
code stringlengths 38 801k | repo_path stringlengths 6 263 |
|---|---|
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # `GiRaFFE_NRPy`: Numerical Methods
#
# ## Authors: <NAME> &
#
# In this module, we will introduce the numerical methods with which we will solve the GRFFE equations.
#
# The contributions from flux terms to the right-hand sides of the conservation equations is found using PPM reconstruction and HLLE approximate Riemann solvers. The other right-hand side terms, as well as the magnetic field from the vector potential, are calculated with sipmle
| in_progress/Tutorial-GiRaFFE_NRPy-Numerical_Methods.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# <table class="ee-notebook-buttons" align="left">
# <td><a target="_blank" href="https://github.com/giswqs/geemap/tree/master/examples/notebooks/usda_naip_imagery.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" /> View source on GitHub</a></td>
# <td><a target="_blank" href="https://nbviewer.jupyter.org/github/giswqs/geemap/blob/master/examples/notebooks/usda_naip_imagery.ipynb"><img width=26px src="https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png" />Notebook Viewer</a></td>
# <td><a target="_blank" href="https://colab.research.google.com/github/giswqs/geemap/blob/master/examples/notebooks/usda_naip_imagery.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" /> Run in Google Colab</a></td>
# </table>
# ## Install Earth Engine API and geemap
# Install the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geemap](https://github.com/giswqs/geemap). The **geemap** Python package is built upon the [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet) and [folium](https://github.com/python-visualization/folium) packages and implements several methods for interacting with Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, and `Map.centerObject()`.
# The following script checks if the geemap package has been installed. If not, it will install geemap, which automatically installs its [dependencies](https://github.com/giswqs/geemap#dependencies), including earthengine-api, folium, and ipyleaflet.
#
# **Important note**: A key difference between folium and ipyleaflet is that ipyleaflet is built upon ipywidgets and allows bidirectional communication between the front-end and the backend enabling the use of the map to capture user input, while folium is meant for displaying static data only ([source](https://blog.jupyter.org/interactive-gis-in-jupyter-with-ipyleaflet-52f9657fa7a)). Note that [Google Colab](https://colab.research.google.com/) currently does not support ipyleaflet ([source](https://github.com/googlecolab/colabtools/issues/60#issuecomment-596225619)). Therefore, if you are using geemap with Google Colab, you should use [`import geemap.eefolium`](https://github.com/giswqs/geemap/blob/master/geemap/eefolium.py). If you are using geemap with [binder](https://mybinder.org/) or a local Jupyter notebook server, you can use [`import geemap`](https://github.com/giswqs/geemap/blob/master/geemap/geemap.py), which provides more functionalities for capturing user input (e.g., mouse-clicking and moving).
# +
# Installs geemap package
import subprocess
try:
import geemap
except ImportError:
print('geemap package not installed. Installing ...')
subprocess.check_call(["python", '-m', 'pip', 'install', 'geemap'])
# Checks whether this notebook is running on Google Colab
try:
import google.colab
import geemap.eefolium as emap
except:
import geemap as emap
# Authenticates and initializes Earth Engine
import ee
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()
# +
import geemap
from ipyleaflet import *
from ipywidgets import *
from geemap.utils import *
Map = geemap.Map(center=(-100, 40), zoom=4)
Map.default_style = {'cursor': 'pointer'}
Map
Map.setOptions('ROADMAP')
# Load National Hydrography Dataset (NHD)
HUC10 = ee.FeatureCollection('USGS/WBD/2017/HUC10'); # 18,487 HUC10 watersheds in the U.S.
# Add HUC layer to the map
Map.setCenter(-99.00, 47.01, 8);
Map.addLayer(ee.Image().paint(HUC10, 0, 1), {}, 'HUC-10 Watershed') # HUC10 for the entire U.S.
label = Label("Click on the map to select a watershed")
widget_control = WidgetControl(widget=label, position='bottomright')
Map.add_control(widget_control)
layer = None
def handle_interaction(**kwargs):
latlon = kwargs.get('coordinates')
if kwargs.get('type') == 'click':
Map.default_style = {'cursor': 'wait'}
xy = ee.Geometry.Point(latlon[::-1])
watershed = HUC10.filterBounds(xy)
huc10_id = watershed.first().get('huc10').getInfo()
Map.layers = Map.layers[:3]
Map.addLayer(ee.Image().paint(watershed, 0, 2), {'palette': 'red'}, 'HUC ID: ' + huc10_id)
NAIP_images = find_NAIP(watershed)
first_image = ee.Image(NAIP_images.toList(5).get(0))
Map.addLayer(first_image, {'bands': ['N', 'R', 'G']}, 'first image')
count = NAIP_images.size().getInfo()
for i in range(0, count):
image = ee.Image(NAIP_images.toList(count).get(i))
Map.addLayer(image, {'bands': ['N', 'R', 'G']}, str(i))
Map.default_style = {'cursor': 'pointer'}
Map.on_interaction(handle_interaction)
Map
# -
Map.layers
| notebooks/naip_imagery.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import pandas as pd
import numpy as np
import pyaf.ForecastEngine as autof
import pyaf.Bench.TS_datasets as tsds
import pyaf.Bench.NN3 as tNN3
# %matplotlib inline
# +
tester1 = tNN3.cNN_Tester(tsds.load_NN3_part1() , "NN3_PART_1");
#tester1.testAllSignals()
tester1.testSignals('NN3-001')
# -
| notebooks_sandbox/NN3_tests.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [Root]
# language: python
# name: Python [Root]
# ---
# # In this notebook, I have used the (earlier) relu functions instead of the abs function and show that it shoots the activations in both directions to nans
# -------------------------------------------------------------------------------------------------------------------
# # Technology used: Tensorflow
# I start with the usual utility cells for this task
# +
# packages used for machine learning
import tensorflow as tf
# packages used for processing:
import matplotlib.pyplot as plt # for visualization
import numpy as np
# for operating system related stuff
import os
import sys # for memory usage of objects
from subprocess import check_output
# import pandas for reading the csv files
import pandas as pd
# to plot the images inline
# %matplotlib inline
# -
# set the random seed to 3 so that the output is repeatable
np.random.seed(3)
# +
# Input data files are available in the "../Data/" directory.
def exec_command(cmd):
'''
function to execute a shell command and see it's
output in the python console
@params
cmd = the command to be executed along with the arguments
ex: ['ls', '../input']
'''
print(check_output(cmd).decode("utf8"))
# -
# check the structure of the project directory
exec_command(['ls', '../..'])
# +
''' Set the constants for the script '''
# various paths of the files
data_path = "../../Data" # the data path
dataset = "MNIST"
data_files = {
'train': os.path.join(data_path, dataset, "train.csv"),
'test' : os.path.join(data_path, dataset, "test.csv")
}
base_model_path = '../../Models'
current_model_path = os.path.join(base_model_path, "IDEA_1")
model_path_name = os.path.join(current_model_path, "Model1_v3")
# constant values:
highest_pixel_value = 255
train_percentage = 95
num_classes = 10
no_of_epochs = 500
batch_size = 64
hidden_neurons = 512
# -
# # Let's load in the data:
# -------------------------------------------------------------------------------------------------------------------
# ## and perform some basic preprocessing on it
raw_data = pd.read_csv(data_files['train'])
n_features = len(raw_data.columns) - 1
n_examples = len(raw_data.label)
print n_features, n_examples
raw_data.head(10)
labels = np.array(raw_data['label'])
labels.shape
# +
# extract the data from the remaining raw_data
features = np.ndarray((n_features, n_examples), dtype=np.float32)
count = 0 # initialize from zero
for pixel in raw_data.columns[1:]:
feature_slice = np.array(raw_data[pixel])
features[count, :] = feature_slice
count += 1 # increment count
# -
features.shape
# normalize the pixel data by dividing the values by the highest_pixel_value
features = features / highest_pixel_value
plt.imshow((features[:, 9]).reshape((28, 28)))
# # use the function to generate the train_dev split
# -------------------------------------------------------------------------------------------------------------------
# link -> https://github.com/akanimax/machine-learning-helpers/blob/master/training/data_setup.py
# shuffle the data using a random permutation
perm = np.random.permutation(n_examples)
features = features[:, perm]
labels = labels[perm]
random_index = np.random.randint(n_examples)
random_image = features[:, random_index].reshape((28, 28))
# use plt to plot the image
plt.figure().suptitle("Label of the image: " + str(labels[random_index]))
plt.imshow(random_image)
# function to split the data into train - dev sets:
def split_train_dev(X, Y, train_percentage):
'''
function to split the given data into two small datasets (train - dev)
@param
X, Y => the data to be split
(** Make sure the train dimension is the first one)
train_percentage => the percentage which should be in the training set.
(**this should be in 100% not decimal)
@return => train_X, train_Y, test_X, test_Y
'''
m_examples = len(X)
assert train_percentage < 100, "Train percentage cannot be greater than 100! NOOB!"
partition_point = int((m_examples * (float(train_percentage) / 100)) + 0.5) # 0.5 is added for rounding
# construct the train_X, train_Y, test_X, test_Y sets:
train_X = X[: partition_point]; train_Y = Y[: partition_point]
test_X = X[partition_point: ]; test_Y = Y[partition_point: ]
assert len(train_X) + len(test_X) == m_examples, "Something wrong in X splitting"
assert len(train_Y) + len(test_Y) == m_examples, "Something wrong in Y splitting"
# return the constructed sets
return train_X, train_Y, test_X, test_Y
train_X, train_Y, test_X, test_Y = split_train_dev(features.T, labels, train_percentage)
train_X.shape, train_Y.shape, test_X.shape, test_Y.shape
train_X = train_X.T; test_X = test_X.T
train_X.shape, test_X.shape
# check by plotting some image
random_index = np.random.randint(train_X.shape[-1])
random_image = train_X[:, random_index].reshape((28, 28))
# use plt to plot the image
plt.figure().suptitle("Label of the image: " + str(train_Y[random_index]))
plt.imshow(random_image)
# # Point to reset from here onwards:
# defining the Tensorflow graph for this task:
tf.reset_default_graph() # reset the graph here:
# define the placeholders:
tf_input_pixels = tf.placeholder(tf.float32, shape=(n_features, None))
tf_integer_labels = tf.placeholder(tf.int32, shape=(None,))
# image shaped pixels for the input_pixels:
tf_input_images = tf.reshape(tf.transpose(tf_input_pixels), shape=(-1, 28, 28, 1))
input_image_summary = tf.summary.image("input_image", tf_input_images)
# define the one hot encoded version fo the integer_labels
tf_one_hot_encoded_labels = tf.one_hot(tf_integer_labels, depth=num_classes, axis=0)
tf_one_hot_encoded_labels
# +
# define the layer 0 biases:
lay_0_b = tf.get_variable("layer_0_biases", shape=(n_features, 1), initializer=tf.zeros_initializer())
# layer 1 weights
lay_1_W = tf.get_variable("layer_1_weights", shape=(hidden_neurons, n_features),
dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer())
lay_1_b = tf.get_variable("layer_1_biases", shape=(hidden_neurons, 1),
dtype=tf.float32, initializer=tf.zeros_initializer())
# layer 2 weights
lay_2_W = tf.get_variable("layer_2_weights", shape=(hidden_neurons, hidden_neurons),
dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer())
lay_2_b = tf.get_variable("layer_2_biases", shape=(hidden_neurons, 1),
dtype=tf.float32, initializer=tf.zeros_initializer())
# layer 3 weights
lay_3_W = tf.get_variable("layer_3_weights", shape=(hidden_neurons, hidden_neurons),
dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer())
lay_3_b = tf.get_variable("layer_3_biases", shape=(hidden_neurons, 1),
dtype=tf.float32, initializer=tf.zeros_initializer())
# layer 4 weights
lay_4_W = tf.get_variable("layer_4_weights", shape=(hidden_neurons, hidden_neurons),
dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer())
lay_4_b = tf.get_variable("layer_4_biases", shape=(hidden_neurons, 1),
dtype=tf.float32, initializer=tf.zeros_initializer())
# layer 5 weights
lay_5_W = tf.get_variable("layer_5_weights", shape=(hidden_neurons, hidden_neurons),
dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer())
lay_5_b = tf.get_variable("layer_5_biases", shape=(hidden_neurons, 1),
dtype=tf.float32, initializer=tf.zeros_initializer())
# layer 6 weights
lay_6_W = tf.get_variable("layer_6_weights", shape=(num_classes, hidden_neurons),
dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer())
lay_6_b = tf.get_variable("layer_6_biases", shape=(num_classes, 1),
dtype=tf.float32, initializer=tf.zeros_initializer())
# -
# # define the forward computation:
# +
# forward computation:
z1 = tf.matmul(lay_1_W, tf_input_pixels) + lay_1_b
a1 = tf.nn.relu(z1)
z2 = tf.matmul(lay_2_W, a1) + lay_2_b
a2 = tf.nn.relu(z2)
z3 = tf.matmul(lay_3_W, a2) + lay_3_b
a3 = tf.nn.relu(z3)
z4 = tf.matmul(lay_4_W, a3) + lay_4_b
a4 = tf.nn.relu(z4)
z5 = tf.matmul(lay_5_W, a4) + lay_5_b
a5 = tf.nn.relu(z5)
z6 = tf.matmul(lay_6_W, a5) + lay_6_b
a6 = tf.nn.relu(z6)
# -
# # define the backward computation:
# +
# in the backward computations, there are no actiavtion functions
y_in_back = a6
a1_back = tf.nn.relu(tf.matmul(tf.transpose(lay_6_W), y_in_back) + lay_5_b)
a2_back = tf.nn.relu(tf.matmul(tf.transpose(lay_5_W), a1_back) + lay_4_b)
a3_back = tf.nn.relu(tf.matmul(tf.transpose(lay_4_W), a2_back) + lay_3_b)
a4_back = tf.nn.relu(tf.matmul(tf.transpose(lay_3_W), a3_back) + lay_2_b)
a5_back = tf.nn.relu(tf.matmul(tf.transpose(lay_2_W), a4_back) + lay_1_b)
a6_back = tf.nn.relu(tf.matmul(tf.transpose(lay_1_W), a5_back) + lay_0_b)
# -
y_in_back
in_back_vector = tf.placeholder(tf.float32, shape=(num_classes, None))
# +
# computations for obtaining predictions:
pred1_back = tf.nn.relu(tf.matmul(tf.transpose(lay_6_W), in_back_vector) + lay_5_b)
pred2_back = tf.nn.relu(tf.matmul(tf.transpose(lay_5_W), pred1_back) + lay_4_b)
pred3_back = tf.nn.relu(tf.matmul(tf.transpose(lay_4_W), pred2_back) + lay_3_b)
pred4_back = tf.nn.relu(tf.matmul(tf.transpose(lay_3_W), pred3_back) + lay_2_b)
pred5_back = tf.nn.relu(tf.matmul(tf.transpose(lay_2_W), pred4_back) + lay_1_b)
pred6_back = tf.nn.relu(tf.matmul(tf.transpose(lay_1_W), pred5_back) + lay_0_b)
# generated digits:
generated_digits = pred6_back
# -
x_out_back = a6_back
x_out_back, tf_input_pixels
x_out_back_image = tf.reshape(tf.transpose(x_out_back), shape=(-1, 28, 28, 1))
output_image_summary = tf.summary.image("output_image", x_out_back_image)
y_in_back
# # Now compute the forward cost
def normalize(x):
'''
function to range normalize the given input tensor
@param
x => the input tensor to be range normalized
@return => range normalized tensor
'''
x_max = tf.reduce_sum(x, axis=0)
# return the range normalized prediction values:
return (x / x_max)
# forward cost
fwd_cost = tf.reduce_mean(tf.abs(normalize(y_in_back) - tf_one_hot_encoded_labels))
fwd_cost_summary = tf.summary.scalar("Forward_cost", fwd_cost)
# # Now compute the backward cost
# backward cost
# The backward cost is the mean squared error function
bwd_cost = tf.reduce_mean(tf.abs(x_out_back - tf_input_pixels))
bwd_cost_summary = tf.summary.scalar("Backward_cost", bwd_cost)
# # The final cost is the addition of both forward and the backward costs
cost = fwd_cost + bwd_cost
final_cost_summary = tf.summary.scalar("Final_cost", cost)
# define an optimizer for this task
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cost)
init = tf.global_variables_initializer()
all_summaries = tf.summary.merge_all()
n_train_examples = train_X.shape[-1]
sess = tf.InteractiveSession()
tensorboard_writer = tf.summary.FileWriter(model_path_name, graph=sess.graph, filename_suffix=".bot")
sess.run(init)
# start training the network for num_iterations and using the batch_size
global_step = 0
for epoch in range(no_of_epochs):
global_index = 0; costs = [] # start with empty list
while(global_index < n_train_examples):
start = global_index; end = start + batch_size
train_X_minibatch = train_X[:, start: end]
train_Y_minibatch = train_Y.astype(np.int32)[start: end]
iteration = global_index / batch_size
# run the computation:
_, loss = sess.run((optimizer, cost), feed_dict={tf_input_pixels: train_X_minibatch,
tf_integer_labels: train_Y_minibatch})
# add the cost to the cost list
costs.append(loss)
if(iteration % 100 == 0):
sums = sess.run(all_summaries, feed_dict={tf_input_pixels: train_X_minibatch,
tf_integer_labels: train_Y_minibatch})
print "Iteration: " + str(global_step) + " Cost: " + str(loss)
tensorboard_writer.add_summary(sums, global_step = global_step)
# increment the global index
global_index = global_index + batch_size
global_step += 1
# print the average epoch cost:
print "Average epoch cost: " + str(sum(costs) / len(costs))
# # Very Important: Save this trained model
model_file_name = os.path.join(model_path_name, model_path_name.split("/")[-1])
model_file_name
saver = tf.train.Saver()
saver.save(sess, model_file_name, global_step=global_step)
# # Model13 seems to be the most promising till now. It has (Mean absolute difference) function as the forward and the backward costs
# -------------------------------------------------------------------------------------------------------------------
# # Model2_v2 (currently being used), is same as Model13 but with the softmax function replaced by the range normalizer function for getting a probability distribution
# # The following cell shows how the network final activations look like upon passing some of the test images that It has never seen before
# -------------------------------------------------------------------------------------------------------------------
# # Run the following cell multiple times to see the effect better
saver.restore(sess, tf.train.latest_checkpoint(model_path_name))
# +
# check by plotting some image
random_index = np.random.randint(test_X.shape[-1])
random_image = test_X[:, random_index].reshape((28, 28))
# use plt to plot the image
plt.figure().suptitle("Label of the image: " + str(test_Y[random_index]))
plt.imshow(random_image)
# generate the predictions for one random image from the test set.
predictions = np.squeeze(sess.run(y_in_back, feed_dict={tf_input_pixels: test_X[:, random_index].reshape((-1, 1))}))
plt.figure().suptitle("Predictions obtained from the network")
plt.plot(range(10), predictions);
print predictions
print "Predicted label: " + str(np.argmax(predictions))
# -
# # Calculate the accuracy of the network on the training and the test dataset
tf_input_pixels, train_X.shape
preds = sess.run(y_in_back, feed_dict={tf_input_pixels: train_X})
correct = np.sum(np.argmax(preds, axis=0) == train_Y)
accuracy = (float(correct) / train_X.shape[-1]) * 100
print "Training accuracy: " + str(accuracy)
# # Calculate the test accuracy:
test_preds = sess.run(y_in_back, feed_dict={tf_input_pixels: test_X})
test_correct = np.sum(np.argmax(test_preds, axis=0) == test_Y)
test_accuracy = (float(test_correct) / test_X.shape[-1]) * 100
print "Testing accuracy:" + str(test_accuracy)
# # Now comes the best part! Can The network generate digits?
# -------------------------------------------------------------------------------------------------------------------
# # Let's generate some digits by tweaking the learned representation
generator_array = np.array([0, 0, 0, 0, 0, 0, 0, 0, 20, 0]).reshape(-1, 1).astype(np.float32)
generator_array.dtype
generated_image = sess.run(generated_digits, feed_dict={in_back_vector: generator_array}).reshape((28, 28))
plt.imshow(generated_image)
# # generate representations for different digits by walking along their respective axes
total_frames = 50
# +
all_digits = [] # start with an empty list
for walking_axis in range(num_classes):
reps = np.zeros(shape=(num_classes, total_frames))
for cnt in range(total_frames):
reps[walking_axis, cnt] = cnt
all_digits.append(reps)
all_digits = np.hstack(all_digits)
# -
all_digits.shape
# obtain the images for these inputs:
images = sess.run(generated_digits, feed_dict={in_back_vector: all_digits}).T.reshape((-1, 28, 28))
images.shape
# +
imagelist = images
import matplotlib.animation as animation
from IPython.display import HTML
fig = plt.figure() # make figure
# make axesimage object
# the vmin and vmax here are very important to get the color map correct
im = plt.imshow(imagelist[0], cmap=plt.get_cmap('jet'), vmin=0, vmax=1);
# function to update figure
def updatefig(j):
# set the data in the axesimage object
im.set_array(imagelist[j])
# return the artists set
return [im]
# kick off the animation
ani = animation.FuncAnimation(fig, updatefig, frames=range(images.shape[0]),
interval=50, blit=True)
# -
HTML(ani.to_html5_video())
# # Hell Yeah! That's a victory! We can indeed generate digits using this neural network
| Scripts/IDEA_1/COMPRESSION_CUM_CLASSIFICATION_v_2_RELU_FAILS.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# fastNLP10 分钟上手教程
# -------
#
# fastNLP提供方便的数据预处理,训练和测试模型的功能
# 如果您还没有通过pip安装fastNLP,可以执行下面的操作加载当前模块
import sys
sys.path.append("../")
# DataSet & Instance
# ------
#
# fastNLP用DataSet和Instance保存和处理数据。每个DataSet表示一个数据集,每个Instance表示一个数据样本。一个DataSet存有多个Instance,每个Instance可以自定义存哪些内容。
#
# 有一些read_*方法,可以轻松从文件读取数据,存成DataSet。
# +
from fastNLP import DataSet
from fastNLP import Instance
# 从csv读取数据到DataSet
dataset = DataSet.read_csv('sample_data/tutorial_sample_dataset.csv', headers=('raw_sentence', 'label'), sep='\t')
print(len(dataset))
# +
# 使用数字索引[k],获取第k个样本
print(dataset[0])
# 索引也可以是负数
print(dataset[-3])
# -
# ## Instance
# Instance表示一个样本,由一个或多个field(域,属性,特征)组成,每个field有名字和值。
#
# 在初始化Instance时即可定义它包含的域,使用 "field_name=field_value"的写法。
# DataSet.append(Instance)加入新数据
dataset.append(Instance(raw_sentence='fake data', label='0'))
dataset[-1]
# ## DataSet.apply方法
# 数据预处理利器
# 将所有数字转为小写
dataset.apply(lambda x: x['raw_sentence'].lower(), new_field_name='raw_sentence')
print(dataset[0])
# label转int
dataset.apply(lambda x: int(x['label']), new_field_name='label')
print(dataset[0])
# 使用空格分割句子
def split_sent(ins):
return ins['raw_sentence'].split()
dataset.apply(split_sent, new_field_name='words')
print(dataset[0])
# 增加长度信息
dataset.apply(lambda x: len(x['words']), new_field_name='seq_len')
print(dataset[0])
# ## DataSet.drop
# 筛选数据
# 删除低于某个长度的词语
dataset.drop(lambda x: x['seq_len'] <= 3)
print(len(dataset))
# ## 配置DataSet
# 1. 哪些域是特征,哪些域是标签
# 2. 切分训练集/验证集
# +
# 设置DataSet中,哪些field要转为tensor
# set target,loss或evaluate中的golden,计算loss,模型评估时使用
dataset.set_target("label")
# set input,模型forward时使用
dataset.set_input("words")
# +
# 分出测试集、训练集
test_data, train_data = dataset.split(0.3)
print(len(test_data))
print(len(train_data))
# -
# Vocabulary
# ------
#
# fastNLP中的Vocabulary轻松构建词表,将词转成数字
# +
from fastNLP import Vocabulary
# 构建词表, Vocabulary.add(word)
vocab = Vocabulary(min_freq=2)
train_data.apply(lambda x: [vocab.add(word) for word in x['words']])
vocab.build_vocab()
# index句子, Vocabulary.to_index(word)
train_data.apply(lambda x: [vocab.to_index(word) for word in x['words']], new_field_name='words')
test_data.apply(lambda x: [vocab.to_index(word) for word in x['words']], new_field_name='words')
print(test_data[0])
# +
# 如果你们需要做强化学习或者GAN之类的项目,你们也可以使用这些数据预处理的工具
from fastNLP.core.batch import Batch
from fastNLP.core.sampler import RandomSampler
batch_iterator = Batch(dataset=train_data, batch_size=2, sampler=RandomSampler())
for batch_x, batch_y in batch_iterator:
print("batch_x has: ", batch_x)
print("batch_y has: ", batch_y)
break
# -
# # Model
# 定义一个PyTorch模型
from fastNLP.models import CNNText
model = CNNText(embed_num=len(vocab), embed_dim=50, num_classes=5, padding=2, dropout=0.1)
model
# 这是上述模型的forward方法。如果你不知道什么是forward方法,请参考我们的PyTorch教程。
#
# 注意两点:
# 1. forward参数名字叫**word_seq**,请记住。
# 2. forward的返回值是一个**dict**,其中有个key的名字叫**output**。
#
# ```Python
# def forward(self, word_seq):
# """
#
# :param word_seq: torch.LongTensor, [batch_size, seq_len]
# :return output: dict of torch.LongTensor, [batch_size, num_classes]
# """
# x = self.embed(word_seq) # [N,L] -> [N,L,C]
# x = self.conv_pool(x) # [N,L,C] -> [N,C]
# x = self.dropout(x)
# x = self.fc(x) # [N,C] -> [N, N_class]
# return {'output': x}
# ```
# 这是上述模型的predict方法,是用来直接输出该任务的预测结果,与forward目的不同。
#
# 注意两点:
# 1. predict参数名也叫**word_seq**。
# 2. predict的返回值是也一个**dict**,其中有个key的名字叫**predict**。
#
# ```
# def predict(self, word_seq):
# """
#
# :param word_seq: torch.LongTensor, [batch_size, seq_len]
# :return predict: dict of torch.LongTensor, [batch_size, seq_len]
# """
# output = self(word_seq)
# _, predict = output['output'].max(dim=1)
# return {'predict': predict}
# ```
# Trainer & Tester
# ------
#
# 使用fastNLP的Trainer训练模型
# +
from fastNLP import Trainer
from copy import deepcopy
from fastNLP.core.losses import CrossEntropyLoss
from fastNLP.core.metrics import AccuracyMetric
# 更改DataSet中对应field的名称,与模型的forward的参数名一致
# 因为forward的参数叫word_seq, 所以要把原本叫words的field改名为word_seq
# 这里的演示是让你了解这种**命名规则**
train_data.rename_field('words', 'word_seq')
test_data.rename_field('words', 'word_seq')
# 顺便把label换名为label_seq
train_data.rename_field('label', 'label_seq')
test_data.rename_field('label', 'label_seq')
# -
# ### loss
# 训练模型需要提供一个损失函数
#
# 下面提供了一个在分类问题中常用的交叉熵损失。注意它的**初始化参数**。
#
# pred参数对应的是模型的forward返回的dict的一个key的名字,这里是"output"。
#
# target参数对应的是dataset作为标签的field的名字,这里是"label_seq"。
loss = CrossEntropyLoss(pred="output", target="label_seq")
# ### Metric
# 定义评价指标
#
# 这里使用准确率。参数的“命名规则”跟上面类似。
#
# pred参数对应的是模型的predict方法返回的dict的一个key的名字,这里是"predict"。
#
# target参数对应的是dataset作为标签的field的名字,这里是"label_seq"。
metric = AccuracyMetric(pred="predict", target="label_seq")
# 实例化Trainer,传入模型和数据,进行训练
# 先在test_data拟合(确保模型的实现是正确的)
copy_model = deepcopy(model)
overfit_trainer = Trainer(model=copy_model, train_data=test_data, dev_data=test_data,
loss=loss,
metrics=metric,
save_path=None,
batch_size=32,
n_epochs=5)
overfit_trainer.train()
# 用train_data训练,在test_data验证
trainer = Trainer(model=model, train_data=train_data, dev_data=test_data,
loss=CrossEntropyLoss(pred="output", target="label_seq"),
metrics=AccuracyMetric(pred="predict", target="label_seq"),
save_path=None,
batch_size=32,
n_epochs=5)
trainer.train()
print('Train finished!')
# +
# 调用Tester在test_data上评价效果
from fastNLP import Tester
tester = Tester(data=test_data, model=model, metrics=AccuracyMetric(pred="predict", target="label_seq"),
batch_size=4)
acc = tester.test()
print(acc)
# -
# # In summary
#
# ## fastNLP Trainer的伪代码逻辑
# ### 1. 准备DataSet,假设DataSet中共有如下的fields
# ['raw_sentence', 'word_seq1', 'word_seq2', 'raw_label','label']
# 通过
# DataSet.set_input('word_seq1', word_seq2', flag=True)将'word_seq1', 'word_seq2'设置为input
# 通过
# DataSet.set_target('label', flag=True)将'label'设置为target
# ### 2. 初始化模型
# class Model(nn.Module):
# def __init__(self):
# xxx
# def forward(self, word_seq1, word_seq2):
# # (1) 这里使用的形参名必须和DataSet中的input field的名称对应。因为我们是通过形参名, 进行赋值的
# # (2) input field的数量可以多于这里的形参数量。但是不能少于。
# xxxx
# # 输出必须是一个dict
# ### 3. Trainer的训练过程
# (1) 从DataSet中按照batch_size取出一个batch,调用Model.forward
# (2) 将 Model.forward的结果 与 标记为target的field 传入Losser当中。
# 由于每个人写的Model.forward的output的dict可能key并不一样,比如有人是{'pred':xxx}, {'output': xxx};
# 另外每个人将target可能也会设置为不同的名称, 比如有人是label, 有人设置为target;
# 为了解决以上的问题,我们的loss提供映射机制
# 比如CrossEntropyLosser的需要的输入是(prediction, target)。但是forward的output是{'output': xxx}; 'label'是target
# 那么初始化losser的时候写为CrossEntropyLosser(prediction='output', target='label')即可
# (3) 对于Metric是同理的
# Metric计算也是从 forward的结果中取值 与 设置target的field中取值。 也是可以通过映射找到对应的值
#
#
#
# ## 一些问题.
# ### 1. DataSet中为什么需要设置input和target
# 只有被设置为input或者target的数据才会在train的过程中被取出来
# (1.1) 我们只会在设置为input的field中寻找传递给Model.forward的参数。
# (1.2) 我们在传递值给losser或者metric的时候会使用来自:
# (a)Model.forward的output
# (b)被设置为target的field
#
#
# ### 2. 我们是通过forwad中的形参名将DataSet中的field赋值给对应的参数
# (1.1) 构建模型过程中,
# 例如:
# DataSet中x,seq_lens是input,那么forward就应该是
# def forward(self, x, seq_lens):
# pass
# 我们是通过形参名称进行匹配的field的
#
#
#
# ### 1. 加载数据到DataSet
# ### 2. 使用apply操作对DataSet进行预处理
# (2.1) 处理过程中将某些field设置为input,某些field设置为target
# ### 3. 构建模型
# (3.1) 构建模型过程中,需要注意forward函数的形参名需要和DataSet中设置为input的field名称是一致的。
# 例如:
# DataSet中x,seq_lens是input,那么forward就应该是
# def forward(self, x, seq_lens):
# pass
# 我们是通过形参名称进行匹配的field的
# (3.2) 模型的forward的output需要是dict类型的。
# 建议将输出设置为{"pred": xx}.
#
#
| tutorials/fastnlp_10min_tutorial.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import pandas as pd
import seaborn as sns
from statannot import add_stat_annotation
import matplotlib.pyplot as plt
# + pycharm={"name": "#%%\n"}
global_eff_auc_df = pd.read_csv('../glob_eff_auc_df.csv')
mean_degree_auc_df = pd.read_csv('../mean_degree_auc_df.csv')
mean_degree_and_gEff_auc_df = pd.merge(global_eff_auc_df, mean_degree_auc_df, on=["subject", "timepoint", "group"])
mean_degree_and_gEff_auc_df = mean_degree_and_gEff_auc_df[mean_degree_and_gEff_auc_df['group']=='st']
# + pycharm={"name": "#%%\n"}
print('Overall Spearmann correlation coefficient:')
mean_degree_and_gEff_auc_df[['mean_degree_auc', 'glob_eff_auc']].corr(method='spearman')
# + pycharm={"name": "#%%\n"}
ax = sns.regplot(x="glob_eff_auc", y="mean_degree_auc", data=mean_degree_and_gEff_auc_df
)
# + pycharm={"name": "#%%\n"}
sns.jointplot(x="glob_eff_auc", y="mean_degree_auc", data=mean_degree_and_gEff_auc_df,
kind="reg"
)
# + pycharm={"name": "#%%\n"}
ax = sns.FacetGrid(mean_degree_and_gEff_auc_df, hue="timepoint", size=7, palette='rocket') \
.map(plt.scatter, "glob_eff_auc", "mean_degree_auc") \
# .add_legend([], [], 'nom')
ax = sns.regplot(x="glob_eff_auc", y="mean_degree_auc", data=mean_degree_and_gEff_auc_df, scatter=False,
line_kws={'alpha':1})
ax.legend(ax.get_legend_handles_labels()[0], ['1', '2', '3'], title="Time points")
ax.annotate('Spearman’s rho=0.785; p=0.001', xy=(.6, .05), xycoords=ax.transAxes)
ax.set_xlabel('Global Efficiency AUC')
ax.set_ylabel('Mean Degree AUC')
fig = ax.get_figure()
plt.show()
# + pycharm={"name": "#%%\n"}
fig.savefig('geff_auc_mean_degree_correlation.svg', bbox_inches="tight", format='svg', dpi=1200)
# + pycharm={"name": "#%%\n"}
g = sns.lmplot(x="glob_eff_auc", y="mean_degree_auc", data=mean_degree_and_gEff_auc_df,
hue='timepoint')
# + [markdown] pycharm={"name": "#%% md\n"}
# ### Plotting: changement de Eglob vs le changement de mean degree entre TP2 et TP3
#
# + pycharm={"name": "#%%\n"}
tp2_mean_degree_and_gEff_auc_df = mean_degree_and_gEff_auc_df[mean_degree_and_gEff_auc_df['timepoint']==1].reset_index()
tp3_mean_degree_and_gEff_auc_df = mean_degree_and_gEff_auc_df[mean_degree_and_gEff_auc_df['timepoint']==2].reset_index()
delta_tp2_vs_tp3_df = pd.DataFrame()
delta_tp2_vs_tp3_df["mean_degree_auc"] = tp3_mean_degree_and_gEff_auc_df["mean_degree_auc"] - tp2_mean_degree_and_gEff_auc_df["mean_degree_auc"]
delta_tp2_vs_tp3_df["glob_eff_auc"] = tp3_mean_degree_and_gEff_auc_df["glob_eff_auc"] - tp2_mean_degree_and_gEff_auc_df["glob_eff_auc"]
# + pycharm={"name": "#%%\n"}
g = sns.jointplot(x="glob_eff_auc", y="mean_degree_auc", data=delta_tp2_vs_tp3_df,
kind="reg"
)
g.ax_joint.annotate('Spearman’s rho=0.785; p=0.001',
xy=(0.1, 0.9), xycoords='axes fraction',
ha='left', va='center')
g.ax_joint.set_xlabel('Change in Global Efficiency')
g.ax_joint.set_ylabel('Change in Mean Degree')
# + pycharm={"name": "#%%\n"}
g.fig.savefig('delta_tp2vs3_geff_auc_mean_degree_correlation.svg', bbox_inches="tight", format='svg', dpi=1200)
# + pycharm={"name": "#%%\n"}
pal = sns.color_palette('rocket', n_colors=3)
rgb_pal = [[value * 255 for value in color] for color in pal]
print(pal)
print(rgb_pal)
pal
# + pycharm={"name": "#%%\n"}
| longitudinal_analysis/figures/globEff_mean_degree_correlation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Validacion de un Modelo de manera incorrecta
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
iris=load_iris()
X=iris.data
Y=iris.target
# **Ahora tenemos que elegir el modelo y los hiperparametros**
from sklearn.neighbors import KNeighborsClassifier
model= KNeighborsClassifier(n_neighbors=1)
model.fit(X,Y)
y_model=model.predict(X)
# +
from sklearn.metrics import accuracy_score
accuracy_score(Y,y_model)
# -
# #### Los resultado obtenidos fueron con una presicion del 100% pero no siempre es asi
# ## Validacion de Modelos de manera Correcta
# Conjunto de retensiones
from sklearn.model_selection import train_test_split
#ahora partimos los datos de entrenamiento y testeo
Xtrain,Xtest,Ytrain,Ytest =train_test_split(X,Y,random_state=0,test_size=0.2)
model.fit(Xtrain,Ytrain)
#ahora evaluamos los modelos con los datos de prueba
y_model=model.predict(Xtest)
accuracy_score(Ytest,y_model)
# ### Metodo de validacion cruzada,
# es un metodo mucho mas eficiente ya que nos permite explorar el conjunto de datos que deseamos testear segun sea la puntuacion obtenida en la presicion de estos
# +
from sklearn.model_selection import cross_val_score
score=cross_val_score(model,X,Y,cv=5)
score
# -
# Pero si en casos extremos deseamos explorar un determinado conjunto de datos igual aal total de estos usaremos, tendriamos que usar la **Validacion Cruzada de salida uno**
# +
from sklearn.model_selection import LeaveOneOut
loo=LeaveOneOut()
score=cross_val_score(model,X,Y,cv=loo)
score.mean()
# -
# ### La compensacion SESGO-VARIANZA
# [Image](https://jakevdp.github.io/PythonDataScienceHandbook/figures/05.03-validation-curve.png)
# * Curvas de validacion
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
import matplotlib.pyplot as plt
def PolynomialRegression(degree=2,**kwargs):
return make_pipeline(PolynomialFeatures(degree),LinearRegression(**kwargs))
def makedata(N=5, err=0.1):
rng=np.random.RandomState(0)
X=rng.rand(N,1)**2
Y=1+X.ravel()**3
if err>=0:
Y+=err*rng.randn(N)
return X,Y
import seaborn as sns; sns.set()
X,Y=makedata(N=200)
# +
Xtest=np.linspace(-1,1,200)[:,np.newaxis]
plt.scatter(X.ravel(),Y,color='black',s=0.2)
axis=plt.axis()
for degree in [1,3,5,7]:
Ytest=PolynomialRegression(degree).fit(X,Y).predict(Xtest)
plt.plot(Xtest.ravel(),Ytest,label='Degree {0}'.format(degree))
plt.xlabel('X')
plt.ylabel('Y')
plt.ylim(0.5,2)
plt.xlim(-0.5,1)
plt.legend(loc='best')
# -
from sklearn.model_selection import validation_curve
train_scores,test_scores=validation_curve(LinearRegression(),X,Y,param_name='fit_intercept',param_range=[True,False],cv=7)
train_scores.mean(axis=1)
test_scores
test_scores.mean(axis=1)
ylb=np.arange(0,2)
plt.plot(train_scores.mean(axis=1),ylb,color='yellow',label='Train score')
plt.plot(test_scores.mean(axis=1),ylb,color='brown',label='Test Score')
plt.legend(loc='best')
# +
degree=np.arange(0,20)
X,Y=makedata(N=500)
train_scores,test_scores=validation_curve(PolynomialRegression(),X,Y,
param_name='polynomialfeatures__degree',
param_range=degree,
cv=7
)
# +
plt.plot(degree,train_scores.mean(axis=1),color='green',label='Train Score')
plt.plot(degree,test_scores.mean(axis=1),color='red',label='Test Score')
plt.legend(loc='best')
plt.xlim(0,5)
# +
plt.scatter(X.ravel(),Y,color='red',alpha=0.3)
Ytest=PolynomialRegression(degree=2).fit(X,Y).predict(Xtest)
axis=plt.axis()
plt.plot(Xtest.ravel(),Ytest,color='blue',label='Predict Ytest')
plt.axis(axis)
plt.legend(loc='best')
# -
from sklearn.model_selection import learning_curve
train_sizes,train_scores,test_scores=learning_curve(PolynomialRegression(degree=4),X,Y,
cv=7,
train_sizes=np.linspace(0.3,1,25)
)
train_sizes
# +
from sklearn.model_selection import GridSearchCV
X,Y=makedata(N=400)
Xtest=10*np.random.rand(200)
# -
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipe=Pipeline(
[('scaler',StandardScaler()),('linear',LinearRegression())]
)
intersection=[True,False]
normalize=[True,False]
grid=GridSearchCV(
estimator=pipe,
param_grid=dict(
linear__fit_intercept=intersection
),
cv=7
)
grid.fit(X,Y)
grid.best_params_
grid.best_estimator_
| Machine Learning/Hiperparametros y validacion de Modelos.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
from matplotlib import pyplot as plt
import ventilation_wall
import envelope_performance_factors
import global_number
# # 通気層を有する壁体の計算テスト
# ## パラメータを設定
# theta_e: 外気温度[degree C]
# theta_r: 室内温度[degree C]
# J_surf: 外気側表面に入射する日射量[W/m2]
# a_surf: 外気側表面日射吸収率[-]
# C_1: 外気側部材の熱コンダクタンス[W/(m2・K)]
# C_2: 室内側部材の熱コンダクタンス[W/(m2・K)]
# l_h: 通気層の長さ[m]
# l_w: 通気層の幅[m]
# l_d: 通気層の厚さ[m]
# angle: 通気層の傾斜角[°]
# v_a: 通気層の平均風速[m/s]
# l_s: 通気胴縁または垂木の間隔[m]
# emissivity_1: 通気層に面する面1の放射率[-]
# emissivity_2: 通気層に面する面2の放射率[-]
# ### 定数を設定
h_out = global_number.get_h_out() # 室外側総合熱伝達率, W/(m2・K)
h_in = global_number.get_h_in() # 室内側総合熱伝達率, W/(m2・K)
# ### 外気温度を設定
theta_e_array = [x for x in range(-20,40)]
# ### パラメータのリストを作成
parms = [ventilation_wall.Parameters(
theta_e = theta_e,
theta_r = 25,
J_surf = 500,
a_surf = 0.9,
C_1 = 10,
C_2 = 0.5,
l_h = 6.0,
l_w = 0.45,
l_d = 0.018,
angle = 90,
v_a = 0.2,
l_s = 0.45,
emissivity_1 = 0.9,
emissivity_2=0.9
) for theta_e in theta_e_array]
# ## 通気層の状態値を取得
# +
# 各点の熱流、温度を格納する配列を用意
x1 = np.ndarray(len(parms))
status = []
q_surf_out = np.ndarray(len(parms))
q_surf_1 = np.ndarray(len(parms))
q_surf_2 = np.ndarray(len(parms))
q_suef_in = np.ndarray(len(parms))
q_suf_vent = np.ndarray(len(parms))
temp_surf_out = np.ndarray(len(parms))
temp_surf_1 = np.ndarray(len(parms))
temp_surf_2 = np.ndarray(len(parms))
temp_suef_in = np.ndarray(len(parms))
temp_suf_vent = np.ndarray(len(parms))
for i, parm in enumerate(parms):
x1[i] = parm.theta_e
# 通気層の状態値を取得
status_buf: ventilation_wall.WallStatusValues = ventilation_wall.get_wall_status_values(parm, h_out, h_in)
status.append(status_buf)
# 各層の熱収支を検算
q = ventilation_wall.get_heat_balance(status_buf.matrix_temp,parm, h_out, h_in)
q_surf_out[i] = q[0][0]
q_surf_1[i] = q[1][0]
q_surf_2[i] = q[2][0]
q_suef_in[i] = q[3][0]
q_suf_vent[i] = q[4][0]
# 各層の温度を取得
temp_surf_out[i] = status_buf.matrix_temp[0][0]
temp_surf_1[i] = status_buf.matrix_temp[1][0]
temp_surf_2[i] = status_buf.matrix_temp[2][0]
temp_suef_in[i] = status_buf.matrix_temp[3][0]
temp_suf_vent[i] = status_buf.matrix_temp[4][0]
# -
# ### 各層の熱収支の検算結果を確認
# +
fig1 = plt.figure()
ax1 = fig1.subplots()
ax1.scatter(x1, q_surf_out, c="r", label="outdoor surface")
ax1.scatter(x1, q_surf_1, c="g", label="surface1")
ax1.scatter(x1, q_surf_2, c="m", label="surface2")
ax1.scatter(x1, q_suef_in, c="c", label="indoor surface")
ax1.scatter(x1, q_suf_vent, c="b", label="ventilation layer")
ax1.set_xlabel('outdoor temperature[degC]')
ax1.set_ylabel('heat balance[W]')
ax1.set_title("layer heat balance")
plt.ylim(-10, 10)
plt.legend()
plt.show()
# -
# ### 各点の温度を確認
# +
fig1 = plt.figure()
ax1 = fig1.subplots()
ax1.scatter(x1, temp_surf_out, c="r", label="outdoor surface")
ax1.scatter(x1, temp_surf_1, c="g", label="surface1")
ax1.scatter(x1, temp_surf_2, c="m", label="surface2")
ax1.scatter(x1, temp_suef_in, c="c", label="indoor surface")
ax1.scatter(x1, temp_suf_vent, c="b", label="ventilation layer")
ax1.set_xlabel('outdoor temperature[degC]')
ax1.set_ylabel('surface temperature[degC]')
ax1.set_title("surface temperaturs")
plt.legend()
plt.show()
# -
# ## 通気層を有する壁体の熱貫流率,日射熱取得率の計算
# ### 熱貫流率(W/(m2・K)),日射熱取得率(-)を計算
# +
u_e = np.ndarray(len(parms))
eta_e = np.ndarray(len(parms))
for i, parm in enumerate(parms):
u_e[i] = envelope_performance_factors.overall_heat_transfer_coefficient(parms[i], status[i].matrix_temp[4][0], status[i].h_cv, status[i].h_rv)
eta_e[i] = envelope_performance_factors.solar_heat_gain_coefficient(parms[i], status[i].matrix_temp[4][0], status[i].h_cv, status[i].h_rv)
# +
fig1 = plt.figure()
ax1 = fig1.subplots()
ax1.scatter(x1, u_e, c="r", label="overall heat transfer coefficient")
ax1.scatter(x1, eta_e, c="g", label="solar heat gain coefficient")
ax1.set_xlabel('outdoor temperature[degC]')
ax1.set_ylabel('coefficient[W/(m^2*K)],[-]')
ax1.set_title("envelope performance factors")
plt.legend()
plt.show()
| ventilation_wall_test.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Projection tutorial
# ### This tutorial shows how to project points and semantic segmentation on a image.
# #### 1.Import required python modules and load sequence data.
# + pycharm={"is_executing": false}
import pandaset
import os
# load dataset
dataset = pandaset.DataSet("/data/PandaSet")
seq002 = dataset["002"]
seq002.load()
print("avaliable cameras: ", seq002.camera.keys())
# -
# #### 2.Use projection function in pandaset.geometry to get projection 2d-points on image.
# - ***geometry.projection***
# - input
# - ***lidar_points***(np.array(\[N, 3\])): lidar points in the world coordinates.
# - ***camera_data***(PIL.Image): image for one camera in one frame.
# - ***camera_pose***: pose in the world coordinates for one camera in one frame.
# - ***camera_intrinsics***: intrinsics for one camera in one frame.
# - ***filter_outliers***(bool): filtering projected 2d-points out of image.
# - output
# - ***projection_points2d***(np.array(\[K, 2\])): projected 2d-points in pixels.
# - ***camera_points_3d***(np.array(\[K, 3\])): 3d-points in pixels in the camera frame.
# - ***inliner_idx***(np.array(\[K, 2\])): the indices for *lidar_points* whose projected 2d-points are inside image.
# + pycharm={"is_executing": false}
from pandaset import geometry
# generate projected points
seq_idx = 1
camera_name = "front_camera"
lidar = seq002.lidar
points3d_lidar_xyz = lidar.data[seq_idx].to_numpy()[:, :3]
choosen_camera = seq002.camera[camera_name]
projected_points2d, camera_points_3d, inner_indices = geometry.projection(lidar_points=points3d_lidar_xyz,
camera_data=choosen_camera[seq_idx],
camera_pose=choosen_camera.poses[seq_idx],
camera_intrinsics=choosen_camera.intrinsics,
filter_outliers=True)
print("projection 2d-points inside image count:", projected_points2d.shape)
# -
# #### 3.Show original image.
# + pycharm={"is_executing": false}
from matplotlib import pyplot as plt
# %pylab inline
# image before projection
ori_image = seq002.camera[camera_name][seq_idx]
plt.imshow(ori_image)
# -
# #### 4.Show projected points on image colorized by distances.
# + pycharm={"is_executing": false}
import matplotlib.cm as cm
import numpy as np
# image after projection
plt.imshow(ori_image)
distances = np.sqrt(np.sum(np.square(camera_points_3d), axis=-1))
colors = cm.jet(distances / np.max(distances))
plt.gca().scatter(projected_points2d[:, 0], projected_points2d[:, 1], color=colors, s=1)
# -
# #### 5.Show projected points on image colorized by semantic segmentation.
# +
import matplotlib.cm as cm
import numpy as np
import random
# image after projection
plt.imshow(ori_image)
# load semseg
semseg = seq002.semseg[seq_idx].to_numpy()
# get semseg on image by filting outside points
semseg_on_image = semseg[inner_indices].flatten()
# random gnerate colors for semseg
max_seg_id = np.max(semseg_on_image)
color_maps = [(random.random(), random.random(), random.random()) for _ in range(max_seg_id + 1)]
colors = np.array([color_maps[seg_id] for seg_id in semseg_on_image])
plt.gca().scatter(projected_points2d[:, 0], projected_points2d[:, 1], color=colors, s=1)
# -
| tutorials/projection/projection.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # Python Course Homework 1: Jupyter Notebook and Python builtin type methods
# # Jupyter Notebook
#
# This notebook file runs on Jupyter Notebook, once called IPython notebook. It is an incredible tool that is geared towards an interactive data exploration workflow and increasing transparancy in how data analysis was performed. It does this by sharing text, code, and figures all in the same place. The format has become very popular, and notebooks be found online for all kinds of analyses!
#
# Please download and open this notebook in the jupyter notebook application on your computer to interact with it and work through the exercises!
# ## Markdown Cells are for Text, Code Cells are for Code.
#
# Keyboard shortcuts for Jupyter Notebook can be found under the Help menu. They will speed up your work immensely!
#
# ### Markdown Cells
#
# To add text to a notebook, click a "cell" (one of the boxes you can type into) and select **Markdown** from the dropdown list on the toolbar near the top of the page. You can tell it worked if there is no "In []" text at the left of the cell. Then, type your sentences, format it using the Markdown text format (details can be found at https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet) and run the cell by:
# - clicking the "Run cell" triangle button on the toolbar,
# - clicking "Run Cell" in the Cell dropdown menu, or
# - pressing Ctrl-Enter.
#
# To see how this cell was formatted, simply double-click it or select it and press the Enter key, and you will see what was typed into the cell.
#
# For great examples of how effective notebooks can be at communication: see the notebooks at the following link: http://nb.bianp.net/sort/views/
# ## Code Cells
#
# Code cells run code! By default, they should be running Python just fine. To change the kernel that is running, go to the Kernel menu, highlight "Change Kernel", and select the language you want started. You'll also see options in that menu for restarting it and running everything in the notebook.
#
# Following is an example of a code cell: Go ahead and run it! You'll should see the output below. Notice that the print() function wasn't necessary here--the notebook will display one line (the last line) that is called without assignment to a variable.
# Code cells run Python.
# This code will fetch an image from the internet, from a site that gives a random image.
# The image will be an Image object!
from IPython.display import Image
rand_pic = Image(url='http://lorempixel.com/400/200/', width=310)
rand_pic
# ## IPython Magicks
#
# IPython has a lot of extension tricks for performing useful tasks or modifying its behavior! You can recognize them as functions prepended by a % sign. If it is used to modify an entire cell or notebook, then two % signs will be used. Here are a couple of my favorites:
#
# # ### %timeit
# Tells you how long a line took to run. For example:
#
#
# %timeit sum([1,2,3,4,5])
# You can also use **%%timeit** to time a whole cell!
# # ### %qtconsole
#
# Launches an IPython console that is tied to the notebook session. Super useful for trying things out, because all variables are shared between them! By habit, I put this line at the top of all my analysis notebooks, making it an essential part of my workflow.
#
# # ### %matplotlib inline
# # ### %matplotlib notebook
#
# Makes all Matplotlib figures appear inside the notebook. If the **inline** option is used, it will appear as an image below (useful, especially when also making plots in the qtconsole). If the **notebook** option is used, a fully interactive plot will appear!
# %qtconsolem
whos
# # Python Built-In Type Methods
#
# As we discussed in the lecture, all Python objects are **Objects**, which means they have **Properties/Attributes** (data) and **Methods** associated with them. These are accessible via the **Dot Notation**.
#
# For example, here we use a string **Class**'s *title()* method:
film = 'the lion king'
bigfilm = film.title()
bigfilm
# It could also have been called like this:
'the lion king'.title()
#
# # Exercises
# **Directions**: Answer the following questions by adding lines of code to perform the task requested on the given data in each data cell. In many exercises, this will only require one line of code, but some may require multiple steps.
#
# **Tip**: Learning a programming language is just as much about learning the names and locations of the functions as it is about learning how the language works. This is akin to how learning the vocabulary of a spoken language is just as important as learning its grammar.
#
# **Tip**: All of these exercises can be completed with the methods of the built-in types: str, int, float, list, tuple, set, dict. **Go to https://docs.python.org/3/library/stdtypes.html for the documentation!**
#
# ## Exercise 2: The Variable Subject
#
# You want to label your figure title with the subject code, and the subject code changes depending on which subject is being shown! How could you stick a subject's name in your title string?
subject = 'NOP234'
title = "Mean Values of SUBJECT NAME's data over Time"
title.replace('SUBJECT NAME', subject)
# If you had formatted your title string in the following way, though, another string method would be more useful. Which one would you use for this title:
# +
subject1 = 'NOP234'
subject2 = 'GHS673'
title = "Performance Comparison between Subjects {subj1} and {subj2}"
title.format(subj2=subject1, subj1=subject2)
# -
# ## Exercise 3: The Wrong Type
#
# Your colleague sent you the data you needed, but in the text of an email! Seriously, who sends data like that, it's ridiculous! Well, now you need to make a list of numbers out of it. How do you do that without typing them by hand?
strdata = '12 40 89 100 41.2 41.2 0.45 1.1'
strdata.split(' ')
# ## Exercise 4: One more time!
#
# You have a list of subjects, and you want to add another one! How do you do it?
# +
subjects = ['NOP234', 'GHS673', 'JGL212']
new_subject = 'ASF193'
subjects + [new_subject]
# -
# ## Exercise 5: Lots at once!
#
# Now, a bunch of new subjcts appeared! How do you add them to the main list?
# +
subjects = ['NOP234', 'GHS673', 'JGL212']
new_subjects = ['ASF193', 'THW994', 'JJZ231']
subjects.extend(new_subjects)
subjects
# -
# ## Exercise 6: Nice and Neat
#
# Please put those subjects in alphabetical order. It looks better that way, doesn't it?
subjects = ['NOP234', 'GHS673', 'jGL212', 'ASF193', 'THW994', 'JJZ231']
subjects.sort()
subjects
# ## Exercise 7: The Bad Subject
#
# Oh, no, 'JGL202' was a terrible subject, he intentionally ruined your study. Well, there's no way you're keeping him. How do you remove him from the list?
subjects = ['NOP234', 'GHS673', 'JGL212', 'ASF193', 'THW994', 'JJZ231']
subjects.remove('JGL212')
subjects
# ## Exercise 8: The Limited Abstract
#
# The conference says it only takes abstracts that have a maximum word count of 100 words. Did our abstract make the cut?
#
# **hint: the len() function is useful here**
# +
abstract = """We analyze the locomotor behavior of the rat during exploration,
and show that digitally collected data (time series of positions)
provide a sufftcient basis for establishing that the rat uses several distinct modes of motion (first, second,
third, and sometimes fourth gear). The distinction between these modes is obtained by first segmenting the
time series into sequences of data points occurring between arrests (as ascertained within the resolution of
the data acquisition system). The statistical distribution of the maximal amount of motion occurring within
each of these episodes is then analyzed and shown to be multi modal. This enables us to decompose motion into
distinct modes."""
len(set(abstract.split(' ')))
# -
# Oh, wait, now that I look closer, it actually says that it's a maximum of 100 **unique** words--duplicated words don't count. How many unique words do we have in our abstract? (What a strange conference...)
#
# **Hint**: There is a useful class for this...
# ## Exercise 9: The Balloon Seller
#
# A balloon seller (oops, I mean the balloon Scientist!) is giving out free balloons to all the, umm, researchers in the neighborhood. He has three balloons, and wants to give them to Jenny, Manny, and Benny.
#
# How can he assign them to them one at a time?
balloons = ['red', 'blue', 'green']
jenny = balloons.pop()
manny = balloons.pop()
benny = balloons.pop()
jenny
# Of course, he could have given them all out in a single step. How?
balloons = ['red', 'blue', 'green']
| notebooks/block1/homework/Homework 1 Jupyter Notebook and Builtin Type Methods.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Initialisation Cell
# You should always put imported modules here
import numpy as np
import numpy.testing as nt
import numpy.linalg as LA
import scipy.sparse as sc
from matplotlib import pyplot as plt
np.set_printoptions(suppress=True, precision=7)
# + [markdown] deletable=false editable=false nbgrader={"checksum": "3fff17e558578058e5cd364c068a553a", "grade": false, "grade_id": "cell-5625cb6b1f6218d6", "locked": true, "schema_version": 1, "solution": false}
# # CDES Honours - Lab 0
#
#
# ## Instructions
#
# * Read all the instructions carefully.
# * Do not rename the notebook, simply answer the questions and resubmit the file to Moodle.
# * **Numpy** has a help file for every function if you get stuck. See: https://docs.scipy.org/doc/numpy-1.15.4/reference/
# * See these useful links:
# * https://docs.scipy.org/doc/numpy/user/numpy-for-matlab-users.html
# * https://docs.scipy.org/doc/numpy/user/quickstart.html
# * **Numpy** is not always required.
# * There are also numerous sources available on the internet, Google is your friend!
# + [markdown] deletable=false editable=false nbgrader={"checksum": "3b07d3df244fcd64fd181b09bd04d2aa", "grade": false, "grade_id": "cell-7d9dd551d370bf3f", "locked": true, "schema_version": 1, "solution": false}
# # Warm-up Exercises
#
# Complete the following warm-up tasks without the use of numpy.
#
# ## Question 1
#
# Given an array of integers, write a function to compute the sum of its elements. You may not use the `sum` function.
# + deletable=false nbgrader={"checksum": "69f590bb5fe53d1347cb784d8f4282f8", "grade": false, "grade_id": "cell-b8cb415b27626ac7", "locked": false, "schema_version": 1, "solution": true}
# Question 1
def simpleArraySum(ar):
# YOUR CODE HERE
raise NotImplementedError()
# + deletable=false editable=false nbgrader={"checksum": "93dc241de164585a9046b8d06b4aee62", "grade": true, "grade_id": "cell-cb6ae809f6265451", "locked": true, "points": 1, "schema_version": 1, "solution": false}
# Run this test cell to check your code
# Do not delete this cell
# 1 mark
# Unit test
test = [1, 2, 3 , 4, 10, 11]
assert(simpleArraySum(test) == 31)
print('Test case passed!!!')
# + deletable=false editable=false nbgrader={"checksum": "314bfb8bf89f688c0e643f3f6603d1e9", "grade": true, "grade_id": "cell-6657ce11342916b0", "locked": true, "points": 4, "schema_version": 1, "solution": false}
# Hidden test
# No output will be produced
# 4 marks
# + [markdown] deletable=false editable=false nbgrader={"checksum": "0b84c3948df1bfaa7c5d93283ffeda0b", "grade": false, "grade_id": "cell-a569a0d835688093", "locked": true, "schema_version": 1, "solution": false}
# ## Question 2
#
# Write a function that takes as inputs, a word (as a string) and an array of letter heights. The function must compute the area required to highlight the entire word. For example, if the string is `'abc'`, and the specific heights of `a`, `b` and `c` are 1, 3, and 1 mm respectively - then the background area to highlight the entire string is the length of the string times the maximum height, therefore $3 \times 3 = 9$mm.
# + deletable=false nbgrader={"checksum": "b1d5d282f2ccfe7d9c0564547b865960", "grade": false, "grade_id": "cell-80ece42e97eee467", "locked": false, "schema_version": 1, "solution": true}
def highlighter(h, word):
# YOUR CODE HERE
raise NotImplementedError()
# + deletable=false editable=false nbgrader={"checksum": "c42f7e55d65537911bb438403a7d364c", "grade": true, "grade_id": "cell-a84aed43f73fc8bf", "locked": true, "points": 1, "schema_version": 1, "solution": false}
# Run this test cell to check your code
# Do not delete this cell
# 1 mark
# Unit test
test = 'abc'
h = [1, 3, 1, 3, 1, 4, 1, 3, 2, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 7]
assert(highlighter(h, test) == 9)
print('Test case passed!!!')
# + deletable=false editable=false nbgrader={"checksum": "ec1d3c9117dca0345c2503c84c8ee82f", "grade": true, "grade_id": "cell-32b96395a033ae8a", "locked": true, "points": 9, "schema_version": 1, "solution": false}
# Hidden test
# No output will be produced
# 9 marks
# + [markdown] deletable=false editable=false nbgrader={"checksum": "ff10c1cf137f5f45a5124c6cd29e4999", "grade": false, "grade_id": "cell-efff7a8b2ac5030e", "locked": true, "schema_version": 1, "solution": false}
# ## Question 3
#
# Write a function that takes in an array, `ar`, of $n$ integers and a positive integer `k`. Find the number of $(i, j)$ pairs where $i < j$ and $ar(i) + ar(j)$ is divisible by `k`. The function should return the answer as a scalar.
# + deletable=false nbgrader={"checksum": "a6f634930e79cc9ecc620ab0a992eae6", "grade": false, "grade_id": "cell-3db470f43b2392f3", "locked": false, "schema_version": 1, "solution": true}
def divisibleSumPairs(k, ar):
# YOUR CODE HERE
raise NotImplementedError()
# + deletable=false editable=false nbgrader={"checksum": "7707a202801966602383da4124a10978", "grade": true, "grade_id": "cell-689c5baf30f5a784", "locked": true, "points": 1, "schema_version": 1, "solution": false}
# Run this test cell to check your code
# Do not delete this cell
# 1 mark
# Unit test
k = 3
test = [1, 3, 2, 6, 1, 2]
assert(divisibleSumPairs(k, test) == 5)
print('Test case passed!!!')
# + deletable=false editable=false nbgrader={"checksum": "dd475fac0525b07e2184fc0e84082d1a", "grade": true, "grade_id": "cell-ddc915205232a73a", "locked": true, "points": 1, "schema_version": 1, "solution": false}
# Run this test cell to check your code
# Do not delete this cell
# 1 mark
# Unit test
k = 3
test = [1, 3, 2, 6, 1, 2, 5, 9, 4]
assert(divisibleSumPairs(k, test) == 12)
print('Test case passed!!!')
# + deletable=false editable=false nbgrader={"checksum": "741da33928c6b3eae4e480dd1846840f", "grade": true, "grade_id": "cell-40c7643c106fb90d", "locked": true, "points": 4, "schema_version": 1, "solution": false}
# Hidden test
# No output will be produced
# 4 marks
# + deletable=false editable=false nbgrader={"checksum": "99651aa2914b93c08abd640415f53c32", "grade": true, "grade_id": "cell-b7ecc45e8c7eb1b0", "locked": true, "points": 4, "schema_version": 1, "solution": false}
# Hidden test
# No output will be produced
# 4 marks
# + [markdown] deletable=false editable=false nbgrader={"checksum": "e307479843934d56d73c51c3df112815", "grade": false, "grade_id": "cell-e16fe4f0df114a15", "locked": true, "schema_version": 1, "solution": false}
# ## Main Exercises
#
# Complete the following problems:
#
# ## Question 1
#
# Write a function implements a finite difference scheme to solve the heat equation. Specifically, the function should implement an explicit scheme which is forward difference in time and central difference in space. It should take as inputs a time step `dt`, a spatial step `dx`, a number of iterations to march forward in time `N`, the coeffient `D`, an initial function `f(x)` passed as a handle and boundary values `alpha` and `beta`. The function should output the solution space matrix `u`. Recall the heat equation problem as:
# $$
# u_{t} = Du_{xx},\ \ \quad u(0, t) = \alpha, \ \ u(1, t) = \beta,\ \ \qquad u(x, 0) = f(x)
# $$
#
# Note: the solution matrix here is matrix of all $x$ through time $t$. That is row one is at time zero.
#
# + deletable=false nbgrader={"checksum": "48b11f50e23ae73d49ba1c8e7b7457e8", "grade": false, "grade_id": "cell-411db28418ab4c2d", "locked": false, "schema_version": 1, "solution": true}
def heat_eq(dt, dx, N, f, D, alpha, beta):
# YOUR CODE HERE
raise NotImplementedError()
# + deletable=false editable=false nbgrader={"checksum": "ceea4f2a51c25b4c2949b39c8002b712", "grade": true, "grade_id": "cell-b946814d8947549d", "locked": true, "points": 2, "schema_version": 1, "solution": false}
# Run this test cell to check your code
# Do not delete this cell
# 2 mark
# Unit test
dt = 0.0013
dx = 0.05
N = 50
f = lambda x: np.sin(np.pi*x)
D = 1
alpha = 0
beta = 0
ans = heat_eq(dt, dx, N, f, D, alpha, beta)
t1 = np.array([0. , 0.156434, 0.309017, 0.45399 , 0.587785, 0.707107,
0.809017, 0.891007, 0.951057, 0.987688, 1. , 0.987688,
0.951057, 0.891007, 0.809017, 0.707107, 0.587785, 0.45399 ,
0.309017, 0.156434, 0. ])
t2 = np.array([0. , 0.082129, 0.162237, 0.238349, 0.308592, 0.371237,
0.424741, 0.467786, 0.499313, 0.518545, 0.525009, 0.518545,
0.499313, 0.467786, 0.424741, 0.371237, 0.308592, 0.238349,
0.162237, 0.082129, 0. ])
nt.assert_array_almost_equal(ans[0, ::], t1, 5)
nt.assert_array_almost_equal(ans[-1, ::], t2, 5)
print('Test case passed!!!')
# + deletable=false editable=false nbgrader={"checksum": "495335d8f982b660b798d1a08f0fbd20", "grade": true, "grade_id": "cell-238404d0090230b5", "locked": true, "points": 13, "schema_version": 1, "solution": false}
# Hidden test
# No output will be produced
# 13 marks
# + [markdown] deletable=false editable=false nbgrader={"checksum": "4200833bd7074f37bb73a1eceb877e31", "grade": false, "grade_id": "cell-a576a5b23ef4a45c", "locked": true, "schema_version": 1, "solution": false}
# ## Question 2
#
# Consider the differential equation given below:
# $$
# \frac{d^{2} u}{d x^{2}}+\frac{2}{x} \frac{d u}{d x}-\frac{2}{x^{2}} u-\sin (\log x)=0, \qquad a<x<b,\quad u(a)=\alpha \text { and } u(b)=\beta.
# $$
# Write a function which implements a finite difference scheme which is central difference in space. The function should return the final approximation `u`.
# + deletable=false nbgrader={"checksum": "43e576b7000054ecb398dcdfb99f8ad6", "grade": false, "grade_id": "cell-8ad504c2e44e6ea1", "locked": false, "schema_version": 1, "solution": true}
def ode(a, b, dx, alpha, beta):
# YOUR CODE HERE
raise NotImplementedError()
# + deletable=false editable=false nbgrader={"checksum": "ac2e36126d13a4e5caaed02566fde149", "grade": true, "grade_id": "cell-754490c6cadd3e4d", "locked": true, "points": 2, "schema_version": 1, "solution": false}
# Run this test cell to check your code
# Do not delete this cell
# 2 mark
# Unit test
a = 1
b = 2
dx = 1/10
alpha = 1
beta = 2
nt.assert_array_almost_equal(np.array([1. , 1.0843325, 1.1719112, 1.2627144, 1.35683 , 1.4544006,
1.5555929, 1.6605808, 1.7695365, 1.8826246, 2. ]), ode(a, b, dx, alpha, beta))
print('Test case passed!!!')
# + deletable=false editable=false nbgrader={"checksum": "f5ee1fb1b91abeb426138bc8633a09b8", "grade": true, "grade_id": "cell-6a784ddea5c8f259", "locked": true, "points": 13, "schema_version": 1, "solution": false}
# Hidden test
# No output will be produced
# 13 marks
| 2019/release/Lab0/lab0.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
from sklearn.datasets import load_iris
iris = load_iris()
# +
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# +
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2)
print(X_train.shape)
print(X_test.shape)
# -
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
y_predict = knn.predict(X_test)
from sklearn import metrics
print(metrics.accuracy_score(y_test,y_predict))
from sklearn.externals import joblib
joblib.dump(knn, 'mlbrain.joblib')
# +
model = joblib.load('mlbrain.joblib')
model.predict(X_test)
sample = [[3,5,4,2], [2,3,5,4]]
predictions = model.predict(sample)
pred_species = [iris.target_names[p] for p in predictions]
print('Predictions: ', pred_species)
# -
| machine_learning/data_science/Untitled.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
print('{:=^30}\n'.format('PRESTAÇÃO'))
valor = float(input('Digite o valor [R$]: '))
taxa = float(input('Digite a taxa [%]: '))
tempo = float(input('Digite o tempo {dias}: '))
prest = valor + (valor * (taxa/100) * tempo)
msg = f'{prest:_.2f}'
msg = msg.replace('.', ',').replace('_', '.')
print(f'A prestação é de R${msg}.')
| Python/livro_exercicios/capitulo03/item_e.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
print(type(52))
fitness = 'average'
print(type(fitness))
print(5-3)
print("hello"-"h")
full_name = 'Ahmed' + ' ' + 'Walsh'
print(full_name)
print(len(full_name))
print(len(52))
print(1+'2')
print(1+int('2'))
print(str(1)+'2')
print('half is', 1 /2.0)
print('three squared is', 3.0 ** 2)
first = 1
second = 5*first
first = 2
print('first', first, 'and second', second)
type(3.4)
type(3.25+4)
| workshop/W7-Python-part-I/swc-novice-inflammation/03-types-conversion.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.7.1 ('nskfv237')
# language: python
# name: python3
# ---
# +
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
# -
import os
os.cpu_count()
| mydebug.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# test pyspark type
sc.master[0:5]
# +
# choose data source
global Path
if sc.master[0:5]=="local":
Path = "file:/home/cloudera/als/"
else:
Path="/user/cloudera/als/"
# +
# loading csv & count all rdd
rawUserData = sc.textFile(Path + "ratings.csv")
rawUserData.count()
# +
# see data
rawUserData.take(10)
# +
# skip first row
header = rawUserData.first()
rawUserData = rawUserData.filter(lambda line:line != header)
rawUserData.take(10)
# +
# import Rating model
from pyspark.mllib.recommendation import Rating
# +
# choose 1-3 colume to Operation (list type)
rawRatings = rawUserData.map(lambda line:line.split(",")[:4])
rawRatings.take(10)
# -
type(rawRatings)
# +
# establish ratingsRDD (tuple type)
RatingsRDD = rawRatings.map(lambda x:(x[0],x[1],x[2]))
RatingsRDD.take(10)
# -
type(RatingsRDD)
# +
# count all rdd
numRatings = RatingsRDD.count()
numRatings
# +
# count unique user
numUsers = RatingsRDD.map(lambda x:x[0]).distinct().count()
numUsers
# +
# count unique movie
numMovies = RatingsRDD.map(lambda x:x[1]).distinct().count()
numMovies
# +
# import ALS model
from pyspark.mllib.recommendation import ALS
# +
# import os
# os.environ["PYSPARK_PYTHON"] = os.environ["CONDA_DIR"] + "/envs/python2/bin/python2"
# +
# Explicit rating
# ALS.train(ratings, rank, iteration=5(default), lambda_=0.01(default))
# return "MatrixFactorizationModel"
# import numpy
model = ALS.train(RatingsRDD, 10, 10, 0.01)
print model
# -
# Implicit rating
# ALS.trainImplicit(ratings, rank, iteration=5(default), lambda_=0.01(default))
# return "MatrixFactorizationModel"
type(model)
# +
# Recommend Movies
# model.recommendProducts(user_id, recommend_movie_num)
model.recommendProducts(100,5)
# +
# Recommend Movie Points
# model.predict(user_id, recommend_movie_id)
model.predict(100,1141)
# +
# Recommend Users
# model.recommendUsers(product_id, recommend_user_num)
model.recommendUsers(product = 200, num = 5)
# +
# show movie name
itemRDD = sc.textFile(Path+"movies.csv")
itemRDD.take(5)
# itemRDD.count()
# +
# skip first row
header = itemRDD.first()
itemRDD = itemRDD.filter(lambda line: line != header)
# type(itemRDD)
itemRDD.take(5)
# itemRDD.count()
# +
# dict with movie id & movie name
movieTitle = itemRDD.map(lambda line: line.split(",")) \
.map(lambda a: (float(a[0]),a[1])) \
.collectAsMap()
# <note> u'' is str
# movieTitle = itemRDD.map(lambda line: line.split(",")) \
# .map(lambda a: (a[0],a[1])) \
# .collectAsMap()
# movieTitle
type(movieTitle)
# len(movieTitle)
# movieTitle[150000]
# movieTitle[6]
# +
# type list
movieTitle.items()[ :6]
# movieTitle.items()
# type(movieTitle.items())
# +
recommendP = model.recommendProducts(100,5)
for row in recommendP:
# print row
print "target user: " + str(row[0]) + " " + \
"recommend movie: "+ str(movieTitle[row[1]]) + " " + \
"point: " + str(row[2])
# type(recommendP)
# -
| spark-mllib/recommendation_ALS.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [default]
# language: python
# name: python3
# ---
# +
import astropy.coordinates as coord
import astropy.units as u
from astropy.table import Table, join, vstack
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
# %matplotlib inline
from astropy.io import ascii
from scipy.interpolate import interp1d
from scipy.stats import binned_statistic
import gala.coordinates as gc
import gala.dynamics as gd
from gala.units import galactic
from pyia import GaiaData
# -
g = GaiaData('/Users/adrian/data/APOGEE_DR15beta/allStar-t9-l31c-58158-with-gaiadr2.fits')
len(g)
galcen = coord.Galactocentric(galcen_distance=8.1*u.kpc, z_sun=0*u.pc)
# ---
orp_rrl = Table.read('/Users/adrian/Downloads/gdr2_orphan_sergey.fits')
rrl_c = coord.SkyCoord(ra=orp_rrl['ra']*u.deg,
dec=orp_rrl['dec']*u.deg,
distance=orp_rrl['heldist']*u.kpc,
pm_ra_cosdec=orp_rrl['pmra'] * u.mas/u.yr,
pm_dec=orp_rrl['pmdec'] * u.mas/u.yr,
radial_velocity=0*u.km/u.s)
# ### Polygonal selections in each observable:
model_c = rrl_c.transform_to(gc.KoposovOrphan)
model_phi1 = model_c.phi1.wrap_at(180*u.deg)
# +
plt.scatter(model_c.phi1.wrap_at(180*u.deg).degree,
model_c.phi2)
phi2_poly = np.poly1d(np.polyfit(model_c.phi1.wrap_at(180*u.deg).degree,
model_c.phi2, deg=3))
_grid = np.linspace(-170, 100, 32)
plt.plot(_grid, phi2_poly(_grid), marker='')
plt.xlim(-180, 180)
plt.ylim(-20, 20)
_l = np.vstack((_grid, phi2_poly(_grid) - 10)).T
_r = np.vstack((_grid, phi2_poly(_grid) + 5)).T
phi12_poly = np.vstack((_l, _r[1:][::-1]))
plt.plot(phi12_poly[:, 0], phi12_poly[:, 1], marker='')
# +
plt.scatter(model_c.pm_phi1_cosphi2, model_c.pm_phi2)
pm_poly = np.array([[-1.5, 2.],
[4, 3],
[5, 1.5],
[4, 0.7],
[3, 0],
[-1, -1]])
plt.plot(pm_poly[:, 0], pm_poly[:, 1])
plt.xlabel(r'$\mu_1$')
plt.ylabel(r'$\mu_2$')
# -
# ---
#
# # APOGEE
# +
c = g.get_skycoord(distance=8*u.kpc,
radial_velocity=np.array(g.VHELIO_AVG)*u.km/u.s)
stream_c = c.transform_to(gc.KoposovOrphan)
apogee_phi1 = stream_c.phi1.wrap_at(180*u.deg)
apogee_phi2 = stream_c.phi2
apogee_mask = ((apogee_phi1 > -100*u.deg) & (apogee_phi1 < 20*u.deg) &
(apogee_phi2 > -10*u.deg) & (apogee_phi2 < 5*u.deg))
stream_c = stream_c[apogee_mask]
apogee_phi1 = stream_c.phi1.wrap_at(180*u.deg)
apogee_phi2 = stream_c.phi2
apogee_pm1 = stream_c.pm_phi1_cosphi2.to(u.mas/u.yr)
apogee_pm2 = stream_c.pm_phi2.to(u.mas/u.yr)
# -
phi12_mask = mpl.patches.Path(phi12_poly).contains_points(np.vstack((apogee_phi1, apogee_phi2)).T)
pm_mask = mpl.patches.Path(pm_poly).contains_points(np.vstack((apogee_pm1, apogee_pm2)).T)
# rv_mask = mpl.patches.Path(rv_poly).contains_points(np.vstack((apogee_phi1, g.VHELIO_AVG[apogee_mask])).T)
rv_mask = np.ones(len(pm_mask), dtype=bool)
kin_mask = phi12_mask & pm_mask & rv_mask
phi12_mask.sum(), pm_mask.sum(), rv_mask.sum(), kin_mask.sum()
# +
fig, ax = plt.subplots(1, 1, figsize=(15, 3))
ax.plot(apogee_phi1[phi12_mask], apogee_phi2[phi12_mask],
marker='o', color='k', ms=2,
ls='none', alpha=0.5)
ax.set_xlim(-180, 100)
ax.set_ylim(-20, 10)
ax.set_aspect('equal')
ax.set_xlabel(r'$\phi_1$')
ax.set_ylabel(r'$\phi_2$')
fig.tight_layout()
# -
feh_mask = (g.M_H[apogee_mask] < -1) & (g.M_H[apogee_mask] > -2.5)
gd1_full_mask = kin_mask & feh_mask
gd1_full_mask.sum()
# +
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
ax.plot(apogee_phi1[gd1_full_mask],
g.VHELIO_AVG[apogee_mask][gd1_full_mask],
marker='o', color='k', ms=2,
ls='none', alpha=0.5)
ax.set_xlim(-180, 100)
# ax.set_ylim(-20, 10)
# ax.set_aspect('equal')
ax.set_xlabel(r'$\phi_1$')
# ax.set_ylabel(r'$\phi_2$')
fig.tight_layout()
# +
fig, ax = plt.subplots(1, 1, figsize=(6, 5))
ax.errorbar(g.M_H[apogee_mask][gd1_full_mask],
g.ALPHA_M[apogee_mask][gd1_full_mask],
xerr=g.M_H_ERR[apogee_mask][gd1_full_mask],
yerr=g.ALPHA_M_ERR[apogee_mask][gd1_full_mask],
marker='o', ls='none', color='tab:red',
label='GD-1?', zorder=100)
H, xe, ye = np.histogram2d(g.M_H[apogee_mask][phi12_mask],
g.ALPHA_M[apogee_mask][phi12_mask],
bins=(np.arange(-3, 0+1e-3, 0.05),
np.arange(-1, 1+1e-3, 0.05)))
ax.pcolormesh(xe, ye, H.T, cmap='Greys', zorder=-100,
norm=mpl.colors.LogNorm())
ax.set_xlim(-3, 0)
ax.set_ylim(-1, 1)
ax.legend(loc='lower left', fontsize=16)
ax.set_xlabel('[M/H]')
ax.set_ylabel(r'[$\alpha$/M]')
ax.set_title('APOGEE')
fig.set_facecolor('w')
# -
| notebooks/Orphan-all-fields.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Noise Removal (remoção de ruído)
#
# ## Conteúdo
#
# - 01 - Introdução ao Noise Removal
# - 02 - Introdução ao método sub() da biblioteca re (regular expression)
# - 03 - Removendo espaços em branco
# - 04 - Removendo pontuações
# ## 01 - Introdução ao Noise Removal
#
# > No processamento de linguagem natural, o **Noise Removal (remoção de ruído)** é uma tarefa de pré-processamento de texto dedicada a retirar a formatação do texto.
#
# A limpeza de texto é uma técnica que os desenvolvedores usam em vários domínios. Dependendo do objetivo do seu projeto e de onde você obtém seus dados, você pode remover informações indesejadas, como:
#
# - Pontuação e acentos;
# - Caracteres especiais;
# - Dígitos numéricos;
# - Espaço em branco inicial, final e vertical
# - Formatação HTML
# ## 02 - Introdução ao método sub() da biblioteca re (regular expression)
#
# Removendo informações indesejadas com o método sub()
#
# Felizmente, você pode usar o método **.sub()** da rebiblioteca **re (regular expression)** do Python para a maioria das suas necessidades de **Noise Removal (remoção de ruído)**.
#
# O método **sub()** tem três argumentos obrigatórios:
#
# - **pattern:**
# - Uma expressão regular que é pesquisada na string de entrada. Deve haver um **"r"** precedente da string para indicar que é uma string bruta, que trata as barras invertidas como caracteres literais.
# - **replacement_text:**
# - Texto que substitui todas as correspondências na string de entrada.
# - **input:**
# - A string de entrada que será editada pelo método **sub()**.
#
# O método retorna uma string com todas as instâncias de **pattern** substituídas por **replacement_text**. Vejamos alguns exemplos de como usar esse método para remover e substituir texto de uma string.
# ## 03 - Removendo espaços em branco
#
# A seguir, vamos remover o espaço em branco do início de um texto. Para esse nosso primeiro exemplo, vamos excluir 4 espaços em brancos do início de um texto:
# +
import re
text = " This is a paragraph"
result = re.sub(r'\s{4}', '', text)
print(result)
# -
# **NOTE:**
# Veja que com o método **sub()** e uma **Expressão Regular** simples nós conseguimos *remover 4 caracteres em branco.*.
# ## 04 - Removendo pontuações
#
# > Ok, mas como eu posso remover pontuações indesejadas?
#
# Veja o código abaixo:
# +
import re
text = "Five fantastic fish flew off to find faraway functions. Maybe find another five fantastic fish? Find my fish with a function please!"
print("Original text:", text)
# Remove punctuation.
result = re.sub(r'[\.\?\!\,\:\;\"]', '', text)
print("Noise Removal: ", result)
# -
# **NOTE:**
# Veja que nesse processo simples de **Noise Removal** nós removemos pontuações predefinidas do texto.
# ---
#
# **REFERÊNCIAS:**
# [CodeAcademy - Text Preprocessing](https://www.codecademy.com/learn/text-preprocessing)
#
# ---
#
# **<NAME> -** *drigols*
| modules/ai-codes/modules/preprocessing/noise-removal.ipynb |
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: SageMath 9.0
# language: sage
# name: sagemath
# ---
# # Calculando o $\mathcal{R}_0$ para o Modelo SEIAHR
# Neste notebook vamos aprender a como utilizar o méto da matriz de próxima geração para calcular o $\mathcal{R}_0$.
# ## SEIAR Model for COVID-19
#
# Neste notebook está implementado um modelo SEIAR com quarentena implícita. Que inclui também assintomáticos e hospitalizações. Veja o Suplemento 2 para maiores detalhes sobre este modelo.
#
# Seja $\lambda=\beta(I+A)$ a força de infeção da doença.
#
# \begin{align}
# \frac{dS}{dt}&=-\lambda (1-\chi) S\\
# \frac{dE}{dt}&= \lambda (1-\chi) S-\alpha E\\
# \frac{dI}{dt}&= (1-p)\alpha E - \delta I\\
# \frac{dA}{dt}&= p\alpha E - \delta A\\
# \frac{dH}{dt}&= \phi \delta I -(\rho+\mu) H\\
# \frac{dR}{dt}&= (1-\phi)\delta I + \rho H+\delta A
# \end{align}
#
# onde $\chi$ é a fração dos suscetíveis em quarentena (distanciamento social)
import sympy
# #%typeset_mode True
# %display typeset
var('S E I A H Lambda beta chi alpha p phi delta rho mu')
# Para esta análise podemos ignorar o compartimento dos Recuperados pois é desacoplado da dinâmica.
Lambda = beta*(I+A)
dsdt = -Lambda*(1-chi)*S
dedt = Lambda*(1-chi)*S - alpha*E
didt = (1-p)*alpha*E -delta*I
dadt = p*alpha*E - delta*A
dhdt = phi*delta*I-(rho+mu)*H
# ## Equilibrios
# Naturalmente para este sistema só conseguimos achar o equilíbrio livre-de-doença.
solve([dsdt,dedt,didt,dadt,dhdt],[S,E,I,A,H])
# ## Matriz Jacobiana
jack=jacobian([dsdt,dedt,didt,dadt,dhdt],[S,E,I,A,H])
jack
cp = jack.characteristic_polynomial()
cp
jack.eigenvalues()
# ## Calculo do $\mathcal{R}_0$
# O método que iremos utilizar foi proposto por <NAME> no seguinte artigo:
#
# [Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission](https://pdfs.semanticscholar.org/3cf7/1968a86800215b4e129ec3eda67520832cf0.pdf)
#
#
#
# Seja $X=(x_1,\ldots, x_n)^t$, tal que $x_i\geq 0$, o número de indivíduos em cada compartimento.
#
# Vamos definir $X_s$ como o conjunto de todos os estados livres de doença.
#
# $$X_s=\{x \geq 0|x_i=0, i=1\ldots,m\}$$
#
#
#
# Supõe-se que cada função é continuamente diferenciável pelo menos duas vezes ($C^2$) em cada variável. As equações são reordenadas para que as $m$ primeiras equação sejam aquelas que contém infectados. Seja ${\cal F}_i(x)$ a taxa de aparecimento de novas infecções no compartimento $i$, ${\cal V}_i^+(x)$ a taxa de entrada de indivíduos no compartimento $i$ por outros meios e ${\cal V}_i^-(x)$ a taxa de saída de indivíduos do compartimento $i$. O modelo de transmissão da doença consiste em condições iniciais não negativas juntamente com o seguinte sistema de equações:
#
# $\dot{x}=f_i(x)={\cal F}_i(x)-{\cal V}_i(x), i=1\ldots, n$
#
# onde, ${\cal V}_i (x) = {\cal V}_i(x)^{-} - {\cal V}_i(x)^+$ e as funções satisfazem os pressupostos (A1) - (A5) descritos abaixo. Desde que cada função representa uma transferência dirigida de indivíduos, todos elas são não-negativos.
#
# (A1) Se $x \geq 0 $, então ${\cal F}_i, {\cal V}_i^+, {\cal V}_i ^- \geq 0$ para $i=1, \ldots, n$
#
# ou seja, se um compartimento estiver vazio, não pode haver saída de indivíduos deste, por morte, infecção ou qualquer outro meio.
#
# (A2) Se $x_i=0$ então ${\cal V}_i^-(x)=0$. Em particular, se $x \in X_s$, então ${\cal V}_i^-(x)=0$ para $i=1,\ldots, m$
#
# (A3) ${\cal F}_i=0$ se $i>m$
#
# (A4) Se $x \in X_S$, então ${\cal F}_i(x) = 0$ e ${\cal V}_i^+(x)=0$ para $i=1,\ldots, m$
#
# (A5) Se ${\cal F}(x)$ é um vetor nulo, então todos os autovalores de $Df(x_0)$ tem parte real negativa.
#
# ---
#
# Para calcular o $R_0$ é importante distinguir as novas infecções de todas as outras mudanças na população. No modelo proposto, os compartimentos que correspondem aos indivíduos infectados são $E$, $I$ E $A$, portanto, ${\bf m=3}$. A fim de clareza, vamos ordenar os $n=5$ compartimentos da seguinte forma: $[E, I, A, H, S]$, separando os $m$ primeiros compartimentos do restante. Vale ressaltar que as transferências dos compartimentos expostos para os infectados e Assintomáticos e de infectados para Hospitalizados não são consideradas novas infecções, mas sim a progressão de um indivíduo infectado através dos vários compartimentos. Portanto,
#
# $$ {\cal F}_i(x): \text{ taxa de surgimento de novos infectados no compartimento } i $$
#
#
# $$ {\cal F} =\begin{bmatrix}
# \Lambda(1-\chi) S\\
# 0\\
# 0\\
# \end{bmatrix} $$
#
#
# Onde, ${\color{red}\Lambda=\beta(I+A)}$.
F_cal = matrix([[Lambda*(1-chi)*S],[0],[0]])
F_cal
#
#
# Além disso, temos
#
# $$ {\cal V}_i(x)^-: \text{ taxa de saída do compartimento } i $$
#
# $$ {\cal V}_i(x)^+: \text{ taxa de entrada do compartimento } i $$
#
# Logo,
#
# $$
# \begin{equation}
# {\cal V^-} = \begin{bmatrix}
# \alpha E\\
# \delta I\\
# \delta A
# \end{bmatrix}
# \end{equation}
# $$
# $$
# \begin{equation}
# \qquad {\cal V^+} = \begin{bmatrix}
# 0\\
# (1-p) \alpha E\\
# p \alpha E\\
# \end{bmatrix}
# \end{equation}
# $$
V_cal_neg = matrix([[alpha*E],[delta*I],[delta*A]])
V_cal_neg
V_cal_pos = matrix([[0],[(1-p)*alpha*E],[p*alpha*E]])
V_cal_pos
#
#
# $${\cal V}_i (x) = {\cal V}_i(x)^{-} - {\cal V}_i(x)^+$$
#
# Então,
# \begin{equation}
# {\cal V} =
# \begin{bmatrix}
# \alpha E\\
# (p-1)\alpha E+\delta I\\
# -p\alpha E+ \delta A\\
# \end{bmatrix}
# \end{equation}
V_cal = V_cal_neg-V_cal_pos
V_cal
# Definimos também $F=\left[\frac{\partial {\cal F}_i (x_0)}{\partial x_j}\right]$ e $V=\left[\frac{\partial {\cal V}_i (x_0) }{\partial x_j}\right]$, onde $x_0$ é um DFE e $1\leq i,j \leq m$.
#
# Isto equivale à jacobiana destas duas matrizes, após substituir $x_0$ ou seja, $S=1$.
F = jacobian(F_cal(S=1),[E,I,A])
F
V = jacobian(V_cal(S=1),[E,I,A])
V
# ${\cal R}_0 = \rho (FV^{-1})$
M= F*V.inverse()
M=M.simplify_full()
M
# Since only the first row of $M$ is non-zero, all but one of the eigenvalues is $0$ and the dominant eigenvalue or spectral radius is $M_{11}$, thus
R0=M[0,0].simplify_full()
R0
R0.variables()
show('$R_t=$')
Rt = M[0,0]
Rt
print(Rt)
plot(R0(chi=0.3,phi=.1,rho=.6,delta=.1,alpha=.3, p=.75),(beta,0.01,0.32))
R0(chi=0.1,phi=.1,rho=.6,delta=.1,alpha=10, p=.75,beta=.5)
plot(Rt(chi=0.3,phi=.1,rho=.6,delta=.1,alpha=10,beta=.2, p=.75),(S,0,1))
| Planilhas Sage/Aula 9 - Calculo do R0.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Original OpenCV Image
from cv2_plt_imshow import cv2_plt_imshow
import cv2
import numpy as np
image_num="000072"
img = cv2.imread(f"logs/segmentation_results/{image_num}_image.png")
cv2_plt_imshow(img)
def infer_cv2_image(sess_ort, img):
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
np_img = img_rgb.reshape((1,*img_rgb.shape))
res = sess_ort.run(output_names=["output:0"], input_feed={"input_rgb:0": np_img.astype(np.float32)})
seg=res[0].astype(np.uint8).squeeze()
return seg
# # Inference on RGB image
#seg = cv2.imread(f"logs/segmentation_results/{image_num}_raw_prediction.png",cv2.IMREAD_GRAYSCALE)
import onnxruntime as ort
sess_ort = ort.InferenceSession("./output/segmentation.onnx")
seg = infer_cv2_image(sess_ort, img)
#img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cv2_plt_imshow(cv2.applyColorMap(seg*64, cv2.COLORMAP_JET))
def get_lines_mask(seg):
yellow = (seg==1).astype(np.uint8)
white = (seg==2).astype(np.uint8)
return yellow, white
yellow, white = get_lines_mask(seg)
class Point:
"""
Point class. Convenience class for storing ROS-independent 3D points.
"""
def __init__(self, x=None, y=None, z=None):
self.x = x #: x-coordinate
self.y = y #: y-coordinate
self.z = z #: z-coordinate
@staticmethod
def from_message(msg):
"""
Generates a class instance from a ROS message. Expects that the message has attributes ``x`` and ``y``.
If the message additionally has a ``z`` attribute, it will take it as well. Otherwise ``z`` will be set to 0.
Args:
msg: A ROS message or another object with ``x`` and ``y`` attributes
Returns:
:py:class:`Point` : A Point object
"""
x = msg.x
y = msg.y
try:
z = msg.z
except AttributeError:
z = 0
return Point(x, y, z)
def __str__(self):
return f"{self.x}, {self.y}, {self.z}"
# +
class GroundProjectionGeometry:
"""
Handles the Ground Projection operations.
Note:
All pixel and image operations in this class assume that the pixels and images are *already rectified*! If
unrectified pixels or images are supplied, the outputs of these operations will be incorrect!
Args:
im_width (``int``): Width of the rectified image
im_height (``int``): Height of the rectified image
homography (``int``): The 3x3 Homography matrix
"""
def __init__(self, im_width, im_height, homography):
self.im_width = im_width
self.im_height = im_height
self.H = np.array(homography).reshape((3, 3))
self.Hinv = np.linalg.inv(self.H)
def vector2pixel(self, vec):
"""
Converts a ``[0,1] X [0,1]`` representation to ``[0, W] X [0, H]`` (from normalized to image coordinates).
Args:
vec (:py:class:`Point`): A :py:class:`Point` object in normalized coordinates. Only the ``x`` and ``y`` values are used.
Returns:
:py:class:`Point` : A :py:class:`Point` object in image coordinates. Only the ``x`` and ``y`` values are used.
"""
x = self.im_width * vec.x
y = self.im_height * vec.y
return Point(x, y)
def pixel2vector(self, pixel):
"""
Converts a ``[0,W] X [0,H]`` representation to ``[0, 1] X [0, 1]`` (from image to normalized coordinates).
Args:
vec (:py:class:`Point`): A :py:class:`Point` object in image coordinates. Only the ``x`` and ``y`` values are used.
Returns:
:py:class:`Point` : A :py:class:`Point` object in normalized coordinates. Only the ``x`` and ``y`` values are used.
"""
x = pixel.x / self.im_width
y = pixel.y / self.im_height
return Point(x, y)
def pixel2ground(self, pixel):
"""
Projects a normalized pixel (``[0, 1] X [0, 1]``) to the ground plane using the homography matrix.
Args:
pixel (:py:class:`Point`): A :py:class:`Point` object in normalized coordinates. Only the ``x`` and ``y`` values are used.
Returns:
:py:class:`Point` : A :py:class:`Point` object on the ground plane. Only the ``x`` and ``y`` values are used.
"""
uv_raw = np.array([pixel.x, pixel.y, 1.0])
ground_point = np.dot(self.H, uv_raw)
point = Point()
x = ground_point[0]
y = ground_point[1]
z = ground_point[2]
point.x = x / z
point.y = y / z
point.z = 0.0
return point
def ground2pixel(self, point):
"""
Projects a point on the ground plane to a normalized pixel (``[0, 1] X [0, 1]``) using the homography matrix.
Args:
point (:py:class:`Point`): A :py:class:`Point` object on the ground plane. Only the ``x`` and ``y`` values are used.
Returns:
:py:class:`Point` : A :py:class:`Point` object in normalized coordinates. Only the ``x`` and ``y`` values are used.
Raises:
ValueError: If the input point's ``z`` attribute is non-zero. The point must be on the ground (``z=0``).
"""
if point.z != 0:
msg = 'This method assumes that the point is a ground point (z=0). '
msg += 'However, the point is (%s,%s,%s)' % (point.x, point.y, point.z)
raise ValueError(msg)
ground_point = np.array([point.x, point.y, 1.0])
image_point = np.dot(self.Hinv, ground_point)
image_point = image_point / image_point[2]
pixel = Point()
pixel.x = image_point[0]
pixel.y = image_point[1]
return pixel
# -
import os, yaml
def load_extrinsics():
"""
Loads the homography matrix from the extrinsic calibration file.
Returns:
:obj:`numpy array`: the loaded homography matrix
"""
# load intrinsic calibration
cali_file = "default_homography.yaml"
# Locate calibration yaml file or use the default otherwise
if not os.path.isfile(cali_file):
self.log("Can't find calibration file: %s.\n Using default calibration instead."
