TBIO_data/RequestsFromTana/all_org_classes/chrj_pr_families'
chrj_families = 'family_members_20190510_v1.xls'
read_chrj_families = '{0}/{1}'.format(filepath, chrj_families)
# -
xls = pd.ExcelFile(read_chrj_families)
chrjDf = pd.read_excel(xls, 'chrj_pr')
chrjDf = chrjDf.fillna(0)
chrjDf.shape, chrjDf.head()
families = chrjDf['name'].unique()
families
len(families)
# +
import stardog
import json
adminFile = '/Users/vincent/Projects/TBIO/tbio-conn-admin.json'
conn_details = {}
with open(adminFile, 'r') as readFile:
conn_details = json.loads(readFile.read())
# -
# # Create Family and assign the leader to the Family
def insertFamilyQry(name):
return """INSERT DATA {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
<http://tbio.orient.cas.cz#%s家族> a <http://www.w3.org/2002/07/owl#Class> ;
<http://www.w3.org/2000/01/rdf-schema#subClassOf> <http://tbio.orient.cas.cz#Family> .
<http://tbio.orient.cas.cz#%s家族__%s> a <http://tbio.orient.cas.cz#Family> ;
<http://tbio.orient.cas.cz#hasFamily> <http://tbio.orient.cas.cz#%s家族> .
<http://tbio.orient.cas.cz#%s> tbio:isMemberOfFamily <http://tbio.orient.cas.cz#%s家族__%s> .
}
}""" % (name, name, name, name, name, name, name)
with stardog.Connection('tbio', **conn_details) as conn:
idx = 0
for family in families:
query = insertFamilyQry(family)
results = conn.update(query)
print(idx, family, results)
# print(results)
idx += 1
# break
# # insert son to the family
def insertSonQry(name):
return """INSERT {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
?familyEvt a <http://tbio.orient.cas.cz#Family> ;
<http://tbio.orient.cas.cz#hasFamily> <http://tbio.orient.cas.cz#%s家族> .
?son tbio:isMemberOfFamily ?familyEvt .
}
}
WHERE {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
<http://tbio.orient.cas.cz#%s> tbio:hasSon ?son .
BIND(STR(?son) AS ?sonStr) .
BIND(REPLACE(?sonStr, "http://tbio.orient.cas.cz#", "") AS ?sonName) .
BIND(CONCAT("http://tbio.orient.cas.cz#%s家族__", ?sonName) AS ?familyStr) .
BIND(IRI(?familyStr) AS ?familyEvt) .
}
}""" % (name, name, name)
with stardog.Connection('tbio', **conn_details) as conn:
idx = 0
for family in families:
query = insertSonQry(family)
results = conn.update(query)
print(idx, family, results)
# print(results)
idx += 1
# break
# # insert daughter to the family
def insertDauQry(name):
return """INSERT {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
?familyEvt a <http://tbio.orient.cas.cz#Family> ;
<http://tbio.orient.cas.cz#hasFamily> <http://tbio.orient.cas.cz#%s家族> .
?daughter tbio:isMemberOfFamily ?familyEvt .
}
}
WHERE {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
<http://tbio.orient.cas.cz#%s> tbio:hasDaughter ?daughter .
BIND(STR(?daughter) AS ?dauStr) .
BIND(REPLACE(?dauStr, "http://tbio.orient.cas.cz#", "") AS ?name) .
BIND(CONCAT("http://tbio.orient.cas.cz#%s家族__", ?name) AS ?familyStr) .
BIND(IRI(?familyStr) AS ?familyEvt) .
}
}""" % (name, name, name)
with stardog.Connection('tbio', **conn_details) as conn:
idx = 0
for family in families:
query = insertDauQry(family)
results = conn.update(query)
print(idx, family, results)
# print(results)
idx += 1
# break
# # insert grandson into family
def insertGrandsonQry(name):
return """INSERT {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
?familyEvt a <http://tbio.orient.cas.cz#Family> ;
<http://tbio.orient.cas.cz#hasFamily> <http://tbio.orient.cas.cz#%s家族> .
?grandChild tbio:isMemberOfFamily ?familyEvt .
}
}
WHERE {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
<http://tbio.orient.cas.cz#%s> tbio:hasSon ?son .
GRAPH ?g {
?son tbio:hasSon ?grandChild .
}
BIND(STR(?grandChild) AS ?grandStr) .
BIND(REPLACE(?grandStr, "http://tbio.orient.cas.cz#", "") AS ?grandName) .
BIND(CONCAT("http://tbio.orient.cas.cz#%s家族__", ?grandName) AS ?familyStr) .
BIND(IRI(?familyStr) AS ?familyEvt) .
}
}""" % (name, name, name)
with stardog.Connection('tbio', **conn_details) as conn:
idx = 0
for family in families:
query = insertGrandsonQry(family)
results = conn.update(query)
print(idx, family, results)
# print(results)
idx += 1
# break
# # insert grand daughter into family
def insertGranddauQry(name):
return """INSERT {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
?familyEvt a <http://tbio.orient.cas.cz#Family> ;
<http://tbio.orient.cas.cz#hasFamily> <http://tbio.orient.cas.cz#%s家族> .
?grandChild tbio:isMemberOfFamily ?familyEvt .
}
}
WHERE {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
<http://tbio.orient.cas.cz#%s> tbio:hasSon ?son .
GRAPH ?g {
?son tbio:hasDaughter ?grandChild .
}
BIND(STR(?grandChild) AS ?grandStr) .
BIND(REPLACE(?grandStr, "http://tbio.orient.cas.cz#", "") AS ?grandName) .
BIND(CONCAT("http://tbio.orient.cas.cz#%s家族__", ?grandName) AS ?familyStr) .
BIND(IRI(?familyStr) AS ?familyEvt) .
}
}""" % (name, name, name)
with stardog.Connection('tbio', **conn_details) as conn:
idx = 0
for family in families:
query = insertGranddauQry(family)
results = conn.update(query)
print(idx, family, results)
# print(results)
idx += 1
# break
# # Check the leader name is a correct name or not
# +
# def sparqlQry(name):
# return """SELECT DISTINCT ?p WHERE {
# GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
# tbio:%s ?p ?o .
# # ?p rdfs:subPropertyOf ?familyOP .
# }
# # ?p rdfs:subPropertyOf ?familyOP .
# FILTER ( ?familyOP = tbio:hasFamilyRelation )
# } ORDER BY (?p)""" % (name)
# +
# import json
# with stardog.Connection('tbio', **conn_details) as conn:
# # conn.begin()
# idx = 0
# for family in families:
# query = sparqlQry(family)
# results = conn.select(query)
# # print(results)
# # jsonRes = json.loads(results)
# # results = conn.update(query)
# print(idx, family, results.get('results').get('bindings'))
# # print(results)
# idx += 1
# # break
# -
# # Special Case
def insertQry(family, name):
return """INSERT DATA {
GRAPH <http://tbio.orient.cas.cz/chrj_pr> {
<http://tbio.orient.cas.cz#%s家族> a <http://www.w3.org/2002/07/owl#Class> ;
<http://www.w3.org/2000/01/rdf-schema#subClassOf> <http://tbio.orient.cas.cz#Family> .
<http://tbio.orient.cas.cz#%s家族__%s> a <http://tbio.orient.cas.cz#Family> ;
<http://tbio.orient.cas.cz#hasFamily> <http://tbio.orient.cas.cz#%s家族> .
<http://tbio.orient.cas.cz#%s> tbio:isMemberOfFamily <http://tbio.orient.cas.cz#%s家族__%s> .
}
}""" % (family, family, name, family, name, family, name)
with stardog.Connection('tbio', **conn_details) as conn:
query = insertQry('翁淑治', '翁淑霞')
results = conn.update(query)
print(family, results)
| tbio/assign_families_in_chrj_pr.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.12 64-bit (''pytorch-gpu'': conda)'
# language: python
# name: python3
# ---
# # XLNet
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name CoLA --do_train --do_eval --do_lower_case --data_dir ./../glue_data/CoLA --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_cola/ --save_steps 0 --evaluate_during_training
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name SST-2 --do_train --do_eval --do_lower_case --data_dir ./../glue_data/SST-2 --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_sst2/ --save_steps 0 --evaluate_during_training
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name MRPC --do_train --do_eval --do_lower_case --data_dir ./../glue_data/MRPC --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_mrpc/ --save_steps 0 --evaluate_during_training
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name QNLI --do_train --do_eval --do_lower_case --data_dir ./../glue_data/QNLI --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_qnli/ --save_steps 0 --evaluate_during_training
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name QQP --do_train --do_eval --do_lower_case --data_dir ./../glue_data/QQP --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_qqp/ --save_steps 0 --evaluate_during_training
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name RTE --do_train --do_eval --do_lower_case --data_dir ./../glue_data/RTE --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_rte/ --save_steps 0 --evaluate_during_training
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name WNLI --do_train --do_eval --do_lower_case --data_dir ./../glue_data/WNLI --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_wnli/ --save_steps 0 --evaluate_during_training
# !python .\examples\run_glue.py --overwrite_output_dir --model_type xlnet --model_name_or_path xlnet-base-cased --task_name MNLI --do_train --do_eval --do_lower_case --data_dir ./../glue_data/MNLI --max_seq_length 128 --per_gpu_train_batch_size 16 --learning_rate 2e-5 --num_train_epochs 15 --output_dir ./../xlnet_mnli/ --save_steps 0 --evaluate_during_training
| run_experiments_xlnet.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
def inp(a,n) :
for i in range(0,n) :
a[i] = int(input(" Enter Value : "))
print('\n')
def display(a,n) :
for i in range(0,n) :
print(" ",a[i],end = " ")
print('\n')
def linearsearch(a,n,key) :
flag = False
for i in range(0,n):
if a[i] == key :
print(" ",key," Found @ ",i+1,'\n')
flag = True
if flag == False :
print(" Data Not Found ")
return flag
def main() :
n = int(input(" Enter Number Of Elements : "))
a = []
a = [0 for i in range(0,n)]
inp(a,n)
display(a,n)
key = int(input(" Enter Data To Be Searched : "))
print("\n")
linearsearch(a,n,key)
main()
| LinearSearch.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ---
# ## Step 0: Load The Data
# +
import os, sys
import pickle
import numpy as np
from sklearn.utils import shuffle
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from config import CURRENT_DIR
DATA_PATH = os.path.abspath(os.path.join(CURRENT_DIR, "../data"))
sys.path.append(os.path.join(CURRENT_DIR, ".."))
training_file = os.path.join(DATA_PATH, "train.p")
validation_file = os.path.join(DATA_PATH, "valid.p")
testing_file = os.path.join(DATA_PATH, "test.p")
with open(training_file, mode='rb') as f:
train = pickle.load(f)
with open(validation_file, mode='rb') as f:
valid = pickle.load(f)
with open(testing_file, mode='rb') as f:
test = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_valid, y_valid = valid['features'], valid['labels']
X_test, y_test = test['features'], test['labels']
# configuration
EPOCHS = 50
BATCH_SIZE = 256
IN_CHANNEL = 1
OUTPUT_PATH = os.path.join(CURRENT_DIR, "../trained_models")
MAX_SAMPLES_PER_CLASS = 2000
# -
# ---
#
# ## Step 1: Dataset Summary & Exploration
#
# The pickled data is a dictionary with 4 key/value pairs:
#
# - `'features'` is a 4D array containing raw pixel data of the traffic sign images, (num examples, width, height, channels).
# - `'labels'` is a 1D array containing the label/class id of the traffic sign. The file `signnames.csv` contains id -> name mappings for each id.
# - `'sizes'` is a list containing tuples, (width, height) representing the original width and height the image.
# - `'coords'` is a list containing tuples, (x1, y1, x2, y2) representing coordinates of a bounding box around the sign in the image. **THESE COORDINATES ASSUME THE ORIGINAL IMAGE. THE PICKLED DATA CONTAINS RESIZED VERSIONS (32 by 32) OF THESE IMAGES**
#
# Complete the basic data summary below. Use python, numpy and/or pandas methods to calculate the data summary rather than hard coding the results. For example, the [pandas shape method](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.shape.html) might be useful for calculating some of the summary results.
# ### Provide a Basic Summary of the Data Set Using Python, Numpy and/or Pandas
# +
n_train = X_train.shape[0]
n_validation = X_valid.shape[0]
n_test = X_test.shape[0]
image_shape = X_train.shape[1:]
n_classes = np.unique(y_train).shape[0]
print("Number of training examples =", n_train)
print("Number of testing examples =", n_test)
print("Image data shape =", image_shape)
print("Number of classes =", n_classes)
# -
# ### Include an exploratory visualization of the dataset
# Visualize the German Traffic Signs Dataset using the pickled file(s). This is open ended, suggestions include: plotting traffic sign images, plotting the count of each sign, etc.
#
# The [Matplotlib](http://matplotlib.org/) [examples](http://matplotlib.org/examples/index.html) and [gallery](http://matplotlib.org/gallery.html) pages are a great resource for doing visualizations in Python.
#
# **NOTE:** It's recommended you start with something simple first. If you wish to do more, come back to it after you've completed the rest of the sections. It can be interesting to look at the distribution of classes in the training, validation and test set. Is the distribution the same? Are there more examples of some classes than others?
