
File size: 3,561 Bytes
79a688a f65d08a 79a688a d4a4a9b 79a688a c817093 79a688a c817093 79a688a c817093 79a688a c817093 79a688a c817093 79a688a c817093 79a688a c817093 79a688a | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 | ---
tags:
- audio
- codec
- speech
- rvq
language:
- en
---
# nano-codec 🔊
A minimal neural audio codec. 16kHz mono • 128x compression • 10.2 kbps • 24M parameters.
Trained on LibriSpeech train-clean-100 (~100 hours) for ~180k steps.
📝 [Blog Post](https://medium.com/@tareshrajput18/i-built-a-neural-audio-codec-from-scratch-48b61791ab44) — in-depth walkthrough of the architecture, training, and lessons learned
🤗 [Model Weights](https://huggingface.co/taresh18/nano-codec) — pretrained model on HuggingFace
💻 [GitHub](https://github.com/taresh18/nano-codec) — full training and inference code
## 🏗️ Architecture
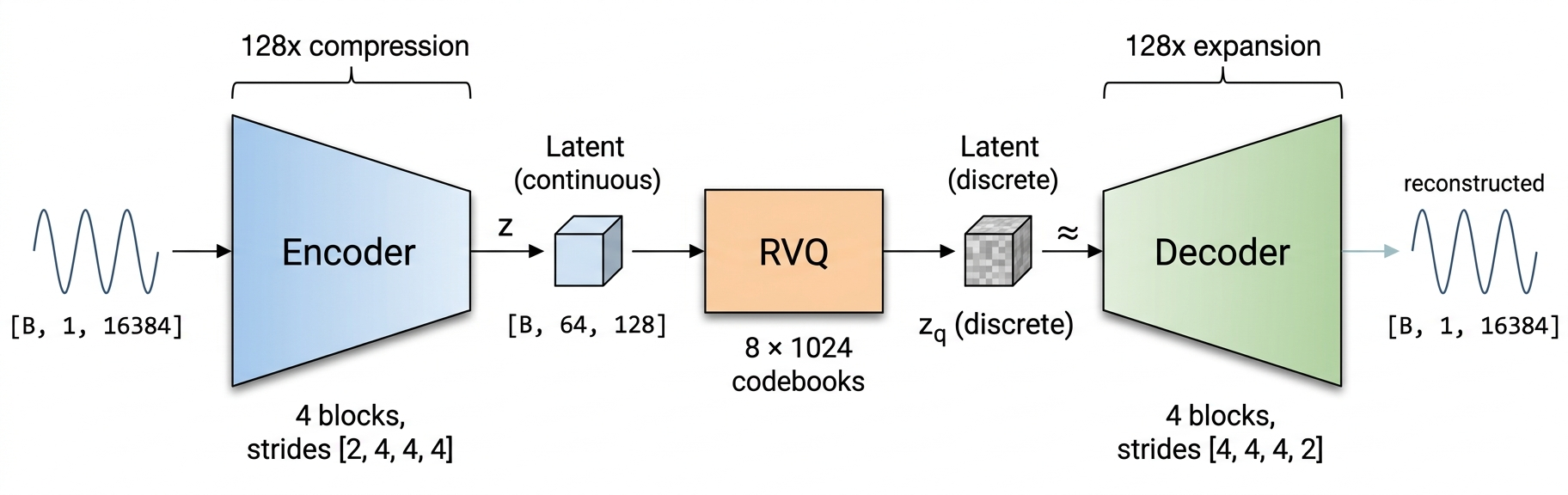
Inspired by [DAC](https://arxiv.org/abs/2306.06546) (Descript Audio Codec). Strided convolutional encoder, 8-level RVQ with factorized L2-normalized codebooks, mirror decoder.
