Hub documentation
Downloading models
Downloading models
Integrated libraries
If a model on the Hub is tied to a supported library, loading the model can be done in just a few lines. For information on accessing the model, you can click on the “Use in Library” button on the model page to see how to do so. For example, distilbert/distilgpt2 shows how to do so with 🤗 Transformers below.


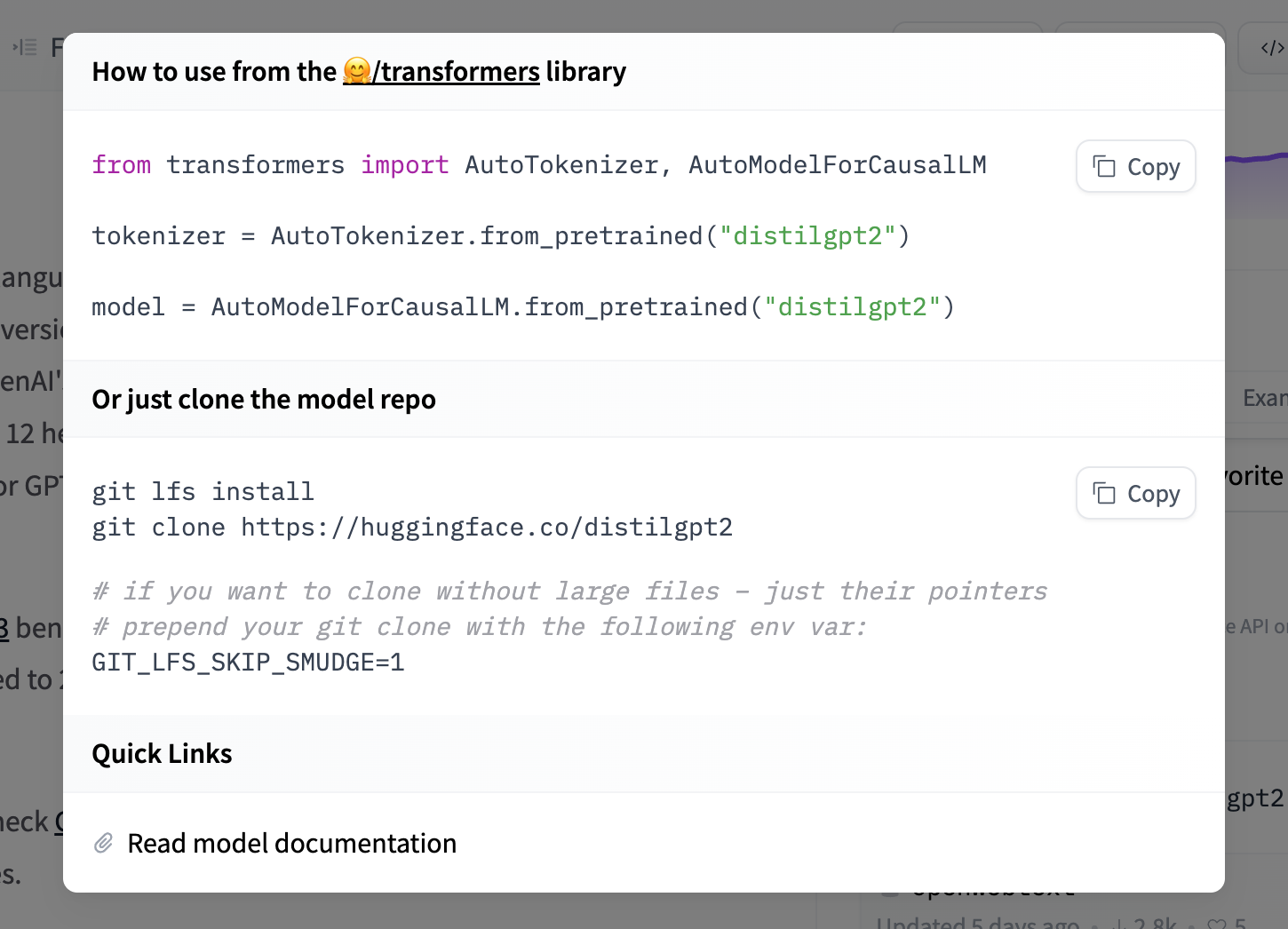
Using the Hugging Face Client Library
You can use the huggingface_hub library to create, delete, update and retrieve information from repos. For example, to download the HuggingFaceH4/zephyr-7b-beta model from the command line, run
hf download HuggingFaceH4/zephyr-7b-beta
See the CLI download documentation for more information.
You can also integrate this into your own library. For example, you can quickly load a Scikit-learn model with a few lines.
from huggingface_hub import hf_hub_download
import joblib
REPO_ID = "YOUR_REPO_ID"
FILENAME = "sklearn_model.joblib"
model = joblib.load(
hf_hub_download(repo_id=REPO_ID, filename=FILENAME)
)Using Git
Since all models on the Model Hub are Xet-backed Git repositories, you can clone the models locally by installing git-xet and running:
git xet install
git lfs install
git clone git@hf.co:<MODEL ID> # example: git clone git@hf.co:bigscience/bloomIf you have write-access to the particular model repo, you’ll also have the ability to commit and push revisions to the model.
Add your SSH public key to your user settings to push changes and/or access private repos.
Faster downloads
Test your download speed
You can test your download speed from Hugging Face’s CDN at fast.hf.co. This runs a quick bandwidth test against the nearest HF edge server, helping you understand your baseline throughput before tuning any settings.
You can also measure download speed directly from the terminal using the hf-speedtest CLI extension:
hf extensions install julien-c/hf-speedtest hf speedtest
Adaptive concurrency with hf_xet
hf_xet is a Rust-based package leveraging the Xet storage backend to optimize file transfers with chunk-based deduplication. By default, hf_xet uses adaptive concurrency — it automatically tunes the number of parallel transfer streams based on real-time network conditions, starting conservatively (1 stream) and scaling up to 64 concurrent streams as bandwidth permits.
For most machines — including data center environments — the default settings will already saturate the available network bandwidth. For advanced users on machines with high bandwidth and at least 64 GB of RAM, HF_XET_HIGH_PERFORMANCE=1 raises concurrency bounds and significantly increases memory buffer sizes, which can help when downloading many large files in parallel.
HF_XET_HIGH_PERFORMANCE=1 hf download ...
Using hf-mount
For large models, you can mount a repo as a local filesystem with hf-mount instead of downloading the full repo. Files are fetched lazily — only the bytes your code reads hit the network.
brew install hf-mount hf-mount start repo openai-community/gpt2 /tmp/gpt2
Repos are mounted read-only. See Mount as a Local Filesystem for full setup details, backend options, and caching.
Update on GitHub