# +
LABEL_NAME_PATH = os.path.join(DATA_PATH, "signnames.csv")
labels = np.loadtxt(LABEL_NAME_PATH, delimiter=",", skiprows=1, usecols=(1), dtype=np.str)
# -
labels
np.where(labels == 'Speed limit (80km/h)')
# +
import matplotlib.pyplot as plt
# %matplotlib inline
fig = plt.figure(figsize=(9, 15))
fig.subplots_adjust(left=0, right=1, bottom=0, top=0.5, hspace=0.05, wspace=0.05)
img_to_plot_idx = np.arange(0, 10000, 1000)
for i in range(10):
ax = fig.add_subplot(1, 10, i + 1, xticks=[], yticks=[])
ax.imshow(X_train[img_to_plot_idx[i]], cmap='gray')
def plot_histogram(ys, num_classes, class_labels, graph_labels, title, colors, figsize=(15, 15)):
"""
Plot a histogram of the frequency of each class in ys
"""
from matplotlib import pyplot as plt
fig = plt.figure(figsize=figsize)
ax = fig.add_subplot(111)
for i, y in enumerate(ys):
ax.bar(range(num_classes), np.bincount(y), width=1.,
align='center', color=colors[i], label=graph_labels[i])
plt.xlim([-1, num_classes])
ax.xaxis.grid(False)
ax.xaxis.set_ticks_position('none')
ax.yaxis.grid(False)
ax.set_xticks(range(num_classes))
ax.set_xticklabels(class_labels, rotation=90, size='xx-small')
legend = ax.legend(loc='upper center', shadow=True)
legend_frame = legend.get_frame()
legend_frame.set_facecolor('white')
legend_frame.set_edgecolor('black')
plt.ylabel('number of samples')
plt.title(title)
plot_histogram([y_train, y_test], n_classes, labels, ["training set", "test set"], "Number of examples per traffic sign class", ['green', 'red'])
# +
from utility import rotate, random_crop, cutout, gray_scale, normalize
def augmentation_pipeline(img):
img_out = rotate(img)
img_out = random_crop(img_out)
img_out = cutout(img_out)
return img_out
# +
orig_num_samples_per_class = np.bincount(y_train)
aug_num_samples_per_class = np.maximum(MAX_SAMPLES_PER_CLASS, np.max(orig_num_samples_per_class))
total_new_samples = aug_num_samples_per_class * len(labels) - len(X_train)
new_X_train = np.zeros((total_new_samples,) + image_shape, dtype=X_train.dtype)
new_y_train = np.zeros((total_new_samples,), dtype=y_train.dtype)
idx = 0
for i, orig_num_samples in enumerate(orig_num_samples_per_class):
sample_ids = np.where(y_train == i)[0]
new_num_samples = aug_num_samples_per_class - orig_num_samples
samples = X_train[np.random.choice(sample_ids, new_num_samples)]
new_y_train[idx:idx+new_num_samples] = i * np.ones(new_num_samples)
for s in samples:
new_X_train[idx] = augmentation_pipeline(s)
idx += 1
aug_X_train = np.vstack((X_train, new_X_train))
aug_y_train = np.concatenate((y_train, new_y_train))
# -
plot_histogram([aug_y_train, y_test], n_classes, labels, ["aug training set", "test set"], "Number of examples per traffic sign class", ['blue', 'red'])
plt.imshow(new_X_train[7])
# ----
#
# ## Step 2: Design and Test a Model Architecture
#
# Design and implement a deep learning model that learns to recognize traffic signs. Train and test your model on the [German Traffic Sign Dataset](http://benchmark.ini.rub.de/?section=gtsrb&subsection=dataset).
#
# The LeNet-5 implementation shown in the [classroom](https://classroom.udacity.com/nanodegrees/nd013/parts/fbf77062-5703-404e-b60c-95b78b2f3f9e/modules/6df7ae49-c61c-4bb2-a23e-6527e69209ec/lessons/601ae704-1035-4287-8b11-e2c2716217ad/concepts/d4aca031-508f-4e0b-b493-e7b706120f81) at the end of the CNN lesson is a solid starting point. You'll have to change the number of classes and possibly the preprocessing, but aside from that it's plug and play!
#
# With the LeNet-5 solution from the lecture, you should expect a validation set accuracy of about 0.89. To meet specifications, the validation set accuracy will need to be at least 0.93. It is possible to get an even higher accuracy, but 0.93 is the minimum for a successful project submission.
#
# There are various aspects to consider when thinking about this problem:
#
# - Neural network architecture (is the network over or underfitting?)
# - Play around preprocessing techniques (normalization, rgb to grayscale, etc)
# - Number of examples per label (some have more than others).
# - Generate fake data.
#
# Here is an example of a [published baseline model on this problem](http://yann.lecun.com/exdb/publis/pdf/sermanet-ijcnn-11.pdf). It's not required to be familiar with the approach used in the paper but, it's good practice to try to read papers like these.
# ### Pre-process the Data Set (normalization, grayscale, etc.)
# Minimally, the image data should be normalized so that the data has mean zero and equal variance. For image data, `(pixel - 128)/ 128` is a quick way to approximately normalize the data and can be used in this project.
#
# Other pre-processing steps are optional. You can try different techniques to see if it improves performance.
#
# Use the code cell (or multiple code cells, if necessary) to implement the first step of your project.
# +
import cv2
from sklearn.preprocessing import Normalizer, StandardScaler
# Shuffle the train set
import random
idx = np.arange(X_train.shape[0])
random.seed(20)
random.shuffle(idx)
X_train = X_train[idx]
y_train = y_train[idx]
img_mean = None
img_std = None
def preprocess(data, in_channel=1):
global img_mean
global img_std
processed_imgs = np.copy(data)
if in_channel == 1:
processed_imgs = np.array(list(map(gray_scale, processed_imgs)))
processed_imgs = processed_imgs / 255
if img_mean is None or img_std is None:
img_mean = processed_imgs.mean()
img_std = processed_imgs.std()
processed_imgs = normalize(img_mean, img_std, processed_imgs)
if in_channel == 1:
tmp_shape = processed_imgs.shape + (1, )
processed_imgs = processed_imgs.reshape(tmp_shape)
return processed_imgs
# -
X_train_preprocessed = preprocess(X_train, in_channel=IN_CHANNEL)
aug_X_train_preprocessed = preprocess(aug_X_train, in_channel=IN_CHANNEL)
X_valid_preprocessed = preprocess(X_valid, in_channel=IN_CHANNEL)
X_test_preprocessed = preprocess(X_test, in_channel=IN_CHANNEL)
X_train_preprocessed.shape
# ### Model Architecture
# +
from models import TrafficSignNet
model = TrafficSignNet(in_channel=IN_CHANNEL, n_out = n_classes)
model_name = "TrafficSignNet"
# -
# ### Train, Validate and Test the Model
# A validation set can be used to assess how well the model is performing. A low accuracy on the training and validation
# sets imply underfitting. A high accuracy on the training set but low accuracy on the validation set implies overfitting.
# +
# tf.reset_default_graph()
normalized_images = np.copy(aug_X_train_preprocessed)
one_hot_y_valid = tf.one_hot(y_valid, n_classes)
train_loss =[]
train_acc = []
val_loss = []
val_acc = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter('../tflogs', sess.graph)
num_examples = len(y_train)
print("Training...\n")
for i in range(EPOCHS):
normalized_images, aug_y_train = shuffle(normalized_images, aug_y_train)
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = normalized_images[offset:end], aug_y_train[offset:end]
sess.run(model.training_operation,
feed_dict={model.x: batch_x, model.y: batch_y, model.keep_prob : 0.5, model.keep_prob_conv: 0.7, model.is_training : True})
training_accuracy, training_loss = model.evaluate(normalized_images, aug_y_train)
validation_accuracy, validation_loss = model.evaluate(X_valid_preprocessed, y_valid)
train_loss.append(training_loss)
train_acc.append(training_accuracy)
val_loss.append(validation_loss)
val_acc.append(validation_accuracy)
print("epoch {} : train_acc, train_loss = {:.3f}%, {:.3f}".format(i+1, (training_accuracy*100), training_loss))
print("epoch {} : val_acc, val_loss = {:.3f}%, {:.3f}".format(i+1, (validation_accuracy*100), validation_loss))
print("-------------------------------------------------")
model.saver.save(sess, os.path.join(OUTPUT_PATH, model_name))
print("Model saved")
# +
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(10,10))
ax[0].set_xlabel("epochs");
ax[0].set_ylabel("loss")
ax[0].set_title("loss")
ax[0].plot(range(0,EPOCHS), train_loss, label="train loss")
ax[0].plot(range(0,EPOCHS), val_loss, label="val loss")
ax[0].legend()
ax[1].set_xlabel("epochs");
ax[1].set_ylabel("val")
ax[1].set_title("accuracy")
ax[1].plot(range(0,EPOCHS), train_acc, label="train acc")
ax[1].plot(range(0,EPOCHS), val_acc, label="val acc")
ax[1].legend()
plt.suptitle("train-val logs")
plt.show()
# -
# ---
#
# ## Step 3: Test a Model on New Images
#
# To give yourself more insight into how your model is working, download at least five pictures of German traffic signs from the web and use your model to predict the traffic sign type.
#
# You may find `signnames.csv` useful as it contains mappings from the class id (integer) to the actual sign name.
# ### Load and Output the Images
with tf.Session() as sess:
model.saver.restore(sess, os.path.join(OUTPUT_PATH, model_name))
y_pred = model.predict(X_test_preprocessed, X_test_preprocessed.shape[0])
test_accuracy = sum(y_test == y_pred)/len(y_test)
print("Test Accuracy = {:.1f}%".format(test_accuracy*100))
# +
# %matplotlib inline
from sklearn.metrics import confusion_matrix
import pandas as pd
import seaborn as sns
cm =confusion_matrix(y_test, y_pred)
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
cm_df = pd.DataFrame(cm, labels, labels)
plt.figure(figsize=(50, 50))
sns.heatmap(cm_df, annot=True)
# -
# ### Predict the Sign Type for Each Image
# +
test_imgs = []
for i in range(1, 6):
img = cv2.imread(os.path.join(DATA_PATH, "test{}.jpg".format(i)))
img = cv2.resize(img, (32,32))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
test_imgs.append(img)
label_idx = [8, 14, 5, 13, 31]
plt.figure(figsize=(20, 20))
for i in range(5):
plt.subplot(2, 5, i+1)
plt.imshow(test_imgs[i])
plt.xlabel(labels[label_idx[i]])
plt.xticks([])
plt.yticks([])
plt.tight_layout(pad=0, h_pad=0, w_pad=0)
plt.show()
test_img_preprocessed = preprocess(np.asarray(test_imgs), in_channel=IN_CHANNEL)
# -
# ### Analyze Performance
# +
def predict_model(data, top_k=5):
num_examples = len(data)
y_pred = np.zeros((num_examples, top_k), dtype=np.int32)
y_prob = np.zeros((num_examples, top_k))
with tf.Session() as sess:
model.saver.restore(sess, os.path.join(OUTPUT_PATH, model_name))
y_prob, y_pred = sess.run(tf.nn.top_k(tf.nn.softmax(model.logits), k=top_k),
feed_dict={model.x:data, model.keep_prob:1, model.keep_prob_conv:1, model.is_training : False})
return y_prob, y_pred
y_prob, y_pred = predict_model(test_img_preprocessed)
test_accuracy = 0
for i in enumerate(test_img_preprocessed):
accu = label_idx[i[0]] == np.asarray(y_pred[i[0]])[0]
if accu == True:
test_accuracy += 0.2
print("New Images Test Accuracy = {:.1f}%".format(test_accuracy*100))
plt.figure(figsize=(20, 20))
for i in range(5):
plt.subplot(5, 2, 2*i+1)
plt.imshow(test_imgs[i])
plt.title("predicted_label:" + labels[y_pred[i][0]])
plt.axis('off')
plt.subplot(5, 2, 2*i+2)
plt.barh(np.arange(1, 6, 1), y_prob[i, :])
fig_labels = [labels[j] for j in y_pred[i]]
plt.yticks(np.arange(1, 6, 1), fig_labels)
plt.show()
| notebooks/Traffic_Sign_Classifier.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from scipy.stats import linregress
import matplotlib.pyplot as plt
import os
import glob
# +
def random_floats(low, high, size):
return [np.random.uniform(low, high) for _ in range(size)]
size = 10000
X = random_floats(0, 1, size)
nu_list = []
[nu_list.append(np.log(0.65)) if i<=0.017 else nu_list.append(0) for i in X]
nu = np.array(nu_list).reshape(-1,1)
ep = np.random.normal(0, 1, size).reshape(-1,1)
log_g = 0.02+0.02*ep+nu
g = np.exp(log_g)
g_list = g.tolist
#Part 1: Hansen–Jagannathan Bound
M_list = []
gamma_list = []
for i in np.arange(1,4,0.02):
M = 0.99*g**-i
M_list.append(M)
gamma_list.append(i)
M = np.array(M_list)
gamma = np.array(gamma_list)
#print(g)
#print(M_list)
#print(M)
#print(np.std(M, axis = 1, ddof = 1))
#print(np.mean(M, axis = 1))
SD_over_mean = np.std(M, axis = 1, ddof = 1)/np.mean(M, axis = 1)
#print(SD_over_mean.T)
#print(gamma)
df= pd.concat([pd.DataFrame(gamma),pd.DataFrame(SD_over_mean)], axis=1)
df.columns= "Gamma","SD(M)/E(M)"
df.to_excel('Gamma_SD_M.xlsx')
plt.scatter(gamma , SD_over_mean.T, s=np.pi*3, alpha=0.5)
# +
#Part 2: Price-Dividend Ratio
M_list2 = []
gamma_list2 = []
for i in np.arange(1,7,0.05):
M2 = 0.99*g**(1-i)
M_list2.append(M2)
gamma_list2.append(i)
#print(M_list2)
#print(gamma_list2)
P1_D = np.mean(np.array(M_list2), axis = 1)
plt.scatter(gamma_list2 ,P1_D, s=np.pi*3, alpha=0.5)
# +
#Part 3: Equity Premium
M_list3 = []
gamma_list3 = []
for i in np.arange(1,7,0.05):
M3 = (0.99*g**(-i))
M_list3.append(M3)
gamma_list3.append(i)
M3 = np.array(M_list3)
Rf = 1/(np.mean(M3, axis = 1))
Rm = np.reciprocal(P1_D)*g.mean()
equity_premium = Rm-Rf
plt.scatter(gamma_list3 ,equity_premium, s=np.pi*3, alpha=0.5)
# -
| Multi-Period Asset Pricing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.9.1 64-bit
# name: python391jvsc74a57bd05271bdc391cb7228ab6e6395e7c6cdc955f1980bb74892059d6755de2b4edae4
# ---
import requests #-> Để gọi API
import re #-> Để xử lý data dạng string
from datetime import datetime as dt #-> Để xử lý data dạng datetime
import gspread #-> Để update data lên Google Spreadsheet
from gspread_dataframe import set_with_dataframe #-> Để update data lên Google Spreadsheet
import pandas as pd #-> Để update data dạng bản
import json
from oauth2client.service_account import ServiceAccountCredentials #-> Để nhập Google Spreadsheet Credentials
import os
with open('..\env_variable.json', 'r') as j:
json_data = json.load(j)
#print(json_data)
## Load SLACK_BEARER_TOKEN
os.environ['SLACK_BEARER_TOKEN'] = json_data['SLACK_BEARER_TOKEN']
# ## 1. Slack API: User List
# Assignment này sẽ dùng Slack API để lấy thông tin về Learners và theo dõi các bài tập đã nộp và được review (sau đó cập nhật lên Google Spreadsheet)
# + tags=[]
## Gọi API từ Endpoints (Input - Token được đưa vào Headers)
endpoint = "https://slack.com/api/users.list"
headers = {"Authorization": "Bearer {}".format(os.environ['SLACK_BEARER_TOKEN'])}
response_json = requests.post(endpoint, headers=headers).json()
user_dat = response_json['members']
# -
## Challenge: Thử gọi API này bằng Postman
from IPython.display import Image
Image('..\img\Capture.JPG')
# # TODO #1
# +
## Loop qua JSON file và extract các thông tin quan trọng (id, name, display_name, real_name_normalized, title, phone, is_bot)
## Hint: Bạn có thể dùng Postman hoặc in user_dat JSON để xem cấu trúc (schema), dùng Ctrl+F để tìm các keys (id, name, display_name, real_name_normalized, title, phone, is_bot)
user_dict = {'user_id':[], 'name':[], 'display_name':[],'real_name':[],'title':[],'phone':[],'is_bot':[]}
for i in range(len(user_dat)):
user_dict['user_id'].append(user_dat[i]['id'])
user_dict['name'].append(user_dat[i]['name'])
user_dict['display_name'].append(user_dat[i]['profile']['display_name'])
user_dict['real_name'].append(user_dat[i]['profile']['real_name_normalized'])
user_dict['title'].append(user_dat[i]['profile']['title'])
user_dict['phone'].append(user_dat[i]['profile']['phone'])
user_dict['is_bot'].append(user_dat[i]['is_bot'])
# -
user_df = pd.DataFrame(user_dict) ## Dùng pandas để convert dictionaries thành bảng
user_df.head(5) ## Chỉ in 5 dòng đầu (chủ yếu để xem cấu trúc)
user_df[user_df.name == 'ngochant'] ## Lọc thông tin của mình
# ## OPTIONAL 1: Update data => Google SpreadSheet
# # TODO #2
## Authorize bằng JSON
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(
'GG API.json', scope)
gc = gspread.authorize(credentials)
print("DONE!")