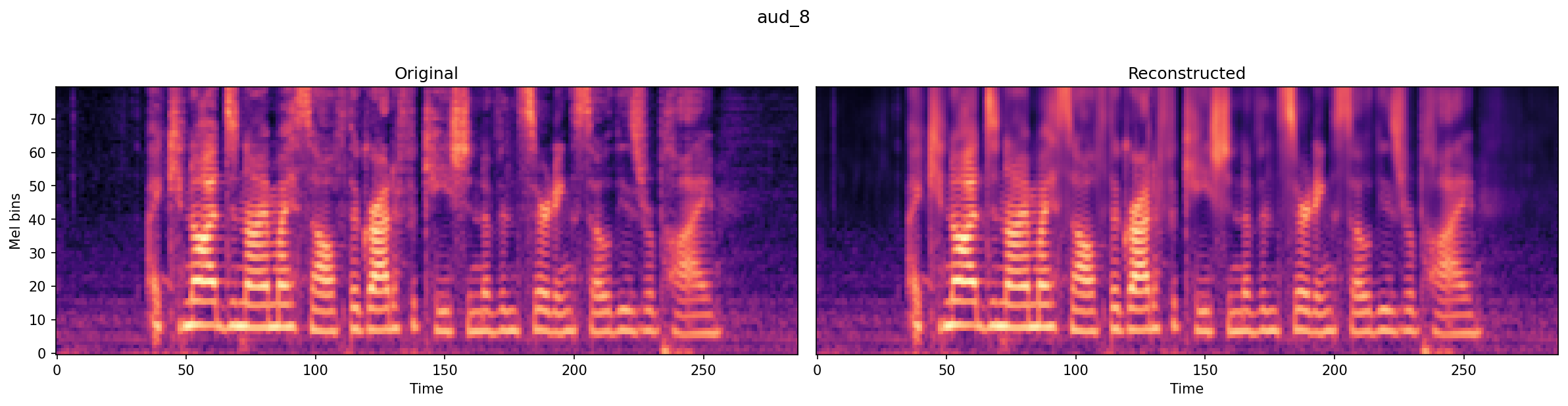
## 🎧 Samples
**Sample 1** — Original:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_2_original.wav"></audio>
Reconstructed:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_2_recon.wav"></audio>
**Sample 2** — Original:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_6_original.wav"></audio>
Reconstructed:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_6_recon.wav"></audio>
**Sample 3** — Original:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_7_original.wav"></audio>
Reconstructed:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_7_recon.wav"></audio>
**Sample 4** — Original:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_8_original.wav"></audio>
Reconstructed:
<audio controls src="https://huggingface.co/taresh18/nano-codec/resolve/main/samples/aud_8_recon.wav"></audio>
## Usage
```python
from huggingface_hub import hf_hub_download
import torch, yaml, soundfile as sf, torchaudio
from model import RVQCodec
# load model
model_path = hf_hub_download("taresh18/nano-codec", "model.pt")
config_path = hf_hub_download("taresh18/nano-codec", "config.yaml")
with open(config_path) as f:
cfg = yaml.safe_load(f)
model = RVQCodec(in_ch=1, latent_ch=cfg['latent_dim'], K=cfg['codebook_size'],
num_rvq_levels=cfg['num_rvq_levels'], codebook_dim=cfg.get('codebook_dim', 8))
model.load_state_dict(torch.load(model_path, map_location="cpu", weights_only=True))
model.eval()
# reconstruct audio
audio, sr = sf.read("input.wav", dtype="float32")
waveform = torch.from_numpy(audio).unsqueeze(0).unsqueeze(0) # [1, 1, T]
if sr != 16000:
waveform = torchaudio.functional.resample(waveform, sr, 16000)
with torch.no_grad():
recon, _, _, _ = model(waveform)
sf.write("reconstructed.wav", recon[0, 0].numpy(), 16000)
```
Or use the inference script from the [GitHub repo](https://github.com/taresh18/nano-codec):
```bash
python inference.py --input audio.wav --output reconstructed.wav
```
## 📚 References
- [Audio Codec Explainer (Kyutai)](https://kyutai.org/codec-explainer)
- [High-Fidelity Audio Compression with Improved RVQGAN (DAC)](https://arxiv.org/abs/2306.06546)
- [Neural Discrete Representation Learning (VQ-VAE)](https://arxiv.org/abs/1711.00937)
|