% cali_file, 'warn')
cali_file = (cali_file_folder + "default.yaml")
# Shutdown if no calibration file not found
if not os.path.isfile(cali_file):
msg = 'Found no calibration file ... aborting'
self.log(msg, 'err')
rospy.signal_shutdown(msg)
try:
with open(cali_file,'r') as stream:
calib_data = yaml.load(stream)
except yaml.YAMLError:
msg = 'Error in parsing calibration file %s ... aborting' % cali_file
self.log(msg, 'err')
rospy.signal_shutdown(msg)
return calib_data['homography']
homography = load_extrinsics()
homography = np.array(homography).reshape((3, 3))
gpg = GroundProjectionGeometry(160,120, homography)
# +
yellow_points=None
if len(contours_yellow)>0:
yellow_points = np.vstack(contours_yellow).reshape(-1,2)
#yellow_points[:,1] = -yellow_points[:,1] + yellow.shape[0]
yellow_points_norm = yellow_points.copy().astype(float)
#yellow_points_norm[:,0]=yellow_points[:,0].astype(float)/160
#yellow_points_norm[:,1]=yellow_points[:,1].astype(float)/120
# -
def get_line_segments_px(mask):
contours,hierarchy = cv2.findContours(mask, 1, cv2.CHAIN_APPROX_SIMPLE )
segments_px = []
for cnt in contours:
i=0
pt1=None
pt2=None
for point in cnt:
if i==0:
pt1 = tuple(point[0])
i=1
continue
if i==1:
pt2 = tuple(point[0])
segment = (pt1, pt2)
segments_px.append(segment)
i=0
continue
return segments_px
#segment = ((cnt[]))
yellow_segments_px = get_line_segments_px(yellow)
white_segments_px = get_line_segments_px(white)
def ground_project_segments_px(segments_px):
x=[]
y=[]
segments=[]
for segment_px in segments_px:
pixel1 = Point(segment_px[0][0]*4,segment_px[0][1]*4) #Conversion. Points are converted in 640x480 for the homography to work
pixel2 = Point(segment_px[1][0]*4,segment_px[1][1]*4) #Conversion. Points are converted in 640x480 for the homography to work
ground_projected_point1 = gpg.pixel2ground(pixel1)
ground_projected_point2 = gpg.pixel2ground(pixel2)
pt1 = (ground_projected_point1.x, ground_projected_point1.y)
pt2 = (ground_projected_point2.x, ground_projected_point2.y)
segment = (pt1,pt2)
segments.append(segment)
return segments
segments = ground_project_segments_px(white_segments_px)
x=[]
y=[]
for segment in segments:
x.append(segment[0][0])
x.append(segment[1][0])
y.append(segment[0][1])
y.append(segment[1][1])
import matplotlib.pyplot as plt
plt.scatter(x,y)
plt.xlim([0,1])
plt.ylim([-1,1])
plt.show()
| follow_point_ground_projected.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/AndrewSLowe/DS-Unit-2-Kaggle-Challenge/blob/master/module1/1_2_1A_kaggle_challenge_1.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] colab_type="text" id="7IXUfiQ2UKj6"
# Lambda School Data Science, Unit 2: Predictive Modeling
#
# # Kaggle Challenge, Module 1
#
# ## Assignment
# - [ ] Do train/validate/test split with the Tanzania Waterpumps data.
# - [ ] Define a function to wrangle train, validate, and test sets in the same way. Clean outliers and engineer features. (For example, [what other columns have zeros and shouldn't?](https://github.com/Quartz/bad-data-guide#zeros-replace-missing-values) What other columns are duplicates, or nearly duplicates? Can you extract the year from date_recorded? Can you engineer new features, such as the number of years from waterpump construction to waterpump inspection?)
# - [ ] Select features. Use a scikit-learn pipeline to encode categoricals, impute missing values, and fit a decision tree classifier.
# - [ ] Get your validation accuracy score.
# - [ ] Get and plot your feature importances.
# - [ ] Submit your predictions to our Kaggle competition. (Go to our Kaggle InClass competition webpage. Use the blue **Submit Predictions** button to upload your CSV file. Or you can use the Kaggle API to submit your predictions.)
# - [ ] Commit your notebook to your fork of the GitHub repo.
#
#
# ## Stretch Goals
#
# ### Reading
#
# - A Visual Introduction to Machine Learning
# - [Part 1: A Decision Tree](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/)
# - [Part 2: Bias and Variance](http://www.r2d3.us/visual-intro-to-machine-learning-part-2/)
# - [Decision Trees: Advantages & Disadvantages](https://christophm.github.io/interpretable-ml-book/tree.html#advantages-2)
# - [How a Russian mathematician constructed a decision tree — by hand — to solve a medical problem](http://fastml.com/how-a-russian-mathematician-constructed-a-decision-tree-by-hand-to-solve-a-medical-problem/)
# - [How decision trees work](https://brohrer.github.io/how_decision_trees_work.html)
# - [Let’s Write a Decision Tree Classifier from Scratch](https://www.youtube.com/watch?v=LDRbO9a6XPU) — _Don’t worry about understanding the code, just get introduced to the concepts. This 10 minute video has excellent diagrams and explanations._
# - [Random Forests for Complete Beginners: The definitive guide to Random Forests and Decision Trees](https://victorzhou.com/blog/intro-to-random-forests/)
#
#
# ### Doing
# - [ ] Add your own stretch goal(s) !
# - [ ] Try other [scikit-learn imputers](https://scikit-learn.org/stable/modules/impute.html).
# - [ ] Make exploratory visualizations and share on Slack.
#
#
# #### Exploratory visualizations
#
# Visualize the relationships between feature(s) and target. I recommend you do this with your training set, after splitting your data.
#
# For this problem, you may want to create a new column to represent the target as a number, 0 or 1. For example:
#
# ```python
# train['functional'] = (train['status_group']=='functional').astype(int)
# ```
#
#
#
# You can try [Seaborn "Categorical estimate" plots](https://seaborn.pydata.org/tutorial/categorical.html) for features with reasonably few unique values. (With too many unique values, the plot is unreadable.)
#
# - Categorical features. (If there are too many unique values, you can replace less frequent values with "OTHER.")
# - Numeric features. (If there are too many unique values, you can [bin with pandas cut / qcut functions](https://pandas.pydata.org/pandas-docs/stable/getting_started/basics.html?highlight=qcut#discretization-and-quantiling).)
#
# You can try [Seaborn linear model plots](https://seaborn.pydata.org/tutorial/regression.html) with numeric features. For this classification problem, you may want to use the parameter `logistic=True`, but it can be slow.
#
# You do _not_ need to use Seaborn, but it's nice because it includes confidence intervals to visualize uncertainty.
#
# #### High-cardinality categoricals
#
# This code from a previous assignment demonstrates how to replace less frequent values with 'OTHER'
#
# ```python
# # Reduce cardinality for NEIGHBORHOOD feature ...
#
# # Get a list of the top 10 neighborhoods
# top10 = train['NEIGHBORHOOD'].value_counts()[:10].index
#
# # At locations where the neighborhood is NOT in the top 10,
# # replace the neighborhood with 'OTHER'
# train.loc[~train['NEIGHBORHOOD'].isin(top10), 'NEIGHBORHOOD'] = 'OTHER'
# test.loc[~test['NEIGHBORHOOD'].isin(top10), 'NEIGHBORHOOD'] = 'OTHER'
# ```
#
# + colab_type="code" id="o9eSnDYhUGD7" colab={"base_uri": "https://localhost:8080/", "height": 224} outputId="b9db30b7-5b2f-4f1d-8520-4310a6d6b6bc"
import sys
# If you're on Colab:
if 'google.colab' in sys.modules:
DATA_PATH = 'https://raw.githubusercontent.com/LambdaSchool/DS-Unit-2-Kaggle-Challenge/master/data/'
# !pip install category_encoders==2.*
# If you're working locally:
else:
DATA_PATH = '../data/'
# + colab_type="code" id="QJBD4ruICm1m" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="aec52802-6d5f-4404-d779-41a9e6e639ba"
import pandas as pd
from sklearn.model_selection import train_test_split
train = pd.merge(pd.read_csv(DATA_PATH+'waterpumps/train_features.csv'),
pd.read_csv(DATA_PATH+'waterpumps/train_labels.csv'))
test = pd.read_csv(DATA_PATH+'waterpumps/test_features.csv')
sample_submission = pd.read_csv(DATA_PATH+'waterpumps/sample_submission.csv')
train.shape, test.shape
# + colab_type="code" id="2Amxyx3xphbb" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="1a979aa5-18a5-442a-8b54-cf6c16528f23"
train, val = train_test_split(train,train_size=.80, test_size=.20,
stratify=train['status_group'], random_state=42)
train.shape, val.shape, test.shape
# + id="KFI3phXJ3dxr" colab_type="code" colab={}
import numpy as np
# + id="4pq1ajQf18YP" colab_type="code" colab={}
def wrangle(X):
"""Wrangle train, validate, and test sets in the same way"""
# Prevent SettingWithCopyWarning
X = X.copy()
# About 3% of the time, latitude has small values near zero,
# outside Tanzania, so we'll treat these values like zero.
X['latitude'] = X['latitude'].replace(-2e-08, 0)
# When columns have zeros and shouldn't, they are like null values.
# So we will replace the zeros with nulls, and impute missing values later.
cols_with_zeros = ['longitude', 'latitude']
for col in cols_with_zeros:
X[col] = X[col].replace(0, np.nan)
# quantity & quantity_group are duplicates, so drop one
X = X.drop(columns=['quantity_group'])
# return the wrangled dataframe
X['gps_height'] = X['gps_height'].mask(X['gps_height'] < 0, 0)
cols_with_zeros = ['gps_height', 'longitude', 'latitude', 'amount_tsh', 'num_private', 'population', 'construction_year']
for col in cols_with_zeros:
X[col] = X[col].replace(0, np.nan)
return X
# + id="OeNwjFEqKdWY" colab_type="code" colab={}
train = wrangle(train)
val = wrangle(val)
test = wrangle(test)
# + id="ChYGZ17dQove" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 102} outputId="227af1e3-4cd4-470c-cf37-54d7bb290dee"
train['status_group'].describe()
# + id="JGnN83TTQgQ6" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 227} outputId="6b135b39-008f-4f09-bff6-0e6029567639"
train.describe(exclude='number')
# + id="tzXzJ4Yz3c14" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 54} outputId="8d7151cb-7c67-4d42-b506-f8d26896e56e"
# The status_group column is the target
target = 'status_group'
# Get a dataframe with all train columns except the target & id
train_features = train.drop(columns=[target, 'id'])
#Dropped the duplicate columns
train_features = train_features.drop(columns=['extraction_type_group',
'extraction_type_class', 'management_group', 'source_class', 'waterpoint_type_group'])
# Get a list of the numeric features
numeric_features = train_features.select_dtypes(include='number').columns.tolist()
# Get a series with the cardinality of the nonnumeric features
cardinality = train_features.select_dtypes(exclude='number').nunique()
# Get a list of all categorical features with cardinality <= 50
categorical_features = cardinality[cardinality <= 50].index.tolist()
# Combine the lists
features = numeric_features + categorical_features
print(features)
# + id="rChr_zMR3nRR" colab_type="code" colab={}
X_train = train[features]
y_train = train[target]
X_val = val[features]
y_val = val[target]
X_test = test[features]
# + id="9FHRyvDYGUdZ" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="0a609602-4cf1-4387-9014-2c2845ffb5ba"
import category_encoders as ce
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
pipeline = make_pipeline(
ce.OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
StandardScaler(),
LogisticRegression(multi_class='auto', solver='lbfgs', n_jobs=-1) #n_jobs is the number of cpu cores used when parallelizing (-1 is all cores)
)
#dir(pipeline) #This tells us about the methods and parameters for pipeline.
# Fit on train
pipeline.fit(X_train, y_train)
# Score on val
print('Validation Accuracy', pipeline.score(X_val, y_val)) #Calling the transformed version of onehotenocder, simpleimputer standardscaler and logreg in the same way as on train sets.
# Predict on test
y_pred = pipeline.predict(X_test)
# + id="vFNXWCBOSn9t" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="c6a77605-0e22-4e77-c68a-b50cfe26ff47"
from sklearn.tree import DecisionTreeClassifier
#Only two changes from previous code: change logreg to DecisionTreeClassifier and took out imputer.
pipeline = make_pipeline(
ce.OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
DecisionTreeClassifier(random_state=42) #n_jobs is the number of cpu cores used when parallelizing (-1 is all cores)
)
#dir(pipeline) #This tells us about the methods and parameters for pipeline.
# Fit on train
pipeline.fit(X_train, y_train)
# Score on val
print('Train Accuracy:', pipeline.score(X_train, y_train))
print('Validation Accuracy', pipeline.score(X_val, y_val)) #Calling the transformed version of onehotenocder, simpleimputer standardscaler and logreg in the same way as on train sets.
# Predict on test
y_pred = pipeline.predict(X_test)
# + id="KAHKPexrSs1P" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 654} outputId="a4198808-0959-44e9-e679-5a6013315c9c"
# Plot tree
# https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html
import graphviz
from sklearn.tree import export_graphviz
model = pipeline.named_steps['decisiontreeclassifier']
encoder = pipeline.named_steps['onehotencoder']
encoded_columns = encoder.transform(X_val).columns
dot_data = export_graphviz(model,
out_file=None,
max_depth=3,
feature_names=encoded_columns,
class_names=model.classes_,
impurity=False,
filled=True,
proportion=True,
rounded=True)
display(graphviz.Source(dot_data))
#SInce the first level is about quantity drive, that's the "most predictive" feature in this model.
# + id="sHvTzEPkTTQ9" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="d989795c-ffd4-4aad-bd06-73e0a5faa05d"
# Increase "minimum node size" / min_samples_leaf, to reduce model complexity,
# This happens to improve validation accuracy here.
pipeline = make_pipeline(
ce.OneHotEncoder(use_cat_names=True),
SimpleImputer(),
DecisionTreeClassifier(min_samples_leaf=8, random_state=42)
)
pipeline.fit(X_train, y_train)
print('Train Accuracy', pipeline.score(X_train, y_train))
print('Validation Accuracy', pipeline.score(X_val, y_val))
# + id="ChrdtzzzX4qA" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="e725a866-3e10-4cb9-8870-0f51764b471f"
y_pred = pipeline.predict(X_test)
y_pred
# + id="C5HMjxhGYd_S" colab_type="code" colab={}
# Formatting submission
submission = sample_submission.copy()
submission['status_group'] = y_pred
submission.to_csv('submission-AndrewLowe4.csv', index = False)
# + [markdown] id="IDrzQTOWTs9x" colab_type="text"
# - `amount_tsh` : Total static head (amount water available to waterpoint)
# - `date_recorded` : The date the row was entered
# - `funder` : Who funded the well
# - `gps_height` : Altitude of the well
# - `installer` : Organization that installed the well
# - `longitude` : GPS coordinate
# - `latitude` : GPS coordinate
# - `wpt_name` : Name of the waterpoint if there is one
# - `num_private` :
# - `basin` : Geographic water basin
# - `subvillage` : Geographic location
# - `region` : Geographic location
# - `region_code` : Geographic location (coded)
# - `district_code` : Geographic location (coded)
# - `lga` : Geographic location
# - `ward` : Geographic location
# - `population` : Population around the well
# - `public_meeting` : True/False
# - `recorded_by` : Group entering this row of data
# - `scheme_management` : Who operates the waterpoint
# - `scheme_name` : Who operates the waterpoint
# - `permit` : If the waterpoint is permitted
# - `construction_year` : Year the waterpoint was constructed
# - `extraction_type` : The kind of extraction the waterpoint uses
# - `extraction_type_group` : The kind of extraction the waterpoint uses
# - `extraction_type_class` : The kind of extraction the waterpoint uses
# - `management` : How the waterpoint is managed
# - `management_group` : How the waterpoint is managed
# - `payment` : What the water costs
# - `payment_type` : What the water costs
# - `water_quality` : The quality of the water
# - `quality_group` : The quality of the water
# - `quantity` : The quantity of water
# - `quantity_group` : The quantity of water
# - `source` : The source of the water
# - `source_type` : The source of the water
# - `source_class` : The source of the water
# - `waterpoint_type` : The kind of waterpoint
# - `waterpoint_type_group` : The kind of waterpoint
| module1/1_2_1A_kaggle_challenge_1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# <img src="images/logo.jpg" style="display: block; margin-left: auto; margin-right: auto;" alt="לוגו של מיזם לימוד הפייתון. נחש מצויר בצבעי צהוב וכחול, הנע בין האותיות של שם הקורס: לומדים פייתון. הסלוגן המופיע מעל לשם הקורס הוא מיזם חינמי ללימוד תכנות בעברית.">
# # <p style="text-align: right; direction: rtl; float: right;">מחרוזות – חלק 2</p>
# ## <p style="text-align: right; direction: rtl; float: right; clear: both;">הברחת מחרוזות</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# לפעמים נרצה שהמחרוזת שלנו תעשה "דברים מיוחדים" – כמו לרדת שורה באמצע המחרוזת, או לעשות ריווח גדול באמצעות <kbd dir="ltr" style="direction: ltr">↹ TAB</kbd> (לצורך טבלאות, לדוגמה).<br>
# המחשב מתייחס להזחה ולשורה חדשה כתווים של ממש, ועבור כל "תו מיוחד" שכזה יצרו רצף של תווים שמייצג אותו.<br>
# לדוגמה, כשנדע מה הוא רצף התווים שמייצגים שורה חדשה, נוכל לכתוב אותם כחלק מהמחרוזת, וכאשר נדפיס אותה נראה ירידת שורה במקום רצף התווים.
# </p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# נלמד את שני התווים המיוחדים שדיברנו עליהם – <code dir="ltr" style="direction: ltr;">\n</code> הוא תו שמסמן ירידת שורה, ו־<code dir="ltr" style="direction: ltr;">\t</code> מסמן ריווח גדול.<br>
# איך נכניס אותם בקוד? פשוט נשלב אותם כחלק מהמחרוזת במקומות שבהם בא לנו שיופיעו:
# </p>
print("Let's print a newline\nVery good. Now let us create a newline\n\twith a nested text!")
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# רצפי התווים האלו משתמשים בסימן <kbd>\</kbd> ("Backslash", לוכסן שמאלי) כדי לסמן תו מיוחד, והם נפוצים גם בשפות אחרות שאינן פייתון.</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# שימושים נוספים שנעשים הם ב־<code dir="ltr" style="direction: ltr;">\'</code> במחרוזת שבה הסימן שמתחיל ומסיים את המחרוזת הוא <code dir="ltr" style="direction: ltr;">'</code>. שימוש דומה נעשה עבור <code dir="ltr" style="direction: ltr;">\"</code>:<br>
# </p>
print('It\'s Friday, Friday\nGotta get down on Friday')
print("<NAME> once said: \"Be yourself; everyone else is already taken.\"")
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# לפעמים גם נרצה פשוט לרשום את התו <em>\</em>. לצורך כך, נשתמש פעמיים בתו הזה.<br>
# השוו את שתי המחרוזות הבאות, לדוגמה:
# </p>
print("The path of the document is C:\nadia\tofes161\advanced_homework.docx")
print("The path of the document is C:\\nadia\\tofes161\\advanced_homework.docx")
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# נוכל גם להבריח את המחרוזת כולה באמצעות התו <code>r</code> <strong>לפני</strong> המחרוזת, בהנתן שאנחנו בכלל לא רוצים להשתמש בתווים מיוחדים:
# </p>
print(r"The path of the document is C:\nadia\tofes161\advanced_homework.docx")
# <div class="align-center" style="display: flex; text-align: right; direction: rtl;">
# <div style="display: flex; width: 10%; float: right; ">
# <img src="images/tip.png" style="height: 50px !important;" alt="טיפ!">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl;">
# פייתון, בניגוד לבני אדם, מסתכל על תווים מיוחדים כמו <code dir="ltr" style="direction: ltr;">\n</code> ו־<code dir="ltr" style="direction: ltr;">\t</code> כתו אחד.<br>
# נסו לבדוק מה ה־<code>len</code> שלהם כדי להיווכח בעצמכם.
# </p>
# </div>
# </div>
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/warning.png" style="height: 50px !important;" alt="אזהרה!">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; clear: both;">
# פייתון לא מתמודד טוב עם התו <em>\</em> בסוף המחרוזת.<br>
# במידה והגעתם למצב שבו זה קורה, פשוט הבריחו את ה־\ עם \ נוסף.
# </p>
# </div>
# </div>
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/exercise.svg" style="height: 50px !important;" alt="תרגול">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# <strong>תרגול</strong>:
# במשבצת מתחתיי יש חלק מהנאום המפורסם של מרטין לותר קינג, "<cite>I Have A Dream</cite>".<br>
# הדפיסו אותו בעזרת משפט <code>print</code> בודד.
# </p>
# </div>
# </div>
# <blockquote>
# With this faith we will be able to work together, to pray together, to struggle together, to go to jail together, to stand up for freedom together, knowing that we will be free one day.
#
# This will be the day when all of God's children will be able to sing with new meaning, "My country 'tis of thee, sweet land of liberty, of thee I sing. Land where my fathers died, land of the Pilgrims' pride, from every mountainside, let freedom ring."
# </blockquote>
# ## <p style="text-align: right; direction: rtl; float: right; clear: both;">מחרוזת קשוחה</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# לפעמים אנחנו פשוט רוצים להדביק גוש של מלל ושפייתון יתמודד איתו.<br>
# לפייתון יש פתרון נהדר. הוא עובד גם אם המלל מפוצל למספר שורות (הוא יכניס תווי <code dir="ltr" style="direction: ltr;">\n</code> ויפצל לשורות בעצמו), ואפילו אם יש תווים כמו <code>'</code> או <code>"</code>.<br>
# קוראים לרעיון "מחרוזת קשוחה" (אוקיי, אם להגיד את האמת, אף אחד לא קורא לה ככה חוץ ממני), ומגדירים אותה על ידי שימוש של 3 פעמים בתו <code>"</code> או בתו <code>'</code> משני צידי המחרוזת.<br>
# </p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# נראה דוגמה:</p>
friday_song = """
It's Friday, Friday
Gotta get down on Friday
Everybody's lookin' forward to the weekend, weekend
Friday, Friday
Gettin' down on Friday
Everybody's lookin' forward to the weekend
Partyin', partyin' (Yeah)
Partyin', partyin' (Yeah)
Fun, fun, fun, fun
Lookin' forward to the weekend
It's Friday, Friday
Gotta get down on Friday
Everybody's lookin' forward to the weekend, weekend
Friday, Friday
Gettin' down on Friday
Everybody's lookin' forward to the weekend
"""
print(friday_song)
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/exercise.svg" style="height: 50px !important;" alt="תרגול">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# <strong>תרגול</strong>:
# בשנת 1963 נשא ג'ון קנדי את נאום "אני ברלינאי". הטקסט המלא שלו מופיע <a href="https://en.wikisource.org/wiki/Ich_bin_ein_Berliner">כאן</a>.<br>
# השתמשו בפקודת <code>print</code> בודדת כדי להדפיס את הנאום כולו.
# </p>
# </div>
# </div>
# ## <p style="text-align: right; direction: rtl; float: right; clear: both;">מחרוזות מעוצבות</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# עד כה שרשרנו מחרוזות בזהירות בעזרת סימן השרשור, <code>+</code>.<br>
# דרך נוספת לעשות זאת היא בעזרת <dfn>fstring</dfn>, או בשמן המלא, <dfn>formatted strings</dfn>.<br>
# נראה דוגמה:
# </p>
age = 18
name = 'Yam'
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# שרשור כמו שאנחנו מכירים עד כה:
# </p>
print("My age is " + str(age) + " and my name is " + name + ".")
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# שימוש ב־<em>fstrings</em>:
# </p>
print(f"My age is {age} and my name is {name}.")
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# כדאי לשים לב לדברים הבאים:
# </p>
# <ul style="text-align: right; direction: rtl; float: right; clear: both;">
# <li>על־מנת להשתמש ב־fstrings, הוספנו את התו f לפני המחרוזת.</li>
# <li>כדי לציין שם של משתנה שאנחנו רוצים להדפיס, השתמשנו בסוגריים מסולסלים מסביב לשם המשתנה.</li>
# <li>בשימוש ב־fstrings, לא היינו צריכים לבצע המרה לפני שהשתמשנו במשתנה מסוג שלם.</li>
# <li>מן הסתם, ניתן להשתמש ב־fstrings גם למטרות שהן לא הדפסה בלבד.</li>
# </ul>
# ## <p style="text-align: right; direction: rtl; float: right; clear: both;">פעולות על מחרוזות</p>
# ### <p style="text-align: right; direction: rtl; float: right;">הגדרה</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# עד כה למדנו פונקציות שעובדות על סוגים שונים של נתונים. אנחנו קוראים להן בשם שלהם, ואז מעבירים להן את הנתון שעליו רוצים לפעול.<br>
# <code>type</code>, לדוגמה, יודעת לעבוד על כל נתון שנעביר לה ולהחזיר לנו את הסוג שלו.<br>
# ישנו רעיון דומה בתכנות שנקרא "<dfn>פעולה</dfn>", או <dfn>method</dfn> (מתודה).<br>
# בניגוד לפונקציות, השם של הפעולות משוייכות לסוג הנתונים שעליו אנחנו הולכים להפעיל את הפעולות.<br>
# </p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# בעתיד נלמד יותר לעומק על ההבדלים בין הרעיונות, והם ישמעו לנו קצת פחות אבסטרקטיים. עד אז אתם פטורים מלדעת את הטריוויה הזו.<br>
# דבר שכדאי לדעת הוא שהפעולות שאנחנו נראה עכשיו עובדות <em>רק</em> על מחרוזות, ולא על טיפוסים אחרים.<br>
# </p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# בשורות הבאות, אנחנו נשחק עם דוגמאות של פעולות ונראה מה הן עושות בתאים שיבואו לאחר־מכן.<br>
# אם נבחין בתא שיש צורך להסביר מה קרה בו – יצורף הסבר מעל התא.
# </p>
# ### <p style="text-align: right; direction: rtl; float: right;">לנקות שטויות מסביב</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# פעמים רבות, בין אם בקבלת קלט מהמשתמש או במחרוזות שקיבלנו ממקור חיצוני כלשהו, נתקל בתווים מיותרים שמקיפים את המחרוזת שלנו.<br>
# הפעולה <dfn>strip</dfn> עוזרת לנו להסיר אותם.
# </p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# בצורתה הפשוטה, כשלא מעבירים לה ארגומנטים, היא תסיר את כל הרווחים, האנטרים והטאבים שנמצאים מסביב למחרוזת:
# </p>
# נסו להכניס הרבה רווחים אחרי או לפני שם המשתמש
username = input("Please enter your user: ")
username = username.strip()
print(f"This string is: {username}.")
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# כאשר מעבירים לה מחרוזת כארגומנט, היא תבצע את האלגוריתם הבא:
# </p>
# <ol style="text-align: right; direction: rtl; float: right; clear: both;">
# <li>עבור על כל תו מתחילת המחרוזת:
# <ul>
# <li>כל עוד התו נמצא בארגומנט – מחק אותו והמשך</li>
# </ul>
# </li>
# <li>עבור על כל תו מסוף המחרוזת:
# <ul>
# <li>כל עוד התו נמצא בארגומנט – מחק אותו והמשך</li>
# </ul>
# </li>
# </ol>
strange_string = '!@#$%!!!^&This! Is! Sparta!!!!!!!!!&^%$!!!#@!'
print(strange_string.strip('~!@#$%^&*'))
# ### <p style="text-align: right; direction: rtl; float: right;">מציאות ומציאות</p>
strange = "This is a very long string which contains strange words, like ululation and lollygag."
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# נמצא את המקומות בהן נמצאות המילים המוזרות.<br>
# הפעולות <em>find</em> ו־<em>index</em> יחזירו לנו את המיקום (האינדקס) של תת מחרוזת בתוך מחרוזת אחרת:
# </p>
strange.find("ululation")
strange.find("lollygag")
strange.index("lollygag")
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# אז רגע, למה צריך 2 מתודות אם הן עושות אותו דבר?<br>
# במידה והמחרוזת לא נמצאה, <em dir="ltr" style="direction: ltr">.find</em> תחזיר לנו <samp dir="ltr" style="direction: ltr">-1</samp>, בעוד <em dir="ltr" style="direction: ltr">.index</em> תחזיר לנו שגיאה.
# </p>
strange.find('luculent')
strange.index('luculent')
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/warning.png" style="height: 50px !important;" alt="אזהרה!">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; clear: both;">
# הפעולות הללו יחזירו רק את התוצאה הראשונה.
# </p>
# </div>
# </div>
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/warning.png" style="height: 50px !important;" alt="אזהרה!">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; clear: both;">
# אינטואיטיבית, מרגיש שנכון תמיד להשתמש בפעולה <em dir="ltr" style="direction: ltr;">.find</em>, אך אליה וקוץ בה.<br>
# כשאנחנו בטוחים שאמורה לחזור תוצאה, עדיף להשתמש ב־<em dir="ltr" style="direction: ltr;">.index</em> כדי לדעת מאיפה מגיעה השגיאה בתוכנית שלנו ולטפל בה במהירות.
# </p>
# </div>
# </div>
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/exercise.svg" style="height: 50px !important;" alt="תרגול">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# <strong>תרגול</strong>:
# קבלו מהמשתמש שתי מחרוזות.<br>
# במידה והמחרוזת השנייה נמצאת לפני האמצע של המחרוזת הראשונה, הדפיסו "<span dir="ltr">Yes!</span>"<br>
# במידה והמחרוזת השנייה לא נמצאת לפני האמצע של המחרוזת הראשונה, הדפיסו "<span dir="ltr">No!</span>"<br>
# בונוס לגיבורים ולגיבורות: נסו להשתמש בשתי הפעולות, <em>index</em> ו־<em>find</em>.
# </p>
# </div>
# </div>
# ### <p style="text-align: right; direction: rtl; float: right;">משחקים עם גודלי אותיות</p>
test1 = "HeLlO WoRlD 123!"
test1
test1.upper()
test1.lower()
test1.capitalize() # רק האות הראשונה תהיה גדולה
test1.title() # מגדיל את האות הראשונה בכל מילה
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# חשוב לזכור שהפעולות לא משנות את המשתנה.<br>
# אם רוצים לשנות אותו, יש להשתמש בהשמה.
# </p>
test1
# ### <p style="text-align: right; direction: rtl; float: right;">סופרים סתם</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# אם נרצה לבדוק כמה פעמים תת־מחרוזת נמצאת בתוך המחרוזת שלנו, נשתמש בפעולה <dfn>count</dfn>.<br>
# ננסה להבין כמה פעמים מילים מעניינות הופיעו בנאום גטיסברג המפורסם:
# </p>
gettysburg_address = """
Four score and seven years ago our fathers brought forth, on this continent, a new nation, conceived in Liberty, and dedicated to the proposition that all men are created equal.
Now we are engaged in a great civil war, testing whether that nation, or any nation so conceived and so dedicated, can long endure. We are met on a great battle-field of that war. We have come to dedicate a portion of that field, as a final resting place for those who here gave their lives that that nation might live. It is altogether fitting and proper that we should do this.
But, in a larger sense, we cannot dedicate—we cannot consecrate—we cannot hallow—this ground. The brave men, living and dead, who struggled here, have consecrated it, far above our poor power to add or detract. The world will little note, nor long remember what we say here, but it can never forget what they did here. It is for us the living, rather, to be dedicated here to the unfinished work which they who fought here have thus far so nobly advanced. It is rather for us to be here dedicated to the great task remaining before us—that from these honored dead we take increased devotion to that cause for which they here gave the last full measure of devotion—that we here highly resolve that these dead shall not have died in vain—that this nation, under God, shall have a new birth of freedom—and that government of the people, by the people, for the people, shall not perish from the earth.
"""
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# ראשית, נעשה טריק מוכר. נשתמש בפעולה <em dir="ltr" style="direction: ltr">.lower()</em> כדי להעיף את האותיות הגדולות.<br>
# בצורה הזו, שימוש בפעולה <em>count</em> יספור לנו גם את המילים שנכתבו באותיות רישיות:
# </p>
gettysburg_address = gettysburg_address.lower()
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# עכשיו נבדוק כמה פעמים לינקולן השתמש בכל אחת מהמילים: we, nation ו־dedicated.</p>
gettysburg_address.count('we')
gettysburg_address.count('dedicated')
gettysburg_address.count('nation')
# ### <p style="text-align: right; direction: rtl; float: right;">החלפה</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# פעולה מאוד נפוצה היא <dfn>replace</dfn>, שעוזרת לנו להחליף את כל המופעים של תת־מחרוזת אחת באחרת.<br>
# לדוגמה, ניקח את הברידג' השני בשיר הנפלא של הביטלס, <cite>Hey Jude</cite>, ונחליף את כל המופעים של <em>Jude</em> ב־<em>Dude</em>:
# </p>
lyrics = """So let it out and let it in, hey Jude, begin
You're waiting for someone to perform with
And don't you know that it's just you, hey Jude, you'll do
The movement you need is on your shoulder
Na na na na na na na na na yeah"""
lyrics.replace('Jude', 'Dude')
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# שימו לב לתווים המוזרים באמצע. אלו ירידות השורה, עליהם למדנו בשיעור. אל דאגה – הם לא יופיעו כשנדפיס את המחרוזת.
# </p>
print(lyrics.replace('Jude', 'Dude'))
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# רק נזכיר שהפעולה לא משנה את המחרוזת עצמה, ועל מנת לשנות אותה נצטרך לבצע השמה.
# </p>
# +
lyrics = """So let it out and let it in, hey Jude, begin
You're waiting for someone to perform with
And don't you know that it's just you, hey Jude, you'll do
The movement you need is on your shoulder
Na na na na na na na na na yeah"""
print("Before: ")
lyrics.replace('Jude', 'Dude')
print(lyrics)
lyrics = lyrics.replace('Jude', 'Dude')
print('-' * 50)
print("After: ")
print(lyrics)
# -
# ### <p style="text-align: right; direction: rtl; float: right;">הפרד ומשול</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# לעיתים קרובות נרצה להפריד את הטקסט שלנו לחלקים.<br>
# הפעולה <dfn>split</dfn> מאפשרת לנו לעשות את זה, ולקבל רשימה של האיברים המופרדים:
# </p>
i_like_to_eat = 'chocolate, fudge, cream, cookies, banana, hummus'
i_like_to_eat.split(', ')
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# בסוגריים כתבנו מה אנחנו רוצים שיהיה התו, או סדרת התווים, שתהיה אחראית להפרדה בין האיברים.<br>
# שימו לב שקיבלנו רשימה לכל דבר:
# </p>
type(i_like_to_eat.split(', '))
i_like_to_eat.split(', ')[0]
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# דרך נוספת להשתמש ב־<em>split</em> היא לא להעביר לה כלום ברשימת הארגומנטים.<br>
# במקרה כזה, <i>split</i> תפצל לנו את המחרוזת לפי רווחים, שורות חדשות וטאבים.
# </p>
some_paragraph = """
Gadsby is a 1939 novel by <NAME> written as a lipogram, which does not include words that contain the letter E. The plot revolves around the dying fictional city of Branton Hills, which is revitalized as a result of the efforts of protagonist <NAME> and a youth group he organizes.
Though vanity published and little noticed in its time, the book is a favourite of fans of constrained writing and is a sought-after rarity among some book collectors. Later editions of the book have sometimes carried the alternative subtitle 50,000 Word Novel Without the Letter "E".
Despite Wright's claim, published versions of the book may contain a handful of uses of the letter "e". The version on Project Gutenberg, for example, contains "the" three times and "officers" once.
"""
some_paragraph.split()
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# הפעולה הזו שימושית בטירוף ונראה אותה עוד הרבה.<br>
# היא מאפשרת לנו לקבל הרבה מידע על כמות גדולה של מלל.
# </p>
# ### <p style="text-align: right; direction: rtl; float: right;">חבר ומשול</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# לפעמים אנחנו רוצים לעשות את הפעולה ההפוכה מפיצול – איחוד!<br>
# הפעולה <dfn>join</dfn> מקבלת כארגומנט רשימה, ופועלת על המחרוזת שתחבר בין איבר לאיבר.<br>
# נראה דוגמה:
# </p>
i_love_to_eat = ['chocolate', 'fudge', 'cream', 'cookies', 'banana', 'hummus']
thing_to_join_by = ", "
thing_to_join_by.join(i_love_to_eat)
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# ואם אנחנו כבר שם, קצת כבוד לספר הישראלי, הכבש השישה־עשר:
# </p>
what_i_love = ["שוקולד", "עוגות גבינה", "ארטיק", "סוכריות", "תות גינה"]
vav_ha_hibur = ' ו'
song = "אני אוהב " + vav_ha_hibur.join(what_i_love)
print(song)
# ### <p style="text-align: right; direction: rtl; float: right;">אני, בוליאני</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# אחד הטריקים השימושיים הוא לבדוק האם המחרוזת שלנו מתחילה או מסתיימת בתת־מחרוזת אחרת.
# </p>
some_test = "Hello, my name is <NAME>, you killed my father, prepare to die!"
is_welcoming = some_test.startswith('Hello,')
print(is_welcoming)
is_shouting = some_test.endswith('!')
print(is_shouting)
is_goodbye = some_test.endswith("Goodbye, my kind sir.")
print(is_goodbye)
address = "Python Street 5, Hadera, Israel"
print("Does the user live in Python Street?... " + str(address.startswith('Python Street')))
print("Does the user live in Scotland?... " + str(address.endswith('Scotland')))
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/exercise.svg" style="height: 50px !important;" alt="תרגול">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# <strong>תרגול</strong>:
# קבלו מהמשתמש נתיב לקובץ מסוים שנמצא על המחשב שלו, ובדקו האם הסיומת שלו היא <i style="direction: ltr" dir="ltr">.docx</i><br>
# הדפיסו לו הודעה מתאימה.<br>
# דוגמה לנתיב תקין: <i>C:\My Documents\Resume.docx</i>.
# </p>
# </div>
# </div>
# <div class="align-center" style="display: flex; text-align: right; direction: rtl; clear: both;">
# <div style="display: flex; width: 10%; float: right; clear: both;">
# <img src="images/warning.png" style="height: 50px !important;" alt="אזהרה!">
# </div>
# <div style="width: 90%">
# <p style="text-align: right; direction: rtl; clear: both;">
# אנשים נוטים לשכוח את ה־<em>s</em> אחרי ה־<em>end</em> או ה־<em>start</em> ב־<em>end<strong>s</strong>with</em> וב־<em>start<strong>s</strong>with</em>.
# </p>
# </div>
# </div>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# נוכל גם לבדוק האם המחרוזת שלנו היא מסוג מסוים:
# </p>
test2 = "HELLO WORLD"
print("test2.isalnum(): " + str(test2.isalnum()))
print("test2.isalpha(): " + str(test2.isalpha()))
print("test2.isdecimal(): " + str(test2.isdecimal()))
test3 = "12345"
print("test3.isalnum(): " + str(test3.isalnum()))
print("test3.isalpha(): " + str(test3.isalpha()))
print("test3.isdecimal(): " + str(test3.isdecimal()))
test4 = "HELLOWORLD"
print("test4.isalnum(): " + str(test4.isalnum()))
print("test4.isalpha(): " + str(test4.isalpha()))
print("test4.isdecimal(): " + str(test4.isdecimal()))
test5 = "ABC123"
print("test5.isalnum(): " + str(test5.isalnum()))
print("test5.isalpha(): " + str(test5.isalpha()))
print("test5.isdecimal(): " + str(test5.isdecimal()))
# ## <p style="align: right; direction: rtl; float: right; clear: both;">תרגולים</p>
# ### <p style="align: right; direction: rtl; float: right; clear: both;">נאום גטיסברג</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# השתמשו בטקסט של נאום גטיסברג, ובדקו כמה מילים יש בו.<br>
# בדקו כמה פעמים הופיעו המילים we, here, great, nation ו־dedicated, וחשבו כמה אחוזים הן מייצגות מהטקסט כולו.
# </p>
gettysburg_address = """
Four score and seven years ago our fathers brought forth, on this continent, a new nation, conceived in Liberty, and dedicated to the proposition that all men are created equal.
Now we are engaged in a great civil war, testing whether that nation, or any nation so conceived and so dedicated, can long endure. We are met on a great battle-field of that war. We have come to dedicate a portion of that field, as a final resting place for those who here gave their lives that that nation might live. It is altogether fitting and proper that we should do this.
But, in a larger sense, we cannot dedicate—we cannot consecrate—we cannot hallow—this ground. The brave men, living and dead, who struggled here, have consecrated it, far above our poor power to add or detract. The world will little note, nor long remember what we say here, but it can never forget what they did here. It is for us the living, rather, to be dedicated here to the unfinished work which they who fought here have thus far so nobly advanced. It is rather for us to be here dedicated to the great task remaining before us—that from these honored dead we take increased devotion to that cause for which they here gave the last full measure of devotion—that we here highly resolve that these dead shall not have died in vain—that this nation, under God, shall have a new birth of freedom—and that government of the people, by the people, for the people, shall not perish from the earth.
"""
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# על־מנת לחשב את האחוזים: סיכמו את כמות הפעמים שכל מילה מופיעה בטקסט. הכפילו את הכמות הזו במאה, וחלקו בכמות המילים בטקסט.
# </p>
# ### <p style="align: right; direction: rtl; float: right; clear: both;">חצי חיים</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# קבלו מהמשתמש מילה מסוימת ומשפט<br>
# בדקו שתחילת המילה מופיעה לפני החצי של המשפט.<br>
# היעזרו בדוגמאות כדי לוודא את עצמכם.
# </p>
# <ul style="text-align: right; direction: rtl; float: right; clear: both;">
# <li>המילה Love במשפט I Love Chocolate תחזיר <samp>True</samp>, מהכיוון שהמילה Love מתחילה במקום 2, ואורך חצי המשפט הוא 8.</li>
# <li>המילה salad במשפט This is the best salad in town תחזיר <samp>False</samp>, מהכיוון שהמילה salad מתחילה במקום 17, ואורך חצי המשפט הוא 15.</li>
# <li>המילה Meow במשפט "All you need is Love" תחזיר <samp>False</samp>, מכיוון ש־Meow לא נמצא בשירים של הביטלס (וחבל שכך).</li>
# </ul>
# ### <p style="align: right; direction: rtl; float: right; clear: both;">שיחדש</p>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# בספר המרתק של ג'ורג' אורוול, 1984, הסלוגן של מפלגת השלטון הוא <q>מלחמה היא שלום, חירות היא עבדות, בורות היא כוח</q>.<br>
# קבלו טקסט מהמשתמש, והחליפו את המילים לפי המילון הבא:
# </p>
# <ul style="text-align: right; direction: rtl; float: right; clear: both;">
# <li>war תוחלף ל־peace</li>
# <li>freedom תוחלף ל־slavery</li>
# <li>ignorance תוחלף ל־strength</li>
# </ul>
# <p style="text-align: right; direction: rtl; float: right; clear: both;">
# לצורך התרגיל, הניחו שכל מה שהמשתמש הכניס כקלט הגיע באותיות קטנות.
# </p>
| week2/5_String_Methods.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Introduction
# This notebook illustrates clustering of Ti crystal orientations using data obtained from a highly deformed specimen, using EBSD.
# This functionaility has been checked to run in orix-0.2.0 (December 2019). Bugs are always possible, do not trust the code blindly, and if you experience any issues please report them here: https://github.com/pyxem/orix-demos/issues
# # Contents
# 1. <a href='#imp'> Import data</a>
# 2. <a href='#dis'> Compute distance matrix</a>
# 3. <a href='#clu'> Clustering</a>
# 4. <a href='#vis'> Visualisation</a>
# Import orix classes and various dependencies
# +
# %matplotlib qt5
# Important external dependencies
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
# orix dependencies (tested with orix 0.1.1)
from orix.quaternion.orientation import Orientation, Misorientation
from orix.quaternion.rotation import Rotation
from orix.quaternion.symmetry import D6
from orix.quaternion.orientation_region import OrientationRegion
from orix.vector.neo_euler import AxAngle
from orix.vector import Vector3d
from orix import plot
# Colorisation
from skimage.color import label2rgb
from matplotlib.colors import to_rgb, to_hex
MPL_COLORS_RGB = [to_rgb('C{}'.format(i)) for i in range(10)]
MPL_COLORS_HEX = [to_hex(c) for c in MPL_COLORS_RGB]
# Animation
import matplotlib.animation as animation
# Visualisation
from mpl_toolkits.mplot3d.art3d import Line3DCollection
from matplotlib.lines import Line2D
plt.rc('font', size=6)
# -
# # <a id='imp'></a> 1. Import data
# Load orientation mapping data specified in a standard CTF file as euler angles in degrees, following the Bunge convention.
filepath = './data/Ti_orientations.ctf'
dat = np.loadtxt(filepath, skiprows=1)[:, :3]
# Initialize an orix Orientation object containing the data
ori = Orientation.from_euler(np.radians(dat))
print(ori.size)
# Reshape the orientation mapping data to the correct spatial dimensions for the scan
ori = ori.reshape(381,507)
# Selct a subset of the data to reduce compute time
ori = ori[-100:,:200]
print(ori.size)
# Define the fundamental region based on the D6 symmetry of Ti
fundamental_region = OrientationRegion.from_symmetry(D6)
# # <a id='dis'></a> 2. Compute distance matrix
# Clustering algorithms require a distance matrix, $D_{ij}$, containing the distance, $d(o_i, o_j)$, between all (mis)orientations to be computed. We define this distance as the minimum rotational angle relating (mis)orientations amongst all symmetry equivalent rotations.
#
# Computation of the distance matrix is the most computationally intensive part of this data processing. Here we provide 3 alternative implementations that use resources differently:
#
# 1. Calculate the outer products needed to determine the distance metric and compute the associated angle. Minimise with respect to the tensor axes corresponding to symmetry. Uses lots of of computer memory.
#
#
# 2. Iterate over each factor updating the distance as it gets smaller. Uses little computer memory but computation takes a long time.
#
#
# 3. Iterating over pairs of data points while performing an outer product minimisation with respect to the symmetry elements for each pair. Uses more computer memory to avoid excessive computation times.
#
#
# **WARNING: The computation in Section 2.1 takes time and may exceed limits on your machine. This section is commented out to avoid unintentional use. A pre-computed solution is provided in Section 2.2!**
# ## 2.1. Compute the distance matrix yourself (optional)
# **Option 1: high (ca. 32 Gb) RAM, fast vectorized computation**
#
# Computes every possibility in a single tensor, then minimises.
# +
#misori_equiv = D6.outer(~ori).outer(ori).outer(D6)
#D = misori_equiv.angle.data.min(axis=(0, 2))
# -
# **Option 2: low RAM, slow iteration**
#
# Iterates through every pair of orientations.
# +
#D = np.empty(ori.shape + ori.shape)
#
#for i, j in tqdm_notebook(list(icombinations(range(ori.size), 2))):
# idx_1, idx_2 = np.unravel_index(i, ori.shape), np.unravel_index(i, ori.shape)
# o_1, o_2 = ori[idx_1], ori[idx_2]
# misori = D6.outer(~o_1).outer(o_2).outer(D6)
# d = misori.angle.data.min(axis=(0, 3))
# D[idx_1[0], idx_1[1], idx_2[0], idx_2[1]] = d
# D[idx_2[0], idx_2[1], idx_1[0], idx_1[1]] = d
# -
# **Option 3: RAM vs. speed compromise**
#
# Precomputes one set of equivalent orientations.
# +
#D = np.zeros(ori.shape + ori.shape)
#D.fill(np.infty)
#
#OS2 = ori.outer(D6)
#
#for i in tqdm_notebook(range(ori.size)):
# idx = np.unravel_index(i, ori.shape)
# misori = D6.outer(~ori[idx]).outer(OS2)
# d = misori.angle.data.min(axis=(0, -1))
# D[idx[0], idx[1], ...] = np.minimum(D[idx[0], idx[1], ...], d)
# -
# ## 2.2. Load a distance matrix we computed for you
# Load the precomputed distance matrix for the data subset
filepath = './data/ori-distance((100, 200)).npy'
D = np.load(filepath)
# # <a id='clu'></a> 3. Clustering
# Perform clustering
dbscan = DBSCAN(0.1, 40, metric='precomputed').fit(D.reshape(ori.size, ori.size))
print('Labels:', np.unique(dbscan.labels_))
labels = dbscan.labels_.reshape(ori.shape)
n_clusters = len(np.unique(dbscan.labels_)) - 1
print('Number of clusters:', n_clusters)
# Calculate the mean orientation for each cluster
cluster_means = Orientation.stack([ori[labels == label].mean() for label in np.unique(dbscan.labels_)[1:]]).flatten()
cluster_means = cluster_means.set_symmetry(D6)
# Inspect rotation axes in the axis-angle representation
cluster_means_axangle = AxAngle.from_rotation(cluster_means)
# Recenter data relative to the matrix cluster and recompute means
ori_recentered = (~cluster_means[0]) * ori
ori_recentered = ori_recentered.set_symmetry(D6)
cluster_means_recentered = Orientation.stack([ori_recentered[labels == label].mean() for label in np.unique(dbscan.labels_)[1:]]).flatten()
cluster_means_axangle = AxAngle.from_rotation(cluster_means_recentered)
# Inspect recentered rotation axes in the axis-angle representation
cluster_means_recentered.axis
# # <a id='vis'></a> 4. Visualisation
# Specify colours and lines to identify each cluster
# +
# get label colors
colors = [to_rgb('C{}'.format(i)) for i in range(10)]
labels_rgb = label2rgb(labels, colors=colors)
# Create map and lines pointing to cluster means
mapping = labels_rgb
collection = Line3DCollection([((0, 0, 0), tuple(cm)) for cm in cluster_means_axangle.data], colors=colors)
# -
# Plot the orientation clusters within the fundamental zone for D6 symmetry Ti
# +
fig = plt.figure(figsize=(3.484252, 3.484252))
gridspec = plt.GridSpec(1, 1, left=0, right=1, bottom=0, top=1, hspace=0.05)
ax_ori = fig.add_subplot(gridspec[0], projection='axangle', proj_type='ortho')
ax_ori.scatter(ori_recentered, c=labels_rgb.reshape(-1, 3), s=1)
ax_ori.plot_wireframe(fundamental_region, color='black', linewidth=0.5, alpha=0.1, rcount=181, ccount=361)
ax_ori.add_collection3d(collection)
ax_ori.set_axis_off()
ax_ori.set_xlim(-1, 1)
ax_ori.set_ylim(-1, 1)
ax_ori.set_zlim(-1, 1)
ax_ori.view_init(90, -30)
handles = [
Line2D(
[0], [0],
marker='o', color='none',
label=i+1,
markerfacecolor=color, markersize=5
) for i, color in enumerate(colors[:n_clusters])
]
ax_ori.legend(handles=handles, loc='lower right', ncol=2, numpoints=1, labelspacing=0.15, columnspacing=0.15, handletextpad=0.05)
# -
# Plot side view of orientation clusters in the fundamental zone for D6 symmetry Ti
# +
plt.close('all')
fig = plt.figure(figsize=(3.484252 * 2, 1.5 * 2))
gridspec = plt.GridSpec(1, 1, left=0, right=1, bottom=0, top=1, hspace=0.05)
ax_ori = fig.add_subplot(gridspec[0], projection='axangle', proj_type='ortho', aspect='equal')
ax_ori.scatter(ori_recentered, c=labels_rgb.reshape(-1, 3), s=1)
ax_ori.plot_wireframe(fundamental_region, color='black', linewidth=0.5, alpha=0.1, rcount=181, ccount=361)
# ax_ori.add_collection3d(collection)
ax_ori.set_axis_off()
ax_ori.set_xlim(-1, 1)
ax_ori.set_ylim(-1, 1)
ax_ori.set_zlim(-1, 1)
ax_ori.view_init(0, -30)
# -
# Plot map indicating spatial locations associated with each cluster
# +
plt.close('all')
map_ax = plt.axes()
map_ax.imshow(mapping)
map_ax.set_xticks([])
map_ax.set_yticks([])
# -
| 02 - Clustering Orientations.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Understanding grounded source EM
# The objective of this lab exercise is to help students develop a better understanding of the physics of the grounded source EM, with the help of the interactive apps that allow students to adjust model and survey parameters and simulate EM fields. <br>
#
# We are going to look at three models that were discussed in class in order to build an understanding of the grounded source EM.
#
# - Halfspace (0.01 S/m)
# - Conductive block in halfspace (1 S/m)
# - Resitive block in halfspace (10$^{-4}$ S/m).
#
# We will also use a canonical layered Earth model to simulate a marine CSEM survey.
#
# After finishing this exercise, students will understand <br>
# * How the currents distribute in a homogenous halfspace;
# * How a resitor and a conductor change the current distribution;
# * How the resistivit of hydrocarbon reservior affect the electric field.
#
# Author: <NAME> at University of Houston, Nov 2nd, 2018.
# !pip install em_examples
from ipywidgets import interact, interactive, FloatSlider, IntSlider, ToggleButtons
from em_examples.TDEMGroundedSource import *
# %pylab inline
# ## Grounded source EM with a halfspace
# Survey Setup:
# +
Q = interact(choose_model,
model=ToggleButtons(
options=["halfspace", "conductor", "resistor"], value="halfspace"
)
)
import matplotlib
matplotlib.rcParams['font.size']=16
options = load_or_run_results(
re_run=False,
fname=choose_model(Q.widget.kwargs['model']),
sigma_block=0.01,
sigma_halfspace=0.01
)
tdem = PlotTDEM(**options)
interact(
tdem.show_3d_survey_geometry,
elev=FloatSlider(min=-180, max=180, step=10, value=30),
azim=FloatSlider(min=-180, max=180, step=10, value=-45),
)
interact(
tdem.plot_input_currents,
itime=IntSlider(min=15, max=50, step=1, value=15, contiusous_update=False),
scale=ToggleButtons(
options=["linear", "log"], value="linear"
),
)
# -
interact(
tdem.plot_electric_currents,
itime=IntSlider(min=15, max=50, step=1, value=15, contiusous_update=False)
)
# <font color = red>**Task 1**</font>: Set itime to 15, i.e., at time 0.00 ms (immediately after the current in the electrical dipole is interrupted), describe the spatial pattern of the induced currents in the x-z plane (i.e., the right panel). <font color=red>**(10 points)**</font>
# <font color = red>**HINT:**</font> The spatial pattern includes the directions, the shapes, and the magnitudes of the induced currents.
# **(answer to Task 1:) **<br>
#
# <font color = red>**Task 2**</font>: As you increase the time (by adjusting the itime slider), summarize what you observe about the current density in x-z plane (i.e. the right panel). <font color=red>**(20 points)**</font>
# <font color = red>**HINT:**</font> Please summarize your observations from the following aspects. First, how does the maximum current density value change when you increase the time? Secondly, how does the location of the peak of the current density change? Thirdly, how does the direction of the currents change?
# **(answer to Task 2:)** <br>
#
# ## Grounded source EM with a conductor
Q = interact(choose_model,
model=ToggleButtons(
options=["halfspace", "conductor", "resistor"], value="conductor"
)
)
import matplotlib
matplotlib.rcParams['font.size']=16
options = load_or_run_results(
re_run=False,
fname=choose_model(Q.widget.kwargs['model']),
sigma_block=0.01,
sigma_halfspace=0.01
)
tdem = PlotTDEM(**options)
interact(
tdem.plot_electric_currents,
itime=IntSlider(min=15, max=50, step=1, value=15, contiusous_update=False)
)
# <font color = red>**Task 3**</font>: Set itime to 15, i.e., at time 0.00 ms (immediately after the current in the electrical dipole is interrupted). How is the induced current in the case of a conductor different from what you have observed above for a homogeneous halfspace? <font color=red>**(10 points)**</font>
# **(answer to Task 3:)**<br>
#
# <font color = red>**Task 4**</font>: Set itime to 42, i.e., at time 8.10 ms. How is the induced current different from what you observed at time 0.00 ms? <font color=red>**(10 points)**</font>
# **(answer to Task 4:) <br>**
#
# ## Grounded source EM with a resistor
Q = interact(choose_model,
model=ToggleButtons(
options=["halfspace", "conductor", "resistor"], value="resistor"
)
)
import matplotlib
matplotlib.rcParams['font.size']=16
options = load_or_run_results(
re_run=False,
fname=choose_model(Q.widget.kwargs['model']),
sigma_block=0.01,
sigma_halfspace=0.01
)
tdem = PlotTDEM(**options)
interact(
tdem.plot_electric_currents,
itime=IntSlider(min=15, max=50, step=1, value=15, contiusous_update=False)
)
# <font color = red>**Task 5**</font>: Set itime to 16, i.e., at time 0.02 ms. Summarize your observations of the induced current in the x-y and x-z plane. <font color=red>**(15 points)**</font>
# **(answer to Task 5:) <br>**
#
# <font color = red>**Task 6**</font>: Now keep increasing the itime index. How does the induced current in the x-z plane change with time? <font color=red>**(15 points)**</font>
# **(answer to Task 6:) <br>**
#
# ## Marine controlled source EM (CSEM)
from em_examples.MarineCSEM1D import show_canonical_model, FieldsApp, DataApp
from IPython.display import HTML
from empymod import utils
# ## Canonical model
#
# We consider a canonical resistivity model, which includes a thin resistive layer (correspond to a reservoir containing signicant amount of hydrocarbon). Five layers having different resistivity values are considered:
#
# - air: perfect insulater ($\rho_0)$~1e8 $\Omega$m)
# - seawater: conductor ($\rho_1)$~0.3 $\Omega$m)
# - sea sediment (upper): conductor ($\rho_2)$~1 $\Omega$m)
# - reservoir: resistor ($\rho_3)$~100 $\Omega$m))
# - sea sediment (lower): conductor ($\rho_4)$~1 $\Omega$m)
#
# Conductive sea sediment can have anisotropy, and often vertical resistivity ($\rho_v$) is greater than horizontal resistivity ($\rho_h$); e.g. $\rho_v/\rho_h \simeq 2$. However, the hydrocarbon reservoir is often assumed to be isotropic.
show_canonical_model()
DataApp()
# Note that in the above panel, the red curve shows the measured electric field as a function of distance (of the receivers) when there is a resistive hydrocarbon reservoir. The black curve summarizes the electric field when no hydrocarbon reservior is present.
# <font color = red>**Task 7**</font>: The resistivity of the hydrocarbon reservoir, $\rho_3$, is set to 100 $\Omega\cdot m$. Now change that to 10 $\Omega\cdot m$. How does the electric field change? In this case, if we still want to detect the reservior, where should we put our receivers? <font color=red>**(10 points)**</font>
# **(answer to Task 7:) <br>**
#
# <font color = red>**Task 8**</font>: Now set the resistivity of the reservoir to 500 $\Omega\cdot m$. How does the electric field change? Does this make the detection of hycarbon reservior easier or harder? Why? <font color=red>**(10 points)**</font>
# **(answer to Task 8:) <br>**
#
# ## Acknowledgments
# The apps that were used in this lab were developed by the [SimPEG](http://www.simpeg.xyz/) team. Most members are graduate students from [UBC-GIF](https://gif.eos.ubc.ca/about). I would like all SimPEG team members for their hard and awesome work!
#
# <img src = "simpegteam.PNG">
| LabExercise_6/Lab6_GroundedSource.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### arxiv
import pandas as pd
import json
data=[]
with open('../csci-544-project/data/longformer_arxiv.txt') as f:
text = f.readline()
while text:
json_data = json.loads(text)
data.append(json_data)
text = f.readline()
final_df = pd.DataFrame(data)
final_df
from torch.utils.data import Dataset, DataLoader
from datasets import load_metric
metric = load_metric("rouge")
# using GPT-3 model with pred of longformer
import os
import openai
from tqdm import tqdm
openai.organization = "org-EisHcNn58Kak28bngV5bsOuz"
openai.api_key = "<KEY>"
engine_list = openai.Engine.list()
#openai.api_key = os.getenv("OPENAI_API_KEY")
output = []
#final_output = []
for i in tqdm(range(len(final_df))):
try:
beginning_tag = "Original:\n"
ending_tag = "\n````\nPolished Sentence:"
text = beginning_tag + str(final_df["predicted_abstract"].iloc[i])+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["````"]
)
output.append(response["choices"][0]['text'])
except:# if the token exceed the maximum tokens number in GPT-3 model,then just use first half text
beginning_tag = "Original:\n"
ending_tag = "\n````\nPolished Sentence:"
a = final_df["predicted_abstract"].iloc[i][:int(len(final_df["predicted_abstract"].iloc[i])/2)]
text = beginning_tag + str(a)+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["````"]
)
output.append(response["choices"][0]['text'])
#final_output.append(output)
pred_df = pd.DataFrame()
pred_df["summary"] = output
pred_df.to_csv("arxiv_after_longformer_summary_100.csv",sep = ' ',index = False,header = False)
from torch.utils.data import Dataset, DataLoader
from datasets import load_metric
metric = load_metric("rouge")
fake_preds = output
fake_labels = final_df['abstract']
rouge_raw_after_longformer = metric.compute(predictions=fake_preds, references=fake_labels)
rouge_raw_after_longformer
# using GPT-3 model with pubmed bigbird pred text with summary method
import os
import openai
from tqdm import tqdm
openai.organization = "org-EisHcNn58Kak28bngV5bsOuz"
openai.api_key = "<KEY>"
engine_list = openai.Engine.list()
#openai.api_key = os.getenv("OPENAI_API_KEY")
output = []
#final_output = []
for i in tqdm(range(len(final_df))):
try:
beginning_tag = "My second grader asked me what this passage means:\n\"\"\"\n"
ending_tag = "\n\"\"\"\nI rephrased it for him, in plain language a second grader can understand:\n\"\"\"\n"
text = beginning_tag + str(final_df["predicted_abstract"].iloc[i])+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["\"\"\""]
)
output.append(response["choices"][0]['text'])
except:# if the token exceed the maximum tokens number in GPT-3 model,then just use first half text
beginning_tag = "My second grader asked me what this passage means:\n\"\"\"\n"
ending_tag = "\n\"\"\"\nI rephrased it for him, in plain language a second grader can understand:\n\"\"\"\n"
a = final_df["predicted_abstract"].iloc[i][:int(len(final_df["predicted_abstract"].iloc[i])/2)]
text = beginning_tag + str(a)+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["\"\"\""]
)
output.append(response["choices"][0]['text'])
#final_output.append(output)
pred_df = pd.DataFrame()
pred_df["summary"] = output
pred_df.to_csv("pubmed_after_bigbird_summary_100.csv",sep = ' ',index = False,header = False)
fake_preds = output
fake_labels = final_df['abstract']
rouge_pubmed_raw_after_longformer = metric.compute(predictions=fake_preds, references=fake_labels)
rouge_pubmed_raw_after_longformer
# ### pubmed
data=[]
with open('../csci-544-project/data/longformer_pubmed.txt') as f:
text = f.readline()
while text:
json_data = json.loads(text)
data.append(json_data)
text = f.readline()
final_df = pd.DataFrame(data)
final_df
# using GPT-3 model with pubmed pred of longformer
import os
import openai
from tqdm import tqdm
openai.organization = "org-EisHcNn58Kak28bngV5bsOuz"
openai.api_key = "<KEY>"
engine_list = openai.Engine.list()
#openai.api_key = os.getenv("OPENAI_API_KEY")
output = []
#final_output = []
for i in tqdm(range(len(final_df))):
try:
beginning_tag = "Original:\n"
ending_tag = "\n````\nPolished Sentence:"
text = beginning_tag + str(final_df["predicted_abstract"].iloc[i])+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["````"]
)
output.append(response["choices"][0]['text'])
except:# if the token exceed the maximum tokens number in GPT-3 model,then just use first half text
beginning_tag = "Original:\n"
ending_tag = "\n````\nPolished Sentence:"
a = final_df["predicted_abstract"].iloc[i][:int(len(final_df["predicted_abstract"].iloc[i])/2)]
text = beginning_tag + str(a)+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["````"]
)
output.append(response["choices"][0]['text'])
#final_output.append(output)
pred_df = pd.DataFrame()
pred_df["summary"] = output
pred_df.to_csv("pubmed_after_longformer_summary_100.csv",sep = ' ',index = False,header = False)
fake_preds = output
fake_labels = final_df['abstract']
rouge_pubmed_raw_after_longformer = metric.compute(predictions=fake_preds, references=fake_labels)
rouge_pubmed_raw_after_longformer
# using GPT-3 model with pubmed bigbird pred text with summary method
import os
import openai
from tqdm import tqdm
openai.organization = "org-EisHcNn58Kak28bngV5bsOuz"
openai.api_key = "<KEY>"
engine_list = openai.Engine.list()
#openai.api_key = os.getenv("OPENAI_API_KEY")
output = []
#final_output = []
for i in tqdm(range(len(final_df))):
try:
beginning_tag = "My second grader asked me what this passage means:\n\"\"\"\n"
ending_tag = "\n\"\"\"\nI rephrased it for him, in plain language a second grader can understand:\n\"\"\"\n"
text = beginning_tag + str(final_df["predicted_abstract"].iloc[i])+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["\"\"\""]
)
output.append(response["choices"][0]['text'])
except:# if the token exceed the maximum tokens number in GPT-3 model,then just use first half text
beginning_tag = "My second grader asked me what this passage means:\n\"\"\"\n"
ending_tag = "\n\"\"\"\nI rephrased it for him, in plain language a second grader can understand:\n\"\"\"\n"
a = final_df["predicted_abstract"].iloc[i][:int(len(final_df["predicted_abstract"].iloc[i])/2)]
text = beginning_tag + str(a)+ ending_tag
response = openai.Completion.create(
engine="curie",
prompt=text,
temperature=0,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["\"\"\""]
)
output.append(response["choices"][0]['text'])
#final_output.append(output)
pred_df = pd.DataFrame()
pred_df["summary"] = output
pred_df.to_csv("pubmed_after_bigbird_summary_100.csv",sep = ' ',index = False,header = False)
fake_preds = output
fake_labels = final_df['abstract']
rouge_pubmed_raw_after_longformer = metric.compute(predictions=fake_preds, references=fake_labels)
rouge_pubmed_raw_after_longformer
report_df = pd.DataFrame(columns = ['data_resource', 'longformer_rough_1','longformer_rough_2','longformer_rough_L'])
# +
arxiv = {'data_resource':'arxiv','longformer_rough_1':34.69,'longformer_rough_2':15.24,'longformer_rough_L':21.52}
pubmed = {'data_resource':'pubmed','longformer_rough_1':35.73,'longformer_rough_2':14.67,'longformer_rough_L':22.44}
report_df = report_df.append(arxiv, ignore_index = True)
report_df = report_df.append(pubmed, ignore_index = True)
# -
report_df
| notebooks/GPT-3_after_longformer.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # 函数
#
# - 函数可以用来定义可重复代码,组织和简化
# - 一般来说一个函数在实际开发中为一个小功能
# - 一个类为一个大功能
# - 同样函数的长度不要超过一屏
def jj():
print('hello')
jj()
def jj2():
print('hello')
jj2()
b = jj2()
print(b)
# pytnon中的所有函数实际上都是有返回值(reture None),
# 如果你没有设置return,那么python将不显示None。
# 如果你设置return,那么将返回reture这个值
# ## 定义一个函数
#
# def function_name(list of parameters):
#
# do something
# 
# - 以前使用的random 或者range 或者print.. 其实都是函数或者类
def JJ():#def 标识符
print('hello')
a=JJ()
print(a)
JJ()#调用函数
def max_(num1,num2):
if num1 > num2:
return num1
else:
return num2
max_(2,4)
max({1,2,3})
def max_(num1,num2,num3):
if num1>num2>num3 or num1>num3>num2:
return num1
if num2>num1>num3 or num2>num3>num1:
return num2
if num3>num1>num2 or num3>num2>num1:
return num3
def good(name):
print('%s is good girl!'%name)
good('ztx')
# 函数参数如果有默认值的情况,当你调用该参数的时候: 可以不给予参数值,那么就会走该参数默认值 否则的话,就走你给予的参数值 含有默认值参数放在后面
def good(name1,name2='wjj'):
print('%s is good girl!'%name1,name2)
#位置传参
good('ztx1','ztx2')
#参数名传参
good(name1='ztx1',name2='ztx2')
#
# ## 调用一个函数
# - functionName()
# - "()" 就代表调用
# 
# ## 带返回值和不带返回值的函数
# - return 返回的内容
# - return 返回多个值
# - 一般情况下,在多个函数协同完成一个功能的时候,那么将会有返回值
# 
#
# - 当然也可以自定义返回None
# ## EP:
# 
def fun1():
print('hahahaha')
def fun2(f):
f()
fun2(fun1)
def num1(n1):
if n1%2==0:
print('是偶')
else:
print('是奇数')
num1(111)
import random
n1=random.randint(0,10)
def num_(n2):
if n1>n2 or n1<n2:
print('猜错了')
else:
print('猜对了')
num_(5)
# # KNN算法
# # 读取图片,进行对比分析
# import matplotlib.pyplot as plt
#
# res = plt.imread('D:/rabbit.jpg')
# print(res)
# ## 类型和关键字参数
# - 普通参数
# - 多个参数
# - 默认值参数
# - 不定长参数
# ## 普通参数
# ## 多个参数
# ## 默认值参数
# - 默认参数只能放在最后 *之后的必须强制命名传入参数,* 之后的变量必须带参数名
# # 强制命名
# - *之后的必须强制命名传入参数,* 之后的变量必须带参数名
def haha(*,name,name2,name4='H'):
print(name)
haha(name='Joker',name2='haha')
def U(str_):
for i in str_:
ASCII = ord(i)
if 97<=ASSCII<=122:
xiaoxie +=1
elif xxxx
print(i)
# ## 不定长参数
# - \*args, 不定长,输入多少参数都可以,不写入参数也可以
# > - 可以输入多个参数
# - 返回输出结果的类型是元组类型,元组可以迭代,输入多少个参数都可以迭代来取出
# - args 名字是可以修改的,只是通常约定为args
# - \**kwargs, 不定长第二种
# > - 可以输入多个参数,但需要带参数名称
# - 返回的数据类型是字典
# - 输入的一定要是表达式(键值对)
# - 一般大的项目传入参数时,使用config文件一次写入所有的参数
# ### \**kwargs, 不定长第二种
# - 第二种不定长参数传入方法,使用字典数据传入
# - 写入参数时,必须先写\*args, 再写\**kwargs。 这是固定写法
def TT(*args):
print(args)
TT(1,2,3)
TT()
TT(1,2,3,4,5,6,7)
def max_(num1,num2):
if num1 > num2:
return num1
else:
return num2
max_(1,5)
def max_(*arge):
res = max(arg)
a = (1,2,3,4)
for i in a:
print(i)
def max_(*args):
res = 0
for i in args:
if i > res:
res = i
return res
max_(1,3,7,4,50)
def sum_(*args,A='sum'):
res = 0
count = 0
for i in args:
res +=i
count += 1
if A == "sum":
return res
elif A == "mean":
mean = res / count
return res,mean
else:
print(A,'还未开放')
sum_(-1,0,1,4,A='var')
a = 'ztx123'
for i in a :
print(i)
def TT(**kwargs):
print(kwargs)
TT(a=100,b=1000)
def TT(*args,**kwargs):
print(kwargs)
print(arge),
TT(1,2,3,4,6,a=100,b=1000)
{'key':'value'}
# ## 变量的作用域
# - 局部变量 local
# - 全局变量 global
# - globals 函数返回一个全局变量的字典,包括所有导入的变量
# - locals() 函数会以字典类型返回当前位置的全部局部变量。
a = 1000
def Y():
global a
a += 100
print(a)
Y()
def YY(a1):
a1 += 100
print(a1)
YY(a1)
print(a1)
# ## 注意:
# - global :在进行赋值操作的时候需要声明
# - 官方解释:This is because when you make an assignment to a variable in a scope, that variable becomes local to that scope and shadows any similarly named variable in the outer scope.
# - 
# ## EP:
# - 定义一个邮箱加密函数,使得输入邮箱后进行ASCII码加密
# - 定义一个判断其是否为闰年的函数
# - 函数的嵌套:定义两个函数A,B,B函数接受A函数的数值并判定是否为奇数或者偶数
def res_(n,m):
for i in range(m):
n+=(10**m)
return n
# # Homework
# - 1
# 
def getpentagonalNumber():
count = 0
for i in range(1,100):
n=(i*(3*i-1))/2
print('%d'%n,end = ' ')
count+=1
if count % 10==0:
print("\n")
getpentagonalNumber()
# - 2
# 
def huhu():
count=0
for i in range(100,1001):
if (i%5==0 and i%6==0) :
print(i,end=' ')
count+=1
if (count%10==0):
print("\n")
huhu()
# - 3
# 
def displaysortednumbers():
x1,x2,x3=eval(input('输入三个整数:'))
print('排序为:',sorted({x1,x2,x3}))
displaysortednumbers()
# # - 4
# 
def num(num1,num2):
sum_=0
for i in range(0,num2):
num=num1*10**i
sum_+=num
print(sum_,'+',end='')
num(2,4)
# - 5
# 
# - 6
# 
def numberofdaysinayear():
for i in range(2010,2020):
if (i%4==0 and i%100!=0) or (i%400==0):
print(i,"有366天")
else:
print(i,'有365天')
numberofdaysinayear()
# - 7
# 
# - 8
# 
def meimei():
i=2
for i in range(2,32):
j=2
for j in range(2,i):
if i%j==0:
break
else:
n=2**i-1
print(i, n)
meimei()
# - 9
# 
# 
# - 10
# 
# - 11
# ### 去网上寻找如何用Python代码发送邮件
# - time.sleep(3) 3秒发送一次
# - 一旦错误后,重新换一个邮箱
def _format_addr(s):
name,addr=parseaddr(s)
return formataddr((Header(name,'utf-8').encode(),addr))
#发送人地址
from_addr = '<EMAIL>'
#邮箱授权密码
password = '<PASSWORD>'
#收件人地址
to_addr ='332745169@qq.com'
#邮箱服务器地址
smtp_server = 'smtp.qq.com'
#设置邮件信息
msg = MIMEText('python爬虫运行异常,异常信息为遇到HTTP 403','plain','utf-8')
msg['From']=_format_addr('python爬虫一号<%s>'%from_addr)
msg['To']=_format_addr('管理员<%s>'%to_addr)
msg['Subject']=Header('一号爬虫运行异常。','utf-8').encode()
#发送邮件
#SMTP协议默认端口是2s
server.set_debuglevel(1)
#方法用来登录SMTP服务器
server.lohin(from_addr,password)
#sendmail()方法就是发邮件,由于可以一次发给多个人,
#所以传入一个list,邮件正文是一个str,as_string()
| 7.20.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # !pip install git+https://github.com/nockchun/rspy --force
import rspy as rsp
import os
import numpy as np
import pandas as pd
# + [markdown] toc-hr-collapsed=true toc-nb-collapsed=true
# # Pandas
# -
# ## DataFrame 만들기
df = pd.DataFrame({
"col1" : ["foo1", "foo2", "foo3"],
"col2" : ["bar1", "bar2", "bar3"],
"col3" : ["A", "B", "C"],
"col4" : [100, 200, 300]
})
df
rsp.showMulti(
type(df["col1"]), df["col1"], df.col1
)
# dictionary로 부터 만들기
dfDict = pd.DataFrame.from_dict({
"row0" : {"col0":0, "col1":"A"},
"row1" : {"col0":1, "col1":"B"}
})
rsp.showMulti(
dfDict, dfDict.T
)
# ## 외부 데이터 Load/Save
dfCsv = pd.read_csv("resources/demo.csv")
dfCsv
dfCsv.to_excel("demo.xls", index=False)
dfXls = pd.read_excel("demo.xls")
dfXls
os.remove("demo.xls")
# ## Dataframe Query
# select where
rsp.showMulti(
df[df.col1 == "foo1"], df[ (df.col1 == "foo1") & (df.col4 <= 200) ]
)
# join
rsp.showMulti(
df, dfDict.T, dfDict.T.rename(columns={"col1":"col3"})
)
rsp.showMulti(
pd.merge(df, dfDict.T.rename(columns={"col1":"col3"}), on="col3", how="inner"),
pd.merge(df, dfDict.T.rename(columns={"col1":"col3"}), on="col3", how="outer"),
pd.merge(df, dfDict.T.rename(columns={"col1":"col3"}), on="col3", how="right"),
)
# + [markdown] toc-hr-collapsed=true toc-nb-collapsed=true
# # Matplotlib
# -
import matplotlib.pyplot as plt
# +
# rsp.getSystemFonts("nanum")
# -
plotConf = rsp.EduPlotConf(font="NanumGothicCoding")
plotConf.set()
rsp.setSystemWarning()
x = np.arange(100)
y = np.random.rand(100)
plt.plot(x, y)
plt.title("회차별 랜덤 값")
plt.ylabel("랜덤 값")
plt.xlabel("회차")
plt.grid(True)
plt.show()
# + [markdown] toc-hr-collapsed=true
# ## 함수 그리기
# +
t = np.arange(.0, 5.0, 0.2)
plt.plot(t, t, "r--")
plt.plot(t, 0.5*t**2, "b:")
plt.plot(t, 0.2*t**3, "g")
plt.title("multiple line")
plt.grid(True)
plt.show()
# -
# ### 색
# | 색 문자 | 의미 |<b>\|</b> | 색 문자 | 의미 | <b>\|</b> | 색 문자 | 의미 |<b>\|</b> | 색 문자 | 의미 |<b>\|</b>| 색 문자 | 의미 |
# |:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
# |b|blue|<b>\|</b>|g|green|<b>\|</b>|r|red|<b>\|</b>|c|cyan|<b>\|</b>|m|magenta|
# |y|yellow|<b>\|</b>|k|black|<b>\|</b>|w|white|
# ### 마커(marker)
# |마커문자|의미|<b>\|</b>|마커문자|의미|<b>\|</b>|마커문자|의미|<b>\|</b>|마커문자|의미|
# |:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
# |.|point marker|<b>\|</b>|,|pixel marker|<b>\|</b>|o|circle marker|<b>\|</b>|v|triangle_down marker|
# |^|triangle_up marker|<b>\|</b>|<|triangle_left marker|<b>\|</b>|>|triangle_right marker|<b>\|</b>|1|tri_down marker|
# |2|tri_up marker|<b>\|</b>|3|tri_left marker|<b>\|</b>|4|tri_right marker|<b>\|</b>|s|square marker|
# |p|pentagon marker|<b>\|</b>|\*|star marker|<b>\|</b>|h|hexagon1 marker|<b>\|</b>|H|hexagon2 marker|
# |+|plus marker|<b>\|</b>|x|x marker|<b>\|</b>|D|diamond marker|<b>\|</b>|d|thin_diamond marker|
# ### 선
# |선 문자|의미|<b>\|</b>|선 문자|의미|<b>\|</b>|선 문자|의미|<b>\|</b>|선 문자|의미|
# |:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
# |-|solid line style|<b>\|</b>|--|dashed line style|<b>\|</b>|-.|desh-dot line style|<b>\|</b>|:|dotted line style|
# ## EduPlot 활용
eduPlot = rsp.EduPlot2D(rsp.EduPlotConf(font="NanumGothicCoding", figScale=1.5))
eduPlot.addFunction("0.05*x**3", name="function01", color="#AAAA00")
x = np.arange(.0, 5.0, 0.2)
y1 = 0.5*x**2
y2 = 0.2*x**3
eduPlot.addXYData(x, x, "demo01", "r--")
eduPlot.addXYData(x, y1, "demo02", "b:")
eduPlot.addXYData(x, y2, "demo03", "g")
eduPlot.addText ([ [ 6, 6] ], ["test demo"])
eduPlot.addMarker([ [ 7, 3] ], "v", color="#FF0000")
eduPlot.addVector([ [-2, 2] ], [ [4, 0] ])
eduPlot.genSpace([-3, 10], [-3, 10], "EduPlot 활용")
# # Seaborn
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
sns.set_style('whitegrid')
iris = sns.load_dataset("iris") # 붓꽃 테스트 데이터
type(iris)
iris.head()
# * Sepal Length : 꽃받침의 길이 정보.
# * Sepal Width : 꽃받침의 너비 정보.
# * Petal Length : 꽃잎의 길이 정보.
# * Petal Width : 꽃잎의 너비 정보.
# * Species : 꽃의 종류 정보 (setosa / versicolor / virginica 의 3종류로 구분).
iris.describe().T
rsp.EduPlotConf(font="NanumGothicCoding").set()
sns.distplot(iris.petal_length.values)
plt.grid(True)
plt.show()
sns.distplot(iris[iris.species=="setosa"].petal_length, color="blue", label="setoas")
sns.distplot(iris[iris.species=="versicolor"].petal_length, color="red", label="versicolor")
sns.distplot(iris[iris.species=="virginica"].petal_length, color="green", label="virginica")
plt.legend(title="Species")
plt.show()
sns.pairplot(iris, hue="species", markers=["o", "s", "D"])
plt.show()
sns.lmplot(data=iris, x="petal_width", y="petal_length", hue="species")
plt.show()
# + [markdown] toc-hr-collapsed=true toc-nb-collapsed=true
# # Numpy & Tensor
# -
import numpy as np
import tensorflow as tf
np.set_printoptions(linewidth=200, precision=2)
np2d = np.random.random([4, 5])
np3d = np.random.random([3, 4, 5])
np2d.shape, np3d.shape
rsp.showMulti(np2d, np3d)
tf2d = tf.convert_to_tensor(np2d)
tf3d = tf.Variable(np3d)
tf2d.shape, tf3d.shape
rsp.showMulti(tf2d, tf3d)
tf2d.numpy()
# ## Slicing
#list slicing
demoList = [1, 2, 3, 4, 5]
rsp.showMulti(demoList[0], demoList[0:2], demoList[-1], demoList[:-1], demoList[1:-2])
np2d[0]
rsp.showMulti(np2d[:, 0], np2d[:, [0]], np2d[:, 0:1])
rsp.showMulti(tf2d[:,0].numpy(), tf.reshape(tf2d[:,0], [-1, 1]).numpy())
np3d[0:2,:,2:3]
np3d
rsp.showMulti(np3d[1], np3d[1][1:3,1:2])
# ## Reshape
rsp.showMulti(np2d, np2d.reshape([-1, 2], order="C"), np2d.reshape([-1, 2], order="F"))
print(np3d.shape)
rsp.showMulti(np3d, np3d.reshape([-1, 20])
)
rsp.showMulti(
np3d.reshape([12, 5]), np3d.reshape([-1, 5])
)
selector = np.array([1, 2, 1, 3, 0, 0, 0])
rsp.showMulti(np2d, np2d[selector])
# ## Compute
rsp.showMulti(np2d, np.max(np2d), np.min(np2d))
np.argmax(np2d), np.argmin(np2d)
rsp.showMulti(
np.max(np2d, axis=1), np.max(np2d, axis=0)
)
rsp.showMulti(
np.average(np2d), tf.reduce_mean(tf2d).numpy()
)
rsp.showMulti(
np.sum(np2d, axis=1), tf.reduce_sum(tf2d, axis=1).numpy()
)
np2d
np.where(np2d > 0.5)
np.where(np2d > 0.5, 1, 0)
# ## Function
# Broadcasting
rsp.showMulti(np2d, np2d+1, np2d/2)
# Transpose
rsp.showMulti(np2d, np2d.T)
# Stack
rsp.showMulti(
np.stack([np2d, np2d]), np.stack([np2d, np2d]).shape, np2d.shape
)
# ones / zeros
rsp.showMulti(np.ones([2, 2]), np.zeros([2, 3]))
rsp.showMulti(tf.ones([2, 2]), tf.zeros([2, 3]))
# +
# One Hot Encoding
# -
selector = np.array([0, 1, 2, 1, 1, 2, 2])
np.eye(3)[selector]
# # Interact
from ipywidgets import interactive
eduPlot = rsp.EduPlot2D(rsp.EduPlotConf(font="NanumGothicCoding"))
def draw2D(srcX, srcY, offset):
eduPlot.addFunction(f"{offset}*x**3")
eduPlot.addVector([ [-1, 1] ], [ [srcX, srcY] ])
return eduPlot.genSpace(4)
interactive(draw2D, srcX=(-2.0, 2.0), srcY=(-2.0, 2.0), offset=(-1.0, 1.0))
target = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
def analysisIris(x, y):
sns.lmplot(data=iris, x=x, y=y, hue="species")
plt.show()
plt.close()
def analysisDist(x):
targetName = target[x]
sns.distplot(iris[iris.species=="setosa"][targetName], color="blue", label="setoas")
sns.distplot(iris[iris.species=="versicolor"][targetName], color="red", label="versicolor")
sns.distplot(iris[iris.species=="virginica"][targetName], color="green", label="virginica")
plt.legend(title="Species")
plt.show()
plt.close()
rsp.showMulti(
interactive(analysisIris, x=target, y=target),
interactive(analysisDist, x=(0, 3))
)
| lecture_source/machine_learning/0103_library_basic.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .sh
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Bash
# language: bash
# name: bash
# ---
echo $SHELL
pwd
ls
cd /
pwd
ls
cd bin
pwd
ls
cd /
pwd
cd media
pwd
ls
ls
ls -a
cd /
pwd
cd home
pwd
ls
cd jupyter-ekdana
pwd
ls
cd /
pwd
cd var
pwd
ls
cd log
pwd
ls
cd /
pwd
cd tmp
pwd
ls
cd /
pwd
cd usr
pwd
ls
cd /
pwd
cd lib
pwd
ls
cd /
pwd
cd mnt
pwd
cd /
pwd
cd etc
pwd
cd
pwd
file ./
man file./
ls -l
| KurmangaliDana/ekdana_USK-CD.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:py37]
# language: python
# name: conda-env-py37-py
# ---
# + [markdown] colab_type="text" id="view-in-github"
# <a href="https://colab.research.google.com/github/probml/pyprobml/blob/master/notebooks/MIC_correlation_2d.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="BbP93U68lIzQ"
# # Illustration of Maximal Information Coefficient in 2d
#
# Code is from here: https://github.com/minepy/minepy
#
# +
# Source code modified from
# https://github.com/minepy/minepy/blob/master/examples/relationships.py
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
try:
from minepy import MINE
except ModuleNotFoundError:
# %pip install -qq minepy
from minepy import MINE
# + id="F1Y43cOJlPyw"
rs = np.random.RandomState(seed=0)
def mysubplot(x, y, numRows, numCols, plotNum, xlim=(-4, 4), ylim=(-4, 4)):
r = np.around(np.corrcoef(x, y)[0, 1], 1)
mine = MINE(alpha=0.6, c=15, est="mic_approx")
mine.compute_score(x, y)
mic = np.around(mine.mic(), 1)
ax = plt.subplot(numRows, numCols, plotNum, xlim=xlim, ylim=ylim)
ax.set_title("Pearson r=%.1f\nMIC=%.1f" % (r, mic), fontsize=10)
ax.set_frame_on(False)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
ax.plot(x, y, ",")
ax.set_xticks([])
ax.set_yticks([])
return ax
def rotation(xy, t):
return np.dot(xy, [[np.cos(t), -np.sin(t)], [np.sin(t), np.cos(t)]])
def mvnormal(n=1000):
cors = [1.0, 0.8, 0.4, 0.0, -0.4, -0.8, -1.0]
for i, cor in enumerate(cors):
cov = [[1, cor], [cor, 1]]
xy = rs.multivariate_normal([0, 0], cov, n)
mysubplot(xy[:, 0], xy[:, 1], 3, 7, i + 1)
def rotnormal(n=1000):
ts = [0, np.pi / 12, np.pi / 6, np.pi / 4, np.pi / 2 - np.pi / 6, np.pi / 2 - np.pi / 12, np.pi / 2]
cov = [[1, 1], [1, 1]]
xy = rs.multivariate_normal([0, 0], cov, n)
for i, t in enumerate(ts):
xy_r = rotation(xy, t)
mysubplot(xy_r[:, 0], xy_r[:, 1], 3, 7, i + 8)
def others(n=1000):
x = rs.uniform(-1, 1, n)
y = 4 * (x**2 - 0.5) ** 2 + rs.uniform(-1, 1, n) / 3
mysubplot(x, y, 3, 7, 15, (-1, 1), (-1 / 3, 1 + 1 / 3))
y = rs.uniform(-1, 1, n)
xy = np.concatenate((x.reshape(-1, 1), y.reshape(-1, 1)), axis=1)
xy = rotation(xy, -np.pi / 8)
lim = np.sqrt(2 + np.sqrt(2)) / np.sqrt(2)
mysubplot(xy[:, 0], xy[:, 1], 3, 7, 16, (-lim, lim), (-lim, lim))
xy = rotation(xy, -np.pi / 8)
lim = np.sqrt(2)
mysubplot(xy[:, 0], xy[:, 1], 3, 7, 17, (-lim, lim), (-lim, lim))
y = 2 * x**2 + rs.uniform(-1, 1, n)
mysubplot(x, y, 3, 7, 18, (-1, 1), (-1, 3))
y = (x**2 + rs.uniform(0, 0.5, n)) * np.array([-1, 1])[rs.random_integers(0, 1, size=n)]
mysubplot(x, y, 3, 7, 19, (-1.5, 1.5), (-1.5, 1.5))
y = np.cos(x * np.pi) + rs.uniform(0, 1 / 8, n)
x = np.sin(x * np.pi) + rs.uniform(0, 1 / 8, n)
mysubplot(x, y, 3, 7, 20, (-1.5, 1.5), (-1.5, 1.5))
xy1 = np.random.multivariate_normal([3, 3], [[1, 0], [0, 1]], int(n / 4))
xy2 = np.random.multivariate_normal([-3, 3], [[1, 0], [0, 1]], int(n / 4))
xy3 = np.random.multivariate_normal([-3, -3], [[1, 0], [0, 1]], int(n / 4))
xy4 = np.random.multivariate_normal([3, -3], [[1, 0], [0, 1]], int(n / 4))
xy = np.concatenate((xy1, xy2, xy3, xy4), axis=0)
mysubplot(xy[:, 0], xy[:, 1], 3, 7, 21, (-7, 7), (-7, 7))
# + colab={"base_uri": "https://localhost:8080/", "height": 537} id="PIl04-53lWm7" outputId="bc8f528f-e09b-4295-f2e8-6c8d9b0c9871"
plt.figure(facecolor="white", figsize=(15, 7))
mvnormal(n=800)
rotnormal(n=200)
others(n=800)
plt.tight_layout()
plt.savefig("MIC-2d-correlation.pdf", dpi=300)
plt.show()
# + id="ur-7HK7wlZX4"
| notebooks/book1/06/MIC_correlation_2d.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="vNPV_CUHkl6O"
# # Sorting
# + [markdown] id="LmjuZGunkw8P"
# ## Bubble sort
#
# Time complexity = O(n<sup>2</sup>)<hr/>
# Derivation:
# <table>
# <tr>
# <th>Iteration</th>
# <th>No. of comparisons</th>
# </tr>
# <tr>
# <td>1</td>
# <td>n-1</td>
# </tr>
# <tr>
# <td>2</td>
# <td>n-2</td>
# </tr>
# <tr>
# <td>...</td>
# <td>...</td>
# </tr>
# <tr>
# <td>n-1</td>
# <td>1</td>
# </table>
#
# First, we assume that we will be sorting the array (of size n) using bubble sort in an ascending order. At the first iteration of the bubble sort, we are iterating through n-1 elements, until the largest element 'bubbles' to the end of the array. Now, we can focus on the remaining n-2 elements. After the second iteration, the second largest element bubbles up to the second last position of the array. This process continues until the whole array is sorted (or no more swaps occur, in the optimised case).
#
# No. of comparisons = 1 + 2 + ... + n-1 = (n-2)*(2+(n-2)) = (n-2)(n) = n<sup>2</sup> (By Arithmetic Progression)
# + colab={"base_uri": "https://localhost:8080/"} id="wfQK7NevYtwK" outputId="8e215c22-05ec-4704-95cb-649c2a4d24b9"
# bubble sort (non-optimised)
def bubble_sort(A):
for passes in range(len(A)):
for i in range(1, len(A)):
if A[i-1] > A[i]:
A[i-1], A[i] = A[i], A[i-1]
return A
# main
A = [4, 5, 2, 1, 3]
print(bubble_sort(A))
# + colab={"base_uri": "https://localhost:8080/"} id="KM9SKmYpkWTW" outputId="9078d2e0-9cd9-4c86-c0ba-937280a98577"
# bubble sort (optimised)
def bubble_sort(A):
passes = len(A) - 1 # for n items, need n-1 passes
swapped = True # assume not sorted
while swapped: # we can terminate once no more swap occurs i.e. array is sorted
swapped = False
i = 1
while i <= passes:
if A[i-1] > A[i]:
A[i-1], A[i] = A[i], A[i-1]
swapped = True
i = i + 1
passes = passes - 1
return A
# main
A = [4, 5, 2, 1, 3]
print(bubble_sort(A))
# + [markdown] id="X5E7x1bskrJt"
# ## Insertion sort
#
# Insertion sort works by maintaining 2 'separate' sublists of the original array. By definition, an array of size 1 is already sorted, so we can assume easily that ```A[0]``` is sorted. Now we are left with the elements ```A[1:n]```, where n is the size of the array. At each iteration, we pick an element ```i```, 1 <= ```i``` < n from ```A``` and put it into its appropriate position in ```A[:i+1]```. This can be thought of as having a deck of cards on two hands: the left hand holds the deck that is already sorted, and the right hand picks a card and put it into the left hand.
# + id="Wq82MGrjkc0p"
# insertion sort
def insertion_sort (A):
n = len(A) # length of the array
for i in range (1, n):
# we maintain two 'sublist', where the first element is sorted initially
cmp = A[i] # we want to find the position to put cmp into the sorted sublist
pos = i
for j in range (i-1, -1, -1):
if A[j] > cmp:
# shift operation
A[j+1] = A[j]
pos -= 1
else:
break
A[pos] = cmp
return A
# main
A = [4, 5, 2, 1, 3]
print(insertion_sort(A))
# + [markdown] id="FizoLT-AkqWd"
# ## Selection sort
# + id="dkEFpNN-ken9"
# selection sort
# + [markdown] id="BlDJ1i41lBum"
# ## Quick sort
#
# The efficiency of the quick sort is largely dependent on the choice of the pivot value. In the best case, we can select a pivot value that optimally splits the list into two equal halves at each iteration, giving rise to a time complexity of O(nlogn), but in the worst case, we may select a pivot value that results in a highly skewed list. Imagine selecting a pivot value such that we split the list into a size of n-1, then n-2... and so on. This leads to a time complexity of O(n<sup>2</sup>).
# * Also, this method of sorting is non-stable, which means that it does not preserve the initial order of the elements.
# + id="O32NygMulBDG"
# quick sort
def quick_sort (A):
if len(A) == 0: # terminating case
return []
less = []
great = []
pivot = A[0] # select first element as pivot
# the aim is to put all elements lesser than pivot into the less array
# and all elements greater than pivot into the great array
for i in range (1, len(A)):
if A[i] < pivot:
less.append(A[i])
else:
great.append(A[i])
# recursive case
lesser = quick_sort(less)
greater = quick_sort(great)
return lesser + [pivot] + greater
# main
A = [4, 5, 2, 1, 3]
print(quick_sort(A))
# + [markdown] id="c713fkXQkr5n"
# ## Merge sort
# + id="jrVvOqDXkiSd"
# merge sort
def merge (A, left, right): # conquer
i = j = k = 0 # running variables
nleft = len(left) # length of left array
nright = len(right) # length of right array
while i < nleft and j < nright: # prevent array access out of bounds error
if left[i] < right[j]: # pick the smaller of the two as we want to sort the array into ascending order
A[k] = left[i]
i += 1
else:
A[k] = right[j]
j += 1
k += 1
# handle leftovers
while i < nleft:
A[k] = left[i]
i += 1
k += 1
while j < nright:
A[k] = right[j]
j += 1
k += 1
def merge_sort (A): # divide
if len(A) > 1: # an array of size 1 is already sorted
mid = len(A) // 2
left = A[:mid]
right = A[mid:]
merge_sort(left)
merge_sort(right)
merge(A, left, right)
return A
# main
A = [4, 5, 2, 1, 3]
print(merge_sort(A))
| computing_sh/Python12_Sorting.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# %matplotlib inline
# -
# train_df = pd.read_csv('./data/london/London_historical_aqi_other_stations_20180331.csv')
# train_df = pd.read_csv('./data/london/London_historical_aqi_forecast_stations_20180331.csv')
train_df = pd.read_csv('./data/beijing/beijing_17_18_aq.csv')
print(train_df.columns.values)
train_df.head()
train_df.tail()
train_df.info()
train_df.describe()
train_df.describe(include=['O'])
train_df[['stationId', 'PM2.5']].groupby(['stationId'], as_index=False).mean().sort_values(by='PM2.5', ascending=False)
train_df[['stationId', 'PM10']].groupby(['stationId'], as_index=False).mean().sort_values(by='PM10', ascending=False)
train_df[['stationId', 'O3']].groupby(['stationId'], as_index=False).mean().sort_values(by='O3', ascending=False)
| visualize.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Generation of custom datasets for prediction data and embedding visualization
# ## Load General Dependencies
# Autoreload is not strictly necessary
# but helpful for development purposes
# as it automates the reload of python files
# %load_ext autoreload
# %autoreload 2
# +
import json
import time
import matplotlib.pyplot as plt
import joblib
import pandas as pd
import numpy as np
from src import loading
# -
# ## Load Mutation Dataset
data = loading.load_dataset('../TestingBackend/data/flask_full.pkl')
# ## Load Test.json
# Because the version of the mutation testing dataset and the current repository version can be different,
# a current output of pytest in json format is used to keep both in sync:
#
# It can be simply generated by using pytest-json:
# Open the directory of the repository and execute:
# ```
# . venv/bin/activate
# pip install pytest-json
# pytest --json=report.json
# ```
#
# Currently, the sync this is done by matching the name of the tests.
# Load into tests
with open('../flask/report.json') as file:
parsed_json = json.load(file)
tests = parsed_json['report']['tests']
# +
test_full_names = []
for test in tests:
test_full_names.append(test['name'])
def filter_nonexistent_tests(data, full_names):
length = len(data)
filtered_data = data[data['full_name'].isin(full_names)]
filtered_length = len(filtered_data)
print(f"Filtered for full names. Deleted {length - filtered_length} entries ({(length-filtered_length) / length * 100}%)")
return filtered_data
data = filter_nonexistent_tests(data, test_full_names)
# -
name_and_number_of_failures = data.groupby(['outcome', 'full_name']).count().loc['outcome' == False]['mutant_id']
# Store Mutant Failures in tests
for test in tests:
test['mutant_failures'] = 0
if test['name'] in name_and_number_of_failures:
test['mutant_failures'] = int(name_and_number_of_failures.at[test['name']])
# ## Train Prediction Model
# Load additional Dependencies
from src import preprocessing
from sklearn import tree
# Apply preprocessing steps to make sure data does not contain invalid information
preprocessing.cleanse_data(data)
preprocessing.add_edit_distance_feature(data)
data = preprocessing.filter_NaN_values('flask', data)
#encoded_column_names = ["modified_method", "modified_file_path", "name", "filepath", "current_line", "previous_line"]
encoded_column_names = ["modified_file_path"]
dangerous_features = ['duration', 'setup_outcome', 'setup_duration', 'call_outcome', 'call_duration', 'teardown_outcome', 'teardown_duration']
unencoded_features = ['repo_path', 'full_name']
# Use a DecisionTreeClassifier
predictor = tree.DecisionTreeClassifier()
# Here, additional features can be selected for the predictor.
# It is important that these features can also be generated on the fly by the TestingBackend.
# Adding a new features requires to add it here, and then activate it in the TestingBackend.
# +
selected_features = [
# Required Features (necessary for process)
'test_id', 'outcome', 'mutant_id',
# Basic features:
'modified_file_path', 'line_number_changed',
]
encoded_data, encoder = preprocessing.encode_columns(data, encoded_column_names)
encoded_data = encoded_data.drop(dangerous_features, axis=1).drop(unencoded_features, axis=1)[selected_features].copy()
X_train, y_train, X_test, y_test = preprocessing.train_test_split(encoded_data)
predictor.fit(X_train.drop(['mutant_id'],axis=1), y_train)
print("Score: " + str(predictor.score(X_test.drop(['mutant_id'], axis=1), y_test)))
# -
# # Embedding from Covariances
# In the embedding view in the TestingPlugins, the tests are mapped to a xy-plane based on their covariances. The embedding algorithm can be customized here.