# ACCES GOOGLE SHEET
sheet_index_no = 0
spreadsheet_key = '<KEY>' # input SPREADSHEET_KEY HERE
sh = gc.open_by_key(spreadsheet_key)
worksheet = sh.get_worksheet(sheet_index_no) #-> 0 - first sheet, 1 - second sheet etc.
# APPEND DATA TO SHEET
set_with_dataframe(worksheet, user_df) #-> Upload user_df vào Sheet đầu tiên trong Spreadsheet
# #### LINK: https://docs.google.com/spreadsheets/d/1jmy1jSgzq4gO-P5bKNRdlrVGXcCkdhkhM68aWAKJ9EQ/edit#gid=0
# ## Option 2: Ai đã nộp bài?
# ## Slack API: Channel List
## Gọi SLACK API để list tất cả các channel
endpoint = "https://slack.com/api/conversations.list"
headers = {"Authorization": "Bearer {}".format(os.environ['SLACK_BEARER_TOKEN'])}
response = requests.post(endpoint, headers=headers).json()
channel_ls = response['channels']
# +
channel_ls[0] ## Thử extract record đầu tiên để xem schema => name: general, id: C01B4PVGLVB
# -
# # TODO #3
# Tìm id của channel #atom-assignment2
# +
#Tìm id của channel #atom-assignment2
for i in channel_ls:
if i['name'] == 'atom-assignment2':
atom_assignment2_id = i['id']
print(atom_assignment2_id)
# -
# ## Slack API: List messages trong 1 channel
endpoint = "https://slack.com/api/conversations.history"
data = {"channel": "C021FSDN7LJ"} ## This is ID of assignment#1 channel
headers = {"Authorization": "Bearer {}".format(os.environ['SLACK_BEARER_TOKEN'])}
response_json = requests.post(endpoint, data=data, headers=headers).json()
msg_ls = response_json['messages']
# + tags=[]
msg_ls[20].keys()
# -
range(len(msg_ls))
msg_ls[9]
# # TODO #4
# Tạo thành 1 bảng chứa các thông tin về assignment 2 và update lên Spreadsheet (Sheet: Assignment#2 Submission)
# + tags=[]
## Summarize all submitted assignments + reviews cnt
not_learners_id = ['U01BE2PR6LU'] # -> Remove MA from the user_id
msg_dict = {'ts':[], 'user':[], 'reply_count': [], 'reply_users_count': [], 'reply_users': [], 'latest_reply':[], 'github': [] }
for i in range(len(msg_ls)):
if msg_ls[i]['user'] not in not_learners_id:
ts = dt.fromtimestamp(float(msg_ls[i]['ts']))
msg_dict['ts'].append(ts)
user = msg_ls[i]['user'] # -> Lấy thông tin người post messages
msg_dict['user'].append(user)
#print(msg_ls[i].keys())
text = msg_ls[i]['text']
github_link = re.findall('(?:https?://)?(?:www[.])?github[.]com/[\w-]+/?', text) #-> Submission là các message có link github
# print(msg_ls[i])
if len(github_link) > 0: msg_dict['github'].append(github_link[0])
else: msg_dict['github'].append('NA')
if 'reply_count' in msg_ls[i].keys(): msg_dict['reply_count'].append(msg_ls[i]['reply_count']) #-> Extract số review
else: msg_dict['reply_count'].append('NA')
if 'reply_users_count' in msg_ls[i].keys(): msg_dict['reply_users_count'].append(msg_ls[i]['reply_users_count'])
else: msg_dict['reply_users_count'].append('NA')
if 'reply_users' in msg_ls[i].keys(): msg_dict['reply_users'].append(msg_ls[i]['reply_users'])
else: msg_dict['reply_users'].append('NA')
if 'latest_reply' in msg_ls[i].keys(): msg_dict['latest_reply'].append(dt.fromtimestamp(float(msg_ls[i]['latest_reply'])))
else: msg_dict['latest_reply'].append('NA')
msg_df = pd.DataFrame(msg_dict)
msg_df.head(10)
# -
# ACCES GOOGLE SHEET
sheet_index_no1 = 1
spreadsheet_key = '<KEY>'
sh1 = gc.open_by_key(spreadsheet_key)
worksheet1 = sh1.get_worksheet(sheet_index_no1) #-> 0 - first sheet, 1 - second sheet
# APPEND DATA TO SHEET
set_with_dataframe(worksheet1,msg_df)
# #### Link: https://docs.google.com/spreadsheets/d/1jmy1jSgzq4gO-P5bKNRdlrVGXcCkdhkhM68aWAKJ9EQ/edit#gid=1885685702
| assignment_3/assignment_3_ngocha-new.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="RfX9oxjYML-a"
#usa chaves tambem porem nao temos pares e sim chaves
# + id="AMvZombTMtNK"
primeiro_conjunto = {2,4,6,8,10}
# + id="rBfmbZNhMtWO" outputId="815b7cef-9e6d-43ca-ca36-a7ff057a8229" colab={"base_uri": "https://localhost:8080/", "height": 34}
#Não mantém a ordem -- Conjunto não é um objeto ordenado
print(primeiro_conjunto)
# + id="em8e6_UNMtcA" outputId="ff3d0e5f-c873-4938-8ba8-5e0222cb060d" colab={"base_uri": "https://localhost:8080/", "height": 34}
type(primeiro_conjunto)
# + id="eljMrvmhMtjN" outputId="b70a12f9-f116-4fdf-df64-ddcdcbf44be9" colab={"base_uri": "https://localhost:8080/", "height": 34}
len(primeiro_conjunto)
# + id="sNYm20JUMtpM" outputId="5d6783bf-e3da-4484-e4bb-5b7cfee16939" colab={"base_uri": "https://localhost:8080/", "height": 69}
#Função set, conjuntos não permitem elementos repetidos
lista = [1,2,5,6,6,7,8,8,9,11]
print(len(lista))
print(set(lista))
print(len(set(lista)))
# + id="Sm6xIrBqOMLq"
#podemos criar conjuntos vazios
conj_vazio = set()
| Conjuntos.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import wnbl
import pandas as pd
# +
# The round is just a filter. URL load whole fixture.abs
# current round (5)
url = "https://hosted.wh.geniussports.com/embednf/WNBL/en/schedule?&iurl=https%3A%2F%2Fwnbl.basketball%2Fstats%2F&_nv=1&_mf=1"
# previous round (4) - use this, round = range 1:5
url = "https://hosted.wh.geniussports.com/embednf/WNBL/en/schedule?phaseName=Regular+Season&poolNumber=0&matchType=REGULAR&roundNumber={ROUND}&&iurl=https%3A%2F%2Fwnbl.basketball%2Fstats%2F&_nv=1&_mf=1"
# +
tmp = url.replace('{ROUND}','4')
soup = wnbl.get_soup(url)
# -
fixture_html = soup.find('div', { 'class':'fixture-wrap'}).find_all('div',{'class':'match-wrap'})
len(fixture_html)
# +
games = []
for game in fixture_html:
g_id = game.attrs['id'].replace('extfix_','')
g_timestamp = game.find('div', {'class':'match-time'}).find('span').text
g_venue = game.find('div', {'class':'match-venue'}).find('a').text
g_home_team = game.find('div', {'class':'home-team'}).find('div',{'class':'team-name'}).find('a').text.replace('\n','')
g_home_score = game.find('div', {'class':'home-team'}).find('div',{'class':'team-score'}).find('div',{'class':'fake-cell'}).text
g_away_team = game.find('div', {'class':'away-team'}).find('div',{'class':'team-name'}).find('a').text
g_away_score = game.find('div', {'class':'away-team'}).find('div',{'class':'team-score'}).find('div',{'class':'fake-cell'}).text
result = [g_id,g_timestamp,g_venue,g_home_team,g_home_score,g_away_team,g_away_score]
games.append(result)
labels = ['id','timestamp','venue','home_team','home_score','away_team','away_score']
games_df = pd.DataFrame.from_records(games,columns=labels)
games_df.head()
# -
games_df.to_csv('results2020.csv',index=False)
| scripts/schedule.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Evaluation
#
# +
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['figure.figsize'] = [10, 5]
# -
# # Continual Learning Metrics
# +
# Because of a mistake in my implementation
# ["no_of_test"] cannot be used but it can be calculated by ["no_of_correct_prediction"]/["accuracy"]
# but it cannot be calculated when ["accuracy"] == 0
# ((raw["no_of_correct_prediction"]/ raw["accuracy"]).apply(np.ceil))
# the mistake have been fixed now but the data have not updated
def calculateContinualMetircs(raw):
task_order = raw["task_order"].unique()
method = raw["method"].unique()
print(task_order, method)
all_MBase = {k:[] for k in method}
all_Mnew = {k:[] for k in method}
all_Mnow = {k:[] for k in method}
for t in task_order:
rows = raw[raw["task_order"]==t]
offline = rows[rows["method"]=="offline"]
for m in method:
if m=="offline":
continue
target = rows[rows["method"]==m]
# calculate m_base
_ideal = offline[offline["task_index"]==1]["accuracy"]
_m = target[target["task_index"]==1][["accuracy", "no_of_test", "no_of_correct_prediction"]]
_N = len(_m)
_m = (_m["accuracy"]/float(_ideal)).sum()
Mbase = float(_m/_N)
all_MBase[m].append(Mbase)
_sum = 0.0
train_session = target["train_session"].unique()
for s in train_session:
s = int(s)
_ideal = offline[offline["task_index"]==s]["accuracy"]
_m = target[target["train_session"]==str(s)]
_m = _m[_m["task_index"]==s]["accuracy"]
assert len(_m)==1
_sum += float(_m)/float(_ideal)
Mnew = _sum/len(train_session)
all_Mnew[m].append(Mnew)
_sum = 0.0
task_index = target["task_index"].unique()
_m = target[target["train_session"]==str(len(task_index))]
for t in task_index:
t = int(t)
_ideal = offline[offline["task_index"]==t]["accuracy"]
_m1 = _m[_m["task_index"]==t]["accuracy"]
assert len(_m1)==1
_sum += float(_m1)/float(_ideal)
Mnow = _sum/len(train_session)
all_Mnow[m].append(Mnow)
return all_MBase, all_Mnew, all_Mnow
# +
from scipy import stats
def printCLMetrics(all_MBase, all_Mnew, all_Mnow):
def p(metric, name):
print("Metric: ", name)
for m in metric:
avg = np.mean(metric[m])
err = stats.sem(metric[m])
print("{0} {1:.3f} {2:.3f}".format(m, avg, err))
print("=====================")
print("")
p(all_MBase, "M base")
p(all_Mnew, "M new")
p(all_Mnow, "M now")
# +
# Result from newsrc/result_iter1000-1000_h500-100_all/
folder = "newsrc/result_iter1000-1000_h500-100_all/"
raw = pd.read_csv(folder+"results.txt")
raw.columns = [c.strip() for c in raw.columns]
raw.head()
b, n, nw = calculateContinualMetircs(raw)
print("")
printCLMetrics(b, n, nw)
# +
# Result from newsrc/result_iter1000-1000_h500-100_all/
folder = "../Results/run_offline_acc/"
raw = pd.read_csv(folder+"results.txt")
raw.columns = [c.strip() for c in raw.columns]
fto = open(folder+"task_orders.txt")
task_orders = [line.strip().split(";") for line in fto]
def offlineAccuracy(raw, task_orders):
acc = {k:[] for k in task_orders[0]}
for i, order in enumerate(task_orders):
m = raw[raw["task_order"]==i]
for k, row in m.iterrows():
c = order[row["task_index"]-1]
acc[c].append(row["accuracy"])
for m in acc:
avg = np.mean(acc[m])
err = stats.sem(acc[m])
print("{0} {1:.3f} {2:.3f}".format(m, avg, err))
offlineAccuracy(raw, task_orders)
# print()
# +
# Result from newsrc/result_iter1000-1000_h500-100_all/
folder = "newsrc/result_iter5000-1000_h500-100_all/"
raw = pd.read_csv(folder+"results.txt")
raw.columns = [c.strip() for c in raw.columns]
raw.head()
b, n, nw = calculateContinualMetircs(raw)
print("")
printCLMetrics(b, n, nw)
# -
# # GAN Metrics
print("Model size")
{'mp-gan': [1490061], 'mp-wgan': [1490061], 'sg-cgan': [151010], 'sg-cwgan': [151010]}
# +
from scipy import stats
def calculateGANMetircs(raw_gan, raw_solver):
task_order = raw_gan["task_order"].unique()
method = raw_gan["method"].unique()
print(task_order, method)
is_score = {k:[] for k in method}
# is_err = {k:[] for k in method}
mmd_score = {k:[] for k in method}
knn_acc = {k:[] for k in method}
knn_TPR = {k:[] for k in method}
knn_TNR = {k:[] for k in method}
offline_acc = {k:[] for k in method}
training_time = {k:[] for k in method}
for t in task_order:
rows = raw_gan[raw_gan["task_order"]==t]
for m in method:
_m = rows[rows["method"]==m]
_n = raw_solver[raw_solver["task_order"]==t]
_n = pd.to_numeric(_n[_n["method"]==m]["generator_training_time"]).sum()
is_score[m].append(float(_m["is"]))
mmd_score[m].append(float(_m["mmd"]))
knn_acc[m].append(float(_m["knn_tp"]+_m["knn_tn"])/float(_m["knn_tp"]+_m["knn_tn"]+_m["knn_fp"]+_m["knn_fn"]))
knn_TPR[m].append(float(_m["knn_tp"])/float(_m["knn_tp"]+_m["knn_fn"]))
knn_TNR[m].append(float(_m["knn_tn"])/float(_m["knn_tn"]+_m["knn_fp"]))
offline_acc[m].append(float(_m["offline_acc_fake"]))