# Load additional Dependencies
from sklearn.manifold import MDS
from sklearn.manifold import TSNE
from sklearn.manifold import SpectralEmbedding
from sklearn.manifold import Isomap
def compute_and_show_embedding(model, data):
pivot = data.set_index('mutant_id').pivot(columns='test_id', values='outcome')
pivot = pivot.astype('bool')
embedding = model.fit_transform(pivot.cov())
plt.scatter(embedding[:, 0], embedding[:, 1])
plt.axis('equal')
return embedding, pivot
# MDS Embedding Model
embedding, pivot = compute_and_show_embedding(MDS(n_components=2, dissimilarity='precomputed', random_state=42), data)
# ISOMap Embedding Model
embedding, pivot = compute_and_show_embedding(Isomap(n_components=2), data)
# Spectral Embedding Model
embedding, pivot = compute_and_show_embedding(SpectralEmbedding(n_components=2), data)
# TSNE Embedding Model
embedding, pivot = compute_and_show_embedding(TSNE(n_components=2, random_state=42), data)
# Store the xy coordinates of the embedding in `tests`
# Which model is used is dependent on which cell of the embeddings get's executed last
xy = pd.DataFrame(embedding, index=list(pivot.columns))
for test in tests:
if test['name'] in xy.index:
test['x'] = float(xy.at[test['name'], 0])
test['y'] = float(xy.at[test['name'], 1])
# ## Store files to disk
# JSON
with open('test_visualization_data.json', 'w') as file:
json.dump(tests, file)
# Joblib Files (Predictor Model)
name = 'flask_decisiontree.joblib'
joblib.dump({'predictor': predictor, 'encoder': encoder, 'test_ids_to_test_names': data.groupby('test_id').sample().set_index('test_id')['full_name']}, name)
# These files now need to be loaded by the backend, by customizing the paths in `TestingBackend/config.cfg`
| preprocessing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="GZacVubxYsVi" colab_type="code" outputId="02e2400c-9e20-4a39-c11e-866ff9d8fd67" executionInfo={"status": "ok", "timestamp": 1583398128213, "user_tz": -60, "elapsed": 9742, "user": {"displayName": "<NAME>\u0142aczek", "photoUrl": "", "userId": "11100563095694681460"}} colab={"base_uri": "https://localhost:8080/", "height": 306}
# !pip install --upgrade tables
# !pip install eli5
# !pip install xgboost
# + id="ZLzADDmyY6tB" colab_type="code" colab={}
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.dummy import DummyRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
from sklearn.metrics import mean_absolute_error as mae
from sklearn.model_selection import cross_val_score, KFold
import eli5
from eli5.sklearn import PermutationImportance
# + id="4nMdJEZDZIpA" colab_type="code" outputId="96424b57-b159-4b57-fe8d-97ee2868fa97" executionInfo={"status": "ok", "timestamp": 1583398130607, "user_tz": -60, "elapsed": 474, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "11100563095694681460"}} colab={"base_uri": "https://localhost:8080/", "height": 34}
# cd '/content/drive/My Drive/Colab Notebooks/dw_matrix/matrix_two/dw_matrix_car'
# + id="mxrCGgy8cbE-" colab_type="code" colab={}
df = pd.read_hdf('data/car.h5')
# + id="5eT3wWu2cdkW" colab_type="code" colab={}
SUFFIX_CAT = '__cat'
for feat in df.columns:
if isinstance(df[feat][0],list): continue
factorized_values = df[feat].factorize()[0]
if SUFFIX_CAT in feat:
df[feat] = factorized_values
else:
df[feat+SUFFIX_CAT] = factorized_values
# + id="YFwbEfKecoBv" colab_type="code" outputId="fea95e97-9c28-4d4d-e8db-a798f152c769" executionInfo={"status": "ok", "timestamp": 1583407648873, "user_tz": -60, "elapsed": 540, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "11100563095694681460"}} colab={"base_uri": "https://localhost:8080/", "height": 34}
cat_feats = [x for x in df.columns if SUFFIX_CAT in x]
cat_feats = [x for x in cat_feats if 'price' not in x]
len(cat_feats)
# + id="B0O6M943Yxci" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 102} outputId="6a1dede6-8290-433a-c609-774f1f2853c8" executionInfo={"status": "ok", "timestamp": 1583406615059, "user_tz": -60, "elapsed": 580, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "11100563095694681460"}}
df.info()
# + id="aYT7x14wcuqH" colab_type="code" colab={}
def run_model(model,feats):
X = df[feats].values
y=df['price_value'].values
model = model
scores = cross_val_score(model,X,y,cv=3,scoring='neg_mean_absolute_error')
return np.mean(scores), np.std(scores)
# + [markdown] id="WQyV31M04RNr" colab_type="text"
# # Decision Tree
# + id="b5S-YCcn4XOm" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="14f8cdae-f15c-4883-bff7-b5142e5d1ab8" executionInfo={"status": "ok", "timestamp": 1583398257647, "user_tz": -60, "elapsed": 4950, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "11100563095694681460"}}
run_model(DecisionTreeRegressor(max_depth=5),cat_feats)
# + [markdown] id="z-9qR_ld5G12" colab_type="text"
# #Random Forest
# + id="W7a0cVRv5Mdm" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="4b4fd65e-b12e-469d-b3d4-47eb019ae40f" executionInfo={"status": "ok", "timestamp": 1583398480973, "user_tz": -60, "elapsed": 122291, "user": {"displayName": "<NAME>\u0142aczek", "photoUrl": "", "userId": "11100563095694681460"}}
model = RandomForestRegressor(max_depth=5,n_estimators=50,random_state=0)
run_model(model,cat_feats)
# + id="Ucy4-72J5Y5e" colab_type="code" colab={}
# + [markdown] id="SA6EWc9a5r3_" colab_type="text"
# #XGBOOST
# + id="xy2Y4ITw5uJN" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 85} outputId="69befde7-f3ba-4945-cf7d-cf43f534babd" executionInfo={"status": "ok", "timestamp": 1583398805701, "user_tz": -60, "elapsed": 116409, "user": {"displayName": "<NAME>\u0142aczek", "photoUrl": "", "userId": "11100563095694681460"}}
xgb_params = {
'max_depth':5,
'n_estimarots' : 50,
'learning_rate' : 0.1,
'seed' : 0
}
model = xgb.XGBRegressor(**xgb_params)
run_model(model,cat_feats)
# + id="ryBH6ntv5_qE" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 408} outputId="f1fe7be3-aac9-4a39-de1a-e46cbe7ee830" executionInfo={"status": "ok", "timestamp": 1583399487863, "user_tz": -60, "elapsed": 596433, "user": {"displayName": "<NAME>\u0142aczek", "photoUrl": "", "userId": "11100563095694681460"}}
model = xgb.XGBRegressor(**xgb_params)
model.fit(X,y)
imp = PermutationImportance(model,random_state=0).fit(X,y)
eli5.show_weights(imp, feature_names=cat_feats)
# + id="mCnJqHQU7a9a" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 85} outputId="b4796af0-d9d4-4268-8753-e5441547d1bb" executionInfo={"status": "ok", "timestamp": 1583406492472, "user_tz": -60, "elapsed": 27673, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "11100563095694681460"}}
feats = ['param_rok-produkcji__cat',
'param_stan__cat',
'param_napęd__cat',
'param_skrzynia-biegów__cat',
'param_moc__cat',
'param_faktura-vat__cat',
'param_marka-pojazdu__cat',
'param_typ__cat',
'feature_kamera-cofania__cat',
'param_wersja__cat',
'param_model-pojazdu__cat',
'param_pojemność-skokowa__cat',
'param_kod-silnika__cat',
'seller_name__cat',
'feature_wspomaganie-kierownicy__cat',
'feature_czujniki-parkowania-przednie__cat',
'param_uszkodzony__cat',
'feature_system-start-stop__cat',
'feature_regulowane-zawieszenie__cat',
'feature_asystent-pasa-ruchu__cat']
run_model(model,feats)
# + id="ZhFaJ4jKMk4A" colab_type="code" colab={}
df['param_rok-produkcji'] = df['param_rok-produkcji'].map(lambda x: -1 if str(x)== 'None' else int(x))
# + id="gYM_CAW9XJyI" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 85} outputId="325030a0-9538-4645-d7a2-a3beb344345f" executionInfo={"status": "ok", "timestamp": 1583406566427, "user_tz": -60, "elapsed": 27535, "user": {"displayName": "<NAME>0142aczek", "photoUrl": "", "userId": "11100563095694681460"}}
feats = ['param_rok-produkcji',
'param_stan__cat',
'param_napęd__cat',
'param_skrzynia-biegów__cat',
'param_moc__cat',
'param_faktura-vat__cat',
'param_marka-pojazdu__cat',
'param_typ__cat',
'feature_kamera-cofania__cat',
'param_wersja__cat',
'param_model-pojazdu__cat',
'param_pojemność-skokowa__cat',
'param_kod-silnika__cat',
'seller_name__cat',
'feature_wspomaganie-kierownicy__cat',
'feature_czujniki-parkowania-przednie__cat',
'param_uszkodzony__cat',
'feature_system-start-stop__cat',
'feature_regulowane-zawieszenie__cat',
'feature_asystent-pasa-ruchu__cat']
run_model(model,feats)
# + id="Y6wjy9UNXWAG" colab_type="code" colab={}
df['param_moc']= df['param_moc'].map(lambda x:-1 if str(x)== 'None' else int(x.split(' ')[0]) )
# + id="zYhEsfDsZkwv" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 85} outputId="74eb70a5-2fbe-42e0-8290-f8d4125768d5" executionInfo={"status": "ok", "timestamp": 1583407013733, "user_tz": -60, "elapsed": 24983, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "11100563095694681460"}}
feats = ['param_rok-produkcji',
'param_stan__cat',
'param_napęd__cat',
'param_skrzynia-biegów__cat',
'param_moc',
'param_faktura-vat__cat',
'param_marka-pojazdu__cat',
'param_typ__cat',
'feature_kamera-cofania__cat',
'param_wersja__cat',
'param_model-pojazdu__cat',
'param_pojemność-skokowa__cat',
'param_kod-silnika__cat',
'seller_name__cat',
'feature_wspomaganie-kierownicy__cat',
'feature_czujniki-parkowania-przednie__cat',
'param_uszkodzony__cat',
'feature_system-start-stop__cat',
'feature_regulowane-zawieszenie__cat',
'feature_asystent-pasa-ruchu__cat']
run_model(model,feats)
# + id="Jg3u8wB6aAp9" colab_type="code" colab={}
df['param_pojemność-skokowa'] = df['param_pojemność-skokowa'].map(lambda x:-1 if str(x)== 'None' else int(x.split('cm')[0].replace(' ','')) )
# + id="R_oaJmd3bpDI" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 85} outputId="b24a365a-a4d7-404b-a3ea-c80d4c5faf56" executionInfo={"status": "ok", "timestamp": 1583407775291, "user_tz": -60, "elapsed": 25398, "user": {"displayName": "<NAME>142aczek", "photoUrl": "", "userId": "11100563095694681460"}}
feats = ['param_rok-produkcji',
'param_stan__cat',
'param_napęd__cat',
'param_skrzynia-biegów__cat',
'param_moc',
'param_faktura-vat__cat',
'param_marka-pojazdu__cat',
'param_typ__cat',
'feature_kamera-cofania__cat',
'param_wersja__cat',
'param_model-pojazdu__cat',
'param_pojemność-skokowa',
'param_kod-silnika__cat',
'seller_name__cat',
'feature_wspomaganie-kierownicy__cat',
'feature_czujniki-parkowania-przednie__cat',
'param_uszkodzony__cat',
'feature_system-start-stop__cat',
'feature_regulowane-zawieszenie__cat',
'feature_asystent-pasa-ruchu__cat']
run_model(model,feats)
# + id="YE5k0is0cIyk" colab_type="code" colab={}
| m2_day4_XGBOOST.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Step 1: Create twitter connection
#It creates the Twitter API connection and the topic (covidtweets) to pass the information.
# !curl -X POST -H "Content-Type: application/json" --data @configs/twitterConnector.json http://connect:8083/connectors | json_pp
# # Step 2: Create streams (ksql)
# It creates the data stream form the covidtweets topic. It is called RAWTWEETS
# !curl -X POST -H "Content-Type: application/json; charset=utf-8" -d @ksql/RawStream.json http://ksqldb-server:8088/ksql | json_pp
# It creates a stream from the RAWTWEETS. It selects some of the features and filters lang = eng. It is called ENGSTREAM
# !curl -X POST -H "Content-Type: application/json; charset=utf-8" -d @ksql/EngStream.json http://ksqldb-server:8088/ksql | json_pp
# It creates a stream from the RAWTWEETS. It selects some of the features and filters country is not null. It is called LOCSTREAM
# !curl -X POST -H "Content-Type: application/json; charset=utf-8" -d @ksql/LocStream.json http://ksqldb-server:8088/ksql | json_pp
# It creates a stream from the RAWTWEETS. It lists the Hashtags on the tweets. It is called HASHSTREAM
# !curl -X POST -H "Content-Type: application/json; charset=utf-8" -d @ksql/HashStream.json http://ksqldb-server:8088/ksql | json_pp
# # Step 3: Create tables (ksql)
# It creates a table from HASHSTREAM which count the tweets per hashtag in a 10 min window (TUMBLING)
# !curl -X POST -H "Content-Type: application/json; charset=utf-8" -d @ksql/HashTable.json http://ksqldb-server:8088/ksql | json_pp
# It creates a table from RAWTWEETS which count the tweets per verified account.
# !curl -X POST -H "Content-Type: application/json; charset=utf-8" -d @ksql/VerTable.json http://ksqldb-server:8088/ksql | json_pp
| 02 Connection Streams Tables.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# An investigation of ERN's post about Prime Harvesting and random Reddit post
#
# * https://earlyretirementnow.com/2017/04/19/the-ultimate-guide-to-safe-withdrawal-rates-part-13-dynamic-stock-bond-allocation-through-prime-harvesting/
# * https://www.reddit.com/r/financialindependence/comments/binb2q/the_clever_market_timing_withdrawal_strategy_an/
#
# Things to test:
# * Look more into OmegaNot.
# * Is 100% the best threshold? What about 90%? Or 110%?
# * *Why* does replenish bonds help? Under what circumstances? What exactly does it do?
# * ERN's stuff.
# * Look at his McClung-Smooth
# * Replicate his results, why is his glidepath so good?
# * Look beyond just 1966
# * Are better results simply caused by higher stock allocations? e.g. a higher SWR might just be due to holding more stocks
# +
import simulate
import withdrawal
import market
import harvesting
import metrics
from decimal import Decimal as D
import decimal
import itertools
import pandas
import numpy
#import ipysheet
# -
# %matplotlib inline
import seaborn
from matplotlib import pyplot as plt
import matplotlib
seaborn.set(style="whitegrid")
seaborn.set_context('poster')
run_calc = simulate.calc_lens
# legacy conversion....these functions used to be defined inline,
# now they're in a module. So we import * and splat them in our namespace
from lens import *
Omegas = [harvesting.make_omeganot(D(n)/100) for n in range(70,140, 10)]
Rebalances = [harvesting.make_rebalancer(D(n)/100) for n in range(20, 110, 10)]
Glidepaths = [harvesting.Glidepath, harvesting.InverseGlidepath, harvesting.AgeBased_100]
Harvest_Strategies = Omegas + Rebalances + Glidepaths
Withdraw_Strategies = [
withdrawal.make_constantdollar(D('.0325')),
withdrawal.make_constantdollar(D('.035')),
withdrawal.make_constantdollar(D('.04')),
withdrawal.make_constantdollar(D('.045')),
withdrawal.make_constantdollar(D('.05')),
]
Lengths = [30, 40, 50]
Combos = list(itertools.product(Lengths, Harvest_Strategies, Withdraw_Strategies))
PALETTE = seaborn.color_palette("Reds", len(Omegas)) + seaborn.color_palette("YlGn", len(Rebalances)) + seaborn.color_palette("Greys", len(Glidepaths))
seaborn.set_palette(PALETTE)
PALETTE_OMEGAS = seaborn.color_palette("husl", len(Omegas))
PALETTE_HARVEST = seaborn.color_palette("husl", len(Harvest_Strategies))
PALETTE_WITHDRAW = seaborn.color_palette("husl", len(Withdraw_Strategies))
# # Failure Rates
def run():
df = pandas.DataFrame(index=range(0, len(Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'Failure Rate'])
i = 0
for (years, harvest, withdraw) in Combos:
s = run_calc(harvest, withdraw, years, calc_success)
failure_rate = len(s[s == False]) / len(s)
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, failure_rate)
i += 1
return df
success_df = run()
g = seaborn.catplot(x='Harvest',
y='Failure Rate',
height=10,
aspect=1.5,
hue='Withdrawal',
data=success_df[success_df['Length'] == 40],
s=12,
palette=PALETTE_WITHDRAW
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(rotation=90)
g.fig.suptitle('Failure Rates for 40 years')
g = seaborn.catplot(x='Withdrawal',
y='Failure Rate',
height=8,
hue='Harvest',
data=success_df[success_df['Length'] == 40],
aspect=1.5,
s=10
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Failure Rates for 40 years')
# ## Detailed Failure Rate Charts
#
# This generates a lot of charts.
# Remove the *break* to re-enable.
for (years, withdraw) in itertools.product(Lengths, Withdraw_Strategies):
g = seaborn.catplot(x='Harvest',
y='Failure Rate',
height=8,
data=success_df[(success_df['Length'] == years) & (success_df['Withdrawal'] == withdraw.__name__)],
aspect=1.5,
s=20
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(rotation=90)
g.fig.suptitle('Failure Rates for %s years @ %s' % (years, withdraw.__name__))
break
# # Perfect Withdrawal Amount ($0 remaining)
#
# n.b. PWAs & MSWRs are a weird thing for strategies that shift their asset allocation because the amount that you withdraw changes the asset allocation which in turn changes the MSWR.
#
# So how do you calculate the true MSWR?
#
# Ugh.
PWA_Combos = list(itertools.product(Lengths, Harvest_Strategies, [withdrawal.ConstantPercentage]))
def run():
df = pandas.DataFrame(index=range(0, len(PWA_Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'PWA'])
i = 0
for (years, harvest, withdraw) in PWA_Combos:
series = run_calc(harvest, withdraw, years, calc_pwa0)
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, float(series.min()))
i += 1
return df
pwa0_df = run()
g = seaborn.catplot(x='Harvest',
y='PWA',
height=10,
data=pwa0_df, kind='bar',
aspect=1.5
)
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('Maximum Sustainable Withdrawal Rate (0% Portfolio at end)')
g.set_xticklabels(rotation=90)
g = seaborn.catplot(x='Length',
y='PWA',
height=10,
s=12,
hue='Harvest',
data=pwa0_df,
)
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('Maximum Sustainable Withdrawal Rate (0% Portfolio at end)')
# # Perfect Withdrawal Amount (100% remaining)
def run():
df = pandas.DataFrame(index=range(0, len(PWA_Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'PWA'])
i = 0
for (years, harvest, withdraw) in PWA_Combos:
series = run_calc(harvest, withdraw, years, calc_pwa1)
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, series.min())
i += 1
return df
pwa1_df = run()
g = seaborn.catplot(x='Length',
y='PWA',
height=10,
s=12,
hue='Harvest',
data=pwa1_df,
)
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('Maximum Sustainable Withdrawal Rate (100% Portfolio at end)')
# # Shortfall Years
#
# Shortfall years is the average number of years the strategy fell short, over all the retirement periods in which it failed.
#
# i.e. "when it failed, on averaged it failed N years early"
#
# This is really just a variant on failure rate & that should probably be folder into this.
def run():
df = pandas.DataFrame(index=range(0, len(Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'Shortfall Years'])
i = 0
for (years, harvest, withdraw) in Combos:
series = run_calc(harvest, withdraw, years, calc_shortfall_years)
shortfalls = series[series > 0]
shortfall_years = shortfalls.mean()
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, shortfall_years)
i += 1
return df
shortfall_years_df = run()
g = seaborn.catplot(x='Withdrawal',
y='Shortfall Years',
height=8,
hue='Harvest',
data=shortfall_years_df[shortfall_years_df['Length'] == 40].fillna(0),
aspect=1.5,
s=10
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Shortfall Years for 40 years')
# +
GoodRebalancers = ['AnnualRebalancer_%s' % s for s in [80, 90, 100]]
GoodOmegas = ['OmegaNot_100', 'OmegaNot_90']
GoodGlidepaths = [harvesting.InverseGlidepath.__name__]
FewerHarvests = GoodRebalancers + GoodOmegas + GoodGlidepaths
GoodPalette = (seaborn.color_palette("Reds", len(GoodOmegas))
+ seaborn.color_palette("Greens", len(GoodRebalancers))
+ seaborn.color_palette("Greys", len(GoodGlidepaths)))
HardWithdraws = ['ConstantDollar_0.04', 'ConstantDollar_0.045', 'ConstantDollar_0.05']
g = seaborn.catplot(x='Withdrawal',
y='Shortfall Years',
height=8,
hue='Harvest',
data=shortfall_years_df[(shortfall_years_df['Length'] == 40)
& (shortfall_years_df['Harvest'].isin(FewerHarvests))
& (shortfall_years_df['Withdrawal'].isin(HardWithdraws))],
aspect=1.5,
s=10,
palette=GoodPalette
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['4%', '4.5%', '5%'])
g.fig.suptitle('Shortfall Years for 40 years')
# +
JustOmegas = [n.__name__ for n in Omegas]
g = seaborn.catplot(x='Withdrawal',
y='Shortfall Years',
height=8,
hue='Harvest',
data=shortfall_years_df[(shortfall_years_df['Length'] == 40)
& (shortfall_years_df['Harvest'].isin(JustOmegas))
& (shortfall_years_df['Withdrawal'].isin(HardWithdraws))],
aspect=1.5,
s=10,
palette=PALETTE_OMEGAS
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['4%', '4.5%', '5%'])
g.fig.suptitle('Shortfall Years for 40 years')
# -
# # Downside Risk-Adjusted Success & Coverage Ratio
#
# Risk-adjusted success is the ratio between the expected value and the standard deviation of years sustained.
#
# Coverage ratio is the number of years the portfolio lasted, run through a utility function so large values are discount and shortfalls penalized.
def run():
df = pandas.DataFrame(index=range(0, len(Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'D-RAS', 'Coverage Ratio'])
i = 0
for (years, harvest, withdraw) in Combos:
series = run_calc(harvest, withdraw, years, calc_years_sustained)
# how many had shortfall years?
failures = series[series < 0]
successes = series[series >= 0]
p_fail = len(failures) / len(series)
L = years
s_y = failures.mean()
b_y = successes.mean()
e_ys = (p_fail * (L + s_y)) + ((1 - p_fail) * (L + b_y))
# semi-deviation with respect to length of retirement
ssd_l_ys = (p_fail * s_y * s_y) ** 1/2
d_ras = e_ys / ssd_l_ys
# now calculate the coverage ratio
coverage_series = series.apply(lambda x: (x+L)/L)
def u_c(c, risk_aversion=D('0.9999'), penalty_coeff=D(10)):
c = D(c)
if c >= 1:
numerator = (c ** (1 - risk_aversion)) - 1
denominator = 1 - risk_aversion
return numerator / denominator
else:
numerator = (1 ** (1 - risk_aversion)) - 1
denominator = 1 - risk_aversion
penalty = penalty_coeff * (1 - c)
return (numerator / denominator) - penalty
U_C = coverage_series.apply(u_c)
coverage = U_C.mean()
# the pandas based clipping isn't working so we manually hack it in there.
# Should really investigate this...why is it so high?
if d_ras > 5000:
d_ras = d_ras
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, d_ras, coverage)
i += 1
return df
dras_df = run()
# ## Downside Risk-Adjusted Success
#
# higher is better
for withdraw in HardWithdraws:
g = seaborn.catplot(x='Withdrawal',
y='D-RAS',
height=8,
hue='Harvest',
data=dras_df[(dras_df['Length'] == 40) & (dras_df['Withdrawal'] == withdraw)],
s=10
)
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('Downside Risk-Adjusted Success for 40 years')
for withdraw in HardWithdraws:
g = seaborn.catplot(x='Withdrawal',
y='D-RAS',
height=8,
hue='Harvest',
data=dras_df[(dras_df['Length'] == 40)
& (dras_df['Harvest'].isin(FewerHarvests))
& (dras_df['Withdrawal'] == withdraw)],
s=10,
palette=GoodPalette
)
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('Downside Risk-Adjusted Success for 40 years')
for withdraw in HardWithdraws:
g = seaborn.catplot(x='Withdrawal',
y='D-RAS',
height=8,
hue='Harvest',
data=dras_df[(dras_df['Length'] == 40)
& (dras_df['Harvest'].isin(JustOmegas))
& (dras_df['Withdrawal'] == withdraw)],
s=10,
palette=PALETTE_OMEGAS
)
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('Downside Risk-Adjusted Success for 40 years')
# ## Coverage Ratio
g = seaborn.catplot(x='Withdrawal',
y='Coverage Ratio',
height=8,
hue='Harvest',
data=dras_df[dras_df['Length'] == 30],
aspect=1.5,
s=10
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Coverage Ratio for 30 years')
g = seaborn.catplot(x='Withdrawal',
y='Coverage Ratio',
height=8,
hue='Harvest',
data=dras_df[(dras_df['Length'] == 30) & (dras_df['Harvest'].isin(FewerHarvests))],
aspect=1.5,
s=10,
palette=GoodPalette
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Coverage Ratio for 30 years')
for withdraw in HardWithdraws:
g = seaborn.catplot(x='Withdrawal',
y='Coverage Ratio',
height=8,
hue='Harvest',
data=dras_df[(dras_df['Length'] == 30)
& (dras_df['Harvest'].isin(JustOmegas))
& (dras_df['Withdrawal'] == withdraw)
],
s=10,
palette=PALETTE_OMEGAS
)
g.despine(left=True, bottom=True, offset=20)
# g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Coverage Ratio for 30 years')
# # Ulcer Index
def run():
df = pandas.DataFrame(index=range(0, len(Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'Ulcer Index (Avg)'])
i = 0
for (years, harvest, withdraw) in Combos:
series = run_calc(harvest, withdraw, years, calc_ulcer)
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, series.mean())
i += 1
return df
ulcer_df = run()
g = seaborn.catplot(x='Withdrawal',
y='Ulcer Index (Avg)',
height=8,
hue='Harvest',
data=ulcer_df[ulcer_df['Length'] == 30],
aspect=1.5,
s=10
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Ulcer Index (Avg) for 30 years')
g = seaborn.catplot(x='Withdrawal',
y='Ulcer Index (Avg)',
height=8,
hue='Harvest',
data=ulcer_df[(ulcer_df['Length'] == 30) & (ulcer_df['Harvest'].isin(FewerHarvests))],
aspect=1.5,
s=10,
palette=GoodPalette
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Ulcer Index (Avg) for 30 years')
# +
GoodRebalancers = []
GoodOmegas = [n.__name__ for n in Omegas]
FewerHarvests = GoodRebalancers + GoodOmegas
g = seaborn.catplot(x='Withdrawal',
y='Ulcer Index (Avg)',
height=8,
hue='Harvest',
data=ulcer_df[(ulcer_df['Length'] == 30) & (ulcer_df['Harvest'].isin(FewerHarvests))],
aspect=1.5,
s=10,
palette=PALETTE_OMEGAS
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Ulcer Index (Avg) for 30 years')
# +
GoodRebalancers = ['AnnualRebalancer_100', 'AnnualRebalancer_90']
GoodOmegas = ['OmegaNot_100', 'OmegaNot_90']
FewerHarvests = GoodRebalancers + GoodOmegas
Palette = seaborn.color_palette("Reds", len(GoodOmegas)) + seaborn.color_palette("Greens", len(GoodRebalancers))
g = seaborn.catplot(x='Withdrawal',
y='Ulcer Index (Avg)',
height=8,
hue='Harvest',
data=ulcer_df[(ulcer_df['Length'] == 30) & (ulcer_df['Harvest'].isin(FewerHarvests))],
s=10,
palette=Palette
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.fig.suptitle('Ulcer Index (Avg) for 30 years')
# -
# # Average Bond holding
#
# Are we getting better results simply because we're holding more bonds?
# +
OmegaCombos = list(itertools.product(Lengths, Omegas, Withdraw_Strategies))
def run():
df = pandas.DataFrame(index=range(0, len(OmegaCombos)), columns=['Length', 'Harvest', 'Withdrawal', 'Bond Pct (Avg)'])
i = 0
for (years, harvest, withdraw) in OmegaCombos:
series = run_calc(harvest, withdraw, years, calc_bond_pct)
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, series.mean())
i += 1
return df
bond_pct_df = run()
# -
g = seaborn.catplot(x='Harvest',
y='Bond Pct (Avg)',
height=8,
hue='Withdrawal',
data=bond_pct_df[(bond_pct_df['Length'] == 30)],
aspect=1.5,
s=10,
palette=PALETTE_WITHDRAW
)
g.despine(left=True, bottom=True, offset=20)
#g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.set_xticklabels(rotation=90)
g.fig.suptitle('Bond Pct (Avg) for 30 years')
omega = Omegas[3]
withdraw = Withdraw_Strategies[0]
years = Lengths[0]
series = run_calc(omega, withdraw, years, calc_bond_pct)
g = seaborn.relplot(
data=series,
kind='line',
color='Green',
aspect=2,
)
g.fig.autofmt_xdate()
g.despine(left=True, bottom=True, offset=20)
#print(omega.__name__, '-', withdraw.__name__, '-', years)
g.fig.suptitle('Bond Percentage by Cohort %s - %s - %s' % (omega.__name__, withdraw.__name__, years))
# ## Equivalent bond holdings
# +
omega = Omegas[3]
withdraw = Withdraw_Strategies[0]
years = Lengths[1]
series_omega = run_calc(omega, withdraw, years, calc_pwa0)
equivalent_pct = bond_pct_df.query('Length == %s & Harvest == "%s" & Withdrawal == "%s"' % (years, omega.__name__, withdraw.__name__))["Bond Pct (Avg)"].item()
rebalancer = harvesting.make_rebalancer(D(1 - equivalent_pct))
series_reb = run_calc(rebalancer, withdraw, years, calc_pwa0)
df_comparison = pandas.DataFrame({omega.__name__: series_omega, rebalancer.__name__: series_reb})
g = seaborn.relplot(
data=df_comparison,
aspect=4,
)
g.fig.autofmt_xdate()
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('MSWR with equivalent bond holding %s - %s' % (withdraw.__name__, years))
# +
omega_wins = df_comparison[df_comparison[omega.__name__] > df_comparison[rebalancer.__name__]]
g = seaborn.relplot(
data=omega_wins,
aspect=4,
)
g.fig.autofmt_xdate()
g.despine(left=True, bottom=True, offset=20)
g.fig.suptitle('MSWR with equivalent bond holding (only OmegaNot wins) %s - %s' % (withdraw.__name__, years))
print('Average when Omega wins', '\n--------\n', omega_wins.mean(), '\n\n')
print('Min when Omega wins', '\n--------\n', omega_wins.min())
# +
omega_diff = (df_comparison[omega.__name__] - df_comparison[rebalancer.__name__]).apply(lambda x: x*100)
g = seaborn.relplot(
data=omega_diff,
aspect=4,
)
g.fig.autofmt_xdate()
g.despine(left=True, bottom=True, offset=20)
#g.fig.suptitle('MSWR with equivalent bond holding %s - %s' % (withdraw.__name__, years))
print('Omega beats Rebalance by (avg)', omega_diff[omega_diff > 0].mean())
print('Omega beats Rebalance by (max)', omega_diff[omega_diff > 0].max())
print('Rebalance beats Omega by (avg)', omega_diff[omega_diff < 0].mean())
print('Rebalance beats Omega by (max)', omega_diff[omega_diff < 0].min())
# -
# # Single Year Highest Withdrawal Rate
#
# Look at current withdrawl rates. i.e. how much money are we pulling from the current portfolio. A higher number is more stressful.
# Are we getting better results with more stress?
# +
def run():
df = pandas.DataFrame(index=range(0, len(Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'Max Withdraw % (Avg)'])
i = 0
for (years, harvest, withdraw) in Combos:
series = run_calc(harvest, withdraw, years, calc_max_wd)
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, series.mean())
i += 1
return df
max_wd_df = run()
# -
g = seaborn.catplot(x='Harvest',
y='Max Withdraw % (Avg)',
height=8,
hue='Withdrawal',
data=max_wd_df[(max_wd_df['Length'] == 40)],
aspect=1.5,
s=10,
palette=PALETTE_WITHDRAW
)
g.despine(left=True, bottom=True, offset=20)
#g.set_xticklabels(['3.25%', '3.5%', '4%', '4.5%', '5%'])
g.set_xticklabels(rotation=90)
g.fig.suptitle('Single Year Highest Withdrawal over 40 years')
# # Certainty-Equivalent Withdrawals (VPW)
# +
def run():
Combos = list(itertools.product(Lengths, Harvest_Strategies))
df = pandas.DataFrame(index=range(0, len(Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'CEW (Avg)', 'CEW (Min)'])
i = 0
for (years, harvest) in Combos:
withdraw = withdrawal.make_vpw(years)
series = run_calc(harvest, withdraw, years, calc_cew)
# Should this be mean? Or also use CEW calculation?
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, series.mean(), series.min())
i += 1
return df
cew_df = run()
# -
g = seaborn.catplot(x='Harvest',
y='CEW (Avg)',
height=8,
hue='Withdrawal',
data=cew_df[(cew_df['Length'] == 30)],
aspect=1.5,
s=10,
palette=PALETTE_HARVEST
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(rotation=90)
g.fig.suptitle('Certainty-Equivalent Withdrawals (Avg) using VPW')
g = seaborn.catplot(x='Harvest',
y='CEW (Min)',
height=8,
hue='Withdrawal',
data=cew_df[(cew_df['Length'] == 30)],
aspect=1.5,
s=10,
palette=PALETTE_HARVEST
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(rotation=90)
g.fig.suptitle('Certainty-Equivalent Withdrawals (Min) using VPW')
# +
def run():
Combos = list(itertools.product(Lengths, Harvest_Strategies))
df = pandas.DataFrame(index=range(0, len(Combos)), columns=['Length', 'Harvest', 'Withdrawal', 'HREFF4 (Avg)', 'HREFF4 (Min)'])
i = 0
for (years, harvest) in Combos:
withdraw = withdrawal.make_vpw(years)
series = run_calc(harvest, withdraw, years, calc_hreff)
# Should this be mean? Or also use HREFF/CEW calculation?
df.iloc[i] = (years, harvest.__name__, withdraw.__name__, series.median(), series.min())
i += 1
return df
hreff_df = run()
# -
g = seaborn.catplot(x='Harvest',
y='HREFF4 (Avg)',
height=8,
hue='Withdrawal',
data=hreff_df[(hreff_df['Length'] == 30)],
aspect=1.5,
s=10,
palette=PALETTE_HARVEST
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(rotation=90)
g.fig.suptitle('HREFF-4 (Avg) using VPW')
g = seaborn.catplot(x='Harvest',
y='HREFF4 (Min)',
height=8,
hue='Withdrawal',
data=hreff_df[(hreff_df['Length'] == 30)],
aspect=1.5,
s=10,
palette=PALETTE_HARVEST
)
g.despine(left=True, bottom=True, offset=20)
g.set_xticklabels(rotation=90)
g.fig.suptitle('HREFF-4 (Min) using VPW')
# # Output everything to a single, big Excel file
# +
xls = pandas.ExcelWriter('omega_all.xlsx', engine='xlsxwriter')
success_df.to_excel(xls, sheet_name='Failure Rate')
pwa0_df.to_excel(xls, sheet_name='MSWR')
pwa1_df.to_excel(xls, sheet_name='Perpetual Rate')
shortfall_years_df.to_excel(xls, sheet_name='Shortfall Years')
dras_df.to_excel(xls, sheet_name='DRAS & Coverage Ratio')
ulcer_df.to_excel(xls, sheet_name='Ulcer Index')
bond_pct_df.to_excel(xls, sheet_name='Bond Percentages')
max_wd_df.to_excel(xls, sheet_name='Highest Single Withdrawal')
cew_df.to_excel(xls, sheet_name='CEW')
hreff_df.to_excel(xls, sheet_name='HREFF4')
xls.save()
# -
| OmegaNot.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# +
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import string
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
import itertools # cleaning lina
import unicodedata as ud # cleaning lina
# from Levenshtein import ratio
# from difflib import ndiff
# from bert_serving.client import BertClient
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# +
# Arabic stop words with nltk
stop_words = stopwords.words()
arabic_diacritics = re.compile("""
ّ | # Shadda
َ | # Fatha
ً | # Tanwin Fath
ُ | # Damma
ٌ | # Tanwin Damm
ِ | # Kasra
ٍ | # Tanwin Kasr
ْ | # Sukun
ـ # Tatwil/Kashida
""", re.VERBOSE)
punctuations = '''`÷×؛<>_()*&^%][ـ،/:"؟.,'{}~¦+|!”…“–ـ;#?''' + string.punctuation
# -
def preprocess(text):
''' Text is an arabic string input, the preprocessed text is returned.
'''
# remove punctuations
text = re.sub('[%s]' % re.escape(punctuations), ' ', text)
text = text.strip(' .?؟!(){}[];')
translator = str.maketrans('', '', punctuations)
text = text.translate(translator)
# removing arabic punctuation
text = ''.join(c for c in text if not ud.category(c).startswith('P')) # lina # duplicate
# remove Tashkeel
text = re.sub(arabic_diacritics, '', text)
# remove HTML Tags # Lina
text = re.sub(r'<.*?>|&([a-z0-9]+|#[0-9]{1,6}|#x[0-9a-f]{1,6});', ' ', text, re.U) # remove HTML Tags
# removing numbers # Lina
text = re.sub(r'\d+', ' ', text).strip()
# remove longation
text = re.sub("[ٱإأآا]", "ا", text)
text = re.sub("ى", "ي", text)
text = re.sub("پ", "ب", text)
text = re.sub("ؤ", "ء", text)
text = re.sub("ئ", "ء", text)
text = re.sub("ة", "ه", text)
text = re.sub("گ", "ك", text)
text = re.sub("\n\r", " ", text)
text = re.sub("\r", " ", text)
text = re.sub("\t", " ", text)
text = re.sub("\n", " ", text)
text = re.sub("[ڨ]", "ق", text)
text = re.sub("ڇ", "ج", text)
text = re.sub("[ݺـ]", "ي", text)
text = re.sub("ڡ", "ف", text)
text = re.sub("ڟ", "ظ", text)
text = re.sub("ࢪ", "ر", text)
# word correction
text = re.sub("فيتمين", "فيتامين", text)
text = re.sub("فايتمين", "فيتامين", text)
text = re.sub("ڤايتمين", "فيتامين", text)
text = re.sub("ڤايتمين", "فيتامين", text)
text = re.sub("يوقفه", "يوقف", text)
text = re.sub("يوقعalt", "alt يوقع", text)
text = re.sub("يوعاني", "يعاني", text)
text = re.sub("يومalt", "alt يوم", text)
text = re.sub("يوميامن", "يوميا من", text)
text = re.sub("يوما", "يوم", text)
text = re.sub("يومين", "يومان", text)
text = re.sub("يوجدالنصف", "يوجد النصف", text)
text = re.sub("يوجدو", "يوجد", text)
text = re.sub("يوحد", "ياخذ", text)
text = re.sub("يوخد", "ياخذ", text)
text = re.sub("ينملو", "ينمل", text)
text = re.sub("يوءلم", "يولم", text)
text = re.sub("يولمني", "يولم", text)
text = re.sub("يوجعني", "يوجع", text)
text = re.sub("يوجعوني", "يوجع", text)
text = re.sub("يوجعوها", "يوجع", text)
text = re.sub("يهدء", "يهدا", text)
text = re.sub("يوحد", "ياخذ", text)
text = re.sub("ينقصه", "ينقص", text)
text = re.sub("يمككني", "يمكنني", text)
text = re.sub("يمكني", "يمكنني", text)
text = re.sub("يمكننا", "يمكنني", text)
text = re.sub("يمشفها", "يمشي فيها", text)
text = re.sub("فها", "فيها", text)
text = re.sub("يموع", "يموت", text)
text = re.sub("ينطونه", "يعطونه", text)
text = re.sub("ينفعش", "لا ينفع", text)
text = re.sub("يقولو", "يقولون", text)
text = re.sub("يقلقلني", "يقلقني", text)
text = re.sub("يكتبلي", "يكتب لي", text)
text = re.sub("يكوم", "يقوم", text)
text = re.sub("يلتءم", "يلتئم", text)
text = re.sub("يلزمه", "يلزم", text)
text = re.sub("يمدي", "يمدد", text)
text = re.sub("يمديني", "يمددني", text)
text = re.sub("يكوون", "يكون", text)
text = re.sub("يكونا", "يكون", text)
text = re.sub("يكتبلي", "يكتب لي", text)
text = re.sub("يعورني", "يولمني", text)
text = re.sub("يسوا", "يسوي", text)
text = re.sub("يصدقوني", "يصدقني", text)
text = re.sub("يظبط", "يضبط", text)
text = re.sub("يطيح", "يقع", text)
text = re.sub("يظهرلي", "يظهر لي", text)
text = re.sub("يعرفو", "يعرف", text)
text = re.sub("يخربت", "يخربط", text)
text = re.sub("يخفني", "يخيفني", text)
text = re.sub("يخلصوا", "يخلص", text)
text = re.sub("يديا", "يداي", text)
text = re.sub("يذداد", "يزداد", text)
text = re.sub("يدينها", "يعطينها", text)
text = re.sub("يرحع", "يرضع", text)
text = re.sub("يزاد", "يزداد", text)
text = re.sub("يزداداكثر", "يزداد اكثر", text)
text = re.sub("يزدداد", "يزداد", text)
text = re.sub("يسارا", "يسار", text)
text = re.sub("يستفد", "يستفيد", text)
text = re.sub("يومعاني", "يوم اعاني", text) # This is not working ??
text = re.sub("وشعوربالتعرق", "و شعور بالتعرق", text)
text = re.sub("ويوجدحبوب", "و يوجد حبوب", text)
text = re.sub("ووالتوتر", "و التوتر", text)
text = re.sub("ومالاشعه", "و مع الاشعه", text)
text = re.sub("وماالعلاح", "و ما العلاج", text)
text = re.sub("وصعوبهباخذنفس", "و بصعوبه باخذ نفس", text)
text = re.sub("وصفوليcipealex", "وصفولي cipealex", text)
text = re.sub("وفيتامينe", "و فيتامين e", text)
text = re.sub("وكوليسترول", "وكلسترول", text)
text = re.sub("والمءخره", "والموخره", text)
text = re.sub("النتاءج", "و النتائج", text)
text = re.sub("والنتاءج", "و النتائج", text)
text = re.sub("وجودانزلاق", "وجود انزلاق", text)
text = re.sub("والنهارده", "و اليوم", text)
text = re.sub("وانااستطعم", "و انا استطعم", text)
text = re.sub("وانخفاضاعدم", "و انخفاض اعدم", text)
text = re.sub("وانطيتها", "و اعطيتها", text)
text = re.sub("وانهارده", "و اليوم", text)
text = re.sub("وبداهذاعندما", "و بدا هذا عندما", text)
text = re.sub("وتعباانه", "و تعبانه", text)
text = re.sub("تعباانه", "تعبانه", text)
text = re.sub("وجودتقلصات", "وجود تقلصات", text)
text = re.sub("وخدرباليداليسري", "و خدر باليد اليسري", text)
text = re.sub("gynotrilللحمل", "gynotril للحمل", text)
text = re.sub("amitriptylineبتنصحوني", "amitriptyline بتنصحوني", text)
text = re.sub("انامريضهضغط", "انا مريضه ضغط", text)
text = re.sub("بالاضافهالي", "بالاضافه الي", text)
text = re.sub("الفقراتوالم", "الفقرات و الم", text)
text = re.sub("الساخنهشفيت", "الساخنه شفيت", text)
text = re.sub("الكهرباءيه", "الكهربائيه", text)
text = re.sub("الصدرالالم", "الصدر الالم", text)
text = re.sub("الحجراليوم", "الحجر اليوم", text)
text = re.sub("المعدهفماهو", "المعده فما هو", text)
text = re.sub("الصدرلازال", "الصدر لازال", text)
text = re.sub("وخزبالصدر", "وخز بالصدر", text)
text = re.sub("الانفلوانزا", "الانفلونزا", text)
text = re.sub("الايسروصداع", "الايسر و صداع", text)
text = re.sub("الايسروكذلك", "الايسر و كذلك", text)
text = re.sub("الثلاسيميا", "التلاسيميا", text)
text = re.sub("الجههاليسري", "الجهه اليسري", text)
text = re.sub("الجههاليمني", "الجهه اليمني", text)
text = re.sub("الدواءالذي", "الدواء الذي", text)
text = re.sub("الرقبهواسفل", "الرقبه و اسفل", text)
text = re.sub("الساخنهبدون", "الساخنه بدون", text)
text = re.sub("يوميه", "يوميا", text)
# remove redundant white spaces
text = re.sub("\s+", " ", text)
# keep only unicode characters # Lina
text = re.sub(r'[^\w\s]', ' ', text, re.U)
# removing words less than 3 letters # Lina # Should be changed to 2
text = re.sub(r'\b\w{1,3}\b', ' ', text).strip()
# remove duplicates
text = re.sub(r'(.)\1+', r"\1\1", text)
text = ' '.join(word for word in text.split() if word not in stop_words)
# we need to find out how many time each word appeared in the entier dataset
return text
QUESTIONS = 'question'
ANSWERS = 'answer'
PREDICTED = 'PREDICTED'
SCORE = 'SCORE'
ACCURACIES = {}
df = pd.read_csv('qa.csv')
print(df.info())
df = df.drop_duplicates()
print(df.info())
df = df.dropna()
print(df.info())
df.head()
for col in df.columns:
df[col] = df[col].apply(preprocess)
df.head(5)
def compare(data, name):
temp = data[data[PREDICTED] == data[ANSWERS]]
info = {}
info['CORRECT'] = temp
info['CORRECT_COUNT'] = len(temp)
info['INCORRECT_COUNT'] = len(data) - len(temp)
info['ACCURACY'] = round(len(temp) / len(data), 3)
ACCURACIES[name] = info
return round(len(temp) / len(data), 3)
# +
def getNaiveAnswer(question):
# regex helps to pass some punctuation signs
row = df.loc[df[QUESTIONS].str.contains(re.sub(r"[^ا-ي\s]+", "", question), case=False)]
if len(row) > 0:
return row[ANSWERS].values[0], 1, row[QUESTIONS].values[0]
return "Sorry, I didn't get you.", 0, ""
naive_answers = pd.DataFrame(
df[QUESTIONS].apply(getNaiveAnswer).tolist(),
index=df.index,
columns=[PREDICTED, SCORE, QUESTIONS]
)
naive_answers[ANSWERS] = df[ANSWERS]
naive_answers[QUESTIONS] = df[QUESTIONS]
print(naive_answers.head())
compare(naive_answers, 'naive')
# -
vec = CountVectorizer() # TfidfVectorizer
df_vec = pd.DataFrame({
QUESTIONS: vec.fit_transform(df[QUESTIONS]),
ANSWERS: vec.transform(df[ANSWERS])
}, index = df.index)
print(df_vec.shape)
# print(df_vec.head())
df_vec.head()
tokens = vec.get_feature_names_out()
vector_matrix = df_vec[QUESTIONS].to_numpy()
# print(vector_matrix[200][0].shape)
# +
# # tokens[-500:-400]
# mylen = np.vectorize(len)
# print(mylen(tokens))
# longs = tokens[ np.logical_and(mylen(tokens) >= 10, mylen(tokens) <= 11) ]
# longs[-200:-100]
# +
def build_word_frequancy_table(matrix, tokens):
# doc_names =
df = pd.DataFrame(index=np.arange(matrix.shape[0]), columns=tokens)
for idx, vec in enumerate(matrix):
arr = np.zeros(vec.shape[-1])
for col in vec.indices:
arr[col] = 1
df.iloc[idx] = arr
return df
word_frequancy_table = build_word_frequancy_table(vector_matrix, tokens)
word_frequancy_table
# -
cosine_similarity_matrix = cosine_similarity(word_frequancy_table)
cosine_similarity_matrix
# +
def biggest_matches(matrix, doc, count=3):
return matrix[doc].argsort()[-(count+1):-1][::], np.sort(matrix[doc])[-(count+1):-1]
res = biggest_matches(cosine_similarity_matrix, 20, count=5)
df.iloc[20][0], df.iloc[res[0][-1]][-1], res[-1][-1]
# -
res
# +
def cosine_predict(q, vec, tokens, count=3):
qv = vec.transform([q])
tmp = build_word_frequancy_table(qv, tokens)
tmp_tbl = word_frequancy_table.copy()
tmp_tbl = pd.concat([tmp_tbl, tmp], ignore_index = True)
cos_tbl = cosine_similarity(tmp_tbl)
return biggest_matches(cos_tbl, -1, count=count)
res = cosine_predict('مصاب بصداع بالراس خفيف ياتي كل يوم بعد القيام من النوم', vec, tokens)
df.iloc[res[0][-1]][-1], res[-1][-1]
# -
# +
# Levenshtein distance
# def getApproximateAnswer(q):
# max_score = 0
# answer = ""
# prediction = ""
# for idx, row in df.iterrows():
# score = ratio(row[QUESTIONS], q)
# if score >= 0.9: # I'm sure, stop here
# return row[ANSWERS], score, row[QUESTIONS]
# elif score > max_score: # I'm unsure, continue
# max_score = score
# answer = row[ANSWERS]
# prediction = row[QUESTIONS]
# if max_score > 0.6:
# return answer, max_score, prediction
# return "Sorry, I didn't get you.", max_score, prediction
# levenshtein = pd.DataFrame(
# df[QUESTIONS].apply(getApproximateAnswer).tolist(),
# index=df.index,
# columns=[PREDICTED_ANSWERS, SCORE, QUESTIONS]
# )
# levenshtein[ANSWERS] = df[ANSWERS]
# print(levenshtein.info())
# levenshtein
# -
dir(vec)
# +
# equdian distance
# def encode_questions(data):
# bc = BertClient()
# questions = data["question"].values.tolist()
# questions_encoder = bc.encode(questions)
# np.save("questions.npy", questions_encoder)
# questions_encoder_len = np.sqrt(
# np.sum(questions_encoder * questions_encoder, axis=1)
# )
# np.save("questions_len.npy", questions_encoder_len)
# print("Encoder ready")
# encode_questions(df)
# +
# class BertAnswer():
# def __init__(self, data):
# self.bc = BertClient()
# self.q_data = data["question"].values.tolist()
# self.a_data = data["answer"].values.tolist()
# self.questions_encoder = np.load("questions.npy")
# self.questions_encoder_len = np.load("questions_len.npy")
# def get(self, q):
# query_vector = self.bc.encode([q])[0]
# score = np.sum((query_vector * self.questions_encoder), axis=1) / (
# self.questions_encoder_len * (np.sum(query_vector * query_vector) ** 0.5)
# )
# top_id = np.argsort(score)[::-1][0]
# if float(score[top_id]) > 0.94:
# return self.a_data[top_id], score[top_id], self.q_data[top_id]
# return "Sorry, I didn't get you.", score[top_id], self.q_data[top_id]
# bm = BertAnswer(df)
# def getBertAnswer(q):
# return bm.get(q)
# +
# def getResults(data, fn):
# return pd.DataFrame(
# data.apply(fn),
# columns=["Q", "Prediction", "A", "Score"]
# )
# getResults(df.question, getBertAnswer)
# -
temp
# +
# def getApproximateAnswer(q):
# max_score = 0
# answer = ""
# prediction = ""
# for idx, row in data.iterrows():
# score = ratio(row["Question"], q)
# if score >= 0.9: # I'm sure, stop here
# return row["Answer"], score, row["Question"]
# elif score > max_score: # I'm unsure, continue
# max_score = score
# answer = row["Answer"]
# prediction = row["Question"]
# if max_score > 0.8:
# return answer, max_score, prediction
# return "Sorry, I didn't get you.", max_score, prediction
# +
# # from autonotebook import tqdm as notebook_tqdm
# from datasets import load_dataset, load_metric
# from transformers import DistilBertTokenizerFast
# from transformers import AutoModelForSequenceClassification, DataCollatorWithPadding
# from transformers import Trainer, TrainingArguments
# checkpoint = "distilbert-base-uncased"
# tokenizer = DistilBertTokenizerFast.from_pretrained(checkpoint)
# -
8.5561e-04
| data/tests.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/BenM1215/fastai-v3/blob/master/lesson3_imdb.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="TgjMz2iHi9VJ" colab_type="text"
# # IMDB
# + id="LK5ejS5Hi9VN" colab_type="code" colab={}
# %reload_ext autoreload
# %autoreload 2
# %matplotlib inline
# + id="VPbSsq3Oi9VW" colab_type="code" colab={}
from fastai.text import *
# + [markdown] id="kGPfwT0ni9Vc" colab_type="text"
# ## Preparing the data
# + [markdown] id="saaZoUR5i9Ve" colab_type="text"
# First let's download the dataset we are going to study. The [dataset](http://ai.stanford.edu/~amaas/data/sentiment/) has been curated by <NAME> et al. and contains a total of 100,000 reviews on IMDB. 25,000 of them are labelled as positive and negative for training, another 25,000 are labelled for testing (in both cases they are highly polarized). The remaning 50,000 is an additional unlabelled data (but we will find a use for it nonetheless).
#
# We'll begin with a sample we've prepared for you, so that things run quickly before going over the full dataset.
# + id="2hmBIc-pi9Vf" colab_type="code" outputId="45b49a48-dc05-47e8-e988-a079a10d16cb" colab={"base_uri": "https://localhost:8080/", "height": 34}
path = untar_data(URLs.IMDB_SAMPLE)
path.ls()
# + [markdown] id="WXjQMD8wi9Vm" colab_type="text"
# It only contains one csv file, let's have a look at it.
# + id="88mEIpugi9Vn" colab_type="code" outputId="63dc10ca-8c7b-4248-835a-c3834fcd11f4" colab={"base_uri": "https://localhost:8080/", "height": 204}
df = pd.read_csv(path/'texts.csv')
df.head()
# + id="zQY82BEti9Vt" colab_type="code" outputId="eb3dc0f5-837e-4032-a655-73691afdaf62" colab={"base_uri": "https://localhost:8080/", "height": 54}
df['text'][1]
# + [markdown] id="5y6orFJdi9Vx" colab_type="text"
# It contains one line per review, with the label ('negative' or 'positive'), the text and a flag to determine if it should be part of the validation set or the training set. If we ignore this flag, we can create a DataBunch containing this data in one line of code:
# + id="9tM0X3DUi9Vz" colab_type="code" colab={}
data_lm = TextDataBunch.from_csv(path, 'texts.csv')
# + [markdown] id="jyT990FXi9V-" colab_type="text"
# By executing this line a process was launched that took a bit of time. Let's dig a bit into it. Images could be fed (almost) directly into a model because they're just a big array of pixel values that are floats between 0 and 1. A text is composed of words, and we can't apply mathematical functions to them directly. We first have to convert them to numbers. This is done in two differents steps: tokenization and numericalization. A `TextDataBunch` does all of that behind the scenes for you.
#
# Before we delve into the explanations, let's take the time to save the things that were calculated.
# + id="kmrRYA_Ji9V_" colab_type="code" colab={}
data_lm.save()
# + [markdown] id="n2Nr5YmNi9WE" colab_type="text"
# Next time we launch this notebook, we can skip the cell above that took a bit of time (and that will take a lot more when you get to the full dataset) and load those results like this:
# + id="eAACb9dYi9WG" colab_type="code" colab={}
data = load_data(path)
# + [markdown] id="4A1aOGrgi9WJ" colab_type="text"
# ### Tokenization
# + [markdown] id="IMFye07oi9WL" colab_type="text"
# The first step of processing we make the texts go through is to split the raw sentences into words, or more exactly tokens. The easiest way to do this would be to split the string on spaces, but we can be smarter:
#
# - we need to take care of punctuation
# - some words are contractions of two different words, like isn't or don't
# - we may need to clean some parts of our texts, if there's HTML code for instance
#
# To see what the tokenizer had done behind the scenes, let's have a look at a few texts in a batch.
# + id="UAv3chpEi9WM" colab_type="code" outputId="634da1e6-0ec4-4f01-e70f-4e999c8b5a0b" colab={"base_uri": "https://localhost:8080/", "height": 289}
data = TextClasDataBunch.from_csv(path, 'texts.csv')
data.show_batch()
# + [markdown] id="Lzr9MLH3i9WT" colab_type="text"
# The texts are truncated at 100 tokens for more readability. We can see that it did more than just split on space and punctuation symbols:
# - the "'s" are grouped together in one token
# - the contractions are separated like this: "did", "n't"
# - content has been cleaned for any HTML symbol and lower cased
# - there are several special tokens (all those that begin by xx), to replace unknown tokens (see below) or to introduce different text fields (here we only have one).
# + [markdown] id="9h9llMkvi9WV" colab_type="text"
# ### Numericalization
# + [markdown] id="6wygajf0i9WW" colab_type="text"
# Once we have extracted tokens from our texts, we convert to integers by creating a list of all the words used. We only keep the ones that appear at least twice with a maximum vocabulary size of 60,000 (by default) and replace the ones that don't make the cut by the unknown token `UNK`.
#
# The correspondance from ids to tokens is stored in the `vocab` attribute of our datasets, in a dictionary called `itos` (for int to string).
# + id="3vKZWC9Ui9WY" colab_type="code" outputId="5c5c5c93-57c3-4742-88d1-4c5ae2e150fa" colab={"base_uri": "https://localhost:8080/", "height": 187}
data.vocab.itos[:10]
# + [markdown] id="igIKWAxci9Wk" colab_type="text"
# And if we look at what a what's in our datasets, we'll see the tokenized text as a representation:
# + id="xhhHI4EMi9Wm" colab_type="code" outputId="4e9cff27-6e09-4890-a09d-13a5d6a736bc" colab={"base_uri": "https://localhost:8080/", "height": 34}
data.train_ds[0][0]
# + [markdown] id="uSmsrMKBi9Wq" colab_type="text"
# But the underlying data is all numbers
# + id="4yvN2MuJi9Wt" colab_type="code" outputId="95c46081-b5f4-45f4-b3cc-f03c5b9ef9d5" colab={"base_uri": "https://localhost:8080/", "height": 34}
data.train_ds[0][0].data[:10]
# + [markdown] id="Asuc287Ki9Wz" colab_type="text"
# ### With the data block API
# + [markdown] id="lCuMCpgCi9W0" colab_type="text"
# We can use the data block API with NLP and have a lot more flexibility than what the default factory methods offer. In the previous example for instance, the data was randomly split between train and validation instead of reading the third column of the csv.
#
# With the data block API though, we have to manually call the tokenize and numericalize steps. This allows more flexibility, and if you're not using the defaults from fastai, the variaous arguments to pass will appear in the step they're revelant, so it'll be more readable.
# + id="zUcy2Rg0i9W2" colab_type="code" colab={}
data = (TextList.from_csv(path, 'texts.csv', cols='text')
.split_from_df(col=2)
.label_from_df(cols=0)
.databunch())
# + [markdown] id="dzF0pewri9W6" colab_type="text"
# ## Language model
# + [markdown] id="Ul-UDsgXi9W9" colab_type="text"
# Note that language models can use a lot of GPU, so you may need to decrease batchsize here.
# + id="5bsoCl_ti9W9" colab_type="code" colab={}
bs=48
# + [markdown] id="ljseBOrvi9XB" colab_type="text"
# Now let's grab the full dataset for what follows.
# + id="AsiCZmo4i9XC" colab_type="code" outputId="43522d19-92c8-4c40-d85a-a4af13469df8" colab={"base_uri": "https://localhost:8080/", "height": 136}
path = untar_data(URLs.IMDB)
path.ls()
# + id="t-T_i6iLi9XH" colab_type="code" outputId="9182435e-1c57-4291-9fb1-9f3122f0c5bf" colab={"base_uri": "https://localhost:8080/", "height": 85}
(path/'train').ls()
# + [markdown] id="nLPJmS3Li9XM" colab_type="text"
# The reviews are in a training and test set following an imagenet structure. The only difference is that there is an `unsup` folder on top of `train` and `test` that contains the unlabelled data.
#
# We're not going to train a model that classifies the reviews from scratch. Like in computer vision, we'll use a model pretrained on a bigger dataset (a cleaned subset of wikipedia called [wikitext-103](https://einstein.ai/research/blog/the-wikitext-long-term-dependency-language-modeling-dataset)). That model has been trained to guess what the next word, its input being all the previous words. It has a recurrent structure and a hidden state that is updated each time it sees a new word. This hidden state thus contains information about the sentence up to that point.
#
# We are going to use that 'knowledge' of the English language to build our classifier, but first, like for computer vision, we need to fine-tune the pretrained model to our particular dataset. Because the English of the reviews left by people on IMDB isn't the same as the English of wikipedia, we'll need to adjust the parameters of our model by a little bit. Plus there might be some words that would be extremely common in the reviews dataset but would be barely present in wikipedia, and therefore might not be part of the vocabulary the model was trained on.
# + [markdown] id="Yj9Xw_-Di9XO" colab_type="text"
# This is where the unlabelled data is going to be useful to us, as we can use it to fine-tune our model. Let's create our data object with the data block API (next line takes a few minutes).
# + id="FFcOa63ti9XO" colab_type="code" colab={}
data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=['train', 'test', 'unsup'])
#We may have other temp folders that contain text files so we only keep what's in train and test
.random_split_by_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
data_lm.save('data_lm.pkl')
# + [markdown] id="FwIEMwQXi9XR" colab_type="text"
# We have to use a special kind of `TextDataBunch` for the language model, that ignores the labels (that's why we put 0 everywhere), will shuffle the texts at each epoch before concatenating them all together (only for training, we don't shuffle for the validation set) and will send batches that read that text in order with targets that are the next word in the sentence.
#
# The line before being a bit long, we want to load quickly the final ids by using the following cell.
# + id="Zxsw0hsYi9XR" colab_type="code" colab={}
data_lm = load_data(path, 'data_lm.pkl', bs=bs)
# + id="ZSHWvMXki9XU" colab_type="code" outputId="38a3abe0-e17f-442f-f1be-f57fc31b644c" colab={"base_uri": "https://localhost:8080/", "height": 289}
data_lm.show_batch()
# + [markdown] id="JDZFgDLFi9XX" colab_type="text"
# We can then put this in a learner object very easily with a model loaded with the pretrained weights. They'll be downloaded the first time you'll execute the following line and stored in `~/.fastai/models/` (or elsewhere if you specified different paths in your config file).
# + id="vbU3rl3ai9XY" colab_type="code" colab={}
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.3)
# + id="UZuN6-8vi9Xb" colab_type="code" outputId="9a936683-695f-4b7e-e409-0cfaf885a5c2" colab={"base_uri": "https://localhost:8080/", "height": 95}
learn.lr_find()
# + id="zVspXN2bi9Xh" colab_type="code" colab={}
learn.recorder.plot(skip_end=15)
# + id="VTKlmyRCi9Xk" colab_type="code" colab={}
learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
# + id="9UP4ytpAi9Xn" colab_type="code" colab={}
learn.save('fit_head')
# + id="M4cKxWgWi9Xp" colab_type="code" colab={}
learn.load('fit_head');
# + [markdown] id="ASIQwVcNi9Xr" colab_type="text"
# To complete the fine-tuning, we can then unfeeze and launch a new training.
# + id="Vy1al5BVi9Xs" colab_type="code" colab={}
learn.unfreeze()
# + id="dmAGVtKxi9Xu" colab_type="code" outputId="84892268-6da0-4415-ca52-a37e96c17b23" colab={}
learn.fit_one_cycle(10, 1e-3, moms=(0.8,0.7))
# + id="7QgotRgti9Xx" colab_type="code" colab={}
learn.save('fine_tuned')
# + [markdown] id="n7hZXR8Wi9Xz" colab_type="text"
# How good is our model? Well let's try to see what it predicts after a few given words.
# + id="HJVFpR68i9Xz" colab_type="code" colab={}
learn.load('fine_tuned');
# + id="YDi_qOuAi9X5" colab_type="code" colab={}
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
# + id="rbkAHeGni9X_" colab_type="code" outputId="ec3f1b72-3d30-4bbb-d7a4-981b7ff5fd84" colab={}
print("\n".join(learn.predict(TEXT, N_WORDS, temperature=0.75) for _ in range(N_SENTENCES)))
# + [markdown] id="d8TQvkavi9YD" colab_type="text"
# We not only have to save the model, but also it's encoder, the part that's responsible for creating and updating the hidden state. For the next part, we don't care about the part that tries to guess the next word.
# + id="2x3ZHRdZi9YE" colab_type="code" colab={}
learn.save_encoder('fine_tuned_enc')
# + [markdown] id="HoAmzxP3i9YH" colab_type="text"
# ## Classifier
# + [markdown] id="a54ddczFi9YH" colab_type="text"
# Now, we'll create a new data object that only grabs the labelled data and keeps those labels. Again, this line takes a bit of time.
# + id="craa_5T5i9YI" colab_type="code" colab={}
path = untar_data(URLs.IMDB)
# + id="zEpmH3fki9YJ" colab_type="code" colab={}
data_clas = (TextList.from_folder(path, vocab=data_lm.vocab)
#grab all the text files in path
.split_by_folder(valid='test')
#split by train and valid folder (that only keeps 'train' and 'test' so no need to filter)
.label_from_folder(classes=['neg', 'pos'])
#label them all with their folders
.databunch(bs=bs))
data_clas.save('data_clas.pkl')
# + id="uWGm2-SBi9YL" colab_type="code" colab={}
data_clas = load_data(path, 'data_clas.pkl', bs=bs)
# + id="X_5IziNWi9YN" colab_type="code" outputId="a089914e-7615-43c8-90f3-7a53b13ffdc4" colab={}
data_clas.show_batch()
# + [markdown] id="7GROHJtPi9YQ" colab_type="text"
# We can then create a model to classify those reviews and load the encoder we saved before.
# + id="Ohc-u0Oti9YQ" colab_type="code" colab={}
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('fine_tuned_enc')
# + id="21G4Rzuci9YS" colab_type="code" colab={}
learn.lr_find()
# + id="HrjnmZTXi9YV" colab_type="code" colab={}
learn.recorder.plot()
# + id="3EfOJihBi9YY" colab_type="code" outputId="4595d7fe-17cf-4d0d-89d7-84336b23c391" colab={}
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7))
# + id="x_it359Ii9Yb" colab_type="code" colab={}
learn.save('first')
# + id="RD1UgLPni9Yd" colab_type="code" colab={}
learn.load('first');
# + id="WFRzgI2Mi9Yf" colab_type="code" outputId="f7985fe0-84a2-4f02-b246-1bae4f14fc2e" colab={}
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))
# + id="m_B9ZWdpi9Yi" colab_type="code" colab={}
learn.save('second')
# + id="S5db4Nkpi9Yk" colab_type="code" colab={}
learn.load('second');
# + id="XtbHvr2Ni9Ym" colab_type="code" outputId="9733fbe0-a684-4066-d19b-65f1dd7711e0" colab={}
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))
# + id="4tPSdumJi9Yo" colab_type="code" colab={}
learn.save('third')
# + id="75zIGMzai9Yp" colab_type="code" colab={}
learn.load('third');
# + id="we0XqMPsi9Yr" colab_type="code" outputId="9f5923e7-fa6a-4476-a201-3eb8a2cbf784" colab={}
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
# + id="fYwcfxphi9Yu" colab_type="code" outputId="b18460c2-06c7-4427-ca41-aabfc154cd04" colab={}
learn.predict("I really loved that movie, it was awesome!")
# + id="VTRfU4sOi9Yx" colab_type="code" colab={}
| lesson3_imdb.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Jupyter Notebook In Depth
#
# Today we are going to dive into some of the interesting features of IPython and the Jupyter notebook, which are useful for a number of daily tasks in data-intensive science.
#
# We will work through these features "live"; feel free to type along with me as we go!
# ## Outline
#
# - IPython command-line vs. Jupyter notebook
# - Input/Output History
# - Tab Completion
# - Getting help and accessing documentation
# - Useful Keyboard Shortcuts
# - Magic Commands
# - Shell commands
# - Interactivity with ``ipywidgets``
# ## IPython Command Line and Jupyter Notebook
# ### Launching the IPython Shell
#
# If you have installed IPython correctly, you should be able to type ``ipython`` in your command prompt and see something like this:
# ```
# IPython 4.0.1 -- An enhanced Interactive Python.
# ? -> Introduction and overview of IPython's features.
# # %quickref -> Quick reference.
# help -> Python's own help system.
# object? -> Details about 'object', use 'object??' for extra details.
# In [1]:
# ```
# With that, you're ready to follow along.
# ### Launching the Jupyter Notebook
#
# The IPython notebook is a browser-based graphical interface to the IPython shell, and builds on it a rich set of dynamic display capabilities.
# As well as executing Python/IPython statements, the notebook allows the user to include formatted text, static and dynamic visualizations, mathematical equations, javascript widgets, and much more.
# Furthermore, these documents can be saved in a way that lets other people open them and execute the code on their own systems.
#
# Though the Jupyter notebook is viewed and edited through your web browser window, it must connect to a running Python process in order to execute code.
# This process (known as a "kernel") can be started by running the following command in your system shell:
#
# ```
# $ jupyter notebook
# ```
#
# This command will launch a local web server which will be visible to your browser.
# It immediately spits out a log showing what it is doing; that log will look something like this:
#
# ```
# jakevdp$ jupyter notebook
# [I 11:02:44.237 NotebookApp] The port 8888 is already in use, trying another port.
# [I 11:02:44.251 NotebookApp] Serving notebooks from local directory: /Users/jakevdp/github/uwseds/LectureNotes-Autumn2017/06-Jupyter-Notebook-In-Depth
# [I 11:02:44.251 NotebookApp] 0 active kernels
# [I 11:02:44.251 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/?token=<PASSWORD>
# [I 11:02:44.251 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation)
#
# ```
#
# At the command, your default browser should automatically open and navigate to the listed local URL;
# the exact address will depend on your system.
# If the browser does not open automatically, you can open a window and copy this address (here ``http://localhost:8888/`` with an authentication token) manually.
# ## Input/Output History
#
# A useful feature of IPython/Jupyter is the storage of input and output history.
# ### Terminal Only
#
# There are a few useful shortcuts that can be used only in the IPython terminal.
# We will demonstrate the following in the terminal:
#
# - up arrow for history
# - partial completion with up arrow
# - reverse search with ctrl-r
# ### Terminal and Notebook
#
# - Previous results can be obtained using underscores: number of underscores is the number of the previous command:
# Beyond three underscores, you can use underscore followed by a number:
# More useful often is the ``Out`` array, which stores all previous results:
# Similarly, you can access the ``In`` array to see the code history:
# To see all history at once, use the ``%history`` magic command (more on magic commands below):
# ## Tab Completion
#
# The feature of Jupyter that I use the most frequently is perhaps the tab completion functionality.
#
# Tab completion works for finishing built-in commands:
# It works for variables that you have defined:
# It works for importing packages:
# It works for finding attributes of packages and other objects:
# It's also possible to use ``shift tab`` within the open-closed parentheses to see the call signature of any Python function:
# ## Accessing Help and Documentation
# After tab completion, I think the next most useful feature of the notebook is the help functionality.
#
# One question mark after any valid object gives you access to its documentation string:
# Two question marks gives you access to its source code (if the object is implemented in Python):
# This even works with user-defined functions:
# In addition, you can use a single question mark with asterisks to do a wildcard match:
# If you are curious about the call signature for a funciton, you can type ``shift tab`` within the open-closed parentheses to see its argument list:
# Hitting ``shift tab`` multiple times will give you progressively more information about the function:
# Using a combination of these, you can quickly remind yourself of how to use various funcitons without ever leaving the terminal/notebook.
# ## Useful Keyboard Shortcuts
#
# One of the keys to working effectively with Jupyter is learning your way around the keyboard.
# Note: some of the shortcuts below will only work on Linux and Mac; many will work on windows as well
# ### Terminal shortcuts
#
# If you are familiar with emacs, vim, and similar tools, many of the terminal-based keyboard shortcuts will feel very familiar to you:
# #### Navigation
#
# | Keystroke | Action |
# |-------------------------------|--------------------------------------------|
# | ``Ctrl-a`` | Move cursor to the beginning of the line |
# | ``Ctrl-e`` | Move cursor to the end of the line |
# | ``Ctrl-b`` or ``left-arrow`` | Move cursor back one character |
# | ``Ctrl-f`` or ``right-arrow`` | Move cursor forward one character |
# #### Text Entry
#
# | Keystroke | Action |
# |-------------------------------|-------------------------------------------------|
# | ``backspace`` | Delete previous character in line |
# | ``Ctrl-d`` | Delete next character in line |
# | ``Ctrl-k`` | Cut text from cursor to end of line |
# | ``Ctrl-u`` | Cut all text in line |
# | ``Ctrl-y`` | Yank (i.e. Paste) text which was previously cut |
# | ``Ctrl-t`` | Transpose (i.e. switch) previous two characters |
# #### Command History
#
# | Keystroke | Action |
# |-------------------------------|--------------------------------------------|
# | ``Ctrl-p`` or ``up-arrow`` | Access previous command in history |
# | ``Ctrl-n`` or ``down-arrow`` | Access next command in history |
# | ``Ctrl-r`` | Reverse-search through command history |
# #### Miscellaneous
#
# | Keystroke | Action |
# |-------------------------------|--------------------------------------------|
# | ``Ctrl-l`` | Clear terminal screen |
# | ``Ctrl-c`` | Interrupt current Python command |
# | ``Ctrl-d`` | Exit Jupyter session |
# ### Notebook Shortcuts
#
# Depending on your operating system and browser, many of the navigation and text-entry shortcuts will work in the notebook as well. In addition, the notebook has many of its own shortcuts.
#
# First, though, we must mention that the notebook has two "modes" of operation: command mode and edit mode.
#
# - In **command mode**, you are doing operations that affect entire cells. You can enable command mode by pressing the escape key (or pressing ``ctrl m``). For example, in command mode, the up and down arrows will navigate from cell to cell.
# - In **edit mode**, you can do operations that affect the contents of a single cell. You can enable edit mode by pressing enter from the command mode. For example, in edit mode, the up and down arrows will navigate lines within the cell
#
# To get a listing of all available shortcuts, enter command mode and press "h"
# ## Magic Commands
#
# IPython & Jupyter extend the functionality of Python with so-called "magic" commands: these are marked with a ``%`` sign.
# We saw one of these above; the ``%history`` command.
#
# Magic commands come in two flavors: *line magics* start with one percent sign, and *cell magics* start with two percent signs.
#
# We'll go through a few examples of magic commands here, but first, using what you've seen above, how do you think you might get a list of all available magic commands? How do you think you might get help on any particular command?
# ### Profiling with ``timeit``
#
# For example, here's the ``%timeit``/``%%timeit`` magic, which can be very useful for quick profiling of your code:
# ### Creating a file with ``%%file``
#
# Sometimes it's useful to create a file programatically from within the notebook
# ### Running a script with ``%run``
# ### Controlling figures: ``%matplotlib``
#
# You can use the ``%matplotlib`` function to specify the matplotlib *backend* you would like to use.
# For example:
#
# - ``%matplotlib`` by itself uses the default system backend
# - ``%matplotlib inline`` creates inline, static figures (great for publication and/or sharing)
# - ``%matplotlib notebook`` creates inline, interactive figures (though in my experience it can be a bit unstable)
# ### Help functions and more info
#
# - The ``%magic`` function will tell you all about magic commands
# - The ``%lsmagic`` function will list all available magic commands
# - Remember that the ``?`` can be used to get documentation!
# - Though we won't cover it here, it is possible to [create and activate your own magic commands](https://ipython.org/ipython-doc/stable/config/custommagics.html)
# ## Shell Commands
#
# Jupyter is meant to be an all-purpose scientific computing environment, and access to the shell is critical.
# Any command that starts with an exclamation point will be passed to the shell.
#
# Note that because windows has a different kind of shell than Linux/OSX, shell commands will be different from operating system to operating system.
#
# All the commands you have learned previously will work here:
# You can even seamlessly pass values to and from the Python interpreter.
# For example, we can store the result of a directory listing:
# We can inject Python variables into a shell command with ``{}``:
# With these tools, you should never have to switch from IPython to a terminal to run a command.
# ## Rich Display
#
# Many Python libraries are designed with Jupyter in mind, and use **rich display** hooks to improve the coding experience.
# One example we've seen is Pandas:
# If you want to do this sort of thing for your own object, you can create a class which defines the ``_repr_html_`` method, and returns a string of HTML:
# ## Exercise:
#
# Try writing a class that, given a Python list, will display the contents of the list using formatted HTML (see example HTML lists at https://www.w3schools.com/html/html_lists.asp)
#
# Recall that a Python list looks like ``x = ["a", "b", "c"]``
# ## IPython Widgets
#
# One incredibly useful feature of the notebook is the interactivity provided by the [``ipywidgets`` package](https://github.com/ipython/ipywidgets). You'll have to install this using, e.g.
#
# $ conda install ipywidgets
#
# You can find a full set of documentation notebooks [here](https://github.com/ipython/ipywidgets/blob/master/examples/notebooks/Index.ipynb).
# We're going to walk through a quick demonstration of the functionality in [WidgetsDemo.ipynb](WidgetsDemo.ipynb)
| Autumn2017/06-Jupyter-Notebook-In-Depth/Jupyter Notebook In Depth.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# image of CNN cifar 10 labels : ---> https://www.samyzaf.com/ML/cifar10/cifar1.jpg
import pandas as pd
import numpy as np
# -----
# # The Data
#
# CIFAR-10 is a dataset of 50,000 32x32 color training images, labeled over 10 categories, and 10,000 test images.
# +
from tensorflow.keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# -
x_train.shape
x_train[0].shape
import matplotlib.pyplot as plt
# FROG
plt.imshow(x_train[0])
# HORSE
plt.imshow(x_train[12])
# # PreProcessing
x_train[0]
x_train[0].shape
x_train.max()
x_train = x_train/225
x_test = x_test/255
x_train.shape
x_test.shape
# ## Labels
from tensorflow.keras.utils import to_categorical
y_train.shape
y_train[0]
y_cat_train = to_categorical(y_train,10)
y_cat_train.shape
y_cat_train[0]
y_cat_test = to_categorical(y_test,10)
# ----------
# # Building the Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPool2D, Flatten
# +
model = Sequential()
## FIRST SET OF LAYERS
# CONVOLUTIONAL LAYER
model.add(Conv2D(filters=32, kernel_size=(4,4),input_shape=(32, 32, 3), activation='relu',))
# POOLING LAYER
model.add(MaxPool2D(pool_size=(2, 2)))
## SECOND SET OF LAYERS
# CONVOLUTIONAL LAYER
model.add(Conv2D(filters=32, kernel_size=(4,4),input_shape=(32, 32, 3), activation='relu',))
# POOLING LAYER
model.add(MaxPool2D(pool_size=(2, 2)))
# FLATTEN IMAGES FROM 28 by 28 to 764 BEFORE FINAL LAYER
model.add(Flatten())
# 256 NEURONS IN DENSE HIDDEN LAYER (YOU CAN CHANGE THIS NUMBER OF NEURONS)
model.add(Dense(256, activation='relu'))
# LAST LAYER IS THE CLASSIFIER, THUS 10 POSSIBLE CLASSES
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# -
model.summary()
from tensorflow.keras.callbacks import EarlyStopping
early_stop = EarlyStopping(monitor='val_loss',patience=3)
model.fit(x_train,y_cat_train,epochs=15,validation_data=(x_test,y_cat_test),callbacks=[early_stop])
losses = pd.DataFrame(model.history.history)
losses.head()
losses[['accuracy','val_accuracy']].plot()
losses[['loss','val_loss']].plot()
model.metrics_names
print(model.metrics_names)
print(model.evaluate(x_test,y_cat_test,verbose=0))
# +
from sklearn.metrics import classification_report,confusion_matrix
predictions = model.predict_classes(x_test)
# -
print(classification_report(y_test,predictions))
confusion_matrix(y_test,predictions)
import seaborn as sns
plt.figure(figsize=(10,6))
sns.heatmap(confusion_matrix(y_test,predictions),annot=True)
# # Predicting a given image
my_image = x_test[16]
plt.imshow(my_image)
# SHAPE --> (num_images,width,height,color_channels)
model.predict_classes(my_image.reshape(1,32,32,3))
# +
# they fore : 5 is a DOG..
| ipynbFile/CNN CIFAR-10 using Keras.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Name :- <NAME>
# # Data Science Intern at LetsGrowMore
# # Task 1- Iris Flowers Classification ML Project
# # 1. Importing the all required Libraries
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import scipy as sp
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
# %matplotlib inline
# # 2. Reading the Data
iris = pd.read_csv('iris.csv')
# Seeing the first five rows
iris.head()
# # 3. Droping the unnecessary column
iris = iris.drop(columns = ['Id'])
iris.head()
# # 4. Show the information about the Data
iris.info()
# # 5. Show the no. of rows and columns
iris.shape
# # 6. Describing Iris data
iris.describe()
iris.isnull().sum()
# # 7. Data Visulization By Different types of graphs
# +
# Scatter plot
iris.plot(kind="scatter", x="SepalLengthCm", y= "SepalWidthCm")
# -
# Scatter plot
iris.plot(kind="scatter", x="PetalLengthCm", y= "PetalWidthCm")
#joint plot
sns.jointplot( data=iris,x="SepalLengthCm", y="SepalWidthCm")
#joint plot
sns.jointplot( data=iris,x="PetalLengthCm", y="PetalWidthCm")
#Density plot
sns.kdeplot(data= iris, x="SepalLengthCm", y="SepalWidthCm")
#Density plot
sns.kdeplot(data= iris, x="PetalLengthCm", y="PetalWidthCm")
#histogram
iris['SepalLengthCm'].hist()
#histogram
iris['SepalWidthCm'].hist()
# # 8. Making Models using KNeighborsClassifiers
X = iris.drop('Species',axis=1)
Y = iris['Species']
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.25)
kmeans=KNeighborsClassifier(n_neighbors=3)
kmeans.fit(x_train,y_train)
print("Accuracy of Model: ",kmeans.score(x_train,y_train)*100)
sns.scatterplot(data=x_train,x='PetalLengthCm',y='PetalWidthCm')
# # Thank you!
| BegineerLevelTasks/Task-1 - Iris_classification.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Cordatus Applcations: Facebook Detectron2
#
# #### Table of Contents
# * [Introduction](#introduction)
# * [What's New](#whatsnew)
# * [COCO Object Detection Baselines](#object_detection)
# * [COCO Instance Segmentation Baselines with Mask R-CNN](#instance_segmentation)
# * [COCO Person Keypoint Detection Baselines with Keypoint R-CNN](#keypoint_detection)
# * [COCO Panoptic Segmentation Baselines with Panoptic FPN](#panoptic_segmentation)
# ## Introduction <a name="introduction"></a>
# Detectron2 is Facebook AI Research's next generation software system that implements state-of-the-art object detection algorithms. It is a ground-up rewrite of the previous version, Detectron, and it originates from maskrcnn-benchmark.
#
# In this notebook, you will find the instructions needed in order to run a live object detection/instance & semantic segmentation/keypoint detection demo using your webcam.
# <div align="center">
# <img src="https://user-images.githubusercontent.com/1381301/66535560-d3422200-eace-11e9-9123-5535d469db19.png"/>
# </div>
#
# ### What's New <a name="whatsnew"></a>
# * It is powered by the [PyTorch](https://pytorch.org) deep learning framework.
# * Includes more features such as panoptic segmentation, densepose, Cascade R-CNN, rotated bounding boxes, etc.
# * Can be used as a library to support [different projects](projects/) on top of it.
# We'll open source more research projects in this way.
# * It [trains much faster](https://detectron2.readthedocs.io/notes/benchmarks.html).
#
# See Facebook's [blog post](https://ai.facebook.com/blog/-detectron2-a-pytorch-based-modular-object-detection-library-/)
# to see more demos and learn about detectron2.
# ### COCO Object Detection Baselines <a name="object_detection"></a>
from utils import xavier_config
od = xavier_config.get_xavier_od_widget()
display(od)
# #### For USB Camera Demo
# **First, you need to adjust device id to the appropriate value with *--vid <device-id>* flag**
# +
import os
od_model = xavier_config.get_model(od.value)
od_demo_cmd = 'python3 /root/detectron2/demo/demo_dene.py --config-file /root/detectron2/configs/COCO-Detection/'+od.value+'.yaml --usb --vid 1 \
--opts MODEL.WEIGHTS '+od_model
os.system(od_demo_cmd)
# -
# #### For CSI Camera Demo
# +
import os
od_model = xavier_config.get_model(od.value)
od_demo_cmd = 'python3 /root/detectron2/demo/demo_dene.py --config-file /root/detectron2/configs/COCO-Detection/'+od.value+'.yaml --csi --vid 0 \
--opts MODEL.WEIGHTS '+od_model
os.system(od_demo_cmd)
# -
# ## Detectron2 Model Zoo
# #### Faster R-CNN:
# <table><tbody>
# <!-- START TABLE -->
# <!-- TABLE HEADER -->
# <th valign="bottom">Name</th>
# <th valign="bottom">lr<br/>sched</th>
# <th valign="bottom">train<br/>time<br/>(s/iter)</th>
# <th valign="bottom">inference<br/>time<br/>(s/im)</th>
# <th valign="bottom">train<br/>mem<br/>(GB)</th>
# <th valign="bottom">box<br/>AP</th>
# <th valign="bottom">model id</th>
# <th valign="bottom">download</th>
# <!-- TABLE BODY -->
# <!-- ROW: faster_rcnn_R_50_C4_1x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_C4_1x.yaml">R50-C4</a></td>
# <td align="center">1x</td>
# <td align="center">0.551</td>
# <td align="center">0.110</td>
# <td align="center">4.8</td>
# <td align="center">35.7</td>
# <td align="center">137257644</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_1x/137257644/model_final_721ade.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_1x/137257644/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_50_DC5_1x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_DC5_1x.yaml">R50-DC5</a></td>
# <td align="center">1x</td>
# <td align="center">0.380</td>
# <td align="center">0.068</td>
# <td align="center">5.0</td>
# <td align="center">37.3</td>
# <td align="center">137847829</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_1x/137847829/model_final_51d356.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_1x/137847829/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_50_FPN_1x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml">R50-FPN</a></td>
# <td align="center">1x</td>
# <td align="center">0.210</td>
# <td align="center">0.055</td>
# <td align="center">3.0</td>
# <td align="center">37.9</td>
# <td align="center">137257794</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_1x/137257794/model_final_b275ba.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_1x/137257794/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_50_C4_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_C4_3x.yaml">R50-C4</a></td>
# <td align="center">3x</td>
# <td align="center">0.543</td>
# <td align="center">0.110</td>
# <td align="center">4.8</td>
# <td align="center">38.4</td>
# <td align="center">137849393</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_3x/137849393/model_final_f97cb7.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_3x/137849393/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_50_DC5_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_DC5_3x.yaml">R50-DC5</a></td>
# <td align="center">3x</td>
# <td align="center">0.378</td>
# <td align="center">0.073</td>
# <td align="center">5.0</td>
# <td align="center">39.0</td>
# <td align="center">137849425</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_3x/137849425/model_final_68d202.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_3x/137849425/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_50_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml">R50-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.209</td>
# <td align="center">0.047</td>
# <td align="center">3.0</td>
# <td align="center">40.2</td>
# <td align="center">137849458</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_101_C4_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_101_C4_3x.yaml">R101-C4</a></td>
# <td align="center">3x</td>
# <td align="center">0.619</td>
# <td align="center">0.149</td>
# <td align="center">5.9</td>
# <td align="center">41.1</td>
# <td align="center">138204752</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_C4_3x/138204752/model_final_298dad.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_C4_3x/138204752/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_101_DC5_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_101_DC5_3x.yaml">R101-DC5</a></td>
# <td align="center">3x</td>
# <td align="center">0.452</td>
# <td align="center">0.082</td>
# <td align="center">6.1</td>
# <td align="center">40.6</td>
# <td align="center">138204841</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_DC5_3x/138204841/model_final_3e0943.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_DC5_3x/138204841/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_R_101_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml">R101-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.286</td>
# <td align="center">0.063</td>
# <td align="center">4.1</td>
# <td align="center">42.0</td>
# <td align="center">137851257</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_FPN_3x/137851257/model_final_f6e8b1.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_FPN_3x/137851257/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: faster_rcnn_X_101_32x8d_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x.yaml">X101-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.638</td>
# <td align="center">0.120</td>
# <td align="center">6.7</td>
# <td align="center">43.0</td>
# <td align="center">139173657</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x/139173657/model_final_68b088.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x/139173657/metrics.json">metrics</a></td>
# </tr>
# </tbody></table>
# #### RetinaNet:
#
# <table><tbody>
# <!-- START TABLE -->
# <!-- TABLE HEADER -->
# <th valign="bottom">Name</th>
# <th valign="bottom">lr<br/>sched</th>
# <th valign="bottom">train<br/>time<br/>(s/iter)</th>
# <th valign="bottom">inference<br/>time<br/>(s/im)</th>
# <th valign="bottom">train<br/>mem<br/>(GB)</th>
# <th valign="bottom">box<br/>AP</th>
# <th valign="bottom">model id</th>
# <th valign="bottom">download</th>
# <!-- TABLE BODY -->
# <!-- ROW: retinanet_R_50_FPN_1x -->
# <tr><td align="left"><a href="configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml">R50</a></td>
# <td align="center">1x</td>
# <td align="center">0.200</td>
# <td align="center">0.062</td>
# <td align="center">3.9</td>
# <td align="center">36.5</td>
# <td align="center">137593951</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_1x/137593951/model_final_b796dc.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_1x/137593951/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: retinanet_R_50_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/retinanet_R_50_FPN_3x.yaml">R50</a></td>
# <td align="center">3x</td>
# <td align="center">0.201</td>
# <td align="center">0.063</td>
# <td align="center">3.9</td>
# <td align="center">37.9</td>
# <td align="center">137849486</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_3x/137849486/model_final_4cafe0.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_3x/137849486/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: retinanet_R_101_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Detection/retinanet_R_101_FPN_3x.yaml">R101</a></td>
# <td align="center">3x</td>
# <td align="center">0.280</td>
# <td align="center">0.080</td>
# <td align="center">5.1</td>
# <td align="center">39.9</td>
# <td align="center">138363263</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_101_FPN_3x/138363263/model_final_59f53c.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_101_FPN_3x/138363263/metrics.json">metrics</a></td>
# </tr>
# </tbody></table>
#
# #### RPN & Fast R-CNN:
#
# <table><tbody>
# <!-- START TABLE -->
# <!-- TABLE HEADER -->
# <th valign="bottom">Name</th>
# <th valign="bottom">lr<br/>sched</th>
# <th valign="bottom">train<br/>time<br/>(s/iter)</th>
# <th valign="bottom">inference<br/>time<br/>(s/im)</th>
# <th valign="bottom">train<br/>mem<br/>(GB)</th>
# <th valign="bottom">box<br/>AP</th>
# <th valign="bottom">prop.<br/>AR</th>
# <th valign="bottom">model id</th>
# <th valign="bottom">download</th>
# <!-- TABLE BODY -->
# <!-- ROW: rpn_R_50_C4_1x -->
# <tr><td align="left"><a href="configs/COCO-Detection/rpn_R_50_C4_1x.yaml">RPN R50-C4</a></td>
# <td align="center">1x</td>
# <td align="center">0.130</td>
# <td align="center">0.051</td>
# <td align="center">1.5</td>
# <td align="center"></td>
# <td align="center">51.6</td>
# <td align="center">137258005</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_C4_1x/137258005/model_final_450694.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_C4_1x/137258005/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: rpn_R_50_FPN_1x -->
# <tr><td align="left"><a href="configs/COCO-Detection/rpn_R_50_FPN_1x.yaml">RPN R50-FPN</a></td>
# <td align="center">1x</td>
# <td align="center">0.186</td>
# <td align="center">0.045</td>
# <td align="center">2.7</td>
# <td align="center"></td>
# <td align="center">58.0</td>
# <td align="center">137258492</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_FPN_1x/137258492/model_final_02ce48.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_FPN_1x/137258492/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: fast_rcnn_R_50_FPN_1x -->
# <tr><td align="left"><a href="configs/COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml">Fast R-CNN R50-FPN</a></td>
# <td align="center">1x</td>
# <td align="center">0.140</td>
# <td align="center">0.035</td>
# <td align="center">2.6</td>
# <td align="center">37.8</td>
# <td align="center"></td>
# <td align="center">137635226</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/fast_rcnn_R_50_FPN_1x/137635226/model_final_e5f7ce.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/fast_rcnn_R_50_FPN_1x/137635226/metrics.json">metrics</a></td>
# </tr>
# </tbody></table>
# ### COCO Instance Segmentation Baselines with Mask R-CNN <a name="instance_segmentation"></a>
from utils import xavier_config
iseg = xavier_config.get_xavier_iseg_widget()
display(iseg)
# #### For USB Camera Demo
# **First, you need to adjust device id to the appropriate value with *--vid <device-id>* flag**
# +
import os
iseg_model = xavier_config.get_model(iseg.value)
iseg_demo_cmd = 'python3 /root/detectron2/demo/demo.py --config-file /root/detectron2/configs/COCO-InstanceSegmentation/'+iseg.value+'.yaml --usb --vid 1 \
--opts MODEL.WEIGHTS '+iseg_model
os.system(iseg_demo_cmd)
# -
# #### For CSI Camera Demo
# +
import os
od_model = xavier_config.get_model(od.value)
od_demo_cmd = 'python3 /root/detectron2/demo/demo_dene.py --config-file /root/detectron2/configs/COCO-Detection/'+od.value+'.yaml --csi --vid 0 \
--opts MODEL.WEIGHTS '+od_model
os.system(od_demo_cmd)
# -
# #### Mask R-CNN
#
# <table><tbody>
# <!-- START TABLE -->
# <!-- TABLE HEADER -->
# <th valign="bottom">Name</th>
# <th valign="bottom">lr<br/>sched</th>
# <th valign="bottom">train<br/>time<br/>(s/iter)</th>
# <th valign="bottom">inference<br/>time<br/>(s/im)</th>
# <th valign="bottom">train<br/>mem<br/>(GB)</th>
# <th valign="bottom">box<br/>AP</th>
# <th valign="bottom">mask<br/>AP</th>
# <th valign="bottom">model id</th>
# <th valign="bottom">download</th>
# <!-- TABLE BODY -->
# <!-- ROW: mask_rcnn_R_50_C4_1x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.yaml">R50-C4</a></td>
# <td align="center">1x</td>
# <td align="center">0.584</td>
# <td align="center">0.117</td>
# <td align="center">5.2</td>
# <td align="center">36.8</td>
# <td align="center">32.2</td>
# <td align="center">137259246</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x/137259246/model_final_9243eb.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x/137259246/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_50_DC5_1x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x.yaml">R50-DC5</a></td>
# <td align="center">1x</td>
# <td align="center">0.471</td>
# <td align="center">0.074</td>
# <td align="center">6.5</td>
# <td align="center">38.3</td>
# <td align="center">34.2</td>
# <td align="center">137260150</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x/137260150/model_final_4f86c3.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x/137260150/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_50_FPN_1x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml">R50-FPN</a></td>
# <td align="center">1x</td>
# <td align="center">0.261</td>
# <td align="center">0.053</td>
# <td align="center">3.4</td>
# <td align="center">38.6</td>
# <td align="center">35.2</td>
# <td align="center">137260431</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/137260431/model_final_a54504.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/137260431/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_50_C4_3x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x.yaml">R50-C4</a></td>
# <td align="center">3x</td>
# <td align="center">0.575</td>
# <td align="center">0.118</td>
# <td align="center">5.2</td>
# <td align="center">39.8</td>
# <td align="center">34.4</td>
# <td align="center">137849525</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x/137849525/model_final_4ce675.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x/137849525/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_50_DC5_3x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x.yaml">R50-DC5</a></td>
# <td align="center">3x</td>
# <td align="center">0.470</td>
# <td align="center">0.075</td>
# <td align="center">6.5</td>
# <td align="center">40.0</td>
# <td align="center">35.9</td>
# <td align="center">137849551</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x/137849551/model_final_84107b.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x/137849551/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_50_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml">R50-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.261</td>
# <td align="center">0.055</td>
# <td align="center">3.4</td>
# <td align="center">41.0</td>
# <td align="center">37.2</td>
# <td align="center">137849600</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_101_C4_3x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x.yaml">R101-C4</a></td>
# <td align="center">3x</td>
# <td align="center">0.652</td>
# <td align="center">0.155</td>
# <td align="center">6.3</td>
# <td align="center">42.6</td>
# <td align="center">36.7</td>
# <td align="center">138363239</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x/138363239/model_final_a2914c.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x/138363239/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_101_DC5_3x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x.yaml">R101-DC5</a></td>
# <td align="center">3x</td>
# <td align="center">0.545</td>
# <td align="center">0.155</td>
# <td align="center">7.6</td>
# <td align="center">41.9</td>
# <td align="center">37.3</td>
# <td align="center">138363294</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x/138363294/model_final_0464b7.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x/138363294/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_R_101_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x.yaml">R101-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.340</td>
# <td align="center">0.070</td>
# <td align="center">4.6</td>
# <td align="center">42.9</td>
# <td align="center">38.6</td>
# <td align="center">138205316</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x/138205316/model_final_a3ec72.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x/138205316/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: mask_rcnn_X_101_32x8d_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml">X101-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.690</td>
# <td align="center">0.129</td>
# <td align="center">7.2</td>
# <td align="center">44.3</td>
# <td align="center">39.5</td>
# <td align="center">139653917</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x/139653917/model_final_2d9806.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x/139653917/metrics.json">metrics</a></td>
# </tr>
# </tbody></table>
# ### COCO Person Keypoint Detection Baselines with Keypoint R-CNN <a name="keypoint_detection"></a>
from utils import xavier_config
pkd = xavier_config.get_xavier_pkd_widget()
display(pkd)
# #### For USB Camera Demo
# **First, you need to adjust device id to the appropriate value with *--vid <device-id>* flag**
# +
import os
pkd_model = xavier_config.get_model(pkd.value)
pkd_demo_cmd = 'python3 /root/detectron2/demo/demo.py --config-file /root/detectron2/configs/COCO-Keypoints/'+pkd.value+'.yaml --usb --vid 0 \
--opts MODEL.WEIGHTS '+pkd_model
os.system(pkd_demo_cmd)
# -
# #### For CSI Camera Demo
# +
import os
od_model = xavier_config.get_model(od.value)
od_demo_cmd = 'python3 /root/detectron2/demo/demo_dene.py --config-file /root/detectron2/configs/COCO-Detection/'+od.value+'.yaml --csi --vid 0 \
--opts MODEL.WEIGHTS '+od_model
os.system(od_demo_cmd)
# -
# <table><tbody>
# <!-- START TABLE -->
# <!-- TABLE HEADER -->
# <th valign="bottom">Name</th>
# <th valign="bottom">lr<br/>sched</th>
# <th valign="bottom">train<br/>time<br/>(s/iter)</th>
# <th valign="bottom">inference<br/>time<br/>(s/im)</th>
# <th valign="bottom">train<br/>mem<br/>(GB)</th>
# <th valign="bottom">box<br/>AP</th>
# <th valign="bottom">kp.<br/>AP</th>
# <th valign="bottom">model id</th>
# <th valign="bottom">download</th>
# <!-- TABLE BODY -->
# <!-- ROW: keypoint_rcnn_R_50_FPN_1x -->
# <tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.yaml">R50-FPN</a></td>
# <td align="center">1x</td>
# <td align="center">0.315</td>
# <td align="center">0.083</td>
# <td align="center">5.0</td>
# <td align="center">53.6</td>
# <td align="center">64.0</td>
# <td align="center">137261548</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x/137261548/model_final_04e291.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x/137261548/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: keypoint_rcnn_R_50_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml">R50-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.316</td>
# <td align="center">0.076</td>
# <td align="center">5.0</td>
# <td align="center">55.4</td>
# <td align="center">65.5</td>
# <td align="center">137849621</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x/137849621/model_final_a6e10b.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x/137849621/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: keypoint_rcnn_R_101_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x.yaml">R101-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.390</td>
# <td align="center">0.090</td>
# <td align="center">6.1</td>
# <td align="center">56.4</td>
# <td align="center">66.1</td>
# <td align="center">138363331</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x/138363331/model_final_997cc7.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x/138363331/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: keypoint_rcnn_X_101_32x8d_FPN_3x -->
# <tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x.yaml">X101-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.738</td>
# <td align="center">0.142</td>
# <td align="center">8.7</td>
# <td align="center">57.3</td>
# <td align="center">66.0</td>
# <td align="center">139686956</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x/139686956/model_final_5ad38f.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x/139686956/metrics.json">metrics</a></td>
# </tr>
# </tbody></table>
# ### COCO Panoptic Segmentation Baselines with Panoptic FPN <a name="panoptic_segmentation"></a>
from utils import xavier_config
ps = xavier_config.get_xavier_ps_widget()
display(ps)
# #### For USB Camera Demo
# **First, you need to adjust device id to the appropriate value with *--vid <device-id>* flag**
# +
import os
ps_model = xavier_config.get_model(ps.value)
ps_demo_cmd = 'python3 /root/detectron2/demo/demo.py --config-file /root/detectron2/configs/COCO-PanopticSegmentation/'+ps.value+'.yaml --usb --vid 0 \
--opts MODEL.WEIGHTS '+ps_model
os.system(ps_demo_cmd)
# -
# #### For CSI Camera Demo
# +
import os
od_model = xavier_config.get_model(od.value)
od_demo_cmd = 'python3 /root/detectron2/demo/demo_dene.py --config-file /root/detectron2/configs/COCO-Detection/'+od.value+'.yaml --csi --vid 0 \
--opts MODEL.WEIGHTS '+od_model
os.system(od_demo_cmd)
# -
# <table><tbody>
# <!-- START TABLE -->
# <!-- TABLE HEADER -->
# <th valign="bottom">Name</th>
# <th valign="bottom">lr<br/>sched</th>
# <th valign="bottom">train<br/>time<br/>(s/iter)</th>
# <th valign="bottom">inference<br/>time<br/>(s/im)</th>
# <th valign="bottom">train<br/>mem<br/>(GB)</th>
# <th valign="bottom">box<br/>AP</th>
# <th valign="bottom">mask<br/>AP</th>
# <th valign="bottom">PQ</th>
# <th valign="bottom">model id</th>
# <th valign="bottom">download</th>
# <!-- TABLE BODY -->
# <!-- ROW: panoptic_fpn_R_50_1x -->
# <tr><td align="left"><a href="configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.yaml">R50-FPN</a></td>
# <td align="center">1x</td>
# <td align="center">0.304</td>
# <td align="center">0.063</td>
# <td align="center">4.8</td>
# <td align="center">37.6</td>
# <td align="center">34.7</td>
# <td align="center">39.4</td>
# <td align="center">139514544</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x/139514544/model_final_dbfeb4.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x/139514544/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: panoptic_fpn_R_50_3x -->
# <tr><td align="left"><a href="configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml">R50-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.302</td>
# <td align="center">0.063</td>
# <td align="center">4.8</td>
# <td align="center">40.0</td>
# <td align="center">36.5</td>
# <td align="center">41.5</td>
# <td align="center">139514569</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x/139514569/model_final_c10459.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x/139514569/metrics.json">metrics</a></td>
# </tr>
# <!-- ROW: panoptic_fpn_R_101_3x -->
# <tr><td align="left"><a href="configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml">R101-FPN</a></td>
# <td align="center">3x</td>
# <td align="center">0.392</td>
# <td align="center">0.078</td>
# <td align="center">6.0</td>
# <td align="center">42.4</td>
# <td align="center">38.5</td>
# <td align="center">43.0</td>
# <td align="center">139514519</td>
# <td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/metrics.json">metrics</a></td>
# </tr>
# </tbody></table>
| Introduction_to_Detectron2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import torch
import pickle as pkl
import pandas as pd
import matplotlib
import glob
import json
import os
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
import torch.nn.functional as F
# %matplotlib inline
os.chdir('/tmp/eigentasks')
from data.taskonomy import TaskonomyDataset, taskonomy_flat_split_to_buildings
from guided_filter.box_filter import BoxFilter
# ### Set up data
# +
# Load data
opts = TaskonomyDataset.Options(
data_path = '/datasets/taskonomy',
tasks = ['rgb', 'depth_euclidean', 'depth_zbuffer'],
buildings = 'debug-val',
force_refresh_tmp=False
)
df = TaskonomyDataset(opts)
# -
def show(im, noshow=False):
n_im = 1
if isinstance(im, list):
n_im = len(im)
im = [np.concatenate([i] * 3, 0) if i.shape[0] == 1 else i for i in im]
im = np.concatenate(im, axis=2)
plt.figure(figsize=(8 * n_im,8))
im = np.transpose(im, [1,2,0])
plt.imshow(im)
if not noshow:
plt.show()
# +
# Load one image
res = df[10]
rgb = res['rgb']
depth = res['depth_euclidean']
depth_zbuffer = res['depth_zbuffer']
rgb = torch.Tensor(rgb).unsqueeze(0)
depth[depth >= 1.0] = depth[depth < 1.0].max()
rgb_cuda = rgb.cuda()
depth_cuda = depth.cuda()
# Load a second image
res = df[12]
rgb2 = res['rgb']
depth2 = res['depth_euclidean']
depth_zbuffer2 = res['depth_zbuffer']
rgb2 = torch.Tensor(rgb2).unsqueeze(0)
depth2[depth2 >= 1.0] = depth2[depth2 < 1.0].max()
rgb2 = rgb2
depth2 = depth2
rgb_cuda2 = rgb2.cuda()
depth_cuda2 = depth2.cuda()
# +
# Form a CPU batch and a GPU batch
rgb_batch_cuda = torch.cat([rgb_cuda, rgb_cuda2], dim=0)
depth_batch_cuda = torch.cat([depth_cuda, depth_cuda2], dim=0)
rgb_batch = torch.cat([rgb, rgb2], dim=0)
depth_batch = torch.cat([depth, depth2], dim=0)
# -
# Show a pretty image
show([rgb[0], depth])
# ### Define filters
# +
def gaussian(M, std, sym=True, device=None):
if M < 1:
return torch.tensor([])
if M == 1:
return torch.ones((1,))
odd = M % 2
if not sym and not odd:
M = M + 1
n = torch.arange(0, M, device=device) - (M - 1.0) / 2.0
sig2 = 2 * std * std
w = torch.exp(-n ** 2 / sig2)
if not sym and not odd:
w = w[:-1]
return w
def separable_gaussian(img, r=3.5, cutoff=None, device=None):
# return img
if device is None:
device = img.device
if r < 1e-1:
return img
if cutoff is None:
cutoff = int(r * 5)
if (cutoff % 2) == 0: cutoff += 1
assert (cutoff % 2) == 1
img = img.to(device)
_, n_channels, w, h = img.shape
std = r
fil = gaussian(cutoff, std, device=device).to(device)
filsum = fil.sum() #/ n_channels
fil = torch.stack([fil] * n_channels, dim=0)
r_pad = int(cutoff)
r_pad_half = r_pad // 2
img = F.pad(img, (r_pad_half, r_pad_half, r_pad_half, r_pad_half), "replicate", 0) # effectively zero padding
filtered = F.conv2d(img, fil.unsqueeze(1).unsqueeze(-2), bias=None, stride=1, padding=0, dilation=1, groups=n_channels)
filtered /= filsum
filtered = F.conv2d(filtered, fil.unsqueeze(1).unsqueeze(-1), bias=None, stride=1, padding=0, dilation=1, groups=n_channels)
filtered /= filsum
return filtered
def boxblur(img, r):
_, _, w, h = img.shape
f = BoxFilter(r)
r_pad = int(r * 2)
r_pad_half = r_pad // 2
im = F.pad(img, (r_pad_half, r_pad_half, r_pad_half, r_pad_half), "replicate", 0) # effectively zero padding
filtered = f(im)
filtered = filtered[..., r_pad_half:w+r_pad_half, r_pad_half:h+r_pad_half]
filtered /= ((2 * r + 1) ** 2)
return filtered
# -
# #### Circle of confusion formula
# LHS is circle of confusion, RHS is magnification
#
#
# 
import torch
from torch.nn.parallel import parallel_apply
# +
def compute_circle_of_confusion(depths, aperture_size, focal_length, focus_distance):
assert focus_distance > focal_length
c = aperture_size * torch.abs(depths - focus_distance) / depths * (focal_length / (focus_distance - focal_length))
return c
def compute_circle_of_confusion_no_magnification(depths, aperture_size, focus_distance):
c = aperture_size * torch.abs(depths - focus_distance) / depths
return c
def compute_quantiles(depth, quantiles, eps=0.0001):
depth_flat = depth.reshape(depth.shape[0], -1)
quantile_vals = torch.quantile(depth_flat, quantiles, dim=1)
quantile_vals[0] -= eps
quantile_vals[-1] += eps
return quantiles, quantile_vals
def compute_quantile_membership(depth, quantile_vals):
quantile_dists = quantile_vals[1:] - quantile_vals[:-1]
depth_flat = depth.reshape(depth.shape[0], -1)
calculated_quantiles = torch.searchsorted(quantile_vals, depth_flat)
calculated_quantiles_left = calculated_quantiles - 1
quantile_vals_unsqueezed = quantile_vals #.unsqueeze(-1).unsqueeze(-1)
quantile_right = torch.gather(quantile_vals_unsqueezed, 1, calculated_quantiles).reshape(depth.shape)
quantile_left = torch.gather(quantile_vals_unsqueezed, 1, calculated_quantiles_left).reshape(depth.shape)
quantile_dists = quantile_right - quantile_left
dist_right = ((quantile_right - depth) / quantile_dists) #/ quantile_dists[calculated_quantiles_left]
dist_left = ((depth - quantile_left) / quantile_dists) #/ quantile_dists[calculated_quantiles_left]
return dist_left, dist_right, calculated_quantiles_left.reshape(depth.shape), calculated_quantiles.reshape(depth.shape)
def get_blur_stack_single_image(rgb, blur_radii, cutoff_multiplier):
args = []
for r in blur_radii:
cutoff = None if cutoff_multiplier is None else int(r * cutoff_multiplier)
if cutoff is not None and (cutoff % 2) == 0:
cutoff += 1
args.append((rgb, r, cutoff))
blurred_ims = parallel_apply([separable_gaussian]*len(args), args)
blurred_ims = torch.stack(blurred_ims, dim=1)
return blurred_ims
def get_blur_stack(rgb, blur_radii, cutoff_multiplier=None):
args = [(image.unsqueeze(0), radii, cutoff_multiplier) for image, radii in zip(rgb, blur_radii)]
modules = [get_blur_stack_single_image for _ in args]
outputs = parallel_apply(modules, args)
return torch.cat(outputs, dim=0)
def composite_blur_stack(blur_stack, dist_left, dist_right, values_left, values_right):
shape = list(blur_stack.shape)
shape[2] = 1
composite_vals = torch.zeros(shape, dtype=torch.float32, device=blur_stack.device)
sim_left = (1 - dist_left**2)
sim_right = (1 - dist_right**2)
_ = composite_vals.scatter_(1, index=values_left.unsqueeze(1).unsqueeze(2), src=sim_left.unsqueeze(1).unsqueeze(2))
_ = composite_vals.scatter_(1, index=values_right.unsqueeze(1).unsqueeze(2), src=sim_right.unsqueeze(1).unsqueeze(2))
composite_vals /= composite_vals.sum(dim=1, keepdims=True)
composited = composite_vals * blur_stack
composited = composited.sum(dim=1)
return composited
def refocus_image(rgb, depth, focus_distance, aperture_size, quantile_vals, return_segments=False):
quantile_vals_squeezed = quantile_vals.squeeze()
dist_left, dist_right, calculated_quantiles_left, calculated_quantiles = compute_quantile_membership(depth, quantile_vals)
blur_radii = compute_circle_of_confusion_no_magnification(quantile_vals, aperture_size, focus_distance)
# print(f'Quantiles: {quantile_vals}')
# print(f'Blurs: {blur_radii.shape}')
blur_stack = get_blur_stack(rgb, blur_radii, cutoff_multiplier=3)
composited = composite_blur_stack(blur_stack, dist_left, dist_right, calculated_quantiles_left, calculated_quantiles)
if return_segments:
return composited, calculated_quantiles_left
else:
return composited
##########################################
#
##########################################
def RefocusImageAugmentation(n_quantiles, aperture_min, aperture_max, return_segments=False):
'''
RefocusImageAugmentation
Given an RGB image and depth image, refocuses the RGB image by blurring according to depth.
- Based on a paraxial thin-lens model for refocusing.
- Bands the depth image into segments of equal size (size given by n_quantiles)
- Finds blur corresponding to each depth segment cutoff
- Creates "blur stack" of n_quantiles + 1 blurred image (separable Gaussian filter)
- For each depth location, composite pixel value as interpolation between two of the
blur images from the stack
Randomly selects:
- focus distance to be one of the quantiles (so that some of the image is always in focus).
- aperture_size log-uniformly from [aperture_min, aperture_max]
Arguments:
n_quantiles: How many quantiles to use in the blur stack. More is better, but slower
aperture_min: Smallest aperture to use
aperture_max: Largest aperture to use (randomly selects one log-uniformly in this range)
return_segments: whether to return the depth segments
'''
def refocus_image_(rgb, depth):
with torch.no_grad():
device = depth.device
quantiles = torch.arange(0, n_quantiles + 1, device=device) / n_quantiles
quantiles, quantile_vals = compute_quantiles(depth, quantiles, eps=0.0001)
quantile_vals = quantile_vals.permute(1, 0)
focus_dist_idxs = torch.randint(low=1, high=n_quantiles, size=(rgb.shape[0],), device=device)
focus_dists = torch.gather(quantile_vals, 1, focus_dist_idxs.unsqueeze(0)).permute(1,0)
log_min = torch.log(torch.tensor(aperture_min, device=device))
log_max = torch.log(torch.tensor(aperture_max, device=device))
apertures = torch.exp(
torch.rand(size=(rgb.shape[0],1), device=device)
* (log_max - log_min) + log_min
)
# print(f'dist: {focus_dists}, apertures: {apertures}')
return refocus_image(rgb, depth, focus_dists, apertures, quantile_vals, return_segments)
return refocus_image_
# -
# Example usage
n_quantiles = 8
aug = RefocusImageAugmentation(8, 0.01, 3.0, return_segments=True)
composited, calculated_quantiles_left = aug(rgb_batch_cuda, depth_batch_cuda)
k = 1
show([rgb_batch[k],
composited[k].detach().cpu(),
depth_batch[k].unsqueeze(0),
calculated_quantiles_left[k].unsqueeze(0).detach().cpu() / n_quantiles])
| paper_code/notebooks/refocus_augmentation (1).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import numpy as np
path = 'data_set/handwriting/testDigits'
a = os.listdir(path)
Y = []
X = []
for i in a:
cache_x = []
Y.append(i.split('_')[0])
PATH = path + '/' + i
with open(PATH,'r') as f:
lines = f.readlines()
for j in lines:
strip_j = j.strip('\n')
for k in strip_j:
cache_x.append(k)
X.append(cache_x)
X = np.array(X)
print(X.shape)
| homework.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import string
import nltk
from nltk.corpus import stopwords
import gensim
import numpy as np
import keras
from keras.models import load_model
import operator
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
def preprocess(text):
stop_words = stopwords.words('english')
lemmatizer=nltk.stem.WordNetLemmatizer()
# tokenazation
tokens_list = []
for sent in nltk.sent_tokenize(text, language='english'):
for word in nltk.word_tokenize(sent, language='english'):
tokens_list.append(word)
output = []
for Token in tokens_list:
# to lowercase
token=Token.lower()
# punctuation removal
for punc in string.punctuation:
token=token.replace(punc,'')
# number digits removal
for digit in string.digits:
token=token.replace(digit,'')
# lemmatzation
token = lemmatizer.lemmatize(token)
# stop words removal
if (token != "") and (token not in stop_words):
output.append(token)
return output
# ### Loading
# +
# %%time
tf_idf = TfidfVectorizer(max_features=8000, min_df=10)
train_set = pd.read_csv("dataset_train_pp.csv")
train_x = train_set["Description"]
tfidf = tf_idf.fit(train_x)
# -
# %%time
nn_model = load_model("nn_tfidf_8000.h5")
def inference(input_text):
text_pp = []
for i in input_text:
text_pp.append(preprocess(i[0]))
text_pp = pd.Series( (i for i in text_pp) )
text_pp = text_pp.apply(lambda x: ''.join(i+' ' for i in x))
text_vec = tfidf.transform(text_pp)
predictions = nn_model.predict(text_vec)
result = {1:'World', 2:'Sports', 3:'Business', 4:'Science', 5:'Corona'}
print([result[r] for r in predictions.argmax(axis=1)+1])
print([max(predictions[p]) for p in range(len(input_text))])
# ### Inference
# #### DW News
# Corona
input_text = [['As France enters the "Green Zone" lower risk state against COVID-19 on Monday, <NAME> vows to prop up the economy along with the rest of Europe. France has been hit hard by the novel coronavirus.'],
['COVID-19 has taken a metaphorical sledgehammer to global tourism, although European nations are trying to revive the industry. Not so in Ireland or the UK, where stringent quarantine rules further threaten the sector.'],
['A man has died after becoming infected with COVID-19 at a Pentecost service in the northern city of Bremerhaven. This isnt the first time a church in Germany has been at the center of an outbreak.'],
['COVID-19 studies are being uploaded in great numbers to preprint servers without lengthy peer review processes. Is that good or bad? The fact is that there is no such thing as an absolute guarantee for good research. '],
['In South Asian nations like Pakistan, where child labor is rampant, COVID-19 has brought more hardship to underage workers. Meanwhile, the resulting economic crisis is pushing even more children into child labor. ']
]
# %%time
inference(input_text)
# Sport
input_text = [['Bayern Munich will win the title for an eighth straight time if they can win for the 11th straight time when they visit Bremen on Tuesday. Elsewhere, the fight for survival has heated up — but Paderborn are all but down. '],
['Bayern Munich are poised to secure an eighth consecutive league title this week, but there is still much to be decided in the Bundesliga with three games to go. DW analyzes the race for Europe and the relegation battle. '],
['A week after <NAME>, <NAME> and others delivered individual statements of support to the Black Lives Matter movement, Bundesliga clubs showed their collective solidarity. '],
['There was early drama as RB Leipzig won on Julian Nagelsmanns first return to Hoffenheim. While the defeat dents Hoffenheim’s hopes of European football, Leipzig are on track for a Champions League place. '],
['Bad news for the chauvinists at the football table. Scientists from Germanys Sport University Cologne have proved that women who play football can implement tactical approaches just as well as men. ']
]
# %%time
inference(input_text)
# Business
input_text = [['The principal bench of the National Company Law Tribunal (NCLT) in New Delhi ruled that the liquidator has overriding powers under the Insolvency and Bankruptcy Code to take over both movable and immovable assets of a corporate debtor.'],
['Shares in German payment service provider Wirecard lost more than half their value within minutes on Thursday after the DAX-listed company said it was not possible for it to publish a delayed annual report due to worrisome audit data.'],
['Berlin says it regrets a US plan to expand sanctions on the Nord Stream 2 gas pipeline. US senators announced new sanctions on the project last week, saying the pipeline would boost Moscow’s influence in Europe.'],
['From bulky spaceship-like devices to sleek black boxes, consoles have come a long way in recent decades. That has gone hand in hand with the targeting of new products not just to kids, but to adults too.'],
['Nord Stream 2, which was originally scheduled to start delivering gas from Russia to Western Europe toward the end of 2019, is almost completed. Of a total of 2,360 kilometers (1,466 miles), 2,200 kilometers of the pipeline have been laid.']
]
# %%time
inference(input_text)
# Science
input_text = [['Every 18 to 24 months, Earth and Mars align in such a way as to make deep-space travel that little bit easier, or at least a bit faster. That reduces a trip or "trajectory" to the Red Planet from about nine months down to seven.'],
['The impressive pyramid-style cities of the ancient Mayan culture, such as at Tikal in Guatemala, can be found described in any travel book.But the many of the other monumental buildings, houses, roads and paths, water works and drainage systems, and terraces still lay hidden in dense rain forest.'],
['Everything about this NASA SpaceX Demo-2 mission is symbolic. It seems that every effort has been made to draw a direct parallel between the last human spaceflight from America, and the Apollo moon missions before that.'],
['Heres a simple fact to start: The oceans are huge. Oceans make up about 96.5% of all Earths water. Theres fresh water in the planet, in the ground or elsewhere on land in rivers and lakes — more than 70% of the planet is covered in water — and theres more all around us in the atmosphere. But the oceans are simply huge.'],
['Second only to leukemia, brain tumors are top of the list of common forms of cancer in children and the young. The German Brain Tumor Association says 25% of all cancer diagnoses in the young involve tumors in the brain and central nervous system. Its often kids at the age of six-and-a-half, and boys more often than girls.']
]
# %%time
inference(input_text)
# World
input_text = [['Three opposition activists from the Movement for Democratic Change-Alliance (MDC-Alliance) disappeared in May after being detained by police while on their way to an anti-government protest The women were found badly injured outside the capital Harare nearly 48 hours later and immediately hospitalized. They say they were abducted, sexually abused and forced to drink their urine.'],
['<NAME>, 75, has been vocal about his views on politics, religion and public life and has often spoken out against religious fundamentalism and restrictions on freedom of speech. He has also heavily criticized communalism within Islam while denouncing the anti-Muslim sentiment advocated by the Hindu right.'],
['UN Secretary-General Antonio Guterres annual report on children and armed conflict, issued at the start of the week, featured a slight tweak for the year: the Saudi-led coalition waging war in Yemen was omitted from its list of offenders.Dubbed the "list of shame," this annex to the report names groups that fail to comply with measures aimed at ensuring the safety of children in armed conflict.'],
['The European Court of Justice (ECJ) ruled Thursday that a Hungarian law concerning the foreign funding of non-governmental organizations (NGOs) was illegal. Hungarys restrictions on the funding of civil organisations by persons established outside that member state do not comply with the Union law, the Luxembourg-based court said in a statement.'],
['United Nations members voted in four new members of the powerful Security Council in New York on Wednesday, but failed to decide on which African nation should fill the African regional seat up for grabs. In Wednesdays vote, Kenya received 113 votes while Djibouti got 78. With both failing to gain the two-thirds majority needed to win the Africa seat on the council, the two countries will face off on in a second round of voting on Thursday morning.']
]
# %%time
inference(input_text)
input_text = [['']]
# %%time
inference(input_text)
input_text = [[''],
[''],
[''],
[''],
['']
]
| inference/inference_tfidf_8000.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="RsUExvAI2pbE" colab_type="text"
# In this notebook, we will create a network for some parties and analyze the patterns obtained. We may focus on 3 parties: PSL (party of the president), PT (party of the previous presidents and the main opposition), NOVO (right-wing and liberal, as they say) and PDT ( floating about center and left-center-wing).
# + id="nDjmU6mDDv2-" colab_type="code" outputId="c6f12636-c0ce-40fe-c675-56713198d8d3" colab={"base_uri": "https://localhost:8080/", "height": 547}
# !pip install nxviz
# !pip install unidecode
# + id="PNtMMhtQ2H1O" colab_type="code" colab={}
# Import necessary modules
import pandas as pd
import matplotlib.pyplot as plt
# Building the graph
import requests
from sklearn.feature_extraction.text import CountVectorizer
from itertools import combinations
import networkx as nx
from nxviz import CircosPlot
from unidecode import unidecode
# + id="BIhgPRylW6MU" colab_type="code" colab={}
dataset = pd.read_csv('speeches.csv')
# + id="vlcHCFfI8jiw" colab_type="code" colab={}
dataset.loc[:, 'speech'] = dataset.speech.str.replace('\r', '')
dataset.loc[:, 'speech'] = dataset.speech.str.replace('\n', '')
dataset.loc[:, 'speech'] = dataset.speech.str.replace('-', '')
# + [markdown] id="8Qcq1EBrK0Zq" colab_type="text"
# ## Graphs
#
# The graphs will be created by following the steps of the methos explained on this [paper](https://scholar.google.com.br/scholar?q=Identifying+the+Pathways+for+Meaning+Circulation+using+Text+Network+Analysis&hl=pt-BR&as_sdt=0&as_vis=1&oi=scholart).
#
# We will use the 2-gram and 5-gram to generate the graph. That is, given a phrase, we extract the words in groups of 2 and 5 words. For exemple:
#
# ```
# Some are born to sweet delight.
# ```
#
# When applying the method to the phrase above, we may get the following tokens:
#
# ```
# [ 'Some are', 'are born', 'born to', 'to sweet', 'sweet delight', 'Some are born to sweet', 'are born to sweet delight' ]
# ```
#
# In this study, each token will have a number attached to it representing the frequency of the token in the text.
#
# Given a token, each word represents a node in the graph. For the 2-gram, the frequency is also the weight of the edge between the words. In the example above, we will have a edge `(Some, are)` with weight 1.
#
# When processing the 5-gram, we have to form combinations of length 2, and then repeat the process used for the 2-gram tokens.
#
# In any case, if the edge aleady exists, the weigth of the edge will be increased. Continuing the example above, the first 5-gram token wll have combinations as below:
#
# ```
# (Some, are), (are, born), (born, to), (to, sweet), (some, born), (Some, to), (Some, sweet)...
# ```
# and so on.
#
# The first pair already exists in the graph, since it was already obtained in a 2-gram token. Thus, its weight will be update for 2.
#
# This whole process will be repeated until the final graph is built.
# + id="WJI0xllyBZex" colab_type="code" colab={}
def is_important(word):
if len(word) < 2:
return False
ends = ['indo', 'ando', 'ondo', 'r', 'em',
'amos', 'imos', 'ente', 'emos','ou','dei',
'iam', 'cido', 'mos', 'am']
for end in ends:
if word.endswith(end):
return False
return True
def norm(word):
exceptions = ['pais', 'pessoas', 'dados', 'companhias', 'juntos']
if word in exceptions:
return word
ends = ['es', 'as']
for end in ends:
if word.endswith(end):
return word[:-2]
if word.endswith('is'):
return word[:-2] + 'l'
if word.endswith('s'):
return word[:-1]
return word
# + id="m9etAE5phDgS" colab_type="code" colab={}
def generate_graph(vocabulary):
"""
"""
# Create a undirected graph
G = nx.Graph()
# Iterate over each item of the vocabulary
for phrase, frequency in vocabulary.items():
# Get words in the phrase
words = phrase.split()
# Using only tokens of length 2 or 5
if len(words) not in [2,5]:
continue
words_norm = [norm(word) for word in words if is_important(word) ]
# Extract unique words in the phrase
words_unique = list(set(words_norm))
# Create a node if it does not exists already
G.add_nodes_from(words_unique)
# Form combinations of 2 from the words
# which will be a edge
pair = combinations(words_unique, 2)
for word1, word2 in pair:
edge = (word1, word2)
# Increments weight of edge
# if it already exists
# Otherwise, create a new edge
if edge in G.edges:
G.edges[word1, word2]['weight'] += frequency
else:
G.add_weighted_edges_from([(word1, word2, frequency)])
return G
# + [markdown] id="RNUxwnlfWDFY" colab_type="text"
# ## PSL
#
# The first party analysed is the one which our president represents.
# + id="S5hpw_3FWB5A" colab_type="code" colab={}
psl = dataset.query('party == "PSL"')
# + [markdown] id="SrRmEJjVPtxH" colab_type="text"
# We will use the [CountVectorizer](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html#sklearn.feature_extraction.text.CountVectorizer) in order to calculate the frequency in which the words, or group of words, appears in the speeches.
#
# It's important to define some stop words, that is, words that are irrelevant because they are repeated too many times (as articles, eg).
# + id="3H1V3Sj0DLq1" colab_type="code" colab={}
stop_words_pt = requests.get('https://gist.githubusercontent.com/alopes/5358189/'+
'raw/2107d809cca6b83ce3d8e04dbd9463283025284f/stopwords.txt')
# + id="VdLzo_-4XUe3" colab_type="code" colab={}
TOKENS_ALPHANUMERIC = '[A-Za-z]+(?=\\s+)'
# Ignore irrelevant words
STOP_WORDS = [unidecode(word.strip()) for word in stop_words_pt.text.split('\n')]
STOP_WORDS += ['neste', 'nesta', 'aqui', 'vou', 'nele', 'mesma', 'faz',
'zero', 'dois', 'duas', 'ir', 'mil', 'vai', 'aa', 'porque', 'pois',
'gostaria', 'cumprimentar', 'quero', 'dizer', 'vez', 'sobre', 'cada',
'deste', 'desta', 'ainda', 'vamos', 'pode', 'vem', 'deixar', 'vao',
'fazer', 'sendo', 'todo', 'todos', 'grande', 'presidente', 'quer',
'qualquer', 'dia', 'deputado', 'deputados', 'deputadas', 'venho',
'ver', 'tudo', 'tao', 'querem', 'correnco', 'corresponda', 'forma',
'fez', 'dar', 'apenas', 'traz', 'varios', 'vim', 'alem', 'sido',
'demos', 'todas', 'dermos', 'vemos', 'vale', 'torno', 'faco', 'espera',
'expressar', 'tentamos', 'pegar', 'queremos', 'usaremos', 'senhores',
'senhoras', 'senhor', 'senhora', 'fazendo', 'veio', 'vi', 'durante',
'ali', 'aqui', 'queria', 'ouvi', 'falando', 'entao', 'parece', 'assistam',
'presenciei', 'falar', 'algumas', 'sei', 'usar', 'fiz', 'usei', 'quiser',
'garantir', 'devida', 'contemplar', 'adianta', 'pensarmos', 'alguns',
'muitas', 'muitos', 'implica', 'fizeram', 'frisar', 'diz', 'poucas',
'usam', 'acho', 'combinamos', 'reiteradamente', 'deferido', 'outro',
'precisamos', 'importante', 'interessante', 'amplie', 'elencar',
'trago', 'outros', 'outras', 'outra', 'parte', 'encaminhado', 'integra',
'vezes', 'seis', 'partir', 'cria', 'atraves', 'anos', 'meses', 'oitava',
'chegou', 'posso', 'referente', 'detinado', 'nenhuma', 'nenhum', 'iv',
'doze', 'medias', 'ultimos', 'esquece', 'colocar', 'unica', 'ano',
'aplicando', 'fica', 'fale', 'concedo', 'fala', 'passaram', 'comum',
'menos', 'mais', 'jamais','sempre', 'querendo', 'ai', 'mexe', 'alguma',
'saber', 'der', 'peco', 'cuide', 'peco', 'estar', 'trazer', 'sabe',
'tirou', 'cumprimento', 'passam', 'facamos', 'fazem', 'quatro',
'muita', 'certeza', 'la', 'quase', 'disse', 'maior', 'feito', 'deve',
'inspecionados', 'inicio', 'citando', 'poder', 'ficar', 'aplicase',
'inicialmente', 'solicito', 'dessa', 'precisa', 'cabe', 'possui',
'terceiro', 'mencionou', 'altura', 'podiam', 'certa', 'bem', 'toda',
'exija', 'trata', 'coisa', 'simples', 'criaram', 'medida', 'momento',
'tentando', 'agradeco', 'pronunciamento', 'inventaram', 'votarmos',
'votar', 'votaram', 'votamos', 'sustarmos', 'criou', 'falei', 'preciso',
'convencam', 'atingiu', 'volta', 'questao', 'chegar', 'destacar',
'causou','prezadas', 'prezados', 'desculpemm', 'encerramento',
'prezado','parece' 'confirmando','excelentissimo', 'escutado',
'orientando','correndo','haver','respeitassem','ora','reconhecemos',
'cumprimentando','informar','orientar','suprimir','profunda',
'destacar','considera','comeca','focar', 'quiserem','encaminhamento',
'dentro', 'obrigar', 'discutida', 'reais', 'gastamse', 'tanta',
'tanto', 'tantas', 'tantos', 'ajudar', 'avanca','messes',
'dispensado', 'chegar', 'previsto', 'preciso', 'convencam', 'duvida',
'agora', 'tomam','tirar', 'unico', 'faca', 'primeiro', 'podemos',
'contra', 'acabar', 'coloca', 'algo', 'uns', 'carregam', 'surgiu',
'rever', 'retiralo', 'ressalto', 'importancia', 'aproveito',
'oportunidade', 'comungo', 'significa', 'parabenizar','hoje',
'conheca', 'invertendo', 'confirmando', 'desenvolveu', 'aprofundar',
'conduz', 'desculpeme', 'excelentissimos', 'roda', 'descaracteriza',
'concedem', 'cresca', 'favoravelmente', 'instalamos', 'autorize',
'determina', 'assim', 'dias', 'onde', 'quando', 'tira', 'pensar',
'implicara', 'horas', 'acredito', 'ninguem', 'procuraria', 'acima',
'deverao', 'falo', 'nada', 'fundamental', 'totalmente', 'nessa',
'fazermos', 'pensar', 'ganhar', 'comete', 'sofre', 'nesse', 'neste',
'existe', 'fere', 'passou', 'tres', 'obstruindo', 'rediscutir',
'assunto', 'assuntos', 'entendo', 'preservar', 'tarde', 'meios',
'desse', 'simplesmente','antes', 'longe', 'perto','aproximadamente',
'mal', 'melhor', 'pior', 'falamos', 'bastasse', 'mostrar', 'meio',
'alguem', 'inclusive', 'colega', 'boa', 'bom', 'nobre', 'primeira',
'primeiro', 'milhoes', 'deputada', 'deputadas', 'ficaria', 'estara',
'desses', 'dessas', 'junto', 'fim', 'semana', 'orientamos', 'claro',
'claros', 'orienta','pouco', 'colegas']
vec_alphanumeric = CountVectorizer(token_pattern=TOKENS_ALPHANUMERIC,decode_error='replace' ,
stop_words=STOP_WORDS, ngram_range=(2,5),
encoding='latin1', strip_accents='unicode')
# + id="kEOgivD6YM7H" colab_type="code" colab={}
# Fit to the data
X = vec_alphanumeric.fit_transform(psl.speech)
# + [markdown] id="qXk4dOjkP2-g" colab_type="text"
# Below, is the number of features (or tokens) obtained with all the speeches.
# + id="c614_MMwYY3e" colab_type="code" outputId="0bbccdbf-2189-4589-b371-29166928dcf7" colab={"base_uri": "https://localhost:8080/", "height": 34}
len(vec_alphanumeric.get_feature_names())
# + id="ntZEIG5Gb8yt" colab_type="code" outputId="7a478f9e-b11f-41a5-be3f-01a2efa485b6" colab={"base_uri": "https://localhost:8080/", "height": 17034}
vec_alphanumeric.vocabulary_
# + id="nFSrHkLaYfDM" colab_type="code" outputId="54961c56-bbd8-4944-cee4-e4518d889209" colab={"base_uri": "https://localhost:8080/", "height": 102}
vec_alphanumeric.get_feature_names()[:5]
# + [markdown] id="4H5BS-VlgAYv" colab_type="text"
# ### Creating the graph
#
# Now, we can use the method defined in the previous section to generate the graph.
#
# + id="YiRKW7Zel_07" colab_type="code" colab={}
G = generate_graph(vec_alphanumeric.vocabulary_)
# + id="dgQmqyc-nryP" colab_type="code" outputId="0e3e8505-6add-4609-ea00-9897db1a71be" colab={"base_uri": "https://localhost:8080/", "height": 34}
len(G.nodes())
# + id="lghimNpyy_-H" colab_type="code" outputId="c73bdf07-0f7b-4c66-a90c-be9471334436" colab={"base_uri": "https://localhost:8080/", "height": 34}
len(G.edges())
# + id="D3IEGi6P1NIp" colab_type="code" colab={}
nx.write_graphml_lxml(G, "psl.graphml")
# + [markdown] id="_f4DaTN2QROH" colab_type="text"
# ### Extracting information from the graph
#
# Connected component is a subgraph in which there is a path between any two vertexes. One graph may have many connected components, as the one below:
#
# 
#
# > *Image from Wikipedia*
#
# In the context of social networks, this can be use for finding some groups that have some connection between them.
# + id="lZ1h1PBb1OwL" colab_type="code" outputId="484d48a9-b659-4887-ed26-1d4db002f1f9" colab={"base_uri": "https://localhost:8080/", "height": 34}
components = list(nx.connected_components(G))
print("There are %i components" % len(components))
# + [markdown] id="k9miGvNGU44E" colab_type="text"
# As there is only one components, we can't extract more interesting information about it.
# + [markdown] id="P7nKbwrOVCcu" colab_type="text"
# #### Centrality
#
# The centraility indicators give us a notion about the most important nodes in the graph.
#
# This can be calculated using the degree of a node.
# + id="UafywonZ7_5c" colab_type="code" outputId="d25ec305-8b80-4723-f7ec-86b9ff4b1bca" colab={"base_uri": "https://localhost:8080/", "height": 269}
# Plot the degree distribution of the GitHub collaboration network
plt.hist(list(nx.degree_centrality(G).values()))
plt.show()
# + id="UDnOnxhEVLpv" colab_type="code" outputId="c8897e7d-caa6-4fd6-cedb-0bc416c4ab30" colab={"base_uri": "https://localhost:8080/", "height": 34}
# Compute the degree centralities of G
deg_cent = nx.degree_centrality(G)
# Compute the maximum degree centrality
max_dc = max(deg_cent.values())
prolific_collaborators = [n for n, dc in deg_cent.items() if dc == max_dc]
# Print the most prolific collaborator(s)
print(prolific_collaborators)
# + [markdown] id="rwqb4wuIJqFV" colab_type="text"
# ### Clique
#
# A clique is a subset of nodes that are fully connected. This concept can be largelly used in study of social network, since in that context they can represent a group of people who all know each other.
#
# When analysing the speeches, we can use the maximal clique to find the biggest group of words that appear in the same context.
# + id="b-tJ_sW1G7lG" colab_type="code" colab={}
cliques = nx.find_cliques(G)
# + id="HiqnxJSVG-Fh" colab_type="code" outputId="ce519786-11d2-4dcc-eb08-64346b9d6ba0" colab={"base_uri": "https://localhost:8080/", "height": 34}
len(list(cliques))
# + id="ghvkVS_THLdl" colab_type="code" colab={}
largest_clique = sorted(nx.find_cliques(G), key=lambda x:len(x))[-1]
# + id="mnvyoHxIHLzb" colab_type="code" outputId="5447b71e-c0fa-49b9-e91f-f774b7b1b5a0" colab={"base_uri": "https://localhost:8080/", "height": 357}
G_lc = G.subgraph(largest_clique)
for n in G_lc.nodes():
G_lc.node[n]['degree centrality'] = deg_cent[n]
# Create the CircosPlot object
c = CircosPlot(G_lc, node_labels=True, node_grouping='degree centrality',
node_order='degree centrality')
# Draw the CircosPlot to the screen
c.draw()
plt.show()
# + id="jrRRRaYOVyOr" colab_type="code" outputId="39f6d776-fae7-456d-d049-c0f978d7013d" colab={"base_uri": "https://localhost:8080/", "height": 357}
from nxviz import ArcPlot
G_lmc = G_lc.copy()
# Go out 1 degree of separation
for node in list(G_lmc.nodes()):
if(deg_cent[node] == max_dc):
G_lmc.add_nodes_from(G.neighbors(node))
G_lmc.add_edges_from(zip([node]*len(list(G.neighbors(node))), G.neighbors(node)))
# Record each node's degree centrality score
for n in G_lmc.nodes():
G_lmc.node[n]['degree centrality'] = deg_cent[n]
# Create the ArcPlot object: a
a = ArcPlot(G_lmc, node_order='degree centrality', node_labels=True)
# Draw the ArcPlot to the screen
a.draw()
plt.show()
# + [markdown] id="MgRFRGTccWK1" colab_type="text"
# ## PT
# + id="IKvFbVn1ccAr" colab_type="code" colab={}
pt = dataset.query('party == "PT"')
# + id="hpKlCweach5b" colab_type="code" colab={}
vec_pt = CountVectorizer(token_pattern=TOKENS_ALPHANUMERIC,decode_error='replace' ,
stop_words=STOP_WORDS, ngram_range=(2,5),
encoding='latin1', strip_accents='unicode')
X = vec_pt.fit_transform(pt.speech)
# + id="R1o5fIYicrpE" colab_type="code" outputId="29048818-6a7c-45fc-ea64-edf52587fcd4" colab={"base_uri": "https://localhost:8080/", "height": 34}
G = generate_graph(vec_pt.vocabulary_)
n_size = len(G.nodes())
e_size = len(G.edges())
print("There are %i nodes and %i edges" % (n_size, e_size))
nx.write_graphml_lxml(G, "pt.graphml")
# + id="tjP1fElLc7wX" colab_type="code" outputId="cb733cbc-688c-4d9e-b838-5bb6ed29904f" colab={"base_uri": "https://localhost:8080/", "height": 34}
# Compute the degree centralities of G
deg_cent = nx.degree_centrality(G)
# Compute the maximum degree centrality
max_dc = max(deg_cent.values())
prolific_collaborators = [n for n, dc in deg_cent.items() if dc == max_dc]
# Print the most prolific collaborator(s)
print(prolific_collaborators)
# + [markdown] id="IYfMEpqRdSjf" colab_type="text"
# ### Clique
# + id="XpebRMBMdN3g" colab_type="code" outputId="28ae433a-5128-4c4b-fb3e-20b2000445e2" colab={"base_uri": "https://localhost:8080/", "height": 357}
largest_clique = sorted(nx.find_cliques(G), key=lambda x:len(x))[-1]
G_lc = G.subgraph(largest_clique)
for n in G_lc.nodes():
G_lc.node[n]['degree centrality'] = deg_cent[n]
# Create the CircosPlot object
c = CircosPlot(G_lc, node_labels=True, node_grouping='degree centrality',
node_order='degree centrality')
# Draw the CircosPlot to the screen
c.draw()
plt.show()
# + [markdown] id="ApxXXakzg1x8" colab_type="text"
# ## NOVO
# + id="tsfQ8Tx-g1H3" colab_type="code" colab={}
novo = dataset.query('party == "NOVO"')
# + id="Q_QnenfKg7nB" colab_type="code" colab={}
vec_novo = CountVectorizer(token_pattern=TOKENS_ALPHANUMERIC,decode_error='replace' ,
stop_words=STOP_WORDS, ngram_range=(2,5),
encoding='latin1', strip_accents='unicode')
X = vec_novo.fit_transform(novo.speech)
# + id="9UTdOKdzhDng" colab_type="code" outputId="72f20411-3182-400a-8ebb-d0e9a72bf7d4" colab={"base_uri": "https://localhost:8080/", "height": 34}
G = generate_graph(vec_novo.vocabulary_)
n_size = len(G.nodes())
e_size = len(G.edges())
print("There are %i nodes and %i edges" % (n_size, e_size))
nx.write_graphml_lxml(G, "novo.graphml")
# + [markdown] id="-TO3wkKthH6x" colab_type="text"
# ### Centrality
# + id="GjYUokUFhJUn" colab_type="code" outputId="2e1a456b-a807-4b6b-f94b-58fb1c0b84fe" colab={"base_uri": "https://localhost:8080/", "height": 34}
# Compute the degree centralities of G
deg_cent = nx.degree_centrality(G)
# Compute the maximum degree centrality
max_dc = max(deg_cent.values())
prolific_collaborators = [n for n, dc in deg_cent.items() if dc == max_dc]
# Print the most prolific collaborator(s)
print(prolific_collaborators)
# + id="aoGUL79qi_f4" colab_type="code" outputId="61e678a3-3a70-4108-fa15-3dfb774ab14f" colab={"base_uri": "https://localhost:8080/", "height": 54}
deg_cent.values()
# + id="K5Fdkyrdi1SG" colab_type="code" outputId="7a8eaa7d-8c1e-4278-b2c8-13fa26520097" colab={"base_uri": "https://localhost:8080/", "height": 269}
# Plot the degree distribution of the GitHub collaboration network
plt.hist(list(nx.degree_centrality(G).values()))
plt.show()
# + id="DvFqVqMtj6sr" colab_type="code" colab={}
# Plot the degree distribution of the GitHub collaboration network
# plt.hist(list(nx.betweenness_centrality(G).values()))
# plt.show()
# + id="IhcBuE0mkh-l" colab_type="code" outputId="297cdcd0-eea2-41af-eba1-dd50c2bf99df" colab={"base_uri": "https://localhost:8080/", "height": 34}
# Compute the degree centralities of G
bet_cent = nx.betweenness_centrality(G)
# Compute the maximum degree centrality
max_bc = max(bet_cent.values())
prolific_collaborators = [n for n, bc in bet_cent.items() if bc == max_bc]
# Print the most prolific collaborator(s)
print(prolific_collaborators)
# + id="-Znz0QmQlPeY" colab_type="code" outputId="ae32ea94-4547-4fa4-d29b-3e012c0af5d2" colab={"base_uri": "https://localhost:8080/", "height": 357}
sorted_bc = sorted(bet_cent.values())
top_ten_bc = sorted_bc[:10]
top_nodes = [n for n, bc in bet_cent.items() if (bc==max_bc) or (bc == top_ten_bc[1])]
G_bc = G.subgraph(top_nodes)
# Create the CircosPlot object
c = CircosPlot(G_bc, node_labels=True)
# Draw the CircosPlot to the screen
c.draw()
plt.show()
# + [markdown] colab_type="text" id="4zQzlqu8hOlf"
# ### Clique
# + colab_type="code" outputId="46458459-207a-43d4-bd2b-1070d93b4ae8" id="YpAIuqo2hOlh" colab={"base_uri": "https://localhost:8080/", "height": 357}
largest_clique = sorted(nx.find_cliques(G), key=lambda x:len(x))[-1]
G_lc = G.subgraph(largest_clique)
for n in G_lc.nodes():
G_lc.node[n]['degree centrality'] = deg_cent[n]
# Create the CircosPlot object
c = CircosPlot(G_lc, node_labels=True, node_grouping='degree centrality',
node_order='degree centrality')
# Draw the CircosPlot to the screen
c.draw()
plt.show()
# + id="B1eMthYBikXC" colab_type="code" outputId="cb02506a-f4ee-4ea7-f79a-9ccfbeb5d297" colab={"base_uri": "https://localhost:8080/", "height": 357}
from nxviz import ArcPlot
i = 0
G_lmc = G_lc.copy()
# Go out 1 degree of separation
for node in list(G_lmc.nodes()):
if((deg_cent[node] > 0.09) and (i < 10)):
i+=1
G_lmc.add_nodes_from(G.neighbors(node))
G_lmc.add_edges_from(zip([node]*len(list(G.neighbors(node))), G.neighbors(node)))
# Record each node's degree centrality score
for n in G_lmc.nodes():
G_lmc.node[n]['degree centrality'] = deg_cent[n]
# Create the ArcPlot object: a
a = ArcPlot(G_lmc, node_order='degree centrality', node_labels=True)
# Draw the ArcPlot to the screen
a.draw()
plt.show()
# + [markdown] colab_type="text" id="cnNFu6JvhpNM"
# ## PDT
# + colab_type="code" id="rDjEMmA7hpNO" colab={}
pdt = dataset.query('party == "PDT"')
# + colab_type="code" id="8ClCNvVMhpNR" colab={}
vec_pdt = CountVectorizer(token_pattern=TOKENS_ALPHANUMERIC,decode_error='replace' ,
stop_words=STOP_WORDS, ngram_range=(2,5),
encoding='latin1', strip_accents='unicode')
X = vec_pdt.fit_transform(pdt.speech)
# + colab_type="code" id="Gxgr2biZhpNV" outputId="4c6243e6-fdcd-4a10-e501-d98228508751" colab={"base_uri": "https://localhost:8080/", "height": 34}
G = generate_graph(vec_pdt.vocabulary_)
n_size = len(G.nodes())
e_size = len(G.edges())
print("There are %i nodes and %i edges" % (n_size, e_size))
nx.write_graphml_lxml(G, "pdt.graphml")
# + [markdown] colab_type="text" id="ylyTZm_whpNY"
# ### Centrality
# + colab_type="code" id="FIklamvXhpNZ" outputId="08ff61e6-01c2-444e-8b92-1b2ffae8bccf" colab={"base_uri": "https://localhost:8080/", "height": 34}
# Compute the degree centralities of G
deg_cent = nx.degree_centrality(G)
# Compute the maximum degree centrality
max_dc = max(deg_cent.values())
prolific_collaborators = [n for n, dc in deg_cent.items() if dc == max_dc]
# Print the most prolific collaborator(s)
print(prolific_collaborators)
# + [markdown] colab_type="text" id="hHbJutIXhpNc"
# ### Clique
# + colab_type="code" outputId="a418c7b1-72cd-4cf7-ab76-482ff5a1b80c" id="p6Mre6RxhpNd" colab={"base_uri": "https://localhost:8080/", "height": 357}
largest_clique = sorted(nx.find_cliques(G), key=lambda x:len(x))[-1]
G_lc = G.subgraph(largest_clique)
for n in G_lc.nodes():
G_lc.node[n]['degree centrality'] = deg_cent[n]
# Create the CircosPlot object
c = CircosPlot(G_lc, node_labels=True, node_grouping='degree centrality',
node_order='degree centrality')
# Draw the CircosPlot to the screen
c.draw()
plt.show()
# + id="Kna25-8A482o" colab_type="code" colab={}
| notebooks/The_network_of_a_party.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Load in CSVs, Libraries, etc.
import pandas as pd
from sqlalchemy import create_engine
import pymongo
summaryDATAFRAME = pd.read_csv('../herokuApp/static/data/witsSummaryData.csv')
glanceDATAFRAME = pd.read_csv('../herokuApp/static/data/witsGlanceData.csv')
# ### 'Summary' DataFrame Transformations
summaryDF = summaryDATAFRAME.copy()
summaryDF = summaryDF.rename(columns={"Reporter":"country","Partner":"trade_partner","Product categories":"category","Indicator Type":"indicator_type","Indicator":"indicator"})
summaryDF.tail(5)
# ### 'At-a-Glance' DataFrame Transformations
glanceDF = glanceDATAFRAME.copy()
glanceDF = glanceDF.rename(columns={"Reporter":"country","Partner":"trade_partner","Product categories":"category","Indicator Type":"indicator_type","Indicator":"indicator","Indicator Value":"indicator_value"})
glanceDF.head(5)
# ### Create Database Connection
engine = create_engine('postgresql://postgres:0607@localhost:5432/WITS')
summaryDF.to_sql('witssummary',engine,index=True)
glanceDF.to_sql('witsglance',engine,index=True)
# +
conn = 'mongodb://localhost:27017'
client = pymongo.MongoClient(conn)
db = client.yourDBName
# -
db.yourDBName.drop()
db.yourDBName.insert_many(yourDF.to_dict('records'))
#OUTPUT
# <pymongo.results.InsertManyResult at 0x21f574fb548>
| resources/.ipynb_checkpoints/WITS Data ETL Process-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# ### Importing relevant modules
# +
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import seaborn as sns
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_addons as tfa
np.set_printoptions(precision=3, suppress=True)
# -
# ### Loading the dataset from file
dataset = pd.read_csv("kc_house_data.csv")
dataset.tail()
# ### Dividing the dataset into training and test datasets
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
# ### The correlations between some columns in dataset
sns.pairplot(train_dataset[['price', 'bedrooms', 'bathrooms', 'sqft_living', 'yr_built']], diag_kind = "kde")
# ### The heatmap of correlations
plt.figure(figsize = (15,8))
sns.heatmap(train_dataset.corr(), annot=True)
# ### Examining the dataset
train_stats = train_dataset.describe()
train_stats.pop("price")
train_stats = train_stats.transpose()
train_stats
# ### Seperate the labels from datasets
train_labels = train_dataset.pop("price")
test_labels = test_dataset.pop("price")
# ### Function responsible for building the model
def build_model(my_learning_rate):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(units=1,
input_shape=(1,)))
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=my_learning_rate),
loss="mean_squared_error",
metrics=[tf.keras.metrics.RootMeanSquaredError()])
return model
# ### Function responsible for training the model
def train_model(model, df, train_labels, feature, label, epochs, batch_size):
history = model.fit(x = df[feature],
y = train_labels,
batch_size = batch_size,
epochs = epochs)
trained_weight = model.get_weights()[0]
trained_bias = model.get_weights()[1]
epochs = history.epoch
hist = pd.DataFrame(history.history)
rmse = hist["root_mean_squared_error"]
return trained_weight, trained_bias, epochs, rmse
# ### Function, which plots the sample of the trained model
def plot_the_model(labels, trained_weight, trained_bias, feature, label):
plt.xlabel(feature)
plt.ylabel(label)
random_examples = train_dataset.sample(n = 250)
plt.scatter(random_examples[feature], labels[random_examples.index])
x0, y0, x1 = 0, trained_bias, 8000
y1 = trained_bias + (trained_weight * x1)
plt.plot([x0, x1], [y0, y1], c = 'r')
plt.show()
# ### Function plotting the loss curve
def plot_the_loss_curve(epochs, rmse):
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Root Mean Squared Error")
plt.plot(epochs, rmse, label = "Loss")
plt.legend()
plt.ylim([rmse.min() * 0.97, rmse.max()])
plt.show()
# ### Function making predictions on test dataset and checking the accuracy of predictions
def predict_house_price(my_model, test_data, test_labels, feature, label):
batch = test_data[feature]
predicted_values = my_model.predict_on_batch(x = batch)
temp = []
y_true = np.array(test_labels, dtype=np.float32)
for i in range(len(predicted_values)):
temp.append(predicted_values[i][0])
y_pred = np.array(temp, dtype=np.float32)
metric = tfa.metrics.r_square.RSquare()
metric.update_state(y_true, y_pred)
result = metric.result()
print("THE ACCURACY OF THE MODEL", round(result.numpy() * 100, 2), "%")
# +
learning_rate = 0.06
epochs = 100
batch_size = 35
my_feature = "sqft_living"
my_label = "price"
my_model = build_model(learning_rate)
weight, bias, epochs, rmse = train_model(my_model, train_dataset, train_labels, my_feature, my_label, epochs, batch_size)
plot_the_model(train_labels, weight, bias, my_feature, my_label)
plot_the_loss_curve(epochs, rmse)
predict_house_price(my_model, test_dataset, test_labels, my_feature, my_label)
| House-Sales-Prediction.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import tensorflow as tf
import numpy as np
import itertools
import matplotlib.pyplot as plt
import gc
from datetime import datetime
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.decomposition import PCA
input_label = []
output_label = []
# +
a,b = 0,0
ficheiro = open("..\\28-02-2018.csv", "r")
ficheiro.readline()
ficheiro.readline()
ficheiro.readline()
linha = ficheiro.readline()
while(linha != ""):
linha = linha.split(",")
out = linha.pop(18)
if(out == "Benign"):
out = 0
b += 1
else:
out = 1
a += 1
output_label.append(out)
input_label.append(linha)
linha = ficheiro.readline()
ficheiro.close()
print(str(a) + " " + str(b))
# -
scaler = MinMaxScaler(feature_range=(0,1))
scaler.fit(input_label)
input_label = scaler.transform(input_label)
# <h2>PCA</h2>
pca = PCA(n_components=18)
pca.fit(input_label)
x_pca = pca.transform(input_label)
input_label.shape
x_pca.shape
x_pca = x_pca.reshape(len(x_pca), 18, 1)
y_pca = np.array(output_label)
x_pca, y_pca = shuffle(x_pca, y_pca)
# <h2>Cross Validation</h2>
confusion_matrixs = []
roc_curvs = []
for i in range(10):
mini = int(len(x_pca) * 0.10) * i
maxi = int((len(x_pca) * 0.10) * (i + 1))
inp_train = np.array([*x_pca[0: mini],*x_pca[maxi:len(x_pca)]])
inp_test = np.array(x_pca[mini: maxi])
out_train = np.array([*y_pca[0: mini],*y_pca[maxi:len(y_pca)]])
out_test = np.array(y_pca[mini:maxi])
model = keras.Sequential([
layers.Input(shape = (18,1)),
layers.Conv1D(filters = 16, kernel_size = 3, padding = "same", activation = "relu", use_bias = True),
layers.MaxPool1D(pool_size = 3),
layers.Conv1D(filters = 8, kernel_size = 3, padding = "same", activation = "relu", use_bias = True),
layers.MaxPool1D(pool_size = 3),
layers.Flatten(),
layers.Dense(units = 2, activation = "softmax")
])
model.compile(optimizer= keras.optimizers.Adam(learning_rate= 0.00025), loss="sparse_categorical_crossentropy", metrics=['accuracy'])
treino = model.fit(x = inp_train, y = out_train, validation_split= 0.1, epochs = 10, shuffle = True,verbose = 0)
res = np.array([np.argmax(resu) for resu in model.predict(inp_test)])
confusion_matrixs.append(confusion_matrix(out_test, res))
fpr, tpr, _ = roc_curve(out_test, res)
auc = roc_auc_score(out_test, res)
roc_curvs.append([fpr, tpr, auc])
print(i)
# <h2>Roc Curves</h2>
cores = ["blue", "orange", "green", "red", "purple", "brown", "pink", "gray", "olive", "cyan"]
for i in range(10):
plt.plot(roc_curvs[i][0],roc_curvs[i][1],label="curva " + str(i) + ", auc=" + str(roc_curvs[i][2]), c = cores[i])
plt.legend(loc=4)
plt.show()
total_conv_matrix = [[0,0],[0,0]]
for cov in confusion_matrixs:
total_conv_matrix[0][0] += cov[0][0]
total_conv_matrix[0][1] += cov[0][1]
total_conv_matrix[1][0] += cov[1][0]
total_conv_matrix[1][1] += cov[1][1]
def plot_confusion_matrix(cm, classes, normaliza = False, title = "Confusion matrix", cmap = plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normaliza:
cm = cm.astype('float') / cm.sum(axis = 1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print("Confusion matrix, without normalization")
print(cm)
thresh = cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i,j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
labels = ["Benign", "Infiltration"]
plot_confusion_matrix(cm = np.array(total_conv_matrix), classes = labels, title = "Infiltration IDS")
| Modelos_com_reducao/Local/CNN/PCA/CNNInfiltrationIDS(28-02-2018).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # LDDS
# # Tutorial 3: Variable time integration
# In this tutorial we will now set up the computation of LDs for a system that blows up in finite time, that is, trajectories when simulated will escape to infinity so fast that the numerically cannot be resolved after some finite simulation time.
#
# The solution to this problem by LDDS is to use _Variable Time integration_ , which given a bounding box of the domain, will turn the vector field off (equal to zero), only for those trajectories escpaing beyond the `box_boundaries`. This is equivalent to stopping integration only for escaping trajectories, such that LD values stop being updated for them.
#
# To illustrate how to set up LDDS for LD calculations to deal with such situations, we study two systems: the _Hamilton-Saddle Node_ and the _Inverse Duffing oscillator_. Both 1DoF autonomous Hamiltonian system, for which trajectories can escape to infinity within the finite time-interval of simulation.
# ## Hamilton Saddle-Node
# _Energy_
#
# \begin{equation*}
# H(x, p_x) = \frac{1}{2} p_x^2 + \frac{1}{2}x^2 + \frac{1}{3} x^3
# \end{equation*}
#
# _Vector field_
#
# \begin{align*}
# \dot{x} &= \frac{\partial H}{\partial p_x} = f_1(x, p_x) = p_x \\
# \dot{p}_x &= -\frac{\partial H}{\partial x} = f_2(x, p_x) = - x - x^2
# \end{align*}
# The setup is initialised as before
# +
import os, sys
import numpy as np
sys.path.insert(1, os.pardir)
from ldds.base import compute_lagrangian_descriptor
from ldds.tools import draw_all_lds
from ldds.vector_fields import HamSN1D
# +
# Integration parameters
tau = 8
# Lp-norm, p-value
p_value = 1/2
# Mesh parameters
x_min,x_max = [-1.5, 1]
y_min,y_max = [-1, 1]
Nx, Ny = [300, 300]
# -
grid_parameters = [(x_min, x_max, Nx), (y_min, y_max, Ny)]
vector_field = HamSN1D
# __BUT__ now, we need a new variable called `box_boundaries`, defined as below
# Box boundaries for Variable Time Integration
box_x_min, box_x_max = [-6, 6] # defined only for configuration space - x axis
box_boundaries = [(box_x_min, box_x_max)]
# box_boundaries = False
# which then, it's passed to `compute_lagrangian_descriptor` as an additional argument, to compute the forward and backward LDs for visualisation, as usual.
LD_forward = compute_lagrangian_descriptor(grid_parameters, vector_field, tau, p_value, box_boundaries)
LD_backward = compute_lagrangian_descriptor(grid_parameters, vector_field, -tau, p_value, box_boundaries)
figs = draw_all_lds(LD_forward, LD_backward, grid_parameters, tau, p_value)
# >__NOTE__ As an exercise, one can see that if `box_boundaries` are equal to `False`, which is set by default, the execution of `compute_lagrangian_descriptor` will throw an error message
# >
# ``` python
# ValueError: need at least one array to concatenate
# ```
# > This is the result of the integrator breaking after failing to numerically integrate `vector_field`, resulting in an empty solution array.
# ## Inverted Duffing oscillator
from ldds.vector_fields import Duffing1D
# _Energy_
#
# \begin{equation*}
# H(x, p_x) = \frac{1}{2} p_x^2 + \frac{1}{2} x^2 - \frac{1}{4} x^4
# \end{equation*}
#
# _Vector field_
#
# \begin{align*}
# \dot{x} &= \frac{\partial H}{\partial p_x} = f_1(x, p_x) = p_x \\
# \dot{p}_x &= -\frac{\partial H}{\partial x} = f_2(x, p_x) = -x + x^3
# \end{align*}
# +
# Integration parameters
tau = 10
# Lp-norm, p-value
p_norm = 1/2
# Mesh parameters
x_min,x_max = [-1.5, 1.5]
y_min,y_max = [-1, 1]
Nx, Ny = [300, 300]
# Box boundaries for Variable Time Integration
box_x_min, box_x_max = [-6, 6]
# +
grid_parameters = [(x_min, x_max, Nx), (y_min, y_max, Ny)]
# define inverted oscillator from redefining parameters of Duffing
alpha, beta = [-1, -1]
vector_field = lambda t,u: Duffing1D(t, u, PARAMETERS = [alpha, beta])
box_boundaries = [(box_x_min, box_x_max)]
# -
LD_forward = compute_lagrangian_descriptor(grid_parameters, vector_field, tau, p_value, box_boundaries)
LD_backward = compute_lagrangian_descriptor(grid_parameters, vector_field, -tau, p_value, box_boundaries)
figs = draw_all_lds(LD_forward, LD_backward, grid_parameters, tau, p_value)
| tutorials/tutorial-3.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] slideshow={"slide_type": "slide"}
# # Variables and Objects in Python
# + [markdown] slideshow={"slide_type": "subslide"}
# * Now we move to the *semantics* of a language which involve the meaning of the statements.
# * We will start with *variables* and *objects*, which are the main ways you store, reference, and operate on data within a Python script.
# + [markdown] slideshow={"slide_type": "slide"}
# ## Python Variables Are Pointers
#
# Assigning variables in Python is as easy as putting a variable name to the left of the equals (``=``) sign:
#
# ```python
# # assign 4 to the variable x
# x = 4
# ```
# Note that you don't have to declare a variable type before the assignment.
# + [markdown] slideshow={"slide_type": "subslide"}
# * In many programming languages, **variables** = **"buckets" of data**
# + [markdown] slideshow={"slide_type": "fragment"}
# * So in FORTRAN, for example, when you write
#
# ```fortran
# # # ! FORTRAN code
# integer x
# x = 4
# ```
# you are essentially defining a "memory bucket" named ``x``, and putting the value ``4`` into it.
# + [markdown] slideshow={"slide_type": "subslide"}
# In **Python**, by contrast, variables $\approx$ pointers.
# + [markdown] slideshow={"slide_type": "fragment"}
# So in Python, when you write
#
# ```python
# x = 4
# ```
# you are essentially defining a *pointer* named ``x`` that points to some other bucket containing the value ``4``.
# + [markdown] slideshow={"slide_type": "fragment"}
# Therefore, there is no need to "declare" the variable.
# + [markdown] slideshow={"slide_type": "fragment"}
# This is the sense in which people say Python is *dynamically-typed*: variable names can point to objects of any type.
# + [markdown] slideshow={"slide_type": "subslide"}
# So in Python, you can do things like this:
# + slideshow={"slide_type": "fragment"}
x = 1 # x is an integer
x = 'hello' # now x is a string
x = [1, 2, 3] # now x is a list
# + [markdown] slideshow={"slide_type": "skip"}
# While users of statically-typed languages might miss the type-safety that comes with declarations like those found in FORTRAN or C, this dynamic typing is one of the pieces that makes Python so quick to write and easy to read.
#
# + [markdown] slideshow={"slide_type": "subslide"}
# ### Dangers of "variable as pointer" model
# + [markdown] slideshow={"slide_type": "fragment"}
# If we have two variable names pointing to the same *mutable* object, then changing one will change the other as well!
# + [markdown] slideshow={"slide_type": "fragment"}
# For example, let's create and modify a list:
# + slideshow={"slide_type": "fragment"}
x = [3, 2, 1]
y = x
# + [markdown] slideshow={"slide_type": "skip"}
# We've created two variables ``x`` and ``y`` which both point to the same object.
# Because of this, if we modify the list via one of its names, we'll see that the "other" list will be modified as well:
# + slideshow={"slide_type": "fragment"}
print(y)
# + slideshow={"slide_type": "fragment"}
x.append(4) # append 4 to the list pointed to by x
print(y) # y's list is modified as well!
# + [markdown] slideshow={"slide_type": "fragment"}
# This behavior might seem confusing if you're wrongly thinking of variables as buckets that contain data.
# But if you're correctly thinking of variables as pointers to objects, then this behavior makes sense.
# + [markdown] slideshow={"slide_type": "skip"}
# Note also that if we use "``=``" to assign another value to ``x``, this will not affect the value of ``y`` - assignment is simply a change of what object the variable points to:
# + slideshow={"slide_type": "skip"}
x = 'something else'
print(y) # y is unchanged
# + [markdown] slideshow={"slide_type": "skip"}
# Again, this makes perfect sense if you think of ``x`` and ``y`` as pointers, and the "``=``" operator as an operation that changes what the name points to.
#
# -
# Figure 1
# 
# ### Bonus Points: Mutable vs. imutable types
# + [markdown] slideshow={"slide_type": "skip"}
# You might wonder whether this pointer idea makes arithmetic operations in Python difficult to track, but Python is set up so that this is not an issue. Numbers, strings, and other *simple types* are immutable: you can't change their value – you can only change what values the variables point to.
# So, for example, it's perfectly safe to do operations like the following:
# + slideshow={"slide_type": "skip"}
x = 10
y = x
x = x + 5 # add 5 to x's value, and assign it to x
print("x =", x)
print("y =", y)
# + [markdown] slideshow={"slide_type": "skip"}
# When we call ``x = x + 5``, we are not modifying the value of the ``5`` object pointed to by ``x``, but rather we are changing the object to which ``x`` points.
# For this reason, the value of ``y`` is not affected by the operation.
# -
# ### Copy that
# When occasionally you actually need a of a mutable object in memory to further modify you can explicit make a copy. In practice this is a rare occasion as it is an ineficient thing to do.
x = [3, 2, 1, 5]
y = x.copy()
y.append(5)
print("x =", x)
print("y =", y)
# More often than not what we want is to generate a new modified variable, instead of an exact copy. In this example we wanted a sorted list.
z = sorted(y)
print("z =", z)
print("y =", y)
# Figure 2
# 
# + [markdown] slideshow={"slide_type": "slide"}
# ## Everything Is an Object
#
# Python is an object-oriented programming language, and in Python everything is an object.
# + [markdown] slideshow={"slide_type": "fragment"}
# In OOP languages, an *object* is an entity that contains data along with associated metadata and/or functionality.
# In Python everything is an object, which means **every entity** has some metadata (called **attributes**) and associated functionality (called **methods**).
# These attributes and methods are accessed via the **dot syntax**.
# + [markdown] slideshow={"slide_type": "subslide"}
# For example, before we saw that lists have an ``append`` method, which adds an item to the list, and is accessed via the dot ("``.``") syntax:
# + slideshow={"slide_type": "fragment"}
L = [1, 2, 3]
L.append(100)
print(L)
# + [markdown] slideshow={"slide_type": "skip"}
# While it might be expected for compound objects like lists to have attributes and methods, what is sometimes unexpected is that in Python even simple types have attached attributes and methods.
# For example, numerical types have a ``real`` and ``imag`` attribute that returns the real and imaginary part of the value, if viewed as a complex number:
# + slideshow={"slide_type": "skip"}
x = 4.5
print(x.real, "+", x.imag, 'i')
# + [markdown] slideshow={"slide_type": "subslide"}
# Methods are like attributes, except they are functions that you can call using opening and closing parentheses.
# For example, floating point numbers have a method called ``is_integer`` that checks whether the value is an integer:
# + slideshow={"slide_type": "fragment"}
x = 4.5
x.is_integer()
# + slideshow={"slide_type": "fragment"}
x = 4.0
x.is_integer()
# -
# ### Bonus Points: "It's turtles all the way down!"
# + [markdown] slideshow={"slide_type": "skip"}
# When we say that everything in Python is an object, we really mean that *everything* is an object – even the attributes and methods of objects are themselves objects with their own ``type`` information:
# + slideshow={"slide_type": "skip"}
type(x.is_integer)
# + [markdown] slideshow={"slide_type": "skip"}
# We'll find that the everything-is-object design choice of Python allows for some very convenient language constructs.
# -
# ## Built-in types of variables
#
# <center>**Python Scalar Types or Simple Types**</center>
#
# | Type | Example | Description |
# |-------------|----------------|--------------------------------------------------------------|
# | ``int`` | ``x = 1`` | integers (i.e., whole numbers) |
# | ``float`` | ``x = 1.0`` | floating-point numbers (i.e., real numbers) |
# | ``complex`` | ``x = 1 + 2j`` | Complex numbers (i.e., numbers with real and imaginary part) |
# | ``bool`` | ``x = True`` | Boolean: True/False values |
# | ``str`` | ``x = 'abc'`` | String: characters or text |
# | ``NoneType``| ``x = None`` | Special object indicating nulls |
#
#
#
# <center>**Data Structures**</center>
#
# | Type Name | Example |Description |
# |-----------|---------------------------|---------------------------------------|
# | ``list`` | ``[1, 2, 3]`` | Ordered collection |
# | ``tuple`` | ``(1, 2, 3)`` | Immutable ordered collection |
# | ``dict`` | ``{'a':1, 'b':2, 'c':3}`` | Unordered (key,value) mapping |
# | ``set`` | ``{1, 2, 3}`` | Unordered collection of unique values |
#
# Note, round, square, and curly brackets have distinct meanings.
# Please read notebooks
# 06-Built-in-Scalar-Types.ipynb
# and
# 07-Built-in-Data-Structures.ipynb
# at your leisure to learn about these various types in great detail.
# + [markdown] slideshow={"slide_type": "skip"}
# ## References
# *A Whirlwind Tour of Python* by <NAME> (O’Reilly). Copyright 2016 O’Reilly Media, Inc., 978-1-491-96465-1
| notebooks/04-Semantics-Variables.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# **INSTRUCTIONS**
#
# `1st Video`: run notebook AS-IS.
#
# **After running the notebook for `1st Video` and getting the output video:**
#
# `2nd Video`: comment lines having the comment `1st Video` and uncomment lines having the comment `2nd Video`, rerun the cells and run notebook AS-IS.
#
# **ALL CELLS WHERE CHANGES ARE REQUIRED HAVE A CELL ABOVE IT TO NOTIFY YOU**
import os
import numpy as np
import pylab
import imageio
from matplotlib import pyplot as plt
import cv2
import time
from os.path import isfile, join
from keras.applications import mobilenet
from keras.models import load_model
from scipy.ndimage.measurements import label
from scipy.ndimage.measurements import center_of_mass
from matplotlib import colors
import skimage
from keras.preprocessing.image import ImageDataGenerator
from skimage.transform import resize
print(os.listdir('.'))
# +
# normalization
# normalize each chip
samplewise_center = True
samplewise_std_normalization = True
# normalize by larger batches
featurewise_center = False
featurewise_std_normalization = False
# adjacent pixel correllation reduction
# never explored
zca_whitening = False
zca_epsilon = 1e-6
# data augmentation
# training only
transform = 0
zoom_range = 0
color_shift = 0
rotate = 0
flip = False
datagen_test = ImageDataGenerator(
samplewise_center=samplewise_center,
featurewise_center=featurewise_center,
featurewise_std_normalization=featurewise_std_normalization,
samplewise_std_normalization=samplewise_std_normalization,
zca_whitening=zca_whitening,
zca_epsilon=zca_epsilon,
rotation_range=rotate,
width_shift_range=transform,
height_shift_range=transform,
shear_range=transform,
zoom_range=zoom_range,
channel_shift_range=color_shift,
fill_mode='constant',
cval=0,
horizontal_flip=flip,
vertical_flip=flip,
rescale=1./255,
preprocessing_function=None)
# -
#Load Weights
model = load_model('bebop_mobilenet_overfit_v1.h5', custom_objects={
'relu6': mobilenet.relu6,
'DepthwiseConv2D': mobilenet.DepthwiseConv2D})
def ProcessChip (frame):
values = np.zeros((9,16,3))
chips = np.zeros((144,128,128,3))
for i in range(0,9):
for j in range(0,16):
chips[16*i+j] = resize(frame[120*i:120*(i+1), 120*j:120*(j+1), :], (128,128,3))
generator_test = datagen_test.flow(
chips,
batch_size=144,
shuffle=False)
return model.predict_generator(generator_test,
steps = 1)
def heatmap (feature_map, frame):
color_mask = np.zeros((1080,1920,3))
temp_frame = skimage.img_as_float(frame)
alpha = 0.6
for i in range (0,9):
for j in range (0,16):
if feature_map[i][j] == 2:
color_mask[120*i:120*(i+1), 120*j:120*(j+1), :] = [0, 0, 1] #Blue, House
elif feature_map[i][j] == 1:
color_mask[120*i:120*(i+1), 120*j:120*(j+1), :] = [0, 1, 0] #Green, Concrete
else:
color_mask[120*i:120*(i+1), 120*j:120*(j+1), :] = [1, 0, 0] #Red, Don't Care
color_mask_hsv = colors.rgb_to_hsv(color_mask)
frame_hsv = colors.rgb_to_hsv(temp_frame)
frame_hsv[..., 0] = color_mask_hsv[..., 0]
frame_hsv[..., 1] = color_mask_hsv[..., 1] * alpha
frame_masked = colors.hsv_to_rgb(frame_hsv)
return frame_masked
def correct_arr (arr) :
arr = arr + 1
arr[arr>2] = 0
return arr
# **Make changes to next cell while running `2nd Video`.**
def VideoToFrames (vid):
count = 0
for image in vid.iter_data():
#image: numpy array containing image information
feature_map = ProcessChip(image)
arr = heatmap(np.reshape(correct_arr(np.argmax(ProcessChip(image), axis=1)), (9,16)), image)
cv2.imwrite('./Frames_1/frame%d.jpg'%count, arr*255) #1st Video
#cv2.imwrite('./Frames_2/frame%d.jpg'%count, arr*255) #2nd Video
count += 1
return
def convert_frames_to_video(pathIn,pathOut,fps):
frame_array = []
files = [f for f in os.listdir(pathIn) if isfile(join(pathIn, f))]
#for sorting the file names properly
files.sort(key = lambda x: int(x[5:-4]))
for i in range(len(files)):
filename=pathIn + files[i]
#reading each file
img = cv2.imread(filename)
height, width, layers = img.shape
size = (width,height)
print(filename)
#inserting the frames into an image array
frame_array.append(img)
out = cv2.VideoWriter(pathOut,cv2.VideoWriter_fourcc(*'DIVX'), fps, size)
for i in range(len(frame_array)):
# writing to a image array
out.write(frame_array[i])
out.release()
# **Make changes to next cell while running `2nd Video`.**
filename = './Bebop/Bebop2_20180422171942-0700.mp4' #1st Video
#filename = './Bebop/Bebop2_20180422171508-0700.mp4' #2nd Video
vid = imageio.get_reader(filename, 'ffmpeg')
VideoToFrames(vid) #Passing the video to be analyzed frame by frame
# **Make changes to next cell while running `2nd Video`.**
convert_frames_to_video('./Frames_1/', 'out_942.mp4', 23.82) #1st Video
#convert_frames_to_video('./Frames_2/', 'out_508.mp4', 23.41) #2nd Video
| InputVideoToHeatMapVideo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Part One: Scrape NASA
# Scrape the NASA Mars News Site and collect the latest News Title and Paragraph Text.
# Assign the text to variables to reference later.
#Import dependencies
import pandas as pd
from bs4 import BeautifulSoup as bs
import requests
import pymongo
from splinter import Browser
import time
conn = 'mongodb://localhost:27017'
client = pymongo.MongoClient(conn)
db = client.mars_db
collection = db.news
mars_news = db.news.find()
# +
url = 'https://mars.nasa.gov/news/'
# Retrieve page with the requests module
response = requests.get(url)
# Create BeautifulSoup object; parse with 'lxml'
soup = bs(response.text, 'lxml')
# -
headlines = soup.find_all('div', class_='content_title')
latest_headline = headlines[0].text
latest_headline = latest_headline.strip()
latest_headline
# +
article = soup.find_all('div', class_='image_and_description_container')
# paragraph
latest_paragraph = article[0]
latest_paragraph = latest_paragraph.find('div', class_='rollover_description_inner')
latest_paragraph = latest_paragraph.text.strip()
latest_paragraph
# +
mars_news_dict = {
"latest_headline": latest_headline,
"latest_paragraph": latest_paragraph
}
db.news.insert_one(mars_news_dict)
# -
# # Part Two: Scrape JPL for featured image
# Visit the url for JPL Featured Space Image here.
# Use splinter to navigate the site and
# Find the image url for the current Featured Mars Image and assign the url string to a variable called featured_image_url.
executable_path = {'executable_path': r'C:\Users\diamo\Bootcamp\chromedriver.exe'}
browser = Browser('chrome', **executable_path, headless=False)
url = 'https://www.jpl.nasa.gov/spaceimages/?search=&category=Mars'
browser.visit(url)
browser.click_link_by_partial_text('FULL IMAGE')
time.sleep(5)
browser.click_link_by_partial_text('more info')
html = browser.html
soup = bs(html, 'html.parser')
image_url = soup.find('figure', class_='lede').a['href']
image_url
base_url = 'https://www.jpl.nasa.gov'
full_image_url = base_url + image_url
full_image_url
image = {
"full_image_url": full_image_url
}
#Put into db w/its own collection?
db.image.insert_one(image)
# # Mars Facts
# Visit the Mars Facts webpage here and use Pandas to scrape the table containing facts about the planet including Diameter, Mass, etc.
# Use Pandas to convert the data to a HTML table string.
mars_url = 'https://space-facts.com/mars/'
mars_facts = pd.read_html(mars_url)[0]
# mars_facts
mars_facts_html = mars_facts.to_html()
mars_facts_html
| Mission_To_Mars/.ipynb_checkpoints/mission_to_mars-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda root]
# language: python
# name: conda-root-py
# ---
# # MNIST Convolutional Neural Network - Dataset Expansion
# The previous experiment gave better results compared to the first one, with a higher accuracy on the test set.
# However we still had lower results compared to the top results on MNIST, with error of 0.21-0.23%, while ours has around 0.55%.
#
# From internal tests, increasing the dropout and reducing the number of epochs did not help (as we will show in this notebook using checkpoints we saved), so out last resort is to use image pre-processing to increase the dataset size and make it more generic applying rotation, scaling and shifts.
# After training on distorted images we'll do some epochs on the normal input to have some bias towards undeformed digits.
# We've also hypothesized that a size of 150 for the hidden layer may have been chosen for computational reasons, so we're going to increase it.
#
# It's worth mentioning that the authors of [Regularization of Neural Networks using DropConnect](http://cs.nyu.edu/~wanli/dropc/) and [Multi-column Deep Neural Networks for Image Classification](http://people.idsia.ch/~ciresan/data/cvpr2012.pdf) also do ensemble learning with 35 neural networks to increase the precision, while we currently don't. Their best result with a single column is pretty close to our current result.
# ## Imports
# +
import os.path
from IPython.display import Image
from util import Util
u = Util()
import numpy as np
# Explicit random seed for reproducibility
np.random.seed(1337)
# -
from keras.callbacks import ModelCheckpoint
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
from keras.preprocessing.image import ImageDataGenerator
from keras import backend as K
from keras.datasets import mnist
# ## Definitions
batch_size = 512
nb_classes = 10
nb_epoch = 800
# checkpoint path
checkpoints_filepath_800 = "checkpoints/02_MNIST_relu_weights.best.hdf5"
checkpoints_filepath_56 = "checkpoints/02_MNIST_relu_weights.best_56_epochs.hdf5"
checkpoints_filepath_new = "checkpoints/03_MNIST_weights.best.hdf5"
# input image dimensions
img_rows, img_cols = 28, 28
# number of convolutional filters to use
nb_filters1 = 20
nb_filters2 = 40
# size of pooling area for max pooling
pool_size1 = (2, 2)
pool_size2 = (3, 3)
# convolution kernel size
kernel_size1 = (4, 4)
kernel_size2 = (5, 5)
# dense layer size
dense_layer_size1 = 150
dense_layer_size1_new = 200
# dropout rate
dropout = 0.15
# activation type
activation = 'relu'
# ## Data load
# the data, shuffled and split between train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
u.plot_images(X_train[0:9], y_train[0:9])
if K.image_dim_ordering() == 'th':
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
# ## Image preprocessing
# As said in the introduction, we're going to apply random transformations: rotation with a window of 40 degrees and both vertical and horizontal shifts, zoom and scale with a range of 10% (so about 3 pixels more or 3 pixels less). We avoid flips and rotations that would basically alter the meaning of the symbol.
# +
datagen = ImageDataGenerator(
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.1,
horizontal_flip=False)
# compute quantities required for featurewise normalization
# (std, mean, and principal components if ZCA whitening is applied)
datagen.fit(X_train)
# -
# ## Model definition
# +
model_800 = Sequential()
model_56 = Sequential()
model_new = Sequential()
def initialize_network(model, checkpoints_filepath, dropout1=dropout, dropout2=dropout, dense_layer_size1=dense_layer_size1):
model.add(Convolution2D(nb_filters1, kernel_size1[0], kernel_size1[1],
border_mode='valid',
input_shape=input_shape, name='covolution_1_' + str(nb_filters1) + '_filters'))
model.add(Activation(activation, name='activation_1_' + activation))
model.add(MaxPooling2D(pool_size=pool_size1, name='max_pooling_1_' + str(pool_size1) + '_pool_size'))
model.add(Convolution2D(nb_filters2, kernel_size2[0], kernel_size2[1]))
model.add(Activation(activation, name='activation_2_' + activation))
model.add(MaxPooling2D(pool_size=pool_size2, name='max_pooling_1_' + str(pool_size2) + '_pool_size'))
model.add(Dropout(dropout))
model.add(Flatten())
model.add(Dense(dense_layer_size1, name='fully_connected_1_' + str(dense_layer_size1) + '_neurons'))
model.add(Activation(activation, name='activation_3_' + activation))
model.add(Dropout(dropout))
model.add(Dense(nb_classes, name='output_' + str(nb_classes) + '_neurons'))
model.add(Activation('softmax', name='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy', 'precision', 'recall', 'mean_absolute_error'])
# loading weights from checkpoints
if os.path.exists(checkpoints_filepath):
model.load_weights(checkpoints_filepath)
else:
print('Warning: ' + checkpoints_filepath + ' could not be loaded')
initialize_network(model_800, checkpoints_filepath_800)
initialize_network(model_56, checkpoints_filepath_56)
initialize_network(model_new, checkpoints_filepath_new, dense_layer_size1_new)
# -
# ## Training and evaluation
# First the evaluations for the network of the previous notebook, with 800 and 56 epochs of training.
# +
# evaluation
print('evaluating 800 epochs model')
score = model_800.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
print('Test error:', (1-score[2])*100, '%')
print('evaluating 56 epochs model')
score = model_56.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
print('Test error:', (1-score[2])*100, '%')
# -
# This part trains the new network (the one using image pre-processing) and then we output the scores.
# We are going to use 800 epochs divided between the pre-processed images and the original ones.
# +
# checkpoint
checkpoint_new = ModelCheckpoint(checkpoints_filepath_new, monitor='val_precision', verbose=1, save_best_only=True, mode='max')
callbacks_list_new = [checkpoint_new]
# fits the model on batches with real-time data augmentation, for nb_epoch-100 epochs
history_new = model_new.fit_generator(datagen.flow(X_train, Y_train,
batch_size=batch_size,
# save_to_dir='distorted_data',
# save_format='png'
seed=1337),
samples_per_epoch=len(X_train), nb_epoch=nb_epoch-25, verbose=0,
validation_data=(X_test, Y_test), callbacks=callbacks_list_new)
# ensuring best val_precision reached during training
model_new.load_weights(checkpoints_filepath_new)
# -
# After epoch 475 nothing will be saved because precision doesn't increase anymore.
# +
# fits the model on clear training set, for nb_epoch-700 epochs
history_new_cont = model_new.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch-775,
verbose=0, validation_data=(X_test, Y_test), callbacks=callbacks_list_new)
# ensuring best val_precision reached during training
model_new.load_weights(checkpoints_filepath_new)
# -
print('evaluating new model')
score = model_new.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
print('Test error:', (1-score[2])*100, '%')
u.plot_history(history_new)
u.plot_history(history_new, 'precision')
u.plot_history(history_new, metric='loss', loc='upper left')
print("Continuation of training with no pre-processing")
u.plot_history(history_new_cont)
u.plot_history(history_new_cont, 'precision')
u.plot_history(history_new_cont, metric='loss', loc='upper left')
# Overall the method seems to work, with the precision converging to 99.4% in the first part of the training, and reaching 99.55% in the second part.
#
# The epochs that make the model overfit and lose val_precision are cut away by the callback function that saves the model.
# ## Inspecting the result
# Results marked with "800" are relative to the network of notebook 02 after 800 epochs, while the ones marked with "56" are for the same network but after 56 epochs.
#
# Results marked with "new" are relative to the network that uses image pre-processing and has a fully connected layer size of 250.
# +
# The predict_classes function outputs the highest probability class
# according to the trained classifier for each input example.
predicted_classes_800 = model_800.predict_classes(X_test)
predicted_classes_56 = model_56.predict_classes(X_test)
predicted_classes_new = model_new.predict_classes(X_test)
# Check which items we got right / wrong
correct_indices_800 = np.nonzero(predicted_classes_800 == y_test)[0]
incorrect_indices_800 = np.nonzero(predicted_classes_800 != y_test)[0]
correct_indices_56 = np.nonzero(predicted_classes_56 == y_test)[0]
incorrect_indices_56 = np.nonzero(predicted_classes_56 != y_test)[0]
correct_indices_new = np.nonzero(predicted_classes_new == y_test)[0]
incorrect_indices_new = np.nonzero(predicted_classes_new != y_test)[0]
# -
# ### Examples of correct predictions (800)
u.plot_images(X_test[correct_indices_800[:9]], y_test[correct_indices_800[:9]],
predicted_classes_800[correct_indices_800[:9]])
# ### Examples of incorrect predictions (800)
u.plot_images(X_test[incorrect_indices_800[:9]], y_test[incorrect_indices_800[:9]],
predicted_classes_800[incorrect_indices_800[:9]])
# ### Examples of correct predictions (56)
u.plot_images(X_test[correct_indices_56[:9]], y_test[correct_indices_56[:9]],
predicted_classes_56[correct_indices_56[:9]])
# ### Examples of incorrect predictions (56)
u.plot_images(X_test[incorrect_indices_56[:9]], y_test[incorrect_indices_56[:9]],
predicted_classes_56[incorrect_indices_56[:9]])
# ### Examples of correct predictions (new)
u.plot_images(X_test[correct_indices_new[:9]], y_test[correct_indices_new[:9]],
predicted_classes_new[correct_indices_new[:9]])
# ### Examples of incorrect predictions (new)
u.plot_images(X_test[incorrect_indices_new[:9]], y_test[incorrect_indices_new[:9]],
predicted_classes_new[incorrect_indices_new[:9]])
# ### Confusion matrix (800)
u.plot_confusion_matrix(y_test, nb_classes, predicted_classes_800)
# ### Confusion matrix (56)
u.plot_confusion_matrix(y_test, nb_classes, predicted_classes_56)
# ### Confusion matrix (56)
u.plot_confusion_matrix(y_test, nb_classes, predicted_classes_new)
# ## Results
# The time required to perform epoch with image preprocessing was significantly higher, with about 20 seconds for each epoch on our average GPU that was previously able to compute one epoch in 6 seconds for the same network. However the error (calculated as 1-precision) decreased from 0.55% to about 0.45% after the same number of epochs. Increasing the size of the dense layer from 150 to 200 gave us a small boost in precision, reaching 0.44% error, but increased the time required to perform the same number of epochs by 5 seconds each.
#
# Without using MCDNN this is a very good result, considering that a single network from the MCDNN paper could only reach 0.52% error. The papers we mentioned in the introduction use ensemble learning on multiple networks (35) to achieve 0.23% error.
#
# It is still unclear if we can use the same pre-processing for the datasets of In Codice Ratio, because characters to classify should be regular as the ones of the training dataset. Also the time required to train this network may not be worth the increase of precision, compared to the one that achieves 0.6% error after just 56 epochs. We are talking about 3 hours of training to improve by 0.15% precision compared to just 4 minutes.
#
# An hybrid approach we tested internally consists in doing 175 epochs with pre-processing and then 25 more without pre-processing. Overall it gives nice performances (between 0.55% and 0.6% error) but takes less then an hour to train.
| Notebooks/03_Mnist-Dataset-Expansion.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Machine Learning and Statistics - Tasks
# Assignment Tasks for Machine Learning and Statistics, GMIT 2020
#
# Lecturer: dr <NAME>
#
#
# >Author: **<NAME>**
# >Github: [andkoc001](https://github.com/andkoc001/)
# >Email: <EMAIL>, <EMAIL>
#
# ___
# ## Introduction
#
# This notebook forms a part of assignment to the Machine Lerning and Statistics module.
#
# The notebook consist of discussion on four problems (tasks):
#
# * Task 1 - Print on screen the square root of 2 to 100 decimal places, without use of external libraries.
# * Task 2 - Verify the value of the $ 𝜒2 $ (chi-squared) test for a sample dataset and calculate the associated $ 𝑝 $ value.
# * Task 3 - Simulate Excel function STDEC.S and STDEV.P using Numpy and explain advantages of the former.
# * Task 4 - Apply k-means clustering algorithm to _Fisher's Iris_ data set using scikit-learn.
#
# Detailed tasks description is available in the [assessment.pdf](https://github.com/andkoc001/Machine-Learning-and-Statistics/blob/main/assessment.pdf) file.
#
# This Notebook should be read in conjunction with the corresponding `README.md` file at the project [repository](https://github.com/andkoc001/Machine-Learning-and-Statistics.git) at GitHub.
# ___
# # Task 1 - square root
#
# ### Objectives
# __Print on screen the square root of 2 to 100 decimal places, without use of external libraries__.
#
# Write a Python function that calculates and prints to the screen the square root of 2 to 100 decimal places. The code should not depend on any module from the standard library or otherwise.
# ### Division of a range method
#
# For any real number $ x $, that $ x > 1 $:
#
# $$ \sqrt{x} \cdot \sqrt{x} = x $$
#
# $$ 1 < \sqrt{x} < x $$
#
# <br/>The last formula is an equivalent to $ 1^2 < (\sqrt{x})^2 < x^2 $.
#
# It can be further shown that the upper limitation follows the formula: $ \sqrt{x} < \frac{1+x}{2} $.
#
# Hence, it is possible to approximate the value of $ \sqrt{x} $ by iteratively testing into which of the halves of the original range will it fall. This is done by performing the test:
#
# $$ (\sqrt{x})^2 < (\frac{1+x}{2})^2 $$
#
# Then in the next iteration new boundary conditions are assumed. If the test is true, $ \frac{1+x}{2} $ becomes the right boundary; if the test is false, $ \frac{1+x}{2} $ becomes the left boundary. This way, the range tightens, increasing the precision, at each iteration.
#
#
# ___
# **Example for $ x = 2 $:
#
# The initial conditions is this: $ 1^2 < (\sqrt{2})^2 < 2^2 $.
#
# In the first iteration, the left boundary is $ 1^2 = 1 $, and the right boundary is $ 2^2 = 4 $.
#
# Then we perform the test: $ (\frac{1+2}{2})^2 = 2.25 $, which is greater than $ (\sqrt{2})^2 = 2 $.
#
# Therefore, in the second iteration the left boundary remains $ 1^2 = 1 $, and the right boundary becomes $ \frac{1+2}{2} = 1.5 $.