training_time[m].append(_n)
return is_score, mmd_score, knn_acc, knn_TPR, knn_TNR, offline_acc, training_time
def printGANMetrics(metrics):
names = ["IS Score", "MMD", "1-NN Acc", "1-NN TPR", "1-NN TNR", "Offline Acc", "Training Time"]
# for i, metric in enumerate(metrics):
# print("Metric", names[i])
# for m in metric:
# avg = np.mean(metric[m])
# err = stats.sem(metric[m])
# print("{0} {1:.3f} {2:.3f}".format(m, avg, err))
# print("===================")
for m in metric[0]:
# for i, n in enumerate(names):
# metric = metrics[i]
# +
folder = "newsrc/result_iter1000-1000_h500-100_all/"
raw_gan = pd.read_csv(folder+"gan_score.txt")
raw_gan.columns = [c.strip() for c in raw_gan.columns]
raw_solver = pd.read_csv(folder+"results.txt")
raw_solver.columns = [c.strip() for c in raw_solver.columns]
m = calculateGANMetircs(raw_gan, raw_solver)
def printGANMetrics(metrics):
names = ["IS Score", "MMD", "1-NN Acc", "1-NN TPR", "1-NN TNR", "Offline Acc", "Training Time"]
# for i, metric in enumerate(metrics):
# print("Metric", names[i])
# for m in metric:
# avg = np.mean(metric[m])
# err = stats.sem(metric[m])
# print("{0} {1:.3f} {2:.3f}".format(m, avg, err))
# print("===================")
for m in metrics[0]:
print(m)
for i, n in enumerate(names):
metric = metrics[i]
avg = np.mean(metric[m])
err = stats.sem(metric[m])
print("{0} {1:.3f} {2:.3f}".format(n, avg, err))
print("===================")
printGANMetrics(m)
# +
folder = "newsrc/result_iter5000-1000_h500-100_all/"
raw_gan = pd.read_csv(folder+"gan_score.txt")
raw_gan.columns = [c.strip() for c in raw_gan.columns]
raw_solver = pd.read_csv(folder+"results.txt")
raw_solver.columns = [c.strip() for c in raw_solver.columns]
m = calculateGANMetircs(raw_gan, raw_solver)
printGANMetrics(m)
# -
| Reports/v0/Evaluation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# After finishing building spe dataset, next step is building a dataset for bulk measurements.
# +
import numpy as np
import pandas as pd
import glob
import matplotlib.pyplot as plt
#plt.style.use('ggplot')
plt.style.use('seaborn-colorblind')
plt.rcParams['figure.dpi'] = 300
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['savefig.bbox'] = 'tight'
# %matplotlib inline
import datetime
date = datetime.datetime.now().strftime('%Y%m%d')
# -
# # Read the bulk measurements
glob.glob('data/Bulk chem/*')
# +
bulk_df = pd.DataFrame()
for core in glob.glob('data/Bulk chem/*'):
X = pd.read_excel(core, sheet_name = 1, usecols = ['mid depth(cm)', 'TC%', 'TOC%', 'CaCO3%'])
X['core'] = [core.split('/')[-1][:-10] for _ in X.index]
bulk_df = pd.concat([bulk_df, X], axis = 0, join = 'outer')
bulk_df
# -
#bulk_df['mid_depth_mm'] = bulk_df['mid depth(cm)'] * 10
#bulk_df.drop('mid depth(cm)', axis = 1, inplace = True)
bulk_df = bulk_df.astype({'mid_depth_mm': 'int'})
bulk_df
# ## Export dataset
bulk_df = bulk_df.reset_index(drop = True)
bulk_df.to_csv('data/bulk_dataset_{}.csv'.format(date))
# # Merge spe and bulk datasets
spe_df = pd.read_csv('data/spe_dataset_20201007.csv', index_col = 0)
# +
mask_c = spe_df.columns[:2048] # only the channels
merge_df = pd.DataFrame()
for index, row in bulk_df.iterrows():
mid = row['mid_depth_mm']
core = row['core']
# get the spe in 10 mm interval
mask_r = (spe_df.composite_depth_mm >= (mid-5)) & (spe_df.composite_depth_mm <= (mid+5)) & (spe_df.core == core)
merge_df = pd.concat(
[merge_df, spe_df.loc[mask_r, mask_c].apply(np.mean, axis = 0).append(row)],
axis = 1
)
merge_df = merge_df.T.reset_index(drop = True)
# -
merge_df
merge_df[merge_df.isnull().any(axis = 1)]
np.unique(merge_df.loc[merge_df.isnull().any(axis = 1), 'core'])
spe_df[spe_df.core == 'SO264-55-1'].to_csv('results/check.csv')
# Hmm...It's weird. After checking the spe files, I found:<br>
# SO264-55-1: the scanning depth of the section Rescan00050 starts at 70.0 mm instead of 0.0 or 10.0 mm. JC confirmed that it's because before 70 mm, the sediments are too soft to be scanned. This cause the shift of the composite depth because the section depth were set to start at 0.<br>
# Since I found SO264-66-2 section also has this problem, I discuss with JC and decide to redo the workflow from the begining to simply sum up the section start depth and scanning depth to be the composite depth, like we did in the pilot_test.ipynb. Ignore the 0.0 or 10.0 mm problem because it's just 1 cm deviation at most.
| build_database_03.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/tqiaowen/LSTrAP-Lite/blob/master/test_new.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="LlZjZJWpqNYR" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 119} outputId="99b0b4be-0240-4e11-8c97-f534c7b996b4"
# !git clone https://github.com/tqiaowen/git_test.git
# + id="pgE0sBF-2T2Y" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="29d7bdf9-b2ff-43fb-a29b-28a9a32201a7"
# !ls
# %cd git_test
# + id="mdJjsnwJ2L7P" colab_type="code" colab={}
# !echo "hello" > hello.txt
# + id="OdhJhm-b2cyG" colab_type="code" colab={}
# !git add .
# + id="f3DfO3DgxJ-o" colab_type="code" colab={}
# !git config user.email "<EMAIL>"
# + id="GT8I1CjrxVmZ" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 68} outputId="417614ad-b6b2-467a-b27d-2c2ce919862e"
# !git commit -am "add hello.txt"
# + id="mHM7GPGn2zIp" colab_type="code" colab={}
# !git remote set-url origin <EMAIL>:tqiaowen/git_test.git
# + id="NUoGAqHAxi8Y" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 102} outputId="1838b1b1-50e8-40fe-da83-43696f4729c1"
# !git pull https://github.com/tqiaowen/git_test master
# + [markdown] id="36qqjVPy5sU5" colab_type="text"
# Checking for ssh issues.
# + id="Kb0OVVik4ibX" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 1000} outputId="a71f1d16-4769-4046-b04c-85fecf090450"
# !ssh git@github.com -vvvv
# + [markdown] id="PHPEMetm50p5" colab_type="text"
# Checking for ssh keys. None observed.
# + id="-HYW9UnP5U6Y" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 68} outputId="05d4dc27-30fd-4c67-ed2f-0ddd55283c6b"
# ls -al ~/.ssh
# + [markdown] id="zxwa3WQI55qS" colab_type="text"
# Creating new ssh key
# https://help.github.com/en/github/authenticating-to-github/checking-for-existing-ssh-keys
#
# https://help.github.com/en/github/authenticating-to-github/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent
# + id="C0F7P03_57Mn" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 357} outputId="4c080a2c-5b68-4969-90fc-b50d9fbae151"
# !ssh-keygen -t rsa -b 4096 -C "<EMAIL>"
# + [markdown] id="yL7-ouiJ6yaG" colab_type="text"
# Adding to key to ssh agent
# + id="aRAWXodB62D8" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="750c6b8a-7822-4c1e-8a35-21c860ade5b1"
# !eval "$(ssh-agent -s)"
# + id="PDRDe5Hv8BQf" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="863ddc6c-8fa7-41d3-f243-4e5984e9bed5"
# !ps aux | grep ssh
# + id="ltl4htE98E7X" colab_type="code" colab={}
# !kill 1122
# + id="SxWfsTon8OFZ" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="d3aef6b9-32ba-4a35-dc29-28548c221480"
# !eval `ssh-agent -s`
# + id="5Po3y_mE8UBA" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="4153f0f1-c03e-42d5-9d93-5f0d02e18c5c"
# !ls ~/.ssh/
# + id="voDrPiXE67Sw" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="4d676cdf-af06-43e8-c39b-7474fc93af84"
# !ssh-add /root/.ssh/id_rsa
# + id="lk1yH6-k0Q1u" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="cbda8272-9cbb-409a-c8c8-4eccb2fa09ea"
# !git remote -v
# !git remote set-url origin git@github.com:tqiaowen/git_test.git
# + id="up3mA7P-8sAU" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 102} outputId="0a8b4909-2f11-4d58-ac69-3ffd2eeca6ee"
# !git pull origin master
| test_new.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: PythonData
# language: python
# name: pythondata
# ---
from splinter import Browser
from bs4 import BeautifulSoup as soup
from webdriver_manager.chrome import ChromeDriverManager
# Set up Splinter
executable_path = {'executable_path': ChromeDriverManager().install()}
browser = Browser('chrome', **executable_path, headless=False)
# Visit the Quotes to Scrape site
url = 'http://quotes.toscrape.com/'
browser.visit(url)
# Parse the HTML
html = browser.html
html_soup = soup(html, 'html.parser')
# Scrape the Title
title = html_soup.find('h2').text
title
# +
# Scrape the top ten tags
tag_box = html_soup.find('div', class_='tags-box')
# tag_box
tags = tag_box.find_all('a', class_='tag')
for tag in tags:
word = tag.text
print(word)
# -
for x in range(1, 6):
html = browser.html
quote_soup = soup(html, 'html.parser')
quotes = quote_soup.find_all('span', class_='text')
for quote in quotes:
print('page:', x, '----------')
print(quote.text)
browser.links.find_by_partial_text('Next').click()
| Practice.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Testing extracting OSM data using Osmium
# +
import os, sys, time, importlib
import osmnx
import geopandas as gpd
import pandas as pd
import networkx as nx
import numpy as np
sys.path.append("../../../GOSTNets")
import GOSTnets as gn
# pip install osmium
import osmium, logging
import shapely.wkb as wkblib
from shapely.geometry import LineString, Point
import time
# -
# set file
some_file = './colombo.osm.pbf'
# ## simplest example of using Osmium
# +
class HotelHandler(osmium.SimpleHandler):
def __init__(self):
super(HotelHandler, self).__init__()
self.hotels = []
def node(self, o):
if o.tags.get('tourism') == 'hotel' and 'name' in o.tags:
self.hotels.append(o.tags['name'])
h = HotelHandler()
h.apply_file(some_file)
print(sorted(h.hotels))
# -
# ## Extracting highways with their nodes using Osmium
# +
start_time = time.time()
wkbfab = osmium.geom.WKBFactory()
# extract highways
class HighwayExtractor(osmium.SimpleHandler):
def __init__(self):
osmium.SimpleHandler.__init__(self)
#self.nodes = []
#self.raw_h = []
self.highways = []
self.broken_highways = []
#self.num_nodes = 0
#do not think that we need to extract nodes, because we can get the nodes from the ways
# this makes it more than two times faster
# def node(self, n):
# wkb = wkbfab.create_point(n)
# shp = wkblib.loads(wkb, hex = True)
# self.nodes.append([n.id, shp, shp.x, shp.y])
#self.num_nodes += 1
#self.nodes.append(shp)
def way(self, w):
#self.raw_h.append(w)
try:
nodes = [x.ref for x in w.nodes]
wkb = wkbfab.create_linestring(w)
shp = wkblib.loads(wkb, hex=True)
if 'highway' in w.tags:
info = [w.id, nodes, shp, w.tags['highway']]
self.highways.append(info)
except:
print('hit exception')
nodes = [x for x in w.nodes if x.location.valid()]
if len(nodes) > 1:
shp = LineString([Point(x.location.x, x.location.y) for x in nodes])
info = [w.id, nodes, shp, w.tags['highway']]
self.highways.append(info)
else:
self.broken_highways.append(w)
logging.warning("Error Processing OSM Way %s" % w.id)
h = HighwayExtractor()
h.apply_file(some_file, locations=True)
#print(len(h.nodes))
print(len(h.highways))
print(len(h.broken_highways))
end_time = time.time()
print(end_time - start_time)
# -
# ### results:
# Extracting just the highways with their nodes took about 44 seconds for Colombo, where as extracting the highway nodes and highways seperately took about 185 seconds.