#
# We do the test again: $ (\frac{1+1.5}{2})^2 = 1.5625 $. This is less than $ (\sqrt{2})^2 = 2 $.
#
# In the third iteration the left boundary becomes $ \frac{1+1.5}{2} = 1.25 $, and the right boundary stays $ \frac{1+2}{2} = 1.5 $.
#
# We do the test again: $ (\frac{1.25+1.5}{2})^2 = 1.890625 $. This is less than $ (\sqrt{2})^2 = 2 $.
#
# In the forth iteration the left boundary becomes $ \frac{1.25+1.5}{2} = 1.375 $, and the right boundary stays $ \frac{1+2}{2} = 1.5 $.
#
# And so on...
# ___
#
# This process may continue until required precision is achieved.
#
# For Python built-in data types, _while_ loop may govern the precision improvement process. However, Python allows only precision only to 15 digits precision.
#
# Let's designate the required precision as $ \tau $. As long as $ (\frac{1+x}{2})^2 >= \tau $, the required precision is not achieved and another iteration is to be performed.
# +
# Define number of which sqare root will be approximated
number = 2
# Define decimal places precision
precision = 15 # fiveteen decimal places appears to be the maximum for this data type
# Initial boundary conditions:
left = 1
right = number
middle = (left+right) / 2
# Implementing the logic
iteration = 0
# Loop exit condition, i.e. requested precision is achieved
while abs(number-middle*middle) >= 10**-precision:
# Testing which half of the range the square root of the number will fall into; tightening the boundaries
if middle*middle > number:
# if the condition is satisfied, the right boundary is changed to the previous mid-point
right = middle
else:
# if the condition is not satisfied, the left boundaries is changed to the previous mid-point
left = middle
# Update the value of the variable 'middle'
middle = (left+right) / 2
# Update number of iteration
iteration = iteration + 1
# Print out intermediate results for each iteration
# print(f"Iteration {iteration:3}, left: {left:18}, Sqare root: {middle:.16}, \tright: {right:18}")
# Print out the result
print(f"Iteration {iteration:3}, The sqare root of {number}: {middle:.16}")
# -
# ### Arbitrary precision
#
# The above method works fine, however, due to build-in data types limitations, the approximation is limited only to a certain precision ([Python documentation](https://docs.python.org/3/tutorial/floatingpoint.html)). The required precision can be easily achieved, with the application of a special-purpose data type - [decimal](https://docs.python.org/3/library/decimal.html#module-decimal) - for handling this kind of problems.
#
# The true challenge of this task is to show the approximation of square root function with arbitrary assumed precision without using external libraries. There is a number of techniques allowing for achieving required (arbitrary) precision.
# ### Bitwise shift
#
# One of the method is by the means of bitwise [arythmetic shift](https://en.wikipedia.org/wiki/Arithmetic_shift).
#
# `>> 1` is a bitwise right shift, e.g. "divide by 2", `>> 2` would be "divide by 4", `>> n` is "divide by 2**(n)" Right shift is an equivalent of powering the number (or squaring) in binary system (https://stackoverflow.com/questions/15557667/square-root-by-bit-shift).
#
# 
# Image source: [Stack Overflow](https://stackoverflow.com/a/20369990)
#
# For square root of 3 in binary (example from [Wikipedia](https://en.wikipedia.org/wiki/Shifting_nth_root_algorithm)):
#
# ```bash
# 1. 7 3 2 0 5
# ----------------------
# _ / 3.00 00 00 00 00
# \/ 1 = 20×0×1+1^2
# -
# 2 00
# 1 89 = 20×1×7+7^2 (27 x 7)
# ----
# 11 00
# 10 29 = 20×17×3+3^2 (343 x 3)
# -----
# 71 00
# 69 24 = 20×173×2+2^2 (3462 x 2)
# -----
# 1 76 00
# 0 = 20×1732×0+0^2 (34640 x 0)
# -------
# 1 76 00 00
# 1 73 20 25 = 20×17320×5+5^2 (346405 x 5)
# ----------
# 2 79 75
# ```
#
# Below application of the binary shift method for approximation of square root is adopted from https://stackoverflow.com/a/28151578.
# +
### Method C - Newton's method
# Adapted from https://stackoverflow.com/a/28151578
''' Long integer square roots. Newton's method.
Written by PM 2Ring. Adapted from C to Python 2008.10.19
'''
# the algorithm
def root(m):
# Get initial approximation
n, a, k = m, 1, 0
while n > a:
n >>= 1
a <<= 1
k += 1
#print('\', k, ':', n, a) # for debugging
# Go back one step & average
a = n + (a>>2)
#print(a) # for debugging
# Apply Newton's method
while k:
a = (a + m // a) >> 1
k >>= 1
#print(k, ':', a) # for debugging
result = a
return result
# body of the main function
def main():
# number to be square rooted, between 1 and 99 - outside the range there is possible error notation, beyond the scope of this task
number = 2
# number of decimal places to be shown
precision = 100
factor = 10 ** (number * precision)
m = number * factor
# print the result converted to a string
string_result = str(root(m))
# Check if the number is in the requested range
if 1 <= number < 100:
# take the first digit followed by a dot
result = string_result[0:1] + "."
# take the remaining digits up to set precision
for i in string_result[1:precision]:
result = result + i
print("The Square Root of " + str(m/factor) + ":")
print(result)
else:
print("Choose number to be squared between 1 and 99")
# execute only if run as a script
if __name__ == '__main__':
main()
# -
# ### Square root by subtraction method
#
# The algorithm has been described by <NAME> in his paper [Square root by subtraction](http://www.afjarvis.staff.shef.ac.uk/maths/jarvisspec02.pdf).
#
# Although this method converges slower than Newtons' method, it's advantage is that, "when finding square roots of integers, no infinite decimals are involved at any step, which can cause loss of precision due to rounding errors" ([ditto](http://www.afjarvis.staff.shef.ac.uk/maths/jarvisspec02.pdf)).
#
# The algorithm is follows.
#
# 1) Initially, assume values of a and b:
#
# `left = 5x`, where `x` is the number, which square root is being approximated and `right = 5`
#
# 2) Then iteratively repeated these steps:
#
# If `left ≥ right`, replace `left` with `left − right`, and add 10 to `right`.
#
# If `left < right`, add two zeros to the end of `left`, and add a zero to `right` just before
# the final digit (which will always be ‘5’).
#
# Keep repeating the above, until the digits of `right` gets sufficiently closely the digits of the square
# root of `x`.
# +
# Adapted from https://www.mathblog.dk/project-euler-80-digits-irrational-square-roots/
def Squareroot(n, prec):
# Set the required parameters
limit = 10**(prec+1) # extra precision to avoid rounding error
left = 5 * n
right = 5
while right < limit:
if left >= right:
left -= right
right += 10
else:
left *= 100
right = 10 * right - 45;
return right;
# body of the main function
def main():
# number to be square-rooted, between 1 and 99 - outside the range there is possible error notation, beyond the scope of this task
number = 2
# number of decimal places to be shown
precision = 100
# call the main algorithm and print the result converted to a string
string_result = str(Squareroot(number, precision))
# Check if the number is in the requested range
if 1 <= number < 100:
# take the first digit followed by a dot
result = string_result[0:1] + "."
iteration = 0
# take the remaining digits up to set precision
for i in string_result[1:precision]:
result = result + i
iteration += 1
# print(f"Iter: {iteration:3}: {result}") # for debugging
# print("Declared precision (including the digits before decimal point):", len(result))
print("The Square Root of " + str(number) + ":")
print(result)
else:
print("Choose number to be squared between 1 and 99")
# execute only if run as a script
if __name__ == '__main__':
main()
# -
# ### Result verification
#
# The results from the above methods can be verified against the approximation of first one million digits of $\sqrt{2}$ published at https://apod.nasa.gov/htmltest/gifcity/sqrt2.1mil. Here, the first 102 digits (including that on the left of the decimal) is shown:
#
# $ \sqrt{2} $= 1.4142 13562 37309 50488 01688 72420 96980 78569 67187 53769 48073 17667 97379 90732 47846 21070 38850 38753 43276 41572 73
#
# Thus, both of the applied methods produce results that are accurate to the specified precision.
# ___
# ### References - Task 1 related
#
# - Wikipedia contributors - Taylor series. [online] Available at: <https://en.wikipedia.org/wiki/Taylor_series> [Accessed December 2020].
# - <NAME> - Matematyka, <NAME> i Maclaurina, Przybliżanie Funkcji (in Polish) [online]. Available at: http://www.kowalskimateusz.pl/matematyka-wzor-taylora-i-maclaurina-przyblizanie-funkcji/ [Accessed December 2020]
# - The Penn Calc Wiki, Taylor Series [online]. Available at: <http://calculus.seas.upenn.edu/?n=Main.TaylorSeries> [Accessed December 2020]
# - NASA - Square root of 2 - the first million digits [online]. Available at: <https://apod.nasa.gov/htmltest/gifcity/sqrt2.1mil> [Accessed December 2020]
# - Python manual on Decimal library [online]. Available at: <https://docs.python.org/3/library/decimal.html> [Accessed December 2020]
# - Python manual on Bitwise Operations [online]. Available at: <https://wiki.python.org/moin/BitwiseOperators> [Accessed December 2020]
# - Stack Overflow - find as many digits of the square root of 2 as possible [online]. Available at: <https://stackoverflow.com/a/15434306> [Accessed December 2020]
# - Wikipedia contributors - Arithmetic shift. [online] Available at: <https://en.wikipedia.org/wiki/Arithmetic_shift> [Accessed December 2020].
# - Wikipedia contributors - Shifting nth root algorithm. [online] Available at: <https://en.wikipedia.org/wiki/Shifting_nth_root_algorithm> [Accessed December 2020].
# - <NAME>, 2003 - Fast Inverse Square Root[pdf]. Available at: <http://www.lomont.org/papers/2003/InvSqrt.pdf> [Accessed December 2020]
# - <NAME>, 2005 - Square root by subtraction [pdf]. Available at: <http://www.afjarvis.staff.shef.ac.uk/maths/jarvisspec02.pdf> [Accessed December 2020]
#
# ___
# # Task 2 - Chi-square test
#
# ### Objectives
# __Verify the value of the $ {\chi}^2 $ (chi-squared) test for a sample dataset and calculate the associated $ p $ value__.
#
# Use `scipy.stats` to verify this value and calculate the associated $ p $ value. You should include a short note with references justifying your analysis in a markdown cell.
#
# ### The Chi-squared test
#
# The chi-squared test is a statistical tool suitable for categorical data values (for instance, colour or academic degree or dog breeds). It can be used for three applications, although in essence they test similar things: 1) the goodness of fit test (how one category data fits the distribution), 2) test for homogeneity (likelihood of different samples coming from the same population) and 3) test of independence [YouTube - Crash Course Statistics](https://www.youtube.com/watch?v=7_cs1YlZoug).
#
# For this task, Chi-squared **Test of independence** applies. Test of independence attempts to answer whether, in statistical terms, being a member of one category is independent of another. In other words, "the chi-square independence test is a procedure for testing if two categorical variables are related in some population" ([SPSS Tutorials](https://www.spss-tutorials.com/chi-square-independence-test/)).
#
# The calculation compares the measured (observed) values against the expected values. The result of the chi-squared test is a numerical value that can be interpreted in such a way that it allows for seeing whether one variable is independent of another. This is often associated with the null hypothesis, and if the results are satisfactory, the null hypothesis is considered true. Otherwise, the alternative hypothesis prevails.
#
# A generic formula of the Chi-squared test is like this (from [Wikipedia](https://en.wikipedia.org/wiki/Chi-squared_test)):
#
# $$ {\chi}^2 = \sum_{k=1}^{n} \frac{(O_k - E_k)^2}{E_k}\ $$
#
# where:
# $ n $ - number of categories,
# $ O $ - measurement from observation,
# $ E $ - expected value if the null hypothesis is true.
#
# It is also worth noting that, in order to render the independence test viable, the expected value $ E_k > 5 $. Although that value is assumed arbitrarily, it is commonly used for practical application.
#
# Also 'degrees of freedom' is required for assessing the independence test. The general formula for the degrees of freedom for tabularised data is as follows:
#
# $$ df = (r-1)(c-1) $$
#
# where:
# $ df $ - degrees of freedom,
# $ r $ - number of rows,
# $ c $ - number of columns.
#
# The degree of freedom will affect the chi-squared distribution. Sample plots for various degrees of freedom are shown in the figure below.
#
# <img src="https://spss-tutorials.com/img/chi-square-distributions-different-degrees-of-freedom.png" alt="Chi-squared distribution" style="width: 600px;"/>
#
# Image source: [SPSS Tutorials ](https://www.spss-tutorials.com/chi-square-independence-test/)
#
# "The value of the chi-square random variable $ {\chi}^2 $ with degree of freedom $ df = k $ that cuts off a right tail of area c is denoted $ {\chi}^2_c $ and is called a critical value." [Saylor Academy](https://saylordotorg.github.io/text_introductory-statistics/s15-01-chi-square-tests-for-independe.html)
#
# <img src="https://saylordotorg.github.io/text_introductory-statistics/section_15/34d06306c2e726f6d5cd7479d9736e5e.jpg" alt="Chi-squared critical value" style="width: 440px;"/>
#
# Image source: [Saylor Academy](https://saylordotorg.github.io/text_introductory-statistics/s15-01-chi-square-tests-for-independe.html)
# ### The problem
#
# This task about evaluating the given data in terms of the Chi-squared test and verify the result also already given given in the Wikipedia article on [Chi-squared test](https://en.wikipedia.org/wiki/Chi-squared_test).
#
# The data from the above Wikipedia page, describes the test scenario as follows. "Suppose there is a city of 1,000,000 residents with four neighborhoods: `A`, `B`, `C`, and `D`. A random sample of 650 residents of the city is taken and their occupation is recorded as "white collar", "blue collar", or "no collar". The null hypothesis is that each person's neighborhood of residence is independent of the person's occupational classification. The data is provided in a form of a contingency table as follows: ([Wikipedia](https://en.wikipedia.org/wiki/Chi-squared_test)):
#
# | | A | B | C | D | Total |
# |--------------|-----|-----|-----|-----|-------|
# | White collar | 90 | 60 | 104 | 95 | 349 |
# | Blue collar | 30 | 50 | 51 | 20 | 151 |
# | No collar | 30 | 40 | 45 | 35 | 150 |
# | | | | | | |
# | Total | 150 | 150 | 200 | 150 | 650 |
#
# The chi-squared test of independence verifies whether or not two categorical variables are independent of each other (statistically meaningful). The test assumes the 'null hypothesis' and the opposing 'alternative hypothesis'.
#
# For the given sample data, the hypotheses are as follows (from the Wikipedia article):
#
# **Null hypothesis** $ H_0 $ - "each person's neighborhood of residence is independent of the person's occupational classification",
#
# **Alternative hypothesis** $ H_a $ - there is such a dependency.
#
# The result of the test is already given in Wikipedia article: $ {\chi}^2 $ = 24.6, and so is the degrees of freedom: $ df $ = 6.
#
# ### Calculation
#
# The chi-squared test of independence can be calculated using the statistical module `scipy.stats` from [Scipy](https://docs.scipy.org/doc/scipy/reference/stats.html) library for Python.
#
# The function `chi2_contingency()` computes the chi-square and the value of $p$ for the hypothesis test of independence. It takes the observed frequencies as an input in a form of an array. As a result the function returns the values of chi-square test (`chi2`), the p-value (`p`), degrees of freedom (`dof`) and the array of the expected frequencies (`expected`).
#
# import required libraries
import numpy as np
from scipy.stats import chi2_contingency
# +
# input the observed data manually into an array
data = np.array([[90, 60, 104, 95], [30, 50, 51, 20], [30, 40, 45, 35]])
# perform the calculation of the chi-square test of independence
chi2, p, dof, expected = chi2_contingency(data)
print(f"Chi-squared test: {chi2:.2f}")
print(f"P-value: {p:.5f}")
print(f"Degrees of freedom: {dof}")
print(f"Expected frequencies:\n {expected}")
# -
# ### The results and conclusion
#
# The test of independence verifies whether or not there is a statistically meaningful relationship between categorical data.
#
# The above calculated results are shown below - the chi-square and the degrees of freedom results are in accord with the information provided in the [Wikipedia](https://en.wikipedia.org/wiki/Chi-squared_tes) page.
#
# $ {\chi}^2 \approx 24,6 $
# $ df = 6 $
# $ p \approx 0.00041 $
#
# Expected values:
#
# | | A | B | C | D |
# |--------------|-------|-------|-------|-------|
# | White collar | 80.5 | 80.5 | 107.4 | 80.5 |
# | Blue collar | 34.8 | 34.8 | 46.5 | 34.8 |
# | No collar | 34.6 | 34.6 | 46.1 | 34.6 |
# | | | | | |
# | Total | 149.9 | 149.9 | 200.0 | 149.9 |
#
#
# From the data provided by the survey and the calculated results, where the value of the chi-square is relatively large and the p-value is relatively small, we can infer that there is not evidence strong enough to support the null hypothesis statement ([NIST/SEMATECH](https://www.itl.nist.gov/div898/handbook/eda/section3/eda3674.htm)). The distribution of the occupational classification is due to the relationship between the person's neighborhood of residence and the person's occupational classification. In other words, there is relationship between the two categorical variables - they are dependent.
# ___
# ### References - Task 2 related
#
# - Chi-squared test - Wikipedia contributors [online]. Available at: <https://en.wikipedia.org/wiki/Chi-squared_test> [Accessed December 2020].
# - Chi-squared test - Wolfram MathWorld contributors. [online] Available at: <https://mathworld.wolfram.com/Chi-SquaredTest.html> [Accessed December 2020].
# - Chi-squared test of independence - SPSS Tutorials [online]. Available at: <https://www.spss-tutorials.com/chi-square-independence-test/> [Accessed December 2020]
# - Chi-squared test of independence - Stat Trek [online]. Available at: <https://stattrek.com/chi-square-test/independence.aspx> [Accessed December 2020]
# - How the Chi-Squared Test of Independence Works - Statistics by Jim [online]. Available at: <https://statisticsbyjim.com/hypothesis-testing/chi-squared-independence/> [Accessed December 2020]
# - Chi-kwadrat - Statystyka pomoc (in Polish) [online]. Available at: <http://statystyka-pomoc.com/Chi-kwadrat.html> [Accessed December 2020]
# - A Gentle Introduction to the Chi-Squared Test for Machine Learning [online]. Available at: <https://machinelearningmastery.com/chi-squared-test-for-machine-learning/> [Accessed December 2020]
# -Saylor Academy - Introductory statistics, Chi-Square Tests for Independence [online]. Available at: <https://saylordotorg.github.io/text_introductory-statistics/s15-01-chi-square-tests-for-independe.html> [Accessed December 2020]
# - CrashCourse - Chi-Square Tests: Crash Course Statistics (YouTube), [online] <https://www.youtube.com/watch?v=7_cs1YlZoug> [Accessed December 2020]
# - <NAME> - Chi-square test - Python (YouTube), [online] Available at: <https://www.youtube.com/watch?v=Pbo7VbHK9cY> [Accessed December 2020]
# - Statistical functions (scipy.stats) - Scipy documentation [online]. Available at: <https://docs.scipy.org/doc/scipy/reference/stats.html> [Accessed December 2020]
# - <NAME> - Chi-Square Distribution Table [pdf] Available at: <http://kisi.deu.edu.tr/joshua.cowley/Chi-square-table.pdf> [Accessed December 2020]
# - NIST/SEMATECH e-Handbook of Statistical Methods - Critical Values of the Chi-Square Distribution [online] Available at: <https://www.itl.nist.gov/div898/handbook/eda/section3/eda3674.htm> [Accessed December 2020]
#
# ___
# # Task 3 - Standard Deviation
#
#
# ### Objectives
# __Simulate Excel function `STDEC.S` and `STDEV.P` using Numpy and explain advantages of the former.__
#
# Use NumPy to perform a simulation demonstrating that the STDEV.S calculation is a better estimate for the standard deviation of a population when performed on a sample.
#
# ### Standard deviation
#
# _Standard deviation_ (SD) is a statistical concept, with a wide range of application, to measure how the data is spread out around the mean. [Dictionary.com](https://www.dictionary.com/browse/standard-deviation) defines it as "a measure of dispersion in a frequency distribution, equal to the square root of the mean of the squares of the deviations from the arithmetic mean of the distribution."
#
# The standard deviation is defined as a square root of the average of the squared differences from the Mean [Mathisfun.com](https://www.mathsisfun.com/data/standard-deviation.html).
#
#  Image source: [Wikipedia](https://simple.wikipedia.org/wiki/File:Comparison_standard_deviations.svg)
#
#
# ### Population and sample SD
#
# There are two main methods of calculating the standard deviation. One that refers to the entire population and the other that consider the data set as a sample of the population. For simplicity, only discrete values are consider in this notebook.
#
# The **standard deviation of population** ($\sigma$), is a measure that could be accurately calculated if the values of the variable were known for all population units; corresponds to the deviation of a random variable whose distribution is identical to the distribution in the population. This kind of standard deviation is often referred as to unbiased or uncorrected.
#
# The the formula for population standard deviation ([Mathisfun.com](https://www.mathsisfun.com/data/standard-deviation-formulas.html)):
# $$
# \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^n (x_i - \mu)^2}
# $$
# where:
# $N$ is the size of the population,
# $x_i$ represents the observed value of the i-th member,
# $\mu$ denotes population mean.
#
# However, if the calculation is based on a part of the population only, the standard deviation of population tends to yield an error. In such cases, standard deviation of sample produces more reliable results. The **standard deviation of sample** ($s$), is a measure that estimates the standard deviation in a population based on the knowledge of only some of its objects, i.e. the random sample. For practical reasons this method is often the only viable option. This kind of standard deviation is often referred as to biased or corrected.
#
# The the formula for sample standard deviation ([Mathisfun.com](https://www.mathsisfun.com/data/standard-deviation-formulas.html)):
# $$
# s = \sqrt{\frac{1}{N-1} \sum_{i=1}^n (x_i - \bar{x})^2}
# $$
# where $\bar{x}$ denotes sample mean.
#
# The Microsoft Excel's functions `STDEC.S` and `STDEV.P` are used to calculate standard deviation of **sample** and **population** respectively.
#
# ### Standard deviation in NumPy
#
# NumPy library for Python allows for calculating the standard deviation The function `numpy.std()` is used for this purpose. The syntax employed for the calculation takes the following form:
# `std = sqrt(mean(abs(x - x.mean())**2))`
# where x is value of an observation.
#
# NumPy allows for calculating the standard deviation both of population and of sample. The correction is controlled by the function parameter `ddof`, which by default equals zero (standard deviation of population).
#
# "The average squared deviation is normally calculated as `x.sum() / N`, where `N = len(x)`. If, however, `ddof` is specified, the divisor `N - ddof` is used instead. In standard statistical practice, `ddof=1` provides an unbiased estimator of the variance of the infinite population. `ddof=0` provides a maximum likelihood estimate of the variance for normally distributed variables. The standard deviation computed in this function is the square root of the estimated variance, so even with `ddof=1`, it will not be an unbiased estimate of the standard deviation per se" ([NumPy](https://numpy.org/doc/stable/reference/generated/numpy.std.html)).
# import NumPy
import numpy as np
# ### Simulation
#
# The task involves development of a simulation that would allow comparing the results of the standard deviation of population and of sample when performed on a sample.
#
# Let's imagine a scenario where a manufacturing plant produces machining parts. One of the production stages is about honing a cylinder to a given diameter. The process target value is 100mm. The actual dimension is achieved with some deviation that follows the normal distribution pattern around the target value ([Statistical Process Control](https://www.moresteam.com/toolbox/statistical-process-control-spc.cfm)). Because it it economically not viable, only certain portion of the workpieces is analysed post-process.
#
# The mock data is generated and assigned as shown below. In order to promote the validity of the experiment and to reduce the repetitiveness, a certain random number generator seed is used.
# +
# setting the seed
seed = 2020 # seed value pre-set, selected arbitrarily
np.random.seed(seed) # ensures the generated numbers are the same
# target diameter
target_diameter = 100
# standard deviation
tolerance = 0.005
# total number of parts
total_number = 1000
# generating the random values of the mechined diameter
mu, sigma = target_diameter, tolerance # mean and standard deviation
diameter = np.random.normal(mu, sigma, 1000)
# sample size
sample_size = 50
# sample elements - first 100 elements from the main data set
sample = diameter[:sample_size]
print("Total number:\t", len(diameter))
print(f"Minimum:\t {diameter.min():.5f}")
print(f"Mean:\t\t {diameter.mean():.5f}")
print(f"Maximum:\t {diameter.max():.5f}")
print(f"Std dev of entire population (NumPy): {diameter.std():.5f}")
# -
# Now, let's evaluate the standard deviation of the population (SD_P) of the sample:
# $
# \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^n (x_i - \mu)^2}
# $
# and standard deviation of the sample (SD_S) of the sample:
# $
# s = \sqrt{\frac{1}{N-1} \sum_{i=1}^n (x_i - \bar{x})^2}
# $
# .
# +
print("Sample size:\t", len(sample))
print(f"Sample Min:\t {sample.min():.5f}")
print(f"Sample Mean:\t {sample.mean():.5f}")
print(f"Sample Max:\t {sample.max():.5f}")
print(12*".")
# Calculate standard deviation of the population (sd_p) based on the sample
# np.sqrt(np.sum((x - np.mean(x))**2)/len(x))
# auxiliary variable
sum = 0
# iterate over elements of the array
for x in np.nditer(sample):
sum = sum + (x - np.mean(sample))**2
sd_p = np.sqrt(sum/sample_size)
print(f"Sample SD_P:\t {sd_p:.5f}")
# Calculate standard deviation of the sample (sd_s) based on the sample
# np.sqrt(np.sum((x - np.mean(x))**2)/len(x-1))
# auxiliary variable
sum = 0
# iterate over elements of the array
for x in np.nditer(sample):
sum = sum + (x - np.mean(sample))**2
sd_s = np.sqrt(sum/(sample_size-1))
print(f"Sample SD_S:\t {sd_s:.5f}")
# -
# The above results needs to be compared to the benchmark, that is standard deviation of population performed on entire population
# +
# standard deviation of population on entire population - benchmark
# auxiliary variable
sum = 0
# iterate over elements of the array
for x in np.nditer(diameter):
sum = sum + (x - np.mean(diameter))**2
SD = np.sqrt(sum/total_number)
print(f"Std deviation on entire population:\t {SD:.5f}")
# Relative error of sd_p
print(f"Relative error of the standard deviation on population performed on sample (sd_p):\t {(abs(sd_p-SD)/SD):.5f}")
# Relative error of sd_s
print(f"Relative error of the standard deviation on sample performed on sample (sd_s):\t\t {(abs(sd_s-SD)/SD):.5f}")
# -
# ### Conclusion
#
# In the example above, the two methods of calculating the standard deviation performed on sample produced an error when compared to standard deviation performed on population (benchmark).
#
# Although standard deviation of the entire population yields an accurate results (every observation is considered), for practical reasons is often not viable (for example, it is hard to imagine taking the height of every person) and measurements are taking on a part of the population only (sample). It is assumed, that the sample is representative to the entire population and the size of the sample is large enough from statistics perspective.
#
# The above simulation revealed that standard deviation of sample yields a biased result. However, by implementing a correction parameter (degree of freedom) - that is standard deviation of sample - reduce the error. Depending on the statistical characteristics of the data set, it can often produce a good estimate.
# ___
# ### References - Task 3 related
#
# - Wikipedia Contributors - Standard Deviation [online] Available at: <https://en.wikipedia.org/wiki/Standard_deviation> [Accessed December 2020]
# - Tech Book Report - Standard Deviation In 30 Seconds [online] Available at: <http://www.techbookreport.com/tutorials/stddev-30-secs.html> [Accessed December 2020]
# - Math is fun - Standard Deviation and Variance [online] Available at: <https://www.mathsisfun.com/data/standard-deviation.html> [Accessed December 2020]
# - Microsoft support - STDEV.P function [online] Available at: <https://support.microsoft.com/en-us/office/stdev-p-function-6e917c05-31a0-496f-ade7-4f4e7462f285> [Accessed December 2020]
# - Microsoft support - STDEV.S function [online] Available at: <https://support.microsoft.com/en-us/office/stdev-s-function-7d69cf97-0c1f-4acf-be27-f3e83904cc23> [Accessed December 2020]
# - Exceltip - How To Use Excel STDEV.P Function [online] Available at: <https://www.exceltip.com/statistical-formulas/how-to-use-excel-stdev-p-function.html> [Accessed December 2020]
# - Good Data - Standard Deviation Functions [online] Available at: <https://help.gooddata.com/doc/en/reporting-and-dashboards/maql-analytical-query-language/maql-expression-reference/aggregation-functions/statistical-functions/standard-deviation-functions> [Accessed December 2020]
# - NumPy documentation - Standard Deviation (numpy.std) [online] Available at: <https://numpy.org/doc/stable/reference/generated/numpy.std.html> [Accessed December 2020]
# - Stack Overflow contributors - STDEV.S and STDEV.P using numpy [online] Available at: <https://stackoverflow.com/questions/64884294/stdev-s-and-stdev-p-using-numpy> [Accessed December 2020]
# - More Steam - Statistical Process Control [online] Available at: <https://www.moresteam.com/toolbox/statistical-process-control-spc.cfmn> [Accessed December 2020]
#
# ___
# # Task 4 - K-means clustering
#
#
# ### Objectives
# __Apply k-means clustering algorithm to Fisher's Iris data set using `scikit-learn`.__
#
# Explain in a Markdown cell how your code works and how accurate it might be, and then explain how your model could be used to make predictions of species
# of iris.
#
#
# ### Fisher's Iris data set
#
# The data set in question is a collection of Iris flowers properties, collated by <NAME>.
#
# The data consist of 150 observations, divided into three classes with 50 observations per each class, representing the iris species. Each observation describe measurements from a flower. The collected properties (data set attributes) represent respectively:
#
# - sepal length, cm,
# - sepal width, cm,
# - petal length, cm,
# - petal width, cm,
# - species of the iris (Setosa, Versicolour, Virginica).
#
# The data set for this task has been obtained from the _UC Irvine Machine Learning Repository_, https://archive.ics.uci.edu/ml/datasets/iris.
# ### K-means classification algorithm
#
# K-means is one of the unsupervised learning clustering algorithms. It is used to categorise elements into groups (clusters) based on the elements properties values.
#
# The aggregation is carried out based on the initial arbitrary division of the population into a specific number (k) of clusters. The process of cluster formation is done iteratively by assigning the elements to clusters. Each cluster is represented by a cluster centre that is the vector of mean attribute values of training instances. Cluster modeling in is typically done by applying the distance function to match instances against cluster centers [IBM.com](https://www.ibm.com/support/producthub/iias/docs/content/SSHRBY/com.ibm.swg.im.dashdb.analytics.doc/doc/r_kmeans_clustering.html). The belonging of an element to the clusters is based on the shortest distance to the cluster centre.
#
# The aim of the technique is to the maximise the similarity of elements in each of the clusters while maximising the difference between the clusters.
#
# The typical steps of the k-means algorithm ([Statystyka.az.pl](https://www.statystyka.az.pl/analiza-skupien/metoda-k-srednich.php)):
# 1. Determine the number of clusters.
# Typically, the number of clusters is chosen arbitrarily and possibly optimised later for better results.
# 2. Establish the initial cluster centres.
# The cluster centres should be selected in such a way as to maximize cluster distances. One of the methods is to run the algorithm several times, with the cluster centers initially being randomized, and choose the best model.
# 3. Calculate the distances of objects from the centers of clusters.
# This step determines which observations are considered similar and which different from each other. The most commonly used distance is the the square of the distance in Euclidean space.
# 4. Assign objects to clusters
# For a given observation, we compare the distances from all clusters and assign them to the cluster with the closest center.
# 5. Create new aggregation centers
# Most often, the new center of focus is a point whose coordinates are the arithmetic mean of the coordinates of the points belonging to a given cluster.
# 6. Follow steps 3, 4, 5 until the stop condition is met.
# The most common stop condition is the number of iterations given at the beginning, or no object moves between clusters.
# K-means algorithm needs data for training. Based on the results, it is possible to predict belonging of other points to the clusters.
# 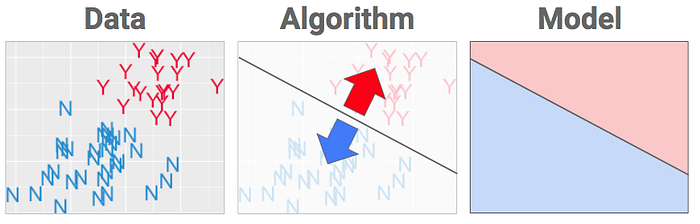
# 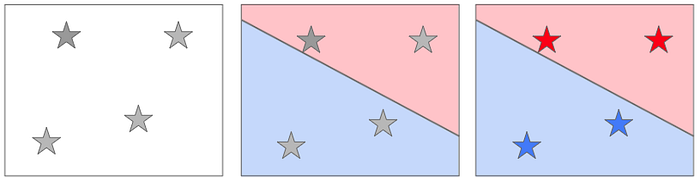
# Image source: [towardsdatascience.com](https://towardsdatascience.com/classification-regression-and-prediction-whats-the-difference-5423d9efe4ec)
# ### Application of the k-means
#
# This section is based on the lecture videos and the `sci-kit learn` tutorial.
# +
# Numerical arrays
import numpy as np
# Data tabularised
import pandas as pd
# Machine learning - KMeans
import sklearn.cluster as skcl
# Plotting
import matplotlib.pyplot as plt
import seaborn as sns
# +
# get the data set
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# assign data set to dataframe 'df'
df = pd.read_csv(url, sep=',', names = ["Sepal_Length", "Sepal_Width", "Petal_Length", "Petal_Width", "Species"])
# -
# the first few observations
df.head(4)
# A single data plot is worth thousand of data pints - data set visualisation.
# a glance into the data set plot
#pd.plotting.scatter_matrix(df, figsize=(12,8))
sns.pairplot(df, hue = "Species")
plt.show()
# Based on the above, _petal length_ and _sepal width_ appear to attributes that discriminate the species best and will be used in the subsequent analysis.
# In order to apply k-means, using scikit-learn, the dataframe must be without any categorical column. Below a new dataframe `X` is created, without the _species_ column.
# Drop the class column (descriptive) in order to apply the KMeans class. Next, assign new data set to variable X
X = df.drop('Species', 1)
X.head(3)
# Perform kmeans fitting.
kmeans = skcl.KMeans(n_clusters=3, random_state=0).fit(X)
# Now, lets see to which cluster each of the observation was assigned by the algorithm
# +
# assign cluster centres to the variable cent
cent = kmeans.cluster_centers_
# convert the cluster centres into a dataframe with appropriate headings
centres = pd.DataFrame({'Sepal_Length': cent[:, 0], 'Sepal_Width': cent[:, 1], 'Petal_Length': cent[:, 2], 'Petal_Width': cent[:, 3]})
# centres # commented out for readibility
# -
# There are three distinct clusters. but do they match the original species? Let's first evaluate the accuracy of the prediction quantitatively.
# add the labels to the dataframe in extra column 'Cluster_label'
df['Cluster_label'] = pd.Series(kmeans.labels_, index=df.index)
# df.tail(3) # commented out for readibility
# As we can see, each observation was assigned to one of three clusters (0, 1 or 2). It appears the labels were to match the species as follows:
#
# | Iris species | Cluster label |
# |:------------:|:-------------:|
# | Setosa | 1 |
# | Versicoulor | 2 |
# | Virginica | 0 |
#
# For a better readability and also further analysis, the numerical clusters designation will be changed to the corresponding species names.
# replace values of 'Cluster_label' column - numerical values with descriptive
df.loc[:,"Cluster_label"] = df.loc[:,"Cluster_label"].replace([1, 2, 0], ["Iris-setosa", "Iris-versicolor", "Iris-virginica"])
# check a few random rows in the dataframe
df.sample(4)
df["Cluster_label"].value_counts()
# +
# asign initial the labels of the points.
kmeans.labels_
# check frequency
df["Cluster_label"].value_counts()
# +
df.loc[:,"Match"] = np.where(df["Species"] == df["Cluster_label"], True, False)
# Filter to show only these observations with correct assignment
df_true = df[df["Match"] == True]
# Filter to show only these observations with incorrect assignment
df_false = df[df["Match"] == False]
# +
# show all data points
# plt.plot(df.loc[:,"Petal_Length"], df.loc[:,"Sepal_Width"], 'g.')
# Plot the data set which were correctly clustered
plt.plot(df_true.loc[:,"Petal_Length"], df_true.loc[:,"Sepal_Width"], 'bo', label="Matched prediction")
# Plot the data set which were not correctly clustered
plt.plot(df_false.loc[:,"Petal_Length"], df_false.loc[:,"Sepal_Width"], 'rs', label="Missed prediction")
plt.rcParams['figure.figsize'] = [16, 10] # change the settings of the plot size
plt.legend()
plt.show()
# -
# Let's see what the predicted clusters look like on the plot.
# +
# Plot the data set discriminated by labels.
plt.plot(X[kmeans.labels_ == 0].loc[:,"Petal_Length"], X[kmeans.labels_ == 0].loc[:,"Sepal_Width"], 'co', label="Setosa - predicted")
plt.plot(X[kmeans.labels_ == 1].loc[:,"Petal_Length"], X[kmeans.labels_ == 1].loc[:,"Sepal_Width"], 'yo', label="Versicolout - predicted")
plt.plot(X[kmeans.labels_ == 2].loc[:,"Petal_Length"], X[kmeans.labels_ == 2].loc[:,"Sepal_Width"], 'mo', label="Virginica - predicted")
plt.rcParams['figure.figsize'] = [16, 10] # change the settings of the plot size
plt.legend()
plt.show()
# -
# As seen, the algorithm put some of the flowers into wrong category (cluster). But let's look deeper at the results and compare the result with the actual classification on a single plot.
# +
# actual - represented with dots
plt.plot(df[df["Species"] == "Iris-setosa"].loc[:,"Petal_Length"], df[df["Species"] == "Iris-setosa"].loc[:,"Sepal_Width"], 'yo', markersize=8, alpha=0.5, label="Setosa - actual")
plt.plot(df[df["Species"] == "Iris-versicolor"].loc[:,"Petal_Length"], df[df["Species"] == "Iris-versicolor"].loc[:,"Sepal_Width"], 'mo', markersize=8, alpha=0.2, label="Versicolour - actual")
plt.plot(df[df["Species"] == "Iris-virginica"].loc[:,"Petal_Length"], df[df["Species"] == "Iris-virginica"].loc[:,"Sepal_Width"], 'co', markersize=8, alpha=0.3, label="Virginica - actual")
# predicted - represented with 'x's
plt.plot(X[kmeans.labels_ == 0].loc[:,"Petal_Length"], X[kmeans.labels_ == 0].loc[:,"Sepal_Width"], 'b+', markersize=12, label="Virginica - predicted")
plt.plot(X[kmeans.labels_ == 1].loc[:,"Petal_Length"], X[kmeans.labels_ == 1].loc[:,"Sepal_Width"], 'g+', markersize=12, label="Setosa - predicted")
plt.plot(X[kmeans.labels_ == 2].loc[:,"Petal_Length"], X[kmeans.labels_ == 2].loc[:,"Sepal_Width"], 'r+', markersize=12, label="Versicolour - predicted")
# centres - represented with stars
plt.scatter(centres.loc[:,"Petal_Length"], centres.loc[:,"Sepal_Width"], marker='*', c='black', s=200, label="Cluster centres - predicted")
plt.legend(loc="upper right")
plt.show()
# -
# Let us see which of the predicted observations were assigned correctly to the corresponding group, and which were not, by comparing the result with the actual classification.
# https://www.kite.com/python/answers/how-to-compare-two-pandas-dataframe-columns-in-python
Match = np.where(df["Species"] == df["Cluster_label"], True, False)
# accurace for iris-setosa - frequency of correct predictions (True)
unique, counts = np.unique(Match[:50], return_counts=True)
dict(zip(unique, counts))
# accurace for iris-versicolor - frequency of correct predictions (True)
unique, counts = np.unique(Match[50:100], return_counts=True)
dict(zip(unique, counts))
# accurace for iris-virginica - frequency of correct predictions (True)
unique, counts = np.unique(Match[100:], return_counts=True)
dict(zip(unique, counts))
# All in all, there is 134 correct elements assignment to the clusters, and 16 incorrect. The overall accuracy of the model for the iris data set is therefore:
accuracy = np.sum(Match) / df.shape[0]
float("{:.2f}".format(accuracy))
# ### Conclusion
#
# K-means is useful and ease to implement clustering algorithm (readily available functions within scikit-learn library). It allows grouping the data points in euclidean space depending on the points location.
#
# The algorithm is not perfect, however, and the occurrence of errors are very likely. In the analysed Iris data set, with _petal length_ and _sepal width_ selected as variables, the model accuracy is 89%.
#
# The accuracy depends on, among others, the properties of the measured values, their distribution in the plot, number of clusters, distance between the clusters and distribution of the data points around the cluster centres. Therefore, a significant care must be taken while interpreting the results.
# ___
# ### References - Task 4 related
# https://en.wikipedia.org/wiki/K-means_clustering
# https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
# https://realpython.com/k-means-clustering-python/
# https://www.ibm.com/support/producthub/iias/docs/content/SSHRBY/com.ibm.swg.im.dashdb.analytics.doc/doc/r_kmeans_clustering.html
# https://blogs.oracle.com/datascience/introduction-to-k-means-clustering
# https://towardsdatascience.com/classification-regression-and-prediction-whats-the-difference-5423d9efe4ec
# https://mmuratarat.github.io/2019-07-23/kmeans_from_scratch
# ___
# <NAME>
| MLaS-Tasks.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + _cell_guid="b1076dfc-b9ad-4769-8c92-a6c4dae69d19" _uuid="8f2839f25d086af736a60e9eeb907d3b93b6e0e5" papermill={"duration": 0.024537, "end_time": "2021-08-31T18:51:31.011799", "exception": false, "start_time": "2021-08-31T18:51:30.987262", "status": "completed"} tags=[]
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# + [markdown] papermill={"duration": 0.006467, "end_time": "2021-08-31T18:51:31.025794", "exception": false, "start_time": "2021-08-31T18:51:31.019327", "status": "completed"} tags=[]
# ### Intuition: Multiple models lead a better model.
#
# ### Open question:
#
# 1. How to decide the weights for different model outputs?
# 1. One way is weight the better performing model more.
#
# ### Credits
#
# 1. https://www.kaggle.com/yus002/tps-lgbm-model by @yus002
# 2. https://www.kaggle.com/carlmcbrideellis/histogram-gradient-boost-starter-script by @carlmcbrideellis
# 3. https://www.kaggle.com/riyajm/baseline-gpu-based-xgb-hyperopt-optimize by @riyajm
# 4. https://www.kaggle.com/andy6804tw/tps-08-21-catboost by @andy6804tw
# 5. https://www.kaggle.com/michael127001/xgbregressor-with-optuna-tuning by @michael127001
# 6. https://www.kaggle.com/pranjalverma08/tps-08-cb-lgbm-xgb-starter by @pranjalverma08
# 7. https://www.kaggle.com/alexryzhkov/aug21-lightautoml-starter by @alexryzhkov
# 8. https://www.kaggle.com/dmitryuarov/falling-below-7-87-voting-cb-xgb-lgbm by @dmitryuarov
# 9. https://www.kaggle.com/alexryzhkov/lightautoml-classifier-regressor-mix by @alexryzhkov
# 10. https://www.kaggle.com/hiro5299834/tps-aug-2021-lgbm-xgb-catboost by @hiro5299834
# 11. https://www.kaggle.com/yus002/blending-tool-tps-aug-2021 by @yus002
# 12. https://www.kaggle.com/pavfedotov/blending-tool-tps-aug-2021 by @pavfedotov
# 13. https://www.kaggle.com/takahiroyoshida012/smart-ensembling-tps-aug-2021-7-84986 by @takahiroyoshida012
#
# **Upvote for support!! and kudos to the above mentioned notebooks!!**
# + papermill={"duration": 0.015537, "end_time": "2021-08-31T18:51:31.048085", "exception": false, "start_time": "2021-08-31T18:51:31.032548", "status": "completed"} tags=[]
# list of (weight, submission file path)
# supports n number of files
# make sure the weights sum up to 1 always.
weight_model_paths_pairs = [
# (.025,'../input/gradientboosting1/submission.csv'),
# (.025, '../input/lgbm1/submission.csv'),
# (.02, '../input/xgboost1/submission1.csv'),
# (.01, '../input/catboost1/submission(1).csv'),
# (.03, '../input/xgbregressor1/submission (4).csv'),
# (.04, '../input/cbxgblgm1/subcat.csv'),
# (.02, '../input/lightautoml/In_LightAutoML_we_trust.csv'),
# (.01, '../input/blend1/voting.csv'),
# (.04, '../input/lightautoml2/LightAutoML_utilized_submission.csv'),
# (.005, '../input/lightautoml3/LightAutoML_utilized_submission (1).csv'),
# (.001, '../input/lightautoml4/LightAutoML_utilized_submission (2).csv'),
# (.1, '../input/blend5/0.part'),
# (.5, '../input/blend5/file1_7.84996_file2_7.85000_blend.csv'),
(.025, '../input/blend6/0 (1).part'),
(.025, '../input/blend7/0 (2).part'),
(.15, '../input/feedback2/submission_weighted_ensemble_24.csv'),
(.1, '../input/blend8/submission (6).csv'),
(.7,'../input/blend9/0 (3).part')]
# + papermill={"duration": 0.016643, "end_time": "2021-08-31T18:51:31.071595", "exception": false, "start_time": "2021-08-31T18:51:31.054952", "status": "completed"} tags=[]
# verify weights sum up to ~1
res = 0
for x, y in weight_model_paths_pairs:
res = res + x;
print(res)
# + papermill={"duration": 0.895115, "end_time": "2021-08-31T18:51:31.974427", "exception": false, "start_time": "2021-08-31T18:51:31.079312", "status": "completed"} tags=[]
targets = ['loss']
submissions = []
for weight, path in weight_model_paths_pairs:
df = pd.read_csv(path)
df[targets] = df[targets] * weight
submissions.append(df)
ensembled_output = pd.concat(submissions).groupby(['id']).sum().reset_index()
# + papermill={"duration": 0.030736, "end_time": "2021-08-31T18:51:32.012668", "exception": false, "start_time": "2021-08-31T18:51:31.981932", "status": "completed"} tags=[]
ensembled_output.head()
# + papermill={"duration": 0.560667, "end_time": "2021-08-31T18:51:32.580925", "exception": false, "start_time": "2021-08-31T18:51:32.020258", "status": "completed"} tags=[]
ensembled_output.to_csv('submission_weighted_ensemble_27.csv', index=False)
| 2021/AUG/tps-aug-2021-simple-weighted-ensemble.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + id="ct2ThVi-iTLd"
# !python3 -m pip install transformers wordcloud tweepy
# + [markdown] id="LLBxiEC303ws"
# ## Imports & Setup
# + id="Zi9HK2ylp8_c"
import pandas as pd
import numpy as np
import zipfile
import re
from datetime import datetime
# + id="VtvhrICMn-xq"
import tweepy
TWITTER_KEY = ''
TWITTER_SECRET = ''
# + id="4zcOf5koqCvQ"
zf = zipfile.ZipFile('/content/drive/MyDrive/electiondata.zip')
df = pd.read_csv(zf.open('uselection_tweets_1jul_11nov.csv'), sep=';')
# + [markdown] id="HPbUpz7G0--a"
# ## Trim down dataset to be feasible with Twitter API rate limits
#
# - First, limit it to tweets solely about the Democratic or Republican party (no independents or mixed subject tweets)
#
# - Pick out tweets with high scores ($|score| > 1$, for now)
# - English language only
# - *then* sample 10k tweets from this subset
# + id="t2luL2K_oTcw"
df["Created-At"] = pd.to_datetime(df["Created-At"])
trimmed_tweets = df.loc[((df["PartyName"] == 'Democrats') |
(df["PartyName"] == "Republicans")) &
(np.abs(df["Score"]) > 1) &
(df["Language"] == 'en')]
tweets_dataset_20k = trimmed_tweets.sample(20000)
# + colab={"base_uri": "https://localhost:8080/", "height": 606} id="PfDOjXEU3s2Y" outputId="802d7a81-a067-4b87-f0ea-7dfb64d9cdb6"
tweets_dataset_20k.reset_index(drop=True, inplace=True)
tweets_dataset_20k
# + [markdown] id="whTa6GEV1Jhp"
# ## Add a 'state' column and new labels
#
# + id="nA7mPp7wCp6n"
STATES_ABBREVIATIONS = ["AL", "AK", "AZ", "AR", "CA", "CO", "CT", "DC", "DE", "FL", "GA",
"HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD",
"MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ",
"NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "RI", "SC",
"SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY"]
STATE_NAMES = ["Alaska", "Alabama", "Arkansas", "Arizona",
"California", "Colorado", "Connecticut", "Delaware",
"Florida", "Georgia", "Hawaii", "Iowa", "Idaho",
"Illinois", "Indiana", "Kansas", "Kentucky", "Louisiana",
"Massachusetts", "Maryland", "Maine", "Michigan", "Minnesota",
"Missouri", "Mississippi", "Montana", "North Carolina",
"North Dakota", "Nebraska", "New Hampshire", "New Jersey",
"New Mexico", "Nevada", "New York", "Ohio", "Oklahoma", "Oregon",
"Pennsylvania", "Rhode Island", "South Carolina",
"South Dakota", "Tennessee", "Texas", "Utah", "Virginia",
"Vermont", "Washington", "Wisconsin", "West Virginia", "Wyoming"]
STATES_FULL = {"AL":"Alabama","AK":"Alaska","AZ":"Arizona","AR":"Arkansas",
"CA":"California","CO":"Colorado","CT":"Connecticut",
"DE":"Delaware", "FL":"Florida","GA":"Georgia","HI":"Hawaii",
"ID":"Idaho","IL":"Illinois","IN":"Indiana","IA":"Iowa",
"KS":"Kansas","KY":"Kentucky","LA":"Louisiana","ME":"Maine",
"MD":"Maryland","MA":"Massachusetts","MI":"Michigan",
"MN":"Minnesota","MS":"Mississippi","MO":"Missouri",
"MT":"Montana","NE":"Nebraska","NV":"Nevada",
"NH":"New Hampshire","NJ":"New Jersey","NM":"New Mexico",
"NY":"New York","NC":"North Carolina","ND":"North Dakota",
"OH":"Ohio","OK":"Oklahoma","OR":"Oregon","PA":"Pennsylvania",
"RI":"Rhode Island","SC":"South Carolina","SD":"South Dakota",
"TN":"Tennessee","TX":"Texas","UT":"Utah","VT":"Vermont",
"VA":"Virginia","WA":"Washington","WV":"West Virginia",
"WI":"Wisconsin","WY":"Wyoming"}
state_regex = re.compile('|'.join(STATES_ABBREVIATIONS + STATE_NAMES))
STATES_ABBREVIATIONS = set(STATES_ABBREVIATIONS)
# + id="ToyxDNO9ocBO"
auth = tweepy.AppAuthHandler(TWITTER_KEY, TWITTER_SECRET)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
tweets_dataset_20k["State"] = ""
tweets_dataset_20k["Text"] = ""
for idx, row in tweets_dataset_20k.iterrows():
if idx % 100 == 0:
print(f"Currently at: {idx}")
try:
tweet = api.get_status(row['Id'])
state_match = state_regex.search(tweet.user.location)
if state_match:
tweets_dataset_20k.at[idx, "State"] = state_match.group(0)
tweets_dataset_20k.at[idx, "Text"] = tweet.text
except tweepy.TweepError:
continue
# + id="zBSb5-x5mTAO"
tweets_dataset_20k.drop(tweets_dataset_20k.index[tweets_dataset_20k["State"] == ""], inplace=True)
tweets_dataset_20k.reset_index(drop=True, inplace=True)
for idx, row in tweets_dataset_20k.iterrows():
if row["State"] in STATES_ABBREVIATIONS:
tweets_dataset_20k.at[idx, "State"] = STATES_FULL.get(row["State"], "")
# + colab={"base_uri": "https://localhost:8080/", "height": 980} id="0BPnr8LPvn0w" outputId="b4acf8e0-f7f3-4baa-d8f8-3acd75465d7d"
tweets_dataset_20k
# + id="EPsBYwBYo8fR"
tweets_dataset_20k.to_csv('/content/drive/MyDrive/tweets_3k.csv')
| data_collection/DataCollection_OLD.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Stencils
#
# In this tutorial we will look at the Stencils in topoGenesis and the computational concept behind them.
import topogenesis as tg
# ### Creation and basic properties
# + tags=[]
# create a stencil based on well-known neighbourhood definitions
von_neumann_stencil = tg.create_stencil("von_neumann", 1, 1)
# check the object type
print(type(von_neumann_stencil))
# see into the representative array
print(von_neumann_stencil)
# + tags=[]
# we can also expand the stencil into the local addresses
print(von_neumann_stencil.expand())
# -
# ### Neigbourhood type in stencils
# + tags=[]
# check the neighborhoud type and origin
print(von_neumann_stencil.ntype)
print(von_neumann_stencil.origin)
# + tags=[]
# create a moore neighbourhood stencil
moore_stencil = tg.create_stencil("moore", 1, 1)
print(moore_stencil)
# -
# ### Customizing stencils
# + tags=[]
# customize the stencil with the help of global indicies: in this case removing the up-center cell
moore_stencil[1,0,1] = 0
print(moore_stencil)
# + tags=[]
# or customize the stencil with the help of local indicies: in this case removing the down-center cell
moore_stencil.set_index([0,1,0], 0)
print(moore_stencil)
# -
# ### Stencils and [Universal Functions](https://numpy.org/doc/stable/reference/ufuncs.html)
# + tags=[]
# we can peform all universal functions(addition, subtraction, multiplication, etc) on stencils
custom_stencil = moore_stencil - von_neumann_stencil
# import numpy as np
# custom_test = np.array(moore_stencil) - np.array(von_neumann_stencil)
print(custom_stencil.ntype)
print(custom_stencil)
| examples/notebooks/stencil_functionalities.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/michaelll22/CPEN-21A-ECE-2-2/blob/main/Lab1.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + colab={"base_uri": "https://localhost:8080/"} id="K9RmfMih2U0Z" outputId="aaa3a01d-9164-4ac3-e8b4-9a0e633748c2"
name = "<NAME>"
age = "19"
address = "Brgy. Inocencio, Trece Martires City, Cavite"
print("Laboratory 1: Welcome to Python Programming\n \nName: {}\nAge: {} \nAddress: {}".format(name, age, address))
| Lab1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + _cell_guid="b1076dfc-b9ad-4769-8c92-a6c4dae69d19" _uuid="8f2839f25d086af736a60e9eeb907d3b93b6e0e5"
# General imports
import numpy as np
import pandas as pd
import os, sys, gc, time, warnings, pickle, psutil, random
# custom imports
from multiprocessing import Pool # Multiprocess Runs
warnings.filterwarnings('ignore')
# +
########################### Helpers
#################################################################################
## Seeder
# :seed to make all processes deterministic # type: int
def seed_everything(seed=0):
random.seed(seed)
np.random.seed(seed)
## Multiprocess Runs
def df_parallelize_run(func, t_split):
num_cores = np.min([N_CORES,len(t_split)])
pool = Pool(num_cores)
df = pd.concat(pool.map(func, t_split), axis=1)
pool.close()
pool.join()
return df
# +
########################### Helper to load data by store ID
#################################################################################
# Read data
def get_data_by_store(store):
# Read and contact basic feature
df = pd.concat([pd.read_pickle(BASE),
pd.read_pickle(PRICE).iloc[:,2:],
pd.read_pickle(CALENDAR).iloc[:,2:]],
axis=1)
# Leave only relevant store
df = df[df['store_id']==store]
# With memory limits we have to read
# lags and mean encoding features
# separately and drop items that we don't need.
# As our Features Grids are aligned
# we can use index to keep only necessary rows
# Alignment is good for us as concat uses less memory than merge.
df2 = pd.read_pickle(MEAN_ENC)[mean_features]
df2 = df2[df2.index.isin(df.index)]
df3 = pd.read_pickle(LAGS).iloc[:,3:]
df3 = df3[df3.index.isin(df.index)]
df = pd.concat([df, df2], axis=1)
del df2 # to not reach memory limit
df = pd.concat([df, df3], axis=1)
del df3 # to not reach memory limit
# Create features list
features = [col for col in list(df) if col not in remove_features]
df = df[['id','d',TARGET]+features]
# Skipping first n rows
df = df[df['d']>=START_TRAIN].reset_index(drop=True)
return df, features
# Recombine Test set after training
def get_base_test():
base_test = pd.DataFrame()
for store_id in STORES_IDS:
temp_df = pd.read_pickle('test_'+store_id+'.pkl')
temp_df['store_id'] = store_id
base_test = pd.concat([base_test, temp_df]).reset_index(drop=True)
return base_test
# -------------------------------------
# def get_base_valid():
# base_test = pd.DataFrame()
# for store_id in STORES_IDS:
# temp_df = pd.read_pickle(MODEL_PATH+'valid_'+store_id+'.pkl')
# temp_df['store_id'] = store_id
# base_test = pd.concat([base_test, temp_df]).reset_index(drop=True)
# return base_test
# -------------------------------------
########################### Helper to make dynamic rolling lags
#################################################################################
def make_lag(LAG_DAY):
lag_df = base_test[['id','d',TARGET]]
col_name = 'sales_lag_'+str(LAG_DAY)
lag_df[col_name] = lag_df.groupby(['id'])[TARGET].transform(lambda x: x.shift(LAG_DAY)).astype(np.float16)
return lag_df[[col_name]]
def make_lag_roll(LAG_DAY):
shift_day = LAG_DAY[0]
roll_wind = LAG_DAY[1]
lag_df = base_test[['id','d',TARGET]]
col_name = 'rolling_mean_tmp_'+str(shift_day)+'_'+str(roll_wind)
lag_df[col_name] = lag_df.groupby(['id'])[TARGET].transform(lambda x: x.shift(shift_day).rolling(roll_wind).mean())
return lag_df[[col_name]]
# +
########################### Model params
#################################################################################
import lightgbm as lgb
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'tweedie',
'tweedie_variance_power': 1.1,
'metric': 'rmse',
'subsample': 0.5,
'subsample_freq': 1,
'learning_rate': 0.05,
'num_leaves': 2**11-1,
'min_data_in_leaf': 2**12-1,
'feature_fraction': 0.5,
'max_bin': 100,
'n_estimators': 1400,
'boost_from_average': False,
'verbose': -1,
'n_jobs':40
}
# Let's look closer on params
## 'boosting_type': 'gbdt'
# we have 'goss' option for faster training
# but it normally leads to underfit.
# Also there is good 'dart' mode
# but it takes forever to train
# and model performance depends
# a lot on random factor
# https://www.kaggle.com/c/home-credit-default-risk/discussion/60921
## 'objective': 'tweedie'
# Tweedie Gradient Boosting for Extremely
# Unbalanced Zero-inflated Data
# https://arxiv.org/pdf/1811.10192.pdf
# and many more articles about tweediie
#
# Strange (for me) but Tweedie is close in results
# to my own ugly loss.
# My advice here - make OWN LOSS function
# https://www.kaggle.com/c/m5-forecasting-accuracy/discussion/140564
# https://www.kaggle.com/c/m5-forecasting-accuracy/discussion/143070
# I think many of you already using it (after poisson kernel appeared)
# (kagglers are very good with "params" testing and tuning).
# Try to figure out why Tweedie works.
# probably it will show you new features options
# or data transformation (Target transformation?).
## 'tweedie_variance_power': 1.1
# default = 1.5
# set this closer to 2 to shift towards a Gamma distribution
# set this closer to 1 to shift towards a Poisson distribution
# my CV shows 1.1 is optimal
# but you can make your own choice
## 'metric': 'rmse'
# Doesn't mean anything to us
# as competition metric is different
# and we don't use early stoppings here.
# So rmse serves just for general
# model performance overview.
# Also we use "fake" validation set
# (as it makes part of the training set)
# so even general rmse score doesn't mean anything))
# https://www.kaggle.com/c/m5-forecasting-accuracy/discussion/133834
## 'subsample': 0.5
# Serves to fight with overfit
# this will randomly select part of data without resampling
# Chosen by CV (my CV can be wrong!)
# Next kernel will be about CV
##'subsample_freq': 1
# frequency for bagging
# default value - seems ok
## 'learning_rate': 0.03
# Chosen by CV
# Smaller - longer training
# but there is an option to stop
# in "local minimum"
# Bigger - faster training
# but there is a chance to
# not find "global minimum" minimum
## 'num_leaves': 2**11-1
## 'min_data_in_leaf': 2**12-1
# Force model to use more features
# We need it to reduce "recursive"
# error impact.
# Also it leads to overfit
# that's why we use small
# 'max_bin': 100
## l1, l2 regularizations
# https://towardsdatascience.com/l1-and-l2-regularization-methods-ce25e7fc831c
# Good tiny explanation
# l2 can work with bigger num_leaves
# but my CV doesn't show boost
## 'n_estimators': 1400
# CV shows that there should be
# different values for each state/store.
# Current value was chosen
# for general purpose.
# As we don't use any early stopings
# careful to not overfit Public LB.
##'feature_fraction': 0.5
# LightGBM will randomly select
# part of features on each iteration (tree).
# We have maaaany features
# and many of them are "duplicates"
# and many just "noise"
# good values here - 0.5-0.7 (by CV)
## 'boost_from_average': False
# There is some "problem"
# to code boost_from_average for
# custom loss
# 'True' makes training faster
# BUT carefull use it
# https://github.com/microsoft/LightGBM/issues/1514
# not our case but good to know cons
# -
# +
########################### Vars
#################################################################################
VER = 1 # Our model version
SEED = 42 # We want all things
seed_everything(SEED) # to be as deterministic
lgb_params['seed'] = SEED # as possible
N_CORES = psutil.cpu_count() # Available CPU cores
#LIMITS and const
TARGET = 'sales' # Our target
START_TRAIN = 0 # We can skip some rows (Nans/faster training)
END_TRAIN = 1941 # End day of our train set
START_VALID = 1913
P_HORIZON = 28 # Prediction horizon
USE_AUX = False # Use or not pretrained models
#FEATURES to remove
## These features lead to overfit
## or values not present in test set
remove_features = ['id','state_id','store_id',
'date','wm_yr_wk','d',TARGET]
mean_features = ['enc_cat_id_mean','enc_cat_id_std',
'enc_dept_id_mean','enc_dept_id_std',
'enc_item_id_mean','enc_item_id_std']
#PATHS for Features
ORIGINAL = 'data/m5-forecasting-accuracy/'
BASE = 'data/m5-simple-fe/grid_part_1.pkl'
PRICE = 'data/m5-simple-fe/grid_part_2.pkl'
CALENDAR = 'data/m5-simple-fe/grid_part_3.pkl'
LAGS = 'data/m5-lags-features/lags_df_28.pkl'
MEAN_ENC = 'data/m5-custom-features/mean_encoding_df.pkl'
# AUX(pretrained) Models paths
AUX_MODELS = 'data/m5-aux-models/'
#STORES ids
STORES_IDS = pd.read_csv(ORIGINAL+'sales_train_evaluation.csv')['store_id']
STORES_IDS = list(STORES_IDS.unique())
#SPLITS for lags creation
SHIFT_DAY = 28
N_LAGS = 15
LAGS_SPLIT = [col for col in range(SHIFT_DAY,SHIFT_DAY+N_LAGS)]
ROLS_SPLIT = []
for i in [1,7,14]:
for j in [7,14,30,60]:
ROLS_SPLIT.append([i,j])
# +
########################### Aux Models
# If you don't want to wait hours and hours
# to have result you can train each store
# in separate kernel and then just join result.
# If we want to use pretrained models we can
## skip training
## (in our case do dummy training
## to show that we are good with memory
## and you can safely use this (all kernel) code)
if USE_AUX:
lgb_params['n_estimators'] = 2
# Here is some 'logs' that can compare
#Train CA_1
#[100] valid_0's rmse: 2.02289
#[200] valid_0's rmse: 2.0017
#[300] valid_0's rmse: 1.99239
#[400] valid_0's rmse: 1.98471
#[500] valid_0's rmse: 1.97923
#[600] valid_0's rmse: 1.97284
#[700] valid_0's rmse: 1.96763
#[800] valid_0's rmse: 1.9624
#[900] valid_0's rmse: 1.95673
#[1000] valid_0's rmse: 1.95201
#[1100] valid_0's rmse: 1.9476
#[1200] valid_0's rmse: 1.9434
#[1300] valid_0's rmse: 1.9392
#[1400] valid_0's rmse: 1.93446
#Train CA_2
#[100] valid_0's rmse: 1.88949
#[200] valid_0's rmse: 1.84767
#[300] valid_0's rmse: 1.83653
#[400] valid_0's rmse: 1.82909
#[500] valid_0's rmse: 1.82265
#[600] valid_0's rmse: 1.81725
#[700] valid_0's rmse: 1.81252
#[800] valid_0's rmse: 1.80736
#[900] valid_0's rmse: 1.80242
#[1000] valid_0's rmse: 1.79821
#[1100] valid_0's rmse: 1.794
#[1200] valid_0's rmse: 1.78973
#[1300] valid_0's rmse: 1.78552
#[1400] valid_0's rmse: 1.78158
# -
# ### Train and Valid
MODEL_PATH = 'models/1914_1941_valid_d2d/'
for day in range(1,28):
for store_id in STORES_IDS:
print('Train', store_id)
# Get grid for current store
grid_df, features_columns = get_data_by_store(store_id)
grid_df['sales'] = grid_df.groupby('item_id')['sales'].shift(-day)
grid_df = grid_df[grid_df.groupby('item_id').cumcount(ascending=False) > 0]
grid_df['sales'] = grid_df['sales'].values * grid_df['sell_price'].values
# break
# Masks for
# Train (All data less than 1913)
# "Validation" (Last 28 days - not real validatio set)
# Test (All data greater than 1913 day,
# with some gap for recursive features)
train_mask = grid_df['d']<=START_VALID
# valid_mask = grid_df['d']>(END_TRAIN-100)
preds_mask = (grid_df['d']<=END_TRAIN)&(grid_df['d']>(START_VALID-100))
# Apply masks and save lgb dataset as bin
# to reduce memory spikes during dtype convertations
# https://github.com/Microsoft/LightGBM/issues/1032
# "To avoid any conversions, you should always use np.float32"
# or save to bin before start training
# https://www.kaggle.com/c/talkingdata-adtracking-fraud-detection/discussion/53773
train_data = lgb.Dataset(grid_df[train_mask][features_columns],
label=grid_df[train_mask][TARGET])
# train_data.save_binary('train_data.bin')
# train_data = lgb.Dataset('train_data.bin')
## valid_data = lgb.Dataset(grid_df[valid_mask][features_columns],
## label=grid_df[valid_mask][TARGET])
# break
# Saving part of the dataset for later predictions
# Removing features that we need to calculate recursively
grid_df = grid_df[preds_mask].reset_index(drop=True)
keep_cols = [col for col in list(grid_df) if '_tmp_' not in col]
grid_df = grid_df[keep_cols]
grid_df.to_pickle(MODEL_PATH+'valid_'+store_id+'.pkl')
del grid_df
# Launch seeder again to make lgb training 100% deterministic
# with each "code line" np.random "evolves"
# so we need (may want) to "reset" it
seed_everything(SEED)
estimator = lgb.train(lgb_params,
train_data,
valid_sets = [train_data],
verbose_eval = 100,
)
# Save model - it's not real '.bin' but a pickle file
# estimator = lgb.Booster(model_file='model.txt')
# can only predict with the best iteration (or the saving iteration)
# pickle.dump gives us more flexibility
# like estimator.predict(TEST, num_iteration=100)
# num_iteration - number of iteration want to predict with,
# NULL or <= 0 means use best iteration
model_name = MODEL_PATH+'lgb_model_'+store_id+'_v'+str(VER)+ '_valid' +'_d_'+ str(day+1) +'.bin'
pickle.dump(estimator, open(model_name, 'wb'))
# Remove temporary files and objects
# to free some hdd space and ram memory
# # !rm train_data.bin
del train_data, estimator
gc.collect()
# "Keep" models features for predictions
MODEL_FEATURES = features_columns
features_columns = ['item_id', 'dept_id', 'cat_id', 'release', 'sell_price', 'price_max', 'price_min', 'price_std', 'price_mean', 'price_norm', 'price_nunique', 'item_nunique', 'price_momentum', 'price_momentum_m', 'price_momentum_y', 'event_name_1', 'event_type_1', 'event_name_2', 'event_type_2', 'snap_CA', 'snap_TX', 'snap_WI', 'tm_d', 'tm_w', 'tm_m', 'tm_y', 'tm_wm', 'tm_dw', 'tm_w_end', 'enc_cat_id_mean', 'enc_cat_id_std', 'enc_dept_id_mean', 'enc_dept_id_std', 'enc_item_id_mean', 'enc_item_id_std', 'sales_lag_28', 'sales_lag_29', 'sales_lag_30', 'sales_lag_31', 'sales_lag_32', 'sales_lag_33', 'sales_lag_34', 'sales_lag_35', 'sales_lag_36', 'sales_lag_37', 'sales_lag_38', 'sales_lag_39', 'sales_lag_40', 'sales_lag_41', 'sales_lag_42', 'sales_lag_43', 'sales_lag_44', 'sales_lag_45', 'sales_lag_46', 'sales_lag_47', 'sales_lag_48', 'sales_lag_49', 'sales_lag_50', 'sales_lag_51', 'sales_lag_52', 'sales_lag_53', 'sales_lag_54', 'sales_lag_55', 'rolling_mean_tmp_1_7', 'rolling_mean_tmp_1_14', 'rolling_mean_tmp_1_30', 'rolling_mean_tmp_1_60', 'rolling_mean_tmp_7_7', 'rolling_mean_tmp_7_14', 'rolling_mean_tmp_7_30', 'rolling_mean_tmp_7_60', 'rolling_mean_tmp_14_7', 'rolling_mean_tmp_14_14', 'rolling_mean_tmp_14_30', 'rolling_mean_tmp_14_60']
MODEL_FEATURES = features_columns
MODEL_PATH = 'models/1914_1941_valid_d2d/'
def get_base_valid():
base_test = pd.DataFrame()
for store_id in STORES_IDS:
temp_df = pd.read_pickle(MODEL_PATH+'valid_'+store_id+'.pkl')
temp_df['store_id'] = store_id
base_test = pd.concat([base_test, temp_df]).reset_index(drop=True)
return base_test
# +
all_preds = pd.DataFrame()
# Join back the Test dataset with
# a small part of the training data
# to make recursive features
base_test = get_base_valid()
base_test = base_test[base_test['d']<=END_TRAIN]
index = base_test[base_test['d']>END_TRAIN-P_HORIZON].index
base_test.loc[index,'sales']=np.NaN
# Timer to measure predictions time
main_time = time.time()
PREDICT_DAY = 3
# +
start_time = time.time()
grid_df = base_test.copy()
grid_df = pd.concat([grid_df, df_parallelize_run(make_lag_roll, ROLS_SPLIT)], axis=1)
for store_id in STORES_IDS:
# Read all our models and make predictions
# for each day/store pairs
model_path = MODEL_PATH + 'lgb_model_'+store_id+'_v'+str(VER)+'_valid'+'_d_'+str(PREDICT_DAY)+'.bin'
if USE_AUX:
model_path = AUX_MODELS + model_path
estimator = pickle.load(open(model_path, 'rb'))
day_mask = base_test['d']==(END_TRAIN-P_HORIZON+PREDICT_DAY)
store_mask = base_test['store_id']==store_id
mask = (day_mask)&(store_mask)
base_test[TARGET][mask] = estimator.predict(grid_df[mask][MODEL_FEATURES])
# Make good column naming and add
# to all_preds DataFrame
temp_df = base_test[day_mask][['id',TARGET]]
temp_df.columns = ['id','F'+str(PREDICT_DAY)]
if 'id' in list(all_preds):
all_preds = all_preds.merge(temp_df, on=['id'], how='left')
else:
all_preds = temp_df.copy()
print('#'*10, ' %0.2f min round |' % ((time.time() - start_time) / 60),
' %0.2f min total |' % ((time.time() - main_time) / 60),
' %0.2f day sales |' % (temp_df['F'+str(PREDICT_DAY)].sum()))
del temp_df
# -
all_preds.to_pickle('revenue_d2d_1914_1941_valid_day_3.pkl')
# +
########################### Validation
#################################################################################
# Create Dummy DataFrame to store predictions
all_preds = pd.DataFrame()
# Join back the Test dataset with
# a small part of the training data
# to make recursive features
base_test = get_base_valid()
base_test = base_test[base_test['d']<=END_TRAIN]
index = base_test[base_test['d']>END_TRAIN-P_HORIZON].index
base_test.loc[index,'sales']=np.NaN
# Timer to measure predictions time
main_time = time.time()
# Loop over each prediction day
# As rolling lags are the most timeconsuming
# we will calculate it for whole day
for PREDICT_DAY in range(1,29):
print('Predict | Day:', PREDICT_DAY)
start_time = time.time()
# Make temporary grid to calculate rolling lags
grid_df = base_test.copy()
grid_df = pd.concat([grid_df, df_parallelize_run(make_lag_roll, ROLS_SPLIT)], axis=1)
for store_id in STORES_IDS:
# Read all our models and make predictions
# for each day/store pairs
model_path = MODEL_PATH + 'lgb_model_'+store_id+'_v'+str(VER)+'_valid'+'_d_'+str(PREDICT_DAY)+'.bin'
if USE_AUX:
model_path = AUX_MODELS + model_path
estimator = pickle.load(open(model_path, 'rb'))
day_mask = base_test['d']==(END_TRAIN-P_HORIZON+PREDICT_DAY)
store_mask = base_test['store_id']==store_id
mask = (day_mask)&(store_mask)
base_test[TARGET][mask] = estimator.predict(grid_df[mask][MODEL_FEATURES])
# Make good column naming and add
# to all_preds DataFrame
temp_df = base_test[day_mask][['id',TARGET]]
temp_df.columns = ['id','F'+str(PREDICT_DAY)]
if 'id' in list(all_preds):
all_preds = all_preds.merge(temp_df, on=['id'], how='left')
else:
all_preds = temp_df.copy()
print('#'*10, ' %0.2f min round |' % ((time.time() - start_time) / 60),
' %0.2f min total |' % ((time.time() - main_time) / 60),
' %0.2f day sales |' % (temp_df['F'+str(PREDICT_DAY)].sum()))
del temp_df
all_preds = all_preds.reset_index(drop=True)
all_preds
# +
########################### Validation
#################################################################################
# Create Dummy DataFrame to store predictions
all_preds = pd.DataFrame()
# Join back the Test dataset with
# a small part of the training data
# to make recursive features
base_test = get_base_valid()
base_test = base_test[base_test['d']<=END_TRAIN]
index = base_test[base_test['d']>END_TRAIN-P_HORIZON].index
base_test.loc[index,'sales']=np.NaN
# Timer to measure predictions time
main_time = time.time()
# Loop over each prediction day
# As rolling lags are the most timeconsuming
# we will calculate it for whole day
for PREDICT_DAY in range(1,29):
print('Predict | Day:', PREDICT_DAY)
start_time = time.time()
# Make temporary grid to calculate rolling lags
grid_df = base_test.copy()
grid_df = pd.concat([grid_df, df_parallelize_run(make_lag_roll, ROLS_SPLIT)], axis=1)
for store_id in STORES_IDS:
# Read all our models and make predictions
# for each day/store pairs
model_path = 'lgb_model_'+store_id+'_v'+str(VER)+'_valid'+'.bin'
if USE_AUX:
model_path = AUX_MODELS + model_path
estimator = pickle.load(open(model_path, 'rb'))
day_mask = base_test['d']==(END_TRAIN-P_HORIZON+PREDICT_DAY)
store_mask = base_test['store_id']==store_id
mask = (day_mask)&(store_mask)
base_test[TARGET][mask] = estimator.predict(grid_df[mask][MODEL_FEATURES])
# Make good column naming and add
# to all_preds DataFrame
temp_df = base_test[day_mask][['id',TARGET]]
temp_df.columns = ['id','F'+str(PREDICT_DAY)]
if 'id' in list(all_preds):
all_preds = all_preds.merge(temp_df, on=['id'], how='left')
else:
all_preds = temp_df.copy()
print('#'*10, ' %0.2f min round |' % ((time.time() - start_time) / 60),
' %0.2f min total |' % ((time.time() - main_time) / 60),
' %0.2f day sales |' % (temp_df['F'+str(PREDICT_DAY)].sum()))
del temp_df
all_preds = all_preds.reset_index(drop=True)
all_preds
# -
all_preds.to_pickle('revenue_1914_1941_valid.pkl')
END_TRAIN-P_HORIZON+PREDICT_DAY
# +
########################### Predict
#################################################################################
# Create Dummy DataFrame to store predictions
all_preds = pd.DataFrame()
# Join back the Test dataset with
# a small part of the training data
# to make recursive features
base_test = get_base_test()
# Timer to measure predictions time
main_time = time.time()
# Loop over each prediction day
# As rolling lags are the most timeconsuming
# we will calculate it for whole day
for PREDICT_DAY in range(1,29):
print('Predict | Day:', PREDICT_DAY)
start_time = time.time()
# Make temporary grid to calculate rolling lags
grid_df = base_test.copy()
grid_df = pd.concat([grid_df, df_parallelize_run(make_lag_roll, ROLS_SPLIT)], axis=1)
for store_id in STORES_IDS:
# Read all our models and make predictions
# for each day/store pairs
model_path = 'lgb_model_'+store_id+'_v'+str(VER)+'.bin'
if USE_AUX:
model_path = AUX_MODELS + model_path
estimator = pickle.load(open(model_path, 'rb'))
day_mask = base_test['d']==(END_TRAIN+PREDICT_DAY)
store_mask = base_test['store_id']==store_id
mask = (day_mask)&(store_mask)
base_test[TARGET][mask] = estimator.predict(grid_df[mask][MODEL_FEATURES])
# Make good column naming and add
# to all_preds DataFrame
temp_df = base_test[day_mask][['id',TARGET]]
temp_df.columns = ['id','F'+str(PREDICT_DAY)]
if 'id' in list(all_preds):
all_preds = all_preds.merge(temp_df, on=['id'], how='left')
else:
all_preds = temp_df.copy()
print('#'*10, ' %0.2f min round |' % ((time.time() - start_time) / 60),
' %0.2f min total |' % ((time.time() - main_time) / 60),
' %0.2f day sales |' % (temp_df['F'+str(PREDICT_DAY)].sum()))
del temp_df
all_preds = all_preds.reset_index(drop=True)
all_preds
# -
########################### Export
#################################################################################
# Reading competition sample submission and
# merging our predictions
# As we have predictions only for "_validation" data
# we need to do fillna() for "_evaluation" items
submission = pd.read_csv(ORIGINAL+'sample_submission.csv')[['id']]
submission = submission.merge(all_preds, on=['id'], how='left').fillna(0)
submission.to_csv('submission_v'+str(VER)+'.csv', index=False)
# +
# Summary
# Of course here is no magic at all.
# No "Novel" features and no brilliant ideas.
# We just carefully joined all
# our previous fe work and created a model.
# Also!
# In my opinion this strategy is a "dead end".
# Overfits a lot LB and with 1 final submission
# you have no option to risk.
# Improvement should come from:
# Loss function
# Data representation
# Stable CV
# Good features reduction strategy
# Predictions stabilization with NN
# Trend prediction
# Real zero sales detection/classification
# Good kernels references
## (the order is random and the list is not complete):
# https://www.kaggle.com/ragnar123/simple-lgbm-groupkfold-cv
# https://www.kaggle.com/jpmiller/grouping-items-by-stockout-pattern
# https://www.kaggle.com/headsortails/back-to-predict-the-future-interactive-m5-eda
# https://www.kaggle.com/sibmike/m5-out-of-stock-feature
# https://www.kaggle.com/mayer79/m5-forecast-attack-of-the-data-table
# https://www.kaggle.com/yassinealouini/seq2seq
# https://www.kaggle.com/kailex/m5-forecaster-v2
# https://www.kaggle.com/aerdem4/m5-lofo-importance-on-gpu-via-rapids-xgboost
# Features were created in these kernels:
##
# Mean encodings and PCA options
# https://www.kaggle.com/kyakovlev/m5-custom-features
##
# Lags and rolling lags
# https://www.kaggle.com/kyakovlev/m5-lags-features
##
# Base Grid and base features (calendar/price/etc)
# https://www.kaggle.com/kyakovlev/m5-simple-fe
# Personal request
# Please don't upvote any ensemble and copypaste kernels
## The worst case is ensemble without any analyse.
## The best choice - just ignore it.
## I would like to see more kernels with interesting and original approaches.
## Don't feed copypasters with upvotes.
## It doesn't mean that you should not fork and improve others kernels
## but I would like to see params and code tuning based on some CV and analyse
## and not only on LB probing.
## Small changes could be shared in comments and authors can improve their kernel.
## Feel free to criticize this kernel as my knowlege is very limited
## and I can be wrong in code and descriptions.
## Thank you.
| Models/m5-validation-d2d-predict(1).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] colab_type="text" id="view-in-github"
# <a href="https://colab.research.google.com/github/NeuromatchAcademy/course-content/blob/mrk-W2D1/tutorials/W2D1_BayesianStatistics/W2D1_Tutorial1.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] colab_type="text" id="YL2_mjdRyaSg"
# # Neuromatch Academy: Week 2, Day 1, Tutorial 1
# # Bayes rule with Gaussians
#
# __Content creators:__ <NAME>, <NAME>, with help from <NAME>
#
# __Content reviewers:__ <NAME>, <NAME>, <NAME>, <NAME>, <NAME>
# + [markdown] colab_type="text" id="erXKPTRakFsK"
# # Tutorial Objectives
# This is the first in a series of three main tutorials (+ one bonus tutorial) on Bayesian statistics. In these tutorials, we will develop a Bayesian model for localizing sounds based on audio and visual cues. This model will combine **prior** information about where sounds generally originate with sensory information about the **likelihood** that a specific sound came from a particular location. As we will see in subsequent lessons, the resulting **posterior distribution** not only allows us to make optimal decision about the sound's origin, but also lets us quantify how uncertain that decision is. Bayesian techniques are therefore useful **normative models**: the behavior of human or animal subjects can be compared against these models to determine how efficiently they make use of information.
#
# This notebook will introduce two fundamental building blocks for Bayesian statistics: the Gaussian distribution and the Bayes Theorem. You will:
#
# 1. Implement a Gaussian distribution
# 2. Use Bayes' Theorem to find the posterior from a Gaussian-distributed prior and likelihood.
# 3. Change the likelihood mean and variance and observe how posterior changes.
# 4. Advanced (*optional*): Observe what happens if the prior is a mixture of two gaussians?
#
# + cellView="form" colab={"base_uri": "https://localhost:8080/", "height": 516} colab_type="code" id="e63KDGa13vMj" outputId="3fd0f192-d565-4140-f64c-7151d8ddcd44"
#@title Video 1: Introduction to Bayesian Statistics
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id='BV1pZ4y1u7PD', width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
video
# + [markdown] colab_type="text" id="JgF7_zvb8d0C"
# ## Setup
# Please execute the cells below to initialize the notebook environment.
# + colab={} colab_type="code" id="KOz4tuF9CEup"
import numpy as np
import matplotlib.pyplot as plt
# + cellView="form" colab={} colab_type="code" id="2wOIfj-UCUJ6"
#@title Figure Settings
import ipywidgets as widgets
plt.style.use("/share/dataset/COMMON/nma.mplstyle.txt")
# %matplotlib inline
# %config InlineBackend.figure_format = 'retina'
# + cellView="form" colab={} colab_type="code" id="m-zOvZtK8mmd"
#@title Helper functions
def my_plot_single(x, px):
"""
Plots normalized Gaussian distribution
Args:
x (numpy array of floats): points at which the likelihood has been evaluated
px (numpy array of floats): normalized probabilities for prior evaluated at each `x`
Returns:
Nothing.
"""
if px is None:
px = np.zeros_like(x)
fig, ax = plt.subplots()
ax.plot(x, px, '-', color='xkcd:green', LineWidth=2, label='Prior')
ax.legend()
ax.set_ylabel('Probability')
ax.set_xlabel('Orientation (Degrees)')
def posterior_plot(x, likelihood=None, prior=None, posterior_pointwise=None, ax=None):
"""
Plots normalized Gaussian distributions and posterior
Args:
x (numpy array of floats): points at which the likelihood has been evaluated
auditory (numpy array of floats): normalized probabilities for auditory likelihood evaluated at each `x`
visual (numpy array of floats): normalized probabilities for visual likelihood evaluated at each `x`
posterior (numpy array of floats): normalized probabilities for the posterior evaluated at each `x`
ax: Axis in which to plot. If None, create new axis.
Returns:
Nothing.
"""
if likelihood is None:
likelihood = np.zeros_like(x)
if prior is None:
prior = np.zeros_like(x)
if posterior_pointwise is None:
posterior_pointwise = np.zeros_like(x)
if ax is None:
fig, ax = plt.subplots()
ax.plot(x, likelihood, '-r', LineWidth=2, label='Auditory')
ax.plot(x, prior, '-b', LineWidth=2, label='Visual')
ax.plot(x, posterior_pointwise, '-g', LineWidth=2, label='Posterior')
ax.legend()
ax.set_ylabel('Probability')
ax.set_xlabel('Orientation (Degrees)')
return ax
def plot_visual(mu_visuals, mu_posteriors, max_posteriors):
"""
Plots the comparison of computing the mean of the posterior analytically and
the max of the posterior empirically via multiplication.
Args:
mu_visuals (numpy array of floats): means of the visual likelihood
mu_posteriors (numpy array of floats): means of the posterior, calculated analytically
max_posteriors (numpy array of floats): max of the posteriors, calculated via maxing the max_posteriors.
posterior (numpy array of floats): normalized probabilities for the posterior evaluated at each `x`
Returns:
Nothing.
"""
fig_w, fig_h = plt.rcParams.get('figure.figsize')
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(fig_w, 2 * fig_h))
ax[0].plot(mu_visuals, max_posteriors, '-g', label='mean')
ax[0].set_xlabel('Visual stimulus position')
ax[0].set_ylabel('Multiplied posterior mean')
ax[0].set_title('Sample output')
ax[1].plot(mu_visuals, mu_posteriors, '--', color='xkcd:gray', label='argmax')
ax[1].set_xlabel('Visual stimulus position')
ax[1].set_ylabel('Analytical posterior mean')
fig.tight_layout()
ax[1].set_title('Hurray for math!')
def multimodal_plot(x, example_prior, example_likelihood,
mu_visuals, posterior_modes):
"""Helper function for plotting Section 4 results"""
fig_w, fig_h = plt.rcParams.get('figure.figsize')
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(fig_w, 2*fig_h), sharex=True)
# Plot the last instance that we tried.
posterior_plot(x,
example_prior,
example_likelihood,
compute_posterior_pointwise(example_prior, example_likelihood),
ax=ax[0]
)
ax[0].set_title('Example combination')
ax[1].plot(mu_visuals, posterior_modes, '-g', label='argmax')
ax[1].set_xlabel('Visual stimulus position\n(Mean of blue dist. above)')
ax[1].set_ylabel('Posterior mode\n(Peak of green dist. above)')
fig.tight_layout()
# + [markdown] colab_type="text" id="h6-SFBNR5An6"
# # Section 1: The Gaussian Distribution
#
# Bayesian analysis operates on probability distributions. Although these can take many forms, the Gaussian distribution is a very common choice. Because of the central limit theorem, many quantities are Gaussian-distributed. Gaussians also have some mathematical properties that permit simple closed-form solutions to several important problems.
#
# In this exercise, you will implement a Gaussian by filling in the missing portion of `my_gaussian` below. Gaussians have two parameters. The **mean** $\mu$, which sets the location of its center. Its "scale" or spread is controlled by its **standard deviation** $\sigma$ or its square, the **variance** $\sigma^2$. (Be careful not to use one when the other is required).
#
# The equation for a Gaussian is:
# $$
# \mathcal{N}(\mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(\frac{-(x-\mu)^2}{2\sigma^2}\right)
# $$
# Also, don't forget that this is a probability distribution and should therefore sum to one. While this happens "automatically" when integrated from $-\infty$ to $\infty$, your version will only be computed over a finite number of points. You therefore need to explicitly normalize it yourself.
#
# Test out your implementation with a $\mu = -1$ and $\sigma = 1$. After you have it working, play with the parameters to develop an intuition for how changing $\mu$ and $\sigma$ alter the shape of the Gaussian. This is important, because subsequent exercises will be built out of Gaussians.
# + [markdown] colab_type="text" id="HkkvOPUN297D"
# ## Exercise 1: Implement a Gaussian
# + cellView="code" colab={} colab_type="code" id="ze86GbV86_iT"
def my_gaussian(x_points, mu, sigma):
"""
Returns normalized Gaussian estimated at points `x_points`, with parameters:
mean `mu` and std `sigma`
Args:
x_points (numpy array of floats): points at which the gaussian is
evaluated
mu (scalar): mean of the Gaussian
sigma (scalar): std of the gaussian
Returns:
(numpy array of floats) : normalized Gaussian evaluated at `x`
"""
###################################################################
## Add code to calcualte the gaussian px as a function of mu and sigma,
## for every x in x_points
## Function Hints: exp -> np.exp()
## power -> z**2
## remove the raise below to test your function
raise NotImplementedError("You need to implement the Gaussian function!")
###################################################################
px = ...
return px
x = np.arange(-8, 9, 0.1)
# Uncomment to plot the results
# px = my_gaussian(x, -1, 1)
# my_plot_single(x, px)
# + colab={"base_uri": "https://localhost:8080/", "height": 329} colab_type="code" id="iBpZQ9Sz7fVy" outputId="a7a15fb4-3a92-4b07-a4de-3e39b5a496f1"
# to_remove solution
def my_gaussian(x_points, mu, sigma):
"""
Returns normalized Gaussian estimated at points `x_points`, with parameters:
mean `mu` and std `sigma`
Args:
x_points (numpy array of floats): points at which the gaussian is
evaluated
mu (scalar): mean of the Gaussian
sigma (scalar): std of the gaussian
Returns:
(numpy array of floats) : normalized Gaussian evaluated at `x`
"""
px = np.exp(- 1/2/sigma**2 * (mu - x_points) ** 2)
px = px / px.sum() # this is the normalization: this part ensures the sum of
# the individual probabilities at each `x` add up to one.
# It makes a very strong assumption though:
# That the `x_points` cover the big portion of
# probability mass around the mean.
# Please think/discuss when this would be a dangerous
# assumption.
# E.g.: What do you think will happen to the values on
# the y-axis
# if the `x` values (x_point) range from -1 to 8 instead
# of -8 to 8?
return px
x = np.arange(-8, 9, 0.1)
px = my_gaussian(x, -1, 1)
with plt.xkcd():
my_plot_single(x, px)
# + [markdown] colab_type="text" id="o1zuDTI5-Via"
# # Section 2. Bayes' Theorem and the Posterior
# + cellView="form" colab={"base_uri": "https://localhost:8080/", "height": 516} colab_type="code" id="kwN71pmo-V_4" outputId="1c125444-92a6-46c4-b527-a7217a542dfb"
#@title Video 2: Bayes' theorem
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id='BV1Hi4y1V7UN', width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
video
# + [markdown] colab_type="text" id="HB2U9wCNyaSo"
#
#
# Bayes' rule tells us how to combine two sources of information: the prior (e.g., a noisy representation of our expectations about where the stimulus might come from) and the likelihood (e.g., a noisy representation of the stimulus position on a given trial), to obtain a posterior distribution taking into account both pieces of information. Bayes' rule states:
#
# \begin{eqnarray}
# \text{Posterior} = \frac{ \text{Likelihood} \times \text{Prior}}{ \text{Normalization constant}}
# \end{eqnarray}
#
# When both the prior and likelihood are Gaussians, this translates into the following form:
#
# $$
# \begin{array}{rcl}
# \text{Likelihood} &=& \mathcal{N}(\mu_{likelihood},\sigma_{likelihood}^2) \\
# \text{Prior} &=& \mathcal{N}(\mu_{prior},\sigma_{prior}^2) \\
# \text{Posterior} &\propto& \mathcal{N}(\mu_{likelihood},\sigma_{likelihood}^2) \times \mathcal{N}(\mu_{prior},\sigma_{prior}^2) \\
# &&= \mathcal{N}\left( \frac{\sigma^2_{likelihood}\mu_{prior}+\sigma^2_{prior}\mu_{likelihood}}{\sigma^2_{likelihood}+\sigma^2_{prior}}, \frac{\sigma^2_{likelihood}\sigma^2_{prior}}{\sigma^2_{likelihood}+\sigma^2_{prior}} \right)
# \end{array}
# $$
#
# In these equations, $\mathcal{N}(\mu,\sigma^2)$ denotes a Gaussian distribution with parameters $\mu$ and $\sigma^2$:
# $$
# \mathcal{N}(\mu, \sigma) = \frac{1}{\sqrt{2 \pi \sigma^2}} \; \exp \bigg( \frac{-(x-\mu)^2}{2\sigma^2} \bigg)
# $$
#
# In Exercise 2A, we will use the first form of the posterior, where the two distributions are combined via pointwise multiplication. Although this method requires more computation, it works for any type of probability distribution. In Exercise 2B, we will see that the closed-form solution shown on the line below produces the same result.
# + [markdown] colab_type="text" id="yjknQx1EyaSo"
# ## Exercise 2A: Finding the posterior computationally
#
# Imagine an experiment where participants estimate the location of a noise-emitting object. To estimate its position, the participants can use two sources of information:
# 1. new noisy auditory information (the likelihood)
# 2. prior visual expectations of where the stimulus is likely to come from (visual prior).
#
# The auditory and visual information are both noisy, so participants will combine these sources of information to better estimate the position of the object.
#
# We will use Gaussian distributions to represent the auditory likelihood (in red), and a Gaussian visual prior (expectations - in blue). Using Bayes rule, you will combine them into a posterior distribution that summarizes the probability that the object is in each location.
#
# We have provided you with a ready-to-use plotting function, and a code skeleton.
#
# * Use `my_gaussian`, the answer to exercise 1, to generate an auditory likelihood with parameters $\mu$ = 3 and $\sigma$ = 1.5
# * Generate a visual prior with parameters $\mu$ = -1 and $\sigma$ = 1.5
# * Calculate the posterior using pointwise multiplication of the likelihood and prior. Don't forget to normalize so the posterior adds up to 1.
# * Plot the likelihood, prior and posterior using the predefined function `posterior_plot`
#
#
# + cellView="code" colab={} colab_type="code" id="KqOpye6JyaSp"
def compute_posterior_pointwise(prior, likelihood):
##############################################################################
# Write code to compute the posterior from the prior and likelihood via
# pointwise multiplication. (You may assume both are defined over the same x-axis)
#
# Comment out the line below to test your solution
raise NotImplementedError("Finish the simulation code first")
##############################################################################
posterior = ...
return posterior
def localization_simulation(mu_auditory=3.0, sigma_auditory=1.5,
mu_visual=-1.0, sigma_visual=1.5):
##############################################################################
## Using the x variable below,
## create a gaussian called 'auditory' with mean 3, and std 1.5
## create a gaussian called 'visual' with mean -1, and std 1.5
#
#
## Comment out the line below to test your solution
raise NotImplementedError("Finish the simulation code first")
###############################################################################
x = np.arange(-8, 9, 0.1)
auditory = ...
visual = ...
posterior = compute_posterior_pointwise(auditory, visual)
return x, auditory, visual, posterior
# Uncomment the lines below to plot the results
# x, auditory, visual, posterior_pointwise = localization_simulation()
# posterior_plot(x, auditory, visual, posterior_pointwise)
# + colab={"base_uri": "https://localhost:8080/", "height": 329} colab_type="code" id="9dAPRIFuyaSt" outputId="b92b5494-8d7f-4feb-ae55-d5320f7e9c6e"
# to_remove solution
def compute_posterior_pointwise(prior, likelihood):
##############################################################################
# Write code to compute the posterior from the prior and likelihood via
# pointwise multiplication. (You may assume both are defined over the same x-axis)
#
# Comment out the line below to test your solution
# raise NotImplementedError("Finish the simulation code first")
##############################################################################
posterior = prior * likelihood
posterior /= posterior.sum()
return posterior
def localization_simulation(mu_auditory=3.0, sigma_auditory=1.5,
mu_visual=-1.0, sigma_visual=1.5):
##############################################################################
## Using the x variable below,
## create a gaussian called 'auditory' with mean 3, and std 1.5
## create a gaussian called 'visual' with mean -1, and std 1.5
#
## Comment out the line below to test your solution
#raise NotImplementedError("Finish the simulation code first")
###############################################################################
x = np.arange(-8, 9, 0.1)
auditory = my_gaussian(x, mu_auditory, sigma_auditory)
visual = my_gaussian(x, mu_visual, sigma_visual)
posterior = compute_posterior_pointwise(auditory, visual)
return x, auditory, visual, posterior
# Uncomment the lines below to plot the results
x, auditory, visual, posterior_pointwise = localization_simulation()
with plt.xkcd():
posterior_plot(x, auditory, visual, posterior_pointwise)
# + [markdown] colab_type="text" id="l37e0INGVel5"
# ## Interactive Demo: What affects the posterior?
#
# Now that we can compute the posterior of two Gaussians with *Bayes rule*, let's vary the parameters of those Gaussians to see how changing the prior and likelihood affect the posterior.
#
# **Hit the Play button or Ctrl+Enter in the cell below** and play with the sliders to get an intuition for how the means and standard deviations of prior and likelihood influence the posterior.
#
# When does the prior have the strongest influence over the posterior? When is it the weakest?
# + cellView="form" colab={"base_uri": "https://localhost:8080/", "height": 424, "referenced_widgets": ["7945823b088f41d9b2dd23cfaca5a02c", "7638bc57394e4373bb83e8d65b58f706", "71b90bfcba9b457f88eb2162b2576b22", "b38f8a52957b48b0919f92e7e83ee9b4", "c58fe72ab22745f69f0da021ed457829", "10b1d18631b4430897bacbf3e26b4c25", "4ba723ad9fc545b0a07806681b24f511", "<KEY>", "087400670c274d9e82bce000efeed833", "68d12614e0f44258894f25aae6af04dc", "45187d7588b44adfa692be8c3f80521b", "be26667a7c8f4ca8aef0e4120ac64b7c", "<KEY>", "6f9e8e29467f4c3f94a98c2baef3e5ec", "e9f5571dfd5643fa9d5be9fb5e4ca47b", "5928733140aa4fb7a36d4367b16d613d"]} colab_type="code" id="xKvQrgFqyaSy" outputId="24fc0ae7-e35d-4345-ccaa-471d9746795c"
#@title
#@markdown Make sure you execute this cell to enable the widget!
x = np.arange(-10, 11, 0.1)
import ipywidgets as widgets
def refresh(mu_auditory=3, sigma_auditory=1.5, mu_visual=-1, sigma_visual=1.5):
auditory = my_gaussian(x, mu_auditory, sigma_auditory)
visual = my_gaussian(x, mu_visual, sigma_visual)
posterior_pointwise = visual * auditory
posterior_pointwise /= posterior_pointwise.sum()
w_auditory = (sigma_visual** 2) / (sigma_auditory**2 + sigma_visual**2)
theoretical_prediction = mu_auditory * w_auditory + mu_visual * (1 - w_auditory)
ax = posterior_plot(x, auditory, visual, posterior_pointwise)
ax.plot([theoretical_prediction, theoretical_prediction],
[0, posterior_pointwise.max() * 1.2], '-.', color='xkcd:medium gray')
ax.set_title(f"Gray line shows analytical mean of posterior: {theoretical_prediction:0.2f}")
plt.show()
style = {'description_width': 'initial'}
_ = widgets.interact(refresh,
mu_auditory=widgets.FloatSlider(value=2, min=-10, max=10, step=0.5, description="mu_auditory:", style=style),
sigma_auditory=widgets.FloatSlider(value=0.5, min=0.5, max=10, step=0.5, description="sigma_auditory:", style=style),
mu_visual=widgets.FloatSlider(value=-2, min=-10, max=10, step=0.5, description="mu_visual:", style=style),
sigma_visual=widgets.FloatSlider(value=0.5, min=0.5, max=10, step=0.5, description="sigma_visual:", style=style)
)
# + [markdown] colab_type="text" id="6e56uSp4yaSx"
# ## Video 3: Multiplying Gaussians
# + cellView="form" colab={"base_uri": "https://localhost:8080/", "height": 516} colab_type="code" id="mPzUEexgVNl_" outputId="51c73791-4291-443b-bf31-d71d74059592"
#@title
from IPython.display import YouTubeVideo
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id='BV1ni4y1V7bQ', width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
video
# + [markdown] colab_type="text" id="mj9r9QqMNoMQ"
# ## Exercise 2B: Finding the posterior analytically
#
# [If you are running short on time, feel free to skip the coding exercise below].
#
# As you may have noticed from the interactive demo, the product of two Gaussian distributions, like our prior and likelihood, remains a Gaussian, regardless of the parameters. We can directly compute the parameters of that Gaussian from the means and variances of the prior and likelihood. For example, the posterior mean is given by:
#
# $$ \mu_{posterior} = \frac{\mu_{auditory} \cdot \frac{1}{\sigma_{auditory}^2} + \mu_{visual} \cdot \frac{1}{\sigma_{visual}^2}}{1/\sigma_{auditory}^2 + 1/\sigma_{visual}^2}
# $$
#
# This formula is a special case for two Gaussians, but is a very useful one because:
# * The posterior has the same form (here, a normal distribution) as the prior, and
# * There is simple, closed-form expression for its parameters.
#
# When these properties hold, we call them **conjugate distributions** or **conjugate priors** (for a particular likelihood). Working with conjugate distributions is very convenient; otherwise, it is often necessary to use computationally-intensive numerical methods to combine the prior and likelihood.
#
# In this exercise, we ask you to verify that property. To do so, we will hold our auditory likelihood constant as an $\mathcal{N}(3, 1.5)$ distribution, while considering visual priors with different means ranging from $\mu=-10$ to $\mu=10$. For each prior,
#
# * Compute the posterior distribution using the function you wrote in Exercise 2A. Next, find its mean. The mean of a probability distribution is $\int_x p(x) dx$ or $\sum_x x\cdot p(x)$.
# * Compute the analytical posterior mean from auditory and visual using the equation above.
# * Use the provided plotting code to plot both estimates of the mean.
#
# Are the estimates of the posterior mean the same in both cases?
#
# Using these results, try to predict the posterior mean for the combination of a $\mathcal{N}(-4,4)$ prior and and $\mathcal{N}(4, 2)$ likelihood. Use the widget above to check your prediction. You can enter values directly by clicking on the numbers to the right of each slider; $\sqrt{2} \approx 1.41$.
# + cellView="code" colab={} colab_type="code" id="UqdWieuNyaS1"
def compare_computational_analytical_means():
x = np.arange(-10, 11, 0.1)
# Fixed auditory likelihood
mu_auditory = 3
sigma_auditory = 1.5
likelihood = my_gaussian(x, mu_auditory, sigma_auditory)
# Varying visual prior
mu_visuals = np.linspace(-10, 10)
sigma_visual = 1.5
# Accumulate results here
mus_by_integration = []
mus_analytical = []
for mu_visual in mu_visuals:
prior = my_gaussian(x, mu_visual, sigma_visual)
posterior = compute_posterior_pointwise(prior, likelihood)
############################################################################
## Add code that will find the posterior mean via numerical integration
#
############################################################################
mu_integrated = ...
############################################################################
## Add more code below that will calculate the posterior mean analytically
#
# Comment out the line below to test your solution
raise NotImplementedError("Please add code to find the mean both ways first")
############################################################################
mu_analytical = ...
mus_by_integration.append(mu_integrated)
mus_analytical.append(mu_analytical)
return mu_visuals, mus_by_integration, mus_analytical
# Uncomment the lines below to visualize your results
# mu_visuals, mu_computational, mu_analytical = compare_computational_analytical_means()
# plot_visual(mu_visuals, mu_computational, mu_analytical)
# + cellView="code" colab={"base_uri": "https://localhost:8080/", "height": 616} colab_type="code" id="JAM-cG9rg53X" outputId="78480dbf-d355-403e-cd82-07197ccb29aa"
#to_remove solution
def compare_computational_analytical_means():
x = np.arange(-10, 11, 0.1)
# Fixed auditory likelihood
mu_auditory = 3
sigma_auditory = 1.5
likelihood = my_gaussian(x, mu_auditory, sigma_auditory)
# Varying visual prior
mu_visuals = np.linspace(-10, 10)
sigma_visual = 1.5
# Accumulate results here
mus_by_integration = []
mus_analytical = []
for mu_visual in mu_visuals:
prior = my_gaussian(x, mu_visual, sigma_visual)
posterior = compute_posterior_pointwise(prior, likelihood)
############################################################################
## Add code that will find the posterior mean via numerical integration
#
############################################################################
mu_integrated = np.sum(x*posterior)
############################################################################
## Add more code below that will calculate the posterior mean analytically
#
# Comment out the line below to test your solution
#raise NotImplementedError("Please add code to find the mean both ways first")
############################################################################
mu_analytical = ((mu_auditory / sigma_auditory ** 2 + mu_visual / sigma_visual ** 2) /
(1 / sigma_auditory ** 2 + 1 / sigma_visual ** 2))
mus_by_integration.append(mu_integrated)
mus_analytical.append(mu_analytical)
return mu_visuals, mus_by_integration, mus_analytical
# Uncomment the lines below to visualize your results
mu_visuals, mu_computational, mu_analytical = compare_computational_analytical_means()
with plt.xkcd():
plot_visual(mu_visuals, mu_computational, mu_analytical)
# + [markdown] colab_type="text" id="Iy9-k6vzxd6m"
# # Section 3: Conclusion
#
# This tutorial introduced the Gaussian distribution and used Bayes' Theorem to combine Gaussians representing priors and likelihoods. In the next tutorial, we will use these concepts to probe how subjects integrate sensory information.
#
#
# + cellView="form" colab={"base_uri": "https://localhost:8080/", "height": 516} colab_type="code" id="wZwVsAV7ZpYE" outputId="9b56907a-807d-49e8-be3e-bd050b4fe1f5"
#@title Video 4: Conclusion
from IPython.display import YouTubeVideo
from IPython.display import IFrame
class BiliVideo(IFrame):
def __init__(self, id, page=1, width=400, height=300, **kwargs):
self.id=id
src = "https://player.bilibili.com/player.html?bvid={0}&page={1}".format(id, page)
super(BiliVideo, self).__init__(src, width, height, **kwargs)
video = BiliVideo(id='BV1wv411q7ex', width=854, height=480, fs=1)
print("Video available at https://www.bilibili.com/video/{0}".format(video.id))
video
# + [markdown] colab_type="text" id="s0IQkuPayaS5"
# # Bonus Section: Multimodal Priors
#
#
# **Only do this if the first half-hour has not yet passed.**
#
# The preceeding exercises used a Gaussian prior, implying that participants expected the stimulus to come from a single location, though they might not know precisely where. However, suppose the subjects actually thought that sound might come from one of two distinct locations. Perhaps they can see two speakers (and know that speakers often emit noise).
#
# We could model this using a Gaussian prior with a large $\sigma$ that covers both locations, but that would also make every point in between seem likely too.A better approach is to adjust the form of the prior so that it better matches the participants' experiences/expectations. In this optional exercise, we will build a bimodal (2-peaked) prior out of Gaussians and examine the resulting posterior and its peaks.
# + [markdown] colab_type="text" id="xae-KbZl3olT"
# ## Exercise 3: Implement and test a multimodal prior
#
# * Complete the `bimodal_prior` function below to create a bimodal prior, comprised of the sum of two Gaussians with means $\mu = -3$ and $\mu = 3$. Use $\sigma=1$ for both Gaussians. Be sure to normalize the result so it is a proper probability distribution.
#
# * In Exercise 2, we used the mean location to summarize the posterior distribution. This is not always the best choice, especially for multimodal distributions. What is the mean of our new prior? Is it a particularly likely location for the stimulus? Instead, we will use the posterior **mode** to summarize the distribution. The mode is the *location* of the most probable part of the distribution. Complete `posterior_mode` below, to find it. (Hint: `np.argmax` returns the *index* of the largest element in an array).
#
# * Run the provided simulation and plotting code. Observe what happens to the posterior as the likelihood gets closer to the different peaks of the prior.
# * Notice what happens to the posterior when the likelihood is exactly in between the two modes of the prior (i.e., $\mu_{Likelihood} = 0$)
# + cellView="code" colab={} colab_type="code" id="Tzl8NFl3yaS6"
def bimodal_prior(x, mu_1=-3, sigma_1=1, mu_2=3, sigma_2=1):
################################################################################
## Finish this function so that it returns a bimodal prior, comprised of the
# sum of two Gaussians
#
# Comment out the line below to test out your solution
raise NotImplementedError("Please implement the bimodal prior")
################################################################################
prior = ...
return prior
def posterior_mode(x, posterior):
################################################################################
## Finish this function so that it returns the location of the mode
#
# Comment out the line below to test out your solution
raise NotImplementedError("Please implement the bimodal prior")
################################################################################
mode = ...
return mode
def multimodal_simulation(x, mus_visual, sigma_visual=1):
"""
Simulate an experiment where bimodal prior is held constant while
a Gaussian visual likelihood is shifted across locations.
Args:
x: array of points at which prior/likelihood/posterior are evaluated
mus_visual: array of means for the Gaussian likelihood
sigma_visual: scalar standard deviation for the Gaussian likelihood
Returns:
posterior_modes: array containing the posterior mode for each mean in mus_visual
"""
prior = bimodal_prior(x, -3, 1, 3, 1)
posterior_modes = []
for mu in mus_visual:
likelihood = my_gaussian(x, mu, 3)
posterior = compute_posterior_pointwise(prior, likelihood)
p_mode = posterior_mode(x, posterior)
posterior_modes.append(p_mode)
return posterior_modes
x = np.arange(-10, 10, 0.1)
mus = np.arange(-8, 8, 0.05)
# Uncomment the lines below to visualize your results
# posterior_modes = multimodal_simulation(x, mus, 1)
# multimodal_plot(x,
# bimodal_prior(x, -3, 1, 3, 1),
# my_gaussian(x, 1, 1),
# mus, posterior_modes)
# + colab={"base_uri": "https://localhost:8080/", "height": 616} colab_type="code" id="F6ov7ISgjGtA" outputId="868e2a1d-0a1f-4e60-e81d-7f100f4504d1"
#to_remove solution
def bimodal_prior(x, mu_1=-3, sigma_1=1, mu_2=3, sigma_2=1):
################################################################################
## Finish this function so that it returns a bimodal prior, comprised of the
# sum of two Gaussians
#
# Comment out the line below to test out your solution
#raise NotImplementedError("Please implement the bimodal prior")
################################################################################
prior = my_gaussian(x, mu_1, sigma_1) + my_gaussian(x, mu_2, sigma_2)
prior /= prior.sum()
return prior
def posterior_mode(x, posterior):
################################################################################
## Finish this function so that it returns the location of the mode
#
# Comment out the line below to test out your solution
#raise NotImplementedError("Please implement the bimodal prior")
################################################################################
mode = x[np.argmax(posterior)]
return mode
def multimodal_simulation(x, mus_visual, sigma_visual=1):
"""
Simulate an experiment where bimodal prior is held constant while
a Gaussian visual likelihood is shifted across locations.
Args:
x: array of points at which prior/likelihood/posterior are evaluated
mus_visual: array of means for the Gaussian likelihood
sigma_visual: scalar standard deviation for the Gaussian likelihood
Returns:
posterior_modes: array containing the posterior mode for each mean in mus_visual
"""
prior = bimodal_prior(x, -3, 1, 3, 1)
posterior_modes = []
for mu in mus_visual:
likelihood = my_gaussian(x, mu, 3)
posterior = compute_posterior_pointwise(prior, likelihood)
p_mode = posterior_mode(x, posterior)
posterior_modes.append(p_mode)
return posterior_modes
x = np.arange(-10, 10, 0.1)
mus = np.arange(-8, 8, 0.05)
# Uncomment the lines below to visualize your results
posterior_modes = multimodal_simulation(x, mus, 1)
with plt.xkcd():
multimodal_plot(x,
bimodal_prior(x, -3, 1, 3, 1),
my_gaussian(x, 1, 1),
mus, posterior_modes)
| tutorials/W2D1_BayesianStatistics/W2D1_Tutorial1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Code For Model Output Analysis
# Imports
from cbrain.imports import *
from cbrain.cam_constants import *
from cbrain.utils import *
from cbrain.model_diagnostics import ModelDiagnostics
# Specifiy the paths to the nueral network config file you used to help train the model, as well as to whereever your validation dataset is.
#
# In SPCAM5 data, it is 2 degree resolution, thus 96 latitudes and 144 longitudes. Also make this change in cbrain.model_diagnostics (line 18), where before it was 64 latitudes and 128 longitudes in SPCAM3
config_path = 'nn_config/precip_predict.yml'
validation_path = '/fast/gmooers/Preprocessed_Data/Very_Small_data/000_valid.nc'
lats = 96
lons = 144
valid_data = nc.Dataset("/fast/gmooers/Preprocessed_Data/Very_Small_data/000_valid.nc")
times = np.array(valid_data.variables['time'])
time = int(len(times)/(lats*lons))
# Function below makes an array of precip precitions and a corresponding array of SPCAM5 truths at each latitiude, longitude and timestep across the globe
# +
def array_finder(timing, config, validation, lat, lon):
truth_array = np.zeros(shape=(lat, lon, timing))
prediction_array = np.zeros(shape=(lat, lon, timing))
truth_array[:,:,:] = np.nan
prediction_array[:,:,:] = np.nan
md = ModelDiagnostics(config, validation)
for i in range(time):
temp = np.squeeze(np.array(md.get_truth_pred(itime=i)))
truth = temp[0,:,:]
prediction = temp[1,:,:]
truth_array[:,:,i] = truth
prediction_array[:,:,i] = prediction
return truth_array, prediction_array
truth_array, prediction_array = array_finder(time, config_path, validation_path, lats, lons)
# -
# Change Precipiation units to mm/day
truth_array = truth_array*86400000.
prediction_array = prediction_array*86400000
# Put array in 1 dimension for the purposes of our analysis
t = truth_array.ravel()
p = prediction_array.ravel()
# Determine the range of predicted values and true precipiation values
max_values = [np.nanmax(t), np.nanmax(p)]
min_values = [np.nanmin(t), np.nanmin(p)]
m = min(min_values)
M = max(max_values)
# Compare a PDF of true and predicted prteciaption values. It can be useful to narrow the range of focus towards lighter precipiation, where the biggest errors tend to occur (e.g. here wee restrict it to everything below 10 mm/day).
# +
def pdf_gen(feat, targ, mini, maxi):
maxi = 10.0
shared_bins = np.histogram_bin_edges(feat, bins=100, range=(0, maxi))
freq, edges = np.histogram(feat, bins = shared_bins, density = True)
freq_targ, edges_targ = np.histogram(targ, bins = shared_bins, density = True)
fig, ax = plt.subplots()
plt.plot(edges[:-1], freq, label = "DNN", alpha = 0.5, color = 'blue')
plt.plot(edges_targ[:-1], freq_targ, label = "SPCAM5", alpha = 0.5, color = 'green')
plt.xlabel('Precipitation Rate (mm/day)', fontsize = 15)
plt.ylabel('Probability', fontsize = 15)
plt.title('Precipitation PDF', fontsize = 15)
plt.legend(loc = 'best')
#plt.xscale('log')
plt.yscale('log')
#plt.savefig('/fast/gmooers/CS_273a_Proj_Figs/PDF_Relu.png')
pdf_gen(p, t, m, M)
# -
# Multiply each bin by the value of the bin in order to get the amount distribtion, whcich can be more revealing of errors in the predictions
# +
def amount_gen(feat, targ, mini, maxi):
maxi = 10.0
shared_bins = np.histogram_bin_edges(feat, bins=100, range=(0, maxi))
freq, edges = np.histogram(feat, bins = shared_bins, density = True)
freq_targ, edges_targ = np.histogram(targ, bins = shared_bins, density = True)
totals = freq*edges[:-1]
totals_targ = freq_targ*edges_targ[:-1]
fig, ax = plt.subplots()
plt.plot(edges[:-1], totals, label = "DNN", alpha = 0.5, color = 'blue')
plt.plot(edges_targ[:-1], totals_targ, label = "SPCAM5", alpha = 0.5, color = 'green')
plt.xlabel('Precipitation Rate (mm/day)', fontsize = 15)
plt.ylabel('Amount (mm/day)', fontsize = 15)
plt.title('Precipitation Amount Distribution', fontsize = 15)
plt.legend(loc = 'best')
#plt.savefig('/fast/gmooers/CS_273a_Proj_Figs/Amount_Relu.png')
amount_gen(p, t, m, M)
# +
#code for R^2 figure
#lats, lons, times
truth_array = truth_array*86400000.
prediction_array = prediction_array*86400000
R = np.zeros(shape=(96, 144))
target_list = []
feature_list = []
for i in range(len(truth_array)):
for j in range(len(truth_array[0])):
for k in range(len(truth_array[0][0])):
target_value = truth_array[i][j][k]
feature_value = prediction_array[i][j][k]
target_list.append(target_value)
feature_list.append(feature_value)
target_list = np.array(target_list)
feature_list = np.array(feature_list)
sse = np.sum((target_list-feature_list)**2.0)
svar = np.sum((target_list-np.mean(target_list))**2.0)
r_2 = 1-(sse/svar)
R[i, j] = r_2
target_list = []
feature_list = []
# +
lons = np.array(valid_data.variables['lon'])
lats = np.array(valid_data.variables['lat'])
#generate the latitudes
lat_var = []
for i in range(len(lats)):
if lats[i] not in lat_var:
lat_var.append(lats[i])
#generate the longtiude
lon_var = []
for i in range(len(lons)):
if lons[i] not in lon_var:
lon_var.append(lons[i])
# -
Xvar, Yvar = np.meshgrid(np.array(lon_var), np.array(lat_var))
Z = R
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j] < -1.0:
Z[i][j] = -1.0
if R[i][j] > 1.0:
Z[i][j] = 1.0
fig, ax = plt.subplots()
im = ax.pcolor(Xvar, Yvar, Z, cmap = 'Spectral', vmin = 0.0, vmax = 1.0)
fig.colorbar(im, label='$R^2$')
plt.xlabel('Longitude',fontsize=20)
plt.ylabel('Latitude', fontsize=20)
plt.title('Precip $R^2$ Error Map', fontsize=13)
#plt.gca().invert_yaxis()
#plt.savefig('/oasis/scratch/comet/gmooers/temp_project/SCRIPTS/Figures/SW_FLX_TOA_SPCAM5_R_squared.png')
| Precip_Editor.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: SageMath 7.0
# language: ''
# name: sagemath
# ---
# # Bedingungen fuer Kubische Spline-Interpolierende
#
# Angenommen $S(x)$ ist eine kubische Spline-Interpolierende für $n$ Punkte, dann muss gelten:
#
# 1. $S_j(x_{j+1}) = S_{j+1}(x_{j+1})$
# 2. $S'_j(x_{j+1}) = S'_{j+1}(x_{j+1})$
# 3. $S''_j(x_{j+1}) = S''_{j+1}(x_{j+1})$
# 4. $S''_0(x_0) = S''_n(x_n)$ = 0
# Aufgabenstellung: Testen ob eine Funktion eine kubische Spline-Interpolierende ist.
#
# - Gegeben: eine Funktion $S(x)$
# - Gesucht: ist $S$ eine kubische spline interpolierende?
# - Vorgehensweise: die Bedinungen testen
# +
var('x')
# input: funktionen der einzelnens splines
S = [
x/5 + 3/5 * x^3,
14/5 - 41/5 * x + 42/5 * x^2 - 2*x^3,
-122/5 + 151/5*x - 54/5* x^2 + 7/5*x^3
]
# input: definitionsbereich der spline funktionen
r = [
(0, 1),
(1, 2),
(2, 3)
]
for i, s in enumerate(S):
print "spline", i
show(s)
show(s.derivative(x))
show(s.derivative(x, 2))
print ""
# +
eqns = []
for i in range(len(S) - 1):
eqns.extend([
(S[i] == S[i + 1]).subs(x=r[i][1]),
(S[i].derivative(x) == S[i + 1].derivative(x)).subs(x=r[i][1]),
(S[i].derivative(x, 2) == S[i + 1].derivative(x, 2)).subs(x=r[i][1])
])
eqns.extend([
(S[0].derivative(x, 2) == 0).subs(x=r[0][0]),
(S[-1].derivative(x, 2) == 0).subs(x=r[-1][1]),
])
for eqn in eqns:
show(eqn)
print "holds? ", eqn == True
print ""
# -
# Aufgabenstellung:
#
# - Gegeben: eine Funktion $S(x)$ mit reellen Konstanten $a,b,c,d \ldots$
# - Gesucht: Werte der Konstanten sodass $S(x)$ eine gültige kubische Spline-Interpolierende ist
# - Vorgehensweise: Basierend auf den Bedingungen ein Gleichunssystem aufstellen und lösen
var('x')
# input:
constants = var('a,b,c,d,e')
S = [
a + b*(x - 1) + c*(x - 1)^2 + d * (x - 1)^3,
(x - 1)^3 + e*x^2 - 1
]
r = [
(0, 1),
(1, 2)
]
for i, s in enumerate(S):
print "S[{}], first, second derivative:".format(i)
for j in range(3):
show(s.derivative(x, j))
print ""
# +
eqns = []
for i in range(len(S) - 1):
eqns.extend([
(S[i] == S[i + 1]).subs(x=r[i][1]),
(S[i].derivative(x) == S[i + 1].derivative(x)).subs(x=r[i][1]),
(S[i].derivative(x, 2) == S[i + 1].derivative(x, 2)).subs(x=r[i][1])
])
eqns.extend([
(S[0].derivative(x, 2) == 0).subs(x=r[0][0]),
(S[-1].derivative(x, 2) == 0).subs(x=r[-1][1]),
])
for eqn in eqns:
show(eqn.simplify())
# -
for i in solve(eqns, *constants):
show(i)
| nrla_testing_cubic_spline.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
import pprint
import sys
if "../" not in sys.path:
sys.path.append("../")
from lib.envs.gridworld import GridworldEnv
pp = pprint.PrettyPrinter(indent=2)
env = GridworldEnv()
# +
# Taken from Policy Evaluation Exercise!
def policy_eval(policy, env, discount_factor=1.0, theta=0.00001):
"""
Evaluate a policy given an environment and a full description of the environment's dynamics.
Args:
policy: [S, A] shaped matrix representing the policy.
env: OpenAI env. env.P represents the transition probabilities of the environment.
env.P[s][a] is a list of transition tuples (prob, next_state, reward, done).
env.nS is a number of states in the environment.
env.nA is a number of actions in the environment.
theta: We stop evaluation once our value function change is less than theta for all states.
discount_factor: Gamma discount factor.
Returns:
Vector of length env.nS representing the value function.
"""
# Start with a random (all 0) value function
V = np.zeros(env.nS)
while True:
delta = 0
# For each state, perform a "full backup"
for s in range(env.nS):
v = 0
# Look at the possible next actions
for a, action_prob in enumerate(policy[s]):
# For each action, look at the possible next states...
for prob, next_state, reward, done in env.P[s][a]:
# Calculate the expected value
v += action_prob * prob * (reward + discount_factor * V[next_state])
# How much our value function changed (across any states)
delta = max(delta, np.abs(v - V[s]))
V[s] = v
# Stop evaluating once our value function change is below a threshold
if delta < theta:
break
return np.array(V)
# -
def policy_improvement(env, policy_eval_fn=policy_eval, discount_factor=1.0, verbose=False):
"""
Policy Improvement Algorithm. Iteratively evaluates and improves a policy
until an optimal policy is found.
Args:
env: The OpenAI envrionment.
policy_eval_fn: Policy Evaluation function that takes 3 arguments:
policy, env, discount_factor.
discount_factor: gamma discount factor.
Returns:
A tuple (policy, V).
policy is the optimal policy, a matrix of shape [S, A] where each state s
contains a valid probability distribution over actions.
V is the value function for the optimal policy.
"""
# Start with a random policy
policy = np.ones([env.nS, env.nA]) / env.nA
while True:
# evaluate the value functon for the current policy
value = policy_eval_fn(policy, env, discount_factor)
if verbose:
print(value.reshape(4,4))
# iterate over states to determine what the best action is for each
for s in range(env.nS):
if verbose:
print(f'state: {s}')
# look at the action space for the state
# determine which action leads to the next state(s) with highest value
# choose that action (greedily). counting ties is unnecessary but fine, and I do it here.
max_action_val = -1*np.inf
best_action = []
for a in env.P[s]:
action_value = 0 # check the action value to be gained from taking a = q(s,a)
for prob, next_state, reward, done in env.P[s][a]:
action_value += prob*(reward + discount_factor*value[next_state])
if verbose:
print(f' action {a} has value {action_value}')
if action_value > max_action_val:
best_action = [a]
max_action_val = action_value
elif action_value == max_action_val:
best_action.append(a)
policy[s] = np.zeros(env.nA)
for a in best_action:
policy[s][a] = 1/len(best_action)
if verbose:
print(f' actions {best_action} are best, yielding {policy[s]}')
# if the value no longer increases (because the policy is stable), the policy has converged
updated_policy_value = policy_eval_fn(policy, env, discount_factor)
if np.max(np.abs(updated_policy_value-value)) <= 0:
break
return policy, updated_policy_value
# My solution is above. The code can be simplified using `np.argmax()` rather than tracking the maximum action-value encountered, and directly tracking changes in the policy is a better way to determine when it has stabilized than my current approach (checking for changes in v sub pi).
# +
policy, v = policy_improvement(env)
print("Policy Probability Distribution:")
print(policy)
print("")
print("Reshaped Grid Policy (0=up, 1=right, 2=down, 3=left):")
print(np.reshape(np.argmax(policy, axis=1), env.shape))
print("")
print("Value Function:")
print(v)
print("")
print("Reshaped Grid Value Function:")
print(v.reshape(env.shape))
print("")
# -
# Test the value function
expected_v = np.array([ 0, -1, -2, -3, -1, -2, -3, -2, -2, -3, -2, -1, -3, -2, -1, 0])
np.testing.assert_array_almost_equal(v, expected_v, decimal=2)
| notes/britz_exercises/Policy Iteration.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Inception Architecture
# + pycharm={"name": "#%%\n"}
import os
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Input, Dropout
from tensorflow.keras.layers import AveragePooling2D, BatchNormalization, concatenate
from tensorflow.keras.regularizers import l2
from tensorflow.keras.initializers import glorot_uniform, constant
from tensorflow.keras.activations import relu, sigmoid
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import binary_crossentropy
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from tensorflow.keras.utils import plot_model
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
from sklearn.preprocessing import MultiLabelBinarizer
# -
# ### Inception model
# + pycharm={"name": "#%%\n"}
kernel_init = glorot_uniform()
bias_init = constant(value=0.2)
def inception_module(x, filter_1x1, filter_3x3_reduce, filter_3x3, filter_5x5_reduce, filter_5x5, filters_pool_proj,
name=None):
conv_1x1 = Conv2D(filter_1x1, kernel_size=(1, 1), padding='same', activation=relu, kernel_initializer=kernel_init,
bias_initializer=bias_init)(x)
# 3x3 layer
conv_3x3_reduce = Conv2D(filter_3x3_reduce, kernel_size=(1, 1), padding='same', activation=relu,
kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filter_3x3, kernel_size=(3, 3), padding='same', activation=relu, kernel_initializer=kernel_init,
bias_initializer=bias_init)(conv_3x3_reduce)
# 5x5 layer
conv_5x5_reduce = Conv2D(filter_5x5_reduce, kernel_size=(1, 1), padding='same', activation=relu,
kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_5x5 = Conv2D(filter_5x5, kernel_size=(5, 5), padding='same', activation=relu, kernel_initializer=kernel_init,
bias_initializer=bias_init)(conv_5x5_reduce)
# pool projection layer
pool_proj = MaxPooling2D(pool_size=(3, 3), padding='same', strides=(1, 1))(x)
pool_proj = Conv2D(filters_pool_proj, kernel_size=(1, 1), padding='same', activation=relu,
kernel_initializer=kernel_init, bias_initializer=bias_init)(pool_proj)
output = concatenate([conv_1x1, conv_3x3, conv_5x5, pool_proj], axis=3, name=name)
return output
# bottom layer
input_layer = Input(shape=(56, 56, 3))
x = Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation=relu,
kernel_initializer=kernel_init, bias_initializer=bias_init)(input_layer)
x = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool_1_3x3/2')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=64, kernel_size=(1, 1), strides=(1, 1), padding='same', activation=relu,
kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
x = Conv2D(filters=192, kernel_size=(3, 3), strides=(1, 1), padding='same', activation=relu,
kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
x = BatchNormalization()(x)
# inception layers
x = inception_module(x, filter_1x1=64, filter_3x3_reduce=96, filter_3x3=128, filter_5x5_reduce=16, filter_5x5=32,
filters_pool_proj=32, name='inception_3a')
x = inception_module(x, filter_1x1=128, filter_3x3_reduce=128, filter_3x3=192, filter_5x5_reduce=32, filter_5x5=96,
filters_pool_proj=64, name='inception_3b')
x = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool_3_3x3/2')(x)
x = inception_module(x, filter_1x1=192, filter_3x3_reduce=96, filter_3x3=208, filter_5x5_reduce=16, filter_5x5=48,
filters_pool_proj=64, name='inception_4a')
x = inception_module(x, filter_1x1=160, filter_3x3_reduce=112, filter_3x3=224, filter_5x5_reduce=24, filter_5x5=64,
filters_pool_proj=64, name='inception_4b')
x = inception_module(x, filter_1x1=128, filter_3x3_reduce=128, filter_3x3=256, filter_5x5_reduce=24, filter_5x5=64,
filters_pool_proj=64, name='inception_4c')
x = inception_module(x, filter_1x1=112, filter_3x3_reduce=144, filter_3x3=288, filter_5x5_reduce=32, filter_5x5=64,
filters_pool_proj=64, name='inception_4d')
x = inception_module(x, filter_1x1=256, filter_3x3_reduce=160, filter_3x3=320, filter_5x5_reduce=32, filter_5x5=128,
filters_pool_proj=128, name='inception_4e')
x = MaxPooling2D(pool_size=(2, 2), padding='same', name='max_pool_4_3x3/2')(x)
x = inception_module(x, filter_1x1=256, filter_3x3_reduce=160, filter_3x3=320, filter_5x5_reduce=32, filter_5x5=128,
filters_pool_proj=128, name='inception_5a')
x = inception_module(x, filter_1x1=384, filter_3x3_reduce=192, filter_3x3=384, filter_5x5_reduce=48, filter_5x5=128,
filters_pool_proj=128, name='inception_5b')
# classifier
x = AveragePooling2D(pool_size=(3, 3), strides=(1, 1), padding='valid')(x)
x = Flatten()(x)
x = Dropout(rate=0.4)(x)
# change #1
x = Dense(units=1024, activation=relu)(x)
x = Dropout(rate=0.4)(x)
output_layer = Dense(units=37, activation=sigmoid)(x)
exp_conv = Model(input_layer, output_layer)
exp_conv.summary()
# + pycharm={"name": "#%%\n"}
plot_model(model=exp_conv,
to_file='Inception.png',
show_shapes=True,
show_dtype=True,
show_layer_names=True)
# + pycharm={"name": "#%%\n"}
tree_types = os.listdir('../../data/image data/train')
X = []
y = []
val_x = []
val_y = []
for tree in tree_types:
if not tree == 'Cassava':
tree_path = os.path.join('../../data/image data/train', tree)
tree_disease_types = os.listdir(tree_path)
for disease in tree_disease_types:
img_name = os.listdir(os.path.join(tree_path, disease))
for img in img_name:
image_path = os.path.join(tree_path, disease, img)
image = img_to_array(load_img(image_path, target_size=(56, 56)))
X.append(image)
y.append([tree, disease])
for tree in tree_types:
if not tree == 'Cassava':
tree_path = os.path.join('../../data/image data/validation', tree)
tree_disease_types = os.listdir(tree_path)
for disease in tree_disease_types:
img_name = os.listdir(os.path.join(tree_path, disease))
for img in img_name:
image_path = os.path.join(tree_path, disease, img)
image = img_to_array(load_img(image_path, target_size=(56, 56)))
val_x.append(image)
val_y.append([tree, disease])
# + pycharm={"name": "#%%\n"}
X = np.asarray(X)
val_x = np.asarray(val_x)
mlb = MultiLabelBinarizer()
y = mlb.fit_transform(y)
val_y = mlb.transform(val_y)
generator = ImageDataGenerator(rescale=1. / 255)
# + pycharm={"name": "#%%\n"}
X.shape, y.shape, val_x.shape, val_y.shape
# + pycharm={"name": "#%%\n"}
train_gen = generator.flow(X, y, batch_size=96)
val_gen = generator.flow(val_x, val_y, batch_size=96)
# -
# #### training
# + pycharm={"name": "#%%\n"}
reduce_lr = ReduceLROnPlateau(monitor='val_loss',
factor=0.1)
check_point = ModelCheckpoint(filepath='Inception.hdf5',
monitor='val_loss',
save_best_only=True)
early_stopping = EarlyStopping(monitor='val_loss',
patience=20,
restore_best_weights=True)
callbacks = [reduce_lr, check_point, early_stopping]
# + pycharm={"name": "#%%\n"}
exp_conv.compile(optimizer=Adam(),
loss=binary_crossentropy,
metrics=['accuracy'])
# + pycharm={"name": "#%%\n"}
exp_conv_history = exp_conv.fit(train_gen,
epochs=200,
callbacks=callbacks,
validation_data=val_gen)
# + pycharm={"name": "#%%\n"}
figure, axes = plt.subplots(nrows=1, ncols=2, figsize=[18, 6], dpi=300)
axes = axes.ravel()
epochs = list(range(len(exp_conv_history.history['loss'])))
sns.lineplot(x=epochs, y=exp_conv_history.history['loss'], ax=axes[0], label='loss')
sns.lineplot(x=epochs, y=exp_conv_history.history['val_loss'], ax=axes[0], label='val loss')
sns.lineplot(x=epochs, y=exp_conv_history.history['accuracy'], ax=axes[1], label='accuracy')
sns.lineplot(x=epochs, y=exp_conv_history.history['val_accuracy'], ax=axes[1], label='val accuracy')
axes[0].set_xlabel('epoch')
axes[0].set_ylabel('loss')
axes[1].set_xlabel('epoch')
axes[1].set_ylabel('accuracy')
plt.savefig('Inception_train_history.png')
plt.show()
# + pycharm={"name": "#%%\n"}
figure_1, axes = plt.subplots(nrows=1, ncols=2, figsize=[12, 6], dpi=300)
axes = axes.ravel()
sns.lineplot(x=epochs, y=exp_conv_history.history['lr'], ax=axes[0], label='learning rate')
sns.lineplot(x=exp_conv_history.history['lr'], y=exp_conv_history.history['val_accuracy'], ax=axes[1],
label='accuracy & lr')
axes[0].set_xlabel('epoch')
axes[0].set_ylabel('learning rate')
axes[1].set_xlabel('learning rate')
axes[1].set_ylabel('accuracy')
plt.savefig('VGGNet_base_conv_lr_history.png')
plt.show()
| models/architecture/inception.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + id="gpGPl3rxD5bt" executionInfo={"status": "ok", "timestamp": 1624643745476, "user_tz": -330, "elapsed": 24, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib notebook
import doctest
import copy
# + id="Cy-IHdN_D5bv" executionInfo={"status": "ok", "timestamp": 1624643745477, "user_tz": -330, "elapsed": 19, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
#https://stackoverflow.com/questions/40137950/possible-to-run-python-doctest-on-a-jupyter-cell-function
def test(func):
'''
Use test as a decorator to a function with doctests in Jupyter notebook.
Run the cell to see the results of the doctests.
'''
globs = copy.copy(globals())
globs.update({func.__name__:func})
doctest.run_docstring_examples(func, globs, verbose=True, name=func.__name__)
return func
# + [markdown] id="wItZX1gwD5bw"
# ### Simulate straight line and circular movements with Bicycle model
#
# Robot is at the origin (0, 0) and facing North, i.e, $\theta = \pi/2$. Assume the wheelbase of the vehicle $L$ = 0.9 m
# + id="Zeb2OgYeD5bx" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1624643746134, "user_tz": -330, "elapsed": 673, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}} outputId="babbfc07-a7bf-43fd-e3d2-00cd15bd2fff"
#uncomment this decorator to test your code
@test
def bicycle_model(curr_pose, v, delta, dt=1.0):
'''
>>> bicycle_model((0.0,0.0,0.0), 1.0, 0.0)
(1.0, 0.0, 0.0)
>>> bicycle_model((0.0,0.0,0.0), 0.0, np.pi/4)
(0.0, 0.0, 0.0)
>>> bicycle_model((0.0, 0.0, 0.0), 1.0, np.pi/4)
(1.0, 0.0, 1.11)
'''
## write code to calculate next_pose
# refer to the kinematic equations of a bicycle model
x_old, y_old, thetha_old = curr_pose[0], curr_pose[1], curr_pose[2]
x = x_old + v * np.cos(thetha_old) *dt
y = y_old + v * np.sin(thetha_old) *dt
w = v * np.tan(delta)/0.9 #L=0.9
theta = thetha_old + w* dt
# Keep theta bounded between [-pi, pi]
theta = np.arctan2(np.sin(theta), np.cos(theta))
# return calculated (x, y, theta)
return (x, y, theta)
# + id="rkAm7KZ5D5by" executionInfo={"status": "ok", "timestamp": 1624643746135, "user_tz": -330, "elapsed": 30, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
#straight line
straight_trajectory = []
pose = (0, 0, np.pi/2)
steps = 10
#fill in v and omega values
v = 1.0
delta = 0
for _ in range(steps):
#instruction to take v, w and compute new pose
pose = bicycle_model(pose, v,delta)
# store new pose
straight_trajectory.append(list(pose))
straight_trajectory = np.array(straight_trajectory)
# + id="9fNbts6TD5bz" executionInfo={"status": "ok", "timestamp": 1624643746137, "user_tz": -330, "elapsed": 28, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
#circle
circle_trajectory = []
pose = (0, 0, np.pi/2)
steps = 22
#fill in v and omega values
v = 1.0
delta = np.pi/12
for _ in range(steps):
#instruction to take v, w and compute new pose
pose = bicycle_model(pose, v,delta)
# store new pose
circle_trajectory.append(list(pose))
circle_trajectory = np.array(circle_trajectory)
# + id="RS90vnzYD5b0" colab={"base_uri": "https://localhost:8080/", "height": 265} executionInfo={"status": "ok", "timestamp": 1624643746138, "user_tz": -330, "elapsed": 28, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}} outputId="93a9d8a1-0ab4-4aca-afa9-50e5eb535cba"
### Plot straight and circular trajectories
plt.figure()
plt.axes().set_aspect("equal","datalim")
plt.plot(straight_trajectory[:,0],straight_trajectory[:,1])
plt.plot(circle_trajectory[:,0],circle_trajectory[:,1])
plt.show()
# + [markdown] id="KPMhUJJBD5b1"
# ### Simulate Bicycle model with Open Loop control
#
# We want the robot to follow these instructions
#
# **straight 10m, right turn, straight 5m, left turn, straight 8m, right turn**
#
# It is in open loop; control commands have to be calculated upfront. How do we do it?
#
# To keep things simple in the first iteration, we can fix $v = v_c$ and change only $\delta$. To make it even simpler, $\delta$ can take only 2 values
# # + 0 when the vehicle is going straight
# # + $\delta = \delta_c$ when turning
#
# This leaves only 2 questions to be answered
# * What should be $v_c$ and $\delta_c$?
# * When should $\delta$ change from 0 and back?
# + id="-U-6NqIoD5b2" executionInfo={"status": "ok", "timestamp": 1624643746141, "user_tz": -330, "elapsed": 25, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
v_c = 1 # m/s
delta_c = np.pi/12 # rad/s
L=0.9
w_c = v_c * np.tan(delta_c)/L
#calculate time taken to finish a quarter turn (pi/4)
# unlike you would need to take into account v_c and L of the vehicle as well
t_turn = int((np.pi/2) / w_c )
#calculate the time taken to finish straight segments
# omega array is to be padded with equivalent zeros
t_straight1, t_straight2, t_straight3 = int(10/v_c) , int(5/v_c) , int(8/v_c)
all_delta = [0]*t_straight1 + [delta_c]*t_turn + \
[0]*t_straight2 + [delta_c]*t_turn + \
[0]*t_straight3 + [-delta_c]*t_turn
all_v = v_c*np.ones_like(all_delta)
# + [markdown] id="lI-eXKo9D5b3"
# Let us make a cool function out of this!
#
# Take in as input a generic route and convert it into open-loop commands
#
# Input format: [("straight", 5), ("right", 90), ("straight", 6), ("left", 85)]
#
# Output: all_v, all_delta
# + id="dydnwuPmD5b4" executionInfo={"status": "ok", "timestamp": 1624643746141, "user_tz": -330, "elapsed": 24, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
from math import ceil
def get_open_loop_commands(route, vc, deltac, dt=1):
all_delta = []
all_v = []
L = 0.9
wc = vc * np.tan(deltac)/L
for (dir,amt) in route:
if dir == "straight":
t_straight = ceil((amt/vc)/dt)
all_delta += [0]*t_straight
else:
amt = (amt/180) * np.pi #Considering that the turn amount in the controls is given in degrees.
t_turn = ceil((amt/wc)/dt)
if dir == "right":
all_delta += [-deltac]*t_turn
elif dir == "left":
all_delta += [deltac]*t_turn
all_v = vc*np.ones_like(all_delta)
# return all_v, all_w
return all_v, all_delta
# + [markdown] id="wPg13GHQD5b5"
# ### Unit test your function with the following inputs
#
# # + [("straight", 5), ("right", 90), ("straight", 6), ("left", 85)]
# # + $v_c = 1$
# # + $delta_c = \pi/12$
# + id="ga3MspwND5b5" executionInfo={"status": "ok", "timestamp": 1624643746142, "user_tz": -330, "elapsed": 24, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
#get_open_loop_commands()
cmd = [("straight", 5), ("right", 90), ("straight", 6), ("left", 85)]
vc = 1
deltac = np.pi/12
all_v, all_delta = get_open_loop_commands(cmd,vc,deltac)
# + id="elCuQPcsD5b6" executionInfo={"status": "ok", "timestamp": 1624643746144, "user_tz": -330, "elapsed": 25, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
robot_trajectory = []
pose = np.array([0, 0, np.pi/2])
for v, delta in zip(all_v, all_delta):
#instruction to take v, w and compute new pose
pose = bicycle_model(pose, v,delta)
# store new pose
robot_trajectory.append(list(pose))
robot_trajectory = np.array(robot_trajectory)
# + id="qK5s5Em9D5b6" colab={"base_uri": "https://localhost:8080/", "height": 341} executionInfo={"status": "ok", "timestamp": 1624643747054, "user_tz": -330, "elapsed": 934, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}} outputId="57b63757-936c-4e2c-943b-169e2d591dd0"
# plot robot trajectory
plt.figure()
plt.grid()
plt.axes().set_aspect("equal","datalim")
plt.plot(robot_trajectory[:,0],robot_trajectory[:,1])
#show first and last robot positions with + markers
# example: plt.plot(0, 0, 'r+', ms=10)
plt.plot(robot_trajectory[0,0],robot_trajectory[0,1], 'r+', ms=10)
plt.plot(robot_trajectory[-1,0],robot_trajectory[-1,1], 'r+', ms=10)
# + [markdown] id="H-ecY7zbD5b7"
# ### Shape the turn
# Let us try something cooler than before (though a bit tricky in open loop). Instead of boring circular arcs, change the steering angle so that the robot orientation changes as shown in the equation below
#
# $\theta = (\theta_i - \theta_f) * (1 - 3x^2 + 2\theta^3) + \theta_f \thinspace \vee x \in [0,1]$
#
# First let us plot this
# + id="DQbmFZmXD5b8" executionInfo={"status": "ok", "timestamp": 1624643747056, "user_tz": -330, "elapsed": 41, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}}
def poly_turn(theta_i, theta_f, n=10):
x = np.linspace(0, 1, num=n)
return (theta_i-theta_f) * (1 - 3 * x * x + 2 * (x**3)) + theta_f
# + [markdown] id="58KMj70TD5b9"
# How does a right turn look?
# + id="7INgEBQvD5b9" colab={"base_uri": "https://localhost:8080/", "height": 282} executionInfo={"status": "ok", "timestamp": 1624643747059, "user_tz": -330, "elapsed": 37, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}} outputId="248d0a7d-1d10-4855-8c03-2eb3492c5c2a"
plt.figure()
plt.plot(poly_turn(np.pi/2, 0,50),'.')
plt.plot(poly_turn(np.pi/2, 0,50))
# + [markdown] id="Gk546i4HD5b-"
# Now plot a left turn (North to West)
# + id="MIcpSAHhD5b_" colab={"base_uri": "https://localhost:8080/", "height": 284} executionInfo={"status": "ok", "timestamp": 1624643747061, "user_tz": -330, "elapsed": 30, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}} outputId="19d62a70-1742-4a06-cb82-1c5c20abe7ba"
plt.figure()
plt.plot(poly_turn(np.pi/2, np.pi),'.')
plt.plot(poly_turn(np.pi/2, np.pi))
# + [markdown] id="rj670M1aD5b_"
# How does $\theta$ change when we had constant $\delta$? Plot it
# + id="ywtHa7z3D5cA" colab={"base_uri": "https://localhost:8080/", "height": 282} executionInfo={"status": "ok", "timestamp": 1624643747878, "user_tz": -330, "elapsed": 841, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}} outputId="2a1b7558-1f16-43cc-87ff-87766b9b5b1e"
del_thetha = np.diff(poly_turn(np.pi/2, np.pi,10))
plt.plot(del_thetha,'.')
plt.plot(del_thetha)
# + [markdown] id="7QGyMtTxD5cA"
# We know the rate of change of $\theta$ is proportional to $\delta$. Can you work out the sequence of $\delta$ to change $\theta$ as in the cubic polynomial shown above?
# + id="UZ590VkxD5cA" colab={"base_uri": "https://localhost:8080/", "height": 282} executionInfo={"status": "ok", "timestamp": 1624643747881, "user_tz": -330, "elapsed": 36, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhTo_tG_gjzTR9FFzD7uY-Kci6YsHM6-IZOSjUUWQ=s64", "userId": "11163953400284403918"}} outputId="b267bf8b-6ccf-4953-92ca-7ef1a04951e6"
n = 10
# dt = 1/n
theta_i = np.pi/2
theta_f = np.pi
thetha = poly_turn(theta_i, theta_f,n)
del_thetha = np.diff(thetha)
L =0.9
v =20
delta = np.arctan(del_thetha * L /v)
plt.plot(delta,'.')
plt.plot(delta)
| week1/parvmaheshwari2002/Q3 - Q/Attempt1_filesubmission_Bicycle_model.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Warehouse Facility 03 - Warehouse Inventory assessment
# *This notebook illustrates how to assess the inventory position of a storage system.
# ***
# <NAME>, Ph.D. 2021
# ### Import packages
# +
# %% append functions path
import sys; sys.path.insert(0, '..') #add the above level with the package
import os
import pandas as pd
import numpy as np
from IPython.display import display, HTML #display dataframe
# -
# ### Set data fields
string_casestudy = 'TOY_DATA'
# ### Import data
# %% import data
from analogistics.data.data_generator_warehouse import generateWarehouseData
D_locations, D_SKUs, D_movements, D_inventory = generateWarehouseData()
#print locations dataframe
display(HTML(D_locations.head().to_html()))
#print SKUs master file dataframe
display(HTML(D_SKUs.head().to_html()))
#print SKUs master file dataframe
display(HTML(D_movements.head().to_html()))
#print SKUs master file dataframe
display(HTML(D_inventory.head().to_html()))
# ### Create folder hierarchy
# +
# %% create folder hierarchy
pathResults = 'C:\\Users\\aletu\\desktop'
root_path = os.path.join(pathResults,f"{string_casestudy}_results")
path_results = os.path.join(root_path,f"P8_warehouseAssessment")
os.makedirs(root_path, exist_ok=True)
os.makedirs(path_results, exist_ok=True)
# -
# ### Set the columns name
# %% SET COLUMNS MOVEMENTS
timecolumn_mov='TIMESTAMP_IN'
itemcodeColumns_mov='ITEMCODE'
inout_column_mov = 'INOUT'
x_col_mov = 'LOCCODEX'
y_col_mov = 'LOCCODEY'
z_col_mov = 'LOCCODEZ'
# %% SET COLUMNS SKUS
itemcodeColumns_sku='ITEMCODE'
# %% SET COLUMNS INVENTORY
itemcodeColumns_inv = 'ITEMCODE'
# ### Generate the inventory curve for each SKU
# generate the inventory curve for each SKU
from analogistics.supply_chain.information_framework import updatePartInventory
D_SKUs= updatePartInventory(D_SKUs,D_movements,D_inventory,timecolumn_mov,itemcodeColumns_sku,itemcodeColumns_mov,itemcodeColumns_inv)
# +
# %% update global inventory
from analogistics.supply_chain.P8_performance_assessment.wh_inventory_assessment import updateGlobalInventory
path_current = os.path.join(path_results,f"Inventory")
os.makedirs(path_current, exist_ok=True)
D_global_inventory = updateGlobalInventory(D_SKUs,inventoryColumn='INVENTORY_QTY')
D_global_inventory.to_excel(path_current+"\\global inventory.xlsx")
# %% analyse the inventory behaviour
from analogistics.supply_chain.P8_performance_assessment.wh_inventory_assessment import inventoryAnalysis
output_figures = inventoryAnalysis(D_global_inventory)
for key in output_figures.keys():
output_figures[key].savefig(path_current+f"\\{key}.png")
# -
# ### INVENTORY design
# +
from analogistics.supply_chain.P8_performance_assessment.wh_inventory_assessment import defineStockoutCurve
output_figure = defineStockoutCurve(D_global_inventory['WH_INVENTORY_VOLUME'])
for key in output_figures.keys():
output_figures[key].savefig(path_current+f"\\{key}.png")
# -
| examples/Warehouse Facility 03 - Warehouse Inventory assessment.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
grid = [i.strip() for i in open("03.data").readlines()]
print(grid[0])
def coord(row, col):
"""What's at the given coordinate in the data?"""
cell = grid[row][col % (len(grid[0]))]
return cell
#
col = 0
count = 0
for row in range(0, len(grid)):
if coord(row, col) == '#':
count += 1
col += 3
print(count)
# +
def count_trees(col_inc, row_inc):
col = 0
count = 0
for row in range(0, len(grid), row_inc):
if coord(row, col) == '#':
count += 1
col += col_inc
return count
print(count_trees(1,1) * count_trees(3, 1) * count_trees(5,1) * count_trees(7,1) * count_trees(1,2))
# -
| 2020/03.ipynb |
;; ---
;; jupyter:
;; jupytext:
;; text_representation:
;; extension: .scm
;; format_name: light
;; format_version: '1.5'
;; jupytext_version: 1.14.4
;; kernelspec:
;; display_name: Calysto Scheme 3
;; language: scheme
;; name: calysto_scheme
;; ---
;; # Lec18 `#16/11`
;;
;; ## OOP
;; ### Inheritance: via Internal Objects
(define (make-prof fname lname) ; Subclass
(let ((int-person (make-person fname lname))) ; Superclass
(lambda (msg)
(case msg
((LECTURE)
(lambda (self args)
(ask self 'SAY (cons 'Therefore args))))
((WHOAREYOU)
(lambda (self)
(display 'Professor)
(ask self 'WHOAREYOU)))
(else (get-method msg int-person)))
)))
;; +
(define (ask object message . args)
(let ((method (get-method message object)))
(cond ((method? method) (apply method (cons object args)))
(else (error "No method for message" message)))))
(define (method? x)
(cond ((procedure? x) #t)
((eq? x (no-method)) #f)
(else (error "Object returned non-message" x))))
(define (no-method) `NO-METHOD)
(define (get-method message object)
(object message))
(define (make-person fname lname)
(lambda (message)
(cond ((eq? message 'WHOAREYOU) (lambda (self) fname))
((eq? message 'CHANGE-MY-NAME)
(lambda (self new-name)
(set! fname new-name)
(ask self 'SAY (list 'Call 'me fname))))
((eq? message 'SAY)
(lambda (self list-of-stuff)
(display list-of-stuff)
'NUF-SAID))
((eq? message 'PERSON?)
(lambda (self) #t))
(else (no-method)))))
;; +
(define e (make-prof 'eric 'grimson))
(ask e 'SAY '(the sky is blue)) (newline)
(ask e 'LECTURE '(the sky is blue)) (newline)
;; -
;; ### Multiple Inheritance
;;
;; Class diagram for : `Person` $ \leftarrow $ `Prof` $ \leftarrow $ `Arrogant Prof` $ \leftarrow $ `S.A.P.` $ \rightarrow $ `Singer`
;;
;; `Arrogant Prof` and `Singer` has `SAY` method, so `S.A.P.` will call which ? (Design choice)
| Lectures/.ipynb_checkpoints/Lec18-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="nv0KwAkxnJYH"
# **references**
#
# https://www.statworx.com/at/blog/how-to-build-a-dashboard-in-python-plotly-dash-step-by-step-tutorial/
# https://github.com/STATWORX/blog/blob/master/DashApp/app_basic.py
#
# https://pierpaolo28.github.io/blog/blog21/
# https://github.com/pierpaolo28/Data-Visualization/tree/master/Dash
#
# https://dash.plotly.com/deployment
# + [markdown] id="qxow6sFBcszo"
# # https://plotly.com/python/filled-area-plots/
#
# between area: same color, but no different colors: color btw PMA and MA
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 16390, "status": "ok", "timestamp": 1612139959635, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="tw5bX-rqdfVy" outputId="51687c59-f340-48c8-fe64-b89faab7ee78"
# !pip install dash
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 7199, "status": "ok", "timestamp": 1612140017496, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="clN7sZtuCFRq" outputId="9112c8af-526f-45ae-b491-801707d2659a"
# !pip install yfinance --upgrade --no-cache-dir
# + executionInfo={"elapsed": 5749, "status": "ok", "timestamp": 1612140017497, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="3UUvVMyCayZa"
# #!pip install dash
import dash ## local
#from jupyter_dash import JupyterDash # colab
import dash_html_components as html
import dash_core_components as dcc
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
from dash.dependencies import Input, Output
from sklearn import preprocessing
import numpy as np
import tensorflow as tf
import yfinance as yf
# + executionInfo={"elapsed": 501, "status": "ok", "timestamp": 1612140021950, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="TOw8STlCcszu"
stock_list = ["FB", "AAPL", "AMZN", "NFLX", "GOOG", "MSFT", "XLK", "QQQ"]
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 1981, "status": "ok", "timestamp": 1612140023604, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="-dGHGL17cszx" outputId="d6063947-7b44-4e7d-9141-690cbaf822ec"
# to get predict data
stock_dic = dict()
for stock in stock_list:
df = yf.download(stock, start="2019-7-25").drop(columns='Adj Close')
df.dropna(inplace=True)
stock_dic[stock] = df
# + [markdown] id="2hfyEWovcsz0"
# # predict1, predict2, predict3, MA, PMA, UpDown
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 2077, "status": "ok", "timestamp": 1612140025733, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="fe1ZP11Mcsz1" outputId="276889dc-570a-4d7e-a095-6d2d58b0b210"
# get normalizer
df1_dic={}
for stock in stock_list:
data = yf.download(stock, start="2012-05-18", end="2020-07-23")
# data, meta_data = ts.get_daily(symbol=stock,outputsize = 'full')
# data.sort_values(by='date', inplace=True)
data = data.drop(columns='Adj Close')
df1_dic[stock] = data
# + executionInfo={"elapsed": 1164, "status": "ok", "timestamp": 1612140025734, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="0eRrPFW-csz3"
history_points = 50
def getXtest(data, data_nor):
data = data.to_numpy()
data2 = data_nor.to_numpy()
data_normaliser = preprocessing.MinMaxScaler()
data_normaliser = data_normaliser.fit(data)
data_normalised = data_normaliser.transform(data)
Xtest = np.array([data_normalised[i : i + history_points].copy() for i in range(len(data) - history_points+1)])
# next_day_open_values = np.array([data2[:,0][i + history_points].copy() for i in range(len(data2) - history_points)])
next_day_open_values = np.array([data[:,0][i + history_points].copy() for i in range(len(data) - history_points)])
next_day_open_values = np.expand_dims(next_day_open_values, -1)
next_day_close_values = np.array([data[:,3][i + history_points].copy() for i in range(len(data) - history_points)])
next_day_close_values = np.expand_dims(next_day_close_values, -1)
y_normaliser_open = preprocessing.MinMaxScaler()
y_normaliser_open.fit(next_day_open_values)
y_normaliser_close = preprocessing.MinMaxScaler()
y_normaliser_close.fit(next_day_close_values)
return Xtest, y_normaliser_open, y_normaliser_close
# + executionInfo={"elapsed": 909, "status": "ok", "timestamp": 1612140025735, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="GQFKr1Rncsz6"
# 1 day prediction: close, open (for candle stick)
def getResult1(stock):
data = stock_dic[stock]
data_nor = df1_dic[stock]
model_open = tf.keras.models.load_model('{}_model_open'.format(stock))
model_close = tf.keras.models.load_model('{}_model'.format(stock))
Xtest, y_normaliser_open, y_normaliser_close = getXtest(data, data_nor)
open_pred = model_open.predict(Xtest)
open_pred = np.reshape(open_pred, (open_pred.shape[0], 1))
open_pred = y_normaliser_open.inverse_transform(open_pred)
close_pred = model_close.predict(Xtest)
close_pred =np.reshape(close_pred, (close_pred.shape[0], 1))
close_pred = y_normaliser_close.inverse_transform(close_pred)
# return open_pred, close_pred
return np.reshape(open_pred, open_pred.shape[0]), np.reshape(close_pred, close_pred.shape[0])
# + executionInfo={"elapsed": 501, "status": "ok", "timestamp": 1612140026199, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="xwJNbyBFcsz9"
def getResult_days(stock, prediction_days):
data = stock_dic[stock]
data_nor = df1_dic[stock]
data1 = data.to_numpy()
data_normaliser = preprocessing.MinMaxScaler()
data_normalised = data_normaliser.fit_transform(data1)
model = tf.keras.models.load_model('{}_model_'.format(stock)+str(prediction_days)+'days')
Xtest, y_normaliser_open, y_normaliser = getXtest(data, data_nor)
y_test_predicted = model.predict(Xtest)
y_test_predicted = np.reshape(y_test_predicted, (y_test_predicted.shape[0], prediction_days))
y_test_predicted = y_normaliser.inverse_transform(y_test_predicted)
y_test_prediction = []
for i in y_test_predicted[:-1]:
y_test_prediction.append(i[0])
y_pred = y_test_prediction + list(y_test_predicted[-1])
if prediction_days != 2:
return y_pred
else: # add PMA, MA if prediction_days = 2
one_day_data = []
day4_data = []
ma = []
period = len(data)-history_points
for i in range(period-1,-1,-1):
ma.append(sum(data['Close'].iloc[-i-7:-i-1])/6)
one_day_data.append(data_normalised[-i-51:-i-1])
day4_data.append(sum(data['Close'].iloc[-i-5:-i-1]))
one_day_data = np.array(one_day_data)
one_day_predict = model.predict(one_day_data)
one_day_predict =np.reshape(one_day_predict, (one_day_predict.shape[0], prediction_days))
one_day_predicted = y_normaliser.inverse_transform(one_day_predict)
day6_sum = []
for i in range(period):
s = day4_data[i] + one_day_predicted[i][0] + one_day_predicted[i][1]
day6_sum.append(s/6)
PMA = [day6_sum[i] for i in range(period)]
MA = [ma[i] for i in range(period)]
UpDown = []
for i in range(len(PMA)):
if PMA[i] >= MA[i]:
UpDown.append(1)
else:
UpDown.append(0)
return y_pred, PMA, MA, UpDown
# + colab={"base_uri": "https://localhost:8080/", "height": 375} executionInfo={"elapsed": 472, "status": "error", "timestamp": 1612140027203, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "08359873075849330876"}, "user_tz": 300} id="KO5-mWd7cs0A" outputId="1bfe07c9-4d1b-4d4c-caeb-ee5d18e8a8f8"
df_dic = dict()
for stock in stock_list:
result_frame = stock_dic[stock].copy().loc[stock_dic[stock].index[history_points]:]
idx = pd.date_range(result_frame.index[-1], periods=4, freq='B')[1:]
open_pred, close_pred = getResult1(stock)
pred2, PMA, MA, UpDown = getResult_days(stock, 2)
pred3 = getResult_days(stock, 3)
# pred30 = getResult_days(stock, 30)
for i, date in enumerate(idx):
# Open High Low Close Volume
# if i ==0:
# openpp = open_pred[-1]
# closepp = close_pred[-1]
# result_frame.loc[pd.to_datetime(date)] = [open_pred[-1], max(openpp,closepp), min(openpp,closepp), close_pred[-1], None]
# else:
result_frame.loc[pd.to_datetime(date)] = [None, None, None, None, None]
result_frame['Open_Pred'] = list(open_pred) + [None for i in range(len(result_frame)-len(open_pred))]
result_frame['Close_Pred1'] = list(close_pred) + [None for i in range(len(result_frame)-len(close_pred))]
result_frame['Close_Pred2'] = list(pred2) + [None for i in range(len(result_frame)-len(pred2))]
result_frame['Close_Pred3'] = list(pred3) + [None for i in range(len(result_frame)-len(pred3))]
# result_frame['Close_Pred30'] = pred30
result_frame['PMA'] = PMA + [None for i in range(len(result_frame)-len(PMA))]
result_frame['MA'] = MA + [None for i in range(len(result_frame)-len(MA))]
result_frame['UpDown'] = UpDown + [None for i in range(len(result_frame)-len(UpDown))]
close = stock_dic[stock].Close[history_points-1:]
colors = list()
for i in range(1, len(close)):
if close[i-1] <= close[i]:
colors.append('green')
else:
colors.append('red')
result_frame['colors'] = colors + ['red' for i in range(len(result_frame)-len(colors))]
df_dic[stock] = result_frame
# + id="kkEqizc-cs0C"
PIndex_MA_1 = {}
PIndex_MA_2 = {}
# + id="0lhp4YWbcs0E"
# Pindex
# 3 days prediction: close prediction (for candle stick)
# 1 day close prediction
for key in stock_list:
data = stock_dic[key]
data_nor = df1_dic[key]
model_close = tf.keras.models.load_model('{}_model'.format(key))
Xtest, y_normaliser_open, y_normaliser_close = getXtest(data, data_nor)
close_pred = model_close.predict(Xtest)
close_pred = np.array([i[0] for i in close_pred])
close_pred = y_normaliser_close.inverse_transform(close_pred)
period = len(data)-history_points
one_year = data.iloc[-period:]
data1 = data.to_numpy()
data_normaliser = preprocessing.MinMaxScaler()
data_normalised = data_normaliser.fit_transform(data1)
one_day_data = []
day1_data = []
ma = []
for i in range(period-1,-1,-1):
ma.append(sum(data['Close'].iloc[-i-4:-i-1])/3)
one_day_data.append(data_normalised[-i-51:-i-1])
day1_data.append(data['Close'].iloc[-i-1])
one_day_data = np.array(one_day_data)
one_day_predict = model_close.predict(one_day_data)
one_day_predict = np.array([i[0] for i in one_day_predict])
one_day_predicted = y_normaliser_close.inverse_transform(one_day_predict)
day3_sum1 = []
day3_sum2 = []
for i in range(period-1):
s = day1_data[i] +one_day_predicted[i][0] + one_day_predicted[i+1][0]
day3_sum1.append(s/3)
for i in range(period-2):
s2 = one_day_predicted[i][0] + one_day_predicted[i+1][0]+ one_day_predicted[i+2][0]
day3_sum2.append(s2/3)
moving_average1 = pd.DataFrame(index = one_year.index[:-1],columns=['PIndex','MA'],data=[[day3_sum1[i],ma[i]] for i in range(period-1)])
list1 = []
for i in moving_average1.index:
if moving_average1['PIndex'][i] >= moving_average1['MA'][i]:
list1.append('green')
else:
list1.append('red')
moving_average1['Trend'] = list1
PIndex_MA_1[key] = moving_average1
# Pindex 2
moving_average2 = pd.DataFrame(index = one_year.index[:-2],columns=['PIndex','MA'],data=[[day3_sum2[i],ma[i]] for i in range(period-2)])
list2 = []
for i in moving_average2.index:
if moving_average2['PIndex'][i] >= moving_average2['MA'][i]:
list2.append('green')
else:
list2.append('red')
moving_average2['Trend'] = list2
PIndex_MA_2[key] = moving_average2
# # model_open = tf.keras.models.load_model('{}_model_open'.format(stock))
# model_close = tf.keras.models.load_model('{}_model'.format(key))
# Xtest, y_normaliser_open, y_normaliser_close = getXtest(data, data_nor)
# # # open_pred = model_open.predict(Xtest)
# # # open_pred = y_normaliser_open.inverse_transform(open_pred)
# close_pred = model_close.predict(Xtest)
# close_pred = np.array([i[0] for i in close_pred]) #np.reshape(close_pred, (close_pred.shape[0], 3))
# close_pred = y_normaliser_close.inverse_transform(close_pred)
# period = len(data)-history_points
# one_year = data.iloc[-period:] # one_month = data.iloc[history_points:]
# data1 = data.to_numpy()
# data_normaliser = preprocessing.MinMaxScaler()
# data_normalised = data_normaliser.fit_transform(data1)
# one_day_data = []
# day1_data = []
# ma = []
# for i in range(period-1,-1,-1):
# ma.append(sum(data['Close'].iloc[-i-4:-i-1])/3)
# one_day_data.append(data_normalised[-i-51:-i-1])
# day1_data.append(data['Close'].iloc[-i-1])
# # for i in range(31,-1,-1):
# # one_day_data.append(data_normalised[-i-51:-i-1])
# one_day_data = np.array(one_day_data)
# one_day_predict = model_close.predict(one_day_data)
# one_day_predict = np.array([i[0] for i in one_day_predict])
# #one_day_predict = np.reshape(one_day_predict, (one_day_predict.shape[0], 3))
# one_day_predicted = y_normaliser_close.inverse_transform(one_day_predict)
# day3_sum1 = []
# day3_sum2 = []
# for i in range(period-1):
# s = day1_data[i] +one_day_predicted[i][0] + one_day_predicted[i+1][0]
# day3_sum1.append(s/3)
# for i in range(period-2):
# s2 = one_day_predicted[i][0] + one_day_predicted[i+1][0]+ one_day_predicted[i+2][0]
# day3_sum2.append(s2/3)
# moving_average1 = pd.DataFrame(index = one_year.index[:-1],columns=['PIndex','MA'],data=[[day3_sum1[i],ma[i]] for i in range(period-1)])
# list1 = []
# for i in moving_average1.index:
# if moving_average1['PIndex'][i] >= moving_average1['MA'][i]:
# list1.append('green')
# else:
# list1.append('red')
# moving_average1['Trend'] = list1
# PIndex_MA_1[key] = moving_average1
# # Pindex 2
# moving_average2 = pd.DataFrame(index = one_year.index[:-2],columns=['PIndex','MA'],data=[[day3_sum2[i],ma[i]] for i in range(period-2)])
# list2 = []
# for i in moving_average2.index:
# if moving_average2['PIndex'][i] >= moving_average2['MA'][i]:
# list2.append('green')
# else:
# list2.append('red')
# moving_average2['Trend'] = list2
# PIndex_MA_2[key] = moving_average2
# + id="fQSBWVoZcs0H"
df_dic2 = dict()
for stock in stock_list:
result_frame = df_dic[stock]
list1 = list(PIndex_MA_1[stock].Trend)
constant1 = [1 for i in range(len(list1))]+ [None, None, None, None]
PIndex_color1 = list1 + ['red', 'red', 'red', 'red']
result_frame['constant1'] = constant1
result_frame['PIndex_color1'] = PIndex_color1
# pindex2
list2 = list(PIndex_MA_2[stock].Trend)
constant2 = [1 for i in range(len(list2))]+ [None, None, None, None, None]
PIndex_color2 = list2 + ['red', 'red', 'red', 'red', 'red']
result_frame['constant2'] = constant2
result_frame['PIndex_color2'] = PIndex_color2
df_dic2[stock] = result_frame
# + id="s9bmnqipcs0K" outputId="b0f449c4-401e-421e-af03-0d16a6054911"
today = df_dic2['FB'].index[-4]
# next_date30 = df_dic['FB'].index[-1]
next_days = pd.date_range(today, periods=4, freq='B')
next_date = next_days[1]
next_date3 = next_days[-1]
# daysBTW = int(str(next_date3-today)[:2])+1
print(today)
print(next_date)
print(next_date3)
# + id="qqAPXiKpcs0M"
candle_dic = dict()
for stock in stock_list:
Open = list()
Close = list()
High = list()
Low = list()
result_frame = df_dic[stock].copy()
for date in result_frame.index:
if date != next_date:
Open.append(result_frame.loc[date].Open)
Close.append(result_frame.loc[date].Close)
High.append(result_frame.loc[date].High)
Low.append(result_frame.loc[date].Low)
else:
Open.append(result_frame.loc[next_date].Open_Pred)
Close.append(result_frame.loc[next_date].Close_Pred1)
High.append(max(result_frame.loc[next_date].Open_Pred,result_frame.loc[next_date].Close_Pred1))
Low.append(min(result_frame.loc[next_date].Open_Pred,result_frame.loc[next_date].Close_Pred1))
df = pd.DataFrame(data={'Open': Open, "High":High,"Low":Low,'Close':Close})
df = df.set_index(result_frame.index)
candle_dic[stock] = df
# + id="wf9o2vb0cs0P"
import pickle
f1 = open("test1.pkl","wb")
f2 = open("test2.pkl","wb")
pickle.dump(df_dic2,f1)
f1.close()
pickle.dump(candle_dic,f2)
f2.close()
# + [markdown] id="wgbAI1Hv4k3l"
# Get result files and then visualization
# + id="H_BLXrN5cs0R"
options_list = [
{'label': 'Apple', 'value': 'AAPL'},
{'label': 'Amazon', 'value': 'AMZN'},
{'label': 'Facebook', 'value': 'FB'},
{'label': 'Google', 'value': 'GOOG'},
{'label': 'Microsoft', 'value': 'MSFT'},
{'label': 'Neflix', 'value': 'NFLX'},
{'label': 'XLK', 'value': 'XLK'},
{'label': 'QQQ', 'value': 'QQQ'}
]
# + id="EqLT_zwVcs0T"
date_options_list = [
{'label': '2 Days', 'value': -5},
{'label': '5 Days', 'value': -8},
{'label': '1 Month', 'value': -27},
{'label': '3 Month', 'value': -69},
{'label': '6 Month', 'value': -133},
{'label': 'All', 'value': 'all'}
]
# + id="O-NL_Poocs0X"
# Initialize the app
app = dash.Dash(__name__) ## local
#app = JupyterDash(__name__) # colab
app.config.suppress_callback_exceptions = True
# + id="kL5ZPLbBcs0Z"
app.layout = html.Div([
# Setting the main title of the Dashboard
html.H1("Stock Price Prediction", style={"textAlign": "center"}),
html.Div([
html.H1("Please select stock and time period.",
style={'textAlign': 'center'}),
# Adding the first dropdown menu and the subsequent time-series graph
dcc.Dropdown(id='stock_select',
options=options_list, # multi=True,
value='AAPL',
style={"display": "block", "margin-left": "auto",
"margin-right": "auto", "width": "60%"}),
dcc.Dropdown(id='date_select',
options=date_options_list, # multi=True,
value=-69,
style={"display": "block", "margin-left": "auto",
"margin-right": "auto", "width": "60%"}),
dcc.Graph(id='basicGraph'),
# dcc.Graph(id='pindexGraph1'),
dcc.Graph(id='pindexGraph2'),
dcc.Graph(id='predictionGraph'),
dcc.Graph(id='volumeGraph'),
])
])
# + id="IS0yE10vcs0c"
@app.callback(Output('basicGraph', 'figure'),
[Input('stock_select', 'value'), Input('date_select', 'value')])
def update_graph(selected_dropdown, selected_date):
trace1 = []
trace2 = []
trace3 = []
trace4 = []
trace5 = []
trace6 = []
trace7 = []
trace8 = []
if selected_date == 'all':
result_frame = df_dic2[selected_dropdown].copy()
candle_frame = candle_dic[selected_dropdown].copy()
else:
result_frame = df_dic2[selected_dropdown].copy().iloc[selected_date:]
candle_frame = candle_dic[selected_dropdown].copy().iloc[selected_date:]
trace1.append(
go.Candlestick(x=candle_frame.index, visible='legendonly',
open=candle_frame.Open,
high=candle_frame.High,
low=candle_frame.Low,
close=candle_frame.Close,
name=f'Candlestick'))
trace2.append(
go.Scatter(x=result_frame.index,
y=result_frame.MA,
mode='lines', opacity=0.8, #fill="tonexty",
name=f'MA', #,textposition='bottom center',
line = dict(color='chocolate')))
trace3.append(
go.Scatter(x=result_frame.index,
y=result_frame.PMA,
mode='lines', opacity=0.9, #fill='tonexty',
name=f'PMA',#textposition='bottom center',
line = dict(color='blue')))
trace4.append(
go.Scatter(x=result_frame.index,
y=result_frame.Open, visible='legendonly',
mode='lines', opacity=0.8, line=dict(color="orange", width=4, dash='dot'),
name=f'Open')) #,textposition='bottom center'))
trace5.append(
go.Scatter(x=result_frame.index,
y=result_frame.Close, visible='legendonly',
mode='lines', opacity=0.6, line=dict(color="teal", width=4, dash='dash'),
name=f'Close')) #,textposition='bottom center'))
trace6.append(
go.Scatter(x=result_frame.index,
y=result_frame.Close_Pred1, visible='legendonly',
mode='lines', opacity=0.8, line_color= "cyan",
name=f'Predict 1day')) #,textposition='bottom center'))
trace7.append(
go.Scatter(x=result_frame.index,
y=result_frame.Close_Pred2, visible='legendonly',
mode='lines', opacity=0.8, line_color= "magenta",
name=f'Predict 2days')) #,textposition='bottom center'))
trace8.append(
go.Scatter(x=result_frame.index,
y=result_frame.Close_Pred3, visible='legendonly',
mode='lines', opacity=0.8, line_color= "navy",
name=f'Predict 3days')) #,textposition='bottom center'))
traces = [trace1, trace2, trace3, trace4, trace5, trace6, trace7, trace8]
data = [val for sublist in traces for val in sublist]
figure = {'data': data,
'layout': go.Layout( #colorway=["#5E0DAC", '#800000', '#FFA500',
# '#00FFFF', '#FF00FF','#0000FF'],
hovermode='x unified',
height=500,
margin=dict(
# t=10, # top margin: 30px, you want to leave around 30 pixels to
# # display the modebar above the graph.
b=20, # bottom margin: 10px
# l=40, # left margin: 10px
# r=40, # right margin: 10px
),
legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1),
title=f"{selected_dropdown}", xaxis={'rangeslider': {'visible': False}, 'type': 'date'},
# yaxis = {"title":"Price", "range":[min(result_frame.Open)*0.75,max(result_frame.Open*1.1)],
# 'fixedrange': False},
# yaxis2={"title":"Volume", "side":"right", "overlaying":"y",
# "range":[min(result_frame.Volume),max(result_frame.Volume)*4]},
shapes=[
dict(
type="rect",
xref="x",
yref="paper",
x0=next_date+pd.DateOffset(-1),
y0="0",
x1=result_frame.index[-1],
y1="1",
fillcolor="lightgray",
opacity=0.4,
line_width=0,
layer="below"
),
],
# # xaxis={#"title":"Date",
# # # 'rangeselector': {'buttons': list([
# # # {'count': daysBTW, 'label': '1D', 'step': 'day','stepmode': 'backward'},
# # # {'count': daysBTW+6, 'label': '5D', 'step': 'day', 'stepmode': 'backward'},
# # # {'count': daysBTW+30, 'label': '1M', 'step': 'day', 'stepmode': 'backward'},
# # # {'count': daysBTW+92, 'label': '3M', 'step': 'day', 'stepmode': 'backward'},
# # # {'count': daysBTW+183, 'label': '6M', 'step': 'day','stepmode': 'backward'},
# # # {'step': 'all'}])},
# # 'rangeslider': {'visible': False},
# # 'type': 'date'},
)}
return figure
# + id="LvDzEylccs0f"
@app.callback(Output('pindexGraph2', 'figure'),
[Input('stock_select', 'value'), Input('date_select', 'value')])
def update_graph4(selected_dropdown, selected_date):
trace21 = []
if selected_date == 'all':
result_frame = df_dic2[selected_dropdown].copy()
else:
result_frame = df_dic2[selected_dropdown].copy().iloc[selected_date:]
trace21.append(
go.Bar(x=result_frame.index, y=result_frame.constant2,opacity=0.7,
name=f'Pindex2',marker_color=result_frame.PIndex_color2))
traces = [trace21]
data = [val for sublist in traces for val in sublist]
figure = {'data': data,
'layout': go.Layout( #colorway=["#5E0DAC", '#800000', '#FFA500',
# '#00FFFF', '#FF00FF','#0000FF'],
height=10,
margin=dict(
t=0, # top margin: 30px, you want to leave around 30 pixels to
# display the modebar above the graph.
b=0, # bottom margin: 10px
# l=40, # left margin: 10px
# r=40, # right margin: 10px
),
legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1),
title=f"{selected_dropdown} Pindex2",
xaxis={'rangeslider': {'visible': False}, 'type': 'date'},
yaxis = {'showticklabels': False, 'showgrid': False},
# yaxis = {"title":"Price", "range":[min(result_frame[:-30].Open)*0.75,max(result_frame[:-30].Open*1.1)],
# 'fixedrange': False},
shapes=[
dict(
type="rect",
xref="x",
yref="paper",
x0=next_date+pd.DateOffset(-1),
y0="0",
x1=result_frame.index[-1],
y1="1",
fillcolor="lightgray",
opacity=0.4,
line_width=0,
layer="below"
),
],
# yaxis2={"title":"Volume", "side":"right", "overlaying":"y",
# "range":[min(result_frame[:-30].Volume),max(result_frame[:-30].Volume)*4]},
)}
return figure
# + id="he_n4A7Fcs0h"
@app.callback(Output('predictionGraph', 'figure'),
[Input('stock_select', 'value'), Input('date_select', 'value')])
def update_graph3(selected_dropdown, selected_date):
trace6 = []
trace7 = []
trace8 = []
trace11 = []
if selected_date == 'all':
result_frame = df_dic2[selected_dropdown].copy()
else:
result_frame = df_dic2[selected_dropdown].copy().iloc[selected_date:]
trace6.append(
go.Scatter(x=result_frame.index,
y=result_frame.Close_Pred1, #visible='legendonly',
mode='lines', opacity=0.8, line_color= "cyan",
name=f'Predict 1day')) #,textposition='bottom center'))
trace7.append(
go.Scatter(x=result_frame.index,
y=result_frame.Close_Pred2, #visible='legendonly',
mode='lines', opacity=0.8, line_color= "magenta",
name=f'Predict 2days')) #,textposition='bottom center'))
trace8.append(
go.Scatter(x=result_frame.index,
y=result_frame.Close_Pred3, #visible='legendonly',
mode='lines', opacity=0.8, line_color= "navy",
name=f'Predict 3days')) #,textposition='bottom center'))
# next day candle: 'Open_Pred', 'Close_Pred1',
Open = list()
Close = list()
High = list()
Low = list()
hovertext = list()
for date in result_frame.index:
if date != next_date:
Open.append(None)
Close.append(None)
High.append(None)
Low.append(None)
hovertext.append(None)
else:
Open.append(result_frame.loc[next_date].Open_Pred)
Close.append(result_frame.loc[next_date].Close_Pred1)
High.append(max(result_frame.loc[next_date].Open_Pred,result_frame.loc[next_date].Close_Pred1))
Low.append(min(result_frame.loc[next_date].Open_Pred,result_frame.loc[next_date].Close_Pred1))
hovertext.append('Open: '+str(result_frame.loc[next_date].Open_Pred)+'<br>Close: '+str(result_frame.loc[next_date].Close_Pred1))
trace11.append(
go.Candlestick(x=result_frame.index, visible='legendonly',
open=Open,
high=High,
low=Low,
close=Close, opacity=0.7,
#increasing_line_color= 'green', decreasing_line_color= 'red',
name=f'next candle',
text = hovertext,
hoverinfo='text'))
traces = [trace6, trace7, trace8, trace11]
data = [val for sublist in traces for val in sublist]
figure = {'data': data,
'layout': go.Layout( #colorway=["#5E0DAC", '#800000', '#FFA500',
# '#00FFFF', '#FF00FF','#0000FF'],
hovermode='x unified',
height=300,
margin=dict(
t=50, # top margin: 30px, you want to leave around 30 pixels to
# # display the modebar above the graph.
b=0, # bottom margin: 10px
# l=40, # left margin: 10px
# r=40, # right margin: 10px
),
legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1),
#title=f"{selected_dropdown}",
xaxis={'rangeslider': {'visible': False}, 'type': 'date'},
# yaxis = {"title":"Price", "range":[min(result_frame[:-30].Open)*0.75,max(result_frame[:-30].Open*1.1)],
# 'fixedrange': False},
shapes=[
dict(
type="rect",
xref="x",
yref="paper",
x0=next_date+pd.DateOffset(-1),
y0="0",
x1=result_frame.index[-1],
y1="1",
fillcolor="lightgray",
opacity=0.4,
line_width=0,
layer="below"
),
],
# yaxis2={"title":"Volume", "side":"right", "overlaying":"y",
# "range":[min(result_frame[:-30].Volume),max(result_frame[:-30].Volume)*4]},
)}
return figure
# + id="BiZtosu4cs0j"
@app.callback(Output('volumeGraph', 'figure'),
[Input('stock_select', 'value'), Input('date_select', 'value')])
def update_graph2(selected_dropdown, selected_date):
trace10 = []
if selected_date == 'all':
result_frame = df_dic2[selected_dropdown].copy()
else:
result_frame = df_dic2[selected_dropdown].copy().iloc[selected_date:]
trace10.append(
go.Bar(x=result_frame.index, y=result_frame.Volume,opacity=0.7,
name=f'Volume',marker_color=result_frame.colors))
traces = [trace10]
data = [val for sublist in traces for val in sublist]
figure = {'data': data,
'layout': go.Layout( #colorway=["#5E0DAC", '#800000', '#FFA500',
# '#00FFFF', '#FF00FF','#0000FF'],
height=300,
margin=dict(
t=50, # top margin: 30px, you want to leave around 30 pixels to
# # display the modebar above the graph.
# b=0, # bottom margin: 10px
# l=40, # left margin: 10px
# r=40, # right margin: 10px
),
legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1),
xaxis={'rangeslider': {'visible': False}, 'type': 'date', "title": f"{selected_dropdown} Volume"},
# yaxis = {"title":"Price", "range":[min(result_frame[:-30].Open)*0.75,max(result_frame[:-30].Open*1.1)],
# 'fixedrange': False},
shapes=[
dict(
type="rect",
xref="x",
yref="paper",
x0=next_date+pd.DateOffset(-1),
y0="0",
x1=result_frame.index[-1],
y1="1",
fillcolor="lightgray",
opacity=0.4,
line_width=0,
layer="below"
),
],
# yaxis2={"title":"Volume", "side":"right", "overlaying":"y",
# "range":[min(result_frame[:-30].Volume),max(result_frame[:-30].Volume)*4]},
)}
return figure
# + executionInfo={"elapsed": 4718, "status": "ok", "timestamp": 1597033673948, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "09294017020174528311"}, "user_tz": 420} id="u6MpW5akb-xz" outputId="9ce57877-696a-4301-f32a-db23a4f62bf6"
# Run the app
#app.run_server(mode='inline') # colab
if __name__ == '__main__':
app.run_server(port = 8050)
# + id="X4tUbXQ0cs0q"
| PredicitingStock.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# <h1> Hyper-parameter tuning </h1>
#
# In this notebook, you will learn how to carry out hyper-parameter tuning.
#
# This notebook takes several hours to run.
# <h2> Environment variables for project and bucket </h2>
#
# Change the cell below to reflect your Project ID and bucket name. See Lab 3a for setup instructions.
import os
PROJECT = 'cloud-training-demos' # CHANGE THIS
BUCKET = 'cloud-training-demos-ml' # CHANGE THIS
REGION = 'us-central1' # CHANGE THIS
# for bash
os.environ['PROJECT'] = PROJECT
os.environ['BUCKET'] = BUCKET
os.environ['REGION'] = REGION
# <h1> 1. Command-line parameters to task.py </h1>
#
# Note the command-line parameters to task.py. These are the things that could be hypertuned if we wanted.
# !grep -A 2 add_argument taxifare/trainer/task.py
# <h1> 2. Evaluation metric </h1>
#
# We add a special evaluation metric. It could be any objective function we want.
# !grep -A 5 eval_metric taxifare/trainer/model.py
# <h1> 3. Make sure outputs do not clobber each other </h1>
#
# We append the trial-number to the output directory.
# !grep -A 9 "arguments.pop('output_dir')" taxifare/trainer/task.py
# <h1> 4. Create hyper-parameter configuration </h1>
#
# The file specifies the search region in parameter space. Cloud MLE carries out a smart search algorithm within these constraints (i.e. it does not try out every single value).
# %writefile hyperparam.yaml
trainingInput:
scaleTier: STANDARD_1
hyperparameters:
goal: MINIMIZE
maxTrials: 30
maxParallelTrials: 1
params:
- parameterName: train_batch_size
type: INTEGER
minValue: 64
maxValue: 512
scaleType: UNIT_LOG_SCALE
- parameterName: nbuckets
type: INTEGER
minValue: 10
maxValue: 20
scaleType: UNIT_LINEAR_SCALE
- parameterName: hidden_units
type: CATEGORICAL
categoricalValues: ["128 32", "256 128 16", "64 64 64 8"]
# <h1> 5. Run the training job </h1>
#
# Just --config to the usual training command.
# + language="bash"
# OUTDIR=gs://${BUCKET}/taxifare/ch4/taxi_trained
# JOBNAME=lab4a_$(date -u +%y%m%d_%H%M%S)
# echo $OUTDIR $REGION $JOBNAME
# gsutil -m rm -rf $OUTDIR
# gcloud ml-engine jobs submit training $JOBNAME \
# --region=$REGION \
# --module-name=trainer.task \
# --package-path=/content/training-data-analyst/courses/machine_learning/feateng/taxifare/trainer \
# --job-dir=$OUTDIR \
# --staging-bucket=gs://$BUCKET \
# --scale-tier=STANDARD_1 \
# --runtime-version=1.2 \
# --config=hyperparam.yaml \
# -- \
# --train_data_paths="gs://$BUCKET/taxifare/ch4/taxi_preproc/train*" \
# --eval_data_paths="gs://${BUCKET}/taxifare/ch4/taxi_preproc/valid*" \
# --output_dir=$OUTDIR \
# --num_epochs=100
# -
# <h2>6. Train chosen model on full dataset</h2>
#
# Look at the last section of the <a href="feateng.ipynb">feature engineering notebook</a>. The extra parameters are based on hyper-parameter tuning.
# Copyright 2016 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License
| courses/machine_learning/feateng/hyperparam.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Session 08: Texture
#
# Now, let's see if we can add a bit more to the types of features that
# we consider when working with image data.
# ## Setup
#
# We need to load the modules within each notebook. Here, we load the
# same set as in the previous question.
# +
# %pylab inline
import numpy as np
import scipy as sp
import pandas as pd
import sklearn
from sklearn import linear_model
import urllib
import os
from os.path import join
# +
import matplotlib.pyplot as plt
import matplotlib.patches as patches
plt.rcParams["figure.figsize"] = (8,8)
# -
# ## Cats and dogs
#
# Read in the cats and dogs dataset once again:
xdf = pd.read_csv(join("..", "data", "catdog.csv"))
df
# Lets create a black and white image and subtract each pixel from the
# pixel to its lower left. What does this show us?
# +
img = imread(join('..', 'images', 'catdog', df.filename[2]))
img_bw = np.sum(img, axis=2)
img_text = img_bw[:-1, :-1] - img_bw[1:, 1:]
plt.imshow(img_text, cmap='gray')
# -
# ## Texture features for learning a model
#
# Let's try to use these features in a machine learning model:
# +
X = np.zeros((len(df), 3))
for i in range(len(df)):
img = imread(join("..", "images", "catdog", df.filename[i]))
img_bw = np.sum(img, axis=2)
img_hsv = matplotlib.colors.rgb_to_hsv(img)
img_text = img_bw[:-1, :-1] - img_bw[1:, 1:]
X[i, 0] = np.mean(img_hsv[:, :, 1])
X[i, 1] = np.mean(img_hsv[:, :, 2])
X[i, 2] = np.mean(img_text)
if i % 25 == 0:
print("Done with {0:d} of {1:d}".format(i, len(df)))
# -
# We will also build an array that is equal to 0 for cats and 1 for dogs:
y = np.int32(df.animal.values == "dog")
y
# We'll make a training and testing split one more time:
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y)
# And then, build a model from the data, testing the accuracy:
model = sklearn.linear_model.LinearRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
yhat = np.int32(pred > 0.5)
sklearn.metrics.accuracy_score(y_test, yhat)
# Let's also see the ROC curve.
fpr, tpr, _ = sklearn.metrics.roc_curve(y_test, pred)
plt.plot(fpr, tpr, 'b')
plt.plot([0,1],[0,1],'r--')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
sklearn.metrics.auc(fpr, tpr)
# We also can try this with the nearest neighbors model.
model = sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)
yhat = model.predict(X_test)
sklearn.metrics.accuracy_score(y_test, yhat)
# Once again, try to change the number of neighbors to improve the model. You
# should be able to get something similar to the linear regression.
| nb/session08-texture.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import pandas as pd
import psycopg2
from dotenv import find_dotenv, load_dotenv
from pathlib import Path
import matplotlib.pyplot as plt
# +
# Set input/output locations
project_path = Path.cwd()
raw_path = str((project_path / 'data' / 'raw').resolve())
# Connect to Retrosheet database
load_dotenv(find_dotenv())
retro_db = os.getenv('RETRO_DB')
retro_user = os.getenv('RETRO_USER')
retro_pass = os.getenv('RETRO_PASS')
conn = psycopg2.connect(database=retro_db, user=retro_user, password=retro_pass)
# -
query = 'select * from raw_events;'
df_all = pd.read_sql(query, conn)
df_all.head()
# +
df_batter = df_all[df_all.ab_flag == 'T'].copy()
batter_list = []
for batter, df_orig in df_batter.groupby('batter'):
df = df_orig.copy()
df['year'] = df.game_id.iloc[0][3:7]
df['H'] = df.hit_value.apply(lambda x: 1 if x > 0 else 0)
df['1B'] = df.event_type.apply(lambda x: 1 if x == 20 else 0)
df['2B'] = df.event_type.apply(lambda x: 1 if x == 21 else 0)
df['3B'] = df.event_type.apply(lambda x: 1 if x == 22 else 0)
df['HR'] = df.event_type.apply(lambda x: 1 if x == 23 else 0)
batter_list.append(df)
df_batter_list = pd.concat(batter_list)
# -
df_batter_list.head()
len(df)
df.batter.nunique()
df.pitcher.nunique()
df[df.ab_flag == 'F'].head(20)
df[(df.batter == 'seguj002') & (df.ab_flag == 'T')][['game_id', 'pitch_sequence', 'event_text', 'event_type', 'hit_value']].head(10)
df_batter = df[(df.batter == 'seguj002') & (df.ab_flag == 'T')].copy()
df_batter['H'] = df_batter.hit_value.apply(lambda x: 1 if x > 0 else 0)
df_batter['1B'] = df_batter.event_type.apply(lambda x: 1 if x == 20 else 0)
df_batter['2B'] = df_batter.event_type.apply(lambda x: 1 if x == 21 else 0)
df_batter['3B'] = df_batter.event_type.apply(lambda x: 1 if x == 22 else 0)
df_batter['HR'] = df_batter.event_type.apply(lambda x: 1 if x == 23 else 0)
df_batter[['game_id', 'pitch_sequence', 'event_text', 'event_type', 'hit_value', 'H', '1B', '2B', '3B', 'HR']].head(30)
df_batter.H.sum() / len(df_batter)
len(df_batter)
| notebooks/raw-event-data-explore.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # 1D Reactor
# +
#load modules
import sys
import numpy as np
import pandas as pd
import cantera as ct
#Initialise chemistry
gas = ct.Solution('./ch41step.xml')
R = rxns = ct.Reaction.listFromFile('./ch41step.xml')
myreaction = R[0]
iCO2 = gas.species_index('CO2')
iH2O = gas.species_index('H2O')
iO2 = gas.species_index('O2')
iCH4 = gas.species_index('CH4')
transient_data = pd.DataFrame()
constant_data = pd.DataFrame()
#run reactor for T = 1000 to 3000
for T in np.arange(1000,3001,1):
print("T: " + str(T))
gas.TPY = T, ct.one_atm, 'CH4:1,O2:2'
r = ct.IdealGasConstPressureReactor(gas, energy = 'off')
sim = ct.ReactorNet([r])
time = 0.0
states = ct.SolutionArray(gas, extra=['t'])
transient_data = transient_data.append({'t [s]': sim.time, 'T [K]': r.T
,'Yco2': r.Y[iCO2],'Yh2o': r.Y[iH2O],'Yo2':r.Y[iO2],'Ych4':r.Y[iCH4]},ignore_index=True)
constant_data = constant_data.append({'T [K]': r.T, 'P [Pa]': r.thermo.P, 'kf': gas.forward_rate_constants,
'kb':gas.reverse_rate_constants, 'Ea':myreaction.rate.activation_energy,
'A': myreaction.rate.pre_exponential_factor,
'b': myreaction.rate.temperature_exponent},ignore_index=True)
for n in range(50):
time += 5.e-7
sim.advance(time)
states.append(r.thermo.state, t=time*1e3)
transient_data = transient_data.append({'t [s]': sim.time, 'T [K]': r.T
,'Yco2': r.Y[iCO2],'Yh2o': r.Y[iH2O],'Yo2':r.Y[iO2],'Ych4':r.Y[iCH4]},ignore_index=True)
#save data
transient_data.to_csv('transient_data_ch41step.csv')
constant_data.to_csv('constant_data_ch41step.csv')
# -
# # Check kf
# +
gas.TPX = 2001.0, ct.one_atm, 'CH4:1,O2:2'
A = 3.47850e+08
b = 0.0
Ea =8.368e+07 #in cal/mol
kf = A*1001**b *np.exp(-Ea/(ct.gas_constant*1001))
kf
| data/generate_data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
import numpy.random as random
import jax.numpy as np
from tqdm import tqdm
from jax import vmap, grad, jit
import matplotlib.pyplot as plt
from cycler import cycler
import cvxpy as cp
plt.rcParams.update({
"text.usetex": True,
"font.family": "sans-serif",
"font.sans-serif": ["Helvetica Neue"],
"font.size": 28,
# "contour.negative_linestyle": 'solid',
})
plt.rc('axes', prop_cycle=cycler('linestyle', ['-', '--', ':', '-.']))