h.highways
h.highways[1]
h.highways[2][2].length
list(h.highways[0][2].coords)
list(h.highways[2][2].coords)[1]
# ## Split up the highways into seperate edges between each node. At the same time create the node list from the highway edges.
# +
start_time = time.time()
all_nodes = []
all_edges = []
for x in h.highways:
for n_idx in range(0, (len(x[1]) - 1)):
try:
osm_id_from = x[1][n_idx].ref
except:
osm_id_from = x[1][n_idx]
try:
osm_id_to = x[1][n_idx+1].ref
except:
osm_id_to = x[1][n_idx+1]
try:
osm_coords_from = list(x[2].coords)[n_idx]
#print(osm_coords_from[0])
#create a node
all_nodes.append([osm_id_from, { 'x' : osm_coords_from[0], 'y' : osm_coords_from[1] }])
osm_coords_to = list(x[2].coords)[n_idx+1]
#print(n_idx)
#print(len(x[1]) - 1)
if n_idx == (len(x[1]) - 2):
#print('last element')
#print(osm_coords_to)
#create a node
all_nodes.append([osm_id_to, { 'x' : osm_coords_to[0], 'y' : osm_coords_to[1]} ])
edge = LineString([osm_coords_from, osm_coords_to])
attr = {'osm_id':x[0], 'Wkt':edge, 'length':edge.length, 'infra_type':x[3]}
#Create an edge from the list of nodes in both directions
all_edges.append([osm_id_from, osm_id_to, attr])
all_edges.append([osm_id_to, osm_id_from, attr])
except:
logging.warning(f"Error adding edge between nodes {osm_id_from} and {osm_id_to}")
end_time = time.time()
print(end_time - start_time)
# -
# ### results:
# Took about 23 seconds to run
all_nodes[:10]
all_edges[:5]
# +
start_time = time.time()
G = nx.MultiDiGraph()
G.add_nodes_from(all_nodes)
G.add_edges_from(all_edges)
end_time = time.time()
print(end_time - start_time)
# -
# ### results:
# Took about 2404 seconds to run
len(G.edges)
| Implementations/FY21/ACC_mapbox_traffic/testing_osmium2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# +
####### XXX
# Step 1: Sign up for a Google Earth Engine Account here:
# https://earthengine.google.com/signup/
# you will use this to authenticate your account with GEE to run the script and
# utilize GEE layers
# -
# get any missing modules
# ! pip install earthengine-api geemap
# +
# setup modules
import numpy as np
#import matplotlib.pyplot as pl
#import matplotlib as mpl
#import pandas as pd
import sys,os,os.path,tempfile
# spatial modules
try:
import google.colab
import geemap.foliumap as geemap # use folium instead so coloramps work on goolge collab
# https://geemap.org/notebooks/geemap_and_folium/
except:
# import geemap as geemap
import geemap.foliumap as geemap
import ee
import geemap.colormaps as cm
import warnings
warnings.filterwarnings('ignore') #don't display warnings
# +
## setup output. defined dir or system temp dir
data_dir=os.path.expanduser(os.path.join(tempfile.gettempdir(),'gee_output'))
if not os.path.exists(data_dir):
os.makedirs(data_dir)
print(" ")
print("****** GEE and script output folder ******")
print("****** Note: In Google Collab, use the dir navigation tool on the left of the screen ******")
print("****** Use the dir navigation to go up one level, then navigate to tmp/gee_output ******")
print(data_dir)
# +
##### initialize ee API - you need to authenticate with GEE and initialize
## Trigger the initialization flow. You only need to do this once while running notebook
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
## After inserting the API key initialize GEE
ee.Initialize()
# +
##### Get GEE datasets
### TIGER roads
roads = ee.FeatureCollection('TIGER/2016/Roads');
### Get Landsat 8 data - select scenes from a specific date range over Long Island
li_roi = ee.Geometry.Rectangle(-71.108102, 40.603476, -74.165714, 41.204794);
l8 = ee.ImageCollection('LANDSAT/LC08/C01/T1_8DAY_NDVI').filterDate('2018-07-01', '2018-09-10')\
.filterBounds(li_roi);
l8_ndvi = l8.select('NDVI');
# Maximum Value Composite
# https://developers.google.com/earth-engine/guides/ic_composite_mosaic
l8_maxval_ndvi_composite = l8_ndvi.max();
# +
#### Map Landsat 8 Maximum Value Composite with RGB UAS image
ndvi_palette = cm.get_palette('viridis', n_class=30)
ndviViz = {'min': 0.0, 'max': 1.0, 'palette': ndvi_palette, 'opacity': 1}
Map = geemap.Map(center=[40.816015,-73.035151], zoom=8)
Map.add_basemap('ROADMAP') # Add Google Map
Map.addLayer(l8_maxval_ndvi_composite, ndviViz, 'Landsat 8 NDVI');
Map.add_colorbar(colors=ndviViz['palette'], vmin=ndviViz['min'],
vmax=ndviViz['max'],
caption = "Landsat 8 NDVI (-)",
layer_name="Landsat 8 NDVI",
position="bottomright")
#Map.addLayer(roads, {}, 'Census roads');
Map
| python/basic_gee_example_1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python (pss)
# language: python
# name: pss
# ---
# # Simulation Class: Tutorial 6
#
# This notebook will demonstrate how to use the `Simulation` class of the pulsar signal simulator for more automated simulation of data. The `Simulation` class is designed as a convenience class within the `PsrSigSim`. Instead of instantiating each step of the simulation, the `Simulation` class allows the input of all desired variables for the simulation at once, and then will run all parts of the simulation. The `Simulation` class also allows for individual running of each step (e.g. `Signal`, `Pulsar`, etc.) if desired. Not all options available within the `Simulation` will be demonstrated in this notebook.
# +
# import some useful packages
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib inline
# import the pulsar signal simulator
import psrsigsim as pss
# -
# Instead of defining each variable individually, the simulation class gets instantiated all at once. This can be done either by defining each variable individually, or by passing a dictionary with all parameters defined to the simulator. The dictionary keys should be the same as the input flags for the `Simulation` class.
sim = pss.simulate.Simulation(
fcent = 430, # center frequency of observation, MHz
bandwidth = 100, # Bandwidth of observation, MHz
sample_rate = 1.0*2048*10**-6, # Sampling rate of the data, MHz
dtype = np.float32, # data type to write out the signal in
Npols = 1, # number of polarizations to simulate, only one available
Nchan = 64, # number of subbands for the observation
sublen = 2.0, # length of subintegration of signal
fold = True, # flag to produce fold-mode, subintegrated data
period = 1.0, # pulsar period in seconds
Smean = 1.0, # mean flux of the pulsar in Jy
profiles = [0.5, 0.05, 1.0], # Profile - may be a data array, list of Gaussian components, or profile class object
tobs = 4.0, # length of observation in seconds
name = 'J0000+0000', # name of the simulated pulsar
dm = 10.0, # dispersion measure in pc cm^-3
tau_d = None, # scattering timescale in seconds
tau_d_ref_f = None, # reference frequency of scattering timescale in seconds
aperture = 100.0, # telescope aperture in meters
area = 5500.0, # telescope area in meters square
Tsys = 35.0, # telescope system temperature
tscope_name = "TestScope", # telescope name (default GBT and Arecibo available)
system_name = "TestSys", # observing system name
rcvr_fcent = 430, # center frequency of the receiver in MHz
rcvr_bw = 100, # receiver bandwidth in MHz
rcvr_name ="TestRCVR", # name of receiver
backend_samprate = 1.5625, # bandend maximum sampling rate in MHz
backend_name = "TestBack", # bandend name
tempfile = None, # optional name of template fits file to simulate
psrdict = None, # optional dictionary to give for input parameters
)
# To give the `Simulation` class a dictionary of these parameters, the input may look something like below (Note - all parameters have the same units and names as above).
# +
pdict = {'fcent' : 430,
'bandwidth' : 100,
'sample_rate' : 1.0*2048*10**-6,
'dtype' : np.float32,
'Npols' : 1,
'Nchan' : 64,
'sublen' : 2.0,
'fold' : True,
'period' : 1.0,
'Smean' : 1.0,
'profiles' : [0.5, 0.05, 1.0],
'tobs' : 4.0,
'name' : 'J0000+0000',
'dm' : 10.0,
'tau_d' : None,
'tau_d_ref_f' : None,
'aperture' : 100.0,
'area' : 5500.0,
'Tsys' : 35.0,
'tscope_name' : "TestScope",
'system_name' : "TestSys",
'rcvr_fcent' : 430,
'rcvr_bw' : 100,
'rcvr_name' : "TestRCVR",
'backend_samprate' : 1.5625,
'backend_name' : "TestBack",
'tempfile' : None,
}
sim = pss.simulate.Simulation(psrdict = pdict)
# -
# ## Simulating the Data
#
# Once the `Simulation` class is initialized with all of the necessary parameters, there are two ways to run the simulation. The first is simply by running the `simulate()` function, which will fully simulate the the data from start to finish.
sim.simulate()
# If we want to look at the data that has been simulated, it can be accessed via `sim.signal.data`. The simulate class has attributes for each of the objects simulated (e.g. `signal`, `pulsar`, etc.) if the user would like to access those parameters. We will look at the simulated data and plot it below.
# We can look at the simulated profiles
plt.plot(np.linspace(0,1,2048), sim.profiles.profiles[0])
plt.xlabel("Phase")
plt.show()
plt.close()
# +
# Get the simulated data
sim_data = sim.signal.data
# Get the phases of the pulse
phases = np.linspace(0, sim.tobs/sim.period, len(sim_data[0,:]))
# Plot just the pulses in the first frequency channels
plt.plot(phases, sim_data[0,:], label = sim.signal.dat_freq[0])
plt.ylabel("Intensity")
plt.xlabel("Phase")
plt.legend(loc = 'best')
plt.show()
plt.close()
# Make the 2-D plot of intensity v. frequency and pulse phase. You can see the slight dispersive sweep here.
plt.imshow(sim_data, aspect = 'auto', interpolation='nearest', origin = 'lower', \
extent = [min(phases), max(phases), sim.signal.dat_freq[0].value, sim.signal.dat_freq[-1].value])
plt.ylabel("Frequency [MHz]")
plt.xlabel("Phase")
plt.colorbar(label = "Intensity")
plt.show()
plt.close()
# -
# ### A second way to simulate
#
# The second way to run these simulations is by initializing all of the different objects separately, instead of through the simulation class. This allows slightly more freedom, as well as modifications to the initially input simulated parameters.
# We start by initializing the signal
sim.init_signal()
# Initialize the profile
sim.init_profile()
# Now the pulsar
sim.init_pulsar()
# Now the ISM
sim.init_ism()
# Now make the pulses
sim.pulsar.make_pulses(sim.signal, tobs = sim.tobs)
# disperse the simulated pulses
sim.ism.disperse(sim.signal, sim.dm)
# Now add the telescope and radiometer noise
sim.init_telescope()
# add radiometer noise
out_array = sim.tscope.observe(sim.signal, sim.pulsar, system=sim.system_name, noise=True)
# If we plot the results here we find that they are identical within the error of the simulated noise to what we have above.