# +
# Problem data
random.seed(1)
m, n = 100, 500
A = random.randn(m, n)
b = random.randn(m)
lam = 4
def f(x):
return .5 * np.linalg.norm(np.dot(A, x) - b, 2)**2 + \
lam * np.linalg.norm(x, 1)
def soft_thresh(x, mu):
return np.maximum(x - mu, 0) - \
np.maximum(-x - mu, 0)
f = jit(f)
f_prime = jit(grad(f))
k_vec = np.arange(1000)
x0 = random.randn(n)
# -
# Solve with cvxpy
x_cp = cp.Variable(n)
f_star = cp.Problem(
cp.Minimize(.5 * cp.sum_squares(A @ x_cp - b) + lam * cp.norm(x_cp, 1))
).solve(solver=cp.ECOS, abstol=1e-10, reltol=1e-10)
x_star = x_cp.value
# +
# Subgradient
step_size_rules = [#lambda k: 0.01/np.sqrt(k+1),
lambda k: 0.001/np.sqrt(k+1),
lambda k: 0.01/(k + 1),
]
step_size_rules_str = [#r"$0.01/\sqrt{k+1}$",
r"$0.0005/\sqrt{k+1}$",
r"$0.005/(k+1)$",
]
x_hist_adapt = {}
subopt_hist_adapt = {}
for i, t in enumerate(tqdm(step_size_rules)):
x_hist_adapt[i] = [x0]
f_best = f(x0)
subopt_hist_adapt[i] = [(f_best - f_star)/f_star]
for k in k_vec:
x_next = x_hist_adapt[i][-1] - t(k) * f_prime(x_hist_adapt[i][-1])
x_hist_adapt[i].append(x_next)
f_next = f(x_next)
if f_next < f_best:
f_best = f_next
subopt_hist_adapt[i].append((f_best - f_star)/f_star)
x_hist_polyak = [x0]
f_best = f(x0)
f_next = f(x0)
subopt_hist_polyak = [(f_best - f_star)/f_star]
for k in k_vec:
f_current = f_next
g = f_prime(x_hist_polyak[-1])
t = (f_current - f_star) / np.linalg.norm(g)**2
x_next = x_hist_polyak[-1] - t * g
x_hist_polyak.append(x_next)
f_next = f(x_next)
if f_next < f_best:
f_best = f_next
subopt_hist_polyak.append((f_best - f_star)/f_star)
# -
# ISTA
x_hist_ista = [x0]
subopt_hist_ista = [(f(x0) - f_star)/f_star]
t_ista = 0.001
for k in k_vec:
x_cur = x_hist_ista[-1]
x_next = x_cur - t_ista * A.T.dot(A.dot(x_cur) - b)
x_next = soft_thresh(x_next, t_ista * lam)
x_hist_ista.append(x_next)
subopt_hist_ista.append((f(x_next) - f_star)/f_star)
# NB. For plotting, not realistic termination
if subopt_hist_ista[-1] < 1e-06:
break
# +
# Plot
fig, ax = plt.subplots(figsize=(16, 9))
for i, _ in enumerate(step_size_rules):
ax.plot(k_vec, subopt_hist_adapt[i][:-1], color="k",
label=r"$\mbox{Subgradient}\;$" + step_size_rules_str[i])
# ax.plot(k_vec, subopt_hist_polyak[:-1], color="k",
# label=r"$\mbox{Polyak}$")
ax.plot(k_vec, subopt_hist_ista[:-1], color="k",
label=r"$\mbox{ISTA}\;t = %.3f$" % t_ista)
ax.set_yscale('log')
ax.set_ylabel(r"$(f - f^\star)/f^\star$")
ax.set_xlabel(r"$k$")
ax.set_xlim([0, 1000])
ax.set_ylim([1e-06, 5e03])
ax.legend()
plt.tight_layout()
plt.savefig("ista_cvx.pdf")
# -
| lectures/18_lecture/ista_strongly_cvx.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # 第4章リストの操作と繰り返し
#
# + [(再掲)編集モードとコマンドモード](#modes)
# + [リストの定義と参照](#list)
# + [リスト要素への一斉操作](#oplist)
# + [条件設定による部分リスト](#sublist)
# + [繰り返し操作](#loop)
# + [文字列の操作](#str)
#
# ## <div id="modes">(再掲)編集モードとコマンドモード </div>
# Jupyter では2つのモードを使って操作を行う
#
# + <font color="green">編集モード(セルの左側が緑)</font>では,セル内にコードを入力する
# + <font color="blue">コマンドモード(セルの左側が青)</font>では,セル全体の操作を行う
#
# キーボートの操作は慣れると便利である.
# コマンドモードで `h` で一覧を表示することは覚えておけば良いだろう.
#
# ### 共通の操作
# | 操作 | マウスでの操作 | キーボードでの操作 |
# |:--:|:--:|:--:|
# | セルの実行 | 上のアイコンから `Run` を選択 | `Ctrl+Enter` |
# | セルを実行して次のセルへ | 上のメニューの `Cell` から選択| `Shift+Enter` |
# |コマンド一覧の呼び出し| (なし) | `Ctrl+Shift+p` |
#
#
# ### <font color="green">編集モードでの操作(セルの左側が緑)</font>
# | 操作 | マウスでの操作 | キーボードでの操作 |
# |:--:|:--:|:--:|
# |コマンドモードへの移行 | セルの左側をクリック | `Escape`|
# |コマンドの補完| (なし) | `Tab`|
# | コード実行 | 上のアイコンから `Run` を選択 | `Shift+Enter` |
#
# ### <font color="blue">コマンドモードでの操作(セルの左側が青)</font>
# | 操作 | マウスでの操作 | キーボードでの操作 |
# |--|--|--|
# |編集モードへの移行 | セルの中身をクリック | `Enter`|
# |セルを `code` に変更 | 上のメニューから選択 | `y`|
# |セルを `Markdown` に変更 | 上のメニューから選択 | `m`|
# |新規セルを上(resp. 下)に挿入 | 上のメニューの `Insert` から選択 | `a` (resp. `b`)|
# |セルのコピー| 上のメニューの `Edit` から選択 | `c` |
# |セルを上(resp. 下)に貼り付け| 上のメニューの `Edit` から選択 | `v` (resp. `Shift+ v`) |
# |セルを削除| 上のメニューの `Edit` から選択 | `d d` |
# |アンドゥ| 上のメニューの `Edit` から選択 | `z` |
# |コマンド一覧の呼び出し | (なし) | `p`|
# |ヘルプの表示 | 上のメニューの `Help` から選択 | `h`|
#
#
# ## <div id="list">リストの定義と参照 </div>
#
# + リストは `[p,q,...]` という形で指定する
# + 末尾に `[i-1]` をつけて `i` 番目の参照
# + `[i:j]` で `[i]`(`i+1` 番目)から `[j-1]`(`j` 番目)までの部分リスト
# + `[-i]` は後ろから `i` 番目
# + リストの長さは `len` で求められる
#
# リストの基本その1:リストの定義
a=[1,2,4,8,16]
print(a) # 全体の表示
i=3
print(a[i-1]) # i 番目の表示(要素)
i,j=0,4
print(a[i:j]) # [i] から [j-1] まで表示(部分リスト)
print(len(a)) # リストの長さ
# リストの基本その2:range による連続データ
mylist = range(3,9)
print(mylist[0])
print(mylist[-2])
# ### 練習
# リスト `[1,2,4,8,16,32,64]` を変数 `b`に代入しなさい.
# その上で,以下を実行してその結果を確認しなさい.
# + 最初の要素
# + 最後の要素
# + 最初から5番目の要素
# + `b` の長さ
# + 最初から8番目の要素
# + 3番目以降の(部分)リスト
# + 最初と最後を除いた(部分)リスト
#
# セルは<font size=10>↓</font>に作成すること
# ## <div id="oplist">リスト要素への一斉操作 </div>
#
# + `[(xに対する処理) for x in (リスト)]` という形で設定する
# + `x` は他の変数名でも構わない
# リストの基本その3:一斉操作によるリストの作成
a = range(1,11)
a2 = [ x**2 for x in a]
print(a2)
# ### 練習
# $1$ から $20$ までの自然数をそれぞれ3乗して得られるリストを求めなさい。
#
# セルは↓に作成すること
# ## <div id="sublist">条件設定による部分リスト</div>
#
# + `[(xに対する処理) for x in (リスト) if (条件式)]` という形で,条件を満たすもののみのリストが作成される
# リストの基本その4:特定の条件を満たす整数
I = range(1,101)
I2 = [ x for x in I if x%17 ==0 ]
I2
# ### 練習
# 次を求めなさい。
# + $1$から$1000$までの自然数で$7$で割り切れ、かつ$11$では割り切れないものの個数
# + $10000$以下の自然数で(10進表記した際の)末尾が $3$ である $13$ の倍数の個数。
#
# セルは↓に作成すること
# ## <div id="loop">繰り返し</div>
# + `for` は実はC言語よりも単純である
# + `for (変数) in (リスト)` で各リストの要素に対して処理をする
# + 使用例:`for i in range(n)` で n 回の繰り返しとなる.
# + `while` はC言語と同様に用いることができる
# + 繰り返しになるが,範囲の指定は<font color="red">セミコロンと字下げ</font>で指定する
# + 以下のコードを比べて,その挙動を比較しなさい
# 繰り返しの例その1 for による繰り返し (range)
# range(N) は [0,..,N-1] に対応
N=5
for i in range(N):
print('ループ中:i= %d'%i)
print('ループ終:i= %d'%i)
# 繰り返しの例その2:for による繰り返し (一般のリスト)
# リスト内の各要素について処理をしている
mylist=[3,1,4,1,5,9]
for i in mylist:
print(i)
# 繰り返しの例その3a:for による繰り返し (一般のリスト)
# 字下げを変えて処理の違いを見る
mylist=[3,1,4,1,5,9]
sum=0
for i in mylist:
sum+=i
print(sum) # ここの字下げに注目
# 繰り返しの例その3b:for による繰り返し (一般のリスト)
# 上と字下げを変えると,処理が異なる
mylist=[3,1,4,1,5,9]
sum=0
for i in mylist:
sum+=i
print(sum) # ここの字下げに注目
# 繰り返しの例その4: while の基本
# 2のべき乗の中でMAX以上となる最小の数を求める
MAX=1000 # これを超える最小のもの
i=1
while(i<MAX):
i=i*2
print(i) # while を抜けてから表示
# 繰り返しの例:入試問題から (その1)
# 初期値 a1 に対して,それを2倍して 64 で割った余りを繰り返す
a1=1 # 初期値(ここを変更して動作確認せよ)
an=a1
r=64
n=1
while an!=0 :
print("a_%d = %2d = %s"%(n,an,bin(an)))
an=(2*an)%r
n+=1
print("a_%d = %2d = %s"%(n,an,bin(an)))
# 繰り返しの例:入試問題から(その2)
# 初項 a1 公差 d の等差数列の第n項までで
# 2の倍数全体の和 D_n, 3の倍数の全体の和 T_n を求める
a1,d=1,1 # 初項a1 公差 d
an=a1
D=T=0 # D: 2の倍数の和,T:3の倍数の和
n=30 # 末項
for i in range(1,n+1):
if an%2==0:
D+=an
print("D_%d = %d"%(i,D))
if an%3==0:
T+=an
print("T_%d = %d"%(i,T))
an+=d
# ## <div id="str">文字列の操作</div>
# + 文字列は `'` または `"` でくくって指定する
# + `bin` や `hex` の結果は文字列である
# + 文字列として日本語(いわゆる全角文字)が利用できるが,これまでの命令(`print` や括弧など)で用いていた,いわゆる半角文字とは異なるので注意
# + 文字列の和は**そのままつなげる**
# 文字列の基本その1:各文字の指定
mystr='Ritsumeikan Mathematics' # 文字列の設定
print(mystr) # 文字列の表示
print(mystr[0]) # 最初の文字の表示
print(mystr[-2]) # 後ろから2文字を表示
print(mystr[0:3],mystr[-4:-1]) # 先頭と末尾の3文字ずつを表示
print(mystr[11]) # 何も表示されていないわけではない.各自確認すること
# 文字列の基本その2:見えない文字
mystr1='立命館 数理'
mystr2='立命館 数理'
print(mystr1) # 一見すると同じだが
print(mystr2)
print(mystr1[5],mystr2[5]) # 実は違う.各自確認すること
# 文字列の基本その3:文字列の和
a, b = 123, 456 # これらは整数
print("%d + %d = %d"%(a,b,a+b)) # 和は当然整数の和
a2, b2 = bin(a), bin(b) # 2進表記を考える
print("%s + %s = %s"%(a2,b2,a2+b2)) # 和がどうなるか確認せよ
# 文字列その4 (応用例:簡単な整形)
n = 543
print('%d = %s_2'%(n,bin(n)[2:])) # bin(n) の接頭 0b を削除して表示
# ---
| 20ds1/20ds1-jupyter-sec04.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + colab={} colab_type="code" id="nGJaw2n4I-Dh"
import os
import pandas as pd
import numpy as np
# + colab={} colab_type="code" id="ZBEgOyVlJ6Ll"
item= pd.read_csv('../main/datasets/1.0v/items.csv', sep = '|')
info = pd.read_csv('../main/datasets/1.0v/infos.csv', sep = '|')
order= pd.read_csv('../main/datasets/1.0v/orders.csv', sep = '|')
# + colab={"base_uri": "https://localhost:8080/", "height": 52} colab_type="code" id="GpwTFdeSJPYr" outputId="07263b4f-2bdc-433f-bd23-bc8e2e997696"
#deixando apenas com promocoes
info_promotion = info[info.promotion.notna()]
print(info_promotion.min().promotion)
print(info_promotion.max().promotion)
# + [markdown] colab_type="text" id="BeNoIqdRjcMp"
# todas as promoçoes acontecem depois de 6/30, ou seja temos APENAS informaçoes de promoçoes que vao acontecer no periodo que temos q prever as vendas
# + colab={"base_uri": "https://localhost:8080/", "height": 52} colab_type="code" id="v82oJUl2lNfF" outputId="90e8855b-1099-407a-ee79-27de88e40c82"
#adicionando coluna recommendedRetailPrice a order
RetailPrice = item[['itemID','recommendedRetailPrice']]
order = pd.merge(order, RetailPrice, on='itemID')
print(len(order[order.salesPrice == order.recommendedRetailPrice]))
print(len(order[order.salesPrice != order.recommendedRetailPrice]))
# + [markdown] colab_type="text" id="eshHJ0PKlQY7"
# grande parte das vendas n~ao utiliza preço recomendado pelo retail
# + [markdown] colab_type="text" id="fqt8JefwT_B9"
# ### **adicionando a feature: moda de cada produto(itemID)**
# + colab={} colab_type="code" id="gD3Y4FF2o9wH"
def get_mode_sales_price(id):
sales_id_certo = order[order['itemID'] == id]
mode = sales_id_certo['salesPrice'].mode()
#a moda pode ter mais de um valor,
#para torna-la um unico foi escolhido arbitrariamente a mediana
return mode.median()
# + colab={} colab_type="code" id="QgGoC59-K2zG"
#adicionando a moda de cada produto no item
item['modeSalesPrice'] =item['itemID'].map(get_mode_sales_price )
# + colab={"base_uri": "https://localhost:8080/", "height": 173} colab_type="code" id="aM-wcYlCppCg" outputId="5787d4ef-77e6-407f-bed9-1aad93503fae"
#colocando valor da moda no order
modeSalesPrice = item[['itemID','modeSalesPrice']]
order = pd.merge(order, modeSalesPrice, on='itemID')
print(order['modeSalesPrice'].describe().round(1))
# + colab={"base_uri": "https://localhost:8080/", "height": 191} colab_type="code" id="bEzj_Fq1ZRIv" outputId="62d39644-b980-47b7-bcf8-3f16da1661f5"
print(order['modeSalesPrice'].describe().round(1))
print(order['modeSalesPrice'].isna().sum() )
# + colab={"base_uri": "https://localhost:8080/", "height": 52} colab_type="code" id="CVGh_uBul1hj" outputId="1d9b3527-4a76-4883-b93b-fe94bb3b070e"
print(len(order[order['salesPrice'] == order['modeSalesPrice']]))
print(len(order[order['salesPrice'] != order['modeSalesPrice']]))
# + [markdown] colab_type="text" id="3l_sz-mo6YlT"
# 80% das vendas seguem o valor da moda
# + colab={"base_uri": "https://localhost:8080/", "height": 34} colab_type="code" id="nFN6t-uq6hFS" outputId="bcb195fd-d08d-4561-dd7a-199a6417b0a4"
print(len(order[order['salesPrice'] < order['modeSalesPrice']]))
# + [markdown] colab_type="text" id="HQkrOGvQ6w2w"
# 11% das vendas tem valor abaixo da moda, poderiam ser considerados promoçoes (?);
# + colab={"base_uri": "https://localhost:8080/", "height": 34} colab_type="code" id="6VrNxP0A6-9p" outputId="375259ee-c694-4722-c807-1de80e8a3446"
print(len(order[order['salesPrice'] > order['modeSalesPrice']]))
# + [markdown] colab_type="text" id="_VzplPtE7Ch5"
# 8% restantes que tem valor acima da moda, o que acho bizarro
# + [markdown] colab_type="text" id="EvdGOZpYW_o4"
# ### **adicionando a feature: diferença da moda com salesPrice**
# + colab={} colab_type="code" id="z61PfIVFEvjk"
order['difModa'] = order['salesPrice'] - order['modeSalesPrice']
# + colab={"base_uri": "https://localhost:8080/", "height": 191} colab_type="code" id="KkUL5Az7ZMHZ" outputId="d452ea38-7995-4a3d-cbd1-5cd072999f43"
print(order['difModa'].describe().round(1))
print(order['difModa'].isna().sum() )
# + [markdown] colab_type="text" id="XpqDQSPuNLB9"
# estou pressuponto que todo produto vendido abaixo da moda estava em promoç~ao, esta feature captura isso
# + [markdown] colab_type="text" id="HtB-Rix4YCoc"
# tamb'em existe o contr'ario, seria algo como um super faturamento
# -
| sasaki/01-featureModa.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: ML
# language: python
# name: ml
# ---
import spacy
nlp = spacy.load("en_core_web_lg")
doc = nlp("Apple reached an all-time high stock price of 143 dollars this January.")
# +
from spacy import displacy
displacy.render(doc, style="ent")
# -
# ---
trf = spacy.load("en_core_web_trf")
doc = trf("Apple reached an all-time high stock price of 143 dollars this January.")
displacy.render(doc, style="ent")
txt = "Total nonfarm payroll employment rose by 266,000 in April, and the unemployment rate was little changed at 6.1 percent, the U.S. Bureau of Labor Statistics reported today. Notable job gains in leisure and hospitality, other services, and local government education were partially offset by employment declines in temporary help services and in couriers and messengers."
doc = trf(txt) # en_core_web_trf
displacy.render(doc, style="ent")
doc = nlp(txt) # en_core_web_lg
displacy.render(doc, style="ent")
txt = """Fastly released its Q1-21 performance on Thursday, after which the stock price dropped a whopping 27%. The company generated revenues of $84.9 million (35% YoY) vs. $85.1 million market consensus. Net loss per share was $0.12 vs. an expected $0.11.
These are not big misses but make the company one of the few high-growth cloud players that underperformed market expectations.
However, the company also lowered its guidance for Q2: Fastly forecasts revenues of $84 - $87 million and a net loss of $0.16 - $0.19 per share, compared to the market consensus of $92 million in revenue and a net loss of $0.08 per share, thereby disappointing investors.
Lastly, <NAME> will step down as CFO of the company after 5 years."""
doc = trf(txt) # en_core_web_trf
displacy.render(doc, style="ent")
doc = nlp(txt) # en_core_web_lg
displacy.render(doc, style="ent")
| course/named_entity_recognition/04_spacy_and_transformers-Copy1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/NeuromatchAcademy/course-content/blob/master/projects/modelingsteps/TrainIllusionDataProject.ipynb" target="_blank"><img alt="Open In Colab" src="https://colab.research.google.com/assets/colab-badge.svg"/></a>
# + [markdown] id="405YDLSvZO1q"
# # Example Data Project: the Train Illusion
#
# <NAME>, <NAME>, <NAME>, <NAME>, <NAME>
#
# **Disclaimer**: this is a "toy" data neuroscience project used to demonstrate the [10 step procedure of how-to-model](https://doi.org/10.1523/ENEURO.0352-19.2019). It is not meant to be state of the art research.
# + [markdown] id="wFG97lgjXP3y"
# **Our 2021 Sponsors, including Presenting Sponsor Facebook Reality Labs**
#
# <p align='center'><img src='https://github.com/NeuromatchAcademy/widgets/blob/master/sponsors.png?raw=True'/></p>
# -
# ## Setup
#
# + id="nxGoAuNfdYEc" tags=["hide-input"]
# @title Setup
# for matrices and plotting:
import numpy as np
import matplotlib.pyplot as plt
# for random distributions:
from scipy.stats import norm, poisson
# for logistic regression:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# !pip install tqdm --quiet
# -
# ## Generate Data
#
# + id="GC7iBP8_dxJF" cellView="form" tags=["hide-input"]
# @title Generate Data
def generateSpikeTrains():
gain = 2
neurons = 50
movements = [0,1,2]
repetitions = 800
np.random.seed(37)
# set up the basic parameters:
dt = 1/100
start, stop = -1.5, 1.5
t = np.arange(start, stop+dt, dt) # a time interval
Velocity_sigma = 0.5 # std dev of the velocity profile
Velocity_Profile = norm.pdf(t,0,Velocity_sigma)/norm.pdf(0,0,Velocity_sigma) # The Gaussian velocity profile, normalized to a peak of 1
# set up the neuron properties:
Gains = np.random.rand(neurons) * gain # random sensitivity between 0 and `gain`
FRs = (np.random.rand(neurons) * 60 ) - 10 # random base firing rate between -10 and 50
# output matrix will have this shape:
target_shape = [len(movements), repetitions, neurons, len(Velocity_Profile)]
# build matrix for spikes, first, they depend on the velocity profile:
Spikes = np.repeat(Velocity_Profile.reshape([1,1,1,len(Velocity_Profile)]),len(movements)*repetitions*neurons,axis=2).reshape(target_shape)
# multiplied by gains:
S_gains = np.repeat(np.repeat(Gains.reshape([1,1,neurons]), len(movements)*repetitions, axis=1).reshape(target_shape[:3]), len(Velocity_Profile)).reshape(target_shape)
Spikes = Spikes * S_gains
# and multiplied by the movement:
S_moves = np.repeat( np.array(movements).reshape([len(movements),1,1,1]), repetitions*neurons*len(Velocity_Profile), axis=3 ).reshape(target_shape)
Spikes = Spikes * S_moves
# on top of a baseline firing rate:
S_FR = np.repeat(np.repeat(FRs.reshape([1,1,neurons]), len(movements)*repetitions, axis=1).reshape(target_shape[:3]), len(Velocity_Profile)).reshape(target_shape)
Spikes = Spikes + S_FR
# can not run the poisson random number generator on input lower than 0:
Spikes = np.where(Spikes < 0, 0, Spikes)
# so far, these were expected firing rates per second, correct for dt:
Spikes = poisson.rvs(Spikes * dt)
return(Spikes)
def subsetPerception(spikes):
movements = [0,1,2]
split = 400
subset = 40
hwin = 3
[num_movements, repetitions, neurons, timepoints] = np.shape(spikes)
decision = np.zeros([num_movements, repetitions])
# ground truth for logistic regression:
y_train = np.repeat([0,1,1],split)
y_test = np.repeat([0,1,1],repetitions-split)
m_train = np.repeat(movements, split)
m_test = np.repeat(movements, split)
# reproduce the time points:
dt = 1/100
start, stop = -1.5, 1.5
t = np.arange(start, stop+dt, dt)
w_idx = list( (abs(t) < (hwin*dt)).nonzero()[0] )
w_0 = min(w_idx)
w_1 = max(w_idx)+1 # python...
# get the total spike counts from stationary and movement trials:
spikes_stat = np.sum( spikes[0,:,:,:], axis=2)
spikes_move = np.sum( spikes[1:,:,:,:], axis=3)
train_spikes_stat = spikes_stat[:split,:]
train_spikes_move = spikes_move[:,:split,:].reshape([-1,neurons])
test_spikes_stat = spikes_stat[split:,:]
test_spikes_move = spikes_move[:,split:,:].reshape([-1,neurons])
# data to use to predict y:
x_train = np.concatenate((train_spikes_stat, train_spikes_move))
x_test = np.concatenate(( test_spikes_stat, test_spikes_move))
# this line creates a logistics regression model object, and immediately fits it:
population_model = LogisticRegression(solver='liblinear', random_state=0).fit(x_train, y_train)
# solver, one of: 'liblinear', 'newton-cg', 'lbfgs', 'sag', and 'saga'
# some of those require certain other options
#print(population_model.coef_) # slope
#print(population_model.intercept_) # intercept
ground_truth = np.array(population_model.predict(x_test))
ground_truth = ground_truth.reshape([3,-1])
output = {}
output['perception'] = ground_truth
output['spikes'] = spikes[:,split:,:subset,:]
return(output)
def getData():
spikes = generateSpikeTrains()
dataset = subsetPerception(spikes=spikes)
return(dataset)
dataset = getData()
perception = dataset['perception']
spikes = dataset['spikes']
# -
# ## Plot Functions
#
# + id="Fa5SDmVvgvMe" cellView="form" tags=["hide-input"]
# @title Plot Functions
def rasterplot(spikes,movement,trial):
[movements, trials, neurons, timepoints] = np.shape(spikes)
trial_spikes = spikes[movement,trial,:,:]
trial_events = [((trial_spikes[x,:] > 0).nonzero()[0]-150)/100 for x in range(neurons)]
plt.figure()
dt=1/100
plt.eventplot(trial_events, linewidths=1);
plt.title('movement: %d - trial: %d'%(movement, trial))
plt.ylabel('neuron')
plt.xlabel('time [s]')
def plotCrossValAccuracies(accuracies):
f, ax = plt.subplots(figsize=(8, 3))
ax.boxplot(accuracies, vert=False, widths=.7)
ax.scatter(accuracies, np.ones(8))
ax.set(
xlabel="Accuracy",
yticks=[],
title=f"Average test accuracy: {accuracies.mean():.2%}"
)
ax.spines["left"].set_visible(False)
# + [markdown] id="Am_lYQFwZh6P"
# ----
# # Phenomenon
# *Part of Steps 1-2*
#
# The train illusion occurs when sitting on a train and viewing another train outside the window. Suddenly, the other train *seems* to move, i.e. you experience visual motion of the other train relative to your train. But which train is actually moving?
#
# Often people mix this up. In particular, they think their own train might be moving when it's the other train that moves; or vice versa. The illusion is usually resolved once you gain vision of the surroundings that lets you disambiguate the relative motion; or if you experience strong vibrations indicating that it is indeed your own train that is in motion.
# + [markdown] id="TmX7l7W2Znak"
# ----
# # Question
#
# *Part of Step 1*
#
# We assume that we have build the train illusion model (see the other example project colab). That model predicts that accumulated sensory evidence from vestibular signals determines the decision of whether self-motion is experienced or not. We now have vestibular neuron data (simulated in our case, but let's pretend) and would like to see if that prediction holds true.
#
# The data contains $N$ neurons and $M$ trials for each of 3 motion conditions: no self-motion, slowly accelerating self-motion and faster accelerating self-motion.
#
# \begin{align}
# N &= 40\\
# M &= 400\\
# \end{align}
#
# **So we can ask the following question**: "Does accumulated vestibular neuron activity correlate with self-motion judgements?"
# + [markdown] id="u-LYhgUSLxD0"
# # Background
#
# _Part of step 2_
# + [markdown] id="d7sSTvjKNK_m"
# While it seems a well-known fact that vestibular signals are noisy, we should check if we can also find this in the literature.
# + [markdown] id="Qam_pxCGMrWk"
# Let's also see what's in our data, there should be a 4d array called `spikes` that has spike counts (positive integers), a 2d array called `perception` with self-motion judgements (0=no motion or 1=motion). Let's see what this data looks like:
# + id="vpht2lCAOcsU"
print(np.shape(spikes))
print(np.shape(perception))
print(np.mean(perception, axis=1))
# + [markdown] id="BGUSacY6N8w_"
# In the `spikes` array, we see our 3 acceleration conditions (first dimension), with 400 trials each (second dimensions) and simultaneous recordings from 40 neurons (third dimension), across 3 seconds in 10 ms bins (fourth dimension). The first two dimensions are also there in the `perception` array.
#
# Perfect perception would have looked like [0, 1, 1]. The average judgements are far from correct (lots of self-motion illusions) but they do make some sense: it's closer to 0 in the no-motion condition and closer to 1 in both of the real-motion conditions.
#
# The idea of our project is that the vestibular signals are noisy so that they might be mis-interpreted by the brain. Let's see if we can reproduce the stimuli from the data:
# + id="JyQQIQlrMM90"
for move_no in range(3):
plt.plot(np.arange(-1.5,1.5+(1/100),(1/100)),np.mean(np.mean(spikes[move_no,:,:,:], axis=0), axis=0), label=['no motion', '$1 m/s^2$', '$2 m/s^2$'][move_no])
plt.xlabel('time [s]');
plt.ylabel('averaged spike counts');
plt.legend()
# + [markdown] id="J_UTBEr5Md5Z"
# Blue is the no-motion condition, and produces flat average spike counts across the 3 s time interval. The orange and green line do show a bell-shaped curve that corresponds to the acceleration profile. But there also seems to be considerable noise: exactly what we need. Let's see what the spike trains for a single trial look like:
# + id="JeDScf02M_Xo"
for move in range(3):
rasterplot(spikes = spikes, movement = move, trial = 0)
# + [markdown] id="epgCnpI9MZ6T"
# You can change the trial number in the bit of code above to compare what the rasterplots look like in different trials. You'll notice that they all look kind of the same: the 3 conditions are very hard (impossible?) to distinguish by eye-balling.
#
# Now that we have seen the data, let's see if we can extract self-motion judgements from the spike counts.
# + [markdown] id="5601vtLzgQo2"
# ----
# # Ingredients
#
# *Part of step 3*
#
# In order to address our question we need to design an appropriate computational data analysis pipeline. We did some brainstorming and think that we need to somehow extract the self-motion judgements from the spike counts of our neurons. Based on that, our algorithm needs to make a decision: was there self motion or not? This is a classical 2-choice classification problem. We will have to transform the raw spike data into the right input for the algorithm (spike pre-processing).
#
# So we determined that we probably needed the following ingredients:
#
# * spike trains $S$ of 3-second trials (10ms spike bins)
# * ground truth movement $m_r$ (real) and perceived movement $m_p$
# * some form of classifier $C$ giving us a classification $c$
# * spike pre-processing
# + [markdown] id="avZl5UFjhHtU"
# ----
# # Hypotheses
#
# *Part of step 4*
#
# We think that noise in the signal drives whether or not people perceive self motion. Maybe the brain uses the strongest signal at peak acceleration to decide on self motion, but we actually think it is better to accumulate evidence over some period of time. We want to test this. The noise idea also means that when the signal-to-noise ratio is higher, the brain does better, and this would be in the faster acceleration condition. We want to test this too.
#
# We came up with the following hypotheses focussing on specific details of our overall research question:
#
# * Hyp 1: Accumulated vestibular spike rates explain self-motion judgements better than average spike rates around peak acceleration.
# * Hyp 2: Classification performance should be better for faster vs slower self-motion.
#
# > There are many other hypotheses you could come up with, but for simplicity, let's go with those.
#
# Mathematically, we can write our hypotheses as follows (using our above ingredients):
# * Hyp 1: $\mathbf{E}(c_{accum})>\mathbf{E}(c_{win})$
# * Hyp 2: $\mathbf{E}(c_{fast})>\mathbf{E}(c_{slow})$
#
# Where $\mathbf{E}$ denotes taking the expected value (in this case the mean) of its argument: classification outcome in a given trial type.
# + [markdown] id="iWsJJMFTkkzE"
# ----
# # Selected toolkit
#
# *Part of step 5*
#
# We want to build some form of classification pipeline. There are many options here, but a simple decoder would be a good start. Since we will learn all about Generalized Linear Models soon, we decided to use that! From W1D4: Generalized Linear Models there were two models that looked relevant:
#
# * Linear-Nonlinear-Poisson GLM: predict spike counts from stimulus
# * Logistic Regression: predict stimulus from spike counts
#
# Here we want to predict self-motion from spike counts, so we pick Logistic Regression.
# + [markdown] id="WS4LiO83mRkv"
# ----
# # Model draft
#
# *Part of step 6*
#
# Brainstorming on the whiteboard, we came up with this set of steps:
#
# 1. convert spike count data into design matrix: trials x neurons (with accumulated or windowed data)
# 2. get the classes each trial belongs to: stimulus (stationary / moving) or self-motion judgements (moving or not?) as a vector array
# 3. split data into train and test sets (200 trials each for the 3 conditions?) with an equal number of each class
# 4. fit logistic regression model on training set, and get predictions for test set
#
# 
#
#
# + [markdown] id="sq7gfERGtSj8"
# ----
# # Model implementation
#
# *Part of step 7*
#
#
# + [markdown] id="zSdzpN2uz05F"
# Below is a function that gets us the design matrix of observations X features (in this case: trials X neurons). It sums all spike counts, either across the whole time interval, or a window, specified in seconds before and after the peak acceleration at time=0 (it is the half-width of the window: `halfwin`).
# + id="3YyfY5vGfxfp"
m_r = np.repeat([0,1,1], 400)
m_p = perception.reshape([-1])
a_r = np.repeat([0,1,2], 400) # for grouping in cross validation? maybe not
def getDesignMatrix(spikes, motions, classes, halfwin=None):
"""
Get the design matrix and vector of classes for a logistic regression.
Args:
spikes (numpy.ndarray): a 4d matrix with spike counts for 1) three motion
conditions, 2) 400 trials, 3) 40 neurons, 4) 301 time bins
motions (list): motion conditions to include, any subset of [0,1,2]
classes (list): list of length 3 * 400 with classes to use for the
logistic regression
halfwin (None or float): None to use the whole 3 s time interval, or a
value between 0 and 1.5 seconds as the extent of the window from 0 (when
acceleration peaks) in both directions.
Returns:
(list of numpy.ndarray): first element of the list is the design matrix
of shape [trials] X [neurons], second elements is a 1d matrix to use as
a vector of classes to predict from the design matrix
This function can be used to get the right design matrix and set of class
labels for a variety of logistic regressions we might want to do.
"""
# select motion conditions:
spikes = spikes[motions,:,:,:]
y = (np.array(classes).reshape([3,-1])[motions,:]).reshape([-1])
[movstims, trials, neurons, timepoints] = np.shape(spikes)
# first we get the window (if any):
if halfwin is None:
return( [ np.sum(spikes, axis=3).reshape([movstims*trials,neurons]), y ] )
else:
dt = 1/100
t = np.arange(-1.5,1.5+dt,dt)
win_idx = (abs(t) < halfwin).nonzero()[0]
w_0, w_1 = min(win_idx), max(win_idx)+1
return( [ np.sum(spikes[:,:,:,w_0:w_1], axis=3).reshape([movstims*trials,neurons]), y ] )
# test the function:
[desmat, y] = getDesignMatrix(spikes, motions=[0,1], classes=m_r)
# let's check the shape:
print(np.shape(desmat))
# and let's check if the mean sum of spikes checks out:
print(np.mean(np.sum(spikes,axis=3),axis=(1,2)))
for mov in range(2):
print(np.mean(desmat[(mov*400):((mov+1)*400),:]))
# + [markdown] id="2Np7bYOA0UdD"
# First, the design matrix: `desmat` has the right shape: 800 trials (for two conditions), by 40 neurons.
#
# We also get the same average spike counts from our function (76.3 and 77.5) as when calculating it 'by hand' ([76.33475 77.53275 78.61975]).
#
# This means our function `getDesignMatrix()` works correctly (unit test).
# + [markdown] id="whuuVTSiUIve"
# It also gets us the classes for each trial. We can use both judgements, $m_p$, and stimuli, $m_r$, as one vector, and `getDesignMatrix()` returns the correct subset (depending on which motion conditions are used) as the second variable.
# + [markdown] id="xYy4AXJQWeXM"
# We wanted to split the data into a training and test set, but we can have scikit-learn do this for us with the `cross_val_score()` function, as we saw in the GLM day:
# + id="GJfWd5t2hmBx"
accuracies = cross_val_score(LogisticRegression(solver='liblinear'), X=desmat, y=y, cv=8)
plotCrossValAccuracies(accuracies) # this plotting function is copied from W1D4: Generalized Linear Models
# + [markdown] id="krXVBCP7jN79"
# We asked for 8 cross validations, which show up as the blue dots in the graph (two have the same accuracy). Prediction accuracy ranges from 56% to 72%, with the average at 65%, and the orange line is the median. Given the noisy data, that is not too bad actually.
#
# But maybe it's better to split it according to the conditions where there is motion but of different magnitude. It should work better to classify higher acceleration motion from no motion as compared to classifying the lower acceleration motion.
#
# Maybe it also works better to ignore some of the noise at the beginning and end of each trial by focussing on the spikes around the maximum acceleration, using our window option. The average spike count plot above, seems to best discriminate between the three motion conditions around peak acceleration (at 0 s).
#
# We also want to test if it's possible to predict the self-motion judgements rather than the actual motion.
#
# So we write a function that brings it all together:
# + id="ykvVA4_XtYsc"
m_r = np.repeat([0,1,1], 400)
m_p = perception.reshape([-1])
def classifyMotionFromSpikes(spikes, classes, halfwin=None, motions=[0,1,2], cv=8):
"""
Runs one logistic regression using the specified parameters.
Args:
spikes (numpy.ndarray): a 4d matrix with spike counts for 1) three motion
conditions, 2) 400 trials, 3) 40 neurons, 4) 301 time bins
classes (list): list of length 3 * 400 with classes to use for the
logistic regression
halfwin: None to use the whole 3 s time interval, or a value between 0
and 0.750 seconds as the extent of the window from 0 (when acceleration
peaks)
motions (list): motion conditions to include, any subset of [0,1,2]
cv (int): number of cross validations to do in logistic regression
Returns:
(numpy.ndarray): 1d array of shape (cv,) with prediction accuracies for
each cross validation
This function uses our getDesignMatrix() function according to specification
and then uses cross-validated logistic regression and returns the accuracy
for each run of the model.
"""
# get the right design matrix:
X, y = getDesignMatrix(spikes, motions, classes=classes, halfwin=halfwin)
# right now, we are not using regularization:
return( cross_val_score(LogisticRegression(solver='liblinear'), X=X, y=y, cv=cv) )
accuracies = classifyMotionFromSpikes(spikes, m_r, motions=[0,1])
plotCrossValAccuracies(accuracies)
# + [markdown] id="Sjai0BkJxccB"
# This is the exact same figure as before, so our function `classifyMotionFromSpikes()` also works as intended.
# + [markdown] id="wx2cFbpvtZzy"
# ----
# # Model completion
#
# *Part of step 8*
#
# **Can we answer our question?** Question: "Does accumulated vestibular neuron activity correlate with self-motion judgements?" Yes, we can get an answer to the question by applying our analysis to predict self-motion judgements.
#
# **Can we speak to our hypothesis?** We had two hypotheses: 1) prediction is better with total accumulated spike counts than from a window around peak acceleration, and 2) prediction is better with higher acceleration as the signal-to-noise ratio increases.
#
# **Does the model reach our goals?** We want to understand if motion judgement and not true motion correlates better with vestibular neural activity.
#
# Note: We have somewhat refined our goal here by explicitly contrasting true motion with motion judgements.
# + [markdown] id="LvIsNCefthEE"
# ----
# # Model evaluation & testing
#
# *Part of step 9*
#
# We can now evaluate the performance of our analysis pipeline.
#
# To do so, we will run the logistic regression quite a few times: on all data or split by the velocities, and then we use the data to predict the presence of real motion, or the judgements of self-motion. We repeat this for total accumulated spikes and for a window around the peak acceleration. And then we'll plot the average classification performance in those 12 cases.
# + id="Uphy1zMY7nGw"
def runAnalysis(spikes):
"""
Runs one logistic regression using the specified parameters.
Args:
spikes (numpy.ndarray): a 4d matrix with spike counts for 1) three motion
conditions, 2) 400 trials, 3) 40 neurons, 4) 301 time bins
Returns:
(numpy.ndarray): array of shape (2, 2, 3, 12), where the first dimension
denotes full interval or 100 ms window, the second dimension denotes
real motion or self-motion judgements, the third dimension denotes slow,
fast or all data, and for each there 12 prediction accuracies for each
of the 12 cross validations
This function uses our classifyMotionFromSpikes()) function according to
specification for all the different ways we want to classify the data and
gives us the classification performance.
"""
# variables we use for testing our analysis pipeline:
m_r = np.repeat([0,1,1], 400)
m_p = perception.reshape([-1])
halfwins = [None, 0.050]
motions = [[0,1],[0,2],[0,1,2]]
class_sets = [m_r, m_p]
cv = 12
# empty array to collect classification performance:
accuracies = np.zeros([len(halfwins),len(class_sets),len(motions),cv])
for halfwin_no in range(len(halfwins)):
halfwin = halfwins[halfwin_no]
lty = ['-','--'][halfwin_no]
leg_hw = ['accumulated', '100 ms window'][halfwin_no]
for classes_no in range(len(class_sets)):
classes = class_sets[classes_no]
leg_class = ['real', 'judgements'][classes_no]
color = ['orange','purple'][classes_no]
for motions_no in range(len(motions)):
motion = motions[motions_no]
cond_acc = classifyMotionFromSpikes(spikes = spikes,
classes = classes,
halfwin = halfwin,
motions = motion,
cv=12)
accuracies[halfwin_no,classes_no,motions_no,:] = cond_acc
m_acc = np.mean(accuracies[halfwin_no,classes_no,:,:], axis=1)
return(accuracies)
# here we run the above function and store the output:
accuracies = runAnalysis(spikes)
# + [markdown] id="xr1n5pSIajAu"
# We will need to plot this output, and to simplify the code, we do that in a separate function, which we write here:
# + id="4BnNP3cqascr"
def plotAccuracies(accuracies):
"""
Plot the accuracies from our main fitting function.
Args:
accuarcies (numpy.ndarray): a 4d matrix with performance accuracy for
1) full interval or 100 ms window, 2) real motion or self-motion
judgements, 3) slow, fast or all conditions, and 4) the 12 cross
validations
Returns:
This function plots the output of our data analysis pipeline and does not
return anything.
"""
ax = plt.figure(figsize=(6,4))
plt.title('classification accuracy')
plt.xlim([0.5,3.5])
plt.ylim([0.4,1.0])
plt.ylabel('proportion correct')
plt.xlabel('velocity condition vs. stationary')
for halfwin_no in range(2):
lty = ['-','--'][halfwin_no]
leg_hw = ['accumulated', '100 ms window'][halfwin_no]
for classes_no in range(2):
leg_class = ['real', 'judgements'][classes_no]
color = ['orange','purple'][classes_no]
m_acc = np.mean(accuracies[halfwin_no,classes_no,:,:], axis=1)
plt.plot([1,2,3], m_acc, lty, color=color, label=leg_class+' '+leg_hw)
plt.xticks(ticks=[1,2,3], labels=['slow ($1 m/s^2$)','fast ($2 m/s^2$)','both'])
plt.legend(loc='lower right')
plt.show()
plotAccuracies(accuracies)
# + [markdown] id="n_SHMXME6p0b"
# Well, that's interesting! The logistic regression doesn't do a perfect job, but there is information in these results.
#
# 1. The dashed lines reflect predictions based on a small window of data, and they do worse than the full data set: this could mean that the brain also integrates signals across longer time frames for perception.
#
# 2. In the predictions based on accumulated spike counts, the slow movements are harder to separate from no movements than the faster movements. This is clearer when predicting real motion than when predicting self-motion judgements.
#
# Those were our two hypotheses, but we notice something else:
#
# 3. Self-motion judgments display higher decoding accuracy than the actual motion.
#
# Actually, if self-motion judgements and our logistic regression use input from the same noisy sensors, it kind of makes sense that they would both give similar output. This is in line the notion that self-motion judgements can be wrong because the underlying sensory signals are noisy. Of course, this only works if we record activity from neuronal populations that contribute to self-motion judgements. On the other hand, we would also see this result if the sensory signal was not noisy and we recorded from one of several populations that contribute to self-motion judgements in a noisy way. So we need to do more research here.
#
# Either way, we learned something today!
# + [markdown] id="zHTTYiRJuA3a"
# ----
# # Summary
# *Part of Step 10*
#
# Let's write a simple abstract following the guidelines.
#
# **A. What is the phenomena?** Here summarize the part of the phenomena which your model addresses.
#
# _When sitting in a stationary train and seeing the train next to them move, people may experience the "train illusion": they feel like they are moving when they are not, or vice versa. Vestibular information can disambiguate self motion from motion of the adjacent train._
#
# **B. What is the key scientific question?** Clearly articulate the question which your model tries to answer.
#
# _However, it is unknown if accumulated, noisy vestibular neuron activity correlates with self-motion judgement._
#
# **C. What was our hypothesis?** Explain the key relationships which we relied on to simulate the phenomena.
#
# _Based on previous modeling efforts, we hypothesized that cumulative spike counts (not instantaneous) recorded from vestibular neurons can better discriminate experienced self motion judgements as opposed to true self motion._
#
# **D. How did your model work?** Give an overview of the model, it's main components, and how the model works. "Here we ..."
#
# _Here we use logistic regression to classify both true self motion and experienced self motion judgements from vestibular neuron activity. This was done both with the vestibular signal accumulated across the full trial and with a 100 ms window ('instantaneous') around peak acceleration, and with 2 different speeds compared to a no-motion condition._
#
# **E. What did we find?** Did the model work? Explain the key outcomes of your model evaluation.
#
# _Decoding performance for accumulated vestibular signals was higher than for instantaneous signals. Further, experienced self motion judgements could be classified better than true self motion._
#
# **F. What can we conclude?** Conclude as much as you can with reference to the hypothesis, within the limits of the model.
#
# _We conclude that accumulated, noisy vestibular signals during slowly-accelerating self motion may drive the train illusion._
#
# **G. What are the limitations and future directions?** What is left to be learned? Briefly argue the plausibility of the approach and/or what you think is essential that may have been left out.
#
# _Future research should examine how visual signals may combine with vestibular signals in real-world scenarios to causally link these sensory signals to self-motion experience and illusions._
#
#
# If we put this all in one paragraph, we have our final complete abstract. But, first, do not include the letters in _your_ abstract, and second, we did paraphrase the answers a little so they fit together.
#
# # Abstract
#
#
# (A) When sitting in a stationary train and seeing the train next to them move, people may experience the "train illusion": they feel like they are moving when they are not, or vice versa. Vestibular information can disambiguate self motion from motion of the adjacent train. (B) However, it is unknown if accumulated, noisy vestibular neuron activity correlates with self-motion judgement. (C) Based on previous modeling efforts, we hypothesized that cumulative spike counts (not instantaneous) recorded from vestibular neurons can better discriminate experienced self motion judgements as opposed to true self motion. (D) Here we use logistic regression to classify both true self motion and experienced self motion judgements from vestibular neuron activity. This was done both with the vestibular signal accumulated across the full trial and with a 100 ms window ('instantaneous') around peak acceleration, and with 2 different speeds compared to a no-motion condition. (E) Decoding performance for accumulated vestibular signals was higher than for instantaneous signals. Further, experienced self motion judgements could be classified better than true self motion. (F) We conclude that accumulated, noisy vestibular signals during slowly-accelerating self motion may drive the train illusion. (G) Future research should model possible mechanisms by which visual signals may combine with vestibular signals to causally link these sensory signals to self-motion experience and illusions.
#
#
#
# + [markdown] id="d6Qg713iuKbY"
# ----
# # Final thoughts
#
# Note that the analysis pipeline we built here was extremely simple and we used artificial data on purpose. It allowed us to go through all the steps of building a data neuroscience project, and hopefully you noticed that it is not always a linear process, you will go back to different steps if you hit a roadblock somewhere.
#
# There are many issues that we did not address, e.g.:
# * we could have tried different decoders
# * or find the optimal window
# * what if we had more data...
# * how do different neurons contribute to the decision? And why?
# * this is something that you want to explore as a neuroscientist
# * we could have run a GLM on the neurons*time array and then analyze the weightings to see if all acceleration steps are weighted equally (perfect integration)... or not?
# * what is the role of visual motion in this phenomenon?
#
# However, this project is not meant to be complete, and yours doesn't have to be either. The goal of the projects is to go through _the process_ of a modeling or data science project and put into practice one or more of the toolkits you learn at NMA with your group.
#
#
| proj-booklet/modeling-step-by-step-guide/train-illusion-data-project.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Classify data w/ Keras
# This notebook is identical to the notebook "Classify data w/ Keras", except I now load in embeddings from bag of words and TF-IDF and assess classifier performance on these embeddings
# +
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM, Embedding, Input, RepeatVector
from keras.optimizers import SGD
from keras.utils import np_utils
from sklearn.preprocessing import LabelEncoder
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import numpy as np
from sklearn.metrics import classification_report
from sklearn.metrics import matthews_corrcoef
import matplotlib.pyplot as plt
import seaborn as sns
import pickle
# +
# load pre-processed data
train_df, test_df, test_df_truncated, solution_df_truncated, desired_class, desired_ID, no1, no2 = pickle.load( open( "cleaned_train_test_d2v.pkl", "rb" ) )
# bag of words
# text_train_arrays, text_test_arrays = pickle.load( open( "cleaned_train_test_BoW.pkl", "rb" ) )
# tf-idf
text_train_arrays_non_runcated, text_train_arrays, text_test_arrays = pickle.load( open( "cleaned_train_test_tfidf.pkl", "rb" ) )
# -
print('X_train shape:', text_train_arrays.shape)
print('X_test shape:', text_test_arrays.shape)
print('X_train shape:', no1.shape)
print('X_train shape:', no2.shape)
# +
# 1. Transform categorical labels to numerical labels between 0 and len(labels) using labelEncoder
# 2. one hot encode our label
y_train = train_df.Class
label_encoder = LabelEncoder()
label_encoder.fit(y_train)
y_train_hot = np_utils.to_categorical(label_encoder.transform(y_train))
# target labels
y_true = [int(x) for x in desired_class.ravel()]
y_true_oh = solution_df_truncated.values
# +
# quick visualization w/ tSNE
# we should have no problem using 300 dimensions
from sklearn.manifold import TSNE
tsne = TSNE(n_components=3, verbose=0, perplexity=40, n_iter=300)
tsne_pca_results = tsne.fit_transform(text_train_arrays)
# +
from mpl_toolkits.mplot3d import Axes3D
df_viz = pd.DataFrame()
df_viz['tsne-one'] = tsne_pca_results[:,0]
df_viz['tsne-two'] = tsne_pca_results[:,1]
df_viz['class'] = train_df['Class']
sns.scatterplot(x="tsne-one", y="tsne-two",
hue="class",
palette=sns.color_palette("hls", 9),
data=df_viz,
legend="full",
alpha=0.3)
plt.show()
# -
tsne_pca_results.shape
# The classes are not at all well-separated! I would not expect our performance to be high, no matter what model we use
# ## A simple model
# +
Text_INPUT_DIM=300
def baseline_model():
model = Sequential()
model.add(Dense(256, input_dim=Text_INPUT_DIM, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(80, activation='relu'))
model.add(Dense(9, activation="softmax"))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
model = baseline_model()
# -
estimator=model.fit(text_train_arrays, y_train_hot, validation_split=0.2, epochs=30, batch_size=64)
estimator.history.keys()
def plot_accuracy(history):
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'valid'], loc='upper left')
plt.show()
plot_accuracy(estimator)
def pred_and_decode(model, x_test):
y_pred_prob = model.predict(x_test)
y_pred_k1 = y_pred_prob.argmax(axis=-1)
y_pred = label_encoder.inverse_transform(y_pred_k1)
#pred_class = y_pred_k1
#pred_class_df = pd.DataFrame({'ID':pred_ID, 'pred_class':pred_class})
#merged_class_df = pd.merge(pred_class_df,desired_class_df,on='ID')
#y_pred = merged_class_df.pred_class
#y_true = merged_class_df.desired_class
return list(y_pred),y_pred_prob
def assess_results(y_true,y_pred):
# build confusion matrix
confusion = pd.crosstab(pd.Series(y_true),pd.Series(y_pred),margins = False)
sns.heatmap(confusion,annot=True)
plt.xlabel('Predicted')
plt.ylabel('Desired')
plt.show()
print(classification_report(y_true,y_pred))
print('MCC:', matthews_corrcoef(y_true,y_pred))
# assess results
y_pred,y_pred_prob = pred_and_decode(model, text_test_arrays)
assess_results(y_true,y_pred)
model.predict(text_test_arrays)
# This baseline model's validation accuracy is pretty bad, but its MCC and weighted-f1 score average are moderately better than Doc2Vec alone. Let's include gene and variation data into the training data.
# ### ROC curves
# Build ROC curves in a one-vs-all manner
# make ROC with these variables
print('model prediction output:', y_pred_prob.shape)
print('target label output:', y_true_oh.shape)
# +
# put everything together into a function
from sklearn.metrics import roc_curve, auc
def plot_roc(y_true,y_pred,title='ROC title',num_classes=9):
# calculate ROC in a one-vs-all manner
# y_true needs to be binary (one-hot encoded)
# y_pred needs to be probabilities
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(num_classes):
fpr[i], tpr[i], _ = roc_curve(y_true[:, i],y_pred[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Plot of a ROC curve for a specific class
plt.figure()
for i in range(num_classes):
plt.plot(fpr[i], tpr[i], label='Class %i (area = %0.2f)' %(i+1,roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(title)
plt.legend(loc="lower right")
plt.show()
return roc_auc
# -
roc_simple_feedforward = plot_roc(y_true_oh,model.predict(text_test_arrays),'Simple Feedforward Network')
# ## Using Gene & Variation data
# +
from sklearn.decomposition import TruncatedSVD
Gene_INPUT_DIM=25
svd = TruncatedSVD(n_components=25, n_iter=Gene_INPUT_DIM, random_state=12)
# one-hot encode Gene and Variation Data
gene_hot_train = pd.get_dummies(train_df['Gene'])
truncated_gene_hot_train = svd.fit_transform(gene_hot_train.values)
var_hot_train = pd.get_dummies(train_df['Variation'])
truncated_var_hot_train = svd.fit_transform(var_hot_train.values)
gene_hot_test = pd.get_dummies(test_df_truncated['Gene'])
truncated_gene_hot_test = svd.fit_transform(gene_hot_test.values)
var_hot_test = pd.get_dummies(test_df_truncated['Variation'])
truncated_var_hot_test = svd.fit_transform(var_hot_test.values)
# -
# combine Gene, Variation into encoded paragraph vectors array
X_train=np.hstack((truncated_gene_hot_train,truncated_var_hot_train,text_train_arrays))
X_test=np.hstack((truncated_gene_hot_test,truncated_var_hot_test,text_test_arrays))
# +
# train the model once more
Text_INPUT_DIM=300
def baseline_model_big():
model = Sequential()
model.add(Dense(256, input_dim=Text_INPUT_DIM+Gene_INPUT_DIM*2, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(80, activation='relu'))
model.add(Dense(9, activation="softmax"))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
model_big = baseline_model_big()
# -
model_big.summary()
estimator2=model_big.fit(X_train, y_train_hot, validation_split=0.2, epochs=30, batch_size=64)
plot_accuracy(estimator2)
y_pred,y_pred_prob = pred_and_decode(model_big, X_test)
assess_results(y_true,y_pred)
roc_simple_gene_var = plot_roc(y_true_oh,y_pred_prob,'Feedforward network w/ Gene & Variation data')
# The validation results seem equally bad, but the MCC and weighted f1 score seems to have improved marginally.
# ## Doc2Vec -> LSTMs
# (inspiration: https://www.kaggle.com/viveksinghub/lstm-with-doc2vec)
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM, Flatten
from keras.utils.np_utils import to_categorical
from keras.callbacks import ModelCheckpoint
from keras.models import load_model
from keras.optimizers import Adam
# +
# Build out our simple LSTM
# I'm skipping the embedding layer because we already created word vectors from Dov2Vec
embed_dim = 128
lstm_out = 196
num_words = 2000
# Model saving callback
ckpt_callback = ModelCheckpoint('keras_lstm_model',
monitor='val_loss',
verbose=1,
save_best_only=True,
mode='auto')
def lstm_model(c,training_weights):
model = Sequential()
#model.add(Embedding(num_words,embed_dim,input_length=c))
model.add(LSTM(lstm_out, return_sequences=True, recurrent_dropout=0.2, dropout=0.2, input_shape=(1,c)))
model.add(Dense(30,activation='relu'))
model.add(Dense(9,activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam', metrics = ['categorical_crossentropy','accuracy'])
return model
model_lstm = lstm_model(X_train.shape[1],X_train)
print(model_lstm.summary())
# -
# not sure why there must be an extra dimension...
print(X_train.shape)
print(y_train_hot.shape)
print(train_df.shape)
y_train_hot
X_train_rs = np.reshape(X_train, (X_train.shape[0],1,X_train.shape[1]))
y_train_rs = np.reshape(y_train_hot, (y_train_hot.shape[0],1,y_train_hot.shape[1]))
X_train_rs.shape
history_lstm = model_lstm.fit(X_train_rs,y_train_rs, validation_split=0.2, epochs=20)
plot_accuracy(history_lstm)
# +
X_test_rs = np.reshape(X_test, (X_test.shape[0],1,X_test.shape[1]))
y_pred,y_pred_prob = pred_and_decode(model_lstm, X_test_rs)
assess_results(y_true,y_pred)
# -
roc_lstm1 = plot_roc(y_true_oh,y_pred_prob.squeeze(),'LSTM model')
aucs = {'simple':list(roc_simple_feedforward.values()),
'simple_gene_var':list(roc_simple_gene_var.values()),
'lstm':list(roc_lstm1.values())}
pd.DataFrame(aucs)
# Other things to note:
# * An example of [Multi-class text classification in Keras](https://towardsdatascience.com/multi-class-text-classification-with-lstm-1590bee1bd17) classifying consumer reports into the topics of complaint is a good reference
# 1. Define functions
# 2. define y_true
# 3. Text clean up & vectorization - both train & test
# 4. run model #1 (logistic classifer) on X_train, X_test, y_train, y_test
# 5. run model #2 (random forest) on X_train, X_test, y_train, y_test
| Classify_w_Keras_Embeddings.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# ## QPO Detection using ABC
#
# We're going to use ABC to detect QPOs in better ways that with dumb frequentist statistics.
#
#
# +
# %matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from BayesPSD import lightcurve, powerspectrum
# +
def qpo(x, loggamma, logamplitude, x0 ):
gamma = np.exp(loggamma)
amplitude = np.exp(logamplitude)
alpha = 0.5*amplitude*gamma/np.pi
y = alpha/((x - x0)**2 + (0.5*gamma)**2)
return y
def powerlaw(x, index, logamplitude):
return np.exp(-np.log(x)*index + logamplitude)
def fake_data(model, m):
noise = np.random.chisquare(2*m, size=model.shape[0])/(2.0*m)
return noise*model
# +
## frequencies
freq = np.arange(1.0, 1000., 1.0)
loggamma = -2
logqpoamp = 4
x0 = 40.0
index = 2.0
logplamp = 8
#m = powerlaw(freq, index, logplamp) + qpo(freq, loggamma, logqpoamp, x0) + 2.0
m = qpo(freq, loggamma, logqpoamp, x0) + 2.0
# -
plt.loglog(freq, m)
mdata = fake_data(m, 1)
plt.loglog(freq, mdata)
# +
from BayesPSD import posterior
import scipy.optimize
#plnoise = lambda x, index, lognorm, noise: powerlaw(x, index, lognorm) + noise
def fit_psd(freq, power):
ps = powerspectrum.PowerSpectrum()
ps.freq = freq
ps.ps = power
ps.df = ps.freq[1]-ps.freq[0]
ps.nphot = ps.ps[0]
lpost = posterior.PerPosterior(ps,plnoise)
res = scipy.optimize.minimize(lpost.loglikelihood, [1, 8, 2.0], method="BFGS", args=(True))
print(res)
print(lpost.loglikelihood(res.x))
return res.x
# -
popt = fit_psd(freq, mdata)
mfit = powerlaw(freq, *popt[:2]) + popt[-1]
plt.loglog(freq, mdata)
plt.loglog(freq, mfit)
plt.plot(freq, mdata-mfit)
plt.xscale("log")
def from_prior():
n = np.random.choice([0,1], size=1,replace=True, p=[0.5, 0.5])
p = []
pl_amp = np.exp(np.random.uniform(-6, 6))
pl_index = np.random.uniform(1, 4)
noise = np.random.uniform(1,3)
p.extend([pl_index, pl_amp, noise])
if n > 0:
f0 = np.exp(np.random.uniform(low=np.log(10), high = np.log(1000.0)))
loggamma = np.log(f0/np.random.uniform(2, 100))
logamp = np.random.uniform(-6, 6)
p.extend([loggamma, logamp, f0])
return n, p
# +
## fit real data
#popt = fit_psd(freq, mdata)
#mfit = powerlaw(freq, *popt[:2]) + popt[-1]
#maxpower = np.max(mdata[10:]/mfit[10:])
maxpower = np.max(mdata)
def model_data_distance(freq, model, maxpower, m):
## fit fake data
fdata = fake_data(model,m)
#fx = fit_psd(freq, fdata)
#fmfit = powerlaw(freq, *fx[:2]) + fx[-1]
#fmaxpower = np.max(fdata[10:]/fmfit[10:])
fmaxpower = np.max(fdata)
dp = np.abs(maxpower - fmaxpower)
return dp
# -
dp_dist = []
nsim = 5000
new_pars = []
for i in xrange(nsim):
n,p = from_prior()
old_model = powerlaw(freq, *p[:2]) + p[2]
if len(p) > 3:
model = qpo(freq, *p[3:])
dp = model_data_distance(freq, model, maxpower, 1)
dp_dist.append(dp)
if dp < 5:
new_pars.append(p)
plt.hist(dp_dist, bins=100, range=[0,200]);
for p in new_pars:
model = powerlaw(freq, *p[:2]) + p[2]
if len(p) > 3:
model = qpo(freq, *p[3:]) + p[2]
plt.loglog(freq, model)
| notebooks/qpoabc.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .r
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: R
# language: R
# name: ir
# ---
# # <NAME>: A game of statistics
# Imagine the following scene in a Hollywood blockbuster movie version of <NAME>:
#
# Sherlock, hears just three pieces of information before letting <NAME> know that the plot has already been foiled.
# "They are in Tulsa, Oklahoma."
#
# "But how could you ever deduce that? We don't even know where they departed from."
#
# "If a tree falls in a forest and no one is around to hear it, does it make a sound?"
#
# "Sherlock, less of the epistimology please, now is not the time!"
#
# "The answer is perfectly logical if the forest is a random one."
#
# At this Watson's deep stare unlocks Sherlock's ever more self satisfactory explaination.
# "The napkin gave away the air carrier and from the times the messages were sent, we know when they departed and how long they were in the air. Just under an hour on American Airlines, I'm over ninety nine percent sure that they are in Tulsa."
#
# After a short sharp outward breath, Watson responds.
# "Sherlock, I'm not quite sure why the epistimolgy of random forests is relevant, but shouldn't we be leaving now?"
# ## Data
# Illogical as it may sound to predict where a flight is going simply from the airline and flight times, we can do so without knowing how airline schedules work. Given a sample of airline data, several techniques lend themselves to classifying aircraft destination (a categorical label) based on seemingly abstracted predictors (both categorical and quantiative).
# First, let's download the airline data, keep only the complete cases, and have a look at the result:
air <- read.csv("https://github.com/rbnsnsd2/quantitative_stats/raw/master/airline_dec_2008_50k.csv", header=TRUE)
air <- air[complete.cases(air),]
head(air)
# For the sake of this example, we can reduce the number of possible locations down to five. For some classifiers there is an upper limit to the number of available labels, but in this case we simply want to be able to render the results cleanly.
suppressWarnings(library("dplyr"))
destinations <- unique(air$Dest)
air <- filter(air, Dest %in% destinations[1:5])
air$Dest <- factor(air$Dest) #Reduce the available labels to those actually present
# Before running the models, we need to pull the necessary libraries.
#install.packages("rpart.plot", dependencies=TRUE)
#install.packages("randomForest", dependencies=TRUE)
library(randomForest)
library(e1071) #SVM and naive Bayes
library(rpart) #Trees & partition
library(rpart.plot) #This allows us to plot the trees in a more interpretable format
set.seed(42) #Create a reproducable "random."
# ## Support vector machines
# SVMs consist of a set of binary linear classifiers which identify if a given sample is from a single category or not. Within SVMs each sample is considered as a vector in a vector-space. A hyperplane of lower dimension is drawn between the categories maximizing the distance between the categorical vectors and the plane (maximum margin hyperplane). With this approach the SVM is linear, but can be extended by first transforming the data in a manner that satisfies the kernel function. The non-linear model version is known as the kernel trick.
# The application of SVM and the resulting confusion matrix and accuracy are as follows:
air.svm <- svm(Dest ~ CRSElapsedTime + CRSDepTime + UniqueCarrier, data=air)
svm.pred=predict(air.svm, air)
table(svm.pred, air$Dest) #Confusion matrix
round(sum(svm.pred == air$Dest)/length(svm.pred), 3)
# ## Naive Bayes
# The naive Bayes classifier assumes that all measures are independent of one another and thus naive. The classification label is given to that which is the most likely from the product of the probabilities of each individual measure.
# For as simple as this model appears, it performs well in many applications. The computational load to train these models is also fairly low.
# The application of naive Bayes and the resulting confusion matrix and accuracy are as follows:
air.nb <- naiveBayes(Dest ~ CRSElapsedTime + CRSDepTime + UniqueCarrier, data=air)
nb.pred=predict(air.nb, air)
table(nb.pred, air$Dest) #Confusion matrix
round(sum(nb.pred == air$Dest)/length(nb.pred), 3)
# ## Decision trees
# Recursive partitioning (rpart) (or decision trees) classify samples by measurement against a repeated series of criteria with a dichotomous outcome until the sample has been classified. The outcome has the benefits of being simple to interpret and performing well. However, care has to be taken with data overfitting and continuous variables.
#
# The application of decision trees and the resulting confusion matrix and accuracy are as follows:
air.tr <- rpart(Dest ~ CRSElapsedTime + CRSDepTime + UniqueCarrier, data=air)
tr.pred=predict(air.tr, type="class")
table(tr.pred, air$Dest) #Confusion matrix
round(sum(tr.pred == air$Dest)/length(tr.pred), 3)
# Here we can see that the decision tree performs very well when compared against the data that was used to fit it. To avoid overfitting, the tree may be "pruned" and the resulting model performance compared with a previously held out set.
# In our particular case this has limited effect:
p.air.tr<- prune(air.tr, cp = air.tr$cptable[which.min(air.tr$cptable[,"xerror"]),"CP"])
p.tr.pred=predict(air.tr, type="class")
round(sum(p.tr.pred == air$Dest)/length(tr.pred), 3)
# Where the decision tree excels is in how simply it can be understood graphically. Below, we can see the fractions separated by each decision, the percentage of the whole and the criteria for each decision branch.
rpart.plot(p.air.tr, type=4)
table(air$Dest)
# ## Random forest
# Random forests (a trademarked title) in essence, are a series of bootstrapped decision trees that are chosen to minimize unexplained variance. From the multitude of tree models created from the bootstrapped samples that form the model, each one is compared to determine the model outcome. Where the outcome is a continuous variable, the mean of the tree outcomes is taken. For catagorical labels, the majority vote of all trees is taken as the outcome. This approach overcomes the overfitting problem of the simple decision tree and generally performs better.
# The application of the random forest and the resulting confusion matrix and accuracy are as follows:
air.rf <- randomForest(Dest ~ CRSElapsedTime + CRSDepTime + UniqueCarrier, data=air, importance=TRUE, proximity=TRUE)
rf.pred=predict(air.rf, air)
table(rf.pred, air$Dest) #Confusion matrix
round(sum(rf.pred == air$Dest)/length(rf.pred), 3)
# As we can see from the result, it performs very well and better than the other approaches demonstrated. This is also true for a larger set of labels. We can repeat our experiment for 50 destinations as follows to equally impressive results:
# +
air <- read.csv("https://github.com/rbnsnsd2/quantitative_stats/raw/master/airline_dec_2008_50k.csv", header=TRUE)
air <- air[complete.cases(air),]
destinations <- unique(air$Dest)
air <- filter(air, Dest %in% destinations[1:50])
air$Dest <- factor(air$Dest) #Reduce the available labels to those actually present
air.rf <- randomForest(Dest ~ CRSElapsedTime + CRSDepTime + UniqueCarrier, data=air, importance=TRUE, proximity=TRUE)
rf.pred=predict(air.rf, air)
#table(rf.pred, air$Dest) #Confusion matrix
round(sum(rf.pred == air$Dest)/length(rf.pred), 3)
# -
| An+introduction+to+several+machine+learning+algorithms.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.7.5 64-bit (''pytorch'': conda)'
# language: python
# name: python37564bitpytorchconda133dde54c45c40c2946593d30b593426
# ---
# +
import gc
import os
import time
import numpy as np
import pandas as pd
from glob import glob
import tqdm
import argparse
import tqdm
from collections import defaultdict, Counter
from PIL import Image
import cv2
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch import nn, cuda
from torch.autograd import Variable
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import CenterCrop
from torch.optim.lr_scheduler import ReduceLROnPlateau, StepLR
# from efficientnet_pytorch import EfficientNet
import torchvision.models as models
# +
import os
import math
import random
import numpy as np
import torch
from torch.optim import Optimizer
from torch.optim.lr_scheduler import _LRScheduler
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
# +
from sklearn.metrics import f1_score
def mae(y_true, y_pred) :
y_true, y_pred = np.array(y_true.detach().numpy()), np.array(y_pred.detach().numpy())
y_true = y_true.reshape(1, -1)[0]
y_pred = y_pred.reshape(1, -1)[0]
over_threshold = y_true >= 0.1
return np.mean(np.abs(y_true[over_threshold] - y_pred[over_threshold]))
def fscore(y_true, y_pred):
y_true, y_pred = np.array(y_true.detach().numpy()), np.array(y_pred.detach().numpy())
y_true = y_true.reshape(1, -1)[0]
y_pred = y_pred.reshape(1, -1)[0]
remove_NAs = y_true >= 0
y_true = np.where(y_true[remove_NAs] >= 0.1, 1, 0)
y_pred = np.where(y_pred[remove_NAs] >= 0.1, 1, 0)
return(f1_score(y_true, y_pred))
def maeOverFscore(y_true, y_pred):
return mae(y_true, y_pred) / (fscore(y_true, y_pred) + 1e-07)
# -
# ### **File info**
# **ex. subset_010462_01**
# > **orbit 010462**
#
# > **subset 01**
#
# > **ortbit 별로 subset 개수는 다를 수 있고 연속적이지 않을 수도 있음**
#
tr_df = pd.read_csv("../D_WEATHER//input/train_df.csv")
te_df = pd.read_csv("../D_WEATHER/input/test_df.csv")
tr_df.head()
# +
ids = tr_df['orbit'].value_counts()
unseen = list(ids[ids<4].index)
train_df = tr_df[~tr_df['orbit'].isin(unseen)]
valid_df = tr_df[tr_df['orbit'].isin(unseen)]
# train_df = tr_df[:int(len(tr_df)*0.8)]
# valid_df = tr_df[int(len(tr_df)*0.8):]
train_df.shape, valid_df.shape
# -
class Weather_Dataset(Dataset):
def __init__(self, df):
self.df = df
self.image_list = []
self.label_list = []
for file in self.df['path']:
data = np.load(file)
image = data[:,:,:9] # use 14 channels except target
image = np.transpose(image, (2,0,1))
image = image.astype(np.float32)
self.image_list.append(image)
label = data[:,:,-1].reshape(40,40,1)
label = np.transpose(label, (2,0,1))
self.label_list.append(label)
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
image = self.image_list[idx]
label = self.label_list[idx]
return image, label
# +
# def worker_init(worker_id):
# np.random.seed(SEED)
def build_dataloader(df, batch_size, shuffle=False):
dataset = Weather_Dataset(df)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=0,
# worker_init_fn=worker_init
)
return dataloader
def build_te_dataloader(df, batch_size, shuffle=False):
dataset = Test_Dataset(df)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=0,
# worker_init_fn=worker_init
)
return dataloader
# -
# # Build Model
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels #
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512, bilinear)
self.up2 = Up(512, 256, bilinear)
self.up3 = Up(256, 128, bilinear)
self.up4 = Up(128, 64 * factor, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
# +
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels // 2, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels , in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
return self.conv(x)
# -
lr = 0.001
batch_size = 512
train_loader = build_dataloader(train_df, batch_size, shuffle=True)
valid_loader = build_dataloader(valid_df, batch_size, shuffle=False)
# +
SEED = 42
seed_everything(SEED)
device = 'cuda:0'
use_gpu = cuda.is_available()
if use_gpu:
print("enable gpu use")
else:
print("enable cpu for debugging")
model = UNet(n_channels=9, n_classes=1, bilinear=False) # if bilinear = True -> non deterministic : not recommended
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr, weight_decay=0.00025)
# optimizer = AdamW(model.parameters(), 2.5e-4, weight_decay=0.000025)
#optimizer = optim.SGD(model.parameters(), args.lr, momentum=0.9, weight_decay=0.025)
###### SCHEDULER #######
scheduler = ReduceLROnPlateau(optimizer, 'min', patience=5, factor=0.5)
#eta_min = 0.00001
#T_max = 10
#T_mult = 1
#restart_decay = 0.97
#scheduler = CosineAnnealingWithRestartsLR(optimizer, T_max=T_max, eta_min=eta_min, T_mult=T_mult, restart_decay=restart_decay)
#scheduler = StepLR(optimizer, step_size=5, gamma=0.5)
#criterion = nn.CrossEntropyLoss()
criterion = nn.L1Loss()
def to_numpy(t):
return t.cpu().detach().numpy()
best_mae_score = 999
best_f_score = 999
best_mof_score = 999
grad_clip_step = 100
grad_clip = 100
step = 0
# accumulation_step = 2
EPOCH = 200
model_fname = '../D_WEATHER/weight/unet_ch9_shuffle_unseen_v1.pt'
# log file
log_df = pd.DataFrame(columns=['epoch_idx', 'train_loss', 'train_mae', 'train_fs', 'train_mof', 'valid_loss', 'valid_mae', 'valid_fs', 'valid_mof'])
print("start training")
for epoch_idx in range(1, EPOCH + 1):
start_time = time.time()
train_loss = 0
train_mae = 0
train_fs = 0
train_mof = 0
# train_total_correct = 0
model.train()
optimizer.zero_grad()
for batch_idx, (image, labels) in enumerate(train_loader):
if use_gpu:
image = image.to(device)
labels = labels.to(device)
output = model(image)
loss = criterion(output, labels)
mae_score = mae(labels.cpu(), output.cpu())
f_score = fscore(labels.cpu(), output.cpu())
mof_score = maeOverFscore(labels.cpu(), output.cpu())
# gradient explosion prevention
if step > grad_clip_step:
torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
step += 1
loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss += loss.item() / len(train_loader)
train_mae += mae_score.item() / len(train_loader)
train_fs += f_score.item() / len(train_loader)
train_mof += mof_score.item() / len(train_loader)
model.eval()
valid_loss = 0
valid_mae = 0
valid_fs = 0
valid_mof = 0
with torch.no_grad():
for batch_idx, (image, labels) in enumerate(valid_loader):
if use_gpu:
image = image.to(device)
labels = labels.to(device)
output = model(image)
loss = criterion(output, labels)
mae_score = mae(labels.cpu(), output.cpu())
f_score = fscore(labels.cpu(), output.cpu())
mof_score = maeOverFscore(labels.cpu(), output.cpu())
# output_prob = F.sigmoid(output)
predict_vector = to_numpy(output)
valid_loss += loss.item() / len(valid_loader)
valid_mae += mae_score.item() / len(valid_loader)
valid_fs += f_score.item() / len(valid_loader)
valid_mof += mof_score.item() / len(valid_loader)
elapsed = time.time() - start_time
# checkpoint
if valid_mof < best_mof_score:
best_mof_score = valid_mof
# print("Improved !! ")
torch.save(model.state_dict(), model_fname)
print("================ ༼ つ ◕_◕ ༽つ BEST epoch : {}, MOF : {} ".format(epoch_idx, best_mof_score))
#file_save_name = 'best_acc' + '_' + str(num_fold)
#print(file_save_name)
# else:
# print("val acc has not improved")
lr = [_['lr'] for _ in optimizer.param_groups]
#if args.scheduler == 'plateau':
scheduler.step(valid_mof)
#else:
# scheduler.step()
# nsml.save(epoch_idx)
print("E {}/{} tr_loss: {:.5f} tr_mae: {:.5f} tr_fs: {:.5f} tr_mof: {:.5f} val_loss: {:.5f} val_mae: {:.5f} val_fs: {:.5f} val_mof: {:.5f} lr: {:.6f} elapsed: {:.0f}".format(
epoch_idx, EPOCH, train_loss, train_mae, train_fs, train_mof, valid_loss, valid_mae, valid_fs, valid_mof, lr[0], elapsed))
#epoch_idx, args.epochs, train_loss, valid_loss, val_acc, lr[0], elapsed
# log file element
# log = []
log_data = [epoch_idx, train_loss, train_mae, train_fs, train_mof, valid_loss, valid_mae, valid_fs, valid_mof]
# log.append(log_data)
log_df.loc[epoch_idx] = log_data
# -
log_df.tail()
# ### Log
log_df.to_csv("../D_WEATHER/log/unet_ch9_shuffle_unseen_v1.csv", index=False)
# ## Prediction
# +
class Test_Dataset(Dataset):
def __init__(self, df):
self.df = df
self.image_list = []
# self.label_list = []
for file in self.df['path']:
data = np.load(file)
# image = data[:,:,:]
image = data[:,:,:9]#.reshape(40,40,-1)
image = np.transpose(image, (2,0,1))
image = image.astype(np.float32)
self.image_list.append(image)
# label = data[:,:,-1].reshape(-1)
# self.label_list.append(label)
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
image = self.image_list[idx]
# label = self.label_list[idx]
return image#, label
# -
test_loader = build_te_dataloader(te_df, batch_size, shuffle=False)
test_loader.dataset.df.shape
train_loader.dataset[0][0].shape
test_loader.dataset[0].shape
model.load_state_dict(torch.load(model_fname))
model.eval()
predictions = np.zeros((len(test_loader.dataset), 1600))
with torch.no_grad():
for i, image in enumerate(test_loader):
image = image.to(device)
output = model(image)
predictions[i*batch_size: (i+1)*batch_size] = output.detach().cpu().numpy().reshape(-1, 1600)
print("predict values check : ",predictions[0])
predictions.shape
predictions[0]
sub = pd.read_csv("../D_WEATHER/input/sample_submission.csv")
sub.head()
sub.iloc[:,1:] = predictions
sub.head()
sub.to_csv('../D_WEATHER/sub/unet_ch9_shuffle_unseen_v1.csv', index = False)
new_sub = sub.copy()
for i in tqdm.tqdm(range(1,1601)):
new_sub.loc[new_sub[new_sub.columns[i]]<0, new_sub.columns[i]] = 0
sub.describe()
new_sub.describe()
new_sub.head()
new_sub.to_csv('../D_WEATHER/sub/unet_ch9_shuffle_unseen_v1_postpro.csv', index = False)
| unet_ch9_shuffle_unseen_v1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Sample Data
#
# `pop-tools` provides some sample data through the `pop_tools.datasets` module.
# ## Where are my data files?
#
# The sample data files are downloaded automatically by [pooch](https://www.fatiando.org/pooch/latest/api/index.html#module-pooch) the first time you load them.
#
import pop_tools
import xarray as xr
xr.set_options(display_style="html") # fancy HTML repr
# To find which data files are available via `pop_tools`, you can run the following:
pop_tools.DATASETS.registry_files
# Once you know which file you are interested in, you can pass the name to the `pop_tools.DATASETS.fetch()` function.
# This function will download the file if it does not exist already on your local system. After the file has been downloaded, the fetch function returns the path:
filepath = pop_tools.DATASETS.fetch('cesm_pop_monthly.T62_g17.nc')
print(filepath)
# Now, we can pass the file path to the appropriate I/O package for loading the content of the file:
ds = xr.open_dataset(filepath)
ds
# %load_ext watermark
# %watermark -d -iv -m -g -h
| docs/source/examples/sample-data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from vnpy.app.cta_strategy.backtesting import BacktestingEngine, OptimizationSetting
from vnpy.app.cta_strategy.strategies.atr_rsi_strategy import AtrRsiStrategy
from vnpy.app.cta_strategy.strategies.boll_channel_strategy import BollChannelStrategy
from datetime import datetime
# +
def run_backtesting(strategy_class, setting, vt_symbol, interval, start, end, rate, slippage, size, pricetick, capital):
engine = BacktestingEngine()
engine.set_parameters(
vt_symbol=vt_symbol,
interval=interval,
start=start,
end=end,
rate=rate,
slippage=slippage,
size=size,
pricetick=pricetick,
capital=capital
)
engine.add_strategy(strategy_class, setting)
engine.load_data()
engine.run_backtesting()
df = engine.calculate_result()
return df
def show_portafolio(df):
engine = BacktestingEngine()
engine.calculate_statistics(df)
engine.show_chart(df)
# -
df1 = run_backtesting(
strategy_class=AtrRsiStrategy,
setting={},
vt_symbol="IF88.CFFEX",
interval="1m",
start=datetime(2019, 1, 1),
end=datetime(2019, 4, 30),
rate=0.3/10000,
slippage=0.2,
size=300,
pricetick=0.2,
capital=1_000_000,
)
df2 = run_backtesting(
strategy_class=BollChannelStrategy,
setting={'fixed_size': 16},
vt_symbol="RB88.SHFE",
interval="1m",
start=datetime(2019, 1, 1),
end=datetime(2019, 4, 30),
rate=1/10000,
slippage=1,
size=10,
pricetick=1,
capital=1_000_000,
)
dfp = df1 + df2
dfp =dfp.dropna()
show_portafolio(dfp)
| examples/cta_backtesting/portfolio_backtesting.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: blog
# language: python
# name: blog
# ---
# ## **Coalgebra Lecture 1**
#
# ### **Who are these notes for?**
#
# This is a set of notes about coalgebra, intended mainly for mathematicians, and mainly those that might be working with coalgebras. Therefore this set of notes has a pretty small audience. However, there are also examples of coalgebras used in Computer Science, and I'll try to add a few of these where relevant. A lot of examples here rely on category theory. I am not great at category theory, so if you spot any mistakes then please let me know. In the first few notes I've tried not to make category theory a prerequisite for understanding coalgebra, but in the later sections about measuring coalgebras, there is a lot reliance on ideas from category theory, which are unavoidable.
#
# A lot of these notes are from Sweedler - Hopf Algebras.
#
# ### **What is Coalgebra?**
#
# Coalgebra is, in a certain sense, the opposite of algebra. At a general level, in mathematics, algebras are vector spaces with an associative multiplication, and an element $1$ that acts like a unit. The canonical example would be the set of all matrices (over some field). In computer science, algebras are even more general structures that have some kind of composition rule from a composed set to a base set, satisfying properties similar to assiciativity and unity - an example might be string concatenation. (This definition already starts using monadic functors, and I'm trying to avoid too much category theory, so the vague definition stated will have to do.)
#
# Here is the formal definition for mathematicians:
#
# **Definition:** A coalgebra $C$ is a vector space over a field $k$ with operations $\Delta$ (called comultiplication) and $\epsilon$ (called the counit) such that:
#
# 1. $$\Delta : C \rightarrow C \otimes C$$ satisfies this diagram (coassociativity).
# 2. $$ \epsilon : C \rightarrow k$$ satisfies this diagram (counit rule).
#
# For mathematicians, there are certain structures that they are bound to have come across all the time which are coalgebraic. Here are some examples:
#
# 1. Homomorphisms/ group representations/ structure preserving maps. In these cases $\Delta g = g \otimes g$, $\epsilon (g) = 1$. In cases like this we say that $g$ is a *group-like* element.
# 2. Derivations - where $\Delta d = 1 \otimes d + d \otimes 1$. Here, $1$ is a group-like element.
# 3. Addition formulae: we can define $s$ and $c$, with properties such that $\Delta s = s \otimes c + c \otimes s$ and $\Delta c = c \otimes c - s \otimes s$. $\epsilon (s) = 0, \epsilon (c) = 1$.
# 4. Graphs - *find the graph example when you have internet!*
# 5. Quantum groups, including the *something something equation*.
# 6. Card shuffling and permutations - if you can find the paper!
# 7. A Marj example - Lie Algebras?
# 8. Group representations!
#
# Some of these things have more properties, making them a bialgebra or Hopf algebra, which is often more useful.
#
# For computer scientists, a coalgebra is more general (and sadly, category heavy) object, and is usually called a $F$-coalgebra, where $F$ is a functor. The definition is this:
#
# 1. A coalgebra is a natural transformation $c : C \rightarrow FC$ satisfying...
#
# The mathematician's coalgebra is a special case of the c.s. coalgebra, where $F$ is the tensor product, $\otimes : C \rightarrow C \otimes C$, over a vector space $k$.
# Here are a few examples that computer scientists care about:
#
# 1. Streams
# 2. Pushdown automata (PDA), finite state machines (FSMs), and context free grammars (CFGs).
# 3. Structural Operator Semantics (?) and possibly even Linear Operator Semantics as the obvious lifting of this over $\mathbb{R}$.
# ### **Relation to algebra**
#
# The first thing to notice is that coalgebra is just algebra with all the arrows reversed. Algebras cover all sorts of familiar objects, e.g. polynomials, matrices, the complex and real numbers, quarternions, function spaces... all are algebras. In computer science, ...... are examples of algebras.
#
# However, there are differences.
# 1. Dualising algebras doesn't work (except in finite dimensions), but dualising coalgebras does work.
# 2. Any element of a coalgebra lives in a finite dimensional subcoalgebra.
#
# This second statement is important enough to be called **the fundamental theorem of coalgebra**, and we will formalise it later. (To see how great this is, compare it to the case of the polynomial algebra, where $X \in \mathbb{C}[X]$ generates $X, X^2, X^3, ...$ so cannot ever be contained in a finite dimensional subalgebra.)
# ### **Duals**
#
# In this section we are going to define a useful operator, called $^\circ: Alg \rightarrow Coalg$. I.e., this operation takes an algebra and generates a coalgebra. The operator is the *cofinite dual*.
#
# **Definion:** The cofinite dual of an algebra $A$ is a coalgebra $A^\circ$, defined as:...
#
# Some examples: ...
# ### **Coalgebra as an extension of homomorphims, and measuring**
#
#
| posts/active/coalgebra_lecture_1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.9.7 ('ml3950')
# language: python
# name: python3
# ---
# +
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import tensorflow as tf
import keras
from keras.datasets import fashion_mnist, cifar10
from keras.layers import Dense, Flatten, Normalization, Dropout, Conv2D, MaxPooling2D, RandomFlip, RandomRotation, RandomZoom, BatchNormalization, Activation, InputLayer
from keras.models import Sequential
from keras.losses import SparseCategoricalCrossentropy, CategoricalCrossentropy
from keras.callbacks import EarlyStopping
from keras.utils import np_utils
from keras import utils
import os
from keras.preprocessing.image import ImageDataGenerator
import matplotlib as mpl
import matplotlib.pyplot as plt
import datetime
# -
# # Transfer Learning
#
# ### Feature Extraction and Classification
#
# One of the key concepts needed with transfer learning is the separating of the feature extraction from the convolutional layers and the classification done in the fully connected layers.
# <ul>
# <li> The convolutional layer finds features in the image. I.e. the output of the end of the convolutional layers is a set of image-y features.
# <li> The fully connected layers take those features and classify the thing.
# </ul>
#
# The idea behind this is that we allow someone (like Google) to train their fancy network on a bunch of fast computers, using millions and millions of images. These classifiers get very good at extracting features from objects.
#
# When using these models we take those convolutional layers and slap on our own classifier at the end, so the pretrained convolutional layers extract a bunch of features with their massive amount of training, then we use those features to predict our data!
# +
epochs = 10
acc = keras.metrics.CategoricalAccuracy(name="accuracy")
pre = keras.metrics.Precision(name="precision")
rec = keras.metrics.Recall(name="recall")
metric_list = [acc, pre, rec]
# -
# ### Download Model
#
# There are several models that are pretrained and available to us to use. VGG16 is one developed to do image recognition, the name stands for "Visual Geometry Group" - a group of researchers at the University of Oxford who developed it, and ‘16’ implies that this architecture has 16 layers. The model got ~93% on the ImageNet test that we mentioned a couple of weeks ago.
#
# 
#
# #### Slide Convolutional Layers from Classifier
#
# When downloading the model we specifiy that we don't want the top - that's the classification part. When we remove the top we also allow the model to adapt to the shape of our images, so we specify the input size as well.
from keras.applications.vgg16 import VGG16
from keras.layers import Input
from keras.models import Model
from keras.applications.vgg16 import preprocess_input
# ### Preprocessing Data
#
# Our VGG 16 model comes with a preprocessing function to prepare the data in a way it is happy with. For this model the color encoding that it was trained on is different, so we should prepare the data properly to get good results.
# +
import pathlib
import PIL
from keras.applications.vgg16 import preprocess_input
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
#Flowers
batch_size = 32
img_height = 180
img_width = 180
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
def preprocess(images, labels):
return tf.keras.applications.vgg16.preprocess_input(images), labels
train_ds = train_ds.map(preprocess)
val_ds = val_ds.map(preprocess)
# -
# #### Add on New Classifier
#
# If we look at the previous summary of the model we can see that the last layer we have is a MaxPool layer. When making our own CNN this is the last layer before we add in the "normal" stuff for making predictions, this is the same.
#
# We need to flatten the data, then use dense layers and an output layer to classify the predictions.
#
# We end up with the pretrained parts finding features in images, and the custom part classifying images based on those features.
# ### Make Model
#
# We take the model without the top, set the input image size, and then add our own classifier. Loading the model is simple, there are just a few things to specify:
# <ul>
# <li> weights="imagenet" - tells the model to use the weights from its imagenet training. This is what brings the "smarts", so we want it.
# <li> include_top=False - tells the model to not bring over the classifier bits that we wnat to replace.
# <li> input_shape - the model is trained on specific data sizes (224x224x3). We can repurpose it by changing the input size.
# </ul>
#
# We also set the VGG model that we download to be not trainable. We don't want to overwrite all of the training that already exists, coming from the original training. What we want to be trained are the final dense parts we added on to classify our specific scenario.
# +
## Loading VGG16 model
from keras.applications.vgg16 import preprocess_input
base_model = VGG16(weights="imagenet", include_top=False, input_shape=(180,180,3))
base_model.trainable = False ## Not trainable weights
# Add Dense Stuff
flatten_layer = Flatten()
dense_layer_1 = Dense(50, activation='relu')
dense_layer_2 = Dense(20, activation='relu')
prediction_layer = Dense(5)
model = Sequential([
base_model,
flatten_layer,
dense_layer_1,
dense_layer_2,
prediction_layer
])
model.summary()
# -
# #### Compile and Train
# +
# Model
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=keras.metrics.SparseCategoricalAccuracy(name="accuracy"))
log_dir = "logs/fit/VGG" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
callback = EarlyStopping(monitor='loss', patience=3, restore_best_weights=True)
model.fit(train_ds,
epochs=epochs,
verbose=1,
validation_data=val_ds,
callbacks=[tensorboard_callback, callback])
# -
# ### Fine Tune Models
#
# Lastly, we can adapt the entire model to our data. We'll unfreeze the original model, and then train the model. The key addition here is that we set the learning rate to be extremely low (here it is 2 orders of magnitude smaller than the default) so the model doesn't totally rewrite all of the weights while training, rather it will only change a little bit - fine tuning its predictions to the actual data!
#
# The end result is a model that can take advantage of all of the training that the original model received before we downloaded it. That ability of extracting features from images is then reapplied to our data for making predictions based on the features identified in the original model. Finally we take the entire model and just gently train it to be a little more suited to our data. The best of all worlds!
# +
#Save a copy of the above model for next test.
copy_model = model
base_model.trainable = True
model.summary()
model.compile(
optimizer=tf.keras.optimizers.Adam(1e-5), # Low learning rate
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=keras.metrics.SparseCategoricalAccuracy(name="accuracy")
)
model.fit(train_ds, epochs=epochs, validation_data=val_ds)
# -
# Yay, that's probably pretty accurate!
# ### More Retraining
#
# If we are extra ambitious we can also potentially slice the model even deeper, and take smaller portions to mix with our own models.
#
# The farther "into" the model you slice, the more of the original training will be removed and the more the model will learn from our training data. If done, this is a balancing act - we want to keep all of the smarts that the model has gotten from the original training, while getting the benefits of adaptation to our data.
## Loading VGG16 model
base_model = VGG16(weights="imagenet", include_top=False, input_shape=(180,180,3))
#base_model.trainable = False ## Not trainable weights
base_model.summary()
for layer in base_model.layers[:12]:
layer.trainable = False
base_model.summary()
# Now we have larger portions of the model that can be trained. We will be losing some of the pretrained knowldge, replacing it with the training coming from our data.
# +
# Add Dense Stuff
flatten_layer = Flatten()
dense_layer_1 = Dense(50, activation='relu')
dense_layer_2 = Dense(20, activation='relu')
prediction_layer = Dense(5)
model = Sequential([
base_model,
flatten_layer,
dense_layer_1,
dense_layer_2,
prediction_layer
])
model.summary()
# +
# Model
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=keras.metrics.SparseCategoricalAccuracy(name="accuracy"))
log_dir = "logs/fit/VGG" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
callback = EarlyStopping(monitor='loss', patience=3, restore_best_weights=True)
model.fit(train_ds,
epochs=epochs,
verbose=1,
validation_data=val_ds,
callbacks=[tensorboard_callback, callback])
# -
# ## Exercise - ResNet50
#
# This is another pretrained network, containing 50 layers. We can use this one similarly to the last.
# +
def preprocess50(images, labels):
return tf.keras.applications.resnet50.preprocess_input(images), labels
train_ds = train_ds.map(preprocess50)
val_ds = val_ds.map(preprocess50)
# +
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(180,180,3))
base_model.trainable = False ## Not trainable weights
# Add Dense Stuff
flatten_layer = Flatten()
dense_layer_1 = Dense(50, activation='relu')
dense_layer_2 = Dense(20, activation='relu')
prediction_layer = Dense(5)
model = Sequential([
base_model,
flatten_layer,
dense_layer_1,
dense_layer_2,
prediction_layer
])
model.summary()
# +
# Model
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=keras.metrics.SparseCategoricalAccuracy(name="accuracy"))
log_dir = "logs/fit/VGG" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
callback = EarlyStopping(monitor='loss', patience=3, restore_best_weights=True)
model.fit(train_ds,
epochs=epochs,
verbose=1,
validation_data=val_ds,
callbacks=[tensorboard_callback, callback])
# +
base_model.trainable = True
model.summary()
model.compile(
optimizer=tf.keras.optimizers.Adam(1e-5), # Low learning rate
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=keras.metrics.SparseCategoricalAccuracy(name="accuracy")
)
model.fit(train_ds, epochs=epochs, validation_data=val_ds)
| 026_transfer_learning_sol.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Copyright (C) 2016 - 2019 <NAME>(<EMAIL>)
#
# https://www.cnblogs.com/pinard
#
# Permission given to modify the code as long as you keep this declaration at the top
#
# 中文文本挖掘预处理流程总结 https://www.cnblogs.com/pinard/p/6744056.html
# +
# -*- coding: utf-8 -*-
import jieba
with open('./nlp_test0.txt') as f:
document = f.read()
document_decode = document.decode('GBK')
document_cut = jieba.cut(document_decode)
#print ' '.join(jieba_cut) //如果打印结果,则分词效果消失,后面的result无法显示
result = ' '.join(document_cut)
result = result.encode('utf-8')
with open('./nlp_test1.txt', 'w') as f2:
f2.write(result)
f.close()
f2.close()
# -
jieba.suggest_freq('沙瑞金', True)
jieba.suggest_freq('易学习', True)
jieba.suggest_freq('王大路', True)
jieba.suggest_freq('京州', True)
with open('./nlp_test0.txt') as f:
document = f.read()
document_decode = document.decode('GBK')
document_cut = jieba.cut(document_decode)
#print ' '.join(jieba_cut)
result = ' '.join(document_cut)
result = result.encode('utf-8')
with open('./nlp_test1.txt', 'w') as f2:
f2.write(result)
f.close()
f2.close()
#从文件导入停用词表
stpwrdpath = "stop_words.txt"
stpwrd_dic = open(stpwrdpath, 'rb')
stpwrd_content = stpwrd_dic.read()
#将停用词表转换为list
stpwrdlst = stpwrd_content.splitlines()
stpwrd_dic.close()
with open('./nlp_test1.txt') as f3:
res1 = f3.read()
print res1
with open('./nlp_test2.txt') as f:
document2 = f.read()
document2_decode = document2.decode('GBK')
document2_cut = jieba.cut(document2_decode)
#print ' '.join(jieba_cut)
result = ' '.join(document2_cut)
result = result.encode('utf-8')
with open('./nlp_test3.txt', 'w') as f2:
f2.write(result)
f.close()
f2.close()
with open('./nlp_test3.txt') as f4:
res2 = f4.read()
print res2
jieba.suggest_freq('桓温', True)
with open('./nlp_test4.txt') as f:
document3 = f.read()
document3_decode = document3.decode('GBK')
document3_cut = jieba.cut(document3_decode)
#print ' '.join(jieba_cut)
result = ' '.join(document3_cut)
result = result.encode('utf-8')
with open('./nlp_test5.txt', 'w') as f3:
f3.write(result)
f.close()
f3.close()
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [res1,res2]
vector = TfidfVectorizer(stop_words=stpwrdlst)
tfidf = vector.fit_transform(corpus)
print tfidf
wordlist = vector.get_feature_names()#获取词袋模型中的所有词
# tf-idf矩阵 元素a[i][j]表示j词在i类文本中的tf-idf权重
weightlist = tfidf.toarray()
#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for i in range(len(weightlist)):
print "-------第",i,"段文本的词语tf-idf权重------"
for j in range(len(wordlist)):
print wordlist[j],weightlist[i][j]
| natural-language-processing/chinese_digging.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # TEST - DEBUG VERSION - NOT TO BE RUN BY USERS!!!!!!