# +
# We can look at the simulated profiles
plt.plot(np.linspace(0,1,2048), sim.profiles.profiles[0])
plt.xlabel("Phase")
plt.show()
plt.close()
# Get the simulated data
sim_data = sim.signal.data
# Get the phases of the pulse
phases = np.linspace(0, sim.tobs/sim.period, len(sim_data[0,:]))
# Plot just the pulses in the first frequency channels
plt.plot(phases, sim_data[0,:], label = sim.signal.dat_freq[0])
plt.ylabel("Intensity")
plt.xlabel("Phase")
plt.legend(loc = 'best')
plt.show()
plt.close()
# Make the 2-D plot of intensity v. frequency and pulse phase. You can see the slight dispersive sweep here.
plt.imshow(sim_data, aspect = 'auto', interpolation='nearest', origin = 'lower', \
extent = [min(phases), max(phases), sim.signal.dat_freq[0].value, sim.signal.dat_freq[-1].value])
plt.ylabel("Frequency [MHz]")
plt.xlabel("Phase")
plt.colorbar(label = "Intensity")
plt.show()
plt.close()
# -
# ### Note about randomly generated pulses and noise
#
# `PsrSigSim` uses `numpy.random` under the hood in order to generate the radio pulses and various types of noise. If a user desires or requires that this randomly generated data is reproducible we recommend using a call the seed generator native to `Numpy` before calling the function that produces the random noise/pulses. Newer versions of `Numpy` are moving toward slightly different [functionality/syntax](https://numpy.org/doc/stable/reference/random/index.html), but is essentially used in the same way.
# ```
# numpy.random.seed(1776)
# sim.pulsar.make_pulses(sim.signal, tobs = sim.tobs)
#
# ```
| docs/_static/notebooks/simulate_tutorial.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# +
def printme( str ):
#This is a print fumction
print (str);
return;
printme("I'm first call to user defined function!");
printme("Again second call to the same function");
# -
def changeme( mylist ):
| Jupyter_Notebook/Chinenye Ajah Jupyter notebook 3rd February 2022/Untitled.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: test-thesis
# language: python
# name: test-thesis
# ---
# + pycharm={"name": "#%%\n"}
import glob
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
metrics = ['f1_cd','f1_ln']
mappings = ['incremental','procrustes','twec']
w2vec_algorithms = ['word2vec','lda2vec']
embeddings = ['pretrained','None']
results_path = './output/**/**/results'
results_df = pd.DataFrame()
# retrieve results from pickle files
path = '../output/**/**/results'
text_files = set(glob.glob(path + "/**/*.pkl", recursive=True))
for file in text_files:
results_df = pd.concat([results_df, pd.read_pickle(file)], ignore_index=True, axis=0)
# save to csv
results_df.to_csv('../language_drift_results', index=False)
results_df = pd.read_csv('../language_drift_results')
# remove unnecessary columns
results_df = results_df.drop(['precision_cd','precision_ln','accuracy_cd','accuracy_ln',
'recall_cd','recall_ln','data_set_id','dim','window_size','t'],axis=1)
print(results_df.head())
# + [markdown] pycharm={"name": "#%% md\n"}
# ## Research Questions
# ### 1. Which vectors' alignment method performs better?
#
# ### Null Hypothesis:
# Αll mapping methods we investigate(‘procrustes’, ‘incremental’, ‘twec’) perform equally across different executions on the same datasets and parameters.
#
# + pycharm={"name": "#%%\n"}
# deep copy
mapping_df = results_df.copy(deep=True)
# remove "lda2vec": there are no execution with all alignment methods, only procrustes
# remove "pretrained": there are no executions with pretrained embeddings and "TWEC" method
mapping_df = mapping_df.drop(mapping_df[((mapping_df['pretrained'] != 'None')
| (mapping_df['w2vec_algorithm'] == 'lda2vec'))].index)
# remove pretrained column
mapping_df = mapping_df.drop(['pretrained'],axis=1)
mapping_df = mapping_df.melt(id_vars=["language", "w2vec_algorithm","mapping"],
var_name="metric",
value_name="f1_score")
# remove rows with Nan values at f1_scores
mapping_df = mapping_df[mapping_df['f1_score'].notna()]
# remove unnecessary columns
mapping_df = mapping_df.drop('metric',axis=1)
print(mapping_df.count(),"\n")
print(mapping_df.head())
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 1.1 Shapiro-Wilk Test (checks normality of distribution)
# + pycharm={"name": "#%%\n"}
# Shapiro-Wilk test
from collections import defaultdict
from scipy import stats
alpha =0.05
print("Shapiro-Wilk test for normal distribution: \n")
mapping_normality_dict = defaultdict()
for mapping in mappings:
stat, p = stats.shapiro( mapping_df.loc[mapping_df['mapping'] == str(mapping),'f1_score'])
print(mapping)
if p >= alpha:
print("\t has a normal distribution with pvalue = "+ str(p) + ", stat=",str(stat))
mapping_normality_dict[mapping] = True
else:
print("\t has NOT a normal distribution with pvalue = ", p, "stat=",stat)
mapping_normality_dict[mapping] = False
# + [markdown] pycharm={"name": "#%% md\n"}
# ### Normality Results
# **Incremental** and **twec** method can be described by the normal distribution.
#
# However since **procrustes** method does not meet the criteria of the normality <u>we have to go through with non parapetric tests.</u>
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 1.2 Kruskal Wallis Test(non parametric - normality is not a prerequisite)
# * Prerequisites (non normal distributions, more than two groups)
# * H0: Populations have same distributions
#
# + pycharm={"name": "#%%\n"}
# Compare groups of incremental, procrustes and twec
alpha =0.05
print("Kruskal Wallis H-test: ")
stat, p = stats.kruskal(
mapping_df.loc[mapping_df['mapping'] == 'incremental','f1_score'],
mapping_df.loc[mapping_df['mapping'] == 'procrustes','f1_score'],
mapping_df.loc[mapping_df['mapping'] == 'twec','f1_score'])
if p >= alpha:
print(" Same distributions (fail to reject H0) with pvalue = ",p, "stat=",stat)
else:
print(" Different distributions (reject H0) = ", p, "stat=",stat)
# + pycharm={"name": "#%%\n"}
### 1.3 Wilcoxon Signed-Rank Test (non parametric - normality is not a prerequisite)
* Prerequisites (non normal distributions, paired samples, two populations)
* Samples are **paired** since all variables except the under investigation variable are shared among the different populations
* H0: Populations have same distributions
# + pycharm={"name": "#%%\n"}
# Wilcoxon Signed-Rank Test (non parametric - normality is not a prerequisite)
# Compare groups of incremental, procrustes and twec
alpha =0.05
print("Wilcoxon Signed-Rank H-test: \n\n incremental-procrustes")
stat, p = stats.wilcoxon(
mapping_df.loc[mapping_df['mapping'] == 'incremental','f1_score'],
mapping_df.loc[mapping_df['mapping'] == 'procrustes','f1_score'])
if p < alpha:
print(" Null Hypothesis REJECTED with pvalue = ", p, "stat=",stat)
else:
print(" Null hypothesis was ACCEPTED with pvalue = ",p, "stat=",stat)
print("\n incremental-twec")
stat, p = stats.wilcoxon(
mapping_df.loc[mapping_df['mapping'] == 'incremental','f1_score'],
mapping_df.loc[mapping_df['mapping'] == 'twec','f1_score'])
if p < alpha:
print(" Null Hypothesis REJECTED with pvalue = ", p, "stat=",stat)
else:
print(" Null hypothesis was ACCEPTED with pvalue = ",p, "stat=",stat)
print("\n procrustes-twec")
stat, p = stats.wilcoxon(
mapping_df.loc[mapping_df['mapping'] == 'procrustes','f1_score'],
mapping_df.loc[mapping_df['mapping'] == 'twec','f1_score'])
if p < alpha:
print(" Null Hypothesis REJECTED with pvalue = ", p, "stat=",stat)
else:
print(" Null hypothesis was ACCEPTED with pvalue = ",p, "stat=",stat)
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 1.4 Results
# After the execution on the following combinations:
# - **cbow-sgns** (algorithm)
# - **incremental-procrustes-twec** (alignment)
# - **en-de-swe-lat** (languages)
# - **cd-ln** (metrics of cosine distance and local_neighborhood measure)
#
# On the following **Word2Vec** parameter setting:
# - **embeddings_dimension = 100**
# - **window_size = 10**
# - **min_count = 3** (number of occurences)
# - **s = 0.001** (threshold for configuring which higher-frequency words are randomly downsampled)
# - **k = 5** number of negative samples parameter
# - **epochs = 5**
#
# We investigated the f1_scores of **48** executions (algorithms * alignment * languages * metrics).
#
# The result was that **there are no significate differences between the embeddings' alignment methods we used**.
# + pycharm={"name": "#%%\n"}
sns.set()
fig, ax = plt.subplots(figsize=(12,8))
sns.boxplot( saturation=1, palette='BuGn',ax=ax, whis=[5, 95],x=mapping_df['mapping'],y=mapping_df['f1_score'])
# specify axis labels
plt.xlabel('', size=14, family='monospace')
plt.ylabel('', size=14, family='monospace')
plt.title('F1 Scores per Alignment Method')
plt.show()
# + [markdown] pycharm={"name": "#%% md\n"}
# ## Research Questions
# ### 2. Do pretrained embeddings improve performance?
#
# ### Null Hypothesis:
# Executions with pretrained embeddings perform equally with those that haven't been prior initialized.
#
#
# + pycharm={"name": "#%%\n"}
# deep copy
pretrained_df = results_df.copy(deep=True)
# remove executions without pretrained embeddings
pretrained_df = pretrained_df.drop(pretrained_df[((pretrained_df['mapping'] == 'twec')
| (pretrained_df['w2vec_algorithm'] == 'lda2vec'))].index)
# remove unnecessary columns
pretrained_df = pretrained_df.drop(['mapping'],axis=1)
pretrained_df = pretrained_df.melt(id_vars=["language", "w2vec_algorithm","pretrained"],
var_name="metric",
value_name="f1_score")
# remove rows with Nan values at f1_scores
pretrained_df = pretrained_df[pretrained_df['f1_score'].notna()]
# remove unnecessary columns
pretrained_df = pretrained_df.drop('metric',axis=1)
print(pretrained_df.count(),"\n")
print(pretrained_df.head())
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 2.1 Shapiro-Wilk Test (checks normality of distribution)
# + pycharm={"name": "#%%\n"}
# Shapiro-Wilk test
from collections import defaultdict
from scipy import stats
alpha =0.05
print("Shapiro-Wilk test for normal distribution: \n")
embedding_normality_dict = defaultdict()
for embedding in embeddings:
if embedding == 'None':
stat, p = stats.shapiro( pretrained_df.loc[pretrained_df['pretrained'] == 'None','f1_score'])
else:
stat, p = stats.shapiro( pretrained_df.loc[pretrained_df['pretrained'] != 'None','f1_score'])
print(embedding)
if p >= alpha:
print("\t has a normal distribution with pvalue = "+ str(p) + ", stat=",str(stat))
embedding_normality_dict[embedding] = True
else:
print("\t has NOT a normal distribution with pvalue = ", p, "stat=",stat)
embedding_normality_dict[embedding] = False
# + [markdown] pycharm={"name": "#%% md\n"}
# ### Normality Results
# Executions with usage of **Pretrained** embeddings and **Non Pretained** embeddings can be described by the normal distribution.
#
# The next step is to conduct a **paired-T test**.</u>
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 2.2 Paired T-Test (parametric - normality is a prerequisite)
# - Prerequisites:
#
# - normal distribution of dependent variable
# - continuous dependent variable
# - independent observations
# - same subject for each group
# - dependent variable does not contain outliers.
#
# - H0: means of the populations are equal to zero
# * H1: p1 is not equal to p2 || p1 – p2 is not equal to zero.
#
# **Samples are paired** since all variables except the under investigation variable are shared among the different populations
#
#
# + pycharm={"name": "#%%\n"}
# Ensure we don't have any outliers
# IQR
Q1 = np.percentile(pretrained_df.loc[(pretrained_df['pretrained'] != 'None'), ['f1_score']],
25,interpolation = 'midpoint')
Q3 = np.percentile(pretrained_df.loc[(pretrained_df['pretrained'] != 'None'), ['f1_score']],
75,interpolation = 'midpoint')
IQR = Q3 - Q1
# Above Upper bound
upper = pretrained_df['f1_score'] >= (Q3+1.5*IQR)
# Below Lower bound
lower = pretrained_df['f1_score'] <= (Q1-1.5*IQR)
if (upper == True).any():
upper_outliers = lower.loc[lower == True].index.tolist()
print("upper_outliers:",upper_outliers)
#print(np.where(upper))
elif (lower == True).any():
lower_outliers = lower.loc[lower == True].index.tolist()
print("lower_outliers:",lower_outliers)
#print(np.where(lower))
print(pretrained_df[pretrained_df.index.isin(lower_outliers)])
pretrained_df = pretrained_df.drop(pretrained_df[((pretrained_df['language'] == 'swe'))].index)
# + pycharm={"name": "#%%\n"}
# Paired T-Test (parametric - normality is not a prerequisite)
# Compare groups of incremental, procrustes and twec
alpha =0.05
print("Paired T-Test H-test: \n\n pretrained - NOT pretrained")
stat, p = stats.ttest_rel(
pretrained_df.loc[pretrained_df['pretrained'] != 'None','f1_score'],
pretrained_df.loc[pretrained_df['pretrained'] == 'None','f1_score'])
if p < alpha:
print(" Null Hypothesis REJECTED with pvalue = ", p, "stat=",stat)
else:
print(" Null hypothesis was ACCEPTED with pvalue = ",p, "stat=",stat)
# + pycharm={"name": "#%%\n"}
# check percentage of increase
none_mean = pretrained_df.loc[pretrained_df['pretrained'] == 'None'].mean()[0]
pretrained_mean = pretrained_df.loc[pretrained_df['pretrained'] != 'None'].mean()[0]
increase_percentage = str(round(((pretrained_mean-none_mean)/none_mean)*100))
print("Pretrained embeddings perform better with an increase of ", increase_percentage + '%')
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 2.3 Results
# After the execution on the following combinations:
# - **cbow-sgns** (algorithm)
# - **incremental-procrustes** (alignment)
# - **en-de-lat** (languages)
# - **cd-ln** (metrics of cosine distance and local_neighborhood measure)
# - **pretrained - not pretrained** (usage of pretrained embeddings)
#
# Half of the models' vector weights were prior initialized with pretrained embeddings e.g. glove.
#
# On the following **Word2Vec** parameter setting:
# - **embeddings_dimension = 100**
# - **window_size = 10**
# - **min_count = 3** (number of occurences)
# - **s = 0.001** (threshold for configuring which higher-frequency words are randomly downsampled)
# - **k = 5** number of negative samples parameter
# - **epochs = 5**
#
#
# We investigated the f1_scores of **48 executions** (algorithms * alignmen * languages * metrics).
#
# The result was that **there are significate differences** between the model which were prior initialized and those hadn't.
# + pycharm={"name": "#%%\n"}
sns.set()
fig, ax = plt.subplots(figsize=(12,8))
pretrained_df.loc[pretrained_df["pretrained"] != "None", "pretrained"] = "pretrained"
sns.boxplot( saturation=1, palette='BuGn',ax=ax, whis=[5, 95],x=pretrained_df['pretrained'],y=pretrained_df['f1_score'])
# specify axis labels
plt.xlabel('', size=14, family='monospace')
plt.ylabel('', size=14, family='monospace')
plt.title('F1 Scores per type of embeddings')
plt.show()
# + [markdown] pycharm={"name": "#%% md\n"}
# ## Research Questions
# ### 3. Lda2Vec and word2vec models performs the same?
#
# ### Null Hypothesis:
# Executions with lda2vec equally perform with those from a word2vec across different executions on the same datasets and parameters.
#
# + pycharm={"name": "#%%\n"}
# deep copy
model_df = results_df.copy(deep=True)
# remove word2vec "pretrained" executions
# since lda2vec does not contain exections with pretrained
model_df = model_df.drop(model_df[((model_df['pretrained'] != 'None') )].index)
# remove unnecessary columns
model_df = model_df.drop(['pretrained'],axis=1)
# 'f1_cd','f1_ln' columns to row info into the newly created metric column
model_df = model_df.melt(id_vars=["language", "w2vec_algorithm","mapping"], var_name="metric", value_name="f1_score")
# remove rows with Nan values at f1_scores
# it stands for the execution of e.g 'f1_cd' where 'f1_ln' was Nan
model_df = model_df[model_df['f1_score'].notna()]
# transform cbow/sgns to word2vec
model_df["w2vec_algorithm"] = np.where(model_df["w2vec_algorithm"] == "lda2vec", 'lda2vec', 'word2vec')
# keep experiments with same mapping method of lda2vec and word2vec
model_df = model_df[(model_df['mapping'] == 'procrustes') ]
# keep experiments with same language
# we have execution only from 'english' and 'latin'
model_df = model_df[model_df['language'].isin(['en','lat'])]
# remove unnecessary columns
model_df = model_df.drop('metric',axis=1)
print(model_df)
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 3.1 Shapiro-Wilk Test (checks normality of distribution)
# + pycharm={"name": "#%%\n"}
# Shapiro-Wilk test
from collections import defaultdict
from scipy import stats
alpha = 0.05
print("Shapiro-Wilk test for normal distribution: \n")
model_normality_dict = defaultdict()
for w2vec_algorithm in w2vec_algorithms:
if w2vec_algorithm in 'lda2vec':
print(w2vec_algorithm)
stat, p = stats.shapiro( model_df.loc[model_df['w2vec_algorithm'] == w2vec_algorithm,'f1_score'])
else:
print(w2vec_algorithm)
stat, p = stats.shapiro( model_df.loc[model_df['w2vec_algorithm'] != 'lda2vec','f1_score'])
if p >= alpha:
print("\t has a normal distribution with pvalue = "+ str(p) + ", stat=",str(stat))
model_normality_dict[mapping] = True
else:
print("\t has NOT a normal distribution with pvalue = ", p, "stat=",stat)
model_normality_dict[mapping] = False
# + [markdown] pycharm={"name": "#%% md\n"}
# ### Normality Results
# **Word2Vec** models can be described by the normal distribution.
#
# However since **Lda2Vec** method does not meet the criteria of the normality <u>we have to go through with non parapetric tests.</u>
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 3.2 Wilcoxon Signed-Rank Test (non parametric - normality is not a prerequisite)
# * Prerequisites (non normal distributions, paired samples, two populations)
# * Samples are paired since all variables except the under investigation variable are shared among the different populations
# * H0: Populations have same distributions
#
# + pycharm={"name": "#%%\n"}
# Wilcoxon Signed-Rank Test (non parametric - normality is not a prerequisite)
# Compare groups of incremental, procrustes and twec
alpha =0.05
print("Wilcoxon Signed-Rank H-test: \n\n lda2vec-word2vec")
stat, p = stats.wilcoxon(
model_df.loc[model_df['w2vec_algorithm'] == 'lda2vec','f1_score'],
model_df.loc[model_df['w2vec_algorithm'] != 'lda2vec','f1_score'])
if p < alpha:
print(" Null Hypothesis REJECTED with pvalue = ", p, "stat=",stat)
else:
print(" Null hypothesis was ACCEPTED with pvalue = ",p, "stat=",stat)
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 3.3 Results
# The usage of pretrained embeddings improves F1 scores.
# + [markdown] pycharm={"name": "#%% md\n"}
# ### 3.3 Results
# After the execution on the following combinations:
# - **lda2vec-word2vec** (model)
# - **procrustes**
# - **en-lat** (languages)
# - **cd-ln** (metrics of cosine distance and local_neighborhood measure)
#
# On the following **Word2Vec** parameter setting:
# - **embeddings_dimension = 100**
# - **window_size = 10**
# - **min_count = 3** (number of occurences)
# - **s = 0.001** (threshold for configuring which higher-frequency words are randomly downsampled)
# - **k = 5** number of negative samples parameter
# - **epochs = 5**
#
# We investigated the f1_scores of **16 executions** (models * languages * metrics).
#
# The result was that **there are NOT significate differences** between the model which were prior initialized and those hadn't.
# We need to mention that there were not executions with twec alignment method at the above analysis.
# + pycharm={"name": "#%%\n"}
sns.set()
fig, ax = plt.subplots(figsize=(12,8))
sns.boxplot( saturation=1, palette='BuGn',ax=ax, whis=[5, 95],x=model_df['w2vec_algorithm'],y=model_df['f1_score'])
# specify axis labels
plt.xlabel('', size=14, family='monospace')
plt.ylabel('', size=14, family='monospace')
plt.title('F1 Scores per Represenation model')
plt.show()
# + [markdown] pycharm={"name": "#%% md\n"}
# ## Results summary
# + [markdown] pycharm={"name": "#%% md\n"}
# We have seen that in our set up (parameter setting) and the limitations (low volume of training data) we found that:
# 1. There are **NO statistical significant** differences among the different methods of alignment
# 2. When models' weights are prior initialized with pretrained weights, there is a **statistical significant** difference with an increase of 16% on the median value.
# 3. There are **NO statistical significant** differences among the models of word2vec and lda2vec.
# However, an other finding is that the metric of local_neighborhood (LN) measure outstands cosine_distance(CD) f1_scores.
# mean(CD_lda2vec_f1_scores) --> 0,844
# mean(LN_lda2vec_f1_scores) --> 2,343
# percentage of increase: (2,343-0,844)/0,844= 170%
#
# **UNDER INVESTIGATION**
# + pycharm={"name": "#%%\n"}
print(model_df.loc[model_df['w2vec_algorithm'] == 'lda2vec','f1_score'])
# + pycharm={"name": "#%%\n"}
sns.set()
fig, ax = plt.subplots(figsize=(12,8))
sns.boxplot( saturation=1, palette='BuGn',ax=ax, whis=[5, 95],x=model_df['w2vec_algorithm'],y=model_df['f1_score'])
# specify axis labels
plt.xlabel('', size=14, family='monospace')
plt.ylabel('', size=14, family='monospace')
plt.title('F1 Scores per Represenation model')
plt.show()
# -
# ## Results summary
# We have seen that in our set up (parameter setting) and the limitations (low volume of training data) we found that:
# 1. There are **NO statistical significant** differences among the different methods of alignment
# 2. When models' weights are prior initialized with pretrained weights, there is a **statistical significant** difference with an increase of 16% on the median value.
# 3. There are **NO statistical significant** differences among the models of word2vec and lda2vec.
# However, an other finding is that the metric of local_neighborhood (LN) measure outstands cosine_distance(CD) f1_scores.
# mean(CD_lda2vec_f1_scores) --> 0,844
# mean(LN_lda2vec_f1_scores) --> 2,343
# percentage of increase: (2,343-0,844)/0,844= 170%
#
# **UNDER INVESTIGATION**
print(model_df.loc[model_df['w2vec_algorithm'] == 'lda2vec','f1_score'])
| visualizations/statistic_tests.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from astropy.io import ascii
import astropy.units as u
import astropy.coordinates as coord
import numpy as np
from numpy.polynomial.polynomial import polyval
import matplotlib.pyplot as pl
pl.style.use('apw-notebook')
# %matplotlib inline
import h5py
from scipy.ndimage import gaussian_filter
from scipy.stats import scoreatpercentile
ps1_filename = "/Users/adrian/projects/globber/data/ngc5897/PS1_stars_pv3_dered_sm.npy"
iso_filename = "/Users/adrian/projects/globber/data/ngc5897/dartmouth_iso_ps1.dat"
# +
cluster_c = coord.SkyCoord(ra=229.352*u.degree,
dec=-21.01*u.degree)
DM = 15.55
color = ('g', 'i')
mag = 'i'
# +
# TODO: swap this out for just using the XCov file instead
ps1 = np.load(ps1_filename)
ps1_c = coord.SkyCoord(ra=ps1['ra']*u.degree, dec=ps1['dec']*u.degree)
mask = (ps1['iErr'] < 0.1) # & (ps1_c.separation(cluster_c) > 1.*u.arcmin)
ps1 = ps1[mask]
ps1_c = ps1_c[mask]
# -
# read dartmoth isochrone
iso = ascii.read(iso_filename, header_start=8)
idx = (ps1_c.separation(cluster_c) < 6*u.arcmin)
pl.figure(figsize=(6,6))
pl.plot(ps1['ra'][~idx], ps1['dec'][~idx], ls='none', marker='.')
pl.plot(ps1['ra'][idx], ps1['dec'][idx], ls='none', marker='.', color='g')
pl.xlim(cluster_c.ra.degree+0.5, cluster_c.ra.degree-0.5)
pl.ylim(cluster_c.dec.degree-0.5, cluster_c.dec.degree+0.5)
# +
x0 = ps1['dered_{}'.format(color[0])]-ps1['dered_{}'.format(color[1])]
m0 = ps1['dered_{}'.format(mag)]
fig,axes = pl.subplots(1,3,figsize=(10,6),sharex=True,sharey=True)
axes[0].plot(x0[~idx], m0[~idx],
ls='none', marker=',', alpha=0.04)
axes[1].plot(x0[idx], m0[idx],
ls='none', marker=',', alpha=1.)
axes[1].plot(iso['{}P1'.format(color[0])]-iso['{}P1'.format(color[1])], iso['{}P1'.format(mag)]+DM,
ls='-', marker=None, alpha=0.5, lw=3)
axes[2].plot(x0[~idx], m0[~idx],
ls='none', marker=',', alpha=0.04)
axes[2].plot(x0[idx], m0[idx],
ls='none', marker=',', alpha=1.)