# + [markdown] run_control={"frozen": false, "read_only": false}
# [](https://neutronimaging.pages.ornl.gov/en/tutorial/notebooks/scale_overlapping_images/)
# + [markdown] run_control={"frozen": false, "read_only": false}
# <img src='__docs/__all/notebook_rules.png' />
# + [markdown] run_control={"frozen": false, "read_only": false}
# # DEBUG
# + run_control={"frozen": false, "read_only": false}
from __code.ui_builder import UiBuilder
o_builder = UiBuilder(ui_name = 'ui_scale_overlapping_images.ui')
from __code import system
from __code.fileselector import FileSelection
from __code.scale_overlapping_images import ScaleOverlappingImagesUi
# + run_control={"frozen": false, "read_only": false}
# %gui qt
# + run_control={"frozen": false, "read_only": false}
import glob
import os
#file_dir = '/Volumes/my_book_thunderbolt_duo/IPTS/IPTS-20139-Hao-Liu/05-07-18_LFR_normalized_light_version/' #MacPro
file_dir = '/Users/j35/IPTS/charles/'
list_files = glob.glob(file_dir + '*.tif')
o_selection = FileSelection()
o_selection.load_files(list_files)
o_scale = ScaleOverlappingImagesUi(working_dir=os.path.dirname(list_files[0]),
data_dict=o_selection.data_dict['sample'])
o_scale.show()
# + run_control={"frozen": false, "read_only": false}
# + run_control={"frozen": false, "read_only": false}
| notebooks/__debugging/TEST_scale_overlapping_images.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.8.2 32-bit
# name: python_defaultSpec_1595260579381
# ---
import os
import numpy as np
import pandas as pd
import datetime
import plotly.graph_objects as go
import plotly.figure_factory as ff
# ## Define Term Dates
# Define the dates
number_of_terms=3
term_start_dates=['28/09/2020','11/01/2021','26/04/2021']
term_end_dates=['18/12/2020','26/03/2021','11/06/2021']
reading_week_dates=['09/11/2020','15/02/2021']
# Convert the string to dates
term_start_dates=[pd.to_datetime(date, format='%d/%m/%Y') for date in term_start_dates]
term_end_dates=[pd.to_datetime(date, format='%d/%m/%Y') for date in term_end_dates]
reading_week_dates=[pd.to_datetime(date, format='%d/%m/%Y') for date in reading_week_dates]
# ## Create the Calendar DataFrame
def get_term_number(df):
if (df['Date']>=reading_week_dates[0]) & (df['Date']<=(reading_week_dates[0] + pd.Timedelta(6,unit='days'))):
return 'Reading Week 1'
elif (df['Date']>=reading_week_dates[1]) & (df['Date']<=(reading_week_dates[1] + pd.Timedelta(6,unit='days'))):
return 'Reading Week 2'
if (df['Date']>=term_start_dates[0]) & (df['Date']<=term_end_dates[0]):
return 'Term 1'
elif (df['Date']>term_end_dates[0]) & (df['Date']<term_start_dates[1]):
return 'Christmas Holidays'
elif (df['Date']>=term_start_dates[1]) & (df['Date']<=term_end_dates[1]):
return 'Term 2'
elif( df['Date']>term_end_dates[1]) & (df['Date']<term_start_dates[2]):
return 'Easter Holidays'
elif (df['Date']>=term_start_dates[2]) & (df['Date']<=term_end_dates[2]):
return 'Term 3'
calendar=pd.DataFrame(columns=['Date'])
calendar['Date']=pd.date_range(start=term_start_dates[0], end=term_end_dates[number_of_terms-1])
if os.name=='nt':
calendar['Date_F']=calendar['Date'].dt.strftime('%#d %B %Y')
else:
calendar['Date_F']=calendar['Date'].dt.strftime('%-d %B %Y')
calendar['Day'] =calendar['Date'].dt.day
calendar['Week Day']=calendar['Date'].dt.day_name()
calendar['Week Day'] = pd.Categorical(calendar['Week Day'], categories=
['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday', 'Sunday'],
ordered=True)
calendar['Academic_Week_Number'] = calendar['Date'].apply(lambda x: (x.isocalendar()[1]-35) if (x.isocalendar()[1]-35)>0 else (x.isocalendar()[1]+18))
calendar['Term Class']=calendar.apply(get_term_number,axis=1)
# ## Add Planned Hours
calendar['Planned_work_hours']=5
# ## Add number of Hours required for Coursework
calendar['Hours_required_for_Coursework']=1
# +
# Adding contingency of 1.2
# -
# ## Calculate the Workload
calendar['Workload']=(calendar['Hours_required_for_Coursework']/calendar['Planned_work_hours'])
calendar.to_csv('calendar.csv')
# ## Get the HeatMap
calendar[calendar['Date'].dt.month==9].head()
academic_year = list(range(9,13)) + list(range(1,7))
monthly=calendar[calendar['Date'].dt.month==10].pivot(index='Academic_Week_Number', columns='Week Day', values='Workload')
yearly=calendar.pivot(index='Week Day', columns='Academic_Week_Number', values='Workload')
monthly
yearly
annotations_monthly=calendar[calendar['Date'].dt.month==10].pivot(index='Academic_Week_Number', columns='Week Day', values='Day')
annotations_yearly=calendar.pivot(index='Week Day', columns='Academic_Week_Number', values='Day')
dates_monthly=calendar[calendar['Date'].dt.month==10].pivot(index='Academic_Week_Number', columns='Week Day', values='Date_F')
dates_yearly = calendar.pivot(index='Week Day', columns='Academic_Week_Number', values='Date_F')
# ## Month wise
def generate_heatmap(df, dates, title='', autosize=True, width=None, height=None, x_label='', y_label='', side="bottom"):
data = go.Heatmap(z=df,
x=df.columns,
y=df.index,
hovertext=dates,
ygap=3,
xgap=3,
hoverongaps = False,
showscale = False,
colorscale=['rgb(0,100,0)', 'rgb(100,0,0)'], zmax=1.5, zmid=0.5, zmin=0,
hovertemplate = '%{hovertext}<br>Workload: <b>%{z:%}</b><extra></extra>')
layout = go.Layout(autosize=autosize,
width=width,
height=height,
title="<b>{}</b>".format(title),
title_x=0.5,
xaxis_title='<b>{}</b>'.format(x_label),
yaxis_title='<b>{}</b>'.format(y_label),
template="simple_white",
xaxis=dict(side=side, showline=False,ticks=''),
yaxis=dict(autorange="reversed", showline=False,ticks=''),
margin=dict(pad=5),
showlegend=False,
hoverlabel=dict(align = 'auto',bordercolor='rgb(48,48,48)',bgcolor='rgb(48,48,48)',font=dict(color='white')))
fig = go.Figure(data=data, layout=layout)
return fig
def generate_month_wise(monthly, annotations, dates_monthly):
fig=generate_heatmap(monthly,dates_monthly,title='October', y_label='Academic Week Number', side="top")
for i in np.arange(len(monthly.columns)):
for j in np.arange(len(monthly.index)):
if not np.isnan(annotations.iloc[j,i]):
fig.add_annotation(x=monthly.columns[i],y=monthly.index[j],text=int((annotations.iloc[j,i])),
font_color='white',showarrow=False)
fig.show()
generate_month_wise(monthly,annotations_monthly,dates_monthly)
# ## Year wise
def generate_yearwise(yearly,annotations,dates_yearly):
fig=generate_heatmap(yearly,dates_yearly, autosize=False, width=1200, height=400, x_label='Academic Week Number')
fig.show()
generate_yearwise(yearly, annotations_yearly,dates_yearly)
# ## Term wise
# ### matplotlib version
# ```python3
# import matplotlib.pyplot as plt
#
# def heatmap(data, ax=None):
#
# if not ax:
# ax = plt.gca()
#
# # Plot the heatmap
# im = ax.imshow(data)
#
# # We want to show all ticks...
# ax.set_xticks(np.arange(data.shape[1]))
# ax.set_yticks(np.arange(data.shape[0]))
#
# # Label them with the respective list entries.
# ax.set_xticklabels(data.columns)
# ax.set_yticklabels(data.index)
#
# # Let the horizontal axes labeling appear on top.
# ax.tick_params(bottom=False, top=False, left=False,right=False,
# labeltop=True, labelbottom=False)
#
#
# # Make spine white and create white grid.
# for edge, spine in ax.spines.items():
# spine.set_color('w')
# spine.set_linewidth(4)
#
# ax.set_xticks(np.arange(data.shape[1]+1)-.5, minor=True)
# ax.set_yticks(np.arange(data.shape[0]+1)-.5, minor=True)
# ax.grid(which="minor", color="w", linestyle='-', linewidth=3)
# ax.tick_params(which="minor", bottom=False, left=False)
#
# return im
#
# # Show colour bar at the Bottom Separately
# # cbar = ax.figure.colorbar(im, ax=ax)
# # cbar.ax.set_ylabel(cbarlabel, rotation=-90, va="bottom")
#
# fig, ax = plt.subplots(figsize=(10,6))
# heatmap(monthly,ax)
# ```
| test.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
digests = {
"trypsin": {
"start" : [
{
"amino_acid": "D",
"cut_position": "left"
}
],
"end" : [
{
"amino_acid": "R",
"cut_position": "right"
}, {
"amino_acid": "K",
"cut_position": "right"
}
]
}
}
def digest(db: Database, digest_type: str, missed_cleavages: int) -> Database:
'''
Digest each protein in the database. If no digest is done, then
the original database is returned.
NOTE:
The entires in the database after digestion are the names of the form
<protein_name>_<start_position>_<end_position>
Inputs:
db: (Database) the input source
digest_type: (str) the digestion to perform
missed_cleavages: (int) the number of missed cleavages allowed
Outputs:
(Database) updated protein entries
'''
if digest_type not in digests:
return db
digest_rules = digests[digest_type]
starts = {s['amino_acid']: s['cut_position'] for s in digest_rules['start']}
ends = {s['amino_acid']: s['cut_position'] for s in digest_rules['end']}
new_prots = {}
for p_name, entry in db.proteins.items():
for pos, aa in enumerate(entry.sequence):
digested = []
if aa in starts:
# get the starting position for this cut based on rule
s = pos if starts[aa] == 'left' else pos + 1
allowed_misses = missed_cleavages
# find all of the next ends. we will keep track of them for up to missed_cleavages
for j in range(pos, len(entry.sequence)):
# if we're out of missed cleavages, break
if allowed_misses < 0:
break
# check if we're at the end
if j == len(entry.sequence) - 1:
# get the cut sequence
digested.append(entry.sequence[s:], s, len(entry.sequence))
break
# check of this aa is an end
if entry.sequence[j] in ends:
# first reduce allowed
allowed_misses -= 1
# determine if we do j or j+1 based on the rule
e = j if ends[entry.sequence[j]] == 'left' else j + 1
digested.append(entry.sequence[s:e], s, e)
for d in digested:
new_prots[f'{prot_name}_{d[1]}_{d[2]}'] = d[0]
db._replace(proteins=new_prots)
return db
p = 'MATPEASGSGEKVEGSEPSVTYYRLEEVAKRNSAEETWMVIHGRVYDITRFLSEHPGGEEVLLEQAGADATESFEDVGHSPDAREMLKQYYIGDVHPSDLKPKGDDKDPSKNNSCQSSWAYWFVPIVGAILIGFLYRHFWADSKSS'
print([i for i, aa in enumerate(p) if aa == 'K' or aa == 'R'])
tryptic(p, 15)
| sandbox/jupyter notebooks/.ipynb_checkpoints/Digests-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] toc=true
# <h1>Table of Contents<span class="tocSkip"></span></h1>
# <div class="toc"><ul class="toc-item"><li><span><a href="#Overall-Recommended-NBExtensions" data-toc-modified-id="Overall-Recommended-NBExtensions-1">Overall Recommended NBExtensions</a></span></li><li><span><a href="#Notebook-Extensions" data-toc-modified-id="Notebook-Extensions-2">Notebook Extensions</a></span><ul class="toc-item"><li><span><a href="#datestamper" data-toc-modified-id="datestamper-2.1">datestamper</a></span></li><li><span><a href="#ToC(2)" data-toc-modified-id="ToC(2)-2.2">ToC(2)</a></span></li><li><span><a href="#ExecuteTime" data-toc-modified-id="ExecuteTime-2.3">ExecuteTime</a></span></li><li><span><a href="#Snippets-Menu" data-toc-modified-id="Snippets-Menu-2.4">Snippets Menu</a></span></li><li><span><a href="#Runtools" data-toc-modified-id="Runtools-2.5">Runtools</a></span></li><li><span><a href="#Hide-input-all" data-toc-modified-id="Hide-input-all-2.6">Hide input all</a></span></li><li><span><a href="#Python-Markdown" data-toc-modified-id="Python-Markdown-2.7">Python Markdown</a></span></li><li><span><a href="#Scratchpad" data-toc-modified-id="Scratchpad-2.8">Scratchpad</a></span></li><li><span><a href="#Variable-Inspector" data-toc-modified-id="Variable-Inspector-2.9">Variable Inspector</a></span></li><li><span><a href="#Code-prettify" data-toc-modified-id="Code-prettify-2.10">Code prettify</a></span></li><li><span><a href="#Collapsible-Headings" data-toc-modified-id="Collapsible-Headings-2.11">Collapsible Headings</a></span></li><li><span><a href="#Notify" data-toc-modified-id="Notify-2.12">Notify</a></span></li></ul></li><li><span><a href="#Outside-Notebooks" data-toc-modified-id="Outside-Notebooks-3">Outside Notebooks</a></span><ul class="toc-item"><li><span><a href="#Codefolding-in-Editor" data-toc-modified-id="Codefolding-in-Editor-3.1">Codefolding in Editor</a></span></li><li><span><a href="#Tree-Filter" data-toc-modified-id="Tree-Filter-3.2">Tree Filter</a></span></li></ul></li></ul></div>
# +
from __future__ import print_function, division
import matplotlib as mpl
import matplotlib.pyplot as plt
# %matplotlib inline
import numpy as np
import pandas as pd
import textwrap
import os
import sys
import warnings
warnings.filterwarnings('ignore')
# special things
from pivottablejs import pivot_ui
from ipywidgets import FloatSlider, interactive, IntSlider
from scipy import interpolate
# sql
# %load_ext sql_magic
import sqlalchemy
import sqlite3
from sqlalchemy import create_engine
sqlite_engine = create_engine('sqlite://')
# autoreload
# %load_ext autoreload
# %autoreload 1
# # %aimport module_to_reload
# ehh...
# import bqplot.pyplot as plt
import ipyvolume as ipv
import altair as alt
from vega_datasets import data
import seaborn as sns
sns.set_context('poster', font_scale=1.3)
# -
np.arange(210).reshape((2,3,5,7)).swapaxes(1,3)
# # Overall Recommended NBExtensions
#
# Last updated: 2018-09-17 16:33:39
# My recommended nbextensions are the checked boxes below:
# 
# # Notebook Extensions
# ## datestamper
#
# Last updated 2018-09-17 19:03:57
# ## ToC(2)
# ## ExecuteTime
print("hello world")
# ## Snippets Menu
from __future__ import print_function, division
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
# %matplotlib inline
import pandas as pd
# ## Runtools
# + hide_input=false run_control={"marked": true}
a = 10
# -
a = 2
# + hide_input=false run_control={"marked": true}
b = 'b'
TTR = 0.13
# + hide_input=false run_control={"marked": true}
print(a, b)
# -
# ## Hide input all
# + [markdown] variables={"a": {}}
# ## Python Markdown
#
# The value of a is {{a}}. Useful for anything you want to report.
# -
# ## Scratchpad
#
# CTRL-B
# ## Variable Inspector
#
julija = "Julija!!"
# ## Code prettify
# +
weight_categories = [
"vlow_weight",
"low_weight",
"mid_weight",
"high_weight",
"vhigh_weight",
]
players['weightclass'] = pd.qcut(players['weight'], len(weight_categories),
weight_categories)
# +
weight_categories = [ "vlow_weight", "low_weight",
"mid_weight", "high_weight",
"vhigh_weight",]
players['weightclass'] = pd.qcut(players['weight'],
len(weight_categories), weight_categories)
# +
weight_categories = [
"vlow_weight",
"low_weight",
"mid_weight",
"high_weight",
"vhigh_weight",
]
players['weightclass'] = pd.qcut(players['weight'], len(weight_categories),
weight_categories)
# -
something, somethingelse = (long_list, of_variables, height, weight, age,
gender, hometown, state, country,
food_intolerances)
# ## Collapsible Headings
# ## Notify
#
# In theory, this will give you a browser notification if your kernel has been busy for at least N seconds (after you give permission).
import time
time.sleep(10)
# # Outside Notebooks
# ## Codefolding in Editor
# +
# np.linspace??
# -
# ## Tree Filter
#
# Filtered home screen
| notebooks/02-NBExtensions.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Geospatial Analysis
# One of the most popular extensions to PostgreSQL is PostGIS,
# which adds support for storing geospatial geometries,
# as well as functionality for reasoning about and performing operations on those geometries.
#
# This is a demo showing how to assemble ibis expressions for a PostGIS-enabled database.
# We will be using a database that has been loaded with an [Open Street Map](https://www.openstreetmap.org/)
# extract for Southern California.
# This extract can be found [here](https://download.geofabrik.de/north-america/us/california/socal.html),
# and loaded into PostGIS using a tool like [ogr2ogr](https://gdal.org/programs/ogr2ogr.html).
# ## Preparation
#
# We first need to set up a demonstration database and load it with the sample data.
# If you have Docker installed, you can download and launch a PostGIS database with the following:
# Launch the postgis container.
# This may take a bit of time if it needs to download the image.
# !docker run -d -p 5432:5432 --name postgis-db -e POSTGRES_PASSWORD=<PASSWORD> mdillon/postgis:9.6-alpine
# Next, we download our OSM extract (about 400 MB):
# !wget https://download.geofabrik.de/north-america/us/california/socal-latest.osm.pbf
# Finally, we load it into the database using `ogr2ogr` (this may take some time):
# !ogr2ogr -f PostgreSQL PG:"dbname='postgres' user='postgres' password='<PASSWORD>' port=5432 host='localhost'" -lco OVERWRITE=yes --config PG_USE_COPY YES socal-latest.osm.pbf
# ## Connecting to the database
#
# We first make the relevant imports, and connect to the PostGIS database:
# +
import os
import geopandas
import ibis
# %matplotlib inline
# -
client = ibis.postgres.connect(
url='postgres://postgres:supersecret@localhost:5432/postgres'
)
# Let's look at the tables available in the database:
client.list_tables()
# As you can see, this Open Street Map extract stores its data according to the geometry type.
# Let's grab references to the polygon and line tables:
polygons = client.table('multipolygons')
lines = client.table('lines')
# ## Querying the data
#
# We query the polygons table for shapes with an administrative level of 8,
# which corresponds to municipalities.
#
# We also reproject some of the column names so we don't have a name collision later.
# +
cities = polygons[polygons.admin_level == '8']
cities = cities[
cities.name.name('city_name'), cities.wkb_geometry.name('city_geometry')
]
# -
# We can assemble a specific query for the city of Los Angeles,
# and execute it to get the geometry of the city.
# This will be useful later when reasoning about other geospatial relationships in the LA area:
los_angeles = cities[cities.city_name == 'Los Angeles']
la_city = los_angeles.execute()
la_city_geom = la_city.iloc[0].city_geometry
la_city_geom
# Let's also extract freeways from the lines table,
# which are indicated by the value `'motorway'` in the highway column:
highways = lines[(lines.highway == 'motorway')]
highways = highways[
highways.name.name('highway_name'),
highways.wkb_geometry.name('highway_geometry'),
]
# ## Making a spatial join
#
# Let's test a spatial join by selecting all the highways that intersect the city of Los Angeles,
# or one if its neighbors.
#
# We begin by assembling an expression for Los Angeles and its neighbors.
# We consider a city to be a neighbor if it has any point of intersection
# (by this critereon we also get Los Angeles itself).
#
# We can pass in the city geometry that we selected above when making our query by marking it as a literal value in `ibis`:
la_neighbors_expr = cities[
cities.city_geometry.intersects(
ibis.literal(la_city_geom, type='multipolygon;4326:geometry')
)
]
la_neighbors = la_neighbors_expr.execute().dropna()
la_neighbors
# Now we join the neighbors expression with the freeways expression,
# on the condition that the highways intersect any of the city geometries:
la_highways_expr = highways.inner_join(
la_neighbors_expr,
highways.highway_geometry.intersects(la_neighbors_expr.city_geometry),
)
la_highways = la_highways_expr.execute()
la_highways.plot()
# ## Combining the results
#
# Now that we have made a number of queries and joins, let's combine them into a single plot.
# To make the plot a bit nicer, we can also load some shapefiles for the coast and land:
ocean = geopandas.read_file(
'https://www.naturalearthdata.com/http//www.naturalearthdata.com/download/10m/physical/ne_10m_ocean.zip'
)
land = geopandas.read_file(
'https://www.naturalearthdata.com/http//www.naturalearthdata.com/download/10m/physical/ne_10m_land.zip'
)
# +
ax = la_neighbors.dropna().plot(figsize=(16, 16), cmap='rainbow', alpha=0.9)
ax.set_autoscale_on(False)
ax.set_axis_off()
land.plot(ax=ax, color='tan', alpha=0.4)
ax = ocean.plot(ax=ax, color='navy')
la_highways.plot(ax=ax, color='maroon')
| docs/tutorial/08-Geospatial-Analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# <img src="../images/aeropython_logo.png" alt="AeroPython" style="width: 300px;"/>
# # Secciones de arrays
# _Hasta ahora sabemos cómo crear arrays y realizar algunas operaciones con ellos, sin embargo, todavía no hemos aprendido cómo acceder a elementos concretos del array_
import numpy as np
# ## Arrays de una dimensión
arr = np.arange(10)
arr
# Accediendo al primer elemento
arr[0]
# Accediendo al último
arr[-1]
# ##### __¡Atención!__
# NumPy devuelve __vistas__ de la sección que le pidamos, no __copias__. Esto quiere decir que debemos prestar mucha atención a este comportamiento:
# +
arr = np.arange(10)
a = arr[5:]
print(arr)
print(a)
# +
arr[5] = 999
print(arr)
print(a)
# -
# Lo mismo ocurre al revés:
# +
arr = np.arange(10)
a = arr[5:]
print(arr)
print(a)
# +
a[-1] = 999
print(arr)
print(a)
# -
# `a` apunta a las direcciones de memoria donde están guardados los elementos del array `arr` que hemos seleccionado, no copia sus valores, a menos que explícitamente hagamos:
# +
arr = np.arange(10)
a = arr[5:].copy()
print(arr)
print(a)
# +
arr[5] = 999
print(arr)
print(a)
# -
# ## Arrays de dos dimensiones
arr = np.arange(9).reshape([3, 3])
arr
arr[0, -1]
arr[2, 2]
# ## Secciones de arrays
# Hasta ahora hemos visto cómo acceder a elementos aislados del array, pero la potencia de NumPy está en poder acceder a secciones enteras. Para ello se usa la sintaxis `inicio:final:paso`: si alguno de estos valores no se pone toma un valor por defecto. Veamos ejemplos:
M = np.arange(36, dtype=float).reshape(4, 9)
M
# De la segunda a la tercera fila, incluida
M[1:3]
# Hasta la tercera fila sin incluir y de la segunda a la quinta columnas saltando dos
M[:2, 1:5:2]
#M[1:2:1, 1:5:2] # Equivalente
# ##### Ejercicio
# Pintar un tablero de ajedrez usando la función `plt.matshow`.
# +
tablero = np.zeros([8, 8], dtype=int)
tablero[0::2, 1::2] = 1
tablero[1::2, 0::2] = 1
tablero
# +
# %matplotlib inline
import matplotlib.pyplot as plt
plt.matshow(tablero, cmap=plt.cm.gray_r)
# -
# ---
# ___Hemos aprendido:___
#
# * A acceder a elementos de un array
# * Que las secciones no devuelven copias, sino vistas
#
# __¡Quiero más!__Algunos enlaces:
#
# Algunos enlaces en Pybonacci:
#
# * [Cómo crear matrices en Python con NumPy](http://pybonacci.wordpress.com/2012/06/11/como-crear-matrices-en-python-con-numpy/).
# * [Números aleatorios en Python con NumPy y SciPy](http://pybonacci.wordpress.com/2013/01/11/numeros-aleatorios-en-python-con-numpy-y-scipy/).
#
#
# Algunos enlaces en otros sitios:
#
# * [100 numpy exercises](http://www.labri.fr/perso/nrougier/teaching/numpy.100/index.html). Es posible que de momento sólo sepas hacer los primeros, pero tranquilo, pronto sabrás más...
# * [NumPy and IPython SciPy 2013 Tutorial](http://conference.scipy.org/scipy2013/tutorial_detail.php?id=100).
# * [NumPy and SciPy documentation](http://docs.scipy.org/doc/).
# ---
# <br/>
# #### <h4 align="right">¡Síguenos en Twitter!
# <br/>
# ###### <a href="https://twitter.com/AeroPython" class="twitter-follow-button" data-show-count="false">Follow @AeroPython</a> <script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs');</script>
# <br/>
# ###### Este notebook ha sido realizado por: <NAME> y <NAME>
# <br/>
# ##### <a rel="license" href="http://creativecommons.org/licenses/by/4.0/deed.es"><img alt="Licencia Creative Commons" style="border-width:0" src="http://i.creativecommons.org/l/by/4.0/88x31.png" /></a><br /><span xmlns:dct="http://purl.org/dc/terms/" property="dct:title">Curso AeroPython</span> por <span xmlns:cc="http://creativecommons.org/ns#" property="cc:attributionName"><NAME> y <NAME></span> se distribuye bajo una <a rel="license" href="http://creativecommons.org/licenses/by/4.0/deed.es">Licencia Creative Commons Atribución 4.0 Internacional</a>.
# ---
# _Las siguientes celdas contienen configuración del Notebook_
#
# _Para visualizar y utlizar los enlaces a Twitter el notebook debe ejecutarse como [seguro](http://ipython.org/ipython-doc/dev/notebook/security.html)_
#
# File > Trusted Notebook
# Esta celda da el estilo al notebook
from IPython.core.display import HTML
css_file = '../styles/aeropython.css'
HTML(open(css_file, "r").read())
| notebooks_completos/013-NumPy-SeccionesArrays.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### LibraryのImport
import datetime, time
# ### メイン関数
# ・サブ関数をcallして1秒待つ、を10回繰り返す
def main():
for count in range(0, 10):
print_current_time()
time.sleep(1)
# ### サブ関数
# ・現在時刻をprintする
def print_current_time():
print (datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'))
# ### 実行
if __name__ == '__main__':
main()
# 出典:https://qiita.com/taka4sato/items/2c3397ff34c440044978#jupyter%E3%81%AE%E4%BD%BF%E3%81%84%E6%96%B9
| JupyterTest1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # 情感分析
#
# 褚则伟 <EMAIL>
#
# 本notebook参考了https://github.com/bentrevett/pytorch-sentiment-analysis
#
# 在这份notebook中,我们会用PyTorch模型和TorchText再来做情感分析(检测一段文字的情感是正面的还是负面的)。我们会使用[IMDb 数据集](http://ai.stanford.edu/~amaas/data/sentiment/),即电影评论。
#
# 模型从简单到复杂,我们会依次构建:
# - Word Averaging模型
# - RNN/LSTM模型
# - CNN模型
# ## 准备数据
#
# - TorchText中的一个重要概念是`Field`。`Field`决定了你的数据会被怎样处理。在我们的情感分类任务中,我们所需要接触到的数据有文本字符串和两种情感,"pos"或者"neg"。
# - `Field`的参数制定了数据会被怎样处理。
# - 我们使用`TEXT` field来定义如何处理电影评论,使用`LABEL` field来处理两个情感类别。
# - 我们的`TEXT` field带有`tokenize='spacy'`,这表示我们会用[spaCy](https://spacy.io) tokenizer来tokenize英文句子。如果我们不特别声明`tokenize`这个参数,那么默认的分词方法是使用空格。
# - 安装spaCy
# ```
# pip install -U spacy
# python -m spacy download en
# ```
# - `LABEL`由`LabelField`定义。这是一种特别的用来处理label的`Field`。我们后面会解释dtype。
# - 更多关于`Fields`,参见https://github.com/pytorch/text/blob/master/torchtext/data/field.py
# - 和之前一样,我们会设定random seeds使实验可以复现。
# +
import torch
from torchtext import data
SEED = 1234
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
# -
# - TorchText支持很多常见的自然语言处理数据集。
# - 下面的代码会自动下载IMDb数据集,然后分成train/test两个`torchtext.datasets`类别。数据被前面的`Fields`处理。IMDb数据集一共有50000电影评论,每个评论都被标注为正面的或负面的。
from torchtext import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
# 查看每个数据split有多少条数据。
print(f'Number of training examples: {len(train_data)}')
print(f'Number of testing examples: {len(test_data)}')
# 查看一个example。
print(vars(train_data.examples[0]))
# - 由于我们现在只有train/test这两个分类,所以我们需要创建一个新的validation set。我们可以使用`.split()`创建新的分类。
# - 默认的数据分割是 70、30,如果我们声明`split_ratio`,可以改变split之间的比例,`split_ratio=0.8`表示80%的数据是训练集,20%是验证集。
# - 我们还声明`random_state`这个参数,确保我们每次分割的数据集都是一样的。
import random
train_data, valid_data = train_data.split(random_state=random.seed(SEED))
# 检查一下现在每个部分有多少条数据。
print(f'Number of training examples: {len(train_data)}')
print(f'Number of validation examples: {len(valid_data)}')
print(f'Number of testing examples: {len(test_data)}')
# - 下一步我们需要创建 _vocabulary_ 。_vocabulary_ 就是把每个单词一一映射到一个数字。
# 
# - 我们使用最常见的25k个单词来构建我们的单词表,用`max_size`这个参数可以做到这一点。
# - 所有其他的单词都用`<unk>`来表示。
# TEXT.build_vocab(train_data, max_size=25000)
# LABEL.build_vocab(train_data)
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}")
print(f"Unique tokens in LABEL vocabulary: {len(LABEL.vocab)}")
# - 当我们把句子传进模型的时候,我们是按照一个个 _batch_ 穿进去的,也就是说,我们一次传入了好几个句子,而且每个batch中的句子必须是相同的长度。为了确保句子的长度相同,TorchText会把短的句子pad到和最长的句子等长。
# 
# - 下面我们来看看训练数据集中最常见的单词。
print(TEXT.vocab.freqs.most_common(20))
# 我们可以直接用 `stoi`(**s**tring **to** **i**nt) 或者 `itos` (**i**nt **to** **s**tring) 来查看我们的单词表。
print(TEXT.vocab.itos[:10])
# 查看labels。
print(LABEL.vocab.stoi)
# - 最后一步数据的准备是创建iterators。每个itartion都会返回一个batch的examples。
# - 我们会使用`BucketIterator`。`BucketIterator`会把长度差不多的句子放到同一个batch中,确保每个batch中不出现太多的padding。
# - 严格来说,我们这份notebook中的模型代码都有一个问题,也就是我们把`<pad>`也当做了模型的输入进行训练。更好的做法是在模型中把由`<pad>`产生的输出给消除掉。在这节课中我们简单处理,直接把`<pad>`也用作模型输入了。由于`<pad>`数量不多,模型的效果也不差。
# - 如果我们有GPU,还可以指定每个iteration返回的tensor都在GPU上。
# +
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device)
# -
# ## Word Averaging模型
#
# - 我们首先介绍一个简单的Word Averaging模型。这个模型非常简单,我们把每个单词都通过`Embedding`层投射成word embedding vector,然后把一句话中的所有word vector做个平均,就是整个句子的vector表示了。接下来把这个sentence vector传入一个`Linear`层,做分类即可。
#
# 
#
# - 我们使用[`avg_pool2d`](https://pytorch.org/docs/stable/nn.html?highlight=avg_pool2d#torch.nn.functional.avg_pool2d)来做average pooling。我们的目标是把sentence length那个维度平均成1,然后保留embedding这个维度。
#
# 
#
# - `avg_pool2d`的kernel size是 (`embedded.shape[1]`, 1),所以句子长度的那个维度会被压扁。
#
# 
#
# 
#
# +
import torch.nn as nn
import torch.nn.functional as F
class WordAVGModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, text):
embedded = self.embedding(text) # [sent len, batch size, emb dim]
embedded = embedded.permute(1, 0, 2) # [batch size, sent len, emb dim]
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1) # [batch size, embedding_dim]
return self.fc(pooled)
# +
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
OUTPUT_DIM = 1
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = WordAVGModel(INPUT_DIM, EMBEDDING_DIM, OUTPUT_DIM, PAD_IDX)
# +
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
# -
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
# +
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
# -
# ## 训练模型
# +
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
# -
# 计算预测的准确率
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum()/len(correct)
return acc
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
# +
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
# +
N_EPOCHS = 10
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'wordavg-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
# +
import spacy
nlp = spacy.load('en')
def predict_sentiment(sentence):
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
prediction = torch.sigmoid(model(tensor))
return prediction.item()
# -
predict_sentiment("This film is terrible")
predict_sentiment("This film is great")
# ## RNN模型
#
# - 下面我们尝试把模型换成一个**recurrent neural network** (RNN)。RNN经常会被用来encode一个sequence
# $$h_t = \text{RNN}(x_t, h_{t-1})$$
# - 我们使用最后一个hidden state $h_T$来表示整个句子。
# - 然后我们把$h_T$通过一个线性变换$f$,然后用来预测句子的情感。
#
# 
#
# 
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim,
n_layers, bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers,
bidirectional=bidirectional, dropout=dropout)
self.fc = nn.Linear(hidden_dim*2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
embedded = self.dropout(self.embedding(text)) #[sent len, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded)
#output = [sent len, batch size, hid dim * num directions]
#hidden = [num layers * num directions, batch size, hid dim]
#cell = [num layers * num directions, batch size, hid dim]
#concat the final forward (hidden[-2,:,:]) and backward (hidden[-1,:,:]) hidden layers
#and apply dropout
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)) # [batch size, hid dim * num directions]
return self.fc(hidden.squeeze(0))
# +
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = RNN(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM,
N_LAYERS, BIDIRECTIONAL, DROPOUT, PAD_IDX)
# -
print(f'The model has {count_parameters(model):,} trainable parameters')
# +
model.embedding.weight.data.copy_(pretrained_embeddings)
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
print(model.embedding.weight.data)
# -
# ## 训练RNN模型
optimizer = optim.Adam(model.parameters())
model = model.to(device)
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'lstm-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
# You may have noticed the loss is not really decreasing and the accuracy is poor. This is due to several issues with the model which we'll improve in the next notebook.
#
# Finally, the metric we actually care about, the test loss and accuracy, which we get from our parameters that gave us the best validation loss.
model.load_state_dict(torch.load('lstm-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
# ## CNN模型
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters,
filter_sizes, output_dim, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels = 1, out_channels = n_filters,
kernel_size = (fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
text = text.permute(1, 0) # [batch size, sent len]
embedded = self.embedding(text) # [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1) # [batch size, 1, sent len, emb dim]
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
#conv_n = [batch size, n_filters, sent len - filter_sizes[n]]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
#pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1))
#cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)
# +
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
N_FILTERS = 100
FILTER_SIZES = [3,4,5]
OUTPUT_DIM = 1
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = CNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
model.embedding.weight.data.copy_(pretrained_embeddings)
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
model = model.to(device)
# +
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
criterion = criterion.to(device)
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'CNN-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
# -
model.load_state_dict(torch.load('CNN-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
| 3/sentiment.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.7.9 64-bit (''tf'': conda)'
# name: python3
# ---
import xgboost as xgb
import numpy as np
import pandas as pd
import tensorflow as tf
import re
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.metrics import f1_score
import pickle
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from copy import deepcopy
# +
track=pd.read_csv("nfl-big-data-bowl-2022/tracking2018.csv")
plays=pd.read_csv("nfl-big-data-bowl-2022/plays.csv")
plays=plays[plays["specialTeamsResult"]=="Return"] #Look only at kick/punt returns
#Identify name of receivers so that we can match both datasets
plays["receiver"]=plays["playDescription"].map(lambda x: re.findall(" ([A-Z])\.([A-Z].*?) ", x)[-1] if len(re.findall(" [A-Z]\.([A-Z].*?) ", x))>=1 else 0)
plays=plays[plays["receiver"]!=0]
plays["receiver"]=plays["receiver"].map(lambda x: x[:-1] if x[-1]=="," else x)
#Match games and plays in both datasets
plays["gamePlayId"]=list(zip(plays["gameId"], plays["playId"]))
track["gamePlayId"]=list(zip(track["gameId"], track["playId"]))
track["gamePlayFrameId"]=list(zip(track["gamePlayId"], track["frameId"]))
track=track[track["gamePlayId"].isin(plays["gamePlayId"])]
plays=plays[plays["gamePlayId"].isin(track["gamePlayId"])]
#Create the datasets that match
track["name"]=track["displayName"].map(lambda x: (x.split(" ")[0][0],x.split(" ")[-1]))
plays["nameGamePlayId"]=list(zip(plays["receiver"], plays["gamePlayId"]))
track["nameGamePlayId"]=list(zip(track["name"], track["gamePlayId"]))
track_ret=track[track["nameGamePlayId"].isin(plays["nameGamePlayId"])]
track_ret["nameGamePlayFrameId"]=list(zip(track_ret["nameGamePlayId"],track_ret["frameId"]))
track_ret=track_ret[~track_ret.duplicated("nameGamePlayFrameId", False)] #Remove seven instances of two players with same initial and last name
plays_ret=plays[plays["nameGamePlayId"].isin(track_ret["nameGamePlayId"])]
track=track[track["gamePlayId"].isin(track_ret["gamePlayId"])] #Only games and plays where we identified the returner
#Sort values so games are in same place
plays_ret=plays_ret.sort_values("gamePlayId")
plays_ret=plays_ret.reset_index()
track_ret=track_ret.sort_values("gamePlayId")
track_ret=track_ret.reset_index()
# -
data=pd.DataFrame()
data[["receiver", "receiverx", "receivery", "receivers", "receivera", "receiverdir", "gamePlayId", "frameId", "gamePlayFrameId"]]=track_ret[["name", "x", "y", "s", "a", "dir", "gamePlayId", "frameId", "gamePlayFrameId"]]
pivot_track=pd.pivot_table(track, index="gamePlayFrameId", aggfunc=lambda x: [y for y in x])
pivot_track.columns
for col in ['event', 'frameId', 'gameId', 'gamePlayId', 'playDirection', 'playId', 'time']:
pivot_track[col]=pivot_track[col].map(lambda x: x[0])
for col in ["x", "y", "s", "a", "dir", "team"]:
for i in range(22):
pivot_track[str(i)+col]=pivot_track[col].map(lambda x: x[i])
pivot_data=pivot_track.drop(["x", "y", "s", "a", "dir", "team", 'dis', 'displayName',"jerseyNumber", "name", "nameGamePlayId", "nflId", "o", "position"], axis=1)
data=data.set_index("gamePlayFrameId")
pivot_data[["receiver", "receiverx", "receivery", "receivers", "receivera", "receiverdir"]]=data[["receiver", "receiverx", "receivery", "receivers", "receivera", "receiverdir"]]
pivot_data["playMaxDist"]=pivot_data.groupby("gamePlayId")["receiverx"].transform("max")
pivot_data["playMinDist"]=pivot_data.groupby("gamePlayId")["receiverx"].transform("min")
pivot_data["direction"]=(pivot_data["playDirection"]=="left").astype("int32")
pivot_data["direction"]=pivot_data["direction"]*2-1
pivot_data.loc[pivot_data["direction"]==1, "dist"]=(pivot_data["playMaxDist"]-pivot_data["receiverx"])*pivot_data["direction"]
pivot_data.loc[pivot_data["direction"]==-1, "dist"]=(pivot_data["playMinDist"]-pivot_data["receiverx"])*pivot_data["direction"]
receive_frames={}
for x in pivot_data[(pivot_data["event"]=="kick_received")|(pivot_data["event"]=="punt_received")].index:
receive_frames[x[0]]=x[1]
pivot_data["received?"]=pivot_data["gamePlayId"].apply(lambda x: receive_frames[x] if x in receive_frames.keys() else 0)
pivot_data["received?"]=(pivot_data["frameId"]>=pivot_data["received?"])
pivot_data
with open("pivot_data_dist_reg.pickle", "wb") as f:
pickle.dump((pivot_data, data), f)
with open("pivot_data_dist_reg.pickle", "rb") as f:
pivot_data, data=pickle.load(f)
y=pivot_data["dist"]
columns=["receiverx", "receivery", "receivers", "receivera", "receiverdir"]
for stat in ["x", "y", "s", "a", "dir"]:
for i in range(22):
columns.append(str(i)+stat)
def perm(n, clust=5, skip=1):
perm=np.random.permutation(range(skip, n+skip)).tolist()
permclust=[]
for i in perm:
for j in range(clust):
permclust+=[clust*i+j]
return permclust
# +
reg_class_scores=pd.DataFrame(columns=["Error"])
scaler=StandardScaler()
X=pivot_data[pivot_data["received?"]==True][columns+["dist"]]
X=X.to_numpy()
for i in range(3): #permutation is not right as it can shuffle different stats not only players
X=np.concatenate([X, X[:, [0,1,2,3,4]+perm(22)+[115]]], axis=0)
y=X[:,115]
X=scaler.fit_transform(X[:, :115])
y_scaler=StandardScaler()
y_scale=y_scaler.fit_transform(np.reshape(y, (-1,1)))
x_train, x_test, y_train, y_test=train_test_split(X, y_scale, test_size=.2, random_state=1)
x_train=pd.DataFrame(x_train, columns=columns)
x_test=pd.DataFrame(x_test, columns=columns)
xg_reg = xgb.XGBRegressor(objective ='reg:squarederror', learning_rate = 0.2, num_parallel_tree=1,
max_depth = 10, reg_lambda = 1, n_estimators = 100)
xg_reg.fit(x_train, y_train)
xgb.plot_importance(xg_reg)
pred=xg_reg.predict(x_test)
reg_class_scores=np.sqrt(mean_squared_error(y_test, pred))
# -
fig, ax = plt.subplots(figsize=(10, 20))
xgb.plot_importance(xg_reg, ax=ax)
mean_squared_error(y_train, xg_reg.predict(x_train))
mean_squared_error(y_test, pred)
x_ax = range(len(y_test))
plt.plot(x_ax[:1000], y_test[:1000], label="original")
plt.plot(x_ax[:1000], pred[:1000], label="predicted")
plt.title("Test predicted data")
plt.legend()
plt.show()
x_ax = range(len(y_train))
plt.plot(x_ax[:1000], y_train[:1000], label="original")
plt.plot(x_ax[:1000], xg_reg.predict(x_train)[:1000], label="predicted")
plt.title("Training predictions")
plt.legend()
plt.show()
| Kaggle/nfl-data-bowl-2021/distance_regression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/elhamalamoudi/deepPID/blob/master/ou_noise.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="puVBqJ0t4yJ6" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 265} outputId="93f38b0c-9d7a-4779-da80-9ef3551318e4"
# --------------------------------------
# Ornstein-Uhlenbeck Noise
# Author: <NAME>
# Date: 2016.5.4
# Reference: https://github.com/rllab/rllab/blob/master/rllab/exploration_strategies/ou_strategy.py
# --------------------------------------
import numpy as np
import numpy.random as nr
class OUNoise:
"""docstring for OUNoise"""
def __init__(self,action_dimension,mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
self.reset()
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * nr.randn(len(x))
self.state = x + dx
return self.state
if __name__ == '__main__':
ou = OUNoise(3, sigma=3)
states = []
for i in range(1000):
states.append(ou.noise())
import matplotlib.pyplot as plt
plt.plot(states)
plt.show()
| ou_noise.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Imports
import os, pprint
import pandas as pd
import matplotlib.pyplot as plt
import re
import wave
import contextlib
import time
# ## Helper funcs
# +
########## Audio duration helper funcs ##########
def get_wavs(path, result_list):
# Adds path to all wav files to result_list
pattern = re.compile("^\S+.wav$")
for file in os.listdir(path):
if os.path.isdir(f"{path}/{file}"):
get_wavs(f"{path}/{file}", result_list)
elif pattern.match(file):
result_list.append(f"{path}/{file}")
def get_duration(fname):
try:
with contextlib.closing(wave.open(fname,'r')) as f:
frames = f.getnframes()
rate = f.getframerate()
duration = frames / float(rate)
return duration
except EOFError:
return 10000000
def get_shorter_than_10s_wavs(path):
wav_paths = []
get_wavs(path, wav_paths)
if True:
return [path_cleaner(i) for i in wav_paths if get_duration(i) <= 10.0]
return [i for i in wav_paths if get_duration(i) <= 10.0]
########## Metadata funcs ##########
def path_cleaner(path_string):
# Removes unnessesary path parts, used for file comparison
return '/'.join(path_string.split('/')[-3:])
def get_sent_paths(dataset_path):
# Get only directorys
dataset = [i for i in os.listdir(dataset_path) if os.path.isdir(f"{dataset_path}/{i}")]
sent_paths = []
for person in dataset:
sent_paths.append(f"{dataset_path}/{person}/sentences.csv")
return sent_paths
def get_metadata(dataset_path, add_22k=True, ignore_longer_than_10s=True):
paths = get_sent_paths(dataset_path)
metadata_list = []
for i in paths:
# Add speaker id to the metadata
speaker_id = i.split('/')[-2]
with open(i) as f:
sentences = f.readlines()
metadata_list.extend([f"{speaker_id}/{row.strip()}|{speaker_id}" for row in sentences])
print("Combined all metadata files")
if add_22k:
# Adds -22k.wav to file ends, because the resampler changes the wav file names
metadata_list = [f"{row.split('.wav')[0]}-22k.wav{row.split('.wav')[1]}" for row in metadata_list]
print("Added -22k to all soundfile paths in metadata")
if ignore_longer_than_10s:
# Filters out rows, that are longer than 10s
print("Starting to remove lines longer than 10s, this might take a while")
shorter_than_10s = get_shorter_than_10s_wavs(dataset_path)
new_metadata_list = [row for row in metadata_list if path_cleaner(row.split("|")[0]) in shorter_than_10s]
print(f"Filtered out lines longer than 10s, because of this removed about {round(100-(len(new_metadata_list)/len(metadata_list))*100,2)}% of the corpus")
metadata_list = new_metadata_list
return metadata_list
def generate_metadata_file(source_path, target_path, file_name):
# Writes the metadata file
metadata_list = get_metadata(source_path)
with open(f"{target_path}/{file_name}", 'w') as f:
f.writelines(f"{row}\n" for row in metadata_list)
print(f"Wrote metadata file to {target_path}")
# -
generate_metadata_file(
'/gpfs/space/home/zuppur/cotatron/data/preprocessed_v2',
'/gpfs/space/home/zuppur/cotatron/datasets/metadata/',
'estonian_metadata.txt')
# # Common Voice
# ## Common voice helper funcs
# +
def read_commonvoice_meta(meta_file, target_path):
# Reads the meta file to df
print("Reading metadata file and formating it")
df = pd.read_csv(meta_file, delimiter='\t')
# Replaces .mp3 with -22k.wav because we change the file type
df['path'] = df['path'].apply(lambda x: x.replace('.mp3', '-22k.wav'))
meta = [f"{target_path}/{row['path']}|{row['sentence']}|{row['client_id']}" for index, row in df.iterrows()]
# Get wav paths that are shorter than 10s
print('Starting to remove lines longer than 10s, this might take a while')
shorter_than_10s = get_shorter_than_10s_wavs('/gpfs/space/home/zuppur/cotatron/data/cv-corpus-6.1-2020-12-11/et/clips_wav')
new_meta = [row for row in meta if row.split('|')[0] in shorter_than_10s]
print(f"Filtered out lines longer than 10s, because of this removed about {round(100-(len(new_meta)/len(meta))*100,2)}% of the corpus")
return new_meta
#meta = read_commonvoice_meta('/gpfs/space/home/zuppur/cotatron/data/cv-corpus-6.1-2020-12-11/et/validated.tsv', 'et/clips_wav')
# -
# # Writing the metadata file
# +
v2_source_path = '/gpfs/space/home/zuppur/cotatron/data/preprocessed_v2'
commonvoice_source_path = '/gpfs/space/home/zuppur/cotatron/data/cv-corpus-6.1-2020-12-11/et/validated.tsv'
commonvoice_audio_target_path = 'et/clips_wav'
print("Starting with preprocessed_v2 metadata")
preprocessed_v2_meta = get_metadata(v2_source_path)
print("Starting to work on commonvoice metadata")
commonvoice_meta = read_commonvoice_meta(commonvoice_source_path, commonvoice_audio_target_path)
# +
# Adding folder names to metadata
preprocessed_v2_meta_2 = [f"preprocessed_v2/{i}" for i in preprocessed_v2_meta]
commonvoice_meta_2 = [f"cv-corpus-6.1-2020-12-11/{i}" for i in commonvoice_meta]
# Combining the two lists
combined_meta = preprocessed_v2_meta_2 + commonvoice_meta_2
target_path = '/gpfs/space/home/zuppur/cotatron/datasets/metadata/'
file_name = 'estonian_metadata.txt'
# Writing the metadata file
with open(f"{target_path}/{file_name}", 'w') as f:
f.writelines(f"{row}\n" for row in combined_meta)
print(f"Wrote metadata file to {target_path}")
# +
with open('/gpfs/space/home/zuppur/cotatron/datasets/metadata/estonian_metadata.txt', 'r') as f:
sentences = f.readlines()
sentences = [i.strip().split('|')[2] for i in sentences]
speaker_ids = set(sentences)
list(speaker_ids)
| jupiter/MetadataPrep.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/Yadukrishnan1/NLP/blob/main/amazon_reviews.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="T6gAVNNt3ieD"
# Adopted to edit and play around from https://mungingdata.wordpress.com/
# + colab={"base_uri": "https://localhost:8080/"} id="iTuD4VJUiBpO" outputId="4403f382-b13d-46fb-c538-29839a9c1512"
# ! pip install fasttext;
# ! pip install numpy_ml;
# + id="yQIzvfE-heqx"
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import fasttext
import bz2
import csv
from sklearn.metrics import roc_auc_score
import os
# + colab={"base_uri": "https://localhost:8080/"} id="2ItMvZLl1YlF" outputId="c486b85c-7145-4b2b-8fb1-199d646ca7aa"
print(os.listdir("/content/drive/MyDrive/Colab Notebooks/Natural_lang_process/"))
# + id="dcrWUUt3YMTX"
myfile = open("/content/drive/MyDrive/Colab Notebooks/Natural_lang_process/train.ft.txt","r")
data = myfile.readlines()
print(len(data), 'number of records in the training set')
data_df = pd.DataFrame(data)
data_df.to_csv("train.txt", index=False, sep=' ', header=False, quoting=csv.QUOTE_NONE, quotechar="", escapechar=" ")
# + colab={"base_uri": "https://localhost:8080/", "height": 220} id="m3n_0ZWjm86-" outputId="710c28b9-2903-4f37-ad03-0cca298b9980"
data_df.loc[:5]
# + colab={"base_uri": "https://localhost:8080/"} id="JgH_CLrikM2S" outputId="7214184b-a183-434e-9ee0-217894be6179"
# Modelling
# This routine takes about 5 to 10 minutes
model = fasttext.train_supervised('train.txt',label_prefix='__label__', thread=5, epoch = 5)
print(model.labels, 'are the labels or targets the model is predicting')
# + id="2UP6FRqCmx4o" colab={"base_uri": "https://localhost:8080/"} outputId="e95dd8d4-2b86-4d62-f642-c553251f0fde"
myfile = open("/content/drive/MyDrive/Colab Notebooks/Natural_lang_process/test.ft.txt","r")
test = myfile.readlines()
print(len(test), 'number of records in the test set')
# + id="4TUFHzY-myYC"
new = [w.replace('__label__2 ', '') for w in test]
new = [w.replace('__label__1 ', '') for w in new]
new = [w.replace('\n', '') for w in new]
# Use the predict function
pred = model.predict(new)
# + colab={"base_uri": "https://localhost:8080/"} id="1b2P7BxRr9l2" outputId="eae1a097-5f11-4d2e-d093-fa2086f06d12"
# check the first record outputs
print(pred[0][1][0], 'is the predicted label with', end=' ')
print(pred[1][1][0], 'as the probability score.')
# + colab={"base_uri": "https://localhost:8080/"} id="aRS_kMzytNhv" outputId="8362ad55-c2df-4b54-c9c8-48a9cd3d9dd7"
# Lets recode the actual targets to 1's and 0's from both the test set and the actual predictions
labels = [0 if x.split(' ')[0] == '__label__1' else 1 for x in test]
pred_labels = [0 if x == ['__label__1'] else 1 for x in pred[0]]
# run the accuracy measure.
print(roc_auc_score(labels, pred_labels))
| amazon_reviews.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="b518b04cbfe0"
# ##### Copyright 2020 The TensorFlow Authors.
# + cellView="form" id="906e07f6e562"
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# + [markdown] id="fb291b62b1aa"
# # Training and evaluation with the built-in methods
# + [markdown] id="b1820d9bdfb9"
# <table class="tfo-notebook-buttons" align="left">
# <td><a target="_blank" href="https://www.tensorflow.org/guide/keras/train_and_evaluate"><img src="https://www.tensorflow.org/images/tf_logo_32px.png">TensorFlow.org에서 보기</a></td>
# <td><a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/ko/guide/keras/train_and_evaluate.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png">Google Colab에서 실행</a></td>
# <td><a target="_blank" href="https://github.com/tensorflow/docs-l10n/blob/master/site/ko/guide/keras/train_and_evaluate.ipynb"> <img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png"> GitHub에서 소스 보기</a></td>
# <td><a href="https://storage.googleapis.com/tensorflow_docs/docs-l10n/site/ko/guide/keras/train_and_evaluate.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png">노트북 다운로드</a></td>
# </table>
# + [markdown] id="8d4ac441b1fc"
# ## 설정
# + id="0472bf67b2bf"
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# + [markdown] id="c16fe7fd6a6c"
# ## 시작하기
#
# 이 안내서는 훈련 및 유효성 검증을 위해 내장 API를 사용할 때의 훈련, 평가 및 예측 (추론) 모델 (예 : `model.fit()` , `model.evaluate()` , `model.predict()` )에 대해 설명합니다.
#
# 고유한 훈련 단계 함수를 지정하면서 `fit()`을 사용하려면 <a href="https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit/" data-md-type="link">" `fit()`에서 이루어지는 작업 사용자 정의하기"</a> 가이드를 참조하세요.
#
# 고유한 훈련 및 평가 루프를 처음부터 작성하려면 ["처음부터 훈련 루프 작성"](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch/) 안내서를 참조하십시오.
#
# 일반적으로, 내장 루프를 사용하든 직접 작성하든 관계없이 모델 훈련 및 유효성 검사는 모든 종류의 Keras 모델(순차 모델, Functional API로 작성된 모델 및 모델 하위 클래스화를 통해 처음부터 작성된 모델)에서 완전히 동일하게 작동합니다.
#
# 이 가이드는 분산 교육에 대해서는 다루지 않습니다. 분산 교육에 대해서는 [멀티 GPU 및 분산 교육 안내서를](https://keras.io/guides/distributed_training/) 참조하십시오.
# + [markdown] id="4e270faa413e"
# ## API 개요 : 첫 번째 엔드 투 엔드 예제
#
# 데이터를 모델의 내장 훈련 루프로 전달할 때는 **NumPy 배열**(데이터가 작고 메모리에 맞는 경우) 또는 **`tf.data Dataset` 객체**를 사용해야 합니다. 다음 몇 단락에서는 옵티마이저, 손실 및 메트릭을 사용하는 방법을 보여주기 위해 MNIST 데이터세트를 NumPy 배열로 사용하겠습니다.
#
# 다음 모델을 고려해 보겠습니다 (여기서는 Functional API를 사용하여 빌드하지만 Sequential 모델 또는 하위 클래스 모델 일 수도 있음).
# + id="170a6a18b2a3"
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, activation="softmax", name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
# + [markdown] id="e6d5724a90ab"
# 일반적인 엔드 투 엔드 워크 플로는 다음과 같이 구성되어 있습니다.
#
# - 학습
# - 원래 교육 데이터에서 생성 된 홀드 아웃 세트에 대한 유효성 검사
# - 테스트 데이터에 대한 평가
#
# 이 예에서는 MNIST 데이터를 사용합니다.
# + id="8b55b3903edb"
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Preprocess the data (these are NumPy arrays)
x_train = x_train.reshape(60000, 784).astype("float32") / 255
x_test = x_test.reshape(10000, 784).astype("float32") / 255
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")
# Reserve 10,000 samples for validation
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
# + [markdown] id="77a84eb1985b"
# 훈련 구성(최적화 프로그램, 손실, 메트릭)을 지정합니다.
# + id="26a7f1819796"
model.compile(
optimizer=keras.optimizers.RMSprop(), # Optimizer
# Loss function to minimize
loss=keras.losses.SparseCategoricalCrossentropy(),
# List of metrics to monitor
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# + [markdown] id="ef28150b1eaa"
# `fit()`를 호출하여 데이터를 "batch_size" 크기의 "배치"로 분할하고 지정된 수의 "epoch"에 대해 전체 데이터세트를 반복 처리하여 모델을 훈련시킵니다.
# + id="0b92f67b105e"
print("Fit model on training data")
history = model.fit(
x_train,
y_train,
batch_size=64,
epochs=2,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(x_val, y_val),
)
# + [markdown] id="0a1b698c6e39"
# 반환되는 "이력" 객체는 훈련 중 손실 값과 메트릭 값에 대한 레코드를 유지합니다.
# + id="a20b8f5b9fcc"
history.history
# + [markdown] id="6105b646df66"
# `evaluate()`를 통해 테스트 데이터에 대해 모델을 평가합니다.
# + id="69f524a93f9d"
# Evaluate the model on the test data using `evaluate`
print("Evaluate on test data")
results = model.evaluate(x_test, y_test, batch_size=128)
print("test loss, test acc:", results)
# Generate predictions (probabilities -- the output of the last layer)
# on new data using `predict`
print("Generate predictions for 3 samples")
predictions = model.predict(x_test[:3])
print("predictions shape:", predictions.shape)
# + [markdown] id="f19d074eb88c"
# 이제이 워크 플로의 각 부분을 자세히 검토하겠습니다.
# + [markdown] id="f3669f026d14"
# ## `compile()` 메소드 : 손실, 메트릭 및 최적화 프로그램 지정
#
# `fit()` 으로 모델을 학습하려면 손실 함수, 최적화 프로그램 및 선택적으로 모니터링 할 일부 메트릭을 지정해야합니다.
#
# 이것을 `compile()` 메소드의 인수로 모델에 전달합니다.
# + id="eb7a8deb494c"
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# + [markdown] id="c4061c977ac3"
# `metrics` 인수는 목록이어야합니다. 모델에는 여러 개의 메트릭이있을 수 있습니다.
#
# 모델에 여러 개의 출력이있는 경우 각 출력에 대해 서로 다른 손실 및 메트릭을 지정하고 모델의 총 손실에 대한 각 출력의 기여도를 조정할 수 있습니다. 이에 대한 자세한 내용은 **"다중 입력, 다중 출력 모델로 데이터 전달"** 섹션에서 확인할 수 있습니다.
#
# 기본 설정에 만족하면 대부분의 경우 최적화, 손실 및 메트릭을 문자열 식별자를 통해 바로 가기로 지정할 수 있습니다.
# + id="6444839ff300"
model.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
# + [markdown] id="5493ab963254"
# 나중에 재사용하기 위해 모델 정의와 컴파일 단계를 함수에 넣겠습니다. 이 안내서의 여러 예에서 여러 번 호출합니다.
# + id="31c3e3c70f06"
def get_uncompiled_model():
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, activation="softmax", name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
def get_compiled_model():
model = get_uncompiled_model()
model.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
return model
# + [markdown] id="21b19c0a6a85"
# ### 많은 내장 옵티 마이저, 손실 및 메트릭을 사용할 수 있습니다
#
# 일반적으로 고유한 손실, 메트릭 또는 최적화 프로그램을 처음부터 새로 만들 필요가 없는데, Keras API에 필요한 것들이 이미 들어 있을 개연성이 높기 때문입니다.
#
# 옵티마이저
#
# - `SGD()` (모멘텀이 있거나 없음)
# - `RMSprop()`
# - `Adam()`
# - 기타
#
# 손실:
#
# - `MeanSquaredError()`
# - `KLDivergence()`
# - `CosineSimilarity()`
# - 기타
#
# 메트릭
#
# - `AUC()`
# - `Precision()`
# - `Recall()`
# - 기타
# + [markdown] id="d7abc0339980"
# ### 관례 손실
#
# Keras로 커스텀 손실을 제공하는 두 가지 방법이 있습니다. 첫 번째 예는 입력 `y_true` 및 `y_pred` 를 받아들이는 함수를 만듭니다. 다음 예는 실제 데이터와 예측 간의 평균 제곱 오차를 계산하는 손실 함수를 보여줍니다.
# + id="cc4edd47bb5a"
def custom_mean_squared_error(y_true, y_pred):
return tf.math.reduce_mean(tf.square(y_true - y_pred))
model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=custom_mean_squared_error)
# We need to one-hot encode the labels to use MSE
y_train_one_hot = tf.one_hot(y_train, depth=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)
# + [markdown] id="25b9fa7941ca"
# `y_true` 및 `y_pred` 이외의 매개 변수를 사용하는 손실 함수가 필요한 경우 `tf.keras.losses.Loss` 클래스를 서브 클래스 화하고 다음 두 메소드를 구현할 수 있습니다.
#
# - `__init__(self)` : 손실 함수 호출 중에 전달할 매개 변수를 승인합니다.
# - `call(self, y_true, y_pred)` : 목표 (y_true)와 모델 예측 (y_pred)을 사용하여 모델의 손실을 계산
#
# 평균 제곱 오차를 사용하려고하지만 예측 값을 0.5에서 멀어지게하는 용어가 추가되었다고 가정 해 보겠습니다 (우리는 범주 형 목표가 원-핫 인코딩되고 0과 1 사이의 값을 취하는 것으로 가정). 이렇게하면 모델이 너무 자신감이없는 인센티브가 생겨 과적 합을 줄이는 데 도움이 될 수 있습니다 (시도 할 때까지 작동하는지 알 수 없음).
#
# 방법은 다음과 같습니다.
# + id="b09463a8c568"
class CustomMSE(keras.losses.Loss):
def __init__(self, regularization_factor=0.1, name="custom_mse"):
super().__init__(name=name)
self.regularization_factor = regularization_factor
def call(self, y_true, y_pred):
mse = tf.math.reduce_mean(tf.square(y_true - y_pred))
reg = tf.math.reduce_mean(tf.square(0.5 - y_pred))
return mse + reg * self.regularization_factor
model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=CustomMSE())
y_train_one_hot = tf.one_hot(y_train, depth=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)
# + [markdown] id="b2141cc075a6"
# ### 맞춤 측정 항목
#
# API의 일부가 아닌 메트릭이 필요한 경우 `tf.keras.metrics.Metric` 클래스를 서브 클래 싱하여 사용자 지정 메트릭을 쉽게 만들 수 있습니다. 4 가지 방법을 구현해야합니다.
#
# - `__init__(self)` . 여기서 메트릭에 대한 상태 변수를 만듭니다.
# - `update_state(self, y_true, y_pred, sample_weight=None)` 대상 y_true 및 모델 예측 y_pred를 사용하여 상태 변수를 업데이트합니다.
# - `result(self)` : 상태 변수를 사용하여 최종 결과를 계산합니다.
# - `reset_states(self)` : 메트릭의 상태를 다시 초기화합니다.
#
# 경우에 따라 결과 계산이 매우 비싸고 주기적으로 만 수행되기 때문에 상태 업데이트와 결과 계산은 각각 `update_state()` 와 `result()` 에서 별도로 유지됩니다.
#
# 다음은 `CategoricalTruePositives` 메트릭을 구현하는 방법을 보여주는 간단한 예제입니다.이 메트릭은 주어진 클래스에 속하는 것으로 올바르게 분류 된 샘플 수를 계산합니다.
# + id="05d6a6e7022d"
class CategoricalTruePositives(keras.metrics.Metric):
def __init__(self, name="categorical_true_positives", **kwargs):
super(CategoricalTruePositives, self).__init__(name=name, **kwargs)
self.true_positives = self.add_weight(name="ctp", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
y_pred = tf.reshape(tf.argmax(y_pred, axis=1), shape=(-1, 1))
values = tf.cast(y_true, "int32") == tf.cast(y_pred, "int32")
values = tf.cast(values, "float32")
if sample_weight is not None:
sample_weight = tf.cast(sample_weight, "float32")
values = tf.multiply(values, sample_weight)
self.true_positives.assign_add(tf.reduce_sum(values))
def result(self):
return self.true_positives
def reset_states(self):
# The state of the metric will be reset at the start of each epoch.
self.true_positives.assign(0.0)
model = get_uncompiled_model()
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[CategoricalTruePositives()],
)
model.fit(x_train, y_train, batch_size=64, epochs=3)
# + [markdown] id="4bca8e959cda"
# ### 표준 서명에 맞지 않는 손실 및 메트릭 처리하기
#
# 거의 대부분의 손실과 메트릭은 `y_true` 및 `y_pred`에서 계산할 수 있습니다(여기서 `y_pred`가 모델의 출력). 그러나 모두가 그런 것은 아닙니다. 예를 들어, 정규화 손실은 레이어의 활성화만 요구할 수 있으며(이 경우 대상이 없음) 이 활성화는 모델 출력이 아닐 수 있습니다.
#
# 이러한 경우 사용자 정의 레이어의 호출 메서드 내에서 `self.add_loss(loss_value)`를 호출할 수 있습니다. 이러한 방식으로 추가된 손실은 훈련 중 "주요" 손실(`compile()`로 전달되는 손실)에 추가됩니다. 다음은 활동 정규화를 추가하는 간단한 예입니다. 참고로 활동 정규화는 모든 Keras 레이어에 내장되어 있으며 이 레이어는 구체적인 예를 제공하기 위한 것입니다.
# + id="b494d47437a0"
class ActivityRegularizationLayer(layers.Layer):
def call(self, inputs):
self.add_loss(tf.reduce_sum(inputs) * 0.1)
return inputs # Pass-through layer.
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
# Insert activity regularization as a layer
x = ActivityRegularizationLayer()(x)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
# The displayed loss will be much higher than before
# due to the regularization component.
model.fit(x_train, y_train, batch_size=64, epochs=1)
# + [markdown] id="aaebb5829011"
# `add_metric()` 사용하여 메트릭 값 로깅에 대해 동일한 작업을 수행 할 수 있습니다.
# + id="aa58091be092"
class MetricLoggingLayer(layers.Layer):
def call(self, inputs):
# The `aggregation` argument defines
# how to aggregate the per-batch values
# over each epoch:
# in this case we simply average them.
self.add_metric(
keras.backend.std(inputs), name="std_of_activation", aggregation="mean"
)
return inputs # Pass-through layer.
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
# Insert std logging as a layer.
x = MetricLoggingLayer()(x)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
model.fit(x_train, y_train, batch_size=64, epochs=1)
# + [markdown] id="f3c18154d057"
# [Functional API](https://www.tensorflow.org/guide/keras/functional/) 에서 `model.add_loss(loss_tensor)` 또는 `model.add_metric(metric_tensor, name, aggregation)` 호출 할 수도 있습니다.
#
# 다음은 간단한 예입니다.
# + id="0e19afe78b3a"
inputs = keras.Input(shape=(784,), name="digits")
x1 = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x2 = layers.Dense(64, activation="relu", name="dense_2")(x1)
outputs = layers.Dense(10, name="predictions")(x2)
model = keras.Model(inputs=inputs, outputs=outputs)
model.add_loss(tf.reduce_sum(x1) * 0.1)
model.add_metric(keras.backend.std(x1), name="std_of_activation", aggregation="mean")
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
model.fit(x_train, y_train, batch_size=64, epochs=1)
# + [markdown] id="b06d48035369"
# `add_loss()` 를 통해 손실을 전달하면 모델에는 이미 손실이 있으므로 손실 함수없이 `compile()` 을 호출 할 수 있습니다.
#
# 다음 `LogisticEndpoint` 레이어를 생각해 보겠습니다. 이 레이어는 입력으로 targets 및 logits를 받아들이고 `add_loss()`를 통해 교차 엔트로피 손실을 추적합니다. 또한 `add_metric()`를 통해 분류 정확도도 추적합니다.
# + id="d56d2c504258"
class LogisticEndpoint(keras.layers.Layer):
def __init__(self, name=None):
super(LogisticEndpoint, self).__init__(name=name)
self.loss_fn = keras.losses.BinaryCrossentropy(from_logits=True)
self.accuracy_fn = keras.metrics.BinaryAccuracy()
def call(self, targets, logits, sample_weights=None):
# Compute the training-time loss value and add it
# to the layer using `self.add_loss()`.
loss = self.loss_fn(targets, logits, sample_weights)
self.add_loss(loss)
# Log accuracy as a metric and add it
# to the layer using `self.add_metric()`.
acc = self.accuracy_fn(targets, logits, sample_weights)
self.add_metric(acc, name="accuracy")
# Return the inference-time prediction tensor (for `.predict()`).
return tf.nn.softmax(logits)
# + [markdown] id="0698f3c98cbe"
# 다음과 같이 `loss` 인수없이 컴파일 된 두 개의 입력 (입력 데이터 및 대상)이있는 모델에서 사용할 수 있습니다.
# + id="0f6842f2bbe6"
import numpy as np
inputs = keras.Input(shape=(3,), name="inputs")
targets = keras.Input(shape=(10,), name="targets")
logits = keras.layers.Dense(10)(inputs)
predictions = LogisticEndpoint(name="predictions")(logits, targets)
model = keras.Model(inputs=[inputs, targets], outputs=predictions)
model.compile(optimizer="adam") # No loss argument!
data = {
"inputs": np.random.random((3, 3)),
"targets": np.random.random((3, 10)),
}
model.fit(data)
# + [markdown] id="328b021aa6b8"
# 다중 입력 모델 교육에 대한 자세한 내용은 **다중 입력, 다중 출력 모델로 데이터 전달** 섹션을 참조하십시오.
# + [markdown] id="0536882b969c"
# ### 유효성 검사 홀드아웃 세트를 자동으로 분리하기
#
# 본 첫 번째 엔드 투 엔드 예제에서, 우리는 `validation_data` 인수를 사용하여 NumPy 배열의 튜플 `(x_val, y_val)` 을 모델에 전달하여 각 에포크의 끝에서 유효성 검증 손실 및 유효성 검증 메트릭을 평가합니다.
#
# 또 다른 옵션: 인수 `validation_split`를 사용하여 유효성 검사 목적으로 훈련 데이터의 일부를 자동으로 예약할 수 있습니다. 인수 값은 유효성 검사를 위해 예약할 데이터 비율을 나타내므로 0보다 크고 1보다 작은 값으로 설정해야 합니다. 예를 들어, `validation_split=0.2`는 "유효성 검사를 위해 데이터의 20%를 사용"한다는 의미이고`validation_split=0.6`은 "유효성 검사를 위해 데이터의 60%를 사용"한다는 의미입니다.
#
# 유효성을 계산하는 방법은 셔플 링 전에 맞춤 호출로 수신 한 배열의 마지막 x % 샘플을 가져 오는 것입니다.
#
# NumPy 데이터를 학습 할 때 `validation_split` 만 사용할 수 있습니다.
# + id="232fd59c751b"
model = get_compiled_model()
model.fit(x_train, y_train, batch_size=64, validation_split=0.2, epochs=1)
# + [markdown] id="42969af7ce01"
# ## tf.data 데이터 세트의 교육 및 평가
#
# 앞서 몇 단락에 걸쳐 손실, 메트릭 및 옵티마이저를 처리하는 방법을 살펴보았으며, 데이터가 NumPy 배열로 전달될 때 fit에서 `validation_data` 및 `validation_split` 인수를 사용하는 방법도 알아보았습니다.
#
# 이제 데이터가 `tf.data.Dataset` 객체의 형태로 제공되는 경우를 살펴 보겠습니다.
#
# `tf.data` API는 빠르고 확장 가능한 방식으로 데이터를 로드하고 사전 처리하기 위한 TensorFlow 2.0의 유틸리티 세트입니다.
#
# `Datasets` 생성에 대한 자세한 설명은 [tf.data 설명서](https://www.tensorflow.org/guide/data)를 참조하세요.
#
# `Dataset` 인스턴스를 메서드 `fit()`, `evaluate()` 및 `predict()`로 직접 전달할 수 있습니다.
# + id="3bf4ded224f8"
model = get_compiled_model()
# First, let's create a training Dataset instance.
# For the sake of our example, we'll use the same MNIST data as before.
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Now we get a test dataset.
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(64)
# Since the dataset already takes care of batching,
# we don't pass a `batch_size` argument.
model.fit(train_dataset, epochs=3)
# You can also evaluate or predict on a dataset.
print("Evaluate")
result = model.evaluate(test_dataset)
dict(zip(model.metrics_names, result))
# + [markdown] id="421d16914ce3"
# 데이터세트는 각 epoch의 끝에서 재설정되므로 다음 epoch에서 재사용할 수 있습니다.
#
# 이 데이터세트의 특정 배치 수에 대해서만 훈련을 실행하려면 다음 epoch로 이동하기 전에 이 데이터세트를 사용하여 모델이 실행해야 하는 훈련 단계의 수를 지정하는 `steps_per_epoch` 인수를 전달할 수 있습니다.
#
# 이렇게 하면 각 epoch가 끝날 때 데이터세트가 재설정되지 않고 다음 배치를 계속 가져오게 됩니다. 무한 반복되는 데이터세트가 아니라면 결국 데이터세트의 데이터가 고갈됩니다.
# + id="273c5dff16b4"
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Only use the 100 batches per epoch (that's 64 * 100 samples)
model.fit(train_dataset, epochs=3, steps_per_epoch=100)
# + [markdown] id="f2dcd180da7b"
# ### 유효성 검사 데이터 집합 사용
#
# `fit()` 에서 `Dataset` 인스턴스를 `validation_data` 인수로 전달할 수 있습니다.
# + id="bf4f3d78e69a"
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(train_dataset, epochs=1, validation_data=val_dataset)
# + [markdown] id="2e7f0ebf5f1d"
# 각 시대가 끝날 때 모델은 유효성 검사 데이터 집합을 반복하고 유효성 검사 손실 및 유효성 검사 메트릭을 계산합니다.
#
# 이 데이터세트의 특정 배치 수에 대해서만 유효성 검사를 실행하려면 유효성 검사를 중단하고 다음 epoch로 넘어가기 전에 유효성 검사 데이터세트에서 모델이 실행해야 하는 유효성 검사 단계의 수를 지정하는 `validation_steps` 인수를 전달할 수 있습니다.
# + id="f47342fed069"
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(
train_dataset,
epochs=1,
# Only run validation using the first 10 batches of the dataset
# using the `validation_steps` argument
validation_data=val_dataset,
validation_steps=10,
)
# + [markdown] id="67b4418e9f26"
# 유효성 검사 데이터 세트는 사용 후마다 재설정되므로 항상 에포크에서 에포크까지 동일한 샘플을 평가하게됩니다.
#
# 인수 `validation_split`(훈련 데이터로부터 홀드아웃 세트 생성)는 `Dataset` 객체로 훈련할 때는 지원되지 않는데, 이를 위해서는 데이터세트 샘플을 인덱싱할 수 있어야 하지만 `Dataset` API에서는 일반적으로 이것이 불가능하기 때문입니다.
# + [markdown] id="8160beb766a0"
# ## 지원되는 다른 입력 형식
#
# NumPy 배열, 즉시 실행 텐서 및 TensorFlow `Datasets` 외에도 Pandas 데이터프레임을 사용하거나 데이터 및 레이블의 배치를 생성하는 Python 생성기에서 Keras 모델을 훈련할 수 있습니다.
#
# 특히, `keras.utils.Sequence` 클래스는 멀티스레딩을 인식하고 셔플이 가능한 Python 데이터 생성기를 빌드하기 위한 간단한 인터페이스를 제공합니다.
#
# 일반적으로 다음을 사용하는 것이 좋습니다.
#
# - 데이터가 작고 메모리에 맞는 경우 NumPy 입력 데이터
# - 큰 데이터세트가 있고 분산 훈련을 수행해야 하는 경우 `Dataset` 객체
# - 큰 데이터세트가 있고 TensorFlow에서 수행할 수 없는 많은 사용자 정의 Python 측 처리를 수행해야 하는 경우(예: 데이터 로드 또는 사전 처리를 위해 외부 라이브러리에 의존하는 경우) `Sequence` 객체
#
# ## `keras.utils.Sequence` 객체를 입력으로 사용하기
#
# `keras.utils.Sequence`는 두 가지 중요한 속성을 가진 Python 생성기를 얻기 위해 하위 클래스화를 수행할 수 있는 유틸리티입니다.
#
# - 멀티 프로세싱과 잘 작동합니다.
# - 셔플할 수 있습니다(예: `fit()`에서 `shuffle=True`를 전달하는 경우).
#
# `Sequence` 는 두 가지 방법을 구현해야합니다.
#
# - `__getitem__`
# - `__len__`
#
# `__getitem__` 메소드는 완전한 배치를 리턴해야합니다. 신기원 사이의 데이터 세트를 수정하려면 `on_epoch_end` 구현할 수 있습니다.
#
# 간단한 예를 들자면 다음과 같습니다.
#
# ```python
# from skimage.io import imread
# from skimage.transform import resize
# import numpy as np
#
# # Here, `filenames` is list of path to the images
# # and `labels` are the associated labels.
#
# class CIFAR10Sequence(Sequence):
# def __init__(self, filenames, labels, batch_size):
# self.filenames, self.labels = filenames, labels
# self.batch_size = batch_size
#
# def __len__(self):
# return int(np.ceil(len(self.filenames) / float(self.batch_size)))
#
# def __getitem__(self, idx):
# batch_x = self.filenames[idx * self.batch_size:(idx + 1) * self.batch_size]
# batch_y = self.labels[idx * self.batch_size:(idx + 1) * self.batch_size]
# return np.array([
# resize(imread(filename), (200, 200))
# for filename in batch_x]), np.array(batch_y)
#
# sequence = CIFAR10Sequence(filenames, labels, batch_size)
# model.fit(sequence, epochs=10)
# ```
# + [markdown] id="2a28343b1967"
# ## 샘플 가중치 및 클래스 가중치 사용
#
# 기본 설정을 사용하면 샘플의 무게가 데이터 세트의 빈도에 따라 결정됩니다. 샘플 빈도와 관계없이 데이터에 가중치를 부여하는 방법에는 두 가지가 있습니다.
#
# - 클래스 가중치
# - 샘플 무게
# + [markdown] id="f234a9a75b6d"
# ### 클래스 가중치
#
# 이 가중치는 `Model.fit()`에 대한 `class_weight` 인수로 사전을 전달하여 설정합니다. 이 사전은 클래스 인덱스를 이 클래스에 속한 샘플에 사용해야 하는 가중치에 매핑합니다.
#
# 이 방법은 샘플링을 다시 수행하지 않고 클래스의 균형을 맞추거나 특정 클래스에 더 중요한 모델을 훈련시키는 데 사용할 수 있습니다.
#
# 예를 들어, 데이터에서 클래스 "0"이 클래스 "1"로 표시된 것의 절반인 경우 `Model.fit(..., class_weight={0: 1., 1: 0.5})`을 사용할 수 있습니다.
# + [markdown] id="9929d26d91b8"
# 다음은 클래스 #5(MNIST 데이터세트에서 숫자 "5")의 올바른 분류에 더 많은 중요성을 두도록 클래스 가중치 또는 샘플 가중치를 사용하는 NumPy 예입니다.
# + id="f1844f2329a6"
import numpy as np
class_weight = {
0: 1.0,
1: 1.0,
2: 1.0,
3: 1.0,
4: 1.0,
# Set weight "2" for class "5",
# making this class 2x more important
5: 2.0,
6: 1.0,
7: 1.0,
8: 1.0,
9: 1.0,
}
print("Fit with class weight")
model = get_compiled_model()
model.fit(x_train, y_train, class_weight=class_weight, batch_size=64, epochs=1)
# + [markdown] id="ce27221fad08"
# ### 샘플 무게
#
# 세밀한 제어를 위해 또는 분류기를 작성하지 않는 경우 "샘플 가중치"를 사용할 수 있습니다.
#
# - NumPy 데이터에서 학습하는 경우 : `sample_weight` 인수를 `Model.fit()` .
# - `tf.data` 또는 다른 종류의 반복자에서 훈련 할 때 : Yield `(input_batch, label_batch, sample_weight_batch)` 튜플.
#
# "샘플 가중치"배열은 배치에서 각 샘플이 총 손실을 계산하는 데 필요한 가중치를 지정하는 숫자 배열입니다. 불균형 분류 문제 (거의 보이지 않는 클래스에 더 많은 가중치를 부여하는 아이디어)에 일반적으로 사용됩니다.
#
# 사용 된 가중치가 1과 0 인 경우, 어레이는 손실 함수에 대한 *마스크* 로 사용될 수 있습니다 (전체 손실에 대한 특정 샘플의 기여를 완전히 버림).
# + id="f9819d647793"
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.0
print("Fit with sample weight")
model = get_compiled_model()
model.fit(x_train, y_train, sample_weight=sample_weight, batch_size=64, epochs=1)
# + [markdown] id="eae5837c5f56"
# 일치하는 `Dataset` 예는 다음과 같습니다.
# + id="c870f3f0c66c"
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.0
# Create a Dataset that includes sample weights
# (3rd element in the return tuple).
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train, sample_weight))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model = get_compiled_model()
model.fit(train_dataset, epochs=1)
# + [markdown] id="3963bfa348b0"
# ## 다중 입력, 다중 출력 모델로 데이터 전달
#
# 이전 예에서는 단일 입력(형상 `(764,)`의 텐서)과 단일 출력(형상 `(10,)`의 예측 텐서)이 있는 모델을 고려했습니다. 그렇다면 입력 또는 출력이 여러 개인 모델은 어떨까요?
#
# shape `(32, 32, 3)` ( `(height, width, channels)` 입력과 shape `(None, 10)` 의 시계열 입력 `(timesteps, features)` 하십시오. 우리의 모델은이 입력들의 조합으로부터 계산 된 두 개의 출력을 가질 것입니다 : "점수"(모양 `(1,)` )와 5 개의 클래스 (모양 `(5,)` )에 대한 확률 분포.
# + id="5f958449a057"
image_input = keras.Input(shape=(32, 32, 3), name="img_input")
timeseries_input = keras.Input(shape=(None, 10), name="ts_input")
x1 = layers.Conv2D(3, 3)(image_input)
x1 = layers.GlobalMaxPooling2D()(x1)
x2 = layers.Conv1D(3, 3)(timeseries_input)
x2 = layers.GlobalMaxPooling1D()(x2)
x = layers.concatenate([x1, x2])
score_output = layers.Dense(1, name="score_output")(x)
class_output = layers.Dense(5, name="class_output")(x)
model = keras.Model(
inputs=[image_input, timeseries_input], outputs=[score_output, class_output]
)
# + [markdown] id="df3ed34fe78b"
# 이 모델을 플로팅하여 여기서 수행중인 작업을 명확하게 확인할 수 있습니다 (플롯에 표시된 셰이프는 샘플 별 셰이프가 아니라 배치 셰이프 임).
# + id="ac8c1baca9e3"
keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True)
# + [markdown] id="4d979e89b335"
# 컴파일 타임에 손실 함수를 목록으로 전달하여 출력마다 다른 손실을 지정할 수 있습니다.
# + id="9655c0084d70"
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
)
# + [markdown] id="f5fc73405283"
# 모델에 단일 손실 함수만 전달하는 경우, 모든 출력에 동일한 손실 함수가 적용됩니다(여기서는 적합하지 않음).
#
# 메트릭의 경우도 마찬가지입니다.
# + id="b4c0c6c564bc"
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
metrics=[
[
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
[keras.metrics.CategoricalAccuracy()],
],
)
# + [markdown] id="4dd9fb0343cc"
# 출력 레이어에 이름을 지정 했으므로 dict를 통해 출력 당 손실 및 메트릭을 지정할 수도 있습니다.
# + id="42cb75110fc3"
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"score_output": keras.losses.MeanSquaredError(),
"class_output": keras.losses.CategoricalCrossentropy(),
},
metrics={
"score_output": [
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
"class_output": [keras.metrics.CategoricalAccuracy()],
},
)
# + [markdown] id="bfd95ac0dd8b"
# 출력이 두 개 이상인 경우 명시적 이름과 사전을 사용하는 것이 좋습니다.
#
# `loss_weights` 인수를 사용하여 출력별 손실에 서로 다른 가중치를 부여할 수 있습니다(예를 들어, 클래스 손실에 2x의 중요도를 부여하여 이 예에서 "score" 손실에 우선권을 줄 수 있음).
# + id="23a71e5f5227"
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"score_output": keras.losses.MeanSquaredError(),
"class_output": keras.losses.CategoricalCrossentropy(),
},
metrics={
"score_output": [
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
"class_output": [keras.metrics.CategoricalAccuracy()],
},
loss_weights={"score_output": 2.0, "class_output": 1.0},
)
# + [markdown] id="367f598029e7"
# 이러한 출력이 예측 용이지만 훈련 용이 아닌 경우 특정 출력에 대한 손실을 계산하지 않도록 선택할 수도 있습니다.
# + id="6d51aa372ef4"
# List loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[None, keras.losses.CategoricalCrossentropy()],
)
# Or dict loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={"class_output": keras.losses.CategoricalCrossentropy()},
)
# + [markdown] id="8314a8b3a7c7"
# 적합하게 다중 입력 또는 다중 출력 모델에 데이터를 전달하는 것은 컴파일에서 손실 함수를 지정하는 것과 유사한 방식으로 작동합니다. **NumPy 배열 목록을** 전달할 수 있습니다 (손실 함수를 수신 한 출력에 1 : 1 매핑). **출력 이름을 NumPy 배열에 매핑합니다** .
# + id="0539da84328b"
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
)
# Generate dummy NumPy data
img_data = np.random.random_sample(size=(100, 32, 32, 3))
ts_data = np.random.random_sample(size=(100, 20, 10))
score_targets = np.random.random_sample(size=(100, 1))
class_targets = np.random.random_sample(size=(100, 5))
# Fit on lists
model.fit([img_data, ts_data], [score_targets, class_targets], batch_size=32, epochs=1)
# Alternatively, fit on dicts
model.fit(
{"img_input": img_data, "ts_input": ts_data},
{"score_output": score_targets, "class_output": class_targets},
batch_size=32,
epochs=1,
)
# + [markdown] id="e53eda8e1399"
# `Dataset` 사용 사례는 다음과 같습니다. NumPy 배열에서 수행 한 것과 유사하게 `Dataset` 은 튜플 튜플을 반환해야합니다.
# + id="4df41a12ed2c"
train_dataset = tf.data.Dataset.from_tensor_slices(
(
{"img_input": img_data, "ts_input": ts_data},
{"score_output": score_targets, "class_output": class_targets},
)
)
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model.fit(train_dataset, epochs=1)
# + [markdown] id="38ebf30ce6ac"
# ## 콜백 사용하기
#
# Keras의 콜백은 훈련 중 다른 시점(epoch의 시작, 배치의 끝, epoch의 끝 등)에서 호출되며 다음과 같은 동작을 구현하는 데 사용할 수 있는 객체입니다.
#
# - 훈련 중 서로 다른 시점에서 유효성 검사 수행(내장된 epoch당 유효성 검사에서 더욱 확장)
# - 정기적으로 또는 특정 정확도 임계값을 초과할 때 모델 검사점 설정
# - 훈련이 정체 된 것처럼 보일 때 모델의 학습 속도 변경
# - 훈련이 정체 된 것처럼 보일 때 최상위 레이어의 미세 조정
# - 교육이 종료되거나 특정 성능 임계 값을 초과 한 경우 전자 메일 또는 인스턴트 메시지 알림 보내기
# - 기타
#
# 콜백은 `fit()` 에 대한 호출에 목록으로 전달 될 수 있습니다.
# + id="15036ddbee42"
model = get_compiled_model()
callbacks = [
keras.callbacks.EarlyStopping(
# Stop training when `val_loss` is no longer improving
monitor="val_loss",
# "no longer improving" being defined as "no better than 1e-2 less"
min_delta=1e-2,
# "no longer improving" being further defined as "for at least 2 epochs"
patience=2,
verbose=1,
)
]
model.fit(
x_train,
y_train,
epochs=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2,
)
# + [markdown] id="303815509732"
# ### 많은 내장 콜백을 사용할 수 있습니다
#
# - `ModelCheckpoint` : 주기적으로 모델을 저장합니다.
# - `EarlyStopping`: 훈련이 더 이상 유효성 검사 메트릭을 개선하지 못하는 경우 훈련을 중단합니다.
# - `TensorBoard` : 시각화 할 수 있습니다 정기적으로 쓰기 모델 로그 [TensorBoard](https://www.tensorflow.org/tensorboard) (섹션 "시각화"에서 자세한 내용).
# - `CSVLogger` : 손실 및 메트릭 데이터를 CSV 파일로 스트리밍합니다.
# - 기타
#
# 전체 목록은 [콜백 설명서](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/) 를 참조하십시오.
#
# ### 자신의 콜백 작성
#
# 기본 클래스 `keras.callbacks.Callback` 을 확장하여 사용자 정의 콜백을 작성할 수 있습니다. 콜백은 클래스 속성 `self.model` 통해 연관된 모델에 액세스 할 수 있습니다.
#
# [사용자 정의 콜백을 작성하기 위한 전체 가이드](https://www.tensorflow.org/guide/keras/custom_callback/)를 꼭 읽어보세요. 다음은 훈련 중 배치별 손실 값 목록을 저장하는 간단한 예입니다.
#
# 다음은 훈련 중 배치 별 손실 값 목록을 저장하는 간단한 예입니다.
# + id="b265d36ce608"
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs):
self.per_batch_losses = []
def on_batch_end(self, batch, logs):
self.per_batch_losses.append(logs.get("loss"))
# + [markdown] id="5ee672524987"
# ## 모델 검사점 설정하기
#
# 상대적으로 큰 데이터세트에 대한 모델을 훈련시킬 때는 모델의 검사점을 빈번하게 저장하는 것이 중요합니다.
#
# 이를 수행하는 가장 쉬운 방법은 `ModelCheckpoint` 콜백을 사용하는 것입니다.
# + id="83614be57725"
model = get_compiled_model()
callbacks = [
keras.callbacks.ModelCheckpoint(
# Path where to save the model
# The two parameters below mean that we will overwrite
# the current checkpoint if and only if
# the `val_loss` score has improved.
# The saved model name will include the current epoch.
filepath="mymodel_{epoch}",
save_best_only=True, # Only save a model if `val_loss` has improved.
monitor="val_loss",
verbose=1,
)
]
model.fit(
x_train, y_train, epochs=2, batch_size=64, callbacks=callbacks, validation_split=0.2
)
# + [markdown] id="7f6afa36950c"
# `ModelCheckpoint` 콜백을 사용하여 내결함성을 구현할 수 있습니다. 훈련이 무작위로 중단 된 경우 모델의 마지막 저장된 상태에서 훈련을 다시 시작할 수있는 기능. 기본 예는 다음과 같습니다.
# + id="27ce92b2ad58"
import os
# Prepare a directory to store all the checkpoints.
checkpoint_dir = "./ckpt"
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
def make_or_restore_model():
# Either restore the latest model, or create a fresh one
# if there is no checkpoint available.
checkpoints = [checkpoint_dir + "/" + name for name in os.listdir(checkpoint_dir)]
if checkpoints:
latest_checkpoint = max(checkpoints, key=os.path.getctime)
print("Restoring from", latest_checkpoint)
return keras.models.load_model(latest_checkpoint)
print("Creating a new model")
return get_compiled_model()
model = make_or_restore_model()
callbacks = [
# This callback saves a SavedModel every 100 batches.
# We include the training loss in the saved model name.
keras.callbacks.ModelCheckpoint(
filepath=checkpoint_dir + "/ckpt-loss={loss:.2f}", save_freq=100
)
]
model.fit(x_train, y_train, epochs=1, callbacks=callbacks)
# + [markdown] id="da3ab58d5235"
# 또한 모델 저장 및 복원을 위해 자체 콜백을 작성하십시오.
#
# 직렬화 및 저장에 대한 전체 안내서는 [모델 저장 및 직렬화 안내서를](https://www.tensorflow.org/guide/keras/save_and_serialize/) 참조하십시오.
# + [markdown] id="b9342cc2ddba"
# ## 학습 속도 일정 사용하기
#
# 딥 러닝 모델을 훈련 할 때 일반적인 패턴은 훈련이 진행됨에 따라 점차적으로 학습을 줄이는 것입니다. 이것을 일반적으로 "학습률 감소"라고합니다.
#
# 학습 붕괴 스케줄은 정적 인 (현재 에포크 또는 현재 배치 인덱스의 함수로서 미리 고정됨) 또는 동적 (모델의 현재 행동, 특히 검증 손실에 대응) 일 수있다.
#
# ### 옵티마이저로 일정 전달하기
#
# 옵티 마이저에서 schedule 객체를 `learning_rate` 인수로 전달하여 정적 학습 속도 감소 스케줄을 쉽게 사용할 수 있습니다.
# + id="684f0ab6d3de"
initial_learning_rate = 0.1
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate, decay_steps=100000, decay_rate=0.96, staircase=True
)
optimizer = keras.optimizers.RMSprop(learning_rate=lr_schedule)
# + [markdown] id="7d742e44f535"
# `ExponentialDecay` , `PiecewiseConstantDecay` , `PolynomialDecay` 및 `InverseTimeDecay` 와 같은 몇 가지 기본 제공 일정을 사용할 수 있습니다.
#
# ### 콜백을 사용하여 동적 학습 속도 일정 구현
#
# 옵티마이저가 유효성 검사 메트릭에 액세스할 수 없으므로 이러한 일정 객체로는 동적 학습률 일정(예: 유효성 검사 손실이 더 이상 개선되지 않을 때 학습률 감소)을 달성할 수 없습니다.
#
# 그러나 콜백은 유효성 검사 메트릭을 포함해 모든 메트릭에 액세스할 수 있습니다! 따라서 옵티마이저에서 현재 학습률을 수정하는 콜백을 사용하여 이 패턴을 달성할 수 있습니다. 실제로 이 부분이`ReduceLROnPlateau` 콜백으로 내장되어 있습니다.
# + [markdown] id="b4a05f880175"
# ## 훈련 중 손실 및 메트릭 시각화하기
#
# 교육 중에 모델을 주시하는 가장 좋은 방법은 로컬에서 실행할 수있는 브라우저 기반 응용 프로그램 인 [TensorBoard](https://www.tensorflow.org/tensorboard) 를 사용하는 것입니다.
#
# - 교육 및 평가를위한 손실 및 지표의 라이브 플롯
# - (옵션) 레이어 활성화 히스토그램 시각화
# - (옵션) `Embedding` 레이어에서 학습한 포함된 공간의 3D 시각화
#
# pip와 함께 TensorFlow를 설치한 경우, 명령줄에서 TensorBoard를 시작할 수 있습니다.
#
# ```
# tensorboard --logdir=/full_path_to_your_logs
# ```
# + [markdown] id="1fcf386a1dad"
# ### TensorBoard 콜백 사용하기
#
# TensorBoard를 Keras 모델 및 fit 메서드와 함께 사용하는 가장 쉬운 방법은 `TensorBoard` 콜백입니다.
#
# 가장 간단한 경우로, 콜백에서 로그를 작성할 위치만 지정하면 바로 쓸 수 있습니다.
# + id="f74247282ff6"
keras.callbacks.TensorBoard(
log_dir="/full_path_to_your_logs",
histogram_freq=0, # How often to log histogram visualizations
embeddings_freq=0, # How often to log embedding visualizations
update_freq="epoch",
) # How often to write logs (default: once per epoch)
# + [markdown] id="50cd5f8631fd"
# 자세한 내용 [`TensorBoard` 콜백 설명서](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/tensorboard/)를 참조하세요.
| site/ko/guide/keras/train_and_evaluate.ipynb |