axes[0].set_xlim(-0.75,1.25)
axes[0].set_ylim(22, 13)
# -
# ## Compare nearby fields to see if CMD is similar
ps1['ra'].min(), ps1['ra'].max()
# +
fig,axes = pl.subplots(1,3,figsize=(10,6),sharex=True,sharey=True)
_ix1 = ps1['ra'] < 221
print(_ix1.sum())
_ix2 = np.random.permutation(_ix1.sum())[:10000]
axes[0].plot(x0[_ix1][_ix2], i0[_ix1][_ix2],
ls='none', marker='.', alpha=0.25)
_ix1 = ps1['ra'] > 239
print(_ix1.sum())
_ix2 = np.random.permutation(_ix1.sum())[:10000]
axes[1].plot(x0[_ix1][_ix2], i0[_ix1][_ix2],
ls='none', marker='.', alpha=0.25)
# ----------------------------------------------------
_ix1 = ps1['ra'] < 221
_ix2 = np.random.permutation(_ix1.sum())[:5000]
axes[2].plot(x0[_ix1][_ix2], i0[_ix1][_ix2], color='k',
ls='none', marker='.', alpha=0.25)
_ix1 = ps1['ra'] > 239
_ix2 = np.random.permutation(_ix1.sum())[:5000]
axes[2].plot(x0[_ix1][_ix2], i0[_ix1][_ix2], color='k',
ls='none', marker='.', alpha=0.25)
axes[0].set_xlim(-0.75,1.25)
axes[0].set_ylim(22, 13)
# -
| notebooks/NGC 5897 - Figure - photometry.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# **Exercise set 7**
# ==============
#
# > The goal of this exercise is to run PCA and PLSR on a real
# data set in order to show how these methods can be used in practice.
# We are considering data that are given by
# [Platikanov et al.](https://doi.org/10.1016/j.watres.2012.10.040) and we are aiming to
# reproduce some of the results found in their work. You may find it useful to
# inspect this article when interpreting your results.
#
# **Exercise 7.1**
#
# In this exercise, we will consider two data sets: one set contains data for bottled mineral water
# (we will call this "data set 1"),
# and the other set contains data for tap water and bottled water (we will call this "data set 2").
#
# The different water samples have been blind-tasted
# by trained panelists, who have rated the different water samples
# according to their liking. Also, the chemical compositions of the
# samples have been determined. All measured quantities are given
# in table 1.
#
# Our end goal is to predict the ratings (the "mean liking" in
# table 1) of the water samples, given
# measurements of the chemical composition. We will define this rating as the
# $y$-variable we are going to predict.
#
# |Variable| Unit|
# |:-------|----:|
# |Conductivity | ($\mu$S/cm) |
# |TDS (total dissolved solids) | (mg/L) |
# |Cl$^{-}$ | (mg/L) |
# |SO$_4^{2-}$ | (mg/L) |
# |NO$_3^-$ | (mg/L) |
# |HCO$_3^-$ | (mg/L) |
# |Ca$^{2+}$ | (mg/L) |
# |Mg$^{2+}$ | (mg/L) |
# |Na$^{+}$ | (mg/L) |
# |K$^{+}$ | (mg/L) |
# |pH | |
# |Si | (mg/L) |
# |Cl$_2$ | (mg/L) |
# |Mean liking | |
# | **Table 1:** *Data columns present in the data sets: [Data/table1.csv](Data/table1.csv) and [Data/table2.csv](Data/table2.csv)* |
#
# **(a)** Begin by exploring the raw data. In the [original article](https://doi.org/10.1016/j.watres.2012.10.040),
# you can find correlation heat maps (see Fig. $1$ in the aforementioned article).
# Create such correlation maps yourself (for data set 1 & 2)
# and compare them with Fig. $1$ in the article. Does the mean liking
# seem to be correlated with some of the variables?
# +
# Your code here
# -
# **Your answer to question 7.1(a):** *Double click here*
# **(b)** We will further explore the raw data with PCA. Perform a principal
# component analysis for data set 1 and for data set 2. How much of the variance is
# explained by the first two principal components? Also, plot the scores
# and the loadings for principal component 1 and 2, and for principal component 1 and 3.
# Does any of the variables seem to be correlated?
# Which variables seem to influence the mean liking most
# for the two data sets?
# +
# Your code here
# -
# **Your answer to question 7.1(b):** *Double click here*
# **(c)** Let us start the modeling by creating a linear least-squares model:
#
# * (i) Create linear least-squares models for the two data sets in which you use all available data in the fitting. Calculate $R^2$ and the root mean squared error (RMSE) of your models. Comment on the values you have obtained.
#
#
# * (ii) Evaluate the root mean squared error of cross-validation (RMSECV) for your two models. Compare the RMSECV values with the previously obtained RMSE values.
#
#
# * (iii) Using the two models you have created, what variables seem to be most important for predicting a high mean liking? Here, you can inspect the regression coefficients (assuming that you have scaled the variables). If you were to create a new brand of bottled water, what chemical components would you focus on to maximize the mean liking?
# +
# Your code here
# -
# **Your answer to question 7.1(c):** *Double click here*
# **(d)** We will now consider partial least-squares regression (PLSR) models.
# Before we do the actual modeling, let us repeat the fundamental
# equations for PLSR. The model itself is based on the following two
# equations:
# \begin{equation}
# \begin{split}
# \mathbf{X} &= \mathbf{T} \mathbf{P}^\top, \\
# \mathbf{Y} &= \mathbf{U} \mathbf{Q}^\top, \\
# \end{split}
# \tag{1}
# \end{equation}
# where $\mathbf{T}$ is the $x$-scores, $\mathbf{P}$ is the $x$-loadings,
# $\mathbf{U}$ is the $y$-scores, and $\mathbf{Q}$ is the $y$-loadings.
# The linear relation between $\mathbf{X}$ and $\mathbf{Y}$ is in this
# case given by,
# \begin{equation}
# \mathbf{Y} = \mathbf{T} \mathbf{Q}^\top.
# \label{eq:plsrreg} \tag{2}
# \end{equation}
#
# When we wish to *predict* new $\mathbf{Y}$-values from new
# $\mathbf{X}$-values, we need to calculate new $x$-scores. This is
# done by introducing an additional matrix, $\mathbf{R}$, so that
# the following is satisfied:
# \begin{equation}
# \mathbf{T} = \mathbf{X} \mathbf{R}.
# \label{eq:plsrscores} \tag{3}
# \end{equation}
# Here, we can think of the $\mathbf{R}$ as a matrix we can use to invert
# the relation $\mathbf{X} = \mathbf{T} \mathbf{P}^\top$. We can then predict
# new $\mathbf{Y}$-values, by combining Eq. \eqref{eq:plsrreg}
# and Eq. \eqref{eq:plsrscores}:
# \begin{equation}
# \mathbf{Y} = \mathbf{T} \mathbf{Q}^\top =
# \mathbf{X} \mathbf{R} \mathbf{Q}^\top =
# \mathbf{X} \mathbf{B}_\text{PLS},
# \tag{4}
# \end{equation}
# where the regression coefficients $\mathbf{B}_\text{PLS}$ are given by:
# \begin{equation}
# \mathbf{B}_\text{PLS} = \mathbf{R} \mathbf{Q}^\top. \tag{5}
# \end{equation}
#
# In `sklearn` we can run PLSR by using `PLSRegression`
# which is found in the module `sklearn.cross_decomposition`.
# After running the regression, we can access the matrices given above with the python code below.
from sklearn.preprocessing import scale
from sklearn.cross_decomposition import PLSRegression
X = scale(X)
y = scale(y)
plsr = PLSRegression(n_components=2)
plsr.fit(X, y)
R = plsr.x_rotations_
B = plsr.coef_
Q = plsr.y_loadings_
# * (i) Create PLSR models for the two data sets in which you use all available data in the fitting. Use
# only two components when you create the model, that is, set `PLSRegression(n_components=2)` when
# you set up the models. Calculate $R^2$ and the root mean squared error (RMSE) of your models.
# Comment on the values you have obtained, and compare them with the corresponding values from your
# linear least-squares models.
#
#
# * (ii) Calculate RMSECV for your two PLSR models. Compare the RMSECV values with the previously obtained
# RMSE values. Would you say that your PLSR models perform better or worse than the least-squares
# models?
#
#
# * (iii) Plot the $x$- and $y$-loadings for the two components. These loadings are available as
# `Q = plsr.y_loadings_`. What variables seem to be most important for predicting the mean liking?
#
#
# * (iv) Inspect the weights (the $\mathbf{R}$ matrix) for PLS component 1 and PLS component 2.
# Compare your results to the results given by
# [Platikanov et al.](https://doi.org/10.1016/j.watres.2012.10.040) in Fig. $6$.
#
#
# * (v) Based on the PLSR results: If you were to create
# a new brand of bottled water, what chemical components
# would you focus on to maximize the mean liking?
#
# +
# Your code here
# -
# **Your answer to question 7.1(d):** *Double click here*
| exercises_2020/07_Exercise_Set_7.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # 1. 다변수 이산확률변수
# ## 1)결합확률 질량함수 Joint pmf
# ## $$P_{XY}(x, y)$$
# ## 50명학생 X,Y 과목에 대한 시험 결과
scores = np.array([[1, 2, 1, 0, 0, 0],
[0, 2, 3, 1, 0, 0],
[0, 4, 7, 4, 1, 0],
[0, 1, 4, 5, 4, 0],
[0, 0, 1, 3, 2, 0],
[0, 0, 0, 1, 2, 1]])
grades = list('ABCDEF')
pd.DataFrame(scores, columns=grades, index=grades)
pmf = scores / scores.sum()
pd.DataFrame(pmf, columns=grades, index=grades)
# %matplotlib inline
ax = sns.heatmap(pmf, cmap=mpl.cm.bone_r, annot=True,
xticklabels=grades,
yticklabels=grades,)
ax.xaxis.tick_top()
plt.title('joint pmf P(x, y)')
plt.tight_layout()
plt.show()
# ### 1.1)Joint pdf section
x = np.arange(6)
plt.subplot(6,1,1)
plt.bar(x, pmf[0, :])
plt.ylabel('P(x,y=A)', rotation=0, labelpad=30)
plt.xticks(range(6), grades)
plt.title("section of joint pmf given Y=A%inline plt")
plt.show()
# ## 2)주변 확률질량함수 Marginal pmf
# ### $$P_{X}(x) = \sum_{y_i} P_{XY}(x, y_i)$$
pmf_marginal_x = pmf.sum(axis=0)
print(pmf, pmf_marginal_x, sep='\n')
pmf_marginal_y=pmf.sum(axis=1)
print(pmf, pmf_marginal_y.reshape(6,1), sep='\n')
# ## 3)조건부 확률질량함수 Conditional pmf
# ### $$P_{X \mid Y}(x \mid y) = \dfrac{P_{XY}(x, y)}{P_{Y}(y)}$$
# ### y = A 결합확률 질량함수 Joint pmf의 단면
x=np.arange(6)
plt.subplot(411)
plt.bar(x, pmf[0, :], data=pmf[0, :])
plt.ylim(0, 0.5)
plt.ylabel("P(x, y=A)", rotation=0, labelpad=30)
plt.xticks(range(6), list('ABCDEF'))
plt.show()
print(pmf[0, :], 'sum: ', pmf[0, :].sum())
# ### y=A 조건부 확률질량함수 conditional pmf
cond_y0 = pmf[0, :]/pmf.sum(axis=1)[0]
plt.subplot(411)
plt.bar(np.arange(6), cond_y0)
plt.ylabel('P(x|y=A)', rotation=0, labelpad=30)
plt.show()
print(cond_y0, 'sum: ', cond_y0.sum())
# # 2. 다변수 연속확률변수
# <img src = "files/MultivariateNorm.png">from wiki
# ## 1)결합 누적확률분포 Joint cdf
# ### $$F_{XY}(x, y) = P(\{ X < x, Y < y\})$$
# ## 2)주변 누적확률분포 Marginal cdf
# ### $$F_{X}(x) = F_{XY}(x, \infty)$$
# ## 3)결합 확률밀도함수 Joint pdf
# - Joint cdf 미분 두 번
# ### $$f_{XY} = \dfrac{\partial^2 F_{XY}(x, y)}{\partial x \partial y}$$
# %matplotlib inline
# +
mu = [70, 170]
cov = [[150, 140], [140, 300]]
# 다변수 가우시안 정규분포
rv = sp.stats.multivariate_normal(mu, cov)
xx = np.linspace(20, 120, 100)
yy = np.linspace(100, 250, 100)
XX, YY = np.meshgrid(xx, yy)
ZZ = rv.pdf(np.dstack([XX, YY]))
plt.xlabel('x')
plt.ylabel('y')
plt.contour(XX, YY, ZZ)
plt.show()
# -
# ### Y=y일 때 단면
for i, j in enumerate(range(59, 47, -2)):
ax = plt.subplot(6, 1, i + 1)
plt.plot(xx, ZZ[j, :])
plt.ylim(0, 0.0012)
if i < 5:
ax.xaxis.set_ticklabels([])
plt.ylabel("P(x, y={:.0f})".format(yy[j]), \
rotation=0, labelpad=40)
plt.tight_layout
plt.show()
# ## 4)주변 확률밀도함수 Marginal pdf
# - Joint pdf에서 적분 한 번
# - 적분하여 더한다
# ### $$f_X(x) = \int_{-\infty}^{\infty} f_{XY}(x, y)dy$$
# ## 5)조건부 확률밀도함수 Conditional pdf
# ### $$f_{X \mid Y}(x \mid y) = \dfrac{f_{XY}(x, y)}{f_{Y}(y)}$$
# +
from scipy.integrate import simps
mag = 10
plt.figure(figsize=(6,12))
for i, j in enumerate(range(59, 49, -2)):
ax = plt.subplot(5, 1, i + 1)
plt.plot(xx, ZZ[j, :] * mag, 'b:', label='joint')
marginal = simps(ZZ[j, :], xx)
plt.plot(xx, ZZ[j, :] / marginal, 'r-', label='conditional')
plt.ylim(0, 0.05)
ax.xaxis.set_ticklabels([])
plt.ylabel("P(x, y={:.0f})".format(yy[j]), rotation=0, labelpad=40)
plt.xlabel("x")
plt.tight_layout()
plt.legend()
plt.show()
# -
# ### cf. meshgrid: make grid point
x = np.arange(3)
y = np.arange(5)
x, y
X, Y = np.meshgrid(x, y)
X
Y
list(zip(X,Y))
[list(zip(x, y)) for x, y in zip(X, Y)]
plt.scatter(X, Y)
| 06.Math/9.1.1_2 Multiple Random Variable_Continuous&Discrete.ipynb |